
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
024c3202dd522d1fec98d154895ad8cbaedb74fb | # Dataset Card for the High-Level Dataset
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
The High-Level (HL) dataset aligns **object-centric descriptions** from [COCO](https://arxiv.org/pdf/1405.0312.pdf)
with **high-level descriptions** crowdsourced along 3 axes: **_scene_, _action_, _rationale_**
The HL dataset contains 14997 images from COCO and a total of 134973 crowdsourced captions (3 captions for each axis) aligned with ~749984 object-centric captions from COCO.
Each axis is collected by asking the following 3 questions:
1) Where is the picture taken?
2) What is the subject doing?
3) Why is the subject doing it?
**The high-level descriptions capture the human interpretations of the images**. These interpretations contain abstract concepts not directly linked to physical objects.
Each high-level description is provided with a _confidence score_, crowdsourced by an independent worker measuring the extent to which
the high-level description is likely given the corresponding image, question, and caption. The higher the score, the more the high-level caption is close to the commonsense (in a Likert scale from 1-5).
- **🗃️ Repository:** [github.com/michelecafagna26/HL-dataset](https://github.com/michelecafagna26/HL-dataset)
- **📜 Paper:** [HL Dataset: Visually-grounded Description of Scenes, Actions and Rationales](https://arxiv.org/abs/2302.12189?context=cs.CL)
- **🧭 Spaces:** [Dataset explorer](https://huggingface.co/spaces/michelecafagna26/High-Level-Dataset-explorer)
- **🖊️ Contact:** [email protected]
### Supported Tasks
- image captioning
- visual question answering
- multimodal text-scoring
- zero-shot evaluation
### Languages
English
## Dataset Structure
The dataset is provided with images from COCO and two metadata jsonl files containing the annotations
### Data Instances
An instance looks like this:
```json
{
"file_name": "COCO_train2014_000000138878.jpg",
"captions": {
"scene": [
"in a car",
"the picture is taken in a car",
"in an office."
],
"action": [
"posing for a photo",
"the person is posing for a photo",
"he's sitting in an armchair."
],
"rationale": [
"to have a picture of himself",
"he wants to share it with his friends",
"he's working and took a professional photo."
],
"object": [
"A man sitting in a car while wearing a shirt and tie.",
"A man in a car wearing a dress shirt and tie.",
"a man in glasses is wearing a tie",
"Man sitting in the car seat with button up and tie",
"A man in glasses and a tie is near a window."
]
},
"confidence": {
"scene": [
5,
5,
4
],
"action": [
5,
5,
4
],
"rationale": [
5,
5,
4
]
},
"purity": {
"scene": [
-1.1760284900665283,
-1.0889461040496826,
-1.442818284034729
],
"action": [
-1.0115827322006226,
-0.5917857885360718,
-1.6931917667388916
],
"rationale": [
-1.0546956062316895,
-0.9740906357765198,
-1.2204363346099854
]
},
"diversity": {
"scene": 25.965358893403383,
"action": 32.713305568898775,
"rationale": 2.658757840479801
}
}
```
### Data Fields
- ```file_name```: original COCO filename
- ```captions```: Dict containing all the captions for the image. Each axis can be accessed with the axis name and it contains a list of captions.
- ```confidence```: Dict containing the captions confidence scores. Each axis can be accessed with the axis name and it contains a list of captions. Confidence scores are not provided for the _object_ axis (COCO captions).t
- ```purity score```: Dict containing the captions purity scores. The purity score measures the semantic similarity of the captions within the same axis (Bleurt-based).
- ```diversity score```: Dict containing the captions diversity scores. The diversity score measures the lexical diversity of the captions within the same axis (Self-BLEU-based).
### Data Splits
There are 14997 images and 134973 high-level captions split into:
- Train-val: 13498 images and 121482 high-level captions
- Test: 1499 images and 13491 high-level captions
## Dataset Creation
The dataset has been crowdsourced on Amazon Mechanical Turk.
From the paper:
>We randomly select 14997 images from the COCO 2014 train-val split. In order to answer questions related to _actions_ and _rationales_ we need to
> ensure the presence of a subject in the image. Therefore, we leverage the entity annotation provided in COCO to select images containing
> at least one person. The whole annotation is conducted on Amazon Mechanical Turk (AMT). We split the workload into batches in order to ease
>the monitoring of the quality of the data collected. Each image is annotated by three different annotators, therefore we collect three annotations per axis.
### Curation Rationale
From the paper:
>In this work, we tackle the issue of **grounding high-level linguistic concepts in the visual modality**, proposing the High-Level (HL) Dataset: a
V\&L resource aligning existing object-centric captions with human-collected high-level descriptions of images along three different axes: _scenes_, _actions_ and _rationales_.
The high-level captions capture the human interpretation of the scene, providing abstract linguistic concepts complementary to object-centric captions
>used in current V\&L datasets, e.g. in COCO. We take a step further, and we collect _confidence scores_ to distinguish commonsense assumptions
>from subjective interpretations and we characterize our data under a variety of semantic and lexical aspects.
### Source Data
- Images: COCO
- object axis annotations: COCO
- scene, action, rationale annotations: crowdsourced
- confidence scores: crowdsourced
- purity score and diversity score: automatically computed
#### Annotation process
From the paper:
>**Pilot:** We run a pilot study with the double goal of collecting feedback and defining the task instructions.
>With the results from the pilot we design a beta version of the task and we run a small batch of cases on the crowd-sourcing platform.
>We manually inspect the results and we further refine the instructions and the formulation of the task before finally proceeding with the
>annotation in bulk. The final annotation form is shown in Appendix D.
>***Procedure:*** The participants are shown an image and three questions regarding three aspects or axes: _scene_, _actions_ and _rationales_
> i,e. _Where is the picture taken?_, _What is the subject doing?_, _Why is the subject doing it?_. We explicitly ask the participants to use
>their personal interpretation of the scene and add examples and suggestions in the instructions to further guide the annotators. Moreover,
>differently from other VQA datasets like (Antol et al., 2015) and (Zhu et al., 2016), where each question can refer to different entities
>in the image, we systematically ask the same three questions about the same subject for each image. The full instructions are reported
>in Figure 1. For details regarding the annotation costs see Appendix A.
#### Who are the annotators?
Turkers from Amazon Mechanical Turk
### Personal and Sensitive Information
There is no personal or sensitive information
## Considerations for Using the Data
[More Information Needed]
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
From the paper:
>**Quantitying grammatical errors:** We ask two expert annotators to correct grammatical errors in a sample of 9900 captions, 900 of which are shared between the two annotators.
> The annotators are shown the image caption pairs and they are asked to edit the caption whenever they identify a grammatical error.
>The most common errors reported by the annotators are:
>- Misuse of prepositions
>- Wrong verb conjugation
>- Pronoun omissions
>In order to quantify the extent to which the corrected captions differ from the original ones, we compute the Levenshtein distance (Levenshtein, 1966) between them.
>We observe that 22.5\% of the sample has been edited and only 5\% with a Levenshtein distance greater than 10. This suggests a reasonable
>level of grammatical quality overall, with no substantial grammatical problems. This can also be observed from the Levenshtein distance
>distribution reported in Figure 2. Moreover, the human evaluation is quite reliable as we observe a moderate inter-annotator agreement
>(alpha = 0.507, (Krippendorff, 2018) computed over the shared sample.
### Dataset Curators
Michele Cafagna
### Licensing Information
The Images and the object-centric captions follow the [COCO terms of Use](https://cocodataset.org/#termsofuse)
The remaining annotations are licensed under Apache-2.0 license.
### Citation Information
```BibTeX
@inproceedings{cafagna2023hl,
title={{HL} {D}ataset: {V}isually-grounded {D}escription of {S}cenes, {A}ctions and
{R}ationales},
author={Cafagna, Michele and van Deemter, Kees and Gatt, Albert},
booktitle={Proceedings of the 16th International Natural Language Generation Conference (INLG'23)},
address = {Prague, Czech Republic},
year={2023}
}
```
| michelecafagna26/hl | [
"task_categories:image-to-text",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_ids:text-scoring",
"annotations_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"arxiv:1405.0312",
"arxiv:2302.12189",
"region:us"
]
| 2023-01-25T16:15:17+00:00 | {"annotations_creators": ["crowdsourced"], "language": ["en"], "license": "apache-2.0", "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "task_categories": ["image-to-text", "question-answering", "zero-shot-classification"], "task_ids": ["text-scoring"], "pretty_name": "HL (High-Level Dataset)", "annotations_origin": ["crowdsourced"], "dataset_info": {"splits": [{"name": "train", "num_examples": 13498}, {"name": "test", "num_examples": 1499}]}} | 2023-08-02T10:50:20+00:00 |
0ea08bf8ff41c8ea54d6671411ce0005fb46113a | # Dataset Card for "RSSCN7"
## Dataset Description
- **Paper** [Deep Learning Based Feature Selection for Remote Sensing Scene Classification](https://ieeexplore.ieee.org/iel7/8859/7305891/07272047.pdf)
### Licensing Information
For research and academic purposes.
## Citation Information
[Deep Learning Based Feature Selection for Remote Sensing Scene Classification](https://ieeexplore.ieee.org/iel7/8859/7305891/07272047.pdf)
```
@article{7272047,
title = {Deep Learning Based Feature Selection for Remote Sensing Scene Classification},
author = {Zou, Qin and Ni, Lihao and Zhang, Tong and Wang, Qian},
year = 2015,
journal = {IEEE Geoscience and Remote Sensing Letters},
volume = 12,
number = 11,
pages = {2321--2325},
doi = {10.1109/LGRS.2015.2475299}
}
``` | jonathan-roberts1/RSSCN7 | [
"task_categories:image-classification",
"task_categories:zero-shot-image-classification",
"license:other",
"region:us"
]
| 2023-01-25T16:16:29+00:00 | {"license": "other", "task_categories": ["image-classification", "zero-shot-image-classification"], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "field", "1": "forest", "2": "grass", "3": "industry", "4": "parking", "5": "resident", "6": "river or lake"}}}}], "splits": [{"name": "train", "num_bytes": 345895442.4, "num_examples": 2800}], "download_size": 367257922, "dataset_size": 345895442.4}} | 2023-03-31T16:20:53+00:00 |
212f53dc625a4caaefa8f105679d3434381158c1 | # Dataset Card for "OxfordPets_test_facebook_opt_2.7b_Attributes_Caption_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_2.7b_Attributes_Caption_ns_3669 | [
"region:us"
]
| 2023-01-25T16:20:51+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121189501.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122187449.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 124265920.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 126336943.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 129454684.375, "num_examples": 3669}], "download_size": 603074119, "dataset_size": 623434498.875}} | 2023-01-25T20:23:48+00:00 |
ac46d216ebaf87e36a4dae607253e6985e6e5a75 | # Dataset Card for "OxfordPets_test_facebook_opt_125m_Visclues_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_125m_Visclues_ns_3669 | [
"region:us"
]
| 2023-01-25T16:23:25+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121460903.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122822438.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 125536937.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 128243714.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 132312290.375, "num_examples": 3669}], "download_size": 604694650, "dataset_size": 630376283.875}} | 2023-01-25T20:30:55+00:00 |
bcb88fa457c2bea86e317aa0fc22e177f1ce49b1 | # Dataset Card for "OxfordPets_test_facebook_opt_350m_Visclues_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_350m_Visclues_ns_3669 | [
"region:us"
]
| 2023-01-25T16:27:08+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121460915.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122822636.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 125537076.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 128243735.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 132312128.375, "num_examples": 3669}], "download_size": 604694442, "dataset_size": 630376491.875}} | 2023-01-25T20:41:27+00:00 |
80b92e231adc6c0cd9314ab5de5e9a3997c0be16 | # Dataset Card for "yuvalkirstain-pickapic-ft-eval-random-prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | yuvalkirstain/yuvalkirstain-pickapic-ft-eval-random-prompts | [
"region:us"
]
| 2023-01-25T16:28:58+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 31392, "num_examples": 200}], "download_size": 11259, "dataset_size": 31392}} | 2023-01-25T16:29:05+00:00 |
c6912d3c9b04c0edc0857e7c4c458b0e3fef1b4b | # Dataset Card for "OxfordPets_test_facebook_opt_1.3b_Visclues_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_1.3b_Visclues_ns_3669 | [
"region:us"
]
| 2023-01-25T16:32:27+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121477284.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122822944.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 125537165.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 128243890.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 132312524.375, "num_examples": 3669}], "download_size": 604685676, "dataset_size": 630393808.875}} | 2023-01-25T21:01:08+00:00 |
83bc4b9a3afda020c5cb388a4fd470a7133301e6 | DewaNyoman/parkir-perahu | [
"license:unknown",
"region:us"
]
| 2023-01-25T16:36:11+00:00 | {"license": "unknown"} | 2023-01-25T16:45:02+00:00 |
|
3e793948e63e15c2ada57984aff1e8848c55c560 | # Dataset Card for "OxfordPets_test_facebook_opt_2.7b_Visclues_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_2.7b_Visclues_ns_3669 | [
"region:us"
]
| 2023-01-25T16:39:10+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121488865.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122822889.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 125537183.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 128243845.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 132312365.375, "num_examples": 3669}], "download_size": 604681164, "dataset_size": 630405148.875}} | 2023-01-25T21:31:11+00:00 |
4228afe8a630ba39652b20c3f12cf34eb80a0cd6 | # Dataset Card for "BusinessNewsDataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | LIDIA-HESSEN/vencortex-BusinessNewsDataset | [
"region:us"
]
| 2023-01-25T17:09:47+00:00 | {"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "image", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "context_id", "dtype": "string"}, {"name": "source", "dtype": "string"}, {"name": "date", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 290733891, "num_examples": 469361}], "download_size": 123671926, "dataset_size": 290733891}} | 2023-01-25T17:09:54+00:00 |
d26e9511bf4570dcba1ea244f93807bdf14750c6 | # Dataset Card for "FAQ_student_accesiblity_for_UTD"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Rami/FAQ_student_accesiblity_for_UTD | [
"region:us"
]
| 2023-01-25T17:15:01+00:00 | {"dataset_info": {"features": [{"name": "Question", "dtype": "string"}, {"name": "Answering", "dtype": "string"}, {"name": "URL", "dtype": "string"}, {"name": "Label", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 86308, "num_examples": 156}], "download_size": 44389, "dataset_size": 86308}} | 2023-03-25T22:17:38+00:00 |
763c2084a6b03532f4b6277818b03e5263d229d3 | # This repository contains the dataset of weather forecasting competition - Datavidia 2022
## Deskripsi File
- train.csv - Data yang digunakan untuk melatih model berisi fitur-fitur dan target
- train_hourly.csv - Data tambahan berisi fitur-fitur untuk setiap jam
- test.csv - Data uji yang berisi fitur-fitur untuk prediksi target
- test_hourly.csv - Data tambahan berisi fitur-fitur untuk setiap jam pada tanggal-tanggal yang termasuk dalam test.csv
- sample_submission.csv - File berisi contoh submisi untuk kompetisi ini
## Deskripsi Fitur
### train.csv
- time – Tanggal pencatatan
- temperature_2m_max (°C) – Temperatur udara tertinggi pada ketinggian 2 m di atas permukaan
- temperature_2m_min (°C) – Temperatur udara terendah pada ketinggian 2 m di atas permukaan
- apparent_temperature_max (°C) – Temperatur semu maksimum yang terasa
- apparent_temperature_min (°C) – Temperatur semu minimum yang terasa
- sunrise (iso8601) – Waktu matahari terbit pada hari itu dengan format ISO 8601
- sunset (iso8601) – Waktu matahari tenggelam pada hari itu dengan format ISO 8601
- shortwave_radiation_sum (MJ/m²) – Total radiasi matahari pada hari tersebut
- rain_sum (mm) – Jumlah curah hujan pada hari tersebut
- snowfall_sum (cm) – Jumlah hujan salju pada hari tersebut
- windspeed_10m_max (km/h) – Kecepatan angin maksimum pada ketinggian 10 m
- windgusts_10m_max (km/h) - Kecepatan angin minimum pada ketinggian 10 m
- winddirection_10m_dominant (°) – Arah angin dominan pada hari tersebut
- et0_fao_evapotranspiration (mm) – Jumlah evaporasi dan transpirasi pada hari tersebut
- elevation – Ketinggian kota yang tercatat
- city – Nama kota yang tercatat
### train_hourly.csv
- time – Tanggal dan jam pencatatan
- temperature_2m (°C) – Temperatur pada ketinggian 2 m
- relativehumidity_2m (%) – Kelembapan pada ketinggian 2 m
- dewpoint_2m (°C) – Titik embun; suhu ambang udara mengembun
- apparent_temperature (°C) – Temperatur semu yang dirasakan
- pressure_msl (hPa) – Tekanan udara pada ketinggian permukaan air laut rata-rata (mean sea level)
- surface_pressure (hPa) – Tekanan udara pada ketinggian permukaan daerah tersebut
- snowfall (cm) – Jumlah hujan salju pada jam tersebut
- cloudcover (%) – Persentase awan yang menutupi langit
- cloudcover_low (%) – Persentase cloud cover pada awan sampai ketinggian 2 km
- cloudcover_mid (%) – Persentase cloud cover pada ketinggian 2-6 km
- cloudcover_high (%) – Persentase cloud cover pada ketinggian di atas 6 km
- shortwave_radiation (W/m²) – Rata-rata energi pancaran matahari pada gelombang inframerah hingga ultraviolet
- direct_radiation (W/m²) – Rata-rata pancaran matahari langsung pada permukaan tanah seluas 1 m2
- diffuse_radiation (W/m²) – Rata-rata pancaran matahari yang dihamburkan oleh permukaan dan atmosfer
- direct_normal_irradiance (W/m²) – Rata-rata pancaran matahari langsung pada luas 1 m2 tegak lurus dengan arah pancaran
- windspeed_10m (km/h) – Kecepatan angin pada ketinggian 10 m
- windspeed_100m (km/h) – Kecepatan angin pada ketinggian 100 m
- winddirection_10m (°) – Arah angin pada ketinggian 10 m
- winddirection_100m (°) – Arah angin pada ketinggian 100 m
- windgusts_10m (km/h) – Kecepatan angin ketika terdapat angin kencang
- et0_fao_evapotranspiration (mm) – Jumlah evapotranspirasi (evaporasi dan transpirasi) pada jam tersebut
- vapor_pressure_deficit (kPa) – Perbedaan tekanan uap air dari udara dengan tekanan uap air ketika udara tersaturasi
- soil_temperature_0_to_7cm (°C) – Rata-rata temperatur tanah pada kedalaman 0-7 cm
- soil_temperature_7_to_28cm (°C) – Rata-rata temperatur tanah pada kedalaman 7-28 cm
- soil_temperature_28_to_100cm (°C) – Rata-rata temperatur tanah pada kedalaman 28-100 cm
- soil_temperature_100_to_255cm (°C) – Rata-rata temperatur tanah pada kedalaman 100-255 cm
- soil_moisture_0_to_7cm (m³/m³) – Rata-rata kelembapan air pada tanah untuk kedalaman 0-7 cm
- soil_moisture_7_to_28cm (m³/m³) – Rata-rata kelembapan air pada tanah untuk kedalaman 7-28 cm
- soil_moisture_28_to_100cm (m³/m³) – Rata-rata kelembapan air pada tanah untuk kedalaman 28-100 cm
- soil_moisture_100_to_255cm (m³/m³) – Rata-rata kelembapan air pada tanah untuk kedalaman 100-255 cm
- city – Nama kota | elskow/Weather4cast | [
"license:unlicense",
"region:us"
]
| 2023-01-25T17:31:20+00:00 | {"license": "unlicense"} | 2023-01-25T17:58:10+00:00 |
a4c789887a5064ddb505b642b381c347ac0c6964 |
# Dataset Card for pile-pii-scrubadub
## Dataset Description
- **Repository: https://github.com/tomekkorbak/aligned-pretraining-objectives**
- **Paper: Arxiv link to be added**
### Dataset Summary
This dataset contains text from [The Pile](https://huggingface.co/datasets/the_pile), annotated based on the toxicity of each sentence.
Each document (row in the dataset) is segmented into sentences, and each sentence is given a score: the toxicity predicted by the [Detoxify](https://github.com/unitaryai/detoxify).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
This dataset is taken from [The Pile](https://huggingface.co/datasets/the_pile), which is English text.
## Dataset Structure
### Data Instances
1949977
### Data Fields
- texts (sequence): a list of the sentences in the document, segmented using SpaCy
- meta (dict): the section of [The Pile](https://huggingface.co/datasets/the_pile) from which it originated
- scores (sequence): a score for each sentence in the `texts` column indicating the toxicity predicted by [Detoxify](https://github.com/unitaryai/detoxify)
- avg_score (float64): the average of the scores listed in the `scores` column
- num_sents (int64): the number of sentences (and scores) in that document
### Data Splits
Training set only
## Dataset Creation
### Curation Rationale
This is labeled text from [The Pile](https://huggingface.co/datasets/the_pile), a large dataset of text in English. The text is scored for toxicity so that generative language models can be trained to avoid generating toxic text.
### Source Data
#### Initial Data Collection and Normalization
This is labeled text from [The Pile](https://huggingface.co/datasets/the_pile).
#### Who are the source language producers?
Please see [The Pile](https://huggingface.co/datasets/the_pile) for the source of the dataset.
### Annotations
#### Annotation process
Each sentence was scored using [Detoxify](https://github.com/unitaryai/detoxify), which is a toxic comment classifier.
We used the `unbiased` model which is based on the 124M parameter [RoBERTa](https://arxiv.org/abs/1907.11692) and trained on the [Jigsaw Unintended Bias in Toxicity Classification dataset](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification).
#### Who are the annotators?
[Detoxify](https://github.com/unitaryai/detoxify)
### Personal and Sensitive Information
This dataset contains all personal identifable information and toxic text that was originally contained in [The Pile](https://huggingface.co/datasets/the_pile).
## Considerations for Using the Data
### Social Impact of Dataset
This dataset contains examples of toxic text and personal identifiable information.
(A version of this datatset with personal identifiable information annotated is [available here](https://huggingface.co/datasets/tomekkorbak/pile-pii-scrubadub).)
Please take care to avoid misusing the toxic text or putting anybody in danger by publicizing their information.
This dataset is intended for research purposes only. We cannot guarantee that all toxic text has been detected, and we cannot guarantee that models trained using it will avoid generating toxic text.
We do not recommend deploying models trained on this data.
### Discussion of Biases
This dataset contains all biases from The Pile discussed in their paper: https://arxiv.org/abs/2101.00027
### Other Known Limitations
The toxic text in this dataset was detected using imperfect automated detection methods. We cannot guarantee that the labels are 100% accurate.
## Additional Information
### Dataset Curators
[The Pile](https://huggingface.co/datasets/the_pile)
### Licensing Information
From [The Pile](https://huggingface.co/datasets/the_pile): PubMed Central: [MIT License](https://github.com/EleutherAI/pile-pubmedcentral/blob/master/LICENSE)
### Citation Information
Paper information to be added
### Contributions
[The Pile](https://huggingface.co/datasets/the_pile) | tomekkorbak/pile-detoxify | [
"task_categories:text-classification",
"task_categories:other",
"task_ids:acceptability-classification",
"task_ids:hate-speech-detection",
"task_ids:text-scoring",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:extended|the_pile",
"language:en",
"license:mit",
"toxicity",
"pretraining-with-human-feedback",
"arxiv:1907.11692",
"arxiv:2101.00027",
"region:us"
]
| 2023-01-25T17:32:30+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["extended|the_pile"], "task_categories": ["text-classification", "other"], "task_ids": ["acceptability-classification", "hate-speech-detection", "text-scoring"], "pretty_name": "pile-detoxify", "tags": ["toxicity", "pretraining-with-human-feedback"]} | 2023-02-07T15:31:11+00:00 |
b61d29f477163034001472614dc97fb9614dddea |
# Dataset Card for DocLayNet small
## About this card (01/27/2023)
### Property and license
All information from this page but the content of this paragraph "About this card (01/27/2023)" has been copied/pasted from [Dataset Card for DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet).
DocLayNet is a dataset created by Deep Search (IBM Research) published under [license CDLA-Permissive-1.0](https://huggingface.co/datasets/ds4sd/DocLayNet#licensing-information).
I do not claim any rights to the data taken from this dataset and published on this page.
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
### Processing into a format facilitating its use by HF notebooks
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately ([doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip), 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- [DocLayNet small](https://huggingface.co/datasets/pierreguillou/DocLayNet-small) (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- [DocLayNet large](https://huggingface.co/datasets/pierreguillou/DocLayNet-large) (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
*Note: the layout HF notebooks will greatly help participants of the IBM [ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents](https://ds4sd.github.io/icdar23-doclaynet/)!*
### About PDFs languages
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"We did not control the document selection with regard to language. **The vast majority of documents contained in DocLayNet (close to 95%) are published in English language.** However, **DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%)**. While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
### About PDFs categories distribution
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"The pages in DocLayNet can be grouped into **six distinct categories**, namely **Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders**. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
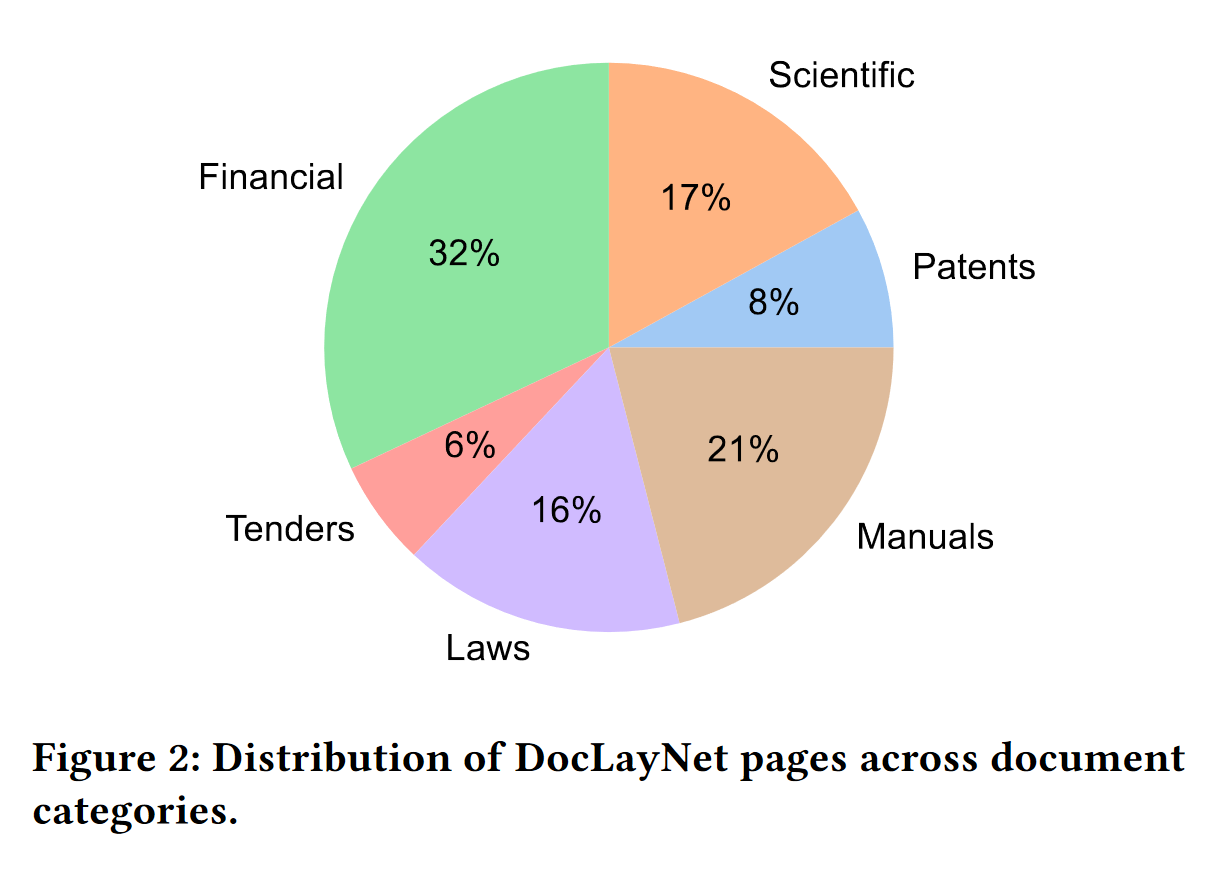
### Download & overview
The size of the DocLayNet small is about 1% of the DocLayNet dataset (random selection respectively in the train, val and test files).
```
# !pip install -q datasets
from datasets import load_dataset
dataset_small = load_dataset("pierreguillou/DocLayNet-small")
# overview of dataset_small
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 691
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 64
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 49
})
})
```
### Annotated bounding boxes
The DocLayNet base makes easy to display document image with the annotaed bounding boxes of paragraphes or lines.
Check the notebook [processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb](https://github.com/piegu/language-models/blob/master/processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb) in order to get the code.
#### Paragraphes

#### Lines

### HF notebooks
- [notebooks LayoutLM](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLM) (Niels Rogge)
- [notebooks LayoutLMv2](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2) (Niels Rogge)
- [notebooks LayoutLMv3](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3) (Niels Rogge)
- [notebooks LiLT](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT) (Niels Rogge)
- [Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers](https://github.com/philschmid/document-ai-transformers/blob/main/training/lilt_funsd.ipynb) ([post](https://www.philschmid.de/fine-tuning-lilt#3-fine-tune-and-evaluate-lilt) of Phil Schmid)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://developer.ibm.com/exchanges/data/all/doclaynet/
- **Repository:** https://github.com/DS4SD/DocLayNet
- **Paper:** https://doi.org/10.1145/3534678.3539043
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
DocLayNet provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories. It provides several unique features compared to related work such as PubLayNet or DocBank:
1. *Human Annotation*: DocLayNet is hand-annotated by well-trained experts, providing a gold-standard in layout segmentation through human recognition and interpretation of each page layout
2. *Large layout variability*: DocLayNet includes diverse and complex layouts from a large variety of public sources in Finance, Science, Patents, Tenders, Law texts and Manuals
3. *Detailed label set*: DocLayNet defines 11 class labels to distinguish layout features in high detail.
4. *Redundant annotations*: A fraction of the pages in DocLayNet are double- or triple-annotated, allowing to estimate annotation uncertainty and an upper-bound of achievable prediction accuracy with ML models
5. *Pre-defined train- test- and validation-sets*: DocLayNet provides fixed sets for each to ensure proportional representation of the class-labels and avoid leakage of unique layout styles across the sets.
### Supported Tasks and Leaderboards
We are hosting a competition in ICDAR 2023 based on the DocLayNet dataset. For more information see https://ds4sd.github.io/icdar23-doclaynet/.
## Dataset Structure
### Data Fields
DocLayNet provides four types of data assets:
1. PNG images of all pages, resized to square `1025 x 1025px`
2. Bounding-box annotations in COCO format for each PNG image
3. Extra: Single-page PDF files matching each PNG image
4. Extra: JSON file matching each PDF page, which provides the digital text cells with coordinates and content
The COCO image record are defined like this example
```js
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
```
The `doc_category` field uses one of the following constants:
```
financial_reports,
scientific_articles,
laws_and_regulations,
government_tenders,
manuals,
patents
```
### Data Splits
The dataset provides three splits
- `train`
- `val`
- `test`
## Dataset Creation
### Annotations
#### Annotation process
The labeling guideline used for training of the annotation experts are available at [DocLayNet_Labeling_Guide_Public.pdf](https://raw.githubusercontent.com/DS4SD/DocLayNet/main/assets/DocLayNet_Labeling_Guide_Public.pdf).
#### Who are the annotators?
Annotations are crowdsourced.
## Additional Information
### Dataset Curators
The dataset is curated by the [Deep Search team](https://ds4sd.github.io/) at IBM Research.
You can contact us at [[email protected]](mailto:[email protected]).
Curators:
- Christoph Auer, [@cau-git](https://github.com/cau-git)
- Michele Dolfi, [@dolfim-ibm](https://github.com/dolfim-ibm)
- Ahmed Nassar, [@nassarofficial](https://github.com/nassarofficial)
- Peter Staar, [@PeterStaar-IBM](https://github.com/PeterStaar-IBM)
### Licensing Information
License: [CDLA-Permissive-1.0](https://cdla.io/permissive-1-0/)
### Citation Information
```bib
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
```
### Contributions
Thanks to [@dolfim-ibm](https://github.com/dolfim-ibm), [@cau-git](https://github.com/cau-git) for adding this dataset. | pierreguillou/DocLayNet-small | [
"task_categories:object-detection",
"task_categories:image-segmentation",
"task_categories:token-classification",
"task_ids:instance-segmentation",
"annotations_creators:crowdsourced",
"size_categories:1K<n<10K",
"language:en",
"language:de",
"language:fr",
"language:ja",
"license:other",
"DocLayNet",
"COCO",
"PDF",
"IBM",
"Financial-Reports",
"Finance",
"Manuals",
"Scientific-Articles",
"Science",
"Laws",
"Law",
"Regulations",
"Patents",
"Government-Tenders",
"object-detection",
"image-segmentation",
"token-classification",
"arxiv:2206.01062",
"region:us"
]
| 2023-01-25T17:47:43+00:00 | {"annotations_creators": ["crowdsourced"], "language": ["en", "de", "fr", "ja"], "license": "other", "size_categories": ["1K<n<10K"], "task_categories": ["object-detection", "image-segmentation", "token-classification"], "task_ids": ["instance-segmentation"], "pretty_name": "DocLayNet small", "tags": ["DocLayNet", "COCO", "PDF", "IBM", "Financial-Reports", "Finance", "Manuals", "Scientific-Articles", "Science", "Laws", "Law", "Regulations", "Patents", "Government-Tenders", "object-detection", "image-segmentation", "token-classification"]} | 2023-05-17T07:56:10+00:00 |
86fa5ebffa3d336210ee1eeeec349b2c7f07899b |
# Dataset Card for DocLayNet base
## About this card (01/27/2023)
### Property and license
All information from this page but the content of this paragraph "About this card (01/27/2023)" has been copied/pasted from [Dataset Card for DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet).
DocLayNet is a dataset created by Deep Search (IBM Research) published under [license CDLA-Permissive-1.0](https://huggingface.co/datasets/ds4sd/DocLayNet#licensing-information).
I do not claim any rights to the data taken from this dataset and published on this page.
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
### Processing into a format facilitating its use by HF notebooks
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately ([doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip), 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- [DocLayNet small](https://huggingface.co/datasets/pierreguillou/DocLayNet-small) (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- [DocLayNet large](https://huggingface.co/datasets/pierreguillou/DocLayNet-large) (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
*Note: the layout HF notebooks will greatly help participants of the IBM [ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents](https://ds4sd.github.io/icdar23-doclaynet/)!*
### About PDFs languages
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"We did not control the document selection with regard to language. **The vast majority of documents contained in DocLayNet (close to 95%) are published in English language.** However, **DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%)**. While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
### About PDFs categories distribution
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"The pages in DocLayNet can be grouped into **six distinct categories**, namely **Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders**. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
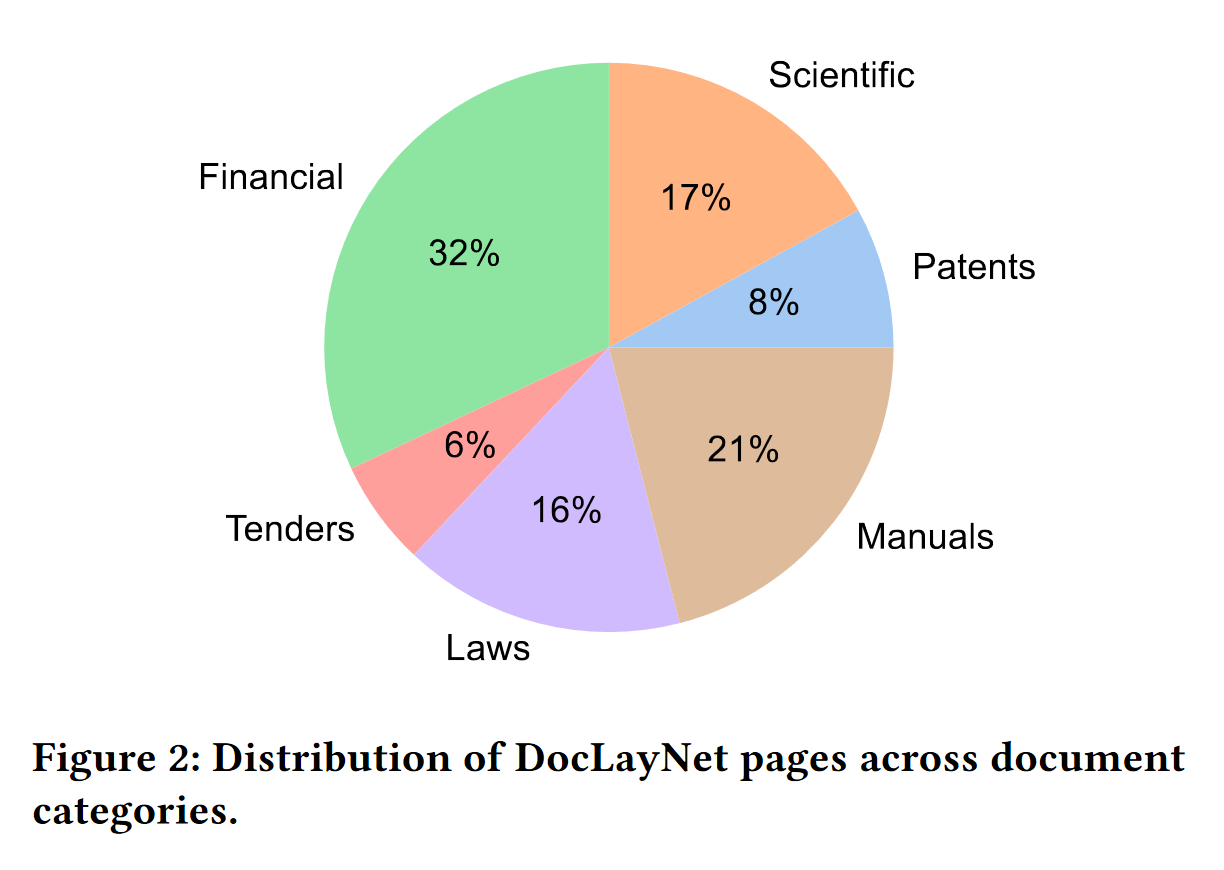
### Download & overview
The size of the DocLayNet small is about 10% of the DocLayNet dataset (random selection respectively in the train, val and test files).
```
# !pip install -q datasets
from datasets import load_dataset
dataset_base = load_dataset("pierreguillou/DocLayNet-base")
# overview of dataset_base
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 6910
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 648
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 499
})
})
```
### Annotated bounding boxes
The DocLayNet base makes easy to display document image with the annotaed bounding boxes of paragraphes or lines.
Check the notebook [processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb](https://github.com/piegu/language-models/blob/master/processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb) in order to get the code.
#### Paragraphes

#### Lines

### HF notebooks
- [notebooks LayoutLM](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLM) (Niels Rogge)
- [notebooks LayoutLMv2](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2) (Niels Rogge)
- [notebooks LayoutLMv3](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3) (Niels Rogge)
- [notebooks LiLT](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT) (Niels Rogge)
- [Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers](https://github.com/philschmid/document-ai-transformers/blob/main/training/lilt_funsd.ipynb) ([post](https://www.philschmid.de/fine-tuning-lilt#3-fine-tune-and-evaluate-lilt) of Phil Schmid)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://developer.ibm.com/exchanges/data/all/doclaynet/
- **Repository:** https://github.com/DS4SD/DocLayNet
- **Paper:** https://doi.org/10.1145/3534678.3539043
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
DocLayNet provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories. It provides several unique features compared to related work such as PubLayNet or DocBank:
1. *Human Annotation*: DocLayNet is hand-annotated by well-trained experts, providing a gold-standard in layout segmentation through human recognition and interpretation of each page layout
2. *Large layout variability*: DocLayNet includes diverse and complex layouts from a large variety of public sources in Finance, Science, Patents, Tenders, Law texts and Manuals
3. *Detailed label set*: DocLayNet defines 11 class labels to distinguish layout features in high detail.
4. *Redundant annotations*: A fraction of the pages in DocLayNet are double- or triple-annotated, allowing to estimate annotation uncertainty and an upper-bound of achievable prediction accuracy with ML models
5. *Pre-defined train- test- and validation-sets*: DocLayNet provides fixed sets for each to ensure proportional representation of the class-labels and avoid leakage of unique layout styles across the sets.
### Supported Tasks and Leaderboards
We are hosting a competition in ICDAR 2023 based on the DocLayNet dataset. For more information see https://ds4sd.github.io/icdar23-doclaynet/.
## Dataset Structure
### Data Fields
DocLayNet provides four types of data assets:
1. PNG images of all pages, resized to square `1025 x 1025px`
2. Bounding-box annotations in COCO format for each PNG image
3. Extra: Single-page PDF files matching each PNG image
4. Extra: JSON file matching each PDF page, which provides the digital text cells with coordinates and content
The COCO image record are defined like this example
```js
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
```
The `doc_category` field uses one of the following constants:
```
financial_reports,
scientific_articles,
laws_and_regulations,
government_tenders,
manuals,
patents
```
### Data Splits
The dataset provides three splits
- `train`
- `val`
- `test`
## Dataset Creation
### Annotations
#### Annotation process
The labeling guideline used for training of the annotation experts are available at [DocLayNet_Labeling_Guide_Public.pdf](https://raw.githubusercontent.com/DS4SD/DocLayNet/main/assets/DocLayNet_Labeling_Guide_Public.pdf).
#### Who are the annotators?
Annotations are crowdsourced.
## Additional Information
### Dataset Curators
The dataset is curated by the [Deep Search team](https://ds4sd.github.io/) at IBM Research.
You can contact us at [[email protected]](mailto:[email protected]).
Curators:
- Christoph Auer, [@cau-git](https://github.com/cau-git)
- Michele Dolfi, [@dolfim-ibm](https://github.com/dolfim-ibm)
- Ahmed Nassar, [@nassarofficial](https://github.com/nassarofficial)
- Peter Staar, [@PeterStaar-IBM](https://github.com/PeterStaar-IBM)
### Licensing Information
License: [CDLA-Permissive-1.0](https://cdla.io/permissive-1-0/)
### Citation Information
```bib
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
```
### Contributions
Thanks to [@dolfim-ibm](https://github.com/dolfim-ibm), [@cau-git](https://github.com/cau-git) for adding this dataset. | pierreguillou/DocLayNet-base | [
"task_categories:object-detection",
"task_categories:image-segmentation",
"task_categories:token-classification",
"task_ids:instance-segmentation",
"annotations_creators:crowdsourced",
"size_categories:1K<n<10K",
"language:en",
"language:de",
"language:fr",
"language:ja",
"license:other",
"DocLayNet",
"COCO",
"PDF",
"IBM",
"Financial-Reports",
"Finance",
"Manuals",
"Scientific-Articles",
"Science",
"Laws",
"Law",
"Regulations",
"Patents",
"Government-Tenders",
"object-detection",
"image-segmentation",
"token-classification",
"arxiv:2206.01062",
"region:us"
]
| 2023-01-25T17:53:26+00:00 | {"annotations_creators": ["crowdsourced"], "language": ["en", "de", "fr", "ja"], "license": "other", "size_categories": ["1K<n<10K"], "task_categories": ["object-detection", "image-segmentation", "token-classification"], "task_ids": ["instance-segmentation"], "pretty_name": "DocLayNet base", "tags": ["DocLayNet", "COCO", "PDF", "IBM", "Financial-Reports", "Finance", "Manuals", "Scientific-Articles", "Science", "Laws", "Law", "Regulations", "Patents", "Government-Tenders", "object-detection", "image-segmentation", "token-classification"]} | 2023-05-17T07:56:30+00:00 |
ade0789f658fd356185f9cc1438d268835b99204 | <h1 style="text-align: center;">MPSC Multi-view Dataset</h1>
<p style='text-align: justify;'>
Deep video representation learning has recently attained state-of-the-art performance in video action recognition. However, when used with video clips from varied perspectives, the performance of these models degrades significantly. Existing VAR models frequently simultaneously contain both view information and action attributes, making it difficult to learn a view-invariant representation. Therefore, to study the attribute of multiview representation, we collected a large-scale time synchronous multiview video dataset from 10 subjects in both indoor and outdoor settings performing 10 different actions with three horizontal and vertical viewpoints using a smartphone, an action camera, and a drone camera. We provide the multiview video dataset with various meta-data information to facilitate further research for robust VAR systems.
</p>
### Collecting multiview videos
<p style='text-align: justify;'>
In our data collection strategy, we choose regular sensors (smartphone camera), wide-angle sensors (go-pro, action camera), and drone cameras covering front views, side views, and top view positions to receive simultaneous three 2D projections of ten action events. To collect multi-angular and positional projections of the same actions, smartphones (Samsung S8 plus, flat-angle sensor), action cameras (Dragon touch EK700, wide-angle sensor), and a drone (Parrot Anafi, flat-angle sensor) capture the action events simultaneously from different positions in 1080p at 30 FPS. Among the cameras, the smartphone was hand-held and tracked the events. The action camera was placed in a stationary position and captured the events using its wide-view sensor. Both of them were positions approximately 6 feet away from the participants to capture two completely different side-views of the actions from horizontal position. Lastly, the drone captures the events' top view while flying at a low altitude of varying distances from 8 feet to 15 feet. Although we positioned the cameras to capture events from a particular angular position with some occasional movement, it effectively captured an almost complete-view of actions, as the volunteers turn in different directions to perform different actions without any constraints.
</p>
<p style='text-align: justify;'>
We have selected ten regular micro-actions in our dataset with both static (poses: sitting, standing, lying with face up, lying with face down) and dynamic actions (temporal patterns: walking, push up, waving hand, leg exercise, object carrying, object pick/drop). We hypothesize this would further foundation for complex action recognition since some complex actions require sequentially performing a subset of these micro-actions. In our target actions selection, some actions have only minor differences to distinguish and require contextual knowledge (walking and object carrying, push-ups and lying down, lying with face down and lying with face up, standing and hand waving in standing position). Further, we have collected the background-only data without the human to provide a no-action/human dataset for the identical backgrounds.
</p>
<p style='text-align: justify;'>
We collect these data [sampled shown in the follwing figure] from 12 volunteer participants with varying traits. The participant performs all ten actions for 30 seconds while being recorded from three-positional cameras simultaneously in each session. The participants provided data multiple times, under different environments with different clothing amassing 30 sessions, yielding approximately ten hours of total video data in a time-controlled and safe setup.
</p>

<p style='text-align: justify;'>
Further, the videos are collected under varying realistic lighting conditions; natural lighting, artificial lighting, and a mix of both indoors, and outdoor environments, and multiple realistic backgrounds like walls, doors, windows, grasses, roads, and reflective tiles with varying camera settings like zoom, brightness and contrast filter, relative motions. Environments and lighting conditions are presented in the above figure. We also provide the videos containing only background to avail further research.
</p>
### Data Preprocessing and AI readiness
<p style='text-align: justify;'>
We align each session's simultaneously recorded videos from the starting time-stamp, and at any given time, all three sensors of any particular session capture their corresponding positional projection of the same event. The alignment allows us to annotate one video file per session for the underlying action in the time duration and receive action annotation for the other two videos, significantly reducing the annotation burden for these multiview videos.
</p>
<p style='text-align: justify;'>
Besides action information, each video is also tagged with the following meta-information: the subjects' ID, backgrounds environments, lighting conditions, camera specifications, settings (varying zoom, brightness), camera-subject distances, and relative movements, for various research directions. Additionally, other information such as the date, time, and the trial number were also listed for each video. Multiple human volunteers manually annotated video files, and these annotations went through multiple cross-checking. Finally, we prepare the video data in pickle file format for quick loading using python/C++/Matlab libraries.
</p>
### Dataset Statistics
Here we provide the our collected dataset characteristics insight.
<p style='text-align: justify;'>
<strong> 1) Inter and Intra action variations:</strong> We ensure fine-grain inter and intra-action variation in our dataset by requesting the participants to perform similar actions in freestyle. Further, we take multiple sessions on different dates and times to incorporate inter-personal variation in the dataset. 80% of our participants provided data in multiple sessions. 58% of the participant provides their data from multiple backgrounds. We have 20% of female participants in for multiple sessions. In actions, we have 40% stable pose as action and 60% dynamic simple actions in our collected dataset. Further, 10% of our volunteers are athletes. Moreover, our dataset are relatively balanced with almost equal duration of each actions.
</p>

<p style='text-align: justify;'>
<strong> 2) Background Variations:</strong> We considered different realistic backgrounds for our data collection while ensuring safety for the participants. We have 75% data for the indoor laboratory environment. Among that, we have 60% of data with white wall background with regular inventories like computers, bookshelves, doors, and windows, 25% with reflective tiles, sunny windows, and 5% under a messy laboratory background with multiple office tables and carpets. Among the 25% outdoor data, we collected 50% of the outdoor data in green fields and concrete parking spaces. We have about 60% of the data in the artificial lighting, and the rest are in natural sunlight conditions. We also provide the backgrounds without the subjects from the three sensors' viewpoints for reference.
</p>

<p style='text-align: justify;'>
<strong>3) Viewpoint and sensor Variations:</strong> We have collected 67% data from the horizontal view and 33% from the top-angular positional viewpoints. Our 67% data are captured by the flat lens from a angular viewpoint, and 33% are captured via the wide angular view from the horizontal position. 40% data are recorded from the stable camera position, and 60% data are captured via moving camera sensors. We have 20% data from the subject-focused zoomed camera lens. Further, the subjects perform the actions while facing away from the sensors 20% of the time.
</p>
### Reference
Please refer to the following papers to cite the dataset.
- Hasan, Z., Ahmed, M., Faridee, A. Z. M., Purushotham, S., Kwon, H., Lee, H., & Roy, N. (2023). NEV-NCD: Negative Learning, Entropy, and Variance regularization based novel action categories discovery. arXiv preprint arXiv:2304.07354.
### Acknowledgement
<p style='text-align: justify;'>
We acknowledge the support of DEVCOM Army Research Laboratory (ARL) and U.S. Army Grant No. W911NF21-20076.
</p> | mahmed10/MPSC_MV | [
"task_categories:video-classification",
"Video Acitvity Recognition",
"region:us"
]
| 2023-01-25T17:53:36+00:00 | {"task_categories": ["video-classification"], "tags": ["Video Acitvity Recognition"]} | 2023-04-28T14:25:02+00:00 |
297227012467386b09e6bf7d270d277d0e2b9325 |
# Dataset Card for pile-pii-scrubadub
## Dataset Description
- **Repository: https://github.com/tomekkorbak/aligned-pretraining-objectives**
- **Paper: Arxiv link to be added**
### Dataset Summary
This dataset contains text from [The Pile](https://huggingface.co/datasets/the_pile), annotated based on the personal idenfitiable information (PII) in each sentence.
Each document (row in the dataset) is segmented into sentences, and each sentence is given a score: the percentage of words in it that are classified as PII by [Scrubadub](https://scrubadub.readthedocs.io/en/stable/).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
This dataset is taken from [The Pile](https://huggingface.co/datasets/the_pile), which is English text.
## Dataset Structure
### Data Instances
1949977
### Data Fields
- texts (sequence): a list of the sentences in the document (segmented using [SpaCy](https://spacy.io/))
- meta (dict): the section of [The Pile](https://huggingface.co/datasets/the_pile) from which it originated
- scores (sequence): a score for each sentence in the `texts` column indicating the percent of words that are detected as PII by [Scrubadub](https://scrubadub.readthedocs.io/en/stable/)
- avg_score (float64): the average of the scores listed in the `scores` column
- num_sents (int64): the number of sentences (and scores) in that document
### Data Splits
Training set only
## Dataset Creation
### Curation Rationale
This is labeled text from [The Pile](https://huggingface.co/datasets/the_pile), a large dataset of text in English. The PII is labeled so that generative language models can be trained to avoid generating PII.
### Source Data
#### Initial Data Collection and Normalization
This is labeled text from [The Pile](https://huggingface.co/datasets/the_pile).
#### Who are the source language producers?
Please see [The Pile](https://huggingface.co/datasets/the_pile) for the source of the dataset.
### Annotations
#### Annotation process
For each sentence, [Scrubadub](https://scrubadub.readthedocs.io/en/stable/) was used to detect:
- email addresses
- addresses and postal codes
- phone numbers
- credit card numbers
- US social security numbers
- vehicle plates numbers
- dates of birth
- URLs
- login credentials
#### Who are the annotators?
[Scrubadub](https://scrubadub.readthedocs.io/en/stable/)
### Personal and Sensitive Information
This dataset contains all PII that was originally contained in [The Pile](https://huggingface.co/datasets/the_pile), with all detected PII annotated.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset contains examples of real PII (conveniently annotated in the text!). Please take care to avoid misusing it or putting anybody in danger by publicizing their information.
This dataset is intended for research purposes only. We cannot guarantee that all PII has been detected, and we cannot guarantee that models trained using it will avoid generating PII.
We do not recommend deploying models trained on this data.
### Discussion of Biases
This dataset contains all biases from The Pile discussed in their paper: https://arxiv.org/abs/2101.00027
### Other Known Limitations
The PII in this dataset was detected using imperfect automated detection methods. We cannot guarantee that the labels are 100% accurate.
## Additional Information
### Dataset Curators
[The Pile](https://huggingface.co/datasets/the_pile)
### Licensing Information
From [The Pile](https://huggingface.co/datasets/the_pile): PubMed Central: [MIT License](https://github.com/EleutherAI/pile-pubmedcentral/blob/master/LICENSE)
### Citation Information
Paper information to be added
### Contributions
[The Pile](https://huggingface.co/datasets/the_pile) | tomekkorbak/pile-pii-scrubadub | [
"task_categories:text-classification",
"task_categories:other",
"task_ids:acceptability-classification",
"task_ids:text-scoring",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:extended|the_pile",
"language:en",
"license:mit",
"pii",
"personal",
"identifiable",
"information",
"pretraining-with-human-feedback",
"arxiv:2101.00027",
"region:us"
]
| 2023-01-25T18:00:01+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["extended|the_pile"], "task_categories": ["text-classification", "other"], "task_ids": ["acceptability-classification", "text-scoring"], "pretty_name": "pile-pii-scrubadub", "tags": ["pii", "personal", "identifiable", "information", "pretraining-with-human-feedback"]} | 2023-02-07T15:26:41+00:00 |
a06d4250163274a43e10baad618e61f097583d27 | # Dataset Card for "lat_en_loeb_morph"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | grosenthal/lat_en_loeb_morph | [
"region:us"
]
| 2023-01-25T18:11:22+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "la", "dtype": "string"}, {"name": "en", "dtype": "string"}, {"name": "file", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 60797479, "num_examples": 99343}, {"name": "test", "num_bytes": 628768, "num_examples": 1014}, {"name": "valid", "num_bytes": 605889, "num_examples": 1014}], "download_size": 31059812, "dataset_size": 62032136}} | 2023-02-28T18:49:30+00:00 |
7c87c5db319dab81696ecb1b7e9ea2eb92c8f6dd |
# Dataset for training Russian language models
Overall: 75G
Scripts: https://github.com/IlyaGusev/rulm/tree/master/data_processing
| Website | Char count (M) | Word count (M) |
|-----------------|---------------|---------------|
| pikabu | 14938 | 2161 |
| lenta | 1008 | 135 |
| stihi | 2994 | 393 |
| stackoverflow | 1073 | 228 |
| habr | 5112 | 753 |
| taiga_fontanka | 419 | 55 |
| librusec | 10149 | 1573 |
| buriy | 2646 | 352 |
| ods_tass | 1908 | 255 |
| wiki | 3473 | 469 |
| math | 987 | 177 |
| IlyaGusev/rulm | [
"task_categories:text-generation",
"size_categories:10M<n<100M",
"language:ru",
"region:us"
]
| 2023-01-25T18:14:38+00:00 | {"language": ["ru"], "size_categories": ["10M<n<100M"], "task_categories": ["text-generation"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 78609111353, "num_examples": 14811026}, {"name": "test", "num_bytes": 397130292, "num_examples": 74794}, {"name": "validation", "num_bytes": 395354867, "num_examples": 74691}], "download_size": 24170140196, "dataset_size": 79401596512}} | 2023-03-20T23:53:53+00:00 |
aa69145a9f971d214419ee3eba2838f3b4522fd0 | # Dataset Card for "lat_en_loeb_split"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | grosenthal/lat_en_loeb_split | [
"region:us"
]
| 2023-01-25T18:27:37+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "la", "dtype": "string"}, {"name": "en", "dtype": "string"}, {"name": "file", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 46936015, "num_examples": 99343}, {"name": "test", "num_bytes": 484664, "num_examples": 1014}, {"name": "valid", "num_bytes": 468616, "num_examples": 1014}], "download_size": 26225698, "dataset_size": 47889295}} | 2023-03-25T00:31:49+00:00 |
9bc3c0c62180045ce419b1a58c9cf14666ece180 | Jupyter notebooks and supporting code | SDbiaseval/notebooks | [
"license:apache-2.0",
"region:us"
]
| 2023-01-25T18:31:00+00:00 | {"license": "apache-2.0", "viewer": false} | 2023-01-31T16:17:43+00:00 |
62c181fb787a3e753e52abc328a7c4fd83af4f00 | # Dataset Card for "methods2test_raw_grouped"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | dembastu/methods2test_raw_grouped | [
"region:us"
]
| 2023-01-25T18:41:08+00:00 | {"dataset_info": {"features": [{"name": "focal_method_test_case", "dtype": "string"}, {"name": "length", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 854772444.2611823, "num_examples": 631120}], "download_size": 339684184, "dataset_size": 854772444.2611823}} | 2023-01-26T23:08:46+00:00 |
3f6210838290d43d58d7fe5a7148b8c489a7fd28 | This is the reporsitory of Turkish fake news dataset which consists of Zaytung posts and Hurriyet news articles.
Code folder contains the web scrapper python files.
Raw folder contains txt files downloaded from sources.
Clean folder contains txt files in lowercase, punctuation and numbers removed. | emreisik/news | [
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:tr",
"license:bsd",
"region:us"
]
| 2023-01-25T18:48:18+00:00 | {"language": ["tr"], "license": "bsd", "size_categories": ["1K<n<10K"], "task_categories": ["text-generation"], "pretty_name": "News"} | 2023-01-25T18:50:02+00:00 |
b480a7d68113a3870224a5c024c642a95ec496e9 | # Dataset Card for "pl-text-images-new-5000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Zombely/pl-text-images-new-5000 | [
"region:us"
]
| 2023-01-25T18:59:51+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2529163044.192, "num_examples": 4036}, {"name": "test", "num_bytes": 314971657.0, "num_examples": 459}, {"name": "validation", "num_bytes": 330087667.0, "num_examples": 505}], "download_size": 3146813826, "dataset_size": 3174222368.192}} | 2023-01-25T19:02:52+00:00 |
2a7fc8d44c1d363df612fe81e61809ed4e1254d5 |
This minimal pair data comes from "Learning to Recognize Dialect Features" by Dorottya Demszky, Devyani Sharma, Jonathan H. Clark, Vinodkumar Prabhakaran, and Jacob Eisenstein. Please cite the original work if
you make use of this data:
```
@inproceedings{demszky2021learning,
title={Learning to Recognize Dialect Features},
author={Demszky, Dorottya and Sharma, Devyani and Clark, Jonathan H and Prabhakaran, Vinodkumar and Eisenstein, Jacob},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
pages={2315--2338}, year={2021}
}
``` | WillHeld/demszky_pairs | [
"region:us"
]
| 2023-01-25T19:15:28+00:00 | {"dataset_info": {"features": [{"name": "phrase_ID", "dtype": "int64"}, {"name": "feature", "dtype": "string"}, {"name": "sentence", "dtype": "string"}, {"name": "feature_present", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 23146, "num_examples": 266}], "download_size": 8919, "dataset_size": 23146}} | 2023-01-25T19:19:46+00:00 |
49ca89f1fa9f6f47e780a1acd4cdf9fa6ca4a47d | dpredrag/Testa | [
"license:creativeml-openrail-m",
"region:us"
]
| 2023-01-25T19:29:37+00:00 | {"license": "creativeml-openrail-m"} | 2023-01-29T16:46:41+00:00 |
|
43af75c5f84f37bca46da517580d94153ac49189 | AminKAli/test | [
"license:openrail",
"region:us"
]
| 2023-01-25T20:11:37+00:00 | {"license": "openrail"} | 2023-01-25T20:11:38+00:00 |
|
784aed5465aa215e30fdc7f12e51880c3f73d149 | year_#ofpeople_location
1833_4_SriLanka
1943_1_USMarine
1952_1_Penang
1966_1_Rabaul
1973_1_Hawaii
1991_1_SriLanka
2001_1_Malaysia
2002_1_Malaysia
2003_1_Malaysia
2009_1_Thailand
2010_1_India
2010_1_Colombia
2013_1_Colombia
2021_1_India
2021_1_Phillipeans
2022_1_India
| CoconutData/Coconutmortalityrate | [
"license:openrail",
"region:us"
]
| 2023-01-25T21:20:17+00:00 | {"license": "openrail"} | 2023-01-25T21:26:00+00:00 |
936408ecc0605c4812794693149401e12422f2f6 | jyang/webshop_inst_goal_pairs_truth | [
"license:mit",
"region:us"
]
| 2023-01-25T21:40:51+00:00 | {"license": "mit"} | 2023-01-25T21:48:15+00:00 |
|
5a236d29310651b70c6fc49865558301c9a12279 | gorar/A-MNIST | [
"task_categories:image-classification",
"size_categories:100K<n<1M",
"license:mit",
"region:us"
]
| 2023-01-25T21:45:57+00:00 | {"license": "mit", "size_categories": ["100K<n<1M"], "task_categories": ["image-classification"]} | 2023-01-25T22:17:05+00:00 |
|
a17a37e5e4abde4c6a920d1ca9abfd18b1356c07 |
# Dataset Card for "relbert/t_rex"
## Dataset Description
- **Repository:** [https://hadyelsahar.github.io/t-rex/](https://hadyelsahar.github.io/t-rex/)
- **Paper:** [https://aclanthology.org/L18-1544/](https://aclanthology.org/L18-1544/)
- **Dataset:** Cleaned T-REX for link prediction.
## Dataset Summary
This is the T-REX dataset proposed in [https://aclanthology.org/L18-1544/](https://aclanthology.org/L18-1544/).
The test split is universal across different version, which is manually checked by the author of [relbert/t_rex](https://huggingface.co/datasets/relbert/t_rex),
and the test split contains predicates that is not included in the train/validation split.
The number of triples in each split is summarized in the table below.
***Note:*** To make it consistent with other datasets ([nell](https://huggingface.co/datasets/relbert/nell) and [conceptnet](https://huggingface.co/datasets/relbert/conceptnet)), we rename predicate/subject/object as relation/head/tail.
- Number of instances
| | train | validation | test |
|:--------------------------------|--------:|-------------:|-------:|
| number of triples | 1,274,264 | 318,566 | 122 |
| number of unique relation types (predicate) | 759 | 676 | 34 |
### Filtering to Remove Noise
We apply filtering to keep triples with named-entities in either of head or tail (`named-entity filter`).
Then, we remove predicates if they have less than three triples (`rare-predicate filter`).
After the filtering, we manually remove too vague and noisy predicate, and unify same predicates with different names (see the annotation [here](https://huggingface.co/datasets/relbert/t_rex/raw/main/predicate_manual_check.csv)).
Finally, we remove triples that contain enties that has frequency less than 5 (`frequnecy`).
| Dataset | `raw` | `named-entity filter` | `rare-predicate` | `unify-denoise-predicate` | `frequnecy` |
|:----------|-----------:|-----------------------:|-----------------:|--------------------------:|------------:|
| Triples | 20,877,472 | 12,561,573 | 12,561,250 | 12,410,726 | 1,616,065 |
| Predicate | 1,616 | 1,470 | 1,237 | 839 | 839 |
## Dataset Structure
An example looks as follows.
```shell
{
"tail": "Persian",
"head": "Tajik",
"title": "Tandoor bread",
"text": "Tandoor bread (Arabic: \u062e\u0628\u0632 \u062a\u0646\u0648\u0631 khubz tannoor, Armenian: \u0569\u0578\u0576\u056b\u0580 \u0570\u0561\u0581 tonir hats, Azerbaijani: T\u0259ndir \u00e7\u00f6r\u0259yi, Georgian: \u10d7\u10dd\u10dc\u10d8\u10e1 \u10de\u10e3\u10e0\u10d8 tonis puri, Kazakh: \u0442\u0430\u043d\u0434\u044b\u0440 \u043d\u0430\u043d tandyr nan, Kyrgyz: \u0442\u0430\u043d\u0434\u044b\u0440 \u043d\u0430\u043d tandyr nan, Persian: \u0646\u0627\u0646 \u062a\u0646\u0648\u0631\u06cc nan-e-tanuri, Tajik: \u043d\u043e\u043d\u0438 \u0442\u0430\u043d\u0443\u0440\u0439 noni tanuri, Turkish: Tand\u0131r ekme\u011fi, Uyghur: ) is a type of leavened bread baked in a clay oven called a tandoor, similar to naan. In Pakistan, tandoor breads are popular especially in the Khyber Pakhtunkhwa and Punjab regions, where naan breads are baked in tandoor clay ovens fired by wood or charcoal. These tandoor-prepared naans are known as tandoori naan.",
"relation": "[Artifact] is a type of [Type]"
}
```
## Reproduce the Dataset
```shell
git clone https://huggingface.co/datasets/relbert/t_rex
cd t_rex
mkdir data_raw
cd data_raw
cd data_raw
wget https://figshare.com/ndownloader/files/8760241
unzip 8760241
cd ../
python process.py
python unify_predicate.py
python min_entity_filter.py
python create_split.py
```
## Citation Information
```
@inproceedings{elsahar2018t,
title={T-rex: A large scale alignment of natural language with knowledge base triples},
author={Elsahar, Hady and Vougiouklis, Pavlos and Remaci, Arslen and Gravier, Christophe and Hare, Jonathon and Laforest, Frederique and Simperl, Elena},
booktitle={Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018)},
year={2018}
}
```
| relbert/t_rex | [
"multilinguality:monolingual",
"size_categories:n<1K",
"language:en",
"license:other",
"region:us"
]
| 2023-01-25T21:47:54+00:00 | {"language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["n<1K"], "pretty_name": "relbert/t_rex"} | 2023-03-31T20:02:35+00:00 |
915458091f5c6b3b99f325f21bd7edf282436ab0 | jyang/webshop_inst_goal_pairs_il | [
"license:mit",
"region:us"
]
| 2023-01-25T22:09:35+00:00 | {"license": "mit"} | 2023-01-25T22:15:08+00:00 |
|
a318ff293895050b848a95de5c108eeef7528ab3 |
# Dataset Card for Dataset Name
UFSAC: Unification of Sense Annotated Corpora and Tools
## Dataset Description
- **Homepage:** https://github.com/getalp/UFSAC
- **Repository:** https://github.com/getalp/UFSAC
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
### Supported Tasks and Leaderboards
WSD: Word Sense Disambiguation
### Languages
English
## Dataset Structure
### Data Instances
```
{'lemmas': ['_',
'be',
'quite',
'_',
'hefty',
'spade',
'_',
'_',
'bicycle',
'_',
'type',
'handlebar',
'_',
'_',
'spring',
'lever',
'_',
'_',
'rear',
'_',
'_',
'_',
'step',
'on',
'_',
'activate',
'_',
'_'],
'pos_tags': ['PRP',
'VBZ',
'RB',
'DT',
'JJ',
'NN',
',',
'IN',
'NN',
':',
'NN',
'NNS',
'CC',
'DT',
'VBN',
'NN',
'IN',
'DT',
'NN',
',',
'WDT',
'PRP',
'VBP',
'RP',
'TO',
'VB',
'PRP',
'.'],
'sense_keys': ['activate%2:36:00::'],
'target_idx': 25,
'tokens': ['It',
'is',
'quite',
'a',
'hefty',
'spade',
',',
'with',
'bicycle',
'-',
'type',
'handlebars',
'and',
'a',
'sprung',
'lever',
'at',
'the',
'rear',
',',
'which',
'you',
'step',
'on',
'to',
'activate',
'it',
'.']}
```
### Data Fields
```
{'tokens': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),
'lemmas': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),
'pos_tags': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),
'target_idx': Value(dtype='int32', id=None),
'sense_keys': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}
```
### Data Splits
Not split. Use `train` split directly.
| liyucheng/UFSAC | [
"task_categories:token-classification",
"size_categories:1M<n<10M",
"language:en",
"license:cc-by-2.0",
"region:us"
]
| 2023-01-25T22:17:54+00:00 | {"language": ["en"], "license": "cc-by-2.0", "size_categories": ["1M<n<10M"], "task_categories": ["token-classification"]} | 2023-01-26T15:41:19+00:00 |
4cc9063942e93200777c789215afde03f8bf44e0 | # Readme | smearle/pcglm | [
"region:us"
]
| 2023-01-25T22:30:41+00:00 | {} | 2023-03-03T17:53:46+00:00 |
012e0c16a562a127ff5f8d13d9e1ac2c786dc406 | # Dataset Card for "semantic"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 000alen/semantic | [
"region:us"
]
| 2023-01-26T00:47:03+00:00 | {"dataset_info": {"features": [{"name": "text1", "dtype": "string"}, {"name": "text2", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 318338808, "num_examples": 834836}, {"name": "test", "num_bytes": 41559777, "num_examples": 99893}], "download_size": 38916398, "dataset_size": 359898585}} | 2023-01-26T00:47:15+00:00 |
69c9f57eaf694037d930486c59a650370bbd79d6 | h4/LCPCA | [
"task_categories:conversational",
"size_categories:n<1K",
"language:en",
"license:openrail",
"region:us"
]
| 2023-01-26T00:51:24+00:00 | {"language": ["en"], "license": "openrail", "size_categories": ["n<1K"], "task_categories": ["conversational"]} | 2023-01-26T02:56:29+00:00 |
|
ab54d9af682a2052a4345b85dccf9de89afd3674 | # Dataset Card for "bloom-dialogue-generate-ds-en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | svjack/bloom-dialogue-generate-ds-en | [
"region:us"
]
| 2023-01-26T03:05:06+00:00 | {"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "dialogue_text", "dtype": "string"}, {"name": "dialogue", "sequence": "string"}, {"name": "repo", "dtype": "string"}, {"name": "embeddings", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 33783729, "num_examples": 8378}], "download_size": 34957337, "dataset_size": 33783729}} | 2023-01-26T03:08:24+00:00 |
70476aa96efc5b7136f95eb81703ee2e20ee11fc | # BabyLM Dataset
This download includes LM Pretraining data for the 2023 CoNLL/CMCL shared task, [The BabyLM Challenge](https://babylm.github.io/). The (unzipped) data is not large, only ~700MB.
## Contents of this download
- `10M`: 10M-word training set for the *strict-small* track.
- `dev`: Development set for both tracks (10M words)
- `test`: Test set for both tracks (10M words)
Each directory above contains a single `.txt` file from each of the 10 domains listed below.
## Composition of the data
All datasets are sampled from a mixture of 10 data domains, shown below, along with their respective weights in the distributed dataset.
| Source | Weight | Domain | Citation | Website | License |
| --- | --- | --- | --- | --- | --- |
| OpenSubtitles | 30% | Dialogue, Scripted | Lison & Tiedermann (2016) | [link](https://opus.nlpl.eu/OpenSubtitles-v2018.php) | Open source |
| Simple English Wikipedia | 15% | Nonfiction | -- | [link](https://dumps.wikimedia.org/simplewiki/20221201/) | [link](https://dumps.wikimedia.org/legal.html) |
| BNC | 10% | Dialogue | BNC Consortium (2007) | [link](http://www.natcorp.ox.ac.uk/) | [link](http://www.natcorp.ox.ac.uk/docs/licence.html) <sup>1</sup> |
| Project Gutenberg | 10% | Fiction, Nonfiction | Gerlach & Font-Clos (2020) | [link](https://github.com/pgcorpus/gutenberg) | [link](https://www.gutenberg.org/policy/license.html) |
| QED | 10% | Dialogue, Education | Abdelali et al. (2014) | [link](https://opus.nlpl.eu/QED.php) | [link](https://opus.nlpl.eu/QED.php) |
| Wikipedia | 10% | Nonfiction | -- | [link](https://dumps.wikimedia.org/enwiki/20221220/) | [link](https://dumps.wikimedia.org/legal.html) |
| Children's Book Test | 6% | Fiction, Child-Directed | Hill et al. (2016) | [link](https://research.facebook.com/downloads/babi/) | Public domain |
| CHILDES | 4% | Dialogue, Child-Directed | MacWhinney (2000) | | [link](https://talkbank.org/share/rules.html) |
| Children's Stories | 4% | Fiction, Child-Directed | -- | [link](https://www.kaggle.com/datasets/edenbd/children-stories-text-corpus) | Public domain |
| Switchboard | 1% | Dialogue | Godfrey et al. (1992), Stolcke et al., (2000) | [link](http://compprag.christopherpotts.net/swda.html) | [link](http://compprag.christopherpotts.net/swda.html) |
<sup>1</sup> Our distribution of part of the BNC Texts is permitted under the fair dealings provision of copyright law (see term (2g) in the BNC license).
## Data preprocessing
Data was minimally preprocessed to conform to a plain text format. We did not tokenize the data. Documents are not necessarily complete are newline separated.
For documentation of the preprocessing pipeline, consult the following repo: https://github.com/babylm/babylm_data_preprocessing
## References
Abdelali, A., Guzman, F., Sajjad, H., & Vogel, S. (2014). The AMARA Corpus: Building parallel language resources for the educational domain. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC 2014). 1856-1862.
BNC Consortium. (2007). The British National Corpus, XML Edition. Oxford Text Archive, http://hdl.handle.net/20.500.12024/2554.
Gerlach, M., & Font-Clos, F. (2020). A standardized Project Gutenberg corpus for statistical analysis of natural language and quantitative linguistics. Entropy, 22(1), 126.
Godfrey, J. J., Holliman, E. C., & McDaniel, J. (1992). SWITCHBOARD: Telephone speech corpus for research and development. In Acoustics, Speech, and Signal Processing, IEEE International Conference on (Vol. 1, pp. 517-520). IEEE Computer Society.
Hill, F., Bordes, A., Chopra, S., Weston, J. (2016). The Goldilocks principle: Reading children’s books with explicit memory representations. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016).
Lison, P. & Tiedemann, J. (2016). OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016).
MacWhinney, B. (2000). The CHILDES Project: Tools for analyzing talk. Third Edition. Mahwah, NJ: Lawrence Erlbaum Associates.
Stolcke, A., Ries, K., Coccaro, N., Shriberg, E., Bates, R., Jurafsky, D., Taylor, P., Martin, R., Van Ess-Dykema, C., & Meteer, M. (2000). Dialogue act modeling for automatic tagging and recognition of conversational speech. Computational linguistics, 26(3), 339-373.
Tiedemann, J. (2012). Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012). | cambridge-climb/BabyLM | [
"size_categories:10M<n<100M",
"language:en",
"language modeling",
"cognitive modeling",
"region:us"
]
| 2023-01-26T03:05:31+00:00 | {"language": ["en"], "size_categories": ["10M<n<100M"], "pretty_name": "Baby Language Modeling Dataset", "tags": ["language modeling", "cognitive modeling"]} | 2023-11-01T12:11:06+00:00 |
58e2a8898d8ddd5c72e9906077d6392359588d86 | # Dataset Card for "bloom-dialogue-generate-ds-zh"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | svjack/bloom-dialogue-generate-ds-zh | [
"region:us"
]
| 2023-01-26T03:52:16+00:00 | {"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "dialogue_text", "dtype": "string"}, {"name": "dialogue", "sequence": "string"}, {"name": "repo", "dtype": "string"}, {"name": "embeddings", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 98021681, "num_examples": 24297}], "download_size": 101459282, "dataset_size": 98021681}} | 2023-01-26T03:53:12+00:00 |
762a774972db5f16a27057ac7516a5fee2cf2fcc | # Dataset Card for "OxfordPets_test_text_davinci_002_Visclues_ns_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_text_davinci_002_Visclues_ns_10 | [
"region:us"
]
| 2023-01-26T04:48:02+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "raw_prediction", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_1", "num_bytes": 128960.0, "num_examples": 10}], "download_size": 127751, "dataset_size": 128960.0}} | 2023-01-26T04:51:57+00:00 |
5a033fda33afbde2223d2d28ce396e4c74315ac6 | # Dataset Card for "OxfordPets_test_text_davinci_002_Visclues_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_text_davinci_002_Visclues_ns_3669 | [
"region:us"
]
| 2023-01-26T05:06:37+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "raw_prediction", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_5", "num_bytes": 129773283.375, "num_examples": 3669}], "download_size": 120461779, "dataset_size": 129773283.375}} | 2023-01-26T05:06:42+00:00 |
172cd7d323f128722ce38308b76fc8b2d34edd8a | # Dataset Card for "food_asia_2017"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | chaeso/food_asia_2017 | [
"region:us"
]
| 2023-01-26T05:40:01+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "100", "1": "101", "2": "102", "3": "103", "4": "104", "5": "105", "6": "106", "7": "107", "8": "108", "9": "109", "10": "110", "11": "111", "12": "112", "13": "113", "14": "114", "15": "115", "16": "116", "17": "117", "18": "118", "19": "119", "20": "12", "21": "120", "22": "121", "23": "122", "24": "123", "25": "124", "26": "125", "27": "126", "28": "127", "29": "128", "30": "129", "31": "13", "32": "130", "33": "131", "34": "132", "35": "133", "36": "134", "37": "135", "38": "136", "39": "137", "40": "138", "41": "139", "42": "14", "43": "140", "44": "141", "45": "142", "46": "143", "47": "144", "48": "145", "49": "146", "50": "147", "51": "148", "52": "149", "53": "15", "54": "150", "55": "151", "56": "152", "57": "153", "58": "154", "59": "155", "60": "156", "61": "157", "62": "158", "63": "159", "64": "16", "65": "160", "66": "161", "67": "162", "68": "163", "69": "164", "70": "165", "71": "166", "72": "167", "73": "168", "74": "169", "75": "17", "76": "170", "77": "171", "78": "172", "79": "173", "80": "174", "81": "175", "82": "176", "83": "177", "84": "178", "85": "179", "86": "18", "87": "180", "88": "181", "89": "182", "90": "183", "91": "184", "92": "185", "93": "186", "94": "187", "95": "188", "96": "189", "97": "19", "98": "190", "99": "191", "100": "192", "101": "193", "102": "194", "103": "195", "104": "196", "105": "197", "106": "198", "107": "199", "108": "20", "109": "200", "110": "201", "111": "202", "112": "203", "113": "204", "114": "205", "115": "206", "116": "207", "117": "208", "118": "209", "119": "21", "120": "210", "121": "211", "122": "212", "123": "213", "124": "214", "125": "215", "126": "216", "127": "217", "128": "218", "129": "219", "130": "22", "131": "220", "132": "221", "133": "222", "134": "223", "135": "224", "136": "225", "137": "226", "138": "227", "139": "228", "140": "229", "141": "23", "142": "230", "143": "231", "144": "232", "145": "233", "146": "234", "147": "235", "148": "236", "149": "237", "150": "238", "151": "239", "152": "24", "153": "240", "154": "241", "155": "242", "156": "243", "157": "244", "158": "245", "159": "246", "160": "247", "161": "248", "162": "249", "163": "25", "164": "250", "165": "251", "166": "252", "167": "253", "168": "254", "169": "255", "170": "256", "171": "26", "172": "27", "173": "28", "174": "29", "175": "3", "176": "30", "177": "31", "178": "32", "179": "33", "180": "34", "181": "35", "182": "36", "183": "37", "184": "38", "185": "39", "186": "4", "187": "40", "188": "41", "189": "42", "190": "43", "191": "44", "192": "45", "193": "46", "194": "47", "195": "48", "196": "49", "197": "50", "198": "51", "199": "52", "200": "53", "201": "54", "202": "55", "203": "56", "204": "57", "205": "58", "206": "59", "207": "60", "208": "61", "209": "62", "210": "63", "211": "64", "212": "65", "213": "66", "214": "67", "215": "68", "216": "69", "217": "70", "218": "71", "219": "72", "220": "73", "221": "74", "222": "75", "223": "76", "224": "77", "225": "78", "226": "79", "227": "8", "228": "80", "229": "81", "230": "82", "231": "83", "232": "84", "233": "85", "234": "86", "235": "87", "236": "88", "237": "89", "238": "9", "239": "90", "240": "91", "241": "92", "242": "93", "243": "94", "244": "95", "245": "96", "246": "97", "247": "98", "248": "99", "249": "beef_currie", "250": "bibimbob", "251": "donburi", "252": "grilled_eel", "253": "rice", "254": "sushi", "255": "tendong"}}}}], "splits": [{"name": "train", "num_bytes": 408215938.23, "num_examples": 31395}], "download_size": 0, "dataset_size": 408215938.23}} | 2023-01-26T07:26:32+00:00 |
d72f52c5745553ed03a0b3ea3c3421585746e867 |
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Point of Contact:** [Vishal Burman](mailto:[email protected])
### Dataset Summary
This dataset comprises of open-domain question-answer pairs obtained from extracting 150K FAQ URLs from C4 dataset. Please refer to the original [`paper`](https://arxiv.org/abs/1910.10683) and [`dataset card`](https://huggingface.co/datasets/c4) for more details.
You can load C4-FAQs as follows:
```python
from datasets import load_dataset
c4_faqs_dataset = load_dataset("vishal-burman/c4-faqs")
```
### Supported Tasks and Leaderboards
C4-FAQs is mainly intended for open-domain end-to-end question generation. It can also be used for open-domain question answering.
### Languages
C4-FAQs only supports English language.
## Dataset Structure
### Data Instances
An example of a single dataset point:
```python
{'url': 'https://www.brusselsghosts.com/things-to-do-brussels/faq.html', 'faq_pairs': [{'question': 'What should I bring for the tour?', 'answer': 'Nothing special, just be ready to walk for bit and potentially something to protect you from poltergeists and rain. Any kind of amulet or protection stone is also welcome.'}, {'question': 'Can kids join too ?', 'answer': 'Yes, we accept kids from 6 years old and on! We also have a family discount, if you book for 2 adults and 2 kids!'}, {'question': 'Where is the meeting point ?', 'answer': 'Brussels has many paved roads and those are hardly accessible with a wheelchair, for that reason we have to unfortunately label our tour as not wheelchair accessible.'}]}
```
### Data Fields
The data have several fields:
- `url`: URL of the webpage containing the FAQs
- `faq_pairs`: A list of question-answer pairs extracted from the webpage
- `question`: A single question as a string
- `answer`: A single answer to the above question as a string
### Data Splits
| subset | total |
|:-------|:------|
| train | 150K |
## Dataset Creation
### Curation Rationale
The dataset was curated to create end-to-end Question Generation pipelines. A large amount of open-source models use [`SQuAD`](https://huggingface.co/datasets/squad) dataset to create answer-agnostic question generation models. While the questions are valid, they often are short factoid in nature. This dataset is curated from FAQs of websites, which are generally hand-crafted and can be used to further improve generated question quality.
## Additional Information
### Dataset Curators
Original data by [Common Crawl](https://commoncrawl.org/).
### Licensing Information
The original dataset was released under the terms of ODC-BY. By using this, you are also bound by the Common Crawl terms of use in respect of the content contained in the dataset.
### Citation Information
If you use this dataset, I would love to hear about it! Reach out on GitHub, twitter or shoot me an email.
To cite the original `c4` dataset:
```bibtex
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
```
| vishal-burman/c4-faqs | [
"task_categories:text2text-generation",
"task_categories:text-generation",
"task_categories:question-answering",
"task_ids:text-simplification",
"task_ids:language-modeling",
"task_ids:open-domain-qa",
"annotations_creators:no-annotation",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:extended|c4",
"language:en",
"license:odc-by",
"question-generation",
"question_generation",
"open-domain-qg",
"qg",
"arxiv:1910.10683",
"region:us"
]
| 2023-01-26T06:15:58+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["machine-generated"], "language": ["en"], "license": ["odc-by"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["extended|c4"], "task_categories": ["text2text-generation", "text-generation", "question-answering"], "task_ids": ["text-simplification", "language-modeling", "open-domain-qa"], "pretty_name": "C4-FAQs", "tags": ["question-generation", "question_generation", "open-domain-qg", "qg"]} | 2023-02-06T04:35:16+00:00 |
0c8017111a0a11c9c00be9c8675b4691da9a7d7d | b-yukky/msmarco-yesno | [
"license:mit",
"region:us"
]
| 2023-01-26T06:50:28+00:00 | {"license": "mit"} | 2023-01-26T06:51:00+00:00 |
|
1613e58d0cee962487c5871bfa27e957cfb8ff90 | chromeNLP/quality | [
"license:mit",
"region:us"
]
| 2023-01-26T07:34:36+00:00 | {"license": "mit"} | 2023-02-08T04:32:55+00:00 |
|
61419d7f2cec9ca67324f28f6a077582643a037c | #SciNLI: A Corpus for Natural Language Inference on Scientific Text
https://github.com/msadat3/SciNLI
```bib
@inproceedings{sadat-caragea-2022-scinli,
title = "{S}ci{NLI}: A Corpus for Natural Language Inference on Scientific Text",
author = "Sadat, Mobashir and
Caragea, Cornelia",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.511",
pages = "7399--7409",
}
``` | tasksource/scinli | [
"license:apache-2.0",
"region:us"
]
| 2023-01-26T08:35:52+00:00 | {"license": "apache-2.0"} | 2023-01-26T09:34:08+00:00 |
c13f83ea610d0f04c8b6ea50a59339b8204dcd44 | # The Argument Reasoning Comprehension Task: Identification and Reconstruction of Implicit Warrants
https://github.com/UKPLab/argument-reasoning-comprehension-task
```bib
@InProceedings{Habernal.et.al.2018.NAACL.ARCT,
title = {The Argument Reasoning Comprehension Task: Identification
and Reconstruction of Implicit Warrants},
author = {Habernal, Ivan and Wachsmuth, Henning and
Gurevych, Iryna and Stein, Benno},
publisher = {Association for Computational Linguistics},
booktitle = {Proceedings of the 2018 Conference of the North American Chapter
of the Association for Computational Linguistics:
Human Language Technologies, Volume 1 (Long Papers)},
pages = {1930--1940},
month = jun,
year = {2018},
address = {New Orleans, Louisiana},
url = {http://aclweb.org/anthology/N18-1175}
}
``` | tasksource/arct | [
"license:apache-2.0",
"region:us"
]
| 2023-01-26T08:41:15+00:00 | {"license": "apache-2.0"} | 2023-05-15T07:19:50+00:00 |
831c0669039ad418e42d196b22d839cf046281b0 | RKodali/MyEmoIMDB | [
"region:us"
]
| 2023-01-26T08:59:34+00:00 | {} | 2023-01-26T09:35:11+00:00 |
|
7b722853d985102b6ab6fe1dd7e10473945de4d0 | # Dataset Card for "food_chinese_2017"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | chaeso/food_chinese_2017 | [
"region:us"
]
| 2023-01-26T08:59:59+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "100", "1": "101", "2": "102", "3": "103", "4": "104", "5": "105", "6": "106", "7": "107", "8": "108", "9": "109", "10": "110", "11": "111", "12": "112", "13": "113", "14": "114", "15": "115", "16": "116", "17": "117", "18": "118", "19": "119", "20": "12", "21": "120", "22": "121", "23": "122", "24": "123", "25": "124", "26": "125", "27": "126", "28": "127", "29": "128", "30": "129", "31": "13", "32": "130", "33": "131", "34": "132", "35": "133", "36": "134", "37": "135", "38": "136", "39": "137", "40": "138", "41": "139", "42": "14", "43": "140", "44": "141", "45": "142", "46": "143", "47": "144", "48": "145", "49": "146", "50": "147", "51": "148", "52": "149", "53": "15", "54": "150", "55": "151", "56": "152", "57": "153", "58": "154", "59": "155", "60": "156", "61": "157", "62": "158", "63": "159", "64": "16", "65": "160", "66": "161", "67": "162", "68": "163", "69": "164", "70": "165", "71": "166", "72": "167", "73": "168", "74": "169", "75": "17", "76": "170", "77": "171", "78": "172", "79": "173", "80": "174", "81": "175", "82": "176", "83": "177", "84": "178", "85": "179", "86": "18", "87": "180", "88": "181", "89": "182", "90": "183", "91": "184", "92": "185", "93": "186", "94": "187", "95": "188", "96": "189", "97": "19", "98": "190", "99": "191", "100": "192", "101": "193", "102": "194", "103": "195", "104": "196", "105": "197", "106": "198", "107": "199", "108": "20", "109": "200", "110": "201", "111": "202", "112": "203", "113": "204", "114": "205", "115": "206", "116": "207", "117": "208", "118": "209", "119": "21", "120": "210", "121": "211", "122": "212", "123": "213", "124": "214", "125": "215", "126": "216", "127": "217", "128": "218", "129": "219", "130": "22", "131": "220", "132": "221", "133": "222", "134": "223", "135": "224", "136": "225", "137": "226", "138": "227", "139": "228", "140": "229", "141": "23", "142": "230", "143": "231", "144": "232", "145": "233", "146": "234", "147": "235", "148": "236", "149": "237", "150": "238", "151": "239", "152": "24", "153": "240", "154": "241", "155": "242", "156": "243", "157": "244", "158": "245", "159": "246", "160": "247", "161": "248", "162": "249", "163": "25", "164": "250", "165": "251", "166": "252", "167": "253", "168": "254", "169": "255", "170": "256", "171": "26", "172": "27", "173": "28", "174": "29", "175": "3", "176": "30", "177": "31", "178": "32", "179": "33", "180": "34", "181": "35", "182": "36", "183": "37", "184": "38", "185": "39", "186": "4", "187": "40", "188": "41", "189": "42", "190": "43", "191": "44", "192": "45", "193": "46", "194": "47", "195": "48", "196": "49", "197": "50", "198": "51", "199": "52", "200": "53", "201": "54", "202": "55", "203": "56", "204": "57", "205": "58", "206": "59", "207": "60", "208": "61", "209": "62", "210": "63", "211": "64", "212": "65", "213": "66", "214": "67", "215": "68", "216": "69", "217": "70", "218": "71", "219": "72", "220": "73", "221": "74", "222": "75", "223": "76", "224": "77", "225": "78", "226": "79", "227": "8", "228": "80", "229": "81", "230": "82", "231": "83", "232": "84", "233": "85", "234": "86", "235": "87", "236": "88", "237": "89", "238": "9", "239": "90", "240": "91", "241": "92", "242": "93", "243": "94", "244": "95", "245": "96", "246": "97", "247": "98", "248": "99", "249": "beef_currie", "250": "bibimbob", "251": "donburi", "252": "grilled_eel", "253": "rice", "254": "sushi", "255": "tendong"}}}}], "splits": [{"name": "train", "num_bytes": 408076826.985, "num_examples": 31395}, {"name": "test", "num_bytes": 135802193.08, "num_examples": 6660}, {"name": "validation", "num_bytes": 137529971.372, "num_examples": 6734}], "download_size": 677961805, "dataset_size": 681408991.437}} | 2023-01-26T09:21:46+00:00 |
746f83a1f110ee7cd4ca4267f28a9ef044fb8d4b | https://github.com/feng-yufei/Neural-Natural-Logic
```bib
@inproceedings{feng2020exploring,
title={Exploring End-to-End Differentiable Natural Logic Modeling},
author={Feng, Yufei, Ziou Zheng, and Liu, Quan and Greenspan, Michael and Zhu, Xiaodan},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={1172--1185},
year={2020}
}
``` | tasksource/naturallogic | [
"task_categories:text-classification",
"language:en",
"license:apache-2.0",
"region:us"
]
| 2023-01-26T09:49:49+00:00 | {"language": ["en"], "license": "apache-2.0", "task_categories": ["text-classification"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "original_id ", "dtype": "int64"}, {"name": " sent1 ", "dtype": "string"}, {"name": " sent2 ", "dtype": "string"}, {"name": " keyword_before ", "dtype": "string"}, {"name": " relation 1to2 ", "dtype": "string"}, {"name": " pattern ", "dtype": "string"}, {"name": " original_label ", "dtype": "string"}, {"name": " original_genre ", "dtype": "string"}, {"name": " consistent ", "dtype": "bool"}, {"name": " formula ", "dtype": "string"}, {"name": " start_ends ", "dtype": "string"}, {"name": " new_label ", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2011728.0534709194, "num_examples": 6390}], "download_size": 227618, "dataset_size": 2011728.0534709194}} | 2023-12-06T08:23:46+00:00 |
8da1ab1711a5f6d7127391f3d68c449daa5bd540 | ERROR: type should be string, got "https://github.com/IKMLab/arct2\n```bib\n@inproceedings{niven-kao-2019-probing,\n title = \"Probing Neural Network Comprehension of Natural Language Arguments\",\n author = \"Niven, Timothy and\n Kao, Hung-Yu\",\n booktitle = \"Proceedings of the 57th Conference of the Association for Computational Linguistics\",\n month = jul,\n year = \"2019\",\n address = \"Florence, Italy\",\n publisher = \"Association for Computational Linguistics\",\n url = \"https://www.aclweb.org/anthology/P19-1459\",\n pages = \"4658--4664\",\n abstract = \"We are surprised to find that BERT{'}s peak performance of 77{\\%} on the Argument Reasoning Comprehension Task reaches just three points below the average untrained human baseline. However, we show that this result is entirely accounted for by exploitation of spurious statistical cues in the dataset. We analyze the nature of these cues and demonstrate that a range of models all exploit them. This analysis informs the construction of an adversarial dataset on which all models achieve random accuracy. Our adversarial dataset provides a more robust assessment of argument comprehension and should be adopted as the standard in future work.\",\n}\n```" | tasksource/arct2 | [
"task_categories:text-classification",
"language:en",
"license:apache-2.0",
"region:us"
]
| 2023-01-26T10:11:15+00:00 | {"language": ["en"], "license": "apache-2.0", "task_categories": ["text-classification"]} | 2023-01-26T10:15:21+00:00 |
d14fc1e72fa656736f2330a1f9250d4080b69aaa | # Dataset Card for "concatenated_librispeech"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | sanchit-gandhi/concatenated_librispeech | [
"region:us"
]
| 2023-01-26T10:26:12+00:00 | {"dataset_info": {"features": [{"name": "audio", "dtype": "audio"}], "splits": [{"name": "train", "num_bytes": 707889.0, "num_examples": 1}], "download_size": 0, "dataset_size": 707889.0}} | 2023-01-26T11:45:39+00:00 |
c5d7b1bd3da912bb0b3c1ab5c5e619b23103dc32 | # Dataset Card for "USTC_SmokeRS"
## Dataset Description
- **Paper:** [SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention](https://www.mdpi.com/2072-4292/11/14/1702/pdf)
### Licensing Information
For research/education purposes.
## Citation Information
[SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention](https://www.mdpi.com/2072-4292/11/14/1702/pdf)
```
@article{ba2019smokenet,
title = {SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention},
author = {Ba, Rui and Chen, Chen and Yuan, Jing and Song, Weiguo and Lo, Siuming},
year = 2019,
journal = {Remote Sensing},
publisher = {MDPI},
volume = 11,
number = 14,
pages = 1702
}
``` | jonathan-roberts1/USTC_SmokeRS | [
"license:other",
"region:us"
]
| 2023-01-26T10:45:45+00:00 | {"license": "other", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "cloud", "1": "dust", "2": "haze", "3": "land", "4": "seaside", "5": "smoke"}}}}], "splits": [{"name": "train", "num_bytes": 1229029078.725, "num_examples": 6225}], "download_size": 1115042620, "dataset_size": 1229029078.725}} | 2023-03-31T13:56:13+00:00 |
d2eedc6a97dd6af5d46ef0eecfbab37b8d9575cb | # Dataset Card for "identities-dalle-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | SDbiaseval/identities-dalle-2 | [
"region:us"
]
| 2023-01-26T11:15:25+00:00 | {"dataset_info": {"features": [{"name": "ethnicity", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "no", "dtype": "int32"}, {"name": "image_path", "dtype": "string"}, {"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 535524743.0, "num_examples": 680}], "download_size": 416250866, "dataset_size": 535524743.0}} | 2023-01-26T22:33:31+00:00 |
28f10b2c257704f348e2b6241106d4206c218206 | # Dataset Card for "identities-sd-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | SDbiaseval/identities-sd-2 | [
"region:us"
]
| 2023-01-26T11:20:38+00:00 | {"dataset_info": {"features": [{"name": "ethnicity", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "no", "dtype": "int32"}, {"name": "image_path", "dtype": "string"}, {"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 22563834.0, "num_examples": 680}], "download_size": 22470423, "dataset_size": 22563834.0}} | 2023-01-26T22:39:17+00:00 |
e4fd4d399c521d7b805c926205db6f8e2cbfc420 | # Dataset Card for "jobs-sd-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | SDbiaseval/jobs-sd-2 | [
"region:us"
]
| 2023-01-26T11:36:22+00:00 | {"dataset_info": {"features": [{"name": "adjective", "dtype": "string"}, {"name": "profession", "dtype": "string"}, {"name": "no", "dtype": "int32"}, {"name": "image_path", "dtype": "string"}, {"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 1061811457.5, "num_examples": 31500}], "download_size": 1040536722, "dataset_size": 1061811457.5}} | 2023-01-26T12:35:08+00:00 |
390b69fe0abd969dd351d0637b18b1b6e0dd8e26 | # Dataset Card for "default_config"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | polinaeterna/default_config | [
"region:us"
]
| 2023-01-26T12:02:23+00:00 | {"pretty_name": "traktor_dodik", "dataset_info": [{"config_name": "default", "features": [{"name": "x", "dtype": "int64"}, {"name": "y", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 93, "num_examples": 6}, {"name": "test", "num_bytes": 28, "num_examples": 2}], "download_size": 1703, "dataset_size": 121}, {"config_name": "v2", "features": [{"name": "x", "dtype": "int64"}, {"name": "y", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 56, "num_examples": 4}, {"name": "test", "num_bytes": 14, "num_examples": 1}], "download_size": 0, "dataset_size": 70}]} | 2023-01-26T16:18:29+00:00 |
e275e545ec573b19bf183bdc566d02ef5e9c3065 | # Dataset Card for "hh_eval_ilql"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | reciprocate/hh_eval_ilql | [
"region:us"
]
| 2023-01-26T12:48:28+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "ilql_hh_125M", "dtype": "string"}, {"name": "ilql_hh_1B", "dtype": "string"}, {"name": "ilql_hh_6B", "dtype": "string"}, {"name": "ilql_hh_20B", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 170467, "num_examples": 100}], "download_size": 108160, "dataset_size": 170467}} | 2023-01-26T12:48:54+00:00 |
48a4df4d99673944db3eaabbf12d2a31348e98f3 | # Dataset Card for "Teamp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | aryanlath/Teamp | [
"region:us"
]
| 2023-01-26T13:06:09+00:00 | {"dataset_info": {"features": [{"name": "pixel_values", "dtype": "image"}, {"name": "label", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 85286.0, "num_examples": 1}], "download_size": 0, "dataset_size": 85286.0}} | 2023-01-26T13:09:34+00:00 |
c27fb4ee81e7b65e534a510ff76a2e694c053650 | huggingface-projects/temp-match-results | [
"license:mit",
"region:us"
]
| 2023-01-26T13:16:21+00:00 | {"license": "mit"} | 2023-11-16T20:35:57+00:00 |
|
6bae908ff21c13d14c13199435d9811184ee5822 | vballoli/D4RL | [
"license:cc-by-4.0",
"region:us"
]
| 2023-01-26T14:23:52+00:00 | {"license": "cc-by-4.0"} | 2023-01-26T14:23:52+00:00 |
|
f91928829ad1815bfd8393a17eeeaed1ffe51993 | # Dataset Card for "Unlabelled_Seg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | aryanlath/Unlabelled_Seg | [
"region:us"
]
| 2023-01-26T14:26:29+00:00 | {"dataset_info": {"features": [{"name": "pixel_values", "dtype": "image"}, {"name": "label", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 17399091.0, "num_examples": 138}], "download_size": 17243457, "dataset_size": 17399091.0}} | 2023-01-26T14:26:39+00:00 |
fc75b07adbf817d7b8875ac23f3542ace8c00c6f | # Dataset Card for "summarize_eval_ilql"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | reciprocate/summarize_eval_ilql | [
"region:us"
]
| 2023-01-26T14:51:13+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "ilql_summarize_125M", "dtype": "string"}, {"name": "ilql_summarize_1B", "dtype": "string"}, {"name": "ilql_summarize_6B", "dtype": "string"}, {"name": "ilql_summarize_20B", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 190740, "num_examples": 100}], "download_size": 131602, "dataset_size": 190740}} | 2023-01-26T14:51:42+00:00 |
3e948872ae78b18cf93370d7eaaa0a2579715a55 | # Dataset Card for "OxfordPets_test_text_davinci_002_Attributes_Caption_ns_300"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_text_davinci_002_Attributes_Caption_ns_300 | [
"region:us"
]
| 2023-01-26T15:08:19+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "raw_prediction", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_5", "num_bytes": 10666447.0, "num_examples": 300}], "download_size": 10031431, "dataset_size": 10666447.0}} | 2023-01-26T15:08:22+00:00 |
a16da9840a55b9ac85e737090a6a1b1ea44f4bc8 | # Dataset Card for "OxfordPets_test_text_davinci_002_Visclues_ns_300"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_text_davinci_002_Visclues_ns_300 | [
"region:us"
]
| 2023-01-26T15:09:48+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "raw_prediction", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_10", "num_bytes": 11471423.0, "num_examples": 300}, {"name": "fewshot_15", "num_bytes": 12083140.0, "num_examples": 300}, {"name": "fewshot_12", "num_bytes": 11719304.0, "num_examples": 300}, {"name": "fewshot_5", "num_bytes": 10858509.0, "num_examples": 300}], "download_size": 40683194, "dataset_size": 46132376.0}} | 2023-01-26T15:46:31+00:00 |
12cb2b33a749314f2180384154f9d541f65687f2 |
# Dataset Summary
**hystoclass** (hybrid social text and tabular classification)has been collected from Instagram stories with privacy in mind. In addition to the texts published in the stories, this dataset has graphic features such as background color, text color, and font. also has a Textual feature named 'content' in the Persian language.
# Classes
This dataset is divided into **18 classes** by human supervision:
Event, Political, Advertising and business, Romantic, Motivational, Literature, Social Networks, Scientific, Social, IT, Advices, Academic, Cosmetic and Feminine, Religious, Sport, Property and housing, Tourism and Medical.
[Github](https://github.com/pooyaphoenix/hystoclass)
[Email](https://[email protected])
| pooyaphoenix/hystoclass | [
"task_categories:text-classification",
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:fa",
"license:openrail",
"tabular_data",
"Text Classification",
"Social Networks",
"Ensemble Learning",
"region:us"
]
| 2023-01-26T15:12:55+00:00 | {"language": ["fa"], "license": "openrail", "size_categories": ["1K<n<10K"], "task_categories": ["text-classification", "token-classification"], "pretty_name": "hystoclass", "tags": ["tabular_data", "Text Classification", "Social Networks", "Ensemble Learning"]} | 2023-02-10T09:55:36+00:00 |
90763dfee177aca8ee44f0a750e8124119b61d39 | # Dataset Card for "OxfordPets_test_text_davinci_003_Visclues_ns_300"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_text_davinci_003_Visclues_ns_300 | [
"region:us"
]
| 2023-01-26T15:43:17+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "raw_prediction", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_12", "num_bytes": 11719655.0, "num_examples": 300}, {"name": "fewshot_5", "num_bytes": 10858951.0, "num_examples": 300}], "download_size": 20270915, "dataset_size": 22578606.0}} | 2023-01-26T15:44:30+00:00 |
9ebf0a6a4f50fb99f6fb9e47f80f0dc79ae4deb8 | # Dataset Card for "nllb-eng-tgl-12k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Ramos-Ramos/nllb-eng-tgl-12k | [
"region:us"
]
| 2023-01-26T15:50:21+00:00 | {"dataset_info": {"features": [{"name": "translation", "dtype": {"translation": {"languages": ["eng_Latn", "tgl_Latn"]}}}, {"name": "laser_score", "dtype": "float32"}, {"name": "source_sentence_lid", "dtype": "float32"}, {"name": "target_sentence_lid", "dtype": "float32"}, {"name": "source_sentence_source", "dtype": "string"}, {"name": "source_sentence_url", "dtype": "string"}, {"name": "target_sentence_source", "dtype": "string"}, {"name": "target_sentence_url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5795415, "num_examples": 12000}], "download_size": 2811921, "dataset_size": 5795415}} | 2023-01-26T15:50:24+00:00 |
47c04abe372718066681b600f65db85cf8a4ff4b |
# VUA20
## Dataset Description
- **Paper:** [A Report on the 2020 VUA and TOEFL Metaphor Detection Shared Task](https://aclanthology.org/2020.figlang-1.3/)
### Dataset Summary
Creative Language Toolkit (CLTK) Metadata
- CL Type: Metaphor
- Task Type: detection
- Size: 200k
- Created time: 2020
VUA20 is (**perhaps**) the largest dataset of metaphor detection used in Figlang2020 workshop.
For the details of this dataset, we refer you to the release [paper](https://aclanthology.org/2020.figlang-1.3/).
The annotation method of VUA20 is elabrated in the paper of [MIP](https://www.tandfonline.com/doi/abs/10.1080/10926480709336752).
### Citation Information
If you find this dataset helpful, please cite:
```
@inproceedings{Leong2020ARO,
title={A Report on the 2020 VUA and TOEFL Metaphor Detection Shared Task},
author={Chee Wee Leong and Beata Beigman Klebanov and Chris Hamill and Egon W. Stemle and Rutuja Ubale and Xianyang Chen},
booktitle={FIGLANG},
year={2020}
}
```
### Contributions
If you have any queries, please open an issue or direct your queries to [mail](mailto:[email protected]). | CreativeLang/vua20_metaphor | [
"license:cc-by-2.0",
"region:us"
]
| 2023-01-26T16:18:53+00:00 | {"license": "cc-by-2.0"} | 2023-06-27T12:51:59+00:00 |
96d1eed0e41ef32a091c000098cb47a0dc226d65 |
This repository contains various Tamazight language datasets created by [Col·lectivaT](https://www.collectivat.cat) in collaboration with CIEMEN and with funding from Municipality of Barcelona and Government of Catalonia.
Under `mono` you can find monolingual sentences.
- `tc_wajdm_v1.txt` - Texts from language learning material “tc wawjdm”
- `IRCAM-clean-tifinagh.txt` - Tifinagh scripted sentences extracted from [IRCAM's text corpus](https://tal.ircam.ma/talam/corpus.php)
Under `parallel` you can find sentences with translations in Catalan, English and Spanish.
- `tatoeba-translit` contains parallel sentences from Tatoeba.org transliterated into Tifinagh.
- `proverbs` contains Tamazight proverbs with translations in Catalan.
| collectivat/amazic | [
"task_categories:translation",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:zgh",
"language:fr",
"language:ca",
"language:en",
"language:es",
"license:cc-by-2.0",
"region:us"
]
| 2023-01-26T16:33:26+00:00 | {"language": ["zgh", "fr", "ca", "en", "es"], "license": "cc-by-2.0", "size_categories": ["100K<n<1M"], "task_categories": ["translation", "text-generation"], "pretty_name": "Tamazight language data"} | 2023-07-27T09:56:40+00:00 |
10e2ecc2882a108819959a062ca7b1a528d6999f | # Dataset Card for "Caltech101_not_background_test_facebook_opt_125m_Attributes_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_125m_Attributes_ns_5647 | [
"region:us"
]
| 2023-01-26T17:08:17+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84088557.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85276022.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 87656291.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 90034037.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 93580093.125, "num_examples": 5647}], "download_size": 415553691, "dataset_size": 440635000.625}} | 2023-01-27T09:38:09+00:00 |
62942e9f6505d5a5e90fa4f675f7c4c1689dfe67 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_350m_Attributes_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_350m_Attributes_ns_5647 | [
"region:us"
]
| 2023-01-26T17:32:11+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84091856.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85276115.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 87656033.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 90033855.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 93580332.125, "num_examples": 5647}], "download_size": 415578350, "dataset_size": 440638191.625}} | 2023-01-27T09:56:58+00:00 |
17fca26fa60bd5b68e3b931516a83adcc1404004 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_1.3b_Attributes_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_1.3b_Attributes_ns_5647 | [
"region:us"
]
| 2023-01-26T17:41:52+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84091875.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85275969.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 87655782.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 90033051.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 93578765.125, "num_examples": 5647}], "download_size": 415550337, "dataset_size": 440635442.625}} | 2023-01-27T10:29:33+00:00 |
3fee92c9d1d9aac33c567e169877f73b3656a9c9 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_2.7b_Attributes_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_2.7b_Attributes_ns_5647 | [
"region:us"
]
| 2023-01-26T17:54:58+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84092194.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85276120.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 87656119.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 90033173.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 93579321.125, "num_examples": 5647}], "download_size": 415540728, "dataset_size": 440636927.625}} | 2023-01-27T11:22:15+00:00 |
2dcadcaa34528d6688508d5da3cc5a1416a516cd | # Dataset Card for "Caltech101_not_background_test_facebook_opt_125m_Attributes_Caption_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_125m_Attributes_Caption_ns_5647 | [
"region:us"
]
| 2023-01-26T18:09:31+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84344156.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85792185.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 88692887.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 91584891.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 95914176.125, "num_examples": 5647}], "download_size": 416469739, "dataset_size": 446328295.625}} | 2023-01-27T11:36:31+00:00 |
68d58fdd810bd3737c9c98f62721875f14c92052 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_350m_Attributes_Caption_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_350m_Attributes_Caption_ns_5647 | [
"region:us"
]
| 2023-01-26T18:23:45+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84345940.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85792356.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 88692846.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 91584840.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 95914371.125, "num_examples": 5647}], "download_size": 416501462, "dataset_size": 446330353.625}} | 2023-01-27T11:58:07+00:00 |
3995288fed4000de6792377a98038ccf36c604ea | # Dataset Card for "Caltech101_not_background_test_facebook_opt_1.3b_Attributes_Caption_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_1.3b_Attributes_Caption_ns_5647 | [
"region:us"
]
| 2023-01-26T18:35:01+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84346377.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85792216.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 88692718.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 91584252.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 95913089.125, "num_examples": 5647}], "download_size": 416449265, "dataset_size": 446328652.625}} | 2023-01-27T12:39:10+00:00 |
a26beb13be2d7b00b62c07ce715b877836323b7f | # Dataset Card for "Caltech101_not_background_test_facebook_opt_2.7b_Attributes_Caption_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_2.7b_Attributes_Caption_ns_5647 | [
"region:us"
]
| 2023-01-26T18:52:00+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84346848.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 85792300.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 88692841.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 91584503.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 95913670.125, "num_examples": 5647}], "download_size": 416433288, "dataset_size": 446330162.625}} | 2023-01-27T13:47:21+00:00 |
3e1ff12ee975fa866b8c6d0352b0384ea7a3ef4e | # Dataset Card for "test_meta_dump"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | polinaeterna/test_meta_dump | [
"region:us"
]
| 2023-01-26T18:54:51+00:00 | {"dataset_info": [{"config_name": "single", "features": [{"name": "x", "dtype": "int64"}, {"name": "y", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 360, "num_examples": 20}], "download_size": 0, "dataset_size": 360}, {"config_name": "v1", "features": [{"name": "x", "dtype": "int64"}, {"name": "y", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 93, "num_examples": 6}, {"name": "test", "num_bytes": 28, "num_examples": 2}], "download_size": 0, "dataset_size": 121}, {"config_name": "v2", "features": [{"name": "x", "dtype": "int64"}, {"name": "y", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 56, "num_examples": 4}, {"name": "test", "num_bytes": 14, "num_examples": 1}], "download_size": 1673, "dataset_size": 70}], "configs_kwargs": [{"config_name": "single", "data_dir": "single"}, {"config_name": "v1", "data_dir": "v1"}, {"config_name": "v2", "data_dir": "v2"}]} | 2023-01-27T18:20:18+00:00 |
b3831f98a3589ad2083fa27ed7e659ffb2a48ec8 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_125m_Visclues_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_125m_Visclues_ns_5647 | [
"region:us"
]
| 2023-01-26T18:58:39+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84810527.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 86719159.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 90542895.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 94355222.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 100059276.125, "num_examples": 5647}], "download_size": 418833711, "dataset_size": 456487079.625}} | 2023-01-27T14:07:24+00:00 |
6d1d7a701f68b1126908169b40a4e00253ae8d53 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_350m_Visclues_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_350m_Visclues_ns_5647 | [
"region:us"
]
| 2023-01-26T19:08:18+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84812320.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 86719140.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 90542803.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 94355249.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 100059471.125, "num_examples": 5647}], "download_size": 418860890, "dataset_size": 456488983.625}} | 2023-01-27T14:38:19+00:00 |
2492d638ab77251333818e72e5601df701c91591 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_1.3b_Visclues_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_1.3b_Visclues_ns_5647 | [
"region:us"
]
| 2023-01-26T19:22:50+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84811910.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 86719029.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 90542558.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 94354619.125, "num_examples": 5647}, {"name": "fewshot_8_bs_16", "num_bytes": 100058064.125, "num_examples": 5647}], "download_size": 418819193, "dataset_size": 456486180.625}} | 2023-01-27T15:39:11+00:00 |
6400a0d39aab6b23746b4d82d3e5261f66d4c127 | # Dataset Card for "Caltech101_not_background_test_facebook_opt_2.7b_Visclues_ns_5647"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/Caltech101_not_background_test_facebook_opt_2.7b_Visclues_ns_5647 | [
"region:us"
]
| 2023-01-26T19:45:27+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 84812225.125, "num_examples": 5647}, {"name": "fewshot_1_bs_16", "num_bytes": 86719164.125, "num_examples": 5647}, {"name": "fewshot_3_bs_16", "num_bytes": 90542888.125, "num_examples": 5647}, {"name": "fewshot_5_bs_16", "num_bytes": 94354856.125, "num_examples": 5647}], "download_size": 333860025, "dataset_size": 356429133.5}} | 2023-01-27T09:25:26+00:00 |
50b7b548754ab0ab3c8334c43030fdc0ee07f673 | ChristophSchuhmann/essays-with-instructions | [
"license:apache-2.0",
"region:us"
]
| 2023-01-26T21:57:19+00:00 | {"license": "apache-2.0"} | 2023-01-26T21:59:21+00:00 |
|
6c258c8c477a799c95246cca4cf8bf734d3c36ad |
# ChatGPT-Prompts Dataset
## Description
This dataset aims to provide an evaluation data for the Language Models to come. It has been generated using [LearnGPT website](https://www.emergentmind.com/).
| MohamedRashad/ChatGPT-prompts | [
"region:us"
]
| 2023-01-26T22:32:41+00:00 | {} | 2023-01-26T22:54:31+00:00 |
aede56159c7772e274dc42493b93348e3c0d3575 | # Dataset Card for "mls_ada_embeddings"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | juancopi81/mls_ada_embeddings | [
"region:us"
]
| 2023-01-26T22:34:59+00:00 | {"dataset_info": {"features": [{"name": "TITLE", "dtype": "string"}, {"name": "URL", "dtype": "string"}, {"name": "TRANSCRIPTION", "dtype": "string"}, {"name": "transcription_length", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "ada_embedding", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 16124584, "num_examples": 410}], "download_size": 10343619, "dataset_size": 16124584}} | 2023-01-26T22:35:02+00:00 |
1683438c06644071153f08fc11f69d9c47ffacea | cyrilzhang/ace | [
"license:mit",
"region:us"
]
| 2023-01-26T23:07:20+00:00 | {"license": "mit"} | 2023-01-27T23:39:01+00:00 |
|
169da140fe10e57ca303c4f9b0d309be088bb309 | # Dataset Card for "methods2test_raw_grouped_tok"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | dembastu/methods2test_raw_grouped_tok | [
"region:us"
]
| 2023-01-26T23:43:03+00:00 | {"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 1110668740, "num_examples": 631120}], "download_size": 361945934, "dataset_size": 1110668740}} | 2023-01-26T23:43:19+00:00 |
b53a0458983714e1488b7a781a460232af20c6f0 | # Dataset Card for "methods2test_raw_grouped_block_tok"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | dembastu/methods2test_raw_grouped_block_tok | [
"region:us"
]
| 2023-01-26T23:44:42+00:00 | {"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 3112626976, "num_examples": 1857176}], "download_size": 818802194, "dataset_size": 3112626976}} | 2023-01-27T01:31:14+00:00 |
09d397ade5a344c568b4cea7936693a030e742cf | RoRuDi - Romanian Rules for Dialects | fmi-unibuc/RoRuDi | [
"task_categories:translation",
"size_categories:n<1K",
"language:ro",
"region:us"
]
| 2023-01-27T00:07:04+00:00 | {"language": ["ro"], "size_categories": ["n<1K"], "task_categories": ["translation"]} | 2023-01-27T15:29:04+00:00 |
205ba26c7c8c4f60ba8278be334e8f1ec9209f52 | RoAcReL - Romanian Archaisms Regionalisms Lexicon | fmi-unibuc/RoAcReL | [
"language:ro",
"region:us"
]
| 2023-01-27T00:08:17+00:00 | {"language": ["ro"]} | 2023-01-27T15:27:46+00:00 |
af4de0a7631e69ee6c0691ece10b776e73b04347 |
# Dataset Card for WikiHow Lists
### Dataset Summary
Contains CSV of a subset of WikiHow articles.
Subsets include articles that have summaries in numbered list format, unordered list of ingredients, or unordered list of items needed for the article.
CSV contains a pageId to reference back to the source, title of the article, result with the list data, and a column specifying the result type (ingredient, needed items, summary)
### Licensing Information
Data is from WikiHow, license for content is located here
https://www.wikihow.com/wikiHow:Creative-Commons | b-mc2/wikihow_lists | [
"task_categories:summarization",
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-nc-sa-3.0",
"lists",
"bullets",
"steps",
"summary",
"region:us"
]
| 2023-01-27T00:36:11+00:00 | {"language": ["en"], "license": "cc-by-nc-sa-3.0", "size_categories": ["10K<n<100K"], "task_categories": ["summarization", "question-answering"], "pretty_name": "wikihow_lists", "tags": ["lists", "bullets", "steps", "summary"]} | 2023-01-27T00:50:59+00:00 |
b00c4292fbc2e03be93809ea0c41445f294f81fc | # Dataset Card for "tib_slides"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | gigant/tib_slides | [
"region:us"
]
| 2023-01-27T01:44:02+00:00 | {"dataset_info": {"features": [{"name": "Image", "dtype": "image"}, {"name": "file_name", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 131956494917.654, "num_examples": 484843}], "download_size": 0, "dataset_size": 131956494917.654}} | 2023-03-25T14:28:21+00:00 |
1d1a6ceafa2c2c9d4dced64b2f70480677d051db | # Dataset Card for "trading_card_display_classification_1_5k_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | connorhoehn/trading_card_display_classification_1_5k_v3 | [
"region:us"
]
| 2023-01-27T02:01:08+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "grid", "1": "solo", "2": "spread", "3": "stack"}}}}], "splits": [{"name": "train", "num_bytes": 1127230775.103, "num_examples": 1249}, {"name": "test", "num_bytes": 155934991.0, "num_examples": 307}], "download_size": 1317201819, "dataset_size": 1283165766.103}} | 2023-01-27T02:06:10+00:00 |
45d054296fd0594d3544acf624a3cd11c2c9e50e | TheSeriousProgrammer/spoken_words_en_ml_commons_filtered_split | [
"task_categories:audio-classification",
"language:en",
"license:mit",
"audio",
"region:us"
]
| 2023-01-27T03:54:25+00:00 | {"language": ["en"], "license": "mit", "task_categories": ["audio-classification"], "tags": ["audio"]} | 2023-01-27T04:37:54+00:00 |
|
e389fcd654e99d14033325da41cc0369a8181c5a |
# Wadhwani AI Pest Management Open Data
This dataset is a Hugging Face adaptor to the official dataset [hosted
on
Github](https://github.com/wadhwani-ai/pest-management-opendata). Please
refer to that repository for detailed and up-to-date documentation.
## Usage
This dataset is large. It is strongly recommended users access it as a
stream:
```python
from datasets import load_dataset
dataset = load_dataset('wadhwani-ai/pest-management-opendata', streaming=True)
```
Bounding boxes are stored as geospatial types. Once loaded, they can be
read as follows:
```python
from shapely.wkb import loads
for (s, data) in dataset.items():
for d in data:
pests = d['pests']
iterable = map(pests.get, ('label', 'geometry'))
for (i, j) in zip(*iterable):
geom = loads(j)
print(i, geom.bounds)
```
The bounds of a geometry are what most object detection systems
require. See the [Shapely
documentation](https://shapely.readthedocs.io/en/stable/manual.html#object.bounds)
for more.
| wadhwani-ai/pest-management-opendata | [
"license:apache-2.0",
"region:us"
]
| 2023-01-27T04:33:23+00:00 | {"license": "apache-2.0"} | 2023-06-02T08:25:17+00:00 |
aef17401c56653155a024ac4f6e6cd8e0400791f | category3/PDBookCovers | [
"license:cc0-1.0",
"region:us"
]
| 2023-01-27T05:09:03+00:00 | {"license": "cc0-1.0"} | 2023-01-27T05:09:04+00:00 |
|
1a56be70e435aff162234895c04b269d0e9e9700 | # Dataset Card for "OxfordPets_test_facebook_opt_125m_Attributes_ns_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_125m_Attributes_ns_10 | [
"region:us"
]
| 2023-01-27T05:57:37+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_1_bs_16", "num_bytes": 123008.0, "num_examples": 10}], "download_size": 0, "dataset_size": 123008.0}} | 2023-01-27T06:01:48+00:00 |
0929957d884b2e67e49ad3de65ea0c5eaf6747c5 | # Dataset Card for "OxfordPets_test_facebook_opt_6.7b_Attributes_ns_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_6.7b_Attributes_ns_10 | [
"region:us"
]
| 2023-01-27T06:24:50+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_1_bs_16", "num_bytes": 123008.0, "num_examples": 10}], "download_size": 122342, "dataset_size": 123008.0}} | 2023-01-27T06:24:53+00:00 |
eec3a6e8186f53efddbcb856c94ab6cec24b5803 | ashutoshmondal/katana | [
"license:bigscience-openrail-m",
"region:us"
]
| 2023-01-27T06:40:07+00:00 | {"license": "bigscience-openrail-m"} | 2023-01-27T10:43:56+00:00 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.