
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
c487313ad85c48d196cd3aa4373ebddb42447e23 | OddBunny/fox_femboy | [
"license:cc-by-nc-nd-4.0",
"region:us"
] | 2022-09-15T07:10:35+00:00 | {"license": "cc-by-nc-nd-4.0"} | 2022-09-18T16:43:18+00:00 |
|
4b1a960c1331c8bf2a9114b9bb8d895a0a317b64 |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Genes_Proteins_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
| Timofey/Genes_Proteins_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T08:38:09+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:01:38+00:00 |
12a67fa2b064a06d7c22d3e32b223f484d2f3a57 |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Diseases_Side-Effects_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
--- | Timofey/Diseases_Side-Effects_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T08:48:34+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:01:08+00:00 |
fc4e15ea42bdae5e66a3df41a9f047acda875ebf |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Pathways_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model. | Timofey/Pathways_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T08:55:55+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:02:39+00:00 |
a8d0fb879ef9b12fd3f2ceb910a25af0bfbea10f |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Cell_Components_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
| Timofey/Cell_Components_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T10:26:27+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:02:12+00:00 |
86daa918401d71f6df102d24db7ed4bc60d39caa |
A PubMed-based dataset, used for the fine-tuning of the [BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://arxiv.org/abs/2007.15779) model for the context-based classification of the names of molecular pathways.
<br><br>
HuggingFace [card](https://huggingface.co/Timofey/PubMedBERT_Drugs_Metabolites_Context_Classifier) of the fine-tuned model.<br>
GitHub [link](https://github.com/ANDDigest/ANDDigest_classification_models) with a notebooks, for the fine-tuning and application of the model.
| Timofey/Drugs_Metabolites_Fine-Tuning_Dataset | [
"ANDDigest",
"ANDSystem",
"PubMed",
"arxiv:2007.15779",
"region:us"
] | 2022-09-15T10:35:21+00:00 | {"tags": ["ANDDigest", "ANDSystem", "PubMed"], "viewer": false, "extra_gated_fields": {"I agree to share my contact Information": "checkbox"}} | 2022-11-11T12:00:35+00:00 |
5e4f6b0f9b29eeb9034c01d76ccaf6e71f3db775 | taspecustu/Nanachi | [
"license:cc-by-4.0",
"region:us"
] | 2022-09-15T11:25:52+00:00 | {"license": "cc-by-4.0"} | 2022-09-15T11:32:36+00:00 |
|
dd7d748ed3c8e00fd078e625a01c2d9addff358b |
# Data card for Internet Archive historic book pages unlabelled.
- `10,844,387` unlabelled pages from historical books from the internet archive.
- Intended to be used for:
- pre-training computer vision models in an unsupervised manner
- using weak supervision to generate labels | ImageIN/IA_unlabelled | [
"region:us"
] | 2022-09-15T12:52:19+00:00 | {"annotations_creators": [], "language_creators": [], "language": [], "license": [], "multilinguality": [], "size_categories": [], "source_datasets": [], "task_categories": [], "task_ids": [], "pretty_name": "Internet Archive historic book pages unlabelled.", "tags": []} | 2022-10-21T13:38:12+00:00 |
bc2dd80f3fe48061b9648e867ef6f41a71ed5660 | Kipol/vs_art | [
"license:cc",
"region:us"
] | 2022-09-15T14:17:14+00:00 | {"license": "cc"} | 2022-09-15T14:18:08+00:00 |
|
e0aa6f54740139a2bde073beac5f93403ed2e990 | annotations_creators:
- no-annotation
languages:
-English
All data pulled from Gene Expression Omnibus website. tab separated file with GSE number followed by title and abstract text. | spiccolo/gene_expression_omnibus_nlp | [
"region:us"
] | 2022-09-15T14:53:44+00:00 | {} | 2022-10-13T15:34:55+00:00 |
7b976142cd87d9b99c4e9841a3c579e99eee09ed | # AutoTrain Dataset for project: ratnakar_1000_sample_curated
## Dataset Description
This dataset has been automatically processed by AutoTrain for project ratnakar_1000_sample_curated.
### Languages
The BCP-47 code for the dataset's language is en.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"tokens": [
"INTRADAY",
"NAHARINDUS",
" ABOVE ",
"128",
" - 129 SL ",
"126",
" TARGET ",
"140",
" "
],
"tags": [
8,
10,
0,
3,
0,
9,
0,
5,
0
]
},
{
"tokens": [
"INTRADAY",
"ASTRON",
" ABV ",
"39",
" SL ",
"37.50",
" TARGET ",
"45",
" "
],
"tags": [
8,
10,
0,
3,
0,
9,
0,
5,
0
]
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"tokens": "Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)",
"tags": "Sequence(feature=ClassLabel(num_classes=12, names=['NANA', 'btst', 'delivery', 'enter', 'entry_momentum', 'exit', 'exit2', 'exit3', 'intraday', 'sl', 'symbol', 'touched'], id=None), length=-1, id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 726 |
| valid | 259 |
# GitHub Link to this project : [Telegram Trade Msg Backtest ML](https://github.com/hemangjoshi37a/TelegramTradeMsgBacktestML)
# Need custom model for your application? : Place a order on hjLabs.in : [Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning](https://hjlabs.in/product/custom-token-classification-or-named-entity-recognition-ner-model-as-in-natural-language-processing-nlp-machine-learning/)
## What this repository contains? :
1. Label data using LabelStudio NER(Named Entity Recognition or Token Classification) tool.
 convert to 
2. Convert LabelStudio CSV or JSON to HuggingFace-autoTrain dataset conversion script

3. Train NER model on Hugginface-autoTrain.

4. Use Hugginface-autoTrain model to predict labels on new data in LabelStudio using LabelStudio-ML-Backend.



5. Define python function to predict labels using Hugginface-autoTrain model.


6. Only label new data from newly predicted-labels-dataset that has falsified labels.

7. Backtest Truely labelled dataset against real historical data of the stock using zerodha kiteconnect and jugaad_trader.
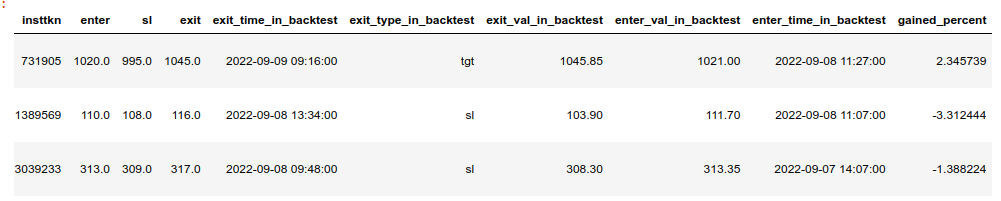
8. Evaluate total gained percentage since inception summation-wise and compounded and plot.

9. Listen to telegram channel for new LIVE messages using telegram API for algotrading.

10. Serve the app as flask web API for web request and respond to it as labelled tokens.
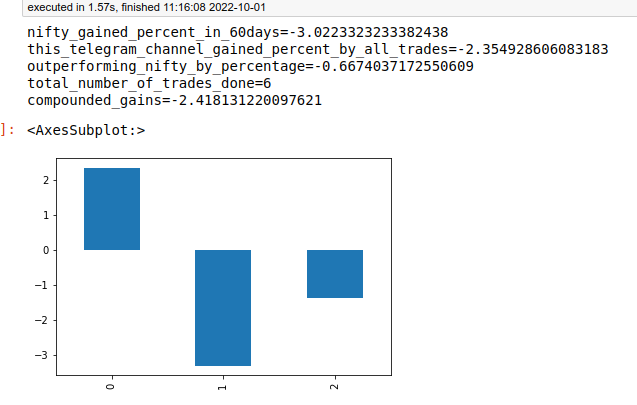
11. Outperforming or underperforming results of the telegram channel tips against exchange index by percentage.
Place a custom order on hjLabs.in : [https://hjLabs.in](https://hjlabs.in/?product=custom-algotrading-software-for-zerodha-and-angel-w-source-code)
----------------------------------------------------------------------
### Contact us
Mobile : [+917016525813](tel:+917016525813)
Whatsapp & Telegram : [+919409077371](tel:+919409077371)
Email : [[email protected]](mailto:[email protected])
Place a custom order on hjLabs.in : [https://hjLabs.in](https://hjlabs.in/)
Please contribute your suggestions and corections to support our efforts.
Thank you.
Buy us a coffee for $5 on PayPal ?
[](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=5JXC8VRCSUZWJ)
----------------------------------------------------------------------
### Checkout Our Other Repositories
- [pyPortMan](https://github.com/hemangjoshi37a/pyPortMan)
- [transformers_stock_prediction](https://github.com/hemangjoshi37a/transformers_stock_prediction)
- [TrendMaster](https://github.com/hemangjoshi37a/TrendMaster)
- [hjAlgos_notebooks](https://github.com/hemangjoshi37a/hjAlgos_notebooks)
- [AutoCut](https://github.com/hemangjoshi37a/AutoCut)
- [My_Projects](https://github.com/hemangjoshi37a/My_Projects)
- [Cool Arduino and ESP8266 or NodeMCU Projects](https://github.com/hemangjoshi37a/my_Arduino)
- [Telegram Trade Msg Backtest ML](https://github.com/hemangjoshi37a/TelegramTradeMsgBacktestML)
### Checkout Our Other Products
- [WiFi IoT LED Matrix Display](https://hjlabs.in/product/wifi-iot-led-display)
- [SWiBoard WiFi Switch Board IoT Device](https://hjlabs.in/product/swiboard-wifi-switch-board-iot-device)
- [Electric Bicycle](https://hjlabs.in/product/electric-bicycle)
- [Product 3D Design Service with Solidworks](https://hjlabs.in/product/product-3d-design-with-solidworks/)
- [AutoCut : Automatic Wire Cutter Machine](https://hjlabs.in/product/automatic-wire-cutter-machine/)
- [Custom AlgoTrading Software Coding Services](https://hjlabs.in/product/custom-algotrading-software-for-zerodha-and-angel-w-source-code//)
- [SWiBoard :Tasmota MQTT Control App](https://play.google.com/store/apps/details?id=in.hjlabs.swiboard)
- [Custom Token Classification or Named Entity Recognition (NER) model as in Natural Language Processing (NLP) Machine Learning](https://hjlabs.in/product/custom-token-classification-or-named-entity-recognition-ner-model-as-in-natural-language-processing-nlp-machine-learning/)
## Some Cool Arduino and ESP8266 (or NodeMCU) IoT projects:
- [IoT_LED_over_ESP8266_NodeMCU : Turn LED on and off using web server hosted on a nodemcu or esp8266](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_LED_over_ESP8266_NodeMCU)
- [ESP8266_NodeMCU_BasicOTA : Simple OTA (Over The Air) upload code from Arduino IDE using WiFi to NodeMCU or ESP8266](https://github.com/hemangjoshi37a/my_Arduino/tree/master/ESP8266_NodeMCU_BasicOTA)
- [IoT_CSV_SD : Read analog value of Voltage and Current and write it to SD Card in CSV format for Arduino, ESP8266, NodeMCU etc](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_CSV_SD)
- [Honeywell_I2C_Datalogger : Log data in A SD Card from a Honeywell I2C HIH8000 or HIH6000 series sensor having external I2C RTC clock](https://github.com/hemangjoshi37a/my_Arduino/tree/master/Honeywell_I2C_Datalogger)
- [IoT_Load_Cell_using_ESP8266_NodeMC : Read ADC value from High Precision 12bit ADS1015 ADC Sensor and Display on SSD1306 SPI Display as progress bar for Arduino or ESP8266 or NodeMCU](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_Load_Cell_using_ESP8266_NodeMC)
- [IoT_SSD1306_ESP8266_NodeMCU : Read from High Precision 12bit ADC seonsor ADS1015 and display to SSD1306 SPI as progress bar in ESP8266 or NodeMCU or Arduino](https://github.com/hemangjoshi37a/my_Arduino/tree/master/IoT_SSD1306_ESP8266_NodeMCU)
## Checkout Our Awesome 3D GrabCAD Models:
- [AutoCut : Automatic Wire Cutter Machine](https://grabcad.com/library/automatic-wire-cutter-machine-1)
- [ESP Matrix Display 5mm Acrylic Box](https://grabcad.com/library/esp-matrix-display-5mm-acrylic-box-1)
- [Arcylic Bending Machine w/ Hot Air Gun](https://grabcad.com/library/arcylic-bending-machine-w-hot-air-gun-1)
- [Automatic Wire Cutter/Stripper](https://grabcad.com/library/automatic-wire-cutter-stripper-1)
## Our HuggingFace Models :
- [hemangjoshi37a/autotrain-ratnakar_1000_sample_curated-1474454086 : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.](https://huggingface.co/hemangjoshi37a/autotrain-ratnakar_1000_sample_curated-1474454086)
## Our HuggingFace Datasets :
- [hemangjoshi37a/autotrain-data-ratnakar_1000_sample_curated : Stock tip message NER(Named Entity Recognition or Token Classification) using HUggingFace-AutoTrain and LabelStudio and Ratnakar Securities Pvt. Ltd.](https://huggingface.co/datasets/hemangjoshi37a/autotrain-data-ratnakar_1000_sample_curated)
## We sell Gigs on Fiverr :
- [code android and ios app for you using flutter firebase software stack](https://business.fiverr.com/share/3v14pr)
- [code custom algotrading software for zerodha or angel broking](https://business.fiverr.com/share/kzkvEy)
## Awesome Fiverr. Gigs:
- [develop machine learning ner model as in nlp using python](https://www.fiverr.com/share/9YNabx)
- [train custom chatgpt question answering model](https://www.fiverr.com/share/rwx6r7)
- [build algotrading, backtesting and stock monitoring tools using python](https://www.fiverr.com/share/A7Y14q)
- [tutor you in your science problems](https://www.fiverr.com/share/zPzmlz)
- [make apps for you crossplatform ](https://www.fiverr.com/share/BGw12l)
| hemangjoshi37a/autotrain-data-ratnakar_1000_sample_curated | [
"language:en",
"region:us"
] | 2022-09-15T16:35:58+00:00 | {"language": ["en"]} | 2023-02-16T12:45:39+00:00 |
f5295abf41f24f8fc5b9790311a2484400dcdf00 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-staging-eval-autoevaluate__zero-shot-classification-sample-autoevalu-acab52-16766274 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T17:06:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["autoevaluate/zero-shot-classification-sample"], "eval_info": {"task": "text_zero_shot_classification", "model": "autoevaluate/zero-shot-classification", "metrics": [], "dataset_name": "autoevaluate/zero-shot-classification-sample", "dataset_config": "autoevaluate--zero-shot-classification-sample", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-15T18:13:14+00:00 |
be8e467ab348721baeae3c5e8761e120f1b9e341 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: Tristan/zero_shot_classification_test
* Config: Tristan--zero_shot_classification_test
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Tristan](https://huggingface.co/Tristan) for evaluating this model. | autoevaluate/autoeval-staging-eval-Tristan__zero_shot_classification_test-Tristan__zero_sh-997db8-16786276 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-15T18:25:59+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["Tristan/zero_shot_classification_test"], "eval_info": {"task": "text_zero_shot_classification", "model": "autoevaluate/zero-shot-classification", "metrics": [], "dataset_name": "Tristan/zero_shot_classification_test", "dataset_config": "Tristan--zero_shot_classification_test", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-15T18:26:29+00:00 |
5993d6f8de645d09e4e076540e6d25f0ee2b747a | polinaeterna/earn | [
"license:cc-by-sa-4.0",
"region:us"
] | 2022-09-15T19:43:48+00:00 | {"license": "cc-by-sa-4.0"} | 2022-09-15T19:48:46+00:00 |
|
64df8d986e65b342699e9dbed622775ae1ce4ba1 | darcksky/Ringsofsaturnlugalkien | [
"license:artistic-2.0",
"region:us"
] | 2022-09-15T21:47:45+00:00 | {"license": "artistic-2.0"} | 2022-09-16T02:01:05+00:00 |
|
e36da016ad8b2fec475e4af1af4ce5e26766b1cd | g0d/BroadcastingCommission_Patois_Dataset | [
"license:other",
"region:us"
] | 2022-09-15T22:19:56+00:00 | {"license": "other"} | 2022-09-15T23:16:22+00:00 |
|
c2a2bfe23d23992408295e0dcaa40e1d06fbacc9 |
# openwebtext_20p
## Dataset Description
- **Origin:** [openwebtext](https://huggingface.co/datasets/openwebtext)
- **Download Size** 4.60 GiB
- **Generated Size** 7.48 GiB
- **Total Size** 12.08 GiB
first 20% of [openwebtext](https://huggingface.co/datasets/openwebtext) | Bingsu/openwebtext_20p | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"source_datasets:extended|openwebtext",
"language:en",
"license:cc0-1.0",
"region:us"
] | 2022-09-16T01:15:16+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["found"], "language": ["en"], "license": ["cc0-1.0"], "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["extended|openwebtext"], "task_categories": ["text-generation", "fill-mask"], "task_ids": ["language-modeling", "masked-language-modeling"], "paperswithcode_id": "openwebtext", "pretty_name": "openwebtext_20p"} | 2022-09-16T01:36:38+00:00 |
a99cdd9ebcda07905cf2d6c5cdf58b70c43cce8e |
# Dataset Card for Kelly
Keywords for Language Learning for Young and adults alike
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://spraakbanken.gu.se/en/resources/kelly
- **Paper:** https://link.springer.com/article/10.1007/s10579-013-9251-2
### Dataset Summary
The Swedish Kelly list is a freely available frequency-based vocabulary list
that comprises general-purpose language of modern Swedish. The list was
generated from a large web-acquired corpus (SweWaC) of 114 million words
dating from the 2010s. It is adapted to the needs of language learners and
contains 8,425 most frequent lemmas that cover 80% of SweWaC.
### Languages
Swedish (sv-SE)
## Dataset Structure
### Data Instances
Here is a sample of the data:
```python
{
'id': 190,
'raw_frequency': 117835.0,
'relative_frequency': 1033.61,
'cefr_level': 'A1',
'source': 'SweWaC',
'marker': 'en',
'lemma': 'dag',
'pos': 'noun-en',
'examples': 'e.g. god dag'
}
```
This can be understood as:
> The common noun "dag" ("day") has a rank of 190 in the list. It was used 117,835
times in SweWaC, meaning it occured 1033.61 times per million words. This word
is among the most important vocabulary words for Swedish language learners and
should be learned at the A1 CEFR level. An example usage of this word is the
phrase "god dag" ("good day").
### Data Fields
- `id`: The row number for the data entry, starting at 1. Generally corresponds
to the rank of the word.
- `raw_frequency`: The raw frequency of the word.
- `relative_frequency`: The relative frequency of the word measured in
number of occurences per million words.
- `cefr_level`: The CEFR level (A1, A2, B1, B2, C1, C2) of the word.
- `source`: Whether the word came from SweWaC, translation lists (T2), or
was manually added (manual).
- `marker`: The grammatical marker of the word, if any, such as an article or
infinitive marker.
- `lemma`: The lemma of the word, sometimes provided with its spelling or
stylistic variants.
- `pos`: The word's part-of-speech.
- `examples`: Usage examples and comments. Only available for some of the words.
Manual entries were prepended to the list, giving them a higher rank than they
might otherwise have had. For example, the manual entry "Göteborg ("Gothenberg")
has a rank of 20, while the first non-manual entry "och" ("and") has a rank of
87. However, a conjunction and common stopword is far more likely to occur than
the name of a city.
### Data Splits
There is a single split, `train`.
## Dataset Creation
Please refer to the article [Corpus-based approaches for the creation of a frequency
based vocabulary list in the EU project KELLY – issues on reliability, validity and
coverage](https://gup.ub.gu.se/publication/148533?lang=en) for information about how
the original dataset was created and considerations for using the data.
**The following changes have been made to the original dataset**:
- Changed header names.
- Normalized the large web-acquired corpus name to "SweWac" in the `source` field.
- Set the relative frequency of manual entries to null rather than 1000000.
## Additional Information
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0)
### Citation Information
Please cite the authors if you use this dataset in your work:
```bibtex
@article{Kilgarriff2013,
doi = {10.1007/s10579-013-9251-2},
url = {https://doi.org/10.1007/s10579-013-9251-2},
year = {2013},
month = sep,
publisher = {Springer Science and Business Media {LLC}},
volume = {48},
number = {1},
pages = {121--163},
author = {Adam Kilgarriff and Frieda Charalabopoulou and Maria Gavrilidou and Janne Bondi Johannessen and Saussan Khalil and Sofie Johansson Kokkinakis and Robert Lew and Serge Sharoff and Ravikiran Vadlapudi and Elena Volodina},
title = {Corpus-based vocabulary lists for language learners for nine languages},
journal = {Language Resources and Evaluation}
}
```
### Contributions
Thanks to [@spraakbanken](https://github.com/spraakbanken) for creating this dataset
and to [@codesue](https://github.com/codesue) for adding it.
| codesue/kelly | [
"task_categories:text-classification",
"task_ids:text-scoring",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:sv",
"license:cc-by-4.0",
"lexicon",
"swedish",
"CEFR",
"region:us"
] | 2022-09-16T01:18:16+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["expert-generated"], "language": ["sv"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": [], "task_categories": ["text-classification"], "task_ids": ["text-scoring"], "pretty_name": "kelly", "tags": ["lexicon", "swedish", "CEFR"]} | 2022-12-18T22:06:55+00:00 |
dc137a6a976f6b5bb8768e9bb51ec58df930ccd1 |
# Dataset Card for "privy-english"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy](https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy)
### Dataset Summary
A synthetic PII dataset generated using [Privy](https://github.com/pixie-io/pixie/tree/main/src/datagen/pii/privy), a tool which parses OpenAPI specifications and generates synthetic request payloads, searching for keywords in API schema definitions to select appropriate data providers. Generated API payloads are converted to various protocol trace formats like JSON and SQL to approximate the data developers might encounter while debugging applications.
This labelled PII dataset consists of protocol traces (JSON, SQL (PostgreSQL, MySQL), HTML, and XML) generated from OpenAPI specifications and includes 60+ PII types.
### Supported Tasks and Leaderboards
Named Entity Recognition (NER) and PII classification.
### Label Scheme
<details>
<summary>View label scheme (26 labels for 60 PII data providers)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `PERSON`, `LOCATION`, `NRP`, `DATE_TIME`, `CREDIT_CARD`, `URL`, `IBAN_CODE`, `US_BANK_NUMBER`, `PHONE_NUMBER`, `US_SSN`, `US_PASSPORT`, `US_DRIVER_LICENSE`, `IP_ADDRESS`, `US_ITIN`, `EMAIL_ADDRESS`, `ORGANIZATION`, `TITLE`, `COORDINATE`, `IMEI`, `PASSWORD`, `LICENSE_PLATE`, `CURRENCY`, `ROUTING_NUMBER`, `SWIFT_CODE`, `MAC_ADDRESS`, `AGE` |
</details>
### Languages
English
## Dataset Structure
### Data Instances
A sample:
```
{
"full_text": "{\"full_name_female\": \"Bethany Williams\", \"NewServerCertificateName\": \"\", \"NewPath\": \"\", \"ServerCertificateName\": \"dCwMNqR\", \"Action\": \"\", \"Version\": \"u zNS zNS\"}",
"masked": "{\"full_name_female\": \"{{name_female}}\", \"NewServerCertificateName\": \"{{string}}\", \"NewPath\": \"{{string}}\", \"ServerCertificateName\": \"{{string}}\", \"Action\": \"{{string}}\", \"Version\": \"{{string}}\"}",
"spans": [
{
"entity_type": "PERSON",
"entity_value": "Bethany Williams",
"start_position": 22,
"end_position": 38
}
],
"template_id": 51889,
"metadata": null
}
```
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@online{WinNT,
author = {Benjamin Kilimnik},
title = {{Privy} Synthetic PII Protocol Trace Dataset},
year = 2022,
url = {https://huggingface.co/datasets/beki/privy},
}
```
### Contributions
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | beki/privy | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"multilinguality:monolingual",
"size_categories:100K<n<200K",
"size_categories:300K<n<400K",
"language:en",
"license:mit",
"pii-detection",
"region:us"
] | 2022-09-16T03:41:28+00:00 | {"language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<200K", "300K<n<400K"], "task_categories": ["token-classification"], "task_ids": ["named-entity-recognition"], "pretty_name": "Privy English", "tags": ["pii-detection"], "train-eval-index": [{"config": "privy-small", "task": "token-classification", "task_id": "entity_extraction", "splits": {"train_split": "train", "eval_split": "test"}, "metrics": [{"type": "seqeval", "name": "seqeval"}]}]} | 2023-04-25T20:45:06+00:00 |
ffe47778949ab10a9d142c9156da20cceae5488e |
# Dataset Card for Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/77?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The data were recorded by 700 Mandarin speakers, 65% of whom were women. There is no pre-made text, and speakers makes phone calls in a natural way while recording the contents of the calls. This data mainly labels the near-end speech, and the speech content is naturally colloquial.
For more details, please refer to the link: https://www.nexdata.ai/datasets/77?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Mandarin
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commercial License
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Mandarin_Spontaneous_Speech_Data_by_Mobile_Phone | [
"task_categories:automatic-speech-recognition",
"language:zh",
"region:us"
] | 2022-09-16T09:10:40+00:00 | {"language": ["zh"], "task_categories": ["automatic-speech-recognition"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-22T09:44:03+00:00 |
2751c683885849b771797fec13e146fe59811180 |
# Dataset Card for Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1103?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
About 700 Korean speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1103?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Korean
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commercial License
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Korean_Conversational_Speech_Data_by_Mobile_Phone | [
"task_categories:conversational",
"language:ko",
"region:us"
] | 2022-09-16T09:13:43+00:00 | {"language": ["ko"], "task_categories": ["conversational"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-22T09:43:54+00:00 |
466e1bbc26e58600d32cfdab7779aea4be5f6c78 |
# Dataset Card for Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/1166?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
About 1000 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1166?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Japanese
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commercial License
### Citation Information
[More Information Needed]
### Contributions | Nexdata/Japanese_Conversational_Speech_by_Mobile_Phone | [
"task_categories:conversational",
"language:ja",
"region:us"
] | 2022-09-16T09:14:35+00:00 | {"language": ["ja"], "task_categories": ["conversational"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-22T09:44:24+00:00 |
9d53d40614e2466e905a48c39d3593ad4ed52b81 |
# Dataset Card for Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone
## Description
About 700 speakers participated in the recording, and conducted face-to-face communication in a natural way. They had free discussion on a number of given topics, with a wide range of fields; the voice was natural and fluent, in line with the actual dialogue scene. Text is transferred manually, with high accuracy.
For more details, please refer to the link: https://www.nexdata.ai/datasets/1178?source=Huggingface
## Format
16kHz, 16bit, uncompressed wav, mono channel;
## Recording Environment
quiet indoor environment, without echo;
## Recording content
dozens of topics are specified, and the speakers make dialogue under those topics while the recording is performed;
## Demographics
About 700 people.
## Annotation
annotating for the transcription text, speaker identification and gender
## Device
Android mobile phone, iPhone;
## Language
Italian
## Application scenarios
speech recognition; voiceprint recognition;
## Accuracy rate
the word accuracy rate is not less than 98%
# Licensing Information
Commercial License
| Nexdata/Italian_Conversational_Speech_Data_by_Mobile_Phone | [
"task_categories:conversational",
"language:it",
"region:us"
] | 2022-09-16T09:15:32+00:00 | {"language": ["it"], "task_categories": ["conversational"], "YAML tags": [{"copy-paste the tags obtained with the tagging app": "https://github.com/huggingface/datasets-tagging"}]} | 2023-11-10T07:48:10+00:00 |
b96e3be1f0db925f88558b78d9092a1269c814e0 |
NLI를 위한 한국어 속담 데이터셋입니다.
'question'은 속담의 의미와 보기(5지선다)가 표시되어 있으며,
'label'에는 정답의 번호(0-4)가 표시되어 있습니다.
licence: cc-by-sa-2.0-kr (원본 출처:국립국어원 표준국어대사전)
|Model| psyche/korean_idioms |
|:------:|:---:|
|klue/bert-base|0.7646| | psyche/korean_idioms | [
"task_categories:text-classification",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:ko",
"region:us"
] | 2022-09-16T10:31:37+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["ko"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "pretty_name": "psyche/korean_idioms", "tags": []} | 2022-10-23T03:02:44+00:00 |
28fb0d7e0d32c1ac7b6dd09f8d9a4e283212e1c0 |
|Model| psyche/bool_sentence (10k) |
|:------:|:---:|
|klue/bert-base|0.9335|
licence: cc-by-sa-2.0-kr (원본 출처:국립국어원 표준국어대사전) | psyche/bool_sentence | [
"task_categories:text-classification",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:ko",
"region:us"
] | 2022-09-16T11:30:21+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["found"], "language": ["ko"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": [], "pretty_name": "psyche/bool_sentence", "tags": []} | 2022-10-23T01:52:40+00:00 |
7dfaa5ab1015d802d08b5ca624675a53d4502bda |
```sh
git clone https://github.com/natir/br.git
git clone https://github.com/natir/pcon
git clone https://github.com/natir/yacrd
git clone https://github.com/natir/rasusa
git clone https://github.com/natir/fpa
git clone https://github.com/natir/kmrf
rm -f RustBioGPT-train.csv && for i in `find . -name "*.rs"`;do paste -d "," <(echo $i|perl -pe "s/\.\/(\w+)\/.+/\"\1\"/g") <(echo $i|perl -pe "s/(.+)/\"\1\"/g") <(perl -pe "s/\n/\\\n/g" $i|perl -pe s"/\"/\'/g" |perl -pe "s/(.+)/\"\1\"/g") <(echo "mit"|perl -pe "s/(.+)/\"\1\"/g") >> RustBioGPT-train.csv; done
sed -i '1i "repo_name","path","content","license"' RustBioGPT-train.csv
``` | jelber2/RustBioGPT | [
"license:mit",
"region:us"
] | 2022-09-16T11:59:39+00:00 | {"license": "mit"} | 2022-09-27T11:02:09+00:00 |
6a10b37e1971cde1ac72ff68a431519efcbe249a | wjm123/wjm123 | [
"license:afl-3.0",
"region:us"
] | 2022-09-16T12:15:45+00:00 | {"license": "afl-3.0"} | 2022-09-16T12:18:02+00:00 |
|
5156a742da7df2bd1796e2e34840ca6231509e82 | cakiki/token-graph | [
"license:apache-2.0",
"region:us"
] | 2022-09-16T12:43:04+00:00 | {"license": "apache-2.0"} | 2022-09-17T08:31:00+00:00 |
|
6ca3d7b3c4711e6f9df5d73ee70958c2750f925c |
# WNLI-es
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Website:** https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html
- **Point of Contact:** [Carlos Rodríguez-Penagos]([email protected]) and [Carme Armentano-Oller]([email protected])
### Dataset Summary
"A Winograd schema is a pair of sentences that differ in only one or two words and that contain an ambiguity that is resolved in opposite ways in the two sentences and requires the use of world knowledge and reasoning for its resolution. The schema takes its name from Terry Winograd." Source: [The Winograd Schema Challenge](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html).
The [Winograd NLI dataset](https://dl.fbaipublicfiles.com/glue/data/WNLI.zip) presents 855 sentence pairs, in which the first sentence contains an ambiguity and the second one a possible interpretation of it. The label indicates if the interpretation is correct (1) or not (0).
This dataset is a professional translation into Spanish of [Winograd NLI dataset](https://dl.fbaipublicfiles.com/glue/data/WNLI.zip) as published in [GLUE Benchmark](https://gluebenchmark.com/tasks).
Both the original dataset and this translation are licenced under a [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/).
### Supported Tasks and Leaderboards
Textual entailment, Text classification, Language Model.
### Languages
* Spanish (es)
## Dataset Structure
### Data Instances
Three tsv files.
### Data Fields
- index
- sentence 1: first sentence of the pair
- sentence 2: second sentence of the pair
- label: relation between the two sentences:
* 0: the second sentence does not entail a correct interpretation of the first one (neutral)
* 1: the second sentence entails a correct interpretation of the first one (entailment)
### Data Splits
- wnli-train-es.csv: 636 sentence pairs
- wnli-dev-es.csv: 72 sentence pairs
- wnli-test-shuffled-es.csv: 147 sentence pairs
## Dataset Creation
### Curation Rationale
We translated this dataset to contribute to the development of language models in Spanish.
### Source Data
- [GLUE Benchmark site](https://gluebenchmark.com)
#### Initial Data Collection and Normalization
This is a professional translation of [WNLI dataset](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html) into Spanish, commissioned by [BSC TeMU](https://temu.bsc.es/) within the the framework of the [Plan-TL](https://plantl.mineco.gob.es/Paginas/index.aspx).
For more information on how the Winograd NLI dataset was created, visit the webpage [The Winograd Schema Challenge](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html).
#### Who are the source language producers?
For more information on how the Winograd NLI dataset was created, visit the webpage [The Winograd Schema Challenge](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html).
### Annotations
#### Annotation process
We comissioned a professional translation of [WNLI dataset](https://cs.nyu.edu/~davise/papers/WinogradSchemas/WS.html) into Spanish.
#### Who are the annotators?
Translation was commisioned to a professional translation agency.
### Personal and Sensitive Information
No personal or sensitive information included.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset contributes to the development of language models in Spanish.
### Discussion of Biases
[N/A]
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center ([email protected]).
For further information, send an email to ([email protected]).
This work was funded by the [Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA)](https://avancedigital.mineco.gob.es/en-us/Paginas/index.aspx) within the framework of the [Plan-TL](https://plantl.mineco.gob.es/Paginas/index.aspx).
### Licensing information
This work is licensed under [CC Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/) License.
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Contributions
[N/A]
| PlanTL-GOB-ES/wnli-es | [
"task_categories:text-classification",
"task_ids:natural-language-inference",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:unknown",
"source_datasets:extended|glue",
"language:es",
"license:cc-by-4.0",
"region:us"
] | 2022-09-16T12:51:45+00:00 | {"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["es"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["unknown"], "source_datasets": ["extended|glue"], "task_categories": ["text-classification"], "task_ids": ["natural-language-inference"], "pretty_name": "wnli-es"} | 2022-11-18T12:03:25+00:00 |
4a15933dcd0acf4d468b13e12f601a4e456deeb6 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-squad_v2-squad_v2-e15d25-1483654271 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T15:14:24+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "Jiqing/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-16T15:19:11+00:00 |
dd8b911a18f8578bdc3a4009ce27af553ff6dd62 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: MYX4567/distilbert-base-uncased-finetuned-squad
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-squad_v2-squad_v2-e15d25-1483654272 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T15:14:27+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "MYX4567/distilbert-base-uncased-finetuned-squad", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-16T15:16:56+00:00 |
ad46374198d1c2b567649b3aef123d746ba4278c | Violence/Cloud | [
"license:afl-3.0",
"region:us"
] | 2022-09-16T16:45:20+00:00 | {"license": "afl-3.0"} | 2022-09-16T16:45:20+00:00 |
|
ecd209ffe06e918e4c7e7ce8684640434697e830 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: mathemakitten/opt-125m
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mathemakitten](https://huggingface.co/mathemakitten) for evaluating this model. | autoevaluate/autoeval-eval-autoevaluate__zero-shot-classification-sample-autoevalu-912bbb-1484454284 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T16:55:47+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["autoevaluate/zero-shot-classification-sample"], "eval_info": {"task": "text_zero_shot_classification", "model": "mathemakitten/opt-125m", "metrics": [], "dataset_name": "autoevaluate/zero-shot-classification-sample", "dataset_config": "autoevaluate--zero-shot-classification-sample", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-16T16:56:15+00:00 |
63a9e740124aeaed97c6cc48ed107b95833d7121 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: mathemakitten/opt-125m
* Dataset: autoevaluate/zero-shot-classification-sample
* Config: autoevaluate--zero-shot-classification-sample
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@mathemakitten](https://huggingface.co/mathemakitten) for evaluating this model. | autoevaluate/autoeval-eval-autoevaluate__zero-shot-classification-sample-autoevalu-c3526e-1484354283 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T16:55:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["autoevaluate/zero-shot-classification-sample"], "eval_info": {"task": "text_zero_shot_classification", "model": "mathemakitten/opt-125m", "metrics": [], "dataset_name": "autoevaluate/zero-shot-classification-sample", "dataset_config": "autoevaluate--zero-shot-classification-sample", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-16T16:56:15+00:00 |
589bf157b543e47fc4bc6e2d681eb765df768a60 | spacemanidol/query-rewriting-dense-retrieval | [
"license:mit",
"region:us"
] | 2022-09-16T17:08:15+00:00 | {"license": "mit"} | 2022-09-16T17:08:15+00:00 |
|
37ea2ff12fdef2021a8068cf76c186aa9c1ca50a | jemale/test | [
"license:mit",
"region:us"
] | 2022-09-16T17:27:16+00:00 | {"license": "mit"} | 2022-09-16T17:27:16+00:00 |
|
4f7cf75267bc4b751a03ed9f668350be69d9ce4a | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: chandrasutrisnotjhong/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554291 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:31+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "chandrasutrisnotjhong/bert-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:22:45+00:00 |
c816be36bf214a2b8ed525580d849ac7df0d2634 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: baptiste/deberta-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554292 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:37+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "baptiste/deberta-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:02+00:00 |
4c2a0ee535002890fffbd6b6a0fe8afc5bc2f6cf | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: mariolinml/roberta_large-ner-conll2003_0818_v0
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554294 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:47+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "mariolinml/roberta_large-ner-conll2003_0818_v0", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:36+00:00 |
5e2e4e90132c48d0b3e0afa6337a75225510eb8a | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: jjglilleberg/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554295 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:21:53+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "jjglilleberg/bert-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:06+00:00 |
2105a9d5dd2b3d9ca6f7a7d51c60455a31a40e2a | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Token Classification
* Model: Yv/bert-finetuned-ner
* Dataset: conll2003
* Config: conll2003
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-conll2003-conll2003-bc26c9-1485554297 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:05+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["conll2003"], "eval_info": {"task": "entity_extraction", "model": "Yv/bert-finetuned-ner", "metrics": [], "dataset_name": "conll2003", "dataset_config": "conll2003", "dataset_split": "test", "col_mapping": {"tokens": "tokens", "tags": "ner_tags"}}} | 2022-09-16T19:23:19+00:00 |
6d4a3c8d5c40bf818348fcef1f6147e947481fef | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: armandnlp/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-fe1aa0-1485654301 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:29+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "armandnlp/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-16T19:22:59+00:00 |
f009dc448491e5daf234a5e867b3fb012e366dc9 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: andreaschandra/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-fe1aa0-1485654303 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:41+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "andreaschandra/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-16T19:23:06+00:00 |
b42408bed4845eabbde9ec840f2c77be1ce455ae | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: bousejin/distilbert-base-uncased-finetuned-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@lewtun](https://huggingface.co/lewtun) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-fe1aa0-1485654304 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T19:22:48+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "bousejin/distilbert-base-uncased-finetuned-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-16T19:23:15+00:00 |
8f69a50e60bac11a0b2f12e5354f0678281aaf50 | # AutoTrain Dataset for project: consbert
## Dataset Description
This dataset has been automatically processed by AutoTrain for project consbert.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "DECLARATION OF PERFORMANCE fermacell Screws 1. unique identification code of the product type 2. purpose of use 3. manufacturer 5. system(s) for assessment and verification of constancy of performance 6. harmonised standard Notified body(ies) 7. Declared performance Essential feature Reaction to fire Tensile strength Length Corrosion protection (Reis oeueelt Nr. FC-0103 A FC-0103 A Drywall screws type TSN for fastening gypsum fibreboards James Hardie Europe GmbH Bennigsen- Platz 1 D-40474 Disseldorf Tel. +49 800 3864001 E-Mail fermacell jameshardie.de System 4 DIN EN 14566:2008+A1:2009 Stichting Hout Research (2590) Performance Al fulfilled <63mm Phosphated - Class 48 The performance of the above product corresponds to the declared performance(s). The manufacturer mentioned aboveis solely responsible for the preparation of the declaration of performancein accordance with Regulation (EU) No. 305/2011. Signed for the manufacturer and on behalf of the manufacturerof: Dusseldorf, 01.01.2020 2020 James Hardie Europe GmbH. and designate registered and incorporated trademarks of James Hardie Technology Limited Dr. J\u00e9rg Brinkmann (CEO) AESTUVER Seite 1/1 ",
"target": 1
},
{
"text": "DERBIGUM\u201d MAKING BUILDINGS SMART 9 - Performances d\u00e9clar\u00e9es selon EN 13707 : 2004 + A2: 2009 Caract\u00e9ristiques essentielles Performances Unit\u00e9s R\u00e9sistance a un feu ext\u00e9rieur (Note 1) FRoof (t3) - R\u00e9action au feu F - Etanch\u00e9it\u00e9 a l\u2019eau Conforme - Propri\u00e9t\u00e9s en traction : R\u00e9sistance en traction LxT* 900 x 700(+4 20%) N/50 mm Allongement LxT* 45 x 45 (+ 15) % R\u00e9sistance aux racines NPD** - R\u00e9sistance au poinconnementstatique (A) 20 kg R\u00e9sistance au choc (A et B) NPD** mm R\u00e9sistance a la d\u00e9chirure LxT* 200 x 200 (+ 20%) N R\u00e9sistance des jonctions: R\u00e9sistance au pelage NPD** N/50 mm R\u00e9sistance au cisaillement NPD** N/50 mm Durabilit\u00e9 : Sous UV, eau et chaleur Conforme - Pliabilit\u00e9 a froid apr\u00e9s vieillissement a la -10 (+ 5) \u00b0C chaleur Pliabilit\u00e9 a froid -18 \u00b0C Substances dangereuses (Note 2) - * L signifie la direction longitudinale, T signifie la direction transversale **NPD signifie Performance Non D\u00e9termin\u00e9e Note 1: Aucune performance ne peut \u00e9tre donn\u00e9e pourle produit seul, la performance de r\u00e9sistance a un feu ext\u00e9rieur d\u2019une toiture d\u00e9pend du syst\u00e9me complet Note 2: En l\u2019absence de norme d\u2019essai europ\u00e9enne harmonis\u00e9e, aucune performanceli\u00e9e au comportementa la lixiviation ne peut \u00e9tre d\u00e9clar\u00e9e, la d\u00e9claration doit \u00e9tre \u00e9tablie selon les dispositions nationales en vigueur. 10 - Les performances du produit identifi\u00e9 aux points 1 et 2 ci-dessus sont conformes aux performances d\u00e9clar\u00e9es indiqu\u00e9es au point 9. La pr\u00e9sente d\u00e9claration des performances est \u00e9tablie sous la seule responsabilit\u00e9 du fabricant identifi\u00e9 au point 4 Sign\u00e9 pourle fabricant et en son nom par: Mr Steve Geubels, Group Operations Director Perwez ,30/09/2016 Page 2 of 2 ",
"target": 8
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "ClassLabel(num_classes=9, names=['0', '1', '2', '3', '4', '5', '6', '7', '8'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 59 |
| valid | 18 |
| Chemsseddine/autotrain-data-consbert | [
"task_categories:text-classification",
"region:us"
] | 2022-09-16T20:00:22+00:00 | {"task_categories": ["text-classification"]} | 2022-09-16T20:03:18+00:00 |
55c4e0884053ad905c6ceccdff7e02e8a0d9c7b8 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Zero-Shot Text Classification
* Model: autoevaluate/zero-shot-classification
* Dataset: Tristan/zero-shot-classification-large-test
* Config: Tristan--zero-shot-classification-large-test
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@Tristan](https://huggingface.co/Tristan) for evaluating this model. | autoevaluate/autoeval-eval-Tristan__zero-shot-classification-large-test-Tristan__z-7873ce-1486054319 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-16T22:52:59+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["Tristan/zero-shot-classification-large-test"], "eval_info": {"task": "text_zero_shot_classification", "model": "autoevaluate/zero-shot-classification", "metrics": [], "dataset_name": "Tristan/zero-shot-classification-large-test", "dataset_config": "Tristan--zero-shot-classification-large-test", "dataset_split": "test", "col_mapping": {"text": "text", "classes": "classes", "target": "target"}}} | 2022-09-16T23:43:54+00:00 |
35d2e5d9f41feed5ca053572780ad7263b060d96 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelfipps123](https://huggingface.co/samuelfipps123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-7cb0ac-1486354325 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-17T00:56:39+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "test", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-17T01:01:53+00:00 |
834a9ec3ad3d01d96e9371cce33ce5a28a721102 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelallen123](https://huggingface.co/samuelallen123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-2c3c14-1486454326 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-17T00:56:42+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "train", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-17T01:46:32+00:00 |
7f5976b44f8b7f02b192b65fd7163c1a5a969940 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum
* Dataset: samsum
* Config: samsum
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@samuelallen123](https://huggingface.co/samuelallen123) for evaluating this model. | autoevaluate/autoeval-eval-samsum-samsum-1bb2ba-1486554327 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-17T00:56:47+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["samsum"], "eval_info": {"task": "summarization", "model": "SamuelAllen123/t5-efficient-large-nl36_fine_tune_sum", "metrics": [], "dataset_name": "samsum", "dataset_config": "samsum", "dataset_split": "validation", "col_mapping": {"text": "dialogue", "target": "summary"}}} | 2022-09-17T01:02:01+00:00 |
a26e48dc333aa4403237068028ac612fe2e9581f | # AutoTrain Dataset for project: opus-mt-en-zh_hanz
## Dataset Description
This dataset has been automatically processed by AutoTrain for project opus-mt-en-zh_hanz.
### Languages
The BCP-47 code for the dataset's language is en2zh.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"source": "And then I hear something.",
"target": "\u63a5\u7740\u542c\u5230\u4ec0\u4e48\u52a8\u9759\u3002",
"feat_en_length": 26,
"feat_zh_length": 9
},
{
"source": "A ghostly iron whistle blows through the tunnels.",
"target": "\u9b3c\u9b45\u7684\u54e8\u58f0\u5439\u8fc7\u96a7\u9053\u3002",
"feat_en_length": 49,
"feat_zh_length": 10
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"source": "Value(dtype='string', id=None)",
"target": "Value(dtype='string', id=None)",
"feat_en_length": "Value(dtype='int64', id=None)",
"feat_zh_length": "Value(dtype='int64', id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 16350 |
| valid | 4088 |
| darcy01/autotrain-data-opus-mt-en-zh_hanz | [
"task_categories:translation",
"language:en",
"language:zh",
"region:us"
] | 2022-09-17T07:52:21+00:00 | {"language": ["en", "zh"], "task_categories": ["translation"]} | 2022-09-17T10:36:03+00:00 |
5875acfc5d2c5bc89e33fed4ba9251591fdb06d6 | darcy01/hanz_en-zh | [
"license:bsd",
"region:us"
] | 2022-09-17T10:38:43+00:00 | {"license": "bsd"} | 2022-09-17T10:38:43+00:00 |
|
f8d2cc4cbdeb4b666ef8342830bcb6525ba09fbb |
# Dataset Card for **slone/myv_ru_2022**
## Dataset Description
- **Repository:** https://github.com/slone-nlp/myv-nmt
- **Paper:**: https://arxiv.org/abs/2209.09368
- **Point of Contact:** @cointegrated
### Dataset Summary
This is a corpus of parallel Erzya-Russian words, phrases and sentences, collected in the paper [The first neural machine translation system for the Erzya language](https://arxiv.org/abs/2209.09368).
Erzya (`myv`) is a language from the Uralic family. It is spoken primarily in the Republic of Mordovia and some other regions of Russia and other post-Soviet countries. We use the Cyrillic version of its script.
The corpus consists of the following parts:
| name | size | composition |
| -----| ---- | -------|
|train | 74503 | parallel words, phrases and sentences, mined from dictionaries, books and web texts |
| dev | 1500 | parallel sentences mined from books and web texts |
| test | 1500 | parallel sentences mined from books and web texts |
| mono | 333651| Erzya sentences mined from books and web texts, translated to Russian by a neural model |
The dev and test splits contain sentences from the following sources
| name | size | description|
| ---------------|----| -------|
|wiki |600 | Aligned sentences from linked Erzya and Russian Wikipedia articles |
|bible |400 | Paired verses from the Bible (https://finugorbib.com) |
|games |250 | Aligned sentences from the book *"Сказовые формы мордовской литературы", И.И. Шеянова, 2017, НИИ гуманитарых наук при Правительстве Республики Мордовия, Саранск* |
|tales |100 | Aligned sentences from the book *"Мордовские народные игры", В.С. Брыжинский, 2009, Мордовское книжное издательство, Саранск* |
|fiction |100 | Aligned sentences from modern Erzya prose and poetry (https://rus4all.ru/myv) |
|constitution | 50 | Aligned sentences from the Soviet 1938 constitution |
To load the first three parts (train, validation and test), use the code:
```Python
from datasets import load_dataset
data = load_dataset('slone/myv_ru_2022')
```
To load all four parts (included the back-translated data), please specify the data files explicitly:
```Python
from datasets import load_dataset
data_extended = load_dataset(
'slone/myv_ru_2022',
data_files={'train':'train.jsonl', 'validation': 'dev.jsonl', 'test': 'test.jsonl', 'mono': 'back_translated.jsonl'}
)
```
### Supported Tasks and Leaderboards
- `translation`: the dataset may be used to train `ru-myv` translation models. There are no specific leaderboards for it yet, but if you feel like discussing it, welcome to the comments!
### Languages
The main part of the dataset (`train`, `dev` and `test`) consists of "natural" Erzya (Cyrillic) and Russian sentences, translated to the other language by humans. There is also a larger Erzya-only part of the corpus (`mono`), translated to Russian automatically.
## Dataset Structure
### Data Instances
All data instances have three string fields: `myv`, `ru` and `src` (the last one is currently meaningful only for dev and test splits), for example:
```
{'myv': 'Сюкпря Пазонтень, кие кирвазтизе Титэнь седейс тынк кисэ секе жо бажамонть, кона палы минек седейсэяк!',
'ru': 'Благодарение Богу, вложившему в сердце Титово такое усердие к вам.',
'src': 'bible'}
```
### Data Fields
- `myv`: the Erzya text (word, phrase, or sentence)
- `ru`: the corresponding Russian text
- `src`: the source of data (only for dev and test splits)
### Data Splits
- train: parallel sentences, words and phrases, collected from various sources. Most of them are aligned automatically. Noisy.
- dev: 1500 parallel sentences, selected from the 6 most reliable and diverse sources.
- test: same as dev.
- mono: Erzya sentences collected from various sources, with the Russian counterpart generated by a neural machine translation model.
## Dataset Creation
### Curation Rationale
This is, as far as we know, the first publicly available parallel Russian-Erzya corpus, and the first medium-sized translation corpus for Erzya.
We hope that it sets a meaningful baseline for Erzya machine translation.
### Source Data
#### Initial Data Collection and Normalization
The dataset was collected from various sources (see below).
The texts were spit in sentences using the [razdel]() package.
For some sources, sentences were filtered by language using the [slone/fastText-LID-323](https://huggingface.co/slone/fastText-LID-323) model.
For most of the sources, `myv` and `ru` sentences were aligned automatically using the [slone/LaBSE-en-ru-myv-v1](https://huggingface.co/slone/LaBSE-en-ru-myv-v1) sentence encoder
and the code from [the paper repository](https://github.com/slone-nlp/myv-nmt).
#### Who are the source language producers?
The dataset comprises parallel `myv-ru` and monolingual `myv` texts from diverse sources:
- 12K parallel sentences from the Bible (http://finugorbib.com);
- 3K parallel Wikimedia sentences from OPUS;
- 42K parallel words or short phrases collected from various online dictionaries ();
- the Erzya Wikipedia and the corresponding articles from the Russian Wikipedia;
- 18 books, including 3 books with Erzya-Russian bitexts (http://lib.e-mordovia.ru);
- Soviet-time books and periodicals (https://fennougrica.kansalliskirjasto.fi);
- The Erzya part of Wikisource (https://wikisource.org/wiki/Main_Page/?oldid=895127);
- Short texts by modern Erzya authors (https://rus4all.ru/myv/);
- News articles from the Erzya Pravda website (http://erziapr.ru);
- Texts found in LiveJournal (https://www.livejournal.com) by searching with the 100 most frequent Erzya words.
### Annotations
No human annotation was involved in the data collection.
### Personal and Sensitive Information
All data was collected from public sources, so no sensitive information is expected in them.
However, some sentences collected, for example, from news articles or LiveJournal posts, can contain personal data.
## Considerations for Using the Data
### Social Impact of Dataset
Publication of this dataset may attract some attention to the endangered Erzya language.
### Discussion of Biases
Most of the dataset has been collected by automatical means, so it may contain errors and noise.
Some types of these errors are systemic: for example, the words for "Erzya" and "Russian" are often aligned together,
because they appear in the corresponding Wikipedias on similar positions.
### Other Known Limitations
The dataset is noisy: some texts in it may be ungrammatical, in a wrong language, or poorly aligned.
## Additional Information
### Dataset Curators
The data was collected by David Dale (https://huggingface.co/cointegrated).
### Licensing Information
The status of the dataset is not final, but after we check everything, we hope to be able to distribute it under the [CC-BY-SA license](http://creativecommons.org/licenses/by-sa/4.0/).
### Citation Information
[TBD]
| slone/myv_ru_2022 | [
"task_categories:translation",
"annotations_creators:found",
"annotations_creators:machine-generated",
"language_creators:found",
"language_creators:machine-generated",
"multilinguality:translation",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:myv",
"language:ru",
"license:cc-by-sa-4.0",
"erzya",
"mordovian",
"arxiv:2209.09368",
"region:us"
] | 2022-09-17T12:53:23+00:00 | {"annotations_creators": ["found", "machine-generated"], "language_creators": ["found", "machine-generated"], "language": ["myv", "ru"], "license": ["cc-by-sa-4.0"], "multilinguality": ["translation"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["translation"], "task_ids": [], "pretty_name": "Erzya-Russian parallel corpus", "tags": ["erzya", "mordovian"]} | 2022-09-28T18:38:26+00:00 |
dbfe82d9d01c08ca01e402d466e1ac817bdbb182 | 256x256 mel spectrograms of 5 second samples of instrumental Hip Hop. The code to convert from audio to spectrogram and vice versa can be found in https://github.com/teticio/audio-diffusion along with scripts to train and run inference using De-noising Diffusion Probabilistic Models.
```
x_res = 256
y_res = 256
sample_rate = 22050
n_fft = 2048
hop_length = 512
``` | teticio/audio-diffusion-instrumental-hiphop-256 | [
"task_categories:image-to-image",
"size_categories:10K<n<100K",
"audio",
"spectrograms",
"region:us"
] | 2022-09-17T13:06:30+00:00 | {"annotations_creators": [], "language_creators": [], "language": [], "license": [], "multilinguality": [], "size_categories": ["10K<n<100K"], "source_datasets": [], "task_categories": ["image-to-image"], "task_ids": [], "pretty_name": "Mel spectrograms of instrumental Hip Hop music", "tags": ["audio", "spectrograms"]} | 2022-11-09T10:50:58+00:00 |
deb6287d02a3b1465a6ea16f6a99f04bac73b348 | anton-l/earnings22_baseline_5_gram | [
"license:apache-2.0",
"region:us"
] | 2022-09-17T14:31:55+00:00 | {"license": "apache-2.0"} | 2022-10-17T17:35:04+00:00 |
|
78e631ea285b694dd251681beb36808bb6f0c58e | Shushant/CovidNepaliTweets | [
"license:other",
"region:us"
] | 2022-09-17T14:35:35+00:00 | {"license": "other"} | 2022-09-17T14:44:00+00:00 |
|
f0cff768b955f714ee7bb948d66c083937eab6a4 | igorknez/clth_dset | [
"license:afl-3.0",
"region:us"
] | 2022-09-17T17:50:13+00:00 | {"license": "afl-3.0"} | 2022-09-17T17:50:13+00:00 |
|
03d627dd1196682431ae80cb27d20f066925d43c | dadtheimpaler/test | [
"license:cc",
"region:us"
] | 2022-09-17T18:09:18+00:00 | {"license": "cc"} | 2022-09-17T18:10:36+00:00 |
|
9f7a6cacd22203e821ffdb3470f1575eb71eedc5 |
# Korpus-frazennou-brezhonek
Corpus de 4532 phrases bilingues (français-breton) alignées et libres de droits provenant de l'Office Public de la Langue Bretonne.
Plus d'informations [ici](https://www.fr.brezhoneg.bzh/212-donnees-libres-de-droits.htm)
# Usage
```
from datasets import load_dataset
dataset = load_dataset("bzh-dataset/Korpus-frazennou-brezhonek", sep=";")
```
| bzh-dataset/Korpus-frazennou-brezhonek | [
"language:fr",
"language:br",
"license:unknown",
"region:us"
] | 2022-09-17T19:58:22+00:00 | {"language": ["fr", "br"], "license": "unknown"} | 2022-09-17T20:26:30+00:00 |
155f133311b4694856b26627cbc61850cee07484 | klimbat85/AnthonyEdwards | [
"license:afl-3.0",
"region:us"
] | 2022-09-17T20:12:44+00:00 | {"license": "afl-3.0"} | 2022-09-17T20:36:18+00:00 |
|
4993f4d62b5c8ccb21a1458b3d1fddbe18c09466 | lapix/UFSC_OCPap | [
"license:cc-by-nc-3.0",
"region:us"
] | 2022-09-17T21:08:59+00:00 | {"license": "cc-by-nc-3.0"} | 2022-09-17T21:08:59+00:00 |
|
edd306b91bcfa55ad02376347c7cfb32e57893e8 | elhawashib/Dataset_Rand | [
"license:other",
"region:us"
] | 2022-09-17T23:02:30+00:00 | {"license": "other"} | 2022-09-18T00:15:42+00:00 |
|
493d1d86e7977892b60f8eeb901a10fe84fd1fc7 |
## Dataset Description
FBAnimeHQ is a dataset with high-quality full-body anime girl images in a resolution of 1024 × 512.
### Dataset Summary
The dataset contains 112,806 images.
All images are on white background
### Collection Method
#### v1.0
Collect from danbooru website.
Use yolov5 to detect and clip image.
Use anime-segmentation to remove background.
Use deepdanbooru to filter image.
Finally clean the dataset manually.
#### v2.0
Base on v1.0, use Novelai image-to-image to enhance and expand the dataset.
### Contributions
Thanks to [@SkyTNT](https://github.com/SkyTNT) for adding this dataset. | skytnt/fbanimehq | [
"task_categories:unconditional-image-generation",
"size_categories:100K<n<1M",
"source_datasets:original",
"license:cc0-1.0",
"region:us"
] | 2022-09-18T00:01:43+00:00 | {"annotations_creators": [], "language_creators": [], "language": [], "license": ["cc0-1.0"], "multilinguality": [], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["unconditional-image-generation"], "task_ids": [], "pretty_name": "Full Body Anime HQ", "tags": []} | 2022-10-23T13:02:23+00:00 |
46f8cc73be38aac9b95090801882532336b56a1b | taskmasterpeace/taskmasterpeace | [
"license:other",
"region:us"
] | 2022-09-18T00:44:17+00:00 | {"license": "other"} | 2022-09-18T00:44:17+00:00 |
|
f81b067a153d11f2a7375d1cb74186cae21cf8d5 | taskmasterpeace/andrea | [
"license:unknown",
"region:us"
] | 2022-09-18T02:17:11+00:00 | {"license": "unknown"} | 2022-09-18T02:17:11+00:00 |
|
ad4d52140c484e159ff5c9ffc3484aba6e46d933 | taskmasterpeace/andrea1 | [
"license:apache-2.0",
"region:us"
] | 2022-09-18T02:18:30+00:00 | {"license": "apache-2.0"} | 2022-09-18T02:19:04+00:00 |
|
4199328f25c6d3de0e783797426affa11dbbf348 |
# Please cite as
```
@InProceedings{Spinde2021f,
title = "Neural Media Bias Detection Using Distant Supervision With {BABE} - Bias Annotations By Experts",
author = "Spinde, Timo and
Plank, Manuel and
Krieger, Jan-David and
Ruas, Terry and
Gipp, Bela and
Aizawa, Akiko",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.101",
doi = "10.18653/v1/2021.findings-emnlp.101",
pages = "1166--1177",
}
``` | mediabiasgroup/BABE | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | 2022-09-18T02:18:38+00:00 | {"license": "cc-by-nc-sa-4.0"} | 2023-08-23T04:24:17+00:00 |
4053a865423b7402ae9ce9ca35e1f9a4b2a5dcce | roupenminassian/StripAI | [
"license:mit",
"region:us"
] | 2022-09-18T04:41:03+00:00 | {"license": "mit"} | 2022-09-18T04:41:03+00:00 |
|
6b1af94c41e300f43a41ec578499df68033f6b14 | prem | premhuggingface/prem | [
"region:us"
] | 2022-09-18T07:49:31+00:00 | {} | 2022-09-18T07:50:31+00:00 |
f058f77c166f37556bf04f99ab1a89ef35007e85 | emma7033/test | [
"license:afl-3.0",
"region:us"
] | 2022-09-18T07:55:02+00:00 | {"license": "afl-3.0"} | 2022-09-18T07:55:02+00:00 |
|
7ecd400426ef7354c6a167e5282b0db424706333 | acaciaca/VR1 | [
"region:us"
] | 2022-09-18T08:55:22+00:00 | {} | 2022-09-18T08:57:24+00:00 |
|
d816d4a05cb89bde39dd99284c459801e1e7e69a |
# Stable Diffusion Dataset
This is a set of about 80,000 prompts filtered and extracted from the image finder for Stable Diffusion: "[Lexica.art](https://lexica.art/)". It was a little difficult to extract the data, since the search engine still doesn't have a public API without being protected by cloudflare.
If you want to test the model with a demo, you can go to: "[spaces/Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion)".
If you want to see the model, go to: "[Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusion)". | Gustavosta/Stable-Diffusion-Prompts | [
"annotations_creators:no-annotation",
"language_creators:found",
"source_datasets:original",
"language:en",
"license:unknown",
"region:us"
] | 2022-09-18T11:13:15+00:00 | {"annotations_creators": ["no-annotation"], "language_creators": ["found"], "language": ["en"], "license": ["unknown"], "source_datasets": ["original"]} | 2022-09-18T21:38:59+00:00 |
61a5b55d423a65338145f63a0247e2d1c0552cd0 | A sampled version of the [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix) dataset for the English-Romanian pair, containing 1M train entries.
Please refer to the original for more info. | din0s/ccmatrix_en-ro | [
"task_categories:translation",
"multilinguality:translation",
"size_categories:100K<n<1M",
"language:en",
"language:ro",
"region:us"
] | 2022-09-18T11:44:19+00:00 | {"annotations_creators": [], "language_creators": [], "language": ["en", "ro"], "license": [], "multilinguality": ["translation"], "size_categories": ["100K<n<1M"], "source_datasets": [], "task_categories": ["translation"], "task_ids": [], "pretty_name": "CCMatrix (en-ro)", "tags": []} | 2022-09-19T21:42:56+00:00 |
fe34485c03a7ea0d7228ca28a68a1a8e6f538662 | BramD/TextInversionTest | [
"license:unknown",
"region:us"
] | 2022-09-18T12:02:46+00:00 | {"license": "unknown"} | 2022-09-21T14:14:53+00:00 |
|
4a08d21e2e71ce0106721aa1c3bca936049fccf6 | The Victoria electricity demand dataset from the [MAPIE github repository](https://github.com/scikit-learn-contrib/MAPIE/tree/master/examples/data).
It consists of hourly electricity demand (in GW)
of the Victoria state in Australia together with the temperature
(in Celsius degrees).
| rajistics/electricity_demand | [
"task_categories:time-series-forecasting",
"region:us"
] | 2022-09-18T18:06:12+00:00 | {"task_categories": ["time-series-forecasting"]} | 2022-10-19T20:03:02+00:00 |
c53dad48e14e0df066905a4e4bd5893b9e790e49 |
# Mario Maker 2 levels
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 levels dataset consists of 26.6 million levels from Nintendo's online service totaling around 100GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 levels dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_level", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 3000004,
'name': 'カベキック',
'description': 'カベキックをとにかくするコースです。',
'uploaded': 1561644329,
'created': 1561674240,
'gamestyle': 4,
'theme': 0,
'difficulty': 0,
'tag1': 7,
'tag2': 10,
'game_version': 1,
'world_record': 8049,
'upload_time': 193540,
'upload_attempts': 1,
'num_comments': 60,
'clear_condition': 0,
'clear_condition_magnitude': 0,
'timer': 300,
'autoscroll_speed': 0,
'clears': 1646,
'attempts': 3168,
'clear_rate': 51.957070707070706,
'plays': 1704,
'versus_matches': 80,
'coop_matches': 27,
'likes': 152,
'boos': 118,
'unique_players_and_versus': 1391,
'weekly_likes': 0,
'weekly_plays': 1,
'uploader_pid': '5218390885570355093',
'first_completer_pid': '16824392528839047213',
'record_holder_pid': '5411258160547085075',
'level_data': [some binary data],
'unk2': 0,
'unk3': [some binary data],
'unk9': 3,
'unk10': 4,
'unk11': 1,
'unk12': 1
}
```
Level data is a binary blob describing the actual level and is equivalent to the level format Nintendo uses in-game. It is gzip compressed and needs to be decompressed to be read. To read it you only need to use the provided `level.ksy` kaitai struct file and install the kaitai struct runtime to parse it into an object:
```python
from datasets import load_dataset
from kaitaistruct import KaitaiStream
from io import BytesIO
from level import Level
import zlib
ds = load_dataset("TheGreatRambler/mm2_level", streaming=True, split="train")
level_data = next(iter(ds))["level_data"]
level = Level(KaitaiStream(BytesIO(zlib.decompress(level_data))))
# NOTE level.overworld.objects is a fixed size (limitation of Kaitai struct)
# must iterate by object_count or null objects will be included
for i in range(level.overworld.object_count):
obj = level.overworld.objects[i]
print("X: %d Y: %d ID: %s" % (obj.x, obj.y, obj.id))
#OUTPUT:
X: 1200 Y: 400 ID: ObjId.block
X: 1360 Y: 400 ID: ObjId.block
X: 1360 Y: 240 ID: ObjId.block
X: 1520 Y: 240 ID: ObjId.block
X: 1680 Y: 240 ID: ObjId.block
X: 1680 Y: 400 ID: ObjId.block
X: 1840 Y: 400 ID: ObjId.block
X: 2000 Y: 400 ID: ObjId.block
X: 2160 Y: 400 ID: ObjId.block
X: 2320 Y: 400 ID: ObjId.block
X: 2480 Y: 560 ID: ObjId.block
X: 2480 Y: 720 ID: ObjId.block
X: 2480 Y: 880 ID: ObjId.block
X: 2160 Y: 880 ID: ObjId.block
```
Rendering the level data into an image can be done using [Toost](https://github.com/TheGreatRambler/toost) if desired.
You can also download the full dataset. Note that this will download ~100GB:
```python
ds = load_dataset("TheGreatRambler/mm2_level", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 3000004,
'name': 'カベキック',
'description': 'カベキックをとにかくするコースです。',
'uploaded': 1561644329,
'created': 1561674240,
'gamestyle': 4,
'theme': 0,
'difficulty': 0,
'tag1': 7,
'tag2': 10,
'game_version': 1,
'world_record': 8049,
'upload_time': 193540,
'upload_attempts': 1,
'num_comments': 60,
'clear_condition': 0,
'clear_condition_magnitude': 0,
'timer': 300,
'autoscroll_speed': 0,
'clears': 1646,
'attempts': 3168,
'clear_rate': 51.957070707070706,
'plays': 1704,
'versus_matches': 80,
'coop_matches': 27,
'likes': 152,
'boos': 118,
'unique_players_and_versus': 1391,
'weekly_likes': 0,
'weekly_plays': 1,
'uploader_pid': '5218390885570355093',
'first_completer_pid': '16824392528839047213',
'record_holder_pid': '5411258160547085075',
'level_data': [some binary data],
'unk2': 0,
'unk3': [some binary data],
'unk9': 3,
'unk10': 4,
'unk11': 1,
'unk12': 1
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|Data IDs are unique identifiers, gaps in the table are due to levels deleted by users or Nintendo|
|name|string|Course name|
|description|string|Course description|
|uploaded|int|UTC timestamp for when the level was uploaded|
|created|int|Local timestamp for when the level was created|
|gamestyle|int|Gamestyle, enum below|
|theme|int|Theme, enum below|
|difficulty|int|Difficulty, enum below|
|tag1|int|The first tag, if it exists, enum below|
|tag2|int|The second tag, if it exists, enum below|
|game_version|int|The version of the game this level was made on|
|world_record|int|The world record in milliseconds|
|upload_time|int|The upload time in milliseconds|
|upload_attempts|int|The number of attempts it took the uploader to upload|
|num_comments|int|Number of comments, may not reflect the archived comments if there were more than 1000 comments|
|clear_condition|int|Clear condition, enum below|
|clear_condition_magnitude|int|If applicable, the magnitude of the clear condition|
|timer|int|The timer of the level|
|autoscroll_speed|int|A unit of how fast the configured autoscroll speed is for the level|
|clears|int|Course clears|
|attempts|int|Course attempts|
|clear_rate|float|Course clear rate as a float between 0 and 1|
|plays|int|Course plays, or "footprints"|
|versus_matches|int|Course versus matches|
|coop_matches|int|Course coop matches|
|likes|int|Course likes|
|boos|int|Course boos|
|unique_players_and_versus|int|All unique players that have ever played this level, including the number of versus matches|
|weekly_likes|int|The weekly likes on this course|
|weekly_plays|int|The weekly plays on this course|
|uploader_pid|string|The player ID of the uploader|
|first_completer_pid|string|The player ID of the user who first cleared this course|
|record_holder_pid|string|The player ID of the user who held the world record at time of archival |
|level_data|bytes|The GZIP compressed decrypted level data, kaitai struct file is provided for reading|
|unk2|int|Unknown|
|unk3|bytes|Unknown|
|unk9|int|Unknown|
|unk10|int|Unknown|
|unk11|int|Unknown|
|unk12|int|Unknown|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
GameStyles = {
0: "SMB1",
1: "SMB3",
2: "SMW",
3: "NSMBU",
4: "SM3DW"
}
Difficulties = {
0: "Easy",
1: "Normal",
2: "Expert",
3: "Super expert"
}
CourseThemes = {
0: "Overworld",
1: "Underground",
2: "Castle",
3: "Airship",
4: "Underwater",
5: "Ghost house",
6: "Snow",
7: "Desert",
8: "Sky",
9: "Forest"
}
TagNames = {
0: "None",
1: "Standard",
2: "Puzzle solving",
3: "Speedrun",
4: "Autoscroll",
5: "Auto mario",
6: "Short and sweet",
7: "Multiplayer versus",
8: "Themed",
9: "Music",
10: "Art",
11: "Technical",
12: "Shooter",
13: "Boss battle",
14: "Single player",
15: "Link"
}
ClearConditions = {
137525990: "Reach the goal without landing after leaving the ground.",
199585683: "Reach the goal after defeating at least/all (n) Mechakoopa(s).",
272349836: "Reach the goal after defeating at least/all (n) Cheep Cheep(s).",
375673178: "Reach the goal without taking damage.",
426197923: "Reach the goal as Boomerang Mario.",
436833616: "Reach the goal while wearing a Shoe.",
713979835: "Reach the goal as Fire Mario.",
744927294: "Reach the goal as Frog Mario.",
751004331: "Reach the goal after defeating at least/all (n) Larry(s).",
900050759: "Reach the goal as Raccoon Mario.",
947659466: "Reach the goal after defeating at least/all (n) Blooper(s).",
976173462: "Reach the goal as Propeller Mario.",
994686866: "Reach the goal while wearing a Propeller Box.",
998904081: "Reach the goal after defeating at least/all (n) Spike(s).",
1008094897: "Reach the goal after defeating at least/all (n) Boom Boom(s).",
1051433633: "Reach the goal while holding a Koopa Shell.",
1061233896: "Reach the goal after defeating at least/all (n) Porcupuffer(s).",
1062253843: "Reach the goal after defeating at least/all (n) Charvaargh(s).",
1079889509: "Reach the goal after defeating at least/all (n) Bullet Bill(s).",
1080535886: "Reach the goal after defeating at least/all (n) Bully/Bullies.",
1151250770: "Reach the goal while wearing a Goomba Mask.",
1182464856: "Reach the goal after defeating at least/all (n) Hop-Chops.",
1219761531: "Reach the goal while holding a Red POW Block. OR Reach the goal after activating at least/all (n) Red POW Block(s).",
1221661152: "Reach the goal after defeating at least/all (n) Bob-omb(s).",
1259427138: "Reach the goal after defeating at least/all (n) Spiny/Spinies.",
1268255615: "Reach the goal after defeating at least/all (n) Bowser(s)/Meowser(s).",
1279580818: "Reach the goal after defeating at least/all (n) Ant Trooper(s).",
1283945123: "Reach the goal on a Lakitu's Cloud.",
1344044032: "Reach the goal after defeating at least/all (n) Boo(s).",
1425973877: "Reach the goal after defeating at least/all (n) Roy(s).",
1429902736: "Reach the goal while holding a Trampoline.",
1431944825: "Reach the goal after defeating at least/all (n) Morton(s).",
1446467058: "Reach the goal after defeating at least/all (n) Fish Bone(s).",
1510495760: "Reach the goal after defeating at least/all (n) Monty Mole(s).",
1656179347: "Reach the goal after picking up at least/all (n) 1-Up Mushroom(s).",
1665820273: "Reach the goal after defeating at least/all (n) Hammer Bro(s.).",
1676924210: "Reach the goal after hitting at least/all (n) P Switch(es). OR Reach the goal while holding a P Switch.",
1715960804: "Reach the goal after activating at least/all (n) POW Block(s). OR Reach the goal while holding a POW Block.",
1724036958: "Reach the goal after defeating at least/all (n) Angry Sun(s).",
1730095541: "Reach the goal after defeating at least/all (n) Pokey(s).",
1780278293: "Reach the goal as Superball Mario.",
1839897151: "Reach the goal after defeating at least/all (n) Pom Pom(s).",
1969299694: "Reach the goal after defeating at least/all (n) Peepa(s).",
2035052211: "Reach the goal after defeating at least/all (n) Lakitu(s).",
2038503215: "Reach the goal after defeating at least/all (n) Lemmy(s).",
2048033177: "Reach the goal after defeating at least/all (n) Lava Bubble(s).",
2076496776: "Reach the goal while wearing a Bullet Bill Mask.",
2089161429: "Reach the goal as Big Mario.",
2111528319: "Reach the goal as Cat Mario.",
2131209407: "Reach the goal after defeating at least/all (n) Goomba(s)/Galoomba(s).",
2139645066: "Reach the goal after defeating at least/all (n) Thwomp(s).",
2259346429: "Reach the goal after defeating at least/all (n) Iggy(s).",
2549654281: "Reach the goal while wearing a Dry Bones Shell.",
2694559007: "Reach the goal after defeating at least/all (n) Sledge Bro(s.).",
2746139466: "Reach the goal after defeating at least/all (n) Rocky Wrench(es).",
2749601092: "Reach the goal after grabbing at least/all (n) 50-Coin(s).",
2855236681: "Reach the goal as Flying Squirrel Mario.",
3036298571: "Reach the goal as Buzzy Mario.",
3074433106: "Reach the goal as Builder Mario.",
3146932243: "Reach the goal as Cape Mario.",
3174413484: "Reach the goal after defeating at least/all (n) Wendy(s).",
3206222275: "Reach the goal while wearing a Cannon Box.",
3314955857: "Reach the goal as Link.",
3342591980: "Reach the goal while you have Super Star invincibility.",
3346433512: "Reach the goal after defeating at least/all (n) Goombrat(s)/Goombud(s).",
3348058176: "Reach the goal after grabbing at least/all (n) 10-Coin(s).",
3353006607: "Reach the goal after defeating at least/all (n) Buzzy Beetle(s).",
3392229961: "Reach the goal after defeating at least/all (n) Bowser Jr.(s).",
3437308486: "Reach the goal after defeating at least/all (n) Koopa Troopa(s).",
3459144213: "Reach the goal after defeating at least/all (n) Chain Chomp(s).",
3466227835: "Reach the goal after defeating at least/all (n) Muncher(s).",
3481362698: "Reach the goal after defeating at least/all (n) Wiggler(s).",
3513732174: "Reach the goal as SMB2 Mario.",
3649647177: "Reach the goal in a Koopa Clown Car/Junior Clown Car.",
3725246406: "Reach the goal as Spiny Mario.",
3730243509: "Reach the goal in a Koopa Troopa Car.",
3748075486: "Reach the goal after defeating at least/all (n) Piranha Plant(s)/Jumping Piranha Plant(s).",
3797704544: "Reach the goal after defeating at least/all (n) Dry Bones.",
3824561269: "Reach the goal after defeating at least/all (n) Stingby/Stingbies.",
3833342952: "Reach the goal after defeating at least/all (n) Piranha Creeper(s).",
3842179831: "Reach the goal after defeating at least/all (n) Fire Piranha Plant(s).",
3874680510: "Reach the goal after breaking at least/all (n) Crates(s).",
3974581191: "Reach the goal after defeating at least/all (n) Ludwig(s).",
3977257962: "Reach the goal as Super Mario.",
4042480826: "Reach the goal after defeating at least/all (n) Skipsqueak(s).",
4116396131: "Reach the goal after grabbing at least/all (n) Coin(s).",
4117878280: "Reach the goal after defeating at least/all (n) Magikoopa(s).",
4122555074: "Reach the goal after grabbing at least/all (n) 30-Coin(s).",
4153835197: "Reach the goal as Balloon Mario.",
4172105156: "Reach the goal while wearing a Red POW Box.",
4209535561: "Reach the Goal while riding Yoshi.",
4269094462: "Reach the goal after defeating at least/all (n) Spike Top(s).",
4293354249: "Reach the goal after defeating at least/all (n) Banzai Bill(s)."
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset consists of levels from many different Mario Maker 2 players globally and as such their titles and descriptions could contain harmful language. Harmful depictions could also be present in the level data, should you choose to render it.
| TheGreatRambler/mm2_level | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:15:00+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 levels", "tags": ["text-mining"]} | 2022-11-11T08:07:34+00:00 |
e1ded9a5fb0f1d052d0a7a44ec46f79a4b27903a |
# Mario Maker 2 level comments
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 level comment dataset consists of 31.9 million level comments from Nintendo's online service totaling around 20GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 level comment dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_level_comments", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 3000006,
'comment_id': '20200430072710528979_302de3722145c7a2_2dc6c6',
'type': 2,
'pid': '3471680967096518562',
'posted': 1561652887,
'clear_required': 0,
'text': '',
'reaction_image_id': 10,
'custom_image': [some binary data],
'has_beaten': 0,
'x': 557,
'y': 64,
'reaction_face': 0,
'unk8': 0,
'unk10': 0,
'unk12': 0,
'unk14': [some binary data],
'unk17': 0
}
```
Comments can be one of three types: text, reaction image or custom image. `type` can be used with the enum below to identify different kinds of comments. Custom images are binary PNGs.
You can also download the full dataset. Note that this will download ~20GB:
```python
ds = load_dataset("TheGreatRambler/mm2_level_comments", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 3000006,
'comment_id': '20200430072710528979_302de3722145c7a2_2dc6c6',
'type': 2,
'pid': '3471680967096518562',
'posted': 1561652887,
'clear_required': 0,
'text': '',
'reaction_image_id': 10,
'custom_image': [some binary data],
'has_beaten': 0,
'x': 557,
'y': 64,
'reaction_face': 0,
'unk8': 0,
'unk10': 0,
'unk12': 0,
'unk14': [some binary data],
'unk17': 0
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|The data ID of the level this comment appears on|
|comment_id|string|Comment ID|
|type|int|Type of comment, enum below|
|pid|string|Player ID of the comment creator|
|posted|int|UTC timestamp of when this comment was created|
|clear_required|bool|Whether this comment requires a clear to view|
|text|string|If the comment type is text, the text of the comment|
|reaction_image_id|int|If this comment is a reaction image, the id of the reaction image, enum below|
|custom_image|bytes|If this comment is a custom drawing, the custom drawing as a PNG binary|
|has_beaten|int|Whether the user had beaten the level when they created the comment|
|x|int|The X position of the comment in game|
|y|int|The Y position of the comment in game|
|reaction_face|int|The reaction face of the mii of this user, enum below|
|unk8|int|Unknown|
|unk10|int|Unknown|
|unk12|int|Unknown|
|unk14|bytes|Unknown|
|unk17|int|Unknown|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
CommentType = {
0: "Custom Image",
1: "Text",
2: "Reaction Image"
}
CommentReactionImage = {
0: "Nice!",
1: "Good stuff!",
2: "So tough...",
3: "EASY",
4: "Seriously?!",
5: "Wow!",
6: "Cool idea!",
7: "SPEEDRUN!",
8: "How?!",
9: "Be careful!",
10: "So close!",
11: "Beat it!"
}
CommentReactionFace = {
0: "Normal",
16: "Wink",
1: "Happy",
4: "Surprised",
18: "Scared",
3: "Confused"
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset consists of comments from many different Mario Maker 2 players globally and as such their text could contain harmful language. Harmful depictions could also be present in the custom images.
| TheGreatRambler/mm2_level_comments | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:15:48+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 level comments", "tags": ["text-mining"]} | 2022-11-11T08:06:48+00:00 |
a2edf6a4a9588b3e81830cac3bd8659e12bdf8a2 |
# Mario Maker 2 level plays
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 level plays dataset consists of 1 billion level plays from Nintendo's online service totaling around 20GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 level plays dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_level_played", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 3000004,
'pid': '6382913755133534321',
'cleared': 1,
'liked': 0
}
```
Each row is a unique play in the level denoted by the `data_id` done by the player denoted by the `pid`, `pid` is a 64 bit integer stored within a string from database limitations. `cleared` and `liked` denote if the player successfully cleared the level during their play and/or liked the level during their play. Every level has only one unique play per player.
You can also download the full dataset. Note that this will download ~20GB:
```python
ds = load_dataset("TheGreatRambler/mm2_level_played", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 3000004,
'pid': '6382913755133534321',
'cleared': 1,
'liked': 0
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|The data ID of the level this play occured in|
|pid|string|Player ID of the player|
|cleared|bool|Whether the player cleared the level during their play|
|liked|bool|Whether the player liked the level during their play|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_level_played | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:1B<n<10B",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:17:04+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["1B<n<10B"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 level plays", "tags": ["text-mining"]} | 2022-11-11T08:05:36+00:00 |
1f06c2b8cd09144b775cd328ed16b2033275cdc8 |
# Mario Maker 2 level deaths
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 level deaths dataset consists of 564 million level deaths from Nintendo's online service totaling around 2.5GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 level deaths dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_level_deaths", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 3000382,
'x': 696,
'y': 0,
'is_subworld': 0
}
```
Each row is a unique death in the level denoted by the `data_id` that occurs at the provided coordinates. `is_subworld` denotes whether the death happened in the main world or the subworld.
You can also download the full dataset. Note that this will download ~2.5GB:
```python
ds = load_dataset("TheGreatRambler/mm2_level_deaths", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 3000382,
'x': 696,
'y': 0,
'is_subworld': 0
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|The data ID of the level this death occured in|
|x|int|X coordinate of death|
|y|int|Y coordinate of death|
|is_subworld|bool|Whether the death happened in the main world or the subworld|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_level_deaths | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:100M<n<1B",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:17:18+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["100M<n<1B"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 level deaths", "tags": ["text-mining"]} | 2022-11-11T08:05:52+00:00 |
0c95c15ed4e4ea278f0fbd57475381eae14eca2b |
# Mario Maker 2 users
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 users dataset consists of 6 million users from Nintendo's online service totaling around 1.2GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 users dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '14608829447232141607',
'data_id': 1,
'region': 0,
'name': 'げんまい',
'country': 'JP',
'last_active': 1578384457,
'mii_data': [some binary data],
'mii_image': '000f165d6574777a7881949e9da1acc1cac7cacad3dad9e0eff2f9faf900430a151c25384258637084878e8b96a0b0',
'pose': 0,
'hat': 0,
'shirt': 0,
'pants': 0,
'wearing_outfit': 0,
'courses_played': 12,
'courses_cleared': 10,
'courses_attempted': 23,
'courses_deaths': 13,
'likes': 0,
'maker_points': 0,
'easy_highscore': 0,
'normal_highscore': 0,
'expert_highscore': 0,
'super_expert_highscore': 0,
'versus_rating': 0,
'versus_rank': 1,
'versus_won': 0,
'versus_lost': 1,
'versus_win_streak': 0,
'versus_lose_streak': 1,
'versus_plays': 1,
'versus_disconnected': 0,
'coop_clears': 1,
'coop_plays': 1,
'recent_performance': 1383,
'versus_kills': 0,
'versus_killed_by_others': 0,
'multiplayer_unk13': 286,
'multiplayer_unk14': 5999927,
'first_clears': 0,
'world_records': 0,
'unique_super_world_clears': 0,
'uploaded_levels': 0,
'maximum_uploaded_levels': 100,
'weekly_maker_points': 0,
'last_uploaded_level': 1561555201,
'is_nintendo_employee': 0,
'comments_enabled': 1,
'tags_enabled': 0,
'super_world_id': '',
'unk3': 0,
'unk12': 0,
'unk16': 0
}
```
Each row is a unique play in the level denoted by the `data_id` done by the player denoted by the `pid`, `pid` is a 64 bit integer stored within a string from database limitations. `cleared` and `liked` denote if the player successfully cleared the level during their play and/or liked the level during their play. Every level has only one unique play per player.
Each row is a unique user associated denoted by the `pid`. `data_id` is not used by Nintendo but, like levels, it counts up sequentially and can be used to determine account age. `mii_data` is a `charinfo` type Switch Mii. `mii_image` can be used with Nintendo's online studio API to generate images:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user", streaming=True, split="train")
mii_image = next(iter(ds))["mii_image"]
print("Face: https://studio.mii.nintendo.com/miis/image.png?data=%s&type=face&width=512&instanceCount=1" % mii_image)
print("Body: https://studio.mii.nintendo.com/miis/image.png?data=%s&type=all_body&width=512&instanceCount=1" % mii_image)
print("Face (x16): https://studio.mii.nintendo.com/miis/image.png?data=%s&type=face&width=512&instanceCount=16" % mii_image)
print("Body (x16): https://studio.mii.nintendo.com/miis/image.png?data=%s&type=all_body&width=512&instanceCount=16" % mii_image)
```
`pose`, `hat`, `shirt` and `pants` has associated enums described below. `last_active` and `last_uploaded_level` are UTC timestamps. `super_world_id`, if not empty, provides the ID of a super world in `TheGreatRambler/mm2_world`.
You can also download the full dataset. Note that this will download ~1.2GB:
```python
ds = load_dataset("TheGreatRambler/mm2_user", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '14608829447232141607',
'data_id': 1,
'region': 0,
'name': 'げんまい',
'country': 'JP',
'last_active': 1578384457,
'mii_data': [some binary data],
'mii_image': '000f165d6574777a7881949e9da1acc1cac7cacad3dad9e0eff2f9faf900430a151c25384258637084878e8b96a0b0',
'pose': 0,
'hat': 0,
'shirt': 0,
'pants': 0,
'wearing_outfit': 0,
'courses_played': 12,
'courses_cleared': 10,
'courses_attempted': 23,
'courses_deaths': 13,
'likes': 0,
'maker_points': 0,
'easy_highscore': 0,
'normal_highscore': 0,
'expert_highscore': 0,
'super_expert_highscore': 0,
'versus_rating': 0,
'versus_rank': 1,
'versus_won': 0,
'versus_lost': 1,
'versus_win_streak': 0,
'versus_lose_streak': 1,
'versus_plays': 1,
'versus_disconnected': 0,
'coop_clears': 1,
'coop_plays': 1,
'recent_performance': 1383,
'versus_kills': 0,
'versus_killed_by_others': 0,
'multiplayer_unk13': 286,
'multiplayer_unk14': 5999927,
'first_clears': 0,
'world_records': 0,
'unique_super_world_clears': 0,
'uploaded_levels': 0,
'maximum_uploaded_levels': 100,
'weekly_maker_points': 0,
'last_uploaded_level': 1561555201,
'is_nintendo_employee': 0,
'comments_enabled': 1,
'tags_enabled': 0,
'super_world_id': '',
'unk3': 0,
'unk12': 0,
'unk16': 0
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of this user, an unsigned 64 bit integer as a string|
|data_id|int|The data ID of this user, while not used internally user codes are generated using this|
|region|int|User region, enum below|
|name|string|User name|
|country|string|User country as a 2 letter ALPHA-2 code|
|last_active|int|UTC timestamp of when this user was last active, not known what constitutes active|
|mii_data|bytes|The CHARINFO blob of this user's Mii|
|mii_image|string|A string that can be fed into Nintendo's studio API to generate an image|
|pose|int|Pose, enum below|
|hat|int|Hat, enum below|
|shirt|int|Shirt, enum below|
|pants|int|Pants, enum below|
|wearing_outfit|bool|Whether this user is wearing pants|
|courses_played|int|How many courses this user has played|
|courses_cleared|int|How many courses this user has cleared|
|courses_attempted|int|How many courses this user has attempted|
|courses_deaths|int|How many times this user has died|
|likes|int|How many likes this user has recieved|
|maker_points|int|Maker points|
|easy_highscore|int|Easy highscore|
|normal_highscore|int|Normal highscore|
|expert_highscore|int|Expert highscore|
|super_expert_highscore|int|Super expert high score|
|versus_rating|int|Versus rating|
|versus_rank|int|Versus rank, enum below|
|versus_won|int|How many courses this user has won in versus|
|versus_lost|int|How many courses this user has lost in versus|
|versus_win_streak|int|Versus win streak|
|versus_lose_streak|int|Versus lose streak|
|versus_plays|int|Versus plays|
|versus_disconnected|int|Times user has disconnected in versus|
|coop_clears|int|Coop clears|
|coop_plays|int|Coop plays|
|recent_performance|int|Unknown variable relating to versus performance|
|versus_kills|int|Kills in versus, unknown what activities constitute a kill|
|versus_killed_by_others|int|Deaths in versus from other users, little is known about what activities constitute a death|
|multiplayer_unk13|int|Unknown, relating to multiplayer|
|multiplayer_unk14|int|Unknown, relating to multiplayer|
|first_clears|int|First clears|
|world_records|int|World records|
|unique_super_world_clears|int|Super world clears|
|uploaded_levels|int|Number of uploaded levels|
|maximum_uploaded_levels|int|Maximum number of levels this user may upload|
|weekly_maker_points|int|Weekly maker points|
|last_uploaded_level|int|UTC timestamp of when this user last uploaded a level|
|is_nintendo_employee|bool|Whether this user is an official Nintendo account|
|comments_enabled|bool|Whether this user has comments enabled on their levels|
|tags_enabled|bool|Whether this user has tags enabled on their levels|
|super_world_id|string|The ID of this user's super world, blank if they do not have one|
|unk3|int|Unknown|
|unk12|int|Unknown|
|unk16|int|Unknown|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
Regions = {
0: "Asia",
1: "Americas",
2: "Europe",
3: "Other"
}
MultiplayerVersusRanks = {
1: "D",
2: "C",
3: "B",
4: "A",
5: "S",
6: "S+"
}
UserPose = {
0: "Normal",
15: "Fidgety",
17: "Annoyed",
18: "Buoyant",
19: "Thrilled",
20: "Let's go!",
21: "Hello!",
29: "Show-Off",
31: "Cutesy",
39: "Hyped!"
}
UserHat = {
0: "None",
1: "Mario Cap",
2: "Luigi Cap",
4: "Mushroom Hairclip",
5: "Bowser Headpiece",
8: "Princess Peach Wig",
11: "Builder Hard Hat",
12: "Bowser Jr. Headpiece",
13: "Pipe Hat",
15: "Cat Mario Headgear",
16: "Propeller Mario Helmet",
17: "Cheep Cheep Hat",
18: "Yoshi Hat",
21: "Faceplant",
22: "Toad Cap",
23: "Shy Cap",
24: "Magikoopa Hat",
25: "Fancy Top Hat",
26: "Doctor Headgear",
27: "Rocky Wrench Manhold Lid",
28: "Super Star Barrette",
29: "Rosalina Wig",
30: "Fried-Chicken Headgear",
31: "Royal Crown",
32: "Edamame Barrette",
33: "Superball Mario Hat",
34: "Robot Cap",
35: "Frog Cap",
36: "Cheetah Headgear",
37: "Ninji Cap",
38: "Super Acorn Hat",
39: "Pokey Hat",
40: "Snow Pokey Hat"
}
UserShirt = {
0: "Nintendo Shirt",
1: "Mario Outfit",
2: "Luigi Outfit",
3: "Super Mushroom Shirt",
5: "Blockstripe Shirt",
8: "Bowser Suit",
12: "Builder Mario Outfit",
13: "Princess Peach Dress",
16: "Nintendo Uniform",
17: "Fireworks Shirt",
19: "Refreshing Shirt",
21: "Reset Dress",
22: "Thwomp Suit",
23: "Slobbery Shirt",
26: "Cat Suit",
27: "Propeller Mario Clothes",
28: "Banzai Bill Shirt",
29: "Staredown Shirt",
31: "Yoshi Suit",
33: "Midnight Dress",
34: "Magikoopa Robes",
35: "Doctor Coat",
37: "Chomp-Dog Shirt",
38: "Fish Bone Shirt",
40: "Toad Outfit",
41: "Googoo Onesie",
42: "Matrimony Dress",
43: "Fancy Tuxedo",
44: "Koopa Troopa Suit",
45: "Laughing Shirt",
46: "Running Shirt",
47: "Rosalina Dress",
49: "Angry Sun Shirt",
50: "Fried-Chicken Hoodie",
51: "? Block Hoodie",
52: "Edamame Camisole",
53: "I-Like-You Camisole",
54: "White Tanktop",
55: "Hot Hot Shirt",
56: "Royal Attire",
57: "Superball Mario Suit",
59: "Partrick Shirt",
60: "Robot Suit",
61: "Superb Suit",
62: "Yamamura Shirt",
63: "Princess Peach Tennis Outfit",
64: "1-Up Hoodie",
65: "Cheetah Tanktop",
66: "Cheetah Suit",
67: "Ninji Shirt",
68: "Ninji Garb",
69: "Dash Block Hoodie",
70: "Fire Mario Shirt",
71: "Raccoon Mario Shirt",
72: "Cape Mario Shirt",
73: "Flying Squirrel Mario Shirt",
74: "Cat Mario Shirt",
75: "World Wear",
76: "Koopaling Hawaiian Shirt",
77: "Frog Mario Raincoat",
78: "Phanto Hoodie"
}
UserPants = {
0: "Black Short-Shorts",
1: "Denim Jeans",
5: "Denim Skirt",
8: "Pipe Skirt",
9: "Skull Skirt",
10: "Burner Skirt",
11: "Cloudwalker",
12: "Platform Skirt",
13: "Parent-and-Child Skirt",
17: "Mario Swim Trunks",
22: "Wind-Up Shoe",
23: "Hoverclown",
24: "Big-Spender Shorts",
25: "Shorts of Doom!",
26: "Doorduroys",
27: "Antsy Corduroys",
28: "Bouncy Skirt",
29: "Stingby Skirt",
31: "Super Star Flares",
32: "Cheetah Runners",
33: "Ninji Slacks"
}
# Checked against user's shirt
UserIsOutfit = {
0: False,
1: True,
2: True,
3: False,
5: False,
8: True,
12: True,
13: True,
16: False,
17: False,
19: False,
21: True,
22: True,
23: False,
26: True,
27: True,
28: False,
29: False,
31: True,
33: True,
34: True,
35: True,
37: False,
38: False,
40: True,
41: True,
42: True,
43: True,
44: True,
45: False,
46: False,
47: True,
49: False,
50: False,
51: False,
52: False,
53: False,
54: False,
55: False,
56: True,
57: True,
59: False,
60: True,
61: True,
62: False,
63: True,
64: False,
65: False,
66: True,
67: False,
68: True,
69: False,
70: False,
71: False,
72: False,
73: False,
74: False,
75: True,
76: False,
77: True,
78: False
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset consists of many different Mario Maker 2 players globally and as such their names could contain harmful language. Harmful depictions could also be present in their Miis, should you choose to render it.
| TheGreatRambler/mm2_user | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:17:35+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 users", "tags": ["text-mining"]} | 2022-11-11T08:04:51+00:00 |
75d9ee5258f795a705fdbfe9fa51e6956df0b71f |
# Mario Maker 2 user badges
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 user badges dataset consists of 9328 user badges (they are capped to 10k globally) from Nintendo's online service and adds onto `TheGreatRambler/mm2_user`. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user_badges", split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '1779763691699286988',
'type': 4,
'rank': 6
}
```
Each row is a badge awarded to the player denoted by `pid`. `TheGreatRambler/mm2_user` contains these players.
## Data Structure
### Data Instances
```python
{
'pid': '1779763691699286988',
'type': 4,
'rank': 6
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|Player ID|
|type|int|The kind of badge, enum below|
|rank|int|The rank of badge, enum below|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
BadgeTypes = {
0: "Maker Points (All-Time)",
1: "Endless Challenge (Easy)",
2: "Endless Challenge (Normal)",
3: "Endless Challenge (Expert)",
4: "Endless Challenge (Super Expert)",
5: "Multiplayer Versus",
6: "Number of Clears",
7: "Number of First Clears",
8: "Number of World Records",
9: "Maker Points (Weekly)"
}
BadgeRanks = {
6: "Bronze",
5: "Silver",
4: "Gold",
3: "Bronze Ribbon",
2: "Silver Ribbon",
1: "Gold Ribbon"
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_user_badges | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:1k<10K",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:17:51+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["1k<10K"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 user badges", "tags": ["text-mining"]} | 2022-11-11T08:05:05+00:00 |
44cde6a1c6338d7706bdabd2bbc42182073b9414 |
# Mario Maker 2 user plays
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 user plays dataset consists of 329.8 million user plays from Nintendo's online service totaling around 2GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 user plays dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user_played", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '4920036968545706712',
'data_id': 25548552
}
```
Each row is a unique play in the level denoted by the `data_id` done by the player denoted by the `pid`.
You can also download the full dataset. Note that this will download ~2GB:
```python
ds = load_dataset("TheGreatRambler/mm2_user_played", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '4920036968545706712',
'data_id': 25548552
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of this user, an unsigned 64 bit integer as a string|
|data_id|int|The data ID of the level this user played|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_user_played | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:100M<n<1B",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:18:08+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["100M<n<1B"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 user plays", "tags": ["text-mining"]} | 2022-11-11T08:04:07+00:00 |
a953a5eeb81d18f6b8dd6c525934797fd2b43248 |
# Mario Maker 2 user likes
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 user likes dataset consists of 105.5 million user likes from Nintendo's online service totaling around 630MB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 user likes dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user_liked", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '14510618610706594411',
'data_id': 25861713
}
```
Each row is a unique like in the level denoted by the `data_id` done by the player denoted by the `pid`.
You can also download the full dataset. Note that this will download ~630MB:
```python
ds = load_dataset("TheGreatRambler/mm2_user_liked", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '14510618610706594411',
'data_id': 25861713
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of this user, an unsigned 64 bit integer as a string|
|data_id|int|The data ID of the level this user liked|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_user_liked | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:100M<n<1B",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:18:19+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["100M<n<1B"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 user likes", "tags": ["text-mining"]} | 2022-11-11T08:04:21+00:00 |
35e87e12b511552496fa9ccecd601629fa7f2a1c |
# Mario Maker 2 user uploaded
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 user uploaded dataset consists of 26.5 million uploaded user levels from Nintendo's online service totaling around 215MB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 user uploaded dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user_posted", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '10491033288855085861',
'data_id': 27359486
}
```
Each row is a unique uploaded level denoted by the `data_id` uploaded by the player denoted by the `pid`.
You can also download the full dataset. Note that this will download ~215MB:
```python
ds = load_dataset("TheGreatRambler/mm2_user_posted", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '10491033288855085861',
'data_id': 27359486
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of this user, an unsigned 64 bit integer as a string|
|data_id|int|The data ID of the level this user uploaded|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_user_posted | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:18:30+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 user uploaded", "tags": ["text-mining"]} | 2022-11-11T08:03:53+00:00 |
15ec37e8e8d6f4806c2fe5947defa8d3e9b41250 |
# Mario Maker 2 user first clears
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 user first clears dataset consists of 17.8 million first clears from Nintendo's online service totaling around 157MB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 user first clears dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user_first_cleared", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '14510618610706594411',
'data_id': 25199891
}
```
Each row is a unique first clear in the level denoted by the `data_id` done by the player denoted by the `pid`.
You can also download the full dataset. Note that this will download ~157MB:
```python
ds = load_dataset("TheGreatRambler/mm2_user_first_cleared", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '14510618610706594411',
'data_id': 25199891
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of this user, an unsigned 64 bit integer as a string|
|data_id|int|The data ID of the level this user first cleared|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_user_first_cleared | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:18:41+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 user first clears", "tags": ["text-mining"]} | 2022-11-11T08:04:34+00:00 |
f653680f7713e6f89eea9fc82bd96cbd498010cc |
# Mario Maker 2 user world records
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 user world records dataset consists of 15.3 million world records from Nintendo's online service totaling around 215MB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 user world records dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_user_world_record", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '14510618610706594411',
'data_id': 24866513
}
```
Each row is a unique world record in the level denoted by the `data_id` done by the player denoted by the `pid`.
You can also download the full dataset. Note that this will download ~215MB:
```python
ds = load_dataset("TheGreatRambler/mm2_user_world_record", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '14510618610706594411',
'data_id': 24866513
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of this user, an unsigned 64 bit integer as a string|
|data_id|int|The data ID of the level this user got world record on|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_user_world_record | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:10M<n<100M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:18:54+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["10M<n<100M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 user world records", "tags": ["text-mining"]} | 2022-11-11T08:03:39+00:00 |
8640ff2491a3298963d72a0f15d28af1919b8b19 |
# Mario Maker 2 super worlds
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 super worlds dataset consists of 289 thousand super worlds from Nintendo's online service totaling around 13.5GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 super worlds dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_world", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '14510618610706594411',
'world_id': 'c96012bef256ba6b_20200513204805563301',
'worlds': 1,
'levels': 5,
'planet_type': 0,
'created': 1589420886,
'unk1': [some binary data],
'unk5': 3,
'unk6': 1,
'unk7': 1,
'thumbnail': [some binary data]
}
```
Each row is a unique super world denoted by the `world_id` created by the player denoted by the `pid`. Thumbnails are binary PNGs. `unk1` describes the super world itself, including the world map, but its format is unknown as of now.
You can also download the full dataset. Note that this will download ~13.5GB:
```python
ds = load_dataset("TheGreatRambler/mm2_world", split="train")
```
## Data Structure
### Data Instances
```python
{
'pid': '14510618610706594411',
'world_id': 'c96012bef256ba6b_20200513204805563301',
'worlds': 1,
'levels': 5,
'planet_type': 0,
'created': 1589420886,
'unk1': [some binary data],
'unk5': 3,
'unk6': 1,
'unk7': 1,
'thumbnail': [some binary data]
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of the user who created this super world|
|world_id|string|World ID|
|worlds|int|Number of worlds|
|levels|int|Number of levels|
|planet_type|int|Planet type, enum below|
|created|int|UTC timestamp of when this super world was created|
|unk1|bytes|Unknown|
|unk5|int|Unknown|
|unk6|int|Unknown|
|unk7|int|Unknown|
|thumbnail|bytes|The thumbnail, as a JPEG binary|
|thumbnail_url|string|The old URL of this thumbnail|
|thumbnail_size|int|The filesize of this thumbnail|
|thumbnail_filename|string|The filename of this thumbnail|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. This can be used to convert back to their string equivalents:
```python
SuperWorldPlanetType = {
0: "Earth",
1: "Moon",
2: "Sand",
3: "Green",
4: "Ice",
5: "Ringed",
6: "Red",
7: "Spiral"
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset consists of super worlds from many different Mario Maker 2 players globally and as such harmful depictions could be present in their super world thumbnails.
| TheGreatRambler/mm2_world | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:19:10+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["100K<n<1M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 super worlds", "tags": ["text-mining"]} | 2022-11-11T08:08:15+00:00 |
acd1e2f4c3e10eeb4315d04d44371cf531e31bcf |
# Mario Maker 2 super world levels
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 super world levels dataset consists of 3.3 million super world levels from Nintendo's online service and adds onto `TheGreatRambler/mm2_world`. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_world_levels", split="train")
print(next(iter(ds)))
#OUTPUT:
{
'pid': '14510618610706594411',
'data_id': 19170881,
'ninjis': 23
}
```
Each row is a level within a super world owned by player `pid` that is denoted by `data_id`. Each level contains some number of ninjis `ninjis`, a rough metric for their popularity.
## Data Structure
### Data Instances
```python
{
'pid': '14510618610706594411',
'data_id': 19170881,
'ninjis': 23
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|pid|string|The player ID of the user who created the super world with this level|
|data_id|int|The data ID of the level|
|ninjis|int|Number of ninjis shown on this level|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_world_levels | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:19:22+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 super world levels", "tags": ["text-mining"]} | 2022-11-11T08:03:22+00:00 |
14d9b109a50274f2a278c22c01af335da683965a |
# Mario Maker 2 ninjis
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 ninjis dataset consists of 3 million ninji replays from Nintendo's online service totaling around 12.5GB of data. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
The Mario Maker 2 ninjis dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`. You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_ninji", streaming=True, split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 12171034,
'pid': '4748613890518923485',
'time': 83388,
'replay': [some binary data]
}
```
Each row is a ninji run in the level denoted by the `data_id` done by the player denoted by the `pid`, The length of this ninji run is `time` in milliseconds.
`replay` is a gzip compressed binary file format describing the animation frames and coordinates of the player throughout the run. Parsing the replay is as follows:
```python
from datasets import load_dataset
import zlib
import struct
ds = load_dataset("TheGreatRambler/mm2_ninji", streaming=True, split="train")
row = next(iter(ds))
replay = zlib.decompress(row["replay"])
frames = struct.unpack(">I", replay[0x10:0x14])[0]
character = replay[0x14]
character_mapping = {
0: "Mario",
1: "Luigi",
2: "Toad",
3: "Toadette"
}
# player_state is between 0 and 14 and varies between gamestyles
# as outlined below. Determining the gamestyle of a particular run
# and rendering the level being played requires TheGreatRambler/mm2_ninji_level
player_state_base = {
0: "Run/Walk",
1: "Jump",
2: "Swim",
3: "Climbing",
5: "Sliding",
7: "Dry bones shell",
8: "Clown car",
9: "Cloud",
10: "Boot",
11: "Walking cat"
}
player_state_nsmbu = {
4: "Sliding",
6: "Turnaround",
10: "Yoshi",
12: "Acorn suit",
13: "Propeller active",
14: "Propeller neutral"
}
player_state_sm3dw = {
4: "Sliding",
6: "Turnaround",
7: "Clear pipe",
8: "Cat down attack",
13: "Propeller active",
14: "Propeller neutral"
}
player_state_smb1 = {
4: "Link down slash",
5: "Crouching"
}
player_state_smw = {
10: "Yoshi",
12: "Cape"
}
print("Frames: %d\nCharacter: %s" % (frames, character_mapping[character]))
current_offset = 0x3C
# Ninji updates are reported every 4 frames
for i in range((frames + 2) // 4):
flags = replay[current_offset] >> 4
player_state = replay[current_offset] & 0x0F
current_offset += 1
x = struct.unpack("<H", replay[current_offset:current_offset + 2])[0]
current_offset += 2
y = struct.unpack("<H", replay[current_offset:current_offset + 2])[0]
current_offset += 2
if flags & 0b00000110:
unk1 = replay[current_offset]
current_offset += 1
in_subworld = flags & 0b00001000
print("Frame %d:\n Flags: %s,\n Animation state: %d,\n X: %d,\n Y: %d,\n In subworld: %s"
% (i, bin(flags), player_state, x, y, in_subworld))
#OUTPUT:
Frames: 5006
Character: Mario
Frame 0:
Flags: 0b0,
Animation state: 0,
X: 2672,
Y: 2288,
In subworld: 0
Frame 1:
Flags: 0b0,
Animation state: 0,
X: 2682,
Y: 2288,
In subworld: 0
Frame 2:
Flags: 0b0,
Animation state: 0,
X: 2716,
Y: 2288,
In subworld: 0
...
Frame 1249:
Flags: 0b0,
Animation state: 1,
X: 59095,
Y: 3749,
In subworld: 0
Frame 1250:
Flags: 0b0,
Animation state: 1,
X: 59246,
Y: 3797,
In subworld: 0
Frame 1251:
Flags: 0b0,
Animation state: 1,
X: 59402,
Y: 3769,
In subworld: 0
```
You can also download the full dataset. Note that this will download ~12.5GB:
```python
ds = load_dataset("TheGreatRambler/mm2_ninji", split="train")
```
## Data Structure
### Data Instances
```python
{
'data_id': 12171034,
'pid': '4748613890518923485',
'time': 83388,
'replay': [some binary data]
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|The data ID of the level this run occured in|
|pid|string|Player ID of the player|
|time|int|Length in milliseconds of the run|
|replay|bytes|Replay file of this run|
### Data Splits
The dataset only contains a train split.
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
The dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_ninji | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:1M<n<10M",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:19:35+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 ninjis", "tags": ["text-mining"]} | 2022-11-11T08:05:22+00:00 |
b5f8a698461f84a65ae06ce54705913b6e0928b8 |
# Mario Maker 2 ninji levels
Part of the [Mario Maker 2 Dataset Collection](https://tgrcode.com/posts/mario_maker_2_datasets)
## Dataset Description
The Mario Maker 2 ninji levels dataset consists of 21 ninji levels from Nintendo's online service and aids `TheGreatRambler/mm2_ninji`. The dataset was created using the self-hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api) over the course of 1 month in February 2022.
### How to use it
You can load and iterate through the dataset with the following code:
```python
from datasets import load_dataset
ds = load_dataset("TheGreatRambler/mm2_ninji_level", split="train")
print(next(iter(ds)))
#OUTPUT:
{
'data_id': 12171034,
'name': 'Rolling Snowballs',
'description': 'Make your way through the snowfields, and keep an eye\nout for Spikes and Snow Pokeys! Stomping on Snow Pokeys\nwill turn them into small snowballs, which you can pick up\nand throw. Play this course as many times as you want,\nand see if you can find the fastest way to the finish!',
'uploaded': 1575532800,
'ended': 1576137600,
'gamestyle': 3,
'theme': 6,
'medal_time': 26800,
'clear_condition': 0,
'clear_condition_magnitude': 0,
'unk3_0': 1309513,
'unk3_1': 62629737,
'unk3_2': 4355893,
'unk5': 1,
'unk6': 0,
'unk9': 0,
'level_data': [some binary data]
}
```
Each row is a ninji level denoted by `data_id`. `TheGreatRambler/mm2_ninji` refers to these levels. `level_data` is the same format used in `TheGreatRambler/mm2_level` and the provided Kaitai struct file and `level.py` can be used to decode it:
```python
from datasets import load_dataset
from kaitaistruct import KaitaiStream
from io import BytesIO
from level import Level
import zlib
ds = load_dataset("TheGreatRambler/mm2_ninji_level", split="train")
level_data = next(iter(ds))["level_data"]
level = Level(KaitaiStream(BytesIO(zlib.decompress(level_data))))
# NOTE level.overworld.objects is a fixed size (limitation of Kaitai struct)
# must iterate by object_count or null objects will be included
for i in range(level.overworld.object_count):
obj = level.overworld.objects[i]
print("X: %d Y: %d ID: %s" % (obj.x, obj.y, obj.id))
#OUTPUT:
X: 1200 Y: 400 ID: ObjId.block
X: 1360 Y: 400 ID: ObjId.block
X: 1360 Y: 240 ID: ObjId.block
X: 1520 Y: 240 ID: ObjId.block
X: 1680 Y: 240 ID: ObjId.block
X: 1680 Y: 400 ID: ObjId.block
X: 1840 Y: 400 ID: ObjId.block
X: 2000 Y: 400 ID: ObjId.block
X: 2160 Y: 400 ID: ObjId.block
X: 2320 Y: 400 ID: ObjId.block
X: 2480 Y: 560 ID: ObjId.block
X: 2480 Y: 720 ID: ObjId.block
X: 2480 Y: 880 ID: ObjId.block
X: 2160 Y: 880 ID: ObjId.block
```
## Data Structure
### Data Instances
```python
{
'data_id': 12171034,
'name': 'Rolling Snowballs',
'description': 'Make your way through the snowfields, and keep an eye\nout for Spikes and Snow Pokeys! Stomping on Snow Pokeys\nwill turn them into small snowballs, which you can pick up\nand throw. Play this course as many times as you want,\nand see if you can find the fastest way to the finish!',
'uploaded': 1575532800,
'ended': 1576137600,
'gamestyle': 3,
'theme': 6,
'medal_time': 26800,
'clear_condition': 0,
'clear_condition_magnitude': 0,
'unk3_0': 1309513,
'unk3_1': 62629737,
'unk3_2': 4355893,
'unk5': 1,
'unk6': 0,
'unk9': 0,
'level_data': [some binary data]
}
```
### Data Fields
|Field|Type|Description|
|---|---|---|
|data_id|int|The data ID of this ninji level|
|name|string|Name|
|description|string|Description|
|uploaded|int|UTC timestamp of when this was uploaded|
|ended|int|UTC timestamp of when this event ended|
|gamestyle|int|Gamestyle, enum below|
|theme|int|Theme, enum below|
|medal_time|int|Time to get a medal in milliseconds|
|clear_condition|int|Clear condition, enum below|
|clear_condition_magnitude|int|If applicable, the magnitude of the clear condition|
|unk3_0|int|Unknown|
|unk3_1|int|Unknown|
|unk3_2|int|Unknown|
|unk5|int|Unknown|
|unk6|int|Unknown|
|unk9|int|Unknown|
|level_data|bytes|The GZIP compressed decrypted level data, a kaitai struct file is provided to read this|
|one_screen_thumbnail|bytes|The one screen course thumbnail, as a JPEG binary|
|one_screen_thumbnail_url|string|The old URL of this thumbnail|
|one_screen_thumbnail_size|int|The filesize of this thumbnail|
|one_screen_thumbnail_filename|string|The filename of this thumbnail|
|entire_thumbnail|bytes|The entire course thumbnail, as a JPEG binary|
|entire_thumbnail_url|string|The old URL of this thumbnail|
|entire_thumbnail_size|int|The filesize of this thumbnail|
|entire_thumbnail_filename|string|The filename of this thumbnail|
### Data Splits
The dataset only contains a train split.
## Enums
The dataset contains some enum integer fields. They match those used by `TheGreatRambler/mm2_level` for the most part, but they are reproduced below:
```python
GameStyles = {
0: "SMB1",
1: "SMB3",
2: "SMW",
3: "NSMBU",
4: "SM3DW"
}
CourseThemes = {
0: "Overworld",
1: "Underground",
2: "Castle",
3: "Airship",
4: "Underwater",
5: "Ghost house",
6: "Snow",
7: "Desert",
8: "Sky",
9: "Forest"
}
ClearConditions = {
137525990: "Reach the goal without landing after leaving the ground.",
199585683: "Reach the goal after defeating at least/all (n) Mechakoopa(s).",
272349836: "Reach the goal after defeating at least/all (n) Cheep Cheep(s).",
375673178: "Reach the goal without taking damage.",
426197923: "Reach the goal as Boomerang Mario.",
436833616: "Reach the goal while wearing a Shoe.",
713979835: "Reach the goal as Fire Mario.",
744927294: "Reach the goal as Frog Mario.",
751004331: "Reach the goal after defeating at least/all (n) Larry(s).",
900050759: "Reach the goal as Raccoon Mario.",
947659466: "Reach the goal after defeating at least/all (n) Blooper(s).",
976173462: "Reach the goal as Propeller Mario.",
994686866: "Reach the goal while wearing a Propeller Box.",
998904081: "Reach the goal after defeating at least/all (n) Spike(s).",
1008094897: "Reach the goal after defeating at least/all (n) Boom Boom(s).",
1051433633: "Reach the goal while holding a Koopa Shell.",
1061233896: "Reach the goal after defeating at least/all (n) Porcupuffer(s).",
1062253843: "Reach the goal after defeating at least/all (n) Charvaargh(s).",
1079889509: "Reach the goal after defeating at least/all (n) Bullet Bill(s).",
1080535886: "Reach the goal after defeating at least/all (n) Bully/Bullies.",
1151250770: "Reach the goal while wearing a Goomba Mask.",
1182464856: "Reach the goal after defeating at least/all (n) Hop-Chops.",
1219761531: "Reach the goal while holding a Red POW Block. OR Reach the goal after activating at least/all (n) Red POW Block(s).",
1221661152: "Reach the goal after defeating at least/all (n) Bob-omb(s).",
1259427138: "Reach the goal after defeating at least/all (n) Spiny/Spinies.",
1268255615: "Reach the goal after defeating at least/all (n) Bowser(s)/Meowser(s).",
1279580818: "Reach the goal after defeating at least/all (n) Ant Trooper(s).",
1283945123: "Reach the goal on a Lakitu's Cloud.",
1344044032: "Reach the goal after defeating at least/all (n) Boo(s).",
1425973877: "Reach the goal after defeating at least/all (n) Roy(s).",
1429902736: "Reach the goal while holding a Trampoline.",
1431944825: "Reach the goal after defeating at least/all (n) Morton(s).",
1446467058: "Reach the goal after defeating at least/all (n) Fish Bone(s).",
1510495760: "Reach the goal after defeating at least/all (n) Monty Mole(s).",
1656179347: "Reach the goal after picking up at least/all (n) 1-Up Mushroom(s).",
1665820273: "Reach the goal after defeating at least/all (n) Hammer Bro(s.).",
1676924210: "Reach the goal after hitting at least/all (n) P Switch(es). OR Reach the goal while holding a P Switch.",
1715960804: "Reach the goal after activating at least/all (n) POW Block(s). OR Reach the goal while holding a POW Block.",
1724036958: "Reach the goal after defeating at least/all (n) Angry Sun(s).",
1730095541: "Reach the goal after defeating at least/all (n) Pokey(s).",
1780278293: "Reach the goal as Superball Mario.",
1839897151: "Reach the goal after defeating at least/all (n) Pom Pom(s).",
1969299694: "Reach the goal after defeating at least/all (n) Peepa(s).",
2035052211: "Reach the goal after defeating at least/all (n) Lakitu(s).",
2038503215: "Reach the goal after defeating at least/all (n) Lemmy(s).",
2048033177: "Reach the goal after defeating at least/all (n) Lava Bubble(s).",
2076496776: "Reach the goal while wearing a Bullet Bill Mask.",
2089161429: "Reach the goal as Big Mario.",
2111528319: "Reach the goal as Cat Mario.",
2131209407: "Reach the goal after defeating at least/all (n) Goomba(s)/Galoomba(s).",
2139645066: "Reach the goal after defeating at least/all (n) Thwomp(s).",
2259346429: "Reach the goal after defeating at least/all (n) Iggy(s).",
2549654281: "Reach the goal while wearing a Dry Bones Shell.",
2694559007: "Reach the goal after defeating at least/all (n) Sledge Bro(s.).",
2746139466: "Reach the goal after defeating at least/all (n) Rocky Wrench(es).",
2749601092: "Reach the goal after grabbing at least/all (n) 50-Coin(s).",
2855236681: "Reach the goal as Flying Squirrel Mario.",
3036298571: "Reach the goal as Buzzy Mario.",
3074433106: "Reach the goal as Builder Mario.",
3146932243: "Reach the goal as Cape Mario.",
3174413484: "Reach the goal after defeating at least/all (n) Wendy(s).",
3206222275: "Reach the goal while wearing a Cannon Box.",
3314955857: "Reach the goal as Link.",
3342591980: "Reach the goal while you have Super Star invincibility.",
3346433512: "Reach the goal after defeating at least/all (n) Goombrat(s)/Goombud(s).",
3348058176: "Reach the goal after grabbing at least/all (n) 10-Coin(s).",
3353006607: "Reach the goal after defeating at least/all (n) Buzzy Beetle(s).",
3392229961: "Reach the goal after defeating at least/all (n) Bowser Jr.(s).",
3437308486: "Reach the goal after defeating at least/all (n) Koopa Troopa(s).",
3459144213: "Reach the goal after defeating at least/all (n) Chain Chomp(s).",
3466227835: "Reach the goal after defeating at least/all (n) Muncher(s).",
3481362698: "Reach the goal after defeating at least/all (n) Wiggler(s).",
3513732174: "Reach the goal as SMB2 Mario.",
3649647177: "Reach the goal in a Koopa Clown Car/Junior Clown Car.",
3725246406: "Reach the goal as Spiny Mario.",
3730243509: "Reach the goal in a Koopa Troopa Car.",
3748075486: "Reach the goal after defeating at least/all (n) Piranha Plant(s)/Jumping Piranha Plant(s).",
3797704544: "Reach the goal after defeating at least/all (n) Dry Bones.",
3824561269: "Reach the goal after defeating at least/all (n) Stingby/Stingbies.",
3833342952: "Reach the goal after defeating at least/all (n) Piranha Creeper(s).",
3842179831: "Reach the goal after defeating at least/all (n) Fire Piranha Plant(s).",
3874680510: "Reach the goal after breaking at least/all (n) Crates(s).",
3974581191: "Reach the goal after defeating at least/all (n) Ludwig(s).",
3977257962: "Reach the goal as Super Mario.",
4042480826: "Reach the goal after defeating at least/all (n) Skipsqueak(s).",
4116396131: "Reach the goal after grabbing at least/all (n) Coin(s).",
4117878280: "Reach the goal after defeating at least/all (n) Magikoopa(s).",
4122555074: "Reach the goal after grabbing at least/all (n) 30-Coin(s).",
4153835197: "Reach the goal as Balloon Mario.",
4172105156: "Reach the goal while wearing a Red POW Box.",
4209535561: "Reach the Goal while riding Yoshi.",
4269094462: "Reach the goal after defeating at least/all (n) Spike Top(s).",
4293354249: "Reach the goal after defeating at least/all (n) Banzai Bill(s)."
}
```
<!-- TODO create detailed statistics -->
## Dataset Creation
The dataset was created over a little more than a month in Febuary 2022 using the self hosted [Mario Maker 2 api](https://tgrcode.com/posts/mario_maker_2_api). As requests made to Nintendo's servers require authentication the process had to be done with upmost care and limiting download speed as to not overload the API and risk a ban. There are no intentions to create an updated release of this dataset.
## Considerations for Using the Data
As these 21 levels were made and vetted by Nintendo the dataset contains no harmful language or depictions.
| TheGreatRambler/mm2_ninji_level | [
"task_categories:other",
"task_categories:object-detection",
"task_categories:text-retrieval",
"task_categories:token-classification",
"task_categories:text-generation",
"multilinguality:multilingual",
"size_categories:n<1K",
"source_datasets:original",
"language:multilingual",
"license:cc-by-nc-sa-4.0",
"text-mining",
"region:us"
] | 2022-09-18T19:19:47+00:00 | {"language": ["multilingual"], "license": ["cc-by-nc-sa-4.0"], "multilinguality": ["multilingual"], "size_categories": ["n<1K"], "source_datasets": ["original"], "task_categories": ["other", "object-detection", "text-retrieval", "token-classification", "text-generation"], "task_ids": [], "pretty_name": "Mario Maker 2 ninji levels", "tags": ["text-mining"]} | 2022-11-11T08:08:00+00:00 |
448fdb1bc7b2d09e46881c4541a14d796a3d41e8 |
# Dataset Card for "yerevann/coco-karpathy"
The Karpathy split of COCO for image captioning.
| yerevann/coco-karpathy | [
"task_categories:image-to-text",
"task_ids:image-captioning",
"language:en",
"coco",
"image-captioning",
"region:us"
] | 2022-09-18T21:50:19+00:00 | {"language": ["en"], "task_categories": ["image-to-text"], "task_ids": ["image-captioning"], "pretty_name": "COCO Karpathy split", "tags": ["coco", "image-captioning"]} | 2022-10-31T11:24:01+00:00 |
98f01722de4b3d391834c5c3afd256598728e170 | J236/testing | [
"license:agpl-3.0",
"region:us"
] | 2022-09-18T22:05:58+00:00 | {"license": "agpl-3.0"} | 2022-09-18T22:11:04+00:00 |
|
8a86b23b745d215c4dbbb058f0c41185c7fab734 |
# Dataset Card for SOAP
| jamil/soap_notes | [
"license:apache-2.0",
"region:us"
] | 2022-09-18T23:54:25+00:00 | {"license": "apache-2.0"} | 2022-09-19T00:33:08+00:00 |
8447c236d6c6bf4986eb3e4330a41d258b727362 |
# Dataset Description
This is a dataset of emotional contexts that was retrieved from the original EmpatheticDialogues (ED) dataset. Respondents were asked to describe an event that was associated with a particular emotion label (i.e. p(event|emotion).
There are 32 emotion labels in total.
There are 19209, 2756, and 2542 instances of emotional descriptions in the train, valid, and test set, respectively. | bdotloh/empathetic-dialogues-contexts | [
"task_categories:text-classification",
"annotations_creators:crowdsourced",
"multilinguality:monolingual",
"language:en",
"region:us"
] | 2022-09-19T04:58:21+00:00 | {"annotations_creators": ["crowdsourced"], "language": ["en"], "multilinguality": ["monolingual"], "task_categories": ["text-classification"]} | 2022-09-21T05:12:44+00:00 |
7d5077a33a8336d2f53095765e22cf9987443996 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: morenolq/bart-base-xsum
* Dataset: xsum
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@morenolq](https://huggingface.co/morenolq) for evaluating this model. | autoevaluate/autoeval-eval-xsum-default-ca7304-1504954794 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-19T06:52:37+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["xsum"], "eval_info": {"task": "summarization", "model": "morenolq/bart-base-xsum", "metrics": ["bertscore"], "dataset_name": "xsum", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "document", "target": "summary"}}} | 2022-09-19T07:01:07+00:00 |
8818654486d5eed521811ebebbb84cdce5ce3bb1 | hkgkjg111/ai_paint_2 | [
"region:us"
] | 2022-09-19T08:52:49+00:00 | {} | 2022-09-19T08:53:25+00:00 |
|
95b112abeaf5782f4326d869e1081816556a5d16 |
A sampled version of the [CCMatrix](https://huggingface.co/datasets/yhavinga/ccmatrix) dataset for the German-English pair, containing 1M train entries. | j0hngou/ccmatrix_de-en | [
"language:en",
"language:de",
"region:us"
] | 2022-09-19T12:08:48+00:00 | {"language": ["en", "de"]} | 2022-09-26T15:35:03+00:00 |
0f9bec2b0fbbfc8643ae5442903d63dd701ff51b |
# Dataset Card for Literary fictions of Gallica
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://doi.org/10.5281/zenodo.4660197
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The collection "Fiction littéraire de Gallica" includes 19,240 public domain documents from the digital platform of the French National Library that were originally classified as novels or, more broadly, as literary fiction in prose. It consists of 372 tables of data in tsv format for each year of publication from 1600 to 1996 (all the missing years are in the 17th and 20th centuries). Each table is structured at the page-level of each novel (5,723,986 pages in all). It contains the complete text with the addition of some metadata. It can be opened in Excel or, preferably, with the new data analysis environments in R or Python (tidyverse, pandas…)
This corpus can be used for large-scale quantitative analyses in computational humanities. The OCR text is presented in a raw format without any correction or enrichment in order to be directly processed for text mining purposes.
The extraction is based on a historical categorization of the novels: the Y2 or Ybis classification. This classification, invented in 1730, is the only one that has been continuously applied to the BNF collections now available in the public domain (mainly before 1950). Consequently, the dataset is based on a definition of "novel" that is generally contemporary of the publication.
A French data paper (in PDF and HTML) presents the construction process of the Y2 category and describes the structuring of the corpus. It also gives several examples of possible uses for computational humanities projects.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
```
{
'main_id': 'bpt6k97892392_p174',
'catalogue_id': 'cb31636383z',
'titre': "L'île du docteur Moreau",
'nom_auteur': 'Wells',
'prenom_auteur': 'Herbert George',
'date': 1946,
'document_ocr': 99,
'date_enligne': '07/08/2017',
'gallica': 'http://gallica.bnf.fr/ark:/12148/bpt6k97892392/f174',
'page': 174,
'texte': "_p_ dans leur expression et leurs gestes souples, d au- c tres semblables à des estropiés, ou si étrangement i défigurées qu'on eût dit les êtres qui hantent nos M rêves les plus sinistres. Au delà, se trouvaient d 'un côté les lignes onduleuses -des roseaux, de l'autre, s un dense enchevêtrement de palmiers nous séparant du ravin des 'huttes et, vers le Nord, l horizon brumeux du Pacifique. - _p_ — Soixante-deux, soixante-trois, compta Mo- H reau, il en manque quatre. J _p_ — Je ne vois pas l'Homme-Léopard, dis-je. | Tout à coup Moreau souffla une seconde fois dans son cor, et à ce son toutes les bêtes humai- ' nes se roulèrent et se vautrèrent dans la poussière. Alors se glissant furtivement hors des roseaux, rampant presque et essayant de rejoindre le cercle des autres derrière le dos de Moreau, parut l'Homme-Léopard. Le dernier qui vint fut le petit Homme-Singe. Les autres, échauffés et fatigués par leurs gesticulations, lui lancèrent de mauvais regards. _p_ — Assez! cria Moreau, de sa voix sonore et ferme. Toutes les bêtes s'assirent sur leurs talons et cessèrent leur adoration. - _p_ — Où est celui |qui enseigne la Loi? demanda Moreau."
}
```
### Data Fields
- `main_id`: Unique identifier of the page of the roman.
- `catalogue_id`: Identifier of the edition in the BNF catalogue.
- `titre`: Title of the edition as it appears in the catalog.
- `nom_auteur`: Author's name.
- `prenom_auteur`: Author's first name.
- `date`: Year of edition.
- `document_ocr`: Estimated quality of ocerization for the whole document as a percentage of words probably well recognized (from 1-100).
- `date_enligne`: Date of the online publishing of the digitization on Gallica.
- `gallica`: URL of the document on Gallica.
- `page`: Document page number (this is the pagination of the digital file, not the one of the original document).
- `texte`: Page text, as rendered by OCR.
### Data Splits
The dataset contains a single "train" split.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[Creative Commons Zero v1.0 Universal](https://creativecommons.org/publicdomain/zero/1.0/legalcode).
### Citation Information
```
@dataset{langlais_pierre_carl_2021_4751204,
author = {Langlais, Pierre-Carl},
title = {{Fictions littéraires de Gallica / Literary
fictions of Gallica}},
month = apr,
year = 2021,
publisher = {Zenodo},
version = 1,
doi = {10.5281/zenodo.4751204},
url = {https://doi.org/10.5281/zenodo.4751204}
}
```
### Contributions
Thanks to [@albertvillanova](https://github.com/albertvillanova) for adding this dataset.
| biglam/gallica_literary_fictions | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"source_datasets:original",
"language:fr",
"license:cc0-1.0",
"region:us"
] | 2022-09-19T12:17:09+00:00 | {"language": "fr", "license": "cc0-1.0", "multilinguality": ["monolingual"], "source_datasets": ["original"], "task_categories": ["text-generation"], "task_ids": ["language-modeling"], "pretty_name": "Literary fictions of Gallica"} | 2022-09-19T12:58:06+00:00 |
559e6e78c86a66b7353e87f78b2eaf5b487e0744 | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: morenolq/bart-base-xsum
* Dataset: xsum
* Config: default
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@morenolq](https://huggingface.co/morenolq) for evaluating this model. | autoevaluate/autoeval-eval-xsum-default-d5c7a7-1507154810 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-19T12:37:20+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["xsum"], "eval_info": {"task": "summarization", "model": "morenolq/bart-base-xsum", "metrics": ["bertscore"], "dataset_name": "xsum", "dataset_config": "default", "dataset_split": "validation", "col_mapping": {"text": "document", "target": "summary"}}} | 2022-09-19T12:45:50+00:00 |
8e4813d4198fd5da65377f6757b4a420c8a6eb5b | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Question Answering
* Model: navteca/roberta-large-squad2
* Dataset: squad_v2
* Config: squad_v2
* Split: validation
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@tvdermeer](https://huggingface.co/tvdermeer) for evaluating this model. | autoevaluate/autoeval-eval-squad_v2-squad_v2-552ce2-1507654811 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-19T12:37:23+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["squad_v2"], "eval_info": {"task": "extractive_question_answering", "model": "navteca/roberta-large-squad2", "metrics": [], "dataset_name": "squad_v2", "dataset_config": "squad_v2", "dataset_split": "validation", "col_mapping": {"context": "context", "question": "question", "answers-text": "answers.text", "answers-answer_start": "answers.answer_start"}}} | 2022-09-19T12:41:56+00:00 |
76fb3cdf9ae1951b111ed14ef24d58d24c39d46c | # Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Multi-class Text Classification
* Model: morenolq/distilbert-base-cased-emotion
* Dataset: emotion
* Config: default
* Split: test
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@morenolq](https://huggingface.co/morenolq) for evaluating this model. | autoevaluate/autoeval-eval-emotion-default-2be497-1508254837 | [
"autotrain",
"evaluation",
"region:us"
] | 2022-09-19T13:17:15+00:00 | {"type": "predictions", "tags": ["autotrain", "evaluation"], "datasets": ["emotion"], "eval_info": {"task": "multi_class_classification", "model": "morenolq/distilbert-base-cased-emotion", "metrics": [], "dataset_name": "emotion", "dataset_config": "default", "dataset_split": "test", "col_mapping": {"text": "text", "target": "label"}}} | 2022-09-19T13:17:42+00:00 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.