
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
bcde0851cbd17616945045ae2f6ab73b7303c6d1
|
データ制作者([t_w](https://dlt.kitetu.com/KNo.EDD2))が[デライト](https://dlt.kitetu.com/)に投稿した5万件の投稿をEmbeddingの学習用にいい感じにしたやつ。
# License
Licenseは設定していないため、日本の法律に従って利用されたい。従って、学習に用いるのは問題ないが再配布は不可。
|
tzmtwtr/tw-posts-japanese
|
[
"language:ja",
"license:other",
"region:us"
] |
2023-06-13T13:31:25+00:00
|
{"language": ["ja"], "license": "other"}
|
2023-06-16T04:17:23+00:00
|
83d5902bb7c9feea19cd482fb7c9b60376269160
|
DaryaCsu/cows
|
[
"license:other",
"region:us"
] |
2023-06-13T13:47:12+00:00
|
{"license": "other", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": " weight", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 23248701.0, "num_examples": 121}], "download_size": 23054425, "dataset_size": 23248701.0}}
|
2023-06-14T17:49:39+00:00
|
|
484027ee138fe56b3c56defd0eb6f42a5d14e385
|
# Dataset Card for "datacomp-small-10-rows"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
nielsr/datacomp-small-10-rows
|
[
"region:us"
] |
2023-06-13T13:47:34+00:00
|
{"dataset_info": {"features": [{"name": "uid", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "original_width", "dtype": "int64"}, {"name": "original_height", "dtype": "int64"}, {"name": "clip_b32_similarity_score", "dtype": "float32"}, {"name": "clip_l14_similarity_score", "dtype": "float32"}, {"name": "face_bboxes", "sequence": {"sequence": "float64"}}, {"name": "sha256", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2954, "num_examples": 10}], "download_size": 9270, "dataset_size": 2954}}
|
2023-06-13T13:47:37+00:00
|
f4d16777c9f0ab71f6ec6f01a33297e8f34281fd
|
*"In the depths of a lush forest, nestled near majestic mountains, thrives an extraordinary female-only tribe. This enchanting community boasts a unique blend of captivating features, as they are distinguished by their striking blonde hair, mesmerizing orange eyes, and a complexion kissed by the sun, adorned with rich dark skin.
Living harmoniously with nature, this tribe has found solace in the vibrant forest that surrounds them. Within their domain, they are blessed with wondrous gifts of the land. Among the wonders that grace their home are natural hot springs, where warm waters rejuvenate their spirits and provide a sanctuary for reflection and relaxation. The forest is also adorned with cherry blossom trees, which burst into bloom each spring, transforming the tribe's surroundings into a surreal canvas of delicate petals in hues of pink and white.
Beyond their physical allure, the women of this tribe possess an inherent charm that captivates all who encounter them. Their allure and sensuality emanate from their deep connection with their surroundings, as they navigate the forest with grace and embrace the natural rhythms of life. It is through this symbiotic relationship with nature that they have honed their mystique, exuding a magnetic presence that leaves a lasting impression on those fortunate enough to witness their radiance.
In this hidden corner of the world, the female-only tribe reigns as guardians of the forest, cherishing its beauty and protecting its secrets. As they wander through the verdant landscape, their presence is an embodiment of the untamed spirit of the wilderness, seamlessly merging their ethereal beauty with the captivating nature that surrounds them."*
Trained with Anime (full-final-pruned) model, using images generated from Waifulabs.com
Activation tags: **mountain tribe** (for general info), and stock character names (the ones founds at the image here) to get an specific design. You may also make your own OC's with this.
Recommended LoRA weight blocks: OUTD and OUTALL (you can still use ALL and MIDD but can be messy, use on your own risk.)
Recommended weights: **0.7 - 1.0**
|
Cheetor1996/mountain_tribe_girls
|
[
"language:en",
"license:cc-by-2.0",
"art",
"region:us"
] |
2023-06-13T14:08:48+00:00
|
{"language": ["en"], "license": "cc-by-2.0", "tags": ["art"]}
|
2023-06-13T14:13:49+00:00
|
ba3d7686d36f303927f48bd044167995cf467f08
|
# Dataset Card for KoLIMA
## Dataset Description
KoLIMA는 Meta에서 공개한 [LIMA: Less Is More for Alignment](https://arxiv.org/abs/2305.11206) (Zhou et al., 2023)의 [학습 데이터](https://huggingface.co/datasets/GAIR/lima)를 한국어로 번역한 데이터셋입니다. 번역에는 [DeepL API](https://www.deepl.com/docs-api)를 활용하였고, SK(주) Tech Collaborative Lab으로부터 비용을 지원받았습니다. 전체 텍스트 중에서 code block이나 수식을 나타내는 특수문자 사이의 텍스트는 원문을 유지하는 형태로 번역을 진행하였으며, `train` 데이터셋 1,030건과 `test` 데이터셋 300건으로 구성된 총 1,330건의 데이터를 활용하실 수 있습니다. 현재 동일한 번역 문장을 `plain`, `vicuna` 두 가지 포멧으로 제공합니다.
데이터셋 관련하여 문의가 있으신 경우 [메일](mailto:[email protected])을 통해 연락주세요! 🥰
This is Korean LIMA dataset, which is translated from the [LIMA dataset](https://huggingface.co/datasets/GAIR/lima) that Meta's [LIMA model](https://arxiv.org/abs/2305.11206) (Zhou et al., 2023) was trained on. The translation has proceeded through [DeepL API](https://www.deepl.com/docs-api) with financial support from Tech Collaborative Lab in SK Inc.
Please feel free to contact me if you have any question on the dataset.
I'm best reached via [email](mailto:[email protected]).
#### Changelog
- [29 June 2023] New format added: `vicuna` format with the same translation is now available.
- [16 June 2023] Enhanced Translation: keep the text enclosed in special characters, e.g. `$` and `` ` ``, intact without translation.
- [14 June 2023] First upload.
### Usage
```python
>>> from datasets import load_dataset
>>> ko_lima = load_dataset('taeshahn/ko-lima', 'plain') # or load_dataset('taeshahn/ko-lima')
>>> ko_lima_vicuna = load_dataset('taeshahn/ko-lima', 'vicuna')
```
```python
>>> ko_lima['train'][1025]
{
'conversations': [
'저는 케냐 출신입니다. 망명을 신청하고 싶은데 비자없이 네덜란드로 망명을 신청하기 위해 여행할 수 있나요? 케냐항공에서 여권을 소지한 경우 스키폴 공항으로 가는 비자없이 비행기에 탑승할 수 있나요?',
'항공사가 탑승을 허용할 가능성은 극히 낮습니다. 네덜란드에 입국하려는 케냐 시민은 비자, 체류 기간에 필요한 충분한 자금 증명, 다음 목적지 입국에 필요한 서류를 소지해야 합니다. 또한 항공사는 케냐에서 출발하는 승객에 대해 특별 조사를 실시해야 합니다:\n\n> 다음 공항에서 네덜란드로 운항하는 항공사:\n\n아부다비(AUH), 아크라(ACC), 바레인(BAH), 베이징 캐피탈(PEK), 보리스필(KBP), 카이로(CAI), 담만(DMM), 다르에스살람(DAR), 두바이(DXB), 엔테베(EBB), 광저우(CAN), 홍콩(HKG), 하마드(DOH), 이스탄불 아타튀르크(IST), 이스탄불 사비하곡첸(SAW), 요하네스버그(JNB), 키갈리(KGL), 킬리만자로(JRO), 쿠알라룸푸르(KUL), 쿠웨이트(KWI), 라고스(LOS), 모스크바 셰레메티예보(SVO), 무스카트(MCT), 나이로비(NB ), 뉴델리(DEL), 상파울루(GRU), 싱가포르(SIN) 및 테헤란(IKA)은 네덜란드 도착 시 적절한 여행 서류가 없어 입국할 수 없는 경우 해당 항공편의 모든 승객의 여행 서류 사본을 제출하셔야 합니다. 사본에는 여권/여행 서류의 데이터 페이지, 비자가 있는 페이지, 출국/통관 스탬프가 있는 페이지(해당되는 경우)가 포함되어야 합니다. 이러한 입국 규정을 준수하지 않을 경우 항공사에 승객 1인당 최대 11,250유로의 벌금이 부과될 수 있습니다.\n\n마지막 문장에서 볼 수 있듯이 항공사는 탑승 전에 여행 서류를 확인해야 하는 강력한 인센티브를 갖게 됩니다.',
'인용된 자료의 출처는 무엇인가요?',
'출처는 항공을 통해 해외로 여행하는 승객의 여권 및 비자 요건과 같은 서류 요건이 포함된 데이터베이스인 Timatic(여행 정보 매뉴얼 자동)에서 가져온 것입니다. 위의 답변은 목적지가 네덜란드이고 귀국/귀국 여행 증빙이 있으며 5일간 체류할 계획이며 케냐 여권의 유효 기간이 약 3년 남은 케냐 시민이 케냐에서 직접 여행하는 시나리오를 기반으로 한 것입니다.'
],
'source': 'multi_turn'
}
```
```python
>>> ko_lima_vicuna['train'][1025]
{
'id': '1026-multi_turn',
'conversations': [
{
'from': '사람',
'value': '저는 케냐 출신입니다. 망명을 신청하고 싶은데 비자없이 네덜란드로 망명을 신청하기 위해 여행할 수 있나요? 케냐항공에서 여권을 소지한 경우 스키폴 공항으로 가는 비자없이 비행기에 탑승할 수 있나요?'
},
{
'from': '어시스턴트',
'value': '항공사가 탑승을 허용할 가능성은 극히 낮습니다. 네덜란드에 입국하려는 케냐 시민은 비자, 체류 기간에 필요한 충분한 자금 증명, 다음 목적지 입국에 필요한 서류를 소지해야 합니다. 또한 항공사는 케냐에서 출발하는 승객에 대해 특별 조사를 실시해야 합니다:\n\n> 다음 공항에서 네덜란드로 운항하는 항공사:\n\n아부다비(AUH), 아크라(ACC), 바레인(BAH), 베이징 캐피탈(PEK), 보리스필(KBP), 카이로(CAI), 담만(DMM), 다르에스살람(DAR), 두바이(DXB), 엔테베(EBB), 광저우(CAN), 홍콩(HKG), 하마드(DOH), 이스탄불 아타튀르크(IST), 이스탄불 사비하곡첸(SAW), 요하네스버그(JNB), 키갈리(KGL), 킬리만자로(JRO), 쿠알라룸푸르(KUL), 쿠웨이트(KWI), 라고스(LOS), 모스크바 셰레메티예보(SVO), 무스카트(MCT), 나이로비(NB ), 뉴델리(DEL), 상파울루(GRU), 싱가포르(SIN) 및 테헤란(IKA)은 네덜란드 도착 시 적절한 여행 서류가 없어 입국할 수 없는 경우 해당 항공편의 모든 승객의 여행 서류 사본을 제출하셔야 합니다. 사본에는 여권/여행 서류의 데이터 페이지, 비자가 있는 페이지, 출국/통관 스탬프가 있는 페이지(해당되는 경우)가 포함되어야 합니다. 이러한 입국 규정을 준수하지 않을 경우 항공사에 승객 1인당 최대 11,250유로의 벌금이 부과될 수 있습니다.\n\n마지막 문장에서 볼 수 있듯이 항공사는 탑승 전에 여행 서류를 확인해야 하는 강력한 인센티브를 갖게 됩니다.'
},
{
'from': '사람',
'value': '인용된 자료의 출처는 무엇인가요?'
},
{
'from': '어시스턴트',
'value': '출처는 항공을 통해 해외로 여행하는 승객의 여권 및 비자 요건과 같은 서류 요건이 포함된 데이터베이스인 Timatic(여행 정보 매뉴얼 자동)에서 가져온 것입니다. 위의 답변은 목적지가 네덜란드이고 귀국/귀국 여행 증빙이 있으며 5일간 체류할 계획이며 케냐 여권의 유효 기간이 약 3년 남은 케냐 시민이 케냐에서 직접 여행하는 시나리오를 기반으로 한 것입니다.'
}
]
}
```
### Citation Information
```
@InProceedings{kolimadataset,
title = {KoLIMA: Korean LIMA Dataset for Efficient Instruction-tuning},
author = {Hahn, Taeseung},
year = {2023}
}
```
|
taeshahn/ko-lima
|
[
"license:cc-by-nc-sa-4.0",
"arxiv:2305.11206",
"region:us"
] |
2023-06-13T14:10:24+00:00
|
{"license": "cc-by-nc-sa-4.0"}
|
2023-11-28T05:25:02+00:00
|
305a96bb7a2fbad6acfaeac88a81ada4f02e264a
|
# Dataset Card for "stable-bias_grounding-images_multimodel_3_12_22_clusters"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
stable-bias/stable-bias_grounding-images_multimodel_3_12_22_clusters
|
[
"license:apache-2.0",
"region:us"
] |
2023-06-13T14:21:09+00:00
|
{"license": "apache-2.0", "dataset_info": {"features": [{"name": "examplar", "dtype": "image"}, {"name": "centroid", "sequence": "float64"}, {"name": "gender_phrases", "sequence": "string"}, {"name": "gender_phrases_counts", "sequence": "int64"}, {"name": "ethnicity_phrases", "sequence": "string"}, {"name": "ethnicity_phrases_counts", "sequence": "int64"}, {"name": "example_ids", "sequence": "int64"}], "splits": [{"name": "12_clusters", "num_bytes": 473144, "num_examples": 12}, {"name": "24_clusters", "num_bytes": 940348, "num_examples": 24}, {"name": "48_clusters", "num_bytes": 1990487, "num_examples": 48}], "download_size": 3509518, "dataset_size": 3403979}}
|
2023-06-13T14:22:24+00:00
|
9a289d95919a27085873ab32ee71415fd426bc41
|
# Dataset Card for "RedPajama-Data-1T-arxiv-filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Abzu/RedPajama-Data-1T-arxiv-filtered
|
[
"region:us"
] |
2023-06-13T14:24:28+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "meta", "dtype": "string"}, {"name": "red_pajama_subset", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 229340859.5333384, "num_examples": 3911}], "download_size": 104435457, "dataset_size": 229340859.5333384}}
|
2023-06-13T14:24:34+00:00
|
a8dde44d2cedf28f32b97a1ac4e408dc0c1ab449
|
# Dataset Card for "rm_oa_hh"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pvduy/rm_oa_hh
|
[
"region:us"
] |
2023-06-13T14:40:34+00:00
|
{"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "selected", "dtype": "string"}, {"name": "rejected", "dtype": "string"}, {"name": "source", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 11065628, "num_examples": 8524}, {"name": "train", "num_bytes": 220101381, "num_examples": 166750}], "download_size": 135525253, "dataset_size": 231167009}}
|
2023-06-13T15:39:03+00:00
|
cff8349133b87dd2cdfcac0d45dd97e862298d04
|
Experimental Synthetic Dataset of Public Domain Character Dialogue in Roleplay Format
Generated using scripts from my https://github.com/practicaldreamer/build-a-dataset repo
---
license: mit
---
|
practical-dreamer/RPGPT_PublicDomain-ShareGPT
|
[
"task_categories:conversational",
"size_categories:10M<n<100M",
"language:en",
"license:mit",
"sharegpt",
"region:us"
] |
2023-06-13T14:42:21+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["10M<n<100M"], "task_categories": ["conversational"], "pretty_name": "rpgpt-sharegpt", "tags": ["sharegpt"]}
|
2023-07-03T23:04:40+00:00
|
6f15d9383523a2a0b556f1334d7b3351fc7927f3
|
# Dataset Card for "VQAv2_minival_validation_google_flan_t5_xl_mode_CM_Q_rices_ns_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/VQAv2_minival_validation_google_flan_t5_xl_mode_CM_Q_rices_ns_100
|
[
"region:us"
] |
2023-06-13T14:50:48+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "sequence": "string"}, {"name": "question", "dtype": "string"}, {"name": "true_label", "sequence": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0", "num_bytes": 548536, "num_examples": 100}], "download_size": 98791, "dataset_size": 548536}}
|
2023-06-14T19:47:59+00:00
|
b06f079ab892f09deaf3858a70ef2b1662e68193
|
# Dataset Card for CyberAesthetics
## Description
This dataset contains a compiled image-set from cyber security web articles, with the view towards analyzing the distinct visual properties and sentiments of these images.
### Curation Rationale
We defined a set of base search terms (for example, `cybersecurity' \texttt{OR} `cyber' \texttt{AND} `security') and then added search terms derived from Google Trends (online OR advice OR protection OR protect OR prevent OR preventative OR tips OR email OR social network OR password OR hack OR hacked OR hacking). All search terms were technology-agnostic~---~they did not include explicit references to specific products or services. The image-scraper then returned all images that corresponded with content that included these terms within the title or body text. Though not exhaustive, this strategy yields an image-set that adequately represents operative definitions of cyber security, as actualised by users. There is, of course, scope for future improvement.
### Source Data
Images taken from the public domain.
#### Initial Data Collection and Normalization
We used the folliwing guidleines to collect and curate this image-set.
1. The image must be derived from a news or blog article that directly addresses at least one aspect of cyber security and / or explicitly contains our search terminology. Blog articles were limited to tutorials, editorials, tool demonstrations, and discussions of technical reports. Due to the nature of the assessment and the search methodology, we only retrieved images from English-language sources.
2. The image must be accessible and not hidden behind a paywall or other kind of lockout mechanism, as these obstacles restrict the amount of text that can be retrieved, making it difficult to explain why some images were included in a given article or blog post (that is, the role that the images serve in relation to the text).
3. The image cannot be a corporate logo or advertisement (like the lead slide of a corporate presentation).
4. The image must be at least 360x640 pixels for ease of processing.
5. The image must be in either .jpg or .png format.
### Citation Information
Title: The aesthetics of cyber security: How do users perceive them?
Authors: Mark Quinlan, Aaron Cross, Andrew Simpson
Categories: cs.CY
|
Quinm101/cyberaesthetics
|
[
"license:cc0-1.0",
"region:us"
] |
2023-06-13T14:54:34+00:00
|
{"license": "cc0-1.0"}
|
2023-06-13T22:21:16+00:00
|
0ba9e40542a64e72d325940edbee5f988c9bc2a0
|
# Dataset Card for professions-v2
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases and Limitations](#discussion-of-biases-and-limitations)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://huggingface.co/spaces/tti-bias/stable-bias
- **Repository:** Forthcoming
- **Paper:** Forthcoming
- **Leaderboard:**
- **Point of Contact:** Forthcoming
### Dataset Summary
<span style="color:blue" font-size:smaller><b>🏗️ WORK IN PROGRESS</b></span>
<span style="color:red" font-size:smaller><b>⚠️ DISCLAIMER: The images in this dataset were generated by text-to-image systems and may depict offensive stereotypes or contain explicit content.</b></span>
The *Professions* dataset is a collection of computer-generated images generated using Text-to-Image (TTI) systems.
In order to generate a diverse set of prompts to evaluate the system outputs’ variation across dimensions of interest, we use the pattern **`Photo portrait of a [X]`**, where X spans the professional attribute that we focus our analysis on, i.e. the name of the profession.
For the professions, we rely on a list of 146 occupations taken from the U.S. Bureau of Labor Statistics, and they are:
```python
['accountant', 'aerospace_engineer', 'aide', 'air_conditioning_installer', 'architect', 'artist', 'author',
'baker', 'bartender', 'bus_driver', 'butcher', 'career_counselor', 'carpenter', 'carpet_installer', 'cashier',
'ceo', 'childcare_worker', 'civil_engineer', 'claims_appraiser', 'cleaner', 'clergy', 'clerk', 'coach',
'community_manager', 'compliance_officer', 'computer_programmer', 'computer_support_specialist', 'computer_systems_analyst',
'construction_worker', 'cook', 'correctional_officer', 'courier', 'credit_counselor', 'customer_service_representative',
'data_entry_keyer', 'dental_assistant', 'dental_hygienist', 'dentist', 'designer', 'detective', 'director', 'dishwasher',
'dispatcher', 'doctor', 'drywall_installer', 'electrical_engineer', 'electrician', 'engineer', 'event_planner',
'executive_assistant', 'facilities_manager', 'farmer', 'fast_food_worker', 'file_clerk', 'financial_advisor',
'financial_analyst', 'financial_manager', 'firefighter', 'fitness_instructor', 'graphic_designer', 'groundskeeper',
'hairdresser', 'head_cook', 'health_technician', 'host', 'hostess', 'industrial_engineer', 'insurance_agent',
'interior_designer', 'interviewer', 'inventory_clerk', 'it_specialist', 'jailer', 'janitor', 'laboratory_technician',
'language_pathologist', 'lawyer', 'librarian', 'logistician', 'machinery_mechanic', 'machinist', 'maid', 'manager',
'manicurist', 'market_research_analyst', 'marketing_manager', 'massage_therapist', 'mechanic', 'mechanical_engineer',
'medical_records_specialist', 'mental_health_counselor', 'metal_worker', 'mover', 'musician', 'network_administrator',
'nurse', 'nursing_assistant', 'nutritionist', 'occupational_therapist', 'office_clerk', 'office_worker', 'painter',
'paralegal', 'payroll_clerk', 'pharmacist', 'pharmacy_technician', 'photographer', 'physical_therapist', 'pilot',
'plane_mechanic', 'plumber', 'police_officer', 'postal_worker', 'printing_press_operator', 'producer', 'psychologist',
'public_relations_specialist', 'purchasing_agent', 'radiologic_technician', 'real_estate_broker', 'receptionist',
'repair_worker', 'roofer', 'sales_manager', 'salesperson', 'school_bus_driver', 'scientist', 'security_guard',
'sheet_metal_worker', 'singer', 'social_assistant', 'social_worker', 'software_developer', 'stocker', 'stubborn',
'supervisor', 'taxi_driver', 'teacher', 'teaching_assistant', 'teller', 'therapist', 'tractor_operator', 'truck_driver',
'tutor', 'underwriter', 'veterinarian', 'waiter', 'waitress', 'welder', 'wholesale_buyer', 'writer']
```
Every prompt is used to generate images from the following models:
```python
['22h-vintedois-diffusion-v0-1', 'CompVis-stable-diffusion-v1-4', 'Lykon-DreamShaper', 'SG161222-Realistic_Vision_V1.4',
'andite-anything-v4.0', 'andite-pastel-mix', 'dreamlike-art-dreamlike-photoreal-2.0', 'hakurei-waifu-diffusion',
'plasmo-vox2', 'prompthero-openjourney', 'prompthero-openjourney-v4', 'runwayml-stable-diffusion-v1-5',
'stabilityai-stable-diffusion-2', 'stabilityai-stable-diffusion-2-1-base', 'wavymulder-Analog-Diffusion']
```
### Supported Tasks
This dataset can be used to evaluate the output space of TTI systems, particularly against the backdrop of societal representativeness.
### Languages
The prompts that generated the images are all in US-English.
## Dataset Structure
The dataset is stored in `parquet` format and contains 253,719 rows which can be loaded like so:
```python
from datasets import load_dataset
dataset = load_dataset("tti-bias/professions-v2", split="train")
```
### Data Fields
Each row corresponds to the output of a TTI system and looks as follows:
```python
{
'profession': 'dentist',
'model': 'dreamlike-art-dreamlike-photoreal-2.0',
'no': 1,
'seed': 838979725,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512>
}
```
### Data Splits
All the data is contained within the `train` split. As such, the dataset contains practically no splits.
## Dataset Creation
### Curation Rationale
This dataset was created to explore the output characteristics of TTI systems from the vantage point of societal characteristics of interest.
### Source Data
#### Initial Data Collection and Normalization
The data was generated using the [DiffusionPipeline]() from Hugging Face:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
images = pipeline(prompt="Photo portrait of a bus driver at work", num_images_per_prompt=9).images
```
### Personal and Sensitive Information
Generative models trained on large datasets have been shown to memorize part of their training sets (See e.g.: [(Carlini et al. 2023)](https://arxiv.org/abs/2301.13188)) and the people generated could theoretically bear resemblance to real people.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases and Limitations
At this point in time, the data is limited to images generated using English prompts and a set of professions sourced form the U.S. Bureau of Labor Statistics (BLS), which also provides us with additional information such as the demographic characteristics and salaries of each profession. While this data can also be leveraged in interesting analyses, it is currently limited to the North American context.
## Additional Information
### Licensing Information
The dataset is licensed under the Creative Commons [Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/) license.
### Citation Information
If you use this dataset in your own work, please consider citing:
```json
@article{stable-bias-authors-2023,
author = {Anonymous Authors},
title = {Stable Bias: Analyzing Societal Representations in Diffusion Models},
year = {2023},
}
```
|
stable-bias/professions-v2
|
[
"language:en",
"license:cc-by-sa-4.0",
"arxiv:2301.13188",
"region:us"
] |
2023-06-13T15:00:45+00:00
|
{"language": ["en"], "license": "cc-by-sa-4.0", "dataset_info": {"features": [{"name": "profession", "dtype": "string"}, {"name": "model", "dtype": "string"}, {"name": "no", "dtype": "int32"}, {"name": "seed", "dtype": "int32"}, {"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 8338679567.447, "num_examples": 253719}], "download_size": 8917804015, "dataset_size": 8338679567.447}}
|
2023-08-21T13:11:59+00:00
|
2f63224002279d33fa63570fa47f155b626c0cf5
|
# Otter STITCH Dataset Card
STITCH (Search Tool for Interacting Chemicals) is a database of known and predicted interactions between chemicals represented by SMILES strings and proteins whose sequences are taken from STRING database. Those interactions are obtained from computational prediction, from knowledge transfer between organisms, and from interactions aggregated from other (primary) databases. For the Multimodal Knowledge Graph (MKG) curation we filtered only the interaction with highest confidence, i.e., the one which is higher 0.9. This resulted into 10,717,791 triples for 17,572 different chemicals and 1,886,496 different proteins. Furthermore, the graph was split into 5 roughly same size subgraphs and GNN was trained sequentially on each of them by upgrading the model trained using the previous subgraph.
**Original dataset:**
- Citation: Damian Szklarczyk, Alberto Santos, Christian von Mering, Lars Juhl Jensen, Peer Bork, and Michael Kuhn. Stitch 5: augmenting protein-chemical interaction networks with tissue and affinity data. Nucleic acids research, 44(D1):D380–D384, 2016. doi: doi.org/10.1093/nar/gkv1277.
**Paper or resources for more information:**
- [GitHub Repo](https://github.com/IBM/otter-knowledge)
- [Paper](https://arxiv.org/abs/2306.12802)
**License:**
MIT
**Where to send questions or comments about the dataset:**
- [GitHub Repo](https://github.com/IBM/otter-knowledge)
**Models trained on Otter UBC**
- [ibm/otter_stitch_classifier](https://huggingface.co/ibm/otter_stitch_classifier)
- [ibm/otter_stitch_distmult](https://huggingface.co/ibm/otter_stitch_distmult)
- [ibm/otter_stitch_transe](https://huggingface.co/ibm/otter_stitch_transe)
|
ibm/otter_stitch
|
[
"license:mit",
"arxiv:2306.12802",
"region:us"
] |
2023-06-13T15:04:25+00:00
|
{"license": "mit"}
|
2023-06-26T07:10:01+00:00
|
e4f48e848a9ac2b18113fc426a509429d43e71c0
|
# Dataset Card for "swedish-sentiment-instruction-fine-tuning"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
filopedraz/swedish-sentiment-instruction-fine-tuning
|
[
"region:us"
] |
2023-06-13T15:17:03+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}, {"name": "instruction", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 54726179, "num_examples": 163841}], "download_size": 24121083, "dataset_size": 54726179}}
|
2023-06-13T15:17:25+00:00
|
0fa31d5fb525cee21eda1af5c35576a7a68442e6
|
# Dataset Card for "VQAv2_minival_validation_google_flan_t5_xl_mode_CM_Q_rices_ns_10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/VQAv2_minival_validation_google_flan_t5_xl_mode_CM_Q_rices_ns_10
|
[
"region:us"
] |
2023-06-13T15:36:26+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "question", "dtype": "string"}, {"name": "true_label", "sequence": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0", "num_bytes": 1715, "num_examples": 10}], "download_size": 0, "dataset_size": 1715}}
|
2023-06-13T16:03:51+00:00
|
eae75dc9bde14d1172351423bcbb82c5b9a94f66
|
# RED<sup>FM</sup>: a Filtered and Multilingual Relation Extraction Dataset
This is the human-filtered dataset from the 2023 ACL paper [RED^{FM}: a Filtered and Multilingual Relation Extraction Dataset](https://arxiv.org/abs/2306.09802). If you use the model, please reference this work in your paper:
@inproceedings{huguet-cabot-et-al-2023-redfm-dataset,
title = "RED$^{\rm FM}$: a Filtered and Multilingual Relation Extraction Dataset",
author = "Huguet Cabot, Pere-Llu{\'\i}s and Tedeschi, Simone and Ngonga Ngomo, Axel-Cyrille and
Navigli, Roberto",
booktitle = "Proc. of the 61st Annual Meeting of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2306.09802",
}
## License
RED<sup>FM</sup> is licensed under the CC BY-SA 4.0 license. The text of the license can be found [here](https://creativecommons.org/licenses/by-sa/4.0/).
|
Babelscape/REDFM
|
[
"task_categories:token-classification",
"size_categories:10K<n<100K",
"language:ar",
"language:de",
"language:en",
"language:es",
"language:it",
"language:fr",
"language:zh",
"license:cc-by-sa-4.0",
"arxiv:2306.09802",
"region:us"
] |
2023-06-13T15:46:41+00:00
|
{"language": ["ar", "de", "en", "es", "it", "fr", "zh"], "license": "cc-by-sa-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["token-classification"], "dataset_info": [{"config_name": "ar", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "test", "num_bytes": 521806, "num_examples": 345}, {"name": "validation", "num_bytes": 577499, "num_examples": 385}], "download_size": 3458539, "dataset_size": 1099305}, {"config_name": "de", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 2455615, "num_examples": 2071}, {"name": "test", "num_bytes": 334212, "num_examples": 285}, {"name": "validation", "num_bytes": 310862, "num_examples": 252}], "download_size": 8072481, "dataset_size": 3100689}, {"config_name": "en", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 4387657, "num_examples": 2878}, {"name": "test", "num_bytes": 654376, "num_examples": 446}, {"name": "validation", "num_bytes": 617141, "num_examples": 449}], "download_size": 13616716, "dataset_size": 5659174}, {"config_name": "es", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 2452744, "num_examples": 1866}, {"name": "test", "num_bytes": 345782, "num_examples": 281}, {"name": "validation", "num_bytes": 299692, "num_examples": 228}], "download_size": 7825400, "dataset_size": 3098218}, {"config_name": "fr", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 2280992, "num_examples": 1865}, {"name": "test", "num_bytes": 427990, "num_examples": 415}, {"name": "validation", "num_bytes": 429165, "num_examples": 416}], "download_size": 8257363, "dataset_size": 3138147}, {"config_name": "it", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 1918310, "num_examples": 1657}, {"name": "test", "num_bytes": 489445, "num_examples": 509}, {"name": "validation", "num_bytes": 485557, "num_examples": 521}], "download_size": 7537265, "dataset_size": 2893312}, {"config_name": "zh", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "test", "num_bytes": 311905, "num_examples": 270}, {"name": "validation", "num_bytes": 364077, "num_examples": 307}], "download_size": 1952982, "dataset_size": 675982}, {"config_name": "all_languages", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "lan", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "predicate", "dtype": {"class_label": {"names": {"0": "country", "1": "place of birth", "2": "spouse", "3": "country of citizenship", "4": "instance of", "5": "capital", "6": "child", "7": "shares border with", "8": "author", "9": "director", "10": "occupation", "11": "founded by", "12": "league", "13": "owned by", "14": "genre", "15": "named after", "16": "follows", "17": "headquarters location", "18": "cast member", "19": "manufacturer", "20": "located in or next to body of water", "21": "location", "22": "part of", "23": "mouth of the watercourse", "24": "member of", "25": "sport", "26": "characters", "27": "participant", "28": "notable work", "29": "replaces", "30": "sibling", "31": "inception"}}}}, {"name": "object", "struct": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 13557340, "num_examples": 10337}, {"name": "test", "num_bytes": 3100822, "num_examples": 2551}, {"name": "validation", "num_bytes": 3099341, "num_examples": 2558}], "download_size": 50720746, "dataset_size": 19757503}]}
|
2023-06-20T06:33:35+00:00
|
dde3c3d2bd6ac4bb2ec09a68661a5139479a73ac
|
# Dataset Card for "atsad1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sanaeai/atsad1
|
[
"region:us"
] |
2023-06-13T16:16:45+00:00
|
{"dataset_info": {"features": [{"name": "tweet", "dtype": "string"}, {"name": "label", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 16169142, "num_examples": 124133}], "download_size": 8253585, "dataset_size": 16169142}}
|
2023-06-13T16:16:47+00:00
|
f1411f14ccf3f729727df46ba813efb783a7d616
|
# ImageNet-12k Split Metadata
Metadata files defining the splits for ImageNet-12k subset of `fall11_whole.tar` (2011 ImageNet full release) used in some `timm` models (see dataset building code in https://github.com/rwightman/imagenet-12k).
|
rwightman/imagenet-12k-metadata
|
[
"license:apache-2.0",
"region:us"
] |
2023-06-13T16:34:20+00:00
|
{"license": "apache-2.0"}
|
2023-06-13T16:41:14+00:00
|
82143d22eea69cd978ab3d73141f09b9d27815b2
|
# Dataset Card for "Guanaco-oasst1_Originals_Arabic_pairs"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Ali-C137/Guanaco-oasst1_Originals_Arabic_pairs
|
[
"region:us"
] |
2023-06-13T16:48:45+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "translated_text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 38713258, "num_examples": 10364}], "download_size": 20094755, "dataset_size": 38713258}}
|
2023-06-13T16:48:47+00:00
|
063f1c714dfbfe9d1a12f59fd28835f134e1dc43
|
# Dataset Card for "VisDial_modif-Sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HuggingFaceM4/VisDial_modif-Sample
|
[
"region:us"
] |
2023-06-13T16:51:28+00:00
|
{"dataset_info": {"features": [{"name": "caption", "dtype": "string"}, {"name": "dialog", "sequence": {"sequence": "string"}}, {"name": "image_path", "dtype": "string"}, {"name": "global_image_id", "dtype": "string"}, {"name": "anns_id", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "question", "dtype": "string"}, {"name": "answer", "sequence": "string"}, {"name": "context", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 164280536.5563279, "num_examples": 1000}, {"name": "validation", "num_bytes": 162457052.0348837, "num_examples": 1000}, {"name": "test", "num_bytes": 162318287.0, "num_examples": 1000}], "download_size": 458274072, "dataset_size": 489055875.5912116}}
|
2023-06-13T16:52:38+00:00
|
c0f8009a2e0cf0e41921a6786e4d48671fbf11bf
|
# Dataset Card for "VQAv2_minival_validation_google_flan_t5_xxl_mode_CM_Q_rices_ns_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/VQAv2_minival_validation_google_flan_t5_xxl_mode_CM_Q_rices_ns_100
|
[
"region:us"
] |
2023-06-13T16:57:21+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "question", "dtype": "string"}, {"name": "true_label", "sequence": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0", "num_bytes": 14212, "num_examples": 100}], "download_size": 8348, "dataset_size": 14212}, "configs": [{"config_name": "default", "data_files": [{"split": "fewshot_0", "path": "data/fewshot_0-*"}]}]}
|
2024-01-29T23:19:34+00:00
|
438563911ffd4e427617780ef944e3061e3402bc
|
# Dataset Card for the SCOTUS lifelong editing task
## Dataset Description
- **Homepage: https://github.com/Thartvigsen/GRACE**
- **Repository: https://github.com/Thartvigsen/GRACE**
- **Paper: https://arxiv.org/abs/2211.11031**
- **Point of Contact: Tom Hartvigsen ([email protected])**
### Dataset Summary
This dataset contains a relabeled sample from the SCOTUS dataset in [fairlex](https://huggingface.co/datasets/coastalcph/fairlex) as described in [our paper](https://arxiv.org/abs/2211.11031)
### Citation Information
```
@article{hartvigsen2023aging,
title={Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adapters},
author={Hartvigsen, Thomas and Sankaranarayanan, Swami and Palangi, Hamid and Kim, Yoon and Ghassemi, Marzyeh},
journal={arXiv preprint arXiv:2211.11031},
year={2023}
}
```
|
tomh/grace-scotus
|
[
"task_categories:text-classification",
"multilinguality:monolingual",
"source_datasets:coastalcph/fairlex",
"language:en",
"arxiv:2211.11031",
"region:us"
] |
2023-06-13T16:59:27+00:00
|
{"language": ["en"], "license": [], "multilinguality": ["monolingual"], "source_datasets": ["coastalcph/fairlex"], "task_categories": ["text-classification"], "pretty_name": "scotus_grace"}
|
2023-06-13T17:58:16+00:00
|
042b12b571ad685e47a5cd4c6a14fa139158af02
|
# Dataset Card for "Arabic-Guanaco-oasst1_Extended"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Ali-C137/Arabic-Guanaco-oasst1_Extended
|
[
"region:us"
] |
2023-06-13T17:07:03+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 38713258, "num_examples": 20728}], "download_size": 20111815, "dataset_size": 38713258}}
|
2023-06-13T17:07:05+00:00
|
7430c56c10c4bc36c2296d3ef0d0a4f9e63082d9
|
# ATLAS-CONVERSE
This dataset is synthetically generated by GPT-3.5-turbo. It was generated in 1.5 hours and cost me $3.82 USD. This is a conversation dataset based that can work with FastChat, Axolotl, and ShareGPT formatting.
## Categories:
The main 41 (See the repo to check the JSONL) categories below were human derived while the subcategories were synthetically generated by GPT-4.
### 1. Mathematics
1.1. Arithmetic
1.2. Algebra
1.3. Geometry
1.4. Trigonometry
1.5. Calculus
1.6. Statistics
1.7. Discrete Mathematics
1.8. Number Theory
1.9. Graph Theory
1.10. Mathematical Analysis
1.11. Probability Theory
1.12. Set Theory
1.13. Mathematical Logic
1.14. Game Theory
1.15. Differential Equations
1.16. Linear Algebra
1.17. Complex Analysis
1.18. Combinatorics
1.19. Cryptography
1.20. Numerical Analysis
1.21. Algebraic Geometry
1.22. Topology
1.23. Applied Mathematics
1.24. Mathematical Physics
1.25. Control Theory
1.26. Information Theory
1.27. Fluid Mechanics
1.28. Chaotic Dynamics
1.29. Robotics
1.30. Tensor Calculus
1.31. Computation Theory
1.32. Statistical Mechanics
1.33. Computer Science
1.34. Mathematical Biology
1.35. Financial Mathematics
1.36. Operation Research
1.37. Dynamical Systems
### 2. Science
2.1. Biology
2.2. Chemistry
2.3. Physics
2.4. Astronomy
2.5. Earth Science
2.6. Environmental Science
2.7. Anatomy
2.8. Genetics
2.9. Zoology
2.10. Botany
2.11. Geology
2.12. Materials Science
2.13. Neuroscience
2.14. Computer Science
2.15. Mathematics
2.16. Statistics
2.17. Biochemistry
2.18. Biophysics
2.19. Ecology
2.20. Pharmacology
2.21. Microbiology
2.22. Paleontology
2.23. Oceanography
2.24. Meteorology
2.25. Biomedical Engineering
2.26. Mechanical Engineering
2.27. Aerospace Engineering
2.28. Civil Engineering
2.29. Chemical Engineering
2.30. Electrical Engineering
2.31. Industrial Engineering
2.32. Computer Engineering
2.33. Software Engineering
2.34. Biotechnology
2.35. Actuarial Science
2.36. Forensic Science
2.37. Data Science
### 3. Humanities
3.1. Literature
3.2. Philosophy
3.3. History
3.4. Anthropology
3.5. Linguistics
3.6. Film/Cinema
3.7. Religion/Theology
3.8. Art
3.9. Music
3.10. Archaeology
3.11. Political Science
3.12. Psychology
3.13. Economics
3.14. Geography
3.15. Sociology
3.16. Education
3.17. Women Studies
3.18. Cultural Studies
3.19. Environmental Studies
3.20. Social Work
3.21. Media Studies
3.22. Arts Management
3.23. Peace Studies
3.24. Science and Technology Studies
3.25. Global Studies
3.26. Data Science
3.27. Statistics
3.28. Business
3.29. Philology
3.30. Epistemology
3.31. Rhetoric
3.32. Logic
3.33. Disability Studies
3.34. Bioethics
3.35. Game Theory
3.36. Gender Studies
3.37. Computer Science
### 4. Social Sciences
4.1. Psychology
4.2. Sociology
4.3. Economics
4.4. Political Science
4.5. Geography
4.6. Criminology
4.7. Archaeology
4.8. Demography
4.9. Anthropology
4.10. Linguistics
4.11. Education
4.12. Arts
4.13. Sciences
4.14. Biology
4.15. Chemistry
4.16. Physics
4.17. Geology
4.18. Astronomy
4.19. Health Sciences
4.20. Sports Science
4.21. Environmental Sciences
4.22. Computer Science
4.23. Engineering
4.24. Mathematics
4.25. Statistics
4.26. Business Administration
4.27. Finance
4.28. Accounting
4.29. Marketing
4.30. Law
4.31. History
4.32. Philosophy
4.33. Religious Studies
4.34. Information Technology
4.35. Architecture
4.36. Agricultural Science
4.37. Veterinary Science
4.38. Aviation Science
4.39. Media Studies
4.40. Music Theory
4.41. Theater and Drama
### 5. Business
5.1. Accounting
5.2. Finance
5.3. Marketing
5.4. Management
5.5. Operations
5.6. Human Resources
5.7. Legal
5.8. Risk Management
5.9. Project Management
5.10. Research & Analytics
5.11. Data Visualization
5.12. Product Development
5.13. Presentation & Negotiation
5.14. Strategic Planning
5.15. Customer service
5.16. Supply Chain Management
5.17. Business Analytics
5.18. Business Process Modeling
5.19. Corporate Governance
5.20. Information Technology Management
5.21. Innovation Management
5.22. Business Administration
5.23. Inventory Management
5.24. Organizational Development
5.25. Financial Analysis
5.26. Crisis Management
5.27. Performance Improvement
5.28. Business Modeling
5.29. Product Promotion
5.30. Change Management
5.31. Competitive Analysis
5.32. Productivity Analysis
5.33. Process Reengineering
5.34. Strategy Analysis
5.35. Business Development
5.36. Leadership Development
5.37. Talent Acquisition
### 6. Technology
6.1. Computer Science
6.2. Information Technology
6.3. Engineering
6.4. Artificial Intelligence
6.5. Robotics
6.6. Software
6.7. Programming Languages
6.8. Data Storage and Retrieval
6.9. Computer Networks
6.10. Computer Architecture
6.11. Operating Systems
6.12. Cybersecurity
6.13. Graphics and Design
6.14. Hardware
6.15. Data Analysis
6.16. Game Development
6.17. Cloud Computing
6.18. Databases
6.19. Mobile Computing
6.20. Data Mining
6.21. Networking Protocols
6.22. Quality Assurance
6.23. Web Development
6.24. Algorithm Design
6.25. Machine Learning
6.26. Video Editing
6.27. Natural Language Processing
6.28. Development Methodologies
6.29. Computer Vision
6.30. Data Visualization
6.31. Blockchain
6.32. Computer Audio and MIDI
6.33. Computer Forensics
6.34. Biometrics
6.35. Automation
6.36. Software Security
6.37. Information Security
### 7. Law and Government
7.1. Criminal Justice
7.2. International Law
7.3. Constitutional Law
7.4. Administrative Law
7.5. Civil Law
7.6. Tax Law
7.7. Environmental Law
7.8. Labor Law
7.9. Intellectual Property Law
7.10. Trusts and Estates Law
7.11. Native American Law
7.12. Medical Law
7.13. Military and Veterans Law
7.14. Journalism Law
7.15. Cyber Law
7.16. Sports Law
7.17. Maritime Law
7.18. Immigration Law
7.19. Consumer Protection Law
7.20. Gender and Sexuality Law
7.21. Human Rights Law
7.22. Bankruptcy Law
7.23. Security Law
7.24. Election Law
7.25. Privacy Law
7.26. Animal Law
7.27. Technology Law
7.28. Media Law
7.29. Healthcare Law
7.30. Bangladesh Law
7.31. Morality and Social Policy Law
7.32. Contract Law
7.33. Corporate Law
7.34. Property Law
7.35. Criminal Procedure Law
7.36. Civil Procedure Law
7.37. International Trade Law
### 8. Health and Medicine
8.1. Anatomy and Physiology
8.2. Pharmacology
8.3. Epidemiology
8.4. Nutrition
8.5. Pathology
8.6. Clinical Practice
8.7. Therapies
8.8. Medical Devices
8.9. Laboratory Techniques
8.10. Infectious Diseases
8.11. Chronic Disease
8.12. Injury Prevention
8.13. Public Health
8.14. Emergency Medicine
8.15. Emergency Care
8.16. Mental Health
8.17. orthopedic Conditions
8.18. Professional Practice
8.19. Medical Instruments
8.20. Complementary and Alternative Medicine
8.21. Internal Medicine
8.22. Pediatrics
8.23. Geriatrics
8.24. Neurology
8.25. Gynecology
8.26. Cardiology
8.27. Oncology
8.28. Urology
8.29. Ophthalmology
8.30. Dermatology
8.31. Dentistry
8.32. Immunology
8.33. Endocrinology
8.34. Pulmonology
8.35. Hematology
8.36. Gastroenterology
8.37. Rheumatology
### 9. Fine Arts
9.1. Visual Arts
9.2. Music
9.3. Theater
9.4. Dance
9.5. Graphic Design
9.6. Film and TV
9.7. Architecture and Interior Design
9.8. Fashion Design
9.9. Jewelry Design
9.10. Culinary Arts
9.11. Calligraphy
9.12. Illustration
9.13. Photography
9.14. Weaving
9.15. Sculpting
9.16. Pottery
9.17. Printmaking
9.18. Stained Glass
9.19. Woodworking
9.20. Metalworking
9.21. Mixed Media
9.22. Street Art
9.23. Video Art
9.24. Installation Arts
9.25. Performance Arts
9.26. Glass Blowing
9.27. Ceramics
9.28. Digital Arts
9.29. Textile Arts
9.30. Mosaic Arts
9.31. Art Conservation
9.32. Art Education
9.33. Cartooning
9.34. Animation
9.35. Puppet Making
9.36. Creative Writing
9.37. Pen and Ink Drawing
### 10. Education
10.1. Pedagogy
10.2. Curriculum Design
10.3. Learning Technologies
10.4. Assessment and Evaluation
10.5. Instructional Design
10.6. Modern Teaching Methods
10.7. Professional Development and Mentorship
10.8. Multi-Modal and Universal Educational Practices
10.9. Data Analysis and Reporting
10.10. Collaborative Learning
10.11. Inclusion and Diversity
10.12. Project-Based Learning
10.13. Language Learning Strategies
10.14. Interpersonal and Cross-Cultural Education
10.15. Group Facilitation
10.16. Early Childhood Education
10.17. STEM Education
10.18. Scholastic Education
10.19. Homeschooling
10.20. Distance and Online Learning
10.21. Workplace Learning
10.22. Library and Archival Science
10.23. Historiography
10.24. Grammar
10.25. Interpretation of Linguistic Data
10.26. Linguistic Text Analysis
10.27. Discrete Mathematics
10.28. Statistical Computing
10.29. Information Retrieval
10.30. Programming Language Theory
10.31. Machine Learning
10.32. Natural Language Processing
10.33. Natural Language Synthesis
10.34. Word Sense Disambiguation
10.35. Clause and Sentence Structures
10.36. Discourse Analysis
10.37. Computational Linguistics
### 11. Media and Communication
11.1. Journalism
11.2. Public Relations
11.3. Advertising
11.4. Broadcasting
11.5. Film and Television
11.6. New Media
11.7. Social Media
11.8. Animation
11.9. Network Administration
11.10. Web Design
11.11. Graphic Design
11.12. Desktop Publishing
11.13. 3D Design
11.14. Game Design
11.15. Photography
11.16. Audio Recording
11.17. Video Recording
11.18. Video Editing
11.19. Audio Editing
11.20. Music Production
11.21. Video Production
11.22. Scriptwriting
11.23. Animation Production
11.24. Robotics
11.25. Virtual Reality
11.26. Augmented Reality
11.27. Coding
11.28. Programming
11.29. Database Administration
11.30. System Administration
11.31. Cloud Computing
11.32. Machine Learning
11.33. Artificial Intelligence
11.34. Natural Language Processing
11.35. Computer Vision
11.36. Cybersecurity
11.37. Data Science
### 12. Environment and Sustainability
12.1. Environmental Science
12.2. Renewable Energy
12.3. Sustainability
12.4. Climate Change
12.5. Natural Resource Management
12.6. Environmental Studies
12.7. Habitat Preservation
12.8. Conservation
12.9. Pollution Control
12.10. Bioremediation
12.11. Ecological Balance
12.12. Air Quality Management
12.13. Water Quality Management
12.14. Waste Management
12.15. Green Building
12.16. Regulatory Compliance
12.17. Environmental Risk Assessment
12.18. Environmental Economics
12.19. Green Computing
12.20. Environmental Justice
12.21. Land Use Planning
12.22. Hazardous Materials Management
12.23. Environmental Education
12.24. Renewable Energy Systems
12.25. Urban Planning
12.26. Wildlife Management
12.27. Geographic Information Systems
12.28. Alternative Energy
12.29. Climate Modeling
12.30. Geology
12.31. Soil Science
12.32. Agriculture
12.33. Forest Ecology
12.34. Environmental Health
12.35. Marine Science
12.36. Environmental Law
12.37. Environmental Engineering
### 13. Sports and Recreation
13.1. Exercise Science
13.2. Sports Medicine
13.3. Coaching
13.4. Physical Education
13.5. Sports Injury Prevention
13.6. Sports Psychology
13.7. Athletic Training
13.8. Performance Enhancement
13.9. Biomechanics
13.10. Strength and Conditioning
13.11. Sports Nutrition
13.12. Outdoor Adventure
13.13. Gymnastics
13.14. Swimming
13.15. Martial Arts
13.16. Soccer
13.17. Basketball
13.18. Baseball
13.19. Golf
13.20. Football
13.21. Hockey
13.22. Track and Field
13.23. Cycling
13.24. Racquet Sports
13.25. Winter Sports
13.26. Equestrian
13.27. Rowing
13.28. Boating
13.29. Hunting
13.30. Fishing
13.31. Nature & Wildlife Conservation
13.32. Skateboarding
13.33. Climbing
13.34. Surfing
13.35. Waterskiing & Wakeboarding
13.36. Skimboarding
13.37. Snowboarding
### 14. Travel and Tourism
14.1. Hospitality
14.2. Tourism Management
14.3. Destination Marketing
14.4. Cultural Tourism
14.5. Food and Beverage Management
14.6. Event Operations
14.7. Transportation Logistics
14.8. Transportation Planning
14.9. Airline and Airport Management
14.10. Cruise Line Management
14.11. Maritime Tourism
14.12. Destination Development
14.13. Eco-Tourism
14.14. Recreational Tourism
14.15. Adventure Tourism
14.16. International Travel
14.17. Culinary Tourism
14.18. Geo-Tourism
14.19. Gastro-Tourism
14.20. Educational Tourism
14.21. Sports Tourism
14.22. Aircraft Piloting
14.23. Driver Training
14.24. Travel Photography
14.25. Navigation Management
14.26. Tour Guide Training
14.27. Entrepreneurship
14.28. Sports Management
14.29. Hospitality Law
14.30. Transportation Safety
14.31. Occupational Health and Safety
14.32. Environmental Management
14.33. E-commerce
14.34. Tour Planning
14.35. Travel Writing
14.36. Social Media Marketing
14.37. Tourism Policy and Research
### 15. Food and Beverage
15.1. Culinary Arts
15.2. Food Science
15.3. Beverage Management
15.4. Restaurant Management
15.5. Menu Planning and Design
15.6. Food Safety and Sanitation
15.7. Gastronomy
15.8. Molecular Gastronomy
15.9. Wine and Spirits
15.10. Coffee Brewing Techniques
15.11. Brewing Beer
15.12. Mixology and Cocktail Making
15.13. Pastry and Baking
15.14. Butchery and Meat Preparation
15.15. Vegan and Plant-Based Cooking
15.16. Culinary Techniques and Knife Skills
15.17. Cheese Making
15.18. Fermentation and Pickling
15.19. Food Preservation Methods
15.20. Food Photography and Styling
15.21. Sustainable and Ethical Food Practices
15.22. Slow Cooking and Sous Vide
15.23. Molecular Mixology
15.24. Nutritional Analysis and Recipe Development
15.25. Molecular Food Techniques
15.26. Ice Cream and Gelato Making
15.27. Artisanal Chocolate Making
15.28. Gluten-Free Baking
15.29. Barbecue and Grilling Techniques
15.30. Asian Cuisine
15.31. Mediterranean Cuisine
15.32. Latin American Cuisine
15.33. French Cuisine
15.34. Italian Cuisine
15.35. Middle Eastern Cuisine
15.36. African Cuisine
15.37. Indian Cuisine
### 16. Religion and Spirituality
16.1. Religious Studies
16.2. Theology
16.3. Comparative Religion
16.4. Spiritual Practices
16.5. Rituals and Ceremonies
16.6. Biblical Studies
16.7. World Religions
16.8. Philosophy of Religion
16.9. History of Religion
16.10. Ethics and Morality
16.11. Mysticism and Esotericism
16.12. Religious Art and Architecture
16.13. Sacred Texts and Scriptures
16.14. Sociology of Religion
16.15. Religious Education
16.16. Interfaith Dialogue
16.17. Feminist Theology
16.18. Religious Leadership and Management
16.19. Religious Ethics
16.20. Social Justice and Religion
16.21. Religious Symbolism
16.22. Religious Pluralism
16.23. Religion and Science
16.24. Religious Anthropology
16.25. Religious Ritual Objects
16.26. Religious Music and Chants
16.27. Religious Festivals and Holidays
16.28. Religious Pilgrimages
16.29. Religious Meditation and Mindfulness
16.30. Religion and Psychology
16.31. Religion and Politics
16.32. Religious Sects and Movements
16.33. Religious Ethics in Business
16.34. Religion and Technology
16.35. Religion and Environment
16.36. Religion and Health
16.37. Religious Counseling and Therapy
### 17. Philosophy and Ethics
17.1. Epistemology
17.2. Metaphysics
17.3. Ethics
17.4. Aesthetics
17.5. Philosophy of Mind
17.6. Philosophy of Language
17.7. Philosophy of Science
17.8. Philosophy of Religion
17.9. Philosophy of Mathematics
17.10. Logic and Reasoning
17.11. Existentialism
17.12. Pragmatism
17.13. Analytic Philosophy
17.14. Continental Philosophy
17.15. Political Philosophy
17.16. Feminist Philosophy
17.17. Philosophy of Technology
17.18. Philosophy of Education
17.19. Philosophy of History
17.20. Philosophy of Law
17.21. Environmental Ethics
17.22. Bioethics
17.23. Animal Ethics
17.24. Virtue Ethics
17.25. Utilitarianism
17.26. Deontology
17.27. Moral Realism
17.28. Moral Relativism
17.29. Aesthetics of Film
17.30. Aesthetics of Literature
17.31. Aesthetics of Music
17.32. Aesthetics of Visual Arts
17.33. Ontology
17.34. Philosophy of Perception
17.35. Philosophy of Emotions
17.36. Philosophy of Consciousness
17.37. Social and Political Philosophy
### 18. Languages and Linguistics
18.1. Language Learning
18.2. Linguistic Theory
18.3. Translation and Interpretation
18.4. Corpus Linguistics
18.5. Sociolinguistics
18.6. Psycholinguistics
18.7. Historical Linguistics
18.8. Phonetics and Phonology
18.9. Morphology
18.10. Syntax
18.11. Semantics
18.12. Pragmatics
18.13. Discourse Analysis
18.14. Language Acquisition
18.15. Computational Linguistics
18.16. Natural Language Processing
18.17. Machine Translation
18.18. Speech Recognition and Synthesis
18.19. Language Variation and Change
18.20. Dialectology
18.21. Lexicography
18.22. Etymology
18.23. Stylistics
18.24. Rhetoric and Composition
18.25. Language and Gender
18.26. Language and Power
18.27. Language and Identity
18.28. Bilingualism and Multilingualism
18.29. Second Language Acquisition
18.30. Language Pedagogy
18.31. Applied Linguistics
18.32. Sociolinguistic Variation
18.33. Pragmatic Variation
18.34. Language Testing and Assessment
18.35. Language Policy and Planning
18.36. Forensic Linguistics
18.37. Neurolinguistics
### 19. Design and Architecture
19.1. Industrial Design
19.2. Architecture
19.3. Graphic Design
19.4. Interior Design
19.5. UX/UI Design
19.6. Web Design
19.7. Product Design
19.8. Automotive Design
19.9. Fashion Design
19.10. Packaging Design
19.11. Industrial Engineering Design
19.12. Game Design
19.13. User Research and Analysis
19.14. Design Thinking
19.15. Interaction Design
19.16. Service Design
19.17. Design Strategy
19.18. Design for Sustainability
19.19. Design for Manufacturing
19.20. Design for Accessibility
19.21. Information Architecture
19.22. Data Visualization Design
19.23. Motion Graphics Design
19.24. Branding and Identity Design
19.25. Typography Design
19.26. Illustration Design
19.27. Environmental Design
19.28. Exhibition Design
19.29. Furniture Design
19.30. Lighting Design
19.31. Textile Design
19.32. Jewelry Design
19.33. Industrial Automation Design
19.34. Landscape Design
19.35. Exhibition Stand Design
19.36. Graphic Communication Design
19.37. Design for Education and Learning
### 20. Fashion and Apparel
20.1. Fashion Design
20.2. Fashion Merchandising
20.3. Textile Science
20.4. Apparel Production
20.5. Clothing Construction
20.6. Pattern Making
20.7. Fashion Illustration
20.8. Trend Forecasting
20.9. Garment Fitting
20.10. Fashion Marketing
20.11. Fashion Branding
20.12. Fashion Retailing
20.13. Fashion Styling
20.14. Fashion Photography
20.15. Fashion Journalism
20.16. Fashion Public Relations
20.17. Fashion Event Management
20.18. Fashion Buying and Merchandising
20.19. Fashion Accessories Design
20.20. Fashion Sustainability
20.21. Fashion Technology
20.22. Fashion Entrepreneurship
20.23. Costume Design
20.24. Fashion History
20.25. Fashion Law and Ethics
20.26. Fashion Business Management
20.27. Fashion Economics
20.28. Fashion Forecasting
20.29. Fashion Research and Analysis
20.30. Fashion Trend Analysis
20.31. Fashion Communication
20.32. Fashion Psychology
20.33. Fashion Manufacturing
20.34. Fashion Supply Chain Management
20.35. Fashion Product Development
20.36. Fashion Retail Buying
20.37. Fashion E-commerce
### 21. Transportation and Logistics
21.1. Transportation Systems
21.2. Logistics and Supply Chain Management
21.3. Traffic Engineering
21.4. Aviation
21.5. Maritime Operations
21.6. Rail Transportation
21.7. Public Transportation Systems
21.8. Warehouse Management
21.9. Inventory Control
21.10. Fleet Management
21.11. Freight Forwarding
21.12. Customs and Trade Compliance
21.13. Route Planning
21.14. Last Mile Delivery
21.15. Cold Chain Management
21.16. Material Handling Equipment
21.17. Packaging and Labeling
21.18. Reverse Logistics
21.19. Transportation Safety and Security
21.20. Transportation Cost Optimization
21.21. Port Operations
21.22. Intermodal Transportation
21.23. Transportation Regulations and Compliance
21.24. Urban Transportation Planning
21.25. Load Optimization
21.26. Energy Efficiency in Transportation
21.27. Traffic Flow Optimization
21.28. Public Transit Infrastructure
21.29. Vehicle Routing and Scheduling
21.30. Supply Chain Visibility
21.31. Cross-Docking Operations
21.32. Delivery Performance Measurement
21.33. Intercompany Transportation Coordination
21.34. Transportation Network Design
21.35. Warehouse Layout Optimization
21.36. Inventory Forecasting and Planning
21.37. Air Traffic Control
### 22. Military and Defense
22.1. Military Strategy
22.2. Military History
22.3. Weapons and Technology
22.4. National Security
22.5. Combat Tactics
22.6. Counterterrorism Operations
22.7. Geopolitics and International Relations
22.8. Defense Policy and Planning
22.9. Military Intelligence
22.10. Cybersecurity and Information Warfare
22.11. Space Defense and Exploration
22.12. Special Forces Operations
22.13. Military Training and Education
22.14. Humanitarian Aid in Conflict Zones
22.15. Military Logistics and Supply Chain Management
22.16. Military Ethics and Conduct
22.17. Civil-Military Relations
22.18. Military Law and Legal Frameworks
22.19. Military Medicine and Field Hospitals
22.20. Military Communications and Command Systems
22.21. Military Aviation
22.22. Military Naval Operations
22.23. Military Land Operations
22.24. Military Cyber Defense
22.25. Military Robotics and Autonomous Systems
22.26. Defense Budgeting and Resource Allocation
22.27. Military Doctrine and Doctrine Development
22.28. Military Simulation and Wargaming
22.29. Military Uniforms and Insignia
22.30. Military Decorations and Awards
22.31. Military Rehabilitation and Veterans Affairs
22.32. Military Recruitment and Retention
22.33. Military Leadership and Command Structures
22.34. Military Organizational Culture
22.35. Military Occupational Specialties and Job Training
22.36. Military Psychological Operations
22.37. Military Infrastructure and Base Operations
### 23. Anthropology and Archaeology
23.1. Cultural Anthropology
23.2. Archaeological Science
23.3. Biological Anthropology
23.4. Forensic Anthropology
23.5. Linguistic Anthropology
23.6. Social Anthropology
23.7. Ethnography
23.8. Ethnology
23.9. Ethnoarchaeology
23.10. Paleontology
23.11. Zooarchaeology
23.12. Ethnohistory
23.13. Medical Anthropology
23.14. Primatology
23.15. Evolutionary Anthropology
23.16. Symbolic Anthropology
23.17. Cultural Materialism
23.18. Economic Anthropology
23.19. Political Anthropology
23.20. Urban Anthropology
23.21. Applied Anthropology
23.22. Indigenous Anthropology
23.23. Visual Anthropology
23.24. Virtual Anthropology
23.25. Digital Anthropology
23.26. Human Osteology
23.27. Biocultural Anthropology
23.28. Cognitive Anthropology
23.29. Psychological Anthropology
23.30. Ecological Anthropology
23.31. Historical Archaeology
23.32. Maritime Archaeology
23.33. Public Archaeology
23.34. Underwater Archaeology
23.35. Prehistoric Archaeology
23.36. Classical Archaeology
23.37. Industrial Archaeology
### 24. Psychology and Mental Health
24.1. Clinical Psychology
24.2. Neuropsychology
24.3. Behavioral Neuroscience
24.4. Mental Health Counseling
24.5. Psychiatric Rehabilitation
24.6. Cognitive Psychology
24.7. Industrial-Organizational Psychology
24.8. Developmental Psychology
24.9. Educational Psychology
24.10. Social Psychology
24.11. Health Psychology
24.12. Forensic Psychology
24.13. Community Psychology
24.14. Geriatric Psychology
24.15. Cross-Cultural Psychology
24.16. Environmental Psychology
24.17. Sports Psychology
24.18. Positive Psychology
24.19. Psychopathology
24.20. Child Psychology
24.21. Adolescent Psychology
24.22. Clinical Neuropsychology
24.23. Experimental Psychology
24.24. Human Factors Psychology
24.25. Rehabilitation Psychology
24.26. School Psychology
24.27. Trauma Psychology
24.28. Personality Psychology
24.29. Quantitative Psychology
24.30. Evolutionary Psychology
24.31. Comparative Psychology
24.32. Counseling Psychology
24.33. Psychopharmacology
24.34. Psychoanalysis
24.35. Psycholinguistics
24.36. Psychometrics
24.37. Parapsychology
### 25. Artificial Intelligence and Machine Learning
25.1. Machine Learning Algorithms
25.2. Natural Language Processing
25.3. Computer Vision
25.4. Robotics
25.5. Deep Learning
25.6. Reinforcement Learning
25.7. Generative Adversarial Networks (GANs)
25.8. Transfer Learning
25.9. Neural Networks
25.10. Decision Trees
25.11. Support Vector Machines (SVM)
25.12. Ensemble Methods
25.13. Dimensionality Reduction
25.14. Clustering Algorithms
25.15. Regression Analysis
25.16. Time Series Analysis
25.17. Anomaly Detection
25.18. Recommender Systems
25.19. Feature Engineering
25.20. Model Evaluation and Validation
25.21. Hyperparameter Tuning
25.22. Data Preprocessing
25.23. Data Visualization
25.24. Data Augmentation
25.25. Model Deployment
25.26. Model Interpretability
25.27. Model Optimization
25.28. Model Compression
25.29. Model Explainability
25.30. AutoML (Automated Machine Learning)
25.31. Natural Language Generation
25.32. Sentiment Analysis
25.33. Named Entity Recognition
25.34. Text Classification
25.35. Text Summarization
25.36. Speech Recognition
25.37. Speech Synthesis
25.38. Emotion Recognition
25.39. Image Classification
25.40. Object Detection
25.41. Image Segmentation
25.42. Image Generation
25.43. Pose Estimation
25.44. Action Recognition
25.45. Autonomous Navigation
25.46. Robot Perception
25.47. Robot Localization and Mapping
25.48. Robot Control Systems
25.49. Reinforcement Learning for Robotics
### 26. Neuroscience and Brain Science
26.1. Cognitive Neuroscience
26.2. Behavioral Neuroscience
26.3. Neuroimaging
26.4. Neuropsychology
26.5. Molecular Neuroscience
26.6. Developmental Neuroscience
26.7. Systems Neuroscience
26.8. Computational Neuroscience
26.9. Neurophysiology
26.10. Neuropharmacology
26.11. Neuroendocrinology
26.12. Neuroimmunology
26.13. Neuropsychiatry
26.14. Neurodegenerative Disorders
26.15. Neurodevelopmental Disorders
26.16. Neurological Disorders
26.17. Neuroplasticity
26.18. Neural Networks
26.19. Brain-Machine Interfaces
26.20. Neuroethics
26.21. Neural Computation
26.22. Neural Coding
26.23. Neurofeedback
26.24. Neurological Rehabilitation
26.25. Neurosurgery
26.26. Neuroanatomy
26.27. Neurochemistry
26.28. Neurogenetics
26.29. Neurolinguistics
26.30. Neuroprosthetics
26.31. Neurophotonics
26.32. Neuroinformatics
26.33. Neuroimaging Techniques
26.34. Neuroplasticity Research Methods
26.35. Neurotransmitters and Receptors
26.36. Neuromodulation Techniques
26.37. Neurological Data Analysis
### 27. Energy and Power Systems
27.1. Renewable Energy Technologies
27.2. Power Electronics
27.3. Energy Storage
27.4. Smart Grids
27.5. High-Voltage Engineering
27.6. Distributed Generation
27.7. Electrical Power Distribution
27.8. Power System Protection
27.9. Power Quality Analysis
27.10. Electrical Grid Integration
27.11. Energy Management Systems
27.12. Microgrid Design and Operation
27.13. Electric Vehicles and Charging Infrastructure
27.14. Wind Power Systems
27.15. Solar Power Systems
27.16. Hydroelectric Power Systems
27.17. Biomass Energy Systems
27.18. Geothermal Energy Systems
27.19. Tidal and Wave Power Systems
27.20. Hybrid Energy Systems
27.21. Energy Efficiency and Conservation
27.22. Power System Control and Operation
27.23. Energy Policy and Regulation
27.24. Advanced Power System Analysis
27.25. Load Forecasting and Demand Response
27.26. Fault Analysis and Diagnosis in Power Systems
27.27. Energy Economics and Markets
27.28. Power System Planning and Reliability Assessment
27.29. Energy System Modeling and Simulation
27.30. Electric Power Transmission
27.31. Protection and Control of Power Transformers
27.32. Energy Audit and Management
27.33. Power System Stability and Dynamics
27.34. Islanding and Black Start Capability
27.35. Energy Harvesting Technologies
27.36. Grid Integration of Energy Storage Systems
27.37. Resilient Power Systems
### 28. Materials Science and Engineering
28.1. Nanomaterials
28.2. Polymers
28.3. Composites
28.4. Ceramics
28.5. Metals
28.6. Biomaterials
28.7. Surface Coatings
28.8. Thin Films
28.9. Crystallography
28.10. Mechanical Properties Analysis
28.11. Electrical Properties Analysis
28.12. Optical Properties Analysis
28.13. Thermal Properties Analysis
28.14. Corrosion Analysis
28.15. Fatigue Analysis
28.16. Fracture Mechanics
28.17. Microscopy Techniques
28.18. Spectroscopy Techniques
28.19. X-ray Diffraction (XRD)
28.20. Scanning Electron Microscopy (SEM)
28.21. Transmission Electron Microscopy (TEM)
28.22. Atomic Force Microscopy (AFM)
28.23. Fourier Transform Infrared Spectroscopy (FTIR)
28.24. Raman Spectroscopy
28.25. UV-Visible Spectroscopy
28.26. Differential Scanning Calorimetry (DSC)
28.27. Thermogravimetric Analysis (TGA)
28.28. Dynamic Mechanical Analysis (DMA)
28.29. Rheological Analysis
28.30. Polymer Processing Techniques
28.31. Casting
28.32. Extrusion
28.33. Injection Molding
28.34. Blow Molding
28.35. Thermoforming
28.36. Compression Molding
28.37. Rotational Molding
### 29. Quantum Science and Technology
29.1. Quantum Computing
29.2. Quantum Communication
29.3. Quantum Sensors
29.4. Quantum Materials
29.5. Quantum Algorithms
29.6. Quantum Error Correction
29.7. Quantum Cryptography
29.8. Quantum Information Theory
29.9. Quantum Metrology
29.10. Quantum Simulation
29.11. Quantum Machine Learning
29.12. Quantum Networking
29.13. Quantum Control
29.14. Quantum Optics
29.15. Quantum Transport
29.16. Quantum Sensing and Imaging
29.17. Quantum Entanglement
29.18. Quantum State Engineering
29.19. Quantum Interferometry
29.20. Quantum Photonic Devices
29.21. Quantum Spintronics
29.22. Quantum Nanomechanics
29.23. Quantum Biology
29.24. Quantum Robotics
29.25. Quantum Computing Architectures
29.26. Quantum Computing Algorithms
29.27. Quantum Communication Protocols
29.28. Quantum Sensor Technologies
29.29. Quantum Material Synthesis
29.30. Quantum Material Characterization
29.31. Quantum Material Devices
29.32. Quantum Material Properties
29.33. Quantum Material Fabrication
29.34. Quantum Material Applications
29.35. Quantum Material Integration
29.36. Quantum Material Testing
29.37. Quantum Material Optimization
### 30. Environmental Science and Engineering
30.1. Environmental Chemistry
30.2. Environmental Biology
30.3. Water Resources Engineering
30.4. Sustainable Infrastructure
30.5. Air Quality Management
30.6. Environmental Policy and Planning
30.7. Environmental Impact Assessment
30.8. Ecological Modeling
30.9. Environmental Microbiology
30.10. Waste Management and Remediation
30.11. Environmental Monitoring and Analysis
30.12. Renewable Energy Systems
30.13. Environmental Hydrology
30.14. Climate Change Mitigation
30.15. Environmental Risk Assessment
30.16. Environmental Geology
30.17. Green Building Design
30.18. Industrial Ecology
30.19. Environmental Fluid Mechanics
30.20. Environmental Health and Safety
30.21. Environmental Ethics and Justice
30.22. Environmental Data Science
30.23. Soil and Water Conservation
30.24. Environmental Noise Control
30.25. Urban Environmental Management
30.26. Environmental Education and Outreach
30.27. Sustainable Agriculture
30.28. Environmental Systems Analysis
30.29. Environmental Economics
30.30. Environmental Sociology
30.31. Coastal Zone Management
30.32. Environmental Remote Sensing
30.33. Environmental Psychology
30.34. Environmental Law and Policy
30.35. Environmental Impact Mitigation
30.36. Environmental Modeling and Simulation
30.37. Environmental Ethics and Governance
### 31. Genetics and Genomics
31.1. Molecular Genetics
31.2. Genomic Medicine
31.3. Epigenetics
31.4. Population Genetics
31.5. Comparative Genomics
31.6. Functional Genomics
31.7. Structural Genomics
31.8. Evolutionary Genomics
31.9. Pharmacogenomics
31.10. Cancer Genomics
31.11. Human Genome Project
31.12. Translational Genomics
31.13. Quantitative Genetics
31.14. Systems Genetics
31.15. Genomic Variation Analysis
31.16. Genomic Data Analysis
31.17. Genomic Sequencing Techniques
31.18. Gene Expression Analysis
31.19. Gene Regulation Analysis
31.20. Genome Editing Techniques
31.21. Genetic Engineering Methods
31.22. Next-Generation Sequencing
31.23. Genomic Data Visualization
31.24. Comparative Genomic Analysis
31.25. Genomic Biomarker Discovery
31.26. Genomic Epidemiology
31.27. Metagenomics
31.28. Transcriptomics
31.29. Proteomics
31.30. Metabolomics
31.31. Single-Cell Genomics
31.32. Functional Annotation of Genomes
31.33. Genomic Databases
31.34. Genomic Privacy and Ethics
31.35. Genomic Data Sharing
31.36. Genomic Data Security
31.37. Genomic Data Interpretation
### 32. Evolution and Ecology
32.1. Evolutionary Biology
32.2. Ecology
32.3. Conservation Biology
32.4. Biodiversity
32.5. Population Dynamics
32.6. Community Interactions
32.7. Ecosystem Functioning
32.8. Behavioral Ecology
32.9. Landscape Ecology
32.10. Biogeography
32.11. Phylogenetics
32.12. Coevolution
32.13. Conservation Genetics
32.14. Ecological Modeling
32.15. Ecotoxicology
32.16. Restoration Ecology
32.17. Urban Ecology
32.18. Evolutionary Genetics
32.19. Macroevolution
32.20. Microevolution
32.21. Molecular Ecology
32.22. Ecological Succession
32.23. Island Biogeography
32.24. Adaptation
32.25. Behavioral Genetics
32.26. Climate Change Biology
32.27. Conservation Planning
32.28. Disease Ecology
32.29. Ecological Networks
32.30. Evolutionary Developmental Biology (Evo-Devo)
32.31. Landscape Genetics
32.32. Phylogeography
32.33. Population Genetics
32.34. Quantitative Ecology
32.35. Species Interactions
32.36. Trophic Dynamics
32.37. Comparative Genomics
### 33. Biomedical Sciences
33.1. Biochemistry
33.2. Pharmacology
33.3. Immunology
33.4. Pathology
33.5. Genetics
33.6. Microbiology
33.7. Epidemiology
33.8. Molecular Biology
33.9. Cell Biology
33.10. Neurobiology
33.11. Physiology
33.12. Biophysics
33.13. Bioinformatics
33.14. Biostatistics
33.15. Biotechnology
33.16. Bioethics
33.17. Toxicology
33.18. Pharmacokinetics
33.19. Virology
33.20. Hematology
33.21. Immunotherapy
33.22. Oncology
33.23. Cardiology
33.24. Pulmonology
33.25. Endocrinology
33.26. Gastroenterology
33.27. Nephrology
33.28. Dermatology
33.29. Rheumatology
33.30. Urology
33.31. Ophthalmology
33.32. Otolaryngology
33.33. Pediatrics
33.34. Gerontology
33.35. Anesthesiology
33.36. Radiology
33.37. Emergency Medicine
### 34. Biotechnology and Biomanufacturing
34.1. Genetic Engineering
34.2. Cell Culture Technology
34.3. Downstream Processing
34.4. Biomanufacturing Operations
34.5. Fermentation Techniques
34.6. Protein Purification
34.7. Gene Cloning and Expression
34.8. Synthetic Biology
34.9. Biosensors and Bioelectronics
34.10. Bioreactors and Fermenters
34.11. Cell Therapy Manufacturing
34.12. Monoclonal Antibody Production
34.13. Tissue Engineering
34.14. Vaccine Production
34.15. Bioprocess Optimization
34.16. Bioinformatics in Biotechnology
34.17. Biopreservation Techniques
34.18. Microbial Fermentation
34.19. Biomaterials in Biomanufacturing
34.20. Downstream Chromatography
34.21. Protein Engineering
34.22. Recombinant DNA Technology
34.23. Biochemical Assays
34.24. Gene Therapy Manufacturing
34.25. Industrial Enzyme Production
34.26. Cell Line Development
34.27. Transgenic Animal Production
34.28. Bioproduction Scale-Up
34.29. Quality Control in Biomanufacturing
34.30. Cell-Free Systems
34.31. Biomolecular Engineering
34.32. Metabolic Engineering
34.33. Stem Cell Manufacturing
34.34. Upstream Processing
34.35. Industrial Microbiology
34.36. Plant Biotechnology
34.37. Environmental Biotechnology
### 35 Genetics and Molecular Biology
35.1 DNA Extraction
35.2 PCR Amplification
35.3 DNA Sequencing
35.4 Gene Expression Analysis
35.5 Genetic Engineering Techniques
35.6 Genomic Library Construction
35.7 Restriction Enzyme Analysis
35.8 Transfection Methods
35.9 Cloning and Recombinant DNA Techniques
35.10 DNA Fingerprinting
35.11 Microarray Analysis
35.12 RNA Interference (RNAi)
35.13 Gene Knockout Techniques
35.14 Mutagenesis Techniques
35.15 Genomic Data Analysis
35.16 Next-Generation Sequencing (NGS)
35.17 Gene Regulation Studies
35.18 Protein Purification Techniques
35.19 Enzyme Kinetics Assays
35.20 Protein Structure Prediction
35.21 Protein-Protein Interaction Analysis
35.22 Protein-DNA Interaction Analysis
35.23 Genomic Editing Techniques (CRISPR-Cas9)
35.24 Gene Therapy Approaches
35.25 Molecular Diagnostic Techniques
35.26 Epigenetics Studies
35.27 Transcriptional Regulation Analysis
35.28 Translation and Protein Synthesis Studies
35.29 DNA Repair Mechanisms
35.30 Comparative Genomics Analysis
35.31 RNA-Seq Analysis
35.32 Metagenomics Analysis
35.33 Phylogenetic Analysis
35.34 Functional Genomics Studies
35.35 Chromosome Analysis
35.36 DNA Methylation Analysis
35.37 Genomic Imprinting Studies
### 36. Astronomy and Astrophysics
36.1. Stellar Astrophysics
36.2. Galactic Astronomy
36.3. Cosmology
36.4. High Energy Astrophysics
36.5. Observational Techniques
36.6. Computational Techniques
36.7. Instrumentation
36.8. Theory and Modeling
36.9. Supermassive Black Holes
36.10. Exoplanets
36.11. Radiative Transfer
36.12. Stellar Evolution
36.13. Novae and Supernovae
36.14. Nebulae and Molecular Clouds
36.15. Galactic Structure
36.16. Star Clusters
36.17. Interstellar Medium
36.18. Spectroscopy
36.19. High Energy Phenomena
36.20. Celestial Mechanics
36.21. Multiwavelength Astronomy
36.22. Atmospheres of Extrasolar Planets
36.23. Radio Astronomy
36.24. Gravitational Astrophysics
36.25. Continuum Emission
36.26. Extragalactic Astronomy
36.27. Solar System Dynamics
36.28. Astrobiology
36.29. Relativistic Astrophysics
36.30. Time-Domain Astronomy
36.31. Neutron Star Astrophysics
36.32. White Dwarf Astrophysics
36.33. Stellar Dynamics and Numerical Simulations
36.34. Fast Radio Bursts and Transient Astronomy
36.35. Nuclear Reactions in Astrophysical Environments
36.36. Gamma-Ray Astronomy
36.37. Cosmic Ray Astrophysics
### 37. Condensed Matter Physics
37.1. Solid State Physics
37.2. Semiconductor Physics
37.3. Superconductivity
37.4. Magnetism
37.5. Computational Solid State Physics
37.6. Quantum Mechanics
37.7. Thermodynamics and Statistical Mechanics
37.8. Optics
37.9. Waves and Fields
37.10. Chemistry
37.11. Biophysics
37.12. Nuclear Physics
37.13. Astrophysics
37.14. Astronomy
37.15. Particle Physics
37.16. Quantum Electrodynamics
37.17. Quantum Field Theory
37.18. Quantum Chromodynamics
37.19. Gauge Theory
37.20. Cosmology
37.21. Geophysics
37.22. String Theory
37.23. General Relativity
37.24. High Energy Physics
37.25. Ionized Gas Dynamics
37.26. Fluid Dynamics
37.27. Acoustics
37.28. Discrete Mathematics
37.29. Mathematical Physics
37.30. Classical Mechanics
37.31. Combustion
37.32. Atomic Physics
37.33. Electronics
37.34. Plasma Physics
37.35. Thermophysics
37.36. Spectroscopy
37.37. Quantum Optics
### 38. Particle Physics and High-Energy Physics
38.1. Quantum Field Theory
38.2. Particle Accelerators
38.3. Dark Matter
38.4. Standard Model Physics
38.5. Grand Unified Theories
38.6. Quantum Mechanics
38.7. String Theory
38.8. Supergravity
38.9. Gravitation Theory
38.10. Quantum Chromodynamics
38.11. General Relativity
38.12. Supersymmetry
38.13. Hadron Physics
38.14. Nuclear Physics
38.15. Neutrino Physics
38.16. Cosmology
38.17. Special Relativity
38.18. Particle Detection
38.19. Thermodynamics
38.20. Atomic and Molecular Physics
38.21. Thermal Physics
38.22. Statistical Mechanics
38.23. Quantum Optics
38.24. Solid State Physics
38.25. Materials Science
38.26. Fluid Mechanics
38.27. Astrophysics
38.28. Optics
38.29. Electromagnetism
38.30. Mathematical Physics
38.31. Mechanics
38.32. Spectroscopy
38.33. Atomic Physics
38.34. Physical Chemistry
38.35. Nanotechnology
38.36. Quantum Computing
38.37. Surface Physics
### 39. Mathematical Sciences
39.1. Number Theory
39.2. Topology
39.3. Analysis
39.4. Mathematical Modeling
39.5. Probability and Statistics
39.6. Algebra
39.7. Discrete Mathematics
39.8. Calculus
39.9. Differential Equations
39.10. Linear Algebra
39.11. Geometry
39.12. Graph Theory
39.13. Dynamical Systems
39.14. Combinatorics
39.15. Statistics
39.16. Numerical Analysis
39.17. Stochastic Modeling
39.18. Optimization
39.19. Game Theory
39.20. Probability Theory
39.21. Financial Mathematics
39.22. Computer Algebra
39.23. Cryptography
39.24. Logic
39.25. Theoretical Computer Science
39.26. Mathematical Physics
39.27. Mathematical Biology
39.28. Group Theory
39.29. Combinatorial Optimization
39.30. Computational Geometry
39.31. Algebraic Geometry
39.32. Computational Complexity
39.33. Real Analysis
39.34. Formal Methods
39.35. Number Theory
39.36. Trigonometry
39.37. Fractal Geometry
### 40. Data Science and Analytics
40.1. Statistical Learning
40.2. Data Mining
40.3. Big Data Analytics
40.4. Predictive Modeling
40.5. Artificial Intelligence
40.6. Machine Learning
40.7. Deep Learning
40.8. Natural Language Processing
40.9. Image Analysis
40.10. Text Analysis
40.11. Recommender Systems
40.12. Cluster Analysis
40.13. Data Visualization
40.14. Quantitative Analysis
40.15. Data Exploration
40.16. Data Quality Assurance
40.17. Data Hygiene
40.18. Data Pre-processing
40.19. Data Cleaning
40.20. Data Transformation
40.21. Data Integration
40.22. Data Warehousing
40.23. Data Processing Methodology
40.24. Robustness Testing
40.25. Data Security
40.26. Data Ethics
40.27. Data Governance
40.28. Data Safeguarding
40.29. Risk Management
40.30. Data Backup Strategies
40.31. Data Retention Policies
40.32. Data Encryption
40.33. Data Governance Compliance
40.34. Data Quality Standards
40.35. Data Mining Techniques
40.36. Data Analysis Algorithms
40.37. Data Modeling and Simulation
### 41. Operations Research and Optimization
41.1. Linear Programming
41.2. Network Optimization
41.3. Nonlinear Optimization
41.4. Stochastic Processes
41.5. Graph Theory
41.6. Discrete Optimization
41.7. Scheduling
41.8. Meta-heuristics
41.9. 42.9 Mathematical Programming
41.10. Integer Programming
41.11. Markov Decision Process
41.12. Dynamic Programming
41.13. Simulation
41.14. Game Theory
41.15. Multi-Objective Optimization
41.16. Granular Computing
41.17. Heuristic Algorithms
41.18. Stochastic Optimization
41.19. Regression Analysis
41.20. Interior Point Methods
41.21. Just-in-time Scheduling
41.22. Evolutionary Computation
41.23. Influence Diagrams
41.24. Simulated Annealing
41.25. Quantum Computing
41.26. Capacity Planning
41.27. Fuzzy Mathematics
41.28. Application of AI in Optimization
41.29. Constraint Programming
41.30. Model Predictive Control
41.31. Parameter Estimation
41.32. Extremum Seeking Control
41.33. Approximation Algorithms
41.34. Combinatorial Optimization
41.35. Knowledge Representation and Reasoning
41.36. Logistics Systems Models
41.37. Computer-Aided Design
|
AtlasUnified/atlas-converse
|
[
"size_categories:1K<n<10K",
"license:mit",
"chemistry",
"biology",
"finance",
"legal",
"music",
"art",
"climate",
"medical",
"region:us"
] |
2023-06-13T17:11:58+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["chemistry", "biology", "finance", "legal", "music", "art", "climate", "medical"]}
|
2023-06-14T08:16:05+00:00
|
0ff3934145a4b4c20997b04be896a9c10cd701f5
|
# Ayaka/MoeDict-cmn-hak-10k
|
Ayaka/MoeDict-cmn-hak-10k
|
[
"task_categories:translation",
"size_categories:10K<n<100K",
"language:zh",
"language:hak",
"language:cmn",
"region:us"
] |
2023-06-13T17:13:49+00:00
|
{"language": ["zh", "hak", "cmn"], "size_categories": ["10K<n<100K"], "task_categories": ["translation"]}
|
2023-06-13T17:18:29+00:00
|
8e623a93e7881aa6550bf88c19a8dc1cd6380c0c
|
yichiac/india_fields
|
[
"license:creativeml-openrail-m",
"region:us"
] |
2023-06-13T17:20:15+00:00
|
{"license": "creativeml-openrail-m"}
|
2023-06-13T17:20:15+00:00
|
|
2732d2834e12e36510aeb2a468163ea2642d55db
|
# RED<sup>FM</sup>: a Filtered and Multilingual Relation Extraction Dataset
This is the automatically-filtered dataset from the 2023 ACL paper [RED^{FM}: a Filtered and Multilingual Relation Extraction Dataset](https://arxiv.org/abs/2306.09802). If you use the model, please reference this work in your paper:
@inproceedings{huguet-cabot-et-al-2023-redfm-dataset,
title = "RED$^{\rm FM}$: a Filtered and Multilingual Relation Extraction Dataset",
author = "Huguet Cabot, Pere-Llu{\'\i}s and Tedeschi, Simone and Ngonga Ngomo, Axel-Cyrille and
Navigli, Roberto",
booktitle = "Proc. of the 61st Annual Meeting of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2306.09802",
}
## License
SRED<sup>FM</sup> is licensed under the CC BY-SA 4.0 license. The text of the license can be found [here](https://creativecommons.org/licenses/by-sa/4.0/).
|
Babelscape/SREDFM
|
[
"task_categories:token-classification",
"size_categories:10M<n<100M",
"language:ar",
"language:ca",
"language:de",
"language:el",
"language:en",
"language:es",
"language:fr",
"language:hi",
"language:it",
"language:ja",
"language:ko",
"language:nl",
"language:pl",
"language:pt",
"language:ru",
"language:sv",
"language:vi",
"language:zh",
"license:cc-by-sa-4.0",
"arxiv:2306.09802",
"region:us"
] |
2023-06-13T17:35:19+00:00
|
{"language": ["ar", "ca", "de", "el", "en", "es", "fr", "hi", "it", "ja", "ko", "nl", "pl", "pt", "ru", "sv", "vi", "zh"], "license": "cc-by-sa-4.0", "size_categories": ["10M<n<100M"], "task_categories": ["token-classification"], "dataset_info": [{"config_name": "ar", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 659105981, "num_examples": 499568}, {"name": "test", "num_bytes": 9015516, "num_examples": 4387}, {"name": "validation", "num_bytes": 7406509, "num_examples": 3783}], "download_size": 3651950669, "dataset_size": 675528006}, {"config_name": "ca", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 406179567, "num_examples": 294856}, {"name": "test", "num_bytes": 5378789, "num_examples": 2541}, {"name": "validation", "num_bytes": 3136722, "num_examples": 1532}], "download_size": 1513026644, "dataset_size": 414695078}, {"config_name": "de", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 1288274676, "num_examples": 1049967}, {"name": "test", "num_bytes": 10773087, "num_examples": 5649}, {"name": "validation", "num_bytes": 8955886, "num_examples": 4994}], "download_size": 4521091910, "dataset_size": 1308003649}, {"config_name": "el", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 133497910, "num_examples": 64221}, {"name": "test", "num_bytes": 2364826, "num_examples": 861}, {"name": "validation", "num_bytes": 1836092, "num_examples": 668}], "download_size": 579372781, "dataset_size": 137698828}, {"config_name": "en", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 3555107736, "num_examples": 2701389}, {"name": "test", "num_bytes": 13160183, "num_examples": 6685}, {"name": "validation", "num_bytes": 27692074, "num_examples": 13236}], "download_size": 11914987368, "dataset_size": 3595959993}, {"config_name": "es", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 888914515, "num_examples": 702785}, {"name": "test", "num_bytes": 16076382, "num_examples": 8561}, {"name": "validation", "num_bytes": 4621760, "num_examples": 2177}], "download_size": 3570403740, "dataset_size": 909612657}, {"config_name": "fr", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 768697146, "num_examples": 870448}, {"name": "test", "num_bytes": 5937745, "num_examples": 3883}, {"name": "validation", "num_bytes": 3233262, "num_examples": 2079}], "download_size": 3269522484, "dataset_size": 777868153}, {"config_name": "hi", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 96926984, "num_examples": 51900}, {"name": "test", "num_bytes": 1340091, "num_examples": 374}, {"name": "validation", "num_bytes": 1222098, "num_examples": 405}], "download_size": 385810623, "dataset_size": 99489173}, {"config_name": "it", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 436879977, "num_examples": 432076}, {"name": "test", "num_bytes": 3798221, "num_examples": 2175}, {"name": "validation", "num_bytes": 2230995, "num_examples": 1276}], "download_size": 1685172398, "dataset_size": 442909193}, {"config_name": "ja", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 708617436, "num_examples": 480785}, {"name": "test", "num_bytes": 7802066, "num_examples": 3392}, {"name": "validation", "num_bytes": 6990637, "num_examples": 3106}], "download_size": 3186065351, "dataset_size": 723410139}, {"config_name": "ko", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 266381416, "num_examples": 213659}, {"name": "test", "num_bytes": 1736809, "num_examples": 803}, {"name": "validation", "num_bytes": 1857229, "num_examples": 917}], "download_size": 1119778167, "dataset_size": 269975454}, {"config_name": "nl", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 695855128, "num_examples": 648029}, {"name": "test", "num_bytes": 5186584, "num_examples": 2715}, {"name": "validation", "num_bytes": 4188877, "num_examples": 2188}], "download_size": 2591997126, "dataset_size": 705230589}, {"config_name": "pl", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 877441685, "num_examples": 675688}, {"name": "test", "num_bytes": 11475559, "num_examples": 6376}, {"name": "validation", "num_bytes": 6618989, "num_examples": 3476}], "download_size": 3365852789, "dataset_size": 895536233}, {"config_name": "pt", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 584986936, "num_examples": 469347}, {"name": "test", "num_bytes": 8678707, "num_examples": 4313}, {"name": "validation", "num_bytes": 5807293, "num_examples": 2973}], "download_size": 2347987926, "dataset_size": 599472936}, {"config_name": "ru", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 604993210, "num_examples": 339697}, {"name": "test", "num_bytes": 5941158, "num_examples": 2296}, {"name": "validation", "num_bytes": 5352859, "num_examples": 2107}], "download_size": 2754576893, "dataset_size": 616287227}, {"config_name": "sv", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 1822863623, "num_examples": 1742082}, {"name": "test", "num_bytes": 13002356, "num_examples": 7531}, {"name": "validation", "num_bytes": 5136097, "num_examples": 2987}], "download_size": 6790489020, "dataset_size": 1841002076}, {"config_name": "vi", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 300641174, "num_examples": 260010}, {"name": "test", "num_bytes": 4304795, "num_examples": 1824}, {"name": "validation", "num_bytes": 3402120, "num_examples": 1461}], "download_size": 1301938106, "dataset_size": 308348089}, {"config_name": "zh", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 449085696, "num_examples": 369249}, {"name": "test", "num_bytes": 5260974, "num_examples": 2667}, {"name": "validation", "num_bytes": 3511103, "num_examples": 1816}], "download_size": 2440525684, "dataset_size": 457857773}, {"config_name": "all_languages", "features": [{"name": "docid", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "uri", "dtype": "string"}, {"name": "lan", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "entities", "list": [{"name": "uri", "dtype": "string"}, {"name": "surfaceform", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "start", "dtype": "int32"}, {"name": "end", "dtype": "int32"}]}, {"name": "relations", "list": [{"name": "subject", "dtype": "int32"}, {"name": "predicate", "dtype": "string"}, {"name": "object", "dtype": "int32"}]}], "splits": [{"name": "train", "num_bytes": 14615645332, "num_examples": 11865756}, {"name": "test", "num_bytes": 131636046, "num_examples": 67033}, {"name": "validation", "num_bytes": 103507688, "num_examples": 51181}], "download_size": 56989165879, "dataset_size": 14850789066}]}
|
2023-06-20T06:33:28+00:00
|
abda846a09f977456de8c8f3b1090db395b57d39
|
# Dataset Card for "VQAv2_minival_validation_google_flan_t5_xxl_mode_CM_Q_rices_ns_2000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/VQAv2_minival_validation_google_flan_t5_xxl_mode_CM_Q_rices_ns_2000
|
[
"region:us"
] |
2023-06-13T17:45:38+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "question", "dtype": "string"}, {"name": "true_label", "sequence": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0", "num_bytes": 285356, "num_examples": 2000}], "download_size": 104686, "dataset_size": 285356}}
|
2023-06-13T17:45:40+00:00
|
76a834a463f100e8d2de780ef9905a44d92eec4b
|
# Dataset Card for "processed_dwi_fixed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
deetsadi/processed_dwi_fixed
|
[
"region:us"
] |
2023-06-13T17:56:41+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}, {"name": "conditioning_image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 15336901.0, "num_examples": 200}], "download_size": 14887177, "dataset_size": 15336901.0}}
|
2023-06-13T17:56:42+00:00
|
99feda186d91c57eda16278bc0803ff8e53c66c6
|
# Dataset Card for "medication_chat_commands_bloom"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
stoddur/medication_chat_commands_bloom
|
[
"region:us"
] |
2023-06-13T18:04:12+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 340308408.0, "num_examples": 220407}], "download_size": 11987145, "dataset_size": 340308408.0}}
|
2023-06-13T21:47:22+00:00
|
7ad81f9054e014dcc04e39d16b80193397c7d103
|
# Dataset Card for "translated_eli5_dataset_sin_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
9wimu9/translated_eli5_dataset_sin_v2
|
[
"region:us"
] |
2023-06-13T18:06:30+00:00
|
{"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "gold_answer", "dtype": "string"}, {"name": "contexts", "sequence": "string"}, {"name": "id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 518688493.0879679, "num_examples": 44842}, {"name": "test", "num_bytes": 57638480.91203211, "num_examples": 4983}, {"name": "validation", "num_bytes": 57638480.91203211, "num_examples": 4983}], "download_size": 256328104, "dataset_size": 633965454.9120321}}
|
2023-06-13T18:07:54+00:00
|
2fa417560bc2ff9f874d46f30833865cdca57d43
|
# Dataset Card for "processed_dwi_soft_edge"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
deetsadi/processed_dwi_soft_edge
|
[
"region:us"
] |
2023-06-13T18:35:24+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}, {"name": "conditioning_image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 16154444.0, "num_examples": 200}], "download_size": 16149714, "dataset_size": 16154444.0}}
|
2023-06-15T12:23:31+00:00
|
7897a731635cec31f966f05cfec491a69367392f
|
# AutoTrain Dataset for project: mnist-analysis
## Dataset Description
This dataset has been automatically processed by AutoTrain for project mnist-analysis.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<28x28 L PIL image>",
"target": 1
},
{
"image": "<28x28 L PIL image>",
"target": 0
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 55996 |
| valid | 14004 |
|
realzdlegend/autotrain-data-mnist-analysis
|
[
"task_categories:image-classification",
"region:us"
] |
2023-06-13T18:43:30+00:00
|
{"task_categories": ["image-classification"]}
|
2023-06-13T19:02:41+00:00
|
d25a3c8ea9bbcf828f36b2f65066cf9f5fca32e4
|
# Dataset Card for "boxes_test_controlnet_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
killah-t-cell/boxes_test_controlnet_dataset
|
[
"region:us"
] |
2023-06-13T18:49:39+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "conditioning_image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 212085.0, "num_examples": 4}], "download_size": 196994, "dataset_size": 212085.0}}
|
2023-06-13T18:49:43+00:00
|
09812d29d779227b5a776d35d9d42160be9e2fab
|
tasksource/kaggle-claim-type
|
[
"license:mit",
"region:us"
] |
2023-06-13T18:54:12+00:00
|
{"license": "mit"}
|
2023-06-13T18:54:34+00:00
|
|
2b5a4f5422e41fc18eae2a14c8e7d7882ecca95d
|
# Dataset Usage
## Description
The Mimic-IV dataset generate data by executing the Pipeline available on https://github.com/healthylaife/MIMIC-IV-Data-Pipeline.
## Function Signature
```python
load_dataset('thbndi/Mimic4Dataset', task, mimic_path=mimic_data, config_path=config_file, encoding=encod, generate_cohort=gen_cohort, val_size=size, cache_dir=cache)
```
## Arguments
1. `task` (string) :
- Description: Specifies the task you want to perform with the dataset.
- Default: "Mortality"
- Note: Possible Values : 'Phenotype', 'Length of Stay', 'Readmission', 'Mortality'
2. `mimic_path` (string) :
- Description: Complete path to the Mimic-IV raw data on user's machine.
- Note: You need to provide the appropriate path where the Mimic-IV data is stored.
3. `config_path` (string) optionnal :
- Description: Path to the configuration file for the cohort generation choices (more infos in '/config/readme.md').
- Default: Configuration file provided in the 'config' folder.
4. `encoding` (string) optionnal :
- Description: Data encoding option for the features.
- Options: "concat", "aggreg", "tensor", "raw", "text"
- Default: "concat"
- Note: Choose one of the following options for data encoding:
- "concat": Concatenates the one-hot encoded diagnoses, demographic data vector, and dynamic features at each measured time instant, resulting in a high-dimensional feature vector.
- "aggreg": Concatenates the one-hot encoded diagnoses, demographic data vector, and dynamic features, where each item_id is replaced by the average of the measured time instants, resulting in a reduced-dimensional feature vector.
- "tensor": Represents each feature as an 2D array. There are separate arrays for labels, demographic data ('DEMO'), diagnosis ('COND'), medications ('MEDS'), procedures ('PROC'), chart/lab events ('CHART/LAB'), and output events data ('OUT'). Dynamic features are represented as 2D arrays where each row contains values at a specific time instant.
- "raw": Provide cohort from the pipeline without any encoding for custom data processing.
- "text": Represents diagnoses as text suitable for BERT or other similar text-based models.
- For 'concat' and 'aggreg' the composition of the vector is given in './data/dict/"task"/features_aggreg.csv' or './data/dict/"task"/features_concat.csv' file and in 'features_names' column of the dataset.
5. `generate_cohort` (bool) optionnal :
- Description: Determines whether to generate a new cohort from Mimic-IV data.
- Default: True
- Note: Set it to True to generate a cohort, or False to skip cohort generation.
6. `val_size`, 'test_size' (float) optionnal :
- Description: Proportion of the dataset used for validation during training.
- Default: 0.1 for validation size and 0.2 for testing size.
- Note: Can be set to 0.
7. `cache_dir` (string) optionnal :
- Description: Directory where the processed dataset will be cached.
- Note: Providing a cache directory for each encoding type can avoid errors when changing the encoding type.
## Example Usage
```python
import datasets
from datasets import load_dataset
# Example 1: Load dataset with default settings
dataset = load_dataset('thbndi/Mimic4Dataset', task="Mortality", mimic_path="/path/to/mimic_data")
# Example 2: Load dataset with custom settings
dataset = load_dataset('thbndi/Mimic4Dataset', task="Phenotype", mimic_path="/path/to/mimic_data", config_path="/path/to/config_file", encoding="aggreg", generate_cohort=False, val_size=0.2, cache_dir="/path/to/cache_dir")
```
Please note that the provided examples are for illustrative purposes only, and you should adjust the paths and settings based on your actual dataset and specific use case.
|
thbndi/Mimic4Dataset
|
[
"region:us"
] |
2023-06-13T19:00:50+00:00
|
{}
|
2023-08-18T09:46:26+00:00
|
4019f491c8ed7dc328c3cc334287983f72d7ac80
|
https://www.kaggle.com/competitions/feedback-prize-english-language-learning
|
tasksource/english-grading
|
[
"region:us"
] |
2023-06-13T19:03:03+00:00
|
{}
|
2024-02-04T09:28:28+00:00
|
7c213acfa226a96c2bd6cac3447cda62fa12fc4d
|
# Dataset Card for "translated_eli5_dataset_sin_v2-gold-answer-removed-from-contexts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
9wimu9/translated_eli5_dataset_sin_v2-gold-answer-removed-from-contexts
|
[
"region:us"
] |
2023-06-13T19:04:23+00:00
|
{"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "gold_answer", "dtype": "string"}, {"name": "contexts", "sequence": "string"}, {"name": "id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 436001746.5264764, "num_examples": 44836}, {"name": "test", "num_bytes": 48446799.473523624, "num_examples": 4982}, {"name": "validation", "num_bytes": 48446799.473523624, "num_examples": 4982}], "download_size": 217824691, "dataset_size": 532895345.4735236}}
|
2023-06-13T19:05:06+00:00
|
04e87eb5003fb6d5922b8b7d96814ee15d30a114
|
# Dataset Card for "boxes_train_controlnet_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
killah-t-cell/boxes_train_controlnet_dataset
|
[
"region:us"
] |
2023-06-13T19:13:32+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "conditioning_image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1365601206.528, "num_examples": 26662}], "download_size": 1257141642, "dataset_size": 1365601206.528}}
|
2023-06-13T19:21:43+00:00
|
4c3f9a0ea94dcd5f7c537f271d82027837ad02bf
|
# Dataset Card for "cool_test_fine_tuning"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Pedrampedram/cool_test_fine_tuning
|
[
"region:us"
] |
2023-06-13T19:20:45+00:00
|
{"dataset_info": {"features": [{"name": "name", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "ad", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3426, "num_examples": 5}], "download_size": 0, "dataset_size": 3426}}
|
2023-06-13T19:21:22+00:00
|
4292c35b2db7f480852b1e82d67dbed4679f0d4e
|
Librico/llmao-data
|
[
"license:apache-2.0",
"region:us"
] |
2023-06-13T19:20:48+00:00
|
{"license": "apache-2.0"}
|
2023-06-13T19:20:48+00:00
|
|
3cb9727f7951fa25801cb5482595d0a0cd8f2508
|
# Dataset Card for "cool_new_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AnjanaSengupta/cool_new_dataset
|
[
"region:us"
] |
2023-06-13T19:24:23+00:00
|
{"dataset_info": {"features": [{"name": "name", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "ad", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3218, "num_examples": 5}], "download_size": 8180, "dataset_size": 3218}}
|
2023-06-13T19:24:27+00:00
|
36d2b4e1732aa96a3f1d9573d5e1a3e5c4ac27a1
|
# Dataset Card for "make_earth_greener"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Pedrampedram/make_earth_greener
|
[
"region:us"
] |
2023-06-13T19:43:02+00:00
|
{"dataset_info": {"features": [{"name": "name", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "ad", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4235, "num_examples": 5}], "download_size": 8562, "dataset_size": 4235}}
|
2023-06-13T19:43:05+00:00
|
622f60ffb6d9dde7a0e26c5b171769a629c03298
|
# Dataset Card for "movie_stills_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
killah-t-cell/movie_stills_dataset
|
[
"region:us"
] |
2023-06-13T19:44:37+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2868263.0, "num_examples": 10}], "download_size": 2869997, "dataset_size": 2868263.0}}
|
2023-06-13T20:11:45+00:00
|
128d4fd5cfda337e6e94e48b736c1602e22e3d5f
|
# Dataset Card for "boxes_full_controlnet_dataset"
FWIW, I didn't get good results with this after 20K training steps for some reason, but feel free to give it a shot!
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
killah-t-cell/boxes_full_controlnet_dataset
|
[
"region:us"
] |
2023-06-13T19:49:02+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "conditioning_image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1365601206.528, "num_examples": 26662}], "download_size": 1257141642, "dataset_size": 1365601206.528}}
|
2023-06-16T04:18:42+00:00
|
d5cec0f0d02adf56d09f6e02e722ea1a0da3ff46
|
# Dataset Card for "Climate_activity_new_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AnjanaSengupta/Climate_activity_new_dataset
|
[
"region:us"
] |
2023-06-13T19:49:45+00:00
|
{"dataset_info": {"features": [{"name": "name", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "ad", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3119, "num_examples": 5}], "download_size": 7479, "dataset_size": 3119}}
|
2023-06-13T19:49:47+00:00
|
20c1e91ed9a9a33bed2399696b85f4b2ed689107
|
# Dataset Card for "b3bc6d59"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/b3bc6d59
|
[
"region:us"
] |
2023-06-13T19:54:40+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 178, "num_examples": 10}], "download_size": 1331, "dataset_size": 178}}
|
2023-06-13T19:54:41+00:00
|
0ff3a093a7abbf65e556b920783604034e85a06a
|
# Dataset Card for ITALIC: An ITALian Intent Classification Dataset
ITALIC is an intent classification dataset for the Italian language, which is the first of its kind.
It includes spoken and written utterances and is annotated with 60 intents.
The dataset is available on [Zenodo](https://zenodo.org/record/8040649) and connectors ara available for the [HuggingFace Hub](https://huggingface.co/datasets/RiTA-nlp/ITALIC).
### Latest Updates
- **June 15th, 2023**: ITALIC dataset has been released on [Zenodo](https://zenodo.org/record/8040649): https://zenodo.org/record/8040649.
## Table of Contents
- [Data collection](#data-collection)
- [Dataset](#dataset)
- [Usage](#usage)
- [Models used in the paper](#models-used-in-the-paper)
- [SLU intent classification](#slu-intent-classification)
- [ASR](#asr)
- [NLU intent classification](#nlu-intent-classification)
- [Citation](#citation)
- [License](#license)
## Data collection
The data collection follows the MASSIVE NLU dataset which contains an annotated textual dataset for 60 intents. The data collection process is described in the paper [Massive Natural Language Understanding](https://arxiv.org/abs/2204.08582).
Following the MASSIVE NLU dataset, a pool of 70+ volunteers has been recruited to annotate the dataset. The volunteers were asked to record their voice while reading the utterances (the original text is available on MASSIVE dataset). Together with the audio, the volunteers were asked to provide a self-annotated description of the recording conditions (e.g., background noise, recording device). The audio recordings have also been validated and, in case of errors, re-recorded by the volunteers.
All the audio recordings included in the dataset have received a validation from at least two volunteers. All the audio recordings have been validated by native italian speakers (self-annotated).
## Dataset
The dataset is available on the [Zenodo](https://zenodo.org/record/8040649). It is composed of 3 different splits:
- `massive`: all the utterances are randomly shuffled and divided into 3 splits (train, validation, test).
- `hard_speaker`: the utterances are divided into 3 splits (train, validation, test) based on the speaker. Each split only contains utterances from a pool of speakers that do not overlap with the other splits.
- `hard_noisy`: the utterances are divided into 3 splits (train, validation, test) based on the recording conditions. The test split only contains utterances with the highest level of noise.
Each split contains the following annotations:
- `utt`: the original text of the utterance.
- `audio`: the audio recording of the utterance.
- `intent`: the intent of the utterance.
- `speaker`: the speaker of the utterance. The speaker is identified by a unique identifier and has been anonymized.
- `age`: the age of the speaker.
- `is_native`: whether the speaker is a native italian speaker or not.
- `gender`: the gender of the speaker (self-annotated).
- `region`: the region of the speaker (self-annotated).
- `nationality`: the nationality of the speaker (self-annotated).
- `lisp`: any kind of lisp of the speaker (self-annotated). It can be empty in case of no lisp.
- `education`: the education level of the speaker (self-annotated).
- `environment`: the environment of the recording (self-annotated).
- `device`: the device used for the recording (self-annotated).
## Usage
The dataset can be loaded using the `datasets` library. You need to install the following dependencies:
```bash
pip install datasets
pip install librosa
pip install soundfile
```
Then, you can load the dataset as follows:
```python
from datasets import load_dataset
# Please be sure to use use_auth_token=True and to set the access token
# using huggingface-cli login
# or follow https://huggingface.co/docs/hub/security-tokens
# configs "hard_speaker" and "hard_noisy" are also available (to substitute "massive")
italic = load_dataset("RiTA-nlp/ITALIC", "massive", use_auth_token=True)
italic_train = italic["train"]
italic_valid = italic["validation"]
italic_test = italic["test"]
```
The dataset has been designed for intent classification tasks. The `intent` column can be used as the label. However, the dataset can be used for other tasks as well.
- **Intent classification**: the `intent` column can be used as the label.
- **Speaker identification**: the `speaker` column can be used as the label.
- **Automatic speech recognition**: the `utt` column can be used as the label.
- **Accent identification**: the `region` column can be used as the label.
For more information about the dataset, please refer to the [paper](https://arxiv.org/abs/2306.08502).
## Models used in the paper
### Hardware settings
All experiments were conducted on a private workstation with Intel Core i9-10980XE CPU, 1 $\times$ NVIDIA RTX A6000 GPU, 64 GB of RAM running Ubuntu 22.04 LTS.
### Parameter settings
The parameters used for the training of the models are set to allow a fair comparison between the different models and to follow the recommendations of the related literature. The parameters are summarized in the following table:
| Model | Task | Parameters | Learning rate | Batch size | Max epochs | Warmup | Weight decay | Avg. training time | Avg. inference time |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| facebook/wav2vec2-xls-r-300m | SLU | 300M | 1e-4 | 128 | 30 | 0.1 ratio | 0.01 | 9m 35s per epoch | 13ms per sample |
| facebook/wav2vec2-xls-r-1b | SLU | 1B | 1e-4 | 32 | 30 | 0.1 ratio | 0.01 | 21m 30s per epoch | 29ms per sample |
| jonatasgrosman/wav2vec2-large-xlsr-53-italian | SLU | 300M | 1e-4 | 128 | 30 | 0.1 ratio | 0.01 | 9m 35s per epoch | 13ms per sample |
| jonatasgrosman/wav2vec2-xls-r-1b-italian | SLU | 1B | 1e-4 | 32 | 30 | 0.1 ratio | 0.01 | 21m 30s per epoch | 29ms per sample |
| ALM/whisper-it-small-augmented | ASR | 224M | 1e-5 | 8 | 5 | 500 steps | 0.01 | 26m 30s per epoch | 25ms per sample |
| EdoAbati/whisper-medium-it-2 | ASR | 769M | 1e-5 | 8 | 5 | 500 steps | 0.01 | 49m per epoch | 94ms per sample |
| EdoAbati/whisper-large-v2-it | ASR | 1.5B | 1e-5 | 8 | 5 | 500 steps | 0.01 | 1h 17m per epoch | 238ms per sample |
| bert-base-multilingual-uncased | NLU | 167M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 1m 22s per epoch | 1.5ms per sample |
| facebook/mbart-large-cc25 | NLU | 611M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 7m 53s per epoch | 4.7ms per sample |
| dbmdz/bert-base-italian-xxl-uncased | NLU | 110M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 1m 30s per epoch | 1.4ms per sample |
| morenolq/bart-it | NLU | 141M | 5e-5 | 8 | 5 | 500 steps | 0.01 | 1m 54s per epoch | 1.9 ms per sample |
In all cases, we opted for the AdamW optimizer. All experiments were run on a single NVIDIA A6000 GPU.
### SLU intent classification
The models used in the paper are available on the [Hugging Face Hub](https://huggingface.co/models).
- 🌍 [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
- 🌍 [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
- 🇮🇹 [jonatasgrosman/wav2vec2-xls-r-1b-italian](https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-italian)
- 🇮🇹 [jonatasgrosman/wav2vec2-large-xlsr-53-italian](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-italian)
### ASR
The models used in the paper are available on the [Hugging Face Hub](https://huggingface.co/models).
- 🌍 Whisper large (zero-shot ASR): [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2)
- 🇮🇹 Whisper small: [ALM/whisper-it-small-augmented](https://huggingface.co/ALM/whisper-it-small-augmented)
- 🇮🇹 Whisper medium: [EdoAbati/whisper-medium-it-2](https://huggingface.co/EdoAbati/whisper-medium-it-2)
- 🇮🇹 Whisper large: [EdoAbati/whisper-large-v2-it](https://huggingface.co/EdoAbati/whisper-large-v2-it)
### NLU intent classification
The models used in the paper are available on the [Hugging Face Hub](https://huggingface.co/models).
- 🌍 [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased)
- 🌍 [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
- 🇮🇹 [dbmdz/bert-base-italian-xxl-uncased](https://huggingface.co/dbmdz/bert-base-italian-xxl-uncased)
- 🇮🇹 [morenolq/bart-it](https://huggingface.co/morenolq/bart-it)
## Citation
If you use this dataset in your research, please cite the following paper (**interspeech 2023** version is coming soon after the proceedings are published):
```bibtex
@article{koudounas2023italic,
title={ITALIC: An Italian Intent Classification Dataset},
author={Koudounas, Alkis and La Quatra, Moreno and Vaiani, Lorenzo and Colomba, Luca and Attanasio, Giuseppe and Pastor, Eliana and Cagliero, Luca and Baralis, Elena},
journal={arXiv preprint arXiv:2306.08502},
year={2023}
}
```
## License
The dataset is licensed under the [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/).
- [Paper describing the dataset and initial experiments](https://arxiv.org/abs/2306.08502)
- [Dataset on Zenodo](https://zenodo.org/record/8040649)
- [https://creativecommons.org/licenses/by-nc-sa/4.0/](https://creativecommons.org/licenses/by/4.0/)https://creativecommons.org/licenses/by/4.0/
|
RiTA-nlp/ITALIC
|
[
"task_categories:automatic-speech-recognition",
"task_categories:audio-classification",
"task_ids:intent-classification",
"annotations_creators:crowdsourced",
"language_creators:Italian",
"license:cc-by-nc-nd-4.0",
"arxiv:2204.08582",
"arxiv:2306.08502",
"region:us"
] |
2023-06-13T20:03:20+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["Italian"], "license": "cc-by-nc-nd-4.0", "size_categories": {"it": "10K<n<100K"}, "task_categories": ["automatic-speech-recognition", "audio-classification"], "task_ids": ["intent-classification"], "pretty_name": "ITALIC", "language_bcp47": ["it"]}
|
2023-06-29T11:58:56+00:00
|
793acf6d2dfcc6046efc028f7755a95b136b80f2
|
Cdaprod/AI-Developer-Prompts
|
[
"task_categories:zero-shot-classification",
"task_categories:summarization",
"region:us"
] |
2023-06-13T20:07:09+00:00
|
{"task_categories": ["zero-shot-classification", "summarization"], "pretty_name": "Cdaprod-Docs"}
|
2023-06-14T02:14:49+00:00
|
|
df3a611ee4bd8ca4d8cb4c9601d86069ccb75643
|
Experimental Synthetic Dataset of Public Domain Character Dialogue in Roleplay Format
Generated using scripts from my https://github.com/practicaldreamer/build-a-dataset repo
---
license: mit
---
|
practical-dreamer/RPGPT_PublicDomain-alpaca
|
[
"task_categories:conversational",
"size_categories:10M<n<100M",
"language:en",
"license:mit",
"alpaca",
"region:us"
] |
2023-06-13T20:11:37+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["10M<n<100M"], "task_categories": ["conversational"], "pretty_name": "rpgpt-alpaca", "tags": ["alpaca"]}
|
2023-07-03T23:04:20+00:00
|
d581808cfdbd1e59f408e052ba6de90682a3502b
|
# Dataset Card for "movie_stills_dataset_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
killah-t-cell/movie_stills_dataset_test
|
[
"region:us"
] |
2023-06-13T20:23:46+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 20557021.0, "num_examples": 100}], "download_size": 20557338, "dataset_size": 20557021.0}}
|
2023-06-13T20:24:06+00:00
|
14ea16ba5c74a05f4187274a12aa761bf0a87b4c
|
longevity-genie/longevity-map-db-llm
|
[
"license:agpl-3.0",
"region:us"
] |
2023-06-13T20:33:14+00:00
|
{"license": "agpl-3.0"}
|
2023-06-13T20:33:14+00:00
|
|
8a69e3e9aa776abd923a685793de3c7a36a9ecba
|
c4iro/king-von
|
[
"task_categories:conversational",
"license:apache-2.0",
"region:us"
] |
2023-06-13T20:33:36+00:00
|
{"license": "apache-2.0", "task_categories": ["conversational"]}
|
2023-06-13T21:09:37+00:00
|
|
52433f1492b17c36aabb780d307206bc595d61d9
|
### Dataset Summary
dataset:- civitai-stable-diffusion-337k this dataset contains 337k civitai images url with prompts etc. i use civitai api to get all prompts.
project:- https://github.com/thefcraft/nsfw-prompt-detection-sd I train a model on this dataset
DATA STRUCTURE for .civitai.json:-
```{
'items':[
{'id': 100657,
'url': 'https://imagecache.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/2338276a-87f7-4a1e-f92a-776a18ee4200/width=768/2338276a-87f7-4a1e-f92a-776a18ee4200.jpeg',
'hash': 'U5Exz_00.8D$t89Z%M0100~VD*RktQxaIU~p',
'width': 768,
'height': 1368,
'nsfw': True,
'createdAt': '2023-02-14T10:05:11.498Z',
'postId': 60841,
'stats': {'cryCount': 0,
'laughCount': 0,
'likeCount': 26,
'dislikeCount': 0,
'heartCount': 50,
'commentCount': 4},
'meta': {'ENSD': '31337',
'Size': '512x912',
'seed': 3994946333,
'Model': 'AbyssOrangeMix2_sfw',
'steps': 20,
'prompt': '<lora:hiqcg_body-epoch-000004:0.5>, <lora:hiqcg_face-epoch-000004:0.4>, hiqcgbody, hiqcgface, 1girl, full body, standing, \ndetailed skin texture, detailed cloth texture, beautiful detailed face,\nmasterpiece, best quality, ultra detailed, 8k, intricate details,',
'sampler': 'DPM++ 2M Karras',
'cfgScale': 7,
'Clip skip': '2',
'resources': [{'hash': '038ba203d8',
'name': 'AbyssOrangeMix2_sfw',
'type': 'model'}],
'Model hash': '038ba203d8',
'Hires upscale': '1.5',
'Hires upscaler': 'Latent',
'negativePrompt': 'EasyNegative, extra fingers,fewer fingers, multiple girls, multiple views,',
'Denoising strength': '0.6'},
'username': 'NeoClassicalRibbon'},
{..},
..],
'metadata':{'totalItems': 327145}
}
```
|
Ar4ikov/civitai-sd-337k
|
[
"annotations_creators:no-annotation",
"language_creators:thefcraft",
"size_categories:1M<n<10M",
"source_datasets:civitai",
"language:en",
"region:us"
] |
2023-06-13T21:07:15+00:00
|
{"annotations_creators": ["no-annotation"], "language_creators": ["thefcraft"], "language": ["en"], "size_categories": ["1M<n<10M"], "source_datasets": ["civitai"], "pretty_name": "civitai-stable-diffusion-337k", "duplicated_from": "thefcraft/civitai-stable-diffusion-337k"}
|
2023-06-13T21:08:02+00:00
|
d40831c0564e1b16159e4e38145cc7f618224336
|
# Update
* (2023.12.30) We added a global transformation to the camera poses to make the objects axis-aligned along the Z axis. This is preferred for some methods such as TensoRF and TriPlane. Please see [here](https://huggingface.co/datasets/OpenIllumination/OpenIllumination/blob/main/others/transforms_alignz_train.json) for the new camera poses.
* (2023.11.9) We fixed some incorrect links in the [download script](https://huggingface.co/datasets/OpenIllumination/OpenIllumination/blob/main/open_illumination.py). Please use the latest script to download the data.
# Dataset Card for OpenIllumination
## Dataset Description
- **Homepage:** https://oppo-us-research.github.io/OpenIllumination
- **Repository:** https://github.com/oppo-us-research/OpenIlluminationCapture.
- **Paper:** https://oppo-us-research.github.io/OpenIllumination/files/openillumination.pdf.
- **Leaderboard:** N/A for now.
- **Point of Contact:** [email protected]
### Dataset Summary
Our dataset comprises 64 objects, each captured from 70 views, under 13 lighting patterns and 142 One-Light-At-Time (OLAT) illumination, respectively.
The 70 views are captured by 48 DSLR cameras and 22 high-speed cameras. The dataset viewer is at the [project page](https://oppo-us-research.github.io/OpenIllumination).
### Supported Tasks
* Novel view synthesis: The dataset can be used to evaluate NVS methods, such as NeRF, TensoRF, and NeuS.
* Inverse rendering: The dataset can be used to evaluate inverse rendering algorithms, which are to decompose illumination, object geometry, and object materials.
### Dataset Download
Since the whole dataset is very large, we provide a script [here](https://huggingface.co/datasets/OpenIllumination/OpenIllumination/blob/main/open_illumination.py]) to download according to the illumination type (lighting pattern or OLAT) and the object ID. You can also modify the code to customize it according to your requirements.
### Languages
English
## Dataset Structure
### Data Fields
For each image, the following fields are provided:
* file_path: str, the file path to an image.
* light_idx: int, the index of illuminations, from 1 to 13 for lighting patterns, or from 0 to 141 for OLAT.
* transform_matrix: list, a 4x4 matrix, representing the camera pose for this image (in OpenCV convention).
* camera_angle_x: float, can be used to compute the corresponding camera intrinsics.
* obj_mask: the object mask, can be read by ```imageio.imread(OBJ_MASK_PATH)>0```, used for PSNR evaluation. **Note that we store 0 and 1 for object masks, so you may not be able to correctly visualize it as png in this repo.**
* com_mask (optional): the union of the object mask and the support mask, can be read by ```imageio.imread(COM_MASK_PATH)>0```, used for training. We store 0 and 255 for combined masks, so you are able to view them as png in this repo correctly.
### Data Splits
The data is split into training and testing views. For each object captured under 13 lighting patterns, the training set and the testing set contain 38 and 10 views, respectively. For each object captured under OLAT, the training set and the testing set contain 17 and 5 views, respectively.
## Dataset Creation
### Curation Rationale
From the paper:
> Recent efforts have introduced some datasets that incorporate multiple illuminations in real-world settings. However, most of them are limited either in the number of views or the number of illuminations; few of them provide object-level data as well. Consequently, these existing datasets prove unsuitable for evaluating inverse rendering methods on real-world objects.
>
>
> To address this, we present a new dataset containing objects with a variety of materials, captured under multiple views and illuminations, allowing for reliable evaluation of various inverse rendering tasks with real data.
### Source Data
#### Initial Data Collection and Normalization
From the paper:
> Our dataset was acquired using a setup similar to a traditional light stage, where densely distributed cameras and controllable lights are attached to a static frame around a central platform.
### Annotations
#### Annotation process
From the paper:
> To obtain high-quality segmentation masks, we propose to use Segment-Anything (SAM) to perform instance segmentation. However,
> we find that the performance is not satisfactory. One reason is that the object categories are highly undefined. In this case, even combining the bounding box and point prompts cannot produce satisfactory results. To address this problem, we propose to use multiple bounding-box prompts to perform segmentation for each possible part and then calculate a union of the masks as the final object mask.
>
> For objects with very detailed and thin structures, e.g. hair, we use an off-the-shelf background matting method to perform object segmentation.
#### Who are the annotators?
Linghao Chen, Isabella Liu, and Ziyang Fu.
## Additional Information
### Dataset Curators
Isabella Liu, Linghao Chen, Ziyang Fu, Liwen Wu, Haian Jin, Zhong Li, Chin Ming Ryan Wong, Yi Xu, Ravi Ramamoorthi, Zexiang Xu and Hao Su
### Licensing Information
CC BY 4.0
### Citation Information
```bash
@article{liu2023openillumination,
title={OpenIllumination: A Multi-Illumination Dateset for Inverse Rendering Evaluation on Real Objects},
author={Liu, Isabella and Chen, Linghao and Fu, Ziyang and Wu, Liwen and Jin, Haian and Li, Zhong and Chin Ming Ryan Wong3 and Xu, Yi and Ravi Ramamoorthi1 and Xu, Zexiang and Su, Hao},
year={2023}
}
```
|
OpenIllumination/OpenIllumination
|
[
"task_categories:other",
"annotations_creators:expert-generated",
"size_categories:100K<n<1M",
"language:en",
"license:cc-by-4.0",
"novel view synthesis",
"inverse rendering",
"material decomposition",
"doi:10.57967/hf/1102",
"region:us"
] |
2023-06-13T21:25:56+00:00
|
{"annotations_creators": ["expert-generated"], "language": ["en"], "license": "cc-by-4.0", "size_categories": ["100K<n<1M"], "task_categories": ["other"], "pretty_name": "OpenIllumination", "tags": ["novel view synthesis", "inverse rendering", "material decomposition"], "download_size": "900G"}
|
2023-12-30T10:23:34+00:00
|
fd769912a4546df22124a49dd12a6fce8a48b63a
|
# Dataset Card for "civitai_sd_337_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Ar4ikov/civitai_sd_337_prompts
|
[
"region:us"
] |
2023-06-13T21:42:23+00:00
|
{"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "negativePrompt", "dtype": "string"}, {"name": "full_prompt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 464451998, "num_examples": 275908}], "download_size": 94523704, "dataset_size": 464451998}}
|
2023-06-13T21:49:56+00:00
|
f95f8c75ad88e695b899120eef3c7331fefffa25
|
# Dataset Card for "ar_sarcasm_v21"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sanaeai/ar_sarcasm_v21
|
[
"region:us"
] |
2023-06-13T21:53:55+00:00
|
{"dataset_info": {"features": [{"name": "tweet", "dtype": "string"}, {"name": "label", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2499149, "num_examples": 15548}], "download_size": 1424196, "dataset_size": 2499149}}
|
2023-06-13T21:53:56+00:00
|
bdf412319e160046fd966f7d72d776d3d7b866a0
|
## Dataset Description
- **Repository:** [wellecks/naturalprover](https://github.com/wellecks/naturalprover)
- **Paper:** [NaturalProver: Grounded Mathematical Proof Generation with Language Models](https://openreview.net/pdf?id=rhdfTOiXBng)
- **Point of Contact:** [Sean Welleck](https://wellecks.com/)
# Naturalproofs-gen
This dataset contains the `Naturalproofs-gen` corpus from:
[NaturalProver: Grounded Mathematical Proof Generation with Language Models](https://arxiv.org/pdf/2205.12910.pdf)\
Sean Welleck\*, Jiacheng Liu\*, Ximing Lu, Hannaneh Hajishirzi, Yejin Choi\
NeurIPS 2022
### Licensing Information
MIT
### Citation Information
Please cite:
```
@inproceedings{welleck2022naturalprover,
title={NaturalProver: Grounded Mathematical Proof Generation with Language Models},
author={Sean Welleck and Jiacheng Liu and Ximing Lu and Hannaneh Hajishirzi and Yejin Choi},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year={2022},
url={https://openreview.net/forum?id=rhdfTOiXBng}
}
```
Naturalproofs-gen was built from the Naturalproofs corpus:
```
@inproceedings{welleck2021naturalproofs,
title={NaturalProofs: Mathematical Theorem Proving in Natural Language},
author={Sean Welleck and Jiacheng Liu and Ronan Le Bras and Hannaneh Hajishirzi and Yejin Choi and Kyunghyun Cho},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)},
year={2021},
url={https://openreview.net/forum?id=Jvxa8adr3iY}
}
```
|
wellecks/naturalproofs-gen
|
[
"license:mit",
"math",
"theorem-proving",
"arxiv:2205.12910",
"region:us"
] |
2023-06-13T22:25:32+00:00
|
{"license": "mit", "tags": ["math", "theorem-proving"]}
|
2023-06-13T23:55:55+00:00
|
2eaee580b90f64683ba754ada77d8d0e829b7589
|
# Dataset Card for "sdcctest"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sdmattpotter/sdcctest
|
[
"region:us"
] |
2023-06-13T22:36:32+00:00
|
{"dataset_info": {"features": [{"name": "ITEMNO.", "dtype": "string"}, {"name": "O", "dtype": "string"}, {"name": "00000", "dtype": "float64"}, {"name": "Motion/Second", "dtype": "string"}, {"name": "Recorder", "dtype": "string"}, {"name": "action", "dtype": "string"}, {"name": "drescpt", "dtype": "string"}, {"name": "Meeting Type", "dtype": "string"}, {"name": "Roll Call", "dtype": "string"}, {"name": "Attendance", "dtype": "string"}, {"name": "DateTimeDate", "dtype": "timestamp[ns]"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 359956, "num_examples": 1185}], "download_size": 137681, "dataset_size": 359956}}
|
2023-06-13T22:48:46+00:00
|
b4c89b6e8ce403e1eb7434ea0ed1c0fb5776177d
|
# Dataset Card for "tead1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sanaeai/tead1
|
[
"region:us"
] |
2023-06-13T22:37:28+00:00
|
{"dataset_info": {"features": [{"name": "tweet", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1098060, "num_examples": 12558}], "download_size": 603080, "dataset_size": 1098060}}
|
2023-06-13T22:37:29+00:00
|
60021a5a7c02622f16edf5b1fc6b943036f38433
|
# Dataset Card for "anthropic-hh-rlhf-conversations-with-toxicities"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
andersonbcdefg/anthropic-hh-rlhf-conversations-with-toxicities
|
[
"region:us"
] |
2023-06-13T22:47:00+00:00
|
{"dataset_info": {"features": [{"name": "messages", "sequence": "string"}, {"name": "length", "dtype": "int64"}, {"name": "toxicity", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 117886688, "num_examples": 104876}], "download_size": 68186422, "dataset_size": 117886688}}
|
2023-06-13T22:47:06+00:00
|
7be58bae34797f43cd3dce6ab9299711292ee931
|
Kapal/Api
|
[
"license:openrail",
"region:us"
] |
2023-06-13T23:37:29+00:00
|
{"license": "openrail"}
|
2023-06-13T23:37:29+00:00
|
|
fa881b177669daf96dfcb3db3ccbffc4066d92a2
|
sruly/RoboThoughts
|
[
"license:apache-2.0",
"region:us"
] |
2023-06-13T23:56:13+00:00
|
{"license": "apache-2.0"}
|
2023-06-14T00:55:09+00:00
|
|
b7c8d864808e2a6d1559fc1fa06905d5e9c1e3dc
|
foilfoilfoil/LaminiChatML
|
[
"license:other",
"region:us"
] |
2023-06-14T01:10:24+00:00
|
{"license": "other"}
|
2023-06-14T01:15:45+00:00
|
|
1d8d4629150d18ca50afab66391866f2085be989
|
# Dataset Card for MagicBrush
## Dataset Description
- **Homepage:** https://osu-nlp-group.github.io/MagicBrush
- **Repository:** https://github.com/OSU-NLP-Group/MagicBrush
- **Point of Contact:** [Kai Zhang](mailto:[email protected])
### Dataset Summary
MagicBrush is the first large-scale, manually-annotated instruction-guided image editing dataset covering diverse scenarios single-turn, multi-turn, mask-provided, and mask-free editing. MagicBrush comprises 10K (source image, instruction, target image) triples, which is sufficient to train large-scale image editing models.
Please check our [website](https://osu-nlp-group.github.io/MagicBrush/) to explore more visual results.
#### Dataset Structure
"img_id" (str): same from COCO id but in string type, for easier test set loading
"turn_index" (int32): the edit turn in the image
"source_img" (str): input image, could be the original real image (turn_index=1) and edited images from last turn (turn_index >=2)
"mask_img" (str): free-form mask image (white region), can be used in mask-provided setting to limit the region to be edited.
"instruction" (str): edit instruction of how the input image should be changed.
"target_img" (str): the edited image corresponding to the input image and instruction.
If you need auxiliary data, please use [training set](https://buckeyemailosu-my.sharepoint.com/:u:/g/personal/zhang_13253_buckeyemail_osu_edu/EYEqf_yG36lAgiXw2GvRl0QBDBOeZHxvNgxO0Ec9WDMcNg) and [dev set](https://buckeyemailosu-my.sharepoint.com/:u:/g/personal/zhang_13253_buckeyemail_osu_edu/EXkXvvC95C1JsgMNWGL_RcEBElmsGxXwAAAdGamN8PNhrg)
### Splits
train: 8,807 edit turns (4,512 edit sessions).
dev: 528 edit turns (266 edit sessions).
test: (To prevent potential data leakage, please check our repo for information on obtaining the test set.)
### Licensing Information
Creative Commons License
This work is licensed under a Creative Commons Attribution 4.0 International License.
## Citation Information
If you find this dataset useful, please consider citing our paper:
```
@inproceedings{Zhang2023MagicBrush,
title={MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing},
author={Kai Zhang and Lingbo Mo and Wenhu Chen and Huan Sun and Yu Su},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}
```
|
osunlp/MagicBrush
|
[
"task_categories:text-to-image",
"task_categories:image-to-image",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"region:us"
] |
2023-06-14T01:20:33+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-to-image", "image-to-image"], "pretty_name": "MagicBrush", "dataset_info": {"features": [{"name": "img_id", "dtype": "string"}, {"name": "turn_index", "dtype": "int32"}, {"name": "source_img", "dtype": "image"}, {"name": "mask_img", "dtype": "image"}, {"name": "instruction", "dtype": "string"}, {"name": "target_img", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 25446150928.986, "num_examples": 8807}, {"name": "dev", "num_bytes": 1521183444, "num_examples": 528}], "download_size": 22358540292, "dataset_size": 26967334372.986}}
|
2023-11-07T20:19:33+00:00
|
1864285e25010d346a842e4f068b1a1d4248ed6d
|
# Dataset Card for HLS Burn Scar Scenes
## Dataset Description
- **Homepage: https://huggingface.co/datasets/nasa-impact/hls_burn_scars**
- **Point of Contact: Dr. Christopher Phillips ([email protected])**
### Dataset Summary
This dataset contains Harmonized Landsat and Sentinel-2 imagery of burn scars and the associated masks for the years 2018-2021 over the contiguous United States. There are 804 512x512 scenes. Its primary purpose is for training geospatial machine learning models.
## Dataset Structure
## TIFF Metadata
Each tiff file contains a 512x512 pixel tiff file. Scenes contain six bands, and masks have one band. For satellite scenes, each band has already been converted to reflectance.
## Band Order
For scenes:
Channel, Name, HLS S30 Band number
1, Blue, B02
2, Green, B03
3, Red, B04
4, NIR, B8A
5, SW 1, B11
6, SW 2, B12
Masks are a single band with values:
1 = Burn scar
0 = Not burned
-1 = Missing data
## Class Distribution
Burn Scar - 11%
Not burned - 88%
No Data - 1%
## Data Splits
The 804 files have been randomly split into training (2/3) and validation (1/3) directories, each containing the masks, scenes, and index files.
## Dataset Creation
After co-locating the shapefile and HLS scene, the 512x512 chip was formed by taking a window with the burn scar in the center. Burn scars near the edges of HLS tiles are offset from the center.
Images were manually filtered for cloud cover and missing data to provide as clean a scene as possible, and burn scar presence was also manually verified.
## Source Data
Imagery are from V1.4 of HLS. A full description and access to HLS may be found at https://hls.gsfc.nasa.gov/
The data were from shapefiles maintained by the Monitoring Trends in Burn Severity (MTBS) group. The original data may be found at:
https://mtbs.gov/
## Citation
If this dataset helped your research, please cite `HLS Burn Scars` in your publications. Here is an example BibTeX entry:
```
@software{HLS_Foundation_2023,
author = {Phillips, Christopher and Roy, Sujit and Ankur, Kumar and Ramachandran, Rahul},
doi = {10.57967/hf/0956},
month = aug,
title = {{HLS Foundation Burnscars Dataset}},
url = {https://huggingface.co/ibm-nasa-geospatial/hls_burn_scars},
year = {2023}
}
```
|
ibm-nasa-geospatial/hls_burn_scars
|
[
"size_categories:n<1K",
"language:en",
"license:cc-by-4.0",
"doi:10.57967/hf/0956",
"region:us"
] |
2023-06-14T01:23:32+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["n<1K"]}
|
2023-09-26T15:08:32+00:00
|
93e3b9fdb866c3cc1455b7a4a298648661b34bc5
|
# Dataset Card for SP500-EDGAR-10K
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains the annual reports for all SP500 historical constituents from 2010-2022 from SEC EDGAR Form 10-K filings.
It also contains n-day future returns of each firm's stock price from each filing date.
## Dataset Structure
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Source Data
#### Initial Data Collection and Normalization
10-K filings data was collected and processed using `edgar-crawler` available <a href='https://github.com/nlpaueb/edgar-crawler'>here.</a>
Return data was computed manually from other price data sources.
### Annotations
#### Annotation process
N/A
#### Who are the annotators?
N/A
### Personal and Sensitive Information
N/A
## Considerations for Using the Data
### Social Impact of Dataset
N/A
### Discussion of Biases
The firms in the dataset are constructed from historical SP500 membership data, removing survival biases.
### Other Known Limitations
N/A
### Licensing Information
MIT
|
jlohding/sp500-edgar-10k
|
[
"license:mit",
"nlp",
"region:us"
] |
2023-06-14T01:28:35+00:00
|
{"license": "mit", "pretty_name": "SP500 EDGAR 10-K Filings", "tags": ["nlp"]}
|
2023-06-15T14:08:31+00:00
|
436862dd6e9edcebc85f6dddb19ddf24a65c4992
|
foilfoilfoil/LaminiChatML1024
|
[
"license:other",
"region:us"
] |
2023-06-14T01:28:49+00:00
|
{"license": "other"}
|
2023-06-14T01:29:44+00:00
|
|
a3c6098505a306e752a79d5be145d9c3dad495a2
|
# Dataset Card for "VQAv2_minival_validation_eachadea_vicuna_13b_1.1_mode_CM_Q_rices_ns_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CVasNLPExperiments/VQAv2_minival_validation_eachadea_vicuna_13b_1.1_mode_CM_Q_rices_ns_100
|
[
"region:us"
] |
2023-06-14T01:37:36+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompt", "sequence": "string"}, {"name": "question", "dtype": "string"}, {"name": "true_label", "sequence": "string"}, {"name": "prediction", "dtype": "string"}], "splits": [{"name": "fewshot_0", "num_bytes": 553653, "num_examples": 100}], "download_size": 100504, "dataset_size": 553653}}
|
2023-06-14T01:37:41+00:00
|
eb58a4e9c05dde7151ca83184848d8c8418dce4b
|
foilfoilfoil/lamini512
|
[
"license:other",
"region:us"
] |
2023-06-14T01:51:48+00:00
|
{"license": "other"}
|
2023-06-14T02:01:07+00:00
|
|
b91e5c27ec1878662f2d6c68728a0c147d48a656
|
ydqe2/kaggle_financial_sentiment_resplit
|
[
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:mit",
"region:us"
] |
2023-06-14T01:53:59+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["text-classification"], "pretty_name": "d"}
|
2023-06-14T01:59:29+00:00
|
|
d38aca2628ccf2cec102fae3c6f4a60c3bf8667a
|
# Dataset Card for "ca039ad3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/ca039ad3
|
[
"region:us"
] |
2023-06-14T02:09:07+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 184, "num_examples": 10}], "download_size": 1343, "dataset_size": 184}}
|
2023-06-14T02:09:07+00:00
|
4b5b43eedc6d1ae050cd2304dd9db02ccef26b94
|
# Dataset Card for "my-shiba-inu-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
zxx-silence/my-shiba-inu-dataset
|
[
"region:us"
] |
2023-06-14T02:43:19+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2997266.0, "num_examples": 13}], "download_size": 2987648, "dataset_size": 2997266.0}}
|
2023-06-14T05:06:32+00:00
|
0c28275a5605f3bfa4cc116d8099bfa0e5abb43b
|
# Ko Lima Vicuna Dataset
GPT4 API를 사용하여 [lima_vicuna_format 데이터](https://huggingface.co/datasets/64bits/lima_vicuna_format)를 한국어로 재생성한 데이터셋입니다.
GPT4 사용시 프롬프트는 "단순 번역이 아닌, 원문 내용을 참조하여 데이터를 재생성하라"는 내용으로 작성하였습니다.
원본 데이터셋 1,030건 중 866건의 데이터가 재생성되었습니다.
*데이터셋 제작은 웹 크롤링 전문 기업, **[해시스크래퍼(HASHSCRAPER)](https://www.hashscraper.com/)** 에서 진행되었습니다.*
*This is the lima_vicuna_format data regenerated into Korean using the GPT4 API.*
*When using GPT4, the prompt was written to read "Regenerate the data by referring to the original content, not just a simple translation".*
*Out of the 1,030 original datasets, 866 data points were regenerated.*
*The dataset was created by [HASHSCRAPER](https://www.hashscraper.com/), a company specializing in web scraping.*
---
# How to use
```python
>>> from datasets import load_dataset
>>> data = load_dataset("changpt/ko-lima-vicuna", data_files="ko_lima_vicuna.json", split="train")
>>> data
Dataset({
features: ['id', 'conversations'],
num_rows: 866
})
```
```python
>>> data[0]
{'id': '7-stackexchange',
'conversations': [{'from': 'human',
'value': '나는 ```ffmpeg```로 비디오를 GIF 파일로 변환하고 있어:\n```ffmpeg \\\n -i input.flv \\\n -ss 00:00:00.000 \\\n -pix_fmt rgb24 \\\n -r 10 \\\n -s 320x240 \\\n -t 00:00:10.000 \\\n output.gif\n```\n잘 작동하는데, 출력된 gif 파일의 품질이 너무 낮아. 변환된 gif의 품질을 어떻게 개선할 수 있을까?'},
{'from': 'gpt',
'value': '중간 이미지 파일을 피하고 싶다면, LordNeckBeard가 제공한 명령어를 ```ffmpeg```와 ImageMagick의 ```convert``` 사이에 파이프로 연결할 수 있습니다. 이렇게 하면 중간 파일이 필요하지 않습니다:\n```ffmpeg -i input.flv -vf scale=320:-1 -r 10 -f image2pipe -vcodec ppm - | convert -delay 10 -loop 0 - output.gif\n```\n```-f image2pipe```는 ffmpeg에게 비디오를 이미지로 분할하고 파이프 출력에 적합하게 만들라고 지시하며, ```-vcodec ppm```은 출력 형식을 ppm으로 지정합니다(png 형식인 경우, ```convert```가 파이프에서 모든 이미지를 읽지 않거나 ffmpeg가 모두 출력하지 않는 것 같습니다). 두 명령어의 ```-```는 각각 출력과 입력에 파이프를 사용하도록 지정합니다.\n파일을 저장하지 않고 결과를 최적화하려면, ```convert```의 출력을 두 번째 ```convert``` 명령어로 파이프할 수 있습니다:\n```ffmpeg -i input.flv -vf scale=320:-1 -r 10 -f image2pipe -vcodec ppm - | convert -delay 10 -loop 0 - gif:- | convert -layers Optimize - output.gif\n```\n```gif:-```는 ```convert```에게 출력을 gif 형식의 데이터로 파이프하도록 지시하고, ```-layers Optimize```는 두 번째 ```convert```에게 ```optimize-frame``` 및 ```optimize-transparancy``` 방법을 수행하도록 지시합니다(ImageMagick 애니메이션 최적화 소개 참조). ```-layers Optimize```의 출력이 항상 더 작은 파일 크기를 제공하지는 않으므로, 먼저 최적화 없이 gif로 변환해 보는 것이 좋습니다.\n이 과정에서 모든 것이 메모리에 있으므로 이미지가 매우 큰 경우 충분한 메모리가 필요할 수 있습니다.'}]}
```
---
# License
[CC BY 2.0 KR](https://creativecommons.org/licenses/by/2.0/kr/)
[Open AI](https://openai.com/policies/terms-of-use)
|
changpt/ko-lima-vicuna
|
[
"task_categories:text-generation",
"size_categories:n<1K",
"language:ko",
"license:cc-by-2.0",
"KoLima",
"region:us"
] |
2023-06-14T02:58:58+00:00
|
{"language": ["ko"], "license": "cc-by-2.0", "size_categories": ["n<1K"], "task_categories": ["text-generation"], "pretty_name": "KoLima(vicuna)", "tags": ["KoLima"]}
|
2023-06-14T06:47:51+00:00
|
b0aa839a5138eac8afbc3282c534cd8651f5350e
|
# Dataset Card for SNLI_zh
## Dataset Description
- **Repository:** [Chinese NLI dataset](https://github.com/shibing624/text2vec)
- **Dataset:** [train data from ChineseTextualInference](https://github.com/liuhuanyong/ChineseTextualInference/)
- **Size of downloaded dataset files:** 54 MB
- **Total amount of disk used:** 54 MB
### Dataset Summary
中文SNLI和MultiNLI数据集,翻译自英文[SNLI](https://huggingface.co/datasets/snli)和[MultiNLI](https://huggingface.co/datasets/multi_nli)
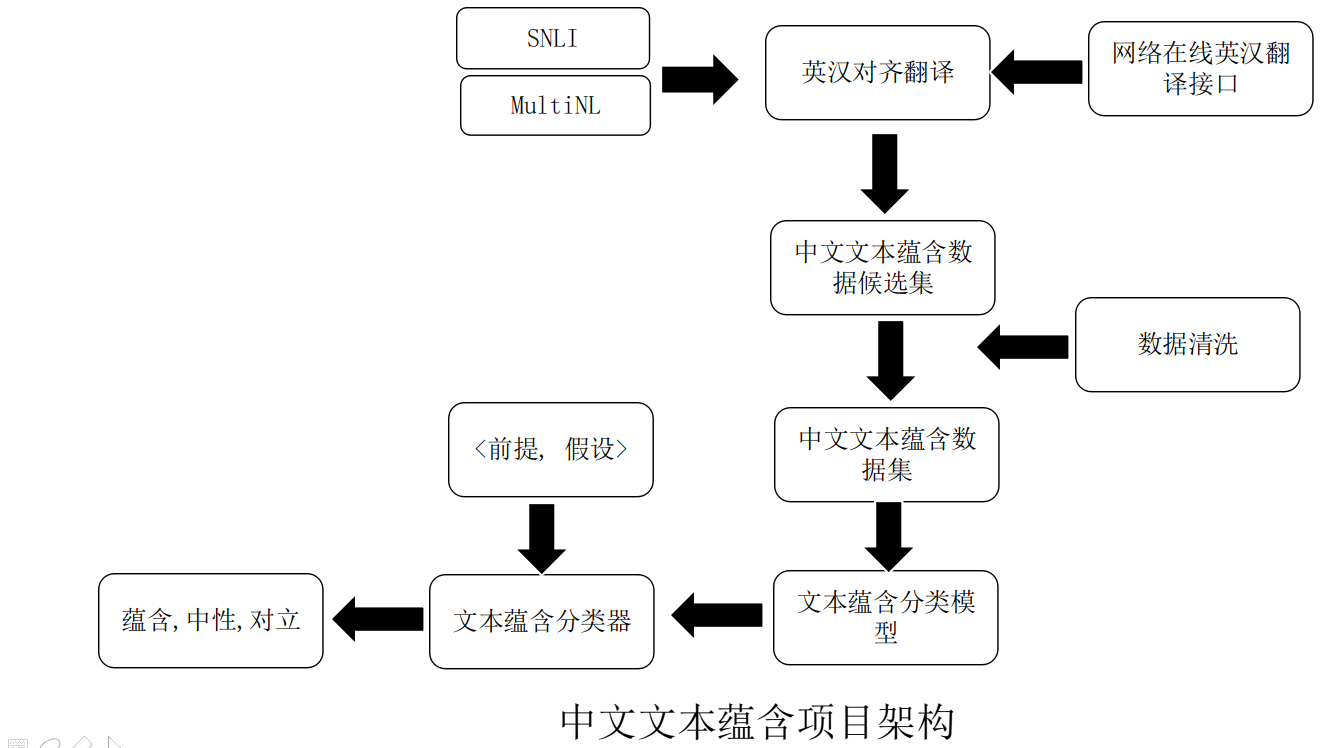
### Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
**Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec)
### Languages
数据集均是简体中文文本。
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
sentence1 sentence2 gold_label
是的,我想一个洞穴也会有这样的问题 我认为洞穴可能会有更严重的问题。 neutral
几周前我带他和一个朋友去看幼儿园警察 我还没看过幼儿园警察,但他看了。 contradiction
航空旅行的扩张开始了大众旅游的时代,希腊和爱琴海群岛成为北欧人逃离潮湿凉爽的夏天的令人兴奋的目的地。 航空旅行的扩大开始了许多旅游业的发展。 entailment
```
### Data Fields
The data fields are the same among all splits.
- `sentence1`: a `string` feature.
- `sentence2`: a `string` feature.
- `label`: a classification label, with possible values including entailment(0), neutral(1), contradiction(2). 注意:此数据集0表示相似,2表示不相似。
-
### Data Splits
after remove None and len(text) < 1 data:
```shell
$ wc -l ChineseTextualInference-train.txt
419402 total
```
### Data Length
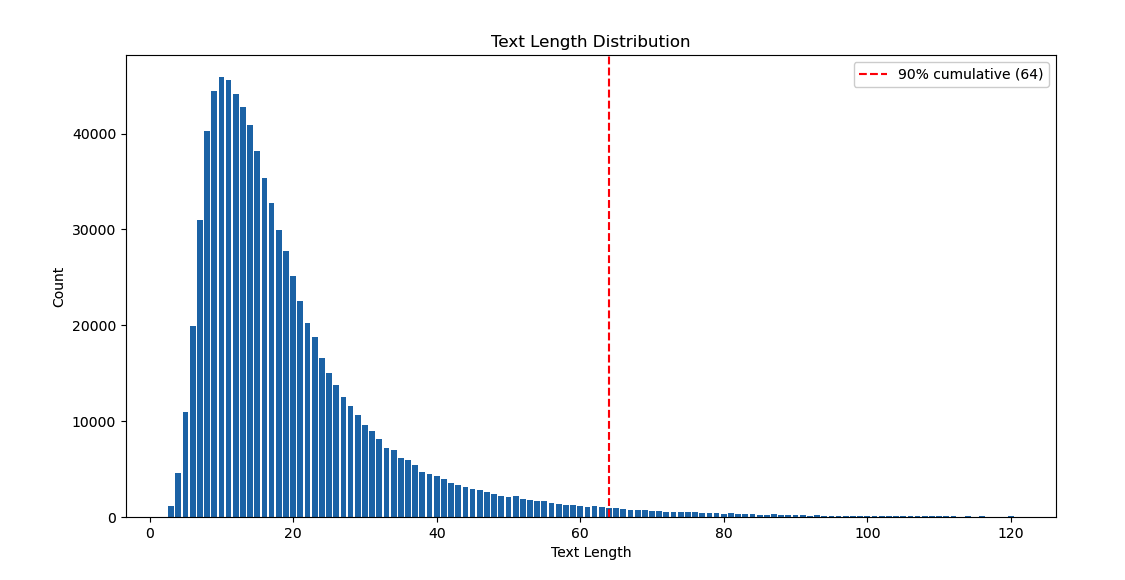
## Dataset Creation
### Curation Rationale
作为中文SNLI(natural langauge inference)数据集,这里把这个数据集上传到huggingface的datasets,方便大家使用。
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
@inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
}
### Annotations
#### Annotation process
#### Who are the annotators?
原作者。
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
- [liuhuanyong](https://github.com/liuhuanyong/ChineseTextualInference/)翻译成中文
- [shibing624](https://github.com/shibing624) 上传到huggingface的datasets
### Licensing Information
用于学术研究。
### Contributions
[shibing624](https://github.com/shibing624) add this dataset.
|
shibing624/snli-zh
|
[
"task_categories:text-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"annotations_creators:shibing624",
"language_creators:liuhuanyong",
"multilinguality:monolingual",
"size_categories:100K<n<20M",
"source_datasets:https://github.com/liuhuanyong/ChineseTextualInference/",
"language:zh",
"license:cc-by-4.0",
"region:us"
] |
2023-06-14T03:33:26+00:00
|
{"annotations_creators": ["shibing624"], "language_creators": ["liuhuanyong"], "language": ["zh"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "size_categories": ["100K<n<20M"], "source_datasets": ["https://github.com/liuhuanyong/ChineseTextualInference/"], "task_categories": ["text-classification"], "task_ids": ["natural-language-inference", "semantic-similarity-scoring", "text-scoring"], "paperswithcode_id": "snli", "pretty_name": "Stanford Natural Language Inference"}
|
2023-06-14T06:15:52+00:00
|
d35f7cb593d682fc1b71b6e631388c4a4375e248
|
Aliissa99/FrenchMedMCQA
|
[
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:fr",
"region:us"
] |
2023-06-14T03:34:51+00:00
|
{"language": ["fr"], "size_categories": ["1K<n<10K"], "task_categories": ["text-classification"], "pretty_name": "FrenchMedMCQA"}
|
2023-06-14T04:15:55+00:00
|
|
2e7d58cde7b98d91e35ec74a8a3b1de3abd2cd36
|
Minnyeong/aihub_NL2SQ
|
[
"size_categories:100K<n<1M",
"language:ko",
"license:other",
"region:us"
] |
2023-06-14T03:41:09+00:00
|
{"language": ["ko"], "license": "other", "size_categories": ["100K<n<1M"]}
|
2023-06-14T03:46:09+00:00
|
|
d9034b79da1dff929a8b9d719a3864e6fb16a7fb
|
# Dataset Card for nli-zh-all
## Dataset Description
- **Repository:** [Chinese NLI dataset](https://github.com/shibing624/text2vec)
- **Dataset:** [zh NLI](https://huggingface.co/datasets/shibing624/nli-zh-all)
- **Size of downloaded dataset files:** 4.7 GB
- **Total amount of disk used:** 4.7 GB
### Dataset Summary
中文自然语言推理(NLI)数据合集(nli-zh-all)
整合了文本推理,相似,摘要,问答,指令微调等任务的820万高质量数据,并转化为匹配格式数据集。
### Supported Tasks and Leaderboards
Supported Tasks: 支持中文文本匹配任务,文本相似度计算等相关任务。
中文匹配任务的结果目前在顶会paper上出现较少,我罗列一个我自己训练的结果:
**Leaderboard:** [NLI_zh leaderboard](https://github.com/shibing624/text2vec)
### Languages
数据集均是简体中文文本。
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
{"text1":"借款后多长时间给打电话","text2":"借款后多久打电话啊","label":1}
{"text1":"没看到微粒贷","text2":"我借那么久也没有提升啊","label":0}
```
- label 有2个标签,1表示相似,0表示不相似。
### Data Fields
The data fields are the same among all splits.
- `text1`: a `string` feature.
- `text2`: a `string` feature.
- `label`: a classification label, with possible values including entailment(1), contradiction(0)。
### Data Splits
after remove None and len(text) < 1 data:
```shell
$ wc -l nli-zh-all/*
48818 nli-zh-all/alpaca_gpt4-train.jsonl
5000 nli-zh-all/amazon_reviews-train.jsonl
519255 nli-zh-all/belle-train.jsonl
16000 nli-zh-all/cblue_chip_sts-train.jsonl
549326 nli-zh-all/chatmed_consult-train.jsonl
10142 nli-zh-all/cmrc2018-train.jsonl
395927 nli-zh-all/csl-train.jsonl
50000 nli-zh-all/dureader_robust-train.jsonl
709761 nli-zh-all/firefly-train.jsonl
9568 nli-zh-all/mlqa-train.jsonl
455875 nli-zh-all/nli_zh-train.jsonl
50486 nli-zh-all/ocnli-train.jsonl
2678694 nli-zh-all/simclue-train.jsonl
419402 nli-zh-all/snli_zh-train.jsonl
3024 nli-zh-all/webqa-train.jsonl
1213780 nli-zh-all/wiki_atomic_edits-train.jsonl
93404 nli-zh-all/xlsum-train.jsonl
1006218 nli-zh-all/zhihu_kol-train.jsonl
8234680 total
```
### Data Length

count text length script: https://github.com/shibing624/text2vec/blob/master/examples/data/count_text_length.py
## Dataset Creation
### Curation Rationale
受[m3e-base](https://huggingface.co/moka-ai/m3e-base#M3E%E6%95%B0%E6%8D%AE%E9%9B%86)启发,合并了中文高质量NLI(natural langauge inference)数据集,
这里把这个数据集上传到huggingface的datasets,方便大家使用。
### Source Data
#### Initial Data Collection and Normalization
如果您想要查看数据集的构建方法,你可以在 [https://github.com/shibing624/text2vec/blob/master/examples/data/build_zh_nli_dataset.py](https://github.com/shibing624/text2vec/blob/master/examples/data/build_zh_nli_dataset.py) 中找到生成 nli-zh-all 数据集的脚本,所有数据均上传到 huggingface datasets。
| 数据集名称 | 领域 | 数量 | 任务类型 | Prompt | 质量 | 数据提供者 | 说明 | 是否开源/研究使用 | 是否商用 | 脚本 | Done | URL | 是否同质 |
|:---------------------| :---- |:-----------|:---------------- |:------ |:----|:-----------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------- |:------|:---- |:---- |:---------------------------------------------------------------------------------------------|:------|
| cmrc2018 | 百科 | 14,363 | 问答 | 问答 | 优 | Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, Guoping Hu | https://github.com/ymcui/cmrc2018/blob/master/README_CN.md 专家标注的基于维基百科的中文阅读理解数据集,将问题和上下文视为正例 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/cmrc2018 | 否 |
| belle_0.5m | 百科 | 500,000 | 指令微调 | 无 | 优 | LianjiaTech/BELLE | belle 的指令微调数据集,使用 self instruct 方法基于 gpt3.5 生成 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/BelleGroup/ | 否 |
| firefily | 百科 | 1,649,399 | 指令微调 | 无 | 优 | YeungNLP | Firefly(流萤) 是一个开源的中文对话式大语言模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。使用了词表裁剪、ZeRO等技术,有效降低显存消耗和提高训练效率。 在训练中,我们使用了更小的模型参数量,以及更少的计算资源。 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M | 否 |
| alpaca_gpt4 | 百科 | 48,818 | 指令微调 | 无 | 优 | Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao | 本数据集是参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条。 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/alpaca-zh | 否 |
| zhihu_kol | 百科 | 1,006,218 | 问答 | 问答 | 优 | wangrui6 | 知乎问答 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wangrui6/Zhihu-KOL | 否 |
| amazon_reviews_multi | 电商 | 210,000 | 问答 文本分类 | 摘要 | 优 | 亚马逊 | 亚马逊产品评论数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/amazon_reviews_multi/viewer/zh/train?row=8 | 否 |
| mlqa | 百科 | 85,853 | 问答 | 问答 | 良 | patrickvonplaten | 一个用于评估跨语言问答性能的基准数据集 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/mlqa/viewer/mlqa-translate-train.zh/train?p=2 | 否 |
| xlsum | 新闻 | 93,404 | 摘要 | 摘要 | 良 | BUET CSE NLP Group | BBC的专业注释文章摘要对 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/csebuetnlp/xlsum/viewer/chinese_simplified/train?row=259 | 否 |
| ocnli | 口语 | 17,726 | 自然语言推理 | 推理 | 良 | Thomas Wolf | 自然语言推理数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/clue/viewer/ocnli | 是 |
| BQ | 金融 | 60,000 | 文本分类 | 相似 | 优 | Intelligent Computing Research Center, Harbin Institute of Technology(Shenzhen) | http://icrc.hitsz.edu.cn/info/1037/1162.htm BQ 语料库包含来自网上银行自定义服务日志的 120,000 个问题对。它分为三部分:100,000 对用于训练,10,000 对用于验证,10,000 对用于测试。 数据提供者: 哈尔滨工业大学(深圳)智能计算研究中心 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/BQ | 是 |
| lcqmc | 口语 | 149,226 | 文本分类 | 相似 | 优 | Ming Xu | 哈工大文本匹配数据集,LCQMC 是哈尔滨工业大学在自然语言处理国际顶会 COLING2018 构建的问题语义匹配数据集,其目标是判断两个问题的语义是否相同 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/LCQMC/train | 是 |
| paws-x | 百科 | 23,576 | 文本分类 | 相似 | 优 | Bhavitvya Malik | PAWS Wiki中的示例 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/paws-x/viewer/zh/train | 是 |
| wiki_atomic_edit | 百科 | 1,213,780 | 平行语义 | 相似 | 优 | abhishek thakur | 基于中文维基百科的编辑记录收集的数据集 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wiki_atomic_edits | 是 |
| chatmed_consult | 医药 | 549,326 | 问答 | 问答 | 优 | Wei Zhu | 真实世界的医学相关的问题,使用 gpt3.5 进行回答 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/michaelwzhu/ChatMed_Consult_Dataset | 否 |
| webqa | 百科 | 42,216 | 问答 | 问答 | 优 | suolyer | 百度于2016年开源的数据集,数据来自于百度知道;格式为一个问题多篇意思基本一致的文章,分为人为标注以及浏览器检索;数据整体质量中,因为混合了很多检索而来的文章 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/suolyer/webqa/viewer/suolyer--webqa/train?p=3 | 否 |
| dureader_robust | 百科 | 65,937 | 机器阅读理解 问答 | 问答 | 优 | 百度 | DuReader robust旨在利用真实应用中的数据样本来衡量阅读理解模型的鲁棒性,评测模型的过敏感性、过稳定性以及泛化能力,是首个中文阅读理解鲁棒性数据集。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/PaddlePaddle/dureader_robust/viewer/plain_text/train?row=96 | 否 |
| csl | 学术 | 395,927 | 语料 | 摘要 | 优 | Yudong Li, Yuqing Zhang, Zhe Zhao, Linlin Shen, Weijie Liu, Weiquan Mao and Hui Zhang | 提供首个中文科学文献数据集(CSL),包含 396,209 篇中文核心期刊论文元信息 (标题、摘要、关键词、学科、门类)。CSL 数据集可以作为预训练语料,也可以构建许多NLP任务,例如文本摘要(标题预测)、 关键词生成和文本分类等。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/neuclir/csl | 否 |
| snli-zh | 口语 | 419,402 | 文本分类 | 推理 | 优 | liuhuanyong | 中文SNLI数据集,翻译自英文SNLI | 是 | 否 | 是 | 是 | https://github.com/liuhuanyong/ChineseTextualInference/ | 是 |
| SimCLUE | 百科 | 2,678,694 | 平行语义 | 相似 | 优 | 数据集合,请在 simCLUE 中查看 | 整合了中文领域绝大多数可用的开源的语义相似度和自然语言推理的数据集,并重新做了数据拆分和整理。 | 是 | 否 | 否 | 是 | https://github.com/CLUEbenchmark/SimCLUE | 是 |
#### Who are the source language producers?
数据集的版权归原作者所有,使用各数据集时请尊重原数据集的版权。
SNLI:
@inproceedings{snli:emnlp2015,
Author = {Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher, and Manning, Christopher D.},
Booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP)},
Publisher = {Association for Computational Linguistics},
Title = {A large annotated corpus for learning natural language inference},
Year = {2015}
}
#### Who are the annotators?
原作者。
### Social Impact of Dataset
This dataset was developed as a benchmark for evaluating representational systems for text, especially including those induced by representation learning methods, in the task of predicting truth conditions in a given context.
Systems that are successful at such a task may be more successful in modeling semantic representations.
### Licensing Information
for reasearch
用于学术研究
### Contributions
[shibing624](https://github.com/shibing624) add this dataset.
|
shibing624/nli-zh-all
|
[
"task_categories:text-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:text-scoring",
"annotations_creators:shibing624",
"language_creators:shibing624",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:https://github.com/shibing624/text2vec",
"language:zh",
"license:cc-by-4.0",
"region:us"
] |
2023-06-14T04:12:45+00:00
|
{"annotations_creators": ["shibing624"], "language_creators": ["shibing624"], "language": ["zh"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["https://github.com/shibing624/text2vec"], "task_categories": ["text-classification"], "task_ids": ["natural-language-inference", "semantic-similarity-scoring", "text-scoring"], "paperswithcode_id": "nli", "pretty_name": "Chinese Natural Language Inference"}
|
2023-06-22T05:39:46+00:00
|
40f7cc7f6a43333e5bf9d7d83c9dadb793e435dc
|
# Dataset Card for "toy"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vvtq/toy
|
[
"region:us"
] |
2023-06-14T04:27:11+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "noised", "dtype": "image"}, {"name": "image_caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 6839293.0, "num_examples": 6}], "download_size": 5138950, "dataset_size": 6839293.0}}
|
2023-06-14T04:27:18+00:00
|
74b26c88f519b69185479a573e44f9296bd2a41e
|
mganesh13/dataset
|
[
"license:mit",
"region:us"
] |
2023-06-14T04:53:22+00:00
|
{"license": "mit"}
|
2023-06-14T04:57:49+00:00
|
|
5d661377ae66a98ddc7d12e7cc49511f484807ff
|
# Dataset Card for "ingredient_to_good_or_bad"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ziq/ingredient_to_good_or_bad
|
[
"region:us"
] |
2023-06-14T04:59:03+00:00
|
{"dataset_info": {"features": [{"name": "src", "dtype": "string"}, {"name": "ingredients", "dtype": "string"}, {"name": "Good", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 12018794, "num_examples": 24889}], "download_size": 5553609, "dataset_size": 12018794}}
|
2023-06-14T05:33:43+00:00
|
b0ae1ecb855111c08e7b8911ab9aa8c88b6dc027
|
# Dataset Card for "diagram_image_to_text"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Kamizuru00/diagram_image_to_text
|
[
"region:us"
] |
2023-06-14T05:09:47+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 19284903.0, "num_examples": 300}], "download_size": 19026610, "dataset_size": 19284903.0}}
|
2023-06-14T05:54:06+00:00
|
d2b8862bd541d10b52b2a788887ef5df28febe01
|
Paper: [MuSiQue: Multi-hop Questions via Single-hop Question Composition](https://arxiv.org/pdf/2108.00573.pdf)
Original repository: https://github.com/StonyBrookNLP/musique
# Data
MuSiQue is distributed under a [CC BY 4.0 License](https://creativecommons.org/licenses/by/4.0/).
**Usage Caution:** If you're using any of our seed single-hop datasets ([SQuAD](https://arxiv.org/abs/1606.05250), [T-REx](https://hadyelsahar.github.io/t-rex/paper.pdf), [Natural Questions](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/1f7b46b5378d757553d3e92ead36bda2e4254244.pdf), [MLQA](https://arxiv.org/pdf/1910.07475.pdf), [Zero Shot RE](https://arxiv.org/pdf/1706.04115.pdf)) in any way (e.g., pretraining on them), please note that MuSiQue was created by composing questions from these seed datasets. Therefore, single-hop questions used in MuSiQue's dev/test sets may occur in the training sets of these seed datasets. To help avoid information leakage, we are releasing the IDs of single-hop questions that are used in MuSiQue dev/test sets. Once you download the data below, these IDs and corresponding questions will be in `data/dev_test_singlehop_questions_v1.0.json`. If you use our seed single-hop datasets in any way in your model, please be sure to **avoid using any single-hop question IDs present in this file**
# Citation
If you use this in your work, please cite use:
```
@article{trivedi2021musique,
title={{M}u{S}i{Q}ue: Multihop Questions via Single-hop Question Composition},
author={Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish},
journal={Transactions of the Association for Computational Linguistics},
year={2022}
publisher={MIT Press}
}
```
|
bdsaglam/musique
|
[
"arxiv:2108.00573",
"arxiv:1606.05250",
"arxiv:1910.07475",
"arxiv:1706.04115",
"region:us"
] |
2023-06-14T05:10:10+00:00
|
{"dataset_info": [{"config_name": "answerable", "features": [{"name": "id", "dtype": "string"}, {"name": "paragraphs", "sequence": [{"name": "idx", "dtype": "int32"}, {"name": "title", "dtype": "string"}, {"name": "paragraph_text", "dtype": "string"}, {"name": "is_supporting", "dtype": "bool"}]}, {"name": "question", "dtype": "string"}, {"name": "question_decomposition", "sequence": [{"name": "id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "paragraph_support_idx", "dtype": "int32"}]}, {"name": "answer", "dtype": "string"}, {"name": "answerable", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 211123672, "num_examples": 19938}, {"name": "validation", "num_bytes": 26760847, "num_examples": 2417}], "download_size": 299853055, "dataset_size": 237884519}, {"config_name": "full", "features": [{"name": "id", "dtype": "string"}, {"name": "paragraphs", "sequence": [{"name": "idx", "dtype": "int32"}, {"name": "title", "dtype": "string"}, {"name": "paragraph_text", "dtype": "string"}, {"name": "is_supporting", "dtype": "bool"}]}, {"name": "question", "dtype": "string"}, {"name": "question_decomposition", "sequence": [{"name": "id", "dtype": "int32"}, {"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "paragraph_support_idx", "dtype": "int32"}]}, {"name": "answer", "dtype": "string"}, {"name": "answerable", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 416868901, "num_examples": 39876}, {"name": "validation", "num_bytes": 52065789, "num_examples": 4834}], "download_size": 591677838, "dataset_size": 468934690}]}
|
2023-06-14T07:19:12+00:00
|
0a1e0e6fe2ace541a4ac9f3b276b72918f428eca
|
# Dataset Card for "cifar10_lt_r10_text"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ashnrk/cifar10_lt_r10_text
|
[
"region:us"
] |
2023-06-14T05:10:34+00:00
|
{"dataset_info": {"features": [{"name": "img", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "airplane", "1": "automobile", "2": "bird", "3": "cat", "4": "deer", "5": "dog", "6": "frog", "7": "horse", "8": "ship", "9": "truck"}}}}, {"name": "text_label", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9133039.5, "num_examples": 4084}], "download_size": 9126904, "dataset_size": 9133039.5}}
|
2023-06-14T05:10:37+00:00
|
d63c57054cb1431901b0cbad8588b00d14c09992
|
# Dataset Card for "human_joined_en_paragraph_19"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
bot-yaya/human_joined_en_paragraph_19
|
[
"region:us"
] |
2023-06-14T05:30:38+00:00
|
{"dataset_info": {"features": [{"name": "record", "dtype": "string"}, {"name": "raw_text", "dtype": "string"}, {"name": "is_hard_linebreak", "sequence": "bool"}], "splits": [{"name": "train", "num_bytes": 2339622, "num_examples": 19}], "download_size": 1143144, "dataset_size": 2339622}}
|
2023-06-14T05:30:51+00:00
|
8eed9641f8281c9146001a16880584736c82a25c
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
pandaman2020/SD
|
[
"license:cc0-1.0",
"region:us"
] |
2023-06-14T05:52:00+00:00
|
{"license": "cc0-1.0"}
|
2023-06-14T05:53:06+00:00
|
660382739ff5fe0c958e880104e7b0a6ff133ee6
|
# Dataset Card for "kmou-2016klp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
soddokayo/kmou-2016klp
|
[
"region:us"
] |
2023-06-14T05:52:58+00:00
|
{"dataset_info": {"features": [{"name": "sentence", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "ner_tags", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 3732093, "num_examples": 2928}, {"name": "dev", "num_bytes": 459796, "num_examples": 366}, {"name": "test", "num_bytes": 449770, "num_examples": 366}], "download_size": 951800, "dataset_size": 4641659}}
|
2023-06-14T05:53:12+00:00
|
b7b69f831817fe0fa3b28339cb5a1877789eea27
|
# Dataset Card for "quan_ocr_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ademax/ocr_scan_vi_01
|
[
"language:vi",
"region:us"
] |
2023-06-14T05:56:33+00:00
|
{"language": "vi", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 410862389.5689411, "num_examples": 11003}, {"name": "test", "num_bytes": 37340942.4310589, "num_examples": 1000}], "download_size": 447854730, "dataset_size": 448203332.0}}
|
2023-07-15T08:20:17+00:00
|
0ab97f890e093c58a86970144b1a31c4b0bbb301
|
# Dataset Card for "sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
byeungchun/sample
|
[
"region:us"
] |
2023-06-14T05:58:24+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 79076.8, "num_examples": 800}, {"name": "test", "num_bytes": 19769.2, "num_examples": 200}], "download_size": 67143, "dataset_size": 98846.0}}
|
2023-06-14T05:59:46+00:00
|
5c5acb40331f55461ce98238e6c452289e28bd5b
|
This is the data used in the paper [Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias](https://github.com/yueyu1030/AttrPrompt).
Checkout the paper https://arxiv.org/abs/2306.15895 for details.
- `label.txt`: the label name for each class
- `train.jsonl`: The original training set.
- `valid.jsonl`: The original validation set.
- `test.jsonl`: The original test set.
- `simprompt.jsonl`: The training data generated by the simple prompt.
- `attrprompt.jsonl`: The training data generated by the attributed prompt.
Please check our original paper for details. Moreover, we provide the generated dataset using LLM as follows:
- `regen.jsonl`: The training data generated by [ReGen](https://github.com/yueyu1030/ReGen).
- `regen_llm_augmented.jsonl`: The training data generated by ReGen, with the subtopics generated by the LLM.
- `progen.jsonl`: The training data generated by [ProGen](https://github.com/hkunlp/progen).
Please cite the original paper if you use this dataset for your study. Thanks!
```
@inproceedings{meng2019weakly,
title={Weakly-supervised hierarchical text classification},
author={Meng, Yu and Shen, Jiaming and Zhang, Chao and Han, Jiawei},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
pages={6826--6833},
year={2019}
}
@article{yu2023large,
title={Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias},
author={Yu, Yue and Zhuang, Yuchen and Zhang, Jieyu and Meng, Yu and Ratner, Alexander and Krishna, Ranjay and Shen, Jiaming and Zhang, Chao},
journal={arXiv preprint arXiv:2306.15895},
year={2023}
}
```
|
yyu/nyt-attrprompt
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"arxiv:2306.15895",
"region:us"
] |
2023-06-14T06:04:17+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "pretty_name": "d"}
|
2023-09-13T19:55:46+00:00
|
c0d9e04b53826e599745ed69ddf7f86fa82a896b
|
### 数据集说明
#### 组成
| 类型 | 文件夹名称 | 来源 | 数量 | 说明 |
| :--------: | :-----: | :-----: | :----: | :----: |
| 电信问答 | telecom_Q&A | 百度知道QA | 87366 | 经过脱敏、数据清洗、人工筛选等处理|
| 行业相关知识数据 | industry_data | 教科书、国际标准等 | 5218 | 通过大模型从文档得到的QA数据,部分原文档保存在source_data中 |
| 通用指令数据集 | general_instruction | firefly | 18123 | 挑选了阅读、情感理解、补全、逻辑推理等主题的通用指令 |
| 混合数据集 | blended_data | - | - | 按照数据集建设进程,混合后组件的训练、测试数据,可直接使用 |
#### 混合数据 - V1
- 组成
| 来源 | 比例 | 条数 | 说明 |
| :--------: | :-----: | :----: | :----: |
| 百度知道 | 64% | 32282 | 经过脱敏、数据清洗、人工筛选等处理|
| firefly | 36% | 18123 | 挑选了阅读、情感理解、补全、逻辑推理等主题的通用指令|
| 标准问答 | - | 18 | 通过联通网上营业厅在线客服整理|
| 合计 | 100% | 50423 | - |
- 文件说明
| 名称 | 条目比例 | token数 | 说明|
| -------- | -----: | :----: | :----: |
| train | 85% | 4,257,817 | 训练数据集 |
| test | 10% | 464,681 | 测试数据集 - 1 |
| test_2 | 5% | 232,898 | 测试数据集 - 2 |
| train_test | 10% | 403,905 | 训练数据集中抽取的测试数据集 |
|
THU-StarLab/CustomerService
|
[
"license:unknown",
"TeleCom",
"region:us"
] |
2023-06-14T06:07:34+00:00
|
{"language": ["\u4e2d\u6587"], "license": "unknown", "task_categories": ["\u95ee\u7b54"], "pretty_name": "TeleCom", "tags": ["TeleCom"]}
|
2023-07-13T06:58:00+00:00
|
78e38c3c8df3b4f6de7ae8bd1fc6a8bd1f31be56
|
https://arxiv.org/pdf/2306.07934.pdf
|
tasksource/Boardgame-QA
|
[
"license:cc-by-4.0",
"arxiv:2306.07934",
"region:us"
] |
2023-06-14T06:12:54+00:00
|
{"license": "cc-by-4.0", "dataset_info": {"features": [{"name": "proof", "dtype": "string"}, {"name": "example", "dtype": "string"}, {"name": "label", "dtype": "string"}, {"name": "rules", "dtype": "string"}, {"name": "preferences", "dtype": "string"}, {"name": "theory", "dtype": "string"}, {"name": "goal", "dtype": "string"}, {"name": "facts", "dtype": "string"}, {"name": "config", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 54209160, "num_examples": 15000}, {"name": "train", "num_bytes": 55055604, "num_examples": 15000}, {"name": "valid", "num_bytes": 27317650, "num_examples": 7500}], "download_size": 34032485, "dataset_size": 136582414}}
|
2023-06-14T06:38:39+00:00
|
fdfd411ddbc2cb7c62a70eb909b46627f4369cc2
|
# Dataset Card for "b9e11bd6"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/b9e11bd6
|
[
"region:us"
] |
2023-06-14T06:18:55+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 182, "num_examples": 10}], "download_size": 1340, "dataset_size": 182}}
|
2023-06-14T06:18:56+00:00
|
39623e8ecb807f51c0114fef18c1311ae4d183a2
|
This is the data used in the paper [Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias](https://github.com/yueyu1030/AttrPrompt).
Check the paper: https://arxiv.org/abs/2306.15895 for details.
- `label.txt`: the label name for each class
- `train.jsonl`: The original training set.
- `valid.jsonl`: The original validation set.
- `test.jsonl`: The original test set.
- `simprompt.jsonl`: The training data generated by the simple prompt.
- `attrprompt.jsonl`: The training data generated by the attributed prompt.
Please check our original paper for details. Moreover, we provide the generated dataset using LLM as follows:
- `regen.jsonl`: The training data generated by [ReGen](https://github.com/yueyu1030/ReGen).
- `regen_llm_augmented.jsonl`: The training data generated by ReGen, with the subtopics generated by the LLM.
- `progen.jsonl`: The training data generated by [ProGen](https://github.com/hkunlp/progen).
Please cite the original paper if you use this dataset for your study. Thanks!
```
@inproceedings{blitzer2007biographies,
title={Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification},
author={Blitzer, John and Dredze, Mark and Pereira, Fernando},
booktitle={Proceedings of the 45th annual meeting of the association of computational linguistics},
pages={440--447},
year={2007}
}
@article{yu2023large,
title={Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias},
author={Yu, Yue and Zhuang, Yuchen and Zhang, Jieyu and Meng, Yu and Ratner, Alexander and Krishna, Ranjay and Shen, Jiaming and Zhang, Chao},
journal={arXiv preprint arXiv:2306.15895},
year={2023}
}
```
|
yyu/amazon-attrprompt
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"product",
"review",
"topic_classification",
"arxiv:2306.15895",
"region:us"
] |
2023-06-14T06:19:51+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "tags": ["product", "review", "topic_classification"]}
|
2023-09-13T19:58:10+00:00
|
0692036ffdeecdc8dc1c69035faa7805a15c38d5
|
# Dataset Card for FELM
## Table of Contents
- [Dataset Card for FELM](#dataset-card-for-FELM)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Dataset Creation](#dataset-creation)
- [Source Data](#source-data)
- [Initial Data Collection and Clean](#initial-data-collection-and-clean)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** https://github.com/hkust-nlp/felm
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
[[Paper]](https://arxiv.org/abs/2310.00741) [[Github Repo]](https://github.com/hkust-nlp/felm)
FELM is a meta-benchmark to evaluate factuality evaluation for large language models.<br>
The benchmark comprises 847 questions that span five distinct domains: world knowledge, science/technology, writing/recommendation, reasoning, and math. We gather prompts corresponding to each domain by various sources including standard datasets like truthfulQA, online platforms like Github repositories, ChatGPT generation or drafted by authors.<br>
We then obtain responses from ChatGPT for these prompts. For each response, we employ fine-grained annotation at the segment level, which includes reference links, identified error types, and the reasons behind these errors as provided by our annotators.
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
The text in the dataset is in English.
## Dataset Structure
### Data Instances
An example looks as follows:
```python
{"index": "0",
"source": "quora",
"prompt": "Which country or city has the maximum number of nuclear power plants?",
"response": "The United States has the highest number of nuclear power plants in the world, with 94 operating reactors. Other countries with a significant number of nuclear power plants include France, China, Russia, and South Korea.",
"segmented_response": ["The United States has the highest number of nuclear power plants in the world, with 94 operating reactors.", "Other countries with a significant number of nuclear power plants include France, China, Russia, and South Korea."],
"labels": [false, true],
"comment": ["As of December 2022, there were 92 operable nuclear power reactors in the United States.", ""],
"type": ["knowledge_error", null],
"ref": ["https://www.eia.gov/tools/faqs/faq.php?id=207&t=3"]}
```
### Data Fields
| Field Name | Field Value | Description |
| ----------- | ----------- | ------------------------------------------- |
| index | Integer | the order number of the data point |
| source | string | the prompt source |
| prompt | string | the prompt for generating response |
| response | string | the response of ChatGPT for prompt |
| segmented_response | list | segments of reponse |
| labels | list | factuality labels for segmented_response |
| comment | list | error reasons for segments with factual error |
| type | list | error types for segments with factual error |
| ref | list | reference links |
## Dataset Creation
### Source Data
#### Initial Data Collection and Clean
We gather prompts corresponding to each domain by various sources including standard datasets like truthfulQA, online platforms like Github repositories, ChatGPT generation or drafted by authors.
The data is cleaned by authors.
### Annotations
#### Annotation process
We have developed an annotation tool and established annotation guidelines. All annotations undergo a double-check process, which involves review by both other annotators and an expert reviewer.
#### Who are the annotators?
The authors of the paper; Yuzhen Huang, Yikai Zhang, Tangjun Su.
## Additional Information
### Licensing Information
This dataset is licensed under the [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License](http://creativecommons.org/licenses/by-nc-sa/4.0/)).
### Citation Information
```bibtex
@inproceedings{
chen2023felm,
title={FELM: Benchmarking Factuality Evaluation of Large Language Models},
author={Chen, Shiqi and Zhao, Yiran and Zhang, Jinghan and Chern, I-Chun and Gao, Siyang and Liu, Pengfei and He, Junxian},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023},
url={http://arxiv.org/abs/2310.00741}
}
```
### Contributions
[Needs More Information]
|
hkust-nlp/felm
|
[
"task_categories:text-generation",
"language:en",
"license:cc-by-nc-sa-4.0",
"arxiv:2310.00741",
"region:us"
] |
2023-06-14T06:24:44+00:00
|
{"language": ["en"], "license": "cc-by-nc-sa-4.0", "task_categories": ["text-generation"], "pretty_name": "FELM"}
|
2023-10-03T16:29:57+00:00
|
723698f154a23aec7155f840351405b0a8e7fd1f
|
This is the data used in the paper [Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias](https://github.com/yueyu1030/AttrPrompt).
Checkout the paper https://arxiv.org/abs/2306.15895 for details.
- `label.txt`: the label name for each class
- `train.jsonl`: The original training set.
- `valid.jsonl`: The original validation set.
- `test.jsonl`: The original test set.
- `simprompt.jsonl`: The training data generated by the simple prompt.
- `attrprompt.jsonl`: The training data generated by the attributed prompt.
Please cite the original paper if you use this dataset for your study. Thanks!
```
@article{geigle:2021:arxiv,
author = {Gregor Geigle and
Nils Reimers and
Andreas R{\"u}ckl{\'e} and
Iryna Gurevych},
title = {TWEAC: Transformer with Extendable QA Agent Classifiers},
journal = {arXiv preprint},
volume = {abs/2104.07081},
year = {2021},
url = {http://arxiv.org/abs/2104.07081},
archivePrefix = {arXiv},
eprint = {2104.07081}
}
@article{yu2023large,
title={Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias},
author={Yu, Yue and Zhuang, Yuchen and Zhang, Jieyu and Meng, Yu and Ratner, Alexander and Krishna, Ranjay and Shen, Jiaming and Zhang, Chao},
journal={arXiv preprint arXiv:2306.15895},
year={2023}
}
```
|
yyu/reddit-attrprompt
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"social_media",
"arxiv:2306.15895",
"arxiv:2104.07081",
"region:us"
] |
2023-06-14T06:24:52+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "tags": ["social_media"]}
|
2023-09-13T19:56:10+00:00
|
8d02a896427eca7646baf58de8a97702ca251d88
|
# Dataset Card for "mnist-outlier"
📚 This dataset is an enriched version of the [MNIST Dataset](http://yann.lecun.com/exdb/mnist/).
The workflow is described in the medium article: [Changes of Embeddings during Fine-Tuning of Transformers](https://medium.com/@markus.stoll/changes-of-embeddings-during-fine-tuning-c22aa1615921).
## Explore the Dataset
The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) allows you to explorer this dataset. You can find a Hugging Face Space running Spotlight with this dataset here: <https://huggingface.co/spaces/renumics/mnist-outlier>.
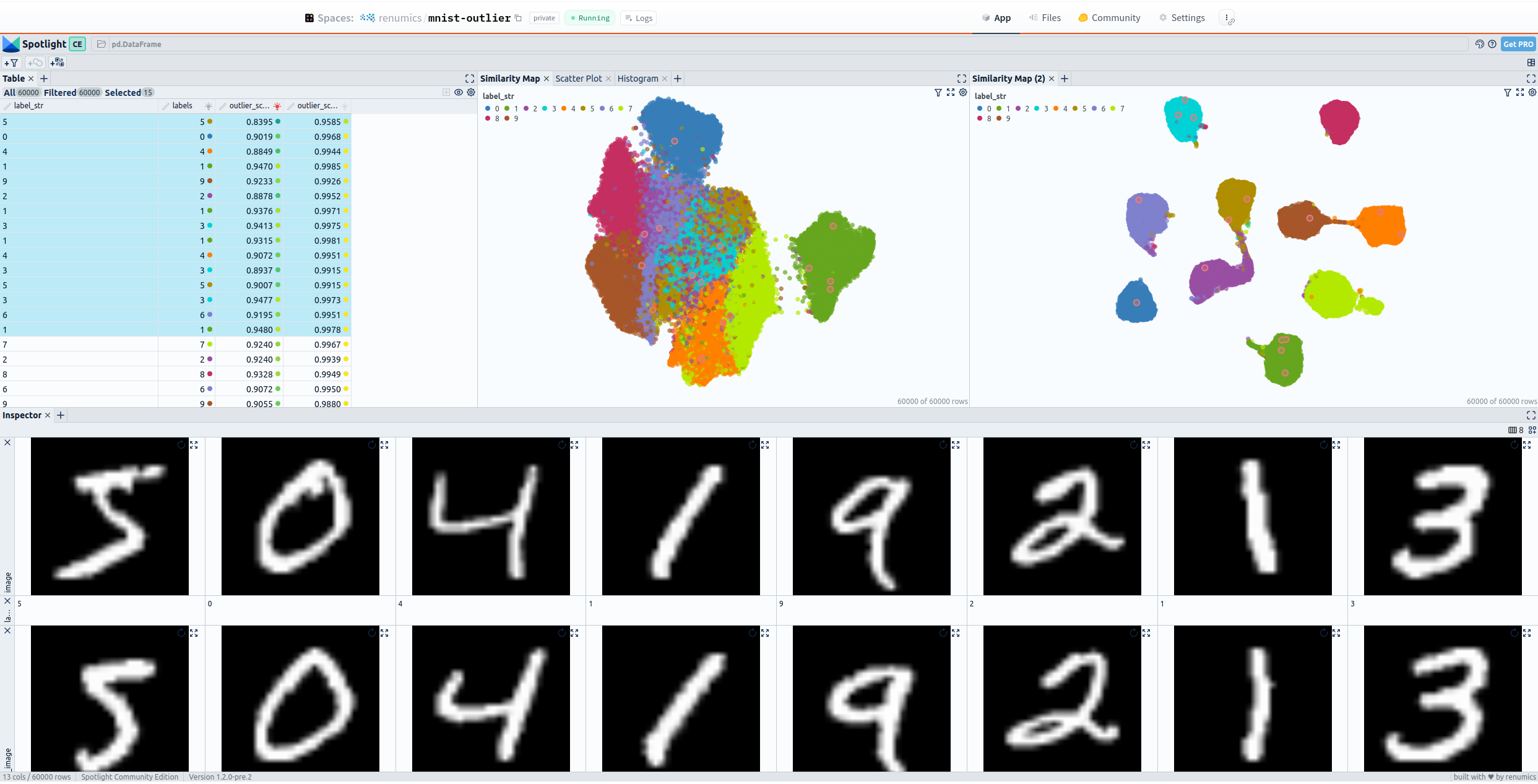
Or you can explorer it locally:
```python
!pip install renumics-spotlight datasets
from renumics import spotlight
import datasets
ds = datasets.load_dataset("renumics/mnist-outlier", split="train")
df = ds.rename_columns({"label":"labels"}).to_pandas()
df["label_str"] = df["labels"].apply(lambda x: ds.features["label"].int2str(x))
dtypes = {
"nn_image": spotlight.Image,
"image": spotlight.Image,
"embedding_ft": spotlight.Embedding,
"embedding_foundation": spotlight.Embedding,
}
spotlight.show(
df,
dtype=dtypes,
layout="https://spotlight.renumics.com/resources/layout_pre_post_ft.json",
)
```
|
renumics/mnist-outlier
|
[
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-nist",
"language:en",
"license:mit",
"region:us"
] |
2023-06-14T06:28:06+00:00
|
{"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|other-nist"], "task_categories": ["image-classification"], "task_ids": ["multi-class-image-classification"], "paperswithcode_id": "mnist", "pretty_name": "MNIST", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "0", "1": "1", "2": "2", "3": "3", "4": "4", "5": "5", "6": "6", "7": "7", "8": "8", "9": "9"}}}}, {"name": "embedding_foundation", "sequence": "float32"}, {"name": "embedding_ft", "sequence": "float32"}, {"name": "outlier_score_ft", "dtype": "float64"}, {"name": "outlier_score_foundation", "dtype": "float64"}, {"name": "nn_image", "struct": [{"name": "bytes", "dtype": "binary"}, {"name": "path", "dtype": "null"}]}], "splits": [{"name": "train", "num_bytes": 404136444.0, "num_examples": 60000}], "download_size": 472581433, "dataset_size": 404136444.0}}
|
2023-06-30T19:08:34+00:00
|
1a08b4bf755c3162b1f7f45bc76e3e82a492b4dd
|
This is the data used in the paper [Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias](https://github.com/yueyu1030/AttrPrompt).
Checkout the paper: https://arxiv.org/abs/2306.15895 for details.
- `label.txt`: the label name for each class
- `train.jsonl`: The original training set.
- `valid.jsonl`: The original validation set.
- `test.jsonl`: The original test set.
- `simprompt.jsonl`: The training data generated by the simple prompt.
- `attrprompt.jsonl`: The training data generated by the attributed prompt.
|
yyu/stackexchange-attrprompt
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"social_media",
"stackexchange",
"arxiv:2306.15895",
"region:us"
] |
2023-06-14T06:28:19+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "tags": ["social_media", "stackexchange"]}
|
2023-09-13T19:56:38+00:00
|
5be5c78b4b62ff1e2047a93340c763b8197ee268
|
This is the data used in the paper [Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias](https://github.com/yueyu1030/AttrPrompt).
- `label.txt`: the label name for each class
- `train.jsonl`: The original training set.
- `valid.jsonl`: The original validation set.
- `test.jsonl`: The original test set.
- `simprompt.jsonl`: The training data generated by the simple prompt.
- `attrprompt.jsonl`: The training data generated by the attributed prompt.
|
yyu/agnews-attrprompt
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-06-14T06:34:38+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"]}
|
2023-08-22T07:27:07+00:00
|
e3be2cc66fb50e6b00aa4dad79cc2f3dd7cf8364
|
This is the data used in the paper [Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias](https://github.com/yueyu1030/AttrPrompt).
- `label.txt`: the label name for each class
- `train.jsonl`: The original training set.
- `valid.jsonl`: The original validation set.
- `test.jsonl`: The original test set.
- `simprompt.jsonl`: The training data generated by the simple prompt.
- `attrprompt.jsonl`: The training data generated by the attributed prompt.
|
yyu/yelp-attrprompt
|
[
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"sentiment",
"restaurant_review",
"region:us"
] |
2023-06-14T06:37:49+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["text-classification"], "tags": ["sentiment", "restaurant_review"], "version": ["v1"]}
|
2023-08-22T07:26:22+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.