
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
listlengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
listlengths 0
25
| languages
listlengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
listlengths 0
352
| processed_texts
listlengths 1
353
| tokens_length
listlengths 1
353
| input_texts
listlengths 1
40
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8e3b664f7ed4151ef095c830885191b6352598aa
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
aaaaaaaqdqd/tech_program
|
[
"region:us"
] |
2023-09-19T05:09:50+00:00
|
{}
|
2023-09-19T07:43:18+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for Dataset Name
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
|
[
"# Dataset Card for Dataset Name",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
6,
8,
24,
32,
10,
4,
6,
6,
5,
5,
5,
7,
4,
10,
10,
5,
5,
9,
8,
8,
7,
8,
7,
5,
6,
6,
5
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:### Dataset Summary\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.### Supported Tasks and Leaderboards### Languages## Dataset Structure### Data Instances### Data Fields### Data Splits## Dataset Creation### Curation Rationale### Source Data#### Initial Data Collection and Normalization#### Who are the source language producers?### Annotations#### Annotation process#### Who are the annotators?### Personal and Sensitive Information## Considerations for Using the Data### Social Impact of Dataset### Discussion of Biases### Other Known Limitations## Additional Information### Dataset Curators### Licensing Information### Contributions"
] |
c3401b007f199147412592c42d912481ddc96949
|
# Dataset Card for "indian_ASR_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
GhayasAhmed/indian_ASR_2
|
[
"region:us"
] |
2023-09-19T05:15:51+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "transcription", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2668422488.192, "num_examples": 16152}], "download_size": 3009401094, "dataset_size": 2668422488.192}}
|
2023-09-19T05:20:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "indian_ASR_2"
More Information needed
|
[
"# Dataset Card for \"indian_ASR_2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"indian_ASR_2\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"indian_ASR_2\"\n\nMore Information needed"
] |
cc4dc5b672989727463fe19c7a9b4bf61baf6ada
|
# COIG Prompt Collection
## License
**Default Licensing for Sub-Datasets Without Specific License Declaration**: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.
**Precedence of Declared Licensing for Sub-Datasets**: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.
Users and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.
## What is COIG-PC?
The COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.
If you think COIG-PC is too huge, please refer to [COIG-PC-Lite](https://huggingface.co/datasets/BAAI/COIG-PC-Lite) which is a subset of COIG-PC with only 200 samples from each task file.
## Why COIG-PC?
The COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:
**Addressing Language Complexity**: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.
**Comprehensive Data Aggregation**: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.
**Data Deduplication and Normalization**: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.
**Fine-tuning and Optimization**: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.
The COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.
## Who builds COIG-PC?
The bedrock of COIG-PC is anchored in the dataset furnished by stardust.ai, which comprises an aggregation of data collected from the Internet.
And COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:
- Beijing Academy of Artificial Intelligence, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/baai.png" alt= “BAAI” height="100" width="150">
- Peking University, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/pku.png" alt= “PKU” height="100" width="200">
- The Hong Kong University of Science and Technology (HKUST), China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/hkust.png" alt= “HKUST” height="100" width="200">
- The University of Waterloo, Canada
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/waterloo.png" alt= “Waterloo” height="100" width="150">
- The University of Sheffield, United Kingdom
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/sheffield.png" alt= “Sheffield” height="100" width="200">
- Beijing University of Posts and Telecommunications, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/bupt.png" alt= “BUPT” height="100" width="200">
- [Multimodal Art Projection](https://huggingface.co/m-a-p)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/map.png" alt= “M.A.P” height="100" width="200">
- stardust.ai, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/stardust.png" alt= “stardust.ai” height="100" width="200">
- LinkSoul.AI, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/linksoul.png" alt= “linksoul.ai” height="100" width="200">
For the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.
## How to use COIG-PC?
COIG-PC is structured in a **.jsonl** file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:
**instruction**: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.
**input**: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.
**output**: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.
**split**: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.
**task_type**: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.
**domain**: Indicates the domain or field to which the data belongs.
**other**: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.
### Example
Here is an example of how a line in the COIG-PC dataset might be structured:
```
{
"instruction": "请把下面的中文句子翻译成英文",
"input": "我爱你。",
"output": "I love you.",
"split": "train",
"task_type": {
"major": ["翻译"],
"minor": ["翻译", "中译英"]
},
"domain": ["通用"],
"other": null
}
```
In this example:
**instruction** tells the model to translate the following Chinese sentence into English.
**input** contains the Chinese text "我爱你" which means "I love you".
**output** contains the expected translation in English: "I love you".
**split** indicates that this data record is part of the training set.
**task_type** specifies that the major category is "Translation" and the minor categories are "Translation" and "Chinese to English".
**domain** specifies that this data record belongs to the general domain.
**other** is set to null as there is no additional information for this data record.
## Update: Aug. 30, 2023
- v1.0: First version of COIG-PC-core.
## COIG-PC Citation
If you want to cite COIG-PC-core dataset, you could use this:
```
```
## Contact Us
To contact us feel free to create an Issue in this repository.
|
BAAI/COIG-PC-core
|
[
"language:zh",
"license:unknown",
"region:us"
] |
2023-09-19T05:24:01+00:00
|
{"language": ["zh"], "license": "unknown", "extra_gated_heading": "Acknowledge license to accept the repository", "extra_gated_prompt": "\u5317\u4eac\u667a\u6e90\u4eba\u5de5\u667a\u80fd\u7814\u7a76\u9662\uff08\u4ee5\u4e0b\u7b80\u79f0\u201c\u6211\u4eec\u201d\u6216\u201c\u7814\u7a76\u9662\u201d\uff09\u901a\u8fc7BAAI DataHub\uff08data.baai.ac.cn\uff09\u548cCOIG-PC HuggingFace\u4ed3\u5e93\uff08https://huggingface.co/datasets/BAAI/COIG-PC\uff09\u5411\u60a8\u63d0\u4f9b\u5f00\u6e90\u6570\u636e\u96c6\uff08\u4ee5\u4e0b\u6216\u79f0\u201c\u6570\u636e\u96c6\u201d\uff09\uff0c\u60a8\u53ef\u901a\u8fc7\u4e0b\u8f7d\u7684\u65b9\u5f0f\u83b7\u53d6\u60a8\u6240\u9700\u7684\u5f00\u6e90\u6570\u636e\u96c6\uff0c\u5e76\u5728\u9075\u5b88\u5404\u539f\u59cb\u6570\u636e\u96c6\u4f7f\u7528\u89c4\u5219\u524d\u63d0\u4e0b\uff0c\u57fa\u4e8e\u5b66\u4e60\u3001\u7814\u7a76\u3001\u5546\u4e1a\u7b49\u76ee\u7684\u4f7f\u7528\u76f8\u5173\u6570\u636e\u96c6\u3002\n\u5728\u60a8\u83b7\u53d6\uff08\u5305\u62ec\u4f46\u4e0d\u9650\u4e8e\u8bbf\u95ee\u3001\u4e0b\u8f7d\u3001\u590d\u5236\u3001\u4f20\u64ad\u3001\u4f7f\u7528\u7b49\u5904\u7406\u6570\u636e\u96c6\u7684\u884c\u4e3a\uff09\u5f00\u6e90\u6570\u636e\u96c6\u524d\uff0c\u60a8\u5e94\u8ba4\u771f\u9605\u8bfb\u5e76\u7406\u89e3\u672c\u300aCOIG-PC\u5f00\u6e90\u6570\u636e\u96c6\u4f7f\u7528\u987b\u77e5\u4e0e\u514d\u8d23\u58f0\u660e\u300b\uff08\u4ee5\u4e0b\u7b80\u79f0\u201c\u672c\u58f0\u660e\u201d\uff09\u3002\u4e00\u65e6\u60a8\u83b7\u53d6\u5f00\u6e90\u6570\u636e\u96c6\uff0c\u65e0\u8bba\u60a8\u7684\u83b7\u53d6\u65b9\u5f0f\u4e3a\u4f55\uff0c\u60a8\u7684\u83b7\u53d6\u884c\u4e3a\u5747\u5c06\u88ab\u89c6\u4e3a\u5bf9\u672c\u58f0\u660e\u5168\u90e8\u5185\u5bb9\u7684\u8ba4\u53ef\u3002\n1.\t\u5e73\u53f0\u7684\u6240\u6709\u6743\u4e0e\u8fd0\u8425\u6743\n\u60a8\u5e94\u5145\u5206\u4e86\u89e3\u5e76\u77e5\u6089\uff0cBAAI DataHub\u548cCOIG-PC HuggingFace\u4ed3\u5e93\uff08\u5305\u62ec\u5f53\u524d\u7248\u672c\u53ca\u5168\u90e8\u5386\u53f2\u7248\u672c\uff09\u7684\u6240\u6709\u6743\u4e0e\u8fd0\u8425\u6743\u5f52\u667a\u6e90\u4eba\u5de5\u667a\u80fd\u7814\u7a76\u9662\u6240\u6709\uff0c\u667a\u6e90\u4eba\u5de5\u667a\u80fd\u7814\u7a76\u9662\u5bf9\u672c\u5e73\u53f0/\u672c\u5de5\u5177\u53ca\u5f00\u6e90\u6570\u636e\u96c6\u5f00\u653e\u8ba1\u5212\u62e5\u6709\u6700\u7ec8\u89e3\u91ca\u6743\u548c\u51b3\u5b9a\u6743\u3002\n\u60a8\u77e5\u6089\u5e76\u7406\u89e3\uff0c\u57fa\u4e8e\u76f8\u5173\u6cd5\u5f8b\u6cd5\u89c4\u66f4\u65b0\u548c\u5b8c\u5584\u4ee5\u53ca\u6211\u4eec\u9700\u5c65\u884c\u6cd5\u5f8b\u5408\u89c4\u4e49\u52a1\u7684\u5ba2\u89c2\u53d8\u5316\uff0c\u6211\u4eec\u4fdd\u7559\u5bf9\u672c\u5e73\u53f0/\u672c\u5de5\u5177\u8fdb\u884c\u4e0d\u5b9a\u65f6\u66f4\u65b0\u3001\u7ef4\u62a4\uff0c\u6216\u8005\u4e2d\u6b62\u4e43\u81f3\u6c38\u4e45\u7ec8\u6b62\u63d0\u4f9b\u672c\u5e73\u53f0/\u672c\u5de5\u5177\u670d\u52a1\u7684\u6743\u5229\u3002\u6211\u4eec\u5c06\u5728\u5408\u7406\u65f6\u95f4\u5185\u5c06\u53ef\u80fd\u53d1\u751f\u524d\u8ff0\u60c5\u5f62\u901a\u8fc7\u516c\u544a\u6216\u90ae\u4ef6\u7b49\u5408\u7406\u65b9\u5f0f\u544a\u77e5\u60a8\uff0c\u60a8\u5e94\u5f53\u53ca\u65f6\u505a\u597d\u76f8\u5e94\u7684\u8c03\u6574\u548c\u5b89\u6392\uff0c\u4f46\u6211\u4eec\u4e0d\u56e0\u53d1\u751f\u524d\u8ff0\u4efb\u4f55\u60c5\u5f62\u5bf9\u60a8\u9020\u6210\u7684\u4efb\u4f55\u635f\u5931\u627f\u62c5\u4efb\u4f55\u8d23\u4efb\u3002\n2.\t\u5f00\u6e90\u6570\u636e\u96c6\u7684\u6743\u5229\u4e3b\u5f20\n\u4e3a\u4e86\u4fbf\u4e8e\u60a8\u57fa\u4e8e\u5b66\u4e60\u3001\u7814\u7a76\u3001\u5546\u4e1a\u7684\u76ee\u7684\u5f00\u5c55\u6570\u636e\u96c6\u83b7\u53d6\u3001\u4f7f\u7528\u7b49\u6d3b\u52a8\uff0c\u6211\u4eec\u5bf9\u7b2c\u4e09\u65b9\u539f\u59cb\u6570\u636e\u96c6\u8fdb\u884c\u4e86\u5fc5\u8981\u7684\u683c\u5f0f\u6574\u5408\u3001\u6570\u636e\u6e05\u6d17\u3001\u6807\u6ce8\u3001\u5206\u7c7b\u3001\u6ce8\u91ca\u7b49\u76f8\u5173\u5904\u7406\u73af\u8282\uff0c\u5f62\u6210\u53ef\u4f9b\u672c\u5e73\u53f0/\u672c\u5de5\u5177\u7528\u6237\u4f7f\u7528\u7684\u5f00\u6e90\u6570\u636e\u96c6\u3002\n\u60a8\u77e5\u6089\u5e76\u7406\u89e3\uff0c\u6211\u4eec\u4e0d\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u4e3b\u5f20\u77e5\u8bc6\u4ea7\u6743\u4e2d\u7684\u76f8\u5173\u8d22\u4ea7\u6027\u6743\u5229\uff0c\u56e0\u6b64\u6211\u4eec\u4ea6\u65e0\u76f8\u5e94\u4e49\u52a1\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u53ef\u80fd\u5b58\u5728\u7684\u77e5\u8bc6\u4ea7\u6743\u8fdb\u884c\u4e3b\u52a8\u8bc6\u522b\u548c\u4fdd\u62a4\uff0c\u4f46\u8fd9\u4e0d\u610f\u5473\u7740\u6211\u4eec\u653e\u5f03\u5f00\u6e90\u6570\u636e\u96c6\u4e3b\u5f20\u7f72\u540d\u6743\u3001\u53d1\u8868\u6743\u3001\u4fee\u6539\u6743\u548c\u4fdd\u62a4\u4f5c\u54c1\u5b8c\u6574\u6743\uff08\u5982\u6709\uff09\u7b49\u4eba\u8eab\u6027\u6743\u5229\u3002\u800c\u539f\u59cb\u6570\u636e\u96c6\u53ef\u80fd\u5b58\u5728\u7684\u77e5\u8bc6\u4ea7\u6743\u53ca\u76f8\u5e94\u5408\u6cd5\u6743\u76ca\u7531\u539f\u6743\u5229\u4eba\u4eab\u6709\u3002\n\u6b64\u5916\uff0c\u5411\u60a8\u5f00\u653e\u548c\u4f7f\u7528\u7ecf\u5408\u7406\u7f16\u6392\u3001\u52a0\u5de5\u548c\u5904\u7406\u540e\u7684\u5f00\u6e90\u6570\u636e\u96c6\uff0c\u5e76\u4e0d\u610f\u5473\u7740\u6211\u4eec\u5bf9\u539f\u59cb\u6570\u636e\u96c6\u77e5\u8bc6\u4ea7\u6743\u3001\u4fe1\u606f\u5185\u5bb9\u7b49\u771f\u5b9e\u3001\u51c6\u786e\u6216\u65e0\u4e89\u8bae\u7684\u8ba4\u53ef\uff0c\u60a8\u5e94\u5f53\u81ea\u884c\u7b5b\u9009\u3001\u4ed4\u7ec6\u7504\u522b\uff0c\u4f7f\u7528\u7ecf\u60a8\u9009\u62e9\u7684\u5f00\u6e90\u6570\u636e\u96c6\u3002\u60a8\u77e5\u6089\u5e76\u540c\u610f\uff0c\u7814\u7a76\u9662\u5bf9\u60a8\u81ea\u884c\u9009\u62e9\u4f7f\u7528\u7684\u539f\u59cb\u6570\u636e\u96c6\u4e0d\u8d1f\u6709\u4efb\u4f55\u65e0\u7f3a\u9677\u6216\u65e0\u7455\u75b5\u7684\u627f\u8bfa\u4e49\u52a1\u6216\u62c5\u4fdd\u8d23\u4efb\u3002\n3.\t\u5f00\u6e90\u6570\u636e\u96c6\u7684\u4f7f\u7528\u9650\u5236\n\u60a8\u4f7f\u7528\u6570\u636e\u96c6\u4e0d\u5f97\u4fb5\u5bb3\u6211\u4eec\u6216\u4efb\u4f55\u7b2c\u4e09\u65b9\u7684\u5408\u6cd5\u6743\u76ca\uff08\u5305\u62ec\u4f46\u4e0d\u9650\u4e8e\u8457\u4f5c\u6743\u3001\u4e13\u5229\u6743\u3001\u5546\u6807\u6743\u7b49\u77e5\u8bc6\u4ea7\u6743\u4e0e\u5176\u4ed6\u6743\u76ca\uff09\u3002\n\u83b7\u53d6\u5f00\u6e90\u6570\u636e\u96c6\u540e\uff0c\u60a8\u5e94\u786e\u4fdd\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u7684\u4f7f\u7528\u4e0d\u8d85\u8fc7\u539f\u59cb\u6570\u636e\u96c6\u7684\u6743\u5229\u4eba\u4ee5\u516c\u793a\u6216\u534f\u8bae\u7b49\u5f62\u5f0f\u660e\u786e\u89c4\u5b9a\u7684\u4f7f\u7528\u89c4\u5219\uff0c\u5305\u62ec\u539f\u59cb\u6570\u636e\u7684\u4f7f\u7528\u8303\u56f4\u3001\u76ee\u7684\u548c\u5408\u6cd5\u7528\u9014\u7b49\u3002\u6211\u4eec\u5728\u6b64\u5584\u610f\u5730\u63d0\u8bf7\u60a8\u7559\u610f\uff0c\u5982\u60a8\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u7684\u4f7f\u7528\u8d85\u51fa\u539f\u59cb\u6570\u636e\u96c6\u7684\u539f\u5b9a\u4f7f\u7528\u8303\u56f4\u53ca\u7528\u9014\uff0c\u60a8\u53ef\u80fd\u9762\u4e34\u4fb5\u72af\u539f\u59cb\u6570\u636e\u96c6\u6743\u5229\u4eba\u7684\u5408\u6cd5\u6743\u76ca\u4f8b\u5982\u77e5\u8bc6\u4ea7\u6743\u7684\u98ce\u9669\uff0c\u5e76\u53ef\u80fd\u627f\u62c5\u76f8\u5e94\u7684\u6cd5\u5f8b\u8d23\u4efb\u3002\n4.\t\u4e2a\u4eba\u4fe1\u606f\u4fdd\u62a4\n\u57fa\u4e8e\u6280\u672f\u9650\u5236\u53ca\u5f00\u6e90\u6570\u636e\u96c6\u7684\u516c\u76ca\u6027\u8d28\u7b49\u5ba2\u89c2\u539f\u56e0\uff0c\u6211\u4eec\u65e0\u6cd5\u4fdd\u8bc1\u5f00\u6e90\u6570\u636e\u96c6\u4e2d\u4e0d\u5305\u542b\u4efb\u4f55\u4e2a\u4eba\u4fe1\u606f\uff0c\u6211\u4eec\u4e0d\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u4e2d\u53ef\u80fd\u6d89\u53ca\u7684\u4e2a\u4eba\u4fe1\u606f\u627f\u62c5\u4efb\u4f55\u6cd5\u5f8b\u8d23\u4efb\u3002\n\u5982\u5f00\u6e90\u6570\u636e\u96c6\u6d89\u53ca\u4e2a\u4eba\u4fe1\u606f\uff0c\u6211\u4eec\u4e0d\u5bf9\u60a8\u4f7f\u7528\u5f00\u6e90\u6570\u636e\u96c6\u53ef\u80fd\u6d89\u53ca\u7684\u4efb\u4f55\u4e2a\u4eba\u4fe1\u606f\u5904\u7406\u884c\u4e3a\u627f\u62c5\u6cd5\u5f8b\u8d23\u4efb\u3002\u6211\u4eec\u5728\u6b64\u5584\u610f\u5730\u63d0\u8bf7\u60a8\u7559\u610f\uff0c\u60a8\u5e94\u4f9d\u636e\u300a\u4e2a\u4eba\u4fe1\u606f\u4fdd\u62a4\u6cd5\u300b\u7b49\u76f8\u5173\u6cd5\u5f8b\u6cd5\u89c4\u7684\u89c4\u5b9a\u5904\u7406\u4e2a\u4eba\u4fe1\u606f\u3002\n\u4e3a\u4e86\u7ef4\u62a4\u4fe1\u606f\u4e3b\u4f53\u7684\u5408\u6cd5\u6743\u76ca\u3001\u5c65\u884c\u53ef\u80fd\u9002\u7528\u7684\u6cd5\u5f8b\u3001\u884c\u653f\u6cd5\u89c4\u7684\u89c4\u5b9a\uff0c\u5982\u60a8\u5728\u4f7f\u7528\u5f00\u6e90\u6570\u636e\u96c6\u7684\u8fc7\u7a0b\u4e2d\u53d1\u73b0\u6d89\u53ca\u6216\u8005\u53ef\u80fd\u6d89\u53ca\u4e2a\u4eba\u4fe1\u606f\u7684\u5185\u5bb9\uff0c\u5e94\u7acb\u5373\u505c\u6b62\u5bf9\u6570\u636e\u96c6\u4e2d\u6d89\u53ca\u4e2a\u4eba\u4fe1\u606f\u90e8\u5206\u7684\u4f7f\u7528\uff0c\u5e76\u53ca\u65f6\u901a\u8fc7\u201c6. \u6295\u8bc9\u4e0e\u901a\u77e5\u201d\u4e2d\u8f7d\u660e\u7684\u8054\u7cfb\u6211\u4eec\u3002\n5.\t\u4fe1\u606f\u5185\u5bb9\u7ba1\u7406\n\u6211\u4eec\u4e0d\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u53ef\u80fd\u6d89\u53ca\u7684\u8fdd\u6cd5\u4e0e\u4e0d\u826f\u4fe1\u606f\u627f\u62c5\u4efb\u4f55\u6cd5\u5f8b\u8d23\u4efb\u3002\n\u5982\u60a8\u5728\u4f7f\u7528\u5f00\u6e90\u6570\u636e\u96c6\u7684\u8fc7\u7a0b\u4e2d\u53d1\u73b0\u5f00\u6e90\u6570\u636e\u96c6\u6d89\u53ca\u6216\u8005\u53ef\u80fd\u6d89\u53ca\u4efb\u4f55\u8fdd\u6cd5\u4e0e\u4e0d\u826f\u4fe1\u606f\uff0c\u60a8\u5e94\u7acb\u5373\u505c\u6b62\u5bf9\u6570\u636e\u96c6\u4e2d\u6d89\u53ca\u8fdd\u6cd5\u4e0e\u4e0d\u826f\u4fe1\u606f\u90e8\u5206\u7684\u4f7f\u7528\uff0c\u5e76\u53ca\u65f6\u901a\u8fc7\u201c6. \u6295\u8bc9\u4e0e\u901a\u77e5\u201d\u4e2d\u8f7d\u660e\u7684\u8054\u7cfb\u6211\u4eec\u3002\n6.\t\u6295\u8bc9\u4e0e\u901a\u77e5\n\u5982\u60a8\u8ba4\u4e3a\u5f00\u6e90\u6570\u636e\u96c6\u4fb5\u72af\u4e86\u60a8\u7684\u5408\u6cd5\u6743\u76ca\uff0c\u60a8\u53ef\u901a\u8fc7010-50955974\u8054\u7cfb\u6211\u4eec\uff0c\u6211\u4eec\u4f1a\u53ca\u65f6\u4f9d\u6cd5\u5904\u7406\u60a8\u7684\u4e3b\u5f20\u4e0e\u6295\u8bc9\u3002\n\u4e3a\u4e86\u5904\u7406\u60a8\u7684\u4e3b\u5f20\u548c\u6295\u8bc9\uff0c\u6211\u4eec\u53ef\u80fd\u9700\u8981\u60a8\u63d0\u4f9b\u8054\u7cfb\u65b9\u5f0f\u3001\u4fb5\u6743\u8bc1\u660e\u6750\u6599\u4ee5\u53ca\u8eab\u4efd\u8bc1\u660e\u7b49\u6750\u6599\u3002\u8bf7\u6ce8\u610f\uff0c\u5982\u679c\u60a8\u6076\u610f\u6295\u8bc9\u6216\u9648\u8ff0\u5931\u5b9e\uff0c\u60a8\u5c06\u627f\u62c5\u7531\u6b64\u9020\u6210\u7684\u5168\u90e8\u6cd5\u5f8b\u8d23\u4efb\uff08\u5305\u62ec\u4f46\u4e0d\u9650\u4e8e\u5408\u7406\u7684\u8d39\u7528\u8d54\u507f\u7b49\uff09\u3002\n7.\t\u8d23\u4efb\u58f0\u660e\n\u60a8\u7406\u89e3\u5e76\u540c\u610f\uff0c\u57fa\u4e8e\u5f00\u6e90\u6570\u636e\u96c6\u7684\u6027\u8d28\uff0c\u6570\u636e\u96c6\u4e2d\u53ef\u80fd\u5305\u542b\u6765\u81ea\u4e0d\u540c\u6765\u6e90\u548c\u8d21\u732e\u8005\u7684\u6570\u636e\uff0c\u5176\u771f\u5b9e\u6027\u3001\u51c6\u786e\u6027\u3001\u5ba2\u89c2\u6027\u7b49\u53ef\u80fd\u4f1a\u6709\u6240\u5dee\u5f02\uff0c\u6211\u4eec\u65e0\u6cd5\u5bf9\u4efb\u4f55\u6570\u636e\u96c6\u7684\u53ef\u7528\u6027\u3001\u53ef\u9760\u6027\u7b49\u505a\u51fa\u4efb\u4f55\u627f\u8bfa\u3002\n\u5728\u4efb\u4f55\u60c5\u51b5\u4e0b\uff0c\u6211\u4eec\u4e0d\u5bf9\u5f00\u6e90\u6570\u636e\u96c6\u53ef\u80fd\u5b58\u5728\u7684\u4e2a\u4eba\u4fe1\u606f\u4fb5\u6743\u3001\u8fdd\u6cd5\u4e0e\u4e0d\u826f\u4fe1\u606f\u4f20\u64ad\u3001\u77e5\u8bc6\u4ea7\u6743\u4fb5\u6743\u7b49\u4efb\u4f55\u98ce\u9669\u627f\u62c5\u4efb\u4f55\u6cd5\u5f8b\u8d23\u4efb\u3002\n\u5728\u4efb\u4f55\u60c5\u51b5\u4e0b\uff0c\u6211\u4eec\u4e0d\u5bf9\u60a8\u56e0\u5f00\u6e90\u6570\u636e\u96c6\u906d\u53d7\u7684\u6216\u4e0e\u4e4b\u76f8\u5173\u7684\u4efb\u4f55\u635f\u5931\uff08\u5305\u62ec\u4f46\u4e0d\u9650\u4e8e\u76f4\u63a5\u635f\u5931\u3001\u95f4\u63a5\u635f\u5931\u4ee5\u53ca\u53ef\u5f97\u5229\u76ca\u635f\u5931\u7b49\uff09\u627f\u62c5\u4efb\u4f55\u6cd5\u5f8b\u8d23\u4efb\u3002\n8.\t\u5176\u4ed6\n\u5f00\u6e90\u6570\u636e\u96c6\u5904\u4e8e\u4e0d\u65ad\u53d1\u5c55\u3001\u53d8\u5316\u7684\u9636\u6bb5\uff0c\u6211\u4eec\u53ef\u80fd\u56e0\u4e1a\u52a1\u53d1\u5c55\u3001\u7b2c\u4e09\u65b9\u5408\u4f5c\u3001\u6cd5\u5f8b\u6cd5\u89c4\u53d8\u52a8\u7b49\u539f\u56e0\u66f4\u65b0\u3001\u8c03\u6574\u6240\u63d0\u4f9b\u7684\u5f00\u6e90\u6570\u636e\u96c6\u8303\u56f4\uff0c\u6216\u4e2d\u6b62\u3001\u6682\u505c\u3001\u7ec8\u6b62\u5f00\u6e90\u6570\u636e\u96c6\u63d0\u4f9b\u4e1a\u52a1\u3002\n", "extra_gated_fields": {"Name": "text", "Affiliation": "text", "Country": "text", "I agree to use this model for non-commercial use ONLY": "checkbox"}, "extra_gated_button_content": "Acknowledge license", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "instruction", "dtype": "string"}, {"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}, {"name": "task_type", "struct": [{"name": "major", "sequence": "string"}, {"name": "minor", "sequence": "string"}]}, {"name": "domain", "sequence": "string"}, {"name": "other", "dtype": "string"}, {"name": "task_name_in_eng", "dtype": "string"}, {"name": "index", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1053129000, "num_examples": 744592}], "download_size": 416315627, "dataset_size": 1053129000}}
|
2023-09-25T09:33:33+00:00
|
[] |
[
"zh"
] |
TAGS
#language-Chinese #license-unknown #region-us
|
# COIG Prompt Collection
## License
Default Licensing for Sub-Datasets Without Specific License Declaration: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.
Precedence of Declared Licensing for Sub-Datasets: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.
Users and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.
## What is COIG-PC?
The COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.
If you think COIG-PC is too huge, please refer to COIG-PC-Lite which is a subset of COIG-PC with only 200 samples from each task file.
## Why COIG-PC?
The COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:
Addressing Language Complexity: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.
Comprehensive Data Aggregation: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.
Data Deduplication and Normalization: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.
Fine-tuning and Optimization: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.
The COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.
## Who builds COIG-PC?
The bedrock of COIG-PC is anchored in the dataset furnished by URL, which comprises an aggregation of data collected from the Internet.
And COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:
- Beijing Academy of Artificial Intelligence, China
<img src="URL alt= “BAAI” height="100" width="150">
- Peking University, China
<img src="URL alt= “PKU” height="100" width="200">
- The Hong Kong University of Science and Technology (HKUST), China
<img src="URL alt= “HKUST” height="100" width="200">
- The University of Waterloo, Canada
<img src="URL alt= “Waterloo” height="100" width="150">
- The University of Sheffield, United Kingdom
<img src="URL alt= “Sheffield” height="100" width="200">
- Beijing University of Posts and Telecommunications, China
<img src="URL alt= “BUPT” height="100" width="200">
- Multimodal Art Projection
<img src="URL alt= “M.A.P” height="100" width="200">
- URL, China
<img src="URL alt= “URL” height="100" width="200">
- LinkSoul.AI, China
<img src="URL alt= “URL” height="100" width="200">
For the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.
## How to use COIG-PC?
COIG-PC is structured in a .jsonl file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:
instruction: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.
input: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.
output: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.
split: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.
task_type: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.
domain: Indicates the domain or field to which the data belongs.
other: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.
### Example
Here is an example of how a line in the COIG-PC dataset might be structured:
In this example:
instruction tells the model to translate the following Chinese sentence into English.
input contains the Chinese text "我爱你" which means "I love you".
output contains the expected translation in English: "I love you".
split indicates that this data record is part of the training set.
task_type specifies that the major category is "Translation" and the minor categories are "Translation" and "Chinese to English".
domain specifies that this data record belongs to the general domain.
other is set to null as there is no additional information for this data record.
## Update: Aug. 30, 2023
- v1.0: First version of COIG-PC-core.
## COIG-PC Citation
If you want to cite COIG-PC-core dataset, you could use this:
## Contact Us
To contact us feel free to create an Issue in this repository.
|
[
"# COIG Prompt Collection",
"## License\nDefault Licensing for Sub-Datasets Without Specific License Declaration: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.\n\nPrecedence of Declared Licensing for Sub-Datasets: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.\n\nUsers and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.",
"## What is COIG-PC?\nThe COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.\n\nIf you think COIG-PC is too huge, please refer to COIG-PC-Lite which is a subset of COIG-PC with only 200 samples from each task file.",
"## Why COIG-PC?\nThe COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:\n\n Addressing Language Complexity: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.\n\nComprehensive Data Aggregation: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.\n\nData Deduplication and Normalization: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.\n\nFine-tuning and Optimization: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.\n\nThe COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.",
"## Who builds COIG-PC?\nThe bedrock of COIG-PC is anchored in the dataset furnished by URL, which comprises an aggregation of data collected from the Internet.\n\nAnd COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:\n\n- Beijing Academy of Artificial Intelligence, China\n<img src=\"URL alt= “BAAI” height=\"100\" width=\"150\">\n- Peking University, China\n<img src=\"URL alt= “PKU” height=\"100\" width=\"200\">\n- The Hong Kong University of Science and Technology (HKUST), China\n<img src=\"URL alt= “HKUST” height=\"100\" width=\"200\">\n- The University of Waterloo, Canada\n<img src=\"URL alt= “Waterloo” height=\"100\" width=\"150\">\n- The University of Sheffield, United Kingdom\n<img src=\"URL alt= “Sheffield” height=\"100\" width=\"200\">\n- Beijing University of Posts and Telecommunications, China\n<img src=\"URL alt= “BUPT” height=\"100\" width=\"200\">\n- Multimodal Art Projection\n<img src=\"URL alt= “M.A.P” height=\"100\" width=\"200\">\n- URL, China\n<img src=\"URL alt= “URL” height=\"100\" width=\"200\">\n- LinkSoul.AI, China\n<img src=\"URL alt= “URL” height=\"100\" width=\"200\">\n\nFor the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.",
"## How to use COIG-PC?\nCOIG-PC is structured in a .jsonl file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:\n\ninstruction: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.\n\ninput: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.\n\noutput: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.\n\nsplit: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.\n\ntask_type: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.\n\ndomain: Indicates the domain or field to which the data belongs.\n\nother: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.",
"### Example\nHere is an example of how a line in the COIG-PC dataset might be structured:\n\n\nIn this example:\ninstruction tells the model to translate the following Chinese sentence into English.\ninput contains the Chinese text \"我爱你\" which means \"I love you\".\noutput contains the expected translation in English: \"I love you\".\nsplit indicates that this data record is part of the training set.\ntask_type specifies that the major category is \"Translation\" and the minor categories are \"Translation\" and \"Chinese to English\".\ndomain specifies that this data record belongs to the general domain.\nother is set to null as there is no additional information for this data record.",
"## Update: Aug. 30, 2023\n- v1.0: First version of COIG-PC-core.",
"## COIG-PC Citation\nIf you want to cite COIG-PC-core dataset, you could use this:",
"## Contact Us\nTo contact us feel free to create an Issue in this repository."
] |
[
"TAGS\n#language-Chinese #license-unknown #region-us \n",
"# COIG Prompt Collection",
"## License\nDefault Licensing for Sub-Datasets Without Specific License Declaration: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.\n\nPrecedence of Declared Licensing for Sub-Datasets: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.\n\nUsers and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.",
"## What is COIG-PC?\nThe COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.\n\nIf you think COIG-PC is too huge, please refer to COIG-PC-Lite which is a subset of COIG-PC with only 200 samples from each task file.",
"## Why COIG-PC?\nThe COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:\n\n Addressing Language Complexity: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.\n\nComprehensive Data Aggregation: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.\n\nData Deduplication and Normalization: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.\n\nFine-tuning and Optimization: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.\n\nThe COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.",
"## Who builds COIG-PC?\nThe bedrock of COIG-PC is anchored in the dataset furnished by URL, which comprises an aggregation of data collected from the Internet.\n\nAnd COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:\n\n- Beijing Academy of Artificial Intelligence, China\n<img src=\"URL alt= “BAAI” height=\"100\" width=\"150\">\n- Peking University, China\n<img src=\"URL alt= “PKU” height=\"100\" width=\"200\">\n- The Hong Kong University of Science and Technology (HKUST), China\n<img src=\"URL alt= “HKUST” height=\"100\" width=\"200\">\n- The University of Waterloo, Canada\n<img src=\"URL alt= “Waterloo” height=\"100\" width=\"150\">\n- The University of Sheffield, United Kingdom\n<img src=\"URL alt= “Sheffield” height=\"100\" width=\"200\">\n- Beijing University of Posts and Telecommunications, China\n<img src=\"URL alt= “BUPT” height=\"100\" width=\"200\">\n- Multimodal Art Projection\n<img src=\"URL alt= “M.A.P” height=\"100\" width=\"200\">\n- URL, China\n<img src=\"URL alt= “URL” height=\"100\" width=\"200\">\n- LinkSoul.AI, China\n<img src=\"URL alt= “URL” height=\"100\" width=\"200\">\n\nFor the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.",
"## How to use COIG-PC?\nCOIG-PC is structured in a .jsonl file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:\n\ninstruction: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.\n\ninput: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.\n\noutput: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.\n\nsplit: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.\n\ntask_type: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.\n\ndomain: Indicates the domain or field to which the data belongs.\n\nother: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.",
"### Example\nHere is an example of how a line in the COIG-PC dataset might be structured:\n\n\nIn this example:\ninstruction tells the model to translate the following Chinese sentence into English.\ninput contains the Chinese text \"我爱你\" which means \"I love you\".\noutput contains the expected translation in English: \"I love you\".\nsplit indicates that this data record is part of the training set.\ntask_type specifies that the major category is \"Translation\" and the minor categories are \"Translation\" and \"Chinese to English\".\ndomain specifies that this data record belongs to the general domain.\nother is set to null as there is no additional information for this data record.",
"## Update: Aug. 30, 2023\n- v1.0: First version of COIG-PC-core.",
"## COIG-PC Citation\nIf you want to cite COIG-PC-core dataset, you could use this:",
"## Contact Us\nTo contact us feel free to create an Issue in this repository."
] |
[
18,
7,
192,
155,
375,
451,
292,
152,
22,
26,
18
] |
[
"passage: TAGS\n#language-Chinese #license-unknown #region-us \n# COIG Prompt Collection## License\nDefault Licensing for Sub-Datasets Without Specific License Declaration: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.\n\nPrecedence of Declared Licensing for Sub-Datasets: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.\n\nUsers and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.## What is COIG-PC?\nThe COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.\n\nIf you think COIG-PC is too huge, please refer to COIG-PC-Lite which is a subset of COIG-PC with only 200 samples from each task file.",
"passage: ## Why COIG-PC?\nThe COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:\n\n Addressing Language Complexity: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.\n\nComprehensive Data Aggregation: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.\n\nData Deduplication and Normalization: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.\n\nFine-tuning and Optimization: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.\n\nThe COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.## Who builds COIG-PC?\nThe bedrock of COIG-PC is anchored in the dataset furnished by URL, which comprises an aggregation of data collected from the Internet.\n\nAnd COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:\n\n- Beijing Academy of Artificial Intelligence, China\n<img src=\"URL alt= “BAAI” height=\"100\" width=\"150\">\n- Peking University, China\n<img src=\"URL alt= “PKU” height=\"100\" width=\"200\">\n- The Hong Kong University of Science and Technology (HKUST), China\n<img src=\"URL alt= “HKUST” height=\"100\" width=\"200\">\n- The University of Waterloo, Canada\n<img src=\"URL alt= “Waterloo” height=\"100\" width=\"150\">\n- The University of Sheffield, United Kingdom\n<img src=\"URL alt= “Sheffield” height=\"100\" width=\"200\">\n- Beijing University of Posts and Telecommunications, China\n<img src=\"URL alt= “BUPT” height=\"100\" width=\"200\">\n- Multimodal Art Projection\n<img src=\"URL alt= “M.A.P” height=\"100\" width=\"200\">\n- URL, China\n<img src=\"URL alt= “URL” height=\"100\" width=\"200\">\n- LinkSoul.AI, China\n<img src=\"URL alt= “URL” height=\"100\" width=\"200\">\n\nFor the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process."
] |
fea724319b02d53fe1e3b8ed298335f25823e542
|
# Dataset Card for "small_CLM"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
nc33/small_CLM
|
[
"region:us"
] |
2023-09-19T05:34:24+00:00
|
{"dataset_info": {"config_name": "train", "features": [{"name": "instruction", "dtype": "string"}, {"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 95210810, "num_examples": 48048}], "download_size": 24474966, "dataset_size": 95210810}, "configs": [{"config_name": "train", "data_files": [{"split": "train", "path": "train/train-*"}]}]}
|
2023-09-19T05:35:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "small_CLM"
More Information needed
|
[
"# Dataset Card for \"small_CLM\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"small_CLM\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"small_CLM\"\n\nMore Information needed"
] |
91b832ddd1daf91e3ae2ea1d82932703f1476043
|
# Dataset Card for "3457e37d"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-muse256-muse512-wuerst-sdv15/3457e37d
|
[
"region:us"
] |
2023-09-19T05:37:27+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 164, "num_examples": 10}], "download_size": 1314, "dataset_size": 164}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T05:37:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "3457e37d"
More Information needed
|
[
"# Dataset Card for \"3457e37d\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"3457e37d\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"3457e37d\"\n\nMore Information needed"
] |
80cdb115ec2ef46d4e926b252f2b59af62d6c070
|
# Dataset Card for "nordjylland-news-summarization"
## Dataset Description
- **Point of Contact:** [Oliver Kinch](mailto:[email protected])
- **Size of dataset:** 148 MB
### Dataset Summary
This dataset consists of pairs containing text and corresponding summaries extracted from the Danish newspaper [TV2 Nord](https://www.tv2nord.dk/).
### Supported Tasks and Leaderboards
Summarization is the intended task for this dataset. No leaderboard is active at this point.
### Languages
The dataset is available in Danish (`da`).
## Dataset Structure
An example from the dataset looks as follows.
```
{
"text": "some text",
"summary": "some summary",
"text_len": <number of chars in text>,
"summary_len": <number of chars in summary>
}
```
### Data Fields
- `text`: a `string` feature.
- `summary`: a `string` feature.
- `text_len`: an `int64` feature.
- `summary_len`: an `int64` feature.
### Dataset Statistics
#### Number of samples
- Train: 75219
- Val: 4178
- Test: 4178
#### Text Length Distribution
- Minimum length: 21
- Maximum length: 35164

#### Summary Length Distribution
- Minimum length: 12
- Maximum length: 499

## Potential Dataset Issues
Within the dataset, there are 181 instances where the length of the summary exceeds the length of the corresponding text.
## Dataset Creation
### Curation Rationale
There are not many large-scale summarization datasets in Danish.
### Source Data
The dataset has been collected through the TV2 Nord API, which can be accessed [here](https://developer.bazo.dk/#876ab6f9-e057-43e3-897a-1563de34397e).
## Additional Information
### Dataset Curators
[Oliver Kinch](https://huggingface.co/oliverkinch) from the [The Alexandra
Institute](https://alexandra.dk/)
### Licensing Information
The dataset is licensed under the [CC0
license](https://creativecommons.org/share-your-work/public-domain/cc0/).
|
alexandrainst/nordjylland-news-summarization
|
[
"task_categories:summarization",
"size_categories:10K<n<100K",
"language:da",
"license:apache-2.0",
"region:us"
] |
2023-09-19T06:18:43+00:00
|
{"language": ["da"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["summarization"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "val", "path": "data/val-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "summary", "dtype": "string"}, {"name": "text_len", "dtype": "int64"}, {"name": "summary_len", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 118935809, "num_examples": 75219}, {"name": "val", "num_bytes": 6551332, "num_examples": 4178}, {"name": "test", "num_bytes": 6670392, "num_examples": 4178}], "download_size": 81334629, "dataset_size": 132157533}}
|
2023-11-28T15:32:41+00:00
|
[] |
[
"da"
] |
TAGS
#task_categories-summarization #size_categories-10K<n<100K #language-Danish #license-apache-2.0 #region-us
|
# Dataset Card for "nordjylland-news-summarization"
## Dataset Description
- Point of Contact: Oliver Kinch
- Size of dataset: 148 MB
### Dataset Summary
This dataset consists of pairs containing text and corresponding summaries extracted from the Danish newspaper TV2 Nord.
### Supported Tasks and Leaderboards
Summarization is the intended task for this dataset. No leaderboard is active at this point.
### Languages
The dataset is available in Danish ('da').
## Dataset Structure
An example from the dataset looks as follows.
### Data Fields
- 'text': a 'string' feature.
- 'summary': a 'string' feature.
- 'text_len': an 'int64' feature.
- 'summary_len': an 'int64' feature.
### Dataset Statistics
#### Number of samples
- Train: 75219
- Val: 4178
- Test: 4178
#### Text Length Distribution
- Minimum length: 21
- Maximum length: 35164
!image/png
#### Summary Length Distribution
- Minimum length: 12
- Maximum length: 499
!image/png
## Potential Dataset Issues
Within the dataset, there are 181 instances where the length of the summary exceeds the length of the corresponding text.
## Dataset Creation
### Curation Rationale
There are not many large-scale summarization datasets in Danish.
### Source Data
The dataset has been collected through the TV2 Nord API, which can be accessed here.
## Additional Information
### Dataset Curators
Oliver Kinch from the The Alexandra
Institute
### Licensing Information
The dataset is licensed under the CC0
license.
|
[
"# Dataset Card for \"nordjylland-news-summarization\"",
"## Dataset Description\n\n- Point of Contact: Oliver Kinch\n- Size of dataset: 148 MB",
"### Dataset Summary\n\nThis dataset consists of pairs containing text and corresponding summaries extracted from the Danish newspaper TV2 Nord.",
"### Supported Tasks and Leaderboards\n\nSummarization is the intended task for this dataset. No leaderboard is active at this point.",
"### Languages\n\nThe dataset is available in Danish ('da').",
"## Dataset Structure\n\nAn example from the dataset looks as follows.",
"### Data Fields\n\n- 'text': a 'string' feature.\n- 'summary': a 'string' feature.\n- 'text_len': an 'int64' feature.\n- 'summary_len': an 'int64' feature.",
"### Dataset Statistics",
"#### Number of samples\n\n- Train: 75219\n- Val: 4178\n- Test: 4178",
"#### Text Length Distribution\n\n- Minimum length: 21\n- Maximum length: 35164\n\n!image/png",
"#### Summary Length Distribution\n\n- Minimum length: 12\n- Maximum length: 499\n\n!image/png",
"## Potential Dataset Issues\n\nWithin the dataset, there are 181 instances where the length of the summary exceeds the length of the corresponding text.",
"## Dataset Creation",
"### Curation Rationale\n\nThere are not many large-scale summarization datasets in Danish.",
"### Source Data\n\nThe dataset has been collected through the TV2 Nord API, which can be accessed here.",
"## Additional Information",
"### Dataset Curators\n\nOliver Kinch from the The Alexandra\nInstitute",
"### Licensing Information\n\nThe dataset is licensed under the CC0\nlicense."
] |
[
"TAGS\n#task_categories-summarization #size_categories-10K<n<100K #language-Danish #license-apache-2.0 #region-us \n",
"# Dataset Card for \"nordjylland-news-summarization\"",
"## Dataset Description\n\n- Point of Contact: Oliver Kinch\n- Size of dataset: 148 MB",
"### Dataset Summary\n\nThis dataset consists of pairs containing text and corresponding summaries extracted from the Danish newspaper TV2 Nord.",
"### Supported Tasks and Leaderboards\n\nSummarization is the intended task for this dataset. No leaderboard is active at this point.",
"### Languages\n\nThe dataset is available in Danish ('da').",
"## Dataset Structure\n\nAn example from the dataset looks as follows.",
"### Data Fields\n\n- 'text': a 'string' feature.\n- 'summary': a 'string' feature.\n- 'text_len': an 'int64' feature.\n- 'summary_len': an 'int64' feature.",
"### Dataset Statistics",
"#### Number of samples\n\n- Train: 75219\n- Val: 4178\n- Test: 4178",
"#### Text Length Distribution\n\n- Minimum length: 21\n- Maximum length: 35164\n\n!image/png",
"#### Summary Length Distribution\n\n- Minimum length: 12\n- Maximum length: 499\n\n!image/png",
"## Potential Dataset Issues\n\nWithin the dataset, there are 181 instances where the length of the summary exceeds the length of the corresponding text.",
"## Dataset Creation",
"### Curation Rationale\n\nThere are not many large-scale summarization datasets in Danish.",
"### Source Data\n\nThe dataset has been collected through the TV2 Nord API, which can be accessed here.",
"## Additional Information",
"### Dataset Curators\n\nOliver Kinch from the The Alexandra\nInstitute",
"### Licensing Information\n\nThe dataset is licensed under the CC0\nlicense."
] |
[
41,
16,
20,
32,
31,
16,
17,
57,
6,
22,
23,
24,
33,
5,
24,
25,
5,
14,
18
] |
[
"passage: TAGS\n#task_categories-summarization #size_categories-10K<n<100K #language-Danish #license-apache-2.0 #region-us \n# Dataset Card for \"nordjylland-news-summarization\"## Dataset Description\n\n- Point of Contact: Oliver Kinch\n- Size of dataset: 148 MB### Dataset Summary\n\nThis dataset consists of pairs containing text and corresponding summaries extracted from the Danish newspaper TV2 Nord.### Supported Tasks and Leaderboards\n\nSummarization is the intended task for this dataset. No leaderboard is active at this point.### Languages\n\nThe dataset is available in Danish ('da').## Dataset Structure\n\nAn example from the dataset looks as follows.### Data Fields\n\n- 'text': a 'string' feature.\n- 'summary': a 'string' feature.\n- 'text_len': an 'int64' feature.\n- 'summary_len': an 'int64' feature.### Dataset Statistics#### Number of samples\n\n- Train: 75219\n- Val: 4178\n- Test: 4178#### Text Length Distribution\n\n- Minimum length: 21\n- Maximum length: 35164\n\n!image/png#### Summary Length Distribution\n\n- Minimum length: 12\n- Maximum length: 499\n\n!image/png## Potential Dataset Issues\n\nWithin the dataset, there are 181 instances where the length of the summary exceeds the length of the corresponding text.## Dataset Creation### Curation Rationale\n\nThere are not many large-scale summarization datasets in Danish.### Source Data\n\nThe dataset has been collected through the TV2 Nord API, which can be accessed here.## Additional Information### Dataset Curators\n\nOliver Kinch from the The Alexandra\nInstitute### Licensing Information\n\nThe dataset is licensed under the CC0\nlicense."
] |
12e07e82eca583988b8759d159d1bed960e80185
|
# Domain Adaptation of Large Language Models
This repo contains the **evaluation datasets** for our **ICLR 2024** paper [Adapting Large Language Models via Reading Comprehension](https://huggingface.co/papers/2309.09530).
We explore **continued pre-training on domain-specific corpora** for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to **transform large-scale pre-training corpora into reading comprehension texts**, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. **Our 7B model competes with much larger domain-specific models like BloombergGPT-50B**.
### 🤗 We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! 🤗
**************************** **Updates** ****************************
* 2024/1/16: 🎉 Our [research paper](https://huggingface.co/papers/2309.09530) has been accepted by ICLR 2024!!!🎉
* 2023/12/19: Released our [13B base models](https://huggingface.co/AdaptLLM/law-LLM-13B) developed from LLaMA-1-13B.
* 2023/12/8: Released our [chat models](https://huggingface.co/AdaptLLM/law-chat) developed from LLaMA-2-Chat-7B.
* 2023/9/18: Released our [paper](https://huggingface.co/papers/2309.09530), [code](https://github.com/microsoft/LMOps), [data](https://huggingface.co/datasets/AdaptLLM/law-tasks), and [base models](https://huggingface.co/AdaptLLM/law-LLM) developed from LLaMA-1-7B.
## Domain-Specific LLaMA-1
### LLaMA-1-7B
In our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: [Biomedicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM), [Finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM) and [Law-LLM](https://huggingface.co/AdaptLLM/law-LLM), the performances of our AdaptLLM compared to other domain-specific LLMs are:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/650801ced5578ef7e20b33d4/6efPwitFgy-pLTzvccdcP.png" width="700">
</p>
### LLaMA-1-13B
Moreover, we scale up our base model to LLaMA-1-13B to see if **our method is similarly effective for larger-scale models**, and the results are consistently positive too: [Biomedicine-LLM-13B](https://huggingface.co/AdaptLLM/medicine-LLM-13B), [Finance-LLM-13B](https://huggingface.co/AdaptLLM/finance-LLM-13B) and [Law-LLM-13B](https://huggingface.co/AdaptLLM/law-LLM-13B).
## Domain-Specific LLaMA-2-Chat
Our method is also effective for aligned models! LLaMA-2-Chat requires a [specific data format](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), and our **reading comprehension can perfectly fit the data format** by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: [Biomedicine-Chat](https://huggingface.co/AdaptLLM/medicine-chat), [Finance-Chat](https://huggingface.co/AdaptLLM/finance-chat) and [Law-Chat](https://huggingface.co/AdaptLLM/law-chat)
For example, to chat with the law-chat model:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("AdaptLLM/law-chat")
tokenizer = AutoTokenizer.from_pretrained("AdaptLLM/law-chat")
# Put your input here:
user_input = '''Question: Which of the following is false about ex post facto laws?
Options:
- They make criminal an act that was innocent when committed.
- They prescribe greater punishment for an act than was prescribed when it was done.
- They increase the evidence required to convict a person than when the act was done.
- They alter criminal offenses or punishment in a substantially prejudicial manner for the purpose of punishing a person for some past activity.
Please provide your choice first and then provide explanations if possible.'''
# Apply the prompt template and system prompt of LLaMA-2-Chat demo for chat models (NOTE: NO prompt template is required for base models!)
our_system_prompt = "\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n" # Please do NOT change this
prompt = f"<s>[INST] <<SYS>>{our_system_prompt}<</SYS>>\n\n{user_input} [/INST]"
# # NOTE:
# # If you want to apply your own system prompt, please integrate it into the instruction part following our system prompt like this:
# your_system_prompt = "Please, answer this question faithfully."
# prompt = f"<s>[INST] <<SYS>>{our_system_prompt}<</SYS>>\n\n{your_system_prompt}\n{user_input} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).input_ids.to(model.device)
outputs = model.generate(input_ids=inputs, max_length=4096)[0]
answer_start = int(inputs.shape[-1])
pred = tokenizer.decode(outputs[answer_start:], skip_special_tokens=True)
print(f'### User Input:\n{user_input}\n\n### Assistant Output:\n{pred}')
```
## Domain-Specific Tasks
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: [biomedicine-tasks](https://huggingface.co/datasets/AdaptLLM/medicine-tasks), [finance-tasks](https://huggingface.co/datasets/AdaptLLM/finance-tasks), and [law-tasks](https://huggingface.co/datasets/AdaptLLM/law-tasks).
**Note:** those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.
## Citation
If you find our work helpful, please cite us:
```bibtex
@article{adaptllm,
title={Adapting large language models via reading comprehension},
author={Cheng, Daixuan and Huang, Shaohan and Wei, Furu},
journal={arXiv preprint arXiv:2309.09530},
year={2023}
}
```
|
AdaptLLM/law-tasks
|
[
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:conversational",
"language:en",
"legal",
"arxiv:2309.09530",
"region:us"
] |
2023-09-19T06:44:48+00:00
|
{"language": ["en"], "task_categories": ["text-classification", "question-answering", "zero-shot-classification", "conversational"], "configs": [{"config_name": "SCOTUS", "data_files": [{"split": "test", "path": "scotus/test.json"}]}, {"config_name": "CaseHOLD", "data_files": [{"split": "test", "path": "case_hold/test.json"}]}, {"config_name": "UNFAIR_ToS", "data_files": [{"split": "test", "path": "unfair_tos/test.json"}]}], "tags": ["legal"]}
|
2024-02-07T12:31:34+00:00
|
[
"2309.09530"
] |
[
"en"
] |
TAGS
#task_categories-text-classification #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-conversational #language-English #legal #arxiv-2309.09530 #region-us
|
# Domain Adaptation of Large Language Models
This repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.
We explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.
### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned!
Updates
* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!
* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.
* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.
* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.
## Domain-Specific LLaMA-1
### LLaMA-1-7B
In our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:
<p align='center'>
<img src="URL width="700">
</p>
### LLaMA-1-13B
Moreover, we scale up our base model to LLaMA-1-13B to see if our method is similarly effective for larger-scale models, and the results are consistently positive too: Biomedicine-LLM-13B, Finance-LLM-13B and Law-LLM-13B.
## Domain-Specific LLaMA-2-Chat
Our method is also effective for aligned models! LLaMA-2-Chat requires a specific data format, and our reading comprehension can perfectly fit the data format by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: Biomedicine-Chat, Finance-Chat and Law-Chat
For example, to chat with the law-chat model:
## Domain-Specific Tasks
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.
Note: those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.
If you find our work helpful, please cite us:
|
[
"# Domain Adaptation of Large Language Models\nThis repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.\n\nWe explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.",
"### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! \n\n Updates \n* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!\n* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.\n* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.\n* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.",
"## Domain-Specific LLaMA-1",
"### LLaMA-1-7B\nIn our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:\n\n<p align='center'>\n <img src=\"URL width=\"700\">\n</p>",
"### LLaMA-1-13B\nMoreover, we scale up our base model to LLaMA-1-13B to see if our method is similarly effective for larger-scale models, and the results are consistently positive too: Biomedicine-LLM-13B, Finance-LLM-13B and Law-LLM-13B.",
"## Domain-Specific LLaMA-2-Chat\nOur method is also effective for aligned models! LLaMA-2-Chat requires a specific data format, and our reading comprehension can perfectly fit the data format by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: Biomedicine-Chat, Finance-Chat and Law-Chat\n\nFor example, to chat with the law-chat model:",
"## Domain-Specific Tasks\nTo easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.\n\nNote: those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.\n\nIf you find our work helpful, please cite us:"
] |
[
"TAGS\n#task_categories-text-classification #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-conversational #language-English #legal #arxiv-2309.09530 #region-us \n",
"# Domain Adaptation of Large Language Models\nThis repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.\n\nWe explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.",
"### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! \n\n Updates \n* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!\n* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.\n* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.\n* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.",
"## Domain-Specific LLaMA-1",
"### LLaMA-1-7B\nIn our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:\n\n<p align='center'>\n <img src=\"URL width=\"700\">\n</p>",
"### LLaMA-1-13B\nMoreover, we scale up our base model to LLaMA-1-13B to see if our method is similarly effective for larger-scale models, and the results are consistently positive too: Biomedicine-LLM-13B, Finance-LLM-13B and Law-LLM-13B.",
"## Domain-Specific LLaMA-2-Chat\nOur method is also effective for aligned models! LLaMA-2-Chat requires a specific data format, and our reading comprehension can perfectly fit the data format by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: Biomedicine-Chat, Finance-Chat and Law-Chat\n\nFor example, to chat with the law-chat model:",
"## Domain-Specific Tasks\nTo easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.\n\nNote: those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.\n\nIf you find our work helpful, please cite us:"
] |
[
67,
153,
116,
10,
97,
72,
101,
103
] |
[
"passage: TAGS\n#task_categories-text-classification #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-conversational #language-English #legal #arxiv-2309.09530 #region-us \n# Domain Adaptation of Large Language Models\nThis repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.\n\nWe explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! \n\n Updates \n* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!\n* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.\n* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.\n* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.## Domain-Specific LLaMA-1### LLaMA-1-7B\nIn our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:\n\n<p align='center'>\n <img src=\"URL width=\"700\">\n</p>"
] |
3381fd0f3841050fc404876453d631220fcf403d
|
## Kazakh Question Paraphrasing Dataset
This dataset, designed for paraphrasing tasks in the Kazakh language, is a valuable resource for natural language processing applications. It aids in the development and evaluation of models capable of understanding and generating paraphrased content while preserving the original meaning.
### Source and Translation Process
The dataset was sourced from the Quora Question Pairs and has been expertly translated into Kazakh. This translation process involved initial machine translation followed by thorough revision by native Kazakh speakers, ensuring the nuances and contextual integrity of the language were maintained.
### Usage and Application
This dataset is primarily intended for researchers and developers in computational linguistics, focusing on the Kazakh language. It's an excellent tool for creating and fine-tuning paraphrasing algorithms, enhancing language models' understanding of semantic similarity and variation in Kazakh.
### Acknowledgments and References
Special thanks go to the original dataset providers and the team of linguists who meticulously adapted this dataset to suit the Kazakh linguistic context. Their contributions are invaluable in advancing language technologies for the Kazakh-speaking community.
### Dataset Summary
The dataset "CCRss/qqp-Quora_Question_Pairs-kz" is a rich collection of question pairs translated into Kazakh, suitable for training and evaluating natural language processing models. Each entry in the dataset contains a 'src' (source question) and 'trg' (target or paraphrased question), providing a comprehensive resource for understanding the nuances of question paraphrasing in Kazakh.
### Acknowledgments and References
We extend our gratitude to the original dataset providers at [https://www.kaggle.com/competitions/quora-question-pairs/data?select=test.csv.zip] and the team of linguists and translators who contributed to the adaptation of this dataset for the Kazakh language.
|
CCRss/qqp-Quora_Question_Pairs-kz
|
[
"task_categories:text2text-generation",
"size_categories:100K<n<1M",
"language:kk",
"license:mit",
"region:us"
] |
2023-09-19T06:48:44+00:00
|
{"language": ["kk"], "license": "mit", "size_categories": ["100K<n<1M"], "task_categories": ["text2text-generation"]}
|
2023-12-21T12:02:52+00:00
|
[] |
[
"kk"
] |
TAGS
#task_categories-text2text-generation #size_categories-100K<n<1M #language-Kazakh #license-mit #region-us
|
## Kazakh Question Paraphrasing Dataset
This dataset, designed for paraphrasing tasks in the Kazakh language, is a valuable resource for natural language processing applications. It aids in the development and evaluation of models capable of understanding and generating paraphrased content while preserving the original meaning.
### Source and Translation Process
The dataset was sourced from the Quora Question Pairs and has been expertly translated into Kazakh. This translation process involved initial machine translation followed by thorough revision by native Kazakh speakers, ensuring the nuances and contextual integrity of the language were maintained.
### Usage and Application
This dataset is primarily intended for researchers and developers in computational linguistics, focusing on the Kazakh language. It's an excellent tool for creating and fine-tuning paraphrasing algorithms, enhancing language models' understanding of semantic similarity and variation in Kazakh.
### Acknowledgments and References
Special thanks go to the original dataset providers and the team of linguists who meticulously adapted this dataset to suit the Kazakh linguistic context. Their contributions are invaluable in advancing language technologies for the Kazakh-speaking community.
### Dataset Summary
The dataset "CCRss/qqp-Quora_Question_Pairs-kz" is a rich collection of question pairs translated into Kazakh, suitable for training and evaluating natural language processing models. Each entry in the dataset contains a 'src' (source question) and 'trg' (target or paraphrased question), providing a comprehensive resource for understanding the nuances of question paraphrasing in Kazakh.
### Acknowledgments and References
We extend our gratitude to the original dataset providers at [URL and the team of linguists and translators who contributed to the adaptation of this dataset for the Kazakh language.
|
[
"## Kazakh Question Paraphrasing Dataset\nThis dataset, designed for paraphrasing tasks in the Kazakh language, is a valuable resource for natural language processing applications. It aids in the development and evaluation of models capable of understanding and generating paraphrased content while preserving the original meaning.",
"### Source and Translation Process\nThe dataset was sourced from the Quora Question Pairs and has been expertly translated into Kazakh. This translation process involved initial machine translation followed by thorough revision by native Kazakh speakers, ensuring the nuances and contextual integrity of the language were maintained.",
"### Usage and Application\nThis dataset is primarily intended for researchers and developers in computational linguistics, focusing on the Kazakh language. It's an excellent tool for creating and fine-tuning paraphrasing algorithms, enhancing language models' understanding of semantic similarity and variation in Kazakh.",
"### Acknowledgments and References\nSpecial thanks go to the original dataset providers and the team of linguists who meticulously adapted this dataset to suit the Kazakh linguistic context. Their contributions are invaluable in advancing language technologies for the Kazakh-speaking community.",
"### Dataset Summary\nThe dataset \"CCRss/qqp-Quora_Question_Pairs-kz\" is a rich collection of question pairs translated into Kazakh, suitable for training and evaluating natural language processing models. Each entry in the dataset contains a 'src' (source question) and 'trg' (target or paraphrased question), providing a comprehensive resource for understanding the nuances of question paraphrasing in Kazakh.",
"### Acknowledgments and References\nWe extend our gratitude to the original dataset providers at [URL and the team of linguists and translators who contributed to the adaptation of this dataset for the Kazakh language."
] |
[
"TAGS\n#task_categories-text2text-generation #size_categories-100K<n<1M #language-Kazakh #license-mit #region-us \n",
"## Kazakh Question Paraphrasing Dataset\nThis dataset, designed for paraphrasing tasks in the Kazakh language, is a valuable resource for natural language processing applications. It aids in the development and evaluation of models capable of understanding and generating paraphrased content while preserving the original meaning.",
"### Source and Translation Process\nThe dataset was sourced from the Quora Question Pairs and has been expertly translated into Kazakh. This translation process involved initial machine translation followed by thorough revision by native Kazakh speakers, ensuring the nuances and contextual integrity of the language were maintained.",
"### Usage and Application\nThis dataset is primarily intended for researchers and developers in computational linguistics, focusing on the Kazakh language. It's an excellent tool for creating and fine-tuning paraphrasing algorithms, enhancing language models' understanding of semantic similarity and variation in Kazakh.",
"### Acknowledgments and References\nSpecial thanks go to the original dataset providers and the team of linguists who meticulously adapted this dataset to suit the Kazakh linguistic context. Their contributions are invaluable in advancing language technologies for the Kazakh-speaking community.",
"### Dataset Summary\nThe dataset \"CCRss/qqp-Quora_Question_Pairs-kz\" is a rich collection of question pairs translated into Kazakh, suitable for training and evaluating natural language processing models. Each entry in the dataset contains a 'src' (source question) and 'trg' (target or paraphrased question), providing a comprehensive resource for understanding the nuances of question paraphrasing in Kazakh.",
"### Acknowledgments and References\nWe extend our gratitude to the original dataset providers at [URL and the team of linguists and translators who contributed to the adaptation of this dataset for the Kazakh language."
] |
[
42,
65,
68,
70,
68,
106,
52
] |
[
"passage: TAGS\n#task_categories-text2text-generation #size_categories-100K<n<1M #language-Kazakh #license-mit #region-us \n## Kazakh Question Paraphrasing Dataset\nThis dataset, designed for paraphrasing tasks in the Kazakh language, is a valuable resource for natural language processing applications. It aids in the development and evaluation of models capable of understanding and generating paraphrased content while preserving the original meaning.### Source and Translation Process\nThe dataset was sourced from the Quora Question Pairs and has been expertly translated into Kazakh. This translation process involved initial machine translation followed by thorough revision by native Kazakh speakers, ensuring the nuances and contextual integrity of the language were maintained.### Usage and Application\nThis dataset is primarily intended for researchers and developers in computational linguistics, focusing on the Kazakh language. It's an excellent tool for creating and fine-tuning paraphrasing algorithms, enhancing language models' understanding of semantic similarity and variation in Kazakh.### Acknowledgments and References\nSpecial thanks go to the original dataset providers and the team of linguists who meticulously adapted this dataset to suit the Kazakh linguistic context. Their contributions are invaluable in advancing language technologies for the Kazakh-speaking community.### Dataset Summary\nThe dataset \"CCRss/qqp-Quora_Question_Pairs-kz\" is a rich collection of question pairs translated into Kazakh, suitable for training and evaluating natural language processing models. Each entry in the dataset contains a 'src' (source question) and 'trg' (target or paraphrased question), providing a comprehensive resource for understanding the nuances of question paraphrasing in Kazakh.### Acknowledgments and References\nWe extend our gratitude to the original dataset providers at [URL and the team of linguists and translators who contributed to the adaptation of this dataset for the Kazakh language."
] |
27f49023219a2826614138ad94332ed0424bd453
|
# Dataset Card for "wmt-en-fr"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
manu/wmt-en-fr
|
[
"region:us"
] |
2023-09-19T07:09:41+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 14956705827, "num_examples": 40836715}, {"name": "validation", "num_bytes": 759439, "num_examples": 3000}, {"name": "test", "num_bytes": 853864, "num_examples": 3003}], "download_size": 3671540079, "dataset_size": 14958319130}}
|
2023-09-19T07:27:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "wmt-en-fr"
More Information needed
|
[
"# Dataset Card for \"wmt-en-fr\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"wmt-en-fr\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"wmt-en-fr\"\n\nMore Information needed"
] |
306ca113a455fc259372e6ed8c4cce5245a16c7c
|
# Dataset Card for "chapter1_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter1_0_prompts
|
[
"region:us"
] |
2023-09-19T07:14:27+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2523, "num_examples": 9}], "download_size": 3966, "dataset_size": 2523}}
|
2023-09-20T09:08:54+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter1_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter1_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter1_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter1_0_prompts\"\n\nMore Information needed"
] |
a719e42370247bd2b1129c3ee3fc960957343e72
|
# Dataset Card for "chapter1_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter1_1_prompts
|
[
"region:us"
] |
2023-09-19T07:14:31+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 289, "num_examples": 1}], "download_size": 2462, "dataset_size": 289}}
|
2023-09-20T09:09:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter1_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter1_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter1_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter1_1_prompts\"\n\nMore Information needed"
] |
0a7fe2537cf7f54f7c9c08942d608800fb7cf370
|
# Dataset Card for "chapter1_2_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter1_2_prompts
|
[
"region:us"
] |
2023-09-19T07:14:35+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 151, "num_examples": 1}], "download_size": 1499, "dataset_size": 151}}
|
2023-09-19T07:22:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter1_2_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter1_2_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter1_2_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter1_2_prompts\"\n\nMore Information needed"
] |
14501221a69ed829355ffff349cfffac0560818d
|
# Dataset Card for "data-parsing-new-dataset-v2-updated-labels"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
tmuzaffarmydost/data-parsing-new-dataset-v2-updated-labels
|
[
"region:us"
] |
2023-09-19T07:36:33+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "struct": [{"name": "gt_parse", "struct": [{"name": "CustomerCompanyAddress", "dtype": "string"}, {"name": "CustomerCompanyName", "dtype": "string"}, {"name": "CustomerCompanyID", "dtype": "string"}, {"name": "VendorCompanyAddress", "dtype": "string"}, {"name": "VendorCompanyName", "dtype": "string"}, {"name": "VendorCompanyID", "dtype": "string"}, {"name": "InvoiceID", "dtype": "string"}, {"name": "InvoiceDate", "dtype": "string"}, {"name": "TotalAmount", "dtype": "string"}, {"name": "TotalTax", "dtype": "string"}, {"name": "Items-table-general/0/Description", "dtype": "string"}, {"name": "Items-table-general/0/Amount", "dtype": "string"}, {"name": "Items-table-general/0/VAT %", "dtype": "string"}, {"name": "TotalwithoutTax", "dtype": "string"}, {"name": "VAT %", "dtype": "string"}, {"name": "DueDate", "dtype": "string"}, {"name": "Items-table-general/0/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/0/Quantity", "dtype": "string"}, {"name": "Items-table-general/0/UnitPrice", "dtype": "string"}, {"name": "Currency", "dtype": "string"}, {"name": "WithholdingTax", "dtype": "string"}, {"name": "taxes-table/0/Base-Amount", "dtype": "string"}, {"name": "taxes-table/0/VAT%", "dtype": "string"}, {"name": "taxes-table/0/VAT", "dtype": "string"}, {"name": "Items-table-general/1/Quantity", "dtype": "string"}, {"name": "Items-table-general/1/Amount", "dtype": "string"}, {"name": "Items-table-general/1/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/2/Quantity", "dtype": "string"}, {"name": "Items-table-general/2/Amount", "dtype": "string"}, {"name": "Items-table-general/2/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/0/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/1/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/2/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/1/Description", "dtype": "string"}, {"name": "Items-table-general/2/Description", "dtype": "string"}, {"name": "Items-table-general/0/VAT", "dtype": "string"}, {"name": "Items-table-general/0/SubTotalAmount", "dtype": "string"}, {"name": "Items-table-general/1/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/2/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/2/Dto %", "dtype": "string"}, {"name": "Items-table-general/1/VAT %", "dtype": "string"}, {"name": "Items-table-general/2/VAT %", "dtype": "string"}, {"name": "Items-table-general/3/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/3/Description", "dtype": "string"}, {"name": "Items-table-general/3/Quantity", "dtype": "string"}, {"name": "Items-table-general/3/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/3/Amount", "dtype": "string"}, {"name": "Items-table-general/4/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/4/Description", "dtype": "string"}, {"name": "Items-table-general/4/Quantity", "dtype": "string"}, {"name": "Items-table-general/4/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/4/Dto %", "dtype": "string"}, {"name": "Items-table-general/4/Amount", "dtype": "string"}, {"name": "Items-table-general/3/VAT %", "dtype": "string"}, {"name": "Items-table-general/4/VAT %", "dtype": "string"}, {"name": "Items-table-general/5/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/5/Description", "dtype": "string"}, {"name": "Items-table-general/5/Quantity", "dtype": "string"}, {"name": "Items-table-general/5/Amount", "dtype": "string"}, {"name": "Items-table-general/5/VAT %", "dtype": "string"}, {"name": "Items-table-general/6/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/6/Description", "dtype": "string"}, {"name": "Items-table-general/6/Quantity", "dtype": "string"}, {"name": "Items-table-general/6/Amount", "dtype": "string"}, {"name": "Items-table-general/6/VAT %", "dtype": "string"}, {"name": "Items-table-general/7/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/7/Description", "dtype": "string"}, {"name": "Items-table-general/7/Quantity", "dtype": "string"}, {"name": "Items-table-general/7/Amount", "dtype": "string"}, {"name": "Items-table-general/7/VAT %", "dtype": "string"}, {"name": "Items-table-general/8/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/8/Description", "dtype": "string"}, {"name": "Items-table-general/8/Quantity", "dtype": "string"}, {"name": "Items-table-general/8/Amount", "dtype": "string"}, {"name": "Items-table-general/8/VAT %", "dtype": "string"}, {"name": "Items-table-general/3/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/5/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/7/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/8/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/7/Dto %", "dtype": "string"}, {"name": "Items-table-general/5/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/6/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/7/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/8/UnitPrice", "dtype": "string"}, {"name": "PONumber", "dtype": "string"}, {"name": "DeliveryNote", "dtype": "string"}, {"name": "taxes-table/1/Base-Amount", "dtype": "string"}, {"name": "taxes-table/1/VAT%", "dtype": "string"}, {"name": "taxes-table/1/VAT", "dtype": "string"}, {"name": "Items-table-general/0/PONumber", "dtype": "string"}, {"name": "Items-table-general/9/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/9/Description", "dtype": "string"}, {"name": "Items-table-general/9/Quantity", "dtype": "string"}, {"name": "Items-table-general/9/Amount", "dtype": "string"}, {"name": "Items-table-general/9/VAT %", "dtype": "string"}, {"name": "Items-table-general/10/Reference~1Code", "dtype": "string"}, {"name": "Items-table-general/10/Description", "dtype": "string"}, {"name": "Items-table-general/10/Quantity", "dtype": "string"}, {"name": "Items-table-general/10/Amount", "dtype": "string"}, {"name": "Items-table-general/10/VAT %", "dtype": "string"}, {"name": "Items-table-general/10/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/10/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/9/UnitPrice", "dtype": "string"}, {"name": "Items-table-general/1/Dto %", "dtype": "string"}, {"name": "Items-table-general/3/Dto %", "dtype": "string"}, {"name": "Items-table-general/5/Dto %", "dtype": "string"}, {"name": "Items-table-general/0/Dto %", "dtype": "string"}, {"name": "Items-table-general/6/DeliveryNote", "dtype": "string"}, {"name": "Items-table-general/4/DeliveryNote", "dtype": "string"}]}, {"name": "meta", "struct": [{"name": "version", "dtype": "string"}, {"name": "split", "dtype": "string"}, {"name": "image_id", "dtype": "int64"}, {"name": "image_size", "struct": [{"name": "width", "dtype": "int64"}, {"name": "height", "dtype": "int64"}]}]}, {"name": "valid_line", "sequence": "null"}]}], "splits": [{"name": "train", "num_bytes": 293897792.0, "num_examples": 146}], "download_size": 31170758, "dataset_size": 293897792.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T07:37:17+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "data-parsing-new-dataset-v2-updated-labels"
More Information needed
|
[
"# Dataset Card for \"data-parsing-new-dataset-v2-updated-labels\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"data-parsing-new-dataset-v2-updated-labels\"\n\nMore Information needed"
] |
[
6,
27
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"data-parsing-new-dataset-v2-updated-labels\"\n\nMore Information needed"
] |
fd0e87738cac92f8e68bab6f85c8c8116a349910
|
# Dataset Card for "donut_vqa_ISynHMP_all_labels"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
warshakhan/donut_vqa_ISynHMP_all_labels
|
[
"region:us"
] |
2023-09-19T07:39:47+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "valid", "path": "data/valid-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 580858079.0, "num_examples": 2800}, {"name": "valid", "num_bytes": 85643829.0, "num_examples": 400}, {"name": "test", "num_bytes": 172886967.0, "num_examples": 800}], "download_size": 804946514, "dataset_size": 839388875.0}}
|
2023-09-19T07:43:22+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "donut_vqa_ISynHMP_all_labels"
More Information needed
|
[
"# Dataset Card for \"donut_vqa_ISynHMP_all_labels\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"donut_vqa_ISynHMP_all_labels\"\n\nMore Information needed"
] |
[
6,
25
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"donut_vqa_ISynHMP_all_labels\"\n\nMore Information needed"
] |
84859f3dd69514204d96544e10d7975d18eda46d
|
# Dataset Card for "librispeech_asr-prompted"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
distil-whisper/librispeech_asr-prompted
|
[
"region:us"
] |
2023-09-19T07:45:04+00:00
|
{"dataset_info": {"config_name": "all", "features": [{"name": "file", "dtype": "string"}, {"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "text", "dtype": "string"}, {"name": "speaker_id", "dtype": "int64"}, {"name": "chapter_id", "dtype": "int64"}, {"name": "id", "dtype": "string"}, {"name": "whisper_transcript_unprompted", "dtype": "string"}, {"name": "whisper_transcript", "dtype": "string"}], "splits": [{"name": "train.clean.100", "num_bytes": 6641615051.062, "num_examples": 28539}, {"name": "train.clean.360", "num_bytes": 23977966959.828, "num_examples": 104014}, {"name": "train.other.500", "num_bytes": 31918849882.584, "num_examples": 148688}, {"name": "validation.clean", "num_bytes": 361026354.966, "num_examples": 2703}, {"name": "validation.other", "num_bytes": 338707588.648, "num_examples": 2864}, {"name": "test.clean", "num_bytes": 369123744.42, "num_examples": 2620}, {"name": "test.other", "num_bytes": 353861942.154, "num_examples": 2939}], "download_size": 61926395211, "dataset_size": 63961151523.662}, "configs": [{"config_name": "all", "data_files": [{"split": "train.clean.100", "path": "all/train.clean.100-*"}, {"split": "train.clean.360", "path": "all/train.clean.360-*"}, {"split": "train.other.500", "path": "all/train.other.500-*"}, {"split": "validation.clean", "path": "all/validation.clean-*"}, {"split": "validation.other", "path": "all/validation.other-*"}, {"split": "test.clean", "path": "all/test.clean-*"}, {"split": "test.other", "path": "all/test.other-*"}]}]}
|
2023-09-19T08:31:43+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "librispeech_asr-prompted"
More Information needed
|
[
"# Dataset Card for \"librispeech_asr-prompted\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"librispeech_asr-prompted\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"librispeech_asr-prompted\"\n\nMore Information needed"
] |
e0faf1fd5e92996e6c4983b487652ff073aa3b35
|
# Dataset Card for "chapter2_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter2_0_prompts
|
[
"region:us"
] |
2023-09-19T07:49:44+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3019, "num_examples": 10}], "download_size": 4623, "dataset_size": 3019}}
|
2023-09-20T09:15:42+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter2_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter2_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter2_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter2_0_prompts\"\n\nMore Information needed"
] |
22a09955442e6f9594d640d109f3df9cd12745f0
|
# Dataset Card for "chapter2_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter2_1_prompts
|
[
"region:us"
] |
2023-09-19T07:49:49+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2873, "num_examples": 14}], "download_size": 3760, "dataset_size": 2873}}
|
2023-09-20T09:15:50+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter2_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter2_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter2_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter2_1_prompts\"\n\nMore Information needed"
] |
9ec2290a6dc449b9f84ea7957141ca3b560dace5
|
# Dataset Card for "chapter3_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter3_0_prompts
|
[
"region:us"
] |
2023-09-19T07:52:13+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4051, "num_examples": 13}], "download_size": 5038, "dataset_size": 4051}}
|
2023-09-20T09:19:41+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter3_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter3_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter3_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter3_0_prompts\"\n\nMore Information needed"
] |
03cf98feb974cbb1d83730954bb562411c39cf81
|
# Dataset Card for "chapter3_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter3_1_prompts
|
[
"region:us"
] |
2023-09-19T07:52:18+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3101, "num_examples": 10}], "download_size": 4529, "dataset_size": 3101}}
|
2023-09-20T09:19:49+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter3_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter3_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter3_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter3_1_prompts\"\n\nMore Information needed"
] |
7bd6d421cb9fa5033b6ace26631cc2ba672f2d98
|
# Dataset Card for "chapter4_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter4_0_prompts
|
[
"region:us"
] |
2023-09-19T07:54:24+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2120, "num_examples": 6}], "download_size": 3737, "dataset_size": 2120}}
|
2023-09-19T07:54:27+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter4_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter4_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter4_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter4_0_prompts\"\n\nMore Information needed"
] |
437af30ba78efe0b471f1371468fa04e1c19b89c
|
# Dataset Card for "chapter4_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter4_1_prompts
|
[
"region:us"
] |
2023-09-19T07:54:29+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3574, "num_examples": 12}], "download_size": 4412, "dataset_size": 3574}}
|
2023-09-19T07:54:31+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter4_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter4_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter4_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter4_1_prompts\"\n\nMore Information needed"
] |
5288b32718225c1a8019724a5fe4c15b303cb174
|
# Dataset Card for "chapter5_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter5_0_prompts
|
[
"region:us"
] |
2023-09-19T07:56:29+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2858, "num_examples": 8}], "download_size": 4636, "dataset_size": 2858}}
|
2023-09-19T07:56:33+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter5_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter5_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter5_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter5_0_prompts\"\n\nMore Information needed"
] |
a8f1b120fdadad414cd6c2a29b54eabeea88f376
|
# Dataset Card for "chapter5_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter5_1_prompts
|
[
"region:us"
] |
2023-09-19T07:56:34+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3741, "num_examples": 9}], "download_size": 5533, "dataset_size": 3741}}
|
2023-09-19T07:56:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter5_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter5_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter5_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter5_1_prompts\"\n\nMore Information needed"
] |
e3b7509772916f9c8d2d35aa0f18d22fc5429683
|
# Dataset Card for "sapolsky_lecture_speaker"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
dzotova/sapolsky_lecture_speaker
|
[
"region:us"
] |
2023-09-19T07:57:47+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 115172.9502762431, "num_examples": 144}, {"name": "test", "num_bytes": 29593.049723756907, "num_examples": 37}], "download_size": 68985, "dataset_size": 144766.0}}
|
2023-09-19T08:46:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "sapolsky_lecture_speaker"
More Information needed
|
[
"# Dataset Card for \"sapolsky_lecture_speaker\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"sapolsky_lecture_speaker\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"sapolsky_lecture_speaker\"\n\nMore Information needed"
] |
b79a351e67079286caa1addbd5fd6242553a8a90
|
# Dataset Card for "chapter6_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter6_0_prompts
|
[
"region:us"
] |
2023-09-19T07:58:19+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3832, "num_examples": 15}], "download_size": 4044, "dataset_size": 3832}}
|
2023-09-19T07:58:22+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter6_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter6_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter6_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter6_0_prompts\"\n\nMore Information needed"
] |
8e2586f6f0d85125cbf129897e1447ad7e9cc86f
|
# Dataset Card for "chapter6_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter6_1_prompts
|
[
"region:us"
] |
2023-09-19T07:58:24+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2772, "num_examples": 9}], "download_size": 3664, "dataset_size": 2772}}
|
2023-09-19T07:58:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter6_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter6_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter6_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter6_1_prompts\"\n\nMore Information needed"
] |
a148929d4cc062e0f3319664f8b361de2286eb33
|
# Dataset Card for "chapter7_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter7_0_prompts
|
[
"region:us"
] |
2023-09-19T07:59:24+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2761, "num_examples": 9}], "download_size": 3857, "dataset_size": 2761}}
|
2023-09-19T07:59:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter7_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter7_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter7_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter7_0_prompts\"\n\nMore Information needed"
] |
86ed9e7a5dce34213a821229ad2dfa64ab8acb3a
|
# Dataset Card for "chapter7_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter7_1_prompts
|
[
"region:us"
] |
2023-09-19T07:59:29+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3050, "num_examples": 10}], "download_size": 3219, "dataset_size": 3050}}
|
2023-09-19T07:59:32+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter7_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter7_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter7_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter7_1_prompts\"\n\nMore Information needed"
] |
54461245919308fceba6c82602623dc037804919
|
# Dataset Card for "chapter8_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter8_0_prompts
|
[
"region:us"
] |
2023-09-19T08:00:30+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3238, "num_examples": 11}], "download_size": 4431, "dataset_size": 3238}}
|
2023-09-19T08:00:33+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter8_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter8_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter8_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter8_0_prompts\"\n\nMore Information needed"
] |
242866e602515a061d7f73092a8ff9d563dc3c7e
|
# Dataset Card for "chapter8_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter8_1_prompts
|
[
"region:us"
] |
2023-09-19T08:00:35+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2646, "num_examples": 9}], "download_size": 3300, "dataset_size": 2646}}
|
2023-09-19T08:00:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter8_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter8_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter8_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter8_1_prompts\"\n\nMore Information needed"
] |
93d97a73772c1a1bebf7d23d6797c82b2a268004
|
# Dataset Card for "chapter9_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter9_0_prompts
|
[
"region:us"
] |
2023-09-19T08:01:45+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2878, "num_examples": 10}], "download_size": 4316, "dataset_size": 2878}}
|
2023-09-19T08:01:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter9_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter9_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter9_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter9_0_prompts\"\n\nMore Information needed"
] |
d97db04a34d2da4a2410e7d8d36830cddacfefe2
|
# Dataset Card for "chapter9_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter9_1_prompts
|
[
"region:us"
] |
2023-09-19T08:01:50+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3673, "num_examples": 11}], "download_size": 4563, "dataset_size": 3673}}
|
2023-09-19T08:01:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter9_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter9_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter9_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter9_1_prompts\"\n\nMore Information needed"
] |
37a3b7c4147085f8fddbfe94a1bedbadd142e3cf
|
# Dataset Card for "celloscope_bangla_ner_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
celloscopeai/celloscope_bangla_ner_dataset
|
[
"region:us"
] |
2023-09-19T08:24:05+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "tokens", "sequence": "string"}, {"name": "ner_tags", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 44407902, "num_examples": 255364}, {"name": "validation", "num_bytes": 5565860, "num_examples": 31920}, {"name": "test", "num_bytes": 5557975, "num_examples": 31921}], "download_size": 8233066, "dataset_size": 55531737}}
|
2023-10-15T06:56:40+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "celloscope_bangla_ner_dataset"
More Information needed
|
[
"# Dataset Card for \"celloscope_bangla_ner_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"celloscope_bangla_ner_dataset\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"celloscope_bangla_ner_dataset\"\n\nMore Information needed"
] |
c37dc33ac99788503cefaa13d6ff093c68c1ee23
|
# Dataset Card for "squad_context_train_10_eval_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
tyzhu/squad_context_train_10_eval_10
|
[
"region:us"
] |
2023-09-19T08:29:40+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": [{"name": "text", "dtype": "string"}, {"name": "answer_start", "dtype": "int32"}]}, {"name": "context_id", "dtype": "string"}, {"name": "inputs", "dtype": "string"}, {"name": "targets", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 351990, "num_examples": 150}, {"name": "validation", "num_bytes": 101044, "num_examples": 48}], "download_size": 101367, "dataset_size": 453034}}
|
2023-09-19T08:29:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "squad_context_train_10_eval_10"
More Information needed
|
[
"# Dataset Card for \"squad_context_train_10_eval_10\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"squad_context_train_10_eval_10\"\n\nMore Information needed"
] |
[
6,
25
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"squad_context_train_10_eval_10\"\n\nMore Information needed"
] |
7cad9cc8d2ae1e8f06060b10e309691ebf9b9731
|
# Dataset Card for "Malayalam_MSA"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
eswardivi/Malayalam_MSA
|
[
"region:us"
] |
2023-09-19T08:35:42+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "Negative", "1": "Neutral", "2": "Positive"}}}}], "splits": [{"name": "train", "num_bytes": 91107974.0, "num_examples": 70}], "download_size": 90971844, "dataset_size": 91107974.0}}
|
2023-09-19T08:37:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Malayalam_MSA"
More Information needed
|
[
"# Dataset Card for \"Malayalam_MSA\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Malayalam_MSA\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Malayalam_MSA\"\n\nMore Information needed"
] |
8b44c5efb7af9d7ecc98d148a40b94594800c647
|
# Dataset Card for "chapter10_0_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter10_0_prompts
|
[
"region:us"
] |
2023-09-19T08:36:02+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2212, "num_examples": 6}], "download_size": 4047, "dataset_size": 2212}}
|
2023-09-19T15:05:31+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter10_0_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter10_0_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter10_0_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter10_0_prompts\"\n\nMore Information needed"
] |
00e31f0ea7651845fea146a2c2364ffd5311fa0e
|
# Dataset Card for "chapter10_1_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/chapter10_1_prompts
|
[
"region:us"
] |
2023-09-19T08:36:07+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2850, "num_examples": 10}], "download_size": 4171, "dataset_size": 2850}}
|
2023-09-19T15:05:34+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chapter10_1_prompts"
More Information needed
|
[
"# Dataset Card for \"chapter10_1_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chapter10_1_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chapter10_1_prompts\"\n\nMore Information needed"
] |
b222d55762310d451ee7203de2a22087ec0b9f22
|
# Dataset Card for "cow_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Andyrasika/cow_dataset
|
[
"region:us"
] |
2023-09-19T08:56:53+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 145565588.0, "num_examples": 51}], "download_size": 130979749, "dataset_size": 145565588.0}}
|
2023-09-19T08:57:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cow_dataset"
More Information needed
|
[
"# Dataset Card for \"cow_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cow_dataset\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cow_dataset\"\n\nMore Information needed"
] |
7fb22f1bbcc4ff726b701848458b30cda54d0461
|
# Dataset Card for "pubmed_subset_c4_10p"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
zxvix/pubmed_subset_c4_10p
|
[
"region:us"
] |
2023-09-19T08:58:54+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2107664795.9043052, "num_examples": 1110859}, {"name": "test", "num_bytes": 1024229, "num_examples": 1000}], "download_size": 149396134, "dataset_size": 2108689024.9043052}}
|
2023-09-19T09:13:12+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pubmed_subset_c4_10p"
More Information needed
|
[
"# Dataset Card for \"pubmed_subset_c4_10p\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pubmed_subset_c4_10p\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pubmed_subset_c4_10p\"\n\nMore Information needed"
] |
6d0dc74b3dd0f9a16362bb8471bff284b3fb2b60
|
# Dataset Card for "commonsense_qa-ID"
## Dataset Description
- **Homepage:** https://github.com/rizquuula/commonsense_qa-ID
- **Repository:** https://github.com/rizquuula/commonsense_qa-ID
### Dataset Summary
CommonsenseQA-ID is Indonesian translation version of CommonsenseQA, translated using Google Translation API v2/v3 Basic, all code used for the translation process available in our public repository.
CommonsenseQA is a new multiple-choice question answering dataset that requires different types of commonsense knowledge
to predict the correct answers . It contains 12,102 questions with one correct answer and four distractor answers.
The dataset is provided in two major training/validation/testing set splits: "Random split" which is the main evaluation
split, and "Question token split", see original paper for details.
### Languages
The dataset is in Indonesian (`id`).
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 4.68 MB
- **Size of the generated dataset:** 2.18 MB
- **Total amount of disk used:** 6.86 MB
An example of 'train' looks as follows:
```
{
'id': '61fe6e879ff18686d7552425a36344c8',
'question': 'Sammy ingin pergi ke tempat orang-orang itu berada. Ke mana dia bisa pergi?',
'question_concept': 'rakyat',
'choices': {
'label': ['A', 'B', 'C', 'D', 'E'],
'text': ['trek balap', 'daerah berpenduduk', 'gurun pasir', 'Apartemen', 'penghalang jalan']
},
'answerKey': 'B'
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `id` (`str`): Unique ID.
- `question`: a `string` feature.
- `question_concept` (`str`): ConceptNet concept associated to the question.
- `choices`: a dictionary feature containing:
- `label`: a `string` feature.
- `text`: a `string` feature.
- `answerKey`: a `string` feature.
### Data Splits
| name | train | validation | test |
|---------|------:|-----------:|-----:|
| default | 9741 | 1221 | 1140 |
### Licensing Information
The dataset is licensed under the MIT License.
### Citation Information
```
@inproceedings{talmor-etal-2019-commonsenseqa,
title = "{C}ommonsense{QA}: A Question Answering Challenge Targeting Commonsense Knowledge",
author = "Talmor, Alon and
Herzig, Jonathan and
Lourie, Nicholas and
Berant, Jonathan",
booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
month = jun,
year = "2019",
address = "Minneapolis, Minnesota",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/N19-1421",
doi = "10.18653/v1/N19-1421",
pages = "4149--4158",
archivePrefix = "arXiv",
eprint = "1811.00937",
primaryClass = "cs",
}
```
|
rizquuula/commonsense_qa-ID
|
[
"task_categories:question-answering",
"task_ids:open-domain-qa",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:machine-translation",
"language:id",
"license:mit",
"region:us"
] |
2023-09-19T09:05:18+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["id"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["machine-translation"], "task_categories": ["question-answering"], "task_ids": ["open-domain-qa"], "paperswithcode_id": "commonsenseqa", "pretty_name": "CommonsenseQA-ID", "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "question_concept", "dtype": "string"}, {"name": "choices", "sequence": [{"name": "label", "dtype": "string"}, {"name": "text", "dtype": "string"}]}, {"name": "answerKey", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2209044, "num_examples": 9741}, {"name": "validation", "num_bytes": 274033, "num_examples": 1221}, {"name": "test", "num_bytes": 258017, "num_examples": 1140}], "download_size": 4680691, "dataset_size": 2741094}}
|
2023-09-19T09:35:24+00:00
|
[] |
[
"id"
] |
TAGS
#task_categories-question-answering #task_ids-open-domain-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-machine-translation #language-Indonesian #license-mit #region-us
|
Dataset Card for "commonsense\_qa-ID"
=====================================
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
### Dataset Summary
CommonsenseQA-ID is Indonesian translation version of CommonsenseQA, translated using Google Translation API v2/v3 Basic, all code used for the translation process available in our public repository.
CommonsenseQA is a new multiple-choice question answering dataset that requires different types of commonsense knowledge
to predict the correct answers . It contains 12,102 questions with one correct answer and four distractor answers.
The dataset is provided in two major training/validation/testing set splits: "Random split" which is the main evaluation
split, and "Question token split", see original paper for details.
### Languages
The dataset is in Indonesian ('id').
Dataset Structure
-----------------
### Data Instances
#### default
* Size of downloaded dataset files: 4.68 MB
* Size of the generated dataset: 2.18 MB
* Total amount of disk used: 6.86 MB
An example of 'train' looks as follows:
### Data Fields
The data fields are the same among all splits.
#### default
* 'id' ('str'): Unique ID.
* 'question': a 'string' feature.
* 'question\_concept' ('str'): ConceptNet concept associated to the question.
* 'choices': a dictionary feature containing:
+ 'label': a 'string' feature.
+ 'text': a 'string' feature.
* 'answerKey': a 'string' feature.
### Data Splits
### Licensing Information
The dataset is licensed under the MIT License.
|
[
"### Dataset Summary\n\n\nCommonsenseQA-ID is Indonesian translation version of CommonsenseQA, translated using Google Translation API v2/v3 Basic, all code used for the translation process available in our public repository.\n\n\nCommonsenseQA is a new multiple-choice question answering dataset that requires different types of commonsense knowledge\nto predict the correct answers . It contains 12,102 questions with one correct answer and four distractor answers.\nThe dataset is provided in two major training/validation/testing set splits: \"Random split\" which is the main evaluation\nsplit, and \"Question token split\", see original paper for details.",
"### Languages\n\n\nThe dataset is in Indonesian ('id').\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### default\n\n\n* Size of downloaded dataset files: 4.68 MB\n* Size of the generated dataset: 2.18 MB\n* Total amount of disk used: 6.86 MB\n\n\nAn example of 'train' looks as follows:",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### default\n\n\n* 'id' ('str'): Unique ID.\n* 'question': a 'string' feature.\n* 'question\\_concept' ('str'): ConceptNet concept associated to the question.\n* 'choices': a dictionary feature containing:\n\t+ 'label': a 'string' feature.\n\t+ 'text': a 'string' feature.\n* 'answerKey': a 'string' feature.",
"### Data Splits",
"### Licensing Information\n\n\nThe dataset is licensed under the MIT License."
] |
[
"TAGS\n#task_categories-question-answering #task_ids-open-domain-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-machine-translation #language-Indonesian #license-mit #region-us \n",
"### Dataset Summary\n\n\nCommonsenseQA-ID is Indonesian translation version of CommonsenseQA, translated using Google Translation API v2/v3 Basic, all code used for the translation process available in our public repository.\n\n\nCommonsenseQA is a new multiple-choice question answering dataset that requires different types of commonsense knowledge\nto predict the correct answers . It contains 12,102 questions with one correct answer and four distractor answers.\nThe dataset is provided in two major training/validation/testing set splits: \"Random split\" which is the main evaluation\nsplit, and \"Question token split\", see original paper for details.",
"### Languages\n\n\nThe dataset is in Indonesian ('id').\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### default\n\n\n* Size of downloaded dataset files: 4.68 MB\n* Size of the generated dataset: 2.18 MB\n* Total amount of disk used: 6.86 MB\n\n\nAn example of 'train' looks as follows:",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### default\n\n\n* 'id' ('str'): Unique ID.\n* 'question': a 'string' feature.\n* 'question\\_concept' ('str'): ConceptNet concept associated to the question.\n* 'choices': a dictionary feature containing:\n\t+ 'label': a 'string' feature.\n\t+ 'text': a 'string' feature.\n* 'answerKey': a 'string' feature.",
"### Data Splits",
"### Licensing Information\n\n\nThe dataset is licensed under the MIT License."
] |
[
95,
144,
23,
6,
49,
17,
100,
5,
17
] |
[
"passage: TAGS\n#task_categories-question-answering #task_ids-open-domain-qa #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-machine-translation #language-Indonesian #license-mit #region-us \n### Dataset Summary\n\n\nCommonsenseQA-ID is Indonesian translation version of CommonsenseQA, translated using Google Translation API v2/v3 Basic, all code used for the translation process available in our public repository.\n\n\nCommonsenseQA is a new multiple-choice question answering dataset that requires different types of commonsense knowledge\nto predict the correct answers . It contains 12,102 questions with one correct answer and four distractor answers.\nThe dataset is provided in two major training/validation/testing set splits: \"Random split\" which is the main evaluation\nsplit, and \"Question token split\", see original paper for details.### Languages\n\n\nThe dataset is in Indonesian ('id').\n\n\nDataset Structure\n-----------------### Data Instances#### default\n\n\n* Size of downloaded dataset files: 4.68 MB\n* Size of the generated dataset: 2.18 MB\n* Total amount of disk used: 6.86 MB\n\n\nAn example of 'train' looks as follows:### Data Fields\n\n\nThe data fields are the same among all splits.#### default\n\n\n* 'id' ('str'): Unique ID.\n* 'question': a 'string' feature.\n* 'question\\_concept' ('str'): ConceptNet concept associated to the question.\n* 'choices': a dictionary feature containing:\n\t+ 'label': a 'string' feature.\n\t+ 'text': a 'string' feature.\n* 'answerKey': a 'string' feature.### Data Splits### Licensing Information\n\n\nThe dataset is licensed under the MIT License."
] |
48c87c494631745bd5735db31fe17aa3860a1aca
|
# Dataset Card for RSNA 2023 Abdominal Trauma Detection (Preprocessed)
## Dataset Description
- **Homepage:** [https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection](https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection)
- **Source:** [https://www.kaggle.com/competitions/rsna-2023-abdominal-trauma-detection/data](https://www.kaggle.com/competitions/rsna-2023-abdominal-trauma-detection/data)
### Dataset Summary
This dataset is the preprocessed version of the dataset from [RSNA 2023 Abdominal Trauma Detection Kaggle Competition](https://www.kaggle.com/competitions/rsna-2023-abdominal-trauma-detection/data).
It is tailored for segmentation and classification tasks. It contains 3 different configs as described below:
- **classification**:
- 4711 instances where each instance includes a CT scan in NIfTI format, target labels, and its relevant metadata.
- **segmentation**:
- 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, and its relevant metadata.
- **classification-with-mask**:
- 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, target labels, and its relevant metadata.
All CT scans and segmentation masks had already been resampled with voxel spacing (2.0, 2.0, 3.0) and thus its reduced file size.
### Usage
```python
from datasets import load_dataset
# Classification dataset
rsna_cls_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", streaming=True) # "classification" is the default configuration
rsna_cls_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification", streaming=True) # download dataset on-demand and in-memory (no caching)
rsna_cls_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification", streaming=False) # download dataset and cache locally (~90.09 GiB)
rsna_cls_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification", streaming=True, test_size=0.05, random_state=42) # specify split size for train-test split
# Classification dataset with segmentation masks
rsna_clsmask_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification-with-mask", streaming=True) # download dataset on-demand and in-memory (no caching)
rsna_clsmask_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification-with-mask", streaming=False) # download dataset and cache locally (~3.91 GiB)
rsna_clsmask_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification-with-mask", streaming=False, test_size=0.05, random_state=42) # specify split size for train-test split
# Segmentation dataset
rsna_seg_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "segmentation", streaming=True) # download dataset on-demand and in-memory (no caching)
rsna_seg_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "segmentation", streaming=False) # download dataset and cache locally (~3.91 GiB)
rsna_seg_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "segmentation", streaming=True, test_size=0.1, random_state=42) # specify split size for train-test split
# Get the dataset splits
train_rsna_cls_ds = rsna_cls_ds["train"]; test_rsna_cls_ds = rsna_cls_ds["test"]
train_rsna_clsmask_ds = rsna_clsmask_ds["train"]; test_rsna_clsmask_ds = rsna_clsmask_ds["test"]
train_rsna_seg_ds = rsna_seg_ds["train"]; test_rsna_seg_ds = rsna_seg_ds["test"]
# Tip: Download speed up with multiprocessing
rsna_cls_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", streaming=False, num_proc=8) # num_proc: num of cpu core used for loading the dataset
```
## Dataset Structure
### Data Instances
#### Configuration 1: classification
- **Size of downloaded dataset files:** 90.09 GiB
An example of an instance in the 'classification' configuration looks as follows:
```json
{
"img_path": "https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection/resolve/main/train_images/25899/21872.nii.gz",
"bowel": 0,
"extravasation": 0,
"kidney": 0,
"liver": 0,
"spleen": 0,
"any_injury": false,
"metadata": {
"series_id": 21872,
"patient_id": 25899,
"incomplete_organ": false,
"aortic_hu": 113.0,
"pixel_representation": 0,
"bits_allocated": 16,
"bits_stored": 12
}
}
```
#### Configuration 2: segmentation
- **Size of downloaded dataset files:** 3.91 GiB
An example of an instance in the 'segmentation' configuration looks as follows:
```json
{
"img_path": "https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection/resolve/main/train_images/4791/4622.nii.gz",
"seg_path": "https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection/resolve/main/segmentations/4622.nii.gz",
"metadata": {
"series_id": 4622,
"patient_id": 4791,
"incomplete_organ": false,
"aortic_hu": 223.0,
"pixel_representation": 1,
"bits_allocated": 16,
"bits_stored": 16
}
}
```
#### Configuration 3: classification-with-mask
- **Size of downloaded dataset files:** 3.91 GiB
An example of an instance in the 'classification-with-mask' configuration looks as follows:
```json
{
"img_path": "https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection/resolve/main/train_images/4791/4622.nii.gz",
"seg_path": "https://huggingface.co/datasets/jherng/rsna-2023-abdominal-trauma-detection/resolve/main/segmentations/4622.nii.gz",
"bowel": 0,
"extravasation": 0,
"kidney": 0,
"liver": 1,
"spleen": 1,
"any_injury": true,
"metadata": {
"series_id": 4622,
"patient_id": 4791,
"incomplete_organ": false,
"aortic_hu": 223.0,
"pixel_representation": 1,
"bits_allocated": 16,
"bits_stored": 16
}
}
```
### Data Fields
The data fields for all configurations are as follows:
- `img_path`: a `string` feature representing the path to the CT scan in NIfTI format.
- `seg_path`: a `string` feature representing the path to the segmentation mask in NIfTI format (only for 'segmentation' and 'classification-with-mask' configurations).
- `bowel`, `extravasation`, `kidney`, `liver`, `spleen`: Class label features indicating the condition of respective organs.
- `any_injury`: a `bool` feature indicating the presence of any injury.
- `metadata`: a dictionary feature containing metadata information with the following fields:
- `series_id`: an `int32` feature.
- `patient_id`: an `int32` feature.
- `incomplete_organ`: a `bool` feature.
- `aortic_hu`: a `float32` feature.
- `pixel_representation`: an `int32` feature.
- `bits_allocated`: an `int32` feature.
- `bits_stored`: an `int32` feature.
### Data Splits
Default split:
- 0.9:0.1 with random_state = 42
| Configuration Name | Train (n_samples) | Test (n_samples) |
| ------------------------ | ----------------: | ---------------: |
| classification | 4239 | 472 |
| segmentation | 185 | 21 |
| classification-with-mask | 185 | 21 |
Modify the split proportion:
```python
rsna_ds = load_dataset("jherng/rsna-2023-abdominal-trauma-detection", "classification", test_size=0.05, random_state=42)
```
## Additional Information
### Citation Information
- Preprocessed dataset:
```
@InProceedings{huggingface:dataset,
title = {RSNA 2023 Abdominal Trauma Detection Dataset (Preprocessed)},
author={Hong Jia Herng},
year={2023}
}
```
- Original dataset:
```
@misc{rsna-2023-abdominal-trauma-detection,
author = {Errol Colak, Hui-Ming Lin, Robyn Ball, Melissa Davis, Adam Flanders, Sabeena Jalal, Kirti Magudia, Brett Marinelli, Savvas Nicolaou, Luciano Prevedello, Jeff Rudie, George Shih, Maryam Vazirabad, John Mongan},
title = {RSNA 2023 Abdominal Trauma Detection},
publisher = {Kaggle},
year = {2023},
url = {https://kaggle.com/competitions/rsna-2023-abdominal-trauma-detection}
}
```
|
jherng/rsna-2023-abdominal-trauma-detection
|
[
"task_categories:image-classification",
"task_categories:image-segmentation",
"size_categories:1K<n<10K",
"license:mit",
"region:us"
] |
2023-09-19T09:10:47+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["image-classification", "image-segmentation"], "pretty_name": "RSNA 2023 Abdominal Trauma Detection (Preprocessed)", "dataset_info": [{"config_name": "classification", "features": [{"name": "img_path", "dtype": "string"}, {"name": "bowel", "dtype": {"class_label": {"names": {"0": "healthy", "1": "injury"}}}}, {"name": "extravasation", "dtype": {"class_label": {"names": {"0": "healthy", "1": "injury"}}}}, {"name": "kidney", "dtype": {"class_label": {"names": {"0": "healthy", "1": "low", "2": "high"}}}}, {"name": "liver", "dtype": {"class_label": {"names": {"0": "healthy", "1": "low", "2": "high"}}}}, {"name": "spleen", "dtype": {"class_label": {"names": {"0": "healthy", "1": "low", "2": "high"}}}}, {"name": "any_injury", "dtype": "bool"}, {"name": "metadata", "struct": [{"name": "series_id", "dtype": "int32"}, {"name": "patient_id", "dtype": "int32"}, {"name": "incomplete_organ", "dtype": "bool"}, {"name": "aortic_hu", "dtype": "float32"}, {"name": "pixel_representation", "dtype": "int32"}, {"name": "bits_allocated", "dtype": "int32"}, {"name": "bits_stored", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 802231, "num_examples": 4239}, {"name": "test", "num_bytes": 89326, "num_examples": 472}], "download_size": 96729254048, "dataset_size": 891557}, {"config_name": "classification-with-mask", "features": [{"name": "img_path", "dtype": "string"}, {"name": "seg_path", "dtype": "string"}, {"name": "bowel", "dtype": {"class_label": {"names": {"0": "healthy", "1": "injury"}}}}, {"name": "extravasation", "dtype": {"class_label": {"names": {"0": "healthy", "1": "injury"}}}}, {"name": "kidney", "dtype": {"class_label": {"names": {"0": "healthy", "1": "low", "2": "high"}}}}, {"name": "liver", "dtype": {"class_label": {"names": {"0": "healthy", "1": "low", "2": "high"}}}}, {"name": "spleen", "dtype": {"class_label": {"names": {"0": "healthy", "1": "low", "2": "high"}}}}, {"name": "any_injury", "dtype": "bool"}, {"name": "metadata", "struct": [{"name": "series_id", "dtype": "int32"}, {"name": "patient_id", "dtype": "int32"}, {"name": "incomplete_organ", "dtype": "bool"}, {"name": "aortic_hu", "dtype": "float32"}, {"name": "pixel_representation", "dtype": "int32"}, {"name": "bits_allocated", "dtype": "int32"}, {"name": "bits_stored", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 58138, "num_examples": 185}, {"name": "test", "num_bytes": 6600, "num_examples": 21}], "download_size": 4196738529, "dataset_size": 64738}, {"config_name": "segmentation", "features": [{"name": "img_path", "dtype": "string"}, {"name": "seg_path", "dtype": "string"}, {"name": "metadata", "struct": [{"name": "series_id", "dtype": "int32"}, {"name": "patient_id", "dtype": "int32"}, {"name": "incomplete_organ", "dtype": "bool"}, {"name": "aortic_hu", "dtype": "float32"}, {"name": "pixel_representation", "dtype": "int32"}, {"name": "bits_allocated", "dtype": "int32"}, {"name": "bits_stored", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 50714, "num_examples": 185}, {"name": "test", "num_bytes": 5757, "num_examples": 21}], "download_size": 4196631843, "dataset_size": 56471}]}
|
2023-12-17T10:01:39+00:00
|
[] |
[] |
TAGS
#task_categories-image-classification #task_categories-image-segmentation #size_categories-1K<n<10K #license-mit #region-us
|
Dataset Card for RSNA 2023 Abdominal Trauma Detection (Preprocessed)
====================================================================
Dataset Description
-------------------
* Homepage: URL
* Source: URL
### Dataset Summary
This dataset is the preprocessed version of the dataset from RSNA 2023 Abdominal Trauma Detection Kaggle Competition.
It is tailored for segmentation and classification tasks. It contains 3 different configs as described below:
* classification:
+ 4711 instances where each instance includes a CT scan in NIfTI format, target labels, and its relevant metadata.
* segmentation:
+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, and its relevant metadata.
* classification-with-mask:
+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, target labels, and its relevant metadata.
All CT scans and segmentation masks had already been resampled with voxel spacing (2.0, 2.0, 3.0) and thus its reduced file size.
### Usage
Dataset Structure
-----------------
### Data Instances
#### Configuration 1: classification
* Size of downloaded dataset files: 90.09 GiB
An example of an instance in the 'classification' configuration looks as follows:
#### Configuration 2: segmentation
* Size of downloaded dataset files: 3.91 GiB
An example of an instance in the 'segmentation' configuration looks as follows:
#### Configuration 3: classification-with-mask
* Size of downloaded dataset files: 3.91 GiB
An example of an instance in the 'classification-with-mask' configuration looks as follows:
### Data Fields
The data fields for all configurations are as follows:
* 'img\_path': a 'string' feature representing the path to the CT scan in NIfTI format.
* 'seg\_path': a 'string' feature representing the path to the segmentation mask in NIfTI format (only for 'segmentation' and 'classification-with-mask' configurations).
* 'bowel', 'extravasation', 'kidney', 'liver', 'spleen': Class label features indicating the condition of respective organs.
* 'any\_injury': a 'bool' feature indicating the presence of any injury.
* 'metadata': a dictionary feature containing metadata information with the following fields:
+ 'series\_id': an 'int32' feature.
+ 'patient\_id': an 'int32' feature.
+ 'incomplete\_organ': a 'bool' feature.
+ 'aortic\_hu': a 'float32' feature.
+ 'pixel\_representation': an 'int32' feature.
+ 'bits\_allocated': an 'int32' feature.
+ 'bits\_stored': an 'int32' feature.
### Data Splits
Default split:
* 0.9:0.1 with random\_state = 42
Modify the split proportion:
Additional Information
----------------------
* Preprocessed dataset:
* Original dataset:
|
[
"### Dataset Summary\n\n\nThis dataset is the preprocessed version of the dataset from RSNA 2023 Abdominal Trauma Detection Kaggle Competition.\n\n\nIt is tailored for segmentation and classification tasks. It contains 3 different configs as described below:\n\n\n* classification:\n\t+ 4711 instances where each instance includes a CT scan in NIfTI format, target labels, and its relevant metadata.\n* segmentation:\n\t+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, and its relevant metadata.\n* classification-with-mask:\n\t+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, target labels, and its relevant metadata.\n\n\nAll CT scans and segmentation masks had already been resampled with voxel spacing (2.0, 2.0, 3.0) and thus its reduced file size.",
"### Usage\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### Configuration 1: classification\n\n\n* Size of downloaded dataset files: 90.09 GiB\n\n\nAn example of an instance in the 'classification' configuration looks as follows:",
"#### Configuration 2: segmentation\n\n\n* Size of downloaded dataset files: 3.91 GiB\n\n\nAn example of an instance in the 'segmentation' configuration looks as follows:",
"#### Configuration 3: classification-with-mask\n\n\n* Size of downloaded dataset files: 3.91 GiB\n\n\nAn example of an instance in the 'classification-with-mask' configuration looks as follows:",
"### Data Fields\n\n\nThe data fields for all configurations are as follows:\n\n\n* 'img\\_path': a 'string' feature representing the path to the CT scan in NIfTI format.\n* 'seg\\_path': a 'string' feature representing the path to the segmentation mask in NIfTI format (only for 'segmentation' and 'classification-with-mask' configurations).\n* 'bowel', 'extravasation', 'kidney', 'liver', 'spleen': Class label features indicating the condition of respective organs.\n* 'any\\_injury': a 'bool' feature indicating the presence of any injury.\n* 'metadata': a dictionary feature containing metadata information with the following fields:\n\t+ 'series\\_id': an 'int32' feature.\n\t+ 'patient\\_id': an 'int32' feature.\n\t+ 'incomplete\\_organ': a 'bool' feature.\n\t+ 'aortic\\_hu': a 'float32' feature.\n\t+ 'pixel\\_representation': an 'int32' feature.\n\t+ 'bits\\_allocated': an 'int32' feature.\n\t+ 'bits\\_stored': an 'int32' feature.",
"### Data Splits\n\n\nDefault split:\n\n\n* 0.9:0.1 with random\\_state = 42\n\n\n\nModify the split proportion:\n\n\nAdditional Information\n----------------------\n\n\n* Preprocessed dataset:\n* Original dataset:"
] |
[
"TAGS\n#task_categories-image-classification #task_categories-image-segmentation #size_categories-1K<n<10K #license-mit #region-us \n",
"### Dataset Summary\n\n\nThis dataset is the preprocessed version of the dataset from RSNA 2023 Abdominal Trauma Detection Kaggle Competition.\n\n\nIt is tailored for segmentation and classification tasks. It contains 3 different configs as described below:\n\n\n* classification:\n\t+ 4711 instances where each instance includes a CT scan in NIfTI format, target labels, and its relevant metadata.\n* segmentation:\n\t+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, and its relevant metadata.\n* classification-with-mask:\n\t+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, target labels, and its relevant metadata.\n\n\nAll CT scans and segmentation masks had already been resampled with voxel spacing (2.0, 2.0, 3.0) and thus its reduced file size.",
"### Usage\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### Configuration 1: classification\n\n\n* Size of downloaded dataset files: 90.09 GiB\n\n\nAn example of an instance in the 'classification' configuration looks as follows:",
"#### Configuration 2: segmentation\n\n\n* Size of downloaded dataset files: 3.91 GiB\n\n\nAn example of an instance in the 'segmentation' configuration looks as follows:",
"#### Configuration 3: classification-with-mask\n\n\n* Size of downloaded dataset files: 3.91 GiB\n\n\nAn example of an instance in the 'classification-with-mask' configuration looks as follows:",
"### Data Fields\n\n\nThe data fields for all configurations are as follows:\n\n\n* 'img\\_path': a 'string' feature representing the path to the CT scan in NIfTI format.\n* 'seg\\_path': a 'string' feature representing the path to the segmentation mask in NIfTI format (only for 'segmentation' and 'classification-with-mask' configurations).\n* 'bowel', 'extravasation', 'kidney', 'liver', 'spleen': Class label features indicating the condition of respective organs.\n* 'any\\_injury': a 'bool' feature indicating the presence of any injury.\n* 'metadata': a dictionary feature containing metadata information with the following fields:\n\t+ 'series\\_id': an 'int32' feature.\n\t+ 'patient\\_id': an 'int32' feature.\n\t+ 'incomplete\\_organ': a 'bool' feature.\n\t+ 'aortic\\_hu': a 'float32' feature.\n\t+ 'pixel\\_representation': an 'int32' feature.\n\t+ 'bits\\_allocated': an 'int32' feature.\n\t+ 'bits\\_stored': an 'int32' feature.",
"### Data Splits\n\n\nDefault split:\n\n\n* 0.9:0.1 with random\\_state = 42\n\n\n\nModify the split proportion:\n\n\nAdditional Information\n----------------------\n\n\n* Preprocessed dataset:\n* Original dataset:"
] |
[
46,
211,
11,
6,
39,
39,
48,
296,
47
] |
[
"passage: TAGS\n#task_categories-image-classification #task_categories-image-segmentation #size_categories-1K<n<10K #license-mit #region-us \n### Dataset Summary\n\n\nThis dataset is the preprocessed version of the dataset from RSNA 2023 Abdominal Trauma Detection Kaggle Competition.\n\n\nIt is tailored for segmentation and classification tasks. It contains 3 different configs as described below:\n\n\n* classification:\n\t+ 4711 instances where each instance includes a CT scan in NIfTI format, target labels, and its relevant metadata.\n* segmentation:\n\t+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, and its relevant metadata.\n* classification-with-mask:\n\t+ 206 instances where each instance includes a CT scan in NIfTI format, a segmentation mask in NIfTI format, target labels, and its relevant metadata.\n\n\nAll CT scans and segmentation masks had already been resampled with voxel spacing (2.0, 2.0, 3.0) and thus its reduced file size.### Usage\n\n\nDataset Structure\n-----------------### Data Instances#### Configuration 1: classification\n\n\n* Size of downloaded dataset files: 90.09 GiB\n\n\nAn example of an instance in the 'classification' configuration looks as follows:#### Configuration 2: segmentation\n\n\n* Size of downloaded dataset files: 3.91 GiB\n\n\nAn example of an instance in the 'segmentation' configuration looks as follows:#### Configuration 3: classification-with-mask\n\n\n* Size of downloaded dataset files: 3.91 GiB\n\n\nAn example of an instance in the 'classification-with-mask' configuration looks as follows:"
] |
32321a6a08b58046bed3daf08e661c3bc129f442
|
# Dataset Card for "french_librispeech_text_only"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
manu/french_librispeech_text_only
|
[
"region:us"
] |
2023-09-19T09:21:35+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 62120933, "num_examples": 258213}], "download_size": 37959942, "dataset_size": 62120933}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T09:21:43+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "french_librispeech_text_only"
More Information needed
|
[
"# Dataset Card for \"french_librispeech_text_only\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"french_librispeech_text_only\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"french_librispeech_text_only\"\n\nMore Information needed"
] |
2747473924a9f4bac110bde70fc298973e6bf9c7
|
# OCR Receipts from Grocery Stores Text Detection
The Grocery Store Receipts Dataset is a collection of photos captured from various **grocery store receipts**. This dataset is specifically designed for tasks related to **Optical Character Recognition (OCR)** and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: **item, store, date_time and total**.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of receipts
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and detected text, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and detected text . For each point, the x and y coordinates are provided.
### Classes:
- **store** - name of the grocery store
- **item** - item in the receipt
- **date_time** - date and time of the receipt
- **total** - total price of the receipt
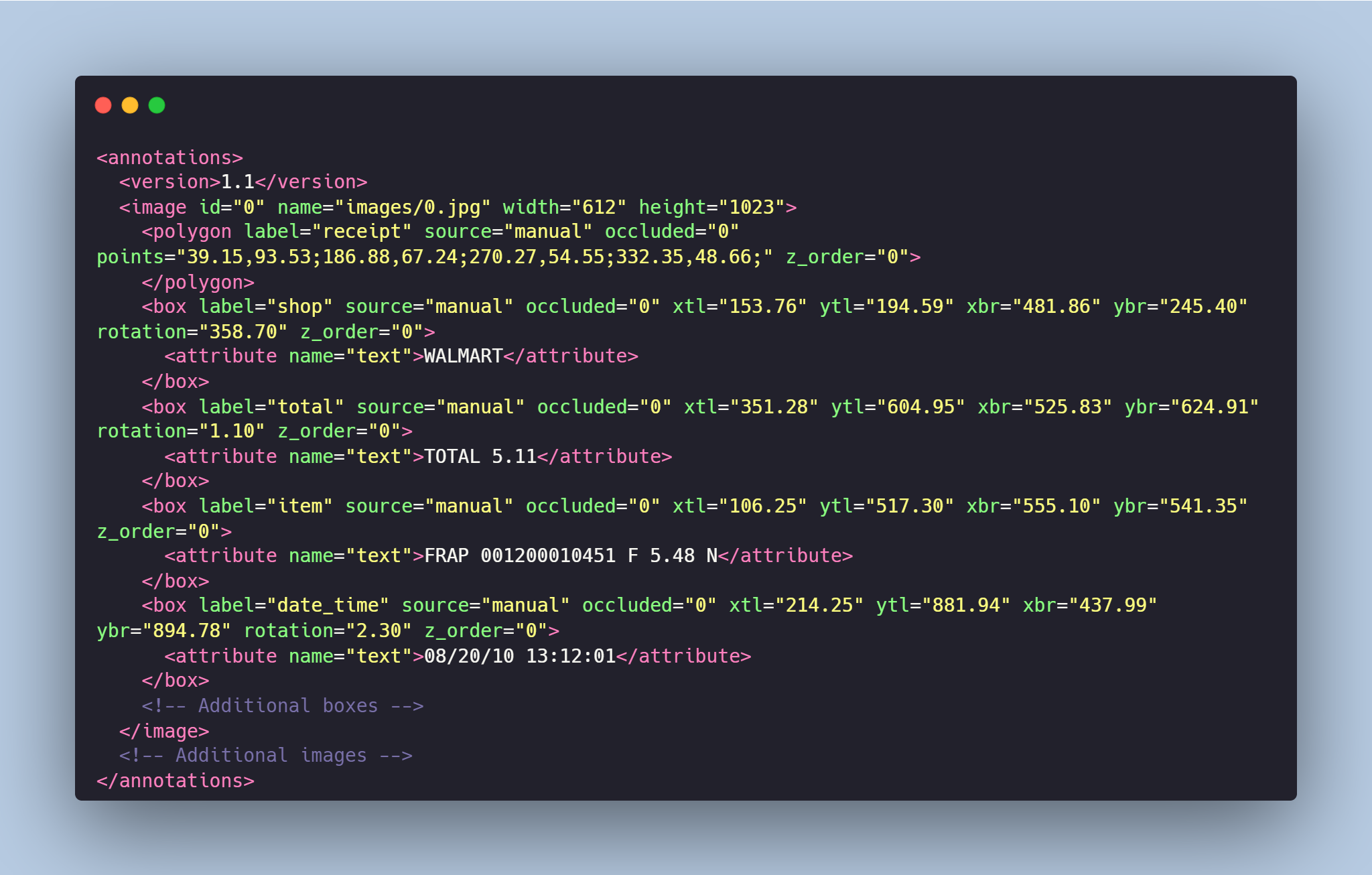
# Text Detection in the Receipts might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro**
|
TrainingDataPro/ocr-receipts-text-detection
|
[
"task_categories:image-to-text",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] |
2023-09-19T09:35:57+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-to-text", "object-detection"], "tags": ["code", "finance"], "dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "width", "dtype": "uint16"}, {"name": "height", "dtype": "uint16"}, {"name": "shapes", "sequence": [{"name": "label", "dtype": {"class_label": {"names": {"0": "receipt", "1": "shop", "2": "item", "3": "date_time", "4": "total"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 55510934, "num_examples": 20}], "download_size": 54557192, "dataset_size": 55510934}}
|
2023-09-26T14:12:40+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-to-text #task_categories-object-detection #language-English #license-cc-by-nc-nd-4.0 #code #finance #region-us
|
# OCR Receipts from Grocery Stores Text Detection
The Grocery Store Receipts Dataset is a collection of photos captured from various grocery store receipts. This dataset is specifically designed for tasks related to Optical Character Recognition (OCR) and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: item, store, date_time and total.
 and is useful for retail. \n\nEach image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: item, store, date_time and total.\n\n and is useful for retail. \n\nEach image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: item, store, date_time and total.\n\n and is useful for retail. \n\nEach image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: item, store, date_time and total.\n\n
|
tmuzaffarmydost/data-parsing-new-dataset-v3-updated-labels
|
[
"region:us"
] |
2023-09-19T10:09:38+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 293773894.0, "num_examples": 146}], "download_size": 31036732, "dataset_size": 293773894.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T10:11:09+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "data-parsing-new-dataset-v3-updated-labels"
More Information needed
|
[
"# Dataset Card for \"data-parsing-new-dataset-v3-updated-labels\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"data-parsing-new-dataset-v3-updated-labels\"\n\nMore Information needed"
] |
[
6,
27
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"data-parsing-new-dataset-v3-updated-labels\"\n\nMore Information needed"
] |
a7c8237e747188d508ec9f605f81dea27d0c0e85
|
# Dataset of 邪神ちゃん
This is the dataset of 邪神ちゃん, containing 299 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 299 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 684 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 299 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 299 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 299 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 299 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 299 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 684 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 684 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 684 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/xie_shen_chiyan_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T10:10:07+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T10:12:33+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of 邪神ちゃん
================
This is the dataset of 邪神ちゃん, containing 299 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
04b4d59473f5bef6f3317fe37b7c3a42cc9f7bbd
|
# Dataset of 花園ゆりね
This is the dataset of 花園ゆりね, containing 276 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 276 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 638 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 276 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 276 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 276 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 276 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 276 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 638 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 638 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 638 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/hua_yuan_yurine_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T10:28:30+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T10:38:22+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of 花園ゆりね
================
This is the dataset of 花園ゆりね, containing 276 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
4699e730fba46badc4ab41e1df9724c2081e1d84
|
# Dataset of Pekora
This is the dataset of Pekora, containing 276 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 276 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 627 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 276 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 276 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 276 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 276 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 276 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 627 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 627 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 627 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/pekora_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T10:53:17+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T10:57:19+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Pekora
=================
This is the dataset of Pekora, containing 276 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
b3e261face5c3ba2d9b65953b75c2a53ff6dc090
|
# Dataset of メデューサ
This is the dataset of メデューサ, containing 268 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 268 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 591 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 268 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 268 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 268 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 268 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 268 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 591 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 591 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 591 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/medeyusa_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T11:13:03+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T11:14:57+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of メデューサ
================
This is the dataset of メデューサ, containing 268 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
0e8f4b387556b33a383dc1bd4f43da26a636ce8f
|
# Dataset of ミノス
This is the dataset of ミノス, containing 283 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 283 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 673 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 283 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 283 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 283 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 283 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 283 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 673 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 673 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 673 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/minosu_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T11:32:48+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T11:35:55+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of ミノス
==============
This is the dataset of ミノス, containing 283 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
6e38e3a92b009d3262b0c8d22fbd37c5d27c5d16
|
# Dataset of ぽぽろん
This is the dataset of ぽぽろん, containing 269 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 269 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 668 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 269 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 269 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 269 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 269 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 269 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 668 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 668 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 668 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/poporon_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T11:56:50+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T12:02:32+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of ぽぽろん
===============
This is the dataset of ぽぽろん, containing 269 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
4f9ffe559b2a7ebc55dadb50a4171968e673ede1
|
# Dataset of ペルセポネ2世
This is the dataset of ペルセポネ2世, containing 144 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 144 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 330 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 144 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 144 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 144 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 144 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 144 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 330 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 330 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 330 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/perusepone2shi_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T12:09:36+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T12:15:05+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of ペルセポネ2世
==================
This is the dataset of ペルセポネ2世, containing 144 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
40172f9466621c06063736113a44fd696b8ae203
|
# Dataset of リエール
This is the dataset of リエール, containing 178 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 178 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 363 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 178 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 178 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 178 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 178 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 178 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 363 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 363 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 363 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/rieru_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T12:23:54+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T12:29:16+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of リエール
===============
This is the dataset of リエール, containing 178 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
335ddc7d48724bc8810cb5ee1caa1d46e9abe08d
|
# Dataset of ぴの
This is the dataset of ぴの, containing 201 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 201 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 480 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 201 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 201 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 201 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 201 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 201 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 480 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 480 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 480 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/pino_jashinchandropkick
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T12:44:21+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T12:51:07+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of ぴの
=============
This is the dataset of ぴの, containing 201 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
7da9a94fde3706d0f384ecbc3b0d114a3813fb68
|
# Dataset Card for "chinese_general_instruction_with_reward_score"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
DialogueCharacter/chinese_general_instruction_with_reward_score
|
[
"region:us"
] |
2023-09-19T13:07:05+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}, {"name": "reward_score", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 1634095908, "num_examples": 1169201}], "download_size": 998968518, "dataset_size": 1634095908}}
|
2023-09-19T13:07:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chinese_general_instruction_with_reward_score"
More Information needed
|
[
"# Dataset Card for \"chinese_general_instruction_with_reward_score\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chinese_general_instruction_with_reward_score\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chinese_general_instruction_with_reward_score\"\n\nMore Information needed"
] |
38b0bcca4bc76e62d8144a70ea6afe2705e52a26
|
# Dataset Card for Land Parcels
## Dataset Description
**Homepage:** [DSSGx Munich](https://sites.google.com/view/dssgx-munich-2023/startseite) organization page.
**Repository:** [GitHub](https://github.com/DSSGxMunich/land-sealing-dataset-and-analysis).
### Dataset Summary
This dataset contains information about land parcels with building plans in the region of Northern-Rhine Westphalia. It was downloaded from the [NRW Geoportal.](https://www.geoportal.nrw/?activetab=portal)
## Dataset Structure
### Data Fields
- **objectid**: Unique ID used for each land parcel.
- **planid**: ID from the Geoportal.
- **levelplan**: Spatial plan level. Classification scheme specified, required according to the INSPIRE term “infra-local”.
- **name**: Name of building plan.
- **kommune**: Municipality.
- **gkz**: Municipal code of the municipality.
- **nr**: In the municipality only once occurring number of the plan. Can also combine letters and numbers. The numbering system should be defined by the municipality before the first plan entry.
- **besch**: Brief description of the building plan.
- **aend**: Use dependent on building name and reference to change.
- **aendert**: The ID of the original plan that is being changed.
- **stand**: According to code list legal status.
- **planart**: Type of plan/statute.
- **datum**: Date of building plan.
- **scanurl**: URL of the scanned building plan.
- **texturl**: URL to textual determinations, necessary if scanned plan does not contain them.
- **legendeurl**: URL to the plan symbols (legend) necessary, if plan symbols and determinations are available separately.
- **sonsturl**: If the URL under "Document" only links to the actual plan drawing (without supplementary documents), then a URL must be added under this field, under which the corresponding additional content (such as expert opinions) can be found.
- **verfahren**: Type of plan procedure.
- **plantyp**: The type of the plan.
- **aendnr**: Number of the modified plan.
- **begruendurl**: URL for justification. Necessary if justification and determinations are available separately.
- **umweltberurl**: URL to the environmental report. Necessary if report and determinations are available separately.
- **erklaerungurl**: URL to the recapitulative statement. Necessary if declaration and determinations are available separately.
- **shape_Length**: The length of the land parcel
- **shape_Area**: The area of the land parcel
- **regional_plan_id**: Unique ID of regional plan the land parcel is in.
- **regional_plan_name**: Name of the regional plan the land parcel is in.
- **ART**: Unique ID of regional plan the land parcel is in.
- **geometry**: Geographical location of the land parcel.
More information on this fields can be found in the NRW documentation [here](https://www.bauportal.nrw/system/files/media/document/file/21-12-08-bauleitplanung_benutzerhandbuch.pdf).
### Source Data
#### Initial Data Collection
The data was downloaded from the NRW Geoportal, selecting the information of building plans and exporting the features as a GeoJSon in QGIS.
|
DSSGxMunich/land_parcels
|
[
"license:mit",
"region:us"
] |
2023-09-19T13:08:44+00:00
|
{"license": "mit"}
|
2023-10-06T09:54:12+00:00
|
[] |
[] |
TAGS
#license-mit #region-us
|
# Dataset Card for Land Parcels
## Dataset Description
Homepage: DSSGx Munich organization page.
Repository: GitHub.
### Dataset Summary
This dataset contains information about land parcels with building plans in the region of Northern-Rhine Westphalia. It was downloaded from the NRW Geoportal.
## Dataset Structure
### Data Fields
- objectid: Unique ID used for each land parcel.
- planid: ID from the Geoportal.
- levelplan: Spatial plan level. Classification scheme specified, required according to the INSPIRE term “infra-local”.
- name: Name of building plan.
- kommune: Municipality.
- gkz: Municipal code of the municipality.
- nr: In the municipality only once occurring number of the plan. Can also combine letters and numbers. The numbering system should be defined by the municipality before the first plan entry.
- besch: Brief description of the building plan.
- aend: Use dependent on building name and reference to change.
- aendert: The ID of the original plan that is being changed.
- stand: According to code list legal status.
- planart: Type of plan/statute.
- datum: Date of building plan.
- scanurl: URL of the scanned building plan.
- texturl: URL to textual determinations, necessary if scanned plan does not contain them.
- legendeurl: URL to the plan symbols (legend) necessary, if plan symbols and determinations are available separately.
- sonsturl: If the URL under "Document" only links to the actual plan drawing (without supplementary documents), then a URL must be added under this field, under which the corresponding additional content (such as expert opinions) can be found.
- verfahren: Type of plan procedure.
- plantyp: The type of the plan.
- aendnr: Number of the modified plan.
- begruendurl: URL for justification. Necessary if justification and determinations are available separately.
- umweltberurl: URL to the environmental report. Necessary if report and determinations are available separately.
- erklaerungurl: URL to the recapitulative statement. Necessary if declaration and determinations are available separately.
- shape_Length: The length of the land parcel
- shape_Area: The area of the land parcel
- regional_plan_id: Unique ID of regional plan the land parcel is in.
- regional_plan_name: Name of the regional plan the land parcel is in.
- ART: Unique ID of regional plan the land parcel is in.
- geometry: Geographical location of the land parcel.
More information on this fields can be found in the NRW documentation here.
### Source Data
#### Initial Data Collection
The data was downloaded from the NRW Geoportal, selecting the information of building plans and exporting the features as a GeoJSon in QGIS.
|
[
"# Dataset Card for Land Parcels",
"## Dataset Description\n\nHomepage: DSSGx Munich organization page. \n\nRepository: GitHub.",
"### Dataset Summary\n\nThis dataset contains information about land parcels with building plans in the region of Northern-Rhine Westphalia. It was downloaded from the NRW Geoportal.",
"## Dataset Structure",
"### Data Fields\n\n- objectid: Unique ID used for each land parcel. \n- planid: ID from the Geoportal. \n- levelplan: Spatial plan level. Classification scheme specified, required according to the INSPIRE term “infra-local”.\n- name: Name of building plan.\n- kommune: Municipality. \n- gkz: Municipal code of the municipality.\n- nr: In the municipality only once occurring number of the plan. Can also combine letters and numbers. The numbering system should be defined by the municipality before the first plan entry.\n- besch: Brief description of the building plan.\n- aend: Use dependent on building name and reference to change.\n- aendert: The ID of the original plan that is being changed.\n- stand: According to code list legal status.\n- planart: Type of plan/statute.\n- datum: Date of building plan.\n- scanurl: URL of the scanned building plan. \n- texturl: URL to textual determinations, necessary if scanned plan does not contain them.\n- legendeurl: URL to the plan symbols (legend) necessary, if plan symbols and determinations are available separately.\n- sonsturl: If the URL under \"Document\" only links to the actual plan drawing (without supplementary documents), then a URL must be added under this field, under which the corresponding additional content (such as expert opinions) can be found.\n- verfahren: Type of plan procedure.\n- plantyp: The type of the plan.\n- aendnr: Number of the modified plan.\n- begruendurl: URL for justification. Necessary if justification and determinations are available separately.\n- umweltberurl: URL to the environmental report. Necessary if report and determinations are available separately.\n- erklaerungurl: URL to the recapitulative statement. Necessary if declaration and determinations are available separately.\n- shape_Length: The length of the land parcel\n- shape_Area: The area of the land parcel\n- regional_plan_id: Unique ID of regional plan the land parcel is in. \n- regional_plan_name: Name of the regional plan the land parcel is in. \n- ART: Unique ID of regional plan the land parcel is in. \n- geometry: Geographical location of the land parcel.\n\nMore information on this fields can be found in the NRW documentation here.",
"### Source Data",
"#### Initial Data Collection\n\nThe data was downloaded from the NRW Geoportal, selecting the information of building plans and exporting the features as a GeoJSon in QGIS."
] |
[
"TAGS\n#license-mit #region-us \n",
"# Dataset Card for Land Parcels",
"## Dataset Description\n\nHomepage: DSSGx Munich organization page. \n\nRepository: GitHub.",
"### Dataset Summary\n\nThis dataset contains information about land parcels with building plans in the region of Northern-Rhine Westphalia. It was downloaded from the NRW Geoportal.",
"## Dataset Structure",
"### Data Fields\n\n- objectid: Unique ID used for each land parcel. \n- planid: ID from the Geoportal. \n- levelplan: Spatial plan level. Classification scheme specified, required according to the INSPIRE term “infra-local”.\n- name: Name of building plan.\n- kommune: Municipality. \n- gkz: Municipal code of the municipality.\n- nr: In the municipality only once occurring number of the plan. Can also combine letters and numbers. The numbering system should be defined by the municipality before the first plan entry.\n- besch: Brief description of the building plan.\n- aend: Use dependent on building name and reference to change.\n- aendert: The ID of the original plan that is being changed.\n- stand: According to code list legal status.\n- planart: Type of plan/statute.\n- datum: Date of building plan.\n- scanurl: URL of the scanned building plan. \n- texturl: URL to textual determinations, necessary if scanned plan does not contain them.\n- legendeurl: URL to the plan symbols (legend) necessary, if plan symbols and determinations are available separately.\n- sonsturl: If the URL under \"Document\" only links to the actual plan drawing (without supplementary documents), then a URL must be added under this field, under which the corresponding additional content (such as expert opinions) can be found.\n- verfahren: Type of plan procedure.\n- plantyp: The type of the plan.\n- aendnr: Number of the modified plan.\n- begruendurl: URL for justification. Necessary if justification and determinations are available separately.\n- umweltberurl: URL to the environmental report. Necessary if report and determinations are available separately.\n- erklaerungurl: URL to the recapitulative statement. Necessary if declaration and determinations are available separately.\n- shape_Length: The length of the land parcel\n- shape_Area: The area of the land parcel\n- regional_plan_id: Unique ID of regional plan the land parcel is in. \n- regional_plan_name: Name of the regional plan the land parcel is in. \n- ART: Unique ID of regional plan the land parcel is in. \n- geometry: Geographical location of the land parcel.\n\nMore information on this fields can be found in the NRW documentation here.",
"### Source Data",
"#### Initial Data Collection\n\nThe data was downloaded from the NRW Geoportal, selecting the information of building plans and exporting the features as a GeoJSon in QGIS."
] |
[
11,
8,
21,
42,
6,
524,
4,
40
] |
[
"passage: TAGS\n#license-mit #region-us \n# Dataset Card for Land Parcels## Dataset Description\n\nHomepage: DSSGx Munich organization page. \n\nRepository: GitHub.### Dataset Summary\n\nThis dataset contains information about land parcels with building plans in the region of Northern-Rhine Westphalia. It was downloaded from the NRW Geoportal.## Dataset Structure"
] |
f96179caf8c6e1d2732f7621f36facfa5323a57f
|
# Dataset Card for "36e1d427"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-kand2-sdxl-wuerst-karlo/36e1d427
|
[
"region:us"
] |
2023-09-19T13:17:00+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 232, "num_examples": 10}], "download_size": 1385, "dataset_size": 232}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T13:17:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "36e1d427"
More Information needed
|
[
"# Dataset Card for \"36e1d427\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"36e1d427\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"36e1d427\"\n\nMore Information needed"
] |
679eba043c4fc9eba160a8d9b52344849b107bc8
|
Webdataset version of: [lambdalabs/pokemon-blip-captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions)
|
justinpinkney/pokemon-blip-captions-wds
|
[
"region:us"
] |
2023-09-19T13:31:16+00:00
|
{}
|
2023-09-19T13:32:11+00:00
|
[] |
[] |
TAGS
#region-us
|
Webdataset version of: lambdalabs/pokemon-blip-captions
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
e5a4a5f9d8c9a5b7476eb8ea8d3e4cadfaec8bbc
|
# Domain Adaptation of Large Language Models
This repo contains the **evaluation datasets** for our **ICLR 2024** paper [Adapting Large Language Models via Reading Comprehension](https://huggingface.co/papers/2309.09530).
We explore **continued pre-training on domain-specific corpora** for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to **transform large-scale pre-training corpora into reading comprehension texts**, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. **Our 7B model competes with much larger domain-specific models like BloombergGPT-50B**.
### 🤗 We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! 🤗
**************************** **Updates** ****************************
* 2024/1/16: 🎉 Our [research paper](https://huggingface.co/papers/2309.09530) has been accepted by ICLR 2024!!!🎉
* 2023/12/19: Released our [13B base models](https://huggingface.co/AdaptLLM/law-LLM-13B) developed from LLaMA-1-13B.
* 2023/12/8: Released our [chat models](https://huggingface.co/AdaptLLM/law-chat) developed from LLaMA-2-Chat-7B.
* 2023/9/18: Released our [paper](https://huggingface.co/papers/2309.09530), [code](https://github.com/microsoft/LMOps), [data](https://huggingface.co/datasets/AdaptLLM/law-tasks), and [base models](https://huggingface.co/AdaptLLM/law-LLM) developed from LLaMA-1-7B.
## Domain-Specific LLaMA-1
### LLaMA-1-7B
In our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: [Biomedicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM), [Finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM) and [Law-LLM](https://huggingface.co/AdaptLLM/law-LLM), the performances of our AdaptLLM compared to other domain-specific LLMs are:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/650801ced5578ef7e20b33d4/6efPwitFgy-pLTzvccdcP.png" width="700">
</p>
### LLaMA-1-13B
Moreover, we scale up our base model to LLaMA-1-13B to see if **our method is similarly effective for larger-scale models**, and the results are consistently positive too: [Biomedicine-LLM-13B](https://huggingface.co/AdaptLLM/medicine-LLM-13B), [Finance-LLM-13B](https://huggingface.co/AdaptLLM/finance-LLM-13B) and [Law-LLM-13B](https://huggingface.co/AdaptLLM/law-LLM-13B).
## Domain-Specific LLaMA-2-Chat
Our method is also effective for aligned models! LLaMA-2-Chat requires a [specific data format](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), and our **reading comprehension can perfectly fit the data format** by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: [Biomedicine-Chat](https://huggingface.co/AdaptLLM/medicine-chat), [Finance-Chat](https://huggingface.co/AdaptLLM/finance-chat) and [Law-Chat](https://huggingface.co/AdaptLLM/law-chat)
For example, to chat with the biomedicine-chat model:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("AdaptLLM/medicine-chat")
tokenizer = AutoTokenizer.from_pretrained("AdaptLLM/medicine-chat")
# Put your input here:
user_input = '''Question: Which of the following is an example of monosomy?
Options:
- 46,XX
- 47,XXX
- 69,XYY
- 45,X
Please provide your choice first and then provide explanations if possible.'''
# Apply the prompt template and system prompt of LLaMA-2-Chat demo for chat models (NOTE: NO prompt template is required for base models!)
our_system_prompt = "\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n" # Please do NOT change this
prompt = f"<s>[INST] <<SYS>>{our_system_prompt}<</SYS>>\n\n{user_input} [/INST]"
# # NOTE:
# # If you want to apply your own system prompt, please integrate it into the instruction part following our system prompt like this:
# your_system_prompt = "Please, answer this question faithfully."
# prompt = f"<s>[INST] <<SYS>>{our_system_prompt}<</SYS>>\n\n{your_system_prompt}\n{user_input} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).input_ids.to(model.device)
outputs = model.generate(input_ids=inputs, max_length=4096)[0]
answer_start = int(inputs.shape[-1])
pred = tokenizer.decode(outputs[answer_start:], skip_special_tokens=True)
print(f'### User Input:\n{user_input}\n\n### Assistant Output:\n{pred}')
```
## Domain-Specific Tasks
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: [biomedicine-tasks](https://huggingface.co/datasets/AdaptLLM/medicine-tasks), [finance-tasks](https://huggingface.co/datasets/AdaptLLM/finance-tasks), and [law-tasks](https://huggingface.co/datasets/AdaptLLM/law-tasks).
**Note:** those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.
## Citation
If you find our work helpful, please cite us:
```bibtex
@article{adaptllm,
title={Adapting large language models via reading comprehension},
author={Cheng, Daixuan and Huang, Shaohan and Wei, Furu},
journal={arXiv preprint arXiv:2309.09530},
year={2023}
}
```
|
AdaptLLM/medicine-tasks
|
[
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:conversational",
"language:en",
"biology",
"medical",
"arxiv:2309.09530",
"region:us"
] |
2023-09-19T13:53:35+00:00
|
{"language": ["en"], "task_categories": ["text-classification", "question-answering", "zero-shot-classification", "conversational"], "configs": [{"config_name": "ChemProt", "data_files": [{"split": "test", "path": "ChemProt/test.json"}]}, {"config_name": "MQP", "data_files": [{"split": "test", "path": "MedQs/test.json"}]}, {"config_name": "PubMedQA", "data_files": [{"split": "test", "path": "pubmed_qa/test.json"}]}, {"config_name": "RCT", "data_files": [{"split": "test", "path": "RCT/test.json"}]}, {"config_name": "USMLE", "data_files": [{"split": "test", "path": "usmle/test.json"}]}], "tags": ["biology", "medical"]}
|
2024-02-07T12:31:54+00:00
|
[
"2309.09530"
] |
[
"en"
] |
TAGS
#task_categories-text-classification #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-conversational #language-English #biology #medical #arxiv-2309.09530 #region-us
|
# Domain Adaptation of Large Language Models
This repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.
We explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.
### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned!
Updates
* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!
* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.
* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.
* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.
## Domain-Specific LLaMA-1
### LLaMA-1-7B
In our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:
<p align='center'>
<img src="URL width="700">
</p>
### LLaMA-1-13B
Moreover, we scale up our base model to LLaMA-1-13B to see if our method is similarly effective for larger-scale models, and the results are consistently positive too: Biomedicine-LLM-13B, Finance-LLM-13B and Law-LLM-13B.
## Domain-Specific LLaMA-2-Chat
Our method is also effective for aligned models! LLaMA-2-Chat requires a specific data format, and our reading comprehension can perfectly fit the data format by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: Biomedicine-Chat, Finance-Chat and Law-Chat
For example, to chat with the biomedicine-chat model:
## Domain-Specific Tasks
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.
Note: those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.
If you find our work helpful, please cite us:
|
[
"# Domain Adaptation of Large Language Models\nThis repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.\n\nWe explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.",
"### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! \n\n Updates \n* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!\n* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.\n* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.\n* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.",
"## Domain-Specific LLaMA-1",
"### LLaMA-1-7B\nIn our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:\n\n<p align='center'>\n <img src=\"URL width=\"700\">\n</p>",
"### LLaMA-1-13B\nMoreover, we scale up our base model to LLaMA-1-13B to see if our method is similarly effective for larger-scale models, and the results are consistently positive too: Biomedicine-LLM-13B, Finance-LLM-13B and Law-LLM-13B.",
"## Domain-Specific LLaMA-2-Chat\nOur method is also effective for aligned models! LLaMA-2-Chat requires a specific data format, and our reading comprehension can perfectly fit the data format by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: Biomedicine-Chat, Finance-Chat and Law-Chat\n\nFor example, to chat with the biomedicine-chat model:",
"## Domain-Specific Tasks\nTo easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.\n\nNote: those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.\n\nIf you find our work helpful, please cite us:"
] |
[
"TAGS\n#task_categories-text-classification #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-conversational #language-English #biology #medical #arxiv-2309.09530 #region-us \n",
"# Domain Adaptation of Large Language Models\nThis repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.\n\nWe explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.",
"### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! \n\n Updates \n* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!\n* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.\n* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.\n* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.",
"## Domain-Specific LLaMA-1",
"### LLaMA-1-7B\nIn our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:\n\n<p align='center'>\n <img src=\"URL width=\"700\">\n</p>",
"### LLaMA-1-13B\nMoreover, we scale up our base model to LLaMA-1-13B to see if our method is similarly effective for larger-scale models, and the results are consistently positive too: Biomedicine-LLM-13B, Finance-LLM-13B and Law-LLM-13B.",
"## Domain-Specific LLaMA-2-Chat\nOur method is also effective for aligned models! LLaMA-2-Chat requires a specific data format, and our reading comprehension can perfectly fit the data format by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: Biomedicine-Chat, Finance-Chat and Law-Chat\n\nFor example, to chat with the biomedicine-chat model:",
"## Domain-Specific Tasks\nTo easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: biomedicine-tasks, finance-tasks, and law-tasks.\n\nNote: those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.\n\nIf you find our work helpful, please cite us:"
] |
[
71,
153,
116,
10,
97,
72,
103,
103
] |
[
"passage: TAGS\n#task_categories-text-classification #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-conversational #language-English #biology #medical #arxiv-2309.09530 #region-us \n# Domain Adaptation of Large Language Models\nThis repo contains the evaluation datasets for our ICLR 2024 paper Adapting Large Language Models via Reading Comprehension.\n\nWe explore continued pre-training on domain-specific corpora for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to transform large-scale pre-training corpora into reading comprehension texts, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. Our 7B model competes with much larger domain-specific models like BloombergGPT-50B.### We are currently working hard on developing models across different domains, scales and architectures! Please stay tuned! \n\n Updates \n* 2024/1/16: Our research paper has been accepted by ICLR 2024!!!\n* 2023/12/19: Released our 13B base models developed from LLaMA-1-13B.\n* 2023/12/8: Released our chat models developed from LLaMA-2-Chat-7B.\n* 2023/9/18: Released our paper, code, data, and base models developed from LLaMA-1-7B.## Domain-Specific LLaMA-1### LLaMA-1-7B\nIn our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: Biomedicine-LLM, Finance-LLM and Law-LLM, the performances of our AdaptLLM compared to other domain-specific LLMs are:\n\n<p align='center'>\n <img src=\"URL width=\"700\">\n</p>"
] |
5b46ff0b4b344935c69115350bbc90cfc97cffdf
|
# Dataset Card for "house_imgs_clip"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jdabello/house_imgs_clip
|
[
"region:us"
] |
2023-09-19T13:55:38+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "file", "dtype": "string"}, {"name": "description", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 463392.0, "num_examples": 4}], "download_size": 464113, "dataset_size": 463392.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T14:14:50+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "house_imgs_clip"
More Information needed
|
[
"# Dataset Card for \"house_imgs_clip\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"house_imgs_clip\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"house_imgs_clip\"\n\nMore Information needed"
] |
775e60daed2896530005415c1ce07567342294b5
|
# Dataset Card for "recipe-nlg-lite-llama-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
skadewdl3/recipe-nlg-lite-llama-2
|
[
"region:us"
] |
2023-09-19T13:56:41+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "uid", "dtype": "string"}, {"name": "name", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "link", "dtype": "string"}, {"name": "ner", "dtype": "string"}, {"name": "ingredients", "sequence": "string"}, {"name": "steps", "sequence": "string"}, {"name": "prompt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 19487310, "num_examples": 6118}, {"name": "test", "num_bytes": 3406278, "num_examples": 1080}], "download_size": 0, "dataset_size": 22893588}}
|
2023-09-20T07:03:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "recipe-nlg-lite-llama-2"
More Information needed
|
[
"# Dataset Card for \"recipe-nlg-lite-llama-2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"recipe-nlg-lite-llama-2\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"recipe-nlg-lite-llama-2\"\n\nMore Information needed"
] |
25f1ee3b99990d44015c120563c57c0eeaa4791e
|
# Dataset Card for "CLEF23-CheckThat-1b-en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
OpenFact/CLEF23-CheckThat-1b-en
|
[
"region:us"
] |
2023-09-19T14:06:47+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "dev", "path": "data/dev-*"}, {"split": "dev_test", "path": "data/dev_test-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "Sentence_id", "dtype": "int64"}, {"name": "Text", "dtype": "string"}, {"name": "Annotation", "dtype": "string"}, {"name": "Verdict", "dtype": "string"}, {"name": "Label", "dtype": "int64"}, {"name": "Label_txt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2484384, "num_examples": 16821}, {"name": "dev", "num_bytes": 816828, "num_examples": 5577}, {"name": "dev_test", "num_bytes": 141909, "num_examples": 1022}, {"name": "test", "num_bytes": 34063, "num_examples": 318}], "download_size": 1636778, "dataset_size": 3477184}}
|
2023-09-19T22:35:12+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "CLEF23-CheckThat-1b-en"
More Information needed
|
[
"# Dataset Card for \"CLEF23-CheckThat-1b-en\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"CLEF23-CheckThat-1b-en\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"CLEF23-CheckThat-1b-en\"\n\nMore Information needed"
] |
1dcfc2b7c51a1ece7a621e8ecb80cb813d10f8d2
|
## Data Summary
Data set Alpaca-cnn-dailymail is a data set version format changed by [ccdv/cnn_dailymail](https://huggingface.co/datasets/ccdv/cnn_dailymail) to meet Alpaca fine-tuning Llama2. Only versions 3.0.0 and 2.0.0 were used for merging and as a key data set for the summary extraction task.
## Licensing Information
The Alpaca-cnn-dailymail dataset version 1.0.0 is released under the Apache-2.0 License.
## Citation Information
```
@inproceedings{see-etal-2017-get,
title = "Get To The Point: Summarization with Pointer-Generator Networks",
author = "See, Abigail and
Liu, Peter J. and
Manning, Christopher D.",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P17-1099",
doi = "10.18653/v1/P17-1099",
pages = "1073--1083",
abstract = "Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: they are liable to reproduce factual details inaccurately, and they tend to repeat themselves. In this work we propose a novel architecture that augments the standard sequence-to-sequence attentional model in two orthogonal ways. First, we use a hybrid pointer-generator network that can copy words from the source text via pointing, which aids accurate reproduction of information, while retaining the ability to produce novel words through the generator. Second, we use coverage to keep track of what has been summarized, which discourages repetition. We apply our model to the CNN / Daily Mail summarization task, outperforming the current abstractive state-of-the-art by at least 2 ROUGE points.",
}
```
```
@inproceedings{DBLP:conf/nips/HermannKGEKSB15,
author={Karl Moritz Hermann and Tomás Kociský and Edward Grefenstette and Lasse Espeholt and Will Kay and Mustafa Suleyman and Phil Blunsom},
title={Teaching Machines to Read and Comprehend},
year={2015},
cdate={1420070400000},
pages={1693-1701},
url={http://papers.nips.cc/paper/5945-teaching-machines-to-read-and-comprehend},
booktitle={NIPS},
crossref={conf/nips/2015}
}
```
|
ZhongshengWang/Alpaca-cnn-dailymail
|
[
"task_categories:summarization",
"task_categories:text-generation",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:apache-2.0",
"conditional-text-generation",
"region:us"
] |
2023-09-19T14:16:44+00:00
|
{"annotations_creators": ["no-annotation"], "language_creators": ["found"], "language": ["en"], "license": ["apache-2.0"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["summarization", "text-generation"], "task_ids": [], "paperswithcode_id": "cnn-daily-mail-1", "pretty_name": "CNN / Daily Mail", "tags": ["conditional-text-generation"]}
|
2023-09-19T14:23:01+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-summarization #task_categories-text-generation #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-English #license-apache-2.0 #conditional-text-generation #region-us
|
## Data Summary
Data set Alpaca-cnn-dailymail is a data set version format changed by ccdv/cnn_dailymail to meet Alpaca fine-tuning Llama2. Only versions 3.0.0 and 2.0.0 were used for merging and as a key data set for the summary extraction task.
## Licensing Information
The Alpaca-cnn-dailymail dataset version 1.0.0 is released under the Apache-2.0 License.
|
[
"## Data Summary\n\nData set Alpaca-cnn-dailymail is a data set version format changed by ccdv/cnn_dailymail to meet Alpaca fine-tuning Llama2. Only versions 3.0.0 and 2.0.0 were used for merging and as a key data set for the summary extraction task.",
"## Licensing Information\n\nThe Alpaca-cnn-dailymail dataset version 1.0.0 is released under the Apache-2.0 License."
] |
[
"TAGS\n#task_categories-summarization #task_categories-text-generation #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-English #license-apache-2.0 #conditional-text-generation #region-us \n",
"## Data Summary\n\nData set Alpaca-cnn-dailymail is a data set version format changed by ccdv/cnn_dailymail to meet Alpaca fine-tuning Llama2. Only versions 3.0.0 and 2.0.0 were used for merging and as a key data set for the summary extraction task.",
"## Licensing Information\n\nThe Alpaca-cnn-dailymail dataset version 1.0.0 is released under the Apache-2.0 License."
] |
[
96,
68,
29
] |
[
"passage: TAGS\n#task_categories-summarization #task_categories-text-generation #annotations_creators-no-annotation #language_creators-found #multilinguality-monolingual #size_categories-100K<n<1M #source_datasets-original #language-English #license-apache-2.0 #conditional-text-generation #region-us \n## Data Summary\n\nData set Alpaca-cnn-dailymail is a data set version format changed by ccdv/cnn_dailymail to meet Alpaca fine-tuning Llama2. Only versions 3.0.0 and 2.0.0 were used for merging and as a key data set for the summary extraction task.## Licensing Information\n\nThe Alpaca-cnn-dailymail dataset version 1.0.0 is released under the Apache-2.0 License."
] |
5c2bd5925576b856f877efe48a6659c622794391
|
# Dataset Card for "norm_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
quocanh34/norm_data
|
[
"region:us"
] |
2023-09-19T14:16:58+00:00
|
{"dataset_info": {"features": [{"name": "audio", "struct": [{"name": "array", "sequence": "float64"}, {"name": "path", "dtype": "string"}, {"name": "sampling_rate", "dtype": "int64"}]}, {"name": "sentence_norm", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4941919516, "num_examples": 9807}, {"name": "test", "num_bytes": 390017289, "num_examples": 748}], "download_size": 1260410218, "dataset_size": 5331936805}}
|
2023-09-19T14:18:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "norm_data"
More Information needed
|
[
"# Dataset Card for \"norm_data\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"norm_data\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"norm_data\"\n\nMore Information needed"
] |
1cca45892d6077ef81ddc848655d418b2287dfac
|
# Dataset Card for "BMO_BASE_TEXT"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
bibidentuhanoi/BMO_BASE_TEXT
|
[
"region:us"
] |
2023-09-19T14:26:35+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 154049, "num_examples": 278}], "download_size": 84465, "dataset_size": 154049}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-11T15:09:08+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "BMO_BASE_TEXT"
More Information needed
|
[
"# Dataset Card for \"BMO_BASE_TEXT\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"BMO_BASE_TEXT\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"BMO_BASE_TEXT\"\n\nMore Information needed"
] |
fa1df197c24b87a4ea2d267745fe8ee9055cfa35
|
# Dataset Card for "squad_wrong_id_train_10_eval_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
tyzhu/squad_wrong_id_train_10_eval_10
|
[
"region:us"
] |
2023-09-19T14:36:44+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": [{"name": "text", "dtype": "string"}, {"name": "answer_start", "dtype": "int32"}]}, {"name": "context_id", "dtype": "string"}, {"name": "inputs", "dtype": "string"}, {"name": "targets", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 237881, "num_examples": 150}, {"name": "validation", "num_bytes": 59884, "num_examples": 48}], "download_size": 28458, "dataset_size": 297765}}
|
2023-09-19T14:54:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "squad_wrong_id_train_10_eval_10"
More Information needed
|
[
"# Dataset Card for \"squad_wrong_id_train_10_eval_10\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"squad_wrong_id_train_10_eval_10\"\n\nMore Information needed"
] |
[
6,
27
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"squad_wrong_id_train_10_eval_10\"\n\nMore Information needed"
] |
3d6ba3d4ee9624747b071cae7d83ebb91790b1e4
|
# Dataset Card for "clean_notebooks_labeled"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vikp/clean_notebooks_labeled
|
[
"region:us"
] |
2023-09-19T14:42:18+00:00
|
{"dataset_info": {"features": [{"name": "code", "dtype": "string"}, {"name": "kind", "dtype": "string"}, {"name": "parsed_code", "dtype": "string"}, {"name": "quality_prob", "dtype": "float64"}, {"name": "learning_prob", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 9995784915, "num_examples": 648628}], "download_size": 4427950019, "dataset_size": 9995784915}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T15:01:42+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "clean_notebooks_labeled"
More Information needed
|
[
"# Dataset Card for \"clean_notebooks_labeled\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"clean_notebooks_labeled\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"clean_notebooks_labeled\"\n\nMore Information needed"
] |
5a6b431a268523a6603f199d859fc25a24c22900
|
# Dataset Card for "meanwhile"
This dataset consists of 64 segments from The Late Show with Stephen Colbert. This dataset was published as
part of the Whisper release by OpenAI. See page 19 of the [Whisper paper](https://arxiv.org/pdf/2212.04356.pdf)
for details.
|
distil-whisper/meanwhile
|
[
"arxiv:2212.04356",
"region:us"
] |
2023-09-19T14:45:32+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "begin", "dtype": "string"}, {"name": "end", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 58250833.0, "num_examples": 64}], "download_size": 58229969, "dataset_size": 58250833.0}}
|
2023-10-17T16:17:28+00:00
|
[
"2212.04356"
] |
[] |
TAGS
#arxiv-2212.04356 #region-us
|
# Dataset Card for "meanwhile"
This dataset consists of 64 segments from The Late Show with Stephen Colbert. This dataset was published as
part of the Whisper release by OpenAI. See page 19 of the Whisper paper
for details.
|
[
"# Dataset Card for \"meanwhile\"\n\nThis dataset consists of 64 segments from The Late Show with Stephen Colbert. This dataset was published as \npart of the Whisper release by OpenAI. See page 19 of the Whisper paper \nfor details."
] |
[
"TAGS\n#arxiv-2212.04356 #region-us \n",
"# Dataset Card for \"meanwhile\"\n\nThis dataset consists of 64 segments from The Late Show with Stephen Colbert. This dataset was published as \npart of the Whisper release by OpenAI. See page 19 of the Whisper paper \nfor details."
] |
[
15,
58
] |
[
"passage: TAGS\n#arxiv-2212.04356 #region-us \n# Dataset Card for \"meanwhile\"\n\nThis dataset consists of 64 segments from The Late Show with Stephen Colbert. This dataset was published as \npart of the Whisper release by OpenAI. See page 19 of the Whisper paper \nfor details."
] |
7dff2d25a0a5e0b4451ba61bc0e63a330bfd7f87
|
# Dataset Card for "clean_notebooks_filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vikp/clean_notebooks_filtered
|
[
"region:us"
] |
2023-09-19T14:46:12+00:00
|
{"dataset_info": {"features": [{"name": "code", "dtype": "string"}, {"name": "kind", "dtype": "string"}, {"name": "parsed_code", "dtype": "string"}, {"name": "quality_prob", "dtype": "float64"}, {"name": "learning_prob", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 3018948094.822456, "num_examples": 195900}], "download_size": 1476349379, "dataset_size": 3018948094.822456}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T15:02:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "clean_notebooks_filtered"
More Information needed
|
[
"# Dataset Card for \"clean_notebooks_filtered\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"clean_notebooks_filtered\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"clean_notebooks_filtered\"\n\nMore Information needed"
] |
d96a8c13561a70b961ce82ff700add7525dd055d
|
# Dataset Card for "Arabic_common_voice_11_0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ayoubkirouane/Arabic_common_voice_11_0
|
[
"region:us"
] |
2023-09-19T14:49:44+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 48000}}}, {"name": "sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 331885627.728, "num_examples": 10438}, {"name": "test", "num_bytes": 318132067.84, "num_examples": 10440}], "download_size": 577509839, "dataset_size": 650017695.568}}
|
2023-09-19T14:51:03+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Arabic_common_voice_11_0"
More Information needed
|
[
"# Dataset Card for \"Arabic_common_voice_11_0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Arabic_common_voice_11_0\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Arabic_common_voice_11_0\"\n\nMore Information needed"
] |
0094ddc9a6bc8c2bbea0f6b70e307f88b38351d6
|
# Dataset Card for "squad_no_id_train_10_eval_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
tyzhu/squad_no_id_train_10_eval_10
|
[
"region:us"
] |
2023-09-19T14:54:59+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": [{"name": "text", "dtype": "string"}, {"name": "answer_start", "dtype": "int32"}]}, {"name": "context_id", "dtype": "string"}, {"name": "inputs", "dtype": "string"}, {"name": "targets", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 237881, "num_examples": 150}, {"name": "validation", "num_bytes": 58313, "num_examples": 48}], "download_size": 72461, "dataset_size": 296194}}
|
2023-09-19T14:55:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "squad_no_id_train_10_eval_10"
More Information needed
|
[
"# Dataset Card for \"squad_no_id_train_10_eval_10\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"squad_no_id_train_10_eval_10\"\n\nMore Information needed"
] |
[
6,
26
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"squad_no_id_train_10_eval_10\"\n\nMore Information needed"
] |
9ad3ea04d99b2c3ce234a6fcb0faccc1d3c5693e
|
# Dataset Card for "data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
demizzzzzz/data
|
[
"region:us"
] |
2023-09-19T15:00:41+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 528565.0, "num_examples": 5}], "download_size": 529708, "dataset_size": 528565.0}}
|
2023-09-20T11:36:09+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "data"
More Information needed
|
[
"# Dataset Card for \"data\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"data\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"data\"\n\nMore Information needed"
] |
7e9964b832a79772fe664c193a6ba8da9a877518
|
# Dataset Card for "data_aug_full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhqyy/data_aug_full
|
[
"region:us"
] |
2023-09-19T15:02:44+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "sentence", "dtype": "string"}, {"name": "intent", "dtype": "string"}, {"name": "entities", "list": [{"name": "type", "dtype": "string"}, {"name": "filler", "dtype": "string"}]}, {"name": "labels", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1710412, "num_examples": 8096}, {"name": "test", "num_bytes": 147335, "num_examples": 704}], "download_size": 439882, "dataset_size": 1857747}}
|
2023-09-19T15:02:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "data_aug_full"
More Information needed
|
[
"# Dataset Card for \"data_aug_full\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"data_aug_full\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"data_aug_full\"\n\nMore Information needed"
] |
098afa4bef9e4213b8a66f6b86909cde3843038e
|
# Dataset of Yoshida Yuko
This is the dataset of Yoshida Yuko, containing 300 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 300 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 729 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 300 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 300 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 300 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 300 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 300 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 729 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 729 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 729 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/yoshida_yuko_thedemongirlnextdoor
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T15:14:44+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T15:18:14+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Yoshida Yuko
=======================
This is the dataset of Yoshida Yuko, containing 300 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
f3fa4fb6d10c94ebb9e48b0affa9f69fa066af28
|
# Dataset of Chiyoda Momo
This is the dataset of Chiyoda Momo, containing 296 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 296 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 749 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 296 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 296 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 296 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 296 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 296 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 749 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 749 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 749 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/chiyoda_momo_thedemongirlnextdoor
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T16:05:03+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T16:07:50+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Chiyoda Momo
=======================
This is the dataset of Chiyoda Momo, containing 296 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
9d1561c0432a0b50be8e8793e514984bb64c34f4
|
# Dataset Card for "data_aug_full_0909"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhqyy/data_aug_full_0909
|
[
"region:us"
] |
2023-09-19T16:18:08+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "sentence", "dtype": "string"}, {"name": "intent", "dtype": "string"}, {"name": "entities", "list": [{"name": "type", "dtype": "string"}, {"name": "filler", "dtype": "string"}]}, {"name": "labels", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1800230, "num_examples": 8478}, {"name": "test", "num_bytes": 152559, "num_examples": 738}], "download_size": 460615, "dataset_size": 1952789}}
|
2023-09-19T16:18:11+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "data_aug_full_0909"
More Information needed
|
[
"# Dataset Card for \"data_aug_full_0909\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"data_aug_full_0909\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"data_aug_full_0909\"\n\nMore Information needed"
] |
fd6f3fb077e8c45120ea579e6a1038904850f2c2
|
# Dataset of Lilith
This is the dataset of Lilith, containing 132 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 132 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 322 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 132 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 132 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 132 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 132 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 132 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 322 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 322 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 322 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/lilith_thedemongirlnextdoor
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T16:18:55+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T16:20:26+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Lilith
=================
This is the dataset of Lilith, containing 132 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
832d3cbb5d65f2947df552145e68ec121dd166f2
|
# Dataset of Hinatsuki Mikan
This is the dataset of Hinatsuki Mikan, containing 291 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 291 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 700 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 291 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 291 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 291 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 291 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 291 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 700 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 700 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 700 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/hinatsuki_mikan_thedemongirlnextdoor
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-19T16:40:31+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-19T16:43:15+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Hinatsuki Mikan
==========================
This is the dataset of Hinatsuki Mikan, containing 291 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
9ef14d73ec7d765cf3ea4ac25948624a53ac8f1f
|
# Dataset Card for "mimic"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ricardosantoss/mimic
|
[
"region:us"
] |
2023-09-19T17:01:51+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "TEXT", "dtype": "string"}, {"name": "ICD9_CODE", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 350160331, "num_examples": 39354}, {"name": "test", "num_bytes": 44827959, "num_examples": 5000}, {"name": "validation", "num_bytes": 44381049, "num_examples": 5000}], "download_size": 245192456, "dataset_size": 439369339}}
|
2023-09-19T17:02:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "mimic"
More Information needed
|
[
"# Dataset Card for \"mimic\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"mimic\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"mimic\"\n\nMore Information needed"
] |
8df5531c55753cef31e8838fa0db15970e7be9b9
|
# Dataset Card for "09f81d33"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-muse256-muse512-wuerst-sdv15/09f81d33
|
[
"region:us"
] |
2023-09-19T17:05:28+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 169, "num_examples": 10}], "download_size": 1352, "dataset_size": 169}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T17:05:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "09f81d33"
More Information needed
|
[
"# Dataset Card for \"09f81d33\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"09f81d33\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"09f81d33\"\n\nMore Information needed"
] |
d16ca4ffc43ff9f70e00f236091b874cffa829d7
|
# Dataset Card for "b985b700"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-muse256-muse512-wuerst-sdv15/b985b700
|
[
"region:us"
] |
2023-09-19T17:08:19+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 208, "num_examples": 10}], "download_size": 1365, "dataset_size": 208}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T17:08:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "b985b700"
More Information needed
|
[
"# Dataset Card for \"b985b700\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"b985b700\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"b985b700\"\n\nMore Information needed"
] |
adebe0a819ba93ffec148548de0e982e9123a328
|
# Dataset Card for "pile-semantic-memorization-filter-results"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
usvsnsp/pile-semantic-memorization-filter-results
|
[
"region:us"
] |
2023-09-19T17:16:50+00:00
|
{"dataset_info": {"features": [{"name": "sequence_id", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "sequence_duplicates", "dtype": "int64"}, {"name": "max_frequency", "dtype": "int64"}, {"name": "avg_frequency", "dtype": "float64"}, {"name": "min_frequency", "dtype": "int64"}, {"name": "median_frequency", "dtype": "float64"}, {"name": "p25_frequency", "dtype": "int64"}, {"name": "p75_frequency", "dtype": "int64"}, {"name": "frequencies", "sequence": "int64"}, {"name": "is_incrementing", "dtype": "bool"}, {"name": "tokens", "sequence": "int64"}, {"name": "repeating_offset", "dtype": "int32"}, {"name": "num_repeating", "dtype": "int32"}, {"name": "smallest_repeating_chunk", "sequence": "int64"}, {"name": "memorization_score", "dtype": "float64"}, {"name": "templating_frequency_0.9", "dtype": "int64"}, {"name": "templating_frequency_0.8", "dtype": "int64"}, {"name": "prompt_perplexity", "dtype": "float32"}, {"name": "generation_perplexity", "dtype": "float32"}, {"name": "sequence_perplexity", "dtype": "float32"}], "splits": [{"name": "pile.duped.70m", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.160m", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.410m", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.1b", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.1.4b", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.2.8b", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.6.9b", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.duped.12b", "num_bytes": 7003348430, "num_examples": 5000000}, {"name": "pile.deduped.70m", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.160m", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.410m", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.1b", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.1.4b", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.2.8b", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.6.9b", "num_bytes": 7013409756, "num_examples": 5000000}, {"name": "pile.deduped.12b", "num_bytes": 7013409756, "num_examples": 5000000}], "download_size": 48107269588, "dataset_size": 112134065488}}
|
2023-09-19T17:56:42+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pile-semantic-memorization-filter-results"
More Information needed
|
[
"# Dataset Card for \"pile-semantic-memorization-filter-results\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pile-semantic-memorization-filter-results\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pile-semantic-memorization-filter-results\"\n\nMore Information needed"
] |
2a49533c9cca3931f536c9e68240100eb0f72322
|
# Dataset Card for "arxiv-abstracts-full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
etanios/arxiv-abstracts-full
|
[
"region:us"
] |
2023-09-19T17:18:30+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "Index", "dtype": "int64"}, {"name": "title", "dtype": "string"}, {"name": "abstract", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 11196483, "num_examples": 9999}], "download_size": 6348986, "dataset_size": 11196483}}
|
2023-09-19T18:23:42+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "arxiv-abstracts-full"
More Information needed
|
[
"# Dataset Card for \"arxiv-abstracts-full\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"arxiv-abstracts-full\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"arxiv-abstracts-full\"\n\nMore Information needed"
] |
ded3c9884b1c8615c4c8e7301ca5d6dd10189f3d
|
# Dataset Card for "chitanka_raw"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mor40/chitanka_raw
|
[
"region:us"
] |
2023-09-19T17:22:58+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1850114657, "num_examples": 6420172}], "download_size": 927214814, "dataset_size": 1850114657}}
|
2023-09-19T18:03:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chitanka_raw"
More Information needed
|
[
"# Dataset Card for \"chitanka_raw\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chitanka_raw\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chitanka_raw\"\n\nMore Information needed"
] |
1f5b27ccc2f0b0a2cad9c29a19bdca5b618e5018
|
# Dataset Card for "guanaco-llama2-1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
kyzor/guanaco-llama2-1k
|
[
"region:us"
] |
2023-09-19T17:55:51+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1654448, "num_examples": 1000}], "download_size": 966693, "dataset_size": 1654448}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T17:55:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "guanaco-llama2-1k"
More Information needed
|
[
"# Dataset Card for \"guanaco-llama2-1k\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"guanaco-llama2-1k\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"guanaco-llama2-1k\"\n\nMore Information needed"
] |
f0b36ac3f788052ae1acc8e9fd8230abce0766bd
|
# Dataset Card for "multilingual"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
orgcatorg/multilingual
|
[
"region:us"
] |
2023-09-19T17:55:56+00:00
|
{"dataset_info": [{"config_name": "eng_Latn-ben_Beng", "features": [{"name": "translation", "struct": [{"name": "ben_Beng", "dtype": "string"}, {"name": "eng_Latn", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 861347100, "num_examples": 3807057}], "download_size": 457359684, "dataset_size": 861347100}, {"config_name": "eng_Latn-hin_Deva", "features": [{"name": "translation", "struct": [{"name": "eng_Latn", "dtype": "string"}, {"name": "hin_Deva", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 1835061414, "num_examples": 5525375}], "download_size": 966770811, "dataset_size": 1835061414}, {"config_name": "eng_Latn-lao_Laoo", "features": [{"name": "translation", "struct": [{"name": "eng_Latn", "dtype": "string"}, {"name": "lao_Laoo", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 42871606, "num_examples": 140265}], "download_size": 23468883, "dataset_size": 42871606}, {"config_name": "eng_Latn-mya_Mymr", "features": [{"name": "translation", "struct": [{"name": "eng_Latn", "dtype": "string"}, {"name": "mya_Mymr", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 70235556, "num_examples": 248767}], "download_size": 34667809, "dataset_size": 70235556}, {"config_name": "eng_Latn-tgl_Latn", "features": [{"name": "translation", "struct": [{"name": "eng_Latn", "dtype": "string"}, {"name": "tgl_Latn", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 860044626, "num_examples": 4335174}], "download_size": 602646732, "dataset_size": 860044626}, {"config_name": "eng_Latn-tha_Thai", "features": [{"name": "translation", "struct": [{"name": "eng_Latn", "dtype": "string"}, {"name": "tha_Thai", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 433620969, "num_examples": 1388326}], "download_size": 231017202, "dataset_size": 433620969}, {"config_name": "eng_Latn-vie_Latn", "features": [{"name": "translation", "struct": [{"name": "eng_Latn", "dtype": "string"}, {"name": "vie_Latn", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 2088114876, "num_examples": 8742176}], "download_size": 1386936411, "dataset_size": 2088114876}], "configs": [{"config_name": "eng_Latn-ben_Beng", "data_files": [{"split": "train", "path": "eng_Latn-ben_Beng/train-*"}]}, {"config_name": "eng_Latn-hin_Deva", "data_files": [{"split": "train", "path": "eng_Latn-hin_Deva/train-*"}]}, {"config_name": "eng_Latn-lao_Laoo", "data_files": [{"split": "train", "path": "eng_Latn-lao_Laoo/train-*"}]}, {"config_name": "eng_Latn-mya_Mymr", "data_files": [{"split": "train", "path": "eng_Latn-mya_Mymr/train-*"}]}, {"config_name": "eng_Latn-tgl_Latn", "data_files": [{"split": "train", "path": "eng_Latn-tgl_Latn/train-*"}]}, {"config_name": "eng_Latn-tha_Thai", "data_files": [{"split": "train", "path": "eng_Latn-tha_Thai/train-*"}]}, {"config_name": "eng_Latn-vie_Latn", "data_files": [{"split": "train", "path": "eng_Latn-vie_Latn/train-*"}]}]}
|
2024-01-17T04:11:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "multilingual"
More Information needed
|
[
"# Dataset Card for \"multilingual\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"multilingual\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"multilingual\"\n\nMore Information needed"
] |
0ea5e24551eb4078ee1a5f10710c59466b42567d
|
# This is a Quranic Bangla Databse
- Here bangla meaning for every quranic verse's word
- Developed By Students of IIT, University of Dhaka
- An Open Source Project of Learn Meaning of Quran in Bangla Movement
|
mdrakibtrofder/quranic_bangla
|
[
"license:mit",
"region:us"
] |
2023-09-19T18:17:14+00:00
|
{"license": "mit"}
|
2023-09-20T01:05:47+00:00
|
[] |
[] |
TAGS
#license-mit #region-us
|
# This is a Quranic Bangla Databse
- Here bangla meaning for every quranic verse's word
- Developed By Students of IIT, University of Dhaka
- An Open Source Project of Learn Meaning of Quran in Bangla Movement
|
[
"# This is a Quranic Bangla Databse\n- Here bangla meaning for every quranic verse's word\n- Developed By Students of IIT, University of Dhaka\n- An Open Source Project of Learn Meaning of Quran in Bangla Movement"
] |
[
"TAGS\n#license-mit #region-us \n",
"# This is a Quranic Bangla Databse\n- Here bangla meaning for every quranic verse's word\n- Developed By Students of IIT, University of Dhaka\n- An Open Source Project of Learn Meaning of Quran in Bangla Movement"
] |
[
11,
51
] |
[
"passage: TAGS\n#license-mit #region-us \n# This is a Quranic Bangla Databse\n- Here bangla meaning for every quranic verse's word\n- Developed By Students of IIT, University of Dhaka\n- An Open Source Project of Learn Meaning of Quran in Bangla Movement"
] |
7a4880ac8ac26b3e67fe879ec4e6bdfd3a43ffc4
|
# Electric Scooters Tracking
The dataset contains frames extracted from videos with people riding electric scooters. Each frame is accompanied by **bounding box** that specifically **tracks the electric scooter** in the image.
This dataset can be useful for *object detection, motion tracking, behavior analysis, autonomous vehicle development and smart city*.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=electric-scooters-tracking) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
The dataset consists of 3 folders with frames from the video with people riding an electric scooter.
Each folder includes:
- **images**: folder with original frames from the video,
- **boxes**: visualized data labeling for the images in the previous folder,
- **.csv file**: file with id and path of each frame in the "images" folder,
- **annotations.xml**: contains coordinates of the bounding boxes and labels, created for the original frames
# Data Format
Each frame from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for electric scooter tracking. For each point, the x and y coordinates are provided.
# Example of the XML-file
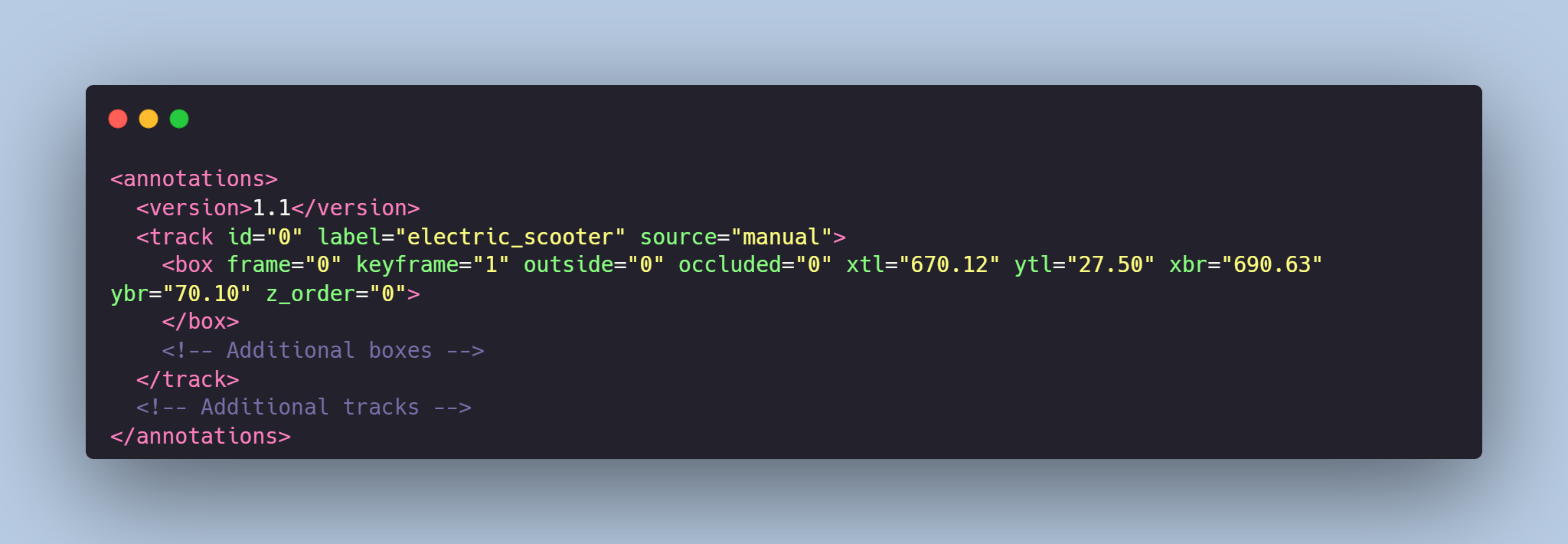
# Object tracking might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=electric-scooters-tracking) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro**
|
TrainingDataPro/electric-scooters-tracking
|
[
"task_categories:image-to-image",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"legal",
"region:us"
] |
2023-09-19T18:29:09+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-to-image", "object-detection"], "tags": ["code", "legal"], "dataset_info": [{"config_name": "video_01", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "sequence": [{"name": "track_id", "dtype": "uint32"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "electric_scooter"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 9312, "num_examples": 22}], "download_size": 8409013, "dataset_size": 9312}, {"config_name": "video_02", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "sequence": [{"name": "track_id", "dtype": "uint32"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "electric_scooter"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 10583, "num_examples": 25}], "download_size": 48396353, "dataset_size": 10583}, {"config_name": "video_03", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "sequence": [{"name": "track_id", "dtype": "uint32"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "electric_scooter"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 8466, "num_examples": 20}], "download_size": 13600750, "dataset_size": 8466}]}
|
2023-10-03T13:01:06+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-to-image #task_categories-object-detection #language-English #license-cc-by-nc-nd-4.0 #code #legal #region-us
|
# Electric Scooters Tracking
The dataset contains frames extracted from videos with people riding electric scooters. Each frame is accompanied by bounding box that specifically tracks the electric scooter in the image.
This dataset can be useful for *object detection, motion tracking, behavior analysis, autonomous vehicle development and smart city*.

|
temasarkisov/EsportLogos1_processed_V2
|
[
"region:us"
] |
2023-09-19T18:45:26+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 8153726.0, "num_examples": 70}], "download_size": 8149750, "dataset_size": 8153726.0}}
|
2023-09-19T18:45:30+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "EsportLogos1_processed_V2"
More Information needed
|
[
"# Dataset Card for \"EsportLogos1_processed_V2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"EsportLogos1_processed_V2\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"EsportLogos1_processed_V2\"\n\nMore Information needed"
] |
be8488f1a929193b6464809df2b7ee0b43d42974
|
This is the query dataset taken directly from https://github.com/openai/summarize-from-feedback/tree/700967448d10004279f138666442bf1497d0e705#reddit-tldr-dataset
|
vwxyzjn/summarize_from_feedback_tldr_3_filtered
|
[
"task_categories:summarization",
"size_categories:1K<n<10K",
"language:en",
"license:mit",
"region:us"
] |
2023-09-19T19:07:59+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["summarization"]}
|
2023-09-19T19:10:04+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-summarization #size_categories-1K<n<10K #language-English #license-mit #region-us
|
This is the query dataset taken directly from URL
|
[] |
[
"TAGS\n#task_categories-summarization #size_categories-1K<n<10K #language-English #license-mit #region-us \n"
] |
[
37
] |
[
"passage: TAGS\n#task_categories-summarization #size_categories-1K<n<10K #language-English #license-mit #region-us \n"
] |
cf16aea9a672af1da7a46fcc45affeb38c8d5aab
|
<h1 align="center">Fin-Fact - Financial Fact-Checking Dataset</h1>
## Table of Contents
- [Overview](#overview)
- [Dataset Description](#dataset-description)
- [Dataset Usage](#dataset-usage)
- [Leaderboard](#leaderboard)
- [Dependencies](#dependencies)
- [Run models for paper metrics](#run-models-for-paper-metrics)
- [Citation](#citation)
- [Contribution](#contribution)
- [License](#license)
- [Contact](#contact)
## Overview
Welcome to the Fin-Fact repository! Fin-Fact is a comprehensive dataset designed specifically for financial fact-checking and explanation generation. This README provides an overview of the dataset, how to use it, and other relevant information. [Click here](https://arxiv.org/abs/2309.08793) to access the paper.
## Dataset Description
- **Name**: Fin-Fact
- **Purpose**: Fact-checking and explanation generation in the financial domain.
- **Labels**: The dataset includes various labels, including Claim, Author, Posted Date, Sci-digest, Justification, Evidence, Evidence href, Image href, Image Caption, Visualisation Bias Label, Issues, and Claim Label.
- **Size**: The dataset consists of 3121 claims spanning multiple financial sectors.
- **Additional Features**: The dataset goes beyond textual claims and incorporates visual elements, including images and their captions.
## Dataset Usage
Fin-Fact is a valuable resource for researchers, data scientists, and fact-checkers in the financial domain. Here's how you can use it:
1. **Download the Dataset**: You can download the Fin-Fact dataset [here](https://github.com/IIT-DM/Fin-Fact/blob/FinFact/finfact.json).
2. **Exploratory Data Analysis**: Perform exploratory data analysis to understand the dataset's structure, distribution, and any potential biases.
3. **Natural Language Processing (NLP) Tasks**: Utilize the dataset for various NLP tasks such as fact-checking, claim verification, and explanation generation.
4. **Fact Checking Experiments**: Train and evaluate machine learning models, including text and image analysis, using the dataset to enhance the accuracy of fact-checking systems.
## Leaderboard
## Dependencies
We recommend you create an anaconda environment:
`conda create --name finfact python=3.6 conda-build`
Then, install Python requirements:
`pip install -r requirements.txt`
## Run models for paper metrics
We provide scripts let you easily run our dataset on existing state-of-the-art models and re-create the metrics published in paper. You should be able to reproduce our results from the paper by following these instructions. Please post an issue if you're unable to do this.
To run existing ANLI models for fact checking.
### Run:
1. BART
```bash
python anli.py --model_name 'ynie/bart-large-snli_mnli_fever_anli_R1_R2_R3-nli' --data_file finfact.json --threshold 0.5
```
2. RoBERTa
```bash
python anli.py --model_name 'ynie/roberta-large-snli_mnli_fever_anli_R1_R2_R3-nli' --data_file finfact.json --threshold 0.5
```
3. ELECTRA
```bash
python anli.py --model_name 'ynie/electra-large-discriminator-snli_mnli_fever_anli_R1_R2_R3-nli' --data_file finfact.json --threshold 0.5
```
4. AlBERT
```bash
python anli.py --model_name 'ynie/albert-xxlarge-v2-snli_mnli_fever_anli_R1_R2_R3-nli' --data_file finfact.json --threshold 0.5
```
5. XLNET
```bash
python anli.py --model_name 'ynie/xlnet-large-cased-snli_mnli_fever_anli_R1_R2_R3-nli' --data_file finfact.json --threshold 0.5
```
6. GPT-2
```bash
python gpt2_nli.py --model_name 'fractalego/fact-checking' --data_file finfact.json
```
## Citation
```
@misc{rangapur2023finfact,
title={Fin-Fact: A Benchmark Dataset for Multimodal Financial Fact Checking and Explanation Generation},
author={Aman Rangapur and Haoran Wang and Kai Shu},
year={2023},
eprint={2309.08793},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
## Contribution
We welcome contributions from the community to help improve Fin-Fact. If you have suggestions, bug reports, or want to contribute code or data, please check our [CONTRIBUTING.md](CONTRIBUTING.md) file for guidelines.
## License
Fin-Fact is released under the [MIT License](/LICENSE). Please review the license before using the dataset.
## Contact
For questions, feedback, or inquiries related to Fin-Fact, please contact `[email protected]`.
We hope you find Fin-Fact valuable for your research and fact-checking endeavors. Happy fact-checking!
|
amanrangapur/Fin-Fact
|
[
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"finance",
"arxiv:2309.08793",
"region:us"
] |
2023-09-19T19:39:54+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["text-classification", "text-generation"], "pretty_name": "FinFact", "tags": ["finance"], "dataset_info": [{"config_name": "generation", "features": [{"name": "url", "dtype": "string"}, {"name": "claim", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "posted", "dtype": "string"}]}]}
|
2023-09-19T21:40:19+00:00
|
[
"2309.08793"
] |
[
"en"
] |
TAGS
#task_categories-text-classification #task_categories-text-generation #size_categories-1K<n<10K #language-English #license-apache-2.0 #finance #arxiv-2309.08793 #region-us
|
<h1 align="center">Fin-Fact - Financial Fact-Checking Dataset</h1>
## Table of Contents
- Overview
- Dataset Description
- Dataset Usage
- Leaderboard
- Dependencies
- Run models for paper metrics
- Citation
- Contribution
- License
- Contact
## Overview
Welcome to the Fin-Fact repository! Fin-Fact is a comprehensive dataset designed specifically for financial fact-checking and explanation generation. This README provides an overview of the dataset, how to use it, and other relevant information. Click here to access the paper.
## Dataset Description
- Name: Fin-Fact
- Purpose: Fact-checking and explanation generation in the financial domain.
- Labels: The dataset includes various labels, including Claim, Author, Posted Date, Sci-digest, Justification, Evidence, Evidence href, Image href, Image Caption, Visualisation Bias Label, Issues, and Claim Label.
- Size: The dataset consists of 3121 claims spanning multiple financial sectors.
- Additional Features: The dataset goes beyond textual claims and incorporates visual elements, including images and their captions.
## Dataset Usage
Fin-Fact is a valuable resource for researchers, data scientists, and fact-checkers in the financial domain. Here's how you can use it:
1. Download the Dataset: You can download the Fin-Fact dataset here.
2. Exploratory Data Analysis: Perform exploratory data analysis to understand the dataset's structure, distribution, and any potential biases.
3. Natural Language Processing (NLP) Tasks: Utilize the dataset for various NLP tasks such as fact-checking, claim verification, and explanation generation.
4. Fact Checking Experiments: Train and evaluate machine learning models, including text and image analysis, using the dataset to enhance the accuracy of fact-checking systems.
## Leaderboard
## Dependencies
We recommend you create an anaconda environment:
'conda create --name finfact python=3.6 conda-build'
Then, install Python requirements:
'pip install -r URL'
## Run models for paper metrics
We provide scripts let you easily run our dataset on existing state-of-the-art models and re-create the metrics published in paper. You should be able to reproduce our results from the paper by following these instructions. Please post an issue if you're unable to do this.
To run existing ANLI models for fact checking.
### Run:
1. BART
2. RoBERTa
3. ELECTRA
4. AlBERT
5. XLNET
6. GPT-2
## Contribution
We welcome contributions from the community to help improve Fin-Fact. If you have suggestions, bug reports, or want to contribute code or data, please check our URL file for guidelines.
## License
Fin-Fact is released under the MIT License. Please review the license before using the dataset.
## Contact
For questions, feedback, or inquiries related to Fin-Fact, please contact 'arangapur@URL'.
We hope you find Fin-Fact valuable for your research and fact-checking endeavors. Happy fact-checking!
|
[
"## Table of Contents\n\n- Overview\n- Dataset Description\n- Dataset Usage\n- Leaderboard\n- Dependencies\n- Run models for paper metrics\n- Citation\n- Contribution\n- License\n- Contact",
"## Overview\n\nWelcome to the Fin-Fact repository! Fin-Fact is a comprehensive dataset designed specifically for financial fact-checking and explanation generation. This README provides an overview of the dataset, how to use it, and other relevant information. Click here to access the paper.",
"## Dataset Description\n\n- Name: Fin-Fact\n- Purpose: Fact-checking and explanation generation in the financial domain.\n- Labels: The dataset includes various labels, including Claim, Author, Posted Date, Sci-digest, Justification, Evidence, Evidence href, Image href, Image Caption, Visualisation Bias Label, Issues, and Claim Label.\n- Size: The dataset consists of 3121 claims spanning multiple financial sectors.\n- Additional Features: The dataset goes beyond textual claims and incorporates visual elements, including images and their captions.",
"## Dataset Usage\n\nFin-Fact is a valuable resource for researchers, data scientists, and fact-checkers in the financial domain. Here's how you can use it:\n\n1. Download the Dataset: You can download the Fin-Fact dataset here.\n\n2. Exploratory Data Analysis: Perform exploratory data analysis to understand the dataset's structure, distribution, and any potential biases.\n\n3. Natural Language Processing (NLP) Tasks: Utilize the dataset for various NLP tasks such as fact-checking, claim verification, and explanation generation.\n\n4. Fact Checking Experiments: Train and evaluate machine learning models, including text and image analysis, using the dataset to enhance the accuracy of fact-checking systems.",
"## Leaderboard",
"## Dependencies\nWe recommend you create an anaconda environment:\n\n'conda create --name finfact python=3.6 conda-build'\n\nThen, install Python requirements:\n\n'pip install -r URL'",
"## Run models for paper metrics\n\nWe provide scripts let you easily run our dataset on existing state-of-the-art models and re-create the metrics published in paper. You should be able to reproduce our results from the paper by following these instructions. Please post an issue if you're unable to do this.\nTo run existing ANLI models for fact checking.",
"### Run:\n1. BART\n\n2. RoBERTa\n\n3. ELECTRA\n\n4. AlBERT\n\n5. XLNET\n\n6. GPT-2",
"## Contribution\n\nWe welcome contributions from the community to help improve Fin-Fact. If you have suggestions, bug reports, or want to contribute code or data, please check our URL file for guidelines.",
"## License\n\nFin-Fact is released under the MIT License. Please review the license before using the dataset.",
"## Contact\nFor questions, feedback, or inquiries related to Fin-Fact, please contact 'arangapur@URL'.\n\nWe hope you find Fin-Fact valuable for your research and fact-checking endeavors. Happy fact-checking!"
] |
[
"TAGS\n#task_categories-text-classification #task_categories-text-generation #size_categories-1K<n<10K #language-English #license-apache-2.0 #finance #arxiv-2309.08793 #region-us \n",
"## Table of Contents\n\n- Overview\n- Dataset Description\n- Dataset Usage\n- Leaderboard\n- Dependencies\n- Run models for paper metrics\n- Citation\n- Contribution\n- License\n- Contact",
"## Overview\n\nWelcome to the Fin-Fact repository! Fin-Fact is a comprehensive dataset designed specifically for financial fact-checking and explanation generation. This README provides an overview of the dataset, how to use it, and other relevant information. Click here to access the paper.",
"## Dataset Description\n\n- Name: Fin-Fact\n- Purpose: Fact-checking and explanation generation in the financial domain.\n- Labels: The dataset includes various labels, including Claim, Author, Posted Date, Sci-digest, Justification, Evidence, Evidence href, Image href, Image Caption, Visualisation Bias Label, Issues, and Claim Label.\n- Size: The dataset consists of 3121 claims spanning multiple financial sectors.\n- Additional Features: The dataset goes beyond textual claims and incorporates visual elements, including images and their captions.",
"## Dataset Usage\n\nFin-Fact is a valuable resource for researchers, data scientists, and fact-checkers in the financial domain. Here's how you can use it:\n\n1. Download the Dataset: You can download the Fin-Fact dataset here.\n\n2. Exploratory Data Analysis: Perform exploratory data analysis to understand the dataset's structure, distribution, and any potential biases.\n\n3. Natural Language Processing (NLP) Tasks: Utilize the dataset for various NLP tasks such as fact-checking, claim verification, and explanation generation.\n\n4. Fact Checking Experiments: Train and evaluate machine learning models, including text and image analysis, using the dataset to enhance the accuracy of fact-checking systems.",
"## Leaderboard",
"## Dependencies\nWe recommend you create an anaconda environment:\n\n'conda create --name finfact python=3.6 conda-build'\n\nThen, install Python requirements:\n\n'pip install -r URL'",
"## Run models for paper metrics\n\nWe provide scripts let you easily run our dataset on existing state-of-the-art models and re-create the metrics published in paper. You should be able to reproduce our results from the paper by following these instructions. Please post an issue if you're unable to do this.\nTo run existing ANLI models for fact checking.",
"### Run:\n1. BART\n\n2. RoBERTa\n\n3. ELECTRA\n\n4. AlBERT\n\n5. XLNET\n\n6. GPT-2",
"## Contribution\n\nWe welcome contributions from the community to help improve Fin-Fact. If you have suggestions, bug reports, or want to contribute code or data, please check our URL file for guidelines.",
"## License\n\nFin-Fact is released under the MIT License. Please review the license before using the dataset.",
"## Contact\nFor questions, feedback, or inquiries related to Fin-Fact, please contact 'arangapur@URL'.\n\nWe hope you find Fin-Fact valuable for your research and fact-checking endeavors. Happy fact-checking!"
] |
[
64,
41,
64,
133,
165,
3,
45,
81,
26,
42,
23,
56
] |
[
"passage: TAGS\n#task_categories-text-classification #task_categories-text-generation #size_categories-1K<n<10K #language-English #license-apache-2.0 #finance #arxiv-2309.08793 #region-us \n## Table of Contents\n\n- Overview\n- Dataset Description\n- Dataset Usage\n- Leaderboard\n- Dependencies\n- Run models for paper metrics\n- Citation\n- Contribution\n- License\n- Contact## Overview\n\nWelcome to the Fin-Fact repository! Fin-Fact is a comprehensive dataset designed specifically for financial fact-checking and explanation generation. This README provides an overview of the dataset, how to use it, and other relevant information. Click here to access the paper.## Dataset Description\n\n- Name: Fin-Fact\n- Purpose: Fact-checking and explanation generation in the financial domain.\n- Labels: The dataset includes various labels, including Claim, Author, Posted Date, Sci-digest, Justification, Evidence, Evidence href, Image href, Image Caption, Visualisation Bias Label, Issues, and Claim Label.\n- Size: The dataset consists of 3121 claims spanning multiple financial sectors.\n- Additional Features: The dataset goes beyond textual claims and incorporates visual elements, including images and their captions.## Dataset Usage\n\nFin-Fact is a valuable resource for researchers, data scientists, and fact-checkers in the financial domain. Here's how you can use it:\n\n1. Download the Dataset: You can download the Fin-Fact dataset here.\n\n2. Exploratory Data Analysis: Perform exploratory data analysis to understand the dataset's structure, distribution, and any potential biases.\n\n3. Natural Language Processing (NLP) Tasks: Utilize the dataset for various NLP tasks such as fact-checking, claim verification, and explanation generation.\n\n4. Fact Checking Experiments: Train and evaluate machine learning models, including text and image analysis, using the dataset to enhance the accuracy of fact-checking systems.## Leaderboard"
] |
e09174df1efba13fd83184f423ed00512820a5e4
|
# Dataset Card for "cifar10_TextLabels"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
MaxReynolds/cifar10_TextLabels
|
[
"region:us"
] |
2023-09-19T21:26:26+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 113699226.0, "num_examples": 50000}], "download_size": 119693021, "dataset_size": 113699226.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T21:26:43+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cifar10_TextLabels"
More Information needed
|
[
"# Dataset Card for \"cifar10_TextLabels\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cifar10_TextLabels\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cifar10_TextLabels\"\n\nMore Information needed"
] |
0282913ff3732027cf6fe0c996f3882bd6fbcf12
|
# Dataset Card for "saleswiz_gpt_is_relevant"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
factored/saleswiz_gpt_is_relevant
|
[
"region:us"
] |
2023-09-19T21:42:03+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 275081, "num_examples": 977}], "download_size": 176589, "dataset_size": 275081}}
|
2023-09-19T21:42:07+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "saleswiz_gpt_is_relevant"
More Information needed
|
[
"# Dataset Card for \"saleswiz_gpt_is_relevant\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"saleswiz_gpt_is_relevant\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"saleswiz_gpt_is_relevant\"\n\nMore Information needed"
] |
87042ec360018b424582095699739b019f8f5d5e
|
# Dataset Card for "github-issues"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jkv53/github-issues
|
[
"region:us"
] |
2023-09-19T21:57:51+00:00
|
{"dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "repository_url", "dtype": "string"}, {"name": "labels_url", "dtype": "string"}, {"name": "comments_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "number", "dtype": "int64"}, {"name": "title", "dtype": "string"}, {"name": "user", "struct": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "labels", "list": [{"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "name", "dtype": "string"}, {"name": "color", "dtype": "string"}, {"name": "default", "dtype": "bool"}, {"name": "description", "dtype": "string"}]}, {"name": "state", "dtype": "string"}, {"name": "locked", "dtype": "bool"}, {"name": "assignee", "struct": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "assignees", "list": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "milestone", "struct": [{"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "labels_url", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "number", "dtype": "int64"}, {"name": "title", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "creator", "struct": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "open_issues", "dtype": "int64"}, {"name": "closed_issues", "dtype": "int64"}, {"name": "state", "dtype": "string"}, {"name": "created_at", "dtype": "timestamp[s]"}, {"name": "updated_at", "dtype": "timestamp[s]"}, {"name": "due_on", "dtype": "null"}, {"name": "closed_at", "dtype": "null"}]}, {"name": "comments", "sequence": "string"}, {"name": "created_at", "dtype": "timestamp[s]"}, {"name": "updated_at", "dtype": "timestamp[s]"}, {"name": "closed_at", "dtype": "timestamp[s]"}, {"name": "author_association", "dtype": "string"}, {"name": "active_lock_reason", "dtype": "null"}, {"name": "draft", "dtype": "bool"}, {"name": "pull_request", "struct": [{"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "diff_url", "dtype": "string"}, {"name": "patch_url", "dtype": "string"}, {"name": "merged_at", "dtype": "timestamp[s]"}]}, {"name": "body", "dtype": "string"}, {"name": "reactions", "struct": [{"name": "url", "dtype": "string"}, {"name": "total_count", "dtype": "int64"}, {"name": "+1", "dtype": "int64"}, {"name": "-1", "dtype": "int64"}, {"name": "laugh", "dtype": "int64"}, {"name": "hooray", "dtype": "int64"}, {"name": "confused", "dtype": "int64"}, {"name": "heart", "dtype": "int64"}, {"name": "rocket", "dtype": "int64"}, {"name": "eyes", "dtype": "int64"}]}, {"name": "timeline_url", "dtype": "string"}, {"name": "performed_via_github_app", "dtype": "null"}, {"name": "state_reason", "dtype": "string"}, {"name": "is_pull_request", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 12210485, "num_examples": 1000}], "download_size": 3297420, "dataset_size": 12210485}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-19T21:57:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "github-issues"
More Information needed
|
[
"# Dataset Card for \"github-issues\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"github-issues\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"github-issues\"\n\nMore Information needed"
] |
d7bd74cd9c2aec3ef9afdf6fe45921842a93a125
|
# Stable Diffusion web UI
A browser interface based on Gradio library for Stable Diffusion.

## Features
[Detailed feature showcase with images](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features):
- Original txt2img and img2img modes
- One click install and run script (but you still must install python and git)
- Outpainting
- Inpainting
- Color Sketch
- Prompt Matrix
- Stable Diffusion Upscale
- Attention, specify parts of text that the model should pay more attention to
- a man in a `((tuxedo))` - will pay more attention to tuxedo
- a man in a `(tuxedo:1.21)` - alternative syntax
- select text and press `Ctrl+Up` or `Ctrl+Down` (or `Command+Up` or `Command+Down` if you're on a MacOS) to automatically adjust attention to selected text (code contributed by anonymous user)
- Loopback, run img2img processing multiple times
- X/Y/Z plot, a way to draw a 3 dimensional plot of images with different parameters
- Textual Inversion
- have as many embeddings as you want and use any names you like for them
- use multiple embeddings with different numbers of vectors per token
- works with half precision floating point numbers
- train embeddings on 8GB (also reports of 6GB working)
- Extras tab with:
- GFPGAN, neural network that fixes faces
- CodeFormer, face restoration tool as an alternative to GFPGAN
- RealESRGAN, neural network upscaler
- ESRGAN, neural network upscaler with a lot of third party models
- SwinIR and Swin2SR ([see here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/2092)), neural network upscalers
- LDSR, Latent diffusion super resolution upscaling
- Resizing aspect ratio options
- Sampling method selection
- Adjust sampler eta values (noise multiplier)
- More advanced noise setting options
- Interrupt processing at any time
- 4GB video card support (also reports of 2GB working)
- Correct seeds for batches
- Live prompt token length validation
- Generation parameters
- parameters you used to generate images are saved with that image
- in PNG chunks for PNG, in EXIF for JPEG
- can drag the image to PNG info tab to restore generation parameters and automatically copy them into UI
- can be disabled in settings
- drag and drop an image/text-parameters to promptbox
- Read Generation Parameters Button, loads parameters in promptbox to UI
- Settings page
- Running arbitrary python code from UI (must run with `--allow-code` to enable)
- Mouseover hints for most UI elements
- Possible to change defaults/mix/max/step values for UI elements via text config
- Tiling support, a checkbox to create images that can be tiled like textures
- Progress bar and live image generation preview
- Can use a separate neural network to produce previews with almost none VRAM or compute requirement
- Negative prompt, an extra text field that allows you to list what you don't want to see in generated image
- Styles, a way to save part of prompt and easily apply them via dropdown later
- Variations, a way to generate same image but with tiny differences
- Seed resizing, a way to generate same image but at slightly different resolution
- CLIP interrogator, a button that tries to guess prompt from an image
- Prompt Editing, a way to change prompt mid-generation, say to start making a watermelon and switch to anime girl midway
- Batch Processing, process a group of files using img2img
- Img2img Alternative, reverse Euler method of cross attention control
- Highres Fix, a convenience option to produce high resolution pictures in one click without usual distortions
- Reloading checkpoints on the fly
- Checkpoint Merger, a tab that allows you to merge up to 3 checkpoints into one
- [Custom scripts](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Custom-Scripts) with many extensions from community
- [Composable-Diffusion](https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/), a way to use multiple prompts at once
- separate prompts using uppercase `AND`
- also supports weights for prompts: `a cat :1.2 AND a dog AND a penguin :2.2`
- No token limit for prompts (original stable diffusion lets you use up to 75 tokens)
- DeepDanbooru integration, creates danbooru style tags for anime prompts
- [xformers](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Xformers), major speed increase for select cards: (add `--xformers` to commandline args)
- via extension: [History tab](https://github.com/yfszzx/stable-diffusion-webui-images-browser): view, direct and delete images conveniently within the UI
- Generate forever option
- Training tab
- hypernetworks and embeddings options
- Preprocessing images: cropping, mirroring, autotagging using BLIP or deepdanbooru (for anime)
- Clip skip
- Hypernetworks
- Loras (same as Hypernetworks but more pretty)
- A separate UI where you can choose, with preview, which embeddings, hypernetworks or Loras to add to your prompt
- Can select to load a different VAE from settings screen
- Estimated completion time in progress bar
- API
- Support for dedicated [inpainting model](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion) by RunwayML
- via extension: [Aesthetic Gradients](https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients), a way to generate images with a specific aesthetic by using clip images embeds (implementation of [https://github.com/vicgalle/stable-diffusion-aesthetic-gradients](https://github.com/vicgalle/stable-diffusion-aesthetic-gradients))
- [Stable Diffusion 2.0](https://github.com/Stability-AI/stablediffusion) support - see [wiki](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#stable-diffusion-20) for instructions
- [Alt-Diffusion](https://arxiv.org/abs/2211.06679) support - see [wiki](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#alt-diffusion) for instructions
- Now without any bad letters!
- Load checkpoints in safetensors format
- Eased resolution restriction: generated image's dimension must be a multiple of 8 rather than 64
- Now with a license!
- Reorder elements in the UI from settings screen
## Installation and Running
Make sure the required [dependencies](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Dependencies) are met and follow the instructions available for:
- [NVidia](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs) (recommended)
- [AMD](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs) GPUs.
- [Intel CPUs, Intel GPUs (both integrated and discrete)](https://github.com/openvinotoolkit/stable-diffusion-webui/wiki/Installation-on-Intel-Silicon) (external wiki page)
Alternatively, use online services (like Google Colab):
- [List of Online Services](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Online-Services)
### Installation on Windows 10/11 with NVidia-GPUs using release package
1. Download `sd.webui.zip` from [v1.0.0-pre](https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre) and extract it's contents.
2. Run `update.bat`.
3. Run `run.bat`.
> For more details see [Install-and-Run-on-NVidia-GPUs](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs)
### Automatic Installation on Windows
1. Install [Python 3.10.6](https://www.python.org/downloads/release/python-3106/) (Newer version of Python does not support torch), checking "Add Python to PATH".
2. Install [git](https://git-scm.com/download/win).
3. Download the stable-diffusion-webui repository, for example by running `git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git`.
4. Run `webui-user.bat` from Windows Explorer as normal, non-administrator, user.
### Automatic Installation on Linux
1. Install the dependencies:
```bash
# Debian-based:
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
# Red Hat-based:
sudo dnf install wget git python3
# Arch-based:
sudo pacman -S wget git python3
```
2. Navigate to the directory you would like the webui to be installed and execute the following command:
```bash
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
```
3. Run `webui.sh`.
4. Check `webui-user.sh` for options.
### Installation on Apple Silicon
Find the instructions [here](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon).
## Contributing
Here's how to add code to this repo: [Contributing](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
## Documentation
The documentation was moved from this README over to the project's [wiki](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki).
For the purposes of getting Google and other search engines to crawl the wiki, here's a link to the (not for humans) [crawlable wiki](https://github-wiki-see.page/m/AUTOMATIC1111/stable-diffusion-webui/wiki).
## Credits
Licenses for borrowed code can be found in `Settings -> Licenses` screen, and also in `html/licenses.html` file.
- Stable Diffusion - https://github.com/CompVis/stable-diffusion, https://github.com/CompVis/taming-transformers
- k-diffusion - https://github.com/crowsonkb/k-diffusion.git
- GFPGAN - https://github.com/TencentARC/GFPGAN.git
- CodeFormer - https://github.com/sczhou/CodeFormer
- ESRGAN - https://github.com/xinntao/ESRGAN
- SwinIR - https://github.com/JingyunLiang/SwinIR
- Swin2SR - https://github.com/mv-lab/swin2sr
- LDSR - https://github.com/Hafiidz/latent-diffusion
- MiDaS - https://github.com/isl-org/MiDaS
- Ideas for optimizations - https://github.com/basujindal/stable-diffusion
- Cross Attention layer optimization - Doggettx - https://github.com/Doggettx/stable-diffusion, original idea for prompt editing.
- Cross Attention layer optimization - InvokeAI, lstein - https://github.com/invoke-ai/InvokeAI (originally http://github.com/lstein/stable-diffusion)
- Sub-quadratic Cross Attention layer optimization - Alex Birch (https://github.com/Birch-san/diffusers/pull/1), Amin Rezaei (https://github.com/AminRezaei0x443/memory-efficient-attention)
- Textual Inversion - Rinon Gal - https://github.com/rinongal/textual_inversion (we're not using his code, but we are using his ideas).
- Idea for SD upscale - https://github.com/jquesnelle/txt2imghd
- Noise generation for outpainting mk2 - https://github.com/parlance-zz/g-diffuser-bot
- CLIP interrogator idea and borrowing some code - https://github.com/pharmapsychotic/clip-interrogator
- Idea for Composable Diffusion - https://github.com/energy-based-model/Compositional-Visual-Generation-with-Composable-Diffusion-Models-PyTorch
- xformers - https://github.com/facebookresearch/xformers
- DeepDanbooru - interrogator for anime diffusers https://github.com/KichangKim/DeepDanbooru
- Sampling in float32 precision from a float16 UNet - marunine for the idea, Birch-san for the example Diffusers implementation (https://github.com/Birch-san/diffusers-play/tree/92feee6)
- Instruct pix2pix - Tim Brooks (star), Aleksander Holynski (star), Alexei A. Efros (no star) - https://github.com/timothybrooks/instruct-pix2pix
- Security advice - RyotaK
- UniPC sampler - Wenliang Zhao - https://github.com/wl-zhao/UniPC
- TAESD - Ollin Boer Bohan - https://github.com/madebyollin/taesd
- LyCORIS - KohakuBlueleaf
- Restart sampling - lambertae - https://github.com/Newbeeer/diffusion_restart_sampling
- Initial Gradio script - posted on 4chan by an Anonymous user. Thank you Anonymous user.
- (You)
|
Kizi-Art/azviya-channel
|
[
"arxiv:2211.06679",
"region:us"
] |
2023-09-19T22:26:03+00:00
|
{}
|
2023-09-19T22:56:21+00:00
|
[
"2211.06679"
] |
[] |
TAGS
#arxiv-2211.06679 #region-us
|
# Stable Diffusion web UI
A browser interface based on Gradio library for Stable Diffusion.

## Features
Detailed feature showcase with images:
- Original txt2img and img2img modes
- One click install and run script (but you still must install python and git)
- Outpainting
- Inpainting
- Color Sketch
- Prompt Matrix
- Stable Diffusion Upscale
- Attention, specify parts of text that the model should pay more attention to
- a man in a '((tuxedo))' - will pay more attention to tuxedo
- a man in a '(tuxedo:1.21)' - alternative syntax
- select text and press 'Ctrl+Up' or 'Ctrl+Down' (or 'Command+Up' or 'Command+Down' if you're on a MacOS) to automatically adjust attention to selected text (code contributed by anonymous user)
- Loopback, run img2img processing multiple times
- X/Y/Z plot, a way to draw a 3 dimensional plot of images with different parameters
- Textual Inversion
- have as many embeddings as you want and use any names you like for them
- use multiple embeddings with different numbers of vectors per token
- works with half precision floating point numbers
- train embeddings on 8GB (also reports of 6GB working)
- Extras tab with:
- GFPGAN, neural network that fixes faces
- CodeFormer, face restoration tool as an alternative to GFPGAN
- RealESRGAN, neural network upscaler
- ESRGAN, neural network upscaler with a lot of third party models
- SwinIR and Swin2SR (see here), neural network upscalers
- LDSR, Latent diffusion super resolution upscaling
- Resizing aspect ratio options
- Sampling method selection
- Adjust sampler eta values (noise multiplier)
- More advanced noise setting options
- Interrupt processing at any time
- 4GB video card support (also reports of 2GB working)
- Correct seeds for batches
- Live prompt token length validation
- Generation parameters
- parameters you used to generate images are saved with that image
- in PNG chunks for PNG, in EXIF for JPEG
- can drag the image to PNG info tab to restore generation parameters and automatically copy them into UI
- can be disabled in settings
- drag and drop an image/text-parameters to promptbox
- Read Generation Parameters Button, loads parameters in promptbox to UI
- Settings page
- Running arbitrary python code from UI (must run with '--allow-code' to enable)
- Mouseover hints for most UI elements
- Possible to change defaults/mix/max/step values for UI elements via text config
- Tiling support, a checkbox to create images that can be tiled like textures
- Progress bar and live image generation preview
- Can use a separate neural network to produce previews with almost none VRAM or compute requirement
- Negative prompt, an extra text field that allows you to list what you don't want to see in generated image
- Styles, a way to save part of prompt and easily apply them via dropdown later
- Variations, a way to generate same image but with tiny differences
- Seed resizing, a way to generate same image but at slightly different resolution
- CLIP interrogator, a button that tries to guess prompt from an image
- Prompt Editing, a way to change prompt mid-generation, say to start making a watermelon and switch to anime girl midway
- Batch Processing, process a group of files using img2img
- Img2img Alternative, reverse Euler method of cross attention control
- Highres Fix, a convenience option to produce high resolution pictures in one click without usual distortions
- Reloading checkpoints on the fly
- Checkpoint Merger, a tab that allows you to merge up to 3 checkpoints into one
- Custom scripts with many extensions from community
- Composable-Diffusion, a way to use multiple prompts at once
- separate prompts using uppercase 'AND'
- also supports weights for prompts: 'a cat :1.2 AND a dog AND a penguin :2.2'
- No token limit for prompts (original stable diffusion lets you use up to 75 tokens)
- DeepDanbooru integration, creates danbooru style tags for anime prompts
- xformers, major speed increase for select cards: (add '--xformers' to commandline args)
- via extension: History tab: view, direct and delete images conveniently within the UI
- Generate forever option
- Training tab
- hypernetworks and embeddings options
- Preprocessing images: cropping, mirroring, autotagging using BLIP or deepdanbooru (for anime)
- Clip skip
- Hypernetworks
- Loras (same as Hypernetworks but more pretty)
- A separate UI where you can choose, with preview, which embeddings, hypernetworks or Loras to add to your prompt
- Can select to load a different VAE from settings screen
- Estimated completion time in progress bar
- API
- Support for dedicated inpainting model by RunwayML
- via extension: Aesthetic Gradients, a way to generate images with a specific aesthetic by using clip images embeds (implementation of URL
- Stable Diffusion 2.0 support - see wiki for instructions
- Alt-Diffusion support - see wiki for instructions
- Now without any bad letters!
- Load checkpoints in safetensors format
- Eased resolution restriction: generated image's dimension must be a multiple of 8 rather than 64
- Now with a license!
- Reorder elements in the UI from settings screen
## Installation and Running
Make sure the required dependencies are met and follow the instructions available for:
- NVidia (recommended)
- AMD GPUs.
- Intel CPUs, Intel GPUs (both integrated and discrete) (external wiki page)
Alternatively, use online services (like Google Colab):
- List of Online Services
### Installation on Windows 10/11 with NVidia-GPUs using release package
1. Download 'URL' from v1.0.0-pre and extract it's contents.
2. Run 'URL'.
3. Run 'URL'.
> For more details see Install-and-Run-on-NVidia-GPUs
### Automatic Installation on Windows
1. Install Python 3.10.6 (Newer version of Python does not support torch), checking "Add Python to PATH".
2. Install git.
3. Download the stable-diffusion-webui repository, for example by running 'git clone URL
4. Run 'URL' from Windows Explorer as normal, non-administrator, user.
### Automatic Installation on Linux
1. Install the dependencies:
2. Navigate to the directory you would like the webui to be installed and execute the following command:
3. Run 'URL'.
4. Check 'URL' for options.
### Installation on Apple Silicon
Find the instructions here.
## Contributing
Here's how to add code to this repo: Contributing
## Documentation
The documentation was moved from this README over to the project's wiki.
For the purposes of getting Google and other search engines to crawl the wiki, here's a link to the (not for humans) crawlable wiki.
## Credits
Licenses for borrowed code can be found in 'Settings -> Licenses' screen, and also in 'html/URL' file.
- Stable Diffusion - URL URL
- k-diffusion - URL
- GFPGAN - URL
- CodeFormer - URL
- ESRGAN - URL
- SwinIR - URL
- Swin2SR - URL
- LDSR - URL
- MiDaS - URL
- Ideas for optimizations - URL
- Cross Attention layer optimization - Doggettx - URL original idea for prompt editing.
- Cross Attention layer optimization - InvokeAI, lstein - URL (originally URL
- Sub-quadratic Cross Attention layer optimization - Alex Birch (URL Amin Rezaei (URL
- Textual Inversion - Rinon Gal - URL (we're not using his code, but we are using his ideas).
- Idea for SD upscale - URL
- Noise generation for outpainting mk2 - URL
- CLIP interrogator idea and borrowing some code - URL
- Idea for Composable Diffusion - URL
- xformers - URL
- DeepDanbooru - interrogator for anime diffusers URL
- Sampling in float32 precision from a float16 UNet - marunine for the idea, Birch-san for the example Diffusers implementation (URL
- Instruct pix2pix - Tim Brooks (star), Aleksander Holynski (star), Alexei A. Efros (no star) - URL
- Security advice - RyotaK
- UniPC sampler - Wenliang Zhao - URL
- TAESD - Ollin Boer Bohan - URL
- LyCORIS - KohakuBlueleaf
- Restart sampling - lambertae - URL
- Initial Gradio script - posted on 4chan by an Anonymous user. Thank you Anonymous user.
- (You)
|
[
"# Stable Diffusion web UI\nA browser interface based on Gradio library for Stable Diffusion.\n\n",
"## Features\nDetailed feature showcase with images:\n- Original txt2img and img2img modes\n- One click install and run script (but you still must install python and git)\n- Outpainting\n- Inpainting\n- Color Sketch\n- Prompt Matrix\n- Stable Diffusion Upscale\n- Attention, specify parts of text that the model should pay more attention to\n - a man in a '((tuxedo))' - will pay more attention to tuxedo\n - a man in a '(tuxedo:1.21)' - alternative syntax\n - select text and press 'Ctrl+Up' or 'Ctrl+Down' (or 'Command+Up' or 'Command+Down' if you're on a MacOS) to automatically adjust attention to selected text (code contributed by anonymous user)\n- Loopback, run img2img processing multiple times\n- X/Y/Z plot, a way to draw a 3 dimensional plot of images with different parameters\n- Textual Inversion\n - have as many embeddings as you want and use any names you like for them\n - use multiple embeddings with different numbers of vectors per token\n - works with half precision floating point numbers\n - train embeddings on 8GB (also reports of 6GB working)\n- Extras tab with:\n - GFPGAN, neural network that fixes faces\n - CodeFormer, face restoration tool as an alternative to GFPGAN\n - RealESRGAN, neural network upscaler\n - ESRGAN, neural network upscaler with a lot of third party models\n - SwinIR and Swin2SR (see here), neural network upscalers\n - LDSR, Latent diffusion super resolution upscaling\n- Resizing aspect ratio options\n- Sampling method selection\n - Adjust sampler eta values (noise multiplier)\n - More advanced noise setting options\n- Interrupt processing at any time\n- 4GB video card support (also reports of 2GB working)\n- Correct seeds for batches\n- Live prompt token length validation\n- Generation parameters\n - parameters you used to generate images are saved with that image\n - in PNG chunks for PNG, in EXIF for JPEG\n - can drag the image to PNG info tab to restore generation parameters and automatically copy them into UI\n - can be disabled in settings\n - drag and drop an image/text-parameters to promptbox\n- Read Generation Parameters Button, loads parameters in promptbox to UI\n- Settings page\n- Running arbitrary python code from UI (must run with '--allow-code' to enable)\n- Mouseover hints for most UI elements\n- Possible to change defaults/mix/max/step values for UI elements via text config\n- Tiling support, a checkbox to create images that can be tiled like textures\n- Progress bar and live image generation preview\n - Can use a separate neural network to produce previews with almost none VRAM or compute requirement\n- Negative prompt, an extra text field that allows you to list what you don't want to see in generated image\n- Styles, a way to save part of prompt and easily apply them via dropdown later\n- Variations, a way to generate same image but with tiny differences\n- Seed resizing, a way to generate same image but at slightly different resolution\n- CLIP interrogator, a button that tries to guess prompt from an image\n- Prompt Editing, a way to change prompt mid-generation, say to start making a watermelon and switch to anime girl midway\n- Batch Processing, process a group of files using img2img\n- Img2img Alternative, reverse Euler method of cross attention control\n- Highres Fix, a convenience option to produce high resolution pictures in one click without usual distortions\n- Reloading checkpoints on the fly\n- Checkpoint Merger, a tab that allows you to merge up to 3 checkpoints into one\n- Custom scripts with many extensions from community\n- Composable-Diffusion, a way to use multiple prompts at once\n - separate prompts using uppercase 'AND'\n - also supports weights for prompts: 'a cat :1.2 AND a dog AND a penguin :2.2'\n- No token limit for prompts (original stable diffusion lets you use up to 75 tokens)\n- DeepDanbooru integration, creates danbooru style tags for anime prompts\n- xformers, major speed increase for select cards: (add '--xformers' to commandline args)\n- via extension: History tab: view, direct and delete images conveniently within the UI\n- Generate forever option\n- Training tab\n - hypernetworks and embeddings options\n - Preprocessing images: cropping, mirroring, autotagging using BLIP or deepdanbooru (for anime)\n- Clip skip\n- Hypernetworks\n- Loras (same as Hypernetworks but more pretty)\n- A separate UI where you can choose, with preview, which embeddings, hypernetworks or Loras to add to your prompt \n- Can select to load a different VAE from settings screen\n- Estimated completion time in progress bar\n- API\n- Support for dedicated inpainting model by RunwayML\n- via extension: Aesthetic Gradients, a way to generate images with a specific aesthetic by using clip images embeds (implementation of URL\n- Stable Diffusion 2.0 support - see wiki for instructions\n- Alt-Diffusion support - see wiki for instructions\n- Now without any bad letters!\n- Load checkpoints in safetensors format\n- Eased resolution restriction: generated image's dimension must be a multiple of 8 rather than 64\n- Now with a license!\n- Reorder elements in the UI from settings screen",
"## Installation and Running\nMake sure the required dependencies are met and follow the instructions available for:\n- NVidia (recommended)\n- AMD GPUs.\n- Intel CPUs, Intel GPUs (both integrated and discrete) (external wiki page)\n\nAlternatively, use online services (like Google Colab):\n\n- List of Online Services",
"### Installation on Windows 10/11 with NVidia-GPUs using release package\n1. Download 'URL' from v1.0.0-pre and extract it's contents.\n2. Run 'URL'.\n3. Run 'URL'.\n> For more details see Install-and-Run-on-NVidia-GPUs",
"### Automatic Installation on Windows\n1. Install Python 3.10.6 (Newer version of Python does not support torch), checking \"Add Python to PATH\".\n2. Install git.\n3. Download the stable-diffusion-webui repository, for example by running 'git clone URL\n4. Run 'URL' from Windows Explorer as normal, non-administrator, user.",
"### Automatic Installation on Linux\n1. Install the dependencies:\n\n2. Navigate to the directory you would like the webui to be installed and execute the following command:\n\n3. Run 'URL'.\n4. Check 'URL' for options.",
"### Installation on Apple Silicon\n\nFind the instructions here.",
"## Contributing\nHere's how to add code to this repo: Contributing",
"## Documentation\n\nThe documentation was moved from this README over to the project's wiki.\n\nFor the purposes of getting Google and other search engines to crawl the wiki, here's a link to the (not for humans) crawlable wiki.",
"## Credits\nLicenses for borrowed code can be found in 'Settings -> Licenses' screen, and also in 'html/URL' file.\n\n- Stable Diffusion - URL URL\n- k-diffusion - URL\n- GFPGAN - URL\n- CodeFormer - URL\n- ESRGAN - URL\n- SwinIR - URL\n- Swin2SR - URL\n- LDSR - URL\n- MiDaS - URL\n- Ideas for optimizations - URL\n- Cross Attention layer optimization - Doggettx - URL original idea for prompt editing.\n- Cross Attention layer optimization - InvokeAI, lstein - URL (originally URL\n- Sub-quadratic Cross Attention layer optimization - Alex Birch (URL Amin Rezaei (URL\n- Textual Inversion - Rinon Gal - URL (we're not using his code, but we are using his ideas).\n- Idea for SD upscale - URL\n- Noise generation for outpainting mk2 - URL\n- CLIP interrogator idea and borrowing some code - URL\n- Idea for Composable Diffusion - URL\n- xformers - URL\n- DeepDanbooru - interrogator for anime diffusers URL\n- Sampling in float32 precision from a float16 UNet - marunine for the idea, Birch-san for the example Diffusers implementation (URL\n- Instruct pix2pix - Tim Brooks (star), Aleksander Holynski (star), Alexei A. Efros (no star) - URL\n- Security advice - RyotaK\n- UniPC sampler - Wenliang Zhao - URL\n- TAESD - Ollin Boer Bohan - URL\n- LyCORIS - KohakuBlueleaf\n- Restart sampling - lambertae - URL\n- Initial Gradio script - posted on 4chan by an Anonymous user. Thank you Anonymous user.\n- (You)"
] |
[
"TAGS\n#arxiv-2211.06679 #region-us \n",
"# Stable Diffusion web UI\nA browser interface based on Gradio library for Stable Diffusion.\n\n",
"## Features\nDetailed feature showcase with images:\n- Original txt2img and img2img modes\n- One click install and run script (but you still must install python and git)\n- Outpainting\n- Inpainting\n- Color Sketch\n- Prompt Matrix\n- Stable Diffusion Upscale\n- Attention, specify parts of text that the model should pay more attention to\n - a man in a '((tuxedo))' - will pay more attention to tuxedo\n - a man in a '(tuxedo:1.21)' - alternative syntax\n - select text and press 'Ctrl+Up' or 'Ctrl+Down' (or 'Command+Up' or 'Command+Down' if you're on a MacOS) to automatically adjust attention to selected text (code contributed by anonymous user)\n- Loopback, run img2img processing multiple times\n- X/Y/Z plot, a way to draw a 3 dimensional plot of images with different parameters\n- Textual Inversion\n - have as many embeddings as you want and use any names you like for them\n - use multiple embeddings with different numbers of vectors per token\n - works with half precision floating point numbers\n - train embeddings on 8GB (also reports of 6GB working)\n- Extras tab with:\n - GFPGAN, neural network that fixes faces\n - CodeFormer, face restoration tool as an alternative to GFPGAN\n - RealESRGAN, neural network upscaler\n - ESRGAN, neural network upscaler with a lot of third party models\n - SwinIR and Swin2SR (see here), neural network upscalers\n - LDSR, Latent diffusion super resolution upscaling\n- Resizing aspect ratio options\n- Sampling method selection\n - Adjust sampler eta values (noise multiplier)\n - More advanced noise setting options\n- Interrupt processing at any time\n- 4GB video card support (also reports of 2GB working)\n- Correct seeds for batches\n- Live prompt token length validation\n- Generation parameters\n - parameters you used to generate images are saved with that image\n - in PNG chunks for PNG, in EXIF for JPEG\n - can drag the image to PNG info tab to restore generation parameters and automatically copy them into UI\n - can be disabled in settings\n - drag and drop an image/text-parameters to promptbox\n- Read Generation Parameters Button, loads parameters in promptbox to UI\n- Settings page\n- Running arbitrary python code from UI (must run with '--allow-code' to enable)\n- Mouseover hints for most UI elements\n- Possible to change defaults/mix/max/step values for UI elements via text config\n- Tiling support, a checkbox to create images that can be tiled like textures\n- Progress bar and live image generation preview\n - Can use a separate neural network to produce previews with almost none VRAM or compute requirement\n- Negative prompt, an extra text field that allows you to list what you don't want to see in generated image\n- Styles, a way to save part of prompt and easily apply them via dropdown later\n- Variations, a way to generate same image but with tiny differences\n- Seed resizing, a way to generate same image but at slightly different resolution\n- CLIP interrogator, a button that tries to guess prompt from an image\n- Prompt Editing, a way to change prompt mid-generation, say to start making a watermelon and switch to anime girl midway\n- Batch Processing, process a group of files using img2img\n- Img2img Alternative, reverse Euler method of cross attention control\n- Highres Fix, a convenience option to produce high resolution pictures in one click without usual distortions\n- Reloading checkpoints on the fly\n- Checkpoint Merger, a tab that allows you to merge up to 3 checkpoints into one\n- Custom scripts with many extensions from community\n- Composable-Diffusion, a way to use multiple prompts at once\n - separate prompts using uppercase 'AND'\n - also supports weights for prompts: 'a cat :1.2 AND a dog AND a penguin :2.2'\n- No token limit for prompts (original stable diffusion lets you use up to 75 tokens)\n- DeepDanbooru integration, creates danbooru style tags for anime prompts\n- xformers, major speed increase for select cards: (add '--xformers' to commandline args)\n- via extension: History tab: view, direct and delete images conveniently within the UI\n- Generate forever option\n- Training tab\n - hypernetworks and embeddings options\n - Preprocessing images: cropping, mirroring, autotagging using BLIP or deepdanbooru (for anime)\n- Clip skip\n- Hypernetworks\n- Loras (same as Hypernetworks but more pretty)\n- A separate UI where you can choose, with preview, which embeddings, hypernetworks or Loras to add to your prompt \n- Can select to load a different VAE from settings screen\n- Estimated completion time in progress bar\n- API\n- Support for dedicated inpainting model by RunwayML\n- via extension: Aesthetic Gradients, a way to generate images with a specific aesthetic by using clip images embeds (implementation of URL\n- Stable Diffusion 2.0 support - see wiki for instructions\n- Alt-Diffusion support - see wiki for instructions\n- Now without any bad letters!\n- Load checkpoints in safetensors format\n- Eased resolution restriction: generated image's dimension must be a multiple of 8 rather than 64\n- Now with a license!\n- Reorder elements in the UI from settings screen",
"## Installation and Running\nMake sure the required dependencies are met and follow the instructions available for:\n- NVidia (recommended)\n- AMD GPUs.\n- Intel CPUs, Intel GPUs (both integrated and discrete) (external wiki page)\n\nAlternatively, use online services (like Google Colab):\n\n- List of Online Services",
"### Installation on Windows 10/11 with NVidia-GPUs using release package\n1. Download 'URL' from v1.0.0-pre and extract it's contents.\n2. Run 'URL'.\n3. Run 'URL'.\n> For more details see Install-and-Run-on-NVidia-GPUs",
"### Automatic Installation on Windows\n1. Install Python 3.10.6 (Newer version of Python does not support torch), checking \"Add Python to PATH\".\n2. Install git.\n3. Download the stable-diffusion-webui repository, for example by running 'git clone URL\n4. Run 'URL' from Windows Explorer as normal, non-administrator, user.",
"### Automatic Installation on Linux\n1. Install the dependencies:\n\n2. Navigate to the directory you would like the webui to be installed and execute the following command:\n\n3. Run 'URL'.\n4. Check 'URL' for options.",
"### Installation on Apple Silicon\n\nFind the instructions here.",
"## Contributing\nHere's how to add code to this repo: Contributing",
"## Documentation\n\nThe documentation was moved from this README over to the project's wiki.\n\nFor the purposes of getting Google and other search engines to crawl the wiki, here's a link to the (not for humans) crawlable wiki.",
"## Credits\nLicenses for borrowed code can be found in 'Settings -> Licenses' screen, and also in 'html/URL' file.\n\n- Stable Diffusion - URL URL\n- k-diffusion - URL\n- GFPGAN - URL\n- CodeFormer - URL\n- ESRGAN - URL\n- SwinIR - URL\n- Swin2SR - URL\n- LDSR - URL\n- MiDaS - URL\n- Ideas for optimizations - URL\n- Cross Attention layer optimization - Doggettx - URL original idea for prompt editing.\n- Cross Attention layer optimization - InvokeAI, lstein - URL (originally URL\n- Sub-quadratic Cross Attention layer optimization - Alex Birch (URL Amin Rezaei (URL\n- Textual Inversion - Rinon Gal - URL (we're not using his code, but we are using his ideas).\n- Idea for SD upscale - URL\n- Noise generation for outpainting mk2 - URL\n- CLIP interrogator idea and borrowing some code - URL\n- Idea for Composable Diffusion - URL\n- xformers - URL\n- DeepDanbooru - interrogator for anime diffusers URL\n- Sampling in float32 precision from a float16 UNet - marunine for the idea, Birch-san for the example Diffusers implementation (URL\n- Instruct pix2pix - Tim Brooks (star), Aleksander Holynski (star), Alexei A. Efros (no star) - URL\n- Security advice - RyotaK\n- UniPC sampler - Wenliang Zhao - URL\n- TAESD - Ollin Boer Bohan - URL\n- LyCORIS - KohakuBlueleaf\n- Restart sampling - lambertae - URL\n- Initial Gradio script - posted on 4chan by an Anonymous user. Thank you Anonymous user.\n- (You)"
] |
[
15,
30,
1293,
76,
70,
79,
51,
11,
18,
52,
407
] |
[
"passage: TAGS\n#arxiv-2211.06679 #region-us \n# Stable Diffusion web UI\nA browser interface based on Gradio library for Stable Diffusion.\n\n",
"passage: ## Features\nDetailed feature showcase with images:\n- Original txt2img and img2img modes\n- One click install and run script (but you still must install python and git)\n- Outpainting\n- Inpainting\n- Color Sketch\n- Prompt Matrix\n- Stable Diffusion Upscale\n- Attention, specify parts of text that the model should pay more attention to\n - a man in a '((tuxedo))' - will pay more attention to tuxedo\n - a man in a '(tuxedo:1.21)' - alternative syntax\n - select text and press 'Ctrl+Up' or 'Ctrl+Down' (or 'Command+Up' or 'Command+Down' if you're on a MacOS) to automatically adjust attention to selected text (code contributed by anonymous user)\n- Loopback, run img2img processing multiple times\n- X/Y/Z plot, a way to draw a 3 dimensional plot of images with different parameters\n- Textual Inversion\n - have as many embeddings as you want and use any names you like for them\n - use multiple embeddings with different numbers of vectors per token\n - works with half precision floating point numbers\n - train embeddings on 8GB (also reports of 6GB working)\n- Extras tab with:\n - GFPGAN, neural network that fixes faces\n - CodeFormer, face restoration tool as an alternative to GFPGAN\n - RealESRGAN, neural network upscaler\n - ESRGAN, neural network upscaler with a lot of third party models\n - SwinIR and Swin2SR (see here), neural network upscalers\n - LDSR, Latent diffusion super resolution upscaling\n- Resizing aspect ratio options\n- Sampling method selection\n - Adjust sampler eta values (noise multiplier)\n - More advanced noise setting options\n- Interrupt processing at any time\n- 4GB video card support (also reports of 2GB working)\n- Correct seeds for batches\n- Live prompt token length validation\n- Generation parameters\n - parameters you used to generate images are saved with that image\n - in PNG chunks for PNG, in EXIF for JPEG\n - can drag the image to PNG info tab to restore generation parameters and automatically copy them into UI\n - can be disabled in settings\n - drag and drop an image/text-parameters to promptbox\n- Read Generation Parameters Button, loads parameters in promptbox to UI\n- Settings page\n- Running arbitrary python code from UI (must run with '--allow-code' to enable)\n- Mouseover hints for most UI elements\n- Possible to change defaults/mix/max/step values for UI elements via text config\n- Tiling support, a checkbox to create images that can be tiled like textures\n- Progress bar and live image generation preview\n - Can use a separate neural network to produce previews with almost none VRAM or compute requirement\n- Negative prompt, an extra text field that allows you to list what you don't want to see in generated image\n- Styles, a way to save part of prompt and easily apply them via dropdown later\n- Variations, a way to generate same image but with tiny differences\n- Seed resizing, a way to generate same image but at slightly different resolution\n- CLIP interrogator, a button that tries to guess prompt from an image\n- Prompt Editing, a way to change prompt mid-generation, say to start making a watermelon and switch to anime girl midway\n- Batch Processing, process a group of files using img2img\n- Img2img Alternative, reverse Euler method of cross attention control\n- Highres Fix, a convenience option to produce high resolution pictures in one click without usual distortions\n- Reloading checkpoints on the fly\n- Checkpoint Merger, a tab that allows you to merge up to 3 checkpoints into one\n- Custom scripts with many extensions from community\n- Composable-Diffusion, a way to use multiple prompts at once\n - separate prompts using uppercase 'AND'\n - also supports weights for prompts: 'a cat :1.2 AND a dog AND a penguin :2.2'\n- No token limit for prompts (original stable diffusion lets you use up to 75 tokens)\n- DeepDanbooru integration, creates danbooru style tags for anime prompts\n- xformers, major speed increase for select cards: (add '--xformers' to commandline args)\n- via extension: History tab: view, direct and delete images conveniently within the UI\n- Generate forever option\n- Training tab\n - hypernetworks and embeddings options\n - Preprocessing images: cropping, mirroring, autotagging using BLIP or deepdanbooru (for anime)\n- Clip skip\n- Hypernetworks\n- Loras (same as Hypernetworks but more pretty)\n- A separate UI where you can choose, with preview, which embeddings, hypernetworks or Loras to add to your prompt \n- Can select to load a different VAE from settings screen\n- Estimated completion time in progress bar\n- API\n- Support for dedicated inpainting model by RunwayML\n- via extension: Aesthetic Gradients, a way to generate images with a specific aesthetic by using clip images embeds (implementation of URL\n- Stable Diffusion 2.0 support - see wiki for instructions\n- Alt-Diffusion support - see wiki for instructions\n- Now without any bad letters!\n- Load checkpoints in safetensors format\n- Eased resolution restriction: generated image's dimension must be a multiple of 8 rather than 64\n- Now with a license!\n- Reorder elements in the UI from settings screen## Installation and Running\nMake sure the required dependencies are met and follow the instructions available for:\n- NVidia (recommended)\n- AMD GPUs.\n- Intel CPUs, Intel GPUs (both integrated and discrete) (external wiki page)\n\nAlternatively, use online services (like Google Colab):\n\n- List of Online Services### Installation on Windows 10/11 with NVidia-GPUs using release package\n1. Download 'URL' from v1.0.0-pre and extract it's contents.\n2. Run 'URL'.\n3. Run 'URL'.\n> For more details see Install-and-Run-on-NVidia-GPUs### Automatic Installation on Windows\n1. Install Python 3.10.6 (Newer version of Python does not support torch), checking \"Add Python to PATH\".\n2. Install git.\n3. Download the stable-diffusion-webui repository, for example by running 'git clone URL\n4. Run 'URL' from Windows Explorer as normal, non-administrator, user.### Automatic Installation on Linux\n1. Install the dependencies:\n\n2. Navigate to the directory you would like the webui to be installed and execute the following command:\n\n3. Run 'URL'.\n4. Check 'URL' for options.### Installation on Apple Silicon\n\nFind the instructions here.## Contributing\nHere's how to add code to this repo: Contributing## Documentation\n\nThe documentation was moved from this README over to the project's wiki.\n\nFor the purposes of getting Google and other search engines to crawl the wiki, here's a link to the (not for humans) crawlable wiki."
] |
1c5647530d6d2ba6cc29f63c345c620973edb08c
|
# Dataset Card for "three_styles_coded"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
kewu93/three_styles_coded
|
[
"region:us"
] |
2023-09-19T22:36:48+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "val", "path": "data/val-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 60392465.7, "num_examples": 2100}, {"name": "val", "num_bytes": 25916253.5, "num_examples": 900}], "download_size": 84975483, "dataset_size": 86308719.2}}
|
2023-09-19T22:37:11+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "three_styles_coded"
More Information needed
|
[
"# Dataset Card for \"three_styles_coded\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"three_styles_coded\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"three_styles_coded\"\n\nMore Information needed"
] |
26af342da676cc26d5ec34341c087b8e0badc423
|
A filtered subset of C4-en containing 13,688,429 pages that are at least 8,000 characters long, useful for training models with longer context windows.
|
vllg/long_c4
|
[
"task_categories:text-generation",
"task_categories:fill-mask",
"size_categories:10M<n<100M",
"language:en",
"license:odc-by",
"region:us"
] |
2023-09-19T23:10:23+00:00
|
{"language": ["en"], "license": "odc-by", "size_categories": ["10M<n<100M"], "task_categories": ["text-generation", "fill-mask"]}
|
2023-09-20T01:50:31+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #task_categories-fill-mask #size_categories-10M<n<100M #language-English #license-odc-by #region-us
|
A filtered subset of C4-en containing 13,688,429 pages that are at least 8,000 characters long, useful for training models with longer context windows.
|
[] |
[
"TAGS\n#task_categories-text-generation #task_categories-fill-mask #size_categories-10M<n<100M #language-English #license-odc-by #region-us \n"
] |
[
52
] |
[
"passage: TAGS\n#task_categories-text-generation #task_categories-fill-mask #size_categories-10M<n<100M #language-English #license-odc-by #region-us \n"
] |
3fc29b02bde95eab47222ea8194bb18aa1a97da8
|
Automatically generated DataSet with: https://github.com/hansalemaos/tools4yolo
Base model (Yolov5) https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt
[](https://www.youtube.com/watch?v=PZxqZA_euTI)
[https://www.youtube.com/watch?v=PZxqZA_euTI]()
|
hansalemao/bandlogos
|
[
"task_categories:image-classification",
"license:mit",
"bands",
"music",
"ac/dc",
"krokus",
"accept",
"iron maiden",
"metallica",
"aerosmith",
"anthrax",
"black sabbath",
"judas priest",
"kiss",
"led zeppelin",
"manowar",
"metal church",
"misfits",
"motörhead",
"ozzy",
"pantera",
"saint vitus",
"saxon",
"scorpions",
"slayer",
"whitesnake",
"logos",
"region:us"
] |
2023-09-19T23:36:21+00:00
|
{"license": "mit", "task_categories": ["image-classification"], "tags": ["bands", "music", "ac/dc", "krokus", "accept", "iron maiden", "metallica", "aerosmith", "anthrax", "black sabbath", "judas priest", "kiss", "led zeppelin", "manowar", "metal church", "misfits", "mot\u00f6rhead", "ozzy", "pantera", "saint vitus", "saxon", "scorpions", "slayer", "whitesnake", "logos"]}
|
2023-09-24T21:28:36+00:00
|
[] |
[] |
TAGS
#task_categories-image-classification #license-mit #bands #music #ac/dc #krokus #accept #iron maiden #metallica #aerosmith #anthrax #black sabbath #judas priest #kiss #led zeppelin #manowar #metal church #misfits #motörhead #ozzy #pantera #saint vitus #saxon #scorpions #slayer #whitesnake #logos #region-us
|
Automatically generated DataSet with: URL
Base model (Yolov5) URL

|
yicozy/dataset_study_dictionary
|
[
"region:us"
] |
2023-09-20T00:21:38+00:00
|
{"dataset_info": {"features": [{"name": "study_ids", "sequence": "string"}, {"name": "corpus", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1120563, "num_examples": 7774}], "download_size": 118282, "dataset_size": 1120563}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-21T05:54:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dataset_study_dictionary"
More Information needed
|
[
"# Dataset Card for \"dataset_study_dictionary\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dataset_study_dictionary\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dataset_study_dictionary\"\n\nMore Information needed"
] |
1f77f09f4a38ae4c7548186e8e6bf3713e3bd402
|
# Dataset Card for "SemEval-Audio"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Tverous/SemEval-Audio
|
[
"region:us"
] |
2023-09-20T00:43:39+00:00
|
{"dataset_info": {"features": [{"name": "video_name", "dtype": "string"}, {"name": "audio", "dtype": "audio"}, {"name": "text", "dtype": "string"}, {"name": "speaker", "dtype": "string"}, {"name": "emotion", "dtype": {"class_label": {"names": {"0": "anger", "1": "disgust", "2": "fear", "3": "joy", "4": "neutral", "5": "sadness", "6": "surprise"}}}}], "splits": [{"name": "train", "num_bytes": 684419162.647, "num_examples": 13353}], "download_size": 695130678, "dataset_size": 684419162.647}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-20T23:06:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "SemEval-Audio"
More Information needed
|
[
"# Dataset Card for \"SemEval-Audio\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"SemEval-Audio\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"SemEval-Audio\"\n\nMore Information needed"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.