
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a4be2629758a7120bcbd4c14560dcacbdfa3ffa
| 7,133 |
ipynb
|
Jupyter Notebook
|
examples/fluorescence.ipynb
|
dezeraecox/GEN_cell_culture
|
70ca933bef53347e916e20e6b86dc9dc9da11825
|
[
"MIT"
] | null | null | null |
examples/fluorescence.ipynb
|
dezeraecox/GEN_cell_culture
|
70ca933bef53347e916e20e6b86dc9dc9da11825
|
[
"MIT"
] | 1 |
2019-08-04T22:44:54.000Z
|
2019-08-04T22:44:54.000Z
|
examples/fluorescence.ipynb
|
dezeraecox/GEN_cell_culture
|
70ca933bef53347e916e20e6b86dc9dc9da11825
|
[
"MIT"
] | null | null | null | 33.331776 | 1,308 | 0.593299 |
[
[
[
"# Fluorescence per phase\n\nThis module allows a calculations for a second fluorescence channel, based on cells that have been binned into cell cycle phases. There is also an option to ignore the phase information.",
"_____no_output_____"
]
],
[
[
"import os\nimport re\nimport string\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom loguru import logger\nfrom GEN_Utils import FileHandling",
"2019-08-04 20:51:33,061 GEN_Utils.FileHandling: [INFO ] Import ok\n"
]
],
[
[
"### Set some sample-specific parameters",
"_____no_output_____"
]
],
[
[
"input_folder = 'python/gauss_models/normalised/'\noutput_folder = 'python/phase_fluorescence/'\nfluorescence_col = 'TPE'\nplate_samples = ['TPE only', '1', '1.5', '2', '3', '4']*4\n\nplate_cords = [f'{x}{y}' for x in string.ascii_uppercase[0:4]\n for y in range(1, 7)]\n\nsample_map = dict(zip(plate_cords, plate_samples))",
"_____no_output_____"
],
[
"if not os.path.exists(output_folder):\n os.mkdir(output_folder)\n# Generate filelist\n\nfile_list = [filename for filename in os.listdir(input_folder)]",
"_____no_output_____"
]
],
[
[
"### Collect important info into summary df, grouped according to phase",
"_____no_output_____"
]
],
[
[
"sample_data = []\n\nfor filename in file_list:\n sample_name = os.path.splitext(filename)[0]\n raw_data = pd.read_csv(f'{input_folder}{filename}')\n raw_data.rename(columns={fluorescence_col: \"fluorescence\"}, inplace=True)\n fluo_data = raw_data.copy()[['phase', 'fluorescence']]\n fluo_data = fluo_data.groupby('phase').median().T\n fluo_data['sample'] = sample_name\n sample_data.append(fluo_data)\n\nsummary_df = pd.concat(sample_data).reset_index(drop=True)",
"_____no_output_____"
],
[
"summary_df.head()",
"_____no_output_____"
],
[
"summary_df['plate'] = summary_df['sample'].str[0]\nsummary_df['well'] = summary_df['sample'].str[1:]\nsummary_df['sample'] = summary_df['well'].map(sample_map)\nsummary_df.sort_values(['sample'], inplace=True)",
"_____no_output_____"
],
[
"summary_df.head(10)",
"_____no_output_____"
]
],
[
[
"### Generate equivalent dataset, ignoring phase",
"_____no_output_____"
]
],
[
[
"sample_data = {}\n\nfor filename in file_list:\n sample_name = os.path.splitext(filename)[0]\n raw_data = pd.read_csv(f'{input_folder}{filename}')\n raw_data.rename(columns={fluorescence_col: \"fluorescence\"}, inplace=True)\n fluo_data = raw_data.copy()['fluorescence']\n sample_data[sample_name] = fluo_data.median()\n\nsummary_df = pd.DataFrame.from_dict(sample_data, orient='index').reset_index()\n\nsummary_df.rename(columns={'index': 'sample',\n 0: 'med_fluorescence'}, inplace=True)\n\nsummary_df['plate'] = summary_df['sample'].str[0]\nsummary_df['well'] = summary_df['sample'].str[1:]\nsummary_df['sample'] = summary_df['well'].map(sample_map)\nsummary_df.sort_values(['plate', 'sample'], inplace=True)",
"_____no_output_____"
],
[
"summary_df.head(10)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4bf23ba1a4ce64676a0e71becc0b49689bb50f
| 2,409 |
ipynb
|
Jupyter Notebook
|
Introduction to Python/.ipynb_checkpoints/GUI - Widget Styling-checkpoint.ipynb
|
Xelepam/Python_Scripts
|
72779c5b1fa4188b7aaf8def39d5d1902002010b
|
[
"MIT"
] | null | null | null |
Introduction to Python/.ipynb_checkpoints/GUI - Widget Styling-checkpoint.ipynb
|
Xelepam/Python_Scripts
|
72779c5b1fa4188b7aaf8def39d5d1902002010b
|
[
"MIT"
] | null | null | null |
Introduction to Python/.ipynb_checkpoints/GUI - Widget Styling-checkpoint.ipynb
|
Xelepam/Python_Scripts
|
72779c5b1fa4188b7aaf8def39d5d1902002010b
|
[
"MIT"
] | null | null | null | 20.415254 | 76 | 0.520963 |
[
[
[
"import ipywidgets as widgets\nfrom IPython.display import display",
"_____no_output_____"
],
[
"'''\n-width\n-height\n-background_color\n-border_color\n-border_width\n-border_style\n-font_style\n-font_weight\n-font_size\n-font_family\n'''",
"_____no_output_____"
],
[
"button = widgets.Button(\n description = 'Hello World!',\n width = 100, # Intergers are interpreted as pixel measurements.\n height = '2em', # em is valid HTML unit of measurement.\n color = 'lime', # Colors can be set by name.\n background_color = '#0022FF', # Can also be set by color code.\n border_color = 'cyan',\n)\n\ndisplay(button)",
"_____no_output_____"
],
[
"from IPython.display import display\n\nfloat_range = widgets.FloatSlider()\nstring = widgets.Text(value = 'hi')\ncontainer = ",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a4bfe86011d94923479548d218208d782d35b2a
| 11,127 |
ipynb
|
Jupyter Notebook
|
Binary_Tree_Implimentations.ipynb
|
volkansonmez/Must_Do_For_a_Coder
|
f13b843b1c98222c4bd03eeafc82fb7cfbb475b8
|
[
"MIT"
] | 1 |
2021-06-20T02:04:10.000Z
|
2021-06-20T02:04:10.000Z
|
Binary_Tree_Implimentations.ipynb
|
volkansonmez/must_do_for_a_coder
|
f13b843b1c98222c4bd03eeafc82fb7cfbb475b8
|
[
"MIT"
] | null | null | null |
Binary_Tree_Implimentations.ipynb
|
volkansonmez/must_do_for_a_coder
|
f13b843b1c98222c4bd03eeafc82fb7cfbb475b8
|
[
"MIT"
] | 1 |
2021-07-07T03:00:51.000Z
|
2021-07-07T03:00:51.000Z
| 38.770035 | 121 | 0.4827 |
[
[
[
"# Binary Tree Basic Implimentations\n# For harder questions and answers, refer to:\n# https://github.com/volkansonmez/Algorithms-and-Data-Structures-1/blob/master/Binary_Tree_All_Methods.ipynb",
"_____no_output_____"
],
[
"import numpy as np\nnp.random.seed(0)\n\nclass BST():\n def __init__(self, root = None):\n self.root = root\n \n \n def add_node(self, value):\n if self.root == None:\n self.root = Node(value)\n else:\n self._add_node(self.root, value)\n \n \n def _add_node(self, key_node, value):\n if key_node == None: return\n if value < key_node.cargo: # go left\n if key_node.left == None:\n key_node.left = Node(value)\n key_node.left.parent = key_node\n else:\n self._add_node(key_node.left, value)\n \n elif value > key_node.cargo: # go right\n if key_node.right == None:\n key_node.right = Node(value)\n key_node.right.parent = key_node\n else:\n self._add_node(key_node.right, value)\n \n else: # if the value already exists\n return\n \n \n def add_random_nodes(self):\n numbers = np.arange(0,20)\n self.random_numbers = np.random.permutation(numbers)\n for i in self.random_numbers:\n self.add_node(i)\n \n \n def find_node(self, value): # find if the value exists in the tree\n if self.root == None: return None\n if self.root.cargo == value: \n return self.root\n else:\n return self._find_node(self.root, value)\n \n \n def _find_node(self, key_node, value):\n if key_node == None: return None\n if key_node.cargo == value: return key_node\n if value < key_node.cargo: # go left\n key_node = key_node.left\n return self._find_node(key_node, value)\n else:\n key_node = key_node.right\n return self._find_node(key_node, value)\n \n \n def print_in_order(self): # do a dfs, print from left leaf to the right leaf\n if self.root == None: return\n key_node = self.root\n self._print_in_order(key_node)\n \n \n def _print_in_order(self, key_node):\n if key_node == None: return\n self._print_in_order(key_node.left)\n print(key_node.cargo, end = ' ')\n self._print_in_order(key_node.right)\n \n \n def print_leaf_nodes_by_stacking(self):\n all_nodes = [] # append the node objects\n leaf_nodes = [] # append the cargos of the leaf nodes\n if self.root == None: return None\n all_nodes.append(self.root)\n while len(all_nodes) > 0:\n curr_node = all_nodes.pop() # pop the last item, last in first out\n if curr_node.left != None:\n all_nodes.append(curr_node.left)\n if curr_node.right != None:\n all_nodes.append(curr_node.right)\n elif curr_node.left == None and curr_node.right == None:\n leaf_nodes.append(curr_node.cargo)\n return leaf_nodes \n \n \n \n def print_bfs(self, todo = None):\n if todo == None: todo = []\n if self.root == None: return\n todo.append(self.root)\n while len(todo) > 0:\n curr_node = todo.pop()\n if curr_node.left != None:\n todo.append(curr_node.left)\n if curr_node.right != None:\n todo.append(curr_node.right)\n print(curr_node.cargo, end = ' ')\n \n \n \n def find_height(self):\n if self.root == None: return 0\n else:\n return self._find_height(self.root, left = 0, right = 0)\n \n \n def _find_height(self, key_node, left, right):\n if key_node == None: return max(left, right)\n return self._find_height(key_node.left, left + 1, right)\n return self._find_height(key_node.right, left, right +1)\n\n \n \n def is_valid(self):\n if self.root == None: return True\n key_node = self.root\n return self._is_valid(self.root, -np.inf, np.inf)\n \n \n def _is_valid(self, key_node, min_value , max_value):\n if key_node == None: return True\n if key_node.cargo > max_value or key_node.cargo < min_value: return False\n left_valid = True\n right_valid = True\n if key_node != None and key_node.left != None:\n left_valid = self._is_valid(key_node.left, min_value, key_node.cargo)\n if key_node != None and key_node.right != None:\n right_valid = self._is_valid(key_node.right, key_node.cargo, max_value)\n return left_valid and right_valid\n \n \n def zig_zag_printing_top_to_bottom(self):\n if self.root == None: return\n even_stack = [] # stack the nodes in levels that are in even numbers\n odd_stack = [] # stack the nodes in levels that are in odd numbers\n print_nodes = [] # append the items' cargos in zigzag order\n even_stack.append(self.root)\n while len(even_stack) > 0 or len(odd_stack) > 0:\n \n while len(even_stack) > 0:\n tmp = even_stack.pop()\n print_nodes.append(tmp.cargo)\n if tmp.right != None:\n odd_stack.append(tmp.right)\n if tmp.left != None:\n odd_stack.append(tmp.left)\n \n \n while len(odd_stack) > 0:\n tmp = odd_stack.pop()\n print_nodes.append(tmp.cargo)\n if tmp.left != None:\n even_stack.append(tmp.left)\n if tmp.right != None:\n even_stack.append(tmp.right)\n \n return print_nodes\n \n \n \n def lowest_common_ancestor(self, node1, node2): # takes two cargos and prints the lca node of them \n if self.root == None: return\n node1_confirm = self.find_node(node1)\n if node1_confirm == None: return\n node2_confirm = self.find_node(node2)\n if node2_confirm == None: return\n key_node = self.root\n print('nodes are in the tree')\n return self._lowest_common_ancestor(key_node, node1, node2)\n \n \n def _lowest_common_ancestor(self, key_node, node1, node2):\n if key_node == None: return\n if node1 < key_node.cargo and node2 < key_node.cargo:\n key_node = key_node.left\n return self._lowest_common_ancestor(key_node, node1, node2)\n elif node1 > key_node.cargo and node2 > key_node.cargo:\n key_node = key_node.right\n return self._lowest_common_ancestor(key_node, node1, node2)\n else:\n return key_node , key_node.cargo\n \n \n def maximum_path_sum(self): # function to find the maximum path sum\n if self.root == None: return\n max_value = -np.inf\n return self._maximum_path_sum(self.root, max_value)\n \n \n def _maximum_path_sum(self, key_node, max_value): # recursive function to search and return the max path sum\n if key_node == None: return 0\n left = self._maximum_path_sum(key_node.left, max_value)\n right = self._maximum_path_sum(key_node.right, max_value)\n max_value = max(max_value, key_node.cargo + left + right)\n return max(left, right) + self.root.cargo\n \n \n \nclass Node():\n def __init__(self, cargo = None, parent = None, left = None, right = None):\n self.cargo = cargo\n self.parent = parent\n self.left = left\n self.right = right\n \n\n\n \ntest_bst = BST()\ntest_bst.add_random_nodes()\n#print(test_bst.print_in_order())\n#test_bst.find_node(11)\n#test_bst.print_leaf_nodes_by_stacking()\n#test_bst.print_bfs() \n#test_bst.find_height()\n#test_bst.is_valid()\ntest_bst.zig_zag_printing_top_to_bottom()\n#test_bst.lowest_common_ancestor(8, 0)\n#test_bst.maximum_path_sum()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a4c2b99e4d829956e4b51cc52715a7b1ddaf15e
| 149,764 |
ipynb
|
Jupyter Notebook
|
code_file/machine_learning_trading_bot.ipynb
|
kseniagorska/algorithmic_trading_with_machine_learning_algortihms
|
67a2c4df3868d0d0f33f215866666a710f6a13a1
|
[
"MIT"
] | null | null | null |
code_file/machine_learning_trading_bot.ipynb
|
kseniagorska/algorithmic_trading_with_machine_learning_algortihms
|
67a2c4df3868d0d0f33f215866666a710f6a13a1
|
[
"MIT"
] | null | null | null |
code_file/machine_learning_trading_bot.ipynb
|
kseniagorska/algorithmic_trading_with_machine_learning_algortihms
|
67a2c4df3868d0d0f33f215866666a710f6a13a1
|
[
"MIT"
] | null | null | null | 69.463822 | 30,428 | 0.714284 |
[
[
[
"# Machine Learning Trading Bot\n\nIn this Challenge, you’ll assume the role of a financial advisor at one of the top five financial advisory firms in the world. Your firm constantly competes with the other major firms to manage and automatically trade assets in a highly dynamic environment. In recent years, your firm has heavily profited by using computer algorithms that can buy and sell faster than human traders.\n\nThe speed of these transactions gave your firm a competitive advantage early on. But, people still need to specifically program these systems, which limits their ability to adapt to new data. You’re thus planning to improve the existing algorithmic trading systems and maintain the firm’s competitive advantage in the market. To do so, you’ll enhance the existing trading signals with machine learning algorithms that can adapt to new data.\n\n## Instructions:\n\nUse the starter code file to complete the steps that the instructions outline. The steps for this Challenge are divided into the following sections:\n\n* Establish a Baseline Performance\n\n* Tune the Baseline Trading Algorithm\n\n* Evaluate a New Machine Learning Classifier\n\n* Create an Evaluation Report\n\n#### Establish a Baseline Performance\n\nIn this section, you’ll run the provided starter code to establish a baseline performance for the trading algorithm. To do so, complete the following steps.\n\nOpen the Jupyter notebook. Restart the kernel, run the provided cells that correspond with the first three steps, and then proceed to step four. \n\n1. Import the OHLCV dataset into a Pandas DataFrame.\n\n2. Generate trading signals using short- and long-window SMA values. \n\n3. Split the data into training and testing datasets.\n\n4. Use the `SVC` classifier model from SKLearn's support vector machine (SVM) learning method to fit the training data and make predictions based on the testing data. Review the predictions.\n\n5. Review the classification report associated with the `SVC` model predictions. \n\n6. Create a predictions DataFrame that contains columns for “Predicted” values, “Actual Returns”, and “Strategy Returns”.\n\n7. Create a cumulative return plot that shows the actual returns vs. the strategy returns. Save a PNG image of this plot. This will serve as a baseline against which to compare the effects of tuning the trading algorithm.\n\n8. Write your conclusions about the performance of the baseline trading algorithm in the `README.md` file that’s associated with your GitHub repository. Support your findings by using the PNG image that you saved in the previous step.\n\n#### Tune the Baseline Trading Algorithm\n\nIn this section, you’ll tune, or adjust, the model’s input features to find the parameters that result in the best trading outcomes. (You’ll choose the best by comparing the cumulative products of the strategy returns.) To do so, complete the following steps:\n\n1. Tune the training algorithm by adjusting the size of the training dataset. To do so, slice your data into different periods. Rerun the notebook with the updated parameters, and record the results in your `README.md` file. Answer the following question: What impact resulted from increasing or decreasing the training window?\n\n> **Hint** To adjust the size of the training dataset, you can use a different `DateOffset` value—for example, six months. Be aware that changing the size of the training dataset also affects the size of the testing dataset.\n\n2. Tune the trading algorithm by adjusting the SMA input features. Adjust one or both of the windows for the algorithm. Rerun the notebook with the updated parameters, and record the results in your `README.md` file. Answer the following question: What impact resulted from increasing or decreasing either or both of the SMA windows?\n\n3. Choose the set of parameters that best improved the trading algorithm returns. Save a PNG image of the cumulative product of the actual returns vs. the strategy returns, and document your conclusion in your `README.md` file.\n\n#### Evaluate a New Machine Learning Classifier\n\nIn this section, you’ll use the original parameters that the starter code provided. But, you’ll apply them to the performance of a second machine learning model. To do so, complete the following steps:\n\n1. Import a new classifier, such as `AdaBoost`, `DecisionTreeClassifier`, or `LogisticRegression`. (For the full list of classifiers, refer to the [Supervised learning page](https://scikit-learn.org/stable/supervised_learning.html) in the scikit-learn documentation.)\n\n2. Using the original training data as the baseline model, fit another model with the new classifier.\n\n3. Backtest the new model to evaluate its performance. Save a PNG image of the cumulative product of the actual returns vs. the strategy returns for this updated trading algorithm, and write your conclusions in your `README.md` file. Answer the following questions: Did this new model perform better or worse than the provided baseline model? Did this new model perform better or worse than your tuned trading algorithm?\n\n#### Create an Evaluation Report\n\nIn the previous sections, you updated your `README.md` file with your conclusions. To accomplish this section, you need to add a summary evaluation report at the end of the `README.md` file. For this report, express your final conclusions and analysis. Support your findings by using the PNG images that you created.\n",
"_____no_output_____"
]
],
[
[
"# Imports\nimport pandas as pd\nimport numpy as np\nfrom pathlib import Path\nimport hvplot.pandas\nimport matplotlib.pyplot as plt\nfrom sklearn import svm\nfrom sklearn.preprocessing import StandardScaler\nfrom pandas.tseries.offsets import DateOffset\nfrom sklearn.metrics import classification_report",
"_____no_output_____"
]
],
[
[
"---\n\n## Establish a Baseline Performance\n\nIn this section, you’ll run the provided starter code to establish a baseline performance for the trading algorithm. To do so, complete the following steps.\n\nOpen the Jupyter notebook. Restart the kernel, run the provided cells that correspond with the first three steps, and then proceed to step four. \n",
"_____no_output_____"
],
[
"### Step 1: mport the OHLCV dataset into a Pandas DataFrame.",
"_____no_output_____"
]
],
[
[
"# Import the OHLCV dataset into a Pandas Dataframe\nohlcv_df = pd.read_csv(\n Path(\"./Resources/emerging_markets_ohlcv.csv\"), \n index_col='date', \n infer_datetime_format=True, \n parse_dates=True\n)\n\n# Review the DataFrame\nohlcv_df.head()",
"_____no_output_____"
],
[
"# Filter the date index and close columns\nsignals_df = ohlcv_df.loc[:, [\"close\"]]\n\n# Use the pct_change function to generate returns from close prices\nsignals_df[\"Actual Returns\"] = signals_df[\"close\"].pct_change()\n\n# Drop all NaN values from the DataFrame\nsignals_df = signals_df.dropna()\n\n# Review the DataFrame\ndisplay(signals_df.head())\ndisplay(signals_df.tail())",
"_____no_output_____"
]
],
[
[
"## Step 2: Generate trading signals using short- and long-window SMA values. ",
"_____no_output_____"
]
],
[
[
"# Set the short window and long window\nshort_window = 4\nlong_window = 100\n\n# Generate the fast and slow simple moving averages (4 and 100 days, respectively)\nsignals_df['SMA_Fast'] = signals_df['close'].rolling(window=short_window).mean()\nsignals_df['SMA_Slow'] = signals_df['close'].rolling(window=long_window).mean()\n\nsignals_df = signals_df.dropna()\n\n# Review the DataFrame\ndisplay(signals_df.head())\ndisplay(signals_df.tail())",
"_____no_output_____"
],
[
"# Initialize the new Signal column\nsignals_df['Signal'] = 0.0\n\n# When Actual Returns are greater than or equal to 0, generate signal to buy stock long\nsignals_df.loc[(signals_df['Actual Returns'] >= 0), 'Signal'] = 1\n\n# When Actual Returns are less than 0, generate signal to sell stock short\nsignals_df.loc[(signals_df['Actual Returns'] < 0), 'Signal'] = -1\n\n# Review the DataFrame\ndisplay(signals_df.head())\ndisplay(signals_df.tail())",
"_____no_output_____"
],
[
"signals_df['Signal'].value_counts()",
"_____no_output_____"
],
[
"# Calculate the strategy returns and add them to the signals_df DataFrame\nsignals_df['Strategy Returns'] = signals_df['Actual Returns'] * signals_df['Signal'].shift()\n\n# Review the DataFrame\ndisplay(signals_df.head())\ndisplay(signals_df.tail())",
"_____no_output_____"
],
[
"# Plot Strategy Returns to examine performance\n(1 + signals_df['Strategy Returns']).cumprod().plot()",
"_____no_output_____"
]
],
[
[
"### Step 3: Split the data into training and testing datasets.",
"_____no_output_____"
]
],
[
[
"# Assign a copy of the sma_fast and sma_slow columns to a features DataFrame called X\nX = signals_df[['SMA_Fast', 'SMA_Slow']].shift().dropna()\n\n# Review the DataFrame\nX.head()",
"_____no_output_____"
],
[
"# Create the target set selecting the Signal column and assiging it to y\ny = signals_df['Signal']\n\n# Review the value counts\ny.value_counts()",
"_____no_output_____"
],
[
"# Select the start of the training period\ntraining_begin = X.index.min()\n\n# Display the training begin date\nprint(training_begin)",
"2015-04-02 15:00:00\n"
],
[
"# Select the ending period for the training data with an offset of 3 months\ntraining_end = X.index.min() + DateOffset(months=3)\n\n# Display the training end date\nprint(training_end)",
"2015-07-02 15:00:00\n"
],
[
"# Generate the X_train and y_train DataFrames\nX_train = X.loc[training_begin:training_end]\ny_train = y.loc[training_begin:training_end]\n\n# Review the X_train DataFrame\nX_train.head()",
"_____no_output_____"
],
[
"# Generate the X_test and y_test DataFrames\nX_test = X.loc[training_end+DateOffset(hours=1):]\ny_test = y.loc[training_end+DateOffset(hours=1):]\n\n# Review the X_test DataFrame\nX_test.head()",
"_____no_output_____"
],
[
"# Scale the features DataFrames\n\n# Create a StandardScaler instance\nscaler = StandardScaler()\n\n# Apply the scaler model to fit the X-train data\nX_scaler = scaler.fit(X_train)\n\n# Transform the X_train and X_test DataFrames using the X_scaler\nX_train_scaled = X_scaler.transform(X_train)\nX_test_scaled = X_scaler.transform(X_test)",
"_____no_output_____"
]
],
[
[
"### Step 4: Use the `SVC` classifier model from SKLearn's support vector machine (SVM) learning method to fit the training data and make predictions based on the testing data. Review the predictions.",
"_____no_output_____"
]
],
[
[
"# From SVM, instantiate SVC classifier model instance\nsvm_model = svm.SVC()\n \n# Fit the model to the data using the training data\nsvm_model = svm_model.fit(X_train_scaled, y_train)\n \n# Use the testing data to make the model predictions\nsvm_pred = svm_model.predict(X_test_scaled)\n\n# Review the model's predicted values\nsvm_pred\n",
"_____no_output_____"
]
],
[
[
"### Step 5: Review the classification report associated with the `SVC` model predictions. ",
"_____no_output_____"
]
],
[
[
"# Use a classification report to evaluate the model using the predictions and testing data\nsvm_testing_report = classification_report(y_test, svm_pred)\n\n# Print the classification report\nprint(svm_testing_report)\n",
" precision recall f1-score support\n\n -1.0 0.43 0.04 0.07 1804\n 1.0 0.56 0.96 0.71 2288\n\n accuracy 0.55 4092\n macro avg 0.49 0.50 0.39 4092\nweighted avg 0.50 0.55 0.43 4092\n\n"
]
],
[
[
"### Step 6: Create a predictions DataFrame that contains columns for “Predicted” values, “Actual Returns”, and “Strategy Returns”.",
"_____no_output_____"
]
],
[
[
"# Create a new empty predictions DataFrame.\n\n# Create a predictions DataFrame\npredictions_df = pd.DataFrame(index=X_test.index)\n\n# Add the SVM model predictions to the DataFrame\npredictions_df['Predicted'] = svm_pred\n\n# Add the actual returns to the DataFrame\npredictions_df['Actual Returns'] = signals_df['Actual Returns'] \n\n# Add the strategy returns to the DataFrame\npredictions_df['Strategy Returns'] = predictions_df[\"Actual Returns\"] * predictions_df['Predicted']\n\n# Review the DataFrame\ndisplay(predictions_df.head())\ndisplay(predictions_df.tail())",
"_____no_output_____"
]
],
[
[
"### Step 7: Create a cumulative return plot that shows the actual returns vs. the strategy returns. Save a PNG image of this plot. This will serve as a baseline against which to compare the effects of tuning the trading algorithm.",
"_____no_output_____"
]
],
[
[
"# Plot the actual returns versus the SVM strategy returns\n(1+predictions_df[[\"Actual Returns\", \"Strategy Returns\"]]).cumprod().plot(title= \"SVM Strategy Returns\")\n",
"_____no_output_____"
]
],
[
[
"---\n\n## Tune the Baseline Trading Algorithm",
"_____no_output_____"
],
[
"## Step 6: Use an Alternative ML Model and Evaluate Strategy Returns",
"_____no_output_____"
],
[
"In this section, you’ll tune, or adjust, the model’s input features to find the parameters that result in the best trading outcomes. You’ll choose the best by comparing the cumulative products of the strategy returns.",
"_____no_output_____"
],
[
"### Step 1: Tune the training algorithm by adjusting the size of the training dataset. \n\nTo do so, slice your data into different periods. Rerun the notebook with the updated parameters, and record the results in your `README.md` file. \n\nAnswer the following question: What impact resulted from increasing or decreasing the training window?",
"_____no_output_____"
],
[
"### Step 2: Tune the trading algorithm by adjusting the SMA input features. \n\nAdjust one or both of the windows for the algorithm. Rerun the notebook with the updated parameters, and record the results in your `README.md` file. \n\nAnswer the following question: What impact resulted from increasing or decreasing either or both of the SMA windows?",
"_____no_output_____"
],
[
"### Step 3: Choose the set of parameters that best improved the trading algorithm returns. \n\nSave a PNG image of the cumulative product of the actual returns vs. the strategy returns, and document your conclusion in your `README.md` file.",
"_____no_output_____"
],
[
"---\n\n## Evaluate a New Machine Learning Classifier\n\nIn this section, you’ll use the original parameters that the starter code provided. But, you’ll apply them to the performance of a second machine learning model. ",
"_____no_output_____"
],
[
"### Step 1: Import a new classifier, such as `AdaBoost`, `DecisionTreeClassifier`, or `LogisticRegression`. (For the full list of classifiers, refer to the [Supervised learning page](https://scikit-learn.org/stable/supervised_learning.html) in the scikit-learn documentation.)",
"_____no_output_____"
]
],
[
[
"# Import a new classifier from SKLearn\nfrom sklearn.ensemble import RandomForestClassifier\n\n# Initiate the model instance\nmodel= RandomForestClassifier(n_estimators=1000)\n",
"_____no_output_____"
]
],
[
[
"### Step 2: Using the original training data as the baseline model, fit another model with the new classifier.",
"_____no_output_____"
]
],
[
[
"# Fit the model using the training data\nmodel = model.fit(X_train_scaled, y_train)\n\n# Use the testing dataset to generate the predictions for the new model\npred = model.predict(X_test_scaled)\n\n# Review the model's predicted values\npred[:10]\n",
"_____no_output_____"
]
],
[
[
"### Step 3: Backtest the new model to evaluate its performance. \n\nSave a PNG image of the cumulative product of the actual returns vs. the strategy returns for this updated trading algorithm, and write your conclusions in your `README.md` file. \n\nAnswer the following questions: \nDid this new model perform better or worse than the provided baseline model? \nDid this new model perform better or worse than your tuned trading algorithm?",
"_____no_output_____"
]
],
[
[
"# Use a classification report to evaluate the model using the predictions and testing data \n# Report based on the RandomForestTree Classifier Model\nreport=classification_report(y_test, pred)\n\n# Print the classification report\nprint(report)\n",
" precision recall f1-score support\n\n -1.0 0.44 0.34 0.38 1804\n 1.0 0.56 0.66 0.61 2288\n\n accuracy 0.52 4092\n macro avg 0.50 0.50 0.49 4092\nweighted avg 0.51 0.52 0.51 4092\n\n"
],
[
"# Create a new empty predictions DataFrame.\n\n# Create a predictions DataFrame\nrfc_predictions_df = pd.DataFrame(index=X_test.index)\n\n# Add the SVM model predictions to the DataFrame\nrfc_predictions_df[\"Random Forest predictions\"]= pred\n\n# Add the actual returns to the DataFrame\nrfc_predictions_df[\"Actual Returns\"]= signals_df[\"Actual Returns\"]\n\n# Add the strategy returns to the DataFrame\nrfc_predictions_df['Strategy Returns'] = rfc_predictions_df['Actual Returns'] * rfc_predictions_df['Random Forest predictions']\n\n# Review the DataFrame\nrfc_predictions_df\n",
"_____no_output_____"
],
[
"# Plot the actual returns versus the strategy returns\n(1+rfc_predictions_df[[\"Actual Returns\", \"Strategy Returns\"]]).cumprod().plot(title= \"Random Forest Classifier Strategy\")",
"_____no_output_____"
]
],
[
[
"The SVM model achieved greater accuracy and produced higher cumulative returns than the RandomForestClassifier",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a4c31e63dedeb6a7829ebcfcff61517ade4e9d2
| 15,645 |
ipynb
|
Jupyter Notebook
|
tutorial/source/svi_part_ii.ipynb
|
DEVESHTARASIA/pyro
|
7fce5508fe4f15a1a65a267e8d6df3aeead1a3ec
|
[
"MIT"
] | null | null | null |
tutorial/source/svi_part_ii.ipynb
|
DEVESHTARASIA/pyro
|
7fce5508fe4f15a1a65a267e8d6df3aeead1a3ec
|
[
"MIT"
] | null | null | null |
tutorial/source/svi_part_ii.ipynb
|
DEVESHTARASIA/pyro
|
7fce5508fe4f15a1a65a267e8d6df3aeead1a3ec
|
[
"MIT"
] | null | null | null | 66.574468 | 810 | 0.652029 |
[
[
[
"# SVI Part II: Conditional Independence, Subsampling, and Amortization\n\n## The Goal: Scaling SVI to Large Datasets\n\nFor a model with $N$ observations, running the `model` and `guide` and constructing the ELBO involves evaluating log pdf's whose complexity scales badly with $N$. This is a problem if we want to scale to large datasets. Luckily, the ELBO objective naturally supports subsampling provided that our model/guide have some conditional independence structure that we can take advantage of. For example, in the case that the observations are conditionally independent given the latents, the log likelihood term in the ELBO can be approximated with\n\n$$ \\sum_{i=1}^N \\log p({\\bf x}_i | {\\bf z}) \\approx \\frac{N}{M}\n\\sum_{i\\in{\\mathcal{I}_M}} \\log p({\\bf x}_i | {\\bf z}) $$\n\nwhere $\\mathcal{I}_M$ is a mini-batch of indices of size $M$ with $M<N$ (for a discussion please see references [1,2]). Great, problem solved! But how do we do this in Pyro?\n\n## Marking Conditional Independence in Pyro\n\nIf a user wants to do this sort of thing in Pyro, he or she first needs to make sure that the model and guide are written in such a way that Pyro can leverage the relevant conditional independencies. Let's see how this is done. Pyro provides two language primitives for marking conditional independencies: `irange` and `iarange`. Let's start with the simpler of the two.\n\n### `irange`\n\nLet's return to the example we used in the [previous tutorial](svi_part_i.html). For convenience let's replicate the main logic of `model` here:\n\n```python\ndef model(data):\n # sample f from the beta prior\n f = pyro.sample(\"latent_fairness\", dist.beta, alpha0, beta0)\n # loop over the observed data using pyro.sample with the obs keyword argument\n for i in range(len(data)):\n # observe datapoint i using the bernoulli likelihood\n pyro.sample(\"obs_{}\".format(i), dist.bernoulli, \n f, obs=data[i])\n```\n\nFor this model the observations are conditionally independent given the latent random variable `latent_fairness`. To explicitly mark this in Pyro we basically just need to replace the Python builtin `range` with the Pyro construct `irange`:\n\n```python\ndef model(data):\n # sample f from the beta prior\n f = pyro.sample(\"latent_fairness\", dist.beta, alpha0, beta0)\n # loop over the observed data [WE ONLY CHANGE THE NEXT LINE]\n for i in pyro.irange(\"data_loop\", len(data)): \n # observe datapoint i using the bernoulli likelihood\n pyro.sample(\"obs_{}\".format(i), dist.bernoulli, \n f, obs=data[i])\n```\n\nWe see that `pyro.irange` is very similar to `range` with one main difference: each invocation of `irange` requires the user to provide a unique name. The second argument is an integer just like for `range`. \n\nSo far so good. Pyro can now leverage the conditional independency of the observations given the latent random variable. But how does this actually work? Basically `pyro.irange` is implemented using a context manager. At every execution of the body of the `for` loop we enter a new (conditional) independence context which is then exited at the end of the `for` loop body. Let's be very explicit about this: \n\n- because each observed `pyro.sample` statement occurs within a different execution of the body of the `for` loop, Pyro marks each observation as independent\n- this independence is properly a _conditional_ independence _given_ `latent_fairness` because `latent_fairness` is sampled _outside_ of the context of `data_loop`.\n\nBefore moving on, let's mention some gotchas to be avoided when using `irange`. Consider the following variant of the above code snippet:\n\n```python\n# WARNING do not do this!\nmy_reified_list = list(pyro.irange(\"data_loop\", len(data)))\nfor i in my_reified_list: \n pyro.sample(\"obs_{}\".format(i), dist.bernoulli, f, obs=data[i])\n```\n\nThis will _not_ achieve the desired behavior, since `list()` will enter and exit the `data_loop` context completely before a single `pyro.sample` statement is called. Similarly, the user needs to take care not to leak mutable computations across the boundary of the context manager, as this may lead to subtle bugs. For example, `pyro.irange` is not appropriate for temporal models where each iteration of a loop depends on the previous iteration; in this case a `range` should be used instead.\n\n## `iarange`\n\nConceptually `iarange` is the same as `irange` except that it is a vectorized operation (as `torch.arange` is to `range`). As such it potentially enables large speed-ups compared to the explicit `for` loop that appears with `irange`. Let's see how this looks for our running example. First we need `data` to be in the form of a tensor:\n\n```python\ndata = Variable(torch.zeros(10, 1))\ndata.data[0:6, 0] = torch.ones(6) # 6 heads and 4 tails\n```\n\nThen we have:\n\n```python\nwith iarange('observe_data'):\n pyro.sample('obs', dist.bernoulli, f, obs=data)\n```\n\nLet's compare this to the analogous `irange` construction point-by-point:\n- just like `irange`, `iarange` requires the user to specify a unique name.\n- note that this code snippet only introduces a single (observed) random variable (namely `obs`), since the entire tensor is considered at once. \n- since there is no need for an iterator in this case, there is no need to specify the length of the tensor(s) involved in the `iarange` context\n\nNote that the gotchas mentioned in the case of `irange` also apply to `iarange`.",
"_____no_output_____"
],
[
"## Subsampling\n\nWe now know how to mark conditional independence in Pyro. This is useful in and of itself (see the [dependency tracking section](svi_part_iii.html) in SVI Part III), but we'd also like to do subsampling so that we can do SVI on large datasets. Depending on the structure of the model and guide, Pyro supports several ways of doing subsampling. Let's go through these one by one.\n\n### Automatic subsampling with `irange` and `iarange`\n\nLet's look at the simplest case first, in which we get subsampling for free with one or two additional arguments to `irange` and `iarange`:\n\n```python\nfor i in pyro.irange(\"data_loop\", len(data), subsample_size=5):\n pyro.sample(\"obs_{}\".format(i), dist.bernoulli, f, obs=data[i])\n``` \n\nThat's all there is to it: we just use the argument `subsample_size`. Whenever we run `model()` we now only evaluate the log likelihood for 5 randomly chosen datapoints in `data`; in addition, the log likelihood will be automatically scaled by the appropriate factor of $\\tfrac{10}{5} = 2$. What about `iarange`? The incantantion is entirely analogous:\n\n```python\nwith iarange('observe_data', size=10, subsample_size=5) as ind:\n pyro.sample('obs', dist.bernoulli, f, \n obs=data.index_select(0, ind))\n```\n\nImportantly, `iarange` now returns a tensor of indices `ind`, which, in this case will be of length 5. Note that in addition to the argument `subsample_size` we also pass the argument `size` so that `iarange` is aware of the full size of the tensor `data` so that it can compute the correct scaling factor. Just like for `irange`, the user is responsible for selecting the correct datapoints using the indices provided by `iarange`. \n\nFinally, note that the user must pass the argument `use_cuda=True` to `irange` or `iarange` if `data` is on the GPU.\n\n### Custom subsampling strategies with `irange` and `iarange`\n\nEvery time the above `model()` is run `irange` and `iarange` will sample new subsample indices. Since this subsampling is stateless, this can lead to some problems: basically for a sufficiently large dataset even after a large number of iterations there's a nonnegligible probability that some of the datapoints will have never been selected. To avoid this the user can take control of subsampling by making use of the `subsample` argument to `irange` and `iarange`. See [the docs](http://docs.pyro.ai/primitives.html#pyro.__init__.iarange) for details.\n\n### Subsampling when there are only local random variables \n\nWe have in mind a model with a joint probability density given by\n\n$$ p({\\bf x}, {\\bf z}) = \\prod_{i=1}^N p({\\bf x}_i | {\\bf z}_i) p({\\bf z}_i) $$\n\nFor a model with this dependency structure the scale factor introduced by subsampling scales all the terms in the ELBO by the same amount. Consequently there's no need to invoke any special Pyro constructs. This is the case, for example, for a vanilla VAE. This explains why for the VAE it's permissible for the user to take complete control over subsampling and pass mini-batches directly to the model and guide without using `irange` or `iarange`. To see how this looks in detail, see the [VAE tutorial](vae.html)\n\n\n### Subsampling when there are both global and local random variables\n\nIn the coin flip examples above `irange` and `iarange` appeared in the model but not in the guide, since the only thing being subsampled was the observations. Let's look at a more complicated example where subsampling appears in both the model and guide. To make things simple let's keep the discussion somewhat abstract and avoid writing a complete model and guide. \n\nConsider the model specified by the following joint distribution:\n\n$$ p({\\bf x}, {\\bf z}, \\beta) = p(\\beta) \n\\prod_{i=1}^N p({\\bf x}_i | {\\bf z}_i) p({\\bf z}_i | \\beta) $$\n\nThere are $N$ observations $\\{ {\\bf x}_i \\}$ and $N$ local latent random variables \n$\\{ {\\bf z}_i \\}$. There is also a global latent random variable $\\beta$. Our guide will be factorized as\n\n$$ q({\\bf z}, \\beta) = q(\\beta) \\prod_{i=1}^N q({\\bf z}_i | \\beta, \\lambda_i) $$\n\nHere we've been explicit about introducing $N$ local variational parameters \n$\\{\\lambda_i \\}$, while the other variational parameters are left implicit. Both the model and guide have conditional independencies. In particular, on the model side, given the $\\{ {\\bf z}_i \\}$ the observations $\\{ {\\bf x}_i \\}$ are independent. In addition, given $\\beta$ the latent random variables $\\{\\bf {z}_i \\}$ are independent. On the guide side, given the variational parameters $\\{\\lambda_i \\}$ and $\\beta$ the latent random variables $\\{\\bf {z}_i \\}$ are independent. To mark these conditional independencies in Pyro and do subsampling we need to make use of either `irange` or `iarange` in _both_ the model _and_ the guide. Let's sketch out the basic logic using `irange` (a more complete piece of code would include `pyro.param` statements, etc.). First, the model:\n\n```python\ndef model(data):\n beta = pyro.sample(\"beta\", ...) # sample the global RV\n for i in pyro.irange(\"locals\", len(data)):\n z_i = pyro.sample(\"z_{}\".format(i), ...)\n # compute the parameter used to define the observation \n # likelihood using the local random variable\n theta_i = compute_something(z_i) \n pyro.sample(\"obs_{}\".format(i), dist.mydist, \n theta_i, obs=data[i])\n```\n\nNote that in contrast to our running coin flip example, here we have `pyro.sample` statements both inside and outside of the `irange` context. Next the guide:\n\n```python\ndef guide(data):\n beta = pyro.sample(\"beta\", ...) # sample the global RV\n for i in pyro.irange(\"locals\", len(data), subsample_size=5):\n # sample the local RVs\n pyro.sample(\"z_{}\".format(i), ..., lambda_i)\n```\n\nNote that crucially the indices will only be subsampled once in the guide; the Pyro backend makes sure that the same set of indices are used during execution of the model. For this reason `subsample_size` only needs to be specified in the guide.",
"_____no_output_____"
],
[
"## Amortization\n\nLet's again consider a model with global and local latent random variables and local variational parameters:\n\n$$ p({\\bf x}, {\\bf z}, \\beta) = p(\\beta) \n\\prod_{i=1}^N p({\\bf x}_i | {\\bf z}_i) p({\\bf z}_i | \\beta) \\qquad \\qquad\nq({\\bf z}, \\beta) = q(\\beta) \\prod_{i=1}^N q({\\bf z}_i | \\beta, \\lambda_i) $$\n\nFor small to medium-sized $N$ using local variational parameters like this can be a good approach. If $N$ is large, however, the fact that the space we're doing optimization over grows with $N$ can be a real probelm. One way to avoid this nasty growth with the size of the dataset is *amortization*.\n\nThis works as follows. Instead of introducing local variational parameters, we're going to learn a single parametric function $f(\\cdot)$ and work with a variational distribution that has the form \n\n$$q(\\beta) \\prod_{n=1}^N q({\\bf z}_i | f({\\bf x}_i))$$\n\nThe function $f(\\cdot)$—which basically maps a given observation to a set of variational parameters tailored to that datapoint—will need to be sufficiently rich to capture the posterior accurately, but now we can handle large datasets without having to introduce an obscene number of variational parameters. \nThis approach has other benefits too: for example, during learning $f(\\cdot)$ effectively allows us to share statistical power among different datapoints. Note that this is precisely the approach used in the [VAE](vae.html).",
"_____no_output_____"
],
[
"## References\n\n[1] `Stochastic Variational Inference`,\n<br/> \nMatthew D. Hoffman, David M. Blei, Chong Wang, John Paisley\n\n[2] `Auto-Encoding Variational Bayes`,<br/> \nDiederik P Kingma, Max Welling",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a4c3a62d700e46591ab218afb877c7f175b919c
| 39,332 |
ipynb
|
Jupyter Notebook
|
Prediction using Supervised ML (Level - Beginner).ipynb
|
omarmamdouhismaiel/Prediction-using-Supervised-ML-Level---Beginner-
|
9eba2b0cc93754cda71173e5d0d18ed13589c3fd
|
[
"MIT"
] | null | null | null |
Prediction using Supervised ML (Level - Beginner).ipynb
|
omarmamdouhismaiel/Prediction-using-Supervised-ML-Level---Beginner-
|
9eba2b0cc93754cda71173e5d0d18ed13589c3fd
|
[
"MIT"
] | null | null | null |
Prediction using Supervised ML (Level - Beginner).ipynb
|
omarmamdouhismaiel/Prediction-using-Supervised-ML-Level---Beginner-
|
9eba2b0cc93754cda71173e5d0d18ed13589c3fd
|
[
"MIT"
] | null | null | null | 57.168605 | 11,944 | 0.731338 |
[
[
[
"# Students Scores Prediction\nPredicting the percentage of an student based on the no. of study hours using a simple linear regressor.",
"_____no_output_____"
],
[
"### Data Importing\nFirst, we need to import our data to our environment using read_csv() method from pandas library.",
"_____no_output_____"
]
],
[
[
"# import pandas under alias pd\nimport pandas as pd\n\n# read our csv_file in 'data' using read_csv(), passing it the path of our file : data\nstudent_scores = pd.read_csv('https://raw.githubusercontent.com/AdiPersonalWorks/Random/master/student_scores%20-%20student_scores.csv')\nprint('Data imported successfully!')",
"Data imported successfully!\n"
]
],
[
[
"### Data Exploration\nWe need to know more information about our dataset, so we use .head() and .info() methods of pandas object 'data'.",
"_____no_output_____"
]
],
[
[
"# view our first data observations\nstudent_scores.head()",
"_____no_output_____"
],
[
"# view meta-data about our dataset\nstudent_scores.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 25 entries, 0 to 24\nData columns (total 2 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Hours 25 non-null float64\n 1 Scores 25 non-null int64 \ndtypes: float64(1), int64(1)\nmemory usage: 528.0 bytes\n"
]
],
[
[
"### Quantitative EDA (Descriptive Statistics)\nWe need some of statistics representing our dataset (statistics describe our dataset).",
"_____no_output_____"
]
],
[
[
"student_scores.describe()",
"_____no_output_____"
]
],
[
[
"There is another statistic describes the correlation between 2 variables called 'Pearson's R', we can see our correlation matrix between all variables in our pandas DataFrame by using .corr() method on our pandas DataFrame object (student_scores).",
"_____no_output_____"
]
],
[
[
"# view correlation between student_scores variables\nstudent_scores.corr()",
"_____no_output_____"
]
],
[
[
"#### We can see that there is 'High Positive Correlation' between the two variables in our dataset 'Hours' and 'Scores' (0.976), so we can predict each variable by the other. \n#### NOTE: \"Correlation not mean Causation\".",
"_____no_output_____"
],
[
"### Graphical EDA\nWe need now to see visually our data points with our only feature variable on the x-axis and our target variable on the y-axis.",
"_____no_output_____"
]
],
[
[
"# import our helpful libraries uder aliases plt for pyplot, and sns for seaborn\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# plotting scatter plot using seaborn and setting up our plot title\nsns.scatterplot(x='Hours', y='Scores', data=student_scores)\nplt.title('Students Studying Hours vs Students Scores')\nplt.show()",
"_____no_output_____"
]
],
[
[
"So, we can see here from the value of R-correlation _which catching the linear relationships between 2 variables_ and from visuals that there is a strong linear relationship between the 2 variables and we can use Linear Regression to find the formula that best describe that relation.",
"_____no_output_____"
],
[
"### Data Modeling using Linear Regression\nWe will use a simple linear regression model to train on our dataset so can find the best fit model (formula).\nWe need first to split our data to training set and validation set, so we can measure our model performance on data unseen before, then we can training the model on our training data, finally measure our score.",
"_____no_output_____"
]
],
[
[
"# import our train_test_split function from sklearn.model_selection\nfrom sklearn.model_selection import train_test_split\n\n# Data Preparing\nX = pd.DataFrame(student_scores.Hours)\ny = pd.DataFrame(student_scores.Scores)\n\n# split our dataset into training data and validation data\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)\n\n# Model building\nfrom sklearn.linear_model import LinearRegression\nregressor = LinearRegression()\n\n# Model Training\nregressor.fit(X_train, y_train)\nprint('Training Complete!')",
"Training Complete!\n"
]
],
[
[
"#### We can plot now our regression line which best fit our data.",
"_____no_output_____"
]
],
[
[
"# Plotting the regression line\nslope = regressor.coef_\ny_intercept = regressor.intercept_\nlinear_equation = slope * X + y_intercept\n\n# Plotting for the training & test data\nplt.scatter(X, y)\nplt.plot(X, linear_equation);\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Making Predictions\nNow that we have trained our algorithm, it's time to make some predictions on our testing data.",
"_____no_output_____"
]
],
[
[
"# Model Predictions on validation set\npreds = regressor.predict(X_test)\npd.DataFrame({'Predicted': [x for x in preds], 'Actual': [y for y in y_test.values]})",
"_____no_output_____"
]
],
[
[
"### Model Evaluation\nAfter we using our model for prediction, Let's validate our model with the 'mean absolute error' MAE metric to measure our model performance.",
"_____no_output_____"
]
],
[
[
"# Model performance measuring by using mean absolute error (MAE) metric\nfrom sklearn.metrics import mean_absolute_error\n\nprint('MAE:', mean_absolute_error(y_test, preds))",
"MAE: 4.130879918502486\n"
]
],
[
[
"we can use our .score() method of model, it uses R-Squared metric as default.",
"_____no_output_____"
]
],
[
[
"print('R2:', regressor.score(X_test, y_test))",
"R2: 0.9367661043365055\n"
]
],
[
[
"### What will be predicted score if a student studies for 9.25 hrs/day?",
"_____no_output_____"
]
],
[
[
"print('Predicted score for student studies for 9.25 hrs/day = ', regressor.predict([[9.25]]))",
"Predicted score for student studies for 9.25 hrs/day = [[93.89272889]]\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4c5fc5bfd72b5098ad511eeeb47ff6435e6223
| 694,368 |
ipynb
|
Jupyter Notebook
|
NBA_stats_visualization/Shot charts Notebook.ipynb
|
JuanIgnacioGil/basket-stats
|
21a862713f98440b8db9bedf162fcda6c526755f
|
[
"MIT"
] | null | null | null |
NBA_stats_visualization/Shot charts Notebook.ipynb
|
JuanIgnacioGil/basket-stats
|
21a862713f98440b8db9bedf162fcda6c526755f
|
[
"MIT"
] | 6 |
2019-08-16T14:19:37.000Z
|
2021-12-13T19:51:52.000Z
|
NBA_stats_visualization/Shot charts Notebook.ipynb
|
JuanIgnacioGil/basket-stats
|
21a862713f98440b8db9bedf162fcda6c526755f
|
[
"MIT"
] | null | null | null | 789.054545 | 129,244 | 0.935312 |
[
[
[
"# How to Create NBA Shot Charts in Python #\n\nIn this post I go over how to extract a player's shot chart data and then plot it using matplotlib and seaborn .",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport requests\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport seaborn as sns\nimport json",
"_____no_output_____"
]
],
[
[
"## Getting the data ##\nGetting the data from stats.nba.com is pretty straightforward. While there isn't a a public API provided by the NBA,\nwe can actually access the API that the NBA uses for stats.nba.com using the requests library. \n\n[This blog post](http://www.gregreda.com/2015/02/15/web-scraping-finding-the-api/) \nby Greg Reda does a great job on explaining how to access this API (or finding an API to any web app for that matter).",
"_____no_output_____"
]
],
[
[
"playerID='2200'\n\nshot_chart_url ='http://stats.nba.com/stats/shotchartdetail?CFID=33&CFPARAMS=2015-16&' \\\n'ContextFilter=&ContextMeasure=FGA&DateFrom=&DateTo=&GameID=&GameSegment=&LastNGames=0&' \\\n'LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PaceAdjust=N&' \\\n'PerMode=PerGame&Period=0&PlayerID='+playerID+'&PlusMinus=N&Position=&Rank=N&RookieYear=&' \\\n'Season=2015-16&SeasonSegment=&SeasonType=Regular+Season&TeamID=0&VsConference=&' \\\n'VsDivision=&mode=Advanced&showDetails=0&showShots=1&showZones=0'\n\nprint(shot_chart_url)",
"http://stats.nba.com/stats/shotchartdetail?CFID=33&CFPARAMS=2015-16&ContextFilter=&ContextMeasure=FGA&DateFrom=&DateTo=&GameID=&GameSegment=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PaceAdjust=N&PerMode=PerGame&Period=0&PlayerID=2200&PlusMinus=N&Position=&Rank=N&RookieYear=&Season=2015-16&SeasonSegment=&SeasonType=Regular+Season&TeamID=0&VsConference=&VsDivision=&mode=Advanced&showDetails=0&showShots=1&showZones=0\n"
]
],
[
[
"The above url sends us to the JSON file contatining the data we want. \nAlso note that the url contains the various API parameters used to access the data. \nThe PlayerID parameter in the url is set to 201935, which is James Harden's PlayerID.\nNow lets use requests to get the data we want",
"_____no_output_____"
]
],
[
[
"# Get the webpage containing the data\nresponse = requests.get(shot_chart_url)\n\n# Grab the headers to be used as column headers for our DataFrame\nheaders = response.json()['resultSets'][0]['headers']\n# Grab the shot chart data\nshots = response.json()['resultSets'][0]['rowSet']",
"_____no_output_____"
]
],
[
[
"Create a pandas DataFrame using the scraped shot chart data.",
"_____no_output_____"
]
],
[
[
"shot_df = pd.DataFrame(shots, columns=headers)\n\n# View the head of the DataFrame and all its columns\nfrom IPython.display import display\nwith pd.option_context('display.max_columns', None):\n display(shot_df.head())",
"_____no_output_____"
]
],
[
[
"The above shot chart data contains all the the field goal attempts James Harden took during the 2014-15 \nregular season. They data we want is found in LOC_X and LOC_Y. These are coordinate values for each shot \nattempt, which can then be plotted onto a set of axes that represent the basketball court.",
"_____no_output_____"
],
[
"### Plotting the Shot Chart Data ###\n\nLets just quickly plot the data just too see how it looks.",
"_____no_output_____"
]
],
[
[
"sns.set_style(\"white\")\nsns.set_color_codes()\nplt.figure(figsize=(12,11))\nplt.scatter(shot_df.LOC_X, shot_df.LOC_Y)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Please note that the above plot misrepresents the data. The x-axis values are the inverse \nof what they actually should be. Lets plot the shots taken from only the right side to see \nthis issue.",
"_____no_output_____"
]
],
[
[
"right = shot_df[shot_df.SHOT_ZONE_AREA == \"Right Side(R)\"]\nplt.figure(figsize=(12,11))\nplt.scatter(right.LOC_X, right.LOC_Y)\nplt.xlim(-300,300)\nplt.ylim(-100,500)\nplt.show()",
"_____no_output_____"
]
],
[
[
"As we can see the shots in categorized as shots from the \"Right Side(R)\", \nwhile to the viewers right, are actually to the left side of the hoop. \nThis is something we will need to fix when creating our final shot chart.",
"_____no_output_____"
],
[
"### Drawing the Court ###\n\nBut first we need to figure out how to draw the court lines onto our plot. By looking at the first plot and \nat the data we can roughly estimate that the center of the hoop is at the origin. We can also estimate that \nevery 10 units on either the x and y axes represents one foot. We can verify this by just look at the first\nobservation in our DataFrame . That shot was taken from the Right Corner 3 spot from a distance of 22 feet\nwith a LOC_X value of 226. So the shot was taken from about 22.6 feet to the right of the hoop. Now that we \nknow this we can actually draw the court onto our plot.\n\nThe dimensions of a basketball court can be seen [here](http://www.sportscourtdimensions.com/wp- content/uploads/2015/02/nba_court_dimensions_h.png), and [here](http://www.sportsknowhow.com/basketball/dimensions/nba-basketball- court-dimensions.html).\n\nUsing those dimensions we can convert them to fit the scale of our plot and just draw them using \n[Matplotlib Patches](http://matplotlib.org/api/patches_api.html). We'll be using and [Arc](http://matplotlib.org/api/patches_api.html#matplotlib.patches.Arc) objects to draw our court. \n\nNow to create our function that draws our basketball court.\n\nNOTE: While you can draw lines onto the plot using [Lines2D](http://matplotlib.org/api/lines_api.html? highlight=line#matplotlib.lines.Line2D) I found it more convenient to use Rectangles (without a height or width) instead.\n\nEDIT (Aug 4, 2015): I made a mistake in drawing the outerlines and the half court arcs. The outer courtlines height was changed from the incorrect value of 442.5 to 470. The y-values for the centers of the center court arcs were changed from 395 to 422.5. The ylim values for the plots were changed from (395, -47.5) to (422.5, -47.5)",
"_____no_output_____"
]
],
[
[
"from matplotlib.patches import Circle, Rectangle, Arc\ndef draw_court(ax=None, color='black', lw=2, outer_lines=False):\n # If an axes object isn't provided to plot onto, just get current one\n if ax is None:\n ax = plt.gca()\n # Create the various parts of an NBA basketball court\n # Create the basketball hoop\n # Diameter of a hoop is 18\" so it has a radius of 9\", which is a value\n # 7.5 in our coordinate system\n hoop = Circle((0, 0), radius=7.5, linewidth=lw, color=color, fill=False)\n # Create backboard\n backboard = Rectangle((-30, -7.5), 60, -1, linewidth=lw, color=color)\n # The paint\n # Create the outer box 0f the paint, width=16ft, height=19ft\n outer_box = Rectangle((-80, -47.5), 160, 190, linewidth=lw, color=color,\n fill=False)\n # Create the inner box of the paint, widt=12ft, height=19ft\n inner_box = Rectangle((-60, -47.5), 120, 190, linewidth=lw, color=color,\n fill=False)\n # Create free throw top arc\n top_free_throw = Arc((0, 142.5), 120, 120, theta1=0, theta2=180,\n linewidth=lw, color=color, fill=False)\n # Create free throw bottom arc\n bottom_free_throw = Arc((0, 142.5), 120, 120, theta1=180, theta2=0,\n linewidth=lw, color=color, linestyle='dashed')\n # Restricted Zone, it is an arc with 4ft radius from center of the hoop\n restricted = Arc((0, 0), 80, 80, theta1=0, theta2=180, linewidth=lw,\n color=color)\n # Three point line\n # Create the side 3pt lines, they are 14ft long before they begin to arc\n corner_three_a = Rectangle((-220, -47.5), 0, 140, linewidth=lw,\n color=color)\n corner_three_b = Rectangle((220, -47.5), 0, 140, linewidth=lw, color=color)\n # 3pt arc - center of arc will be the hoop, arc is 23'9\" away from hoop\n # I just played around with the theta values until they lined up with the\n # threes\n three_arc = Arc((0, 0), 475, 475, theta1=22, theta2=158, linewidth=lw,\n color=color)\n # Center Court\n center_outer_arc = Arc((0, 422.5), 120, 120, theta1=180, theta2=0,\n linewidth=lw, color=color)\n center_inner_arc = Arc((0, 422.5), 40, 40, theta1=180, theta2=0,\n linewidth=lw, color=color)\n # List of the court elements to be plotted onto the axes\n court_elements = [hoop, backboard, outer_box, inner_box, top_free_throw,\n bottom_free_throw, restricted, corner_three_a,\n corner_three_b, three_arc, center_outer_arc,\n center_inner_arc]\n if outer_lines:\n # Draw the half court line, baseline and side out bound lines\n outer_lines = Rectangle((-250, -47.5), 500, 470, linewidth=lw,\n color=color, fill=False)\n court_elements.append(outer_lines)\n \n #Add the court elements onto the axes\n for element in court_elements:\n ax.add_patch(element)\n return ax\n",
"_____no_output_____"
]
],
[
[
"Lets draw our court",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(12,11))\ndraw_court(outer_lines=True)\nplt.xlim(-300,300)\nplt.ylim(-100,500)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Creating some Shot Charts ###\nNow plot our properly adjusted shot chart data along with the court. We can adjust \nthe x-values in two ways. We can either pass in the the negative inverse of LOC_X to \nplt.scatter or we can pass in descending values to plt.xlim . We'll do the latter to plot\nour shot chart.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(12,11))\nplt.scatter(shot_df.LOC_X, shot_df.LOC_Y)\ndraw_court(outer_lines=True)\n# Descending values along the axis from left to right\nplt.xlim(300,-300)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Lets orient our shot chart with the hoop by the top of the chart, which is the same orientation as the shot charts on stats.nba.com. We do this by settting descending y-values from the bottom to the top of the y-axis. When we do this we no longer need to adjust the x-values of our plot.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(12,11))\nplt.scatter(shot_df.LOC_X, shot_df.LOC_Y)\ndraw_court(outer_lines=True)\n# Adjust plot limits to just fit in half court\nplt.xlim(-250,250)\n# Descending values along th y axis from bottom to top\n# in order to place the hoop by the top of plot\nplt.ylim(422.5, -47.5)\n# get rid of axis tick labels\nplt.tick_params(labelbottom=False, labelleft=False)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Lets create a few shot charts using jointplot from seaborn .",
"_____no_output_____"
]
],
[
[
" # create our jointplot\njoint_shot_chart = sns.jointplot(shot_df.LOC_X, shot_df.LOC_Y, \n stat_func=None,kind='scatter', space=0, alpha=0.5)\njoint_shot_chart.fig.set_size_inches(12,11)\n# A joint plot has 3 Axes, the first one called ax_joint\n# is the one we want to draw our court onto and adjust some other settings\nax = joint_shot_chart.ax_joint\ndraw_court(ax, outer_lines=True)\n# Adjust the axis limits and orientation of the plot in order\n# to plot half court, with the hoop by the top of the plot\nax.set_xlim(-250,250)\nax.set_ylim(422.5, -47.5)\n# Get rid of axis labels and tick marks\nax.set_xlabel('')\nax.set_ylabel('')\nax.tick_params(labelbottom='off', labelleft='off')\n# Add a title\nax.set_title('James Harden FGA \\n2015-16 Reg. Season',\n y=1.2, fontsize=18)\n# Add Data Scource and Author\nauthors=\"\"\"Data Source: stats.nba.com\nAuthor: Juan Ignacio Gil\nOriginal code by Savvas Tjortjoglou (savvastjortjoglou.com)\"\"\"\n \nax.text(-250,460,authors,fontsize=12)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Getting a Player's Image ###\n\nWe could also scrape Jame Harden's picture from stats.nba.com and place it on our plot. \nWe can find his image at [this url](http://stats.nba.com/media/players/230x185/201935.png).\nTo retrieve the image for our plot we can use urlretrieve from url.requests as follows:",
"_____no_output_____"
]
],
[
[
"import urllib.request\n\n# we pass in the link to the image as the 1st argument\n# the 2nd argument tells urlretrieve what we want to scrape\n\npic = urllib.request.urlretrieve(\"http://stats.nba.com/media/players/230x185/\"+playerID+\".png\",\n playerID+\".png\")\n\n# urlretrieve returns a tuple with our image as the first\n# element and imread reads in the image as a\n# mutlidimensional numpy array so matplotlib can plot it\nharden_pic = plt.imread(pic[0])\n# plot the image\nplt.imshow(harden_pic)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Now to plot Harden's face on a jointplot we will import OffsetImage from matplotlib. \nOffset, which will allow us to place the image at the top right corner of the plot. \nSo lets create our shot chart like we did above, but this time we will create a [KDE](https://en.wikipedia.org/wiki/Kernel_density_estimation) jointplot and at the end add \non our image.",
"_____no_output_____"
]
],
[
[
"from matplotlib.offsetbox import OffsetImage\n\n# create our jointplot\n# get our colormap for the main kde plot\n# Note we can extract a color from cmap to use for\n# the plots that lie on the side and top axes\ncmap=plt.cm.YlOrRd_r\n\n# n_levels sets the number of contour lines for the main kde plot\njoint_shot_chart = sns.jointplot(shot_df.LOC_X, shot_df.LOC_Y, stat_func=None,\n kind='kde', space=0, color=cmap(0.1),\n cmap=cmap, n_levels=50)\njoint_shot_chart.fig.set_size_inches(12,11)\n# A joint plot has 3 Axes, the first one called ax_joint\n# is the one we want to draw our court onto and adjust some other settings\nax = joint_shot_chart.ax_joint\ndraw_court(ax,outer_lines=True)\n# Adjust the axis limits and orientation of the plot in order\n# to plot half court, with the hoop by the top of the plot\nax.set_xlim(-250,250)\nax.set_ylim(422.5, -47.5)\n# Get rid of axis labels and tick marks\nax.set_xlabel('')\nax.set_ylabel('')\nax.tick_params(labelbottom='off', labelleft='off')\n# Add a title\nax.set_title('James Harden FGA \\n2015-16 Reg. Season',\n y=1.2, fontsize=18)\n# Add Data Scource and Author\nax.text(-250,460,authors,fontsize=12)\n# Add Harden's image to the top right\n# First create our OffSetImage by passing in our image\n# and set the zoom level to make the image small enough\n# to fit on our plot\nimg = OffsetImage(harden_pic, zoom=0.6)\n# Pass in a tuple of x,y coordinates to set_offset\n# to place the plot where you want, I just played around\n# with the values until I found a spot where I wanted\n# the image to be\nimg.set_offset((625,621))\n# add the image\nax.add_artist(img)\nplt.show()",
"_____no_output_____"
]
],
[
[
"And another jointplot but with hexbins.",
"_____no_output_____"
]
],
[
[
"# create our jointplot\n\ncmap=plt.cm.gist_heat_r\njoint_shot_chart = sns.jointplot(shot_df.LOC_X, shot_df.LOC_Y, stat_func=None,\n kind='hex', space=0, color=cmap(.2), cmap=cmap)\n\njoint_shot_chart.fig.set_size_inches(12,11)\n\n# A joint plot has 3 Axes, the first one called ax_joint \n# is the one we want to draw our court onto \nax = joint_shot_chart.ax_joint\ndraw_court(ax)\n\n# Adjust the axis limits and orientation of the plot in order\n# to plot half court, with the hoop by the top of the plot\nax.set_xlim(-250,250)\nax.set_ylim(422.5, -47.5)\n\n# Get rid of axis labels and tick marks\nax.set_xlabel('')\nax.set_ylabel('')\nax.tick_params(labelbottom='off', labelleft='off')\n\n# Add a title\nax.set_title('FGA 2015-16 Reg. Season', y=1.2, fontsize=14)\n\n# Add Data Source and Author\nax.text(-250,450,authors, fontsize=12)\n\n# Add James Harden's image to the top right\nimg = OffsetImage(harden_pic, zoom=0.6)\nimg.set_offset((625,621))\nax.add_artist(img)\n\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4c6c9aa5106f26142b1122931dfb9b0d2aba6a
| 31,504 |
ipynb
|
Jupyter Notebook
|
Cassava Leaf Disease Classification/code/05. RegNetY_40(DATASET_2019+2020).ipynb
|
choco9966/kaggle
|
253c089625c67f34dc8868d97842ecf9a479d617
|
[
"MIT"
] | 36 |
2019-12-26T13:07:44.000Z
|
2022-03-27T09:59:19.000Z
|
code/05. RegNetY_40(DATASET_2019+2020).ipynb
|
choco9966/Cassava-Leaf-Disease-Classification
|
48059e37dd436ed9f68624e25e309029b4e68543
|
[
"Apache-2.0"
] | null | null | null |
code/05. RegNetY_40(DATASET_2019+2020).ipynb
|
choco9966/Cassava-Leaf-Disease-Classification
|
48059e37dd436ed9f68624e25e309029b4e68543
|
[
"Apache-2.0"
] | 8 |
2020-04-15T10:26:11.000Z
|
2021-04-05T11:27:54.000Z
| 38.186667 | 154 | 0.506317 |
[
[
[
"import os\nos.environ['CUDA_VISIBLE_DEVICES'] = '0' # specify GPUs locally",
"_____no_output_____"
],
[
"package_paths = [\n './input/pytorch-image-models/pytorch-image-models-master', #'../input/efficientnet-pytorch-07/efficientnet_pytorch-0.7.0'\n './input/pytorch-gradual-warmup-lr-master'\n]\nimport sys; \n\nfor pth in package_paths:\n sys.path.append(pth)",
"_____no_output_____"
],
[
"from glob import glob\nfrom sklearn.model_selection import GroupKFold, StratifiedKFold\nimport cv2\nfrom skimage import io\nimport torch\nfrom torch import nn\nimport os\nfrom datetime import datetime\nimport time\nimport random\nimport cv2\nimport torchvision\nfrom torchvision import transforms\nimport pandas as pd\nimport numpy as np\nfrom tqdm import tqdm\n\nimport matplotlib.pyplot as plt\nfrom torch.utils.data import Dataset,DataLoader\nfrom torch.utils.data.sampler import SequentialSampler, RandomSampler\nfrom torch.cuda.amp import autocast, GradScaler\nfrom torch.nn.modules.loss import _WeightedLoss\nimport torch.nn.functional as F\n\nimport timm\n\nimport sklearn\nimport warnings\nimport joblib\nfrom sklearn.metrics import roc_auc_score, log_loss\nfrom sklearn import metrics\nimport warnings\nimport cv2\n#from efficientnet_pytorch import EfficientNet\nfrom scipy.ndimage.interpolation import zoom\nfrom adamp import AdamP",
"_____no_output_____"
],
[
"CFG = {\n 'fold_num': 5,\n 'seed': 719,\n 'model_arch': 'regnety_040',\n 'model_path' : 'regnety_040_bs24_epoch20_reset_swalr_step',\n 'img_size': 512,\n 'epochs': 20,\n 'train_bs': 24,\n 'valid_bs': 8,\n 'T_0': 10,\n 'lr': 1e-4,\n 'min_lr': 1e-6,\n 'weight_decay':1e-6,\n 'num_workers': 4,\n 'accum_iter': 1, # suppoprt to do batch accumulation for backprop with effectively larger batch size\n 'verbose_step': 1,\n 'device': 'cuda:0',\n 'target_size' : 5, \n 'smoothing' : 0.2\n}\n",
"_____no_output_____"
],
[
"if not os.path.isdir(CFG['model_path']):\n os.mkdir(CFG['model_path'])",
"_____no_output_____"
],
[
"train = pd.read_csv('./input/cassava-leaf-disease-classification/merged.csv')\n\n# delete_id \n## 2019 : 이미지의 한 변이 500보다 작거나 1000보다 큰 경우 \n## 2020 : 중복되는 3개 이미지\ndelete_id = ['train-cbb-1.jpg', 'train-cbb-12.jpg', 'train-cbb-126.jpg', 'train-cbb-134.jpg', 'train-cbb-198.jpg', \n 'train-cbb-244.jpg', 'train-cbb-245.jpg', 'train-cbb-30.jpg', 'train-cbb-350.jpg', 'train-cbb-369.jpg', \n 'train-cbb-65.jpg', 'train-cbb-68.jpg', 'train-cbb-77.jpg', 'train-cbsd-1354.jpg', 'train-cbsd-501.jpg', \n 'train-cgm-418.jpg', 'train-cmd-1145.jpg', 'train-cmd-2080.jpg', 'train-cmd-2096.jpg', 'train-cmd-332.jpg', \n 'train-cmd-494.jpg', 'train-cmd-745.jpg', 'train-cmd-896.jpg', 'train-cmd-902.jpg', 'train-healthy-118.jpg', \n 'train-healthy-181.jpg', 'train-healthy-5.jpg','train-cbb-69.jpg', 'train-cbsd-463.jpg', 'train-cgm-547.jpg', \n 'train-cgm-626.jpg', 'train-cgm-66.jpg', 'train-cgm-768.jpg', 'train-cgm-98.jpg', 'train-cmd-110.jpg', \n 'train-cmd-1208.jpg', 'train-cmd-1566.jpg', 'train-cmd-1633.jpg', 'train-cmd-1703.jpg', 'train-cmd-1917.jpg', \n 'train-cmd-2197.jpg', 'train-cmd-2289.jpg', 'train-cmd-2304.jpg', 'train-cmd-2405.jpg', 'train-cmd-2490.jpg', \n 'train-cmd-412.jpg', 'train-cmd-587.jpg', 'train-cmd-678.jpg', 'train-healthy-250.jpg']\ndelete_id += ['2947932468.jpg', '2252529694.jpg', '2278017076.jpg']\ntrain = train[~train['image_id'].isin(delete_id)].reset_index(drop=True)\nprint(train.shape)",
"(26285, 3)\n"
],
[
"submission = pd.read_csv('./input/cassava-leaf-disease-classification/sample_submission.csv')\nsubmission.head()",
"_____no_output_____"
],
[
"def seed_everything(seed):\n random.seed(seed)\n os.environ['PYTHONHASHSEED'] = str(seed)\n np.random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.backends.cudnn.deterministic = True\n torch.backends.cudnn.benchmark = False\n \ndef get_img(path):\n im_bgr = cv2.imread(path)\n im_rgb = im_bgr[:, :, ::-1]\n #print(im_rgb)\n return im_rgb",
"_____no_output_____"
],
[
"def rand_bbox(size, lam):\n W = size[0]\n H = size[1]\n cut_rat = np.sqrt(1. - lam)\n cut_w = np.int(W * cut_rat)\n cut_h = np.int(H * cut_rat)\n\n # uniform\n cx = np.random.randint(W)\n cy = np.random.randint(H)\n\n bbx1 = np.clip(cx - cut_w // 2, 0, W)\n bby1 = np.clip(cy - cut_h // 2, 0, H)\n bbx2 = np.clip(cx + cut_w // 2, 0, W)\n bby2 = np.clip(cy + cut_h // 2, 0, H)\n return bbx1, bby1, bbx2, bby2",
"_____no_output_____"
],
[
"class CassavaDataset(Dataset):\n def __init__(self, df, data_root, \n transforms=None, \n output_label=True, \n ):\n \n super().__init__()\n self.df = df.reset_index(drop=True).copy()\n self.transforms = transforms\n self.data_root = data_root\n \n self.output_label = output_label\n self.labels = self.df['label'].values\n\n \n def __len__(self):\n return self.df.shape[0]\n \n def __getitem__(self, index: int):\n \n # get labels\n if self.output_label:\n target = self.labels[index]\n \n img = get_img(\"{}/{}\".format(self.data_root, self.df.loc[index]['image_id']))\n\n if self.transforms:\n img = self.transforms(image=img)['image']\n \n if self.output_label == True:\n return img, target\n else:\n return img",
"_____no_output_____"
],
[
"from albumentations.core.transforms_interface import DualTransform\nfrom albumentations.augmentations import functional as F\nclass GridMask(DualTransform):\n \"\"\"GridMask augmentation for image classification and object detection.\n \n Author: Qishen Ha\n Email: [email protected]\n 2020/01/29\n\n Args:\n num_grid (int): number of grid in a row or column.\n fill_value (int, float, lisf of int, list of float): value for dropped pixels.\n rotate ((int, int) or int): range from which a random angle is picked. If rotate is a single int\n an angle is picked from (-rotate, rotate). Default: (-90, 90)\n mode (int):\n 0 - cropout a quarter of the square of each grid (left top)\n 1 - reserve a quarter of the square of each grid (left top)\n 2 - cropout 2 quarter of the square of each grid (left top & right bottom)\n\n Targets:\n image, mask\n\n Image types:\n uint8, float32\n\n Reference:\n | https://arxiv.org/abs/2001.04086\n | https://github.com/akuxcw/GridMask\n \"\"\"\n\n def __init__(self, num_grid=3, fill_value=0, rotate=0, mode=0, always_apply=False, p=0.5):\n super(GridMask, self).__init__(always_apply, p)\n if isinstance(num_grid, int):\n num_grid = (num_grid, num_grid)\n if isinstance(rotate, int):\n rotate = (-rotate, rotate)\n self.num_grid = num_grid\n self.fill_value = fill_value\n self.rotate = rotate\n self.mode = mode\n self.masks = None\n self.rand_h_max = []\n self.rand_w_max = []\n\n def init_masks(self, height, width):\n if self.masks is None:\n self.masks = []\n n_masks = self.num_grid[1] - self.num_grid[0] + 1\n for n, n_g in enumerate(range(self.num_grid[0], self.num_grid[1] + 1, 1)):\n grid_h = height / n_g\n grid_w = width / n_g\n this_mask = np.ones((int((n_g + 1) * grid_h), int((n_g + 1) * grid_w))).astype(np.uint8)\n for i in range(n_g + 1):\n for j in range(n_g + 1):\n this_mask[\n int(i * grid_h) : int(i * grid_h + grid_h / 2),\n int(j * grid_w) : int(j * grid_w + grid_w / 2)\n ] = self.fill_value\n if self.mode == 2:\n this_mask[\n int(i * grid_h + grid_h / 2) : int(i * grid_h + grid_h),\n int(j * grid_w + grid_w / 2) : int(j * grid_w + grid_w)\n ] = self.fill_value\n \n if self.mode == 1:\n this_mask = 1 - this_mask\n\n self.masks.append(this_mask)\n self.rand_h_max.append(grid_h)\n self.rand_w_max.append(grid_w)\n\n def apply(self, image, mask, rand_h, rand_w, angle, **params):\n h, w = image.shape[:2]\n mask = F.rotate(mask, angle) if self.rotate[1] > 0 else mask\n mask = mask[:,:,np.newaxis] if image.ndim == 3 else mask\n image *= mask[rand_h:rand_h+h, rand_w:rand_w+w].astype(image.dtype)\n return image\n\n def get_params_dependent_on_targets(self, params):\n img = params['image']\n height, width = img.shape[:2]\n self.init_masks(height, width)\n\n mid = np.random.randint(len(self.masks))\n mask = self.masks[mid]\n rand_h = np.random.randint(self.rand_h_max[mid])\n rand_w = np.random.randint(self.rand_w_max[mid])\n angle = np.random.randint(self.rotate[0], self.rotate[1]) if self.rotate[1] > 0 else 0\n\n return {'mask': mask, 'rand_h': rand_h, 'rand_w': rand_w, 'angle': angle}\n\n @property\n def targets_as_params(self):\n return ['image']\n\n def get_transform_init_args_names(self):\n return ('num_grid', 'fill_value', 'rotate', 'mode')",
"_____no_output_____"
],
[
"from albumentations import (\n HorizontalFlip, VerticalFlip, IAAPerspective, ShiftScaleRotate, CLAHE, RandomRotate90,\n Transpose, ShiftScaleRotate, Blur, OpticalDistortion, GridDistortion, HueSaturationValue,\n IAAAdditiveGaussianNoise, GaussNoise, MotionBlur, MedianBlur, IAAPiecewiseAffine, RandomResizedCrop,\n IAASharpen, IAAEmboss, RandomBrightnessContrast, Flip, OneOf, Compose, Normalize, Cutout, CoarseDropout, ShiftScaleRotate, CenterCrop, Resize\n)\n\nfrom albumentations.pytorch import ToTensorV2\n\ndef get_train_transforms():\n return Compose([\n Resize(600, 800),\n RandomResizedCrop(CFG['img_size'], CFG['img_size']),\n Transpose(p=0.5),\n HorizontalFlip(p=0.5),\n VerticalFlip(p=0.5),\n ShiftScaleRotate(p=0.5),\n HueSaturationValue(hue_shift_limit=0.2, sat_shift_limit=0.2, val_shift_limit=0.2, p=0.5),\n RandomBrightnessContrast(brightness_limit=(-0.1,0.1), contrast_limit=(-0.1, 0.1), p=0.5),\n Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], max_pixel_value=255.0, p=1.0),\n CoarseDropout(p=0.5),\n GridMask(num_grid=3, p=0.5),\n ToTensorV2(p=1.0),\n ], p=1.)\n \n \ndef get_valid_transforms():\n return Compose([\n Resize(600, 800),\n CenterCrop(CFG['img_size'], CFG['img_size'], p=1.),\n Resize(CFG['img_size'], CFG['img_size']),\n Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], max_pixel_value=255.0, p=1.0),\n ToTensorV2(p=1.0),\n ], p=1.)\n\ndef get_inference_transforms():\n return Compose([\n Resize(600, 800),\n OneOf([\n Resize(CFG['img_size'], CFG['img_size'], p=1.),\n CenterCrop(CFG['img_size'], CFG['img_size'], p=1.),\n RandomResizedCrop(CFG['img_size'], CFG['img_size'], p=1.)\n ], p=1.), \n Transpose(p=0.5),\n HorizontalFlip(p=0.5),\n #VerticalFlip(p=0.5),\n Resize(CFG['img_size'], CFG['img_size']),\n Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], max_pixel_value=255.0, p=1.0),\n ToTensorV2(p=1.0),\n ], p=1.)",
"_____no_output_____"
],
[
"class CassvaImgClassifier(nn.Module):\n def __init__(self, model_arch, n_class, pretrained=False):\n super().__init__()\n self.model = timm.create_model(model_arch, pretrained=pretrained)\n if model_arch == 'regnety_040':\n self.model.head = nn.Sequential(\n nn.AdaptiveAvgPool2d((1,1)),\n nn.Flatten(),\n nn.Linear(1088, n_class)\n )\n elif model_arch == 'regnety_320':\n self.model.head = nn.Sequential(\n nn.AdaptiveAvgPool2d((1,1)),\n nn.Flatten(),\n nn.Linear(3712, n_class)\n )\n elif model_arch == 'regnety_080':\n self.model.head = nn.Sequential(\n nn.AdaptiveAvgPool2d((1,1)),\n nn.Flatten(),\n nn.Linear(2016, n_class)\n )\n \n elif model_arch == 'regnety_160':\n self.model.head = nn.Sequential(\n nn.AdaptiveAvgPool2d((1,1)),\n nn.Flatten(),\n nn.Linear(3024, n_class)\n )\n \n else:\n n_features = self.model.classifier.in_features\n self.model.classifier = nn.Linear(n_features, n_class)\n\n def forward(self, x):\n x = self.model(x)\n return x",
"_____no_output_____"
],
[
"def prepare_dataloader(df, trn_idx, val_idx, data_root='./input/cassava-leaf-disease-classification/train_images/'):\n \n # from catalyst.data.sampler import BalanceClassSampler\n \n train_ = df.loc[trn_idx,:].reset_index(drop=True)\n valid_ = df.loc[val_idx,:].reset_index(drop=True)\n \n train_ds = CassavaDataset(train_, data_root, transforms=get_train_transforms(), output_label=True)\n valid_ds = CassavaDataset(valid_, data_root, transforms=get_valid_transforms(), output_label=True)\n \n train_loader = torch.utils.data.DataLoader(\n train_ds,\n batch_size=CFG['train_bs'],\n pin_memory=False,\n drop_last=False,\n shuffle=True, \n num_workers=CFG['num_workers'],\n #sampler=BalanceClassSampler(labels=train_['label'].values, mode=\"downsampling\")\n )\n val_loader = torch.utils.data.DataLoader(\n valid_ds, \n batch_size=CFG['valid_bs'],\n num_workers=CFG['num_workers'],\n shuffle=False,\n pin_memory=False,\n )\n return train_loader, val_loader\n\ndef train_one_epoch(epoch, model, loss_fn, optimizer, train_loader, device, scheduler=None, schd_batch_update=False):\n model.train()\n\n t = time.time()\n running_loss = None\n\n # pbar = tqdm(enumerate(train_loader), total=len(train_loader))\n for step, (imgs, image_labels) in enumerate(train_loader):\n imgs = imgs.to(device).float()\n image_labels = image_labels.to(device).long()\n\n with autocast():\n image_preds = model(imgs) #output = model(input)\n loss = loss_fn(image_preds, image_labels)\n \n scaler.scale(loss).backward()\n\n if running_loss is None:\n running_loss = loss.item()\n else:\n running_loss = running_loss * .99 + loss.item() * .01\n\n if ((step + 1) % CFG['accum_iter'] == 0) or ((step + 1) == len(train_loader)):\n\n scaler.step(optimizer)\n scaler.update()\n optimizer.zero_grad() \n \n if scheduler is not None and schd_batch_update:\n scheduler.step()\n\n if scheduler is not None and not schd_batch_update:\n scheduler.step()\n \ndef valid_one_epoch(epoch, model, loss_fn, val_loader, device, scheduler=None, schd_loss_update=False):\n model.eval()\n\n t = time.time()\n loss_sum = 0\n sample_num = 0\n image_preds_all = []\n image_targets_all = []\n \n # pbar = tqdm(enumerate(val_loader), total=len(val_loader))\n for step, (imgs, image_labels) in enumerate(val_loader):\n imgs = imgs.to(device).float()\n image_labels = image_labels.to(device).long()\n \n image_preds = model(imgs) #output = model(input)\n image_preds_all += [torch.argmax(image_preds, 1).detach().cpu().numpy()]\n image_targets_all += [image_labels.detach().cpu().numpy()]\n \n loss = loss_fn(image_preds, image_labels)\n \n loss_sum += loss.item()*image_labels.shape[0]\n sample_num += image_labels.shape[0] \n\n # if ((step + 1) % CFG['verbose_step'] == 0) or ((step + 1) == len(val_loader)):\n # description = f'epoch {epoch} loss: {loss_sum/sample_num:.4f}'\n # pbar.set_description(description)\n \n image_preds_all = np.concatenate(image_preds_all)\n image_targets_all = np.concatenate(image_targets_all)\n print('epoch = {}'.format(epoch+1), 'validation multi-class accuracy = {:.4f}'.format((image_preds_all==image_targets_all).mean()))\n \n if scheduler is not None:\n if schd_loss_update:\n scheduler.step(loss_sum/sample_num)\n else:\n scheduler.step()\n \ndef inference_one_epoch(model, data_loader, device):\n model.eval()\n image_preds_all = []\n # pbar = tqdm(enumerate(data_loader), total=len(data_loader))\n with torch.no_grad():\n for step, (imgs, _labels) in enumerate(data_loader):\n imgs = imgs.to(device).float()\n\n image_preds = model(imgs) #output = model(input)\n image_preds_all += [torch.softmax(image_preds, 1).detach().cpu().numpy()]\n \n \n image_preds_all = np.concatenate(image_preds_all, axis=0)\n return image_preds_all",
"_____no_output_____"
],
[
"# reference: https://www.kaggle.com/c/siim-isic-melanoma-classification/discussion/173733\nclass MyCrossEntropyLoss(_WeightedLoss):\n def __init__(self, weight=None, reduction='mean'):\n super().__init__(weight=weight, reduction=reduction)\n self.weight = weight\n self.reduction = reduction\n\n def forward(self, inputs, targets):\n lsm = F.log_softmax(inputs, -1)\n\n if self.weight is not None:\n lsm = lsm * self.weight.unsqueeze(0)\n\n loss = -(targets * lsm).sum(-1)\n\n if self.reduction == 'sum':\n loss = loss.sum()\n elif self.reduction == 'mean':\n loss = loss.mean()\n\n return loss",
"_____no_output_____"
],
[
"# ====================================================\n# Label Smoothing\n# ====================================================\nclass LabelSmoothingLoss(nn.Module): \n def __init__(self, classes, smoothing=0.0, dim=-1): \n super(LabelSmoothingLoss, self).__init__() \n self.confidence = 1.0 - smoothing \n self.smoothing = smoothing \n self.cls = classes \n self.dim = dim \n \n def forward(self, pred, target): \n pred = pred.log_softmax(dim=self.dim) \n with torch.no_grad():\n true_dist = torch.zeros_like(pred) \n true_dist.fill_(self.smoothing / (self.cls - 1)) \n true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence) \n return torch.mean(torch.sum(-true_dist * pred, dim=self.dim))",
"_____no_output_____"
],
[
"from torchcontrib.optim import SWA\nfrom sklearn.metrics import accuracy_score",
"_____no_output_____"
],
[
"for c in range(5): \n train[c] = 0\n\nfolds = StratifiedKFold(n_splits=CFG['fold_num'], shuffle=True, random_state=CFG['seed']).split(np.arange(train.shape[0]), train.label.values)\nfor fold, (trn_idx, val_idx) in enumerate(folds):\n print('Training with {} started'.format(fold))\n print(len(trn_idx), len(val_idx))\n train_loader, val_loader = prepare_dataloader(train, trn_idx, val_idx, data_root='./input/cassava-leaf-disease-classification/train/')\n\n device = torch.device(CFG['device'])\n\n model = CassvaImgClassifier(CFG['model_arch'], train.label.nunique(), pretrained=True).to(device)\n\n scaler = GradScaler() \n base_opt = AdamP(model.parameters(), lr=CFG['lr'], weight_decay=CFG['weight_decay'])\n # base_opt = torch.optim.Adam(model.parameters(), lr=CFG['lr'], weight_decay=CFG['weight_decay'])\n optimizer = SWA(base_opt, swa_start=2*len(trn_idx)//CFG['train_bs'], swa_freq=len(trn_idx)//CFG['train_bs'])\n scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=CFG['T_0'], T_mult=1, eta_min=CFG['min_lr'], last_epoch=-1)\n\n loss_tr = LabelSmoothingLoss(classes=CFG['target_size'], smoothing=CFG['smoothing']).to(device)\n loss_fn = nn.CrossEntropyLoss().to(device)\n\n for epoch in range(CFG['epochs']):\n train_one_epoch(epoch, model, loss_tr, optimizer, train_loader, device, scheduler=scheduler, schd_batch_update=False)\n\n with torch.no_grad():\n valid_one_epoch(epoch, model, loss_fn, val_loader, device, scheduler=None, schd_loss_update=False)\n optimizer.swap_swa_sgd()\n optimizer.bn_update(train_loader, model, device)\n\n with torch.no_grad():\n valid_one_epoch(epoch, model, loss_fn, val_loader, device, scheduler=None, schd_loss_update=False)\n torch.save(model.state_dict(),'./{}/swa_{}_fold_{}_{}'.format(CFG['model_path'],CFG['model_arch'], fold, epoch)) \n\n tst_preds = []\n for tta in range(5):\n tst_preds += [inference_one_epoch(model, val_loader, device)]\n\n train.loc[val_idx, [0, 1, 2, 3, 4]] = np.mean(tst_preds, axis=0)\n\n del model, optimizer, train_loader, val_loader, scaler, scheduler\n torch.cuda.empty_cache()\n\ntrain['pred'] = np.array(train[[0, 1, 2, 3, 4]]).argmax(axis=1)\nprint(accuracy_score(train['label'].values, train['pred'].values))",
"Training with 0 started\n1600 401\nepoch = 1 validation multi-class accuracy = 0.8329\nepoch = 2 validation multi-class accuracy = 0.7905\nepoch = 3 validation multi-class accuracy = 0.8229\nepoch = 4 validation multi-class accuracy = 0.8778\nepoch = 5 validation multi-class accuracy = 0.8504\nepoch = 5 validation multi-class accuracy = 0.8678\nTraining with 1 started\n1601 400\nepoch = 1 validation multi-class accuracy = 0.8100\nepoch = 2 validation multi-class accuracy = 0.7850\nepoch = 3 validation multi-class accuracy = 0.8300\nepoch = 4 validation multi-class accuracy = 0.8175\nepoch = 5 validation multi-class accuracy = 0.8425\nepoch = 5 validation multi-class accuracy = 0.8650\nTraining with 2 started\n1601 400\nepoch = 1 validation multi-class accuracy = 0.7950\nepoch = 2 validation multi-class accuracy = 0.8375\nepoch = 3 validation multi-class accuracy = 0.8400\nepoch = 4 validation multi-class accuracy = 0.8500\nepoch = 5 validation multi-class accuracy = 0.8325\nepoch = 5 validation multi-class accuracy = 0.8625\nTraining with 3 started\n1601 400\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4c6d31b3dcd5f2581067b853c5a50cf8a12a47
| 61,425 |
ipynb
|
Jupyter Notebook
|
Fraud_Detection_Algorithm(Using_SOMs).ipynb
|
temiafeye/Colab-Projects
|
feffdc229bb1ea0afce3c874789c4315018a54ab
|
[
"Apache-2.0"
] | 1 |
2019-03-18T14:42:07.000Z
|
2019-03-18T14:42:07.000Z
|
Fraud_Detection_Algorithm(Using_SOMs).ipynb
|
temiafeye/Colab-Projects
|
feffdc229bb1ea0afce3c874789c4315018a54ab
|
[
"Apache-2.0"
] | null | null | null |
Fraud_Detection_Algorithm(Using_SOMs).ipynb
|
temiafeye/Colab-Projects
|
feffdc229bb1ea0afce3c874789c4315018a54ab
|
[
"Apache-2.0"
] | null | null | null | 110.278276 | 31,306 | 0.835214 |
[
[
[
"<a href=\"https://colab.research.google.com/github/temiafeye/Colab-Projects/blob/master/Fraud_Detection_Algorithm(Using_SOMs).ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"!pip install numpy",
"Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (1.14.6)\n"
],
[
"#Build Hybrid Deep Learning Model \nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd",
"_____no_output_____"
],
[
"#Importing The Dataset\nfrom google.colab import files\nuploaded = files.upload()",
"_____no_output_____"
],
[
"dataset = pd.read_csv(io.BytesIO(uploaded['Credit_Card_Applications.csv']))",
"_____no_output_____"
],
[
"\nX = dataset.iloc[:, :-1].values\ny = dataset.iloc[:, -1].values",
"_____no_output_____"
],
[
"# Feature Scaling\nfrom sklearn.preprocessing import MinMaxScaler\nsc = MinMaxScaler(feature_range = (0, 1))\nX = sc.fit_transform(X)",
"_____no_output_____"
],
[
"#Importing the SOM\nfrom google.colab import files \nuploaded = files.upload()",
"_____no_output_____"
],
[
"# Training the SOM\nfrom minisom import MiniSom\nsom = MiniSom(x = 10, y = 10, input_len = 15, sigma = 1.0, learning_rate = 0.5)\nsom.random_weights_init(X)\nsom.train_random(data = X, num_iteration = 100)",
"_____no_output_____"
],
[
" #Visualizing the results\nfrom pylab import bone, pcolor, colorbar, plot, show\nbone()\npcolor(som.distance_map().T)\ncolorbar()\nmarkers = ['o', 's']\ncolors = ['r', 'g']\nfor i, x in enumerate(X):\n w = som.winner(x)\n plot(w[0] + 0.5,\n w[1] + 0.5,\n markers[y[i]],\n markeredgecolor = colors[y[i]],\n markerfacecolor = 'None',\n markersize = 10,\n markeredgewidth = 2)\nshow()",
"_____no_output_____"
],
[
"# Finding the frauds\nmappings = som.win_map(X)",
"_____no_output_____"
],
[
"frauds = np.concatenate((mappings[(2,4)], mappings[(8,8)]), axis = 0)\n",
"_____no_output_____"
],
[
"frauds = sc.inverse_transform(frauds)\n",
"_____no_output_____"
],
[
"#Part 2 - Create a supervised deep learning model\n#Creates a matrix of features\ncustomers = dataset.iloc[:, 1:].values",
"_____no_output_____"
],
[
"#Create the dependent variable\nis_fraud = np.zeros(len(dataset)) #creates an array of zeroes, scanning through dataset\n#initiate a loop, to append values of 1 if fraud data found in dataset \nfor i in range(len(dataset)): \n if dataset.iloc[i,0] in frauds:\n is_fraud[i] = 1",
"_____no_output_____"
],
[
"#train artificial neural network \n\n# Feature Scaling\nfrom sklearn.preprocessing import StandardScaler\nsc = StandardScaler()\ncustomers = sc.fit_transform(customers)\n\n\nfrom keras.models import Sequential\nfrom keras.layers import Dense",
"Using TensorFlow backend.\n"
],
[
"# Initialising the ANN\nclassifier = Sequential()\n\n# Adding the input layer and the first hidden layer\nclassifier.add(Dense(units = 2, kernel_initializer = 'uniform', activation = 'relu', input_dim = 15))\n\n# Adding the output layer\nclassifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))\n\n# Compiling the ANN\nclassifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])\n\n# Fitting the ANN to the Training set\nclassifier.fit(customers, is_fraud, batch_size = 1, epochs = 2)",
"WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.cast instead.\nEpoch 1/2\n690/690 [==============================] - 1s 2ms/step - loss: 0.4273 - acc: 1.0000\nEpoch 2/2\n690/690 [==============================] - 1s 881us/step - loss: 0.0785 - acc: 1.0000\n"
],
[
"# Part 3 - Making predictions and evaluating the model\n# Predicting the probabilities of fraud \ny_pred= classifier.predict(customers)\ny_pred = np.concatenate((dataset.iloc[:,0:1].values, y_pred), axis = 1)",
"_____no_output_____"
],
[
"#Sorts numpy array in one colum \ny_pred = y_pred[y_pred[:,1].argsort()]",
"_____no_output_____"
],
[
"y_pred.shape",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a4c81386c376086c2a2418bb5cd7fd9f3106b26
| 4,020 |
ipynb
|
Jupyter Notebook
|
notebooks/0.0-hwant-STI-read-in-data-daily-OCBC.ipynb
|
howewenann/stocks_analysis
|
ad7662e3c60b47c62ec391c6661085be402b9f9b
|
[
"FTL"
] | null | null | null |
notebooks/0.0-hwant-STI-read-in-data-daily-OCBC.ipynb
|
howewenann/stocks_analysis
|
ad7662e3c60b47c62ec391c6661085be402b9f9b
|
[
"FTL"
] | 6 |
2020-11-13T18:56:08.000Z
|
2022-02-10T01:48:32.000Z
|
notebooks/0.0-hwant-STI-read-in-data-daily-OCBC.ipynb
|
howewenann/stocks_analysis
|
ad7662e3c60b47c62ec391c6661085be402b9f9b
|
[
"FTL"
] | null | null | null | 19.609756 | 95 | 0.461692 |
[
[
[
"import pandas as pd\nimport yfinance as yf",
"_____no_output_____"
],
[
"import os\ndirname = os.getcwd()\nparent_dirname = os.path.dirname(dirname)",
"_____no_output_____"
],
[
"parent_dirname",
"_____no_output_____"
],
[
"STI_symbols = pd.Series([\n 'C31',\n 'C38U',\n 'C52',\n 'D05',\n 'BN4',\n 'O32',\n 'O39',\n 'U96',\n 'S51',\n 'C6L',\n 'S68',\n 'T39',\n 'S63',\n 'Z74',\n 'CC3',\n 'U11',\n 'F34'\n])\n\nSTI_symbols = STI_symbols + '.SI'",
"_____no_output_____"
],
[
"STI_ETF_symbols = pd.Series([\n 'G3B',\n 'MBH',\n 'CLR'\n])",
"_____no_output_____"
],
[
"# Convert to format that is readable for API\nSTI_components = STI_symbols.str.cat(sep=' ')",
"_____no_output_____"
],
[
"# Get numeric data\ndata = yf.download(STI_components, period='2y', interval='1d', group_by='column')",
"[*********************100%***********************] 17 of 17 completed\n"
],
[
"# Get additional datas\ntickers = yf.Tickers(STI_components)",
"_____no_output_____"
],
[
"# Get adjusted price\ndata_adj = data['Adj Close']",
"_____no_output_____"
],
[
"# names = []\n# symbols = []\n\n# # Get names for lookup\n# for i in range(data_adj.shape[1]):\n# print(i)\n# temp = tickers.tickers[i].info\n# names.append(temp['shortName'])\n# symbols.append(temp['symbol'])",
"_____no_output_____"
],
[
"# lookup = pd.DataFrame({\n# 'symbol':symbols,\n# 'name':names\n# })",
"_____no_output_____"
],
[
"data_adj.to_csv(os.path.join(parent_dirname, 'data/raw/sti_adj_price_daily_OCBC.csv'))\n# lookup.to_csv(os.path.join(parent_dirname, 'data/raw/lookup.csv'))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4c94626fc3419790379b1f5104903aea980d86
| 167,146 |
ipynb
|
Jupyter Notebook
|
notebooks/doge_svr_sigmoid.ipynb
|
AnLong98/SIAP_2022
|
76c2a8d7b3fcd5e68a282463c668719b14f40bb0
|
[
"MIT"
] | null | null | null |
notebooks/doge_svr_sigmoid.ipynb
|
AnLong98/SIAP_2022
|
76c2a8d7b3fcd5e68a282463c668719b14f40bb0
|
[
"MIT"
] | null | null | null |
notebooks/doge_svr_sigmoid.ipynb
|
AnLong98/SIAP_2022
|
76c2a8d7b3fcd5e68a282463c668719b14f40bb0
|
[
"MIT"
] | null | null | null | 120.248921 | 81,207 | 0.762058 |
[
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.svm import SVR\nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight')",
"_____no_output_____"
],
[
"df = pd.read_csv('../doge_v1.csv')\n\ndf = df.set_index(pd.DatetimeIndex(df['Date'].values))\ndf",
"_____no_output_____"
],
[
"df = df.resample('D').ffill()\ndf.Close.plot(figsize=(16, 2), color=\"red\", label='Close price', lw=2, alpha =.7)",
"_____no_output_____"
],
[
"future_days = 1\ncolumnName = str(future_days)+'_day_price_forecast'",
"_____no_output_____"
],
[
"#added new column\ndf[columnName] = df[['Close']].shift(-future_days)\n\ndf[['Close', columnName]]",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nDatetimeIndex: 1549 entries, 2017-11-09 to 2022-02-04\nFreq: D\nData columns (total 25 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Date 1549 non-null object \n 1 Open 1549 non-null float64\n 2 High 1549 non-null float64\n 3 Low 1549 non-null float64\n 4 Close 1549 non-null float64\n 5 Adj Close 1549 non-null float64\n 6 Volume 1549 non-null int64 \n 7 twitter_followers 1549 non-null float64\n 8 reddit_average_posts_48h 1549 non-null float64\n 9 reddit_average_comments_48h 1549 non-null float64\n 10 reddit_subscribers 1549 non-null float64\n 11 reddit_accounts_active_48h 1549 non-null float64\n 12 forks 1549 non-null float64\n 13 stars 1549 non-null float64\n 14 subscribers 1549 non-null float64\n 15 total_issues 1549 non-null float64\n 16 closed_issues 1549 non-null float64\n 17 pull_requests_merged 1549 non-null float64\n 18 pull_request_contributors 1549 non-null float64\n 19 commit_count_4_weeks 1549 non-null float64\n 20 dogecoin_unscaled 1549 non-null int64 \n 21 dogecoin_monthly 1549 non-null float64\n 22 scale 1549 non-null float64\n 23 dogecoin 1549 non-null float64\n 24 1_day_price_forecast 1548 non-null float64\ndtypes: float64(22), int64(2), object(1)\nmemory usage: 314.6+ KB\n"
],
[
"X = np.array(df[[\"High\", \"Low\", \"Volume\", \"Open\", \"twitter_followers\", \"reddit_average_posts_48h\",\n \"reddit_average_comments_48h\", \"reddit_subscribers\", \"reddit_accounts_active_48h\", \"forks\", \"stars\",\n \"subscribers\", \"total_issues\", \"closed_issues\", \"pull_requests_merged\", \"pull_request_contributors\",\n \"commit_count_4_weeks\", \"dogecoin_monthly\", \"dogecoin\"]])\n\n\nprint(df.shape)\n\nX = X[:df.shape[0] - future_days]\nprint(X)",
"(1549, 25)\n[[1.41500000e-03 1.18100000e-03 6.25955000e+06 ... 0.00000000e+00\n 1.00000000e+00 5.70000000e-01]\n [1.43100000e-03 1.12500000e-03 4.24652000e+06 ... 0.00000000e+00\n 1.00000000e+00 2.40000000e-01]\n [1.25700000e-03 1.14100000e-03 2.23108000e+06 ... 0.00000000e+00\n 1.00000000e+00 2.30000000e-01]\n ...\n [1.44129000e-01 1.41125000e-01 4.09432267e+08 ... 0.00000000e+00\n 4.00000000e+00 3.72000000e+00]\n [1.45253000e-01 1.36918000e-01 4.83194691e+08 ... 0.00000000e+00\n 4.00000000e+00 3.48000000e+00]\n [1.38747000e-01 1.35565000e-01 3.83506507e+08 ... 0.00000000e+00\n 4.00000000e+00 3.28000000e+00]]\n"
],
[
"y = np.array(df[columnName])\ny = y[:-future_days]\nprint(y)",
"[0.001163 0.001201 0.001038 ... 0.137235 0.137541 0.141685]\n"
],
[
"from sklearn.model_selection import train_test_split\n\nx_train, x_test, y_train, y_test = train_test_split(X,y, test_size = 0.2, shuffle=False)",
"_____no_output_____"
],
[
"from sklearn.preprocessing import StandardScaler\n\n\nStdS_X = StandardScaler()\nStdS_y = StandardScaler()\nX_l = StdS_X.fit_transform(x_train)\ny_p = StdS_y.fit_transform(y_train.reshape(-1,1))\n\nprint(\"Scaled X_l:\")\nprint(X_l)\nprint(\"Scaled y_p:\")\nprint(y_p)",
"Scaled X_l:\n[[-0.39367943 -0.41385857 -0.2014769 ... -0.31944861 -0.10595194\n -0.04440799]\n [-0.39238134 -0.41915265 -0.20310446 ... -0.31944861 -0.10595194\n -0.14081802]\n [-0.406498 -0.41764006 -0.20473396 ... -0.31944861 -0.10595194\n -0.14373953]\n ...\n [ 3.93356113 4.48618801 0.16575939 ... 0.57790687 0.65488621\n 0.27988029]\n [ 3.92536698 4.50150302 0.22837542 ... -0.31944861 0.65488621\n 0.43764216]\n [ 3.98889191 4.55085138 0.38279042 ... -0.31944861 0.65488621\n 0.45517125]]\nScaled y_p:\n[[-0.41644404]\n [-0.41315149]\n [-0.42727479]\n ...\n [ 4.1661761 ]\n [ 4.15300591]\n [ 4.13195093]]\n"
],
[
"\nStdS_X_test = StandardScaler()\nStdS_y_test = StandardScaler()\n\nX_l_test = StdS_X_test.fit_transform(x_test)\ny_p_test = StdS_y_test.fit_transform(y_test.reshape(-1,1))\n\nprint(\"Scaled X_l_test:\")\nprint(X_l_test)\nprint(\"Scaled y_p_test:\")\nprint(y_p_test)",
"Scaled X_l_test:\n[[-1.85848319 -2.11900651 -0.48809287 ... -0.44664227 -0.47087352\n -0.45317956]\n [-1.71853358 -2.10261672 0.22048017 ... -0.44664227 -0.47087352\n -0.59946706]\n [-1.78887072 -2.05864441 -0.28036058 ... -0.44664227 -0.47087352\n -0.60488512]\n ...\n [-1.05633384 -1.05985672 -0.52157589 ... -0.44664227 -0.55783854\n -0.2906379 ]\n [-1.04627801 -1.11000351 -0.51145202 ... -0.44664227 -0.55783854\n -0.31231012]\n [-1.10448373 -1.12613106 -0.52513419 ... -0.44664227 -0.55783854\n -0.3303703 ]]\nScaled y_p_test:\n[[-1.90109281e+00]\n [-1.94558719e+00]\n [-1.96473563e+00]\n [-1.94826386e+00]\n [-1.92466804e+00]\n [-1.87564392e+00]\n [-1.93154500e+00]\n [-1.90646673e+00]\n [-1.90420186e+00]\n [-1.88195467e+00]\n [-1.77072902e+00]\n [-1.81069366e+00]\n [-1.57722685e+00]\n [-1.28822958e+00]\n [-6.63434603e-01]\n [ 1.22735003e+00]\n [ 3.86290962e-01]\n [ 7.60014923e-01]\n [ 1.65405134e+00]\n [ 7.49977436e-01]\n [ 6.20519587e-01]\n [ 1.47388470e-01]\n [ 1.91351203e-02]\n [ 2.42564439e-01]\n [ 4.59223427e-02]\n [ 2.47320664e-01]\n [ 2.62907080e-01]\n [ 7.93030535e-01]\n [ 6.02441815e-01]\n [ 9.35912879e-01]\n [ 1.50651572e+00]\n [ 1.33211052e+00]\n [ 2.00808124e+00]\n [ 3.03372713e+00]\n [ 4.23100890e+00]\n [ 3.44006520e+00]\n [ 4.51045254e+00]\n [ 4.01281966e+00]\n [ 3.32956019e+00]\n [ 2.09308588e+00]\n [ 2.55910325e+00]\n [ 1.42816155e+00]\n [ 2.50910112e+00]\n [ 3.22181419e+00]\n [ 2.69027005e+00]\n [ 2.76154136e+00]\n [ 2.48354929e+00]\n [ 2.36230673e+00]\n [ 8.90224296e-01]\n [ 1.58071077e+00]\n [ 1.16055699e+00]\n [ 9.85431150e-01]\n [ 6.32317495e-01]\n [ 1.23035613e+00]\n [ 1.02590024e+00]\n [ 1.10198954e+00]\n [ 8.88391811e-01]\n [ 6.64581583e-01]\n [ 5.81244701e-01]\n [ 5.72123457e-01]\n [ 8.14937994e-01]\n [ 1.27066051e+00]\n [ 1.81934559e+00]\n [ 1.57833265e+00]\n [ 1.33496219e+00]\n [ 1.29227971e+00]\n [ 1.28847061e+00]\n [ 8.68883054e-01]\n [ 8.34261444e-01]\n [ 9.95314214e-01]\n [ 8.20507513e-01]\n [ 7.48525861e-01]\n [ 6.73630763e-01]\n [ 8.00236936e-01]\n [ 8.79538233e-01]\n [ 8.41406076e-01]\n [ 6.29126089e-01]\n [ 6.16103093e-01]\n [ 4.82022853e-01]\n [ 4.19059497e-01]\n [ 3.52595889e-01]\n [-6.99631326e-01]\n [-5.72592769e-01]\n [-1.49031397e-01]\n [ 1.66073639e-01]\n [-7.71835779e-02]\n [-1.92132284e-02]\n [ 1.83245463e-01]\n [ 1.05076601e-01]\n [ 1.65939806e-01]\n [ 7.78775842e-02]\n [-2.16325202e-02]\n [-1.42716962e-02]\n [-2.46349327e-03]\n [-1.72226345e-03]\n [-1.54796518e-01]\n [-1.25888554e-01]\n [-2.31884420e-01]\n [-4.02048140e-01]\n [-2.75761108e-01]\n [-3.36953748e-01]\n [-3.17022901e-01]\n [-3.97405158e-01]\n [-4.80227297e-01]\n [-5.07807223e-01]\n [-6.35834086e-01]\n [-7.64962499e-01]\n [-6.23099346e-01]\n [-6.63166936e-01]\n [-7.52495425e-01]\n [-7.80857761e-01]\n [-5.79613863e-01]\n [-5.69792568e-01]\n [-5.34162062e-01]\n [-5.07858698e-01]\n [-5.02248000e-01]\n [-4.34765201e-01]\n [-4.19528810e-01]\n [-4.24748303e-01]\n [-4.32706229e-01]\n [-3.89447233e-01]\n [-3.94666726e-01]\n [-4.34579893e-01]\n [-4.43196690e-01]\n [-5.21777347e-01]\n [-4.64918842e-01]\n [-4.70230989e-01]\n [-4.31995884e-01]\n [ 1.40943889e-01]\n [-6.80005639e-02]\n [ 1.05488395e-01]\n [ 1.09894595e-01]\n [ 1.91615183e-01]\n [ 1.77799483e-01]\n [ 4.13417914e-01]\n [ 4.78326999e-01]\n [ 9.75856931e-01]\n [ 7.62485689e-01]\n [ 5.43483160e-01]\n [ 5.87720167e-01]\n [ 7.25722749e-01]\n [ 8.32243652e-01]\n [ 7.22150433e-01]\n [ 7.03269662e-01]\n [ 7.33649790e-01]\n [ 4.33297287e-01]\n [ 4.69195459e-01]\n [ 2.29150238e-01]\n [ 4.91916212e-01]\n [ 4.01280276e-01]\n [ 3.54912232e-01]\n [ 2.62258504e-01]\n [ 3.27404370e-01]\n [ 4.91586777e-01]\n [ 5.07584987e-01]\n [ 5.10858752e-01]\n [ 5.42927237e-01]\n [ 6.98781103e-01]\n [ 6.39462127e-01]\n [ 7.30287057e-02]\n [ 1.07712085e-01]\n [ 6.12102079e-02]\n [-6.86491400e-02]\n [-5.37215948e-02]\n [ 4.08366825e-02]\n [-1.10610984e-01]\n [-6.11647777e-02]\n [ 1.07756950e-02]\n [-4.21604685e-02]\n [-6.91844726e-02]\n [-5.41951583e-02]\n [-1.39065974e-01]\n [-4.07463235e-01]\n [-4.69685361e-01]\n [-2.24348583e-01]\n [-2.24616250e-01]\n [-3.82961472e-01]\n [-3.91310602e-01]\n [-4.29175092e-01]\n [-4.77560928e-01]\n [-5.13160550e-01]\n [-4.91829603e-01]\n [-4.36566801e-01]\n [-2.43373482e-01]\n [-2.83286649e-01]\n [-2.56365594e-01]\n [-5.96926129e-02]\n [ 5.52391899e-02]\n [ 8.73385593e-02]\n [-3.83719605e-02]\n [-2.88183316e-02]\n [-5.58944410e-04]\n [-1.73419917e-01]\n [-1.55939247e-01]\n [-2.10100499e-01]\n [-1.44934043e-01]\n [-1.48012206e-01]\n [-1.32477264e-01]\n [-9.63423099e-02]\n [-9.01036256e-02]\n [ 6.49303381e-03]\n [-8.87719026e-03]\n [ 7.66216114e-02]\n [-4.38488253e-02]\n [-2.50092339e-02]\n [ 5.23257448e-02]\n [ 3.12940093e-01]\n [ 1.85891242e-01]\n [ 9.34948849e-02]\n [-9.22449562e-02]\n [ 5.53829493e-01]\n [ 4.24176042e-01]\n [ 2.23343938e-01]\n [ 3.45842462e-01]\n [ 2.58171445e-01]\n [ 2.72512183e-01]\n [ 2.34277078e-01]\n [ 1.71200478e-01]\n [ 1.52515310e-01]\n [ 1.56972984e-01]\n [ 2.02445375e-01]\n [ 3.67616088e-01]\n [ 2.76681601e-01]\n [ 9.32581031e-02]\n [ 1.49447442e-01]\n [ 1.31400555e-01]\n [ 1.54996371e-01]\n [ 1.67411970e-01]\n [ 1.01699887e-01]\n [-9.67849889e-02]\n [-9.43348125e-02]\n [-2.60123217e-01]\n [-1.39395409e-01]\n [-1.40280767e-01]\n [-2.09215141e-01]\n [-2.77696541e-01]\n [-2.07320887e-01]\n [-2.55572890e-01]\n [-3.12184318e-01]\n [-4.71126642e-01]\n [-4.25211572e-01]\n [-4.03334997e-01]\n [-3.24033700e-01]\n [-3.28769335e-01]\n [-3.82590857e-01]\n [-3.80130385e-01]\n [-4.80330245e-01]\n [-6.97963559e-01]\n [-7.76183895e-01]\n [-7.02627130e-01]\n [-7.19047429e-01]\n [-6.94895691e-01]\n [-7.94416090e-01]\n [-8.46528665e-01]\n [-7.99203199e-01]\n [-7.90226083e-01]\n [-9.17120511e-01]\n [-6.84539063e-01]\n [-6.75016319e-01]\n [-7.53545501e-01]\n [-7.99295853e-01]\n [-7.64396282e-01]\n [-7.93468963e-01]\n [-8.16673575e-01]\n [-7.77007484e-01]\n [-7.56016267e-01]\n [-6.39931440e-01]\n [-6.17982801e-01]\n [-5.76443046e-01]\n [-5.83000871e-01]\n [-6.06833469e-01]\n [-7.46720010e-01]\n [-8.12112952e-01]\n [-7.75586793e-01]\n [-7.83997693e-01]\n [-7.57859047e-01]\n [-7.43775680e-01]\n [-7.88197995e-01]\n [-8.01426889e-01]\n [-8.98023548e-01]\n [-8.89859725e-01]\n [-9.43290042e-01]\n [-9.74884963e-01]\n [-9.84037093e-01]\n [-1.06336927e+00]\n [-9.60008893e-01]\n [-8.75045424e-01]\n [-7.68071547e-01]\n [-6.49618902e-01]\n [-6.33620692e-01]\n [-7.15228037e-01]\n [-7.77316330e-01]\n [-8.35585230e-01]\n [-8.67797843e-01]\n [-9.41426673e-01]\n [-1.07077128e+00]\n [-1.17112556e+00]\n [-1.07877038e+00]\n [-1.12061898e+00]\n [-1.06656068e+00]\n [-1.05894248e+00]\n [-1.08511202e+00]\n [-1.08090142e+00]\n [-1.06648862e+00]\n [-1.10339568e+00]\n [-1.07936748e+00]\n [-1.07086393e+00]\n [-1.12641499e+00]\n [-1.12326476e+00]\n [-1.08060287e+00]]\n"
],
[
"from sklearn.svm import SVR\nsvr_sigmoid = SVR(kernel='sigmoid', C = 0.0185, epsilon=0.0002)\nsvr_sigmoid.fit(X_l, y_p)",
"C:\\Users\\nikol\\Desktop\\SIAP - projekat\\SIAP_2022\\venv\\lib\\site-packages\\sklearn\\utils\\validation.py:993: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().\n y = column_or_1d(y, warn=True)\n"
],
[
"from sklearn.linear_model import LinearRegression\n# Create and train the Linear Regression Model\nlr = LinearRegression()\n# Train the model\nlr.fit(X_l, y_p)",
"_____no_output_____"
],
[
"# Testing Model: Score returns the coefficient of determination R^2 of the prediction.\n# The best possible score is 1.0\nlr_confidence = lr.score(X_l_test, y_p_test)\nprint(\"lr confidence: \", lr_confidence)\n\nsvr_linear_confidence = svr_sigmoid.score(X_l_test, y_p_test)\nprint('svr_linear confidence', svr_linear_confidence)",
"lr confidence: 0.7745555395734195\nsvr_linear confidence 0.48734196452574097\n"
],
[
"svr_prediction = svr_sigmoid.predict(X_l_test)\nprint(svr_prediction)",
"[-6.81050571e-02 -2.19698713e-01 -1.15511294e-01 4.65672982e-02\n 7.43209132e-02 1.02139209e-01 -8.42283609e-02 -1.01472993e-01\n 1.68364149e-02 -3.57005236e-03 -6.08126493e-02 -2.10075269e-01\n -1.00645388e-01 -4.24815275e-02 9.76594677e-02 2.97554186e-01\n 7.03205161e-01 8.19858916e-01 7.28803944e-01 7.02433421e-01\n 7.59525586e-01 7.46181040e-01 6.51246537e-01 4.76193620e-01\n 4.27777879e-01 1.17203126e-01 1.83198847e-02 2.08384557e-02\n 1.75275149e-01 1.92416008e-01 1.49099363e-01 2.97781090e-01\n 6.60544747e-01 7.46145173e-01 1.24045583e+00 1.89697146e+00\n 1.99590256e+00 1.97745109e+00 2.21917163e+00 2.10235467e+00\n 1.91932022e+00 1.72520121e+00 1.45740306e+00 1.27820329e+00\n 1.79552366e+00 1.81465784e+00 1.61896202e+00 1.61956888e+00\n 1.60901700e+00 1.43801520e+00 9.74065260e-01 1.01148508e+00\n 7.65388721e-01 4.77912481e-01 7.29701688e-01 1.07583120e+00\n 9.12990196e-01 7.59664777e-01 6.56343372e-01 4.63075591e-01\n 4.07901526e-01 5.58786577e-01 9.90675142e-01 1.48669983e+00\n 1.61542060e+00 1.46240495e+00 1.36753085e+00 1.16640537e+00\n 1.09806572e+00 8.49882569e-01 8.51975855e-01 8.68433070e-01\n 7.56558610e-01 6.91880653e-01 6.28666252e-01 8.18999704e-01\n 7.74634672e-01 5.72984667e-01 4.79529569e-01 4.79658220e-01\n 4.10715813e-01 3.96697586e-01 2.44582054e-01 4.62044500e-02\n 1.19819705e-01 1.92309807e-01 4.22882459e-01 1.54139450e-01\n 2.16265573e-01 3.04646982e-01 2.70900967e-01 1.56398622e-01\n 2.76260076e-01 2.17479546e-01 2.26892355e-01 1.47954079e-01\n 3.58983429e-02 7.07975832e-03 3.56382058e-03 -6.50390460e-02\n -9.32447724e-02 -7.07687206e-02 -1.50467072e-01 -1.59119543e-01\n -1.94457789e-01 -2.38708797e-01 -2.63298372e-01 -3.28889421e-01\n -3.01995633e-01 -2.82606306e-01 -3.42072431e-01 -3.84433448e-01\n -2.47506986e-01 -2.44920841e-01 -2.96526592e-01 -2.53814676e-01\n -2.70690519e-01 -5.68985573e-02 -1.82437520e-01 -1.80035202e-01\n -2.18607143e-01 -2.11209927e-01 -1.58236004e-01 -1.78861775e-01\n -2.17590748e-01 -2.65173504e-01 -2.89095185e-01 -2.74048550e-01\n -2.23485792e-01 9.62614218e-02 5.19386108e-01 2.23315571e-01\n 2.73692979e-01 4.88548099e-01 5.17951262e-01 5.03621458e-01\n 6.77476002e-01 9.17509642e-01 1.09614838e+00 9.65255693e-01\n 8.02838589e-01 7.68501866e-01 8.90642626e-01 8.72349779e-01\n 7.48809039e-01 7.74045201e-01 7.08797381e-01 5.96667708e-01\n 5.80480224e-01 5.31792704e-01 6.22009624e-01 5.56652412e-01\n 5.24525616e-01 5.07590869e-01 5.70150871e-01 7.39012504e-01\n 7.14920466e-01 6.66419793e-01 6.86917939e-01 7.25847160e-01\n 5.70220896e-01 4.12359717e-01 3.93638307e-01 3.41770524e-01\n 2.83404597e-01 2.97595068e-01 2.86130987e-01 2.51337090e-01\n 2.72775408e-01 2.74592153e-01 3.04371248e-01 2.14624401e-01\n 1.58080858e-01 7.41130575e-02 2.25304691e-02 3.91738940e-02\n 1.52222672e-01 6.44824950e-02 -1.94475605e-02 -1.03802017e-01\n -9.42874499e-02 -1.32944530e-01 -1.25082250e-01 -9.11789887e-02\n -2.38113090e-02 5.66045730e-02 6.33523160e-02 1.51969543e-01\n 3.38603213e-01 4.30013180e-01 3.56731835e-01 3.12601717e-01\n 2.89511173e-01 2.37220576e-01 1.78292749e-01 1.47251522e-01\n 1.46711756e-01 2.14168033e-01 2.18593298e-01 2.59891441e-01\n 2.15611547e-01 3.93115878e-01 3.30776941e-01 3.52906097e-01\n 3.65312846e-01 2.83785435e-01 3.06210376e-01 5.15043487e-01\n 5.80986752e-01 5.41773696e-01 4.84188714e-01 7.72890712e-01\n 8.09919304e-01 6.95608313e-01 5.59536748e-01 6.01913009e-01\n 6.04622741e-01 6.00560785e-01 5.47180143e-01 5.22676385e-01\n 4.94807576e-01 5.12979035e-01 6.49239444e-01 6.23400484e-01\n 4.92811223e-01 5.59864426e-01 5.27211865e-01 4.16455614e-01\n 4.24921012e-01 4.35897217e-01 3.68475971e-01 3.21099143e-01\n 3.09362604e-01 2.39460711e-01 2.97428553e-01 3.11659274e-01\n 2.62001230e-01 2.73044238e-01 2.72764753e-01 2.11898939e-01\n 1.86875404e-01 1.84146276e-01 1.56881570e-01 2.28905459e-01\n 2.73988285e-01 2.04771756e-01 2.08211051e-01 1.64479522e-01\n 6.64686876e-02 -1.24500274e-04 -2.43813053e-02 1.15661703e-02\n -5.11048688e-02 -4.04258997e-02 -8.38361998e-02 -1.04111617e-01\n -5.84920192e-02 -1.01706703e-01 1.79359729e-01 1.34698965e-01\n 5.23912695e-02 -2.08770894e-02 -3.89478919e-02 -4.23228640e-02\n -7.38543533e-02 -5.49654647e-02 -2.06199905e-02 5.10245316e-03\n 8.39923280e-02 1.19933289e-01 9.20446566e-02 9.94100077e-02\n 4.34172486e-02 -2.02858974e-03 -5.14006896e-02 -3.06977579e-02\n -1.99263746e-02 -1.51931317e-02 -1.42466000e-02 -4.78800050e-02\n -6.90493893e-02 -1.00129473e-01 -9.36980370e-02 -1.64021462e-01\n -1.31568020e-01 -1.15689181e-01 -9.06392437e-02 -8.10225425e-02\n 8.28633970e-03 1.92918007e-01 1.76179592e-01 8.41780330e-02\n 2.45018503e-02 -2.44597613e-02 -4.48743741e-02 -6.61745812e-02\n -1.13759652e-01 -1.68761080e-01 -1.91234550e-01 -1.79393384e-01\n -1.55501016e-01 -1.09112211e-01 -1.31404380e-01 -1.49564218e-01\n -1.49919451e-01 -1.62454990e-01 -1.81229823e-01 -1.39709777e-01\n -1.40737903e-01 -1.87392423e-01]\n"
],
[
"final_prediction =svr_prediction.reshape(-1,1)\nfinal_prediction = StdS_y_test.inverse_transform(final_prediction)\nprint(final_prediction)",
"[[0.24003485]\n [0.22530967]\n [0.23543 ]\n [0.25117365]\n [0.25386952]\n [0.25657167]\n [0.2384687 ]\n [0.23679363]\n [0.24828571]\n [0.24630351]\n [0.2407432 ]\n [0.22624445]\n [0.23687402]\n [0.24252381]\n [0.25613653]\n [0.27555348]\n [0.31495673]\n [0.326288 ]\n [0.31744329]\n [0.31488177]\n [0.32042747]\n [0.31913123]\n [0.30990969]\n [0.29290577]\n [0.28820287]\n [0.25803492]\n [0.24842981]\n [0.24867445]\n [0.2636758 ]\n [0.26534079]\n [0.26113319]\n [0.27557552]\n [0.31081288]\n [0.31912775]\n [0.36714304]\n [0.43091426]\n [0.44052401]\n [0.43873171]\n [0.46221145]\n [0.45086433]\n [0.43308512]\n [0.4142292 ]\n [0.3882164 ]\n [0.37080968]\n [0.42106004]\n [0.42291865]\n [0.40390957]\n [0.40396852]\n [0.40294355]\n [0.38633314]\n [0.34126696]\n [0.34490177]\n [0.32099699]\n [0.29307274]\n [0.3175305 ]\n [0.35115209]\n [0.33533439]\n [0.32044099]\n [0.31040477]\n [0.29163154]\n [0.28627216]\n [0.30092851]\n [0.34288038]\n [0.39106217]\n [0.40356557]\n [0.38870226]\n [0.37948658]\n [0.35995009]\n [0.35331186]\n [0.32920437]\n [0.3294077 ]\n [0.33100629]\n [0.32013927]\n [0.31385672]\n [0.30771633]\n [0.32620454]\n [0.3218951 ]\n [0.30230765]\n [0.29322981]\n [0.29324231]\n [0.28654553]\n [0.28518386]\n [0.27040798]\n [0.2511384 ]\n [0.25828908]\n [0.26533047]\n [0.28772735]\n [0.26162276]\n [0.26765744]\n [0.27624244]\n [0.27296449]\n [0.26184221]\n [0.27348505]\n [0.26777536]\n [0.26868968]\n [0.26102194]\n [0.25013731]\n [0.24733799]\n [0.24699647]\n [0.24033267]\n [0.23759288]\n [0.23977611]\n [0.23203454]\n [0.23119408]\n [0.22776147]\n [0.22346311]\n [0.22107458]\n [0.21470334]\n [0.21731569]\n [0.21919909]\n [0.21342279]\n [0.20930802]\n [0.22260849]\n [0.2228597 ]\n [0.21784693]\n [0.22199579]\n [0.22035654]\n [0.2411234 ]\n [0.22892907]\n [0.22916242]\n [0.2254157 ]\n [0.22613423]\n [0.2312799 ]\n [0.2292764 ]\n [0.22551443]\n [0.22089244]\n [0.21856878]\n [0.22003035]\n [0.22494181]\n [0.25600073]\n [0.29710131]\n [0.26834224]\n [0.2732357 ]\n [0.29410584]\n [0.29696194]\n [0.29557 ]\n [0.31245751]\n [0.33577339]\n [0.35312561]\n [0.34041124]\n [0.32463471]\n [0.32129939]\n [0.33316363]\n [0.33138674]\n [0.31938651]\n [0.32183784]\n [0.31549994]\n [0.30460813]\n [0.30303574]\n [0.29830644]\n [0.30706974]\n [0.30072121]\n [0.29760054]\n [0.29595557]\n [0.30203239]\n [0.31843491]\n [0.31609471]\n [0.31138356]\n [0.31337466]\n [0.31715608]\n [0.30203919]\n [0.28670521]\n [0.28488669]\n [0.27984847]\n [0.27417904]\n [0.27555745]\n [0.27444387]\n [0.27106414]\n [0.27314657]\n [0.27332304]\n [0.27621566]\n [0.26749802]\n [0.26200561]\n [0.25384933]\n [0.24883881]\n [0.25045548]\n [0.26143657]\n [0.25291386]\n [0.24476124]\n [0.23656739]\n [0.2374916 ]\n [0.23373661]\n [0.23450032]\n [0.23779354]\n [0.24433736]\n [0.25214863]\n [0.25280408]\n [0.26141199]\n [0.27954081]\n [0.28842 ]\n [0.28130175]\n [0.27701513]\n [0.27477221]\n [0.26969292]\n [0.26396891]\n [0.2609537 ]\n [0.26090127]\n [0.26745369]\n [0.26788354]\n [0.27189507]\n [0.26759391]\n [0.28483594]\n [0.2787806 ]\n [0.28093013]\n [0.28213527]\n [0.27421604]\n [0.2763943 ]\n [0.29667949]\n [0.30308494]\n [0.29927595]\n [0.29368238]\n [0.3217257 ]\n [0.32532251]\n [0.31421881]\n [0.30100138]\n [0.30511763]\n [0.30538085]\n [0.30498628]\n [0.29980111]\n [0.29742092]\n [0.29471386]\n [0.29647896]\n [0.30971473]\n [0.30720484]\n [0.29451994]\n [0.30103321]\n [0.29786147]\n [0.28710307]\n [0.28792536]\n [0.28899155]\n [0.28244253]\n [0.27784054]\n [0.2767005 ]\n [0.26991052]\n [0.27554127]\n [0.27692359]\n [0.27210001]\n [0.27317268]\n [0.27314553]\n [0.26723328]\n [0.2648026 ]\n [0.2645375 ]\n [0.26188912]\n [0.26888522]\n [0.27326438]\n [0.26654098]\n [0.26687505]\n [0.26262715]\n [0.25310679]\n [0.2466382 ]\n [0.24428199]\n [0.24777378]\n [0.24168618]\n [0.24272349]\n [0.23850679]\n [0.23653732]\n [0.24096862]\n [0.23677093]\n [0.26407256]\n [0.25973439]\n [0.25173936]\n [0.24462238]\n [0.24286706]\n [0.24253923]\n [0.23947639]\n [0.24131118]\n [0.24464735]\n [0.24714592]\n [0.25480896]\n [0.25830012]\n [0.25559113]\n [0.25630657]\n [0.25086767]\n [0.24645324]\n [0.24165744]\n [0.24366844]\n [0.24471473]\n [0.2451745 ]\n [0.24526644]\n [0.24199943]\n [0.23994312]\n [0.23692413]\n [0.23754885]\n [0.23071793]\n [0.23387032]\n [0.23541272]\n [0.23784597]\n [0.2387801 ]\n [0.24745519]\n [0.26538955]\n [0.26376365]\n [0.254827 ]\n [0.2490303 ]\n [0.24427437]\n [0.24229138]\n [0.24022237]\n [0.23560015]\n [0.23025754]\n [0.22807456]\n [0.22922476]\n [0.23154557]\n [0.23605158]\n [0.23388622]\n [0.23212224]\n [0.23208774]\n [0.23087009]\n [0.22904638]\n [0.23307946]\n [0.2329796 ]\n [0.22844777]]\n"
],
[
"print(y_test)",
"[0.061986 0.057664 0.055804 0.057404 0.059696 0.064458 0.059028 0.061464\n 0.061684 0.063845 0.074649 0.070767 0.093445 0.121517 0.182207 0.36587\n 0.284173 0.320475 0.407318 0.3195 0.306925 0.260967 0.248509 0.270212\n 0.251111 0.270674 0.272188 0.323682 0.305169 0.337561 0.392987 0.376046\n 0.441707 0.541334 0.657633 0.580804 0.684777 0.636439 0.57007 0.449964\n 0.495231 0.385376 0.490374 0.559604 0.507972 0.514895 0.487892 0.476115\n 0.333123 0.400194 0.359382 0.342371 0.308071 0.366162 0.346302 0.353693\n 0.332945 0.311205 0.30311 0.302224 0.32581 0.370077 0.423374 0.399963\n 0.376323 0.372177 0.371807 0.33105 0.327687 0.343331 0.326351 0.319359\n 0.312084 0.324382 0.332085 0.328381 0.307761 0.306496 0.293472 0.287356\n 0.2809 0.178691 0.191031 0.232174 0.262782 0.239153 0.244784 0.26445\n 0.256857 0.262769 0.254215 0.244549 0.245264 0.246411 0.246483 0.231614\n 0.234422 0.224126 0.207597 0.219864 0.21392 0.215856 0.208048 0.200003\n 0.197324 0.184888 0.172345 0.186125 0.182233 0.173556 0.170801 0.190349\n 0.191303 0.194764 0.197319 0.197864 0.204419 0.205899 0.205392 0.204619\n 0.208821 0.208314 0.204437 0.2036 0.195967 0.20149 0.200974 0.204688\n 0.260341 0.240045 0.256897 0.257325 0.265263 0.263921 0.286808 0.293113\n 0.341441 0.320715 0.299442 0.303739 0.317144 0.327491 0.316797 0.314963\n 0.317914 0.288739 0.292226 0.268909 0.294433 0.285629 0.281125 0.272125\n 0.278453 0.294401 0.295955 0.296273 0.299388 0.314527 0.308765 0.253744\n 0.257113 0.252596 0.239982 0.241432 0.250617 0.235906 0.240709 0.247697\n 0.242555 0.23993 0.241386 0.233142 0.207071 0.201027 0.224858 0.224832\n 0.209451 0.20864 0.204962 0.200262 0.196804 0.198876 0.204244 0.22301\n 0.219133 0.221748 0.240852 0.252016 0.255134 0.242923 0.243851 0.246596\n 0.229805 0.231503 0.226242 0.232572 0.232273 0.233782 0.237292 0.237898\n 0.247281 0.245788 0.254093 0.242391 0.244221 0.251733 0.277048 0.264707\n 0.255732 0.23769 0.300447 0.287853 0.268345 0.280244 0.271728 0.273121\n 0.269407 0.26328 0.261465 0.261898 0.266315 0.282359 0.273526 0.255709\n 0.261167 0.259414 0.261706 0.262912 0.256529 0.237249 0.237487 0.221383\n 0.23311 0.233024 0.226328 0.219676 0.226512 0.221825 0.216326 0.200887\n 0.205347 0.207472 0.215175 0.214715 0.209487 0.209726 0.199993 0.178853\n 0.171255 0.1784 0.176805 0.179151 0.169484 0.164422 0.169019 0.169891\n 0.157565 0.180157 0.181082 0.173454 0.16901 0.1724 0.169576 0.167322\n 0.171175 0.173214 0.18449 0.186622 0.190657 0.19002 0.187705 0.174117\n 0.167765 0.171313 0.170496 0.173035 0.174403 0.170088 0.168803 0.15942\n 0.160213 0.155023 0.151954 0.151065 0.143359 0.153399 0.161652 0.172043\n 0.183549 0.185103 0.177176 0.171145 0.165485 0.162356 0.155204 0.14264\n 0.132892 0.141863 0.137798 0.143049 0.143789 0.141247 0.141656 0.143056\n 0.139471 0.141805 0.142631 0.137235 0.137541 0.141685]\n"
],
[
"print(len(final_prediction))\nprint(len(y_test))",
"310\n310\n"
],
[
"df",
"_____no_output_____"
],
[
"plt.figure(figsize=(17,5))\nplt.plot(final_prediction, label='Prediction', lw=2, alpha =.7, color = \"green\")\nplt.plot(y_test, label='Actual', lw=2, alpha =.7, color = \"red\")\nplt.legend(['predicted', \"actual\"])\nplt.title('Prediction vs Actual')\nplt.ylabel('Price in USD')\nplt.xlabel('Time')\n\nplt.show()",
"_____no_output_____"
],
[
"from math import sqrt\nfrom sklearn.metrics import mean_absolute_error, mean_squared_error\n\n\nprint(\"R^2\")\nprint(svr_linear_confidence)\n\nprint(\"\\nMAE\")\nprint(mean_absolute_error(y_test,final_prediction))\n\nprint(\"\\nRMSE\")\nprint(sqrt(mean_squared_error(y_test, final_prediction)))",
"R^2\n0.48734196452574097\n\nMAE\n0.05262152735425412\n\nRMSE\n0.06954941693091701\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4cd96f1450456c2132f47c5ae637d2c1e0fa39
| 2,645 |
ipynb
|
Jupyter Notebook
|
CH40208/python_basics/loops_exercises.ipynb
|
pythoninchemistry/ch40208
|
0d978f048644825fae7113d7bd65da709c6fef09
|
[
"CC-BY-4.0"
] | null | null | null |
CH40208/python_basics/loops_exercises.ipynb
|
pythoninchemistry/ch40208
|
0d978f048644825fae7113d7bd65da709c6fef09
|
[
"CC-BY-4.0"
] | 84 |
2019-06-21T06:32:55.000Z
|
2021-06-22T12:11:01.000Z
|
CH40208/python_basics/loops_exercises.ipynb
|
pythoninchemistry/ch40208
|
0d978f048644825fae7113d7bd65da709c6fef09
|
[
"CC-BY-4.0"
] | 6 |
2019-06-21T06:58:29.000Z
|
2021-11-02T14:01:48.000Z
| 22.801724 | 173 | 0.520605 |
[
[
[
"# Exercise\n\nWe can improve on our previous code in a few ways. \nOne is that we can use a loop to make the distance calculation shorter. ",
"_____no_output_____"
]
],
[
[
"atom_1 = [0.1, 0.5, 3.2]\natom_2 = [0.4, 0.5, 2.3]\natom_3 = [-0.3, 0.3, 1.7]",
"_____no_output_____"
],
[
"from math import sqrt",
"_____no_output_____"
],
[
"r_12 = sqrt(sum([(atom_1[i] - atom_2[i]) ** 2 for i in [0, 1, 2]]))\nr_13 = sqrt(sum([(atom_1[i] - atom_3[i]) ** 2 for i in [0, 1, 2]]))\nr_23 = sqrt(sum([(atom_2[i] - atom_3[i]) ** 2 for i in [0, 1, 2]]))\nprint(r_12, r_13, r_23)",
"0.9486832980505141 1.565247584249853 0.9433981132056602\n"
]
],
[
[
"Note above we use [list comprehensions](https://pythoninchemistry.org/ch40208/python_basics/loops.html#list-comprehensions) to make the long equation a bit shorter.\n\nWe can also use a nested loop to iterate over each pair of atoms. ",
"_____no_output_____"
]
],
[
[
"distances = []\n\natoms = [atom_1, atom_2, atom_3]\nfor i, a_i in enumerate(atoms):\n for a_j in atoms[i+1:]:\n distances.append(sqrt(sum([(a_i[k] - a_j[k]) ** 2 for k in [0, 1, 2]])))\n \nprint(distances)",
"[0.9486832980505141, 1.565247584249853, 0.9433981132056602]\n"
]
],
[
[
"We advise you review the LOILs for a better understanding of nested loops. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a4ce370e15199dfeefec685350a9a9209e8052f
| 4,428 |
ipynb
|
Jupyter Notebook
|
SRC/aula/verificar_dados_duplicados.ipynb
|
larissasayurifutino/dou
|
479d790f962c685ffb631b643ac2578eba23d48a
|
[
"CC0-1.0"
] | null | null | null |
SRC/aula/verificar_dados_duplicados.ipynb
|
larissasayurifutino/dou
|
479d790f962c685ffb631b643ac2578eba23d48a
|
[
"CC0-1.0"
] | null | null | null |
SRC/aula/verificar_dados_duplicados.ipynb
|
larissasayurifutino/dou
|
479d790f962c685ffb631b643ac2578eba23d48a
|
[
"CC0-1.0"
] | null | null | null | 22.363636 | 102 | 0.386405 |
[
[
[
"# diferenca entre dois datasets\n\nimport pandas as pd\n\n#df1 = 'result.csv'\n#df2 = 'result1.csv'\n\ndf1=pd.DataFrame({'A':[1,2,3,3],'B':[2,3,4,4]})\ndf2=pd.DataFrame({'A':[1],'B':[2]})\n\nnovos_dados_diario_oficial = df1[~df1.apply(tuple,1).isin(df2.apply(tuple,1))]",
"_____no_output_____"
],
[
"novos_dados_diario_oficial.head(5)",
"_____no_output_____"
],
[
"df1=pd.DataFrame({'A':['oi, tudo bem','diario oficial 3547','jbf sdjkf','iu'],'B':[2,3,4,4]})\ndf2=pd.DataFrame({'A':['oi, tudo bem'],'B':[2]})",
"_____no_output_____"
],
[
"mask = df1['A'].isin(df2['A'])\nresult = df1[mask].copy()\n",
"_____no_output_____"
],
[
"result",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a4ce76f98a94644bedd7609e33813bc56443f27
| 93,008 |
ipynb
|
Jupyter Notebook
|
src/aggregate_explanations_for_findings.ipynb
|
anguyen8/effectiveness-attribution-maps
|
5e28c4879c320fe9326e969caa62de53df7c0bc9
|
[
"MIT"
] | 11 |
2022-02-18T05:13:59.000Z
|
2022-02-25T01:04:48.000Z
|
src/aggregate_explanations_for_findings.ipynb
|
anguyen8/effectiveness-attribution-maps
|
5e28c4879c320fe9326e969caa62de53df7c0bc9
|
[
"MIT"
] | null | null | null |
src/aggregate_explanations_for_findings.ipynb
|
anguyen8/effectiveness-attribution-maps
|
5e28c4879c320fe9326e969caa62de53df7c0bc9
|
[
"MIT"
] | null | null | null | 100.008602 | 39,420 | 0.772041 |
[
[
[
"# THIS SCRIPT IS TO GENERATE AGGREGATIONS OF EXPLANATIONS for interesting FINDINGS",
"_____no_output_____"
],
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import os\nimport json\nimport numpy as np\nfrom matplotlib.colors import LinearSegmentedColormap\n\nimport torch.nn.functional as F\nimport torchvision\nfrom torchvision import models\nfrom torchvision import transforms\n\nimport torch\nimport torchvision\n\ntorch.set_num_threads(1)\ntorch.manual_seed(0)\nnp.random.seed(0)\n\nfrom torchvision.models import *\nfrom visualisation.core.utils import device, image_net_postprocessing\nfrom torch import nn\nfrom operator import itemgetter\nfrom visualisation.core.utils import imshow\nfrom IPython.core.debugger import Tracer\n\nNN_flag = True",
"_____no_output_____"
],
[
"layer = 4\nif NN_flag:\n feature_extractor = nn.Sequential(*list(resnet34(pretrained=True).children())[:layer-6]).to(device)\n \nmodel = resnet34(pretrained=True).to(device)\nmodel.eval()",
"_____no_output_____"
],
[
"# %matplotlib notebook \nimport glob\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport torch \nfrom utils import *\nfrom PIL import Image\n\nplt.rcParams[\"figure.figsize\"]= 16,8\n\n\ndef make_dir(path):\n if os.path.isdir(path) == False:\n os.mkdir(path)",
"_____no_output_____"
],
[
"import glob\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom matplotlib.pyplot import imshow\n\nfrom visualisation.core.utils import device \nfrom PIL import Image\nfrom torchvision.transforms import ToTensor, Resize, Compose, ToPILImage\nfrom visualisation.core import *\nfrom visualisation.core.utils import image_net_preprocessing\n\nsize = 224\n\n# Pre-process the image and convert into a tensor\ntransform = torchvision.transforms.Compose([\n torchvision.transforms.Resize(256),\n torchvision.transforms.CenterCrop(224),\n torchvision.transforms.ToTensor(),\n torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],\n std=[0.229, 0.224, 0.225]),\n])\n\nimg_num = 50\n\n# methods = ['Conf', 'GradCAM', 'EP', 'SHAP', 'NNs', 'PoolNet', 'AIonly']\nmethods = ['Conf', 'GradCAM', 'EP', 'NNs', 'PoolNet', 'AIonly']\n\ntask = 'Natural'\n# Adversarial_Nat",
"_____no_output_____"
],
[
"# Added for loading ImageNet classes\ndef load_imagenet_label_map():\n \"\"\"\n Load ImageNet label dictionary.\n return:\n \"\"\"\n\n input_f = open(\"input_txt_files/imagenet_classes.txt\")\n label_map = {}\n for line in input_f:\n parts = line.strip().split(\": \")\n (num, label) = (int(parts[0]), parts[1].replace('\"', \"\"))\n label_map[num] = label\n\n input_f.close()\n return label_map\n\n\n# Added for loading ImageNet classes\ndef load_imagenet_id_map():\n \"\"\"\n Load ImageNet ID dictionary.\n return;\n \"\"\"\n\n input_f = open(\"input_txt_files/synset_words.txt\")\n label_map = {}\n for line in input_f:\n parts = line.strip().split(\" \")\n (num, label) = (parts[0], ' '.join(parts[1:]))\n label_map[num] = label\n\n input_f.close()\n return label_map\n\ndef convert_imagenet_label_to_id(label_map, key_list, val_list, prediction_class):\n \"\"\"\n Convert imagenet label to ID: for example - 245 -> \"French bulldog\" -> n02108915\n :param label_map:\n :param key_list:\n :param val_list:\n :param prediction_class:\n :return:\n \"\"\"\n class_to_label = label_map[prediction_class]\n prediction_id = key_list[val_list.index(class_to_label)]\n return prediction_id\n\n\n# gt_dict = load_imagenet_validation_gt()\nid_map = load_imagenet_id_map()\nlabel_map = load_imagenet_label_map()\n\nkey_list = list(id_map.keys())\nval_list = list(id_map.values())\n\ndef convert_imagenet_id_to_label(label_map, key_list, val_list, class_id):\n \"\"\"\n Convert imagenet label to ID: for example - n02108915 -> \"French bulldog\" -> 245\n :param label_map:\n :param key_list:\n :param val_list:\n :param prediction_class:\n :return:\n \"\"\"\n return key_list.index(str(class_id))\n\nfrom torchray.attribution.extremal_perturbation import extremal_perturbation, contrastive_reward\nfrom torchray.attribution.grad_cam import grad_cam\nimport PIL.Image\n\ndef get_EP_saliency_maps(model, path):\n img_index = (path.split('.jpeg')[0]).split('images/')[1]\n img = PIL.Image.open(path)\n x = transform(img).unsqueeze(0).to(device)\n out = model(x)\n p = torch.nn.functional.softmax(out, dim=1)\n score, index = torch.topk(p, 1)\n category_id_1 = index[0][0].item()\n \n gt_label_id = img_index.split('val_')[1][9:18]\n input_prediction_id = convert_imagenet_label_to_id(label_map, key_list, val_list, category_id_1)\n\n masks, energy = extremal_perturbation(\n model, x, category_id_1,\n areas=[0.025, 0.05, 0.1, 0.2],\n num_levels=8,\n step=7,\n sigma=7 * 3,\n max_iter=800,\n debug=False,\n jitter=True,\n smooth=0.09,\n perturbation='blur'\n )\n saliency = masks.sum(dim=0, keepdim=True)\n saliency = saliency.detach()\n\n return saliency[0].to('cpu')",
"_____no_output_____"
],
[
"# import os\nimport os.path\nfrom visualisation.core.utils import tensor2cam\npostprocessing_t = image_net_postprocessing\nimport cv2 as cv\nimport sys\n\nimagenet_train_path = '/home/dexter/Downloads/train'\n\n## Creating colormap\ncMap = 'Reds'\n\nid_list= list()\nconf_dict = {}\neps=1e-5\ncnt = 0\nK = 3 # Change to your expected number of nearest neighbors",
"_____no_output_____"
],
[
"import csv\nreader = csv.reader(open('csv_files/definition.csv'))\ndefinition_dict = dict()\nfor row in reader:\n key = row[0][:9]\n definition = row[0][12:]\n definition_dict[key] = definition\n# Added for loading ImageNet classes\ndef load_imagenet_id_map():\n \"\"\"\n Load ImageNet ID dictionary.\n return;\n \"\"\"\n\n input_f = open(\"input_txt_files/synset_words.txt\")\n label_map = {}\n for line in input_f:\n parts = line.strip().split(\" \")\n (num, label) = (parts[0], ' '.join(parts[1:]))\n label_map[num] = label\n\n input_f.close()\n return label_map\nid_map = load_imagenet_id_map()",
"_____no_output_____"
],
[
"Q1_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/SOD_wrong_dogs_aggregate'\nQ2_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/NNs_hard_imagenet_aggregate'\nQ3_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/NNs_adversarial_imagenet_aggregate'\nQ4_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/Conf_adversarial_dog_aggregate'\nQ5_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/GradCAM_norm_imagenet_aggregate'\nQ6_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/NNs_easy_imagenet_aggregate'\nQ_datapath = ['/home/dexter/Downloads/Human_experiments/Dataset/Dog/mixed_images',\n '/home/dexter/Downloads/Human_experiments/Dataset/Natural/mixed_images',\n '/home/dexter/Downloads/Human_experiments/Dataset/Adversarial_Nat/mixed_images',\n '/home/dexter/Downloads/Human_experiments/Dataset/Adversarial_Dog/mixed_images',\n '/home/dexter/Downloads/Human_experiments/Dataset/Natural/mixed_images',\n '/home/dexter/Downloads/Human_experiments/Dataset/Natural/mixed_images']",
"_____no_output_____"
],
[
"for idx, question_path in enumerate([Q1_path, Q2_path, Q3_path, Q4_path, Q5_path, Q6_path]):\n representatives = glob.glob(question_path + '/*.*')\n# Tracer()()\n if idx != 1:\n continue\n for representative in representatives:\n if '21805' not in representative:\n continue\n sample_idx = representative.split('aggregate/')[1]\n image_path = os.path.join(Q_datapath[idx], sample_idx)\n# image_path = os.path.join('/home/dexter/Downloads/val', sample_folder, sample_idx)\n# if '6952' not in image_path:\n# continue\n distance_dict = dict()\n neighbors = list()\n categories_confidences = list()\n confidences= list ()\n\n img = Image.open(image_path)\n\n if NN_flag:\n embedding = feature_extractor(transform(img).unsqueeze(0).to(device)).flatten(start_dim=1) \n\n input_image = img.resize((size,size), Image.ANTIALIAS)\n\n # Get the ground truth of the input image\n gt_label_id = image_path.split('val_')[1][9:18]\n\n\n gt_label = id_map.get(gt_label_id)\n id = key_list.index(gt_label_id)\n gt_label = gt_label.split(',')[0]\n\n # Get the prediction for the input image\n img = Image.open(image_path)\n x = transform(img).unsqueeze(0).to(device)\n out = model(x)\n p = torch.nn.functional.softmax(out, dim=1)\n score, index = torch.topk(p, 1)\n input_category_id = index[0][0].item()\n predicted_confidence = score[0][0].item()\n predicted_confidence = (\"%.2f\") %(predicted_confidence)\n\n\n input_prediction_id = convert_imagenet_label_to_id(label_map, key_list, val_list, input_category_id)\n predicted_label = id_map.get(input_prediction_id).split(',')[0]\n predicted_label = predicted_label[0].lower() + predicted_label[1:]\n\n print(predicted_label)\n print(predicted_confidence)\n\n # Original image\n \n plt.gca().set_axis_off()\n plt.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0, \n hspace = 0, wspace = 0)\n plt.margins(0,0)\n plt.gca().xaxis.set_major_locator(plt.NullLocator())\n plt.gca().yaxis.set_major_locator(plt.NullLocator())\n \n fig = plt.figure()\n# plt.figure(figsize=(6.0,4.5), dpi=300)\n plt.axis('off')\n #predicted_label = 'african hunting dog'\n plt.title('{}: {}'.format(predicted_label, predicted_confidence), fontsize=30)\n plt.imshow(input_image)\n plt.savefig('tmp/original.jpeg', figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n plt.close()\n cmd = 'convert tmp/original.jpeg -resize 630x600\\! tmp/original.jpeg'\n os.system(cmd)\n\n\n # Edge image\n img = cv.resize(cv.imread(image_path,0),((size,size)))\n edges = cv.Canny(img,100,200)\n edges = edges - 255\n\n fig = plt.figure()\n \n# plt.figure(figsize=(6.0,4.5), dpi=300)\n plt.axis('off')\n plt.title(' ', fontsize=60)\n plt.imshow(edges, cmap = 'gray')\n plt.savefig('tmp/Edge.jpeg', figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n plt.close()\n\n # GradCAM\n saliency = grad_cam(\n model, x, input_category_id,\n saliency_layer='layer4',\n resize=True\n )\n\n saliency *= 1.0/saliency.max()\n GradCAM = saliency[0][0].cpu().detach().numpy()\n\n fig = plt.figure()\n \n# plt.figure(figsize=(6.0,4.5), dpi=300)\n plt.axis('off')\n plt.title('GradCAM', fontsize=30)\n mlb = plt.imshow(GradCAM, cmap=cMap, vmin=0, vmax=1)\n # plt.colorbar(orientation='vertical')\n plt.savefig('tmp/heatmap.jpeg', figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n# plt.close()\n\n myCmd = 'composite -blend 10 tmp/Edge.jpeg -gravity SouthWest tmp/heatmap.jpeg tmp/GradCAM.jpeg'\n os.system(myCmd)\n cmd = 'convert tmp/GradCAM.jpeg -resize 600x600\\! tmp/GradCAM.jpeg'\n os.system(cmd)\n \n # draw a new figure and replot the colorbar there\n fig,ax = plt.subplots()\n cbar = plt.colorbar(mlb,ax=ax)\n cbar.ax.tick_params(labelsize=20)\n ax.remove()\n # save the same figure with some approximate autocropping\n \n plt.title(' ', fontsize=30)\n plt.savefig('tmp/color_bar.jpeg', dpi=300, bbox_inches='tight')\n cmd = 'convert tmp/color_bar.jpeg -resize 100x600\\! tmp/color_bar.jpeg'\n os.system(cmd)\n \n # Extremal Perturbation\n saliency = get_EP_saliency_maps(model, image_path)\n ep_saliency_map = tensor2img(saliency)\n ep_saliency_map *= 1.0/ep_saliency_map.max()\n\n fig = plt.figure()\n# plt.figure(figsize=(6.0,4.5), dpi=300)\n plt.axis('off')\n plt.title('EP', fontsize=30)\n plt.imshow(ep_saliency_map, cmap=cMap, vmin=0, vmax=1)\n# plt.colorbar(orientation='vertical')\n plt.savefig('tmp/heatmap.jpeg', figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n plt.close()\n\n # Get overlay version\n myCmd = 'composite -blend 10 tmp/Edge.jpeg -gravity SouthWest tmp/heatmap.jpeg tmp/EP.jpeg'\n os.system(myCmd)\n cmd = 'convert tmp/EP.jpeg -resize 600x600\\! tmp/EP.jpeg'\n os.system(cmd)\n\n # Salient Object Detection \n from shutil import copyfile, rmtree\n def rm_and_mkdir(path):\n if os.path.isdir(path) == True:\n rmtree(path)\n os.mkdir(path)\n\n # Prepare dataset\n rm_and_mkdir('/home/dexter/Downloads/run-0/run-0-sal-p/')\n rm_and_mkdir('/home/dexter/Downloads/PoolNet-master/data/PASCALS/Imgs/')\n if os.path.isdir('/home/dexter/Downloads/PoolNet-master/data/PASCALS/test.lst'):\n os.remove('/home/dexter/Downloads/PoolNet-master/data/PASCALS/test.lst')\n\n src_paths = [image_path]\n for src_path in src_paths:\n dst_path = '/home/dexter/Downloads/PoolNet-master/data/PASCALS/Imgs/' + src_path.split('images/')[1]\n copyfile(src_path, dst_path)\n\n cmd = 'ls /home/dexter/Downloads/PoolNet-master/data/PASCALS/Imgs/ > /home/dexter/Downloads/PoolNet-master/data/PASCALS/test.lst'\n os.system(cmd)\n cmd = 'python /home/dexter/Downloads/PoolNet-master/main.py --mode=\\'test\\' --model=\\'/home/dexter/Downloads/run-0/run-0/models/final.pth\\' --test_fold=\\'/home/dexter/Downloads/run-0/run-0-sal-p/\\' --sal_mode=\\'p\\''\n os.system(cmd)\n\n\n npy_file_paths = glob.glob('/home/dexter/Downloads/run-0/run-0-sal-p/*.*')\n npy_file = np.load(npy_file_paths[0])\n fig = plt.figure()\n# plt.figure(figsize=(6.0,4.5), dpi=300)\n plt.axis('off')\n plt.title('SOD', fontsize=30)\n plt.imshow(npy_file, cmap=cMap, vmin=0, vmax=1)\n # plt.colorbar(orientation='vertical')\n plt.savefig('tmp/heatmap.jpeg', figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n plt.close()\n\n # Get overlay version\n myCmd = 'composite -blend 10 tmp/Edge.jpeg -gravity SouthWest tmp/heatmap.jpeg tmp/SOD.jpeg'\n os.system(myCmd)\n cmd = 'convert tmp/SOD.jpeg -resize 600x600\\! tmp/SOD.jpeg'\n os.system(cmd)\n\n # Nearest Neighbors\n imagenet_train_path = '/home/dexter/Downloads/train'\n if NN_flag:\n from utils import *\n ## Nearest Neighbors\n\n predicted_set_path = os.path.join(imagenet_train_path, input_prediction_id)\n predicted_set_img_paths = glob.glob(predicted_set_path + '/*.*')\n predicted_set_color_images= list()\n\n embedding = embedding.detach()\n embedding.to(device)\n # Build search space for nearest neighbors\n for i, path in enumerate(predicted_set_img_paths):\n img = Image.open(path)\n if img.mode != 'RGB':\n img.close()\n del img\n continue\n\n x = transform(img).unsqueeze(0).to(device)\n out = model(x)\n p = torch.nn.functional.softmax(out, dim=1)\n del out\n score, index = torch.topk(p, 1)\n del p\n category_id = index[0][0].item()\n del score, index\n\n # This is to avoid the confusion from crane 134 and crane 517 and to make NNs work :)\n # Because in Imagenet, annotators mislabeled 134 and 517\n\n if input_category_id != 134 and input_category_id != 517 and category_id != 134 and category_id != 517:\n if input_category_id != category_id:\n continue\n\n f = feature_extractor(x)\n feature_vector = f.flatten(start_dim=1).to(device)\n feature_vector = feature_vector.detach()\n\n del f\n distance_dict[path] = torch.dist(embedding, feature_vector)\n\n del feature_vector \n torch.cuda.empty_cache()\n img.close()\n del img\n predicted_set_color_images.append(path)\n\n # Get K most similar images\n res = dict(sorted(distance_dict.items(), key = itemgetter(1))[:K]) \n print(\"Before...\")\n print(res)\n # Tracer()()\n while distance_dict[list(res.keys())[0]] < 100:\n del distance_dict[list(res.keys())[0]]\n res = dict(sorted(distance_dict.items(), key = itemgetter(1))[:K]) \n print(\"After...\")\n print(res)\n # del distance_dict\n del embedding\n\n similar_images = list(res.keys())\n\n for similar_image in similar_images:\n img = Image.open(similar_image)\n neighbors.append(img.resize((size,size), Image.ANTIALIAS))\n x = transform(img).unsqueeze(0).to(device)\n out = model(x)\n p = torch.nn.functional.softmax(out, dim=1)\n score, index = torch.topk(p, 1) # Get 1 most probable classes\n category_id = index[0][0].item()\n confidence = score[0][0].item()\n\n label = label_map.get(category_id).split(',')[0].replace(\"\\\"\", \"\")\n label = label[0].lower() + label[1:]\n print(label + \": %.2f\" %(confidence))\n\n categories_confidences.append((label + \": %.2f\" %(confidence)))\n confidences.append(confidence)\n img.close()\n\n for index, neighbor in enumerate(neighbors):\n fig = plt.figure()\n# plt.figure(figsize=(6.0,4.5), dpi=300)\n plt.axis('off')\n if index == 1: # Make title for the middle image (2nd image) to annotate the 3 NNs\n plt.title('3-NN'.format(predicted_label), fontsize=30)\n else:\n plt.title(' ', fontsize=30)\n plt.imshow(neighbor)\n plt.savefig('tmp/{}.jpeg'.format(index), figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n plt.close()\n cmd = 'convert tmp/{}.jpeg -resize 600x600\\! tmp/{}.jpeg'.format(index, index)\n os.system(cmd)\n\n\n myCmd = 'montage tmp/[0-2].jpeg -tile 3x1 -geometry +0+0 tmp/NN.jpeg'\n os.system(myCmd)\n\n # Sample images and definition\n print(image_path)\n gt_label = image_path.split('images/')[1][34:43]\n print(image_path)\n print(gt_label)\n sample_path = '/home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/sample_images'\n predicted_sample_path = os.path.join(sample_path, gt_label + '.jpeg')\n textual_label = id_map.get(gt_label).split(',')[0]\n textual_label = textual_label[0].lower() + textual_label[1:]\n definition = '{}: {}'.format(textual_label, definition_dict[gt_label])\n definition = definition.replace(\"'s\", \"\")\n print(definition)\n \n# definition = 'any sluggish bottom-dwelling ray of the order Torpediniformes having a rounded body and electric organs on each side of the head capable of emitting strong electric discharges'\n\n # Responsive annotation of imagemagick (only caption has responsive functions)\n cmd = 'convert {} -resize 2400x600\\! tmp/sample_def.jpeg'.format(predicted_sample_path)\n os.system(cmd)\n cmd = 'convert tmp/sample_def.jpeg -background White -size 2395x \\\n -pointsize 50 -gravity Center \\\n caption:\\'{}\\' \\\n +swap -gravity Center -append tmp/sample_def.jpeg'.format(definition)\n os.system(cmd)\n\n # Top-k predictions\n img = Image.open(image_path)\n x = transform(img).unsqueeze(0).to(device)\n out = model(x)\n p = torch.nn.functional.softmax(out, dim=1)\n score, index = torch.topk(p, 5)\n # Tracer()()\n\n predicted_labels = []\n predicted_confidences = []\n colors = []\n\n for i in range(5):\n input_prediction_id = convert_imagenet_label_to_id(label_map, key_list, val_list, index[0][i].item())\n if input_prediction_id == gt_label:\n colors.append('lightcoral')\n else:\n colors.append('mediumslateblue')\n predicted_label = id_map.get(input_prediction_id).split(',')[0]\n predicted_label = predicted_label[0].lower() + predicted_label[1:]\n predicted_labels.append(predicted_label)\n predicted_confidences.append(score[0][i].item())\n\n # plt.rcdefaults()\n fig, ax = plt.subplots()\n\n y_pos = np.arange(len(predicted_labels))\n ax.tick_params(axis='y', direction='in',pad=-100)\n ax.tick_params(axis = \"x\", which = \"both\", bottom = False, top = False) # turn off xtick\n ax.barh(predicted_labels, predicted_confidences, align='center', color=colors, height=1.0)\n\n ax.set_xlim(0,1)\n ax.set_yticklabels(predicted_labels, horizontalalignment = \"left\", fontsize=64, weight='bold')\n ax.invert_yaxis() # labels read top-to-bottom\n ax.set_title(textual_label, fontsize=60, weight='bold') #1\n\n # remove the x and y ticks\n ax.set_xticks([])\n\n plt.savefig('tmp/top5.jpeg', figsize=(6.0,4.5), dpi=300, bbox_inches='tight', pad_inches=0)\n plt.close()\n #cmd = 'convert tmp/top5.jpeg -resize 570x400\\! tmp/top5.jpeg'\n cmd = 'convert tmp/top5.jpeg -resize 580x400\\! tmp/top5.jpeg'\n os.system(cmd)\n cmd = 'convert tmp/top5.jpeg -gravity North -background white -extent 100x150% tmp/top5.jpeg'\n os.system(cmd)\n\n# cmd = 'montage original.jpeg GradCAM.jpeg EP.jpeg SOD.jpeg color_bar.jpeg -tile 5x1 -geometry 600x600+0+0 agg1.jpeg'\n cmd = 'convert tmp/original.jpeg tmp/GradCAM.jpeg tmp/EP.jpeg tmp/SOD.jpeg tmp/color_bar.jpeg -gravity center +append tmp/agg1.jpeg'\n os.system(cmd)\n # cmd = 'montage top5.jpeg NN.jpeg -tile 2x1 -geometry +0+0 agg2.jpeg'\n# cmd = 'montage top5.jpeg [0-2].jpeg -tile 4x1 -geometry 600x600+0+0 agg2.jpeg'\n cmd = 'convert tmp/top5.jpeg tmp/[0-2].jpeg -gravity center +append tmp/agg2.jpeg'\n os.system(cmd)\n cmd = 'convert tmp/agg2.jpeg -gravity West -background white -extent 101.5x100% tmp/agg2.jpeg'\n os.system(cmd)\n\n cmd = 'convert tmp/agg1.jpeg tmp/agg2.jpeg tmp/sample_def.jpeg -gravity center -append {}'.format(representative)\n print(cmd)\n os.system(cmd)\n",
"caldron\n0.30\nBefore...\n{'/home/dexter/Downloads/train/n02939185/n02939185_54592.JPEG': tensor(255.8752, device='cuda:0'), '/home/dexter/Downloads/train/n02939185/n02939185_3473.JPEG': tensor(259.4665, device='cuda:0'), '/home/dexter/Downloads/train/n02939185/n02939185_6902.JPEG': tensor(259.8627, device='cuda:0')}\nAfter...\n{'/home/dexter/Downloads/train/n02939185/n02939185_54592.JPEG': tensor(255.8752, device='cuda:0'), '/home/dexter/Downloads/train/n02939185/n02939185_3473.JPEG': tensor(259.4665, device='cuda:0'), '/home/dexter/Downloads/train/n02939185/n02939185_6902.JPEG': tensor(259.8627, device='cuda:0')}\ncaldron: 0.56\ncaldron: 0.95\ncaldron: 1.00\n/home/dexter/Downloads/Human_experiments/Dataset/Natural/mixed_images/n02939185_ILSVRC2012_val_00021805_n02939185.jpeg\n/home/dexter/Downloads/Human_experiments/Dataset/Natural/mixed_images/n02939185_ILSVRC2012_val_00021805_n02939185.jpeg\nn02939185\ncaldron: a very large pot that is used for boiling\nconvert tmp/agg1.jpeg tmp/agg2.jpeg tmp/sample_def.jpeg -gravity center -append /home/dexter/Downloads/A-journey-into-Convolutional-Neural-Network-visualization-/Finding_explanations/NNs_hard_imagenet_aggregate/n02939185_ILSVRC2012_val_00021805_n02939185.jpeg\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4ce79101d11a66c965149c6276aa433ddd54e0
| 11,068 |
ipynb
|
Jupyter Notebook
|
M1890-Hidrologia/AguaSubterranea/docs/Ej1_AguaSubterranea.ipynb
|
NorAhmed1/Clases
|
da0f90c2a9da99a973d01b27e1c1bfaced443c69
|
[
"MIT"
] | 5 |
2020-07-06T00:02:46.000Z
|
2022-03-01T03:47:59.000Z
|
M1890-Hidrologia/AguaSubterranea/docs/Ej1_AguaSubterranea.ipynb
|
Ahmed-Yahia-cs/Clases
|
104a7632c41c278444fca4cd2ca76d986062768f
|
[
"MIT"
] | 14 |
2020-01-08T11:11:03.000Z
|
2020-01-12T16:42:32.000Z
|
M1890-Hidrologia/AguaSubterranea/docs/Ej1_AguaSubterranea.ipynb
|
casadoj/GISH_Hidrologia
|
104a7632c41c278444fca4cd2ca76d986062768f
|
[
"MIT"
] | 16 |
2020-04-22T06:39:42.000Z
|
2022-02-01T13:20:58.000Z
| 31.002801 | 299 | 0.508222 |
[
[
[
"# Ejercicios de agua subterránea",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nimport pandas as pd\n\nfrom matplotlib import pyplot as plt\n%matplotlib inline\nplt.style.use('dark_background')\n#plt.style.use('seaborn-whitegrid')",
"_____no_output_____"
]
],
[
[
"## <font color=steelblue>Ejercicio 1 - Infiltración. Método de Green-Ampt\n\n<font color=steelblue>Usando el modelo de Green-Ampt, calcula la __infiltración acumulada__, la __tasa de infiltración__ y la __profundidad del frente de mojado__ durante una precipitación constante de 5 cm/h que dure 2 h en un _loam_ limoso típico con un contenido de agua inicial de 0,45.\n \nLas propiedades típicas del _loam_ limoso son: <br>\n$\\phi=0.485$ <br>\n$K_{s}=2.59 cm/h$ <br>\n$|\\Psi_{ae}|=78.6 cm$ <br>\n$b=5.3$ <br>",
"_____no_output_____"
]
],
[
[
"# datos del enunciado\nphi = 0.485 # -\ntheta_o = 0.45 # -\nKs = 2.59 # cm/h\npsi_ae = 78.6 # cm\nb = 5.3 # -\n\nho = 0 # cm\ni = 5 # cm/h\ntc = 2 # h\n\nepsilon = 0.001 # cm",
"_____no_output_____"
]
],
[
[
"### Modelo de infiltración de Green-Ampt\n\nHipótesis:\n* Suelo encharcado con una lámina de altura $h_o$ desde el inicio.\n* Frente de avance de la humedad plano (frente pistón).\n* Suelo profundo y homogéneo ($\\theta_o$, $\\theta_s$, $K_s$ constantes).\n\nTasa de infiltración, $f \\left[ \\frac{L}{T} \\right]$:\n\n$$f = K_s \\left( 1 + \\frac{\\Psi_f · \\Delta\\theta}{F} \\right) \\qquad \\textrm{(1)}$$ \n\nInfiltración acumulada, $f \\left[ L \\right]$:\n$$F = K_s · t + \\Psi_f · \\Delta\\theta · \\ln \\left(1 + \\frac{F}{\\Psi_f · \\Delta\\theta} \\right) \\qquad \\textrm{(2)}$$\n\nEs una ecuación implícita. Para resolverla, se puede utilizar, por ejemplo, el método de Picard. Se establece un valor inicial de ($F_o=K_s·t$) y se itera el siguiente cálculo hasta converger ($F_{m+1}-F_m<\\varepsilon$):\n$$F_{m+1} = K_s · t + \\Psi_f · \\Delta\\theta · \\ln \\left(1 + \\frac{F_m}{\\Psi_f · \\Delta\\theta} \\right) \\qquad \\textrm{(3)}$$\n\n\n##### Suelo no encharcado al inicio\nSi no se cumple la hipótesis de encharcamiento desde el inicio, se debe calcular el tiempo de encharcamiento ($t_p$) y la cantidad de agua infiltrada hata ese momento ($F_p$):\n$$t_p = \\frac{K_s · \\Psi_f · \\Delta\\theta}{i \\left( i - K_s \\right)} \\qquad \\textrm{(4)}$$\n$$F_p = i · t_p = \\frac{K_s · \\Psi_f · \\Delta\\theta}{i - K_s} \\qquad \\textrm{(5)}$$\n\nConocidos $t_p$ y $F_p$, se ha de resolver la ecuación (1) sobre una nueva variable tiempo $t_p'=t_p-t_o$, con lo que se llega a la siguiente ecuación emplícita:\n$$F_{m+1} = K_s · (t - t_o) + \\Psi_f · \\Delta\\theta · \\ln \\left(1 + \\frac{F_m}{\\Psi_f · \\Delta\\theta} \\right) \\qquad \\textrm{(6)}$$\ndonde $t_o$ es:<br>\n$$t_o = t_p - \\frac{F_p - \\Psi_f · \\Delta\\theta · \\ln \\left(1 + \\frac{F_p}{\\Psi_f · \\Delta\\theta} \\right)}{K_s} \\qquad \\textrm{(7)}$$",
"_____no_output_____"
]
],
[
[
"# calcular variables auxiliares\nAtheta = phi - theta_o # incremento de la humedad del suelo\npsi_f = (2 * b + 3) / (2 * b + 6) * psi_ae # tensión en el frente húmedo",
"_____no_output_____"
],
[
"# tiempo hasta el encharcamiento\ntp = psi_f * Atheta * Ks / (i * (i - Ks))",
"_____no_output_____"
],
[
"# infiltración acumulada cuando ocurre el encharcamiento\nFp = tp * i",
"_____no_output_____"
],
[
"# tiempo de inicio de la curva de infiltración\nto = tp - (Fp - psi_f * Atheta * np.log(1 + Fp / (psi_f * Atheta))) / Ks",
"_____no_output_____"
],
[
"# infiltración acumulada en el tiempo de cálculo\nFo = Ks * (tc - to)\nFi = Ks * (tc - to) + psi_f * Atheta * np.log(1 + Fo / (psi_f * Atheta))\nwhile (Fi - Fo) > epsilon:\n Fo = Fi\n Fi = Ks * (tc - to) + psi_f * Atheta * np.log(1 + Fo / (psi_f * Atheta))\n print(Fo, Fi)\nFc = Fi\n\nprint()\nprint('Fc = {0:.3f} cm'.format(Fc))",
"7.242764529773666 7.9443030676516635\n7.9443030676516635 8.10493677607936\n8.10493677607936 8.140160823388143\n8.140160823388143 8.147811770684696\n8.147811770684696 8.149470190373284\n8.149470190373284 8.149829508633662\n\nFc = 8.150 cm\n"
],
[
"# tasa de infiltración en el tiempo de cálculo\nfc = Ks * (1 + psi_f * Atheta / Fc)\n\nprint('fc = {0:.3f} cm/h'.format(fc))",
"fc = 3.306 cm/h\n"
],
[
"# profundidad del frente de húmedo\nL = Fc / Atheta\n\nprint('L = {0:.3f} cm'.format(L))",
"L = 232.852 cm\n"
],
[
"def GreenAmpt(i, tc, ho, phi, theta_o, Ks, psi_ae, b=5.3, epsilon=0.001):\n \"\"\"Se calcula la infiltración en un suelo para una precipitación constante mediante el método de Green-Ampt.\n \n Entradas:\n ---------\n i: float. Intensidad de precipitación (cm/h)\n tc: float. Tiempo de cálculo (h)\n ho: float. Altura de la lámina de agua del encharcamiento en el inicio (cm)\n phi: float. Porosidad (-)\n theta_o: float. Humedad del suelo en el inicio (-)\n Ks: float. Conductividad saturada (cm/h)\n psi_ae: float. Tensión del suelo para el punto de entrada de aire (cm)\n b: float. Coeficiente para el cálculo de la tensión en el frente húmedo (cm)\n epsilo: float. Error tolerable en el cálculo (cm)\n \n Salidas:\n --------\n Fc: float. Infiltración acumulada en el tiempo de cálculo (cm)\n fc: float. Tasa de infiltración en el tiempo de cálculo (cm/h)\n L: float. Profundidad del frente húmedo en el tiempo de cálculo (cm)\"\"\"\n \n # calcular variables auxiliares\n Atheta = phi - theta_o # incremento de la humedad del suelo\n psi_f = (2 * b + 3) / (2 * b + 6) * psi_ae # tensión en el frente húmedo\n \n if ho > 0: # encharcamiento inicial\n tp = 0\n to = 0\n elif ho == 0: # NO hay encharcamiento inicial\n # tiempo hasta el encharcamiento\n tp = psi_f * Atheta * Ks / (i * (i - Ks))\n # infiltración acumulada cuando ocurre el encharcamiento\n Fp = tp * i\n # tiempo de inicio de la curva de infiltración\n to = tp - (Fp - psi_f * Atheta * np.log(1 + Fp / (psi_f * Atheta))) / Ks\n \n # infiltración acumulada en el tiempo de cálculo\n if tc <= tp:\n Fc = i * tc\n elif tc > tp:\n Fo = Ks * (tc - to)\n Fi = Ks * (tc - to) + psi_f * Atheta * np.log(1 + Fo / (psi_f * Atheta))\n while (Fi - Fo) > epsilon:\n Fo = Fi\n Fi = Ks * (tc - to) + psi_f * Atheta * np.log(1 + Fo / (psi_f * Atheta))\n Fc = Fi\n \n # tasa de infiltración en el tiempo de cálculo\n fc = Ks * (1 + psi_f * Atheta / Fc)\n \n # profundidad del frente de húmedo\n L = Fc / Atheta\n \n return Fc, fc, L",
"_____no_output_____"
],
[
"Fc, fc, L = GreenAmpt(i, tc, ho, phi, theta_o, Ks, psi_ae, b, epsilon)\n\nprint('Fc = {0:.3f} cm'.format(Fc))\nprint('fc = {0:.3f} cm/h'.format(fc))\nprint('L = {0:.3f} cm'.format(L))",
"Fc = 8.150 cm\nfc = 3.306 cm/h\nL = 232.852 cm\n"
],
[
"# Guardar resultados\nresults = pd.DataFrame([Fc, fc, L], index=['Fc (cm)', 'fc (cm/h)', 'L (cm)']).transpose()\nresults.to_csv('../output/Ej1_resultados.csv', index=False, float_format='%.3f')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4ce82a1c3f8e847783356aa4a267cfe2ce2cb6
| 21,630 |
ipynb
|
Jupyter Notebook
|
code/CNN_pool_class.ipynb
|
Ernie-Wang/Handcraft_CNN
|
cca5c1ae844a9e79fa03098c1a99d5bcb374bbc4
|
[
"MIT"
] | null | null | null |
code/CNN_pool_class.ipynb
|
Ernie-Wang/Handcraft_CNN
|
cca5c1ae844a9e79fa03098c1a99d5bcb374bbc4
|
[
"MIT"
] | null | null | null |
code/CNN_pool_class.ipynb
|
Ernie-Wang/Handcraft_CNN
|
cca5c1ae844a9e79fa03098c1a99d5bcb374bbc4
|
[
"MIT"
] | null | null | null | 42.411765 | 268 | 0.518262 |
[
[
[
"import numpy as np",
"_____no_output_____"
],
[
"'''\nConvolution class using no padding\n\nparam func - activation function\nparam d_func - derivative of activation function\nparam last_layer - point to last layer, which pass the value over\nparam input_num - numbers of input feature maps/images \nparam input_size - input feature maps/images size\nparam filter_size - size of the filter/kernel\nparam filter_num - numbers of filters, refer to number of output feature maps/images \nparam stride - moving step of the kernel function\nparam is_first - whether this layer is the first layer\n'''\nclass ConvLayer():\n def __init__(self, func, d_func, last_layer, input_size, input_num, filter_size, filter_num, stride, is_first):\n # Activation Functions\n self.act_func = func # Activation function\n self.d_act_func = d_func # Derivative of activate function\n \n self.last_layer = last_layer\n self.input_num = int(input_num)\n self.input_size = int(input_size)\n self.filter_size = int(filter_size)\n self.filter_num = int(filter_num)\n self.stride = int(stride)\n self.is_first = is_first\n \n # Initial kernel\n bound = np.sqrt(6 / ((input_num + filter_num) * filter_size * filter_size))\n self.kernel = np.random.uniform(-bound, bound, (int(filter_num),int(input_num),int(filter_size),int(filter_size)))\n# self.kernel = np.random.randn(int(filter_num),int(input_num),int(filter_size),int(filter_size))\n# self.kernel = np.random.randn(int(filter_num),int(input_num),int(filter_size),int(filter_size)) / np.sqrt(1/(filter_size*filter_size)\n # Initial bias\n self.bias = np.zeros(self.filter_num)\n \n self.delta_w_sum = np.zeros((int(filter_num),int(input_num),int(filter_size),int(filter_size)))\n self.delta_bias_sum = np.zeros(self.filter_num)\n \n # Check if the parameters of input size, filter size, stride is legel\n self.output_size = (input_size + stride - filter_size) / stride\n if(self.output_size%1 != 0):\n print(\"Invalid ! Please check your parameters\");\n return -1\n \n \n self.input_img = 0\n self.stride_shape = (int(input_num),int(self.output_size),int(self.output_size),int(filter_size),int(filter_size))\n self.strides = (int(input_size*input_size*8), int(input_size*stride*8), int(stride*8), int(input_size*8), 8)\n self.conv_img = 0\n self.output_img = 0\n self.d_func_img = 0\n \n self.delta_bias = 0 # Correction of bias\n self.pass_error = 0 # Error passed to previous layer\n self.delta_w = 0 # Weight correction\n self.error = 0 # input error * derivative of activation function\n \n \n def forwrad_pass(self):\n if not self.is_first:\n self.extract_value()\n self.strided_img = np.lib.stride_tricks.as_strided(self.input_img, shape=self.stride_shape, strides=self.strides) # Cut the image with kernel size\n \n # Convolution operations\n self.conv_img = np.einsum(\"ijklm,ailm->ajk\", self.strided_img, self.kernel)\n# print(\"=================self.conv_img=================\")\n# print(self.conv_img)\n# print(\"=================self.bias=================\")\n# print(self.bias)\n\n self.conv_img += self.bias.reshape(len(self.bias),1, 1)\n \n# print(\"=================self.conv_img=================\")\n# print(self.conv_img)\n \n self.output_img = self.act_func(self.conv_img) # Through activation function\n self.d_func_img = self.d_act_func(self.conv_img) # Through derivative of activation function\n# print(\"=================self.input_img=================\")\n# print(self.input_img[0])\n# print(\"=================self.strided_img=================\")\n# print(self.strided_img[0][13])\n# print(\"=================self.kernel=================\")\n# print(self.kernel[0])\n# print(\"=================self.conv_img=================\")\n# print(self.conv_img)\n# print(\"=================self.output_img=================\")\n# print(self.output_img)\n \n '''\n Adjust weights, using backpropagation\n For error function, e = y_predict - y_desire\n For weight correction, w_n+1 = w_n - delta_w\n '''\n def adjust_weight(self, lr_rate, need_update):\n # Calculate error \n self.error = self.d_func_img * self.bp_vec\n# print(self.bp_vec)\n \n # Adjust weight\n self.delta_w = np.einsum(\"ijklm,ajk->ailm\", self.strided_img, self.error)\n self.delta_w_sum += self.delta_w\n \n # Adjust bias\n self.delta_bias = np.einsum(\"ijk->i\", self.error)\n self.delta_bias_sum += self.delta_bias\n \n # Update weight if reach bias\n if need_update:\n# print(\"update\")\n self.kernel -= lr_rate * self.delta_w_sum\n self.bias -= lr_rate * self.delta_bias\n self.delta_w_sum.fill(0)\n self.delta_bias_sum.fill(0)\n \n# print(\"=================self.d_func_img=================\")\n# print(self.d_func_img)\n# print(\"=================self.bp_vec=================\")\n# print(self.bp_vec)\n# print(\"=================self.strided_img=================\")\n# print(self.strided_img)\n# print(\"=================self.error=================\")\n# print(self.error)\n# print(\"=================self.delta_w=================\")\n# print(self.delta_w)\n# print(\"=================self.delta_bias=================\")\n# print(self.delta_bias)\n\n\n # Calculate pass error\n if not self.is_first:\n pass_error_tmp = np.einsum(\"aijk,alm->ilmjk\", self.kernel, self.error)\n\n img_shape = (int(self.input_num),int(self.output_size),int(self.output_size),int(self.filter_size),int(self.filter_size))\n img_strides = (int(self.output_size*self.output_size*self.input_size*self.input_size*8), int((self.input_size * self.input_size + self.input_size)*self.stride*8), int((self.input_size * self.input_size + self.stride)*8), int(self.input_size*8), 8)\n\n # Use to map error position\n self.pass_error = np.zeros((int(self.input_num),int(self.output_size),int(self.output_size),int(self.input_size),int(self.input_size)), dtype=np.float)\n \n inv_stride = self.pass_error.strides\n inv_shape = self.pass_error.shape\n\n A = np.lib.stride_tricks.as_strided(self.pass_error, shape=img_shape, strides=img_strides) # Cut the image with kernel size\n\n A += pass_error_tmp\n A = np.lib.stride_tricks.as_strided(A, shape=inv_shape, strides=inv_stride) # Cut the image with kernel size\n self.pass_error = np.einsum(\"ijklm->ilm\", A)\n \n self.last_layer.pass_bp(self.pass_error)\n\n# for i in range(len(pass_error_tmp[0])):\n# for j in range(len(pass_error_tmp[0][0])):\n# print(A[:,i,j], pass_error_tmp[:,i,j])\n# self.pass_error[:,i,j] += pass_error_tmp[:,i,j]\n# for img_h in range(len(self.error[0])):\n# for img_w in range(len(self.error[0][0])):\n# left_corner_h = img_h * self.stride\n# left_corner_w = img_w * self.stride\n\n# for feature in range(len(self.error)):\n# # error pass to previous layer\n# self.pass_error[:,int(left_corner_h):int(left_corner_h+self.filter_size),int(left_corner_w):int(left_corner_w+self.filter_size)] += self.kernel[feature] * self.error[feature][img_h][img_w]\n\n \n \n \n def extract_value(self):\n self.input_img = self.last_layer.get_output()\n return self.input_img\n \n def get_output(self):\n return self.output_img.copy()\n \n def get_output_size(self):\n return self.output_size\n \n '''\n Set input variable, used for first layer which recieve input value\n @param x - input value for the network\n '''\n def set_input(self, x):\n self.input_img = x.copy()\n \n '''\n Pass backpropagation value back to previous layer\n '''\n def pass_bp(self, bp_value):\n self.bp_vec = bp_value.copy()",
"_____no_output_____"
],
[
"'''\nPooling class using no padding\n\nparam last_layer - point to last layer, which pass the value over\nparam input_size - input feature maps/images size\nparam input_num - numbers of input feature maps/images \nparam filter_pattern - pattern of the filter\nparam stride - moving step of the kernel function\n'''\nclass AvgPooling():\n def __init__(self, last_layer, input_size, input_num, filter_size, stride, is_first):\n self.last_layer = last_layer\n self.input_size = int(input_size)\n self.input_num = int(input_num)\n self.filter_size = int(filter_size)\n self.filter_pattern = np.full((int(input_num), int(input_num), int(filter_size), int(filter_size)), 1/(filter_size * filter_size))\n self.d_filter_pattern = np.full((int(input_num),int(input_num),int(filter_size),int(filter_size)), 1/(filter_size * filter_size))\n self.stride = stride\n self.is_first = is_first\n \n # Check if the parameters of input size, filter size, stride is legel\n self.output_size = (input_size + stride - self.filter_size) / stride\n if(self.output_size%1 != 0):\n print(\"Invalid ! Please check your parameters\");\n return -1\n \n self.input_img = 0\n self.stride_shape = (int(input_num),int(self.output_size),int(self.output_size),int(filter_size),int(filter_size))\n self.strides = (int(input_size*input_size*8), int(input_size*stride*8), int(stride*8), int(input_size*8), 8)\n self.conv_img = 0\n self.output_img = 0\n self.d_func_img = 0\n \n self.pass_error = 0 # Error passed to previous layer\n self.error = 0 # input error * derivative of activation function\n \n def forwrad_pass(self):\n if not self.is_first:\n self.extract_value()\n strided_img = np.lib.stride_tricks.as_strided(self.input_img, shape=self.stride_shape, strides=self.strides) # Cut the image with kernel size\n \n # Convolution operations\n self.output_img = np.einsum(\"ijklm,ailm->ajk\", strided_img, self.filter_pattern)\n ## In max pooling, need to record last max value position\n \n '''\n Adjust weights, using backpropagation\n For error function, e = y_predict - y_desire\n For weight correction, w_n+1 = w_n - delta_w\n '''\n def adjust_weight(self, lr_rate, need_update):\n \n if not self.is_first:\n self.error = self.bp_vec # error\n # print(self.bp_vec )\n\n # Calculate pass error\n pass_error_tmp = np.einsum(\"aijk,alm->ilmjk\", self.d_filter_pattern, self.error)\n\n img_shape = (int(self.input_num),int(self.output_size),int(self.output_size),int(self.filter_size),int(self.filter_size))\n img_strides = (int(self.output_size*self.output_size*self.input_size*self.input_size*8), int((self.input_size * self.input_size + self.input_size)*self.stride*8), int((self.input_size * self.input_size + self.stride)*8), int(self.input_size*8), 8)\n\n # Use to map error position\n self.pass_error = np.zeros((int(self.input_num),int(self.output_size),int(self.output_size),int(self.input_size),int(self.input_size)), dtype=np.float)\n inv_stride = self.pass_error.strides\n inv_shape = self.pass_error.shape\n\n A = np.lib.stride_tricks.as_strided(self.pass_error, shape=img_shape, strides=img_strides) # Cut the image with kernel size\n\n A += pass_error_tmp\n A = np.lib.stride_tricks.as_strided(A, shape=inv_shape, strides=inv_stride) # Cut the image with kernel size\n self.pass_error = np.einsum(\"ijklm->ilm\", A)\n \n self.last_layer.pass_bp(self.pass_error)\n \n def extract_value(self):\n self.input_img = self.last_layer.get_output()\n return self.input_img\n \n def get_output(self):\n return self.output_img.copy()\n \n def get_output_size(self):\n return self.output_size\n \n '''\n Set input variable, used for first layer which recieve input value\n @param x - input value for the network\n '''\n def set_input(self, x):\n self.input_img = x.copy()\n \n '''\n Pass backpropagation value back to previous layer\n '''\n def pass_bp(self, bp_value):\n self.bp_vec = bp_value.copy()",
"_____no_output_____"
],
[
"'''\nFlattening class using no padding\n\nparam last_layer - point to last layer, which pass the value over\nparam input_size - input feature maps/images size\nparam input_num - numbers of input feature maps/images\n'''\nclass Flattening():\n def __init__(self, last_layer, input_size, input_num, is_first):\n self.last_layer = last_layer\n self.input_size = int(input_size)\n self.input_num = int(input_num)\n self.is_first = is_first\n \n def forwrad_pass(self):\n if not self.is_first:\n self.extract_value()\n self.output_img = self.input_img.reshape(int(self.input_num*self.input_size*self.input_size))\n \n \n def extract_value(self):\n self.input_img = self.last_layer.get_output()\n return self.input_img\n \n def get_output(self):\n return self.output_img.copy() \n \n '''\n Set input variable, used for first layer which recieve input value\n @param x - input value for the network\n '''\n def set_input(self, x):\n self.input_img = x.copy()\n \n def get_node_num(self):\n self.neuron_num = self.input_num*self.input_size*self.input_size\n return self.neuron_num\n \n '''\n Pass backpropagation value back to previous layer\n '''\n def pass_bp(self, bp_value):\n self.bp_vec = bp_value.copy()\n \n '''\n Adjust weights, using backpropagation\n For error function, e = y_predict - y_desire\n For weight correction, w_n+1 = w_n - delta_w\n '''\n def adjust_weight(self, lr_rate, need_update):\n if not self.is_first:\n self.pass_error = self.bp_vec.reshape(int(self.input_num), int(self.input_size), int(self.input_size))\n self.last_layer.pass_bp(self.pass_error)",
"_____no_output_____"
],
[
"#@title\n'''\nActivation function for the network\n'''\ndef test_act_func(x):\n return x*11\n\n'''\nReLU\n'''\ndef ReLU(x):\n x[x<=0] = 0\n return x.copy()\n\n'''\nSigmoid\n'''\ndef Sigmoid(x):\n return 1/(1+np.exp(-x))\n",
"_____no_output_____"
],
[
"#@title\n'''\nDiviation of the activation function for the network\n'''\ndef d_test_act_func(x):\n return x+2\n\n'''\nDiviation of ReLU\n'''\ndef d_ReLU(x):\n x[x > 0] = 1\n x[x < 0] = 0\n return x.copy()\n\n'''\nDiviation of Sigmoid\n'''\ndef d_Sigmoid(x):\n s = 1/(1+np.exp(-x))\n return s * (1 - s)",
"_____no_output_____"
]
],
[
[
"input_size = 5\ninput_num = 1\nfilter_size = 3\nfilter_num = 1\nstride = 1\nlr_rate = 1\nimg = np.arange(input_size*input_size, dtype=np.float).reshape(input_num, input_size, input_size)\nerror = np.random.randn(filter_num, filter_size, filter_size) / np.sqrt(filter_size*filter_size)\n# print(error)\nmodel = ConvLayer(ReLU, d_ReLU, 1, input_size, input_num, filter_size, filter_num, stride) \nmodel1 = AvgPooling(ReLU, input_size, input_num, filter_size, stride) #last_layer, input_size, input_num, filter_size, stride\nmodel.set_input(img)\nmodel.forwrad_pass()\nmodel.pass_bp(error)\nmodel.adjust_weight(lr_rate)\n# print(\"model.filter_pattern\")\n# print(model.filter_pattern)\nprint(\"model.output_img\")\nprint(model.output_img)\n\nprint(\"model.error\")\nprint(model.error)\nprint(\"model.pass_error\")\nprint(model.pass_error)\n# print(\"model.delta_w\")\n# print(model.delta_w)\n# print(\"model.delta_bias\")\n# print(model.delta_bias)",
"_____no_output_____"
],
[
"model = Flattening(model1, input_size, input_num) #last_layer, input_size, input_num, filter_size, stride\nmodel.set_input(img)\nmodel.forwrad_pass()\nmodel.pass_bp(img)\nmodel.adjust_weight(lr_rate)\n\nprint(\"model.output_img\")\nprint(model.output_img)\n\nprint(\"model.pass_error\")\nprint(model.pass_error)",
"_____no_output_____"
]
]
] |
[
"code",
"raw"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"raw",
"raw"
]
] |
4a4cf2913fb6184c950b141c14baa3fcaae378f0
| 66,340 |
ipynb
|
Jupyter Notebook
|
03.PyTorch/PyTorch_04_cifar10_tutorial.ipynb
|
cuicaihao/Data_Science_Python
|
ca4cb64bf9afc1011c192586362d0dd036e9441e
|
[
"MIT"
] | 2 |
2018-04-26T12:11:41.000Z
|
2018-10-09T19:37:57.000Z
|
03.PyTorch/PyTorch_04_cifar10_tutorial.ipynb
|
cuicaihao/Data_Science_Python
|
ca4cb64bf9afc1011c192586362d0dd036e9441e
|
[
"MIT"
] | null | null | null |
03.PyTorch/PyTorch_04_cifar10_tutorial.ipynb
|
cuicaihao/Data_Science_Python
|
ca4cb64bf9afc1011c192586362d0dd036e9441e
|
[
"MIT"
] | 4 |
2018-10-09T19:37:59.000Z
|
2021-01-23T11:31:16.000Z
| 100.060332 | 23,428 | 0.832967 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\nTraining a Classifier\n=====================\n\nThis is it. You have seen how to define neural networks, compute loss and make\nupdates to the weights of the network.\n\nNow you might be thinking,\n\nWhat about data?\n----------------\n\nGenerally, when you have to deal with image, text, audio or video data,\nyou can use standard python packages that load data into a numpy array.\nThen you can convert this array into a ``torch.*Tensor``.\n\n- For images, packages such as Pillow, OpenCV are useful\n- For audio, packages such as scipy and librosa\n- For text, either raw Python or Cython based loading, or NLTK and\n SpaCy are useful\n\nSpecifically for vision, we have created a package called\n``torchvision``, that has data loaders for common datasets such as\nImagenet, CIFAR10, MNIST, etc. and data transformers for images, viz.,\n``torchvision.datasets`` and ``torch.utils.data.DataLoader``.\n\nThis provides a huge convenience and avoids writing boilerplate code.\n\nFor this tutorial, we will use the CIFAR10 dataset.\nIt has the classes: ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’,\n‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’. The images in CIFAR-10 are of\nsize 3x32x32, i.e. 3-channel color images of 32x32 pixels in size.\n\n.. figure:: /_static/img/cifar10.png\n :alt: cifar10\n\n cifar10\n\n\nTraining an image classifier\n----------------------------\n\nWe will do the following steps in order:\n\n1. Load and normalizing the CIFAR10 training and test datasets using\n ``torchvision``\n2. Define a Convolution Neural Network\n3. Define a loss function\n4. Train the network on the training data\n5. Test the network on the test data\n\n1. Loading and normalizing CIFAR10\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n\nUsing ``torchvision``, it’s extremely easy to load CIFAR10.\n\n",
"_____no_output_____"
]
],
[
[
"import torch\nimport torchvision\nimport torchvision.transforms as transforms",
"_____no_output_____"
]
],
[
[
"The output of torchvision datasets are PILImage images of range [0, 1].\nWe transform them to Tensors of normalized range [-1, 1].\n\n",
"_____no_output_____"
]
],
[
[
"transform = transforms.Compose(\n [transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n\ntrainset = torchvision.datasets.CIFAR10(root='./data', train=True,\n download=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=4,\n shuffle=True, num_workers=2)\n\ntestset = torchvision.datasets.CIFAR10(root='./data', train=False,\n download=True, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=4,\n shuffle=False, num_workers=2)\n\nclasses = ('plane', 'car', 'bird', 'cat',\n 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')",
"Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data\\cifar-10-python.tar.gz\nFiles already downloaded and verified\n"
]
],
[
[
"Let us show some of the training images, for fun.\n\n",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\n\n# functions to show an image\n\n\ndef imshow(img):\n img = img / 2 + 0.5 # unnormalize\n npimg = img.numpy()\n plt.imshow(np.transpose(npimg, (1, 2, 0)))\n\n\n# get some random training images\ndataiter = iter(trainloader)\nimages, labels = dataiter.next()\n\n# show images\nimshow(torchvision.utils.make_grid(images))\n# print labels\nprint(' '.join('%5s' % classes[labels[j]] for j in range(4)))",
"plane frog horse ship\n"
]
],
[
[
"2. Define a Convolution Neural Network\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\nCopy the neural network from the Neural Networks section before and modify it to\ntake 3-channel images (instead of 1-channel images as it was defined).\n\n",
"_____no_output_____"
]
],
[
[
"import torch.nn as nn\nimport torch.nn.functional as F\n\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(3, 6, 5)\n self.pool = nn.MaxPool2d(2, 2)\n self.conv2 = nn.Conv2d(6, 16, 5)\n self.fc1 = nn.Linear(16 * 5 * 5, 120)\n self.fc2 = nn.Linear(120, 84)\n self.fc3 = nn.Linear(84, 10)\n\n def forward(self, x):\n x = self.pool(F.relu(self.conv1(x)))\n x = self.pool(F.relu(self.conv2(x)))\n x = x.view(-1, 16 * 5 * 5)\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n\n\nnet = Net()",
"_____no_output_____"
]
],
[
[
"3. Define a Loss function and optimizer\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\nLet's use a Classification Cross-Entropy loss and SGD with momentum.\n\n",
"_____no_output_____"
]
],
[
[
"import torch.optim as optim\n\ncriterion = nn.CrossEntropyLoss()\noptimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)",
"_____no_output_____"
]
],
[
[
"4. Train the network\n^^^^^^^^^^^^^^^^^^^^\n\nThis is when things start to get interesting.\nWe simply have to loop over our data iterator, and feed the inputs to the\nnetwork and optimize.\n\n",
"_____no_output_____"
]
],
[
[
"for epoch in range(2): # loop over the dataset multiple times\n\n running_loss = 0.0\n for i, data in enumerate(trainloader, 0):\n # get the inputs\n inputs, labels = data\n\n # zero the parameter gradients\n optimizer.zero_grad()\n\n # forward + backward + optimize\n outputs = net(inputs)\n loss = criterion(outputs, labels)\n loss.backward()\n optimizer.step()\n\n # print statistics\n running_loss += loss.item()\n if i % 2000 == 1999: # print every 2000 mini-batches\n print('[%d, %5d] loss: %.3f' %\n (epoch + 1, i + 1, running_loss / 2000))\n running_loss = 0.0\n\nprint('Finished Training')",
"[1, 2000] loss: 2.200\n[1, 4000] loss: 1.842\n[1, 6000] loss: 1.682\n[1, 8000] loss: 1.581\n[1, 10000] loss: 1.526\n[1, 12000] loss: 1.460\n[2, 2000] loss: 1.398\n[2, 4000] loss: 1.373\n[2, 6000] loss: 1.328\n[2, 8000] loss: 1.328\n[2, 10000] loss: 1.318\n[2, 12000] loss: 1.284\nFinished Training\n"
]
],
[
[
"5. Test the network on the test data\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n\nWe have trained the network for 2 passes over the training dataset.\nBut we need to check if the network has learnt anything at all.\n\nWe will check this by predicting the class label that the neural network\noutputs, and checking it against the ground-truth. If the prediction is\ncorrect, we add the sample to the list of correct predictions.\n\nOkay, first step. Let us display an image from the test set to get familiar.\n\n",
"_____no_output_____"
]
],
[
[
"dataiter = iter(testloader)\nimages, labels = dataiter.next()\n\n# print images\nimshow(torchvision.utils.make_grid(images))\nprint('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))",
"GroundTruth: cat ship ship plane\n"
]
],
[
[
"Okay, now let us see what the neural network thinks these examples above are:\n\n",
"_____no_output_____"
]
],
[
[
"outputs = net(images)",
"_____no_output_____"
]
],
[
[
"The outputs are energies for the 10 classes.\nHigher the energy for a class, the more the network\nthinks that the image is of the particular class.\nSo, let's get the index of the highest energy:\n\n",
"_____no_output_____"
]
],
[
[
"_, predicted = torch.max(outputs, 1)\n\nprint('Predicted: ', ' '.join('%5s' % classes[predicted[j]]\n for j in range(4)))",
"Predicted: cat ship ship ship\n"
]
],
[
[
"The results seem pretty good.\n\nLet us look at how the network performs on the whole dataset.\n\n",
"_____no_output_____"
]
],
[
[
"correct = 0\ntotal = 0\nwith torch.no_grad():\n for data in testloader:\n images, labels = data\n outputs = net(images)\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\nprint('Accuracy of the network on the 10000 test images: %d %%' % (\n 100 * correct / total))",
"Accuracy of the network on the 10000 test images: 54 %\n"
]
],
[
[
"That looks waaay better than chance, which is 10% accuracy (randomly picking\na class out of 10 classes).\nSeems like the network learnt something.\n\nHmmm, what are the classes that performed well, and the classes that did\nnot perform well:\n\n",
"_____no_output_____"
]
],
[
[
"class_correct = list(0. for i in range(10))\nclass_total = list(0. for i in range(10))\nwith torch.no_grad():\n for data in testloader:\n images, labels = data\n outputs = net(images)\n _, predicted = torch.max(outputs, 1)\n c = (predicted == labels).squeeze()\n for i in range(4):\n label = labels[i]\n class_correct[label] += c[i].item()\n class_total[label] += 1\n\n\nfor i in range(10):\n print('Accuracy of %5s : %2d %%' % (\n classes[i], 100 * class_correct[i] / class_total[i]))",
"Accuracy of plane : 49 %\nAccuracy of car : 62 %\nAccuracy of bird : 31 %\nAccuracy of cat : 27 %\nAccuracy of deer : 43 %\nAccuracy of dog : 67 %\nAccuracy of frog : 79 %\nAccuracy of horse : 56 %\nAccuracy of ship : 69 %\nAccuracy of truck : 60 %\n"
]
],
[
[
"Okay, so what next?\n\nHow do we run these neural networks on the GPU?\n\nTraining on GPU\n----------------\nJust like how you transfer a Tensor on to the GPU, you transfer the neural\nnet onto the GPU.\n\nLet's first define our device as the first visible cuda device if we have\nCUDA available:\n\n",
"_____no_output_____"
]
],
[
[
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\n# Assume that we are on a CUDA machine, then this should print a CUDA device:\n\nprint(device)",
"cuda:0\n"
],
[
"net.to(device)\n\nfor epoch in range(2): # loop over the dataset multiple times\n running_loss = 0.0\n for i, data in enumerate(trainloader, 0):\n # get the inputs\n inputs, labels = data \n inputs, labels = inputs.to(device), labels.to(device)\n # zero the parameter gradients\n optimizer.zero_grad() \n\n # forward + backward + optimize\n outputs = net(inputs).to(device)\n loss = criterion(outputs, labels)\n loss.backward()\n optimizer.step() \n\n # print statistics\n running_loss += loss.item()\n if i % 2000 == 1999: # print every 2000 mini-batches\n print('[%d, %5d] loss: %.3f' %\n (epoch + 1, i + 1, running_loss / 2000))\n running_loss = 0.0\n\nprint('Finished Training')\n",
"_____no_output_____"
]
],
[
[
"The rest of this section assumes that `device` is a CUDA device.\n\nThen these methods will recursively go over all modules and convert their\nparameters and buffers to CUDA tensors:\n\n.. code:: python\n\n net.to(device)\n\n\nRemember that you will have to send the inputs and targets at every step\nto the GPU too:\n\n.. code:: python\n\n inputs, labels = inputs.to(device), labels.to(device)\n\nWhy dont I notice MASSIVE speedup compared to CPU? Because your network\nis realllly small.\n\n**Exercise:** Try increasing the width of your network (argument 2 of\nthe first ``nn.Conv2d``, and argument 1 of the second ``nn.Conv2d`` –\nthey need to be the same number), see what kind of speedup you get.\n\n**Goals achieved**:\n\n- Understanding PyTorch's Tensor library and neural networks at a high level.\n- Train a small neural network to classify images\n\nTraining on multiple GPUs\n-------------------------\nIf you want to see even more MASSIVE speedup using all of your GPUs,\nplease check out :doc:`data_parallel_tutorial`.\n\nWhere do I go next?\n-------------------\n\n- :doc:`Train neural nets to play video games </intermediate/reinforcement_q_learning>`\n- `Train a state-of-the-art ResNet network on imagenet`_\n- `Train a face generator using Generative Adversarial Networks`_\n- `Train a word-level language model using Recurrent LSTM networks`_\n- `More examples`_\n- `More tutorials`_\n- `Discuss PyTorch on the Forums`_\n- `Chat with other users on Slack`_\n\n\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a4cf6758ca3177fefc5750e308bb824bf64fe73
| 116,204 |
ipynb
|
Jupyter Notebook
|
nbs/00_examples.ipynb
|
perceptualrobots/pct
|
9690d64fa89c2802299229d4f4b01baea7c1a881
|
[
"Apache-2.0"
] | 6 |
2021-03-26T22:15:15.000Z
|
2021-11-17T14:33:13.000Z
|
nbs/00_examples.ipynb
|
perceptualrobots/pct
|
9690d64fa89c2802299229d4f4b01baea7c1a881
|
[
"Apache-2.0"
] | null | null | null |
nbs/00_examples.ipynb
|
perceptualrobots/pct
|
9690d64fa89c2802299229d4f4b01baea7c1a881
|
[
"Apache-2.0"
] | null | null | null | 224.765957 | 95,928 | 0.904306 |
[
[
[
"#from nbdev import *",
"_____no_output_____"
],
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"#%nbdev_hide\n#import sys\n#sys.path.append(\"..\")",
"_____no_output_____"
]
],
[
[
"# Examples\n\n> Examples of the PCT library in use.",
"_____no_output_____"
]
],
[
[
"import gym \nrender=False\nruns=1",
"_____no_output_____"
],
[
"#gui\nrender=True\nruns=2000",
"_____no_output_____"
]
],
[
[
"## Cartpole\n\nCartpole is an Open AI gym environment for the inverted pendulum problem. The goal is to keep the pole balanced, by moving the cart left or right.\n\nThe environment provides observations (perceptions) for the state of the cart and pole.\n\n0 - Cart Position \n1 - Cart Velocity \n2 - Pole Angle \n3 - Pole Angular Velocity \n \nIt takes one value, of 0 or 1, for applying a force to the left or right, respectively.\n\nThe PCT solution is a four-level hierarchy for controlling the perceptions at goal values. Only one goal reference is manually set, the highest level which is the pole angle of 0. \n\nThis example shows how a perceptual control hierarchy can be implemented with this library.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nfrom pct.hierarchy import PCTHierarchy\nfrom pct.putils import FunctionsList\nfrom pct.environments import CartPoleV1\nfrom pct.functions import IndexedParameter\nfrom pct.functions import Integration\nfrom pct.functions import GreaterThan\nfrom pct.functions import PassOn",
"_____no_output_____"
]
],
[
[
"Create a hierarchy of 4 levels each with one node.",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy = PCTHierarchy(levels=4, cols=1, name=\"cartpoleh\", build=False)\nnamespace=cartpole_hierarchy.namespace\ncartpole_hierarchy.get_node(0, 0).name = 'cart_velocity_node'\ncartpole_hierarchy.get_node(1, 0).name = 'cart_position_node'\ncartpole_hierarchy.get_node(2, 0).name = 'pole_velocity_node'\ncartpole_hierarchy.get_node(3, 0).name = 'pole_angle_node'\n#FunctionsList.getInstance().report()\n#cartpole_hierarchy.summary(build=True)",
"_____no_output_____"
]
],
[
[
"Create the Cartpole gym environment function. This will apply the \"action\" output from the hierarchy and provide the new observations.",
"_____no_output_____"
]
],
[
[
"cartpole = CartPoleV1(name=\"CartPole-v1\", render=render, namespace=namespace)",
"_____no_output_____"
]
],
[
[
"Create functions for each of the observation parameters of the Cartpole environment. Insert them into the hierarchy at the desired places.",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy.insert_function(level=0, col=0, collection=\"perception\", function=IndexedParameter(index=1, name=\"cart_velocity\", links=[cartpole], namespace=namespace))\ncartpole_hierarchy.insert_function(level=1, col=0, collection=\"perception\", function=IndexedParameter(index=0, name=\"cart_position\", links=[cartpole], namespace=namespace))\ncartpole_hierarchy.insert_function(level=2, col=0, collection=\"perception\", function=IndexedParameter(index=3, name=\"pole_velocity\", links=[cartpole], namespace=namespace))\ncartpole_hierarchy.insert_function(level=3, col=0, collection=\"perception\", function=IndexedParameter(index=2, name=\"pole_angle\", links=[cartpole], namespace=namespace))",
"_____no_output_____"
]
],
[
[
"Link the references to the outputs of the level up.",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy.insert_function(level=0, col=0, collection=\"reference\", function=PassOn(name=\"cart_velocity_reference\", links=['proportional1'], namespace=namespace))\ncartpole_hierarchy.insert_function(level=1, col=0, collection=\"reference\", function=PassOn(name=\"cart_position_reference\", links=['proportional2'], namespace=namespace))\ncartpole_hierarchy.insert_function(level=2, col=0, collection=\"reference\", function=PassOn(name=\"pole_velocity_reference\", links=['proportional3'], namespace=namespace))",
"_____no_output_____"
]
],
[
[
"Set the highest level reference.",
"_____no_output_____"
]
],
[
[
"top = cartpole_hierarchy.get_function(level=3, col=0, collection=\"reference\")\ntop.set_name(\"pole_angle_reference\")\ntop.set_value(0)",
"_____no_output_____"
]
],
[
[
"Link the output of the hierarchy back to the Cartpole environment.",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy.summary(build=True)",
"cartpoleh PCTHierarchy\n**************************\nPRE: None\nLevel 0 Cols 1\ncart_velocity_node PCTNode\n----------------------------\nREF: cart_velocity_reference PassOn | 0 | links proportional1 \nPER: cart_velocity IndexedParameter | index 1 | 0 | links CartPole-v1 \nCOM: subtract Subtract | 0 | links cart_velocity_reference cart_velocity \nOUT: proportional Proportional | gain 1 | 0 | links subtract \n----------------------------\nLevel 1 Cols 1\ncart_position_node PCTNode\n----------------------------\nREF: cart_position_reference PassOn | 0 | links proportional2 \nPER: cart_position IndexedParameter | index 0 | 0 | links CartPole-v1 \nCOM: subtract1 Subtract | 0 | links cart_position_reference cart_position \nOUT: proportional1 Proportional | gain 1 | 0 | links subtract1 \n----------------------------\nLevel 2 Cols 1\npole_velocity_node PCTNode\n----------------------------\nREF: pole_velocity_reference PassOn | 0 | links proportional3 \nPER: pole_velocity IndexedParameter | index 3 | 0 | links CartPole-v1 \nCOM: subtract2 Subtract | 0 | links pole_velocity_reference pole_velocity \nOUT: proportional2 Proportional | gain 1 | 0 | links subtract2 \n----------------------------\nLevel 3 Cols 1\npole_angle_node PCTNode\n----------------------------\nREF: pole_angle_reference Constant | 0 \nPER: pole_angle IndexedParameter | index 2 | 0 | links CartPole-v1 \nCOM: subtract3 Subtract | 0 | links pole_angle_reference pole_angle \nOUT: proportional3 Proportional | gain 1 | 0 | links subtract3 \n----------------------------\nPOST: None\n**************************\n"
],
[
"cartpole_hierarchy.insert_function(level=0, col=0, collection=\"output\", function=Integration(gain=-0.05, slow=4, name=\"force\", links='subtract', namespace=namespace))",
"_____no_output_____"
]
],
[
[
"Set the names and gains of the output functions. This also shows another way of getting a function, by name.",
"_____no_output_____"
]
],
[
[
"FunctionsList.getInstance().get_function(namespace=namespace, name=\"proportional3\").set_name(\"pole_angle_output\")\nFunctionsList.getInstance().get_function(namespace=namespace, name=\"pole_angle_output\").set_property('gain', 3.5)\n\nFunctionsList.getInstance().get_function(namespace=namespace, name=\"proportional2\").set_name(\"pole_velocity_output\")\nFunctionsList.getInstance().get_function(namespace=namespace, name=\"pole_velocity_output\").set_property('gain', 0.5)\n\nFunctionsList.getInstance().get_function(namespace=namespace, name=\"proportional1\").set_name(\"cart_position_output\")\nFunctionsList.getInstance().get_function(namespace=namespace, name=\"cart_position_output\").set_property('gain', 2)",
"_____no_output_____"
]
],
[
[
"Add a post function to convert the output to 1 or 0 as required by the Cartpole environment. ",
"_____no_output_____"
]
],
[
[
"greaterthan = GreaterThan(threshold=0, upper=1, lower=0, links='force', namespace=namespace)\ncartpole_hierarchy.add_postprocessor(greaterthan)",
"_____no_output_____"
]
],
[
[
"Add the cartpole function as one that is executed before the actual hierarchy.",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy.add_preprocessor(cartpole)",
"_____no_output_____"
]
],
[
[
"Set the output of the hierachy as the action input to the Cartpole environment. ",
"_____no_output_____"
]
],
[
[
"#link = cartpole_hierarchy.get_output_function()\ncartpole.add_link(greaterthan)",
"_____no_output_____"
]
],
[
[
"Sit back and observe the brilliance of your efforts. ",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy.set_order(\"Down\")",
"_____no_output_____"
],
[
"cartpole_hierarchy.summary()",
"cartpoleh PCTHierarchy\n**************************\nPRE: CartPole-v1 CartPoleV1 | 0 | links greaterthan \nLevel 3 Cols 1\npole_angle_node PCTNode\n----------------------------\nREF: pole_angle_reference Constant | 0 \nPER: pole_angle IndexedParameter | index 2 | 0 | links CartPole-v1 \nCOM: subtract3 Subtract | 0 | links pole_angle_reference pole_angle \nOUT: pole_angle_output Proportional | gain 3.5 | 0 | links subtract3 \n----------------------------\nLevel 2 Cols 1\npole_velocity_node PCTNode\n----------------------------\nREF: pole_velocity_reference PassOn | 0 | links pole_angle_output \nPER: pole_velocity IndexedParameter | index 3 | 0 | links CartPole-v1 \nCOM: subtract2 Subtract | 0 | links pole_velocity_reference pole_velocity \nOUT: pole_velocity_output Proportional | gain 0.5 | 0 | links subtract2 \n----------------------------\nLevel 1 Cols 1\ncart_position_node PCTNode\n----------------------------\nREF: cart_position_reference PassOn | 0 | links pole_velocity_output \nPER: cart_position IndexedParameter | index 0 | 0 | links CartPole-v1 \nCOM: subtract1 Subtract | 0 | links cart_position_reference cart_position \nOUT: cart_position_output Proportional | gain 2 | 0 | links subtract1 \n----------------------------\nLevel 0 Cols 1\ncart_velocity_node PCTNode\n----------------------------\nREF: cart_velocity_reference PassOn | 0 | links cart_position_output \nPER: cart_velocity IndexedParameter | index 1 | 0 | links CartPole-v1 \nCOM: subtract Subtract | 0 | links cart_velocity_reference cart_velocity \nOUT: force Integration | gain -0.05 slow 4 | 0 | links subtract \n----------------------------\nPOST: greaterthan GreaterThan | threshold 0 upper 1 lower 0 | 0 | links force \n**************************\n"
],
[
"#gui\ncartpole_hierarchy.draw(font_size=10, figsize=(8,12), move={'CartPole-v1': [-0.075, 0]}, node_size=1000, node_color='red')",
"_____no_output_____"
],
[
"cartpole_hierarchy.save(\"cartpole.json\")",
"_____no_output_____"
],
[
"import networkx as nx\ngr = cartpole_hierarchy.graph()\nprint(nx.info(gr))\nprint(gr.nodes())",
"_____no_output_____"
]
],
[
[
"Run the hierarchy for 500 steps.",
"_____no_output_____"
]
],
[
[
"cartpole_hierarchy.run(1,verbose=False)",
"_____no_output_____"
],
[
"cartpole_hierarchy.run(runs,verbose=False)",
"_____no_output_____"
],
[
"cartpole.close()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a4d07fc7d299ef94731479d3a4c90f971679a7b
| 743,033 |
ipynb
|
Jupyter Notebook
|
Docs/Notebooks/RGroupDecomposition-Tests.ipynb
|
DrrDom/rdkit
|
d0cf7e2fca1578f8d7d696c196e4da4bc579666f
|
[
"BSD-3-Clause"
] | null | null | null |
Docs/Notebooks/RGroupDecomposition-Tests.ipynb
|
DrrDom/rdkit
|
d0cf7e2fca1578f8d7d696c196e4da4bc579666f
|
[
"BSD-3-Clause"
] | 1 |
2021-02-17T07:26:29.000Z
|
2021-02-17T07:26:29.000Z
|
Docs/Notebooks/RGroupDecomposition-Tests.ipynb
|
DrrDom/rdkit
|
d0cf7e2fca1578f8d7d696c196e4da4bc579666f
|
[
"BSD-3-Clause"
] | null | null | null | 379.4857 | 11,980 | 0.847133 |
[
[
[
"A notebook to visualize some of the test systems in the C++ test code in `Code/GraphMol/RGroupDecomposition/testRGroupDecomp.cpp`",
"_____no_output_____"
]
],
[
[
"from rdkit import Chem\nfrom rdkit.Chem import AllChem\nfrom rdkit.Chem.Draw import IPythonConsole\nIPythonConsole.ipython_useSVG=True\nfrom rdkit.Chem.rdRGroupDecomposition import RGroupDecomposition, RGroupDecompositionParameters, \\\n RGroupMatching, RGroupScore, RGroupLabels, RGroupCoreAlignment\nimport pandas as pd\nfrom rdkit.Chem import PandasTools\nfrom collections import OrderedDict\nfrom IPython.display import HTML\nfrom rdkit import rdBase\nfrom io import StringIO\nfrom rdkit.Chem import Draw\n\nrdBase.DisableLog(\"rdApp.debug\")",
"_____no_output_____"
]
],
[
[
"### testSDFGRoupMultiCoreNoneShouldMatch\n\nCores, compounds and python code ",
"_____no_output_____"
]
],
[
[
"sdcores = \"\"\"\nMrv1813 05061918272D \n\n 13 14 0 0 0 0 999 V2000\n -1.1505 0.0026 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.1505 -0.8225 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -0.4360 -1.2350 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.2784 -0.8225 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.2784 0.0026 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n -0.4360 0.4151 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.9354 0.2575 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n -2.4202 -0.4099 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.9354 -1.0775 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n 0.9907 -1.2333 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n -0.4360 1.2373 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.2784 1.6497 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n -3.2452 -0.4098 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n 6 1 1 0 0 0 0\n 1 7 1 0 0 0 0\n 1 2 1 0 0 0 0\n 2 3 1 0 0 0 0\n 9 2 1 0 0 0 0\n 3 4 1 0 0 0 0\n 4 5 1 0 0 0 0\n 4 10 1 0 0 0 0\n 5 6 1 0 0 0 0\n 6 11 1 0 0 0 0\n 7 8 1 0 0 0 0\n 8 13 1 0 0 0 0\n 8 9 1 0 0 0 0\n 11 12 1 0 0 0 0\nM RGP 3 10 1 12 2 13 3\nM END\n$$$$\n\n Mrv1813 05061918272D \n\n 13 14 0 0 0 0 999 V2000\n 6.9524 0.1684 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 6.9524 -0.6567 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 7.6668 -1.0692 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 8.3813 -0.6567 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 8.3813 0.1684 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 7.6668 0.5809 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 6.1674 0.4233 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n 5.6827 -0.2441 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 6.1674 -0.9117 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n 9.0935 -1.0675 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n 7.6668 1.4031 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 8.3813 1.8155 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n 4.8576 -0.2440 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n 6 1 1 0 0 0 0\n 1 7 1 0 0 0 0\n 1 2 1 0 0 0 0\n 2 3 1 0 0 0 0\n 9 2 1 0 0 0 0\n 3 4 1 0 0 0 0\n 4 5 1 0 0 0 0\n 4 10 1 0 0 0 0\n 5 6 1 0 0 0 0\n 6 11 1 0 0 0 0\n 7 8 1 0 0 0 0\n 8 13 1 0 0 0 0\n 8 9 1 0 0 0 0\n 11 12 1 0 0 0 0\nM RGP 3 10 1 12 2 13 3\nM END\n$$$$)CTAB\"\"\"\n\nsupplier = Chem.SDMolSupplier()\nsupplier.SetData(sdcores)\ncores = [x for x in supplier]\nfor core in cores:\n AllChem.Compute2DCoords(core)\nDraw.MolsToGridImage(cores)",
"_____no_output_____"
],
[
"sdmols=\"\"\"CTAB(\n Mrv1813 05061918322D \n\n 15 17 0 0 0 0 999 V2000\n 0.1742 0.6899 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.8886 0.2774 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.8886 -0.5476 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.1742 -0.9601 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.1742 -1.7851 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.8886 -2.1976 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.8886 -3.0226 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.1742 -3.4351 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n -0.5403 -3.0226 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.3249 -3.2775 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n -1.8099 -2.6101 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.3249 -1.9426 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -0.5403 -2.1976 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -0.5403 -0.5476 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -0.5403 0.2774 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 1 2 1 0 0 0 0\n 1 15 1 0 0 0 0\n 2 3 1 0 0 0 0\n 3 4 1 0 0 0 0\n 4 5 1 0 0 0 0\n 4 14 1 0 0 0 0\n 5 6 1 0 0 0 0\n 5 13 1 0 0 0 0\n 6 7 1 0 0 0 0\n 7 8 1 0 0 0 0\n 8 9 1 0 0 0 0\n 9 10 1 0 0 0 0\n 9 13 1 0 0 0 0\n 10 11 1 0 0 0 0\n 11 12 1 0 0 0 0\n 12 13 1 0 0 0 0\n 14 15 1 0 0 0 0\nM END\n$$$$\n\n Mrv1813 05061918322D \n\n 14 15 0 0 0 0 999 V2000\n 6.4368 0.3002 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 5.7223 -0.1123 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 5.7223 -0.9373 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 6.4368 -1.3498 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 6.4368 -2.1748 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 5.7223 -2.5873 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 5.0078 -2.1748 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 4.2232 -2.4297 0.0000 S 0 0 0 0 0 0 0 0 0 0 0 0\n 3.7383 -1.7623 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 4.2232 -1.0949 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 3.9683 -0.3102 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 3.1613 -0.1387 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 4.5203 0.3029 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 5.0078 -1.3498 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 1 2 1 0 0 0 0\n 2 3 1 0 0 0 0\n 3 4 1 0 0 0 0\n 3 14 1 0 0 0 0\n 4 5 1 0 0 0 0\n 5 6 1 0 0 0 0\n 6 7 1 0 0 0 0\n 7 8 1 0 0 0 0\n 7 14 1 0 0 0 0\n 8 9 1 0 0 0 0\n 9 10 1 0 0 0 0\n 10 11 1 0 0 0 0\n 10 14 1 0 0 0 0\n 11 13 1 0 0 0 0\n 11 12 1 0 0 0 0\nM END\n$$$$\n\n Mrv1813 05061918322D \n\n 14 15 0 0 0 0 999 V2000\n 0.8289 -7.9643 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.1144 -8.3768 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.1144 -9.2018 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.8289 -9.6143 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.8289 -10.4393 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.1144 -10.8518 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -0.6000 -10.4393 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.3847 -10.6942 0.0000 S 0 0 0 0 0 0 0 0 0 0 0 0\n -1.8696 -10.0268 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.3847 -9.3593 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.6396 -8.5747 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -2.4466 -8.4032 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -1.0876 -7.9616 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -0.6000 -9.6143 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 1 2 1 0 0 0 0\n 2 3 1 0 0 0 0\n 3 4 1 0 0 0 0\n 3 14 1 0 0 0 0\n 4 5 1 0 0 0 0\n 5 6 1 0 0 0 0\n 6 7 1 0 0 0 0\n 7 8 1 0 0 0 0\n 7 14 1 0 0 0 0\n 8 9 1 0 0 0 0\n 9 10 1 0 0 0 0\n 10 11 1 0 0 0 0\n 10 14 1 0 0 0 0\n 11 13 1 0 0 0 0\n 11 12 1 0 0 0 0\nM END\n$$$$\n\n Mrv1813 05061918322D \n\n 12 13 0 0 0 0 999 V2000\n 5.3295 -8.1871 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 5.5844 -7.4025 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 5.0995 -6.7351 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 5.5844 -6.0676 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 6.3690 -6.3226 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 7.0835 -5.9101 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 7.0835 -5.0851 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 7.7980 -6.3226 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 7.7980 -7.1476 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 8.5124 -7.5601 0.0000 O 0 0 0 0 0 0 0 0 0 0 0 0\n 7.0835 -7.5601 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 6.3690 -7.1476 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 1 2 1 0 0 0 0\n 2 3 1 0 0 0 0\n 2 12 1 0 0 0 0\n 3 4 1 0 0 0 0\n 4 5 1 0 0 0 0\n 5 12 1 0 0 0 0\n 5 6 1 0 0 0 0\n 6 7 1 0 0 0 0\n 6 8 1 0 0 0 0\n 8 9 1 0 0 0 0\n 9 10 1 0 0 0 0\n 9 11 1 0 0 0 0\n 11 12 1 0 0 0 0\nM END\n$$$$)CTAB\"\"\"\nsupplier = Chem.SDMolSupplier()\nsupplier.SetData(sdmols)\nmols = [x for x in supplier]\nfor mol in mols:\n AllChem.Compute2DCoords(mol)\nDraw.MolsToGridImage(mols)",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.onlyMatchAtRGroups = False\noptions.removeHydrogensPostMatch = False\ndecomp = RGroupDecomposition(cores, options)\nfor mol in mols:\n decomp.Add(mol)\ndecomp.Process()\ncols= decomp.GetRGroupsAsColumns()\ncols['mol'] = mols\nfor c in cols['Core']:\n AllChem.Compute2DCoords(c)\nDraw.MolsToGridImage(cols['Core'])\n\ndf = pd.DataFrame(cols);\nPandasTools.ChangeMoleculeRendering(df)\nHTML(df.to_html())\n",
"_____no_output_____"
],
[
"rows = decomp.GetRGroupsAsRows();\nfor i, r in enumerate(rows):\n labels = ['{}:{}'.format(l, Chem.MolToSmiles(r[l])) for l in r]\n print('{} {}'.format(str(i+1), ' '.join(labels)))",
"1 Core:N1C(N([*:2])[*:4])C2C(NC1[*:1])[*:5]C([*:3])[*:6]2 R1:[H][*:1] R2:[H]C([H])(C([H])([H])C([H])([H])[*:2])C([H])([H])C([H])([H])[*:4] R4:[H]C([H])(C([H])([H])C([H])([H])[*:2])C([H])([H])C([H])([H])[*:4] R5:[H]N([*:5])[*:5] R6:[H]C([H])([*:6])[*:6]\n2 Core:N1C(N([*:2])[*:4])C2C(NC1[*:1])[*:5]C([*:3])[*:6]2 R1:[H][*:1] R2:[H]C([H])([H])[*:2] R4:[H][*:4] R5:S([*:5])[*:5] R6:[H]C([H])([H])C([H])(C([H])([H])[H])C([H])([*:6])[*:6]\n3 Core:C1C([*:1])NC(N([*:2])[*:4])C2C1[*:5]C([*:3])[*:6]2 R1:[H][*:1] R2:[H]C([H])([H])[*:2] R4:[H][*:4] R5:S([*:5])[*:5] R6:[H]C([H])([H])C([H])(C([H])([H])[H])C([H])([*:6])[*:6]\n4 Core:C1C([*:1])NC(N([*:2])[*:4])C2C1[*:5]C([*:3])[*:6]2 R1:[H]O[*:1] R2:[H][*:2] R4:[H][*:4] R5:[H]C([H])([H])N([*:5])[*:5] R6:[H]N([*:6])[*:6]\n"
]
],
[
[
"### testMultiCorePreLabelled",
"_____no_output_____"
]
],
[
[
"sdcores = \"\"\"CTAB(\n RDKit 2D\n\n 9 9 0 0 0 0 0 0 0 0999 V2000\n 1.1100 -1.3431 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 1.5225 -0.6286 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.9705 -0.0156 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.2168 -0.3511 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n 0.3029 -1.1716 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 1.1419 0.7914 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n 0.5289 1.3431 0.0000 O 0 0 0 0 0 0 0 0 0 0 0 0\n 1.9266 1.0463 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n -0.4976 0.0613 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n 1 2 1 0\n 2 3 2 0\n 3 4 1 0\n 4 5 1 0\n 1 5 2 0\n 3 6 1 0\n 6 7 2 0\n 6 8 1 0\n 4 9 1 0\nM RGP 2 8 1 9 2\nV 8 *\nV 9 *\nM END\n$$$$\n\n RDKit 2D\n\n 12 13 0 0 0 0 0 0 0 0999 V2000\n -6.5623 0.3977 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n -5.8478 -0.0147 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -5.1333 0.3977 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n -4.4188 -0.0147 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -4.4188 -0.8397 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -5.1333 -1.2522 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n -5.8478 -0.8397 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -3.7044 -1.2522 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n -3.7044 0.3977 0.0000 N 0 0 0 0 0 0 0 0 0 0 0 0\n -2.9899 -0.0147 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0\n -2.9899 -0.8397 0.0000 A 0 0 0 0 0 0 0 0 0 0 0 0\n -2.2754 0.3978 0.0000 R# 0 0 0 0 0 0 0 0 0 0 0 0\n 3 4 1 0\n 4 5 2 0\n 5 6 1 0\n 6 7 2 0\n 2 3 2 0\n 2 7 1 0\n 9 10 2 0\n 10 11 1 0\n 8 11 2 0\n 8 5 1 0\n 4 9 1 0\n 10 12 1 0\n 1 2 1 0\nM RGP 2 1 2 12 1\nV 1 *\nV 12 *\nM END\n$$$$\n)CTAB\"\"\"\n\nsupplier = Chem.SDMolSupplier()\nsupplier.SetData(sdcores)\ncores = [x for x in supplier]\nfor core in cores:\n AllChem.Compute2DCoords(core)\nDraw.MolsToGridImage(cores)",
"_____no_output_____"
],
[
"smiles = [\"CNC(=O)C1=CN=CN1CC\", \"Fc1ccc2ccc(Br)nc2n1\"]\nmols = [Chem.MolFromSmiles(s) for s in smiles]\nDraw.MolsToGridImage(mols)",
"_____no_output_____"
],
[
"\ndef decomp(options):\n options.onlyMatchAtRGroups = True\n options.removeHydrogensPostMatch = True\n decomp = RGroupDecomposition(cores, options)\n for mol in mols:\n decomp.Add(mol)\n decomp.Process()\n cols = decomp.GetRGroupsAsColumns()\n return cols\n\ndef show_decomp(cols):\n cols['mol'] = mols\n df = pd.DataFrame(cols);\n PandasTools.ChangeMoleculeRendering(df)\n return HTML(df.to_html())\n\n# for when we can't display structures (\"non-ring aromatic\")\ndef show_decomp_smiles(cols):\n cols['mol'] = mols\n for c in cols:\n cols[c] = ['{}:{}'.format(c, Chem.MolToSmiles(m)) for m in cols[c]]\n df = pd.DataFrame(cols);\n PandasTools.ChangeMoleculeRendering(df)\n return HTML(df.to_html())\n",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.labels = RGroupLabels.AutoDetect\noptions.alignment = RGroupCoreAlignment.MCS\ncols = decomp(options)\nDraw.MolsToGridImage(cols['Core'])",
"_____no_output_____"
],
[
"show_decomp(cols)",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.labels = RGroupLabels.MDLRGroupLabels | RGroupLabels.RelabelDuplicateLabels\noptions.alignment = RGroupCoreAlignment.MCS\ncols=decomp(options)\nDraw.MolsToGridImage(cols['Core'])",
"_____no_output_____"
],
[
"show_decomp(cols)",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.labels = RGroupLabels.AutoDetect\noptions.alignment = RGroupCoreAlignment.NoAlignment\ncols=decomp(options)\nDraw.MolsToGridImage(cols['Core'])",
"_____no_output_____"
],
[
"show_decomp(cols)",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.labels = RGroupLabels.MDLRGroupLabels | RGroupLabels.RelabelDuplicateLabels\noptions.alignment = RGroupCoreAlignment.NoAlignment\ncols=decomp(options)\nDraw.MolsToGridImage(cols['Core'])",
"_____no_output_____"
],
[
"show_decomp(cols)",
"_____no_output_____"
],
[
"for core in cores:\n for atom in core.GetAtoms():\n if atom.HasProp(\"_MolFileRLabel\"):\n atom.ClearProp(\"_MolFileRLabel\")\n if atom.GetIsotope():\n atom.SetIsotope(0)\n if atom.GetAtomMapNum():\n print(\"atom map num\")\n atom.SetAtomMapNum(0)\n ",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.labels = RGroupLabels.AutoDetect\noptions.alignment = RGroupCoreAlignment.MCS\ncols=decomp(options)\nDraw.MolsToGridImage(cols['Core'])",
"_____no_output_____"
],
[
"show_decomp_smiles(cols)",
"_____no_output_____"
],
[
"options = RGroupDecompositionParameters()\noptions.labels = RGroupLabels.DummyAtomLabels | RGroupLabels.RelabelDuplicateLabels\noptions.alignment = RGroupCoreAlignment.MCS\ncols=decomp(options)\nDraw.MolsToGridImage(cols['Core'])",
"_____no_output_____"
],
[
"show_decomp_smiles(cols)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4d0a6a399b359f9ed923a6b6423ad9802e2aac
| 17,079 |
ipynb
|
Jupyter Notebook
|
notebooks/bytopic/numpy/01_getting_started_with_numpy.ipynb
|
jukent/ncar-python-tutorial
|
85c899e865c1861777e99764ef697219355e0585
|
[
"CC-BY-4.0"
] | 38 |
2019-09-10T05:00:52.000Z
|
2021-12-06T17:39:14.000Z
|
notebooks/bytopic/numpy/01_getting_started_with_numpy.ipynb
|
jukent/ncar-python-tutorial
|
85c899e865c1861777e99764ef697219355e0585
|
[
"CC-BY-4.0"
] | 60 |
2019-08-28T22:34:17.000Z
|
2021-01-25T22:53:21.000Z
|
notebooks/bytopic/numpy/01_getting_started_with_numpy.ipynb
|
NCAR/ncar-pangeo-tutorial
|
54d536d40cfaf6f8990c58edb438286c19d32a67
|
[
"CC-BY-4.0"
] | 22 |
2019-08-29T18:11:57.000Z
|
2021-01-07T02:23:46.000Z
| 27.998361 | 1,591 | 0.525558 |
[
[
[
"# Getting Started with NumPy",
"_____no_output_____"
],
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Getting-Started-with-NumPy\" data-toc-modified-id=\"Getting-Started-with-NumPy-1\"><span class=\"toc-item-num\">1 </span>Getting Started with NumPy</a></span><ul class=\"toc-item\"><li><span><a href=\"#Learning-Objectives\" data-toc-modified-id=\"Learning-Objectives-1.1\"><span class=\"toc-item-num\">1.1 </span>Learning Objectives</a></span></li><li><span><a href=\"#What-is-NumPy?\" data-toc-modified-id=\"What-is-NumPy?-1.2\"><span class=\"toc-item-num\">1.2 </span>What is NumPy?</a></span></li><li><span><a href=\"#The-NumPy-Array-Object\" data-toc-modified-id=\"The-NumPy-Array-Object-1.3\"><span class=\"toc-item-num\">1.3 </span>The NumPy Array Object</a></span></li><li><span><a href=\"#Data-types\" data-toc-modified-id=\"Data-types-1.4\"><span class=\"toc-item-num\">1.4 </span>Data types</a></span><ul class=\"toc-item\"><li><span><a href=\"#Basic-Numerical-Data-Types-Available-in-NumPy\" data-toc-modified-id=\"Basic-Numerical-Data-Types-Available-in-NumPy-1.4.1\"><span class=\"toc-item-num\">1.4.1 </span>Basic Numerical Data Types Available in NumPy</a></span></li><li><span><a href=\"#Data-Type-Promotion\" data-toc-modified-id=\"Data-Type-Promotion-1.4.2\"><span class=\"toc-item-num\">1.4.2 </span>Data Type Promotion</a></span></li></ul></li><li><span><a href=\"#Going-Further\" data-toc-modified-id=\"Going-Further-1.5\"><span class=\"toc-item-num\">1.5 </span>Going Further</a></span></li></ul></li></ul></div>",
"_____no_output_____"
],
[
"## Learning Objectives\n\n- Understand NumPy Array Object",
"_____no_output_____"
],
[
"## What is NumPy?\n\n\n\n- NumPy provides the numerical backend for nearly every scientific or technical library for Python. In fact, NumPy is the foundation library for scientific computing in Python since it provides data structures and high-performing functions that the basic Python standard library cannot provide. Therefore, knowledge of this library is essential in terms of numerical calculations since its correct use can greatly influence the performance of your computations.\n\n- NumPy provides the following additional features:\n - `Ndarray`: A multidimensional array much faster and more efficient\nthan those provided by the basic package of Python. The core of NumPy is implemented in C and provides efficient functions for manipulating and processing arrays.\n\n - `Element-wise computation`: A set of functions for performing this type of calculation with arrays and mathematical operations between arrays.\n\n - `Integration with other languages such as C, C++, and FORTRAN`: A\nset of tools to integrate code developed with these programming\nlanguages.\n\n- At a first glance, NumPy arrays bear some resemblance to Python’s list data structure. But an important difference is that while Python lists are generic containers of objects:\n - NumPy arrays are homogenous and typed arrays of fixed size.\n - Homogenous means that all elements in the array have the same data type.\n - Fixed size means that an array cannot be resized (without creating a new array).\n",
"_____no_output_____"
],
[
"## The NumPy Array Object\n\n- The core of the NumPy Library is one main object: `ndarray` (which stands for N-dimensional array)\n- This object is a multi-dimensional homogeneous array with a predetermined number of items\n- In addition to the data stored in the array, this data structure also contains important metadata about the array, such as its shape, size, data type, and other attributes. \n\n\n**Basic Attributes of the ndarray Class**\n\n| Attribute | Description |\n|-----------|----------------------------------------------------------------------------------------------------------|\n| shape | A tuple that contains the number of elements (i.e., the length) for each dimension (axis) of the array. |\n| size | The total number elements in the array. |\n| ndim | Number of dimensions (axes). |\n| nbytes | Number of bytes used to store the data. |\n| dtype | The data type of the elements in the array. |\n| itemsize | Defines teh size in bytes of each item in the array. |\n| data | A buffer containing the actual elements of the array. |",
"_____no_output_____"
],
[
"In order to use the NumPy library, we need to import it in our program. By convention,\nthe numPy module imported under the alias np, like so:",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
],
[
[
"After this, we can access functions and classes in the numpy module using the np\nnamespace. Throughout this notebook, we assume that the NumPy module is imported in\nthis way.",
"_____no_output_____"
]
],
[
[
"data = np.array([[10, 2], [5, 8], [1, 1]])\ndata",
"_____no_output_____"
]
],
[
[
"Here the ndarray instance data is created from a nested Python list using the\nfunction `np.array`. More ways to create ndarray instances from data and from rules of\nvarious kinds are introduced later in this tutorial. ",
"_____no_output_____"
]
],
[
[
"type(data)",
"_____no_output_____"
],
[
"data.ndim",
"_____no_output_____"
],
[
"data.size",
"_____no_output_____"
],
[
"data.dtype",
"_____no_output_____"
],
[
"data.nbytes",
"_____no_output_____"
],
[
"data.itemsize",
"_____no_output_____"
],
[
"data.data",
"_____no_output_____"
]
],
[
[
"## Data types\n\n- `dtype` attribute of the `ndarray` describes the data type of each element in the array.\n- Since NumPy arrays are homogeneous, all elements have the same data type. \n\n### Basic Numerical Data Types Available in NumPy\n\n\n| dtype | Variants | Description |\n|---------|-------------------------------------|---------------------------------------|\n| int | int8, int16, int32, int64 | Integers |\n| uint | uint8, uint16, uint32, uint64 | Unsigned (non-negative) integers |\n| bool | Bool | Boolean (True or False) |\n| float | float16, float32, float64, float128 | Floating-point numbers |\n| complex | complex64, complex128, complex256 | Complex-valued floating-point numbers |",
"_____no_output_____"
],
[
"Once a NumPy array is created, its `dtype` cannot be changed, other than by creating a new copy with type-casted array values",
"_____no_output_____"
]
],
[
[
"data = np.array([5, 9, 87], dtype=np.float32)\ndata",
"_____no_output_____"
],
[
"data = np.array(data, dtype=np.int32) # use np.array function for type-casting\ndata",
"_____no_output_____"
],
[
"data = np.array([5, 9, 87], dtype=np.float32)\ndata",
"_____no_output_____"
],
[
"data = data.astype(np.int32) # Use astype method of the ndarray class for type-casting\ndata",
"_____no_output_____"
]
],
[
[
"### Data Type Promotion\n\nWhen working with NumPy arrays, the data type might get promoted from one type to another, if required by the operation. \nFor instance, adding float-value and integer-valued arrays, the resulting array is a float-valued array:",
"_____no_output_____"
]
],
[
[
"arr1 = np.array([0, 2, 3], dtype=float)\narr1",
"_____no_output_____"
],
[
"arr2 = np.array([10, 20, 30], dtype=int)\narr2",
"_____no_output_____"
],
[
"res = arr1 + arr2\nres",
"_____no_output_____"
],
[
"res.dtype",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-block alert-info\">\n\nIn some cases, depending on the application and its requirements, it is essential to create arrays with data type appropriately set to right data type. The default data type is `float`:\n\n<div>",
"_____no_output_____"
]
],
[
[
"np.sqrt(np.array([0, -1, 2]))",
"/Users/abanihi/opt/miniconda3/envs/dev/lib/python3.6/site-packages/ipykernel_launcher.py:1: RuntimeWarning: invalid value encountered in sqrt\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"np.sqrt(np.array([0, -1, 2], dtype=complex))",
"_____no_output_____"
]
],
[
[
"Here, using the `np.sqrt` function to compute the square root of each element in\nan array gives different results depending on the data type of the array. Only when the data type of the array is complex is the square root of `–1` resulting in the imaginary unit (denoted as `1j` in Python).",
"_____no_output_____"
],
[
"## Going Further\n\n\nThe NumPy library is the topic of several books, including the Guide to NumPy, by the creator of the NumPy T. Oliphant, available for free online at http://web.mit.edu/dvp/Public/numpybook.pdf, and *Numerical Python (2019)*, and *Python for Data Analysis (2017)*.\n\n\n\n- [NumPy Reference Documentation](https://docs.scipy.org/doc/numpy/reference/)\n- Robert Johansson, Numerical Python 2nd.Urayasu-shi, Apress, 2019.\n- McKinney, Wes. Python for Data Analysis 2nd. Sebastopol: O’Reilly, 2017.\n",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-success\">\n <p>Next: <a href=\"02_memory_layout.ipynb\">Memory Layout</a></p>\n</div>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a4d1e61dae559f4f95b2ec033d3fc48a244f328
| 7,519 |
ipynb
|
Jupyter Notebook
|
jupyter/jupyter_phase3.ipynb
|
jfklorenz/Python-RMedian
|
8c490e003459e94b73fa2a4f51019d880dbb80b2
|
[
"MIT"
] | 1 |
2020-10-27T19:58:31.000Z
|
2020-10-27T19:58:31.000Z
|
jupyter/jupyter_phase3.ipynb
|
jfklorenz/Python-RMedian
|
8c490e003459e94b73fa2a4f51019d880dbb80b2
|
[
"MIT"
] | null | null | null |
jupyter/jupyter_phase3.ipynb
|
jfklorenz/Python-RMedian
|
8c490e003459e94b73fa2a4f51019d880dbb80b2
|
[
"MIT"
] | null | null | null | 27.745387 | 225 | 0.342865 |
[
[
[
"RMedian : Phase 3 / Clean Up Phase",
"_____no_output_____"
]
],
[
[
"import math\nimport random\nimport statistics",
"_____no_output_____"
]
],
[
[
"Testfälle :",
"_____no_output_____"
]
],
[
[
"# User input\ntestcase = 3\n\n# Automatic\nX = [i for i in range(101)]\ncnt = [0 for _ in range(101)]\n\n# ------------------------------------------------------------\n# Testcase 1 : Det - max(sumL, sumR) > n/2\n# Unlabanced\nif testcase == 1:\n X = [i for i in range(101)]\n L = [[i, i+1] for i in reversed(range(0, 21, 2))]\n C = [i for i in range(21, 28)]\n R = [[i, i+1] for i in range(28, 100, 2)]\n\n# ------------------------------------------------------------\n# Testcase 2 : AKS - |C| < log(n)\nelif testcase == 2:\n X = [i for i in range(101)]\n L = [[i, i+1] for i in reversed(range(0, 48, 2))]\n C = [i for i in range(48, 53)]\n R = [[i, i+1] for i in range(53, 100, 2)]\n \n# ------------------------------------------------------------\n# Testcase 3 : Rek - Neither\nelif testcase == 3:\n L = [[i, i+1] for i in reversed(range(0, 30, 2))]\n C = [i for i in range(30, 71)]\n R = [[i, i+1] for i in range(71, 110, 2)]\n# ------------------------------------------------------------\nlc = len(C)\n# ------------------------------------------------------------\n# Show Testcase\nprint('L :', L)\nprint('C :', C)\nprint('R :', R)",
"L : [[28, 29], [26, 27], [24, 25], [22, 23], [20, 21], [18, 19], [16, 17], [14, 15], [12, 13], [10, 11], [8, 9], [6, 7], [4, 5], [2, 3], [0, 1]]\nC : [30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70]\nR : [[71, 72], [73, 74], [75, 76], [77, 78], [79, 80], [81, 82], [83, 84], [85, 86], [87, 88], [89, 90], [91, 92], [93, 94], [95, 96], [97, 98], [99, 100], [101, 102], [103, 104], [105, 106], [107, 108], [109, 110]]\n"
]
],
[
[
"Algorithmus : Phase 3",
"_____no_output_____"
]
],
[
[
"def phase3(X, L, C, R, cnt):\n res = 'error'\n n = len(X)\n\n sumL, sumR = 0, 0\n for l in L:\n sumL += len(l)\n for r in R:\n sumR += len(r)\n \n s = sumL - sumR\n \n # Det Median\n if max(sumL, sumR) > n/2:\n res = 'DET'\n if len(X) % 2 == 0:\n return (X[int(len(X)/2 - 1)] + X[int(len(X)/2)]) / 2, cnt, res, s\n else:\n return X[int(len(X) / 2 - 0.5)], cnt, res, s\n\n # AKS\n if len(C) < math.log(n) / math.log(2):\n res = 'AKS'\n C.sort()\n if len(C) % 2 == 0:\n return (C[int(len(C)/2 - 1)] + C[int(len(C)/2)]) / 2, cnt, res, s\n else:\n return C[int(len(C) / 2 - 0.5)], cnt, res, s\n\n print(sumR)\n \n # Expand\n if s < 0:\n rs = []\n for r in R:\n rs += r\n random.shuffle(rs)\n for i in range(-s):\n C.append(rs[i])\n for r in R:\n if rs[i] in r:\n r.remove(rs[i])\n else:\n ls = []\n for l in L:\n ls += l\n random.shuffle(ls)\n for i in range(s):\n C.append(ls[i])\n for l in L:\n if ls[i] in l:\n l.remove(ls[i])\n\n res = 'Expand'\n \n return -1, cnt, res, s\n\n# Testfall\nmed, cnt, res, s = phase3(X, L, C, R, cnt)",
"40\n30\n"
]
],
[
[
"Resultat :",
"_____no_output_____"
]
],
[
[
"def test(X, L, C, R, lc, med, cnt, res, s):\n n, l, c, r, sumL, sumR, mx = len(X), len(L), len(C), len(R), 0, 0, max(cnt)\n m = statistics.median(X)\n\n for i in range(len(L)):\n sumL += len(L[i])\n sumR += len(R[i])\n\n print('')\n print('Testfall:')\n print('=======================================')\n print('|X| / |L| / |C| / |R| :', n, '/', sumL, '/', c, '/', sumR)\n print('=======================================')\n print('Case :', res)\n print('SumL - SumR :', s)\n print('|C| / |C_new| :', lc, '/', len(C))\n print('---------------------------------------')\n print('Algo / Median :', med, '/', m)\n print('=======================================')\n print('max(cnt) :', mx)\n \n print('=======================================')\n return\n\n# Testfall\ntest(X, L, C, R, lc, med, cnt, res, s)",
"\nTestfall:\n=======================================\n|X| / |L| / |C| / |R| : 101 / 30 / 51 / 30\n=======================================\nCase : Expand\nSumL - SumR : -10\n|C| / |C_new| : 41 / 51\n---------------------------------------\nAlgo / Median : -1 / 50\n=======================================\nmax(cnt) : 0\n=======================================\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4d26dfdc7604d9fe65e8522cec8b7b65da17f9
| 9,279 |
ipynb
|
Jupyter Notebook
|
Machine Learning/Problem1/3_Gaussian_Discriminant_Analysis.ipynb
|
bayeslabs/AiGym
|
30c126fc2e140f9f164ff3f20638242b230e7e52
|
[
"MIT"
] | 22 |
2019-07-15T08:26:31.000Z
|
2022-01-17T06:29:17.000Z
|
Machine Learning/Problem1/3_Gaussian_Discriminant_Analysis.ipynb
|
bayeslabs/AiGym
|
30c126fc2e140f9f164ff3f20638242b230e7e52
|
[
"MIT"
] | 26 |
2020-03-24T17:18:21.000Z
|
2022-03-11T23:54:37.000Z
|
Machine Learning/Problem1/3_Gaussian_Discriminant_Analysis.ipynb
|
bayeslabs/AiGym
|
30c126fc2e140f9f164ff3f20638242b230e7e52
|
[
"MIT"
] | 8 |
2019-07-17T09:13:11.000Z
|
2021-04-16T11:20:51.000Z
| 59.480769 | 613 | 0.440457 |
[
[
[
"# CS229: Problem Set 1\n## Problem 3: Gaussian Discriminant Analysis\n\n\n**C. Combier**\n\nThis iPython Notebook provides solutions to Stanford's CS229 (Machine Learning, Fall 2017) graduate course problem set 1, taught by Andrew Ng.\n\nThe problem set can be found here: [./ps1.pdf](ps1.pdf)\n\nI chose to write the solutions to the coding questions in Python, whereas the Stanford class is taught with Matlab/Octave.\n\n## Notation\n\n- $x^i$ is the $i^{th}$ feature vector\n- $y^i$ is the expected outcome for the $i^{th}$ training example\n- $m$ is the number of training examples\n- $n$ is the number of features",
"_____no_output_____"
],
[
"### Question 3.a)\n\nThe gist of the solution is simply to apply Bayes rule, and simplify the exponential terms in the denominator which gives us the sigmoid function. The calculations are somewhat heavy:\n\n$$\n\\begin{align*}\np(y=1 \\mid x) & = \\frac{p(x \\mid y=1)p(y=1)}{p(x)} \\\\\n & = \\frac{p(x \\mid y=1)p(y=1)}{p(x \\mid y=1)p(y=1)+ p(x \\mid y=-1)p(y=-1)} \\\\\n & = \\frac{\\frac{1}{(2\\pi)^{\\frac{n}{2}} \\lvert \\Sigma \\rvert^{\\frac{1}{2}}} \\exp \\left(-\\frac{1}{2} \\left(x-\\mu_{1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{1} \\right) \\right) \\phi }{ \\frac{1}{(2\\pi)^{\\frac{n}{2}} \\lvert \\Sigma \\rvert^{\\frac{1}{2}}} \\exp \\left(-\\frac{1}{2} \\left(x-\\mu_{1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{1} \\right) \\right) \\phi + \\frac{1}{(2\\pi)^{\\frac{n}{2}} \\lvert \\Sigma \\rvert^{\\frac{1}{2}}} \\exp \\left(-\\frac{1}{2} \\left(x-\\mu_{-1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{-1} \\right) \\right)\\left(1-\\phi \\right)} \\\\\n & = \\frac{\\phi \\exp \\left(-\\frac{1}{2} \\left(x-\\mu_{1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{1} \\right) \\right) }{\\phi \\exp \\left(-\\frac{1}{2} \\left(x-\\mu_{1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{1} \\right) \\right) + \\left(1-\\phi \\right) \\exp \\left(-\\frac{1}{2} \\left(x-\\mu_{-1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{-1} \\right) \\right)} \\\\\n & = \\frac{1}{1+ \\exp \\left(\\log\\left(\\frac{\\left(1-\\phi \\right)}{\\phi}\\right) -\\frac{1}{2} \\left(x-\\mu_{-1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{-1} \\right) + \\frac{1}{2} \\left(x-\\mu_{1} \\right)^T\\Sigma^{-1} \\left(x-\\mu_{1} \\right) \\right)} \\\\\n & = \\frac{1}{1+\\exp \\left(\\log \\left(\\frac{1-\\phi}{\\phi}\\right) -\\frac{1}{2} \\left(x^T \\Sigma^{-1}x -2x^T \\Sigma^{-1}\\mu_{-1}+ \\mu_{-1}^T \\Sigma^{-1} \\mu_{-1}\\right) + \\frac{1}{2} \\left(x^T \\Sigma^{-1}x -2x^T \\Sigma^{-1}\\mu_{1}+ \\mu_{1}^T \\Sigma^{-1} \\mu_{1} \\right)\\right)} \\\\\n & = \\frac{1}{1+\\exp \\left(\\log \\left(\\frac{1-\\phi}{\\phi}\\right) + x^T \\Sigma^{-1} \\mu_{-1} - x^T \\Sigma^{-1} \\mu_1 - \\frac{1}{2} \\mu_{-1}^T \\Sigma^{-1} \\mu_{-1} + \\frac{1}{2} \\mu_1^T\\Sigma^{-1}\\mu_1 \\right)} \\\\\n & = \\frac{1}{1+ \\exp\\left(\\log\\left(\\frac{1-\\phi}{\\phi}\\right) + x^T \\Sigma^{-1} \\left(\\mu_{-1}-\\mu_1 \\right) - \\frac{1}{2}\\mu_{-1}^T\\Sigma^{-1}\\mu_{-1} + \\mu_1^T \\Sigma^{-1} \\mu_1 \\right)} \\\\\n \\\\\n\\end{align*}\n$$\n\nWith:\n- $\\theta_0 = \\frac{1}{2}\\left(\\mu_{-1}^T \\Sigma^{-1} \\mu_{-1}- \\mu_1^T \\Sigma^{-1}\\mu_1 \\right)-\\log\\frac{1-\\phi}{\\phi} $\n- $\\theta = \\Sigma^{-1}\\left(\\mu_{1}-\\mu_{-1} \\right)$\n\nwe have:\n\n$$\np(y=1 \\mid x) = \\frac{1}{1+\\exp \\left(-y(\\theta^Tx + \\theta_0) \\right)}\n$$",
"_____no_output_____"
],
[
"### Questions 3.b) and 3.c)\nQuestion 3.b) is the special case where $n=1$. Let us prove the general case directly, as required in 3.c):\n\n$$\n\\begin{align*}\n\\ell \\left(\\phi, \\mu_{-1}, \\mu_1, \\Sigma \\right) & = \\log \\prod_{i=1}^m p(x^{i}\\mid y^i; \\phi, \\mu_{-1}, \\mu_1, \\Sigma)p(y^{i};\\phi) \\\\\n & = \\sum_{i=1}^m \\log p(x^{i}\\mid y^{i}; \\phi, \\mu_{-1}, \\mu_1, \\Sigma) + \\sum_{i=1}^m \\log p(y^{i};\\phi) \\\\\n & = \\sum_{i=1}^m \\left[\\log \\frac{1}{\\left(2 \\pi \\right)^{\\frac{n}{2}} \\lvert \\Sigma \\rvert^{\\frac{1}{2}}} - \\frac{1}{2} \\left(x^{i} - \\mu_{y^{i}} \\right)^T \\Sigma^{-1} \\left(x^{i} - \\mu_{y^{i}} \\right) + \\log \\phi^{y^{i}} + \\log \\left(1- \\phi \\right)^{\\left(1-y^{i} \\right)} \\right] \\\\\n & \\simeq \\sum_{i=1}^m \\left[- \\frac{1}{2} \\log \\lvert \\Sigma \\rvert - \\frac{1}{2} \\left(x^{i} - \\mu_{y^{i}} \\right)^T \\Sigma^{-1} \\left(x^{i} - \\mu_{y^{i}} \\right) + y^{i} \\log \\phi + \\left(1-y^{i} \\right) \\log \\left(1- \\phi \\right) \\right] \\\\\n\\end{align*}\n$$\n\nNow we calculate the maximum likelihood be calculating the gradient of the log-likelihood with respect to the parameters and setting it to $0$:\n\n$$\n\\begin{align*}\n\\frac{\\partial \\ell}{\\partial \\phi} &= \\sum_{i=1}^{m}( \\frac{y^i}{\\phi} - \\frac{1-y^i}{1-\\phi}) \\\\\n&= \\sum_{i=1}^{m}\\frac{1(y^i = 1)}{\\phi} + \\frac{m-\\sum_{i=1}^{m}1(y^i = 1)}{1-\\phi}\n\\end{align*}\n$$\n\nTherefore, $\\phi = \\frac{1}{m} \\sum_{i=1}^m 1(y^i =1 )$, i.e. the percentage of the training examples such that $y^i = 1$\n\nNow for $\\mu_{-1}:$\n$$\n\\begin{align*}\n\\nabla_{\\mu_{-1}} \\ell & = - \\frac{1}{2} \\sum_{i : y^{i}=-1} \\nabla_{\\mu_{-1}} \\left[ -2 \\mu_{-1}^T \\Sigma^{-1} x^{(i)} + \\mu_{-1}^T \\Sigma^{-1} \\mu_{-1} \\right] \\\\\n & = - \\frac{1}{2} \\sum_{i : y^{i}=-1} \\left[-2 \\Sigma^{-1}x^{(i)} + 2 \\Sigma^{-1} \\mu_{-1} \\right]\n\\end{align*}\n$$\n\nAgain, we set the gradient to $0$:\n\n$$\n\\begin{align*}\n \\sum_{i:y^i=-1} \\left[\\Sigma^{-1}x^{i}-\\Sigma^{-1} \\mu_{-1} \\right] &= 0 \\\\\n \\sum_{i=1}^m 1 \\left\\{y^{i}=-1\\right\\} \\Sigma^{-1} x^{(i)} - \\sum_{i=1}^m 1 \\left\\{y^{i}=-1 \\right\\} \\Sigma^{-1} \\mu_{-1} &=0 \\\\\n\\end{align*}\n$$\nThis yields:\n$$\n\\Sigma^{-1} \\mu_{-1} \\sum_{i=1}^m 1 \\left\\{y^{i}=-1 \\right\\} = \\Sigma^{-1} \\sum_{i=1}^m 1 \\left\\{y^{(i)}=-1\\right\\} x^{i}\n$$\nAllowing us to finally write:\n$$\\mu_{-1} = \\frac{\\sum_{i=1}^m 1 \\left\\{y^{i}=-1\\right\\} x^{i}}{\\sum_{i=1}^m 1 \\left\\{y^{(i)}=-1 \\right\\}}$$\n\nThe calculations are similar for $\\mu_1$, and we obtain:\n$$\\mu_{1} = \\frac{\\sum_{i=1}^m 1 \\left\\{y^{i}=1\\right\\} x^{i}}{\\sum_{i=1}^m 1 \\left\\{y^{i}=1 \\right\\}}$$\n\n\nThe last step is to calculate the gradient with respect to $\\Sigma$. To simplify calculations, let us calculate the gradient for $S = \\frac{1}{\\Sigma}$.\n\n$$\n\\begin{align*}\n\\nabla_{S} \\ell & = - \\frac{1}{2}\\sum_{i=1}^m \\nabla_{\\Sigma} \\left[-\\log \\lvert S \\rvert + \\left(x^{i}- \\mu_{y^{i}} \\right)^T S \\left(x^{i}- \\mu_{y^{i}} \\right) \\right] \\\\\n & = - \\frac{1}{2}\\sum_{i=1}^m \\left[-S^{-1} + \\left(x^{i}- \\mu_{y^{i}} \\right)\\left(x^{i}- \\mu_{y^{i}} \\right)^T \\right] \\\\\n & = \\sum_{i=1}^m \\frac{1}{2} \\Sigma - \\frac{1}{2} \\sum_{i=1}^m \\left(x^{i}- \\mu_{y^{i}} \\right)\\left(x^{i}- \\mu_{y^{i}} \\right)^T\\\\\n\\end{align*}\n$$\nAgain, we set the gradient to $0$, allowing us to write:\n$$\n\\frac{1}{2} m \\Sigma = \\frac{1}{2} \\sum_{i=1}^m \\left(x^{i}- \\mu_{y^{i}} \\right)\\left(x^{i}- \\mu_{y^{i}} \\right)^T \\\\\n$$\nFinally, we obtain the maximum likelihood estimate for $\\Sigma$:\n$$\n\\Sigma = \\frac{1}{m}\\sum_{i=1}^m \\left(x^{i}- \\mu_{y^{i}} \\right)\\left(x^{i}- \\mu_{y^{i}} \\right)^T\n$$\n",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
]
] |
4a4d36ec48593bc4df69ea993e1ccc13af8af661
| 4,181 |
ipynb
|
Jupyter Notebook
|
Modulo1/2. Hello World Python.ipynb
|
EddieRodriguezRojas/CURSOPYTHOND
|
7293551a3c3d8dd8fff2f1bac36d70840ea7c1ad
|
[
"Apache-2.0"
] | null | null | null |
Modulo1/2. Hello World Python.ipynb
|
EddieRodriguezRojas/CURSOPYTHOND
|
7293551a3c3d8dd8fff2f1bac36d70840ea7c1ad
|
[
"Apache-2.0"
] | null | null | null |
Modulo1/2. Hello World Python.ipynb
|
EddieRodriguezRojas/CURSOPYTHOND
|
7293551a3c3d8dd8fff2f1bac36d70840ea7c1ad
|
[
"Apache-2.0"
] | null | null | null | 21.776042 | 354 | 0.554174 |
[
[
[
"# HELLO WORLD IN PYTHON",
"_____no_output_____"
],
[
"## 1. Python ",
"_____no_output_____"
],
[
"<b>Python es un lenguaje de programación de código abierto</b>, orientado a objetos, muy simple y fácil de entender. Tiene una sintaxis sencilla que cuenta con una vasta biblioteca de herramientas, que hacen de Python un lenguaje de programación único.",
"_____no_output_____"
],
[
"### Principales Usos",
"_____no_output_____"
],
[
"- Python para la automatización de tareas\n- Python en Big Data\n- Python en Data Science\n- Python en Desarrollo Web\n- Python en la Inteligencia Artificial (AI)",
"_____no_output_____"
],
[
"<h3>Lenguaje de programación interpretado</h3>\n\nUn lenguaje interpretado es un tipo de lenguaje de programación para el cual la mayoría de sus implementaciones ejecutan instrucciones directa y libremente, sin compilar previamente un programa en instrucciones de lenguaje máquina.\n",
"_____no_output_____"
],
[
"<img src='https://www.cursosgis.com/wp-content/uploads/4-97.jpg' >",
"_____no_output_____"
],
[
"#### Nota\nEl tipo de extensión de un programa en python es .py",
"_____no_output_____"
],
[
"## <a href=\"https://jupyter.org/\"> 2. Jupyter Notebook</a>",
"_____no_output_____"
],
[
"Es un <b>entorno de trabajo interactivo que permite desarrollar código en Python</b> de manera dinámica, a la vez que integrar en un mismo documento tanto bloques de código como texto, gráficas o imágenes. Es un SaaS utilizado ampliamente en análisis numérico, estadística y machine learning, entre otros campos de la informática y las matemáticas.",
"_____no_output_____"
]
],
[
[
"# ctrl+Enter -- correr celda\n# shift+Enter -- correr celda y dirigirse al siguiente bloque de código(siguiente celda)\nprint(\"hola mundo\")",
"hola mundo\n"
]
],
[
[
"## 3. Hello World in Python",
"_____no_output_____"
]
],
[
[
"print(\"hola mundo\")",
"hola mundo\n"
]
],
[
[
"# EJERCICIOS",
"_____no_output_____"
],
[
"Escribir un programa que almacene la cadena ¡Hola Mundo! en una variable y luego muestre por pantalla el contenido de la variable.",
"_____no_output_____"
]
],
[
[
"a = '¡Hola mundo!'\nprint(a)",
"¡Hola mundo!\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a4d4c7d2919a41f8e53fa34ca6036c9cd697b3f
| 23,639 |
ipynb
|
Jupyter Notebook
|
notebooks/05 - Images.ipynb
|
ivanCanaveral/tensorflow-tips
|
1f97380e392bdf897330d0ae085ca2df9dab0694
|
[
"MIT"
] | null | null | null |
notebooks/05 - Images.ipynb
|
ivanCanaveral/tensorflow-tips
|
1f97380e392bdf897330d0ae085ca2df9dab0694
|
[
"MIT"
] | null | null | null |
notebooks/05 - Images.ipynb
|
ivanCanaveral/tensorflow-tips
|
1f97380e392bdf897330d0ae085ca2df9dab0694
|
[
"MIT"
] | null | null | null | 23.017527 | 195 | 0.504209 |
[
[
[
"# Images",
"_____no_output_____"
]
],
[
[
"import pathlib\nimport tensorflow as tf\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"dataset_url = \"https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz\"\ndata_dir = tf.keras.utils.get_file(origin=dataset_url, \n fname='flower_photos', \n untar=True)\ndata_dir = pathlib.Path(data_dir)",
"_____no_output_____"
],
[
"image_count = len(list(data_dir.glob('*/*.jpg')))\nimage_count",
"_____no_output_____"
]
],
[
[
"### Loading images",
"_____no_output_____"
]
],
[
[
"dataset = tf.data.Dataset.list_files(str(data_dir/'*/*'))",
"_____no_output_____"
],
[
"for f in dataset.take(5):\n print(f.numpy())",
"_____no_output_____"
],
[
"def load_image(path):\n img_height = 180\n img_width = 180\n binary_format = tf.io.read_file(path)\n image = tf.image.decode_jpeg(binary_format, channels=3)\n return tf.image.resize(image, [img_height, img_width])",
"_____no_output_____"
],
[
"dataset = dataset.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)\ndataset = dataset.cache().shuffle(buffer_size=1000) # cache only if the dataset fits in memory\ndataset = dataset.batch(2)\ndataset = dataset.prefetch(buffer_size=tf.data.AUTOTUNE)",
"_____no_output_____"
],
[
"for f in dataset.take(5):\n print(f.numpy().shape)",
"_____no_output_____"
],
[
"images = next(iter(dataset))\nimages.shape",
"_____no_output_____"
]
],
[
[
"### Filters\n\nFilters are 3-dimensional tensors. Tensorflow stores the different filter weights for a given pixel and channel in the last dimension. Therefore, the structure of a tensor of filters is:\n\n```python\n[rows, columns, channels, filters]\n```\n\nwhere channels are the filters in the input thensor for a given layer.",
"_____no_output_____"
]
],
[
[
"hfilter = tf.stack([tf.stack([tf.zeros(3), tf.ones(3), tf.zeros(3)]) for _ in range(3)])\nhfilter",
"_____no_output_____"
],
[
"vfilter = tf.transpose(hfilter, [0, 2, 1])\nvfilter",
"_____no_output_____"
]
],
[
[
"Given that the values of each filter (for a concrete pixel and channel) are in the last axis, we are goint to stack both filters in the last axis.",
"_____no_output_____"
]
],
[
[
"filters = tf.stack([hfilter, vfilter], axis=-1)\nfilters.shape",
"_____no_output_____"
],
[
"outputs = tf.nn.conv2d(images, filters, strides=1, padding=\"SAME\")",
"_____no_output_____"
],
[
"plt.figure(figsize=(20,60))\nax = plt.subplot(1, 3, 1)\nplt.axis(\"off\")\nplt.imshow(images[1].numpy().astype(\"uint8\"))\nfor i in range(2):\n ax = plt.subplot(1, 3, i + 2)\n plt.imshow(outputs[1, :, :, i], cmap=\"gray\")\n plt.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"### Pooling",
"_____no_output_____"
]
],
[
[
"outputs = tf.nn.max_pool(images, ksize=(1,2,2,1), strides=(1,2,2,1), padding='SAME')\nimages.shape, outputs.shape",
"_____no_output_____"
],
[
"plt.figure(figsize=(8, 8))\nfor i in range(2):\n ax = plt.subplot(2, 2, i*2 + 1)\n plt.imshow(images[i, :, :, i], cmap=\"gray\")\n plt.axis(\"off\")\n ax = plt.subplot(2, 2, i*2 + 2)\n plt.imshow(outputs[i, :, :, i], cmap=\"gray\")\n plt.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"### Depthwise pooling",
"_____no_output_____"
],
[
"Pooling along all the channels for each pixel.",
"_____no_output_____"
]
],
[
[
"outputs = tf.nn.max_pool(images, ksize=(1,1,1,3), strides=(1,1,1,3), padding='SAME')\nimages.shape, outputs.shape",
"_____no_output_____"
],
[
"plt.figure(figsize=(8, 8))\nfor i in range(2):\n ax = plt.subplot(2, 2, i*2 + 1)\n plt.imshow(images[i, :, :, i], cmap=\"gray\")\n plt.axis(\"off\")\n ax = plt.subplot(2, 2, i*2 + 2)\n plt.imshow(outputs[i, :, :, 0], cmap=\"gray\")\n plt.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"## Keras vs Tensorflow",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy as np",
"_____no_output_____"
],
[
"batch_size = 32\nimg_height = 180\nimg_width = 180",
"_____no_output_____"
],
[
"list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)\nlist_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)",
"_____no_output_____"
],
[
"class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != \"LICENSE.txt\"]))\nprint(class_names)",
"_____no_output_____"
],
[
"val_size = int(image_count * 0.2)\ntrain_ds = list_ds.skip(val_size)\nval_ds = list_ds.take(val_size)",
"_____no_output_____"
],
[
"print(tf.data.experimental.cardinality(train_ds).numpy())\nprint(tf.data.experimental.cardinality(val_ds).numpy())",
"_____no_output_____"
],
[
"def get_label(file_path):\n # convert the path to a list of path components\n parts = tf.strings.split(file_path, os.path.sep)\n # The second to last is the class-directory\n one_hot = parts[-2] == class_names\n # Integer encode the label\n return tf.argmax(one_hot)",
"_____no_output_____"
],
[
"get_label(b'/Users/nerea/.keras/datasets/flower_photos/tulips/8686332852_c6dcb2e86b.jpg').numpy()",
"_____no_output_____"
],
[
"def decode_img(img):\n # convert the compressed string to a 3D uint8 tensor\n img = tf.image.decode_jpeg(img, channels=3)\n # resize the image to the desired size\n return tf.image.resize(img, [img_height, img_width])",
"_____no_output_____"
],
[
"def process_path(file_path):\n label = get_label(file_path)\n # load the raw data from the file as a string\n img = tf.io.read_file(file_path)\n img = decode_img(img)\n return img, label",
"_____no_output_____"
],
[
"# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.\ntrain_ds = train_ds.map(process_path, num_parallel_calls=tf.data.AUTOTUNE)\nval_ds = val_ds.map(process_path, num_parallel_calls=tf.data.AUTOTUNE)",
"_____no_output_____"
],
[
"def configure_for_performance(ds):\n ds = ds.cache()\n ds = ds.shuffle(buffer_size=1000)\n ds = ds.batch(batch_size)\n ds = ds.prefetch(buffer_size=tf.data.AUTOTUNE)\n return ds\n\ntrain_ds = configure_for_performance(train_ds)\nval_ds = configure_for_performance(val_ds)",
"_____no_output_____"
],
[
"image_batch, label_batch = next(iter(train_ds))\n\nplt.figure(figsize=(10, 10))\nfor i in range(9):\n ax = plt.subplot(3, 3, i + 1)\n plt.imshow(image_batch[i].numpy().astype(\"uint8\"))\n label = label_batch[i]\n plt.title(class_names[label])\n plt.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"### Keras",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras import layers\n\nnormalization_layer = tf.keras.layers.experimental.preprocessing.Rescaling(1./255)",
"_____no_output_____"
],
[
"normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))\nimage_batch, labels_batch = next(iter(normalized_ds))",
"_____no_output_____"
],
[
"num_classes = 5\n\nmodel = tf.keras.Sequential([\n layers.experimental.preprocessing.Rescaling(1./255),\n layers.Conv2D(16, 3, activation='relu'),\n layers.MaxPooling2D(),\n layers.Conv2D(32, 3, activation='relu'),\n layers.MaxPooling2D(),\n layers.Conv2D(64, 3, activation='relu'),\n #layers.MaxPooling2D(),\n layers.GlobalAvgPool2D(),\n layers.Flatten(),\n layers.Dense(64, activation='relu'),\n layers.Dense(num_classes)\n])",
"_____no_output_____"
],
[
"model.compile(\n optimizer='adam',\n loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.fit(\n train_ds,\n validation_data=val_ds,\n epochs=1\n)",
"_____no_output_____"
],
[
"model.summary()",
"_____no_output_____"
]
],
[
[
"### Tensorflow",
"_____no_output_____"
],
[
"#### Model Implementation ",
"_____no_output_____"
]
],
[
[
"images = tf.divide(images, 255.)",
"_____no_output_____"
],
[
"shape = tf.TensorShape([3,3,3,16])",
"_____no_output_____"
],
[
"filters_1 = tf.Variable(\n initial_value=tf.initializers.glorot_uniform()(shape),\n shape=shape,\n name='filters_1',\n dtype=tf.float32,\n trainable=True,\n synchronization=tf.VariableSynchronization.AUTO,\n caching_device=None\n)",
"_____no_output_____"
],
[
"feature_maps_1 = tf.nn.leaky_relu(\n tf.nn.conv2d(images, filters_1, strides=[1, 1, 1, 1], padding=\"SAME\"),\n alpha=0.2\n)",
"_____no_output_____"
],
[
"pooled_maps_1 = tf.nn.max_pool(\n feature_maps_1,\n ksize=(1,3,3,1),\n strides=(1,3,3,1),\n padding='SAME'\n)\npooled_maps_1.shape",
"_____no_output_____"
],
[
"shape = tf.TensorShape([3,3,16,32])",
"_____no_output_____"
],
[
"filters_2 = tf.Variable(\n initial_value=tf.initializers.glorot_uniform()(shape),\n shape=shape,\n name='filters_2',\n dtype=tf.float32,\n trainable=True,\n synchronization=tf.VariableSynchronization.AUTO,\n caching_device=None\n)",
"_____no_output_____"
],
[
"feature_maps_2 = tf.nn.leaky_relu(\n tf.nn.conv2d(\n pooled_maps_1,\n filters_2,\n strides=[1, 1, 1, 1],\n padding=\"SAME\"\n ),\n alpha=0.2\n)",
"_____no_output_____"
],
[
"pooled_maps_2 = tf.nn.max_pool(\n feature_maps_2,\n ksize=(1,3,3,1),\n strides=(1,3,3,1),\n padding='SAME'\n)\npooled_maps_2.shape",
"_____no_output_____"
],
[
"shape = tf.TensorShape([3,3,32,64])",
"_____no_output_____"
],
[
"filters_3 = tf.Variable(\n initial_value=tf.initializers.glorot_uniform()(shape),\n shape=shape,\n name='filters_3',\n dtype=tf.float32,\n trainable=True,\n synchronization=tf.VariableSynchronization.AUTO,\n caching_device=None\n)",
"_____no_output_____"
],
[
"feature_maps_3 = tf.nn.leaky_relu(\n tf.nn.conv2d(\n pooled_maps_2,\n filters_3,\n strides=[1, 1, 1, 1],\n padding=\"SAME\"\n ),\n alpha=0.2\n)",
"_____no_output_____"
],
[
"feature_maps_3.shape",
"_____no_output_____"
],
[
"pooled_maps_3 = tf.nn.max_pool(\n feature_maps_3,\n ksize=(1,60,60,1),\n strides=(1,60,60,1),\n padding='SAME'\n)\npooled_maps_3.shape",
"_____no_output_____"
],
[
"flatten = tf.reshape(\n pooled_maps_3,\n shape=tf.TensorShape((2, 64))\n)",
"_____no_output_____"
],
[
"shape = tf.TensorShape([64, 64])",
"_____no_output_____"
],
[
"W_1 = tf.Variable(\n initial_value=tf.initializers.glorot_uniform()(shape),\n shape=shape,\n name='W_1',\n dtype=tf.float32,\n trainable=True,\n synchronization=tf.VariableSynchronization.AUTO,\n caching_device=None\n)",
"_____no_output_____"
],
[
"X_1 = tf.nn.dropout(\n tf.nn.leaky_relu(\n tf.matmul(flatten, W_1)\n ),\n rate=0.3\n)",
"_____no_output_____"
],
[
"shape = tf.TensorShape([64, 5])",
"_____no_output_____"
],
[
"W_2 = tf.Variable(\n initial_value=tf.initializers.glorot_uniform()(shape),\n shape=shape,\n name='W_2',\n dtype=tf.float32,\n trainable=True,\n synchronization=tf.VariableSynchronization.AUTO,\n caching_device=None\n)",
"_____no_output_____"
],
[
"X_2 = tf.nn.dropout(\n tf.nn.leaky_relu(\n tf.matmul(X_1, W_2)\n ),\n rate=0.3\n)",
"_____no_output_____"
],
[
"scores = tf.nn.softmax(X_2)",
"_____no_output_____"
]
],
[
[
"#### Training",
"_____no_output_____"
]
],
[
[
"weights = {\n \"filters_1\": filters_1,\n \"filters_2\": filters_2,\n \"filters_3\": filters_3,\n \"W_1\": W_1,\n \"W_2\": W_2\n}",
"_____no_output_____"
],
[
"@tf.function\ndef classify(images, weights):\n normalized_images = tf.divide(images, 255.)\n feature_maps_1 = tf.nn.leaky_relu(\n tf.nn.conv2d(normalized_images, filters_1, strides=[1, 1, 1, 1], padding=\"SAME\"),\n alpha=0.2\n )\n pooled_maps_1 = tf.nn.max_pool(\n feature_maps_1,\n ksize=(1,3,3,1),\n strides=(1,3,3,1),\n padding='SAME'\n )\n feature_maps_2 = tf.nn.leaky_relu(\n tf.nn.conv2d(\n pooled_maps_1,\n filters_2,\n strides=[1, 1, 1, 1],\n padding=\"SAME\"\n ),\n alpha=0.2\n )\n pooled_maps_2 = tf.nn.max_pool(\n feature_maps_2,\n ksize=(1,3,3,1),\n strides=(1,3,3,1),\n padding='SAME'\n )\n feature_maps_3 = tf.nn.leaky_relu(\n tf.nn.conv2d(\n pooled_maps_2,\n filters_3,\n strides=[1, 1, 1, 1],\n padding=\"SAME\"\n ),\n alpha=0.2\n )\n pooled_maps_3 = tf.nn.max_pool(\n feature_maps_3,\n ksize=(1,60,60,1),\n strides=(1,60,60,1),\n padding='SAME'\n )\n print(pooled_maps_3.shape)\n flatten = tf.reshape(\n pooled_maps_3,\n shape=tf.TensorShape((32, 64))\n )\n X_1 = tf.nn.dropout(\n tf.nn.leaky_relu(\n tf.matmul(flatten, W_1)\n ),\n rate=0.3\n )\n X_2 = tf.nn.dropout(\n tf.nn.leaky_relu(\n tf.matmul(X_1, W_2)\n ),\n rate=0.3\n )\n scores = tf.nn.softmax(X_2)\n return scores",
"_____no_output_____"
],
[
"optimizer = tf.optimizers.Adam(0.01)",
"_____no_output_____"
],
[
"grads",
"_____no_output_____"
],
[
"num_epochs = 2\n\nfor e in range(num_epochs):\n for imgs, labels in train_ds:\n with tf.GradientTape() as tape:\n #print(imgs.shape)\n outputs = classify(imgs, weights)\n #current_loss = tf.losses.SparseCategoricalCrossentropy(labels, outputs)\n current_loss = tf.losses.categorical_crossentropy(outputs, tf.one_hot(labels, 5))\n grads = tape.gradient(current_loss, weights)\n #optimizer.apply_gradients(zip(grads, weights))\n print(tf.reduce_mean(current_loss))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a4d60ff82a8d2e4ede640676bbaac6b02b879b9
| 7,423 |
ipynb
|
Jupyter Notebook
|
Jupyter Notebooks/LUVOIR/17_debug_centering.ipynb
|
ivalaginja/PASTIS
|
ed52a4c838c93cd933f7a8c0bf52113cddd5a415
|
[
"BSD-3-Clause"
] | null | null | null |
Jupyter Notebooks/LUVOIR/17_debug_centering.ipynb
|
ivalaginja/PASTIS
|
ed52a4c838c93cd933f7a8c0bf52113cddd5a415
|
[
"BSD-3-Clause"
] | null | null | null |
Jupyter Notebooks/LUVOIR/17_debug_centering.ipynb
|
ivalaginja/PASTIS
|
ed52a4c838c93cd933f7a8c0bf52113cddd5a415
|
[
"BSD-3-Clause"
] | null | null | null | 21.961538 | 122 | 0.541291 |
[
[
[
"# Debug centering issue",
"_____no_output_____"
]
],
[
[
"# Imports\nimport os\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import LogNorm\n%matplotlib inline\nfrom astropy.io import fits\nimport astropy.units as u\nimport hcipy as hc\nfrom hcipy.optics.segmented_mirror import SegmentedMirror\n\nos.chdir('../../pastis/')\nimport util_pastis as util\nfrom e2e_simulators.luvoir_imaging import LuvoirAPLC",
"_____no_output_____"
],
[
"# Instantiate LUVOIR\napodizer_design = 'small'\nsampling = 4\n# This path is specific to the paths used in the LuvoirAPLC class\noptics_input = '/Users/ilaginja/Documents/LabWork/ultra/LUVOIR_delivery_May2019/'\n\nluvoir = LuvoirAPLC(optics_input, apodizer_design, sampling)",
"_____no_output_____"
],
[
"# Make reference image\nluvoir.flatten()\npsf_unaber, ref, inter = luvoir.calc_psf(ref=True, return_intermediate='efield')",
"_____no_output_____"
],
[
"# Make dark hole\ndh_outer = hc.circular_aperture(2*luvoir.apod_dict[apodizer_design]['owa'] * luvoir.lam_over_d)(luvoir.focal_det)\ndh_inner = hc.circular_aperture(2*luvoir.apod_dict[apodizer_design]['iwa'] * luvoir.lam_over_d)(luvoir.focal_det)\ndh_mask = (dh_outer - dh_inner).astype('bool')",
"_____no_output_____"
],
[
"inter.keys()",
"_____no_output_____"
],
[
"to_plot = inter['before_lyot']",
"_____no_output_____"
],
[
"plt.figure(figsize=(12,12))\n\nplt.subplot(2, 2, 1)\nplt.title(\"Intensity\")\nhc.imshow_field(np.log10(to_plot.intensity))\n\nplt.subplot(2, 2, 2)\nplt.title(\"Phase\")\nhc.imshow_field(to_plot.phase)\n\nplt.subplot(2, 2, 3)\nplt.title(\"Real\")\nhc.imshow_field(to_plot.real)\n\nplt.subplot(2, 2, 4)\nplt.title(\"Imaginary\")\nhc.imshow_field(to_plot.imag)",
"_____no_output_____"
],
[
"(np.arange(10) + 0.5 - 10/2)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,10))\nhc.imshow_field(luvoir.fpm)\n#plt.grid(color='w', linestyle='-', linewidth=2)",
"_____no_output_____"
],
[
"plt.figure(figsize=(6, 6))\nplt.imshow(luvoir.fpm.shaped)",
"_____no_output_____"
],
[
"print(luvoir.fpm.shaped)\nutil.write_fits(luvoir.fpm.shaped, '/Users/ilaginja/Documents/fpm.fits')",
"_____no_output_____"
],
[
"res = util.FFT(luvoir.fpm.shaped)",
"_____no_output_____"
],
[
"new_plot = res\n\nim = util.zoom_point(new_plot, new_plot.shape[0]/2, new_plot.shape[0]/2, 200)",
"_____no_output_____"
],
[
"plt.figure(figsize=(12,12))\n\nplt.subplot(2, 2, 1)\nplt.title(\"Intensity\")\nplt.imshow(np.log10(np.abs(new_plot)**2))\n\nplt.subplot(2, 2, 2)\nplt.title(\"Phase\")\nplt.imshow(np.angle(new_plot))\nplt.colorbar()\n\nplt.subplot(2, 2, 3)\nplt.title(\"Real\")\n#hc.imshow_field(to_plot.real)\n\nplt.subplot(2, 2, 4)\nplt.title(\"Imaginary\")\n#hc.imshow_field(to_plot.imag)",
"_____no_output_____"
],
[
"np.angle(new_plot)",
"_____no_output_____"
],
[
"print(np.min(np.angle(new_plot)))",
"_____no_output_____"
],
[
"# Plot\nplt.figure(figsize=(18, 6))\nplt.subplot(131)\nhc.imshow_field(psf_unaber.intensity/ref.intensity.max(), norm=LogNorm())\nplt.subplot(132)\nhc.imshow_field(dh_mask)\nplt.subplot(133)\nhc.imshow_field(psf_unaber.intensity/ref.intensity.max(), norm=LogNorm(), mask=dh_mask)",
"_____no_output_____"
],
[
"dh_intensity = psf_unaber.intensity/ref.intensity.max() * dh_mask\nbaseline_contrast = util.dh_mean(dh_intensity, dh_mask)\n#np.mean(dh_intensity[np.where(dh_intensity != 0)])\nprint('Baseline contrast:', baseline_contrast)",
"_____no_output_____"
],
[
"imsize = 10\nim = np.zeros((imsize, imsize))\nfocal_plane_mask = util.circle_mask(im, imsize/2, imsize/2, imsize/2)",
"_____no_output_____"
],
[
"plt.imshow(focal_plane_mask)",
"_____no_output_____"
],
[
"out = util.FFT(focal_plane_mask)",
"_____no_output_____"
],
[
"plt.imshow(np.abs(out))",
"_____no_output_____"
],
[
"plt.imshow(np.angle(out))",
"_____no_output_____"
],
[
"np.angle(out)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4d615788d82efd457a2cf8146de5060e3cc4f0
| 231,111 |
ipynb
|
Jupyter Notebook
|
FunFractalFunctions.ipynb
|
fenna/BFVP3INF2_DEMO
|
75f9c86adfdfe20989a63af464a7f537a326bdc5
|
[
"CNRI-Python"
] | null | null | null |
FunFractalFunctions.ipynb
|
fenna/BFVP3INF2_DEMO
|
75f9c86adfdfe20989a63af464a7f537a326bdc5
|
[
"CNRI-Python"
] | null | null | null |
FunFractalFunctions.ipynb
|
fenna/BFVP3INF2_DEMO
|
75f9c86adfdfe20989a63af464a7f537a326bdc5
|
[
"CNRI-Python"
] | null | null | null | 64.574183 | 922 | 0.679072 |
[
[
[
"# Some fun with functions and fractals (Informatics II)",
"_____no_output_____"
],
[
"author: Tsjerk Wassenaar\n\nThe topic of this tutorial is advanced functions in Python. This consists of several aspects:\n\n* Functions with variable arguments lists (\\*args and \\*\\*kwargs)\n* Recursive functions\n* Functions as objects\n* Functions returning functions (closures)\n\nThe last two of these are mainly to give a bit of feel of what functions are (in Python) and what you can do with them and are there for *passive learning*. The first two are part of the core of Informatics 2. \n\nThe aspects of functions named above are here demonstrated by making fractals, which are mathematical images with *scaled symmetry*: the image consists of smaller copies of itself, which consist of smaller copies of themselves. Such fractals actually occur in biological systems, and can be seen in the structures of weeds and trees. Nice examples are to be find <a href=\"http://paulbourke.net/fractals/fracintro/\">here</a>\n\nWe'll be drawing the fractals first in 2D with turtle graphics. Towards the end, we'll be able to extend to 3D and generate a fractal structure for drawing with **pypovray** (optional).",
"_____no_output_____"
],
[
"Just to set a few things straight:\n\n* You **don't** need to know fractals, L-systems and any of the specific ones named and used.\n* You **do** need to understand *recursive functions* and *recursion depth*\n\n\n* You **don't** need to know (reproduce) the functions used in this tutorial\n* You **do** need to understand how the functions work and be able to put them to use in the template\n\n\n* You **do** need to write a template and put the functions in to make this work. Although... you can also work interactively to try things out.\n\nWhen writing a turtle program using the template, you can start with the following basic main function, to keep the image until you press the _any_ key:",
"_____no_output_____"
]
],
[
[
"def main(args):\n \"\"\"Docstring goes here\"\"\"\n \n # Preparation\n \n # Processing\n\n # Finishing\n input('Press any key to continue')\n\n return 0",
"_____no_output_____"
]
],
[
[
"## Recursion",
"_____no_output_____"
]
],
[
[
"def recurse():\n print(\"A recursive function is a function that calls itself, like:\")\n recurse()\n \nrecurse()",
"A recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\nA recursive function is a function that calls itself, like:\n"
]
],
[
[
"So, a recursive function is one that calls itself.\n\nWell, that's that. So, we can continue to the next topic...\n\nOn the other hand, maybe it is good to think about how that works in practice and good to think about why you'd want to do that. Just to set things straight: there is nothing you can do with recursion that you can't do with a for loop and creative use of (nested) lists. However, in some cases, you'll have to get really creative, and you may be better off if you can split your problem into parts and do try the same function/strategy on the parts.\n\nA classic example of a recursive function is the factorial. The factorial of an integer is the joint product of that number and *all* foregoing positive numbers. It's typically written as n!. So the outcome of 5! is 5\\*4\\*3\\*2\\*1 = 120. There is one additional rule: by definition 0! = 1\n\nWith that, we can write a factorial function. First, look at the for-loop way:",
"_____no_output_____"
]
],
[
[
"def factorial(n):\n result = 1\n for num in range(n,0,-1):\n result *= num\n return result",
"_____no_output_____"
]
],
[
[
"We can turn this into a recursive function, by considering two cases: n is 0, or n is not. If n is 0, then the result is 1 (by definition). If n is not (yet) zero, then the result is n * (n-1)!, so n times the factorial of n-1:",
"_____no_output_____"
]
],
[
[
"def factorial(n):\n if not n:\n return 1\n return n * factorial(n - 1)",
"_____no_output_____"
]
],
[
[
"### Assignment:\n\nWrite a program factorial.py that takes a number as command line argument and prints the factorial of that number. Start with a correct template and use the recursive function. Write docstrings!",
"_____no_output_____"
],
[
"## Fractals and recursion\n\nFor fractals, we'll focus on Lindenmayer fractals (L-systems). These are written as a series of steps, like forward, right, and left. The trick is that a step can be replaced by a sequence of steps, in which steps can be replaced by that sequence of steps again, and so on and so forth. Because of time, that has to end somewhere, and we'll call that the depth of the sequence.\n\nSo, the L-system consists of:\n\n* the **axiom**: the start sequence\n* the **rules**: the replacement rules\n* the **depth**: the depth of the recursion\n\nThe result is a sequence of instructions (forward, right, and left) that we can nicely pass to our turtle friend Don.",
"_____no_output_____"
]
],
[
[
"import turtle\n\ndon = turtle.Turtle(shape=\"turtle\")",
"_____no_output_____"
]
],
[
[
"We start off with the **Hilbert function**, which can be written as an L-system (thanks Wikipedia):\n\n\n* axiom: A\n* rules:\n - A → -BF+AFA+FB-\n - B → +AF-BFB-FA+\n\nHere, \"F\" means \"draw forward\", \"−\" means \"turn left 90°\", \"+\" means \"turn right 90°\" (see turtle graphics), and \"A\" and \"B\" are ignored during drawing.\n\n**This means** that we start with 'A', and then replace 'A' with '-BF+AFA+FB-'. In the result, we replace each 'A' with that same string, but each B is replaced with '+AF-BFB-FA+'. And we can repeat that...",
"_____no_output_____"
]
],
[
[
"def hilbert(depth, sequence='A'):\n if not depth: \n return sequence\n out = []\n for character in sequence:\n if character == 'A':\n out.extend('-BF+AFA+FB-')\n elif character == 'B':\n out.extend('+AF-BFB-FA+')\n else:\n out.append(character)\n return hilbert(depth - 1, out)",
"_____no_output_____"
],
[
"print(\"\".join(hilbert(0)))",
"A\n"
],
[
"print(\"\".join(hilbert(1)))",
"-BF+AFA+FB-\n"
],
[
"print(\"\".join(hilbert(2)))",
"-+AF-BFB-FA+F+-BF+AFA+FB-F-BF+AFA+FB-+F+AF-BFB-FA+-\n"
],
[
"print(\"\".join(hilbert(3)))",
"-+-BF+AFA+FB-F-+AF-BFB-FA+F+AF-BFB-FA+-F-BF+AFA+FB-+F+-+AF-BFB-FA+F+-BF+AFA+FB-F-BF+AFA+FB-+F+AF-BFB-FA+-F-+AF-BFB-FA+F+-BF+AFA+FB-F-BF+AFA+FB-+F+AF-BFB-FA+-+F+-BF+AFA+FB-F-+AF-BFB-FA+F+AF-BFB-FA+-F-BF+AFA+FB-+-\n"
]
],
[
[
"Now, for each F in the sequence don goes forward, for each - he goes left and for each + he goes right. We can write this with an if/elif clause:",
"_____no_output_____"
]
],
[
[
"for char in hilbert(3):\n if char == 'F':\n don.forward(10)\n elif char == '+':\n don.right(90)\n elif char == '-':\n don.left(90)\n",
"_____no_output_____"
]
],
[
[
"This is a function specific for the Hilbert function, which is pretty cool, as it generates a maze-like drawing. But there are many other interesting L-systems, and we can capture more of them, using the advanced function syntax, which allows us to specify an arbitrary number of keyword arguments:",
"_____no_output_____"
]
],
[
[
"def l_system(depth, axiom, **rules):\n if not depth:\n return axiom\n \n # Basic, most straight-forward implementation\n # Note 1: it doesn't matter if axiom is a string or a list\n # Note 2: consider the difference between .extend() and .append()\n out = []\n for char in axiom:\n if char in rules:\n out.extend(rules[char])\n else:\n out.append(char)\n \n # Two alternative implementations. If you want to try \n # an alternative, comment out the original first.\n # It won't change the answer, but it will take more time\n # if you keep the code active.\n \n # I. Alternative implementation using dict.get\n # --------------------------------------------\n # out = []\n # for char in axiom:\n # out.extend(rules.get(char, [char]))\n \n # II. Alternative implementation in one line using list comprehension\n # -------------------------------------------------------------------\n # out = [i for char in axiom for i in rules.get(char, char)]\n \n # Note 3: See how comments are used to annotate the code... :)\n \n return l_system(depth - 1, out, **rules)",
"_____no_output_____"
]
],
[
[
"With this, we can write the Hilbert function much shorter:",
"_____no_output_____"
]
],
[
[
"def hilbert(depth):\n return l_system(depth, axiom='A', A='-BF+AFA+FB-', B='+AF-BFB-FA+')",
"_____no_output_____"
]
],
[
[
"And we can write a Sierpinski gasket, using\n\n* **axiom**: f\n* **rules**:\n - F: f+F+f\n - f: F-f-F\n\nWith the note that both f and F mean forward.",
"_____no_output_____"
]
],
[
[
"def sierpinski_gasket(depth):\n return l_system(depth, axiom='f', F='f+F+f', f='F-f-F')",
"_____no_output_____"
],
[
"for char in sierpinski_gasket(7):\n if char in 'Ff':\n don.forward(1)\n elif char == '+':\n don.right(60)\n elif char == '-':\n don.left(60)",
"_____no_output_____"
]
],
[
[
"The next step is getting rid of the if/elif/elif/... clause, to make the handling of actions a bit nicer.",
"_____no_output_____"
],
[
"## Functions as objects",
"_____no_output_____"
],
[
"Getting rid of an if/elif/.. construct typically involves introducing a dictionary. A good reason to do that is that a dictionary requires less bookkeeping. However, in our case, we deal with actions, not values. Then again, actions are processes, which can be described as functions. So, we'll put *functions* in a dictionary!\n\nAgain, what we'll do is just a different way, whether it's actually better depends on the situation.\n\nThe idea of putting functions in a dictionary hinges on using functions as objects. Functions are objects that are *callable*: you can add parentheses to invoke the action. Without parentheses, it's just the function object. Consider the following example:",
"_____no_output_____"
]
],
[
[
"blabla = print\nblabla(\"Hello World!\")",
"Hello World!\n"
]
],
[
[
"So, we assign the print *object* to a new variable, called *blabla*, and we can use that name too as print function. Likewise, we can store the function in a tuple, list, set or dictionary:",
"_____no_output_____"
]
],
[
[
"actions = {\"p\": print}\nactions[\"p\"](\"Hello World!\")",
"Hello World!\n"
]
],
[
[
"Notice what happens there. We store the print function in a dictionary, bound to the key \"p\". Then we use the key \"p\" to get the corresponding value from the dictionary, and we *call* the process, by adding the parentheses with the argument \"Hello World!\".\n\nNow let's do that with the actions for Don.",
"_____no_output_____"
]
],
[
[
"def forward(turt, step=5):\n turt.forward(step)\n\n\ndef right(turt, angle=90):\n turt.right(angle)\n\n \ndef left(turt, angle=90):\n turt.left(angle)\n\n\nactions = {'F': forward, 'f': forward, '+': right, '-': left}",
"_____no_output_____"
]
],
[
[
"Take a moment and think about the function definitions (and write docstrings!). The functions are very simple, but it's not easily possible to actually put the turtle functions in the dictionary. Well, actually it *is* easy once you know how, but it's not actually easy to call them nicely then. The approach above is easier to deal with:",
"_____no_output_____"
]
],
[
[
"for char in hilbert(5):\n if char in actions:\n actions[char](don)",
"_____no_output_____"
]
],
[
[
"## Functions with function definitions",
"_____no_output_____"
],
[
"And now we'll be taking a step further. Note: **this is not mandatory stuff for the exam**. However, the following things may give you a good feel for the idea of functions being objects, just like (other) variables. So, to allow the actions to have different angles/steps, to deal with the Sierpinski thing, we'll generate the actions dictionary with a function, in which we can set the angle and the step:",
"_____no_output_____"
]
],
[
[
"def actions(step, angle):\n \n def forward(turt):\n turt.forward(step)\n \n def right(turt):\n turt.right(angle)\n \n def left(turt):\n turt.left(angle)\n \n return {'F': forward, 'f': forward, '+': right, '-': left}",
"_____no_output_____"
]
],
[
[
"Now, put this function in your code and write the docstring. Take a moment to see what is happening here. *Within the function **actions** we define three functions, which take a **turt** as argument. The three functions are put in a dictionary, and this dictionary is returned.* The dictionary can then be used:",
"_____no_output_____"
]
],
[
[
"actions_dict = actions(step=1, angle=60)\nfor char in sierpinski_gasket(7):\n if char in actions_dict:\n actions_dict[char](don)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4d69333b8a7f400afc7398c5b7f4459261dd26
| 28,592 |
ipynb
|
Jupyter Notebook
|
clases/ML/clasificacion_binaria.ipynb
|
soren-hub/Neural_networks_material
|
ad8d0422b3d3bb66ff061e7e3902ca48d981f93c
|
[
"Apache-2.0"
] | null | null | null |
clases/ML/clasificacion_binaria.ipynb
|
soren-hub/Neural_networks_material
|
ad8d0422b3d3bb66ff061e7e3902ca48d981f93c
|
[
"Apache-2.0"
] | null | null | null |
clases/ML/clasificacion_binaria.ipynb
|
soren-hub/Neural_networks_material
|
ad8d0422b3d3bb66ff061e7e3902ca48d981f93c
|
[
"Apache-2.0"
] | null | null | null | 55.090559 | 16,892 | 0.784065 |
[
[
[
"## Importamos librerías",
"_____no_output_____"
]
],
[
[
"from keras.datasets import imdb\nfrom keras import models, layers, optimizers\nimport numpy as np\n",
"_____no_output_____"
]
],
[
[
"## Descargamos los datos de imdb - Keras",
"_____no_output_____"
]
],
[
[
"(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)",
"<string>:6: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray\nC:\\Users\\joaqu\\anaconda3\\envs\\book\\lib\\site-packages\\tensorflow\\python\\keras\\datasets\\imdb.py:159: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray\n x_train, y_train = np.array(xs[:idx]), np.array(labels[:idx])\nC:\\Users\\joaqu\\anaconda3\\envs\\book\\lib\\site-packages\\tensorflow\\python\\keras\\datasets\\imdb.py:160: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray\n x_test, y_test = np.array(xs[idx:]), np.array(labels[idx:])\n"
],
[
"#train_data[0]",
"_____no_output_____"
],
[
"train_labels[1]",
"_____no_output_____"
]
],
[
[
"### Diccionario de palabras",
"_____no_output_____"
]
],
[
[
"word_index = imdb.get_word_index()\nword_index = dict([(value,key) for (key,value) in word_index.items()])",
"_____no_output_____"
],
[
"#for _ in train_data[0]:\n# print(word_index.get( _ - 3))",
"_____no_output_____"
]
],
[
[
"## Función de one-hot encoding",
"_____no_output_____"
]
],
[
[
"def vectorizar(sequences, dim=10000):\n restults = np.zeros((len(sequences),dim))\n for i, sequences in enumerate(sequences):\n restults[i,sequences]=1\n return restults ",
"_____no_output_____"
]
],
[
[
"## Transformamos datos",
"_____no_output_____"
]
],
[
[
"x_train = vectorizar(train_data)\nx_test = vectorizar(test_data)",
"_____no_output_____"
],
[
"y_train = np.asarray(train_labels).astype('float32')\ny_test = np.asarray(test_labels).astype('float32')",
"_____no_output_____"
]
],
[
[
"## Creamos el modelo",
"_____no_output_____"
]
],
[
[
"model = models.Sequential()\nmodel.add(layers.Dense(16, activation='relu', input_shape=(10000,)))\nmodel.add(layers.Dense(16, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid'))",
"_____no_output_____"
],
[
"model.compile(optimizer='rmsprop',\n loss='binary_crossentropy',\n metrics=['acc'])",
"_____no_output_____"
],
[
"x_val = x_train[:10000]\npartial_x_train = x_train[10000:]\n\ny_val = y_train[:10000]\npartial_y_train = y_train[10000:]",
"_____no_output_____"
]
],
[
[
"## Entrenando",
"_____no_output_____"
]
],
[
[
"history = model.fit(partial_x_train,\n partial_y_train,\n epochs=7,\n batch_size=512,\n validation_data=(x_val,y_val))",
"Epoch 1/7\n30/30 [==============================] - 1s 23ms/step - loss: 0.5140 - acc: 0.7930 - val_loss: 0.3932 - val_acc: 0.8690\nEpoch 2/7\n30/30 [==============================] - 0s 12ms/step - loss: 0.3142 - acc: 0.9001 - val_loss: 0.3184 - val_acc: 0.8754\nEpoch 3/7\n30/30 [==============================] - 0s 12ms/step - loss: 0.2299 - acc: 0.9271 - val_loss: 0.3017 - val_acc: 0.8766\nEpoch 4/7\n30/30 [==============================] - 0s 12ms/step - loss: 0.1822 - acc: 0.9407 - val_loss: 0.2956 - val_acc: 0.8808\nEpoch 5/7\n30/30 [==============================] - 0s 12ms/step - loss: 0.1501 - acc: 0.9515 - val_loss: 0.2778 - val_acc: 0.8878\nEpoch 6/7\n30/30 [==============================] - 0s 12ms/step - loss: 0.1236 - acc: 0.9615 - val_loss: 0.2895 - val_acc: 0.8859\nEpoch 7/7\n30/30 [==============================] - 0s 11ms/step - loss: 0.1029 - acc: 0.9675 - val_loss: 0.3074 - val_acc: 0.8845\n"
]
],
[
[
"## Analizamos resultados",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt \n\nhistory_dict = history.history\nloss_values = history_dict['loss']\nval_loss_values = history_dict['val_loss']\n\nfig = plt.figure(figsize=(10,10))\nepoch = range(1,len(loss_values)+1)\nplt.plot(epoch,loss_values, 'o',label='training')\nplt.plot(epoch,val_loss_values, '--',label='val')\nplt.legend()\nplt.show()",
"_____no_output_____"
],
[
"model.evaluate(x_test, y_test)[1]*100",
"782/782 [==============================] - 1s 1ms/step - loss: 0.3342 - acc: 0.8728\n"
]
],
[
[
"## Predicciones",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(x_test)",
"_____no_output_____"
],
[
"predictions[1]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4d726f1580aba9b320d43f04386d604feeee6e
| 161,794 |
ipynb
|
Jupyter Notebook
|
notebooks/orbit.ipynb
|
abonaca/ngc5907_stream
|
1fd2ea4f2943e106ce87c820ffcb0815b38095fb
|
[
"MIT"
] | null | null | null |
notebooks/orbit.ipynb
|
abonaca/ngc5907_stream
|
1fd2ea4f2943e106ce87c820ffcb0815b38095fb
|
[
"MIT"
] | null | null | null |
notebooks/orbit.ipynb
|
abonaca/ngc5907_stream
|
1fd2ea4f2943e106ce87c820ffcb0815b38095fb
|
[
"MIT"
] | null | null | null | 409.605063 | 89,476 | 0.940245 |
[
[
[
"import numpy as np\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nimport astropy.coordinates as coord\nfrom astropy.table import Table\nimport astropy.units as u\n\nimport gala.coordinates as gc\nimport gala.dynamics as gd\nfrom gala.dynamics import mockstream\nimport gala.potential as gp\nfrom gala.units import galactic",
"_____no_output_____"
],
[
"plt.style.use('notebook')",
"_____no_output_____"
],
[
"t = Table.read('../data/stream_track.txt', format='ascii.commented_header', delimiter=',')\ntp = Table.read('../data/pvd_stream.dat', format='ascii.commented_header', delimiter=' ')",
"_____no_output_____"
]
],
[
[
"### Rotate the galaxy to lie along z=0",
"_____no_output_____"
]
],
[
[
"pa = 154*u.deg # https://www.flickr.com/photos/dcrowson/35166799656\ntheta = 64*u.deg",
"_____no_output_____"
],
[
"x = np.cos(theta)*t['x'] + np.sin(theta)*t['y']\nz = -np.sin(theta)*t['x'] + np.cos(theta)*t['y']\n\nxpvd = np.cos(theta)*tp['x_pvd_kpc'] + np.sin(theta)*tp['y_pvd_kpc']\nzpvd = -np.sin(theta)*tp['x_pvd_kpc'] + np.cos(theta)*tp['y_pvd_kpc']",
"_____no_output_____"
],
[
"# progenitor as densest location on the stream\nxp_rot, zp_rot = -38.7, -2.3\nxp_ = np.cos(theta)*xp_rot + np.sin(theta)*zp_rot\nzp_ = -np.sin(theta)*xp_rot + np.cos(theta)*zp_rot",
"_____no_output_____"
],
[
"plt.plot(t['x'], t['y'], 'ko', alpha=0.1)\nplt.plot(x, z, 'ko')\nplt.plot(xp_, zp_, 'kx', ms=10, mew=2)\n\nplt.xlabel('x [kpc]')\nplt.ylabel('z [kpc]')\n\nplt.gca().set_aspect('equal')",
"_____no_output_____"
]
],
[
[
"### Set up gravitational potential",
"_____no_output_____"
]
],
[
[
"# most params from Martinez-Delgado paper, + tuned halo mass to reproduce Casertano measurement of max vcirc\n# https://ui.adsabs.harvard.edu/abs/2008ApJ...689..184M/abstract\n# adopted halo flattening of 0.95 to match the trailing tail curvature\nham = gp.Hamiltonian(gp.MilkyWayPotential(nucleus=dict(m=0), \n halo=dict(c=0.95, m=1.96e11*u.Msun, r_s=8.2*u.kpc),\n bulge=dict(m=2.3e10*u.Msun, c=0.6*u.kpc),\n disk=dict(m=8.4e10*u.Msun, a=6.24*u.kpc, b=0.26*u.kpc)))",
"_____no_output_____"
],
[
"xyz = np.zeros((3, 128))\nxyz[0] = np.linspace(1, 25, 128)\nprint('maximal circular velocity {:.0f}'.format(np.max(ham.potential.circular_velocity(xyz))))\n\nplt.figure(figsize=(8,5))\nplt.plot(xyz[0], ham.potential.circular_velocity(xyz))\nplt.axhline(227, color='k')\n\nplt.xlabel('r [kpc]')\nplt.ylabel('$V_c$ [km s$^{-1}$]')\nplt.tight_layout()",
"maximal circular velocity 227 km / s\n"
],
[
"for d in [200,225,250]:\n print('{:.0f} kpc {:.2g}'.format(d, ham.potential.mass_enclosed(d*u.kpc)[0]))",
"200 kpc 5.5e+11 solMass\n225 kpc 5.7e+11 solMass\n250 kpc 5.9e+11 solMass\n"
]
],
[
[
"### Pick orbit for the satellite",
"_____no_output_____"
]
],
[
[
"# trial progenitor 6D location\nxp = np.array([xp_, 0, zp_]) * u.kpc\nvp = np.array([30,85,165]) * u.km/u.s\n\nw0 = gd.PhaseSpacePosition(xp, vel=vp)\n\ndt = 0.5*u.Myr\nn_steps = 900\n\norbit_fwd = ham.integrate_orbit(w0, dt=dt, n_steps=n_steps)\norbit_rr = ham.integrate_orbit(w0, dt=-dt, n_steps=n_steps)\n\nplt.plot(x, z, 'ko')\nfor orbit in [orbit_fwd, orbit_rr]:\n plt.plot(orbit.cartesian.x, orbit.cartesian.z, '-', color='tab:blue')\n\nplt.xlabel('x [kpc]')\nplt.ylabel('z [kpc]')\n\nplt.gca().set_aspect('equal')",
"_____no_output_____"
]
],
[
[
"### Create a stream model",
"_____no_output_____"
]
],
[
[
"f = 3\nprog_orbit = ham.integrate_orbit(w0, dt=-dt/f, n_steps=5200*f)\nprog_orbit = prog_orbit[::-1]\n\nn_times = np.size(prog_orbit.t)\nprog_mass = np.linspace(2e8, 0, n_times)\n# stream = mockstream.fardal_stream(ham, prog_orbit, prog_mass=prog_mass, release_every=1, seed=4359)\n\n# fardal values for particle release conditions\nk_mean = np.array([2., 0, 0, 0, 0.3, 0])\nk_disp = np.array([0.5, 0, 0.5, 0, 0.5, 0.5])\n\n# tweaks to reproduce smaller offset of tidal arms, trailing tail extension\nk_mean = np.array([1.2, 0, 0, 0.0, 0.1, 0])\nk_disp = np.array([0.5, 0, 0.5, 0.02, 0.5, 0.5])\n\nstream = mockstream.mock_stream(ham, prog_orbit, prog_mass=prog_mass, release_every=1, seed=4359,\n k_mean=k_mean, k_disp=k_disp)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,10))\n\nplt.plot(x, z, 'ko', ms=4, label='Dragonfly (Colleen)')\nplt.plot(xpvd, zpvd, 'ro', ms=4, label='Dragonfly (Pieter)')\nplt.plot(prog_orbit.cartesian.x, prog_orbit.cartesian.z, '-', color='tab:blue', label='Orbit', alpha=0.5)\nplt.plot(stream.cartesian.x, stream.cartesian.z, '.', color='0.3', ms=1, alpha=0.05, label='Stream model')\n\nplt.legend(fontsize='small', loc=1)\nplt.xlabel('x [kpc]')\nplt.ylabel('z [kpc]')\nplt.xlim(-40,130)\nplt.ylim(-60,70)\n\nplt.gca().set_aspect('equal')\nplt.savefig('../plots/trial_model_xz.png', dpi=200)",
"_____no_output_____"
],
[
"Ns = np.size(stream.cartesian.x)\nNsh = int(Ns/2)\nNsq = int(Ns/4)",
"_____no_output_____"
],
[
"xp, vp",
"_____no_output_____"
],
[
"tout_stream = Table([stream.cartesian.x, stream.cartesian.z], names=('x', 'z'))\ntout_stream.write('../data/stream.fits', overwrite=True)",
"_____no_output_____"
],
[
"tout_orbit = Table([prog_orbit.cartesian.x, prog_orbit.cartesian.z, prog_orbit.t], names=('x', 'z', 't'))\ntout_orbit.write('../data/orbit.fits', overwrite=True)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4d7dd9e78a20a2e52885ff8c1432b4656d266e
| 3,447 |
ipynb
|
Jupyter Notebook
|
assignments/array/Kth Smallest Element.ipynb
|
Anjani100/logicmojo
|
25763e401f5cc7e874d28866c06cf39ad42b3a8d
|
[
"MIT"
] | null | null | null |
assignments/array/Kth Smallest Element.ipynb
|
Anjani100/logicmojo
|
25763e401f5cc7e874d28866c06cf39ad42b3a8d
|
[
"MIT"
] | null | null | null |
assignments/array/Kth Smallest Element.ipynb
|
Anjani100/logicmojo
|
25763e401f5cc7e874d28866c06cf39ad42b3a8d
|
[
"MIT"
] | 2 |
2021-09-15T19:16:18.000Z
|
2022-03-31T11:14:26.000Z
| 27.141732 | 127 | 0.388164 |
[
[
[
"# Time: O(n)\n# Space: O(1)\n\ndef kth_smallest_element(nums1, nums2, k):\n m, n = len(nums1), len(nums2)\n i = j = 0\n while i < m and j < n:\n if nums1[i] <= nums2[j]:\n if k == 1:\n return nums1[i]\n i += 1\n else:\n if k == 1:\n return nums2[j]\n j += 1\n k -= 1\n while i < m:\n if k == 1:\n return nums1[i]\n i += 1\n k -= 1\n while j < n:\n if k == 1:\n return nums2[j]\n j += 1\n k -= 1\n\nif __name__=='__main__':\n tc = [[[2, 3, 6, 7, 9],[1, 4, 8, 10], 5],\n [[-2, -1, 3, 5, 6, 8],[1, 4, 8, 10], 4],\n [[100 ,112, 256, 349, 770],[72, 86, 113, 119, 265, 445, 892], 7],\n [[10, 20, 40, 60],[15, 35, 50, 70, 100], 4]]\n for nums1, nums2, k in tc:\n print(k_smallest_element(nums1, nums2, k))",
"6\n3\n256\n35\n"
],
[
"def kth_smallest_element(nums1, nums2, m, n, k):\n if n < m: return kth_smallest_element(nums2, nums1, n, m, k)\n low, high = max(0, k - n), min(k, m)\n while low <= high:\n mid = (low + high) // 2\n l1, r1 = nums1[mid - 1] if mid > 0 else float('-inf'), nums1[mid] if mid < m else float('inf')\n l2, r2 = nums2[k - mid - 1] if k - mid > 0 else float('-inf'), nums2[k - mid] if k - mid < n else float('inf')\n if l1 > r2: high = mid - 1\n elif l2 > r1: low = mid + 1\n else: return max(l1, l2)\n\nif __name__=='__main__':\n tc = [[[2, 3, 6, 7, 9],[1, 4, 8, 10],5,4,5],\n [[-2, -1, 3, 5, 6, 8],[1, 4, 8, 10],6,4,4],\n [[100 ,112, 256, 349, 770],[72, 86, 113, 119, 265, 445, 892],5,7,7],\n [[10, 20, 40, 60],[15, 35, 50, 70, 100],4,5,4],\n [[2, 3, 6, 7, 9],[1, 4, 8, 10],5,4,5],\n [[1],[2],1,1,1]]\n for nums1, nums2, m, n, k in tc:\n print(kth_smallest_element(nums1, nums2, m, n, k))",
"6\n3\n256\n35\n6\n1\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a4d80158369835760fef9a12033b8397956db4c
| 3,747 |
ipynb
|
Jupyter Notebook
|
docs_src/widgets.ipynb
|
MartinGer/fastai
|
5a5de8b3a6c2a4ba04f1e5873083808172a6903a
|
[
"Apache-2.0"
] | 2 |
2019-02-08T04:59:27.000Z
|
2020-05-15T21:17:23.000Z
|
docs_src/widgets.ipynb
|
MartinGer/fastai
|
5a5de8b3a6c2a4ba04f1e5873083808172a6903a
|
[
"Apache-2.0"
] | 2 |
2021-05-20T20:04:51.000Z
|
2022-02-26T09:14:00.000Z
|
docs_src/widgets.ipynb
|
MartinGer/fastai
|
5a5de8b3a6c2a4ba04f1e5873083808172a6903a
|
[
"Apache-2.0"
] | 1 |
2020-01-09T15:44:46.000Z
|
2020-01-09T15:44:46.000Z
| 26.202797 | 423 | 0.593008 |
[
[
[
"# Widgets",
"_____no_output_____"
]
],
[
[
"from fastai import *\nfrom fastai.vision import *\nfrom fastai.widgets import DatasetFormatter, ImageCleaner",
"_____no_output_____"
]
],
[
[
"fastai offers several widgets to support the workflow of a deep learning practitioner. The purpose of the widgets are to help you organize, clean, and prepare your data for your model. Widgets are separated by data type.",
"_____no_output_____"
],
[
"## Images",
"_____no_output_____"
],
[
"### DatasetFormatter\nThe [`DatasetFormatter`](/widgets.image_cleaner.html#DatasetFormatter) class prepares your image dataset for widgets by returning a formatted [`DatasetTfm`](/vision.data.html#DatasetTfm) based on the [`DatasetType`](/basic_data.html#DatasetType) specified. Use `from_toplosses` to grab the most problematic images directly from your learner. Optionally, you can restrict the formatted dataset returned to `n_imgs`.\n\nSpecify the [`DatasetType`](/basic_data.html#DatasetType) you'd like to process:\n- DatasetType.Train\n- DatasetType.Valid\n- DatasetType.Test",
"_____no_output_____"
]
],
[
[
"path = untar_data(URLs.MNIST_SAMPLE)\ndata = ImageDataBunch.from_folder(path)",
"_____no_output_____"
],
[
"learner = create_cnn(data, models.resnet18, metrics=[accuracy])\nds, idxs = DatasetFormatter().from_toplosses(learner, ds_type=DatasetType.Valid)",
"_____no_output_____"
]
],
[
[
"### ImageCleaner",
"_____no_output_____"
],
[
"[`ImageDeleter`](/widgets.image_cleaner.html#ImageDeleter) is for cleaning up images that don't belong in your dataset. It renders images in a row and gives you the opportunity to delete the file from your file system.",
"_____no_output_____"
]
],
[
[
"ImageCleaner(ds, idxs)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a4d8116e00036956a2f00ff1fcdbc2ca16626d9
| 113,583 |
ipynb
|
Jupyter Notebook
|
docs/900-system-setup/950_viz_jupyter.ipynb
|
adioshun/just-the-docs
|
d39dc7ff8705b8c99a4e4be890d472830234d60b
|
[
"MIT"
] | null | null | null |
docs/900-system-setup/950_viz_jupyter.ipynb
|
adioshun/just-the-docs
|
d39dc7ff8705b8c99a4e4be890d472830234d60b
|
[
"MIT"
] | null | null | null |
docs/900-system-setup/950_viz_jupyter.ipynb
|
adioshun/just-the-docs
|
d39dc7ff8705b8c99a4e4be890d472830234d60b
|
[
"MIT"
] | null | null | null | 518.643836 | 90,980 | 0.950935 |
[
[
[
"## Jupyter에서 Point cloud를 시각화 \n\n- Matplotlib 기반 시각화\n- k3d 기반 시각화\n\n> 코드는 [[여기에]](https://github.com/hunjung-lim/3D_People_Detection_Tracking/tree/master/include/visualization_helper.py)에 올려 두었습니다. ",
"_____no_output_____"
]
],
[
[
"# -*- coding: utf-8 -*-\nfrom __future__ import print_function\n\nimport os\nos.chdir(\"/workspace/3D_People_Detection_Tracking\") \nfrom include.visualization_helper import *\n\n%matplotlib inline",
"_____no_output_____"
],
[
"import pcl\npc = pcl.load(\"/workspace/_pcd/test_pypcd_xyzrgb.pcd\") \npc_arr = pc.to_array()",
"_____no_output_____"
]
],
[
[
"## Matplotlib 기반 시각화",
"_____no_output_____"
]
],
[
[
"visualization2D_xyz(pc_arr)",
"(x) : 18.9m\n(y) : 12.5m\n(z) : 1.8m\n"
],
[
"visualization3D_xyz(pc_arr)",
"(x) : 18.9m\n(y) : 12.5m\n(z) : 1.8m\n"
]
],
[
[
"## k3d 기반 시각화\n\n설치 및 Jupyter 설정이 필요 합니다. [[참고]](https://github.com/K3D-tools/K3D-jupyter)\n\n배포하는 [Docker](https://hub.docker.com/r/adioshun/pcl_to_all/)에는 설정이 되어 있으니 바로 실행 하면 됩니다. ",
"_____no_output_____"
]
],
[
[
"visualization_inter3D_xyz(pc_arr) # import k3d",
"2750\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4d82bc019d24006bcf2a682805a35b7027613d
| 941,608 |
ipynb
|
Jupyter Notebook
|
models/pystan.ipynb
|
sethaxen/arviz-probprog-2020
|
1c23e0438cb0840f7bee49b10f7a18bd42385581
|
[
"Apache-2.0"
] | null | null | null |
models/pystan.ipynb
|
sethaxen/arviz-probprog-2020
|
1c23e0438cb0840f7bee49b10f7a18bd42385581
|
[
"Apache-2.0"
] | null | null | null |
models/pystan.ipynb
|
sethaxen/arviz-probprog-2020
|
1c23e0438cb0840f7bee49b10f7a18bd42385581
|
[
"Apache-2.0"
] | null | null | null | 189.649144 | 245,586 | 0.764799 |
[
[
[
"import arviz as az\nimport pystan\nimport numpy as np\nimport ujson as json",
"_____no_output_____"
],
[
"with open(\"radon.json\", \"rb\") as f:\n radon_data = json.load(f)\n\nkey_renaming = {\"x\": \"floor_idx\", \"county\": \"county_idx\", \"u\": \"uranium\"}\nradon_data = {\n key_renaming.get(key, key): np.array(value) if isinstance(value, list) else value\n for key, value in radon_data.items()\n}\nradon_data[\"county_idx\"] = radon_data[\"county_idx\"] + 1",
"_____no_output_____"
],
[
"prior_code = \"\"\"\ndata {\n int<lower=0> J;\n int<lower=0> N;\n int floor_idx[N];\n int county_idx[N];\n real uranium[J];\n}\n\ngenerated quantities {\n real g[2];\n real<lower=0> sigma_a = exponential_rng(1);\n real<lower=0> sigma = exponential_rng(1);\n real b = normal_rng(0, 1);\n real za_county[J]; \n real y_hat[N];\n real a[J];\n real a_county[J];\n \n g[1] = normal_rng(0, 10);\n g[2] = normal_rng(0, 10);\n \n for (i in 1:J) {\n za_county[i] = normal_rng(0, 1);\n a[i] = g[1] + g[2] * uranium[i];\n a_county[i] = a[i] + za_county[i] * sigma_a;\n }\n \n for (j in 1:N) {\n y_hat[j] = normal_rng(a_county[county_idx[j]] + b * floor_idx[j], sigma);\n }\n}\n\"\"\"",
"_____no_output_____"
],
[
"prior_model = pystan.StanModel(model_code=prior_code)",
"INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_51a6e73bb4685d9d898431904d164252 NOW.\n"
],
[
"prior_data = {key: value for key, value in radon_data.items() if key not in (\"county_name\", \"y\")}\nprior = prior_model.sampling(data=prior_data, iter=500, algorithm=\"Fixed_param\")",
"WARNING:pystan:`warmup=0` forced with `algorithm=\"Fixed_param\"`.\n"
],
[
"radon_code = \"\"\"\ndata {\n int<lower=0> J;\n int<lower=0> N;\n int floor_idx[N];\n int county_idx[N];\n real uranium[J];\n real y[N];\n}\n\nparameters {\n real g[2];\n real<lower=0> sigma_a;\n real<lower=0> sigma;\n real za_county[J];\n real b;\n}\n\ntransformed parameters {\n real theta[N];\n real a[J];\n real a_county[J];\n \n for (i in 1:J) {\n a[i] = g[1] + g[2] * uranium[i];\n a_county[i] = a[i] + za_county[i] * sigma_a;\n }\n for (j in 1:N)\n theta[j] = a_county[county_idx[j]] + b * floor_idx[j];\n}\n\nmodel {\n g ~ normal(0, 10);\n sigma_a ~ exponential(1);\n \n za_county ~ normal(0, 1);\n b ~ normal(0, 1);\n sigma ~ exponential(1);\n \n for (j in 1:N)\n y[j] ~ normal(theta[j], sigma);\n}\n\ngenerated quantities {\n real log_lik[N];\n real y_hat[N];\n for (j in 1:N) {\n log_lik[j] = normal_lpdf(y[j] | theta[j], sigma);\n y_hat[j] = normal_rng(theta[j], sigma);\n }\n}\n\"\"\"",
"_____no_output_____"
],
[
"stan_model = pystan.StanModel(model_code=radon_code)",
"INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_3ab5b33b0aee1c122fca5450e04a6494 NOW.\n"
],
[
"model_data = {key: value for key, value in radon_data.items() if key not in (\"county_name\",)}\nfit = stan_model.sampling(data=model_data, control={\"adapt_delta\": 0.99}, iter=1500, warmup=1000)",
"WARNING:pystan:Maximum (flat) parameter count (1000) exceeded: skipping diagnostic tests for n_eff and Rhat.\nTo run all diagnostics call pystan.check_hmc_diagnostics(fit)\n"
],
[
"coords = {\n \"level\": [\"basement\", \"floor\"],\n \"obs_id\": np.arange(radon_data[\"y\"].size),\n \"county\": radon_data[\"county_name\"],\n \"g_coef\": [\"intercept\", \"slope\"],\n}\ndims = {\n \"g\" : [\"g_coef\"],\n \"za_county\" : [\"county\"],\n \"y\" : [\"obs_id\"],\n \"y_hat\" : [\"obs_id\"],\n \"floor_idx\" : [\"obs_id\"],\n \"county_idx\" : [\"obs_id\"],\n \"theta\" : [\"obs_id\"],\n \"uranium\" : [\"county\"],\n \"a\" : [\"county\"],\n \"a_county\" : [\"county\"], \n}\nidata = az.from_pystan(\n posterior=fit,\n posterior_predictive=\"y_hat\",\n prior=prior,\n prior_predictive=\"y_hat\",\n observed_data=[\"y\"],\n constant_data=[\"floor_idx\", \"county_idx\", \"uranium\"],\n log_likelihood={\"y\": \"log_lik\"},\n coords=coords,\n dims=dims,\n).rename({\"y_hat\": \"y\"}) # renames both prior and posterior predictive",
"_____no_output_____"
],
[
"idata",
"_____no_output_____"
],
[
"idata.to_netcdf(\"pystan.nc\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4d86a0cfaada6949d8115db7f3838122e4022b
| 150,646 |
ipynb
|
Jupyter Notebook
|
07 - Inferential Stats with Python/notebooks/02_VariableDistributionTypeTests(Gaussian).ipynb
|
hossainlab/PY4R
|
cd905ce424de67b4b9fea2b371f286db9d147cb6
|
[
"CC0-1.0"
] | 2 |
2021-09-06T14:05:27.000Z
|
2021-09-11T14:42:25.000Z
|
07 - Inferential Stats with Python/notebooks/02_VariableDistributionTypeTests(Gaussian).ipynb
|
hossainlab/PY4R
|
cd905ce424de67b4b9fea2b371f286db9d147cb6
|
[
"CC0-1.0"
] | null | null | null |
07 - Inferential Stats with Python/notebooks/02_VariableDistributionTypeTests(Gaussian).ipynb
|
hossainlab/PY4R
|
cd905ce424de67b4b9fea2b371f286db9d147cb6
|
[
"CC0-1.0"
] | 3 |
2021-09-06T13:05:27.000Z
|
2021-09-11T14:42:27.000Z
| 275.908425 | 47,360 | 0.918139 |
[
[
[
"# Variable Distribution Type Tests (Gaussian)\n- Shapiro-Wilk Test\n- D’Agostino’s K^2 Test\n- Anderson-Darling Test",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nimport numpy as np \nimport matplotlib.pyplot as plt\nimport seaborn as sns \nsns.set(font_scale=2, palette= \"viridis\")\nfrom scipy import stats",
"_____no_output_____"
],
[
"data = pd.read_csv('../data/pulse_data.csv')\ndata.head() ",
"_____no_output_____"
]
],
[
[
"## Visual Normality Check ",
"_____no_output_____"
]
],
[
[
"data.Height.describe() ",
"_____no_output_____"
],
[
"data.skew()",
"_____no_output_____"
],
[
"data.kurtosis() ",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\nsns.histplot(data=data, x='Height')\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,8))\nsns.histplot(data=data, x='Age', kde=True)\nplt.show()",
"_____no_output_____"
],
[
"# Checking for normality by Q-Q plot graph\nplt.figure(figsize=(12, 8))\nstats.probplot(data['Age'], plot=plt, dist='norm')\nplt.show()",
"_____no_output_____"
]
],
[
[
"__the data should be on the red line. If there are data points that are far off of it, it’s an indication that there are some deviations from normality.__",
"_____no_output_____"
]
],
[
[
"# Checking for normality by Q-Q plot graph\nplt.figure(figsize=(12, 8))\nstats.probplot(data['Height'], plot=plt, dist='norm')\nplt.show()",
"_____no_output_____"
]
],
[
[
"__the data should be on the red line. If there are data points that are far off of it, it’s an indication that there are some deviations from normality.__",
"_____no_output_____"
],
[
"## Shapiro-Wilk Test\nTests whether a data sample has a Gaussian distribution/normal distribution.\n\n### Assumptions\nObservations in each sample are independent and identically distributed (iid).\n\n### Interpretation\n- H0: The sample has a Gaussian/normal distribution.\n- Ha: The sample does not have a Gaussian/normal distribution.",
"_____no_output_____"
]
],
[
[
"stats.shapiro(data['Age'])",
"_____no_output_____"
],
[
"stat, p_value = stats.shapiro(data['Age'])\nprint(f'statistic = {stat}, p-value = {p_value}')\n\nalpha = 0.05 \nif p_value > alpha: \n print(\"The sample has normal distribution(Fail to reject the null hypothesis, the result is not significant)\")\nelse: \n print(\"The sample does not have a normal distribution(Reject the null hypothesis, the result is significant)\")",
"statistic = 0.5615497827529907, p-value = 1.9952150916661683e-16\nThe sample does not have a normal distribution(Reject the null hypothesis, the result is significant)\n"
]
],
[
[
"## D’Agostino’s K^2 Test\nTests whether a data sample has a Gaussian distribution/normal distribution.\n\n### Assumptions\nObservations in each sample are independent and identically distributed (iid).\n\n### Interpretation\n- H0: The sample has a Gaussian/normal distribution.\n- Ha: The sample does not have a Gaussian/normal distribution.",
"_____no_output_____"
]
],
[
[
"stats.normaltest(data['Age'])",
"_____no_output_____"
],
[
"stat, p_value = stats.normaltest(data['Age'])\nprint(f'statistic = {stat}, p-value = {p_value}')\nalpha = 0.05 \nif p_value > alpha: \n print(\"The sample has normal distribution(Fail to reject the null hypothesis, the result is not significant)\")\nelse: \n print(\"The sample does not have a normal distribution(Reject the null hypothesis, the result is significant)\")",
"_____no_output_____"
]
],
[
[
"__Remember__\n- If Data Is Gaussian:\n\t- Use Parametric Statistical Methods\n- Else:\n\t- Use Nonparametric Statistical Methods",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a4d884702ef3aba0d3c55ff9433714f74d5f1b6
| 2,282 |
ipynb
|
Jupyter Notebook
|
Section 2/05 List Comprehensions.ipynb
|
PacktPublishing/Migrating-from-R-to-Python-for-Data-Analysis
|
db6dc513f2646330174479b833de4817f8c77bab
|
[
"MIT"
] | 6 |
2019-11-01T09:30:08.000Z
|
2021-11-08T13:10:29.000Z
|
Section 2/05 List Comprehensions.ipynb
|
ma0511/Migrating-from-R-to-Python-for-Data-Analysis
|
a4671f44e2d897f2be4e41c3271730e9dd7c7f82
|
[
"MIT"
] | null | null | null |
Section 2/05 List Comprehensions.ipynb
|
ma0511/Migrating-from-R-to-Python-for-Data-Analysis
|
a4671f44e2d897f2be4e41c3271730e9dd7c7f82
|
[
"MIT"
] | 4 |
2019-11-15T16:51:10.000Z
|
2021-04-15T09:38:44.000Z
| 19.176471 | 151 | 0.495618 |
[
[
[
"# List Comprehensions\n\n\nPython makes it simple to generate a required list with a single line of code using list comprehensions. For example \n",
"_____no_output_____"
],
[
"##### Writing the loop way",
"_____no_output_____"
]
],
[
[
"res = []\nfor i in range(1,11): \n x=27*i \n res.append(x)\nprint(res)",
"[27, 54, 81, 108, 135, 162, 189, 216, 243, 270]\n"
]
],
[
[
"##### The List Comprehension way:\nSince you are generating another list altogether and that is what is required, List comprehensions is a more efficient way to solve this problem.",
"_____no_output_____"
]
],
[
[
"[27*i for i in range(1,11) ]",
"_____no_output_____"
],
[
"[27*x for x in range(1,11) if x <3]",
"_____no_output_____"
]
],
[
[
"You are good to go move up the ladder! Congratulations.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a4d9847f3a79be2dff616c7dea115398503de25
| 76,678 |
ipynb
|
Jupyter Notebook
|
notebooks/Drafts/merge_with_price.ipynb
|
ThomasDelatte/ethereum-analytics
|
19e94a7f05cea7535561da1cc4b73d1b73a7e281
|
[
"MIT"
] | 2 |
2021-09-02T08:36:36.000Z
|
2021-09-23T16:28:29.000Z
|
notebooks/Drafts/merge_with_price.ipynb
|
ThomasDelatte/ethereum-analytics
|
19e94a7f05cea7535561da1cc4b73d1b73a7e281
|
[
"MIT"
] | null | null | null |
notebooks/Drafts/merge_with_price.ipynb
|
ThomasDelatte/ethereum-analytics
|
19e94a7f05cea7535561da1cc4b73d1b73a7e281
|
[
"MIT"
] | null | null | null | 38.609265 | 93 | 0.378727 |
[
[
[
"import pandas as pd\nimport pickle",
"_____no_output_____"
],
[
"eth_ds = pd.read_csv(\"../data/processed/eth_dataset_complete.csv\")",
"_____no_output_____"
],
[
"eth_ds",
"_____no_output_____"
],
[
"eth_ds.drop([\"Unnamed: 0\"], axis=1, inplace=True)",
"_____no_output_____"
],
[
"eth_ds[205:215]",
"_____no_output_____"
],
[
"eth_ds",
"_____no_output_____"
],
[
"for i, row in eth_ds.iterrows():\n mined = row.mined_blocks\n try:\n eth_ds.iat[i+1, 4] = mined\n except IndexError:\n continue",
"_____no_output_____"
],
[
"eth_ds[205:215]",
"_____no_output_____"
],
[
"eth_ds.to_csv(\"../data/processed/eth_dataset.csv\", index=False)",
"_____no_output_____"
],
[
"price_ds = pickle.load(open(\"../../data/external/dflabel.p\", \"rb\")) ",
"_____no_output_____"
],
[
"price_ds",
"_____no_output_____"
],
[
"price_ds.rename({\"address\": \"ethereum_address\"}, axis=1, inplace=True)",
"_____no_output_____"
],
[
"eth_with_price = pd.merge(price_ds, eth_ds, how=\"inner\", on=\"ethereum_address\")",
"_____no_output_____"
],
[
"eth_with_price",
"_____no_output_____"
],
[
"eth_with_price.Entity_y.value_counts()",
"_____no_output_____"
],
[
"# Sanity check: do eth_addresses labeled as \"Miners\" actually have mined_blocks\n\neth_with_price[eth_with_price[\"Entity_y\"] == \"Mining\"]",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4d9f687f9058648c02d01b09a586efd248efb6
| 3,680 |
ipynb
|
Jupyter Notebook
|
jupyter-notebooks/[01] [02] Gerador de Atributos.ipynb
|
AbnerBissolli/Malicious-DNS-Detection
|
0764d719f9a361d2d4b615382fbed87db0f478a0
|
[
"MIT"
] | null | null | null |
jupyter-notebooks/[01] [02] Gerador de Atributos.ipynb
|
AbnerBissolli/Malicious-DNS-Detection
|
0764d719f9a361d2d4b615382fbed87db0f478a0
|
[
"MIT"
] | null | null | null |
jupyter-notebooks/[01] [02] Gerador de Atributos.ipynb
|
AbnerBissolli/Malicious-DNS-Detection
|
0764d719f9a361d2d4b615382fbed87db0f478a0
|
[
"MIT"
] | null | null | null | 21.149425 | 68 | 0.447554 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv('../Dataset/Domains/Clean/domains.csv')",
"_____no_output_____"
],
[
"# Defining Class and Sublcass\ndef get_class(s):\n # Benign = 0\n # Malware = 1\n if s == 'benign':\n return 0\n return 1\n\ndef get_sub_class(s):\n # Benign = 0\n # Spam = 1\n # Phishing = 2\n # Malware = 3 \n sub_classes = ['benign', 'spam', 'phishing', 'malware']\n return sub_classes.index(s)\n\ndf['sub_class'] = df['class'].apply(get_sub_class)\ndf['class'] = df['class'].apply(get_class)",
"_____no_output_____"
],
[
"from IPy import IP\n\ndef ip_check(s):\n try:\n IP(s)\n return 1\n except:\n return 0\n\ndf['ip_format'] = df['domain'].apply(ip_check)",
"_____no_output_____"
],
[
"# Parsing Attributes\n\nfrom tld import parse_tld\n\ndef parse_domain(s):\n if ip_check(s):\n return ('', '', '')\n \n parse = parse_tld(s, fix_protocol=True)\n if parse == (None, None, None):\n return ('', s, '')\n return parse\n\ndf['parse'] = df['domain'].apply(parse_domain)",
"_____no_output_____"
],
[
"# Setting Attributes\n\ndef get_ssd(t):\n if t[1] == '':\n return t[2]\n elif t[2] == '':\n return t[1]\n else:\n return t[2]+'.'+t[1]\n\ndf['SSD'] = df['parse'].apply(get_ssd)\n\n\ndef get_sub(t):\n return t[2]\n\ndf['SUB'] = df['parse'].apply(get_sub) \n\ndef get_sld(t):\n return t[1]\n\ndf['SLD'] = df['parse'].apply(get_sld) \n\ndef get_tld(t):\n return t[0]\n\ndf['TLD'] = df['parse'].apply(get_tld) ",
"_____no_output_____"
],
[
"# Dropping Unwanted Columns\n\ndf = df.drop(columns=['parse'])",
"_____no_output_____"
],
[
"# Saving the dataset\n\ndf.to_csv('../Dataset/Attributes/attributes.csv', index=False)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4da8e75169d5b639c6199b33fa06282c955488
| 24,887 |
ipynb
|
Jupyter Notebook
|
matplotlib&seaborn/Part 1 Univariate dist/Histogram_Practice/Histogram_Practice.ipynb
|
dilayercelik/AIPND-learning
|
93a11b42f92eef4ca31147ffd79b3c2f2fe1815c
|
[
"MIT"
] | null | null | null |
matplotlib&seaborn/Part 1 Univariate dist/Histogram_Practice/Histogram_Practice.ipynb
|
dilayercelik/AIPND-learning
|
93a11b42f92eef4ca31147ffd79b3c2f2fe1815c
|
[
"MIT"
] | null | null | null |
matplotlib&seaborn/Part 1 Univariate dist/Histogram_Practice/Histogram_Practice.ipynb
|
dilayercelik/AIPND-learning
|
93a11b42f92eef4ca31147ffd79b3c2f2fe1815c
|
[
"MIT"
] | null | null | null | 83.513423 | 6,340 | 0.776309 |
[
[
[
"# prerequisite package imports\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sb\n\n%matplotlib inline\n\nfrom solutions_univ import histogram_solution_1",
"_____no_output_____"
]
],
[
[
"We'll continue working with the Pokémon dataset in this workspace.",
"_____no_output_____"
]
],
[
[
"pokemon = pd.read_csv('./data/pokemon.csv')\npokemon.head()",
"_____no_output_____"
]
],
[
[
"**Task**: Pokémon have a number of different statistics that describe their combat capabilities. Here, create a _histogram_ that depicts the distribution of 'special-defense' values taken. **Hint**: Try playing around with different bin width sizes to see what best depicts the data.",
"_____no_output_____"
]
],
[
[
"# using seaborn's distplot() function\n\nred = sb.color_palette()[3]\n\nsb.distplot(pokemon['special-defense'], kde = False, hist_kws = {'alpha' : 1}, color = red);",
"_____no_output_____"
],
[
"# using matplotlib's hist() function\n\ncolor = sb.color_palette()[3]\nbins = np.arange(0, pokemon['special-defense'].max() + 5, 5)\n\nplt.hist(data = pokemon, x = 'special-defense', bins = bins, color = red);",
"_____no_output_____"
],
[
"# run this cell to check your work against ours\nhistogram_solution_1()",
"I've used matplotlib's hist function to plot the data. I have also used numpy's arange function to set the bin edges. A bin size of 5 hits the main cut points, revealing a smooth, but skewed curves. Are there similar characteristics among Pokemon with the highest special defenses?\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a4dbd2983feb35e129be889373883956ab2578e
| 77,549 |
ipynb
|
Jupyter Notebook
|
brokenFunction.ipynb
|
AzNo21/JupyterWorkflow
|
840c9821b0f9158ffa36d158bada2cd0ca091e6a
|
[
"MIT"
] | null | null | null |
brokenFunction.ipynb
|
AzNo21/JupyterWorkflow
|
840c9821b0f9158ffa36d158bada2cd0ca091e6a
|
[
"MIT"
] | null | null | null |
brokenFunction.ipynb
|
AzNo21/JupyterWorkflow
|
840c9821b0f9158ffa36d158bada2cd0ca091e6a
|
[
"MIT"
] | null | null | null | 371.047847 | 72,132 | 0.927014 |
[
[
[
"### fixing a broken function",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport pandas as pd",
"_____no_output_____"
],
[
"from jnoteworkflow.data import get_Fremont_data\ndata = get_Fremont_data()\npivoted = data.pivot_table('Total', index=data.index.time, columns=data.index.date)\npivoted.plot(legend=False, alpha=0.01)",
"_____no_output_____"
],
[
"pivoted.index",
"_____no_output_____"
],
[
"data.index",
"_____no_output_____"
],
[
"import numpy as np\nnp.unique(data.index.time)",
"_____no_output_____"
]
],
[
[
" one has to make sure when parsing the string the format is correct. Basically using %H with %p (am-pm) not working mainly due to the fact that %H is for 24 hours and one uses pm-am only with 12 hours format (i.e. %I)",
"_____no_output_____"
],
[
"this can be transfered to test.py and checked for. => changes in test.py",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a4dbdbbcb7d058046cc1eb9eb34d7c9382b3693
| 20,547 |
ipynb
|
Jupyter Notebook
|
approximating-cont-controller/notebooks/Tustin's approximation of harmonic oscillator.ipynb
|
alfkjartan/control-computarizado
|
5b9a3ae67602d131adf0b306f3ffce7a4914bf8e
|
[
"MIT"
] | 1 |
2020-12-22T09:57:05.000Z
|
2020-12-22T09:57:05.000Z
|
approximating-cont-controller/notebooks/Tustin's approximation of harmonic oscillator.ipynb
|
alfkjartan/control-computarizado
|
5b9a3ae67602d131adf0b306f3ffce7a4914bf8e
|
[
"MIT"
] | null | null | null |
approximating-cont-controller/notebooks/Tustin's approximation of harmonic oscillator.ipynb
|
alfkjartan/control-computarizado
|
5b9a3ae67602d131adf0b306f3ffce7a4914bf8e
|
[
"MIT"
] | 1 |
2019-09-25T20:02:23.000Z
|
2019-09-25T20:02:23.000Z
| 62.075529 | 3,472 | 0.743174 |
[
[
[
"# Tustin's approximation, harmonic oscillator\n\nWrite the approximation as\n$$ F_d(z) = F(s')|_{s'=g\\frac{z-1}{z+1}}, \\quad g > 0 $$\nclearly for the standard Tustin's approximation we have $g = \\frac{2}{h}$.\n\nApply the approximation to the system\n$$F(s) = \\frac{\\omega_n^2}{s^2 + \\omega_n^2} = \\frac{\\omega_n^2}{(s + i\\omega_n)(s -i\\omega_n)}$$\n\n**Determine the poles. What is the angle (argument) of the discrete-time poles?**\n",
"_____no_output_____"
],
[
"\\begin{align}\nF(z) &= \\frac{\\omega_n^2}{(g\\frac{z-1}{z+1})^2 + \\omega_n^2}\\\\\n &= \\frac{\\omega_n^2}{(g\\frac{z-1}{z+1})^2 + \\omega_n^2}\\\\\n &= \\frac{\\omega_n^2(z+1)^2}{g^2(z^2 -2z + 1) + \\omega_n^2(z^2 + 2z + 1)}\\\\\n &= \\frac{\\omega_n^2(z+1)^2}{(g^2+\\omega_n^2)z^2 + 2(\\omega_n^2 -g^2)z + (g^2 + \\omega_n^2)}\n &= = \\frac{ \\frac{\\omega_n^2}{g^2 + \\omega_n^2}(z+1)^2}{z^2 + 2\\frac{\\omega_n^2 - g^2}{\\omega_n^2 + g^2}z + 1}\n\\end{align}\nThe denominator has the form of the characteristic polynomial for two poles on the unit circle. Note that \n$$ (z+\\cos\\theta + i\\sin\\theta)(z+\\cos\\theta -i\\sin\\theta) = z^2 + 2\\cos\\theta z + 1. $$\nSo the two poles of $F(z)$ are on the unit circle with argument given by the solution $\\theta$ to \n$$ 2\\cos\\theta = 2\\frac{\\omega_n^2 -g^2}{\\omega_n^2 + g^2}$$\n$$ \\cos\\theta = \\frac{\\omega_n^2 -g^2}{\\omega_n^2 + g^2} $$",
"_____no_output_____"
],
[
"To find the imaginary part of the poles, use $\\sin^2\\theta = 1 - \\cos^2\\theta$.\n$$ \\sin\\theta = \\sqrt{1 - \\cos^2\\theta} = \\sqrt{1 - \\frac{(\\omega_n^2 - g^2)^2}{(\\omega_n^2 + g^2)^2}}$$",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport sympy as sy\nimport control.matlab as cm\nsy.init_printing() ",
"_____no_output_____"
],
[
"s, z = sy.symbols('s,z', real=False)\nwn,h,g = sy.symbols('omega_n, h,g', real=True, positive=True)",
"_____no_output_____"
],
[
"F = wn**2/(s**2 + wn**2)\nF",
"_____no_output_____"
],
[
"Fd = sy.simplify(F.subs({s:g*(z-1)/(z+1)}))\nFd",
"_____no_output_____"
],
[
"(num, den) = sy.fraction(Fd)\nden",
"_____no_output_____"
],
[
"(p1,p2) = sy.solve(den,z)\np2",
"_____no_output_____"
],
[
"(p2real, p2im) = p2.as_real_imag()\nsy.simplify(p2im/p2real)",
"_____no_output_____"
],
[
"sy.arg(p2)",
"_____no_output_____"
],
[
"sy.simplify(p2real**2 + p2im**2)",
"_____no_output_____"
],
[
"tanwnh = sy.tan(wn*h)\nsy.trigsimp(sy.solve(p2im/p2real - tanwnh, g))",
"_____no_output_____"
]
],
[
[
"Note that \n$$ \\tan(\\frac{\\omega_n h}{2}) = \\frac{\\sin(\\omega_n h)}{1 + \\cos(\\omega_n h)} $$\nand so\n$$ \\frac{\\omega_n (1 + \\frac{1}{\\cos(\\omega_n h)})}{\\tan(\\omega_n h)} = \\frac{\\omega_n (1 + \\frac{1}{\\cos(\\omega_n h)})}{\\frac{\\sin(\\omega_n h)}{\\cos (\\omega_n h)}}\n= \\frac{\\omega_n}{\\tan(\\omega_n h)} $$",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a4dc46b76297b7cd45465f6ea872696cce2cb57
| 219,082 |
ipynb
|
Jupyter Notebook
|
weibull_fit.ipynb
|
New-England-Offshore-Wind-Energy/Remote-Sensing-2021
|
8a5b6de47b75c18d99b575d61e2059e5f0a70ff3
|
[
"MIT"
] | null | null | null |
weibull_fit.ipynb
|
New-England-Offshore-Wind-Energy/Remote-Sensing-2021
|
8a5b6de47b75c18d99b575d61e2059e5f0a70ff3
|
[
"MIT"
] | null | null | null |
weibull_fit.ipynb
|
New-England-Offshore-Wind-Energy/Remote-Sensing-2021
|
8a5b6de47b75c18d99b575d61e2059e5f0a70ff3
|
[
"MIT"
] | null | null | null | 185.348562 | 34,928 | 0.888932 |
[
[
[
"#data manipulation\nfrom pathlib import Path\nimport numpy as np\nfrom numpy import percentile\nfrom datetime import datetime, timedelta\nimport xarray as xr\nimport pandas as pd\nimport statsmodels.api as sm\nfrom statsmodels.sandbox.regression.predstd import wls_prediction_std\nfrom sklearn.model_selection import train_test_split \nfrom sklearn.linear_model import LinearRegression\nfrom sklearn import metrics\nfrom sklearn.metrics import r2_score\nfrom sklearn.metrics import mean_squared_error\nfrom math import sqrt\nimport scipy.stats\nfrom scipy.stats import weibull_min\n#plotting\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker as mticker\nimport matplotlib.patches as mpatch\nfrom matplotlib.transforms import offset_copy\nimport matplotlib.colors as colors\nimport seaborn as seabornInstance\nimport seaborn as sns\nfrom reliability.Fitters import Fit_Weibull_2P\n\n%matplotlib inline",
"_____no_output_____"
],
[
"#CSVfilelocation\n#swh_sa is the list of Saral-Altika wind speed and Hs data\ndf=pd.read_csv(\"swh_sa.csv\", sep='\\t')\ndf.head()",
"_____no_output_____"
],
[
"#Satellite wind speed data within 0.5 dd of 44017\ncolocated7= df[((df[['lon','lat']] - [287.951,40.693])**2).sum(axis=1) < 0.5**2]\nyy=colocated7['swh']\nxx=colocated7['wind_speed_alt']",
"_____no_output_____"
],
[
"data = colocated7[\"wind_speed_alt\"]",
"_____no_output_____"
],
[
"\nfig,ax=plt.subplots(figsize=(10,9))\nshape, loc, scale = weibull_min.fit(data, floc=0,fc=2) # if you want to fix shape as 2: set fc=2\nx = np.linspace(data.min(), data.max(), 100)\nplt.plot(x, weibull_min(shape, loc, scale).pdf(x),color=\"blue\",label=\"Buoy44097-0.25 decimal degrees Saral/ALtika\"+\"(Scale:\"+str(round(scale,2))+\";Shape:\"+str(round(shape,2))+\")\")\nsns.distplot(xx,hist_kws=dict(alpha=1),color='lightskyblue',kde_kws=dict(alpha=0))\n\ndef change_width(ax, new_value) :\n for patch in ax.patches :\n current_width = patch.get_width()\n diff = current_width - new_value\n\n # we change the bar width\n patch.set_width(new_value)\n\n # we recenter the bar\n patch.set_x(patch.get_x() + diff * .5)\n\nchange_width(ax, 1.6)\n\nplt.xlabel('Wind Speed (m/s)', fontsize=15)\nplt.ylabel('Density Function', fontsize=15)\nplt.tick_params(axis='both', which='major', labelsize=15)\nplt.xlim(0,25)\nplt.ylim(0,0.17)",
"C:\\Users\\panmits86\\Anaconda3\\envs\\thesis\\lib\\site-packages\\seaborn\\distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"# parameters\nA = round(scale,4) # from weibull\nk = round(shape,4) \nair_density = 1.225 # kg/m^3\n\nfrom scipy.special import gamma, factorial\nmean_energy_density = 0.5*air_density*A**3*gamma(1+3/k)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"k",
"_____no_output_____"
],
[
"mean_energy_density ",
"_____no_output_____"
],
[
"#Corresponding buoy wind speed data at 0.5 decimal degrees radius\ndf2=pd.read_csv('44017_df_50.csv')\nx1=df2['Buoy 44017 U10']\ny1=df2['Buoy 44017 Wave Height']\ndf2",
"_____no_output_____"
],
[
"df2['Date'] = pd.to_datetime(df2[\"Buoy 44017 Time\"])\ndf2['month'] = df2['Date'].dt.month_name()\ndf2['day'] = df2['Date'].dt.day_name()\ndf2.describe()",
"_____no_output_____"
],
[
"data = df2[\"Buoy 44017 U10\"]\nfig,ax=plt.subplots(figsize=(10,9))\nsns.distplot(x1,hist_kws=dict(alpha=1),color='lightskyblue',kde_kws=dict(alpha=0))\n\nshape, loc, scale = weibull_min.fit(data, floc=0,fc=2) # if you want to fix shape as 2: set fc=2\nx = np.linspace(data.min(), data.max(), 100)\nplt.plot(x, weibull_min(shape, loc, scale).pdf(x),color=\"blue\",label=\"Buoy44097-0.25 decimal degrees Saral/ALtika\"+\"(Scale:\"+str(round(scale,2))+\";Shape:\"+str(round(shape,2))+\")\")\ndef change_width(ax, new_value) :\n for patch in ax.patches :\n current_width = patch.get_width()\n diff = current_width - new_value\n\n # we change the bar width\n patch.set_width(new_value)\n\n # we recenter the bar\n patch.set_x(patch.get_x() + diff * .5)\n\nchange_width(ax, 1.6)\nplt.xlabel('$u_{10}$ (m/s)', fontsize=15)\nplt.ylabel('Density Function', fontsize=15)\nplt.tick_params(axis='both', which='major', labelsize=15)\nplt.xlim(0,25)\nplt.ylim(0,0.17)",
"C:\\Users\\panmits86\\Anaconda3\\envs\\thesis\\lib\\site-packages\\seaborn\\distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"# parameters\nA = round(scale,4) # from weibull\nk = round(shape,4) \nair_density = 1.225 # kg/m^3\n\nfrom scipy.special import gamma, factorial\nmean_energy_density = 0.5*air_density*A**3*gamma(1+3/k)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"k",
"_____no_output_____"
],
[
"#satellite wave height 0.5 dd around buoy 55017\ndata = colocated7['swh']\nfig,ax=plt.subplots(figsize=(10,9))\nshape, loc, scale = weibull_min.fit(data, floc=0) # if you want to fix shape as 2: set fc=2\nx = np.linspace(data.min(), data.max(), 100)\nplt.plot(x, weibull_min(shape, loc, scale).pdf(x),color=\"blue\",label=\"Buoy44097-0.25 decimal degrees Saral/ALtika\"+\"(Scale:\"+str(round(scale,2))+\";Shape:\"+str(round(shape,2))+\")\")\nsns.distplot(yy,hist_kws=dict(alpha=1),color='lightskyblue',kde_kws=dict(alpha=0))\ndef change_width(ax, new_value) :\n for patch in ax.patches :\n current_width = patch.get_width()\n diff = current_width - new_value\n\n # we change the bar width\n patch.set_width(new_value)\n\n # we recenter the bar\n patch.set_x(patch.get_x() + diff * .5)\n\nchange_width(ax, 0.31)\n\nplt.xlabel('$H_s$ (m)', fontsize=15)\nplt.ylabel('Density Function', fontsize=15)\nplt.tick_params(axis='both', which='major', labelsize=15)\nplt.xlim(0,6)\nplt.ylim(0,0.89)",
"C:\\Users\\panmits86\\Anaconda3\\envs\\thesis\\lib\\site-packages\\seaborn\\distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"# parameters\nA = round(scale,4) # from weibull\nk = round(shape,4) \nair_density = 1.225 # kg/m^3\n\nfrom scipy.special import gamma, factorial\nmean_energy_density = 0.5*air_density*A**3*gamma(1+3/k)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"k",
"_____no_output_____"
],
[
"#corresponding buoy wave height\ndata = df2['Buoy 44017 Wave Height']\nfig,ax=plt.subplots(figsize=(10,9))\nsns.distplot(y1,hist_kws=dict(alpha=1),color='lightskyblue',kde_kws=dict(alpha=0))\n\nshape, loc, scale = weibull_min.fit(data, floc=0) # if you want to fix shape as 2: set fc=2\nx = np.linspace(data.min(), data.max(), 100)\nplt.plot(x, weibull_min(shape, loc, scale).pdf(x),color=\"blue\",label=\"Buoy44097-0.25 decimal degrees Saral/ALtika\"+\"(Scale:\"+str(round(scale,2))+\";Shape:\"+str(round(shape,2))+\")\")\ndef change_width(ax, new_value) :\n for patch in ax.patches :\n current_width = patch.get_width()\n diff = current_width - new_value\n\n # we change the bar width\n patch.set_width(new_value)\n\n # we recenter the bar\n patch.set_x(patch.get_x() + diff * .5)\n\nchange_width(ax, 0.3)\n\nplt.xlabel('$H_s$ (m)', fontsize=15)\nplt.ylabel('Density Function', fontsize=15)\nplt.xlim(0,6)\nplt.ylim(0,0.89)\nplt.tick_params(axis='both', which='major', labelsize=15)",
"C:\\Users\\panmits86\\Anaconda3\\envs\\thesis\\lib\\site-packages\\seaborn\\distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"# parameters\nA = round(scale,4) # from weibull\nk = round(shape,4) \nair_density = 1.225 # kg/m^3\n\nfrom scipy.special import gamma, factorial\nmean_energy_density = 0.5*air_density*A**3*gamma(1+3/k)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"k",
"_____no_output_____"
],
[
"#directory to buoy 44017 files\ndf1=pd.read_csv('b44017_wind_wave.csv', sep='\\t')\nx2=df1['u10']\ny2=df1['WVHT']",
"_____no_output_____"
],
[
"data = df1['u10']\nfig,ax=plt.subplots(figsize=(10,9))\n#plt.hist(data, density=True, alpha=0.5)\nshape, loc, scale = weibull_min.fit(data, floc=0,fc=2) # if you want to fix shape as 2: set fc=2\nx = np.linspace(data.min(), data.max(), 100)\nplt.plot(x, weibull_min(shape, loc, scale).pdf(x),color=\"blue\",label=\"Buoy44097-0.25 decimal degrees Saral/ALtika\"+\"(Scale:\"+str(round(scale,2))+\";Shape:\"+str(round(shape,2))+\")\")\n\nsns.distplot(x2,hist_kws=dict(alpha=1),color='lightskyblue',kde_kws=dict(alpha=0))\ndef change_width(ax, new_value) :\n for patch in ax.patches :\n current_width = patch.get_width()\n diff = current_width - new_value\n\n # we change the bar width\n patch.set_width(new_value)\n\n # we recenter the bar\n patch.set_x(patch.get_x() + diff * .5)\n\nchange_width(ax, 1.6)\n\n\nplt.xlabel('$u_{10}$ (m/s)', fontsize=15)\nplt.ylabel('Density Function', fontsize=15)\nplt.xlim(0,25)\nplt.ylim(0,0.17)\nplt.tick_params(axis='both', which='major', labelsize=15)",
"C:\\Users\\panmits86\\Anaconda3\\envs\\thesis\\lib\\site-packages\\seaborn\\distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"# parameters\nA = round(scale,4) # from weibull\nk = round(shape,4) \nair_density = 1.225 # kg/m^3\n\nfrom scipy.special import gamma, factorial\nmean_energy_density = 0.5*air_density*A**3*gamma(1+3/k)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"data = df1['WVHT']\nfig,ax=plt.subplots(figsize=(10,9))\nshape, loc, scale = weibull_min.fit(data, floc=0) # if you want to fix shape as 2: set fc=2\nx = np.linspace(data.min(), data.max(), 100)\nplt.plot(x, weibull_min(shape, loc, scale).pdf(x),color=\"blue\",label=\"Buoy44097-0.25 decimal degrees Saral/ALtika\"+\"(Scale:\"+str(round(scale,2))+\";Shape:\"+str(round(shape,2))+\")\")\n\nsns.distplot(y2,hist_kws=dict(alpha=1),color='lightskyblue',kde_kws=dict(alpha=0))\ndef change_width(ax, new_value) :\n for patch in ax.patches :\n current_width = patch.get_width()\n diff = current_width - new_value\n\n # we change the bar width\n patch.set_width(new_value)\n\n # we recenter the bar\n patch.set_x(patch.get_x() + diff * .5)\n\nchange_width(ax, 0.3)\n\nplt.xlabel('$H_s$ (m)', fontsize=15)\nplt.ylabel('Density Function', fontsize=15)\nplt.xlim(0,6)\nplt.ylim(0,0.89)\nplt.tick_params(axis='both', which='major', labelsize=15)",
"C:\\Users\\panmits86\\Anaconda3\\envs\\thesis\\lib\\site-packages\\seaborn\\distributions.py:2551: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"# parameters\nA = round(scale,4) # from weibull\nk = round(shape,4) \nair_density = 1.225 # kg/m^3\n\nfrom scipy.special import gamma, factorial\nmean_energy_density = 0.5*air_density*A**3*gamma(1+3/k)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"k",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4dccf5aa620f0ef14230515522b41029a2c4ba
| 51,541 |
ipynb
|
Jupyter Notebook
|
p3_collab-compet/Tennis_Solved.ipynb
|
bongsang/udacity-drl-solution
|
4a5f9c0698543cf80e83020d333cb8589a179243
|
[
"MIT"
] | 1 |
2019-02-11T15:53:20.000Z
|
2019-02-11T15:53:20.000Z
|
p3_collab-compet/Tennis_Solved.ipynb
|
bongsang/udacity-drl-solution
|
4a5f9c0698543cf80e83020d333cb8589a179243
|
[
"MIT"
] | null | null | null |
p3_collab-compet/Tennis_Solved.ipynb
|
bongsang/udacity-drl-solution
|
4a5f9c0698543cf80e83020d333cb8589a179243
|
[
"MIT"
] | null | null | null | 94.05292 | 27,384 | 0.791137 |
[
[
[
"# Collaboration and Competition\n\n---\n\nIn this notebook, you will learn how to use the Unity ML-Agents environment for the third project of the [Deep Reinforcement Learning Nanodegree](https://www.udacity.com/course/deep-reinforcement-learning-nanodegree--nd893) program.\n\n### 1. Start the Environment\n\nWe begin by importing the necessary packages. If the code cell below returns an error, please revisit the project instructions to double-check that you have installed [Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation.md) and [NumPy](http://www.numpy.org/).",
"_____no_output_____"
]
],
[
[
"from unityagents import UnityEnvironment\nimport numpy as np\n\nimport copy\nfrom collections import namedtuple, deque\nimport random\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Next, we will start the environment! **_Before running the code cell below_**, change the `file_name` parameter to match the location of the Unity environment that you downloaded.\n\n- **Mac**: `\"path/to/Tennis.app\"`\n- **Windows** (x86): `\"path/to/Tennis_Windows_x86/Tennis.exe\"`\n- **Windows** (x86_64): `\"path/to/Tennis_Windows_x86_64/Tennis.exe\"`\n- **Linux** (x86): `\"path/to/Tennis_Linux/Tennis.x86\"`\n- **Linux** (x86_64): `\"path/to/Tennis_Linux/Tennis.x86_64\"`\n- **Linux** (x86, headless): `\"path/to/Tennis_Linux_NoVis/Tennis.x86\"`\n- **Linux** (x86_64, headless): `\"path/to/Tennis_Linux_NoVis/Tennis.x86_64\"`\n\nFor instance, if you are using a Mac, then you downloaded `Tennis.app`. If this file is in the same folder as the notebook, then the line below should appear as follows:\n```\nenv = UnityEnvironment(file_name=\"Tennis.app\")\n```",
"_____no_output_____"
]
],
[
[
"env = UnityEnvironment(file_name=\"Tennis_Linux_NoVis/Tennis.x86_64\")",
"_____no_output_____"
]
],
[
[
"Environments contain **_brains_** which are responsible for deciding the actions of their associated agents. Here we check for the first brain available, and set it as the default brain we will be controlling from Python.",
"_____no_output_____"
]
],
[
[
"# get the default brain\nbrain_name = env.brain_names[0]\nbrain = env.brains[brain_name]",
"_____no_output_____"
]
],
[
[
"### 2. Examine the State and Action Spaces\n\nIn this environment, two agents control rackets to bounce a ball over a net. If an agent hits the ball over the net, it receives a reward of +0.1. If an agent lets a ball hit the ground or hits the ball out of bounds, it receives a reward of -0.01. Thus, the goal of each agent is to keep the ball in play.\n\nThe observation space consists of 8 variables corresponding to the position and velocity of the ball and racket. Two continuous actions are available, corresponding to movement toward (or away from) the net, and jumping. \n\nRun the code cell below to print some information about the environment.",
"_____no_output_____"
]
],
[
[
"# reset the environment\nenv_info = env.reset(train_mode=True)[brain_name]\n\n# number of agents \nnum_agents = len(env_info.agents)\nprint('Number of agents:', num_agents)\n\n# size of each action\naction_size = brain.vector_action_space_size\nprint('Size of each action:', action_size)\n\n# examine the state space \nstates = env_info.vector_observations\nstate_size = states.shape[1]\nprint('There are {} agents. Each observes a state with length: {}'.format(states.shape[0], state_size))\nprint('The state for the first agent looks like:', states[0])",
"Number of agents: 2\nSize of each action: 2\nThere are 2 agents. Each observes a state with length: 24\nThe state for the first agent looks like: [ 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. -6.65278625 -1.5\n -0. 0. 6.83172083 6. -0. 0. ]\n"
]
],
[
[
"### 3. Take Random Actions in the Environment\n\nIn the next code cell, you will learn how to use the Python API to control the agents and receive feedback from the environment.\n\nOnce this cell is executed, you will watch the agents' performance, if they select actions at random with each time step. A window should pop up that allows you to observe the agents.\n\nOf course, as part of the project, you'll have to change the code so that the agents are able to use their experiences to gradually choose better actions when interacting with the environment!",
"_____no_output_____"
]
],
[
[
"for i in range(1, 6): # play game for 5 episodes\n env_info = env.reset(train_mode=False)[brain_name] # reset the environment \n states = env_info.vector_observations # get the current state (for each agent)\n scores = np.zeros(num_agents) # initialize the score (for each agent)\n while True:\n actions = np.random.randn(num_agents, action_size) # select an action (for each agent)\n actions = np.clip(actions, -1, 1) # all actions between -1 and 1\n env_info = env.step(actions)[brain_name] # send all actions to tne environment\n next_states = env_info.vector_observations # get next state (for each agent)\n rewards = env_info.rewards # get reward (for each agent)\n dones = env_info.local_done # see if episode finished\n scores += env_info.rewards # update the score (for each agent)\n states = next_states # roll over states to next time step\n if np.any(dones): # exit loop if episode finished\n break\n print('Score (max over agents) from episode {}: {}'.format(i, np.max(scores)))",
"_____no_output_____"
]
],
[
[
"When finished, you can close the environment.",
"_____no_output_____"
]
],
[
[
"# env.close()",
"_____no_output_____"
]
],
[
[
"### 4. It's Your Turn!\n\nNow it's your turn to train your own agent to solve the environment! When training the environment, set `train_mode=True`, so that the line for resetting the environment looks like the following:\n```python\nenv_info = env.reset(train_mode=True)[brain_name]\n```",
"_____no_output_____"
],
[
"### 5. My Multi DDPG",
"_____no_output_____"
]
],
[
[
"from ddpg.multi_ddpg_agent import Agent",
"_____no_output_____"
],
[
"agent_0 = Agent(state_size, action_size, num_agents=1, random_seed=0)\nagent_1 = Agent(state_size, action_size, num_agents=1, random_seed=0)",
"_____no_output_____"
],
[
"def get_actions(states, add_noise):\n '''gets actions for each agent and then combines them into one array'''\n action_0 = agent_0.act(states, add_noise) # agent 0 chooses an action\n action_1 = agent_1.act(states, add_noise) # agent 1 chooses an action\n return np.concatenate((action_0, action_1), axis=0).flatten()",
"_____no_output_____"
],
[
"SOLVED_SCORE = 0.5\nCONSEC_EPISODES = 100\nPRINT_EVERY = 10\nADD_NOISE = True",
"_____no_output_____"
],
[
"def run_multi_ddpg(n_episodes=2000, max_t=1000, train_mode=True):\n \"\"\"Multi-Agent Deep Deterministic Policy Gradient (MADDPG)\n \n Params\n ======\n n_episodes (int) : maximum number of training episodes\n max_t (int) : maximum number of timesteps per episode\n train_mode (bool) : if 'True' set environment to training mode\n\n \"\"\"\n scores_window = deque(maxlen=CONSEC_EPISODES)\n scores_all = []\n moving_average = []\n best_score = -np.inf\n best_episode = 0\n already_solved = False \n\n for i_episode in range(1, n_episodes+1):\n env_info = env.reset(train_mode=train_mode)[brain_name] # reset the environment\n states = np.reshape(env_info.vector_observations, (1,48)) # get states and combine them\n agent_0.reset()\n agent_1.reset()\n scores = np.zeros(num_agents)\n while True:\n actions = get_actions(states, ADD_NOISE) # choose agent actions and combine them\n env_info = env.step(actions)[brain_name] # send both agents' actions together to the environment\n next_states = np.reshape(env_info.vector_observations, (1, 48)) # combine the agent next states\n rewards = env_info.rewards # get reward\n done = env_info.local_done # see if episode finished\n agent_0.step(states, actions, rewards[0], next_states, done, 0) # agent 1 learns\n agent_1.step(states, actions, rewards[1], next_states, done, 1) # agent 2 learns\n scores += np.max(rewards) # update the score for each agent\n states = next_states # roll over states to next time step\n if np.any(done): # exit loop if episode finished\n break\n\n ep_best_score = np.max(scores)\n scores_window.append(ep_best_score)\n scores_all.append(ep_best_score)\n moving_average.append(np.mean(scores_window))\n\n # save best score \n if ep_best_score > best_score:\n best_score = ep_best_score\n best_episode = i_episode\n \n # print results\n if i_episode % PRINT_EVERY == 0:\n print(f'Episodes {i_episode}\\tMax Reward: {np.max(scores_all[-PRINT_EVERY:]):.3f}\\tMoving Average: {moving_average[-1]:.3f}')\n\n # determine if environment is solved and keep best performing models\n if moving_average[-1] >= SOLVED_SCORE:\n if not already_solved:\n print(f'Solved in {i_episode-CONSEC_EPISODES} episodes! \\\n \\n<-- Moving Average: {moving_average[-1]:.3f} over past {CONSEC_EPISODES} episodes')\n already_solved = True\n torch.save(agent_0.actor_local.state_dict(), 'checkpoint_actor_0.pth')\n torch.save(agent_0.critic_local.state_dict(), 'checkpoint_critic_0.pth')\n torch.save(agent_1.actor_local.state_dict(), 'checkpoint_actor_1.pth')\n torch.save(agent_1.critic_local.state_dict(), 'checkpoint_critic_1.pth')\n elif ep_best_score >= best_score:\n print(f'Best episode {i_episode}\\tMax Reward: {ep_best_score:.3f}\\tMoving Average: {moving_average[-1]:.3f}')\n torch.save(agent_0.actor_local.state_dict(), 'checkpoint_actor_0.pth')\n torch.save(agent_0.critic_local.state_dict(), 'checkpoint_critic_0.pth')\n torch.save(agent_1.actor_local.state_dict(), 'checkpoint_actor_1.pth')\n torch.save(agent_1.critic_local.state_dict(), 'checkpoint_critic_1.pth')\n elif (i_episode-best_episode) >= 200:\n # stop training if model stops converging\n print('Done')\n break\n else:\n continue\n \n return scores_all, moving_average",
"_____no_output_____"
],
[
"scores, avgs = run_multi_ddpg()",
"Episodes 10\tMax Reward: 0.100\tMoving Average: 0.010\nEpisodes 20\tMax Reward: 0.000\tMoving Average: 0.005\nEpisodes 30\tMax Reward: 0.000\tMoving Average: 0.003\nEpisodes 40\tMax Reward: 0.000\tMoving Average: 0.003\nEpisodes 50\tMax Reward: 0.000\tMoving Average: 0.002\nEpisodes 60\tMax Reward: 0.000\tMoving Average: 0.002\nEpisodes 70\tMax Reward: 0.100\tMoving Average: 0.004\nEpisodes 80\tMax Reward: 0.100\tMoving Average: 0.005\nEpisodes 90\tMax Reward: 0.100\tMoving Average: 0.009\nEpisodes 100\tMax Reward: 0.100\tMoving Average: 0.012\nEpisodes 110\tMax Reward: 0.100\tMoving Average: 0.013\nEpisodes 120\tMax Reward: 0.100\tMoving Average: 0.015\nEpisodes 130\tMax Reward: 0.100\tMoving Average: 0.017\nEpisodes 140\tMax Reward: 0.200\tMoving Average: 0.022\nEpisodes 150\tMax Reward: 0.000\tMoving Average: 0.022\nEpisodes 160\tMax Reward: 0.100\tMoving Average: 0.023\nEpisodes 170\tMax Reward: 0.100\tMoving Average: 0.026\nEpisodes 180\tMax Reward: 0.100\tMoving Average: 0.027\nEpisodes 190\tMax Reward: 0.200\tMoving Average: 0.030\nEpisodes 200\tMax Reward: 0.100\tMoving Average: 0.029\nEpisodes 210\tMax Reward: 0.200\tMoving Average: 0.034\nEpisodes 220\tMax Reward: 0.100\tMoving Average: 0.039\nEpisodes 230\tMax Reward: 0.100\tMoving Average: 0.042\nEpisodes 240\tMax Reward: 0.100\tMoving Average: 0.040\nEpisodes 250\tMax Reward: 0.100\tMoving Average: 0.044\nEpisodes 260\tMax Reward: 0.100\tMoving Average: 0.048\nEpisodes 270\tMax Reward: 0.100\tMoving Average: 0.047\nEpisodes 280\tMax Reward: 0.100\tMoving Average: 0.051\nEpisodes 290\tMax Reward: 0.200\tMoving Average: 0.052\nEpisodes 300\tMax Reward: 0.200\tMoving Average: 0.058\nEpisodes 310\tMax Reward: 0.200\tMoving Average: 0.057\nEpisodes 320\tMax Reward: 0.200\tMoving Average: 0.054\nEpisodes 330\tMax Reward: 0.100\tMoving Average: 0.051\nEpisodes 340\tMax Reward: 0.200\tMoving Average: 0.053\nEpisodes 350\tMax Reward: 0.100\tMoving Average: 0.055\nEpisodes 360\tMax Reward: 0.200\tMoving Average: 0.055\nEpisodes 370\tMax Reward: 0.200\tMoving Average: 0.055\nEpisodes 380\tMax Reward: 0.200\tMoving Average: 0.057\nEpisodes 390\tMax Reward: 0.300\tMoving Average: 0.063\nEpisodes 400\tMax Reward: 0.100\tMoving Average: 0.058\nEpisodes 410\tMax Reward: 0.200\tMoving Average: 0.062\nEpisodes 420\tMax Reward: 0.300\tMoving Average: 0.072\nEpisodes 430\tMax Reward: 0.300\tMoving Average: 0.078\nEpisodes 440\tMax Reward: 0.200\tMoving Average: 0.079\nEpisodes 450\tMax Reward: 0.200\tMoving Average: 0.087\nEpisodes 460\tMax Reward: 0.300\tMoving Average: 0.095\nEpisodes 470\tMax Reward: 0.300\tMoving Average: 0.100\nEpisodes 480\tMax Reward: 0.200\tMoving Average: 0.103\nEpisodes 490\tMax Reward: 0.300\tMoving Average: 0.099\nEpisodes 500\tMax Reward: 0.300\tMoving Average: 0.107\nEpisodes 510\tMax Reward: 0.300\tMoving Average: 0.109\nEpisodes 520\tMax Reward: 0.200\tMoving Average: 0.103\nEpisodes 530\tMax Reward: 0.200\tMoving Average: 0.104\nEpisodes 540\tMax Reward: 0.200\tMoving Average: 0.112\nEpisodes 550\tMax Reward: 0.400\tMoving Average: 0.111\nEpisodes 560\tMax Reward: 0.900\tMoving Average: 0.132\nEpisodes 570\tMax Reward: 0.100\tMoving Average: 0.130\nEpisodes 580\tMax Reward: 0.200\tMoving Average: 0.125\nEpisodes 590\tMax Reward: 0.300\tMoving Average: 0.126\nEpisodes 600\tMax Reward: 0.600\tMoving Average: 0.133\nEpisodes 610\tMax Reward: 0.100\tMoving Average: 0.126\nEpisodes 620\tMax Reward: 0.500\tMoving Average: 0.128\nEpisodes 630\tMax Reward: 0.300\tMoving Average: 0.129\nEpisodes 640\tMax Reward: 0.400\tMoving Average: 0.125\nEpisodes 650\tMax Reward: 0.500\tMoving Average: 0.128\nEpisodes 660\tMax Reward: 0.600\tMoving Average: 0.114\nEpisodes 670\tMax Reward: 0.800\tMoving Average: 0.125\nEpisodes 680\tMax Reward: 0.700\tMoving Average: 0.158\nEpisodes 690\tMax Reward: 2.300\tMoving Average: 0.205\nEpisodes 700\tMax Reward: 1.900\tMoving Average: 0.214\nEpisodes 710\tMax Reward: 2.600\tMoving Average: 0.258\nEpisodes 720\tMax Reward: 3.100\tMoving Average: 0.305\nEpisodes 730\tMax Reward: 1.800\tMoving Average: 0.376\nEpisodes 740\tMax Reward: 2.800\tMoving Average: 0.417\nEpisodes 750\tMax Reward: 2.200\tMoving Average: 0.438\nEpisodes 760\tMax Reward: 4.500\tMoving Average: 0.468\nSolved in 668 episodes! \n<-- Moving Average: 0.501 over past 100 episodes\nEpisodes 770\tMax Reward: 1.500\tMoving Average: 0.507\nEpisodes 780\tMax Reward: 1.100\tMoving Average: 0.490\nEpisodes 790\tMax Reward: 1.400\tMoving Average: 0.470\nEpisodes 800\tMax Reward: 0.700\tMoving Average: 0.468\nEpisodes 810\tMax Reward: 0.700\tMoving Average: 0.433\nEpisodes 820\tMax Reward: 0.800\tMoving Average: 0.392\nEpisodes 830\tMax Reward: 2.600\tMoving Average: 0.396\nEpisodes 840\tMax Reward: 0.700\tMoving Average: 0.359\nEpisodes 850\tMax Reward: 2.300\tMoving Average: 0.385\nEpisodes 860\tMax Reward: 2.300\tMoving Average: 0.419\nEpisodes 870\tMax Reward: 5.200\tMoving Average: 0.460\nEpisodes 880\tMax Reward: 3.400\tMoving Average: 0.516\nEpisodes 890\tMax Reward: 1.900\tMoving Average: 0.524\nEpisodes 900\tMax Reward: 3.800\tMoving Average: 0.579\nEpisodes 910\tMax Reward: 2.200\tMoving Average: 0.636\nEpisodes 920\tMax Reward: 2.200\tMoving Average: 0.706\nEpisodes 930\tMax Reward: 2.500\tMoving Average: 0.708\nEpisodes 940\tMax Reward: 4.000\tMoving Average: 0.791\nEpisodes 950\tMax Reward: 1.000\tMoving Average: 0.759\nEpisodes 960\tMax Reward: 0.400\tMoving Average: 0.697\nEpisodes 970\tMax Reward: 2.700\tMoving Average: 0.669\nEpisodes 980\tMax Reward: 0.500\tMoving Average: 0.606\nEpisodes 990\tMax Reward: 2.100\tMoving Average: 0.652\nEpisodes 1000\tMax Reward: 1.200\tMoving Average: 0.616\nEpisodes 1010\tMax Reward: 0.600\tMoving Average: 0.557\nEpisodes 1020\tMax Reward: 0.600\tMoving Average: 0.485\nBest episode 1022\tMax Reward: 5.200\tMoving Average: 0.533\nBest episode 1023\tMax Reward: 5.300\tMoving Average: 0.586\nEpisodes 1030\tMax Reward: 5.300\tMoving Average: 0.532\nEpisodes 1040\tMax Reward: 0.800\tMoving Average: 0.450\nEpisodes 1050\tMax Reward: 0.300\tMoving Average: 0.430\nEpisodes 1060\tMax Reward: 1.100\tMoving Average: 0.434\nEpisodes 1070\tMax Reward: 0.300\tMoving Average: 0.371\nEpisodes 1080\tMax Reward: 2.100\tMoving Average: 0.403\nEpisodes 1090\tMax Reward: 1.690\tMoving Average: 0.369\nEpisodes 1100\tMax Reward: 0.300\tMoving Average: 0.344\nEpisodes 1110\tMax Reward: 1.600\tMoving Average: 0.355\nEpisodes 1120\tMax Reward: 0.400\tMoving Average: 0.356\nEpisodes 1130\tMax Reward: 3.100\tMoving Average: 0.295\nEpisodes 1140\tMax Reward: 2.800\tMoving Average: 0.358\nEpisodes 1150\tMax Reward: 5.200\tMoving Average: 0.466\nEpisodes 1160\tMax Reward: 2.200\tMoving Average: 0.473\nEpisodes 1170\tMax Reward: 3.100\tMoving Average: 0.542\nEpisodes 1180\tMax Reward: 3.200\tMoving Average: 0.581\nEpisodes 1190\tMax Reward: 2.100\tMoving Average: 0.599\nEpisodes 1200\tMax Reward: 5.200\tMoving Average: 0.678\nBest episode 1205\tMax Reward: 5.300\tMoving Average: 0.765\nEpisodes 1210\tMax Reward: 5.300\tMoving Average: 0.805\nEpisodes 1220\tMax Reward: 5.200\tMoving Average: 0.936\nDone\n"
],
[
"plt.plot(np.arange(1, len(scores)+1), scores, label='Score')\nplt.plot(np.arange(len(scores)), avgs, c='r', label='100 Average')\nplt.legend(loc=0)\nplt.ylabel('Score')\nplt.xlabel('Episode #')\nplt.title('Udacity Project3 Solution by Bongsang')\n\nplt.savefig('result.png')\nplt.show()",
"_____no_output_____"
],
[
"env.close()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4dd7a90b5fe5fc5eab0bbeff737bd4de20838e
| 1,004,880 |
ipynb
|
Jupyter Notebook
|
notebook/M2_insiders_cluster.ipynb
|
djalmajr07/all_in_insiders
|
864497cb7f1a7a938dd4090a9b3557d6e5d9b1fa
|
[
"MIT"
] | null | null | null |
notebook/M2_insiders_cluster.ipynb
|
djalmajr07/all_in_insiders
|
864497cb7f1a7a938dd4090a9b3557d6e5d9b1fa
|
[
"MIT"
] | null | null | null |
notebook/M2_insiders_cluster.ipynb
|
djalmajr07/all_in_insiders
|
864497cb7f1a7a938dd4090a9b3557d6e5d9b1fa
|
[
"MIT"
] | null | null | null | 50.168747 | 239,038 | 0.719389 |
[
[
[
" # PAOO5: High Value Customer Identification (Insiders)",
"_____no_output_____"
],
[
"## Planejamento da solução (IoT)",
"_____no_output_____"
],
[
"### Input",
"_____no_output_____"
],
[
"1. Problema de negocio\n * selecionar os clientes mais valiosos para integrar um programa de fidelizacao.\n2. Conjunto de dados\n * Vendas de um e-commerce online, durante o periodo de um ano.",
"_____no_output_____"
],
[
"### Output",
"_____no_output_____"
],
[
"1. A indicacao das pessoas que farao parte do programa de Insiders\n - Lista: client_id|is_insider\n\n\n2. Relatorio com as respostas das perguntas de negocio\n- Quem sao as pessoas elegiveis para participar do programa insiders ?\n 1. **Who are the people eligible to participate in the Insiders program?**\n 2. **How many customers will be part of the group?**\n 3. **What are the main characteristics of these customers?**\n 4. **What percentage of revenue contribution comes from Insiders?**\n 5. **What is this group's expected revenue for the coming months?**\n 6. **What are the conditions for a person to be eligible for Insiders?**\n 7. **What are the conditions for a person to be removed from Insiders?**\n 8. **What is the guarantee that the Insiders program is better than the rest of the base?**\n 9. **What actions can the marketing team take to increase revenue?**",
"_____no_output_____"
],
[
"### Tasks",
"_____no_output_____"
],
[
"1. **Quem são as pessoas elegíveis para participar do programa de Insiders ?**\n - O que é ser elegível ? O que é um cliente \"valioso\" para a empresa ?\n - Faturamento:\n - Alto Ticket Médio\n - Alto LTV\n - Baixa Recência ou Alta Frequência ( tempo entre as compras )\n - Alto Basket Size ( quantidade média de produtos comprados )\n - Baixa probabilidade de Churn\n - Previsão alta de LTV\n - Alta propensão de compra\n\n - Custo:\n - Baixo número de devoluções\n\n - Experiência: \n - Média alta de avaliações\n \n \n2. **Quantos clientes farão parte do grupo?**\n - Número de clientes\n - % em relação ao total de clients\n \n \n3. **Quais as principais características desses clientes ?**\n - Escrever os principais atributos dos clientes\n - Idade\n - País\n - Salário\n \n - Escrever os principais comportamentos de compra dos clients ( métricas de negócio )\n - Vide acima\n \n \n4. **Qual a porcentagem de contribuição do faturamento, vinda do Insiders ?**\n - Calcular o faturamento total da empresa durante o ano.\n - Calcular o faturamento (%) apenas do cluster Insiders.\n \n \n5. **Qual a expectativa de faturamento desse grupo para os próximos meses ?**\n - Cálculo do LTV do grupo Insiders\n - Séries Temporais ( ARMA, ARIMA, HoltWinter, etc )\n \n\n6. **Quais as condições para uma pessoa ser elegível ao Insiders ?**\n - Qual o período de avaliação ?\n - O \"desempenho\" do cliente está próximo da média do cluster Insiders. \n \n \n7. **Quais as condições para uma pessoa ser removida do Insiders ?**\n - O \"desempenho\" do cliente não está mais próximo da média do cluster Insiders. \n \n \n8. **Qual a garantia que o programa Insiders é melhor que o restante da base ?**\n - Teste de Hipóteses\n - Teste A/B\n \n \n9. **Quais ações o time de marketing pode realizar para aumentar o faturamento?**\n - Descontos\n - Preferências de escolha\n - Produtos exclusivos",
"_____no_output_____"
],
[
"# 0 IMPORTS",
"_____no_output_____"
]
],
[
[
"# %pip install plotly",
"_____no_output_____"
],
[
"import pandas as pd \nimport numpy as np\nimport seaborn as sns\n\nfrom matplotlib import pyplot as plt\nfrom IPython.display import HTML\nimport inflection\nfrom sklearn import cluster as c\nfrom yellowbrick.cluster import KElbowVisualizer,SilhouetteVisualizer\nfrom sklearn import metrics as m\nfrom plotly import express as px\nimport umap.umap_ as umap",
"_____no_output_____"
]
],
[
[
"## 0.1 Helper Functions",
"_____no_output_____"
]
],
[
[
"def jupyter_settings():\n %matplotlib inline\n %pylab inline\n \n plt.style.use( 'bmh' )\n plt.rcParams['figure.figsize'] = [25, 12]\n plt.rcParams['font.size'] = 24\n \n display( HTML( '<style>.container { width:100% !important; }</style>') )\n pd.options.display.max_columns = None\n pd.options.display.max_rows = None\n pd.set_option( 'display.expand_frame_repr', False )\n \n sns.set()\njupyter_settings()",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"# 0.2 Loadind dataset",
"_____no_output_____"
]
],
[
[
"df_raw=pd.read_csv('/home/tc0019/DS/insiders_cluster/dataset/Ecommerce.csv', encoding='unicode_escape')\ndf_raw=df_raw.drop( columns = ['Unnamed: 8'], axis=1)\ndf_raw.head()",
"_____no_output_____"
]
],
[
[
"# 1.0 Descricao dos dados",
"_____no_output_____"
]
],
[
[
"df1=df_raw.copy()",
"_____no_output_____"
]
],
[
[
"## 1.1 Rename columns",
"_____no_output_____"
]
],
[
[
"cols_old=['InvoiceNo', 'StockCode', 'Description', 'Quantity', 'InvoiceDate',\n 'UnitPrice', 'CustomerID', 'Country']\n\nsnakecase = lambda x: inflection.underscore(x)\n\ncols_new = list( map( snakecase, cols_old ) )\n\ndf1.columns=cols_new\n\ndf1.sample()",
"_____no_output_____"
]
],
[
[
"## 1.2. Data Dimensions",
"_____no_output_____"
]
],
[
[
"print('Number of Rows: {}'.format(df1.shape[0]))\nprint('Number of Cols: {}'.format(df1.shape[1]))",
"Number of Rows: 541909\nNumber of Cols: 8\n"
]
],
[
[
"## 1.3. Data Types",
"_____no_output_____"
]
],
[
[
"df1.dtypes",
"_____no_output_____"
]
],
[
[
"## 1.4. Check NA",
"_____no_output_____"
]
],
[
[
"df1.isna().sum()",
"_____no_output_____"
]
],
[
[
"### 1.4.1 Remove NA",
"_____no_output_____"
]
],
[
[
"df1 = df1.dropna(subset=['description', 'customer_id'])\nprint('Removed data: {:.2f}'.format(1-(df1.shape[0]/df_raw.shape[0])))",
"Removed data: 0.25\n"
],
[
"df1.isna().sum()\n",
"_____no_output_____"
],
[
"df1.shape",
"_____no_output_____"
]
],
[
[
"## 1.5. Descriptive Statistics",
"_____no_output_____"
],
[
"### 1.5.1. Numerical Atributes",
"_____no_output_____"
],
[
"## 1.6 Change dtypes",
"_____no_output_____"
]
],
[
[
"# invoice date\ndf1['invoice_date'] = pd.to_datetime(df1['invoice_date'], format='%d-%b-%y')\n",
"_____no_output_____"
]
],
[
[
"# 2.0 Feature Engineering",
"_____no_output_____"
]
],
[
[
"df2=df1.copy()",
"_____no_output_____"
],
[
"# data reference\ndf_ref=df2.drop(['invoice_no', 'stock_code', 'description',\n 'quantity', 'invoice_date', 'unit_price', 'country'], axis=1).drop_duplicates(ignore_index=True)\n\ndf_ref.head()",
"_____no_output_____"
],
[
"# Gross revenue (quantity * price)\ndf2['gross_revenue'] = df2['quantity'] * df2['unit_price']\n\n# Monetary \ndf_monetary=df2[['customer_id', 'gross_revenue']].groupby('customer_id').sum().reset_index()\ndf_ref=pd.merge(df_ref, df_monetary, on='customer_id', how='left')\n\n# Recency - last day purchase\ndf_recency=df2[['customer_id', 'invoice_date']].groupby('customer_id').max().reset_index()\ndf_recency['recency_days'] = (df2['invoice_date'].max()-df_recency['invoice_date']).dt.days\ndf_recency=df_recency[['customer_id','recency_days']].groupby('customer_id').sum().reset_index()\ndf_ref=pd.merge(df_ref, df_recency, on='customer_id', how='left')\n\n# Frequency\ndf_freq=df2[['customer_id', 'invoice_no']].drop_duplicates().groupby('customer_id').count().reset_index()\ndf_ref=pd.merge(df_ref,df_freq, on='customer_id', how='left')\ndf_ref.isna().sum()\n\n# AVG ticket\n\ndf_avg_ticket = df2[['customer_id', 'gross_revenue']].groupby('customer_id').mean().reset_index().rename(columns={'gross_revenue': 'avg_ticket'})\ndf_ref = pd.merge(df_ref,df_avg_ticket, on='customer_id', how='left')",
"_____no_output_____"
],
[
"df_ref.head()",
"_____no_output_____"
]
],
[
[
"# 3.0 Filtragem de variaveis",
"_____no_output_____"
]
],
[
[
"df3=df_ref.copy()",
"_____no_output_____"
]
],
[
[
"# 4.0 EDA",
"_____no_output_____"
]
],
[
[
"df4=df3.copy()\n",
"_____no_output_____"
]
],
[
[
"# 5.0 Data preparation",
"_____no_output_____"
]
],
[
[
"df5=df4.copy()\n",
"_____no_output_____"
]
],
[
[
"# 6.0 Feature Selection",
"_____no_output_____"
]
],
[
[
"df6=df5.copy()\n",
"_____no_output_____"
]
],
[
[
"# 7.0 Hyperparameter fine tuning",
"_____no_output_____"
]
],
[
[
"df7=df6.copy()\nX = df6.drop(columns='customer_id')\nclusters = [2, 3, 4, 5, 6, 7]",
"_____no_output_____"
]
],
[
[
"## 7.1 Within-Cluster Sum of Square (WSS)",
"_____no_output_____"
]
],
[
[
"wss = []\nfor k in clusters:\n # model definition\n kmeans=c.KMeans( init='random', n_clusters=k, n_init=10, max_iter=300, random_state=42 )\n\n # model Training\n kmeans.fit(X)\n\n # validation\n wss.append( kmeans.inertia_)\n\n# plot wss elbow method\nplt.plot(clusters, wss, linestyle='--', marker='o', color='b')\nplt.xlabel('K');\nplt.ylabel('Within-Cluster Sum Square');\nplt.title('WSS vs K')",
"_____no_output_____"
],
[
"kmeans = KElbowVisualizer( c.KMeans(), k=clusters, timings=False )\nkmeans.fit(X)\nkmeans.show()",
"_____no_output_____"
]
],
[
[
"## 7.2 Sillhouette Score",
"_____no_output_____"
]
],
[
[
"kmeans = KElbowVisualizer( c.KMeans(), k=clusters, metric='silhouette', timings=False )\nkmeans.fit(X)\nkmeans.show()",
"_____no_output_____"
]
],
[
[
"## 7.3 Silhouette Analysis",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots( 3, 2, figsize=(25, 18))\n\n\nfor k in clusters:\n km = c.KMeans(n_clusters=k, init='random', n_init=10, max_iter=100, random_state=42)\n q, mod = divmod(k,2)\n visualizer = SilhouetteVisualizer(km, color='yellowbrick', ax=ax[q-1][mod])\n visualizer.fit(X)\n visualizer.finalize()",
"_____no_output_____"
]
],
[
[
"# 8.0 Model Training",
"_____no_output_____"
]
],
[
[
"df8=df7.copy()\n",
"_____no_output_____"
]
],
[
[
"## 8.1 K-Means",
"_____no_output_____"
]
],
[
[
"# model definition\nk=4\nkmeans = c.KMeans( init='random', n_clusters=k, n_init=10, max_iter=300, random_state=42)\n\n\n# model training\nkmeans.fit(X)\n\n\n# clustering\nlabels=kmeans.labels_",
"_____no_output_____"
]
],
[
[
"## 8.2 Cluster Validation",
"_____no_output_____"
]
],
[
[
"## WSS (within -cluster sum of squares)\nprint ('WSS Value: {}'.format(kmeans.inertia_))\n\n## SS (silhouette score)\nprint ('SS Value: {}'.format(m.silhouette_score(X, labels, metric='euclidean')))",
"WSS Value: 40056506734.602486\nSS Value: 0.8139972028952444\n"
]
],
[
[
"# 9.0 Cluster Analysis",
"_____no_output_____"
]
],
[
[
"df9=df8.copy()\ndf9['cluster'] = labels\ndf9.head()",
"_____no_output_____"
]
],
[
[
"## 9.1 Visualization Inspections",
"_____no_output_____"
]
],
[
[
"visualizer = SilhouetteVisualizer( kmeans, colors='yellowbricks')",
"_____no_output_____"
]
],
[
[
"### 9.1.1 2D Plot",
"_____no_output_____"
]
],
[
[
"df_viz= df9.drop(columns='customer_id', axis=1)\nsns.pairplot( df_viz, hue='cluster')",
"_____no_output_____"
],
[
"fig = px.scatter_3d(df9, x='recency_days', y='invoice_no', z='gross_revenue', color='cluster')\nfig.show()",
"_____no_output_____"
]
],
[
[
"## 9.2 Cluster Profile",
"_____no_output_____"
]
],
[
[
"# Number of customer\ndf_cluster = df9[['customer_id', 'cluster']].groupby( 'cluster' ).count().reset_index()\ndf_cluster['perc_customer'] = 100*( df_cluster['customer_id'] / df_cluster['customer_id'].sum() )\n\n# Avg Gross revenue\ndf_avg_gross_revenue = df9[['gross_revenue', 'cluster']].groupby( 'cluster' ).mean().reset_index()\ndf_cluster = pd.merge( df_cluster, df_avg_gross_revenue, how='inner', on='cluster' )\n\n# Avg recency days\ndf_avg_recency_days = df9[['recency_days', 'cluster']].groupby( 'cluster' ).mean().reset_index()\ndf_cluster = pd.merge( df_cluster, df_avg_recency_days, how='inner', on='cluster' )\n\n# Avg invoice_no\ndf_invoice_no = df9[['invoice_no', 'cluster']].groupby( 'cluster' ).mean().reset_index()\ndf_cluster = pd.merge( df_cluster, df_invoice_no, how='inner', on='cluster' )\n\n# Avg Ticket\ndf_ticket = df9[['avg_ticket', 'cluster']].groupby( 'cluster' ).mean().reset_index()\ndf_cluster = pd.merge( df_cluster, df_ticket, how='inner', on='cluster' )\n\ndf_cluster ",
"_____no_output_____"
]
],
[
[
"## 9.3 UMAP",
"_____no_output_____"
]
],
[
[
"reducer = umap.UMAP( n_neighbors=90, random_state=42 )\nembedding = reducer.fit_transform( X )\n\n# embedding\ndf_viz['embedding_x'] = embedding[:, 0]\ndf_viz['embedding_y'] = embedding[:, 1]\n\n# plot UMAP\nsns.scatterplot( x='embedding_x', y='embedding_y', \n hue='cluster', \n palette=sns.color_palette( 'hls', n_colors=len( df_viz['cluster'].unique() ) ),\n data=df_viz )\n",
"_____no_output_____"
]
],
[
[
"### Cluster 01: ( Candidato à Insider )\n - Número de customers: 6 (0.14% do customers )\n - Recência em média: 7 dias\n - Compras em média: 89 compras\n - Receita em média: $182.182,00 dólares\n \n### Cluster 02: \n - Número de customers: 31 (0.71% do customers )\n - Recência em média: 14 dias\n - Compras em média: 53 compras\n - Receita em média: $40.543,52 dólares\n \n### Cluster 03: \n - Número de customers: 4.335 (99% do customers )\n - Recência em média: 92 dias\n - Compras em média: 5 compras\n - Receita em média: $1.372,57 dólares",
"_____no_output_____"
],
[
"# 10.0 Deploy to production",
"_____no_output_____"
]
],
[
[
"df10=df9.copy()\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a4dd995e7f586f29b5589e9019c6aeb727c243c
| 7,584 |
ipynb
|
Jupyter Notebook
|
notebooks/Learning Units/K-Nearest Neighbours/K-Nearest Neighbours - Chapter 2 - K-Nearest-Neighbours.ipynb
|
ValentinCalomme/skratch
|
f234a9b95adfdb20d231d7f8c761ab1098733cb8
|
[
"MIT"
] | 4 |
2017-10-27T07:23:34.000Z
|
2020-02-11T18:02:39.000Z
|
notebooks/Learning Units/K-Nearest Neighbours/K-Nearest Neighbours - Chapter 2 - K-Nearest-Neighbours.ipynb
|
ValentinCalomme/skratch
|
f234a9b95adfdb20d231d7f8c761ab1098733cb8
|
[
"MIT"
] | null | null | null |
notebooks/Learning Units/K-Nearest Neighbours/K-Nearest Neighbours - Chapter 2 - K-Nearest-Neighbours.ipynb
|
ValentinCalomme/skratch
|
f234a9b95adfdb20d231d7f8c761ab1098733cb8
|
[
"MIT"
] | null | null | null | 30.457831 | 337 | 0.569488 |
[
[
[
"# K-Nearest Neighbours\n\nLet’s build a K-Nearest Neighbours model from scratch.\n\nFirst, we will define some generic `KNN` object. In the constructor, we pass three parameters:\n\n- The number of neighbours being used to make predictions\n- The distance measure we want to use\n- Whether or not we want to use weighted distances",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append(\"D:/source/skratch/source\")\nfrom collections import Counter\n \nimport numpy as np\n \nfrom utils.distances import euclidean\n \n \nclass KNN:\n \n def __init__(self, k, distance=euclidean, weighted=False):\n \n self.k = k\n self.weighted = weighted # Whether or not to use weighted distances\n self.distance = distance",
"_____no_output_____"
]
],
[
[
"Now we will define the fit function, which is the function which describes how to train a model. For a K-Nearest Neighbours model, the training is rather simplistic. Indeed, all there needs to be done is to store the training instances as the model’s parameters.",
"_____no_output_____"
]
],
[
[
" def fit(self, X, y):\n\n self.X_ = X\n self.y_ = y\n\n return self",
"_____no_output_____"
]
],
[
[
"Similarly, we can build an update function which will update the state of the model as more data points are provided for training. Training a model by feeding it data in a stream-like fashion is often referred to as online learning. Not all models allow for computationally efficient online learning, but K-Nearest Neighbours does.",
"_____no_output_____"
]
],
[
[
" def update(self, X, y):\n\n self.X_ = np.concatenate((self.X_, X))\n self.y_ = np.concatenate((self.y_, y))\n\n return self",
"_____no_output_____"
]
],
[
[
"In order to make predictions, we also need to create a predict function. For a K-Nearest Neighbours model, a prediction is made in two steps:\n\n- Find the K-nearest neighbours by computing their distances to the data point we want to predict\n- Given these neighbours and their distances, compute the predicted output",
"_____no_output_____"
]
],
[
[
" def predict(self, X):\n\n predictions = []\n\n for x in X:\n\n neighbours, distances = self._get_neighbours(x)\n\n prediction = self._vote(neighbours, distances)\n\n predictions.append(prediction)\n\n return np.array(predictions)",
"_____no_output_____"
]
],
[
[
"Retrieving the neighbours can be done by calculating all pairwise distances between the data point and the data stored inside the state of the model. Once these distances are known, the K instances that have the shortest distance to the example are returned.",
"_____no_output_____"
]
],
[
[
" def _get_neighbours(self, x):\n\n distances = np.array([self._distance(x, x_) for x_ in self.X_])\n indices = np.argsort(distances)[:self.k]\n\n return self.y_[indices], distances[indices]",
"_____no_output_____"
]
],
[
[
"In case we would like to use weighted distances, we need to compute the weights. By default, these weights are all set to 1 to make all instances equal. To weigh the instances, neighbours that are closer are typically favoured by given them a weight equal to 1 divided by their distance.\n\n>If neighbours have distance 0, since we can’t divide by zero, their weight is set to 1, and all other weights are set to 0. This is also how scikit-learn deals with this problem according to their source code.",
"_____no_output_____"
]
],
[
[
" def _get_weights(self, distances):\n\n weights = np.ones_like(distances, dtype=float)\n\n if self.weighted:\n if any(distances == 0):\n weights[distances != 0] = 0\n else:\n weights /= distances\n\n return weights",
"_____no_output_____"
]
],
[
[
"The only function that we have yet to define is the vote function that is called in the predict function. Depending on the implementation of that function, K-Nearest Neighbours can be used for regression, classification, or even as a meta-learner. \n\n## KNN for Regression\n\nIn order to use K-Nearest Neighbour for regression, the vote function is defined as the average of the neighbours. In case weighting is used, the vote function returns the weighted average, favouring closer instances.",
"_____no_output_____"
]
],
[
[
"class KNN_Regressor(KNN):\n \n def _vote(self, targets, distances):\n \n weights = self._get_weights(distances)\n \n return np.sum(weights * targets) / np.sum(weights)\n",
"_____no_output_____"
]
],
[
[
"## KNN for Classification\n\nIn the classification case, the vote function uses a majority voting scheme. If weighting is used, each neighbour has a different impact on the prediction.",
"_____no_output_____"
]
],
[
[
"class KNN_Classifier(KNN):\n \n def _vote(self, classes, distances):\n \n weights = self._get_weights(distances)\n \n prediction = None\n max_weighted_frequency = 0\n \n for c in classes:\n \n weighted_frequency = np.sum(weights[classes == c])\n \n if weighted_frequency > max_weighted_frequency:\n \n prediction = c\n max_weighted_frequency = weighted_frequency\n \n return prediction",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4ddc7882c6814cff00238a9e1807b051e7ce03
| 13,565 |
ipynb
|
Jupyter Notebook
|
Scala Programming for Data Science/Data Science with Scala/Module 1: Basis Statistics and Data Types/3.1.5.ipynb
|
helpthx/Big_Data
|
27ad822ed075631f4093bd9e329d70ce6a2424e4
|
[
"MIT"
] | null | null | null |
Scala Programming for Data Science/Data Science with Scala/Module 1: Basis Statistics and Data Types/3.1.5.ipynb
|
helpthx/Big_Data
|
27ad822ed075631f4093bd9e329d70ce6a2424e4
|
[
"MIT"
] | 5 |
2019-06-23T18:24:27.000Z
|
2019-06-23T23:22:40.000Z
|
Scala Programming for Data Science/Data Science with Scala/Module 1: Basis Statistics and Data Types/3.1.5.ipynb
|
helpthx/Big_Data
|
27ad822ed075631f4093bd9e329d70ce6a2424e4
|
[
"MIT"
] | null | null | null | 29.747807 | 257 | 0.578695 |
[
[
[
"<a href=\"https://cocl.us/Data_Science_with_Scalla_top\"><img src = \"https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/SC0103EN/adds/Data_Science_with_Scalla_notebook_top.png\" width = 750, align = \"center\"></a>\n <br/>\n<a><img src=\"https://ibm.box.com/shared/static/ugcqz6ohbvff804xp84y4kqnvvk3bq1g.png\" width=\"200\" align=\"center\"></a>\"\n\n# Basic Statistics and Data Types\n\n## Hypothesis Testing \n\n## Lesson Objectives \n\nAfter completing this lesson, you should be able to:\n\n-\tPerform hypothesis testing for goodness of fit and independence \n-\tPerform hypothesis testing for equality and probability distributions\n-\tPerform kernel density estimation \n\n## Hypothesis Testing \n\n- Used to determine whether a result is statistically significant, that is, whether it occurred by chance or not \n-\tSupported tests:\n -\tPearson's Chi-Squared test for goodness of fit \n -\tPearson's Chi-Squared test for independence\n-\tKolmogorov-Smirnov test for equality of distribution \n-\tInputs of type `RDD[LabeledPoint]` are also supported, enabling feature selection\n\n\n### Pearson's Chi-Squared Test for Goodness of Fit \n\n-\tDetermines whether an observed frequency distribution differs from a given distribution or not \n-\tRequires an input of type Vector containing the frequencies of the events \n-\tIt runs against a uniform distribution, if a second vector to test against is not supplied \n-\tAvailable as `chiSqTest`() function in Statistics \n\n\n\n### Libraries required for examples",
"_____no_output_____"
]
],
[
[
"import org.apache.spark.mllib.linalg.{Vector, Vectors}\nimport org.apache.spark.mllib.linalg.{Matrix, Matrices}\n\nimport org.apache.spark.mllib.stat.Statistics\n\nval vec: Vector = Vectors.dense(0.3, 0.2, 0.15, 0.1, 0.1, 0.1, 0.05)\n\nval goodnessOfFitTestResult = Statistics.chiSqTest(vec)\n\ngoodnessOfFitTestResult",
"_____no_output_____"
]
],
[
[
"### Pearson's Chi-Squared Test for Independence\n\n-\tDetermines whether unpaired observations on two variables are independent of each other \n-\tRequires an input of type Matrix, representing a contingency table, or an `RDD[LabeledPoint]`\n-\tAvailable as `chiSqTest()` function in Statistics \n-\tMay be used for feature selection",
"_____no_output_____"
]
],
[
[
"// Testing for Independence \n\nimport org.apache.spark.mllib.linalg.{Matrix, Matrices}\nimport org.apache.spark.mllib.stat.Statistics \nimport org.apache.spark.rdd.RDD\n\nval mat: Matrix = Matrices.dense(3, 2,\nArray(13.0, 47.0, 40.0, 80.0, 11.0, 9.0))\n\nval independenceTestResult = Statistics.chiSqTest(mat)\nindependenceTestResult",
"_____no_output_____"
],
[
"import org.apache.spark.mllib.regression.LabeledPoint\nimport org.apache.spark.mllib.stat.test.ChiSqTestResult\n\nval obs: RDD[LabeledPoint] = sc.parallelize(Array(\n LabeledPoint(0, Vectors.dense(1.0, 2.0)),\n LabeledPoint(0, Vectors.dense(0.5, 1.5)),\n LabeledPoint(1, Vectors.dense(1.0, 8.0))))\n\nval featureTestResults: Array[ChiSqTestResult] = Statistics.chiSqTest(obs)\nfeatureTestResults",
"_____no_output_____"
]
],
[
[
"### Kolmogorov-Smirnov Test\n\n-\tDetermines whether nor not two probability distributions are equal \n-\tOne sample, two sided test \n-\tSupported distributions to test against:\n-\tnormal distribution (distName='norm')\n- customized cumulative density function (CDF)\n-\tAvailable as `kolmogorovSmirnovTest()` function in Statistics",
"_____no_output_____"
]
],
[
[
"// Test for Equality of Distribution\nimport org.apache.spark.mllib.random.RandomRDDs.normalRDD\n\nval data: RDD[Double] = normalRDD(sc, size=100, numPartitions=1, seed=13L)\n\nval testResult = Statistics.kolmogorovSmirnovTest(data, \"norm\", 0, 1)\n \n// Test for Equality of Distribution \n\nimport org.apache.spark.mllib.random.RandomRDDs.uniformRDD\n\nval data1: RDD[Double] = uniformRDD(sc, size = 100, numPartitions=1, seed=13L)\n\nval testResult1 = Statistics.kolmogorovSmirnovTest(data1, \"norm\", 0, 1)",
"_____no_output_____"
]
],
[
[
"### Kernel Density Estimation \n\n-\tComputes an estimate of the probability density function of a random variable, evaluated at a given set of points \n-\tDoes not require assumptions about the particular distribution that the observed samples are drawn from \n-\tRequires an RDD of samples\n-\tAvailable as `estimate()` function in KernelDensity\n-\tIn Spark, only Gaussian kernel is supported",
"_____no_output_____"
]
],
[
[
"\n// Kernel Density Estimation I\n\nimport org.apache.spark.mllib.stat.KernelDensity\n\nval data: RDD[Double] = normalRDD(sc, size=1000, numPartitions=1, seed=17L)\n\nval kd = new KernelDensity().setSample(data).setBandwidth(0.1)\n\nval densities = kd.estimate(Array(-1.5, -1, -0.5, 1, 1.5))\n\ndensities ",
"_____no_output_____"
],
[
"// Kernel Density Estimation II \n\nval data: RDD[Double] = uniformRDD(sc, size=1000, numPartitions=1, seed=17L)\n\nval kd = new KernelDensity().setSample(data).setBandwidth(0.1)\n\nval densities = kd.estimate(Array(-0.25, 0.25, 0.5, 0.75, 1.25))\n\ndensities ",
"_____no_output_____"
]
],
[
[
"## Lesson Summary\n\n-\tHaving completed this lesson, you should be able to:\n- Perform hypothesis testing for goodness of fit and independence \n-\tPerform hypothesis testing for equality of probability distributions \n-\tPerform kernel density estimation\n\n### About the Authors\n\n[Petro Verkhogliad](https://www.linkedin.com/in/vpetro) is Consulting Manager at Lightbend. He holds a Masters degree in Computer Science with specialization in Intelligent Systems. He is passionate about functional programming and applications of AI.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a4de7c5386964743d9e8d1cc560946ba3d7855c
| 81,038 |
ipynb
|
Jupyter Notebook
|
cold_start_process.ipynb
|
jnawjux/recommendation-case-study
|
e2619f12c79684d1a9b07b062cf216a64f7bce3d
|
[
"MIT"
] | 1 |
2019-06-11T13:13:12.000Z
|
2019-06-11T13:13:12.000Z
|
cold_start_process.ipynb
|
jnawjux/recommendation-case-study
|
e2619f12c79684d1a9b07b062cf216a64f7bce3d
|
[
"MIT"
] | null | null | null |
cold_start_process.ipynb
|
jnawjux/recommendation-case-study
|
e2619f12c79684d1a9b07b062cf216a64f7bce3d
|
[
"MIT"
] | null | null | null | 29.297903 | 2,400 | 0.368321 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport json\nfrom cold_start import get_cold_start_rating",
"_____no_output_____"
],
[
"import pyspark\nspark = pyspark.sql.SparkSession.builder.getOrCreate()\nsc = spark.sparkContext",
"_____no_output_____"
],
[
"ratings_df = spark.read.json('data/ratings.json').toPandas()\nmetadata = pd.read_csv('data/movies_metadata.csv')\nrequest_df = spark.read.json('data/requests.json').toPandas()",
"/Users/nawjux/anaconda3/envs/learn-env/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (10) have mixed types. Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
],
[
"ratings_df['user_id'].nunique()",
"_____no_output_____"
],
[
"ratings_df['rating'].value_counts()",
"_____no_output_____"
],
[
"ratings_df.isna().sum()",
"_____no_output_____"
],
[
"len(metadata), metadata['tagline'].isna().sum()",
"_____no_output_____"
],
[
"metadata.loc[0]['genres']",
"_____no_output_____"
],
[
"len(requests_df)",
"_____no_output_____"
],
[
"users = []\nfor line in open('data/users.dat', 'r'):\n item = line.split('\\n')\n users.append(item[0].split(\"::\"))",
"_____no_output_____"
],
[
"user_df = pd.read_csv('data/users.dat', sep='::', header=None, names=['id', 'gender', 'age', 'occupation', 'zip'])\nmovie_info_df = pd.read_csv('data/movies.dat', sep='::', header=None, names=['id', 'name', 'genres'])",
"/Users/nawjux/anaconda3/envs/learn-env/lib/python3.6/site-packages/ipykernel_launcher.py:1: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.\n \"\"\"Entry point for launching an IPython kernel.\n/Users/nawjux/anaconda3/envs/learn-env/lib/python3.6/site-packages/ipykernel_launcher.py:2: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.\n \n"
],
[
"user_df[20:53]",
"_____no_output_____"
],
[
"movie_info_df.head()",
"_____no_output_____"
],
[
"movie_info_df['genres'] = movie_info_df['genres'].apply(lambda x: x.split('|'))",
"_____no_output_____"
],
[
"movie_info_df.head()",
"_____no_output_____"
],
[
"all_genres = set([item for movie in movie_info_df['genres'] for item in movie])",
"_____no_output_____"
],
[
"all_genres",
"_____no_output_____"
],
[
"user_df = user_df.drop('zip', axis=1)",
"_____no_output_____"
],
[
"user_df.head()",
"_____no_output_____"
],
[
"from sklearn.preprocessing import OneHotEncoder\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.cluster import KMeans",
"_____no_output_____"
],
[
"def ohe_columns(series, name):\n ohe = OneHotEncoder(categories='auto')\n ohe.fit(series)\n cols = ohe.get_feature_names(name)\n ohe = ohe.transform(series)\n final_df = pd.DataFrame(ohe.toarray(), columns=cols)\n return final_df",
"_____no_output_____"
],
[
"# OHE the user cols\nmy_cols = ['gender', 'age', 'occupation']\n\nohe_multi = OneHotEncoder(categories='auto')\nohe_multi.fit(user_df[my_cols])\nohe_mat = ohe_multi.transform(user_df[my_cols])",
"_____no_output_____"
],
[
"# Then KMeans cluster\nk_clusters = KMeans(n_clusters=8, random_state=42)\nk_clusters.fit(ohe_mat)\n\npreds = k_clusters.predict(ohe_mat)",
"_____no_output_____"
],
[
"preds",
"_____no_output_____"
],
[
"preds.shape",
"_____no_output_____"
],
[
"def add_clusters_to_users(n_clusters=8):\n \"\"\"\n parameters:number of clusters\n \n return: user dataframe\n \"\"\"\n \n # Get the user data\n user_df = pd.read_csv('data/users.dat', sep='::', header=None\n , names=['id', 'gender', 'age', 'occupation', 'zip'])\n \n # OHE for clustering\n my_cols = ['gender', 'age', 'occupation']\n\n ohe_multi = OneHotEncoder(categories='auto')\n ohe_multi.fit(user_df[my_cols])\n ohe_mat = ohe_multi.transform(user_df[my_cols])\n\n # Then KMeans cluster\n k_clusters = KMeans(n_clusters=8, random_state=42)\n k_clusters.fit(ohe_mat)\n\n preds = k_clusters.predict(ohe_mat)\n \n # Add clusters to user df\n user_df['cluster'] = preds\n \n return user_df\n",
"_____no_output_____"
],
[
"test_df = add_clusters_to_users()",
"/Users/nawjux/anaconda3/envs/learn-env/lib/python3.6/site-packages/ipykernel_launcher.py:10: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.\n # Remove the CWD from sys.path while we load stuff.\n"
],
[
"test_df.to_csv('data/u_info.csv')",
"_____no_output_____"
],
[
"temp_ohe = ohe_2.get_feature_names(['age'])\n",
"_____no_output_____"
],
[
"gender_df = pd.DataFrame(gender_ohe.toarray(), columns=['F', 'M'])\ngender_df.head()",
"_____no_output_____"
],
[
"ohe.fit(user_df[['gender']])\ngender_ohe = ohe.transform(user_df[['gender']])\ngender_df = pd.DataFrame(gender_ohe.toarray(), columns=['F', 'M'])\ngender_df.head()",
"_____no_output_____"
],
[
"ohe_2.fit(user_df[['age']])\ntemp_ohe = ohe_2.get_feature_names(['age'])\nage_ohe = ohe_2.transform(user_df[['age']])\nage_df = pd.DataFrame(age_ohe.toarray(), columns=temp_ohe)\nage_df.head()",
"_____no_output_____"
],
[
"ohe_3.fit(user_df[['occupation']])\ncols = ohe_3.get_feature_names(['occupation'])\nocc_ohe = ohe_3.transform(user_df[['occupation']])\nocc_df = pd.DataFrame(occ_ohe.toarray(), columns=cols)\nocc_df.head()",
"_____no_output_____"
],
[
"all_cat = pd.concat([gender_df, age_df, occ_df], axis=1)",
"_____no_output_____"
],
[
"all_cat.head()",
"_____no_output_____"
],
[
"k_clusters = KMeans(n_clusters=8, random_state=42)",
"_____no_output_____"
],
[
"k_clusters.fit(all_cat)",
"_____no_output_____"
],
[
"preds = k_clusters.predict(all_cat)",
"_____no_output_____"
],
[
"preds",
"_____no_output_____"
],
[
"user_df['cluster'] = preds",
"_____no_output_____"
],
[
"user_df[user_df['id'] == 6040]",
"_____no_output_____"
],
[
"cluster_dict = {}\nfor k, v in zip(user_df['id'].tolist(), user_df['cluster'].tolist()):\n cluster_dict[k] = v",
"_____no_output_____"
],
[
"ratings_df['cluster'] = ratings_df['user_id'].apply(lambda x: cluster_dict[x])",
"_____no_output_____"
],
[
"def add_cluster_to_ratings(user_df):\n \"\"\"\n given user_df with clusters, add clusters to ratings data\n parameters\n ---------\n user_df: df with user data\n\n returns\n -------\n ratings_df: ratings_df with cluster column\n \"\"\"\n # Read in ratings file\n #Get ratings file\n ratings_df = spark.read.json('data/ratings.json').toPandas()\n \n # Set up clusters\n cluster_dict = {}\n for k, v in zip(user_df['id'].tolist(), user_df['cluster'].tolist()):\n cluster_dict[k] = v\n \n # Add cluster to ratings\n ratings_df['cluster'] = ratings_df['user_id'].apply(lambda x: cluster_dict[x])\n \n return ratings_df",
"_____no_output_____"
],
[
"all_df = add_cluster_to_ratings(user_df)",
"_____no_output_____"
],
[
"all_df.to_csv('data/user_cluster.csv')",
"_____no_output_____"
],
[
"movie_by_cluster = all_df.groupby(by=['cluster', 'movie_id']).agg({'rating': 'mean'}).reset_index()",
"_____no_output_____"
],
[
"movie_by_cluster.head()",
"_____no_output_____"
],
[
"movie_by_cluster = pd.read_csv('data/u_info.csv', index_col=0)\nmovie_by_cluster.head()",
"_____no_output_____"
],
[
"ratings_df.head()",
"_____no_output_____"
],
[
"request_df.head()",
"_____no_output_____"
],
[
"def cluster_rating(df, movie_id, cluster):\n cluster_rating = df[(df['movie_id'] == movie_id) & (df['cluster'] == cluster)]\n return cluster_rating['rating'].mean()\n\ndef user_bias(df, user_id):\n return df.loc[df['user_id'] == user_id, 'rating'].mean() - df['rating'].mean()\n\ndef item_bias(df, movie_id):\n return df.loc[df['movie_id'] == movie_id, 'rating'].mean() - df['rating'].mean()",
"_____no_output_____"
],
[
"avg = cluster_rating(df=ratings_df, movie_id=1617, cluster=1)",
"_____no_output_____"
],
[
"u = user_bias(ratings_df, 6040)",
"_____no_output_____"
],
[
"i = item_bias(ratings_df, 2019)",
"_____no_output_____"
],
[
"avg + u + i",
"_____no_output_____"
],
[
"movie_info_df[movie_info_df['id'] == 1617]",
"_____no_output_____"
],
[
"def get_cold_start_rating(user_id, movie_id):\n \"\"\"\n Given user_id and movie_id, return a predicted rating\n \n parameters\n ----------\n user_id, movie_id\n \n returns\n -------\n movie rating (float)\n \"\"\"\n # Get user df with clusters \n user_df = pd.read_csv('data/user_cluster.csv', index_col=0) \n u_clusters = pd.read_csv('data/u_info.csv', index_col=0)\n \n # Get ratings data, with clusters\n ratings_df = pd.read_csv('data/movie_cluster_avg.csv', index_col=0)\n \n # User Cluster\n user_cluster = u_clusters.loc[u_clusters['id'] == user_id]['cluster'].tolist()[0]\n \n # Get score components\n avg = ratings_df.loc[ratings_df['user_id'] == movie_id]['rating'].tolist()[0]\n u = user_bias(user_df, user_id)\n i = item_bias(user_df, movie_id)\n \n pred_rating = avg + u + i\n \n return pred_rating\n ",
"_____no_output_____"
],
[
"blah = get_cold_start_rating(user_id=53, movie_id=9999)",
"_____no_output_____"
],
[
"blah",
"_____no_output_____"
],
[
"df = pd.read_csv('data/user_cluster.csv', index_col=0)",
"_____no_output_____"
],
[
"ratings_df = pd.read_csv('data/movie_cluster_avg.csv', index_col=0)\nratings_df.head()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4df0a7d82d8b5eb425f473a502ecd2ba643e52
| 172,973 |
ipynb
|
Jupyter Notebook
|
notebooks/Models_and_Miscellaneous.ipynb
|
ajoseph12/JFRDataChallenge
|
c66aecfb1a5dbe6ce899be7654e07ba03e672d12
|
[
"MIT"
] | 2 |
2021-08-08T23:00:34.000Z
|
2021-09-14T12:51:34.000Z
|
notebooks/Models_and_Miscellaneous.ipynb
|
ajoseph12/JFRDataChallenge
|
c66aecfb1a5dbe6ce899be7654e07ba03e672d12
|
[
"MIT"
] | 1 |
2021-03-07T02:30:33.000Z
|
2021-03-07T02:30:33.000Z
|
notebooks/Models_and_Miscellaneous.ipynb
|
ajoseph12/JFRDataChallenge
|
c66aecfb1a5dbe6ce899be7654e07ba03e672d12
|
[
"MIT"
] | 1 |
2021-05-03T05:19:12.000Z
|
2021-05-03T05:19:12.000Z
| 45.162663 | 1,716 | 0.386899 |
[
[
[
"import os\nimport sys\n\nimport numpy as np\nimport pandas as pd\n\nimport torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torch.nn.functional as F\nfrom torchsummary import summary\n\nsys.path.append('../')\nsys.path.append('../src/')\nfrom src import utils\nfrom src import generators\nimport imp\n\n",
"_____no_output_____"
],
[
"os.environ['CUDA_VISIBLE_DEVICES'] = \"0\"",
"_____no_output_____"
]
],
[
[
"# Inference",
"_____no_output_____"
]
],
[
[
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\nmodel_LoadWeights = '../data/trainings/train_UNETA_class/vgg_5.pkl'\nmvcnn = torch.load(model_LoadWeights)",
"_____no_output_____"
],
[
"test_patient_information = utils.get_PatientInfo('/home/alex/Dataset3/', test=True)",
"_____no_output_____"
],
[
"sep = generators.SEPGenerator(base_DatabasePath='/home/alex/Dataset3/', \n channels=1,\n resize=296,\n normalization='min-max')\ntest_generator = sep.generator(test_patient_information, dataset='test') \n",
"_____no_output_____"
],
[
"final = []\nwith torch.no_grad():\n for v_m, v_item in enumerate(test_generator):\n image_3D, p_id = torch.tensor(v_item[0], device=device).float(), v_item[1]\n if image_3D.shape[0] == 0:\n print(p_id)\n continue\n output = mvcnn(image_3D, batch_size=1, mvcnn=True)\n print(output, p_id)\n final.append((p_id, output.to('cpu').detach().numpy()))\n if v_m == len(test_patient_information) - 1:\n break",
"/home/allwyn/venv36/lib/python3.6/site-packages/torch/nn/modules/container.py:92: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.\n input = module(input)\n"
],
[
"keys = {0: 0.0,\n 1: 1.0,\n 2: 1.5,\n 3: 2.0,\n 4: 2.5,\n 5: 3.0,\n 6: 3.5,\n 7: 4.0,\n 8: 4.5,\n 9: 5.0,\n 10: 5.5,\n 11: 6.0,\n 12: 6.5,\n 13: 7.0,\n 14: 7.5,\n 15: 8.0,\n 16: 8.5,\n 17: 9.0}\n",
"_____no_output_____"
],
[
"list(map(lambda a : [[int(a[0])], [keys[np.argmax(a[1])]]], (final)))",
"_____no_output_____"
],
[
"final[1][1]",
"_____no_output_____"
],
[
"import csv\ncsvData = [[\"Sequence_id\"],[\"EDSS\"]] + list(map(lambda a : [int(a[0]), keys[np.argmax(a[1])]], (final)))\nwith open('AZmed_Unet.csv', 'w') as csvFile:\n writer = csv.writer(csvFile)\n writer.writerows(csvData)\ncsvFile.close()",
"_____no_output_____"
],
[
"csvData",
"_____no_output_____"
],
[
"database_path = \ntrain_patient_information, valid_patient_information = get_PatientInfo(database_path)\n\n# Create train and valid generators\nsep = SEPGenerator(database_path, \n channels=channels,\n resize=resize,\n normalization=normalization)\ntrain_generator = sep.generator(train_patient_information) \nvalid_generator = sep.generator(valid_patient_information, train=False)",
"_____no_output_____"
],
[
"train_patient_information, valid_patient_information = get_PatientInfo(database_path)\n\n # Create train and valid generators\n sep = SEPGenerator(database_path, \n channels=channels,\n resize=resize,\n normalization=normalization)\n train_generator = sep.generator(train_patient_information) \n valid_generator = sep.generator(valid_patient_information, train=False)",
"_____no_output_____"
],
[
"with torch.no_grad():\n for v_m, v_item in enumerate(valid_generator):\n image_3D, label = torch.tensor(v_item[0], device=device).float(), torch.tensor(v_item[1], device=device).float()\n if image_3D.shape[0] == 0:\n continue\n output = mvcnn(image_3D, batch_size, use_mvcnn)\n total_ValidLoss += criterion(output, label)",
"_____no_output_____"
]
],
[
[
"# Models",
"_____no_output_____"
],
[
"## Base Mode - CNN_1",
"_____no_output_____"
]
],
[
[
"class VGG(nn.Module):\n \n def __init__(self):\n \n super(VGG,self).__init__()\n pad = 1\n \n self.cnn = nn.Sequential(nn.BatchNorm2d(1),\n nn.Conv2d(1,32,3,padding=pad),\n nn.ReLU(),\n nn.BatchNorm2d(32),\n nn.Conv2d(32,32,3,padding=pad),\n nn.ReLU(),\n nn.MaxPool2d(2,2), \n \n nn.BatchNorm2d(32),\n nn.Conv2d(32,64,3,padding=pad),\n nn.ReLU(),\n nn.BatchNorm2d(64),\n nn.Conv2d(64,64,3,padding=pad),\n nn.ReLU(),\n nn.MaxPool2d(2,2),\n \n nn.BatchNorm2d(64),\n nn.Conv2d(64,128,3,padding=pad),\n nn.ReLU(),\n nn.BatchNorm2d(128),\n nn.Conv2d(128,128,3,padding=pad),\n nn.ReLU(),\n nn.MaxPool2d(2,2),\n \n nn.BatchNorm2d(128),\n nn.Conv2d(128,256,3,padding=pad),\n nn.ReLU(),\n nn.BatchNorm2d(256),\n nn.Conv2d(256,256,3,padding=pad),\n nn.ReLU(),\n nn.MaxPool2d(2,2), \n \n nn.BatchNorm2d(256),\n nn.Conv2d(256,256,3,padding=pad),\n nn.ReLU(),\n nn.BatchNorm2d(256),\n nn.Conv2d(256,256,3,padding=pad),\n nn.ReLU(),\n nn.MaxPool2d(2,2),\n \n nn.BatchNorm2d(256),\n nn.Conv2d(256,512,3,padding=pad),\n nn.ReLU(),\n nn.BatchNorm2d(512),\n nn.Conv2d(512,512,3,padding=pad),\n nn.ReLU(),\n nn.MaxPool2d(2,2))\n \n self.fc1 = nn.Sequential(nn.Linear(8192, 1096), \n nn.ReLU(),\n nn.Dropout(0.8),\n nn.Linear(1096, 96),\n nn.ReLU(),\n nn.Dropout(0.9),\n nn.Linear(96, 1))\n\n # self.fc2 = nn.Sequential(nn.Linear(8192, 4096), \n # nn.ReLU(),\n # nn.Dropout(0.8),\n # nn.Linear(4096, 4096),\n # nn.ReLU(),\n # nn.Dropout(0.9),\n # nn.Linear(4096, 1))\n \n def forward(self, x, batch_size=1, mvcnn=False):\n \n if mvcnn:\n view_pool = []\n # Assuming x has shape (x, 1, 299, 299)\n for n, v in enumerate(x):\n v = v.unsqueeze(0)\n v = self.cnn(v)\n v = v.view(v.size(0), 512 * 4 * 4)\n view_pool.append(v)\n\n pooled_view = view_pool[0]\n for i in range(1, len(view_pool)):\n pooled_view = torch.max(pooled_view, view_pool[i])\n\n output = self.fc1(pooled_view)\n \n else:\n x = self.cnn(x)\n x = x.view(-1, 512 * 4* 4)\n x = self.fc1(x)\n output = F.sigmoid(x)\n \n return output",
"_____no_output_____"
],
[
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\") # PyTorch v0.4.0\nmodel = VGG().to(device)\nsummary(model, (1, 299, 299))",
"----------------------------------------------------------------\n Layer (type) Output Shape Param #\n================================================================\n BatchNorm2d-1 [-1, 1, 299, 299] 2\n Conv2d-2 [-1, 32, 299, 299] 320\n ReLU-3 [-1, 32, 299, 299] 0\n BatchNorm2d-4 [-1, 32, 299, 299] 64\n Conv2d-5 [-1, 32, 299, 299] 9,248\n ReLU-6 [-1, 32, 299, 299] 0\n MaxPool2d-7 [-1, 32, 149, 149] 0\n BatchNorm2d-8 [-1, 32, 149, 149] 64\n Conv2d-9 [-1, 64, 149, 149] 18,496\n ReLU-10 [-1, 64, 149, 149] 0\n BatchNorm2d-11 [-1, 64, 149, 149] 128\n Conv2d-12 [-1, 64, 149, 149] 36,928\n ReLU-13 [-1, 64, 149, 149] 0\n MaxPool2d-14 [-1, 64, 74, 74] 0\n BatchNorm2d-15 [-1, 64, 74, 74] 128\n Conv2d-16 [-1, 128, 74, 74] 73,856\n ReLU-17 [-1, 128, 74, 74] 0\n BatchNorm2d-18 [-1, 128, 74, 74] 256\n Conv2d-19 [-1, 128, 74, 74] 147,584\n ReLU-20 [-1, 128, 74, 74] 0\n MaxPool2d-21 [-1, 128, 37, 37] 0\n BatchNorm2d-22 [-1, 128, 37, 37] 256\n Conv2d-23 [-1, 256, 37, 37] 295,168\n ReLU-24 [-1, 256, 37, 37] 0\n BatchNorm2d-25 [-1, 256, 37, 37] 512\n Conv2d-26 [-1, 256, 37, 37] 590,080\n ReLU-27 [-1, 256, 37, 37] 0\n MaxPool2d-28 [-1, 256, 18, 18] 0\n BatchNorm2d-29 [-1, 256, 18, 18] 512\n Conv2d-30 [-1, 256, 18, 18] 590,080\n ReLU-31 [-1, 256, 18, 18] 0\n BatchNorm2d-32 [-1, 256, 18, 18] 512\n Conv2d-33 [-1, 256, 18, 18] 590,080\n ReLU-34 [-1, 256, 18, 18] 0\n MaxPool2d-35 [-1, 256, 9, 9] 0\n BatchNorm2d-36 [-1, 256, 9, 9] 512\n Conv2d-37 [-1, 512, 9, 9] 1,180,160\n ReLU-38 [-1, 512, 9, 9] 0\n BatchNorm2d-39 [-1, 512, 9, 9] 1,024\n Conv2d-40 [-1, 512, 9, 9] 2,359,808\n ReLU-41 [-1, 512, 9, 9] 0\n MaxPool2d-42 [-1, 512, 4, 4] 0\n Linear-43 [-1, 1096] 8,979,528\n ReLU-44 [-1, 1096] 0\n Dropout-45 [-1, 1096] 0\n Linear-46 [-1, 96] 105,312\n ReLU-47 [-1, 96] 0\n Dropout-48 [-1, 96] 0\n Linear-49 [-1, 1] 97\n================================================================\nTotal params: 14,980,715\nTrainable params: 14,980,715\nNon-trainable params: 0\n----------------------------------------------------------------\nInput size (MB): 0.34\nForward/backward pass size (MB): 229.40\nParams size (MB): 57.15\nEstimated Total Size (MB): 286.89\n----------------------------------------------------------------\n"
]
],
[
[
"Since patients have varying images, create single images where the channels occupy the slices of the patient",
"_____no_output_____"
]
],
[
[
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\nmvcnn = MVCNN().to(device)\n\ncriterion = nn.MSELoss()\noptimizer = optim.Adam(mvcnn.parameters(), lr=0.0003)",
"_____no_output_____"
],
[
"file_path = '/home/alex/Dataset 1/Dataset - 1.xlsx'\ndf = pd.read_excel(file_path, sheet_name='Feuil1')\n\nedss = df['EDSS'].tolist()\np_id = df['Sequence_id'].tolist()\nchannels = 1\nresize = 299\nnormalization = 'min-max'\n\npatient_information = [(p_id[i], edss[i]) for i in range(df.shape[0])]\ntrain_patient_information = patient_information[:int(0.9*len(patient_information))]\nvalid_patient_information = patient_information[int(0.9*len(patient_information)):]\nbase_DatabasePath = '/home/alex/Dataset 1'",
"_____no_output_____"
],
[
"generator_inst = generators.SEPGenerator(base_DatabasePath, \n channels=channels,\n resize=resize,\n normalization=normalization)\n\ntrain_generator = generator_inst.generator(train_patient_information)\nvalid_generator = generator_inst.generator(valid_patient_information)\n\n#dataloader = torch.utils.data.DataLoader(train_generator, batch_size=1, shuffle=True)",
"_____no_output_____"
],
[
"valid_iterations",
"_____no_output_____"
],
[
"total_loss = 0\ntrain_iterations = 100\nvalid_iterations = len(valid_patient_information)\nepochs = 5\n\nfor epoch in range(epochs):\n total_TrainLoss = 0\n\n for t_m, t_item in enumerate(train_generator):\n\n image_3D, label = torch.tensor(t_item[0], device=device).float(), torch.tensor(t_item[1], device=device).float()\n output = mvcnn(image_3D, 1)\n loss = criterion(output, label)\n loss.backward()\n optimizer.step()\n\n total_TrainLoss += loss\n\n if not (t_m+1)%50:\n print(\"On_Going_Epoch : {} \\t | Iteration : {} \\t | Training Loss : {}\".format(epoch+1, t_m+1, total_TrainLoss/(t_m+1)))\n\n if (t_m+1) == train_iterations:\n total_ValidLoss = 0\n\n with torch.no_grad():\n for v_m, v_item in enumerate(valid_generator):\n image_3D, label = torch.tensor(v_item[0], device=device).float(), torch.tensor(v_item[1], device=device).float()\n output = mvcnn(image_3D, 1)\n total_ValidLoss += criterion(output, label)\n print(total_ValidLoss)\n if (v_m + 1) == valid_iterations:\n break\n \n print(\"Epoch : {} \\t | Training Loss : {} \\t | Validation Loss : {} \".format(epoch+1, total_TrainLoss/(t_m+1), total_ValidLoss/(v_m+1)) ) \n\n torch.save(mvcnn, './' + 'vgg_' + str(epoch) + '.pkl')\n break",
"On_Going_Epoch : 1 \t | Iteration : 50 \t | Training Loss : 4511.05859375\nOn_Going_Epoch : 1 \t | Iteration : 100 \t | Training Loss : 2339.1357421875\ntensor(7.8825, device='cuda:0')\ntensor(7.8826, device='cuda:0')\ntensor(8.5348, device='cuda:0')\ntensor(10.2445, device='cuda:0')\ntensor(18.1271, device='cuda:0')\ntensor(18.1641, device='cuda:0')\ntensor(19.9259, device='cuda:0')\ntensor(20.5781, device='cuda:0')\ntensor(20.6151, device='cuda:0')\ntensor(28.4977, device='cuda:0')\ntensor(203.7557, device='cuda:0')\ntensor(211.6382, device='cuda:0')\ntensor(970.9899, device='cuda:0')\ntensor(985.4875, device='cuda:0')\ntensor(999.9852, device='cuda:0')\ntensor(1000.0223, device='cuda:0')\ntensor(1000.0593, device='cuda:0')\ntensor(1820.6040, device='cuda:0')\ntensor(1831.5441, device='cuda:0')\ntensor(1842.4841, device='cuda:0')\ntensor(1853.4242, device='cuda:0')\ntensor(1864.3643, device='cuda:0')\ntensor(1864.4012, device='cuda:0')\ntensor(1864.4382, device='cuda:0')\ntensor(1872.3208, device='cuda:0')\ntensor(1926.3999, device='cuda:0')\ntensor(1960.1279, device='cuda:0')\ntensor(1993.8560, device='cuda:0')\ntensor(2176.1489, device='cuda:0')\ntensor(2197.5427, device='cuda:0')\ntensor(2212.0405, device='cuda:0')\ntensor(2226.5383, device='cuda:0')\ntensor(2241.0361, device='cuda:0')\ntensor(2241.0732, device='cuda:0')\ntensor(2244.3406, device='cuda:0')\ntensor(2278.0686, device='cuda:0')\ntensor(2311.7966, device='cuda:0')\ntensor(2345.5247, device='cuda:0')\ntensor(2345.5618, device='cuda:0')\ntensor(2497.3787, device='cuda:0')\ntensor(2498.9541, device='cuda:0')\ntensor(2502.2214, device='cuda:0')\ntensor(2542.0071, device='cuda:0')\ntensor(2581.7927, device='cuda:0')\ntensor(2905.2920, device='cuda:0')\ntensor(6808.9893, device='cuda:0')\ntensor(6835.3154, device='cuda:0')\ntensor(6837.0254, device='cuda:0')\nEpoch : 1 \t | Training Loss : 2339.1357421875 \t | Validation Loss : 142.4380340576172 \n"
],
[
"total_ValidLoss",
"_____no_output_____"
],
[
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\nc = torch.randn(90, 512, 4, 4).to(device)",
"_____no_output_____"
],
[
"#torch.randn(90, 1, 299, 299)\nfor n,v in enumerate(c):\n \n v = v.view(1, 512*4*4).to(device)\n print(n)\n if n:\n pooled_view = torch.max(pooled_view, v).to(device)\n else:\n pooled_view = v.to(device)",
"0\n1\n2\n3\n4\n5\n6\n7\n8\n9\n10\n11\n12\n13\n14\n15\n16\n17\n18\n19\n20\n21\n22\n23\n24\n25\n26\n27\n28\n29\n30\n31\n32\n33\n34\n35\n36\n37\n38\n39\n40\n41\n42\n43\n44\n45\n46\n47\n48\n49\n50\n51\n52\n53\n54\n55\n56\n57\n58\n59\n60\n61\n62\n63\n64\n65\n66\n67\n68\n69\n70\n71\n72\n73\n74\n75\n76\n77\n78\n79\n80\n81\n82\n83\n84\n85\n86\n87\n88\n89\n"
]
],
[
[
"# Augmenter",
"_____no_output_____"
]
],
[
[
"def generate_images(image, transformation='original', angle=30):\n \"\"\"\n Function to generate images based on the requested transfomations\n Args:\n - image (nd.array) : input image array\n - transformation (str) : image transformation to be effectuated\n - angle \t\t(int)\t : rotation angle if transformation is a rotation\n Returns:\n - trans_image (nd.array) : transformed image array\n \"\"\"\n\n def rotateImage(image, angle):\n \"\"\"\n Function to rotate an image at its center\n \"\"\"\n image_center = tuple(np.array(image.shape[1::-1]) / 2)\n rot_mat = cv2.getRotationMatrix2D(image_center, angle, 1.0)\n result = cv2.warpAffine(image, rot_mat, image.shape[1::-1], flags=cv2.INTER_LINEAR)\n return result\n \n # Image transformations\n if transformation == 'original':\n trans_image = image\n elif transformation == 'flip_v':\n trans_image = cv2.flip(image, 0)\n elif transformation == 'flip_h':\n trans_image = cv2.flip(image, 1)\n elif transformation == 'flip_vh':\n trans_image = cv2.flip(image, -1)\n elif transformation == 'rot_c':\n trans_image = rotateImage(image, -angle)\n elif transformation == 'rot_ac':\n trans_image = rotateImage(image, angle)\n else:\n raise ValueError(\"In valid transformation value passed : {}\".format(transformation))\n\n return trans_image",
"_____no_output_____"
],
[
"\"\"\"\nThe agumenter ought to be able to do the following:\n- Get list of patient paths and their respective scores (make sure to do the validation and test splits before)\n - Select a random augmentation (flag='test')\n - Select a patient path and his/her corresponding score\n - With each .dcm file do following: \n - read image\n - normalized image\n - resize image\n - get percentage of white matter (%, n) and append to list\n - transform image\n - store in an array\n - yield image_3D (top 70 images with white matter), label\n\"\"\"",
"_____no_output_____"
],
[
"def SEP_generator(object):\n \n def __init__(self, \n resize,\n normalization,\n transformations)\n \n ",
"_____no_output_____"
],
[
"import imgaug as ia\nfrom imgaug import augmenters as iaa",
"_____no_output_____"
],
[
"import imgaug as ia\nfrom imgaug import augmenters as iaa\n\nclass ImageBaseAug(object):\n def __init__(self):\n sometimes = lambda aug: iaa.Sometimes(0.5, aug)\n self.seq = iaa.Sequential(\n [\n # Blur each image with varying strength using\n # gaussian blur (sigma between 0 and 3.0),\n # average/uniform blur (kernel size between 2x2 and 7x7)\n # median blur (kernel size between 3x3 and 11x11).\n iaa.OneOf([\n iaa.GaussianBlur((0, 3.0)),\n iaa.AverageBlur(k=(2, 7)),\n iaa.MedianBlur(k=(3, 11)),\n ]),\n # Sharpen each image, overlay the result with the original\n # image using an alpha between 0 (no sharpening) and 1\n # (full sharpening effect).\n sometimes(iaa.Sharpen(alpha=(0, 0.5), lightness=(0.75, 1.5))),\n # Add gaussian noise to some images.\n sometimes(iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.05*255), per_channel=0.5)),\n # Add a value of -5 to 5 to each pixel.\n sometimes(iaa.Add((-5, 5), per_channel=0.5)),\n # Change brightness of images (80-120% of original value).\n sometimes(iaa.Multiply((0.8, 1.2), per_channel=0.5)),\n # Improve or worsen the contrast of images.\n sometimes(iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5)),\n ],\n # do all of the above augmentations in random order\n random_order=True\n )\n\n def __call__(self, sample):\n seq_det = self.seq.to_deterministic()\n image, label = sample['image'], sample['label']\n image = seq_det.augment_images([image])[0]\n return {'image': image, 'label': label}",
"_____no_output_____"
]
],
[
[
"# UNET",
"_____no_output_____"
]
],
[
[
"\ndef double_conv(in_channels, out_channels):\n return nn.Sequential(\n nn.Conv2d(in_channels, out_channels, 3, padding=1),\n nn.ReLU(inplace=True),\n nn.Conv2d(out_channels, out_channels, 3, padding=1),\n nn.ReLU(inplace=True)\n ) \n\nclass UNet(nn.Module):\n\n def __init__(self, n_class=1):\n super().__init__()\n \n self.dconv_down1 = double_conv(1, 32)\n self.dconv_down2 = double_conv(32, 64)\n self.dconv_down3 = double_conv(64, 128)\n self.dconv_down4 = double_conv(128, 256) \n\n self.maxpool = nn.MaxPool2d(2)\n self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) \n \n self.dconv_up3 = double_conv(128 + 256, 128)\n self.dconv_up2 = double_conv(64 + 128, 64)\n self.dconv_up1 = double_conv(32 + 64, 32)\n \n self.conv_last = nn.Sequential(nn.BatchNorm2d(32),\n nn.MaxPool2d(2,2))\n \n \n def forward(self, x):\n conv1 = self.dconv_down1(x)\n x = self.maxpool(conv1)\n\n conv2 = self.dconv_down2(x)\n x = self.maxpool(conv2)\n \n conv3 = self.dconv_down3(x)\n x = self.maxpool(conv3) \n \n x = self.dconv_down4(x)\n \n x = self.upsample(x) \n x = torch.cat([x, conv3], dim=1)\n \n x = self.dconv_up3(x)\n x = self.upsample(x) \n x = torch.cat([x, conv2], dim=1) \n\n x = self.dconv_up2(x)\n x = self.upsample(x) \n x = torch.cat([x, conv1], dim=1) \n \n x = self.dconv_up1(x)\n \n out = self.conv_last(x)\n \n return out",
"_____no_output_____"
],
[
"import torch\nimport torch.nn as nn\n\ndef attention_block():\n \n return nn.Sequential(\n nn.ReLU(),\n nn.Conv2d(1, 1, 1, padding=0),\n nn.BatchNorm2d(1),\n nn.Sigmoid()\n )\n\n\ndef double_conv(in_channels, out_channels):\n return nn.Sequential(\n nn.BatchNorm2d(in_channels),\n nn.Conv2d(in_channels, out_channels, 3, padding=1),\n nn.ReLU(inplace=True),\n nn.BatchNorm2d(out_channels),\n nn.Conv2d(out_channels, out_channels, 3, padding=1),\n nn.ReLU(inplace=True))\n\n\ndef one_conv(in_channels, padding=0):\n return nn.Sequential(\n nn.BatchNorm2d(in_channels),\n nn.Conv2d(in_channels, 1, 1, padding=padding))\n\n\nclass UNet(nn.Module):\n\n def __init__(self, n_class):\n super().__init__()\n \n self.dconv_down1 = double_conv(1, 32)\n self.dconv_down2 = double_conv(32, 64)\n self.dconv_down3 = double_conv(64, 128)\n self.dconv_down4 = double_conv(128, 256) \n\n self.maxpool = nn.MaxPool2d(2)\n self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) \n self.oneconv = one_conv\n self.attention = attention_block()\n \n self.oneconvx3 = one_conv(128)\n self.oneconvg3 = one_conv(256)\n self.dconv_up3 = double_conv(128 + 256, 128)\n \n self.oneconvx2 = one_conv(64)\n self.oneconvg2 = one_conv(128)\n self.dconv_up2 = double_conv(64 + 128, 64)\n \n \n self.conv_last = nn.Sequential(nn.BatchNorm2d(64),\n nn.Conv2d(64,32,3,padding=0),\n nn.ReLU(),\n nn.MaxPool2d(2,2),\n nn.BatchNorm2d(32),\n nn.Conv2d(32,8,3,padding=0),\n nn.ReLU(),\n nn.MaxPool2d(2,2))\n \n self.fc1 = nn.Sequential(nn.Linear(9800, 1096), \n nn.ReLU(),\n nn.Dropout(0.8),\n nn.Linear(1096, 96),\n nn.ReLU(),\n nn.Dropout(0.9),\n nn.Linear(96, 1))\n \n \n def forward(self, x):\n\n conv1 = self.dconv_down1(x) # 1 -> 32 filters\n x = self.maxpool(conv1)\n\n conv2 = self.dconv_down2(x) # 32 -> 64 filters\n x = self.maxpool(conv2)\n \n conv3 = self.dconv_down3(x) # 64 -> 128 filters\n x = self.maxpool(conv3) \n \n x = self.dconv_down4(x) # 128 -> 256 filters\n \n x = self.upsample(x) \n _g = self.oneconvg3(x)\n _x = self.oneconvx3(conv3)\n _xg = _g + _x\n psi = self.attention(_xg)\n conv3 = conv3*psi\n x = torch.cat([x, conv3], dim=1) \n \n x = self.dconv_up3(x) # 128 + 256 -> 128 filters\n \n x = self.upsample(x)\n _g = self.oneconvg2(x)\n _x = self.oneconvx2(conv2)\n _xg = _g + _x\n psi = self.attention(_xg) \n conv2 = conv2*psi\n x = torch.cat([x, conv2], dim=1) \n\n x = self.dconv_up2(x)\n \n# x = self.upsample(x)\n# _g = self.oneconvg1(x)\n# _x = self.oneconvx1(conv1)\n# _xg = _g + _x\n# psi = self.attention(_xg)\n# conv1 = conv1*psi\n# x = torch.cat([x, conv1], dim=1) \n \n# x = self.dconv_up1(x)\n \n x = self.conv_last(x)\n x = x.view(-1, 35*35*8)\n x = self.fc1(x)\n \n return x",
"_____no_output_____"
],
[
"net = UNet(1)",
"_____no_output_____"
],
[
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\") # PyTorch v0.4.0\nmodel = UNet(1).to(device)\nsummary(model, (1, 296, 296))",
"----------------------------------------------------------------\n Layer (type) Output Shape Param #\n================================================================\n BatchNorm2d-1 [-1, 1, 296, 296] 2\n Conv2d-2 [-1, 32, 296, 296] 320\n ReLU-3 [-1, 32, 296, 296] 0\n BatchNorm2d-4 [-1, 32, 296, 296] 64\n Conv2d-5 [-1, 32, 296, 296] 9,248\n ReLU-6 [-1, 32, 296, 296] 0\n MaxPool2d-7 [-1, 32, 148, 148] 0\n BatchNorm2d-8 [-1, 32, 148, 148] 64\n Conv2d-9 [-1, 64, 148, 148] 18,496\n ReLU-10 [-1, 64, 148, 148] 0\n BatchNorm2d-11 [-1, 64, 148, 148] 128\n Conv2d-12 [-1, 64, 148, 148] 36,928\n ReLU-13 [-1, 64, 148, 148] 0\n MaxPool2d-14 [-1, 64, 74, 74] 0\n BatchNorm2d-15 [-1, 64, 74, 74] 128\n Conv2d-16 [-1, 128, 74, 74] 73,856\n ReLU-17 [-1, 128, 74, 74] 0\n BatchNorm2d-18 [-1, 128, 74, 74] 256\n Conv2d-19 [-1, 128, 74, 74] 147,584\n ReLU-20 [-1, 128, 74, 74] 0\n MaxPool2d-21 [-1, 128, 37, 37] 0\n BatchNorm2d-22 [-1, 128, 37, 37] 256\n Conv2d-23 [-1, 256, 37, 37] 295,168\n ReLU-24 [-1, 256, 37, 37] 0\n BatchNorm2d-25 [-1, 256, 37, 37] 512\n Conv2d-26 [-1, 256, 37, 37] 590,080\n ReLU-27 [-1, 256, 37, 37] 0\n Upsample-28 [-1, 256, 74, 74] 0\n BatchNorm2d-29 [-1, 256, 74, 74] 512\n Conv2d-30 [-1, 1, 74, 74] 257\n BatchNorm2d-31 [-1, 128, 74, 74] 256\n Conv2d-32 [-1, 1, 74, 74] 129\n ReLU-33 [-1, 1, 74, 74] 0\n Conv2d-34 [-1, 1, 74, 74] 2\n BatchNorm2d-35 [-1, 1, 74, 74] 2\n Sigmoid-36 [-1, 1, 74, 74] 0\n BatchNorm2d-37 [-1, 384, 74, 74] 768\n Conv2d-38 [-1, 128, 74, 74] 442,496\n ReLU-39 [-1, 128, 74, 74] 0\n BatchNorm2d-40 [-1, 128, 74, 74] 256\n Conv2d-41 [-1, 128, 74, 74] 147,584\n ReLU-42 [-1, 128, 74, 74] 0\n Upsample-43 [-1, 128, 148, 148] 0\n BatchNorm2d-44 [-1, 128, 148, 148] 256\n Conv2d-45 [-1, 1, 148, 148] 129\n BatchNorm2d-46 [-1, 64, 148, 148] 128\n Conv2d-47 [-1, 1, 148, 148] 65\n ReLU-48 [-1, 1, 148, 148] 0\n Conv2d-49 [-1, 1, 148, 148] 2\n BatchNorm2d-50 [-1, 1, 148, 148] 2\n Sigmoid-51 [-1, 1, 148, 148] 0\n BatchNorm2d-52 [-1, 192, 148, 148] 384\n Conv2d-53 [-1, 64, 148, 148] 110,656\n ReLU-54 [-1, 64, 148, 148] 0\n BatchNorm2d-55 [-1, 64, 148, 148] 128\n Conv2d-56 [-1, 64, 148, 148] 36,928\n ReLU-57 [-1, 64, 148, 148] 0\n BatchNorm2d-58 [-1, 64, 148, 148] 128\n Conv2d-59 [-1, 32, 146, 146] 18,464\n ReLU-60 [-1, 32, 146, 146] 0\n MaxPool2d-61 [-1, 32, 73, 73] 0\n BatchNorm2d-62 [-1, 32, 73, 73] 64\n Conv2d-63 [-1, 8, 71, 71] 2,312\n ReLU-64 [-1, 8, 71, 71] 0\n MaxPool2d-65 [-1, 8, 35, 35] 0\n Linear-66 [-1, 1096] 10,741,896\n ReLU-67 [-1, 1096] 0\n Dropout-68 [-1, 1096] 0\n Linear-69 [-1, 96] 105,312\n ReLU-70 [-1, 96] 0\n Dropout-71 [-1, 96] 0\n Linear-72 [-1, 1] 97\n================================================================\nTotal params: 12,782,303\nTrainable params: 12,782,303\nNon-trainable params: 0\n----------------------------------------------------------------\nInput size (MB): 0.33\nForward/backward pass size (MB): 454.16\nParams size (MB): 48.76\nEstimated Total Size (MB): 503.25\n----------------------------------------------------------------\n"
],
[
"transform = transforms.Compose(\n [transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n\ntrainset = torchvision.datasets.CIFAR10(root='./data', train=True,\n download=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=4,\n shuffle=True, num_workers=2)\n\ntestset = torchvision.datasets.CIFAR10(root='./data', train=False,\n download=True, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=4,\n shuffle=False, num_workers=2)",
"_____no_output_____"
]
],
[
[
"# Trails (Pytorch)",
"_____no_output_____"
]
],
[
[
"import os\nimport torch\nimport numpy as np\n\nos.environ['CUDA_VISIBLE_DEVICES'] = \"2\"",
"_____no_output_____"
],
[
"## TENSORS\n\n# create an 'un-initialized' matrix\nx = torch.empty(5, 3)\nprint(x)\n\n# construct a randomly 'initialized' matrix\nx = torch.rand(5, 3)\nprint(x)\n\n# construct a matrix filled with zeros an dtype=long\nx = torch.zeros(5, 3, dtype=torch.long)\nprint(x)\n\n# construct a tensor from data\nx = torch.tensor([[5.5, 3]])\nprint(x)\n\n# Create a tensor based on existing tensor\nx = x.new_ones(5, 3, dtype=torch.double)\nprint(x)\nx = torch.randn_like(x, dtype=torch.float)\nprint(x)",
"tensor([[7.0976e+22, 1.8515e+28, 4.1988e+07],\n [3.0357e+32, 2.7224e+20, 7.7782e+31],\n [4.7429e+30, 1.3818e+31, 1.7225e+22],\n [1.4602e-19, 1.8617e+25, 1.1835e+22],\n [4.3066e+21, 6.3828e+28, 1.4603e-19]])\ntensor([[0.3337, 0.6211, 0.9639],\n [0.1094, 0.2283, 0.4058],\n [0.6591, 0.8595, 0.0782],\n [0.7474, 0.8065, 0.0429],\n [0.4577, 0.5123, 0.5054]])\ntensor([[0, 0, 0],\n [0, 0, 0],\n [0, 0, 0],\n [0, 0, 0],\n [0, 0, 0]])\ntensor([[5.5000, 3.0000]])\ntensor([[1., 1., 1.],\n [1., 1., 1.],\n [1., 1., 1.],\n [1., 1., 1.],\n [1., 1., 1.]], dtype=torch.float64)\ntensor([[ 1.6513, -0.3198, -1.5212],\n [-1.4167, -0.5110, -1.1456],\n [ 0.9274, 2.0594, -1.2510],\n [ 0.0256, -0.2712, -0.4079],\n [-0.0939, -1.1903, 1.3387]])\n"
],
[
"## OPERATIONS\n\n# Addition syntax 1\ny = torch.rand(5, 3)\nprint(x + y)\n\n# Addition syntax 2\nprint(torch.add(x, y))\n\n# Addtion output towards a tensor\nresult = torch.empty(5,3)\ntorch.add(x, y, out=result)\nprint(result)\n\n# Addition in place\ny.add(x)\nprint(y)\n\n# Any operation that mutates a tensor in-place is post-fixed with an _.\nx.copy_(y)\nx.t_()\n\n# Resizing tensors\nx = torch.randn(4, 4)\ny = x.view(16)\nz = x.view(-1,8)\nprint(x.size(), y.size(), z.size())\n\n# Use get value off a one element tensor\nx = torch.randn(1)\nprint(x)\nprint(x.item())\n\n",
"tensor([[ 2.3659, -0.1678, -0.7175],\n [-0.5564, -0.1421, -0.5350],\n [ 1.0469, 3.0384, -0.9379],\n [ 0.9468, 0.2249, 0.0415],\n [ 0.0893, -0.8271, 1.6718]])\ntensor([[ 2.3659, -0.1678, -0.7175],\n [-0.5564, -0.1421, -0.5350],\n [ 1.0469, 3.0384, -0.9379],\n [ 0.9468, 0.2249, 0.0415],\n [ 0.0893, -0.8271, 1.6718]])\ntensor([[ 2.3659, -0.1678, -0.7175],\n [-0.5564, -0.1421, -0.5350],\n [ 1.0469, 3.0384, -0.9379],\n [ 0.9468, 0.2249, 0.0415],\n [ 0.0893, -0.8271, 1.6718]])\ntensor([[0.7146, 0.1521, 0.8037],\n [0.8603, 0.3689, 0.6106],\n [0.1195, 0.9790, 0.3132],\n [0.9212, 0.4961, 0.4493],\n [0.1832, 0.3632, 0.3331]])\ntorch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])\ntensor([1.0785])\n1.0785350799560547\n"
],
[
"## NUMPY BRIDGE\n\n# Torch tensor to numpy array\na = torch.ones(5)\nb = a.numpy()\nprint(a)\nprint(b)\n\na.add_(1)\nprint(a)\nprint(b)\n\n\n# Numpy array to torch tensor\na = np.ones(5)\nb = torch.from_numpy(a)\nnp.add(a, 1, out=a)\nprint(a)\nprint(b)",
"tensor([1., 1., 1., 1., 1.])\n[1. 1. 1. 1. 1.]\ntensor([2., 2., 2., 2., 2.])\n[2. 2. 2. 2. 2.]\n[2. 2. 2. 2. 2.]\ntensor([2., 2., 2., 2., 2.], dtype=torch.float64)\n"
],
[
"## USING CUDA\n\nif torch.cuda.is_available():\n device = torch.device(\"cuda\") # Cuda device object\n y = torch.ones_like(x, device=device) # Directly creates a tensor on GPU\n x = x.to(device) # \n z = x + y\n print(z)\n print(z.to(\"cpu\", torch.double))\n ",
"tensor([2.0785], device='cuda:0')\ntensor([2.0785], dtype=torch.float64)\n"
],
[
"\"\"\"\nAUTO-GRAD\n- The autograd package provides automatic differntation for all\nopeations on tensors. \n- A define-by-run framework i.e backprop defined by how code \nis run and every single iteration can be different.\n\nTENSOR\n- torch.tensor is the central class of the 'torch' package.\n- If one sets attribute '.requires_grad()' as 'True', all \noperations on it are tracked. \n- When computations are finished one can call'backward()' \nand have all the gradients computed.\n- Gradient of a tensor is accumulated into '.grad' attribute.\n- To stop tensor from tracking history, call '.detach()' to detach \nit from computation history and prevent future computation \nfrom being tracked\n- To prevent tacking histroy and using memory, wrap the code \nblock in 'with torch.no_grad()'. Helpful when evaluating a model\ncause model has trainable parameters with 'requires_grad=True'\n- 'Function' class is very important for autograd implementation\n- 'Tensor' and 'Function' are interconnected and buid up an acyclic\ngraph that encodes a complete history of computation.\n- Each tensor has a '.grad_fn' attribute that references a 'Function'\nthat has created the 'Tensor' (except for tensors created by user)\n- To compute derivates, '.backward()' is called on a Tensor. If \ntensor is a scalar, no arguments ought to be passed to '.backward()'\nif not, a 'gradient' argument ought to be specified.\n\"\"\"",
"_____no_output_____"
],
[
"## TENSORS\n\n# Create tenor to track all operations\nx = torch.ones(2,2, requires_grad=True)\nprint(x)\ny = x + 2\nprint(y)\nz = y * y * 3\nout = z.mean()\nprint(z, out)\n\n## GRADIENTS\n\n# Peforming backprop on 'out'\nout.backward()\nprint(x.grad)\n\n# An example of vector-Jacobian product\nx = torch.randn(3, requires_grad=True)\ny = x * 2\nwhile y.data.norm() < 1000:\n y = y * 2\nprint(y)\nv = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)\ny.backward(v)\nprint(x.grad)\n\n# Stop autograd from tracking history on Tensors \n# with .requires_grad=True \nprint(x.requires_grad)\nprint((x ** 2).requires_grad)\nwith torch.no_grad():\n print((x**2).requires_grad)",
"tensor([[1., 1.],\n [1., 1.]], requires_grad=True)\ntensor([[3., 3.],\n [3., 3.]], grad_fn=<AddBackward0>)\ntensor([[27., 27.],\n [27., 27.]], grad_fn=<MulBackward0>) tensor(27., grad_fn=<MeanBackward0>)\ntensor([[4.5000, 4.5000],\n [4.5000, 4.5000]])\ntensor([ -388.7856, 198.8780, -1300.0267], grad_fn=<MulBackward0>)\ntensor([2.0480e+02, 2.0480e+03, 2.0480e-01])\nTrue\nTrue\nFalse\n"
],
[
"image.requires_grad_(True)",
"_____no_output_____"
],
[
"image",
"_____no_output_____"
],
[
"\"\"\"\n## NEURAL NETWORKS\n\n- Can be constructed using 'torch.nn' package\n- 'nn' depends on 'autograd' to define models and differentiate\nthem. \n- 'nn.Module' contains layers and a method forward(input) that \nreturns the 'output'.\n- Training procedure:\n - Define neural network that has some learnable parameter\n - Iterate over a dataset of inputs\n - Process input through the network\n - Compute loss\n - Propagate gradients back into the network's parameters\n - Update weights\n\n\"\"\"",
"_____no_output_____"
],
[
"import torch.nn as nn\nimport torch.nn.functional as F",
"_____no_output_____"
],
[
"class Net(nn.Module):\n \n def __init__(self):\n super().__init__()\n \n # Convolutional Layers\n self.conv1 = nn.Conv2d(1, 6, 3)\n self.conv2 = nn.Conv2d(6, 16, 3)\n \n # An affine operation \n self.fc1 = nn.Linear(16*6*6, 128)\n self.fc2 = nn.Linear(128, 84)\n self.fc3 = nn.Linear(84, 10)\n \n def forward(self, x):\n \n x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))\n x = F.max_pool2d(F.relu(self.conv2(x)), 2)\n x = x.view(-1, self.num_flat_features(x))\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n \n return x\n \n def num_flat_features(self, x):\n \n size = x.size()[1:]\n num_features = 1\n for s in size:\n num_features *= s\n return num_features\n \nnet = Net()\nprint(net)",
"Net(\n (conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))\n (conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))\n (fc1): Linear(in_features=576, out_features=128, bias=True)\n (fc2): Linear(in_features=128, out_features=84, bias=True)\n (fc3): Linear(in_features=84, out_features=10, bias=True)\n)\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4df9ef283741874633c21acff1df68bb86c0bd
| 95,660 |
ipynb
|
Jupyter Notebook
|
notebookshow/atshow.ipynb
|
seanzhangJM/torch_nlp_job_default
|
fe9126c4abbde441fcc65d14d42477e4fff9d509
|
[
"MIT"
] | null | null | null |
notebookshow/atshow.ipynb
|
seanzhangJM/torch_nlp_job_default
|
fe9126c4abbde441fcc65d14d42477e4fff9d509
|
[
"MIT"
] | null | null | null |
notebookshow/atshow.ipynb
|
seanzhangJM/torch_nlp_job_default
|
fe9126c4abbde441fcc65d14d42477e4fff9d509
|
[
"MIT"
] | null | null | null | 63.435013 | 27,564 | 0.560736 |
[
[
[
"import math\nimport torch\nfrom d2l.torch import load_data_nmt\nfrom torch import nn\nfrom d2l import torch as d2l",
"_____no_output_____"
],
[
"x = torch.randint(1,4,size=(3,3),dtype=torch.float)",
"_____no_output_____"
],
[
"x.dim()",
"_____no_output_____"
],
[
"x.reshape(-1)",
"_____no_output_____"
],
[
"torch.repeat_interleave(x.reshape(-1),repeats=2,dim=0)",
"_____no_output_____"
],
[
"#@save\ndef sequence_mask(X, valid_len, value=0):\n \"\"\"在序列中屏蔽不相关的项\"\"\"\n maxlen = X.size(1)\n mask = torch.arange((maxlen), dtype=torch.float32,\n device=X.device)[None, :] < valid_len[:, None]\n X[~mask] = value\n return X\n\nX = torch.tensor([[1, 2, 3], [4, 5, 6]])\nsequence_mask(X, torch.tensor([1, 2]))",
"_____no_output_____"
],
[
"X = torch.ones(2, 3, 4)\nsequence_mask(X, torch.tensor([1, 2]), value=False)\n",
"_____no_output_____"
],
[
"#@save\ndef masked_softmax(X, valid_lens):\n \"\"\"通过在最后一个轴上掩蔽元素来执行softmax操作\"\"\"\n # X:3D张量,valid_lens:1D或2D张量\n if valid_lens is None:\n return nn.functional.softmax(X, dim=-1)\n else:\n shape = X.shape\n if valid_lens.dim() == 1:\n valid_lens = torch.repeat_interleave(valid_lens, shape[1])\n else:\n valid_lens = valid_lens.reshape(-1)\n # 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0\n X = sequence_mask(X.reshape(-1, shape[-1]), valid_lens,\n value=-1e6)\n return nn.functional.softmax(X.reshape(shape), dim=-1)",
"_____no_output_____"
],
[
"#[batch_size,query_nums,key_nums]\nmasked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))",
"_____no_output_____"
],
[
"#score shape:[batch_size,query_nums,key_nums]\nmasked_softmax(torch.rand(2, 4, 4), torch.tensor([[1,2,3,4],[1,2,3,4]]))\n",
"_____no_output_____"
],
[
"\n#@save\nclass AdditiveAttention(nn.Module):\n \"\"\"加性注意力\"\"\"\n def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):\n super(AdditiveAttention, self).__init__(**kwargs)\n self.W_k = nn.Linear(key_size, num_hiddens, bias=False)\n self.W_q = nn.Linear(query_size, num_hiddens, bias=False)\n self.w_v = nn.Linear(num_hiddens, 1, bias=False)\n self.dropout = nn.Dropout(dropout)\n\n def forward(self, queries, keys, values, valid_lens):\n queries, keys = self.W_q(queries), self.W_k(keys)\n # 在维度扩展后,\n # queries的形状:(batch_size,查询的个数,1,num_hidden)\n # key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)\n # 使用广播方式进行求和\n features = queries.unsqueeze(2) + keys.unsqueeze(1)\n features = torch.tanh(features)\n # self.w_v仅有一个输出,因此从形状中移除最后那个维度。\n # scores的形状:(batch_size,查询的个数,“键-值”对的个数)\n scores = self.w_v(features).squeeze(-1)\n self.attention_weights = masked_softmax(scores, valid_lens)\n # values的形状:(batch_size,“键-值”对的个数,值的维度)\n return torch.bmm(self.dropout(self.attention_weights), values)\nqueries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))\n# values的小批量,两个值矩阵是相同的\nvalues = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(\n 2, 1, 1)\n\nvalid_lens = torch.tensor([2, 6])\n\nattention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,\n dropout=0.1)\nattention.eval()\nres = attention(queries, keys, values, valid_lens)",
"_____no_output_____"
],
[
"res.shape",
"_____no_output_____"
],
[
"attention.attention_weights.shape",
"_____no_output_____"
],
[
"#@save\nclass DotProductAttention(nn.Module):\n \"\"\"缩放点积注意力\"\"\"\n def __init__(self, dropout, **kwargs):\n super(DotProductAttention, self).__init__(**kwargs)\n self.dropout = nn.Dropout(dropout)\n\n # queries的形状:(batch_size,查询的个数,d)\n # keys的形状:(batch_size,“键-值”对的个数,d)\n # values的形状:(batch_size,“键-值”对的个数,值的维度)\n # valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)\n def forward(self, queries, keys, values, valid_lens=None):\n d = queries.shape[-1]\n # 设置transpose_b=True为了交换keys的最后两个维度\n scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)\n self.attention_weights = masked_softmax(scores, valid_lens)\n return torch.bmm(self.dropout(self.attention_weights), values)",
"_____no_output_____"
],
[
"queries = torch.normal(0, 1, (2, 1, 2))\nattention = DotProductAttention(dropout=0.5)\nattention.eval()\nattention(queries, keys, values, valid_lens)",
"_____no_output_____"
],
[
"keys.shape,values.shape",
"_____no_output_____"
],
[
"#@save\nclass AttentionDecoder(d2l.Decoder):\n \"\"\"带有注意力机制解码器的基本接口\"\"\"\n def __init__(self, **kwargs):\n super(AttentionDecoder, self).__init__(**kwargs)\n\n @property\n def attention_weights(self):\n raise NotImplementedError",
"_____no_output_____"
],
[
"class Seq2SeqAttentionDecoder(AttentionDecoder):\n def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,\n dropout=0, **kwargs):\n super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)\n self.attention = d2l.AdditiveAttention(\n num_hiddens, num_hiddens, num_hiddens, dropout)\n self.embedding = nn.Embedding(vocab_size, embed_size)\n self.rnn = nn.GRU(\n embed_size + num_hiddens, num_hiddens, num_layers,\n dropout=dropout)\n self.dense = nn.Linear(num_hiddens, vocab_size)\n\n def init_state(self, enc_outputs, enc_valid_lens, *args):\n # outputs的形状为(batch_size,num_steps,num_hiddens).\n # hidden_state的形状为(num_layers,batch_size,num_hiddens)\n outputs, hidden_state = enc_outputs\n return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)\n\n def forward(self, X, state):\n # enc_outputs的形状为(batch_size,num_steps,num_hiddens).\n # hidden_state的形状为(num_layers,batch_size,\n # num_hiddens)\n enc_outputs, hidden_state, enc_valid_lens = state\n # 输出X的形状为(num_steps,batch_size,embed_size)\n X = self.embedding(X).permute(1, 0, 2)\n outputs, self._attention_weights = [], []\n for x in X:\n # query的形状为(batch_size,1,num_hiddens)\n query = torch.unsqueeze(hidden_state[-1], dim=1)\n # context的形状为(batch_size,1,num_hiddens)\n context = self.attention(\n query, enc_outputs, enc_outputs, enc_valid_lens)\n # 在特征维度上连结\n x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)\n # shape [batch_size,1,embed_size+num_hiddens]\n # 将x变形为(1,batch_size,embed_size+num_hiddens)\n out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)\n outputs.append(out)\n self._attention_weights.append(self.attention.attention_weights)\n # 全连接层变换后,outputs的形状为\n # (num_steps,batch_size,vocab_size)\n outputs = self.dense(torch.cat(outputs, dim=0))\n return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,\n enc_valid_lens]\n\n @property\n def attention_weights(self):\n return self._attention_weights",
"_____no_output_____"
],
[
"encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,\n num_layers=2)\nencoder.eval()\ndecoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,\n num_layers=2)\ndecoder.eval()\nX = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)\nstate = decoder.init_state(encoder(X), None)\noutput, state = decoder(X, state)\noutput.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape",
"_____no_output_____"
],
[
"torch.cat(decoder.attention_weights,dim=1).shape",
"_____no_output_____"
],
[
"decoder.attention_weights[0].shape",
"_____no_output_____"
],
[
"import os\ndef read_data_nmt():\n \"\"\"Load the English-French dataset.\n\n Defined in :numref:`sec_machine_translation`\"\"\"\n data_dir = d2l.download_extract('fra-eng')\n with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:\n return f.read()\n\ndef preprocess_nmt(text):\n \"\"\"Preprocess the English-French dataset.\n\n Defined in :numref:`sec_machine_translation`\"\"\"\n def no_space(char, prev_char):\n return char in set(',.!?') and prev_char != ' '\n\n # Replace non-breaking space with space, and convert uppercase letters to\n # lowercase ones\n text = text.replace('\\u202f', ' ').replace('\\xa0', ' ').lower()\n # Insert space between words and punctuation marks\n out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char\n for i, char in enumerate(text)]\n return ''.join(out)\n\ndef truncate_pad(line, num_steps, padding_token):\n \"\"\"Truncate or pad sequences.\n\n Defined in :numref:`sec_machine_translation`\"\"\"\n if len(line) > num_steps:\n return line[:num_steps] # Truncate\n return line + [padding_token] * (num_steps - len(line)) # Pad\n\ndef build_array_nmt(lines, vocab, num_steps):\n \"\"\"Transform text sequences of machine translation into minibatches.\n\n Defined in :numref:`subsec_mt_data_loading`\"\"\"\n lines = [vocab[l] for l in lines]\n lines = [l + [vocab['<eos>']] for l in lines]\n array = d2l.tensor([truncate_pad(\n l, num_steps, vocab['<pad>']) for l in lines])\n valid_len = d2l.reduce_sum(\n d2l.astype(array != vocab['<pad>'], d2l.int32), 1)\n return array, valid_len\n\ndef load_data_nmt(batch_size, num_steps, num_examples=600):\n \"\"\"Return the iterator and the vocabularies of the translation dataset.\n\n Defined in :numref:`subsec_mt_data_loading`\"\"\"\n text = preprocess_nmt(read_data_nmt())\n source, target = d2l.tokenize_nmt(text, num_examples)\n src_vocab = d2l.Vocab(source, min_freq=2,\n reserved_tokens=['<pad>', '<bos>', '<eos>'])\n tgt_vocab = d2l.Vocab(target, min_freq=2,\n reserved_tokens=['<pad>', '<bos>', '<eos>'])\n src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)\n tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)\n data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)\n data_iter = d2l.load_array(data_arrays, batch_size)\n return data_iter, src_vocab, tgt_vocab",
"_____no_output_____"
],
[
"embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1\nbatch_size, num_steps = 64, 10\nlr, num_epochs, device = 0.005, 250, d2l.try_gpu()\n\ntrain_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size, num_steps)\nencoder = d2l.Seq2SeqEncoder(\n len(src_vocab), embed_size, num_hiddens, num_layers, dropout)\ndecoder = Seq2SeqAttentionDecoder(\n len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)\nnet = d2l.EncoderDecoder(encoder, decoder)\nd2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)",
"loss 0.020, 2482.5 tokens/sec on cpu\n"
],
[
"engs = ['go .', \"i lost .\", 'he\\'s calm .', 'i\\'m home .']\nfras = ['va !', 'j\\'ai perdu .', 'il est calme .', 'je suis chez moi .']\nfor eng, fra in zip(engs, fras):\n translation, dec_attention_weight_seq = d2l.predict_seq2seq(\n net, eng, src_vocab, tgt_vocab, num_steps, device, True)\n print(f'{eng} => {translation}, ',\n f'bleu {d2l.bleu(translation, fra, k=2):.3f}')",
"go . => va !, bleu 1.000\ni lost . => j'ai perdu ., bleu 1.000\nhe's calm . => il est riche ., bleu 0.658\ni'm home . => je suis chez moi ., bleu 1.000\n"
],
[
"#@save\nclass MultiHeadAttention(nn.Module):\n \"\"\"多头注意力\"\"\"\n def __init__(self, key_size, query_size, value_size, num_hiddens,\n num_heads, dropout, bias=False, **kwargs):\n super(MultiHeadAttention, self).__init__(**kwargs)\n self.num_heads = num_heads\n self.attention = d2l.DotProductAttention(dropout)\n self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)\n self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)\n self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)\n self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)\n\n def forward(self, queries, keys, values, valid_lens):\n # queries,keys,values的形状:\n # (batch_size,查询或者“键-值”对的个数,num_hiddens)(batch_size,qk_nums,num_hiddens)\n # valid_lens 的形状:\n # (batch_size,)或(batch_size,查询的个数)\n # 经过变换后,输出的queries,keys,values 的形状:\n # (batch_size*num_heads,查询或者“键-值”对的个数,\n # num_hiddens/num_heads)\n queries = transpose_qkv(self.W_q(queries), self.num_heads)\n keys = transpose_qkv(self.W_k(keys), self.num_heads)\n values = transpose_qkv(self.W_v(values), self.num_heads)\n #q,k,v shape: [batch_size,num_heads,qkv_nums,num_hiddens/num_heads]\n\n if valid_lens is not None:\n # 在轴0,将第一项(标量或者矢量)复制num_heads次,\n # 然后如此复制第二项,然后诸如此类。\n valid_lens = torch.repeat_interleave(\n valid_lens, repeats=self.num_heads, dim=0)\n\n # output的形状:(batch_size*num_heads,查询的个数,\n # num_hiddens/num_heads)\n output = self.attention(queries, keys, values, valid_lens)\n\n # output_concat的形状:(batch_size,查询的个数,num_hiddens)\n output_concat = transpose_output(output, self.num_heads)\n return self.W_o(output_concat)\n\n#@save\ndef transpose_qkv(X, num_heads):\n \"\"\"为了多注意力头的并行计算而变换形状\"\"\"\n # 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)\n # 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,\n # num_hiddens/num_heads)\n X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)\n\n # 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,\n # num_hiddens/num_heads)\n X = X.permute(0, 2, 1, 3)\n\n # 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,\n # num_hiddens/num_heads)\n return X.reshape(-1, X.shape[2], X.shape[3])\n\n\n#@save\ndef transpose_output(X, num_heads):\n \"\"\"逆转transpose_qkv函数的操作\"\"\"\n X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])\n X = X.permute(0, 2, 1, 3)\n return X.reshape(X.shape[0], X. shape[1], -1)",
"_____no_output_____"
],
[
"valid_lens = torch.tensor([[1,2,3],[4,5,6]])\ntorch.repeat_interleave(valid_lens, repeats=3, dim=0)",
"_____no_output_____"
],
[
"x = torch.arange(16).reshape(2,2,4)\nx,x[1]",
"_____no_output_____"
],
[
"x.reshape(2,2,2,2)",
"_____no_output_____"
],
[
"x.reshape(2,2,2,2).permute(0,2,1,3).reshape(-1,2,2)",
"_____no_output_____"
],
[
"num_hiddens, num_heads = 100, 5\nattention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,\n num_hiddens, num_heads, 0.5)\nattention.eval()",
"_____no_output_____"
],
[
"batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])\nX = torch.ones((batch_size, num_queries, num_hiddens))\nattention(X, X, X, valid_lens).shape",
"_____no_output_____"
],
[
"#@save\nclass PositionalEncoding(nn.Module):\n \"\"\"位置编码\"\"\"\n def __init__(self, num_hiddens, dropout, max_len=1000):\n super(PositionalEncoding, self).__init__()\n self.dropout = nn.Dropout(dropout)\n # 创建一个足够长的P\n self.P = torch.zeros((1, max_len, num_hiddens))\n X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) / torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)\n self.P[:, :, 0::2] = torch.sin(X)\n self.P[:, :, 1::2] = torch.cos(X)\n\n def forward(self, X):\n X = X + self.P[:, :X.shape[1], :].to(X.device)\n return self.dropout(X)",
"_____no_output_____"
],
[
"max_len = 1000\nnum_hiddens=100\nP = torch.zeros((1, max_len, num_hiddens))\n",
"_____no_output_____"
],
[
"P[:].shape",
"_____no_output_____"
],
[
"class PositionWiseFFN(nn.Module):\n def __init__(self,ffn_num_input,ffn_num_hiddens,ffn_num_outputs,**kwargs):\n super(PositionWiseFFN, self).__init__(**kwargs)\n self.dense1 = nn.Linear(ffn_num_input,ffn_num_hiddens)\n self.relu = nn.ReLU()\n self.dense2 = nn.Linear(ffn_num_hiddens,ffn_num_outputs)\n\n def forward(self,X):\n return self.dense2(self.relu(self.dense1(X)))\n",
"_____no_output_____"
],
[
"ln = nn.LayerNorm(2)\nbn = nn.BatchNorm1d(2)\nX = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)\n# 在训练模式下计算X的均值和方差\nprint('layer norm:', ln(X), '\\nbatch norm:', bn(X))",
"layer norm: tensor([[-1.0000, 1.0000],\n [-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward>) \nbatch norm: tensor([[-1.0000, -1.0000],\n [ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward>)\n"
],
[
"class AddNorm(nn.Module):\n def __init__(self,normalized_shape,dropout,**kwargs):\n super(AddNorm, self).__init__(**kwargs)\n self.dropout = nn.Dropout(dropout)\n self.ln = nn.LayerNorm(normalized_shape)\n\n def forward(self,X,Y):\n return self.ln(self.dropout(Y)+X)",
"_____no_output_____"
],
[
"add_norm = AddNorm([3, 4], 0.5)\nadd_norm.eval()\nadd_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape\n\n",
"_____no_output_____"
],
[
"class EncoderBlock(nn.Module):\n def __init__(self,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,\n ffn_num_hiddens,num_heads,dropout,use_bias=False,**kwargs):\n super(EncoderBlock, self).__init__(**kwargs)\n self.attention = MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout,use_bias)\n self.addnorm1 = AddNorm(norm_shape,dropout)\n self.ffn = PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)\n self.addnorm2 = AddNorm(norm_shape,dropout)\n\n def forward(self,X,valid_lens):\n Y = self.addnorm1(X,self.attention(X,X,X,valid_lens))\n return self.addnorm2(Y,self.ffn(Y))\n",
"_____no_output_____"
],
[
"X = torch.ones((2, 100, 24))\nvalid_lens = torch.tensor([50, 60])\nencoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)\nencoder_blk.eval()\nencoder_blk(X, valid_lens).shape",
"_____no_output_____"
],
[
"#@save\nclass TransformerEncoder(d2l.Encoder):\n \"\"\"transformer编码器\"\"\"\n def __init__(self, vocab_size, key_size, query_size, value_size,\n num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,\n num_heads, num_layers, dropout, use_bias=False, **kwargs):\n super(TransformerEncoder, self).__init__(**kwargs)\n self.num_hiddens = num_hiddens\n self.embedding = nn.Embedding(vocab_size, num_hiddens)\n self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)\n self.blks = nn.Sequential()\n for i in range(num_layers):\n self.blks.add_module(\"block\"+str(i),\n EncoderBlock(key_size, query_size, value_size, num_hiddens,\n norm_shape, ffn_num_input, ffn_num_hiddens,\n num_heads, dropout, use_bias))\n\n def forward(self, X, valid_lens, *args):\n # 因为位置编码值在-1和1之间,\n # 因此嵌入值乘以嵌入维度的平方根进行缩放,\n # 然后再与位置编码相加。\n X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))\n self.attention_weights = [None] * len(self.blks)\n for i, blk in enumerate(self.blks):\n X = blk(X, valid_lens)\n self.attention_weights[\n i] = blk.attention.attention.attention_weights\n return X",
"_____no_output_____"
],
[
"encoder = TransformerEncoder(\n 200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)\nencoder.eval()\nencoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape",
"_____no_output_____"
],
[
"class DecoderBlock(nn.Module):\n \"\"\"解码器中第i个块\"\"\"\n def __init__(self, key_size, query_size, value_size, num_hiddens,\n norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,\n dropout, i, **kwargs):\n super(DecoderBlock, self).__init__(**kwargs)\n self.i = i\n self.attention1 = d2l.MultiHeadAttention(\n key_size, query_size, value_size, num_hiddens, num_heads, dropout)\n self.addnorm1 = AddNorm(norm_shape, dropout)\n self.attention2 = d2l.MultiHeadAttention(\n key_size, query_size, value_size, num_hiddens, num_heads, dropout)\n self.addnorm2 = AddNorm(norm_shape, dropout)\n self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,num_hiddens)\n self.addnorm3 = AddNorm(norm_shape, dropout)\n\n def forward(self, X, state):\n enc_outputs, enc_valid_lens = state[0], state[1]\n # 训练阶段,输出序列的所有词元都在同一时间处理,\n # 因此state[2][self.i]初始化为None。\n # 预测阶段,输出序列是通过词元一个接着一个解码的,\n # 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示\n if state[2][self.i] is None:\n key_values = X\n else:\n key_values = torch.cat((state[2][self.i], X), axis=1)\n state[2][self.i] = key_values\n if self.training:\n batch_size, num_steps, _ = X.shape\n # dec_valid_lens的开头:(batch_size,num_steps),\n # 其中每一行是[1,2,...,num_steps]\n # 用于自注意力计算,每到一个新单词就把这个单词加到注意力里,而不是把全部单词加进来\n dec_valid_lens = torch.arange(\n 1, num_steps + 1, device=X.device).repeat(batch_size, 1)\n else:\n dec_valid_lens = None\n\n # 自注意力,这边dec_valid_lens考虑了\n X2 = self.attention1(X, key_values, key_values, dec_valid_lens)\n Y = self.addnorm1(X, X2)\n # 编码器-解码器注意力。\n # enc_outputs的开头:(batch_size,num_steps,num_hiddens)\n Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)\n Z = self.addnorm2(Y, Y2)\n return self.addnorm3(Z, self.ffn(Z)), state",
"_____no_output_____"
],
[
"X = torch.ones((2, 100, 24))\nY = torch.ones((2, 100, 24))\ntorch.cat((X,Y),dim=1).shape",
"_____no_output_____"
],
[
"batch_size\ntorch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)",
"_____no_output_____"
],
[
"decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)\ndecoder_blk.eval()\nX = torch.ones((2, 100, 24))\nstate = [encoder_blk(X, valid_lens), valid_lens, [None]]\ndecoder_blk(X, state)[0].shape",
"_____no_output_____"
],
[
"class TransformerDecoder(d2l.AttentionDecoder):\n def __init__(self, vocab_size, key_size, query_size, value_size,\n num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,\n num_heads, num_layers, dropout, **kwargs):\n super(TransformerDecoder, self).__init__(**kwargs)\n self.num_hiddens = num_hiddens\n self.num_layers = num_layers\n self.embedding = nn.Embedding(vocab_size, num_hiddens)\n self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)\n self.blks = nn.Sequential()\n for i in range(num_layers):\n self.blks.add_module(\"block\"+str(i),\n DecoderBlock(key_size, query_size, value_size, num_hiddens,\n norm_shape, ffn_num_input, ffn_num_hiddens,\n num_heads, dropout, i))\n self.dense = nn.Linear(num_hiddens, vocab_size)\n\n def init_state(self, enc_outputs, enc_valid_lens, *args):\n return [enc_outputs, enc_valid_lens, [None] * self.num_layers]\n\n def forward(self, X, state):\n X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))\n self._attention_weights = [[None] * len(self.blks) for _ in range (2)]\n for i, blk in enumerate(self.blks):\n X, state = blk(X, state)\n # 解码器自注意力权重\n self._attention_weights[0][\n i] = blk.attention1.attention.attention_weights\n # “编码器-解码器”自注意力权重\n self._attention_weights[1][\n i] = blk.attention2.attention.attention_weights\n return self.dense(X), state\n\n @property\n def attention_weights(self):\n return self._attention_weights",
"_____no_output_____"
],
[
"num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10\nlr, num_epochs, device = 0.005, 200, d2l.try_gpu()\nffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4\nkey_size, query_size, value_size = 32, 32, 32\nnorm_shape = [32]\n\ntrain_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size, num_steps)\n\nencoder = TransformerEncoder(\n len(src_vocab), key_size, query_size, value_size, num_hiddens,\n norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,\n num_layers, dropout)\ndecoder = TransformerDecoder(\n len(tgt_vocab), key_size, query_size, value_size, num_hiddens,\n norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,\n num_layers, dropout)\nnet = d2l.EncoderDecoder(encoder, decoder)\nd2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)",
"loss 0.283, 2183.0 tokens/sec on cpu\n"
],
[
"engs = ['go .', \"i lost .\", 'he\\'s calm .', 'i\\'m home .']\nfras = ['va !', 'j\\'ai perdu .', 'il est calme .', 'je suis chez moi .']\nfor eng, fra in zip(engs, fras):\n translation, dec_attention_weight_seq = d2l.predict_seq2seq(\n net, eng, src_vocab, tgt_vocab, num_steps, device, True)\n print(f'{eng} => {translation}, ',\n f'bleu {d2l.bleu(translation, fra, k=2):.3f}')",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4dfa3a0716a5192506523f0a83c7065e0832d8
| 960,939 |
ipynb
|
Jupyter Notebook
|
plots.ipynb
|
BigData-MielPops/Project1
|
dbc9376f8566ad172ffd8daa719ee14809c2a28a
|
[
"Apache-2.0"
] | null | null | null |
plots.ipynb
|
BigData-MielPops/Project1
|
dbc9376f8566ad172ffd8daa719ee14809c2a28a
|
[
"Apache-2.0"
] | null | null | null |
plots.ipynb
|
BigData-MielPops/Project1
|
dbc9376f8566ad172ffd8daa719ee14809c2a28a
|
[
"Apache-2.0"
] | null | null | null | 1,997.794179 | 110,036 | 0.945083 |
[
[
[
"import matplotlib.pyplot as plt\nimport matplotlib.patches as mpatches\nimport matplotlib\nmatplotlib.rcParams['figure.figsize'] = [12.0, 8.0]",
"_____no_output_____"
],
[
"def plot_project_data(data_x, data_list_y, plt_range_min_x, plt_range_max_x, \n short_colors = ['b', 'g', 'r'],\n labels = ['mapreduce', 'hive', 'spark'], types = ['', '', ''], \n title='Job', loc=2): \n plt_range_min_y = int(min(data_list_y[0]) * 0.9)\n plt_range_max_y = int(max(data_list_y[0]) * 1.1)\n for dy in data_list_y:\n plt_range_min_y = int(min(dy + [plt_range_min_y]) * 0.99)\n plt_range_max_y = int(max(dy + [plt_range_max_y]) * 1.01) \n \n handles = [];\n for i in range(len(data_list_y)):\n app, _ = plt.plot(data_x[:len(data_list_y[i])], data_list_y[i], short_colors[i]+types[i], data_x[:len(data_list_y[i])], data_list_y[i], short_colors[i]+'o', label=labels[i])\n handles = handles + [app]\n \n plt.axis([plt_range_min_x, plt_range_max_x, plt_range_min_y, plt_range_max_y])\n plt.ylabel('seconds')\n plt.xlabel('MB')\n plt.title(title)\n plt.legend(handles=handles, loc=loc)\n plt.show()",
"_____no_output_____"
],
[
"data_x = [5, 26, 70, 184, 292, 591]\nmax_x = 600\ndata_mr1L = [12, 14, 18, 25, 33, 40]\ndata_hive1L = [8, 8, 9, 12, 17, 21]\ndata_spark1L = [7, 11, 14, 19, 25, 27]\n\nplot_project_data(data_x, [data_mr1L, data_hive1L, data_spark1L], \n 0, max_x, title='Job 1 - Local')",
"_____no_output_____"
],
[
"data_mr2L = [12, 15, 19, 31, 43, 81]\ndata_hive2L = [7, 8, 10, 16, 19, 25]\ndata_spark2L = [8, 12, 16, 28, 39, 71]\n\nplot_project_data(data_x, [data_mr2L, data_hive2L, data_spark2L], \n 0, max_x, title='Job 2 - Local')",
"_____no_output_____"
],
[
"data_mr31FL = [12, 12, 13, 20, 27, 69]\ndata_mr31SL = [11, 12, 19, 34, 65, 275]\ndata_mr31L = [12+11+5, 12+12+5, 13+19+5, 20+34+5, 27+65+5, 69+275+5]\ndata_mr32L = [11, 13, 30, 210]\ndata_hive3L = [13, 14, 53, 145, 308, 482]\ndata_spark3L = [9, 13, 46, 225, 405, 417]\n\nplot_project_data(data_x, \n [data_mr31FL, data_mr31SL, data_mr31L, data_mr32L, data_hive3L, data_spark3L],\n 0, max_x, \n short_colors = ['y', 'c', 'b', 'm', 'g', 'r'], \n labels = ['mapreduce v1 (first)', 'mapreduce v1 (second)', 'mapreduce v1 - total', 'mapreduce v2', 'hive', 'spark'], \n types = ['--', '--', '', '', '', '', ''],\n title='Job 3 - Local')",
"_____no_output_____"
],
[
"data_mr1C = [12, 14, 16, 20, 27, 30]\ndata_hive1C = [68, 69, 70, 71, 76, 88]\ndata_spark1C = [28, 28, 36, 41, 43, 46]\n\nplot_project_data(data_x, [data_mr1C, data_hive1C, data_spark1C], \n 0, max_x, title='Job 1 - Cluster')",
"_____no_output_____"
],
[
"data_mr2C = [11, 15, 16, 22, 24, 29]\ndata_hive2C = [68, 70, 73, 77, 59, 89]\ndata_hive2C_no = [68, 70, 73, 77, 80, 89]\ndata_spark2C = [21, 33, 36, 44, 52, 70]\n\nplot_project_data(data_x, [data_mr2C, data_hive2C, data_hive2C_no, data_spark2C],\n 0, max_x, \n short_colors = ['b', 'g', 'g', 'r'], \n labels = ['mapreduce', 'hive (real)', 'hive (no outlier)', 'spark'], \n types = ['', '', '--', ''],\n title='Job 2 - Cluster', loc=4)",
"_____no_output_____"
],
[
"data_mr31FC = [11, 11, 13, 14, 28, 72]\ndata_mr31SC = [10, 12, 19, 21, 54, 162]\ndata_mr31C = [11+10+5, 11+12+5, 13+19+5, 14+21+5, 28+54+5, 72+162+5]\ndata_mr32C = [11, 12, 25, 193]\ndata_hive3C = [34, 43, 56, 102, 206, 245]\ndata_spark3C = [29, 30, 45, 108, 244, 303]\n\nplot_project_data(data_x, \n [data_mr31FC, data_mr31SC, data_mr31C, data_mr32C, data_hive3C, data_spark3C],\n 0, max_x, \n short_colors = ['y', 'c', 'b', 'm', 'g', 'r'], \n labels = ['mapreduce v1 (first)', 'mapreduce v1 (second)', 'mapreduce v1 - total', 'mapreduce v2', 'hive', 'spark'], \n types = ['--', '--', '', '', '', '', ''],\n title='Job 3 - Cluster')",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_mr1L, data_mr1C], \n 0, max_x, title='Job 1 - MapReduce', \n labels = ['local', 'cluster'])",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_mr2L, data_mr2C], \n 0, max_x, title='Job 2 - MapReduce', \n labels = ['local', 'cluster'])",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_mr31L, data_mr31C, data_mr32L, data_mr32C], \n 0, max_x, title='Job 3 - MapReduce', \n short_colors = ['b', 'g', 'c', 'y'], \n types = ['', '', '', '', ''],\n labels = ['local (v1)', 'cluster (v1)', 'local (v2)', 'cluster (v2)'])",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_hive1L, data_hive1C, [x-60 for x in data_hive1C]], \n 0, max_x, title='Job 1 - Hive',\n short_colors = ['b', 'g', 'c'],\n labels = ['local', 'cluster', 'cluster (compare)'],\n types = ['', '', '--'])",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_hive2L, data_hive2C, data_hive2C_no, [x-61 for x in data_hive2C_no]], \n 0, max_x, title='Job 2 - Hive', \n labels = ['local', 'cluster (real)', 'cluster (no outlier)', 'cluster (compare)'],\n short_colors = ['b', 'g', 'g', 'c'], \n types = ['', '', '--', '--'], loc=4)",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_hive3L, data_hive3C], \n 0, max_x, title='Job 3 - Hive',\n labels = ['local', 'cluster'])",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_spark1L, data_spark1C, [x-21 for x in data_spark1C]], \n 0, max_x, title='Job 1 - Spark',\n short_colors = ['b', 'g', 'c'],\n labels = ['local', 'cluster', 'cluster (compare)'],\n types = ['', '', '--'], loc=4)",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_spark2L, data_spark2C], \n 0, max_x, title='Job 2 - Spark',\n labels = ['local', 'cluster'])",
"_____no_output_____"
],
[
"plot_project_data(data_x, [data_spark3L, data_spark3C], \n 0, max_x, title='Job 3 - Spark',\n labels = ['local', 'cluster'])",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4e032ccc8fcf36c6d7f6b2795605471381752b
| 6,833 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Proyecto3_GalindoA_PimentelB-checkpoint.ipynb
|
ariadnagalindom/proyecto_modulo3
|
e70d391111d6364f58f75fad47e9941a04b5f34c
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Proyecto3_GalindoA_PimentelB-checkpoint.ipynb
|
ariadnagalindom/proyecto_modulo3
|
e70d391111d6364f58f75fad47e9941a04b5f34c
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Proyecto3_GalindoA_PimentelB-checkpoint.ipynb
|
ariadnagalindom/proyecto_modulo3
|
e70d391111d6364f58f75fad47e9941a04b5f34c
|
[
"MIT"
] | null | null | null | 36.736559 | 138 | 0.491292 |
[
[
[
"import random\nimport time\nimport os",
"_____no_output_____"
],
[
"print()\nprint('''Bienvenido a la máquina tragamonedas\nComenzarás con $ 50 pesos. Se te preguntará si quieres jugar.\nResponda con sí / no. también puedes usar y / n\nNo hay sensibilidad de mayúsculas, escríbela como quieras!\nPara ganar debes obtener una de las siguientes combinaciones:\nBAR\\tBAR\\tBAR\\t\\tpays\\t$250\nBELL\\tBELL\\tBELL/BAR\\tpays\\t$20\nPLUM\\tPLUM\\tPLUM/BAR\\tpays\\t$14\nORANGE\\tORANGE\\tORANGE/BAR\\tpays\\t$10\nCHERRY\\tCHERRY\\tCHERRY\\t\\tpays\\t$7\nCHERRY\\tCHERRY\\t -\\t\\tpays\\t$5\nCHERRY\\t -\\t -\\t\\tpays\\t$2\n7\\t 7\\t 7\\t\\tpays\\t The Jackpot!\n''')\ntime.sleep(10)\n#Constants:\nINIT_STAKE = 50\nINIT_BALANCE = 1000\nITEMS = [\"CHERRY\", \"LEMON\", \"ORANGE\", \"PLUM\", \"BELL\", \"BAR\", \"7\"]\n\nfirstWheel = None\nsecondWheel = None\nthirdWheel = None\nstake = INIT_STAKE\nbalance = INIT_BALANCE\n\ndef play():\n global stake, firstWheel, secondWheel, thirdWheel\n playQuestion = askPlayer()\n while(stake != 0 and playQuestion == True):\n firstWheel = spinWheel()\n secondWheel = spinWheel()\n thirdWheel = spinWheel()\n printScore()\n playQuestion = askPlayer()\n\ndef askPlayer():\n '''\n Le pregunta al jugador si quiere volver a jugar.\n esperando que el usuario responda con sí, y, no o n\n No hay sensibilidad a mayúsculas en la respuesta. sí, sí, y, y, no. . . todas las obras\n '''\n global stake\n global balance\n while(True):\n os.system('cls' if os.name == 'nt' else 'clear')\n if (balance <=1):\n print (\"Reinicio de la máquina.\")\n balance = 1000\n\n print (\"El Jackpot es actualmente: $\" + str(balance) + \".\")\n answer = input(\"¿Quisieras jugar? ¿O revisar tu dinero? \")\n answer = answer.lower()\n if(answer == \"si\" or answer == \"y\"):\n return True\n elif(answer == \"no\" or answer == \"n\"):\n print(\"Terminaste el juego con $\" + str(stake) + \" en tu mano. Gran trabajo!\")\n time.sleep(5)\n return False\n elif(answer == \"check\" or answer == \"CHECK\"):\n print (\"Tu Actualmente tienes $\" + str(stake) + \".\")\n else:\n print(\"Whoops! No entendi eso.\")\n\ndef spinWheel():\n '''\n returns a random item from the wheel\n '''\n randomNumber = random.randint(0, 5)\n return ITEMS[randomNumber]\n\ndef printScore():\n '''\n prints the current score\n '''\n global stake, firstWheel, secondWheel, thirdWheel, balance\n if((firstWheel == \"CHERRY\") and (secondWheel != \"CHERRY\")):\n win = 2\n balance = balance - 2\n elif((firstWheel == \"CHERRY\") and (secondWheel == \"CHERRY\") and (thirdWheel != \"CHERRY\")):\n win = 5\n balance = balance - 5\n elif((firstWheel == \"CHERRY\") and (secondWheel == \"CHERRY\") and (thirdWheel == \"CHERRY\")):\n win = 7\n balance = balance - 7\n elif((firstWheel == \"ORANGE\") and (secondWheel == \"ORANGE\") and ((thirdWheel == \"ORANGE\") or (thirdWheel == \"BAR\"))):\n win = 10\n balance = balance - 10\n elif((firstWheel == \"PLUM\") and (secondWheel == \"PLUM\") and ((thirdWheel == \"PLUM\") or (thirdWheel == \"BAR\"))):\n win = 14\n balance = balance - 14\n elif((firstWheel == \"BELL\") and (secondWheel == \"BELL\") and ((thirdWheel == \"BELL\") or (thirdWheel == \"BAR\"))):\n win = 20\n balance = balance - 20\n elif((firstWheel == \"BAR\") and (secondWheel == \"BAR\") and (thirdWheel == \"BAR\")):\n win = 250\n balance = balance - 250\n elif((firstWheel == \"7\") and (secondWheel == \"7\") and (thridWheel == \"7\")):\n win = balance\n balance = balance - win\n else:\n win = -1\n balance = balance + 1\n\n stake += win\n if win == balance:\n print (\"Ganaste el JACKPOT!!\")\n if(win > 0):\n print(firstWheel + '\\t' + secondWheel + '\\t' + thirdWheel + ' -- Ganaste $' + str(win))\n time.sleep(3)\n os.system('cls' if os.name == 'nt' else 'clear')\n else:\n print(firstWheel + '\\t' + secondWheel + '\\t' + thirdWheel + ' -- Perdiste')\n time.sleep(2)\n os.system('cls' if os.name == 'nt' else 'clear')\n\nplay()",
"\nBienvenido a la máquina tragamonedas\nComenzarás con $ 50 pesos. Se te preguntará si quieres jugar.\nResponda con sí / no. también puedes usar y / n\nNo hay sensibilidad de mayúsculas, escríbela como quieras!\nPara ganar debes obtener una de las siguientes combinaciones:\nBAR\tBAR\tBAR\t\tpays\t$250\nBELL\tBELL\tBELL/BAR\tpays\t$20\nPLUM\tPLUM\tPLUM/BAR\tpays\t$14\nORANGE\tORANGE\tORANGE/BAR\tpays\t$10\nCHERRY\tCHERRY\tCHERRY\t\tpays\t$7\nCHERRY\tCHERRY\t -\t\tpays\t$5\nCHERRY\t -\t -\t\tpays\t$2\n7\t 7\t 7\t\tpays\t The Jackpot!\n\nEl Jackpot es actualmente: $1000.\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a4e09e5467cebe6cf26bcbb1d38bab878c36305
| 38,010 |
ipynb
|
Jupyter Notebook
|
Project_pH/pH.ipynb
|
anyangpeng/DS_Portfolio
|
1d233e39ed839126d18587400924707fdf04b6ea
|
[
"MIT"
] | null | null | null |
Project_pH/pH.ipynb
|
anyangpeng/DS_Portfolio
|
1d233e39ed839126d18587400924707fdf04b6ea
|
[
"MIT"
] | null | null | null |
Project_pH/pH.ipynb
|
anyangpeng/DS_Portfolio
|
1d233e39ed839126d18587400924707fdf04b6ea
|
[
"MIT"
] | null | null | null | 140.777778 | 22,194 | 0.610366 |
[
[
[
"# pH Recognition",
"_____no_output_____"
],
[
"The goal is to predict the pH values given the RGB color code. The task can be viewed as a classification problem or a regression problem.",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nimport matplotlib.pyplot as plt \nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import classification_report,mean_squared_error\nimport cv2\n",
"_____no_output_____"
],
[
"pH = pd.read_csv('ph-data.csv.xls')\npH.head()",
"_____no_output_____"
]
],
[
[
"Now we need to check the integrity of the data, to see if there is any NULL values.",
"_____no_output_____"
]
],
[
[
"pH.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 653 entries, 0 to 652\nData columns (total 4 columns):\n # Column Non-Null Count Dtype\n--- ------ -------------- -----\n 0 blue 653 non-null int64\n 1 green 653 non-null int64\n 2 red 653 non-null int64\n 3 label 653 non-null int64\ndtypes: int64(4)\nmemory usage: 20.5 KB\n"
]
],
[
[
"The data seems to be complete and properly tabulated. Before feeding the data into machine learning models, we need to check if the data is balanced; otherwise, we need to consider stratified sampling.",
"_____no_output_____"
]
],
[
[
"pH.label.value_counts().plot(kind='bar')",
"_____no_output_____"
]
],
[
[
"In general, the data looks balanced. We can split it into train set and test set.",
"_____no_output_____"
]
],
[
[
"X = pH[['red','green','blue']]\ny = pH.label\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)",
"_____no_output_____"
]
],
[
[
"### Classification Method",
"_____no_output_____"
]
],
[
[
"# Random forest\nfrom sklearn.ensemble import RandomForestClassifier\ntree_model = RandomForestClassifier(n_estimators=50)\ntree_model.fit(X_train,y_train)\ntree_prd = tree_model.predict(X_test)\nprint(classification_report(tree_prd,y_test))\nprint('Mean squared error is {}'.format(mean_squared_error(tree_prd,y_test)))",
" precision recall f1-score support\n\n 0 0.89 1.00 0.94 8\n 1 0.91 0.83 0.87 12\n 2 0.91 0.83 0.87 12\n 3 0.60 0.75 0.67 12\n 4 0.69 0.50 0.58 18\n 5 0.69 0.60 0.64 15\n 6 0.62 0.91 0.74 11\n 7 0.78 0.54 0.64 13\n 8 0.67 0.60 0.63 10\n 9 0.69 0.92 0.79 12\n 10 0.81 0.72 0.76 18\n 11 0.65 1.00 0.79 11\n 12 0.91 0.83 0.87 12\n 13 0.64 0.64 0.64 11\n 14 0.84 0.76 0.80 21\n\n accuracy 0.74 196\n macro avg 0.75 0.76 0.75 196\nweighted avg 0.76 0.74 0.74 196\n\nMean squared error is 0.8571428571428571\n"
],
[
"# Logistic Regression\nfrom sklearn.linear_model import LogisticRegression \n\nlog_model = LogisticRegression()\nlog_model.fit(X_train,y_train)\nlog_prd = log_model.predict(X_test)\nprint(classification_report(log_prd,y_test))\nprint('Mean squared error is {}'.format(mean_squared_error(log_prd,y_test)))",
" precision recall f1-score support\n\n 0 1.00 0.90 0.95 10\n 1 0.36 0.67 0.47 6\n 2 0.64 0.39 0.48 18\n 3 0.40 0.50 0.44 12\n 4 0.38 0.38 0.38 13\n 5 0.62 0.53 0.57 15\n 6 0.06 0.33 0.11 3\n 7 0.56 0.24 0.33 21\n 8 0.67 0.55 0.60 11\n 9 0.81 0.81 0.81 16\n 10 0.75 0.80 0.77 15\n 11 0.65 0.85 0.73 13\n 12 0.73 0.62 0.67 13\n 13 0.27 0.15 0.19 20\n 14 0.16 0.30 0.21 10\n\n accuracy 0.52 196\n macro avg 0.54 0.53 0.52 196\nweighted avg 0.57 0.52 0.52 196\n\nMean squared error is 1.1683673469387754\n"
]
],
[
[
"Logistic regression performed much worse than RandomForest.",
"_____no_output_____"
],
[
"### Regression model",
"_____no_output_____"
]
],
[
[
"# Linear regression with regularization\nfrom sklearn.linear_model import Ridge\n\n\nridge_model = Ridge()\nridge_model.fit(X_train,y_train)\nridge_prd = ridge_model.predict(X_test)\nprint(classification_report(np.round(ridge_prd),y_test))\nprint('Mean squared error is {}'.format(mean_squared_error(ridge_prd,y_test)))",
" precision recall f1-score support\n\n 0.0 0.00 0.00 0.00 0\n 1.0 0.00 0.00 0.00 5\n 2.0 0.73 0.31 0.43 26\n 3.0 0.20 0.12 0.15 24\n 4.0 0.46 0.35 0.40 17\n 5.0 0.08 0.20 0.11 5\n 6.0 0.19 0.33 0.24 9\n 7.0 0.22 0.18 0.20 11\n 8.0 0.11 0.11 0.11 9\n 9.0 0.00 0.00 0.00 22\n 10.0 0.00 0.00 0.00 18\n 11.0 0.47 0.36 0.41 22\n 12.0 0.36 0.21 0.27 19\n 13.0 0.00 0.00 0.00 9\n 14.0 0.00 0.00 0.00 0\n\n accuracy 0.18 196\n macro avg 0.19 0.15 0.16 196\nweighted avg 0.28 0.18 0.21 196\n\nMean squared error is 5.728271472559605\n"
]
],
[
[
"Clearly, classification is a better option here.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a4e19210936bf52aeb83113bf7f9afd5d13911b
| 190,485 |
ipynb
|
Jupyter Notebook
|
Trabalho_Final_Inception_V3.ipynb
|
rafaelgssa/face-mask-detection
|
1bee56f5089da18b851720d60bafaac102f90e09
|
[
"MIT"
] | 2 |
2020-06-03T23:32:56.000Z
|
2020-06-06T08:40:04.000Z
|
Trabalho_Final_Inception_V3.ipynb
|
rafaelgomesxyz/face-mask-detection
|
1bee56f5089da18b851720d60bafaac102f90e09
|
[
"MIT"
] | null | null | null |
Trabalho_Final_Inception_V3.ipynb
|
rafaelgomesxyz/face-mask-detection
|
1bee56f5089da18b851720d60bafaac102f90e09
|
[
"MIT"
] | null | null | null | 145.076161 | 68,258 | 0.821723 |
[
[
[
"Corrigir versao de scipy para Inception",
"_____no_output_____"
]
],
[
[
"pip install scipy==1.3.3",
"Collecting scipy==1.3.3\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/54/18/d7c101d5e93b6c78dc206fcdf7bd04c1f8138a7b1a93578158fa3b132b08/scipy-1.3.3-cp36-cp36m-manylinux1_x86_64.whl (25.2MB)\n\u001b[K |████████████████████████████████| 25.2MB 143kB/s \n\u001b[?25hRequirement already satisfied: numpy>=1.13.3 in /usr/local/lib/python3.6/dist-packages (from scipy==1.3.3) (1.18.4)\n\u001b[31mERROR: tensorflow 2.2.0 has requirement scipy==1.4.1; python_version >= \"3\", but you'll have scipy 1.3.3 which is incompatible.\u001b[0m\n\u001b[31mERROR: albumentations 0.1.12 has requirement imgaug<0.2.7,>=0.2.5, but you'll have imgaug 0.2.9 which is incompatible.\u001b[0m\nInstalling collected packages: scipy\n Found existing installation: scipy 1.4.1\n Uninstalling scipy-1.4.1:\n Successfully uninstalled scipy-1.4.1\nSuccessfully installed scipy-1.3.3\n"
]
],
[
[
"Importar bibliotecas",
"_____no_output_____"
]
],
[
[
"from __future__ import division, print_function\nfrom torchvision import datasets, models, transforms\nimport copy\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport os\nimport shutil\nimport time\nimport torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torchvision\nimport zipfile",
"_____no_output_____"
]
],
[
[
"Montar Google Drive",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly\n\nEnter your authorization code:\n··········\nMounted at /content/drive\n"
]
],
[
[
"Definir constantes",
"_____no_output_____"
]
],
[
[
"DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\n\nZIP_FILE_PATH = './dataset.zip'\nDATASET_PATH = './dataset'\n\nINCEPTION = 'inception'\nVGG19 = 'vgg-19'\nMODEL = INCEPTION # Define o tipo de modelo a ser usado.\nIMG_SIZE = {\n INCEPTION: 299,\n VGG19: 224,\n}[MODEL]\nNORMALIZE_MEAN = [0.485, 0.456, 0.406]\nNORMALIZE_STD = [0.229, 0.224, 0.225]\n\nBATCH_SIZE = 4\nNUM_WORKERS = 4\n\nTRAIN = 'train'\nVAL = 'val'\nTEST = 'test'\nPHASES = {\n TRAIN: 'train',\n VAL: 'val',\n TEST: 'test',\n}\n\nprint(DEVICE)",
"cuda:0\n"
]
],
[
[
"Limpar diretorio do dataset\n",
"_____no_output_____"
]
],
[
[
"shutil.rmtree(DATASET_PATH)",
"_____no_output_____"
]
],
[
[
"Extrair dataset",
"_____no_output_____"
]
],
[
[
"zip_file = zipfile.ZipFile(ZIP_FILE_PATH)\nzip_file.extractall()\nzip_file.close()",
"_____no_output_____"
]
],
[
[
"Carregar dataset",
"_____no_output_____"
]
],
[
[
"# Augmentacao de dados para treinamento,\n# apenas normalizacao para validacao e teste.\ndata_transforms = {\n TRAIN: transforms.Compose([\n transforms.Resize(IMG_SIZE),\n transforms.RandomHorizontalFlip(),\n transforms.RandomRotation(15),\n transforms.ToTensor(),\n transforms.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),\n ]),\n VAL: transforms.Compose([\n transforms.Resize(IMG_SIZE),\n transforms.ToTensor(),\n transforms.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),\n ]),\n TEST: transforms.Compose([\n transforms.Resize(IMG_SIZE),\n transforms.ToTensor(),\n transforms.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),\n ]),\n}\ndata_sets = {\n phase: datasets.ImageFolder(\n os.path.join(DATASET_PATH, PHASES[phase]),\n data_transforms[phase],\n ) for phase in PHASES\n}\ndata_loaders = {\n phase: torch.utils.data.DataLoader(\n data_sets[phase],\n batch_size = BATCH_SIZE,\n shuffle = True,\n num_workers = NUM_WORKERS,\n ) for phase in PHASES\n}\ndata_sizes = {\n phase: len(data_sets[phase]) for phase in PHASES\n}\nclass_names = data_sets[TRAIN].classes\n\nprint(data_sets)\nprint(data_loaders)\nprint(data_sizes)\nprint(class_names)",
"{'train': Dataset ImageFolder\n Number of datapoints: 8984\n Root location: ./dataset/train\n StandardTransform\nTransform: Compose(\n Resize(size=299, interpolation=PIL.Image.BILINEAR)\n RandomHorizontalFlip(p=0.5)\n RandomRotation(degrees=(-15, 15), resample=False, expand=False)\n ToTensor()\n Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n ), 'val': Dataset ImageFolder\n Number of datapoints: 1492\n Root location: ./dataset/val\n StandardTransform\nTransform: Compose(\n Resize(size=299, interpolation=PIL.Image.BILINEAR)\n ToTensor()\n Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n ), 'test': Dataset ImageFolder\n Number of datapoints: 1492\n Root location: ./dataset/test\n StandardTransform\nTransform: Compose(\n Resize(size=299, interpolation=PIL.Image.BILINEAR)\n ToTensor()\n Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n )}\n{'train': <torch.utils.data.dataloader.DataLoader object at 0x7fa9a91abf98>, 'val': <torch.utils.data.dataloader.DataLoader object at 0x7fa9a91a52e8>, 'test': <torch.utils.data.dataloader.DataLoader object at 0x7fa9a91a53c8>}\n{'train': 8984, 'val': 1492, 'test': 1492}\n['mask', 'no-mask']\n"
]
],
[
[
"Helper functions",
"_____no_output_____"
]
],
[
[
"# Exibe uma imagem a partir de um Tensor.\ndef imshow(data):\n mean = np.array(NORMALIZE_MEAN)\n std = np.array(NORMALIZE_STD)\n image = data.numpy().transpose((1, 2, 0))\n image = std * image + mean\n image = np.clip(image, 0, 1)\n plt.imshow(image)",
"_____no_output_____"
],
[
"# Treina o modelo e retorna o modelo treinado.\ndef train_model(model_type, model, optimizer, criterion, num_epochs = 25):\n start_time = time.time()\n\n num_epochs_without_improvement = 0\n\n best_acc = 0.0\n best_model = copy.deepcopy(model.state_dict())\n torch.save(best_model, 'model.pth')\n\n for epoch in range(num_epochs):\n print('Epoch {}/{} ...'.format(epoch + 1, num_epochs))\n\n for phase in PHASES:\n if phase == TRAIN:\n model.train()\n elif phase == VAL:\n model.eval()\n else:\n continue\n\n running_loss = 0.0\n running_corrects = 0\n\n for data, labels in data_loaders[phase]:\n data = data.to(DEVICE)\n labels = labels.to(DEVICE)\n\n optimizer.zero_grad()\n\n with torch.set_grad_enabled(phase == TRAIN):\n outputs = model(data)\n if phase == TRAIN and model_type == INCEPTION:\n outputs = outputs.logits\n _, preds = torch.max(outputs, 1)\n loss = criterion(outputs, labels)\n\n if phase == TRAIN:\n loss.backward()\n optimizer.step()\n\n running_loss += loss.item() * data.size(0)\n running_corrects += torch.sum(preds == labels.data)\n\n epoch_loss = running_loss / data_sizes[phase]\n epoch_acc = running_corrects.double() / data_sizes[phase]\n\n print('{} => Loss: {:.4f}, Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))\n\n if phase == VAL:\n if epoch_acc > best_acc:\n num_epochs_without_improvement = 0\n best_acc = epoch_acc\n best_model = copy.deepcopy(model.state_dict())\n torch.save(best_model, 'model.pth')\n else:\n num_epochs_without_improvement += 1\n \n if num_epochs_without_improvement == 50:\n print('Exiting early...')\n break\n\n elapsed_time = time.time() - start_time\n print('Took {:.0f}m {:.0f}s'.format(elapsed_time // 60, elapsed_time % 60))\n print('Best Acc: {:4f}'.format(best_acc))\n\n model.load_state_dict(best_model)\n\n return model",
"_____no_output_____"
],
[
"# Visualiza algumas predicoes do modelo.\ndef visualize_model(model, num_images = 6):\n was_training = model.training\n\n model.eval()\n\n fig = plt.figure()\n images_so_far = 0\n\n with torch.no_grad():\n for i, (data, labels) in enumerate(data_loaders[TEST]):\n data = data.to(DEVICE)\n labels = labels.to(DEVICE)\n\n outputs = model(data)\n _, preds = torch.max(outputs, 1)\n\n for j in range(data.size()[0]):\n images_so_far += 1\n ax = plt.subplot(num_images // 2, 2, images_so_far)\n ax.axis('off')\n ax.set_title('Predicted: {}'.format(class_names[preds[j]]))\n imshow(data.cpu().data[j])\n\n if images_so_far == num_images:\n model.train(mode = was_training)\n return\n\n model.train(mode = was_training)",
"_____no_output_____"
],
[
"# Testa o modelo.\ndef test_model(model, criterion):\n was_training = model.training\n\n model.eval()\n\n running_loss = 0.0\n running_corrects = 0\n\n with torch.no_grad():\n for data, labels in data_loaders[TEST]:\n data = data.to(DEVICE)\n labels = labels.to(DEVICE)\n\n outputs = model(data)\n _, preds = torch.max(outputs, 1)\n loss = criterion(outputs, labels)\n\n running_loss += loss.item() * data.size(0)\n running_corrects += torch.sum(preds == labels.data)\n\n loss = running_loss / data_sizes[TEST]\n acc = running_corrects.double() / data_sizes[TEST]\n\n print('Loss: {:4f}, Acc: {:4f}'.format(loss, acc))\n\n model.train(mode = was_training)",
"_____no_output_____"
]
],
[
[
"Exibir amostra do dataset",
"_____no_output_____"
]
],
[
[
"data, labels = next(iter(data_loaders[TRAIN]))\ngrid = torchvision.utils.make_grid(data)\nimshow(grid)",
"_____no_output_____"
]
],
[
[
"Definir modelo",
"_____no_output_____"
]
],
[
[
"if MODEL == INCEPTION:\n model = models.inception_v3(pretrained = True, progress = True)\n\n print(model.fc)\n\n for param in model.parameters():\n param.requires_grad = False\n \n num_features = model.fc.in_features\n model.fc = nn.Linear(num_features, len(class_names))\n model = model.to(DEVICE)\n optimizer = optim.SGD(model.fc.parameters(), lr = 0.001, momentum = 0.9)\nelif MODEL == VGG19:\n model = models.vgg19(pretrained = True, progress = True)\n\n print(model.classifier[6])\n\n for param in model.parameters():\n param.requires_grad = False\n \n num_features = model.classifier[6].in_features\n model.classifier[6] = nn.Linear(num_features, len(class_names))\n model = model.to(DEVICE)\n optimizer = optim.SGD(model.classifier[6].parameters(), lr = 0.001, momentum = 0.9)\nelse:\n print('ERRO: Nenhum tipo de modelo definido!')\n\ncriterion = nn.CrossEntropyLoss()\n\nprint(model)",
"Linear(in_features=2048, out_features=1000, bias=True)\nInception3(\n (Conv2d_1a_3x3): BasicConv2d(\n (conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)\n (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (Conv2d_2a_3x3): BasicConv2d(\n (conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (Conv2d_2b_3x3): BasicConv2d(\n (conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (Conv2d_3b_1x1): BasicConv2d(\n (conv): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(80, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (Conv2d_4a_3x3): BasicConv2d(\n (conv): Conv2d(80, 192, kernel_size=(3, 3), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (Mixed_5b): InceptionA(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch5x5_1): BasicConv2d(\n (conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch5x5_2): BasicConv2d(\n (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_1): BasicConv2d(\n (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_2): BasicConv2d(\n (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3): BasicConv2d(\n (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_5c): InceptionA(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch5x5_1): BasicConv2d(\n (conv): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch5x5_2): BasicConv2d(\n (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_1): BasicConv2d(\n (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_2): BasicConv2d(\n (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3): BasicConv2d(\n (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_5d): InceptionA(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch5x5_1): BasicConv2d(\n (conv): Conv2d(288, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch5x5_2): BasicConv2d(\n (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_1): BasicConv2d(\n (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_2): BasicConv2d(\n (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3): BasicConv2d(\n (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_6a): InceptionB(\n (branch3x3): BasicConv2d(\n (conv): Conv2d(288, 384, kernel_size=(3, 3), stride=(2, 2), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_1): BasicConv2d(\n (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_2): BasicConv2d(\n (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3): BasicConv2d(\n (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), bias=False)\n (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_6b): InceptionC(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_1): BasicConv2d(\n (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_2): BasicConv2d(\n (conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_3): BasicConv2d(\n (conv): Conv2d(128, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_1): BasicConv2d(\n (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_2): BasicConv2d(\n (conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_3): BasicConv2d(\n (conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_4): BasicConv2d(\n (conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_5): BasicConv2d(\n (conv): Conv2d(128, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_6c): InceptionC(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_1): BasicConv2d(\n (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_2): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_3): BasicConv2d(\n (conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_1): BasicConv2d(\n (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_2): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_3): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_4): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_5): BasicConv2d(\n (conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_6d): InceptionC(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_1): BasicConv2d(\n (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_2): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_3): BasicConv2d(\n (conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_1): BasicConv2d(\n (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_2): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_3): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_4): BasicConv2d(\n (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_5): BasicConv2d(\n (conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_6e): InceptionC(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_2): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7_3): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_2): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_3): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_4): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7dbl_5): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (AuxLogits): InceptionAux(\n (conv0): BasicConv2d(\n (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (conv1): BasicConv2d(\n (conv): Conv2d(128, 768, kernel_size=(5, 5), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(768, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (fc): Linear(in_features=768, out_features=1000, bias=True)\n )\n (Mixed_7a): InceptionD(\n (branch3x3_1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_2): BasicConv2d(\n (conv): Conv2d(192, 320, kernel_size=(3, 3), stride=(2, 2), bias=False)\n (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7x3_1): BasicConv2d(\n (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7x3_2): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7x3_3): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch7x7x3_4): BasicConv2d(\n (conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_7b): InceptionE(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_1): BasicConv2d(\n (conv): Conv2d(1280, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_2a): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_2b): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_1): BasicConv2d(\n (conv): Conv2d(1280, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_2): BasicConv2d(\n (conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3a): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3b): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(1280, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (Mixed_7c): InceptionE(\n (branch1x1): BasicConv2d(\n (conv): Conv2d(2048, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_1): BasicConv2d(\n (conv): Conv2d(2048, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_2a): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3_2b): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_1): BasicConv2d(\n (conv): Conv2d(2048, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_2): BasicConv2d(\n (conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3a): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch3x3dbl_3b): BasicConv2d(\n (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)\n (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n (branch_pool): BasicConv2d(\n (conv): Conv2d(2048, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n (fc): Linear(in_features=2048, out_features=2, bias=True)\n)\n"
]
],
[
[
"Treinar modelo",
"_____no_output_____"
]
],
[
[
"model = train_model(MODEL, model, optimizer, criterion)",
"Epoch 1/25 ...\ntrain => Loss: 0.4843, Acc: 0.7777\nval => Loss: 0.3477, Acc: 0.8458\nEpoch 2/25 ...\ntrain => Loss: 0.4682, Acc: 0.8038\nval => Loss: 0.2949, Acc: 0.8727\nEpoch 3/25 ...\ntrain => Loss: 0.4837, Acc: 0.8020\nval => Loss: 0.2188, Acc: 0.9303\nEpoch 4/25 ...\ntrain => Loss: 0.4684, Acc: 0.8088\nval => Loss: 0.2142, Acc: 0.9283\nEpoch 5/25 ...\ntrain => Loss: 0.5015, Acc: 0.8015\nval => Loss: 0.2524, Acc: 0.8968\nEpoch 6/25 ...\ntrain => Loss: 0.4965, Acc: 0.8021\nval => Loss: 0.2148, Acc: 0.9196\nEpoch 7/25 ...\ntrain => Loss: 0.4960, Acc: 0.8018\nval => Loss: 0.2067, Acc: 0.9296\nEpoch 8/25 ...\ntrain => Loss: 0.4781, Acc: 0.8083\nval => Loss: 0.2058, Acc: 0.9249\nEpoch 9/25 ...\ntrain => Loss: 0.4786, Acc: 0.8132\nval => Loss: 0.2041, Acc: 0.9182\nEpoch 10/25 ...\ntrain => Loss: 0.5388, Acc: 0.7901\nval => Loss: 0.2251, Acc: 0.9135\nEpoch 11/25 ...\ntrain => Loss: 0.4930, Acc: 0.8057\nval => Loss: 0.2275, Acc: 0.9182\nEpoch 12/25 ...\ntrain => Loss: 0.4944, Acc: 0.8045\nval => Loss: 0.4300, Acc: 0.8251\nEpoch 13/25 ...\ntrain => Loss: 0.4802, Acc: 0.8055\nval => Loss: 0.5228, Acc: 0.7808\nEpoch 14/25 ...\ntrain => Loss: 0.5139, Acc: 0.8006\nval => Loss: 0.2437, Acc: 0.8995\nEpoch 15/25 ...\ntrain => Loss: 0.4793, Acc: 0.8074\nval => Loss: 0.5636, Acc: 0.7594\nEpoch 16/25 ...\ntrain => Loss: 0.4969, Acc: 0.7999\nval => Loss: 0.3063, Acc: 0.8767\nEpoch 17/25 ...\ntrain => Loss: 0.4993, Acc: 0.8081\nval => Loss: 0.1910, Acc: 0.9229\nEpoch 18/25 ...\ntrain => Loss: 0.4954, Acc: 0.8008\nval => Loss: 0.2456, Acc: 0.8934\nEpoch 19/25 ...\ntrain => Loss: 0.4957, Acc: 0.8021\nval => Loss: 0.2761, Acc: 0.8847\nEpoch 20/25 ...\ntrain => Loss: 0.4914, Acc: 0.8033\nval => Loss: 0.3397, Acc: 0.8505\nEpoch 21/25 ...\ntrain => Loss: 0.5105, Acc: 0.7962\nval => Loss: 0.2612, Acc: 0.8941\nEpoch 22/25 ...\ntrain => Loss: 0.4779, Acc: 0.8103\nval => Loss: 0.4241, Acc: 0.8143\nEpoch 23/25 ...\ntrain => Loss: 0.4996, Acc: 0.7995\nval => Loss: 0.5201, Acc: 0.7714\nEpoch 24/25 ...\ntrain => Loss: 0.5079, Acc: 0.7981\nval => Loss: 0.4069, Acc: 0.8190\nEpoch 25/25 ...\ntrain => Loss: 0.4950, Acc: 0.8025\nval => Loss: 0.2028, Acc: 0.9236\nTook 31m 43s\nBest Acc: 0.930295\n"
]
],
[
[
"Visualizar modelo",
"_____no_output_____"
]
],
[
[
"visualize_model(model)",
"_____no_output_____"
]
],
[
[
"Testar modelo",
"_____no_output_____"
]
],
[
[
"model.load_state_dict(torch.load('model.pth'))\ntest_model(model, criterion)",
"Loss: 0.232413, Acc: 0.922922\n"
]
],
[
[
"Salvar modelo para CPU",
"_____no_output_____"
]
],
[
[
"model = model.cpu()\ntorch.save(model.state_dict(), 'model-cpu.pth')",
"_____no_output_____"
]
],
[
[
"Salvar no Google Drive",
"_____no_output_____"
]
],
[
[
"torch.save(model.state_dict(), '/content/drive/My Drive/model-inception.pth')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4e1d707f780c34b7fb489b6f6a17476e0981a3
| 48,381 |
ipynb
|
Jupyter Notebook
|
wandb/run-20210825_142216-1ahxl5op/tmp/code/00.ipynb
|
Programmer-RD-AI/House-Prices-Advanced-Regression-Techniques-V9-Competition
|
bba67581d4edaa7929d53780a01ba68dd56d63bd
|
[
"Apache-2.0"
] | null | null | null |
wandb/run-20210825_142216-1ahxl5op/tmp/code/00.ipynb
|
Programmer-RD-AI/House-Prices-Advanced-Regression-Techniques-V9-Competition
|
bba67581d4edaa7929d53780a01ba68dd56d63bd
|
[
"Apache-2.0"
] | null | null | null |
wandb/run-20210825_142216-1ahxl5op/tmp/code/00.ipynb
|
Programmer-RD-AI/House-Prices-Advanced-Regression-Techniques-V9-Competition
|
bba67581d4edaa7929d53780a01ba68dd56d63bd
|
[
"Apache-2.0"
] | null | null | null | 32.040397 | 375 | 0.474773 |
[
[
[
"# WorkFlow\n### Imports\n### Load the data\n### Cleanning\n### FE\n### Data.corr()\n### Analytics\n### Preproccessing\n### Decomposition\n### Feature Selection\n### Modelling\n### Random Search\n### Gird Search",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"import random\nimport seaborn as sns\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport sklearn\nimport torch,torchvision\nfrom torch.nn import *\nfrom torch.optim import *\n# Preproccessing\nfrom sklearn.preprocessing import (\n StandardScaler,\n RobustScaler,\n MinMaxScaler,\n MaxAbsScaler,\n OneHotEncoder,\n Normalizer,\n Binarizer\n)\n# Decomposition\nfrom sklearn.decomposition import PCA\nfrom sklearn.decomposition import KernelPCA\n# Feature Selection\nfrom sklearn.feature_selection import VarianceThreshold\nfrom sklearn.feature_selection import SelectKBest\nfrom sklearn.feature_selection import RFECV\nfrom sklearn.feature_selection import SelectFromModel\n# Model Eval\nfrom sklearn.compose import make_column_transformer\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.model_selection import cross_val_score,train_test_split\nfrom sklearn.metrics import mean_absolute_error,mean_squared_error,accuracy_score,precision_score,f1_score,recall_score\n# Models\nfrom sklearn.neighbors import KNeighborsRegressor\nfrom sklearn.linear_model import LogisticRegression,LogisticRegressionCV\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import GradientBoostingRegressor,AdaBoostRegressor,VotingRegressor,BaggingRegressor,RandomForestRegressor\nfrom sklearn.svm import SVR\nfrom sklearn.ensemble import BaggingRegressor\nfrom sklearn.ensemble import ExtraTreesRegressor\nfrom catboost import CatBoost,CatBoostRegressor\nfrom xgboost import XGBRegressor,XGBRFRegressor\nfrom flaml import AutoML\n# Other\nimport pickle\nimport wandb\n\nPROJECT_NAME = 'House-Prices-Advanced-Regression-Techniques-V9'\ndevice = 'cuda'\nnp.random.seed(21)\nrandom.seed(21)\ntorch.manual_seed(21)",
"_____no_output_____"
]
],
[
[
"### Funtions",
"_____no_output_____"
]
],
[
[
"def make_submission(model):\n pass",
"_____no_output_____"
],
[
"def valid(model,X,y,valid=False):\n preds = model.predict(X)\n if valid:\n results = {\n 'val mean_absolute_error':mean_absolute_error(y_true=y,y_pred=preds),\n 'val mean_squared_error':mean_squared_error(y_true=y,y_pred=preds),\n }\n else:\n results = {\n 'mean_absolute_error':mean_absolute_error(y_true=y,y_pred=preds),\n 'mean_squared_error':mean_squared_error(y_true=y,y_pred=preds),\n }\n return results",
"_____no_output_____"
],
[
"def train(model,X_train,X_test,y_train,y_test,name):\n wandb.init(project=PROJECT_NAME,name=name)\n model.fit(X_train,y_train)\n wandb.log(valid(model,X_train,y_train))\n wandb.log(valid(model,X_test,y_test,True))\n make_submission(model)\n return model",
"_____no_output_____"
],
[
"def object_to_int(data,col):\n data_col = data[col].to_dict()\n idx = -1\n labels_and_int_index = {}\n for data_col_vals in data_col.values():\n if data_col_vals not in labels_and_int_index.keys():\n idx += 1\n labels_and_int_index[data_col_vals] = idx\n new_data = []\n for data_col_vals in data_col.values():\n new_data.append(labels_and_int_index[data_col_vals])\n data[col] = new_data\n return data,idx,labels_and_int_index,new_data",
"_____no_output_____"
],
[
"def fe(data,col,quantile_max_num=0.99,quantile_min_num=0.05):\n max_num = data[col].quantile(quantile_max_num)\n min_num = data[col].quantile(quantile_min_num)\n print(max_num)\n print(min_num)\n data = data[data[col] < max_num]\n data = data[data[col] > min_num]\n return data",
"_____no_output_____"
],
[
"def decomposition(X,pca=False,kernal_pca=False):\n if pca:\n pca = PCA()\n X = pca.fit_transform(X)\n if kernal_pca:\n kernal_pca = KernelPCA()\n X = kernal_pca.fit_transform(X)\n return X",
"_____no_output_____"
],
[
"def feature_selection_prep_data(model,X,y,select_from_model=False,variance_threshold=False,select_k_best=False,rfecv=False):\n if select_from_model:\n transform = SelectFromModel(estimator=model.fit(X, y))\n X = transform.transform(X)\n if variance_threshold:\n transform = VarianceThreshold()\n X = transform.fit_transform(X)\n if select_k_best:\n X = SelectKBest(chi2, k='all').fit_transform(X, y)\n if rfecv:\n X = RFECV(model, step=1, cv=5).fit(X, y)\n X = X.transform(X)\n return X",
"_____no_output_____"
],
[
"def prep_data(X,transformer):\n mct = make_column_transformer(\n (transformer,list(X.columns)),\n remainder='passthrough'\n )\n X = mct.fit_transform(X)\n return X",
"_____no_output_____"
]
],
[
[
"## Load the data",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('./data/train.csv')",
"_____no_output_____"
],
[
"preproccessings = [StandardScaler,RobustScaler,MinMaxScaler,MaxAbsScaler,OneHotEncoder,Normalizer,Binarizer]",
"_____no_output_____"
],
[
"models = [\n ['KNeighborsRegressor',KNeighborsRegressor],\n ['LogisticRegression',LogisticRegression],\n ['LogisticRegressionCV',LogisticRegressionCV],\n ['DecisionTreeRegressor',DecisionTreeRegressor],\n ['GradientBoostingRegressor',GradientBoostingRegressor],\n ['AdaBoostRegressor',AdaBoostRegressor],\n ['RandomForestRegressor',RandomForestRegressor],\n ['BaggingRegressor',BaggingRegressor],\n ['GaussianNB',GaussianNB],\n ['ExtraTreesRegressor',ExtraTreesRegressor],\n ['CatBoost',CatBoost],\n ['CatBoostRegressor',CatBoostRegressor],\n ['XGBRegressor',XGBRegressor],\n ['XGBRFRegressor',XGBRFRegressor],\n ['ExtraTreesRegressor',ExtraTreesRegressor],\n]",
"_____no_output_____"
]
],
[
[
"## Cleanning the data",
"_____no_output_____"
]
],
[
[
"X = data.drop('SalePrice',axis=1)\ny = data['SalePrice']",
"_____no_output_____"
],
[
"str_cols = []\nint_cols = []",
"_____no_output_____"
],
[
"for col_name,num_of_missing_rows,dtype in zip(list(X.columns),X.isna().sum(),X.dtypes):\n if dtype == object:\n str_cols.append(col_name)\n else:\n int_cols.append(col_name)",
"_____no_output_____"
],
[
"for str_col in str_cols:\n X,idx,labels_and_int_index,new_data = object_to_int(X,str_col)",
"_____no_output_____"
],
[
"X.head()",
"_____no_output_____"
],
[
"nan_cols = []\nfor col_name,num_of_missing_rows,dtype in zip(list(X.columns),X.isna().sum(),X.dtypes):\n if num_of_missing_rows > 0:\n nan_cols.append(col_name)",
"_____no_output_____"
],
[
"for nan_col in nan_cols:\n X[nan_col].fillna(X[nan_col].median(),inplace=True)",
"_____no_output_____"
],
[
"nan_cols = []\nfor col_name,num_of_missing_rows,dtype in zip(list(X.columns),X.isna().sum(),X.dtypes):\n if num_of_missing_rows > 0:\n nan_cols.append(col_name)",
"_____no_output_____"
],
[
"# train(GradientBoostingRegressor(),X,X,y,y,name='baseline-without-fe')",
"_____no_output_____"
],
[
"X_old = X.copy()",
"_____no_output_____"
]
],
[
[
"## FE",
"_____no_output_____"
]
],
[
[
"# for col_name in list(X.columns):\n# try:\n# X = X_old.copy()\n# X = fe(X,col_name)\n# train(GradientBoostingRegressor(),X,X,y,y,name=f'baseline-with-fe-{col_name}')\n# except:\n# print('*'*50)\n# print('*'*50)",
"_____no_output_____"
],
[
"# X = X_old.copy()",
"_____no_output_____"
],
[
"X_corr = X_old.corr()",
"_____no_output_____"
],
[
"keep_cols = []",
"_____no_output_____"
]
],
[
[
"## Data.corr()",
"_____no_output_____"
]
],
[
[
"# for key,val in zip(X_corr.to_dict().keys(),X_corr.to_dict().values()):\n# for val_key,val_vals in zip(val.keys(),val.values()):\n# if val_key == key:\n# pass\n# else:\n# if val_vals > 0.0:\n# if val_key not in keep_cols:\n# print(val_vals)\n# keep_cols.append(val_key)",
"_____no_output_____"
],
[
"# fig,ax = plt.subplots(figsize=(25,12))\n# ax = sns.heatmap(X_corr,annot=True,linewidths=0.5,fmt='.2f',cmap='YlGnBu')",
"_____no_output_____"
],
[
"# keep_cols",
"_____no_output_____"
],
[
"# len(keep_cols)",
"_____no_output_____"
]
],
[
[
"## Analytics",
"_____no_output_____"
]
],
[
[
"X.head()",
"_____no_output_____"
]
],
[
[
"## Preproccessing",
"_____no_output_____"
]
],
[
[
"X_old = X.copy()",
"_____no_output_____"
],
[
"for preproccessing in preproccessings:\n X = X_old.copy()\n preproccessing = preproccessing()\n X = preproccessing.fit_transform(X)\n train(GradientBoostingRegressor(),X,X,y,y,name=f'{preproccessing}-preproccessing')",
"\u001b[34m\u001b[1mwandb\u001b[0m: Currently logged in as: \u001b[33mranuga-d\u001b[0m (use `wandb login --relogin` to force relogin)\n"
],
[
"X = X_old.copy()",
"_____no_output_____"
],
[
"X = decomposition(True,False)\ntrain(GradientBoostingRegressor(),X,X,y,y,name=f'PCA=True-kernal_pca=False-decomposition')",
"_____no_output_____"
],
[
"X = X_old.copy()",
"_____no_output_____"
],
[
"X = decomposition(False,True)\ntrain(GradientBoostingRegressor(),X,X,y,y,name=f'PCA=False-kernal_pca=True-decomposition')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4e21c9da54d629b3ca1856346614dd1d3612f4
| 125,173 |
ipynb
|
Jupyter Notebook
|
ex04/matheus_xavier/IA025_A04.ipynb
|
flych3r/IA025_2022S1
|
8a5a92a0d22c3a602906bdc3b8c7eb8ae325e88b
|
[
"MIT"
] | 2 |
2022-03-20T21:16:14.000Z
|
2022-03-20T22:20:26.000Z
|
ex04/matheus_xavier/IA025_A04.ipynb
|
flych3r/IA025_2022S1
|
8a5a92a0d22c3a602906bdc3b8c7eb8ae325e88b
|
[
"MIT"
] | null | null | null |
ex04/matheus_xavier/IA025_A04.ipynb
|
flych3r/IA025_2022S1
|
8a5a92a0d22c3a602906bdc3b8c7eb8ae325e88b
|
[
"MIT"
] | 9 |
2022-03-16T15:39:36.000Z
|
2022-03-27T14:04:34.000Z
| 125.173 | 18,109 | 0.845989 |
[
[
[
"<a href=\"https://colab.research.google.com/github/flych3r/IA025_2022S1/blob/main/ex04/matheus_xavier/IA025_A04.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Regressão Softmax com dados do MNIST utilizando gradiente descendente estocástico por minibatches",
"_____no_output_____"
],
[
"Este exercicío consiste em treinar um modelo de uma única camada linear no MNIST **sem** usar as seguintes funções do pytorch:\n\n- torch.nn.Linear\n- torch.nn.CrossEntropyLoss\n- torch.nn.NLLLoss\n- torch.nn.LogSoftmax\n- torch.optim.SGD\n- torch.utils.data.Dataloader",
"_____no_output_____"
],
[
"## Importação das bibliotecas",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport random\nimport torch\nimport torchvision\nfrom torchvision.datasets import MNIST",
"_____no_output_____"
]
],
[
[
"## Fixando as seeds",
"_____no_output_____"
]
],
[
[
"random.seed(123)\nnp.random.seed(123)\ntorch.manual_seed(123)",
"_____no_output_____"
]
],
[
[
"## Dataset e dataloader",
"_____no_output_____"
],
[
"### Definição do tamanho do minibatch",
"_____no_output_____"
]
],
[
[
"batch_size = 50",
"_____no_output_____"
]
],
[
[
"### Carregamento, criação dataset e do dataloader",
"_____no_output_____"
]
],
[
[
"dataset_dir = '../data/'\n\ndataset_train_full = MNIST(\n dataset_dir, train=True, download=True,\n transform=torchvision.transforms.ToTensor()\n)\nprint(dataset_train_full.data.shape)\nprint(dataset_train_full.targets.shape)",
"torch.Size([60000, 28, 28])\ntorch.Size([60000])\n"
]
],
[
[
"### Usando apenas 1000 amostras do MNIST\n\nNeste exercício utilizaremos 1000 amostras de treinamento.",
"_____no_output_____"
]
],
[
[
"indices = torch.randperm(len(dataset_train_full))[:1000]\ndataset_train = torch.utils.data.Subset(dataset_train_full, indices)",
"_____no_output_____"
],
[
"# Escreva aqui o equivalente do código abaixo:\n# loader_train = torch.utils.data.DataLoader(dataset_train, batch_size=batch_size, shuffle=False)\nimport math\n\n\nclass DataLoader:\n def __init__(self, dataset: torch.utils.data.Dataset, batch_size: int = 1, shuffle: bool = True):\n self.dataset = dataset\n self.batch_size = batch_size\n self.shuffle = shuffle\n self.idx = 0\n self.indexes = np.arange(len(dataset))\n self._size = math.ceil(len(dataset) / self.batch_size)\n\n def __iter__(self):\n self.idx = 0\n return self\n\n def __next__(self):\n if self.idx < len(self):\n if self.idx == 0 and self.shuffle:\n np.random.shuffle(self.indexes)\n batch = self.indexes[self.idx * self.batch_size: (self.idx + 1) * self.batch_size]\n self.idx += 1\n x_batch, y_batch = [], []\n for b in batch:\n x, y = self.dataset[b]\n x_batch.append(x)\n y_batch.append(y)\n return torch.stack(x_batch), torch.tensor(y_batch)\n raise StopIteration\n\n def __len__(self):\n return self._size\n\nloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=False)",
"_____no_output_____"
],
[
"print('Número de minibatches de trenamento:', len(loader_train))\n\nx_train, y_train = next(iter(loader_train))\nprint(\"\\nDimensões dos dados de um minibatch:\", x_train.size())\nprint(\"Valores mínimo e máximo dos pixels: \", torch.min(x_train), torch.max(x_train))\nprint(\"Tipo dos dados das imagens: \", type(x_train))\nprint(\"Tipo das classes das imagens: \", type(y_train))",
"Número de minibatches de trenamento: 20\n\nDimensões dos dados de um minibatch: torch.Size([50, 1, 28, 28])\nValores mínimo e máximo dos pixels: tensor(0.) tensor(1.)\nTipo dos dados das imagens: <class 'torch.Tensor'>\nTipo das classes das imagens: <class 'torch.Tensor'>\n"
]
],
[
[
"## Modelo",
"_____no_output_____"
]
],
[
[
"# Escreva aqui o codigo para criar um modelo cujo o equivalente é: \n# model = torch.nn.Linear(28*28, 10)\n# model.load_state_dict(dict(weight=torch.zeros(model.weight.shape), bias=torch.zeros(model.bias.shape)))\n\nclass Model:\n def __init__(self, in_features: int, out_features: int):\n self.weight = torch.zeros(out_features, in_features, requires_grad=True)\n self.bias = torch.zeros(out_features, requires_grad=True)\n\n def __call__(self, x: torch.Tensor) -> torch.Tensor:\n y_pred = x.mm(torch.t(self.weight)) + self.bias.unsqueeze(0)\n return y_pred\n \n def parameters(self):\n return self.weight, self.bias\n\nmodel = Model(28*28, 10)",
"_____no_output_____"
]
],
[
[
"## Treinamento",
"_____no_output_____"
],
[
"### Inicialização dos parâmetros",
"_____no_output_____"
]
],
[
[
"n_epochs = 50\nlr = 0.1",
"_____no_output_____"
]
],
[
[
"## Definição da Loss\n\n",
"_____no_output_____"
]
],
[
[
"# Escreva aqui o equivalente de:\n# criterion = torch.nn.CrossEntropyLoss()\n\nclass CrossEntropyLoss:\n def __init__(self):\n self.loss = 0\n\n def __call__(self, inputs: torch.Tensor, targets: torch.Tensor): \n log_sum_exp = torch.log(torch.sum(torch.exp(inputs), dim=1, keepdim=True))\n logits = inputs.gather(dim=1, index=targets.unsqueeze(dim=1))\n return torch.mean(-logits + log_sum_exp)\n\ncriterion = CrossEntropyLoss()",
"_____no_output_____"
]
],
[
[
"# Definição do Optimizer",
"_____no_output_____"
]
],
[
[
"# Escreva aqui o equivalente de:\n# optimizer = torch.optim.SGD(model.parameters(), lr)\nfrom typing import Iterable\n\nclass SGD:\n def __init__(self, parameters: Iterable[torch.Tensor], learning_rate: float):\n self.parameters = parameters\n self.learning_rate = learning_rate\n\n def step(self):\n for p in self.parameters:\n p.data -= self.learning_rate * p.grad\n\n def zero_grad(self):\n for p in self.parameters:\n p.grad = torch.zeros_like(p.data)\n\noptimizer = SGD(model.parameters(), lr)",
"_____no_output_____"
]
],
[
[
"### Laço de treinamento dos parâmetros",
"_____no_output_____"
]
],
[
[
"epochs = []\nloss_history = []\nloss_epoch_end = []\ntotal_trained_samples = 0\nfor i in range(n_epochs):\n # Substitua aqui o loader_train de acordo com sua implementação do dataloader.\n for x_train, y_train in loader_train:\n # Transforma a entrada para uma dimensão\n inputs = x_train.view(-1, 28 * 28)\n # predict da rede\n outputs = model(inputs)\n\n # calcula a perda\n loss = criterion(outputs, y_train)\n\n # zero, backpropagation, ajusta parâmetros pelo gradiente descendente\n # Escreva aqui o código cujo o resultado é equivalente às 3 linhas abaixo:\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n total_trained_samples += x_train.size(0)\n epochs.append(total_trained_samples / len(dataset_train))\n loss_history.append(loss.item())\n\n loss_epoch_end.append(loss.item())\n print(f'Epoch: {i:d}/{n_epochs - 1:d} Loss: {loss.item()}')",
"Epoch: 0/49 Loss: 1.1979684829711914\nEpoch: 1/49 Loss: 0.867622971534729\nEpoch: 2/49 Loss: 0.7226786613464355\nEpoch: 3/49 Loss: 0.6381281018257141\nEpoch: 4/49 Loss: 0.5809750556945801\nEpoch: 5/49 Loss: 0.5387411713600159\nEpoch: 6/49 Loss: 0.5056463479995728\nEpoch: 7/49 Loss: 0.47862708568573\nEpoch: 8/49 Loss: 0.4558936655521393\nEpoch: 9/49 Loss: 0.4363219141960144\nEpoch: 10/49 Loss: 0.4191650152206421\nEpoch: 11/49 Loss: 0.403904527425766\nEpoch: 12/49 Loss: 0.39016804099082947\nEpoch: 13/49 Loss: 0.3776799738407135\nEpoch: 14/49 Loss: 0.3662315011024475\nEpoch: 15/49 Loss: 0.35566142201423645\nEpoch: 16/49 Loss: 0.34584280848503113\nEpoch: 17/49 Loss: 0.33667415380477905\nEpoch: 18/49 Loss: 0.3280735909938812\nEpoch: 19/49 Loss: 0.31997358798980713\nEpoch: 20/49 Loss: 0.3123184144496918\nEpoch: 21/49 Loss: 0.30506110191345215\nEpoch: 22/49 Loss: 0.2981624901294708\nEpoch: 23/49 Loss: 0.29158854484558105\nEpoch: 24/49 Loss: 0.2853103280067444\nEpoch: 25/49 Loss: 0.27930304408073425\nEpoch: 26/49 Loss: 0.2735445499420166\nEpoch: 27/49 Loss: 0.2680158317089081\nEpoch: 28/49 Loss: 0.26270005106925964\nEpoch: 29/49 Loss: 0.2575823664665222\nEpoch: 30/49 Loss: 0.25264933705329895\nEpoch: 31/49 Loss: 0.24788936972618103\nEpoch: 32/49 Loss: 0.24329166114330292\nEpoch: 33/49 Loss: 0.23884664475917816\nEpoch: 34/49 Loss: 0.23454585671424866\nEpoch: 35/49 Loss: 0.23038141429424286\nEpoch: 36/49 Loss: 0.22634631395339966\nEpoch: 37/49 Loss: 0.22243395447731018\nEpoch: 38/49 Loss: 0.2186385691165924\nEpoch: 39/49 Loss: 0.21495485305786133\nEpoch: 40/49 Loss: 0.21137763559818268\nEpoch: 41/49 Loss: 0.20790255069732666\nEpoch: 42/49 Loss: 0.20452527701854706\nEpoch: 43/49 Loss: 0.20124195516109467\nEpoch: 44/49 Loss: 0.19804900884628296\nEpoch: 45/49 Loss: 0.19494293630123138\nEpoch: 46/49 Loss: 0.1919206976890564\nEpoch: 47/49 Loss: 0.1889793425798416\nEpoch: 48/49 Loss: 0.1861160844564438\nEpoch: 49/49 Loss: 0.1833283007144928\n"
]
],
[
[
"### Visualizando gráfico de perda durante o treinamento",
"_____no_output_____"
]
],
[
[
"plt.plot(epochs, loss_history)\nplt.xlabel('época')",
"_____no_output_____"
]
],
[
[
"### Visualização usual da perda, somente no final de cada minibatch",
"_____no_output_____"
]
],
[
[
"n_batches_train = len(loader_train)\nplt.plot(epochs[::n_batches_train], loss_history[::n_batches_train])\nplt.xlabel('época')",
"_____no_output_____"
],
[
"# Assert do histórico de losses\ntarget_loss_epoch_end = np.array([\n 1.1979684829711914,\n 0.867622971534729,\n 0.7226786613464355,\n 0.6381281018257141,\n 0.5809749960899353,\n 0.5387411713600159,\n 0.5056464076042175,\n 0.4786270558834076,\n 0.4558936357498169,\n 0.4363219141960144,\n 0.4191650450229645,\n 0.4039044976234436,\n 0.3901679515838623,\n 0.3776799440383911,\n 0.3662314713001251,\n 0.35566139221191406,\n 0.34584277868270874,\n 0.33667415380477905,\n 0.32807353138923645,\n 0.31997355818748474,\n 0.312318354845047,\n 0.3050611615180969,\n 0.29816246032714844,\n 0.29158851504325867,\n 0.28531041741371155,\n 0.2793029546737671,\n 0.273544579744339,\n 0.2680158317089081,\n 0.26270008087158203,\n 0.2575823664665222,\n 0.25264936685562134,\n 0.24788929522037506,\n 0.24329163134098053,\n 0.23884665966033936,\n 0.23454584181308746,\n 0.23038141429424286,\n 0.22634628415107727,\n 0.22243399918079376,\n 0.2186385989189148,\n 0.21495483815670013,\n 0.21137762069702148,\n 0.20790249109268188,\n 0.20452524721622467,\n 0.20124195516109467,\n 0.19804897904396057,\n 0.1949428766965866,\n 0.19192075729370117,\n 0.188979372382164,\n 0.18611609935760498,\n 0.1833282858133316])\n\nassert np.allclose(np.array(loss_epoch_end), target_loss_epoch_end, atol=1e-6)",
"_____no_output_____"
]
],
[
[
"## Exercício \n\nEscreva um código que responda às seguintes perguntas:\n\nQual é a amostra classificada corretamente, com maior probabilidade?\n\nQual é a amostra classificada erradamente, com maior probabilidade?\n\nQual é a amostra classificada corretamente, com menor probabilidade?\n\nQual é a amostra classificada erradamente, com menor probabilidade?",
"_____no_output_____"
]
],
[
[
"# Escreva o código aqui:\nloader_eval = DataLoader(dataset_train, batch_size=len(dataset_train), shuffle=False)\n\nx, y = next(loader_eval)\nlogits = model(x.view(-1, 28 * 28))\n\nexp_logits = torch.exp(logits)\nsum_exp_logits = torch.sum(exp_logits, dim=1, keepdim=True)\nsoftmax = (exp_logits / sum_exp_logits).detach()\n\ny_pred = torch.argmax(softmax, dim=1)\ny_proba = softmax.gather(-1, y_pred.view(-1, 1)).ravel()\n\ncorret_preditions = (y == y_pred)\nwrong_predictions = (y != y_pred)",
"_____no_output_____"
],
[
"def plot_image_and_proba(images, probas, idx, title):\n plt.figure(figsize=(16, 8))\n x_labels = list(range(10))\n plt.subplot(121)\n plt.imshow(images[idx][0])\n plt.subplot(122)\n plt.bar(x_labels, probas[idx])\n plt.xticks(x_labels)\n plt.suptitle(title)\n plt.show()",
"_____no_output_____"
],
[
"# Qual é a amostra classificada corretamente, com maior probabilidade?\n\nmask = corret_preditions\nidx = torch.argmax(y_proba[mask])\n\ntitle = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(\n y_pred[mask][idx],\n y_proba[mask][idx],\n y[mask][idx],\n)\nplot_image_and_proba(x[mask], softmax[mask], idx, title)",
"_____no_output_____"
],
[
"# Qual é a amostra classificada erradamente, com maior probabilidade?\n\nmask = wrong_predictions\nidx = torch.argmax(y_proba[mask])\n\ntitle = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(\n y_pred[mask][idx],\n y_proba[mask][idx],\n y[mask][idx],\n)\nplot_image_and_proba(x[mask], softmax[mask], idx, title)",
"_____no_output_____"
],
[
"# Qual é a amostra classificada corretamente, com menor probabilidade?\n\nmask = corret_preditions\nidx = torch.argmin(y_proba[mask])\n\ntitle = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(\n y_pred[mask][idx],\n y_proba[mask][idx],\n y[mask][idx],\n)\nplot_image_and_proba(x[mask], softmax[mask], idx, title)",
"_____no_output_____"
],
[
"# Qual é a amostra classificada erradamente, com menor probabilidade?\n\nmask = wrong_predictions\nidx = torch.argmin(y_proba[mask])\n\ntitle = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(\n y_pred[mask][idx],\n y_proba[mask][idx],\n y[mask][idx],\n)\nplot_image_and_proba(x[mask], softmax[mask], idx, title)",
"_____no_output_____"
]
],
[
[
"## Exercício Bonus\n\nImplemente um dataloader que aceite como parâmetro de entrada a distribuição probabilidade das classes que deverão compor um batch.\nPor exemplo, se a distribuição de probabilidade passada como entrada for:\n\n`[0.01, 0.01, 0.72, 0.2, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]`\n\nEm média, 72% dos exemplos do batch deverão ser da classe 2, 20% deverão ser da classe 3, e os demais deverão ser das outras classes.\n\nMostre também que sua implementação está correta.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a4e456e54850ed4c4f2d28bd1b9d9c4e9eba7bd
| 4,820 |
ipynb
|
Jupyter Notebook
|
Python_lab_3.ipynb
|
Real-Raj-kumar/Rajendra
|
1ac15d2b421870ca5e47456368a1e0f14addaad0
|
[
"MIT"
] | null | null | null |
Python_lab_3.ipynb
|
Real-Raj-kumar/Rajendra
|
1ac15d2b421870ca5e47456368a1e0f14addaad0
|
[
"MIT"
] | null | null | null |
Python_lab_3.ipynb
|
Real-Raj-kumar/Rajendra
|
1ac15d2b421870ca5e47456368a1e0f14addaad0
|
[
"MIT"
] | null | null | null | 28.352941 | 234 | 0.443983 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Real-Raj-kumar/Rajendra/blob/master/Python_lab_3.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"#Create a list with Tuples inside it(Series) calculate the sum of elements in tuple and store thew sum of tuples in record\ndef test(lst):\n result = map(sum, lst)\n return list(result)\nnums = [(1,2,5), (2,3,8), (3,4,6)]\nprint(\"Original list of tuples:\")\nprint(nums)\nprint(\"\\nSum of all the elements of each tuple stored the sum of tuples:\")\nprint(test(nums))\nnums = [(1,2,6), (2,3,-6), (3,4), (2,2,2,2)]",
"Original list of tuples:\n[(1, 2, 5), (2, 3, 8), (3, 4, 6)]\n\nSum of all the elements of each tuple stored the sum of tuples:\n[8, 13, 13]\n"
],
[
"#Wap a to create a list and input numbers into it,then remove the repeated elements from it and display it back\ndef Remove(duplicate):\n\tfinal_list = []\n\tfor num in duplicate:\n\t\tif num not in final_list:\n\t\t\tfinal_list.append(num)\n\treturn final_list\nduplicate = [2, 4, 10, 20, 5, 2, 20, 4]\nprint(Remove(duplicate))\n",
"[2, 4, 10, 20, 5]\n"
],
[
"#Wap a to create a list and input numbers into it,then remove the repeated elements from it and display it back\ndef Remove(duplicate):\n\tfinal_list = []\n\tfor num in duplicate:\n\t\tif num not in final_list:\n\t\t\tfinal_list.append(num)\n\treturn final_list\nnum=int(input(\"enter how many number you want to insert\\n\"))\nlist=[]\nprint(\"Enter the value for the list\")\nfor i in range(0,num):\n x = int(input(\"\\n\"))\n list.append(x)\nprint(\"Given list is\")\nprint(list)\nprint(\"List wiothout duplication\")\nprint(Remove(list))",
"enter how many number you want to insert\n8\nEnter the value for the list\n\n1\n\n2\n\n1\n\n1\n\n4\n\n5\n\n6\n\n4\nGiven list is\n[1, 2, 1, 1, 4, 5, 6, 4]\nList wiothout duplication\n[1, 2, 4, 5, 6]\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a4e4aeadcf5d1e86366ec03dac7645f2f3921e7
| 161,263 |
ipynb
|
Jupyter Notebook
|
notebook/3_association_rules/pattern_mining.ipynb
|
alessandrocuda/carvana
|
dbe89ea41a2fb7a46d22cab28c20871f3e4e95ff
|
[
"MIT"
] | null | null | null |
notebook/3_association_rules/pattern_mining.ipynb
|
alessandrocuda/carvana
|
dbe89ea41a2fb7a46d22cab28c20871f3e4e95ff
|
[
"MIT"
] | null | null | null |
notebook/3_association_rules/pattern_mining.ipynb
|
alessandrocuda/carvana
|
dbe89ea41a2fb7a46d22cab28c20871f3e4e95ff
|
[
"MIT"
] | 1 |
2020-03-17T09:07:35.000Z
|
2020-03-17T09:07:35.000Z
| 69.211588 | 17,664 | 0.669075 |
[
[
[
"%matplotlib notebook\nimport sys\nsys.path.insert(1, '../../../script/')",
"_____no_output_____"
],
[
"import math\nimport numpy as np\nimport pandas as pd\nimport scipy.stats as stats\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n#import missingno as msno\nfrom scipy.stats import mode\nfrom scipy.spatial.distance import pdist\nfrom scipy.cluster.hierarchy import linkage, dendrogram, fcluster\nfrom sklearn.preprocessing import StandardScaler, MinMaxScaler\nfrom sklearn.cluster import KMeans\nfrom sklearn.metrics import silhouette_score\n\nfrom collections import defaultdict\nfrom scipy.stats.stats import pearsonr\nfrom fim import apriori",
"_____no_output_____"
],
[
"df = pd.read_csv('data/training.csv') ",
"_____no_output_____"
],
[
"df[:10]",
"_____no_output_____"
],
[
"X = df[['Make', 'Model']]\ngkk = X.groupby(['Make', 'Model']) \ngkk.first()\n#for key, item in gkk:\n# print(key)",
"_____no_output_____"
],
[
"df[\"Model\"].value_counts()",
"_____no_output_____"
]
],
[
[
"# Data Cleaning",
"_____no_output_____"
],
[
"We can't use here our cleaning function because it also works with missing values, but the main task of pattern mining is to find rules to substitute missing values. So here we do all the data cleaning EXCEPT dealing with missing values",
"_____no_output_____"
],
[
"<b>Typo correction</b>",
"_____no_output_____"
]
],
[
[
"df.iat[6895, 11] = 'MANUAL'\ndf.iat[42627, 6] = 'SCION'\n\n#a = df[(df['Nationality']=='TOP LINE ASIAN') | (df['Nationality']=='OTHER ASIAN')].index\n#for x in a:\n# df['Nationality'].values[x] = 'ASIAN'\n\n# WheelTypeID 0.0 correction\ndf.iat[3897, 12] = 1.0\ndf.iat[23432, 12] = 1.0\ndf.iat[23831, 12] = 2.0\ndf.iat[45666, 12] = 1.0\n\n# submodel la mode sui group by \n# Praticamente è la mode sui group by (più o meno specifici)\n\ndf.iat[28961, 9] = '4D SEDAN SE1'\ndf.iat[35224, 9] = '4D SEDAN SXT FFV'\ndf.iat[48641, 9] = '4D SEDAN SXT FFV'\ndf.iat[28280, 9] = 'PASSENGER 3.9L SE'\ndf.iat[33225, 9] = '4D SUV 4.6L'\ndf.iat[50661, 9] = 'REG CAB 2.2L FFV'\ndf.iat[23019, 9] = '4D SEDAN'\n\n# size la mode sui group by\ndf.iat[18532, 16] = 'MEDIUM SUV'\ndf.iat[20016, 16] = 'SMALL SUV'\ndf.iat[35157, 16] = 'SMALL SUV'\ndf.iat[15769, 16] = 'MEDIUM SUV'",
"_____no_output_____"
]
],
[
[
"<b>Dropped features</b>",
"_____no_output_____"
]
],
[
[
"del df['PRIMEUNIT']\ndel df['AUCGUART']\ndel df['RefId']\ndel df['VNZIP1']\ndel df['Auction']\ndel df['IsOnlineSale']\ndel df['SubModel']\ndel df['Color']\ndel df['VehYear']\ndel df['PurchDate']\ndel df['Trim']\ndel df['TopThreeAmericanName']\ndel df['WheelType']\ndel df['BYRNO']\ndel df['MMRAcquisitionAuctionCleanPrice']\ndel df['MMRAcquisitionRetailAveragePrice']\ndel df['MMRAcquisitonRetailCleanPrice']\ndel df['MMRCurrentAuctionAveragePrice']\ndel df['MMRCurrentAuctionCleanPrice']\ndel df['MMRCurrentRetailAveragePrice']\ndel df['MMRCurrentRetailCleanPrice']",
"_____no_output_____"
]
],
[
[
"<b>Row deletion outliers</b>",
"_____no_output_____"
]
],
[
[
"features = ['VehOdo',\n 'MMRAcquisitionAuctionAveragePrice',\n 'VehBCost',\n 'WarrantyCost',\n 'VehicleAge']\nfor feature in features:\n for isBadBuy in [0,1]:\n q1 = df[(df.IsBadBuy == isBadBuy)][feature].quantile(0.25)\n q3 = df[(df.IsBadBuy == isBadBuy)][feature].quantile(0.75)\n iqr = q3 - q1\n qlow = q1 - 1.5*iqr\n qhigh = q3 + 1.5*iqr\n\n df.drop(df[(df.IsBadBuy == isBadBuy) & (df[feature] <= qlow)].index, inplace=True)\n df.drop(df[(df.IsBadBuy == isBadBuy) & (df[feature] >= qhigh)].index, inplace=True)",
"_____no_output_____"
]
],
[
[
"# Data Preparation",
"_____no_output_____"
],
[
"We have 5 numerical variables: VehicleAge, VehOdo, MMRAcquisitionAuctionAveragePrice, VehBCost and WarrantyCost.\nThe VehicleAge is almost categorical variable (it has only 8 possible values: from 1 to 8), but all the others have thousands of possible unique values. For Pattern Mining it will means that all these values will create different patterns which is not really useful for us. So we have decided to cluster these 4 variables: VehOdo, MMRAcquisitionAuctionAveragePrice, VehBCost and WarrantyCost - and substitute these variables with their class.",
"_____no_output_____"
],
[
"As the method of the clustering we choose hierarchical one. We are not sure if it is true in general but we saw that for VehBCost hierarchical clustering gives us clusters that have almost equal range between minimal value of the cost and the maximum one, the size of the clusters was not the same, but the range, as we said, was plus minus the same. On the other hand, k-means gave us clusters of the same size but the range was very different.\nWe thought that in real life when we want to buy a new car, the groups don't have the same number of options (there is a lot of cars in medium range and only few super expensive ones), but we start our search from the amount of money that we have, so the key factor is the range, not the size of the cluster.",
"_____no_output_____"
],
[
"Also in other papers we saw that they just write: we chose 7 cluster (or 4 clusters, the number here is not important). Nothing else. We at least watched the possible cluster and found some explanation why we chose this one and not another one. We don't want to reopen here from the begining all the discussion about clustering. So lets just assume we use hierarchical clustering.",
"_____no_output_____"
]
],
[
[
"df[:10]",
"_____no_output_____"
]
],
[
[
"<b>VehBCost clustering</b>",
"_____no_output_____"
],
[
"What we did here: took VehBCost, made hierarchical clustering for this variable, chose the threshold and then substituted the VehBCost column with VehBCost-Class which has 5 different classes: all of them have names [min; max] - [1720.0; 3815.0], [3820.0; 5745.0], [5750.0; 7450.0], [7455.0; 9815.0], [9820.0; 11645.0]",
"_____no_output_____"
]
],
[
[
"X = df[[\"VehBCost\"]]\n\nscaler = StandardScaler()\nscaler.fit(X)\nX = scaler.transform(X)",
"_____no_output_____"
],
[
"data_dist = pdist(X, metric='euclidean')",
"_____no_output_____"
],
[
"data_link = linkage(data_dist, method='complete', metric='euclidean')",
"_____no_output_____"
],
[
"res = dendrogram(data_link, color_threshold=2, truncate_mode='lastp')",
"_____no_output_____"
],
[
"color_threshold = 2\nnum_clusters = 5\nclusters = fcluster(data_link, color_threshold, criterion='distance')\ndf['VehBCost-Class'] = clusters\nmapClassName = {}\nfor i in range(1, num_clusters+1):\n classVehBCost = df[df['VehBCost-Class'] == i]['VehBCost']\n mapClassName[i] = \"[\" + str(classVehBCost.min()) + \"; \" + str(classVehBCost.max()) + \"]\"\ndf['VehBCost-Class'] = df['VehBCost-Class'].map(mapClassName).astype(str)\ndel df['VehBCost']",
"_____no_output_____"
],
[
"df['VehBCost-Class'].value_counts()",
"_____no_output_____"
]
],
[
[
"<b>VehOdo clustering</b>",
"_____no_output_____"
],
[
"What we did here: took VehOdo, made hierarchical clustering for this variable, chose the threshold and then substituted the VehOdo column with VehOdo-Class which has 5 different classes: all of them have names [min; max] - [30212; 45443], [45449; 61627], [61630; 71437], [71439; 91679], [91683; 112029]",
"_____no_output_____"
]
],
[
[
"X = df[[\"VehOdo\"]]\n\nscaler = StandardScaler()\nscaler.fit(X)\nX = scaler.transform(X)",
"_____no_output_____"
],
[
"data_dist = pdist(X, metric='euclidean')",
"_____no_output_____"
],
[
"data_link = linkage(data_dist, method='complete', metric='euclidean')",
"_____no_output_____"
],
[
"res = dendrogram(data_link, color_threshold=1.8, truncate_mode='lastp')",
"_____no_output_____"
],
[
"color_threshold = 1.8\nnum_clusters = 5\nclusters = fcluster(data_link, color_threshold, criterion='distance')\ndf['VehOdo-Class'] = clusters\nmapClassName = {}\nfor i in range(1, num_clusters+1):\n classVehBCost = df[df['VehOdo-Class'] == i]['VehOdo']\n mapClassName[i] = \"[\" + str(classVehBCost.min()) + \"; \" + str(classVehBCost.max()) + \"]\"\ndf['VehOdo-Class'] = df['VehOdo-Class'].map(mapClassName).astype(str)\ndel df['VehOdo']",
"_____no_output_____"
],
[
"df['VehOdo-Class'].value_counts()",
"_____no_output_____"
]
],
[
[
"<b>MMRAcquisitionAuctionAveragePrice</b>",
"_____no_output_____"
],
[
"What we did here: took MMRAcquisitionAuctionAveragePrice, made hierarchical clustering for this variable, chose the threshold and then substituted the MMRAcquisitionAuctionAveragePrice column with MMRAcquisitionAuctionAveragePrice-Class which has 4 different classes: all of them have names [min; max] - [884.0; 3619.0], [3620.0; 6609.0], [6610.0; 10416.0], [10417.0; 12951.0].\nHere we also have missing values, so there is one more group: group NaN. We should also not forget that here we have values 0.0 that are not real values! They are missing values, so as the first step we change 0.0 to NaN.",
"_____no_output_____"
]
],
[
[
"# 0 as acquisition price is still Missing value so here we just make controll\ndf.loc[df[\"MMRAcquisitionAuctionAveragePrice\"] == 0] = np.nan\nX = df[df['MMRAcquisitionAuctionAveragePrice'].notnull()][['MMRAcquisitionAuctionAveragePrice']]\n\nscaler = StandardScaler()\nscaler.fit(X)\nX = scaler.transform(X)",
"_____no_output_____"
],
[
"data_dist = pdist(X, metric='euclidean')",
"_____no_output_____"
],
[
"data_link = linkage(data_dist, method='complete', metric='euclidean')",
"_____no_output_____"
],
[
"res = dendrogram(data_link, color_threshold=1.8, truncate_mode='lastp')",
"_____no_output_____"
],
[
"color_threshold = 1.8\nnum_clusters = 4\nclusters = fcluster(data_link, color_threshold, criterion='distance')\ndf[\"MMRAcquisitionAuctionAveragePrice-Class\"] = np.nan\ndf.loc[df[\"MMRAcquisitionAuctionAveragePrice\"].notnull(), \"MMRAcquisitionAuctionAveragePrice-Class\"] = clusters\nmapClassName = {}\nfor i in range(1, num_clusters+1):\n classVehBCost = df[df['MMRAcquisitionAuctionAveragePrice-Class'] == i]['MMRAcquisitionAuctionAveragePrice']\n mapClassName[i] = \"[\" + str(classVehBCost.min()) + \"; \" + str(classVehBCost.max()) + \"]\"\ndf['MMRAcquisitionAuctionAveragePrice-Class'] = df['MMRAcquisitionAuctionAveragePrice-Class'].map(mapClassName).astype(str)\ndel df['MMRAcquisitionAuctionAveragePrice']",
"_____no_output_____"
],
[
"df['MMRAcquisitionAuctionAveragePrice-Class'].value_counts()",
"_____no_output_____"
]
],
[
[
"<b>WarrantyCost</b>",
"_____no_output_____"
],
[
"What we did here: took WarrantyCost, made hierarchical clustering for this variable, chose the threshold and then substituted the WarrantyCost column with WarrantyCost-Class which has 5 different classes: all of them have names [min; max] - [462.0; 728.0], [754.0; 1223.0], [1241.0; 1808.0], [1857.0; 2282.0], [2322.0; 2838.0]. Here we also have missing values, so there is one more group: group NaN.",
"_____no_output_____"
]
],
[
[
"X = df[df['WarrantyCost'].notnull()][['WarrantyCost']]\n\nscaler = StandardScaler()\nscaler.fit(X)\nX = scaler.transform(X)",
"_____no_output_____"
],
[
"data_dist = pdist(X, metric='euclidean')",
"_____no_output_____"
],
[
"data_link = linkage(data_dist, method='complete', metric='euclidean')",
"_____no_output_____"
],
[
"res = dendrogram(data_link, color_threshold=1.2, truncate_mode='lastp')",
"_____no_output_____"
],
[
"color_threshold = 1.2\nnum_clusters = 5\nclusters = fcluster(data_link, color_threshold, criterion='distance')\ndf[\"WarrantyCost-Class\"] = np.nan\ndf.loc[df[\"WarrantyCost\"].notnull(), \"WarrantyCost-Class\"] = clusters\nmapClassName = {}\nfor i in range(1, num_clusters+1):\n classVehBCost = df[df['WarrantyCost-Class'] == i]['WarrantyCost']\n mapClassName[i] = \"[\" + str(classVehBCost.min()) + \"; \" + str(classVehBCost.max()) + \"]\"\ndf['WarrantyCost-Class'] = df['WarrantyCost-Class'].map(mapClassName).astype(str)\ndel df['WarrantyCost']",
"_____no_output_____"
],
[
"df['WarrantyCost-Class'].value_counts()",
"_____no_output_____"
]
],
[
[
"So after all the transformations we should get something like this:",
"_____no_output_____"
]
],
[
[
"df[:10]",
"_____no_output_____"
]
],
[
[
"But to get this result I did hierarchical clustering 4 times, which is really time consuming, so I created the shortcut of division into clusters, so from now we didn't have to wait for so long to have our division for numerical values",
"_____no_output_____"
]
],
[
[
"# VehBCost\ndf[\"VehBCost-Class\"] = np.nan\ncriteria = [df['VehBCost'].between(1720, 3815), df['VehBCost'].between(3820, 5745), df['VehBCost'].between(5750, 7450), df['VehBCost'].between(7455, 9815), df['VehBCost'].between(9820, 11645)]\nvalues = [\"[1720; 3815]\", \"[3820; 5745]\", \"[5750; 7450]\", \"[7455; 9815]\", \"[9820; 11645]\"]\ndf['VehBCost-Class'] = np.select(criteria, values, 0)\ndel df[\"VehBCost\"]\n\n# VehOdo\ndf[\"VehOdo-Class\"] = np.nan\ncriteria = [df['VehOdo'].between(30212, 45443), df['VehOdo'].between(45449, 61627), df['VehOdo'].between(61630, 71437), df['VehOdo'].between(71439, 91679), df['VehOdo'].between(91683, 112029)]\nvalues = [\"[30212; 45443]\", \"[45449; 61627]\", \"[61630; 71437]\", \"[71439; 91679]\", \"[91683; 112029]\"]\ndf['VehOdo-Class'] = np.select(criteria, values, 0)\ndel df[\"VehOdo\"]\n\n# MMRAcquisitionAuctionAveragePrice\ndf.loc[df[\"MMRAcquisitionAuctionAveragePrice\"] == 0, \"MMRAcquisitionAuctionAveragePrice\"] = np.nan\ndf[\"MMRAcquisitionAuctionAveragePrice-Class\"] = np.nan\ncriteria = [df['MMRAcquisitionAuctionAveragePrice'].between(884, 3619), df['MMRAcquisitionAuctionAveragePrice'].between(3620, 6609), df['MMRAcquisitionAuctionAveragePrice'].between(6610, 10416), df['MMRAcquisitionAuctionAveragePrice'].between(10417, 12951)]\nvalues = [\"[884; 3619]\", \"[3620; 6609]\", \"[6610; 10416]\", \"[10417; 12951]\"]\ndf['MMRAcquisitionAuctionAveragePrice-Class'] = np.select(criteria, values, np.nan)\ndel df[\"MMRAcquisitionAuctionAveragePrice\"]\n\n# MMRAcquisitionAuctionAveragePrice\ndf[\"WarrantyCost-Class\"] = np.nan\ncriteria = [df['WarrantyCost'].between(462, 728), df['WarrantyCost'].between(754, 1223), df['WarrantyCost'].between(1241, 1808), df['WarrantyCost'].between(1857, 2282), df['WarrantyCost'].between(2322, 2838)]\nvalues = [\"[462; 728]\", \"[754; 1223]\", \"[1241; 1808]\", \"[1857; 2282]\", \"[2322; 2838]\"]\ndf['WarrantyCost-Class'] = np.select(criteria, values, np.nan)\ndel df[\"WarrantyCost\"]",
"_____no_output_____"
]
],
[
[
"# Apriori algorythm",
"_____no_output_____"
]
],
[
[
"help(apriori)",
"Help on built-in function apriori in module fim:\n\napriori(...)\n apriori (tracts, target='s', supp=10, zmin=1, zmax=None, report='a',\n eval='x', agg='x', thresh=10, prune=None, algo='b', mode='',\n border=None)\n Find frequent item sets with the Apriori algorithm.\n tracts transaction database to mine (mandatory)\n The database must be an iterable of transactions;\n each transaction must be an iterable of items;\n each item must be a hashable object.\n If the database is a dictionary, the transactions are\n the keys, the values their (integer) multiplicities.\n target type of frequent item sets to find (default: s)\n s/a sets/all all frequent item sets\n c closed closed frequent item sets\n m maximal maximal frequent item sets\n g gens generators\n r rules association rules\n supp minimum support of an item set (default: 10)\n (positive: percentage, negative: absolute number)\n conf minimum confidence of an assoc. rule (default: 80%)\n zmin minimum number of items per item set (default: 1)\n zmax maximum number of items per item set (default: no limit)\n report values to report with an item set (default: a)\n a absolute item set support (number of transactions)\n s relative item set support as a fraction\n S relative item set support as a percentage\n e value of item set evaluation measure\n E value of item set evaluation measure as a percentage\n ( combine values in a tuple (must be first character)\n [ combine values in a list (must be first character)\n # pattern spectrum as a dictionary (no patterns)\n = pattern spectrum as a list (no patterns)\n | pattern spectrum as three columns (no patterns)\n for target 'r' (association rules) also available:\n b absolute body set support (number of transactions)\n x relative body set support as a fraction\n X relative body set support as a percentage\n h absolute head item support (number of transactions)\n y relative head item support as a fraction\n Y relative head item support as a percentage\n c rule confidence as a fraction\n C rule confidence as a percentage\n l lift value of a rule (confidence/prior)\n L lift value of a rule as a percentage\n Q support of the empty set (total number of transactions)\n eval measure for item set evaluation (default: x)\n x none no measure / zero (default)\n b ldratio binary logarithm of support quotient (+)\n c conf rule confidence (+)\n d confdiff absolute confidence difference to prior (+)\n l lift lift value (confidence divided by prior) (+)\n a liftdiff absolute difference of lift value to 1 (+)\n q liftquot difference of lift quotient to 1 (+)\n v cvct conviction (inverse lift for negated head) (+)\n e cvctdiff absolute difference of conviction to 1 (+)\n r cvctquot difference of conviction quotient to 1 (+)\n k cprob conditional probability ratio (+)\n j import importance (binary log. of prob. ratio) (+)\n z cert certainty factor (relative conf. change) (+)\n n chi2 normalized chi^2 measure (+)\n p chi2pval p-value from (unnormalized) chi^2 measure (-)\n y yates normalized chi^2 with Yates' correction (+)\n t yatespval p-value from Yates-corrected chi^2 measure (-)\n i info information difference to prior (+)\n g infopval p-value from G statistic/info. difference (-)\n f fetprob Fisher's exact test (table probability) (-)\n h fetchi2 Fisher's exact test (chi^2 measure) (-)\n m fetinfo Fisher's exact test (mutual information) (-)\n s fetsupp Fisher's exact test (support) (-)\n Measures marked with (+) must meet or exceed the threshold,\n measures marked with (-) must not exceed the threshold\n in order for the item set to be reported.\n agg evaluation measure aggregation mode (default: x)\n x none no aggregation (use first value)\n m min minimum of individual measure values\n n max maximum of individual measure values\n a avg average of individual measure values\n thresh threshold for evaluation measure (default: 10%)\n prune min. size for evaluation filtering (default: no pruning)\n = 0 backward filtering (no subset check)\n < 0 weak forward filtering (one subset must qualify)\n > 0 strong forward filtering (all subsets must qualify)\n algo algorithm variant to use (default: a)\n b basic standard algorithm (only choice)\n mode operation mode indicators/flags (default: None)\n x do not use perfect extension pruning\n t/T do not organize transactions as a prefix tree\n y a-posteriori pruning of infrequent item sets\n z invalidate evaluation below expected support\n o use original rule support definition (body & head)\n border support border for filtering item sets (default: None)\n Must be a list or tuple of (absolute) minimum support values\n per item set size (by which the list/tuple is indexed).\n appear dictionary mapping items to item appearance indicators,\n with the key None referring to the default item appearance.\n (If None does not occur as a key or no dictionary is given,\n the default item appearance indicator is 'both'.)\n This parameter is only used if the target type is rules.\n * item may not appear anywhere in a rule:\n '-', 'n', 'none', 'neither', 'ignore'\n * item may appear only in rule body/antecedent:\n 'i', 'in', 'inp', 'input', 'b', 'body',\n 'a', 'ante', 'antecedent'\n * item may appear only in rule head/consequent:\n 'o', 'out', 'output', 'h', 'head',\n 'c', 'cons', 'consequent'\n * item may appear anywhere in a rule:\n 'io', 'i&o', 'inout', 'in&out', 'bh', 'b&h', 'both'\n returns if report is not in ['#','=','|']:\n if the target is association rules:\n a list of rules (i.e. tuples with two or more elements),\n each consisting of a head/consequent item, a tuple with\n a body/antecedent item set, and the values selected by\n the parameter 'report', which may be combined into a\n tuple or a list if report[0] is '(' or '[', respectively.\n if the target is a type of item sets:\n a list of patterns (i.e. tuples with one or more elements),\n each consisting of a tuple with a found frequent item set\n and the values selected by the parameter 'report', which\n may be combined into a tuple or list if report[0] is '('\n or '[', respectively\n if report in ['#','=','|']:\n a pattern spectrum as a dictionary mapping pattern sizes\n to the corresponding occurrence support ranges, as a list\n of triplets (size, min. support, max. support) or as three\n columns for sizes and minimum and maximum support values\n\n"
],
[
"baskets = df.values.tolist()",
"_____no_output_____"
],
[
"baskets[0]",
"_____no_output_____"
],
[
"itemsets = apriori(baskets, supp=80, zmin=1, target='a') \nprint('Number of itemsets:', len(itemsets))\nitemsets",
"Number of itemsets: 5\n"
],
[
"itemsets = apriori(baskets, supp=80, zmin=1, target='a') \nprint('Number of itemsets:', len(itemsets))\nitemsets",
"_____no_output_____"
],
[
"rules = apriori(baskets, supp=10, zmin=2, target='r', conf=60, report='ascl') \nprint('Number of rule:', len(rules))",
"Number of rule: 1704\n"
],
[
"for r in rules:\n if r[0] == 1:\n print(r)",
"(1, ('MEDIUM SUV', 'AUTO'), 5238, 0.09509631270310996, 0.8953846153846153, 1.5243456759596958)\n(1, ('MEDIUM SUV',), 5341, 0.09696628601514133, 0.8943402545210984, 1.522567705979991)\n(1, (6, 'AUTO'), 4400, 0.07988235507706831, 0.7525226611937745, 1.281130639216613)\n(1, (6,), 4603, 0.08356783645903305, 0.7468765211747526, 1.2715183798858425)\n(1, ('[884; 3619]', 'AMERICAN', 'AUTO'), 3689, 0.06697409269984204, 0.6249364729798408, 1.0639217984855847)\n(1, ('[884; 3619]', 'AMERICAN'), 3875, 0.07035093770991813, 0.620695178600032, 1.056701215691054)\n(1, ('[884; 3619]', 'AUTO'), 4112, 0.07465369183566022, 0.6004672897196262, 1.0222642883429167)\n(1, ('FORD', 'AMERICAN', 0, 'AUTO'), 4927, 0.08945008260561718, 0.730358731099911, 1.2433977025318106)\n(1, ('FORD', 'AMERICAN', 0), 5143, 0.09337158003667326, 0.7253878702397744, 1.2349350708004267)\n(1, ('FORD', 'AMERICAN', 'AUTO'), 6203, 0.11261596557796699, 0.7732485664422837, 1.316415413494697)\n(1, ('FORD', 'AMERICAN'), 6462, 0.11731813147909442, 0.7684623617552622, 1.3082671492811275)\n(1, ('FORD', 0, 'AUTO'), 4927, 0.08945008260561718, 0.730358731099911, 1.2433977025318106)\n(1, ('FORD', 0), 5143, 0.09337158003667326, 0.7253878702397744, 1.2349350708004267)\n(1, ('FORD', 'AUTO'), 6203, 0.11261596557796699, 0.7732485664422837, 1.316415413494697)\n(1, ('FORD',), 6462, 0.11731813147909442, 0.7684623617552622, 1.3082671492811275)\n(1, (5, '[71439; 91679]'), 3928, 0.0713131569869828, 0.6993056791881788, 1.190531498898562)\n(1, (5, 'AMERICAN', 0, 'AUTO'), 4337, 0.0787385849930103, 0.6412834540884222, 1.0917516824703093)\n(1, (5, 'AMERICAN', 0), 4467, 0.08109874548392368, 0.6365968362548098, 1.0837729596881738)\n(1, (5, 'AMERICAN', 'AUTO'), 5518, 0.1001797352989234, 0.6946122860020141, 1.1825412414315677)\n(1, (5, 'AMERICAN'), 5679, 0.10310270329151613, 0.6901203062340503, 1.1748938798194266)\n(1, (5, 0, 'AUTO'), 5069, 0.09202810406492257, 0.6193036041539401, 1.054332132669938)\n(1, (5, 0), 5263, 0.09555018972059331, 0.6136178150868602, 1.0446523728997759)\n(1, (5, 'AUTO'), 6510, 0.11818957535266245, 0.6762933721171827, 1.1513542445937608)\n(1, (5,), 6757, 0.12267388028539787, 0.6709363519014994, 1.142234196670782)\n(1, ('TX', '[71439; 91679]'), 3743, 0.06795446705760608, 0.6751443001443002, 1.1493980094037275)\n(1, ('TX', 'AMERICAN', 'AUTO'), 5355, 0.09722045714493201, 0.6378796902918403, 1.0859569518750343)\n(1, ('TX', 'AMERICAN'), 5494, 0.0997440133621394, 0.6364689527340129, 1.0835552446542056)\n(1, ('TX', 'AUTO'), 6199, 0.11254334525516967, 0.6227021597187343, 1.0601179965218397)\n(1, ('TX',), 6404, 0.11626513679853306, 0.6204223987599302, 1.0562368222196858)\n(1, (4, '[71439; 91679]', 'AMERICAN', 'AUTO'), 3483, 0.0632341460757793, 0.6209663041540382, 1.0571627928264997)\n(1, (4, '[71439; 91679]', 'AMERICAN'), 3531, 0.06410558994934733, 0.6184971098265896, 1.05295911807994)\n(1, (4, '[71439; 91679]', 'AUTO'), 4080, 0.07407272925328152, 0.6120612061206121, 1.0420023272031105)\n(1, (4, '[71439; 91679]'), 4172, 0.07574299667762023, 0.6099415204678362, 1.0383936727727294)\n(1, ('[1241; 1808]', '[7455; 9815]', 'AMERICAN', 'AUTO'), 3988, 0.07240246182894283, 0.7136721546170365, 1.2149896751085179)\n(1, ('[1241; 1808]', '[7455; 9815]', 'AMERICAN'), 3993, 0.0724932372324395, 0.7135453895639743, 1.2147738642076178)\n(1, ('[1241; 1808]', '[7455; 9815]', 'AUTO'), 4308, 0.07821208765272962, 0.7235471951629157, 1.2318014173446423)\n(1, ('[1241; 1808]', '[7455; 9815]'), 4326, 0.07853887910531762, 0.7240167364016736, 1.2326007868498667)\n(1, ('[1241; 1808]', '[6610; 10416]', 'AMERICAN', 0, 'AUTO'), 3696, 0.06710117826473738, 0.6330935251798561, 1.0778087550359046)\n(1, ('[1241; 1808]', '[6610; 10416]', 'AMERICAN', 0), 3710, 0.06735534939452806, 0.6334300836605771, 1.078381728321328)\n(1, ('[1241; 1808]', '[6610; 10416]', 'AMERICAN', 'AUTO'), 4249, 0.07714093789146893, 0.664841182913472, 1.1318574889057598)\n(1, ('[1241; 1808]', '[6610; 10416]', 'AMERICAN'), 4264, 0.07741326410195894, 0.6651068476056777, 1.1323097692083925)\n(1, ('[1241; 1808]', '[6610; 10416]', 0, 'AUTO'), 3977, 0.07220275594125015, 0.6423841059602649, 1.0936254849600466)\n(1, ('[1241; 1808]', '[6610; 10416]', 0), 4005, 0.0727110982008315, 0.643270157404433, 1.095133941398083)\n(1, ('[1241; 1808]', '[6610; 10416]', 'AUTO'), 4611, 0.08371307710462773, 0.6756043956043956, 1.150181297962716)\n(1, ('[1241; 1808]', '[6610; 10416]'), 4644, 0.08431219476770574, 0.6764748725418791, 1.1516632396142437)\n(1, ('[1241; 1808]', '[3620; 6609]', 'AUTO'), 4050, 0.07352807683230152, 0.6134504695546804, 1.0443674758466142)\n(1, ('[1241; 1808]', '[3620; 6609]'), 4145, 0.07525280949873822, 0.6143471172372906, 1.0458939718287448)\n(1, ('[1241; 1808]', '[71439; 91679]', 'AMERICAN', 0, 'AUTO'), 5407, 0.09816452134129736, 0.6179428571428571, 1.0520155317514284)\n(1, ('[1241; 1808]', '[71439; 91679]', 'AMERICAN', 0), 5473, 0.09936275666745338, 0.6159126716182759, 1.048559246628122)\n(1, ('[1241; 1808]', '[71439; 91679]', 'AMERICAN', 'AUTO'), 6710, 0.12182059149252919, 0.667462449020193, 1.1363200579366153)\n(1, ('[1241; 1808]', '[71439; 91679]', 'AMERICAN'), 6810, 0.12363609956246256, 0.6661449672307542, 1.1340771138046972)\n(1, ('[1241; 1808]', '[71439; 91679]', 0, 'AUTO'), 5785, 0.1050271418456455, 0.6268964022540096, 1.0672584760015176)\n(1, ('[1241; 1808]', '[71439; 91679]', 0), 5871, 0.1065884787857882, 0.6254394375199744, 1.0647780694207118)\n(1, ('[1241; 1808]', '[71439; 91679]', 'AUTO'), 7237, 0.13138831902107806, 0.677621722846442, 1.1536156925296677)\n(1, ('[1241; 1808]', '[71439; 91679]'), 7361, 0.13363954902779543, 0.6767491036131286, 1.1521301037310607)\n(1, ('[1241; 1808]', 'AMERICAN', 'AUTO'), 10155, 0.18436484450173382, 0.6441892920578534, 1.0966987202768936)\n(1, ('[1241; 1808]', 'AMERICAN'), 10319, 0.18734227773642453, 0.6434896482913445, 1.0955076132019392)\n(1, ('[1241; 1808]', 0, 'AUTO'), 8745, 0.15876618071567328, 0.6038947586492646, 1.0280993756926544)\n(1, ('[1241; 1808]', 0), 8891, 0.161416822497776, 0.6031886024423337, 1.0268971815270505)\n(1, ('[1241; 1808]', 'AUTO'), 10895, 0.19779960421924075, 0.6551019181047442, 1.1152768977909195)\n(1, ('[1241; 1808]',), 11100, 0.20152139576260417, 0.6549058941530473, 1.1149431772221055)\n(1, ('[7455; 9815]', '[754; 1223]', 0), 3861, 0.07009676658012745, 0.6970572305470302, 1.1867036321864675)\n(1, ('[7455; 9815]', '[754; 1223]', 'AUTO'), 4308, 0.07821208765272962, 0.7210041841004184, 1.227472073451046)\n(1, ('[7455; 9815]', '[754; 1223]'), 4364, 0.07922877217189231, 0.7222773915921881, 1.229639642896993)\n(1, ('[7455; 9815]', '[6610; 10416]', '[71439; 91679]', 0, 'AUTO'), 3550, 0.06445053648263467, 0.6392940752746263, 1.0883648686468965)\n(1, ('[7455; 9815]', '[6610; 10416]', '[71439; 91679]', 0), 3588, 0.06514042954920934, 0.6411722659042173, 1.0915623903773937)\n(1, ('[7455; 9815]', '[6610; 10416]', '[71439; 91679]', 'AUTO'), 4156, 0.0754525153864309, 0.6747848676733236, 1.1487860943411738)\n(1, ('[7455; 9815]', '[6610; 10416]', '[71439; 91679]'), 4196, 0.07617871861440424, 0.6763378465506125, 1.1514299600004416)\n(1, ('[7455; 9815]', '[6610; 10416]', 'AMERICAN', 0, 'AUTO'), 6296, 0.11430438808300503, 0.6302302302302303, 1.072934144504893)\n(1, ('[7455; 9815]', '[6610; 10416]', 'AMERICAN', 0), 6337, 0.11504874639167771, 0.6311124390000996, 1.0744360589900626)\n(1, ('[7455; 9815]', '[6610; 10416]', 'AMERICAN', 'AUTO'), 7155, 0.1298996024037327, 0.659507788736289, 1.1227776630828812)\n(1, ('[7455; 9815]', '[6610; 10416]', 'AMERICAN'), 7199, 0.13069842595450337, 0.6602769879849583, 1.1240871847437561)\n(1, ('[7455; 9815]', '[6610; 10416]', 0, 'AUTO'), 7220, 0.13107968264918937, 0.627716918796731, 1.068655362682906)\n(1, ('[7455; 9815]', '[6610; 10416]', 0), 7306, 0.13264101958933208, 0.6288517817180238, 1.070587407702617)\n(1, ('[7455; 9815]', '[6610; 10416]', 'AUTO'), 8237, 0.14954339972041175, 0.6579599009505551, 1.1201424647418412)\n(1, ('[7455; 9815]', '[6610; 10416]'), 8330, 0.15123182222544979, 0.6589147286821705, 1.1217680092273794)\n(1, ('[7455; 9815]', '[71439; 91679]', 'AMERICAN', 0, 'AUTO'), 4551, 0.0826237722626677, 0.6894409937888198, 1.173737385760091)\n(1, ('[7455; 9815]', '[71439; 91679]', 'AMERICAN', 0), 4573, 0.08302318403805305, 0.6898476391612611, 1.174429678328535)\n(1, ('[7455; 9815]', '[71439; 91679]', 'AMERICAN', 'AUTO'), 5291, 0.09605853198017465, 0.7207464923035009, 1.2270333665874122)\n(1, ('[7455; 9815]', '[71439; 91679]', 'AMERICAN'), 5315, 0.09649425391695866, 0.7210690544023878, 1.2275825117616963)\n(1, ('[7455; 9815]', '[71439; 91679]', 0, 'AUTO'), 5242, 0.0951689330259073, 0.6774360299819074, 1.1532995600987033)\n(1, ('[7455; 9815]', '[71439; 91679]', 0), 5299, 0.09620377262576932, 0.6786629098360656, 1.1553882591543652)\n(1, ('[7455; 9815]', '[71439; 91679]', 'AUTO'), 6158, 0.11179898694649698, 0.7115784608273631, 1.2114252704714095)\n(1, ('[7455; 9815]', '[71439; 91679]'), 6221, 0.11294275703055501, 0.7126002290950745, 1.2131647777333805)\n(1, ('[7455; 9815]', 'AMERICAN', 0, 'AUTO'), 8734, 0.1585664748279806, 0.6633753607777609, 1.1293620030598952)\n(1, ('[7455; 9815]', 'AMERICAN', 0), 8793, 0.1596376245892413, 0.6640235613955596, 1.1304655308533356)\n(1, ('[7455; 9815]', 'AMERICAN', 'AUTO'), 9980, 0.18118770537935042, 0.6924784901470996, 1.1789085651169067)\n(1, ('[7455; 9815]', 'AMERICAN'), 10043, 0.18233147546340844, 0.6930030361578802, 1.1798015773818447)\n(1, ('[7455; 9815]', 0, 'AUTO'), 10132, 0.18394727764564914, 0.6557079989645354, 1.1163087188899539)\n(1, ('[7455; 9815]', 0), 10256, 0.1861985076523665, 0.6564260112647209, 1.1175310974368577)\n(1, ('[7455; 9815]', 'AUTO'), 11654, 0.21157931047003503, 0.686579474490397, 1.1688657981827768)\n(1, ('[7455; 9815]',), 11791, 0.21406655652584375, 0.687161256483478, 1.1698562517267248)\n(1, ('[754; 1223]', '[6610; 10416]', 'AMERICAN', 'AUTO'), 4500, 0.08169786314700168, 0.6205184776613348, 1.0564003915455271)\n(1, ('[754; 1223]', '[6610; 10416]', 'AMERICAN'), 4540, 0.08242406637497504, 0.6211520043781639, 1.057478937786785)\n(1, ('[754; 1223]', '[6610; 10416]', 0, 'AUTO'), 4441, 0.080626713385741, 0.6053707742639041, 1.030612215405517)\n(1, ('[754; 1223]', '[6610; 10416]', 0), 4513, 0.08193387919609303, 0.6065860215053763, 1.032681110543909)\n(1, ('[754; 1223]', '[6610; 10416]', 'AUTO'), 5053, 0.09173762277373324, 0.6357574232511324, 1.0823439027661377)\n(1, ('[754; 1223]', '[6610; 10416]'), 5136, 0.09324449447177793, 0.6369837529455538, 1.0844316652035002)\n(1, ('[754; 1223]', '[71439; 91679]', 'AMERICAN', 'AUTO'), 3748, 0.06804524246110275, 0.6231088944305901, 1.0608104411859844)\n(1, ('[754; 1223]', '[71439; 91679]', 'AMERICAN'), 3873, 0.07031462754851946, 0.6187889439207541, 1.0534559504265024)\n(1, ('[754; 1223]', '[71439; 91679]', 'AUTO'), 4590, 0.08333182040994172, 0.6399888455103179, 1.0895476787894487)\n(1, ('[754; 1223]', '[71439; 91679]'), 4788, 0.0869265263884098, 0.6367021276595745, 1.0839522128211974)\n(1, ('[6610; 10416]', '[71439; 91679]', 'AMERICAN', 0, 'AUTO'), 5147, 0.0934442003594706, 0.6058858151854032, 1.0314890457509795)\n(1, ('[6610; 10416]', '[71439; 91679]', 'AMERICAN', 0), 5187, 0.09417040358744394, 0.606453875833041, 1.0324561394189198)\n(1, ('[6610; 10416]', '[71439; 91679]', 'AMERICAN', 'AUTO'), 5998, 0.10889417403460358, 0.6417718810186176, 1.0925832038816368)\n(1, ('[6610; 10416]', '[71439; 91679]', 'AMERICAN'), 6042, 0.10969299758537426, 0.642219387755102, 1.0933450607942998)\n(1, ('[6610; 10416]', '[71439; 91679]', 0, 'AUTO'), 5855, 0.10629799749459887, 0.6038572607260726, 1.0280355374313161)\n(1, ('[6610; 10416]', '[71439; 91679]', 0), 5941, 0.10785933443474156, 0.6048666259417634, 1.0297539291431745)\n(1, ('[6610; 10416]', '[71439; 91679]', 'AUTO'), 6896, 0.12519743650260526, 0.6422650647294402, 1.0934228234642487)\n(1, ('[6610; 10416]', '[71439; 91679]'), 6993, 0.12695847933044063, 0.643093617803936, 1.0948333919224391)\n(1, ('[6610; 10416]', 'AMERICAN', 'AUTO'), 11623, 0.2110165029683557, 0.6224828620394173, 1.0597446536438506)\n(1, ('[6610; 10416]', 'AMERICAN'), 11733, 0.2130135618452824, 0.623101433882103, 1.0607977399907311)\n(1, ('[6610; 10416]', 'AUTO'), 13449, 0.24416768032533906, 0.624576231830214, 1.0633085066897454)\n(1, ('[6610; 10416]',), 13659, 0.2479802472721991, 0.6250400402690706, 1.0640981164017023)\n(1, ('[3620; 6609]', '[71439; 91679]', 'AMERICAN', 'AUTO'), 5341, 0.09696628601514133, 0.6041855203619909, 1.028594382365668)\n(1, ('[3620; 6609]', '[71439; 91679]', 'AMERICAN'), 5491, 0.0996895481200414, 0.6030090050516144, 1.026591426322803)\n(1, ('[3620; 6609]', '[71439; 91679]', 'AUTO'), 6373, 0.11570232929685373, 0.604362256993836, 1.0288952672769203)\n(1, ('[3620; 6609]', '[71439; 91679]'), 6609, 0.11998692834189648, 0.602955934677493, 1.0265010767747724)\n(1, ('[71439; 91679]', 'AMERICAN', 'AUTO'), 14405, 0.26152393747390207, 0.637445791662979, 1.0852182620568878)\n(1, ('[71439; 91679]', 'AMERICAN'), 14705, 0.2669704616837022, 0.6362495673243337, 1.0831817524198437)\n(1, ('[71439; 91679]', 'AUTO'), 16668, 0.30260888509649425, 0.6328979343863913, 1.0774757718964214)\n(1, ('[71439; 91679]',), 17134, 0.3110691527023838, 0.6314121462264151, 1.0749462949340782)\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4e55fc2b9ab6b0f9438bf8ffeb520bc3c73273
| 7,138 |
ipynb
|
Jupyter Notebook
|
EXERCISE-InspectingACandidateList.ipynb
|
trjaffe/aas_workshop_2020_winter
|
f1891e87fe5326966227faf90674044d8ffc5584
|
[
"BSD-3-Clause"
] | 3 |
2018-09-13T17:13:11.000Z
|
2019-11-20T21:30:17.000Z
|
EXERCISE-InspectingACandidateList.ipynb
|
trjaffe/aas_workshop_2020_winter
|
f1891e87fe5326966227faf90674044d8ffc5584
|
[
"BSD-3-Clause"
] | 22 |
2019-08-14T17:23:44.000Z
|
2020-02-19T18:46:43.000Z
|
EXERCISE-InspectingACandidateList.ipynb
|
trjaffe/aas_workshop_2020_winter
|
f1891e87fe5326966227faf90674044d8ffc5584
|
[
"BSD-3-Clause"
] | 4 |
2019-11-07T21:25:17.000Z
|
2019-11-20T21:30:26.000Z
| 30.504274 | 419 | 0.608714 |
[
[
[
"# Science User Case - Inspecting a Candidate List",
"_____no_output_____"
],
[
"Ogle et al. (2016) mined the NASA/IPAC Extragalactic Database (NED) to identify a new type of galaxy: Superluminous Spiral Galaxies. Here's the paper:\n\nHere's the paper: https://ui.adsabs.harvard.edu//#abs/2016ApJ...817..109O/abstract\n\nTable 1 lists the positions of these Super Spirals. Based on those positions, let's create multiwavelength cutouts for each super spiral to see what is unique about this new class of objects.",
"_____no_output_____"
],
[
"## 1. Import the Python modules we'll be using.",
"_____no_output_____"
]
],
[
[
"# Suppress unimportant warnings.\nimport warnings\nwarnings.filterwarnings(\"ignore\", module=\"astropy.io.votable.*\")\nwarnings.filterwarnings(\"ignore\", module=\"pyvo.utils.xml.*\")\nwarnings.filterwarnings('ignore', '.*RADECSYS=*', append=True)\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom astropy.coordinates import SkyCoord\nfrom astropy.io import fits\nfrom astropy.nddata import Cutout2D\nimport astropy.visualization as vis\nfrom astropy.wcs import WCS\nfrom astroquery.ned import Ned\n\nimport pyvo as vo",
"_____no_output_____"
]
],
[
[
"## 2. Search NED for objects in this paper.\n\nConsult QuickReference.md to figure out how to use astroquery to search NED for all objects in a paper, based on the refcode of the paper. Inspect the resulting astropy table.",
"_____no_output_____"
],
[
"## 3. Filter the NED results.\n\nThe results from NED will include galaxies, but also other kinds of objects. Print the 'Type' column to see the full range of classifications. Next, print the 'Type' of just the first source in the table, in order to determine its data type (since Python 3 distinguishes between strings and byte strings). Finally, use the data type information to filter the results so that we only keep the galaxies in the list.",
"_____no_output_____"
],
[
"## 4. Search the NAVO Registry for image resources.\n\nThe paper selected super spirals using WISE, SDSS, and GALEX images. Search the NAVO registry for all image resources, using the 'service_type' search parameter. How many image resources are currently available?",
"_____no_output_____"
],
[
"## 5. Search the NAVO Registry for image resources that will allow you to search for AllWISE images.\n\nThere are hundreds of image resources...too many to quickly read through. Try adding the 'keyword' search parameter to your registry search, and find the image resource you would need to search the AllWISE images. Remember from the Known Issues that 'keywords' must be a list.",
"_____no_output_____"
],
[
"## 6. Select the AllWISE image service that you are interested in.\n\nHint: there should be only one service after searching with ['allwise']",
"_____no_output_____"
],
[
"## 7. Make a SkyCoord from the first galaxy in the NED list.",
"_____no_output_____"
]
],
[
[
"ra = galaxies['RA'][0]\ndec = galaxies['DEC'][0]\npos = SkyCoord(ra, dec, unit = 'deg')",
"_____no_output_____"
]
],
[
[
"## 8. Search for a list of AllWISE images that cover this galaxy.\n\nHow many images are returned? Which are you most interested in?",
"_____no_output_____"
],
[
"## 9. Use the .to_table() method to view the results as an Astropy table.",
"_____no_output_____"
],
[
"## 10. From the result in 8., select the first record for an image taken in WISE band W1 (3.6 micron)\n\nHints: \n* Loop over records and test on the `.bandpass_id` attribute of each record\n* Print the `.title` and `.bandpass_id` of the record you find, to verify it is the right one.",
"_____no_output_____"
],
[
"## 11. Visualize this AllWISE image.",
"_____no_output_____"
]
],
[
[
"allwise_w1_image = fits.open(allwise_image_record.getdataurl())",
"_____no_output_____"
],
[
"fig = plt.figure()\n\nwcs = WCS(allwise_w1_image[0].header)\nax = fig.add_subplot(1, 1, 1, projection=wcs)\nax.imshow(allwise_w1_image[0].data, cmap='gray_r', origin='lower', vmax = 10)\nax.scatter(ra, dec, transform=ax.get_transform('fk5'), s=500, edgecolor='red', facecolor='none')",
"_____no_output_____"
]
],
[
[
"## 12. Plot a cutout of the AllWISE image, centered on your position.\n\nTry a 60 arcsecond cutout. Use `Cutout2D` that we imported earlier.",
"_____no_output_____"
],
[
"## 13. Try visualizing a cutout of a GALEX image that covers your position.\n\nRepeat steps 4, 5, 6, 8 through 12 for GALEX.",
"_____no_output_____"
],
[
"## 14. Try visualizing a cutout of an SDSS image that covers your position.\n\nHints:\n* Search the registry using `keywords=['sloan']\n* Find the service with a `short_name` of `b'SDSS SIAP'`\n* From Known Issues, recall that an empty string must be specified to the `format` parameter dues to a bug in the service.\n* After obtaining your search results, select r-band images using the `.title` attribute of the records that are returned, since `.bandpass_id` is not populated.",
"_____no_output_____"
],
[
"## 15. Try looping over the first few positions and plotting multiwavelength cutouts.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a4e5b31a0cdd1d4e510c9acebdbfd927feb50de
| 12,691 |
ipynb
|
Jupyter Notebook
|
cnn.ipynb
|
jamessingizi/Convolutional-Neural-Network
|
85029025a5feb81d8e78e11ea0234d6426e42fdc
|
[
"MIT"
] | null | null | null |
cnn.ipynb
|
jamessingizi/Convolutional-Neural-Network
|
85029025a5feb81d8e78e11ea0234d6426e42fdc
|
[
"MIT"
] | null | null | null |
cnn.ipynb
|
jamessingizi/Convolutional-Neural-Network
|
85029025a5feb81d8e78e11ea0234d6426e42fdc
|
[
"MIT"
] | null | null | null | 28.328125 | 145 | 0.512489 |
[
[
[
"### Importing Libraries",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom keras.preprocessing.image import ImageDataGenerator",
"_____no_output_____"
],
[
"tf.__version__",
"_____no_output_____"
]
],
[
[
"### Data Preprocessing",
"_____no_output_____"
],
[
"#### Preprocessing trainingset\n- preprocessing training set helps prevent overfitting\n- generatig new images with feature scaling (rescale param)\n- data augmentation transformations: i) shear ii) zoom iii) horizontal flip\n\n**taget_size is the final image size when they get fed in to the CNN (Bigger images are slower)**",
"_____no_output_____"
]
],
[
[
"train_datagen = ImageDataGenerator(\n rescale=1./255,\n shear_range=0.2,\n zoom_range=0.2,\n horizontal_flip=True)\n\ntraining_set = train_datagen.flow_from_directory(\n 'dataset/training_set',\n target_size=(64, 64),\n batch_size=32,\n class_mode='binary')",
"Found 8000 images belonging to 2 classes.\n"
]
],
[
[
"#### Preprocessing the test set\n\n- Only do feature scaling\n- dont apply transformations",
"_____no_output_____"
]
],
[
[
"test_datagen = ImageDataGenerator(rescale=1./255)\n\ntest_set = test_datagen.flow_from_directory(\n 'dataset/test_set',\n target_size=(64, 64),\n batch_size=32,\n class_mode='binary')",
"Found 2000 images belonging to 2 classes.\n"
]
],
[
[
"### Building the CNN model",
"_____no_output_____"
],
[
"##### Initialising the CNN model",
"_____no_output_____"
]
],
[
[
"cnn = tf.keras.models.Sequential()",
"_____no_output_____"
]
],
[
[
"##### Add Convolution layer",
"_____no_output_____"
]
],
[
[
"cnn.add(tf.keras.layers.Conv2D(filters=32, kernel_size=3, activation='relu',input_shape=[64,64,3]))",
"_____no_output_____"
]
],
[
[
"##### Add Pooling Layer to convolutional layer (max pooling)",
"_____no_output_____"
]
],
[
[
"cnn.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))",
"_____no_output_____"
]
],
[
[
"##### Add second Convolutional Layer",
"_____no_output_____"
]
],
[
[
"cnn.add(tf.keras.layers.Conv2D(filters=32, kernel_size=3, activation='relu'))\ncnn.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))",
"_____no_output_____"
]
],
[
[
"##### Add flattening layer",
"_____no_output_____"
]
],
[
[
"cnn.add(tf.keras.layers.Flatten())",
"_____no_output_____"
]
],
[
[
"#### Add Fully Connected Layer",
"_____no_output_____"
]
],
[
[
"#units refers to hidden neurons\ncnn.add(tf.keras.layers.Dense(units=128, activation='relu'))",
"_____no_output_____"
]
],
[
[
"#### Output layer",
"_____no_output_____"
]
],
[
[
"#units =1 because this is a binary classification\ncnn.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))",
"_____no_output_____"
]
],
[
[
"### Compiling the CNN",
"_____no_output_____"
]
],
[
[
"cnn.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"#### Train the CNN\n- train on training set and evaluating on the test set",
"_____no_output_____"
]
],
[
[
"cnn.fit(x=training_set, validation_data=test_set, epochs=25)",
"Epoch 1/25\n250/250 [==============================] - 164s 655ms/step - loss: 0.6678 - accuracy: 0.5794 - val_loss: 0.6396 - val_accuracy: 0.6655\nEpoch 2/25\n250/250 [==============================] - 40s 159ms/step - loss: 0.5990 - accuracy: 0.6762 - val_loss: 0.5561 - val_accuracy: 0.7285\nEpoch 3/25\n250/250 [==============================] - 41s 165ms/step - loss: 0.5586 - accuracy: 0.7126 - val_loss: 0.5258 - val_accuracy: 0.7385\nEpoch 4/25\n250/250 [==============================] - 43s 172ms/step - loss: 0.5260 - accuracy: 0.7366 - val_loss: 0.5068 - val_accuracy: 0.7600\nEpoch 5/25\n250/250 [==============================] - 43s 172ms/step - loss: 0.4977 - accuracy: 0.7574 - val_loss: 0.4884 - val_accuracy: 0.7630\nEpoch 6/25\n250/250 [==============================] - 43s 171ms/step - loss: 0.4780 - accuracy: 0.7738 - val_loss: 0.4813 - val_accuracy: 0.7710\nEpoch 7/25\n250/250 [==============================] - 41s 163ms/step - loss: 0.4618 - accuracy: 0.7763 - val_loss: 0.5157 - val_accuracy: 0.7535\nEpoch 8/25\n250/250 [==============================] - 39s 158ms/step - loss: 0.4479 - accuracy: 0.7906 - val_loss: 0.5230 - val_accuracy: 0.7505\nEpoch 9/25\n250/250 [==============================] - 43s 173ms/step - loss: 0.4333 - accuracy: 0.7928 - val_loss: 0.4655 - val_accuracy: 0.7850\nEpoch 10/25\n250/250 [==============================] - 43s 171ms/step - loss: 0.4156 - accuracy: 0.8051 - val_loss: 0.4480 - val_accuracy: 0.7985\nEpoch 11/25\n250/250 [==============================] - 42s 168ms/step - loss: 0.4119 - accuracy: 0.8079 - val_loss: 0.4665 - val_accuracy: 0.7920\nEpoch 12/25\n250/250 [==============================] - 43s 171ms/step - loss: 0.3908 - accuracy: 0.8213 - val_loss: 0.5187 - val_accuracy: 0.7445\nEpoch 13/25\n250/250 [==============================] - 176s 703ms/step - loss: 0.3808 - accuracy: 0.8267 - val_loss: 0.4350 - val_accuracy: 0.8070\nEpoch 14/25\n250/250 [==============================] - 163s 651ms/step - loss: 0.3615 - accuracy: 0.8367 - val_loss: 0.4575 - val_accuracy: 0.7915\nEpoch 15/25\n250/250 [==============================] - 45s 178ms/step - loss: 0.3485 - accuracy: 0.8457 - val_loss: 0.4745 - val_accuracy: 0.7985\nEpoch 16/25\n250/250 [==============================] - 39s 156ms/step - loss: 0.3346 - accuracy: 0.8539 - val_loss: 0.4443 - val_accuracy: 0.7970\nEpoch 17/25\n250/250 [==============================] - 39s 156ms/step - loss: 0.3228 - accuracy: 0.8618 - val_loss: 0.5631 - val_accuracy: 0.7845\nEpoch 18/25\n250/250 [==============================] - 39s 156ms/step - loss: 0.3107 - accuracy: 0.8674 - val_loss: 0.4901 - val_accuracy: 0.7895\nEpoch 19/25\n250/250 [==============================] - 41s 165ms/step - loss: 0.2957 - accuracy: 0.8729 - val_loss: 0.4903 - val_accuracy: 0.7945\nEpoch 20/25\n250/250 [==============================] - 40s 161ms/step - loss: 0.2883 - accuracy: 0.8745 - val_loss: 0.4727 - val_accuracy: 0.8040\nEpoch 21/25\n250/250 [==============================] - 39s 155ms/step - loss: 0.2672 - accuracy: 0.8856 - val_loss: 0.5269 - val_accuracy: 0.8030\nEpoch 22/25\n250/250 [==============================] - 41s 163ms/step - loss: 0.2582 - accuracy: 0.8935 - val_loss: 0.5067 - val_accuracy: 0.7860\nEpoch 23/25\n250/250 [==============================] - 41s 163ms/step - loss: 0.2504 - accuracy: 0.8936 - val_loss: 0.5255 - val_accuracy: 0.7985\nEpoch 24/25\n250/250 [==============================] - 39s 157ms/step - loss: 0.2350 - accuracy: 0.9024 - val_loss: 0.5284 - val_accuracy: 0.8080\nEpoch 25/25\n250/250 [==============================] - 42s 167ms/step - loss: 0.2190 - accuracy: 0.9145 - val_loss: 0.5218 - val_accuracy: 0.8055\n"
]
],
[
[
"#### Making a single prediction",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom keras.preprocessing import image\ntest_image = image.load_img('dataset/single_prediction/cat_or_dog_2.jpg', target_size=(64,64))\ntest_image = image.img_to_array(test_image)\n#add the batch dimension to test image since images were trained in batches\ntest_image = np.expand_dims(test_image, axis=0)\nresult = cnn.predict(test_image)\nprint(training_set.class_indices)\n\n#in result[0][0] the first index represents the batch and the second index represents the actual prediction\nif result[0][0] > 0.5:\n prediction = 'dog'\nelse:\n prediction = 'cat'\n\nprint(prediction)",
"{'cats': 0, 'dogs': 1}\n[[3.485288e-37]]\ncat\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4e6f67784bd396c1c322261dda311f92a31a89
| 73,160 |
ipynb
|
Jupyter Notebook
|
Sesion_11_EcosistemaPython_Pandas.ipynb
|
UNADCdD/Python-intro
|
15aa68b1804ffe72a27908278f11ce20e2555870
|
[
"MIT"
] | 1 |
2021-05-21T03:44:09.000Z
|
2021-05-21T03:44:09.000Z
|
Sesion_11_EcosistemaPython_Pandas.ipynb
|
UNADCdD/Python-intro
|
15aa68b1804ffe72a27908278f11ce20e2555870
|
[
"MIT"
] | null | null | null |
Sesion_11_EcosistemaPython_Pandas.ipynb
|
UNADCdD/Python-intro
|
15aa68b1804ffe72a27908278f11ce20e2555870
|
[
"MIT"
] | 6 |
2020-04-09T23:08:16.000Z
|
2021-01-23T19:05:03.000Z
| 29.193935 | 1,314 | 0.517305 |
[
[
[
"\n\n<font size=3 color=\"midnightblue\" face=\"arial\">\n<h1 align=\"center\">Escuela de Ciencias Básicas, Tecnología e Ingeniería</h1>\n</font>\n\n<font size=3 color=\"navy\" face=\"arial\">\n<h1 align=\"center\">ECBTI</h1>\n</font>\n\n<font size=2 color=\"darkorange\" face=\"arial\">\n<h1 align=\"center\">Curso:</h1>\n</font>\n\n<font size=2 color=\"navy\" face=\"arial\">\n<h1 align=\"center\">Introducción al lenguaje de programación Python</h1>\n</font>\n\n<font size=1 color=\"darkorange\" face=\"arial\">\n<h1 align=\"center\">Febrero de 2020</h1>\n</font>",
"_____no_output_____"
],
[
"<h2 align=\"center\">Sesión 11 - Ecosistema Python - Pandas</h2>",
"_____no_output_____"
],
[
"## Instructor:\n> <strong> *Carlos Alberto Álvarez Henao, I.C. Ph.D.* </strong> ",
"_____no_output_____"
],
[
"## *Pandas*",
"_____no_output_____"
],
[
"Es un módulo (biblioteca) en *Python* de código abierto (open source) que proporciona estructuras de datos flexibles y permite trabajar con la información de forma eficiente (gran parte de Pandas está implementado usando `C/Cython` para obtener un buen rendimiento).\n\nDesde [este enlace](http://pandas.pydata.org \"Pandas\") podrás acceder a la página oficial de Pandas.",
"_____no_output_____"
],
[
"Antes de *Pandas*, *Python* se utilizó principalmente para la manipulación y preparación de datos. Tenía muy poca contribución al análisis de datos. *Pandas* resolvió este problema. Usando *Pandas*, podemos lograr cinco pasos típicos en el procesamiento y análisis de datos, independientemente del origen de los datos: \n\n- cargar, \n\n\n- preparar, \n\n\n- manipular, \n\n\n- modelar, y \n\n\n- analizar.",
"_____no_output_____"
],
[
"## Principales características de *Pandas*\n\n- Objeto tipo DataFrame rápido y eficiente con indexación predeterminada y personalizada.\n\n- Herramientas para cargar datos en objetos de datos en memoria desde diferentes formatos de archivo.\n\n- Alineación de datos y manejo integrado de datos faltantes.\n\n- Remodelación y pivoteo de conjuntos de datos.\n\n- Etiquetado de corte, indexación y subconjunto de grandes conjuntos de datos.\n\n- Las columnas de una estructura de datos se pueden eliminar o insertar.\n\n- Agrupamiento por datos para agregación y transformaciones.\n\n- Alto rendimiento de fusión y unión de datos.\n\n- Funcionalidad de series de tiempo\n",
"_____no_output_____"
],
[
"### Configuración de *Pandas*",
"_____no_output_____"
],
[
"La distribución estándar del no incluye el módulo de `pandas`. Es necesario realizar el procedimiento de instalacion y difiere del ambiente o el sistema operativo empleados.\n\nSi usa el ambiente *[Anaconda](https://anaconda.org/)*, la alternativa más simple es usar el comando:",
"_____no_output_____"
]
],
[
[
"pip install pandas",
"_____no_output_____"
]
],
[
[
"o empleando *conda*:",
"_____no_output_____"
]
],
[
[
"conda install -c anaconda pandas",
"_____no_output_____"
]
],
[
[
"### Estructuras de datos en *Pandas*\n\nOfrece varias estructuras de datos que nos resultarán de mucha utilidad y que vamos a ir viendo poco a poco. Todas las posibles estructuras de datos que ofrece a día de hoy son:\n\n\n- **`Series`:** Son arrays unidimensionales con indexación (arrays con índice o etiquetados), similar a los diccionarios. Pueden generarse a partir de diccionarios o de listas.\n \n \n- **`DataFrame`:** Similares a las tablas de bases de datos relacionales como `SQL`.\n \n \n- **`Panel`, `Panel4D` y `PanelND`:** Permiten trabajar con más de dos dimensiones. Dado que es algo complejo y poco utilizado trabajar con arrays de más de dos dimensiones no trataremos los paneles en estos tutoriales de introducción a Pandas.",
"_____no_output_____"
],
[
"## Dimensionado y Descripción",
"_____no_output_____"
],
[
"La mejor manera para pensar sobre estas estructuras de datos es que la estructura de dato de dimension mayor contiene a la estructura de datos de menor dimensión.\n\n`DataFrame` contiene a las `Series`, `Panel` contiene al `DataFrame`\n\n\n| Data Structure | Dimension | Descripción |\n|----------------|:---------:|-------------|\n|`Series` | 1 | Arreglo 1-Dimensional homogéneo de tamaño inmutable |\n|`DataFrames` | 2 | Estructura tabular 2-Dimensional, tamaño mutable con columnas heterogéneas|\n|`Panel` | 3 | Arreglo general 3-Dimensional, tamaño variable|\n\nLa construcción y el manejo de dos o más matrices dimensionales es una tarea tediosa, se le impone una carga al usuario para considerar la orientación del conjunto de datos cuando se escriben las funciones. Pero al usar las estructuras de datos de *Pandas*, se reduce el esfuerzo mental del usuario.\n\n- Por ejemplo, con datos tabulares (`DataFrame`), es más útil semánticamente pensar en el índice (las filas) y las columnas, en lugar del eje 0 y el eje 1.",
"_____no_output_____"
],
[
"### Mutabilidad\n\nLas estructuras en *Pandas* son de valor mutable (se pueden cambiar), y excepto las `Series`, todas son de tamaño mutables. Los `DataFrames` son los más usados, los `Panel` no se usan tanto.",
"_____no_output_____"
],
[
"## Cargando el módulo *Pandas*",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"## `Series`:\n\nLas series se definen de la siguiente manera:",
"_____no_output_____"
]
],
[
[
"serie = pd.Series(data, index, dtype, copy)",
"_____no_output_____"
]
],
[
[
"donde: \n\n- `data` es el vector de datos \n\n\n- `index` (opcional) es el vector de índices que usará la serie. Si los índices son datos de fechas directamente se creará una instancia de una `TimeSeries` en lugar de una instancia de `Series`. Si se omite, por defecto es: `np.arrange(n)`\n\n- `dtype`, tipo de dato. Si se omite, el tipo de dato se infiere.\n\n\n- `copy`, copia datos, por defecto es `False`.\n\n\nVeamos un ejemplo de como crear este tipo de contenedor de datos. Primero vamos a crear una `Series` y `Pandas` nos creará índices automáticamente:",
"_____no_output_____"
],
[
"#### Creando una `Series` sin datos (vacía, `empty`)",
"_____no_output_____"
]
],
[
[
"s = pd.Series()\nprint(s)",
"Series([], dtype: float64)\n"
]
],
[
[
"#### Creando una *Serie* con datos",
"_____no_output_____"
],
[
"Si los datos provienen de un `ndarray`, el índice pasado debe ser de la misma longitud. Si no se pasa ningún índice, el índice predeterminado será `range(n)` donde `n` es la longitud del arreglo, es decir, $[0,1,2, \\ldots rango(len(array))-1]$.",
"_____no_output_____"
]
],
[
[
"data = np.array(['a','b','c','d'])\ns = pd.Series(data)\nprint(s)",
"0 a\n1 b\n2 c\n3 d\ndtype: object\n"
]
],
[
[
"- Obsérvese que no se pasó ningún índice, por lo que, de forma predeterminada, se asignaron los índices que van de `0` a `len(datos) - 1`, es decir, de `0` a `3`.",
"_____no_output_____"
]
],
[
[
"data = np.array(['a','b','c','d'])\ns = pd.Series(data,index=[150,1,\"can?\",10])\nprint(s)",
"150 a\n1 b\ncan? c\n10 d\ndtype: object\n"
]
],
[
[
"- Aquí pasamos los valores del índice. Ahora podemos ver los valores indexados de forma personalizada en la salida.",
"_____no_output_____"
],
[
"#### Creando una `Series` desde un diccionario",
"_____no_output_____"
]
],
[
[
"data = {'a' : 0., 'b' : 1.,True : 2.}\ns = pd.Series(data)\nprint(s)",
"a 0.0\nb 1.0\nTrue 2.0\ndtype: float64\n"
]
],
[
[
"- La `clave` del diccionario es usada para construir el índice.",
"_____no_output_____"
]
],
[
[
"data = {'a' : 0., 'b' : 1., 'c' : 2.}\ns = pd.Series(data,index=['b','c','d','a'])\nprint(s)",
"b 1.0\nc 2.0\nd NaN\na 0.0\ndtype: float64\n"
]
],
[
[
"- El orden del índice se conserva y el elemento faltante se llena con `NaN` (*Not a Number*).",
"_____no_output_____"
],
[
"#### Creando una *Serie* desde un escalar",
"_____no_output_____"
]
],
[
[
"s = pd.Series(5, index=[0, 1, 2, 3])\nprint(s)",
"0 5\n1 5\n2 5\n3 5\ndtype: int64\n"
]
],
[
[
"#### Accesando a los datos desde la `Series` con la posición",
"_____no_output_____"
],
[
"Los datos en una `Series` se pueden acceder de forma similar a un `ndarray`",
"_____no_output_____"
]
],
[
[
"s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])\nprint(s['c']) # recupera el primer elemento",
"3\n"
]
],
[
[
"Ahora, recuperemos los tres primeros elementos en la `Series`. Si se inserta `a:` delante, se extraerán todos los elementos de ese índice en adelante. Si se usan dos parámetros (con `:` entre ellos), se extraerán los elementos entre los dos índices (sin incluir el índice de detención).",
"_____no_output_____"
]
],
[
[
"print(s[:3]) # recupera los tres primeros elementos",
"a 1\nb 2\nc 3\ndtype: int64\n"
]
],
[
[
"Recupere los tres últimos elementos",
"_____no_output_____"
]
],
[
[
"print(s[-3:])",
"c 3\nd 4\ne 5\ndtype: int64\n"
]
],
[
[
"#### Recuperando los datos usando indexación\n\nRecupere un único elemento usando el valor del índice",
"_____no_output_____"
]
],
[
[
"print(s['a'])",
"_____no_output_____"
]
],
[
[
"Recupere múltiples elementos usando una lista de valores de los índices",
"_____no_output_____"
]
],
[
[
"print(s[['a','c','d']])",
"a 1\nc 3\nd 4\ndtype: int64\n"
]
],
[
[
"Si una etiqueta no está contenida, se emitirá un mensaje de excepción (error)",
"_____no_output_____"
]
],
[
[
"print(s['f'])",
"_____no_output_____"
]
],
[
[
" * Vamos a crear una serie con índices generados aleatoriamente (de forma automática)",
"_____no_output_____"
]
],
[
[
"# serie con índices automáticos\nserie = pd.Series(np.random.random(10))\nprint('Serie con índices automáticos'.format())\nprint('{}'.format(serie))\nprint(type(serie))",
"Serie con índices automáticos\n0 0.975859\n1 0.638077\n2 0.448323\n3 0.436982\n4 0.291624\n5 0.137938\n6 0.850435\n7 0.554056\n8 0.595432\n9 0.060182\ndtype: float64\n<class 'pandas.core.series.Series'>\n"
]
],
[
[
" * Ahora vamos a crear una serie donde nosotros le vamos a decir los índices que queremos usar (definidos por el usuario)",
"_____no_output_____"
]
],
[
[
"serie = pd.Series(np.random.randn(4),\n index = ['itzi','kikolas','dieguete','nicolasete'])\nprint('Serie con índices definidos')\nprint('{}'.format(serie))\nprint(type(serie))",
"Serie con índices definidos\nitzi 0.472222\nkikolas -0.241706\ndieguete 0.095845\nnicolasete -0.497357\ndtype: float64\n<class 'pandas.core.series.Series'>\n"
]
],
[
[
" * Por último, vamos a crear una serie temporal usando índices que son fechas.",
"_____no_output_____"
]
],
[
[
"# serie(serie temporal) con índices que son fechas\nn = 60\nserie = pd.Series(np.random.randn(n),\n index = pd.date_range('2001/01/01', periods = n))\nprint('Serie temporal con índices de fechas')\nprint('{}'.format(serie))\nprint(type(serie))",
"Serie temporal con índices de fechas\n2001-01-01 -0.644895\n2001-01-02 0.565821\n2001-01-03 -0.373456\n2001-01-04 -1.804044\n2001-01-05 0.789562\n2001-01-06 1.089039\n2001-01-07 0.555049\n2001-01-08 -1.117275\n2001-01-09 0.951007\n2001-01-10 0.570231\n2001-01-11 -0.621267\n2001-01-12 0.783843\n2001-01-13 0.166866\n2001-01-14 0.038586\n2001-01-15 1.266768\n2001-01-16 0.133382\n2001-01-17 -0.014160\n2001-01-18 -0.519427\n2001-01-19 2.213708\n2001-01-20 0.779634\n2001-01-21 0.803705\n2001-01-22 -0.307845\n2001-01-23 0.255089\n2001-01-24 -0.208658\n2001-01-25 0.372216\n2001-01-26 -0.019649\n2001-01-27 2.962986\n2001-01-28 -2.282310\n2001-01-29 0.021721\n2001-01-30 -0.156564\n2001-01-31 1.459959\n2001-02-01 0.124899\n2001-02-02 0.927461\n2001-02-03 1.080677\n2001-02-04 0.244661\n2001-02-05 -0.293810\n2001-02-06 -0.497230\n2001-02-07 -0.216070\n2001-02-08 -0.036613\n2001-02-09 0.539374\n2001-02-10 0.462854\n2001-02-11 -0.206390\n2001-02-12 -1.735542\n2001-02-13 -0.229763\n2001-02-14 0.198808\n2001-02-15 1.120697\n2001-02-16 1.251387\n2001-02-17 -0.512982\n2001-02-18 1.906729\n2001-02-19 0.638418\n2001-02-20 -0.171920\n2001-02-21 -0.409196\n2001-02-22 0.630868\n2001-02-23 0.232251\n2001-02-24 -0.009072\n2001-02-25 0.844716\n2001-02-26 -0.555795\n2001-02-27 -0.154690\n2001-02-28 -0.351706\n2001-03-01 1.815298\nFreq: D, dtype: float64\n<class 'pandas.core.series.Series'>\n"
],
[
"pd.",
"_____no_output_____"
]
],
[
[
"En los ejemplos anteriores hemos creado las series a partir de un `numpy array` pero las podemos crear a partir de muchas otras cosas: listas, diccionarios, numpy arrays,... Veamos ejemplos:",
"_____no_output_____"
]
],
[
[
"Serie a partir de una lista...",
"_____no_output_____"
]
],
[
[
"serie_lista = pd.Series([i*i for i in range(10)])\nprint('Serie a partir de una lista')\nprint('{}'.format(serie_lista))",
"Serie a partir de una lista\n0 0\n1 1\n2 4\n3 9\n4 16\n5 25\n6 36\n7 49\n8 64\n9 81\ndtype: int64\n"
]
],
[
[
"Serie a partir de un diccionario",
"_____no_output_____"
]
],
[
[
"dicc = {'cuadrado de {}'.format(i) : i*i for i in range(10)}\nserie_dicc = pd.Series(dicc)\nprint('Serie a partir de un diccionario ')\nprint('{}'.format(serie_dicc))",
"Serie a partir de un diccionario \ncuadrado de 0 0\ncuadrado de 1 1\ncuadrado de 2 4\ncuadrado de 3 9\ncuadrado de 4 16\ncuadrado de 5 25\ncuadrado de 6 36\ncuadrado de 7 49\ncuadrado de 8 64\ncuadrado de 9 81\ndtype: int64\n"
]
],
[
[
"Serie a partir de valores de otra serie...",
"_____no_output_____"
]
],
[
[
"serie_serie = pd.Series(serie_dicc.values)\nprint('Serie a partir de los valores de otra (pandas) serie')\nprint('{}'.format(serie_serie))",
"Serie a partir de los valores de otra (pandas) serie\n0 0\n1 1\n2 4\n3 9\n4 16\n5 25\n6 36\n7 49\n8 64\n9 81\ndtype: int64\n"
]
],
[
[
"Serie a partir de un valor constante ...",
"_____no_output_____"
]
],
[
[
"serie_cte = pd.Series(-999, index = np.arange(10))\nprint('Serie a partir de un valor constante')\nprint('{}'.format(serie_cte))",
"Serie a partir de un valor constante\n0 -999\n1 -999\n2 -999\n3 -999\n4 -999\n5 -999\n6 -999\n7 -999\n8 -999\n9 -999\ndtype: int64\n"
]
],
[
[
"Una serie (`Series` o `TimeSeries`) se puede manejar igual que si tuviéramos un `numpy array` de una dimensión o igual que si tuviéramos un diccionario. Vemos ejemplos de esto:",
"_____no_output_____"
]
],
[
[
"serie = pd.Series(np.random.randn(10),\n index = ['a','b','c','d','e','f','g','h','i','j'])\nprint('Serie que vamos a usar en este ejemplo:')\nprint('{}'.format(serie))",
"Serie que vamos a usar en este ejemplo:\na -0.156616\nb 0.633206\nc 0.131619\nd -1.255318\ne -0.511742\nf -1.823514\ng -2.185952\nh 0.228921\ni 2.373985\nj -0.557017\ndtype: float64\n"
]
],
[
[
"Ejemplos de comportamiento como `numpy array`",
"_____no_output_____"
]
],
[
[
"print('serie.max() {}'.format(serie.max()))\nprint('serie.sum() {}'.format(serie.sum()))\nprint('serie.abs()')\nprint('{}'.format(serie.abs()))\nprint('serie[serie > 0]')\nprint('{}'.format(serie[serie > 0]))\n#...\nprint('\\n')",
"serie.max() 2.373985183706578\nserie.sum() -3.1224268780098985\nserie.abs()\na 0.156616\nb 0.633206\nc 0.131619\nd 1.255318\ne 0.511742\nf 1.823514\ng 2.185952\nh 0.228921\ni 2.373985\nj 0.557017\ndtype: float64\nserie[serie > 0]\nb 0.633206\nc 0.131619\nh 0.228921\ni 2.373985\ndtype: float64\n\n\n"
]
],
[
[
"Ejemplos de comportamiento como diccionario",
"_____no_output_____"
]
],
[
[
"print(\"Se comporta como un diccionario:\")\nprint(\"================================\")\nprint(\"serie['a'] \\n {}\".format(serie['a']))\nprint(\"'a' en la serie \\n {}\".format('a' in serie))\nprint(\"'z' en la serie \\n {}\".format('z' in serie))",
"Se comporta como un diccionario:\n================================\nserie['a'] \n -0.15661590864805106\n'a' en la serie \n True\n'z' en la serie \n False\n"
]
],
[
[
"Las operaciones están 'vectorizadas' y se hacen elemento a elemento con los elementos alineados en función del índice. \n\n\n- Si se hace, por ejemplo, una suma de dos series, si en una de las dos series no existe un elemento, i.e. el índice no existe en la serie, el resultado para ese índice será `NAN`. \n\n\n- En resumen, estamos haciendo una unión de los índices y funciona diferente a los `numpy arrays`. \n\n\nSe puede ver el esquema en el siguiente ejemplo:",
"_____no_output_____"
]
],
[
[
"s1 = serie[1:]\ns2 = serie[:-1]\nsuma = s1 + s2\nprint(' s1 s2 s1 + s2')\nprint('------------------ ------------------ ------------------')\nfor clave in sorted(set(list(s1.keys()) + list(s2.keys()))):\n print('{0:1} {1:20} + {0:1} {2:20} = {0:1} {3:20}'.format(clave,\n s1.get(clave),\n s2.get(clave),\n suma.get(clave)))",
"_____no_output_____"
]
],
[
[
"En la anterior línea de código se usa el método `get` para no obtener un `KeyError`, como sí obtendría si se usa, p.e., `s1['a']`",
"_____no_output_____"
],
[
"## `DataFrame`",
"_____no_output_____"
],
[
"Un `DataFrame` es una estructura 2-Dimensional, es decir, los datos se alinean en forma tabular por filas y columnas.",
"_____no_output_____"
],
[
"### Características del`DataFrame`\n\n- Las columnas pueden ser de diferente tipo.\n\n- Tamaño cambiable.\n\n- Ejes etiquetados (filas y columnas).\n\n- Se pueden desarrollar operaciones aritméticas en filas y columnas.",
"_____no_output_____"
],
[
"### `pandas.DataFrame`\n\nuna estructura de `DataFrame` puede crearse usando el siguiente constructor:",
"_____no_output_____"
]
],
[
[
"pandas.DataFrame(data, index, columns, dtype, copy) ",
"_____no_output_____"
]
],
[
[
"Los parámetros de este constructor son los siguientes:",
"_____no_output_____"
],
[
"- **`data`:** Pueden ser de diferentes formas como `ndarray`, `Series`, `map`, `lists`, `dict`, constantes o también otro `DataFrame`.\n\n- **`index`:** para las etiquetas de fila, el índice que se utilizará para la trama resultante es dado de forma opcional por defecto por `np.arange(n)`, si no se especifica ningún índice.\n\n- **`columns`:** para las etiquetas de columnas, la sintaxis por defecto es `np.arange(n)`. Esto es así si no se especifíca ningún índice.\n\n- **`dtype`:** tipo de dato para cada columna\n\n- **`copy`:*** Es usado para copiar los datos. Por defecto es `False`.",
"_____no_output_____"
],
[
"#### Creando un `DataFrame`\n\nUn `DataFrame` en Pandas se puede crear usando diferentes entradas, como: `listas`, `diccionarios`, `Series`, `ndarrays`, otros `DataFrame`.",
"_____no_output_____"
],
[
"#### Creando un `DataFrame`\nvacío",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame()\nprint(df)",
"Empty DataFrame\nColumns: []\nIndex: []\n"
]
],
[
[
"#### Creando un `DataFrame` desde listas",
"_____no_output_____"
]
],
[
[
"data = [1,2,3,4,5]\ndf = pd.DataFrame(data)\nprint(df)",
" 0\n0 1\n1 2\n2 3\n3 4\n4 5\n"
],
[
"data = [['Alex',10],['Bob',12],['Clarke',13]]\ndf = pd.DataFrame(data,columns=['Name','Age'])\nprint(df)",
" Name Age\n0 Alex 10\n1 Bob 12\n2 Clarke 13\n"
],
[
"df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)\nprint(df)",
" Name Age\n0 Alex 10.0\n1 Bob 12.0\n2 Clarke 13.0\n"
]
],
[
[
"#### Creando un `DataFrame` desde diccionarios de `ndarrays`/`lists`\n\nTodos los `ndarrays` deben ser de la misma longitud. Si se pasa el índice, entonces la longitud del índice debe ser igual a la longitud de las matrices.\n\nSi no se pasa ningún índice, de manera predeterminada, el índice será `range(n)`, donde `n` es la longitud del arreglo.",
"_____no_output_____"
]
],
[
[
"data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}\ndf = pd.DataFrame(data)\nprint(df)",
" Name Age\n0 Tom 28\n1 Jack 34\n2 Steve 29\n3 Ricky 42\n"
]
],
[
[
"- Observe los valores $0,1,2,3$. Son el índice predeterminado asignado a cada uno usando la función `range(n)`.",
"_____no_output_____"
],
[
"Ahora crearemos un `DataFrame` indexado usando `arrays`",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])\nprint(df)",
" Name Age\nrank1 Tom 28\nrank2 Jack 34\nrank3 Steve 29\nrank4 Ricky 42\n"
]
],
[
[
"#### Creando un `DataFrame` desde listas de diccionarios\n\nSe puede pasar una lista de diccionarios como datos de entrada para crear un `DataFrame`. Las `claves` serán usadas por defecto como los nombres de las columnas.",
"_____no_output_____"
]
],
[
[
"data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]\ndf = pd.DataFrame(data)\nprint(df)",
" a b c\n0 1 2 NaN\n1 5 10 20.0\n"
]
],
[
[
"- un `NaN` aparece en donde no hay datos.",
"_____no_output_____"
],
[
"El siguiente ejemplo muestra como se crea un `DataFrame` pasando una lista de diccionarios y los índices de las filas:",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(data, index=['first', 'second'])\nprint(df)",
" a b c\nfirst 1 2 NaN\nsecond 5 10 20.0\n"
]
],
[
[
"El siguiente ejemplo muestra como se crea un `DataFrame` pasando una lista de diccionarios, y los índices de las filas y columnas:",
"_____no_output_____"
]
],
[
[
"# Con dos índices de columnas, los valores son iguales que las claves del diccionario\ndf1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])\n\n# Con dos índices de columna y con un índice con otro nombre\ndf2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])\nprint(df1)\nprint(df2)",
" a b\nfirst 1 2\nsecond 5 10\n a b1\nfirst 1 NaN\nsecond 5 NaN\n"
]
],
[
[
"- Observe que el `DataFrame` `df2` se crea con un índice de columna que no es la clave del diccionario; por lo tanto, se generan los `NaN` en su lugar. Mientras que, `df1` se crea con índices de columnas iguales a las claves del diccionario, por lo que no se agrega `NaN`.",
"_____no_output_____"
],
[
"#### Creando un `DataFrame` desde un diccionario de `Series`\n\nSe puede pasar una Serie de diccionarios para formar un `DataFrame`. El índice resultante es la unión de todos los índices de serie pasados.",
"_____no_output_____"
]
],
[
[
"d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),\n 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}\n\ndf = pd.DataFrame(d)\nprint(df)",
" one two\na 1.0 1\nb 2.0 2\nc 3.0 3\nd NaN 4\n"
]
],
[
[
"- para la serie `one`, no hay una etiqueta `'d'` pasada, pero en el resultado, para la etiqueta `d`, se agrega `NaN`.\n\nAhora vamos a entender la selección, adición y eliminación de columnas a través de ejemplos.",
"_____no_output_____"
],
[
"#### Selección de columna",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(d)\nprint(df['one'])",
"a 1.0\nb 2.0\nc 3.0\nd NaN\nName: one, dtype: float64\n"
]
],
[
[
"#### Adición de columna",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(d)\n\n# Adding a new column to an existing DataFrame object with column label by passing new series\n\nprint (\"Adicionando una nueva columna pasando como Serie:, \\n\")\ndf['three']=pd.Series([10,20,30],index=['a','b','c'])\nprint(df,'\\n')\n\nprint (\"Adicionando una nueva columna usando las columnas existentes en el DataFrame:\\n\")\ndf['four']=df['one']+df['three']\n\nprint(df)",
"Adicionando una nueva columna pasando como Serie:, \n\n one two three\na 1.0 1 10.0\nb 2.0 2 20.0\nc 3.0 3 30.0\nd NaN 4 NaN \n\nAdicionando una nueva columna usando las columnas existentes en el DataFrame:\n\n one two three four\na 1.0 1 10.0 11.0\nb 2.0 2 20.0 22.0\nc 3.0 3 30.0 33.0\nd NaN 4 NaN NaN\n"
]
],
[
[
"#### Borrado de columna",
"_____no_output_____"
]
],
[
[
"d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), \n 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']), \n 'three' : pd.Series([10,20,30], index=['a','b','c'])}\n\ndf = pd.DataFrame(d)\nprint (\"Our dataframe is:\\n\")\nprint(df, '\\n')\n\n# using del function\nprint (\"Deleting the first column using DEL function:\\n\")\ndel df['one']\nprint(df,'\\n')\n\n# using pop function\nprint (\"Deleting another column using POP function:\\n\")\ndf.pop('two')\nprint(df)",
"Our dataframe is:\n\n one two three\na 1.0 1 10.0\nb 2.0 2 20.0\nc 3.0 3 30.0\nd NaN 4 NaN \n\nDeleting the first column using DEL function:\n\n two three\na 1 10.0\nb 2 20.0\nc 3 30.0\nd 4 NaN \n\nDeleting another column using POP function:\n\n three\na 10.0\nb 20.0\nc 30.0\nd NaN\n"
]
],
[
[
"### Selección, Adición y Borrado de fila",
"_____no_output_____"
],
[
"#### Selección por etiqueta\n\nLas filas se pueden seleccionar pasando la etiqueta de fila por la función `loc`",
"_____no_output_____"
]
],
[
[
"d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), \n 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}\n\ndf = pd.DataFrame(d)\nprint(df)\nprint(df.loc['b'])",
" one two\na 1.0 1\nb 2.0 2\nc 3.0 3\nd NaN 4\none 2.0\ntwo 2.0\nName: b, dtype: float64\n"
]
],
[
[
"- El resultado es una serie con etiquetas como nombres de columna del `DataFrame`. Y, el Nombre de la serie es la etiqueta con la que se recupera.",
"_____no_output_____"
],
[
"#### Selección por ubicación entera\n\nLas filas se pueden seleccionar pasando la ubicación entera a una función `iloc`.",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(d)\nprint(df.iloc[2])",
"one 3.0\ntwo 3.0\nName: c, dtype: float64\n"
]
],
[
[
"#### Porcion de fila\n\nMúltiples filas se pueden seleccionar usando el operador `:`",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(d)\nprint(df[2:4])",
" one two\nc 3.0 3\nd NaN 4\n"
]
],
[
[
"#### Adición de filas\n\nAdicionar nuevas filas al `DataFrame` usando la función `append`. Esta función adiciona las filas al final.",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame([[1, 2], [3, 4]])\ndf2 = pd.DataFrame([[5, 6], [7, 8]])\n\nprint(df)\n\ndf = df.append(df2)\nprint(df)",
" 0 1\n0 1 2\n1 3 4\n 0 1\n0 1 2\n1 3 4\n0 5 6\n1 7 8\n"
]
],
[
[
"#### Borrado de filas\n\nUse la etiqueta de índice para eliminar o cortar filas de un `DataFrame`. Si la etiqueta está duplicada, se eliminarán varias filas.\n\nSi observa, en el ejemplo anterior, las etiquetas están duplicadas. Cortemos una etiqueta y veamos cuántas filas se descartarán.",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])\ndf2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])\n\ndf = df.append(df2)\nprint(df)\n# Drop rows with label 0\ndf = df.drop(1)\n\nprint(df)",
" a b\n0 1 2\n1 3 4\n0 5 6\n1 7 8\n a b\n0 1 2\n0 5 6\n"
]
],
[
[
"- En el ejemplo anterior se quitaron dos filas porque éstas dos contenían la misma etiqueta `0`.",
"_____no_output_____"
],
[
"### Lectura / Escritura en Pandas",
"_____no_output_____"
],
[
"Una de las grandes capacidades de *`Pandas`* es la potencia que aporta a lo hora de leer y/o escribir archivos de datos.\n\n- Pandas es capaz de leer datos de archivos `csv`, `excel`, `HDF5`, `sql`, `json`, `html`,...\n\nSi se emplean datos de terceros, que pueden provenir de muy diversas fuentes, una de las partes más tediosas del trabajo será tener los datos listos para empezar a trabajar: Limpiar huecos, poner fechas en formato usable, saltarse cabeceros,...\n\nSin duda, una de las funciones que más se usarán será `read_csv()` que permite una gran flexibilidad a la hora de leer un archivo de texto plano.",
"_____no_output_____"
]
],
[
[
"help(pd.read_csv)",
"_____no_output_____"
]
],
[
[
"En [este enlace](http://pandas.pydata.org/pandas-docs/stable/io.html \"pandas docs\") se pueden encontrar todos los posibles formatos con los que Pandas trabaja:\n\nCada uno de estos métodos de lectura de determinados formatos (`read_NombreFormato`) tiene infinidad de parámetros que se pueden ver en la documentación y que no vamos a explicar por lo extensísima que seria esta explicación. \n\nPara la mayoría de los casos que nos vamos a encontrar los parámetros serían los siguientes:",
"_____no_output_____"
]
],
[
[
"pd.read_table(dir_fichero, engine='python', sep=';', header=True|False, names=[lista con nombre columnas])",
"_____no_output_____"
]
],
[
[
"Básicamente hay que pasarle el archivo a leer, cual es su separador, si la primera linea del archivo contiene el nombre de las columnas y en el caso de que no las tenga pasarle en `names` el nombre de las columnas. \n\n\nVeamos un ejemplo de un dataset del cómo leeriamos el archivo con los datos de los usuarios, siendo el contenido de las 10 primeras lineas el siguiente:",
"_____no_output_____"
]
],
[
[
"# Load users info\nuserHeader = ['ID', 'Sexo', 'Edad', 'Ocupacion', 'PBOX']\nusers = pd.read_csv('Datasets/users.txt', engine='python', sep='::', header=None, names=userHeader)\n\n# print 5 first users\nprint ('# 10 primeros usuarios: \\n%s' % users[:100])",
"# 10 primeros usuarios: \n ID Sexo Edad Ocupacion PBOX\n0 1 F 1 10 48067\n1 2 M 56 16 70072\n2 3 M 25 15 55117\n3 4 M 45 7 02460\n4 5 M 25 20 55455\n5 6 F 50 9 55117\n6 7 M 35 1 06810\n7 8 M 25 12 11413\n8 9 M 25 17 61614\n9 10 F 35 1 95370\n10 11 F 25 1 04093\n11 12 M 25 12 32793\n12 13 M 45 1 93304\n13 14 M 35 0 60126\n14 15 M 25 7 22903\n15 16 F 35 0 20670\n16 17 M 50 1 95350\n17 18 F 18 3 95825\n18 19 M 1 10 48073\n19 20 M 25 14 55113\n20 21 M 18 16 99353\n21 22 M 18 15 53706\n22 23 M 35 0 90049\n23 24 F 25 7 10023\n24 25 M 18 4 01609\n25 26 M 25 7 23112\n26 27 M 25 11 19130\n27 28 F 25 1 14607\n28 29 M 35 7 33407\n29 30 F 35 7 19143\n.. ... ... ... ... ...\n70 71 M 25 14 95008\n71 72 F 45 0 55122\n72 73 M 18 4 53706\n73 74 M 35 14 94530\n74 75 F 1 10 01748\n75 76 M 35 7 55413\n76 77 M 18 4 15321\n77 78 F 45 1 98029\n78 79 F 45 0 98103\n79 80 M 56 1 49327\n80 81 F 25 0 60640\n81 82 M 25 17 48380\n82 83 F 25 2 94609\n83 84 M 18 4 53140\n84 85 M 18 4 94945\n85 86 F 1 10 54467\n86 87 M 25 14 48360\n87 88 F 45 1 02476\n88 89 F 56 9 85749\n89 90 M 56 13 85749\n90 91 M 35 7 07650\n91 92 F 18 4 44243\n92 93 M 25 17 95825\n93 94 M 25 17 28601\n94 95 M 45 0 98201\n95 96 F 25 16 78028\n96 97 F 35 3 66210\n97 98 F 35 7 33547\n98 99 F 1 10 19390\n99 100 M 35 17 95401\n\n[100 rows x 5 columns]\n"
]
],
[
[
"Para escribir un `DataFrame` en un archivo de texto se pueden utilizar los [método de escritura](http://pandas.pydata.org/pandas-docs/stable/io.html) para escribirlos en el formato que se quiera. \n\n\n- Por ejemplo si utilizamos el método `to_csv()` nos escribirá el `DataFrame` en este formato estandar que separa los campos por comas; pero por ejemplo, podemos decirle al método que en vez de que utilice como separador una coma, que utilice por ejemplo un guión. \n\n\nSi queremos escribir en un archivo el `DataFrame` `users` con estas características lo podemos hacer de la siguiente manera:",
"_____no_output_____"
]
],
[
[
"users.to_csv('Datasets/MyUsers3.txt', sep='-')",
"_____no_output_____"
]
],
[
[
"### Merge",
"_____no_output_____"
],
[
"Una funcionalidad muy potente que ofrece Pandas es la de poder juntar, `merge` (en bases de datos sería hacer un `JOIN`) datos siempre y cuando este sea posible. \n\n\nEn el ejemplo que estamos haciendo con el dataset podemos ver esta funcionalidad de forma muy intuitiva, ya que los datos de este data set se han obtenido a partir de una bases de datos relacional. \n\n\nVeamos a continuación como hacer un `JOIN` o un `merge` de los archivos `users.txt` y `ratings.txt` a partir del `user_id`:",
"_____no_output_____"
]
],
[
[
"# Load users info\nuserHeader = ['user_id', 'gender', 'age', 'ocupation', 'zip']\nusers = pd.read_csv('Datasets/users.txt', engine='python', sep='::', header=None, names=userHeader)\n# Load ratings\nratingHeader = ['user_id', 'movie_id', 'rating', 'timestamp']\nratings = pd.read_csv('Datasets/ratings.txt', engine='python', sep='::', header=None, names=ratingHeader)\n\n# Merge tables users + ratings by user_id field\nmerger_ratings_users = pd.merge(users, ratings)\nprint('%s' % merger_ratings_users[:10])",
" user_id gender age ocupation zip movie_id rating timestamp\n0 1 F 1 10 48067 1193 5 978300760\n1 1 F 1 10 48067 661 3 978302109\n2 1 F 1 10 48067 914 3 978301968\n3 1 F 1 10 48067 3408 4 978300275\n4 1 F 1 10 48067 2355 5 978824291\n5 1 F 1 10 48067 1197 3 978302268\n6 1 F 1 10 48067 1287 5 978302039\n7 1 F 1 10 48067 2804 5 978300719\n8 1 F 1 10 48067 594 4 978302268\n9 1 F 1 10 48067 919 4 978301368\n"
]
],
[
[
"De la misma forma que hemos hecho el `JOIN` de los usuarios y los votos, podemos hacer lo mismo añadiendo también los datos relativos a las películas:",
"_____no_output_____"
]
],
[
[
"userHeader = ['user_id', 'gender', 'age', 'ocupation', 'zip']\nusers = pd.read_csv('Datasets/users.txt', engine='python', sep='::', header=None, names=userHeader)\n\nmovieHeader = ['movie_id', 'title', 'genders']\nmovies = pd.read_csv('Datasets/movies.txt', engine='python', sep='::', header=None, names=movieHeader)\n\nratingHeader = ['user_id', 'movie_id', 'rating', 'timestamp']\nratings = pd.read_csv('Datasets/ratings.txt', engine='python', sep='::', header=None, names=ratingHeader)\n\n# Merge data\n#mergeRatings = pd.merge(pd.merge(users, ratings), movies)\nmergeRatings = pd.merge(merger_ratings_users, movies)",
"_____no_output_____"
]
],
[
[
"Si quisiésemos ver por ejemplo un elemento de este nuevo `JOIN` creado (por ejemplo la posición 1000), lo podríamos hacer de la siguiente forma:",
"_____no_output_____"
]
],
[
[
"info1000 = mergeRatings.loc[1000]\nprint('Info of 1000 position of the table: \\n%s' % info1000[:1000])",
"Info of 1000 position of the table: \nuser_id 3612\ngender M\nage 25\nocupation 14\nzip 29609\nmovie_id 1193\nrating 5\ntimestamp 966605873\ntitle One Flew Over the Cuckoo's Nest (1975)\ngenders Drama\nName: 1000, dtype: object\n"
]
],
[
[
"### Trabajando con Datos, Indexación, Selección\n\n¿Cómo podemos seleccionar, añadir, eliminar, mover,..., columnas, filas,...?\n\n\n- Para seleccionar una columna solo hay que usar el nombre de la columna y pasarlo como si fuera un diccionario (o un atributo).\n\n\n- Para añadir una columna simplemente hay que usar un nombre de columna no existente y pasarle los valores para esa columna.\n\n\n- Para eliminar una columna podemos usar `del` o el método `pop` del `DataFrame`.\n\n\n- Para mover una columna podemos usar una combinación de las metodologías anteriores.\n\n\nComo ejemplo, vamos crear un `DataFrame`con datos aleatorios y a seleccionar los valores de una columna:",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(np.random.randn(5,3),\n index = ['primero','segundo','tercero','cuarto','quinto'],\n columns = ['velocidad', 'temperatura','presion'])\nprint(df)\nprint(df['velocidad'])\nprint(df.velocidad)",
" velocidad temperatura presion\nprimero 1.657614 1.106117 -0.465712\nsegundo 0.024792 -0.569864 -0.131773\ntercero -0.245517 -0.821585 0.693599\ncuarto -0.642441 -0.803830 1.145184\nquinto 0.491180 -1.159043 -0.627036\nprimero 1.657614\nsegundo 0.024792\ntercero -0.245517\ncuarto -0.642441\nquinto 0.491180\nName: velocidad, dtype: float64\nprimero 1.657614\nsegundo 0.024792\ntercero -0.245517\ncuarto -0.642441\nquinto 0.491180\nName: velocidad, dtype: float64\n"
]
],
[
[
"Para acceder a la columna `velocidad` lo podemos hacer de dos formas. \n\n\n- O bien usando el nombre de la columna como si fuera una clave de un diccionario \n\n\n- O bien usando el nombre de la columna como si fuera un atributo. \n\n\nEn el caso de que los nombres de las columnas sean números, la segunda opción no podríais usarla...\n\n\nVamos a añadir una columna nueva al `DataFrame`. Es algo tan sencillo como usar un nombre de columna no existente y pasarle los datos:",
"_____no_output_____"
]
],
[
[
"df['velocidad_maxima'] = np.random.randn(df.shape[0])\nprint(df)",
" velocidad temperatura presion velocidad_maxima\nprimero 1.657614 1.106117 -0.465712 0.522077\nsegundo 0.024792 -0.569864 -0.131773 0.990787\ntercero -0.245517 -0.821585 0.693599 0.927056\ncuarto -0.642441 -0.803830 1.145184 -0.147118\nquinto 0.491180 -1.159043 -0.627036 -0.016672\n"
]
],
[
[
"Pero qué pasa si quiero añadir la columna en un lugar específico. Para ello podemos usar el método `insert` (y de paso vemos como podemos borrar una columna):\n\n**Forma 1:**\n\n- Borramos la columna 'velocidad_maxima' que está al final del df usando `del`\n\n\n- Colocamos la columna eliminada en la posición que especifiquemos",
"_____no_output_____"
]
],
[
[
"print(df)\ncolumna = df['velocidad_maxima']\ndel df['velocidad_maxima']\ndf.insert(1, 'velocidad_maxima', columna)\nprint(df)",
" velocidad temperatura presion velocidad_maxima\nprimero 1.657614 1.106117 -0.465712 0.522077\nsegundo 0.024792 -0.569864 -0.131773 0.990787\ntercero -0.245517 -0.821585 0.693599 0.927056\ncuarto -0.642441 -0.803830 1.145184 -0.147118\nquinto 0.491180 -1.159043 -0.627036 -0.016672\n velocidad velocidad_maxima temperatura presion\nprimero 1.657614 0.522077 1.106117 -0.465712\nsegundo 0.024792 0.990787 -0.569864 -0.131773\ntercero -0.245517 0.927056 -0.821585 0.693599\ncuarto -0.642441 -0.147118 -0.803830 1.145184\nquinto 0.491180 -0.016672 -1.159043 -0.627036\n"
]
],
[
[
"**Forma 2:** Usando el método `pop`: borramos usando el método `pop` y añadimos la columna borrada en la última posición de nuevo.",
"_____no_output_____"
]
],
[
[
"print(df)\ncolumna = df.pop('velocidad_maxima')\nprint(df)\n#print(columna)\ndf.insert(3, 'velocidad_maxima', columna)\nprint(df)",
" velocidad velocidad_maxima temperatura presion\nprimero 1.657614 0.522077 1.106117 -0.465712\nsegundo 0.024792 0.990787 -0.569864 -0.131773\ntercero -0.245517 0.927056 -0.821585 0.693599\ncuarto -0.642441 -0.147118 -0.803830 1.145184\nquinto 0.491180 -0.016672 -1.159043 -0.627036\n velocidad temperatura presion\nprimero 1.657614 1.106117 -0.465712\nsegundo 0.024792 -0.569864 -0.131773\ntercero -0.245517 -0.821585 0.693599\ncuarto -0.642441 -0.803830 1.145184\nquinto 0.491180 -1.159043 -0.627036\n velocidad temperatura presion velocidad_maxima\nprimero 1.657614 1.106117 -0.465712 0.522077\nsegundo 0.024792 -0.569864 -0.131773 0.990787\ntercero -0.245517 -0.821585 0.693599 0.927056\ncuarto -0.642441 -0.803830 1.145184 -0.147118\nquinto 0.491180 -1.159043 -0.627036 -0.016672\n"
]
],
[
[
"Para seleccionar datos concretos de un `DataFrame` podemos usar el índice, una rebanada (*slicing*), valores booleanos, la columna,...\n\n\n- Seleccionamos la columna de velocidades:",
"_____no_output_____"
]
],
[
[
"print(df.velocidad)",
"primero 1.657614\nsegundo 0.024792\ntercero -0.245517\ncuarto -0.642441\nquinto 0.491180\nName: velocidad, dtype: float64\n"
]
],
[
[
"- Seleccionamos todas las columnas cuyo índice es igual a tercero:",
"_____no_output_____"
]
],
[
[
"print(df.xs('tercero'))",
"_____no_output_____"
]
],
[
[
"- Seleccionamos todas las columnas cuyo índice está entre tercero y quinto (en este caso los índices son inclusivos)",
"_____no_output_____"
]
],
[
[
"print(df.loc['tercero':'quinto'])",
"_____no_output_____"
]
],
[
[
"- Seleccionamos todos los valores de velocidad donde la temperatura > 0",
"_____no_output_____"
]
],
[
[
"print(df['velocidad'][df['temperatura']>0])",
"_____no_output_____"
]
],
[
[
"Seleccionamos todos los valores de una columna por índice usando una rebanada (`slice`) de enteros.\n\n\n- En este caso el límite superior de la rebanada no se incluye (Python tradicional)",
"_____no_output_____"
]
],
[
[
"print(df.iloc[1:3])",
"_____no_output_____"
]
],
[
[
"- Seleccionamos filas y columnas",
"_____no_output_____"
]
],
[
[
"print(df.iloc[1:3, ['velocidad', 'presion']])",
"_____no_output_____"
],
[
"help(df.ix)",
"_____no_output_____"
]
]
] |
[
"markdown",
"raw",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4e7677d9a4e4cf003f2cd5c83db19646ac02ae
| 144,360 |
ipynb
|
Jupyter Notebook
|
src/plotting/luminescence_plotsold.ipynb
|
Switham1/PromoterArchitecture
|
0a9021b869ac66cdd622be18cd029950314d111e
|
[
"MIT"
] | null | null | null |
src/plotting/luminescence_plotsold.ipynb
|
Switham1/PromoterArchitecture
|
0a9021b869ac66cdd622be18cd029950314d111e
|
[
"MIT"
] | null | null | null |
src/plotting/luminescence_plotsold.ipynb
|
Switham1/PromoterArchitecture
|
0a9021b869ac66cdd622be18cd029950314d111e
|
[
"MIT"
] | null | null | null | 75.541601 | 33,292 | 0.677424 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport skbio\nfrom collections import Counter\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom scipy import stats\nfrom statsmodels.formula.api import ols\nimport researchpy as rp",
"_____no_output_____"
],
[
"luminescence_means = \"../../data/luminescence/to_be_sorted/24.11.19/output_means.csv\"\nluminescence_raw = \"../../data/luminescence/to_be_sorted/24.11.19/output_raw.csv\"",
"_____no_output_____"
],
[
"luminescence_means_df = pd.read_csv(luminescence_means, header=0)\nluminescence_raw_df = pd.read_csv(luminescence_raw, header=0)",
"_____no_output_____"
],
[
"luminescence_means_df",
"_____no_output_____"
],
[
"luminescence_raw_df",
"_____no_output_____"
],
[
"#add promoter names column\nluminescence_raw_df['Promoter'] = luminescence_raw_df.name ",
"_____no_output_____"
],
[
"luminescence_raw_df.loc[luminescence_raw_df.name == '71 + 72', 'Promoter'] = 'UBQ10'\nluminescence_raw_df.loc[luminescence_raw_df.name == '25+72', 'Promoter'] = 'NIR1'\nluminescence_raw_df.loc[luminescence_raw_df.name == '35+72', 'Promoter'] = 'NOS'\nluminescence_raw_df.loc[luminescence_raw_df.name == '36+72', 'Promoter'] = 'STAP4'\nluminescence_raw_df.loc[luminescence_raw_df.name == '92+72', 'Promoter'] = 'NRP'",
"_____no_output_____"
],
[
"luminescence_raw_df",
"_____no_output_____"
],
[
"#set style to ticks\nsns.set(style=\"ticks\", color_codes=True)",
"_____no_output_____"
],
[
"plot = sns.catplot(x=\"Promoter\", y=\"nluc/fluc\", data=luminescence_raw_df, hue='condition', kind='violin')\n#plot points\nax = sns.swarmplot(x=\"Promoter\", y=\"nluc/fluc\", data=luminescence_raw_df, color=\".25\").get_figure().savefig('../../data/plots/luminescence/24.11.19/luminescence_violin.pdf', format='pdf')",
"_____no_output_____"
],
[
"#bar chart, 95% confidence intervals\nplot = sns.barplot(x=\"Promoter\", y=\"nluc/fluc\", hue=\"condition\", data=luminescence_raw_df)\nplt.ylabel(\"Mean_luminescence\")",
"_____no_output_____"
],
[
"#plot raw UBQ10\nplot = sns.barplot(x=\"Promoter\", y=\"fluc_luminescence\", hue=\"condition\", data=luminescence_raw_df[luminescence_raw_df.Promoter == 'UBQ10'])\nplt.ylabel(\"Mean_luminescence\")",
"_____no_output_____"
]
],
[
[
"### get names of each condition for later",
"_____no_output_____"
]
],
[
[
"pd.Categorical(luminescence_raw_df.condition)\nnames = luminescence_raw_df.condition.unique()\nfor name in names:\n print(name)",
"nitrate_free\nnitrate_2hrs_morning\nnitrate_overnight\n"
],
[
"#get list of promoters\npd.Categorical(luminescence_raw_df.Promoter)\nprom_names = luminescence_raw_df.Promoter.unique()\nfor name in prom_names:\n print(name)",
"UBQ10\nNIR1\nNOS\nSTAP4\nNRP\n"
]
],
[
[
"### test normality",
"_____no_output_____"
]
],
[
[
"#returns test statistic, p-value\nfor name1 in prom_names:\n for name in names:\n print('{}: {}'.format(name, stats.shapiro(luminescence_raw_df['nluc/fluc'][luminescence_raw_df.condition == name])))\n",
"_____no_output_____"
]
],
[
[
"#### not normal",
"_____no_output_____"
]
],
[
[
"#test variance\nstats.levene(luminescence_raw_df['nluc/fluc'][luminescence_raw_df.condition == names[0]], \n luminescence_raw_df['nluc/fluc'][luminescence_raw_df.condition == names[1]], \n luminescence_raw_df['nluc/fluc'][luminescence_raw_df.condition == names[2]])",
"_____no_output_____"
],
[
"test = luminescence_raw_df.groupby('Promoter')['nluc/fluc'].apply",
"_____no_output_____"
],
[
"test",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a4e7ee3e725998115f14b4aa8e00b87013c2fe4
| 13,308 |
ipynb
|
Jupyter Notebook
|
assignments/assignment10/ODEsEx01.ipynb
|
SJSlavin/phys202-2015-work
|
60311479d6a27ca4c530b057036a326e87805b61
|
[
"MIT"
] | null | null | null |
assignments/assignment10/ODEsEx01.ipynb
|
SJSlavin/phys202-2015-work
|
60311479d6a27ca4c530b057036a326e87805b61
|
[
"MIT"
] | null | null | null |
assignments/assignment10/ODEsEx01.ipynb
|
SJSlavin/phys202-2015-work
|
60311479d6a27ca4c530b057036a326e87805b61
|
[
"MIT"
] | null | null | null | 32.537897 | 1,488 | 0.549294 |
[
[
[
"# Ordinary Differential Equations Exercise 1",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\nfrom scipy.integrate import odeint\nfrom IPython.html.widgets import interact, fixed",
":0: FutureWarning: IPython widgets are experimental and may change in the future.\n"
]
],
[
[
"## Euler's method",
"_____no_output_____"
],
[
"[Euler's method](http://en.wikipedia.org/wiki/Euler_method) is the simplest numerical approach for solving a first order ODE numerically. Given the differential equation\n\n$$ \\frac{dy}{dx} = f(y(x), x) $$\n\nwith the initial condition:\n\n$$ y(x_0)=y_0 $$\n\nEuler's method performs updates using the equations:\n\n$$ y_{n+1} = y_n + h f(y_n,x_n) $$\n\n$$ h = x_{n+1} - x_n $$\n\nWrite a function `solve_euler` that implements the Euler method for a 1d ODE and follows the specification described in the docstring:",
"_____no_output_____"
]
],
[
[
"def solve_euler(derivs, y0, x):\n \"\"\"Solve a 1d ODE using Euler's method.\n \n Parameters\n ----------\n derivs : function\n The derivative of the diff-eq with the signature deriv(y,x) where\n y and x are floats.\n y0 : float\n The initial condition y[0] = y(x[0]).\n x : np.ndarray, list, tuple\n The array of times at which of solve the diff-eq.\n \n Returns\n -------\n y : np.ndarray\n Array of solutions y[i] = y(x[i])\n \"\"\"\n y = [y0]\n for n in range(1, len(x)):\n y.append(y[n-1] + (x[n] - x[n-1])*derivs(y[n-1], x[n-1]))\n \n return np.asarray(y)",
"_____no_output_____"
],
[
"assert np.allclose(solve_euler(lambda y, x: 1, 0, [0,1,2]), [0,1,2])",
"_____no_output_____"
]
],
[
[
"The [midpoint method]() is another numerical method for solving the above differential equation. In general it is more accurate than the Euler method. It uses the update equation:\n\n$$ y_{n+1} = y_n + h f\\left(y_n+\\frac{h}{2}f(y_n,x_n),x_n+\\frac{h}{2}\\right) $$\n\nWrite a function `solve_midpoint` that implements the midpoint method for a 1d ODE and follows the specification described in the docstring:",
"_____no_output_____"
]
],
[
[
"def solve_midpoint(derivs, y0, x):\n \"\"\"Solve a 1d ODE using the Midpoint method.\n \n Parameters\n ----------\n derivs : function\n The derivative of the diff-eq with the signature deriv(y,x) where y\n and x are floats.\n y0 : float\n The initial condition y[0] = y(x[0]).\n x : np.ndarray, list, tuple\n The array of times at which of solve the diff-eq.\n \n Returns\n -------\n y : np.ndarray\n Array of solutions y[i] = y(x[i])\n \"\"\"\n # YOUR CODE HERE\n y = [y0]\n for n in range(1, len(x)):\n h = x[n] - x[n-1]\n y.append(y[n-1] + h*derivs(y[n-1] + h/2*derivs(y[n-1], x[n-1]), x[n-1] + h/2))\n \n return np.asarray(y)",
"_____no_output_____"
],
[
"assert np.allclose(solve_midpoint(lambda y, x: 1, 0, [0,1,2]), [0,1,2])",
"_____no_output_____"
]
],
[
[
"You are now going to solve the following differential equation:\n\n$$\n\\frac{dy}{dx} = x + 2y\n$$\n\nwhich has the analytical solution:\n\n$$\ny(x) = 0.25 e^{2x} - 0.5 x - 0.25\n$$\n\nFirst, write a `solve_exact` function that compute the exact solution and follows the specification described in the docstring:",
"_____no_output_____"
]
],
[
[
"def solve_exact(x):\n \"\"\"compute the exact solution to dy/dx = x + 2y.\n \n Parameters\n ----------\n x : np.ndarray\n Array of x values to compute the solution at.\n \n Returns\n -------\n y : np.ndarray\n Array of solutions at y[i] = y(x[i]).\n \"\"\"\n # YOUR CODE HERE\n return 0.25*np.exp(2*x) - 0.5*x - 0.25",
"_____no_output_____"
],
[
"assert np.allclose(solve_exact(np.array([0,1,2])),np.array([0., 1.09726402, 12.39953751]))",
"_____no_output_____"
]
],
[
[
"In the following cell you are going to solve the above ODE using four different algorithms:\n\n1. Euler's method\n2. Midpoint method\n3. `odeint`\n4. Exact\n\nHere are the details:\n\n* Generate an array of x values with $N=11$ points over the interval $[0,1]$ ($h=0.1$).\n* Define the `derivs` function for the above differential equation.\n* Using the `solve_euler`, `solve_midpoint`, `odeint` and `solve_exact` functions to compute\n the solutions using the 4 approaches.\n\nVisualize the solutions on a sigle figure with two subplots:\n\n1. Plot the $y(x)$ versus $x$ for each of the 4 approaches.\n2. Plot $\\left|y(x)-y_{exact}(x)\\right|$ versus $x$ for each of the 3 numerical approaches.\n\nYour visualization should have legends, labeled axes, titles and be customized for beauty and effectiveness.\n\nWhile your final plot will use $N=10$ points, first try making $N$ larger and smaller to see how that affects the errors of the different approaches.",
"_____no_output_____"
]
],
[
[
"# YOUR CODE HERE\nx = np.linspace(0, 1, 11)\n\ndef derivs(yvec, x):\n y = yvec\n dy = x + 2*y\n return np.array([dy])\n\ny0 = np.array([1.0])\nprint(y0.shape)\n\n \nprint(solve_euler(derivs, 1.0, x))\nprint(solve_midpoint(derivs, 1.0, x))\n#gives error \"object too deep for desired array\". thinks y0 is a 2d array?\nprint(odeint(derivs, y0, x))",
"(1,)\n[ 1. 1.2 1.45 1.76 2.142 2.6104\n 3.18248 3.878976 4.7247712 5.74972544 6.98967053]\n[ 1. 1.225 1.5105 1.86981 2.3191682 2.8783852\n 3.57162995 4.42838854 5.48463402 6.7842535 8.38078927]\n"
],
[
"assert True # leave this for grading the plots",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4e9a32b5a090e14ba29e48ae503a4ee1d95fb0
| 4,819 |
ipynb
|
Jupyter Notebook
|
keywordlist-cleaner-singular-plural.ipynb
|
Aurora-Network-Global/small-bibliometric-tools
|
1b544fc6d8ac4fce3c570231a34322ff65f2c8b7
|
[
"Apache-2.0"
] | null | null | null |
keywordlist-cleaner-singular-plural.ipynb
|
Aurora-Network-Global/small-bibliometric-tools
|
1b544fc6d8ac4fce3c570231a34322ff65f2c8b7
|
[
"Apache-2.0"
] | null | null | null |
keywordlist-cleaner-singular-plural.ipynb
|
Aurora-Network-Global/small-bibliometric-tools
|
1b544fc6d8ac4fce3c570231a34322ff65f2c8b7
|
[
"Apache-2.0"
] | 1 |
2021-03-29T12:04:44.000Z
|
2021-03-29T12:04:44.000Z
| 26.190217 | 133 | 0.52542 |
[
[
[
"# enkelvoud/meervoud oplosser",
"_____no_output_____"
]
],
[
[
"# case: we willen niet beide vormen in keywords, maar alleen 1 (maakt niet uit welke)\n# aanname: we negeren speciale woorden waar de 2 vormen andere betekenis/rol hebben (zoals fish/fishes)",
"_____no_output_____"
],
[
"# soft-ware paketten binnenhalen\nfrom nltk.stem import PorterStemmer",
"_____no_output_____"
],
[
"# voorbeeld keyword lijst\n# bijvoorbeeld appels\n\nkeywords = ['apple',\n 'apples',\n 'pears',\n 'pear',\n 'mango']\n\n\n\n# maak object voor woordstam isolatie:\nps = PorterStemmer()\n\n# maak lijsten klaar\nkeywords_clean = []\nstem_list = []\n\n# loop over de keywords\nfor word in keywords:\n \n # vind de woordstam\n cur_stem = ps.stem(word)\n \n # als we de stam nog niet hebben, voeg de stam en originele keyword toe aan de lijsten\n if not(cur_stem in stem_list):\n stem_list = stem_list + [cur_stem]\n keywords_clean = keywords_clean + [word]\n \n# print het resultaat\nprint('All unique stems: ' + str(stem_list))\nprint('All unique keywords: ' + str(keywords_clean))",
"All unique stems: ['appl', 'pear', 'mango']\nAll unique keywords: ['apple', 'pears', 'mango']\n"
],
[
"# enkelvoud/meervoud oplosser / plural-singular-solver\n\n# case: we willen niet beide vormen in keywords, maar alleen 1 (maakt niet uit welke)\n# aanname: we negeren speciale woorden waar de 2 vormen andere betekenis/rol hebben (zoals fish/fishes)\n# / we want to have 1 form of every word, plural or singular. we ignore issues like with fish/fishes in meaning.\n\n# soft-ware paketten binnenhalen / import packages\nfrom nltk.stem import PorterStemmer\n\n# voorbeeld keyword lijst / exampe keyword list\n# bijvoorbeeld appels\n\nkeywords = ['apple',\n 'apples',\n 'pears',\n 'pear',\n 'mango']\n\n\n\n# maak object voor woordstam isolatie: / make stemmer\nps = PorterStemmer()\n\n# maak lijsten klaar / initialize lists\nkeywords_clean = []\nstem_list = []\n\n# loop over de keywords\nfor word in keywords:\n \n # vind de woordstam / find stem\n cur_stem = ps.stem(word)\n \n # als we de stam nog niet hebben, voeg de stam en originele keyword toe aan de lijsten / add stem if new and word itself\n if not(cur_stem in stem_list):\n stem_list = stem_list + [cur_stem]\n keywords_clean = keywords_clean + [word]\n \n# print het resultaat / print the result\nprint('All unique stems: ' + str(stem_list))\nprint('All unique keywords: ' + str(keywords_clean))\n\n\n# example output \n# print: All unique stems: ['appl', 'pear', 'mango']\n# print: All unique keywords: ['apple', 'pears', 'mango']\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a4ea8be5d0d8c2e391aaf9f9d17c1949c9787c0
| 10,027 |
ipynb
|
Jupyter Notebook
|
01.getting-started/11.production-deploy-to-aks/11.production-deploy-to-aks.ipynb
|
maryxavier2002/AutomatedML
|
e7ce245674010fafdcd65ba3148229027193958b
|
[
"MIT"
] | 1 |
2019-04-10T16:50:58.000Z
|
2019-04-10T16:50:58.000Z
|
01.getting-started/11.production-deploy-to-aks/11.production-deploy-to-aks.ipynb
|
maryxavier2002/AutomatedML
|
e7ce245674010fafdcd65ba3148229027193958b
|
[
"MIT"
] | null | null | null |
01.getting-started/11.production-deploy-to-aks/11.production-deploy-to-aks.ipynb
|
maryxavier2002/AutomatedML
|
e7ce245674010fafdcd65ba3148229027193958b
|
[
"MIT"
] | null | null | null | 29.233236 | 212 | 0.543931 |
[
[
[
"Copyright (c) Microsoft Corporation. All rights reserved.\n\nLicensed under the MIT License.",
"_____no_output_____"
],
[
"# Deploying a web service to Azure Kubernetes Service (AKS)\nThis notebook shows the steps for deploying a service: registering a model, creating an image, provisioning a cluster (one time action), and deploying a service to it. \nWe then test and delete the service, image and model.",
"_____no_output_____"
]
],
[
[
"from azureml.core import Workspace\nfrom azureml.core.compute import AksCompute, ComputeTarget\nfrom azureml.core.webservice import Webservice, AksWebservice\nfrom azureml.core.image import Image\nfrom azureml.core.model import Model",
"_____no_output_____"
],
[
"import azureml.core\nprint(azureml.core.VERSION)",
"_____no_output_____"
]
],
[
[
"# Get workspace\nLoad existing workspace from the config file info.",
"_____no_output_____"
]
],
[
[
"from azureml.core.workspace import Workspace\n\nws = Workspace.from_config()\nprint(ws.name, ws.resource_group, ws.location, ws.subscription_id, sep = '\\n')",
"_____no_output_____"
]
],
[
[
"# Register the model\nRegister an existing trained model, add descirption and tags.",
"_____no_output_____"
]
],
[
[
"#Register the model\nfrom azureml.core.model import Model\nmodel = Model.register(model_path = \"sklearn_regression_model.pkl\", # this points to a local file\n model_name = \"sklearn_regression_model.pkl\", # this is the name the model is registered as\n tags = {'area': \"diabetes\", 'type': \"regression\"},\n description = \"Ridge regression model to predict diabetes\",\n workspace = ws)\n\nprint(model.name, model.description, model.version)",
"_____no_output_____"
]
],
[
[
"# Create an image\nCreate an image using the registered model the script that will load and run the model.",
"_____no_output_____"
]
],
[
[
"%%writefile score.py\nimport pickle\nimport json\nimport numpy\nfrom sklearn.externals import joblib\nfrom sklearn.linear_model import Ridge\nfrom azureml.core.model import Model\n\ndef init():\n global model\n # note here \"sklearn_regression_model.pkl\" is the name of the model registered under\n # this is a different behavior than before when the code is run locally, even though the code is the same.\n model_path = Model.get_model_path('sklearn_regression_model.pkl')\n # deserialize the model file back into a sklearn model\n model = joblib.load(model_path)\n\n# note you can pass in multiple rows for scoring\ndef run(raw_data):\n try:\n data = json.loads(raw_data)['data']\n data = numpy.array(data)\n result = model.predict(data)\n # you can return any data type as long as it is JSON-serializable\n return result.tolist()\n except Exception as e:\n error = str(e)\n return error",
"_____no_output_____"
],
[
"from azureml.core.conda_dependencies import CondaDependencies \n\nmyenv = CondaDependencies.create(conda_packages=['numpy','scikit-learn'])\n\nwith open(\"myenv.yml\",\"w\") as f:\n f.write(myenv.serialize_to_string())",
"_____no_output_____"
],
[
"from azureml.core.image import ContainerImage\n\nimage_config = ContainerImage.image_configuration(execution_script = \"score.py\",\n runtime = \"python\",\n conda_file = \"myenv.yml\",\n description = \"Image with ridge regression model\",\n tags = {'area': \"diabetes\", 'type': \"regression\"}\n )\n\nimage = ContainerImage.create(name = \"myimage1\",\n # this is the model object\n models = [model],\n image_config = image_config,\n workspace = ws)\n\nimage.wait_for_creation(show_output = True)",
"_____no_output_____"
]
],
[
[
"# Provision the AKS Cluster\nThis is a one time setup. You can reuse this cluster for multiple deployments after it has been created. If you delete the cluster or the resource group that contains it, then you would have to recreate it.",
"_____no_output_____"
]
],
[
[
"# Use the default configuration (can also provide parameters to customize)\nprov_config = AksCompute.provisioning_configuration()\n\naks_name = 'my-aks-9' \n# Create the cluster\naks_target = ComputeTarget.create(workspace = ws, \n name = aks_name, \n provisioning_configuration = prov_config)",
"_____no_output_____"
],
[
"%%time\naks_target.wait_for_completion(show_output = True)\nprint(aks_target.provisioning_state)\nprint(aks_target.provisioning_errors)",
"_____no_output_____"
]
],
[
[
"## Optional step: Attach existing AKS cluster\n\nIf you have existing AKS cluster in your Azure subscription, you can attach it to the Workspace.",
"_____no_output_____"
]
],
[
[
"'''\n# Use the default configuration (can also provide parameters to customize)\nresource_id = '/subscriptions/92c76a2f-0e1c-4216-b65e-abf7a3f34c1e/resourcegroups/raymondsdk0604/providers/Microsoft.ContainerService/managedClusters/my-aks-0605d37425356b7d01'\n\ncreate_name='my-existing-aks' \n# Create the cluster\naks_target = AksCompute.attach(workspace=ws, name=create_name, resource_id=resource_id)\n# Wait for the operation to complete\naks_target.wait_for_completion(True)\n'''",
"_____no_output_____"
]
],
[
[
"# Deploy web service to AKS",
"_____no_output_____"
]
],
[
[
"#Set the web service configuration (using default here)\naks_config = AksWebservice.deploy_configuration()",
"_____no_output_____"
],
[
"%%time\naks_service_name ='aks-service-1'\n\naks_service = Webservice.deploy_from_image(workspace = ws, \n name = aks_service_name,\n image = image,\n deployment_config = aks_config,\n deployment_target = aks_target)\naks_service.wait_for_deployment(show_output = True)\nprint(aks_service.state)",
"_____no_output_____"
]
],
[
[
"# Test the web service\nWe test the web sevice by passing data.",
"_____no_output_____"
]
],
[
[
"%%time\nimport json\n\ntest_sample = json.dumps({'data': [\n [1,2,3,4,5,6,7,8,9,10], \n [10,9,8,7,6,5,4,3,2,1]\n]})\ntest_sample = bytes(test_sample,encoding = 'utf8')\n\nprediction = aks_service.run(input_data = test_sample)\nprint(prediction)",
"_____no_output_____"
]
],
[
[
"# Clean up\nDelete the service, image and model.",
"_____no_output_____"
]
],
[
[
"%%time\naks_service.delete()\nimage.delete()\nmodel.delete()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4ea92543d76fd651b20bfc53774e500ea706d7
| 4,262 |
ipynb
|
Jupyter Notebook
|
src/VioNet/bench.ipynb
|
zViolett/AVSS2019
|
6c3f1a22dfd651c6b81fdc54195b055f7d7f0559
|
[
"MIT"
] | 14 |
2020-01-06T10:09:24.000Z
|
2021-09-09T20:03:17.000Z
|
src/VioNet/bench.ipynb
|
zViolett/AVSS2019
|
6c3f1a22dfd651c6b81fdc54195b055f7d7f0559
|
[
"MIT"
] | 12 |
2020-01-06T10:11:35.000Z
|
2021-09-27T08:01:09.000Z
|
src/VioNet/bench.ipynb
|
zViolett/AVSS2019
|
6c3f1a22dfd651c6b81fdc54195b055f7d7f0559
|
[
"MIT"
] | 8 |
2020-08-02T15:14:17.000Z
|
2022-01-24T14:56:07.000Z
| 25.070588 | 102 | 0.504693 |
[
[
[
"import time\n\nimport numpy as np\n\nimport torch\nimport torch.nn as nn\nimport torch.backends.cudnn as cudnn\n\nfrom models.densenet import densenet88\nfrom models.c3d import C3D\nfrom models.convlstm import ConvLSTM",
"_____no_output_____"
],
[
"def measure(model, x, y=None):\n # synchronize gpu time and measure forward-pass time\n torch.cuda.synchronize()\n t0 = time.time()\n y_pred = model(x)\n torch.cuda.synchronize()\n elapsed_fp = time.time() - t0\n if y == None:\n return elapsed_fp, None\n\n # zero gradients, synchronize gpu time and measure backward-pass time\n model.zero_grad()\n t0 = time.time()\n y_pred.backward(y)\n torch.cuda.synchronize()\n elapsed_bp = time.time() - t0\n return elapsed_fp, elapsed_bp\n\ndef benchmark(model, x, y=None):\n\n # dry runs to warm-up\n for _ in range(5):\n _, _ = measure(model, x, y)\n\n print('DONE WITH DRY RUNS, NOW BENCHMARKING')\n\n # start benchmarking\n t_forward = []\n t_backward = []\n for _ in range(10):\n t_fp, t_bp = measure(model, x, y)\n t_forward.append(t_fp)\n t_backward.append(t_bp)\n\n return t_forward, t_backward\n\ndef result(t_list):\n t_array = np.asarray(t_list)\n avg = np.mean(t_array) * 1e3\n std = np.std(t_array) * 1e3\n \n print(\n avg, 'ms', '+/-',\n std, 'ms'\n )\n \n return avg, std\n ",
"_____no_output_____"
],
[
"use_cuda = True\nmultigpus = True\n\n# set cudnn backend to benchmark config\ncudnn.benchmark = True\ndevice = torch.device('cuda')",
"_____no_output_____"
],
[
"densenet88 = densenet88(num_classes=2, sample_size=112, sample_duration=16).eval().to(device)\nc3d = C3D(num_classes=2).eval().to(device)\nconvlstm = ConvLSTM(256, device).eval().to(device)\n\nresult_list = []\n\nfor batch_size in [1, 8, 16]:\n batch_list = []\n x = torch.rand(batch_size, 3, 16, 112, 112).to(device)\n t_forward,_ = benchmark(densenet88,x)\n avg, _ = result(t_forward)\n batch_list.append(avg)\n t_forward,_ = benchmark(c3d,x)\n avg, _ = result(t_forward)\n batch_list.append(avg)\n x = torch.rand(batch_size, 3, 2, 224, 224).to(device)\n t_forward,_ = benchmark(convlstm, x)\n avg, _ = result(t_forward)\n batch_list.append(avg)\n result_list.append(batch_list)",
"_____no_output_____"
],
[
"import numpy as np\n\ndata = np.array(result_list)",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4eabddd62458ad029870d26cc406f71a3853c9
| 13,599 |
ipynb
|
Jupyter Notebook
|
site/en-snapshot/lattice/tutorials/custom_estimators.ipynb
|
tigerneil/docs-l10n
|
b267908f83f5a1467a12efb1960a295095976f79
|
[
"Apache-2.0"
] | 2 |
2021-03-12T18:02:29.000Z
|
2021-06-18T19:32:41.000Z
|
site/en-snapshot/lattice/tutorials/custom_estimators.ipynb
|
tigerneil/docs-l10n
|
b267908f83f5a1467a12efb1960a295095976f79
|
[
"Apache-2.0"
] | null | null | null |
site/en-snapshot/lattice/tutorials/custom_estimators.ipynb
|
tigerneil/docs-l10n
|
b267908f83f5a1467a12efb1960a295095976f79
|
[
"Apache-2.0"
] | null | null | null | 34.082707 | 521 | 0.519156 |
[
[
[
"##### Copyright 2020 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# TF Lattice Custom Estimators",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/lattice/tutorials/custom_estimators\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/lattice/blob/master/docs/tutorials/custom_estimators.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/lattice/blob/master/docs/tutorials/custom_estimators.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/lattice/docs/tutorials/custom_estimators.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"## Overview\n\nYou can use custom estimators to create arbitrarily monotonic models using TFL layers. This guide outlines the steps needed to create such estimators.",
"_____no_output_____"
],
[
"## Setup",
"_____no_output_____"
],
[
"Installing TF Lattice package:",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\n!pip install tensorflow-lattice",
"_____no_output_____"
]
],
[
[
"Importing required packages:",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\n\nimport logging\nimport numpy as np\nimport pandas as pd\nimport sys\nimport tensorflow_lattice as tfl\nfrom tensorflow import feature_column as fc\n\nfrom tensorflow_estimator.python.estimator.canned import optimizers\nfrom tensorflow_estimator.python.estimator.head import binary_class_head\nlogging.disable(sys.maxsize)",
"_____no_output_____"
]
],
[
[
"Downloading the UCI Statlog (Heart) dataset:",
"_____no_output_____"
]
],
[
[
"csv_file = tf.keras.utils.get_file(\n 'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')\ndf = pd.read_csv(csv_file)\ntarget = df.pop('target')\ntrain_size = int(len(df) * 0.8)\ntrain_x = df[:train_size]\ntrain_y = target[:train_size]\ntest_x = df[train_size:]\ntest_y = target[train_size:]\ndf.head()",
"_____no_output_____"
]
],
[
[
"Setting the default values used for training in this guide:",
"_____no_output_____"
]
],
[
[
"LEARNING_RATE = 0.1\nBATCH_SIZE = 128\nNUM_EPOCHS = 1000",
"_____no_output_____"
]
],
[
[
"## Feature Columns\n\nAs for any other TF estimator, data needs to be passed to the estimator, which is typically via an input_fn and parsed using [FeatureColumns](https://www.tensorflow.org/guide/feature_columns).",
"_____no_output_____"
]
],
[
[
"# Feature columns.\n# - age\n# - sex\n# - ca number of major vessels (0-3) colored by flourosopy\n# - thal 3 = normal; 6 = fixed defect; 7 = reversable defect\nfeature_columns = [\n fc.numeric_column('age', default_value=-1),\n fc.categorical_column_with_vocabulary_list('sex', [0, 1]),\n fc.numeric_column('ca'),\n fc.categorical_column_with_vocabulary_list(\n 'thal', ['normal', 'fixed', 'reversible']),\n]",
"_____no_output_____"
]
],
[
[
"Note that categorical features do not need to be wrapped by a dense feature column, since `tfl.laysers.CategoricalCalibration` layer can directly consume category indices.",
"_____no_output_____"
],
[
"## Creating input_fn\n\nAs for any other estimator, you can use input_fn to feed data to the model for training and evaluation.",
"_____no_output_____"
]
],
[
[
"train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(\n x=train_x,\n y=train_y,\n shuffle=True,\n batch_size=BATCH_SIZE,\n num_epochs=NUM_EPOCHS,\n num_threads=1)\n\ntest_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(\n x=test_x,\n y=test_y,\n shuffle=False,\n batch_size=BATCH_SIZE,\n num_epochs=1,\n num_threads=1)",
"_____no_output_____"
]
],
[
[
"## Creating model_fn\n\nThere are several ways to create a custom estimator. Here we will construct a `model_fn` that calls a Keras model on the parsed input tensors. To parse the input features, you can use `tf.feature_column.input_layer`, `tf.keras.layers.DenseFeatures`, or `tfl.estimators.transform_features`. If you use the latter, you will not need to wrap categorical features with dense feature columns, and the resulting tensors will not be concatenated, which makes it easier to use the features in the calibration layers.\n\nTo construct a model, you can mix and match TFL layers or any other Keras layers. Here we create a calibrated lattice Keras model out of TFL layers and impose several monotonicity constraints. We then use the Keras model to create the custom estimator.\n",
"_____no_output_____"
]
],
[
[
"def model_fn(features, labels, mode, config):\n \"\"\"model_fn for the custom estimator.\"\"\"\n del config\n input_tensors = tfl.estimators.transform_features(features, feature_columns)\n inputs = {\n key: tf.keras.layers.Input(shape=(1,), name=key) for key in input_tensors\n }\n\n lattice_sizes = [3, 2, 2, 2]\n lattice_monotonicities = ['increasing', 'none', 'increasing', 'increasing']\n lattice_input = tf.keras.layers.Concatenate(axis=1)([\n tfl.layers.PWLCalibration(\n input_keypoints=np.linspace(10, 100, num=8, dtype=np.float32),\n # The output range of the calibrator should be the input range of\n # the following lattice dimension.\n output_min=0.0,\n output_max=lattice_sizes[0] - 1.0,\n monotonicity='increasing',\n )(inputs['age']),\n tfl.layers.CategoricalCalibration(\n # Number of categories including any missing/default category.\n num_buckets=2,\n output_min=0.0,\n output_max=lattice_sizes[1] - 1.0,\n )(inputs['sex']),\n tfl.layers.PWLCalibration(\n input_keypoints=[0.0, 1.0, 2.0, 3.0],\n output_min=0.0,\n output_max=lattice_sizes[0] - 1.0,\n # You can specify TFL regularizers as tuple\n # ('regularizer name', l1, l2).\n kernel_regularizer=('hessian', 0.0, 1e-4),\n monotonicity='increasing',\n )(inputs['ca']),\n tfl.layers.CategoricalCalibration(\n num_buckets=3,\n output_min=0.0,\n output_max=lattice_sizes[1] - 1.0,\n # Categorical monotonicity can be partial order.\n # (i, j) indicates that we must have output(i) <= output(j).\n # Make sure to set the lattice monotonicity to 'increasing' for this\n # dimension.\n monotonicities=[(0, 1), (0, 2)],\n )(inputs['thal']),\n ])\n output = tfl.layers.Lattice(\n lattice_sizes=lattice_sizes, monotonicities=lattice_monotonicities)(\n lattice_input)\n\n training = (mode == tf.estimator.ModeKeys.TRAIN)\n model = tf.keras.Model(inputs=inputs, outputs=output)\n logits = model(input_tensors, training=training)\n\n if training:\n optimizer = optimizers.get_optimizer_instance_v2('Adagrad', LEARNING_RATE)\n else:\n optimizer = None\n\n head = binary_class_head.BinaryClassHead()\n return head.create_estimator_spec(\n features=features,\n mode=mode,\n labels=labels,\n optimizer=optimizer,\n logits=logits,\n trainable_variables=model.trainable_variables,\n update_ops=model.updates)",
"_____no_output_____"
]
],
[
[
"## Training and Estimator\n\nUsing the `model_fn` we can create and train the estimator.",
"_____no_output_____"
]
],
[
[
"estimator = tf.estimator.Estimator(model_fn=model_fn)\nestimator.train(input_fn=train_input_fn)\nresults = estimator.evaluate(input_fn=test_input_fn)\nprint('AUC: {}'.format(results['auc']))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4ecd5619f0bb9fa3d43316612bc1e7714547bf
| 17,775 |
ipynb
|
Jupyter Notebook
|
notebooks/.ipynb_checkpoints/S15A_Introduction_To_Spark_Notes-checkpoint.ipynb
|
ZhechangYang/STA663
|
0dcf48e3e7a2d1f698b15e84946e44344b8153f5
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/.ipynb_checkpoints/S15A_Introduction_To_Spark_Notes-checkpoint.ipynb
|
ZhechangYang/STA663
|
0dcf48e3e7a2d1f698b15e84946e44344b8153f5
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/.ipynb_checkpoints/S15A_Introduction_To_Spark_Notes-checkpoint.ipynb
|
ZhechangYang/STA663
|
0dcf48e3e7a2d1f698b15e84946e44344b8153f5
|
[
"BSD-3-Clause"
] | null | null | null | 40.397727 | 1,264 | 0.62616 |
[
[
[
"Introduction to Spark\n====\n\nThis lecture is an introduction to the Spark framework for distributed computing, the basic data and control flow abstractions, and getting comfortable with the functional programming style needed to write a Spark application.\n\n- What problem does Spark solve?\n- SparkContext and the master configuration\n- RDDs\n- Actions\n- Transforms\n- Key-value RDDs\n- Example - word count\n- Persistence\n- Merging key-value RDDs",
"_____no_output_____"
],
[
"Learning objectives\n----\n\n- Overview of Spark\n- Working with Spark RDDs\n- Actions and transforms\n- Working with Spark DataFrames\n- Using the `ml` and `mllib` for machine learning\n\n#### Not covered\n\n- Spark GraphX (library for graph algorithms)\n- Spark Streaming (library for streaming (microbatch) data)",
"_____no_output_____"
],
[
"Installation\n----\n\nYou should use the current version of Spark at https://spark.apache.org/downloads.html. Choose the package `Pre-built for Hadoop2.7 and later`. The instructions below use the version current as of 9 April 2018.\n```bash\ncd ~\nwget https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz\ntar spark-2.3.0-bin-hadoop2.7.tgz\nrm spark-2.3.0-bin-hadoop2.7.tgz\nmv spark-2.3.0-bin-hadoop2.7 spark\n```\n\nInstall the `py4j` Python package needed for `pyspark`\n```\npip install py4j\n```\n\nYou need to define these environment variables before starting the notebook.\n\n```bash\nexport SPARK_HOME=~/spark\nexport PYSPARK_PYTHON=python3\nexport PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH\nexport PYSPARK_SUBMIT_ARGS=\"--packages ${PACKAGES} pyspark-shell\"\n```\n\nIn Unix/Mac, this can be done in `.bashrc` or `.bash_profile`.\n\nFor the adventurous, see [Running Spark on an AWS EMR cluster](https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark.html).",
"_____no_output_____"
],
[
"Resources\n----\n\n- [Quick Start](http://spark.apache.org/docs/latest/quick-start.html)\n- [Spark Programming Guide](http://spark.apache.org/docs/latest/programming-guide.html)\n- [DataFramews, DataSets and SQL](http://spark.apache.org/docs/latest/sql-programming-guide.html)\n- [MLLib](http://spark.apache.org/docs/latest/mllib-guide.html)\n- [GraphX](http://spark.apache.org/docs/latest/graphx-programming-guide.html)\n- [Streaming](http://spark.apache.org/docs/latest/streaming-programming-guide.html)",
"_____no_output_____"
],
[
"Overview of Spark\n----\n\nWith massive data, we need to load, extract, transform and analyze the data on multiple computers to overcome I/O and processing bottlenecks. However, when working on multiple computers (possibly hundreds to thousands), there is a high risk of failure in one or more nodes. Distributed computing frameworks are designed to handle failures gracefully, allowing the developer to focus on algorithm development rather than system administration.\n\nThe first such widely used open source framework was the Hadoop MapReduce framework. This provided transparent fault tolerance, and popularized the functional programming approach to distributed computing. The Hadoop work-flow uses repeated invocations of the following instructions:\n\n```\nload dataset from disk to memory\nmap function to elements of dataset\nreduce results of map to get new aggregate dataset\nsave new dataset to disk\n```\n\nHadoop has two main limitations:\n\n- the repeated saving and loading of data to disk can be slow, and makes interactive development very challenging\n- restriction to only `map` and `reduce` constructs results in increased code complexity, since every problem must be tailored to the `map-reduce` format\n\nSpark is a more recent framework for distributed computing that addresses the limitations of Hadoop by allowing the use of in-memory datasets for iterative computation, and providing a rich set of functional programming constructs to make the developer's job easier. Spark also provides libraries for common big data tasks, such as the need to run SQL queries, perform machine learning and process large graphical structures.",
"_____no_output_____"
],
[
"Languages supported\n----\n\nFully supported\n\n- Java\n- Scala\n- Python\n- R",
"_____no_output_____"
],
[
"## Distributed computing bakkground\n\nWith distributed computing, you interact with a network of computers that communicate via message passing as if issuing instructions to a single computer.\n\n\n\nSource: https://image.slidesharecdn.com/distributedcomputingwithspark-150414042905-conversion-gate01/95/distributed-computing-with-spark-21-638.jpg\n\n### Hadoop and Spark\n\n- There are 3 major components to a distributed system\n - storage\n - cluster management\n - computing engine\n\n- Hadoop is a framework that provides all 3 \n - distributed storage (HDFS) \n - clsuter managemnet (YARN)\n - computing eneine (MapReduce)\n \n- Spakr only provides the (in-memory) distributed computing engine, and relies on other frameworks for storage and clsuter manageemnt. It is most frequently used on top of the Hadoop framework, but can also use other distribtued storage(e.g. S3 and Cassandra) or cluster mangement (e.g. Mesos) software.\n\n### Distributed stoage\n\n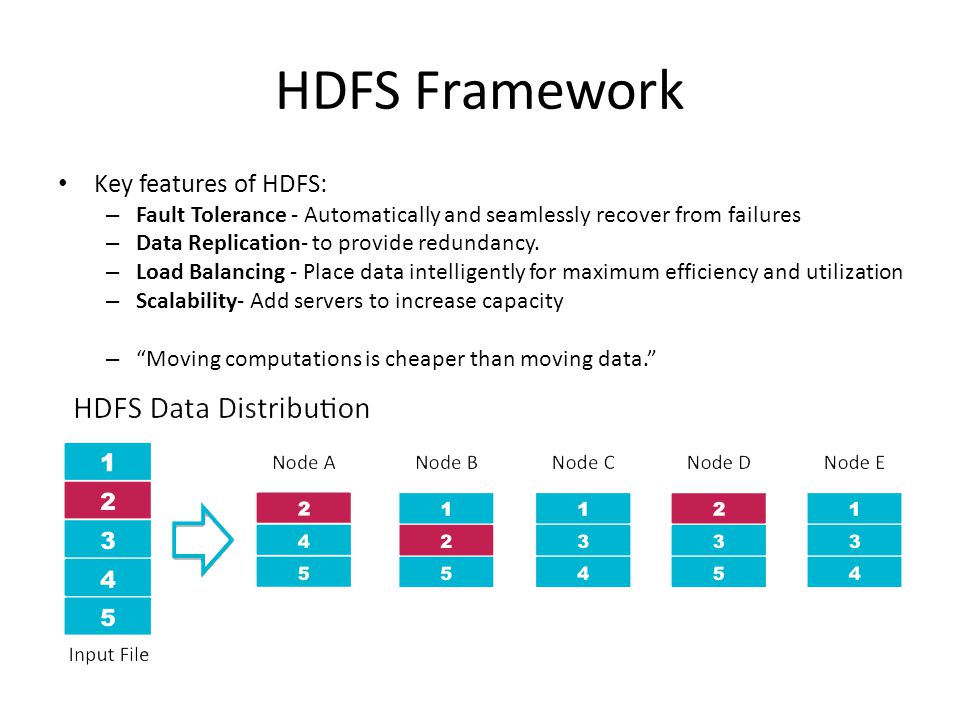\n\nSource: http://slideplayer.com/slide/3406872/12/images/15/HDFS+Framework+Key+features+of+HDFS:.jpg\n\n### Role of YARN\n\n- Resource manageer (manages cluster resources)\n - Scheduler\n - Applicaitons manager\n- Ndoe manager (manages single machine/node)\n - manages data containers/partitions\n - monitors reosurce usage\n - reprots to resource manager\n\n\n\nSource: https://kannandreams.files.wordpress.com/2013/11/yarn1.png\n\n### YARN operations\n\n\n\nSource: https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/yarn_architecture.gif\n\n### Hadoop MapReduce versus Spark\n\nSpark has several advantages over Hadoop MapReduce\n\n- Use of RAM rahter than disk mean fsater processing for multi-step operations\n- Allows interactive applicaitons\n- Allows real-time applications\n- More flexible programming API (full range of functional constructs)\n\n\n\nSource: https://i0.wp.com/s3.amazonaws.com/acadgildsite/wordpress_images/bigdatadeveloper/10+steps+to+master+apache+spark/hadoop_spark_1.png\n\n### Overall Ecosystem\n\n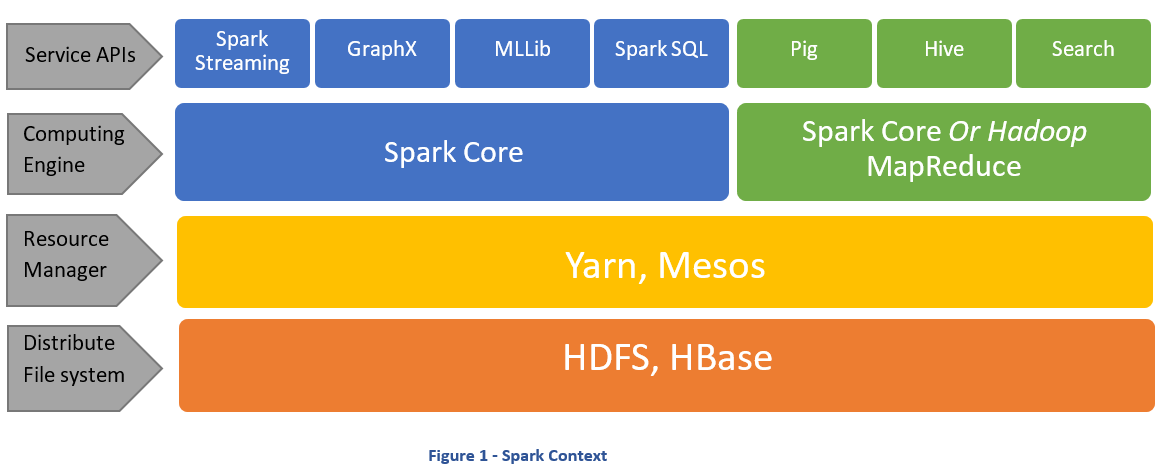\n\nSource: https://cdn-images-1.medium.com/max/1165/1*z0Vm749Pu6mHdlyPsznMRg.png\n\n### Spark Ecosystem\n\n- Spark is written in Scala, a functional programming language built on top of the Java Virtual Machine (JVM)\n- Traditionally, you have to code in Scala to get the best performacne from Spark\n- With Spark DataFrames and vectorized operations (Spark 2.3 onwards) Python is now competitive\n\n\n\nSource: https://data-flair.training/blogs/wp-content/uploads/apache-spark-ecosystem-components.jpg\n\n### Livy and Spark magic\n\n- Livy provides a REST interface to a Spark cluster.\n\n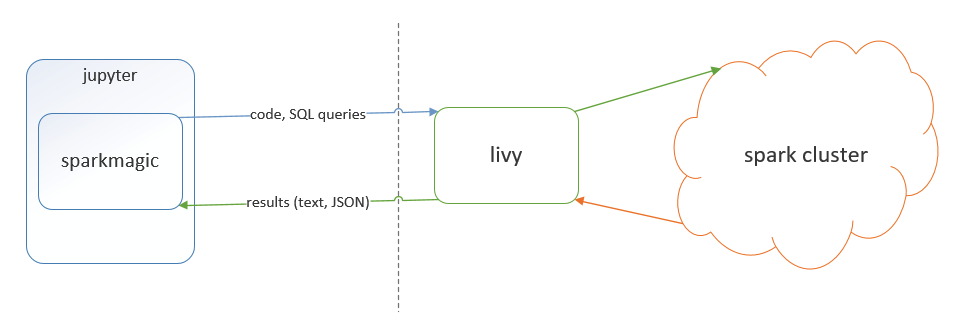\n\nSource: https://cdn-images-1.medium.com/max/956/0*-lwKpnEq0Tpi3Tlj.png\n\n### PySpark\n\n\n\nSource: http://i.imgur.com/YlI8AqEl.png\n\n### Resilident distributed datasets (RDDs)\n\n\n\nSource: https://mapr.com/blog/real-time-streaming-data-pipelines-apache-apis-kafka-spark-streaming-and-hbase/assets/blogimages/msspark/imag12.png\n\n### Spark fault tolerance\n\n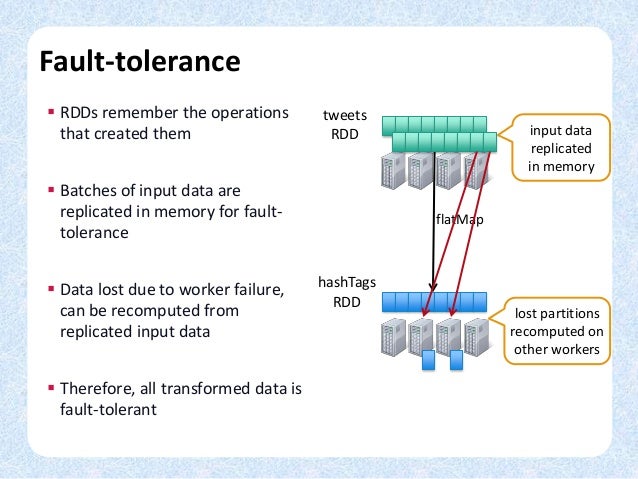\n\nSource: https://image.slidesharecdn.com/deep-dive-with-spark-streamingtathagata-dasspark-meetup2013-06-17-130623151510-phpapp02/95/deep-dive-with-spark-streaming-tathagata-das-spark-meetup-20130617-13-638.jpg",
"_____no_output_____"
]
],
[
[
"%%spark",
"Starting Spark application\n"
],
[
"%%info",
"_____no_output_____"
]
],
[
[
"### Configuring allocated resources\n\nNote the proxyUser from `%%info`.",
"_____no_output_____"
]
],
[
[
"%%configure -f\n {\"driverMemory\": \"2G\", \n \"numExecutors\": 10, \n \"executorCores\": 2, \n \"executorMemory\": \"2048M\", \n \"proxyUser\": \"user06021\",\n \"conf\": {\"spark.master\": \"yarn\"}}",
"Starting Spark application\n"
]
],
[
[
"### Python version\n\nThe default version of Python with the PySpark kernel is Python 2.",
"_____no_output_____"
]
],
[
[
"import sys\nsys.version_info",
"sys.version_info(major=2, minor=7, micro=12, releaselevel='final', serial=0)"
]
],
[
[
"### Remember to shut down the notebook after use\n\nWhen you are done running Sark jobs with this notebook, go to the notebook's file menu, and select the \"Close and Halt\" option to terminate the notebook's kernel and clear the Spark session.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a4ed6c32b85e95645ada448f5d1f45f53ba0c2d
| 161,019 |
ipynb
|
Jupyter Notebook
|
2 - City Center Diversity Analysis.ipynb
|
DiversiTree/TreeDiversity
|
5de30fce3e9edf13e151c09b8484fd75cb946721
|
[
"CC-BY-4.0"
] | 12 |
2021-04-06T16:31:15.000Z
|
2021-09-22T03:12:45.000Z
|
2 - City Center Diversity Analysis.ipynb
|
DiversiTree/TreeDiversity
|
5de30fce3e9edf13e151c09b8484fd75cb946721
|
[
"CC-BY-4.0"
] | null | null | null |
2 - City Center Diversity Analysis.ipynb
|
DiversiTree/TreeDiversity
|
5de30fce3e9edf13e151c09b8484fd75cb946721
|
[
"CC-BY-4.0"
] | 3 |
2021-03-08T03:18:43.000Z
|
2021-11-15T22:07:07.000Z
| 182.354473 | 52,688 | 0.878132 |
[
[
[
"# Analyzing Street Trees: Diversity Indices and the 10/20/30 Rule\n\nThis notebook analyzes the diversity indices of the street trees inside and outside the city center you've selected, and then check the tree inventory according to the 10/20/30 rule, discussed below.",
"_____no_output_____"
]
],
[
[
"# library import\nimport pandas as pd\nimport geopandas as gpd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport descartes\nimport treeParsing as tP",
"_____no_output_____"
]
],
[
[
"# Import Tree Inventory and City Center Boundary\n\nImport your tree data and city center boundary data below. These data may use any geospatial data format (SHP, Geojson, Geopackage) and should be in the same coordinate projection.\n\nYour tree data will need the following columns:\n* Point geographic location\n* Diameter at breast height (DBH)\n* Tree Scientific Name\n* Tree Genus Name\n* Tree Family Name\n\nYour city center geography simply needs to be a single, dissolved geometry representing your city center area.",
"_____no_output_____"
]
],
[
[
"### Enter the path to your data below ###\ntree_data_path = 'example_data/trees_paris.gpkg'\ntree_data = gpd.read_file(tree_data_path)",
"_____no_output_____"
],
[
"tree_data.plot()",
"_____no_output_____"
],
[
"### Enter the path to your data below ###\ncity_center_boundary_path = 'example_data/paris.gpkg'\ncity_center = gpd.read_file(city_center_boundary_path)",
"_____no_output_____"
],
[
"city_center.plot()",
"_____no_output_____"
]
],
[
[
"# Clean Data and Calculate Basal Area\n\nTo start, we need to remove features missing data and remove the top quantile of data. Removing any missing data and the top quantile helps remove erroneous entries that are too large or too small than what we would expect. If your data has already been cleaned, feel free to skip the second cell below.",
"_____no_output_____"
]
],
[
[
"### Enter your column names here ###\nscientific_name_column = 'Scientific'\ngenus_name_column = 'genus'\nfamily_name_column = 'family'\ndiameter_breast_height_column = 'DBH'",
"_____no_output_____"
],
[
"### Ignore if data is already cleaned ###\n# Exclude Data Missing DBH\ntree_data = tree_data[tree_data[diameter_breast_height_column]>0]\n\n# Exclude data larger than the 99th quantile (often erroneously large)\ntree_data = tree_data[tree_data[diameter_breast_height_column]<=tree_data.quantile(0.99).DBH]",
"_____no_output_____"
],
[
"# Calculate Basal Area\nbasal_area_column = 'BA'\ntree_data[basal_area_column] = tree_data[diameter_breast_height_column]**2 * 0.00007854",
"_____no_output_____"
]
],
[
[
"# Calculating Simpson and Shannon Diversity Indices\n\nThe following cells spatially join your city center geometry to your tree inventory data, and then calculates the simpson and shannon diversity indices for the city center, area outside the city center -- based on area and tree count.",
"_____no_output_____"
]
],
[
[
"# Add dummy column to city center geometry\ncity_center['inside'] = True\ncity_center = city_center[['geometry','inside']]",
"_____no_output_____"
],
[
"# Spatial Join -- this may take a while\nsjoin_tree_data = gpd.sjoin(tree_data, city_center, how=\"left\")",
"_____no_output_____"
],
[
"def GenerateIndices(label, df, scientific_name_column, genus_name_column, family_name_column, basal_area_column):\n # Derive counts, areas, for species, genus, and family\n species_count = df[[scientific_name_column, basal_area_column]].groupby(scientific_name_column).count().reset_index()\n species_area = df[[scientific_name_column, basal_area_column]].groupby(scientific_name_column).sum().reset_index()\n\n genus_count = df[[genus_name_column, basal_area_column]].groupby(genus_name_column).count().reset_index()\n genus_area = df[[genus_name_column, basal_area_column]].groupby(genus_name_column).sum().reset_index()\n\n family_count = df[[family_name_column, basal_area_column]].groupby(family_name_column).count().reset_index()\n family_area = df[[family_name_column, basal_area_column]].groupby(family_name_column).sum().reset_index()\n\n\n # Calculate Percentages by count and area\n species_count[\"Pct\"] = species_count[basal_area_column]/sum(species_count[basal_area_column])\n species_area[\"Pct\"] = species_area[basal_area_column]/sum(species_area[basal_area_column])\n\n genus_count[\"Pct\"] = genus_count[basal_area_column]/sum(genus_count[basal_area_column])\n genus_area[\"Pct\"] = genus_area[basal_area_column]/sum(genus_area[basal_area_column])\n\n family_count[\"Pct\"] = family_count[basal_area_column]/sum(family_count[basal_area_column])\n family_area[\"Pct\"] = family_area[basal_area_column]/sum(family_area[basal_area_column])\n\n # Calculate Shannon Indices\n species_shannon_count = tP.ShannonEntropy(list(species_count[\"Pct\"]))\n species_shannon_area = tP.ShannonEntropy(list(species_area[\"Pct\"]))\n\n genus_shannon_count = tP.ShannonEntropy(list(genus_count[\"Pct\"]))\n genus_shannon_area = tP.ShannonEntropy(list(genus_area[\"Pct\"]))\n\n family_shannon_count = tP.ShannonEntropy(list(family_count[\"Pct\"]))\n family_shannon_area = tP.ShannonEntropy(list(family_area[\"Pct\"]))\n\n # Calculate Simpson Indices\n species_simpson_count = tP.simpson_di(list(species_count[scientific_name_column]), list(species_count[basal_area_column]))\n species_simpson_area = tP.simpson_di(list(species_area[scientific_name_column]),list(species_area[basal_area_column]))\n\n genus_simpson_count = tP.simpson_di(list(genus_count[genus_name_column]), list(genus_count[basal_area_column]))\n genus_simpson_area = tP.simpson_di(list(genus_area[genus_name_column]), list(genus_area[basal_area_column]))\n\n family_simpson_count = tP.simpson_di(list(family_count[family_name_column]), list(family_count[basal_area_column]))\n family_simpson_area = tP.simpson_di(list(family_area[family_name_column]), list(family_area[basal_area_column]))\n\n return {\n 'Geography':label,\n 'species_simpson_count': species_simpson_count,\n 'species_simpson_area': species_simpson_area,\n 'genus_simpson_count': genus_simpson_count,\n 'genus_simpson_area': genus_simpson_area,\n 'family_simpson_count': family_simpson_count,\n 'family_simpson_area': family_simpson_area,\n 'species_shannon_count': species_shannon_count,\n 'species_shannon_area': species_shannon_area,\n 'genus_shannon_count': genus_shannon_count,\n 'genus_shannon_area': genus_shannon_area,\n 'family_shannon_count': family_shannon_count,\n 'family_shannon_area': family_shannon_area\n }",
"_____no_output_____"
],
[
"# Generate results and load into dataframe\ntemp_results = []\n\ncity_center_data = sjoin_tree_data[sjoin_tree_data.inside == True]\noutside_center_data = sjoin_tree_data[sjoin_tree_data.inside != True]\n\ntemp_results.append(\n GenerateIndices(\n 'Inside City Center', \n city_center_data,\n scientific_name_column, \n genus_name_column, \n family_name_column, \n basal_area_column\n )\n)\n\n\ntemp_results.append(\n GenerateIndices(\n 'Outside City Center', \n outside_center_data,\n scientific_name_column, \n genus_name_column, \n family_name_column, \n basal_area_column\n )\n)\n\nresults = pd.DataFrame(temp_results)\nresults.head()",
"_____no_output_____"
],
[
"# Split up results for plotting\nshannon_area = results.round(4)[['species_shannon_area','genus_shannon_area','family_shannon_area']].values\nshannon_count = results.round(4)[['species_shannon_count','genus_shannon_count','family_shannon_count']].values\nsimpson_area = results.round(4)[['species_simpson_area','genus_simpson_area','family_simpson_area']].values\nsimpson_count = results.round(4)[['species_simpson_count','genus_simpson_count','family_simpson_count']].values",
"_____no_output_____"
],
[
"def autolabel(rects, axis):\n \"\"\"Attach a text label above each bar in *rects*, displaying its height.\"\"\"\n for rect in rects:\n height = rect.get_height()\n axis.annotate('{}'.format(height),\n xy=(rect.get_x() + rect.get_width() / 2, height),\n xytext=(0, 3), # 3 points vertical offset\n textcoords=\"offset points\",\n ha='center', va='bottom')\n \nlabels = ['Species', 'Genus', 'Family']\nplt.rcParams[\"figure.figsize\"] = [14, 7]\n\nx = np.arange(len(labels)) # the label locations\nwidth = 0.35 # the width of the bars\n\nfig, axs = plt.subplots(2, 2)\n\nrects1 = [axs[0,0].bar(x - width/2, shannon_area[0], width, color=\"lightsteelblue\", label='City Center'), axs[0,0].bar(x + width/2, shannon_area[1], width, color=\"darkgreen\", label='Outside City Center')]\nrects2 = [axs[0,1].bar(x - width/2, shannon_count[0], width, color=\"lightsteelblue\", label='City Center'), axs[0,1].bar(x + width/2, shannon_count[1], width, color=\"darkgreen\", label='Outside City Center')]\nrects3 = [axs[1,0].bar(x - width/2, simpson_area[0], width, color=\"lightsteelblue\", label='City Center'), axs[1,0].bar(x + width/2, simpson_area[1], width, color=\"darkgreen\", label='Outside City Center')]\nrects4 = [axs[1,1].bar(x - width/2, simpson_count[0], width, color=\"lightsteelblue\", label='City Center'), axs[1,1].bar(x + width/2, simpson_count[1], width, color=\"darkgreen\", label='Outside City Center')]\n\naxs[0,0].set_ylabel('Diversity Index')\naxs[0,0].set_title('Shannon Diversity by Basal Area')\naxs[0,0].set_xticks(x)\naxs[0,0].set_xticklabels(labels)\naxs[0,0].legend()\n\naxs[0,1].set_ylabel('Diversity Index')\naxs[0,1].set_title('Shannon Diversity by Count')\naxs[0,1].set_xticks(x)\naxs[0,1].set_xticklabels(labels)\naxs[0,1].legend()\n\naxs[1,0].set_ylabel('Diversity Index')\naxs[1,0].set_title('Simpson Diversity by Basal Area')\naxs[1,0].set_xticks(x)\naxs[1,0].set_xticklabels(labels)\naxs[1,0].legend()\n\naxs[1,1].set_ylabel('Diversity Index')\naxs[1,1].set_title('Simpson Diversity by Count')\naxs[1,1].set_xticks(x)\naxs[1,1].set_xticklabels(labels)\naxs[1,1].legend()\n\nautolabel(rects1[0], axs[0,0])\nautolabel(rects1[1], axs[0,0])\nautolabel(rects2[0], axs[0,1])\nautolabel(rects2[1], axs[0,1])\nautolabel(rects3[0], axs[1,0])\nautolabel(rects3[1], axs[1,0])\nautolabel(rects4[0], axs[1,1])\nautolabel(rects4[1], axs[1,1])\n\n\naxs[0,0].set_ylim([0,max(shannon_count.max(), shannon_area.max())+0.5])\naxs[0,1].set_ylim([0,max(shannon_count.max(), shannon_area.max())+0.5])\naxs[1,0].set_ylim([0,1])\naxs[1,1].set_ylim([0,1])\n\nfig.tight_layout()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Interpreting these Results\n\nFor both indices, a higher score represents a more diverse body of street trees. If your city follows our general findings, the city center tends to be less diverse. The results provide some context on the evenness of the diversity in the city center and outside areas. The cells below calculate how well your street trees adhere to the 10/20/30 standard.",
"_____no_output_____"
],
[
"____\n# 10/20/30 Standard\n\nThe 10/20/30 rule suggests that urban forests should be made up of no more than 10% from one species, 20% from one genus, or 30% from one family. A more optimistic version, the 5/10/15 rule, argues that those values should be halved. \n\nBelow, we'll calculate how well your tree inventory data adheres to these rules and then chart the results.",
"_____no_output_____"
]
],
[
[
"def GetPctRule(df, column, basal_area_column, predicate, location):\n if predicate == 'area':\n tempData = df[[basal_area_column,column]].groupby(column).sum().sort_values(basal_area_column, ascending=False).reset_index()\n else:\n tempData = df[[basal_area_column,column]].groupby(column).count().sort_values(basal_area_column, ascending=False).reset_index()\n \n total = tempData[basal_area_column].sum()\n \n return {\n 'name':column,\n 'location': location,\n 'predicate':predicate,\n 'most common': tempData.iloc[0][column],\n 'amount': tempData.iloc[0][basal_area_column],\n 'percent': round(tempData.iloc[0][basal_area_column]/total*100,2),\n 'total': total,\n }",
"_____no_output_____"
],
[
"temp_results = []\n\nfor location in ['City Center', 'Outside City Center']:\n for column in [scientific_name_column, genus_name_column, family_name_column]:\n for predicate in ['area', 'count']:\n if location == 'City Center':\n df = city_center_data\n else:\n df = outside_center_data\n temp_results.append(GetPctRule(df, column, basal_area_column, predicate, location))\n \nresults = pd.DataFrame(temp_results)\nresults.head()",
"_____no_output_____"
],
[
"results[results.name=='Scientific']",
"_____no_output_____"
],
[
"fig, axs = plt.subplots(3,2)\n\ncolumns = [scientific_name_column, genus_name_column, family_name_column]\npredicates=['area', 'count']\nmax_value = results.percent.max() * 1.2\n\nfor row in [0,1,2]:\n temp_data = results[results.name==columns[row]]\n for col in [0,1]:\n temp_col_data = temp_data[temp_data.predicate==predicates[col]]\n if row == 0:\n x_value = 10\n text=\"Species Benchmark\"\n elif row == 1:\n x_value = 20\n text=\"Genus Benchmark\"\n else:\n x_value = 30\n text=\"Family Benchmark\"\n \n if col == 0:\n title = text + ' (Area)'\n else:\n title = text + ' (Count)'\n \n axs[row,col].set_xlabel('Percent of Tree Inventory')\n axs[row,col].set_xlim([0,max_value])\n axs[row,col].set_ylim([-0.1,0.1])\n axs[row,col].get_yaxis().set_visible(False)\n axs[row,col].plot([0,max_value], [0,0], c='darkgray')\n axs[row,col].scatter(x=x_value, y=0, marker='|', s=1000, c='darkgray')\n axs[row,col].text(x=x_value+1, y=0.02, linespacing=2, s=text, c='black')\n axs[row,col].set_title(title)\n axs[row,col].scatter(x=float(temp_col_data[temp_col_data.location=='City Center'].percent), y=0, s=100, c='lightsteelblue', label='City Center')\n axs[row,col].scatter(x=float(temp_col_data[temp_col_data.location=='Outside City Center'].percent), y=0, s=100, c='darkgreen', label='Outside City Center')\n axs[row,col].legend()\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Interpreting these Results\n\nThe closer the green dots are to the vertical benchmark line, the closer the tree inventory is to meeting the benchmark. Ideally, each dot should be at or to the left of that taxonomy level's benchmark (10, 20, or 30%). The charts on the left reflect tree species diversity by area, which may better reflect the street trees scaled to their mass, and the right column tracks the count of trees, which is more widely used in urban forestry. \n\nThese charts do not define the success of the street tree inventory you are exploring, but they do highlight whether or not the data adheres to suggested urban forestry standards.\n___\n\nWant to share you results? Contact us at ***[email protected]***, we'd love to hear how you used this notebook!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a4ed970430d953b162c74aecdda7162f45416dc
| 32,169 |
ipynb
|
Jupyter Notebook
|
pandas/.ipynb_checkpoints/pandas basic lecture04. Merge, concat-checkpoint.ipynb
|
ikelee22/pythonlib
|
cbf0faf548dfc35d799898178bf7e8c3461e5776
|
[
"MIT"
] | null | null | null |
pandas/.ipynb_checkpoints/pandas basic lecture04. Merge, concat-checkpoint.ipynb
|
ikelee22/pythonlib
|
cbf0faf548dfc35d799898178bf7e8c3461e5776
|
[
"MIT"
] | null | null | null |
pandas/.ipynb_checkpoints/pandas basic lecture04. Merge, concat-checkpoint.ipynb
|
ikelee22/pythonlib
|
cbf0faf548dfc35d799898178bf7e8c3461e5776
|
[
"MIT"
] | null | null | null | 26.874687 | 1,839 | 0.358264 |
[
[
[
"<img src='./img/intel-logo.jpg' width=30%> \n \n<font size=7><div align='left'>판다스 기초강의<br>\n<br>\n<font size=6><div align='left'>04. 데이터 합치기<br>\n \n<font size=3><div align='right'>\n<div align='right'>성 민 석 (Minsuk Sung)</div>\n<div align='right'>류 회 성 (Hoesung Ryu)</div>\n<div align='right'>이 인 구 (Ike Lee)</div>",
"_____no_output_____"
],
[
"<h1>강의목차<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#pd.concat()\" data-toc-modified-id=\"pd.concat()-1\"><span class=\"toc-item-num\">1 </span>pd.concat()</a></span><ul class=\"toc-item\"><li><span><a href=\"#concat(-axis-=1-)\" data-toc-modified-id=\"concat(-axis-=1-)-1.1\"><span class=\"toc-item-num\">1.1 </span>concat( axis =1 )</a></span></li><li><span><a href=\"#concat(axis=0)\" data-toc-modified-id=\"concat(axis=0)-1.2\"><span class=\"toc-item-num\">1.2 </span>concat(axis=0)</a></span></li><li><span><a href=\"#concat(axis=0)-ignore_index\" data-toc-modified-id=\"concat(axis=0)-ignore_index-1.3\"><span class=\"toc-item-num\">1.3 </span>concat(axis=0) ignore_index</a></span></li></ul></li><li><span><a href=\"#pd.merge()\" data-toc-modified-id=\"pd.merge()-2\"><span class=\"toc-item-num\">2 </span>pd.merge()</a></span><ul class=\"toc-item\"><li><span><a href=\"#주요-파라미터-(-pd.merge(df1,df2,-on-=-???))\" data-toc-modified-id=\"주요-파라미터-(-pd.merge(df1,df2,-on-=-???))-2.1\"><span class=\"toc-item-num\">2.1 </span>주요 파라미터 ( pd.merge(df1,df2, on = ???))</a></span></li><li><span><a href=\"#inner-join\" data-toc-modified-id=\"inner-join-2.2\"><span class=\"toc-item-num\">2.2 </span>inner join</a></span></li><li><span><a href=\"#left-outer-join\" data-toc-modified-id=\"left-outer-join-2.3\"><span class=\"toc-item-num\">2.3 </span>left outer join</a></span></li><li><span><a href=\"#right-outer-join\" data-toc-modified-id=\"right-outer-join-2.4\"><span class=\"toc-item-num\">2.4 </span>right outer join</a></span></li><li><span><a href=\"#fully-outer-join\" data-toc-modified-id=\"fully-outer-join-2.5\"><span class=\"toc-item-num\">2.5 </span>fully outer join</a></span></li></ul></li></ul></div>",
"_____no_output_____"
],
[
"## pd.concat()\n\n$n$ 개의 데이터 프레임을 컬럼 기준의 합치고 싶은 경우 `axis`를 설정 한 후`concate()`함수를 사용한다. \n",
"_____no_output_____"
],
[
"### concat( axis =1 )\n<img src=\"img/concat_axis1.png\" style=\"width: 700px;\"/>\n\n",
"_____no_output_____"
]
],
[
[
"# DataFrame 생성\n\nimport pandas as pd\n\n# df1 생성\ndf1 = pd.DataFrame([\n ['Hong', 'Gildong'],\n ['Sung', 'Munsuk'],\n ['Ryu', 'Hoesung'],\n ['Hwang', 'Jinha'],\n ], index=['1','2','3', '4'], columns=['Last name', 'First name']\n )\n# print 대신 display를 쓰면 이쁘게 출력된다. \ndisplay(df1)",
"_____no_output_____"
],
[
"# df2 생성\ndf2 = pd.DataFrame([\n ['Pyonyang', 21],\n ['Seoul', 27],\n ['Jeju', 29],\n ['Gyeonggi-do', 30]\n ], index=['1','2','3', '4'], columns=['City', 'Age']\n )\ndisplay(df2)",
"_____no_output_____"
],
[
"# concat with axis = 1 수행\ndf = pd.concat([df1,df2], axis=1,sort=True)\ndf",
"_____no_output_____"
]
],
[
[
"### concat(axis=0)\n\n<img src=\"img/concat_axis0.png\" style=\"width: 700px;\"/>",
"_____no_output_____"
]
],
[
[
"# df1 생성\ndf1 = pd.DataFrame([\n ['Hong', 'Gildong'],\n ['Sung', 'Munsuk'],\n ['Ryu', 'Hoesung'],\n ['Hwang', 'Jinha'],\n ], index=['1','2','3', '4'], columns=['Last name', 'First name']\n )",
"_____no_output_____"
],
[
"# df2 생성\ndf2 = pd.DataFrame([\n ['Lee', 'Chang'],\n ['Kim', 'Chi'],\n ], index=['1','2'], columns=['Last name', 'First name']\n )",
"_____no_output_____"
],
[
"# concat with axis = 0 수행\ndf = pd.concat([df1,df2], axis=0,sort=True)\ndf",
"_____no_output_____"
]
],
[
[
"### concat(axis=0) ignore_index\n<img src=\"img/concat_axis0_ignore.png\" style=\"width: 700px;\"/>",
"_____no_output_____"
]
],
[
[
"df = pd.concat([df1,df2], axis=0,sort=True,ignore_index=True)\ndf",
"_____no_output_____"
]
],
[
[
"## pd.merge()",
"_____no_output_____"
],
[
"### 주요 파라미터 ( pd.merge(df1,df2, on = ???))\n\n- 키를 기준으로 DataFrame의 로우를 합친다. SQL이나 다른 관계형 데이터베이스의 join 연산과 동일함.\n- 주요 파라미터 \n . left, right : merge할 DataFrame 객체이름\n\n . how = 'inner', #left, right, outer\n\n . on = None, #merge의 기준이 되는 컬럼\n\n . left_on = None, #left DataFrame의 기준 컬럼\n\n . right_on = None, #right DataFrame의 기준 컬럼",
"_____no_output_____"
]
],
[
[
"# DataFrame 생성\ndf_left = pd.DataFrame({'KEY': ['k0', 'k1', 'k2', 'k3'],\n 'A': ['a0', 'a1', 'a2', 'a3'],\n 'B': ['b0', 'b1', 'b2', 'b3']})\ndf_right = pd.DataFrame({'KEY': ['k2', 'k3', 'k4', 'k5'],\n 'C': ['c2', 'c3', 'c4', 'c5'],\n 'D': ['d2', 'd3', 'd4', 'd5']})\n\n",
"_____no_output_____"
],
[
"print('df_left:')\ndisplay(df_left)\nprint('-'*15)\nprint('df_right:')\ndisplay(df_right)",
"df_left:\n"
]
],
[
[
"### inner join",
"_____no_output_____"
]
],
[
[
"# 4 * 4 = 16번의 연산이 이루어짐\n# key값이 같은 놈이 나옴 => k2,k3\npd.merge(df_left,df_right,how='inner') # inner join이란것을 알려주기 위해서",
"_____no_output_____"
]
],
[
[
"### left outer join",
"_____no_output_____"
]
],
[
[
"# left에 있는 데이터는 일단 다 출력해달라 -> 없는 놈은 NaN 처리하더라도\npd.merge(df_left,df_right,how='left')",
"_____no_output_____"
]
],
[
[
"### right outer join",
"_____no_output_____"
]
],
[
[
"pd.merge(df_left,df_right,how='right')",
"_____no_output_____"
]
],
[
[
"### fully outer join",
"_____no_output_____"
]
],
[
[
"pd.merge(df_left,df_right,how='outer') # 둘 중 한군데라도 있으면 출력",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4edd57445262a4b8a7a4e9ccecd1d671697086
| 9,866 |
ipynb
|
Jupyter Notebook
|
website/dev/migrate.ipynb
|
ongzhixian/hci-admin
|
25564d0b906df466390ff7124ac75b765be87429
|
[
"MIT"
] | null | null | null |
website/dev/migrate.ipynb
|
ongzhixian/hci-admin
|
25564d0b906df466390ff7124ac75b765be87429
|
[
"MIT"
] | null | null | null |
website/dev/migrate.ipynb
|
ongzhixian/hci-admin
|
25564d0b906df466390ff7124ac75b765be87429
|
[
"MIT"
] | null | null | null | 38.389105 | 189 | 0.366004 |
[
[
[
"import sqlite3\r\nfrom urllib.parse import urlparse, urlsplit\r\nfrom hashlib import sha256 as hash\r\n",
"_____no_output_____"
],
[
"sqlite_file = 'D:/data/sqlite3/url_kb.sqlite3'",
"_____no_output_____"
],
[
"\r\nbatch_size = 10000\r\nwith sqlite3.connect(sqlite_file) as conn:\r\n cur = conn.cursor()\r\n cur.execute(\"SELECT * FROM raw_url;\")\r\n while True:\r\n all = cur.fetchmany(batch_size)\r\n if len(all) > 0:\r\n print(len(all))\r\n else:\r\n break\r\n cur.close()",
"10000\n10000\n10000\n10000\n10000\n10000\n10000\n10000\n10000"
],
[
"with sqlite3.connect(sqlite_file) as conn:\r\n cur = conn.cursor()\r\n cur.execute(\"SELECT * FROM raw_url;\")\r\n all = cur.fetchmany(10)\r\n cur.close()\r\n",
"_____no_output_____"
],
[
"t = all[0]\r\ntarget_url = t[2]\r\ntarget_url",
"_____no_output_____"
],
[
"urlparse(target_url)",
"_____no_output_____"
],
[
"def create_table_parsed_urls():\r\n sql = \"\"\"\r\n CREATE TABLE IF NOT EXISTS parsed_urls (\r\n hash text NOT NULL PRIMARY KEY,\r\n scheme text NOT NULL,\r\n netloc text NOT NULL,\r\n path text NOT NULL,\r\n params text NOT NULL,\r\n query text NOT NULL,\r\n fragment text NOT NULL,\r\n count integer NOT NULL, \r\n url text NOT NULL\r\n \t\r\n );\r\n \"\"\"\r\n\r\n with sqlite3.connect(sqlite_file) as conn:\r\n try:\r\n cur = conn.cursor()\r\n cur.execute(sql)\r\n cur.close()\r\n except Error as e:\r\n print(e)\r\n\r\ndef insert_parsed_urls(sql_params):\r\n sql = ''' INSERT INTO parsed_urls(hash, scheme, netloc, path, params, query, fragment, count, url) VALUES (?,?,?,?,?,?,?,?,?)\r\n ON CONFLICT (hash) DO\r\n UPDATE \r\n SET count = count + 1\r\n WHERE hash=?\r\n ;'''\r\n with sqlite3.connect(sqlite_file) as conn:\r\n try:\r\n cur = conn.cursor()\r\n cur.execute(sql, sql_params)\r\n cur.close()\r\n #conn.commit()\r\n except Exception as e:\r\n print(e)\r\n\r\ndef get_page(page_number):\r\n batch_size = 10000\r\n offset = (page_number - 1) * batch_size\r\n with sqlite3.connect(sqlite_file) as conn:\r\n cur = conn.cursor()\r\n cur.execute(\"SELECT * FROM raw_url where id > 86301 LIMIT ? OFFSET ?;\", (batch_size, offset))\r\n all = cur.fetchall()\r\n cur.close()\r\n return all\r\n\r\ndef process_raw_url():\r\n page_number = 1\r\n while True:\r\n records = get_page(page_number)\r\n record_count = len(records)\r\n if record_count > 0:\r\n for r in records:\r\n target_url = r[2]\r\n parse_result = urlparse(target_url)\r\n h = hash(target_url.encode('UTF8')).hexdigest()\r\n q = (h, parse_result.scheme, parse_result.netloc, parse_result.path, parse_result.params, parse_result.query, parse_result.fragment, 1, target_url, h)\r\n insert_parsed_urls(q)\r\n page_number = page_number + 1\r\n else:\r\n break",
"_____no_output_____"
],
[
"create_table_parsed_urls()\r\n\r\nparse_result = urlparse(target_url)\r\nprint(parse_result)\r\nprint(parse_result.scheme)\r\n\r\nh = hash(target_url.encode('UTF8')).hexdigest()\r\nq = (h, parse_result.scheme, parse_result.netloc, parse_result.path, parse_result.params, parse_result.query, parse_result.fragment, 1, target_url, h)\r\nq\r\ninsert_parsed_urls(q)\r\n",
"ParseResult(scheme='https', netloc='www.venea.net', path='/', params='', query='', fragment='')\nhttps\n"
],
[
"process_raw_url()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4ee42dcc964a57bf5486d298001cc9f7057d0c
| 1,717 |
ipynb
|
Jupyter Notebook
|
backups/jupyter/my-jupyter/general-python.ipynb
|
roskenet/Playground
|
3cce70eeb38646b0f2ffbd071c3aaec7b8f5b9cb
|
[
"MIT"
] | null | null | null |
backups/jupyter/my-jupyter/general-python.ipynb
|
roskenet/Playground
|
3cce70eeb38646b0f2ffbd071c3aaec7b8f5b9cb
|
[
"MIT"
] | null | null | null |
backups/jupyter/my-jupyter/general-python.ipynb
|
roskenet/Playground
|
3cce70eeb38646b0f2ffbd071c3aaec7b8f5b9cb
|
[
"MIT"
] | 1 |
2020-10-02T04:57:25.000Z
|
2020-10-02T04:57:25.000Z
| 17.520408 | 90 | 0.446709 |
[
[
[
"# General Python Stuff\n\n\n",
"_____no_output_____"
],
[
"This is an example for an equation in $$\\LaTeX$$:\n$e^{i\\pi} + 1 = 0$\n\nThis is a Sum: $$e^x=\\sum_{i=0}^\\infty \\frac{1}{i!}x^i$$",
"_____no_output_____"
]
],
[
[
"list1 = ['a', 'b', 'c']\nlist2 = [1, 2, 3]\n\nziplist = zip(list1, list2)\n\nfor _, value in enumerate(list1):\n print(value)",
"a\nb\nc\n"
]
],
[
[
"Dies ist nun ein Absatz, der eher dazu da ist, das IntelliJ Vim plugin zu testen.\n\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a4ef0d29232b7c39cbc36fbdd0469e1717a7c57
| 420,483 |
ipynb
|
Jupyter Notebook
|
GradientDescent.ipynb
|
Homedepot5/DataScience
|
b0e265696f562db101345fcca341b6fff6827b2b
|
[
"Apache-2.0"
] | null | null | null |
GradientDescent.ipynb
|
Homedepot5/DataScience
|
b0e265696f562db101345fcca341b6fff6827b2b
|
[
"Apache-2.0"
] | null | null | null |
GradientDescent.ipynb
|
Homedepot5/DataScience
|
b0e265696f562db101345fcca341b6fff6827b2b
|
[
"Apache-2.0"
] | null | null | null | 63.57469 | 242 | 0.386905 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Homedepot5/DataScience/blob/deeplearning/GradientDescent.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport tensorflow as tf\nfrom tensorflow import keras\nimport pandas as pd\nfrom matplotlib import pyplot as plt\n%matplotlib inline\nimport io",
"_____no_output_____"
],
[
"\ndf=pd.read_csv('insurance_data.csv')\ndf",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(df[['age','affordibility']],df.bought_insurance,test_size=0.2, random_state=25)",
"_____no_output_____"
],
[
"X_train",
"_____no_output_____"
],
[
"X_trainscaled= X_train.copy()\nX_trainscaled['age']=X_trainscaled['age']/100\nX_testscaled=X_test.copy()\nX_testscaled.age=X_testscaled['age']/100\nX_trainscaled",
"_____no_output_____"
],
[
"model = keras.Sequential([\n keras.layers.Dense(1, input_shape=(2,), activation='sigmoid', kernel_initializer='ones', bias_initializer='zeros')\n])\n",
"_____no_output_____"
]
],
[
[
"binary_crossentropy is equal to log loss function\n\n\n",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.fit(X_trainscaled, y_train, epochs=5000)",
"\u001b[1;30;43mStreaming output truncated to the last 5000 lines.\u001b[0m\n1/1 [==============================] - 0s 4ms/step - loss: 0.5321 - accuracy: 0.7273\nEpoch 2502/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5321 - accuracy: 0.7273\nEpoch 2503/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5321 - accuracy: 0.7273\nEpoch 2504/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5320 - accuracy: 0.7273\nEpoch 2505/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5320 - accuracy: 0.7273\nEpoch 2506/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5320 - accuracy: 0.7273\nEpoch 2507/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5319 - accuracy: 0.7273\nEpoch 2508/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5319 - accuracy: 0.7273\nEpoch 2509/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5318 - accuracy: 0.7273\nEpoch 2510/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5318 - accuracy: 0.7273\nEpoch 2511/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5318 - accuracy: 0.7273\nEpoch 2512/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5317 - accuracy: 0.7273\nEpoch 2513/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5317 - accuracy: 0.7273\nEpoch 2514/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5316 - accuracy: 0.7273\nEpoch 2515/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5316 - accuracy: 0.7273\nEpoch 2516/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5316 - accuracy: 0.7273\nEpoch 2517/5000\n1/1 [==============================] - 0s 13ms/step - loss: 0.5315 - accuracy: 0.7273\nEpoch 2518/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5315 - accuracy: 0.7273\nEpoch 2519/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5315 - accuracy: 0.7273\nEpoch 2520/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5314 - accuracy: 0.7273\nEpoch 2521/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5314 - accuracy: 0.7273\nEpoch 2522/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5313 - accuracy: 0.7273\nEpoch 2523/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5313 - accuracy: 0.7273\nEpoch 2524/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5313 - accuracy: 0.7273\nEpoch 2525/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5312 - accuracy: 0.7273\nEpoch 2526/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5312 - accuracy: 0.7273\nEpoch 2527/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5311 - accuracy: 0.7273\nEpoch 2528/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5311 - accuracy: 0.7273\nEpoch 2529/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5311 - accuracy: 0.7273\nEpoch 2530/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5310 - accuracy: 0.7273\nEpoch 2531/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5310 - accuracy: 0.7273\nEpoch 2532/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5310 - accuracy: 0.7273\nEpoch 2533/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5309 - accuracy: 0.7273\nEpoch 2534/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5309 - accuracy: 0.7273\nEpoch 2535/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5308 - accuracy: 0.7273\nEpoch 2536/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5308 - accuracy: 0.7273\nEpoch 2537/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5308 - accuracy: 0.7273\nEpoch 2538/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5307 - accuracy: 0.7273\nEpoch 2539/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5307 - accuracy: 0.7273\nEpoch 2540/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5307 - accuracy: 0.7273\nEpoch 2541/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5306 - accuracy: 0.7273\nEpoch 2542/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5306 - accuracy: 0.7273\nEpoch 2543/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5305 - accuracy: 0.7273\nEpoch 2544/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5305 - accuracy: 0.7273\nEpoch 2545/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5305 - accuracy: 0.7273\nEpoch 2546/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5304 - accuracy: 0.7273\nEpoch 2547/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5304 - accuracy: 0.7273\nEpoch 2548/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5303 - accuracy: 0.7273\nEpoch 2549/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5303 - accuracy: 0.7273\nEpoch 2550/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5303 - accuracy: 0.7273\nEpoch 2551/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5302 - accuracy: 0.7273\nEpoch 2552/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5302 - accuracy: 0.7273\nEpoch 2553/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5302 - accuracy: 0.7273\nEpoch 2554/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5301 - accuracy: 0.7273\nEpoch 2555/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5301 - accuracy: 0.7273\nEpoch 2556/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5300 - accuracy: 0.7273\nEpoch 2557/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5300 - accuracy: 0.7273\nEpoch 2558/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5300 - accuracy: 0.7273\nEpoch 2559/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5299 - accuracy: 0.7273\nEpoch 2560/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5299 - accuracy: 0.7273\nEpoch 2561/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5299 - accuracy: 0.7273\nEpoch 2562/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5298 - accuracy: 0.7273\nEpoch 2563/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5298 - accuracy: 0.7273\nEpoch 2564/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5297 - accuracy: 0.7273\nEpoch 2565/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5297 - accuracy: 0.7273\nEpoch 2566/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5297 - accuracy: 0.7273\nEpoch 2567/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5296 - accuracy: 0.7273\nEpoch 2568/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5296 - accuracy: 0.7273\nEpoch 2569/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5295 - accuracy: 0.7273\nEpoch 2570/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5295 - accuracy: 0.7273\nEpoch 2571/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5295 - accuracy: 0.7273\nEpoch 2572/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5294 - accuracy: 0.7273\nEpoch 2573/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5294 - accuracy: 0.7273\nEpoch 2574/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5294 - accuracy: 0.7273\nEpoch 2575/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5293 - accuracy: 0.7273\nEpoch 2576/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5293 - accuracy: 0.7273\nEpoch 2577/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5292 - accuracy: 0.7273\nEpoch 2578/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5292 - accuracy: 0.7273\nEpoch 2579/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5292 - accuracy: 0.7273\nEpoch 2580/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5291 - accuracy: 0.7273\nEpoch 2581/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5291 - accuracy: 0.7273\nEpoch 2582/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5291 - accuracy: 0.7273\nEpoch 2583/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5290 - accuracy: 0.7273\nEpoch 2584/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5290 - accuracy: 0.7273\nEpoch 2585/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5289 - accuracy: 0.7273\nEpoch 2586/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5289 - accuracy: 0.7273\nEpoch 2587/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5289 - accuracy: 0.7273\nEpoch 2588/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5288 - accuracy: 0.7273\nEpoch 2589/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5288 - accuracy: 0.7273\nEpoch 2590/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5288 - accuracy: 0.7273\nEpoch 2591/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5287 - accuracy: 0.7273\nEpoch 2592/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5287 - accuracy: 0.7273\nEpoch 2593/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5286 - accuracy: 0.7273\nEpoch 2594/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5286 - accuracy: 0.7273\nEpoch 2595/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5286 - accuracy: 0.7273\nEpoch 2596/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5285 - accuracy: 0.7273\nEpoch 2597/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5285 - accuracy: 0.7273\nEpoch 2598/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5285 - accuracy: 0.7273\nEpoch 2599/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5284 - accuracy: 0.7273\nEpoch 2600/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5284 - accuracy: 0.7273\nEpoch 2601/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5283 - accuracy: 0.7273\nEpoch 2602/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5283 - accuracy: 0.7273\nEpoch 2603/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5283 - accuracy: 0.7273\nEpoch 2604/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5282 - accuracy: 0.7273\nEpoch 2605/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5282 - accuracy: 0.7273\nEpoch 2606/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5282 - accuracy: 0.7273\nEpoch 2607/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5281 - accuracy: 0.7273\nEpoch 2608/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5281 - accuracy: 0.7273\nEpoch 2609/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5280 - accuracy: 0.7273\nEpoch 2610/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5280 - accuracy: 0.7273\nEpoch 2611/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5280 - accuracy: 0.7273\nEpoch 2612/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5279 - accuracy: 0.7273\nEpoch 2613/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5279 - accuracy: 0.7273\nEpoch 2614/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5279 - accuracy: 0.7273\nEpoch 2615/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5278 - accuracy: 0.7273\nEpoch 2616/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5278 - accuracy: 0.7273\nEpoch 2617/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5277 - accuracy: 0.7273\nEpoch 2618/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5277 - accuracy: 0.7273\nEpoch 2619/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5277 - accuracy: 0.7273\nEpoch 2620/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.5276 - accuracy: 0.7273\nEpoch 2621/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5276 - accuracy: 0.7273\nEpoch 2622/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5276 - accuracy: 0.7273\nEpoch 2623/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5275 - accuracy: 0.7273\nEpoch 2624/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5275 - accuracy: 0.7273\nEpoch 2625/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5274 - accuracy: 0.7273\nEpoch 2626/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5274 - accuracy: 0.7273\nEpoch 2627/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5274 - accuracy: 0.7273\nEpoch 2628/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5273 - accuracy: 0.7273\nEpoch 2629/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5273 - accuracy: 0.7273\nEpoch 2630/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5273 - accuracy: 0.7273\nEpoch 2631/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5272 - accuracy: 0.7273\nEpoch 2632/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5272 - accuracy: 0.7273\nEpoch 2633/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5271 - accuracy: 0.7273\nEpoch 2634/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5271 - accuracy: 0.7273\nEpoch 2635/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5271 - accuracy: 0.7273\nEpoch 2636/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5270 - accuracy: 0.7273\nEpoch 2637/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5270 - accuracy: 0.7273\nEpoch 2638/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5270 - accuracy: 0.7273\nEpoch 2639/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5269 - accuracy: 0.7273\nEpoch 2640/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5269 - accuracy: 0.7273\nEpoch 2641/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5268 - accuracy: 0.7273\nEpoch 2642/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5268 - accuracy: 0.7727\nEpoch 2643/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5268 - accuracy: 0.7727\nEpoch 2644/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5267 - accuracy: 0.7727\nEpoch 2645/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5267 - accuracy: 0.7727\nEpoch 2646/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5267 - accuracy: 0.7727\nEpoch 2647/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5266 - accuracy: 0.7727\nEpoch 2648/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5266 - accuracy: 0.7727\nEpoch 2649/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5265 - accuracy: 0.7727\nEpoch 2650/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5265 - accuracy: 0.7727\nEpoch 2651/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5265 - accuracy: 0.7727\nEpoch 2652/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5264 - accuracy: 0.7727\nEpoch 2653/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5264 - accuracy: 0.7727\nEpoch 2654/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5264 - accuracy: 0.7727\nEpoch 2655/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5263 - accuracy: 0.7727\nEpoch 2656/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5263 - accuracy: 0.7727\nEpoch 2657/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5263 - accuracy: 0.7727\nEpoch 2658/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5262 - accuracy: 0.7727\nEpoch 2659/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5262 - accuracy: 0.7727\nEpoch 2660/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5261 - accuracy: 0.7727\nEpoch 2661/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5261 - accuracy: 0.7727\nEpoch 2662/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5261 - accuracy: 0.7727\nEpoch 2663/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.5260 - accuracy: 0.7727\nEpoch 2664/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5260 - accuracy: 0.7727\nEpoch 2665/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5260 - accuracy: 0.7727\nEpoch 2666/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5259 - accuracy: 0.7727\nEpoch 2667/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5259 - accuracy: 0.7727\nEpoch 2668/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5258 - accuracy: 0.7727\nEpoch 2669/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5258 - accuracy: 0.7727\nEpoch 2670/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5258 - accuracy: 0.7727\nEpoch 2671/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5257 - accuracy: 0.7727\nEpoch 2672/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5257 - accuracy: 0.7727\nEpoch 2673/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5257 - accuracy: 0.7727\nEpoch 2674/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5256 - accuracy: 0.7727\nEpoch 2675/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5256 - accuracy: 0.7727\nEpoch 2676/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5256 - accuracy: 0.7727\nEpoch 2677/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5255 - accuracy: 0.7727\nEpoch 2678/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5255 - accuracy: 0.7727\nEpoch 2679/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5254 - accuracy: 0.7727\nEpoch 2680/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5254 - accuracy: 0.7727\nEpoch 2681/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5254 - accuracy: 0.7727\nEpoch 2682/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5253 - accuracy: 0.7727\nEpoch 2683/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5253 - accuracy: 0.7727\nEpoch 2684/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5253 - accuracy: 0.7727\nEpoch 2685/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5252 - accuracy: 0.7727\nEpoch 2686/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5252 - accuracy: 0.7727\nEpoch 2687/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5251 - accuracy: 0.7727\nEpoch 2688/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5251 - accuracy: 0.7727\nEpoch 2689/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5251 - accuracy: 0.7727\nEpoch 2690/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5250 - accuracy: 0.7727\nEpoch 2691/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5250 - accuracy: 0.7727\nEpoch 2692/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5250 - accuracy: 0.7727\nEpoch 2693/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5249 - accuracy: 0.7727\nEpoch 2694/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5249 - accuracy: 0.7727\nEpoch 2695/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5249 - accuracy: 0.7727\nEpoch 2696/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5248 - accuracy: 0.7727\nEpoch 2697/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5248 - accuracy: 0.7727\nEpoch 2698/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5247 - accuracy: 0.7727\nEpoch 2699/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5247 - accuracy: 0.7727\nEpoch 2700/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5247 - accuracy: 0.7727\nEpoch 2701/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5246 - accuracy: 0.7727\nEpoch 2702/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5246 - accuracy: 0.7727\nEpoch 2703/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5246 - accuracy: 0.7727\nEpoch 2704/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5245 - accuracy: 0.7727\nEpoch 2705/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5245 - accuracy: 0.7727\nEpoch 2706/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5245 - accuracy: 0.7727\nEpoch 2707/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5244 - accuracy: 0.7727\nEpoch 2708/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5244 - accuracy: 0.7727\nEpoch 2709/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5243 - accuracy: 0.7727\nEpoch 2710/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5243 - accuracy: 0.7727\nEpoch 2711/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5243 - accuracy: 0.7727\nEpoch 2712/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5242 - accuracy: 0.7727\nEpoch 2713/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5242 - accuracy: 0.7727\nEpoch 2714/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.5242 - accuracy: 0.7727\nEpoch 2715/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5241 - accuracy: 0.7727\nEpoch 2716/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5241 - accuracy: 0.7727\nEpoch 2717/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5241 - accuracy: 0.7727\nEpoch 2718/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5240 - accuracy: 0.7727\nEpoch 2719/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5240 - accuracy: 0.7727\nEpoch 2720/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5239 - accuracy: 0.7727\nEpoch 2721/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5239 - accuracy: 0.7727\nEpoch 2722/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5239 - accuracy: 0.7727\nEpoch 2723/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5238 - accuracy: 0.7727\nEpoch 2724/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5238 - accuracy: 0.7727\nEpoch 2725/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5238 - accuracy: 0.7727\nEpoch 2726/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5237 - accuracy: 0.7727\nEpoch 2727/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5237 - accuracy: 0.7727\nEpoch 2728/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5237 - accuracy: 0.7727\nEpoch 2729/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5236 - accuracy: 0.7727\nEpoch 2730/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5236 - accuracy: 0.7727\nEpoch 2731/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5235 - accuracy: 0.7727\nEpoch 2732/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5235 - accuracy: 0.7727\nEpoch 2733/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5235 - accuracy: 0.7727\nEpoch 2734/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5234 - accuracy: 0.7727\nEpoch 2735/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5234 - accuracy: 0.7727\nEpoch 2736/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5234 - accuracy: 0.7727\nEpoch 2737/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5233 - accuracy: 0.7727\nEpoch 2738/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5233 - accuracy: 0.7727\nEpoch 2739/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5233 - accuracy: 0.7727\nEpoch 2740/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5232 - accuracy: 0.7727\nEpoch 2741/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5232 - accuracy: 0.7727\nEpoch 2742/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5231 - accuracy: 0.7727\nEpoch 2743/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5231 - accuracy: 0.7727\nEpoch 2744/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5231 - accuracy: 0.7727\nEpoch 2745/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5230 - accuracy: 0.7727\nEpoch 2746/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5230 - accuracy: 0.7727\nEpoch 2747/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5230 - accuracy: 0.7727\nEpoch 2748/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5229 - accuracy: 0.7727\nEpoch 2749/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5229 - accuracy: 0.7727\nEpoch 2750/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5229 - accuracy: 0.7727\nEpoch 2751/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7727\nEpoch 2752/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7727\nEpoch 2753/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5227 - accuracy: 0.7727\nEpoch 2754/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5227 - accuracy: 0.7727\nEpoch 2755/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5227 - accuracy: 0.7727\nEpoch 2756/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5226 - accuracy: 0.7727\nEpoch 2757/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5226 - accuracy: 0.7727\nEpoch 2758/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5226 - accuracy: 0.7727\nEpoch 2759/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5225 - accuracy: 0.7727\nEpoch 2760/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5225 - accuracy: 0.7727\nEpoch 2761/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5225 - accuracy: 0.7727\nEpoch 2762/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5224 - accuracy: 0.7727\nEpoch 2763/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5224 - accuracy: 0.7727\nEpoch 2764/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5224 - accuracy: 0.7727\nEpoch 2765/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5223 - accuracy: 0.7727\nEpoch 2766/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5223 - accuracy: 0.7727\nEpoch 2767/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5222 - accuracy: 0.7727\nEpoch 2768/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5222 - accuracy: 0.7727\nEpoch 2769/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5222 - accuracy: 0.7727\nEpoch 2770/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5221 - accuracy: 0.7727\nEpoch 2771/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5221 - accuracy: 0.7727\nEpoch 2772/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5221 - accuracy: 0.7727\nEpoch 2773/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5220 - accuracy: 0.7727\nEpoch 2774/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5220 - accuracy: 0.7727\nEpoch 2775/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5220 - accuracy: 0.7727\nEpoch 2776/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5219 - accuracy: 0.7727\nEpoch 2777/5000\n1/1 [==============================] - 0s 954us/step - loss: 0.5219 - accuracy: 0.7727\nEpoch 2778/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5219 - accuracy: 0.7727\nEpoch 2779/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5218 - accuracy: 0.7727\nEpoch 2780/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5218 - accuracy: 0.7727\nEpoch 2781/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5217 - accuracy: 0.7727\nEpoch 2782/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5217 - accuracy: 0.7727\nEpoch 2783/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5217 - accuracy: 0.7727\nEpoch 2784/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5216 - accuracy: 0.7727\nEpoch 2785/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5216 - accuracy: 0.7727\nEpoch 2786/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5216 - accuracy: 0.7727\nEpoch 2787/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5215 - accuracy: 0.7727\nEpoch 2788/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5215 - accuracy: 0.7727\nEpoch 2789/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5215 - accuracy: 0.7727\nEpoch 2790/5000\n1/1 [==============================] - 0s 957us/step - loss: 0.5214 - accuracy: 0.7727\nEpoch 2791/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5214 - accuracy: 0.7727\nEpoch 2792/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5214 - accuracy: 0.8182\nEpoch 2793/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5213 - accuracy: 0.8182\nEpoch 2794/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5213 - accuracy: 0.8182\nEpoch 2795/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5212 - accuracy: 0.8182\nEpoch 2796/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5212 - accuracy: 0.8182\nEpoch 2797/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5212 - accuracy: 0.8182\nEpoch 2798/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5211 - accuracy: 0.8182\nEpoch 2799/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5211 - accuracy: 0.8182\nEpoch 2800/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5211 - accuracy: 0.8182\nEpoch 2801/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5210 - accuracy: 0.8182\nEpoch 2802/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5210 - accuracy: 0.8182\nEpoch 2803/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5210 - accuracy: 0.8182\nEpoch 2804/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5209 - accuracy: 0.8182\nEpoch 2805/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5209 - accuracy: 0.8182\nEpoch 2806/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5209 - accuracy: 0.8182\nEpoch 2807/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5208 - accuracy: 0.8182\nEpoch 2808/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5208 - accuracy: 0.8182\nEpoch 2809/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5207 - accuracy: 0.8182\nEpoch 2810/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5207 - accuracy: 0.8182\nEpoch 2811/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5207 - accuracy: 0.8182\nEpoch 2812/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5206 - accuracy: 0.8182\nEpoch 2813/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5206 - accuracy: 0.8182\nEpoch 2814/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5206 - accuracy: 0.8182\nEpoch 2815/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5205 - accuracy: 0.8182\nEpoch 2816/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5205 - accuracy: 0.8182\nEpoch 2817/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5205 - accuracy: 0.8182\nEpoch 2818/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5204 - accuracy: 0.8182\nEpoch 2819/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5204 - accuracy: 0.8182\nEpoch 2820/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5204 - accuracy: 0.8182\nEpoch 2821/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5203 - accuracy: 0.8182\nEpoch 2822/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5203 - accuracy: 0.8182\nEpoch 2823/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5203 - accuracy: 0.8182\nEpoch 2824/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5202 - accuracy: 0.8182\nEpoch 2825/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5202 - accuracy: 0.8182\nEpoch 2826/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5201 - accuracy: 0.8182\nEpoch 2827/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5201 - accuracy: 0.8182\nEpoch 2828/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5201 - accuracy: 0.8182\nEpoch 2829/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5200 - accuracy: 0.8182\nEpoch 2830/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5200 - accuracy: 0.8182\nEpoch 2831/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5200 - accuracy: 0.8182\nEpoch 2832/5000\n1/1 [==============================] - 0s 929us/step - loss: 0.5199 - accuracy: 0.8182\nEpoch 2833/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5199 - accuracy: 0.8182\nEpoch 2834/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5199 - accuracy: 0.8182\nEpoch 2835/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5198 - accuracy: 0.8182\nEpoch 2836/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5198 - accuracy: 0.8182\nEpoch 2837/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5198 - accuracy: 0.8182\nEpoch 2838/5000\n1/1 [==============================] - 0s 991us/step - loss: 0.5197 - accuracy: 0.8182\nEpoch 2839/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5197 - accuracy: 0.8182\nEpoch 2840/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5197 - accuracy: 0.8182\nEpoch 2841/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5196 - accuracy: 0.8182\nEpoch 2842/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5196 - accuracy: 0.8182\nEpoch 2843/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5195 - accuracy: 0.8182\nEpoch 2844/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5195 - accuracy: 0.8182\nEpoch 2845/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5195 - accuracy: 0.8182\nEpoch 2846/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5194 - accuracy: 0.8182\nEpoch 2847/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5194 - accuracy: 0.8182\nEpoch 2848/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5194 - accuracy: 0.8182\nEpoch 2849/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5193 - accuracy: 0.8182\nEpoch 2850/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5193 - accuracy: 0.8182\nEpoch 2851/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5193 - accuracy: 0.8182\nEpoch 2852/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.5192 - accuracy: 0.8182\nEpoch 2853/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5192 - accuracy: 0.8182\nEpoch 2854/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5192 - accuracy: 0.8182\nEpoch 2855/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5191 - accuracy: 0.8182\nEpoch 2856/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5191 - accuracy: 0.8182\nEpoch 2857/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5191 - accuracy: 0.8182\nEpoch 2858/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5190 - accuracy: 0.8182\nEpoch 2859/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5190 - accuracy: 0.8182\nEpoch 2860/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5190 - accuracy: 0.8182\nEpoch 2861/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5189 - accuracy: 0.8182\nEpoch 2862/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5189 - accuracy: 0.8182\nEpoch 2863/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5188 - accuracy: 0.8182\nEpoch 2864/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5188 - accuracy: 0.8182\nEpoch 2865/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5188 - accuracy: 0.8182\nEpoch 2866/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5187 - accuracy: 0.8182\nEpoch 2867/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5187 - accuracy: 0.8182\nEpoch 2868/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5187 - accuracy: 0.8182\nEpoch 2869/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5186 - accuracy: 0.8182\nEpoch 2870/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5186 - accuracy: 0.8182\nEpoch 2871/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5186 - accuracy: 0.8182\nEpoch 2872/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5185 - accuracy: 0.8182\nEpoch 2873/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5185 - accuracy: 0.8182\nEpoch 2874/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5185 - accuracy: 0.8182\nEpoch 2875/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5184 - accuracy: 0.8182\nEpoch 2876/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5184 - accuracy: 0.8182\nEpoch 2877/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5184 - accuracy: 0.8182\nEpoch 2878/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5183 - accuracy: 0.8182\nEpoch 2879/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5183 - accuracy: 0.8182\nEpoch 2880/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5183 - accuracy: 0.8182\nEpoch 2881/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5182 - accuracy: 0.8182\nEpoch 2882/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5182 - accuracy: 0.8182\nEpoch 2883/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5181 - accuracy: 0.8182\nEpoch 2884/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5181 - accuracy: 0.8182\nEpoch 2885/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5181 - accuracy: 0.8182\nEpoch 2886/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5180 - accuracy: 0.8182\nEpoch 2887/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5180 - accuracy: 0.8182\nEpoch 2888/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5180 - accuracy: 0.8182\nEpoch 2889/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5179 - accuracy: 0.8182\nEpoch 2890/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5179 - accuracy: 0.8182\nEpoch 2891/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5179 - accuracy: 0.8182\nEpoch 2892/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5178 - accuracy: 0.8182\nEpoch 2893/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5178 - accuracy: 0.8182\nEpoch 2894/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5178 - accuracy: 0.8182\nEpoch 2895/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5177 - accuracy: 0.8182\nEpoch 2896/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5177 - accuracy: 0.8182\nEpoch 2897/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5177 - accuracy: 0.8182\nEpoch 2898/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5176 - accuracy: 0.8182\nEpoch 2899/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5176 - accuracy: 0.8182\nEpoch 2900/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5176 - accuracy: 0.8182\nEpoch 2901/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5175 - accuracy: 0.8182\nEpoch 2902/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5175 - accuracy: 0.8182\nEpoch 2903/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5175 - accuracy: 0.8182\nEpoch 2904/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5174 - accuracy: 0.8182\nEpoch 2905/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5174 - accuracy: 0.8182\nEpoch 2906/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5174 - accuracy: 0.8182\nEpoch 2907/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5173 - accuracy: 0.8182\nEpoch 2908/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5173 - accuracy: 0.8182\nEpoch 2909/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5172 - accuracy: 0.8182\nEpoch 2910/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5172 - accuracy: 0.8182\nEpoch 2911/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5172 - accuracy: 0.8182\nEpoch 2912/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5171 - accuracy: 0.8182\nEpoch 2913/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5171 - accuracy: 0.8182\nEpoch 2914/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5171 - accuracy: 0.8182\nEpoch 2915/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5170 - accuracy: 0.8182\nEpoch 2916/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5170 - accuracy: 0.8182\nEpoch 2917/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5170 - accuracy: 0.8182\nEpoch 2918/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5169 - accuracy: 0.8182\nEpoch 2919/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5169 - accuracy: 0.8182\nEpoch 2920/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5169 - accuracy: 0.8182\nEpoch 2921/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5168 - accuracy: 0.8182\nEpoch 2922/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5168 - accuracy: 0.8182\nEpoch 2923/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5168 - accuracy: 0.8182\nEpoch 2924/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5167 - accuracy: 0.8182\nEpoch 2925/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5167 - accuracy: 0.8182\nEpoch 2926/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5167 - accuracy: 0.8182\nEpoch 2927/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5166 - accuracy: 0.8182\nEpoch 2928/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5166 - accuracy: 0.8182\nEpoch 2929/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5166 - accuracy: 0.8182\nEpoch 2930/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5165 - accuracy: 0.8182\nEpoch 2931/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5165 - accuracy: 0.8182\nEpoch 2932/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5165 - accuracy: 0.8182\nEpoch 2933/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5164 - accuracy: 0.8182\nEpoch 2934/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5164 - accuracy: 0.8182\nEpoch 2935/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5164 - accuracy: 0.8182\nEpoch 2936/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5163 - accuracy: 0.8182\nEpoch 2937/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5163 - accuracy: 0.8182\nEpoch 2938/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5163 - accuracy: 0.8182\nEpoch 2939/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5162 - accuracy: 0.8182\nEpoch 2940/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5162 - accuracy: 0.8182\nEpoch 2941/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5162 - accuracy: 0.8182\nEpoch 2942/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5161 - accuracy: 0.8182\nEpoch 2943/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5161 - accuracy: 0.8182\nEpoch 2944/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5160 - accuracy: 0.8182\nEpoch 2945/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5160 - accuracy: 0.8182\nEpoch 2946/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5160 - accuracy: 0.8182\nEpoch 2947/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5159 - accuracy: 0.8182\nEpoch 2948/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5159 - accuracy: 0.8182\nEpoch 2949/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5159 - accuracy: 0.8182\nEpoch 2950/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5158 - accuracy: 0.8182\nEpoch 2951/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5158 - accuracy: 0.8182\nEpoch 2952/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5158 - accuracy: 0.8182\nEpoch 2953/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5157 - accuracy: 0.8182\nEpoch 2954/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5157 - accuracy: 0.8182\nEpoch 2955/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5157 - accuracy: 0.8182\nEpoch 2956/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5156 - accuracy: 0.8182\nEpoch 2957/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5156 - accuracy: 0.8182\nEpoch 2958/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5156 - accuracy: 0.8182\nEpoch 2959/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5155 - accuracy: 0.8182\nEpoch 2960/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5155 - accuracy: 0.8636\nEpoch 2961/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5155 - accuracy: 0.8636\nEpoch 2962/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5154 - accuracy: 0.8636\nEpoch 2963/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5154 - accuracy: 0.8636\nEpoch 2964/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5154 - accuracy: 0.8636\nEpoch 2965/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5153 - accuracy: 0.8636\nEpoch 2966/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5153 - accuracy: 0.8636\nEpoch 2967/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5153 - accuracy: 0.8636\nEpoch 2968/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5152 - accuracy: 0.8636\nEpoch 2969/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5152 - accuracy: 0.8636\nEpoch 2970/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5152 - accuracy: 0.8636\nEpoch 2971/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5151 - accuracy: 0.8636\nEpoch 2972/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5151 - accuracy: 0.8636\nEpoch 2973/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.5151 - accuracy: 0.8636\nEpoch 2974/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5150 - accuracy: 0.8636\nEpoch 2975/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5150 - accuracy: 0.8636\nEpoch 2976/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5150 - accuracy: 0.8636\nEpoch 2977/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5149 - accuracy: 0.8636\nEpoch 2978/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5149 - accuracy: 0.8636\nEpoch 2979/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5149 - accuracy: 0.8636\nEpoch 2980/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5148 - accuracy: 0.8636\nEpoch 2981/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5148 - accuracy: 0.8636\nEpoch 2982/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5148 - accuracy: 0.8636\nEpoch 2983/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5147 - accuracy: 0.8636\nEpoch 2984/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5147 - accuracy: 0.8636\nEpoch 2985/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5147 - accuracy: 0.8636\nEpoch 2986/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5146 - accuracy: 0.8636\nEpoch 2987/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5146 - accuracy: 0.8636\nEpoch 2988/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5146 - accuracy: 0.8636\nEpoch 2989/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5145 - accuracy: 0.8636\nEpoch 2990/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5145 - accuracy: 0.8636\nEpoch 2991/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5145 - accuracy: 0.8636\nEpoch 2992/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5144 - accuracy: 0.8636\nEpoch 2993/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5144 - accuracy: 0.8636\nEpoch 2994/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5144 - accuracy: 0.8636\nEpoch 2995/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5143 - accuracy: 0.8636\nEpoch 2996/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5143 - accuracy: 0.8636\nEpoch 2997/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5143 - accuracy: 0.8636\nEpoch 2998/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5142 - accuracy: 0.8636\nEpoch 2999/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5142 - accuracy: 0.8636\nEpoch 3000/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5142 - accuracy: 0.8636\nEpoch 3001/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5141 - accuracy: 0.8636\nEpoch 3002/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5141 - accuracy: 0.8636\nEpoch 3003/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5141 - accuracy: 0.8636\nEpoch 3004/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5140 - accuracy: 0.8636\nEpoch 3005/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5140 - accuracy: 0.8636\nEpoch 3006/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5140 - accuracy: 0.8636\nEpoch 3007/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5139 - accuracy: 0.8636\nEpoch 3008/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5139 - accuracy: 0.8636\nEpoch 3009/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5138 - accuracy: 0.8636\nEpoch 3010/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5138 - accuracy: 0.8636\nEpoch 3011/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5138 - accuracy: 0.8636\nEpoch 3012/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5137 - accuracy: 0.8636\nEpoch 3013/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5137 - accuracy: 0.8636\nEpoch 3014/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5137 - accuracy: 0.8636\nEpoch 3015/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5136 - accuracy: 0.8636\nEpoch 3016/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5136 - accuracy: 0.8636\nEpoch 3017/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5136 - accuracy: 0.8636\nEpoch 3018/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5135 - accuracy: 0.8636\nEpoch 3019/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5135 - accuracy: 0.8636\nEpoch 3020/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5135 - accuracy: 0.8636\nEpoch 3021/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5134 - accuracy: 0.8636\nEpoch 3022/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5134 - accuracy: 0.8636\nEpoch 3023/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5134 - accuracy: 0.8636\nEpoch 3024/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5133 - accuracy: 0.8636\nEpoch 3025/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5133 - accuracy: 0.8636\nEpoch 3026/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5133 - accuracy: 0.8636\nEpoch 3027/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5132 - accuracy: 0.8636\nEpoch 3028/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5132 - accuracy: 0.8636\nEpoch 3029/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5132 - accuracy: 0.8636\nEpoch 3030/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5131 - accuracy: 0.8636\nEpoch 3031/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5131 - accuracy: 0.8636\nEpoch 3032/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5131 - accuracy: 0.8636\nEpoch 3033/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5130 - accuracy: 0.8636\nEpoch 3034/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.5130 - accuracy: 0.8636\nEpoch 3035/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5130 - accuracy: 0.8636\nEpoch 3036/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5129 - accuracy: 0.8636\nEpoch 3037/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5129 - accuracy: 0.8636\nEpoch 3038/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5129 - accuracy: 0.8636\nEpoch 3039/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5128 - accuracy: 0.8636\nEpoch 3040/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5128 - accuracy: 0.8636\nEpoch 3041/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5128 - accuracy: 0.8636\nEpoch 3042/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5127 - accuracy: 0.8636\nEpoch 3043/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5127 - accuracy: 0.8636\nEpoch 3044/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5127 - accuracy: 0.8636\nEpoch 3045/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5126 - accuracy: 0.8636\nEpoch 3046/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5126 - accuracy: 0.8636\nEpoch 3047/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5126 - accuracy: 0.8636\nEpoch 3048/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5126 - accuracy: 0.8636\nEpoch 3049/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5125 - accuracy: 0.8636\nEpoch 3050/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5125 - accuracy: 0.8636\nEpoch 3051/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5125 - accuracy: 0.8636\nEpoch 3052/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5124 - accuracy: 0.8636\nEpoch 3053/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5124 - accuracy: 0.8636\nEpoch 3054/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5124 - accuracy: 0.8636\nEpoch 3055/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5123 - accuracy: 0.8636\nEpoch 3056/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5123 - accuracy: 0.8636\nEpoch 3057/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5123 - accuracy: 0.8636\nEpoch 3058/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5122 - accuracy: 0.8636\nEpoch 3059/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5122 - accuracy: 0.8636\nEpoch 3060/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5122 - accuracy: 0.8636\nEpoch 3061/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5121 - accuracy: 0.8636\nEpoch 3062/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5121 - accuracy: 0.8636\nEpoch 3063/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5121 - accuracy: 0.8636\nEpoch 3064/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5120 - accuracy: 0.8636\nEpoch 3065/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5120 - accuracy: 0.8636\nEpoch 3066/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5120 - accuracy: 0.8636\nEpoch 3067/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5119 - accuracy: 0.8636\nEpoch 3068/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5119 - accuracy: 0.8636\nEpoch 3069/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5119 - accuracy: 0.8636\nEpoch 3070/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5118 - accuracy: 0.8636\nEpoch 3071/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5118 - accuracy: 0.8636\nEpoch 3072/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5118 - accuracy: 0.8636\nEpoch 3073/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5117 - accuracy: 0.8636\nEpoch 3074/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5117 - accuracy: 0.8636\nEpoch 3075/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5117 - accuracy: 0.8636\nEpoch 3076/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5116 - accuracy: 0.8636\nEpoch 3077/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5116 - accuracy: 0.8636\nEpoch 3078/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5116 - accuracy: 0.8636\nEpoch 3079/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5115 - accuracy: 0.8636\nEpoch 3080/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5115 - accuracy: 0.8636\nEpoch 3081/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5115 - accuracy: 0.8636\nEpoch 3082/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5114 - accuracy: 0.8636\nEpoch 3083/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5114 - accuracy: 0.8636\nEpoch 3084/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5114 - accuracy: 0.8636\nEpoch 3085/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5113 - accuracy: 0.8636\nEpoch 3086/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5113 - accuracy: 0.8636\nEpoch 3087/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5113 - accuracy: 0.8636\nEpoch 3088/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5112 - accuracy: 0.8636\nEpoch 3089/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5112 - accuracy: 0.8636\nEpoch 3090/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.5112 - accuracy: 0.8636\nEpoch 3091/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5111 - accuracy: 0.8636\nEpoch 3092/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5111 - accuracy: 0.8636\nEpoch 3093/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5111 - accuracy: 0.8636\nEpoch 3094/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5110 - accuracy: 0.8636\nEpoch 3095/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5110 - accuracy: 0.8636\nEpoch 3096/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5110 - accuracy: 0.8636\nEpoch 3097/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5109 - accuracy: 0.8636\nEpoch 3098/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5109 - accuracy: 0.8636\nEpoch 3099/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5109 - accuracy: 0.8636\nEpoch 3100/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5108 - accuracy: 0.8636\nEpoch 3101/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5108 - accuracy: 0.8636\nEpoch 3102/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5108 - accuracy: 0.8636\nEpoch 3103/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5107 - accuracy: 0.8636\nEpoch 3104/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5107 - accuracy: 0.8636\nEpoch 3105/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5107 - accuracy: 0.8636\nEpoch 3106/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5106 - accuracy: 0.8636\nEpoch 3107/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5106 - accuracy: 0.8636\nEpoch 3108/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5106 - accuracy: 0.8636\nEpoch 3109/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5105 - accuracy: 0.8636\nEpoch 3110/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5105 - accuracy: 0.8636\nEpoch 3111/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5105 - accuracy: 0.8636\nEpoch 3112/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5104 - accuracy: 0.8636\nEpoch 3113/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5104 - accuracy: 0.8636\nEpoch 3114/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5104 - accuracy: 0.8636\nEpoch 3115/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5104 - accuracy: 0.8636\nEpoch 3116/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5103 - accuracy: 0.8636\nEpoch 3117/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5103 - accuracy: 0.8636\nEpoch 3118/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5103 - accuracy: 0.8636\nEpoch 3119/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5102 - accuracy: 0.8636\nEpoch 3120/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5102 - accuracy: 0.8636\nEpoch 3121/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5102 - accuracy: 0.8636\nEpoch 3122/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5101 - accuracy: 0.8636\nEpoch 3123/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5101 - accuracy: 0.8636\nEpoch 3124/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5101 - accuracy: 0.8636\nEpoch 3125/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5100 - accuracy: 0.8636\nEpoch 3126/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5100 - accuracy: 0.8636\nEpoch 3127/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5100 - accuracy: 0.8636\nEpoch 3128/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5099 - accuracy: 0.8636\nEpoch 3129/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5099 - accuracy: 0.8636\nEpoch 3130/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5099 - accuracy: 0.8636\nEpoch 3131/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5098 - accuracy: 0.8636\nEpoch 3132/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5098 - accuracy: 0.8636\nEpoch 3133/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5098 - accuracy: 0.8636\nEpoch 3134/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5097 - accuracy: 0.8636\nEpoch 3135/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5097 - accuracy: 0.8636\nEpoch 3136/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5097 - accuracy: 0.8636\nEpoch 3137/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5096 - accuracy: 0.8636\nEpoch 3138/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5096 - accuracy: 0.8636\nEpoch 3139/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.5096 - accuracy: 0.8636\nEpoch 3140/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5095 - accuracy: 0.8636\nEpoch 3141/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5095 - accuracy: 0.8636\nEpoch 3142/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5095 - accuracy: 0.8636\nEpoch 3143/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5094 - accuracy: 0.8636\nEpoch 3144/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5094 - accuracy: 0.8636\nEpoch 3145/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5094 - accuracy: 0.8636\nEpoch 3146/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5093 - accuracy: 0.8636\nEpoch 3147/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5093 - accuracy: 0.8636\nEpoch 3148/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5093 - accuracy: 0.8636\nEpoch 3149/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5093 - accuracy: 0.8636\nEpoch 3150/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5092 - accuracy: 0.8636\nEpoch 3151/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5092 - accuracy: 0.8636\nEpoch 3152/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5092 - accuracy: 0.8636\nEpoch 3153/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5091 - accuracy: 0.8636\nEpoch 3154/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5091 - accuracy: 0.8636\nEpoch 3155/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5091 - accuracy: 0.8636\nEpoch 3156/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5090 - accuracy: 0.8636\nEpoch 3157/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5090 - accuracy: 0.8636\nEpoch 3158/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5090 - accuracy: 0.8636\nEpoch 3159/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5089 - accuracy: 0.8636\nEpoch 3160/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5089 - accuracy: 0.8636\nEpoch 3161/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5089 - accuracy: 0.8636\nEpoch 3162/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5088 - accuracy: 0.8636\nEpoch 3163/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5088 - accuracy: 0.8636\nEpoch 3164/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5088 - accuracy: 0.8636\nEpoch 3165/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5087 - accuracy: 0.8636\nEpoch 3166/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5087 - accuracy: 0.8636\nEpoch 3167/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5087 - accuracy: 0.8636\nEpoch 3168/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5086 - accuracy: 0.8636\nEpoch 3169/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5086 - accuracy: 0.8636\nEpoch 3170/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5086 - accuracy: 0.8636\nEpoch 3171/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5085 - accuracy: 0.8636\nEpoch 3172/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5085 - accuracy: 0.8636\nEpoch 3173/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5085 - accuracy: 0.8636\nEpoch 3174/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5084 - accuracy: 0.8636\nEpoch 3175/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5084 - accuracy: 0.8636\nEpoch 3176/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5084 - accuracy: 0.8636\nEpoch 3177/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5084 - accuracy: 0.8636\nEpoch 3178/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5083 - accuracy: 0.8636\nEpoch 3179/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5083 - accuracy: 0.8636\nEpoch 3180/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5083 - accuracy: 0.8636\nEpoch 3181/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5082 - accuracy: 0.8636\nEpoch 3182/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5082 - accuracy: 0.8636\nEpoch 3183/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5082 - accuracy: 0.8636\nEpoch 3184/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5081 - accuracy: 0.8636\nEpoch 3185/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5081 - accuracy: 0.8636\nEpoch 3186/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5081 - accuracy: 0.8636\nEpoch 3187/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5080 - accuracy: 0.8636\nEpoch 3188/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5080 - accuracy: 0.8636\nEpoch 3189/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5080 - accuracy: 0.8636\nEpoch 3190/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5079 - accuracy: 0.8636\nEpoch 3191/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5079 - accuracy: 0.8636\nEpoch 3192/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5079 - accuracy: 0.8636\nEpoch 3193/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5078 - accuracy: 0.8636\nEpoch 3194/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5078 - accuracy: 0.8636\nEpoch 3195/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5078 - accuracy: 0.8636\nEpoch 3196/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5077 - accuracy: 0.8636\nEpoch 3197/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5077 - accuracy: 0.8636\nEpoch 3198/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5077 - accuracy: 0.8636\nEpoch 3199/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5077 - accuracy: 0.8636\nEpoch 3200/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5076 - accuracy: 0.8636\nEpoch 3201/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5076 - accuracy: 0.8636\nEpoch 3202/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5076 - accuracy: 0.8636\nEpoch 3203/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5075 - accuracy: 0.8636\nEpoch 3204/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5075 - accuracy: 0.8636\nEpoch 3205/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5075 - accuracy: 0.8636\nEpoch 3206/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5074 - accuracy: 0.8636\nEpoch 3207/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5074 - accuracy: 0.8636\nEpoch 3208/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5074 - accuracy: 0.8636\nEpoch 3209/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5073 - accuracy: 0.8636\nEpoch 3210/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5073 - accuracy: 0.8636\nEpoch 3211/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5073 - accuracy: 0.8636\nEpoch 3212/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5072 - accuracy: 0.8636\nEpoch 3213/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5072 - accuracy: 0.8636\nEpoch 3214/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5072 - accuracy: 0.8636\nEpoch 3215/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5071 - accuracy: 0.8636\nEpoch 3216/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5071 - accuracy: 0.8636\nEpoch 3217/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5071 - accuracy: 0.8636\nEpoch 3218/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5071 - accuracy: 0.8636\nEpoch 3219/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5070 - accuracy: 0.8636\nEpoch 3220/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5070 - accuracy: 0.8636\nEpoch 3221/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5070 - accuracy: 0.8636\nEpoch 3222/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5069 - accuracy: 0.8636\nEpoch 3223/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5069 - accuracy: 0.8636\nEpoch 3224/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5069 - accuracy: 0.8636\nEpoch 3225/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5068 - accuracy: 0.8636\nEpoch 3226/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5068 - accuracy: 0.8636\nEpoch 3227/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5068 - accuracy: 0.8636\nEpoch 3228/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5067 - accuracy: 0.8636\nEpoch 3229/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5067 - accuracy: 0.8636\nEpoch 3230/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5067 - accuracy: 0.8636\nEpoch 3231/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5066 - accuracy: 0.8636\nEpoch 3232/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5066 - accuracy: 0.8636\nEpoch 3233/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5066 - accuracy: 0.8636\nEpoch 3234/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5065 - accuracy: 0.8636\nEpoch 3235/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5065 - accuracy: 0.8636\nEpoch 3236/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5065 - accuracy: 0.8636\nEpoch 3237/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5065 - accuracy: 0.8636\nEpoch 3238/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5064 - accuracy: 0.8636\nEpoch 3239/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5064 - accuracy: 0.8636\nEpoch 3240/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5064 - accuracy: 0.8636\nEpoch 3241/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5063 - accuracy: 0.8636\nEpoch 3242/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5063 - accuracy: 0.8636\nEpoch 3243/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5063 - accuracy: 0.8636\nEpoch 3244/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5062 - accuracy: 0.8636\nEpoch 3245/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5062 - accuracy: 0.8636\nEpoch 3246/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5062 - accuracy: 0.8636\nEpoch 3247/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5061 - accuracy: 0.8636\nEpoch 3248/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5061 - accuracy: 0.8636\nEpoch 3249/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5061 - accuracy: 0.9091\nEpoch 3250/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5060 - accuracy: 0.9091\nEpoch 3251/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5060 - accuracy: 0.9091\nEpoch 3252/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5060 - accuracy: 0.9091\nEpoch 3253/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5060 - accuracy: 0.9091\nEpoch 3254/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5059 - accuracy: 0.9091\nEpoch 3255/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5059 - accuracy: 0.9091\nEpoch 3256/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5059 - accuracy: 0.9091\nEpoch 3257/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5058 - accuracy: 0.9091\nEpoch 3258/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5058 - accuracy: 0.9091\nEpoch 3259/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5058 - accuracy: 0.9091\nEpoch 3260/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5057 - accuracy: 0.9091\nEpoch 3261/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5057 - accuracy: 0.9091\nEpoch 3262/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5057 - accuracy: 0.9091\nEpoch 3263/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5056 - accuracy: 0.9091\nEpoch 3264/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5056 - accuracy: 0.9091\nEpoch 3265/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5056 - accuracy: 0.9091\nEpoch 3266/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5055 - accuracy: 0.9091\nEpoch 3267/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5055 - accuracy: 0.9091\nEpoch 3268/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5055 - accuracy: 0.9091\nEpoch 3269/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5055 - accuracy: 0.9091\nEpoch 3270/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5054 - accuracy: 0.9091\nEpoch 3271/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5054 - accuracy: 0.9091\nEpoch 3272/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5054 - accuracy: 0.9091\nEpoch 3273/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5053 - accuracy: 0.9091\nEpoch 3274/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5053 - accuracy: 0.9091\nEpoch 3275/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5053 - accuracy: 0.9091\nEpoch 3276/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5052 - accuracy: 0.9091\nEpoch 3277/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5052 - accuracy: 0.9091\nEpoch 3278/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5052 - accuracy: 0.9091\nEpoch 3279/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5051 - accuracy: 0.9091\nEpoch 3280/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5051 - accuracy: 0.9091\nEpoch 3281/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5051 - accuracy: 0.9091\nEpoch 3282/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5050 - accuracy: 0.9091\nEpoch 3283/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5050 - accuracy: 0.9091\nEpoch 3284/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5050 - accuracy: 0.9091\nEpoch 3285/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5050 - accuracy: 0.9091\nEpoch 3286/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5049 - accuracy: 0.9091\nEpoch 3287/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5049 - accuracy: 0.9091\nEpoch 3288/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5049 - accuracy: 0.9091\nEpoch 3289/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5048 - accuracy: 0.9091\nEpoch 3290/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5048 - accuracy: 0.9091\nEpoch 3291/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5048 - accuracy: 0.9091\nEpoch 3292/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5047 - accuracy: 0.9091\nEpoch 3293/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5047 - accuracy: 0.9091\nEpoch 3294/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5047 - accuracy: 0.9091\nEpoch 3295/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5046 - accuracy: 0.9091\nEpoch 3296/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5046 - accuracy: 0.9091\nEpoch 3297/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5046 - accuracy: 0.9091\nEpoch 3298/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5046 - accuracy: 0.9091\nEpoch 3299/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5045 - accuracy: 0.9091\nEpoch 3300/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5045 - accuracy: 0.9091\nEpoch 3301/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5045 - accuracy: 0.9091\nEpoch 3302/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5044 - accuracy: 0.9091\nEpoch 3303/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5044 - accuracy: 0.9091\nEpoch 3304/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5044 - accuracy: 0.9091\nEpoch 3305/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5043 - accuracy: 0.9091\nEpoch 3306/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5043 - accuracy: 0.9091\nEpoch 3307/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5043 - accuracy: 0.9091\nEpoch 3308/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5042 - accuracy: 0.9091\nEpoch 3309/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5042 - accuracy: 0.9091\nEpoch 3310/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5042 - accuracy: 0.9091\nEpoch 3311/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5042 - accuracy: 0.9091\nEpoch 3312/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5041 - accuracy: 0.9091\nEpoch 3313/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5041 - accuracy: 0.9091\nEpoch 3314/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5041 - accuracy: 0.9091\nEpoch 3315/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5040 - accuracy: 0.9091\nEpoch 3316/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5040 - accuracy: 0.9091\nEpoch 3317/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5040 - accuracy: 0.9091\nEpoch 3318/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5039 - accuracy: 0.9091\nEpoch 3319/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5039 - accuracy: 0.9091\nEpoch 3320/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5039 - accuracy: 0.9091\nEpoch 3321/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5038 - accuracy: 0.9091\nEpoch 3322/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5038 - accuracy: 0.9091\nEpoch 3323/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5038 - accuracy: 0.9091\nEpoch 3324/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5038 - accuracy: 0.9091\nEpoch 3325/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5037 - accuracy: 0.9091\nEpoch 3326/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5037 - accuracy: 0.9091\nEpoch 3327/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5037 - accuracy: 0.9091\nEpoch 3328/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5036 - accuracy: 0.9091\nEpoch 3329/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5036 - accuracy: 0.9091\nEpoch 3330/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5036 - accuracy: 0.9091\nEpoch 3331/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5035 - accuracy: 0.9091\nEpoch 3332/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5035 - accuracy: 0.9091\nEpoch 3333/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5035 - accuracy: 0.9091\nEpoch 3334/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5035 - accuracy: 0.9091\nEpoch 3335/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5034 - accuracy: 0.9091\nEpoch 3336/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.5034 - accuracy: 0.9091\nEpoch 3337/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5034 - accuracy: 0.9091\nEpoch 3338/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5033 - accuracy: 0.9091\nEpoch 3339/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5033 - accuracy: 0.9091\nEpoch 3340/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5033 - accuracy: 0.9091\nEpoch 3341/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5032 - accuracy: 0.9091\nEpoch 3342/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5032 - accuracy: 0.9091\nEpoch 3343/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5032 - accuracy: 0.9091\nEpoch 3344/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5031 - accuracy: 0.9091\nEpoch 3345/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5031 - accuracy: 0.9091\nEpoch 3346/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5031 - accuracy: 0.9091\nEpoch 3347/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5031 - accuracy: 0.9091\nEpoch 3348/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5030 - accuracy: 0.9091\nEpoch 3349/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5030 - accuracy: 0.9091\nEpoch 3350/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5030 - accuracy: 0.9091\nEpoch 3351/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5029 - accuracy: 0.9091\nEpoch 3352/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5029 - accuracy: 0.9091\nEpoch 3353/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5029 - accuracy: 0.9091\nEpoch 3354/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5028 - accuracy: 0.9091\nEpoch 3355/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5028 - accuracy: 0.9091\nEpoch 3356/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5028 - accuracy: 0.9091\nEpoch 3357/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5028 - accuracy: 0.9091\nEpoch 3358/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5027 - accuracy: 0.9091\nEpoch 3359/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5027 - accuracy: 0.9091\nEpoch 3360/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5027 - accuracy: 0.9091\nEpoch 3361/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5026 - accuracy: 0.9091\nEpoch 3362/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5026 - accuracy: 0.9091\nEpoch 3363/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5026 - accuracy: 0.9091\nEpoch 3364/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5025 - accuracy: 0.9091\nEpoch 3365/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5025 - accuracy: 0.9091\nEpoch 3366/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5025 - accuracy: 0.9091\nEpoch 3367/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5024 - accuracy: 0.9091\nEpoch 3368/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5024 - accuracy: 0.9091\nEpoch 3369/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5024 - accuracy: 0.9091\nEpoch 3370/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5024 - accuracy: 0.9091\nEpoch 3371/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5023 - accuracy: 0.9091\nEpoch 3372/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5023 - accuracy: 0.9091\nEpoch 3373/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5023 - accuracy: 0.9091\nEpoch 3374/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5022 - accuracy: 0.9091\nEpoch 3375/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5022 - accuracy: 0.9091\nEpoch 3376/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5022 - accuracy: 0.9091\nEpoch 3377/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5021 - accuracy: 0.9091\nEpoch 3378/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5021 - accuracy: 0.9091\nEpoch 3379/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5021 - accuracy: 0.9091\nEpoch 3380/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5021 - accuracy: 0.9091\nEpoch 3381/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5020 - accuracy: 0.9091\nEpoch 3382/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5020 - accuracy: 0.9091\nEpoch 3383/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5020 - accuracy: 0.9091\nEpoch 3384/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5019 - accuracy: 0.9091\nEpoch 3385/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5019 - accuracy: 0.9091\nEpoch 3386/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5019 - accuracy: 0.9091\nEpoch 3387/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5018 - accuracy: 0.9091\nEpoch 3388/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5018 - accuracy: 0.9091\nEpoch 3389/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5018 - accuracy: 0.9091\nEpoch 3390/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5018 - accuracy: 0.9091\nEpoch 3391/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5017 - accuracy: 0.9091\nEpoch 3392/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5017 - accuracy: 0.9091\nEpoch 3393/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5017 - accuracy: 0.9091\nEpoch 3394/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5016 - accuracy: 0.9091\nEpoch 3395/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5016 - accuracy: 0.9091\nEpoch 3396/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5016 - accuracy: 0.9091\nEpoch 3397/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5015 - accuracy: 0.9091\nEpoch 3398/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5015 - accuracy: 0.9091\nEpoch 3399/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5015 - accuracy: 0.9091\nEpoch 3400/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5015 - accuracy: 0.9091\nEpoch 3401/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5014 - accuracy: 0.9091\nEpoch 3402/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5014 - accuracy: 0.9091\nEpoch 3403/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5014 - accuracy: 0.9091\nEpoch 3404/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5013 - accuracy: 0.9091\nEpoch 3405/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5013 - accuracy: 0.9091\nEpoch 3406/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5013 - accuracy: 0.9091\nEpoch 3407/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5012 - accuracy: 0.9091\nEpoch 3408/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5012 - accuracy: 0.9091\nEpoch 3409/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5012 - accuracy: 0.9091\nEpoch 3410/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5012 - accuracy: 0.9091\nEpoch 3411/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5011 - accuracy: 0.9091\nEpoch 3412/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5011 - accuracy: 0.9091\nEpoch 3413/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5011 - accuracy: 0.9091\nEpoch 3414/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5010 - accuracy: 0.9091\nEpoch 3415/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.5010 - accuracy: 0.9091\nEpoch 3416/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5010 - accuracy: 0.9091\nEpoch 3417/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5009 - accuracy: 0.9091\nEpoch 3418/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5009 - accuracy: 0.9091\nEpoch 3419/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5009 - accuracy: 0.9091\nEpoch 3420/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5009 - accuracy: 0.9091\nEpoch 3421/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5008 - accuracy: 0.9091\nEpoch 3422/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.5008 - accuracy: 0.9091\nEpoch 3423/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5008 - accuracy: 0.9091\nEpoch 3424/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5007 - accuracy: 0.9091\nEpoch 3425/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5007 - accuracy: 0.9091\nEpoch 3426/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5007 - accuracy: 0.9091\nEpoch 3427/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.5006 - accuracy: 0.9091\nEpoch 3428/5000\n1/1 [==============================] - 0s 857us/step - loss: 0.5006 - accuracy: 0.9091\nEpoch 3429/5000\n1/1 [==============================] - 0s 767us/step - loss: 0.5006 - accuracy: 0.9091\nEpoch 3430/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5006 - accuracy: 0.9091\nEpoch 3431/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5005 - accuracy: 0.9091\nEpoch 3432/5000\n1/1 [==============================] - 0s 904us/step - loss: 0.5005 - accuracy: 0.9091\nEpoch 3433/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5005 - accuracy: 0.9091\nEpoch 3434/5000\n1/1 [==============================] - 0s 997us/step - loss: 0.5004 - accuracy: 0.9091\nEpoch 3435/5000\n1/1 [==============================] - 0s 932us/step - loss: 0.5004 - accuracy: 0.9091\nEpoch 3436/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5004 - accuracy: 0.9091\nEpoch 3437/5000\n1/1 [==============================] - 0s 919us/step - loss: 0.5004 - accuracy: 0.9091\nEpoch 3438/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5003 - accuracy: 0.9091\nEpoch 3439/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5003 - accuracy: 0.9091\nEpoch 3440/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.5003 - accuracy: 0.9091\nEpoch 3441/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5002 - accuracy: 0.9091\nEpoch 3442/5000\n1/1 [==============================] - 0s 7ms/step - loss: 0.5002 - accuracy: 0.9091\nEpoch 3443/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5002 - accuracy: 0.9091\nEpoch 3444/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5001 - accuracy: 0.9091\nEpoch 3445/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5001 - accuracy: 0.9091\nEpoch 3446/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5001 - accuracy: 0.9091\nEpoch 3447/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5001 - accuracy: 0.9091\nEpoch 3448/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5000 - accuracy: 0.9091\nEpoch 3449/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.5000 - accuracy: 0.9091\nEpoch 3450/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.5000 - accuracy: 0.9091\nEpoch 3451/5000\n1/1 [==============================] - 0s 12ms/step - loss: 0.4999 - accuracy: 0.9091\nEpoch 3452/5000\n1/1 [==============================] - 0s 16ms/step - loss: 0.4999 - accuracy: 0.9091\nEpoch 3453/5000\n1/1 [==============================] - 0s 7ms/step - loss: 0.4999 - accuracy: 0.9091\nEpoch 3454/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4998 - accuracy: 0.9091\nEpoch 3455/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4998 - accuracy: 0.9091\nEpoch 3456/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4998 - accuracy: 0.9091\nEpoch 3457/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4998 - accuracy: 0.9091\nEpoch 3458/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4997 - accuracy: 0.9091\nEpoch 3459/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4997 - accuracy: 0.9091\nEpoch 3460/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4997 - accuracy: 0.9091\nEpoch 3461/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4996 - accuracy: 0.9091\nEpoch 3462/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4996 - accuracy: 0.9091\nEpoch 3463/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4996 - accuracy: 0.9091\nEpoch 3464/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4996 - accuracy: 0.9091\nEpoch 3465/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4995 - accuracy: 0.9091\nEpoch 3466/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4995 - accuracy: 0.9091\nEpoch 3467/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4995 - accuracy: 0.9091\nEpoch 3468/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4994 - accuracy: 0.9091\nEpoch 3469/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4994 - accuracy: 0.9091\nEpoch 3470/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4994 - accuracy: 0.9091\nEpoch 3471/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4993 - accuracy: 0.9091\nEpoch 3472/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4993 - accuracy: 0.9091\nEpoch 3473/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4993 - accuracy: 0.9091\nEpoch 3474/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4993 - accuracy: 0.9091\nEpoch 3475/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4992 - accuracy: 0.9091\nEpoch 3476/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4992 - accuracy: 0.9091\nEpoch 3477/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4992 - accuracy: 0.9091\nEpoch 3478/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4991 - accuracy: 0.9091\nEpoch 3479/5000\n1/1 [==============================] - 0s 10ms/step - loss: 0.4991 - accuracy: 0.9091\nEpoch 3480/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4991 - accuracy: 0.9091\nEpoch 3481/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4991 - accuracy: 0.9091\nEpoch 3482/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4990 - accuracy: 0.9091\nEpoch 3483/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4990 - accuracy: 0.9091\nEpoch 3484/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4990 - accuracy: 0.9091\nEpoch 3485/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4989 - accuracy: 0.9091\nEpoch 3486/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4989 - accuracy: 0.9091\nEpoch 3487/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4989 - accuracy: 0.9091\nEpoch 3488/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4989 - accuracy: 0.9091\nEpoch 3489/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4988 - accuracy: 0.9091\nEpoch 3490/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4988 - accuracy: 0.9091\nEpoch 3491/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4988 - accuracy: 0.9091\nEpoch 3492/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4987 - accuracy: 0.9091\nEpoch 3493/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4987 - accuracy: 0.9091\nEpoch 3494/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4987 - accuracy: 0.9091\nEpoch 3495/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4986 - accuracy: 0.9091\nEpoch 3496/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4986 - accuracy: 0.9091\nEpoch 3497/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4986 - accuracy: 0.9091\nEpoch 3498/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4986 - accuracy: 0.9091\nEpoch 3499/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4985 - accuracy: 0.9091\nEpoch 3500/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4985 - accuracy: 0.9091\nEpoch 3501/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4985 - accuracy: 0.9091\nEpoch 3502/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4984 - accuracy: 0.9091\nEpoch 3503/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4984 - accuracy: 0.9091\nEpoch 3504/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4984 - accuracy: 0.9091\nEpoch 3505/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4984 - accuracy: 0.9091\nEpoch 3506/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4983 - accuracy: 0.9091\nEpoch 3507/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4983 - accuracy: 0.9091\nEpoch 3508/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4983 - accuracy: 0.9091\nEpoch 3509/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4982 - accuracy: 0.9091\nEpoch 3510/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4982 - accuracy: 0.9091\nEpoch 3511/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4982 - accuracy: 0.9091\nEpoch 3512/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4982 - accuracy: 0.9091\nEpoch 3513/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4981 - accuracy: 0.9091\nEpoch 3514/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4981 - accuracy: 0.9091\nEpoch 3515/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4981 - accuracy: 0.9091\nEpoch 3516/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4980 - accuracy: 0.9091\nEpoch 3517/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4980 - accuracy: 0.9091\nEpoch 3518/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4980 - accuracy: 0.9091\nEpoch 3519/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4980 - accuracy: 0.9091\nEpoch 3520/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4979 - accuracy: 0.9091\nEpoch 3521/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4979 - accuracy: 0.9091\nEpoch 3522/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4979 - accuracy: 0.9091\nEpoch 3523/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4978 - accuracy: 0.9091\nEpoch 3524/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4978 - accuracy: 0.9091\nEpoch 3525/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4978 - accuracy: 0.9091\nEpoch 3526/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4977 - accuracy: 0.9091\nEpoch 3527/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4977 - accuracy: 0.9091\nEpoch 3528/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4977 - accuracy: 0.9091\nEpoch 3529/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4977 - accuracy: 0.9091\nEpoch 3530/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4976 - accuracy: 0.9091\nEpoch 3531/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4976 - accuracy: 0.9091\nEpoch 3532/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4976 - accuracy: 0.9091\nEpoch 3533/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4975 - accuracy: 0.9091\nEpoch 3534/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4975 - accuracy: 0.9091\nEpoch 3535/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4975 - accuracy: 0.9091\nEpoch 3536/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4975 - accuracy: 0.9091\nEpoch 3537/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4974 - accuracy: 0.9091\nEpoch 3538/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4974 - accuracy: 0.9091\nEpoch 3539/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4974 - accuracy: 0.9091\nEpoch 3540/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4973 - accuracy: 0.9091\nEpoch 3541/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4973 - accuracy: 0.9091\nEpoch 3542/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4973 - accuracy: 0.9091\nEpoch 3543/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4973 - accuracy: 0.9091\nEpoch 3544/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4972 - accuracy: 0.9091\nEpoch 3545/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4972 - accuracy: 0.9091\nEpoch 3546/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4972 - accuracy: 0.9091\nEpoch 3547/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4971 - accuracy: 0.9091\nEpoch 3548/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4971 - accuracy: 0.9091\nEpoch 3549/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4971 - accuracy: 0.9091\nEpoch 3550/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4971 - accuracy: 0.9091\nEpoch 3551/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4970 - accuracy: 0.9091\nEpoch 3552/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4970 - accuracy: 0.9091\nEpoch 3553/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4970 - accuracy: 0.9091\nEpoch 3554/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4969 - accuracy: 0.9091\nEpoch 3555/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4969 - accuracy: 0.9091\nEpoch 3556/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4969 - accuracy: 0.9091\nEpoch 3557/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4969 - accuracy: 0.9091\nEpoch 3558/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4968 - accuracy: 0.9091\nEpoch 3559/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4968 - accuracy: 0.9091\nEpoch 3560/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4968 - accuracy: 0.9091\nEpoch 3561/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4967 - accuracy: 0.9091\nEpoch 3562/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4967 - accuracy: 0.9091\nEpoch 3563/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4967 - accuracy: 0.9091\nEpoch 3564/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4967 - accuracy: 0.9091\nEpoch 3565/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4966 - accuracy: 0.9091\nEpoch 3566/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4966 - accuracy: 0.9091\nEpoch 3567/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4966 - accuracy: 0.9091\nEpoch 3568/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4965 - accuracy: 0.9091\nEpoch 3569/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4965 - accuracy: 0.9091\nEpoch 3570/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4965 - accuracy: 0.9091\nEpoch 3571/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4965 - accuracy: 0.9091\nEpoch 3572/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4964 - accuracy: 0.9091\nEpoch 3573/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4964 - accuracy: 0.9091\nEpoch 3574/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4964 - accuracy: 0.9091\nEpoch 3575/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4963 - accuracy: 0.9091\nEpoch 3576/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4963 - accuracy: 0.9091\nEpoch 3577/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4963 - accuracy: 0.9091\nEpoch 3578/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4963 - accuracy: 0.9091\nEpoch 3579/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4962 - accuracy: 0.9091\nEpoch 3580/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4962 - accuracy: 0.9091\nEpoch 3581/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4962 - accuracy: 0.9091\nEpoch 3582/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4961 - accuracy: 0.9091\nEpoch 3583/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4961 - accuracy: 0.9091\nEpoch 3584/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4961 - accuracy: 0.9091\nEpoch 3585/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4961 - accuracy: 0.9091\nEpoch 3586/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4960 - accuracy: 0.9091\nEpoch 3587/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4960 - accuracy: 0.9091\nEpoch 3588/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4960 - accuracy: 0.9091\nEpoch 3589/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4959 - accuracy: 0.9091\nEpoch 3590/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4959 - accuracy: 0.9091\nEpoch 3591/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4959 - accuracy: 0.9091\nEpoch 3592/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4959 - accuracy: 0.9091\nEpoch 3593/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4958 - accuracy: 0.9091\nEpoch 3594/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4958 - accuracy: 0.9091\nEpoch 3595/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4958 - accuracy: 0.9091\nEpoch 3596/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4957 - accuracy: 0.9091\nEpoch 3597/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4957 - accuracy: 0.9091\nEpoch 3598/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4957 - accuracy: 0.9091\nEpoch 3599/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4957 - accuracy: 0.9091\nEpoch 3600/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4956 - accuracy: 0.9091\nEpoch 3601/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4956 - accuracy: 0.9091\nEpoch 3602/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4956 - accuracy: 0.9091\nEpoch 3603/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4955 - accuracy: 0.9091\nEpoch 3604/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4955 - accuracy: 0.9091\nEpoch 3605/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4955 - accuracy: 0.9091\nEpoch 3606/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4955 - accuracy: 0.9091\nEpoch 3607/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4954 - accuracy: 0.9091\nEpoch 3608/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4954 - accuracy: 0.9091\nEpoch 3609/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4954 - accuracy: 0.9091\nEpoch 3610/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4954 - accuracy: 0.9091\nEpoch 3611/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4953 - accuracy: 0.9091\nEpoch 3612/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4953 - accuracy: 0.9091\nEpoch 3613/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4953 - accuracy: 0.9091\nEpoch 3614/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4952 - accuracy: 0.9091\nEpoch 3615/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4952 - accuracy: 0.9091\nEpoch 3616/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4952 - accuracy: 0.9091\nEpoch 3617/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4952 - accuracy: 0.9091\nEpoch 3618/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4951 - accuracy: 0.9091\nEpoch 3619/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4951 - accuracy: 0.9091\nEpoch 3620/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4951 - accuracy: 0.9091\nEpoch 3621/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4950 - accuracy: 0.9091\nEpoch 3622/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4950 - accuracy: 0.9091\nEpoch 3623/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4950 - accuracy: 0.9091\nEpoch 3624/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4950 - accuracy: 0.9091\nEpoch 3625/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4949 - accuracy: 0.9091\nEpoch 3626/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4949 - accuracy: 0.9091\nEpoch 3627/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4949 - accuracy: 0.9091\nEpoch 3628/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4948 - accuracy: 0.9091\nEpoch 3629/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4948 - accuracy: 0.9091\nEpoch 3630/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4948 - accuracy: 0.9091\nEpoch 3631/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4948 - accuracy: 0.9091\nEpoch 3632/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4947 - accuracy: 0.9091\nEpoch 3633/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4947 - accuracy: 0.9091\nEpoch 3634/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4947 - accuracy: 0.9091\nEpoch 3635/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4946 - accuracy: 0.9091\nEpoch 3636/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4946 - accuracy: 0.9091\nEpoch 3637/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4946 - accuracy: 0.9091\nEpoch 3638/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4946 - accuracy: 0.9091\nEpoch 3639/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4945 - accuracy: 0.9091\nEpoch 3640/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4945 - accuracy: 0.9091\nEpoch 3641/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4945 - accuracy: 0.9091\nEpoch 3642/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4945 - accuracy: 0.9091\nEpoch 3643/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4944 - accuracy: 0.9091\nEpoch 3644/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4944 - accuracy: 0.9091\nEpoch 3645/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4944 - accuracy: 0.9091\nEpoch 3646/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4943 - accuracy: 0.9091\nEpoch 3647/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4943 - accuracy: 0.9091\nEpoch 3648/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4943 - accuracy: 0.9091\nEpoch 3649/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4943 - accuracy: 0.9091\nEpoch 3650/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4942 - accuracy: 0.9091\nEpoch 3651/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4942 - accuracy: 0.9091\nEpoch 3652/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4942 - accuracy: 0.9091\nEpoch 3653/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4941 - accuracy: 0.9091\nEpoch 3654/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4941 - accuracy: 0.9091\nEpoch 3655/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4941 - accuracy: 0.9091\nEpoch 3656/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4941 - accuracy: 0.9091\nEpoch 3657/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4940 - accuracy: 0.9091\nEpoch 3658/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4940 - accuracy: 0.9091\nEpoch 3659/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4940 - accuracy: 0.9091\nEpoch 3660/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4940 - accuracy: 0.9091\nEpoch 3661/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4939 - accuracy: 0.9091\nEpoch 3662/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4939 - accuracy: 0.9091\nEpoch 3663/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4939 - accuracy: 0.9091\nEpoch 3664/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4938 - accuracy: 0.9091\nEpoch 3665/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4938 - accuracy: 0.9091\nEpoch 3666/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4938 - accuracy: 0.9091\nEpoch 3667/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4938 - accuracy: 0.9091\nEpoch 3668/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4937 - accuracy: 0.9091\nEpoch 3669/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4937 - accuracy: 0.9091\nEpoch 3670/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4937 - accuracy: 0.9091\nEpoch 3671/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4936 - accuracy: 0.9091\nEpoch 3672/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4936 - accuracy: 0.9091\nEpoch 3673/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4936 - accuracy: 0.9091\nEpoch 3674/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4936 - accuracy: 0.9091\nEpoch 3675/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4935 - accuracy: 0.9091\nEpoch 3676/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4935 - accuracy: 0.9091\nEpoch 3677/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4935 - accuracy: 0.9091\nEpoch 3678/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4935 - accuracy: 0.9091\nEpoch 3679/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4934 - accuracy: 0.9091\nEpoch 3680/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4934 - accuracy: 0.9091\nEpoch 3681/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4934 - accuracy: 0.9091\nEpoch 3682/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4933 - accuracy: 0.9091\nEpoch 3683/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4933 - accuracy: 0.9091\nEpoch 3684/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4933 - accuracy: 0.9091\nEpoch 3685/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4933 - accuracy: 0.9091\nEpoch 3686/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4932 - accuracy: 0.9091\nEpoch 3687/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4932 - accuracy: 0.9091\nEpoch 3688/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4932 - accuracy: 0.9091\nEpoch 3689/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4932 - accuracy: 0.9091\nEpoch 3690/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4931 - accuracy: 0.9091\nEpoch 3691/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4931 - accuracy: 0.9091\nEpoch 3692/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4931 - accuracy: 0.9091\nEpoch 3693/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4930 - accuracy: 0.9091\nEpoch 3694/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4930 - accuracy: 0.9091\nEpoch 3695/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4930 - accuracy: 0.9091\nEpoch 3696/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4930 - accuracy: 0.9091\nEpoch 3697/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4929 - accuracy: 0.9091\nEpoch 3698/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4929 - accuracy: 0.9091\nEpoch 3699/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4929 - accuracy: 0.9091\nEpoch 3700/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4928 - accuracy: 0.9091\nEpoch 3701/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4928 - accuracy: 0.9091\nEpoch 3702/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4928 - accuracy: 0.9091\nEpoch 3703/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4928 - accuracy: 0.9091\nEpoch 3704/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4927 - accuracy: 0.9091\nEpoch 3705/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4927 - accuracy: 0.9091\nEpoch 3706/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4927 - accuracy: 0.9091\nEpoch 3707/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4927 - accuracy: 0.9091\nEpoch 3708/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4926 - accuracy: 0.9091\nEpoch 3709/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4926 - accuracy: 0.9091\nEpoch 3710/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4926 - accuracy: 0.9091\nEpoch 3711/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4925 - accuracy: 0.9091\nEpoch 3712/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4925 - accuracy: 0.9091\nEpoch 3713/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4925 - accuracy: 0.9091\nEpoch 3714/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4925 - accuracy: 0.9091\nEpoch 3715/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4924 - accuracy: 0.9091\nEpoch 3716/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4924 - accuracy: 0.9091\nEpoch 3717/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4924 - accuracy: 0.9091\nEpoch 3718/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4924 - accuracy: 0.9091\nEpoch 3719/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4923 - accuracy: 0.9091\nEpoch 3720/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4923 - accuracy: 0.9091\nEpoch 3721/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4923 - accuracy: 0.9091\nEpoch 3722/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4922 - accuracy: 0.9091\nEpoch 3723/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4922 - accuracy: 0.9091\nEpoch 3724/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4922 - accuracy: 0.9091\nEpoch 3725/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4922 - accuracy: 0.9091\nEpoch 3726/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4921 - accuracy: 0.9091\nEpoch 3727/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4921 - accuracy: 0.9091\nEpoch 3728/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4921 - accuracy: 0.9091\nEpoch 3729/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4921 - accuracy: 0.9091\nEpoch 3730/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4920 - accuracy: 0.9091\nEpoch 3731/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4920 - accuracy: 0.9091\nEpoch 3732/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4920 - accuracy: 0.9091\nEpoch 3733/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4919 - accuracy: 0.9091\nEpoch 3734/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4919 - accuracy: 0.9091\nEpoch 3735/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4919 - accuracy: 0.9091\nEpoch 3736/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4919 - accuracy: 0.9091\nEpoch 3737/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4918 - accuracy: 0.9091\nEpoch 3738/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4918 - accuracy: 0.9091\nEpoch 3739/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4918 - accuracy: 0.9091\nEpoch 3740/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4918 - accuracy: 0.9091\nEpoch 3741/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4917 - accuracy: 0.9091\nEpoch 3742/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4917 - accuracy: 0.9091\nEpoch 3743/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4917 - accuracy: 0.9091\nEpoch 3744/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4916 - accuracy: 0.9091\nEpoch 3745/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4916 - accuracy: 0.9091\nEpoch 3746/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4916 - accuracy: 0.9091\nEpoch 3747/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4916 - accuracy: 0.9091\nEpoch 3748/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4915 - accuracy: 0.9091\nEpoch 3749/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4915 - accuracy: 0.9091\nEpoch 3750/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4915 - accuracy: 0.9091\nEpoch 3751/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4915 - accuracy: 0.9091\nEpoch 3752/5000\n1/1 [==============================] - 0s 7ms/step - loss: 0.4914 - accuracy: 0.9091\nEpoch 3753/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4914 - accuracy: 0.9091\nEpoch 3754/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4914 - accuracy: 0.9091\nEpoch 3755/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4913 - accuracy: 0.9091\nEpoch 3756/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4913 - accuracy: 0.9091\nEpoch 3757/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4913 - accuracy: 0.9091\nEpoch 3758/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4913 - accuracy: 0.9091\nEpoch 3759/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4912 - accuracy: 0.9091\nEpoch 3760/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4912 - accuracy: 0.9091\nEpoch 3761/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4912 - accuracy: 0.9091\nEpoch 3762/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4912 - accuracy: 0.9091\nEpoch 3763/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4911 - accuracy: 0.9091\nEpoch 3764/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4911 - accuracy: 0.9091\nEpoch 3765/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4911 - accuracy: 0.9091\nEpoch 3766/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4911 - accuracy: 0.9091\nEpoch 3767/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4910 - accuracy: 0.9091\nEpoch 3768/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4910 - accuracy: 0.9091\nEpoch 3769/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4910 - accuracy: 0.9091\nEpoch 3770/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4909 - accuracy: 0.9091\nEpoch 3771/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4909 - accuracy: 0.9091\nEpoch 3772/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4909 - accuracy: 0.9091\nEpoch 3773/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4909 - accuracy: 0.9091\nEpoch 3774/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4908 - accuracy: 0.9091\nEpoch 3775/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4908 - accuracy: 0.9091\nEpoch 3776/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4908 - accuracy: 0.9091\nEpoch 3777/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4908 - accuracy: 0.9091\nEpoch 3778/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4907 - accuracy: 0.9091\nEpoch 3779/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4907 - accuracy: 0.9091\nEpoch 3780/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4907 - accuracy: 0.9091\nEpoch 3781/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4906 - accuracy: 0.9091\nEpoch 3782/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4906 - accuracy: 0.9091\nEpoch 3783/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4906 - accuracy: 0.9091\nEpoch 3784/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4906 - accuracy: 0.9091\nEpoch 3785/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4905 - accuracy: 0.9091\nEpoch 3786/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4905 - accuracy: 0.9091\nEpoch 3787/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4905 - accuracy: 0.9091\nEpoch 3788/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4905 - accuracy: 0.9091\nEpoch 3789/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4904 - accuracy: 0.9091\nEpoch 3790/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4904 - accuracy: 0.9091\nEpoch 3791/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4904 - accuracy: 0.9091\nEpoch 3792/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4904 - accuracy: 0.9091\nEpoch 3793/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4903 - accuracy: 0.9091\nEpoch 3794/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4903 - accuracy: 0.9091\nEpoch 3795/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4903 - accuracy: 0.9091\nEpoch 3796/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4902 - accuracy: 0.9091\nEpoch 3797/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4902 - accuracy: 0.9091\nEpoch 3798/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4902 - accuracy: 0.9091\nEpoch 3799/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4902 - accuracy: 0.9091\nEpoch 3800/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4901 - accuracy: 0.9091\nEpoch 3801/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4901 - accuracy: 0.9091\nEpoch 3802/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4901 - accuracy: 0.9091\nEpoch 3803/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4901 - accuracy: 0.9091\nEpoch 3804/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4900 - accuracy: 0.9091\nEpoch 3805/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4900 - accuracy: 0.9091\nEpoch 3806/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4900 - accuracy: 0.9091\nEpoch 3807/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4900 - accuracy: 0.9091\nEpoch 3808/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4899 - accuracy: 0.9091\nEpoch 3809/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4899 - accuracy: 0.9091\nEpoch 3810/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4899 - accuracy: 0.9091\nEpoch 3811/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4898 - accuracy: 0.9091\nEpoch 3812/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4898 - accuracy: 0.9091\nEpoch 3813/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4898 - accuracy: 0.9091\nEpoch 3814/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4898 - accuracy: 0.9091\nEpoch 3815/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4897 - accuracy: 0.9091\nEpoch 3816/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4897 - accuracy: 0.9091\nEpoch 3817/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4897 - accuracy: 0.9091\nEpoch 3818/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4897 - accuracy: 0.9091\nEpoch 3819/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4896 - accuracy: 0.9091\nEpoch 3820/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4896 - accuracy: 0.9091\nEpoch 3821/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4896 - accuracy: 0.9091\nEpoch 3822/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4896 - accuracy: 0.9091\nEpoch 3823/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4895 - accuracy: 0.9091\nEpoch 3824/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4895 - accuracy: 0.9091\nEpoch 3825/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4895 - accuracy: 0.9091\nEpoch 3826/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4894 - accuracy: 0.9091\nEpoch 3827/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4894 - accuracy: 0.9091\nEpoch 3828/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4894 - accuracy: 0.9091\nEpoch 3829/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4894 - accuracy: 0.9091\nEpoch 3830/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4893 - accuracy: 0.9091\nEpoch 3831/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4893 - accuracy: 0.9091\nEpoch 3832/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4893 - accuracy: 0.9091\nEpoch 3833/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4893 - accuracy: 0.9091\nEpoch 3834/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4892 - accuracy: 0.9091\nEpoch 3835/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4892 - accuracy: 0.9091\nEpoch 3836/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4892 - accuracy: 0.9091\nEpoch 3837/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4892 - accuracy: 0.9091\nEpoch 3838/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4891 - accuracy: 0.9091\nEpoch 3839/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4891 - accuracy: 0.9091\nEpoch 3840/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4891 - accuracy: 0.9091\nEpoch 3841/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4891 - accuracy: 0.9091\nEpoch 3842/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4890 - accuracy: 0.9091\nEpoch 3843/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4890 - accuracy: 0.9091\nEpoch 3844/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4890 - accuracy: 0.9091\nEpoch 3845/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4889 - accuracy: 0.9091\nEpoch 3846/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4889 - accuracy: 0.9091\nEpoch 3847/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4889 - accuracy: 0.9091\nEpoch 3848/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4889 - accuracy: 0.9091\nEpoch 3849/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4888 - accuracy: 0.9091\nEpoch 3850/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4888 - accuracy: 0.9091\nEpoch 3851/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4888 - accuracy: 0.9091\nEpoch 3852/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4888 - accuracy: 0.9091\nEpoch 3853/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4887 - accuracy: 0.9091\nEpoch 3854/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4887 - accuracy: 0.9091\nEpoch 3855/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4887 - accuracy: 0.9091\nEpoch 3856/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4887 - accuracy: 0.9091\nEpoch 3857/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4886 - accuracy: 0.9091\nEpoch 3858/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4886 - accuracy: 0.9091\nEpoch 3859/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4886 - accuracy: 0.9091\nEpoch 3860/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4886 - accuracy: 0.9091\nEpoch 3861/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4885 - accuracy: 0.9091\nEpoch 3862/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4885 - accuracy: 0.9091\nEpoch 3863/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4885 - accuracy: 0.9091\nEpoch 3864/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4884 - accuracy: 0.9091\nEpoch 3865/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4884 - accuracy: 0.9091\nEpoch 3866/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4884 - accuracy: 0.9091\nEpoch 3867/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4884 - accuracy: 0.9091\nEpoch 3868/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4883 - accuracy: 0.9091\nEpoch 3869/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4883 - accuracy: 0.9091\nEpoch 3870/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4883 - accuracy: 0.9091\nEpoch 3871/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4883 - accuracy: 0.9091\nEpoch 3872/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4882 - accuracy: 0.9091\nEpoch 3873/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4882 - accuracy: 0.9091\nEpoch 3874/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4882 - accuracy: 0.9091\nEpoch 3875/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4882 - accuracy: 0.9091\nEpoch 3876/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4881 - accuracy: 0.9091\nEpoch 3877/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4881 - accuracy: 0.9091\nEpoch 3878/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4881 - accuracy: 0.9091\nEpoch 3879/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4881 - accuracy: 0.9091\nEpoch 3880/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4880 - accuracy: 0.9091\nEpoch 3881/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4880 - accuracy: 0.9091\nEpoch 3882/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4880 - accuracy: 0.9091\nEpoch 3883/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4880 - accuracy: 0.9091\nEpoch 3884/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4879 - accuracy: 0.9091\nEpoch 3885/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4879 - accuracy: 0.9091\nEpoch 3886/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4879 - accuracy: 0.9091\nEpoch 3887/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4878 - accuracy: 0.9091\nEpoch 3888/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4878 - accuracy: 0.9091\nEpoch 3889/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4878 - accuracy: 0.9091\nEpoch 3890/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4878 - accuracy: 0.9091\nEpoch 3891/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4877 - accuracy: 0.9091\nEpoch 3892/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4877 - accuracy: 0.9091\nEpoch 3893/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4877 - accuracy: 0.9091\nEpoch 3894/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4877 - accuracy: 0.9091\nEpoch 3895/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4876 - accuracy: 0.9091\nEpoch 3896/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4876 - accuracy: 0.9091\nEpoch 3897/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4876 - accuracy: 0.9091\nEpoch 3898/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4876 - accuracy: 0.9091\nEpoch 3899/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4875 - accuracy: 0.9091\nEpoch 3900/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4875 - accuracy: 0.9091\nEpoch 3901/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4875 - accuracy: 0.9091\nEpoch 3902/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4875 - accuracy: 0.9091\nEpoch 3903/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4874 - accuracy: 0.9091\nEpoch 3904/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4874 - accuracy: 0.9091\nEpoch 3905/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4874 - accuracy: 0.9091\nEpoch 3906/5000\n1/1 [==============================] - 0s 942us/step - loss: 0.4874 - accuracy: 0.9091\nEpoch 3907/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4873 - accuracy: 0.9091\nEpoch 3908/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4873 - accuracy: 0.9091\nEpoch 3909/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4873 - accuracy: 0.9091\nEpoch 3910/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4873 - accuracy: 0.9091\nEpoch 3911/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4872 - accuracy: 0.9091\nEpoch 3912/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4872 - accuracy: 0.9091\nEpoch 3913/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4872 - accuracy: 0.9091\nEpoch 3914/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4871 - accuracy: 0.9091\nEpoch 3915/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4871 - accuracy: 0.9091\nEpoch 3916/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4871 - accuracy: 0.9091\nEpoch 3917/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4871 - accuracy: 0.9091\nEpoch 3918/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4870 - accuracy: 0.9091\nEpoch 3919/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4870 - accuracy: 0.9091\nEpoch 3920/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4870 - accuracy: 0.9091\nEpoch 3921/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4870 - accuracy: 0.9091\nEpoch 3922/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4869 - accuracy: 0.9091\nEpoch 3923/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4869 - accuracy: 0.9091\nEpoch 3924/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4869 - accuracy: 0.9091\nEpoch 3925/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4869 - accuracy: 0.9091\nEpoch 3926/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4868 - accuracy: 0.9091\nEpoch 3927/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4868 - accuracy: 0.9091\nEpoch 3928/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4868 - accuracy: 0.9091\nEpoch 3929/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4868 - accuracy: 0.9091\nEpoch 3930/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4867 - accuracy: 0.9091\nEpoch 3931/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4867 - accuracy: 0.9091\nEpoch 3932/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4867 - accuracy: 0.9091\nEpoch 3933/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4867 - accuracy: 0.9091\nEpoch 3934/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4866 - accuracy: 0.9091\nEpoch 3935/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4866 - accuracy: 0.9091\nEpoch 3936/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4866 - accuracy: 0.9091\nEpoch 3937/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4866 - accuracy: 0.9091\nEpoch 3938/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4865 - accuracy: 0.9091\nEpoch 3939/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4865 - accuracy: 0.9091\nEpoch 3940/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4865 - accuracy: 0.9091\nEpoch 3941/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4865 - accuracy: 0.9091\nEpoch 3942/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4864 - accuracy: 0.9091\nEpoch 3943/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4864 - accuracy: 0.9091\nEpoch 3944/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4864 - accuracy: 0.9091\nEpoch 3945/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4864 - accuracy: 0.9091\nEpoch 3946/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4863 - accuracy: 0.9091\nEpoch 3947/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4863 - accuracy: 0.9091\nEpoch 3948/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4863 - accuracy: 0.9091\nEpoch 3949/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4862 - accuracy: 0.9091\nEpoch 3950/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4862 - accuracy: 0.9091\nEpoch 3951/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4862 - accuracy: 0.9091\nEpoch 3952/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4862 - accuracy: 0.9091\nEpoch 3953/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4861 - accuracy: 0.9091\nEpoch 3954/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4861 - accuracy: 0.9091\nEpoch 3955/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4861 - accuracy: 0.9091\nEpoch 3956/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4861 - accuracy: 0.9091\nEpoch 3957/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4860 - accuracy: 0.9091\nEpoch 3958/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4860 - accuracy: 0.9091\nEpoch 3959/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4860 - accuracy: 0.9091\nEpoch 3960/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4860 - accuracy: 0.9091\nEpoch 3961/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4859 - accuracy: 0.9091\nEpoch 3962/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4859 - accuracy: 0.9091\nEpoch 3963/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4859 - accuracy: 0.9091\nEpoch 3964/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4859 - accuracy: 0.9091\nEpoch 3965/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4858 - accuracy: 0.9091\nEpoch 3966/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4858 - accuracy: 0.9091\nEpoch 3967/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4858 - accuracy: 0.9091\nEpoch 3968/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4858 - accuracy: 0.9091\nEpoch 3969/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4857 - accuracy: 0.9091\nEpoch 3970/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4857 - accuracy: 0.9091\nEpoch 3971/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4857 - accuracy: 0.9091\nEpoch 3972/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4857 - accuracy: 0.9091\nEpoch 3973/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4856 - accuracy: 0.9091\nEpoch 3974/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4856 - accuracy: 0.9091\nEpoch 3975/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4856 - accuracy: 0.9091\nEpoch 3976/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4856 - accuracy: 0.9091\nEpoch 3977/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4855 - accuracy: 0.9091\nEpoch 3978/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4855 - accuracy: 0.9091\nEpoch 3979/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4855 - accuracy: 0.9091\nEpoch 3980/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4855 - accuracy: 0.9091\nEpoch 3981/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4854 - accuracy: 0.9091\nEpoch 3982/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4854 - accuracy: 0.9091\nEpoch 3983/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4854 - accuracy: 0.9091\nEpoch 3984/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4854 - accuracy: 0.9091\nEpoch 3985/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4853 - accuracy: 0.9091\nEpoch 3986/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4853 - accuracy: 0.9091\nEpoch 3987/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4853 - accuracy: 0.9091\nEpoch 3988/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4853 - accuracy: 0.9091\nEpoch 3989/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4852 - accuracy: 0.9091\nEpoch 3990/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4852 - accuracy: 0.9091\nEpoch 3991/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4852 - accuracy: 0.9091\nEpoch 3992/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4852 - accuracy: 0.9091\nEpoch 3993/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4851 - accuracy: 0.9091\nEpoch 3994/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4851 - accuracy: 0.9091\nEpoch 3995/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4851 - accuracy: 0.9091\nEpoch 3996/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4851 - accuracy: 0.9091\nEpoch 3997/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4850 - accuracy: 0.9091\nEpoch 3998/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4850 - accuracy: 0.9091\nEpoch 3999/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4850 - accuracy: 0.9091\nEpoch 4000/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4850 - accuracy: 0.9091\nEpoch 4001/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4849 - accuracy: 0.9091\nEpoch 4002/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4849 - accuracy: 0.9091\nEpoch 4003/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4849 - accuracy: 0.9091\nEpoch 4004/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4849 - accuracy: 0.9091\nEpoch 4005/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4848 - accuracy: 0.9091\nEpoch 4006/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4848 - accuracy: 0.9091\nEpoch 4007/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4848 - accuracy: 0.9091\nEpoch 4008/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4848 - accuracy: 0.9091\nEpoch 4009/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4847 - accuracy: 0.9091\nEpoch 4010/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4847 - accuracy: 0.9091\nEpoch 4011/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4847 - accuracy: 0.9091\nEpoch 4012/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4847 - accuracy: 0.9091\nEpoch 4013/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4846 - accuracy: 0.9091\nEpoch 4014/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4846 - accuracy: 0.9091\nEpoch 4015/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4846 - accuracy: 0.9091\nEpoch 4016/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4846 - accuracy: 0.9091\nEpoch 4017/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4845 - accuracy: 0.9091\nEpoch 4018/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4845 - accuracy: 0.9091\nEpoch 4019/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4845 - accuracy: 0.9091\nEpoch 4020/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4845 - accuracy: 0.9091\nEpoch 4021/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4844 - accuracy: 0.9091\nEpoch 4022/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4844 - accuracy: 0.9091\nEpoch 4023/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4844 - accuracy: 0.9091\nEpoch 4024/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4844 - accuracy: 0.9091\nEpoch 4025/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4843 - accuracy: 0.9091\nEpoch 4026/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4843 - accuracy: 0.9091\nEpoch 4027/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4843 - accuracy: 0.9091\nEpoch 4028/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4843 - accuracy: 0.9091\nEpoch 4029/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4842 - accuracy: 0.9091\nEpoch 4030/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4842 - accuracy: 0.9091\nEpoch 4031/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4842 - accuracy: 0.9091\nEpoch 4032/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4842 - accuracy: 0.9091\nEpoch 4033/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4841 - accuracy: 0.9091\nEpoch 4034/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4841 - accuracy: 0.9091\nEpoch 4035/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4841 - accuracy: 0.9091\nEpoch 4036/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4841 - accuracy: 0.9091\nEpoch 4037/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4840 - accuracy: 0.9091\nEpoch 4038/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4840 - accuracy: 0.9091\nEpoch 4039/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4840 - accuracy: 0.9091\nEpoch 4040/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4840 - accuracy: 0.9091\nEpoch 4041/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4839 - accuracy: 0.9091\nEpoch 4042/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4839 - accuracy: 0.9091\nEpoch 4043/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4839 - accuracy: 0.9091\nEpoch 4044/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4839 - accuracy: 0.9091\nEpoch 4045/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4838 - accuracy: 0.9091\nEpoch 4046/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4838 - accuracy: 0.9091\nEpoch 4047/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4838 - accuracy: 0.9091\nEpoch 4048/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4838 - accuracy: 0.9091\nEpoch 4049/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4837 - accuracy: 0.9091\nEpoch 4050/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4837 - accuracy: 0.9091\nEpoch 4051/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4837 - accuracy: 0.9091\nEpoch 4052/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4837 - accuracy: 0.9091\nEpoch 4053/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4836 - accuracy: 0.9091\nEpoch 4054/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4836 - accuracy: 0.9091\nEpoch 4055/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4836 - accuracy: 0.9091\nEpoch 4056/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4836 - accuracy: 0.9091\nEpoch 4057/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4835 - accuracy: 0.9091\nEpoch 4058/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4835 - accuracy: 0.9091\nEpoch 4059/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4835 - accuracy: 0.9091\nEpoch 4060/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4835 - accuracy: 0.9091\nEpoch 4061/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4834 - accuracy: 0.9091\nEpoch 4062/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4834 - accuracy: 0.9091\nEpoch 4063/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4834 - accuracy: 0.9091\nEpoch 4064/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4834 - accuracy: 0.9091\nEpoch 4065/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4833 - accuracy: 0.9091\nEpoch 4066/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4833 - accuracy: 0.9091\nEpoch 4067/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4833 - accuracy: 0.9091\nEpoch 4068/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4833 - accuracy: 0.9091\nEpoch 4069/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4832 - accuracy: 0.9091\nEpoch 4070/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4832 - accuracy: 0.9091\nEpoch 4071/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4832 - accuracy: 0.9091\nEpoch 4072/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4832 - accuracy: 0.9091\nEpoch 4073/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4831 - accuracy: 0.9091\nEpoch 4074/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4831 - accuracy: 0.9091\nEpoch 4075/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4831 - accuracy: 0.9091\nEpoch 4076/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4831 - accuracy: 0.9091\nEpoch 4077/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4830 - accuracy: 0.9091\nEpoch 4078/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4830 - accuracy: 0.9091\nEpoch 4079/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4830 - accuracy: 0.9091\nEpoch 4080/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4830 - accuracy: 0.9091\nEpoch 4081/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4829 - accuracy: 0.9091\nEpoch 4082/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4829 - accuracy: 0.9091\nEpoch 4083/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4829 - accuracy: 0.9091\nEpoch 4084/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4829 - accuracy: 0.9091\nEpoch 4085/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4828 - accuracy: 0.9091\nEpoch 4086/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4828 - accuracy: 0.9091\nEpoch 4087/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4828 - accuracy: 0.9091\nEpoch 4088/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4828 - accuracy: 0.9091\nEpoch 4089/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4827 - accuracy: 0.9091\nEpoch 4090/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4827 - accuracy: 0.9091\nEpoch 4091/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4827 - accuracy: 0.9091\nEpoch 4092/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4827 - accuracy: 0.9091\nEpoch 4093/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4826 - accuracy: 0.9091\nEpoch 4094/5000\n1/1 [==============================] - 0s 7ms/step - loss: 0.4826 - accuracy: 0.9091\nEpoch 4095/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4826 - accuracy: 0.9091\nEpoch 4096/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4826 - accuracy: 0.9091\nEpoch 4097/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4825 - accuracy: 0.9091\nEpoch 4098/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4825 - accuracy: 0.9091\nEpoch 4099/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4825 - accuracy: 0.9091\nEpoch 4100/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4825 - accuracy: 0.9091\nEpoch 4101/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4824 - accuracy: 0.9091\nEpoch 4102/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4824 - accuracy: 0.9091\nEpoch 4103/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4824 - accuracy: 0.9091\nEpoch 4104/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4824 - accuracy: 0.9091\nEpoch 4105/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4824 - accuracy: 0.9091\nEpoch 4106/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4823 - accuracy: 0.9091\nEpoch 4107/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4823 - accuracy: 0.9091\nEpoch 4108/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4823 - accuracy: 0.9091\nEpoch 4109/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4823 - accuracy: 0.9091\nEpoch 4110/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4822 - accuracy: 0.9091\nEpoch 4111/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4822 - accuracy: 0.9091\nEpoch 4112/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4822 - accuracy: 0.9091\nEpoch 4113/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4822 - accuracy: 0.9091\nEpoch 4114/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4821 - accuracy: 0.9091\nEpoch 4115/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4821 - accuracy: 0.9091\nEpoch 4116/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4821 - accuracy: 0.9091\nEpoch 4117/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4821 - accuracy: 0.9091\nEpoch 4118/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4820 - accuracy: 0.9091\nEpoch 4119/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4820 - accuracy: 0.9091\nEpoch 4120/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4820 - accuracy: 0.9091\nEpoch 4121/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4820 - accuracy: 0.9091\nEpoch 4122/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4819 - accuracy: 0.9091\nEpoch 4123/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4819 - accuracy: 0.9091\nEpoch 4124/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4819 - accuracy: 0.9091\nEpoch 4125/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4819 - accuracy: 0.9091\nEpoch 4126/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4818 - accuracy: 0.9091\nEpoch 4127/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4818 - accuracy: 0.9091\nEpoch 4128/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4818 - accuracy: 0.9091\nEpoch 4129/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4818 - accuracy: 0.9091\nEpoch 4130/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4817 - accuracy: 0.9091\nEpoch 4131/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4817 - accuracy: 0.9091\nEpoch 4132/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4817 - accuracy: 0.9091\nEpoch 4133/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4817 - accuracy: 0.9091\nEpoch 4134/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4816 - accuracy: 0.9091\nEpoch 4135/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4816 - accuracy: 0.9091\nEpoch 4136/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4816 - accuracy: 0.9091\nEpoch 4137/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4816 - accuracy: 0.9091\nEpoch 4138/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4815 - accuracy: 0.9091\nEpoch 4139/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4815 - accuracy: 0.9091\nEpoch 4140/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4815 - accuracy: 0.9091\nEpoch 4141/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4815 - accuracy: 0.9091\nEpoch 4142/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4815 - accuracy: 0.9091\nEpoch 4143/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4814 - accuracy: 0.9091\nEpoch 4144/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4814 - accuracy: 0.9091\nEpoch 4145/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.9091\nEpoch 4146/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.9091\nEpoch 4147/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4813 - accuracy: 0.9091\nEpoch 4148/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4813 - accuracy: 0.9091\nEpoch 4149/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4813 - accuracy: 0.9091\nEpoch 4150/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4813 - accuracy: 0.9091\nEpoch 4151/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4812 - accuracy: 0.9091\nEpoch 4152/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4812 - accuracy: 0.9091\nEpoch 4153/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4812 - accuracy: 0.9091\nEpoch 4154/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4812 - accuracy: 0.9091\nEpoch 4155/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4811 - accuracy: 0.9091\nEpoch 4156/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4811 - accuracy: 0.9091\nEpoch 4157/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4811 - accuracy: 0.9091\nEpoch 4158/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4811 - accuracy: 0.9091\nEpoch 4159/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4810 - accuracy: 0.9091\nEpoch 4160/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4810 - accuracy: 0.9091\nEpoch 4161/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4810 - accuracy: 0.9091\nEpoch 4162/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4810 - accuracy: 0.9091\nEpoch 4163/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4809 - accuracy: 0.9091\nEpoch 4164/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4809 - accuracy: 0.9091\nEpoch 4165/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4809 - accuracy: 0.9091\nEpoch 4166/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4809 - accuracy: 0.9091\nEpoch 4167/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4809 - accuracy: 0.9091\nEpoch 4168/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4808 - accuracy: 0.9091\nEpoch 4169/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4808 - accuracy: 0.9091\nEpoch 4170/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4808 - accuracy: 0.9091\nEpoch 4171/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4808 - accuracy: 0.9091\nEpoch 4172/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4807 - accuracy: 0.9091\nEpoch 4173/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4807 - accuracy: 0.9091\nEpoch 4174/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4807 - accuracy: 0.9091\nEpoch 4175/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4807 - accuracy: 0.9091\nEpoch 4176/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4806 - accuracy: 0.9091\nEpoch 4177/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4806 - accuracy: 0.9091\nEpoch 4178/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4806 - accuracy: 0.9091\nEpoch 4179/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4806 - accuracy: 0.9091\nEpoch 4180/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4805 - accuracy: 0.9091\nEpoch 4181/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4805 - accuracy: 0.9091\nEpoch 4182/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4805 - accuracy: 0.9091\nEpoch 4183/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4805 - accuracy: 0.9091\nEpoch 4184/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4804 - accuracy: 0.9091\nEpoch 4185/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4804 - accuracy: 0.9091\nEpoch 4186/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4804 - accuracy: 0.9091\nEpoch 4187/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4804 - accuracy: 0.9091\nEpoch 4188/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4803 - accuracy: 0.9091\nEpoch 4189/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4803 - accuracy: 0.9091\nEpoch 4190/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4803 - accuracy: 0.9091\nEpoch 4191/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4803 - accuracy: 0.9091\nEpoch 4192/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4803 - accuracy: 0.9091\nEpoch 4193/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4802 - accuracy: 0.9091\nEpoch 4194/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4802 - accuracy: 0.9091\nEpoch 4195/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4802 - accuracy: 0.9091\nEpoch 4196/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4802 - accuracy: 0.9091\nEpoch 4197/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4801 - accuracy: 0.9091\nEpoch 4198/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4801 - accuracy: 0.9091\nEpoch 4199/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4801 - accuracy: 0.9091\nEpoch 4200/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4801 - accuracy: 0.9091\nEpoch 4201/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4800 - accuracy: 0.9091\nEpoch 4202/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4800 - accuracy: 0.9091\nEpoch 4203/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4800 - accuracy: 0.9091\nEpoch 4204/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4800 - accuracy: 0.9091\nEpoch 4205/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4799 - accuracy: 0.9091\nEpoch 4206/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4799 - accuracy: 0.9091\nEpoch 4207/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4799 - accuracy: 0.9091\nEpoch 4208/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4799 - accuracy: 0.9091\nEpoch 4209/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4798 - accuracy: 0.9091\nEpoch 4210/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4798 - accuracy: 0.9091\nEpoch 4211/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4798 - accuracy: 0.9091\nEpoch 4212/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4798 - accuracy: 0.9091\nEpoch 4213/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4798 - accuracy: 0.9091\nEpoch 4214/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4797 - accuracy: 0.9091\nEpoch 4215/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4797 - accuracy: 0.9091\nEpoch 4216/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4797 - accuracy: 0.9091\nEpoch 4217/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4797 - accuracy: 0.9091\nEpoch 4218/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4796 - accuracy: 0.9091\nEpoch 4219/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4796 - accuracy: 0.9091\nEpoch 4220/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4796 - accuracy: 0.9091\nEpoch 4221/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4796 - accuracy: 0.9091\nEpoch 4222/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4795 - accuracy: 0.9091\nEpoch 4223/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4795 - accuracy: 0.9091\nEpoch 4224/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4795 - accuracy: 0.9091\nEpoch 4225/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4795 - accuracy: 0.9091\nEpoch 4226/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4794 - accuracy: 0.9091\nEpoch 4227/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4794 - accuracy: 0.9091\nEpoch 4228/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4794 - accuracy: 0.9091\nEpoch 4229/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4794 - accuracy: 0.9091\nEpoch 4230/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4794 - accuracy: 0.9091\nEpoch 4231/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4793 - accuracy: 0.9091\nEpoch 4232/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4793 - accuracy: 0.9091\nEpoch 4233/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4793 - accuracy: 0.9091\nEpoch 4234/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4793 - accuracy: 0.9091\nEpoch 4235/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4792 - accuracy: 0.9091\nEpoch 4236/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4792 - accuracy: 0.9091\nEpoch 4237/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4792 - accuracy: 0.9091\nEpoch 4238/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4792 - accuracy: 0.9091\nEpoch 4239/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4791 - accuracy: 0.9091\nEpoch 4240/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4791 - accuracy: 0.9091\nEpoch 4241/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4791 - accuracy: 0.9091\nEpoch 4242/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4791 - accuracy: 0.9091\nEpoch 4243/5000\n1/1 [==============================] - 0s 7ms/step - loss: 0.4790 - accuracy: 0.9091\nEpoch 4244/5000\n1/1 [==============================] - 0s 12ms/step - loss: 0.4790 - accuracy: 0.9091\nEpoch 4245/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4790 - accuracy: 0.9091\nEpoch 4246/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4790 - accuracy: 0.9091\nEpoch 4247/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4790 - accuracy: 0.9091\nEpoch 4248/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4789 - accuracy: 0.9091\nEpoch 4249/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4789 - accuracy: 0.9091\nEpoch 4250/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4789 - accuracy: 0.9091\nEpoch 4251/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4789 - accuracy: 0.9091\nEpoch 4252/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4788 - accuracy: 0.9091\nEpoch 4253/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4788 - accuracy: 0.9091\nEpoch 4254/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4788 - accuracy: 0.9091\nEpoch 4255/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4788 - accuracy: 0.9091\nEpoch 4256/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4787 - accuracy: 0.9091\nEpoch 4257/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4787 - accuracy: 0.9091\nEpoch 4258/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4787 - accuracy: 0.9091\nEpoch 4259/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4787 - accuracy: 0.9091\nEpoch 4260/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4786 - accuracy: 0.9091\nEpoch 4261/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4786 - accuracy: 0.9091\nEpoch 4262/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4786 - accuracy: 0.9091\nEpoch 4263/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4786 - accuracy: 0.9091\nEpoch 4264/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4786 - accuracy: 0.9091\nEpoch 4265/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4785 - accuracy: 0.9091\nEpoch 4266/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4785 - accuracy: 0.9091\nEpoch 4267/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4785 - accuracy: 0.9091\nEpoch 4268/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4785 - accuracy: 0.9091\nEpoch 4269/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4784 - accuracy: 0.9091\nEpoch 4270/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4784 - accuracy: 0.9091\nEpoch 4271/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4784 - accuracy: 0.9091\nEpoch 4272/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4784 - accuracy: 0.9091\nEpoch 4273/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4783 - accuracy: 0.9091\nEpoch 4274/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4783 - accuracy: 0.9091\nEpoch 4275/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4783 - accuracy: 0.9091\nEpoch 4276/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4783 - accuracy: 0.9091\nEpoch 4277/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4783 - accuracy: 0.9091\nEpoch 4278/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4782 - accuracy: 0.9091\nEpoch 4279/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4782 - accuracy: 0.9091\nEpoch 4280/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4782 - accuracy: 0.9091\nEpoch 4281/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4782 - accuracy: 0.9091\nEpoch 4282/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4781 - accuracy: 0.9091\nEpoch 4283/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4781 - accuracy: 0.9091\nEpoch 4284/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4781 - accuracy: 0.9091\nEpoch 4285/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4781 - accuracy: 0.9091\nEpoch 4286/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4780 - accuracy: 0.9091\nEpoch 4287/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4780 - accuracy: 0.9091\nEpoch 4288/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4780 - accuracy: 0.9091\nEpoch 4289/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4780 - accuracy: 0.9091\nEpoch 4290/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4780 - accuracy: 0.9091\nEpoch 4291/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4779 - accuracy: 0.9091\nEpoch 4292/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4779 - accuracy: 0.9091\nEpoch 4293/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4779 - accuracy: 0.9091\nEpoch 4294/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4779 - accuracy: 0.9091\nEpoch 4295/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4778 - accuracy: 0.9091\nEpoch 4296/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4778 - accuracy: 0.9091\nEpoch 4297/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4778 - accuracy: 0.9091\nEpoch 4298/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4778 - accuracy: 0.9091\nEpoch 4299/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4777 - accuracy: 0.9091\nEpoch 4300/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4777 - accuracy: 0.9091\nEpoch 4301/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4777 - accuracy: 0.9091\nEpoch 4302/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4777 - accuracy: 0.9091\nEpoch 4303/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4776 - accuracy: 0.9091\nEpoch 4304/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4776 - accuracy: 0.9091\nEpoch 4305/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4776 - accuracy: 0.9091\nEpoch 4306/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4776 - accuracy: 0.9091\nEpoch 4307/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.4776 - accuracy: 0.9091\nEpoch 4308/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4775 - accuracy: 0.9091\nEpoch 4309/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4775 - accuracy: 0.9091\nEpoch 4310/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4775 - accuracy: 0.9091\nEpoch 4311/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4775 - accuracy: 0.9091\nEpoch 4312/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4774 - accuracy: 0.9091\nEpoch 4313/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4774 - accuracy: 0.9091\nEpoch 4314/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4774 - accuracy: 0.9091\nEpoch 4315/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4774 - accuracy: 0.9091\nEpoch 4316/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4774 - accuracy: 0.9091\nEpoch 4317/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4773 - accuracy: 0.9091\nEpoch 4318/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4773 - accuracy: 0.9091\nEpoch 4319/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4773 - accuracy: 0.9091\nEpoch 4320/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4773 - accuracy: 0.9091\nEpoch 4321/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4772 - accuracy: 0.9091\nEpoch 4322/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4772 - accuracy: 0.9091\nEpoch 4323/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4772 - accuracy: 0.9091\nEpoch 4324/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4772 - accuracy: 0.9091\nEpoch 4325/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4771 - accuracy: 0.9091\nEpoch 4326/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4771 - accuracy: 0.9091\nEpoch 4327/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4771 - accuracy: 0.9091\nEpoch 4328/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4771 - accuracy: 0.9091\nEpoch 4329/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4771 - accuracy: 0.9091\nEpoch 4330/5000\n1/1 [==============================] - 0s 880us/step - loss: 0.4770 - accuracy: 0.9091\nEpoch 4331/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4770 - accuracy: 0.9091\nEpoch 4332/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4770 - accuracy: 0.9091\nEpoch 4333/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4770 - accuracy: 0.9091\nEpoch 4334/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4769 - accuracy: 0.9091\nEpoch 4335/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4769 - accuracy: 0.9091\nEpoch 4336/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4769 - accuracy: 0.9091\nEpoch 4337/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4769 - accuracy: 0.9091\nEpoch 4338/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4768 - accuracy: 0.9091\nEpoch 4339/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4768 - accuracy: 0.9091\nEpoch 4340/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4768 - accuracy: 0.9091\nEpoch 4341/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4768 - accuracy: 0.9091\nEpoch 4342/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4768 - accuracy: 0.9091\nEpoch 4343/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4767 - accuracy: 0.9091\nEpoch 4344/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4767 - accuracy: 0.9091\nEpoch 4345/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4767 - accuracy: 0.9091\nEpoch 4346/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4767 - accuracy: 0.9091\nEpoch 4347/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4766 - accuracy: 0.9091\nEpoch 4348/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4766 - accuracy: 0.9091\nEpoch 4349/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4766 - accuracy: 0.9091\nEpoch 4350/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4766 - accuracy: 0.9091\nEpoch 4351/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4765 - accuracy: 0.9091\nEpoch 4352/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4765 - accuracy: 0.9091\nEpoch 4353/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4765 - accuracy: 0.9091\nEpoch 4354/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4765 - accuracy: 0.9091\nEpoch 4355/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4765 - accuracy: 0.9091\nEpoch 4356/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4764 - accuracy: 0.9091\nEpoch 4357/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4764 - accuracy: 0.9091\nEpoch 4358/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4764 - accuracy: 0.9091\nEpoch 4359/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4764 - accuracy: 0.9091\nEpoch 4360/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4763 - accuracy: 0.9091\nEpoch 4361/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4763 - accuracy: 0.9091\nEpoch 4362/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4763 - accuracy: 0.9091\nEpoch 4363/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4763 - accuracy: 0.9091\nEpoch 4364/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4763 - accuracy: 0.9091\nEpoch 4365/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4762 - accuracy: 0.9091\nEpoch 4366/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4762 - accuracy: 0.9091\nEpoch 4367/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4762 - accuracy: 0.9091\nEpoch 4368/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4762 - accuracy: 0.9091\nEpoch 4369/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4761 - accuracy: 0.9091\nEpoch 4370/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4761 - accuracy: 0.9091\nEpoch 4371/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4761 - accuracy: 0.9091\nEpoch 4372/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4761 - accuracy: 0.9091\nEpoch 4373/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4761 - accuracy: 0.9091\nEpoch 4374/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4760 - accuracy: 0.9091\nEpoch 4375/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4760 - accuracy: 0.9091\nEpoch 4376/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4760 - accuracy: 0.9091\nEpoch 4377/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4760 - accuracy: 0.9091\nEpoch 4378/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4759 - accuracy: 0.9091\nEpoch 4379/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4759 - accuracy: 0.9091\nEpoch 4380/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4759 - accuracy: 0.9091\nEpoch 4381/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4759 - accuracy: 0.9091\nEpoch 4382/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4758 - accuracy: 0.9091\nEpoch 4383/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4758 - accuracy: 0.9091\nEpoch 4384/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4758 - accuracy: 0.9091\nEpoch 4385/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4758 - accuracy: 0.9091\nEpoch 4386/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4758 - accuracy: 0.9091\nEpoch 4387/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4757 - accuracy: 0.9091\nEpoch 4388/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4757 - accuracy: 0.9091\nEpoch 4389/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4757 - accuracy: 0.9091\nEpoch 4390/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4757 - accuracy: 0.9091\nEpoch 4391/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4756 - accuracy: 0.9091\nEpoch 4392/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4756 - accuracy: 0.9091\nEpoch 4393/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4756 - accuracy: 0.9091\nEpoch 4394/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4756 - accuracy: 0.9091\nEpoch 4395/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4756 - accuracy: 0.9091\nEpoch 4396/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4755 - accuracy: 0.9091\nEpoch 4397/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4755 - accuracy: 0.9091\nEpoch 4398/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4755 - accuracy: 0.9091\nEpoch 4399/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4755 - accuracy: 0.9091\nEpoch 4400/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4754 - accuracy: 0.9091\nEpoch 4401/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4754 - accuracy: 0.9091\nEpoch 4402/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4754 - accuracy: 0.9091\nEpoch 4403/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4754 - accuracy: 0.9091\nEpoch 4404/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4754 - accuracy: 0.9091\nEpoch 4405/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4753 - accuracy: 0.9091\nEpoch 4406/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4753 - accuracy: 0.9091\nEpoch 4407/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4753 - accuracy: 0.9091\nEpoch 4408/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4753 - accuracy: 0.9091\nEpoch 4409/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4752 - accuracy: 0.9091\nEpoch 4410/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4752 - accuracy: 0.9091\nEpoch 4411/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4752 - accuracy: 0.9091\nEpoch 4412/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4752 - accuracy: 0.9091\nEpoch 4413/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4752 - accuracy: 0.9091\nEpoch 4414/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4751 - accuracy: 0.9091\nEpoch 4415/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4751 - accuracy: 0.9091\nEpoch 4416/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4751 - accuracy: 0.9091\nEpoch 4417/5000\n1/1 [==============================] - 0s 10ms/step - loss: 0.4751 - accuracy: 0.9091\nEpoch 4418/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4750 - accuracy: 0.9091\nEpoch 4419/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4750 - accuracy: 0.9091\nEpoch 4420/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4750 - accuracy: 0.9091\nEpoch 4421/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4750 - accuracy: 0.9091\nEpoch 4422/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4750 - accuracy: 0.9091\nEpoch 4423/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4749 - accuracy: 0.9091\nEpoch 4424/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4749 - accuracy: 0.9091\nEpoch 4425/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4749 - accuracy: 0.9091\nEpoch 4426/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4749 - accuracy: 0.9091\nEpoch 4427/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4748 - accuracy: 0.9091\nEpoch 4428/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4748 - accuracy: 0.9091\nEpoch 4429/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4748 - accuracy: 0.9091\nEpoch 4430/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4748 - accuracy: 0.9091\nEpoch 4431/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4747 - accuracy: 0.9091\nEpoch 4432/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4747 - accuracy: 0.9091\nEpoch 4433/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4747 - accuracy: 0.9091\nEpoch 4434/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4747 - accuracy: 0.9091\nEpoch 4435/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4747 - accuracy: 0.9091\nEpoch 4436/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4746 - accuracy: 0.9091\nEpoch 4437/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4746 - accuracy: 0.9091\nEpoch 4438/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4746 - accuracy: 0.9091\nEpoch 4439/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4746 - accuracy: 0.9091\nEpoch 4440/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4745 - accuracy: 0.9091\nEpoch 4441/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4745 - accuracy: 0.9091\nEpoch 4442/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4745 - accuracy: 0.9091\nEpoch 4443/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4745 - accuracy: 0.9091\nEpoch 4444/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4745 - accuracy: 0.9091\nEpoch 4445/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4744 - accuracy: 0.9091\nEpoch 4446/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4744 - accuracy: 0.9091\nEpoch 4447/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4744 - accuracy: 0.9091\nEpoch 4448/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4744 - accuracy: 0.9091\nEpoch 4449/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4744 - accuracy: 0.9091\nEpoch 4450/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4743 - accuracy: 0.9091\nEpoch 4451/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4743 - accuracy: 0.9091\nEpoch 4452/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4743 - accuracy: 0.9091\nEpoch 4453/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4743 - accuracy: 0.9091\nEpoch 4454/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4742 - accuracy: 0.9091\nEpoch 4455/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4742 - accuracy: 0.9091\nEpoch 4456/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4742 - accuracy: 0.9091\nEpoch 4457/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4742 - accuracy: 0.9091\nEpoch 4458/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4742 - accuracy: 0.9091\nEpoch 4459/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4741 - accuracy: 0.9091\nEpoch 4460/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4741 - accuracy: 0.9091\nEpoch 4461/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4741 - accuracy: 0.9091\nEpoch 4462/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4741 - accuracy: 0.9091\nEpoch 4463/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4740 - accuracy: 0.9091\nEpoch 4464/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4740 - accuracy: 0.9091\nEpoch 4465/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4740 - accuracy: 0.9091\nEpoch 4466/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4740 - accuracy: 0.9091\nEpoch 4467/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4740 - accuracy: 0.9091\nEpoch 4468/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4739 - accuracy: 0.9091\nEpoch 4469/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4739 - accuracy: 0.9091\nEpoch 4470/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4739 - accuracy: 0.9091\nEpoch 4471/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4739 - accuracy: 0.9091\nEpoch 4472/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4738 - accuracy: 0.9091\nEpoch 4473/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4738 - accuracy: 0.9091\nEpoch 4474/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4738 - accuracy: 0.9091\nEpoch 4475/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4738 - accuracy: 0.9091\nEpoch 4476/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4738 - accuracy: 0.9091\nEpoch 4477/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4737 - accuracy: 0.9091\nEpoch 4478/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4737 - accuracy: 0.9091\nEpoch 4479/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4737 - accuracy: 0.9091\nEpoch 4480/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4737 - accuracy: 0.9091\nEpoch 4481/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4736 - accuracy: 0.9091\nEpoch 4482/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4736 - accuracy: 0.9091\nEpoch 4483/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4736 - accuracy: 0.9091\nEpoch 4484/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4736 - accuracy: 0.9091\nEpoch 4485/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4736 - accuracy: 0.9091\nEpoch 4486/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4735 - accuracy: 0.9091\nEpoch 4487/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4735 - accuracy: 0.9091\nEpoch 4488/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4735 - accuracy: 0.9091\nEpoch 4489/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4735 - accuracy: 0.9091\nEpoch 4490/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4734 - accuracy: 0.9091\nEpoch 4491/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4734 - accuracy: 0.9091\nEpoch 4492/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4734 - accuracy: 0.9091\nEpoch 4493/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4734 - accuracy: 0.9091\nEpoch 4494/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4734 - accuracy: 0.9091\nEpoch 4495/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4733 - accuracy: 0.9091\nEpoch 4496/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4733 - accuracy: 0.9091\nEpoch 4497/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4733 - accuracy: 0.9091\nEpoch 4498/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4733 - accuracy: 0.9091\nEpoch 4499/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4733 - accuracy: 0.9091\nEpoch 4500/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4732 - accuracy: 0.9091\nEpoch 4501/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4732 - accuracy: 0.9091\nEpoch 4502/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4732 - accuracy: 0.9091\nEpoch 4503/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4732 - accuracy: 0.9091\nEpoch 4504/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4731 - accuracy: 0.9091\nEpoch 4505/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4731 - accuracy: 0.9091\nEpoch 4506/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4731 - accuracy: 0.9091\nEpoch 4507/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4731 - accuracy: 0.9091\nEpoch 4508/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4731 - accuracy: 0.9091\nEpoch 4509/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4730 - accuracy: 0.9091\nEpoch 4510/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4730 - accuracy: 0.9091\nEpoch 4511/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4730 - accuracy: 0.9091\nEpoch 4512/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4730 - accuracy: 0.9091\nEpoch 4513/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4729 - accuracy: 0.9091\nEpoch 4514/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4729 - accuracy: 0.9091\nEpoch 4515/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4729 - accuracy: 0.9091\nEpoch 4516/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4729 - accuracy: 0.9091\nEpoch 4517/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4729 - accuracy: 0.9091\nEpoch 4518/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4728 - accuracy: 0.9091\nEpoch 4519/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4728 - accuracy: 0.9091\nEpoch 4520/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4728 - accuracy: 0.9091\nEpoch 4521/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4728 - accuracy: 0.9091\nEpoch 4522/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4728 - accuracy: 0.9091\nEpoch 4523/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4727 - accuracy: 0.9091\nEpoch 4524/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4727 - accuracy: 0.9091\nEpoch 4525/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4727 - accuracy: 0.9091\nEpoch 4526/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4727 - accuracy: 0.9091\nEpoch 4527/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4726 - accuracy: 0.9091\nEpoch 4528/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4726 - accuracy: 0.9091\nEpoch 4529/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4726 - accuracy: 0.9091\nEpoch 4530/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4726 - accuracy: 0.9091\nEpoch 4531/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4726 - accuracy: 0.9091\nEpoch 4532/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4725 - accuracy: 0.9091\nEpoch 4533/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4725 - accuracy: 0.9091\nEpoch 4534/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4725 - accuracy: 0.9091\nEpoch 4535/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4725 - accuracy: 0.9091\nEpoch 4536/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4724 - accuracy: 0.9091\nEpoch 4537/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4724 - accuracy: 0.9091\nEpoch 4538/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4724 - accuracy: 0.9091\nEpoch 4539/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4724 - accuracy: 0.9091\nEpoch 4540/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4724 - accuracy: 0.9091\nEpoch 4541/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4723 - accuracy: 0.9091\nEpoch 4542/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4723 - accuracy: 0.9091\nEpoch 4543/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4723 - accuracy: 0.9091\nEpoch 4544/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4723 - accuracy: 0.9091\nEpoch 4545/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4723 - accuracy: 0.9091\nEpoch 4546/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4722 - accuracy: 0.9091\nEpoch 4547/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4722 - accuracy: 0.9091\nEpoch 4548/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4722 - accuracy: 0.9091\nEpoch 4549/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4722 - accuracy: 0.9091\nEpoch 4550/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4721 - accuracy: 0.9091\nEpoch 4551/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4721 - accuracy: 0.9091\nEpoch 4552/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4721 - accuracy: 0.9091\nEpoch 4553/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4721 - accuracy: 0.9091\nEpoch 4554/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4721 - accuracy: 0.9091\nEpoch 4555/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4720 - accuracy: 0.9091\nEpoch 4556/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4720 - accuracy: 0.9091\nEpoch 4557/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4720 - accuracy: 0.9091\nEpoch 4558/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4720 - accuracy: 0.9091\nEpoch 4559/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4720 - accuracy: 0.9091\nEpoch 4560/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4719 - accuracy: 0.9091\nEpoch 4561/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4719 - accuracy: 0.9091\nEpoch 4562/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4719 - accuracy: 0.9091\nEpoch 4563/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4719 - accuracy: 0.9091\nEpoch 4564/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4718 - accuracy: 0.9091\nEpoch 4565/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4718 - accuracy: 0.9091\nEpoch 4566/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4718 - accuracy: 0.9091\nEpoch 4567/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4718 - accuracy: 0.9091\nEpoch 4568/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4718 - accuracy: 0.9091\nEpoch 4569/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4717 - accuracy: 0.9091\nEpoch 4570/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4717 - accuracy: 0.9091\nEpoch 4571/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4717 - accuracy: 0.9091\nEpoch 4572/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4717 - accuracy: 0.9091\nEpoch 4573/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4717 - accuracy: 0.9091\nEpoch 4574/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4716 - accuracy: 0.9091\nEpoch 4575/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4716 - accuracy: 0.9091\nEpoch 4576/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4716 - accuracy: 0.9091\nEpoch 4577/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4716 - accuracy: 0.9091\nEpoch 4578/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4715 - accuracy: 0.9091\nEpoch 4579/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4715 - accuracy: 0.9091\nEpoch 4580/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4715 - accuracy: 0.9091\nEpoch 4581/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4715 - accuracy: 0.9091\nEpoch 4582/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4715 - accuracy: 0.9091\nEpoch 4583/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4714 - accuracy: 0.9091\nEpoch 4584/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4714 - accuracy: 0.9091\nEpoch 4585/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4714 - accuracy: 0.9091\nEpoch 4586/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4714 - accuracy: 0.9091\nEpoch 4587/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4714 - accuracy: 0.9091\nEpoch 4588/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4713 - accuracy: 0.9091\nEpoch 4589/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4713 - accuracy: 0.9091\nEpoch 4590/5000\n1/1 [==============================] - 0s 14ms/step - loss: 0.4713 - accuracy: 0.9091\nEpoch 4591/5000\n1/1 [==============================] - 0s 8ms/step - loss: 0.4713 - accuracy: 0.9091\nEpoch 4592/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4713 - accuracy: 0.9091\nEpoch 4593/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4712 - accuracy: 0.9091\nEpoch 4594/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4712 - accuracy: 0.9091\nEpoch 4595/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4712 - accuracy: 0.9091\nEpoch 4596/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4712 - accuracy: 0.9091\nEpoch 4597/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4711 - accuracy: 0.9091\nEpoch 4598/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4711 - accuracy: 0.9091\nEpoch 4599/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4711 - accuracy: 0.9091\nEpoch 4600/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4711 - accuracy: 0.9091\nEpoch 4601/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4711 - accuracy: 0.9091\nEpoch 4602/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4710 - accuracy: 0.9091\nEpoch 4603/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4710 - accuracy: 0.9091\nEpoch 4604/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4710 - accuracy: 0.9091\nEpoch 4605/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4710 - accuracy: 0.9091\nEpoch 4606/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4710 - accuracy: 0.9091\nEpoch 4607/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4709 - accuracy: 0.9091\nEpoch 4608/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4709 - accuracy: 0.9091\nEpoch 4609/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4709 - accuracy: 0.9091\nEpoch 4610/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4709 - accuracy: 0.9091\nEpoch 4611/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4708 - accuracy: 0.9091\nEpoch 4612/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4708 - accuracy: 0.9091\nEpoch 4613/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4708 - accuracy: 0.9091\nEpoch 4614/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4708 - accuracy: 0.9091\nEpoch 4615/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4708 - accuracy: 0.9091\nEpoch 4616/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4707 - accuracy: 0.9091\nEpoch 4617/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4707 - accuracy: 0.9091\nEpoch 4618/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4707 - accuracy: 0.9091\nEpoch 4619/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4707 - accuracy: 0.9091\nEpoch 4620/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4707 - accuracy: 0.9091\nEpoch 4621/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4706 - accuracy: 0.9091\nEpoch 4622/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4706 - accuracy: 0.9091\nEpoch 4623/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4706 - accuracy: 0.9091\nEpoch 4624/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4706 - accuracy: 0.9091\nEpoch 4625/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4706 - accuracy: 0.9091\nEpoch 4626/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4705 - accuracy: 0.9091\nEpoch 4627/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4705 - accuracy: 0.9091\nEpoch 4628/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4705 - accuracy: 0.9091\nEpoch 4629/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4705 - accuracy: 0.9091\nEpoch 4630/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4704 - accuracy: 0.9091\nEpoch 4631/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4704 - accuracy: 0.9091\nEpoch 4632/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4704 - accuracy: 0.9091\nEpoch 4633/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4704 - accuracy: 0.9091\nEpoch 4634/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4704 - accuracy: 0.9091\nEpoch 4635/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4703 - accuracy: 0.9091\nEpoch 4636/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4703 - accuracy: 0.9091\nEpoch 4637/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4703 - accuracy: 0.9091\nEpoch 4638/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4703 - accuracy: 0.9091\nEpoch 4639/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4703 - accuracy: 0.9091\nEpoch 4640/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4702 - accuracy: 0.9091\nEpoch 4641/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4702 - accuracy: 0.9091\nEpoch 4642/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4702 - accuracy: 0.9091\nEpoch 4643/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4702 - accuracy: 0.9091\nEpoch 4644/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4702 - accuracy: 0.9091\nEpoch 4645/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4701 - accuracy: 0.9091\nEpoch 4646/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4701 - accuracy: 0.9091\nEpoch 4647/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4701 - accuracy: 0.9091\nEpoch 4648/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4701 - accuracy: 0.9091\nEpoch 4649/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4700 - accuracy: 0.9091\nEpoch 4650/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4700 - accuracy: 0.9091\nEpoch 4651/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4700 - accuracy: 0.9091\nEpoch 4652/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4700 - accuracy: 0.9091\nEpoch 4653/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4700 - accuracy: 0.9091\nEpoch 4654/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4699 - accuracy: 0.9091\nEpoch 4655/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4699 - accuracy: 0.9091\nEpoch 4656/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4699 - accuracy: 0.9091\nEpoch 4657/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4699 - accuracy: 0.9091\nEpoch 4658/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4699 - accuracy: 0.9091\nEpoch 4659/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4698 - accuracy: 0.9091\nEpoch 4660/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4698 - accuracy: 0.9091\nEpoch 4661/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4698 - accuracy: 0.9091\nEpoch 4662/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4698 - accuracy: 0.9091\nEpoch 4663/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4698 - accuracy: 0.9091\nEpoch 4664/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4697 - accuracy: 0.9091\nEpoch 4665/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4697 - accuracy: 0.9091\nEpoch 4666/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4697 - accuracy: 0.9091\nEpoch 4667/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4697 - accuracy: 0.9091\nEpoch 4668/5000\n1/1 [==============================] - 0s 1ms/step - loss: 0.4697 - accuracy: 0.9091\nEpoch 4669/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4696 - accuracy: 0.9091\nEpoch 4670/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4696 - accuracy: 0.9091\nEpoch 4671/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4696 - accuracy: 0.9091\nEpoch 4672/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4696 - accuracy: 0.9091\nEpoch 4673/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4695 - accuracy: 0.9091\nEpoch 4674/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4695 - accuracy: 0.9091\nEpoch 4675/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4695 - accuracy: 0.9091\nEpoch 4676/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4695 - accuracy: 0.9091\nEpoch 4677/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4695 - accuracy: 0.9091\nEpoch 4678/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4694 - accuracy: 0.9091\nEpoch 4679/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4694 - accuracy: 0.9091\nEpoch 4680/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4694 - accuracy: 0.9091\nEpoch 4681/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4694 - accuracy: 0.9091\nEpoch 4682/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4694 - accuracy: 0.9091\nEpoch 4683/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4693 - accuracy: 0.9091\nEpoch 4684/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4693 - accuracy: 0.9091\nEpoch 4685/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4693 - accuracy: 0.9091\nEpoch 4686/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4693 - accuracy: 0.9091\nEpoch 4687/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4693 - accuracy: 0.9091\nEpoch 4688/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4692 - accuracy: 0.9091\nEpoch 4689/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4692 - accuracy: 0.9091\nEpoch 4690/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4692 - accuracy: 0.9091\nEpoch 4691/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4692 - accuracy: 0.9091\nEpoch 4692/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4692 - accuracy: 0.9091\nEpoch 4693/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4691 - accuracy: 0.9091\nEpoch 4694/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4691 - accuracy: 0.9091\nEpoch 4695/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4691 - accuracy: 0.9091\nEpoch 4696/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4691 - accuracy: 0.9091\nEpoch 4697/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4691 - accuracy: 0.9091\nEpoch 4698/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4690 - accuracy: 0.9091\nEpoch 4699/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4690 - accuracy: 0.9091\nEpoch 4700/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4690 - accuracy: 0.9091\nEpoch 4701/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4690 - accuracy: 0.9091\nEpoch 4702/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4690 - accuracy: 0.9091\nEpoch 4703/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4689 - accuracy: 0.9091\nEpoch 4704/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4689 - accuracy: 0.9091\nEpoch 4705/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4689 - accuracy: 0.9091\nEpoch 4706/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4689 - accuracy: 0.9091\nEpoch 4707/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4688 - accuracy: 0.9091\nEpoch 4708/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4688 - accuracy: 0.9091\nEpoch 4709/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4688 - accuracy: 0.9091\nEpoch 4710/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4688 - accuracy: 0.9091\nEpoch 4711/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4688 - accuracy: 0.9091\nEpoch 4712/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4687 - accuracy: 0.9091\nEpoch 4713/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4687 - accuracy: 0.9091\nEpoch 4714/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4687 - accuracy: 0.9091\nEpoch 4715/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4687 - accuracy: 0.9091\nEpoch 4716/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4687 - accuracy: 0.9091\nEpoch 4717/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4686 - accuracy: 0.9091\nEpoch 4718/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4686 - accuracy: 0.9091\nEpoch 4719/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4686 - accuracy: 0.9091\nEpoch 4720/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4686 - accuracy: 0.9091\nEpoch 4721/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4686 - accuracy: 0.9091\nEpoch 4722/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4685 - accuracy: 0.9091\nEpoch 4723/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4685 - accuracy: 0.9091\nEpoch 4724/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4685 - accuracy: 0.9091\nEpoch 4725/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4685 - accuracy: 0.9091\nEpoch 4726/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4685 - accuracy: 0.9091\nEpoch 4727/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4684 - accuracy: 0.9091\nEpoch 4728/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4684 - accuracy: 0.9091\nEpoch 4729/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4684 - accuracy: 0.9091\nEpoch 4730/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4684 - accuracy: 0.9091\nEpoch 4731/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4684 - accuracy: 0.9091\nEpoch 4732/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4683 - accuracy: 0.9091\nEpoch 4733/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4683 - accuracy: 0.9091\nEpoch 4734/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4683 - accuracy: 0.9091\nEpoch 4735/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4683 - accuracy: 0.9091\nEpoch 4736/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4683 - accuracy: 0.9091\nEpoch 4737/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4682 - accuracy: 0.9091\nEpoch 4738/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4682 - accuracy: 0.9091\nEpoch 4739/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4682 - accuracy: 0.9091\nEpoch 4740/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4682 - accuracy: 0.9091\nEpoch 4741/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4682 - accuracy: 0.9091\nEpoch 4742/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4681 - accuracy: 0.9091\nEpoch 4743/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4681 - accuracy: 0.9091\nEpoch 4744/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4681 - accuracy: 0.9091\nEpoch 4745/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4681 - accuracy: 0.9091\nEpoch 4746/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4681 - accuracy: 0.9091\nEpoch 4747/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4680 - accuracy: 0.9091\nEpoch 4748/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4680 - accuracy: 0.9091\nEpoch 4749/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4680 - accuracy: 0.9091\nEpoch 4750/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4680 - accuracy: 0.9091\nEpoch 4751/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4679 - accuracy: 0.9091\nEpoch 4752/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4679 - accuracy: 0.9091\nEpoch 4753/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4679 - accuracy: 0.9091\nEpoch 4754/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4679 - accuracy: 0.9091\nEpoch 4755/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4679 - accuracy: 0.9091\nEpoch 4756/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4678 - accuracy: 0.9091\nEpoch 4757/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4678 - accuracy: 0.9091\nEpoch 4758/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4678 - accuracy: 0.9091\nEpoch 4759/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4678 - accuracy: 0.9091\nEpoch 4760/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4678 - accuracy: 0.9091\nEpoch 4761/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4677 - accuracy: 0.9091\nEpoch 4762/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4677 - accuracy: 0.9091\nEpoch 4763/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4677 - accuracy: 0.9091\nEpoch 4764/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4677 - accuracy: 0.9091\nEpoch 4765/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4677 - accuracy: 0.9091\nEpoch 4766/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4676 - accuracy: 0.9091\nEpoch 4767/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4676 - accuracy: 0.9091\nEpoch 4768/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4676 - accuracy: 0.9091\nEpoch 4769/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4676 - accuracy: 0.9091\nEpoch 4770/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4676 - accuracy: 0.9091\nEpoch 4771/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4675 - accuracy: 0.9091\nEpoch 4772/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4675 - accuracy: 0.9091\nEpoch 4773/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4675 - accuracy: 0.9091\nEpoch 4774/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4675 - accuracy: 0.9091\nEpoch 4775/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4675 - accuracy: 0.9091\nEpoch 4776/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4674 - accuracy: 0.9091\nEpoch 4777/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4674 - accuracy: 0.9091\nEpoch 4778/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4674 - accuracy: 0.9091\nEpoch 4779/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4674 - accuracy: 0.9091\nEpoch 4780/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4674 - accuracy: 0.9091\nEpoch 4781/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4673 - accuracy: 0.9091\nEpoch 4782/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4673 - accuracy: 0.9091\nEpoch 4783/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4673 - accuracy: 0.9091\nEpoch 4784/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4673 - accuracy: 0.9091\nEpoch 4785/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4673 - accuracy: 0.9091\nEpoch 4786/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4672 - accuracy: 0.9091\nEpoch 4787/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4672 - accuracy: 0.9091\nEpoch 4788/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4672 - accuracy: 0.9091\nEpoch 4789/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4672 - accuracy: 0.9091\nEpoch 4790/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4672 - accuracy: 0.9091\nEpoch 4791/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4671 - accuracy: 0.9091\nEpoch 4792/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4671 - accuracy: 0.9091\nEpoch 4793/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4671 - accuracy: 0.9091\nEpoch 4794/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4671 - accuracy: 0.9091\nEpoch 4795/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4671 - accuracy: 0.9091\nEpoch 4796/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4670 - accuracy: 0.9091\nEpoch 4797/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4670 - accuracy: 0.9091\nEpoch 4798/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4670 - accuracy: 0.9091\nEpoch 4799/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4670 - accuracy: 0.9091\nEpoch 4800/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4670 - accuracy: 0.9091\nEpoch 4801/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4669 - accuracy: 0.9091\nEpoch 4802/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4669 - accuracy: 0.9091\nEpoch 4803/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4669 - accuracy: 0.9091\nEpoch 4804/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4669 - accuracy: 0.9091\nEpoch 4805/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4669 - accuracy: 0.9091\nEpoch 4806/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4668 - accuracy: 0.9091\nEpoch 4807/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4668 - accuracy: 0.9091\nEpoch 4808/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4668 - accuracy: 0.9091\nEpoch 4809/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4668 - accuracy: 0.9091\nEpoch 4810/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4668 - accuracy: 0.9091\nEpoch 4811/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4667 - accuracy: 0.9091\nEpoch 4812/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4667 - accuracy: 0.9091\nEpoch 4813/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4667 - accuracy: 0.9091\nEpoch 4814/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4667 - accuracy: 0.9091\nEpoch 4815/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4667 - accuracy: 0.9091\nEpoch 4816/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4666 - accuracy: 0.9091\nEpoch 4817/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4666 - accuracy: 0.9091\nEpoch 4818/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4666 - accuracy: 0.9091\nEpoch 4819/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4666 - accuracy: 0.9091\nEpoch 4820/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4666 - accuracy: 0.9091\nEpoch 4821/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4665 - accuracy: 0.9091\nEpoch 4822/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4665 - accuracy: 0.9091\nEpoch 4823/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4665 - accuracy: 0.9091\nEpoch 4824/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4665 - accuracy: 0.9091\nEpoch 4825/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4665 - accuracy: 0.9091\nEpoch 4826/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4664 - accuracy: 0.9091\nEpoch 4827/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4664 - accuracy: 0.9091\nEpoch 4828/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4664 - accuracy: 0.9091\nEpoch 4829/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4664 - accuracy: 0.9091\nEpoch 4830/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4664 - accuracy: 0.9091\nEpoch 4831/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4663 - accuracy: 0.9091\nEpoch 4832/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4663 - accuracy: 0.9091\nEpoch 4833/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4663 - accuracy: 0.9091\nEpoch 4834/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4663 - accuracy: 0.9091\nEpoch 4835/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4663 - accuracy: 0.9091\nEpoch 4836/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4662 - accuracy: 0.9091\nEpoch 4837/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4662 - accuracy: 0.9091\nEpoch 4838/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4662 - accuracy: 0.9091\nEpoch 4839/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4662 - accuracy: 0.9091\nEpoch 4840/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4662 - accuracy: 0.9091\nEpoch 4841/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4661 - accuracy: 0.9091\nEpoch 4842/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4661 - accuracy: 0.9091\nEpoch 4843/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4661 - accuracy: 0.9091\nEpoch 4844/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4661 - accuracy: 0.9091\nEpoch 4845/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4661 - accuracy: 0.9091\nEpoch 4846/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4660 - accuracy: 0.9091\nEpoch 4847/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4660 - accuracy: 0.9091\nEpoch 4848/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4660 - accuracy: 0.9091\nEpoch 4849/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4660 - accuracy: 0.9091\nEpoch 4850/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4660 - accuracy: 0.9091\nEpoch 4851/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4659 - accuracy: 0.9091\nEpoch 4852/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4659 - accuracy: 0.9091\nEpoch 4853/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4659 - accuracy: 0.9091\nEpoch 4854/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4659 - accuracy: 0.9091\nEpoch 4855/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4659 - accuracy: 0.9091\nEpoch 4856/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4659 - accuracy: 0.9091\nEpoch 4857/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4658 - accuracy: 0.9091\nEpoch 4858/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4658 - accuracy: 0.9091\nEpoch 4859/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4658 - accuracy: 0.9091\nEpoch 4860/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4658 - accuracy: 0.9091\nEpoch 4861/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4658 - accuracy: 0.9091\nEpoch 4862/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4657 - accuracy: 0.9091\nEpoch 4863/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4657 - accuracy: 0.9091\nEpoch 4864/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4657 - accuracy: 0.9091\nEpoch 4865/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4657 - accuracy: 0.9091\nEpoch 4866/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4657 - accuracy: 0.9091\nEpoch 4867/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4656 - accuracy: 0.9091\nEpoch 4868/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4656 - accuracy: 0.9091\nEpoch 4869/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4656 - accuracy: 0.9091\nEpoch 4870/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4656 - accuracy: 0.9091\nEpoch 4871/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4656 - accuracy: 0.9091\nEpoch 4872/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4655 - accuracy: 0.9091\nEpoch 4873/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4655 - accuracy: 0.9091\nEpoch 4874/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4655 - accuracy: 0.9091\nEpoch 4875/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4655 - accuracy: 0.9091\nEpoch 4876/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4655 - accuracy: 0.9091\nEpoch 4877/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4654 - accuracy: 0.9091\nEpoch 4878/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4654 - accuracy: 0.9091\nEpoch 4879/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4654 - accuracy: 0.9091\nEpoch 4880/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4654 - accuracy: 0.9091\nEpoch 4881/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4654 - accuracy: 0.9091\nEpoch 4882/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4653 - accuracy: 0.9091\nEpoch 4883/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4653 - accuracy: 0.9091\nEpoch 4884/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4653 - accuracy: 0.9091\nEpoch 4885/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4653 - accuracy: 0.9091\nEpoch 4886/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4653 - accuracy: 0.9091\nEpoch 4887/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4652 - accuracy: 0.9091\nEpoch 4888/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4652 - accuracy: 0.9091\nEpoch 4889/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4652 - accuracy: 0.9091\nEpoch 4890/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4652 - accuracy: 0.9091\nEpoch 4891/5000\n1/1 [==============================] - 0s 13ms/step - loss: 0.4652 - accuracy: 0.9091\nEpoch 4892/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4651 - accuracy: 0.9091\nEpoch 4893/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4651 - accuracy: 0.9091\nEpoch 4894/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4651 - accuracy: 0.9091\nEpoch 4895/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4651 - accuracy: 0.9091\nEpoch 4896/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4651 - accuracy: 0.9091\nEpoch 4897/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4650 - accuracy: 0.9091\nEpoch 4898/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4650 - accuracy: 0.9091\nEpoch 4899/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4650 - accuracy: 0.9091\nEpoch 4900/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4650 - accuracy: 0.9091\nEpoch 4901/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4650 - accuracy: 0.9091\nEpoch 4902/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4650 - accuracy: 0.9091\nEpoch 4903/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4649 - accuracy: 0.9091\nEpoch 4904/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4649 - accuracy: 0.9091\nEpoch 4905/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4649 - accuracy: 0.9091\nEpoch 4906/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4649 - accuracy: 0.9091\nEpoch 4907/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4649 - accuracy: 0.9091\nEpoch 4908/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4648 - accuracy: 0.9091\nEpoch 4909/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4648 - accuracy: 0.9091\nEpoch 4910/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4648 - accuracy: 0.9091\nEpoch 4911/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4648 - accuracy: 0.9091\nEpoch 4912/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4648 - accuracy: 0.9091\nEpoch 4913/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4647 - accuracy: 0.9091\nEpoch 4914/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4647 - accuracy: 0.9091\nEpoch 4915/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4647 - accuracy: 0.9091\nEpoch 4916/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4647 - accuracy: 0.9091\nEpoch 4917/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4647 - accuracy: 0.9091\nEpoch 4918/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4646 - accuracy: 0.9091\nEpoch 4919/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4646 - accuracy: 0.9091\nEpoch 4920/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4646 - accuracy: 0.9091\nEpoch 4921/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4646 - accuracy: 0.9091\nEpoch 4922/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4646 - accuracy: 0.9091\nEpoch 4923/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4645 - accuracy: 0.9091\nEpoch 4924/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4645 - accuracy: 0.9091\nEpoch 4925/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4645 - accuracy: 0.9091\nEpoch 4926/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4645 - accuracy: 0.9091\nEpoch 4927/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4645 - accuracy: 0.9091\nEpoch 4928/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4644 - accuracy: 0.9091\nEpoch 4929/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4644 - accuracy: 0.9091\nEpoch 4930/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4644 - accuracy: 0.9091\nEpoch 4931/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4644 - accuracy: 0.9091\nEpoch 4932/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4644 - accuracy: 0.9091\nEpoch 4933/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4644 - accuracy: 0.9091\nEpoch 4934/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4643 - accuracy: 0.9091\nEpoch 4935/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4643 - accuracy: 0.9091\nEpoch 4936/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4643 - accuracy: 0.9091\nEpoch 4937/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4643 - accuracy: 0.9091\nEpoch 4938/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4643 - accuracy: 0.9091\nEpoch 4939/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4642 - accuracy: 0.9091\nEpoch 4940/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4642 - accuracy: 0.9091\nEpoch 4941/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4642 - accuracy: 0.9091\nEpoch 4942/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4642 - accuracy: 0.9091\nEpoch 4943/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4642 - accuracy: 0.9091\nEpoch 4944/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4641 - accuracy: 0.9091\nEpoch 4945/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4641 - accuracy: 0.9091\nEpoch 4946/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4641 - accuracy: 0.9091\nEpoch 4947/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4641 - accuracy: 0.9091\nEpoch 4948/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4641 - accuracy: 0.9091\nEpoch 4949/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4640 - accuracy: 0.9091\nEpoch 4950/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4640 - accuracy: 0.9091\nEpoch 4951/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4640 - accuracy: 0.9091\nEpoch 4952/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4640 - accuracy: 0.9091\nEpoch 4953/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4640 - accuracy: 0.9091\nEpoch 4954/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4639 - accuracy: 0.9091\nEpoch 4955/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4639 - accuracy: 0.9091\nEpoch 4956/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4639 - accuracy: 0.9091\nEpoch 4957/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4639 - accuracy: 0.9091\nEpoch 4958/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4639 - accuracy: 0.9091\nEpoch 4959/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4639 - accuracy: 0.9091\nEpoch 4960/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4638 - accuracy: 0.9091\nEpoch 4961/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4638 - accuracy: 0.9091\nEpoch 4962/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4638 - accuracy: 0.9091\nEpoch 4963/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4638 - accuracy: 0.9091\nEpoch 4964/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4638 - accuracy: 0.9091\nEpoch 4965/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4637 - accuracy: 0.9091\nEpoch 4966/5000\n1/1 [==============================] - 0s 923us/step - loss: 0.4637 - accuracy: 0.9091\nEpoch 4967/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4637 - accuracy: 0.9091\nEpoch 4968/5000\n1/1 [==============================] - 0s 6ms/step - loss: 0.4637 - accuracy: 0.9091\nEpoch 4969/5000\n1/1 [==============================] - 0s 5ms/step - loss: 0.4637 - accuracy: 0.9091\nEpoch 4970/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4636 - accuracy: 0.9091\nEpoch 4971/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4636 - accuracy: 0.9091\nEpoch 4972/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4636 - accuracy: 0.9091\nEpoch 4973/5000\n1/1 [==============================] - 0s 13ms/step - loss: 0.4636 - accuracy: 0.9091\nEpoch 4974/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4636 - accuracy: 0.9091\nEpoch 4975/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4635 - accuracy: 0.9091\nEpoch 4976/5000\n1/1 [==============================] - 0s 9ms/step - loss: 0.4635 - accuracy: 0.9091\nEpoch 4977/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4635 - accuracy: 0.9091\nEpoch 4978/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4635 - accuracy: 0.9091\nEpoch 4979/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4635 - accuracy: 0.9091\nEpoch 4980/5000\n1/1 [==============================] - 0s 4ms/step - loss: 0.4635 - accuracy: 0.9091\nEpoch 4981/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4634 - accuracy: 0.9091\nEpoch 4982/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4634 - accuracy: 0.9091\nEpoch 4983/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4634 - accuracy: 0.9091\nEpoch 4984/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4634 - accuracy: 0.9091\nEpoch 4985/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4634 - accuracy: 0.9091\nEpoch 4986/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4633 - accuracy: 0.9091\nEpoch 4987/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4633 - accuracy: 0.9091\nEpoch 4988/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4633 - accuracy: 0.9091\nEpoch 4989/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4633 - accuracy: 0.9091\nEpoch 4990/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4633 - accuracy: 0.9091\nEpoch 4991/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4632 - accuracy: 0.9091\nEpoch 4992/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4632 - accuracy: 0.9091\nEpoch 4993/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4632 - accuracy: 0.9091\nEpoch 4994/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4632 - accuracy: 0.9091\nEpoch 4995/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4632 - accuracy: 0.9091\nEpoch 4996/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4631 - accuracy: 0.9091\nEpoch 4997/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4631 - accuracy: 0.9091\nEpoch 4998/5000\n1/1 [==============================] - 0s 3ms/step - loss: 0.4631 - accuracy: 0.9091\nEpoch 4999/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4631 - accuracy: 0.9091\nEpoch 5000/5000\n1/1 [==============================] - 0s 2ms/step - loss: 0.4631 - accuracy: 0.9091\n"
],
[
"model.evaluate(X_testscaled,y_test)",
"1/1 [==============================] - 0s 1ms/step - loss: 0.3550 - accuracy: 1.0000\n"
],
[
"model.predict(X_testscaled)",
"_____no_output_____"
],
[
"y_test",
"_____no_output_____"
],
[
"coef, intercept = model.get_weights()",
"_____no_output_____"
],
[
"coef, intercept",
"_____no_output_____"
],
[
"def sigmoid(x):\n import math\n return 1 / (1 + math.exp(-x))\nsigmoid(18)",
"_____no_output_____"
],
[
"X_test",
"_____no_output_____"
],
[
"def prediction_function(age, affordibility):\n weighted_sum = coef[0]*age + coef[1]*affordibility + intercept\n return sigmoid(weighted_sum)\n\nprediction_function(.47, 1)",
"_____no_output_____"
],
[
"prediction_function(.18, 1)",
"_____no_output_____"
],
[
"def sigmoid_numpy(X):\n return 1/(1+np.exp(-X))\n\nsigmoid_numpy(np.array([12,0,1]))",
"_____no_output_____"
],
[
"def log_loss(y_true, y_predicted):\n epsilon = 1e-15\n y_predicted_new = [max(i,epsilon) for i in y_predicted]\n y_predicted_new = [min(i,1-epsilon) for i in y_predicted_new]\n y_predicted_new = np.array(y_predicted_new)\n return -np.mean(y_true*np.log(y_predicted_new)+(1-y_true)*np.log(1-y_predicted_new))",
"_____no_output_____"
],
[
"def gradient_descent(age, affordability, y_true, epochs, loss_thresold):\n w1 = w2 = 1\n bias = 0\n rate = 0.5\n n = len(age)\n for i in range(epochs):\n weighted_sum = w1 * age + w2 * affordability + bias\n y_predicted = sigmoid_numpy(weighted_sum)\n loss = log_loss(y_true, y_predicted)\n\n w1d = (1/n)*np.dot(np.transpose(age),(y_predicted-y_true)) \n w2d = (1/n)*np.dot(np.transpose(affordability),(y_predicted-y_true)) \n\n bias_d = np.mean(y_predicted-y_true)\n w1 = w1 - rate * w1d\n w2 = w2 - rate * w2d\n bias = bias - rate * bias_d\n\n print (f'Epoch:{i}, w1:{w1}, w2:{w2}, bias:{bias}, loss:{loss}')\n\n if loss<=loss_thresold:\n break\n\n return w1, w2, bias",
"_____no_output_____"
],
[
"gradient_descent(X_trainscaled['age'],X_trainscaled['affordibility'],y_train,1000, 0.4631)",
"Epoch:0, w1:0.974907633470177, w2:0.948348125394529, bias:-0.11341867736368583, loss:0.7113403233723417\nEpoch:1, w1:0.9556229728273669, w2:0.9058873696677865, bias:-0.2122349122718517, loss:0.6812647787377568\nEpoch:2, w1:0.9416488476693794, w2:0.8719790823960313, bias:-0.29775789977965383, loss:0.6591474252715025\nEpoch:3, w1:0.9323916996249162, w2:0.8457541517722915, bias:-0.37150947240035115, loss:0.6431523291301916\nEpoch:4, w1:0.9272267472726993, w2:0.8262362885332687, bias:-0.4350664302689159, loss:0.6316873063379158\nEpoch:5, w1:0.9255469396815343, w2:0.8124402814952774, bias:-0.4899449005893882, loss:0.6234717079975919\nEpoch:6, w1:0.9267936114129968, w2:0.8034375029757677, bias:-0.5375299543522855, loss:0.6175321183044205\nEpoch:7, w1:0.93047170420295, w2:0.7983920007454487, bias:-0.5790424270894964, loss:0.6131591858705934\nEpoch:8, w1:0.9361540784567943, w2:0.7965748796787705, bias:-0.6155315088627656, loss:0.6098518179750948\nEpoch:9, w1:0.9434791243557358, w2:0.7973647616854131, bias:-0.6478828179413607, loss:0.6072639970231438\nEpoch:10, w1:0.9521448361628083, w2:0.8002404280558159, bias:-0.6768343869109612, loss:0.6051606942838051\nEpoch:11, w1:0.9619014360798377, w2:0.8047697991276092, bias:-0.7029956527236099, loss:0.6033841405177726\nEpoch:12, w1:0.9725437902239877, w2:0.8105978078160995, bias:-0.7268665798879942, loss:0.6018292976282693\nEpoch:13, w1:0.983904282864182, w2:0.8174345999952901, bias:-0.7488554155033404, loss:0.6004266142491014\nEpoch:14, w1:0.995846454651659, w2:0.8250447751055391, bias:-0.7692944188177452, loss:0.5991301804031036\nEpoch:15, w1:1.0082595007242083, w2:0.8332379503132499, bias:-0.788453391813388, loss:0.5979097221992563\nEpoch:16, w1:1.0210536111133568, w2:0.8418606908070436, bias:-0.8065510935633606, loss:0.596745254034085\nEpoch:17, w1:1.0341560806664811, w2:0.8507897246509063, bias:-0.823764741587896, loss:0.5956235357679642\nEpoch:18, w1:1.047508093968269, w2:0.8599263049589658, bias:-0.8402378469114855, loss:0.5945357398126384\nEpoch:19, w1:1.0610620872868055, w2:0.8691915649552581, bias:-0.8560866317233404, loss:0.5934759216594546\nEpoch:20, w1:1.0747795953648007, w2:0.8785227146485403, bias:-0.8714052604012275, loss:0.5924400203169505\nEpoch:21, w1:1.0886295007650377, w2:0.8878699408379153, bias:-0.8862700880092957, loss:0.5914252065214394\nEpoch:22, w1:1.1025866146156014, w2:0.8971938890119441, bias:-0.9007431016492756, loss:0.5904294583596236\nEpoch:23, w1:1.1166305284975317, w2:0.9064636231844676, bias:-0.9148747025148295, loss:0.589451285203924\nEpoch:24, w1:1.1307446871662332, w2:0.9156549761872753, bias:-0.9287059516737736, loss:0.5884895481881011\nEpoch:25, w1:1.1449156405234904, w2:0.9247492176815199, bias:-0.9422703810055987, loss:0.5875433434377383\nEpoch:26, w1:1.159132440717547, w2:0.9337319799254573, bias:-0.9555954523596438, loss:0.5866119260562088\nEpoch:27, w1:1.173386156519817, w2:0.9425923921787205, bias:-0.9687037326284237, loss:0.5856946605640079\nEpoch:28, w1:1.1876694823356404, w2:0.9513223836938425, bias:-0.9816138397030204, loss:0.5847909885040026\nEpoch:29, w1:1.20197642349612, w2:0.9599161227563919, bias:-0.9943412038207972, loss:0.5839004071862918\nEpoch:30, w1:1.2163020429886016, w2:0.9683695654077998, bias:-1.006898680274023, loss:0.5830224556644095\nEpoch:31, w1:1.2306422576428846, w2:0.9766800925300213, bias:-1.0192970425003876, loss:0.5821567054089575\nEpoch:32, w1:1.2449936741113292, w2:0.9848462180774323, bias:-1.0315453789434794, loss:0.5813027540359855\nEpoch:33, w1:1.2593534568600258, w2:0.9928673545729692, bias:-1.0436514125153917, loss:0.5804602210251409\nEpoch:34, w1:1.2737192219062516, w2:1.0007436246821175, bias:-1.0556217578155669, loss:0.5796287447370063\nEpoch:35, w1:1.2880889512619977, w2:1.0084757098569885, bias:-1.067462128294764, loss:0.57880798028165\nEpoch:36, w1:1.3024609240300045, w2:1.0160647288004139, bias:-1.079177503164993, loss:0.5779975979476322\nEpoch:37, w1:1.3168336608930387, w2:1.0235121399165894, bias:-1.0907722619345364, loss:0.5771972820026156\nEpoch:38, w1:1.3312058793761512, w2:1.0308196630555955, bias:-1.1022502929016078, loss:0.5764067297427645\nEpoch:39, w1:1.3455764577755072, w2:1.03798921677727, bias:-1.1136150806976406, loss:0.5756256507109632\nEpoch:40, w1:1.3599444060604629, w2:1.0450228680985851, bias:-1.124869776972519, loss:0.5748537660316542\nEpoch:41, w1:1.374308842387555, w2:1.0519227922827652, bias:-1.1360172575115421, loss:0.5740908078281305\nEpoch:42, w1:1.388668974131872, w2:1.0586912407061275, bias:-1.1470601684290498, loss:0.5733365186998217\nEpoch:43, w1:1.4030240825556772, w2:1.065330515222758, bias:-1.1580009635655026, loss:0.5725906512447178\nEpoch:44, w1:1.4173735104064384, w2:1.0718429477560005, bias:-1.1688419347984433, loss:0.5718529676170188\nEpoch:45, w1:1.431716651874893, w2:1.0782308840940895, bias:-1.1795852366431911, loss:0.5711232391133308\nEpoch:46, w1:1.446052944455051, w2:1.0844966710669584, bias:-1.1902329062502135, loss:0.5704012457828124\nEpoch:47, w1:1.4603818623375084, w2:1.0906426464418717, bias:-1.2007868796899672, loss:0.5696867760580652\nEpoch:48, w1:1.474702911039356, w2:1.0966711310047097, bias:-1.2112490052422353, loss:0.5689796264044564\nEpoch:49, w1:1.4890156230318012, w2:1.1025844223976542, bias:-1.2216210542672539, loss:0.5682796009861607\nEpoch:50, w1:1.503319554173139, w2:1.108384790367645, bias:-1.2319047301235464, loss:0.5675865113475955\nEpoch:51, w1:1.5176142807921111, w2:1.1140744731472638, bias:-1.2421016755069894, loss:0.5669001761092021\nEpoch:52, w1:1.5318993972968091, w2:1.1196556747438646, bias:-1.2522134785128962, loss:0.566220420676692\nEpoch:53, w1:1.546174514208496, w2:1.1251305629563741, bias:-1.2622416776643735, loss:0.5655470769630154\nEpoch:54, w1:1.5604392565392238, w2:1.1305012679742994, bias:-1.2721877661030871, loss:0.5648799831223866\nEpoch:55, w1:1.5746932624478314, w2:1.1357698814417572, bias:-1.2820531951006382, loss:0.5642189832957765\nEpoch:56, w1:1.5889361821215457, w2:1.1409384558921223, bias:-1.2918393770181935, loss:0.5635639273673235\nEpoch:57, w1:1.6031676768405996, w2:1.1460090044772484, bias:-1.3015476878174077, loss:0.562914670731162\nEpoch:58, w1:1.6173874181914885, w2:1.150983500930006, bias:-1.3111794692058374, loss:0.5622710740681858\nEpoch:59, w1:1.6315950874010996, w2:1.155863879710811, bias:-1.320736030484068, loss:0.5616330031323112\nEpoch:60, w1:1.6457903747692835, w2:1.1606520362984267, bias:-1.3302186501488862, loss:0.5610003285458063\nEpoch:61, w1:1.6599729791817353, w2:1.1653498275930778, bias:-1.3396285772964385, loss:0.5603729256032908\nEpoch:62, w1:1.6741426076885264, w2:1.1699590724061661, bias:-1.348967032860937, loss:0.5597506740840237\nEpoch:63, w1:1.6882989751364197, w2:1.1744815520159209, bias:-1.3582352107177078, loss:0.559133458072109\nEpoch:64, w1:1.7024418038453646, w2:1.1789190107723873, bias:-1.3674342786739169, loss:0.5585211657842806\nEpoch:65, w1:1.7165708233213919, w2:1.1832731567384374, bias:-1.3765653793659074, loss:0.5579136894049259\nEpoch:66, w1:1.7306857699995972, w2:1.1875456623561378, bias:-1.385629631078514, loss:0.5573109249280388\nEpoch:67, w1:1.744786387012096, w2:1.1917381651299463, bias:-1.3946281284988502, loss:0.556712772005794\nEpoch:68, w1:1.7588724239767908, w2:1.1958522683199346, bias:-1.4035619434147377, loss:0.5561191338034575\nEpoch:69, w1:1.7729436368035707, w2:1.199889541639625, bias:-1.412432125366066, loss:0.5555299168603557\nEpoch:70, w1:1.786999787515191, w2:1.2038515219541523, bias:-1.4212397022558536, loss:0.5549450309566399\nEpoch:71, w1:1.8010406440805895, w2:1.2077397139753707, bias:-1.4299856809265468, loss:0.5543643889855958\nEpoch:72, w1:1.815065980258806, w2:1.21155559095125, bias:-1.4386710477060998, loss:0.5537879068312538\nEpoch:73, w1:1.8290755754520085, w2:1.2153005953475013, bias:-1.4472967689275704, loss:0.5532155032510755\nEpoch:74, w1:1.8430692145663952, w2:1.2189761395198406, bias:-1.4558637914253105, loss:0.5526470997634942\nEpoch:75, w1:1.857046687879965, w2:1.2225836063756854, bias:-1.4643730430103006, loss:0.5520826205400979\nEpoch:76, w1:1.8710077909163219, w2:1.2261243500243837, bias:-1.472825432926746, loss:0.5515219923022592\nEpoch:77, w1:1.8849523243238275, w2:1.2295996964153224, bias:-1.4812218522917016, loss:0.5509651442220168\nEpoch:78, w1:1.898880093759531, w2:1.2330109439634602, bias:-1.4895631745192046, loss:0.5504120078270268\nEpoch:79, w1:1.9127909097773987, w2:1.2363593641619885, bias:-1.4978502557301687, loss:0.5498625169094129\nEpoch:80, w1:1.9266845877204517, w2:1.2396462021819508, bias:-1.5060839351490927, loss:0.5493166074383391\nEpoch:81, w1:1.9405609476164691, w2:1.2428726774587495, bias:-1.5142650354884937, loss:0.5487742174761587\nEpoch:82, w1:1.9544198140769822, w2:1.2460399842655545, bias:-1.5223943633218386, loss:0.5482352870979753\nEpoch:83, w1:1.968261016199314, w2:1.2491492922736824, bias:-1.530472709445648, loss:0.5476997583144769\nEpoch:84, w1:1.9820843874714607, w2:1.252201747100074, bias:-1.538500849231359, loss:0.5471675749979029\nEpoch:85, w1:1.995889765679638, w2:1.2551984708420285, bias:-1.5464795429674643, loss:0.5466386828110088\nEpoch:86, w1:2.0096769928183367, w2:1.2581405625993878, bias:-1.554409536192387, loss:0.5461130291389041\nEpoch:87, w1:2.023445915002755, w2:1.2610290989843815, bias:-1.5622915600184968, loss:0.545590563023641\nEpoch:88, w1:2.037196382383489, w2:1.2638651346193672, bias:-1.5701263314476384, loss:0.5450712351014357\nEpoch:89, w1:2.0509282490633733, w2:1.2666497026227028, bias:-1.577914553678509, loss:0.5445549975424178\nEpoch:90, w1:2.0646413730163813, w2:1.2693838150830055, bias:-1.585656916406187, loss:0.544041803992791\nEpoch:91, w1:2.0783356160084976, w2:1.2720684635220503, bias:-1.5933540961140944, loss:0.5435316095193146\nEpoch:92, w1:2.092010843520487, w2:1.2747046193465692, bias:-1.6010067563586592, loss:0.5430243705560022\nEpoch:93, w1:2.1056669246724873, w2:1.2772932342892063, bias:-1.6086155480469115, loss:0.5425200448529465\nEpoch:94, w1:2.1193037321503643, w2:1.2798352408388918, bias:-1.6161811097072503, loss:0.5420185914271817\nEpoch:95, w1:2.1329211421337653, w2:1.282331552660889, bias:-1.62370406775359, loss:0.5415199705154982\nEpoch:96, w1:2.1465190342258187, w2:1.2847830650067702, bias:-1.6311850367430925, loss:0.5410241435291298\nEpoch:97, w1:2.1600972913844236, w2:1.2871906551145709, bias:-1.638624619627673, loss:0.5405310730102341\nEpoch:98, w1:2.173655799855084, w2:1.2895551825993699, bias:-1.6460234079994696, loss:0.5400407225900913\nEpoch:99, w1:2.1871944491052364, w2:1.2918774898345378, bias:-1.6533819823304428, loss:0.5395530569489538\nEpoch:100, w1:2.200713131760032, w2:1.2941584023238903, bias:-1.6607009122062801, loss:0.5390680417774752\nEpoch:101, w1:2.2142117435395288, w2:1.2963987290649803, bias:-1.667980756554761, loss:0.5385856437396538\nEpoch:102, w1:2.227690183197251, w2:1.298599262903754, bias:-1.675222063868738, loss:0.5381058304372313\nEpoch:103, w1:2.241148352460086, w2:1.300760780880796, bias:-1.6824253724238831, loss:0.5376285703754837\nEpoch:104, w1:2.2545861559694704, w2:1.302884044569378, bias:-1.68959121049134, loss:0.5371538329303491\nEpoch:105, w1:2.268003501223843, w2:1.3049698004055226, bias:-1.696720096545423, loss:0.5366815883168387\nEpoch:106, w1:2.281400298522321, w2:1.30701878001029, bias:-1.7038125394664934, loss:0.5362118075586769\nEpoch:107, w1:2.294776460909571, w2:1.3090317005044871, bias:-1.7108690387391425, loss:0.5357444624591193\nEpoch:108, w1:2.308131904121845, w2:1.3110092648159952, bias:-1.717890084645807, loss:0.5352795255729065\nEpoch:109, w1:2.3214665465341486, w2:1.3129521619799067, bias:-1.7248761584559342, loss:0.5348169701793003\nEpoch:110, w1:2.334780309108516, w2:1.3148610674316565, bias:-1.7318277326108187, loss:0.5343567702561651\nEpoch:111, w1:2.3480731153433556, w2:1.3167366432933292, bias:-1.7387452709042173, loss:0.5338989004550466\nEpoch:112, w1:2.361344891223853, w2:1.318579538653317, bias:-1.7456292286588566, loss:0.5334433360772121\nEpoch:113, w1:2.3745955651733888, w2:1.3203903898394993, bias:-1.752480052898938, loss:0.5329900530506113\nEpoch:114, w1:2.387825068005961, w2:1.3221698206861112, bias:-1.759298182518741, loss:0.532539027907722\nEpoch:115, w1:2.4010333328795768, w2:1.3239184427944621, bias:-1.7660840484474298, loss:0.5320902377642432\nEpoch:116, w1:2.4142202952505927, w2:1.3256368557876617, bias:-1.772838073810153, loss:0.5316436602986057\nEpoch:117, w1:2.427385892828985, w2:1.3273256475595065, bias:-1.7795606740855376, loss:0.5311992737322607\nEpoch:118, w1:2.440530065534521, w2:1.328985394517677, bias:-1.7862522572596642, loss:0.5307570568107249\nEpoch:119, w1:2.4536527554538115, w2:1.3306166618213877, bias:-1.7929132239766132, loss:0.5303169887853427\nEpoch:120, w1:2.46675390679823, w2:1.332220003613633, bias:-1.7995439676856702, loss:0.5298790493957434\nEpoch:121, w1:2.479833465862666, w2:1.3337959632481655, bias:-1.8061448747852695, loss:0.5294432188529624\nEpoch:122, w1:2.4928913809851023, w2:1.3353450735113397, bias:-1.8127163247637639, loss:0.5290094778232024\nEpoch:123, w1:2.505927602506996, w2:1.336867856838949, bias:-1.8192586903370926, loss:0.5285778074122077\nEpoch:124, w1:2.518942082734439, w2:1.3383648255281848, bias:-1.82577233758343, loss:0.5281481891502279\nEpoch:125, w1:2.5319347759000843, w2:1.3398364819448387, bias:-1.832257626074885, loss:0.5277206049775485\nEpoch:126, w1:2.5449056381258233, w2:1.341283318725866, bias:-1.8387149090063277, loss:0.5272950372305654\nEpoch:127, w1:2.557854627386187, w2:1.3427058189774277, bias:-1.8451445333214114, loss:0.5268714686283814\nEpoch:128, w1:2.570781703472466, w2:1.3441044564685243, bias:-1.851546839835858, loss:0.5264498822599073\nEpoch:129, w1:2.583686827957526, w2:1.345479695820328, bias:-1.857922163358077, loss:0.5260302615714415\nEpoch:130, w1:2.596569964161304, w2:1.346831992691322, bias:-1.8642708328071762, loss:0.5256125903547197\nEpoch:131, w1:2.6094310771169726, w2:1.3481617939583521, bias:-1.8705931713284367, loss:0.5251968527354035\nEpoch:132, w1:2.6222701335377554, w2:1.3494695378936876, bias:-1.8768894964063034, loss:0.524783033162003\nEpoch:133, w1:2.635087101784378, w2:1.3507556543381913, bias:-1.8831601199749577, loss:0.5243711163952075\nEpoch:134, w1:2.647881951833145, w2:1.3520205648706964, bias:-1.8894053485265268, loss:0.5239610874976152\nEpoch:135, w1:2.660654655244622, w2:1.353264682973678, bias:-1.8956254832169885, loss:0.5235529318238407\nEpoch:136, w1:2.6734051851329177, w2:1.3544884141953148, bias:-1.901820819969824, loss:0.5231466350109902\nEpoch:137, w1:2.686133516135547, w2:1.3556921563080242, bias:-1.9079916495774736, loss:0.5227421829694883\nEpoch:138, w1:2.6988396243838655, w2:1.3568762994635601, bias:-1.9141382578006458, loss:0.5223395618742418\nEpoch:139, w1:2.7115234874740595, w2:1.3580412263447545, bias:-1.920260925465534, loss:0.5219387581561296\nEpoch:140, w1:2.724185084438686, w2:1.3591873123139828, bias:-1.9263599285589843, loss:0.5215397584938061\nEpoch:141, w1:2.736824395718745, w2:1.3603149255584348, bias:-1.9324355383216678, loss:0.5211425498058037\nEpoch:142, w1:2.7494414031362733, w2:1.3614244272322646, bias:-1.9384880213393003, loss:0.5207471192429268\nEpoch:143, w1:2.7620360898674554, w2:1.3625161715956964, bias:-1.9445176396319575, loss:0.5203534541809204\nEpoch:144, w1:2.7746084404162294, w2:1.363590506151157, bias:-1.9505246507415273, loss:0.5199615422134104\nEpoch:145, w1:2.787158440588389, w2:1.364647771776508, bias:-1.9565093078173448, loss:0.5195713711450982\nEpoch:146, w1:2.7996860774661636, w2:1.3656883028554423, bias:-1.9624718597000501, loss:0.5191829289852048\nEpoch:147, w1:2.812191339383268, w2:1.3667124274051172, bias:-1.9684125510037105, loss:0.5187962039411523\nEpoch:148, w1:2.824674215900416, w2:1.3677204672010856, bias:-1.974331622196247, loss:0.5184111844124737\nEpoch:149, w1:2.8371346977812824, w2:1.3687127378995887, bias:-1.9802293096782038, loss:0.5180278589849454\nEpoch:150, w1:2.8495727769689085, w2:1.3696895491572745, bias:-1.986105845859897, loss:0.5176462164249293\nEpoch:151, w1:2.861988446562542, w2:1.3706512047484, bias:-1.9919614592369834, loss:0.517266245673921\nEpoch:152, w1:2.8743817007948973, w2:1.3715980026795769, bias:-1.9977963744644796, loss:0.5168879358432925\nEpoch:153, w1:2.886752535009837, w2:1.3725302353021163, bias:-2.003610812429271, loss:0.5165112762092271\nEpoch:154, w1:2.899100945640455, w2:1.373448189422031, bias:-2.009404990321143, loss:0.5161362562078318\nEpoch:155, w1:2.9114269301875644, w2:1.3743521464077455, bias:-2.015179121702366, loss:0.5157628654304282\nEpoch:156, w1:2.9237304871985708, w2:1.3752423822955708, bias:-2.0209334165758692, loss:0.5153910936190104\nEpoch:157, w1:2.9360116162467342, w2:1.376119167892991, bias:-2.0266680814520357, loss:0.515020930661866\nEpoch:158, w1:2.9482703179108047, w2:1.3769827688798149, bias:-2.032383319414142, loss:0.5146523665893519\nEpoch:159, w1:2.960506593755025, w2:1.3778334459072408, bias:-2.038079330182483, loss:0.514285391569821\nEpoch:160, w1:2.9727204463094963, w2:1.3786714546948804, bias:-2.0437563101772027, loss:0.5139199959056945\nEpoch:161, w1:2.984911879050898, w2:1.3794970461257903, bias:-2.0494144525798648, loss:0.5135561700296717\nEpoch:162, w1:2.9970808963835545, w2:1.3803104663395542, bias:-2.0550539473937857, loss:0.5131939045010747\nEpoch:163, w1:3.0092275036208402, w2:1.3811119568234618, bias:-2.0606749815031633, loss:0.5128331900023231\nEpoch:164, w1:3.0213517069669225, w2:1.3819017545018246, bias:-2.0662777387310216, loss:0.5124740173355311\nEpoch:165, w1:3.0334535134988276, w2:1.382680091823474, bias:-2.071862399896002, loss:0.5121163774192251\nEpoch:166, w1:3.045532931148832, w2:1.3834471968474789, bias:-2.077429142868024, loss:0.5117602612851783\nEpoch:167, w1:3.0575899686871653, w2:1.384203293327124, bias:-2.0829781426228395, loss:0.5114056600753522\nEpoch:168, w1:3.069624635705023, w2:1.384948600792189, bias:-2.0885095712955053, loss:0.5110525650389492\nEpoch:169, w1:3.081636942597884, w2:1.385683334629563, bias:-2.0940235982327984, loss:0.5107009675295656\nEpoch:170, w1:3.093626900549122, w2:1.386407706162234, bias:-2.099520390044595, loss:0.5103508590024443\nEpoch:171, w1:3.105594521513913, w2:1.387121922726688, bias:-2.105000110654235, loss:0.5100022310118231\nEpoch:172, w1:3.117539818203424, w2:1.387826187748753, bias:-2.1104629213478976, loss:0.5096550752083746\nEpoch:173, w1:3.1294628040692873, w2:1.3885207008179221, bias:-2.115908980823003, loss:0.5093093833367357\nEpoch:174, w1:3.141363493288346, w2:1.3892056577601883, bias:-2.1213384452356676, loss:0.5089651472331199\nEpoch:175, w1:3.1532419007476733, w2:1.389881250709425, bias:-2.1267514682472273, loss:0.5086223588230152\nEpoch:176, w1:3.165098042029856, w2:1.390547668177342, bias:-2.1321482010698514, loss:0.5082810101189588\nEpoch:177, w1:3.176931933398537, w2:1.3912050951220503, bias:-2.1375287925112674, loss:0.5079410932183874\nEpoch:178, w1:3.188743591784215, w2:1.3918537130152622, bias:-2.1428933890186115, loss:0.5076026003015643\nEpoch:179, w1:3.200533034770296, w2:1.3924936999081612, bias:-2.1482421347214276, loss:0.5072655236295737\nEpoch:180, w1:3.212300280579388, w2:1.3931252304959654, bias:-2.1535751714738307, loss:0.5069298555423847\nEpoch:181, w1:3.2240453480598403, w2:1.3937484761812156, bias:-2.158892638895851, loss:0.5065955884569808\nEpoch:182, w1:3.235768256672519, w2:1.3943636051358148, bias:-2.1641946744139777, loss:0.5062627148655543\nEpoch:183, w1:3.2474690264778157, w2:1.394970782361845, bias:-2.1694814133009186, loss:0.505931227333758\nEpoch:184, w1:3.2591476781228836, w2:1.3955701697511878, bias:-2.1747529887145927, loss:0.5056011184990193\nEpoch:185, w1:3.270804232829102, w2:1.3961619261439753, bias:-2.1800095317363692, loss:0.505272381068909\nEpoch:186, w1:3.2824387123797556, w2:1.3967462073858943, bias:-2.185251171408572, loss:0.5049450078195659\nEpoch:187, w1:3.294051139107937, w2:1.3973231663843697, bias:-2.1904780347712607, loss:0.5046189915941715\nEpoch:188, w1:3.3056415358846545, w2:1.3978929531636493, bias:-2.1956902468983084, loss:0.5042943253014793\nEpoch:189, w1:3.317209926107157, w2:1.3984557149188142, bias:-2.2008879309327845, loss:0.5039710019143897\nEpoch:190, w1:3.3287563336874557, w2:1.3990115960687382, bias:-2.2060712081216627, loss:0.5036490144685731\nEpoch:191, w1:3.340280783041054, w2:1.3995607383080155, bias:-2.211240197849864, loss:0.5033283560611389\nEpoch:192, w1:3.351783299075871, w2:1.400103280657881, bias:-2.21639501767365, loss:0.5030090198493474\nEpoch:193, w1:3.3632639071813593, w2:1.4006393595161428, bias:-2.221535783353378, loss:0.502690999049364\nEpoch:194, w1:3.3747226332178184, w2:1.401169108706148, bias:-2.2266626088856363, loss:0.502374286935055\nEpoch:195, w1:3.3861595035058896, w2:1.4016926595248012, bias:-2.231775606534763, loss:0.5020588768368215\nEpoch:196, w1:3.3975745448162384, w2:1.4022101407896574, bias:-2.236874886863771, loss:0.5017447621404708\nEpoch:197, w1:3.408967784359416, w2:1.4027216788851056, bias:-2.2419605587646827, loss:0.501431936286126\nEpoch:198, w1:3.4203392497759015, w2:1.4032273978076624, bias:-2.247032729488292, loss:0.5011203927671692\nEpoch:199, w1:3.4316889691263146, w2:1.4037274192103975, bias:-2.252091504673362, loss:0.5008101251292182\nEpoch:200, w1:3.443016970881803, w2:1.4042218624465033, bias:-2.2571369883752723, loss:0.5005011269691375\nEpoch:201, w1:3.4543232839145968, w2:1.4047108446120309, bias:-2.2621692830941247, loss:0.5001933919340792\nEpoch:202, w1:3.4656079374887283, w2:1.4051944805878065, bias:-2.2671884898023182, loss:0.4998869137205551\nEpoch:203, w1:3.4768709612509157, w2:1.4056728830805474, bias:-2.2721947079716065, loss:0.49958168607353887\nEpoch:204, w1:3.4881123852216054, w2:1.4061461626631908, bias:-2.2771880355996448, loss:0.4992777027855931\nEpoch:205, w1:3.4993322397861726, w2:1.406614427814455, bias:-2.282168569236039, loss:0.4989749576960279\nEpoch:206, w1:3.510530555686274, w2:1.407077784957646, bias:-2.287136404007907, loss:0.4986734446900829\nEpoch:207, w1:3.5217073640113545, w2:1.407536338498725, bias:-2.2920916336449575, loss:0.49837315769813556\nEpoch:208, w1:3.5328626961903016, w2:1.4079901908636536, bias:-2.2970343505041027, loss:0.49807409069493364\nEpoch:209, w1:3.5439965839832466, w2:1.4084394425350295, bias:-2.30196464559361, loss:0.4977762376988512\nEpoch:210, w1:3.5551090594735104, w2:1.4088841920880264, bias:-2.3068826085968004, loss:0.49747959277116743\nEpoch:211, w1:3.5662001550596885, w2:1.4093245362256548, bias:-2.3117883278953073, loss:0.4971841500153676\nEpoch:212, w1:3.577269903447877, w2:1.4097605698133546, bias:-2.3166818905919, loss:0.4968899035764641\nEpoch:213, w1:3.5883183376440364, w2:1.4101923859129344, bias:-2.321563382532884, loss:0.49659684764033984\nEpoch:214, w1:3.5993454909464844, w2:1.4106200758158696, bias:-2.32643288833008, loss:0.4963049764331085\nEpoch:215, w1:3.610351396938527, w2:1.4110437290759732, bias:-2.331290491382403, loss:0.49601428422049737\nEpoch:216, w1:3.6213360894812157, w2:1.4114634335414504, bias:-2.3361362738970306, loss:0.49572476530724396\nEpoch:217, w1:3.6322996027062318, w2:1.4118792753863514, bias:-2.3409703169101865, loss:0.4954364140365152\nEpoch:218, w1:3.6432419710088983, w2:1.4122913391414305, bias:-2.345792700307536, loss:0.49514922478933926\nEpoch:219, w1:3.6541632290413135, w2:1.4126997077244283, bias:-2.350603502844203, loss:0.4948631919840572\nEpoch:220, w1:3.6650634117056042, w2:1.4131044624697842, bias:-2.3554028021644196, loss:0.49457831007578845\nEpoch:221, w1:3.6759425541473023, w2:1.4135056831577921, bias:-2.360190674820809, loss:0.4942945735559119\nEpoch:222, w1:3.6868006917488327, w2:1.4139034480432113, bias:-2.3649671962933168, loss:0.49401197695156235\nEpoch:223, w1:3.6976378601231215, w2:1.4142978338833405, bias:-2.3697324410077902, loss:0.4937305148251413\nEpoch:224, w1:3.7084540951073124, w2:1.4146889159655687, bias:-2.3744864823542158, loss:0.49345018177384004\nEpoch:225, w1:3.719249432756598, w2:1.4150767681344103, bias:-2.3792293927046226, loss:0.49317097242917785\nEpoch:226, w1:3.7300239093381586, w2:1.4154614628180373, bias:-2.3839612434306536, loss:0.4928928814565523\nEpoch:227, w1:3.740777561325208, w2:1.4158430710543157, bias:-2.388682104920817, loss:0.4926159035548014\nEpoch:228, w1:3.751510425391147, w2:1.4162216625163582, bias:-2.393392046597421, loss:0.4923400334557781\nEpoch:229, w1:3.7622225384038157, w2:1.4165973055376, bias:-2.398091136933194, loss:0.4920652659239369\nEpoch:230, w1:3.772913937419856, w2:1.4169700671364103, bias:-2.4027794434676064, loss:0.49179159575593034\nEpoch:231, w1:3.783584659679165, w2:1.417340013040245, bias:-2.407457032822888, loss:0.49151901778021734\nEpoch:232, w1:3.7942347425994543, w2:1.4177072077093518, bias:-2.412123970719756, loss:0.4912475268566808\nEpoch:233, w1:3.804864223770903, w2:1.4180717143600363, bias:-2.4167803219928548, loss:0.4909771178762568\nEpoch:234, w1:3.8154731409509055, w2:1.418433594987496, bias:-2.4214261506059125, loss:0.49070778576057195\nEpoch:235, w1:3.8260615320589157, w2:1.4187929103882317, bias:-2.426061519666623, loss:0.49043952546159064\nEpoch:236, w1:3.83662943517138, w2:1.4191497201820455, bias:-2.4306864914412545, loss:0.4901723319612717\nEpoch:237, w1:3.8471768885167634, w2:1.41950408283363, bias:-2.4353011273689953, loss:0.4899062002712329\nEpoch:238, w1:3.857703930470663, w2:1.4198560556737607, bias:-2.4399054880760342, loss:0.48964112543242444\nEpoch:239, w1:3.8682105995510105, w2:1.4202056949200956, bias:-2.444499633389389, loss:0.48937710251481087\nEpoch:240, w1:3.8786969344133597, w2:1.4205530556975927, bias:-2.4490836223504795, loss:0.48911412661705983\nEpoch:241, w1:3.8891629738462594, w2:1.4208981920585493, bias:-2.45365751322846, loss:0.48885219286623927\nEpoch:242, w1:3.8996087567667086, w2:1.4212411570022738, bias:-2.4582213635333026, loss:0.4885912964175221\nEpoch:243, w1:3.910034322215694, w2:1.4215820024943946, bias:-2.4627752300286496, loss:0.48833143245389615\nEpoch:244, w1:3.920439709353808, w2:1.4219207794858135, bias:-2.4673191687444302, loss:0.48807259618588394\nEpoch:245, w1:3.930824957456947, w2:1.4222575379313118, bias:-2.471853234989249, loss:0.48781478285126634\nEpoch:246, w1:3.9411901059120837, w2:1.422592326807813, bias:-2.4763774833625503, loss:0.4875579877148141\nEpoch:247, w1:3.9515351942131214, w2:1.422925194132311, bias:-2.4808919677665644, loss:0.4873022060680255\nEpoch:248, w1:3.9618602619568177, w2:1.4232561869794709, bias:-2.485396741418036, loss:0.487047433228868\nEpoch:249, w1:3.972165348838788, w2:1.4235853514989025, bias:-2.489891856859742, loss:0.48679366454152934\nEpoch:250, w1:3.982450494649576, w2:1.4239127329321233, bias:-2.494377365971801, loss:0.48654089537617085\nEpoch:251, w1:3.9927157392707997, w2:1.4242383756292052, bias:-2.49885331998278, loss:0.4862891211286877\nEpoch:252, w1:4.002961122671366, w2:1.42456232306512, bias:-2.503319769480601, loss:0.48603833722047357\nEpoch:253, w1:4.013186684903756, w2:1.4248846178557855, bias:-2.50777676442325, loss:0.485788539098192\nEpoch:254, w1:4.023392466100375, w2:1.4252053017738153, bias:-2.512224354149295, loss:0.4855397222335498\nEpoch:255, w1:4.033578506469971, w2:1.425524415763985, bias:-2.516662587388215, loss:0.48529188212307867\nEpoch:256, w1:4.043744846294124, w2:1.4258419999584127, bias:-2.5210915122705426, loss:0.4850450142879176\nEpoch:257, w1:4.053891525923789, w2:1.4261580936914633, bias:-2.525511176337824, loss:0.48479911427360317\nEpoch:258, w1:4.064018585775913, w2:1.4264727355143816, bias:-2.529921626552404, loss:0.48455417764986114\nEpoch:259, w1:4.074126066330109, w2:1.4267859632096573, bias:-2.534322909307031, loss:0.48431020001040465\nEpoch:260, w1:4.084214008125393, w2:1.4270978138051291, bias:-2.5387150704342933, loss:0.48406717697273477\nEpoch:261, w1:4.094282451756979, w2:1.4274083235878308, bias:-2.5430981552158864, loss:0.48382510417794483\nEpoch:262, w1:4.104331437873139, w2:1.4277175281175865, bias:-2.5474722083917123, loss:0.4835839772905306\nEpoch:263, w1:4.114361007172114, w2:1.428025462240357, bias:-2.5518372741688182, loss:0.4833437919982008\nEpoch:264, w1:4.124371200399091, w2:1.4283321601013441, bias:-2.5561933962301766, loss:0.4831045440116945\nEpoch:265, w1:4.134362058343228, w2:1.4286376551578572, bias:-2.5605406177433045, loss:0.48286622906459864\nEpoch:266, w1:4.144333621834739, w2:1.4289419801919439, bias:-2.564878981368735, loss:0.48262884291317165\nEpoch:267, w1:4.1542859317420335, w2:1.429245167322793, bias:-2.569208529268332, loss:0.4823923813361684\nEpoch:268, w1:4.164219028968911, w2:1.4295472480189122, bias:-2.573529303113461, loss:0.4821568401346694\nEpoch:269, w1:4.174132954451802, w2:1.4298482531100827, bias:-2.577841344093013, loss:0.481922215131912\nEpoch:270, w1:4.184027749157071, w2:1.430148212799099, bias:-2.5821446929212852, loss:0.4816885021731252\nEpoch:271, w1:4.1939034540783595, w2:1.4304471566732948, bias:-2.5864393898457227, loss:0.4814556971253665\nEpoch:272, w1:4.203760110233989, w2:1.4307451137158596, bias:-2.5907254746545223, loss:0.4812237958773629\nEpoch:273, w1:4.213597758664405, w2:1.4310421123169506, bias:-2.5950029866841016, loss:0.480992794339352\nEpoch:274, w1:4.223416440429678, w2:1.4313381802846028, bias:-2.5992719648264337, loss:0.48076268844292946\nEpoch:275, w1:4.233216196607044, w2:1.4316333448554421, bias:-2.6035324475362565, loss:0.48053347414089403\nEpoch:276, w1:4.242997068288498, w2:1.4319276327052033, bias:-2.607784472838149, loss:0.48030514740709995\nEpoch:277, w1:4.252759096578431, w2:1.4322210699590585, bias:-2.612028078333486, loss:0.4800777042363081\nEpoch:278, w1:4.262502322591309, w2:1.4325136822017583, bias:-2.616263301207267, loss:0.4798511406440403\nEpoch:279, w1:4.272226787449408, w2:1.4328054944875899, bias:-2.620490178234828, loss:0.47962545266643786\nEpoch:280, w1:4.281932532280578, w2:1.433096531350154, bias:-2.6247087457884315, loss:0.47940063636011826\nEpoch:281, w1:4.291619598216061, w2:1.4333868168119661, bias:-2.628919039843741, loss:0.4791766878020384\nEpoch:282, w1:4.301288026388348, w2:1.4336763743938834, bias:-2.633121095986182, loss:0.4789536030893553\nEpoch:283, w1:4.3109378579290745, w2:1.4339652271243617, bias:-2.637314949417191, loss:0.47873137833929297\nEpoch:284, w1:4.320569133966964, w2:1.4342533975485452, bias:-2.6415006349603525, loss:0.47851000968900853\nEpoch:285, w1:4.330181895625803, w2:1.4345409077371913, bias:-2.6456781870674306, loss:0.47828949329546017\nEpoch:286, w1:4.339776184022467, w2:1.4348277792954356, bias:-2.6498476398242916, loss:0.47806982533527886\nEpoch:287, w1:4.349352040264972, w2:1.435114033371397, bias:-2.6540090269567256, loss:0.4778510020046394\nEpoch:288, w1:4.358909505450577, w2:1.4353996906646287, bias:-2.658162381836163, loss:0.47763301951913495\nEpoch:289, w1:4.368448620663914, w2:1.4356847714344168, bias:-2.6623077374852917, loss:0.47741587411365194\nEpoch:290, w1:4.377969426975163, w2:1.4359692955079275, bias:-2.666445126583577, loss:0.4771995620422475\nEpoch:291, w1:4.387471965438257, w2:1.43625328228821, bias:-2.6705745814726813, loss:0.47698407957802774\nEpoch:292, w1:4.396956277089129, w2:1.436536750762052, bias:-2.674696134161793, loss:0.4767694230130281\nEpoch:293, w1:4.406422402943988, w2:1.4368197195076962, bias:-2.6788098163328593, loss:0.47655558865809444\nEpoch:294, w1:4.415870383997634, w2:1.4371022067024166, bias:-2.682915659345727, loss:0.4763425728427668\nEpoch:295, w1:4.425300261221806, w2:1.437384230129958, bias:-2.6870136942431952, loss:0.47613037191516305\nEpoch:296, w1:4.434712075563564, w2:1.4376658071878416, bias:-2.69110395175598, loss:0.47591898224186396\nEpoch:297, w1:4.4441058679436996, w2:1.4379469548945394, bias:-2.6951864623075887, loss:0.4757084002078021\nEpoch:298, w1:4.453481679255187, w2:1.4382276898965187, bias:-2.6992612560191143, loss:0.47549862221614797\nEpoch:299, w1:4.462839550361659, w2:1.4385080284751603, bias:-2.703328362713941, loss:0.4752896446882009\nEpoch:300, w1:4.472179522095915, w2:1.438787986553552, bias:-2.707387811922373, loss:0.4750814640632793\nEpoch:301, w1:4.4815016352584625, w2:1.439067579703159, bias:-2.711439632886177, loss:0.47487407679861204\nEpoch:302, w1:4.49080593061609, w2:1.4393468231503754, bias:-2.7154838545630504, loss:0.4746674793692325\nEpoch:303, w1:4.500092448900464, w2:1.4396257317829577, bias:-2.7195205056310083, loss:0.4744616682678718\nEpoch:304, w1:4.5093612308067605, w2:1.4399043201563404, bias:-2.723549614492697, loss:0.4742566400048545\nEpoch:305, w1:4.518612316992322, w2:1.440182602499841, bias:-2.72757120927963, loss:0.4740523911079949\nEpoch:306, w1:4.527845748075346, w2:1.4404605927227512, bias:-2.731585317856352, loss:0.4738489181224942\nEpoch:307, w1:4.537061564633595, w2:1.440738304420319, bias:-2.7355919678245306, loss:0.47364621761083875\nEpoch:308, w1:4.546259807203141, w2:1.441015750879624, bias:-2.7395911865269764, loss:0.47344428615270023\nEpoch:309, w1:4.555440516277136, w2:1.4412929450853456, bias:-2.7435830010515936, loss:0.47324312034483446\nEpoch:310, w1:4.564603732304602, w2:1.4415698997254285, bias:-2.747567438235262, loss:0.4730427168009839\nEpoch:311, w1:4.573749495689255, w2:1.441846627196646, bias:-2.7515445246676515, loss:0.4728430721517802\nEpoch:312, w1:4.58287784678835, w2:1.4421231396100629, bias:-2.7555142866949733, loss:0.4726441830446452\nEpoch:313, w1:4.591988825911552, w2:1.4423994487964005, bias:-2.759476750423661, loss:0.4724460461436974\nEpoch:314, w1:4.601082473319831, w2:1.4426755663113053, bias:-2.763431941723993, loss:0.47224865812965516\nEpoch:315, w1:4.610158829224385, w2:1.4429515034405223, bias:-2.7673798862336514, loss:0.47205201569974303\nEpoch:316, w1:4.619217933785582, w2:1.4432272712049754, bias:-2.7713206093612155, loss:0.47185611556759816\nEpoch:317, w1:4.628259827111926, w2:1.4435028803657577, bias:-2.7752541362896017, loss:0.4716609544631776\nEpoch:318, w1:4.63728454925905, w2:1.44377834142903, bias:-2.7791804919794383, loss:0.47146652913266657\nEpoch:319, w1:4.646292140228726, w2:1.4440536646508326, bias:-2.7830997011723855, loss:0.4712728363383867\nEpoch:320, w1:4.655282639967903, w2:1.4443288600418103, bias:-2.787011788394397, loss:0.4710798728587066\nEpoch:321, w1:4.664256088367763, w2:1.4446039373718518, bias:-2.7909167779589263, loss:0.4708876354879519\nEpoch:322, w1:4.673212525262796, w2:1.4448789061746472, bias:-2.7948146939700766, loss:0.470696121036316\nEpoch:323, w1:4.682151990429907, w2:1.445153775752162, bias:-2.7987055603256983, loss:0.4705053263297722\nEpoch:324, w1:4.691074523587528, w2:1.445428555179031, bias:-2.8025894007204317, loss:0.4703152482099871\nEpoch:325, w1:4.6999801643947645, w2:1.4457032533068734, bias:-2.8064662386487, loss:0.47012588353423135\nEpoch:326, w1:4.708868952450553, w2:1.445977878768531, bias:-2.8103360974076472, loss:0.4699372291752969\nEpoch:327, w1:4.7177409272928434, w2:1.4462524399822285, bias:-2.81419900010003, loss:0.4697492820214089\nEpoch:328, w1:4.726596128397797, w2:1.4465269451556608, bias:-2.818054969637057, loss:0.4695620389761422\nEpoch:329, w1:4.735434595179007, w2:1.446801402290005, bias:-2.82190402874118, loss:0.4693754969583367\nEpoch:330, w1:4.744256366986734, w2:1.4470758191838622, bias:-2.82574619994884, loss:0.46918965290201436\nEpoch:331, w1:4.753061483107164, w2:1.4473502034371264, bias:-2.8295815056131626, loss:0.4690045037562959\nEpoch:332, w1:4.76184998276168, w2:1.4476245624547852, bias:-2.833409967906611, loss:0.46882004648531833\nEpoch:333, w1:4.770621905106156, w2:1.4478989034506518, bias:-2.8372316088235907, loss:0.46863627806815394\nEpoch:334, w1:4.779377289230264, w2:1.448173233451029, bias:-2.841046450183012, loss:0.46845319549872855\nEpoch:335, w1:4.7881161741568015, w2:1.4484475592983093, bias:-2.8448545136308083, loss:0.46827079578574116\nEpoch:336, w1:4.796838598841035, w2:1.448721887654507, bias:-2.848655820642411, loss:0.46808907595258425\nEpoch:337, w1:4.805544602170057, w2:1.4489962250047304, bias:-2.852450392525183, loss:0.467908033037264\nEpoch:338, w1:4.814234222962166, w2:1.4492705776605888, bias:-2.8562382504208115, loss:0.46772766409232197\nEpoch:339, w1:4.822907499966253, w2:1.4495449517635393, bias:-2.860019415307658, loss:0.4675479661847561\nEpoch:340, w1:4.831564471861215, w2:1.4498193532881727, bias:-2.8637939080030708, loss:0.46736893639594346\nEpoch:341, w1:4.840205177255373, w2:1.4500937880454414, bias:-2.8675617491656573, loss:0.4671905718215625\nEpoch:342, w1:4.848829654685914, w2:1.4503682616858278, bias:-2.8713229592975185, loss:0.46701286957151705\nEpoch:343, w1:4.85743794261834, w2:1.4506427797024561, bias:-2.875077558746444, loss:0.4668358267698594\nEpoch:344, w1:4.866030079445939, w2:1.450917347434149, bias:-2.8788255677080725, loss:0.4666594405547148\nEpoch:345, w1:4.874606103489267, w2:1.4511919700684275, bias:-2.882567006228014, loss:0.4664837080782067\nEpoch:346, w1:4.883166052995643, w2:1.4514666526444582, bias:-2.8863018942039362, loss:0.4663086265063812\nEpoch:347, w1:4.891709966138657, w2:1.4517414000559465, bias:-2.8900302513876173, loss:0.46613419301913306\nEpoch:348, w1:4.900237881017698, w2:1.4520162170539788, bias:-2.893752097386962, loss:0.4659604048101324\nEpoch:349, w1:4.9087498356574875, w2:1.4522911082498116, bias:-2.8974674516679864, loss:0.4657872590867513\nEpoch:350, w1:4.917245868007634, w2:1.4525660781176122, bias:-2.901176333556766, loss:0.46561475306999006\nEpoch:351, w1:4.925726015942192, w2:1.4528411309971487, bias:-2.9048787622413546, loss:0.4654428839944057\nEpoch:352, w1:4.9341903172592385, w2:1.453116271096432, bias:-2.9085747567736684, loss:0.4652716491080398\nEpoch:353, w1:4.942638809680464, w2:1.45339150249431, bias:-2.91226433607134, loss:0.4651010456723471\nEpoch:354, w1:4.95107153085077, w2:1.453666829143015, bias:-2.9159475189195407, loss:0.4649310709621243\nEpoch:355, w1:4.959488518337886, w2:1.453942254870665, bias:-2.919624323972772, loss:0.46476172226543927\nEpoch:356, w1:4.967889809631988, w2:1.4542177833837202, bias:-2.9232947697566276, loss:0.4645929968835612\nEpoch:357, w1:4.976275442145338, w2:1.4544934182693938, bias:-2.9269588746695274, loss:0.46442489213089116\nEpoch:358, w1:4.984645453211936, w2:1.4547691629980217, bias:-2.93061665698442, loss:0.464257405334892\nEpoch:359, w1:4.9929998800871696, w2:1.4550450209253871, bias:-2.934268134850457, loss:0.46409053383601956\nEpoch:360, w1:5.001338759947489, w2:1.4553209952950035, bias:-2.9379133262946424, loss:0.4639242749876548\nEpoch:361, w1:5.00966212989009, w2:1.4555970892403576, bias:-2.9415522492234514, loss:0.46375862615603475\nEpoch:362, w1:5.0179700269326, w2:1.45587330578711, bias:-2.9451849214244237, loss:0.46359358472018636\nEpoch:363, w1:5.026262488012782, w2:1.456149647855258, bias:-2.94881136056773, loss:0.4634291480718572\nEpoch:364, w1:5.0345395499882475, w2:1.456426118261257, bias:-2.952431584207713, loss:0.46326531361545037\nEpoch:365, w1:5.042801249636176, w2:1.4567027197201048, bias:-2.956045609784402, loss:0.46310207876795667\nEpoch:366, w1:5.051047623653049, w2:1.4569794548473887, bias:-2.9596534546250037, loss:0.46293944095888906\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4ef3bab5962caf9a92fb1d0ca8e858e90f6074
| 8,743 |
ipynb
|
Jupyter Notebook
|
scripts/analysis_pyton/tnac_ROI_transformation_nativespace(anatomical).ipynb
|
C0C0AN/MSc_thesis_BenediktWei-
|
47ea160193f5c28c33d2ee93821820b547ba7071
|
[
"MIT"
] | null | null | null |
scripts/analysis_pyton/tnac_ROI_transformation_nativespace(anatomical).ipynb
|
C0C0AN/MSc_thesis_BenediktWei-
|
47ea160193f5c28c33d2ee93821820b547ba7071
|
[
"MIT"
] | null | null | null |
scripts/analysis_pyton/tnac_ROI_transformation_nativespace(anatomical).ipynb
|
C0C0AN/MSc_thesis_BenediktWei-
|
47ea160193f5c28c33d2ee93821820b547ba7071
|
[
"MIT"
] | 1 |
2017-10-16T12:14:05.000Z
|
2017-10-16T12:14:05.000Z
| 36.58159 | 156 | 0.581379 |
[
[
[
"##### import modules #####\n\nfrom os.path import join as opj\nfrom nipype.interfaces.ants import ApplyTransforms\nfrom nipype.interfaces.utility import IdentityInterface\nfrom nipype.interfaces.freesurfer import FSCommand, MRIConvert\nfrom nipype.interfaces.io import SelectFiles, DataSink, FreeSurferSource\nfrom nipype.pipeline.engine import Workflow, Node, MapNode\nfrom nipype.algorithms.misc import Gunzip ",
"_____no_output_____"
],
[
"# FreeSurfer - Specify the location of the freesurfer folder\nfs_dir = '/media/lmn/86A406A0A406933B2/TNAC_BIDS/derivatives/mindboggle/freesurfer_subjects/'\nFSCommand.set_default_subjects_dir(fs_dir)",
"_____no_output_____"
],
[
"##### set paths and define parameters #####\n\nexperiment_dir = '/media/lmn/86A406A0A406933B2/TNAC_BIDS/'\noutput_dir = 'derivatives/masks/output_inverse_transform_ROIs'\nworking_dir = 'derivatives/masks/workingdir_inverse_transform_ROIs' \ninput_dir_preproc = 'derivatives/preprocessing/output_preproc'\ninput_dir_reg = 'derivatives/preprocessing/output_registration'\n\n#location of atlas --> downloaded from alpaca\ninput_dir_ROIs = 'derivatives/anat_rois_norman-haignere/anatlabels_surf_mni/mni152_te11-te10-te12-pt-pp'\n\n# list of subjects\nsubject_list = ['sub-03', 'sub-04', 'sub-05', 'sub-06', 'sub-07', 'sub-08', 'sub-09', 'sub-10', 'sub-11', 'sub-12', 'sub-13', 'sub-14'] \n",
"_____no_output_____"
],
[
"#### specify workflow-nodes #####\n\n# FreeSurferSource - Data grabber specific for FreeSurfer data\nfssource = Node(FreeSurferSource(subjects_dir=fs_dir),\n run_without_submitting=True,\n name='fssource')\n\n# Convert FreeSurfer's MGZ format into NIfTI.gz-format (brain.mgz-anatomical)\nconvert2niigz = Node(MRIConvert(out_type='niigz'), name='convert2niigz')\n\n# Transform the volumetric ROIs to the target space\ninverse_transform_rois = MapNode(ApplyTransforms(args='--float',\n input_image_type=3,\n interpolation='Linear',\n invert_transform_flags=[False],\n num_threads=1,\n terminal_output='file'),\n name='inverse_transform_rois', iterfield=['input_image'])\n \n# Gunzip - unzip the output ROI-images to use them in further DCM-analysis\ngunzip_rois = MapNode(Gunzip(), name=\"gunzip_rois\", iterfield=['in_file'])\n\n# Gunzip - unzip the anatomical reference-image to use it in further DCM-analysis\ngunzip_anat = Node(Gunzip(), name=\"gunzip_anat\")",
"_____no_output_____"
],
[
"##### specify input and output stream #####\n\n# Infosource - a function free node to iterate over the list of subject names\ninfosource = Node(IdentityInterface(fields=['subject_id']),\n name=\"infosource\")\ninfosource.iterables = [('subject_id', subject_list)]\n\ntemplates = {'inverse_transform_composite': opj(input_dir_reg, 'registrationtemp', '{subject_id}', 'transformInverseComposite.h5'),\n 'atlas_ROIs': opj(input_dir_ROIs, '*.nii.gz')\n } \n\n# SelectFiles - to grab the data (alternativ to DataGrabber),\nselectfiles = Node(SelectFiles(templates,\n base_directory=experiment_dir),\n name=\"selectfiles\")\n\n# Datasink - creates output folder for important outputs\ndatasink = Node(DataSink(base_directory=experiment_dir,\n container=output_dir),\n name=\"datasink\")\n\n# Use the following DataSink output substitutions\nsubstitutions = [('_subject_id_', '')]\n\ndatasink.inputs.substitutions = substitutions",
"_____no_output_____"
],
[
"##### initiate the workflow and connect nodes #####\n\n# Initiation of the inverse transform ROIs workflow\ninverse_transform_ROIs = Workflow(name='inverse_transform_ROIs')\ninverse_transform_ROIs.base_dir = opj(experiment_dir, working_dir)\n\n# Connect up ANTS normalization components\ninverse_transform_ROIs.connect([(fssource, convert2niigz, [('brain', 'in_file')]), \n (convert2niigz, inverse_transform_rois, [('out_file', 'reference_image')]), \n (inverse_transform_rois, gunzip_rois, [('output_image', 'in_file')]),\n (convert2niigz, gunzip_anat, [('out_file', 'in_file')]), \n ])",
"_____no_output_____"
],
[
"# Connect SelectFiles and DataSink to the workflow\ninverse_transform_ROIs.connect([(infosource, selectfiles, [('subject_id', 'subject_id')]),\n (infosource, fssource, [('subject_id', 'subject_id')]), \n (selectfiles, inverse_transform_rois, [('atlas_ROIs', 'input_image')]),\n (selectfiles, inverse_transform_rois, [('inverse_transform_composite', 'transforms')]),\n \n (convert2niigz, datasink, [('out_file', 'convert2niigz.@anatomical_niigz_transform')]), \n (gunzip_rois, datasink, [('out_file', 'inverse_transform_rois.@roi_transform')]),\n (gunzip_anat, datasink, [('out_file', 'unzipped_anatomical.@unzipped_anatomical')]), \n ])",
"_____no_output_____"
],
[
"##### visualize the pipeline #####\n\n# Create a colored output graph\ninverse_transform_ROIs.write_graph(graph2use='colored',format='png', simple_form=True)\n\n# Create a detailed output graph\ninverse_transform_ROIs.write_graph(graph2use='flat',format='png', simple_form=True)",
"_____no_output_____"
],
[
"# Visualize the simple graph\nfrom IPython.display import Image\nImage(filename='/media/lmn/86A406A0A406933B2/TNAC_BIDS/derivatives/masks/workingdir_inverse_transform_ROIs/inverse_transform_ROIs/graph.png')",
"_____no_output_____"
],
[
"# Visualize the detailed graph\nfrom IPython.display import Image\nImage(filename='/media/lmn/86A406A0A406933B2/TNAC_BIDS/derivatives/masks/workingdir_inverse_transform_ROIs/inverse_transform_ROIs/graph_detailed.png')",
"_____no_output_____"
],
[
"##### run the workflow using multiple cores #####\n\ninverse_transform_ROIs.run('MultiProc', plugin_args={'n_procs':4})",
"_____no_output_____"
],
[
"!tree /media/lmn/86A406A0A406933B2/TNAC_BIDS/derivatives/masks/output_inverse_transform_ROIs/",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4ef4bf0594b348e5f329a945265d9f385d3691
| 9,250 |
ipynb
|
Jupyter Notebook
|
Machine-Learning-Fundamentals/regression_linear.ipynb
|
XGBTrain5/07.ml_diegoinacio
|
6fb927b953e476cb07c19496e51ffb500ad10fcb
|
[
"MIT"
] | 56 |
2020-01-20T15:23:25.000Z
|
2022-03-20T00:00:07.000Z
|
Machine-Learning-Fundamentals/regression_linear.ipynb
|
XGBTrain5/07.ml_diegoinacio
|
6fb927b953e476cb07c19496e51ffb500ad10fcb
|
[
"MIT"
] | 10 |
2019-12-09T13:45:49.000Z
|
2021-03-05T22:19:13.000Z
|
Machine-Learning-Fundamentals/regression_linear.ipynb
|
XGBTrain5/07.ml_diegoinacio
|
6fb927b953e476cb07c19496e51ffb500ad10fcb
|
[
"MIT"
] | 12 |
2020-02-07T18:07:04.000Z
|
2021-06-26T23:24:02.000Z
| 23.77892 | 171 | 0.469514 |
[
[
[
"# Linear Regression\n---\n- Author: Diego Inácio\n- GitHub: [github.com/diegoinacio](https://github.com/diegoinacio)\n- Notebook: [regression_linear.ipynb](https://github.com/diegoinacio/machine-learning-notebooks/blob/master/Machine-Learning-Fundamentals/regression_linear.ipynb)\n---\nOverview and implementation of *Linear Regression* analysis.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom regression__utils import *",
"_____no_output_____"
],
[
"# Synthetic data 1\nx, yA, yB, yC, yD = synthData1()",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"## 1. Simple\n---\n$$ \\large\n y_i=mx_i+b\n$$\n\nWhere **m** describes the angular coefficient (or line slope) and **b** the linear coefficient (or line y-intersept).\n\n$$ \\large\n m=\\frac{\\sum_i^n (x_i-\\overline{x})(y_i-\\overline{y})}{\\sum_i^n (x_i-\\overline{x})^2}\n$$\n\n$$ \\large\n b=\\overline{y}-m\\overline{x}\n$$",
"_____no_output_____"
]
],
[
[
"class linearRegression_simple(object):\n def __init__(self):\n self._m = 0\n self._b = 0\n \n def fit(self, X, y):\n X = np.array(X)\n y = np.array(y)\n X_ = X.mean()\n y_ = y.mean()\n num = ((X - X_)*(y - y_)).sum()\n den = ((X - X_)**2).sum()\n self._m = num/den\n self._b = y_ - self._m*X_\n \n def pred(self, x):\n x = np.array(x)\n return self._m*x + self._b",
"_____no_output_____"
],
[
"lrs = linearRegression_simple()",
"_____no_output_____"
],
[
"%%time\n\nlrs.fit(x, yA)\nyA_ = lrs.pred(x)\n\nlrs.fit(x, yB)\nyB_ = lrs.pred(x)\n\nlrs.fit(x, yC)\nyC_ = lrs.pred(x)\n\nlrs.fit(x, yD)\nyD_ = lrs.pred(x)",
"Wall time: 998 µs\n"
]
],
[
[
"\n\n$$ \\large\nMSE=\\frac{1}{n} \\sum_i^n (Y_i- \\hat{Y}_i)^2\n$$\n\n",
"_____no_output_____"
],
[
"## 2. Multiple\n---\n$$ \\large\ny=m_1x_1+m_2x_2+...+m_nx_n+b\n$$",
"_____no_output_____"
]
],
[
[
"class linearRegression_multiple(object):\n def __init__(self):\n self._m = 0\n self._b = 0\n \n def fit(self, X, y):\n X = np.array(X).T\n y = np.array(y).reshape(-1, 1)\n X_ = X.mean(axis = 0)\n y_ = y.mean(axis = 0)\n num = ((X - X_)*(y - y_)).sum(axis = 0)\n den = ((X - X_)**2).sum(axis = 0)\n self._m = num/den\n self._b = y_ - (self._m*X_).sum()\n \n def pred(self, x):\n x = np.array(x).T\n return (self._m*x).sum(axis = 1) + self._b",
"_____no_output_____"
],
[
"lrm = linearRegression_multiple()",
"_____no_output_____"
],
[
"%%time \n# Synthetic data 2\nM = 10\ns, t, x1, x2, y = synthData2(M)\n\n# Prediction\nlrm.fit([x1, x2], y)\ny_ = lrm.pred([x1, x2])",
"Wall time: 998 µs\n"
]
],
[
[
"\n",
"_____no_output_____"
],
[
"## 3. Gradient Descent\n---\n$$ \\large\n e_{m,b}=\\frac{1}{n} \\sum_i^n (y_i-(mx_i+b))^2\n$$\n\nTo perform the gradient descent as a function of the error, it is necessary to calculate the gradient vector $\\nabla$ of the function, described by:\n\n$$ \\large\n\\nabla e_{m,b}=\\Big\\langle\\frac{\\partial e}{\\partial m},\\frac{\\partial e}{\\partial b}\\Big\\rangle\n$$\n\nwhere:\n\n$$ \\large\n\\begin{aligned}\n \\frac{\\partial e}{\\partial m}&=\\frac{2}{n} \\sum_{i}^{n}-x_i(y_i-(mx_i+b)), \\\\\n \\frac{\\partial e}{\\partial b}&=\\frac{2}{n} \\sum_{i}^{n}-(y_i-(mx_i+b))\n\\end{aligned}\n$$",
"_____no_output_____"
]
],
[
[
"class linearRegression_GD(object):\n def __init__(self,\n mo = 0,\n bo = 0,\n rate = 0.001):\n self._m = mo\n self._b = bo\n self.rate = rate\n \n def fit_step(self, X, y):\n X = np.array(X)\n y = np.array(y)\n n = X.size\n dm = (2/n)*np.sum(-x*(y - (self._m*x + self._b)))\n db = (2/n)*np.sum(-(y - (self._m*x + self._b)))\n self._m -= dm*self.rate\n self._b -= db*self.rate\n \n def pred(self, x):\n x = np.array(x)\n return self._m*x + self._b",
"_____no_output_____"
],
[
"%%time\nlrgd = linearRegression_GD(rate=0.01)\n\n# Synthetic data 3\nx, x_, y = synthData3()\n\niterations = 3072\nfor i in range(iterations):\n lrgd.fit_step(x, y)\ny_ = lrgd.pred(x)",
"Wall time: 123 ms\n"
]
],
[
[
"",
"_____no_output_____"
],
[
"## 4. Non-linear analysis\n---",
"_____no_output_____"
]
],
[
[
"# Synthetic data 4\n# Anscombe's quartet\nx1, y1, x2, y2, x3, y3, x4, y4 = synthData4()",
"_____no_output_____"
],
[
"%%time\nlrs.fit(x1, y1)\ny1_ = lrs.pred(x1)\n\nlrs.fit(x2, y2)\ny2_ = lrs.pred(x2)\n\nlrs.fit(x3, y3)\ny3_ = lrs.pred(x3)\n\nlrs.fit(x4, y4)\ny4_ = lrs.pred(x4)",
"Wall time: 499 µs\n"
]
],
[
[
"\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a4f16ad016dcd694e3ee9adb8d988c5914b7d4d
| 868 |
ipynb
|
Jupyter Notebook
|
hello_world_py.ipynb
|
mafreitas/regex1
|
36070d114b3813800b3cfcf5ca6065077e2cb16a
|
[
"Apache-2.0"
] | null | null | null |
hello_world_py.ipynb
|
mafreitas/regex1
|
36070d114b3813800b3cfcf5ca6065077e2cb16a
|
[
"Apache-2.0"
] | null | null | null |
hello_world_py.ipynb
|
mafreitas/regex1
|
36070d114b3813800b3cfcf5ca6065077e2cb16a
|
[
"Apache-2.0"
] | null | null | null | 16.692308 | 34 | 0.496544 |
[
[
[
"print(\"Hello World\")",
"Hello World\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4a4f21fb3584b66e57fc6bd0368577a9bc69cb26
| 513,426 |
ipynb
|
Jupyter Notebook
|
Examples/Running Simulations.ipynb
|
dapias/ST1Ds
|
cda54245d0fad8e3a0d53b8ce6f3835c89e2dff9
|
[
"MIT"
] | null | null | null |
Examples/Running Simulations.ipynb
|
dapias/ST1Ds
|
cda54245d0fad8e3a0d53b8ce6f3835c89e2dff9
|
[
"MIT"
] | null | null | null |
Examples/Running Simulations.ipynb
|
dapias/ST1Ds
|
cda54245d0fad8e3a0d53b8ce6f3835c89e2dff9
|
[
"MIT"
] | 1 |
2018-06-29T12:50:21.000Z
|
2018-06-29T12:50:21.000Z
| 465.903811 | 172,158 | 0.937442 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a4f34736c1b6a211e87fb6d9e2f1bd31c92cf41
| 71,095 |
ipynb
|
Jupyter Notebook
|
tutorial/source/gplvm.ipynb
|
ludkinm/pyro
|
d24c808a9d86d79c43a99990fe9e418ce5976613
|
[
"Apache-2.0"
] | null | null | null |
tutorial/source/gplvm.ipynb
|
ludkinm/pyro
|
d24c808a9d86d79c43a99990fe9e418ce5976613
|
[
"Apache-2.0"
] | null | null | null |
tutorial/source/gplvm.ipynb
|
ludkinm/pyro
|
d24c808a9d86d79c43a99990fe9e418ce5976613
|
[
"Apache-2.0"
] | 1 |
2020-01-06T03:19:17.000Z
|
2020-01-06T03:19:17.000Z
| 129.972578 | 39,940 | 0.836613 |
[
[
[
"## Gaussian Process Latent Variable Model",
"_____no_output_____"
],
[
"The [Gaussian Process Latent Variable Model](https://en.wikipedia.org/wiki/Nonlinear_dimensionality_reduction#Gaussian_process_latent_variable_models) (GPLVM) is a dimensionality reduction method that uses a Gaussian process to learn a low-dimensional representation of (potentially) high-dimensional data. In the typical setting of Gaussian process regression, where we are given inputs $X$ and outputs $y$, we choose a kernel and learn hyperparameters that best describe the mapping from $X$ to $y$. In the GPLVM, we are not given $X$: we are only given $y$. So we need to learn $X$ along with the kernel hyperparameters.",
"_____no_output_____"
],
[
"We do not do maximum likelihood inference on $X$. Instead, we set a Gaussian prior for $X$ and learn the mean and variance of the approximate (gaussian) posterior $q(X|y)$. In this notebook, we show how this can be done using the `pyro.contrib.gp` module. In particular we reproduce a result described in [2].",
"_____no_output_____"
]
],
[
[
"import os\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport torch\nfrom torch.nn import Parameter\n\nimport pyro\nimport pyro.contrib.gp as gp\nimport pyro.distributions as dist\nimport pyro.ops.stats as stats\n\nsmoke_test = ('CI' in os.environ) # ignore; used to check code integrity in the Pyro repo\nassert pyro.__version__.startswith('1.1.0')\npyro.enable_validation(True) # can help with debugging\npyro.set_rng_seed(1)",
"_____no_output_____"
]
],
[
[
"### Dataset",
"_____no_output_____"
],
[
"The data we are going to use consists of [single-cell](https://en.wikipedia.org/wiki/Single-cell_analysis) [qPCR](https://en.wikipedia.org/wiki/Real-time_polymerase_chain_reaction) data for 48 genes obtained from mice (Guo *et al.*, [1]). This data is available at the [Open Data Science repository](https://github.com/sods/ods). The data contains 48 columns, with each column corresponding to (normalized) measurements of each gene. Cells differentiate during their development and these data were obtained at various stages of development. The various stages are labelled from the 1-cell stage to the 64-cell stage. For the 32-cell stage, the data is further differentiated into 'trophectoderm' (TE) and 'inner cell mass' (ICM). ICM further differentiates into 'epiblast' (EPI) and 'primitive endoderm' (PE) at the 64-cell stage. Each of the rows in the dataset is labelled with one of these stages.",
"_____no_output_____"
]
],
[
[
"# license: Copyright (c) 2014, the Open Data Science Initiative\n# license: https://www.elsevier.com/legal/elsevier-website-terms-and-conditions\nURL = \"https://raw.githubusercontent.com/sods/ods/master/datasets/guo_qpcr.csv\"\n\ndf = pd.read_csv(URL, index_col=0)\nprint(\"Data shape: {}\\n{}\\n\".format(df.shape, \"-\" * 21))\nprint(\"Data labels: {}\\n{}\\n\".format(df.index.unique().tolist(), \"-\" * 86))\nprint(\"Show a small subset of the data:\")\ndf.head()",
"Data shape: (437, 48)\n---------------------\n\nData labels: ['1', '2', '4', '8', '16', '32 TE', '32 ICM', '64 PE', '64 TE', '64 EPI']\n--------------------------------------------------------------------------------------\n\nShow a small subset of the data:\n"
]
],
[
[
"### Modelling",
"_____no_output_____"
],
[
"First, we need to define the output tensor $y$. To predict values for all $48$ genes, we need $48$ Gaussian processes. So the required shape for $y$ is `num_GPs x num_data = 48 x 437`.",
"_____no_output_____"
]
],
[
[
"data = torch.tensor(df.values, dtype=torch.get_default_dtype())\n# we need to transpose data to correct its shape\ny = data.t()",
"_____no_output_____"
]
],
[
[
"Now comes the most interesting part. We know that the observed data $y$ has latent structure: in particular different datapoints correspond to different cell stages. We would like our GPLVM to learn this structure in an unsupervised manner. In principle, if we do a good job of inference then we should be able to discover this structure---at least if we choose reasonable priors. First, we have to choose the dimension of our latent space $X$. We choose $dim(X)=2$, since we would like our model to disentangle 'capture time' ($1$, $2$, $4$, $8$, $16$, $32$, and $64$) from cell branching types (TE, ICM, PE, EPI). Next, when we set the mean of our prior over $X$, we set the first dimension to be equal to the observed capture time. This will help the GPLVM discover the structure we are interested in and will make it more likely that that structure will be axis-aligned in a way that is easier for us to interpret.",
"_____no_output_____"
]
],
[
[
"capture_time = y.new_tensor([int(cell_name.split(\" \")[0]) for cell_name in df.index.values])\n# we scale the time into the interval [0, 1]\ntime = capture_time.log2() / 6\n\n# we setup the mean of our prior over X\nX_prior_mean = torch.zeros(y.size(1), 2) # shape: 437 x 2\nX_prior_mean[:, 0] = time",
"_____no_output_____"
]
],
[
[
"We will use a sparse version of Gaussian process inference to make training faster. Remember that we also need to define $X$ as a `Parameter` so that we can set a prior and guide (variational distribution) for it.",
"_____no_output_____"
]
],
[
[
"kernel = gp.kernels.RBF(input_dim=2, lengthscale=torch.ones(2))\n\n# we clone here so that we don't change our prior during the course of training\nX = Parameter(X_prior_mean.clone())\n\n# we will use SparseGPRegression model with num_inducing=32;\n# initial values for Xu are sampled randomly from X_prior_mean\nXu = stats.resample(X_prior_mean.clone(), 32)\ngplvm = gp.models.SparseGPRegression(X, y, kernel, Xu, noise=torch.tensor(0.01), jitter=1e-5)",
"_____no_output_____"
]
],
[
[
"We will use the [autoguide()](http://docs.pyro.ai/en/dev/contrib.gp.html#pyro.contrib.gp.parameterized.Parameterized.autoguide) method from the [Parameterized](http://docs.pyro.ai/en/dev/contrib.gp.html#module-pyro.contrib.gp.parameterized) class to set an auto Normal guide for $X$.",
"_____no_output_____"
]
],
[
[
"# we use `.to_event()` to tell Pyro that the prior distribution for X has no batch_shape\ngplvm.X = pyro.nn.PyroSample(dist.Normal(X_prior_mean, 0.1).to_event())\ngplvm.autoguide(\"X\", dist.Normal)",
"_____no_output_____"
]
],
[
[
"### Inference",
"_____no_output_____"
],
[
"As mentioned in the [Gaussian Processes tutorial](gp.ipynb), we can use the helper function [gp.util.train](http://docs.pyro.ai/en/dev/contrib.gp.html#pyro.contrib.gp.util.train) to train a Pyro GP module. By default, this helper function uses the Adam optimizer with a learning rate of `0.01`.",
"_____no_output_____"
]
],
[
[
"# note that training is expected to take a minute or so\nlosses = gp.util.train(gplvm, num_steps=4000)\n\n# let's plot the loss curve after 4000 steps of training\nplt.plot(losses)\nplt.show()",
"_____no_output_____"
]
],
[
[
"After inference, the mean and standard deviation of the approximated posterior $q(X) \\sim p(X | y)$ will be stored in the parameters `X_loc` and `X_scale`. To get a sample from $q(X)$, we need to set the `mode` of `gplvm` to `\"guide\"`.",
"_____no_output_____"
]
],
[
[
"gplvm.mode = \"guide\"\nX = gplvm.X # draw a sample from the guide of the variable X",
"_____no_output_____"
]
],
[
[
"### Visualizing the result",
"_____no_output_____"
],
[
"Let’s see what we got by applying GPLVM to our dataset.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(8, 6))\ncolors = plt.get_cmap(\"tab10\").colors[::-1]\nlabels = df.index.unique()\n\nX = gplvm.X_loc.detach().numpy()\nfor i, label in enumerate(labels):\n X_i = X[df.index == label]\n plt.scatter(X_i[:, 0], X_i[:, 1], c=[colors[i]], label=label)\n\nplt.legend()\nplt.xlabel(\"pseudotime\", fontsize=14)\nplt.ylabel(\"branching\", fontsize=14)\nplt.title(\"GPLVM on Single-Cell qPCR data\", fontsize=16)\nplt.show()",
"_____no_output_____"
]
],
[
[
"We can see that the first dimension of the latent $X$ for each cell (horizontal axis) corresponds well with the observed capture time (colors). On the other hand, the 32 TE cell and 64 TE cell are clustered near each other. And the fact that ICM cells differentiate into PE and EPI can also be observed from the figure!",
"_____no_output_____"
],
[
"### Remarks\n\n+ The sparse version scales well (linearly) with the number of data points. So the GPLVM can be used with large datasets. Indeed in [2] the authors have applied GPLVM to a dataset with 68k peripheral blood mononuclear cells.\n\n+ Much of the power of Gaussian Processes lies in the function prior defined by the kernel. We recommend users try out different combinations of kernels for different types of datasets! For example, if the data contains periodicities, it might make sense to use a [Periodic kernel](http://docs.pyro.ai/en/dev/contrib.gp.html#periodic). Other kernels can also be found in the [Pyro GP docs](http://docs.pyro.ai/en/dev/contrib.gp.html#module-pyro.contrib.gp.kernels).",
"_____no_output_____"
],
[
"### References\n\n[1] `Resolution of Cell Fate Decisions Revealed by Single-Cell Gene Expression Analysis from Zygote to Blastocyst`,<br /> \nGuoji Guo, Mikael Huss, Guo Qing Tong, Chaoyang Wang, Li Li Sun, Neil D. Clarke, Paul Robson\n\n[2] `GrandPrix: Scaling up the Bayesian GPLVM for single-cell data`,<br /> \nSumon Ahmed, Magnus Rattray, Alexis Boukouvalas\n\n[3] `Bayesian Gaussian Process Latent Variable Model`,<br /> \nMichalis K. Titsias, Neil D. Lawrence\n\n[4] `A novel approach for resolving differences in single-cell gene expression patterns from zygote to blastocyst`,<br /> \nFlorian Buettner, Fabian J. Theis",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a4f35903b70a4216f853bb2be1680e02630dc7a
| 147,532 |
ipynb
|
Jupyter Notebook
|
notebooks/1.0_nc_testing_pipeline.ipynb
|
ashish1610dhiman/learning_norms_with_mcmc_from_pcfg_IJCAI21
|
90d42333e7d810822ccf19864f5badc743b066a1
|
[
"MIT"
] | 1 |
2021-05-19T08:30:20.000Z
|
2021-05-19T08:30:20.000Z
|
notebooks/1.0_nc_testing_pipeline.ipynb
|
ashish1610dhiman/learning_norms_with_mcmc_from_pcfg_IJCAI21
|
90d42333e7d810822ccf19864f5badc743b066a1
|
[
"MIT"
] | null | null | null |
notebooks/1.0_nc_testing_pipeline.ipynb
|
ashish1610dhiman/learning_norms_with_mcmc_from_pcfg_IJCAI21
|
90d42333e7d810822ccf19864f5badc743b066a1
|
[
"MIT"
] | null | null | null | 142.680851 | 62,660 | 0.839696 |
[
[
[
"import sys\nsys.path.append('../src')",
"_____no_output_____"
],
[
"import csv\nimport yaml\nimport tqdm\nimport math\nimport pickle\nimport numpy as np\nimport pandas as pd\nimport itertools\nimport operator\nfrom operator import concat, itemgetter\nfrom pickle_wrapper import unpickle, pickle_it\nimport matplotlib.pyplot as plt\nimport dask\nfrom dask.distributed import Client\nfrom pathlib import Path\nfrom collections import defaultdict\nfrom functools import reduce\nfrom operator import concat, itemgetter\nimport ast\n\n\n\nfrom pickle_wrapper import unpickle, pickle_it\nfrom mcmc_norm_learning.algorithm_1_v4 import to_tuple\nfrom mcmc_norm_learning.algorithm_1_v4 import create_data\nfrom mcmc_norm_learning.rules_4 import get_prob, get_log_prob\nfrom mcmc_norm_learning.environment import position,plot_env\nfrom mcmc_norm_learning.robot_task_new import task, robot, plot_task\nfrom mcmc_norm_learning.algorithm_1_v4 import algorithm_1, over_dispersed_starting_points\nfrom mcmc_norm_learning.mcmc_convergence import prepare_sequences, calculate_R\nfrom mcmc_norm_learning.rules_4 import q_dict, rule_dict, get_log_prob\nfrom algorithm_2_utilities import Likelihood\nfrom mcmc_norm_learning.mcmc_performance import performance\nfrom collections import Counter",
"_____no_output_____"
],
[
"with open(\"../params_nc.yaml\", 'r') as fd:\n params = yaml.safe_load(fd)",
"_____no_output_____"
]
],
[
[
"### Step 1: Default Environment and params",
"_____no_output_____"
]
],
[
[
"##Get default env\nenv = unpickle('../data/env.pickle')",
"_____no_output_____"
],
[
"##Get default task\ntrue_norm_exp = params['true_norm']['exp']\nnum_observations = params['num_observations']\nobs_data_set = params['obs_data_set']\n\nw_nc=params[\"w_nc\"]\nn = params['n']\nm = params['m']\nrf = params['rf']\nrhat_step_size = params['rhat_step_size']\ntop_n = params[\"top_norms_n\"]\n\n\ncolour_specific = params['colour_specific']\nshape_specific = params['shape_specific']\ntarget_area_parts = params['target_area'].replace(' ','').split(';')\ntarget_area_part0 = position(*map(float, target_area_parts[0].split(',')))\ntarget_area_part1 = position(*map(float, target_area_parts[1].split(',')))\ntarget_area = (target_area_part0, target_area_part1)\nprint(target_area_part0.coordinates())\nprint(target_area_part1.coordinates())\nthe_task = task(colour_specific, shape_specific,target_area)",
"(-0.8, 0.7)\n(0.25, 0.99)\n"
],
[
"fig,axs=plt.subplots(1,2,figsize=(9,4),dpi=100);\nplot_task(env,axs[0],\"Initial Task State\",the_task,True)\naxs[1].text(0,0.5,\"\\n\".join([str(x) for x in true_norm_exp]),wrap=True)\naxs[1].axis(\"off\")",
"_____no_output_____"
]
],
[
[
"### Step 2: Non Compliant Obs",
"_____no_output_____"
]
],
[
[
"obs = nc_obs= create_data(true_norm_exp,env,name=None,task=the_task,random_task=False,\n num_actionable=np.nan,num_repeat=num_observations,w_nc=w_nc,verbose=False)",
"Repetition of Task: 100%|██████████| 100/100 [00:00<00:00, 665.00it/s]\n"
],
[
"true_norm_prior = get_prob(\"NORMS\",true_norm_exp) \ntrue_norm_log_prior = get_log_prob(\"NORMS\",true_norm_exp) ",
"_____no_output_____"
],
[
"if not Path('../data_nc/observations_ad_0.1.pickle').exists():\n pickle_it(obs, '../data_nc/observations_ad_0.1.pickle')",
"_____no_output_____"
]
],
[
[
"### Step 3: MCMC chains",
"_____no_output_____"
]
],
[
[
"%%time\n%%capture\nnum_chains = math.ceil(m/2)\nstarts, info = over_dispersed_starting_points(num_chains,obs,env,\\\n the_task,time_threshold=math.inf,w_normative=(1-w_nc))",
"\nKeyboardInterrupt\n\n"
],
[
"with open('../metrics/starts_info_nc_parallel.txt', 'w') as chain_info:\n chain_info.write(info)",
"_____no_output_____"
],
[
"@dask.delayed\ndef delayed_alg1(obs,env,the_task,q_dict,rule_dict,start,rf,max_iters,w_nc):\n exp_seq,log_likelihoods = algorithm_1(obs,env,the_task,q_dict,rule_dict,\n \"dummy value\",start = start,relevance_factor=rf,\\\n max_iterations=max_iters,w_normative=1-w_nc,verbose=False)\n log_posteriors = [None]*len(exp_seq)\n for i in range(len(exp_seq)):\n exp = exp_seq[i]\n ll = log_likelihoods[i]\n log_prior = get_log_prob(\"NORMS\",exp) # Note: this imports the rules dict from rules_4.py\n log_posteriors[i] = log_prior + ll\n return {'chain': exp_seq, 'log_posteriors': log_posteriors}",
"_____no_output_____"
],
[
"%%time\n%%capture\nchains_and_log_posteriors=[]\nfor i in tqdm.tqdm(range(num_chains),desc=\"Loop for Individual Chains\"):\n chains_and_log_posteriors.append(\n delayed_alg1(obs,env,the_task,q_dict,rule_dict,starts[i],rf,4*n,w_nc).compute())",
"CPU times: user 5min 19s, sys: 1.16 s, total: 5min 20s\nWall time: 5min 22s\n"
],
[
"from joblib import Parallel, delayed",
"_____no_output_____"
],
[
"def delayed_alg1_joblib(start_i):\n alg1_result=delayed_alg1(obs=obs,env=env,the_task=the_task,q_dict=q_dict,\\\n rule_dict=rule_dict,start=start_i,rf=rf,\\\n max_iters=4*n,w_nc=w_nc).compute()\n return (alg1_result)",
"_____no_output_____"
],
[
"%%time\n%%capture\nchains_and_log_posteriors=[]\nchains_and_log_posteriors=Parallel(verbose = 2,n_jobs = -1\\\n )(delayed( delayed_alg1_joblib )(starts[run])\\\n for run in tqdm.tqdm(range(num_chains),desc=\"Loop for Individual Chains\"))",
"CPU times: user 16.2 ms, sys: 5.02 ms, total: 21.2 ms\nWall time: 2min 27s\n"
],
[
"pickle_it(chains_and_log_posteriors, '../data_nc/chains_and_log_posteriors.pickle')",
"_____no_output_____"
]
],
[
[
"### Step 4: Pass to analyse chains",
"_____no_output_____"
]
],
[
[
"with open('../metrics/chain_posteriors_nc.csv', 'w', newline='') as csvfile, \\\n open('../metrics/chain_info.txt', 'w') as chain_info:\n chain_info.write(f'Number of chains: {len(chains_and_log_posteriors)}\\n')\n chain_info.write(f'Length of each chain: {len(chains_and_log_posteriors[0][\"chain\"])}\\n')\n \n csv_writer = csv.writer(csvfile)\n csv_writer.writerow(('chain_number', 'chain_pos', 'expression', 'log_posterior'))\n exps_in_chains = [None]*len(chains_and_log_posteriors)\n for i,chain_data in enumerate(chains_and_log_posteriors): # Consider skipping first few entries\n chain = chain_data['chain']\n log_posteriors = chain_data['log_posteriors']\n exp_lp_pairs = list(zip(chain,log_posteriors))\n\n exps_in_chains[i] = set(map(to_tuple, chain))\n\n #print(sorted(log_posteriors, reverse=True))\n\n lps_to_exps = defaultdict(set)\n for exp,lp in exp_lp_pairs:\n lps_to_exps[lp].add(to_tuple(exp))\n\n num_exps_in_chain = len(exps_in_chains[i])\n\n print(lps_to_exps.keys())\n print('\\n')\n\n chain_info.write(f'Num. expressions in chain {i}: {num_exps_in_chain}\\n')\n decreasing_lps = sorted(lps_to_exps.keys(), reverse=True)\n chain_info.write(\"Expressions by decreasing log posterior\\n\")\n for lp in decreasing_lps:\n chain_info.write(f'lp = {lp} [{len(lps_to_exps[lp])} exps]:\\n')\n for exp in lps_to_exps[lp]:\n chain_info.write(f' {exp}\\n')\n chain_info.write('\\n')\n chain_info.write('\\n')\n\n changed_exp_indices = [i for i in range(1,len(chain)) if chain[i] != chain[i-1]]\n print(f'Writing {len(exp_lp_pairs)} rows to CSV file\\n')\n csv_writer.writerows(((i,j,chain_lp_pair[0],chain_lp_pair[1]) for j,chain_lp_pair in enumerate(exp_lp_pairs)))\n\n all_exps = set(itertools.chain(*exps_in_chains))\n chain_info.write(f'Total num. distinct exps across all chains (including warm-up): {len(all_exps)}\\n')\n\n true_norm_exp = params['true_norm']['exp']\n true_norm_tuple = to_tuple(true_norm_exp)\n \n chain_info.write(f'True norm in some chain(s): {true_norm_tuple in all_exps}\\n')\n\n num_chains_in_to_exps = defaultdict(set)\n for exp in all_exps:\n num_chains_in = operator.countOf(map(operator.contains, \n exps_in_chains,\n (exp for _ in range(len(exps_in_chains)))\n ),\n True)\n num_chains_in_to_exps[num_chains_in].add(exp)\n for num in sorted(num_chains_in_to_exps.keys(), reverse=True):\n chain_info.write(f'Out of {len(exps_in_chains)} chains ...\\n')\n chain_info.write(f'{len(num_chains_in_to_exps[num])} exps are in {num} chains.\\n')\ncsvfile.close()\nchain_info.close()",
"dict_keys([-18862.095952127733, -13741.494622661046, -13740.396010372377, -13742.593234949714, -13744.79045952705, -13733.346755531122, -13592.544771527248, -13591.44615923858, -13541.063800668202, -13542.16241295687, -13543.261025245538])\n\n\nWriting 800 rows to CSV file\n\ndict_keys([-13740.396010372377, -13741.494622661046, -13733.346755531122, -13739.820646227474, -13739.415181119366, -13752.768427620178, -13753.867039908846, -13751.66981533151, -13746.582218996278, -13747.680831284946, -13656.886202498481, -13604.306619350768, -13605.405231639435, -13603.2080070621, -13606.503843928103, -13602.210359029255, -13603.308971317923, -13604.407583606591])\n\n\nWriting 800 rows to CSV file\n\n"
],
[
"result=pd.read_csv(\"../metrics/chain_posteriors_nc.csv\")",
"_____no_output_____"
],
[
"log_post_no_norm=Likelihood([\"Norms\",[\"No-Norm\"]],the_task,obs,env,w_normative=1-w_nc)\nlog_post_true_norm=Likelihood(true_norm_exp,the_task,obs,env,w_normative=1-w_nc)\n\nprint(log_post_no_norm,log_post_true_norm)",
"-13732.653608350562 -13201.800300297418\n"
],
[
"result.groupby(\"chain_number\")[[\"log_posterior\"]].agg(['min','max','mean','std'])",
"_____no_output_____"
],
[
"hist_plot=result['log_posterior'].hist(by=result['chain_number'],bins=10)\nplt.savefig(\"../data_nc/nc_hist.jpg\")",
"_____no_output_____"
],
[
"grouped = result.groupby('chain_number')[[\"log_posterior\"]]\n\nncols=2\nnrows = int(np.ceil(grouped.ngroups/ncols))\n\nfig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(14,5), sharey=False)\n\nfor (key, ax) in zip(grouped.groups.keys(), axes.flatten()):\n grouped.get_group(key).plot(ax=ax)\n ax.axhline(y=log_post_no_norm,label=\"No Norm\",c='r')\n ax.axhline(y=log_post_true_norm,label=\"True Norm\",c='g')\n ax.title.set_text(\"For chain={}\".format(key))\n ax.legend()\nplt.show()\nplt.savefig(\"../plots/nc_movement.jpg\")",
"_____no_output_____"
]
],
[
[
"### Step 5: Convergence Tests",
"_____no_output_____"
]
],
[
[
"def conv_test(chains):\n convergence_result, split_data = calculate_R(chains, rhat_step_size)\n with open('../metrics/conv_test_nc.txt', 'w') as f:\n f.write(convergence_result.to_string())\n return reduce(concat, split_data)",
"_____no_output_____"
],
[
"chains = list(map(itemgetter('chain'), chains_and_log_posteriors))\nposterior_sample = conv_test(prepare_sequences(chains, warmup=True))\npickle_it(posterior_sample, '../data_nc/posterior_nc.pickle')",
"_____no_output_____"
]
],
[
[
"### Step 6: Extract Top Norms",
"_____no_output_____"
]
],
[
[
"learned_expressions=Counter(map(to_tuple, posterior_sample))",
"_____no_output_____"
],
[
"top_norms_with_freq = learned_expressions.most_common(top_n)\ntop_norms = list(map(operator.itemgetter(0), top_norms_with_freq))",
"_____no_output_____"
],
[
"exp_posterior_df = pd.read_csv('../metrics/chain_posteriors_nc.csv', usecols=['expression','log_posterior'])\nexp_posterior_df = exp_posterior_df.drop_duplicates()\nexp_posterior_df['post_rank'] = exp_posterior_df['log_posterior'].rank(method='dense',ascending=False)\nexp_posterior_df.sort_values('post_rank', inplace=True)\nexp_posterior_df['expression'] = exp_posterior_df['expression'].transform(ast.literal_eval)\nexp_posterior_df['expression'] = exp_posterior_df['expression'].transform(to_tuple)",
"_____no_output_____"
],
[
"exp_posterior_df",
"_____no_output_____"
],
[
"def log_posterior(exp, exp_lp_df):\n return exp_lp_df.loc[exp_lp_df['expression'] == exp]['log_posterior'].iloc[0]",
"_____no_output_____"
],
[
"with open('../metrics/precision_recall_nc.txt', 'w') as f:\n f.write(f\"Number of unique Norms in sequence={len(learned_expressions)}\\n\")\n f.write(f\"Top {top_norms} norms:\\n\")\n for expression,freq in top_norms_with_freq:\n f.write(f\"Freq. {freq}, lp {log_posterior(expression, exp_posterior_df)}: \")\n f.write(f\"{expression}\\n\")\n f.write(\"\\n\")",
"_____no_output_____"
],
[
"pr_result=performance(the_task,env,true_norm_exp,learned_expressions,\n folder_name=\"temp\",file_name=\"top_norm\",\n top_n=n,beta=1,repeat=100000,verbose=False)",
"Repetition of Task: 0%| | 126/100000 [00:00<02:44, 608.65it/s]"
],
[
"top_norms[3]",
"_____no_output_____"
],
[
"true_norm_exp",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f3c9bcc12e5f2a36d779a2882dd2b987c02c9
| 694,820 |
ipynb
|
Jupyter Notebook
|
docs/jupyter_notebooks/cluster_simulated_annotators_nb.ipynb
|
mherde/annotlib
|
a45dc9d9bebca277cad123f9cb830a3a63231674
|
[
"MIT"
] | 3 |
2020-09-22T00:50:23.000Z
|
2022-01-24T12:41:34.000Z
|
docs/jupyter_notebooks/cluster_simulated_annotators_nb.ipynb
|
scikit-activeml/annotlib
|
a45dc9d9bebca277cad123f9cb830a3a63231674
|
[
"MIT"
] | null | null | null |
docs/jupyter_notebooks/cluster_simulated_annotators_nb.ipynb
|
scikit-activeml/annotlib
|
a45dc9d9bebca277cad123f9cb830a3a63231674
|
[
"MIT"
] | null | null | null | 1,438.550725 | 249,464 | 0.956818 |
[
[
[
"# Clusters as Knowledge Areas of Annotators",
"_____no_output_____"
]
],
[
[
"# import required packages\nimport sys\nsys.path.append(\"../..\")\nimport warnings\nwarnings.filterwarnings('ignore')\n\nimport numpy as np\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n\nfrom annotlib import ClusterBasedAnnot\n\nfrom sklearn.datasets import make_classification\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.cluster import KMeans\nfrom sklearn.metrics import accuracy_score",
"_____no_output_____"
]
],
[
[
"A popular approach to simulate annotators is to use clustering methods. \nBy using clustering methods, we can emulate areas of knowledge. \nThe assumption is that the knowledge of an annotator is not constant for a whole classification problem, but there are areas where the annotator has a wider knowledge compared to areas of sparse knowledge. \n\nAs the samples lie in a feature space, we can model the area of knowledge as an area in the feature space.\n\nThe simulation of annotators by means of clustering is implemented by the class [ClusterBasedAnnot](../annotlib.cluster_based.rst). \nTo create such annotators, you have to provide the samples `X`, their corresponding true class labels `y_true` and the cluster labels `y_cluster`.\n\nIn this section, we introduce the following simulation options:\n\n- class labels as clustering,\n- clustering algorithms to find clustering,\n- and feature space as a single cluster.\n\nThe code below generates a two-dimensional (`n_features=2`) artificial data set with `n_samples=500` samples and `n_classes=4` classes.",
"_____no_output_____"
]
],
[
[
"X, y_true = make_classification(n_samples=500, n_features=2, \n n_informative=2, n_redundant=0, \n n_repeated=0, n_classes=4, \n n_clusters_per_class=1, \n flip_y=0.1, random_state=4)\nplt.figure(figsize=(5, 3), dpi=150)\nplt.scatter(X[:, 0], X[:, 1], marker='o', c=y_true, s=10)\nplt.title('artificial data set: samples with class labels', fontsize=7)\nplt.xticks(fontsize=7)\nplt.yticks(fontsize=7)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 1. Class Labels as Clustering\nIf you do not provide any cluster labels `y_cluster`, the true class labels `y_true` are assumed to be a representive clustering. \nAs a result the class labels and cluster labels are equivalent `y_cluster = y_true` and define the knowledge areas of the simulated annotators. \n\nTo simulate annotators on this dataset, we create an instance of the [ClusterBasedAnnot](../annotlib.cluster_based.rst) class by providing the samples `X` with the true labels `y_true` as input.",
"_____no_output_____"
]
],
[
[
"# simulate annotators where the clusters are defined by the class labels\nclust_annot_cls = ClusterBasedAnnot(X=X, y_true=y_true, random_state=42)",
"_____no_output_____"
]
],
[
[
"The above simulated annotators have knowledge areas defined by the class label distribution. \nAs a result, there are four knowledge areas respectively clusters. \n\nIn the default setting, the number of annotators is equal to the number of defined clusters. \nCorrespondingly, there are four simulated annotators in our example.\n☝🏽An important aspect is the simulation of the labelling performances of the annotators on the different clusters.\n\nBy default, each annotator is assumed to be an expert on a single cluster.\nSince we have four clusters and four annotators, each cluster has only one annotator as expert.\n\nBeing an expert means that an annotator has a higher probability for providing the correct class label for a sample than in the clusters of low expertise.\n\nLet the number of clusters be $K$ (`n_clusters`) and the number of annotators be $A$ (`n_annotators`). \nFor the case $K=A$, an annotator $a_i$ is expert on cluster $c_i$ with $i \\in \\{0,\\dots,A-1\\}$, the probability of providing the correct class label $y^{\\text{true}}_\\mathbf{x}$ for sample $\\mathbf{x} \\in c_i$ is defined by \n\n$$p(y^{\\text{true}}_\\mathbf{x} \\mid \\mathbf{x}, a_i, c_i) = U(0.8, 1.0)$$\n\nwhere $U(a,b)$ means that a value is uniformly drawn from the interval $[0.8, 1.0]$.\nIn contrast for the clusters of low expertise, the default probability for providing a correct class label is defined by\n\n$$p(y^{\\text{true}}_\\mathbf{x} \\mid \\mathbf{x}, a_i, c_j) = U\\left(\\frac{1}{C}, \\text{min}(\\frac{1}{C}+0.1,1)\\right),$$\n\nwhere $j=0,\\dots,A-1$, $j\\neq i$ and $C$ denotes the number of classes (`n_classes`).\n\nThese properties apply only for the default settings.\nThe actual labelling accuracies per cluster are exemplary plotted for annotator $a_0$ below.",
"_____no_output_____"
]
],
[
[
"acc_cluster = clust_annot_cls.labelling_performance_per_cluster(accuracy_score)\nx = np.arange(len(np.unique(clust_annot_cls.y_cluster_)))\nplt.figure(figsize=(4, 2), dpi=150)\nplt.bar(x, acc_cluster[0])\nplt.xticks(x, ('cluster $c_0$', 'cluster $c_1$', 'cluster $c_2$', \n 'cluster $c_3$'), fontsize=7)\nplt.ylabel('labelling accuracy', fontsize=7)\nplt.title('labelling accuracy of annotator $a_0$', \n fontsize=7)\nplt.show()",
"_____no_output_____"
]
],
[
[
"The above figure matches the description of the default behaviour.\nWe can see that the accuracy of annotator $a_0$ is high in cluster $c_0$, whereas the labelling accuracy on the remaining clusters is comparable to randomly guessing of class labels.\n\nYou can also manually define properties of the annotators.\nThis may be interesting when you want to evaluate the performance of a developed method coping with multiple uncertain annotators. \n\nLet's see how the ranges of uniform distributions for correct class labels on the clusters can be defined manually. For the default setting, we observe the following ranges:",
"_____no_output_____"
]
],
[
[
"print('ranges of uniform distributions for correct' \n +' class labels on the clusters:')\nfor a in range(clust_annot_cls.n_annotators()):\n print('annotator a_' + str(a) + ':\\n' \n + str(clust_annot_cls.cluster_labelling_acc_[a]))",
"ranges of uniform distributions for correct class labels on the clusters:\nannotator a_0:\n[[0.8 1. ]\n [0.25 0.35]\n [0.25 0.35]\n [0.25 0.35]]\nannotator a_1:\n[[0.25 0.35]\n [0.8 1. ]\n [0.25 0.35]\n [0.25 0.35]]\nannotator a_2:\n[[0.25 0.35]\n [0.25 0.35]\n [0.8 1. ]\n [0.25 0.35]]\nannotator a_3:\n[[0.25 0.35]\n [0.25 0.35]\n [0.25 0.35]\n [0.8 1. ]]\n"
]
],
[
[
"The attribute `cluster_labelling_acc_` is an array with the shape `(n_annotators, n_clusters, 2)` and can be defined by means of the parameter `cluster_labelling_acc`.\nThis parameter may be either a `str` or array-like.\n\nBy default, `cluster_labelling_acc='one_hot'` is valid, which indicates that each annotator is expert on one cluster.\n\nAnother option is `cluster_labelling_acc='equidistant'` and is explained in one of the following examples. \n\nThe entry `cluster_labelling_acc_[i, j , 0]` indicates the lower limit of the uniform distribution for correct class labels of annotator $a_i$ on cluster $c_j$. Analogous, the entry `cluster_labelling_acc_[i, j ,1]` represents the upper limit.\n\nThe sampled probabilities for correct class labels are also the confidence scores of the annotators.\nAn illustration of the annotators $a_0$ and $a_1$ simulated with default values on the predefined data set is given in the following plots. \nThe confidence scores correspond to the size of the crosses and dots.",
"_____no_output_____"
]
],
[
[
"clust_annot_cls.plot_class_labels(X=X, y_true=y_true, annotator_ids=[0, 1], \n plot_confidences=True)\nprint('The confidence scores correspond to the size of the crosses and dots.')\nplt.tight_layout()\nplt.show()",
"The confidence scores correspond to the size of the crosses and dots.\n"
]
],
[
[
"☝🏽To sum up, by using the true class labels `y_true` as proxy of a clustering and specifying the input parameter `cluster_labelling_acc`, annotators being experts on different classes can be simulated. ",
"_____no_output_____"
],
[
"## 2. Clustering Algorithms to Find Clustering\nThere are several algorithms available for perfoming clustering on a data set. The framework *scikit-learn* provides many clustering algorithms, e.g.\n\n- `sklearn.cluster.KMeans`,\n- `sklearn.cluster.DBSCAN`,\n- `sklearn.cluster.AgglomerativeClustering`,\n- `sklearn.cluster.bicluster.SpectralBiclusterin`,\n- `sklearn.mixture.BayesianGaussianMixture`,\n- and `sklearn.mixture.GaussianMixture`.\n\nWe examplary apply the `KMeans` algorithm being a very popular clustering algorithm. \nFor this purpose, you have to specify the number of clusters. \nBy doing so, you determine the number of different knowledge areas in the feature space with reference to the simulation of annotators.\n\nWe set `n_clusters = 3` as number of clusters. \nThe clusters found by `KMeans` on the previously defined data set are given in the following:",
"_____no_output_____"
]
],
[
[
"# standardize features of samples\nX_z = StandardScaler().fit_transform(X)\n\n# apply k-means algorithm\ny_cluster_k_means = KMeans(n_clusters=3).fit_predict(X_z)\n\n# plot found clustering\nplt.figure(figsize=(5, 3), dpi=150)\nplt.scatter(X[:, 0], X[:, 1], c=y_cluster_k_means, s=10)\nplt.title('samples with cluster labels of k-means algorithm', fontsize=7)\nplt.xticks(fontsize=7)\nplt.yticks(fontsize=7)\nplt.show()",
"_____no_output_____"
]
],
[
[
"The clusters are found on the standardised data set, so that the mean of each feature is 0 and the variance is 1.\nThe computed cluster labels `y_cluster` are used as input parameter to simulate two annotators, where the annotator $a_0$ is expert on two clusters and the annotator $a_1$ is expert on one cluster.",
"_____no_output_____"
]
],
[
[
"# define labelling accuracy ranges on four clusters for three annotators\nclu_label_acc_km = np.array([[[0.8, 1], [0.8, 1], [0.3, 0.5]],\n [[0.3, 0.5], [0.3, 0.5], [0.8, 1]]])\n\n# simulate annotators\ncluster_annot_kmeans = ClusterBasedAnnot(X=X, y_true=y_true, \n y_cluster=y_cluster_k_means, \n n_annotators=2, \n cluster_labelling_acc=clu_label_acc_km)\n\n# scatter plots of annotators\ncluster_annot_kmeans.plot_class_labels(X=X, y_true=y_true, \n plot_confidences=True, \n annotator_ids=[0, 1])\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"☝🏽The employment of different clustering allows to define almost arbitrarily knowledge areas and offers a huge flexibiility. \nHowever, the clusters should reflect the actual regions within a feature space.",
"_____no_output_____"
],
[
"## 3. Feature Space as a Single Cluster\nFinally, you can simulate annotators whose knowledge does not depend on clusters.\nHence, their knowledge level is constant over the whole feature space. \nTo emulate such a behaviour, you create a clustering array `y_cluster_const`, in which all samples in the feature space are assigned to the same cluster.",
"_____no_output_____"
]
],
[
[
"y_cluster_const = np.zeros(len(X), dtype=int)\ncluster_annot_const = ClusterBasedAnnot(X=X, y_true=y_true, \n y_cluster=y_cluster_const, \n n_annotators=5, \n cluster_labelling_acc='equidistant')\n\n# plot labelling accuracies\ncluster_annot_const.plot_labelling_accuracy(X=X, y_true=y_true, \n figsize=(4, 2), fontsize=6)\nplt.show()\n\n# print predefined labelling accuracies\nprint('ranges of uniform distributions for correct class ' \n + 'labels on the clusters:')\nfor a in range(cluster_annot_const.n_annotators()):\n print('annotator a_' + str(a) + ': ' \n + str(cluster_annot_const.cluster_labelling_acc_[a]))",
"_____no_output_____"
]
],
[
[
"Five annotators are simulated whose labelling accuracy intervals are increasing with the index number of the annotator. \n☝🏽The input parameter `cluster_labelling_acc='equidistant'` means that the lower bounds of the labelling accuracy intervals between two annotators have always the same distance. \n\nIn general, the interval of the correct labelling probability for annotator $a_i$ is computed by\n\n$$d = \\frac{1 - \\frac{1}{C}}{A+1},$$\n\n$$p(y^{(\\text{true})}_\\mathbf{x} \\mid \\mathbf{x}, a_i, c_j) \\in U(\\frac{1}{C} + i \\cdot d, \\frac{1}{C} + 2 \\cdot i \\cdot d),$$\n\nwhere $i=0,\\dots,A-1$ and $j=0,\\dots,K-1$ with $K$.\n\nThis procedure ensures that the intervals of the correct labelling probabilities are overlapping.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a4f4d3441e77c9e0878bda6fd2ac1f37d64f071
| 19,385 |
ipynb
|
Jupyter Notebook
|
9-Day-First-Machine-Learning-Model-and-Model-Validation/exercise-your-first-machine-learning-model.ipynb
|
Ivanbh214/30-Days-of-ML-Kaggle
|
45222511fa9ca725007e84b2665d3c4ec30377e7
|
[
"MIT"
] | 109 |
2021-08-16T03:54:30.000Z
|
2022-03-21T11:43:54.000Z
|
9-Day-First-Machine-Learning-Model-and-Model-Validation/exercise-your-first-machine-learning-model.ipynb
|
Juan-glitch/30-Days-of-ML-Kaggle
|
d401a62ada9f517390dc333b667b8b6c841dbc8c
|
[
"MIT"
] | null | null | null |
9-Day-First-Machine-Learning-Model-and-Model-Validation/exercise-your-first-machine-learning-model.ipynb
|
Juan-glitch/30-Days-of-ML-Kaggle
|
d401a62ada9f517390dc333b667b8b6c841dbc8c
|
[
"MIT"
] | 47 |
2021-08-16T03:58:44.000Z
|
2022-03-23T01:34:46.000Z
| 19,385 | 19,385 | 0.647924 |
[
[
[
"**This notebook is an exercise in the [Introduction to Machine Learning](https://www.kaggle.com/learn/intro-to-machine-learning) course. You can reference the tutorial at [this link](https://www.kaggle.com/dansbecker/your-first-machine-learning-model).**\n\n---\n",
"_____no_output_____"
],
[
"## Recap\nSo far, you have loaded your data and reviewed it with the following code. Run this cell to set up your coding environment where the previous step left off.",
"_____no_output_____"
]
],
[
[
"# Code you have previously used to load data\nimport pandas as pd\n\n# Path of the file to read\niowa_file_path = '../input/home-data-for-ml-course/train.csv'\n\nhome_data = pd.read_csv(iowa_file_path)\n\n# Set up code checking\nfrom learntools.core import binder\nbinder.bind(globals())\nfrom learntools.machine_learning.ex3 import *\n\nprint(\"Setup Complete\")",
"Setup Complete\n"
]
],
[
[
"# Exercises\n\n## Step 1: Specify Prediction Target\nSelect the target variable, which corresponds to the sales price. Save this to a new variable called `y`. You'll need to print a list of the columns to find the name of the column you need.\n",
"_____no_output_____"
]
],
[
[
"# print the list of columns in the dataset to find the name of the prediction target\nhome_data.columns",
"_____no_output_____"
],
[
"y = home_data.SalePrice\n\n# Check your answer\nstep_1.check()",
"_____no_output_____"
],
[
"# The lines below will show you a hint or the solution.\n# step_1.hint() \n# step_1.solution()",
"_____no_output_____"
]
],
[
[
"## Step 2: Create X\nNow you will create a DataFrame called `X` holding the predictive features.\n\nSince you want only some columns from the original data, you'll first create a list with the names of the columns you want in `X`.\n\nYou'll use just the following columns in the list (you can copy and paste the whole list to save some typing, though you'll still need to add quotes):\n\n* LotArea\n* YearBuilt\n* 1stFlrSF\n* 2ndFlrSF\n* FullBath\n* BedroomAbvGr\n* TotRmsAbvGrd\n\nAfter you've created that list of features, use it to create the DataFrame that you'll use to fit the model.",
"_____no_output_____"
]
],
[
[
"# Create the list of features below\nfeature_names = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']\n\n# Select data corresponding to features in feature_names\nX = home_data[feature_names]\n\n# Check your answer\nstep_2.check()",
"_____no_output_____"
],
[
"# step_2.hint()\n# step_2.solution()",
"_____no_output_____"
]
],
[
[
"## Review Data\nBefore building a model, take a quick look at **X** to verify it looks sensible",
"_____no_output_____"
]
],
[
[
"# Review data\n# print description or statistics from X\nX.describe()",
"_____no_output_____"
],
[
"# print the top few lines\nX.head()",
"_____no_output_____"
]
],
[
[
"## Step 3: Specify and Fit Model\nCreate a `DecisionTreeRegressor` and save it iowa_model. Ensure you've done the relevant import from sklearn to run this command.\n\nThen fit the model you just created using the data in `X` and `y` that you saved above.",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeRegressor\n#specify the model. \n#For model reproducibility, set a numeric value for random_state when specifying the model\niowa_model = DecisionTreeRegressor(random_state=2021)\n\n# Fit the model\niowa_model.fit(X, y)\n\n# Check your answer\nstep_3.check()",
"_____no_output_____"
],
[
"# step_3.hint()\n# step_3.solution()",
"_____no_output_____"
]
],
[
[
"## Step 4: Make Predictions\nMake predictions with the model's `predict` command using `X` as the data. Save the results to a variable called `predictions`.",
"_____no_output_____"
]
],
[
[
"predictions = iowa_model.predict(X)\nprint(predictions)\n\n# Check your answer\nstep_4.check()",
"[208500. 181500. 223500. ... 266500. 142125. 147500.]\n"
],
[
"# step_4.hint()\n# step_4.solution()",
"_____no_output_____"
]
],
[
[
"## Think About Your Results\n\nUse the `head` method to compare the top few predictions to the actual home values (in `y`) for those same homes. Anything surprising?\n",
"_____no_output_____"
]
],
[
[
"# You can write code in this cell\ny.head()",
"_____no_output_____"
]
],
[
[
"It's natural to ask how accurate the model's predictions will be and how you can improve that. That will be you're next step.\n\n# Keep Going\n\nYou are ready for **[Model Validation](https://www.kaggle.com/dansbecker/model-validation).**\n",
"_____no_output_____"
],
[
"---\n\n\n\n\n*Have questions or comments? Visit the [Learn Discussion forum](https://www.kaggle.com/learn-forum/161285) to chat with other Learners.*",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a4f51dcb5395577f54feb8b076dc4bf4712e8eb
| 407,894 |
ipynb
|
Jupyter Notebook
|
Deep Dream.ipynb
|
nileshpatra/Deep-Dream
|
5df8f65173229550c003c4afafb70fd66ab5d287
|
[
"MIT"
] | null | null | null |
Deep Dream.ipynb
|
nileshpatra/Deep-Dream
|
5df8f65173229550c003c4afafb70fd66ab5d287
|
[
"MIT"
] | null | null | null |
Deep Dream.ipynb
|
nileshpatra/Deep-Dream
|
5df8f65173229550c003c4afafb70fd66ab5d287
|
[
"MIT"
] | null | null | null | 1,796.889868 | 203,672 | 0.959742 |
[
[
[
"import torch\nfrom torchvision import models , transforms\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom torch.autograd import Variable \n\nimport skimage.io as io\nfrom skimage.transform import resize\n\n%matplotlib inline",
"_____no_output_____"
],
[
"model = models.vgg16(pretrained=True)",
"_____no_output_____"
],
[
"normalise = transforms.Normalize(\n mean=[0.485, 0.456, 0.406],\n std=[0.229, 0.224, 0.225]\n)\n\npreprocess = transforms.Compose([\n transforms.ToPILImage(),\n transforms.Resize((224, 224)),\n transforms.ToTensor(),\n normalise\n])\n\ndef deprocess(image):\n return image * torch.Tensor([0.229, 0.224, 0.225]) + torch.Tensor([0.485, 0.456, 0.406])",
"_____no_output_____"
],
[
"layers = list(model.features.modules())\ndef forward_pass(x , N):\n for i in range(N):\n x = layers[i+1](x)\n return x",
"_____no_output_____"
],
[
"model",
"_____no_output_____"
],
[
"def deep_dream(image , layer , iteration , lr):\n inp = Variable(preprocess(image).unsqueeze(0) , requires_grad = True)\n model.zero_grad()\n \n for i in range(iteration):\n out = forward_pass(inp , layer)\n loss = out.norm()\n loss.backward()\n inp.data = inp.data + lr*inp.grad.data\n \n inp = inp.data.squeeze()\n inp.transpose_(0, 1)\n inp.transpose_(1, 2)\n inp = np.clip(deprocess(inp), 0, 1)\n im = np.uint8(inp * 255)\n \n return im",
"_____no_output_____"
],
[
"def final_image(image , layer , iteration , lr):\n result = deep_dream(image , layer , iteration , lr)\n result = resize(result , result.shape)",
"_____no_output_____"
],
[
"im = io.imread('/home/nilesh/Desktop/MY FILES/ML_REVIEW/mountain_top.jpg')\nimg = deep_dream(im, layer=8, iteration=20, lr=0.3)\n\nplt.imshow(im)\nplt.show()\nplt.imshow(img)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f60580de3f5dd3813eedef7f5d1824cd39b5c
| 97,352 |
ipynb
|
Jupyter Notebook
|
All_1DCNN.ipynb
|
Rich2006/GPS-Spoofing
|
b8657dc85bc82fa100920dcdd67dc9517163eab4
|
[
"MIT"
] | null | null | null |
All_1DCNN.ipynb
|
Rich2006/GPS-Spoofing
|
b8657dc85bc82fa100920dcdd67dc9517163eab4
|
[
"MIT"
] | null | null | null |
All_1DCNN.ipynb
|
Rich2006/GPS-Spoofing
|
b8657dc85bc82fa100920dcdd67dc9517163eab4
|
[
"MIT"
] | null | null | null | 74.48508 | 26,762 | 0.66955 |
[
[
[
"from six.moves import cPickle as pickle\nimport keras\nfrom keras.models import Sequential\nfrom keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout\nfrom keras.callbacks import ModelCheckpoint",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Mounted at /content/drive\n"
],
[
"data_dir = '/content/drive/My Drive/Colab Notebooks/HEX New folder'",
"_____no_output_____"
],
[
"import glob\nimport os\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\nfrom scipy import stats\n\nimport matplotlib.pyplot as plt\n\nimport statsmodels.api as sm\nfrom sklearn.cluster import KMeans\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.decomposition import PCA\n\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error\n\n%matplotlib inline\n\n\n\n# normalize inputs from 0-255 to 0-1\nimport keras\nimport tensorflow as tf\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nfrom keras.layers import Dropout\n#from keras.utils import to_categorical\nfrom tensorflow.keras.utils import to_categorical\nfrom sklearn.preprocessing import LabelEncoder\n\nimport pandas.util.testing as tm",
"/usr/local/lib/python3.7/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
],
[
"def ReshapeY(Y_train,n):\n Y = list()\n for x in Y_train:\n Y.append(find_1(x, n))\n\n Y = np.array(Y)\n return Y\n print(Y.shape)\n \n \n# look for 1 ( spoof) in each \ndef find_1(x, n):\n if 1 in x:\n res = 1\n else: \n res = 0\n return res \n\n\n\n\n \ndef LOAD_data(path ):\n filenames = glob.glob(path + \"/*.csv\")\n\n dfs = []\n for filename in filenames:\n df=pd.read_csv(filename)\n if 'le0.csv'== filename[-7:]:\n df['attack'] = 0\n df = df[190:]\n\n else:\n df['attack'] = 1\n dfa = df['attack']\n df = df[14:]\n df = df.iloc[:-180]\n df = df.select_dtypes(exclude=['object','bool']) #remove nan\n df = df.loc[:, (df != 0).any(axis=0)] #remove zeros\n df = df.drop(df.std()[(df.std() == 0)].index, axis=1) #remove equals\n df=((df-df.min())/(df.max()-df.min()))*1\n\n df['attack'] = dfa\n dfs.append(df)\n\n\n # Concatenate all data into one DataFrame\n df = pd.concat(dfs, ignore_index=True)\n #df.head()\n \n \n # Concatenate all data into one DataFrame\n df = pd.concat(dfs, ignore_index=True)\n #df.head()\n\n df = df.select_dtypes(exclude=['object','bool']) #remove nan\n df = df.loc[:, (df != 0).any(axis=0)] #remove zeros\n df = df.drop(df.std()[(df.std() == 0)].index, axis=1) #remove equals\n\n sf = df[['roll', 'pitch', 'heading', 'rollRate', 'pitchRate', 'yawRate',\n 'groundSpeed', 'altitudeRelative', \n 'throttlePct', 'estimatorStatus.horizPosRatio',\n 'estimatorStatus.vertPosRatio',\n 'estimatorStatus.horizPosAccuracy','gps.courseOverGround']]\n scaled_data = scale(sf)\n \n\n pca = PCA(n_components = 9)\n pca.fit(scaled_data)\n pca_data = pca.transform(scaled_data)\n\n pca_data = pd.DataFrame(pca_data)\n\n df_sf = pd.concat([pca_data, df[['attack']]], axis=1)\n\n sf_t =df_sf\n\n data_dim = sf_t.shape[1] -1\n timesteps = 60\n num_classes = 2\n\n\n X = sf_t.drop(['attack'], axis =1).values\n Y = sf_t[['attack']].values\n\n\n ll = sf_t.shape[0] // timesteps\n ll\n\n x = np.array(X[0: (timesteps*ll)])\n y = np.array(Y[0: (timesteps*ll)])\n x.shape\n\n X_t = np.reshape(x,(-1,timesteps,data_dim))\n Y_t = np.reshape(y,(-1,timesteps,1))\n\n\n Y_t = ReshapeY(Y_t,timesteps )\n print(X_t.shape)\n print(Y_t.shape)\n\n # lb_make = LabelEncoder()\n # Y_t = lb_make.fit_transform(Y_t)\n # Y_t = tf.keras.utils.to_categorical(Y_t)\n # X_t = X_t.astype(\"float32\")\n # Y_t = Y_t.astype(\"float32\")\n # X_t /= 255\n \n return (X_t,Y_t)\n\n\ndef put_together(combined_array, asd):\n combined_array = np.concatenate((combined_array, asd), axis=0)\n #combined_array = np.delete(combined_array, 0, axis=0)\n return combined_array\n\n\ndef Delete_first(combined_array):\n combined_array = np.delete(combined_array, 0, axis=0)\n return combined_array",
"_____no_output_____"
],
[
"import os\n \npaths = [] \n# rootdir = r'C:\\Users\\lenovo\\OneDrive - aggies.ncat.edu\\Desktop\\new correct files\\HEX New folder'\nfor file in os.listdir(data_dir):\n d = os.path.join(data_dir, file)\n if os.path.isdir(d):\n paths.append(d)\n\n\n",
"_____no_output_____"
],
[
"paths",
"_____no_output_____"
],
[
"from sklearn.preprocessing import scale\n\ni = 0\nfor path in paths:\n (Xa,Ya) = LOAD_data(path)\n if (i == 0):\n X_ = Xa \n Y_ = Ya\n i = i + 1 \n else:\n X_ = np.concatenate((X_, Xa), axis=0)\n Y_ = np.concatenate((Y_, Ya), axis=0)",
"(461, 60, 9)\n(461,)\n"
],
[
"print(X_.shape)\nprint(Y_.shape)",
"(3844, 60, 9)\n(3844,)\n"
],
[
"",
"_____no_output_____"
],
[
"X_train_D,X_test_D, Y_train_D, Y_test_D = train_test_split(X_, Y_, test_size=0.10, random_state=1)",
"_____no_output_____"
],
[
"print(Y_test_D.shape, ':y test')\nprint(Y_train_D.shape, ':y train')",
"(846,) :y test\n(2998,) :y train\n"
],
[
"def ReshapeY(Y_train,n):\n Y = list()\n for x in Y_train:\n Y.append(find_1(x, n))\n\n Y = np.array(Y)\n return Y\n print(Y.shape)\n \n \n# look for 1 ( spoof) in each \ndef find_1(x, n):\n if 1 in x:\n res = 1\n else: \n res = 0\n return res",
"_____no_output_____"
],
[
"# normalize inputs from 0-255 to 0-1\nimport keras\nimport tensorflow as tf\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nfrom keras.layers import Dropout\n#from keras.utils import to_categorical\nfrom tensorflow.keras.utils import to_categorical\nfrom sklearn.preprocessing import LabelEncoder\n\n# one-hot encode the labels\nnum_classes = 2\nY_train_D_hot = tf.keras.utils.to_categorical(Y_train_D-1, num_classes)\nY_test_D_hot = tf.keras.utils.to_categorical(Y_test_D-1, num_classes)\n\n# # break training set into training and validation sets\n# (X_train, X_valid) = X_train_D[300:], X_train_D[:300]\n# (Y_train, Y_valid) = Y_train_D_hot[300:], Y_train_D_hot[:300]\nX_train,X_valid, Y_train, Y_valid = train_test_split(X_train_D, Y_train_D_hot, test_size=0.1, random_state=1)\n\n# X_train = X_train_D\n# Y_train = Y_train_D_hot\nX_test = X_test_D\nY_test = Y_test_D_hot",
"_____no_output_____"
],
[
"Y_valid.shape",
"_____no_output_____"
],
[
"# X_train = np.transpose(X_train, (1, 0, 2))\n# X_test = np.transpose(X_test, (1, 0, 2))\n# X_valid = np.transpose(X_valid, (1, 0, 2))\n\n# Y_train = np.transpose(Y_train, (1, 0, 2))\n# Y_test = np.transpose(Y_test, (1, 0, 2))\n# Y_valid = np.transpose(Y_valid, (1, 0, 2))",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"CNNch = 9\n\n# epch\nne = 100\n\nmodelC2 = Sequential()\n#1\nmodelC2.add(Conv1D(filters=16, kernel_size=64,strides = 16, padding='same', activation='relu', \n input_shape=(60, CNNch)))\nmodelC2.add(MaxPooling1D(pool_size=1))\n#2\nmodelC2.add(Conv1D(filters=16, kernel_size=3, strides = 1, padding='same', activation='relu'))\nmodelC2.add(MaxPooling1D(pool_size=1))\n#3\nmodelC2.add(Conv1D(filters=32, kernel_size=3, strides = 1, padding='same', activation='relu'))\nmodelC2.add(MaxPooling1D(pool_size=1))\nmodelC2.add(Dropout(0.2))\n#4\nmodelC2.add(Conv1D(filters=32, kernel_size=3, strides = 1, padding='same', activation='relu'))\nmodelC2.add(MaxPooling1D(pool_size=1))\nmodelC2.add(Dropout(0.2))\n#5\nmodelC2.add(Conv1D(filters=32, kernel_size=3, strides = 1, padding='same', activation='relu'))\n#paper no padding?, Yes, to make 5th layer output 6 width and 3 after pooling\n#-> same seems to perform little better because of more parameter? \n# little diffrernt from the paper but keep it as padding = 'same'\nmodelC2.add(MaxPooling1D(pool_size=1)) \n\nmodelC2.add(Flatten())\nmodelC2.add(Dense(10, activation='relu'))\nmodelC2.add(Dropout(0.2))\nmodelC2.add(Dense(2, activation='softmax'))\n\nmodelC2.summary()\n\n\n# compile the model\nmodelC2.compile(loss='categorical_crossentropy', optimizer='rmsprop', \n metrics=['accuracy'])\n\n# train the model\ncheckpointer = ModelCheckpoint(filepath='CNNC2.weights.best.hdf5', verbose=1, \n save_best_only=True)\n\nhist = modelC2.fit(X_train[:,:,0:CNNch], Y_train, batch_size=32, epochs=ne,\n validation_data=(X_valid[:,:,0:CNNch], Y_valid), callbacks=[checkpointer], \n verbose=1, shuffle=True)\n\n# load the weights that yielded the best validation accuracy\nmodelC2.load_weights('CNNC2.weights.best.hdf5')\n\n# evaluate and print test accuracy\nscore = modelC2.evaluate(X_test[:,:,0:CNNch], Y_test, verbose=0)\nprint('\\n', 'CNN Test accuracy:', score[1])\n\nscore = modelC2.evaluate(X_train[:,:,0:CNNch], Y_train, verbose=0)\nprint('\\n', 'CNN train accuracy:', score[1])\n\nscore = modelC2.evaluate(X_valid[:,:,0:CNNch], Y_valid, verbose=0)\nprint('\\n', 'CNN validation accuracy:', score[1])",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv1d (Conv1D) (None, 4, 16) 9232 \n_________________________________________________________________\nmax_pooling1d (MaxPooling1D) (None, 4, 16) 0 \n_________________________________________________________________\nconv1d_1 (Conv1D) (None, 4, 16) 784 \n_________________________________________________________________\nmax_pooling1d_1 (MaxPooling1 (None, 4, 16) 0 \n_________________________________________________________________\nconv1d_2 (Conv1D) (None, 4, 32) 1568 \n_________________________________________________________________\nmax_pooling1d_2 (MaxPooling1 (None, 4, 32) 0 \n_________________________________________________________________\ndropout (Dropout) (None, 4, 32) 0 \n_________________________________________________________________\nconv1d_3 (Conv1D) (None, 4, 32) 3104 \n_________________________________________________________________\nmax_pooling1d_3 (MaxPooling1 (None, 4, 32) 0 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 4, 32) 0 \n_________________________________________________________________\nconv1d_4 (Conv1D) (None, 4, 32) 3104 \n_________________________________________________________________\nmax_pooling1d_4 (MaxPooling1 (None, 4, 32) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 128) 0 \n_________________________________________________________________\ndense (Dense) (None, 10) 1290 \n_________________________________________________________________\ndropout_2 (Dropout) (None, 10) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 2) 22 \n=================================================================\nTotal params: 19,104\nTrainable params: 19,104\nNon-trainable params: 0\n_________________________________________________________________\nEpoch 1/100\n98/98 [==============================] - 3s 9ms/step - loss: 0.2846 - accuracy: 0.8783 - val_loss: 0.1601 - val_accuracy: 0.9393\n\nEpoch 00001: val_loss improved from inf to 0.16008, saving model to CNNC2.weights.best.hdf5\nEpoch 2/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.1460 - accuracy: 0.9512 - val_loss: 0.1124 - val_accuracy: 0.9480\n\nEpoch 00002: val_loss improved from 0.16008 to 0.11238, saving model to CNNC2.weights.best.hdf5\nEpoch 3/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0914 - accuracy: 0.9711 - val_loss: 0.1054 - val_accuracy: 0.9595\n\nEpoch 00003: val_loss improved from 0.11238 to 0.10539, saving model to CNNC2.weights.best.hdf5\nEpoch 4/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0821 - accuracy: 0.9759 - val_loss: 0.0914 - val_accuracy: 0.9595\n\nEpoch 00004: val_loss improved from 0.10539 to 0.09140, saving model to CNNC2.weights.best.hdf5\nEpoch 5/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0660 - accuracy: 0.9823 - val_loss: 0.5475 - val_accuracy: 0.8786\n\nEpoch 00005: val_loss did not improve from 0.09140\nEpoch 6/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0509 - accuracy: 0.9865 - val_loss: 0.0712 - val_accuracy: 0.9798\n\nEpoch 00006: val_loss improved from 0.09140 to 0.07124, saving model to CNNC2.weights.best.hdf5\nEpoch 7/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0395 - accuracy: 0.9913 - val_loss: 0.1874 - val_accuracy: 0.9624\n\nEpoch 00007: val_loss did not improve from 0.07124\nEpoch 8/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0254 - accuracy: 0.9929 - val_loss: 0.0771 - val_accuracy: 0.9855\n\nEpoch 00008: val_loss did not improve from 0.07124\nEpoch 9/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0263 - accuracy: 0.9936 - val_loss: 0.0597 - val_accuracy: 0.9769\n\nEpoch 00009: val_loss improved from 0.07124 to 0.05966, saving model to CNNC2.weights.best.hdf5\nEpoch 10/100\n98/98 [==============================] - 0s 5ms/step - loss: 0.0173 - accuracy: 0.9945 - val_loss: 0.0959 - val_accuracy: 0.9827\n\nEpoch 00010: val_loss did not improve from 0.05966\nEpoch 11/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0173 - accuracy: 0.9961 - val_loss: 0.0963 - val_accuracy: 0.9827\n\nEpoch 00011: val_loss did not improve from 0.05966\nEpoch 12/100\n98/98 [==============================] - 0s 5ms/step - loss: 0.0252 - accuracy: 0.9952 - val_loss: 0.1010 - val_accuracy: 0.9798\n\nEpoch 00012: val_loss did not improve from 0.05966\nEpoch 13/100\n98/98 [==============================] - 0s 5ms/step - loss: 0.0134 - accuracy: 0.9978 - val_loss: 0.1993 - val_accuracy: 0.9711\n\nEpoch 00013: val_loss did not improve from 0.05966\nEpoch 14/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0160 - accuracy: 0.9958 - val_loss: 0.0435 - val_accuracy: 0.9884\n\nEpoch 00014: val_loss improved from 0.05966 to 0.04353, saving model to CNNC2.weights.best.hdf5\nEpoch 15/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0155 - accuracy: 0.9971 - val_loss: 0.0639 - val_accuracy: 0.9855\n\nEpoch 00015: val_loss did not improve from 0.04353\nEpoch 16/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0053 - accuracy: 0.9978 - val_loss: 0.1574 - val_accuracy: 0.9740\n\nEpoch 00016: val_loss did not improve from 0.04353\nEpoch 17/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0123 - accuracy: 0.9965 - val_loss: 0.1515 - val_accuracy: 0.9798\n\nEpoch 00017: val_loss did not improve from 0.04353\nEpoch 18/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0073 - accuracy: 0.9984 - val_loss: 0.1476 - val_accuracy: 0.9769\n\nEpoch 00018: val_loss did not improve from 0.04353\nEpoch 19/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0029 - accuracy: 0.9994 - val_loss: 0.1786 - val_accuracy: 0.9769\n\nEpoch 00019: val_loss did not improve from 0.04353\nEpoch 20/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0160 - accuracy: 0.9974 - val_loss: 0.1183 - val_accuracy: 0.9798\n\nEpoch 00020: val_loss did not improve from 0.04353\nEpoch 21/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0070 - accuracy: 0.9974 - val_loss: 0.0512 - val_accuracy: 0.9855\n\nEpoch 00021: val_loss did not improve from 0.04353\nEpoch 22/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0099 - accuracy: 0.9971 - val_loss: 0.0395 - val_accuracy: 0.9855\n\nEpoch 00022: val_loss improved from 0.04353 to 0.03949, saving model to CNNC2.weights.best.hdf5\nEpoch 23/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0062 - accuracy: 0.9990 - val_loss: 0.1780 - val_accuracy: 0.9769\n\nEpoch 00023: val_loss did not improve from 0.03949\nEpoch 24/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0112 - accuracy: 0.9968 - val_loss: 0.0919 - val_accuracy: 0.9827\n\nEpoch 00024: val_loss did not improve from 0.03949\nEpoch 25/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0028 - accuracy: 0.9997 - val_loss: 0.0388 - val_accuracy: 0.9913\n\nEpoch 00025: val_loss improved from 0.03949 to 0.03879, saving model to CNNC2.weights.best.hdf5\nEpoch 26/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0039 - accuracy: 0.9987 - val_loss: 0.0984 - val_accuracy: 0.9855\n\nEpoch 00026: val_loss did not improve from 0.03879\nEpoch 27/100\n98/98 [==============================] - 0s 5ms/step - loss: 0.0168 - accuracy: 0.9974 - val_loss: 0.0748 - val_accuracy: 0.9798\n\nEpoch 00027: val_loss did not improve from 0.03879\nEpoch 28/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0030 - accuracy: 0.9990 - val_loss: 0.0859 - val_accuracy: 0.9827\n\nEpoch 00028: val_loss did not improve from 0.03879\nEpoch 29/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0022 - accuracy: 0.9990 - val_loss: 0.1540 - val_accuracy: 0.9827\n\nEpoch 00029: val_loss did not improve from 0.03879\nEpoch 30/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0031 - accuracy: 0.9990 - val_loss: 0.1628 - val_accuracy: 0.9827\n\nEpoch 00030: val_loss did not improve from 0.03879\nEpoch 31/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0068 - accuracy: 0.9990 - val_loss: 0.1246 - val_accuracy: 0.9913\n\nEpoch 00031: val_loss did not improve from 0.03879\nEpoch 32/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0079 - accuracy: 0.9987 - val_loss: 0.1672 - val_accuracy: 0.9884\n\nEpoch 00032: val_loss did not improve from 0.03879\nEpoch 33/100\n98/98 [==============================] - 1s 5ms/step - loss: 7.5229e-04 - accuracy: 0.9997 - val_loss: 0.2331 - val_accuracy: 0.9884\n\nEpoch 00033: val_loss did not improve from 0.03879\nEpoch 34/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0167 - accuracy: 0.9984 - val_loss: 0.2368 - val_accuracy: 0.9798\n\nEpoch 00034: val_loss did not improve from 0.03879\nEpoch 35/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0187 - accuracy: 0.9984 - val_loss: 0.0069 - val_accuracy: 0.9971\n\nEpoch 00035: val_loss improved from 0.03879 to 0.00693, saving model to CNNC2.weights.best.hdf5\nEpoch 36/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0037 - accuracy: 0.9990 - val_loss: 0.1149 - val_accuracy: 0.9913\n\nEpoch 00036: val_loss did not improve from 0.00693\nEpoch 37/100\n98/98 [==============================] - 1s 6ms/step - loss: 4.3666e-04 - accuracy: 1.0000 - val_loss: 0.1377 - val_accuracy: 0.9855\n\nEpoch 00037: val_loss did not improve from 0.00693\nEpoch 38/100\n98/98 [==============================] - 1s 5ms/step - loss: 3.5119e-04 - accuracy: 1.0000 - val_loss: 0.2120 - val_accuracy: 0.9827\n\nEpoch 00038: val_loss did not improve from 0.00693\nEpoch 39/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0135 - accuracy: 0.9974 - val_loss: 0.1574 - val_accuracy: 0.9855\n\nEpoch 00039: val_loss did not improve from 0.00693\nEpoch 40/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0139 - accuracy: 0.9987 - val_loss: 0.1451 - val_accuracy: 0.9855\n\nEpoch 00040: val_loss did not improve from 0.00693\nEpoch 41/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0022 - accuracy: 0.9997 - val_loss: 0.1275 - val_accuracy: 0.9884\n\nEpoch 00041: val_loss did not improve from 0.00693\nEpoch 42/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0070 - accuracy: 0.9990 - val_loss: 0.1012 - val_accuracy: 0.9942\n\nEpoch 00042: val_loss did not improve from 0.00693\nEpoch 43/100\n98/98 [==============================] - 1s 5ms/step - loss: 1.5674e-04 - accuracy: 1.0000 - val_loss: 0.2837 - val_accuracy: 0.9798\n\nEpoch 00043: val_loss did not improve from 0.00693\nEpoch 44/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0075 - accuracy: 0.9994 - val_loss: 0.0646 - val_accuracy: 0.9913\n\nEpoch 00044: val_loss did not improve from 0.00693\nEpoch 45/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0100 - accuracy: 0.9990 - val_loss: 0.0751 - val_accuracy: 0.9884\n\nEpoch 00045: val_loss did not improve from 0.00693\nEpoch 46/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0112 - accuracy: 0.9984 - val_loss: 0.0905 - val_accuracy: 0.9913\n\nEpoch 00046: val_loss did not improve from 0.00693\nEpoch 47/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0115 - accuracy: 0.9990 - val_loss: 0.0748 - val_accuracy: 0.9884\n\nEpoch 00047: val_loss did not improve from 0.00693\nEpoch 48/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0042 - accuracy: 0.9994 - val_loss: 0.0652 - val_accuracy: 0.9884\n\nEpoch 00048: val_loss did not improve from 0.00693\nEpoch 49/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0031 - accuracy: 0.9997 - val_loss: 0.0930 - val_accuracy: 0.9942\n\nEpoch 00049: val_loss did not improve from 0.00693\nEpoch 50/100\n98/98 [==============================] - 1s 5ms/step - loss: 4.7228e-04 - accuracy: 0.9997 - val_loss: 0.0784 - val_accuracy: 0.9942\n\nEpoch 00050: val_loss did not improve from 0.00693\nEpoch 51/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0041 - accuracy: 0.9990 - val_loss: 0.0996 - val_accuracy: 0.9855\n\nEpoch 00051: val_loss did not improve from 0.00693\nEpoch 52/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.9132e-04 - accuracy: 1.0000 - val_loss: 0.1132 - val_accuracy: 0.9855\n\nEpoch 00052: val_loss did not improve from 0.00693\nEpoch 53/100\n98/98 [==============================] - 1s 5ms/step - loss: 0.0084 - accuracy: 0.9984 - val_loss: 0.1485 - val_accuracy: 0.9884\n\nEpoch 00053: val_loss did not improve from 0.00693\nEpoch 54/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0112 - accuracy: 0.9994 - val_loss: 0.2137 - val_accuracy: 0.9855\n\nEpoch 00054: val_loss did not improve from 0.00693\nEpoch 55/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.9079e-04 - accuracy: 1.0000 - val_loss: 0.1951 - val_accuracy: 0.9855\n\nEpoch 00055: val_loss did not improve from 0.00693\nEpoch 56/100\n98/98 [==============================] - 1s 6ms/step - loss: 4.2153e-04 - accuracy: 1.0000 - val_loss: 0.2879 - val_accuracy: 0.9855\n\nEpoch 00056: val_loss did not improve from 0.00693\nEpoch 57/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0109 - accuracy: 0.9990 - val_loss: 0.6503 - val_accuracy: 0.9798\n\nEpoch 00057: val_loss did not improve from 0.00693\nEpoch 58/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0102 - accuracy: 0.9997 - val_loss: 0.1401 - val_accuracy: 0.9855\n\nEpoch 00058: val_loss did not improve from 0.00693\nEpoch 59/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0120 - accuracy: 0.9987 - val_loss: 0.1816 - val_accuracy: 0.9855\n\nEpoch 00059: val_loss did not improve from 0.00693\nEpoch 60/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0068 - accuracy: 0.9994 - val_loss: 0.1307 - val_accuracy: 0.9884\n\nEpoch 00060: val_loss did not improve from 0.00693\nEpoch 61/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0087 - accuracy: 0.9990 - val_loss: 0.1566 - val_accuracy: 0.9855\n\nEpoch 00061: val_loss did not improve from 0.00693\nEpoch 62/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0020 - accuracy: 0.9997 - val_loss: 0.1789 - val_accuracy: 0.9855\n\nEpoch 00062: val_loss did not improve from 0.00693\nEpoch 63/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0033 - accuracy: 0.9987 - val_loss: 0.1510 - val_accuracy: 0.9855\n\nEpoch 00063: val_loss did not improve from 0.00693\nEpoch 64/100\n98/98 [==============================] - 1s 6ms/step - loss: 7.0828e-07 - accuracy: 1.0000 - val_loss: 0.1541 - val_accuracy: 0.9884\n\nEpoch 00064: val_loss did not improve from 0.00693\nEpoch 65/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0138 - accuracy: 0.9990 - val_loss: 0.2358 - val_accuracy: 0.9827\n\nEpoch 00065: val_loss did not improve from 0.00693\nEpoch 66/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.4290e-05 - accuracy: 1.0000 - val_loss: 0.1195 - val_accuracy: 0.9913\n\nEpoch 00066: val_loss did not improve from 0.00693\nEpoch 67/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0045 - accuracy: 0.9997 - val_loss: 0.1002 - val_accuracy: 0.9942\n\nEpoch 00067: val_loss did not improve from 0.00693\nEpoch 68/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.6962e-04 - accuracy: 1.0000 - val_loss: 0.1583 - val_accuracy: 0.9884\n\nEpoch 00068: val_loss did not improve from 0.00693\nEpoch 69/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0204 - accuracy: 0.9984 - val_loss: 0.2266 - val_accuracy: 0.9913\n\nEpoch 00069: val_loss did not improve from 0.00693\nEpoch 70/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0022 - accuracy: 0.9997 - val_loss: 0.1345 - val_accuracy: 0.9884\n\nEpoch 00070: val_loss did not improve from 0.00693\nEpoch 71/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0100 - accuracy: 0.9990 - val_loss: 0.0999 - val_accuracy: 0.9971\n\nEpoch 00071: val_loss did not improve from 0.00693\nEpoch 72/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0015 - accuracy: 0.9994 - val_loss: 0.2597 - val_accuracy: 0.9884\n\nEpoch 00072: val_loss did not improve from 0.00693\nEpoch 73/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0099 - accuracy: 0.9994 - val_loss: 0.1378 - val_accuracy: 0.9769\n\nEpoch 00073: val_loss did not improve from 0.00693\nEpoch 74/100\n98/98 [==============================] - 1s 6ms/step - loss: 1.3124e-04 - accuracy: 1.0000 - val_loss: 0.1562 - val_accuracy: 0.9884\n\nEpoch 00074: val_loss did not improve from 0.00693\nEpoch 75/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0082 - accuracy: 0.9984 - val_loss: 0.2785 - val_accuracy: 0.9769\n\nEpoch 00075: val_loss did not improve from 0.00693\nEpoch 76/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0186 - accuracy: 0.9987 - val_loss: 0.1083 - val_accuracy: 0.9827\n\nEpoch 00076: val_loss did not improve from 0.00693\nEpoch 77/100\n98/98 [==============================] - 1s 6ms/step - loss: 6.4857e-04 - accuracy: 0.9997 - val_loss: 0.2251 - val_accuracy: 0.9827\n\nEpoch 00077: val_loss did not improve from 0.00693\nEpoch 78/100\n98/98 [==============================] - 1s 6ms/step - loss: 3.0524e-04 - accuracy: 1.0000 - val_loss: 0.3390 - val_accuracy: 0.9855\n\nEpoch 00078: val_loss did not improve from 0.00693\nEpoch 79/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0118 - accuracy: 0.9994 - val_loss: 0.1279 - val_accuracy: 0.9827\n\nEpoch 00079: val_loss did not improve from 0.00693\nEpoch 80/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0047 - accuracy: 0.9994 - val_loss: 0.1700 - val_accuracy: 0.9769\n\nEpoch 00080: val_loss did not improve from 0.00693\nEpoch 81/100\n98/98 [==============================] - 1s 6ms/step - loss: 1.5513e-04 - accuracy: 1.0000 - val_loss: 0.1660 - val_accuracy: 0.9827\n\nEpoch 00081: val_loss did not improve from 0.00693\nEpoch 82/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.6836e-04 - accuracy: 1.0000 - val_loss: 0.2116 - val_accuracy: 0.9884\n\nEpoch 00082: val_loss did not improve from 0.00693\nEpoch 83/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0045 - accuracy: 0.9997 - val_loss: 0.2973 - val_accuracy: 0.9769\n\nEpoch 00083: val_loss did not improve from 0.00693\nEpoch 84/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.2197e-04 - accuracy: 1.0000 - val_loss: 0.3138 - val_accuracy: 0.9827\n\nEpoch 00084: val_loss did not improve from 0.00693\nEpoch 85/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0087 - accuracy: 0.9994 - val_loss: 0.2683 - val_accuracy: 0.9855\n\nEpoch 00085: val_loss did not improve from 0.00693\nEpoch 86/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.4201e-04 - accuracy: 1.0000 - val_loss: 0.2426 - val_accuracy: 0.9884\n\nEpoch 00086: val_loss did not improve from 0.00693\nEpoch 87/100\n98/98 [==============================] - 1s 6ms/step - loss: 1.2477e-04 - accuracy: 1.0000 - val_loss: 0.4919 - val_accuracy: 0.9769\n\nEpoch 00087: val_loss did not improve from 0.00693\nEpoch 88/100\n98/98 [==============================] - 1s 6ms/step - loss: 3.4738e-04 - accuracy: 1.0000 - val_loss: 0.3780 - val_accuracy: 0.9798\n\nEpoch 00088: val_loss did not improve from 0.00693\nEpoch 89/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0051 - accuracy: 0.9997 - val_loss: 0.2717 - val_accuracy: 0.9855\n\nEpoch 00089: val_loss did not improve from 0.00693\nEpoch 90/100\n98/98 [==============================] - 1s 6ms/step - loss: 1.5618e-04 - accuracy: 1.0000 - val_loss: 0.5780 - val_accuracy: 0.9827\n\nEpoch 00090: val_loss did not improve from 0.00693\nEpoch 91/100\n98/98 [==============================] - 1s 6ms/step - loss: 1.1799e-04 - accuracy: 1.0000 - val_loss: 0.5782 - val_accuracy: 0.9827\n\nEpoch 00091: val_loss did not improve from 0.00693\nEpoch 92/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0127 - accuracy: 0.9994 - val_loss: 0.2860 - val_accuracy: 0.9798\n\nEpoch 00092: val_loss did not improve from 0.00693\nEpoch 93/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0121 - accuracy: 0.9994 - val_loss: 0.4925 - val_accuracy: 0.9740\n\nEpoch 00093: val_loss did not improve from 0.00693\nEpoch 94/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.7581e-04 - accuracy: 1.0000 - val_loss: 0.2433 - val_accuracy: 0.9798\n\nEpoch 00094: val_loss did not improve from 0.00693\nEpoch 95/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0129 - accuracy: 0.9997 - val_loss: 0.5063 - val_accuracy: 0.9769\n\nEpoch 00095: val_loss did not improve from 0.00693\nEpoch 96/100\n98/98 [==============================] - 1s 6ms/step - loss: 7.2939e-04 - accuracy: 0.9997 - val_loss: 0.4879 - val_accuracy: 0.9798\n\nEpoch 00096: val_loss did not improve from 0.00693\nEpoch 97/100\n98/98 [==============================] - 1s 6ms/step - loss: 3.1890e-04 - accuracy: 1.0000 - val_loss: 0.3678 - val_accuracy: 0.9769\n\nEpoch 00097: val_loss did not improve from 0.00693\nEpoch 98/100\n98/98 [==============================] - 1s 6ms/step - loss: 0.0046 - accuracy: 0.9990 - val_loss: 0.2332 - val_accuracy: 0.9884\n\nEpoch 00098: val_loss did not improve from 0.00693\nEpoch 99/100\n98/98 [==============================] - 1s 6ms/step - loss: 2.2361e-04 - accuracy: 1.0000 - val_loss: 0.1588 - val_accuracy: 0.9884\n\nEpoch 00099: val_loss did not improve from 0.00693\nEpoch 100/100\n98/98 [==============================] - 1s 6ms/step - loss: 1.1083e-04 - accuracy: 1.0000 - val_loss: 0.1970 - val_accuracy: 0.9884\n\nEpoch 00100: val_loss did not improve from 0.00693\n\n CNN Test accuracy: 0.9896103739738464\n\n CNN train accuracy: 1.0\n\n CNN validation accuracy: 0.9971098303794861\n"
],
[
"import keras\nfrom matplotlib import pyplot as plt\n#history = model.fit(train_x, train_y,validation_split = 0.1, epochs=50, batch_size=4)\nplt.plot(hist.history['accuracy'])\nplt.plot(hist.history['val_accuracy'])\nplt.title('Model Accuracy')\nplt.ylabel('Accuracy')\nplt.xlabel('Epoch')\nplt.legend(['Training accuracy', 'Validation accuracy'], loc='lower right')\nplt.show()",
"_____no_output_____"
],
[
"def plot_confusion_matrix(cm, classes,\n normalize=False,\n title='Confusion matrix',\n cmap=plt.cm.Blues):\n \"\"\"\n This function prints and plots the confusion matrix.\n Normalization can be applied by setting `normalize=True`.\n \"\"\"\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(classes))\n plt.xticks(tick_marks, classes, rotation=45)\n plt.yticks(tick_marks, classes)\n\n if normalize:\n cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]\n print(\"Normalized confusion matrix\")\n else:\n print('Confusion matrix, without normalization')\n\n print(cm)\n\n thresh = cm.max() / 2.\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n plt.text(j, i, cm[i, j],\n horizontalalignment=\"center\",\n color=\"white\" if cm[i, j] > thresh else \"black\")\n\n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predicted label')",
"_____no_output_____"
],
[
" y_pred = modelC2.predict(X_test)",
"_____no_output_____"
],
[
" y_pred.round()",
"_____no_output_____"
],
[
"ypreddf = pd.DataFrame(y_pred.round())\nytestdf = pd.DataFrame(Y_test)\n\nfrom sklearn.metrics import classification_report, confusion_matrix\nimport itertools\n\nprint (classification_report(Y_test, y_pred.round()))\n\n\ncm = confusion_matrix(ytestdf[0], ypreddf[0])\ncm_plot_labels = ['Normal','Spoofed']\nplot_confusion_matrix(cm=cm, classes=cm_plot_labels, title='Confusion Matrix')",
" precision recall f1-score support\n\n 0 0.98 0.98 0.98 603\n 1 0.95 0.95 0.95 243\n\n micro avg 0.97 0.97 0.97 846\n macro avg 0.97 0.97 0.97 846\nweighted avg 0.97 0.97 0.97 846\n samples avg 0.97 0.97 0.97 846\n\nConfusion matrix, without normalization\n[[231 12]\n [ 11 592]]\n"
],
[
"from sklearn.metrics import jaccard_score, f1_score, accuracy_score,recall_score, precision_score\n\nprint(\"Avg F1-score: %.4f\" % f1_score(Y_test, y_pred.round(), average='weighted'))\nprint(\"Jaccard score: %.4f\" % jaccard_score(Y_test, y_pred.round(), average='weighted'))\nprint(\"Recall score: %.4f\" % recall_score(Y_test, y_pred.round(), average='weighted'))\nprint(\"Precision score: %.4f\" % precision_score(Y_test, y_pred.round(), average='weighted'))",
"Avg F1-score: 0.9728\nJaccard score: 0.9473\nRecall score: 0.9728\nPrecision score: 0.9728\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f6a5c15d4fa340ef7f3f96bf2c7aee87af558
| 11,208 |
ipynb
|
Jupyter Notebook
|
Laboratorio1.ipynb
|
VitoriaCampos/Super-Computador-Projeto-C125
|
79ea1c27a5334cb16a657dbb57cf164868a3c528
|
[
"MIT"
] | null | null | null |
Laboratorio1.ipynb
|
VitoriaCampos/Super-Computador-Projeto-C125
|
79ea1c27a5334cb16a657dbb57cf164868a3c528
|
[
"MIT"
] | null | null | null |
Laboratorio1.ipynb
|
VitoriaCampos/Super-Computador-Projeto-C125
|
79ea1c27a5334cb16a657dbb57cf164868a3c528
|
[
"MIT"
] | null | null | null | 30.129032 | 252 | 0.457084 |
[
[
[
"<a href=\"https://colab.research.google.com/github/VitoriaCampos/Super-Computador-Projeto-C125/blob/main/Laboratorio1.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Laboratório #1\n\n### Instruções\n\n1. Para cada um dos exercícios a seguir, faça o seguinte:\n * Sempre que possível, adicione comentários ao seu código. Os comentários servem para documentar o código.\n * Use **docstrings** explicando sucintamente o que cada função implementada faz.\n + **docstrings** são os comentários de múltiplas linhas que aparecem **logo após** o cabeçalho da função.\n * Escolha nomes explicativos para suas funções e variáveis.\n2. Quando você terminar os exercícios do laboratório, vá ao menu do Jupyter ou Colab e selecione a opção para fazer download do notebook.\n * Os notebooks tem extensão .ipynb. \n * Este deve ser o arquivo que você irá entregar.\n * No Jupyter vá até a opção **File** -> **Download as** -> **Notebook (.ipynb)**.\n * No Colab vá até a opção **File** -> **Download .ipynb**.\n3. Após o download do notebook, vá até a aba de tarefas do MS Teams, localize a tarefa referente a este laboratório e faça o upload do seu notebook. Veja que há uma opção para anexar arquivos à tarefa.",
"_____no_output_____"
],
[
"**NOME:** Vitória Campos Neves\n\n**MATRÍCULA:** 651",
"_____no_output_____"
],
[
"## Exercícios",
"_____no_output_____"
],
[
"#### 1) Implemente 4 funções diferentes que recebam dois valores, x e y, e retornem o resultado das operações abaixo. Adicione uma docstring a cada uma das funções.\n\n1. **adição**: \n\n * Exemplo: 2 + 3 = 5\n * Trecho de código para teste:\n```python\nprint('O resultado da adição é:', adição(2, 3))\n```\n\n2. **subtração**: \n\n * Exemplo: 7 – 4 = 3\n * Trecho de código para teste:\n```python\nprint('O resultado da subtração é:', subtração(7, 4))\n```\n\n3. **divisão**: \n\n * Exemplo: 8 / 2 = 4\n * Trecho de código para teste: \n```python\nprint('O resultado da divisão é:', divisão(8, 2))\n```\n\n4. **multiplicação**: \n\n * Exemplo: 3 * 5 = 15\n * Trecho de código para teste: \n```python\nprint('O resultado da multiplicação é:', multiplicação(3, 5))\n```\n\n**Operadores artiméticos**\n\nAbaixo segue a lista de operadores aritméticos usados em Python.\n\n| Operador | Nome | Exemplo | Resultado |\n|:--------:|:---------------:|:--------:|:---------:|\n| + | Adição | a = 1 + 1 | 2 |\n| - | Subtração | a = 2 - 1 | 1 |\n| * | Multiplicação | a = 2 * 2 | 4 |\n| / | Divisão | a = 100 / 4 | 25.0 |\n| % | Módulo | a = 5 % 3 | 2 |\n| ** | Exponenciação | a = 2 ** 3 | 8 |\n| // | Divisão inteira | a = 100 // 4 | 25 |\n\n**OBS.: Não se esqueça de depois de implementar as funções, invocá-las com alguns valores de teste como mostrado acima.**\n\n#### Função de adição",
"_____no_output_____"
]
],
[
[
"# Defina aqui o código da função 'adição' e em seguida \n# a invoque com alguns valores de teste.\n\ndef adição(x,y):\n return x+y\n \nprint('O resultado da adição é:', adição(2, 3))\n",
"O resultado da adição é: 5\n"
]
],
[
[
"#### Função de subtração",
"_____no_output_____"
]
],
[
[
"# Defina aqui o código da função 'subtração' e em seguida \n# a invoque com alguns valores de teste.\n\ndef subtração(x,y):\n return x-y\n \nprint('O resultado da subtração é:', subtração(7, 4))\n",
"O resultado da subtração é: 3\n"
]
],
[
[
"#### Função de divisão",
"_____no_output_____"
]
],
[
[
"# Defina aqui o código da função 'divisão' e em seguida \n# a invoque com alguns valores de teste.\n\ndef divisão(x,y):\n return x/y\n \nprint('O resultado da divisão é:', divisão(8, 2))\n",
"O resultado da divisão é: 4.0\n"
]
],
[
[
"#### Função de multiplicação",
"_____no_output_____"
]
],
[
[
"# Defina aqui o código da função 'multiplicação' e em seguida \n# a invoque com alguns valores de teste.\n\ndef multiplicação(x,y):\n return x*y\n \nprint('O resultado da multiplicação é:', multiplicação(3, 5))\n",
"O resultado da multiplicação é: 15\n"
]
],
[
[
"#### 2) Dado o valor da conta de um restaurante, crie uma função chamada de `gorjeta` que calcule o valor da gorjeta do garçom, considerando que a gorjeta é sempre de 10% do valor da conta.\n\n**OBS.: Não se esqueça de depois de implementar a função, invocá-la com algum valor de teste, como mostrado no trecho de código abaixo.**\n\n```python\nprint('O valor da gorjeta é de:', gorjeta(100))\n```",
"_____no_output_____"
]
],
[
[
"# Defina aqui o código da função 'gorjeta' e em seguida \n# a invoque com algum valor de teste.\n\ndef gorjeta(x):\n return x*(10/100)\n \n\nprint('O valor da gorjeta é de:', gorjeta(100))\n",
"O valor da gorjeta é de: 10.0\n"
]
],
[
[
"#### 3) Execute o código abaixo e veja que ocorre um erro. Em seguida, corrija os erros até que o código execute corretamente.\n\n**Dica**: Lembre-se do que foi discutido sobre as diferenças entre Python e outras linguagens de programação e sobre a definição de funções em Python.",
"_____no_output_____"
]
],
[
[
"def foo(a,b,c): \n var = a + b * c\n return var\n\n'''\nInvocando a função chamada de 'foo' \ne imprimindo o resultado retornado por ela.\n'''\nprint('A função foo retorna o valor: ', foo(1,2,3))",
"A função foo retorna o valor: 7\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4f76781f33196c0dffcdac9aff1ae60d1c632a
| 716,554 |
ipynb
|
Jupyter Notebook
|
nbs/dl1/lesson2-bikes.ipynb
|
greyestapps/course-v3
|
6f2ed6f7537ca14be958dd160cfbfaee0638e0c5
|
[
"Apache-2.0"
] | null | null | null |
nbs/dl1/lesson2-bikes.ipynb
|
greyestapps/course-v3
|
6f2ed6f7537ca14be958dd160cfbfaee0638e0c5
|
[
"Apache-2.0"
] | null | null | null |
nbs/dl1/lesson2-bikes.ipynb
|
greyestapps/course-v3
|
6f2ed6f7537ca14be958dd160cfbfaee0638e0c5
|
[
"Apache-2.0"
] | null | null | null | 412.049454 | 436,912 | 0.92921 |
[
[
[
"# Creating your own dataset from Google Images\n\n*by: Francisco Ingham and Jeremy Howard. Inspired by [Adrian Rosebrock](https://www.pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/)*",
"_____no_output_____"
]
],
[
[
"!pip install fastai\n#!pip install -upgrade pip\n#!pip install -q fastai —upgrade pip",
"Requirement already satisfied: fastai in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (1.0.57)\nRequirement already satisfied: bottleneck in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (1.2.1)\nRequirement already satisfied: spacy>=2.0.18 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (2.1.8)\nRequirement already satisfied: numexpr in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (2.6.5)\nRequirement already satisfied: packaging in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (17.1)\nRequirement already satisfied: numpy>=1.15 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (1.17.2)\nRequirement already satisfied: nvidia-ml-py3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (7.352.0)\nRequirement already satisfied: pyyaml in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (3.12)\nRequirement already satisfied: requests in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (2.20.0)\nRequirement already satisfied: pandas in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (0.24.2)\nRequirement already satisfied: torchvision in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (0.4.0)\nRequirement already satisfied: beautifulsoup4 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (4.6.0)\nRequirement already satisfied: torch>=1.0.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (1.2.0)\nRequirement already satisfied: scipy in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (1.1.0)\nRequirement already satisfied: dataclasses; python_version < \"3.7\" in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (0.6)\nRequirement already satisfied: matplotlib in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (3.0.3)\nRequirement already satisfied: typing; python_version < \"3.7\" in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (3.6.4)\nRequirement already satisfied: fastprogress>=0.1.19 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (0.1.21)\nRequirement already satisfied: Pillow in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from fastai) (5.2.0)\nRequirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (1.0.2)\nRequirement already satisfied: thinc<7.1.0,>=7.0.8 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (7.0.8)\nRequirement already satisfied: blis<0.3.0,>=0.2.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (0.2.4)\nRequirement already satisfied: preshed<2.1.0,>=2.0.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (2.0.1)\nRequirement already satisfied: plac<1.0.0,>=0.9.6 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (0.9.6)\nRequirement already satisfied: cymem<2.1.0,>=2.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (2.0.2)\nRequirement already satisfied: srsly<1.1.0,>=0.0.6 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (0.1.0)\nRequirement already satisfied: wasabi<1.1.0,>=0.2.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from spacy>=2.0.18->fastai) (0.2.2)\nRequirement already satisfied: pyparsing>=2.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from packaging->fastai) (2.2.0)\nRequirement already satisfied: six in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from packaging->fastai) (1.11.0)\nRequirement already satisfied: idna<2.8,>=2.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->fastai) (2.6)\nRequirement already satisfied: chardet<3.1.0,>=3.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->fastai) (3.0.4)\nRequirement already satisfied: certifi>=2017.4.17 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->fastai) (2019.6.16)\nRequirement already satisfied: urllib3<1.25,>=1.21.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->fastai) (1.23)\nRequirement already satisfied: pytz>=2011k in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from pandas->fastai) (2018.4)\nRequirement already satisfied: python-dateutil>=2.5.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from pandas->fastai) (2.7.3)\nRequirement already satisfied: kiwisolver>=1.0.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib->fastai) (1.0.1)\nRequirement already satisfied: cycler>=0.10 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from matplotlib->fastai) (0.10.0)\nRequirement already satisfied: tqdm<5.0.0,>=4.10.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from thinc<7.1.0,>=7.0.8->spacy>=2.0.18->fastai) (4.35.0)\nRequirement already satisfied: setuptools in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from kiwisolver>=1.0.1->matplotlib->fastai) (39.1.0)\n\u001b[33mYou are using pip version 10.0.1, however version 19.2.3 is available.\nYou should consider upgrading via the 'pip install --upgrade pip' command.\u001b[0m\n"
]
],
[
[
"In this tutorial we will see how to easily create an image dataset through Google Images. **Note**: You will have to repeat these steps for any new category you want to Google (e.g once for dogs and once for cats).",
"_____no_output_____"
]
],
[
[
"from fastai.vision import *",
"_____no_output_____"
]
],
[
[
"## Get a list of URLs",
"_____no_output_____"
],
[
"### Search and scroll",
"_____no_output_____"
],
[
"Go to [Google Images](http://images.google.com) and search for the images you are interested in. The more specific you are in your Google Search, the better the results and the less manual pruning you will have to do.\n\nScroll down until you've seen all the images you want to download, or until you see a button that says 'Show more results'. All the images you scrolled past are now available to download. To get more, click on the button, and continue scrolling. The maximum number of images Google Images shows is 700.\n\nIt is a good idea to put things you want to exclude into the search query, for instance if you are searching for the Eurasian wolf, \"canis lupus lupus\", it might be a good idea to exclude other variants:\n\n \"canis lupus lupus\" -dog -arctos -familiaris -baileyi -occidentalis\n\nYou can also limit your results to show only photos by clicking on Tools and selecting Photos from the Type dropdown.",
"_____no_output_____"
],
[
"### Download into file",
"_____no_output_____"
],
[
"Now you must run some Javascript code in your browser which will save the URLs of all the images you want for you dataset.\n\nPress <kbd>Ctrl</kbd><kbd>Shift</kbd><kbd>J</kbd> in Windows/Linux and <kbd>Cmd</kbd><kbd>Opt</kbd><kbd>J</kbd> in Mac, and a small window the javascript 'Console' will appear. That is where you will paste the JavaScript commands.\n\nYou will need to get the urls of each of the images. Before running the following commands, you may want to disable ad blocking extensions (uBlock, AdBlockPlus etc.) in Chrome. Otherwise the window.open() command doesn't work. Then you can run the following commands:\n\n```javascript\nurls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);\nwindow.open('data:text/csv;charset=utf-8,' + escape(urls.join('\\n')));\n```",
"_____no_output_____"
],
[
"### Create directory and upload urls file into your server",
"_____no_output_____"
],
[
"Choose an appropriate name for your labeled images. You can run these steps multiple times to create different labels.",
"_____no_output_____"
]
],
[
[
"folder = 'mountainbikes'\nfile = 'urls_mountainbikes.csv'",
"_____no_output_____"
],
[
"folder = 'racingcycles'\nfile = 'urls_racingcycles.csv'",
"_____no_output_____"
]
],
[
[
"You will need to run this cell once per each category.",
"_____no_output_____"
]
],
[
[
"path = Path('data/bikes')\ndest = path/folder\ndest.mkdir(parents=True, exist_ok=True)",
"_____no_output_____"
],
[
"path.ls()",
"_____no_output_____"
]
],
[
[
"Finally, upload your urls file. You just need to press 'Upload' in your working directory and select your file, then click 'Upload' for each of the displayed files.\n\n",
"_____no_output_____"
],
[
"## Download images",
"_____no_output_____"
],
[
"Now you will need to download your images from their respective urls.\n\nfast.ai has a function that allows you to do just that. You just have to specify the urls filename as well as the destination folder and this function will download and save all images that can be opened. If they have some problem in being opened, they will not be saved.\n\nLet's download our images! Notice you can choose a maximum number of images to be downloaded. In this case we will not download all the urls.\n\nYou will need to run this line once for every category.",
"_____no_output_____"
]
],
[
[
"file",
"_____no_output_____"
],
[
"path",
"_____no_output_____"
],
[
"folder",
"_____no_output_____"
],
[
"classes = ['mountainbikes','racingcycles']",
"_____no_output_____"
],
[
"download_images(path/file, dest, max_pics=200)",
"_____no_output_____"
],
[
"# If you have problems download, try with `max_workers=0` to see exceptions:\ndownload_images(path/file, dest, max_pics=20, max_workers=0)",
"_____no_output_____"
]
],
[
[
"Then we can remove any images that can't be opened:",
"_____no_output_____"
]
],
[
[
"for c in classes:\n print(c)\n verify_images(path/c, delete=True, max_size=500)",
"_____no_output_____"
]
],
[
[
"## View data",
"_____no_output_____"
]
],
[
[
"#np.random.seed(42)\n#data = ImageDataBunch.from_folder(path, train=\".\", valid_pct=0.2,\n# ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)",
"_____no_output_____"
],
[
"# If you already cleaned your data, run this cell instead of the one before\nnp.random.seed(42)\ndata = ImageDataBunch.from_csv(path, folder=\".\", valid_pct=0.2, csv_labels='cleaned.csv',\n ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)",
"_____no_output_____"
]
],
[
[
"Good! Let's take a look at some of our pictures then.",
"_____no_output_____"
]
],
[
[
"data.classes",
"_____no_output_____"
],
[
"data.show_batch(rows=3, figsize=(7,8))",
"_____no_output_____"
],
[
"data.classes, data.c, len(data.train_ds), len(data.valid_ds)",
"_____no_output_____"
]
],
[
[
"## Train model",
"_____no_output_____"
]
],
[
[
"learn = cnn_learner(data, models.resnet34, metrics=error_rate)",
"_____no_output_____"
],
[
"learn.fit_one_cycle(4)",
"_____no_output_____"
],
[
"learn.save('stage-1')",
"_____no_output_____"
],
[
"learn.unfreeze()",
"_____no_output_____"
],
[
"learn.lr_find()",
"_____no_output_____"
],
[
"# If the plot is not showing try to give a start and end learning rate\n# learn.lr_find(start_lr=1e-5, end_lr=1e-1)\nlearn.recorder.plot()",
"_____no_output_____"
],
[
"learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4))",
"_____no_output_____"
],
[
"learn.save('stage-2')",
"_____no_output_____"
]
],
[
[
"## Interpretation",
"_____no_output_____"
]
],
[
[
"learn.load('stage-2');",
"_____no_output_____"
],
[
"interp = ClassificationInterpretation.from_learner(learn)",
"_____no_output_____"
],
[
"interp.plot_confusion_matrix()",
"_____no_output_____"
]
],
[
[
"## Cleaning Up\n\nSome of our top losses aren't due to bad performance by our model. There are images in our data set that shouldn't be.\n\nUsing the `ImageCleaner` widget from `fastai.widgets` we can prune our top losses, removing photos that don't belong.",
"_____no_output_____"
]
],
[
[
"from fastai.widgets import *",
"_____no_output_____"
]
],
[
[
"First we need to get the file paths from our top_losses. We can do this with `.from_toplosses`. We then feed the top losses indexes and corresponding dataset to `ImageCleaner`.\n\nNotice that the widget will not delete images directly from disk but it will create a new csv file `cleaned.csv` from where you can create a new ImageDataBunch with the corrected labels to continue training your model.",
"_____no_output_____"
],
[
"In order to clean the entire set of images, we need to create a new dataset without the split. The video lecture demostrated the use of the `ds_type` param which no longer has any effect. See [the thread](https://forums.fast.ai/t/duplicate-widget/30975/10) for more details.",
"_____no_output_____"
]
],
[
[
"db = (ImageList.from_folder(path)\n .split_none()\n .label_from_folder()\n .transform(get_transforms(), size=224)\n .databunch()\n )",
"_____no_output_____"
],
[
"# If you already cleaned your data using indexes from `from_toplosses`,\n# run this cell instead of the one before to proceed with removing duplicates.\n# Otherwise all the results of the previous step would be overwritten by\n# the new run of `ImageCleaner`.\n\ndb = (ImageList.from_csv(path, 'cleaned.csv', folder='.')\n .split_none()\n .label_from_df()\n .transform(get_transforms(), size=224)\n .databunch()\n )",
"_____no_output_____"
]
],
[
[
"Then we create a new learner to use our new databunch with all the images.",
"_____no_output_____"
]
],
[
[
"learn_cln = cnn_learner(db, models.resnet34, metrics=error_rate)\n\nlearn_cln.load('stage-2');",
"_____no_output_____"
],
[
"ds, idxs = DatasetFormatter().from_toplosses(learn_cln)",
"_____no_output_____"
]
],
[
[
"Make sure you're running this notebook in Jupyter Notebook, not Jupyter Lab. That is accessible via [/tree](/tree), not [/lab](/lab). Running the `ImageCleaner` widget in Jupyter Lab is [not currently supported](https://github.com/fastai/fastai/issues/1539).",
"_____no_output_____"
]
],
[
[
"# Don't run this in google colab or any other instances running jupyter lab.\n# If you do run this on Jupyter Lab, you need to restart your runtime and\n# runtime state including all local variables will be lost.\nImageCleaner(ds, idxs, path)",
"_____no_output_____"
]
],
[
[
"\nIf the code above does not show any GUI(contains images and buttons) rendered by widgets but only text output, that may caused by the configuration problem of ipywidgets. Try the solution in this [link](https://github.com/fastai/fastai/issues/1539#issuecomment-505999861) to solve it.\n",
"_____no_output_____"
],
[
"Flag photos for deletion by clicking 'Delete'. Then click 'Next Batch' to delete flagged photos and keep the rest in that row. `ImageCleaner` will show you a new row of images until there are no more to show. In this case, the widget will show you images until there are none left from `top_losses.ImageCleaner(ds, idxs)`",
"_____no_output_____"
],
[
"You can also find duplicates in your dataset and delete them! To do this, you need to run `.from_similars` to get the potential duplicates' ids and then run `ImageCleaner` with `duplicates=True`. The API works in a similar way as with misclassified images: just choose the ones you want to delete and click 'Next Batch' until there are no more images left.",
"_____no_output_____"
],
[
"Make sure to recreate the databunch and `learn_cln` from the `cleaned.csv` file. Otherwise the file would be overwritten from scratch, losing all the results from cleaning the data from toplosses.",
"_____no_output_____"
]
],
[
[
"ds, idxs = DatasetFormatter().from_similars(learn_cln)",
"Getting activations...\n"
],
[
"ImageCleaner(ds, idxs, path, duplicates=True)",
"_____no_output_____"
],
[
"??ImageCleaner",
"_____no_output_____"
]
],
[
[
"Remember to recreate your ImageDataBunch from your `cleaned.csv` to include the changes you made in your data!",
"_____no_output_____"
],
[
"## Putting your model in production",
"_____no_output_____"
],
[
"First thing first, let's export the content of our `Learner` object for production:",
"_____no_output_____"
]
],
[
[
"learn.export()",
"_____no_output_____"
]
],
[
[
"This will create a file named 'export.pkl' in the directory where we were working that contains everything we need to deploy our model (the model, the weights but also some metadata like the classes or the transforms/normalization used).",
"_____no_output_____"
],
[
"You probably want to use CPU for inference, except at massive scale (and you almost certainly don't need to train in real-time). If you don't have a GPU that happens automatically. You can test your model on CPU like so:",
"_____no_output_____"
]
],
[
[
"defaults.device = torch.device('cpu')",
"_____no_output_____"
],
[
"img = open_image(path/'mountainbikes'/'00000021.jpg')\nimg",
"_____no_output_____"
]
],
[
[
"We create our `Learner` in production enviromnent like this, jsut make sure that `path` contains the file 'export.pkl' from before.",
"_____no_output_____"
]
],
[
[
"learn = load_learner(path)",
"_____no_output_____"
],
[
"pred_class,pred_idx,outputs = learn.predict(img)\npred_class",
"_____no_output_____"
]
],
[
[
"So you might create a route something like this ([thanks](https://github.com/simonw/cougar-or-not) to Simon Willison for the structure of this code):\n\n```python\[email protected](\"/classify-url\", methods=[\"GET\"])\nasync def classify_url(request):\n bytes = await get_bytes(request.query_params[\"url\"])\n img = open_image(BytesIO(bytes))\n _,_,losses = learner.predict(img)\n return JSONResponse({\n \"predictions\": sorted(\n zip(cat_learner.data.classes, map(float, losses)),\n key=lambda p: p[1],\n reverse=True\n )\n })\n```\n\n(This example is for the [Starlette](https://www.starlette.io/) web app toolkit.)",
"_____no_output_____"
],
[
"## Things that can go wrong",
"_____no_output_____"
],
[
"- Most of the time things will train fine with the defaults\n- There's not much you really need to tune (despite what you've heard!)\n- Most likely are\n - Learning rate\n - Number of epochs",
"_____no_output_____"
],
[
"### Learning rate (LR) too high",
"_____no_output_____"
]
],
[
[
"learn = cnn_learner(data, models.resnet34, metrics=error_rate)",
"_____no_output_____"
],
[
"learn.fit_one_cycle(1, max_lr=0.5)",
"_____no_output_____"
]
],
[
[
"### Learning rate (LR) too low",
"_____no_output_____"
]
],
[
[
"learn = cnn_learner(data, models.resnet34, metrics=error_rate)",
"_____no_output_____"
]
],
[
[
"Previously we had this result:\n\n```\nTotal time: 00:57\nepoch train_loss valid_loss error_rate\n1 1.030236 0.179226 0.028369 (00:14)\n2 0.561508 0.055464 0.014184 (00:13)\n3 0.396103 0.053801 0.014184 (00:13)\n4 0.316883 0.050197 0.021277 (00:15)\n```",
"_____no_output_____"
]
],
[
[
"learn.fit_one_cycle(5, max_lr=1e-5)",
"_____no_output_____"
],
[
"learn.recorder.plot_losses()",
"_____no_output_____"
]
],
[
[
"As well as taking a really long time, it's getting too many looks at each image, so may overfit.",
"_____no_output_____"
],
[
"### Too few epochs",
"_____no_output_____"
]
],
[
[
"learn = cnn_learner(data, models.resnet34, metrics=error_rate, pretrained=False)",
"_____no_output_____"
],
[
"learn.fit_one_cycle(1)",
"_____no_output_____"
]
],
[
[
"### Too many epochs",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\ndata = ImageDataBunch.from_folder(path, train=\".\", valid_pct=0.9, bs=32, \n ds_tfms=get_transforms(do_flip=False, max_rotate=0, max_zoom=1, max_lighting=0, max_warp=0\n ),size=224, num_workers=4).normalize(imagenet_stats)",
"_____no_output_____"
],
[
"learn = cnn_learner(data, models.resnet50, metrics=error_rate, ps=0, wd=0)\nlearn.unfreeze()",
"_____no_output_____"
],
[
"learn.fit_one_cycle(40, slice(1e-6,1e-4))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a4f7ab62ef407a0cc0bb0a8f1186f304a21a144
| 8,238 |
ipynb
|
Jupyter Notebook
|
data/external/numpy-working-with-multidimensional-data/02/demos/m01_demo04_UniversalFunctions.ipynb
|
vickykatoch/pyTitanic
|
a2ce0278db4b5b4d454e426eb0f80007082bc4a1
|
[
"MIT"
] | null | null | null |
data/external/numpy-working-with-multidimensional-data/02/demos/m01_demo04_UniversalFunctions.ipynb
|
vickykatoch/pyTitanic
|
a2ce0278db4b5b4d454e426eb0f80007082bc4a1
|
[
"MIT"
] | null | null | null |
data/external/numpy-working-with-multidimensional-data/02/demos/m01_demo04_UniversalFunctions.ipynb
|
vickykatoch/pyTitanic
|
a2ce0278db4b5b4d454e426eb0f80007082bc4a1
|
[
"MIT"
] | null | null | null | 20.492537 | 244 | 0.504249 |
[
[
[
"## Universal Functions",
"_____no_output_____"
],
[
"NumPy provides standard trigonometric functions, functions for arithmetic operations, handling complex numbers, statistical functions,etc. In NumPy, these are called “universal functions”(ufunc).",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
],
[
[
"### Trigonometric Functions",
"_____no_output_____"
]
],
[
[
"angles = np.array([0,30,45,60,90]) ",
"_____no_output_____"
]
],
[
[
"#### Angles need to be converted to radians by multiplying by pi/180 \nOnly then can we appy trigonometric functions to our array",
"_____no_output_____"
]
],
[
[
"angles_radians = angles * np.pi/180\nangles_radians",
"_____no_output_____"
],
[
"print('Sine of angles in the array:')\nprint(np.sin(angles_radians)) ",
"Sine of angles in the array:\n[0. 0.5 0.70710678 0.8660254 1. ]\n"
]
],
[
[
"#### Alternatively, use the np.radians() function to convert to radians",
"_____no_output_____"
]
],
[
[
"angles_radians = np.radians(angles)\nangles_radians",
"_____no_output_____"
],
[
"print('Cosine of angles in the array:')\nprint(np.cos(angles_radians))",
"Cosine of angles in the array:\n[1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01\n 6.12323400e-17]\n"
],
[
"print('Tangent of angles in the array:')\nprint(np.tan(angles_radians))",
"Tangent of angles in the array:\n[0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00\n 1.63312394e+16]\n"
]
],
[
[
"<b>arcsin</b>, <b>arcos</b>, and <b>arctan</b> functions return the trigonometric inverse of sin, cos, and tan of the given angle. The result of these functions can be verified by numpy.degrees() function by converting radians to degrees.",
"_____no_output_____"
]
],
[
[
"sin = np.sin(angles * np.pi/180) \nprint ('Compute sine inverse of angles. Returned values are in radians.')\n\ninv = np.arcsin(sin) \nprint (inv) ",
"Compute sine inverse of angles. Returned values are in radians.\n[0. 0.52359878 0.78539816 1.04719755 1.57079633]\n"
]
],
[
[
"#### np.degrees() converts radians to degrees",
"_____no_output_____"
]
],
[
[
"print ('Check result by converting to degrees:' )\nprint (np.degrees(inv)) ",
"Check result by converting to degrees:\n[ 0. 30. 45. 60. 90.]\n"
]
],
[
[
"### Statistical Functions",
"_____no_output_____"
]
],
[
[
"test_scores = np.array([32.32, 56.98, 21.52, 44.32, \n 55.63, 13.75, 43.47, 43.34])",
"_____no_output_____"
],
[
"print('Mean test scores of the students: ')\nprint(np.mean(test_scores))",
"Mean test scores of the students: \n38.91625\n"
],
[
"print('Median test scores of the students: ')\nprint(np.median(test_scores))",
"Median test scores of the students: \n43.405\n"
]
],
[
[
"We will now perform basic statistical methods on real life dataset. We will use salary data of 1147 European developers.",
"_____no_output_____"
]
],
[
[
"salaries = np.genfromtxt('data/salary.csv', \n delimiter=',')",
"_____no_output_____"
],
[
"salaries",
"_____no_output_____"
],
[
"salaries.shape",
"_____no_output_____"
],
[
"mean = np.mean(salaries)\nmedian = np.median(salaries)\nsd = np.std(salaries)\nvariance = np.var(salaries)",
"_____no_output_____"
],
[
"print('Mean = %i' %mean)\nprint('Median = %i' %median)\nprint('Standard Deviation = %i' %sd)\nprint('Variance = %i' %variance)",
"Mean = 55894\nMedian = 48000\nStandard Deviation = 55170\nVariance = 3043770333\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f7d5b6ca017cac08b92edb47b394fc98c69e5
| 2,473 |
ipynb
|
Jupyter Notebook
|
00_core.ipynb
|
CailleauThierry/tcai_nbdev_tutorial
|
70dca2d88fcf2b5925d261cba3fb130a8df01279
|
[
"Apache-2.0"
] | null | null | null |
00_core.ipynb
|
CailleauThierry/tcai_nbdev_tutorial
|
70dca2d88fcf2b5925d261cba3fb130a8df01279
|
[
"Apache-2.0"
] | null | null | null |
00_core.ipynb
|
CailleauThierry/tcai_nbdev_tutorial
|
70dca2d88fcf2b5925d261cba3fb130a8df01279
|
[
"Apache-2.0"
] | null | null | null | 19.626984 | 98 | 0.498585 |
[
[
[
"# default_exp core",
"_____no_output_____"
]
],
[
[
"# Core\n\n> Note: unused section yet",
"_____no_output_____"
]
],
[
[
"#hide\nfrom nbdev.showdoc import *",
"_____no_output_____"
],
[
"#export\ndef say_hello(to):\n \"Say hello to somebody\"\n return f'Hello {to}!'",
"_____no_output_____"
],
[
"#export\nsay_hello(\"Sylvain\")",
"_____no_output_____"
],
[
"#export\nfrom IPython.display import display,SVG\ndisplay(SVG('<svg height=\"100\"><circle cx=\"50\" cy=\"50\" r=\"40\"/></svg>'))",
"_____no_output_____"
],
[
"#export\nassert say_hello(\"Jeremy\")==\"Hello Jeremy!\"",
"_____no_output_____"
],
[
"#export\nyourName = input()\nprint()\n#the previous print() is only to workaround AN nbdev_build_docs/jupyter input() bug\nprint(\"Hello\", yourName)\nprint(\"Hello\", yourName , \"Welcome!\")",
"\nHello Thierry\nHello Thierry Welcome!\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f7ffe04fc1e4977d3f8505811e61578d5d0a5
| 5,851 |
ipynb
|
Jupyter Notebook
|
simple-exercises/basic-cryptography/5-meet-in-the-middle-attack.ipynb
|
mithi/algorithm-playground
|
ee35df7e343544b56c145b3912eca263c566d819
|
[
"MIT"
] | 85 |
2017-12-19T19:51:51.000Z
|
2021-05-26T20:00:39.000Z
|
simple-exercises/basic-cryptography/5-meet-in-the-middle-attack.ipynb
|
mithi/algorithm-playground
|
ee35df7e343544b56c145b3912eca263c566d819
|
[
"MIT"
] | 1 |
2019-01-02T07:00:40.000Z
|
2019-01-02T07:00:40.000Z
|
simple-exercises/basic-cryptography/5-meet-in-the-middle-attack.ipynb
|
mithi/algorithm-playground
|
ee35df7e343544b56c145b3912eca263c566d819
|
[
"MIT"
] | 34 |
2018-03-29T11:51:53.000Z
|
2020-11-17T08:24:51.000Z
| 29.40201 | 177 | 0.518031 |
[
[
[
"# Meet in the Middle Attack\n- Given prime `p`\n- then `Zp* = {1, 2, 3, ..., p-1}`\n- let `g` and `h` be elements in `Zp*` such that\n- such that `h mod p = g^x mod p` where ` 0 < x < 2^40`\n- find `x` given `h`, `g`, and `p`\n\n# Idea\n- let `B = 2^20` then `B^2 = 2^40` \n- then `x= xo * B + x1` where `xo` and `x1` are in `{0, 1, ..., B-1}`\n- Then smallest x is `x = 0 * B + O = 0`\n- Largest x is `x = B * (B-1) + B - 1 = B^2 - B + B -1 = B^2 - 1 = 2^40 - 1`\n- Then:\n```\nh = g^x\nh = g^(xo * B + x1) \nh = g^(xo * B) * g^(x1)\nh / g^(x1) = g^(xo *B) \n```\n- Find `xo` and `x1` given `g`, `h`, `B` \n\n# Strategy\n- Build a hash table key: `h / g^(x1)`, with value `x1` for `x1` in `{ 0, 1, 2, .., 2^20 - 1}`\n- For each value `x0` in `{0, 1, 2, ... 20^20 -1}` check if `(g^B)^(x0) mod P` is in hashtable. If it is then you've found `x0` and `x1`\n- Return `x = xo * B + x1`\n\n### Modulo Division\n```\n (x mod p) / ( y mod p) = ((x mod p) * (y_inverse mod p)) mod p \n \n```\n\n### Definition of inverse\n```\n Definition of modular inverse in Zp\n y_inverse * y mod P = 1 \n``` \n\n### Inverse of `x` in `Zp*`\n```\nGiven p is prime,\nthen for every element x in set Zp* = {1, ..., p - 1}\nthe element x is invertible (there exist an x_inverse such that: \nx_inverse * x mod p = 1\n\nThe following is true (according to Fermat's 1640)\n\n> x^(p - 1) mod = 1 \n> x ^ (p - 2) * x mod p = 1\n> x_inverse = x^(p-2)\n \n ```\n# Notes\n- Work is `2^20` multiplications and `2^20` lookups in the worst case\n- If we brute forced it, we would do `2^40` multiplications\n- So the work is squareroot of brute force\n\n# Test Numbers\n\n```\np = 134078079299425970995740249982058461274793658205923933\\\n 77723561443721764030073546976801874298166903427690031\\\n 858186486050853753882811946569946433649006084171\n\ng = 11717829880366207009516117596335367088558084999998952205\\\n 59997945906392949973658374667057217647146031292859482967\\\n 5428279466566527115212748467589894601965568\n\nh = 323947510405045044356526437872806578864909752095244\\\n 952783479245297198197614329255807385693795855318053\\\n 2878928001494706097394108577585732452307673444020333\n```\n\n# Library used\n- https://gmpy2.readthedocs.io/en/latest/mpz.html",
"_____no_output_____"
]
],
[
[
"from gmpy2 import mpz\nfrom gmpy2 import t_mod, invert, powmod, add, mul, is_prime",
"_____no_output_____"
],
[
"def build_table(h, g, p, B):\n table, z = {}, h\n g_inverse = invert(g, p)\n table[h] = 0\n for x1 in range(1, B):\n z = t_mod(mul(z, g_inverse), p)\n table[z] = x1\n return table",
"_____no_output_____"
],
[
"def lookup(table, g, p, B):\n gB, z = powmod(g, B, p), 1\n for x0 in range(B):\n if z in table:\n x1 = table[z]\n return x0, x1\n z = t_mod(mul(z, gB), p)\n return None, None",
"_____no_output_____"
],
[
"def find_x(h, g, p, B):\n table = build_table(h, g, p, B)\n x0, x1 = lookup(table, g, p, B)\n # assert x0 != None and x1 != None\n Bx0 = mul(x0, B)\n x = add(Bx0, x1)\n print(x0, x1)\n return x",
"_____no_output_____"
],
[
"p_string = '13407807929942597099574024998205846127479365820592393377723561443721764030073546976801874298166903427690031858186486050853753882811946569946433649006084171'\ng_string = '11717829880366207009516117596335367088558084999998952205599979459063929499736583746670572176471460312928594829675428279466566527115212748467589894601965568'\nh_string = '3239475104050450443565264378728065788649097520952449527834792452971981976143292558073856937958553180532878928001494706097394108577585732452307673444020333'\n\np = mpz(p_string)\ng = mpz(g_string)\nh = mpz(h_string)\nB = mpz(2) ** mpz(20)\n\nassert is_prime(p)\nassert g < p\nassert h < p\n\nx = find_x(h, g, p, B)\nprint(x)\n\nassert h == powmod(g, x, p)",
"357984 787046\n375374217830\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f82b95578d30e675b667204e1a153c115bdad
| 5,852 |
ipynb
|
Jupyter Notebook
|
Models/.ipynb_checkpoints/models-checkpoint.ipynb
|
csantanaes/Sentiment-Analysis-Twitter-PT
|
2260b5767bd315f340946e1c9be1f9acf807f722
|
[
"MIT"
] | null | null | null |
Models/.ipynb_checkpoints/models-checkpoint.ipynb
|
csantanaes/Sentiment-Analysis-Twitter-PT
|
2260b5767bd315f340946e1c9be1f9acf807f722
|
[
"MIT"
] | null | null | null |
Models/.ipynb_checkpoints/models-checkpoint.ipynb
|
csantanaes/Sentiment-Analysis-Twitter-PT
|
2260b5767bd315f340946e1c9be1f9acf807f722
|
[
"MIT"
] | null | null | null | 24.588235 | 78 | 0.460014 |
[
[
[
"import os\nos.chdir(os.getcwd() + '/Models/')\nfrom leia import SentimentIntensityAnalyzer\nfrom textblob import TextBlob\nfrom textblob.classifiers import NaiveBayesClassifier\nimport spacy\nimport re",
"_____no_output_____"
]
],
[
[
"## LeIA",
"_____no_output_____"
]
],
[
[
"analyzer = SentimentIntensityAnalyzer()\ndef leia(text):\n text = str(text)\n result = analyzer.polarity_scores(text)\n \n #analisa a frase utilizando o compound\n if result['compound'] >= 0.05:\n return 'positivo'\n elif result['compound'] <= -0.05:\n return 'negativo'\n else:\n return 'neutro'",
"_____no_output_____"
]
],
[
[
"## TextBlob + ReLi",
"_____no_output_____"
]
],
[
[
"base_path = 'ReLi-Lex'\ntrain = []\nwordsPT = []\nwordsPT_sentiments = []\n\nfiles = [os.path.join(base_path, f) for f in os.listdir(base_path)]\n\nfor file in files:\n t = 1 if '_Positivos' in file else -1\n with open(file, 'r', encoding=\"ISO-8859-1\") as content_file:\n content = content_file.read()\n all = re.findall('\\[.*?\\]',content)\n for w in all:\n wordsPT.append((w[1:-1]))\n wordsPT_sentiments.append(t)\n train.append((w[1:-1], t))",
"_____no_output_____"
],
[
"def textblob(sentence):\n sentence = str(sentence)\n blob = TextBlob(sentence, classifier=NaiveBayesClassifier(train))\n result = 0\n \n for sent in blob.sentences:\n result += sent.classify()\n \n if result > 0:\n return 'positivo'\n elif result < 0:\n return 'negativo'\n else:\n return 'neutro'",
"_____no_output_____"
]
],
[
[
"## OpLexion",
"_____no_output_____"
]
],
[
[
"with open('lexico_v3.0.txt', 'r') as f:\n lines = f.readlines()\n\nlines = [str(x.strip()) for x in lines]\npol_dict = {}\n\nfor line in lines:\n word, _, pol, _ = line.split(',')\n \n if word not in pol_dict.keys():\n pol_dict[word] = pol",
"_____no_output_____"
],
[
"nlp = spacy.load('pt_core_news_sm')\ndef oplexion(text):\n text = str(text)\n doc = nlp(text)\n pol = 0\n \n for token in doc:\n if token.text in pol_dict.keys():\n if token.pos_ == 'VERB':\n if token.lemma_ in pol_dict.keys():\n pol += int(pol_dict[str(token.lemma_)])\n else:\n pol += int(pol_dict[str(token.text)])\n else:\n pol += int(pol_dict[str(token.text)])\n else:\n pol += 0\n \n return pol",
"_____no_output_____"
]
],
[
[
"## SentiLex",
"_____no_output_____"
]
],
[
[
"with open('SentiLex-lem-PT01.txt', 'r') as f:\n lines = f.readlines()\n\nlines = [str(x.strip()) for x in lines]\npol_dict = {}\n\nfor line in lines:\n word, infos = line.split('.')\n pol = infos.split(';')\n pol = pol[3]\n pol = pol[4:]\n \n if word not in pol_dict.keys():\n pol_dict[word] = pol",
"_____no_output_____"
],
[
"def sentilex(text):\n text = str(text)\n doc = nlp(text)\n pol = 0\n \n for token in doc:\n try:\n if token.pos_ == 'VERB':\n pol += int(pol_dict[str(token.lemma_)])\n else:\n pol += int(pol_dict[str(token.text)])\n except KeyError:\n pol += 0\n \n return pol",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4f8a3c47e0c15bf1dedec706a96c18f76cf2be
| 2,663 |
ipynb
|
Jupyter Notebook
|
ObjectOriented/Setting and Getting Property.ipynb
|
cusey/PythonExamples
|
7e60ad683c323601d84631199b10ada107ef4982
|
[
"MIT"
] | null | null | null |
ObjectOriented/Setting and Getting Property.ipynb
|
cusey/PythonExamples
|
7e60ad683c323601d84631199b10ada107ef4982
|
[
"MIT"
] | null | null | null |
ObjectOriented/Setting and Getting Property.ipynb
|
cusey/PythonExamples
|
7e60ad683c323601d84631199b10ada107ef4982
|
[
"MIT"
] | null | null | null | 21.475806 | 315 | 0.51258 |
[
[
[
"# Setting and Getting Property",
"_____no_output_____"
],
[
"The class with a property looks like this:\n\nA method that is used for getting a value is decorated with **@property**. We put this line directly in front of the header. The method which has to function as the setter is decorated with **@name.setter**. If the function had been called \"name\", we would have to decorate it with **@name.setter**. \n \nThe interesting thing is that we wrote \"two\" methods with the same name and a different number of parameters def **name(self)** and **def name(self,val)**. We have learned in a previous chapter of our course that this is not possible. It works here due to the decorating:",
"_____no_output_____"
],
[
"## Example ",
"_____no_output_____"
]
],
[
[
"class lovely():\n def __init__(self):\n self._name = \"Albert\"\n\n # GETTER \n @property\n def name(self):\n return self._name + \" is awesome\"\n\n # SETTER\n @name.setter\n def name(self, val):\n self._name = val",
"_____no_output_____"
],
[
"gao = lovely()",
"_____no_output_____"
],
[
"print(gao.name)",
"Albert is awesome\n"
],
[
"gao.name = \"Gao\"",
"_____no_output_____"
],
[
"print(gao.name)",
"Gao is awesome\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f95ae329387de18977bd350c91a8ae419495e
| 436,018 |
ipynb
|
Jupyter Notebook
|
examples/diff_plotter_demo.ipynb
|
LBJ-Wade/uvtools
|
b1bbe5fd8cff06354bed6ca4ab195bf82b8db976
|
[
"MIT"
] | null | null | null |
examples/diff_plotter_demo.ipynb
|
LBJ-Wade/uvtools
|
b1bbe5fd8cff06354bed6ca4ab195bf82b8db976
|
[
"MIT"
] | 122 |
2017-06-26T21:09:41.000Z
|
2022-03-29T17:36:09.000Z
|
examples/diff_plotter_demo.ipynb
|
LBJ-Wade/uvtools
|
b1bbe5fd8cff06354bed6ca4ab195bf82b8db976
|
[
"MIT"
] | 1 |
2018-01-27T06:58:54.000Z
|
2018-01-27T06:58:54.000Z
| 1,375.451104 | 101,300 | 0.960733 |
[
[
[
"The purpose of this notebook is to provide some examples for how to use the visibility difference plotting tools `plot_diff_waterfall` and `plot_diff_uv`. These tools accept a pair of `UVData` objects—along with some extra parameters—and visualize the difference between the data (or a subset thereof) stored in the objects' `data_array` attributes. To briefly summarize: `plot_diff_waterfall` is intended to be used to investigate differences between two sets of visibilities for a single baseline and polarization, and may be used to investigate these differences in a variety of spaces (any combination of the following four sets of parameters: time and frequency; time and delay; fringe rate and frequency; fringe rate and delay); on the other hand, `plot_diff_uv` is intended to be used as a summarizing tool, as it visualizes the differences of the entire `data_array` in the $uv$-plane.",
"_____no_output_____"
]
],
[
[
"import hera_sim\nimport uvtools\nimport copy\n%matplotlib inline",
"/home/bobby/anaconda3/envs/hera/lib/python3.7/site-packages/hera_sim/__init__.py:35: FutureWarning: \nIn the next major release, all HERA-specific variables will be removed from the codebase. The following variables will need to be accessed through new class-like structures to be introduced in the next major release: \n\nnoise.HERA_Tsky_mdl\nnoise.HERA_BEAM_POLY\nsigchain.HERA_NRAO_BANDPASS\nrfi.HERA_RFI_STATIONS\n\nAdditionally, the next major release will involve modifications to the package's API, which move toward a regularization of the way in which hera_sim methods are interfaced with; in particular, changes will be made such that the Simulator class is the most intuitive way of interfacing with the hera_sim package features.\n FutureWarning)\n"
],
[
"# make some antennas for generating a Simulator object\nants = hera_sim.antpos.hex_array(5)\n\n# activate the H1C defaults for hera_sim\nhera_sim.defaults.set('h1c')\n\n# use a modest number of times and frequencies\nsim = hera_sim.Simulator(n_freq=100, n_times=20, antennas=ants)",
"_____no_output_____"
],
[
"# add some foregrounds\nsim.add_foregrounds(\"diffuse_foreground\")\n\n# make a copy of the Simulator object\nsim2 = copy.deepcopy(sim)\n\n# add EoR to one of the copies\nsim.add_eor(\"noiselike_eor\")",
"_____no_output_____"
],
[
"# let's look at the waterfall plots for the (0,1,'xx') baseline\nantpairpol = (0,1,'xx')\n\n# Simulator.data accesses the wrapped UVData object\nuvtools.plot.plot_diff_waterfall(sim.data, sim2.data, antpairpol)",
"_____no_output_____"
],
[
"# if you want to check out the extra parameters you can list, uncomment the following line\n#uvtools.plot.plot_diff_waterfall?",
"_____no_output_____"
]
],
[
[
"Note that in the above figure, four sets of plots were made; this is the default behavior of the `plot_diff_waterfall` function, but a subset of the plots may be chosen. A subset of the plots may be chosen by passing the kwarg `plot_type` a tuple or list of plot identifiers. The four identifiers are as follows: `\"time_vs_freq\"`, `\"time_vs_dly\"`, `\"fr_vs_freq\"`, `\"fr_vs_dly\"`. Also note that by default the `plot_diff_waterfall` runs a check on the `UVData` objects `uvd1` and `uvd2` passed as the first and second required arguments; this ensures that the simulated times, frequencies, and baselines all agree, but the check may be skipped by passing `skip_check=True` to the function call. Finally, the resulting figure may be saved by passing a string or tuple/list of strings to the function call using the kwarg `save_path`.",
"_____no_output_____"
]
],
[
[
"# now let's look at the summary of the differences\n# this one takes a while...\nuvtools.plot.plot_diff_uv(sim.data, sim2.data)",
"invalid value encountered in less_equal\n"
],
[
"# again, if you want to check out the extra parameters...\n#uvtools.plot.plot_diff_uv?",
"_____no_output_____"
],
[
"# something a little more interesting\nsim = copy.deepcopy(sim2)\nsim.add_gains()",
"_____no_output_____"
],
[
"uvtools.plot.plot_diff_waterfall(sim.data, sim2.data, antpairpol)",
"_____no_output_____"
],
[
"uvtools.plot.plot_diff_uv(sim.data, sim2.data)",
"_____no_output_____"
],
[
"# what about if we add crosstalk?\nsim = copy.deepcopy(sim2)\nsim.add_xtalk(\"gen_whitenoise_xtalk\")",
"_____no_output_____"
],
[
"uvtools.plot.plot_diff_waterfall(sim.data, sim2.data, antpairpol)",
"_____no_output_____"
],
[
"uvtools.plot.plot_diff_uv(sim.data, sim2.data)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4f9addaef0f01b2d455ecd3a7f7c87dcd1efcd
| 15,575 |
ipynb
|
Jupyter Notebook
|
docs/pt-br/usage.ipynb
|
LucasRGoes/futpedia-crawler
|
432cc06fe8c7a80493814b21a0dfc624ead67ea8
|
[
"MIT"
] | null | null | null |
docs/pt-br/usage.ipynb
|
LucasRGoes/futpedia-crawler
|
432cc06fe8c7a80493814b21a0dfc624ead67ea8
|
[
"MIT"
] | 1 |
2021-06-02T00:28:18.000Z
|
2021-06-02T00:28:18.000Z
|
docs/pt-br/usage.ipynb
|
LucasRGoes/futpedia-crawler
|
432cc06fe8c7a80493814b21a0dfc624ead67ea8
|
[
"MIT"
] | null | null | null | 29.003724 | 202 | 0.402247 |
[
[
[
"Scrapedia: Um _web scraper_ da Futpédia\n=======================================\n</br>\n\n## Documentação\n1. **RootScraper**\n 1. *teams()*\n 2. *championships()*\n 3. *championship(int)*\n2. **ChampionshipScraper**\n 1. *seasons()*\n 2. *season(int)*\n3. **SeasonScraper**\n 1. *games()*",
"_____no_output_____"
]
],
[
[
"from scrapedia import RootScraper",
"_____no_output_____"
]
],
[
[
"## 1. RootScraper\n\nO RootScraper é o *scraper* principal do Scrapedia. Ele possui métodos para listagem de times e de campeonatos. Além disso ele oferece métodos para acesso mais detalhado a cada time ou campeonato.",
"_____no_output_____"
]
],
[
[
"scraper = RootScraper()",
"_____no_output_____"
]
],
[
[
"### A. teams()\nMétodo para listagem de times:",
"_____no_output_____"
]
],
[
[
"teams = scraper.teams()\nteams.head()",
"_____no_output_____"
]
],
[
[
"### B. championships()\nMétodo para listagem de campeonatos:",
"_____no_output_____"
]
],
[
[
"championships = scraper.championships()\nchampionships.head()",
"_____no_output_____"
]
],
[
[
"### C. championship(int)\nMétodo para obtenção de um *scraper* voltado a página de um campeonato específico:",
"_____no_output_____"
]
],
[
[
"championship_scraper = scraper.championship(0)",
"_____no_output_____"
]
],
[
[
"## 2. ChampionshipScraper\n\nO ChampionshipScraper é o *scraper* responsável por obter informações relativas as diversas temporadas de cada campeonato.\n\n### A. seasons()\nMétodo para listagem de temporadas de um campeonato:",
"_____no_output_____"
]
],
[
[
"seasons = championship_scraper.seasons()\nseasons.head()",
"_____no_output_____"
]
],
[
[
"### B. season(int)\nMétodo para obtenção de um *scraper* voltado a página de uma temporada específica:",
"_____no_output_____"
]
],
[
[
"season_scraper = championship_scraper.season(2003)",
"_____no_output_____"
]
],
[
[
"## 3. SeasonScraper\n\nO SeasonScraper é o *scraper* responsável por obter informações relativas aos jogos de uma temporada específica de algum campeonato.\n\n### A. games()\nMétodo para listagem de jogos de uma temporada:",
"_____no_output_____"
]
],
[
[
"games = season_scraper.games()\ngames.head()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4f9c0c6ca75cc08338a6dd4d83058ed6e8a124
| 47,580 |
ipynb
|
Jupyter Notebook
|
day3_simple_model.ipynb
|
slon101/dw_matrix_car
|
4adcdf4fb410fa005bb25ab090f755d2f3889301
|
[
"MIT"
] | null | null | null |
day3_simple_model.ipynb
|
slon101/dw_matrix_car
|
4adcdf4fb410fa005bb25ab090f755d2f3889301
|
[
"MIT"
] | null | null | null |
day3_simple_model.ipynb
|
slon101/dw_matrix_car
|
4adcdf4fb410fa005bb25ab090f755d2f3889301
|
[
"MIT"
] | null | null | null | 47,580 | 47,580 | 0.560172 |
[
[
[
"!pip install --upgrade tables",
"Collecting tables\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/ed/c3/8fd9e3bb21872f9d69eb93b3014c86479864cca94e625fd03713ccacec80/tables-3.6.1-cp36-cp36m-manylinux1_x86_64.whl (4.3MB)\n\u001b[K |████████████████████████████████| 4.3MB 2.8MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: numpy>=1.9.3 in /usr/local/lib/python3.6/dist-packages (from tables) (1.17.5)\nRequirement already satisfied, skipping upgrade: numexpr>=2.6.2 in /usr/local/lib/python3.6/dist-packages (from tables) (2.7.1)\nInstalling collected packages: tables\n Found existing installation: tables 3.4.4\n Uninstalling tables-3.4.4:\n Successfully uninstalled tables-3.4.4\nSuccessfully installed tables-3.6.1\n"
],
[
"!pip install eli5",
"Collecting eli5\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/97/2f/c85c7d8f8548e460829971785347e14e45fa5c6617da374711dec8cb38cc/eli5-0.10.1-py2.py3-none-any.whl (105kB)\n\u001b[K |████████████████████████████████| 112kB 2.8MB/s \n\u001b[?25hRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from eli5) (1.12.0)\nRequirement already satisfied: attrs>16.0.0 in /usr/local/lib/python3.6/dist-packages (from eli5) (19.3.0)\nRequirement already satisfied: jinja2 in /usr/local/lib/python3.6/dist-packages (from eli5) (2.11.1)\nRequirement already satisfied: graphviz in /usr/local/lib/python3.6/dist-packages (from eli5) (0.10.1)\nRequirement already satisfied: scikit-learn>=0.18 in /usr/local/lib/python3.6/dist-packages (from eli5) (0.22.1)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from eli5) (1.4.1)\nRequirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from eli5) (1.17.5)\nRequirement already satisfied: tabulate>=0.7.7 in /usr/local/lib/python3.6/dist-packages (from eli5) (0.8.6)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.6/dist-packages (from jinja2->eli5) (1.1.1)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn>=0.18->eli5) (0.14.1)\nInstalling collected packages: eli5\nSuccessfully installed eli5-0.10.1\n"
],
[
"import pandas as pd\nimport numpy as np\n\nfrom sklearn.dummy import DummyRegressor\nfrom sklearn.tree import DecisionTreeRegressor\n\nfrom sklearn.metrics import mean_absolute_error as mae\nfrom sklearn.model_selection import cross_val_score\n\nimport eli5\nfrom eli5.sklearn import PermutationImportance\n",
"/usr/local/lib/python3.6/dist-packages/sklearn/utils/deprecation.py:144: FutureWarning: The sklearn.metrics.scorer module is deprecated in version 0.22 and will be removed in version 0.24. The corresponding classes / functions should instead be imported from sklearn.metrics. Anything that cannot be imported from sklearn.metrics is now part of the private API.\n warnings.warn(message, FutureWarning)\n/usr/local/lib/python3.6/dist-packages/sklearn/utils/deprecation.py:144: FutureWarning: The sklearn.feature_selection.base module is deprecated in version 0.22 and will be removed in version 0.24. The corresponding classes / functions should instead be imported from sklearn.feature_selection. Anything that cannot be imported from sklearn.feature_selection is now part of the private API.\n warnings.warn(message, FutureWarning)\nUsing TensorFlow backend.\n"
],
[
"cd '/content/drive/My Drive/Colab Notebooks/matrix/matrix_two/dw_matrix_car'",
"/content/drive/My Drive/Colab Notebooks/matrix/matrix_two/dw_matrix_car\n"
],
[
"ls",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly\n\nEnter your authorization code:\n··········\nMounted at /content/drive\n"
],
[
"df = pd.read_hdf(\"data/car.h5\")\ndf.shape",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"#DM",
"_____no_output_____"
],
[
"df.select_dtypes(np.number).columns",
"_____no_output_____"
],
[
"feats = ['car_id']\nX = df[ feats].values\ny = df['price_value'].values\n\nmodel = DummyRegressor()\nmodel.fit(X, y)\n\ny_pred = model.predict(X)\n\nmae(y, y_pred)",
"_____no_output_____"
],
[
"df = df[df['price_currency'] != 'EUR']\ndf.shape",
"_____no_output_____"
],
[
"# feats",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"SUFFIX_CAT = '__cat'\nfor feat in df.columns:\n if isinstance(df[feat][0], list): continue\n \n factorized_values = df[feat].factorize()[0]\n if SUFFIX_CAT in feat:\n df[feat] = factorized_values\n else:\n df[feat + SUFFIX_CAT]= factorized_values\n \n",
"_____no_output_____"
],
[
"cat_feats = [x for x in df.columns if SUFFIX_CAT in x]\ncat_feats = [x for x in cat_feats if 'price' not in x]\ncat_feats",
"_____no_output_____"
],
[
"len(cat_feats)",
"_____no_output_____"
],
[
"X = df[cat_feats].values\ny = df['price_value'].values\n\nmodel = DecisionTreeRegressor(max_depth=5)\nscores = cross_val_score(model, X, y, cv=3, scoring='neg_mean_absolute_error')\nnp.mean(scores)",
"_____no_output_____"
],
[
"m = DecisionTreeRegressor(max_depth=5)\nm.fit(X, y)\n\nimp = PermutationImportance(m, random_state=0).fit(X,y)\neli5.show_weights(imp, feature_names=cat_feats)",
"_____no_output_____"
],
[
"!pwd",
"/content/drive/My Drive/Colab Notebooks/matrix/matrix_two/dw_matrix_car\n"
],
[
"!pwd",
"/content/drive/My Drive/Colab Notebooks/matrix/matrix_two/dw_matrix_car\n"
],
[
"!git add d3_s_m.ipynb",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4fbcdf7d2c7e6f544382bca7f134a191aa4f5e
| 10,796 |
ipynb
|
Jupyter Notebook
|
examples/performance-charts.ipynb
|
domoritz/ibis-vega-transform
|
3a56f096e4c94671ba24aafe28556c153f5ff298
|
[
"Apache-2.0"
] | 20 |
2019-08-12T17:18:10.000Z
|
2021-09-15T15:38:28.000Z
|
examples/performance-charts.ipynb
|
domoritz/ibis-vega-transform
|
3a56f096e4c94671ba24aafe28556c153f5ff298
|
[
"Apache-2.0"
] | 63 |
2019-07-29T00:07:02.000Z
|
2022-01-30T21:57:22.000Z
|
examples/performance-charts.ipynb
|
domoritz/ibis-vega-transform
|
3a56f096e4c94671ba24aafe28556c153f5ff298
|
[
"Apache-2.0"
] | 6 |
2019-07-19T15:13:36.000Z
|
2022-03-06T03:01:54.000Z
| 30.934097 | 318 | 0.546591 |
[
[
[
"# Vega, Ibis, and OmniSci Performance",
"_____no_output_____"
],
[
"In this notebook we will show two charts. The first generally works, albeit is a bit slow. The second is basically inoperable because of performance issues.\n\nI believe these performance issues are primarily due to two limitations in Vega currently:\n\n1. Each transform in the dataflow graph is executed syncronously. Ideally, we should be able to parallilize the database queries launched by each transform.\n2. The UI blocks while waiting for an async transform to complete. This isn't noticeable normally in Vega, but when running all the transforms takes multiple seconds, it makes scrolling and panning basically inoperable.\n\nWe will use Jaeger / OpenTracing to look at the timing of the various events to understand the performance.",
"_____no_output_____"
],
[
"## Setup\n\nBefore launching these, first open the \"Jager UI\" in a new window, so traces will be collected. You can do this by going to `./jaeger` instead of `./lab` or by clicking the `Jaeger` button in the JupyterLab launcher.",
"_____no_output_____"
],
[
"## Time Series Chart",
"_____no_output_____"
],
[
"1. Run these cells to create a chart",
"_____no_output_____"
]
],
[
[
"import altair as alt\nimport ibis_vega_transform\n\nimport warnings\ntry:\n from ibis.backends import omniscidb as ibis_omniscidb\nexcept ImportError as msg:\n warnings.warn(str(msg))\n from ibis import omniscidb as ibis_omniscidb\n\nconn = ibis_omniscidb.connect(\n host='metis.mapd.com', user='demouser', password='HyperInteractive',\n port=443, database='mapd', protocol= 'https'\n)",
"_____no_output_____"
],
[
"t = conn.table(\"flights_donotmodify\")\n\nstates = alt.selection_multi(fields=['origin_state'])\nairlines = alt.selection_multi(fields=['carrier_name'])\n\n# Copy default from \n# https://github.com/vega/vega-lite/blob/8936751a75c3d3713b97a85b918fb30c35262faf/src/selection.ts#L281\n# but add debounce\n# https://vega.github.io/vega/docs/event-streams/#basic-selectors\n\nDEBOUNCE_MS = 400\n\ndates = alt.selection_interval(\n fields=['dep_timestamp'],\n encodings=['x'],\n on=f'[mousedown, window:mouseup] > window:mousemove!{{0, {DEBOUNCE_MS}}}',\n translate=f'[mousedown, window:mouseup] > window:mousemove!{{0, {DEBOUNCE_MS}}}',\n zoom=False\n)\n\nHEIGHT = 800\nWIDTH = 1000\n\ncount_filter = alt.Chart(\n t[t.dep_timestamp, t.depdelay, t.origin_state, t.carrier_name],\n title=\"Selected Rows\"\n).transform_filter(\n airlines\n).transform_filter(\n dates\n).transform_filter(\n states\n).mark_text().encode(\n text='count()'\n)\n\ncount_total = alt.Chart(\n t,\n title=\"Total Rows\"\n).mark_text().encode(\n text='count()'\n)\n\nflights_by_state = alt.Chart(\n t[t.origin_state, t.carrier_name, t.dep_timestamp],\n title=\"Total Number of Flights by State\"\n).transform_filter(\n airlines\n).transform_filter(\n dates\n).mark_bar().encode(\n x='count()',\n y=alt.Y('origin_state', sort=alt.Sort(encoding='x', order='descending')),\n color=alt.condition(states, alt.ColorValue(\"steelblue\"), alt.ColorValue(\"grey\"))\n).add_selection(\n states\n).properties(\n height= 2 * HEIGHT / 3,\n width=WIDTH / 2\n) + alt.Chart(\n t[t.origin_state, t.carrier_name, t.dep_timestamp],\n).transform_filter(\n airlines\n).transform_filter(\n dates\n).mark_text(dx=20).encode(\n x='count()',\n y=alt.Y('origin_state', sort=alt.Sort(encoding='x', order='descending')),\n text='count()'\n).properties(\n height= 2 * HEIGHT / 3,\n width=WIDTH / 2\n)\n\ncarrier_delay = alt.Chart(\n t[t.depdelay, t.arrdelay, t.carrier_name, t.origin_state, t.dep_timestamp],\n title=\"Carrier Departure Delay by Arrival Delay (Minutes)\"\n).transform_filter(\n states\n).transform_filter(\n dates\n).transform_aggregate(\n depdelay='mean(depdelay)',\n arrdelay='mean(arrdelay)',\n groupby=[\"carrier_name\"]\n).mark_point(filled=True, size=200).encode(\n x='depdelay',\n y='arrdelay',\n color=alt.condition(airlines, alt.ColorValue(\"steelblue\"), alt.ColorValue(\"grey\")),\n tooltip=['carrier_name', 'depdelay', 'arrdelay']\n).add_selection(\n airlines\n).properties(\n height=2 * HEIGHT / 3,\n width=WIDTH / 2\n) + alt.Chart(\n t[t.depdelay, t.arrdelay, t.carrier_name, t.origin_state, t.dep_timestamp],\n).transform_filter(\n states\n).transform_filter(\n dates\n).transform_aggregate(\n depdelay='mean(depdelay)',\n arrdelay='mean(arrdelay)',\n groupby=[\"carrier_name\"]\n).mark_text().encode(\n x='depdelay',\n y='arrdelay',\n text='carrier_name',\n).properties(\n height=2 * HEIGHT / 3,\n width=WIDTH / 2\n)\n\ntime = alt.Chart(\n t[t.dep_timestamp, t.depdelay, t.origin_state, t.carrier_name],\n title='Number of Flights by Departure Time'\n).transform_filter(\n 'datum.dep_timestamp != null'\n).transform_filter(\n airlines\n).transform_filter(\n states\n).mark_line().encode(\n alt.X(\n 'yearmonthdate(dep_timestamp):T',\n ),\n alt.Y(\n 'count():Q',\n scale=alt.Scale(zero=False)\n )\n).add_selection(\n dates\n).properties(\n height=HEIGHT / 3,\n width=WIDTH + 50\n)\n\n(\n (count_filter | count_total) &\n (flights_by_state | carrier_delay) &\n time\n).configure_axis(\n grid=False\n).configure_view(\n strokeOpacity=0\n)",
"_____no_output_____"
]
],
[
[
"1. Wait for it to render\n2. Reload the Jaeger UI page\n3. Select the \"kernel\" service\n4. Select \"Find Traces\"\n5. Select the first trace.\n6. Now you should be able to see that each transform happens syncronously.\n7. If you click on each trace, you should also be able to see logs, including the original Vega Lite spec, the original Vega Spec, and the transformed Vega spec.",
"_____no_output_____"
],
[
"If filter based on the top charts, things seem to work OK, even though the UI is a bit slow.\n\nHowever, if you try to filter based on the bottom chart, by clicking and dragging, you will see it does work, but the UI is not ideal, because you can't see your selection until it finishes getting the data. Ideally, it would show your current time selectiona show some sort of loading UI in the other sections.",
"_____no_output_____"
],
[
"## Geospatial Chart",
"_____no_output_____"
],
[
"Now we will try to render a geospatial chart, by binning by pixel: ",
"_____no_output_____"
]
],
[
[
"t2 = conn.table(\"tweets_nov_feb\")\nx, y = t2.goog_x, t2.goog_y\n\nWIDTH = 385\nHEIGHT = 564\nX_DOMAIN = [\n -3650484.1235206556,\n 7413325.514451755\n]\nY_DOMAIN = [\n -5778161.9183506705,\n 10471808.487466192\n]\n\nscales = alt.selection_interval(bind='scales')\n\nalt.Chart(t2[x, y], width=WIDTH, height=HEIGHT).mark_rect().encode(\n alt.X(\n 'bin_x:Q',\n bin=alt.Bin(binned=True),\n title='goog_x',\n scale=alt.Scale(domain=X_DOMAIN)\n ),\n alt.X2('bin_x_end'),\n alt.Y(\n 'bin_y:Q',\n bin=alt.Bin(binned=True),\n title='goog_y',\n scale=alt.Scale(domain=Y_DOMAIN)\n ),\n alt.Y2('bin_y_end'),\n tooltip='count()',\n color=alt.Color(\n 'count()',\n scale=alt.Scale(type='log')\n )\n).add_selection(\n scales\n).transform_filter(\n scales\n).transform_bin(\n 'bin_x',\n 'goog_x',\n bin=alt.Bin(maxbins=WIDTH)\n).transform_bin(\n 'bin_y',\n 'goog_y',\n bin=alt.Bin(maxbins=HEIGHT)\n)",
"_____no_output_____"
]
],
[
[
"Now try to drag this to pan around.\n\nYou will notice a few things. First, it actually will does work, but it takes so long to move that it's hard to control. Second, It seems like the initial bin is different than the later bins.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a4fccf1a3bb195984786fccc2c526cb842e5904
| 738,673 |
ipynb
|
Jupyter Notebook
|
example_noteboks/Old Versions/200419_Single_Cell_Simulation.ipynb
|
roschkoenig/SodMod
|
144824ea6ba5bbe8f078fe0622cef9a58b8fd47e
|
[
"MIT"
] | null | null | null |
example_noteboks/Old Versions/200419_Single_Cell_Simulation.ipynb
|
roschkoenig/SodMod
|
144824ea6ba5bbe8f078fe0622cef9a58b8fd47e
|
[
"MIT"
] | null | null | null |
example_noteboks/Old Versions/200419_Single_Cell_Simulation.ipynb
|
roschkoenig/SodMod
|
144824ea6ba5bbe8f078fe0622cef9a58b8fd47e
|
[
"MIT"
] | null | null | null | 738,673 | 738,673 | 0.609201 |
[
[
[
"## Simulation for biallelic dynamics of SCN1A",
"_____no_output_____"
]
],
[
[
"# The following section only needs to be executed when running off of google drive\n\n# from google.colab import drive\n# drive.mount('/content/drive')\n\n# This needs to be run only once at the beginning to access the models\n#-------------------------------------------------------------------------------\n!pip install --upgrade git+https://github.com/roschkoenig/SodMod.git@Single_Cell_Sim\n",
"Collecting git+https://github.com/roschkoenig/SodMod.git@Single_Cell_Sim\n Cloning https://github.com/roschkoenig/SodMod.git (to revision Single_Cell_Sim) to /tmp/pip-req-build-q9ivzgw6\n Running command git clone -q https://github.com/roschkoenig/SodMod.git /tmp/pip-req-build-q9ivzgw6\n Running command git checkout -b Single_Cell_Sim --track origin/Single_Cell_Sim\n Switched to a new branch 'Single_Cell_Sim'\n Branch 'Single_Cell_Sim' set up to track remote branch 'Single_Cell_Sim' from 'origin'.\nBuilding wheels for collected packages: sodmod\n Building wheel for sodmod (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for sodmod: filename=sodmod-0.1-cp36-none-any.whl size=9888 sha256=9f486ae9a6481c9c7b16a373c3ae44326568938309ebdc64a95e4d2f5633f69b\n Stored in directory: /tmp/pip-ephem-wheel-cache-9m5q0eco/wheels/25/8a/db/fb8c9e25d5464a664514bd9bca7d2997503c64069ae1f3d291\nSuccessfully built sodmod\nInstalling collected packages: sodmod\n Found existing installation: sodmod 0.1\n Uninstalling sodmod-0.1:\n Successfully uninstalled sodmod-0.1\nSuccessfully installed sodmod-0.1\n"
],
[
"import matplotlib.pyplot as plt\nimport numpy as np\nfrom importlib import reload\nfrom scipy.integrate import odeint\nfrom torch import multiprocessing as mp\nfrom itertools import repeat\nfrom IPython.display import set_matplotlib_formats\nfrom google.colab import files\nimport matplotlib as mpl\n\nimport sodmod as sm\nfrom sodmod import params as pr\nfrom sodmod import cells as cl\nfrom sodmod import incurr as ic",
"_____no_output_____"
],
[
"# Manual definitions\n#===============================================================================\n# Simulations\n#-------------------------------------------------------------------------------\nV0 = -80\nsteps = 150 # Number of simulations to be ru\nctyp = 'IN' # Cell type to be used 'IN', 'PY', 'RE'\nconds = ['WT37', 'AS37', 'TI37'] # Conditions to be modelled\ncols = ['k', 'b', 'r'] # Colours for plotting \nno_parallel = False\nwhichplot = 'bifurcation' # 'bifurcation', 'ramp', or 'phasespace' \n\n# Define parameters for the selected plot type\n#-------------------------------------------------------------------------------\nif whichplot == 'bifurcation':\n ptype = 'bifurcation'\n paradigm = 'constant'\n T = np.linspace(0,250,5000)\n\nif whichplot == 'ramp':\n ptype = 'timeseries'\n paradigm = 'ramp' \n T = np.linspace(0,1000,10000) \n\nif whichplot == 'phasespace':\n ptype = 'phasespace'\n paradigm = 'constant'\n T = np.linspace(0, 250, 5000) \n \n# Initial conditions\n#-------------------------------------------------------------------------------\nnp.random.seed(1000)\n\n\n################################## ODE Solver ##################################\n\n#===============================================================================\n# Simulation executor\n#===============================================================================\ndef runsim(i_scl, conds, cell, V0, Y0 = None, paradigm='constant'):\n Vy = {}\n\n # Run simulation across conditions\n #------------------------------------------------------------------------------- \n for ci in range(len(conds)):\n par = pr.params(conds[ci], i_scl, ctyp, paradigm)\n if Y0 == None: \n y0 = np.random.rand(len(par['snames']))\n y0[0] = V0\n else: y0 = Y0[conds[ci]][-1,:]\n Vy.update({conds[ci]:odeint(cell, y0, T, args=(par,))})\n\n return Vy\n\n\n############################### Plotting Routines ##############################\n#===============================================================================\n# Time series plots\n#===============================================================================\ndef plot_timeseries(Vy, I_scl, ctyp, Nplots = 0, paradigm='constant'):\n\n if Nplots == 0: Nplots = len(Vy)\n conds = list(Vy[0].keys())\n\n # Set up plot\n #--------------------------------------------------------------------\n fig, ax = plt.subplots(Nplots+1,1, figsize=(24, Nplots*6))\n plotid = 0\n\n for i in range(0,len(Vy),round(len(Vy)/Nplots)):\n \n for ci in range(len(conds)):\n cond = conds[ci]\n V = Vy[i][cond][:,0]\n\n # Do the plotting\n #------------------------------------------------------------\n if Nplots == 1: \n ax[plotid].plot(T, V-ci*100, cols[ci], label=conds[ci])\n ax[plotid].set_title(\"Max Input current \" + str(I_scl))\n ax[plotid].legend()\n else:\n ax[plotid].plot(T, V-ci*100, cols[ci], label = conds[ci]) \n ax[plotid].set_title(\"Input current\" + str(I_scl[i]))\n ax[plotid].legend()\n\n plotid = plotid + 1\n ax[plotid].plot(T,[ic.Id(t,paradigm) for t in T])\n \n\n\n#===============================================================================\n# Phase space plots\n#===============================================================================\ndef plot_phasespace(Vy, I_scl, ctyp, states = ['Vm', 'm_Na'], Nplots = 0):\n\n if Nplots == 0: Nplots = len(Vy)\n conds = list(Vy[0].keys())\n \n # Set up plot\n #--------------------------------------------------------------------\n fig, ax = plt.subplots(2,len(conds), figsize=(12*len(conds), 12))\n testpar = pr.params(typ = ctyp)\n\n for ci in range(len(conds)):\n if ci == 0: cmap = plt.get_cmap('Greys')\n if ci == 1: cmap = plt.get_cmap('Blues')\n if ci == 2: cmap = plt.get_cmap('Reds')\n ndcmap = cmap(np.linspace(0,1,Nplots))\n\n setall = [i for i in range(0,len(Vy),int(np.floor(len(Vy)/Nplots)))]\n set1 = np.intersect1d(np.where(np.log(I_scl) > -1)[0], np.where(np.log(I_scl) < 1)[0])\n\n k = 0 \n for i in setall:\n cond = conds[ci]\n s0 = Vy[i][cond][4500:5000,testpar[\"snames\"].index(states[0])]\n s1 = Vy[i][cond][4500:5000,testpar[\"snames\"].index(states[1])]\n\n # Do the plotting\n #------------------------------------------------------------\n ax[0,ci].plot(s0, s1, cols[ci], color=ndcmap[k,:]) \n ax[0,ci].set_title(cond + \"Input current \" + str(I_scl[i]))\n\n k = k + 1\n norm = mpl.colors.Normalize(vmin=np.log(I_scl[0]), vmax=np.log(I_scl[-1]))\n cb = mpl.colorbar.ColorbarBase(ax[1,ci], cmap=cmap, norm=norm, \n orientation='horizontal')\n \n#===============================================================================\n# Bifurcation plots\n#===============================================================================\ndef plot_bifurcation(Vy_fwd, Vy_bwd, I_fwd, I_bwd, ctyp, Nplots = None, direction = [0,1]):\n if Nplots == None: Nplots = len(Vy_fwd)\n conds = list(Vy_fwd[0].keys())\n\n # Set up plot\n #--------------------------------------------------------------------\n fig, ax = plt.subplots(len(conds),1, figsize=(24,6*len(conds)))\n testpar = pr.params(typ = ctyp)\n\n plotid = 0\n for ci in range(len(conds)):\n for i in range(0,len(Vy_fwd),round(len(Vy_fwd)/Nplots)):\n\n cond = conds[ci]\n f = np.zeros([2,1])\n b = np.zeros([2,1])\n i_fwd = np.multiply([1,1],np.log(I_fwd[i]))\n i_bwd = np.multiply([1,1],np.log(I_bwd[i])) \n\n f[0] = np.min(Vy_fwd[i][cond][1000:5000,0])\n f[1] = np.max(Vy_fwd[i][cond][1000:5000,0])\n\n b[0] = np.min(Vy_bwd[i][cond][1000:5000,0])\n b[1] = np.max(Vy_bwd[i][cond][1000:5000,0])\n\n # Do the plotting\n #------------------------------------------------------------\n\n if 0 in direction: ax[plotid].scatter(i_fwd, f, color=cols[ci])\n if 1 in direction: ax[plotid].scatter(i_bwd, b, color=cols[ci], facecolor='none') \n\n plotid = plotid + 1",
"_____no_output_____"
],
[
"################################## Run ODE #####################################\n\n#-------------------------------------------------------------------------------\n# Ramp model execution - only executes one time series\n#-------------------------------------------------------------------------------\nif whichplot == 'ramp':\n Vy = []\n i_scl = np.exp(6) # Run all the way up to maximum value\n Vy.append( runsim(i_scl, conds, getattr(cl, ctyp), V0, paradigm=paradigm) )\n\n#-------------------------------------------------------------------------------\n# Bifurcation execution - runs several iteration, forward and backward\n#-------------------------------------------------------------------------------\nif whichplot == 'bifurcation':\n\n # Define conditions to be tested\n #-------------------------------------------------------------------------------\n I_scl = np.exp(np.arange(-2,6,6/steps)) # Input currents to be modelled\n\n # Looped execution (for bifurcation analysis)\n #-------------------------------------------------------------------------------\n print('Running forward simulation')\n Vy_fwd = []\n I_fwd = []\n for i in I_scl:\n if len(Vy_fwd) == 0: Vy_fwd.append(runsim(i, conds, getattr(cl, ctyp), \n V0, paradigm=paradigm))\n else: Vy_fwd.append(runsim(i, conds, getattr(cl, ctyp), \n V0, Vy_fwd[-1], paradigm=paradigm))\n I_fwd.append(i)\n \n print('Running backward simulation')\n Vy_bwd = []\n I_bwd = []\n for i in np.flip(I_scl):\n if len(Vy_bwd) == 0: Vy_bwd.append(runsim(i, conds, getattr(cl, ctyp), \n V0, paradigm=paradigm))\n else: Vy_bwd.append(runsim(i, conds, getattr(cl, ctyp), \n V0, Vy_bwd[-1], paradigm=paradigm))\n I_bwd.append(i) \n\n Vy = Vy_fwd\n I_scl = I_fwd\n\n#-------------------------------------------------------------------------------\n# Phasespace execution - runs only if required - forward only\n#-------------------------------------------------------------------------------\nif whichplot == 'phasespace':\n # Only actually run estimation of required\n #-----------------------------------------------------------------------------\n if not ('Vy' in locals() and len(Vy) > 1): # Only run if bifurcation hasn't been run before \n I_scl = np.exp(np.arange(-2,6,6/steps))\n\n if not no_parallel: # Run on parallel pool if allowed\n p = mp.Pool(len(I_scl)) \n Vy = p.starmap(runsim, zip(I_scl, repeat(conds), repeat(getattr(cl, ctyp)), \n repeat(V0), repeat(None), repeat(paradigm)))\n\n else: # Run in sequence if no parallel \n Vy = []\n for i in I_scl:\n if len(Vy) == 0: Vy.append(runsim(i, conds, getattr(cl, ctyp), \n V0, paradigm=paradigm))\n else: Vy.append(runsim(i, conds, getattr(cl, ctyp), \n V0, Vy[-1], paradigm=paradigm))\n \n else: print('Didn\\'t neet to calculate anything')\n",
"Running forward simulation\n"
],
[
"set_matplotlib_formats('svg')\nif whichplot == 'ramp': plot_timeseries(Vy, i_scl, ctyp, paradigm=paradigm)\nif whichplot == 'bifurcation': plot_bifurcation(Vy_fwd, Vy_bwd, I_fwd, I_bwd, ctyp, direction=[0,1])\nif whichplot == 'phasespace': plot_phasespace(Vy, I_scl, ctyp, ['m_Na', 'h_Na'], Nplots = 50)\n\nplt.savefig(whichplot+'.pdf')\nfiles.download(whichplot+'.pdf')\n",
"/usr/local/lib/python3.6/dist-packages/sodmod/chans.py:12: RuntimeWarning: invalid value encountered in double_scalars\n alpha_m = (-0.32*(Vm-p['Vt']-13.0)) / (np.exp(-(Vm-p['Vt']-13.0)/4)-1)\n/usr/local/lib/python3.6/dist-packages/sodmod/chans.py:13: RuntimeWarning: invalid value encountered in double_scalars\n beta_m = (0.28*(Vm-p['Vt']-40.0)) / (np.exp((Vm-p['Vt']-40.0)/5)-1)\n"
],
[
"np.intersect1d(np.where(np.log(I_scl) > -1)[0], np.where(np.log(I_scl) < 1)[0])",
"_____no_output_____"
],
[
"len(Vy)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4fe2d0971f649c0d8009f611760bfd128f27a0
| 138,729 |
ipynb
|
Jupyter Notebook
|
nbs/13a_learner.ipynb
|
Paperspace/fastai
|
beaa630d78c44617857cd685368db0b377655bfe
|
[
"Apache-2.0"
] | null | null | null |
nbs/13a_learner.ipynb
|
Paperspace/fastai
|
beaa630d78c44617857cd685368db0b377655bfe
|
[
"Apache-2.0"
] | null | null | null |
nbs/13a_learner.ipynb
|
Paperspace/fastai
|
beaa630d78c44617857cd685368db0b377655bfe
|
[
"Apache-2.0"
] | null | null | null | 37.363049 | 9,496 | 0.591599 |
[
[
[
"# default_exp learner",
"_____no_output_____"
],
[
"#export\nfrom fastai.data.all import *\nfrom fastai.optimizer import *\nfrom fastai.callback.core import *",
"_____no_output_____"
],
[
"#hide\nfrom nbdev.showdoc import *",
"_____no_output_____"
],
[
"#export\n_all_ = ['CancelFitException', 'CancelEpochException', 'CancelTrainException', 'CancelValidException', 'CancelBatchException']",
"_____no_output_____"
],
[
"#export\n_loop = ['Start Fit', 'before_fit', 'Start Epoch Loop', 'before_epoch', 'Start Train', 'before_train',\n 'Start Batch Loop', 'before_batch', 'after_pred', 'after_loss', 'before_backward', 'after_backward',\n 'after_step', 'after_cancel_batch', 'after_batch','End Batch Loop','End Train',\n 'after_cancel_train', 'after_train', 'Start Valid', 'before_validate','Start Batch Loop',\n '**CBs same as train batch**', 'End Batch Loop', 'End Valid', 'after_cancel_validate',\n 'after_validate', 'End Epoch Loop', 'after_cancel_epoch', 'after_epoch', 'End Fit',\n 'after_cancel_fit', 'after_fit']",
"_____no_output_____"
]
],
[
[
"# Learner\n\n> Basic class for handling the training loop",
"_____no_output_____"
],
[
"You probably want to jump directly to the definition of `Learner`.",
"_____no_output_____"
],
[
"## Utils function",
"_____no_output_____"
]
],
[
[
"#hide\n#For tests\nfrom torch.utils.data import TensorDataset\n\ndef synth_dbunch(a=2, b=3, bs=16, n_train=10, n_valid=2, cuda=False):\n \"A simple dataset where `x` is random and `y = a*x + b` plus some noise.\"\n def get_data(n):\n x = torch.randn(int(bs*n))\n return TensorDataset(x, a*x + b + 0.1*torch.randn(int(bs*n)))\n train_ds = get_data(n_train)\n valid_ds = get_data(n_valid)\n device = default_device() if cuda else None\n train_dl = TfmdDL(train_ds, bs=bs, shuffle=True, num_workers=0)\n valid_dl = TfmdDL(valid_ds, bs=bs, num_workers=0)\n return DataLoaders(train_dl, valid_dl, device=device)\n\nclass RegModel(Module):\n \"A r\"\n def __init__(self): self.a,self.b = nn.Parameter(torch.randn(1)),nn.Parameter(torch.randn(1))\n def forward(self, x): return x*self.a + self.b",
"_____no_output_____"
],
[
"# export\ndefaults.lr = 1e-3",
"_____no_output_____"
],
[
"# export\ndef replacing_yield(o, attr, val):\n \"Context manager to temporarily replace an attribute\"\n old = getattr(o,attr)\n try: yield setattr(o,attr,val)\n finally: setattr(o,attr,old)",
"_____no_output_____"
],
[
"class _A:\n def __init__(self, a): self.a = a\n @contextmanager\n def a_changed(self, v): return replacing_yield(self, 'a', v)\n\na = _A(42)\nwith a.a_changed(32):\n test_eq(a.a, 32)\ntest_eq(a.a, 42)",
"_____no_output_____"
],
[
"#export\ndef mk_metric(m):\n \"Convert `m` to an `AvgMetric`, unless it's already a `Metric`\"\n return m if isinstance(m, Metric) else AvgMetric(m)",
"_____no_output_____"
]
],
[
[
"See the class `Metric` below for more information.",
"_____no_output_____"
]
],
[
[
"#export\ndef save_model(file, model, opt, with_opt=True, pickle_protocol=2):\n \"Save `model` to `file` along with `opt` (if available, and if `with_opt`)\"\n if rank_distrib(): return # don't save if child proc\n if opt is None: with_opt=False\n state = get_model(model).state_dict()\n if with_opt: state = {'model': state, 'opt':opt.state_dict()}\n torch.save(state, file, pickle_protocol=pickle_protocol)",
"_____no_output_____"
]
],
[
[
"`file` can be a `Path` object, a string or an opened file object. `pickle_protocol` is passed along to `torch.save`",
"_____no_output_____"
]
],
[
[
"# export\ndef load_model(file, model, opt, with_opt=None, device=None, strict=True):\n \"Load `model` from `file` along with `opt` (if available, and if `with_opt`)\"\n distrib_barrier()\n if isinstance(device, int): device = torch.device('cuda', device)\n elif device is None: device = 'cpu'\n state = torch.load(file, map_location=device)\n hasopt = set(state)=={'model', 'opt'}\n model_state = state['model'] if hasopt else state\n get_model(model).load_state_dict(model_state, strict=strict)\n if hasopt and ifnone(with_opt,True):\n try: opt.load_state_dict(state['opt'])\n except:\n if with_opt: warn(\"Could not load the optimizer state.\")\n elif with_opt: warn(\"Saved filed doesn't contain an optimizer state.\")",
"_____no_output_____"
]
],
[
[
"`file` can be a `Path` object, a string or an opened file object. If a `device` is passed, the model is loaded on it, otherwise it's loaded on the CPU. \n\nIf `strict` is `True`, the file must exactly contain weights for every parameter key in `model`, if `strict` is `False`, only the keys that are in the saved model are loaded in `model`.",
"_____no_output_____"
]
],
[
[
"# export\ndef _try_concat(o):\n try: return torch.cat(o)\n except: return sum([L(o_[i,:] for i in range_of(o_)) for o_ in o], L())",
"_____no_output_____"
],
[
"#export\n_before_epoch = [event.before_fit, event.before_epoch]\n_after_epoch = [event.after_epoch, event.after_fit]",
"_____no_output_____"
],
[
"#export\nclass _ConstantFunc():\n \"Returns a function that returns `o`\"\n def __init__(self, o): self.o = o\n def __call__(self, *args, **kwargs): return self.o",
"_____no_output_____"
]
],
[
[
"## Learner -",
"_____no_output_____"
]
],
[
[
"# export\n@log_args(but='dls,model,opt_func,cbs')\nclass Learner():\n def __init__(self, dls, model, loss_func=None, opt_func=Adam, lr=defaults.lr, splitter=trainable_params, cbs=None,\n metrics=None, path=None, model_dir='models', wd=None, wd_bn_bias=False, train_bn=True,\n moms=(0.95,0.85,0.95)):\n store_attr(self, \"dls,model,opt_func,lr,splitter,model_dir,wd,wd_bn_bias,train_bn,metrics,moms\")\n self.training,self.create_mbar,self.logger,self.opt,self.cbs = False,True,print,None,L()\n if loss_func is None:\n loss_func = getattr(dls.train_ds, 'loss_func', None)\n assert loss_func is not None, \"Could not infer loss function from the data, please pass a loss function.\"\n self.loss_func = loss_func\n self.path = Path(path) if path is not None else getattr(dls, 'path', Path('.'))\n self.add_cbs([(cb() if isinstance(cb, type) else cb) for cb in L(defaults.callbacks)+L(cbs)])\n self.epoch,self.n_epoch,self.loss = 0,1,tensor(0.)\n\n @property\n def metrics(self): return self._metrics\n @metrics.setter\n def metrics(self,v): self._metrics = L(v).map(mk_metric)\n\n def _grab_cbs(self, cb_cls): return L(cb for cb in self.cbs if isinstance(cb, cb_cls))\n def add_cbs(self, cbs): L(cbs).map(self.add_cb)\n def remove_cbs(self, cbs): L(cbs).map(self.remove_cb)\n def add_cb(self, cb):\n old = getattr(self, cb.name, None)\n assert not old or isinstance(old, type(cb)), f\"self.{cb.name} already registered\"\n cb.learn = self\n setattr(self, cb.name, cb)\n self.cbs.append(cb)\n return self\n\n def remove_cb(self, cb):\n if isinstance(cb, type): self.remove_cbs(self._grab_cbs(cb))\n else:\n cb.learn = None\n if hasattr(self, cb.name): delattr(self, cb.name)\n if cb in self.cbs: self.cbs.remove(cb)\n\n @contextmanager\n def added_cbs(self, cbs):\n self.add_cbs(cbs)\n try: yield\n finally: self.remove_cbs(cbs)\n\n @contextmanager\n def removed_cbs(self, cbs):\n self.remove_cbs(cbs)\n try: yield self\n finally: self.add_cbs(cbs)\n\n def ordered_cbs(self, event): return [cb for cb in sort_by_run(self.cbs) if hasattr(cb, event)]\n\n def __call__(self, event_name): L(event_name).map(self._call_one)\n\n def _call_one(self, event_name):\n assert hasattr(event, event_name), event_name\n [cb(event_name) for cb in sort_by_run(self.cbs)]\n\n def _bn_bias_state(self, with_bias): return norm_bias_params(self.model, with_bias).map(self.opt.state)\n def create_opt(self):\n self.opt = self.opt_func(self.splitter(self.model), lr=self.lr)\n if not self.wd_bn_bias:\n for p in self._bn_bias_state(True ): p['do_wd'] = False\n if self.train_bn:\n for p in self._bn_bias_state(False): p['force_train'] = True\n\n def _split(self, b):\n i = getattr(self.dls, 'n_inp', 1 if len(b)==1 else len(b)-1)\n self.xb,self.yb = b[:i],b[i:]\n\n def _step(self): self.opt.step()\n def _backward(self): self.loss.backward()\n\n def _with_events(self, f, event_type, ex, final=noop):\n try: self(f'before_{event_type}') ;f()\n except ex: self(f'after_cancel_{event_type}')\n finally: self(f'after_{event_type}') ;final()\n\n def all_batches(self):\n self.n_iter = len(self.dl)\n for o in enumerate(self.dl): self.one_batch(*o)\n\n def _do_one_batch(self):\n self.pred = self.model(*self.xb); self('after_pred')\n if len(self.yb) == 0: return\n self.loss = self.loss_func(self.pred, *self.yb); self('after_loss')\n if not self.training: return\n self('before_backward')\n self._backward(); self('after_backward')\n self._step(); self('after_step')\n self.opt.zero_grad()\n\n def one_batch(self, i, b):\n self.iter = i\n self._split(b)\n self._with_events(self._do_one_batch, 'batch', CancelBatchException)\n\n def _do_epoch_train(self):\n self.dl = self.dls.train\n self._with_events(self.all_batches, 'train', CancelTrainException)\n\n def _do_epoch_validate(self, ds_idx=1, dl=None):\n if dl is None: dl = self.dls[ds_idx]\n self.dl = dl;\n with torch.no_grad(): self._with_events(self.all_batches, 'validate', CancelValidException)\n\n def _do_epoch(self):\n self._do_epoch_train()\n self._do_epoch_validate()\n\n def _do_fit(self):\n for epoch in range(self.n_epoch):\n self.epoch=epoch\n self._with_events(self._do_epoch, 'epoch', CancelEpochException)\n\n @log_args(but='cbs')\n def fit(self, n_epoch, lr=None, wd=None, cbs=None, reset_opt=False):\n with self.added_cbs(cbs):\n if reset_opt or not self.opt: self.create_opt()\n if wd is None: wd = self.wd\n if wd is not None: self.opt.set_hypers(wd=wd)\n self.opt.set_hypers(lr=self.lr if lr is None else lr)\n self.n_epoch,self.loss = n_epoch,tensor(0.)\n self._with_events(self._do_fit, 'fit', CancelFitException, self._end_cleanup)\n\n def _end_cleanup(self): self.dl,self.xb,self.yb,self.pred,self.loss = None,(None,),(None,),None,None\n def __enter__(self): self(_before_epoch); return self\n def __exit__(self, exc_type, exc_value, tb): self(_after_epoch)\n\n def validation_context(self, cbs=None, inner=False):\n cms = [self.no_logging(),self.no_mbar()]\n if cbs: cms.append(self.added_cbs(cbs))\n if not inner: cms.append(self)\n return ContextManagers(cms)\n\n def validate(self, ds_idx=1, dl=None, cbs=None):\n if dl is None: dl = self.dls[ds_idx]\n with self.validation_context(cbs=cbs): self._do_epoch_validate(ds_idx, dl)\n return getattr(self, 'final_record', None)\n\n @delegates(GatherPredsCallback.__init__)\n def get_preds(self, ds_idx=1, dl=None, with_input=False, with_decoded=False, with_loss=False, act=None,\n inner=False, reorder=True, cbs=None, **kwargs):\n if dl is None: dl = self.dls[ds_idx].new(shuffled=False, drop_last=False)\n if reorder and hasattr(dl, 'get_idxs'):\n idxs = dl.get_idxs()\n dl = dl.new(get_idxs = _ConstantFunc(idxs))\n cb = GatherPredsCallback(with_input=with_input, with_loss=with_loss, **kwargs)\n ctx_mgrs = self.validation_context(cbs=L(cbs)+[cb], inner=inner)\n if with_loss: ctx_mgrs.append(self.loss_not_reduced())\n with ContextManagers(ctx_mgrs):\n self._do_epoch_validate(dl=dl)\n if act is None: act = getattr(self.loss_func, 'activation', noop)\n res = cb.all_tensors()\n pred_i = 1 if with_input else 0\n if res[pred_i] is not None:\n res[pred_i] = act(res[pred_i])\n if with_decoded: res.insert(pred_i+2, getattr(self.loss_func, 'decodes', noop)(res[pred_i]))\n if reorder and hasattr(dl, 'get_idxs'): res = nested_reorder(res, tensor(idxs).argsort())\n return tuple(res)\n self._end_cleanup()\n\n def predict(self, item, rm_type_tfms=None, with_input=False):\n dl = self.dls.test_dl([item], rm_type_tfms=rm_type_tfms, num_workers=0)\n inp,preds,_,dec_preds = self.get_preds(dl=dl, with_input=True, with_decoded=True)\n i = getattr(self.dls, 'n_inp', -1)\n inp = (inp,) if i==1 else tuplify(inp)\n dec = self.dls.decode_batch(inp + tuplify(dec_preds))[0]\n dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])\n res = dec_targ,dec_preds[0],preds[0]\n if with_input: res = (dec_inp,) + res\n return res\n\n def show_results(self, ds_idx=1, dl=None, max_n=9, shuffle=True, **kwargs):\n if dl is None: dl = self.dls[ds_idx].new(shuffle=shuffle)\n b = dl.one_batch()\n _,_,preds = self.get_preds(dl=[b], with_decoded=True)\n self.dls.show_results(b, preds, max_n=max_n, **kwargs)\n\n def show_training_loop(self):\n indent = 0\n for s in _loop:\n if s.startswith('Start'): print(f'{\" \"*indent}{s}'); indent += 2\n elif s.startswith('End'): indent -= 2; print(f'{\" \"*indent}{s}')\n else: print(f'{\" \"*indent} - {s:15}:', self.ordered_cbs(s))\n\n @contextmanager\n def no_logging(self): return replacing_yield(self, 'logger', noop)\n @contextmanager\n def no_mbar(self): return replacing_yield(self, 'create_mbar', False)\n\n @contextmanager\n def loss_not_reduced(self):\n if hasattr(self.loss_func, 'reduction'): return replacing_yield(self.loss_func, 'reduction', 'none')\n else: return replacing_yield(self, 'loss_func', partial(self.loss_func, reduction='none'))\n\n @delegates(save_model)\n def save(self, file, **kwargs):\n file = join_path_file(file, self.path/self.model_dir, ext='.pth')\n save_model(file, self.model, getattr(self,'opt',None), **kwargs)\n return file\n\n @delegates(load_model)\n def load(self, file, with_opt=None, device=None, **kwargs):\n if device is None and hasattr(self.dls, 'device'): device = self.dls.device\n if self.opt is None: self.create_opt()\n file = join_path_file(file, self.path/self.model_dir, ext='.pth')\n load_model(file, self.model, self.opt, device=device, **kwargs)\n return self\n\nLearner.x,Learner.y = add_props(lambda i,x: detuplify((x.xb,x.yb)[i]))",
"_____no_output_____"
],
[
"#export\nadd_docs(Learner, \"Group together a `model`, some `dls` and a `loss_func` to handle training\",\n add_cbs=\"Add `cbs` to the list of `Callback` and register `self` as their learner\",\n add_cb=\"Add `cb` to the list of `Callback` and register `self` as their learner\",\n remove_cbs=\"Remove `cbs` from the list of `Callback` and deregister `self` as their learner\",\n remove_cb=\"Add `cb` from the list of `Callback` and deregister `self` as their learner\",\n added_cbs=\"Context manage that temporarily adds `cbs`\",\n removed_cbs=\"Context manage that temporarily removes `cbs`\",\n ordered_cbs=\"List of `Callback`s, in order, for an `event` in the training loop\",\n create_opt=\"Create an optimizer with default hyper-parameters\",\n one_batch=\"Train or evaluate `self.model` on batch `(xb,yb)`\",\n all_batches=\"Train or evaluate `self.model` on all the batches of `self.dl`\",\n fit=\"Fit `self.model` for `n_epoch` using `cbs`. Optionally `reset_opt`.\",\n validate=\"Validate on `dl` with potential new `cbs`.\",\n get_preds=\"Get the predictions and targets on the `ds_idx`-th dbunchset or `dl`, optionally `with_input` and `with_loss`\",\n predict=\"Prediction on `item`, fully decoded, loss function decoded and probabilities\",\n validation_context=\"A `ContextManagers` suitable for validation, with optional `cbs`\",\n show_results=\"Show some predictions on `ds_idx`-th dataset or `dl`\",\n show_training_loop=\"Show each step in the training loop\",\n no_logging=\"Context manager to temporarily remove `logger`\",\n no_mbar=\"Context manager to temporarily prevent the master progress bar from being created\",\n loss_not_reduced=\"A context manager to evaluate `loss_func` with reduction set to none.\",\n save=\"Save model and optimizer state (if `with_opt`) to `self.path/self.model_dir/file`\",\n load=\"Load model and optimizer state (if `with_opt`) from `self.path/self.model_dir/file` using `device`\",\n __call__=\"Call `event_name` for all `Callback`s in `self.cbs`\"\n)",
"_____no_output_____"
],
[
"show_doc(Learner)",
"_____no_output_____"
]
],
[
[
"`opt_func` will be used to create an optimizer when `Learner.fit` is called, with `lr` as a default learning rate. `splitter` is a function that takes `self.model` and returns a list of parameter groups (or just one parameter group if there are no different parameter groups). The default is `trainable_params`, which returns all trainable parameters of the model.\n\n`cbs` is one or a list of `Callback`s to pass to the `Learner`. `Callback`s are used for every tweak of the training loop. Each `Callback` is registered as an attribute of `Learner` (with camel case). At creation, all the callbacks in `defaults.callbacks` (`TrainEvalCallback`, `Recorder` and `ProgressCallback`) are associated to the `Learner`.\n\n`metrics` is an optional list of metrics, that can be either functions or `Metric`s (see below). \n\n`path` and `model_dir` are used to save and/or load models. Often `path` will be inferred from `dls`, but you can override it or pass a `Path` object to `model_dir`. Make sure you can write in `path/model_dir`!\n\n`wd` is the default weight decay used when training the model; `moms`, the default momentums used in `Learner.fit_one_cycle`. `wd_bn_bias` controls if weight decay is applied to `BatchNorm` layers and bias. \n\nLastly, `train_bn` controls if `BatchNorm` layers are trained even when they are supposed to be frozen according to the `splitter`. Our empirical experiments have shown that it's the best behavior for those layers in transfer learning.",
"_____no_output_____"
],
[
"### PyTorch interrop",
"_____no_output_____"
],
[
"You can use regular PyTorch functionality for most of the arguments of the `Learner`, although the experience will be smoother with pure fastai objects and you will be able to use the full functionality of the library. The expectation is that the training loop will work smoothly even if you did not use fastai end to end. What you might lose are interpretation objects or showing functionality. The list below explains how to use plain PyTorch objects for all the arguments and what you might lose.\n\nThe most important is `opt_func`. If you are not using a fastai optimizer, you will need to write a function that wraps your PyTorch optimizer in an `OptimWrapper`. See the [optimizer module](http://docs.fast.ai/optimizer) for more details. This is to ensure the library's schedulers/freeze API work with your code.\n\n- `dls` is a `DataLoaders` object, that you can create from standard PyTorch dataloaders. By doing so, you will lose all showing functionality like `show_batch`/`show_results`. You can check the [data block API](http://docs.fast.ai/tutorial.datablock) or the [mid-level data API tutorial](http://docs.fast.ai/tutorial.pets) to learn how to use fastai to gather your data!\n- `model` is a standard PyTorch model. You can use anyone you like, just make sure it accepts the number of inputs you have in your `DataLoaders` and returns as many outputs as you have targets.\n- `loss_func` can be any loss function you like. It needs to be one of fastai's if you want to use `Learn.predict` or `Learn.get_preds`, or you will have to implement special methods (see more details after the `BaseLoss` documentation).",
"_____no_output_____"
],
[
"Now let's look at the main thing the `Learner` class implements: the training loop.",
"_____no_output_____"
],
[
"### Training loop",
"_____no_output_____"
]
],
[
[
"show_doc(Learner.fit)",
"_____no_output_____"
]
],
[
[
"Uses `lr` and `wd` if they are provided, otherwise use the defaults values given by the `lr` and `wd` attributes of `Learner`.",
"_____no_output_____"
],
[
"All the examples use `synth_learner` which is a simple `Learner` training a linear regression model.",
"_____no_output_____"
]
],
[
[
"#hide\ndef synth_learner(n_train=10, n_valid=2, cuda=False, lr=defaults.lr, **kwargs):\n data = synth_dbunch(n_train=n_train,n_valid=n_valid, cuda=cuda)\n return Learner(data, RegModel(), loss_func=MSELossFlat(), lr=lr, **kwargs)",
"_____no_output_____"
],
[
"#Training a few epochs should make the model better\nlearn = synth_learner(lr=5e-2)\nlearn.model = learn.model.cpu()\nxb,yb = learn.dls.one_batch()\ninit_loss = learn.loss_func(learn.model(xb), yb)\nlearn.fit(6)\nxb,yb = learn.dls.one_batch()\nfinal_loss = learn.loss_func(learn.model(xb), yb)\nassert final_loss < init_loss",
"_____no_output_____"
],
[
"#hide\n#Test of TrainEvalCallback\nclass TestTrainEvalCallback(Callback):\n run_after,run_valid = TrainEvalCallback,False\n def before_fit(self): \n test_eq([self.pct_train,self.train_iter], [0., 0])\n self.old_pct_train,self.old_train_iter = self.pct_train,self.train_iter\n \n def before_batch(self): test_eq(next(self.model.parameters()).device, find_device(self.xb))\n \n def after_batch(self):\n assert self.training\n test_eq(self.pct_train , self.old_pct_train+1/(self.n_iter*self.n_epoch))\n test_eq(self.train_iter, self.old_train_iter+1)\n self.old_pct_train,self.old_train_iter = self.pct_train,self.train_iter\n \n def before_train(self):\n assert self.training and self.model.training\n test_eq(self.pct_train, self.epoch/self.n_epoch)\n self.old_pct_train = self.pct_train\n \n def before_validate(self):\n assert not self.training and not self.model.training\n \nlearn = synth_learner(cbs=TestTrainEvalCallback)\nlearn.fit(1)\n#Check order is properly taken into account\nlearn.cbs = L(reversed(learn.cbs))",
"_____no_output_____"
],
[
"#hide\n#cuda\n#Check model is put on the GPU if needed\nlearn = synth_learner(cbs=TestTrainEvalCallback, cuda=True)\nlearn.fit(1)",
"_____no_output_____"
],
[
"#hide\n#Check wd is not applied on bn/bias when option wd_bn_bias=False\nclass _TstModel(nn.Module):\n def __init__(self):\n super().__init__()\n self.a,self.b = nn.Parameter(torch.randn(1)),nn.Parameter(torch.randn(1))\n self.tst = nn.Sequential(nn.Linear(4,5), nn.BatchNorm1d(3))\n self.tst[0].bias.data,self.tst[1].bias.data = torch.randn(5),torch.randn(3) \n def forward(self, x): return x * self.a + self.b\n \nclass _PutGrad(Callback):\n def after_backward(self):\n for p in self.learn.model.tst.parameters():\n p.grad = torch.ones_like(p.data)\n \nlearn = synth_learner(n_train=5, opt_func = partial(SGD, wd=1, decouple_wd=True), cbs=_PutGrad)\nlearn.model = _TstModel()\ninit = [p.clone() for p in learn.model.tst.parameters()]\nlearn.fit(1, lr=1e-2)\nend = list(learn.model.tst.parameters())\nfor i in [0]: assert not torch.allclose(end[i]-init[i], -0.05 * torch.ones_like(end[i]))\nfor i in [1,2,3]: test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]))",
"_____no_output_____"
],
[
"show_doc(Learner.one_batch)",
"_____no_output_____"
]
],
[
[
"This is an internal method called by `Learner.fit`. If passed, `i` is the index of this iteration in the epoch. In training mode, this does a full training step on the batch (compute predictions, loss, gradients, update the model parameters and zero the gradients). In validation mode, it stops at the loss computation. Training or validation is controlled internally by the `TrainEvalCallback` through the `training` attribute.\n\nNothing is returned, but the attributes `x`, `y`, `pred`, `loss` of the `Learner` are set with the propet values:",
"_____no_output_____"
]
],
[
[
"b = learn.dls.one_batch()\nlearn.one_batch(0, b)\ntest_eq(learn.x, b[0])\ntest_eq(learn.y, b[1])\nout = learn.model(learn.x)\ntest_eq(learn.pred, out)\ntest_eq(learn.loss, learn.loss_func(out, b[1]))",
"_____no_output_____"
]
],
[
[
"More generally, the following attributes of `Learner` are available and updated during the training loop:\n- `model`: the model used for training/validation\n- `data`: the underlying `DataLoaders`\n- `loss_func`: the loss function used\n- `opt`: the optimizer used to udpate the model parameters\n- `opt_func`: the function used to create the optimizer\n- `cbs`: the list containing all `Callback`s\n- `dl`: current `DataLoader` used for iteration\n- `x`/`xb`: last input drawn from `self.dl` (potentially modified by callbacks). `xb` is always a tuple (potentially with one element) and `x` is detuplified. You can only assign to `xb`.\n- `y`/`yb`: last target drawn from `self.dl` (potentially modified by callbacks). `yb` is always a tuple (potentially with one element) and `y` is detuplified. You can only assign to `yb`.\n- `pred`: last predictions from `self.model` (potentially modified by callbacks)\n- `loss`: last computed loss (potentially modified by callbacks)\n- `n_epoch`: the number of epochs in this training\n- `n_iter`: the number of iterations in the current `self.dl`\n- `epoch`: the current epoch index (from 0 to `n_epoch-1`)\n- `iter`: the current iteration index in `self.dl` (from 0 to `n_iter-1`)\n\nThe following attributes are added by `TrainEvalCallback` and should be available unless you went out of your way to remove that callback:\n\n- `train_iter`: the number of training iterations done since the beginning of this training\n- `pct_train`: from 0. to 1., the percentage of training iterations completed\n- `training`: flag to indicate if we're in training mode or not\n\nThe following attribute is added by `Recorder` and should be available unless you went out of your way to remove that callback:\n\n- `smooth_loss`: an exponentially-averaged version of the training loss",
"_____no_output_____"
]
],
[
[
"#hide\nclass VerboseCallback(Callback):\n \"Callback that prints the name of each event called\"\n def __call__(self, event_name):\n print(event_name)\n super().__call__(event_name)",
"_____no_output_____"
],
[
"#hide\nclass TestOneBatch(VerboseCallback):\n def __init__(self, xb, yb, i):\n self.save_xb,self.save_yb,self.i = xb,yb,i\n self.old_pred,self.old_loss = None,tensor(0.)\n \n def before_batch(self):\n self.old_a,self.old_b = self.model.a.data.clone(),self.model.b.data.clone()\n test_eq(self.iter, self.i)\n test_eq(self.save_xb, *self.xb)\n test_eq(self.save_yb, *self.yb)\n if hasattr(self.learn, 'pred'): test_eq(self.pred, self.old_pred)\n \n def after_pred(self):\n self.old_pred = self.pred\n test_eq(self.pred, self.model.a.data * self.x + self.model.b.data)\n test_eq(self.loss, self.old_loss)\n \n def after_loss(self):\n self.old_loss = self.loss\n test_eq(self.loss, self.loss_func(self.old_pred, self.save_yb))\n for p in self.model.parameters(): \n if not hasattr(p, 'grad') or p.grad is not None: test_eq(p.grad, tensor([0.]))\n \n def after_backward(self):\n self.grad_a = (2 * self.x * (self.pred.data - self.y)).mean()\n self.grad_b = 2 * (self.pred.data - self.y).mean()\n test_close(self.model.a.grad.data, self.grad_a)\n test_close(self.model.b.grad.data, self.grad_b)\n test_eq(self.model.a.data, self.old_a)\n test_eq(self.model.b.data, self.old_b)\n \n def after_step(self):\n test_close(self.model.a.data, self.old_a - self.lr * self.grad_a)\n test_close(self.model.b.data, self.old_b - self.lr * self.grad_b)\n self.old_a,self.old_b = self.model.a.data.clone(),self.model.b.data.clone()\n test_close(self.model.a.grad.data, self.grad_a)\n test_close(self.model.b.grad.data, self.grad_b)\n \n def after_batch(self):\n for p in self.model.parameters(): test_eq(p.grad, tensor([0.]))",
"_____no_output_____"
],
[
"#hide\nlearn = synth_learner()\nb = learn.dls.one_batch()\nlearn = synth_learner(cbs=TestOneBatch(*b, 42), lr=1e-2)\n#Remove train/eval\nlearn.cbs = learn.cbs[1:]\n#Setup\nlearn.loss,learn.training = tensor(0.),True\nlearn.opt = SGD(learn.model.parameters(), lr=learn.lr)\nlearn.model.train()\nbatch_events = ['before_batch', 'after_pred', 'after_loss', 'before_backward', 'after_backward', 'after_step', 'after_batch']\ntest_stdout(lambda: learn.one_batch(42, b), '\\n'.join(batch_events))\ntest_stdout(lambda: learn.one_batch(42, b), '\\n'.join(batch_events)) #Check it works for a second batch",
"_____no_output_____"
],
[
"show_doc(Learner.all_batches)",
"_____no_output_____"
],
[
"#hide\nlearn = synth_learner(n_train=5, cbs=VerboseCallback())\nlearn.opt = SGD(learn.model.parameters(), lr=learn.lr)\nwith redirect_stdout(io.StringIO()): \n learn(_before_epoch)\n learn.epoch,learn.dl = 0,learn.dls.train\n learn('before_epoch')\n learn('before_train')\ntest_stdout(learn.all_batches, '\\n'.join(batch_events * 5))\ntest_eq(learn.train_iter, 5)\n\nvalid_events = ['before_batch', 'after_pred', 'after_loss', 'after_batch']\nwith redirect_stdout(io.StringIO()): \n learn.dl = learn.dls.valid\n learn('before_validate')\ntest_stdout(learn.all_batches, '\\n'.join(valid_events * 2))\ntest_eq(learn.train_iter, 5)",
"_____no_output_____"
],
[
"#hide\nlearn = synth_learner(n_train=5, cbs=VerboseCallback())\ntest_stdout(lambda: learn(_before_epoch), 'before_fit\\nbefore_epoch')\ntest_eq(learn.loss, tensor(0.))",
"_____no_output_____"
],
[
"#hide\nlearn.opt = SGD(learn.model.parameters(), lr=learn.lr)\nlearn.epoch = 0\ntest_stdout(lambda: learn._do_epoch_train(), '\\n'.join(['before_train'] + batch_events * 5 + ['after_train']))",
"_____no_output_____"
],
[
"#hide\ntest_stdout(learn._do_epoch_validate, '\\n'.join(['before_validate'] + valid_events * 2+ ['after_validate']))",
"_____no_output_____"
],
[
"show_doc(Learner.create_opt)",
"_____no_output_____"
]
],
[
[
"This method is called internally to create the optimizer, the hyper-parameters are then adjusted by what you pass to `Learner.fit` or your particular schedulers (see `callback.schedule`).",
"_____no_output_____"
]
],
[
[
"learn = synth_learner(n_train=5, cbs=VerboseCallback())\nassert learn.opt is None\nlearn.create_opt()\nassert learn.opt is not None\ntest_eq(learn.opt.hypers[0]['lr'], learn.lr)",
"_____no_output_____"
]
],
[
[
"### Serializing",
"_____no_output_____"
]
],
[
[
"show_doc(Learner.save)",
"_____no_output_____"
]
],
[
[
"`file` can be a `Path`, a `string` or a buffer. `pickle_protocol` is passed along to `torch.save`.",
"_____no_output_____"
]
],
[
[
"show_doc(Learner.load)",
"_____no_output_____"
]
],
[
[
"`file` can be a `Path`, a `string` or a buffer. Use `device` to load the model/optimizer state on a device different from the one it was saved.",
"_____no_output_____"
]
],
[
[
"with tempfile.TemporaryDirectory() as d:\n learn = synth_learner(path=d)\n learn.fit(1)\n \n #Test save created a file\n learn.save('tmp')\n assert (Path(d)/'models/tmp.pth').exists()\n \n #Test load did load the model\n learn1 = synth_learner(path=d)\n learn1 = learn1.load('tmp')\n test_eq(learn.model.a, learn1.model.a)\n test_eq(learn.model.b, learn1.model.b)\n test_eq(learn.opt.state_dict(), learn1.opt.state_dict())",
"_____no_output_____"
],
[
"#hide\n#Test load works when the model is saved without opt\nwith tempfile.TemporaryDirectory() as d:\n learn = synth_learner(path=d)\n learn.fit(1)\n learn.save('tmp', with_opt=False)\n learn1 = synth_learner(path=d)\n learn1 = learn1.load('tmp')\n test_eq(learn.model.a, learn1.model.a)\n test_eq(learn.model.b, learn1.model.b)\n test_ne(learn.opt.state_dict(), learn1.opt.state_dict())",
"_____no_output_____"
]
],
[
[
"### Callback handling",
"_____no_output_____"
],
[
"We only describe the basic functionality linked to `Callback`s here. To learn more about `Callback`s an how to write them, check the [callback.core](http://docs.fast.ai/callback.core) module documentation.\n\nLet's first see how the `Callback`s become attributes of `Learner`:",
"_____no_output_____"
]
],
[
[
"#Test init with callbacks\nclass TstCallback(Callback):\n def batch_begin(self): self.learn.a = self.a + 1\n\ntst_learn = synth_learner()\ntest_eq(len(tst_learn.cbs), 1)\nassert isinstance(tst_learn.cbs[0], TrainEvalCallback)\nassert hasattr(tst_learn, ('train_eval'))\n\ntst_learn = synth_learner(cbs=TstCallback())\ntest_eq(len(tst_learn.cbs), 2)\nassert isinstance(tst_learn.cbs[1], TstCallback)\nassert hasattr(tst_learn, ('tst'))",
"_____no_output_____"
]
],
[
[
"A name that becomes an existing attribute of the `Learner` will throw an exception (here add_cb is a method of `Learner`).",
"_____no_output_____"
]
],
[
[
"class AddCbCallback(Callback): pass\ntest_fail(lambda: synth_learner(cbs=AddCbCallback()))",
"_____no_output_____"
],
[
"show_doc(Learner.__call__)",
"_____no_output_____"
]
],
[
[
"This how the `Callback`s are called internally. For instance a `VerboseCallback` just prints the event names (can be useful for debugging):",
"_____no_output_____"
]
],
[
[
"learn = synth_learner(cbs=VerboseCallback())\nlearn('after_fit')",
"after_fit\n"
],
[
"show_doc(Learner.add_cb)",
"_____no_output_____"
],
[
"learn = synth_learner()\nlearn.add_cb(TestTrainEvalCallback())\ntest_eq(len(learn.cbs), 2)\nassert isinstance(learn.cbs[1], TestTrainEvalCallback)\ntest_eq(learn.train_eval.learn, learn)",
"_____no_output_____"
],
[
"show_doc(Learner.add_cbs)",
"_____no_output_____"
],
[
"learn.add_cbs([TestTrainEvalCallback(), TestTrainEvalCallback()])\ntest_eq(len(learn.cbs), 4)",
"_____no_output_____"
],
[
"show_doc(Learner.added_cbs)",
"_____no_output_____"
],
[
"learn = synth_learner()\ntest_eq(len(learn.cbs), 1)\nwith learn.added_cbs(TestTrainEvalCallback()):\n test_eq(len(learn.cbs), 2)",
"_____no_output_____"
],
[
"show_doc(Learner.ordered_cbs)",
"_____no_output_____"
]
],
[
[
"By order, we mean using the internal ordering of the `Callback`s (see `callbcak.core` for more information on how it works).",
"_____no_output_____"
]
],
[
[
"learn = synth_learner()\nlearn.add_cb(TestTrainEvalCallback())\nlearn.ordered_cbs('before_fit')",
"_____no_output_____"
],
[
"show_doc(Learner.remove_cb)",
"_____no_output_____"
],
[
"learn = synth_learner()\nlearn.add_cb(TestTrainEvalCallback())\ncb = learn.cbs[1]\nlearn.remove_cb(learn.cbs[1])\ntest_eq(len(learn.cbs), 1)\nassert cb.learn is None\nassert not getattr(learn,'test_train_eval',None)",
"_____no_output_____"
]
],
[
[
"`cb` can simply be the class of the `Callback` we want to remove (in which case all instances of that callback are removed).",
"_____no_output_____"
]
],
[
[
"learn = synth_learner()\nlearn.add_cbs([TestTrainEvalCallback(), TestTrainEvalCallback()])\nlearn.remove_cb(TestTrainEvalCallback)\ntest_eq(len(learn.cbs), 1)\nassert not getattr(learn,'test_train_eval',None)",
"_____no_output_____"
],
[
"show_doc(Learner.remove_cbs)",
"_____no_output_____"
]
],
[
[
"Elements of `cbs` can either be types of callbacks or actual callbacks of the `Learner`.",
"_____no_output_____"
]
],
[
[
"learn = synth_learner()\nlearn.add_cbs([TestTrainEvalCallback() for _ in range(3)])\ncb = learn.cbs[1]\nlearn.remove_cbs(learn.cbs[1:])\ntest_eq(len(learn.cbs), 1)",
"_____no_output_____"
],
[
"show_doc(Learner.removed_cbs)",
"_____no_output_____"
]
],
[
[
"Elements of `cbs` can either be types of callbacks or actual callbacks of the `Learner`.",
"_____no_output_____"
]
],
[
[
"learn = synth_learner()\nlearn.add_cb(TestTrainEvalCallback())\nwith learn.removed_cbs(learn.cbs[1]):\n test_eq(len(learn.cbs), 1)\ntest_eq(len(learn.cbs), 2)",
"_____no_output_____"
],
[
"show_doc(Learner.show_training_loop)",
"_____no_output_____"
]
],
[
[
"At each step, callbacks are shown in order, which can help debugging.",
"_____no_output_____"
]
],
[
[
"learn = synth_learner()\nlearn.show_training_loop()",
"Start Fit\n - before_fit : [TrainEvalCallback]\n Start Epoch Loop\n - before_epoch : []\n Start Train\n - before_train : [TrainEvalCallback]\n Start Batch Loop\n - before_batch : []\n - after_pred : []\n - after_loss : []\n - before_backward: []\n - after_backward : []\n - after_step : []\n - after_cancel_batch: []\n - after_batch : [TrainEvalCallback]\n End Batch Loop\n End Train\n - after_cancel_train: []\n - after_train : []\n Start Valid\n - before_validate: [TrainEvalCallback]\n Start Batch Loop\n - **CBs same as train batch**: []\n End Batch Loop\n End Valid\n - after_cancel_validate: []\n - after_validate : []\n End Epoch Loop\n - after_cancel_epoch: []\n - after_epoch : []\nEnd Fit\n - after_cancel_fit: []\n - after_fit : []\n"
],
[
"#export\ndef _before_batch_cb(f, self):\n xb,yb = f(self, self.xb, self.yb)\n self.learn.xb,self.learn.yb = xb,yb",
"_____no_output_____"
],
[
"#export\ndef before_batch_cb(f):\n \"Shortcut for creating a Callback on the `before_batch` event, which takes and returns `xb,yb`\"\n return Callback(before_batch=partial(_before_batch_cb, f))",
"_____no_output_____"
]
],
[
[
"In order to change the data passed to your model, you will generally want to hook into the `before_batch` event, like so:",
"_____no_output_____"
]
],
[
[
"class TstCallback(Callback):\n def before_batch(self):\n self.learn.xb = self.xb + 1000\n self.learn.yb = self.yb - 1000",
"_____no_output_____"
]
],
[
[
"Since that is so common, we provide the `before_batch_cb` decorator to make it easier.",
"_____no_output_____"
]
],
[
[
"@before_batch_cb\ndef cb(self, xb, yb): return xb+1000,yb-1000",
"_____no_output_____"
]
],
[
[
"### Control flow testing -",
"_____no_output_____"
]
],
[
[
"#hide\nbatch_events = ['before_batch', 'after_pred', 'after_loss', 'before_backward', 'after_backward', 'after_step', 'after_batch']\nbatchv_events = ['before_batch', 'after_pred', 'after_loss', 'after_batch']\ntrain_events = ['before_train'] + batch_events + ['after_train']\nvalid_events = ['before_validate'] + batchv_events + ['after_validate']\nepoch_events = ['before_epoch'] + train_events + valid_events + ['after_epoch']\ncycle_events = ['before_fit'] + epoch_events + ['after_fit']",
"_____no_output_____"
],
[
"#hide\nlearn = synth_learner(n_train=1, n_valid=1)\ntest_stdout(lambda: learn.fit(1, cbs=VerboseCallback()), '\\n'.join(cycle_events))",
"_____no_output_____"
],
[
"#hide\nclass TestCancelCallback(VerboseCallback):\n def __init__(self, cancel_at=event.before_batch, exception=CancelBatchException, train=None):\n def _interrupt(): \n if train is None or train == self.training: raise exception()\n setattr(self, cancel_at, _interrupt)",
"_____no_output_____"
],
[
"#hide\n#test cancel batch\nfor i,e in enumerate(batch_events[:-1]):\n be = batch_events[:i+1] + ['after_cancel_batch', 'after_batch']\n bev = be if i <3 else batchv_events\n cycle = cycle_events[:3] + be + ['after_train', 'before_validate'] + bev + cycle_events[-3:]\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(cancel_at=e)), '\\n'.join(cycle))\n\n#CancelBatchException not caught if thrown in any other event\nfor e in cycle_events:\n if e not in batch_events[:-1]:\n with redirect_stdout(io.StringIO()):\n cb = TestCancelCallback(cancel_at=e)\n test_fail(lambda: learn.fit(1, cbs=cb))\n learn.remove_cb(cb) #Have to remove it manually",
"_____no_output_____"
],
[
"#hide\n#test cancel train\nfor i,e in enumerate(['before_train'] + batch_events):\n be = batch_events[:i] + (['after_batch'] if i >=1 and i < len(batch_events) else []) \n be += ['after_cancel_train', 'after_train']\n cycle = cycle_events[:3] + be + ['before_validate'] + batchv_events + cycle_events[-3:]\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(e, CancelTrainException, True)), '\\n'.join(cycle))\n\n#CancelTrainException not caught if thrown in any other event\nfor e in cycle_events:\n if e not in ['before_train'] + batch_events[:-1]:\n with redirect_stdout(io.StringIO()):\n cb = TestCancelCallback(e, CancelTrainException)\n test_fail(lambda: learn.fit(1, cbs=cb))\n learn.remove_cb(cb) #Have to remove it manually ",
"_____no_output_____"
],
[
"#hide\n#test cancel valid\nfor i,e in enumerate(['before_validate'] + batchv_events):\n bev = batchv_events[:i] + (['after_batch'] if i >=1 and i < len(batchv_events) else []) + ['after_cancel_validate']\n cycle = cycle_events[:3] + batch_events + ['after_train', 'before_validate'] + bev + cycle_events[-3:]\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(e, CancelValidException, False)), '\\n'.join(cycle))\n \n#CancelValidException not caught if thrown in any other event\nfor e in cycle_events:\n if e not in ['before_validate'] + batch_events[:3]:\n with redirect_stdout(io.StringIO()):\n cb = TestCancelCallback(e, CancelValidException)\n test_fail(lambda: learn.fit(1, cbs=cb))\n learn.remove_cb(cb) #Have to remove it manually ",
"_____no_output_____"
],
[
"#hide\n#test cancel epoch\n#In train\nfor i,e in enumerate(['before_train'] + batch_events):\n be = batch_events[:i] + (['after_batch'] if i >=1 and i<len(batch_events) else []) \n cycle = cycle_events[:3] + be + ['after_train', 'after_cancel_epoch'] + cycle_events[-2:]\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(e, CancelEpochException, True)), '\\n'.join(cycle))\n\n#In valid\nfor i,e in enumerate(['before_validate'] + batchv_events):\n bev = batchv_events[:i] + (['after_batch'] if i >=1 and i<len(batchv_events) else [])\n cycle = cycle_events[:3] + batch_events + ['after_train', 'before_validate'] + bev \n cycle += ['after_validate', 'after_cancel_epoch'] + cycle_events[-2:]\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(e, CancelEpochException, False)), '\\n'.join(cycle))\n\n#In begin epoch\ntest_stdout(lambda: learn.fit(1, cbs=TestCancelCallback('before_epoch', CancelEpochException, False)), \n '\\n'.join(cycle_events[:2] + ['after_cancel_epoch'] + cycle_events[-2:]))\n\n#CancelEpochException not caught if thrown in any other event\nfor e in ['before_fit', 'after_epoch', 'after_fit']:\n if e not in ['before_validate'] + batch_events[:3]:\n with redirect_stdout(io.StringIO()):\n cb = TestCancelCallback(e, CancelEpochException)\n test_fail(lambda: learn.fit(1, cbs=cb))\n learn.remove_cb(cb) #Have to remove it manually ",
"_____no_output_____"
],
[
"#hide\n#test cancel fit\n#In begin fit\ntest_stdout(lambda: learn.fit(1, cbs=TestCancelCallback('before_fit', CancelFitException)), \n '\\n'.join(['before_fit', 'after_cancel_fit', 'after_fit']))\n\n#In begin epoch\ntest_stdout(lambda: learn.fit(1, cbs=TestCancelCallback('before_epoch', CancelFitException, False)), \n '\\n'.join(cycle_events[:2] + ['after_epoch', 'after_cancel_fit', 'after_fit']))\n#In train\nfor i,e in enumerate(['before_train'] + batch_events):\n be = batch_events[:i] + (['after_batch'] if i >=1 and i<len(batch_events) else []) \n cycle = cycle_events[:3] + be + ['after_train', 'after_epoch', 'after_cancel_fit', 'after_fit']\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(e, CancelFitException, True)), '\\n'.join(cycle))\n \n#In valid\nfor i,e in enumerate(['before_validate'] + batchv_events):\n bev = batchv_events[:i] + (['after_batch'] if i >=1 and i<len(batchv_events) else [])\n cycle = cycle_events[:3] + batch_events + ['after_train', 'before_validate'] + bev \n cycle += ['after_validate', 'after_epoch', 'after_cancel_fit', 'after_fit']\n test_stdout(lambda: learn.fit(1, cbs=TestCancelCallback(e, CancelFitException, False)), '\\n'.join(cycle))\n \n#CancelEpochException not caught if thrown in any other event\nwith redirect_stdout(io.StringIO()):\n cb = TestCancelCallback('after_fit', CancelEpochException)\n test_fail(lambda: learn.fit(1, cbs=cb))\n learn.remove_cb(cb) #Have to remove it manually ",
"_____no_output_____"
]
],
[
[
"## Metrics -",
"_____no_output_____"
]
],
[
[
"#export\n@docs\nclass Metric():\n \"Blueprint for defining a metric\"\n def reset(self): pass\n def accumulate(self, learn): pass\n @property\n def value(self): raise NotImplementedError\n\n @property\n def name(self): return class2attr(self, 'Metric')\n\n _docs = dict(\n reset=\"Reset inner state to prepare for new computation\",\n name=\"Name of the `Metric`, camel-cased and with Metric removed\",\n accumulate=\"Use `learn` to update the state with new results\",\n value=\"The value of the metric\")",
"_____no_output_____"
],
[
"show_doc(Metric, title_level=3)",
"_____no_output_____"
]
],
[
[
"Metrics can be simple averages (like accuracy) but sometimes their computation is a little bit more complex and can't be averaged over batches (like precision or recall), which is why we need a special class for them. For simple functions that can be computed as averages over batches, we can use the class `AvgMetric`, otherwise you'll need to implement the following methods.\n\n> Note: If your <code>Metric</code> has state depending on tensors, don't forget to store it on the CPU to avoid any potential memory leaks.",
"_____no_output_____"
]
],
[
[
"show_doc(Metric.reset)",
"_____no_output_____"
],
[
"show_doc(Metric.accumulate)",
"_____no_output_____"
],
[
"show_doc(Metric.value, name='Metric.value')",
"_____no_output_____"
],
[
"show_doc(Metric.name, name='Metric.name')",
"_____no_output_____"
],
[
"#export\ndef _maybe_reduce(val):\n if num_distrib()>1:\n val = val.clone()\n torch.distributed.all_reduce(val, op=torch.distributed.ReduceOp.SUM)\n val /= num_distrib()\n return val",
"_____no_output_____"
],
[
"#export\nclass AvgMetric(Metric):\n \"Average the values of `func` taking into account potential different batch sizes\"\n def __init__(self, func): self.func = func\n def reset(self): self.total,self.count = 0.,0\n def accumulate(self, learn):\n bs = find_bs(learn.yb)\n self.total += to_detach(self.func(learn.pred, *learn.yb))*bs\n self.count += bs\n @property\n def value(self): return self.total/self.count if self.count != 0 else None\n @property\n def name(self): return self.func.func.__name__ if hasattr(self.func, 'func') else self.func.__name__",
"_____no_output_____"
],
[
"show_doc(AvgMetric, title_level=3)",
"_____no_output_____"
],
[
"learn = synth_learner()\ntst = AvgMetric(lambda x,y: (x-y).abs().mean())\nt,u = torch.randn(100),torch.randn(100)\ntst.reset()\nfor i in range(0,100,25): \n learn.pred,learn.yb = t[i:i+25],(u[i:i+25],)\n tst.accumulate(learn)\ntest_close(tst.value, (t-u).abs().mean())",
"_____no_output_____"
],
[
"#hide\n#With varying batch size\ntst.reset()\nsplits = [0, 30, 50, 60, 100]\nfor i in range(len(splits )-1): \n learn.pred,learn.yb = t[splits[i]:splits[i+1]],(u[splits[i]:splits[i+1]],)\n tst.accumulate(learn)\ntest_close(tst.value, (t-u).abs().mean())",
"_____no_output_____"
],
[
"#export\nclass AvgLoss(Metric):\n \"Average the losses taking into account potential different batch sizes\"\n def reset(self): self.total,self.count = 0.,0\n def accumulate(self, learn):\n bs = find_bs(learn.yb)\n self.total += to_detach(learn.loss.mean())*bs\n self.count += bs\n @property\n def value(self): return self.total/self.count if self.count != 0 else None\n @property\n def name(self): return \"loss\"",
"_____no_output_____"
],
[
"show_doc(AvgLoss, title_level=3)",
"_____no_output_____"
],
[
"tst = AvgLoss()\nt = torch.randn(100)\ntst.reset()\nfor i in range(0,100,25): \n learn.yb,learn.loss = t[i:i+25],t[i:i+25].mean()\n tst.accumulate(learn)\ntest_close(tst.value, t.mean())",
"_____no_output_____"
],
[
"#hide\n#With varying batch size\ntst.reset()\nsplits = [0, 30, 50, 60, 100]\nfor i in range(len(splits )-1): \n learn.yb,learn.loss = t[splits[i]:splits[i+1]],t[splits[i]:splits[i+1]].mean()\n tst.accumulate(learn)\ntest_close(tst.value, t.mean())",
"_____no_output_____"
],
[
"#export\nclass AvgSmoothLoss(Metric):\n \"Smooth average of the losses (exponentially weighted with `beta`)\"\n def __init__(self, beta=0.98): self.beta = beta\n def reset(self): self.count,self.val = 0,tensor(0.)\n def accumulate(self, learn):\n self.count += 1\n self.val = torch.lerp(to_detach(learn.loss.mean(), gather=False), self.val, self.beta)\n @property\n def value(self): return self.val/(1-self.beta**self.count)",
"_____no_output_____"
],
[
"show_doc(AvgSmoothLoss, title_level=3)",
"_____no_output_____"
],
[
"tst = AvgSmoothLoss()\nt = torch.randn(100)\ntst.reset()\nval = tensor(0.)\nfor i in range(4): \n learn.loss = t[i*25:(i+1)*25].mean()\n tst.accumulate(learn)\n val = val*0.98 + t[i*25:(i+1)*25].mean()*(1-0.98)\n test_close(val/(1-0.98**(i+1)), tst.value)",
"_____no_output_____"
],
[
"#export\nclass ValueMetric(Metric):\n \"Use to include a pre-calculated metric value (for insance calculated in a `Callback`) and returned by `func`\"\n def __init__(self, func, metric_name=None): store_attr(self, 'func, metric_name')\n\n @property\n def value(self): return self.func()\n\n @property\n def name(self): return self.metric_name if self.metric_name else self.func.__name__",
"_____no_output_____"
],
[
"show_doc(ValueMetric, title_level=3)",
"_____no_output_____"
],
[
"def metric_value_fn(): return 5e-3\n\nvm = ValueMetric(metric_value_fn, 'custom_value_metric')\ntest_eq(vm.value, 5e-3)\ntest_eq(vm.name, 'custom_value_metric')\n\nvm = ValueMetric(metric_value_fn)\ntest_eq(vm.name, 'metric_value_fn')",
"_____no_output_____"
]
],
[
[
"## Recorder --",
"_____no_output_____"
]
],
[
[
"#export\nfrom fastprogress.fastprogress import format_time\n\ndef _maybe_item(t):\n t = t.value\n return t.item() if isinstance(t, Tensor) and t.numel()==1 else t",
"_____no_output_____"
],
[
"#export\nclass Recorder(Callback):\n \"Callback that registers statistics (lr, loss and metrics) during training\"\n remove_on_fetch,run_after = True,TrainEvalCallback\n\n def __init__(self, add_time=True, train_metrics=False, valid_metrics=True, beta=0.98):\n store_attr(self, 'add_time,train_metrics,valid_metrics')\n self.loss,self.smooth_loss = AvgLoss(),AvgSmoothLoss(beta=beta)\n\n def before_fit(self):\n \"Prepare state for training\"\n self.lrs,self.iters,self.losses,self.values = [],[],[],[]\n names = self.metrics.attrgot('name')\n if self.train_metrics and self.valid_metrics:\n names = L('loss') + names\n names = names.map('train_{}') + names.map('valid_{}')\n elif self.valid_metrics: names = L('train_loss', 'valid_loss') + names\n else: names = L('train_loss') + names\n if self.add_time: names.append('time')\n self.metric_names = 'epoch'+names\n self.smooth_loss.reset()\n\n def after_batch(self):\n \"Update all metrics and records lr and smooth loss in training\"\n if len(self.yb) == 0: return\n mets = self._train_mets if self.training else self._valid_mets\n for met in mets: met.accumulate(self.learn)\n if not self.training: return\n self.lrs.append(self.opt.hypers[-1]['lr'])\n self.losses.append(self.smooth_loss.value)\n self.learn.smooth_loss = self.smooth_loss.value\n\n def before_epoch(self):\n \"Set timer if `self.add_time=True`\"\n self.cancel_train,self.cancel_valid = False,False\n if self.add_time: self.start_epoch = time.time()\n self.log = L(getattr(self, 'epoch', 0))\n\n def before_train (self): self._train_mets[1:].map(Self.reset())\n def before_validate(self): self._valid_mets.map(Self.reset())\n def after_train (self): self.log += self._train_mets.map(_maybe_item)\n def after_validate(self): self.log += self._valid_mets.map(_maybe_item)\n def after_cancel_train(self): self.cancel_train = True\n def after_cancel_validate(self): self.cancel_valid = True\n\n def after_epoch(self):\n \"Store and log the loss/metric values\"\n self.learn.final_record = self.log[1:].copy()\n self.values.append(self.learn.final_record)\n if self.add_time: self.log.append(format_time(time.time() - self.start_epoch))\n self.logger(self.log)\n self.iters.append(self.smooth_loss.count)\n\n @property\n def _train_mets(self):\n if getattr(self, 'cancel_train', False): return L()\n return L(self.smooth_loss) + (self.metrics if self.train_metrics else L())\n\n @property\n def _valid_mets(self):\n if getattr(self, 'cancel_valid', False): return L()\n return (L(self.loss) + self.metrics if self.valid_metrics else L())\n\n def plot_loss(self, skip_start=5, with_valid=True):\n plt.plot(list(range(skip_start, len(self.losses))), self.losses[skip_start:], label='train')\n if with_valid:\n idx = (np.array(self.iters)<skip_start).sum()\n plt.plot(self.iters[idx:], L(self.values[idx:]).itemgot(1), label='valid')\n plt.legend()",
"_____no_output_____"
],
[
"#export\nadd_docs(Recorder,\n before_train = \"Reset loss and metrics state\",\n after_train = \"Log loss and metric values on the training set (if `self.training_metrics=True`)\",\n before_validate = \"Reset loss and metrics state\",\n after_validate = \"Log loss and metric values on the validation set\",\n after_cancel_train = \"Ignore training metrics for this epoch\",\n after_cancel_validate = \"Ignore validation metrics for this epoch\",\n plot_loss = \"Plot the losses from `skip_start` and onward\")\n\nif not hasattr(defaults, 'callbacks'): defaults.callbacks = [TrainEvalCallback, Recorder]\nelif Recorder not in defaults.callbacks: defaults.callbacks.append(Recorder)",
"_____no_output_____"
]
],
[
[
"By default, metrics are computed on the validation set only, although that can be changed by adjusting `train_metrics` and `valid_metrics`. `beta` is the weight used to compute the exponentially weighted average of the losses (which gives the `smooth_loss` attribute to `Learner`).\n\nThe `logger` attribute of a `Learner` determines what happens to those metrics. By default, it just print them:",
"_____no_output_____"
]
],
[
[
"#Test printed output\ndef tst_metric(out, targ): return F.mse_loss(out, targ)\nlearn = synth_learner(n_train=5, metrics=tst_metric)\npat = r\"[tensor\\(\\d.\\d*\\), tensor\\(\\d.\\d*\\), tensor\\(\\d.\\d*\\), 'dd:dd']\"\ntest_stdout(lambda: learn.fit(1), pat, regex=True)",
"_____no_output_____"
],
[
"#hide\nclass TestRecorderCallback(Callback):\n run_after=Recorder\n \n def before_fit(self): \n self.train_metrics,self.add_time = self.recorder.train_metrics,self.recorder.add_time\n self.beta = self.recorder.smooth_loss.beta\n for m in self.metrics: assert isinstance(m, Metric)\n test_eq(self.recorder.smooth_loss.val, 0.)\n #To test what the recorder logs, we use a custom logger function.\n self.learn.logger = self.test_log\n self.old_smooth,self.count = tensor(0.),0\n \n def after_batch(self):\n if self.training:\n self.count += 1\n test_eq(len(self.recorder.lrs), self.count)\n test_eq(self.recorder.lrs[-1], self.opt.hypers[-1]['lr'])\n test_eq(len(self.recorder.losses), self.count)\n smooth = (1 - self.beta**(self.count-1)) * self.old_smooth * self.beta + self.loss * (1-self.beta)\n smooth /= 1 - self.beta**self.count\n test_close(self.recorder.losses[-1], smooth, eps=1e-4)\n test_close(self.smooth_loss, smooth, eps=1e-4)\n self.old_smooth = self.smooth_loss\n self.bs += find_bs(self.yb)\n if not self.training: test_eq(self.recorder.loss.count, self.bs)\n if self.train_metrics or not self.training: \n for m in self.metrics: test_eq(m.count, self.bs)\n self.losses.append(self.loss.detach().cpu())\n \n def before_epoch(self): \n if self.add_time: self.start_epoch = time.time()\n self.log = [self.epoch]\n \n def before_train(self):\n self.bs = 0\n self.losses = []\n for m in self.recorder._train_mets: test_eq(m.count, self.bs)\n \n def after_train(self):\n mean = tensor(self.losses).mean()\n self.log += [self.smooth_loss, mean] if self.train_metrics else [self.smooth_loss]\n test_eq(self.log, self.recorder.log)\n self.losses = []\n \n def before_validate(self):\n self.bs = 0\n self.losses = []\n for m in [self.recorder.loss] + self.metrics: test_eq(m.count, self.bs)\n \n def test_log(self, log):\n res = tensor(self.losses).mean()\n self.log += [res, res]\n if self.add_time: self.log.append(format_time(time.time() - self.start_epoch))\n test_eq(log, self.log)",
"_____no_output_____"
],
[
"#hide\nlearn = synth_learner(n_train=5, metrics = tst_metric, cbs = TestRecorderCallback)\nlearn.fit(1)\ntest_eq(learn.recorder.metric_names, ['epoch', 'train_loss', 'valid_loss', 'tst_metric', 'time'])\n\nlearn = synth_learner(n_train=5, metrics = tst_metric, cbs = TestRecorderCallback)\nlearn.recorder.train_metrics=True\nlearn.fit(1)\ntest_eq(learn.recorder.metric_names, \n ['epoch', 'train_loss', 'train_tst_metric', 'valid_loss', 'valid_tst_metric', 'time'])\n\nlearn = synth_learner(n_train=5, metrics = tst_metric, cbs = TestRecorderCallback)\nlearn.recorder.add_time=False\nlearn.fit(1)\ntest_eq(learn.recorder.metric_names, ['epoch', 'train_loss', 'valid_loss', 'tst_metric'])",
"_____no_output_____"
],
[
"#hide\n#Test numpy metric\ndef tst_metric_np(out, targ): return F.mse_loss(out, targ).numpy()\nlearn = synth_learner(n_train=5, metrics=tst_metric_np)\nlearn.fit(1)",
"(#5) [0,24.660259246826172,16.824329376220703,16.824329376220703,'00:00']\n"
]
],
[
[
"### Internals",
"_____no_output_____"
]
],
[
[
"show_doc(Recorder.before_fit)",
"_____no_output_____"
],
[
"show_doc(Recorder.before_epoch)",
"_____no_output_____"
],
[
"show_doc(Recorder.before_validate)",
"_____no_output_____"
],
[
"show_doc(Recorder.after_batch)",
"_____no_output_____"
],
[
"show_doc(Recorder.after_epoch)",
"_____no_output_____"
]
],
[
[
"### Plotting tools",
"_____no_output_____"
]
],
[
[
"show_doc(Recorder.plot_loss)",
"_____no_output_____"
],
[
"#hide\nlearn.recorder.plot_loss(skip_start=1)",
"_____no_output_____"
]
],
[
[
"## Inference functions",
"_____no_output_____"
]
],
[
[
"show_doc(Learner.validate)",
"_____no_output_____"
],
[
"#Test result\nlearn = synth_learner(n_train=5, metrics=tst_metric)\nres = learn.validate()\ntest_eq(res[0], res[1])\nx,y = learn.dls.valid_ds.tensors\ntest_close(res[0], F.mse_loss(learn.model(x), y))",
"_____no_output_____"
],
[
"#hide\n#Test other dl\nres = learn.validate(dl=learn.dls.train)\ntest_eq(res[0], res[1])\nx,y = learn.dls.train_ds.tensors\ntest_close(res[0], F.mse_loss(learn.model(x), y))\n\n#Test additional callback is executed.\ncycle = cycle_events[:2] + ['before_validate'] + batchv_events * 2 + cycle_events[-3:]\ntest_stdout(lambda: learn.validate(cbs=VerboseCallback()), '\\n'.join(cycle))",
"_____no_output_____"
],
[
"show_doc(Learner.get_preds)",
"_____no_output_____"
]
],
[
[
"`with_decoded` will also return the decoded predictions using the <code>decodes</code> function of the loss function (if it exists). For instance, fastai's `CrossEntropyFlat` takes the argmax or predictions in its decodes. \n\nDepending on the `loss_func` attribute of `Learner`, an activation function will be picked automatically so that the predictions make sense. For instance if the loss is a case of cross-entropy, a softmax will be applied, or if the loss is binary cross entropy with logits, a sigmoid will be applied. If you want to make sure a certain activation function is applied, you can pass it with `act`.\n\n`save_preds` and `save_targs` should be used when your predictions are too big to fit all in memory. Give a `Path` object that points to a folder where the predictions and targets will be saved.\n\n`concat_dim` is the batch dimension, where all the tensors will be concatenated.\n\n`inner` is an internal attribute that tells `get_preds` it's called internally, inside another training loop, to avoid recursion errors.",
"_____no_output_____"
],
[
"> Note: If you want to use the option `with_loss=True` on a custom loss function, make sure you have implemented a `reduction` attribute that supports 'none' ",
"_____no_output_____"
]
],
[
[
"#Test result\nlearn = synth_learner(n_train=5, metrics=tst_metric)\npreds,targs = learn.get_preds()\nx,y = learn.dls.valid_ds.tensors\ntest_eq(targs, y)\ntest_close(preds, learn.model(x))\n\npreds,targs = learn.get_preds(act = torch.sigmoid)\ntest_eq(targs, y)\ntest_close(preds, torch.sigmoid(learn.model(x)))",
"_____no_output_____"
],
[
"#hide\n#Test get_preds work with ds not evenly divisible by bs\nlearn = synth_learner(n_train=2.5, metrics=tst_metric)\npreds,targs = learn.get_preds(ds_idx=0)",
"_____no_output_____"
],
[
"#hide\n#Test other dataset\nx = torch.randn(16*5)\ny = 2*x + 3 + 0.1*torch.randn(16*5)\ndl = TfmdDL(TensorDataset(x, y), bs=16)\npreds,targs = learn.get_preds(dl=dl)\ntest_eq(targs, y)\ntest_close(preds, learn.model(x))\n\n#Test with loss\npreds,targs,losses = learn.get_preds(dl=dl, with_loss=True)\ntest_eq(targs, y)\ntest_close(preds, learn.model(x))\ntest_close(losses, F.mse_loss(preds, targs, reduction='none'))\n\n#Test with inputs\ninps,preds,targs = learn.get_preds(dl=dl, with_input=True)\ntest_eq(inps,x)\ntest_eq(targs, y)\ntest_close(preds, learn.model(x))",
"_____no_output_____"
],
[
"#hide\n#Test with no target\nlearn = synth_learner(n_train=5)\nx = torch.randn(16*5)\ndl = TfmdDL(TensorDataset(x), bs=16)\npreds,targs = learn.get_preds(dl=dl)\nassert targs is None",
"_____no_output_____"
],
[
"#hide\n#Test with targets that are tuples\ndef _fake_loss(x,y,z,reduction=None): return F.mse_loss(x,y)\n\nlearn = synth_learner(n_train=5)\nx = torch.randn(16*5)\ny = 2*x + 3 + 0.1*torch.randn(16*5)\nlearn.dls.n_inp=1\nlearn.loss_func = _fake_loss\ndl = TfmdDL(TensorDataset(x, y, y), bs=16)\npreds,targs = learn.get_preds(dl=dl)\ntest_eq(targs, [y,y])",
"_____no_output_____"
],
[
"#hide\n#Test with inputs that are tuples\nclass _TupleModel(Module):\n def __init__(self, model): self.model=model\n def forward(self, x1, x2): return self.model(x1)\n\nlearn = synth_learner(n_train=5)\n#learn.dls.n_inp=2\nx = torch.randn(16*5)\ny = 2*x + 3 + 0.1*torch.randn(16*5)\nlearn.model = _TupleModel(learn.model)\nlearn.dls = DataLoaders(TfmdDL(TensorDataset(x, x, y), bs=16),TfmdDL(TensorDataset(x, x, y), bs=16))\ninps,preds,targs = learn.get_preds(ds_idx=0, with_input=True)\ntest_eq(inps, [x,x])\nt = learn.get_preds(ds_idx=0, with_input=True)",
"_____no_output_____"
],
[
"#hide\n#Test auto activation function is picked\nlearn = synth_learner(n_train=5)\nlearn.loss_func = BCEWithLogitsLossFlat()\nx = torch.randn(16*5)\ny = 2*x + 3 + 0.1*torch.randn(16*5)\ndl = TfmdDL(TensorDataset(x, y), bs=16)\npreds,targs = learn.get_preds(dl=dl)\ntest_close(preds, torch.sigmoid(learn.model(x)))",
"_____no_output_____"
],
[
"#hide\n#Test reorder is done\nlearn = synth_learner(n_train=5)\nx = torch.randn(16*5)\ny = 2*x + 3 + 0.1*torch.randn(16*5)\ndl = TfmdDL(TensorDataset(x, y), bs=16, shuffle=True)\npreds,targs = learn.get_preds(dl=dl)\ntest_eq(targs, y)",
"_____no_output_____"
],
[
"#hide\ninps,preds,targs = learn.get_preds(ds_idx=0, with_input=True)\ntst = learn.get_preds(ds_idx=0, with_input=True, with_decoded=True)",
"_____no_output_____"
],
[
"show_doc(Learner.predict)",
"_____no_output_____"
]
],
[
[
"It returns a tuple of three elements with, in reverse order,\n- the prediction from the model, potentially passed through the activation of the loss function (if it has one)\n- the decoded prediction, using the poential <code>decodes</code> method from it\n- the fully decoded prediction, using the transforms used to buil the `Datasets`/`DataLoaders`",
"_____no_output_____"
],
[
"`rm_type_tfms` is a deprecated argument that should not be used and will be removed in a future version. `with_input` will add the decoded inputs to the result.",
"_____no_output_____"
]
],
[
[
"class _FakeLossFunc(Module):\n reduction = 'none'\n def forward(self, x, y): return F.mse_loss(x,y)\n def activation(self, x): return x+1\n def decodes(self, x): return 2*x\n\nclass _Add1(Transform):\n def encodes(self, x): return x+1\n def decodes(self, x): return x-1\n \nlearn = synth_learner(n_train=5)\ndl = TfmdDL(Datasets(torch.arange(50), tfms = [L(), [_Add1()]]))\nlearn.dls = DataLoaders(dl, dl)\nlearn.loss_func = _FakeLossFunc()\n\ninp = tensor([2.])\nout = learn.model(inp).detach()+1 #applying model + activation\ndec = 2*out #decodes from loss function\nfull_dec = dec-1 #decodes from _Add1\ntest_eq(learn.predict(inp), [full_dec,dec,out])\ntest_eq(learn.predict(inp, with_input=True), [inp,full_dec,dec,out])",
"_____no_output_____"
],
[
"show_doc(Learner.show_results)",
"_____no_output_____"
]
],
[
[
"Will show `max_n` samples (unless the batch size of `ds_idx` or `dl` is less than `max_n`, in which case it will show as many samples) and `shuffle` the data unless you pass `false` to that flag. `kwargs` are application-dependant.\n\nWe can't show an example on our synthetic `Learner`, but check all the beginners tutorials which will show you how that method works accross applications.",
"_____no_output_____"
],
[
"The last functions in this section are used internally for inference, but should be less useful to you.",
"_____no_output_____"
]
],
[
[
"show_doc(Learner.no_logging)",
"_____no_output_____"
],
[
"learn = synth_learner(n_train=5, metrics=tst_metric)\nwith learn.no_logging():\n test_stdout(lambda: learn.fit(1), '')\ntest_eq(learn.logger, print)",
"_____no_output_____"
],
[
"show_doc(Learner.loss_not_reduced)",
"_____no_output_____"
]
],
[
[
"This requires your loss function to either have a `reduction` attribute or a `reduction` argument (like all fastai and PyTorch loss functions).",
"_____no_output_____"
]
],
[
[
"#hide\ntest_eq(learn.loss_func.reduction, 'mean')\nwith learn.loss_not_reduced():\n test_eq(learn.loss_func.reduction, 'none')\n x,y = learn.dls.one_batch()\n p = learn.model(x)\n losses = learn.loss_func(p, y)\n test_eq(losses.shape, y.shape)\n test_eq(losses, F.mse_loss(p,y, reduction='none'))\ntest_eq(learn.loss_func.reduction, 'mean')",
"_____no_output_____"
]
],
[
[
"## Transfer learning",
"_____no_output_____"
]
],
[
[
"#export\n@patch\ndef freeze_to(self:Learner, n):\n if self.opt is None: self.create_opt()\n self.opt.freeze_to(n)\n self.opt.clear_state()\n\n@patch\ndef freeze(self:Learner): self.freeze_to(-1)\n\n@patch\ndef unfreeze(self:Learner): self.freeze_to(0)\n\nadd_docs(Learner,\n freeze_to=\"Freeze parameter groups up to `n`\",\n freeze=\"Freeze up to last parameter group\",\n unfreeze=\"Unfreeze the entire model\")",
"_____no_output_____"
],
[
"#hide\nclass _TstModel(nn.Module):\n def __init__(self):\n super().__init__()\n self.a,self.b = nn.Parameter(torch.randn(1)),nn.Parameter(torch.randn(1))\n self.tst = nn.Sequential(nn.Linear(4,5), nn.BatchNorm1d(3))\n self.tst[0].bias.data,self.tst[1].bias.data = torch.randn(5),torch.randn(3) \n def forward(self, x): return x * self.a + self.b\n \nclass _PutGrad(Callback):\n def after_backward(self):\n for p in self.learn.model.tst.parameters():\n if p.requires_grad: p.grad = torch.ones_like(p.data)\n\ndef _splitter(m): return [list(m.tst[0].parameters()), list(m.tst[1].parameters()), [m.a,m.b]]\n \nlearn = synth_learner(n_train=5, opt_func = partial(SGD), cbs=_PutGrad, splitter=_splitter, lr=1e-2)\nlearn.model = _TstModel()\nlearn.freeze()\ninit = [p.clone() for p in learn.model.tst.parameters()]\nlearn.fit(1, wd=0.)\nend = list(learn.model.tst.parameters())\n#linear was not trained\nfor i in [0,1]: test_close(end[i],init[i])\n#bn was trained even frozen since `train_bn=True` by default\nfor i in [2,3]: test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]))",
"(#4) [0,20.0687313079834,14.64988899230957,'00:00']\n"
],
[
"#hide\nlearn = synth_learner(n_train=5, opt_func = partial(SGD), cbs=_PutGrad, splitter=_splitter, train_bn=False, lr=1e-2)\nlearn.model = _TstModel()\nlearn.freeze()\ninit = [p.clone() for p in learn.model.tst.parameters()]\nlearn.fit(1, wd=0.)\nend = list(learn.model.tst.parameters())\n#linear and bn were not trained\nfor i in range(4): test_close(end[i],init[i])\n\nlearn.freeze_to(-2)\ninit = [p.clone() for p in learn.model.tst.parameters()]\nlearn.fit(1, wd=0.)\nend = list(learn.model.tst.parameters())\n#linear was not trained\nfor i in [0,1]: test_close(end[i],init[i])\n#bn was trained \nfor i in [2,3]: test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]))\n \nlearn.unfreeze()\ninit = [p.clone() for p in learn.model.tst.parameters()]\nlearn.fit(1, wd=0.)\nend = list(learn.model.tst.parameters())\n#linear and bn were trained\nfor i in range(4): test_close(end[i]-init[i], -0.05 * torch.ones_like(end[i]), 1e-3)",
"(#4) [0,11.669595718383789,13.129606246948242,'00:00']\n(#4) [0,9.353687286376953,10.432827949523926,'00:00']\n(#4) [0,7.3920769691467285,8.294020652770996,'00:00']\n"
]
],
[
[
"### Exporting a `Learner`",
"_____no_output_____"
]
],
[
[
"#export\n@patch\ndef export(self:Learner, fname='export.pkl', pickle_protocol=2):\n \"Export the content of `self` without the items and the optimizer state for inference\"\n if rank_distrib(): return # don't export if child proc\n self._end_cleanup()\n old_dbunch = self.dls\n self.dls = self.dls.new_empty()\n state = self.opt.state_dict() if self.opt is not None else None\n self.opt = None\n with warnings.catch_warnings():\n #To avoid the warning that come from PyTorch about model not being checked\n warnings.simplefilter(\"ignore\")\n torch.save(self, self.path/fname, pickle_protocol=pickle_protocol)\n self.create_opt()\n if state is not None: self.opt.load_state_dict(state)\n self.dls = old_dbunch",
"_____no_output_____"
]
],
[
[
"The `Learner` is saved in `self.path/fname`, using `pickle_protocol`. Note that serialization in Python saves the names of functions, not the code itself. Therefore, any custom code you have for models, data transformation, loss function etc... should be put in a module that you will import in your training environment before exporting, and in your deployment environment before loading it.",
"_____no_output_____"
]
],
[
[
"#export\ndef load_learner(fname, cpu=True):\n \"Load a `Learner` object in `fname`, optionally putting it on the `cpu`\"\n distrib_barrier()\n res = torch.load(fname, map_location='cpu' if cpu else None)\n if hasattr(res, 'to_fp32'): res = res.to_fp32()\n if cpu: res.dls.cpu()\n return res",
"_____no_output_____"
]
],
[
[
"> Warning: `load_learner` requires all your custom code be in the exact same place as when exporting your `Learner` (the main script, or the module you imported it from).",
"_____no_output_____"
],
[
"## TTA",
"_____no_output_____"
]
],
[
[
"#export\ndef _tta(self:Learner, ds_idx=1, dl=None, n=4, item_tfms=None, batch_tfms=None, beta=0.25, use_max=False):\n with dl.dataset.set_split_idx(0), self.no_mbar():\n if hasattr(self,'progress'): self.progress.mbar = master_bar(list(range(n)))\n aug_preds = []\n for i in self.progress.mbar if hasattr(self,'progress') else range(n):\n self.epoch = i #To keep track of progress on mbar since the progress callback will use self.epoch\n aug_preds.append(self.get_preds(dl=dl, inner=True)[0][None])\n aug_preds = torch.cat(aug_preds)\n aug_preds = aug_preds.max(0)[0] if use_max else aug_preds.mean(0)\n self.epoch = n\n with dl.dataset.set_split_idx(1): preds,targs = self.get_preds(dl=dl, inner=True)",
"_____no_output_____"
],
[
"#export\n@patch\ndef tta(self:Learner, ds_idx=1, dl=None, n=4, item_tfms=None, batch_tfms=None, beta=0.25, use_max=False):\n \"Return predictions on the `ds_idx` dataset or `dl` using Test Time Augmentation\"\n if dl is None: dl = self.dls[ds_idx]\n if item_tfms is not None or batch_tfms is not None: dl = dl.new(after_item=item_tfms, after_batch=batch_tfms)\n try:\n self(_before_epoch)\n with dl.dataset.set_split_idx(0), self.no_mbar():\n if hasattr(self,'progress'): self.progress.mbar = master_bar(list(range(n)))\n aug_preds = []\n for i in self.progress.mbar if hasattr(self,'progress') else range(n):\n self.epoch = i #To keep track of progress on mbar since the progress callback will use self.epoch\n aug_preds.append(self.get_preds(dl=dl, inner=True)[0][None])\n aug_preds = torch.cat(aug_preds)\n aug_preds = aug_preds.max(0)[0] if use_max else aug_preds.mean(0)\n self.epoch = n\n with dl.dataset.set_split_idx(1): preds,targs = self.get_preds(dl=dl, inner=True)\n except CancelFitException: self(event.after_cancel_fit)\n finally: self(event.after_fit)\n\n if use_max: return torch.stack([preds, aug_preds], 0).max(0)[0],targs\n preds = (aug_preds,preds) if beta is None else torch.lerp(aug_preds, preds, beta)\n return preds,targs",
"_____no_output_____"
]
],
[
[
"In practice, we get the predictions `n` times with the transforms of the training set and average those. The final predictions are `(1-beta)` multiplied by this average + `beta` multiplied by the predictions obtained with the transforms of the dataset. Set `beta` to `None` to get a tuple of the predictions and tta results. You can also use the maximum of all predictions instead of an average by setting `use_max=True`.\n\nIf you want to use new transforms, you can pass them with `item_tfms` and `batch_tfms`.",
"_____no_output_____"
]
],
[
[
"#hide\nlearn = synth_learner()\ndl = TfmdDL(Datasets(torch.arange(50)))\nlearn.dls = DataLoaders(dl, dl)\npreds,targs = learn.tta()",
"_____no_output_____"
]
],
[
[
"## Gather arguments",
"_____no_output_____"
]
],
[
[
"#export\n@patch\ndef gather_args(self:Learner):\n \"Gather config parameters accessible to the learner\"\n # init_args\n cb_args = {k:v for cb in self.cbs for k,v in getattr(cb,'init_args',{}).items()}\n args = {**getattr(self,'init_args',{}), **cb_args, **getattr(self.dls,'init_args',{}),\n **getattr(self.opt,'init_args',{}), **getattr(self.loss_func,'init_args',{})}\n # callbacks used\n args.update({f'{cb}':True for cb in self.cbs})\n # input dimensions\n try:\n n_inp = self.dls.train.n_inp\n args['n_inp'] = n_inp\n xb = self.dls.train.one_batch()[:n_inp]\n args.update({f'input {n+1} dim {i+1}':d for n in range(n_inp) for i,d in enumerate(list(detuplify(xb[n]).shape))})\n except: print(f'Could not gather input dimensions')\n # other useful information\n with ignore_exceptions(): args['batch size'] = self.dls.bs\n with ignore_exceptions(): args['batch per epoch'] = len(self.dls.train)\n with ignore_exceptions(): args['model parameters'] = total_params(self.model)[0]\n with ignore_exceptions(): args['loss function'] = f'{self.loss_func}'\n with ignore_exceptions(): args['device'] = self.dls.device.type\n with ignore_exceptions(): args['optimizer'] = self.opt_func.__name__\n with ignore_exceptions(): args['frozen'] = bool(self.opt.frozen_idx)\n with ignore_exceptions(): args['frozen idx'] = self.opt.frozen_idx\n with ignore_exceptions(): args['dataset.tfms'] = f'{self.dls.dataset.tfms}'\n with ignore_exceptions(): args['dls.after_item'] = f'{self.dls.after_item}'\n with ignore_exceptions(): args['dls.before_batch'] = f'{self.dls.before_batch}'\n with ignore_exceptions(): args['dls.after_batch'] = f'{self.dls.after_batch}'\n return args",
"_____no_output_____"
],
[
"learn = synth_learner(lr=1e-2)\ntest_eq(learn.init_args['Learner.__init__.lr'], 0.01)",
"_____no_output_____"
]
],
[
[
"## Export -",
"_____no_output_____"
]
],
[
[
"#hide\nfrom nbdev.export import notebook2script\nnotebook2script()",
"Converted 00_torch_core.ipynb.\nConverted 01_layers.ipynb.\nConverted 02_data.load.ipynb.\nConverted 03_data.core.ipynb.\nConverted 04_data.external.ipynb.\nConverted 05_data.transforms.ipynb.\nConverted 06_data.block.ipynb.\nConverted 07_vision.core.ipynb.\nConverted 08_vision.data.ipynb.\nConverted 09_vision.augment.ipynb.\nConverted 09b_vision.utils.ipynb.\nConverted 09c_vision.widgets.ipynb.\nConverted 10_tutorial.pets.ipynb.\nConverted 11_vision.models.xresnet.ipynb.\nConverted 12_optimizer.ipynb.\nConverted 13_callback.core.ipynb.\nConverted 13a_learner.ipynb.\nConverted 13b_metrics.ipynb.\nConverted 14_callback.schedule.ipynb.\nConverted 14a_callback.data.ipynb.\nConverted 15_callback.hook.ipynb.\nConverted 15a_vision.models.unet.ipynb.\nConverted 16_callback.progress.ipynb.\nConverted 17_callback.tracker.ipynb.\nConverted 18_callback.fp16.ipynb.\nConverted 18a_callback.training.ipynb.\nConverted 19_callback.mixup.ipynb.\nConverted 20_interpret.ipynb.\nConverted 20a_distributed.ipynb.\nConverted 21_vision.learner.ipynb.\nConverted 22_tutorial.imagenette.ipynb.\nConverted 23_tutorial.vision.ipynb.\nConverted 24_tutorial.siamese.ipynb.\nConverted 24_vision.gan.ipynb.\nConverted 30_text.core.ipynb.\nConverted 31_text.data.ipynb.\nConverted 32_text.models.awdlstm.ipynb.\nConverted 33_text.models.core.ipynb.\nConverted 34_callback.rnn.ipynb.\nConverted 35_tutorial.wikitext.ipynb.\nConverted 36_text.models.qrnn.ipynb.\nConverted 37_text.learner.ipynb.\nConverted 38_tutorial.text.ipynb.\nConverted 39_tutorial.transformers.ipynb.\nConverted 40_tabular.core.ipynb.\nConverted 41_tabular.data.ipynb.\nConverted 42_tabular.model.ipynb.\nConverted 43_tabular.learner.ipynb.\nConverted 44_tutorial.tabular.ipynb.\nConverted 45_collab.ipynb.\nConverted 46_tutorial.collab.ipynb.\nConverted 50_tutorial.datablock.ipynb.\nConverted 60_medical.imaging.ipynb.\nConverted 61_tutorial.medical_imaging.ipynb.\nConverted 65_medical.text.ipynb.\nConverted 70_callback.wandb.ipynb.\nConverted 71_callback.tensorboard.ipynb.\nConverted 72_callback.neptune.ipynb.\nConverted 73_callback.captum.ipynb.\nConverted 74_callback.cutmix.ipynb.\nConverted 97_test_utils.ipynb.\nConverted 99_pytorch_doc.ipynb.\nConverted index.ipynb.\nConverted tutorial.ipynb.\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4ff0cbe9655939ba15ed0afc97ea4729082ee0
| 1,812 |
ipynb
|
Jupyter Notebook
|
display/convert_ISL_training_labels_for_display.ipynb
|
Project-Canopy/SSRC_New_Model_Development
|
464a4477131ddd902ad95940ec0e0c6e744204ba
|
[
"MIT"
] | 2 |
2021-04-22T02:13:28.000Z
|
2021-12-28T19:41:29.000Z
|
display/convert_ISL_training_labels_for_display.ipynb
|
Project-Canopy/SSRC_New_Model_Development
|
464a4477131ddd902ad95940ec0e0c6e744204ba
|
[
"MIT"
] | 12 |
2021-08-25T15:12:09.000Z
|
2022-02-10T06:16:15.000Z
|
display/convert_ISL_training_labels_for_display.ipynb
|
Project-Canopy/SSRC_New_Model_Development
|
464a4477131ddd902ad95940ec0e0c6e744204ba
|
[
"MIT"
] | 3 |
2021-03-03T05:14:10.000Z
|
2022-03-16T07:55:12.000Z
| 22.936709 | 108 | 0.525938 |
[
[
[
"from glob import glob\nimport geopandas as gpd\nimport pandas as pd",
"_____no_output_____"
],
[
"dir_path = \"/Users/user/Downloads/ISL_Labels\"\nout_file = \"/Users/user/Documents/GitHub/cb_feature_detection/analytics/ISL_Training_Labels.geojson\"",
"_____no_output_____"
],
[
"def output_label_file(dir_path, out_file):\n \n file_list = glob(f'{dir_path}/*/*.shp')\n gdf1 = None\n for file in file_list: \n if gdf1 is None:\n gdf1 = gpd.read_file(file)\n else:\n gdf2 = gpd.read_file(file)\n gdf1 = pd.concat([gdf1, gdf2])\n gdf1 = gdf1.set_crs(epsg=3257)\n gdf1 = gdf1.to_crs(epsg=4326)\n gdf1.to_file(out_file, driver='GeoJSON')\n return gdf1\n ",
"_____no_output_____"
],
[
"ISL_Training_Labels = output_label_file(dir_path,out_file)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a5020de44b81c7679cb779ff2687720b0290d4d
| 27,970 |
ipynb
|
Jupyter Notebook
|
notebooks/keras/basic_classification.ipynb
|
cnodadiaz/tf-workshop
|
b5bf332d3771ec2474613e0ce15f419acecdeb3c
|
[
"Apache-2.0"
] | null | null | null |
notebooks/keras/basic_classification.ipynb
|
cnodadiaz/tf-workshop
|
b5bf332d3771ec2474613e0ce15f419acecdeb3c
|
[
"Apache-2.0"
] | null | null | null |
notebooks/keras/basic_classification.ipynb
|
cnodadiaz/tf-workshop
|
b5bf332d3771ec2474613e0ce15f419acecdeb3c
|
[
"Apache-2.0"
] | null | null | null | 31.286353 | 474 | 0.511083 |
[
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"#@title MIT License\n#\n# Copyright (c) 2017 François Chollet\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
],
[
[
"# Train your first neural network: basic classification",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/keras/basic_classification\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/models/blob/master/samples/core/tutorials/keras/basic_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/models/blob/master/samples/core/tutorials/keras/basic_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"This guide trains a neural network model to classify images of clothing, like sneakers and shirts. It's okay if you don't understand all the details, this is a fast-paced overview of a complete TensorFlow program with the details explained as we go.\n\nThis guide uses [tf.keras](https://www.tensorflow.org/guide/keras), a high-level API to build and train models in TensorFlow.",
"_____no_output_____"
]
],
[
[
"# TensorFlow and tf.keras\nimport tensorflow as tf\nfrom tensorflow import keras\n\n# Helper libraries\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nprint(tf.__version__)",
"_____no_output_____"
]
],
[
[
"## Import the Fashion MNIST dataset",
"_____no_output_____"
],
[
"This guide uses the [Fashion MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset which contains 70,000 grayscale images in 10 categories. The images show individual articles of clothing at low resolution (28 by 28 pixels), as seen here:\n\n<table>\n <tr><td>\n <img src=\"https://tensorflow.org/images/fashion-mnist-sprite.png\"\n alt=\"Fashion MNIST sprite\" width=\"600\">\n </td></tr>\n <tr><td align=\"center\">\n <b>Figure 1.</b> <a href=\"https://github.com/zalandoresearch/fashion-mnist\">Fashion-MNIST samples</a> (by Zalando, MIT License).<br/> \n </td></tr>\n</table>\n\nFashion MNIST is intended as a drop-in replacement for the classic [MNIST](http://yann.lecun.com/exdb/mnist/) dataset—often used as the \"Hello, World\" of machine learning programs for computer vision. The MNIST dataset contains images of handwritten digits (0, 1, 2, etc) in an identical format to the articles of clothing we'll use here.\n\nThis guide uses Fashion MNIST for variety, and because it's a slightly more challenging problem than regular MNIST. Both datasets are relatively small and are used to verify that an algorithm works as expected. They're good starting points to test and debug code. \n\nWe will use 60,000 images to train the network and 10,000 images to evaluate how accurately the network learned to classify images. You can access the Fashion MNIST directly from TensorFlow, just import and load the data:",
"_____no_output_____"
]
],
[
[
"fashion_mnist = keras.datasets.fashion_mnist\n\n(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()",
"_____no_output_____"
]
],
[
[
"Loading the dataset returns four NumPy arrays:\n\n* The `train_images` and `train_labels` arrays are the *training set*—the data the model uses to learn.\n* The model is tested against the *test set*, the `test_images`, and `test_labels` arrays.\n\nThe images are 28x28 NumPy arrays, with pixel values ranging between 0 and 255. The *labels* are an array of integers, ranging from 0 to 9. These correspond to the *class* of clothing the image represents:\n\n<table>\n <tr>\n <th>Label</th>\n <th>Class</th> \n </tr>\n <tr>\n <td>0</td>\n <td>T-shirt/top</td> \n </tr>\n <tr>\n <td>1</td>\n <td>Trouser</td> \n </tr>\n <tr>\n <td>2</td>\n <td>Pullover</td> \n </tr>\n <tr>\n <td>3</td>\n <td>Dress</td> \n </tr>\n <tr>\n <td>4</td>\n <td>Coat</td> \n </tr>\n <tr>\n <td>5</td>\n <td>Sandal</td> \n </tr>\n <tr>\n <td>6</td>\n <td>Shirt</td> \n </tr>\n <tr>\n <td>7</td>\n <td>Sneaker</td> \n </tr>\n <tr>\n <td>8</td>\n <td>Bag</td> \n </tr>\n <tr>\n <td>9</td>\n <td>Ankle boot</td> \n </tr>\n</table>\n\nEach image is mapped to a single label. Since the *class names* are not included with the dataset, store them here to use later when plotting the images:",
"_____no_output_____"
]
],
[
[
"class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', \n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']",
"_____no_output_____"
]
],
[
[
"## Explore the data\n\nLet's explore the format of the dataset before training the model. The following shows there are 60,000 images in the training set, with each image represented as 28 x 28 pixels:",
"_____no_output_____"
]
],
[
[
"train_images.shape",
"_____no_output_____"
]
],
[
[
"Likewise, there are 60,000 labels in the training set:",
"_____no_output_____"
]
],
[
[
"len(train_labels)",
"_____no_output_____"
]
],
[
[
"Each label is an integer between 0 and 9:",
"_____no_output_____"
]
],
[
[
"train_labels",
"_____no_output_____"
]
],
[
[
"There are 10,000 images in the test set. Again, each image is represented as 28 x 28 pixels:",
"_____no_output_____"
]
],
[
[
"test_images.shape",
"_____no_output_____"
]
],
[
[
"And the test set contains 10,000 images labels:",
"_____no_output_____"
]
],
[
[
"len(test_labels)",
"_____no_output_____"
]
],
[
[
"## Preprocess the data\n\nThe data must be preprocessed before training the network. If you inspect the first image in the training set, you will see that the pixel values fall in the range of 0 to 255:",
"_____no_output_____"
]
],
[
[
"plt.figure()\nplt.imshow(train_images[0])\nplt.colorbar()\nplt.gca().grid(False)",
"_____no_output_____"
]
],
[
[
"We scale these values to a range of 0 to 1 before feeding to the neural network model. For this, cast the datatype of the image components from an integer to a float, and divide by 255. Here's the function to preprocess the images:",
"_____no_output_____"
],
[
"It's important that the *training set* and the *testing set* are preprocessed in the same way:",
"_____no_output_____"
]
],
[
[
"train_images = train_images / 255.0\n\ntest_images = test_images / 255.0",
"_____no_output_____"
]
],
[
[
"Display the first 25 images from the *training set* and display the class name below each image. Verify that the data is in the correct format and we're ready to build and train the network.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline\n\nplt.figure(figsize=(10,10))\nfor i in range(25):\n plt.subplot(5,5,i+1)\n plt.xticks([])\n plt.yticks([])\n plt.grid('off')\n plt.imshow(train_images[i], cmap=plt.cm.binary)\n plt.xlabel(class_names[train_labels[i]])",
"_____no_output_____"
]
],
[
[
"## Build the model\n\nBuilding the neural network requires configuring the layers of the model, then compiling the model.",
"_____no_output_____"
],
[
"### Setup the layers\n\nThe basic building block of a neural network is the *layer*. Layers extract representations from the data fed into them. And, hopefully, these representations are more meaningful for the problem at hand.\n\nMost of deep learning consists of chaining together simple layers. Most layers, like `tf.keras.layers.Dense`, have parameters that are learned during training.",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential([\n keras.layers.Flatten(input_shape=(28, 28)),\n keras.layers.Dense(128, activation=tf.nn.relu),\n keras.layers.Dense(10, activation=tf.nn.softmax)\n])",
"_____no_output_____"
]
],
[
[
"The first layer in this network, `tf.keras.layers.Flatten`, transforms the format of the images from a 2d-array (of 28 by 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. Think of this layer as unstacking rows of pixels in the image and lining them up. This layer has no parameters to learn; it only reformats the data.\n\nAfter the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are densely-connected, or fully-connected, neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer is a 10-node *softmax* layer—this returns an array of 10 probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the 10 digit classes.\n\n### Compile the model\n\nBefore the model is ready for training, it needs a few more settings. These are added during the model's *compile* step:\n\n* *Loss function* —This measures how accurate the model is during training. We want to minimize this function to \"steer\" the model in the right direction.\n* *Optimizer* —This is how the model is updated based on the data it sees and its loss function.\n* *Metrics* —Used to monitor the training and testing steps. The following example uses *accuracy*, the fraction of the images that are correctly classified.",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer=tf.train.AdamOptimizer(), \n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"## Train the model\n\nTraining the neural network model requires the following steps:\n\n1. Feed the training data to the model—in this example, the `train_images` and `train_labels` arrays.\n2. The model learns to associate images and labels.\n3. We ask the model to make predictions about a test set—in this example, the `test_images` array. We verify that the predictions match the labels from the `test_labels` array. \n\nTo start training, call the `model.fit` method—the model is \"fit\" to the training data:",
"_____no_output_____"
]
],
[
[
"model.fit(train_images, train_labels, epochs=5)",
"_____no_output_____"
]
],
[
[
"As the model trains, the loss and accuracy metrics are displayed. This model reaches an accuracy of about 0.88 (or 88%) on the training data.",
"_____no_output_____"
],
[
"## Evaluate accuracy\n\nNext, compare how the model performs on the test dataset:",
"_____no_output_____"
]
],
[
[
"test_loss, test_acc = model.evaluate(test_images, test_labels)\n\nprint('Test accuracy:', test_acc)",
"_____no_output_____"
]
],
[
[
"It turns out, the accuracy on the test dataset is a little less than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*. Overfitting is when a machine learning model performs worse on new data than on their training data. ",
"_____no_output_____"
],
[
"## Make predictions\n\nWith the model trained, we can use it to make predictions about some images.",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(test_images)",
"_____no_output_____"
]
],
[
[
"Here, the model has predicted the label for each image in the testing set. Let's take a look at the first prediction:",
"_____no_output_____"
]
],
[
[
"predictions[0]",
"_____no_output_____"
]
],
[
[
"A prediction is an array of 10 numbers. These describe the \"confidence\" of the model that the image corresponds to each of the 10 different articles of clothing. We can see which label has the highest confidence value:",
"_____no_output_____"
]
],
[
[
"np.argmax(predictions[0])",
"_____no_output_____"
]
],
[
[
"So the model is most confident that this image is an ankle boot, or `class_names[9]`. And we can check the test label to see this is correct:",
"_____no_output_____"
]
],
[
[
"test_labels[0]",
"_____no_output_____"
]
],
[
[
"Let's plot several images with their predictions. Correct prediction labels are green and incorrect prediction labels are red.",
"_____no_output_____"
]
],
[
[
"# Plot the first 25 test images, their predicted label, and the true label\n# Color correct predictions in green, incorrect predictions in red\nplt.figure(figsize=(10,10))\nfor i in range(25):\n plt.subplot(5,5,i+1)\n plt.xticks([])\n plt.yticks([])\n plt.grid('off')\n plt.imshow(test_images[i], cmap=plt.cm.binary)\n predicted_label = np.argmax(predictions[i])\n true_label = test_labels[i]\n if predicted_label == true_label:\n color = 'green'\n else:\n color = 'red'\n plt.xlabel(\"{} ({})\".format(class_names[predicted_label], \n class_names[true_label]),\n color=color)\n ",
"_____no_output_____"
]
],
[
[
"Finally, use the trained model to make a prediction about a single image. ",
"_____no_output_____"
]
],
[
[
"# Grab an image from the test dataset\nimg = test_images[0]\n\nprint(img.shape)",
"_____no_output_____"
]
],
[
[
"`tf.keras` models are optimized to make predictions on a *batch*, or collection, of examples at once. So even though we're using a single image, we need to add it to a list:",
"_____no_output_____"
]
],
[
[
"# Add the image to a batch where it's the only member.\nimg = (np.expand_dims(img,0))\n\nprint(img.shape)",
"_____no_output_____"
]
],
[
[
"Now predict the image:",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(img)\n\nprint(predictions)",
"_____no_output_____"
]
],
[
[
"`model.predict` returns a list of lists, one for each image in the batch of data. Grab the predictions for our (only) image in the batch:",
"_____no_output_____"
]
],
[
[
"prediction = predictions[0]\n\nnp.argmax(prediction)",
"_____no_output_____"
]
],
[
[
"And, as before, the model predicts a label of 9.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a502b7a4b3a3ecd876f5a6a896e84b68b86aa3c
| 40,611 |
ipynb
|
Jupyter Notebook
|
Notebooks/Scala/Hitchikers Guide to Delta Lake - Scala.ipynb
|
revinjchalil/Synapse
|
d0fc2413217b7c3471bb93db0f348d933f4524ac
|
[
"MIT"
] | 1 |
2020-08-27T15:05:35.000Z
|
2020-08-27T15:05:35.000Z
|
Notebooks/Scala/Hitchikers Guide to Delta Lake - Scala.ipynb
|
revinjchalil/Synapse
|
d0fc2413217b7c3471bb93db0f348d933f4524ac
|
[
"MIT"
] | null | null | null |
Notebooks/Scala/Hitchikers Guide to Delta Lake - Scala.ipynb
|
revinjchalil/Synapse
|
d0fc2413217b7c3471bb93db0f348d933f4524ac
|
[
"MIT"
] | 1 |
2021-09-07T07:49:33.000Z
|
2021-09-07T07:49:33.000Z
| 57.932953 | 5,773 | 0.4517 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a5037f91747fc89524ecaddb836eb87af5cbe6f
| 5,506 |
ipynb
|
Jupyter Notebook
|
Julia/Problem064/Problem064.ipynb
|
cazacov/ProjectEuler
|
c226ae11c92e1830e84f74ab0062708910b02154
|
[
"MIT"
] | null | null | null |
Julia/Problem064/Problem064.ipynb
|
cazacov/ProjectEuler
|
c226ae11c92e1830e84f74ab0062708910b02154
|
[
"MIT"
] | null | null | null |
Julia/Problem064/Problem064.ipynb
|
cazacov/ProjectEuler
|
c226ae11c92e1830e84f74ab0062708910b02154
|
[
"MIT"
] | null | null | null | 24.914027 | 181 | 0.42717 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a504274ff6902448a205161a8f299bf71d687c9
| 806,408 |
ipynb
|
Jupyter Notebook
|
3. Facial Keypoint Detection, Complete Pipeline.ipynb
|
BB-Y/P1_Facial_Keypoints
|
95bf4fb39f8ea52e7abaa320d12dc70f0aa14882
|
[
"MIT"
] | null | null | null |
3. Facial Keypoint Detection, Complete Pipeline.ipynb
|
BB-Y/P1_Facial_Keypoints
|
95bf4fb39f8ea52e7abaa320d12dc70f0aa14882
|
[
"MIT"
] | null | null | null |
3. Facial Keypoint Detection, Complete Pipeline.ipynb
|
BB-Y/P1_Facial_Keypoints
|
95bf4fb39f8ea52e7abaa320d12dc70f0aa14882
|
[
"MIT"
] | null | null | null | 2,016.02 | 325,748 | 0.960903 |
[
[
[
"## 人脸与人脸关键点检测\n\n在训练用于检测面部关键点的神经网络之后,你可以将此网络应用于包含人脸的*任何一个*图像。该神经网络需要一定大小的Tensor作为输入,因此,要检测任何一个人脸,你都首先必须进行一些预处理。\n\n1. 使用人脸检测器检测图像中的所有人脸。在这个notebook中,我们将使用Haar级联检测器。\n2. 对这些人脸图像进行预处理,使其成为灰度图像,并转换为你期望的输入尺寸的张量。这个步骤与你在Notebook 2中创建和应用的`data_transform` 类似,其作用是重新缩放、归一化,并将所有图像转换为Tensor,作为CNN的输入。\n3. 使用已被训练的模型检测图像上的人脸关键点。\n\n---\n\n在下一个python单元格中,我们要加载项目此部分所需的库。",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\n%matplotlib inline\n",
"_____no_output_____"
]
],
[
[
"#### 选择图像 \n\n选择一张图像,执行人脸关键点检测。你可以在`images/`目录中选择任何一张人脸图像。",
"_____no_output_____"
]
],
[
[
"import cv2\n# load in color image for face detection\nimage = cv2.imread('images/obamas.jpg')\n\n# switch red and blue color channels \n# --> by default OpenCV assumes BLUE comes first, not RED as in many images\nimage = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n\n# plot the image\nfig = plt.figure(figsize=(9,9))\nplt.imshow(image)",
"_____no_output_____"
]
],
[
[
"## 检测该图像中的所有人脸\n\n要想检测到所选图像中的所有人脸,接下来,你要用到的是OpenCV预先训练的一个Haar级联分类器,所有这些分类器都可以在`detector_architectures/`目录中找到。\n\n在下面的代码中,我们要遍历原始图像中的每个人脸,并在原始图像的副本中的每个人脸上绘制一个红色正方形,而原始图像不需要修改。此外,你也可以 [新增一项眼睛检测 ](https://docs.opencv.org/3.4.1/d7/d8b/tutorial_py_face_detection.html) ,作为使用Haar检测器的一个可选练习。\n\n下面是各种图像上的人脸检测示例。\n\n<img src='images/haar_cascade_ex.png' width=80% height=80%/>",
"_____no_output_____"
]
],
[
[
"# load in a haar cascade classifier for detecting frontal faces\nface_cascade = cv2.CascadeClassifier('detector_architectures/haarcascade_frontalface_default.xml')\n\n# run the detector\n# the output here is an array of detections; the corners of each detection box\n# if necessary, modify these parameters until you successfully identify every face in a given image\nfaces = face_cascade.detectMultiScale(image, 1.2, 2)\n\n# make a copy of the original image to plot detections on\nimage_with_detections = image.copy()\n\n# loop over the detected faces, mark the image where each face is found\nfor (x,y,w,h) in faces:\n # draw a rectangle around each detected face\n # you may also need to change the width of the rectangle drawn depending on image resolution\n cv2.rectangle(image_with_detections,(x,y),(x+w,y+h),(255,0,0),3) \n\nfig = plt.figure(figsize=(9,9))\n\nplt.imshow(image_with_detections)",
"_____no_output_____"
]
],
[
[
"## 加载到已训练的模型中\n\n有了一个可以使用的图像后(在这里,你可以选择`images/` 目录中的任何一张人脸图像),下一步是对该图像进行预处理并将其输入进CNN人脸关键点检测器。\n\n首先,按文件名加载你选定的最佳模型。",
"_____no_output_____"
]
],
[
[
"import torch\nfrom models import Net\n\nnet = Net()\n## TODO: load the best saved model parameters (by your path name)\n## You'll need to un-comment the line below and add the correct name for *your* saved model\npath = 'saved_models/keypoints_model_5.pt'\nnet.load_state_dict(torch.load(path),strict=False)\n\n## print out your net and prepare it for testing (uncomment the line below)\nnet.eval()",
"_____no_output_____"
]
],
[
[
"## 关键点检测\n\n现在,我们需要再一次遍历图像中每个检测到的人脸,只是这一次,你需要将这些人脸转换为CNN可以接受的张量形式的输入图像。\n\n### TODO: 将每个检测到的人脸转换为输入Tensor\n\n你需要对每个检测到的人脸执行以下操作:\n1. 将人脸从RGB图转换为灰度图\n2. 把灰度图像归一化,使其颜色范围落在[0,1]范围,而不是[0,255]\n3. 将检测到的人脸重新缩放为CNN的预期方形尺寸(我们建议为 224x224)\n4. 将numpy图像变形为torch图像。\n\n**提示**: Haar检测器检测到的人脸大小与神经网络训练过的人脸大小不同。如果你发现模型生成的关键点对给定的人脸来说,显得太小,请尝试在检测到的`roi`中添加一些填充,然后将其作为模型的输入。\n\n你可能会发现,参看`data_load.py`中的转换代码对帮助执行这些处理步骤很有帮助。\n\n\n### TODO: 检测并显示预测到的关键点\n\n将每个人脸适当地转换为网络的输入Tensor之后,就可以将`net` 应用于每个人脸。输出应该是预测到的人脸关键点,这些关键点需要“非归一化”才能显示。你可能会发现,编写一个类似`show_keypoints`的辅助函数会很有帮助。最后,你会得到一张如下的图像,其中人脸关键点与每张人脸上的面部特征非常匹配:\n\n<img src='images/michelle_detected.png' width=30% height=30%/>",
"_____no_output_____"
]
],
[
[
"image_copy = np.copy(image)\nfrom torch.autograd import Variable \nkeypoints = []\nimages = []\n# loop over the detected faces from your haar cascade\nfor (x,y,w,h) in faces:\n \n # Select the region of interest that is the face in the image\n expand = 20\n roi = image_copy[(y-expand):y+h+expand, (x-expand):x+w+expand]\n \n ## TODO: Convert the face region from RGB to grayscale\n \n roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)\n\n images.append(roi)\n ## TODO: Normalize the grayscale image so that its color range falls in [0,1] instead of [0,255]\n roi= roi/255.0\n ## TODO: Rescale the detected face to be the expected square size for your CNN (224x224, suggested)\n roi = cv2.resize(roi,(224,224))\n ## TODO: Reshape the numpy image shape (H x W x C) into a torch image shape (C x H x W)\n if(len(roi.shape) == 2):\n img_train = roi.reshape(roi.shape[0], roi.shape[1], 1)\n img_train = img_train.transpose((2, 0, 1))\n \n #img_train = np.expand_dims(img_train, 0)\n #img_train = np.expand_dims(img_train, 0)\n img_train = torch.from_numpy(img_train)\n img_train = img_train.type(torch.FloatTensor)\n img_train = img_train.float().unsqueeze(0)\n ## TODO: Make facial keypoint predictions using your loaded, trained network \n predicted_key_pts = net(img_train)\n predicted_key_pts = predicted_key_pts.view(predicted_key_pts.size()[0], 68, -1)\n\n keypoints.append(predicted_key_pts)\n \n\n ## TODO: Display each detected face and the corresponding keypoints \n #show_all_keypoints(roi, predicted_key_pts)\n ",
"_____no_output_____"
],
[
"def visualize_output(test_images, test_outputs):\n\n for i in range(2):\n plt.figure(figsize=(10,5))\n ax = plt.subplot(1, 2, i+1)\n\n \n \n image = test_images[i] \n \n\n # un-transform the predicted key_pts data\n predicted_key_pts = test_outputs[i].data\n\n predicted_key_pts = predicted_key_pts.detach().numpy()[0]\n\n\n # undo normalization of keypoints \n predicted_key_pts = predicted_key_pts*50+100\n \n plt.imshow(image, cmap='gray')\n plt.scatter(predicted_key_pts[:, 0], predicted_key_pts[:, 1], s=20, marker='.', c='m')\n \n plt.axis('off')\n\n plt.show()",
"_____no_output_____"
],
[
"visualize_output(images, keypoints)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a5047d638014f3d0376579f6b78617696ca5c81
| 18,173 |
ipynb
|
Jupyter Notebook
|
Day2/4_linalg.ipynb
|
michaellass/JuliaNRW21
|
337eacb40950ea37c5e0de485fe7ecb9192efb68
|
[
"MIT"
] | 14 |
2021-02-24T05:08:46.000Z
|
2021-05-28T11:13:52.000Z
|
Day2/4_linalg.ipynb
|
michaellass/JuliaNRW21
|
337eacb40950ea37c5e0de485fe7ecb9192efb68
|
[
"MIT"
] | 6 |
2021-03-02T19:10:00.000Z
|
2021-03-03T20:28:17.000Z
|
Day2/4_linalg.ipynb
|
michaellass/JuliaNRW21
|
337eacb40950ea37c5e0de485fe7ecb9192efb68
|
[
"MIT"
] | 6 |
2021-03-01T07:14:26.000Z
|
2021-06-21T08:50:25.000Z
| 23.328626 | 296 | 0.554449 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a504ab18381c3f8d7e050f30ee8bfef00e09c6d
| 173,603 |
ipynb
|
Jupyter Notebook
|
Deep_Features2.ipynb
|
absbin/AGCWD
|
73d08e880fad3f19ff8a44e9924f06d66f30e524
|
[
"MIT"
] | null | null | null |
Deep_Features2.ipynb
|
absbin/AGCWD
|
73d08e880fad3f19ff8a44e9924f06d66f30e524
|
[
"MIT"
] | null | null | null |
Deep_Features2.ipynb
|
absbin/AGCWD
|
73d08e880fad3f19ff8a44e9924f06d66f30e524
|
[
"MIT"
] | null | null | null | 115.581225 | 116,872 | 0.841518 |
[
[
[
"<a href=\"https://colab.research.google.com/github/absbin/AGCWD/blob/master/Deep_Features2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"\n%reload_ext autoreload\n%autoreload 2\n%matplotlib inline\n\nimport math\nfrom tqdm import tqdm\n\nimport os\nimport sys\nimport cv2\nimport glob\nimport time\nimport json\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom PIL import Image\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nfrom torch.utils.data import Dataset, DataLoader\n\nimport torchvision\nimport torchvision.models as models\nimport torchvision.datasets as datasets\nimport torchvision.transforms as transforms\n\nfrom sklearn import svm\nfrom sklearn import datasets\nfrom sklearn import metrics\nfrom sklearn.metrics import pairwise_distances\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.cluster import KMeans\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import StratifiedKFold\nfrom sklearn import svm\nfrom sklearn.model_selection import GridSearchCV\nimport zipfile\nfrom sklearn.manifold import TSNE\nfrom sklearn.decomposition import PCA\nimport pandas as pd\n\nuse_gpu = torch.cuda.is_available()",
"_____no_output_____"
],
[
"#cd \"/content/drive/My Drive/kargah DL with python code/Week07/Persian_Image_Captioning\"\n\n",
"_____no_output_____"
],
[
"#os.chdir('/content/drive/My Drive/kargah DL with python code/Week07/Persian_Image_Captioning')\n",
"_____no_output_____"
],
[
"!ls",
"sample_data\n"
],
[
"#from utils import *",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=email%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdocs.test%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.photos.readonly%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fpeopleapi.readonly&response_type=code\n\nEnter your authorization code:\n··········\nMounted at /content/drive\n"
],
[
"!git clone https://github.com/absbin/umap.git\nimport umap",
"Cloning into 'umap'...\nremote: Enumerating objects: 20, done.\u001b[K\nremote: Counting objects: 100% (20/20), done.\u001b[K\nremote: Compressing objects: 100% (13/13), done.\u001b[K\nremote: Total 2739 (delta 7), reused 19 (delta 7), pack-reused 2719\u001b[K\nReceiving objects: 100% (2739/2739), 13.44 MiB | 5.03 MiB/s, done.\nResolving deltas: 100% (1809/1809), done.\n"
],
[
"!ls \"/content/drive/My Drive\"",
" classifierCATvsDOG.pt\t\t 'kargah DL with python code'\n code\t\t\t\t laparoscopy\n'Colab Notebooks'\t\t resnet152_weights_tf.h5\n'Copy of Untitled1.ipynb'\t sesssion1_DL_cnn_pytorch.ipynb\n data\t\t\t\t Untitled1.ipynb\n DeepFeatures\t\t\t week1snrDL\n Deep_Features_classifier_cv.ipynb\n"
],
[
"local_zip = '/content/drive/My Drive/data/totoroframes.zip'\n\n",
"_____no_output_____"
],
[
"zip_ref = zipfile.ZipFile(local_zip, 'r')\nzip_ref.extractall('/data')\nzip_ref.close()\n\n",
"_____no_output_____"
],
[
"#base_dir = '/content/drive/My Drive/data/WCE_dataset_3'\ntrn_dir = '/data/totoroframes'\n",
"_____no_output_____"
],
[
"classes=os.listdir(trn_dir)",
"_____no_output_____"
],
[
"classes[0]",
"_____no_output_____"
],
[
"import re\ndef sorted_aphanumeric(data):\n convert = lambda text: int(text) if text.isdigit() else text.lower()\n alphanum_key = lambda key: [ convert(c) for c in re.split('([0-9]+)', key) ] \n return sorted(data, key=alphanum_key)",
"_____no_output_____"
],
[
"classes=sorted_aphanumeric(classes)",
"_____no_output_____"
],
[
"#classes",
"_____no_output_____"
],
[
"classes[0]",
"_____no_output_____"
],
[
"trn_frames = glob.glob(f'{trn_dir}/*.jpg')\n\nlen(trn_frames)\n",
"_____no_output_____"
],
[
"trn_frames[0]",
"_____no_output_____"
],
[
"from natsort import natsorted, ns\ntrn_frames=natsorted(trn_frames, key=lambda y: y.lower())",
"_____no_output_____"
],
[
"#trn_frames",
"_____no_output_____"
],
[
"!ls",
"drive sample_data umap\n"
],
[
"print( os.getcwd() )",
"/content\n"
]
],
[
[
"**Model**",
"_____no_output_____"
]
],
[
[
"img=plt.imread(trn_frames[155])\nplt.imshow(img)",
"_____no_output_____"
]
],
[
[
"**`Super pixel segmentation`**\n\n---\n\n",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(14,3))\nplt.subplot(1,3,1)\nbin_counts,_,_ = plt.hist(img[:,:,0].ravel(), bins=10)\nplt.subplot(1,3,2)\nbin_counts,_,_ = plt.hist(img[:,:,1].ravel(), bins=10)\nplt.subplot(1,3,3)\nbin_counts,_,_ = plt.hist(img[:,:,2].ravel(), bins=10)\n",
"_____no_output_____"
],
[
"from keras.preprocessing import image\nfrom keras.applications.resnet50 import ResNet50\nfrom keras.applications.resnet50 import preprocess_input\ndef feature_extractor(X):\n\n frames=X\n #model_vgg16 = VGG16(weights='imagenet', include_top=False)\n model_vgg16 = ResNet50(weights='imagenet', include_top=False)\n vgg16_feature_list = []\n vgg16_feature_list_np=[]\n labels_true=[]\n hsv=[]\n img_address=[]\n for i, fname in enumerate(frames ):\n img = image.load_img(fname, target_size=(224, 224)) \n\n img_data = image.img_to_array(img)\n img_data = np.expand_dims(img_data, axis=0)\n img_data = preprocess_input(img_data)\n vgg16_feature = model_vgg16.predict(img_data)\n vgg16_feature_np = np.array(vgg16_feature)\n vgg16_feature_list.append(vgg16_feature_np.flatten())\n img_address.append(fname)\n print(i,' ', fname)\n vgg16_feature_list_np = np.array(vgg16_feature_list)\n return vgg16_feature_list_np ,img_address",
"Using TensorFlow backend.\n"
],
[
"from google.colab import files\ndef getLocalFiles():\n _files = files.upload()\n if len(_files) >0:\n for k,v in _files.items():\n open(k,'wb').write(v)\ngetLocalFiles()",
"_____no_output_____"
],
[
"import torch\nimport torch.nn as nn\nimport torch.optim as optim\nfrom torch.nn.utils.rnn import pack_padded_sequence\n\nimport torchvision.transforms as transforms\nimport torchvision.models as models\nfrom torch.autograd import Variable",
"_____no_output_____"
],
[
"resnet50 = ResNet50(weights='imagenet', include_top=True)",
"WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nColocations handled automatically by placer.\nDownloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels.h5\n 10969088/102853048 [==>...........................] - ETA: 3:13"
],
[
"\ndef to_var(x, volatile=False):\n if torch.cuda.is_available():\n x = x.cuda()\n return Variable(x, volatile=volatile)\n",
"_____no_output_____"
],
[
"\ndef load_image(image_path, transform=None):\n \"Load an image and perform given transformations.\"\n image = Image.open(image_path) \n if transform is not None:\n image = transform(image).unsqueeze(0)\n return image\n \ndef load_cnn_model(model_name, pretrained=True):\n \"Load and return a convolutional neural network.\"\n assert model_name in ['ResNet50','resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']\n return models.__dict__[model_name](pretrained)\n\n\nclass EncoderCNN(nn.Module):\n def __init__(self, model_name):\n super(EncoderCNN, self).__init__()\n \n # load cnn and remove last layer\n cnn = load_cnn_model(model_name)\n modules = list(cnn.children())[:-1] # remove last layer\n \n self.cnn = nn.Sequential(*modules)\n\n def encoder(self, x):\n x = self.cnn(x) # extract features from input image\n print(x.size())\n x = Variable(x.data)\n print(x.size())\n return x",
"_____no_output_____"
],
[
"cnn_name = 'resnet152'\n",
"_____no_output_____"
],
[
"\nmodel = EncoderCNN(cnn_name)\nif use_gpu:\n model = model.cuda()",
"_____no_output_____"
],
[
"image = load_image(img_filenames[0], val_transform) \nimage_tensor = to_var(image, volatile=False)\nfeatures= model.encoder(image_tensor)",
"_____no_output_____"
],
[
"features=torch.tensor([])\nimg_filenames =trn_frames \nfrom PIL import Image\nimage_size = (224,224)\n\nval_transform = transforms.Compose([\n transforms.Resize(image_size), \n transforms.ToTensor()\n])\n\n\nfor img_filename in img_filenames:\n print(img_filename)\n # prepare test image\n image = load_image(img_filename, val_transform)\n print(image[0].size())\n plt.imshow( image[0].permute(1, 2, 0) )\n image_tensor = to_var(image, volatile=False)\n # Generate features from image\n feature = model.encoder(image_tensor) \n print(features.size)\n features=torch.cat([features,feature],dim=0)\n print(features.size)\n #feature=torch.squeeze(feature,3)\n \n #cnn_feature.append(feature) \n ",
"_____no_output_____"
],
[
"print(np.shape(features))",
"_____no_output_____"
],
[
"trn_frames",
"_____no_output_____"
],
[
"feature.size",
"_____no_output_____"
],
[
"image_tensor.Session().run((image_tensor))",
"_____no_output_____"
],
[
"x_data,address=feature_extractor(trn_frames)",
"_____no_output_____"
],
[
"x_data.shape\n",
"_____no_output_____"
],
[
"!ls",
"_____no_output_____"
],
[
"!ls \"/content/drive/My Drive\"",
"_____no_output_____"
],
[
"cd \"/content/drive/My Drive/data\"",
"_____no_output_____"
],
[
"!ls",
"_____no_output_____"
],
[
"#import numpy as np\n#np.savetxt('data.csv', (x_data), delimiter=',')",
"_____no_output_____"
],
[
"os.chdir('/content/drive/My Drive/data')",
"_____no_output_____"
],
[
"#!mkdir demo\n#%cd demo\n#!pwd",
"_____no_output_____"
],
[
"#%cd ",
"_____no_output_____"
],
[
"!pwd2",
"_____no_output_____"
],
[
"!ls",
"_____no_output_____"
],
[
"x_data.shape",
"_____no_output_____"
]
],
[
[
"# **Visual Comparison UMAP T-SNE PCA**",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import load_digits\n\ndigits = load_digits()\n\nembedding = umap.UMAP().fit_transform(digits.data)\ndigits.data.shape\nembedding.shape\ndigits.target\nplt.figure(figsize=(16,6))\nplt.subplot(1,3,1)\nplt.scatter(embedding[:, 0], embedding[:, 1],c=digits.target, cmap='Spectral', s=5,alpha=.5)\nplt.gca().set_aspect('equal', 'datalim')\n#plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))\nplt.title('UMAP projection of the digits', fontsize=14);\n\ntsne = TSNE(perplexity=30,n_components=2,init='pca',n_iter=2000)\nx_data_tsne=tsne.fit_transform(digits.data)\nplt.subplot(1,3,2)\nplt.scatter(x_data_tsne[:, 0], x_data_tsne[:, 1],c=digits.target, cmap='Spectral', s=5)\nplt.gca().set_aspect('equal', 'datalim')\n#plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))\nplt.title('T-SNE projection of the digits', fontsize=14);\n\n\nplt.subplot(1,3,3)\npca=PCA(n_components=2)\nx_data_pca = pca.fit(digits.data) \nx_data_pca= x_data_pca.transform(digits.data)\nplt.scatter(x_data_pca[:, 0], x_data_pca[:, 1],c=digits.target, cmap='Spectral', s=5)\nplt.gca().set_aspect('equal', 'datalim')\n#plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))\nplt.title('PCA projection of the digits', fontsize=14);",
"_____no_output_____"
]
],
[
[
"**Performing PCA for dimentionality reduction**\n\n\n> \n\n---\n\n\n\n\n> \n\n",
"_____no_output_____"
]
],
[
[
"from sklearn.decomposition import PCA\npca=PCA(n_components=2)\n# pca = PCA(.05) \nx_data_pca = pca.fit_transform(x_data) \n#x_data_pca= x_data_pca.transform(x_data)\nprint(x_data_pca.shape)\nprint(x_data.shape)",
"_____no_output_____"
]
],
[
[
"# umap",
"_____no_output_____"
]
],
[
[
"!git clone https://github.com/absbin/umap.git",
"_____no_output_____"
],
[
"import umap\n",
"_____no_output_____"
],
[
"embedding = umap.UMAP(n_components=2).fit_transform(x_data)\nx_data_umap=embedding\nembedding.shape\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"from sklearn.manifold import TSNE\ntsne = TSNE(perplexity=30,n_components=2,init='pca',n_iter=300)\nx_data_tsne=tsne.fit_transform(x_data)\nx_data_tsne.shape",
"_____no_output_____"
]
],
[
[
"# **Totoro 2 component UMAP T-SNE PCA**",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(16,6))\nplt.subplot(1,3,1)\nplt.scatter(x_data_pca[:, 0], x_data_pca[:, 1], cmap='Spectral', s=5)\nplt.gca().set_aspect('equal', 'datalim')\n#plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))\nplt.title('PCA projection of the Totoro', fontsize=14);\n\nplt.subplot(1,3,2)\nplt.scatter(x_data_tsne[:, 0], x_data_tsne[:, 1], cmap='Spectral', s=5)\nplt.gca().set_aspect('equal', 'datalim')\n#plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))\nplt.title('TSNE projection of the Totoro ', fontsize=14);\n\nplt.subplot(1,3,3)\nplt.scatter(embedding[:, 0], embedding[:, 1], cmap='Spectral', s=5)\nplt.gca().set_aspect('equal', 'datalim')\n#plt.colorbar(boundaries=np.arange(11)-0.5).set_ticks(np.arange(10))\nplt.title('UMAP projection of the Totoro', fontsize=14);",
"_____no_output_____"
],
[
"pca = PCA(.05) \npca=PCA(n_components=20)\nx_data_pca = pca.fit_transform(x_data) \nprint(x_data_pca.shape)\n\n",
"_____no_output_____"
],
[
"\ntsne = TSNE(perplexity=30,n_components=5,init='pca',n_iter=300)\nx_data_tsne=tsne.fit_transform(x_data)\nprint(x_data_tsne.shape)\n",
"_____no_output_____"
],
[
"\n\nembedding = umap.UMAP(n_components=20).fit_transform(x_data)\nx_data_umap=embedding\nprint(x_data_umap.shape)\n",
"_____no_output_____"
],
[
"cd \"/content/drive/My Drive/data\"",
"_____no_output_____"
],
[
"# construct dataframe, index [0] to make 2d\ndf = pd.DataFrame(x_data_pca)\n# save to Excel, exclude index and headers\ndf.to_excel('x_data_pca.xlsx', index=False, header=False)\n\ndf = pd.DataFrame(x_data_tsne)\ndf.to_excel('x_data_tsne.xlsx', index=False, header=False)\n\ndf = pd.DataFrame(x_data_umap)\ndf.to_excel('x_data_umap.xlsx', index=False, header=False)",
"_____no_output_____"
],
[
"import csv\nf = open('totoro.csv', 'w')\nwith f:\n writer = csv.writer(f)\n \n for row in x_data:\n writer.writerow(row)",
"_____no_output_____"
],
[
"generate_excel(x_data=x_data_pca, excel_loc='A1' ,sheet_='Sheet1)\n ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.