
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
3b5677affdc0e7dcc398d27e66e8844ca1419cdf
|
suolyer/pile_ubuntu-irc
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-26T15:40:24+00:00
|
{"license": "apache-2.0"}
|
2023-03-27T01:04:37+00:00
|
|
57ffa880eb4aa89a075cefa95b93640c1770244a
|
suolyer/pile_wikipedia
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-26T15:40:41+00:00
|
{"license": "apache-2.0"}
|
2023-03-27T02:58:20+00:00
|
|
fb4be1f72e6f0606695f61408da0dde867fc160c
|
suolyer/pile_youtubesubtitles
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-26T15:40:55+00:00
|
{"license": "apache-2.0"}
|
2023-03-26T15:49:20+00:00
|
|
f9515654fd18096756ed42de658c4a8a5b755334
|
suolyer/zhihu
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-26T15:57:14+00:00
|
{"license": "apache-2.0"}
|
2023-03-27T02:54:44+00:00
|
|
8fb9af26c640dbfa04549b776a5830172d91fb72
|
# Dataset Card for "somos-clean-alpaca-es-validations"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
alarcon7a/somos-clean-alpaca-es-validations
|
[
"region:us"
] |
2023-03-26T16:51:42+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "null"}, {"name": "inputs", "struct": [{"name": "1-instruction", "dtype": "string"}, {"name": "2-input", "dtype": "string"}, {"name": "3-output", "dtype": "string"}]}, {"name": "prediction", "dtype": "null"}, {"name": "prediction_agent", "dtype": "null"}, {"name": "annotation", "dtype": "string"}, {"name": "annotation_agent", "dtype": "string"}, {"name": "vectors", "struct": [{"name": "input", "sequence": "float64"}, {"name": "instruction", "sequence": "float64"}, {"name": "output", "sequence": "float64"}]}, {"name": "multi_label", "dtype": "bool"}, {"name": "explanation", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "metadata", "dtype": "null"}, {"name": "status", "dtype": "string"}, {"name": "event_timestamp", "dtype": "timestamp[us]"}, {"name": "metrics", "struct": [{"name": "text_length", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 739721, "num_examples": 39}], "download_size": 0, "dataset_size": 739721}}
|
2023-04-05T03:29:02+00:00
|
0ec4b0966ee3d54441474ceaac8ca08f19de3edb
|
# Dataset Card for "somos-clean-alpaca-es"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
alarcon7a/somos-clean-alpaca-es
|
[
"region:us"
] |
2023-03-26T17:16:33+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "null"}, {"name": "inputs", "struct": [{"name": "1-instruction", "dtype": "string"}, {"name": "2-input", "dtype": "string"}, {"name": "3-output", "dtype": "string"}]}, {"name": "prediction", "dtype": "null"}, {"name": "prediction_agent", "dtype": "null"}, {"name": "annotation", "dtype": "string"}, {"name": "annotation_agent", "dtype": "string"}, {"name": "vectors", "struct": [{"name": "input", "sequence": "float64"}, {"name": "instruction", "sequence": "float64"}, {"name": "output", "sequence": "float64"}]}, {"name": "multi_label", "dtype": "bool"}, {"name": "explanation", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "metadata", "dtype": "null"}, {"name": "status", "dtype": "string"}, {"name": "event_timestamp", "dtype": "timestamp[us]"}, {"name": "metrics", "struct": [{"name": "text_length", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 551730, "num_examples": 29}], "download_size": 437686, "dataset_size": 551730}}
|
2023-03-28T15:36:36+00:00
|
f62c271446c113401efa897e6a47a330359818c8
|
# Dataset Card for "somos-clean-alpaca-es-test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
dvilasuero/somos-clean-alpaca-es-test
|
[
"region:us"
] |
2023-03-26T17:55:58+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "null"}, {"name": "inputs", "struct": [{"name": "1-instruction", "dtype": "string"}, {"name": "2-input", "dtype": "string"}, {"name": "3-output", "dtype": "string"}]}, {"name": "prediction", "dtype": "null"}, {"name": "prediction_agent", "dtype": "null"}, {"name": "annotation", "dtype": "string"}, {"name": "annotation_agent", "dtype": "string"}, {"name": "vectors", "struct": [{"name": "input", "sequence": "float64"}, {"name": "instruction", "sequence": "float64"}, {"name": "output", "sequence": "float64"}]}, {"name": "multi_label", "dtype": "bool"}, {"name": "explanation", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "metadata", "dtype": "null"}, {"name": "status", "dtype": "string"}, {"name": "event_timestamp", "dtype": "timestamp[us]"}, {"name": "metrics", "struct": [{"name": "text_length", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 361340, "num_examples": 19}], "download_size": 301641, "dataset_size": 361340}}
|
2023-03-26T18:00:25+00:00
|
cf005d6ffaa3501ce01599a6cf66ac72584ce36f
|
HyperionHF/winogenerated
|
[
"license:cc-by-4.0",
"region:us"
] |
2023-03-26T18:09:21+00:00
|
{"license": "cc-by-4.0"}
|
2023-03-26T18:09:47+00:00
|
|
3ca3aef388aa2a77d6ae11a68a2fc24d32f94bc7
|
This dataset includes 4,080 texts that were generated by the [**ManaGPT-1020**](https://huggingface.co/NeuraXenetica/ManaGPT-1020) large language model, in response to particular input sequences.
ManaGPT-1020 is a free, open-source model available for download and use via Hugging Face’s “transformers” Python package. The model is a 1.5-billion-parameter LLM that’s capable of generating text in order to complete a sentence whose first words have been provided via a user-supplied input sequence. The model represents an elaboration of GPT-2 that has been fine-tuned (using Python and TensorFlow) on a specialized English-language corpus of over 509,000 words from the domain of organizational futures studies. In particular, the model has been trained to generate analysis, predictions, and recommendations regarding the emerging role of advanced AI, social robotics, ubiquitous computing, virtual reality, neurocybernetic augmentation, and other “posthumanizing” technologies in organizational life.
In generating the texts, 102 different prompts were used, each of which was employed to generate 20 responses. The 102 input sequences were created by concatenating 12 different "subjects" with 17 different "modal variants," in every possible combination. The subjects included 6 grammatically singular subjects:
- "The workplace of tomorrow"
- "Technological posthumanization"
- "The organizational use of AI"
- "A robotic boss"
- "An artificially intelligent coworker"
- "Business culture within Society 5.0"
Also included were 6 grammatically plural subjects:
- "Social robots"
- "Hybrid human-robotic organizations"
- "Artificially intelligent businesses"
- "The posthumanized workplaces of the future"
- "Cybernetically augmented workers"
- "Organizations in Society 5.0"
For the 6 grammatically singular subjects, the 17 modal variants included one "blank" variant (an empty string) and 16 phrases that lend the input sequence diverse forms of "modal shading," by indicating varying degrees of certainty, probability, predictability, logical necessity, or moral obligation or approbation. These modal variants were:
- ""
- " is"
- " is not"
- " will"
- " will be"
- " may"
- " might never"
- " is likely to"
- " is unlikely to"
- " should"
- " can"
- " cannot"
- " can never"
- " must"
- " must not"
- " is like"
- " will be like"
The variants used with grammatically plural subjects were identical, apart from the fact that the word “is” was changed to “are,” wherever it appeared.
In a small number of cases (only occurring when the empty string "" was used as part of the input sequence), the model failed to generate any output beyond the input sequence itself.
|
NeuraXenetica/managpt-4080-nlp-prompts-and-generated-texts
|
[
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"region:us"
] |
2023-03-26T18:25:25+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["1K<n<10K"], "task_categories": ["text-generation"], "pretty_name": "ManaGPT: 4,080 NLP prompts and generated texts"}
|
2023-03-29T16:52:49+00:00
|
76bd37c4a0fe978bc5bef0e6cb40fca4c6e4c997
|
This dataset contains 44 screenshots of the game Return To Monkey Island, scraped from the web and initially used to fine-tune a Stable Diffusion model with Dreambooth.
|
keras-dreambooth/monkey_island_screenshots
|
[
"size_categories:n<1K",
"license:apache-2.0",
"keras-dreambooth",
"region:us"
] |
2023-03-26T18:29:53+00:00
|
{"license": "apache-2.0", "size_categories": ["n<1K"], "pretty_name": "Return To Monkey Island Screenshots", "tags": ["keras-dreambooth"]}
|
2023-03-26T18:32:41+00:00
|
512d2cb5e7a9b73a27df84acbcdb778056b0fe8b
|
# Dataset Card for "WikiArt_mini_demos"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Artificio/WikiArt_mini_demos
|
[
"region:us"
] |
2023-03-26T18:58:44+00:00
|
{"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "artist", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "genre", "dtype": "string"}, {"name": "style", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "filename", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "resnet50_non_robust_features_2048", "sequence": "float32"}, {"name": "resnet50_robust_features_2048", "sequence": "float32"}, {"name": "resnet50_robust_feats", "sequence": "float32"}, {"name": "resnet50_non_robust_feats", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 467403497.0, "num_examples": 10000}], "download_size": 445315266, "dataset_size": 467403497.0}}
|
2023-04-12T03:09:09+00:00
|
dbdbea42140c25ee8fc47a73348fa76eab237abf
|
# Dataset Card for "training-invoices"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
lowem1/training-invoices
|
[
"region:us"
] |
2023-03-26T19:21:32+00:00
|
{"dataset_info": {"features": [{"name": "label", "dtype": "string"}, {"name": "line_data", "dtype": "string"}, {"name": "source", "dtype": "string"}, {"name": "noise_factor", "dtype": "null"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 10301, "num_examples": 132}], "download_size": 6493, "dataset_size": 10301}}
|
2023-03-26T19:21:34+00:00
|
a7e72ccf205d51593e44da89bc88f13aab7fac19
|
See [Allamanis et al., 2021](https://arxiv.org/pdf/2105.12787.pdf) (NeurIPS 2021) for more information.
|
Nadav-Timor/PyPiBugs
|
[
"size_categories:1K<n<10K",
"license:other",
"code",
"bugs",
"diff",
"repair",
"arxiv:2105.12787",
"region:us"
] |
2023-03-26T19:27:24+00:00
|
{"license": "other", "size_categories": ["1K<n<10K"], "tags": ["code", "bugs", "diff", "repair"]}
|
2023-06-07T19:39:12+00:00
|
00e543a4cadbbb97cf5eeeddb2f2e404d2272892
|
# Dataset Card for "procedural_gen"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sethapun/procedural_gen
|
[
"region:us"
] |
2023-03-26T19:27:41+00:00
|
{"dataset_info": {"features": [{"name": "expression", "dtype": "string"}, {"name": "answer", "dtype": "float64"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "false", "1": "true"}}}}], "splits": [{"name": "train", "num_bytes": 99358, "num_examples": 2000}, {"name": "validation", "num_bytes": 19864, "num_examples": 400}], "download_size": 46579, "dataset_size": 119222}}
|
2023-03-28T23:02:31+00:00
|
8c480d9cc769004882b0c17a59097d79a54429ba
|
# AutoTrain Dataset for project: trial
## Dataset Description
This dataset has been automatically processed by AutoTrain for project trial.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<32x36 RGBA PIL image>",
"target": 0
},
{
"image": "<32x36 RGBA PIL image>",
"target": 2
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['Healer_f', 'healer_m', 'ninja_m', 'ranger_m', 'rpgsprites1'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 45 |
| valid | 15 |
|
Fahad-7864/autotrain-data-trial
|
[
"task_categories:image-classification",
"region:us"
] |
2023-03-26T20:55:43+00:00
|
{"task_categories": ["image-classification"]}
|
2023-03-26T21:40:59+00:00
|
152bb5e9a29651266b018106053980070a0521a1
|
sahil2801/CodeAlpaca-20k
|
[
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"code",
"region:us"
] |
2023-03-26T21:09:47+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-generation"], "pretty_name": "CodeAlpaca 20K", "tags": ["code"]}
|
2023-10-03T10:46:04+00:00
|
|
2c570e86ec1bb306446b6538d094299ca84c5595
|
# Dataset Card for "test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Artificio/test
|
[
"region:us"
] |
2023-03-26T21:14:30+00:00
|
{"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "artist", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "genre", "dtype": "string"}, {"name": "style", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "filename", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "resnet50_non_robust_features_2048", "sequence": "float32"}, {"name": "resnet50_robust_features_2048", "sequence": "float32"}, {"name": "resnet50_non_robust_feats", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 385443497.0, "num_examples": 10000}], "download_size": 368839559, "dataset_size": 385443497.0}}
|
2023-04-12T02:55:29+00:00
|
48520df3115a25d73a4bbc1434a4078394db44c2
|
# Datasets for VF prediction
## File Description
- toxvf.xlsx: Table S4 from [Li et al. (2018)](https://doi.org/10.1016/j.scitotenv.2017.10.308)
- data_train.csv: Training set
- data_test.csv: Tesing set
- df_train.csv: Molecule information for training set
- df_test.csv: Molecule information for testing set
## Column Description
Table below describes the columns in data_train.csv and data_test.csv.
| Column Range | Description |
| --- | --- |
| 1 - 208 | RDKit descriptors |
| 209 - 1821 | Mordred descriptors |
| 1822 - 1988 | MACCSKeys fingerprint |
| 1989 - 4036 | Circular fingerprint |
| 4037 - 4917 | PubChem fingerprint |
| 4918 - 6965 | RDKit fingerprints |
| 6966 | Toxicity |
## DIY
Run `python featurize.py` to reproduce these datasets.
|
hhaootian/toxvf
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-26T21:29:25+00:00
|
{"license": "apache-2.0"}
|
2023-03-27T12:24:03+00:00
|
4c29bf40853be7b51118a1413953058edd7ae58c
|
# Dataset Card for "gpt2-chitchat-learn"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
wujohns/gpt2-chitchat-learn
|
[
"region:us"
] |
2023-03-26T23:06:17+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "input_ids", "sequence": "int32"}], "splits": [{"name": "train", "num_bytes": 161238019, "num_examples": 490001}, {"name": "valid", "num_bytes": 3190972, "num_examples": 10000}], "download_size": 89438438, "dataset_size": 164428991}}
|
2023-03-27T00:47:06+00:00
|
c56d7dc0dcc7c6e27d0a917a0ab0f40083999465
|
# Dataset Card for IWSLT 2014 with fairseq preprocess
## Dataset Description
- **Homepage:** [https://sites.google.com/site/iwsltevaluation2014](https://sites.google.com/site/iwsltevaluation2014)
dataset_info:
- config_name: de-en
features:
- name: translation
languages:
- de
- en
splits:
- name: train
num_examples: 160239
- name: test
num_examples: 6750
- name: validation
num_examples: 7283
|
bbaaaa/iwslt14-de-en-preprocess
|
[
"task_categories:translation",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:translation",
"source_datasets:original",
"language:de",
"language:en",
"license:cc-by-nc-nd-4.0",
"region:us"
] |
2023-03-27T02:34:37+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["expert-generated"], "language": ["de", "en"], "license": ["cc-by-nc-nd-4.0"], "multilinguality": ["translation"], "source_datasets": ["original"], "task_categories": ["translation"], "task_ids": [], "paperswithcode_id": "iwslt-2014 with fairseq preprocess", "pretty_name": "IWSLT 2014 with fairseq preprocess"}
|
2023-03-28T15:19:35+00:00
|
3220ddf85889d2537fe4ca8df622673a18c75c93
|
HaiboinLeeds/eee3_bug
|
[
"license:mit",
"region:us"
] |
2023-03-27T06:29:32+00:00
|
{"license": "mit"}
|
2023-03-27T06:38:43+00:00
|
|
15934441b9bfa29f2236e0bf3c92bd9f18277b03
|
# Dataset Card for "somos-clean-alpaca-es-herrius"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
dvilasuero/somos-clean-alpaca-es-herrius
|
[
"region:us"
] |
2023-03-27T06:59:48+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "null"}, {"name": "inputs", "struct": [{"name": "1-instruction", "dtype": "string"}, {"name": "2-input", "dtype": "string"}, {"name": "3-output", "dtype": "string"}]}, {"name": "prediction", "dtype": "null"}, {"name": "prediction_agent", "dtype": "null"}, {"name": "annotation", "dtype": "string"}, {"name": "annotation_agent", "dtype": "string"}, {"name": "vectors", "struct": [{"name": "input", "sequence": "float64"}, {"name": "instruction", "sequence": "float64"}, {"name": "output", "sequence": "float64"}]}, {"name": "multi_label", "dtype": "bool"}, {"name": "explanation", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "metadata", "dtype": "null"}, {"name": "status", "dtype": "string"}, {"name": "event_timestamp", "dtype": "timestamp[us]"}, {"name": "metrics", "struct": [{"name": "text_length", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 1821652, "num_examples": 96}], "download_size": 1475326, "dataset_size": 1821652}}
|
2023-03-27T06:59:51+00:00
|
49487e95e42f4532534e8d7d8bc17d42795b5af8
|
# Dataset Card for "pile-duped-pythia-random-sampled"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
EleutherAI/pile-duped-pythia-random-sampled
|
[
"region:us"
] |
2023-03-27T07:03:38+00:00
|
{"dataset_info": {"features": [{"name": "Index", "dtype": "int64"}, {"name": "70M", "dtype": "float64"}, {"name": "160M", "dtype": "float64"}, {"name": "410M", "dtype": "float64"}, {"name": "1B", "dtype": "float64"}, {"name": "1.4B", "dtype": "float64"}, {"name": "2.8B", "dtype": "float64"}, {"name": "6.9B", "dtype": "float64"}, {"name": "12B", "dtype": "float64"}, {"name": "Tokens", "sequence": "uint16"}], "splits": [{"name": "train", "num_bytes": 1020000000, "num_examples": 5000000}], "download_size": 915501044, "dataset_size": 1020000000}}
|
2023-08-25T07:07:30+00:00
|
0a749cfb3ceb1bf49dd529c25dc7f8846f2b0d81
|
* [功能](#功能)
* [输出](#输出)
* [实例](#实例)
* [运行环境](#运行环境)
* [使用说明](#使用说明)
* [下载脚本](#1下载脚本)
* [安装依赖](#2安装依赖)
* [程序设置](#3程序设置)
* [设置数据库(可选)](#4设置数据库可选)
* [运行脚本](#5运行脚本)
* [按需求修改脚本(可选)](#6按需求修改脚本可选)
* [定期自动爬取微博(可选)](#7定期自动爬取微博可选)
* [如何获取user_id](#如何获取user_id)
* [添加cookie与不添加cookie的区别(可选)](#添加cookie与不添加cookie的区别可选)
* [如何获取cookie(可选)](#如何获取cookie可选)
* [如何检测cookie是否有效(可选)](#如何检测cookie是否有效可选)
## 功能
连续爬取**一个**或**多个**新浪微博用户(如[Dear-迪丽热巴](https://weibo.cn/u/1669879400)、[郭碧婷](https://weibo.cn/u/1729370543))的数据,并将结果信息写入文件。写入信息几乎包括了用户微博的所有数据,主要有**用户信息**和**微博信息**两大类,前者包含用户昵称、关注数、粉丝数、微博数等等;后者包含微博正文、发布时间、发布工具、评论数等等,因为内容太多,这里不再赘述,详细内容见[输出](#输出)部分。具体的写入文件类型如下:
* 写入**csv文件**(默认)
* 写入**json文件**(可选)
* 写入**MySQL数据库**(可选)
* 写入**MongoDB数据库**(可选)
* 写入**SQLite数据库**(可选)
* 下载用户**原创**微博中的原始**图片**(可选)
* 下载用户**转发**微博中的原始**图片**(可选)
* 下载用户**原创**微博中的**视频**(可选)
* 下载用户**转发**微博中的**视频**(可选)
* 下载用户**原创**微博**Live Photo**中的**视频**(可选)
* 下载用户**转发**微博**Live Photo**中的**视频**(可选)
* 下载用户**原创和转发**微博下的一级评论(可选)
* 下载用户**原创和转发**微博下的转发(可选)
如果你只对用户信息感兴趣,而不需要爬用户的微博,也可以通过设置实现只爬取微博用户信息的功能。程序也可以实现**爬取结果自动更新**,即:现在爬取了目标用户的微博,几天之后,目标用户可能又发新微博了。通过设置,可以实现每隔几天**增量爬取**用户这几天发的新微博。具体方法见[定期自动爬取微博](#7定期自动爬取微博可选)。
## 输出
**用户信息**
* 用户id:微博用户id,如"1669879400"
* 用户昵称:微博用户昵称,如"Dear-迪丽热巴"
* 性别:微博用户性别
* 生日:用户出生日期
* 所在地:用户所在地
* 教育经历:用户上学时学校的名字
* 公司:用户所属公司名字
* 阳光信用:用户的阳光信用
* 微博注册时间:用户微博注册日期
* 微博数:用户的全部微博数(转发微博+原创微博)
* 粉丝数:用户的粉丝数
* 关注数:用户关注的微博数量
* 简介:用户简介
* 主页地址:微博移动版主页url,如<https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400>
* 头像url:用户头像url
* 高清头像url:用户高清头像url
* 微博等级:用户微博等级
* 会员等级:微博会员用户等级,普通用户该等级为0
* 是否认证:用户是否认证,为布尔类型
* 认证类型:用户认证类型,如个人认证、企业认证、政府认证等
* 认证信息:为认证用户特有,用户信息栏显示的认证信息
***
**微博信息**
* 微博id:微博的id,为一串数字形式
* 微博bid:微博的bid,与[cookie版](https://github.com/dataabc/weiboSpider)中的微博id是同一个值
* 微博内容:微博正文
* 头条文章url:微博中头条文章的url,如果微博中存在头条文章,就获取该头条文章的url,否则该值为''
* 原始图片url:原创微博图片和转发微博转发理由中图片的url,若某条微博存在多张图片,则每个url以英文逗号分隔,若没有图片则值为''
* 视频url: 微博中的视频url和Live Photo中的视频url,若某条微博存在多个视频,则每个url以英文分号分隔,若没有视频则值为''
* 微博发布位置:位置微博中的发布位置
* 微博发布时间:微博发布时的时间,精确到天
* 点赞数:微博被赞的数量
* 转发数:微博被转发的数量
* 评论数:微博被评论的数量
* 微博发布工具:微博的发布工具,如iPhone客户端、HUAWEI Mate 20 Pro等,若没有则值为''
* 话题:微博话题,即两个#中的内容,若存在多个话题,每个url以英文逗号分隔,若没有则值为''
* @用户:微博@的用户,若存在多个@用户,每个url以英文逗号分隔,若没有则值为''
* 原始微博:为转发微博所特有,是转发微博中那条被转发的微博,存储为字典形式,包含了上述微博信息中的所有内容,如微博id、微博内容等等
* 结果文件:保存在当前目录weibo文件夹下以用户昵称为名的文件夹里,名字为"user_id.csv"形式
* 微博图片:微博中的图片,保存在以用户昵称为名的文件夹下的img文件夹里
* 微博视频:微博中的视频,保存在以用户昵称为名的文件夹下的video文件夹里
## 实例
以爬取迪丽热巴的微博为例,我们需要修改**config.json**文件,文件内容如下:
```
{
"user_id_list": ["1669879400"],
"filter": 1,
"since_date": "1900-01-01",
"query_list": [],
"write_mode": ["csv"],
"original_pic_download": 1,
"retweet_pic_download": 0,
"original_video_download": 1,
"retweet_video_download": 0,
"cookie": "your cookie"
}
```
对于上述参数的含义以及取值范围,这里仅作简单介绍,详细信息见[程序设置](#3程序设置)。
>**user_id_list**代表我们要爬取的微博用户的user_id,可以是一个或多个,也可以是文件路径,微博用户Dear-迪丽热巴的user_id为1669879400,具体如何获取user_id见[如何获取user_id](#如何获取user_id);
**filter**的值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发);
**since_date**代表我们要爬取since_date日期之后发布的微博,因为我要爬迪丽热巴的全部原创微博,所以since_date设置了一个非常早的值;
query_list代表要爬取的微博关键词,为空([])则爬取全部;
**write_mode**代表结果文件的保存类型,我想要把结果写入csv文件和json文件,所以它的值为["csv", "json"],如果你想写入数据库,具体设置见[设置数据库](#4设置数据库可选);
**original_pic_download**值为1代表下载原创微博中的图片,值为0代表不下载;
**retweet_pic_download**值为1代表下载转发微博中的图片,值为0代表不下载;
**original_video_download**值为1代表下载原创微博中的视频,值为0代表不下载;
**retweet_video_download**值为1代表下载转发微博中的视频,值为0代表不下载;
**cookie**是可选参数,可填可不填,具体区别见[添加cookie与不添加cookie的区别](#添加cookie与不添加cookie的区别可选)。
配置完成后运行程序:
```bash
python weibo.py
```
程序会自动生成一个weibo文件夹,我们以后爬取的所有微博都被存储在weibo文件夹里。然后程序在该文件夹下生成一个名为"Dear-迪丽热巴"的文件夹,迪丽热巴的所有微博爬取结果都在这里。"Dear-迪丽热巴"文件夹里包含一个csv文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见[设置数据库](#4设置数据库可选)部分。
**csv文件结果如下所示:**
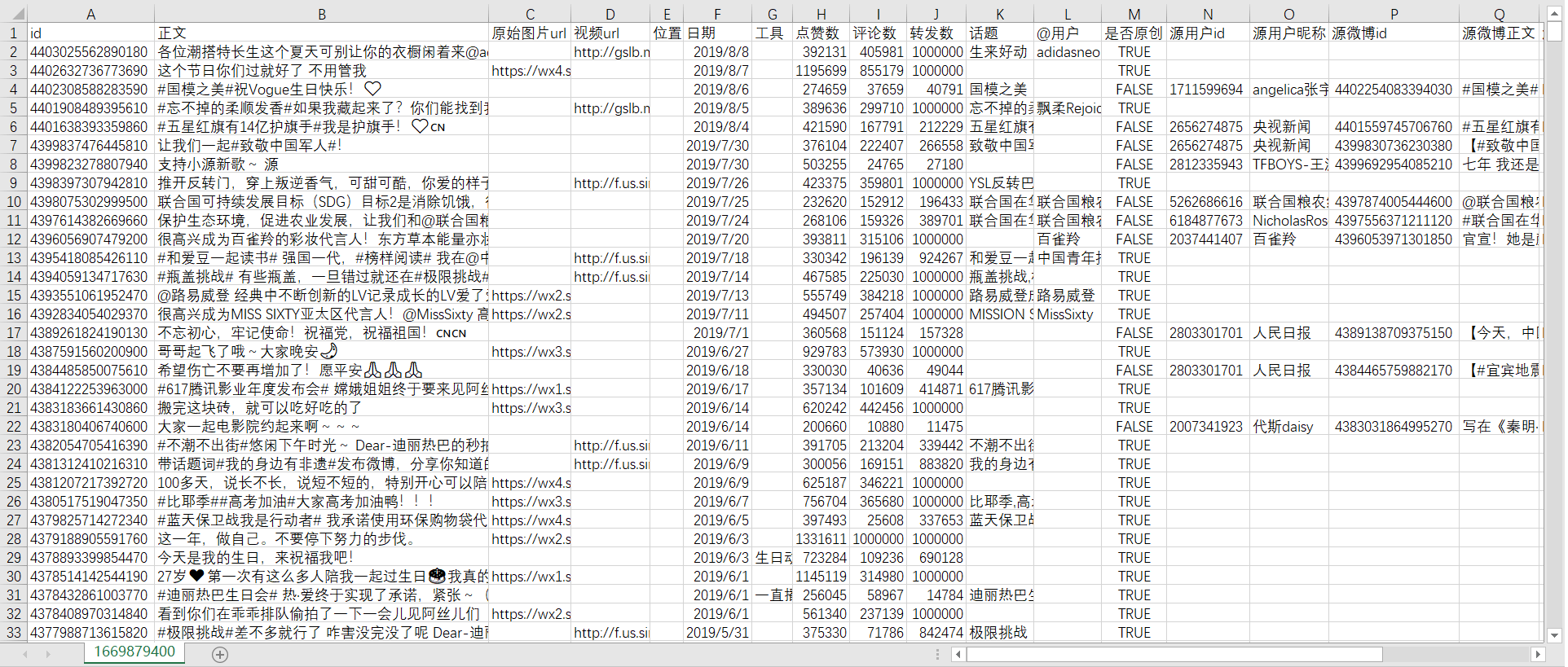*1669879400.csv*
本csv文件是爬取“全部微博”(原创微博+转发微博)的结果文件。因为迪丽热巴很多微博本身都没有图片、发布工具、位置、话题和@用户等信息,所以当这些内容没有时对应位置为空。"是否原创"列用来标记是否为原创微博,
当为转发微博时,文件中还包含转发微博的信息。为了简便起见,姑且将转发微博中被转发的原始微博称为**源微博**,它的用户id、昵称、微博id等都在名称前加上源字,以便与目标用户自己发的微博区分。对于转发微博,程序除了获取用户原创部分的信息,还会获取**源用户id**、**源用户昵称**、**源微博id**、**源微博正文**、**源微博原始图片url**、**源微博位置**、**源微博日期**、**源微博工具**、**源微博点赞数**、**源微博评论数**、**源微博转发数**、**源微博话题**、**源微博@用户**等信息。原创微博因为没有这些转发信息,所以对应位置为空。若爬取的是"全部**原创**微博",则csv文件中不会包含"是否原创"及其之后的转发属性列;
为了说明json结果文件格式,这里以迪丽热巴2019年12月27日到2019年12月28日发的2条微博为例。
**json结果文件格式如下:**
```
{
"user": {
"id": "1669879400",
"screen_name": "Dear-迪丽热巴",
"gender": "f",
"birthday": "双子座",
"location": "上海",
"education": "上海戏剧学院",
"company": "嘉行传媒",
"registration_time": "2010-07-02",
"sunshine": "信用极好",
"statuses_count": 1121,
"followers_count": 66395881,
"follow_count": 250,
"description": "一只喜欢默默表演的小透明。工作联系[email protected] 🍒",
"profile_url": "https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400",
"profile_image_url": "https://tvax2.sinaimg.cn/crop.0.0.1080.1080.180/63885668ly8gb5sqc19mqj20u00u0mz5.jpg?KID=imgbed,tva&Expires=1584108150&ssig=Zay1N7KhK1",
"avatar_hd": "https://wx2.sinaimg.cn/orj480/63885668ly8gb5sqc19mqj20u00u0mz5.jpg",
"urank": 44,
"mbrank": 7,
"verified": true,
"verified_type": 0,
"verified_reason": "嘉行传媒签约演员 "
},
"weibo": [
{
"user_id": 1669879400,
"screen_name": "Dear-迪丽热巴",
"id": 4454572602912349,
"bid": "ImTGkcdDn",
"text": "今天的#星光大赏# ",
"pics": "https://wx3.sinaimg.cn/large/63885668ly1gacppdn1nmj21yi2qp7wk.jpg,https://wx4.sinaimg.cn/large/63885668ly1gacpphkj5gj22ik3t0b2d.jpg,https://wx4.sinaimg.cn/large/63885668ly1gacppb4atej22yo4g04qr.jpg,https://wx2.sinaimg.cn/large/63885668ly1gacpn0eeyij22yo4g04qr.jpg",
"video_url": "",
"location": "",
"created_at": "2019-12-28",
"source": "",
"attitudes_count": 551894,
"comments_count": 182010,
"reposts_count": 1000000,
"topics": "星光大赏",
"at_users": ""
},
{
"user_id": 1669879400,
"screen_name": "Dear-迪丽热巴",
"id": 4454081098040623,
"bid": "ImGTzxJJt",
"text": "我最爱用的娇韵诗双萃精华穿上限量“金”装啦,希望阿丝儿们跟我一起在新的一年更美更年轻,喜笑颜开没有细纹困扰!限定新春礼盒还有祝福悄悄话,大家了解一下~",
"pics": "",
"video_url": "",
"location": "",
"created_at": "2019-12-27",
"source": "",
"attitudes_count": 190840,
"comments_count": 43523,
"reposts_count": 1000000,
"topics": "",
"at_users": "",
"retweet": {
"user_id": 1684832145,
"screen_name": "法国娇韵诗",
"id": 4454028484570123,
"bid": "ImFwIjaTF",
"text": "#点萃成金 年轻焕新# 将源自天然的植物力量,转化为滴滴珍贵如金的双萃精华。这份点萃成金的独到匠心,只为守护娇粉们的美丽而来。点击视频,与@Dear-迪丽热巴 一同邂逅新年限量版黄金双萃,以闪耀开运金,送上新春宠肌臻礼。 跟着迪迪选年货,还有双重新春惊喜,爱丽丝们看这里! 第一重参与微淘活动邀请好友关注娇韵诗天猫旗舰店,就有机会赢取限量款热巴新年礼盒,打开就能聆听仙女迪亲口送出的新春祝福哦!点击网页链接下单晒热巴同款黄金双萃,并且@法国娇韵诗,更有机会获得热巴亲笔签名的礼盒哦! 第二重转评说出新年希望娇韵诗为你解决的肌肤愿望,截止至1/10,小娇将从铁粉中抽取1位娇粉送出限量版热巴定制礼盒,抽取3位娇粉送出热巴明信片1张~ #迪丽热巴代言娇韵诗#养成同款御龄美肌,就从现在开始。法国娇韵诗的微博视频",
"pics": "",
"video_url": "http://f.video.weibocdn.com/003vQjnRlx07zFkxIMjS010412003bNx0E010.mp4?label=mp4_hd&template=852x480.25.0&trans_finger=62b30a3f061b162e421008955c73f536&Expires=1578322522&ssig=P3ozrNA3mv&KID=unistore,video",
"location": "",
"created_at": "2019-12-27",
"source": "微博 weibo.com",
"attitudes_count": 18389,
"comments_count": 3201,
"reposts_count": 1000000,
"topics": "点萃成金 年轻焕新,迪丽热巴代言娇韵诗",
"at_users": "Dear-迪丽热巴,法国娇韵诗"
}
}
]
}
```
*1669879400.json*
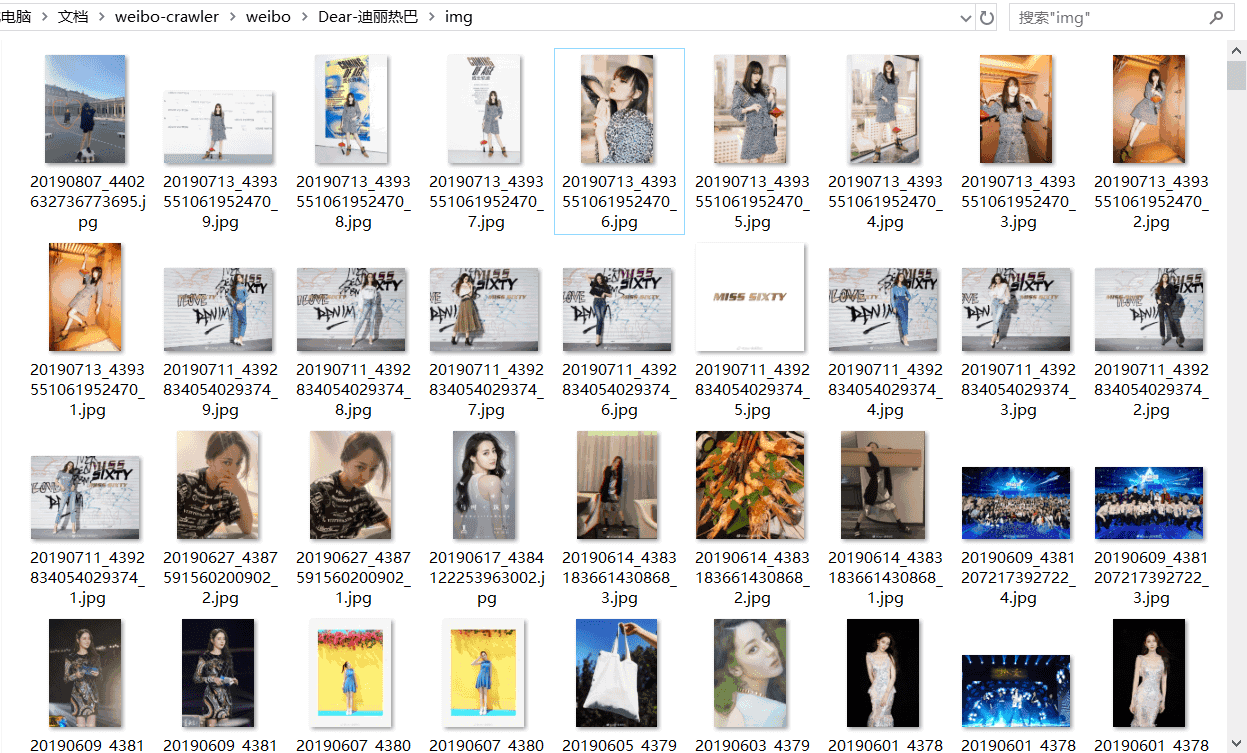
**下载的图片如下所示:**
*img文件夹*
本次下载了788张图片,大小一共1.21GB,包括她原创微博中的所有图片。图片名为yyyymmdd+微博id的形式,若某条微博存在多张图片,则图片名中还会包括它在微博图片中的序号。若某图片下载失败,程序则会以“weibo_id:pic_url”的形式将出错微博id和图片url写入同文件夹下的not_downloaded.txt里;若图片全部下载成功则不会生成not_downloaded.txt;
**下载的视频如下所示:**
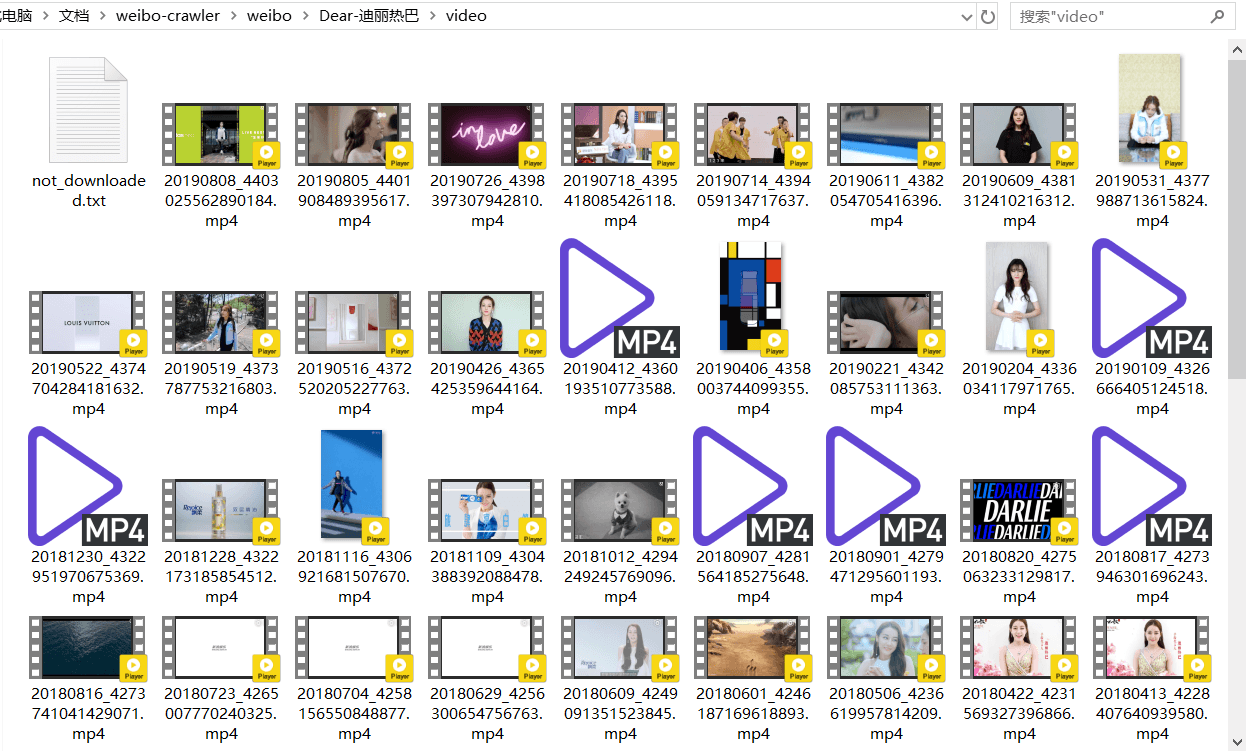*video文件夹*
本次下载了66个视频,是她原创微博中的视频和原创微博Live Photo中的视频,视频名为yyyymmdd+微博id的形式。有三个视频因为网络原因下载失败,程序将它们的微博id和视频url分别以“weibo_id:video_url”的形式写到了同文件夹下的not_downloaded.txt里。
因为我本地没有安装MySQL数据库和MongoDB数据库,所以暂时设置成不写入数据库。如果你想要将爬取结果写入数据库,只需要先安装数据库(MySQL或MongoDB),再安装对应包(pymysql或pymongo),然后将mysql_write或mongodb_write值设置为1即可。写入MySQL需要用户名、密码等配置信息,这些配置如何设置见[设置数据库](#4设置数据库可选)部分。
## 运行环境
* 开发语言:python2/python3
* 系统: Windows/Linux/macOS
## 使用说明
### 1.下载脚本
```bash
git clone https://github.com/dataabc/weibo-crawler.git
```
运行上述命令,将本项目下载到当前目录,如果下载成功当前目录会出现一个名为"weibo-crawler"的文件夹;
### 2.安装依赖
```bash
pip install -r requirements.txt
```
### 3.程序设置
打开**config.json**文件,你会看到如下内容:
```
{
"user_id_list": ["1669879400"],
"filter": 1,
"remove_html_tag": 1,
"since_date": "2018-01-01",
"write_mode": ["csv"],
"original_pic_download": 1,
"retweet_pic_download": 0,
"original_video_download": 1,
"retweet_video_download": 0,
"download_comment":1,
"comment_max_download_count":1000,
"download_repost": 1,
"repost_max_download_count": 1000,
"result_dir_name": 0,
"cookie": "your cookie",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
}
}
```
下面讲解每个参数的含义与设置方法。
**设置user_id_list**
user_id_list是我们要爬取的微博的id,可以是一个,也可以是多个,例如:
```
"user_id_list": ["1223178222", "1669879400", "1729370543"],
```
上述代码代表我们要连续爬取user_id分别为“1223178222”、 “1669879400”、 “1729370543”的三个用户的微博,具体如何获取user_id见[如何获取user_id](#如何获取user_id)。
user_id_list的值也可以是文件路径,我们可以把要爬的所有微博用户的user_id都写到txt文件里,然后把文件的位置路径赋值给user_id_list。
在txt文件中,每个user_id占一行,也可以在user_id后面加注释(可选),如用户昵称等信息,user_id和注释之间必需要有空格,文件名任意,类型为txt,位置位于本程序的同目录下,文件内容示例如下:
```
1223178222 胡歌
1669879400 迪丽热巴
1729370543 郭碧婷
```
假如文件叫user_id_list.txt,则user_id_list设置代码为:
```
"user_id_list": "user_id_list.txt",
```
**设置filter**
filter控制爬取范围,值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发)。例如,如果要爬全部原创微博,请使用如下代码:
```
"filter": 1,
```
**设置since_date**
since_date值可以是日期,也可以是整数。如果是日期,代表爬取该日期之后的微博,格式应为“yyyy-mm-dd”,如:
```
"since_date": "2018-01-01",
```
代表爬取从2018年1月1日到现在的微博。
如果是整数,代表爬取最近n天的微博,如:
```
"since_date": 10,
```
代表爬取最近10天的微博,这个说法不是特别准确,准确说是爬取发布时间从**10天前到本程序开始执行时**之间的微博。
**since_date是所有user的爬取起始时间,非常不灵活。如果你要爬多个用户,并且想单独为每个用户设置一个since_date,可以使用[定期自动爬取微博](#7定期自动爬取微博可选)方法二中的方法,该方法可以为多个用户设置不同的since_date,非常灵活**。
**设置query_list(可选)**
query_list是一个关键词字符串列表或以`,`分隔关键词的字符串,用于指定关键词搜索爬取,若为空`[]`或`""`则爬取全部微博。例如要爬取用户包含“梦想”和“希望”的微博,则设定如下:
```
"query_list": ["梦想","希望"],
"query_list": "梦想,希望",
```
请注意,关键词搜索必须设定`cookie`信息。
**query_list是所有user的爬取关键词,非常不灵活。如果你要爬多个用户,并且想单独为每个用户设置一个query_list,可以使用[定期自动爬取微博](#7定期自动爬取微博可选)方法二中的方法,该方法可以为多个用户设置不同的query_list,非常灵活**。
**设置remove_html_tag**
remove_html_tag控制是否移除抓取到的weibo正文和评论中的html tag,值为1代表移除,值为0代表不移除,如
```
"remove_html_tag": 1,
```
代表移除html tag。例如`专属新意,色彩启程~<a href='/n/路易威登'>@路易威登</a> CAPUCINES 手袋正合我意,打开灵感包袋的搭配新方式!`会被处理成`专属新意,色彩启程~@路易威登 CAPUCINES 手袋正合我意,打开灵感包袋的搭配新方式!`。
**设置write_mode**
write_mode控制结果文件格式,取值范围是csv、json、mongo、mysql和sqlite,分别代表将结果文件写入csv、json、MongoDB、MySQL和SQLite数据库。write_mode可以同时包含这些取值中的一个或几个,如:
```
"write_mode": ["csv", "json"],
```
代表将结果信息写入csv文件和json文件。特别注意,如果你想写入数据库,除了在write_mode添加对应数据库的名字外,还应该安装相关数据库和对应python模块,具体操作见[设置数据库](#4设置数据库可选)部分。
**设置original_pic_download**
original_pic_download控制是否下载**原创**微博中的图片,值为1代表下载,值为0代表不下载,如
```
"original_pic_download": 1,
```
代表下载原创微博中的图片。
**设置retweet_pic_download**
retweet_pic_download控制是否下载**转发**微博中的图片,值为1代表下载,值为0代表不下载,如
```
"retweet_pic_download": 0,
```
代表不下载转发微博中的图片。特别注意,本设置只有在爬全部微博(原创+转发),即filter值为0时生效,否则程序会跳过转发微博的图片下载。
**设置original_video_download**
original_video_download控制是否下载**原创**微博中的视频和**原创**微博**Live Photo**中的视频,值为1代表下载,值为0代表不下载,如
```
"original_video_download": 1,
```
代表下载原创微博中的视频和原创微博Live Photo中的视频。
**设置retweet_video_download**
retweet_video_download控制是否下载**转发**微博中的视频和**转发**微博**Live Photo**中的视频,值为1代表下载,值为0代表不下载,如
```
"retweet_video_download": 0,
```
代表不下载转发微博中的视频和转发微博Live Photo中的视频。特别注意,本设置只有在爬全部微博(原创+转发),即filter值为0时生效,否则程序会跳过转发微博的视频下载。
**设置result_dir_name**
result_dir_name控制结果文件的目录名,可取值为0和1,默认为0:
```
"result_dir_name": 0,
```
值为0,表示将结果文件保存在以用户昵称为名的文件夹里,这样结果更清晰;值为1表示将结果文件保存在以用户id为名的文件夹里,这样能保证多次爬取的一致性,因为用户昵称可变,用户id不可变。
**设置download_comment**
download_comment控制是否下载每条微博下的一级评论(不包括对评论的评论),仅当write_mode中有sqlite时有效,可取值为0和1,默认为1:
```
"download_comment": 1,
```
值为1,表示下载微博评论;值为0,表示不下载微博评论。
**设置comment_max_download_count**
comment_max_download_count控制下载评论的最大数量,仅当write_mode中有sqlite时有效,默认为1000:
```
"comment_max_download_count": 1000,
```
**设置download_repost**
download_repost控制是否下载每条微博下的转发,仅当write_mode中有sqlite时有效,可取值为0和1,默认为1:
```
"download_repost": 1,
```
值为1,表示下载微博转发;值为0,表示不下载微博转发。
**设置repost_max_download_count**
repost_max_download_count控制下载转发的最大数量,仅当write_mode中有sqlite时有效,默认为1000:
```
"repost_max_download_count": 1000,
```
值为1000,表示最多下载每条微博下的1000条转发。
**设置cookie(可选)**
cookie为可选参数,即可填可不填,具体区别见[添加cookie与不添加cookie的区别](#添加cookie与不添加cookie的区别可选)。cookie默认配置如下:
```
"cookie": "your cookie",
```
如果想要设置cookie,可以按照[如何获取cookie](#如何获取cookie可选)中的方法,获取cookie,并将上面的"your cookie"替换成真实的cookie即可。
**设置mysql_config(可选)**
mysql_config控制mysql参数配置。如果你不需要将结果信息写入mysql,这个参数可以忽略,即删除或保留都无所谓;如果你需要写入mysql且config.json文件中mysql_config的配置与你的mysql配置不一样,请将该值改成你自己mysql中的参数配置。
**设置start_page(可选)**
start_page为爬取微博的初始页数,默认参数为1,即从所爬取用户的当前第一页微博内容开始爬取。
若在大批量爬取微博时出现中途被限制中断的情况,可通过查看csv文件内目前已爬取到的微博数除以10,向下取整后的值即为中断页数,手动设置start_page参数为中断页数,重新运行即可从被中断的节点继续爬取剩余微博内容。
### 4.设置数据库(可选)
本部分是可选部分,如果不需要将爬取信息写入数据库,可跳过这一步。本程序目前支持MySQL数据库和MongoDB数据库,如果你需要写入其它数据库,可以参考这两个数据库的写法自己编写。
**MySQL数据库写入**
要想将爬取信息写入MySQL,请根据自己的系统环境安装MySQL,然后命令行执行:
```bash
pip install pymysql
```
**MongoDB数据库写入**
要想将爬取信息写入MongoDB,请根据自己的系统环境安装MongoDB,然后命令行执行:
```
pip install pymongo
```
MySQL和MongDB数据库的写入内容一样。程序首先会创建一个名为"weibo"的数据库,然后再创建"user"表和"weibo"表,包含爬取的所有内容。爬取到的微博**用户信息**或插入或更新,都会存储到user表里;爬取到的**微博信息**或插入或更新,都会存储到weibo表里,两个表通过user_id关联。如果想了解两个表的具体字段,请点击"详情"。
<details>
<summary>详情</summary>
**user**表
**id**:微博用户id,如"1669879400";
**screen_name**:微博用户昵称,如"Dear-迪丽热巴";
**gender**:微博用户性别,取值为f或m,分别代表女和男;
**birthday**:生日;
**location**:所在地;
**education**:教育经历;
**company**:公司;
**sunshine**:阳光信用;
**registration_time**:注册时间;
**statuses_count**:微博数;
**followers_count**:粉丝数;
**follow_count**:关注数;
**description**:微博简介;
**profile_url**:微博主页,如<https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400>;
**profile_image_url**:微博头像url;
**avatar_hd**:微博高清头像url;
**urank**:微博等级;
**mbrank**:微博会员等级,普通用户会员等级为0;
**verified**:微博是否认证,取值为true和false;
**verified_type**:微博认证类型,没有认证值为-1,个人认证值为0,企业认证值为2,政府认证值为3,这些类型仅是个人猜测,应该不全,大家可以根据实际情况判断;
**verified_reason**:微博认证信息,只有认证用户拥有此属性。
***
**weibo**表
**user_id**:存储微博用户id,如"1669879400";
**screen_name**:存储微博昵称,如"Dear-迪丽热巴";
**id**:存储微博id;
**text**:存储微博正文;
**article_url**:存储微博中头条文章的url,如果微博中存在头条文章,就获取该头条文章的url,否则该值为'';
**pics**:存储原创微博的原始图片url。若某条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为'';
**video_url**:存储原创微博的视频url和Live Photo中的视频url。若某条微博有多个视频,则存储多个url,以英文分号分割;若该微博没有视频,则值为'';
**location**:存储微博的发布位置。若某条微博没有位置信息,则值为'';
**created_at**:存储微博的发布时间;
**source**:存储微博的发布工具;
**attitudes_count**:存储微博获得的点赞数;
**comments_count**:存储微博获得的评论数;
**reposts_count**:存储微博获得的转发数;
**topics**:存储微博话题,即两个#中的内容。若某条微博没有话题信息,则值为'';
**at_users**:存储微博@的用户。若某条微博没有@的用户,则值为'';
**retweet_id**:存储转发微博中原始微博的微博id。若某条微博为原创微博,则值为''。
</details>
**SQLite数据库写入**
脚本会自动建立并配置数据库文件`weibodata.db`。
### 5.运行脚本
大家可以根据自己的运行环境选择运行方式,Linux可以通过
```bash
python weibo.py
```
运行;
### 6.按需求修改脚本(可选)
本部分为可选部分,如果你不需要自己修改代码或添加新功能,可以忽略此部分。
本程序所有代码都位于weibo.py文件,程序主体是一个Weibo类,上述所有功能都是通过在main函数调用Weibo类实现的,默认的调用代码如下:
```python
if not os.path.isfile('./config.json'):
sys.exit(u'当前路径:%s 不存在配置文件config.json' %
(os.path.split(os.path.realpath(__file__))[0] + os.sep))
with open('./config.json') as f:
config = json.loads(f.read())
wb = Weibo(config)
wb.start() # 爬取微博信息
```
用户可以按照自己的需求调用或修改Weibo类。
通过执行本程序,我们可以得到很多信息:
**wb.user**:存储目标微博用户信息;
wb.user包含爬取到的微博用户信息,如**用户id**、**用户昵称**、**性别**、**生日**、**所在地**、**教育经历**、**公司**、**阳光信用**、**微博注册时间**、**微博数**、**粉丝数**、**关注数**、**简介**、**主页地址**、**头像url**、**高清头像url**、**微博等级**、**会员等级**、**是否认证**、**认证类型**、**认证信息**等,大家可以点击"详情"查看具体用法。
<details>
<summary>详情</summary>
**id**:微博用户id,取值方式为wb.user['id'],由一串数字组成;
**screen_name**:微博用户昵称,取值方式为wb.user['screen_name'];
**gender**:微博用户性别,取值方式为wb.user['gender'],取值为f或m,分别代表女和男;
**birthday**:微博用户生日,取值方式为wb.user['birthday'],若用户没有填写该信息,则值为'';
**location**:微博用户所在地,取值方式为wb.user['location'],若用户没有填写该信息,则值为'';
**education**:微博用户上学时的学校,取值方式为wb.user['education'],若用户没有填写该信息,则值为'';
**company**:微博用户所属的公司,取值方式为wb.user['company'],若用户没有填写该信息,则值为'';
**sunshine**:微博用户的阳光信用,取值方式为wb.user['sunshine'];
**registration_time**:微博用户的注册时间,取值方式为wb.user['registration_time'];
**statuses_count**:微博数,取值方式为wb.user['statuses_count'];
**followers_count**:微博粉丝数,取值方式为wb.user['followers_count'];
**follow_count**:微博关注数,取值方式为wb.user['follow_count'];
**description**:微博简介,取值方式为wb.user['description'];
**profile_url**:微博主页,取值方式为wb.user['profile_url'];
**profile_image_url**:微博头像url,取值方式为wb.user['profile_image_url'];
**avatar_hd**:微博高清头像url,取值方式为wb.user['avatar_hd'];
**urank**:微博等级,取值方式为wb.user['urank'];
**mbrank**:微博会员等级,取值方式为wb.user['mbrank'],普通用户会员等级为0;
**verified**:微博是否认证,取值方式为wb.user['verified'],取值为true和false;
**verified_type**:微博认证类型,取值方式为wb.user['verified_type'],没有认证值为-1,个人认证值为0,企业认证值为2,政府认证值为3,这些类型仅是个人猜测,应该不全,大家可以根据实际情况判断;
**verified_reason**:微博认证信息,取值方式为wb.user['verified_reason'],只有认证用户拥有此属性。
</details>
**wb.weibo**:存储爬取到的所有微博信息;
wb.weibo包含爬取到的所有微博信息,如**微博id**、**正文**、**原始图片url**、**视频url**、**位置**、**日期**、**发布工具**、**点赞数**、**转发数**、**评论数**、**话题**、**@用户**等。如果爬的是全部微博(原创+转发),除上述信息之外,还包含**原始用户id**、**原始用户昵称**、**原始微博id**、**原始微博正文**、**原始微博原始图片url**、**原始微博位置**、**原始微博日期**、**原始微博工具**、**原始微博点赞数**、**原始微博评论数**、**原始微博转发数**、**原始微博话题**、**原始微博@用户**等信息。wb.weibo是一个列表,包含了爬取的所有微博信息。wb.weibo[0]为爬取的第一条微博,wb.weibo[1]为爬取的第二条微博,以此类推。当filter=1时,wb.weibo[0]为爬取的第一条**原创**微博,以此类推。wb.weibo[0]['id']为第一条微博的id,wb.weibo[0]['text']为第一条微博的正文,wb.weibo[0]['created_at']为第一条微博的发布时间,还有其它很多信息不在赘述,大家可以点击下面的"详情"查看具体用法。
<details>
<summary>详情</summary>
**user_id**:存储微博用户id。如wb.weibo[0]['user_id']为最新一条微博的用户id;
**screen_name**:存储微博昵称。如wb.weibo[0]['screen_name']为最新一条微博的昵称;
**id**:存储微博id。如wb.weibo[0]['id']为最新一条微博的id;
**text**:存储微博正文。如wb.weibo[0]['text']为最新一条微博的正文;
**article_url**:存储微博中头条文章的url。如wb.weibo[0]['article_url']为最新一条微博的头条文章url,若微博中不存在头条文章,则该值为'';
**pics**:存储原创微博的原始图片url。如wb.weibo[0]['pics']为最新一条微博的原始图片url,若该条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为'';
**video_url**:存储原创微博的视频url和原创微博Live Photo中的视频url。如wb.weibo[0]['video_url']为最新一条微博的视频url,若该条微博有多个视频,则存储多个url,以英文分号分割;若该微博没有视频,则值为'';
**location**:存储微博的发布位置。如wb.weibo[0]['location']为最新一条微博的发布位置,若该条微博没有位置信息,则值为'';
**created_at**:存储微博的发布时间。如wb.weibo[0]['created_at']为最新一条微博的发布时间;
**source**:存储微博的发布工具。如wb.weibo[0]['source']为最新一条微博的发布工具;
**attitudes_count**:存储微博获得的点赞数。如wb.weibo[0]['attitudes_count']为最新一条微博获得的点赞数;
**comments_count**:存储微博获得的评论数。如wb.weibo[0]['comments_count']为最新一条微博获得的评论数;
**reposts_count**:存储微博获得的转发数。如wb.weibo[0]['reposts_count']为最新一条微博获得的转发数;
**topics**:存储微博话题,即两个#中的内容。如wb.weibo[0]['topics']为最新一条微博的话题,若该条微博没有话题信息,则值为'';
**at_users**:存储微博@的用户。如wb.weibo[0]['at_users']为最新一条微博@的用户,若该条微博没有@的用户,则值为'';
**retweet**:存储转发微博中原始微博的全部信息。假如wb.weibo[0]为转发微博,则wb.weibo[0]['retweet']为该转发微博的原始微博,它存储的属性与wb.weibo[0]一样,只是没有retweet属性;若该条微博为原创微博,则wb[0]没有"retweet"属性,大家可以点击"详情"查看具体用法。
<details>
<summary>详情</summary>
假设爬取到的第i条微博为转发微博,则它存在以下信息:
**user_id**:存储原始微博用户id。wb.weibo[i-1]['retweet']['user_id']为该原始微博的用户id;
**screen_name**:存储原始微博昵称。wb.weibo[i-1]['retweet']['screen_name']为该原始微博的昵称;
**id**:存储原始微博id。wb.weibo[i-1]['retweet']['id']为该原始微博的id;
**text**:存储原始微博正文。wb.weibo[i-1]['retweet']['text']为该原始微博的正文;
**article_url**:存储原始微博中头条文章的url。如wb.weibo[i-1]['retweet']['article_url']为该原始微博的头条文章url,若原始微博中不存在头条文章,则该值为'';
**pics**:存储原始微博的原始图片url。wb.weibo[i-1]['retweet']['pics']为该原始微博的原始图片url,若该原始微博有多张图片,则存储多个url,以英文逗号分割;若该原始微博没有图片,则值为'';
**video_url**:存储原始微博的视频url和原始微博Live Photo中的视频url。如wb.weibo[i-1]['retweet']['video_url']为该原始微博的视频url,若该原始微博有多个视频,则存储多个url,以英文分号分割;若该微博没有视频,则值为'';
**location**:存储原始微博的发布位置。wb.weibo[i-1]['retweet']['location']为该原始微博的发布位置,若该原始微博没有位置信息,则值为'';
**created_at**:存储原始微博的发布时间。wb.weibo[i-1]['retweet']['created_at']为该原始微博的发布时间;
**source**:存储原始微博的发布工具。wb.weibo[i-1]['retweet']['source']为该原始微博的发布工具;
**attitudes_count**:存储原始微博获得的点赞数。wb.weibo[i-1]['retweet']['attitudes_count']为该原始微博获得的点赞数;
**comments_count**:存储原始微博获得的评论数。wb.weibo[i-1]['retweet']['comments_count']为该原始微博获得的评论数;
**reposts_count**:存储原始微博获得的转发数。wb.weibo[i-1]['retweet']['reposts_count']为该原始微博获得的转发数;
**topics**:存储原始微博话题,即两个#中的内容。wb.weibo[i-1]['retweet']['topics']为该原始微博的话题,若该原始微博没有话题信息,则值为'';
**at_users**:存储原始微博@的用户。wb.weibo[i-1]['retweet']['at_users']为该原始微博@的用户,若该原始微博没有@的用户,则值为''。
</details>
</details>
### 7.定期自动爬取微博(可选)
我们爬取了微博以后,很多微博账号又可能发了一些新微博,定期自动爬取微博就是每隔一段时间自动运行程序,自动爬取这段时间产生的新微博(忽略以前爬过的旧微博)。本部分为可选部分,如果不需要可以忽略。
思路是**利用第三方软件,如crontab,让程序每隔一段时间运行一次**。因为是要跳过以前爬过的旧微博,只爬新微博。所以需要**设置一个动态的since_date**。很多时候我们使用的since_date是固定的,比如since_date="2018-01-01",程序就会按照这个设置从最新的微博一直爬到发布时间为2018-01-01的微博(包括这个时间)。因为我们想追加新微博,跳过旧微博。第二次爬取时since_date值就应该是当前时间到上次爬取的时间。 如果我们使用最原始的方式实现追加爬取,应该是这样:
```
假如程序第一次执行时间是2019-06-06,since_date假如为2018-01-01,那这一次就是爬取从2018-01-01到2019-06-06这段时间用户所发的微博;
第二次爬取,我们想要接着上次的爬,需要手动将since_date值设置为上次程序执行的日期,即2019-06-06
```
上面的方法太麻烦,因为每次都要手动设置since_date。因此我们需要动态设置since_date,即程序根据实际情况,自动生成since_date。
有两种方法实现动态更新since_date:
**方法一:将since_date设置成整数**
将config.json文件中的since_date设置成整数,如:
```
"since_date": 10,
```
这个配置告诉程序爬取最近10天的微博,更准确说是爬取发布时间从10天前到本程序开始执行时之间的微博。这样since_date就是一个动态的变量,每次程序执行时,它的值就是当前日期减10。配合crontab每9天或10天执行一次,就实现了定期追加爬取。
**方法二:将上次执行程序的时间写入文件(推荐)**
这个方法很简单,就是用户把要爬的用户id写入txt文件,然后再把文件路径赋值给config.json中的user_id_list参数。
txt文件名格式可以参考[程序设置](#3程序设置)中的设置user_id_list部分,这样设置就全部结束了。
说下这个方法的原理和好处,假如你的txt文件内容为:
```
1669879400
1223178222 胡歌
1729370543 郭碧婷 2019-01-01
```
第一次执行时,因为第一行和第二行都没有写时间,程序会按照config.json文件中since_date的值爬取,第三行有时间“2019-01-01”,程序就会把这个时间当作since_date。每个用户爬取结束程序都会自动更新txt文件,每一行第一部分是user_id,第二部分是用户昵称,第三部分是程序准备爬取该用户第一条微博(最新微博)时的日期。爬完三个用户后,txt文件的内容自动更新为:
```
1669879400 Dear-迪丽热巴 2020-01-18
1223178222 胡歌 2020-01-18
1729370543 郭碧婷 2020-01-18
```
下次再爬取微博的时候,程序会把每行的时间数据作为since_date。这样的好处一是不用修改since_date,程序自动更新;二是每一个用户都可以单独拥有只属于自己的since_date,每个用户的since_date相互独立,互不干扰,格式为`yyyy-mm-dd`或整数。比如,现在又添加了一个新用户,以杨紫的微博为例,你想获取她2018-01-23到现在的全部微博,可以这样修改txt文件:
```
1669879400 迪丽热巴 2020-01-18
1223178222 胡歌 2020-01-18
1729370543 郭碧婷 2020-01-18
1227368500 杨紫 3 梦想,希望
```
注意每一行的用户配置参数以空格分隔,如果第一个参数全部由数字组成,程序就认为此行为一个用户的配置,否则程序会认为该行只是注释,跳过该行;第二个参数可以为任意格式,建议写用户昵称;第三个如果是日期格式(yyyy-mm-dd),程序就将该日期设置为用户自己的since_date,否则使用config.json中的since_date爬取该用户的微博,第二个参数和第三个参数也可以不填。
也可以设置第四个参数,将被读取为query_list。
**方法三:将`const.py`文件中的运行模式改为`append`**
以追加模式运行程序,每次运行,每个id只获取最新的微博,而不是全部,避免频繁备份微博导致过多的请求次数。
注意:
* 该模式会跳过置顶微博。
* 若采集信息后用户又编辑微博,则不会记录编辑内容。
## 如何获取user_id
1.打开网址<https://weibo.cn>,搜索我们要找的人,如"迪丽热巴",进入她的主页;
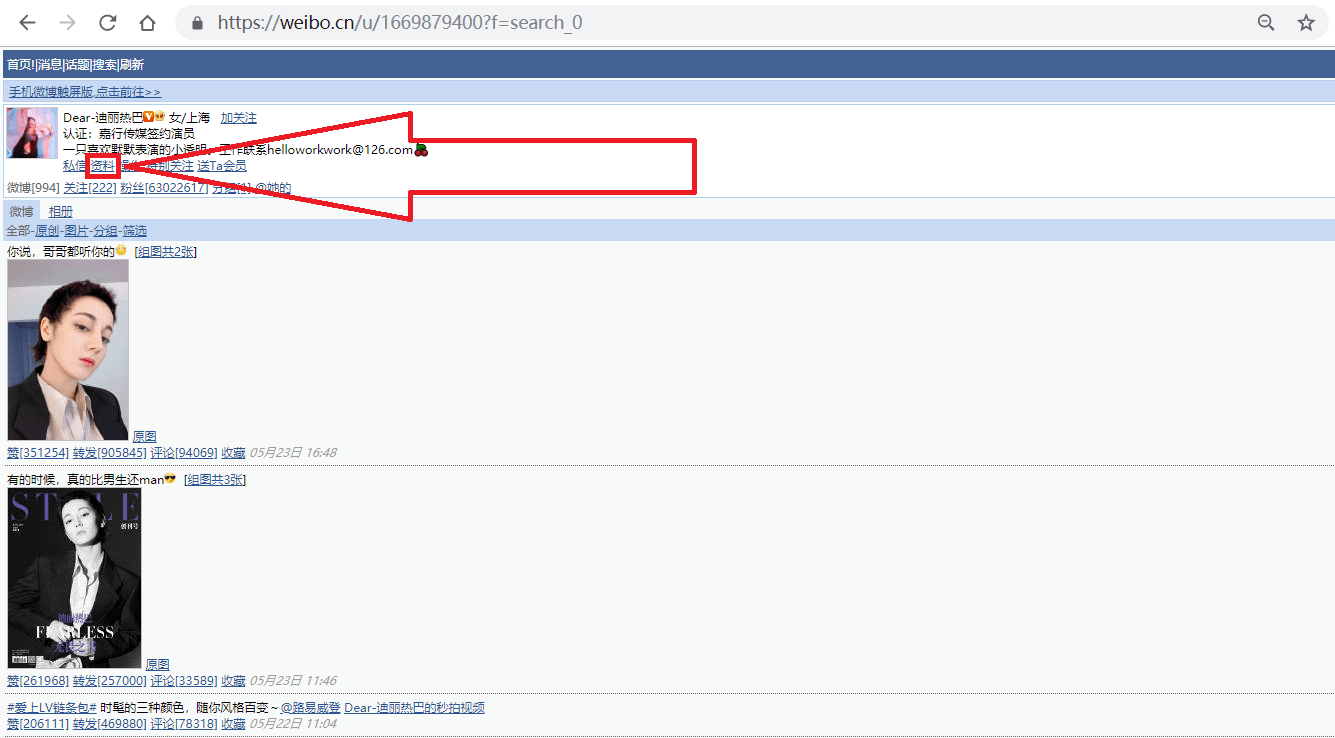
2.按照上图箭头所指,点击"资料"链接,跳转到用户资料页面;
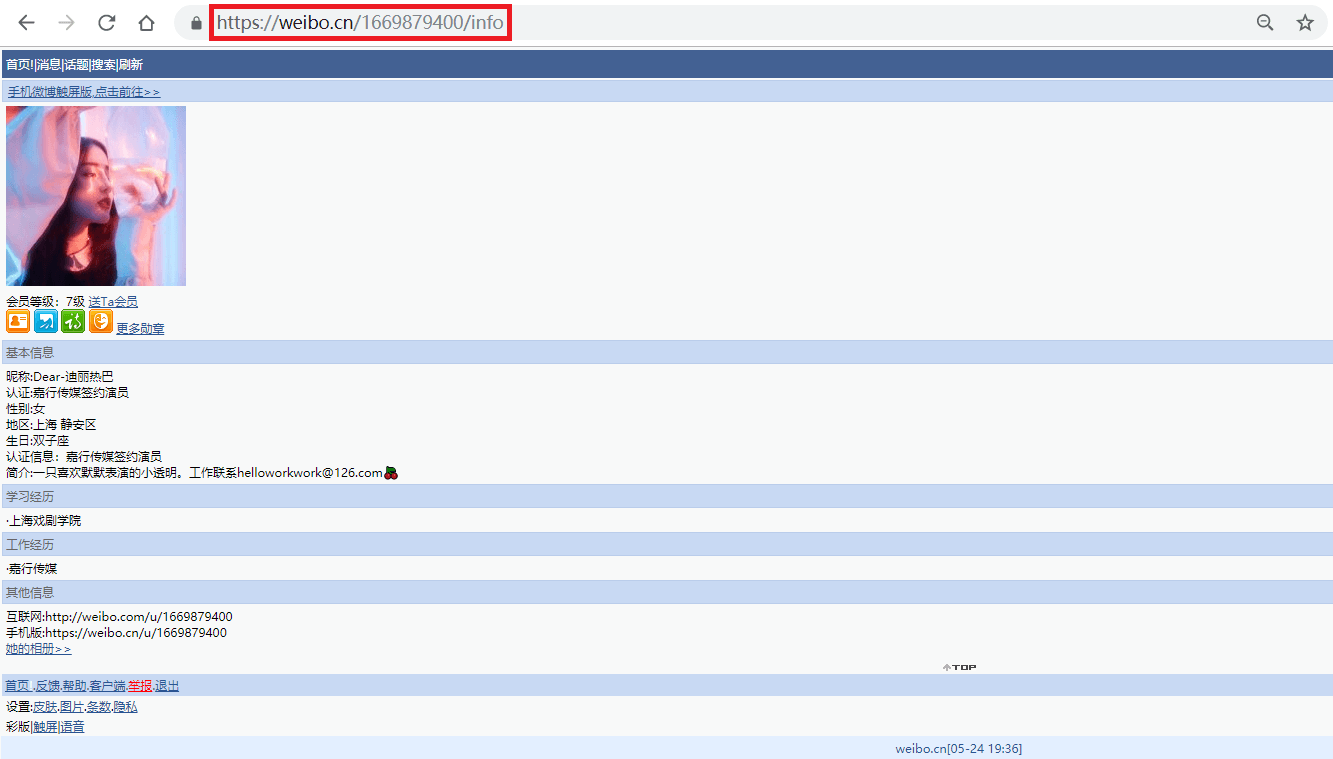
如上图所示,迪丽热巴微博资料页的地址为"<https://weibo.cn/1669879400/info>",其中的"1669879400"即为此微博的user_id。
事实上,此微博的user_id也包含在用户主页(<https://weibo.cn/u/1669879400?f=search_0>)中,之所以我们还要点击主页中的"资料"来获取user_id,是因为很多用户的主页不是"<https://weibo.cn/user_id?f=search_0>"的形式,而是"<https://weibo.cn/个性域名?f=search_0>"或"<https://weibo.cn/微号?f=search_0>"的形式。其中"微号"和user_id都是一串数字,如果仅仅通过主页地址提取user_id,很容易将"微号"误认为user_id。
## 添加cookie与不添加cookie的区别(可选)
对于微博数2000条及以下的微博用户,不添加cookie可以获取其用户信息和大部分微博;对于微博数2000条以上的微博用户,不添加cookie可以获取其用户信息和最近2000条微博中的大部分,添加cookie可以获取其全部微博。以2020年1月2日迪丽热巴的微博为例,此时她共有1085条微博,在不添加cookie的情况下,可以获取到1026条微博,大约占全部微博的94.56%,而在添加cookie后,可以获取全部微博。其他用户类似,大部分都可以在不添加cookie的情况下获取到90%以上的微博,在添加cookie后可以获取全部微博。具体原因是,大部分微博内容都可以在[移动版](https://m.weibo.cn/)匿名获取,少量微博需要用户登录才可以获取,所以这部分微博在不添加cookie时是无法获取的。
有少部分微博用户,不添加cookie可以获取其微博,无法获取其用户信息。对于这种情况,要想获取其用户信息,是需要cookie的。
如需抓取微博转发,请添加cookie。
## 如何获取cookie(可选)
1.用Chrome打开<https://passport.weibo.cn/signin/login>;
2.输入微博的用户名、密码,登录,如图所示:
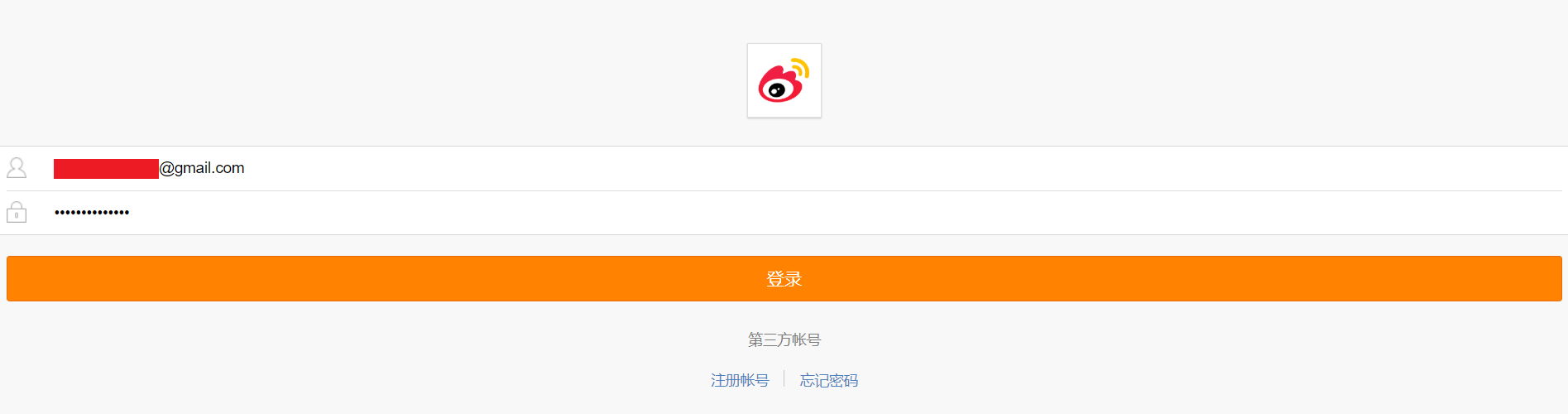
登录成功后会跳转到<https://m.weibo.cn>;
3.按F12键打开Chrome开发者工具,在地址栏输入并跳转到<https://weibo.cn>,跳转后会显示如下类似界面:
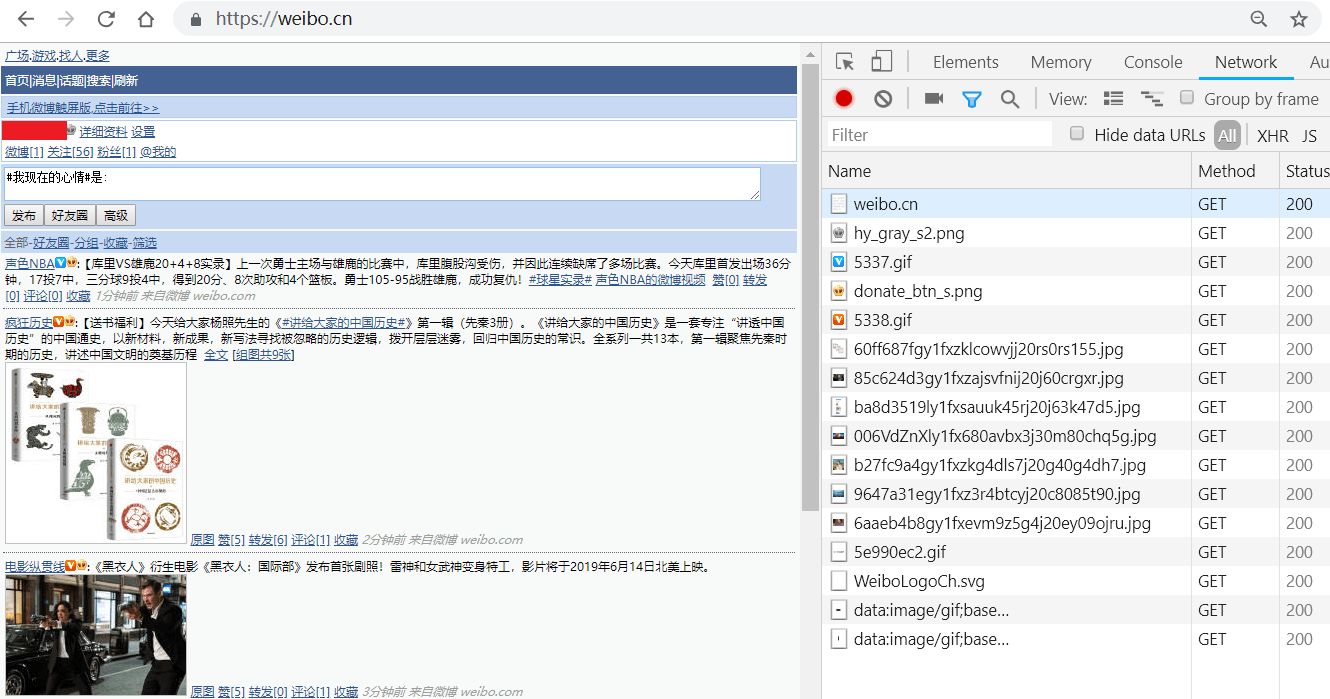
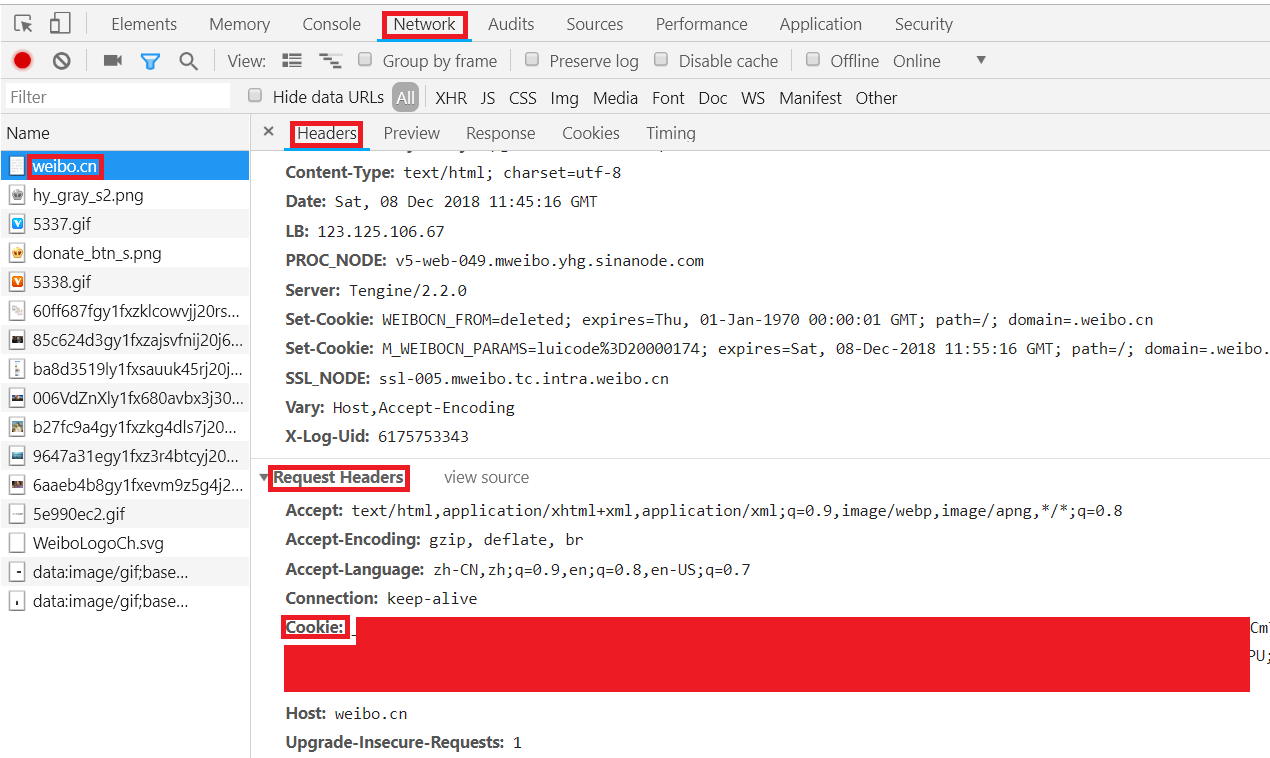
4.依此点击Chrome开发者工具中的Network->Name中的weibo.cn->Headers->Request Headers,"Cookie:"后的值即为我们要找的cookie值,复制即可,如图所示:
## 如何检测cookie是否有效(可选)
本程序cookie检查的逻辑是:使用cookie来源账号发布**限定范围的**微博,若cookie可用,则可以读取到该微博,否则读取不到。
**操作方法**
1. 使用cookie的来源账号发布一条微博,该账号和微博需要满足以下条件:
* 该微博必须是**非公开可见**的,后续需要根据可见性判断cookie是否有效;
* 该微博需要是最近5条微博,不能在发布测试用微博内容后又发很多新微博;
* 在`config.json`配置中的since_date之后,该账号必须有大于9条微博。
2. 将`const.py`文件中`'CHECK': False`中的`False`改为`True`,`'HIDDEN_WEIBO': '微博内容'`中的`微博内容`改为你发的限定范围的微博。
3. 将提供cookie的微博id放置在`config.json`文件中`"user_id_list"`设置项数组中的第一个。例如提供cookie的微博id为`123456`,则`"user_id_list"`设置为`"user_id_list":["123456", "<其余id...>"]`。
注:本方法也将会抓取提供cookie账号的微博内容。
在间歇运行程序时,cookie无效会导致程序不能按照预设目标执行,因此可以打开cookie通知功能。本项目使用开源项目[pushdeer](https://github.com/easychen/pushdeer)进行通知,在使用前用户需要申请push_key,具体可查看官网了解。打开方法为:
1. 在`const.py`文件中,将`'NOTIFY': False`中的`False`设为`True`;
2. 将`'PUSH_KEY': ''`的`''`替换为`'<你的push_key>'`
|
yajun06/TEST_TEXT_DATAS
|
[
"region:us"
] |
2023-03-27T07:22:47+00:00
|
{}
|
2023-03-27T07:25:18+00:00
|
289f4e734f4320f9f8cb47e0d0ffd8f1220505a4
|
AndrewMetaBlock/123
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-27T07:27:45+00:00
|
{"license": "apache-2.0"}
|
2023-03-27T07:27:45+00:00
|
|
2074f3dbb4a6339ae463ce951fce93af8e12aea9
|
# Dataset Card for WikiAnc HR
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Repository:** [WikiAnc repository](https://github.com/cyanic-selkie/wikianc)
### Dataset Summary
The WikiAnc HR datasets is an automatically generated dataset from Wikipedia (hr) and Wikidata dumps (March 1, 2023).
The code for generating the dataset can be found [here](https://github.com/cyanic-selkie/wikianc).
### Supported Tasks
- `wikificiation`: The dataset can be used to train a model for Wikification.
### Languages
The text in the dataset is in Croatian. The associated BCP-47 code is `hr`.
You can find the English version [here](https://huggingface.co/datasets/cyanic-selkie/wikianc-en).
## Dataset Structure
### Data Instances
A typical data point represents a paragraph in a Wikipedia article.
The `paragraph_text` field contains the original text in an NFC normalized, UTF-8 encoded string.
The `paragraph_anchors` field contains a list of anchors, each represented by a struct with the inclusive starting UTF-8 code point `start` field, exclusive ending UTF-8 code point `end` field, a nullable `qid` field, a nullable `pageid` field, and an NFC normalized, UTF-8 encoded `title` (Wikipedia) field.
Additionally, each paragraph has `article_title`, `article_pageid`, and (nullable) `article_qid` fields referring to the article the paragraph came from.
There is also a nullable, NFC normalized, UTF-8 encoded `section_heading` field, and an integer `section_level` field referring to the heading (if it exists) of the article section, and the level in the section hierarchy that the paragraph came from.
The `qid` fields refers to Wikidata's QID identifiers, while the `pageid` and `title` fields refer to Wikipedia's pageID and title identifiers (there is a one-to-one mapping between pageIDs and titles).
**NOTE:** An anchor will always have a `title`, but that doesn't mean it has to have a `pageid`. This is because Wikipedia allows defining anchors to nonexistent articles.
An example from the WikiAnc HR test set looks as follows:
```
{
"uuid": "8a9569ea-a398-4d14-8bce-76c263a8c0ac",
"article_title": "Špiro_Dmitrović",
"article_pageid": 70957,
"article_qid": 16116278,
"section_heading": null,
"section_level": 0,
"paragraph_text": "Špiro Dmitrović (Benkovac, 1803. – Zagreb, 6. veljače 1868.) hrvatski časnik i politički borac u doba ilirizma.",
"paragraph_anchors": [
{
"start": 17,
"end": 25,
"qid": 397443,
"pageid": 14426,
"title": "Benkovac"
},
{
"start": 27,
"end": 32,
"qid": 6887,
"pageid": 1876,
"title": "1803."
},
{
"start": 35,
"end": 41,
"qid": 1435,
"pageid": 5903,
"title": "Zagreb"
},
{
"start": 43,
"end": 53,
"qid": 2320,
"pageid": 496,
"title": "6._veljače"
},
{
"start": 54,
"end": 59,
"qid": 7717,
"pageid": 1811,
"title": "1868."
},
{
"start": 102,
"end": 110,
"qid": 680821,
"pageid": 54622,
"title": "Ilirizam"
}
]
}
```
### Data Fields
- `uuid`: a UTF-8 encoded string representing a v4 UUID that uniquely identifies the example
- `article_title`: an NFC normalized, UTF-8 encoded Wikipedia title of the article; spaces are replaced with underscores
- `article_pageid`: an integer representing the Wikipedia pageID of the article
- `article_qid`: an integer representing the Wikidata QID this article refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `section_heading`: a nullable, NFC normalized, UTF-8 encoded string representing the section heading
- `section_level`: an integer representing the level of the section in the section hierarchy
- `paragraph_text`: an NFC normalized, UTF-8 encoded string representing the paragraph
- `paragraph_anchors`: a list of structs representing anchors, each anchor has:
- `start`: an integer representing the inclusive starting UTF-8 code point of the anchors
- `end`: an integer representing the exclusive ending UTF-8 code point of the anchor
- `qid`: a nullable integer representing the Wikidata QID this anchor refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `pageid`: a nullable integer representing the Wikipedia pageID of the anchor; it can be null if the article didn't exist in Wikipedia at the time of the creation of the original dataset
- `title`: an NFC normalized, UTF-8 encoded string representing the Wikipedia title of the anchor; spaces are replaced with underscores; can refer to a nonexistent Wikipedia article
### Data Splits
The data is split into training, validation and test sets; paragraphs belonging to the same article aren't necessarily in the same split. The final split sizes are as follows:
| | Train | Validation | Test |
| :----- | :------: | :-----: | :----: |
| WikiAnc HR - articles | 192,653 | 116,375 | 116,638 |
| WikiAnc HR - paragraphs | 2,346,651 | 292,590 | 293,557 |
| WikiAnc HR - anchors | 8,368,928 | 1,039,851 | 1,044,828 |
| WikiAnc HR - anchors with QIDs | 7,160,367 | 891,959 | 896,414 |
| WikiAnc HR - anchors with pageIDs | 7,179,116 | 894,313 | 898,692 |
**NOTE:** The number of articles in the table above refers to the number of articles that have at least one paragraph belonging to the article appear in the split.
## Additional Information
### Licensing Information
The WikiAnc HR dataset is given under the [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/) license.
|
cyanic-selkie/wikianc-hr
|
[
"task_categories:token-classification",
"size_categories:1M<n<10M",
"language:hr",
"license:cc-by-sa-3.0",
"wikidata",
"wikipedia",
"wikification",
"region:us"
] |
2023-03-27T07:30:50+00:00
|
{"language": ["hr"], "license": "cc-by-sa-3.0", "size_categories": ["1M<n<10M"], "task_categories": ["token-classification"], "pretty_name": "WikiAnc HR", "tags": ["wikidata", "wikipedia", "wikification"]}
|
2023-06-01T12:58:07+00:00
|
6ad03808ae8c95c61140002832157e570b9107c3
|
# Dataset Card for "notebooks_by_user"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
davanstrien/notebooks_by_user
|
[
"region:us"
] |
2023-03-27T08:14:54+00:00
|
{"dataset_info": {"features": [{"name": "user", "dtype": "large_string"}, {"name": "repo_notebook_count", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 140436, "num_examples": 5604}], "download_size": 74860, "dataset_size": 140436}}
|
2024-02-17T02:14:50+00:00
|
2510ab6bfcf7892032721b361c9264a0cfe3e46d
|
# Dataset Card for "notebooks_by_repo_type"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
davanstrien/notebooks_by_repo_type
|
[
"region:us"
] |
2023-03-27T08:16:12+00:00
|
{"dataset_info": {"features": [{"name": "repo_type", "dtype": "large_string"}, {"name": "repo_notebook_count", "dtype": "int64"}, {"name": "date", "dtype": "date32"}], "splits": [{"name": "train", "num_bytes": 14350, "num_examples": 574}], "download_size": 0, "dataset_size": 14350}}
|
2024-02-17T02:15:03+00:00
|
fbf4729676ebae143213d10a62caad41f6b4b3c2
|
MorsZhu/Valorant_Imge_DataAsset
|
[
"license:openrail",
"region:us"
] |
2023-03-27T08:23:10+00:00
|
{"license": "openrail"}
|
2023-03-27T08:34:24+00:00
|
|
b405b6c44964e075d9ebde2b0c796eeb8f830fab
|
# Dataset Card for "dummy-controlnet-100000-samples"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sayakpaul/dummy-controlnet-100000-samples
|
[
"region:us"
] |
2023-03-27T08:24:52+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "condtioning_image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 157617435976.0, "num_examples": 100000}], "download_size": 157623508466, "dataset_size": 157617435976.0}}
|
2023-03-29T09:24:14+00:00
|
b70f81b24fc04a2b0cff88e6ec3cd296808dae6a
|
# Dataset Card for DWIE
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://opendatalab.com/DWIE](https://opendatalab.com/DWIE)
- **Repository:** [https://github.com/klimzaporojets/DWIE](https://github.com/klimzaporojets/DWIE)
- **Paper:** [DWIE: an entity-centric dataset for multi-task document-level information extraction](https://arxiv.org/abs/2009.12626)
- **Leaderboard:** [https://opendatalab.com/DWIE](https://opendatalab.com/DWIE)
- **Size of downloaded dataset files:** 40.8 MB
### Dataset Summary
DWIE (Deutsche Welle corpus for Information Extraction) is a new dataset for document-level multi-task Information Extraction (IE).
It combines four main IE sub-tasks:
1.Named Entity Recognition: 23,130 entities classified in 311 multi-label entity types (tags).
2.Coreference Resolution: 43,373 entity mentions clustered in 23,130 entities.
3.Relation Extraction: 21,749 annotated relations between entities classified in 65 multi-label relation types.
4.Entity Linking: the named entities are linked to Wikipedia (version 20181115).
For details, see the paper https://arxiv.org/pdf/2009.12626v2.pdf.
### Supported Tasks and Leaderboards
- **Tasks:** Named Entity Recognition, Coreference Resolution, Relation extraction and entity linking in scientific papers
- **Leaderboards:** [https://opendatalab.com/DWIE](https://opendatalab.com/DWIE)
### Languages
The language in the dataset is English.
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 40.8 MB
An example of 'train' looks as follows, provided sample of the data:
```json
{'id': 'DW_3980038',
'content': 'Proposed Nabucco Gas Pipeline Gets European Bank Backing\nThe heads of the EU\'s European Investment Bank and the European Bank for Reconstruction and Development (EBRD) said Tuesday, Jan. 27, that they are prepared to provide financial backing for the Nabucco gas pipeline.\nSpurred on by Europe\'s worst-ever gas crisis earlier this month, which left millions of homes across the continent without heat in the depths of winter, Hungarian Prime Minister Ferenc Gyurcsany invited top-ranking officials from both the EU and the countries involved in Nabucco to inject fresh momentum into the slow-moving project. Nabucco, an ambitious but still-unbuilt gas pipeline aimed at reducing Europe\'s energy reliance on Russia, is a 3,300-kilometer (2,050-mile) pipeline between Turkey and Austria. Costing an estimated 7.9 billion euros, the aim is to transport up to 31 billion cubic meters of gas each year from the Caspian Sea to Western Europe, bypassing Russia and Ukraine. Nabucco currently has six shareholders -- OMV of Austria, MOL of Hungary, Transgaz of Romania, Bulgargaz of Bulgaria, Botas of Turkey and RWE of Germany. But for the pipeline to get moving, Nabucco would need an initial cash injection of an estimated 300 million euros. Both the EIB and EBRD said they were willing to invest in the early stages of the project through a series of loans, providing certain conditions are met. "The EIB is ready to finance projects that further EU objectives of increased sustainability and energy security," said Philippe Maystadt, president of the European Investment Bank, during the opening addresses by participants at the "Nabucco summit" in Hungary. The EIB is prepared to finance "up to 25 percent of project cost," provided a secure intergovernmental agreement on the Nabucco pipeline is reached, he said. Maystadt noted that of 48 billion euros of financing it provided last year, a quarter was for energy projects. EBRD President Thomas Mirow also offered financial backing to the Nabucco pipeline, on the condition that it "meets the requirements of solid project financing." The bank would need to see concrete plans and completion guarantees, besides a stable political agreement, said Mirow. EU wary of future gas crises Czech Prime Minister Mirek Topolanek, whose country currently holds the rotating presidency of the EU, spoke about the recent gas crisis caused by a pricing dispute between Russia and Ukraine that affected supplies to Europe. "A new crisis could emerge at any time, and next time it could be even worse," Topolanek said. He added that reaching an agreement on Nabucco is a "test of European solidarity." The latest gas row between Russia and Ukraine has highlighted Europe\'s need to diversify its energy sources and thrown the spotlight on Nabucco. But critics insist that the vast project will remain nothing but a pipe dream because its backers cannot guarantee that they will ever have sufficient gas supplies to make it profitable. EU Energy Commissioner Andris Piebalgs urged political leaders to commit firmly to Nabucco by the end of March, or risk jeopardizing the project. In his opening address as host, Hungarian Prime Minister Ferenc Gyurcsany called on the EU to provide 200 to 300 million euros within the next few weeks to get the construction of the pipeline off the ground. Gyurcsany stressed that he was not hoping for a loan, but rather for starting capital from the EU. US Deputy Assistant Secretary of State Matthew Bryza noted that the Tuesday summit had made it clear that Gyurcsany, who dismissed Nabucco as "a dream" in 2007, was now fully committed to the energy supply diversification project. On the supply side, Turkmenistan and Azerbaijan both indicated they would be willing to supply some of the gas. "Azerbaijan, which is according to current plans is a transit country, could eventually serve as a supplier as well," Azerbaijani President Ilham Aliyev said. Azerbaijan\'s gas reserves of some two or three trillion cubic meters would be sufficient to last "several decades," he said. Austrian Economy Minister Reinhold Mitterlehner suggested that Egypt and Iran could also be brought in as suppliers in the long term. But a deal currently seems unlikely with Iran given the long-running international standoff over its disputed nuclear program. Russia, Ukraine still wrangling Meanwhile, Russia and Ukraine were still wrangling over the details of the deal which ended their gas quarrel earlier this month. Ukrainian President Viktor Yushchenko said on Tuesday he would stand by the terms of the agreement with Russia, even though not all the details are to his liking. But Russian officials questioned his reliability, saying that the political rivalry between Yushchenko and Prime Minister Yulia Timoshenko could still lead Kiev to cancel the contract. "The agreements signed are not easy ones, but Ukraine fully takes up the performance (of its commitments) and guarantees full-fledged transit to European consumers," Yushchenko told journalists in Brussels after a meeting with the head of the European Commission, Jose Manuel Barroso. The assurance that Yushchenko would abide by the terms of the agreement finalized by Timoshenko was "an important step forward in allowing us to focus on our broader relationship," Barroso said. But the spokesman for Russian Prime Minister Vladimir Putin said that Moscow still feared that the growing rivalry between Yushchenko and Timoshenko, who are set to face off in next year\'s presidential election, could torpedo the deal. EU in talks to upgrade Ukraine\'s transit system Yushchenko\'s working breakfast with Barroso was dominated by the energy question, with both men highlighting the need to upgrade Ukraine\'s gas-transit system and build more links between Ukrainian and European energy markets. The commission is set to host an international conference aimed at gathering donations to upgrade Ukraine\'s gas-transit system on March 23 in Brussels. The EU and Ukraine have agreed to form a joint expert group to plan the meeting, the leaders said Tuesday. During the conflict, Barroso had warned that both Russia and Ukraine were damaging their credibility as reliable partners. But on Monday he said that "in bilateral relations, we are not taking any negative consequences from (the gas row) because we believe Ukraine wants to deepen the relationship with the EU, and we also want to deepen the relationship with Ukraine." He also said that "we have to state very clearly that we were disappointed by the problems between Ukraine and Russia," and called for political stability and reform in Ukraine. His diplomatic balancing act is likely to have a frosty reception in Moscow, where Peskov said that Russia "would prefer to hear from the European states a very serious and severe evaluation of who is guilty for interrupting the transit."',
'tags': "['all', 'train']",
'mentions': [{'begin': 9,
'end': 29,
'text': 'Nabucco Gas Pipeline',
'concept': 1,
'candidates': [],
'scores': []},
{'begin': 287,
'end': 293,
'text': 'Europe',
'concept': 2,
'candidates': ['Europe',
'UEFA',
'Europe_(band)',
'UEFA_competitions',
'European_Athletic_Association',
'European_theatre_of_World_War_II',
'European_Union',
'Europe_(dinghy)',
'European_Cricket_Council',
'UEFA_Champions_League',
'Senior_League_World_Series_(Europe–Africa_Region)',
'Big_League_World_Series_(Europe–Africa_Region)',
'Sailing_at_the_2004_Summer_Olympics_–_Europe',
'Neolithic_Europe',
'History_of_Europe',
'Europe_(magazine)'],
'scores': [0.8408304452896118,
0.10987312346696854,
0.01377162616699934,
0.002099192701280117,
0.0015916954725980759,
0.0015686274273321033,
0.001522491336800158,
0.0013148789294064045,
0.0012456747936084867,
0.000991926179267466,
0.0008073817589320242,
0.0007843137136660516,
0.000761245668400079,
0.0006920415326021612,
0.0005536332027986646,
0.000530565157532692]},
0.00554528646171093,
0.004390018526464701,
0.003234750358387828,
0.002772643230855465,
0.001617375179193914]},
{'begin': 6757,
'end': 6765,
'text': 'European',
'concept': 13,
'candidates': None,
'scores': []}],
'concepts': [{'concept': 0,
'text': 'European Investment Bank',
'keyword': True,
'count': 5,
'link': 'European_Investment_Bank',
'tags': ['iptc::11000000',
'slot::keyword',
'topic::politics',
'type::entity',
'type::igo',
'type::organization']},
{'concept': 66,
'text': None,
'keyword': False,
'count': 0,
'link': 'Czech_Republic',
'tags': []}],
'relations': [{'s': 0, 'p': 'institution_of', 'o': 2},
{'s': 0, 'p': 'part_of', 'o': 2},
{'s': 3, 'p': 'institution_of', 'o': 2},
{'s': 3, 'p': 'part_of', 'o': 2},
{'s': 6, 'p': 'head_of', 'o': 0},
{'s': 6, 'p': 'member_of', 'o': 0},
{'s': 7, 'p': 'agent_of', 'o': 4},
{'s': 7, 'p': 'citizen_of', 'o': 4},
{'s': 7, 'p': 'citizen_of-x', 'o': 55},
{'s': 7, 'p': 'head_of_state', 'o': 4},
{'s': 7, 'p': 'head_of_state-x', 'o': 55},
{'s': 8, 'p': 'agent_of', 'o': 4},
{'s': 8, 'p': 'citizen_of', 'o': 4},
{'s': 8, 'p': 'citizen_of-x', 'o': 55},
{'s': 8, 'p': 'head_of_gov', 'o': 4},
{'s': 8, 'p': 'head_of_gov-x', 'o': 55},
{'s': 9, 'p': 'head_of', 'o': 59},
{'s': 9, 'p': 'member_of', 'o': 59},
{'s': 10, 'p': 'head_of', 'o': 3},
{'s': 10, 'p': 'member_of', 'o': 3},
{'s': 11, 'p': 'citizen_of', 'o': 66},
{'s': 11, 'p': 'citizen_of-x', 'o': 36},
{'s': 11, 'p': 'head_of_state', 'o': 66},
{'s': 11, 'p': 'head_of_state-x', 'o': 36},
{'s': 12, 'p': 'agent_of', 'o': 24},
{'s': 12, 'p': 'citizen_of', 'o': 24},
{'s': 12, 'p': 'citizen_of-x', 'o': 15},
{'s': 12, 'p': 'head_of_gov', 'o': 24},
{'s': 12, 'p': 'head_of_gov-x', 'o': 15},
{'s': 15, 'p': 'gpe0', 'o': 24},
{'s': 22, 'p': 'based_in0', 'o': 18},
{'s': 22, 'p': 'based_in0-x', 'o': 50},
{'s': 23, 'p': 'based_in0', 'o': 24},
{'s': 23, 'p': 'based_in0-x', 'o': 15},
{'s': 25, 'p': 'based_in0', 'o': 26},
{'s': 27, 'p': 'based_in0', 'o': 28},
{'s': 29, 'p': 'based_in0', 'o': 17},
{'s': 30, 'p': 'based_in0', 'o': 31},
{'s': 33, 'p': 'event_in0', 'o': 24},
{'s': 36, 'p': 'gpe0', 'o': 66},
{'s': 38, 'p': 'member_of', 'o': 2},
{'s': 43, 'p': 'agent_of', 'o': 41},
{'s': 43, 'p': 'citizen_of', 'o': 41},
{'s': 48, 'p': 'gpe0', 'o': 47},
{'s': 49, 'p': 'agent_of', 'o': 47},
{'s': 49, 'p': 'citizen_of', 'o': 47},
{'s': 49, 'p': 'citizen_of-x', 'o': 48},
{'s': 49, 'p': 'head_of_state', 'o': 47},
{'s': 49, 'p': 'head_of_state-x', 'o': 48},
{'s': 50, 'p': 'gpe0', 'o': 18},
{'s': 52, 'p': 'agent_of', 'o': 18},
{'s': 52, 'p': 'citizen_of', 'o': 18},
{'s': 52, 'p': 'citizen_of-x', 'o': 50},
{'s': 52, 'p': 'minister_of', 'o': 18},
{'s': 52, 'p': 'minister_of-x', 'o': 50},
{'s': 55, 'p': 'gpe0', 'o': 4},
{'s': 56, 'p': 'gpe0', 'o': 5},
{'s': 57, 'p': 'in0', 'o': 4},
{'s': 57, 'p': 'in0-x', 'o': 55},
{'s': 58, 'p': 'in0', 'o': 65},
{'s': 59, 'p': 'institution_of', 'o': 2},
{'s': 59, 'p': 'part_of', 'o': 2},
{'s': 60, 'p': 'agent_of', 'o': 5},
{'s': 60, 'p': 'citizen_of', 'o': 5},
{'s': 60, 'p': 'citizen_of-x', 'o': 56},
{'s': 60, 'p': 'head_of_gov', 'o': 5},
{'s': 60, 'p': 'head_of_gov-x', 'o': 56},
{'s': 61, 'p': 'in0', 'o': 5},
{'s': 61, 'p': 'in0-x', 'o': 56}],
'frames': [{'type': 'none', 'slots': []}],
'iptc': ['04000000',
'11000000',
'20000344',
'20000346',
'20000378',
'20000638']}
```
### Data Fields
- `id` : unique identifier of the article.
- `content` : textual content of the article downloaded with src/dwie_download.py script.
- `tags` : used to differentiate between train and test sets of documents.
- `mentions`: a list of entity mentions in the article each with the following keys:
- `begin` : offset of the first character of the mention (inside content field).
- `end` : offset of the last character of the mention (inside content field).
- `text` : the textual representation of the entity mention.
- `concept` : the id of the entity that represents the entity mention (multiple entity mentions in the article can refer to the same concept).
- `candidates` : the candidate Wikipedia links.
- `scores` : the prior probabilities of the candidates entity links calculated on Wikipedia corpus.
- `concepts` : a list of entities that cluster each of the entity mentions. Each entity is annotated with the following keys:
- `concept` : the unique document-level entity id.
- `text` : the text of the longest mention that belong to the entity.
- `keyword` : indicates whether the entity is a keyword.
- `count` : the number of entity mentions in the document that belong to the entity.
- `link` : the entity link to Wikipedia.
- `tags` : multi-label classification labels associated to the entity.
- `relations` : a list of document-level relations between entities (concepts). Each of the relations is annotated with the following keys:
- `s` : the subject entity id involved in the relation.
- `p` : the predicate that defines the relation name (i.e., "citizen_of", "member_of", etc.).
- `o` : the object entity id involved in the relation.
- `iptc` : multi-label article IPTC classification codes. For detailed meaning of each of the codes, please refer to the official IPTC code list.
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{zaporojets2021dwie,
title={DWIE: An entity-centric dataset for multi-task document-level information extraction},
author={Zaporojets, Klim and Deleu, Johannes and Develder, Chris and Demeester, Thomas},
journal={Information Processing \& Management},
volume={58},
number={4},
pages={102563},
year={2021},
publisher={Elsevier}
}
```
### Contributions
Thanks to [@basvoju](https://github.com/basvoju) for adding this dataset.
|
DFKI-SLT/DWIE
|
[
"task_categories:feature-extraction",
"task_categories:text-classification",
"task_ids:entity-linking-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:en",
"license:other",
"Named Entity Recognition, Coreference Resolution, Relation Extraction, Entity Linking",
"arxiv:2009.12626",
"region:us"
] |
2023-03-27T08:27:59+00:00
|
{"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "license": "other", "multilinguality": ["monolingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["feature-extraction", "text-classification"], "task_ids": ["entity-linking-classification"], "paperswithcode_id": "acronym-identification", "pretty_name": "DWIE (Deutsche Welle corpus for Information Extraction) is a new dataset for document-level multi-task Information Extraction (IE).", "tags": ["Named Entity Recognition, Coreference Resolution, Relation Extraction, Entity Linking"], "train-eval-index": [{"col_mapping": {"labels": "tags", "tokens": "tokens"}, "config": "default", "splits": {"eval_split": "test"}, "task_id": "entity_extraction"}]}
|
2023-03-27T09:24:00+00:00
|
18e91b14f205d9ce0cff01073b5ba09e05fe27da
|
# Dataset Card for WikiAnc EN
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Repository:** [WikiAnc repository](https://github.com/cyanic-selkie/wikianc)
### Dataset Summary
The WikiAnc EN datasets is an automatically generated dataset from Wikipedia (en) and Wikidata dumps (March 1, 2023).
The code for generating the dataset can be found [here](https://github.com/cyanic-selkie/wikianc).
### Supported Tasks
- `wikificiation`: The dataset can be used to train a model for Wikification.
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en`.
You can find the Croatian version [here](https://huggingface.co/datasets/cyanic-selkie/wikianc-hr).
## Dataset Structure
### Data Instances
A typical data point represents a paragraph in a Wikipedia article.
The `paragraph_text` field contains the original text in an NFC normalized, UTF-8 encoded string.
The `paragraph_anchors` field contains a list of anchors, each represented by a struct with the inclusive starting UTF-8 code point `start` field, exclusive ending UTF-8 code point `end` field, a nullable `qid` field, a nullable `pageid` field, and an NFC normalized, UTF-8 encoded `title` (Wikipedia) field.
Additionally, each paragraph has `article_title`, `article_pageid`, and (nullable) `article_qid` fields referring to the article the paragraph came from.
There is also a nullable, NFC normalized, UTF-8 encoded `section_heading` field, and an integer `section_level` field referring to the heading (if it exists) of the article section, and the level in the section hierarchy that the paragraph came from.
The `qid` fields refers to Wikidata's QID identifiers, while the `pageid` and `title` fields refer to Wikipedia's pageID and title identifiers (there is a one-to-one mapping between pageIDs and titles).
**NOTE:** An anchor will always have a `title`, but that doesn't mean it has to have a `pageid`. This is because Wikipedia allows defining anchors to nonexistent articles.
An example from the WikiAnc EN test set looks as follows:
```
{
"uuid": "5f74e678-944f-4761-a5e0-b6426f6f61b8",
"article_title": "Climatius",
"article_pageid": 5394373,
"article_qid": 867987,
"section_heading": null,
"section_level": 0,
"paragraph_text": "It was a small fish, at 7.5 cm, and to discourage predators, Climatius sported fifteen sharp spines. There was one spine each on the paired pelvic and pectoral fins, and on the aingle anal and two dorsal fins, and a four pairs without fins on the fish's underside.",
"paragraph_anchors": [
{
"start": 140,
"end": 146,
"qid": 3335089,
"pageid": 56849833,
"title": "Pelvic_fin"
},
{
"start": 151,
"end": 159,
"qid": 4162555,
"pageid": 331956,
"title": "Pectoral_fin"
},
{
"start": 184,
"end": 188,
"qid": 4162555,
"pageid": 331958,
"title": "Anal_fin"
},
{
"start": 197,
"end": 208,
"qid": 1568355,
"pageid": 294244,
"title": "Dorsal_fin"
}
]
}
```
### Data Fields
- `uuid`: a UTF-8 encoded string representing a v4 UUID that uniquely identifies the example
- `article_title`: an NFC normalized, UTF-8 encoded Wikipedia title of the article; spaces are replaced with underscores
- `article_pageid`: an integer representing the Wikipedia pageID of the article
- `article_qid`: an integer representing the Wikidata QID this article refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `section_heading`: a nullable, NFC normalized, UTF-8 encoded string representing the section heading
- `section_level`: an integer representing the level of the section in the section hierarchy
- `paragraph_text`: an NFC normalized, UTF-8 encoded string representing the paragraph
- `paragraph_anchors`: a list of structs representing anchors, each anchor has:
- `start`: an integer representing the inclusive starting UTF-8 code point of the anchors
- `end`: an integer representing the exclusive ending UTF-8 code point of the anchor
- `qid`: a nullable integer representing the Wikidata QID this anchor refers to; it can be null if the entity didn't exist in Wikidata at the time of the creation of the original dataset
- `pageid`: a nullable integer representing the Wikipedia pageID of the anchor; it can be null if the article didn't exist in Wikipedia at the time of the creation of the original dataset
- `title`: an NFC normalized, UTF-8 encoded string representing the Wikipedia title of the anchor; spaces are replaced with underscores; can refer to a nonexistent Wikipedia article
### Data Splits
The data is split into training, validation and test sets; paragraphs belonging to the same article aren't necessarily in the same split. The final split sizes are as follows:
| | Train | Validation | Test |
| :----- | :------: | :-----: | :----: |
| WikiAnc EN - articles | 5,883,342 | 2,374,055 | 2,375,830 |
| WikiAnc EN - paragraphs | 34,555,183 | 4,317,326 | 4,321,613 |
| WikiAnc EN - anchors | 87,060,158 | 10,876,572 | 10,883,232 |
| WikiAnc EN - anchors with QIDs | 85,414,610 | 10,671,262 | 10,677,412 |
| WikiAnc EN - anchors with pageIDs | 85,421,513 | 10,672,138 | 10,678,262 |
**NOTE:** The number of articles in the table above refers to the number of articles that have at least one paragraph belonging to the article appear in the split.
## Additional Information
### Licensing Information
The WikiAnc EN dataset is given under the [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/) license.
|
cyanic-selkie/wikianc-en
|
[
"task_categories:token-classification",
"size_categories:10M<n<100M",
"language:en",
"license:cc-by-sa-3.0",
"wikidata",
"wikipedia",
"wikification",
"region:us"
] |
2023-03-27T08:49:06+00:00
|
{"language": ["en"], "license": "cc-by-sa-3.0", "size_categories": ["10M<n<100M"], "task_categories": ["token-classification"], "pretty_name": "WikiAnc EN", "tags": ["wikidata", "wikipedia", "wikification"]}
|
2023-06-02T13:08:17+00:00
|
5c476b96b0becf2a78c60419b4a14d71b7b85707
|
pbms/flan-t5-small
|
[
"license:unknown",
"region:us"
] |
2023-03-27T08:58:27+00:00
|
{"license": "unknown"}
|
2023-03-27T08:58:27+00:00
|
|
132da4a39ec7b58afce9c5f2b5fdf2823cf6932f
|
adihaviv/idiomem
|
[
"license:mit",
"region:us"
] |
2023-03-27T09:10:37+00:00
|
{"license": "mit"}
|
2023-03-27T09:18:20+00:00
|
|
b34e116c53646cd4e95a97c32196e831e025593d
|
# Dataset Card for "logo-combined-exclusive"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Babypotatotang/logo-combined-exclusive
|
[
"region:us"
] |
2023-03-27T09:27:47+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 166362980.253, "num_examples": 12907}], "download_size": 166890745, "dataset_size": 166362980.253}}
|
2023-03-27T09:30:12+00:00
|
70da6c990bfb71357b2115bc6e2383c2db5c388f
|
# Dataset Card for "ada-no-pii_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/ada-no-pii_checks
|
[
"region:us"
] |
2023-03-27T09:40:47+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 276915088.37363416, "num_examples": 10886}], "download_size": 100410446, "dataset_size": 276915088.37363416}}
|
2023-03-27T10:48:03+00:00
|
5b65608081d3b6d89d5bc12c464bec55f59480d1
|
# Mathematics StackExchange Dataset
This dataset contains questions and answers from Mathematics StackExchange (math.stackexchange.com). The data was collected using the Stack Exchange API. Total collected questions 465.295.
## Data Format
The dataset is provided in JSON Lines format, with one JSON object per line. Each object contains the following fields:
- `id`: the unique ID of the question
- `asked_at`: the timestamp when the question was asked
- `author_name`: the name of the author who asked the question
- `author_rep`: the reputation of the author who asked the question
- `score`: the score of the question
- `title`: the title of the question
- `tags`: a list of tags associated with the question
- `body`: the body of the question
- `comments`: a list of comments on the question, where each comment is represented as a dictionary with the following fields:
- `id`: the unique ID of the comment
- `body`: the body of the comment
- `at`: the timestamp when the comment was posted
- `score`: the score of the comment
- `author`: the name of the author who posted the comment
- `author_rep`: the reputation of the author who posted the comment
- `answers`: a list of answers to the question, where each answer is represented as a dictionary with the following fields:
- `id`: the unique ID of the answer
- `body`: the body of the answer
- `score`: the score of the answer
- `ts`: the timestamp when the answer was posted
- `author`: the name of the author who posted the answer
- `author_rep`: the reputation of the author who posted the answer
- `accepted`: whether the answer has been accepted
- `comments`: a list of comments on the answer, where each comment is represented as a dictionary with the following fields:
- `id`: the unique ID of the comment
- `body`: the body of the comment
- `at`: the timestamp when the comment was posted
- `score`: the score of the comment
- `author`: the name of the author who posted the comment
- `author_rep`: the reputation of the author who posted the comment
## Preprocessing
There was no preprocessing done, this dataset contains raw unfiltered data, also there might be problems with redundant line breaks or spacings
## License
This dataset is released under the [WTFPL](http://www.wtfpl.net/txt/copying/) license.
## Contact
For any questions or comments about the dataset, please contact [email protected].
|
nurik040404/mse
|
[
"task_categories:question-answering",
"task_categories:text-generation",
"task_categories:text-classification",
"task_ids:closed-domain-qa",
"task_ids:extractive-qa",
"task_ids:open-domain-qa",
"task_ids:dialogue-modeling",
"task_ids:language-modeling",
"task_ids:acceptability-classification",
"task_ids:text-scoring",
"annotations_creators:no-annotation",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:wtfpl",
"math",
"region:us"
] |
2023-03-27T09:43:46+00:00
|
{"annotations_creators": ["no-annotation"], "language_creators": ["machine-generated"], "language": ["en"], "license": "wtfpl", "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["question-answering", "text-generation", "text-classification"], "task_ids": ["closed-domain-qa", "extractive-qa", "open-domain-qa", "dialogue-modeling", "language-modeling", "acceptability-classification", "text-scoring"], "pretty_name": "math-stackexchange-qa", "tags": ["math"]}
|
2023-03-30T21:49:43+00:00
|
e3797e49ee4769fe75414491fad55e3f56bb282f
|
# SourceData Dataset
> The largest annotated biomedical corpus for machine learning and AI in the publishing context.
SourceData is the largest annotated biomedical dataset for NER and NEL.
It is unique on its focus on the core of scientific evidence:
figure captions. It is also unique on its real-world configuration, since it does not
present isolated sentences out of more general context. It offers full annotated figure
captions that can be further enriched in context using full text, abstracts, or titles.
The goal is to extract the nature of the experiments on them described.
SourceData presents also its uniqueness by labelling the causal relationship
between biological entities present in experiments, assigning experimental roles
to each biomedical entity present in the corpus.
SourceData consistently annotates
nine different biological entities (genes, proteins, cells, tissues,
subcellular components, species, small molecules, and diseases). It is
the first dataset annotating experimental assays
and the roles played on them by the biological entities.
Each entity is linked to their correspondent ontology, allowing
for entity disambiguation and NEL.
## Cite our work
```latex
@ARTICLE{2023arXiv231020440A,
author = {{Abreu-Vicente}, Jorge and {Sonntag}, Hannah and {Eidens}, Thomas and {Lemberger}, Thomas},
title = "{The SourceData-NLP dataset: integrating curation into scientific publishing for training large language models}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language},
year = 2023,
month = oct,
eid = {arXiv:2310.20440},
pages = {arXiv:2310.20440},
archivePrefix = {arXiv},
eprint = {2310.20440},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2023arXiv231020440A},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
@article {Liechti2017,
author = {Liechti, Robin and George, Nancy and Götz, Lou and El-Gebali, Sara and Chasapi, Anastasia and Crespo, Isaac and Xenarios, Ioannis and Lemberger, Thomas},
title = {SourceData - a semantic platform for curating and searching figures},
year = {2017},
volume = {14},
number = {11},
doi = {10.1038/nmeth.4471},
URL = {https://doi.org/10.1038/nmeth.4471},
eprint = {https://www.biorxiv.org/content/early/2016/06/20/058529.full.pdf},
journal = {Nature Methods}
}
```
## Dataset usage
The dataset has a semantic versioning.
Specifying the version at loaded will give different versions.
Below we is shown the code needed to load the latest available version of the dataset.
Check below at `Changelog` to see the changes in the different versions.
```python
from datasets import load_dataset
# Load NER
ds = load_dataset("EMBO/SourceData", "NER", version="2.0.3")
# Load PANELIZATION
ds = load_dataset("EMBO/SourceData", "PANELIZATION", version="2.0.3")
# Load GENEPROD ROLES
ds = load_dataset("EMBO/SourceData", "ROLES_GP", version="2.0.3")
# Load SMALL MOLECULE ROLES
ds = load_dataset("EMBO/SourceData", "ROLES_SM", version="2.0.3")
# Load MULTI ROLES
ds = load_dataset("EMBO/SourceData", "ROLES_MULTI", version="2.0.3")
```
## Dataset Description
- **Homepage:** https://sourcedata.embo.org
- **Repository:** https://github.com/source-data/soda-data
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** [email protected], [email protected]
Note that we offer the `XML` serialized dataset. This includes all the data needed to perform NEL in SourceData.
For reproducibility, for each big version of the dataset we provide `split_vx.y.z.json` files to generate the
train, validation, test splits.
### Supported Tasks and Leaderboards
Tags are provided as [IOB2-style tags](https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)).
`PANELIZATION`: figure captions (or figure legends) are usually composed of segments that each refer to one of several 'panels' of the full figure. Panels tend to represent results obtained with a coherent method and depicts data points that can be meaningfully compared to each other. `PANELIZATION` provide the start (B-PANEL_START) of these segments and allow to train for recogntion of the boundary between consecutive panel lengends.
`NER`: biological and chemical entities are labeled. Specifically the following entities are tagged:
- `SMALL_MOLECULE`: small molecules
- `GENEPROD`: gene products (genes and proteins)
- `SUBCELLULAR`: subcellular components
- `CELL_LINE`: cell lines
- `CELL_TYPE`: cell types
- `TISSUE`: tissues and organs
- `ORGANISM`: species
- `DISEASE`: diseases (see limitations)
- `EXP_ASSAY`: experimental assays
`ROLES`: the role of entities with regard to the causal hypotheses tested in the reported results. The tags are:
- `CONTROLLED_VAR`: entities that are associated with experimental variables and that subjected to controlled and targeted perturbations.
- `MEASURED_VAR`: entities that are associated with the variables measured and the object of the measurements.
In the case of experimental roles, it is generated separatedly for `GENEPROD` and `SMALL_MOL` and there is also the `ROLES_MULTI`
that takes both at the same time.
### Languages
The text in the dataset is English.
## Dataset Structure
### Data Instances
### Data Fields
- `words`: `list` of `strings` text tokenized into words.
- `panel_id`: ID of the panel to which the example belongs to in the SourceData database.
- `label_ids`:
- `entity_types`: `list` of `strings` for the IOB2 tags for entity type; possible value in `["O", "I-SMALL_MOLECULE", "B-SMALL_MOLECULE", "I-GENEPROD", "B-GENEPROD", "I-SUBCELLULAR", "B-SUBCELLULAR", "I-CELL_LINE", "B-CELL_LINE", "I-CELL_TYPE", "B-CELL_TYPE", "I-TISSUE", "B-TISSUE", "I-ORGANISM", "B-ORGANISM", "I-EXP_ASSAY", "B-EXP_ASSAY"]`
- `roles`: `list` of `strings` for the IOB2 tags for experimental roles; values in `["O", "I-CONTROLLED_VAR", "B-CONTROLLED_VAR", "I-MEASURED_VAR", "B-MEASURED_VAR"]`
- `panel_start`: `list` of `strings` for IOB2 tags `["O", "B-PANEL_START"]`
- `multi roles`: There are two different label sets. `labels` is like in `roles`. `is_category` tags `GENEPROD` and `SMALL_MOLECULE`.
### Data Splits
* NER and ROLES
```
DatasetDict({
train: Dataset({
features: ['words', 'labels', 'tag_mask', 'text'],
num_rows: 55250
})
test: Dataset({
features: ['words', 'labels', 'tag_mask', 'text'],
num_rows: 6844
})
validation: Dataset({
features: ['words', 'labels', 'tag_mask', 'text'],
num_rows: 7951
})
})
```
* PANELIZATION
```
DatasetDict({
train: Dataset({
features: ['words', 'labels', 'tag_mask'],
num_rows: 14655
})
test: Dataset({
features: ['words', 'labels', 'tag_mask'],
num_rows: 1871
})
validation: Dataset({
features: ['words', 'labels', 'tag_mask'],
num_rows: 2088
})
})
```
## Dataset Creation
### Curation Rationale
The dataset was built to train models for the automatic extraction of a knowledge graph based from the scientific literature. The dataset can be used to train models for text segmentation, named entity recognition and semantic role labeling.
### Source Data
#### Initial Data Collection and Normalization
Figure legends were annotated according to the SourceData framework described in Liechti et al 2017 (Nature Methods, 2017, https://doi.org/10.1038/nmeth.4471). The curation tool at https://curation.sourcedata.io was used to segment figure legends into panel legends, tag enities, assign experiemental roles and normalize with standard identifiers (not available in this dataset). The source data was downloaded from the SourceData API (https://api.sourcedata.io) on 21 Jan 2021.
#### Who are the source language producers?
The examples are extracted from the figure legends from scientific papers in cell and molecular biology.
### Annotations
#### Annotation process
The annotations were produced manually with expert curators from the SourceData project (https://sourcedata.embo.org)
#### Who are the annotators?
Curators of the SourceData project.
### Personal and Sensitive Information
None known.
## Considerations for Using the Data
### Social Impact of Dataset
Not applicable.
### Discussion of Biases
The examples are heavily biased towards cell and molecular biology and are enriched in examples from papers published in EMBO Press journals (https://embopress.org)
The annotation of diseases has been added recently to the dataset. Although they appear, the number is very low and they are not consistently tagged through the entire dataset.
We recommend to use the diseases by filtering the examples that contain them.
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Thomas Lemberger, EMBO.
Jorge Abreu Vicente, EMBO
### Licensing Information
CC BY 4.0
### Citation Information
We are currently working on a paper to present the dataset. It is expected to be ready by 2023 spring. In the meantime, the following paper should be cited.
```latex
@article {Liechti2017,
author = {Liechti, Robin and George, Nancy and Götz, Lou and El-Gebali, Sara and Chasapi, Anastasia and Crespo, Isaac and Xenarios, Ioannis and Lemberger, Thomas},
title = {SourceData - a semantic platform for curating and searching figures},
year = {2017},
volume = {14},
number = {11},
doi = {10.1038/nmeth.4471},
URL = {https://doi.org/10.1038/nmeth.4471},
eprint = {https://www.biorxiv.org/content/early/2016/06/20/058529.full.pdf},
journal = {Nature Methods}
}
```
### Contributions
Thanks to [@tlemberger](https://github.com/tlemberger>) and [@drAbreu](https://github.com/drAbreu>) for adding this dataset.
## Changelog
* **v2.0.3** - Data curated until 20.09.2023. Correction of 2,000+ unnormalized cell entities that have been now divided into cell line and cell type. Specially relevant for NER, not that important for NEL.
* **v2.0.2** - Data curated until 20.09.2023. This version will also include the patch for milti-word generic terms.
* **v1.0.2** - Modification of the generic patch in v1.0.1 to include generic terms of more than a word.
* **v1.0.1** - Added a first patch of generic terms. Terms such as cells, fluorescence, or animals where originally tagged, but in this version they are removed.
* **v1.0.0** - First publicly available version of the dataset. Data curated until March 2023.
|
EMBO/SourceData
|
[
"task_categories:token-classification",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"biology",
"medical",
"NER",
"NEL",
"arxiv:2310.20440",
"doi:10.57967/hf/0495",
"region:us"
] |
2023-03-27T10:19:24+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["token-classification"], "pretty_name": "SODA-NLP", "tags": ["biology", "medical", "NER", "NEL"]}
|
2023-11-22T20:11:49+00:00
|
5851ae43677d73ad00af3f2ab117b8bf3bb51cca
|
# Dataset Card for StaQC (A Systematically Mined Question-Code Dataset from Stack Overflow)
## Dataset Description
- **Homepage: [GitHub](https://github.com/LittleYUYU/StackOverflow-Question-Code-Dataset)**
- **Paper: [StaQC: A Systematically Mined Question-Code Dataset from Stack Overflow](https://arxiv.org/abs/1803.09371)**
### Dataset Summary
StaQC (Stack Overflow Question-Code pairs) is a large dataset of around 148K Python and 120K SQL domain question-code pairs,
which are automatically mined from Stack Overflow using a Bi-View Hierarchical Neural Network. StaQC is collected from three sources: multi-code answer posts, single-code answer posts, and manual annotations on multi-code answer posts.
The dataset was originally released by the main authors on [GitHub](https://github.com/LittleYUYU/StackOverflow-Question-Code-Dataset). This version is a *non-modified* redistributed copy (under the [license](#licensing-information) permission) made available on the hub for easier access.
#### Standalone solutions
As noted in the paper, the authors *define a code snippet as a code solution when the
questioner can solve the problem solely based on it (also named as
“standalone” solution).*
#### Manual annotations
The manual annotations are the collection of multi-code answer posts for which each code snippet was annotated with a boolean indicating whether or not the snippet is a *standalone solution* to the question.
#### Multi-code answer posts
A *Multi-code answer post* is an (accepted) answer post that contains multiple code snippets,
some of which may not be a *standalone* code solution to the question (see Section 1 in [paper](http://web.cse.ohio-state.edu/~sun.397/docs/StaQC-www18.pdf)).
For example, in [this multi-code answer post](https://stackoverflow.com/a/5996949),
the third code snippet is not a code solution to the question "How to limit a number to be within a specified range? (Python)".
Note: the multi-code answer posts contain also the manual annotations.
#### Single-code answer posts
A *Single-code answer post* is an (accepted) answer post that contains only one code snippet.
We pair such code snippets with the question title as a question-code pair.
### Supported Tasks and Leaderboards
This dataset can be used for Natural Language to Code Generation tasks.
### Languages
Python, SQL, English
## Dataset Structure
### Data Instances
Each configuration correspond to one of the three parts, in a given programming language.
There are three parts for the dataset:
- mca (Multi-code answer posts)
- sca (Single-code answer posts)
- man (Manual annotations)
And two programming/query languages:
- python
- sql
One can obtain obtain a configuration as a combination of a part in a programing language. For instance, one can obtain the automatically mined multi-code answers in python using:
```python
dataset = load_dataset("koutch/staqc", 'mca_python')
DatasetDict({
train: Dataset({
features: ['id', 'question_id', 'question', 'snippet'],
num_rows: 40391
})
})
```
or the manual annotations using:
```python
dataset = load_dataset("koutch/staqc", 'man_sql')
DatasetDict({
train: Dataset({
features: ['id', 'question_id', 'question', 'snippet'],
num_rows: 1587
})
})
```
#### Manual annotations
The manual annotations contain, for a given stackoverflow questions, for each individual code block in the accepted answer of that post, information on whether or not the given code block is a *standalone* solution to the question asked (the question title).
```
{
'question_id': 5947137,
'question': 'How can I use a list comprehension to extend a list in python?',
'snippet': {'text': ['import itertools as it\n\nreturn sum(it.imap(doSomething, originalList), [])\n',
'return sum(map(doSomething, originalList), [])\n',
'return sum((doSomething(x) for x in originalList), [])\n',
'accumulationList = []\nfor x in originalList:\n accumulationList.extend(doSomething(x))\nreturn accumulationList\n'],
'is_sda': [True, True, True, True]}
}
```
#### Multi-code answer posts
```
{
'question_id': 35349290,
'question': 'Python: Generating YYMM string between two dates',
'snippet': ['start_year = 2005\nend_year = 2007\nstart_month = 3\nend_month = 2\nyymm = [(yy, mm) for yy in range(start_year, end_year + 1) for mm in range(1, 13)\n if (start_year, start_month) <= (yy, mm) <= (end_year, end_month)]\n',
"formatted_yymm = ['{:>02}{:>02}.mat'.format(yy % 100, mm) for yy, mm in yymm]\n"]
}
```
#### Single-code answer posts
```
{
'question_id': 19387200,
'question': 'Python: get OS language',
'snippet': "import locale\nloc = locale.getlocale() # get current locale\nlocale.getdefaultlocale() # Tries to determine the default locale settings and returns them as a tuple of the form (language code, encoding); e.g, ('en_US', 'UTF-8').\n"
}
```
### Data Fields
- `question_id`: id of the stackoverflow question
- `question`: title of the stackoverflow question repurposed as the natural language intent
- `snippet`: mined or annotated standalone solution(s) (potentially) answerring the question
- `is_sda`: for the manual annotations, whether or not the given code snippet is a standalone solution to the question.
### Data Splits
Each configuration of the dataset contains only a training split.
## Dataset Creation
### Source Data
StackOverflow data dump.
### Annotations
See section 2.3 "Annotating QC Pairs for Model Training" of the [paper](https://arxiv.org/abs/1803.09371)
## Additional Information
### Licensing Information
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a><br />This work is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>.
### Citation Information
If you use the dataset or the code in your research, please cite the following paper:
```
@inproceedings{yao2018staqc,
title={StaQC: A Systematically Mined Question-Code Dataset from Stack Overflow},
author={Yao, Ziyu and Weld, Daniel S and Chen, Wei-Peng and Sun, Huan},
booktitle={Proceedings of the 2018 World Wide Web Conference on World Wide Web},
pages={1693--1703},
year={2018},
organization={International World Wide Web Conferences Steering Committee}
}
```
### Contributions information
I did *not* contribute to the *creation* of this dataset, only to the redistribution. All credits should be attributed to the original authors.
|
koutch/staqc
|
[
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"code",
"arxiv:1803.09371",
"region:us"
] |
2023-03-27T10:43:26+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["question-answering"], "pretty_name": "staqc", "dataset_info": [{"config_name": "mca_python", "features": [{"name": "id", "dtype": "int32"}, {"name": "question_id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "snippet", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 23286786, "num_examples": 40391}], "download_size": 72054260, "dataset_size": 23286786}, {"config_name": "mca_sql", "features": [{"name": "id", "dtype": "int32"}, {"name": "question_id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "snippet", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 15164206, "num_examples": 26052}], "download_size": 50304531, "dataset_size": 15164206}, {"config_name": "sca_python", "features": [{"name": "id", "dtype": "int32"}, {"name": "question_id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "snippet", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 39678168, "num_examples": 85294}], "download_size": 47378850, "dataset_size": 39678168}, {"config_name": "sca_sql", "features": [{"name": "id", "dtype": "int32"}, {"name": "question_id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "snippet", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 28656467, "num_examples": 75637}], "download_size": 34194025, "dataset_size": 28656467}, {"config_name": "man_python", "features": [{"name": "id", "dtype": "int32"}, {"name": "question_id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "snippet", "sequence": [{"name": "text", "dtype": "string"}, {"name": "is_sda", "dtype": "bool"}]}], "splits": [{"name": "train", "num_bytes": 1445103, "num_examples": 2052}], "download_size": 71250225, "dataset_size": 1445103}, {"config_name": "man_sql", "features": [{"name": "id", "dtype": "int32"}, {"name": "question_id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "snippet", "sequence": [{"name": "text", "dtype": "string"}, {"name": "is_sda", "dtype": "bool"}]}], "splits": [{"name": "train", "num_bytes": 1123721, "num_examples": 1587}], "download_size": 49745860, "dataset_size": 1123721}], "tags": ["code"]}
|
2023-03-27T13:53:22+00:00
|
24e59c96346b8ce38ec6ca1508d8de53b2a54f60
|
albertvillanova/tmp-mse
|
[
"region:us"
] |
2023-03-27T11:11:39+00:00
|
{"dataset_info": [{"config_name": "default", "features": [{"name": "id", "dtype": "string"}, {"name": "asked_at", "dtype": "timestamp[s]"}, {"name": "author_name", "dtype": "string"}, {"name": "author_rep", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "title", "dtype": "string"}, {"name": "tags", "sequence": "string"}, {"name": "body", "dtype": "string"}, {"name": "answers", "list": [{"name": "id", "dtype": "string"}, {"name": "body", "dtype": "string"}, {"name": "score", "dtype": "string"}, {"name": "ts", "dtype": "timestamp[s]"}, {"name": "author", "dtype": "string"}, {"name": "author_rep", "dtype": "null"}, {"name": "accepted", "dtype": "bool"}, {"name": "comments", "sequence": "null"}]}, {"name": "comments", "list": [{"name": "id", "dtype": "string"}, {"name": "body", "dtype": "string"}, {"name": "at", "dtype": "timestamp[s]"}, {"name": "score", "dtype": "string"}, {"name": "author", "dtype": "string"}, {"name": "author_rep", "dtype": "int64"}]}]}]}
|
2023-03-27T11:25:15+00:00
|
|
a48ac80d7612bf157989e0549e117bb7b5794c2a
|
# Dataset Card for "shoes_aice"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ttoavina/shoes_aice
|
[
"region:us"
] |
2023-03-27T11:12:26+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 18833548.0, "num_examples": 5000}], "download_size": 15980996, "dataset_size": 18833548.0}}
|
2023-03-27T11:12:38+00:00
|
0ad96974327d7ba746fc96aa1c8503967f1971bf
|
# Dataset Card for "cleaned_deduplicated_oscar"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ClementRomac/cleaned_deduplicated_oscar
|
[
"region:us"
] |
2023-03-27T11:42:39+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 978937483730, "num_examples": 232133013}, {"name": "test", "num_bytes": 59798696914, "num_examples": 12329126}], "download_size": 37220219718, "dataset_size": 1038736180644}}
|
2023-10-25T13:05:19+00:00
|
a86dfd9286a30081e362683f266d24a9803fa3f2
|
HEROBRINE7GAMER/test
|
[
"license:gpl-3.0",
"region:us"
] |
2023-03-27T12:01:11+00:00
|
{"license": "gpl-3.0"}
|
2023-03-27T12:02:11+00:00
|
|
0dcab5e001dc98eca94463ffc585afc3dc170c5d
|
Denliner/LoRA
|
[
"license:openrail",
"region:us"
] |
2023-03-27T12:01:14+00:00
|
{"license": "openrail"}
|
2023-05-01T18:29:03+00:00
|
|
b2f85348e5bbc25ddac9f55234f1f2c139d98fde
|
martingrzzler/mnemonics_benchmark
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"language learning",
"keyword mnemonics",
"region:us"
] |
2023-03-27T12:30:14+00:00
|
{"language": ["en"], "size_categories": ["n<1K"], "task_categories": ["text-classification"], "tags": ["language learning", "keyword mnemonics"]}
|
2023-03-27T13:37:14+00:00
|
|
bb0e36377c0877c6992f2f29eab3b21193e7f0e4
|
# Dataset Card for "rmarkdown_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/rmarkdown_checks
|
[
"region:us"
] |
2023-03-27T12:41:34+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 113015277.61771259, "num_examples": 3493}], "download_size": 62607907, "dataset_size": 113015277.61771259}}
|
2023-03-27T12:41:43+00:00
|
8b8eaca809cd6676a73297327b5410b768562df9
|
# Dataset Card for "clojure_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/clojure_checks
|
[
"region:us"
] |
2023-03-27T12:41:50+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 158919605.17633805, "num_examples": 14174}], "download_size": 152797407, "dataset_size": 158919605.17633805}}
|
2023-03-27T12:42:07+00:00
|
7aa29e9f3e6cc3a73d973e26854452dea80d910e
|
# Dataset Card for "emacs-lisp_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/emacs-lisp_checks
|
[
"region:us"
] |
2023-03-27T12:48:57+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 449327198.32550436, "num_examples": 19261}], "download_size": 384578487, "dataset_size": 449327198.32550436}}
|
2023-03-27T12:49:33+00:00
|
77fea080376c65c73e6b7d90fc00545b9c8fbdfb
|
# Dataset Card for "common-lisp_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/common-lisp_checks
|
[
"region:us"
] |
2023-03-27T12:49:03+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1335613357.8516302, "num_examples": 31455}], "download_size": 418687191, "dataset_size": 1335613357.8516302}}
|
2023-03-27T12:49:47+00:00
|
617c8da1117b6bc655d92cbdd482c3a36c11cb78
|
# Dataset Card for "mathematica_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/mathematica_checks
|
[
"region:us"
] |
2023-03-27T12:49:09+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 900191188.2540944, "num_examples": 5440}], "download_size": 1546159637, "dataset_size": 900191188.2540944}}
|
2023-03-27T12:51:11+00:00
|
3704070077f612ba5a91ebfa8f89823651b37b64
|
# Dataset Card for "coffeescript_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/coffeescript_checks
|
[
"region:us"
] |
2023-03-27T12:49:12+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 202822078.3919738, "num_examples": 23874}], "download_size": 202150872, "dataset_size": 202822078.3919738}}
|
2023-03-27T12:49:34+00:00
|
0b0475dd89fb3bd8a44828a0f0fcb2e6a5942d69
|
# Dataset Card for "makefile_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/makefile_checks
|
[
"region:us"
] |
2023-03-27T12:49:55+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 332308322.1515968, "num_examples": 57421}], "download_size": 271711545, "dataset_size": 332308322.1515968}}
|
2023-03-27T12:50:26+00:00
|
57bd98b4c041c65d61ea61a61b319d3064cf3d77
|
# Dataset Card for "dockerfile_checks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/dockerfile_checks
|
[
"region:us"
] |
2023-03-27T12:49:55+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float32"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 304825212.1287143, "num_examples": 137651}], "download_size": 265293128, "dataset_size": 304825212.1287143}}
|
2023-03-27T12:50:33+00:00
|
2252ec8b45a3be686d28e1b91ebec886015ad610
|
* The objective of this work is to construct a method for analyzing waveforms of signals obtained during microseismic monitoring using a neural network in order to localize the coordinates of the sources of seismic events, and their differentiation.
* Microseismic monitoring is one of the existing methods of analyzing the condition of the studied geophysical object: mineral deposits, large-scale industrial facilities, etc. It includes a system of sensors that detect weak seismic or acoustic signals, a data collection system and algorithms for their processing. The main task of monitoring is to determine the characteristics of a microseismic event: the time of the first entry, magnitude, and its location in space.
* This dataset contains synthetic waveforms to form a training and validation samples. The advantage ofusing synthetic data is that for it, all the necessary parameters of each seismic event are known in advance (time of entry, coordinates of the source, magnitude, parameters of the source mechanism, velocity model of the medium). This makes it possible to create and train models based on data generated taking into account the features characteristic of a given monitoring area, while the resulting models may have a greater generalizing ability than those trained on real waveforms. In addition, this approach, unlike using banks of real waveforms to train the model, eliminates the possibility of distortion of the results associated with the use of manual data markup. The main disadvantage of using synthetic data for training models is the need to adapt the resulting models to real data.
The synthetic waveforms used in this work were created using Pyrocko, an open–source set of libraries for seismological modeling [Heimann et al., 2018]. The propagation of seismic waves was modeled for an elastically viscous layered medium. The velocity model of the medium was taken from [Málek, Horálek, Janský, 2005]. The choice was determined by the freely available pre-calculated bank of Green's functions necessary to obtain waveforms. The sources of seismic signals were modeled by a double pair of forces with a random distribution of displacement directions (strike, deep, rake) and magnitudes uniformly distributed within the specified boundaries (0-2). The epicenters and depths of the sources were randomly set inside an area with a radius of 1.5 km and a depth of 1000 meters. Waveforms (displacement) were obtained for five stations (four symmetrically located at a distance of 500 meters from the origin, and one in the center) for three channels (two horizontal N, E and vertical Z) with a sampling frequency of 100 Hz, the length of each recording is 4 seconds. A priori moments of arrival of p and s waves were obtained for each waveform. As a result of the simulation, training and test samples were formed from 106 and 103 events, respectively (15 waveforms in each).
|
mexalon/Synth_Seism
|
[
"task_categories:feature-extraction",
"size_categories:100K<n<1M",
"region:us"
] |
2023-03-27T13:20:42+00:00
|
{"size_categories": ["100K<n<1M"], "task_categories": ["feature-extraction"]}
|
2023-11-01T09:41:11+00:00
|
89eda23fddc0135007aad37b769bf32333b3c2cb
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
eduardosanchez/wmt22
|
[
"task_categories:translation",
"size_categories:n<1K",
"language:liv",
"language:en",
"region:us"
] |
2023-03-27T13:26:59+00:00
|
{"language": ["liv", "en"], "size_categories": ["n<1K"], "task_categories": ["translation"]}
|
2023-03-27T13:30:12+00:00
|
b706d6d2040ab0c76a86c96c05f3d7f295da1538
|
# Dataset Card for "pii_checks_data_elm"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
loubnabnl/pii_checks_data_elm
|
[
"region:us"
] |
2023-03-27T14:46:45+00:00
|
{"dataset_info": {"features": [{"name": "entities", "list": [{"name": "context", "dtype": "string"}, {"name": "end", "dtype": "int64"}, {"name": "score", "dtype": "float64"}, {"name": "start", "dtype": "int64"}, {"name": "tag", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "max_stars_repo_path", "dtype": "string"}, {"name": "max_stars_repo_name", "dtype": "string"}, {"name": "max_stars_count", "dtype": "int64"}, {"name": "content", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "new_content", "dtype": "string"}, {"name": "modified", "dtype": "bool"}, {"name": "references", "dtype": "string"}, {"name": "language", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 37294354, "num_examples": 1000}], "download_size": 13081864, "dataset_size": 37294354}}
|
2023-03-27T14:46:49+00:00
|
f52b066c8d0970e99e69942f25a1221fc36fca11
|
# Dataset Card for "simple_arch_1400"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ossaili/simple_arch_1400
|
[
"region:us"
] |
2023-03-27T14:52:24+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 452101969.2, "num_examples": 1400}], "download_size": 473418121, "dataset_size": 452101969.2}}
|
2023-03-27T14:59:55+00:00
|
80a1d10616b34eba7acd148bd22d31647d67bd7d
|
# Dataset Card for "StanfordCars_test_google_flan_t5_xl_mode_C_A_T_ns_8041"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/StanfordCars_test_google_flan_t5_xl_mode_C_A_T_ns_8041
|
[
"region:us"
] |
2023-03-27T14:54:05+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0_clip_tags_ViT_L_14_LLM_Description_gpt3_downstream_tasks_visual_genome_ViT_L_14_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 3521193, "num_examples": 8041}, {"name": "fewshot_1_clip_tags_ViT_L_14_LLM_Description_gpt3_downstream_tasks_visual_genome_ViT_L_14_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 6704901, "num_examples": 8041}], "download_size": 2725683, "dataset_size": 10226094}}
|
2023-03-27T15:55:00+00:00
|
5c74d9c6195880eb05ea5ad27098424708c1a639
|
# AutoTrain Dataset for project: tableros_factibilidad
## Dataset Description
This dataset has been automatically processed by AutoTrain for project tableros_factibilidad.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<217x409 RGB PIL image>",
"target": 1
},
{
"image": "<311x574 RGB PIL image>",
"target": 2
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['sin adecuaciones', 'tablero', 'tablero 2 medidores', 'tablero varios medidores'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 13 |
| valid | 5 |
|
SebasV/autotrain-data-tableros_factibilidad
|
[
"task_categories:image-classification",
"region:us"
] |
2023-03-27T15:25:26+00:00
|
{"task_categories": ["image-classification"]}
|
2023-03-27T15:28:56+00:00
|
2455cad551767fd43b27e4fe499b95b76d87f115
|
# Dataset Card for "test-image"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
lhoestq/test-image
|
[
"region:us"
] |
2023-03-27T15:34:05+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 173136.0, "num_examples": 1}], "download_size": 174237, "dataset_size": 173136.0}}
|
2023-03-27T15:34:28+00:00
|
8555cd118e88c89a4eb3a5cfd4ab9f29f7dae3c1
|
# Dataset Card for "test-image-list"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
lhoestq/test-image-list
|
[
"region:us"
] |
2023-03-27T15:34:58+00:00
|
{"dataset_info": {"features": [{"name": "image", "list": "image"}], "splits": [{"name": "train", "num_bytes": 346275.0, "num_examples": 1}], "download_size": 174383, "dataset_size": 346275.0}}
|
2023-03-27T15:35:34+00:00
|
da57e995e1e056d6b1a87453dd3cc5e7619d2bbe
|
# Dataset Card for "test-image-nested"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
lhoestq/test-image-nested
|
[
"region:us"
] |
2023-03-27T15:36:17+00:00
|
{"dataset_info": {"features": [{"name": "image", "struct": [{"name": "nested", "list": "image"}]}], "splits": [{"name": "train", "num_bytes": 346275.0, "num_examples": 1}], "download_size": 174512, "dataset_size": 346275.0}}
|
2023-03-27T15:36:23+00:00
|
386b04307706ed61f50beea955ac34515c751faf
|
# Dataset Card for "somos-clean-alpaca-es-validations"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
dariolopez/somos-clean-alpaca-es-validations
|
[
"region:us"
] |
2023-03-27T16:15:13+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "null"}, {"name": "inputs", "struct": [{"name": "1-instruction", "dtype": "string"}, {"name": "2-input", "dtype": "string"}, {"name": "3-output", "dtype": "string"}]}, {"name": "prediction", "dtype": "null"}, {"name": "prediction_agent", "dtype": "null"}, {"name": "annotation", "dtype": "string"}, {"name": "annotation_agent", "dtype": "string"}, {"name": "vectors", "struct": [{"name": "input", "sequence": "float64"}, {"name": "instruction", "sequence": "float64"}, {"name": "output", "sequence": "float64"}]}, {"name": "multi_label", "dtype": "bool"}, {"name": "explanation", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "metadata", "dtype": "null"}, {"name": "status", "dtype": "string"}, {"name": "event_timestamp", "dtype": "timestamp[us]"}, {"name": "metrics", "struct": [{"name": "text_length", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 131073, "num_examples": 7}], "download_size": 0, "dataset_size": 131073}}
|
2023-05-04T12:41:07+00:00
|
a7224295466d2370359bc31ebb7b9e185c3eacfc
|
# Dataset
## Topic-independent split
Topics are randomly selected in datasets. For a common purpose, we suggest THESE DATASETS.
* test_random.json
* training_random.json
* validation_random.json
# GitHub
* https://github.com/declare-lab/WikiDes/
# Citation
## APA
Ta, H. T., Rahman, A. B. S., Majumder, N., Hussain, A., Najjar, L., Howard, N., ... & Gelbukh, A. (2022). WikiDes: A Wikipedia-based dataset for generating short descriptions from paragraphs. *Information Fusion*.
## BibTeX
```
@article{Ta_2022,
doi = {10.1016/j.inffus.2022.09.022},
url = {https://doi.org/10.1016%2Fj.inffus.2022.09.022},
year = 2022,
month = {sep},
publisher = {Elsevier {BV}},
author = {Hoang Thang Ta and Abu Bakar Siddiqur Rahman and Navonil Majumder and Amir Hussain and Lotfollah Najjar and Newton Howard and Soujanya Poria and Alexander Gelbukh},
title = {{WikiDes}: A Wikipedia-based dataset for generating short descriptions from paragraphs},
journal = {Information Fusion}}
```
# Paper links
* https://doi.org/10.1016%2Fj.inffus.2022.09.022
* https://arxiv.org/abs/2209.13101
# Contact
Hoang Thang Ta, [email protected]
|
Thang/wikides
|
[
"license:cc-by-sa-4.0",
"arxiv:2209.13101",
"doi:10.57967/hf/0480",
"region:us"
] |
2023-03-27T16:19:44+00:00
|
{"license": "cc-by-sa-4.0"}
|
2023-05-16T06:44:14+00:00
|
d196005ec587b9654ea544b9553b2a142d67165f
|
# Dataset Card for "UA_speech_noisereduced_test-0.7_train-0.3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AravindVadlapudi02/UA_speech_noisereduced_test-0.7_train-0.3
|
[
"region:us"
] |
2023-03-27T16:30:06+00:00
|
{"dataset_info": {"features": [{"name": "label", "dtype": {"class_label": {"names": {"0": "healthy control", "1": "pathology"}}}}, {"name": "input_features", "sequence": {"sequence": "float32"}}], "splits": [{"name": "train", "num_bytes": 1609516432, "num_examples": 1676}, {"name": "test", "num_bytes": 3757779116, "num_examples": 3913}], "download_size": 619867591, "dataset_size": 5367295548}}
|
2023-03-27T16:31:15+00:00
|
0da3e6ad01ea5e419bcce7a355c2f11b8dfea063
|
HEROBRINE7GAMER/my-dataset
|
[
"license:gpl-3.0",
"region:us"
] |
2023-03-27T16:38:09+00:00
|
{"license": "gpl-3.0"}
|
2023-03-27T16:45:59+00:00
|
|
fe036f735ed32e5b763472f093e934207e88328c
|
Radar captures of indoor environments
|
qlairvoyance/indoor_radar
|
[
"task_categories:object-detection",
"task_categories:image-segmentation",
"size_categories:10K<n<100K",
"region:us"
] |
2023-03-27T16:57:03+00:00
|
{"size_categories": ["10K<n<100K"], "task_categories": ["object-detection", "image-segmentation"]}
|
2023-03-27T16:58:00+00:00
|
16ffc5a88fb197b99495e9d3f73781dea7674d7e
|
# Dataset Card for "flores200_eng_input_scaffolding_mix2_mt5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
hlillemark/flores200_eng_input_scaffolding_mix2_mt5
|
[
"region:us"
] |
2023-03-27T16:57:52+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 8041305043, "num_examples": 10240000}, {"name": "val", "num_bytes": 3827042, "num_examples": 5000}, {"name": "test", "num_bytes": 7670994, "num_examples": 10000}], "download_size": 3959567422, "dataset_size": 8052803079}}
|
2023-03-27T17:07:06+00:00
|
da0eaaa5319a11c118d5624e5c955cee90e36788
|
# Dataset Card for "flores200_eng_input_scaffolding_mix3_mt5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
hlillemark/flores200_eng_input_scaffolding_mix3_mt5
|
[
"region:us"
] |
2023-03-27T17:25:23+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 9290803477, "num_examples": 10240000}, {"name": "val", "num_bytes": 3827042, "num_examples": 5000}, {"name": "test", "num_bytes": 7670994, "num_examples": 10000}], "download_size": 4445111273, "dataset_size": 9302301513}}
|
2023-03-27T17:35:32+00:00
|
259fdf5e66dbe8da75f6697fd7d417e8b9ba4dea
|
vietgpt/alpaca_vi
|
[
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:vi",
"SFT",
"region:us"
] |
2023-03-27T17:32:58+00:00
|
{"language": ["vi"], "size_categories": ["10K<n<100K"], "task_categories": ["text-generation"], "dataset_info": {"features": [{"name": "messages", "list": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 26909147, "num_examples": 51548}], "download_size": 13361628, "dataset_size": 26909147}, "tags": ["SFT"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-03T21:23:33+00:00
|
|
1570c3c9d8147467a85cc86c0be6a60930f0044b
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:** https://rucola-benchmark.com
- **Repository:** https://github.com/RussianNLP/RuCoLA
- **Paper:** https://aclanthology.org/2022.emnlp-main.348/
- **ArXiv:** https://arxiv.org/abs/2210.12814
- **Leaderboard:** https://rucola-benchmark.com/leaderboard
- **Point of Contact:** [email protected]
- **Language:** Russian
### Dataset Summary

Russian Corpus of Linguistic Acceptability (RuCoLA) is a novel benchmark of 13.4k sentences labeled as acceptable or not. RuCoLA combines in-domain sentences manually collected from linguistic literature and out-of-domain sentences produced by nine machine translation and paraphrase generation models.
The motivation behind the out-of-domain set is to facilitate the practical use of acceptability judgments for improving language generation.
Each unacceptable sentence is additionally labeled with four standard and machine-specific coarse-grained categories: morphology, syntax, semantics, and hallucinations.
## Dataset Structure
### Supported Tasks and Leaderboards
- **Task:** binary classification.
- **Metrics:** MCC/Acc.
- **Leaderboard:** https://rucola-benchmark.com/leaderboard
### Languages
Russian.
### Data Instances
```
{
"id": 19,
"sentence": "Люк останавливает удачу от этого.",
"label": 0,
"error_type": "Hallucination",
"detailed_source": "WikiMatrix"}
}
```
The example in English for illustration purposes:
```
{
"id": 19,
"sentence": "Luck stops luck from doing this.",
"label": 0,
"error_type": "Hallucination",
"detailed_source": "WikiMatrix"}
}
```
### Data Fields
- ```id (int64)```: the sentence's id.
- ```sentence (str)```: the sentence.
- ```label (str)```: the target class. "1" refers to "acceptable", while "0" corresponds to "unacceptable".
- ```error_type (str)```: the coarse-grained violation category (Morphology, Syntax, Semantics, or Hallucination); "0" if the sentence is acceptable.
- ```detailed_source```: the data source.
### Data Splits
RuCoLA consists of the training, development, and private test sets organised under two subsets: in-domain (linguistic publications) and out-of-domain (texts produced by natural language generation models).
- ```train```: 7869 in-domain samples (```"data/in_domain_train.csv"```).
- ```validation```: 2787 in-domain and out-of-domain samples. The in-domain (```"data/in_domain_dev.csv"```) and out-of-domain (```"data/out_of_domain_dev.csv"```) validation sets are merged into ```"data/dev.csv"``` for convenience.
- ```test```: 2789 in-domain and out-of-domain samples (```"data/test.csv"```).
## Dataset Creation
### Curation Rationale
- **In-domain Subset:** The in-domain sentences and the corresponding authors’ acceptability judgments are *manually* drawn from fundamental linguistic textbooks, academic publications, and methodological materials.
- **Out-of-domain Subset:** The out-of-domain sentences are produced by nine open-source MT and paraphrase generation models.
### Source Data
<details>
<summary>Linguistic publications and resources</summary>
|Original source |Transliterated source |Source id |
|---|---|---|
|[Проект корпусного описания русской грамматики](http://rusgram.ru) | [Proekt korpusnogo opisaniya russkoj grammatiki](http://rusgram.ru/)|Rusgram |
|Тестелец, Я.Г., 2001. *Введение в общий синтаксис*. Федеральное государственное бюджетное образовательное учреждение высшего образования Российский государственный гуманитарный университет.|Yakov Testelets. 2001. Vvedeniye v obschiy sintaksis. Russian State University for the Humanities. |Testelets |
|Лютикова, Е.А., 2010. *К вопросу о категориальном статусе именных групп в русском языке*. Вестник Московского университета. Серия 9. Филология, (6), pp.36-76. |Ekaterina Lutikova. 2010. K voprosu o kategorial’nom statuse imennykh grup v russkom yazyke. Moscow University Philology Bulletin. |Lutikova |
|Митренина, О.В., Романова, Е.Е. and Слюсарь, Н.А., 2017. *Введение в генеративную грамматику*. Общество с ограниченной ответственностью "Книжный дом ЛИБРОКОМ". |Olga Mitrenina et al. 2017. Vvedeniye v generativnuyu grammatiku. Limited Liability Company “LIBROCOM”. |Mitrenina |
|Падучева, Е.В., 2004. *Динамические модели в семантике лексики*. М.: Языки славянской культуры.| Elena Paducheva. 2004. Dinamicheskiye modeli v semantike leksiki. Languages of Slavonic culture. |Paducheva2004 |
|Падучева, Е.В., 2010. *Семантические исследования: Семантика времени и вида в русском языке; Семантика нарратива*. М.: Языки славянской культуры. | Elena Paducheva. 2010. Semanticheskiye issledovaniya: Semantika vremeni i vida v russkom yazyke; Semantika narrativa. Languages of Slavonic culture.|Paducheva2010 |
|Падучева, Е.В., 2013. *Русское отрицательное предложение*. М.: Языки славянской культуры |Elena Paducheva. 2013. Russkoye otritsatel’noye predlozheniye. Languages of Slavonic culture. |Paducheva2013 |
|Селиверстова, О.Н., 2004. *Труды по семантике*. М.: Языки славянской культуры | Olga Seliverstova. 2004. Trudy po semantike. Languages of Slavonic culture.|Seliverstova |
| Набор данных ЕГЭ по русскому языку | Shavrina et al. 2020. [Humans Keep It One Hundred: an Overview of AI Journey](https://aclanthology.org/2020.lrec-1.277/) |USE5, USE7, USE8 |
</details>
<details>
<summary>Machine-generated sentences</summary>
<br>
**Datasets**
|Original source |Source id|
|---|---|
|Mikel Artetxe and Holger Schwenk. 2019. [Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond](https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00288/43523/Massively-Multilingual-Sentence-Embeddings-for)|Tatoeba |
|Holger Schwenk et al. 2021. [WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia](https://aclanthology.org/2021.eacl-main.115/)|WikiMatrix |
|Ye Qi et al. 2018. [When and Why Are Pre-Trained Word Embeddings Useful for Neural Machine Translation?](https://aclanthology.org/N18-2084/)|TED |
|Alexandra Antonova and Alexey Misyurev. 2011. [Building a Web-Based Parallel Corpus and Filtering Out Machine-Translated Text](https://aclanthology.org/W11-1218/)|YandexCorpus |
**Models**
[EasyNMT models](https://github.com/UKPLab/EasyNMT):
1. OPUS-MT. Jörg Tiedemann and Santhosh Thottingal. 2020. [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/)
2. M-BART50. Yuqing Tang et al. 2020. [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401)
3. M2M-100. Angela Fan et al. 2021. [Beyond English-Centric Multilingual Machine Translation](https://jmlr.org/papers/volume22/20-1307/20-1307.pdf)
[Paraphrase generation models](https://github.com/RussianNLP/russian_paraphrasers):
1. [ruGPT2-Large](https://huggingface.co/sberbank-ai/rugpt2large)
2. [ruT5](https://huggingface.co/cointegrated/rut5-base-paraphraser)
3. mT5. Linting Xue et al. 2021. [mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer](https://aclanthology.org/2021.naacl-main.41/)
</details>
### Annotations
#### Annotation process
The out-of-domain sentences undergo a two-stage annotation procedure on [Toloka](https://toloka.ai), a crowd-sourcing platform for data labeling.
Each stage includes an unpaid training phase with explanations, control tasks for tracking annotation quality, and the main annotation task. Before starting, the worker is given detailed instructions describing the task, explaining the labels, and showing plenty of examples.
The instruction is available at any time during both the training and main annotation phases. To get access to the main phase, the worker should first complete the training phase by labeling more than 70% of its examples correctly. Each trained worker receives a page with five sentences, one of which is a control one.
We collect the majority vote labels via a dy- namic overlap from three to five workers after filtering them by response time and performance on control tasks.
- **Stage 1: Acceptability Judgments**
The first annotation stage defines whether a given sentence is acceptable or not. Access to the project is granted to workers certified as native speakers of Russian by Toloka and ranked top-60% workers according to the Toloka rating system.
Each worker answers 30 examples in the training phase. Each training example is accompanied by an explanation that appears in an incorrect answer.
The main annotation phase counts 3.6k machine-generated sentences. The pay rate is on average $2.55/hr, which is twice the amount of the hourly minimum wage in Russia. Each of 1.3k trained workers get paid, but we keep votes from only 960 workers whose annotation quality rate on the control sentences is more than 50%.
- **Stage 2: Violation Categories**
The second stage includes validation and annotation of sentences labeled unacceptable on Stage 1 according to five answer options: “Morphology”, “Syntax”, “Semantics”, “Hallucinations” and “Other”. The task is framed as a multi-label classification, i.e., the sentence may contain more than one violation in some rare cases or be re-labeled as acceptable.
We create a team of 30 annotators who are undergraduate BA and MA in philology and linguistics from several Russian universities. The students are asked to study the works on CoLA, TGEA, and hallucinations. We also hold an online seminar to discuss the works and clarify the task specifics. Each student undergoes platform-based training on 15 examples before moving onto the main phase of 1.3k sentences.
The students are paid on average $5.42/hr and are eligible to get credits for an academic course or an internship. This stage provides direct interaction between authors and students in a group chat. We keep submissions with more than 30 seconds of response time per page and collect the majority vote labels for each answer independently.
Sentences having more than one violation category or labeled as “Other” by the majority are filtered out.
### Personal and Sensitive Information
The annotators are warned about potentially sensitive topics in data (e.g., politics, culture, and religion).
## Considerations for Using the Data
### Social Impact of Dataset
RuCoLA may serve as training data for acceptability classifiers, which may benefit the quality of generated texts.
We recognize that such improvements in text generation may lead to misuse of LMs for malicious purposes. However, our corpus can be used to train adversarial defense and artificial text detection models.
We introduce a novel dataset for **research and development needs**, and the potential negative uses are not lost on us.
### Discussion of Biases
Although we aim to control the number of high-frequency tokens in the RuCoLA’s sentences, we assume that potential word frequency distribution shift between LMs’ pretraining corpora and our corpus can introduce bias in the evaluation.
Furthermore, linguistic publications represent a specific domain as the primary source of acceptability judgments. On the one hand, it can lead to a domain shift when using RuCoLA for practical purposes.
On the other hand, we observe moderate acceptability classification performance on the out-of-domain test, which spans multiple domains, ranging from subtitles to Wikipedia.
### Other Known Limitations
- **Data Collection**
Acceptability judgments datasets require a source of unacceptable sentences.
Collecting judgments from linguistic literature has become a standard practice replicated in multiple languages. However, this approach has several limitations. First, many studies raise concerns about the reliability and reproducibility of acceptability judgments. Second, the linguists’ judgments may limit data representativeness, as they may not reflect the errors that speakers tend to produce. Third, enriching acceptability judgments datasets is time-consuming, while creating new ones can be challenging due to limited resources, e.g., in low-resource languages.
- **Expert vs. Non-expert**
One of the open methodological questions on acceptability judgments is whether they should be collected from expert or non-expert speakers.
On the one hand, prior linguistic knowledge can introduce bias in reporting judgments. On the other hand, expertise may increase the quality of the linguists’ judgments over the ones of non-linguists. At the same time, the latter tend to be influenced by an individual’s exposure to ungrammatical language use.
The objective of involving students with a linguistic background is to maximize the annotation quality.
- **Fine-grained Annotation**
The coarse-grained annotation scheme of the RuCoLA’s unacceptable sentences relies on four major categories. While the annotation can be helpful for model error analysis, it limits the scope of LMs’ diagnostic evaluation concerning linguistic and machine-specific phenomena.
## Additional Information
### Dataset Curators
Correspondence: ```[email protected]```
### Licensing Information
Our baseline code and acceptability labels are available under the Apache 2.0 license. The copyright (where applicable) of texts from the linguistic publications and resources remains with the original authors or publishers.
### Citation Information
```
@inproceedings{mikhailov-etal-2022-rucola,
title = "{R}u{C}o{LA}: {R}ussian Corpus of Linguistic Acceptability",
author = "Mikhailov, Vladislav and
Shamardina, Tatiana and
Ryabinin, Max and
Pestova, Alena and
Smurov, Ivan and
Artemova, Ekaterina",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.348",
pages = "5207--5227",
abstract = "Linguistic acceptability (LA) attracts the attention of the research community due to its many uses, such as testing the grammatical knowledge of language models and filtering implausible texts with acceptability classifiers.However, the application scope of LA in languages other than English is limited due to the lack of high-quality resources.To this end, we introduce the Russian Corpus of Linguistic Acceptability (RuCoLA), built from the ground up under the well-established binary LA approach. RuCoLA consists of 9.8k in-domain sentences from linguistic publications and 3.6k out-of-domain sentences produced by generative models. The out-of-domain set is created to facilitate the practical use of acceptability for improving language generation.Our paper describes the data collection protocol and presents a fine-grained analysis of acceptability classification experiments with a range of baseline approaches.In particular, we demonstrate that the most widely used language models still fall behind humans by a large margin, especially when detecting morphological and semantic errors. We release RuCoLA, the code of experiments, and a public leaderboard to assess the linguistic competence of language models for Russian.",
}
```
### Other
Please refer to our [paper](https://aclanthology.org/2022.emnlp-main.348/) for more details.
|
RussianNLP/rucola
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:ru",
"license:apache-2.0",
"arxiv:2210.12814",
"arxiv:2008.00401",
"region:us"
] |
2023-03-27T17:35:06+00:00
|
{"language": ["ru"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"]}
|
2023-03-27T17:47:12+00:00
|
e22605ec5cdcb3fe539bbb45bdc2291ad5a52a7e
|
# ORB Transformation Applied on diffusiondb Dataset
This dataset consists of images, captions and images that are transformed to extract features using [ORB transform](https://docs.opencv.org/4.x/d1/d89/tutorial_py_orb.html).
You can find the original dataset [here](https://huggingface.co/datasets/poloclub/diffusiondb).
An example sample is below:
Caption: "spider - man, cinematic, photography "
Image: 
Transformation: 
|
jax-diffusers-event/example-dataset
|
[
"region:us"
] |
2023-03-27T17:36:37+00:00
|
{"dataset_info": {"features": [{"name": "original_image", "dtype": "image"}, {"name": "prompt", "dtype": "string"}, {"name": "transformed_image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 1226376776.0, "num_examples": 997}], "download_size": 1222888812, "dataset_size": 1226376776.0}}
|
2023-03-29T09:57:38+00:00
|
64dbd1a935adbcf4f0f8a6d40fbebc4dc19c6c58
|
Vishnu1/fyi
|
[
"license:cc-by-nc-4.0",
"region:us"
] |
2023-03-27T17:41:54+00:00
|
{"license": "cc-by-nc-4.0"}
|
2023-03-27T17:42:42+00:00
|
|
5d1329b68b19a510bb09cc1a10d4722b58f3fba2
|
# Dataset Card for "tokenized_large_corpus_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ZurabDz/tokenized_large_corpus_v2
|
[
"region:us"
] |
2023-03-27T17:49:01+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "token_type_ids", "sequence": "int8"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "special_tokens_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 6701093568, "num_examples": 14442012}], "download_size": 2431678404, "dataset_size": 6701093568}}
|
2023-03-27T18:14:14+00:00
|
357075831a7343a3f11cc92a0a082b52c0ad7bd7
|
# Dataset Card for "Dialogsum-german"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fathyshalab/Dialogsum-german
|
[
"region:us"
] |
2023-03-27T18:40:46+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "dialogue", "dtype": "string"}, {"name": "summary", "dtype": "string"}, {"name": "topic", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12886236, "num_examples": 12460}, {"name": "test", "num_bytes": 1539886, "num_examples": 1500}, {"name": "validation", "num_bytes": 504815, "num_examples": 500}], "download_size": 7946878, "dataset_size": 14930937}}
|
2023-03-27T18:41:04+00:00
|
b25db74879f6117366c0057cee030fe19cc07a7f
|
# Dataset Card for "Dialogsum-german-kurz"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fathyshalab/Dialogsum-german-kurz
|
[
"region:us"
] |
2023-03-27T18:43:48+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "dialogue", "dtype": "string"}, {"name": "summary", "dtype": "string"}, {"name": "topic", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9824979.293739967, "num_examples": 9500}, {"name": "test", "num_bytes": 1539886, "num_examples": 1500}, {"name": "validation", "num_bytes": 504815, "num_examples": 500}], "download_size": 6219922, "dataset_size": 11869680.293739967}}
|
2023-03-27T18:44:06+00:00
|
45593666f74991e17dbc1b2b66cd6c6f53d623c7
|
Chendi/ibm_transactions
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-27T18:57:49+00:00
|
{"license": "apache-2.0"}
|
2023-03-27T18:59:52+00:00
|
|
c74c0a1ffca39cc1ef4939289dc7e18137268a2a
|
nimaster/Devign_for_VD
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"region:us"
] |
2023-03-27T19:02:36+00:00
|
{"size_categories": ["10K<n<100K"], "task_categories": ["text-classification"]}
|
2023-03-27T19:21:00+00:00
|
|
8299ac2331e961452451d08e4055c96b22351e97
|
# Dataset Validated from https://huggingface.co/spaces/dariolopez/argilla-reddit-c-ssrs-suicide-dataset-es
https://huggingface.co/spaces/dariolopez/argilla-reddit-c-ssrs-suicide-dataset-es
|
dariolopez/argilla-reddit-c-ssrs-suicide-dataset-es-old
|
[
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:es",
"region:us"
] |
2023-03-27T19:19:14+00:00
|
{"language": ["es"], "size_categories": ["1K<n<10K"], "task_categories": ["text-classification"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "inputs", "struct": [{"name": "text", "dtype": "string"}]}, {"name": "prediction", "dtype": "null"}, {"name": "prediction_agent", "dtype": "null"}, {"name": "annotation", "dtype": "string"}, {"name": "annotation_agent", "dtype": "string"}, {"name": "vectors", "struct": [{"name": "all-MiniLM-L6-v2", "sequence": "float64"}]}, {"name": "multi_label", "dtype": "bool"}, {"name": "explanation", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "metadata", "dtype": "null"}, {"name": "status", "dtype": "string"}, {"name": "event_timestamp", "dtype": "timestamp[us]"}, {"name": "metrics", "struct": [{"name": "text_length", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 60733, "num_examples": 14}], "download_size": 61140, "dataset_size": 60733}}
|
2023-03-28T21:21:24+00:00
|
e4cd0160f6a759e857d192995f9a4bbdb3060e36
|
abdullahhaider33/fooditems
|
[
"license:unknown",
"region:us"
] |
2023-03-27T19:23:10+00:00
|
{"license": "unknown"}
|
2023-05-20T14:56:22+00:00
|
|
e6a6dbbccf7cad2e057770cae5ebf8257ec36382
|
# Dataset Card for Dataset Name
## Dataset Description
- **Repository:** https://github.com/vladsavelyev/guitart
### Dataset Summary
GuitarPro files with song tablatures, converted into [alphaTex](https://alphatab.net/docs/alphatex/introduction) format using this Python [converter](https://github.com/vladsavelyev/guitartab/blob/main/gp_to_tex.py).
### Supported Tasks and Leaderboards
Supported are NLP tasks, and potentially could be augmented with audio and used to auto-generate tabs from music.
### Source Data
GuitarPro tabs archive.
|
vldsavelyev/guitar_tab
|
[
"task_categories:text-generation",
"size_categories:10K<n<100K",
"music",
"music-notation",
"guitar",
"tablature",
"region:us"
] |
2023-03-27T20:03:23+00:00
|
{"size_categories": ["10K<n<100K"], "task_categories": ["text-generation"], "tags": ["music", "music-notation", "guitar", "tablature"], "dataset_info": [{"config_name": "default", "features": [{"name": "text", "dtype": "string"}, {"name": "file", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 961930414, "num_examples": 47299}], "download_size": 75369951, "dataset_size": 961930414}, {"config_name": "all", "features": [{"name": "file", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "track_name", "dtype": "string"}, {"name": "track_number", "dtype": "int32"}, {"name": "instrument_name", "dtype": "string"}, {"name": "instrument_number", "dtype": "int32"}, {"name": "tempo", "dtype": "int32"}, {"name": "tuning", "dtype": "string"}, {"name": "frets", "dtype": "int32"}], "splits": [{"name": "train", "num_bytes": 951605310, "num_examples": 188297}], "download_size": 75369951, "dataset_size": 951605310}]}
|
2023-04-09T09:45:36+00:00
|
9a067ff2191e090881b807d067a4720a9d90f5bd
|
# Dataset Card for "simple_arch_BLIP_captions"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ossaili/simple_arch_BLIP_captions
|
[
"region:us"
] |
2023-03-27T20:10:56+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 417750052.2, "num_examples": 1400}], "download_size": 383610787, "dataset_size": 417750052.2}}
|
2023-03-27T20:12:38+00:00
|
2bbed3933ae6bcc2dc17291e6401d4d933affe5e
|
kingsley9494/ks
|
[
"license:bigscience-openrail-m",
"region:us"
] |
2023-03-27T20:15:24+00:00
|
{"license": "bigscience-openrail-m"}
|
2023-03-27T20:15:24+00:00
|
|
b1cec4149933b09594c4b7a837e7263942449147
|
# Leyzer: A Dataset for Multilingual Virtual Assistants
Leyzer is a multilingual text corpus designed to study multilingual and cross-lingual natural language understanding (NLU) models and the strategies of localization of
virtual assistants. It consists of 20 domains across three languages: English, Spanish and Polish, with 186 intents and a wide range of samples, ranging from 1 to 672
sentences per intent. For more stats please refer to wiki.
|
cartesinus/leyzer-fedcsis-translated
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:pl",
"license:cc-by-4.0",
"natural-language-understanding",
"region:us"
] |
2023-03-27T20:51:34+00:00
|
{"language": ["pl"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "tags": ["natural-language-understanding"]}
|
2023-03-27T20:52:34+00:00
|
b81defe139dc7767929331e1adf205233f8d409c
|
This dataset splits the original [Self-instruct dataset](https://huggingface.co/datasets/yizhongw/self_instruct) into training (90%) and test (10%).
|
HuggingFaceH4/self_instruct
|
[
"task_categories:text-generation",
"license:apache-2.0",
"region:us"
] |
2023-03-27T20:58:57+00:00
|
{"license": "apache-2.0", "task_categories": ["text-generation"]}
|
2023-03-27T21:03:01+00:00
|
9b3347abf7a91392b61270c7977015b49cd78eb2
|
cloudqi/abreviacoes_e_girias_pt_v0
|
[
"license:c-uda",
"region:us"
] |
2023-03-27T21:14:28+00:00
|
{"license": "c-uda"}
|
2023-03-27T21:14:28+00:00
|
|
dd030425bd308a469dab418ac91e2a40ade54ca9
|
cloudqi/gpt_analise_booleana_pt
|
[
"license:c-uda",
"region:us"
] |
2023-03-27T21:16:16+00:00
|
{"license": "c-uda"}
|
2023-03-27T21:16:16+00:00
|
|
164602cc456281103450cfc477698164218eff46
|
This splits the original [helpful_instructions dataset](https://huggingface.co/datasets/HuggingFaceH4/helpful_instructions/blob/main/create_dataset.py) into train and test splits.
|
HuggingFaceH4/helpful_instructions_splits
|
[
"region:us"
] |
2023-03-27T21:25:51+00:00
|
{}
|
2023-03-27T21:36:16+00:00
|
f4d01d5c02b9a4db238eecfa0728ce443885189c
|
# Dataset Card for "StanfordCars_test_google_flan_t5_xxl_mode_C_A_T_ns_8041"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/StanfordCars_test_google_flan_t5_xxl_mode_C_A_T_ns_8041
|
[
"region:us"
] |
2023-03-27T21:32:49+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0_clip_tags_ViT_L_14_LLM_Description_gpt3_downstream_tasks_visual_genome_ViT_L_14_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 3519798, "num_examples": 8041}, {"name": "fewshot_1_clip_tags_ViT_L_14_LLM_Description_gpt3_downstream_tasks_visual_genome_ViT_L_14_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 6705042, "num_examples": 8041}], "download_size": 2725283, "dataset_size": 10224840}}
|
2023-03-28T17:27:21+00:00
|
804c8a6c74acbe1191e58474d961693bc9efa80a
|
0xaryan/music-classifier
|
[
"size_categories:100M<n<1B",
"region:us"
] |
2023-03-27T21:41:48+00:00
|
{"size_categories": ["100M<n<1B"]}
|
2023-03-27T22:30:02+00:00
|
|
c1017998145e19d43769e2789fffa02db258605a
|
# Dataset Card for [GPT4All Prompt Generations]
## Dataset Description
Dataset used to train [GPT4All](https://huggingface.co/nomic-ai/gpt4all-lora)
- **Homepage:**
- **Repository:** [gpt4all](https://github.com/nomic-ai/gpt4all)
- **Paper:** [Technical Report](https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf)
- **Atlas Map:** [Map of Cleaned Data](https://atlas.nomic.ai/map/gpt4all_data_clean)
|
nomic-ai/gpt4all_prompt_generations
|
[
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-03-27T22:08:01+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["100K<n<1M"], "task_categories": ["text-generation"], "dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "response", "dtype": "string"}, {"name": "source", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 782175193, "num_examples": 437604}], "download_size": 397878357, "dataset_size": 782175193}}
|
2023-04-13T20:42:15+00:00
|
021c28e350f0f0d1d01e8607232782b8660f70ff
|
# Dataset Card for "indian_food_images"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
MohitK/indian_food_images
|
[
"region:us"
] |
2023-03-27T23:42:24+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "burger", "1": "butter_naan", "2": "chai", "3": "chapati", "4": "chole_bhature", "5": "dal_makhani", "6": "dhokla", "7": "fried_rice", "8": "idli", "9": "jalebi", "10": "kaathi_rolls", "11": "kadai_paneer", "12": "kulfi", "13": "masala_dosa", "14": "momos", "15": "paani_puri", "16": "pakode", "17": "pav_bhaji", "18": "pizza", "19": "samosa"}}}}], "splits": [{"name": "train", "num_bytes": 1622005508.6394334, "num_examples": 5328}, {"name": "test", "num_bytes": 251982030.3925666, "num_examples": 941}], "download_size": 1599894487, "dataset_size": 1873987539.032}}
|
2023-03-27T23:52:34+00:00
|
b880553f9584d1c2ccb9a107479684505a23d1cd
|
farrael004/CynicAI
|
[
"license:apache-2.0",
"region:us"
] |
2023-03-28T00:28:45+00:00
|
{"license": "apache-2.0"}
|
2023-03-28T00:49:07+00:00
|
|
27e5db83dc96df3e12700fd1202b0cd72d9c3be5
|
# Dataset Card for "logo-combined-weighted-a"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Babypotatotang/logo-combined-weighted-a
|
[
"region:us"
] |
2023-03-28T00:37:18+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 167421354.253, "num_examples": 12907}, {"name": "test", "num_bytes": 42192314.76, "num_examples": 3232}], "download_size": 209236463, "dataset_size": 209613669.01299998}}
|
2023-03-28T00:42:05+00:00
|
4f80c4fbd47e62268ed900d269aa00f097bf1b7a
|
__The Online Indonesian Learning (OIL) Dataset__
The Online Indonesian Learning (OIL) dataset or corpus currently contains lessons from three Indonesian teachers who have posted content on YouTube.
For further details please see Zara Maxwell-Smith and Ben Foley, (forthcoming), Automated speech recognition of Indonesian-English language lessons on YouTube using transfer learning, Field Matters Workshop, EACL 2023
How to cite this dataset.
Please use the following .bib to reference this work.
```
{@inproceedings{Maxwell-Smith_Foley_2023_Automated,
title={{Automated speech recognition of Indonesian-English language lessons on YouTube using transfer learning}},
author={Maxwell-Smith, Zara and Foley, Ben},
booktitle={Proceedings of the {Second Workshop on NLP Applications to Field Linguistics (EACL)}},
pages={},
year={forthcoming}
}
```
To stream the videos of these teachers please visit:
Indonesian Language for Beginners - https://www.youtube.com/@learningindonesianlanguage3334
5-Minute Indonesian - https://www.youtube.com/@5-minuteindonesian534/featured
Dua Budaya - https://www.youtube.com/@DuaBudaya/about
Copies of some lessons on these channels are available as part of this dataset in mp4 and wav formats.
A select number of lessons have matching ELAN files with human and human/machine generated orthographic transcriptions of the audio, as well 'tiers' with machine inference only.
Detailed information about the audio quality, remarks on background noise, code-switching behaviour and lesson content is available in the paper above.
Almost all videos contain a mix of languages, with some dominated by Indonesian or English.
Some videos explicitly focused on variation in Indonesian or words from other languages which are commonly mixed into Indonesian by speakers.
|
ZMaxwell-Smith/OIL
|
[
"license:cc-by-nc-nd-4.0",
"doi:10.57967/hf/0489",
"region:us"
] |
2023-03-28T00:51:55+00:00
|
{"license": "cc-by-nc-nd-4.0"}
|
2023-03-30T00:40:05+00:00
|
b26f790ab133ef8941f6aa08751b517ecfcfcd53
|
# Dataset Card for "logo-combined-weighted-b"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Babypotatotang/logo-combined-weighted-b
|
[
"region:us"
] |
2023-03-28T00:56:32+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 167147766.253, "num_examples": 12907}, {"name": "test", "num_bytes": 42122543.76, "num_examples": 3232}], "download_size": 209180456, "dataset_size": 209270310.01299998}}
|
2023-03-28T01:03:08+00:00
|
0bfc6eece4c1c532f3e2cec75b6f7161c673232c
|
airt-ml/twitter-human-bots
|
[
"license:cc-by-sa-3.0",
"region:us"
] |
2023-03-28T01:31:03+00:00
|
{"license": "cc-by-sa-3.0"}
|
2023-03-28T01:33:40+00:00
|
|
8a9f7515dbfb22867b00f5e2f2b82790108d4b98
|
# Dataset Card for "emr_info_extract"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
arfu/emr_info_extract
|
[
"region:us"
] |
2023-03-28T01:31:07+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "dialogue", "dtype": "string"}, {"name": "summary", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1842245, "num_examples": 2019}, {"name": "test", "num_bytes": 123971, "num_examples": 120}], "download_size": 440433, "dataset_size": 1966216}}
|
2023-03-28T01:31:14+00:00
|
e1082ae17672a7dbdc40852166fdd4f65e380dd4
|
Edspeedy/spam
|
[
"region:us"
] |
2023-03-28T01:40:02+00:00
|
{}
|
2023-03-28T01:41:16+00:00
|
|
5e66c32b4f0d6c9f8a3ab137282d6734fb25f37d
|
# Dataset Card for AdvertiseGen
- **formal url:** https://www.luge.ai/#/luge/dataDetail?id=9
## Dataset Description
数据集介绍
AdvertiseGen是电商广告文案生成数据集。
AdvertiseGen以商品网页的标签与文案的信息对应关系为基础构造,是典型的开放式生成任务,在模型基于key-value输入生成开放式文案时,与输入信息的事实一致性需要得到重点关注。
- 任务描述:给定商品信息的关键词和属性列表kv-list,生成适合该商品的广告文案adv;
- 数据规模:训练集114k,验证集1k,测试集3k;
- 数据来源:清华大学CoAI小组;
### Supported Tasks and Leaderboards
The dataset designed for generate e-commerce advertise.
### Languages
The data in AdvertiseGen are in Chinese.
## Dataset Structure
### Data Instances
An example of "train" looks as follows:
```json
{
"content": "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞",
"summary": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。"
}
```
### Citation Information
数据集引用
如在学术论文中使用本数据集,请添加相关引用说明,具体如下:
```
Shao, Zhihong, et al. "Long and Diverse Text Generation with Planning-based Hierarchical Variational Model." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
```
|
shibing624/AdvertiseGen
|
[
"task_categories:text-generation",
"language:zh",
"license:cc-by-4.0",
"text-generation",
"e-commerce advertise",
"region:us"
] |
2023-03-28T01:42:56+00:00
|
{"language": ["zh"], "license": "cc-by-4.0", "task_categories": ["text-generation"], "pretty_name": "AdvertiseGen", "tags": ["text-generation", "e-commerce advertise"]}
|
2023-05-12T06:25:00+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.