
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
aadb0061d3c7863529ce2a47bbf2353c2d1223d1 | Joe02/mizushima_oonari | [
"license:other",
"region:us"
]
| 2023-01-24T08:19:11+00:00 | {"license": "other"} | 2023-01-24T08:37:41+00:00 |
|
5f9ed9a1790bafe23dc3f84710602b4bb3a137ef |
```
@inproceedings{yanaka-etal-2019-neural,
title = "Can Neural Networks Understand Monotonicity Reasoning?",
author = "Yanaka, Hitomi and
Mineshima, Koji and
Bekki, Daisuke and
Inui, Kentaro and
Sekine, Satoshi and
Abzianidze, Lasha and
Bos, Johan",
booktitle = "Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP",
year = "2019",
pages = "31--40",
}
```
| tasksource/monotonicity-entailment | [
"license:apache-2.0",
"region:us"
]
| 2023-01-24T08:29:45+00:00 | {"license": "apache-2.0"} | 2023-01-24T08:35:27+00:00 |
a450ba4b1b6d2216c3674d3e576b2e85ce729add |
# Dataset Card for NusaX-Senti
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [GitHub](https://github.com/IndoNLP/nusax/tree/main/datasets/sentiment)
- **Paper:** [EACL 2022](https://arxiv.org/abs/2205.15960)
- **Point of Contact:** [GitHub](https://github.com/IndoNLP/nusax/tree/main/datasets/sentiment)
### Dataset Summary
NusaX is a high-quality multilingual parallel corpus that covers 12 languages, Indonesian, English, and 10 Indonesian local languages, namely Acehnese, Balinese, Banjarese, Buginese, Madurese, Minangkabau, Javanese, Ngaju, Sundanese, and Toba Batak.
NusaX-Senti is a 3-labels (positive, neutral, negative) sentiment analysis dataset for 10 Indonesian local languages + Indonesian and English.
### Supported Tasks and Leaderboards
- Sentiment analysis for Indonesian languages
### Languages
- ace: acehnese,
- ban: balinese,
- bjn: banjarese,
- bug: buginese,
- eng: english,
- ind: indonesian,
- jav: javanese,
- mad: madurese,
- min: minangkabau,
- nij: ngaju,
- sun: sundanese,
- bbc: toba_batak,
## Dataset Creation
### Curation Rationale
There is a shortage of NLP research and resources for the Indonesian languages, despite the country having over 700 languages. With this in mind, we have created this dataset to support future research for the underrepresented languages in Indonesia.
### Source Data
#### Initial Data Collection and Normalization
NusaX-senti is a dataset for sentiment analysis in Indonesian that has been expertly translated by native speakers.
#### Who are the source language producers?
The data was produced by humans (native speakers).
### Annotations
#### Annotation process
NusaX-senti is derived from SmSA, which is the biggest publicly available dataset for Indonesian sentiment analysis. It comprises of comments and reviews from multiple online platforms. To ensure the quality of our dataset, we have filtered it by removing any abusive language and personally identifying information by manually reviewing all sentences. To ensure balance in the label distribution, we randomly picked 1,000 samples through stratified sampling and then translated them to the corresponding languages.
#### Who are the annotators?
Native speakers of both Indonesian and the corresponding languages.
Annotators were compensated based on the number of translated samples.
### Personal and Sensitive Information
Personal information is removed.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
NusaX is created from review text. These data sources may contain some bias.
### Other Known Limitations
No other known limitations
## Additional Information
### Licensing Information
CC-BY-SA 4.0.
Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
ShareAlike — If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
Please contact authors for any information on the dataset.
### Citation Information
```
@misc{winata2022nusax,
title={NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages},
author={Winata, Genta Indra and Aji, Alham Fikri and Cahyawijaya,
Samuel and Mahendra, Rahmad and Koto, Fajri and Romadhony,
Ade and Kurniawan, Kemal and Moeljadi, David and Prasojo,
Radityo Eko and Fung, Pascale and Baldwin, Timothy and Lau,
Jey Han and Sennrich, Rico and Ruder, Sebastian},
year={2022},
eprint={2205.15960},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@afaji](https://github.com/afaji) for adding this dataset.
| indonlp/NusaX-senti | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:multilingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:ace",
"language:ban",
"language:bjn",
"language:bug",
"language:en",
"language:id",
"language:jv",
"language:mad",
"language:min",
"language:nij",
"language:su",
"language:bbc",
"license:cc-by-sa-4.0",
"arxiv:2205.15960",
"region:us"
]
| 2023-01-24T09:28:21+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["ace", "ban", "bjn", "bug", "en", "id", "jv", "mad", "min", "nij", "su", "bbc"], "license": ["cc-by-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["sentiment-classification"], "pretty_name": "NusaX-senti", "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "lang", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "negative", "1": "neutral", "2": "positive"}}}}]}} | 2023-01-24T17:02:06+00:00 |
711fcc4879e8e6010da56433da578c47fd8b50ad | itsmeshaktisingh/images | [
"license:openrail",
"region:us"
]
| 2023-01-24T09:50:27+00:00 | {"license": "openrail"} | 2023-01-24T10:01:06+00:00 |
|
e3ee8eaae30a7e5d7fd343e82013bcdaf17116ce | # California Burned Areas Dataset
**Working on adding more data**
## Dataset Description
- **Paper:** [Pre-Print](https://arxiv.org/abs/2401.11519) and [Version of Record](https://ieeexplore.ieee.org/document/10261881)
### Dataset Summary
This dataset contains images from Sentinel-2 satellites taken before and after a wildfire.
The ground truth masks are provided by the California Department of Forestry and Fire Protection and they are mapped on the images.
### Supported Tasks
The dataset is designed to do binary semantic segmentation of burned vs unburned areas.
## Dataset Structure
We opted to use HDF5 to grant better portability and lower file size than GeoTIFF.
### Dataset opening
Using the dataset library, you download only the pre-patched raw version for simplicity.
```python
from dataset import load_dataset
# There are two available configurations, "post-fire" and "pre-post-fire."
dataset = load_dataset("DarthReca/california_burned_areas", name="post-fire")
```
The dataset was compressed using `h5py` and BZip2 from `hdf5plugin`. **WARNING: `hdf5plugin` is necessary to extract data**.
### Data Instances
Each matrix has a shape of 5490x5490xC, where C is 12 for pre-fire and post-fire images, while it is 0 for binary masks.
Pre-patched version is provided with matrices of size 512x512xC, too. In this case, only mask with at least one positive pixel is present.
You can find two versions of the dataset: _raw_ (without any transformation) and _normalized_ (with data normalized in the range 0-255).
Our suggestion is to use the _raw_ version to have the possibility to apply any wanted pre-processing step.
### Data Fields
In each standard HDF5 file, you can find post-fire, pre-fire images, and binary masks. The file is structured in this way:
```bash
├── foldn
│ ├── uid0
│ │ ├── pre_fire
│ │ ├── post_fire
│ │ ├── mask
│ ├── uid1
│ ├── post_fire
│ ├── mask
│
├── foldm
├── uid2
│ ├── post_fire
│ ├── mask
├── uid3
├── pre_fire
├── post_fire
├── mask
...
```
where `foldn` and `foldm` are fold names and `uidn` is a unique identifier for the wildfire.
For the pre-patched version, the structure is:
```bash
root
|
|-- uid0_x: {post_fire, pre_fire, mask}
|
|-- uid0_y: {post_fire, pre_fire, mask}
|
|-- uid1_x: {post_fire, mask}
|
...
```
the fold name is stored as an attribute.
### Data Splits
There are 5 random splits whose names are: 0, 1, 2, 3, and 4.
### Source Data
Data are collected directly from Copernicus Open Access Hub through the API. The band files are aggregated into one single matrix.
## Additional Information
### Licensing Information
This work is under OpenRAIL license.
### Citation Information
If you plan to use this dataset in your work please give the credit to Sentinel-2 mission and the California Department of Forestry and Fire Protection and cite using this BibTex:
```
@ARTICLE{cabuar,
author={Cambrin, Daniele Rege and Colomba, Luca and Garza, Paolo},
journal={IEEE Geoscience and Remote Sensing Magazine},
title={CaBuAr: California burned areas dataset for delineation [Software and Data Sets]},
year={2023},
volume={11},
number={3},
pages={106-113},
doi={10.1109/MGRS.2023.3292467}
}
``` | DarthReca/california_burned_areas | [
"task_categories:image-segmentation",
"size_categories:n<1K",
"license:openrail",
"climate",
"arxiv:2401.11519",
"doi:10.57967/hf/0389",
"region:us"
]
| 2023-01-24T10:31:47+00:00 | {"license": "openrail", "size_categories": ["n<1K"], "task_categories": ["image-segmentation"], "pretty_name": "California Burned Areas", "tags": ["climate"]} | 2024-01-23T09:41:05+00:00 |
71e465b80cb7e61e7237236283ab210ffda6b706 | # Dataset Card for NB Tale, module 1 and 2 (< 15 sec. segments)
## Dataset Description
- **Homepage:**
- **Repository:** <https://github.com/scribe-project/nodalida_2023_combined_training>
- **Paper:**
```
@inproceedings{
solberg2023improving,
title={Improving Generalization of Norwegian {ASR} with Limited Linguistic Resources},
author={Per Erik Solberg and Pablo Ortiz and Phoebe Parsons and Torbj{\o}rn Svendsen and Giampiero Salvi},
booktitle={The 24rd Nordic Conference on Computational Linguistics},
year={2023}
}
```
- **Point of Contact:** [Per Erik Solberg](mailto:[email protected])
### Dataset Summary
This is the version of the Bokmål segments of module 1 and 2 of NB Tale used for testing the models
in the paper *Improving Generalization of Norwegian ASR with Limited Linguistic Resources* presented at NoDaLiDa 2023.
It only contains segments of a length < 15 sec. This dataset contains both native and non-native speakers.
Speakers with `region` set to `foreign` were filtered out [when analyzing the data in the paper](https://github.com/scribe-project/nodalida_2023_combined_training/blob/main/analysis/analysis.ipynb).
### Languages
Norwegian Bokmål
## Dataset Creation
### Source Data
The full version of this dataset is found in [the repository of the Norwegian Language Bank](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-31/)
#### Initial Data Collection and Normalization
The data was retrieved using the [Spraakbanken downloader](https://pypi.org/project/spraakbanken-downloader/) and standardized
using the [combined dataset standardization scripts](https://github.com/scribe-project/asr-standardized-combined). Bokmål segments with a duration < 15 seconds were
extracted using [this code](https://github.com/scribe-project/nodalida_2023_combined_training/blob/main/make_datasets/make_nbtale_csvs.ipynb).
## Licensing Information
[CC0](https://creativecommons.org/share-your-work/public-domain/cc0/)
### Citation Information
```
@inproceedings{
solberg2023improving,
title={Improving Generalization of Norwegian {ASR} with Limited Linguistic Resources},
author={Per Erik Solberg and Pablo Ortiz and Phoebe Parsons and Torbj{\o}rn Svendsen and Giampiero Salvi},
booktitle={The 24rd Nordic Conference on Computational Linguistics},
year={2023}
}
``` | scribe-project/nbtale12 | [
"region:us"
]
| 2023-01-24T10:43:42+00:00 | {"dataset_info": {"features": [{"name": "speaker_id", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "utterance_id", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "raw_text", "dtype": "string"}, {"name": "full_audio_file", "dtype": "string"}, {"name": "original_data_split", "dtype": "string"}, {"name": "region", "dtype": "string"}, {"name": "duration", "dtype": "float64"}, {"name": "start", "dtype": "float64"}, {"name": "end", "dtype": "float64"}, {"name": "utterance_audio_file", "dtype": "audio"}, {"name": "standardized_text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2078070414.74, "num_examples": 6630}], "download_size": 1624762124, "dataset_size": 2078070414.74}} | 2023-04-25T09:30:50+00:00 |
723b15939b1b6f0253404732b6192ebfadb33b29 | # Dataset Card for NB Tale, module 3 (< 15 sec. segments)
## Dataset Description
- **Homepage:**
- **Repository:** <https://github.com/scribe-project/nodalida_2023_combined_training>
- **Paper:**
```
@inproceedings{
solberg2023improving,
title={Improving Generalization of Norwegian {ASR} with Limited Linguistic Resources},
author={Per Erik Solberg and Pablo Ortiz and Phoebe Parsons and Torbj{\o}rn Svendsen and Giampiero Salvi},
booktitle={The 24rd Nordic Conference on Computational Linguistics},
year={2023}
}
```
- **Point of Contact:** [Per Erik Solberg](mailto:[email protected])
### Dataset Summary
This is the version of the Bokmål segments of module 3 of NB Tale used for testing the models
in the paper *Improving Generalization of Norwegian ASR with Limited Linguistic Resources* presented at NoDaLiDa 2023.
It only contains segments of a length < 15 sec. This dataset contains both native and non-native speakers.
Speakers with `region` set to `foreign` were filtered out [when analyzing the data in the paper](https://github.com/scribe-project/nodalida_2023_combined_training/blob/main/analysis/analysis.ipynb).
### Languages
Norwegian Bokmål
## Dataset Creation
### Source Data
The full version of this dataset is found in [the repository of the Norwegian Language Bank](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-31/)
#### Initial Data Collection and Normalization
The data was retrieved using the [Spraakbanken downloader](https://pypi.org/project/spraakbanken-downloader/) and standardized
using the [combined dataset standardization scripts](https://github.com/scribe-project/asr-standardized-combined). Bokmål segments with a duration < 15 seconds were
extracted using [this code](https://github.com/scribe-project/nodalida_2023_combined_training/blob/main/make_datasets/make_nbtale_csvs.ipynb).
## Licensing Information
[CC0](https://creativecommons.org/share-your-work/public-domain/cc0/)
### Citation Information
```
@inproceedings{
solberg2023improving,
title={Improving Generalization of Norwegian {ASR} with Limited Linguistic Resources},
author={Per Erik Solberg and Pablo Ortiz and Phoebe Parsons and Torbj{\o}rn Svendsen and Giampiero Salvi},
booktitle={The 24rd Nordic Conference on Computational Linguistics},
year={2023}
}
``` | scribe-project/nbtale3 | [
"region:us"
]
| 2023-01-24T10:44:07+00:00 | {"dataset_info": {"features": [{"name": "speaker_id", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "utterance_id", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "raw_text", "dtype": "string"}, {"name": "full_audio_file", "dtype": "string"}, {"name": "original_data_split", "dtype": "string"}, {"name": "region", "dtype": "string"}, {"name": "duration", "dtype": "float64"}, {"name": "start", "dtype": "float64"}, {"name": "end", "dtype": "float64"}, {"name": "utterance_audio_file", "dtype": "audio"}, {"name": "standardized_text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1233495883.99, "num_examples": 8033}], "download_size": 1287266972, "dataset_size": 1233495883.99}} | 2023-04-25T09:32:19+00:00 |
0c930e96cb7c548a40101f0462080bd27a5d38b5 | # Dataset Card for "AToMiC-Qrels-v0.2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | TREC-AToMiC/AToMiC-Qrels-v0.2 | [
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T13:11:24+00:00 | {"license": "cc-by-sa-4.0", "dataset_info": {"features": [{"name": "text_id", "dtype": "string"}, {"name": "Q0", "dtype": "string"}, {"name": "image_id", "dtype": "string"}, {"name": "rel", "dtype": "int64"}], "splits": [{"name": "test", "num_bytes": 789840, "num_examples": 9873}, {"name": "validation", "num_bytes": 1424080, "num_examples": 17801}, {"name": "train", "num_bytes": 352152240, "num_examples": 4401903}], "download_size": 205636566, "dataset_size": 354366160}} | 2023-02-14T21:31:18+00:00 |
0fb6736f06a9edabca384e5d8a08235701eab1c3 |
# Dataset Card for "relbert/nell"
## Dataset Description
- **Repository:** [https://github.com/xwhan/One-shot-Relational-Learning](https://github.com/xwhan/One-shot-Relational-Learning)
- **Paper:** [https://aclanthology.org/D18-1223/](https://aclanthology.org/D18-1223/)
- **Dataset:** Never Ending Language Learner (NELL) dataset for one-shot link prediction.
### Dataset Summary
This is NELL-ONE dataset for the few-shots link prediction proposed in [https://aclanthology.org/D18-1223/](https://aclanthology.org/D18-1223/).
Please see [NELL paper](https://www.cs.cmu.edu/~tom/pubs/NELL_aaai15.pdf) to know more about the original dataset.
- Number of instances
| | train | validation | test |
|:--------------------------------|--------:|-------------:|-------:|
| number of pairs | 5498 | 878 | 1352 |
| number of unique relation types | 32 | 4 | 6 |
- Number of pairs in each relation type
| | number of pairs (train) | number of pairs (validation) | number of pairs (test) |
|:---------------------------------------------------|--------------------------:|-------------------------------:|-------------------------:|
| concept:airportincity | 210 | 0 | 0 |
| concept:athleteledsportsteam | 424 | 0 | 0 |
| concept:automobilemakercardealersinstateorprovince | 78 | 0 | 0 |
| concept:bankboughtbank | 58 | 0 | 0 |
| concept:ceoof | 271 | 0 | 0 |
| concept:cityradiostation | 99 | 0 | 0 |
| concept:citytelevisionstation | 316 | 0 | 0 |
| concept:countriessuchascountries | 100 | 0 | 0 |
| concept:countrycapital | 211 | 0 | 0 |
| concept:countryhascitizen | 182 | 0 | 0 |
| concept:countryoforganizationheadquarters | 166 | 0 | 0 |
| concept:countrystates | 169 | 0 | 0 |
| concept:drugpossiblytreatsphysiologicalcondition | 91 | 0 | 0 |
| concept:fatherofperson | 108 | 0 | 0 |
| concept:fooddecreasestheriskofdisease | 1 | 0 | 0 |
| concept:hasofficeincountry | 283 | 0 | 0 |
| concept:leaguecoaches | 71 | 0 | 0 |
| concept:leaguestadiums | 279 | 0 | 0 |
| concept:musicartistmusician | 118 | 0 | 0 |
| concept:musicgenressuchasmusicgenres | 107 | 0 | 0 |
| concept:organizationnamehasacronym | 61 | 0 | 0 |
| concept:personalsoknownas | 78 | 0 | 0 |
| concept:personleadsgeopoliticalorganization | 120 | 0 | 0 |
| concept:personmovedtostateorprovince | 225 | 0 | 0 |
| concept:politicianrepresentslocation | 258 | 0 | 0 |
| concept:politicianusholdsoffice | 216 | 0 | 0 |
| concept:statehascapital | 151 | 0 | 0 |
| concept:stateorprovinceoforganizationheadquarters | 118 | 0 | 0 |
| concept:teamhomestadium | 138 | 0 | 0 |
| concept:teamplaysincity | 338 | 0 | 0 |
| concept:topmemberoforganization | 354 | 0 | 0 |
| concept:wifeof | 99 | 0 | 0 |
| concept:bankbankincountry | 0 | 229 | 0 |
| concept:cityalsoknownas | 0 | 356 | 0 |
| concept:parentofperson | 0 | 217 | 0 |
| concept:politicalgroupofpoliticianus | 0 | 76 | 0 |
| concept:automobilemakerdealersincity | 0 | 0 | 177 |
| concept:automobilemakerdealersincountry | 0 | 0 | 96 |
| concept:geopoliticallocationresidenceofpersion | 0 | 0 | 143 |
| concept:politicianusendorsespoliticianus | 0 | 0 | 386 |
| concept:producedby | 0 | 0 | 209 |
| concept:teamcoach | 0 | 0 | 341 |
- Number of entity types
| | head (train) | tail (train) | head (validation) | tail (validation) | head (test) | tail (test) |
|:-------------------------|---------------:|---------------:|--------------------:|--------------------:|--------------:|--------------:|
| actor | 6 | 2 | 0 | 0 | 0 | 0 |
| airport | 152 | 0 | 0 | 0 | 0 | 0 |
| astronaut | 4 | 0 | 0 | 1 | 0 | 1 |
| athlete | 353 | 21 | 1 | 2 | 0 | 59 |
| attraction | 4 | 1 | 0 | 0 | 0 | 0 |
| automobilemaker | 131 | 29 | 0 | 0 | 273 | 54 |
| bank | 109 | 126 | 144 | 0 | 0 | 0 |
| biotechcompany | 14 | 80 | 0 | 0 | 0 | 10 |
| building | 4 | 0 | 0 | 0 | 0 | 0 |
| celebrity | 6 | 5 | 0 | 0 | 4 | 2 |
| ceo | 423 | 0 | 0 | 0 | 0 | 0 |
| city | 342 | 852 | 316 | 316 | 42 | 161 |
| coach | 29 | 61 | 0 | 3 | 0 | 245 |
| comedian | 1 | 0 | 0 | 0 | 0 | 0 |
| company | 76 | 549 | 1 | 0 | 1 | 144 |
| country | 755 | 455 | 0 | 197 | 27 | 91 |
| county | 36 | 39 | 11 | 11 | 10 | 4 |
| creditunion | 1 | 0 | 0 | 0 | 0 | 0 |
| criminal | 3 | 0 | 1 | 0 | 0 | 1 |
| director | 2 | 0 | 0 | 0 | 0 | 1 |
| drug | 91 | 0 | 0 | 0 | 1 | 0 |
| female | 116 | 8 | 38 | 9 | 3 | 3 |
| geopoliticallocation | 184 | 112 | 96 | 29 | 24 | 8 |
| geopoliticalorganization | 28 | 68 | 8 | 21 | 1 | 7 |
| governmentorganization | 25 | 95 | 74 | 0 | 0 | 0 |
| island | 15 | 4 | 4 | 6 | 1 | 0 |
| journalist | 4 | 0 | 0 | 0 | 0 | 1 |
| male | 132 | 78 | 37 | 52 | 1 | 5 |
| model | 2 | 0 | 0 | 0 | 0 | 0 |
| monarch | 4 | 3 | 4 | 1 | 0 | 0 |
| museum | 1 | 5 | 0 | 0 | 0 | 0 |
| musicartist | 118 | 5 | 0 | 0 | 0 | 0 |
| musicgenre | 107 | 107 | 0 | 0 | 0 | 0 |
| musician | 5 | 124 | 0 | 0 | 0 | 0 |
| newspaper | 3 | 2 | 0 | 0 | 0 | 0 |
| organization | 23 | 86 | 1 | 1 | 32 | 2 |
| person | 350 | 256 | 116 | 131 | 0 | 96 |
| personafrica | 1 | 3 | 0 | 0 | 0 | 0 |
| personasia | 1 | 3 | 0 | 0 | 0 | 0 |
| personaustralia | 38 | 5 | 0 | 0 | 0 | 5 |
| personcanada | 19 | 14 | 0 | 0 | 0 | 0 |
| personeurope | 9 | 7 | 14 | 4 | 0 | 1 |
| personmexico | 57 | 14 | 0 | 0 | 0 | 20 |
| personnorthamerica | 9 | 6 | 0 | 0 | 0 | 3 |
| personsouthamerica | 1 | 1 | 0 | 17 | 0 | 0 |
| personus | 41 | 21 | 2 | 0 | 1 | 6 |
| planet | 1 | 0 | 0 | 0 | 0 | 1 |
| politician | 107 | 5 | 0 | 1 | 23 | 58 |
| politicianus | 408 | 12 | 3 | 71 | 352 | 360 |
| politicsblog | 2 | 3 | 0 | 0 | 0 | 0 |
| port | 7 | 0 | 0 | 0 | 0 | 0 |
| professor | 7 | 2 | 0 | 0 | 1 | 0 |
| publication | 1 | 21 | 0 | 0 | 0 | 0 |
| recordlabel | 1 | 13 | 0 | 0 | 0 | 0 |
| retailstore | 1 | 15 | 0 | 0 | 0 | 0 |
| school | 54 | 1 | 0 | 0 | 11 | 0 |
| scientist | 5 | 2 | 0 | 1 | 0 | 0 |
| sportsleague | 356 | 12 | 0 | 0 | 0 | 0 |
| sportsteam | 392 | 430 | 0 | 0 | 295 | 0 |
| stateorprovince | 254 | 602 | 0 | 0 | 38 | 0 |
| transportation | 36 | 2 | 0 | 0 | 0 | 0 |
| university | 3 | 15 | 0 | 0 | 0 | 0 |
| visualizablescene | 20 | 7 | 3 | 3 | 3 | 3 |
| visualizablething | 1 | 1 | 1 | 1 | 0 | 0 |
| website | 7 | 31 | 0 | 0 | 0 | 0 |
| caf_ | 0 | 1 | 0 | 0 | 0 | 0 |
| continent | 0 | 1 | 0 | 0 | 0 | 0 |
| disease | 0 | 92 | 0 | 0 | 0 | 0 |
| hotel | 0 | 1 | 0 | 0 | 0 | 0 |
| magazine | 0 | 5 | 0 | 0 | 0 | 0 |
| nongovorganization | 0 | 4 | 0 | 0 | 0 | 0 |
| nonprofitorganization | 0 | 2 | 0 | 0 | 0 | 0 |
| park | 0 | 1 | 0 | 0 | 0 | 0 |
| petroleumrefiningcompany | 0 | 6 | 0 | 0 | 0 | 0 |
| politicaloffice | 0 | 216 | 0 | 0 | 0 | 0 |
| politicalparty | 0 | 6 | 2 | 0 | 0 | 0 |
| radiostation | 0 | 93 | 0 | 0 | 0 | 0 |
| river | 0 | 4 | 0 | 0 | 0 | 0 |
| stadiumoreventvenue | 0 | 417 | 0 | 0 | 0 | 0 |
| televisionnetwork | 0 | 1 | 0 | 0 | 0 | 0 |
| televisionstation | 0 | 221 | 0 | 0 | 0 | 0 |
| trainstation | 0 | 2 | 0 | 0 | 0 | 0 |
| writer | 0 | 3 | 1 | 0 | 0 | 0 |
| zoo | 0 | 1 | 0 | 0 | 0 | 0 |
| automobilemodel | 0 | 0 | 0 | 0 | 100 | 0 |
| product | 0 | 0 | 0 | 0 | 62 | 0 |
| software | 0 | 0 | 0 | 0 | 42 | 0 |
| videogame | 0 | 0 | 0 | 0 | 4 | 0 |
## Dataset Structure
An example of `test` looks as below.
```shell
{
"relation": "concept:producedby",
"head": "Toyota Tacoma",
"head_type": "automobilemodel",
"tail": "Toyota",
"tail_type": "automobilemaker"
}
```
## Citation Information
```
@inproceedings{xiong-etal-2018-one,
title = "One-Shot Relational Learning for Knowledge Graphs",
author = "Xiong, Wenhan and
Yu, Mo and
Chang, Shiyu and
Guo, Xiaoxiao and
Wang, William Yang",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
month = oct # "-" # nov,
year = "2018",
address = "Brussels, Belgium",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D18-1223",
doi = "10.18653/v1/D18-1223",
pages = "1980--1990",
abstract = "Knowledge graphs (KG) are the key components of various natural language processing applications. To further expand KGs{'} coverage, previous studies on knowledge graph completion usually require a large number of positive examples for each relation. However, we observe long-tail relations are actually more common in KGs and those newly added relations often do not have many known triples for training. In this work, we aim at predicting new facts under a challenging setting where only one training instance is available. We propose a one-shot relational learning framework, which utilizes the knowledge distilled by embedding models and learns a matching metric by considering both the learned embeddings and one-hop graph structures. Empirically, our model yields considerable performance improvements over existing embedding models, and also eliminates the need of re-training the embedding models when dealing with newly added relations.",
}
```
| relbert/nell | [
"multilinguality:monolingual",
"size_categories:n<1K",
"language:en",
"license:other",
"region:us"
]
| 2023-01-24T13:35:37+00:00 | {"language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["n<1K"], "pretty_name": "relbert/nell"} | 2023-02-02T15:25:04+00:00 |
f13fba1ee71663a99c369a02501663d773e751c8 | # Dataset Card for "yannic_ada_embeddings"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | juancopi81/yannic_ada_embeddings | [
"region:us"
]
| 2023-01-24T13:45:56+00:00 | {"dataset_info": {"features": [{"name": "TITLE", "dtype": "string"}, {"name": "URL", "dtype": "string"}, {"name": "TRANSCRIPTION", "dtype": "string"}, {"name": "transcription_length", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "ada_embedding", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 127436085, "num_examples": 3194}], "download_size": 81996580, "dataset_size": 127436085}} | 2023-01-24T13:46:03+00:00 |
bdd59e10860746202dfdc452e0ac3a9eaa25268d | # The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions
- Original Paper and Dataset [here](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T)
- Kaggle dataset [here](https://www.kaggle.com/datasets/kmader/skin-cancer-mnist-ham10000?resource=download)
# Introduction to datasets
Training of neural networks for automated diagnosis of pigmented skin lesions is hampered by the small size and lack of diversity of available dataset of dermatoscopic images. We tackle this problem by releasing the HAM10000 ("Human Against Machine with 10000 training images") dataset. We collected dermatoscopic images from different populations, acquired and stored by different modalities. The final dataset consists of 10015 dermatoscopic images which can serve as a training set for academic machine learning purposes. Cases include a representative collection of all important diagnostic categories in the realm of pigmented lesions: Actinic keratoses and intraepithelial carcinoma / Bowen's disease (akiec), basal cell carcinoma (bcc), benign keratosis-like lesions (solar lentigines / seborrheic keratoses and lichen-planus like keratoses, bkl), dermatofibroma (df), melanoma (mel), melanocytic nevi (nv) and vascular lesions (angiomas, angiokeratomas, pyogenic granulomas and hemorrhage, vasc).
More than 50% of lesions are confirmed through histopathology (histo), the ground truth for the rest of the cases is either follow-up examination (follow_up), expert consensus (consensus), or confirmation by in-vivo confocal microscopy (confocal).
The test set is not public, but the evaluation server remains running (see the challenge website). Any publications written using the HAM10000 data should be evaluated on the official test set hosted there, so that methods can be fairly compared.
- Test site can be accessed [here](https://challenge.isic-archive.com/landing/2018/)
# Disclaimer and additional information
This is a contribution to open sourced data in hugging face for image data. Images can be obtained from above links.
Train test split was done using a stratified splitting by cancer/diagnosis type. The code to stratify the dataset can be obtained on my github [here](https://github.com/marmal88/skin_cancer).
I do not own any rights to above images.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | marmal88/skin_cancer | [
"task_categories:image-classification",
"task_categories:image-segmentation",
"size_categories:1K<n<10K",
"language:en",
"skin_cancer",
"HAM10000",
"region:us"
]
| 2023-01-24T13:53:28+00:00 | {"language": ["en"], "size_categories": ["1K<n<10K"], "task_categories": ["image-classification", "image-segmentation"], "pretty_name": "HAM10000", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "image_id", "dtype": "string"}, {"name": "lesion_id", "dtype": "string"}, {"name": "dx", "dtype": "string"}, {"name": "dx_type", "dtype": "string"}, {"name": "age", "dtype": "float64"}, {"name": "sex", "dtype": "string"}, {"name": "localization", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2490501038.358, "num_examples": 9577}, {"name": "test", "num_bytes": 351507473.24, "num_examples": 1285}, {"name": "validation", "num_bytes": 681758880.144, "num_examples": 2492}], "download_size": 3693626934, "dataset_size": 3523767391.7419996}, "tags": ["skin_cancer", "HAM10000"]} | 2023-01-25T02:21:28+00:00 |
36b558057afaa3643872d44ccf35a9a8c0e7d57f | SQUAD dataset with incorrect answers options generated with a T5-base fine-tuned on multiqad-200k dataset | b-yukky/squad-augmented-hq | [
"region:us"
]
| 2023-01-24T14:23:57+00:00 | {} | 2023-01-30T04:15:35+00:00 |
37a77001f48db65c0322b3bab6d78f27abd96856 |
# Dataset Card for DBLP-QuAD
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [DBLP-QuAD Homepage]()
- **Repository:** [DBLP-QuAD Repository](https://github.com/awalesushil/DBLP-QuAD)
- **Paper:** DBLP-QuAD: A Question Answering Dataset over the DBLP Scholarly Knowledge Graph
- **Point of Contact:** [Sushil Awale](mailto:[email protected])
### Dataset Summary
DBLP-QuAD is a scholarly knowledge graph question answering dataset with 10,000 question - SPARQL query pairs targeting the DBLP knowledge graph. The dataset is split into 7,000 training, 1,000 validation and 2,000 test questions.
## Dataset Structure
### Data Instances
An example of a question is given below:
```
{
"id": "Q0577",
"query_type": "MULTI_FACT",
"question": {
"string": "What are the primary affiliations of the authors of the paper 'Graphical Partitions and Graphical Relations'?"
},
"paraphrased_question": {
"string": "List the primary affiliations of the authors of 'Graphical Partitions and Graphical Relations'."
},
"query": {
"sparql": "SELECT DISTINCT ?answer WHERE { <https://dblp.org/rec/journals/fuin/ShaheenS19> <https://dblp.org/rdf/schema#authoredBy> ?x . ?x <https://dblp.org/rdf/schema#primaryAffiliation> ?answer }"
},
"template_id": "TP11",
"entities": [
"<https://dblp.org/rec/journals/fuin/ShaheenS19>"
],
"relations": [
"<https://dblp.org/rdf/schema#authoredBy>",
"<https://dblp.org/rdf/schema#primaryAffiliation>"
],
"temporal": false,
"held_out": true
}
```
### Data Fields
- `id`: the id of the question
- `question`: a string containing the question
- `paraphrased_question`: a paraphrased version of the question
- `query`: a SPARQL query that answers the question
- `query_type`: the type of the query
- `query_template`: the template of the query
- `entities`: a list of entities in the question
- `relations`: a list of relations in the question
- `temporal`: a boolean indicating whether the question contains a temporal expression
- `held_out`: a boolean indicating whether the question is held out from the training set
### Data Splits
The dataset is split into 7,000 training, 1,000 validation and 2,000 test questions.
## Additional Information
### Licensing Information
DBLP-QuAD is licensed under the [Creative Commons Attribution 4.0 International License (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
In review.
### Contributions
Thanks to [@awalesushil](https://github.com/awalesushil) for adding this dataset.
| awalesushil/DBLP-QuAD | [
"task_categories:question-answering",
"annotations_creators:expert-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"knowledge-base-qa",
"region:us"
]
| 2023-01-24T15:04:12+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["machine-generated"], "language": ["en"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["question-answering"], "task_ids": [], "pretty_name": "DBLP-QuAD: A Question Answering Dataset over the DBLP Scholarly Knowledge Graph", "tags": ["knowledge-base-qa"]} | 2023-02-15T17:32:06+00:00 |
b3662175d3b2482d711f18559b7acc2a5bccc600 |
## Loading the dataset with a specific configuration
There are 3 different OCR versions to choose from with their original format or standardized DUE format, as well as the option to load the documents as filepaths or as binaries (PDF).
To load a specific configuration, pass a config from one of the following:
```python
#{bin_}{Amazon,Azure,Tesseract}_{original,due}
['Amazon_due', 'Amazon_original', 'Azure_due', 'Azure_original', 'Tesseract_due', 'Tesseract_original',
'bin_Amazon_due', 'bin_Amazon_original', 'bin_Azure_due', 'bin_Azure_original', 'bin_Tesseract_due', 'bin_Tesseract_original']
```
Loading the dataset:
```python
from datasets import load_dataset
ds = load_dataset("jordyvl/DUDE_loader", 'Amazon_original')
```
This dataset repository contains helper functions to convert the dataset to ImDB (image database) format.
We advise to clone the repository and run it according to your preferences (OCR version, lowercasing, ...).
When running the above data loading script, you should be able to find the extracted binaries under the [HF_CACHE](https://huggingface.co/docs/datasets/cache):
`HF_CACHE/datasets/downloads/extracted/<hash>/DUDE_train-val-test_binaries`, which can be reused for the `data_dir` argument.
For example:
```bash
python3 DUDE_imdb_loader.py \
--data_dir ~/.cache/huggingface/datasets/downloads/extracted/7adde0ed7b0150b7f6b32e52bcad452991fde0f3407c8a87e74b1cb475edaa5b/DUDE_train-val-test_binaries/
```
For baselines, we recommend having a look at the [MP-DocVQA repository](https://github.com/rubenpt91/MP-DocVQA-Framework)
We strongly encourage you to benchmark your best models and submit test set predictions on the [DUDE competition leaderboard](https://rrc.cvc.uab.es/?ch=23)
To help with test set predictions, we have included a sample submission file `RRC_DUDE_testset_submission_example.json`.
| jordyvl/DUDE_loader | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"region:us"
]
| 2023-01-24T15:20:01+00:00 | {"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["question-answering"], "pretty_name": "DUDE"} | 2023-10-03T09:54:36+00:00 |
2a2b792e3d85d053a9b9d1123411fc85c491ed47 | # Dataset Card for "PickaPic-random-prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | yuvalkirstain/PickaPic-random-prompts | [
"region:us"
]
| 2023-01-24T15:27:44+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9702, "num_examples": 200}], "download_size": 8488, "dataset_size": 9702}} | 2023-01-24T15:27:52+00:00 |
457eb6f6d134d340b93eeed4374b224928a870e8 | # Dataset Card for "runwayml-stable-diffusion-v1-5-eval-random-prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | yuvalkirstain/runwayml-stable-diffusion-v1-5-eval-random-prompts | [
"region:us"
]
| 2023-01-24T15:37:11+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 32392, "num_examples": 200}], "download_size": 11291, "dataset_size": 32392}} | 2023-01-24T15:37:19+00:00 |
f017f3fb62da2088f7dd13669c7dbf3b81e77272 | # Dataset Card for "julioprofe"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | juancopi81/julioprofe | [
"task_categories:automatic-speech-recognition",
"whisper",
"whispering",
"medium",
"region:us"
]
| 2023-01-24T15:38:53+00:00 | {"task_categories": ["automatic-speech-recognition"], "dataset_info": {"features": [{"name": "CHANNEL_NAME", "dtype": "string"}, {"name": "URL", "dtype": "string"}, {"name": "TITLE", "dtype": "string"}, {"name": "DESCRIPTION", "dtype": "string"}, {"name": "TRANSCRIPTION", "dtype": "string"}, {"name": "SEGMENTS", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 17940671, "num_examples": 1285}], "download_size": 6527309, "dataset_size": 17940671}, "tags": ["whisper", "whispering", "medium"]} | 2023-02-11T23:31:32+00:00 |
59db562a3f9702050bc3ea050528607a38fac89d |
# LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
A collaboration between [reciTAL](https://recital.ai/en/), [MLIA](https://mlia.lip6.fr/) (ISIR, Sorbonne Université), [Meta AI](https://ai.facebook.com/), and [Università di Trento](https://www.unitn.it/)
## PubMed-Lay dataset for summarization
PubMed-Lay is an enhanced version of the PubMed summarization dataset, for which layout information is provided.
### Data Fields
- `article_id`: article id
- `article_words`: sequence of words constituting the body of the article
- `article_bboxes`: sequence of corresponding word bounding boxes
- `norm_article_bboxes`: sequence of corresponding normalized word bounding boxes
- `abstract`: a string containing the abstract of the article
- `article_pdf_url`: URL of the article's PDF
### Data Splits
This dataset has 3 splits: _train_, _validation_, and _test_.
| Dataset Split | Number of Instances |
| ------------- | --------------------|
| Train | 78,234 |
| Validation | 4,084 |
| Test | 4,350 |
## Citation
``` latex
@article{nguyen2023loralay,
title={LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization},
author={Nguyen, Laura and Scialom, Thomas and Piwowarski, Benjamin and Staiano, Jacopo},
journal={arXiv preprint arXiv:2301.11312},
year={2023}
}
```
| nglaura/pubmedlay-summarization | [
"task_categories:summarization",
"language:en",
"license:apache-2.0",
"region:us"
]
| 2023-01-24T15:46:55+00:00 | {"language": ["en"], "license": "apache-2.0", "task_categories": ["summarization"], "pretty_name": "PubMed-Lay"} | 2023-04-11T09:10:19+00:00 |
bd31cee198284006b4d48b0a1a4235c4cc83083a | anytp/entidades | [
"region:us"
]
| 2023-01-24T16:10:45+00:00 | {} | 2023-09-14T14:51:02+00:00 |
|
43ff36807a2d8d082de5198418a235cd9d7871a6 | # Dataset Card for "utd_reddit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Rami/utd_reddit | [
"region:us"
]
| 2023-01-24T16:31:10+00:00 | {"dataset_info": {"features": [{"name": "j52edo", "struct": [{"name": "title", "dtype": "string"}, {"name": "selftext", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "permalink", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "comments", "struct": [{"name": "g7p723l", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7pmgai", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7q0gtr", "struct": [{"name": "body", "dtype": "string"}]}]}]}, {"name": "g7p6z8q", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7q37rw", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7qjj6o", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7p4ynr", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7paxsm", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7p543c", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7pvhwr", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7qgcr3", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7p8y1o", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7pajp9", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7pn8t5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7psgy5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7s767n", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7qrjeu", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7r3brk", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7q48td", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7q3j2n", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7ujauu", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7pt766", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7pyov9", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7q1j3w", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7qvvrm", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7t8u30", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7sqe5g", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "gn3icng", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "gn3id7g", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7qjzq9", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "grxwrut", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "is1ekdj", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7q0gtr", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7qn1hx", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7qjj6o", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7tdb88", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7pvhwr", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7psgy5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7psssg", "struct": [{"name": "body", "dtype": "string"}]}]}]}, {"name": "g7r3brk", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7ujauu", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7ujcwo", "struct": [{"name": "body", "dtype": "string"}]}]}]}, {"name": "g7q1j3w", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7q1ukv", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7t8u30", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "gn3id7g", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7qn1hx", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7tdb88", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7psssg", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g7qvgs1", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g7ujcwo", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7q1ukv", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g7qvgs1", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "ifj62g", "struct": [{"name": "title", "dtype": "string"}, {"name": "selftext", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "permalink", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "comments", "struct": [{"name": "g2nxs5d", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2ny1wp", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2osx1j", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2r3t1s", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r35ej", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2o556k", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2nz3v6", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2p9hay", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pe858", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2r3ep9", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2pt4x2", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2o20i5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2o5voj", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2ny31m", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2o5u5o", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2ps6hi", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pwxb2", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pjb4a", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pr7em", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r0ck8", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2r2cyw", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2osrsu", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2oufy3", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2owmjz", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2oxnj7", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2oyah5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2p1zws", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2p3nqr", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2p3y9o", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pgk3z", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pjc47", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pjnxk", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2pnlsq", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qa3j8", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qcaqi", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2r389i", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2qecdl", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qjkzi", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qk2c6", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2r2tox", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2ql8ya", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qlcmq", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qluxa", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qmyws", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qvvvn", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2qzzpt", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "iixxup5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r3t1s", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2rcw47", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r40la", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r64tc", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2r35ej", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r3ep9", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2rbg5x", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2o5u5o", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r2cyw", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r389i", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r2tox", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2r5j57", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2rcw47", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r40la", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r64tc", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2rbg5x", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g2r5j57", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g2ri4uy", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g2ri4uy", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "hqiywt", "struct": [{"name": "title", "dtype": "string"}, {"name": "selftext", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "permalink", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "comments", "struct": [{"name": "fxy35ua", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "fxy5xpk", "struct": [{"name": "body", "dtype": "string"}]}]}]}, {"name": "fxy55uj", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxy4sgh", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxygu2d", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxy6rae", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxy886f", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxyvrz8", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "fxz0jvw", "struct": [{"name": "body", "dtype": "string"}]}]}]}, {"name": "fy0701b", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxyeeq6", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "fxyj4z7", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "fxylllu", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxynrt5", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fy0jlme", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxybjxh", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxy6599", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "fxy68z3", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g0xlk31", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "i5l4ggd", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxy5xpk", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxz0jvw", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "fxz99mc", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "fxzllof", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fy6gnr4", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxyj4z7", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxy68z3", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fxz99mc", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "ib2vgk", "struct": [{"name": "title", "dtype": "string"}, {"name": "selftext", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "permalink", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "comments", "struct": [{"name": "g1sc0uy", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sg44w", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1soo64", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g1vzh5l", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1ws9xb", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g1sro41", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1su0kc", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g21q7id", "struct": [{"name": "body", "dtype": "string"}]}]}]}, {"name": "g1si692", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sifmk", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1st6fn", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sgnub", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sjtor", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sm6hm", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1surmp", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1ss1su", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1vjexl", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1stb1z", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1ukvzh", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sjd63", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g1sk9u4", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1skaax", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g1vcsw1", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1viwmm", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1w7ytc", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1wz1vj", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g22s3kf", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g22s9rp", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g1vzh5l", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g3h3gtp", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g1ws9xb", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g21q7id", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g21y37e", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g1sk9u4", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g1sp4ik", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g1skaax", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "g1sp53s", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "g22s9rp", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g3h3gtp", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g21y37e", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sp4ik", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "g1sp53s", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "fhyrnn", "struct": [{"name": "title", "dtype": "string"}, {"name": "selftext", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "permalink", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "comments", "struct": [{"name": "fke7x2u", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "replies", "struct": [{"name": "fkey0q0", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}, {"name": "fkford6", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fkg43nm", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fkid63u", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fkexb6s", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fkf8651", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fkebbky", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "fkey0q0", "struct": [{"name": "body", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}]}]}], "splits": [{"name": "train", "num_bytes": 22386, "num_examples": 1}], "download_size": 368145, "dataset_size": 22386}} | 2023-01-24T16:57:10+00:00 |
05230cc51e502fad9ffc2349fbe777d84ff30569 |
# Dataset Card for Dataset Name
## Dataset Description
- **Repository: [Self-Instruct](https://github.com/yizhongw/self-instruct)**
- **Paper: [Self-Instruct: Aligning Language Model with Self Generated Instructions](https://arxiv.org/abs/2212.10560)**
### Dataset Summary
This dataset is a copy of yizhongw's data from the github above, note this was created on 24th Jan 2023.
## Dataset Structure
GPT3-finetuning format (prompt + completion)
### Data Fields
Prompt
"Task: [Instruction] Output:"
Completion
"[Answer]<|endoftext|>"
### Data Splits
No splits
## Dataset Creation
### Curation Rationale
Effeciently create a large dataset by using GPT3 to generate the data
### Annotations
The dataset was made and annotated by GPT3
### Dataset Curators
yizhongw
### Licensing Information
Apache 2.0
### Citation Information
I am not the creator of this dataset, please see the GitHub link above.
| eastwind/self-instruct-base | [
"license:apache-2.0",
"arxiv:2212.10560",
"region:us"
]
| 2023-01-24T16:58:51+00:00 | {"license": "apache-2.0"} | 2023-01-24T17:44:49+00:00 |
1d5773ce7f66782a89a6439a81261c84c298e2a3 |
# Dataset Card for NusaX-MT
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [GitHub](https://github.com/IndoNLP/nusax/tree/main/datasets/mt)
- **Paper:** [EACL 2022](https://arxiv.org/abs/2205.15960)
- **Point of Contact:** [GitHub](https://github.com/IndoNLP/nusax/tree/main/datasets/mt)
### Dataset Summary
NusaX is a high-quality multilingual parallel corpus that covers 12 languages, Indonesian, English, and 10 Indonesian local languages, namely Acehnese, Balinese, Banjarese, Buginese, Madurese, Minangkabau, Javanese, Ngaju, Sundanese, and Toba Batak.
NusaX-MT is a parallel corpus for training and benchmarking machine translation models across 10 Indonesian local languages + Indonesian and English. The data is presented in csv format with 12 columns, one column for each language.
### Supported Tasks and Leaderboards
- Machine translation for Indonesian languages
### Languages
All possible pairs of the following:
- ace: acehnese,
- ban: balinese,
- bjn: banjarese,
- bug: buginese,
- eng: english,
- ind: indonesian,
- jav: javanese,
- mad: madurese,
- min: minangkabau,
- nij: ngaju,
- sun: sundanese,
- bbc: toba_batak,
## Dataset Creation
### Curation Rationale
There is a shortage of NLP research and resources for the Indonesian languages, despite the country having over 700 languages. With this in mind, we have created this dataset to support future research for the underrepresented languages in Indonesia.
### Source Data
#### Initial Data Collection and Normalization
NusaX-MT is a dataset for machine translation in Indonesian langauges that has been expertly translated by native speakers.
#### Who are the source language producers?
The data was produced by humans (native speakers).
### Annotations
#### Annotation process
NusaX-MT is derived from SmSA, which is the biggest publicly available dataset for Indonesian sentiment analysis. It comprises of comments and reviews from multiple online platforms. To ensure the quality of our dataset, we have filtered it by removing any abusive language and personally identifying information by manually reviewing all sentences. To ensure balance in the label distribution, we randomly picked 1,000 samples through stratified sampling and then translated them to the corresponding languages.
#### Who are the annotators?
Native speakers of both Indonesian and the corresponding languages.
Annotators were compensated based on the number of translated samples.
### Personal and Sensitive Information
Personal information is removed.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
NusaX is created from review text. These data sources may contain some bias.
### Other Known Limitations
No other known limitations
## Additional Information
### Licensing Information
CC-BY-SA 4.0.
Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
ShareAlike — If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
Please contact authors for any information on the dataset.
### Citation Information
```
@misc{winata2022nusax,
title={NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages},
author={Winata, Genta Indra and Aji, Alham Fikri and Cahyawijaya,
Samuel and Mahendra, Rahmad and Koto, Fajri and Romadhony,
Ade and Kurniawan, Kemal and Moeljadi, David and Prasojo,
Radityo Eko and Fung, Pascale and Baldwin, Timothy and Lau,
Jey Han and Sennrich, Rico and Ruder, Sebastian},
year={2022},
eprint={2205.15960},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@afaji](https://github.com/afaji) for adding this dataset.
| indonlp/NusaX-MT | [
"task_categories:translation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:multilingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:ace",
"language:ban",
"language:bjn",
"language:bug",
"language:en",
"language:id",
"language:jv",
"language:mad",
"language:min",
"language:nij",
"language:su",
"language:bbc",
"license:cc-by-sa-4.0",
"arxiv:2205.15960",
"region:us"
]
| 2023-01-24T17:05:31+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["ace", "ban", "bjn", "bug", "en", "id", "jv", "mad", "min", "nij", "su", "bbc"], "license": ["cc-by-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["translation"], "pretty_name": "NusaX-MT", "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "text_1", "dtype": "string"}, {"name": "text_2", "dtype": "string"}, {"name": "text_1_lang", "dtype": "string"}, {"name": "text_2_lang", "dtype": "string"}]}} | 2023-01-24T17:21:03+00:00 |
0226c3b54722d272ae56448c4a3f9387d463a7ec | # Dataset Card for "stabilityai-stable-diffusion-2-1-eval-random-prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | yuvalkirstain/stabilityai-stable-diffusion-2-1-eval-random-prompts | [
"region:us"
]
| 2023-01-24T17:06:03+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 32792, "num_examples": 200}], "download_size": 11301, "dataset_size": 32792}} | 2023-01-24T17:06:12+00:00 |
7867be796849bb70003075b3932083102dd1c4e0 | # Dataset Card for "pile-tokenized-10b"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | NeelNanda/pile-tokenized-10b | [
"region:us"
]
| 2023-01-24T17:14:07+00:00 | {"dataset_info": {"features": [{"name": "tokens", "sequence": "uint16"}], "splits": [{"name": "train", "num_bytes": 22153340700, "num_examples": 10795975}], "download_size": 19746448291, "dataset_size": 22153340700}} | 2023-01-24T20:52:44+00:00 |
eda848e5bd7df7a2e50e46886e20c9df8f70ab8e |
# Chinese Metaphor Corpus (CMC)
## Dataset Description
- **Homepage:** https://github.com/liyucheng09/Metaphor_Generator
- **Repository:** https://github.com/liyucheng09/Metaphor_Generator
- **Paper:** CM-Gen: A Neural Framework for Chinese Metaphor Generation with Explicit Context Modelling
- **Leaderboard:**
- **Point of Contact:** [email protected]
### Dataset Summary
The first Chinese metaphor corpus serving both metaphor identification and generation. We construct a big metaphor resoruce in Chinese with around 9000 metaphorical sentences with tenor and vehicle annotated. Check out more details in the [github repo](https://github.com/liyucheng09/Metaphor_Generator) and our [paper](https://aclanthology.org/2022.coling-1.563/) presenting at COLING 2022.
首个中文比喻数据集,可以用于中文比喻识别与中文比喻生成。在[知乎](https://zhuanlan.zhihu.com/p/572740322)查看更多细节。
### Languages
Chinese
### Citation Information
```
@inproceedings{li-etal-2022-cm,
title = "{CM}-Gen: A Neural Framework for {C}hinese Metaphor Generation with Explicit Context Modelling",
author = "Li, Yucheng and
Lin, Chenghua and
Guerin, Frank",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.563",
pages = "6468--6479",
}
``` | liyucheng/chinese_metaphor_dataset | [
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:zh",
"license:cc-by-nc-sa-4.0",
"metaphor",
"figurative language",
"region:us"
]
| 2023-01-24T17:16:26+00:00 | {"language": ["zh"], "license": "cc-by-nc-sa-4.0", "size_categories": ["1K<n<10K"], "task_categories": ["text-generation"], "pretty_name": "CMC", "tags": ["metaphor", "figurative language"]} | 2023-07-06T19:29:33+00:00 |
3adfe5ce52bb8d547d2f0b54a687810d9422880e | # Dataset Card for "es_hate_speech"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | pysentimiento/es_hate_speech | [
"region:us"
]
| 2023-01-24T17:53:38+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "HS", "dtype": {"class_label": {"names": {"0": "OK", "1": "HATEFUL"}}}}, {"name": "TR", "dtype": {"class_label": {"names": {"0": "GROUP", "1": "INDIVIDUAL"}}}}, {"name": "AG", "dtype": {"class_label": {"names": {"0": "NOT AGGRESSIVE", "1": "AGGRESSIVE"}}}}], "splits": [{"name": "dev", "num_bytes": 84567, "num_examples": 500}, {"name": "test", "num_bytes": 279000, "num_examples": 1600}, {"name": "train", "num_bytes": 752199, "num_examples": 4500}], "download_size": 698251, "dataset_size": 1115766}} | 2023-01-24T17:53:58+00:00 |
2fd28ca55e93f20a16394e6cc4c7761d6d758164 | # Dataset Card for "es_sentiment"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | pysentimiento/es_sentiment | [
"region:us"
]
| 2023-01-24T17:54:20+00:00 | {"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "lang", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "neg", "1": "neu", "2": "pos"}}}}], "splits": [{"name": "dev", "num_bytes": 273826, "num_examples": 2443}, {"name": "test", "num_bytes": 747378, "num_examples": 7264}, {"name": "train", "num_bytes": 520221, "num_examples": 4802}], "download_size": 1009181, "dataset_size": 1541425}} | 2023-01-24T17:54:40+00:00 |
e821c725fd2fd66186f4b19b6e3628091cbb921b | # Dataset Card for "academia2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | juancopi81/academia2 | [
"task_categories:automatic-speech-recognition",
"whisper",
"whispering",
"base",
"region:us"
]
| 2023-01-24T18:34:54+00:00 | {"task_categories": ["automatic-speech-recognition"], "dataset_info": {"features": [{"name": "CHANNEL_NAME", "dtype": "string"}, {"name": "URL", "dtype": "string"}, {"name": "TITLE", "dtype": "string"}, {"name": "DESCRIPTION", "dtype": "string"}, {"name": "TRANSCRIPTION", "dtype": "string"}, {"name": "SEGMENTS", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 13790539, "num_examples": 388}], "download_size": 4608890, "dataset_size": 13790539}, "tags": ["whisper", "whispering", "base"]} | 2023-01-25T16:11:01+00:00 |
fc9bcda0640617e6baa6946071f424beedc4f922 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/nfcorpus-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T18:57:21+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:18:39+00:00 |
0fb93dd23a7339b6dcd27e241cb9b5eca62d4d18 |
Original dataset introduced by Jin et al. in [What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams](https://paperswithcode.com/paper/what-disease-does-this-patient-have-a-large)
<h4>Citation information:</h4>
@article{jin2020disease,
title={What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams},
author={Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter},
journal={arXiv preprint arXiv:2009.13081},
year={2020}
}
| GBaker/MedQA-USMLE-4-options | [
"language:en",
"license:cc-by-4.0",
"region:us"
]
| 2023-01-24T19:08:56+00:00 | {"language": ["en"], "license": "cc-by-4.0"} | 2023-01-24T19:18:09+00:00 |
b13bd7ebd4a08ec3385b0d6e3df6da8b94449949 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/fiqa-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:21:16+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:21:20+00:00 |
ead875e08787c559c82fc4f9b09810f5492140e8 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/scifact-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:21:39+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:21:40+00:00 |
e7cbffa3aa5cbe6613fc7d81d0d823cf87d69b19 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/trec-news-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:22:47+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:23:15+00:00 |
d3fd37c14bb6cf5886688e2c871ee6600bf8c353 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/robust04-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:23:26+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:23:50+00:00 |
cb4c02768580fc18b4f6968a9dde08d31a39183f | # Dataset Card for "PickaPic-ft-ranked"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | yuvalkirstain/PickaPic-ft-ranked | [
"region:us"
]
| 2023-01-24T19:24:08+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}, {"name": "width", "dtype": "int64"}, {"name": "height", "dtype": "int64"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1546519335.752, "num_examples": 3748}, {"name": "validation", "num_bytes": 78674902.0, "num_examples": 200}], "download_size": 1546455134, "dataset_size": 1625194237.752}} | 2023-01-26T06:49:31+00:00 |
6adc54411f0c00683ecfad33eb21b912cd50933d |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/scidocs-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:26:50+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:26:52+00:00 |
f46d2212247b77aed6d05ecfcecadfaedc75f8bb |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/arguana-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:26:57+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:26:59+00:00 |
d69c13f113c079cd2777c9260e8d054ac4041977 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/trec-covid-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:27:07+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:27:17+00:00 |
a0ee7b8ac5d3d7397d21d458d8aec81f49d79df8 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/quora-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:27:55+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:28:14+00:00 |
cbe7a3a74261624564c24615aba58b10ec7f1a1b |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/webis-touche2020-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:29:28+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:29:44+00:00 |
aac925e88256b223e413a1088489adfd0915c7a3 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/hotpotqa-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:29:51+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:31:59+00:00 |
7f2b2d3356af939381bf3798f5be97c3bbaa56bc | # Dataset Card for "oxford_pets_with_l14_emb"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Isamu136/oxford_pets_with_l14_emb | [
"region:us"
]
| 2023-01-24T19:30:19+00:00 | {"dataset_info": {"features": [{"name": "path", "dtype": "string"}, {"name": "label", "dtype": "string"}, {"name": "dog", "dtype": "bool"}, {"name": "image", "dtype": "image"}, {"name": "embeddings", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 257189204.25, "num_examples": 7390}], "download_size": 261518905, "dataset_size": 257189204.25}} | 2023-01-24T19:30:50+00:00 |
5cf16c02f47d75a50a93b9b641fefd7845e96cc2 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/dbpedia-entity-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:32:09+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:34:05+00:00 |
920b718d60c417adf6928e1a5bdfbeb22a9f6117 | DebateLabKIT/parquet-stream | [
"license:apache-2.0",
"region:us"
]
| 2023-01-24T19:36:02+00:00 | {"license": "apache-2.0"} | 2023-01-24T19:47:45+00:00 |
|
77c321dc940a437b5f8e06486f708b421ce4f75d |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/fever-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:36:21+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:38:47+00:00 |
0c838bb2f062e54c2f1f91b3c3691270f03c3446 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/climate-fever-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:39:40+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:42:05+00:00 |
56a8a7fc3e8ab80e8bde4c905c3eaf329cecf174 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/signal1m-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:42:23+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:44:12+00:00 |
3a0447e841f716d4c696864c9890faa84ae4d58e |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/nq-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:45:03+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:46:36+00:00 |
b13373686d536c6a45b0069e96cf83bab72f33db |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-android-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:50:29+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:50:32+00:00 |
cdf2b8c35902f0878ed23f8b77c9cdbd15f3d0b8 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-english-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:03+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:09+00:00 |
7bc9f799538604098291b78dc27f8de287295697 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-gaming-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:15+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:18+00:00 |
6cd1d4c86302bccf6a1a884e362dad6a49a4af96 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-gis-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:23+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:26+00:00 |
86c17b0e3b216cf3b658610fd07ba2f59624a73b |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-mathematica-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:31+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:33+00:00 |
d00ec7b4129c7106a28a6b311ae5fdba2e45891a |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-physics-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:38+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:41+00:00 |
6b00f8c5c20225ed7e203b5f4f11ba8d5cd2fc81 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-programmers-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:46+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:48+00:00 |
ba226477db4a8d347624d59274d64d89500ef99e |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-stats-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:52:53+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:52:56+00:00 |
5f1c8bbc6dbb56a8c7a8813332dd7a38300fdebe |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-tex-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:53:01+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:53:05+00:00 |
790844a3d3bc8342b0ad0e35d2f8b397b77b2784 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-unix-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:53:13+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:53:16+00:00 |
6f8523361c6b87bd3f9f949b4cb65c323f703de1 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-webmasters-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:53:22+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:53:24+00:00 |
58a61313d0896efecc695368b61ec2b14dff70e7 |
# NFCorpus: 20 generated queries (BEIR Benchmark)
This HF dataset contains the top-20 synthetic queries generated for each passage in the above BEIR benchmark dataset.
- DocT5query model used: [BeIR/query-gen-msmarco-t5-base-v1](https://huggingface.co/BeIR/query-gen-msmarco-t5-base-v1)
- id (str): unique document id in NFCorpus in the BEIR benchmark (`corpus.jsonl`).
- Questions generated: 20
- Code used for generation: [evaluate_anserini_docT5query_parallel.py](https://github.com/beir-cellar/beir/blob/main/examples/retrieval/evaluation/sparse/evaluate_anserini_docT5query_parallel.py)
Below contains the old dataset card for the BEIR benchmark.
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset.Top-20 generated queries for every passage in NFCorpus
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** [email protected]
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | income/cqadupstack-wordpress-top-20-gen-queries | [
"task_categories:text-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T19:53:30+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": {"msmarco": ["1M<n<10M"], "trec-covid": ["100k<n<1M"], "nfcorpus": ["1K<n<10K"], "nq": ["1M<n<10M"], "hotpotqa": ["1M<n<10M"], "fiqa": ["10K<n<100K"], "arguana": ["1K<n<10K"], "touche-2020": ["100K<n<1M"], "cqadupstack": ["100K<n<1M"], "quora": ["100K<n<1M"], "dbpedia": ["1M<n<10M"], "scidocs": ["10K<n<100K"], "fever": ["1M<n<10M"], "climate-fever": ["1M<n<10M"], "scifact": ["1K<n<10K"]}, "source_datasets": [], "task_categories": ["text-retrieval"], "paperswithcode_id": "beir", "pretty_name": "BEIR Benchmark"} | 2023-01-24T19:53:33+00:00 |
409801b9372048fc7ef27a8056a334c149451565 | NKLPAWAR/images | [
"license:openrail",
"region:us"
]
| 2023-01-24T20:18:30+00:00 | {"license": "openrail"} | 2023-01-24T20:20:29+00:00 |
|
17af9355ef89fba60de966eabaeba797c695f86e | Original dataset introduced by Jin et al. in [What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams](https://paperswithcode.com/paper/what-disease-does-this-patient-have-a-large)
<h4>Citation information:</h4>
@article{jin2020disease,
title={What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams},
author={Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter},
journal={arXiv preprint arXiv:2009.13081},
year={2020}
} | GBaker/MedQA-USMLE-4-options-hf | [
"license:cc-by-sa-4.0",
"region:us"
]
| 2023-01-24T20:32:54+00:00 | {"license": "cc-by-sa-4.0"} | 2023-01-30T22:57:33+00:00 |
23ff83b18ed76882f3af1a403a7c464b72efcd86 | ERROR: type should be string, got "\nhttps://github.com/allenai/csqa2\n\n```\n@article{talmor2022commonsenseqa,\n title={CommonsenseQA 2.0: Exposing the limits of AI through gamification},\n author={Talmor, Alon and Yoran, Ori and Bras, Ronan Le and Bhagavatula, Chandra and Goldberg, Yoav and Choi, Yejin and Berant, Jonathan},\n journal={arXiv preprint arXiv:2201.05320},\n year={2022}\n}\n```" | tasksource/commonsense_qa_2.0 | [
"task_categories:question-answering",
"language:en",
"license:cc-by-4.0",
"region:us"
]
| 2023-01-24T21:45:47+00:00 | {"language": ["en"], "license": "cc-by-4.0", "task_categories": ["question-answering"]} | 2023-06-21T11:48:33+00:00 |
e548eae008a43d71df22d230476db873b7ad7228 |
# DMV-Plates
This datasets contains various plates and their DMV responses.
Props to avery for making this jsonl file! | DarwinAnim8or/DMV-Plate-Review | [
"license:mit",
"region:us"
]
| 2023-01-24T22:13:04+00:00 | {"license": "mit"} | 2023-01-24T22:17:51+00:00 |
d130cde11d599ea68b91ec6bb9d2e87ae2724d78 | # Dataset Card for "blimp"
HuggingFace Hub Upload of BLiMP: The Benchmark of Linguistic Minimal Pairs from https://github.com/alexwarstadt/blimp
If you use this dataset in your work, please cite the original authors and paper.
```
@article{warstadt2020blimp,
author = {Warstadt, Alex and Parrish, Alicia and Liu, Haokun and Mohananey, Anhad and Peng, Wei and Wang, Sheng-Fu and Bowman, Samuel R.},
title = {BLiMP: The Benchmark of Linguistic Minimal Pairs for English},
journal = {Transactions of the Association for Computational Linguistics},
volume = {8},
number = {},
pages = {377-392},
year = {2020},
doi = {10.1162/tacl\_a\_00321},
URL = {https://doi.org/10.1162/tacl_a_00321},
eprint = {https://doi.org/10.1162/tacl_a_00321},
abstract = { We introduce The Benchmark of Linguistic Minimal Pairs (BLiMP),1 a challenge set for evaluating the linguistic knowledge of language models (LMs) on major grammatical phenomena in English. BLiMP consists of 67 individual datasets, each containing 1,000 minimal pairs—that is, pairs of minimally different sentences that contrast in grammatical acceptability and isolate specific phenomenon in syntax, morphology, or semantics. We generate the data according to linguist-crafted grammar templates, and human aggregate agreement with the labels is 96.4\%. We evaluate n-gram, LSTM, and Transformer (GPT-2 and Transformer-XL) LMs by observing whether they assign a higher probability to the acceptable sentence in each minimal pair. We find that state-of-the-art models identify morphological contrasts related to agreement reliably, but they struggle with some subtle semantic and syntactic phenomena, such as negative polarity items and extraction islands. }
}
``` | WillHeld/blimp | [
"region:us"
]
| 2023-01-24T22:33:00+00:00 | {"dataset_info": {"features": [{"name": "sentence_good", "dtype": "string"}, {"name": "sentence_bad", "dtype": "string"}, {"name": "two_prefix_prefix_good", "dtype": "string"}, {"name": "two_prefix_prefix_bad", "dtype": "string"}, {"name": "two_prefix_word", "dtype": "string"}, {"name": "field", "dtype": "string"}, {"name": "linguistics_term", "dtype": "string"}, {"name": "UID", "dtype": "string"}, {"name": "simple_LM_method", "dtype": "bool"}, {"name": "one_prefix_method", "dtype": "bool"}, {"name": "two_prefix_method", "dtype": "bool"}, {"name": "lexically_identical", "dtype": "bool"}, {"name": "pairID", "dtype": "string"}, {"name": "feature_name", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 15550503, "num_examples": 67000}], "download_size": 4374212, "dataset_size": 15550503}} | 2023-01-24T22:34:34+00:00 |
3bce22812744303f47f02a3049ba8e4af20c708e | ncoop57/mmmlu | [
"license:mit",
"region:us"
]
| 2023-01-24T23:50:14+00:00 | {"license": "mit"} | 2023-02-01T07:02:32+00:00 |
|
68514b11f3882443a2149cda711dbc12e07db3dc | Joe02/Remu_Refs | [
"license:other",
"region:us"
]
| 2023-01-25T00:37:01+00:00 | {"license": "other"} | 2023-01-25T00:37:42+00:00 |
|
f123ca8a58f7a593c4f27ad68304ebf1647614e2 | chansung/me | [
"license:apache-2.0",
"region:us"
]
| 2023-01-25T01:03:26+00:00 | {"license": "apache-2.0"} | 2023-01-25T08:17:05+00:00 |
|
ddb1f829b4c693bd29f91cf466d76e0065593358 | # Dataset Card for "OxfordPets_test_facebook_opt_125m_Attributes_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_125m_Attributes_ns_3669 | [
"region:us"
]
| 2023-01-25T02:40:56+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121000492.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 121909173.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 123709349.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 125501892.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 128203231.375, "num_examples": 3669}], "download_size": 602523943, "dataset_size": 620324138.875}} | 2023-01-25T02:56:08+00:00 |
7bd99fb29d7ce6498fd5b4ab15880c36d5179cd7 | # Dataset Card for "OxfordPets_test_facebook_opt_350m_Attributes_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_350m_Attributes_ns_3669 | [
"region:us"
]
| 2023-01-25T03:02:29+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121000490.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 121909413.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 123709541.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 125502094.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 128203377.375, "num_examples": 3669}], "download_size": 602524552, "dataset_size": 620324916.875}} | 2023-01-25T03:24:23+00:00 |
4126b85d57349927a4b886d5924ab4735fffa6a1 |
# Perturbed Faces
This dataset contains 1000 images from [CelebA dataset](!https://www.kaggle.com/datasets/jessicali9530/celeba-dataset). For each of the thousand images dataset also has [LowKey](https://openreview.net/forum?id=hJmtwocEqzc) perturbed version and [Fawkes](https://sandlab.cs.uchicago.edu/fawkes/) perturbed version.
LowKey and Fawkes perturbed images have _attacked & _cloaked at the end of the filename respectively.
| File Name | Version |
|---------------------|--------------------------|
| 000001.jpg | Original |
| 000001_cloaked.png | Fawkes perturbed version |
| 000001_attacked.png | LowKey perturbed version |
The Fawkes perturbed images are created using CLI provided in the [github repository](https://github.com/Shawn-Shan/fawkes) with protection mode set to mid. The LowKey version of
images are created using Python code provided with the paper.
## Citation
If you found this work helpful for your research, please cite it as following:
```
@misc{2301.07315,
Author = {Aaditya Bhat and Shrey Jain},
Title = {Face Recognition in the age of CLIP & Billion image datasets},
Year = {2023},
Eprint = {arXiv:2301.07315},
}
``` | aadityaubhat/perturbed_faces | [
"task_categories:feature-extraction",
"task_categories:image-classification",
"task_categories:zero-shot-image-classification",
"size_categories:1K<n<10K",
"arxiv:2301.07315",
"region:us"
]
| 2023-01-25T03:43:47+00:00 | {"size_categories": ["1K<n<10K"], "task_categories": ["feature-extraction", "image-classification", "zero-shot-image-classification"], "pretty_name": "Perturbed Faces"} | 2023-01-25T04:29:39+00:00 |
035adf51a4bd7b56e516f2bf9a0cb0e018166fd1 | Joe02/ZOL_refs | [
"license:other",
"region:us"
]
| 2023-01-25T03:51:00+00:00 | {"license": "other"} | 2023-01-25T21:14:52+00:00 |
|
a435eb8767b9a5667e56d53bbb7c3a154c1b9670 | # Dataset Card for "OxfordPets_test_facebook_opt_1.3b_Attributes_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_1.3b_Attributes_ns_3669 | [
"region:us"
]
| 2023-01-25T04:23:01+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121038204.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 121909027.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 123709262.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 125502039.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 128203307.375, "num_examples": 3669}], "download_size": 602521012, "dataset_size": 620361840.875}} | 2023-01-25T04:55:11+00:00 |
17f66ff52eb1a7c8bebca582ee6567d29ba17308 | # Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | samkenxstream/turnkey-triumph-326606_SamKenX-imdb | [
"task_categories:token-classification",
"task_categories:text-classification",
"size_categories:100K<n<1M",
"language:aa",
"language:an",
"language:av",
"license:bsl-1.0",
"region:us"
]
| 2023-01-25T05:03:32+00:00 | {"language": ["aa", "an", "av"], "license": "bsl-1.0", "size_categories": ["100K<n<1M"], "task_categories": ["token-classification", "text-classification"]} | 2023-02-11T18:28:49+00:00 |
3b897a8283ee3be6bc53e6732261cd97e9bf182e | PinkysMusing/SerAnthony | [
"license:cc",
"region:us"
]
| 2023-01-25T06:02:51+00:00 | {"license": "cc"} | 2023-01-25T06:05:25+00:00 |
|
2235745e5e53eac10295334dfb18ef829a34705b | # Dataset Card for "noto-emoji-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | kuotient/noto-emoji-dataset | [
"region:us"
]
| 2023-01-25T06:10:35+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 24395327.773, "num_examples": 1001}], "download_size": 24218126, "dataset_size": 24395327.773}} | 2023-02-01T08:15:25+00:00 |
9f01f21d68e292dc1f272a055ec7aa1c964f9a6f | # Dataset Card for "Uniref90_large_temp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Oshan/Uniref90_large_temp | [
"region:us"
]
| 2023-01-25T06:11:58+00:00 | {"dataset_info": {"features": [{"name": "cluster_id", "dtype": "string"}, {"name": "cluster_size", "dtype": "int64"}, {"name": "taxon_id", "dtype": "int64"}, {"name": "aa_len", "dtype": "int64"}, {"name": "aa_seq", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 15035559, "num_examples": 500}], "download_size": 0, "dataset_size": 15035559}} | 2023-01-25T06:20:03+00:00 |
780f16b700490f763b6baf0f3254d5c858221310 | Joe02/Nanahoshi_refs | [
"license:other",
"region:us"
]
| 2023-01-25T06:29:34+00:00 | {"license": "other"} | 2023-08-06T21:13:31+00:00 |
|
e03d3b8b37d4f3959c556843869f7fba5e3d0020 | # Dataset Card for "skin"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | vgg/skin | [
"region:us"
]
| 2023-01-25T07:36:42+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 1751364.0, "num_examples": 80}], "download_size": 1758461, "dataset_size": 1751364.0}} | 2023-03-23T12:55:41+00:00 |
0d1b646d0ee85375b13a35ac16c1e2e9e8ba0ec9 | Joe02/AkiyamaRinko_refs | [
"license:other",
"region:us"
]
| 2023-01-25T08:36:29+00:00 | {"license": "other"} | 2023-01-25T09:37:18+00:00 |
|
2dbb4c1be6a481a4d5ef52fdc4cbd4f09f52379c |
# LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
A collaboration between [reciTAL](https://recital.ai/en/), [MLIA](https://mlia.lip6.fr/) (ISIR, Sorbonne Université), [Meta AI](https://ai.facebook.com/), and [Università di Trento](https://www.unitn.it/)
## Arxiv-Lay dataset for summarization
ArXiv-Lay is an enhanced version of the arXiv summarization dataset, for which layout information is provided.
### Data Fields
- `article_id`: article id
- `article_words`: sequence of words constituting the body of the article
- `article_bboxes`: sequence of corresponding word bounding boxes
- `norm_article_bboxes`: sequence of corresponding normalized word bounding boxes
- `abstract`: a string containing the abstract of the article
- `article_pdf_url`: URL of the article's PDF
### Data Splits
This dataset has 3 splits: _train_, _validation_, and _test_.
| Dataset Split | Number of Instances |
| ------------- | --------------------|
| Train | 122,189 |
| Validation | 4,374 |
| Test | 4,356 |
## Citation
``` latex
@article{nguyen2023loralay,
title={LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization},
author={Nguyen, Laura and Scialom, Thomas and Piwowarski, Benjamin and Staiano, Jacopo},
journal={arXiv preprint arXiv:2301.11312},
year={2023}
}
``` | nglaura/arxivlay-summarization | [
"task_categories:summarization",
"language:en",
"license:apache-2.0",
"region:us"
]
| 2023-01-25T10:56:42+00:00 | {"language": ["en"], "license": "apache-2.0", "task_categories": ["summarization"], "pretty_name": "arXiv-Lay"} | 2023-04-11T09:08:36+00:00 |
ce3fee7e5609889764b2006ed9d5629617315a1b | b-yukky/msmarco-short | [
"license:mit",
"region:us"
]
| 2023-01-25T11:00:49+00:00 | {"license": "mit"} | 2023-01-25T11:01:53+00:00 |
|
95c9b8a3018e54c13f030dd2ec807a9dcd34b7d8 | Anonymous2023/KGSum | [
"license:openrail",
"region:us"
]
| 2023-01-25T11:17:26+00:00 | {"license": "openrail"} | 2023-02-11T16:15:43+00:00 |
|
05d4e370515ef41f534d3f87d5c54da0e66e2d1c |
# LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
A collaboration between [reciTAL](https://recital.ai/en/), [MLIA](https://mlia.lip6.fr/) (ISIR, Sorbonne Université), [Meta AI](https://ai.facebook.com/), and [Università di Trento](https://www.unitn.it/)
## HAL dataset for summarization
HAL is a dataset for summarization of research papers written in French, for which layout information is provided.
### Data Fields
- `article_id`: article id
- `article_words`: sequence of words constituting the body of the article
- `article_bboxes`: sequence of corresponding word bounding boxes
- `norm_article_bboxes`: sequence of corresponding normalized word bounding boxes
- `abstract`: a string containing the abstract of the article
- `article_pdf_url`: URL of the article's PDF
### Data Splits
This dataset has 3 splits: _train_, _validation_, and _test_.
| Dataset Split | Number of Instances |
| ------------- | --------------------|
| Train | 43,379 |
| Validation | 1,384 |
| Test | 1,385 |
## Citation
``` latex
@article{nguyen2023loralay,
title={LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization},
author={Nguyen, Laura and Scialom, Thomas and Piwowarski, Benjamin and Staiano, Jacopo},
journal={arXiv preprint arXiv:2301.11312},
year={2023}
}
``` | nglaura/hal-summarization | [
"task_categories:summarization",
"language:fr",
"license:apache-2.0",
"region:us"
]
| 2023-01-25T11:55:33+00:00 | {"language": ["fr"], "license": "apache-2.0", "task_categories": ["summarization"], "pretty_name": "HAL"} | 2023-04-11T09:15:37+00:00 |
e99e680bf47316b8d3f9445c1d449434ab02ef8a |
# LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
A collaboration between [reciTAL](https://recital.ai/en/), [MLIA](https://mlia.lip6.fr/) (ISIR, Sorbonne Université), [Meta AI](https://ai.facebook.com/), and [Università di Trento](https://www.unitn.it/)
## SciELO dataset for summarization
SciELO is a dataset for summarization of research papers written in Spanish and Portuguese, for which layout information is provided.
### Data Fields
- `article_id`: article id
- `article_words`: sequence of words constituting the body of the article
- `article_bboxes`: sequence of corresponding word bounding boxes
- `norm_article_bboxes`: sequence of corresponding normalized word bounding boxes
- `abstract`: a string containing the abstract of the article
- `article_pdf_url`: URL of the article's PDF
### Data Splits
This dataset has 3 splits: _train_, _validation_, and _test_.
| Dataset Split | Number of Instances (ES/PT) |
| ------------- | ----------------------------|
| Train | 20,853 / 19,407 |
| Validation | 1,158 / 1,078 |
| Test | 1,159 / 1,078 |
## Citation
``` latex
@article{nguyen2023loralay,
title={LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization},
author={Nguyen, Laura and Scialom, Thomas and Piwowarski, Benjamin and Staiano, Jacopo},
journal={arXiv preprint arXiv:2301.11312},
year={2023}
}
``` | nglaura/scielo-summarization | [
"task_categories:summarization",
"language:fr",
"license:apache-2.0",
"region:us"
]
| 2023-01-25T12:02:33+00:00 | {"language": ["fr"], "license": "apache-2.0", "task_categories": ["summarization"], "pretty_name": "SciELO"} | 2023-04-11T09:21:45+00:00 |
7fea0ce76dc9deb26bc27027b9c143701b6d5030 | # Dataset Card for "bookcorpus_stochastic_subset_compact_1024"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | saibo/bookcorpus_stochastic_subset_compact_1024 | [
"region:us"
]
| 2023-01-25T13:32:09+00:00 | {"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 27536698, "num_examples": 6160}], "download_size": 16803321, "dataset_size": 27536698}} | 2023-01-25T13:32:31+00:00 |
96e6ad0a454751aad0eeb07705aca1b5574eb8dc | polinaeterna/audio_configs2 | [
"region:us"
]
| 2023-01-25T14:29:15+00:00 | {"configs_kwargs": [{"config_name": "v1", "data_dir": "v1", "drop_labels": true}, {"config_name": "v2", "data_dir": "v2", "drop_labels": false}], "duplicated_from": "polinaeterna/audio_configs"} | 2023-01-25T14:29:16+00:00 |
|
5ba05938d8d038270614705397b9306ee7716ff0 | # Dataset Card for "OxfordPets_test_facebook_opt_2.7b_Attributes_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_2.7b_Attributes_ns_3669 | [
"region:us"
]
| 2023-01-25T14:35:11+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121046369.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 121909353.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 123709332.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 125501830.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 128203042.375, "num_examples": 3669}], "download_size": 602512072, "dataset_size": 620369927.875}} | 2023-01-25T15:22:28+00:00 |
d36b28325622ab4865ca64225fa38df9d219599b | # Dataset Card for "gesture_pred"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Jsevisal/gesture_pred | [
"task_categories:token-classification",
"language:en",
"region:us"
]
| 2023-01-25T14:48:47+00:00 | {"language": ["en"], "task_categories": ["token-classification"], "dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}, {"name": "gestures", "sequence": "string"}, {"name": "label", "sequence": {"class_label": {"names": {"0": "B-BUT", "1": "I-BUT", "2": "B-CALM_DOWN", "3": "I-CALM_DOWN", "4": "B-COME_ON", "5": "I-COME_ON", "6": "B-EMPHATIC", "7": "I-EMPHATIC", "8": "B-ENTHUSIASTIC", "9": "I-ENTHUSIASTIC", "10": "B-EXPLAIN", "11": "I-EXPLAIN", "12": "B-FRONT", "13": "I-FRONT", "14": "B-GREET", "15": "I-GREET", "16": "B-ITERATE", "17": "I-ITERATE", "18": "B-NEUTRAL", "19": "I-NEUTRAL", "20": "B-NO", "21": "I-NO", "22": "B-NO_GESTURE", "23": "I-NO_GESTURE", "24": "B-OTHER_PEER", "25": "I-OTHER_PEER", "26": "B-PLEASE", "27": "I-PLEASE", "28": "B-QUESTION", "29": "I-QUESTION", "30": "B-SELF", "31": "I-SELF", "32": "B-SORRY", "33": "I-SORRY", "34": "B-THANKS", "35": "I-THANKS", "36": "B-THINKING", "37": "I-THINKING", "38": "B-THIRD_PERSON", "39": "I-THIRD_PERSON", "40": "B-YES", "41": "I-YES"}}}}], "splits": [{"name": "train", "num_bytes": 714214, "num_examples": 2339}, {"name": "test", "num_bytes": 40730, "num_examples": 130}, {"name": "validation", "num_bytes": 41891, "num_examples": 130}], "download_size": 140110, "dataset_size": 796835}} | 2023-09-14T10:31:43+00:00 |
19144fa7c99ff5185443bd425c5ee9fe4ce950d7 | # Dataset Card for "yuvalkirstain-sd_15_pexel_people-eval-random-prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | yuvalkirstain/yuvalkirstain-sd_15_pexel_people-eval-random-prompts | [
"region:us"
]
| 2023-01-25T14:54:26+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 32792, "num_examples": 200}], "download_size": 11301, "dataset_size": 32792}} | 2023-01-25T14:54:34+00:00 |
9f45f40d711d83695172619bf59b82135a520678 | # Dataset Card for "wild-rabbit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | purplebear/wild-rabbit | [
"region:us"
]
| 2023-01-25T14:59:21+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 77534644.0, "num_examples": 20}], "download_size": 0, "dataset_size": 77534644.0}} | 2023-01-25T15:09:13+00:00 |
38ff443244c1b496c33ed237d3d4468daf24265c |
# Dataset Card for DocLayNet large
## About this card (01/27/2023)
### Property and license
All information from this page but the content of this paragraph "About this card (01/27/2023)" has been copied/pasted from [Dataset Card for DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet).
DocLayNet is a dataset created by Deep Search (IBM Research) published under [license CDLA-Permissive-1.0](https://huggingface.co/datasets/ds4sd/DocLayNet#licensing-information).
I do not claim any rights to the data taken from this dataset and published on this page.
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
### Processing into a format facilitating its use by HF notebooks
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately ([doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip), 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- [DocLayNet small](https://huggingface.co/datasets/pierreguillou/DocLayNet-small) (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- [DocLayNet large](https://huggingface.co/datasets/pierreguillou/DocLayNet-large) (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
*Note: the layout HF notebooks will greatly help participants of the IBM [ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents](https://ds4sd.github.io/icdar23-doclaynet/)!*
### About PDFs languages
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"We did not control the document selection with regard to language. **The vast majority of documents contained in DocLayNet (close to 95%) are published in English language.** However, DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%). While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
### About PDFs categories distribution
Citation of the page 3 of the [DocLayNet paper](https://arxiv.org/abs/2206.01062):
"The pages in DocLayNet can be grouped into **six distinct categories**, namely Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
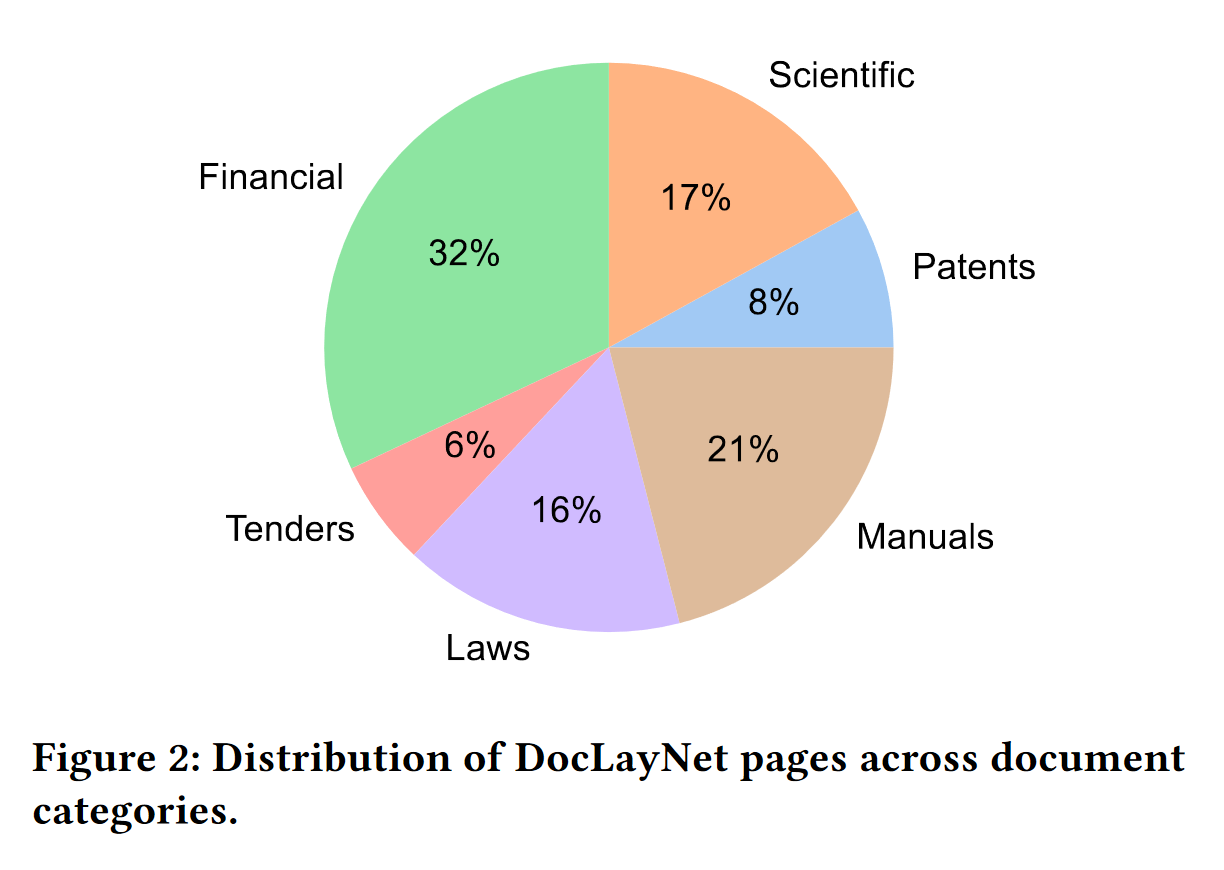
### Download & overview
The size of the DocLayNet large is about 100% of the DocLayNet dataset.
**WARNING** The following code allows to download DocLayNet large but it can not run until the end in Google Colab because of the size needed to store cache data and the CPU RAM to download the data (for example, the cache data in /home/ubuntu/.cache/huggingface/datasets/ needs almost 120 GB during the downloading process). And even with a suitable instance, the download time of the DocLayNet large dataset is around 1h50. This is one more reason to test your fine-tuning code on [DocLayNet small](https://huggingface.co/datasets/pierreguillou/DocLayNet-small) and/or [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) 😊
```
# !pip install -q datasets
from datasets import load_dataset
dataset_large = load_dataset("pierreguillou/DocLayNet-large")
# overview of dataset_large
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 69103
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 6480
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'pdf', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 4994
})
})
```
### Annotated bounding boxes
The DocLayNet base makes easy to display document image with the annotaed bounding boxes of paragraphes or lines.
Check the notebook [processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb](https://github.com/piegu/language-models/blob/master/processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb) in order to get the code.
#### Paragraphes

#### Lines

### HF notebooks
- [notebooks LayoutLM](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLM) (Niels Rogge)
- [notebooks LayoutLMv2](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2) (Niels Rogge)
- [notebooks LayoutLMv3](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3) (Niels Rogge)
- [notebooks LiLT](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT) (Niels Rogge)
- [Document AI: Fine-tuning LiLT for document-understanding using Hugging Face Transformers](https://github.com/philschmid/document-ai-transformers/blob/main/training/lilt_funsd.ipynb) ([post](https://www.philschmid.de/fine-tuning-lilt#3-fine-tune-and-evaluate-lilt) of Phil Schmid)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Annotations](#annotations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://developer.ibm.com/exchanges/data/all/doclaynet/
- **Repository:** https://github.com/DS4SD/DocLayNet
- **Paper:** https://doi.org/10.1145/3534678.3539043
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
DocLayNet provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories. It provides several unique features compared to related work such as PubLayNet or DocBank:
1. *Human Annotation*: DocLayNet is hand-annotated by well-trained experts, providing a gold-standard in layout segmentation through human recognition and interpretation of each page layout
2. *Large layout variability*: DocLayNet includes diverse and complex layouts from a large variety of public sources in Finance, Science, Patents, Tenders, Law texts and Manuals
3. *Detailed label set*: DocLayNet defines 11 class labels to distinguish layout features in high detail.
4. *Redundant annotations*: A fraction of the pages in DocLayNet are double- or triple-annotated, allowing to estimate annotation uncertainty and an upper-bound of achievable prediction accuracy with ML models
5. *Pre-defined train- test- and validation-sets*: DocLayNet provides fixed sets for each to ensure proportional representation of the class-labels and avoid leakage of unique layout styles across the sets.
### Supported Tasks and Leaderboards
We are hosting a competition in ICDAR 2023 based on the DocLayNet dataset. For more information see https://ds4sd.github.io/icdar23-doclaynet/.
## Dataset Structure
### Data Fields
DocLayNet provides four types of data assets:
1. PNG images of all pages, resized to square `1025 x 1025px`
2. Bounding-box annotations in COCO format for each PNG image
3. Extra: Single-page PDF files matching each PNG image
4. Extra: JSON file matching each PDF page, which provides the digital text cells with coordinates and content
The COCO image record are defined like this example
```js
...
{
"id": 1,
"width": 1025,
"height": 1025,
"file_name": "132a855ee8b23533d8ae69af0049c038171a06ddfcac892c3c6d7e6b4091c642.png",
// Custom fields:
"doc_category": "financial_reports" // high-level document category
"collection": "ann_reports_00_04_fancy", // sub-collection name
"doc_name": "NASDAQ_FFIN_2002.pdf", // original document filename
"page_no": 9, // page number in original document
"precedence": 0, // Annotation order, non-zero in case of redundant double- or triple-annotation
},
...
```
The `doc_category` field uses one of the following constants:
```
financial_reports,
scientific_articles,
laws_and_regulations,
government_tenders,
manuals,
patents
```
### Data Splits
The dataset provides three splits
- `train`
- `val`
- `test`
## Dataset Creation
### Annotations
#### Annotation process
The labeling guideline used for training of the annotation experts are available at [DocLayNet_Labeling_Guide_Public.pdf](https://raw.githubusercontent.com/DS4SD/DocLayNet/main/assets/DocLayNet_Labeling_Guide_Public.pdf).
#### Who are the annotators?
Annotations are crowdsourced.
## Additional Information
### Dataset Curators
The dataset is curated by the [Deep Search team](https://ds4sd.github.io/) at IBM Research.
You can contact us at [[email protected]](mailto:[email protected]).
Curators:
- Christoph Auer, [@cau-git](https://github.com/cau-git)
- Michele Dolfi, [@dolfim-ibm](https://github.com/dolfim-ibm)
- Ahmed Nassar, [@nassarofficial](https://github.com/nassarofficial)
- Peter Staar, [@PeterStaar-IBM](https://github.com/PeterStaar-IBM)
### Licensing Information
License: [CDLA-Permissive-1.0](https://cdla.io/permissive-1-0/)
### Citation Information
```bib
@article{doclaynet2022,
title = {DocLayNet: A Large Human-Annotated Dataset for Document-Layout Segmentation},
doi = {10.1145/3534678.353904},
url = {https://doi.org/10.1145/3534678.3539043},
author = {Pfitzmann, Birgit and Auer, Christoph and Dolfi, Michele and Nassar, Ahmed S and Staar, Peter W J},
year = {2022},
isbn = {9781450393850},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages = {3743–3751},
numpages = {9},
location = {Washington DC, USA},
series = {KDD '22}
}
```
### Contributions
Thanks to [@dolfim-ibm](https://github.com/dolfim-ibm), [@cau-git](https://github.com/cau-git) for adding this dataset. | pierreguillou/DocLayNet-large | [
"task_categories:object-detection",
"task_categories:image-segmentation",
"task_categories:token-classification",
"task_ids:instance-segmentation",
"annotations_creators:crowdsourced",
"size_categories:10K<n<100K",
"language:en",
"language:de",
"language:fr",
"language:ja",
"license:other",
"DocLayNet",
"COCO",
"PDF",
"IBM",
"Financial-Reports",
"Finance",
"Manuals",
"Scientific-Articles",
"Science",
"Laws",
"Law",
"Regulations",
"Patents",
"Government-Tenders",
"object-detection",
"image-segmentation",
"token-classification",
"arxiv:2206.01062",
"region:us"
]
| 2023-01-25T15:14:52+00:00 | {"annotations_creators": ["crowdsourced"], "language": ["en", "de", "fr", "ja"], "license": "other", "size_categories": ["10K<n<100K"], "task_categories": ["object-detection", "image-segmentation", "token-classification"], "task_ids": ["instance-segmentation"], "pretty_name": "DocLayNet large", "tags": ["DocLayNet", "COCO", "PDF", "IBM", "Financial-Reports", "Finance", "Manuals", "Scientific-Articles", "Science", "Laws", "Law", "Regulations", "Patents", "Government-Tenders", "object-detection", "image-segmentation", "token-classification"]} | 2023-05-17T07:56:48+00:00 |
cdf40085b54db16615c767e1c840054a249d7dfb |
# Dataset Card for aiornot
Dataset for the [aiornot competition](https://hf.co/spaces/competitions/aiornot).
By accessing this dataset, you accept the rules of the AI or Not competition.
Please note that dataset may contain images which are not considered safe for work.
## Usage
### With Hugging Face Datasets 🤗
You can download and use this dataset using the `datasets` library.
📝 **Note:** You must be logged in to you Hugging Face account for the snippet below to work. You can do this with `huggingface-cli login` or `huggingface_hub.notebook_login` if you have the `huggingface_hub` python library installed (`pip install huggingface_hub`).
```python
from datasets import load_dataset
ds = load_dataset('competitions/aiornot')
```
### From Original Files
The original files and sample submission can be found in the `.extras` folder (under the files and versions tab of this repo). Feel free to download them and use them directly if you don't wish to use the `datasets` library.
| competitions/aiornot | [
"task_categories:image-classification",
"image-classification",
"autotrain",
"competitions",
"region:us"
]
| 2023-01-25T15:22:37+00:00 | {"task_categories": ["image-classification"], "tags": ["image-classification", "autotrain", "competitions"], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "label", "dtype": "int64"}]}} | 2023-03-30T11:32:32+00:00 |
177973aad7fd299f63ccde74824c5a0233998d8b |
# LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization
A collaboration between [reciTAL](https://recital.ai/en/), [MLIA](https://mlia.lip6.fr/) (ISIR, Sorbonne Université), [Meta AI](https://ai.facebook.com/), and [Università di Trento](https://www.unitn.it/)
## KoreaScience dataset for summarization
KoreaScience is a dataset for summarization of research papers written in Korean, for which layout information is provided.
### Data Fields
- `article_id`: article id
- `article_words`: sequence of words constituting the body of the article
- `article_bboxes`: sequence of corresponding word bounding boxes
- `norm_article_bboxes`: sequence of corresponding normalized word bounding boxes
- `abstract`: a string containing the abstract of the article
- `article_pdf_url`: URL of the article's PDF
### Data Splits
This dataset has 3 splits: _train_, _validation_, and _test_.
| Dataset Split | Number of Instances |
| ------------- | --------------------|
| Train | 35,248 |
| Validation | 1,125 |
| Test | 1,125 |
## Citation
``` latex
@article{nguyen2023loralay,
title={LoRaLay: A Multilingual and Multimodal Dataset for Long Range and Layout-Aware Summarization},
author={Nguyen, Laura and Scialom, Thomas and Piwowarski, Benjamin and Staiano, Jacopo},
journal={arXiv preprint arXiv:2301.11312},
year={2023}
}
``` | nglaura/koreascience-summarization | [
"task_categories:summarization",
"language:fr",
"license:apache-2.0",
"region:us"
]
| 2023-01-25T15:27:10+00:00 | {"language": ["fr"], "license": "apache-2.0", "task_categories": ["summarization"], "pretty_name": "KoreaScience"} | 2023-04-11T09:23:00+00:00 |
d06f14028e58ec8177c13dbacad981b7efca5c21 |
# Multiclass Semantic Segmentation Duckietown Dataset
A dataset of multiclass semantic segmentation image annotations for the first 250 images of the ["Duckietown Object Detection Dataset"](https://docs.duckietown.org/daffy/AIDO/out/object_detection_dataset.html).
| Raw Image | Segmentated Image |
| --- | --- |
| <img width="915" alt="raw_image" src="https://user-images.githubusercontent.com/42655977/211690204-301193c3-a651-4a3a-bd66-6458cf3a8778.png"> | <img width="915" alt="segmentation_mask" src="https://user-images.githubusercontent.com/42655977/211690212-2c9ca63a-f3ae-4d65-a4e0-ea76b20a616f.png"> |
# Semantic Classes
This dataset defines 8 semantic classes (7 distinct classes + implicit background class):
| Class | XML Label | Description | Color (RGB) |
| --- | --- | --- | --- |
| Ego Lane | `Ego Lane` | The lane the agent is supposed to be driving in (default right-hand traffic assumed) | `[102,255,102]` |
| Opposite Lane | `Opposite Lane` | The lane opposite to the one the agent is supposed to be driving in (default right-hand traffic assumed) | `[245,147,49]` |
| Road End | `Road End` | Perpendicular red indicator found in Duckietown indicating the end of the road or the beginning of an intersection | `[184,61,245]` |
| Intersection | `Intersection` | Road tile with no lane markings that has either 3 (T-intersection) or 4 (X-intersection) adjacent road tiles | `[50,183,250]` |
| Middle Lane | `Middle Lane` | Broken yellow lane in the middle of the road separating lanes | `[255,255,0]` |
| Side Lane | `Side Lane` | Solid white lane marking the road boundary | `[255,255,255]` |
| Background | `Background` | Unclassified | - (implicit class) |
### **Notice**:
(1) The color assignment is purely a suggestion as the color information encoded in the annotation file is not used by the `cvat_preprocessor.py` and can therefore be overwritten by any other mapping. The specified color mapping is mentioned here for explanatory and consistency reasons as this mapping is used in `dataloader.py` (see [Usage](#usage) for more information).
(2) `[Ego Lane, Opposite Lane, Intersection]` are three semantic classes for essentially the same road tiles - the three classes were added to introduce more information for some use cases. Keep in mind, that some semantic segmentation neural network have a hard time learning the difference between these classes, leading to a poor performance on detecting these classes. In such case, treating these three classes as one *"Road"* class helps improving the segmentation performance.
(3) The `Middle Lane` and `Side Lane` classes were added later and thus only the first 125 images were annotated. If you want to use these, use the `segmentation_annotation.xml` annotation file. Otherwise, `segmentation_annotation_old.xml` stores 250 images (including the 125 images from the other annotation file) but without these two classes.
(4) `Background` is a special semantic class as it is not stored in the annotation file. This class is assigned to all pixels that don't have any other class (see `dataloader.py` for a reference solution for that).
# Usage
[](#usage)
Due to the rather large size of the original dataset *(~750MB)*, this repository only contains annotations file stored in `CVAT for Images 1.1` format as well as two python files:
- `cvat_preprocessor.py`: A collection of helper functions to read the annotations file and extract the annotation masks stored as polygons.
- `dataloader.py`: A [_PyTorch_](https://pytorch.org)-specific example implementation of a wrapper-dataset to use with PyTorch machine learning models.
| hamnaanaa/Duckietown-Multiclass-Semantic-Segmentation-Dataset | [
"task_categories:image-segmentation",
"size_categories:n<1K",
"license:openrail",
"Duckietown",
"Lane Following",
"Autonomous Driving",
"region:us"
]
| 2023-01-25T15:56:22+00:00 | {"license": "openrail", "size_categories": ["n<1K"], "task_categories": ["image-segmentation"], "pretty_name": "Duckietown Multiclass Semantic Segmentation Dataset", "tags": ["Duckietown", "Lane Following", "Autonomous Driving"]} | 2023-01-25T16:03:13+00:00 |
822d1e0b605e23fef52f510a0b68624d34d8245f | Noidriy/chaika-images | [
"license:cc-by-3.0",
"region:us"
]
| 2023-01-25T16:02:07+00:00 | {"license": "cc-by-3.0"} | 2023-01-25T16:03:45+00:00 |
|
2728275fd4936eff670cd0e558946883e9c1b4c0 | # Dataset Card for "OxfordPets_test_facebook_opt_125m_Attributes_Caption_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_125m_Attributes_Caption_ns_3669 | [
"region:us"
]
| 2023-01-25T16:06:40+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121139246.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122186317.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 124265700.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 126336927.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 129454684.375, "num_examples": 3669}], "download_size": 603084427, "dataset_size": 623382875.875}} | 2023-01-25T19:42:28+00:00 |
2efd6f74ea9c8e62ae0f1cd5199aebac0251142b | # Dataset Card for "OxfordPets_test_facebook_opt_350m_Attributes_Caption_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_350m_Attributes_Caption_ns_3669 | [
"region:us"
]
| 2023-01-25T16:10:06+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121139633.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122187541.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 124265948.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 126337212.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 129454918.375, "num_examples": 3669}], "download_size": 603082667, "dataset_size": 623385253.875}} | 2023-01-25T19:49:43+00:00 |
f4dd676a131bdc3f7c689438e1c4bd1f81d7c057 | # Dataset Card for "WHU-RS19"
## Dataset Description
- **Paper:** [Structural high-resolution satellite image indexing](https://hal.science/hal-00458685/document)
- **Paper:** [Satellite image classification via two-layer sparse coding with biased image representation](https://ieeexplore.ieee.org/iel5/8859/4357975/05545358.pdf)
### Licensing Information
Public Domain
## Citation Information
[Structural high-resolution satellite image indexing](https://hal.science/hal-00458685/document)
[Satellite image classification via two-layer sparse coding with biased image representation](https://ieeexplore.ieee.org/iel5/8859/4357975/05545358.pdf)
```
@article{xia2009structural,
title={Structural high-resolution satellite image indexing},
author={Xia, Gui-Song and Yang, Wen and Delon, Julie and Gousseau, Yann and Sun, Hong and Ma{\^\i}tre, Henri},
year={2009}
}
@article{dai2010satellite,
title={Satellite image classification via two-layer sparse coding with biased image representation},
author={Dai, Dengxin and Yang, Wen},
journal={IEEE Geoscience and remote sensing letters},
volume={8},
number={1},
pages={173--176},
year={2010},
publisher={IEEE}
}
``` | jonathan-roberts1/WHU-RS19 | [
"license:cc-by-4.0",
"region:us"
]
| 2023-01-25T16:10:10+00:00 | {"license": "cc-by-4.0", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "airport", "1": "beach", "2": "bridge", "3": "commercial", "4": "desert", "5": "farmland", "6": "football field", "7": "forest", "8": "industrial", "9": "meadow", "10": "mountain", "11": "park", "12": "parking", "13": "pond", "14": "port", "15": "railway station", "16": "residential", "17": "river", "18": "viaduct"}}}}], "splits": [{"name": "train", "num_bytes": 115362308.8, "num_examples": 1005}], "download_size": 113327264, "dataset_size": 115362308.8}} | 2023-03-26T10:22:05+00:00 |
022634c2043cdd0487c5e13a874454535ab26c4b | # Dataset Card for "OxfordPets_test_facebook_opt_1.3b_Attributes_Caption_ns_3669"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Multimodal-Fatima/OxfordPets_test_facebook_opt_1.3b_Attributes_Caption_ns_3669 | [
"region:us"
]
| 2023-01-25T16:14:14+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}, {"name": "scores", "sequence": "float64"}], "splits": [{"name": "fewshot_0_bs_16", "num_bytes": 121144412.375, "num_examples": 3669}, {"name": "fewshot_1_bs_16", "num_bytes": 122187081.375, "num_examples": 3669}, {"name": "fewshot_3_bs_16", "num_bytes": 124265835.375, "num_examples": 3669}, {"name": "fewshot_5_bs_16", "num_bytes": 126337236.375, "num_examples": 3669}, {"name": "fewshot_8_bs_16", "num_bytes": 129454816.375, "num_examples": 3669}], "download_size": 603079760, "dataset_size": 623389381.875}} | 2023-01-25T20:02:57+00:00 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.