
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
8991746993241cb05c6e57f0270b969e78597dfb
|
```
@inproceedings{mohammad-etal-2016-metaphor,
title = "Metaphor as a Medium for Emotion: An Empirical Study",
author = "Mohammad, Saif and
Shutova, Ekaterina and
Turney, Peter",
booktitle = "Proceedings of the Fifth Joint Conference on Lexical and Computational Semantics",
month = aug,
year = "2016",
address = "Berlin, Germany",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/S16-2003",
doi = "10.18653/v1/S16-2003",
pages = "23--33",
}
```
|
tasksource/MOH
|
[
"language:en",
"region:us"
] |
2023-05-30T12:11:46+00:00
|
{"language": ["en"]}
|
2023-05-30T12:33:03+00:00
|
0b26cd45832c21a229044d9d20ea3af412dc00d9
|
https://github.com/yunx-z/MOVER
```
@inproceedings{zhang-wan-2022-mover,
title = "{MOVER}: Mask, Over-generate and Rank for Hyperbole Generation",
author = "Zhang, Yunxiang and
Wan, Xiaojun",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.440",
doi = "10.18653/v1/2022.naacl-main.440",
pages = "6018--6030",
abstract = "Despite being a common figure of speech, hyperbole is under-researched in Figurative Language Processing. In this paper, we tackle the challenging task of hyperbole generation to transfer a literal sentence into its hyperbolic paraphrase. To address the lack of available hyperbolic sentences, we construct HYPO-XL, the first large-scale English hyperbole corpus containing 17,862 hyperbolic sentences in a non-trivial way. Based on our corpus, we propose an unsupervised method for hyperbole generation that does not require parallel literal-hyperbole pairs. During training, we fine-tune BART to infill masked hyperbolic spans of sentences from HYPO-XL. During inference, we mask part of an input literal sentence and over-generate multiple possible hyperbolic versions. Then a BERT-based ranker selects the best candidate by hyperbolicity and paraphrase quality. Automatic and human evaluation results show that our model is effective at generating hyperbolic paraphrase sentences and outperforms several baseline systems.",
}
```
|
tasksource/HYPO-L
|
[
"task_categories:text-classification",
"language:en",
"license:mit",
"hyperbola",
"exageration",
"region:us"
] |
2023-05-30T12:24:25+00:00
|
{"language": ["en"], "license": "mit", "task_categories": ["text-classification"], "tags": ["hyperbola", "exageration"]}
|
2023-05-31T10:34:17+00:00
|
de6e18c3c0859468da3af07c989ab10f85ad6c94
|
# Dataset Card for "dataset_combined_3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
michalby24/dataset_combined_3
|
[
"region:us"
] |
2023-05-30T12:31:25+00:00
|
{"dataset_info": {"features": [{"name": "client_id", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "audio", "dtype": {"audio": {"sampling_rate": 48000}}}, {"name": "sentence", "dtype": "string"}, {"name": "up_votes", "dtype": "int64"}, {"name": "down_votes", "dtype": "int64"}, {"name": "age", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "accent", "dtype": "string"}, {"name": "locale", "dtype": "string"}, {"name": "segment", "dtype": "string"}, {"name": "language", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1714220128.398, "num_examples": 39509}], "download_size": 1326264043, "dataset_size": 1714220128.398}}
|
2023-05-30T12:33:28+00:00
|
a1eff9d1e794caeb6da924955bfa8d8e0961528b
|
# Dataset Card for "dataset_combined_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
michalby24/dataset_combined_2
|
[
"region:us"
] |
2023-05-30T12:40:30+00:00
|
{"dataset_info": {"features": [{"name": "client_id", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "audio", "dtype": {"audio": {"sampling_rate": 48000}}}, {"name": "sentence", "dtype": "string"}, {"name": "up_votes", "dtype": "int64"}, {"name": "down_votes", "dtype": "int64"}, {"name": "age", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "accent", "dtype": "string"}, {"name": "locale", "dtype": "string"}, {"name": "segment", "dtype": "string"}, {"name": "language", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1418468696.398, "num_examples": 39509}], "download_size": 1326275005, "dataset_size": 1418468696.398}}
|
2023-05-30T12:44:01+00:00
|
039fa40eb1d5fa27372bd5712bd01a78e281454c
|
# Dataset Card for DUQA
## Table of Contents
- [Dataset Description](#dataset-description)
* [Abstract](#abstract)
* [Languages](#languages)
- [Dataset Structure](#dataset-structure)
* [Data Instances](#data-instances)
* [Data Fields](#data-fields)
- [Data Statistics](#data-statistics)
- [Dataset Creation](#dataset-creation)
* [Curation Rationale](#curation-rationale)
* [Source Data](#source-data)
* [Annotations](#annotations)
- [Considerations for Using the Data](#considerations-for-using-the-data)
* [Discussion of Social Impact and Biases](#discussion-of-social-impact-and-biases)
* [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
* [Dataset Curators](#dataset-curators)
* [Licensing Information](#licensing-information)
* [Citation Information](#citation-information)
## Dataset Description
### Abstract
DUQA is a dataset for single-step unit conversion questions. It comes in three sizes, ”DUQA10k”, ”DUQA100k” and ”DUQA1M”, with 10,000, 100,000 and 1,000,000 entries respectively. Each size contains a mixture of basic and complex conversion questions, including simple conversion, multiple answer, max/min, argmax/argmin, and noisy/q-noisy questions. The complexity level varies based on the amount of information present in the sentence and the number of reasoning steps required to calculate a correct answer.
### Languages
The text in the dataset is in English.
## Dataset Structure
### Data Instances
A single instance in the dataset consists of a question related to a single-step unit conversion problem, along with its corresponding correct answer.
### Data Fields
The dataset contains fields for the question, answer, and additional context about the question, along with multiple choices answers.
## Data Statistics
The dataset comes in three sizes, with 10,000, 100,000 and 1,000,000 entries respectively.
## Dataset Creation
### Curation Rationale
The dataset is curated to help machine learning models understand and perform single-step unit conversions. This ability is essential for many real-world applications, including but not limited to physical sciences, engineering, and data analysis tasks.
### Source Data
The source data for the dataset is generated using a Python library provided with the dataset, which can create new datasets from a list of templates.
### Annotations
The dataset does not contain any annotations.
## Considerations for Using the Data
### Discussion of Social Impact and Biases
The dataset is neutral and does not contain any explicit biases or social implications as it deals primarily with mathematical conversion problems.
### Other Known Limitations
The complexity of the questions is limited to single-step unit conversions. It does not cover multi-step or more complex unit conversion problems.
## Additional Information
### Dataset Curators
The dataset was created by a team of researchers. More information might be needed to provide specific names or organizations.
### Licensing Information
The licensing information for this dataset is not provided. Please consult the dataset provider for more details.
### Citation Information
The citation information for this dataset is not provided. Please consult the dataset provider for more details.
|
nattiey1/diverse-unit-QA
|
[
"task_categories:question-answering",
"size_categories:100K<n<1M",
"region:us"
] |
2023-05-30T13:01:55+00:00
|
{"size_categories": ["100K<n<1M"], "task_categories": ["question-answering"]}
|
2023-05-31T06:51:28+00:00
|
fba19ffac26c8f796aa2a822a8f8977113c98248
|
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [Huggingface Dataset](https://huggingface.co/datasets/speech_commands)
- **Paper:** [Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition](https://www.researchgate.net/publication/324435399_Speech_Commands_A_Dataset_for_Limited-Vocabulary_Speech_Recognition)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [speech_commands dataset](https://huggingface.co/datasets/speech_commands).
It provides predicted labels, their annotations and embeddings, trained with Huggingface's AutoModel and
AutoFeatureExtractor. If you would like to have a closer look at the dataset and model's performance, you can use Spotlight by Renumics to find complex sub-relationships between classes.
### Explore the Dataset
<!-- 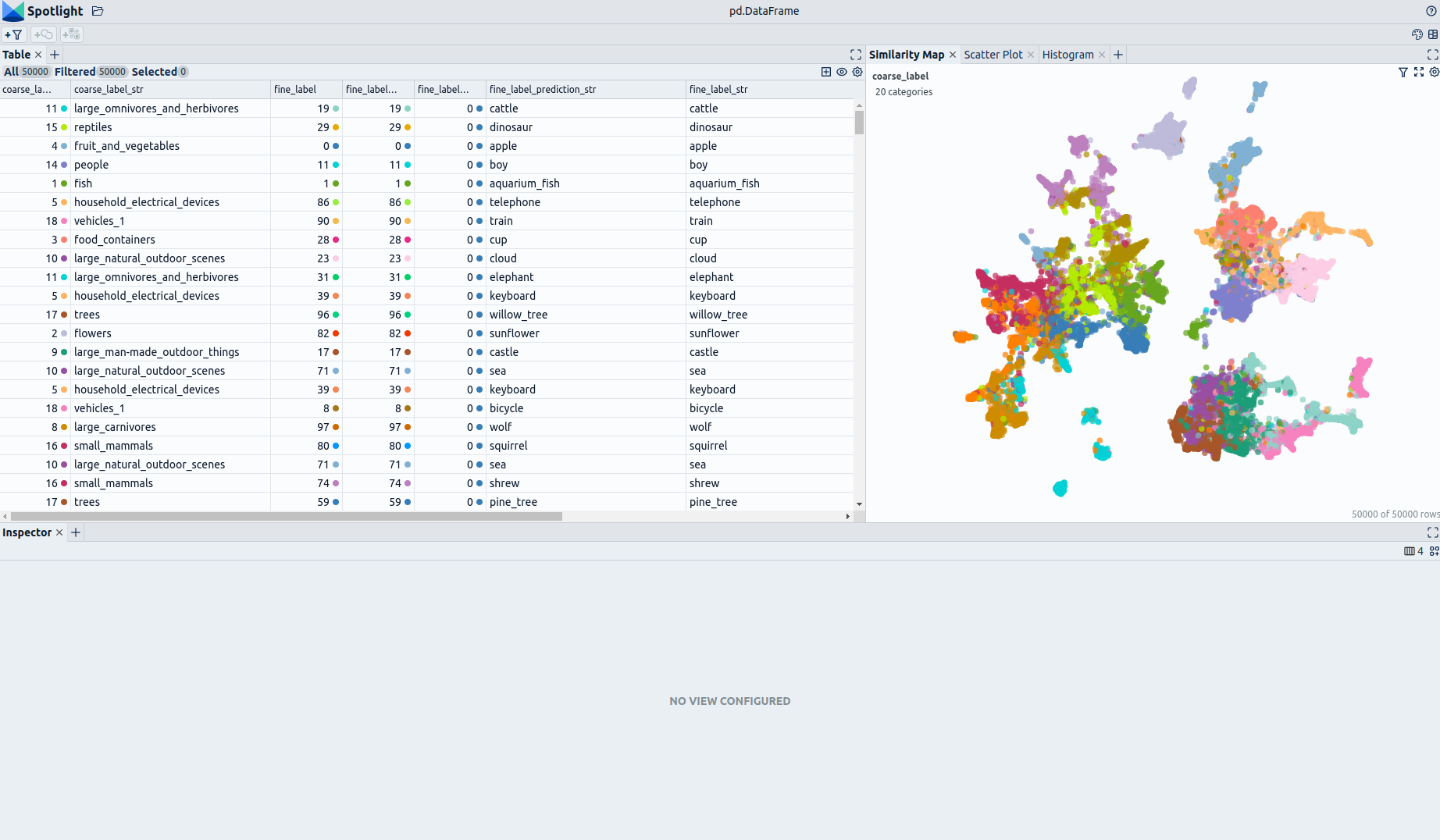 -->
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("soerenray/speech_commands_enriched_and_annotated", split="train")
```
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'logits'])
spotlight.show(df_show, port=8000, dtype={"audio": spotlight.Audio, "embedding_reduced": spotlight.Embedding})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### Speech commands Dataset
The speech commands dataset consists of 60,973 samples in 30 classes (with an additional silence class).
The classes are completely mutually exclusive. It was designed to evaluate keyword spotting models.
We have enriched the dataset by adding **audio embeddings** generated with a [MIT's AST](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2).
Here is the list of classes in the speech commands:
| Class |
|---------------------------------|
| "Yes" |
| "No" |
| "Up" |
| "Down" |
| "Left" |
| "Right" |
| "On" |
| "Off" |
| "Stop" |
| "Go" |
| "Zero" |
| "One" |
| "Two" |
| "Three" |
| "Four" |
| "Five" |
| "Six" |
| "Seven" |
| "Eight" |
| "Nine" |
| "Bed" |
| "Bird"|
| "Cat"|
| "Dog"|
| "Happy"|
| "House"|
| "Marvin"|
| "Sheila"|
| "Tree"|
| "Wow"|
### Supported Tasks and Leaderboards
- `TensorFlow Speech Recognition Challenge`: The goal of this task is to build a speech detector. The leaderboard is available [here](https://www.kaggle.com/c/tensorflow-speech-recognition-challenge).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the dataset is provided below:
```python
{
"audio": {
"path":'bed/4a294341_nohash_0.wav',
"array": array([0.00126146 0.00647549 0.01160542 ... 0.00740056 0.00798924 0.00504583]),
"sampling_rate": 16000
},
"label": 20, # "bed"
"is_unknown": True,
"speaker_id": "4a294341",
"utterance_id": 0,
"logits": array([-9.341216087341309, -10.528160095214844, -8.605941772460938, ..., -9.13764476776123,
-9.4379243850708, -9.254714012145996]),
"Probability": 0.99669,
"Predicted Label": "bed",
"Annotated Labels": "bed",
"embedding": array([ 1.5327608585357666, -3.3523001670837402, 2.5896875858306885, ..., 0.1423477828502655,
2.0368740558624268, 0.6912304759025574]),
"embedding_reduced": array([-5.691406726837158, -0.15976890921592712])
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|------------------------------------------------|
|audio| Audio(sampling_rate=16000, mono=True, decode=True, id=None)|
| label| Value(dtype='int64', id=None)|
| is_unknown| Value(dtype='bool', id=None)|
| speaker_id| Value(dtype='string', id=None)|
| utterance_id| Value(dtype='int8', id=None)|
| logits| Sequence(feature=Value(dtype='float32', id=None), length=35, id=None)|
| Probability| Value(dtype='float64', id=None)|
| Predicted Label| Value(dtype='string', id=None)|
| Annotated Labels| Value(dtype='string', id=None)|
| embedding| Sequence(feature=Value(dtype='float32', id=None), length=768, id=None)|
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{speechcommandsv2,
author = { {Warden}, P.},
title = "{Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition}",
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprint = {1804.03209},
primaryClass = "cs.CL",
keywords = {Computer Science - Computation and Language, Computer Science - Human-Computer Interaction},
year = 2018,
month = apr,
url = {https://arxiv.org/abs/1804.03209},
}
```
### Contributions
Pete Warden and Soeren Raymond(Renumics GmbH).
|
soerenray/speech_commands_enriched_and_annotated
|
[
"license:openrail",
"arxiv:1804.03209",
"region:us"
] |
2023-05-30T13:03:21+00:00
|
{"license": "openrail", "dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "label", "dtype": "int64"}, {"name": "is_unknown", "dtype": "bool"}, {"name": "speaker_id", "dtype": "string"}, {"name": "utterance_id", "dtype": "int8"}, {"name": "logits", "sequence": "float32"}, {"name": "Probability", "dtype": "float64"}, {"name": "Predicted Label", "dtype": "string"}, {"name": "Annotated Labels", "dtype": "string"}, {"name": "embedding", "sequence": "float32"}, {"name": "embedding_reduced", "sequence": "float64"}], "splits": [{"name": "train", "num_bytes": 1774663023.432, "num_examples": 51093}], "download_size": 1701177850, "dataset_size": 1774663023.432}}
|
2023-07-31T12:25:33+00:00
|
aa3a377d68c5863840db744c79700cff309e3a91
|
https://github.com/Strong-AI-Lab/Multi-Step-Deductive-Reasoning-Over-Natural-Language
```
@inproceedings{bao2022multi,
title={Multi-Step Deductive Reasoning Over Natural Language: An Empirical Study on Out-of-Distribution Generalisation},
author={Qiming Bao and Alex Yuxuan Peng and Tim Hartill and Neset Tan and Zhenyun Deng and Michael Witbrock and Jiamou Liu},
year={2022},
publisher={The 2nd International Joint Conference on Learning and Reasoning and 16th International Workshop on Neural-Symbolic Learning and Reasoning (IJCLR-NeSy 2022)}
}
```
|
tasksource/conceptrules_v2
|
[
"language:en",
"license:mit",
"region:us"
] |
2023-05-30T13:07:44+00:00
|
{"language": ["en"], "license": "mit"}
|
2023-05-31T07:16:14+00:00
|
34acd9cc5eb1f9855d3485c7783f28a235dd87bd
|
Dataset card for the dataset used in :
## Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect?
Paper: https://gitlab.inria.fr/wantoun/robust-chatgpt-detection/-/raw/main/towards_chatgpt_detection.pdf
Source Code: https://gitlab.inria.fr/wantoun/robust-chatgpt-detection
## Dataset Summary
#### overview:
This dataset is made of two parts:
- First, an extension of the [Human ChatGPT Comparison Corpus (HC3) dataset](https://huggingface.co/datasets/Hello-SimpleAI/HC3) with French data automatically translated from the English source.
- Second, out-of-domain and adversarial French data set have been gathereed (Human adversarial, BingGPT, Native French ChatGPT responses).
#### Details:
- We first format the data into three subsets: `sentence`, `question` and `full` following the original paper.
- We then extend the data by translating the English questions and answers to French.
- We provide native French ChatGPT responses to a sample of the translated questions.
- We added a subset with QA pairs from BingGPT
- We included an adversarial subset with human-written answers in the style of conversational LLMs like Bing/ChatGPT.
## Available Subsets
### Out-of-domain:
- `hc3_fr_qa_chatgpt`: Translated French questions and native French ChatGPT answers pairs from HC3. This is the `ChatGPT-Native` subset from the paper.
- Features: `id`, `question`, `answer`, `chatgpt_answer`, `label`, `source`
- Size:
- test: `113` examples, `25592` words
- `qa_fr_binggpt`: French questions and BingGPT answers pairs. This is the `BingGPT` subset from the paper.
- Features: `id`, `question`, `answer`, `label`, `deleted_clues`, `deleted_sources`, `remarks`
- Size:
- test: `106` examples, `26291` words
- `qa_fr_binglikehuman`: French questions and human written BingGPT-like answers pairs. This is the `Adversarial` subset from the paper.
- Features: `id`, `question`, `answer`, `label`, `source`
- Size:
- test: `61` examples, `17328` words
- `faq_fr_gouv`: French FAQ questions and answers pairs from domain ending with `.gouv` from the MQA dataset (subset 'fr-faq-page'). https://huggingface.co/datasets/clips/mqa. This is the `FAQ-Gouv` subset from the paper.
- Features: `id`, `page_id`, `question_id`, `answer_id`, `bucket`, `domain`, `question`, `answer`, `label`
- Size:
- test: `235` examples, `22336` words
- `faq_fr_random`: French FAQ questions and answers pairs from random domain from the MQA dataset (subset 'fr-faq-page'). https://huggingface.co/datasets/clips/mqa. This is the `FAQ-Rand` subset from the paper.
- Features: `id`, `page_id`, `question_id`, `answer_id`, `bucket`, `domain`, `question`, `answer`, `label`
- Size:
- test: `4454` examples, `271823` words
### In-domain:
- `hc3_en_qa`: English questions and answers pairs from HC3.
- Features: `id`, `question`, `answer`, `label`, `source`
- Size:
- train: `68335` examples, `12306363` words
- validation: `17114` examples, `3089634` words
- test: `710` examples, `117001` words
- `hc3_en_sentence`: English answers split into sentences from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `455320` examples, `9983784` words
- validation: `113830` examples, `2510290` words
- test: `4366` examples, `99965` words
- `hc3_en_full`: English questions and answers pairs concatenated from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `68335` examples, `9982863` words
- validation: `17114` examples, `2510058` words
- test: `710` examples, `99926` words
- `hc3_fr_qa`: Translated French questions and answers pairs from HC3.
- Features: `id`, `question`, `answer`, `label`, `source`
- Size:
- train: `68283` examples, `12660717` words
- validation: `17107` examples, `3179128` words
- test: `710` examples, `127193` words
- `hc3_fr_sentence`: Translated French answers split into sentences from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `464885` examples, `10189606` words
- validation: `116524` examples, `2563258` words
- test: `4366` examples, `108374` words
- `hc3_fr_full`: Translated French questions and answers pairs concatenated from HC3.
- Features: `id`, `text`, `label`, `source`
- Size:
- train: `68283` examples, `10188669` words
- validation: `17107` examples, `2563037` words
- test: `710` examples, `108352` words
## How to load
```python
from datasets import load_dataset
dataset = load_dataset("almanach/hc3_multi", "hc3_fr_qa")
```
## Dataset Copyright
If the source datasets used in this corpus has a specific license which is stricter than CC-BY-SA, our products follow the same.
If not, they follow CC-BY-SA license.
| English Split | Source | Source License | Note |
|----------|-------------|--------|-------------|
| reddit_eli5 | [ELI5](https://github.com/facebookresearch/ELI5) | BSD License | |
| open_qa | [WikiQA](https://www.microsoft.com/en-us/download/details.aspx?id=52419) | [PWC Custom](https://paperswithcode.com/datasets/license) | |
| wiki_csai | Wikipedia | CC-BY-SA | | [Wiki FAQ](https://en.wikipedia.org/wiki/Wikipedia:FAQ/Copyright) |
| medicine | [Medical Dialog](https://github.com/UCSD-AI4H/Medical-Dialogue-System) | Unknown| [Asking](https://github.com/UCSD-AI4H/Medical-Dialogue-System/issues/10)|
| finance | [FiQA](https://paperswithcode.com/dataset/fiqa-1) | Unknown | Asking by 📧 |
| FAQ | [MQA]( https://huggingface.co/datasets/clips/mqa) | CC0 1.0| |
| ChatGPT/BingGPT | | Unknown | This is ChatGPT/BingGPT generated data. |
| Human | | CC-BY-SA | |
## Citation
```bibtex
@proceedings{towards-a-robust-2023-antoun,
title = "Towards a Robust Detection of Language Model-Generated Text: Is ChatGPT that easy to detect?",
editor = "Antoun, Wissam and
Mouilleron, Virginie and
Sagot, Benoit and
Seddah, Djam{\'e}",
month = "6",
year = "2023",
address = "Paris, France",
publisher = "ATALA",
url = "https://gitlab.inria.fr/wantoun/robust-chatgpt-detection/-/raw/main/towards_chatgpt_detection.pdf",
}
```
```bibtex
@article{guo-etal-2023-hc3,
title = "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection",
author = "Guo, Biyang and
Zhang, Xin and
Wang, Ziyuan and
Jiang, Minqi and
Nie, Jinran and
Ding, Yuxuan and
Yue, Jianwei and
Wu, Yupeng",
journal={arXiv preprint arxiv:2301.07597}
year = "2023",
url ="https://arxiv.org/abs/2301.07597"
}
```
|
almanach/hc3_french_ood
|
[
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:sentence-similarity",
"task_categories:zero-shot-classification",
"size_categories:10K<n<100K",
"language:en",
"language:fr",
"license:cc-by-sa-4.0",
"ChatGPT",
"Bing",
"LM Detection",
"Detection",
"OOD",
"arxiv:2301.07597",
"region:us"
] |
2023-05-30T13:16:14+00:00
|
{"language": ["en", "fr"], "license": "cc-by-sa-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification", "question-answering", "sentence-similarity", "zero-shot-classification"], "tags": ["ChatGPT", "Bing", "LM Detection", "Detection", "OOD"]}
|
2023-06-05T09:19:19+00:00
|
91f786d85161674e40397719de62a8d1b14a5ce3
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 自有基于alpaca生成英文问答对
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-alpaca-en-50k')
```
|
TigerResearch/tigerbot-alpaca-en-50k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T13:33:53+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T00:56:04+00:00
|
a7ea4a2dafbbe1a399a96b6c1e2b1976f80d64d9
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于cmu开放在的wiki问答数据集整理的sft数据
<p align="center" width="40%">
原始来源:[http://www.cs.cmu.edu/~ark/QA-data/](http://www.cs.cmu.edu/~ark/QA-data/)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-cmu-wiki-en')
```
|
TigerResearch/tigerbot-cmu-wiki-en
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T13:59:57+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T01:30:10+00:00
|
cba1928cc26310af3d00fd5cc1e79fd3cdd1be30
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于dolly数据集加工的头脑风暴Brainstorming相关分类的的sft。
原始来源:[https://huggingface.co/datasets/databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k/)
<p align="center" width="40%">
databricks-dolly-15k is an open source dataset of instruction-following records generated by thousands of Databricks employees in several of the behavioral categories outlined in the InstructGPT paper
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-dolly-Brainstorming-en-1.7k')
```
|
TigerResearch/tigerbot-dolly-Brainstorming-en-1.7k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:01:57+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T01:28:32+00:00
|
343a7d7a0ae3b7137274bf7a56c94f0e3a783ca5
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于dolly数据集加工的分类classification相关分类的的sft。
原始来源:[https://huggingface.co/datasets/databricks/databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k/)
<p align="center" width="40%">
databricks-dolly-15k is an open source dataset of instruction-following records generated by thousands of Databricks employees in several of the behavioral categories outlined in the InstructGPT paper
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-dolly-classification-en-2k')
```
|
TigerResearch/tigerbot-dolly-classification-en-2k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:04:16+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T00:34:13+00:00
|
4548b8e397edeb0384c614e941d25b650d766b04
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于stackexchange问答站点dump数据生成sft数据集
<p align="center" width="40%">
原始来源:[https://archive.org/details/stackexchange](https://archive.org/details/stackexchange)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-stackexchange-qa-en-0.5m')
```
|
TigerResearch/tigerbot-stackexchange-qa-en-0.5m
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:06:49+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T01:21:45+00:00
|
620bd8d0c653153525451957e6f0978117167540
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 英文wiki类的问答数据
<p align="center" width="40%">
原始来源:[https://huggingface.co/datasets/michaelthwan/oa_wiki_qa_bart_10000row](https://huggingface.co/datasets/michaelthwan/oa_wiki_qa_bart_10000row)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-wiki-qa-bart-en-10k')
```
|
TigerResearch/tigerbot-wiki-qa-bart-en-10k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:07:55+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-10-07T04:46:02+00:00
|
8310e869b8169050767267f46b4679d8ff25f143
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于公开的数据集生成的食谱类sft数据集
<p align="center" width="40%">
原始来源:[https://www.kaggle.com/datasets/zeeenb/recipes-from-tasty?select=ingredient_and_instructions.json](https://www.kaggle.com/datasets/zeeenb/recipes-from-tasty?select=ingredient_and_instructions.json)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-kaggle-recipes-en-2k')
```
|
TigerResearch/tigerbot-kaggle-recipes-en-2k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:09:09+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T01:23:57+00:00
|
aaf5fce34b1d673a60ea2e1fc49182698c6a65c5
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于leetcode-solutions数据集,加工生成的代码类sft数据集
<p align="center" width="40%">
原始来源:[https://www.kaggle.com/datasets/erichartford/leetcode-solutions](https://www.kaggle.com/datasets/erichartford/leetcode-solutions)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k')
```
|
TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:10:06+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T01:01:37+00:00
|
812f56d19b5a4af41bd2095088a1b9a332dff3fc
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于开源数据加工的sft,youtube中如何做(howto)系列。
原始来源:[https://www.di.ens.fr/willow/research/howto100m/](https://www.di.ens.fr/willow/research/howto100m/)
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-youtube-howto-en-50k')
```
|
TigerResearch/tigerbot-youtube-howto-en-50k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:10:42+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T00:28:23+00:00
|
cdc520b93b8715b97e39a60a462cb4a0958b1919
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于开源OIG数据集加工生成的多轮对话sft数据集
<p align="center" width="40%">
原始来源:[https://huggingface.co/datasets/laion/OIG](https://huggingface.co/datasets/laion/OIG)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-OIG-multichat-en-50k')
```
|
TigerResearch/tigerbot-OIG-multichat-en-50k
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:11:34+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T00:52:02+00:00
|
677cb4eca5bb3dfebe8d3948cad825008a622642
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 自有中文书籍-名著相关知识问答数据。
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-book-qa-1k')
```
|
TigerResearch/tigerbot-book-qa-1k
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:13:50+00:00
|
{"license": "apache-2.0"}
|
2023-05-31T00:24:08+00:00
|
14101774e35107ba5a18566da1e8e64d0b8f0174
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 自有基于alpaca生成中文问答对
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-alpaca-zh-0.5m')
```
|
TigerResearch/tigerbot-alpaca-zh-0.5m
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:15:00+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-05-31T00:14:23+00:00
|
9377cb32a3bfcafd7cfe43c98a7eb4a9e2b88c5e
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于开源搜集的知乎数据生成的sft问答对
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-zhihu-zh-10k')
```
|
TigerResearch/tigerbot-zhihu-zh-10k
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:15:37+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-05-31T01:59:43+00:00
|
817cdc57cffc69a28ed0ae5fa17922e8c7854fb9
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于firefly数据集生成的问答sft数据
<p align="center" width="40%">
本数据集分享遵循apache-2.0协议,如来源数据有更严格的协议,将继承使用来源数据协议
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-firefly-zh-20k')
```
|
TigerResearch/tigerbot-firefly-zh-20k
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:16:40+00:00
|
{"license": "apache-2.0"}
|
2023-05-31T01:18:43+00:00
|
cd037721a03f86be5881019b6d368c83286f6063
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于公开的HC3数据集加工生成的常识问答sft数据集
<p align="center" width="40%">
原始来源:[https://huggingface.co/datasets/Hello-SimpleAI/HC3](https://huggingface.co/datasets/Hello-SimpleAI/HC3)
If the source datasets used in this corpus has a specific license which is stricter than CC-BY-SA, our products follow the same.
If not, they follow CC-BY-SA license.
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-HC3-zh-12k')
```
|
TigerResearch/tigerbot-HC3-zh-12k
|
[
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] |
2023-05-30T14:18:06+00:00
|
{"language": ["en"], "license": "cc-by-sa-4.0"}
|
2023-05-31T01:11:06+00:00
|
f5f9da2e2355576c1941efb4a16dfa59bd6e2a7f
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于cluebenchmark公开的数据集加工生成的阅读理解sft数据集
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-superclue-c3-zh-5k')
```
|
TigerResearch/tigerbot-superclue-c3-zh-5k
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:18:43+00:00
|
{"license": "apache-2.0"}
|
2023-05-31T01:05:46+00:00
|
08ec05dd6b7b8d620f6dff165b86b733ebb46195
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 自有中文百科问答 数据。
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-wiki-qa-zh-1k')
```
|
TigerResearch/tigerbot-wiki-qa-zh-1k
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:19:23+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-05-31T00:22:23+00:00
|
d352c488aecd4dda61174836808d95e1713d4b9d
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 搜集整理加工的中文-猜谜语sft数据集
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-riddle-qa-1k')
```
|
TigerResearch/tigerbot-riddle-qa-1k
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:20:44+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-05-31T01:03:23+00:00
|
75c0a58bbf9babc640dda2ce4f3ded9a3e9a9358
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 模型rethink时使用的外脑原始数据,财报类
- 共2500篇财报,抽取后按段落保存
- 发布时间区间为: 2022-02-28 至 2023-05-10
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-earning-plugin')
```
|
TigerResearch/tigerbot-earning-plugin
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:23:08+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-06-01T09:19:33+00:00
|
434f01a05a200dc358fefe98abfb9ca47df2ee91
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 模型rethink时使用的外脑原始数据,研报类
- 共2W篇完整研报,按段落保存
- 发布时间区间: 2022-09-30 至 2023-05-19
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-research-plugin')
```
|
TigerResearch/tigerbot-research-plugin
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:23:53+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-06-01T09:18:59+00:00
|
f53d14621bd8ed3ac6ffcefe7d6dfb962fa75a2b
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 模型rethink时使用的外脑原始数据,百科类
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-wiki-plugin')
```
|
TigerResearch/tigerbot-wiki-plugin
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:24:41+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T00:45:59+00:00
|
d6837fa6596d8c9dd1aa051c07a046597b1d5092
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 模型rethink时使用的外脑原始数据,法律11大类,共5.5W+条款
- 宪法
- 刑法
- 行政法
- 司法解释
- 民法商法
- 民法典
- 行政法规
- 社会法
- 部门规章
- 经济法
- 诉讼与非诉讼程序法
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-law-plugin')
```
|
TigerResearch/tigerbot-law-plugin
|
[
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:25:17+00:00
|
{"language": ["zh"], "license": "apache-2.0"}
|
2023-06-01T02:11:47+00:00
|
487a1729f4801a5f7c6f874a73d3667f1578aea7
|
# Dataset Card for "til_nlp_test_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
lzh7522/til_nlp_test_dataset
|
[
"region:us"
] |
2023-05-30T14:26:10+00:00
|
{"dataset_info": {"features": [{"name": "path", "dtype": "string"}, {"name": "input_features", "sequence": {"sequence": "float32"}}], "splits": [{"name": "train", "num_bytes": 11524464000, "num_examples": 12000}], "download_size": 1788670661, "dataset_size": 11524464000}}
|
2023-05-31T05:49:38+00:00
|
17f8795ec8fea33cf2a421a2a9bc18215f4b4179
|
# Dataset Card for "CIFAR10_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_10000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/CIFAR10_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_10000
|
[
"region:us"
] |
2023-05-30T14:31:18+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 3987747, "num_examples": 10000}, {"name": "fewshot_0__Attributes_ViT_L_14_descriptors_text_davinci_003_full_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 4083411, "num_examples": 10000}, {"name": "fewshot_1__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 7730103, "num_examples": 10000}, {"name": "fewshot_1__Attributes_ViT_L_14_descriptors_text_davinci_003_full_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 7933974, "num_examples": 10000}, {"name": "fewshot_3__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 15219389, "num_examples": 10000}, {"name": "fewshot_3__Attributes_ViT_L_14_descriptors_text_davinci_003_full_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 15621655, "num_examples": 10000}], "download_size": 13306711, "dataset_size": 54576279}}
|
2023-06-12T16:07:06+00:00
|
184d8fc6f1b2c14db26be95ffa23a7409cacb7fc
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 病历生成相关的sft数据集
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-mt-note-generation-en')
```
|
TigerResearch/tigerbot-mt-note-generation-en
|
[
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-05-30T14:42:27+00:00
|
{"language": ["en"], "license": "apache-2.0"}
|
2023-05-31T00:41:16+00:00
|
cbfa2cfadf252bf9fdc54b81ad9742679b14466c
|
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于gsm8k数据集加工而来
GSM8K(Grade School Math 8K)是一个包含 8.5K 高质量语言多样化小学数学单词问题的数据集。创建数据集是为了支持对需要多步推理的基本数学问题的问答任务。
原始来源:[https://huggingface.co/datasets/gsm8k](https://huggingface.co/datasets/gsm8k)
<p align="center" width="40%">
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-gsm-8k-en')
```
|
TigerResearch/tigerbot-gsm-8k-en
|
[
"language:en",
"license:mit",
"region:us"
] |
2023-05-30T14:44:37+00:00
|
{"language": ["en"], "license": "mit"}
|
2023-05-31T00:38:37+00:00
|
74e2c427b060aad151eda3195c42e9c155880b54
|
# Dataset Card for "CIFAR10_test_google_flan_t5_xxl_mode_T_SPECIFIC_A_ns_10000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/CIFAR10_test_google_flan_t5_xxl_mode_T_SPECIFIC_A_ns_10000
|
[
"region:us"
] |
2023-05-30T14:54:58+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0__Attributes_ViT_L_14_descriptors_text_davinci_003_full_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 4083416, "num_examples": 10000}, {"name": "fewshot_1__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 7730178, "num_examples": 10000}, {"name": "fewshot_1__Attributes_ViT_L_14_descriptors_text_davinci_003_full_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 7933976, "num_examples": 10000}, {"name": "fewshot_3__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 15219519, "num_examples": 10000}, {"name": "fewshot_3__Attributes_ViT_L_14_descriptors_text_davinci_003_full_clip_tags_ViT_L_14_simple_specific_rices", "num_bytes": 15621831, "num_examples": 10000}, {"name": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 3997776, "num_examples": 10000}], "download_size": 13306984, "dataset_size": 54586696}, "configs": [{"config_name": "default", "data_files": [{"split": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "path": "data/fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices-*"}]}]}
|
2024-01-30T05:51:11+00:00
|
7b711f855988206c6ce663633380120005018c72
|
# Dataset Card for "CIFAR100_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_10000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/CIFAR100_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_10000
|
[
"region:us"
] |
2023-05-30T15:24:26+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 4049453, "num_examples": 10000}], "download_size": 1298535, "dataset_size": 4049453}}
|
2023-05-30T15:24:35+00:00
|
d94a6eff0b1a8334c7b488bf542da9799d45c6e9
|
# Dataset Card for "CIFAR100_test_google_flan_t5_xxl_mode_T_SPECIFIC_A_ns_1000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/CIFAR100_test_google_flan_t5_xxl_mode_T_SPECIFIC_A_ns_1000
|
[
"region:us"
] |
2023-05-30T15:39:00+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 406685, "num_examples": 1000}], "download_size": 131652, "dataset_size": 406685}}
|
2023-05-30T15:39:05+00:00
|
40170cf224311e8324fdf30feaeaf7a1d77c01e0
|
# Dataset Card for "CIFAR100_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_1000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/CIFAR100_test_google_flan_t5_xl_mode_T_SPECIFIC_A_ns_1000
|
[
"region:us"
] |
2023-05-30T15:43:08+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "true_label", "dtype": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0__Attributes_LAION_ViT_H_14_2B_descriptors_text_davinci_003_full_clip_tags_LAION_ViT_H_14_2B_simple_specific_rices", "num_bytes": 406640, "num_examples": 1000}], "download_size": 131659, "dataset_size": 406640}}
|
2023-05-30T15:43:14+00:00
|
63ef1f6eafee77092491cde9fec15c5a4ae7719b
|
# Dataset Card for "dataset_combined_4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
michalby24/dataset_combined_4
|
[
"region:us"
] |
2023-05-30T16:15:32+00:00
|
{"dataset_info": {"features": [{"name": "language", "dtype": "string"}, {"name": "input_values", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 2023164070, "num_examples": 31607}, {"name": "test", "num_bytes": 505807020, "num_examples": 7902}], "download_size": 1287752556, "dataset_size": 2528971090}}
|
2023-05-30T16:22:50+00:00
|
98d17a50747c44952ca7ce9e96cc812ea783512d
|
# Dataset Card for "monchidataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
alexisolme/monchidataset
|
[
"region:us"
] |
2023-05-30T16:40:43+00:00
|
{"dataset_info": {"features": [{"name": "pairs", "sequence": {"sequence": "string"}}, {"name": "review", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 8990, "num_examples": 17}], "download_size": 9889, "dataset_size": 8990}}
|
2023-05-30T16:40:45+00:00
|
f044766f9f1e7a95f352c27dbc8806225c92682f
|
akiraaaa/m
|
[
"license:openrail",
"region:us"
] |
2023-05-30T16:55:43+00:00
|
{"license": "openrail"}
|
2023-05-30T16:55:43+00:00
|
|
87a357290aa01acafd6d6818183b71718e30bb4c
|
arthe/qa
|
[
"license:mit",
"region:us"
] |
2023-05-30T17:11:43+00:00
|
{"license": "mit"}
|
2023-05-30T17:21:31+00:00
|
|
8e2080981d4709eeb82677ea78000a5ef148ef75
|
# Dataset Card for "syn_few0_32500_q2_pvi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
FanChen0116/syn_few0_32500_q2_pvi
|
[
"region:us"
] |
2023-05-30T17:16:13+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": {"class_label": {"names": {"0": "O", "1": "I-time", "2": "B-date", "3": "B-last_name", "4": "B-people", "5": "I-date", "6": "I-people", "7": "I-last_name", "8": "I-first_name", "9": "B-first_name", "10": "B-time"}}}}, {"name": "request_slot", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 5267655, "num_examples": 28446}, {"name": "validation", "num_bytes": 144579, "num_examples": 819}, {"name": "test", "num_bytes": 646729, "num_examples": 3731}], "download_size": 900981, "dataset_size": 6058963}}
|
2023-05-31T04:45:29+00:00
|
b332aa0d3a72cfedc592b2a866c5a08ceb116d3f
|
# Dataset Card for "syn_few0_32500_q2_all_data_pvi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
FanChen0116/syn_few0_32500_q2_all_data_pvi
|
[
"region:us"
] |
2023-05-30T17:16:37+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}, {"name": "labels", "sequence": {"class_label": {"names": {"0": "O", "1": "I-time", "2": "B-date", "3": "B-last_name", "4": "B-people", "5": "I-date", "6": "I-people", "7": "I-last_name", "8": "I-first_name", "9": "B-first_name", "10": "B-time"}}}}, {"name": "request_slot", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 5412234, "num_examples": 29265}, {"name": "validation", "num_bytes": 646729, "num_examples": 3731}, {"name": "test", "num_bytes": 646729, "num_examples": 3731}], "download_size": 929049, "dataset_size": 6705692}}
|
2023-05-31T05:35:03+00:00
|
177a04722c8becb290e609fe6a2b3b54ee698fcf
|
# Dataset Card for Algorithmic Reasoning (seed)
**Note: This dataset is WIP and most question's answer section is empty or incomplete! See also "Other Known Limitations" section**
**Warning: If you somehow do use this dataset, remember to NOT do any eval after training on the questions in this dataset!**
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:** [email protected] or https://github.com/lemonteaa
### Dataset Summary
Dataset to help LLM learn how to reason about code, especially on algorithmic tasks, by seeing human demostration.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
- Question title
- Question
- Thought - Internal thought process that reason step by step/in an organized manner
- Answer presented to user (proof or code) - with explanation if necessary
### Data Splits
No split as of now - all are in the training section.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
Questions are those I personally remember in my career, selected based on:
- interesting
- involving CS, math, or similar knowledge
- Target specific known weaknesses of existing open source/source available LLM (eg index notation handling)
- pratical/likely to appear in production work settings
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
Manually created by me entirely, writing in a level of details exceeeding what usually appears on the internet (bootcamp/FANNG interview prep/leetcode style training website etc) to help AI/LLM access knowledge that may be too obvious to human to write down.
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
None as they are general, objective knowledge.
## Considerations for Using the Data
### Social Impact of Dataset
Although it is doubtful this dataset can actually work, in the event it does this may result in enhancing coding capability of LLM (which is intended), but which may create downstream effect simply due to LLM capability enhancement.
### Discussion of Biases
As questions are selected partly based on my taste, areas in CS that I am not interested in may be underrepresented.
### Other Known Limitations
- While I try to cover various mainstream programming language, each problem target only one specific language.
- It is currently in free-style markdown file. Maybe could make a script to convert to more structured format.
- Questions are asked in a conversational tone instead of leetcode style with strict I/O specification, hence may be more suitable for human eval than automated eval (eg extract and run code output in sandbox against test case automatically).
- As the dataset is completely manually created by a single human, the dataset size is extremely small.
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
MIT
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
lemonteaa/algorithmic-reasoning-seed
|
[
"task_categories:text-generation",
"task_categories:question-answering",
"size_categories:n<1K",
"language:en",
"license:mit",
"code",
"region:us"
] |
2023-05-30T18:09:56+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-generation", "question-answering"], "tags": ["code"]}
|
2023-05-30T20:14:39+00:00
|
c3598e1913c0adbf6051b1378ca405828c3056ba
|
# Dataset Card for "chunk_183"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_183
|
[
"region:us"
] |
2023-05-30T18:10:25+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 720635116.0, "num_examples": 141523}], "download_size": 736141427, "dataset_size": 720635116.0}}
|
2023-05-30T18:12:03+00:00
|
90d03f9b7f0a66dd9ad035f2e9b88b0a33c33227
|
# Dataset Card for "chunk_0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_0
|
[
"region:us"
] |
2023-05-30T18:12:24+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1165125980.0, "num_examples": 228815}], "download_size": 1186780121, "dataset_size": 1165125980.0}}
|
2023-05-30T18:13:40+00:00
|
fff65342f3585edbd3718f3a8c00832e31acc380
|
# Dataset Card for "chunk_92"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_92
|
[
"region:us"
] |
2023-05-30T18:13:14+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1262316984.0, "num_examples": 247902}], "download_size": 1288780570, "dataset_size": 1262316984.0}}
|
2023-05-30T18:14:24+00:00
|
bd19d304b4b14a24582aa8eb1015012ecb1aa0b1
|
# Dataset Card for "chunk_184"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_184
|
[
"region:us"
] |
2023-05-30T18:13:27+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 702268272.0, "num_examples": 137916}], "download_size": 708901076, "dataset_size": 702268272.0}}
|
2023-05-30T18:14:44+00:00
|
306616f843dd1bffe44b9790f7113ad72ffb97f1
|
# Dataset Card for "chunk_185"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_185
|
[
"region:us"
] |
2023-05-30T18:16:12+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 742912616.0, "num_examples": 145898}], "download_size": 757567739, "dataset_size": 742912616.0}}
|
2023-05-30T18:17:32+00:00
|
080bdfb0daed7573ec6bd3c6ccda165f479f93ea
|
# Dataset Card for "chunk_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_1
|
[
"region:us"
] |
2023-05-30T18:16:28+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 936352604.0, "num_examples": 183887}], "download_size": 950695832, "dataset_size": 936352604.0}}
|
2023-05-30T18:17:38+00:00
|
19bdfadfef8516cfbc24a760781a5c7fabf52089
|
# Dataset Card for "chunk_93"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_93
|
[
"region:us"
] |
2023-05-30T18:18:01+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1258044796.0, "num_examples": 247063}], "download_size": 1285124928, "dataset_size": 1258044796.0}}
|
2023-05-30T18:19:09+00:00
|
729ef8e85a2694f7a0255a040557a2fb43c064a9
|
# Dataset Card for "chunk_186"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_186
|
[
"region:us"
] |
2023-05-30T18:18:45+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 641495252.0, "num_examples": 125981}], "download_size": 647860754, "dataset_size": 641495252.0}}
|
2023-05-30T18:19:55+00:00
|
eae405ff2419b7d2b706a770cb54f72db1a4be16
|
# Dataset Card for "chunk_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_2
|
[
"region:us"
] |
2023-05-30T18:20:28+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 907867956.0, "num_examples": 178293}], "download_size": 922520202, "dataset_size": 907867956.0}}
|
2023-05-30T18:21:27+00:00
|
71d34988fdabba6ac12cbf91b5570c4718eec511
|
# Dataset Card for "cofrico-v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sfblaauw/cofrico-v1
|
[
"region:us"
] |
2023-05-30T18:20:44+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3325495.8, "num_examples": 4}, {"name": "test", "num_bytes": 738553.0, "num_examples": 1}], "download_size": 3361263, "dataset_size": 4064048.8}}
|
2023-05-30T18:20:47+00:00
|
2f83fb2d8dbc39cc45d702ba94a1f8b391aa82ca
|
# Dataset Card for "dolly-curated-comparison-falcon-7b-instruct"
This dataset contains two generated responses using the `falcon-7b-instruct` model and the original, curated, prompt + responses from the Dolly v2 curated dataset. For now only 50% of the original dataset is available but we plan to complete it.
This dataset can be used for training a reward model for RLHF using [Argilla Feedback](https://docs.argilla.io/en/latest/guides/llms/conceptual_guides/conceptual_guides.html)
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
argilla/dolly-curated-comparison-falcon-7b-instruct
|
[
"language:en",
"region:us"
] |
2023-05-30T18:21:21+00:00
|
{"language": "en", "dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "response-1", "dtype": "string"}, {"name": "response-2", "dtype": "string"}, {"name": "category", "dtype": "string"}, {"name": "original_response", "dtype": "string"}, {"name": "external_id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 10328235, "num_examples": 7401}], "download_size": 6598297, "dataset_size": 10328235}}
|
2023-07-13T10:28:57+00:00
|
7966835fb47343f24f6a5b1e6d387cd571cbacd6
|
# Dataset Card for "chunk_187"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_187
|
[
"region:us"
] |
2023-05-30T18:21:30+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 783516224.0, "num_examples": 153872}], "download_size": 797716983, "dataset_size": 783516224.0}}
|
2023-05-30T18:22:59+00:00
|
47df2b7ba727951f4c7f6ae560792b5d367c3a93
|
# Dataset Card for "chunk_94"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_94
|
[
"region:us"
] |
2023-05-30T18:23:07+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1235253004.0, "num_examples": 242587}], "download_size": 1261765733, "dataset_size": 1235253004.0}}
|
2023-05-30T18:24:17+00:00
|
65a893022a939c64c214380ef8b9855b1dcf759e
|
# Dataset Card for "chunk_3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_3
|
[
"region:us"
] |
2023-05-30T18:24:23+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 993046932.0, "num_examples": 195021}], "download_size": 1008097373, "dataset_size": 993046932.0}}
|
2023-05-30T18:25:27+00:00
|
1fb864563d88d6d2c6fd680c79f5849d0802bef0
|
# Dataset Card for "chunk_188"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_188
|
[
"region:us"
] |
2023-05-30T18:24:27+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 765037356.0, "num_examples": 150243}], "download_size": 774888361, "dataset_size": 765037356.0}}
|
2023-05-30T18:25:54+00:00
|
e980d21e0d7da093a27c28702c1da9bdc72866ff
|
# Dataset Card for "chunk_95"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_95
|
[
"region:us"
] |
2023-05-30T18:27:56+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1249082876.0, "num_examples": 245303}], "download_size": 1275054606, "dataset_size": 1249082876.0}}
|
2023-05-30T18:29:05+00:00
|
80185b04dd8c0a30d9b831b37f232f4263d6ded0
|
# Dataset Card for "chunk_4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_4
|
[
"region:us"
] |
2023-05-30T18:28:28+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 917277972.0, "num_examples": 180141}], "download_size": 934494910, "dataset_size": 917277972.0}}
|
2023-05-30T18:29:31+00:00
|
9d436d7aebeca7b65841f5f12d69452fcbc63603
|
# Dataset Card for "chunk_189"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_189
|
[
"region:us"
] |
2023-05-30T18:28:29+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1297981352.0, "num_examples": 254906}], "download_size": 1323128010, "dataset_size": 1297981352.0}}
|
2023-05-30T18:31:04+00:00
|
871b80e1db3bebfc54ec5665020c0cb5499043da
|
# Dataset Card for "chunk_5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_5
|
[
"region:us"
] |
2023-05-30T18:32:26+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 977144616.0, "num_examples": 191898}], "download_size": 994659843, "dataset_size": 977144616.0}}
|
2023-05-30T18:33:46+00:00
|
08f553abf86e82165ce24e1cac778f4af0a0e742
|
# Dataset Card for "chunk_96"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_96
|
[
"region:us"
] |
2023-05-30T18:33:14+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1248125580.0, "num_examples": 245115}], "download_size": 1274476518, "dataset_size": 1248125580.0}}
|
2023-05-30T18:34:26+00:00
|
245445e9654ee12bd76f0a2599d2f37f9ebd8ced
|
# Dataset Card for "chunk_190"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_190
|
[
"region:us"
] |
2023-05-30T18:33:55+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1355312180.0, "num_examples": 266165}], "download_size": 1383051494, "dataset_size": 1355312180.0}}
|
2023-05-30T18:36:27+00:00
|
880f00ef91a8d431e9a82e8f15fcc87f50d5b409
|
# Dataset Card for "chunk_6"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_6
|
[
"region:us"
] |
2023-05-30T18:37:10+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1134813304.0, "num_examples": 222862}], "download_size": 1153363244, "dataset_size": 1134813304.0}}
|
2023-05-30T18:38:46+00:00
|
9a466d3481aa822af790c0cd0c9d2e042798c197
|
# Dataset Card for "chunk_97"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_97
|
[
"region:us"
] |
2023-05-30T18:38:02+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1233282400.0, "num_examples": 242200}], "download_size": 1259036003, "dataset_size": 1233282400.0}}
|
2023-05-30T18:39:12+00:00
|
b98588241ce0f32e066706254ac7e2f3ef3b3ccb
|
# Dataset Card for "chunk_191"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_191
|
[
"region:us"
] |
2023-05-30T18:39:08+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1308756024.0, "num_examples": 257022}], "download_size": 1335935590, "dataset_size": 1308756024.0}}
|
2023-05-30T18:41:31+00:00
|
282fb08da6b42e1df21745b0ed49ea11f6a9ca47
|
# Dataset Card for "chunk_7"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_7
|
[
"region:us"
] |
2023-05-30T18:42:21+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1139024388.0, "num_examples": 223689}], "download_size": 1159307084, "dataset_size": 1139024388.0}}
|
2023-05-30T18:43:36+00:00
|
509455e485295b9032ddb81f567886675c22abb3
|
# Dataset Card for "chunk_98"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_98
|
[
"region:us"
] |
2023-05-30T18:43:18+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1247076628.0, "num_examples": 244909}], "download_size": 1272986790, "dataset_size": 1247076628.0}}
|
2023-05-30T18:44:31+00:00
|
07f47d35aa3bab537fb2393b78aebff3f3696afe
|
# Dataset Card for "chunk_192"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_192
|
[
"region:us"
] |
2023-05-30T18:44:21+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1326781704.0, "num_examples": 260562}], "download_size": 1353209603, "dataset_size": 1326781704.0}}
|
2023-05-30T18:46:49+00:00
|
bc3e2971bf6a85e1ddf971f5090ab53983191044
|
# Dataset Card for "chunk_8"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_8
|
[
"region:us"
] |
2023-05-30T18:46:53+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1118926264.0, "num_examples": 219742}], "download_size": 1140517158, "dataset_size": 1118926264.0}}
|
2023-05-30T18:48:11+00:00
|
f97222773956851fd2f71bf904562c47e9e286ea
|
# Dataset Card for "cofrico-v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sfblaauw/cofrico-v2
|
[
"region:us"
] |
2023-05-30T18:47:34+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 266372.6, "num_examples": 3}, {"name": "test", "num_bytes": 122883.2, "num_examples": 1}, {"name": "validation", "num_bytes": 42102.2, "num_examples": 1}], "download_size": 425753, "dataset_size": 431358.0}}
|
2023-05-30T19:58:50+00:00
|
eb4c76028e57cfb53e0c2b2d65ec2c26aa0d1f77
|
# Dataset Card for "chunk_99"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_99
|
[
"region:us"
] |
2023-05-30T18:48:14+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1285760552.0, "num_examples": 252506}], "download_size": 1314221788, "dataset_size": 1285760552.0}}
|
2023-05-30T18:49:29+00:00
|
5dfa04b9884878d4abba12b48c204675c5b5ecd9
|
# Dataset Card for "chunk_193"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_193
|
[
"region:us"
] |
2023-05-30T18:48:41+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 983356856.0, "num_examples": 193118}], "download_size": 1001961085, "dataset_size": 983356856.0}}
|
2023-05-30T18:51:02+00:00
|
b0597044bca7dbdae779be83d09ffdd07cc6622f
|
# Dataset Card for "chunk_9"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_9
|
[
"region:us"
] |
2023-05-30T18:52:00+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1078490692.0, "num_examples": 211801}], "download_size": 1098404186, "dataset_size": 1078490692.0}}
|
2023-05-30T18:53:50+00:00
|
5480694f9e83900b4b62f37a1c28e7db0dfbd322
|
# Dataset Card for "chunk_194"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_194
|
[
"region:us"
] |
2023-05-30T18:53:11+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1008210908.0, "num_examples": 197999}], "download_size": 1020408217, "dataset_size": 1008210908.0}}
|
2023-05-30T18:55:00+00:00
|
1ca643b6e72668f3581692b6f8af1933fa0ead62
|
# Dataset Card for "chunk_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_100
|
[
"region:us"
] |
2023-05-30T18:53:41+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1289981820.0, "num_examples": 253335}], "download_size": 1318311624, "dataset_size": 1289981820.0}}
|
2023-05-30T18:54:52+00:00
|
858261625acae08a1c29d76abbec3c6fded458ca
|
# Dataset Card for "chunk_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_10
|
[
"region:us"
] |
2023-05-30T18:56:55+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1029683872.0, "num_examples": 202216}], "download_size": 1047224083, "dataset_size": 1029683872.0}}
|
2023-05-30T18:58:04+00:00
|
6a8f52639e06549783c64fdc0054551ac123d6cc
|
# Dataset Card for "chunk_195"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_195
|
[
"region:us"
] |
2023-05-30T18:57:01+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1018863372.0, "num_examples": 200091}], "download_size": 1034332443, "dataset_size": 1018863372.0}}
|
2023-05-30T18:59:14+00:00
|
5df0372d9b91d57e97cffa20d5cd1460679436cb
|
# Dataset Card for "chunk_101"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_101
|
[
"region:us"
] |
2023-05-30T18:59:17+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1346518296.0, "num_examples": 264438}], "download_size": 1376379084, "dataset_size": 1346518296.0}}
|
2023-05-30T19:00:35+00:00
|
322f56e88563f7258c000b01fc5159d7e07db335
|
# Dataset Card for "chunk_11"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_11
|
[
"region:us"
] |
2023-05-30T19:01:37+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1003694304.0, "num_examples": 197112}], "download_size": 1021514071, "dataset_size": 1003694304.0}}
|
2023-05-30T19:02:43+00:00
|
d417b2de9b19e2e6ad43d8ecb6b87aabcf424d0f
|
# Dataset Card for "chunk_196"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_196
|
[
"region:us"
] |
2023-05-30T19:01:39+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1100956596.0, "num_examples": 216213}], "download_size": 1122287506, "dataset_size": 1100956596.0}}
|
2023-05-30T19:03:37+00:00
|
a51790dda3659b493d72469c7a856740470aab88
|
# Dataset Card for "chunk_102"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_102
|
[
"region:us"
] |
2023-05-30T19:04:53+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1307824188.0, "num_examples": 256839}], "download_size": 1336815408, "dataset_size": 1307824188.0}}
|
2023-05-30T19:06:07+00:00
|
e2aa7ab7aeca3f21099c602694a32489124183a4
|
# Dataset Card for "chunk_197"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_197
|
[
"region:us"
] |
2023-05-30T19:05:25+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 897006720.0, "num_examples": 176160}], "download_size": 916279975, "dataset_size": 897006720.0}}
|
2023-05-30T19:07:02+00:00
|
644416496e08b582168d170f6f7334fc633f2057
|
# Dataset Card for "chunk_12"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_12
|
[
"region:us"
] |
2023-05-30T19:05:44+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 996086856.0, "num_examples": 195618}], "download_size": 1016163774, "dataset_size": 996086856.0}}
|
2023-05-30T19:06:48+00:00
|
64c9df63dd91d6f8c0db06f50ea3e52a057d36b2
|
# Dataset Card for "chunk_198"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_198
|
[
"region:us"
] |
2023-05-30T19:09:08+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1071458640.0, "num_examples": 210420}], "download_size": 1093799592, "dataset_size": 1071458640.0}}
|
2023-05-30T19:11:03+00:00
|
5f0e707f726348022e6f14b7aa1f39ab0c562284
|
# To join all training set files together
run `python join_dataset.py` file, final result will be `join_dataset.json` file
|
talmp/en-vi-translation
|
[
"task_categories:translation",
"size_categories:1M<n<10M",
"language:en",
"language:vi",
"license:wtfpl",
"region:us"
] |
2023-05-30T19:09:35+00:00
|
{"language": ["en", "vi"], "license": "wtfpl", "size_categories": ["1M<n<10M"], "task_categories": ["translation"]}
|
2023-05-31T21:45:58+00:00
|
bbbd292bfc715c05c26e5ec4192a40dd4b100755
|
# Dataset Card for "chunk_103"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_103
|
[
"region:us"
] |
2023-05-30T19:10:06+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1388990668.0, "num_examples": 272779}], "download_size": 1392974489, "dataset_size": 1388990668.0}}
|
2023-05-30T19:11:25+00:00
|
25299f325fc367ed0fe9e6e1bcb2cac31fcaeab2
|
# Dataset Card for "chunk_13"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_13
|
[
"region:us"
] |
2023-05-30T19:10:54+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1187036856.0, "num_examples": 233118}], "download_size": 1203444722, "dataset_size": 1187036856.0}}
|
2023-05-30T19:12:12+00:00
|
ce0ed787bc7ff4187613c331722613db6ff48023
|
# Dataset Card for "chunk_199"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_199
|
[
"region:us"
] |
2023-05-30T19:13:33+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1099627584.0, "num_examples": 215952}], "download_size": 1120568825, "dataset_size": 1099627584.0}}
|
2023-05-30T19:15:36+00:00
|
7e1d0fa88f3a02d27dc64415fad55a8dcca019d5
|
# Dataset Card for "chunk_14"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_14
|
[
"region:us"
] |
2023-05-30T19:15:25+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1068215036.0, "num_examples": 209783}], "download_size": 1085666582, "dataset_size": 1068215036.0}}
|
2023-05-30T19:16:35+00:00
|
6a1d8966647d4ff9d7db04fe2287d71b004ec06e
|
# Dataset Card for "chunk_104"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_104
|
[
"region:us"
] |
2023-05-30T19:16:13+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1466949188.0, "num_examples": 288089}], "download_size": 1493070751, "dataset_size": 1466949188.0}}
|
2023-05-30T19:17:36+00:00
|
cbbe4f82ed26fdbd80ea46de237d6e294cc94de4
|
# Dataset Card for "chunk_200"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_200
|
[
"region:us"
] |
2023-05-30T19:17:21+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 903015280.0, "num_examples": 177340}], "download_size": 921531148, "dataset_size": 903015280.0}}
|
2023-05-30T19:18:56+00:00
|
bc0402714dd0c7dadfc5706f8ade55076c7146cd
|
# Dataset Card for "chunk_15"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_15
|
[
"region:us"
] |
2023-05-30T19:19:35+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1016353016.0, "num_examples": 199598}], "download_size": 1035382690, "dataset_size": 1016353016.0}}
|
2023-05-30T19:20:48+00:00
|
a00bdae2c6064b27b1ddffe43a839c09b790cf06
|
# Dataset Card for "chunk_105"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_105
|
[
"region:us"
] |
2023-05-30T19:20:20+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 970581028.0, "num_examples": 190609}], "download_size": 991148111, "dataset_size": 970581028.0}}
|
2023-05-30T19:21:13+00:00
|
f175655496c75b67d3564b8547713b6d3ce9bd24
|
# Dataset Card for "chunk_201"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_201
|
[
"region:us"
] |
2023-05-30T19:21:01+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 974568064.0, "num_examples": 191392}], "download_size": 995177916, "dataset_size": 974568064.0}}
|
2023-05-30T19:22:53+00:00
|
42da5452edea38e1ae6ed8af49e7e47be3d82953
|
# Dataset Card for "chunk_106"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_106
|
[
"region:us"
] |
2023-05-30T19:24:14+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 887841120.0, "num_examples": 174360}], "download_size": 905816663, "dataset_size": 887841120.0}}
|
2023-05-30T19:25:07+00:00
|
26539ce695d11b593ab92d9663db088cecdf0b3d
|
# Dataset Card for "chunk_16"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-onesec-cv12-each-chunk-uniq/chunk_16
|
[
"region:us"
] |
2023-05-30T19:24:48+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1233587920.0, "num_examples": 242260}], "download_size": 1256097292, "dataset_size": 1233587920.0}}
|
2023-05-30T19:26:36+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.