
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
54b0a72d9bcabc17310bf43692483e0859ae64d6
|
# Dataset Card for "batch_indexing_machine_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Circularmachines/batch_indexing_machine_test
|
[
"region:us"
] |
2023-05-29T16:21:40+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "test", "num_bytes": 88034570.0, "num_examples": 400}], "download_size": 88040937, "dataset_size": 88034570.0}}
|
2023-05-29T16:46:12+00:00
|
1d2165c54a40f2eb86b7b44514d2fc722d41e4b1
|
# Dataset Card for "NSynth_Bass_Captions"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
DaveLoay/NSynth_Bass_Captions
|
[
"region:us"
] |
2023-05-29T16:35:37+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 75191120.0, "num_examples": 843}], "download_size": 0, "dataset_size": 75191120.0}}
|
2023-05-29T16:40:18+00:00
|
756c3d4e45dd0bfa2402fb4dd127258ef9e9524b
|
# Dataset Card for "diffusers-checkpoint-downloads"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
open-source-metrics/diffusers-checkpoint-downloads
|
[
"region:us"
] |
2023-05-29T16:49:57+00:00
|
{"dataset_info": {"features": [{"name": "dates", "dtype": "string"}, {"name": "all", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 24067, "num_examples": 587}], "download_size": 7213, "dataset_size": 24067}}
|
2023-05-29T16:49:59+00:00
|
c306cc76d56fc48905a7f7faaab63b6ab0af84cb
|
ESCx2/Tester
|
[
"language:de",
"license:cc-by-nc-2.0",
"region:us"
] |
2023-05-29T16:55:47+00:00
|
{"language": ["de"], "license": "cc-by-nc-2.0", "pretty_name": "test"}
|
2023-05-29T16:59:29+00:00
|
|
73bc9dd49a93017d3bb0ecbd7a55848737ef3b2d
|
ModernNoob/Deyui_Dataset
|
[
"license:artistic-2.0",
"region:us"
] |
2023-05-29T17:12:13+00:00
|
{"license": "artistic-2.0"}
|
2023-05-29T17:12:13+00:00
|
|
caf3e6947bfe90ffc60f4ef6c67e0ff3f2b45ba2
|
# Dataset Card for "labeled_aesthetics_simpsons"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
megantron/labeled_aesthetics_simpsons
|
[
"region:us"
] |
2023-05-29T17:12:20+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 69240975.0, "num_examples": 178}], "download_size": 69245463, "dataset_size": 69240975.0}}
|
2023-05-29T17:27:01+00:00
|
7a9f05c31596e661ea59c4b4bfa3befb98138a94
|
# Dataset Card for "CIFAR10_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/CIFAR10_train
|
[
"region:us"
] |
2023-05-29T17:28:41+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "airplane", "1": "automobile", "2": "bird", "3": "cat", "4": "deer", "5": "dog", "6": "frog", "7": "horse", "8": "ship", "9": "truck"}}}}, {"name": "id", "dtype": "int64"}, {"name": "clip_tags_LAION_ViT_H_14_2B_simple_specific", "dtype": "string"}, {"name": "clip_tags_LAION_ViT_H_14_2B_ensemble_specific", "dtype": "string"}, {"name": "clip_tags_ViT_L_14_simple_specific", "dtype": "string"}, {"name": "Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full", "sequence": "string"}, {"name": "Attributes_ViT_L_14_descriptors_text_davinci_003_full", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 140322483.0, "num_examples": 50000}], "download_size": 119393875, "dataset_size": 140322483.0}}
|
2023-06-12T04:58:00+00:00
|
1ccf8b62d254b40d8d5c1ef9daf25f30a76ecb4d
|
# Dataset Card for "labeled_aesthetics_simpsons2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
megantron/labeled_aesthetics_simpsons2
|
[
"region:us"
] |
2023-05-29T17:28:50+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 69240975.0, "num_examples": 178}], "download_size": 69245463, "dataset_size": 69240975.0}}
|
2023-05-29T17:30:35+00:00
|
be8b470d791c16dd689d591ba6aec20ace7aa466
|
# Dataset Card for "CIFAR10_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/CIFAR10_test
|
[
"region:us"
] |
2023-05-29T17:28:57+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "airplane", "1": "automobile", "2": "bird", "3": "cat", "4": "deer", "5": "dog", "6": "frog", "7": "horse", "8": "ship", "9": "truck"}}}}, {"name": "id", "dtype": "int64"}, {"name": "clip_tags_LAION_ViT_H_14_2B_simple_specific", "dtype": "string"}, {"name": "clip_tags_LAION_ViT_H_14_2B_ensemble_specific", "dtype": "string"}, {"name": "Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full", "sequence": "string"}, {"name": "Attributes_ViT_L_14_descriptors_text_davinci_003_full", "sequence": "string"}, {"name": "clip_tags_ViT_L_14_simple_specific", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 28072025.0, "num_examples": 10000}], "download_size": 23890989, "dataset_size": 28072025.0}}
|
2023-06-05T02:17:33+00:00
|
306cb3b2ba602f53f28526cd678224293f935be0
|
# Dataset Card for "CIFAR100_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/CIFAR100_train
|
[
"region:us"
] |
2023-05-29T17:30:41+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "apple", "1": "aquarium_fish", "2": "baby", "3": "bear", "4": "beaver", "5": "bed", "6": "bee", "7": "beetle", "8": "bicycle", "9": "bottle", "10": "bowl", "11": "boy", "12": "bridge", "13": "bus", "14": "butterfly", "15": "camel", "16": "can", "17": "castle", "18": "caterpillar", "19": "cattle", "20": "chair", "21": "chimpanzee", "22": "clock", "23": "cloud", "24": "cockroach", "25": "couch", "26": "cra", "27": "crocodile", "28": "cup", "29": "dinosaur", "30": "dolphin", "31": "elephant", "32": "flatfish", "33": "forest", "34": "fox", "35": "girl", "36": "hamster", "37": "house", "38": "kangaroo", "39": "keyboard", "40": "lamp", "41": "lawn_mower", "42": "leopard", "43": "lion", "44": "lizard", "45": "lobster", "46": "man", "47": "maple_tree", "48": "motorcycle", "49": "mountain", "50": "mouse", "51": "mushroom", "52": "oak_tree", "53": "orange", "54": "orchid", "55": "otter", "56": "palm_tree", "57": "pear", "58": "pickup_truck", "59": "pine_tree", "60": "plain", "61": "plate", "62": "poppy", "63": "porcupine", "64": "possum", "65": "rabbit", "66": "raccoon", "67": "ray", "68": "road", "69": "rocket", "70": "rose", "71": "sea", "72": "seal", "73": "shark", "74": "shrew", "75": "skunk", "76": "skyscraper", "77": "snail", "78": "snake", "79": "spider", "80": "squirrel", "81": "streetcar", "82": "sunflower", "83": "sweet_pepper", "84": "table", "85": "tank", "86": "telephone", "87": "television", "88": "tiger", "89": "tractor", "90": "train", "91": "trout", "92": "tulip", "93": "turtle", "94": "wardrobe", "95": "whale", "96": "willow_tree", "97": "wolf", "98": "woman", "99": "worm"}}}}, {"name": "id", "dtype": "int64"}, {"name": "clip_tags_LAION_ViT_H_14_2B_simple_specific", "dtype": "string"}, {"name": "clip_tags_LAION_ViT_H_14_2B_ensemble_specific", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 113602267.0, "num_examples": 50000}], "download_size": 112951195, "dataset_size": 113602267.0}}
|
2023-05-30T14:43:31+00:00
|
ae33823f501b654a08ec8373fcc506b3240b96d1
|
# Dataset Card for "CIFAR100_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/CIFAR100_test
|
[
"region:us"
] |
2023-05-29T17:31:15+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "apple", "1": "aquarium_fish", "2": "baby", "3": "bear", "4": "beaver", "5": "bed", "6": "bee", "7": "beetle", "8": "bicycle", "9": "bottle", "10": "bowl", "11": "boy", "12": "bridge", "13": "bus", "14": "butterfly", "15": "camel", "16": "can", "17": "castle", "18": "caterpillar", "19": "cattle", "20": "chair", "21": "chimpanzee", "22": "clock", "23": "cloud", "24": "cockroach", "25": "couch", "26": "cra", "27": "crocodile", "28": "cup", "29": "dinosaur", "30": "dolphin", "31": "elephant", "32": "flatfish", "33": "forest", "34": "fox", "35": "girl", "36": "hamster", "37": "house", "38": "kangaroo", "39": "keyboard", "40": "lamp", "41": "lawn_mower", "42": "leopard", "43": "lion", "44": "lizard", "45": "lobster", "46": "man", "47": "maple_tree", "48": "motorcycle", "49": "mountain", "50": "mouse", "51": "mushroom", "52": "oak_tree", "53": "orange", "54": "orchid", "55": "otter", "56": "palm_tree", "57": "pear", "58": "pickup_truck", "59": "pine_tree", "60": "plain", "61": "plate", "62": "poppy", "63": "porcupine", "64": "possum", "65": "rabbit", "66": "raccoon", "67": "ray", "68": "road", "69": "rocket", "70": "rose", "71": "sea", "72": "seal", "73": "shark", "74": "shrew", "75": "skunk", "76": "skyscraper", "77": "snail", "78": "snake", "79": "spider", "80": "squirrel", "81": "streetcar", "82": "sunflower", "83": "sweet_pepper", "84": "table", "85": "tank", "86": "telephone", "87": "television", "88": "tiger", "89": "tractor", "90": "train", "91": "trout", "92": "tulip", "93": "turtle", "94": "wardrobe", "95": "whale", "96": "willow_tree", "97": "wolf", "98": "woman", "99": "worm"}}}}, {"name": "id", "dtype": "int64"}, {"name": "clip_tags_LAION_ViT_H_14_2B_simple_specific", "dtype": "string"}, {"name": "Attributes_ViT_L_14_descriptors_text_davinci_003_full", "sequence": "string"}, {"name": "Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full", "sequence": "string"}], "splits": [{"name": "test", "num_bytes": 27693774.0, "num_examples": 10000}], "download_size": 23948177, "dataset_size": 27693774.0}}
|
2023-05-30T14:52:01+00:00
|
944f4d85c18bd55eed596b15c1bee321643a7f67
|
luist18/portuguese-parliament-interventions
|
[
"size_categories:n<1K",
"language:pt",
"license:mit",
"legal",
"parliament",
"region:us"
] |
2023-05-29T17:44:50+00:00
|
{"language": ["pt"], "license": "mit", "size_categories": ["n<1K"], "pretty_name": "Portuguese Parliament Interventions", "tags": ["legal", "parliament"]}
|
2023-06-01T21:59:38+00:00
|
|
357d24230c910eda42b72c6f926a3e4a9bb18575
|
# Dataset Card
To access a notebook which will generate a .parquet with the HEAD from the git repository, use [this notebook](https://colab.research.google.com/drive/1n9z3znVZy4tOe-9lMvXcQXnP8f2Jeg5Q?usp=sharing)
## Features
- `function_name`: Holds the original name of the function
- `framework`: Holds the original framework where the function was implemented
- `source_code`: Holds the original source code from the Ivy codebase that implements the specific backend function for a given framework
- `docstring`: Holds the docstring from the Ivy codebase
- `annotations`: Holds the annotations for a given function from the Ivy codebase
- `instruction`: Holds the strictly-generated prompt instruction to ideally generate a given source code implementation
|
suvadityamuk/ai-developer-ivy
|
[
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"language:en",
"license:unknown",
"region:us"
] |
2023-05-29T17:56:43+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["en"], "license": "unknown", "pretty_name": "Ivy AI-Developer Instruction-tuning Dataset", "dataset_info": {"features": [{"name": "function_name", "dtype": "string"}, {"name": "framework", "dtype": "string"}, {"name": "source_code", "dtype": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "annotations", "dtype": "string"}, {"name": "instruction", "dtype": "string"}]}}
|
2023-05-29T18:19:20+00:00
|
d4c33bee7efcbf2f9d967fa013223f36c4ceafb7
|
# Dataset Card for "character-prepared-seeds"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AlekseyKorshuk/character-prepared-seeds
|
[
"region:us"
] |
2023-05-29T17:58:06+00:00
|
{"dataset_info": {"features": [{"name": "name", "dtype": "string"}, {"name": "label", "dtype": "string"}, {"name": "greating", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "conversation", "list": [{"name": "from", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "image", "dtype": "image"}, {"name": "original_name", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 15158625.0, "num_examples": 22}], "download_size": 15150151, "dataset_size": 15158625.0}}
|
2023-05-29T18:42:31+00:00
|
c7b41bf5045da6406346b3c5b5dd5e45d6650132
|
Khavee/Khavee-klon
|
[
"license:mit",
"region:us"
] |
2023-05-29T18:02:25+00:00
|
{"license": "mit"}
|
2023-05-29T18:03:26+00:00
|
|
24ab874d4834cc2559ad5f4bf9de51bbcd937d46
|
# Medical Transcriptions
Medical transcription data scraped from mtsamples.com
### Content
This dataset contains sample medical transcriptions for various medical specialties.
<br>
More information can be found [here](https://www.kaggle.com/datasets/tboyle10/medicaltranscriptions?resource=download)
Due to data availability only transcripts for the following medical specialties were selected for the model training:
- Surgery
- Cardiovascular / Pulmonary
- Orthopedic
- Radiology
- General Medicine
- Gastroenterology
- Neurology
- Obstetrics / Gynecology
- Urology
---
**task_categories:**
- text-classification
- feature-extraction
**language:** en <br>
**tags:** medical <br>
**size_categories:** 1K<n<10K
|
tchebonenko/MedicalTranscriptions
|
[
"region:us"
] |
2023-05-29T18:04:30+00:00
|
{}
|
2023-05-29T18:39:18+00:00
|
254f4f5b4fc5445e33066eba001bc8aea8ba0dff
|
bdjordjevic/first-dataset
|
[
"license:mit",
"region:us"
] |
2023-05-29T18:18:43+00:00
|
{"license": "mit"}
|
2023-05-29T18:19:27+00:00
|
|
86b9c36d09c85bf27ead54795733a7485144efdb
|
# Dataset Card for "autotrain-data-gtzs-bj3r-fz0k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
EinfachOlder/autotrain-data-gtzs-bj3r-fz0k
|
[
"region:us"
] |
2023-05-29T18:25:31+00:00
|
{"dataset_info": {"features": [{"name": "content", "dtype": "string"}, {"name": "autotrain_text", "dtype": "string"}, {"name": "autotrain_label", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12258, "num_examples": 6}, {"name": "validation", "num_bytes": 3200, "num_examples": 2}], "download_size": 33851, "dataset_size": 15458}}
|
2023-05-29T18:26:46+00:00
|
a3cce1c213c335e99ea98a4adfe8df130cef4fe1
|
# Dataset Card for Dataset Name
This is an edit of original work from Bertie Vidgen, Tristan Thrush, Zeerak Waseem and Douwe Kiela. Which I have uploaded to Huggingface [here](https://huggingface.co/datasets/LennardZuendorf/Dynamically-Generated-Hate-Speech-Dataset/edit/main/README.md). It is not my original work, I just edited it.
Data is used in the similarly named Interpretor Model.
## Dataset Description
- **Homepage:** [zuendorf.me](https://www.zuendorf.me)
- **Repository:** [GitHub Monorepo](https://github.com/LennardZuendorf/interpretor)
- **Author:** Lennard Zündorf
### Original Dataset Description
- **Original Source Contact:** [[email protected]](mailto:[email protected])
- **Original Source:** [Dynamically-Generated-Hate-Speech-Dataset](https://github.com/bvidgen/Dynamically-Generated-Hate-Speech-Dataset)
- **Original Author List:** Bertie Vidgen (The Alan Turing Institute), Tristan Thrush (Facebook AI Research), Zeerak Waseem (University of Sheffield) and Douwe Kiela (Facebook AI Research).
**Refer to the Huggingface or GitHub Repo for more information**
### Dataset Summary
This Dataset contains dynamically generated hate-speech, processed to be used in classification tasks with i.E. BERT.
### Edit Summary
- I have edited the dataset to use it in training the similarly named [Interpretor Classifier]()
- see data/label fields below and the original dataset [here](https://huggingface.co/datasets/LennardZuendorf/Dynamically-Generated-Hate-Speech-Dataset/edit/main/README.md)
- Edits mostly include cleaning out information not needed for a simple binary classification tasks and adding a numerical binary label
## Dataset Structure
### Split
- The dataset is split into train and test, in a 90% to 10% split
- Train = ~ 74k entries
- Test = ~ 8k entries
### Data Fields
| id | text | label | label_text |
| - | - | - | - |
| numeric id | text of the comment | binary label, 0 = not hate, 1 = hate | label in text form
## Additional Information
### Licensing Information
- The original repository does not provide any license, but is free for use with proper citation of the original paper (see link above)
- This dataset can be used under the MIT license, with proper citation of both the original and this source.
- But I suggest taking data from the original source and doing your own editing.
### Citation Information
Please cite this repository and the original authors (see above) when using it.
### Contributions
I removed some data fields and did a new split with hugging face datasets.
|
LennardZuendorf/interpretor
|
[
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"not-for-all-audiences",
"legal",
"region:us"
] |
2023-05-29T18:59:04+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["10K<n<100K"], "dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "label_text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12150228.415975923, "num_examples": 74159}, {"name": "test", "num_bytes": 1350043.584024078, "num_examples": 8240}], "download_size": 8392302, "dataset_size": 13500272}, "tags": ["not-for-all-audiences", "legal"]}
|
2023-10-16T10:49:27+00:00
|
d0d9da6c6d220b94b4de0cf8a34d855cbb030b3d
|
# Dataset Card for US Accidents (2016 - 2023)
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://kaggle.com/datasets/sobhanmoosavi/us-accidents
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
### Description
This is a countrywide car accident dataset, which covers __49 states of the USA__. The accident data are collected from __February 2016 to Mar 2023__, using multiple APIs that provide streaming traffic incident (or event) data. These APIs broadcast traffic data captured by a variety of entities, such as the US and state departments of transportation, law enforcement agencies, traffic cameras, and traffic sensors within the road-networks. Currently, there are about __7.7 million__ accident records in this dataset. Check [here](https://smoosavi.org/datasets/us_accidents) to learn more about this dataset.
### Acknowledgements
Please cite the following papers if you use this dataset:
- Moosavi, Sobhan, Mohammad Hossein Samavatian, Srinivasan Parthasarathy, and Rajiv Ramnath. “[A Countrywide Traffic Accident Dataset](https://arxiv.org/abs/1906.05409).”, 2019.
- Moosavi, Sobhan, Mohammad Hossein Samavatian, Srinivasan Parthasarathy, Radu Teodorescu, and Rajiv Ramnath. ["Accident Risk Prediction based on Heterogeneous Sparse Data: New Dataset and Insights."](https://arxiv.org/abs/1909.09638) In proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, ACM, 2019.
### Content
This dataset has been collected in real-time, using multiple Traffic APIs. Currently, it contains accident data that are collected from February 2016 to Dec 2021 for the Contiguous United States. Check [here](https://smoosavi.org/datasets/us_accidents) to learn more about this dataset.
### Inspiration
US-Accidents can be used for numerous applications such as real-time car accident prediction, studying car accidents hotspot locations, casualty analysis and extracting cause and effect rules to predict car accidents, and studying the impact of precipitation or other environmental stimuli on accident occurrence. The most recent release of the dataset can also be useful to study the impact of COVID-19 on traffic behavior and accidents.
### Usage Policy and Legal Disclaimer
This dataset is being distributed only for __Research__ purposes, under Creative Commons Attribution-Noncommercial-ShareAlike license (CC BY-NC-SA 4.0). By clicking on download button(s) below, you are agreeing to use this data only for non-commercial, research, or academic applications. You may need to cite the above papers if you use this dataset.
### Inquiries or need help?
For any inquiries, contact me at [email protected]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
This dataset was shared by [@sobhanmoosavi](https://kaggle.com/sobhanmoosavi)
### Licensing Information
The license for this dataset is cc-by-nc-sa-4.0
### Citation Information
```bibtex
[More Information Needed]
```
### Contributions
[More Information Needed]
|
yuvidhepe/us-accidents-updated
|
[
"license:cc-by-nc-sa-4.0",
"arxiv:1906.05409",
"arxiv:1909.09638",
"region:us"
] |
2023-05-29T19:09:43+00:00
|
{"license": ["cc-by-nc-sa-4.0"], "kaggle_id": "sobhanmoosavi/us-accidents", "dataset_info": {"features": [{"name": "ID", "dtype": "string"}, {"name": "Source", "dtype": "string"}, {"name": "Severity", "dtype": "int64"}, {"name": "Start_Time", "dtype": "string"}, {"name": "End_Time", "dtype": "string"}, {"name": "Start_Lat", "dtype": "float64"}, {"name": "Start_Lng", "dtype": "float64"}, {"name": "End_Lat", "dtype": "float64"}, {"name": "End_Lng", "dtype": "float64"}, {"name": "Distance(mi)", "dtype": "float64"}, {"name": "Description", "dtype": "string"}, {"name": "Street", "dtype": "string"}, {"name": "City", "dtype": "string"}, {"name": "County", "dtype": "string"}, {"name": "State", "dtype": "string"}, {"name": "Zipcode", "dtype": "string"}, {"name": "Country", "dtype": "string"}, {"name": "Timezone", "dtype": "string"}, {"name": "Airport_Code", "dtype": "string"}, {"name": "Weather_Timestamp", "dtype": "string"}, {"name": "Temperature(F)", "dtype": "float64"}, {"name": "Wind_Chill(F)", "dtype": "float64"}, {"name": "Humidity(%)", "dtype": "float64"}, {"name": "Pressure(in)", "dtype": "float64"}, {"name": "Visibility(mi)", "dtype": "float64"}, {"name": "Wind_Direction", "dtype": "string"}, {"name": "Wind_Speed(mph)", "dtype": "float64"}, {"name": "Precipitation(in)", "dtype": "float64"}, {"name": "Weather_Condition", "dtype": "string"}, {"name": "Amenity", "dtype": "bool"}, {"name": "Bump", "dtype": "bool"}, {"name": "Crossing", "dtype": "bool"}, {"name": "Give_Way", "dtype": "bool"}, {"name": "Junction", "dtype": "bool"}, {"name": "No_Exit", "dtype": "bool"}, {"name": "Railway", "dtype": "bool"}, {"name": "Roundabout", "dtype": "bool"}, {"name": "Station", "dtype": "bool"}, {"name": "Stop", "dtype": "bool"}, {"name": "Traffic_Calming", "dtype": "bool"}, {"name": "Traffic_Signal", "dtype": "bool"}, {"name": "Turning_Loop", "dtype": "bool"}, {"name": "Sunrise_Sunset", "dtype": "string"}, {"name": "Civil_Twilight", "dtype": "string"}, {"name": "Nautical_Twilight", "dtype": "string"}, {"name": "Astronomical_Twilight", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3147354997, "num_examples": 7728394}], "download_size": 1088140045, "dataset_size": 3147354997}}
|
2023-05-29T19:57:40+00:00
|
9c8cf04ccd33f662b814e773e775c8143e133735
|
# Dataset Card for "eli5_mult_answers_en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
9wimu9/eli5_mult_answers_en
|
[
"region:us"
] |
2023-05-29T19:27:22+00:00
|
{"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "contexts", "sequence": "string"}, {"name": "gold_answer", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 370188345.3824035, "num_examples": 71236}, {"name": "test", "num_bytes": 41136657.61759652, "num_examples": 7916}], "download_size": 248739104, "dataset_size": 411325003.0}}
|
2023-05-29T19:27:50+00:00
|
22d0f9dd9336c223e8564acf2e864aa124abe19f
|
# Dataset Card for "S2D"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
cburger/S2D
|
[
"region:us"
] |
2023-05-29T19:27:40+00:00
|
{"dataset_info": {"features": [{"name": "label", "dtype": {"class_label": {"names": {"0": "allergy", "1": "arthritis", "2": "bronchial asthma", "3": "cervical spondylosis", "4": "chicken pox", "5": "common cold", "6": "dengue", "7": "diabetes", "8": "drug reaction", "9": "fungal infection", "10": "gastroesophageal reflux disease", "11": "hypertension", "12": "impetigo", "13": "jaundice", "14": "malaria", "15": "migraine", "16": "peptic ulcer disease", "17": "pneumonia", "18": "psoriasis", "19": "typhoid", "20": "urinary tract infection", "21": "varicose veins"}}}}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 138195, "num_examples": 853}, {"name": "test", "num_bytes": 34356, "num_examples": 212}], "download_size": 77571, "dataset_size": 172551}}
|
2023-05-29T19:28:24+00:00
|
dc32a3df97cf569fdacb8c4d656b84ede050a2e6
|
ari7thomas/bible-ai
|
[
"license:creativeml-openrail-m",
"region:us"
] |
2023-05-29T20:24:45+00:00
|
{"license": "creativeml-openrail-m"}
|
2023-05-29T20:24:45+00:00
|
|
ebab29f6ef0f86e240aa6440f7fa65e46a9765e9
|
# Dataset Card for "stable-bias_grounding-images_SD-21-base_6789012345_clusters"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yjernite/stable-bias_grounding-images_SD-21-base_6789012345_clusters
|
[
"region:us"
] |
2023-05-29T20:44:54+00:00
|
{"dataset_info": {"features": [{"name": "examplar", "dtype": "image"}, {"name": "centroid", "sequence": "float64"}, {"name": "gender_phrases", "sequence": "string"}, {"name": "gender_phrases_counts", "sequence": "int64"}, {"name": "ethnicity_phrases", "sequence": "string"}, {"name": "ethnicity_phrases_counts", "sequence": "int64"}, {"name": "example_ids", "sequence": "int64"}], "splits": [{"name": "12_clusters", "num_bytes": 542010.0, "num_examples": 12}, {"name": "24_clusters", "num_bytes": 926544.0, "num_examples": 24}, {"name": "48_clusters", "num_bytes": 1903455.0, "num_examples": 48}], "download_size": 2890107, "dataset_size": 3372009.0}}
|
2023-05-29T20:45:53+00:00
|
aa5549222c9614f54309a0d61e927b80e7d860b6
|
JCTN/hypernetworks
|
[
"license:other",
"region:us"
] |
2023-05-29T20:52:53+00:00
|
{"license": "other"}
|
2023-05-29T21:13:53+00:00
|
|
245313f170bf56cd5a98b8b3163d6bc0a2cee368
|
# Dataset Card for "975e558e"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/975e558e
|
[
"region:us"
] |
2023-05-29T21:24:27+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 180, "num_examples": 10}], "download_size": 1340, "dataset_size": 180}}
|
2023-05-29T21:24:29+00:00
|
216fa2057d89fc5c7a8456de1c9b94f02d4d1fab
|
nihany/car-object-detection
|
[
"license:unknown",
"region:us"
] |
2023-05-29T21:32:02+00:00
|
{"license": "unknown"}
|
2023-05-29T21:36:45+00:00
|
|
43cf12f502a02a61652d88687c66f6bc91a0505a
|
sxdave/emotion_detection
|
[
"task_categories:image-classification",
"size_categories:n<1K",
"language:en",
"happy",
"sad",
"neutral",
"region:us"
] |
2023-05-29T21:37:35+00:00
|
{"language": ["en"], "size_categories": ["n<1K"], "task_categories": ["image-classification"], "tags": ["happy", "sad", "neutral"]}
|
2023-05-29T21:55:36+00:00
|
|
a8b4aa8f817be388aacd879c9dff340dabb1d482
|
# Dataset Card for "summary_seq_label_balanced_subject"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Astonzzh/summary_seq_label_balanced_subject
|
[
"region:us"
] |
2023-05-29T21:40:14+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "ids", "sequence": "string"}, {"name": "words", "sequence": "string"}, {"name": "labels", "sequence": "int64"}, {"name": "summary", "dtype": "string"}, {"name": "sentences", "sequence": "string"}, {"name": "sentence_labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 8968082, "num_examples": 7360}, {"name": "validation", "num_bytes": 539444, "num_examples": 409}, {"name": "test", "num_bytes": 509938, "num_examples": 409}], "download_size": 3846123, "dataset_size": 10017464}}
|
2023-05-29T21:40:25+00:00
|
95e6c2ac1af293e533b95d61b97a6f9a82bc0fd6
|
# Dataset Card for "StanfordCars_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_1000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/StanfordCars_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_1000
|
[
"region:us"
] |
2023-05-29T21:50:35+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 537329, "num_examples": 1000}], "download_size": 118758, "dataset_size": 537329}}
|
2023-05-29T22:36:57+00:00
|
ec2b12954324da600951775f60c2cdeb0a4e285b
|
janPiljan/tokidb
|
[
"size_categories:n<1K",
"language:tok",
"language:en",
"license:mit",
"region:us"
] |
2023-05-29T22:21:59+00:00
|
{"language": ["tok", "en"], "license": "mit", "size_categories": ["n<1K"], "pretty_name": "TokiDS"}
|
2023-05-29T22:23:18+00:00
|
|
0f9147e10fe304b9b89d45d21a83517a89cd5d43
|
# Dataset Card for multi-figqa
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** [Multi-FigQA](https://github.com/simran-khanuja/Multilingual-Fig-QA)
- **Paper:** [Multi-lingual and Multi-cultural Figurative Language Understanding
](https://arxiv.org/abs/2305.16171)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Emmy Liu]([email protected])
### Dataset Summary
A multilingual dataset of human-written creative figurative expressions in many languages (mostly metaphors and similes). The English version (with the same format) can be found [here](https://huggingface.co/datasets/nightingal3/fig-qa)
### Languages
Languages included are Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili, and Yoruba. The language codes are respectively `hi`, `id`, `kn`, `su`, `sw`, and `yo`.
## Dataset Structure
### Data Instances
```
{
'startphrase': the phrase,
'ending1': one possible answer,
'ending2': another possible answer,
'labels': 0 if ending1 is correct else 1
}
```
### Data Splits
All data in each language is originally intended to be used as a test set for that language.
## Dataset Creation
### Curation Rationale
Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. We created this dataset as part of an effort to introduce more culturally relevant training data for different languages and cultures.
### Source Data
#### Who are the source language producers?
The language producers were hired to write creative sentences in their native languages.
## Additional Information
### Citation Information
Please use this citation if you found this helpful:
```
@misc{kabra2023multilingual,
title={Multi-lingual and Multi-cultural Figurative Language Understanding},
author={Anubha Kabra and Emmy Liu and Simran Khanuja and Alham Fikri Aji and Genta Indra Winata and Samuel Cahyawijaya and Anuoluwapo Aremu and Perez Ogayo and Graham Neubig},
year={2023},
eprint={2305.16171},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
cmu-lti/multi-figqa
|
[
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:hi",
"language:id",
"language:su",
"language:jv",
"language:kn",
"language:sw",
"language:yo",
"license:mit",
"arxiv:2305.16171",
"region:us"
] |
2023-05-29T22:36:39+00:00
|
{"language": ["hi", "id", "su", "jv", "kn", "sw", "yo"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["question-answering"]}
|
2023-05-31T00:17:24+00:00
|
ecbf789d0d90e36807828c9c83a664493fb447e5
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
VirtualRoyalty/20ng_not_enough_data
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"region:us"
] |
2023-05-29T22:36:46+00:00
|
{"language": ["en"], "size_categories": ["n<1K"], "task_categories": ["text-classification"], "pretty_name": "20ng_not_enough_data"}
|
2023-05-30T00:03:15+00:00
|
cc1f45749318238963c1db85a2341930f28b23d6
|
First version of the [can-ai-code](https://github.com/the-crypt-keeper/can-ai-code/) junior-dev interview.
|
mike-ravkine/can-ai-code_junior-dev_v1
|
[
"language:en",
"region:us"
] |
2023-05-29T23:09:39+00:00
|
{"language": ["en"]}
|
2023-05-29T23:14:12+00:00
|
b825c9fd53341f1a847b518ad599fed90c27a42d
|
# Dataset Card for "review_sample_with_aspect"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vincha77/review_sample_with_aspect
|
[
"region:us"
] |
2023-05-29T23:26:12+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "aspect", "dtype": "string"}, {"name": "food", "dtype": "string"}, {"name": "service", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "review_length", "dtype": "int64"}, {"name": "price", "dtype": "string"}, {"name": "ambience", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 114005.35714285714, "num_examples": 100}, {"name": "test", "num_bytes": 13680.642857142857, "num_examples": 12}], "download_size": 96925, "dataset_size": 127686.0}}
|
2023-05-29T23:26:18+00:00
|
d0799e9594349d92f8ba22f4bfefbd7565707776
|
# Contextual Semantic Labels (Small) Benchmark Dataset
Please see [https://github.com/docugami/DFM-benchmarks](https://github.com/docugami/DFM-benchmarks) for more details, eval code, and current scores for different models.
# Using Dataset
Please refer to standard huggingface documentation to use this dataset: [https://huggingface.co/docs/datasets/index](https://huggingface.co/docs/datasets/index)
The [explore.ipynb](./explore.ipynb) notebook has some reference code.
|
Docugami/dfm-csl-small-benchmark
|
[
"task_categories:text2text-generation",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:mit",
"docugami",
"dfm-csl",
"xml-knowledge-graphs",
"region:us"
] |
2023-05-30T00:00:38+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text2text-generation", "text-generation"], "pretty_name": "Contextual Semantic Lables (Small)", "dataset_info": {"features": [{"name": "Text", "dtype": "string"}, {"name": "Small Chunk", "dtype": "string"}, {"name": "Ground Truth", "dtype": "string"}, {"name": "docugami/dfm-cs-small", "dtype": "string"}], "splits": [{"name": "eval", "num_bytes": 240040, "num_examples": 1099}, {"name": "train", "num_bytes": 20906, "num_examples": 100}], "download_size": 143986, "dataset_size": 260946}, "tags": ["docugami", "dfm-csl", "xml-knowledge-graphs"]}
|
2023-10-04T07:44:17+00:00
|
a5626eba76b1985c41e769ff115b0ad55dd5e7b6
|
# Contextual Semantic Labels (Large) Benchmark Dataset
Please see [https://github.com/docugami/DFM-benchmarks](https://github.com/docugami/DFM-benchmarks) for more details, eval code, and current scores for different models.
# Using Dataset
Please refer to standard huggingface documentation to use this dataset: [https://huggingface.co/docs/datasets/index](https://huggingface.co/docs/datasets/index)
The [explore.ipynb](./explore.ipynb) notebook has some reference code.
|
Docugami/dfm-csl-large-benchmark
|
[
"task_categories:text2text-generation",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:mit",
"docugami",
"dfm-csl",
"xml-knowledge-graphs",
"region:us"
] |
2023-05-30T00:01:02+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text2text-generation", "text-generation"], "pretty_name": "Contextual Semantic Lables (Large)", "dataset_info": {"features": [{"name": "Text", "dtype": "string"}, {"name": "Ground Truth", "dtype": "string"}, {"name": "docugami/dfm-csl-large", "dtype": "string"}], "splits": [{"name": "eval", "num_bytes": 1137328, "num_examples": 1088}, {"name": "train", "num_bytes": 83236, "num_examples": 104}], "download_size": 572546, "dataset_size": 1220564}, "tags": ["docugami", "dfm-csl", "xml-knowledge-graphs"]}
|
2023-10-04T07:41:01+00:00
|
2a365ff408c9fdd2051d9851a3182c89caf129fa
|
# Dataset Card for "american_snacks"
- This dataset contains a list of popular American snack items along with their ingredient list. Additionally, it also contains a column containing the reason if certain snack item is suitable for vegan/vegtarians based on certain ingredient.
- It has been generated using Open AI `gpt3.5-turbo` with prompt "please create me a dataset in csv format with 20 rows containing columns "product_name", "ingredients", "reasons". The "product_name" columns will contain 20 most common packaged snacks in the US with their full brand name. The "ingredients" column for each row will contain the respective snack's ingredient list. The "reasons" columns for each rows will contain a reason why that snack item is vegan suitable or not."
- The ingredient list may or may not be exhaustive.
- This is a synthetic dataset augmented by human (addtional verbiage in `reasons` column.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
nehatarey/american_snacks
|
[
"region:us"
] |
2023-05-30T00:09:07+00:00
|
{"dataset_info": {"features": [{"name": "product_name", "dtype": "string"}, {"name": "ingredients", "dtype": "string"}, {"name": "reasons", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 13230, "num_examples": 49}], "download_size": 7079, "dataset_size": 13230}}
|
2023-05-30T00:15:01+00:00
|
8fb4ac2de70ed2505a70ce623ca1e8af11fedbb5
|
# Dataset Card for "0-9up_ft_ensemble_distilled_from_cv12_balanced_mfcc"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mazkooleg/0-9up_ft_ensemble_distilled_from_cv12_balanced_mfcc
|
[
"region:us"
] |
2023-05-30T00:29:41+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 10556482944.0, "num_examples": 2056992}], "download_size": 10805553123, "dataset_size": 10556482944.0}}
|
2023-05-30T03:53:00+00:00
|
9459e7000aa38d0eef9f49633e17afc6d12d0f85
|
# Dataset Card for "tang_poems"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
xmj2002/tang_poems
|
[
"region:us"
] |
2023-05-30T01:35:14+00:00
|
{"dataset_info": {"features": [{"name": "author", "dtype": "string"}, {"name": "paragraphs", "dtype": "string"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 6199272.5686873095, "num_examples": 36000}, {"name": "test", "num_bytes": 908193.4313126908, "num_examples": 5274}], "download_size": 5867663, "dataset_size": 7107466.0}}
|
2023-05-30T01:45:48+00:00
|
8065f5b819b1a848a52eab2e8a025af93cb24e07
|
# Dataset Card for "a0e1beb1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/a0e1beb1
|
[
"region:us"
] |
2023-05-30T01:59:58+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 180, "num_examples": 10}], "download_size": 1331, "dataset_size": 180}}
|
2023-05-30T01:59:59+00:00
|
d66613bde39df797aa4763c7fc1062991f70857d
|
# Dataset Card for "SST2_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/SST2_train
|
[
"region:us"
] |
2023-05-30T02:17:50+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "negative", "1": "positive"}}}}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 117277546.0, "num_examples": 6920}], "download_size": 114148970, "dataset_size": 117277546.0}}
|
2023-05-30T02:18:08+00:00
|
48d8fee52aaee595aaccfe81fef9169e11bb1cbc
|
# Dataset Card for "SST2_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/SST2_test
|
[
"region:us"
] |
2023-05-30T02:18:08+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "negative", "1": "positive"}}}}, {"name": "id", "dtype": "int64"}, {"name": "blip_caption_beam_5", "dtype": "string"}, {"name": "blip_caption_beam_5_Salesforce_blip_image_captioning_large", "dtype": "string"}, {"name": "blip_caption_beam_False_5_source", "dtype": "string"}, {"name": "clip_tags_LAION_ViT_H_14_2B_with_openai", "sequence": "string"}, {"name": "clip_tags_LAION_ViT_H_14_2B_with_openai_wordnet", "sequence": "string"}, {"name": "clip_tags_ViT_L_14_with_openai", "sequence": "string"}, {"name": "clip_tags_ViT_L_14_with_openai_wordnet", "sequence": "string"}, {"name": "Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full", "sequence": "string"}, {"name": "Attributes_ViT_L_14_descriptors_text_davinci_003_full", "sequence": "string"}], "splits": [{"name": "test", "num_bytes": 32821778.375, "num_examples": 1821}], "download_size": 30635496, "dataset_size": 32821778.375}}
|
2023-06-01T21:00:11+00:00
|
955f970aae0c2e5606c4664ab88589aaabd7bc32
|
# Dataset Card for "mlsum-spanish-truncated-512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jganzabalseenka/mlsum-spanish-truncated-512
|
[
"region:us"
] |
2023-05-30T02:24:28+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "summary", "dtype": "string"}, {"name": "topic", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "decoder_input_ids", "sequence": "int64"}, {"name": "decoder_attention_mask", "sequence": "int64"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 2720064586, "num_examples": 266367}, {"name": "validation", "num_bytes": 109186816, "num_examples": 10358}, {"name": "test", "num_bytes": 149939505, "num_examples": 13920}], "download_size": 1157591855, "dataset_size": 2979190907}}
|
2023-05-30T03:19:10+00:00
|
bea0505dc4b7e3aa3b902b3e5aeae9d94d160a4d
|
matrixhanson/dataset1
|
[
"license:openrail",
"region:us"
] |
2023-05-30T02:33:32+00:00
|
{"license": "openrail"}
|
2023-08-24T07:15:13+00:00
|
|
bf6c684cf5f673aea5f0e61ce3d0d6ed063c6077
|
# Dataset Card for "mathqa_rationale_vi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vietgpt-archive/mathqa_rationale_vi
|
[
"region:us"
] |
2023-05-30T03:19:13+00:00
|
{"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "rationale", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9500373, "num_examples": 24889}], "download_size": 5372275, "dataset_size": 9500373}}
|
2023-05-30T03:31:15+00:00
|
5dcbfe8c1b4f83fbfed552a98726dd7651680642
|
taesiri/arxiv_audio_archived
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-30T03:50:20+00:00
|
{"license": "apache-2.0"}
|
2023-06-19T05:18:54+00:00
|
|
1e533aa5d3271bd7fed51a9f3fe3bd7016f4825d
|
# Dataset Card for "tiny_math"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
keirp/tiny_math
|
[
"region:us"
] |
2023-05-30T03:58:34+00:00
|
{"dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "metadata", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 134067703, "num_examples": 17063}], "download_size": 60407086, "dataset_size": 134067703}}
|
2023-05-30T04:00:22+00:00
|
c5376b695386f8959909d77add012f10cb55e14a
|
# Dataset Card for "98e1bdf3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/98e1bdf3
|
[
"region:us"
] |
2023-05-30T04:16:51+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 188, "num_examples": 10}], "download_size": 1337, "dataset_size": 188}}
|
2023-05-30T04:16:52+00:00
|
1a4aef0c0560e218cab36541d8bbe592e3200af4
|
# Dataset Card for "d042346d"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/d042346d
|
[
"region:us"
] |
2023-05-30T04:20:20+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 182, "num_examples": 10}], "download_size": 1342, "dataset_size": 182}}
|
2023-05-30T04:20:21+00:00
|
314f4898f3107d1eb3781e65aa07671b5da20e90
|
TigerResearch/en_books
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-30T04:35:15+00:00
|
{"license": "apache-2.0"}
|
2023-05-30T04:35:15+00:00
|
|
11f77b705c65328dce6e737ab5011808f07c1ba7
|
# Dataset Card for "entity_centric_summary_cnn"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Xmm/entity_centric_summary_cnn
|
[
"region:us"
] |
2023-05-30T04:35:30+00:00
|
{"dataset_info": {"features": [{"name": "content", "dtype": "string"}, {"name": "summary", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5725960.9593572775, "num_examples": 2539}, {"name": "test", "num_bytes": 1432054.040642722, "num_examples": 635}], "download_size": 3806992, "dataset_size": 7158015.0}}
|
2023-08-04T01:07:18+00:00
|
f872f95f3b0239c0119bc0f7f212dcfb4111cbbe
|
bharath32/Medicare_testing
|
[
"license:other",
"region:us"
] |
2023-05-30T04:42:48+00:00
|
{"license": "other"}
|
2023-05-30T04:44:28+00:00
|
|
a3ce75a907087f4bd2512ca832728f6c93acfbe3
|
## Table of Contents
- [Benchmark Summary](#benchmark-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
<p><h1>🧪🔋 Chemical Language Understanding Benchmark 🛢️🧴</h1></p>
<a name="benchmark-summary"></a>
Benchmark Summary
Chemistry Language Understanding Benchmark is published in ACL2023 industry track to facilitate NLP research in chemical industry [ACL2023 Paper Link Not Available Yet](link).
From our understanding, it is one of the first benchmark datasets with tasks for both patent and literature articles provided by the industrial organization.
All the datasets are annotated by professional chemists.
<a name="languages"></a>
Languages
The language of this benchmark is English.
<a name="dataset-structure"></a>
Data Structure
Benchmark has 4 datasets: 2 for text classification and 2 for token classification.
| Dataset | Task | # Examples | Avg. Token Length | # Classes / Entity Groups |
| ----- | ------ | ---------- | ------------ | ------------------------- |
| PETROCHEMICAL | Patent Area Classification | 2,775 | 448.19 | 7 |
| RHEOLOGY | Sentence Classification | 2,017 | 55.03 | 5 |
| CATALYST | Catalyst Entity Recognition | 4,663 | 42.07 | 5 |
| BATTERY | Battery Entity Recognition | 3,750 | 40.73 | 3 |
You can refer to the paper for detailed description of the datasets.
<a name="data-instances"></a>
Data Instances
Each example is a paragraph/setence of an academic paper or patent with annotations in a json format.
<a name="data-fields"></a>
Data Fields
The fields for the text classification task are:
1) 'id', a unique numbered identifier sequentially assigned.
2) 'sentence', the input text.
3) 'label', the class for the text.
The fields for the text classification task are:
1) 'id', a unique numbered identifier sequentially assigned.
2) 'tokens', the input text tokenized by BPE tokenizer.
3) 'ner_tags', the entity label for the tokens.
<a name="data-splits"></a>
Data Splits
The data is split into 80 (train) / 20 (development).
<a name="dataset-creation"></a>
Dataset Creation
<a name="curation-rationale"></a>
Curation Rationale
The dataset was created to provide a benchmark in chemical language model for researchers and developers.
<a name="source-data"></a>
Source Data
The dataset consists of open-access chemistry publications and patents annotated by professional chemists.
<a name="licensing-information"></a>
Licensing Information
The manual annotations created for CLUB are licensed under a [Creative Commons Attribution 4.0 International License (CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/).
<a name="citation-information"></a>
Citation Information
We will provide the citation information once ACL2023 industry track paper is published.
|
bluesky333/chemical_language_understanding_benchmark
|
[
"task_categories:text-classification",
"task_categories:token-classification",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"chemistry",
"region:us"
] |
2023-05-30T04:52:05+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification", "token-classification"], "pretty_name": "CLUB", "tags": ["chemistry"]}
|
2023-07-09T09:36:44+00:00
|
aa5a932157eba153aa54ddaee42fe60860befdd1
|
# Dataset Card for "medium_title_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
addy88/medium_title_dataset
|
[
"region:us"
] |
2023-05-30T05:13:21+00:00
|
{"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "authors", "dtype": "string"}, {"name": "timestamp", "dtype": "string"}, {"name": "tags", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1012160809.2968477, "num_examples": 186368}, {"name": "validation", "num_bytes": 16292938.851576146, "num_examples": 3000}, {"name": "test", "num_bytes": 16292938.851576146, "num_examples": 3000}], "download_size": 620447127, "dataset_size": 1044746686.9999999}}
|
2023-05-30T05:22:29+00:00
|
f4e933ca86fe9eed19c6147e4fe53d00c8082a88
|
waleedfarooq51/my_dataset
|
[
"language:en",
"region:us"
] |
2023-05-30T06:19:50+00:00
|
{"language": ["en"]}
|
2023-05-30T06:47:51+00:00
|
|
4108307cb6f1722a626e9baf585bdacb24334996
|
# Dataset Card for "ah"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Deojoandco/ah
|
[
"region:us"
] |
2023-05-30T06:22:53+00:00
|
{"dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "name", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "body", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "upvote_ratio", "dtype": "float64"}, {"name": "distinguished", "dtype": "null"}, {"name": "over_18", "dtype": "bool"}, {"name": "created_utc", "dtype": "float64"}, {"name": "comments", "list": [{"name": "body", "dtype": "string"}, {"name": "created_utc", "dtype": "float64"}, {"name": "distinguished", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "permalink", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "best_num_comments", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 90583, "num_examples": 26}], "download_size": 75015, "dataset_size": 90583}}
|
2023-05-30T06:22:58+00:00
|
2f2aeb45d3af33edda634215334c08cea9310452
|
Collection of differnt NSFW Captions, the date is mostly hand written and took quite some time to gather.
If you find caption texts in here that are from you and you want them to be removed please contact me, and i will do my best to quickly remove them.
TODOS:
- Find more Data to add to train/validation: Goal is around 500 Training and 50 Validation/Testing Captions
- Train a text classification model with the dataset
- Train a text2text or text generation model to generate text in the style of the captions in this dataset
- Optionally Pass in labels/tags/classes to influence the content of the text
|
soopy/cai
|
[
"task_categories:text-generation",
"task_categories:text-classification",
"task_categories:text2text-generation",
"size_categories:n<1K",
"language:en",
"license:mit",
"not-for-all-audiences",
"region:us"
] |
2023-05-30T06:29:39+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-generation", "text-classification", "text2text-generation"], "pretty_name": "captionai", "tags": ["not-for-all-audiences"]}
|
2024-01-03T13:05:27+00:00
|
466978f31aebf4d052287f32ea3ae393f178f386
| ERROR: type should be string, got "\nhttps://github.com/heyunh2015/PARADE_dataset\n\n```\n@inproceedings{he-etal-2020-parade,\n title = \"{PARADE}: {A} {N}ew {D}ataset for {P}araphrase {I}dentification {R}equiring {C}omputer {S}cience {D}omain {K}nowledge\",\n author = \"He, Yun and\n Wang, Zhuoer and\n Zhang, Yin and\n Huang, Ruihong and\n Caverlee, James\",\n booktitle = \"Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)\",\n month = nov,\n year = \"2020\",\n address = \"Online\",\n publisher = \"Association for Computational Linguistics\",\n url = \"https://aclanthology.org/2020.emnlp-main.611\",\n doi = \"10.18653/v1/2020.emnlp-main.611\",\n pages = \"7572--7582\",\n abstract = \"We present a new benchmark dataset called PARADE for paraphrase identification that requires specialized domain knowledge. PARADE contains paraphrases that overlap very little at the lexical and syntactic level but are semantically equivalent based on computer science domain knowledge, as well as non-paraphrases that overlap greatly at the lexical and syntactic level but are not semantically equivalent based on this domain knowledge. Experiments show that both state-of-the-art neural models and non-expert human annotators have poor performance on PARADE. For example, BERT after fine-tuning achieves an F1 score of 0.709, which is much lower than its performance on other paraphrase identification datasets. PARADE can serve as a resource for researchers interested in testing models that incorporate domain knowledge. We make our data and code freely available.\",\n}\n```" |
tasksource/parade
|
[
"task_categories:sentence-similarity",
"task_categories:text-classification",
"language:en",
"region:us"
] |
2023-05-30T06:42:30+00:00
|
{"language": ["en"], "task_categories": ["sentence-similarity", "text-classification"]}
|
2023-05-31T07:20:40+00:00
|
95228143e785a68012f606c024333ee3ac395e6b
|
# Dataset Card for "crime_posts_reddit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Binaryy/crime_posts_reddit
|
[
"region:us"
] |
2023-05-30T06:55:46+00:00
|
{"dataset_info": {"features": [{"name": "posts_name", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 900458, "num_examples": 10765}], "download_size": 508915, "dataset_size": 900458}}
|
2023-05-30T08:50:33+00:00
|
b3e4661d45d1fbe7a5e8e7f95af5e2823ac71a0f
|
WikiQA dataset with answers grouped together for each question.
|
lucadiliello/wikiqa_grouped
|
[
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"region:us"
] |
2023-05-30T07:12:28+00:00
|
{"language": ["en"], "size_categories": ["1K<n<10K"], "task_categories": ["text-classification"], "pretty_name": "WikiQA"}
|
2023-05-30T07:14:53+00:00
|
bbb977b76c8d3edbf4f11bacf437ac5e1cd881b3
|
# Dataset Card for "syn_few0_32500_chat_pvi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
FanChen0116/syn_few0_32500_chat_pvi
|
[
"region:us"
] |
2023-05-30T07:24:10+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": {"class_label": {"names": {"0": "O", "1": "I-time", "2": "B-date", "3": "B-last_name", "4": "B-people", "5": "I-date", "6": "I-people", "7": "I-last_name", "8": "I-first_name", "9": "B-first_name", "10": "B-time"}}}}, {"name": "request_slot", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 3789658, "num_examples": 22156}, {"name": "validation", "num_bytes": 144579, "num_examples": 819}, {"name": "test", "num_bytes": 646729, "num_examples": 3731}], "download_size": 669196, "dataset_size": 4580966}}
|
2023-06-01T15:21:28+00:00
|
916f8042e26f138ba73a12ec0a13cc043a2ef720
|
# Dataset Card for "pretrain_en"
[Tigerbot](https://github.com/TigerResearch/TigerBot) pretrain数据的英文部分。
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/pretrain_en')
```
|
TigerResearch/pretrain_en
|
[
"task_categories:text-generation",
"size_categories:10M<n<100M",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T07:40:36+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10M<n<100M"], "task_categories": ["text-generation"], "dataset_info": {"features": [{"name": "content", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 48490123196, "num_examples": 22690306}], "download_size": 5070161762, "dataset_size": 48490123196}}
|
2023-05-30T09:01:55+00:00
|
e3e7cea5d2a269fd590690d70106fe9e32ca6da8
|
# Low Quality Live Attacks
The dataset includes live-recorded Anti-Spoofing videos from around the world, captured via **low-quality** webcams with resolutions like QVGA, QQVGA and QCIF.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=low_quality_webcam_video_attacks) to discuss your requirements, learn about the price and buy the dataset.

# Webcam Resolution
The collection of different video resolutions is provided, like:
- QVGA (320p x 240p),
- QQVGA (120p x 160p),
- QCIF (176p x 144p) and others.
# Metadata
Each attack instance is accompanied by the following details:
- Unique attack identifier
- Identifier of the user recording the attack
- User's age
- User's gender
- User's country of origin
- Attack resolution
Additionally, the model of the webcam is also specified.
Metadata is represented in the `file_info.csv`.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=low_quality_webcam_video_attacks) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: https://www.kaggle.com/trainingdatapro/datasets
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/low_quality_webcam_video_attacks
|
[
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"finance",
"legal",
"code",
"region:us"
] |
2023-05-30T07:48:08+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["video-classification"], "tags": ["finance", "legal", "code"]}
|
2023-09-14T15:48:24+00:00
|
d0303a48624d3ae0dfbebd32ffb2a3e4c46337fc
|
# Dataset Card for "b6645655"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/b6645655
|
[
"region:us"
] |
2023-05-30T07:48:50+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 184, "num_examples": 10}], "download_size": 1340, "dataset_size": 184}}
|
2023-05-30T07:48:51+00:00
|
0164efe648b3b1dc42ce9612318f2aa78d4f878f
|
# High Definition Live Attacks
The dataset includes live-recorded Anti-Spoofing videos from around the world, captured via **high-quality** webcams with Full HD resolution and above.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=high_quality_webcam_video_attacks) to discuss your requirements, learn about the price and buy the dataset.
.png?generation=1684702390091084&alt=media)
# Webcam Resolution
The collection of different video resolutions from Full HD (1080p) up to 4K (2160p) is provided, including several intermediate resolutions like QHD (1440p)
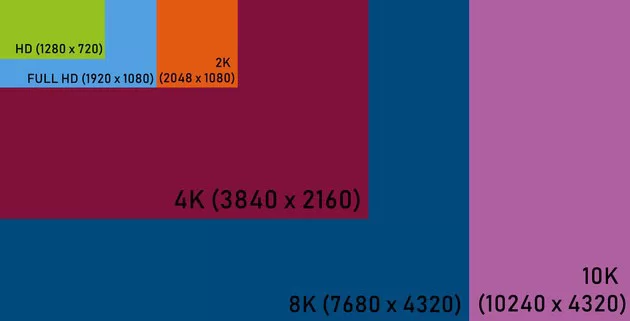
# Metadata
Each attack instance is accompanied by the following details:
- Unique attack identifier
- Identifier of the user recording the attack
- User's age
- User's gender
- User's country of origin
- Attack resolution
Additionally, the model of the webcam is also specified.
Metadata is represented in the `file_info.csv`.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=high_quality_webcam_video_attacks) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/high_quality_webcam_video_attacks
|
[
"task_categories:video-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"finance",
"legal",
"code",
"region:us"
] |
2023-05-30T07:52:17+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["video-classification"], "tags": ["finance", "legal", "code"], "dataset_info": {"features": [{"name": "video_file", "dtype": "string"}, {"name": "assignment_id", "dtype": "string"}, {"name": "worker_id", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "age", "dtype": "uint8"}, {"name": "country", "dtype": "string"}, {"name": "resolution", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1547, "num_examples": 10}], "download_size": 623356178, "dataset_size": 1547}}
|
2023-09-14T15:47:53+00:00
|
c945f2af29efd107ba400976c3237bfcafbad812
|
Tarive/nepact
|
[
"license:openrail",
"region:us"
] |
2023-05-30T08:06:10+00:00
|
{"license": "openrail"}
|
2023-05-30T08:07:12+00:00
|
|
48fd69f2de54025a8a73f95cd580826f8963d95f
|
# Dataset Card for "usummary"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mirfan899/usummary
|
[
"region:us"
] |
2023-05-30T08:12:01+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "summary", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 37261391, "num_examples": 8458}, {"name": "train", "num_bytes": 335094323, "num_examples": 67665}, {"name": "validation", "num_bytes": 37296120, "num_examples": 8458}], "download_size": 191022704, "dataset_size": 409651834}}
|
2023-05-30T08:12:15+00:00
|
0474129486413a7654eab313d2c03532625fa9ae
|
```
@misc{antici2023corpus,
title={A Corpus for Sentence-level Subjectivity Detection on English News Articles},
author={Francesco Antici and Andrea Galassi and Federico Ruggeri and Katerina Korre and Arianna Muti and Alessandra Bardi and Alice Fedotova and Alberto Barrón-Cedeño},
year={2023},
eprint={2305.18034},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
datasheet:
https://www.dropbox.com/sh/pterfc16inz0h7b/AADN9w-O0KTalP48jk2CK36Ha/data?dl=0&preview=datasheet.pdf&subfolder_nav_tracking=1
|
tasksource/subjectivity
|
[
"license:mit",
"arxiv:2305.18034",
"region:us"
] |
2023-05-30T08:15:29+00:00
|
{"license": "mit"}
|
2023-06-02T13:44:17+00:00
|
97af287816937a65facb5b6159136756818c6a7e
|
# Dataset Card for "amazon-shoe-reviews"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Nauryzbek/amazon-shoe-reviews
|
[
"region:us"
] |
2023-05-30T08:31:03+00:00
|
{"dataset_info": {"features": [{"name": "labels", "dtype": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 16847665.2, "num_examples": 90000}, {"name": "test", "num_bytes": 1871962.8, "num_examples": 10000}], "download_size": 11141108, "dataset_size": 18719628.0}}
|
2023-05-30T08:34:08+00:00
|
4dcd1dedbe148307a833c931b21ca456a1fc4281
|
## Guidelines
In this dataset, you will find a collection of records that show a category, an instruction, a context and a response to that instruction. The aim of the project is to correct the instructions, intput and responses to make sure they are of the highest quality and that they match the task category that they belong to. All three texts should be clear and include real information. In addition, the response should be as complete but concise as possible.
To curate the dataset, you will need to provide an answer to the following text fields:
1 - Final instruction:
The final version of the instruction field. You may copy it using the copy icon in the instruction field. Leave it as it is if it's ok or apply any necessary corrections. Remember to change the instruction if it doesn't represent well the task category of the record.
2 - Final context:
The final version of the instruction field. You may copy it using the copy icon in the context field. Leave it as it is if it's ok or apply any necessary corrections. If the task category and instruction don't need of an context to be completed, leave this question blank.
3 - Final response:
The final version of the response field. You may copy it using the copy icon in the response field. Leave it as it is if it's ok or apply any necessary corrections. Check that the response makes sense given all the fields above.
You will need to provide at least an instruction and a response for all records. If you are not sure about a record and you prefer not to provide a response, click Discard.
## Fields
* `id` is of type <class 'str'>
* `category` is of type <class 'str'>
* `original-instruction` is of type <class 'str'>
* `original-context` is of type <class 'str'>
* `original-response` is of type <class 'str'>
## Questions
* `new-instruction` : Write the final version of the instruction, making sure that it matches the task category. If the original instruction is ok, copy and paste it here.
* `new-context` : Write the final version of the context, making sure that it makes sense with the task category. If the original context is ok, copy and paste it here. If an context is not needed, leave this empty.
* `new-response` : Write the final version of the response, making sure that it matches the task category and makes sense for the instruction (and context) provided. If the original response is ok, copy and paste it here.
## Load with Argilla
To load this dataset with Argilla, you'll just need to install Argilla as `pip install argilla --upgrade` and then use the following code:
```python
import argilla as rg
ds = rg.FeedbackDataset.from_huggingface('argilla/databricks-dolly-15k-curated-en')
```
## Load with Datasets
To load this dataset with Datasets, you'll just need to install Datasets as `pip install datasets --upgrade` and then use the following code:
```python
from datasets import load_dataset
ds = load_dataset('argilla/databricks-dolly-15k-curated-en')
```
|
argilla/databricks-dolly-15k-curated-en
|
[
"language:en",
"region:us"
] |
2023-05-30T08:54:44+00:00
|
{"language": ["en"]}
|
2023-10-02T11:32:53+00:00
|
10c5f4d1ea70d045518a6ed5a36df6c56dd94a8a
|
# Dataset Card for CaSET, the Catalan Stance and Emotions Dataset from Twitter
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Point of Contact:** [Language Technologies Unit]([email protected])
### Dataset Summary
The CaSET dataset is a Catalan corpus of Tweets annotated with Emotions, Static Stance, and Dynamic Stance. The dataset contains 11k unique sentences on five controversial topics, grouped in 6k pairs of sentences, paired as parent messages and replies to these messages.
### Supported Tasks and Leaderboards
This dataset can be used to train models for emotion detection, static stance detection, and dynamic stance detection.
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
Each instance in the dataset is a pair of parent-reply messages, annotated with the relation between the two messages (the dynamic stance) and the topic of the messages. For each message there is the id to retrieve it with the Twitter API, the emotions identified in the message, and the relation between the message and the topic (static stance). The text fields have to be retrieved using the Twitter API.
### Data Instances
```
{
"id_parent": "1413960970066710533",
"id_reply": "1413968453690658816",
"parent_text": "",
"reply_text": "",
"topic": "vaccines",
"dynamic_stance": "Disagree",
"parent_stance": "FAVOUR",
"reply_stance": "AGAINST",
"parent_emotion": ["distrust", "joy", "disgust"],
"reply_emotion": ["distrust"]
}
```
### Data Splits
The dataset does not contain splits.
## Dataset Creation
### Curation Rationale
We created this corpus to contribute to the development of language models in Catalan, a low-resource language.
### Source Data
The data was collected using the Twitter API by the Barcelona Supercomputing Center.
#### Initial Data Collection and Normalization
The data was collected based on a list of keywords related to the five topics included in the dataset: vaccines, rent regulation, surrogate pregnancy, airport expansion, and a TV show rigging. Specific periods in which the topic was under discussion were also selected.
#### Who are the source language producers?
The source language producers are users of Twitter.
### Annotations
- Emotions are annotated in a multi-label fashion. The labels can be: Anger, Anticipation, Disgust, Fear, Joy, Sadness, Surprise, Distrust, and No emotion.
CA
- Static stance is annotated per message. The labels can be: FAVOUR, AGAINST, NEUTRAL, NA.
- Dynamic stance is annotated per pair. The labels can be: Agree, Disagree, Elaborate, Query, Neutral, Unrelated, NA.
#### Annotation process
- For emotions there were 3 annotators. The gold labels are an aggregation of all the labels annotated by the 3. The IAA calculated with Fleiss' Kappa per label was, on average, 45.38.
- For static stance there were 2 annotators, in the cases of disagreement a third annotated chose the gold label. The overall Fleiss' Kappa between the 2 annotators is 82.71.
- For dynamic stance there were 4 annotators. If at least 3 of the annotators disagreed, a fifth annotator chose the gold label. The overall Fleiss' Kappa between the 4 annotators was 56.51, and the average Fleiss' Kappa of the annotators with the gold labels is 85.17.
#### Who are the annotators?
All the annotators are native speakers of Catalan.
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
We hope this corpus contributes to the development of language models in Catalan, a low-resource language.
### Discussion of Biases
We are aware that, since the data comes from social media, this will contain biases, hate speech and toxic content. We have not applied any steps to reduce their impact.
### Other Known Limitations
The dataset has to be downloaded using the Twitter API, therefore some instances might be lost.
## Additional Information
### Dataset Curators
Language Technologies Unit (LangTech) at the Barcelona Supercomputing Center.
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Licensing Information
[Creative Commons Attribution 4.0](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
```
@inproceedings{figueras-etal-2023-dynamic,
title = "Dynamic Stance: Modeling Discussions by Labeling the Interactions",
author = "Figueras, Blanca and
Baucells, Irene and
Caselli, Tommaso",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.432",
doi = "10.18653/v1/2023.findings-emnlp.432",
pages = "6503--6515",
}
```
### Contact information
For further information, please send an email to [email protected].
|
projecte-aina/CaSET-catalan-stance-emotions-twitter
|
[
"task_categories:text-classification",
"annotations_creators:Barcelona Supercomputing Center",
"language_creators:Twitter",
"multilinguality:monolingual",
"language:ca",
"license:cc-by-4.0",
"region:us"
] |
2023-05-30T08:56:52+00:00
|
{"annotations_creators": ["Barcelona Supercomputing Center"], "language_creators": ["Twitter"], "language": ["ca"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "task_categories": ["text-classification"], "task_ids": [], "pretty_name": "CaSET"}
|
2023-12-22T14:54:05+00:00
|
9ffdd2ae3e5d0ac58df7728950b0daed7ce16642
|
# Dataset Card for CaSERa, the Catalan Stance and Emotions Dataset from Racó Català
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Point of Contact:** [Language Technologies Unit]([email protected])
### Dataset Summary
The CaSERa dataset is a Catalan corpus from the forum Racó Català annotated with Emotions and Dynamic Stance. The dataset contains 15.782 unique sentences grouped in 10.745 pairs of sentences, paired as parent messages and replies to these messages.
### Supported Tasks and Leaderboards
This dataset can be used to train models for emotion detection and dynamic stance detection tasks.
### Languages
The dataset is in Catalan (`ca-ES`).
## Dataset Structure
Each instance in the dataset is a pair of parent-reply messages annotated with the relation between the two messages (the dynamic stance). For each message there is an individual id and the emotions identified in the message.
### Data Instances
```
{
"id_conversation": "782135",
"id_reply": "782135_2_2",
"parent_text": "Alguns petits apunts que s'haurien de tenir en compte en la creació d'aquesta hipotètica grada jove: -Renúncia total i explícita a la violència, aquest per mi és el punt clau i bàsic que la directiva tindria en compte, sense renúncia no hi ha grup. -Edat de la gent: indispensable establir un mínim i un màxim d'edat per adquirir entrades de la grada jove, s'ha d'acabar amb els freaks de 40-50 anys amb esperit jove i ganes d\'animar (sona discriminatori, però crec que és òbvi que s'ha de limitar l'edat) -Seguretat bàsica: Agradi o no, s'hauria d'incrementar moltíssim la seguretat privada (és un dels punts que no agrada a la directiva). Els indesitjables de sempre no tolerarien cap grada jove sense ells. -Per tant doncs, absteniu-vos i oblideu-vos tots els hooligans potencials (n'hi ha a grapats per tot Catalunya) de crear una grada hooligan amb skins, punkis i resta d'estètiques "característiques", també seria un punt clau (confirmat per un directiu!) En definitiva, ara per ara veig força difícil i inviable la creació d'una grada jove nombrosa i contundent, s'hauria d'optar per opcions més "descafeïnades" rotllo Sang Culé o Dracs.",
"reply_text": "Doncs si es creés una grada jove ja et dic jo que sompliria d'skins, i els primers en entrari serien els Boixos que han expulsat del seu lloc. Tot i aìxò que hi hagin skins no vol dir que hi hagi violència, no crec que es peguessin amb els del mateix equip. Si es creés un grada jove l'ambient al camp nou seria brutal, si 200 Boixos feien bivrar el camp nou, imaginat a 4000 perones o la gent que hi capigués a la grada jove.",
"dynamic_stance": "Elaborate",
"parent_emotion": ["fear", "distrust", "anticipation"],
"reply_emotion": ["anger", "sadness", "fear", "distrust", "anticipation"]
}
```
### Data Splits
The dataset does not contain splits.
## Dataset Creation
### Curation Rationale
We created this corpus to contribute to the development of language models in Catalan, a low-resource language.
### Source Data
The data was collected using the messages of the forum Racó Català by the Barcelona Supercomputing Center.
#### Initial Data Collection and Normalization
The data was collected selecting random messages from 13 of the thematic sections in Racó Català that had at least 15 tokens and at most 300. Then, we kept the messages that had at least one replying message with the same length requirement. We got a maximum of 3 replying messages per parent message.
#### Who are the source language producers?
The source language producers are users of Racó Català.
### Annotations
- Emotions are annotated in a multi-label fashion. The labels can be: Anger, Anticipation, Disgust, Fear, Joy, Sadness, Surprise, Distrust, and No emotion.
- Dynamic stance is annotated per pair. The labels can be: Agree, Disagree, Elaborate, Query, Neutral, Unrelated, NA.
#### Annotation process
- For emotions there were 3 annotators. The gold labels are an aggregation of all the labels annotated by the 3. The IAA calculated with Fleiss' Kappa per label was, on average, 38.73.
- For dynamic stance there were 4 annotators. If at least 3 of the annotators disagreed, a fifth annotator chose the gold label. The overall Fleiss' Kappa between the 4 annotators was 57.63, and the average Fleiss' Kappa of the annotators with the gold labels is 85.98.
#### Who are the annotators?
All the annotators are native speakers of Catalan.
### Personal and Sensitive Information
The data was annonymised to remove user names and emails, which were changed to random Catalan names. The mentions to the chat itself have also been changed.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this corpus contributes to the development of language models in Catalan, a low-resource language.
### Discussion of Biases
We are aware that, since the data comes from a public forum, this will contain biases, hate speech and toxic content. We have not applied any steps to reduce their impact.
### Other Known Limitations
## Additional Information
### Dataset Curators
Language Technologies Unit (LangTech) at the Barcelona Supercomputing Center.
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Licensing Information
[Creative Commons Attribution 4.0](https://creativecommons.org/licenses/by/4.0/).
### Citation Information
```
@inproceedings{figueras-etal-2023-dynamic,
title = "Dynamic Stance: Modeling Discussions by Labeling the Interactions",
author = "Figueras, Blanca and
Baucells, Irene and
Caselli, Tommaso",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.432",
doi = "10.18653/v1/2023.findings-emnlp.432",
pages = "6503--6515",
}
```
### Contact Information
For further information, please send an email to [email protected].
|
projecte-aina/CaSERa-catalan-stance-emotions-raco
|
[
"task_categories:text-classification",
"annotations_creators:Barcelona Supercomputing Center",
"language_creators:Racó Català",
"multilinguality:monolingual",
"language:ca",
"license:cc-by-nc-4.0",
"region:us"
] |
2023-05-30T08:57:50+00:00
|
{"annotations_creators": ["Barcelona Supercomputing Center"], "language_creators": ["Rac\u00f3 Catal\u00e0"], "language": ["ca"], "license": ["cc-by-nc-4.0"], "multilinguality": ["monolingual"], "task_categories": ["text-classification"], "task_ids": [], "pretty_name": "CaSERa"}
|
2023-12-22T14:53:11+00:00
|
8f590eba97f3bf9294c94542f0d2cef12ed09255
|
wzy1990s/sdconfig
|
[
"license:openrail",
"region:us"
] |
2023-05-30T09:03:36+00:00
|
{"license": "openrail"}
|
2023-06-06T10:56:10+00:00
|
|
7826c837aabb60002f6faf4072aebc73ddc34834
|
# Dataset Card for "a77515c4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/a77515c4
|
[
"region:us"
] |
2023-05-30T09:06:20+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 178, "num_examples": 10}], "download_size": 1331, "dataset_size": 178}}
|
2023-05-30T09:06:21+00:00
|
1fbb4ff6ed6ba2a6ec57a1ad9431a01165593443
|
# Dataset Card for "kbis_qa_train03_ph01"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HEN10/kbis_qa_train03_ph01
|
[
"region:us"
] |
2023-05-30T09:08:13+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4062172422.0, "num_examples": 350}], "download_size": 49266315, "dataset_size": 4062172422.0}}
|
2023-05-30T09:08:55+00:00
|
6c7f9971d169c171a2bb8a87fd14b8e6166318b6
|
# Dataset Card for "eli5_mult_answers_en_no_answer_in_context"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
9wimu9/eli5_mult_answers_en_no_answer_in_context
|
[
"region:us"
] |
2023-05-30T09:09:52+00:00
|
{"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "contexts", "sequence": "string"}, {"name": "gold_answer", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 308894070, "num_examples": 71236}, {"name": "test", "num_bytes": 34558419, "num_examples": 7916}], "download_size": 209630607, "dataset_size": 343452489}}
|
2023-05-30T09:28:09+00:00
|
86a823973d7d99ccbb0a4b28e9ac160a6e2da4b8
|
# Dataset Card for "kbis_qa_test03_ph01"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HEN10/kbis_qa_test03_ph01
|
[
"region:us"
] |
2023-05-30T09:11:14+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 812434148.0, "num_examples": 70}], "download_size": 8648105, "dataset_size": 812434148.0}}
|
2023-05-30T09:11:22+00:00
|
6a050187407169c303ed65022be04c84c58a7ae8
|
riyadhiman/riya_database
|
[
"license:mit",
"region:us"
] |
2023-05-30T09:15:34+00:00
|
{"license": "mit"}
|
2023-05-30T09:23:24+00:00
|
|
09c6998d53a3e6c7e0c3ac520fe4f6f63fc19950
|
awyuhka/filemonlinexi
|
[
"license:other",
"region:us"
] |
2023-05-30T09:38:27+00:00
|
{"license": "other"}
|
2023-05-30T09:38:28+00:00
|
|
e1d6b1e5c069c7f3f3aeb8a40a1045271d258db7
|
# Dataset Card for "synth-HTR"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sivan22/synth-HTR
|
[
"region:us"
] |
2023-05-30T09:52:48+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "labels", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2904123997.0, "num_examples": 30000}], "download_size": 0, "dataset_size": 2904123997.0}}
|
2023-05-30T11:30:07+00:00
|
8b37b70af0b7a11d88ec4a7946900326b0e72bd7
|
# Dataset Card for "kaz-data-media-label"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Nauryzbek/kaz-data-media-label
|
[
"region:us"
] |
2023-05-30T09:57:50+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 3651026.450643777, "num_examples": 1258}, {"name": "test", "num_bytes": 406314.5493562232, "num_examples": 140}], "download_size": 1687693, "dataset_size": 4057341.0}}
|
2023-05-30T09:58:02+00:00
|
d12df2618e0273a68e7535a0ff7f65b30c7e82a0
|
muwenxin/bishe
|
[
"license:unknown",
"region:us"
] |
2023-05-30T10:00:42+00:00
|
{"license": "unknown"}
|
2023-05-30T10:30:54+00:00
|
|
1bcda0a282ff9c88c4df0cb44784fd2db020252d
|
# Dataset Card for "validator_38h"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ZLSCompLing/validator_38h
|
[
"region:us"
] |
2023-05-30T10:18:01+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "Unnamed: 0", "dtype": "int64"}, {"name": "transcription", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4941483067.266, "num_examples": 22398}, {"name": "test", "num_bytes": 47511110.0, "num_examples": 239}, {"name": "validation", "num_bytes": 244663633.339, "num_examples": 1193}], "download_size": 4781822310, "dataset_size": 5233657810.605}}
|
2023-05-30T10:26:53+00:00
|
5f899b64920d238801293bf221d46a23652f53ae
|
# Dataset Card for "ah100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Deojoandco/ah100
|
[
"region:us"
] |
2023-05-30T10:20:32+00:00
|
{"dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "num_comments", "dtype": "int64"}, {"name": "name", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "body", "dtype": "string"}, {"name": "score", "dtype": "int64"}, {"name": "upvote_ratio", "dtype": "float64"}, {"name": "distinguished", "dtype": "null"}, {"name": "over_18", "dtype": "bool"}, {"name": "created_utc", "dtype": "float64"}, {"name": "comments", "list": [{"name": "body", "dtype": "string"}, {"name": "created_utc", "dtype": "float64"}, {"name": "distinguished", "dtype": "null"}, {"name": "id", "dtype": "string"}, {"name": "permalink", "dtype": "string"}, {"name": "score", "dtype": "int64"}]}, {"name": "best_num_comments", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 91748, "num_examples": 29}], "download_size": 75134, "dataset_size": 91748}}
|
2023-05-30T10:20:38+00:00
|
ec241cbc1983302a09f48996558279bee699f972
|
# Quiz Datasets for NLP
Question answering (QA) datasets created from Japanese quiz (trivia) questions.
Please refer to [cl-tohoku/quiz-datasets](https://github.com/cl-tohoku/quiz-datasets) for details, as well as the licenses of the question data.
|
tohoku-nlp/quiz-datasets
|
[
"region:us"
] |
2023-05-30T10:23:15+00:00
|
{"dataset_info": [{"config_name": "datasets.jawiki-20220404-c400-small.aio_02", "features": [{"name": "qid", "dtype": "string"}, {"name": "competition", "dtype": "string"}, {"name": "timestamp", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "number", "dtype": "string"}, {"name": "original_question", "dtype": "string"}, {"name": "original_answer", "dtype": "string"}, {"name": "original_additional_info", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": "string"}, {"name": "passages", "sequence": [{"name": "passage_id", "dtype": "int32"}, {"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}]}, {"name": "positive_passage_indices", "sequence": "int32"}, {"name": "negative_passage_indices", "sequence": "int32"}], "splits": [{"name": "train", "num_bytes": 2041349194, "num_examples": 22335}, {"name": "validation", "num_bytes": 91754993, "num_examples": 1000}], "download_size": 805138940, "dataset_size": 2133104187}, {"config_name": "datasets.jawiki-20220404-c400-medium.aio_02", "features": [{"name": "qid", "dtype": "string"}, {"name": "competition", "dtype": "string"}, {"name": "timestamp", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "number", "dtype": "string"}, {"name": "original_question", "dtype": "string"}, {"name": "original_answer", "dtype": "string"}, {"name": "original_additional_info", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": "string"}, {"name": "passages", "sequence": [{"name": "passage_id", "dtype": "int32"}, {"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}]}, {"name": "positive_passage_indices", "sequence": "int32"}, {"name": "negative_passage_indices", "sequence": "int32"}], "splits": [{"name": "train", "num_bytes": 1875144339, "num_examples": 22335}, {"name": "validation", "num_bytes": 84499229, "num_examples": 1000}], "download_size": 723119604, "dataset_size": 1959643568}, {"config_name": "datasets.jawiki-20220404-c400-large.aio_02", "features": [{"name": "qid", "dtype": "string"}, {"name": "competition", "dtype": "string"}, {"name": "timestamp", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "number", "dtype": "string"}, {"name": "original_question", "dtype": "string"}, {"name": "original_answer", "dtype": "string"}, {"name": "original_additional_info", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": "string"}, {"name": "passages", "sequence": [{"name": "passage_id", "dtype": "int32"}, {"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}]}, {"name": "positive_passage_indices", "sequence": "int32"}, {"name": "negative_passage_indices", "sequence": "int32"}], "splits": [{"name": "train", "num_bytes": 1743060319, "num_examples": 22335}, {"name": "validation", "num_bytes": 78679502, "num_examples": 1000}], "download_size": 665253451, "dataset_size": 1821739821}, {"config_name": "passages.jawiki-20220404-c400-small", "features": [{"name": "id", "dtype": "int32"}, {"name": "pageid", "dtype": "int32"}, {"name": "revid", "dtype": "int32"}, {"name": "text", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 348002946, "num_examples": 394124}], "download_size": 121809648, "dataset_size": 348002946}, {"config_name": "passages.jawiki-20220404-c400-medium", "features": [{"name": "id", "dtype": "int32"}, {"name": "pageid", "dtype": "int32"}, {"name": "revid", "dtype": "int32"}, {"name": "text", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1322478989, "num_examples": 1678986}], "download_size": 469426075, "dataset_size": 1322478989}, {"config_name": "passages.jawiki-20220404-c400-large", "features": [{"name": "id", "dtype": "int32"}, {"name": "pageid", "dtype": "int32"}, {"name": "revid", "dtype": "int32"}, {"name": "text", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3054493919, "num_examples": 4288198}], "download_size": 1110830651, "dataset_size": 3054493919}, {"config_name": "datasets.no_passages.aio_02", "features": [{"name": "qid", "dtype": "string"}, {"name": "competition", "dtype": "string"}, {"name": "timestamp", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "number", "dtype": "string"}, {"name": "original_question", "dtype": "string"}, {"name": "original_answer", "dtype": "string"}, {"name": "original_additional_info", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 9464003, "num_examples": 22335}, {"name": "validation", "num_bytes": 409779, "num_examples": 1000}], "download_size": 2267163, "dataset_size": 9873782}]}
|
2023-05-30T11:27:33+00:00
|
d729f1e66fbda7b1d7f9d0682ec7ec37a4506395
|
# Dataset Card for "kbis_qa_train03_ph02"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HEN10/kbis_qa_train03_ph02
|
[
"region:us"
] |
2023-05-30T10:25:08+00:00
|
{"dataset_info": {"features": [{"name": "image", "sequence": {"sequence": {"sequence": "uint8"}}}, {"name": "input_ids", "sequence": "int32"}, {"name": "token_type_ids", "sequence": "int8"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "bbox", "sequence": {"sequence": "int64"}}, {"name": "start_positions", "dtype": "int64"}, {"name": "end_positions", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 61168800, "num_examples": 350}], "download_size": 3132705, "dataset_size": 61168800}}
|
2023-05-30T10:25:11+00:00
|
8afe8963ee3169278e739d7ed124ac44f88c2dae
|
# Dataset Card for "kbis_qa_test03_ph02"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HEN10/kbis_qa_test03_ph02
|
[
"region:us"
] |
2023-05-30T10:25:11+00:00
|
{"dataset_info": {"features": [{"name": "image", "sequence": {"sequence": {"sequence": "uint8"}}}, {"name": "input_ids", "sequence": "int32"}, {"name": "token_type_ids", "sequence": "int8"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "bbox", "sequence": {"sequence": "int64"}}, {"name": "start_positions", "dtype": "int64"}, {"name": "end_positions", "dtype": "int64"}], "splits": [{"name": "test", "num_bytes": 12233760, "num_examples": 70}], "download_size": 630452, "dataset_size": 12233760}}
|
2023-05-30T10:25:13+00:00
|
1d3e080f7a2d437d8fb1f55270c3c7c9db7ab1c9
|
bavest/fin-llama-dataset
|
[
"license:bigscience-openrail-m",
"region:us"
] |
2023-05-30T10:36:16+00:00
|
{"license": "bigscience-openrail-m"}
|
2023-05-31T08:06:46+00:00
|
|
f932c5f0d0003d483069982f489939d161710a8c
|
# Dataset Card for "286ef489"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/286ef489
|
[
"region:us"
] |
2023-05-30T11:22:27+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 178, "num_examples": 10}], "download_size": 1340, "dataset_size": 178}}
|
2023-05-30T11:22:28+00:00
|
2c53f5ab9ac46c94164965c6b3432d0c932ef7d2
|
# ParaNMTDetox: Detoxification with Parallel Data (English)
This repository contains information about filtered [ParaNMT](https://aclanthology.org/P18-1042/) dataset for text detoxification task. Here, we have paraphrasing pairs where one text is toxic and another is non-toxic. Toxicity levels were defined by English toxicity [classifier](https://huggingface.co/s-nlp/roberta_toxicity_classifier).
The original paper ["ParaDetox: Detoxification with Parallel Data"](https://aclanthology.org/2022.acl-long.469/) with SOTA text detoxification was presented at ACL 2022 main conference.
## ParaNMTDetox Filtering Pipeline
The ParaNMT filtering for text detoxiifcation was done by adapting [ParaDetox](https://huggingface.co/datasets/s-nlp/paradetox) Dataset collection [Yandex.Toloka](https://toloka.yandex.com/) crowdsource platform. The filtering was done in three steps:
* *Task 1:* **Content Preservation Check**: We show users the generated paraphrases along with their original variants and ask them to indicate if they have close meanings.
* *Task 2:* **Toxicity Check**: Finally, we check if the workers succeeded in removing toxicity.
## Citation
```
@inproceedings{logacheva-etal-2022-paradetox,
title = "{P}ara{D}etox: Detoxification with Parallel Data",
author = "Logacheva, Varvara and
Dementieva, Daryna and
Ustyantsev, Sergey and
Moskovskiy, Daniil and
Dale, David and
Krotova, Irina and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.469",
pages = "6804--6818",
abstract = "We present a novel pipeline for the collection of parallel data for the detoxification task. We collect non-toxic paraphrases for over 10,000 English toxic sentences. We also show that this pipeline can be used to distill a large existing corpus of paraphrases to get toxic-neutral sentence pairs. We release two parallel corpora which can be used for the training of detoxification models. To the best of our knowledge, these are the first parallel datasets for this task.We describe our pipeline in detail to make it fast to set up for a new language or domain, thus contributing to faster and easier development of new parallel resources.We train several detoxification models on the collected data and compare them with several baselines and state-of-the-art unsupervised approaches. We conduct both automatic and manual evaluations. All models trained on parallel data outperform the state-of-the-art unsupervised models by a large margin. This suggests that our novel datasets can boost the performance of detoxification systems.",
}
```
## Contacts
If you find some issue, do not hesitate to add it to [Github Issues](https://github.com/skoltech-nlp/paradetox/issues).
For any questions, please contact: Daryna Dementieva ([email protected])
|
s-nlp/paranmt_for_detox
|
[
"task_categories:text-generation",
"language:en",
"license:openrail++",
"region:us"
] |
2023-05-30T11:23:16+00:00
|
{"language": ["en"], "license": "openrail++", "task_categories": ["text-generation"]}
|
2023-09-08T07:35:36+00:00
|
f5fda442bffab2d01cac3d9f8da2033f6cb04db6
|
# Dataset Card for "voxelgym_5c_42x42_50000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Cubpaw/voxelgym_5c_42x42_50000
|
[
"region:us"
] |
2023-05-30T11:31:28+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": "image"}, {"name": "rgb_label", "dtype": "image"}, {"name": "path_label", "dtype": "image"}, {"name": "path_rgb_label", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 36592800.0, "num_examples": 40000}, {"name": "validation", "num_bytes": 9160230.0, "num_examples": 10000}], "download_size": 34264797, "dataset_size": 45753030.0}}
|
2023-05-30T11:32:19+00:00
|
4f47b59ce559c18d27a3cfc5fc62c44898c063ff
|
pablosssss/btcpub
|
[
"license:gpl",
"region:us"
] |
2023-05-30T11:33:44+00:00
|
{"license": "gpl"}
|
2023-05-30T11:33:45+00:00
|
|
3f21abc36bdaba7c9e662206827ba497a9692050
|
# Dataset Card for Dataset Name
## Dataset Description
- Homepage: https://www.kaggle.com/datasets/disisbig/hindi-text-short-and-large-summarization-corpus?select=test.csv
### Dataset Summary
Hindi Text Short and Large Summarization Corpus is a collection of ~180k articles with their headlines and summary collected from Hindi News Websites.
This is a first of its kind Dataset in Hindi which can be used to benchmark models for Text summarization in Hindi. This does not contain articles contained in Hindi Text Short Summarization Corpus which is being released parallely with this Dataset.
The dataset retains original punctuation, numbers etc in the articles.
### Languages
The language is Hindi.
### Licensing Information
MIT
### Citation Information
https://www.kaggle.com/datasets/disisbig/hindi-text-short-and-large-summarization-corpus?select=test.csv
### Contributions
|
Someman/hindi-summarization
|
[
"task_categories:summarization",
"size_categories:10K<n<100K",
"language:hi",
"license:mit",
"region:us"
] |
2023-05-30T11:39:11+00:00
|
{"language": "hi", "license": "mit", "size_categories": ["10K<n<100K"], "task_categories": ["summarization"], "pretty_name": "hindi summarization", "original_source": "https://www.kaggle.com/datasets/disisbig/hindi-text-short-and-large-summarization-corpus", "dataset_info": {"features": [{"name": "headline", "dtype": "string"}, {"name": "summary", "dtype": "string"}, {"name": "article", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 410722079.5542422, "num_examples": 55226}, {"name": "test", "num_bytes": 102684238.44575782, "num_examples": 13807}, {"name": "valid", "num_bytes": 128376473, "num_examples": 17265}], "download_size": 150571314, "dataset_size": 641782791}}
|
2023-05-30T11:55:13+00:00
|
000162b4ed5749f4d4974dfaaaee8714a1d654f0
|
Ranjan22/Marvel_Characters_Face_Data
|
[
"license:odc-by",
"region:us"
] |
2023-05-30T11:48:46+00:00
|
{"license": "odc-by"}
|
2023-05-30T12:12:58+00:00
|
|
8993d6f6b2858fb6cb889a8e94cfdbbba4135183
|
dineshpatil341341/demo
|
[
"license:c-uda",
"region:us"
] |
2023-05-30T11:50:04+00:00
|
{"license": "c-uda"}
|
2023-05-30T11:50:04+00:00
|
|
f381ab19261dddb4f38db9bb0a683dc0c5329f8d
|
Marenz/crowdset
|
[
"license:cc0-1.0",
"region:us"
] |
2023-05-30T11:52:42+00:00
|
{"license": "cc0-1.0"}
|
2023-05-30T11:52:42+00:00
|
|
bcd4cba32fefc7aac3cc65f751b862d2e8c2bfb5
|
# Socio-Moral Image Database
This is a duplicate of the [Socio-Moral Image Database](https://osf.io/2rqad/) (SMID) presented in [The Socio-Moral Image Database (SMID): A novel stimulus set for the study of social, moral and affective processes](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0190954).
The dataset includes a set of images in the ```images``` directory along with all relevant meta data in ```metadata.csv```
## Abstract
A major obstacle for the design of rigorous, reproducible studies in moral psychology is the lack of suitable stimulus sets. Here, we present the Socio-Moral Image Database (SMID), the largest standardized moral stimulus set assembled to date, containing 2,941 freely available photographic images, representing a wide range of morally (and affectively) positive, negative and neutral content. The SMID was validated with over 820,525 individual judgments from 2,716 participants, with normative ratings currently available for all images on affective valence and arousal, moral wrongness, and relevance to each of the five moral values posited by Moral Foundations Theory. We present a thorough analysis of the SMID regarding (1) inter-rater consensus, (2) rating precision, and (3) breadth and variability of moral content. Additionally, we provide recommendations for use aimed at efficient study design and reproducibility, and outline planned extensions to the database. We anticipate that the SMID will serve as a useful resource for psychological, neuroscientific and computational (e.g., natural language processing or computer vision) investigations of social, moral and affective processes. The SMID images, along with associated normative data and additional resources are available at
|
AIML-TUDA/smid
|
[
"language:en",
"license:cc-by-4.0",
"region:us"
] |
2023-05-30T11:54:27+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "pretty_name": "Socio-Moral Image Database"}
|
2023-06-01T08:48:04+00:00
|
1a7b7766b2f6830b7471e38c337eee7c7236a2e7
|
# Dataset Card for "VUAC"
```
@article{steen2010method,
title={A method for linguistic metaphor identification},
author={Steen, Gerard and Dorst, Aletta G and Herrmann, J Berenike and Kaal, Anna and Krennmayr, Tina and Pasma, Trijntje},
journal={Amsterdam: Benjamins},
year={2010}
}
```
|
tasksource/VUAC
|
[
"region:us"
] |
2023-05-30T12:11:23+00:00
|
{"dataset_info": {"features": [{"name": "label", "dtype": "string"}, {"name": "expression", "dtype": "string"}, {"name": "dataset", "dtype": "string"}, {"name": "position", "sequence": "int32"}, {"name": "id", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "previous_sentence", "dtype": "string"}, {"name": "next_sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5671035, "num_examples": 14929}, {"name": "validation", "num_bytes": 866481, "num_examples": 2311}, {"name": "test", "num_bytes": 2054321, "num_examples": 5873}], "download_size": 4444711, "dataset_size": 8591837}}
|
2023-05-30T12:35:45+00:00
|
69e6baed2fe03e9618f4785cc985fcd15676c834
|
http://natlang.cs.sfu.ca/software/trofi.html
```
@inproceedings{birke-sarkar-2007-active,
title = "Active Learning for the Identification of Nonliteral Language",
author = "Birke, Julia and
Sarkar, Anoop",
booktitle = "Proceedings of the Workshop on Computational Approaches to Figurative Language",
month = apr,
year = "2007",
address = "Rochester, New York",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W07-0104",
pages = "21--28",
}
```
|
tasksource/TroFi
|
[
"language:en",
"license:gpl",
"region:us"
] |
2023-05-30T12:11:32+00:00
|
{"language": ["en"], "license": "gpl"}
|
2023-05-31T10:32:21+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.