
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
listlengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
listlengths 0
25
| languages
listlengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
listlengths 0
352
| processed_texts
listlengths 1
353
| tokens_length
listlengths 1
353
| input_texts
listlengths 1
40
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
728a543d9970fb8431503fec3d488fba19573fea
|
# Dataset Card for "amazon-shoe-reviews"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Anas986/amazon-shoe-reviews
|
[
"region:us"
] |
2023-09-29T05:38:49+00:00
|
{"dataset_info": {"features": [{"name": "labels", "dtype": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 15128362.8, "num_examples": 81000}, {"name": "test", "num_bytes": 1680929.2, "num_examples": 9000}], "download_size": 10009431, "dataset_size": 16809292.0}}
|
2023-09-29T09:00:32+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "amazon-shoe-reviews"
More Information needed
|
[
"# Dataset Card for \"amazon-shoe-reviews\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"amazon-shoe-reviews\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"amazon-shoe-reviews\"\n\nMore Information needed"
] |
6b293d0b49570446d59774b26b81238370d9fb08
|
# Fights Segmentation Dataset
The dataset consists of a collection of photos extracted from **videos of fights**. It includes **segmentation masks** for **fighters, referees, mats, and the background**.
The dataset offers a resource for *object detection, instance segmentation, action recognition, or pose estimation*.
It could be useful for **sport community** in identification and detection of the violations, dispute resolution and general optimisation of referee's work using computer vision.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=fights-segmentation) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images extracted from the videos of fights
- **masks** - includes segmentation masks created for the original images
- **annotations.xml** - contains coordinates of the polygons and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the polygons and labels. For each point, the x and y coordinates are provided.
### Сlasses:
- **human**: fighter or fighters,
- **referee**: referee,
- **wrestling**: mat's area,
- **background**: area above the mat
# Example of XML file structure
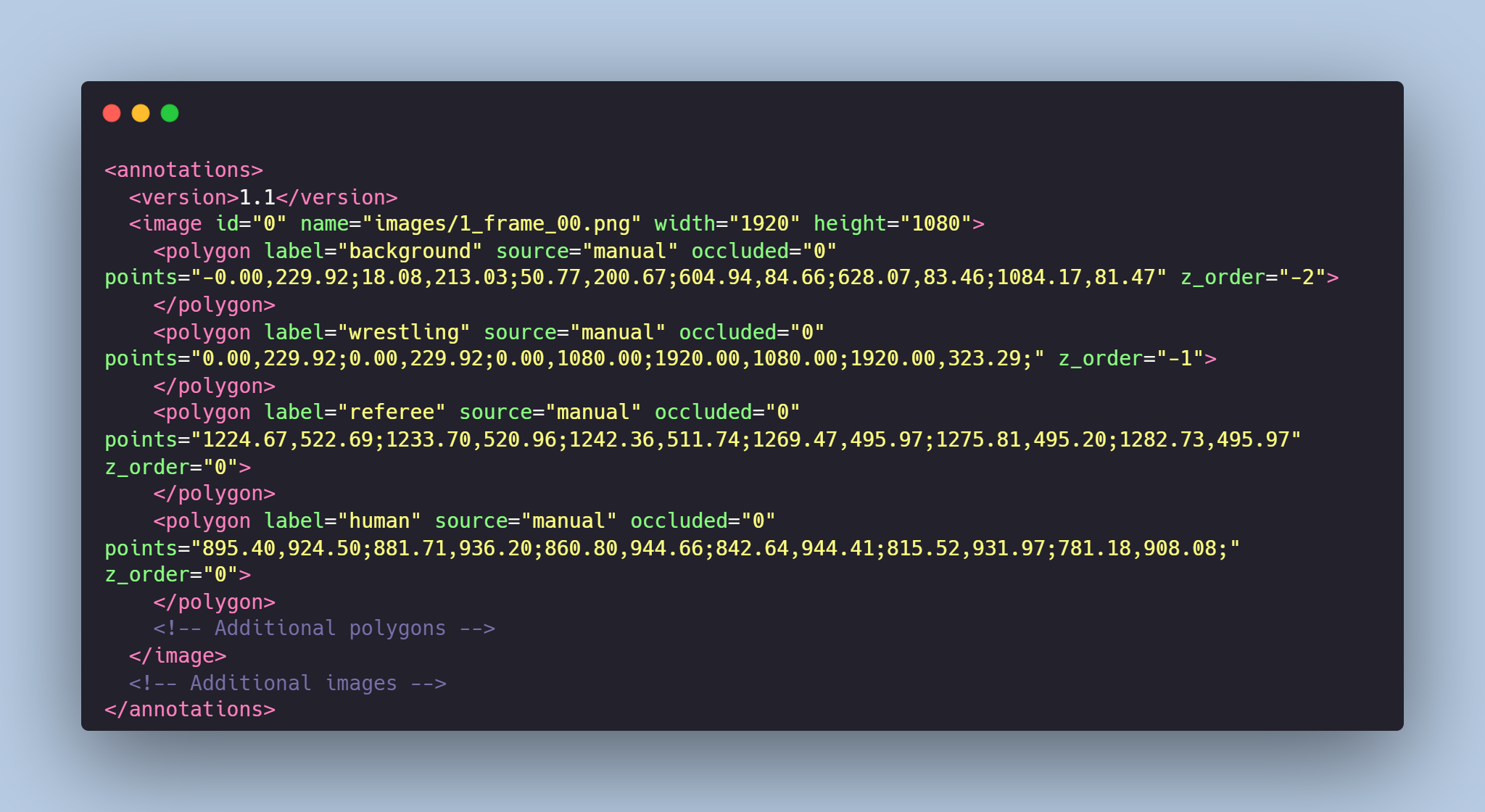
# Fights Segmentation might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=fights-segmentation) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/fights-segmentation
|
[
"task_categories:image-segmentation",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] |
2023-09-29T05:48:00+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-segmentation"], "tags": ["code"], "dataset_info": [{"config_name": "video_01", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "width", "dtype": "uint16"}, {"name": "height", "dtype": "uint16"}, {"name": "shapes", "sequence": [{"name": "label", "dtype": {"class_label": {"names": {"0": "referee", "1": "background", "2": "wrestling", "3": "human"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "z_order", "dtype": "int16"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 45562, "num_examples": 10}], "download_size": 16130822, "dataset_size": 45562}, {"config_name": "video_02", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "width", "dtype": "uint16"}, {"name": "height", "dtype": "uint16"}, {"name": "shapes", "sequence": [{"name": "label", "dtype": {"class_label": {"names": {"0": "referee", "1": "background", "2": "wrestling", "3": "human"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "z_order", "dtype": "int16"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 61428, "num_examples": 10}], "download_size": 14339242, "dataset_size": 61428}, {"config_name": "video_03", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "width", "dtype": "uint16"}, {"name": "height", "dtype": "uint16"}, {"name": "shapes", "sequence": [{"name": "label", "dtype": {"class_label": {"names": {"0": "referee", "1": "background", "2": "wrestling", "3": "human"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "z_order", "dtype": "int16"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 42854, "num_examples": 9}], "download_size": 13763862, "dataset_size": 42854}]}
|
2023-10-12T05:36:32+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-segmentation #language-English #license-cc-by-nc-nd-4.0 #code #region-us
|
# Fights Segmentation Dataset
The dataset consists of a collection of photos extracted from videos of fights. It includes segmentation masks for fighters, referees, mats, and the background.
The dataset offers a resource for *object detection, instance segmentation, action recognition, or pose estimation*.
It could be useful for sport community in identification and detection of the violations, dispute resolution and general optimisation of referee's work using computer vision.
 on Github which explains the steps that were taken to prepare this dataset for a text generation task.
At a high level, these are steps that were taken:
- Sourced a high-quality dataset of English-translated Akkadian by experts
- Enforced a minimum line length
- Removed duplicate lines
- Removed textual notes and other generic notes within parantheses
- Inserted translation notes and literal notes in place (preserving grammar and adding clarity to the corpus)
## Credit
Credit for the aggregation of the raw data belongs to the [Akkademia](https://github.com/gaigutherz/Akkademia/tree/master) project. Specifically, the exact data file used as the starting dataset is linked [here](https://github.com/gaigutherz/Akkademia/blob/master/NMT_input/train.en) and was also used to train their SOTA neural machine translation Akkadian->English model as described in their recent [paper](https://academic.oup.com/pnasnexus/article/2/5/pgad096/7147349) Gutherz et al. 2023 [1].
Credit for the original source of the raw data belongs to the incredible Open Richly Annotated Cuneiform Corpus ([ORACC](http://oracc.org)) project [2]. Specifically, as noted by the Akkademia project above, the RINAP 1, 3, 4, and 5 datasets are the source of the original raw data.
## Citations
[1] Gai Gutherz, Shai Gordin, Luis Sáenz, Omer Levy, Jonathan Berant, Translating Akkadian to English with neural machine translation, PNAS Nexus, Volume 2, Issue 5, May 2023, pgad096, https://doi.org/10.1093/pnasnexus/pgad096
[2] Jamie Novotny, Eleanor Robson, Steve Tinney, Niek Veldhuis, et al. Open Richly Annotated Cuneiform Corpus, http://oracc.org
|
veezbo/akkadian_english_corpus
|
[
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:en",
"license:mit",
"region:us"
] |
2023-09-29T06:22:07+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["text-generation"], "pretty_name": "English-translated Akkadian Corpus"}
|
2023-09-30T20:32:28+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #size_categories-1K<n<10K #language-English #license-mit #region-us
|
# Akkadian English Corpus
This dataset is a cleaned English-translated Akkadian language dataset. This dataset can and has been used for text generation tasks, for example to fine-tune LLMs.
## How it was generated
Please visit my repo on Github which explains the steps that were taken to prepare this dataset for a text generation task.
At a high level, these are steps that were taken:
- Sourced a high-quality dataset of English-translated Akkadian by experts
- Enforced a minimum line length
- Removed duplicate lines
- Removed textual notes and other generic notes within parantheses
- Inserted translation notes and literal notes in place (preserving grammar and adding clarity to the corpus)
## Credit
Credit for the aggregation of the raw data belongs to the Akkademia project. Specifically, the exact data file used as the starting dataset is linked here and was also used to train their SOTA neural machine translation Akkadian->English model as described in their recent paper Gutherz et al. 2023 [1].
Credit for the original source of the raw data belongs to the incredible Open Richly Annotated Cuneiform Corpus (ORACC) project [2]. Specifically, as noted by the Akkademia project above, the RINAP 1, 3, 4, and 5 datasets are the source of the original raw data.
s
[1] Gai Gutherz, Shai Gordin, Luis Sáenz, Omer Levy, Jonathan Berant, Translating Akkadian to English with neural machine translation, PNAS Nexus, Volume 2, Issue 5, May 2023, pgad096, URL
[2] Jamie Novotny, Eleanor Robson, Steve Tinney, Niek Veldhuis, et al. Open Richly Annotated Cuneiform Corpus, URL
|
[
"# Akkadian English Corpus\nThis dataset is a cleaned English-translated Akkadian language dataset. This dataset can and has been used for text generation tasks, for example to fine-tune LLMs.",
"## How it was generated\nPlease visit my repo on Github which explains the steps that were taken to prepare this dataset for a text generation task.\n\nAt a high level, these are steps that were taken:\n- Sourced a high-quality dataset of English-translated Akkadian by experts\n- Enforced a minimum line length\n- Removed duplicate lines\n- Removed textual notes and other generic notes within parantheses\n- Inserted translation notes and literal notes in place (preserving grammar and adding clarity to the corpus)",
"## Credit\nCredit for the aggregation of the raw data belongs to the Akkademia project. Specifically, the exact data file used as the starting dataset is linked here and was also used to train their SOTA neural machine translation Akkadian->English model as described in their recent paper Gutherz et al. 2023 [1].\n\nCredit for the original source of the raw data belongs to the incredible Open Richly Annotated Cuneiform Corpus (ORACC) project [2]. Specifically, as noted by the Akkademia project above, the RINAP 1, 3, 4, and 5 datasets are the source of the original raw data.\n\ns\n[1] Gai Gutherz, Shai Gordin, Luis Sáenz, Omer Levy, Jonathan Berant, Translating Akkadian to English with neural machine translation, PNAS Nexus, Volume 2, Issue 5, May 2023, pgad096, URL \n[2] Jamie Novotny, Eleanor Robson, Steve Tinney, Niek Veldhuis, et al. Open Richly Annotated Cuneiform Corpus, URL"
] |
[
"TAGS\n#task_categories-text-generation #size_categories-1K<n<10K #language-English #license-mit #region-us \n",
"# Akkadian English Corpus\nThis dataset is a cleaned English-translated Akkadian language dataset. This dataset can and has been used for text generation tasks, for example to fine-tune LLMs.",
"## How it was generated\nPlease visit my repo on Github which explains the steps that were taken to prepare this dataset for a text generation task.\n\nAt a high level, these are steps that were taken:\n- Sourced a high-quality dataset of English-translated Akkadian by experts\n- Enforced a minimum line length\n- Removed duplicate lines\n- Removed textual notes and other generic notes within parantheses\n- Inserted translation notes and literal notes in place (preserving grammar and adding clarity to the corpus)",
"## Credit\nCredit for the aggregation of the raw data belongs to the Akkademia project. Specifically, the exact data file used as the starting dataset is linked here and was also used to train their SOTA neural machine translation Akkadian->English model as described in their recent paper Gutherz et al. 2023 [1].\n\nCredit for the original source of the raw data belongs to the incredible Open Richly Annotated Cuneiform Corpus (ORACC) project [2]. Specifically, as noted by the Akkademia project above, the RINAP 1, 3, 4, and 5 datasets are the source of the original raw data.\n\ns\n[1] Gai Gutherz, Shai Gordin, Luis Sáenz, Omer Levy, Jonathan Berant, Translating Akkadian to English with neural machine translation, PNAS Nexus, Volume 2, Issue 5, May 2023, pgad096, URL \n[2] Jamie Novotny, Eleanor Robson, Steve Tinney, Niek Veldhuis, et al. Open Richly Annotated Cuneiform Corpus, URL"
] |
[
38,
49,
120,
237
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-1K<n<10K #language-English #license-mit #region-us \n# Akkadian English Corpus\nThis dataset is a cleaned English-translated Akkadian language dataset. This dataset can and has been used for text generation tasks, for example to fine-tune LLMs.## How it was generated\nPlease visit my repo on Github which explains the steps that were taken to prepare this dataset for a text generation task.\n\nAt a high level, these are steps that were taken:\n- Sourced a high-quality dataset of English-translated Akkadian by experts\n- Enforced a minimum line length\n- Removed duplicate lines\n- Removed textual notes and other generic notes within parantheses\n- Inserted translation notes and literal notes in place (preserving grammar and adding clarity to the corpus)## Credit\nCredit for the aggregation of the raw data belongs to the Akkademia project. Specifically, the exact data file used as the starting dataset is linked here and was also used to train their SOTA neural machine translation Akkadian->English model as described in their recent paper Gutherz et al. 2023 [1].\n\nCredit for the original source of the raw data belongs to the incredible Open Richly Annotated Cuneiform Corpus (ORACC) project [2]. Specifically, as noted by the Akkademia project above, the RINAP 1, 3, 4, and 5 datasets are the source of the original raw data.\n\ns\n[1] Gai Gutherz, Shai Gordin, Luis Sáenz, Omer Levy, Jonathan Berant, Translating Akkadian to English with neural machine translation, PNAS Nexus, Volume 2, Issue 5, May 2023, pgad096, URL \n[2] Jamie Novotny, Eleanor Robson, Steve Tinney, Niek Veldhuis, et al. Open Richly Annotated Cuneiform Corpus, URL"
] |
3059953fbeb3f3acc988874f4bc026b5c551f58f
|
# Dataset Card for "marathi_asr_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
TheAIchemist13/marathi_asr_dataset
|
[
"region:us"
] |
2023-09-29T06:24:34+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcriptions", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1647819015.0, "num_examples": 40000}, {"name": "test", "num_bytes": 264302111.0, "num_examples": 4675}], "download_size": 2743243940, "dataset_size": 1912121126.0}}
|
2023-09-29T06:31:57+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "marathi_asr_dataset"
More Information needed
|
[
"# Dataset Card for \"marathi_asr_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"marathi_asr_dataset\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"marathi_asr_dataset\"\n\nMore Information needed"
] |
84129d80b5c44ebdafd43124f670a99c9452e939
|
Various ai voice models I made of voices that may ore may not beiing made before.
Only use them under fair use or with licence from original authors.
|
Minecrafter/AiVoiceModels
|
[
"region:us"
] |
2023-09-29T06:37:38+00:00
|
{}
|
2023-11-12T21:17:08+00:00
|
[] |
[] |
TAGS
#region-us
|
Various ai voice models I made of voices that may ore may not beiing made before.
Only use them under fair use or with licence from original authors.
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
874c7399b68f58a3803b5442e5f681bd23f41781
|
Total: 408MB
40.907.183 tokens, 1.250.825 being unique
195.413 lines
|
turkish-nlp-suite/Akademik-Ozetler
|
[
"task_categories:text-generation",
"task_categories:summarization",
"task_categories:fill-mask",
"size_categories:100K<n<1M",
"language:tr",
"license:cc-by-sa-4.0",
"chemistry",
"biology",
"finance",
"legal",
"climate",
"academical_paper",
"region:us"
] |
2023-09-29T06:53:37+00:00
|
{"language": ["tr"], "license": "cc-by-sa-4.0", "size_categories": ["100K<n<1M"], "task_categories": ["text-generation", "summarization", "fill-mask"], "pretty_name": "Akademik-Ozetler", "tags": ["chemistry", "biology", "finance", "legal", "climate", "academical_paper"]}
|
2024-01-15T20:57:53+00:00
|
[] |
[
"tr"
] |
TAGS
#task_categories-text-generation #task_categories-summarization #task_categories-fill-mask #size_categories-100K<n<1M #language-Turkish #license-cc-by-sa-4.0 #chemistry #biology #finance #legal #climate #academical_paper #region-us
|
Total: 408MB
40.907.183 tokens, 1.250.825 being unique
195.413 lines
|
[] |
[
"TAGS\n#task_categories-text-generation #task_categories-summarization #task_categories-fill-mask #size_categories-100K<n<1M #language-Turkish #license-cc-by-sa-4.0 #chemistry #biology #finance #legal #climate #academical_paper #region-us \n"
] |
[
89
] |
[
"passage: TAGS\n#task_categories-text-generation #task_categories-summarization #task_categories-fill-mask #size_categories-100K<n<1M #language-Turkish #license-cc-by-sa-4.0 #chemistry #biology #finance #legal #climate #academical_paper #region-us \n"
] |
6464b41787f925907a84dfa31ad8b8fc7bced458
|
# Dataset Card for "databricks-dolly-15k-llama"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
daveokpare/databricks-dolly-15k-llama
|
[
"region:us"
] |
2023-09-29T08:06:08+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12198878, "num_examples": 15011}], "download_size": 7287301, "dataset_size": 12198878}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T08:06:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "databricks-dolly-15k-llama"
More Information needed
|
[
"# Dataset Card for \"databricks-dolly-15k-llama\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"databricks-dolly-15k-llama\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"databricks-dolly-15k-llama\"\n\nMore Information needed"
] |
f8254dc6908fe00c0f970c19bca97bdfb3615cc4
|
# Dataset Card for "odunola"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
odunola/foodie-large-context
|
[
"region:us"
] |
2023-09-29T08:45:44+00:00
|
{"dataset_info": {"features": [{"name": "texts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12575909, "num_examples": 2105}], "download_size": 5056309, "dataset_size": 12575909}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T08:45:45+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "odunola"
More Information needed
|
[
"# Dataset Card for \"odunola\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"odunola\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"odunola\"\n\nMore Information needed"
] |
d80b67f7b12bc6c48f80dbe8792e553f92047383
|
# Dataset Card for "ceval_all"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
liyucheng/ceval_all
|
[
"region:us"
] |
2023-09-29T09:04:27+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "A", "dtype": "string"}, {"name": "B", "dtype": "string"}, {"name": "C", "dtype": "string"}, {"name": "D", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "explanation", "dtype": "string"}], "splits": [{"name": "val", "num_bytes": 406528, "num_examples": 1346}, {"name": "test", "num_bytes": 3720917, "num_examples": 12342}, {"name": "dev", "num_bytes": 172688, "num_examples": 260}], "download_size": 2792076, "dataset_size": 4300133}}
|
2023-09-29T09:07:50+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "ceval_all"
More Information needed
|
[
"# Dataset Card for \"ceval_all\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"ceval_all\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"ceval_all\"\n\nMore Information needed"
] |
8f1e3437d19755c7c81ffd2d664223fdbe7dbdd9
|
# Dataset Card for "c09c453b"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-kand2-sdxl-wuerst-karlo/c09c453b
|
[
"region:us"
] |
2023-09-29T09:08:13+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 195, "num_examples": 10}], "download_size": 1353, "dataset_size": 195}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T09:08:13+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "c09c453b"
More Information needed
|
[
"# Dataset Card for \"c09c453b\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"c09c453b\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"c09c453b\"\n\nMore Information needed"
] |
df713453a1198dbde70a4a147fa4ea6d79c2a09f
|
# Dataset Card for "llama_traindata"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Rageshhf/llama_traindata
|
[
"region:us"
] |
2023-09-29T09:16:02+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "Combined", "dtype": "string"}, {"name": "Recommendation", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 11536719, "num_examples": 3283}], "download_size": 3272005, "dataset_size": 11536719}}
|
2023-09-29T09:16:04+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "llama_traindata"
More Information needed
|
[
"# Dataset Card for \"llama_traindata\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"llama_traindata\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"llama_traindata\"\n\nMore Information needed"
] |
32d1677b77195f3018c229fd73cf3c9b341d6dbe
|
# Dataset Card for "discofuse_1percent"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
reza-alipour/discofuse_1percent
|
[
"region:us"
] |
2023-09-29T09:22:05+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "connective_string", "dtype": "string"}, {"name": "discourse_type", "dtype": "string"}, {"name": "coherent_second_sentence", "dtype": "string"}, {"name": "has_coref_type_pronoun", "dtype": "float32"}, {"name": "incoherent_first_sentence", "dtype": "string"}, {"name": "incoherent_second_sentence", "dtype": "string"}, {"name": "has_coref_type_nominal", "dtype": "float32"}, {"name": "coherent_first_sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 63778517.906742156, "num_examples": 163105}], "download_size": 42876638, "dataset_size": 63778517.906742156}}
|
2023-09-29T09:23:43+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "discofuse_1percent"
More Information needed
|
[
"# Dataset Card for \"discofuse_1percent\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"discofuse_1percent\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"discofuse_1percent\"\n\nMore Information needed"
] |
48705408fac176bbe6ed5d2e36d9f3a5743e08e0
|
This is the dataset presented in my [ASRU-2023 paper](https://arxiv.org/abs/2309.17267).
It consists of multiple files:
Keys2Paragraphs.txt (internal name in scripts: yago_wiki.txt):
4.3 million unique words/phrases (English Wikipedia titles or their parts) occurring in 33.8 million English Wikipedia paragraphs.
Keys2Corruptions.txt (internal name in scripts: sub_misspells.txt):
26 million phrase pairs in the corrupted phrase inventory, as recognized by different ASR models
Keys2Related.txt (internal name in scripts: related_phrases.txt):
62.7 million phrase pairs in the related phrase inventory
FalsePositives.txt (internal name in scripts: false_positives.txt):
449 thousand phrase pairs in the false positive phrase inventory
NgramMappings.txt (internal name in scripts: replacement_vocab_filt.txt):
5.5 million character n-gram mappings dictionary
asr
outputs of g2p+tts+asr using 4 different ASR systems (conformer ctc was used twice),
gives pairs of initial phrase and its recognition result.
Does not include .wav files, but these can be reproduced by feeding g2p to tts
giza
raw outputs of GIZA++ alignments for each corpus,
from these we get NgramMappings.txt and Keys2Corruptions.txt
This [example code](https://github.com/bene-ges/nemo_compatible/blob/spellmapper_new_false_positive_sampling/scripts/nlp/en_spellmapper/dataset_preparation/build_training_data_from_wiki_en_asr_adapt.sh) shows how to generate training data from this dataset.
|
bene-ges/wiki-en-asr-adapt
|
[
"size_categories:10M<n<100M",
"language:en",
"license:cc-by-sa-4.0",
"arxiv:2309.17267",
"region:us"
] |
2023-09-29T09:23:21+00:00
|
{"language": ["en"], "license": "cc-by-sa-4.0", "size_categories": ["10M<n<100M"]}
|
2023-12-14T10:59:19+00:00
|
[
"2309.17267"
] |
[
"en"
] |
TAGS
#size_categories-10M<n<100M #language-English #license-cc-by-sa-4.0 #arxiv-2309.17267 #region-us
|
This is the dataset presented in my ASRU-2023 paper.
It consists of multiple files:
URL (internal name in scripts: yago_wiki.txt):
4.3 million unique words/phrases (English Wikipedia titles or their parts) occurring in 33.8 million English Wikipedia paragraphs.
URL (internal name in scripts: sub_misspells.txt):
26 million phrase pairs in the corrupted phrase inventory, as recognized by different ASR models
URL (internal name in scripts: related_phrases.txt):
62.7 million phrase pairs in the related phrase inventory
URL (internal name in scripts: false_positives.txt):
449 thousand phrase pairs in the false positive phrase inventory
URL (internal name in scripts: replacement_vocab_filt.txt):
5.5 million character n-gram mappings dictionary
asr
outputs of g2p+tts+asr using 4 different ASR systems (conformer ctc was used twice),
gives pairs of initial phrase and its recognition result.
Does not include .wav files, but these can be reproduced by feeding g2p to tts
giza
raw outputs of GIZA++ alignments for each corpus,
from these we get URL and URL
This example code shows how to generate training data from this dataset.
|
[] |
[
"TAGS\n#size_categories-10M<n<100M #language-English #license-cc-by-sa-4.0 #arxiv-2309.17267 #region-us \n"
] |
[
41
] |
[
"passage: TAGS\n#size_categories-10M<n<100M #language-English #license-cc-by-sa-4.0 #arxiv-2309.17267 #region-us \n"
] |
640244adc4e177e3bf2b3e98ba26da7a1080ce3c
|
# JADE
[Decisions of the Council of State, administrative courts of appeal, and the Court of Conflicts.](https://echanges.dila.gouv.fr/OPENDATA/JADE/)<br>
For the Council of State:
- the "landmark judgments" that established administrative law;
- decisions published in the Official Collection of Council of State Decisions (Lebon collection) since 1965;
- a limited selection of unpublished decisions in the collection between 1975 and 1986, with an expanded selection since 1986.
For the Administrative Courts of Appeal (CAA):
- a selection of judgments, varying for each of the 8 Courts, dating back to the establishment of the respective Court (1989 for the oldest CAAs).
For the administrative tribunals:
- A very limited selection starting in 1965, consisting of judgments chosen for publication or reference in the Lebon collection.
|
Nicolas-BZRD/JADE_opendata
|
[
"size_categories:100K<n<1M",
"language:fr",
"license:odc-by",
"legal",
"region:us"
] |
2023-09-29T09:31:19+00:00
|
{"language": ["fr"], "license": "odc-by", "size_categories": ["100K<n<1M"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5674266682, "num_examples": 558649}], "download_size": 2253639724, "dataset_size": 5674266682}, "tags": ["legal"]}
|
2023-09-29T13:55:39+00:00
|
[] |
[
"fr"
] |
TAGS
#size_categories-100K<n<1M #language-French #license-odc-by #legal #region-us
|
# JADE
Decisions of the Council of State, administrative courts of appeal, and the Court of Conflicts.<br>
For the Council of State:
- the "landmark judgments" that established administrative law;
- decisions published in the Official Collection of Council of State Decisions (Lebon collection) since 1965;
- a limited selection of unpublished decisions in the collection between 1975 and 1986, with an expanded selection since 1986.
For the Administrative Courts of Appeal (CAA):
- a selection of judgments, varying for each of the 8 Courts, dating back to the establishment of the respective Court (1989 for the oldest CAAs).
For the administrative tribunals:
- A very limited selection starting in 1965, consisting of judgments chosen for publication or reference in the Lebon collection.
|
[
"# JADE\n\nDecisions of the Council of State, administrative courts of appeal, and the Court of Conflicts.<br>\nFor the Council of State:\n- the \"landmark judgments\" that established administrative law;\n- decisions published in the Official Collection of Council of State Decisions (Lebon collection) since 1965;\n- a limited selection of unpublished decisions in the collection between 1975 and 1986, with an expanded selection since 1986.\n\nFor the Administrative Courts of Appeal (CAA):\n- a selection of judgments, varying for each of the 8 Courts, dating back to the establishment of the respective Court (1989 for the oldest CAAs).\n\nFor the administrative tribunals:\n- A very limited selection starting in 1965, consisting of judgments chosen for publication or reference in the Lebon collection."
] |
[
"TAGS\n#size_categories-100K<n<1M #language-French #license-odc-by #legal #region-us \n",
"# JADE\n\nDecisions of the Council of State, administrative courts of appeal, and the Court of Conflicts.<br>\nFor the Council of State:\n- the \"landmark judgments\" that established administrative law;\n- decisions published in the Official Collection of Council of State Decisions (Lebon collection) since 1965;\n- a limited selection of unpublished decisions in the collection between 1975 and 1986, with an expanded selection since 1986.\n\nFor the Administrative Courts of Appeal (CAA):\n- a selection of judgments, varying for each of the 8 Courts, dating back to the establishment of the respective Court (1989 for the oldest CAAs).\n\nFor the administrative tribunals:\n- A very limited selection starting in 1965, consisting of judgments chosen for publication or reference in the Lebon collection."
] |
[
34,
173
] |
[
"passage: TAGS\n#size_categories-100K<n<1M #language-French #license-odc-by #legal #region-us \n# JADE\n\nDecisions of the Council of State, administrative courts of appeal, and the Court of Conflicts.<br>\nFor the Council of State:\n- the \"landmark judgments\" that established administrative law;\n- decisions published in the Official Collection of Council of State Decisions (Lebon collection) since 1965;\n- a limited selection of unpublished decisions in the collection between 1975 and 1986, with an expanded selection since 1986.\n\nFor the Administrative Courts of Appeal (CAA):\n- a selection of judgments, varying for each of the 8 Courts, dating back to the establishment of the respective Court (1989 for the oldest CAAs).\n\nFor the administrative tribunals:\n- A very limited selection starting in 1965, consisting of judgments chosen for publication or reference in the Lebon collection."
] |
6bfa1c8092f2f13cfa8f06fc82588b63ec92d134
|
## Dataset Card for Anthropic_HH_Golden
This dataset is constructed to test the **ULMA** technique as mentioned in the paper *Unified Language Model Alignment with Demonstration and Point-wise Human Preference* (under review, and an arxiv link will be provided soon). They show that replacing the positive samples in a preference dataset by high-quality demonstration data (golden data) greatly improves the performance of various alignment methods (RLHF, DPO, ULMA). In particular, the ULMA method exploits the high-quality demonstration data in the preference dataset by treating the positive and negative samples differently, and boosting the performance by removing the KL regularizer for positive samples.
### Dataset Summary
This repository contains a new preference dataset extending the harmless dataset of Anthropic's Helpful and Harmless (HH) datasets. The origin positive response in HH is generated by a supervised fined-tuned model of Anthropic, where harmful and unhelpful responses are freqently encountered. In this dataset, the positive responses are replaced by re-rewritten responses generated by GPT4.

**Comparison with the origin HH dataset.** Left is the data sampled from the origin HH dataset, and right is the corresponding answer in our Anthropic_HH_Golden dataset. The highlighted parts are the differences. It is clear that after the rewritten, the "chosen" responses is more harmless, and the "rejected" response are left unchanged.
### Usage
```
from datasets import load_dataset
# Load the harmless dataset with golden demonstration
dataset = load_dataset("Unified-Language-Model-Alignment/Anthropic_HH_Golden")
```
or download the data files directly with:
```
git clone https://huggingface.co/datasets/Unified-Language-Model-Alignment/Anthropic_HH_Golden
```
|
Unified-Language-Model-Alignment/Anthropic_HH_Golden
|
[
"task_categories:conversational",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"harmless",
"region:us"
] |
2023-09-29T09:33:56+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["conversational"], "tags": ["harmless"]}
|
2023-10-04T12:36:29+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-conversational #size_categories-10K<n<100K #language-English #license-apache-2.0 #harmless #region-us
|
## Dataset Card for Anthropic_HH_Golden
This dataset is constructed to test the ULMA technique as mentioned in the paper *Unified Language Model Alignment with Demonstration and Point-wise Human Preference* (under review, and an arxiv link will be provided soon). They show that replacing the positive samples in a preference dataset by high-quality demonstration data (golden data) greatly improves the performance of various alignment methods (RLHF, DPO, ULMA). In particular, the ULMA method exploits the high-quality demonstration data in the preference dataset by treating the positive and negative samples differently, and boosting the performance by removing the KL regularizer for positive samples.
### Dataset Summary
This repository contains a new preference dataset extending the harmless dataset of Anthropic's Helpful and Harmless (HH) datasets. The origin positive response in HH is generated by a supervised fined-tuned model of Anthropic, where harmful and unhelpful responses are freqently encountered. In this dataset, the positive responses are replaced by re-rewritten responses generated by GPT4.
!Comparison with the origin HH dataset
Comparison with the origin HH dataset. Left is the data sampled from the origin HH dataset, and right is the corresponding answer in our Anthropic_HH_Golden dataset. The highlighted parts are the differences. It is clear that after the rewritten, the "chosen" responses is more harmless, and the "rejected" response are left unchanged.
### Usage
or download the data files directly with:
|
[
"## Dataset Card for Anthropic_HH_Golden\n\nThis dataset is constructed to test the ULMA technique as mentioned in the paper *Unified Language Model Alignment with Demonstration and Point-wise Human Preference* (under review, and an arxiv link will be provided soon). They show that replacing the positive samples in a preference dataset by high-quality demonstration data (golden data) greatly improves the performance of various alignment methods (RLHF, DPO, ULMA). In particular, the ULMA method exploits the high-quality demonstration data in the preference dataset by treating the positive and negative samples differently, and boosting the performance by removing the KL regularizer for positive samples.",
"### Dataset Summary\n\nThis repository contains a new preference dataset extending the harmless dataset of Anthropic's Helpful and Harmless (HH) datasets. The origin positive response in HH is generated by a supervised fined-tuned model of Anthropic, where harmful and unhelpful responses are freqently encountered. In this dataset, the positive responses are replaced by re-rewritten responses generated by GPT4.\n\n!Comparison with the origin HH dataset\n\nComparison with the origin HH dataset. Left is the data sampled from the origin HH dataset, and right is the corresponding answer in our Anthropic_HH_Golden dataset. The highlighted parts are the differences. It is clear that after the rewritten, the \"chosen\" responses is more harmless, and the \"rejected\" response are left unchanged.",
"### Usage\n\nor download the data files directly with:"
] |
[
"TAGS\n#task_categories-conversational #size_categories-10K<n<100K #language-English #license-apache-2.0 #harmless #region-us \n",
"## Dataset Card for Anthropic_HH_Golden\n\nThis dataset is constructed to test the ULMA technique as mentioned in the paper *Unified Language Model Alignment with Demonstration and Point-wise Human Preference* (under review, and an arxiv link will be provided soon). They show that replacing the positive samples in a preference dataset by high-quality demonstration data (golden data) greatly improves the performance of various alignment methods (RLHF, DPO, ULMA). In particular, the ULMA method exploits the high-quality demonstration data in the preference dataset by treating the positive and negative samples differently, and boosting the performance by removing the KL regularizer for positive samples.",
"### Dataset Summary\n\nThis repository contains a new preference dataset extending the harmless dataset of Anthropic's Helpful and Harmless (HH) datasets. The origin positive response in HH is generated by a supervised fined-tuned model of Anthropic, where harmful and unhelpful responses are freqently encountered. In this dataset, the positive responses are replaced by re-rewritten responses generated by GPT4.\n\n!Comparison with the origin HH dataset\n\nComparison with the origin HH dataset. Left is the data sampled from the origin HH dataset, and right is the corresponding answer in our Anthropic_HH_Golden dataset. The highlighted parts are the differences. It is clear that after the rewritten, the \"chosen\" responses is more harmless, and the \"rejected\" response are left unchanged.",
"### Usage\n\nor download the data files directly with:"
] |
[
44,
162,
216,
12
] |
[
"passage: TAGS\n#task_categories-conversational #size_categories-10K<n<100K #language-English #license-apache-2.0 #harmless #region-us \n## Dataset Card for Anthropic_HH_Golden\n\nThis dataset is constructed to test the ULMA technique as mentioned in the paper *Unified Language Model Alignment with Demonstration and Point-wise Human Preference* (under review, and an arxiv link will be provided soon). They show that replacing the positive samples in a preference dataset by high-quality demonstration data (golden data) greatly improves the performance of various alignment methods (RLHF, DPO, ULMA). In particular, the ULMA method exploits the high-quality demonstration data in the preference dataset by treating the positive and negative samples differently, and boosting the performance by removing the KL regularizer for positive samples.### Dataset Summary\n\nThis repository contains a new preference dataset extending the harmless dataset of Anthropic's Helpful and Harmless (HH) datasets. The origin positive response in HH is generated by a supervised fined-tuned model of Anthropic, where harmful and unhelpful responses are freqently encountered. In this dataset, the positive responses are replaced by re-rewritten responses generated by GPT4.\n\n!Comparison with the origin HH dataset\n\nComparison with the origin HH dataset. Left is the data sampled from the origin HH dataset, and right is the corresponding answer in our Anthropic_HH_Golden dataset. The highlighted parts are the differences. It is clear that after the rewritten, the \"chosen\" responses is more harmless, and the \"rejected\" response are left unchanged.### Usage\n\nor download the data files directly with:"
] |
0844174f58e56714da50b3f6b88fd9c196fce7f6
|
# Dataset Card for "gov_report_bp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
learn3r/gov_report_bp
|
[
"region:us"
] |
2023-09-29T10:03:30+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1030500829, "num_examples": 17457}, {"name": "validation", "num_bytes": 60867802, "num_examples": 972}, {"name": "test", "num_bytes": 56606131, "num_examples": 973}], "download_size": 547138870, "dataset_size": 1147974762}}
|
2023-09-29T10:05:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "gov_report_bp"
More Information needed
|
[
"# Dataset Card for \"gov_report_bp\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"gov_report_bp\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"gov_report_bp\"\n\nMore Information needed"
] |
578b74cb765b678e36565fe0af93a3cfd290d6b6
|
# Dataset Card for "TTS_03"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
DataStudio/TTS_03
|
[
"region:us"
] |
2023-09-29T10:10:44+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "content", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2562519623.008, "num_examples": 9916}], "download_size": 2113587189, "dataset_size": 2562519623.008}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T10:11:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "TTS_03"
More Information needed
|
[
"# Dataset Card for \"TTS_03\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"TTS_03\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"TTS_03\"\n\nMore Information needed"
] |
cf0ebc59b1013af93aa754a9e5551b1fa8ab70ff
|
This dataset has been created using <path ..... > added to the dataset.
|
text2font/full_words_with_path_tags
|
[
"region:us"
] |
2023-09-29T10:10:47+00:00
|
{}
|
2023-09-29T10:17:16+00:00
|
[] |
[] |
TAGS
#region-us
|
This dataset has been created using <path ..... > added to the dataset.
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
8181933c394d9a55fcb2c007a5d4acf1da3d9c16
|
# Dataset Card for "gov_report_memsum_bp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
learn3r/gov_report_memsum_bp
|
[
"region:us"
] |
2023-09-29T10:14:11+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 169706535, "num_examples": 17457}, {"name": "validation", "num_bytes": 11085755, "num_examples": 972}, {"name": "test", "num_bytes": 11134235, "num_examples": 973}], "download_size": 87102306, "dataset_size": 191926525}}
|
2023-09-29T10:14:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "gov_report_memsum_bp"
More Information needed
|
[
"# Dataset Card for \"gov_report_memsum_bp\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"gov_report_memsum_bp\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"gov_report_memsum_bp\"\n\nMore Information needed"
] |
51d05b091a2a6b1997d53b145621baf8a524fabc
|
tune-ft-series (abstract-to-class-0.7k)
```
categories: 146
samples/category: 5
total: 730
dataset_type: "sharegpt:chat"
wandb_project: "arxiv-single-class"
```
|
yashnbx/arxiv-abstract-cat-0.7k
|
[
"region:us"
] |
2023-09-29T10:26:57+00:00
|
{}
|
2023-09-29T12:38:39+00:00
|
[] |
[] |
TAGS
#region-us
|
tune-ft-series (abstract-to-class-0.7k)
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
f4ade3904d0097ccfb88e262fccd7352d8e92e1b
|
# Dataset Card for "NER_AR_wikiann"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ayoubkirouane/NER_AR_wikiann
|
[
"region:us"
] |
2023-09-29T10:31:47+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}, {"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "tokens", "sequence": "string"}, {"name": "ner_tags", "sequence": {"class_label": {"names": {"0": "O", "1": "B-PER", "2": "I-PER", "3": "B-ORG", "4": "I-ORG", "5": "B-LOC", "6": "I-LOC"}}}}, {"name": "langs", "sequence": "string"}, {"name": "spans", "sequence": "string"}], "splits": [{"name": "validation", "num_bytes": 2325660, "num_examples": 10000}, {"name": "test", "num_bytes": 2334636, "num_examples": 10000}, {"name": "train", "num_bytes": 4671613, "num_examples": 20000}], "download_size": 2581113, "dataset_size": 9331909}}
|
2023-09-29T10:31:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "NER_AR_wikiann"
More Information needed
|
[
"# Dataset Card for \"NER_AR_wikiann\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"NER_AR_wikiann\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"NER_AR_wikiann\"\n\nMore Information needed"
] |
b9ad5913d1bb110e02b0c556e0efe2e441bd14e3
|
# Dataset Card for "malyalam_asr_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
TheAIchemist13/malyalam_asr_dataset
|
[
"region:us"
] |
2023-09-29T11:09:43+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": " transcriptions", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1437332887.196, "num_examples": 3023}, {"name": "test", "num_bytes": 576755142.814, "num_examples": 1103}], "download_size": 1668143452, "dataset_size": 2014088030.0100002}}
|
2023-09-29T11:16:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "malyalam_asr_dataset"
More Information needed
|
[
"# Dataset Card for \"malyalam_asr_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"malyalam_asr_dataset\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"malyalam_asr_dataset\"\n\nMore Information needed"
] |
b4ecd92732c1d1bb603cccbe692d15aaef54d1ce
|
# StableAnime dataset
# Overview
# License: openrail
# Description:
This dataset contains 1K images produced by StableDiffusion models. I finetuned models to generate excellent quality anime images.
|
absinc/stable-anime
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"language:en",
"license:openrail",
"ArtGen Art",
"Art",
"StableDiffusion",
"NFT",
"anime",
"region:us"
] |
2023-09-29T11:40:12+00:00
|
{"language": ["en"], "license": "openrail", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "pretty_name": "StableAnime", "tags": ["ArtGen Art", "Art", "StableDiffusion", "NFT", "anime"]}
|
2023-09-29T11:59:56+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #language-English #license-openrail #ArtGen Art #Art #StableDiffusion #NFT #anime #region-us
|
# StableAnime dataset
# Overview
# License: openrail
# Description:
This dataset contains 1K images produced by StableDiffusion models. I finetuned models to generate excellent quality anime images.
|
[
"# StableAnime dataset",
"# Overview",
"# License: openrail",
"# Description:\nThis dataset contains 1K images produced by StableDiffusion models. I finetuned models to generate excellent quality anime images."
] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #language-English #license-openrail #ArtGen Art #Art #StableDiffusion #NFT #anime #region-us \n",
"# StableAnime dataset",
"# Overview",
"# License: openrail",
"# Description:\nThis dataset contains 1K images produced by StableDiffusion models. I finetuned models to generate excellent quality anime images."
] |
[
56,
7,
3,
5,
32
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #language-English #license-openrail #ArtGen Art #Art #StableDiffusion #NFT #anime #region-us \n# StableAnime dataset# Overview# License: openrail# Description:\nThis dataset contains 1K images produced by StableDiffusion models. I finetuned models to generate excellent quality anime images."
] |
5d32a5d6b6775dcfa05a15011afbc811814ca7eb
|
# Dataset Card for "mmlu_mini"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
liyucheng/mmlu_mini
|
[
"region:us"
] |
2023-09-29T11:54:42+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "A", "dtype": "string"}, {"name": "B", "dtype": "string"}, {"name": "C", "dtype": "string"}, {"name": "D", "dtype": "string"}, {"name": "target", "dtype": "string"}, {"name": "task", "dtype": "string"}], "splits": [{"name": "val", "num_bytes": 494633.0905282202, "num_examples": 1000}, {"name": "test", "num_bytes": 489506.01082613575, "num_examples": 1000}, {"name": "train", "num_bytes": 435903.50877192983, "num_examples": 1000}], "download_size": 587231, "dataset_size": 1420042.6101262858}}
|
2023-09-29T12:02:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "mmlu_mini"
More Information needed
|
[
"# Dataset Card for \"mmlu_mini\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"mmlu_mini\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"mmlu_mini\"\n\nMore Information needed"
] |
d88e7b14d477f2265ced3f2577f0c2bafe768a45
|
Original datasets: https://www.kaggle.com/datasets/firqaaa/indonesian-vehicle-plate-numbers
|
DamarJati/IND-number-plate
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"region:us"
] |
2023-09-29T11:59:36+00:00
|
{"size_categories": ["n<1K"], "task_categories": ["text-classification"]}
|
2023-09-29T21:06:24+00:00
|
[] |
[] |
TAGS
#task_categories-text-classification #size_categories-n<1K #region-us
|
Original datasets: URL
|
[] |
[
"TAGS\n#task_categories-text-classification #size_categories-n<1K #region-us \n"
] |
[
27
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-n<1K #region-us \n"
] |
03975ce91b184e2f225ac69b3818ae06d6e4361b
|
# Dataset Card for "spotlight-beans-enrichment"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
renumics/spotlight-beans-enrichment
|
[
"region:us"
] |
2023-09-29T12:12:54+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image_file_path.embedding", "sequence": "float32", "length": 2}, {"name": "image.embedding", "sequence": "float32", "length": 2}], "splits": [{"name": "train", "num_bytes": 16544, "num_examples": 1034}, {"name": "validation", "num_bytes": 2128, "num_examples": 133}, {"name": "test", "num_bytes": 2048, "num_examples": 128}], "download_size": 33961, "dataset_size": 20720}}
|
2023-10-13T08:05:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "spotlight-beans-enrichment"
More Information needed
|
[
"# Dataset Card for \"spotlight-beans-enrichment\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"spotlight-beans-enrichment\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"spotlight-beans-enrichment\"\n\nMore Information needed"
] |
bafacbd12c95982f0bef4dd5f94260663e59fc1b
|
# DOLE
This [section](https://echanges.dila.gouv.fr/OPENDATA/DOLE/) covers laws published since the start of the twelfth parliamentary term (June 2002), ordinances published since 2002, and laws in preparation (drafts and proposals).
The legislative files provide information before and after the enactment of legislation.
Legislative files concern laws covered by article 39 of the Constitution. A legislative file is also opened when a parliamentary assembly decides not to examine texts covered by Article 53 of the Constitution in simplified form.
Since the entry into force of the 2008 constitutional reform, legislative files on bills are only opened after the text has been adopted by the first assembly to which it is referred.
|
Nicolas-BZRD/DOLE_opendata
|
[
"size_categories:1K<n<10K",
"language:fr",
"license:odc-by",
"legal",
"region:us"
] |
2023-09-29T12:28:20+00:00
|
{"language": ["fr"], "license": "odc-by", "size_categories": ["1K<n<10K"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 86993000, "num_examples": 4120}], "download_size": 36263044, "dataset_size": 86993000}, "tags": ["legal"]}
|
2023-09-29T13:52:42+00:00
|
[] |
[
"fr"
] |
TAGS
#size_categories-1K<n<10K #language-French #license-odc-by #legal #region-us
|
# DOLE
This section covers laws published since the start of the twelfth parliamentary term (June 2002), ordinances published since 2002, and laws in preparation (drafts and proposals).
The legislative files provide information before and after the enactment of legislation.
Legislative files concern laws covered by article 39 of the Constitution. A legislative file is also opened when a parliamentary assembly decides not to examine texts covered by Article 53 of the Constitution in simplified form.
Since the entry into force of the 2008 constitutional reform, legislative files on bills are only opened after the text has been adopted by the first assembly to which it is referred.
|
[
"# DOLE\n\nThis section covers laws published since the start of the twelfth parliamentary term (June 2002), ordinances published since 2002, and laws in preparation (drafts and proposals).\nThe legislative files provide information before and after the enactment of legislation.\nLegislative files concern laws covered by article 39 of the Constitution. A legislative file is also opened when a parliamentary assembly decides not to examine texts covered by Article 53 of the Constitution in simplified form.\nSince the entry into force of the 2008 constitutional reform, legislative files on bills are only opened after the text has been adopted by the first assembly to which it is referred."
] |
[
"TAGS\n#size_categories-1K<n<10K #language-French #license-odc-by #legal #region-us \n",
"# DOLE\n\nThis section covers laws published since the start of the twelfth parliamentary term (June 2002), ordinances published since 2002, and laws in preparation (drafts and proposals).\nThe legislative files provide information before and after the enactment of legislation.\nLegislative files concern laws covered by article 39 of the Constitution. A legislative file is also opened when a parliamentary assembly decides not to examine texts covered by Article 53 of the Constitution in simplified form.\nSince the entry into force of the 2008 constitutional reform, legislative files on bills are only opened after the text has been adopted by the first assembly to which it is referred."
] |
[
34,
153
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #language-French #license-odc-by #legal #region-us \n# DOLE\n\nThis section covers laws published since the start of the twelfth parliamentary term (June 2002), ordinances published since 2002, and laws in preparation (drafts and proposals).\nThe legislative files provide information before and after the enactment of legislation.\nLegislative files concern laws covered by article 39 of the Constitution. A legislative file is also opened when a parliamentary assembly decides not to examine texts covered by Article 53 of the Constitution in simplified form.\nSince the entry into force of the 2008 constitutional reform, legislative files on bills are only opened after the text has been adopted by the first assembly to which it is referred."
] |
e7987d2c27883dc34ea523a57763c97966c587b7
|
# Dataset Card for "Market_Mail_Synthetic_DataSet1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
amitraheja82/Market_Mail_Synthetic_DataSet1
|
[
"region:us"
] |
2023-09-29T12:37:17+00:00
|
{"dataset_info": {"features": [{"name": "product", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "marketing_email", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 19809, "num_examples": 10}], "download_size": 25170, "dataset_size": 19809}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T12:37:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Market_Mail_Synthetic_DataSet1"
More Information needed
|
[
"# Dataset Card for \"Market_Mail_Synthetic_DataSet1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Market_Mail_Synthetic_DataSet1\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Market_Mail_Synthetic_DataSet1\"\n\nMore Information needed"
] |
948fa7d73e798df51bd3751726b3e12a02df44bb
|
# JORF ("Laws and decrees" edition of the Official Journal)
The documents published in the ["Laws and decrees" edition of the Official Journal](https://echanges.dila.gouv.fr/OPENDATA/JORF/) since 1990 comprise :
- laws, ordinances, decrees, orders and circulars.
- decisions issued by institutions or courts that must be published in the Official Journal (Constitutional Council, Conseil supérieur de l'audiovisuel, Autorité de régulation des télécommunications, etc.)
- notices and communications since 1 January 2002 (notices to importers and exporters, competition notices and job vacancy notices).
In the interests of privacy and the protection of personal data, certain sensitive nominative measures are not reproduced in this section:
- decrees concerning naturalisation, reinstatement, mention of a minor child benefiting from the collective effect attached to the acquisition of French nationality by the parents and the francization of surnames and forenames
- change of name decrees
- rulings by the Court of Budgetary and Financial Discipline.
|
Nicolas-BZRD/JORF_opendata
|
[
"size_categories:1M<n<10M",
"language:fr",
"license:odc-by",
"legal",
"region:us"
] |
2023-09-29T12:39:14+00:00
|
{"language": ["fr"], "license": "odc-by", "size_categories": ["1M<n<10M"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4361779320, "num_examples": 3616038}], "download_size": 1747268676, "dataset_size": 4361779320}, "tags": ["legal"]}
|
2023-09-29T13:37:00+00:00
|
[] |
[
"fr"
] |
TAGS
#size_categories-1M<n<10M #language-French #license-odc-by #legal #region-us
|
# JORF ("Laws and decrees" edition of the Official Journal)
The documents published in the "Laws and decrees" edition of the Official Journal since 1990 comprise :
- laws, ordinances, decrees, orders and circulars.
- decisions issued by institutions or courts that must be published in the Official Journal (Constitutional Council, Conseil supérieur de l'audiovisuel, Autorité de régulation des télécommunications, etc.)
- notices and communications since 1 January 2002 (notices to importers and exporters, competition notices and job vacancy notices).
In the interests of privacy and the protection of personal data, certain sensitive nominative measures are not reproduced in this section:
- decrees concerning naturalisation, reinstatement, mention of a minor child benefiting from the collective effect attached to the acquisition of French nationality by the parents and the francization of surnames and forenames
- change of name decrees
- rulings by the Court of Budgetary and Financial Discipline.
|
[
"# JORF (\"Laws and decrees\" edition of the Official Journal)\n\nThe documents published in the \"Laws and decrees\" edition of the Official Journal since 1990 comprise :\n- laws, ordinances, decrees, orders and circulars.\n- decisions issued by institutions or courts that must be published in the Official Journal (Constitutional Council, Conseil supérieur de l'audiovisuel, Autorité de régulation des télécommunications, etc.)\n- notices and communications since 1 January 2002 (notices to importers and exporters, competition notices and job vacancy notices).\n\nIn the interests of privacy and the protection of personal data, certain sensitive nominative measures are not reproduced in this section:\n- decrees concerning naturalisation, reinstatement, mention of a minor child benefiting from the collective effect attached to the acquisition of French nationality by the parents and the francization of surnames and forenames\n- change of name decrees\n- rulings by the Court of Budgetary and Financial Discipline."
] |
[
"TAGS\n#size_categories-1M<n<10M #language-French #license-odc-by #legal #region-us \n",
"# JORF (\"Laws and decrees\" edition of the Official Journal)\n\nThe documents published in the \"Laws and decrees\" edition of the Official Journal since 1990 comprise :\n- laws, ordinances, decrees, orders and circulars.\n- decisions issued by institutions or courts that must be published in the Official Journal (Constitutional Council, Conseil supérieur de l'audiovisuel, Autorité de régulation des télécommunications, etc.)\n- notices and communications since 1 January 2002 (notices to importers and exporters, competition notices and job vacancy notices).\n\nIn the interests of privacy and the protection of personal data, certain sensitive nominative measures are not reproduced in this section:\n- decrees concerning naturalisation, reinstatement, mention of a minor child benefiting from the collective effect attached to the acquisition of French nationality by the parents and the francization of surnames and forenames\n- change of name decrees\n- rulings by the Court of Budgetary and Financial Discipline."
] |
[
34,
230
] |
[
"passage: TAGS\n#size_categories-1M<n<10M #language-French #license-odc-by #legal #region-us \n# JORF (\"Laws and decrees\" edition of the Official Journal)\n\nThe documents published in the \"Laws and decrees\" edition of the Official Journal since 1990 comprise :\n- laws, ordinances, decrees, orders and circulars.\n- decisions issued by institutions or courts that must be published in the Official Journal (Constitutional Council, Conseil supérieur de l'audiovisuel, Autorité de régulation des télécommunications, etc.)\n- notices and communications since 1 January 2002 (notices to importers and exporters, competition notices and job vacancy notices).\n\nIn the interests of privacy and the protection of personal data, certain sensitive nominative measures are not reproduced in this section:\n- decrees concerning naturalisation, reinstatement, mention of a minor child benefiting from the collective effect attached to the acquisition of French nationality by the parents and the francization of surnames and forenames\n- change of name decrees\n- rulings by the Court of Budgetary and Financial Discipline."
] |
f6d9b9cbaa640178ab880bf7b77e4167342619c9
|
# SARDE (Système d'Aide à la Recherche Documentaire Elaborée)
[SARDE](https://echanges.dila.gouv.fr/OPENDATA/SARDE/) is a repository designed to provide a thematic search mode for the majority of legislative and regulatory texts in force.
The texts referenced are those published in the "Laws and Decrees" edition of the Journal officiel and in the Bulletins officiels distributed by the DILA.
|
Nicolas-BZRD/SARDE_opendata
|
[
"size_categories:100K<n<1M",
"language:fr",
"license:odc-by",
"legal",
"region:us"
] |
2023-09-29T12:42:27+00:00
|
{"language": ["fr"], "license": "odc-by", "size_categories": ["100K<n<1M"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 96924578, "num_examples": 224476}], "download_size": 36650583, "dataset_size": 96924578}, "tags": ["legal"]}
|
2023-09-29T13:40:36+00:00
|
[] |
[
"fr"
] |
TAGS
#size_categories-100K<n<1M #language-French #license-odc-by #legal #region-us
|
# SARDE (Système d'Aide à la Recherche Documentaire Elaborée)
SARDE is a repository designed to provide a thematic search mode for the majority of legislative and regulatory texts in force.
The texts referenced are those published in the "Laws and Decrees" edition of the Journal officiel and in the Bulletins officiels distributed by the DILA.
|
[
"# SARDE (Système d'Aide à la Recherche Documentaire Elaborée)\n\nSARDE is a repository designed to provide a thematic search mode for the majority of legislative and regulatory texts in force.\n\nThe texts referenced are those published in the \"Laws and Decrees\" edition of the Journal officiel and in the Bulletins officiels distributed by the DILA."
] |
[
"TAGS\n#size_categories-100K<n<1M #language-French #license-odc-by #legal #region-us \n",
"# SARDE (Système d'Aide à la Recherche Documentaire Elaborée)\n\nSARDE is a repository designed to provide a thematic search mode for the majority of legislative and regulatory texts in force.\n\nThe texts referenced are those published in the \"Laws and Decrees\" edition of the Journal officiel and in the Bulletins officiels distributed by the DILA."
] |
[
34,
87
] |
[
"passage: TAGS\n#size_categories-100K<n<1M #language-French #license-odc-by #legal #region-us \n# SARDE (Système d'Aide à la Recherche Documentaire Elaborée)\n\nSARDE is a repository designed to provide a thematic search mode for the majority of legislative and regulatory texts in force.\n\nThe texts referenced are those published in the \"Laws and Decrees\" edition of the Journal officiel and in the Bulletins officiels distributed by the DILA."
] |
022b78cd2b3e69c7a0c61577900c67365e58d029
|
# Dataset Card for "WNC"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
reza-alipour/WNC
|
[
"region:us"
] |
2023-09-29T13:05:57+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "edited_text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 17931422, "num_examples": 53803}, {"name": "validation", "num_bytes": 234313, "num_examples": 700}, {"name": "test", "num_bytes": 327719, "num_examples": 1000}], "download_size": 13075328, "dataset_size": 18493454}}
|
2023-11-24T20:00:15+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "WNC"
More Information needed
|
[
"# Dataset Card for \"WNC\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"WNC\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"WNC\"\n\nMore Information needed"
] |
a61d208bc79050530ced39d7a052d9e9bbe3e762
|
# 🤗 Huggingface User and Organizations Dataset
🗒️ This dataset contains usernames and organization names in a TXT file.
⌛ This dataset is automatically updated using GitHub Actions.
|
Weyaxi/users-and-organizations
|
[
"size_categories:100K<n<1M",
"region:us"
] |
2023-09-29T13:28:50+00:00
|
{"size_categories": ["100K<n<1M"], "configs": [{"config_name": "default", "data_files": [{"split": "users", "path": "user_names.txt"}, {"split": "organizations", "path": "org_names.txt"}]}]}
|
2024-02-17T12:17:37+00:00
|
[] |
[] |
TAGS
#size_categories-100K<n<1M #region-us
|
# Huggingface User and Organizations Dataset
️ This dataset contains usernames and organization names in a TXT file.
⌛ This dataset is automatically updated using GitHub Actions.
|
[
"# Huggingface User and Organizations Dataset\n\n️ This dataset contains usernames and organization names in a TXT file.\n\n⌛ This dataset is automatically updated using GitHub Actions."
] |
[
"TAGS\n#size_categories-100K<n<1M #region-us \n",
"# Huggingface User and Organizations Dataset\n\n️ This dataset contains usernames and organization names in a TXT file.\n\n⌛ This dataset is automatically updated using GitHub Actions."
] |
[
18,
44
] |
[
"passage: TAGS\n#size_categories-100K<n<1M #region-us \n# Huggingface User and Organizations Dataset\n\n️ This dataset contains usernames and organization names in a TXT file.\n\n⌛ This dataset is automatically updated using GitHub Actions."
] |
bbddc4dde94d11ac317e7112a793050a3be13386
|
# Dataset Card for "lecture-audio"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
temi/lecture-audio
|
[
"region:us"
] |
2023-09-29T13:30:00+00:00
|
{"dataset_info": {"features": [{"name": "audio_data", "struct": [{"name": "audio_path", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 81, "num_examples": 1}], "download_size": 1447, "dataset_size": 81}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T13:30:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "lecture-audio"
More Information needed
|
[
"# Dataset Card for \"lecture-audio\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"lecture-audio\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"lecture-audio\"\n\nMore Information needed"
] |
66082ad55724edca8cc858948d9c4b9edb401c12
|
# Dataset Card for "my-guanaco-llama2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
hzsushiqiren/my-guanaco-llama2
|
[
"region:us"
] |
2023-09-29T13:40:47+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 301487, "num_examples": 924}], "download_size": 134131, "dataset_size": 301487}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T13:40:49+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "my-guanaco-llama2"
More Information needed
|
[
"# Dataset Card for \"my-guanaco-llama2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"my-guanaco-llama2\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"my-guanaco-llama2\"\n\nMore Information needed"
] |
8628e11b9e6ffe1301fefafdc73418a80eeb8f01
|
# Dataset Card for EuroSat
## Table of Contents
- [How to Use](#How-to-Use)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- How to use in Python
```py
from datasets import load_dataset
train_data = load_dataset("Honaker/eurosat_dataset", split="train")
```
## Dataset Description
- **Homepage:** https://zenodo.org/record/7711810#.ZAm3k-zMKEA
### Dataset Summary
EuroSat is an image classification dataset with 10 different classes on satellite imagery. There is over 27,000 labeled images.
## Dataset Structure
The dataset is structured as follows:
```py
DatasetDict({
train: Dataset({
features: ['image', 'labels'],
num_rows: 21600
})
validation: Dataset({
features: ['image', 'labels'],
num_rows: 2700
})
test: Dataset({
features: ['image', 'labels'],
num_rows: 2700
})
})
```
### Data Instances
An example of the data for one image is:
```py
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=64x64>,
'labels': 0
}
```
With the type of each field being defined as:
```py
{
'image': <PIL.JpegImagePlugin.JpegImageFile>,
'labels': Integer
```
### Data Fields
The dataset has the following fields:
- 'image': Satellite image that is of type <PIL.TiffImagePlugin.TiffImageFile image>
- 'labels': the label of the Satellite image as an integer
### Data Splits
| | Train | Validation | Test |
|----------------|--------|------------|------|
| Images | 21600 | 2700 | 2700 |
## Additional Information
### Licensing Information
EuroSat is licensed under a MIT
|
Honaker/eurosat_dataset
|
[
"task_categories:image-classification",
"license:mit",
"region:us"
] |
2023-09-29T14:07:13+00:00
|
{"license": "mit", "task_categories": ["image-classification"], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "AnnualCrop", "1": "Forest", "2": "HerbaceousVegetation", "3": "Highway", "4": "Industrial", "5": "Pasture", "6": "PermanentCrop", "7": "Residential", "8": "River", "9": "SeaLake"}}}}], "splits": [{"name": "train", "num_bytes": 70666516.8, "num_examples": 21600}, {"name": "validation", "num_bytes": 8700747.8, "num_examples": 2700}, {"name": "test", "num_bytes": 8631409.1, "num_examples": 2700}], "download_size": 93886033, "dataset_size": 87998673.69999999}}
|
2023-10-24T12:01:03+00:00
|
[] |
[] |
TAGS
#task_categories-image-classification #license-mit #region-us
|
Dataset Card for EuroSat
========================
Table of Contents
-----------------
* How to Use
* Dataset Description
+ Dataset Summary
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Additional Information
+ Licensing Information
How to Use
----------
* Install datasets:
* How to use in Python
Dataset Description
-------------------
* Homepage: URL
### Dataset Summary
EuroSat is an image classification dataset with 10 different classes on satellite imagery. There is over 27,000 labeled images.
Dataset Structure
-----------------
The dataset is structured as follows:
### Data Instances
An example of the data for one image is:
With the type of each field being defined as:
### Data Fields
The dataset has the following fields:
* 'image': Satellite image that is of type <PIL.TiffImagePlugin.TiffImageFile image>
* 'labels': the label of the Satellite image as an integer
### Data Splits
Additional Information
----------------------
### Licensing Information
EuroSat is licensed under a MIT
|
[
"### Dataset Summary\n\n\nEuroSat is an image classification dataset with 10 different classes on satellite imagery. There is over 27,000 labeled images.\n\n\nDataset Structure\n-----------------\n\n\nThe dataset is structured as follows:",
"### Data Instances\n\n\nAn example of the data for one image is:\n\n\nWith the type of each field being defined as:",
"### Data Fields\n\n\nThe dataset has the following fields:\n\n\n* 'image': Satellite image that is of type <PIL.TiffImagePlugin.TiffImageFile image>\n* 'labels': the label of the Satellite image as an integer",
"### Data Splits\n\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nEuroSat is licensed under a MIT"
] |
[
"TAGS\n#task_categories-image-classification #license-mit #region-us \n",
"### Dataset Summary\n\n\nEuroSat is an image classification dataset with 10 different classes on satellite imagery. There is over 27,000 labeled images.\n\n\nDataset Structure\n-----------------\n\n\nThe dataset is structured as follows:",
"### Data Instances\n\n\nAn example of the data for one image is:\n\n\nWith the type of each field being defined as:",
"### Data Fields\n\n\nThe dataset has the following fields:\n\n\n* 'image': Satellite image that is of type <PIL.TiffImagePlugin.TiffImageFile image>\n* 'labels': the label of the Satellite image as an integer",
"### Data Splits\n\n\n\nAdditional Information\n----------------------",
"### Licensing Information\n\n\nEuroSat is licensed under a MIT"
] |
[
22,
52,
27,
57,
12,
15
] |
[
"passage: TAGS\n#task_categories-image-classification #license-mit #region-us \n### Dataset Summary\n\n\nEuroSat is an image classification dataset with 10 different classes on satellite imagery. There is over 27,000 labeled images.\n\n\nDataset Structure\n-----------------\n\n\nThe dataset is structured as follows:### Data Instances\n\n\nAn example of the data for one image is:\n\n\nWith the type of each field being defined as:### Data Fields\n\n\nThe dataset has the following fields:\n\n\n* 'image': Satellite image that is of type <PIL.TiffImagePlugin.TiffImageFile image>\n* 'labels': the label of the Satellite image as an integer### Data Splits\n\n\n\nAdditional Information\n----------------------### Licensing Information\n\n\nEuroSat is licensed under a MIT"
] |
16ab3bd8b7ab3f5011b2b572efe139b5ca8175ee
|
所有的书籍,已经转化成pkl格式了
|
yazhou80/books-all-pkl
|
[
"region:us"
] |
2023-09-29T14:22:27+00:00
|
{}
|
2023-10-14T12:01:07+00:00
|
[] |
[] |
TAGS
#region-us
|
所有的书籍,已经转化成pkl格式了
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
7837437c12379d04b51d2b59cefb79a8b7c3cbe8
|
# OpenOrca-KO
- OpenOrca dataset 중 약 2만개를 sampling하여 번역한 데이터셋
- 데이터셋 이용하셔서 모델이나 데이터셋을 만드실 때, 간단한 출처 표기를 해주신다면 연구에 큰 도움이 됩니다😭😭
## Dataset inf0
1. **NIV** // 1571개
2. **FLAN** // 9434개
3. **T0** // 6351개
4. **CoT** // 2117개
5. **[KoCoT](https://huggingface.co/datasets/kyujinpy/KoCoT_2000)** // 2159개
## Translation
Using DeepL Pro API. Thanks.
---
>Below is original dataset card
## Table of Contents
- [Dataset Summary](#dataset-summary)
- [Dataset Attribution](#dataset-attribution)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Dataset Use](#dataset-use)
- [Use Cases](#use-cases)
- [Usage Caveats](#usage-caveats)
- [Getting Started](#getting-started)
<p><h1>🐋 The OpenOrca Dataset! 🐋</h1></p>

<a name="dataset-announcement"></a>
We are thrilled to announce the release of the OpenOrca dataset!
This rich collection of augmented FLAN data aligns, as best as possible, with the distributions outlined in the [Orca paper](https://arxiv.org/abs/2306.02707).
It has been instrumental in generating high-performing model checkpoints and serves as a valuable resource for all NLP researchers and developers!
# Official Models
## OpenOrca-Platypus2-13B
Our [latest release](https://huggingface.co/Open-Orca/OpenOrca-Platypus2-13B), the first 13B model to score higher than LLaMA1-65B on the HuggingFace Leaderboard!
Released in partnership with Platypus.
## LlongOrca 7B & 13B
* Our [first 7B release](https://huggingface.co/Open-Orca/LlongOrca-7B-16k), trained on top of LLongMA2 to achieve 16,000 tokens context. #1 long context 7B model at release time, with >99% of the overall #1 model's performance.
* [LlongOrca-13B-16k](https://huggingface.co/Open-Orca/LlongOrca-13B-16k), trained on top of LLongMA2. #1 long context 13B model at release time, with >97% of the overall #1 model's performance.
## OpenOrcaxOpenChat-Preview2-13B
Our [second model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B), highlighting that we've surpassed the performance reported in the Orca paper.
Was #1 at release time, now surpassed by our own OpenOrca-Platypus2-13B.
Released in partnership with OpenChat.
## OpenOrca-Preview1-13B
[OpenOrca-Preview1-13B](https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B)
This model was trained in less than a day, for <$200, with <10% of our data.
At release, it beat the current state of the art models on BigBench-Hard and AGIEval. Achieves ~60% of the improvements reported in the Orca paper.
<a name="dataset-summary"></a>
# Dataset Summary
The OpenOrca dataset is a collection of augmented [FLAN Collection data](https://arxiv.org/abs/2301.13688).
Currently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.
It is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.
The data is primarily used for training and evaluation in the field of natural language processing.
<a name="dataset-attribution"></a>
# Dataset Attribution
We would like to give special recognition to the following contributors for their significant efforts and dedication:
Teknium
WingLian/Caseus
Eric Hartford
NanoBit
Pankaj
Winddude
Rohan
http://AlignmentLab.ai:
Autometa
Entropi
AtlasUnified
NeverendingToast
NanoBit
WingLian/Caseus
Also of course, as always, TheBloke, for being the backbone of the whole community.
Many thanks to NanoBit and Caseus, makers of [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl), for lending us their expertise on the platform that developed and trained manticore, minotaur, and many others!
We are welcoming sponsors or collaborators to help us build these models to the scale they deserve. Please reach out via our socials:
http://Alignmentlab.ai https://discord.gg/n9hXaBPWxx
Want to visualize our full dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
[<img src="https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B/resolve/main/OpenOrca%20Nomic%20Atlas.png" alt="Atlas Nomic Dataset Map" width="400" height="400" />](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2)
<a name="supported-tasks-and-leaderboards"></a>
# Supported Tasks and Leaderboards
This dataset supports a range of tasks including language modeling, text generation, and text augmentation.
It has been instrumental in the generation of multiple high-performing model checkpoints which have exhibited exceptional performance in our unit testing.
Further information on leaderboards will be updated as they become available.
<a name="languages"></a>
# Languages
The language of the data is primarily English.
<a name="dataset-structure"></a>
# Dataset Structure
<a name="data-instances"></a>
## Data Instances
A data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.
The response is then entered into the response field.
<a name="data-fields"></a>
## Data Fields
The fields are:
1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.
2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint
3) 'question', representing a question entry as provided by the FLAN Collection
4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.
<a name="data-splits"></a>
## Data Splits
The data is unsplit.
<a name="dataset-creation"></a>
# Dataset Creation
<a name="curation-rationale"></a>
## Curation Rationale
The dataset was created to provide a source of augmented text data for researchers and developers.
The datapoints are intended primarily to provide an enhancement of the core FLAN Collection data which relies upon the detailed step by step reasoning capabilities of GPT-3.5 and GPT-4.
This "reasoning trace" augmentation has demonstrated exceptional results, allowing a LLaMA-13B model trained with this data to rival or beat GPT-3.5 on broad sets of hard reasoning tasks which all models below 100B parameters had previously performed dramatically worse on.
<a name="source-data"></a>
## Source Data
The data is generated using techniques in alignment with the distributions outlined in the Orca paper, except as noted below:
1) There is not enough CoT data in the FLAN Collection to generate 150K zero-shot entries, as the paper purports to use.
We suspect this portion was either undocumented or misrepresented. We have used the ~75K points available.
2) We used the pre-generated FLAN Collection datasets hosted on HuggingFace under conceptofmind, e.g. [conceptofmind/flan2021](https://huggingface.co/datasets/conceptofmind/flan2021_submix_original).
These are referenced by the [official FLAN Collection repo](https://github.com/google-research/FLAN/tree/main/flan/v2) as the preferred data source.
However, these are a subset of the full FLAN Collection data, and have less than the required entries for the flan2021 and t0 submixes, by ~1.25M and 200k respectively.
Combined, this gave us ~1.5M fewer datapoints than in the original Orca paper. Completing the set is an ongoing work.
<a name="dataset-use"></a>
# Dataset Use
<a name="use-cases"></a>
## Use Cases
The dataset can be used for tasks related to language understanding, natural language processing, machine learning model training, and model performance evaluation.
<a name="usage-caveats"></a>
## Usage Caveats
Given that this is a work-in-progress dataset, it is recommended to regularly check for updates and improvements.
Further, the data should be used in accordance with the guidelines and recommendations outlined in the Orca paper.
<a name="getting-started"></a>
## Getting Started
This dataset is organized such that it can be naively loaded via Hugging Face datasets library.
We recommend using streaming due to the large size of the files.
Regular updates and data generation progress can be monitored through the OpenOrca repository on Hugging Face.
# Citation
```bibtex
@misc{OpenOrca,
title = {OpenOrca: An Open Dataset of GPT Augmented FLAN Reasoning Traces},
author = {Wing Lian and Bleys Goodson and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://https://huggingface.co/Open-Orca/OpenOrca},
}
```
```bibtex
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
```bibtex
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint= arXiv 2307.09288
}
@software{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
```
|
kyujinpy/OpenOrca-KO
|
[
"task_categories:conversational",
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:summarization",
"task_categories:feature-extraction",
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:10K<n<50K",
"language:ko",
"license:mit",
"arxiv:2306.02707",
"arxiv:2301.13688",
"region:us"
] |
2023-09-29T14:26:20+00:00
|
{"language": ["ko"], "license": "mit", "size_categories": ["10K<n<50K"], "task_categories": ["conversational", "text-classification", "token-classification", "table-question-answering", "question-answering", "zero-shot-classification", "summarization", "feature-extraction", "text-generation", "text2text-generation"], "pretty_name": "OpenOrca", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "input", "dtype": "string"}, {"name": "instruction", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 44220539, "num_examples": 21632}], "download_size": 22811589, "dataset_size": 44220539}}
|
2023-10-12T18:55:47+00:00
|
[
"2306.02707",
"2301.13688"
] |
[
"ko"
] |
TAGS
#task_categories-conversational #task_categories-text-classification #task_categories-token-classification #task_categories-table-question-answering #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-summarization #task_categories-feature-extraction #task_categories-text-generation #task_categories-text2text-generation #size_categories-10K<n<50K #language-Korean #license-mit #arxiv-2306.02707 #arxiv-2301.13688 #region-us
|
# OpenOrca-KO
- OpenOrca dataset 중 약 2만개를 sampling하여 번역한 데이터셋
- 데이터셋 이용하셔서 모델이나 데이터셋을 만드실 때, 간단한 출처 표기를 해주신다면 연구에 큰 도움이 됩니다
## Dataset inf0
1. NIV // 1571개
2. FLAN // 9434개
3. T0 // 6351개
4. CoT // 2117개
5. KoCoT // 2159개
## Translation
Using DeepL Pro API. Thanks.
---
>Below is original dataset card
## Table of Contents
- Dataset Summary
- Dataset Attribution
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Dataset Use
- Use Cases
- Usage Caveats
- Getting Started
<p><h1> The OpenOrca Dataset! </h1></p>
!OpenOrca Logo
<a name="dataset-announcement"></a>
We are thrilled to announce the release of the OpenOrca dataset!
This rich collection of augmented FLAN data aligns, as best as possible, with the distributions outlined in the Orca paper.
It has been instrumental in generating high-performing model checkpoints and serves as a valuable resource for all NLP researchers and developers!
# Official Models
## OpenOrca-Platypus2-13B
Our latest release, the first 13B model to score higher than LLaMA1-65B on the HuggingFace Leaderboard!
Released in partnership with Platypus.
## LlongOrca 7B & 13B
* Our first 7B release, trained on top of LLongMA2 to achieve 16,000 tokens context. #1 long context 7B model at release time, with >99% of the overall #1 model's performance.
* LlongOrca-13B-16k, trained on top of LLongMA2. #1 long context 13B model at release time, with >97% of the overall #1 model's performance.
## OpenOrcaxOpenChat-Preview2-13B
Our second model, highlighting that we've surpassed the performance reported in the Orca paper.
Was #1 at release time, now surpassed by our own OpenOrca-Platypus2-13B.
Released in partnership with OpenChat.
## OpenOrca-Preview1-13B
OpenOrca-Preview1-13B
This model was trained in less than a day, for <$200, with <10% of our data.
At release, it beat the current state of the art models on BigBench-Hard and AGIEval. Achieves ~60% of the improvements reported in the Orca paper.
<a name="dataset-summary"></a>
# Dataset Summary
The OpenOrca dataset is a collection of augmented FLAN Collection data.
Currently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.
It is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.
The data is primarily used for training and evaluation in the field of natural language processing.
<a name="dataset-attribution"></a>
# Dataset Attribution
We would like to give special recognition to the following contributors for their significant efforts and dedication:
Teknium
WingLian/Caseus
Eric Hartford
NanoBit
Pankaj
Winddude
Rohan
URL:
Autometa
Entropi
AtlasUnified
NeverendingToast
NanoBit
WingLian/Caseus
Also of course, as always, TheBloke, for being the backbone of the whole community.
Many thanks to NanoBit and Caseus, makers of Axolotl, for lending us their expertise on the platform that developed and trained manticore, minotaur, and many others!
We are welcoming sponsors or collaborators to help us build these models to the scale they deserve. Please reach out via our socials:
URL URL
Want to visualize our full dataset? Check out our Nomic Atlas Map.
<img src="URL alt="Atlas Nomic Dataset Map" width="400" height="400" />
<a name="supported-tasks-and-leaderboards"></a>
# Supported Tasks and Leaderboards
This dataset supports a range of tasks including language modeling, text generation, and text augmentation.
It has been instrumental in the generation of multiple high-performing model checkpoints which have exhibited exceptional performance in our unit testing.
Further information on leaderboards will be updated as they become available.
<a name="languages"></a>
# Languages
The language of the data is primarily English.
<a name="dataset-structure"></a>
# Dataset Structure
<a name="data-instances"></a>
## Data Instances
A data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.
The response is then entered into the response field.
<a name="data-fields"></a>
## Data Fields
The fields are:
1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.
2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint
3) 'question', representing a question entry as provided by the FLAN Collection
4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.
<a name="data-splits"></a>
## Data Splits
The data is unsplit.
<a name="dataset-creation"></a>
# Dataset Creation
<a name="curation-rationale"></a>
## Curation Rationale
The dataset was created to provide a source of augmented text data for researchers and developers.
The datapoints are intended primarily to provide an enhancement of the core FLAN Collection data which relies upon the detailed step by step reasoning capabilities of GPT-3.5 and GPT-4.
This "reasoning trace" augmentation has demonstrated exceptional results, allowing a LLaMA-13B model trained with this data to rival or beat GPT-3.5 on broad sets of hard reasoning tasks which all models below 100B parameters had previously performed dramatically worse on.
<a name="source-data"></a>
## Source Data
The data is generated using techniques in alignment with the distributions outlined in the Orca paper, except as noted below:
1) There is not enough CoT data in the FLAN Collection to generate 150K zero-shot entries, as the paper purports to use.
We suspect this portion was either undocumented or misrepresented. We have used the ~75K points available.
2) We used the pre-generated FLAN Collection datasets hosted on HuggingFace under conceptofmind, e.g. conceptofmind/flan2021.
These are referenced by the official FLAN Collection repo as the preferred data source.
However, these are a subset of the full FLAN Collection data, and have less than the required entries for the flan2021 and t0 submixes, by ~1.25M and 200k respectively.
Combined, this gave us ~1.5M fewer datapoints than in the original Orca paper. Completing the set is an ongoing work.
<a name="dataset-use"></a>
# Dataset Use
<a name="use-cases"></a>
## Use Cases
The dataset can be used for tasks related to language understanding, natural language processing, machine learning model training, and model performance evaluation.
<a name="usage-caveats"></a>
## Usage Caveats
Given that this is a work-in-progress dataset, it is recommended to regularly check for updates and improvements.
Further, the data should be used in accordance with the guidelines and recommendations outlined in the Orca paper.
<a name="getting-started"></a>
## Getting Started
This dataset is organized such that it can be naively loaded via Hugging Face datasets library.
We recommend using streaming due to the large size of the files.
Regular updates and data generation progress can be monitored through the OpenOrca repository on Hugging Face.
|
[
"# OpenOrca-KO\n- OpenOrca dataset 중 약 2만개를 sampling하여 번역한 데이터셋\n- 데이터셋 이용하셔서 모델이나 데이터셋을 만드실 때, 간단한 출처 표기를 해주신다면 연구에 큰 도움이 됩니다",
"## Dataset inf0\n1. NIV // 1571개 \n2. FLAN // 9434개 \n3. T0 // 6351개 \n4. CoT // 2117개 \n5. KoCoT // 2159개",
"## Translation\nUsing DeepL Pro API. Thanks.\n\n---\n>Below is original dataset card",
"## Table of Contents\n- Dataset Summary\n- Dataset Attribution\n- Supported Tasks and Leaderboards\n- Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n- Dataset Use\n - Use Cases\n - Usage Caveats\n - Getting Started\n\n\n<p><h1> The OpenOrca Dataset! </h1></p>\n\n!OpenOrca Logo\n\n<a name=\"dataset-announcement\"></a>\n\nWe are thrilled to announce the release of the OpenOrca dataset!\nThis rich collection of augmented FLAN data aligns, as best as possible, with the distributions outlined in the Orca paper.\nIt has been instrumental in generating high-performing model checkpoints and serves as a valuable resource for all NLP researchers and developers!",
"# Official Models",
"## OpenOrca-Platypus2-13B\n\nOur latest release, the first 13B model to score higher than LLaMA1-65B on the HuggingFace Leaderboard!\nReleased in partnership with Platypus.",
"## LlongOrca 7B & 13B\n\n* Our first 7B release, trained on top of LLongMA2 to achieve 16,000 tokens context. #1 long context 7B model at release time, with >99% of the overall #1 model's performance.\n* LlongOrca-13B-16k, trained on top of LLongMA2. #1 long context 13B model at release time, with >97% of the overall #1 model's performance.",
"## OpenOrcaxOpenChat-Preview2-13B\n\nOur second model, highlighting that we've surpassed the performance reported in the Orca paper.\nWas #1 at release time, now surpassed by our own OpenOrca-Platypus2-13B.\nReleased in partnership with OpenChat.",
"## OpenOrca-Preview1-13B\n\nOpenOrca-Preview1-13B\nThis model was trained in less than a day, for <$200, with <10% of our data.\nAt release, it beat the current state of the art models on BigBench-Hard and AGIEval. Achieves ~60% of the improvements reported in the Orca paper.\n\n<a name=\"dataset-summary\"></a>",
"# Dataset Summary\n\nThe OpenOrca dataset is a collection of augmented FLAN Collection data.\nCurrently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.\nIt is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.\nThe data is primarily used for training and evaluation in the field of natural language processing.\n\n<a name=\"dataset-attribution\"></a>",
"# Dataset Attribution\n\nWe would like to give special recognition to the following contributors for their significant efforts and dedication:\n \n\n Teknium \n WingLian/Caseus\n Eric Hartford\n NanoBit\n Pankaj\n Winddude\n Rohan\n\n URL:\n Autometa\n Entropi\n AtlasUnified\n NeverendingToast\n NanoBit\n WingLian/Caseus\n\nAlso of course, as always, TheBloke, for being the backbone of the whole community.\n\nMany thanks to NanoBit and Caseus, makers of Axolotl, for lending us their expertise on the platform that developed and trained manticore, minotaur, and many others! \n\nWe are welcoming sponsors or collaborators to help us build these models to the scale they deserve. Please reach out via our socials:\nURL URL\n\nWant to visualize our full dataset? Check out our Nomic Atlas Map.\n <img src=\"URL alt=\"Atlas Nomic Dataset Map\" width=\"400\" height=\"400\" />\n\n\n<a name=\"supported-tasks-and-leaderboards\"></a>",
"# Supported Tasks and Leaderboards\n\nThis dataset supports a range of tasks including language modeling, text generation, and text augmentation.\nIt has been instrumental in the generation of multiple high-performing model checkpoints which have exhibited exceptional performance in our unit testing.\nFurther information on leaderboards will be updated as they become available.\n\n<a name=\"languages\"></a>",
"# Languages\n\nThe language of the data is primarily English.\n\n<a name=\"dataset-structure\"></a>",
"# Dataset Structure\n\n<a name=\"data-instances\"></a>",
"## Data Instances\n\nA data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.\nThe response is then entered into the response field.\n\n<a name=\"data-fields\"></a>",
"## Data Fields\n\nThe fields are:\n1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.\n2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint\n3) 'question', representing a question entry as provided by the FLAN Collection\n4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.\n\n<a name=\"data-splits\"></a>",
"## Data Splits\n\nThe data is unsplit.\n\n<a name=\"dataset-creation\"></a>",
"# Dataset Creation\n\n<a name=\"curation-rationale\"></a>",
"## Curation Rationale\n\nThe dataset was created to provide a source of augmented text data for researchers and developers.\nThe datapoints are intended primarily to provide an enhancement of the core FLAN Collection data which relies upon the detailed step by step reasoning capabilities of GPT-3.5 and GPT-4.\nThis \"reasoning trace\" augmentation has demonstrated exceptional results, allowing a LLaMA-13B model trained with this data to rival or beat GPT-3.5 on broad sets of hard reasoning tasks which all models below 100B parameters had previously performed dramatically worse on.\n\n<a name=\"source-data\"></a>",
"## Source Data\n\nThe data is generated using techniques in alignment with the distributions outlined in the Orca paper, except as noted below:\n\n1) There is not enough CoT data in the FLAN Collection to generate 150K zero-shot entries, as the paper purports to use.\n We suspect this portion was either undocumented or misrepresented. We have used the ~75K points available.\n2) We used the pre-generated FLAN Collection datasets hosted on HuggingFace under conceptofmind, e.g. conceptofmind/flan2021.\n These are referenced by the official FLAN Collection repo as the preferred data source.\n However, these are a subset of the full FLAN Collection data, and have less than the required entries for the flan2021 and t0 submixes, by ~1.25M and 200k respectively.\n\nCombined, this gave us ~1.5M fewer datapoints than in the original Orca paper. Completing the set is an ongoing work.\n\n<a name=\"dataset-use\"></a>",
"# Dataset Use\n\n<a name=\"use-cases\"></a>",
"## Use Cases\n\nThe dataset can be used for tasks related to language understanding, natural language processing, machine learning model training, and model performance evaluation.\n\n<a name=\"usage-caveats\"></a>",
"## Usage Caveats\n\nGiven that this is a work-in-progress dataset, it is recommended to regularly check for updates and improvements.\nFurther, the data should be used in accordance with the guidelines and recommendations outlined in the Orca paper.\n\n<a name=\"getting-started\"></a>",
"## Getting Started\n\nThis dataset is organized such that it can be naively loaded via Hugging Face datasets library.\nWe recommend using streaming due to the large size of the files.\nRegular updates and data generation progress can be monitored through the OpenOrca repository on Hugging Face."
] |
[
"TAGS\n#task_categories-conversational #task_categories-text-classification #task_categories-token-classification #task_categories-table-question-answering #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-summarization #task_categories-feature-extraction #task_categories-text-generation #task_categories-text2text-generation #size_categories-10K<n<50K #language-Korean #license-mit #arxiv-2306.02707 #arxiv-2301.13688 #region-us \n",
"# OpenOrca-KO\n- OpenOrca dataset 중 약 2만개를 sampling하여 번역한 데이터셋\n- 데이터셋 이용하셔서 모델이나 데이터셋을 만드실 때, 간단한 출처 표기를 해주신다면 연구에 큰 도움이 됩니다",
"## Dataset inf0\n1. NIV // 1571개 \n2. FLAN // 9434개 \n3. T0 // 6351개 \n4. CoT // 2117개 \n5. KoCoT // 2159개",
"## Translation\nUsing DeepL Pro API. Thanks.\n\n---\n>Below is original dataset card",
"## Table of Contents\n- Dataset Summary\n- Dataset Attribution\n- Supported Tasks and Leaderboards\n- Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n- Dataset Use\n - Use Cases\n - Usage Caveats\n - Getting Started\n\n\n<p><h1> The OpenOrca Dataset! </h1></p>\n\n!OpenOrca Logo\n\n<a name=\"dataset-announcement\"></a>\n\nWe are thrilled to announce the release of the OpenOrca dataset!\nThis rich collection of augmented FLAN data aligns, as best as possible, with the distributions outlined in the Orca paper.\nIt has been instrumental in generating high-performing model checkpoints and serves as a valuable resource for all NLP researchers and developers!",
"# Official Models",
"## OpenOrca-Platypus2-13B\n\nOur latest release, the first 13B model to score higher than LLaMA1-65B on the HuggingFace Leaderboard!\nReleased in partnership with Platypus.",
"## LlongOrca 7B & 13B\n\n* Our first 7B release, trained on top of LLongMA2 to achieve 16,000 tokens context. #1 long context 7B model at release time, with >99% of the overall #1 model's performance.\n* LlongOrca-13B-16k, trained on top of LLongMA2. #1 long context 13B model at release time, with >97% of the overall #1 model's performance.",
"## OpenOrcaxOpenChat-Preview2-13B\n\nOur second model, highlighting that we've surpassed the performance reported in the Orca paper.\nWas #1 at release time, now surpassed by our own OpenOrca-Platypus2-13B.\nReleased in partnership with OpenChat.",
"## OpenOrca-Preview1-13B\n\nOpenOrca-Preview1-13B\nThis model was trained in less than a day, for <$200, with <10% of our data.\nAt release, it beat the current state of the art models on BigBench-Hard and AGIEval. Achieves ~60% of the improvements reported in the Orca paper.\n\n<a name=\"dataset-summary\"></a>",
"# Dataset Summary\n\nThe OpenOrca dataset is a collection of augmented FLAN Collection data.\nCurrently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.\nIt is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.\nThe data is primarily used for training and evaluation in the field of natural language processing.\n\n<a name=\"dataset-attribution\"></a>",
"# Dataset Attribution\n\nWe would like to give special recognition to the following contributors for their significant efforts and dedication:\n \n\n Teknium \n WingLian/Caseus\n Eric Hartford\n NanoBit\n Pankaj\n Winddude\n Rohan\n\n URL:\n Autometa\n Entropi\n AtlasUnified\n NeverendingToast\n NanoBit\n WingLian/Caseus\n\nAlso of course, as always, TheBloke, for being the backbone of the whole community.\n\nMany thanks to NanoBit and Caseus, makers of Axolotl, for lending us their expertise on the platform that developed and trained manticore, minotaur, and many others! \n\nWe are welcoming sponsors or collaborators to help us build these models to the scale they deserve. Please reach out via our socials:\nURL URL\n\nWant to visualize our full dataset? Check out our Nomic Atlas Map.\n <img src=\"URL alt=\"Atlas Nomic Dataset Map\" width=\"400\" height=\"400\" />\n\n\n<a name=\"supported-tasks-and-leaderboards\"></a>",
"# Supported Tasks and Leaderboards\n\nThis dataset supports a range of tasks including language modeling, text generation, and text augmentation.\nIt has been instrumental in the generation of multiple high-performing model checkpoints which have exhibited exceptional performance in our unit testing.\nFurther information on leaderboards will be updated as they become available.\n\n<a name=\"languages\"></a>",
"# Languages\n\nThe language of the data is primarily English.\n\n<a name=\"dataset-structure\"></a>",
"# Dataset Structure\n\n<a name=\"data-instances\"></a>",
"## Data Instances\n\nA data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.\nThe response is then entered into the response field.\n\n<a name=\"data-fields\"></a>",
"## Data Fields\n\nThe fields are:\n1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.\n2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint\n3) 'question', representing a question entry as provided by the FLAN Collection\n4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.\n\n<a name=\"data-splits\"></a>",
"## Data Splits\n\nThe data is unsplit.\n\n<a name=\"dataset-creation\"></a>",
"# Dataset Creation\n\n<a name=\"curation-rationale\"></a>",
"## Curation Rationale\n\nThe dataset was created to provide a source of augmented text data for researchers and developers.\nThe datapoints are intended primarily to provide an enhancement of the core FLAN Collection data which relies upon the detailed step by step reasoning capabilities of GPT-3.5 and GPT-4.\nThis \"reasoning trace\" augmentation has demonstrated exceptional results, allowing a LLaMA-13B model trained with this data to rival or beat GPT-3.5 on broad sets of hard reasoning tasks which all models below 100B parameters had previously performed dramatically worse on.\n\n<a name=\"source-data\"></a>",
"## Source Data\n\nThe data is generated using techniques in alignment with the distributions outlined in the Orca paper, except as noted below:\n\n1) There is not enough CoT data in the FLAN Collection to generate 150K zero-shot entries, as the paper purports to use.\n We suspect this portion was either undocumented or misrepresented. We have used the ~75K points available.\n2) We used the pre-generated FLAN Collection datasets hosted on HuggingFace under conceptofmind, e.g. conceptofmind/flan2021.\n These are referenced by the official FLAN Collection repo as the preferred data source.\n However, these are a subset of the full FLAN Collection data, and have less than the required entries for the flan2021 and t0 submixes, by ~1.25M and 200k respectively.\n\nCombined, this gave us ~1.5M fewer datapoints than in the original Orca paper. Completing the set is an ongoing work.\n\n<a name=\"dataset-use\"></a>",
"# Dataset Use\n\n<a name=\"use-cases\"></a>",
"## Use Cases\n\nThe dataset can be used for tasks related to language understanding, natural language processing, machine learning model training, and model performance evaluation.\n\n<a name=\"usage-caveats\"></a>",
"## Usage Caveats\n\nGiven that this is a work-in-progress dataset, it is recommended to regularly check for updates and improvements.\nFurther, the data should be used in accordance with the guidelines and recommendations outlined in the Orca paper.\n\n<a name=\"getting-started\"></a>",
"## Getting Started\n\nThis dataset is organized such that it can be naively loaded via Hugging Face datasets library.\nWe recommend using streaming due to the large size of the files.\nRegular updates and data generation progress can be monitored through the OpenOrca repository on Hugging Face."
] |
[
163,
55,
41,
20,
199,
4,
48,
98,
67,
95,
122,
233,
86,
25,
19,
67,
153,
24,
18,
146,
235,
16,
46,
70,
66
] |
[
"passage: TAGS\n#task_categories-conversational #task_categories-text-classification #task_categories-token-classification #task_categories-table-question-answering #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-summarization #task_categories-feature-extraction #task_categories-text-generation #task_categories-text2text-generation #size_categories-10K<n<50K #language-Korean #license-mit #arxiv-2306.02707 #arxiv-2301.13688 #region-us \n# OpenOrca-KO\n- OpenOrca dataset 중 약 2만개를 sampling하여 번역한 데이터셋\n- 데이터셋 이용하셔서 모델이나 데이터셋을 만드실 때, 간단한 출처 표기를 해주신다면 연구에 큰 도움이 됩니다## Dataset inf0\n1. NIV // 1571개 \n2. FLAN // 9434개 \n3. T0 // 6351개 \n4. CoT // 2117개 \n5. KoCoT // 2159개## Translation\nUsing DeepL Pro API. Thanks.\n\n---\n>Below is original dataset card## Table of Contents\n- Dataset Summary\n- Dataset Attribution\n- Supported Tasks and Leaderboards\n- Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n- Dataset Use\n - Use Cases\n - Usage Caveats\n - Getting Started\n\n\n<p><h1> The OpenOrca Dataset! </h1></p>\n\n!OpenOrca Logo\n\n<a name=\"dataset-announcement\"></a>\n\nWe are thrilled to announce the release of the OpenOrca dataset!\nThis rich collection of augmented FLAN data aligns, as best as possible, with the distributions outlined in the Orca paper.\nIt has been instrumental in generating high-performing model checkpoints and serves as a valuable resource for all NLP researchers and developers!# Official Models",
"passage: ## OpenOrca-Platypus2-13B\n\nOur latest release, the first 13B model to score higher than LLaMA1-65B on the HuggingFace Leaderboard!\nReleased in partnership with Platypus.## LlongOrca 7B & 13B\n\n* Our first 7B release, trained on top of LLongMA2 to achieve 16,000 tokens context. #1 long context 7B model at release time, with >99% of the overall #1 model's performance.\n* LlongOrca-13B-16k, trained on top of LLongMA2. #1 long context 13B model at release time, with >97% of the overall #1 model's performance.## OpenOrcaxOpenChat-Preview2-13B\n\nOur second model, highlighting that we've surpassed the performance reported in the Orca paper.\nWas #1 at release time, now surpassed by our own OpenOrca-Platypus2-13B.\nReleased in partnership with OpenChat.## OpenOrca-Preview1-13B\n\nOpenOrca-Preview1-13B\nThis model was trained in less than a day, for <$200, with <10% of our data.\nAt release, it beat the current state of the art models on BigBench-Hard and AGIEval. Achieves ~60% of the improvements reported in the Orca paper.\n\n<a name=\"dataset-summary\"></a># Dataset Summary\n\nThe OpenOrca dataset is a collection of augmented FLAN Collection data.\nCurrently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.\nIt is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.\nThe data is primarily used for training and evaluation in the field of natural language processing.\n\n<a name=\"dataset-attribution\"></a>",
"passage: # Dataset Attribution\n\nWe would like to give special recognition to the following contributors for their significant efforts and dedication:\n \n\n Teknium \n WingLian/Caseus\n Eric Hartford\n NanoBit\n Pankaj\n Winddude\n Rohan\n\n URL:\n Autometa\n Entropi\n AtlasUnified\n NeverendingToast\n NanoBit\n WingLian/Caseus\n\nAlso of course, as always, TheBloke, for being the backbone of the whole community.\n\nMany thanks to NanoBit and Caseus, makers of Axolotl, for lending us their expertise on the platform that developed and trained manticore, minotaur, and many others! \n\nWe are welcoming sponsors or collaborators to help us build these models to the scale they deserve. Please reach out via our socials:\nURL URL\n\nWant to visualize our full dataset? Check out our Nomic Atlas Map.\n <img src=\"URL alt=\"Atlas Nomic Dataset Map\" width=\"400\" height=\"400\" />\n\n\n<a name=\"supported-tasks-and-leaderboards\"></a># Supported Tasks and Leaderboards\n\nThis dataset supports a range of tasks including language modeling, text generation, and text augmentation.\nIt has been instrumental in the generation of multiple high-performing model checkpoints which have exhibited exceptional performance in our unit testing.\nFurther information on leaderboards will be updated as they become available.\n\n<a name=\"languages\"></a># Languages\n\nThe language of the data is primarily English.\n\n<a name=\"dataset-structure\"></a># Dataset Structure\n\n<a name=\"data-instances\"></a>## Data Instances\n\nA data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.\nThe response is then entered into the response field.\n\n<a name=\"data-fields\"></a>## Data Fields\n\nThe fields are:\n1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.\n2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint\n3) 'question', representing a question entry as provided by the FLAN Collection\n4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.\n\n<a name=\"data-splits\"></a>## Data Splits\n\nThe data is unsplit.\n\n<a name=\"dataset-creation\"></a># Dataset Creation\n\n<a name=\"curation-rationale\"></a>"
] |
932e3f46255585b9a83cd3f0d74bf1c806fea5a0
|
# Dataset Card for Camelyon16-features
### Dataset Summary
The Camelyon16 dataset is a very popular benchmark dataset used in the field of cancer classification.
The dataset we've uploaded here is the result of features extracted from the Camelyon16 dataset using the Phikon model, which is also openly available on Hugging Face.
## Dataset Creation
### Initial Data Collection and Normalization
The initial collection of the Camelyon16 Whole Slide Images is credited to:
Radboud University Medical Center (Nijmegen, the Netherlands),
University Medical Center Utrecht (Utrecht, the Netherlands).
### Licensing Information
This dataset is under [Owkin non-commercial license](https://github.com/owkin/HistoSSLscaling/blob/main/LICENSE.txt).
### Citation Information
Owkin claims no ownership of this dataset. This is simply an extraction of features from the original dataset.
[Link to original dataset](https://camelyon16.grand-challenge.org/) [Link to original paper](https://jamanetwork.com/journals/jama/fullarticle/2665774)
|
owkin/camelyon16-features
|
[
"task_categories:feature-extraction",
"task_categories:image-classification",
"size_categories:n<1K",
"language:en",
"license:other",
"biology",
"medical",
"cancer",
"region:us"
] |
2023-09-29T14:26:47+00:00
|
{"language": ["en"], "license": "other", "size_categories": ["n<1K"], "task_categories": ["feature-extraction", "image-classification"], "pretty_name": "Camelyon16 Features", "dataset_info": {"features": [{"name": "features", "sequence": {"sequence": "float32"}}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "Phikon_test", "num_bytes": 401342744, "num_examples": 130}, {"name": "Phikon_train", "num_bytes": 808932620, "num_examples": 269}], "download_size": 1210840794, "dataset_size": 1210275364}, "configs": [{"config_name": "default", "data_files": [{"split": "Phikon_test", "path": "data/Phikon_test-*"}, {"split": "Phikon_train", "path": "data/Phikon_train-*"}]}], "tags": ["biology", "medical", "cancer"]}
|
2023-10-30T11:20:51+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-feature-extraction #task_categories-image-classification #size_categories-n<1K #language-English #license-other #biology #medical #cancer #region-us
|
# Dataset Card for Camelyon16-features
### Dataset Summary
The Camelyon16 dataset is a very popular benchmark dataset used in the field of cancer classification.
!Example of Camelyon16 slide
The dataset we've uploaded here is the result of features extracted from the Camelyon16 dataset using the Phikon model, which is also openly available on Hugging Face.
## Dataset Creation
### Initial Data Collection and Normalization
The initial collection of the Camelyon16 Whole Slide Images is credited to:
Radboud University Medical Center (Nijmegen, the Netherlands),
University Medical Center Utrecht (Utrecht, the Netherlands).
### Licensing Information
This dataset is under Owkin non-commercial license.
Owkin claims no ownership of this dataset. This is simply an extraction of features from the original dataset.
Link to original dataset Link to original paper
|
[
"# Dataset Card for Camelyon16-features",
"### Dataset Summary\n\nThe Camelyon16 dataset is a very popular benchmark dataset used in the field of cancer classification. \n\n!Example of Camelyon16 slide\n\nThe dataset we've uploaded here is the result of features extracted from the Camelyon16 dataset using the Phikon model, which is also openly available on Hugging Face.",
"## Dataset Creation",
"### Initial Data Collection and Normalization\n\nThe initial collection of the Camelyon16 Whole Slide Images is credited to:\n\nRadboud University Medical Center (Nijmegen, the Netherlands),\nUniversity Medical Center Utrecht (Utrecht, the Netherlands).",
"### Licensing Information\n\nThis dataset is under Owkin non-commercial license.\n\n\n\nOwkin claims no ownership of this dataset. This is simply an extraction of features from the original dataset. \n\nLink to original dataset Link to original paper"
] |
[
"TAGS\n#task_categories-feature-extraction #task_categories-image-classification #size_categories-n<1K #language-English #license-other #biology #medical #cancer #region-us \n",
"# Dataset Card for Camelyon16-features",
"### Dataset Summary\n\nThe Camelyon16 dataset is a very popular benchmark dataset used in the field of cancer classification. \n\n!Example of Camelyon16 slide\n\nThe dataset we've uploaded here is the result of features extracted from the Camelyon16 dataset using the Phikon model, which is also openly available on Hugging Face.",
"## Dataset Creation",
"### Initial Data Collection and Normalization\n\nThe initial collection of the Camelyon16 Whole Slide Images is credited to:\n\nRadboud University Medical Center (Nijmegen, the Netherlands),\nUniversity Medical Center Utrecht (Utrecht, the Netherlands).",
"### Licensing Information\n\nThis dataset is under Owkin non-commercial license.\n\n\n\nOwkin claims no ownership of this dataset. This is simply an extraction of features from the original dataset. \n\nLink to original dataset Link to original paper"
] |
[
56,
11,
77,
5,
52,
56
] |
[
"passage: TAGS\n#task_categories-feature-extraction #task_categories-image-classification #size_categories-n<1K #language-English #license-other #biology #medical #cancer #region-us \n# Dataset Card for Camelyon16-features### Dataset Summary\n\nThe Camelyon16 dataset is a very popular benchmark dataset used in the field of cancer classification. \n\n!Example of Camelyon16 slide\n\nThe dataset we've uploaded here is the result of features extracted from the Camelyon16 dataset using the Phikon model, which is also openly available on Hugging Face.## Dataset Creation### Initial Data Collection and Normalization\n\nThe initial collection of the Camelyon16 Whole Slide Images is credited to:\n\nRadboud University Medical Center (Nijmegen, the Netherlands),\nUniversity Medical Center Utrecht (Utrecht, the Netherlands).### Licensing Information\n\nThis dataset is under Owkin non-commercial license.\n\n\n\nOwkin claims no ownership of this dataset. This is simply an extraction of features from the original dataset. \n\nLink to original dataset Link to original paper"
] |
ec09c6dda70e5c0271bc8a5ce821434aa8403e67
|
# Dataset Card for "imdb_push_to_hub_single_commit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mariosasko/imdb_push_to_hub_single_commit
|
[
"region:us"
] |
2023-09-29T14:30:50+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "neg", "1": "pos"}}}}], "splits": [{"name": "train", "num_bytes": 33432823, "num_examples": 25000}], "download_size": 21062498, "dataset_size": 33432823, "description": "dummy description"}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-12T16:53:39+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "imdb_push_to_hub_single_commit"
More Information needed
|
[
"# Dataset Card for \"imdb_push_to_hub_single_commit\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"imdb_push_to_hub_single_commit\"\n\nMore Information needed"
] |
[
6,
25
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"imdb_push_to_hub_single_commit\"\n\nMore Information needed"
] |
abd691961003f578425aa87825efa8feb462a3be
|
# Dataset Card for "korquad_v2_sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fiveflow/korquad_v2_sample
|
[
"region:us"
] |
2023-09-29T14:41:39+00:00
|
{"dataset_info": {"features": [{"name": "context", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 61993804, "num_examples": 3034}, {"name": "validation", "num_bytes": 38581196, "num_examples": 1916}], "download_size": 24996643, "dataset_size": 100575000}}
|
2023-09-29T14:41:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "korquad_v2_sample"
More Information needed
|
[
"# Dataset Card for \"korquad_v2_sample\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"korquad_v2_sample\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"korquad_v2_sample\"\n\nMore Information needed"
] |
d21352d8cb681951a0ce8f5be574e1ff7e0f75a6
|
Created from various interviews/quotes by Steve Jobs
|
AustinMcMike/steve_jobs
|
[
"license:apache-2.0",
"region:us"
] |
2023-09-29T14:52:03+00:00
|
{"license": "apache-2.0"}
|
2023-09-29T16:30:12+00:00
|
[] |
[] |
TAGS
#license-apache-2.0 #region-us
|
Created from various interviews/quotes by Steve Jobs
|
[] |
[
"TAGS\n#license-apache-2.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-apache-2.0 #region-us \n"
] |
302988db663b199d7de3e115795087d11c3e44c9
|
# Dataset Card for "toolwear_segmentsai"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HorcruxNo13/toolwear_segmentsai
|
[
"region:us"
] |
2023-09-29T14:55:50+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "pixel_values", "dtype": "image"}, {"name": "label", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 44532017.0, "num_examples": 27}], "download_size": 4527506, "dataset_size": 44532017.0}}
|
2023-09-29T14:56:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "toolwear_segmentsai"
More Information needed
|
[
"# Dataset Card for \"toolwear_segmentsai\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"toolwear_segmentsai\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"toolwear_segmentsai\"\n\nMore Information needed"
] |
370b65fcfe316d7f6d296d4aa3bf2fe9c594c3f0
|
Graded by gpt4-0314 with this prompt:
```
A textbook entry has been proposed that would be written following the instruction:
{instruction}
Rate the educational value of the proposal from 1-100 for a LLM trying to learn english, general knowledge, python coding, logic, reasoning, etc.
Simply give the numerical rating with no explanation.
```
Currently unfinished
|
totally-not-an-llm/airoboros-textbook-gpt4-graded
|
[
"license:other",
"region:us"
] |
2023-09-29T15:14:21+00:00
|
{"license": "other", "license_name": "airoboros", "license_link": "LICENSE"}
|
2023-10-01T04:12:45+00:00
|
[] |
[] |
TAGS
#license-other #region-us
|
Graded by gpt4-0314 with this prompt:
Currently unfinished
|
[] |
[
"TAGS\n#license-other #region-us \n"
] |
[
11
] |
[
"passage: TAGS\n#license-other #region-us \n"
] |
a561224c656fbd5ca929181debc00046e8c73da6
|
开放领域三元组抽取数据(主要为人物关系,职务头衔等),个人手动收集整理。
训练数据(train):spo.json,共 5259 条数据。
测试数据(test):evaluate_data.xlsx,共 100 条数据。
|
jclian91/open_domain_triple_extraction
|
[
"license:mit",
"region:us"
] |
2023-09-29T15:22:55+00:00
|
{"license": "mit"}
|
2023-09-29T15:29:37+00:00
|
[] |
[] |
TAGS
#license-mit #region-us
|
开放领域三元组抽取数据(主要为人物关系,职务头衔等),个人手动收集整理。
训练数据(train):URL,共 5259 条数据。
测试数据(test):evaluate_data.xlsx,共 100 条数据。
|
[] |
[
"TAGS\n#license-mit #region-us \n"
] |
[
11
] |
[
"passage: TAGS\n#license-mit #region-us \n"
] |
cd6ad4eb6af2985f1c4787d23cfc67b02d1b6381
|
# Bangumi Image Base of Gabriel Dropout
This is the image base of bangumi Gabriel Dropout, we detected 20 characters, 1684 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 340 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 27 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 12 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 84 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 13 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 11 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 312 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 12 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 8 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 8 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 382 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 40 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 19 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 14 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 54 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 11 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 9 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 23 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 228 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 77 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/gabrieldropout
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-29T15:31:06+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-29T16:23:04+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Gabriel Dropout
=====================================
This is the image base of bangumi Gabriel Dropout, we detected 20 characters, 1684 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
250a2e6ab51421a2bcf1f47c4957d76a55ad0c8f
|
# FIBO: The Financial Industry Business Ontology
### Overview
In the world of financial technology, the vastness of data and the
complexity of financial instruments present both challenges and
opportunities. The Financial Industry Business Ontology (FIBO) offers
a structured framework that bridges the gap between theoretical
financial concepts and real-world data. I believe machine learning
researchers interested in the financial sector could use the
relationships in FIBO to innovate in financial feature engineering to
fine-tune existing models or build new ones.
#### Open Source
The FIBO ontology is developed on GitHub at
https://github.com/edmcouncil/fibo/.
### Use-cases
- Comprehensive Data Structure: FIBO offers a broad spectrum of
financial concepts, ranging from derivatives to securities. This
design, rooted in expert knowledge from both the knowledge
representation and financial sectors, ensures a profound
understanding of financial instruments.
- Decoding Complex Relationships: The financial domain is
characterized by its intricate interdependencies. FIBO's structured
approach provides clarity on these relationships, enabling machine
learning algorithms to identify patterns and correlations within
large datasets.
- Linkage with Real-world Data: A distinguishing feature of FIBO is
its capability to associate financial concepts with real-world
financial data and controlled vocabularies. This connection is
crucial for researchers aiming to apply theoretical insights in
practical contexts in financial enterprises with their existing
data.
- Retrieval Augmented Generation: The advent of Large Language Models,
particularly in conjunction with Retrieval Augmented Generation
(RAG), holds promise for revolutionizing the way financial data is
processed and interpreted.
- Document Classification: With the surge in financial documents,
utilizing RAG to categorize financial datasets classifed by FIBO
concepts can assist financial analysts in achieving enhanced
accuracy and depth in data interpretation, facilitated by
intelligent prompting.
#### Building and Verification:
1. **Construction**: The ontology was imported from
[AboutFIBOProd-IncludingReferenceData](https://github.com/edmcouncil/fibo/blob/master/AboutFIBOProd-IncludingReferenceData.rdf)
into Protege version 5.6.1.
2. **Reasoning**: Due to the large size of the ontology I used the ELK
reasoner plugin to materialize (make explicit) inferences in the
ontology.
3. **Coherence Check**: The Debug Ontology plugin in Protege was used
to ensure the ontology's coherence and consistency.
4. **Export**: After verification, inferred axioms, along with
asserted axioms and annotations, were [exported using Protege](https://www.michaeldebellis.com/post/export-inferred-axioms).
5. **Encoding and Compression**: [Apache Jena's
riot](https://jena.apache.org/documentation/tools/) was used to convert the
result to ntriples, which was then compressed with gzip. This
compressed artifact is downloaded and extracted by the Hugging Face
datasets library to yield the examples in the dataset.
### Usage
First make sure you have the requirements installed:
```python
pip install datasets
pip install rdflib
```
You can load the dataset using the Hugging Face Datasets library with the following Python code:
```python
from datasets import load_dataset
dataset = load_dataset('wikipunk/fibo2023Q3', split='train')
```
## Features
The FIBO dataset is composed of triples representing the relationships
between different financial concepts and named individuals such as
market participants, corporations, and contractual agents.
#### Note on Format:
The subject, predicate, and object features are stored in N3 notation
with no prefix mappings. This allows users to parse each component
using `rdflib.util.from_n3` from the RDFLib Python library.
### 1. **Subject** (`string`)
The subject of a triple is the primary entity or focus of the statement. In this dataset, the subject often represents a specific financial instrument or entity. For instance:
`<https://spec.edmcouncil.org/fibo/ontology/SEC/Equities/EquitiesExampleIndividuals/XNYSListedTheCoca-ColaCompanyCommonStock>`
refers to the common stock of The Coca-Cola Company that is listed on
the NYSE.
### 2. **Predicate** (`string`)
The predicate of a triple indicates the nature of the relationship between the subject and the object. It describes a specific property, characteristic, or connection of the subject. In our example:
`<https://spec.edmcouncil.org/fibo/ontology/SEC/Securities/SecuritiesListings/isTradedOn>`
signifies that the financial instrument (subject) is traded on a
particular exchange (object).
### 3. **Object** (`string`)
The object of a triple is the entity or value that is associated with the subject via the predicate. It can be another financial concept, a trading platform, or any other related entity. In the context of our example:
`<https://spec.edmcouncil.org/fibo/ontology/FBC/FunctionalEntities/NorthAmericanEntities/USMarketsAndExchangesIndividuals/NewYorkStockExchange>`
represents the New York Stock Exchange where the aforementioned
Coca-Cola common stock is traded.
#### Continued
Here is an another example of a triple in the dataset:
- Subject: `"<https://spec.edmcouncil.org/fibo/ontology/FBC/FunctionalEntities/MarketsIndividuals/ServiceProvider-L-JEUVK5RWVJEN8W0C9M24>"`
- Predicate: `"<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>`
- Object: `"<https://spec.edmcouncil.org/fibo/ontology/BE/FunctionalEntities/FunctionalEntities/FunctionalEntity>"`
This triple represents the statement that the market individual
[ServiceProvider-L-JEUVK5RWVJEN8W0C9M24](https://spec.edmcouncil.org/fibo/ontology/FBC/FunctionalEntities/MarketsIndividuals/ServiceProvider-L-JEUVK5RWVJEN8W0C9M24)
has a type of
[FunctionalEntity](https://spec.edmcouncil.org/fibo/ontology/BE/FunctionalEntities/FunctionalEntities/FunctionalEntity).
#### Note:
The dataset contains example individuals from the ontology as
reference points. These examples provide a structured framework for
understanding the relationships and entities within the financial
domain. However, the individuals included are not exhaustive. With
advancements in Large Language Models, especially Retrieval Augmented
Generation (RAG), there's potential to generate and expand upon these
examples, enriching the dataset with more structured data and
insights.
### FIBO Viewer
Use the [FIBO Viewer](https://spec.edmcouncil.org/fibo/ontology) to
explore the ontology on the web. One of the coolest features about
FIBO is that entities with a prefix of
https://spec.edmcouncil.org/fibo/ontology/ can be looked up in the web
just by opening its URL in a browser or in any HTTP client.
## Ideas for Deriving Graph Neural Network Features from FIBO:
Graph Neural Networks (GNNs) have emerged as a powerful tool for
machine learning on structured data. FIBO, with its structured
ontology, can be leveraged to derive features for GNNs.
### Node Features:
- **rdf:type**: Each entity in FIBO has one or more associated `rdf:type`,
`<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>`, that
indicates its class or category. This can serve as a primary node
feature to encode.
- **Entity Attributes**: Attributes of each entity, such as names or
descriptions, can be used as additional node features. Consider
embedding descriptions using a semantic text embedding model.
### Edge Features:
- **RDF Predicates**: The relationships between entities in FIBO are
represented using RDF predicates. These predicates can serve as edge
features in a GNN, capturing the nature of the relationship between
nodes.
### Potential Applications:
1. **Entity Classification**: Using the derived node and edge
features, GNNs can classify entities into various financial
categories, enhancing the granularity of financial data analysis.
2. **Relationship Prediction**: GNNs can predict potential
relationships between entities, aiding in the discovery of hidden
patterns or correlations within the financial data.
3. **Anomaly Detection**: By training GNNs on the structured data from
FIBO and interlinked financial datasets, anomalies or
irregularities in them may be detected, ensuring data integrity and
accuracy.
### Acknowledgements
We extend our sincere gratitude to the FIBO contributors for their
meticulous efforts in knowledge representation. Their expertise and
dedication have been instrumental in shaping a comprehensive and
insightful framework that serves as a cornerstone for innovation in
the financial industry.
If you are interested in modeling the financial industry you should
consider [contributing to
FIBO](https://github.com/edmcouncil/fibo/blob/master/CONTRIBUTING.md).
### Citation
```bibtex
@misc{fibo2023Q3,
title={Financial Industry Business Ontology (FIBO)},
author={Object Management Group, Inc. and EDM Council, Inc. and Various Contributors},
year={2023},
note={Available as OWL 2 ontologies and UML models compliant with the Semantics for Information Modeling and Federation (SMIF) draft specification. Contributions are open on GitHub, consult the repository for a list of contributors.},
howpublished={\url{https://spec.edmcouncil.org/fibo/}},
abstract={The Financial Industry Business Ontology (FIBO) is a collaborative effort to standardize the language used to define the terms, conditions, and characteristics of financial instruments; the legal and relationship structure of business entities; the content and time dimensions of market data; and the legal obligations and process aspects of corporate actions.},
license={MIT License, \url{https://opensource.org/licenses/MIT}}
}
```
|
wikipunk/fibo2023Q3
|
[
"task_categories:graph-ml",
"annotations_creators:expert-generated",
"size_categories:100K<n<1M",
"language:en",
"license:mit",
"knowledge-graph",
"rdf",
"owl",
"ontology",
"region:us"
] |
2023-09-29T15:32:18+00:00
|
{"annotations_creators": ["expert-generated"], "language": ["en"], "license": "mit", "size_categories": ["100K<n<1M"], "task_categories": ["graph-ml"], "pretty_name": "FIBO", "tags": ["knowledge-graph", "rdf", "owl", "ontology"], "dataset_info": {"features": [{"name": "subject", "dtype": "string"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "string"}], "config_name": "default", "splits": [{"name": "train", "num_bytes": 56045523, "num_examples": 236579}], "dataset_size": 56045523}, "viewer": false}
|
2023-10-04T19:03:28+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-graph-ml #annotations_creators-expert-generated #size_categories-100K<n<1M #language-English #license-mit #knowledge-graph #rdf #owl #ontology #region-us
|
# FIBO: The Financial Industry Business Ontology
### Overview
In the world of financial technology, the vastness of data and the
complexity of financial instruments present both challenges and
opportunities. The Financial Industry Business Ontology (FIBO) offers
a structured framework that bridges the gap between theoretical
financial concepts and real-world data. I believe machine learning
researchers interested in the financial sector could use the
relationships in FIBO to innovate in financial feature engineering to
fine-tune existing models or build new ones.
#### Open Source
The FIBO ontology is developed on GitHub at
URL
### Use-cases
- Comprehensive Data Structure: FIBO offers a broad spectrum of
financial concepts, ranging from derivatives to securities. This
design, rooted in expert knowledge from both the knowledge
representation and financial sectors, ensures a profound
understanding of financial instruments.
- Decoding Complex Relationships: The financial domain is
characterized by its intricate interdependencies. FIBO's structured
approach provides clarity on these relationships, enabling machine
learning algorithms to identify patterns and correlations within
large datasets.
- Linkage with Real-world Data: A distinguishing feature of FIBO is
its capability to associate financial concepts with real-world
financial data and controlled vocabularies. This connection is
crucial for researchers aiming to apply theoretical insights in
practical contexts in financial enterprises with their existing
data.
- Retrieval Augmented Generation: The advent of Large Language Models,
particularly in conjunction with Retrieval Augmented Generation
(RAG), holds promise for revolutionizing the way financial data is
processed and interpreted.
- Document Classification: With the surge in financial documents,
utilizing RAG to categorize financial datasets classifed by FIBO
concepts can assist financial analysts in achieving enhanced
accuracy and depth in data interpretation, facilitated by
intelligent prompting.
#### Building and Verification:
1. Construction: The ontology was imported from
AboutFIBOProd-IncludingReferenceData
into Protege version 5.6.1.
2. Reasoning: Due to the large size of the ontology I used the ELK
reasoner plugin to materialize (make explicit) inferences in the
ontology.
3. Coherence Check: The Debug Ontology plugin in Protege was used
to ensure the ontology's coherence and consistency.
4. Export: After verification, inferred axioms, along with
asserted axioms and annotations, were exported using Protege.
5. Encoding and Compression: Apache Jena's
riot was used to convert the
result to ntriples, which was then compressed with gzip. This
compressed artifact is downloaded and extracted by the Hugging Face
datasets library to yield the examples in the dataset.
### Usage
First make sure you have the requirements installed:
You can load the dataset using the Hugging Face Datasets library with the following Python code:
## Features
The FIBO dataset is composed of triples representing the relationships
between different financial concepts and named individuals such as
market participants, corporations, and contractual agents.
#### Note on Format:
The subject, predicate, and object features are stored in N3 notation
with no prefix mappings. This allows users to parse each component
using 'URL.from_n3' from the RDFLib Python library.
### 1. Subject ('string')
The subject of a triple is the primary entity or focus of the statement. In this dataset, the subject often represents a specific financial instrument or entity. For instance:
'<URL
refers to the common stock of The Coca-Cola Company that is listed on
the NYSE.
### 2. Predicate ('string')
The predicate of a triple indicates the nature of the relationship between the subject and the object. It describes a specific property, characteristic, or connection of the subject. In our example:
'<URL
signifies that the financial instrument (subject) is traded on a
particular exchange (object).
### 3. Object ('string')
The object of a triple is the entity or value that is associated with the subject via the predicate. It can be another financial concept, a trading platform, or any other related entity. In the context of our example:
'<URL
represents the New York Stock Exchange where the aforementioned
Coca-Cola common stock is traded.
#### Continued
Here is an another example of a triple in the dataset:
- Subject: '"<URL
- Predicate: '"<URL
- Object: '"<URL
This triple represents the statement that the market individual
ServiceProvider-L-JEUVK5RWVJEN8W0C9M24
has a type of
FunctionalEntity.
#### Note:
The dataset contains example individuals from the ontology as
reference points. These examples provide a structured framework for
understanding the relationships and entities within the financial
domain. However, the individuals included are not exhaustive. With
advancements in Large Language Models, especially Retrieval Augmented
Generation (RAG), there's potential to generate and expand upon these
examples, enriching the dataset with more structured data and
insights.
### FIBO Viewer
Use the FIBO Viewer to
explore the ontology on the web. One of the coolest features about
FIBO is that entities with a prefix of
URL can be looked up in the web
just by opening its URL in a browser or in any HTTP client.
## Ideas for Deriving Graph Neural Network Features from FIBO:
Graph Neural Networks (GNNs) have emerged as a powerful tool for
machine learning on structured data. FIBO, with its structured
ontology, can be leveraged to derive features for GNNs.
### Node Features:
- rdf:type: Each entity in FIBO has one or more associated 'rdf:type',
'<URL that
indicates its class or category. This can serve as a primary node
feature to encode.
- Entity Attributes: Attributes of each entity, such as names or
descriptions, can be used as additional node features. Consider
embedding descriptions using a semantic text embedding model.
### Edge Features:
- RDF Predicates: The relationships between entities in FIBO are
represented using RDF predicates. These predicates can serve as edge
features in a GNN, capturing the nature of the relationship between
nodes.
### Potential Applications:
1. Entity Classification: Using the derived node and edge
features, GNNs can classify entities into various financial
categories, enhancing the granularity of financial data analysis.
2. Relationship Prediction: GNNs can predict potential
relationships between entities, aiding in the discovery of hidden
patterns or correlations within the financial data.
3. Anomaly Detection: By training GNNs on the structured data from
FIBO and interlinked financial datasets, anomalies or
irregularities in them may be detected, ensuring data integrity and
accuracy.
### Acknowledgements
We extend our sincere gratitude to the FIBO contributors for their
meticulous efforts in knowledge representation. Their expertise and
dedication have been instrumental in shaping a comprehensive and
insightful framework that serves as a cornerstone for innovation in
the financial industry.
If you are interested in modeling the financial industry you should
consider contributing to
FIBO.
|
[
"# FIBO: The Financial Industry Business Ontology",
"### Overview\nIn the world of financial technology, the vastness of data and the\ncomplexity of financial instruments present both challenges and\nopportunities. The Financial Industry Business Ontology (FIBO) offers\na structured framework that bridges the gap between theoretical\nfinancial concepts and real-world data. I believe machine learning\nresearchers interested in the financial sector could use the\nrelationships in FIBO to innovate in financial feature engineering to\nfine-tune existing models or build new ones.",
"#### Open Source\nThe FIBO ontology is developed on GitHub at\nURL",
"### Use-cases\n- Comprehensive Data Structure: FIBO offers a broad spectrum of\n financial concepts, ranging from derivatives to securities. This\n design, rooted in expert knowledge from both the knowledge\n representation and financial sectors, ensures a profound\n understanding of financial instruments.\n- Decoding Complex Relationships: The financial domain is\n characterized by its intricate interdependencies. FIBO's structured\n approach provides clarity on these relationships, enabling machine\n learning algorithms to identify patterns and correlations within\n large datasets.\n- Linkage with Real-world Data: A distinguishing feature of FIBO is\n its capability to associate financial concepts with real-world\n financial data and controlled vocabularies. This connection is\n crucial for researchers aiming to apply theoretical insights in\n practical contexts in financial enterprises with their existing\n data.\n- Retrieval Augmented Generation: The advent of Large Language Models,\n particularly in conjunction with Retrieval Augmented Generation\n (RAG), holds promise for revolutionizing the way financial data is\n processed and interpreted.\n- Document Classification: With the surge in financial documents,\n utilizing RAG to categorize financial datasets classifed by FIBO\n concepts can assist financial analysts in achieving enhanced\n accuracy and depth in data interpretation, facilitated by\n intelligent prompting.",
"#### Building and Verification:\n1. Construction: The ontology was imported from\n AboutFIBOProd-IncludingReferenceData\n into Protege version 5.6.1.\n2. Reasoning: Due to the large size of the ontology I used the ELK\n reasoner plugin to materialize (make explicit) inferences in the\n ontology.\n3. Coherence Check: The Debug Ontology plugin in Protege was used\n to ensure the ontology's coherence and consistency.\n4. Export: After verification, inferred axioms, along with\n asserted axioms and annotations, were exported using Protege.\n5. Encoding and Compression: Apache Jena's\n riot was used to convert the\n result to ntriples, which was then compressed with gzip. This\n compressed artifact is downloaded and extracted by the Hugging Face\n datasets library to yield the examples in the dataset.",
"### Usage\nFirst make sure you have the requirements installed:\n\n\n\nYou can load the dataset using the Hugging Face Datasets library with the following Python code:",
"## Features\nThe FIBO dataset is composed of triples representing the relationships\nbetween different financial concepts and named individuals such as\nmarket participants, corporations, and contractual agents.",
"#### Note on Format:\nThe subject, predicate, and object features are stored in N3 notation\nwith no prefix mappings. This allows users to parse each component\nusing 'URL.from_n3' from the RDFLib Python library.",
"### 1. Subject ('string')\nThe subject of a triple is the primary entity or focus of the statement. In this dataset, the subject often represents a specific financial instrument or entity. For instance:\n'<URL\nrefers to the common stock of The Coca-Cola Company that is listed on\nthe NYSE.",
"### 2. Predicate ('string')\nThe predicate of a triple indicates the nature of the relationship between the subject and the object. It describes a specific property, characteristic, or connection of the subject. In our example:\n'<URL\nsignifies that the financial instrument (subject) is traded on a\nparticular exchange (object).",
"### 3. Object ('string')\nThe object of a triple is the entity or value that is associated with the subject via the predicate. It can be another financial concept, a trading platform, or any other related entity. In the context of our example:\n'<URL\nrepresents the New York Stock Exchange where the aforementioned\nCoca-Cola common stock is traded.",
"#### Continued\nHere is an another example of a triple in the dataset:\n- Subject: '\"<URL \n- Predicate: '\"<URL\n- Object: '\"<URL\n\nThis triple represents the statement that the market individual\nServiceProvider-L-JEUVK5RWVJEN8W0C9M24\nhas a type of\nFunctionalEntity.",
"#### Note:\nThe dataset contains example individuals from the ontology as\nreference points. These examples provide a structured framework for\nunderstanding the relationships and entities within the financial\ndomain. However, the individuals included are not exhaustive. With\nadvancements in Large Language Models, especially Retrieval Augmented\nGeneration (RAG), there's potential to generate and expand upon these\nexamples, enriching the dataset with more structured data and\ninsights.",
"### FIBO Viewer\nUse the FIBO Viewer to\nexplore the ontology on the web. One of the coolest features about\nFIBO is that entities with a prefix of\nURL can be looked up in the web\njust by opening its URL in a browser or in any HTTP client.",
"## Ideas for Deriving Graph Neural Network Features from FIBO:\nGraph Neural Networks (GNNs) have emerged as a powerful tool for\nmachine learning on structured data. FIBO, with its structured\nontology, can be leveraged to derive features for GNNs.",
"### Node Features:\n\n- rdf:type: Each entity in FIBO has one or more associated 'rdf:type',\n '<URL that\n indicates its class or category. This can serve as a primary node\n feature to encode.\n \n- Entity Attributes: Attributes of each entity, such as names or\n descriptions, can be used as additional node features. Consider\n embedding descriptions using a semantic text embedding model.",
"### Edge Features:\n\n- RDF Predicates: The relationships between entities in FIBO are\n represented using RDF predicates. These predicates can serve as edge\n features in a GNN, capturing the nature of the relationship between\n nodes.",
"### Potential Applications:\n\n1. Entity Classification: Using the derived node and edge\n features, GNNs can classify entities into various financial\n categories, enhancing the granularity of financial data analysis.\n\n2. Relationship Prediction: GNNs can predict potential\n relationships between entities, aiding in the discovery of hidden\n patterns or correlations within the financial data.\n\n3. Anomaly Detection: By training GNNs on the structured data from\n FIBO and interlinked financial datasets, anomalies or\n irregularities in them may be detected, ensuring data integrity and\n accuracy.",
"### Acknowledgements\nWe extend our sincere gratitude to the FIBO contributors for their\nmeticulous efforts in knowledge representation. Their expertise and\ndedication have been instrumental in shaping a comprehensive and\ninsightful framework that serves as a cornerstone for innovation in\nthe financial industry.\n\nIf you are interested in modeling the financial industry you should\nconsider contributing to\nFIBO."
] |
[
"TAGS\n#task_categories-graph-ml #annotations_creators-expert-generated #size_categories-100K<n<1M #language-English #license-mit #knowledge-graph #rdf #owl #ontology #region-us \n",
"# FIBO: The Financial Industry Business Ontology",
"### Overview\nIn the world of financial technology, the vastness of data and the\ncomplexity of financial instruments present both challenges and\nopportunities. The Financial Industry Business Ontology (FIBO) offers\na structured framework that bridges the gap between theoretical\nfinancial concepts and real-world data. I believe machine learning\nresearchers interested in the financial sector could use the\nrelationships in FIBO to innovate in financial feature engineering to\nfine-tune existing models or build new ones.",
"#### Open Source\nThe FIBO ontology is developed on GitHub at\nURL",
"### Use-cases\n- Comprehensive Data Structure: FIBO offers a broad spectrum of\n financial concepts, ranging from derivatives to securities. This\n design, rooted in expert knowledge from both the knowledge\n representation and financial sectors, ensures a profound\n understanding of financial instruments.\n- Decoding Complex Relationships: The financial domain is\n characterized by its intricate interdependencies. FIBO's structured\n approach provides clarity on these relationships, enabling machine\n learning algorithms to identify patterns and correlations within\n large datasets.\n- Linkage with Real-world Data: A distinguishing feature of FIBO is\n its capability to associate financial concepts with real-world\n financial data and controlled vocabularies. This connection is\n crucial for researchers aiming to apply theoretical insights in\n practical contexts in financial enterprises with their existing\n data.\n- Retrieval Augmented Generation: The advent of Large Language Models,\n particularly in conjunction with Retrieval Augmented Generation\n (RAG), holds promise for revolutionizing the way financial data is\n processed and interpreted.\n- Document Classification: With the surge in financial documents,\n utilizing RAG to categorize financial datasets classifed by FIBO\n concepts can assist financial analysts in achieving enhanced\n accuracy and depth in data interpretation, facilitated by\n intelligent prompting.",
"#### Building and Verification:\n1. Construction: The ontology was imported from\n AboutFIBOProd-IncludingReferenceData\n into Protege version 5.6.1.\n2. Reasoning: Due to the large size of the ontology I used the ELK\n reasoner plugin to materialize (make explicit) inferences in the\n ontology.\n3. Coherence Check: The Debug Ontology plugin in Protege was used\n to ensure the ontology's coherence and consistency.\n4. Export: After verification, inferred axioms, along with\n asserted axioms and annotations, were exported using Protege.\n5. Encoding and Compression: Apache Jena's\n riot was used to convert the\n result to ntriples, which was then compressed with gzip. This\n compressed artifact is downloaded and extracted by the Hugging Face\n datasets library to yield the examples in the dataset.",
"### Usage\nFirst make sure you have the requirements installed:\n\n\n\nYou can load the dataset using the Hugging Face Datasets library with the following Python code:",
"## Features\nThe FIBO dataset is composed of triples representing the relationships\nbetween different financial concepts and named individuals such as\nmarket participants, corporations, and contractual agents.",
"#### Note on Format:\nThe subject, predicate, and object features are stored in N3 notation\nwith no prefix mappings. This allows users to parse each component\nusing 'URL.from_n3' from the RDFLib Python library.",
"### 1. Subject ('string')\nThe subject of a triple is the primary entity or focus of the statement. In this dataset, the subject often represents a specific financial instrument or entity. For instance:\n'<URL\nrefers to the common stock of The Coca-Cola Company that is listed on\nthe NYSE.",
"### 2. Predicate ('string')\nThe predicate of a triple indicates the nature of the relationship between the subject and the object. It describes a specific property, characteristic, or connection of the subject. In our example:\n'<URL\nsignifies that the financial instrument (subject) is traded on a\nparticular exchange (object).",
"### 3. Object ('string')\nThe object of a triple is the entity or value that is associated with the subject via the predicate. It can be another financial concept, a trading platform, or any other related entity. In the context of our example:\n'<URL\nrepresents the New York Stock Exchange where the aforementioned\nCoca-Cola common stock is traded.",
"#### Continued\nHere is an another example of a triple in the dataset:\n- Subject: '\"<URL \n- Predicate: '\"<URL\n- Object: '\"<URL\n\nThis triple represents the statement that the market individual\nServiceProvider-L-JEUVK5RWVJEN8W0C9M24\nhas a type of\nFunctionalEntity.",
"#### Note:\nThe dataset contains example individuals from the ontology as\nreference points. These examples provide a structured framework for\nunderstanding the relationships and entities within the financial\ndomain. However, the individuals included are not exhaustive. With\nadvancements in Large Language Models, especially Retrieval Augmented\nGeneration (RAG), there's potential to generate and expand upon these\nexamples, enriching the dataset with more structured data and\ninsights.",
"### FIBO Viewer\nUse the FIBO Viewer to\nexplore the ontology on the web. One of the coolest features about\nFIBO is that entities with a prefix of\nURL can be looked up in the web\njust by opening its URL in a browser or in any HTTP client.",
"## Ideas for Deriving Graph Neural Network Features from FIBO:\nGraph Neural Networks (GNNs) have emerged as a powerful tool for\nmachine learning on structured data. FIBO, with its structured\nontology, can be leveraged to derive features for GNNs.",
"### Node Features:\n\n- rdf:type: Each entity in FIBO has one or more associated 'rdf:type',\n '<URL that\n indicates its class or category. This can serve as a primary node\n feature to encode.\n \n- Entity Attributes: Attributes of each entity, such as names or\n descriptions, can be used as additional node features. Consider\n embedding descriptions using a semantic text embedding model.",
"### Edge Features:\n\n- RDF Predicates: The relationships between entities in FIBO are\n represented using RDF predicates. These predicates can serve as edge\n features in a GNN, capturing the nature of the relationship between\n nodes.",
"### Potential Applications:\n\n1. Entity Classification: Using the derived node and edge\n features, GNNs can classify entities into various financial\n categories, enhancing the granularity of financial data analysis.\n\n2. Relationship Prediction: GNNs can predict potential\n relationships between entities, aiding in the discovery of hidden\n patterns or correlations within the financial data.\n\n3. Anomaly Detection: By training GNNs on the structured data from\n FIBO and interlinked financial datasets, anomalies or\n irregularities in them may be detected, ensuring data integrity and\n accuracy.",
"### Acknowledgements\nWe extend our sincere gratitude to the FIBO contributors for their\nmeticulous efforts in knowledge representation. Their expertise and\ndedication have been instrumental in shaping a comprehensive and\ninsightful framework that serves as a cornerstone for innovation in\nthe financial industry.\n\nIf you are interested in modeling the financial industry you should\nconsider contributing to\nFIBO."
] |
[
64,
11,
102,
17,
302,
211,
36,
39,
57,
69,
75,
83,
81,
98,
60,
68,
103,
56,
138,
81
] |
[
"passage: TAGS\n#task_categories-graph-ml #annotations_creators-expert-generated #size_categories-100K<n<1M #language-English #license-mit #knowledge-graph #rdf #owl #ontology #region-us \n# FIBO: The Financial Industry Business Ontology### Overview\nIn the world of financial technology, the vastness of data and the\ncomplexity of financial instruments present both challenges and\nopportunities. The Financial Industry Business Ontology (FIBO) offers\na structured framework that bridges the gap between theoretical\nfinancial concepts and real-world data. I believe machine learning\nresearchers interested in the financial sector could use the\nrelationships in FIBO to innovate in financial feature engineering to\nfine-tune existing models or build new ones.#### Open Source\nThe FIBO ontology is developed on GitHub at\nURL### Use-cases\n- Comprehensive Data Structure: FIBO offers a broad spectrum of\n financial concepts, ranging from derivatives to securities. This\n design, rooted in expert knowledge from both the knowledge\n representation and financial sectors, ensures a profound\n understanding of financial instruments.\n- Decoding Complex Relationships: The financial domain is\n characterized by its intricate interdependencies. FIBO's structured\n approach provides clarity on these relationships, enabling machine\n learning algorithms to identify patterns and correlations within\n large datasets.\n- Linkage with Real-world Data: A distinguishing feature of FIBO is\n its capability to associate financial concepts with real-world\n financial data and controlled vocabularies. This connection is\n crucial for researchers aiming to apply theoretical insights in\n practical contexts in financial enterprises with their existing\n data.\n- Retrieval Augmented Generation: The advent of Large Language Models,\n particularly in conjunction with Retrieval Augmented Generation\n (RAG), holds promise for revolutionizing the way financial data is\n processed and interpreted.\n- Document Classification: With the surge in financial documents,\n utilizing RAG to categorize financial datasets classifed by FIBO\n concepts can assist financial analysts in achieving enhanced\n accuracy and depth in data interpretation, facilitated by\n intelligent prompting.",
"passage: #### Building and Verification:\n1. Construction: The ontology was imported from\n AboutFIBOProd-IncludingReferenceData\n into Protege version 5.6.1.\n2. Reasoning: Due to the large size of the ontology I used the ELK\n reasoner plugin to materialize (make explicit) inferences in the\n ontology.\n3. Coherence Check: The Debug Ontology plugin in Protege was used\n to ensure the ontology's coherence and consistency.\n4. Export: After verification, inferred axioms, along with\n asserted axioms and annotations, were exported using Protege.\n5. Encoding and Compression: Apache Jena's\n riot was used to convert the\n result to ntriples, which was then compressed with gzip. This\n compressed artifact is downloaded and extracted by the Hugging Face\n datasets library to yield the examples in the dataset.### Usage\nFirst make sure you have the requirements installed:\n\n\n\nYou can load the dataset using the Hugging Face Datasets library with the following Python code:## Features\nThe FIBO dataset is composed of triples representing the relationships\nbetween different financial concepts and named individuals such as\nmarket participants, corporations, and contractual agents.#### Note on Format:\nThe subject, predicate, and object features are stored in N3 notation\nwith no prefix mappings. This allows users to parse each component\nusing 'URL.from_n3' from the RDFLib Python library.### 1. Subject ('string')\nThe subject of a triple is the primary entity or focus of the statement. In this dataset, the subject often represents a specific financial instrument or entity. For instance:\n'<URL\nrefers to the common stock of The Coca-Cola Company that is listed on\nthe NYSE.### 2. Predicate ('string')\nThe predicate of a triple indicates the nature of the relationship between the subject and the object. It describes a specific property, characteristic, or connection of the subject. In our example:\n'<URL\nsignifies that the financial instrument (subject) is traded on a\nparticular exchange (object).### 3. Object ('string')\nThe object of a triple is the entity or value that is associated with the subject via the predicate. It can be another financial concept, a trading platform, or any other related entity. In the context of our example:\n'<URL\nrepresents the New York Stock Exchange where the aforementioned\nCoca-Cola common stock is traded.#### Continued\nHere is an another example of a triple in the dataset:\n- Subject: '\"<URL \n- Predicate: '\"<URL\n- Object: '\"<URL\n\nThis triple represents the statement that the market individual\nServiceProvider-L-JEUVK5RWVJEN8W0C9M24\nhas a type of\nFunctionalEntity."
] |
7bfe8dffb583c2a31bcd4cc88d6b189c99ea86e1
|
# Dataset Card for "asr_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/asr_data
|
[
"region:us"
] |
2023-09-29T16:18:02+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcription", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1076159.0, "num_examples": 44}], "download_size": 1016436, "dataset_size": 1076159.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T17:02:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "asr_data"
More Information needed
|
[
"# Dataset Card for \"asr_data\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"asr_data\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"asr_data\"\n\nMore Information needed"
] |
7f33a80fb5d846315a5344bfefdc9b0c15e0eda1
|
# Dataset Card for "wmt-mqm-fine-grained"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
nllg/wmt-mqm-fine-grained
|
[
"region:us"
] |
2023-09-29T16:20:24+00:00
|
{"dataset_info": [{"config_name": "en-de-2020", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 10157636, "num_examples": 14180}], "download_size": 4974562, "dataset_size": 10157636}, {"config_name": "en-de-2021", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 4274145, "num_examples": 9909}], "download_size": 2035384, "dataset_size": 4274145}, {"config_name": "en-de-2021-ted", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 2272575, "num_examples": 7406}], "download_size": 883686, "dataset_size": 2272575}, {"config_name": "en-de-2022", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 6558498, "num_examples": 21040}], "download_size": 3344843, "dataset_size": 6558498}, {"config_name": "en-ru-2022", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 8317110, "num_examples": 20512}], "download_size": 3992973, "dataset_size": 8317110}, {"config_name": "zh-en-2021", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 4860958, "num_examples": 9750}], "download_size": 2344324, "dataset_size": 4860958}, {"config_name": "zh-en-2021-ted", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 2271660, "num_examples": 7935}], "download_size": 896202, "dataset_size": 2271660}, {"config_name": "zh-en-2022", "features": [{"name": "id", "dtype": "string"}, {"name": "system_id", "dtype": "string"}, {"name": "src", "dtype": "string"}, {"name": "hyp", "dtype": "string"}, {"name": "errors", "list": [{"name": "category", "dtype": "string"}, {"name": "severity", "dtype": "string"}, {"name": "span", "dtype": "string"}, {"name": "span-loc", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 11078650, "num_examples": 26656}], "download_size": 6061211, "dataset_size": 11078650}], "configs": [{"config_name": "en-de-2020", "data_files": [{"split": "train", "path": "en-de-2020/train-*"}]}, {"config_name": "en-de-2021", "data_files": [{"split": "train", "path": "en-de-2021/train-*"}]}, {"config_name": "en-de-2021-ted", "data_files": [{"split": "train", "path": "en-de-2021-ted/train-*"}]}, {"config_name": "en-de-2022", "data_files": [{"split": "train", "path": "en-de-2022/train-*"}]}, {"config_name": "en-ru-2022", "data_files": [{"split": "train", "path": "en-ru-2022/train-*"}]}, {"config_name": "zh-en-2021", "data_files": [{"split": "train", "path": "zh-en-2021/train-*"}]}, {"config_name": "zh-en-2021-ted", "data_files": [{"split": "train", "path": "zh-en-2021-ted/train-*"}]}, {"config_name": "zh-en-2022", "data_files": [{"split": "train", "path": "zh-en-2022/train-*"}]}]}
|
2023-09-29T16:21:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "wmt-mqm-fine-grained"
More Information needed
|
[
"# Dataset Card for \"wmt-mqm-fine-grained\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"wmt-mqm-fine-grained\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"wmt-mqm-fine-grained\"\n\nMore Information needed"
] |
836a18d8e60853e1c54095f542f2e6096f414767
|
tune-ft-series (abstract-to-class-0.7k) v2
```
categories: 146
samples/category: 5
total: 730
dataset_type: "sharegpt:chat"
wandb_project: "arxiv-single-class"
```
|
yashnbx/arxiv-abstract-cat-0.7k-2
|
[
"region:us"
] |
2023-09-29T16:23:33+00:00
|
{}
|
2023-09-29T16:24:48+00:00
|
[] |
[] |
TAGS
#region-us
|
tune-ft-series (abstract-to-class-0.7k) v2
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
1f9627954264d2ecbb0f9061c2bb07f68d0e5c2d
|
# Dataset Card for "dart_fdistill_format"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
rookshanks/dart_fdistill_format
|
[
"region:us"
] |
2023-09-29T17:37:14+00:00
|
{"dataset_info": {"features": [{"name": "context", "dtype": "string"}, {"name": "response", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 16093785, "num_examples": 62659}, {"name": "validation", "num_bytes": 531172, "num_examples": 2775}, {"name": "test", "num_bytes": 982476, "num_examples": 5106}], "download_size": 4417222, "dataset_size": 17607433}}
|
2023-09-29T17:37:21+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dart_fdistill_format"
More Information needed
|
[
"# Dataset Card for \"dart_fdistill_format\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dart_fdistill_format\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dart_fdistill_format\"\n\nMore Information needed"
] |
8cc96b590a423e424d059bf2968271f832a67275
|
Every 10th row from https://github.com/THUDM/MathGLM (original dataset has 50M entries)
|
jonathanasdf/MathGLM-dataset-5M
|
[
"license:afl-3.0",
"region:us"
] |
2023-09-29T17:50:11+00:00
|
{"license": "afl-3.0"}
|
2023-09-29T18:10:31+00:00
|
[] |
[] |
TAGS
#license-afl-3.0 #region-us
|
Every 10th row from URL (original dataset has 50M entries)
|
[] |
[
"TAGS\n#license-afl-3.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-afl-3.0 #region-us \n"
] |
931a85d1ca0470e3bac535e668e8e1d3f35d9dc1
|
# Dataset Card for "rlcd"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
TaylorAI/rlcd
|
[
"region:us"
] |
2023-09-29T17:51:41+00:00
|
{"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 145740702, "num_examples": 167999}], "download_size": 86967331, "dataset_size": 145740702}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T17:53:15+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "rlcd"
More Information needed
|
[
"# Dataset Card for \"rlcd\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"rlcd\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"rlcd\"\n\nMore Information needed"
] |
394ca8f18094daaaf3f92084079f1ad0cc27bd75
|
https://github.com/THUDM/MathGLM
|
jonathanasdf/MathGLM-dataset
|
[
"license:afl-3.0",
"region:us"
] |
2023-09-29T17:57:53+00:00
|
{"license": "afl-3.0"}
|
2023-09-29T19:05:59+00:00
|
[] |
[] |
TAGS
#license-afl-3.0 #region-us
|
URL
|
[] |
[
"TAGS\n#license-afl-3.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-afl-3.0 #region-us \n"
] |
9b166f70b6404414d2570051c29dcfcf55eeb400
|
References: https://huggingface.co/datasets/cais/mmlu
# MMLU (Vietnamese translation version)
## Install
To install `lm-eval` from the github repository main branch, run:
```bash
git clone https://github.com/hieunguyen1053/lm-evaluation-harness
cd lm-evaluation-harness
pip install -e .
```
## Basic Usage
> **Note**: When reporting results from eval harness, please include the task versions (shown in `results["versions"]`) for reproducibility. This allows bug fixes to tasks while also ensuring that previously reported scores are reproducible. See the [Task Versioning](#task-versioning) section for more info.
### Hugging Face `transformers`
To evaluate a model hosted on the [HuggingFace Hub](https://huggingface.co/models) (e.g. vlsp-2023-vllm/hoa-1b4) on `mmlu` you can use the following command:
```bash
python main.py \
--model hf-causal \
--model_args pretrained=vlsp-2023-vllm/hoa-1b4 \
--tasks mmlu_vi \
--device cuda:0
```
Additional arguments can be provided to the model constructor using the `--model_args` flag. Most notably, this supports the common practice of using the `revisions` feature on the Hub to store partially trained checkpoints, or to specify the datatype for running a model:
```bash
python main.py \
--model hf-causal \
--model_args pretrained=vlsp-2023-vllm/hoa-1b4,revision=step100000,dtype="float" \
--tasks mmlu_vi \
--device cuda:0
```
To evaluate models that are loaded via `AutoSeq2SeqLM` in Huggingface, you instead use `hf-seq2seq`. *To evaluate (causal) models across multiple GPUs, use `--model hf-causal-experimental`*
> **Warning**: Choosing the wrong model may result in erroneous outputs despite not erroring.
|
vlsp-2023-vllm/mmlu
|
[
"region:us"
] |
2023-09-29T18:08:22+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "validation", "path": "data/validation-*"}, {"split": "dev", "path": "data/dev-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "answer", "dtype": "int64"}, {"name": "question", "dtype": "string"}, {"name": "choices", "sequence": "string"}], "splits": [{"name": "validation", "num_bytes": 890402, "num_examples": 1456}, {"name": "dev", "num_bytes": 140819, "num_examples": 271}, {"name": "test", "num_bytes": 7615124, "num_examples": 13062}], "download_size": 4415183, "dataset_size": 8646345}}
|
2023-09-30T02:37:34+00:00
|
[] |
[] |
TAGS
#region-us
|
References: URL
# MMLU (Vietnamese translation version)
## Install
To install 'lm-eval' from the github repository main branch, run:
## Basic Usage
> Note: When reporting results from eval harness, please include the task versions (shown in 'results["versions"]') for reproducibility. This allows bug fixes to tasks while also ensuring that previously reported scores are reproducible. See the Task Versioning section for more info.
### Hugging Face 'transformers'
To evaluate a model hosted on the HuggingFace Hub (e.g. vlsp-2023-vllm/hoa-1b4) on 'mmlu' you can use the following command:
Additional arguments can be provided to the model constructor using the '--model_args' flag. Most notably, this supports the common practice of using the 'revisions' feature on the Hub to store partially trained checkpoints, or to specify the datatype for running a model:
To evaluate models that are loaded via 'AutoSeq2SeqLM' in Huggingface, you instead use 'hf-seq2seq'. *To evaluate (causal) models across multiple GPUs, use '--model hf-causal-experimental'*
> Warning: Choosing the wrong model may result in erroneous outputs despite not erroring.
|
[
"# MMLU (Vietnamese translation version)",
"## Install\n\nTo install 'lm-eval' from the github repository main branch, run:",
"## Basic Usage\n\n> Note: When reporting results from eval harness, please include the task versions (shown in 'results[\"versions\"]') for reproducibility. This allows bug fixes to tasks while also ensuring that previously reported scores are reproducible. See the Task Versioning section for more info.",
"### Hugging Face 'transformers'\n\nTo evaluate a model hosted on the HuggingFace Hub (e.g. vlsp-2023-vllm/hoa-1b4) on 'mmlu' you can use the following command:\n\n\n\n\nAdditional arguments can be provided to the model constructor using the '--model_args' flag. Most notably, this supports the common practice of using the 'revisions' feature on the Hub to store partially trained checkpoints, or to specify the datatype for running a model:\n\n\n\nTo evaluate models that are loaded via 'AutoSeq2SeqLM' in Huggingface, you instead use 'hf-seq2seq'. *To evaluate (causal) models across multiple GPUs, use '--model hf-causal-experimental'*\n\n> Warning: Choosing the wrong model may result in erroneous outputs despite not erroring."
] |
[
"TAGS\n#region-us \n",
"# MMLU (Vietnamese translation version)",
"## Install\n\nTo install 'lm-eval' from the github repository main branch, run:",
"## Basic Usage\n\n> Note: When reporting results from eval harness, please include the task versions (shown in 'results[\"versions\"]') for reproducibility. This allows bug fixes to tasks while also ensuring that previously reported scores are reproducible. See the Task Versioning section for more info.",
"### Hugging Face 'transformers'\n\nTo evaluate a model hosted on the HuggingFace Hub (e.g. vlsp-2023-vllm/hoa-1b4) on 'mmlu' you can use the following command:\n\n\n\n\nAdditional arguments can be provided to the model constructor using the '--model_args' flag. Most notably, this supports the common practice of using the 'revisions' feature on the Hub to store partially trained checkpoints, or to specify the datatype for running a model:\n\n\n\nTo evaluate models that are loaded via 'AutoSeq2SeqLM' in Huggingface, you instead use 'hf-seq2seq'. *To evaluate (causal) models across multiple GPUs, use '--model hf-causal-experimental'*\n\n> Warning: Choosing the wrong model may result in erroneous outputs despite not erroring."
] |
[
6,
11,
23,
77,
216
] |
[
"passage: TAGS\n#region-us \n# MMLU (Vietnamese translation version)## Install\n\nTo install 'lm-eval' from the github repository main branch, run:## Basic Usage\n\n> Note: When reporting results from eval harness, please include the task versions (shown in 'results[\"versions\"]') for reproducibility. This allows bug fixes to tasks while also ensuring that previously reported scores are reproducible. See the Task Versioning section for more info.### Hugging Face 'transformers'\n\nTo evaluate a model hosted on the HuggingFace Hub (e.g. vlsp-2023-vllm/hoa-1b4) on 'mmlu' you can use the following command:\n\n\n\n\nAdditional arguments can be provided to the model constructor using the '--model_args' flag. Most notably, this supports the common practice of using the 'revisions' feature on the Hub to store partially trained checkpoints, or to specify the datatype for running a model:\n\n\n\nTo evaluate models that are loaded via 'AutoSeq2SeqLM' in Huggingface, you instead use 'hf-seq2seq'. *To evaluate (causal) models across multiple GPUs, use '--model hf-causal-experimental'*\n\n> Warning: Choosing the wrong model may result in erroneous outputs despite not erroring."
] |
d99e8c870f05f1697b598d8675d2fa8a4dae5a0c
|
# Dataset Card for "asr_data_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/asr_data_v2
|
[
"region:us"
] |
2023-09-29T18:10:49+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}], "splits": [{"name": "train", "num_bytes": 3656462.0, "num_examples": 44}], "download_size": 3639719, "dataset_size": 3656462.0}}
|
2023-09-29T18:10:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "asr_data_v2"
More Information needed
|
[
"# Dataset Card for \"asr_data_v2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"asr_data_v2\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"asr_data_v2\"\n\nMore Information needed"
] |
944387c121c1fb14978146cbd27ecae2a3821538
|
# Bangumi Image Base of Watashi Ni Tenshi Ga Maiorita!
This is the image base of bangumi Watashi ni Tenshi ga Maiorita!, we detected 24 characters, 2822 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 431 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 34 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 184 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 435 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 36 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 452 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 55 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 22 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 6 | [Download](8/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| 9 | 59 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 70 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 8 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 593 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 18 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 43 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 17 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 10 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 7 | [Download](17/dataset.zip) |  |  |  |  |  |  |  | N/A |
| 18 | 166 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 12 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| 20 | 6 | [Download](20/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| 21 | 7 | [Download](21/dataset.zip) |  |  |  |  |  |  |  | N/A |
| 22 | 18 | [Download](22/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 133 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/watashinitenshigamaiorita
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-29T18:17:22+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-29T19:22:42+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Watashi Ni Tenshi Ga Maiorita!
====================================================
This is the image base of bangumi Watashi ni Tenshi ga Maiorita!, we detected 24 characters, 2822 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
3ee5d1da78c6a5df9514b6b410121130588a67d4
|
test dataset
|
yashnbx/iamgroot-2
|
[
"region:us"
] |
2023-09-29T18:17:24+00:00
|
{}
|
2023-09-29T18:18:59+00:00
|
[] |
[] |
TAGS
#region-us
|
test dataset
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
c2fdf3c4d7074ab66641d73d073ff24aa791b412
|
Every 100th row from https://github.com/THUDM/MathGLM (original dataset has 50M entries)
|
jonathanasdf/MathGLM-dataset-500k
|
[
"license:afl-3.0",
"region:us"
] |
2023-09-29T18:27:14+00:00
|
{"license": "afl-3.0"}
|
2023-09-29T18:35:38+00:00
|
[] |
[] |
TAGS
#license-afl-3.0 #region-us
|
Every 100th row from URL (original dataset has 50M entries)
|
[] |
[
"TAGS\n#license-afl-3.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-afl-3.0 #region-us \n"
] |
0918222c18fbb26c86a74e174ba2504a3523a669
|
# French Government Open Data (DILA) Dataset - 2023
## Overview
The French Government Open Data (DILA) Dataset is a collection of text data extracted from various sources provided by the French government, specifically the Direction de l'information légale et administrative (DILA). This dataset contains a wide range of legal, administrative, and legislative documents. The data has been organized into several categories for easy access and analysis.
## Dataset Splits
The dataset is organized into the following splits or categories:
- acco: Legal documents related to accounting and finance.
- balo: Documents related to the Bulletin des Annonces Légales Obligatoires (BALO), which publishes legal notices.
- capp: Administrative documents related to public policies and planning.
- cass: Documents related to the Cour de cassation (Court of Cassation), France's highest judicial court.
- cnil: Documents related to the Commission nationale de l'informatique et des libertés (CNIL), which deals with data protection and privacy.
- constit: Documents related to the French constitution and constitutional law.
- debats: Transcripts of parliamentary debates and discussions.
- dole: Documents related to employment and unemployment benefits.
- inca: Documents related to the Institut National du Cancer (INCa), which deals with cancer research and policy.
- jade: Legal documents related to jurisprudence and legal decisions.
- jorf: Documents related to the Journal Officiel de la République Française (JORF), the official journal of the French government.
- kali: Documents related to the Kali database, which contains collective agreements.
- legi: Legal documents related to French legislation.
- qr: Questions and answers related to parliamentary sessions.
- sarde: Documents related to the Service d'administration des réseaux de l'État (SARDE), which manages government networks.
## Dataset Details
Size: 25.65 GB (25 647 979 364 bytes)<br>
Languages: French<br>
Data Format: Plain text<br>
License: OPEN LICENCE<br>
Data Sources: https://echanges.dila.gouv.fr/OPENDATA/<br>
Data Collection Date: October, 2023<br>
Data Structure: Id, Text<br>
- Id: A unique identifier for each document, consisting of the split name and the file name (split/file_name.txt).
- Text: The main text content of the document.
## Acknowledgments
We would like to acknowledge the French government and the Direction de l'information légale et administrative (DILA) for providing access to the data used in this dataset.
## License Information
The French Government Open Data (DILA) Dataset is made available under the terms of the "LICENCE OUVERTE / OPEN LICENCE Version 2.0."
LICENCE OUVERTE / OPEN LICENCE Version 2.0<br>
License Name: LICENCE OUVERTE / OPEN LICENCE Version 2.0<br>
License Text: The full text of the LICENCE OUVERTE / OPEN LICENCE Version 2.0 can be found [here](https://www.etalab.gouv.fr/wp-content/uploads/2017/04/ETALAB-Licence-Ouverte-v2.0.pdf) (in French).<br>
Summary: This license allows you to:
- Copy, modify, publish, translate, distribute, or otherwise exploit the data, in any medium, mode, or format, for any lawful purpose.
- Acknowledge the source of the data by providing appropriate attribution when using the data.
- Ensure that you do not use the data in a way that suggests any official status or endorsement by the French Government or the Direction de l'information légale et administrative (DILA).
- Comply with the terms and conditions of the license.
By using this dataset, you agree to comply with the terms and conditions specified in the LICENCE OUVERTE / OPEN LICENCE Version 2.0.
For more details, please review the full text of the license provided at the link above.
|
Nicolas-BZRD/DILA_OPENDATA_FR_2023
|
[
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:10M<n<100M",
"language:fr",
"license:odc-by",
"finance",
"legal",
"region:us"
] |
2023-09-29T19:08:00+00:00
|
{"language": ["fr"], "license": "odc-by", "size_categories": ["10M<n<100M"], "task_categories": ["text-classification", "question-answering", "text-generation"], "pretty_name": "French Government Open Data (DILA) Dataset - 2023", "configs": [{"config_name": "default", "data_files": [{"split": "acco", "path": "data/acco/*.arrow"}, {"split": "balo", "path": "data/balo/*.arrow"}, {"split": "capp", "path": "data/capp/*.arrow"}, {"split": "cass", "path": "data/cass/*.arrow"}, {"split": "cnil", "path": "data/cnil/*.arrow"}, {"split": "constit", "path": "data/constit/*.arrow"}, {"split": "debats", "path": "data/debats/*.arrow"}, {"split": "dole", "path": "data/dole/*.arrow"}, {"split": "inca", "path": "data/inca/*.arrow"}, {"split": "jade", "path": "data/jade/*.arrow"}, {"split": "jorf", "path": "data/jorf/*.arrow"}, {"split": "kali", "path": "data/kali/*.arrow"}, {"split": "legi", "path": "data/legi/*.arrow"}, {"split": "qr", "path": "data/qr/*.arrow"}, {"split": "sarde", "path": "data/sarde/*.arrow"}]}], "tags": ["finance", "legal"]}
|
2023-10-17T09:21:04+00:00
|
[] |
[
"fr"
] |
TAGS
#task_categories-text-classification #task_categories-question-answering #task_categories-text-generation #size_categories-10M<n<100M #language-French #license-odc-by #finance #legal #region-us
|
# French Government Open Data (DILA) Dataset - 2023
## Overview
The French Government Open Data (DILA) Dataset is a collection of text data extracted from various sources provided by the French government, specifically the Direction de l'information légale et administrative (DILA). This dataset contains a wide range of legal, administrative, and legislative documents. The data has been organized into several categories for easy access and analysis.
## Dataset Splits
The dataset is organized into the following splits or categories:
- acco: Legal documents related to accounting and finance.
- balo: Documents related to the Bulletin des Annonces Légales Obligatoires (BALO), which publishes legal notices.
- capp: Administrative documents related to public policies and planning.
- cass: Documents related to the Cour de cassation (Court of Cassation), France's highest judicial court.
- cnil: Documents related to the Commission nationale de l'informatique et des libertés (CNIL), which deals with data protection and privacy.
- constit: Documents related to the French constitution and constitutional law.
- debats: Transcripts of parliamentary debates and discussions.
- dole: Documents related to employment and unemployment benefits.
- inca: Documents related to the Institut National du Cancer (INCa), which deals with cancer research and policy.
- jade: Legal documents related to jurisprudence and legal decisions.
- jorf: Documents related to the Journal Officiel de la République Française (JORF), the official journal of the French government.
- kali: Documents related to the Kali database, which contains collective agreements.
- legi: Legal documents related to French legislation.
- qr: Questions and answers related to parliamentary sessions.
- sarde: Documents related to the Service d'administration des réseaux de l'État (SARDE), which manages government networks.
## Dataset Details
Size: 25.65 GB (25 647 979 364 bytes)<br>
Languages: French<br>
Data Format: Plain text<br>
License: OPEN LICENCE<br>
Data Sources: URL
Data Collection Date: October, 2023<br>
Data Structure: Id, Text<br>
- Id: A unique identifier for each document, consisting of the split name and the file name (split/file_name.txt).
- Text: The main text content of the document.
## Acknowledgments
We would like to acknowledge the French government and the Direction de l'information légale et administrative (DILA) for providing access to the data used in this dataset.
## License Information
The French Government Open Data (DILA) Dataset is made available under the terms of the "LICENCE OUVERTE / OPEN LICENCE Version 2.0."
LICENCE OUVERTE / OPEN LICENCE Version 2.0<br>
License Name: LICENCE OUVERTE / OPEN LICENCE Version 2.0<br>
License Text: The full text of the LICENCE OUVERTE / OPEN LICENCE Version 2.0 can be found here (in French).<br>
Summary: This license allows you to:
- Copy, modify, publish, translate, distribute, or otherwise exploit the data, in any medium, mode, or format, for any lawful purpose.
- Acknowledge the source of the data by providing appropriate attribution when using the data.
- Ensure that you do not use the data in a way that suggests any official status or endorsement by the French Government or the Direction de l'information légale et administrative (DILA).
- Comply with the terms and conditions of the license.
By using this dataset, you agree to comply with the terms and conditions specified in the LICENCE OUVERTE / OPEN LICENCE Version 2.0.
For more details, please review the full text of the license provided at the link above.
|
[
"# French Government Open Data (DILA) Dataset - 2023",
"## Overview\nThe French Government Open Data (DILA) Dataset is a collection of text data extracted from various sources provided by the French government, specifically the Direction de l'information légale et administrative (DILA). This dataset contains a wide range of legal, administrative, and legislative documents. The data has been organized into several categories for easy access and analysis.",
"## Dataset Splits\nThe dataset is organized into the following splits or categories:\n\n- acco: Legal documents related to accounting and finance.\n- balo: Documents related to the Bulletin des Annonces Légales Obligatoires (BALO), which publishes legal notices.\n- capp: Administrative documents related to public policies and planning.\n- cass: Documents related to the Cour de cassation (Court of Cassation), France's highest judicial court.\n- cnil: Documents related to the Commission nationale de l'informatique et des libertés (CNIL), which deals with data protection and privacy.\n- constit: Documents related to the French constitution and constitutional law.\n- debats: Transcripts of parliamentary debates and discussions.\n- dole: Documents related to employment and unemployment benefits.\n- inca: Documents related to the Institut National du Cancer (INCa), which deals with cancer research and policy.\n- jade: Legal documents related to jurisprudence and legal decisions.\n- jorf: Documents related to the Journal Officiel de la République Française (JORF), the official journal of the French government.\n- kali: Documents related to the Kali database, which contains collective agreements.\n- legi: Legal documents related to French legislation.\n- qr: Questions and answers related to parliamentary sessions.\n- sarde: Documents related to the Service d'administration des réseaux de l'État (SARDE), which manages government networks.",
"## Dataset Details\nSize: 25.65 GB (25 647 979 364 bytes)<br>\nLanguages: French<br>\nData Format: Plain text<br>\nLicense: OPEN LICENCE<br>\nData Sources: URL\nData Collection Date: October, 2023<br>\nData Structure: Id, Text<br>\n\n- Id: A unique identifier for each document, consisting of the split name and the file name (split/file_name.txt).\n- Text: The main text content of the document.",
"## Acknowledgments\n\nWe would like to acknowledge the French government and the Direction de l'information légale et administrative (DILA) for providing access to the data used in this dataset.",
"## License Information\nThe French Government Open Data (DILA) Dataset is made available under the terms of the \"LICENCE OUVERTE / OPEN LICENCE Version 2.0.\"\n\nLICENCE OUVERTE / OPEN LICENCE Version 2.0<br>\nLicense Name: LICENCE OUVERTE / OPEN LICENCE Version 2.0<br>\nLicense Text: The full text of the LICENCE OUVERTE / OPEN LICENCE Version 2.0 can be found here (in French).<br>\nSummary: This license allows you to:\n- Copy, modify, publish, translate, distribute, or otherwise exploit the data, in any medium, mode, or format, for any lawful purpose.\n- Acknowledge the source of the data by providing appropriate attribution when using the data.\n- Ensure that you do not use the data in a way that suggests any official status or endorsement by the French Government or the Direction de l'information légale et administrative (DILA).\n- Comply with the terms and conditions of the license.\n\nBy using this dataset, you agree to comply with the terms and conditions specified in the LICENCE OUVERTE / OPEN LICENCE Version 2.0.\nFor more details, please review the full text of the license provided at the link above."
] |
[
"TAGS\n#task_categories-text-classification #task_categories-question-answering #task_categories-text-generation #size_categories-10M<n<100M #language-French #license-odc-by #finance #legal #region-us \n",
"# French Government Open Data (DILA) Dataset - 2023",
"## Overview\nThe French Government Open Data (DILA) Dataset is a collection of text data extracted from various sources provided by the French government, specifically the Direction de l'information légale et administrative (DILA). This dataset contains a wide range of legal, administrative, and legislative documents. The data has been organized into several categories for easy access and analysis.",
"## Dataset Splits\nThe dataset is organized into the following splits or categories:\n\n- acco: Legal documents related to accounting and finance.\n- balo: Documents related to the Bulletin des Annonces Légales Obligatoires (BALO), which publishes legal notices.\n- capp: Administrative documents related to public policies and planning.\n- cass: Documents related to the Cour de cassation (Court of Cassation), France's highest judicial court.\n- cnil: Documents related to the Commission nationale de l'informatique et des libertés (CNIL), which deals with data protection and privacy.\n- constit: Documents related to the French constitution and constitutional law.\n- debats: Transcripts of parliamentary debates and discussions.\n- dole: Documents related to employment and unemployment benefits.\n- inca: Documents related to the Institut National du Cancer (INCa), which deals with cancer research and policy.\n- jade: Legal documents related to jurisprudence and legal decisions.\n- jorf: Documents related to the Journal Officiel de la République Française (JORF), the official journal of the French government.\n- kali: Documents related to the Kali database, which contains collective agreements.\n- legi: Legal documents related to French legislation.\n- qr: Questions and answers related to parliamentary sessions.\n- sarde: Documents related to the Service d'administration des réseaux de l'État (SARDE), which manages government networks.",
"## Dataset Details\nSize: 25.65 GB (25 647 979 364 bytes)<br>\nLanguages: French<br>\nData Format: Plain text<br>\nLicense: OPEN LICENCE<br>\nData Sources: URL\nData Collection Date: October, 2023<br>\nData Structure: Id, Text<br>\n\n- Id: A unique identifier for each document, consisting of the split name and the file name (split/file_name.txt).\n- Text: The main text content of the document.",
"## Acknowledgments\n\nWe would like to acknowledge the French government and the Direction de l'information légale et administrative (DILA) for providing access to the data used in this dataset.",
"## License Information\nThe French Government Open Data (DILA) Dataset is made available under the terms of the \"LICENCE OUVERTE / OPEN LICENCE Version 2.0.\"\n\nLICENCE OUVERTE / OPEN LICENCE Version 2.0<br>\nLicense Name: LICENCE OUVERTE / OPEN LICENCE Version 2.0<br>\nLicense Text: The full text of the LICENCE OUVERTE / OPEN LICENCE Version 2.0 can be found here (in French).<br>\nSummary: This license allows you to:\n- Copy, modify, publish, translate, distribute, or otherwise exploit the data, in any medium, mode, or format, for any lawful purpose.\n- Acknowledge the source of the data by providing appropriate attribution when using the data.\n- Ensure that you do not use the data in a way that suggests any official status or endorsement by the French Government or the Direction de l'information légale et administrative (DILA).\n- Comply with the terms and conditions of the license.\n\nBy using this dataset, you agree to comply with the terms and conditions specified in the LICENCE OUVERTE / OPEN LICENCE Version 2.0.\nFor more details, please review the full text of the license provided at the link above."
] |
[
71,
13,
80,
336,
117,
41,
282
] |
[
"passage: TAGS\n#task_categories-text-classification #task_categories-question-answering #task_categories-text-generation #size_categories-10M<n<100M #language-French #license-odc-by #finance #legal #region-us \n# French Government Open Data (DILA) Dataset - 2023## Overview\nThe French Government Open Data (DILA) Dataset is a collection of text data extracted from various sources provided by the French government, specifically the Direction de l'information légale et administrative (DILA). This dataset contains a wide range of legal, administrative, and legislative documents. The data has been organized into several categories for easy access and analysis.## Dataset Splits\nThe dataset is organized into the following splits or categories:\n\n- acco: Legal documents related to accounting and finance.\n- balo: Documents related to the Bulletin des Annonces Légales Obligatoires (BALO), which publishes legal notices.\n- capp: Administrative documents related to public policies and planning.\n- cass: Documents related to the Cour de cassation (Court of Cassation), France's highest judicial court.\n- cnil: Documents related to the Commission nationale de l'informatique et des libertés (CNIL), which deals with data protection and privacy.\n- constit: Documents related to the French constitution and constitutional law.\n- debats: Transcripts of parliamentary debates and discussions.\n- dole: Documents related to employment and unemployment benefits.\n- inca: Documents related to the Institut National du Cancer (INCa), which deals with cancer research and policy.\n- jade: Legal documents related to jurisprudence and legal decisions.\n- jorf: Documents related to the Journal Officiel de la République Française (JORF), the official journal of the French government.\n- kali: Documents related to the Kali database, which contains collective agreements.\n- legi: Legal documents related to French legislation.\n- qr: Questions and answers related to parliamentary sessions.\n- sarde: Documents related to the Service d'administration des réseaux de l'État (SARDE), which manages government networks."
] |
36d4a09193ae2128c05a08777702ab6a06834570
|
## Overview
This dataset is a continuation of the airoboros datasets, with two main new contributions:
* MathJSON - math questions, prefixed with __"Create a MathJSON solution to the following:"__, which then outputs a JSON between __`<mathjson>`__ and __`</mathjson>`__ tags, which can be parsed and passed to a deterministic library to perform calculations.
* Anon-contributed RP dataset to enhance multi-turn coherency.
Some of the MathJSON data was adapted from https://huggingface.co/datasets/meta-math/MetaMathQA
## Format
The format is now in ShareGPT format, to better accomodate the OS ecosystem fine-tuning tooling.
## MathJSON
As we all know, math is really difficult for LLMs, especially floating point operations, trig functions, factorials, and several-digit numbers.
Instead of sending millions and millions of examples to the LLM for fine-tuning, I've created a new category `mathjson` which simply presents the solution to the problem as a JSON string that can be evaluated by traditional computation.
The dataset has roughly 4k samples, as a proof of concept. This can be expanded fairly easily, now that the fine-tuned models have a basic understanding of how to represent the problems.
For example:
```
Create a MathJSON solution to the following: Calculate the area of a circle with radius of 17.2456cm. Include your reasoning. [/INST]
```
```
The area (A) of a circle is given by the formula A = πr², where r is the radius of the circle. Since the radius is given in centimeters, we need to convert it to meters first. We know that 1 meter equals 100 centimeters. Therefore, we can represent the radius as: r = 17.2456 cm * 100/1.
Once we have the radius in meters, we can calculate the area of the circle using the formula A = πr².
Solution as MathJSON:
<mathjson>
[
"Multiply",
"Pi",
[
"Power",
17.2456,
2
]
]
</mathjson>
```
Simply extract the JSON string between the mathjson tags, and evaluate it with https://cortexjs.io/compute-engine/ or my ultra-hacky limited-functionality python version of it https://github.com/jondurbin/airoboros/blob/mathjson/airoboros/mathjson.py
|
jondurbin/airoboros-3.0
|
[
"license:apache-2.0",
"region:us"
] |
2023-09-29T19:56:48+00:00
|
{"license": "apache-2.0"}
|
2023-10-12T13:53:54+00:00
|
[] |
[] |
TAGS
#license-apache-2.0 #region-us
|
## Overview
This dataset is a continuation of the airoboros datasets, with two main new contributions:
* MathJSON - math questions, prefixed with __"Create a MathJSON solution to the following:"__, which then outputs a JSON between __'<mathjson>'__ and __'</mathjson>'__ tags, which can be parsed and passed to a deterministic library to perform calculations.
* Anon-contributed RP dataset to enhance multi-turn coherency.
Some of the MathJSON data was adapted from URL
## Format
The format is now in ShareGPT format, to better accomodate the OS ecosystem fine-tuning tooling.
## MathJSON
As we all know, math is really difficult for LLMs, especially floating point operations, trig functions, factorials, and several-digit numbers.
Instead of sending millions and millions of examples to the LLM for fine-tuning, I've created a new category 'mathjson' which simply presents the solution to the problem as a JSON string that can be evaluated by traditional computation.
The dataset has roughly 4k samples, as a proof of concept. This can be expanded fairly easily, now that the fine-tuned models have a basic understanding of how to represent the problems.
For example:
Simply extract the JSON string between the mathjson tags, and evaluate it with URL or my ultra-hacky limited-functionality python version of it URL
|
[
"## Overview\n\nThis dataset is a continuation of the airoboros datasets, with two main new contributions:\n* MathJSON - math questions, prefixed with __\"Create a MathJSON solution to the following:\"__, which then outputs a JSON between __'<mathjson>'__ and __'</mathjson>'__ tags, which can be parsed and passed to a deterministic library to perform calculations.\n* Anon-contributed RP dataset to enhance multi-turn coherency.\n\nSome of the MathJSON data was adapted from URL",
"## Format\n\nThe format is now in ShareGPT format, to better accomodate the OS ecosystem fine-tuning tooling.",
"## MathJSON\n\nAs we all know, math is really difficult for LLMs, especially floating point operations, trig functions, factorials, and several-digit numbers.\n\nInstead of sending millions and millions of examples to the LLM for fine-tuning, I've created a new category 'mathjson' which simply presents the solution to the problem as a JSON string that can be evaluated by traditional computation.\n\nThe dataset has roughly 4k samples, as a proof of concept. This can be expanded fairly easily, now that the fine-tuned models have a basic understanding of how to represent the problems.\n\nFor example:\n\n\n\n\n\nSimply extract the JSON string between the mathjson tags, and evaluate it with URL or my ultra-hacky limited-functionality python version of it URL"
] |
[
"TAGS\n#license-apache-2.0 #region-us \n",
"## Overview\n\nThis dataset is a continuation of the airoboros datasets, with two main new contributions:\n* MathJSON - math questions, prefixed with __\"Create a MathJSON solution to the following:\"__, which then outputs a JSON between __'<mathjson>'__ and __'</mathjson>'__ tags, which can be parsed and passed to a deterministic library to perform calculations.\n* Anon-contributed RP dataset to enhance multi-turn coherency.\n\nSome of the MathJSON data was adapted from URL",
"## Format\n\nThe format is now in ShareGPT format, to better accomodate the OS ecosystem fine-tuning tooling.",
"## MathJSON\n\nAs we all know, math is really difficult for LLMs, especially floating point operations, trig functions, factorials, and several-digit numbers.\n\nInstead of sending millions and millions of examples to the LLM for fine-tuning, I've created a new category 'mathjson' which simply presents the solution to the problem as a JSON string that can be evaluated by traditional computation.\n\nThe dataset has roughly 4k samples, as a proof of concept. This can be expanded fairly easily, now that the fine-tuned models have a basic understanding of how to represent the problems.\n\nFor example:\n\n\n\n\n\nSimply extract the JSON string between the mathjson tags, and evaluate it with URL or my ultra-hacky limited-functionality python version of it URL"
] |
[
14,
132,
28,
180
] |
[
"passage: TAGS\n#license-apache-2.0 #region-us \n## Overview\n\nThis dataset is a continuation of the airoboros datasets, with two main new contributions:\n* MathJSON - math questions, prefixed with __\"Create a MathJSON solution to the following:\"__, which then outputs a JSON between __'<mathjson>'__ and __'</mathjson>'__ tags, which can be parsed and passed to a deterministic library to perform calculations.\n* Anon-contributed RP dataset to enhance multi-turn coherency.\n\nSome of the MathJSON data was adapted from URL## Format\n\nThe format is now in ShareGPT format, to better accomodate the OS ecosystem fine-tuning tooling.## MathJSON\n\nAs we all know, math is really difficult for LLMs, especially floating point operations, trig functions, factorials, and several-digit numbers.\n\nInstead of sending millions and millions of examples to the LLM for fine-tuning, I've created a new category 'mathjson' which simply presents the solution to the problem as a JSON string that can be evaluated by traditional computation.\n\nThe dataset has roughly 4k samples, as a proof of concept. This can be expanded fairly easily, now that the fine-tuned models have a basic understanding of how to represent the problems.\n\nFor example:\n\n\n\n\n\nSimply extract the JSON string between the mathjson tags, and evaluate it with URL or my ultra-hacky limited-functionality python version of it URL"
] |
d1f32b98a2971a3588ba6ed3a671a554ab908a23
|
# Dataset Card for "rl-bench-test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AlekseyKorshuk/rl-bench-test
|
[
"region:us"
] |
2023-09-29T20:06:54+00:00
|
{"dataset_info": {"features": [{"name": "user_name", "dtype": "string"}, {"name": "bot_name", "dtype": "string"}, {"name": "memory", "dtype": "string"}, {"name": "prompt", "dtype": "string"}, {"name": "chat_history", "list": [{"name": "message", "dtype": "string"}, {"name": "sender", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 1657185, "num_examples": 240}], "download_size": 491605, "dataset_size": 1657185}}
|
2023-10-03T17:14:07+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "rl-bench-test"
More Information needed
|
[
"# Dataset Card for \"rl-bench-test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"rl-bench-test\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"rl-bench-test\"\n\nMore Information needed"
] |
ca593a4edea6bfb20cf009baf25c2f89c6c83471
|
VideoInstruct100K is a high-quality video conversation dataset generated using human-assisted and semi-automatic annotation techniques. The question answers in the dataset are related to,
- Video Summariazation
- Description-based question-answers (exploring spatial, temporal, relationships, and reasoning concepts)
- Creative/generative question-answers
For mored details, please visit [Oryx/VideoChatGPT/video-instruction-data-generation](https://github.com/mbzuai-oryx/Video-ChatGPT/blob/main/data/README.md).
If you find this dataset useful, please consider citing the paper,
```bibtex
@article{Maaz2023VideoChatGPT,
title={Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models},
author={Muhammad Maaz, Hanoona Rasheed, Salman Khan and Fahad Khan},
journal={ArXiv 2306.05424},
year={2023}
}
```
|
MBZUAI/VideoInstruct-100K
|
[
"license:cc-by-sa-4.0",
"region:us"
] |
2023-09-29T20:46:07+00:00
|
{"license": "cc-by-sa-4.0"}
|
2023-09-29T20:58:17+00:00
|
[] |
[] |
TAGS
#license-cc-by-sa-4.0 #region-us
|
VideoInstruct100K is a high-quality video conversation dataset generated using human-assisted and semi-automatic annotation techniques. The question answers in the dataset are related to,
- Video Summariazation
- Description-based question-answers (exploring spatial, temporal, relationships, and reasoning concepts)
- Creative/generative question-answers
For mored details, please visit Oryx/VideoChatGPT/video-instruction-data-generation.
If you find this dataset useful, please consider citing the paper,
|
[] |
[
"TAGS\n#license-cc-by-sa-4.0 #region-us \n"
] |
[
17
] |
[
"passage: TAGS\n#license-cc-by-sa-4.0 #region-us \n"
] |
4faa6b6441dd389492b3d0c04cff05b46e5d72a2
|
WER evaluation asosoft test set with large v2 whisper model
|
abdulhade/Test_Asosoft_WER
|
[
"task_categories:feature-extraction",
"size_categories:n<1K",
"language:ku",
"license:apache-2.0",
"code",
"region:us"
] |
2023-09-29T20:49:49+00:00
|
{"language": ["ku"], "license": "apache-2.0", "size_categories": ["n<1K"], "task_categories": ["feature-extraction"], "pretty_name": "wer", "tags": ["code"]}
|
2023-09-29T21:03:32+00:00
|
[] |
[
"ku"
] |
TAGS
#task_categories-feature-extraction #size_categories-n<1K #language-Kurdish #license-apache-2.0 #code #region-us
|
WER evaluation asosoft test set with large v2 whisper model
|
[] |
[
"TAGS\n#task_categories-feature-extraction #size_categories-n<1K #language-Kurdish #license-apache-2.0 #code #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-feature-extraction #size_categories-n<1K #language-Kurdish #license-apache-2.0 #code #region-us \n"
] |
0665d6c7fab2916f7555664038cf80b4acdfc090
|
# Dataset Card for "cantonese-cot"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
indiejoseph/cantonese-cot
|
[
"region:us"
] |
2023-09-29T21:04:12+00:00
|
{"dataset_info": {"features": [{"name": "instruction", "dtype": "string"}, {"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 27894398, "num_examples": 74771}], "download_size": 0, "dataset_size": 27894398}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T21:19:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cantonese-cot"
More Information needed
|
[
"# Dataset Card for \"cantonese-cot\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cantonese-cot\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cantonese-cot\"\n\nMore Information needed"
] |
37087c714300a70ac18c37d82ae31c563af3a507
|
# Dataset Card for "sep28k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
amansingh203/sep28k
|
[
"region:us"
] |
2023-09-29T21:13:18+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "0", "1": "1", "2": "10", "3": "100", "4": "101", "5": "102", "6": "103", "7": "104", "8": "105", "9": "106", "10": "107", "11": "108", "12": "109", "13": "11", "14": "12", "15": "13", "16": "14", "17": "15", "18": "16", "19": "17", "20": "18", "21": "19", "22": "2", "23": "20", "24": "21", "25": "22", "26": "23", "27": "24", "28": "25", "29": "26", "30": "27", "31": "28", "32": "29", "33": "3", "34": "30", "35": "31", "36": "32", "37": "33", "38": "34", "39": "35", "40": "36", "41": "37", "42": "38", "43": "39", "44": "4", "45": "40", "46": "41", "47": "42", "48": "43", "49": "44", "50": "45", "51": "46", "52": "47", "53": "48", "54": "49", "55": "5", "56": "50", "57": "51", "58": "52", "59": "53", "60": "54", "61": "55", "62": "56", "63": "57", "64": "58", "65": "59", "66": "6", "67": "60", "68": "61", "69": "62", "70": "63", "71": "64", "72": "65", "73": "66", "74": "67", "75": "68", "76": "69", "77": "7", "78": "70", "79": "71", "80": "72", "81": "73", "82": "74", "83": "75", "84": "76", "85": "77", "86": "78", "87": "79", "88": "8", "89": "80", "90": "81", "91": "82", "92": "83", "93": "84", "94": "85", "95": "86", "96": "87", "97": "88", "98": "89", "99": "9", "100": "90", "101": "91", "102": "92", "103": "93", "104": "94", "105": "95", "106": "96", "107": "97", "108": "98", "109": "99"}}}}], "splits": [{"name": "train", "num_bytes": 1589865751.4886355, "num_examples": 16568}, {"name": "test", "num_bytes": 530517141.4073644, "num_examples": 5523}], "download_size": 1993007832, "dataset_size": 2120382892.896}}
|
2023-09-29T22:05:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "sep28k"
More Information needed
|
[
"# Dataset Card for \"sep28k\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"sep28k\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"sep28k\"\n\nMore Information needed"
] |
b06c4b9bde32f90210c1c9939f8a0a4be4ab444e
|
Original Datasets: https://www.kaggle.com/datasets/techsash/waste-classification-data?select=DATASET
|
DamarJati/GreenLabel-Waste-Types
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"region:us"
] |
2023-09-29T21:14:22+00:00
|
{"language": ["en"], "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "pretty_name": "GreenLabel-Waste-Types", "viewer": true}
|
2023-09-30T05:54:29+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-classification #size_categories-10K<n<100K #language-English #region-us
|
Original Datasets: URL
|
[] |
[
"TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-English #region-us \n"
] |
[
33
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-English #region-us \n"
] |
e3b1b00f09930468d0fc1d07c9f22b463abcd9f6
|
# Dataset Card for "asr_data_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/asr_data_v3
|
[
"region:us"
] |
2023-09-29T21:32:21+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "transcription", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3658424.0, "num_examples": 44}], "download_size": 3640862, "dataset_size": 3658424.0}}
|
2023-09-29T21:32:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "asr_data_v3"
More Information needed
|
[
"# Dataset Card for \"asr_data_v3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"asr_data_v3\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"asr_data_v3\"\n\nMore Information needed"
] |
82db2bd957af5311fa1311443a60dcb70087c144
|
# GlotSparse Corpus
Collection of news websites in low-resource languages.
- **Homepage:** [homepage](https://github.com/cisnlp/GlotSparse)
- **Repository:** [github](https://github.com/cisnlp/GlotSparse)
- **Paper:** [paper](https://arxiv.org/abs/2310.16248)
- **Point of Contact:** [email protected]
These languages are supported:
```
('azb_Arab', 'South-Azerbaijani_Arab')
('bal_Arab', 'Balochi_Arab')
('brh_Arab', 'Brahui_Arab')
('fat_Latn', 'Fanti_Latn') # aka
('glk_Arab', 'Gilaki_Arab')
('hac_Arab', 'Gurani_Arab')
('kiu_Latn', 'Kirmanjki_Latn') # zza
('sdh_Arab', 'Southern-Kurdish_Arab')
('twi_Latn', 'Twi_Latn') # aka
('uzs_Arab', 'Southern-Uzbek_Arab')
```
## Usage (HF Loader)
Replace `twi_Latn` with your specific language.
```python
from datasets import load_dataset
dataset = load_dataset('cis-lmu/GlotSparse', 'twi_Latn')
print(dataset['train'][0]) # First row of Twi_Latn
```
## Download
If you are not a fan of the HF dataloader or are just interested in a specific language, download it directly:
Replace `twi_Latn` with your specific language.
```python
! wget https://huggingface.co/datasets/cis-lmu/GlotSparse/resolve/main/twi_Latn/twi_Latn.csv
```
## Sources
- **Balochi (bal)**
- News: https://sunnionline.us/balochi/
- Stories: https://kissah.org/
- Deiverse Contents such as poems, stories, posts, etc: https://baask.com/archive/category/balochi/
- **Gilaki (glk)**
- Social Media: The original source of this content is Twitter, but Twitter typically doesn't support Gilaki as part of its language identifier due to gilaki is a low resource language. We obtained this content from a Telegram channel (https://t.me/gilaki_twitter) that re-posts Gilaki Twitter content. The admins of the channel are native Gilaki speakers, and after manual inspection, these tweets are selected. At present, there isn't a readily available mapping for Twitter IDs. The primary reason for reposting Twitter content on Telegram in Iran is the relative ease of access to Telegram compared to Twitter.
- **Brahui (brh)**
- News: https://talarbrahui.com/category/news/ and https://talarbrahui.com/category/articles/
- **Southern-Kurdish (sdh)**
- News: https://shafaq.com/ku/ (Feyli)
- **Gurani (hac)**
- News: https://anfsorani.com/هۆرامی (Hawrami)
- **Kirmanjki (kiu)**
- News: https://anfkirmancki.com/
- **Fanti (fat)**
- News: https://akannews.com/fante/
- **Twi (twi)**
- News: https://akannews.com/asante-twi/
- **South-Azerbaijani (azb)**
- News: https://www.trt.net.tr/turki/
- **Southern Uzbek (uzs)**
- News: https://www.trt.net.tr/afghaniuzbek/
## Tools
To compute the script of each text and removing unwanted langauges we used Glotscript ([code](https://github.com/cisnlp/GlotScript) and [paper](https://arxiv.org/abs/2309.13320)).
## License
We do not own any of the text from which these data has been extracted.
We license the actual packaging, the metadata and the annotations of these data under the cc0-1.0 (waiving all of the rights under copyright law).
If you are a website/dataset owner and do not want your data to be included in this corpra, please send us an email at [email protected] .
## Ethical Considerations
**1. Biases:** The text corpus may reflect the perspectives, opinions, or demographics of its sources or creators. It is important for users to critically evaluate the text in context especially for **news sources** and **social medias** (e.g., sunnionline, twitter, ...).
**2. Representativeness:** While we have aimed for diversity and inclusivity, the text corpus may not fully represent all native speakers. Users should be mindful of any potential underrepresentation.
**3. Ethics:** We acknowledge that the collection and use of text data can have ethical implications. We have strived to handle the data responsibly, but we encourage users to consider the broader ethical implications of their own research or applications.
## Github
We also host a GitHub version with representing similar metadata from other sources:
https://github.com/cisnlp/GlotSparse
## Citation
If you use any part of this code and data in your research, please cite it using the following BibTeX entry.
All the sources related to news, social media, and without mentioned datasets are crawled and compiled in this work.
This work is part of the [GlotLID](https://github.com/cisnlp/GlotLID) project.
```
@inproceedings{
kargaran2023glotlid,
title={{GlotLID}: Language Identification for Low-Resource Languages},
author={Kargaran, Amir Hossein and Imani, Ayyoob and Yvon, Fran{\c{c}}ois and Sch{\"u}tze, Hinrich},
booktitle={The 2023 Conference on Empirical Methods in Natural Language Processing},
year={2023},
url={https://openreview.net/forum?id=dl4e3EBz5j}
}
```
|
cis-lmu/GlotSparse
|
[
"language:bal",
"language:glk",
"language:brh",
"language:sdh",
"language:kur",
"language:hac",
"language:kiu",
"language:zza",
"language:twi",
"language:fat",
"language:aka",
"license:cc0-1.0",
"arxiv:2310.16248",
"arxiv:2309.13320",
"region:us"
] |
2023-09-29T22:38:41+00:00
|
{"language": ["bal", "glk", "brh", "sdh", "kur", "hac", "kiu", "zza", "twi", "fat", "aka"], "license": "cc0-1.0", "pretty_name": "GlotSparse Corpus", "configs": [{"config_name": "azb_Arab", "data_files": "azb_Arab/azb_Arab.csv"}, {"config_name": "bal_Arab", "data_files": "bal_Arab/bal_Arab.csv"}, {"config_name": "brh_Arab", "data_files": "brh_Arab/brh_Arab.csv"}, {"config_name": "fat_Latn", "data_files": "fat_Latn/fat_Latn.csv"}, {"config_name": "glk_Arab", "data_files": "glk_Arab/glk_Arab.csv"}, {"config_name": "hac_Arab", "data_files": "hac_Arab/hac_Arab.csv"}, {"config_name": "kiu_Latn", "data_files": "kiu_Latn/kiu_Latn.csv"}, {"config_name": "sdh_Arab", "data_files": "sdh_Arab/sdh_Arab.csv"}, {"config_name": "twi_Latn", "data_files": "twi_Latn/twi_Latn.csv"}, {"config_name": "uzs_Arab", "data_files": "uzs_Arab/uzs_Arab.csv"}]}
|
2023-10-26T09:23:24+00:00
|
[
"2310.16248",
"2309.13320"
] |
[
"bal",
"glk",
"brh",
"sdh",
"kur",
"hac",
"kiu",
"zza",
"twi",
"fat",
"aka"
] |
TAGS
#language-Baluchi #language-Gilaki #language-Brahui #language-Southern Kurdish #language-Kurdish #language-Gurani #language-Kirmanjki (individual language) #language-Zaza #language-Twi #language-Fanti #language-Akan #license-cc0-1.0 #arxiv-2310.16248 #arxiv-2309.13320 #region-us
|
# GlotSparse Corpus
Collection of news websites in low-resource languages.
- Homepage: homepage
- Repository: github
- Paper: paper
- Point of Contact: amir@URL
These languages are supported:
## Usage (HF Loader)
Replace 'twi_Latn' with your specific language.
## Download
If you are not a fan of the HF dataloader or are just interested in a specific language, download it directly:
Replace 'twi_Latn' with your specific language.
## Sources
- Balochi (bal)
- News: URL
- Stories: URL
- Deiverse Contents such as poems, stories, posts, etc: URL
- Gilaki (glk)
- Social Media: The original source of this content is Twitter, but Twitter typically doesn't support Gilaki as part of its language identifier due to gilaki is a low resource language. We obtained this content from a Telegram channel (https://t.me/gilaki_twitter) that re-posts Gilaki Twitter content. The admins of the channel are native Gilaki speakers, and after manual inspection, these tweets are selected. At present, there isn't a readily available mapping for Twitter IDs. The primary reason for reposting Twitter content on Telegram in Iran is the relative ease of access to Telegram compared to Twitter.
- Brahui (brh)
- News: URL and URL
- Southern-Kurdish (sdh)
- News: URL (Feyli)
- Gurani (hac)
- News: URL/هۆرامی (Hawrami)
- Kirmanjki (kiu)
- News: URL
- Fanti (fat)
- News: URL
- Twi (twi)
- News: URL
- South-Azerbaijani (azb)
- News: URL
- Southern Uzbek (uzs)
- News: URL
## Tools
To compute the script of each text and removing unwanted langauges we used Glotscript (code and paper).
## License
We do not own any of the text from which these data has been extracted.
We license the actual packaging, the metadata and the annotations of these data under the cc0-1.0 (waiving all of the rights under copyright law).
If you are a website/dataset owner and do not want your data to be included in this corpra, please send us an email at amir@URL .
## Ethical Considerations
1. Biases: The text corpus may reflect the perspectives, opinions, or demographics of its sources or creators. It is important for users to critically evaluate the text in context especially for news sources and social medias (e.g., sunnionline, twitter, ...).
2. Representativeness: While we have aimed for diversity and inclusivity, the text corpus may not fully represent all native speakers. Users should be mindful of any potential underrepresentation.
3. Ethics: We acknowledge that the collection and use of text data can have ethical implications. We have strived to handle the data responsibly, but we encourage users to consider the broader ethical implications of their own research or applications.
## Github
We also host a GitHub version with representing similar metadata from other sources:
URL
If you use any part of this code and data in your research, please cite it using the following BibTeX entry.
All the sources related to news, social media, and without mentioned datasets are crawled and compiled in this work.
This work is part of the GlotLID project.
|
[
"# GlotSparse Corpus\n\nCollection of news websites in low-resource languages.\n\n- Homepage: homepage\n- Repository: github\n- Paper: paper\n- Point of Contact: amir@URL\n\nThese languages are supported:",
"## Usage (HF Loader)\nReplace 'twi_Latn' with your specific language.",
"## Download\nIf you are not a fan of the HF dataloader or are just interested in a specific language, download it directly:\nReplace 'twi_Latn' with your specific language.",
"## Sources\n\n- Balochi (bal)\n - News: URL\n - Stories: URL\n - Deiverse Contents such as poems, stories, posts, etc: URL\n\n- Gilaki (glk)\n - Social Media: The original source of this content is Twitter, but Twitter typically doesn't support Gilaki as part of its language identifier due to gilaki is a low resource language. We obtained this content from a Telegram channel (https://t.me/gilaki_twitter) that re-posts Gilaki Twitter content. The admins of the channel are native Gilaki speakers, and after manual inspection, these tweets are selected. At present, there isn't a readily available mapping for Twitter IDs. The primary reason for reposting Twitter content on Telegram in Iran is the relative ease of access to Telegram compared to Twitter.\n\n- Brahui (brh)\n - News: URL and URL\n\n- Southern-Kurdish (sdh)\n - News: URL (Feyli)\n\n- Gurani (hac)\n - News: URL/هۆرامی (Hawrami)\n\n- Kirmanjki (kiu)\n - News: URL\n\n- Fanti (fat)\n - News: URL\n \n- Twi (twi)\n - News: URL\n\n- South-Azerbaijani (azb)\n - News: URL\n \n- Southern Uzbek (uzs)\n - News: URL",
"## Tools\n\nTo compute the script of each text and removing unwanted langauges we used Glotscript (code and paper).",
"## License\nWe do not own any of the text from which these data has been extracted.\nWe license the actual packaging, the metadata and the annotations of these data under the cc0-1.0 (waiving all of the rights under copyright law).\n\nIf you are a website/dataset owner and do not want your data to be included in this corpra, please send us an email at amir@URL .",
"## Ethical Considerations\n\n1. Biases: The text corpus may reflect the perspectives, opinions, or demographics of its sources or creators. It is important for users to critically evaluate the text in context especially for news sources and social medias (e.g., sunnionline, twitter, ...).\n\n2. Representativeness: While we have aimed for diversity and inclusivity, the text corpus may not fully represent all native speakers. Users should be mindful of any potential underrepresentation.\n\n3. Ethics: We acknowledge that the collection and use of text data can have ethical implications. We have strived to handle the data responsibly, but we encourage users to consider the broader ethical implications of their own research or applications.",
"## Github\nWe also host a GitHub version with representing similar metadata from other sources:\nURL\n\nIf you use any part of this code and data in your research, please cite it using the following BibTeX entry.\nAll the sources related to news, social media, and without mentioned datasets are crawled and compiled in this work.\nThis work is part of the GlotLID project."
] |
[
"TAGS\n#language-Baluchi #language-Gilaki #language-Brahui #language-Southern Kurdish #language-Kurdish #language-Gurani #language-Kirmanjki (individual language) #language-Zaza #language-Twi #language-Fanti #language-Akan #license-cc0-1.0 #arxiv-2310.16248 #arxiv-2309.13320 #region-us \n",
"# GlotSparse Corpus\n\nCollection of news websites in low-resource languages.\n\n- Homepage: homepage\n- Repository: github\n- Paper: paper\n- Point of Contact: amir@URL\n\nThese languages are supported:",
"## Usage (HF Loader)\nReplace 'twi_Latn' with your specific language.",
"## Download\nIf you are not a fan of the HF dataloader or are just interested in a specific language, download it directly:\nReplace 'twi_Latn' with your specific language.",
"## Sources\n\n- Balochi (bal)\n - News: URL\n - Stories: URL\n - Deiverse Contents such as poems, stories, posts, etc: URL\n\n- Gilaki (glk)\n - Social Media: The original source of this content is Twitter, but Twitter typically doesn't support Gilaki as part of its language identifier due to gilaki is a low resource language. We obtained this content from a Telegram channel (https://t.me/gilaki_twitter) that re-posts Gilaki Twitter content. The admins of the channel are native Gilaki speakers, and after manual inspection, these tweets are selected. At present, there isn't a readily available mapping for Twitter IDs. The primary reason for reposting Twitter content on Telegram in Iran is the relative ease of access to Telegram compared to Twitter.\n\n- Brahui (brh)\n - News: URL and URL\n\n- Southern-Kurdish (sdh)\n - News: URL (Feyli)\n\n- Gurani (hac)\n - News: URL/هۆرامی (Hawrami)\n\n- Kirmanjki (kiu)\n - News: URL\n\n- Fanti (fat)\n - News: URL\n \n- Twi (twi)\n - News: URL\n\n- South-Azerbaijani (azb)\n - News: URL\n \n- Southern Uzbek (uzs)\n - News: URL",
"## Tools\n\nTo compute the script of each text and removing unwanted langauges we used Glotscript (code and paper).",
"## License\nWe do not own any of the text from which these data has been extracted.\nWe license the actual packaging, the metadata and the annotations of these data under the cc0-1.0 (waiving all of the rights under copyright law).\n\nIf you are a website/dataset owner and do not want your data to be included in this corpra, please send us an email at amir@URL .",
"## Ethical Considerations\n\n1. Biases: The text corpus may reflect the perspectives, opinions, or demographics of its sources or creators. It is important for users to critically evaluate the text in context especially for news sources and social medias (e.g., sunnionline, twitter, ...).\n\n2. Representativeness: While we have aimed for diversity and inclusivity, the text corpus may not fully represent all native speakers. Users should be mindful of any potential underrepresentation.\n\n3. Ethics: We acknowledge that the collection and use of text data can have ethical implications. We have strived to handle the data responsibly, but we encourage users to consider the broader ethical implications of their own research or applications.",
"## Github\nWe also host a GitHub version with representing similar metadata from other sources:\nURL\n\nIf you use any part of this code and data in your research, please cite it using the following BibTeX entry.\nAll the sources related to news, social media, and without mentioned datasets are crawled and compiled in this work.\nThis work is part of the GlotLID project."
] |
[
97,
50,
23,
43,
294,
29,
90,
168,
88
] |
[
"passage: TAGS\n#language-Baluchi #language-Gilaki #language-Brahui #language-Southern Kurdish #language-Kurdish #language-Gurani #language-Kirmanjki (individual language) #language-Zaza #language-Twi #language-Fanti #language-Akan #license-cc0-1.0 #arxiv-2310.16248 #arxiv-2309.13320 #region-us \n# GlotSparse Corpus\n\nCollection of news websites in low-resource languages.\n\n- Homepage: homepage\n- Repository: github\n- Paper: paper\n- Point of Contact: amir@URL\n\nThese languages are supported:## Usage (HF Loader)\nReplace 'twi_Latn' with your specific language.## Download\nIf you are not a fan of the HF dataloader or are just interested in a specific language, download it directly:\nReplace 'twi_Latn' with your specific language.## Sources\n\n- Balochi (bal)\n - News: URL\n - Stories: URL\n - Deiverse Contents such as poems, stories, posts, etc: URL\n\n- Gilaki (glk)\n - Social Media: The original source of this content is Twitter, but Twitter typically doesn't support Gilaki as part of its language identifier due to gilaki is a low resource language. We obtained this content from a Telegram channel (https://t.me/gilaki_twitter) that re-posts Gilaki Twitter content. The admins of the channel are native Gilaki speakers, and after manual inspection, these tweets are selected. At present, there isn't a readily available mapping for Twitter IDs. The primary reason for reposting Twitter content on Telegram in Iran is the relative ease of access to Telegram compared to Twitter.\n\n- Brahui (brh)\n - News: URL and URL\n\n- Southern-Kurdish (sdh)\n - News: URL (Feyli)\n\n- Gurani (hac)\n - News: URL/هۆرامی (Hawrami)\n\n- Kirmanjki (kiu)\n - News: URL\n\n- Fanti (fat)\n - News: URL\n \n- Twi (twi)\n - News: URL\n\n- South-Azerbaijani (azb)\n - News: URL\n \n- Southern Uzbek (uzs)\n - News: URL"
] |
185d74d3423789b4feec6632039f2ff4c84e4ab3
|
# Dataset Card for "Lee_Souder_RocketLauncher"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
MaxReynolds/Lee_Souder_RocketLauncher
|
[
"region:us"
] |
2023-09-29T22:50:29+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 279829.0, "num_examples": 28}], "download_size": 0, "dataset_size": 279829.0}}
|
2023-09-30T00:57:33+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Lee_Souder_RocketLauncher"
More Information needed
|
[
"# Dataset Card for \"Lee_Souder_RocketLauncher\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Lee_Souder_RocketLauncher\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Lee_Souder_RocketLauncher\"\n\nMore Information needed"
] |
9074c1d80ad61e9cb8271b5c641bfebb3f752867
|
# Dataset Card for "distillation_code_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jitx/distillation_code_2
|
[
"region:us"
] |
2023-09-29T23:16:33+00:00
|
{"dataset_info": {"features": [{"name": "santacoder_prompts", "dtype": "string"}, {"name": "fim_inputs", "dtype": "string"}, {"name": "label_middles", "dtype": "string"}, {"name": "santacoder_outputs", "dtype": "string"}, {"name": "openai_rationales", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 8311, "num_examples": 2}], "download_size": 30507, "dataset_size": 8311}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T23:25:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "distillation_code_2"
More Information needed
|
[
"# Dataset Card for \"distillation_code_2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"distillation_code_2\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"distillation_code_2\"\n\nMore Information needed"
] |
edbc255b722c9933ac6d6f2b4c37d1803852563a
|
# Dataset Card for "distillation_code_4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jitx/distillation_code_4
|
[
"region:us"
] |
2023-09-29T23:32:03+00:00
|
{"dataset_info": {"features": [{"name": "santacoder_prompts", "dtype": "string"}, {"name": "fim_inputs", "dtype": "string"}, {"name": "label_middles", "dtype": "string"}, {"name": "santacoder_outputs", "dtype": "string"}, {"name": "openai_rationales", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 16254, "num_examples": 4}], "download_size": 32557, "dataset_size": 16254}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-29T23:32:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "distillation_code_4"
More Information needed
|
[
"# Dataset Card for \"distillation_code_4\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"distillation_code_4\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"distillation_code_4\"\n\nMore Information needed"
] |
2f2ceeb39658696fd3f462403562b6eea5306287
|
# Jailbreak Classification
### Dataset Summary
Dataset used to classify prompts as jailbreak vs. benign.
## Dataset Structure
### Data Fields
- `prompt`: an LLM prompt
- `type`: classification label, either `jailbreak` or `benign`
## Dataset Creation
### Curation Rationale
Created to help detect & prevent harmful jailbreak prompts when users interact with LLMs.
### Source Data
Jailbreak prompts sourced from: <https://github.com/verazuo/jailbreak_llms>
Benign prompts sourced from:
- [OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- <https://github.com/teknium1/GPTeacher>
|
jackhhao/jailbreak-classification
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"jailbreak",
"security",
"moderation",
"region:us"
] |
2023-09-29T23:56:39+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "pretty_name": "Jailbreak Classification", "tags": ["jailbreak", "security", "moderation"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "balanced/jailbreak_dataset_train_balanced.csv"}, {"split": "test", "path": "balanced/jailbreak_dataset_test_balanced.csv"}]}]}
|
2023-09-30T00:55:08+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-classification #size_categories-10K<n<100K #language-English #license-apache-2.0 #jailbreak #security #moderation #region-us
|
# Jailbreak Classification
### Dataset Summary
Dataset used to classify prompts as jailbreak vs. benign.
## Dataset Structure
### Data Fields
- 'prompt': an LLM prompt
- 'type': classification label, either 'jailbreak' or 'benign'
## Dataset Creation
### Curation Rationale
Created to help detect & prevent harmful jailbreak prompts when users interact with LLMs.
### Source Data
Jailbreak prompts sourced from: <URL
Benign prompts sourced from:
- OpenOrca
- <URL
|
[
"# Jailbreak Classification",
"### Dataset Summary\n\nDataset used to classify prompts as jailbreak vs. benign.",
"## Dataset Structure",
"### Data Fields\n\n- 'prompt': an LLM prompt\n- 'type': classification label, either 'jailbreak' or 'benign'",
"## Dataset Creation",
"### Curation Rationale\nCreated to help detect & prevent harmful jailbreak prompts when users interact with LLMs.",
"### Source Data\n\nJailbreak prompts sourced from: <URL\n\nBenign prompts sourced from:\n- OpenOrca\n- <URL"
] |
[
"TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-English #license-apache-2.0 #jailbreak #security #moderation #region-us \n",
"# Jailbreak Classification",
"### Dataset Summary\n\nDataset used to classify prompts as jailbreak vs. benign.",
"## Dataset Structure",
"### Data Fields\n\n- 'prompt': an LLM prompt\n- 'type': classification label, either 'jailbreak' or 'benign'",
"## Dataset Creation",
"### Curation Rationale\nCreated to help detect & prevent harmful jailbreak prompts when users interact with LLMs.",
"### Source Data\n\nJailbreak prompts sourced from: <URL\n\nBenign prompts sourced from:\n- OpenOrca\n- <URL"
] |
[
50,
6,
22,
6,
37,
5,
30,
31
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-English #license-apache-2.0 #jailbreak #security #moderation #region-us \n# Jailbreak Classification### Dataset Summary\n\nDataset used to classify prompts as jailbreak vs. benign.## Dataset Structure### Data Fields\n\n- 'prompt': an LLM prompt\n- 'type': classification label, either 'jailbreak' or 'benign'## Dataset Creation### Curation Rationale\nCreated to help detect & prevent harmful jailbreak prompts when users interact with LLMs.### Source Data\n\nJailbreak prompts sourced from: <URL\n\nBenign prompts sourced from:\n- OpenOrca\n- <URL"
] |
d0d13d0931ad41cd7783c967d12a86371346e0c0
|
# Dataset Card for "echo_testing"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
12345testing/echo_testing
|
[
"region:us"
] |
2023-09-30T00:01:11+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 524579.0, "num_examples": 8}], "download_size": 525593, "dataset_size": 524579.0}}
|
2023-09-30T00:01:15+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "echo_testing"
More Information needed
|
[
"# Dataset Card for \"echo_testing\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"echo_testing\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"echo_testing\"\n\nMore Information needed"
] |
8bc49aafed8fb2938740ff977f5350c262a6d4c0
|
# Dataset Card for "plat-clean"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
amphora/plat-clean
|
[
"region:us"
] |
2023-09-30T00:19:31+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 33608338, "num_examples": 24926}], "download_size": 16086395, "dataset_size": 33608338}}
|
2023-09-30T00:19:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "plat-clean"
More Information needed
|
[
"# Dataset Card for \"plat-clean\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"plat-clean\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"plat-clean\"\n\nMore Information needed"
] |
c27d6c892ae44cfa1dca4bec68edcca1db45f03a
|
# Dataset Card for "distillation_code_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jitx/distillation_code_100
|
[
"region:us"
] |
2023-09-30T00:30:16+00:00
|
{"dataset_info": {"features": [{"name": "santacoder_prompts", "dtype": "string"}, {"name": "fim_inputs", "dtype": "string"}, {"name": "label_middles", "dtype": "string"}, {"name": "santacoder_outputs", "dtype": "string"}, {"name": "openai_rationales", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 399654, "num_examples": 100}], "download_size": 155882, "dataset_size": 399654}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-30T00:30:18+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "distillation_code_100"
More Information needed
|
[
"# Dataset Card for \"distillation_code_100\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"distillation_code_100\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"distillation_code_100\"\n\nMore Information needed"
] |
97af22f79038ab6e8f70a02e8800eae022ef10a5
|
# Dataset Card for "code_5p_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
manu/code_5p_data
|
[
"region:us"
] |
2023-09-30T01:30:14+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "dataset_id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9842414063, "num_examples": 2211562}, {"name": "test", "num_bytes": 4833827, "num_examples": 642}], "download_size": 4214480484, "dataset_size": 9847247890}}
|
2023-09-30T02:31:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "code_5p_data"
More Information needed
|
[
"# Dataset Card for \"code_5p_data\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"code_5p_data\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"code_5p_data\"\n\nMore Information needed"
] |
4234a19d7b0932dcdbaf7bbf30bf83fc267be97f
|
# Dataset Card for "guanaco-llama2-1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
madmaxima/guanaco-llama2-1k
|
[
"region:us"
] |
2023-09-30T01:47:12+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1654448, "num_examples": 1000}], "download_size": 966693, "dataset_size": 1654448}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-30T01:47:14+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "guanaco-llama2-1k"
More Information needed
|
[
"# Dataset Card for \"guanaco-llama2-1k\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"guanaco-llama2-1k\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"guanaco-llama2-1k\"\n\nMore Information needed"
] |
38c47a57e09448e322d70a0ea5a1f7fb9ae157b5
|
# Bangumi Image Base of New Game!
This is the image base of bangumi New Game!, we detected 25 characters, 4097 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 1097 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 319 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 10 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 14 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 288 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 227 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 231 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 38 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 10 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 114 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 142 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 282 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 26 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 335 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 9 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 483 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 48 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 23 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 11 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 12 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| 20 | 130 | [Download](20/dataset.zip) |  |  |  |  |  |  |  |  |
| 21 | 7 | [Download](21/dataset.zip) |  |  |  |  |  |  |  | N/A |
| 22 | 12 | [Download](22/dataset.zip) |  |  |  |  |  |  |  |  |
| 23 | 6 | [Download](23/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| noise | 223 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/newgame
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-30T02:17:20+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-30T03:56:10+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of New Game!
===============================
This is the image base of bangumi New Game!, we detected 25 characters, 4097 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
67a592122bc070a64aa177e65b642f794e3f5e8c
|
## RLHF Reward Model Dataset
奖励模型数据集。
数据集从网上收集整理如下:
| 数据 | 语言 | 原始数据/项目地址 | 样本个数 | 原始数据描述 | 替代数据下载地址 |
| :--- | :---: | :---: | :---: | :---: | :---: |
| beyond | chinese | [beyond/rlhf-reward-single-round-trans_chinese](https://huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese) | 24858 | | |
| helpful_and_harmless | chinese | [dikw/hh_rlhf_cn](https://huggingface.co/datasets/dikw/hh_rlhf_cn) | harmless train 42394 条,harmless test 2304 条,helpful train 43722 条,helpful test 2346 条, | 基于 Anthropic 论文 [Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2204.05862) 开源的 helpful 和harmless 数据,使用翻译工具进行了翻译。 | [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) |
| zhihu_3k | chinese | [liyucheng/zhihu_rlhf_3k](https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k) | 3460 | 知乎上的问答有用户的点赞数量,它应该是根据点赞数量来判断答案的优先级。 | |
| SHP | english | [stanfordnlp/SHP](https://huggingface.co/datasets/stanfordnlp/SHP) | 385K | 涉及18个子领域,偏好表示是否有帮助。 | |
<details>
<summary>参考的数据来源,展开查看</summary>
<pre><code>
https://huggingface.co/datasets/ticoAg/rlhf_zh
https://huggingface.co/datasets/beyond/rlhf-reward-single-round-trans_chinese
https://huggingface.co/datasets/dikw/hh_rlhf_cn
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k
</code></pre>
</details>
|
qgyd2021/rlhf_reward_dataset
|
[
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:100M<n<1B",
"language:zh",
"language:en",
"license:apache-2.0",
"reward model",
"rlhf",
"arxiv:2204.05862",
"region:us"
] |
2023-09-30T02:23:01+00:00
|
{"language": ["zh", "en"], "license": "apache-2.0", "size_categories": ["100M<n<1B"], "task_categories": ["question-answering", "text-generation"], "tags": ["reward model", "rlhf"]}
|
2023-10-10T10:11:01+00:00
|
[
"2204.05862"
] |
[
"zh",
"en"
] |
TAGS
#task_categories-question-answering #task_categories-text-generation #size_categories-100M<n<1B #language-Chinese #language-English #license-apache-2.0 #reward model #rlhf #arxiv-2204.05862 #region-us
|
RLHF Reward Model Dataset
-------------------------
奖励模型数据集。
数据集从网上收集整理如下:
参考的数据来源,展开查看
```
URL
URL
URL
URL
```
|
[] |
[
"TAGS\n#task_categories-question-answering #task_categories-text-generation #size_categories-100M<n<1B #language-Chinese #language-English #license-apache-2.0 #reward model #rlhf #arxiv-2204.05862 #region-us \n"
] |
[
75
] |
[
"passage: TAGS\n#task_categories-question-answering #task_categories-text-generation #size_categories-100M<n<1B #language-Chinese #language-English #license-apache-2.0 #reward model #rlhf #arxiv-2204.05862 #region-us \n"
] |
d0c4d781e1349f66c0599dcbe2ac0bad9c498142
|
# Dataset Card for "code_5p_data_separate"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
manu/code_5p_data_separate
|
[
"region:us"
] |
2023-09-30T02:31:46+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "StarcoderdataPythonTrain", "path": "data/StarcoderdataPythonTrain-*"}, {"split": "StarcoderdataPythonTest", "path": "data/StarcoderdataPythonTest-*"}, {"split": "StarcoderdataMarkdownTrain", "path": "data/StarcoderdataMarkdownTrain-*"}, {"split": "StarcoderdataMarkdownTest", "path": "data/StarcoderdataMarkdownTest-*"}, {"split": "StarcoderdataJupyterScriptsDedupFilteredTrain", "path": "data/StarcoderdataJupyterScriptsDedupFilteredTrain-*"}, {"split": "StarcoderdataJupyterScriptsDedupFilteredTest", "path": "data/StarcoderdataJupyterScriptsDedupFilteredTest-*"}, {"split": "StarcoderdataJupyterStructuredCleanDedupTrain", "path": "data/StarcoderdataJupyterStructuredCleanDedupTrain-*"}, {"split": "StarcoderdataJupyterStructuredCleanDedupTest", "path": "data/StarcoderdataJupyterStructuredCleanDedupTest-*"}, {"split": "StarcoderdataJsonTrain", "path": "data/StarcoderdataJsonTrain-*"}, {"split": "StarcoderdataJsonTest", "path": "data/StarcoderdataJsonTest-*"}, {"split": "CodeContestsTrain", "path": "data/CodeContestsTrain-*"}, {"split": "CodeContestsTest", "path": "data/CodeContestsTest-*"}, {"split": "PypiCleanTrain", "path": "data/PypiCleanTrain-*"}, {"split": "PypiCleanTest", "path": "data/PypiCleanTest-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "dataset_id", "dtype": "string"}], "splits": [{"name": "StarcoderdataPythonTrain", "num_bytes": 3077290405, "num_examples": 643232}, {"name": "StarcoderdataPythonTest", "num_bytes": 546326, "num_examples": 100}, {"name": "StarcoderdataMarkdownTrain", "num_bytes": 4054448273, "num_examples": 1051364}, {"name": "StarcoderdataMarkdownTest", "num_bytes": 680799, "num_examples": 100}, {"name": "StarcoderdataJupyterScriptsDedupFilteredTrain", "num_bytes": 401590417, "num_examples": 45626}, {"name": "StarcoderdataJupyterScriptsDedupFilteredTest", "num_bytes": 724111, "num_examples": 100}, {"name": "StarcoderdataJupyterStructuredCleanDedupTrain", "num_bytes": 316718609, "num_examples": 33337}, {"name": "StarcoderdataJupyterStructuredCleanDedupTest", "num_bytes": 971655, "num_examples": 100}, {"name": "StarcoderdataJsonTrain", "num_bytes": 291208312, "num_examples": 237477}, {"name": "StarcoderdataJsonTest", "num_bytes": 112941, "num_examples": 100}, {"name": "CodeContestsTrain", "num_bytes": 151487748, "num_examples": 78717}, {"name": "CodeContestsTest", "num_bytes": 79396, "num_examples": 42}, {"name": "PypiCleanTrain", "num_bytes": 1549670299, "num_examples": 121809}, {"name": "PypiCleanTest", "num_bytes": 1718599, "num_examples": 100}], "download_size": 4213817063, "dataset_size": 9847247890}}
|
2023-09-30T02:36:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "code_5p_data_separate"
More Information needed
|
[
"# Dataset Card for \"code_5p_data_separate\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"code_5p_data_separate\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"code_5p_data_separate\"\n\nMore Information needed"
] |
46f969a07ebebabd527699cf66786a7973d03dde
|
# Bangumi Image Base of Majo No Tabitabi
This is the image base of bangumi Majo no Tabitabi, we detected 35 characters, 1477 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 494 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 33 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 16 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 29 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 32 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 20 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 11 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 13 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 79 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 33 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 18 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 82 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 41 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 30 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 18 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 15 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 16 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 21 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 17 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 13 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| 20 | 15 | [Download](20/dataset.zip) |  |  |  |  |  |  |  |  |
| 21 | 16 | [Download](21/dataset.zip) |  |  |  |  |  |  |  |  |
| 22 | 9 | [Download](22/dataset.zip) |  |  |  |  |  |  |  |  |
| 23 | 28 | [Download](23/dataset.zip) |  |  |  |  |  |  |  |  |
| 24 | 11 | [Download](24/dataset.zip) |  |  |  |  |  |  |  |  |
| 25 | 8 | [Download](25/dataset.zip) |  |  |  |  |  |  |  |  |
| 26 | 6 | [Download](26/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| 27 | 6 | [Download](27/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| 28 | 11 | [Download](28/dataset.zip) |  |  |  |  |  |  |  |  |
| 29 | 17 | [Download](29/dataset.zip) |  |  |  |  |  |  |  |  |
| 30 | 29 | [Download](30/dataset.zip) |  |  |  |  |  |  |  |  |
| 31 | 15 | [Download](31/dataset.zip) |  |  |  |  |  |  |  |  |
| 32 | 67 | [Download](32/dataset.zip) |  |  |  |  |  |  |  |  |
| 33 | 10 | [Download](33/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 198 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/majonotabitabi
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-30T02:58:42+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-30T04:00:42+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Majo No Tabitabi
======================================
This is the image base of bangumi Majo no Tabitabi, we detected 35 characters, 1477 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
ab95e897b11d83d09332385f6bac8870166a02d0
|
booksum数据集,谷歌翻译成中文。
任务:将一本书的某个章节总结为几句话。
源数据来自 togethercomputer/Long-Data-Collections
|
yuyijiong/booksum-zh
|
[
"task_categories:summarization",
"task_categories:text-generation",
"language:zh",
"license:unknown",
"region:us"
] |
2023-09-30T04:15:38+00:00
|
{"language": ["zh"], "license": "unknown", "task_categories": ["summarization", "text-generation"]}
|
2023-09-30T04:19:30+00:00
|
[] |
[
"zh"
] |
TAGS
#task_categories-summarization #task_categories-text-generation #language-Chinese #license-unknown #region-us
|
booksum数据集,谷歌翻译成中文。
任务:将一本书的某个章节总结为几句话。
源数据来自 togethercomputer/Long-Data-Collections
|
[] |
[
"TAGS\n#task_categories-summarization #task_categories-text-generation #language-Chinese #license-unknown #region-us \n"
] |
[
39
] |
[
"passage: TAGS\n#task_categories-summarization #task_categories-text-generation #language-Chinese #license-unknown #region-us \n"
] |
dfdf48cb5a4813747832d88d779da948f11942f8
|
# Dataset Card for "60k_dataset_multichoice_384"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
VuongQuoc/60k_dataset_multichoice_384
|
[
"region:us"
] |
2023-09-30T04:17:24+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": {"sequence": "int32"}}, {"name": "token_type_ids", "sequence": {"sequence": "int8"}}, {"name": "attention_mask", "sequence": {"sequence": "int8"}}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 695952828, "num_examples": 60000}, {"name": "test", "num_bytes": 2320000, "num_examples": 200}], "download_size": 71338055, "dataset_size": 698272828}}
|
2023-09-30T04:17:36+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "60k_dataset_multichoice_384"
More Information needed
|
[
"# Dataset Card for \"60k_dataset_multichoice_384\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"60k_dataset_multichoice_384\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"60k_dataset_multichoice_384\"\n\nMore Information needed"
] |
5d26e8bd8dae458d3d9ccefec6bace54f1a14b8f
|
多文档qa数据集,谷歌翻译成中文,用于微调长度更大的模型。\
任务:给定多个参考文档和一个问题,只有一个文档包含有用信息,模型需要根据参考文档回答问题,并指出哪个文档包含有用信息。\
对于每个question,会提供几十或上百个文档片段,只有一个文档包含有用信息,gold_document_id表示含有有用信息的文档序号,注意文档是从1开始编号。\
源数据来自 togethercomputer/Long-Data-Collections\
|
yuyijiong/multi-doc-qa-zh
|
[
"task_categories:text-generation",
"task_categories:question-answering",
"language:zh",
"license:unknown",
"region:us"
] |
2023-09-30T04:20:03+00:00
|
{"language": ["zh"], "license": "unknown", "task_categories": ["text-generation", "question-answering"]}
|
2023-10-11T04:35:16+00:00
|
[] |
[
"zh"
] |
TAGS
#task_categories-text-generation #task_categories-question-answering #language-Chinese #license-unknown #region-us
|
多文档qa数据集,谷歌翻译成中文,用于微调长度更大的模型。\
任务:给定多个参考文档和一个问题,只有一个文档包含有用信息,模型需要根据参考文档回答问题,并指出哪个文档包含有用信息。\
对于每个question,会提供几十或上百个文档片段,只有一个文档包含有用信息,gold_document_id表示含有有用信息的文档序号,注意文档是从1开始编号。\
源数据来自 togethercomputer/Long-Data-Collections\
|
[] |
[
"TAGS\n#task_categories-text-generation #task_categories-question-answering #language-Chinese #license-unknown #region-us \n"
] |
[
41
] |
[
"passage: TAGS\n#task_categories-text-generation #task_categories-question-answering #language-Chinese #license-unknown #region-us \n"
] |
a462e19ac67f1f48b675adcfaf704ff76e4fee96
|
# Dataset Card for "patacon-730.rar"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
frncscp/patacon-730.rar
|
[
"region:us"
] |
2023-09-30T04:55:50+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "Patacon-False", "1": "Patacon-True"}}}}, {"name": "index", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 798131556.0, "num_examples": 874}, {"name": "validation", "num_bytes": 131098374.0, "num_examples": 143}, {"name": "test", "num_bytes": 403631748.0, "num_examples": 442}], "download_size": 929557514, "dataset_size": 1332861678.0}}
|
2023-09-30T04:56:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "URL"
More Information needed
|
[
"# Dataset Card for \"URL\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"URL\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"URL\"\n\nMore Information needed"
] |
44598a09b2e5dad1ac90455eef9ac5fa9150480b
|
# Dataset Card for "patacon-730-redux"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
frncscp/patacon-730-redux
|
[
"region:us"
] |
2023-09-30T05:03:31+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "Patacon-False", "1": "Patacon-True"}}}}, {"name": "pca", "sequence": {"sequence": "float64"}}, {"name": "index", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2109516792.0, "num_examples": 874}, {"name": "validation", "num_bytes": 345897375.0, "num_examples": 143}, {"name": "test", "num_bytes": 1068105458.0, "num_examples": 442}], "download_size": 2084100119, "dataset_size": 3523519625.0}}
|
2023-09-30T05:04:43+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "patacon-730-redux"
More Information needed
|
[
"# Dataset Card for \"patacon-730-redux\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"patacon-730-redux\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"patacon-730-redux\"\n\nMore Information needed"
] |
0063b704013f081c12d03ef7564a1d42e78ba845
|
# Dataset Card for "patacon-730-redux3d"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
frncscp/patacon-730-redux3d
|
[
"region:us"
] |
2023-09-30T05:20:16+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "Patacon-False", "1": "Patacon-True"}}}}, {"name": "pca", "sequence": {"sequence": "float64"}}, {"name": "index", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2907513752.0, "num_examples": 874}, {"name": "validation", "num_bytes": 476973727.0, "num_examples": 143}, {"name": "test", "num_bytes": 1471669138.0, "num_examples": 442}], "download_size": 3108353305, "dataset_size": 4856156617.0}}
|
2023-09-30T05:22:17+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "patacon-730-redux3d"
More Information needed
|
[
"# Dataset Card for \"patacon-730-redux3d\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"patacon-730-redux3d\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"patacon-730-redux3d\"\n\nMore Information needed"
] |
1fa17b6f31e4e3952857687cb963bd5b3025d638
|
# Dataset Card for "pokemon_caption_data_CLIP"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
SminC/pokemon_caption_data_CLIP
|
[
"region:us"
] |
2023-09-30T05:26:41+00:00
|
{"dataset_info": {"features": [{"name": "original_image", "dtype": "image"}, {"name": "edit_prompt", "dtype": "string"}, {"name": "colored_image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 69617745.0, "num_examples": 829}], "download_size": 69422090, "dataset_size": 69617745.0}}
|
2023-09-30T05:27:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pokemon_caption_data_CLIP"
More Information needed
|
[
"# Dataset Card for \"pokemon_caption_data_CLIP\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pokemon_caption_data_CLIP\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pokemon_caption_data_CLIP\"\n\nMore Information needed"
] |
81742a15f740086655287e115e2179f9d1f6ed81
|
# programming-languages [TXT dataset]
A dataset consisting of a compilation of programming languages obtained from diverse and multiple sources.
## Data Source
* [List of programming languages](https://en.wikipedia.org/wiki/List_of_programming_languages)
* [List of programming languages by type](https://en.wikipedia.org/wiki/List_of_programming_languages_by_type)
* [Programming Languages - Rosetta Code](https://www.rosettacode.org/wiki/Category:Programming_Languages)
* [Full List Of Computer Languages - AntiFandom Wiki](https://antifandom.com/computerscience/wiki/Full_List_Of_Computer_Languages)
* [List of Markup Languages - AntiFandom Wiki](https://antifandom.com/computerscience/wiki/List_Of_Markup_Languages)
* [Awesome low-level programming languages](https://github.com/robertmuth/awesome-low-level-programming-languages)
* [Awesome programming languages](https://github.com/ChessMax/awesome-programming-languages)
* [List of All the 700+ Programming Languages in the World - Compile Blog](https://compile.blog/programming-languages-list/)
## TODO
Add JSON dataset which will contain the following fields:
```json
[
{
"name": "...",
"description": "...",
"type": "...",
"paradigm": "...",
"license": "...",
}
]
```
## Disclaimer
Please note that while I strive to maintain data quality, I cannot guarantee the accuracy or quality of all entries in this dataset. Use it responsibly and exercise caution when relying on the data for any critical applications. Your feedback and contributions are greatly appreciated for improving the dataset's overall quality.
|
Tanvir1337/programming-languages
|
[
"size_categories:n<1K",
"language:en",
"license:cc-by-4.0",
"List",
"Name",
"region:us"
] |
2023-09-30T05:49:52+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["n<1K"], "pretty_name": "Programming Languages", "tags": ["List", "Name"]}
|
2023-09-30T07:15:18+00:00
|
[] |
[
"en"
] |
TAGS
#size_categories-n<1K #language-English #license-cc-by-4.0 #List #Name #region-us
|
# programming-languages [TXT dataset]
A dataset consisting of a compilation of programming languages obtained from diverse and multiple sources.
## Data Source
* List of programming languages
* List of programming languages by type
* Programming Languages - Rosetta Code
* Full List Of Computer Languages - AntiFandom Wiki
* List of Markup Languages - AntiFandom Wiki
* Awesome low-level programming languages
* Awesome programming languages
* List of All the 700+ Programming Languages in the World - Compile Blog
## TODO
Add JSON dataset which will contain the following fields:
## Disclaimer
Please note that while I strive to maintain data quality, I cannot guarantee the accuracy or quality of all entries in this dataset. Use it responsibly and exercise caution when relying on the data for any critical applications. Your feedback and contributions are greatly appreciated for improving the dataset's overall quality.
|
[
"# programming-languages [TXT dataset]\n\nA dataset consisting of a compilation of programming languages obtained from diverse and multiple sources.",
"## Data Source\n\n* List of programming languages\n* List of programming languages by type\n* Programming Languages - Rosetta Code\n* Full List Of Computer Languages - AntiFandom Wiki\n* List of Markup Languages - AntiFandom Wiki\n* Awesome low-level programming languages\n* Awesome programming languages\n* List of All the 700+ Programming Languages in the World - Compile Blog",
"## TODO\n\nAdd JSON dataset which will contain the following fields:",
"## Disclaimer\n\nPlease note that while I strive to maintain data quality, I cannot guarantee the accuracy or quality of all entries in this dataset. Use it responsibly and exercise caution when relying on the data for any critical applications. Your feedback and contributions are greatly appreciated for improving the dataset's overall quality."
] |
[
"TAGS\n#size_categories-n<1K #language-English #license-cc-by-4.0 #List #Name #region-us \n",
"# programming-languages [TXT dataset]\n\nA dataset consisting of a compilation of programming languages obtained from diverse and multiple sources.",
"## Data Source\n\n* List of programming languages\n* List of programming languages by type\n* Programming Languages - Rosetta Code\n* Full List Of Computer Languages - AntiFandom Wiki\n* List of Markup Languages - AntiFandom Wiki\n* Awesome low-level programming languages\n* Awesome programming languages\n* List of All the 700+ Programming Languages in the World - Compile Blog",
"## TODO\n\nAdd JSON dataset which will contain the following fields:",
"## Disclaimer\n\nPlease note that while I strive to maintain data quality, I cannot guarantee the accuracy or quality of all entries in this dataset. Use it responsibly and exercise caution when relying on the data for any critical applications. Your feedback and contributions are greatly appreciated for improving the dataset's overall quality."
] |
[
33,
34,
85,
16,
73
] |
[
"passage: TAGS\n#size_categories-n<1K #language-English #license-cc-by-4.0 #List #Name #region-us \n# programming-languages [TXT dataset]\n\nA dataset consisting of a compilation of programming languages obtained from diverse and multiple sources.## Data Source\n\n* List of programming languages\n* List of programming languages by type\n* Programming Languages - Rosetta Code\n* Full List Of Computer Languages - AntiFandom Wiki\n* List of Markup Languages - AntiFandom Wiki\n* Awesome low-level programming languages\n* Awesome programming languages\n* List of All the 700+ Programming Languages in the World - Compile Blog## TODO\n\nAdd JSON dataset which will contain the following fields:## Disclaimer\n\nPlease note that while I strive to maintain data quality, I cannot guarantee the accuracy or quality of all entries in this dataset. Use it responsibly and exercise caution when relying on the data for any critical applications. Your feedback and contributions are greatly appreciated for improving the dataset's overall quality."
] |
dd0d33ac46324983bf5ac824ba297a1e7023f9ec
|
# Dataset Card for "l27b-E02-b05-0584-3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yashnbx/l27b-E02-b05-0584-3
|
[
"region:us"
] |
2023-09-30T06:41:17+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "conversations", "list": [{"name": "from", "dtype": "string"}, {"name": "value", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 4032267, "num_examples": 584}], "download_size": 662022, "dataset_size": 4032267}}
|
2023-09-30T09:22:11+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "l27b-E02-b05-0584-3"
More Information needed
|
[
"# Dataset Card for \"l27b-E02-b05-0584-3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"l27b-E02-b05-0584-3\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"l27b-E02-b05-0584-3\"\n\nMore Information needed"
] |
4fbfcf382fba1b1dbeb4d710a670351fb42ebbc9
|
# Dataset Card for "mcqa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
amphora/mcqa
|
[
"region:us"
] |
2023-09-30T06:57:08+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 5458608, "num_examples": 8620}], "download_size": 2682433, "dataset_size": 5458608}}
|
2023-09-30T06:57:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "mcqa"
More Information needed
|
[
"# Dataset Card for \"mcqa\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"mcqa\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"mcqa\"\n\nMore Information needed"
] |
45e1b194a163b8567f8b3c71e5ed7b4a63f49fb7
|
# Bangumi Image Base of Adachi To Shimamura
This is the image base of bangumi Adachi to Shimamura, we detected 20 characters, 2012 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 630 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 86 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 15 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 63 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 20 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 145 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 560 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 16 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 40 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 12 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 93 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 11 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 11 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 22 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 13 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 46 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 14 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 79 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 13 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 123 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/adachitoshimamura
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-30T07:01:51+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-30T09:32:24+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Adachi To Shimamura
=========================================
This is the image base of bangumi Adachi to Shimamura, we detected 20 characters, 2012 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
2abda53638ef96c0ff1fe9aa67a9332cae6bd957
|
# Bangumi Image Base of Sakura Trick
This is the image base of bangumi Sakura Trick, we detected 17 characters, 1556 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 322 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 16 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 103 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 167 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 22 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 153 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 94 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 11 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 27 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 243 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 45 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 139 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 13 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 11 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 51 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 8 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 131 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/sakuratrick
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-30T07:07:07+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-30T08:02:27+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Sakura Trick
==================================
This is the image base of bangumi Sakura Trick, we detected 17 characters, 1556 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
be6fbbf34c1421a35bc7dc6157cc3ffdf975a7f2
|
# Dataset Card for "wiki_medical_terms_llama2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mychen76/wiki_medical_terms_llama2
|
[
"region:us"
] |
2023-09-30T08:16:15+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 42966707.83151144, "num_examples": 5488}, {"name": "test", "num_bytes": 10749506.168488558, "num_examples": 1373}, {"name": "validation", "num_bytes": 2153032.917941991, "num_examples": 275}], "download_size": 29713610, "dataset_size": 55869246.91794199}}
|
2023-09-30T08:16:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "wiki_medical_terms_llama2"
More Information needed
|
[
"# Dataset Card for \"wiki_medical_terms_llama2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"wiki_medical_terms_llama2\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"wiki_medical_terms_llama2\"\n\nMore Information needed"
] |
8f5fe6b241b9b8e34e5fb816ac03ca2ca195cea9
|
"The First Real Estate Pre-Sale System in Tehran"
The "First Real Estate Pre-Sale System in Tehran" represents a significant innovation in the real estate industry, offering remarkable benefits to individuals and prospective property buyers in Tehran. This system acts as a bridge between sellers and buyers, providing easy access to properties of interest.
This system alleviates common concerns and challenges associated with the property-buying process, such as finding accurate and up-to-date information, estimating fair prices, and negotiating deals. Some key features of this system include:
1. **Precise Search**: The ability to search for properties based on criteria such as location, property type, price, size, and other specifications, allowing you to quickly find your desired property.
2. **Comprehensive Property Information**: Detailed and comprehensive property information, including photos, technical specifications, descriptions, and property maps, is provided.
3. **Negotiations and Consultations**: The system enables direct communication with sellers to negotiate prices and deal terms. Additionally, real estate consultants are available to help you make informed decisions about property purchases.
4. **Property Pre-Sale**: You have the opportunity to consider properties that have not yet been released to the market and benefit from fair prices during the pre-sale phase.
5. **Comparison of Options**: You can compare various options and make the best choice for your needs.
6. **Customer-Centric Services**: The system offers post-sale services, legal consultation, and credit facilities.
7. https://www.tehran-borj.ir
The "First Real Estate Pre-Sale System in Tehran" allows you to navigate the property market with ease and confidence, making it one of the prominent examples of innovation in the real estate industry.
|
rezanayebi/Data0
|
[
"license:apache-2.0",
"region:us"
] |
2023-09-30T09:04:34+00:00
|
{"license": "apache-2.0"}
|
2023-09-30T09:06:08+00:00
|
[] |
[] |
TAGS
#license-apache-2.0 #region-us
|
"The First Real Estate Pre-Sale System in Tehran"
The "First Real Estate Pre-Sale System in Tehran" represents a significant innovation in the real estate industry, offering remarkable benefits to individuals and prospective property buyers in Tehran. This system acts as a bridge between sellers and buyers, providing easy access to properties of interest.
This system alleviates common concerns and challenges associated with the property-buying process, such as finding accurate and up-to-date information, estimating fair prices, and negotiating deals. Some key features of this system include:
1. Precise Search: The ability to search for properties based on criteria such as location, property type, price, size, and other specifications, allowing you to quickly find your desired property.
2. Comprehensive Property Information: Detailed and comprehensive property information, including photos, technical specifications, descriptions, and property maps, is provided.
3. Negotiations and Consultations: The system enables direct communication with sellers to negotiate prices and deal terms. Additionally, real estate consultants are available to help you make informed decisions about property purchases.
4. Property Pre-Sale: You have the opportunity to consider properties that have not yet been released to the market and benefit from fair prices during the pre-sale phase.
5. Comparison of Options: You can compare various options and make the best choice for your needs.
6. Customer-Centric Services: The system offers post-sale services, legal consultation, and credit facilities.
7. URL
The "First Real Estate Pre-Sale System in Tehran" allows you to navigate the property market with ease and confidence, making it one of the prominent examples of innovation in the real estate industry.
|
[] |
[
"TAGS\n#license-apache-2.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-apache-2.0 #region-us \n"
] |
e24ac691f18d09a3f477643d6650e865274a3a2a
|
# Dataset Card for "research_llm"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
adhok/research_llm
|
[
"region:us"
] |
2023-09-30T09:09:21+00:00
|
{"dataset_info": {"features": [{"name": "Unnamed: 0", "dtype": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 461494, "num_examples": 771}], "download_size": 100066, "dataset_size": 461494}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-30T09:10:53+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "research_llm"
More Information needed
|
[
"# Dataset Card for \"research_llm\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"research_llm\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"research_llm\"\n\nMore Information needed"
] |
89eebcf7eb750cc8cb838abdca0713033dd7df55
|
## Google/MusicCapsの音楽をスペクトログラムにしたもの
* Google/MusicCapsのスペクトログラム。カラーバージョンも作っておく.
### 基本情報
* sampling_rate: int = 44100
## 参考資料とメモ
* (memo)ぶっちゃけグレースケールもカラーバージョンをtorchvision.transformのグレースケール変換すればいいだけかも?
* ダウンロードに使ったコードは<a href="https://colab.research.google.com/drive/1HmDorbxD5g6C2WDjLierUqbhecTdRvgA?usp=sharing">こちら</a>
* 参考:https://www.kaggle.com/code/osanseviero/musiccaps-explorer
* 仕組み:Kaggleの参考コードでwavファイルをダウンロードする->スペクトログラムつくりながらmetadata.jsonlに
```
{"filename":"spectrogram_*.png", "caption":"This is beautiful music"}
```
をなどと言ったjson列を書き込み、これをアップロードした
* Huggingfaceのデータビューアが動かなくなったら、一度GoogleColabでそのデータセットをダウンロードしてみることもおすすめ
* 意外とHuggingfaceがバグっているだけかも(実話(´;ω;`))
|
mickylan2367/ColorSpectrogram
|
[
"language:en",
"music",
"art",
"region:us"
] |
2023-09-30T09:42:55+00:00
|
{"language": ["en"], "tags": ["music", "art"]}
|
2023-09-30T11:33:24+00:00
|
[] |
[
"en"
] |
TAGS
#language-English #music #art #region-us
|
## Google/MusicCapsの音楽をスペクトログラムにしたもの
* Google/MusicCapsのスペクトログラム。カラーバージョンも作っておく.
### 基本情報
* sampling_rate: int = 44100
## 参考資料とメモ
* (memo)ぶっちゃけグレースケールもカラーバージョンをtorchvision.transformのグレースケール変換すればいいだけかも?
* ダウンロードに使ったコードは<a href="URL>こちら</a>
* 参考:URL
* 仕組み:Kaggleの参考コードでwavファイルをダウンロードする->スペクトログラムつくりながらmetadata.jsonlに
をなどと言ったjson列を書き込み、これをアップロードした
* Huggingfaceのデータビューアが動かなくなったら、一度GoogleColabでそのデータセットをダウンロードしてみることもおすすめ
* 意外とHuggingfaceがバグっているだけかも(実話(´;ω;`))
|
[
"## Google/MusicCapsの音楽をスペクトログラムにしたもの\n* Google/MusicCapsのスペクトログラム。カラーバージョンも作っておく.",
"### 基本情報\n* sampling_rate: int = 44100",
"## 参考資料とメモ\n* (memo)ぶっちゃけグレースケールもカラーバージョンをtorchvision.transformのグレースケール変換すればいいだけかも?\n* ダウンロードに使ったコードは<a href=\"URL>こちら</a>\n * 参考:URL\n * 仕組み:Kaggleの参考コードでwavファイルをダウンロードする->スペクトログラムつくりながらmetadata.jsonlに\n \n をなどと言ったjson列を書き込み、これをアップロードした\n* Huggingfaceのデータビューアが動かなくなったら、一度GoogleColabでそのデータセットをダウンロードしてみることもおすすめ\n* 意外とHuggingfaceがバグっているだけかも(実話(´;ω;`))"
] |
[
"TAGS\n#language-English #music #art #region-us \n",
"## Google/MusicCapsの音楽をスペクトログラムにしたもの\n* Google/MusicCapsのスペクトログラム。カラーバージョンも作っておく.",
"### 基本情報\n* sampling_rate: int = 44100",
"## 参考資料とメモ\n* (memo)ぶっちゃけグレースケールもカラーバージョンをtorchvision.transformのグレースケール変換すればいいだけかも?\n* ダウンロードに使ったコードは<a href=\"URL>こちら</a>\n * 参考:URL\n * 仕組み:Kaggleの参考コードでwavファイルをダウンロードする->スペクトログラムつくりながらmetadata.jsonlに\n \n をなどと言ったjson列を書き込み、これをアップロードした\n* Huggingfaceのデータビューアが動かなくなったら、一度GoogleColabでそのデータセットをダウンロードしてみることもおすすめ\n* 意外とHuggingfaceがバグっているだけかも(実話(´;ω;`))"
] |
[
14,
38,
17,
160
] |
[
"passage: TAGS\n#language-English #music #art #region-us \n## Google/MusicCapsの音楽をスペクトログラムにしたもの\n* Google/MusicCapsのスペクトログラム。カラーバージョンも作っておく.### 基本情報\n* sampling_rate: int = 44100## 参考資料とメモ\n* (memo)ぶっちゃけグレースケールもカラーバージョンをtorchvision.transformのグレースケール変換すればいいだけかも?\n* ダウンロードに使ったコードは<a href=\"URL>こちら</a>\n * 参考:URL\n * 仕組み:Kaggleの参考コードでwavファイルをダウンロードする->スペクトログラムつくりながらmetadata.jsonlに\n \n をなどと言ったjson列を書き込み、これをアップロードした\n* Huggingfaceのデータビューアが動かなくなったら、一度GoogleColabでそのデータセットをダウンロードしてみることもおすすめ\n* 意外とHuggingfaceがバグっているだけかも(実話(´;ω;`))"
] |
15df31e441abbad3a136ec8a8c057410298ee761
|
# Dataset Summary
Inflation is a critical economic indicator that reflects the overall increase in prices of goods and services within an economy over a specific period. Understanding inflation trends on a global scale is crucial for economists, policymakers, investors, and businesses. This dataset provides comprehensive insights into the inflation rates of various countries for the year 2022. The data is sourced from reputable international organizations and government reports, making it a valuable resource for economic analysis and research.
This dataset includes four essential columns:
1. Countries: The names of countries for which inflation data is recorded. Each row represents a specific country.
1. Inflation, 2022: The inflation rate for each country in the year 2022. Inflation rates are typically expressed as a percentage and indicate the average increase in prices for that year.
1. Global Rank: The rank of each country based on its inflation rate in 2022. Countries with the highest inflation rates will have a lower rank, while those with lower inflation rates will have a higher rank.
1. Available Data: A binary indicator (Yes/No) denoting whether complete and reliable data for inflation in 2022 is available for a particular country. This column helps users identify the data quality and coverage.
## Potential Use Cases
**Economic Analysis:** Researchers and economists can use this dataset to analyze inflation trends globally, identify countries with high or low inflation rates, and make comparisons across regions.
**Investment Decisions:** Investors and financial analysts can incorporate inflation data into their risk assessments and investment strategies.
**Business Planning:** Companies operating in multiple countries can assess the impact of inflation on their costs and pricing strategies, helping them make informed decisions.
## Data Accuracy:
Efforts have been made to ensure the accuracy and reliability of the data; however, users are encouraged to cross-reference this dataset with official sources for critical decision-making processes.
## Updates:
This dataset will be periodically updated to include the latest available inflation data, making it an ongoing resource for tracking global inflation trends.
|
aswin1906/countries-inflation
|
[
"task_categories:tabular-regression",
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-09-30T09:54:30+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["n<1K"], "task_categories": ["tabular-regression", "text-classification", "text-generation"], "pretty_name": "Countries by Inflation rate of 2022"}
|
2023-09-30T10:05:59+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-tabular-regression #task_categories-text-classification #task_categories-text-generation #size_categories-n<1K #language-English #license-apache-2.0 #region-us
|
# Dataset Summary
Inflation is a critical economic indicator that reflects the overall increase in prices of goods and services within an economy over a specific period. Understanding inflation trends on a global scale is crucial for economists, policymakers, investors, and businesses. This dataset provides comprehensive insights into the inflation rates of various countries for the year 2022. The data is sourced from reputable international organizations and government reports, making it a valuable resource for economic analysis and research.
This dataset includes four essential columns:
1. Countries: The names of countries for which inflation data is recorded. Each row represents a specific country.
1. Inflation, 2022: The inflation rate for each country in the year 2022. Inflation rates are typically expressed as a percentage and indicate the average increase in prices for that year.
1. Global Rank: The rank of each country based on its inflation rate in 2022. Countries with the highest inflation rates will have a lower rank, while those with lower inflation rates will have a higher rank.
1. Available Data: A binary indicator (Yes/No) denoting whether complete and reliable data for inflation in 2022 is available for a particular country. This column helps users identify the data quality and coverage.
## Potential Use Cases
Economic Analysis: Researchers and economists can use this dataset to analyze inflation trends globally, identify countries with high or low inflation rates, and make comparisons across regions.
Investment Decisions: Investors and financial analysts can incorporate inflation data into their risk assessments and investment strategies.
Business Planning: Companies operating in multiple countries can assess the impact of inflation on their costs and pricing strategies, helping them make informed decisions.
## Data Accuracy:
Efforts have been made to ensure the accuracy and reliability of the data; however, users are encouraged to cross-reference this dataset with official sources for critical decision-making processes.
## Updates:
This dataset will be periodically updated to include the latest available inflation data, making it an ongoing resource for tracking global inflation trends.
|
[
"# Dataset Summary\nInflation is a critical economic indicator that reflects the overall increase in prices of goods and services within an economy over a specific period. Understanding inflation trends on a global scale is crucial for economists, policymakers, investors, and businesses. This dataset provides comprehensive insights into the inflation rates of various countries for the year 2022. The data is sourced from reputable international organizations and government reports, making it a valuable resource for economic analysis and research.\n\nThis dataset includes four essential columns:\n1. Countries: The names of countries for which inflation data is recorded. Each row represents a specific country.\n1. Inflation, 2022: The inflation rate for each country in the year 2022. Inflation rates are typically expressed as a percentage and indicate the average increase in prices for that year.\n1. Global Rank: The rank of each country based on its inflation rate in 2022. Countries with the highest inflation rates will have a lower rank, while those with lower inflation rates will have a higher rank.\n1. Available Data: A binary indicator (Yes/No) denoting whether complete and reliable data for inflation in 2022 is available for a particular country. This column helps users identify the data quality and coverage.",
"## Potential Use Cases\n\nEconomic Analysis: Researchers and economists can use this dataset to analyze inflation trends globally, identify countries with high or low inflation rates, and make comparisons across regions.\nInvestment Decisions: Investors and financial analysts can incorporate inflation data into their risk assessments and investment strategies.\nBusiness Planning: Companies operating in multiple countries can assess the impact of inflation on their costs and pricing strategies, helping them make informed decisions.",
"## Data Accuracy:\nEfforts have been made to ensure the accuracy and reliability of the data; however, users are encouraged to cross-reference this dataset with official sources for critical decision-making processes.",
"## Updates:\nThis dataset will be periodically updated to include the latest available inflation data, making it an ongoing resource for tracking global inflation trends."
] |
[
"TAGS\n#task_categories-tabular-regression #task_categories-text-classification #task_categories-text-generation #size_categories-n<1K #language-English #license-apache-2.0 #region-us \n",
"# Dataset Summary\nInflation is a critical economic indicator that reflects the overall increase in prices of goods and services within an economy over a specific period. Understanding inflation trends on a global scale is crucial for economists, policymakers, investors, and businesses. This dataset provides comprehensive insights into the inflation rates of various countries for the year 2022. The data is sourced from reputable international organizations and government reports, making it a valuable resource for economic analysis and research.\n\nThis dataset includes four essential columns:\n1. Countries: The names of countries for which inflation data is recorded. Each row represents a specific country.\n1. Inflation, 2022: The inflation rate for each country in the year 2022. Inflation rates are typically expressed as a percentage and indicate the average increase in prices for that year.\n1. Global Rank: The rank of each country based on its inflation rate in 2022. Countries with the highest inflation rates will have a lower rank, while those with lower inflation rates will have a higher rank.\n1. Available Data: A binary indicator (Yes/No) denoting whether complete and reliable data for inflation in 2022 is available for a particular country. This column helps users identify the data quality and coverage.",
"## Potential Use Cases\n\nEconomic Analysis: Researchers and economists can use this dataset to analyze inflation trends globally, identify countries with high or low inflation rates, and make comparisons across regions.\nInvestment Decisions: Investors and financial analysts can incorporate inflation data into their risk assessments and investment strategies.\nBusiness Planning: Companies operating in multiple countries can assess the impact of inflation on their costs and pricing strategies, helping them make informed decisions.",
"## Data Accuracy:\nEfforts have been made to ensure the accuracy and reliability of the data; however, users are encouraged to cross-reference this dataset with official sources for critical decision-making processes.",
"## Updates:\nThis dataset will be periodically updated to include the latest available inflation data, making it an ongoing resource for tracking global inflation trends."
] |
[
62,
273,
109,
49,
35
] |
[
"passage: TAGS\n#task_categories-tabular-regression #task_categories-text-classification #task_categories-text-generation #size_categories-n<1K #language-English #license-apache-2.0 #region-us \n# Dataset Summary\nInflation is a critical economic indicator that reflects the overall increase in prices of goods and services within an economy over a specific period. Understanding inflation trends on a global scale is crucial for economists, policymakers, investors, and businesses. This dataset provides comprehensive insights into the inflation rates of various countries for the year 2022. The data is sourced from reputable international organizations and government reports, making it a valuable resource for economic analysis and research.\n\nThis dataset includes four essential columns:\n1. Countries: The names of countries for which inflation data is recorded. Each row represents a specific country.\n1. Inflation, 2022: The inflation rate for each country in the year 2022. Inflation rates are typically expressed as a percentage and indicate the average increase in prices for that year.\n1. Global Rank: The rank of each country based on its inflation rate in 2022. Countries with the highest inflation rates will have a lower rank, while those with lower inflation rates will have a higher rank.\n1. Available Data: A binary indicator (Yes/No) denoting whether complete and reliable data for inflation in 2022 is available for a particular country. This column helps users identify the data quality and coverage.## Potential Use Cases\n\nEconomic Analysis: Researchers and economists can use this dataset to analyze inflation trends globally, identify countries with high or low inflation rates, and make comparisons across regions.\nInvestment Decisions: Investors and financial analysts can incorporate inflation data into their risk assessments and investment strategies.\nBusiness Planning: Companies operating in multiple countries can assess the impact of inflation on their costs and pricing strategies, helping them make informed decisions.## Data Accuracy:\nEfforts have been made to ensure the accuracy and reliability of the data; however, users are encouraged to cross-reference this dataset with official sources for critical decision-making processes."
] |
235004dc1e5bf6a0fed4680939614aaadc86160d
|
# Dataset Card for "ShareGPT-Vicuna-v3-cleaned-unfiltered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AtAndDev/ShareGPT-Vicuna-v3-cleaned-unfiltered
|
[
"region:us"
] |
2023-09-30T10:10:54+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1211675, "num_examples": 145}], "download_size": 0, "dataset_size": 1211675}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-30T11:03:18+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "ShareGPT-Vicuna-v3-cleaned-unfiltered"
More Information needed
|
[
"# Dataset Card for \"ShareGPT-Vicuna-v3-cleaned-unfiltered\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"ShareGPT-Vicuna-v3-cleaned-unfiltered\"\n\nMore Information needed"
] |
[
6,
27
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"ShareGPT-Vicuna-v3-cleaned-unfiltered\"\n\nMore Information needed"
] |
10a5277645d3b1883d44e54f5e30e23916e6938b
|
# Dataset Card for "HSE_project_VK_NLP"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
marcus2000/HSE_project_VK_NLP
|
[
"region:us"
] |
2023-09-30T10:12:20+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "sentiment", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 425667.1102204409, "num_examples": 848}, {"name": "test", "num_bytes": 75294.88977955912, "num_examples": 150}], "download_size": 274658, "dataset_size": 500962.0}}
|
2023-09-30T10:12:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "HSE_project_VK_NLP"
More Information needed
|
[
"# Dataset Card for \"HSE_project_VK_NLP\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"HSE_project_VK_NLP\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"HSE_project_VK_NLP\"\n\nMore Information needed"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.