
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-03 12:31:03
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 537
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-03 12:30:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
dkqjrm/20230903015507
|
dkqjrm
| 2023-09-02T22:02:46Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:super_glue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-02T16:55:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- super_glue
metrics:
- accuracy
model-index:
- name: '20230903015507'
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 20230903015507
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the super_glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8747
- Accuracy: 0.6505
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 11
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 80.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| No log | 1.0 | 340 | 0.6715 | 0.5172 |
| 0.6923 | 2.0 | 680 | 0.6802 | 0.5 |
| 0.6863 | 3.0 | 1020 | 0.6721 | 0.5 |
| 0.6863 | 4.0 | 1360 | 0.7046 | 0.5 |
| 0.6843 | 5.0 | 1700 | 0.6757 | 0.5 |
| 0.6885 | 6.0 | 2040 | 0.6788 | 0.5 |
| 0.6885 | 7.0 | 2380 | 0.6702 | 0.5 |
| 0.686 | 8.0 | 2720 | 0.6763 | 0.5 |
| 0.6858 | 9.0 | 3060 | 0.6777 | 0.5 |
| 0.6858 | 10.0 | 3400 | 0.6804 | 0.5 |
| 0.6868 | 11.0 | 3740 | 0.6711 | 0.5 |
| 0.6817 | 12.0 | 4080 | 0.6777 | 0.5 |
| 0.6817 | 13.0 | 4420 | 0.6960 | 0.5 |
| 0.6805 | 14.0 | 4760 | 0.6901 | 0.5 |
| 0.6823 | 15.0 | 5100 | 0.6715 | 0.5 |
| 0.6823 | 16.0 | 5440 | 0.6738 | 0.5016 |
| 0.6776 | 17.0 | 5780 | 0.6813 | 0.5 |
| 0.676 | 18.0 | 6120 | 0.6718 | 0.5 |
| 0.676 | 19.0 | 6460 | 0.6727 | 0.5 |
| 0.6762 | 20.0 | 6800 | 0.6742 | 0.4984 |
| 0.6748 | 21.0 | 7140 | 0.6699 | 0.5282 |
| 0.6748 | 22.0 | 7480 | 0.6624 | 0.5141 |
| 0.6749 | 23.0 | 7820 | 0.7549 | 0.5705 |
| 0.6441 | 24.0 | 8160 | 0.6447 | 0.6238 |
| 0.6189 | 25.0 | 8500 | 0.6692 | 0.6113 |
| 0.6189 | 26.0 | 8840 | 0.6171 | 0.6771 |
| 0.582 | 27.0 | 9180 | 0.7757 | 0.5831 |
| 0.5622 | 28.0 | 9520 | 0.8074 | 0.6050 |
| 0.5622 | 29.0 | 9860 | 0.6636 | 0.6614 |
| 0.5303 | 30.0 | 10200 | 0.7353 | 0.6458 |
| 0.5188 | 31.0 | 10540 | 0.6546 | 0.6536 |
| 0.5188 | 32.0 | 10880 | 0.8451 | 0.6082 |
| 0.5007 | 33.0 | 11220 | 0.7618 | 0.6442 |
| 0.4847 | 34.0 | 11560 | 0.6832 | 0.6583 |
| 0.4847 | 35.0 | 11900 | 0.7070 | 0.6442 |
| 0.4719 | 36.0 | 12240 | 0.6991 | 0.6536 |
| 0.4523 | 37.0 | 12580 | 0.7525 | 0.6661 |
| 0.4523 | 38.0 | 12920 | 0.7912 | 0.6348 |
| 0.4447 | 39.0 | 13260 | 0.7760 | 0.6536 |
| 0.439 | 40.0 | 13600 | 0.8018 | 0.6458 |
| 0.439 | 41.0 | 13940 | 0.7104 | 0.6708 |
| 0.4248 | 42.0 | 14280 | 0.7607 | 0.6599 |
| 0.4063 | 43.0 | 14620 | 0.6979 | 0.6803 |
| 0.4063 | 44.0 | 14960 | 0.7796 | 0.6614 |
| 0.4123 | 45.0 | 15300 | 0.7394 | 0.6708 |
| 0.3984 | 46.0 | 15640 | 0.7791 | 0.6599 |
| 0.3984 | 47.0 | 15980 | 0.7433 | 0.6614 |
| 0.3871 | 48.0 | 16320 | 0.7870 | 0.6442 |
| 0.3787 | 49.0 | 16660 | 0.7256 | 0.6755 |
| 0.3884 | 50.0 | 17000 | 0.8035 | 0.6536 |
| 0.3884 | 51.0 | 17340 | 0.7809 | 0.6489 |
| 0.373 | 52.0 | 17680 | 0.7920 | 0.6567 |
| 0.3704 | 53.0 | 18020 | 0.8107 | 0.6661 |
| 0.3704 | 54.0 | 18360 | 0.8759 | 0.6113 |
| 0.3628 | 55.0 | 18700 | 0.8727 | 0.6332 |
| 0.3518 | 56.0 | 19040 | 0.8756 | 0.6254 |
| 0.3518 | 57.0 | 19380 | 0.8555 | 0.6317 |
| 0.3536 | 58.0 | 19720 | 0.8082 | 0.6254 |
| 0.3504 | 59.0 | 20060 | 0.7880 | 0.6614 |
| 0.3504 | 60.0 | 20400 | 0.9100 | 0.6301 |
| 0.3466 | 61.0 | 20740 | 0.8614 | 0.6207 |
| 0.3425 | 62.0 | 21080 | 0.8712 | 0.6301 |
| 0.3425 | 63.0 | 21420 | 0.8285 | 0.6614 |
| 0.339 | 64.0 | 21760 | 0.9010 | 0.6599 |
| 0.3339 | 65.0 | 22100 | 0.9055 | 0.6426 |
| 0.3339 | 66.0 | 22440 | 0.8365 | 0.6646 |
| 0.3294 | 67.0 | 22780 | 0.8333 | 0.6505 |
| 0.3365 | 68.0 | 23120 | 0.8414 | 0.6426 |
| 0.3365 | 69.0 | 23460 | 0.8855 | 0.6395 |
| 0.332 | 70.0 | 23800 | 0.9028 | 0.6364 |
| 0.3171 | 71.0 | 24140 | 0.8584 | 0.6364 |
| 0.3171 | 72.0 | 24480 | 0.8482 | 0.6536 |
| 0.3204 | 73.0 | 24820 | 0.8713 | 0.6426 |
| 0.3289 | 74.0 | 25160 | 0.8881 | 0.6473 |
| 0.3139 | 75.0 | 25500 | 0.8588 | 0.6473 |
| 0.3139 | 76.0 | 25840 | 0.8772 | 0.6473 |
| 0.3159 | 77.0 | 26180 | 0.9019 | 0.6536 |
| 0.306 | 78.0 | 26520 | 0.8819 | 0.6505 |
| 0.306 | 79.0 | 26860 | 0.8837 | 0.6473 |
| 0.3091 | 80.0 | 27200 | 0.8747 | 0.6505 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
actionpace/limarp-13b-merged
|
actionpace
| 2023-09-02T21:55:51Z | 5 | 0 | null |
[
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-09-01T18:43:20Z |
---
license: other
language:
- en
---
Some of my own quants:
* limarp-13b-merged_Q5_1.gguf
* limarp-13b-merged_Q5_1_4K.gguf
* limarp-13b-merged_Q5_1_8K.gguf
Original Model: [limarp-13b-merged](https://huggingface.co/Oniichat/limarp-13b-merged)
|
dt-and-vanilla-ardt/dt-d4rl_medium_hopper-0209_2131-33
|
dt-and-vanilla-ardt
| 2023-09-02T21:50:03Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
] | null | 2023-09-02T21:31:56Z |
---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_hopper-0209_2131-33
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_hopper-0209_2131-33
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
actionpace/ReMM-L2-13B
|
actionpace
| 2023-09-02T21:48:53Z | 1 | 0 | null |
[
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-09-02T21:33:44Z |
---
license: other
language:
- en
---
Some of my own quants:
* ReMM-L2-13B_Q5_1_4K.gguf
* ReMM-L2-13B_Q5_1_8K.gguf
Original Model: [ReMM-L2-13B](https://huggingface.co/Undi95/ReMM-L2-13B)
|
KingKazma/xsum_t5-small_p_tuning_500_3_50000_8_e-1_s6789_v4_l4_v100_resume_manual
|
KingKazma
| 2023-09-02T21:23:08Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T21:23:07Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
jjluo/my_awesome_food_model
|
jjluo
| 2023-09-02T21:20:53Z | 191 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:food101",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-02T21:10:12Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- food101
metrics:
- accuracy
model-index:
- name: my_awesome_food_model
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: food101
type: food101
config: default
split: train[:5000]
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6222
- Accuracy: 0.908
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7507 | 0.99 | 62 | 2.5634 | 0.831 |
| 1.8341 | 2.0 | 125 | 1.7980 | 0.87 |
| 1.6407 | 2.98 | 186 | 1.6222 | 0.908 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_420
|
The-matt
| 2023-09-02T21:02:34Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T21:02:30Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
ZukoVZA/Morfonica
|
ZukoVZA
| 2023-09-02T20:57:47Z | 0 | 0 | null |
[
"license:openrail",
"region:us"
] | null | 2023-04-23T22:07:39Z |
---
license: openrail
---
liuwei : Rui
qinshen : Nanami
touzi : Touko
zenbai : Mashiro
zuzhi : Futaba
|
actionpace/UndiMix-v1-13b
|
actionpace
| 2023-09-02T20:57:35Z | 2 | 0 | null |
[
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-09-02T20:38:02Z |
---
license: other
language:
- en
---
Some of my own quants:
* UndiMix-v1-13b_Q5_1_4K.gguf
* UndiMix-v1-13b_Q5_1_8K.gguf
Original Model: [UndiMix-v1-13b](https://huggingface.co/Undi95/UndiMix-v1-13b)
|
jaober/CartPole-v1
|
jaober
| 2023-09-02T20:57:06Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-02T20:56:57Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
santoro/distilbert-base-uncased-finetuned-emotion
|
santoro
| 2023-09-02T20:55:08Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-02T18:22:40Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.922
- name: F1
type: f1
value: 0.9218197070909727
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2228
- Accuracy: 0.922
- F1: 0.9218
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8615 | 1.0 | 250 | 0.3301 | 0.9055 | 0.9045 |
| 0.261 | 2.0 | 500 | 0.2228 | 0.922 | 0.9218 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_410
|
The-matt
| 2023-09-02T20:54:06Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T20:54:03Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
actionpace/MythoMax-L2-Kimiko-v2-13b
|
actionpace
| 2023-09-02T20:48:28Z | 10 | 0 | null |
[
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-09-02T20:23:18Z |
---
license: other
language:
- en
---
Some of my own quants:
* MythoMax-L2-Kimiko-v2-13b_Q5_1_4K.gguf
* MythoMax-L2-Kimiko-v2-13b_Q5_1_8K.gguf
Original Model: [MythoMax-L2-Kimiko-v2-13b](https://huggingface.co/Undi95/MythoMax-L2-Kimiko-v2-13b)
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e3_s6789_v4_l4_v100
|
KingKazma
| 2023-09-02T20:43:27Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T16:15:43Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
caveli/bloom_prompt_tuning_1693686452.0382597
|
caveli
| 2023-09-02T20:32:52Z | 4 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T20:32:50Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
skipperjo/wav2vec2-large-xls-r-300m-slowakisch-colab
|
skipperjo
| 2023-09-02T20:30:03Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_11_0",
"base_model:facebook/wav2vec2-xls-r-300m",
"base_model:finetune:facebook/wav2vec2-xls-r-300m",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-09-02T19:15:33Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-xls-r-300m
tags:
- generated_from_trainer
datasets:
- common_voice_11_0
model-index:
- name: wav2vec2-large-xls-r-300m-slowakisch-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-slowakisch-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice_11_0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_380
|
The-matt
| 2023-09-02T20:26:25Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T20:26:21Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_p_tuning_500_3_50000_8_e1_s6789_v4_l4_v100
|
KingKazma
| 2023-09-02T20:19:06Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T20:19:05Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
actionpace/Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged
|
actionpace
| 2023-09-02T20:17:30Z | 3 | 0 | null |
[
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-09-02T19:51:33Z |
---
license: other
language:
- en
---
Some of my own quants:
* Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged_Q5_1_4K.gguf
* Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged_Q5_1_8K.gguf
Original Model: [Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged](https://huggingface.co/Doctor-Shotgun/Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged)
|
nmitchko/i2b2-querybuilder-codellama-34b
|
nmitchko
| 2023-09-02T20:14:51Z | 6 | 0 |
peft
|
[
"peft",
"medical",
"text-generation",
"en",
"arxiv:2106.09685",
"license:llama2",
"region:us"
] |
text-generation
| 2023-09-01T18:55:52Z |
---
language:
- en
library_name: peft
pipeline_tag: text-generation
tags:
- medical
license: llama2
---
# i2b2 QueryBuilder - 34b
<!-- TODO: Add a link here N: DONE-->
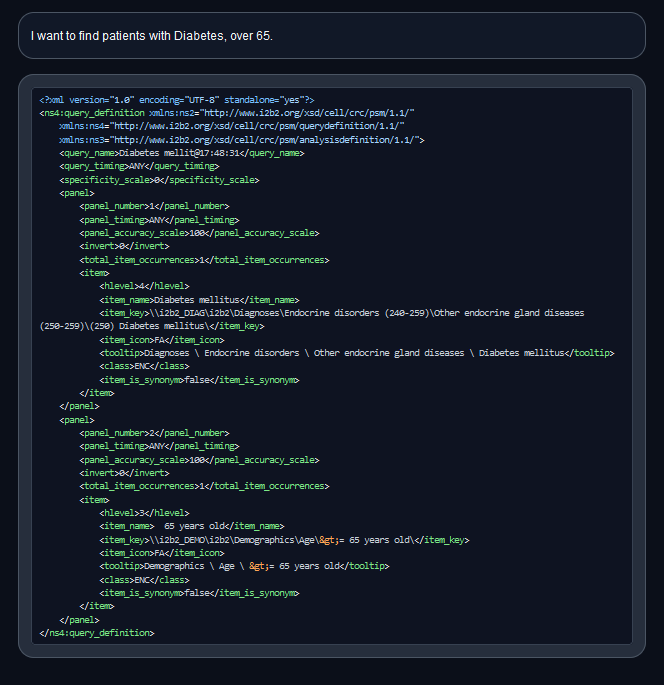
## Model Description
This model will generate queries for your i2b2 query builder trained on [this dataset](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0) for `10 epochs` . For evaluation use.
* Do not use as a final research query builder.
* Results may be incorrect or mal-formatted.
* The onus of research accuracy is on the researcher, not the AI model.
## Prompt Format
If you are using text-generation-webui, you can download the instruction template [i2b2.yaml](https://huggingface.co/nmitchko/i2b2-querybuilder-codellama-34b/resolve/main/i2b2.yaml)
```md
Below is an instruction that describes a task.
### Instruction:
{input}
### Response:
```xml
```
### Architecture
`nmitchko/i2b2-querybuilder-codellama-34b` is a large language model LoRa specifically fine-tuned for generating queries in the [i2b2 query builder](https://community.i2b2.org/wiki/display/webclient/3.+Query+Tool).
It is based on [`codellama-34b-hf`](https://huggingface.co/codellama/CodeLlama-34b-hf) at 34 billion parameters.
The primary goal of this model is to improve research accuracy with the i2b2 tool.
It was trained using [LoRA](https://arxiv.org/abs/2106.09685), specifically [QLora Multi GPU](https://github.com/ChrisHayduk/qlora-multi-gpu), to reduce memory footprint.
See Training Parameters for more info This Lora supports 4-bit and 8-bit modes.
### Requirements
```
bitsandbytes>=0.41.0
peft@main
transformers@main
```
Steps to load this model:
1. Load base model (codellama-34b-hf) using transformers
2. Apply LoRA using peft
```python
# Sample Code Coming
```
## Training Parameters
The model was trained for or 10 epochs on [i2b2-query-data-1.0](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0)
`i2b2-query-data-1.0` contains only tasks and outputs for i2b2 queries xsd schemas.
| Item | Amount | Units |
|---------------|--------|-------|
| LoRA Rank | 64 | ~ |
| LoRA Alpha | 16 | ~ |
| Learning Rate | 1e-4 | SI |
| Dropout | 5 | % |
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
dammyogt/common_voice_8_0_ha
|
dammyogt
| 2023-09-02T20:12:00Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:common_voice_8_0",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2023-09-01T23:30:15Z |
---
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- common_voice_8_0
model-index:
- name: common_voice_8_0_ha
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# common_voice_8_0_ha
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the common_voice_8_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4741
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5416 | 18.31 | 1000 | 0.4974 |
| 0.505 | 36.61 | 2000 | 0.4760 |
| 0.4898 | 54.92 | 3000 | 0.4758 |
| 0.5004 | 73.23 | 4000 | 0.4741 |
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_360
|
The-matt
| 2023-09-02T19:51:05Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T19:51:01Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e10_s6789_v4_l4_r4
|
KingKazma
| 2023-09-02T19:42:43Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T19:42:39Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_350
|
The-matt
| 2023-09-02T19:42:34Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T19:42:30Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
johaanm/test-planner-alpha-V5.10
|
johaanm
| 2023-09-02T19:40:45Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T19:40:41Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
ComradeBallin/PixelLlama
|
ComradeBallin
| 2023-09-02T19:33:37Z | 77 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-02T18:59:14Z |
---
about: PixelLlama is a Llama 2 7B model that has been trained on a question set
of 640 tasks related to creation and recognition of arrays representing simple
sprite images
license: llama2
---
|
The-matt/autumn-shadow-48_340
|
The-matt
| 2023-09-02T19:27:57Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T19:27:54Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
bayartsogt/wav2vec2-large-xlsr-53-mn-demo
|
bayartsogt
| 2023-09-02T19:23:45Z | 169 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-11-02T17:44:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xlsr-53-mn-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-mn-demo
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9290
- Wer: 0.5461
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.8767 | 6.77 | 400 | 2.9239 | 1.0 |
| 1.0697 | 13.55 | 800 | 0.8546 | 0.6191 |
| 0.3069 | 20.34 | 1200 | 0.9258 | 0.5652 |
| 0.2004 | 27.12 | 1600 | 0.9290 | 0.5461 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bayartsogt/wav2vec2-large-mn-pretrain-42h-100-epochs
|
bayartsogt
| 2023-09-02T19:23:25Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-01T17:30:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-mn-pretrain-42h-100-epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-mn-pretrain-42h-100-epochs
This model is a fine-tuned version of [bayartsogt/wav2vec2-large-mn-pretrain-42h](https://huggingface.co/bayartsogt/wav2vec2-large-mn-pretrain-42h) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 6.4172
- Wer: 1.0
- Cer: 0.9841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:---:|:------:|
| 7.6418 | 1.59 | 400 | 6.4239 | 1.0 | 0.9841 |
| 5.5936 | 3.19 | 800 | 6.4154 | 1.0 | 0.9841 |
| 5.5208 | 4.78 | 1200 | 6.5248 | 1.0 | 0.9841 |
| 5.4869 | 6.37 | 1600 | 6.3805 | 1.0 | 0.9841 |
| 5.4757 | 7.97 | 2000 | 6.3988 | 1.0 | 0.9841 |
| 5.4624 | 9.56 | 2400 | 6.4058 | 1.0 | 0.9841 |
| 5.517 | 11.16 | 2800 | 6.3991 | 1.0 | 0.9841 |
| 5.4821 | 12.75 | 3200 | 6.4066 | 1.0 | 0.9841 |
| 5.487 | 14.34 | 3600 | 6.4281 | 1.0 | 0.9841 |
| 5.4786 | 15.93 | 4000 | 6.4174 | 1.0 | 0.9841 |
| 5.5017 | 17.53 | 4400 | 6.4338 | 1.0 | 0.9841 |
| 5.4967 | 19.12 | 4800 | 6.4653 | 1.0 | 0.9841 |
| 5.4619 | 20.72 | 5200 | 6.4499 | 1.0 | 0.9841 |
| 5.4883 | 22.31 | 5600 | 6.4345 | 1.0 | 0.9841 |
| 5.4899 | 23.9 | 6000 | 6.4224 | 1.0 | 0.9841 |
| 5.493 | 25.5 | 6400 | 6.4374 | 1.0 | 0.9841 |
| 5.4549 | 27.09 | 6800 | 6.4320 | 1.0 | 0.9841 |
| 5.4531 | 28.68 | 7200 | 6.4137 | 1.0 | 0.9841 |
| 5.4738 | 30.28 | 7600 | 6.4155 | 1.0 | 0.9841 |
| 5.4309 | 31.87 | 8000 | 6.4193 | 1.0 | 0.9841 |
| 5.4669 | 33.47 | 8400 | 6.4109 | 1.0 | 0.9841 |
| 5.47 | 35.06 | 8800 | 6.4111 | 1.0 | 0.9841 |
| 5.4623 | 36.65 | 9200 | 6.4102 | 1.0 | 0.9841 |
| 5.4583 | 38.25 | 9600 | 6.4150 | 1.0 | 0.9841 |
| 5.4551 | 39.84 | 10000 | 6.4172 | 1.0 | 0.9841 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bayartsogt/wav2vec2-base-mn-pretrain-42h-mn-silence-speech-commands
|
bayartsogt
| 2023-09-02T19:17:43Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:bayartsogt/mongolian_speech_commands",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-08-15T03:51:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- bayartsogt/mongolian_speech_commands
model-index:
- name: wav2vec2-base-mn-pretrain-42h-mn-silence-speech-commands
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-mn-pretrain-42h-mn-silence-speech-commands
This model is a fine-tuned version of [bayartsogt/wav2vec2-base-mn-pretrain-42h](https://huggingface.co/bayartsogt/wav2vec2-base-mn-pretrain-42h) on the Mongolian Speech Commands dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0562
- Mn Acc: 0.9830
- Mn F1: 0.9832
- Silence Acc: 1.0
- Silence F1: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mn Acc | Mn F1 | Silence Acc | Silence F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:-----------:|:----------:|
| No log | 0.4 | 8 | 2.0276 | 0.0455 | 0.0239 | 1.0 | 1.0 |
| 2.3615 | 0.8 | 16 | 1.1112 | 0.0057 | 0.0108 | 1.0 | 1.0 |
| 2.0154 | 1.2 | 24 | 0.6836 | 0.6307 | 0.5627 | 0.9975 | 0.9988 |
| 1.5733 | 1.6 | 32 | 0.4493 | 0.7898 | 0.7652 | 0.9975 | 0.9988 |
| 1.1148 | 2.0 | 40 | 0.3264 | 0.8409 | 0.8202 | 1.0 | 1.0 |
| 1.1148 | 2.4 | 48 | 0.2490 | 0.8864 | 0.8768 | 1.0 | 1.0 |
| 0.7937 | 2.8 | 56 | 0.1739 | 0.9545 | 0.9540 | 1.0 | 1.0 |
| 0.586 | 3.2 | 64 | 0.1425 | 0.9659 | 0.9664 | 1.0 | 1.0 |
| 0.4445 | 3.6 | 72 | 0.1137 | 0.9659 | 0.9659 | 1.0 | 1.0 |
| 0.3892 | 4.0 | 80 | 0.0942 | 0.9773 | 0.9772 | 1.0 | 1.0 |
| 0.3892 | 4.4 | 88 | 0.0914 | 0.9716 | 0.9717 | 1.0 | 1.0 |
| 0.3341 | 4.8 | 96 | 0.0748 | 0.9773 | 0.9775 | 1.0 | 1.0 |
| 0.2863 | 5.2 | 104 | 0.0670 | 0.9886 | 0.9886 | 1.0 | 1.0 |
| 0.2622 | 5.6 | 112 | 0.0697 | 0.9830 | 0.9832 | 1.0 | 1.0 |
| 0.2222 | 6.0 | 120 | 0.0638 | 0.9830 | 0.9832 | 1.0 | 1.0 |
| 0.2222 | 6.4 | 128 | 0.0580 | 0.9886 | 0.9886 | 1.0 | 1.0 |
| 0.213 | 6.8 | 136 | 0.0575 | 0.9830 | 0.9832 | 1.0 | 1.0 |
| 0.2082 | 7.2 | 144 | 0.0587 | 0.9830 | 0.9832 | 1.0 | 1.0 |
| 0.202 | 7.6 | 152 | 0.0582 | 0.9830 | 0.9832 | 1.0 | 1.0 |
| 0.1936 | 8.0 | 160 | 0.0562 | 0.9830 | 0.9832 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
bayartsogt/wav2vec2-large-mn-pretrain-42h-finetuned
|
bayartsogt
| 2023-09-02T19:17:06Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-08-07T22:28:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-mn-pretrain-42h-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-mn-pretrain-42h-finetuned
This model is a fine-tuned version of [bayartsogt/wav2vec2-large-mn-pretrain-42h](https://huggingface.co/bayartsogt/wav2vec2-large-mn-pretrain-42h) on the common_voice dataset.
It achieves the following results on the evaluation set:
- eval_loss: 3.2032
- eval_wer: 1.0
- eval_cer: 1.0
- eval_runtime: 229.9508
- eval_samples_per_second: 8.202
- eval_steps_per_second: 1.026
- epoch: 25.4
- step: 3200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
SoyGema/tst-translation
|
SoyGema
| 2023-09-02T19:15:40Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"en",
"hi",
"dataset:opus100",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-08-21T15:52:06Z |
---
language:
- en
- hi
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- opus100
metrics:
- bleu
model-index:
- name: tst-translation
results:
- task:
name: Translation
type: translation
dataset:
name: opus100 en-hi
type: opus100
config: en-hi
split: validation
args: en-hi
metrics:
- name: Bleu
type: bleu
value: 15.633747222567068
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tst-translation
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the opus100 en-hi dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1287
- Bleu: 15.6337
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.32.0.dev0
- Pytorch 2.0.1
- Datasets 2.14.4
- Tokenizers 0.13.3
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e9_s6789_v4_l4_r4
|
KingKazma
| 2023-09-02T19:14:44Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T19:14:41Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
narno/hickeykiss
|
narno
| 2023-09-02T19:08:27Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-09-02T19:08:10Z |
---
license: creativeml-openrail-m
---
|
smoo7h/JackDiffusion
|
smoo7h
| 2023-09-02T19:03:25Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-09-02T18:59:02Z |
# JackDiffusion
Jack Diffusion Model
Jack's token: k7&
Example prompt: a photo of k7&
|
mgmeskill/downstrike-80m
|
mgmeskill
| 2023-09-02T18:58:10Z | 9 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-09-02T18:56:54Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: mgmeskill/downstrike-80m
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
georgeiac00/experiments
|
georgeiac00
| 2023-09-02T18:50:37Z | 0 | 0 |
peft
|
[
"peft",
"generated_from_trainer",
"region:us"
] | null | 2023-09-02T18:48:35Z |
---
tags:
- generated_from_trainer
model-index:
- name: experiments
results: []
library_name: peft
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# experiments
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 5
### Training results
### Framework versions
- PEFT 0.4.0
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.10.1
- Tokenizers 0.13.3
|
narno/milkynips
|
narno
| 2023-09-02T18:44:10Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2023-09-02T18:43:39Z |
---
license: bigscience-openrail-m
---
|
narno/openbra
|
narno
| 2023-09-02T18:44:08Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2023-09-02T18:43:31Z |
---
license: bigscience-openrail-m
---
|
The-matt/autumn-shadow-48_280
|
The-matt
| 2023-09-02T18:30:41Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T18:30:36Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
bigmorning/whisper_syl_noforce__0055
|
bigmorning
| 2023-09-02T18:25:51Z | 60 | 0 |
transformers
|
[
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-09-02T18:25:42Z |
---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce__0055
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce__0055
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0297
- Train Accuracy: 0.0362
- Train Wermet: 0.0054
- Validation Loss: 0.6695
- Validation Accuracy: 0.0232
- Validation Wermet: 0.2557
- Epoch: 54
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 5.2961 | 0.0113 | 1.9043 | 3.9402 | 0.0116 | 0.9526 | 0 |
| 4.6207 | 0.0121 | 0.8740 | 3.7957 | 0.0120 | 0.9397 | 1 |
| 4.4142 | 0.0128 | 0.8473 | 3.6045 | 0.0124 | 0.8988 | 2 |
| 4.1915 | 0.0135 | 0.8361 | 3.4445 | 0.0128 | 0.9019 | 3 |
| 4.0072 | 0.0140 | 0.8260 | 3.3268 | 0.0131 | 0.8816 | 4 |
| 3.8559 | 0.0145 | 0.8084 | 3.2440 | 0.0133 | 0.8592 | 5 |
| 3.7359 | 0.0149 | 0.7986 | 3.1751 | 0.0135 | 0.8598 | 6 |
| 3.6368 | 0.0152 | 0.7891 | 3.1298 | 0.0136 | 0.8398 | 7 |
| 3.5465 | 0.0154 | 0.7775 | 3.0736 | 0.0138 | 0.8606 | 8 |
| 3.4710 | 0.0157 | 0.7681 | 3.0318 | 0.0138 | 0.8455 | 9 |
| 3.3988 | 0.0159 | 0.7603 | 3.0159 | 0.0139 | 0.8770 | 10 |
| 3.3279 | 0.0162 | 0.7504 | 2.9672 | 0.0141 | 0.8241 | 11 |
| 3.2611 | 0.0164 | 0.7397 | 2.9541 | 0.0141 | 0.8676 | 12 |
| 3.1996 | 0.0167 | 0.7284 | 2.8913 | 0.0144 | 0.7990 | 13 |
| 3.1311 | 0.0169 | 0.7162 | 2.8671 | 0.0145 | 0.7934 | 14 |
| 3.0590 | 0.0172 | 0.7044 | 2.8241 | 0.0146 | 0.7907 | 15 |
| 2.9692 | 0.0177 | 0.6843 | 2.7517 | 0.0149 | 0.7645 | 16 |
| 2.8783 | 0.0181 | 0.6630 | 2.6682 | 0.0152 | 0.7263 | 17 |
| 2.7622 | 0.0187 | 0.6417 | 2.5586 | 0.0156 | 0.7220 | 18 |
| 2.6164 | 0.0194 | 0.6138 | 2.4121 | 0.0161 | 0.6909 | 19 |
| 2.4405 | 0.0203 | 0.5838 | 2.2417 | 0.0167 | 0.6527 | 20 |
| 2.2404 | 0.0213 | 0.5486 | 2.1401 | 0.0170 | 0.6662 | 21 |
| 2.0196 | 0.0225 | 0.5086 | 1.8907 | 0.0180 | 0.5774 | 22 |
| 1.7917 | 0.0237 | 0.4665 | 1.7073 | 0.0186 | 0.5446 | 23 |
| 1.5286 | 0.0253 | 0.4182 | 1.5139 | 0.0194 | 0.4919 | 24 |
| 1.2991 | 0.0267 | 0.3736 | 1.3605 | 0.0200 | 0.4570 | 25 |
| 1.1117 | 0.0279 | 0.3336 | 1.2304 | 0.0205 | 0.4262 | 26 |
| 0.9643 | 0.0289 | 0.2986 | 1.1387 | 0.0209 | 0.4040 | 27 |
| 0.8404 | 0.0298 | 0.2663 | 1.0514 | 0.0213 | 0.3776 | 28 |
| 0.7408 | 0.0305 | 0.2408 | 0.9883 | 0.0216 | 0.3596 | 29 |
| 0.6542 | 0.0311 | 0.2155 | 0.9281 | 0.0218 | 0.3418 | 30 |
| 0.5800 | 0.0316 | 0.1936 | 0.8801 | 0.0221 | 0.3269 | 31 |
| 0.5168 | 0.0321 | 0.1737 | 0.8401 | 0.0222 | 0.3168 | 32 |
| 0.4595 | 0.0326 | 0.1552 | 0.8071 | 0.0224 | 0.3077 | 33 |
| 0.4080 | 0.0330 | 0.1375 | 0.7825 | 0.0225 | 0.2994 | 34 |
| 0.3646 | 0.0333 | 0.1225 | 0.7550 | 0.0226 | 0.2887 | 35 |
| 0.3234 | 0.0337 | 0.1095 | 0.7369 | 0.0227 | 0.2847 | 36 |
| 0.2878 | 0.0340 | 0.0950 | 0.7270 | 0.0228 | 0.2796 | 37 |
| 0.2542 | 0.0343 | 0.0823 | 0.7096 | 0.0229 | 0.2728 | 38 |
| 0.2238 | 0.0346 | 0.0718 | 0.6963 | 0.0229 | 0.2697 | 39 |
| 0.1974 | 0.0348 | 0.0609 | 0.6857 | 0.0230 | 0.2669 | 40 |
| 0.1714 | 0.0351 | 0.0500 | 0.6843 | 0.0230 | 0.2663 | 41 |
| 0.1488 | 0.0353 | 0.0411 | 0.6770 | 0.0230 | 0.2630 | 42 |
| 0.1296 | 0.0355 | 0.0339 | 0.6754 | 0.0231 | 0.2612 | 43 |
| 0.1117 | 0.0356 | 0.0270 | 0.6702 | 0.0231 | 0.2585 | 44 |
| 0.0954 | 0.0358 | 0.0211 | 0.6695 | 0.0231 | 0.2574 | 45 |
| 0.0822 | 0.0359 | 0.0163 | 0.6711 | 0.0231 | 0.2572 | 46 |
| 0.0715 | 0.0360 | 0.0137 | 0.6685 | 0.0231 | 0.2583 | 47 |
| 0.0591 | 0.0361 | 0.0093 | 0.6696 | 0.0231 | 0.2590 | 48 |
| 0.0494 | 0.0361 | 0.0068 | 0.6663 | 0.0232 | 0.2609 | 49 |
| 0.0412 | 0.0362 | 0.0051 | 0.6726 | 0.0231 | 0.2577 | 50 |
| 0.0343 | 0.0362 | 0.0042 | 0.6756 | 0.0232 | 0.2609 | 51 |
| 0.0287 | 0.0362 | 0.0031 | 0.6700 | 0.0232 | 0.2549 | 52 |
| 0.0245 | 0.0362 | 0.0035 | 0.6796 | 0.0232 | 0.2639 | 53 |
| 0.0297 | 0.0362 | 0.0054 | 0.6695 | 0.0232 | 0.2557 | 54 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e8_s6789_v4_l4_r4
|
KingKazma
| 2023-09-02T18:22:30Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T18:22:29Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
GraphicsMonster/LSTM-Sentiment-Analysis
|
GraphicsMonster
| 2023-09-02T18:16:25Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-09-02T18:09:28Z |
# Sentiment analysis with LSTM architecture - Pytorch
This project aims to build a Sentiment analysis model using the LSTM(Long-Short term memory) architecture.
## Project Structure
The project has the following structure:
- `Dataset`: This directory contains the dataset files used for training and evaluation.
- `model.py`: This file contains the relevant piece of code required to run the model for inference after training.
- `train.py`: You train the modle by running this script. If you make any hyperparam changes in the model.py file make sure to make those changes here as well.
- `requirements.txt`: requirements file to automate the process of installing the required dependencies.
- `model_test.py`: This is the script you'll run to test the model on your own text data.
## Dependencies
The project requires the following dependencies:
- Python 3.9 or higher
- numpy
- pandas
- scikit-learn
- tensorflow
- keras
- torch
- torchtext
- tweet-preprocessor
- pickle
Ensure that you have the necessary dependencies installed before running the project.
You may install the above dependencies simply by using:
pip install -r requirements.txt
## Installation
- Open the terminal in your code editor and type this in
`git clone https://github.com/GraphicsMonster/LSTM-sentiment-analysis-model`
- To install the required dependencies, type this in
`pip install -r requirements.txt`
- Once the dependencies are installed you are ready to train the model and evaluate its performance. If you have your own data to train the model on, you can update the code in the model.py to refer to the location of your dataset on your local machine. Be sure to update the preprocessing steps accordingly!!
- Train the model run this command in the terminal
`python train.py`
- Once you've successfully trained the model, it will automatically be saved in the same directory with the name `model.pt`
- Test the model on your own text data
`python model_test.py`
## Contributing
Contributions to this project are heavily encouraged! If you find any issues or have suggestions for improvements, please open an issue or submit a pull request. Any kind of contribution will be appreciated.
## License
This project is licensed under the [MIT License](LICENSE).
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e7_s6789_v4_l4_v100
|
KingKazma
| 2023-09-02T18:15:45Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T18:15:41Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
bigmorning/whisper_syl_noforce__0050
|
bigmorning
| 2023-09-02T18:12:41Z | 52 | 0 |
transformers
|
[
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-09-02T18:12:32Z |
---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce__0050
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce__0050
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0494
- Train Accuracy: 0.0361
- Train Wermet: 0.0068
- Validation Loss: 0.6663
- Validation Accuracy: 0.0232
- Validation Wermet: 0.2609
- Epoch: 49
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 5.2961 | 0.0113 | 1.9043 | 3.9402 | 0.0116 | 0.9526 | 0 |
| 4.6207 | 0.0121 | 0.8740 | 3.7957 | 0.0120 | 0.9397 | 1 |
| 4.4142 | 0.0128 | 0.8473 | 3.6045 | 0.0124 | 0.8988 | 2 |
| 4.1915 | 0.0135 | 0.8361 | 3.4445 | 0.0128 | 0.9019 | 3 |
| 4.0072 | 0.0140 | 0.8260 | 3.3268 | 0.0131 | 0.8816 | 4 |
| 3.8559 | 0.0145 | 0.8084 | 3.2440 | 0.0133 | 0.8592 | 5 |
| 3.7359 | 0.0149 | 0.7986 | 3.1751 | 0.0135 | 0.8598 | 6 |
| 3.6368 | 0.0152 | 0.7891 | 3.1298 | 0.0136 | 0.8398 | 7 |
| 3.5465 | 0.0154 | 0.7775 | 3.0736 | 0.0138 | 0.8606 | 8 |
| 3.4710 | 0.0157 | 0.7681 | 3.0318 | 0.0138 | 0.8455 | 9 |
| 3.3988 | 0.0159 | 0.7603 | 3.0159 | 0.0139 | 0.8770 | 10 |
| 3.3279 | 0.0162 | 0.7504 | 2.9672 | 0.0141 | 0.8241 | 11 |
| 3.2611 | 0.0164 | 0.7397 | 2.9541 | 0.0141 | 0.8676 | 12 |
| 3.1996 | 0.0167 | 0.7284 | 2.8913 | 0.0144 | 0.7990 | 13 |
| 3.1311 | 0.0169 | 0.7162 | 2.8671 | 0.0145 | 0.7934 | 14 |
| 3.0590 | 0.0172 | 0.7044 | 2.8241 | 0.0146 | 0.7907 | 15 |
| 2.9692 | 0.0177 | 0.6843 | 2.7517 | 0.0149 | 0.7645 | 16 |
| 2.8783 | 0.0181 | 0.6630 | 2.6682 | 0.0152 | 0.7263 | 17 |
| 2.7622 | 0.0187 | 0.6417 | 2.5586 | 0.0156 | 0.7220 | 18 |
| 2.6164 | 0.0194 | 0.6138 | 2.4121 | 0.0161 | 0.6909 | 19 |
| 2.4405 | 0.0203 | 0.5838 | 2.2417 | 0.0167 | 0.6527 | 20 |
| 2.2404 | 0.0213 | 0.5486 | 2.1401 | 0.0170 | 0.6662 | 21 |
| 2.0196 | 0.0225 | 0.5086 | 1.8907 | 0.0180 | 0.5774 | 22 |
| 1.7917 | 0.0237 | 0.4665 | 1.7073 | 0.0186 | 0.5446 | 23 |
| 1.5286 | 0.0253 | 0.4182 | 1.5139 | 0.0194 | 0.4919 | 24 |
| 1.2991 | 0.0267 | 0.3736 | 1.3605 | 0.0200 | 0.4570 | 25 |
| 1.1117 | 0.0279 | 0.3336 | 1.2304 | 0.0205 | 0.4262 | 26 |
| 0.9643 | 0.0289 | 0.2986 | 1.1387 | 0.0209 | 0.4040 | 27 |
| 0.8404 | 0.0298 | 0.2663 | 1.0514 | 0.0213 | 0.3776 | 28 |
| 0.7408 | 0.0305 | 0.2408 | 0.9883 | 0.0216 | 0.3596 | 29 |
| 0.6542 | 0.0311 | 0.2155 | 0.9281 | 0.0218 | 0.3418 | 30 |
| 0.5800 | 0.0316 | 0.1936 | 0.8801 | 0.0221 | 0.3269 | 31 |
| 0.5168 | 0.0321 | 0.1737 | 0.8401 | 0.0222 | 0.3168 | 32 |
| 0.4595 | 0.0326 | 0.1552 | 0.8071 | 0.0224 | 0.3077 | 33 |
| 0.4080 | 0.0330 | 0.1375 | 0.7825 | 0.0225 | 0.2994 | 34 |
| 0.3646 | 0.0333 | 0.1225 | 0.7550 | 0.0226 | 0.2887 | 35 |
| 0.3234 | 0.0337 | 0.1095 | 0.7369 | 0.0227 | 0.2847 | 36 |
| 0.2878 | 0.0340 | 0.0950 | 0.7270 | 0.0228 | 0.2796 | 37 |
| 0.2542 | 0.0343 | 0.0823 | 0.7096 | 0.0229 | 0.2728 | 38 |
| 0.2238 | 0.0346 | 0.0718 | 0.6963 | 0.0229 | 0.2697 | 39 |
| 0.1974 | 0.0348 | 0.0609 | 0.6857 | 0.0230 | 0.2669 | 40 |
| 0.1714 | 0.0351 | 0.0500 | 0.6843 | 0.0230 | 0.2663 | 41 |
| 0.1488 | 0.0353 | 0.0411 | 0.6770 | 0.0230 | 0.2630 | 42 |
| 0.1296 | 0.0355 | 0.0339 | 0.6754 | 0.0231 | 0.2612 | 43 |
| 0.1117 | 0.0356 | 0.0270 | 0.6702 | 0.0231 | 0.2585 | 44 |
| 0.0954 | 0.0358 | 0.0211 | 0.6695 | 0.0231 | 0.2574 | 45 |
| 0.0822 | 0.0359 | 0.0163 | 0.6711 | 0.0231 | 0.2572 | 46 |
| 0.0715 | 0.0360 | 0.0137 | 0.6685 | 0.0231 | 0.2583 | 47 |
| 0.0591 | 0.0361 | 0.0093 | 0.6696 | 0.0231 | 0.2590 | 48 |
| 0.0494 | 0.0361 | 0.0068 | 0.6663 | 0.0232 | 0.2609 | 49 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
lseancs/models
|
lseancs
| 2023-09-02T18:04:04Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"custom-diffusion",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:adapter:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-08-25T23:08:52Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: photo of a <new1> cat
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
# Custom Diffusion - lseancs/models
These are Custom Diffusion adaption weights for CompVis/stable-diffusion-v1-4. The weights were trained on photo of a <new1> cat using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following.
For more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
|
BadreddineHug/LayoutLMv3_large_2
|
BadreddineHug
| 2023-09-02T17:57:05Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-09-02T17:38:21Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: LayoutLMv3_large_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LayoutLMv3_large_2
This model is a fine-tuned version of [BadreddineHug/LayoutLM_5](https://huggingface.co/BadreddineHug/LayoutLM_5) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4678
- Precision: 0.7444
- Recall: 0.8462
- F1: 0.792
- Accuracy: 0.9431
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 2000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 2.44 | 100 | 0.2604 | 0.8049 | 0.8462 | 0.8250 | 0.9487 |
| No log | 4.88 | 200 | 0.2887 | 0.6923 | 0.8462 | 0.7615 | 0.9294 |
| No log | 7.32 | 300 | 0.3961 | 0.6711 | 0.8547 | 0.7519 | 0.9248 |
| No log | 9.76 | 400 | 0.3117 | 0.7778 | 0.8376 | 0.8066 | 0.9465 |
| 0.1255 | 12.2 | 500 | 0.3344 | 0.7698 | 0.8291 | 0.7984 | 0.9419 |
| 0.1255 | 14.63 | 600 | 0.3892 | 0.7197 | 0.8120 | 0.7631 | 0.9339 |
| 0.1255 | 17.07 | 700 | 0.3865 | 0.7143 | 0.8547 | 0.7782 | 0.9419 |
| 0.1255 | 19.51 | 800 | 0.4737 | 0.6690 | 0.8291 | 0.7405 | 0.9226 |
| 0.1255 | 21.95 | 900 | 0.3876 | 0.7405 | 0.8291 | 0.7823 | 0.9442 |
| 0.0206 | 24.39 | 1000 | 0.3845 | 0.7444 | 0.8462 | 0.792 | 0.9465 |
| 0.0206 | 26.83 | 1100 | 0.4179 | 0.75 | 0.8205 | 0.7837 | 0.9442 |
| 0.0206 | 29.27 | 1200 | 0.3942 | 0.7576 | 0.8547 | 0.8032 | 0.9510 |
| 0.0206 | 31.71 | 1300 | 0.4521 | 0.7293 | 0.8291 | 0.776 | 0.9408 |
| 0.0206 | 34.15 | 1400 | 0.4725 | 0.7050 | 0.8376 | 0.7656 | 0.9328 |
| 0.0051 | 36.59 | 1500 | 0.4874 | 0.6849 | 0.8547 | 0.7605 | 0.9317 |
| 0.0051 | 39.02 | 1600 | 0.4366 | 0.7519 | 0.8547 | 0.8 | 0.9453 |
| 0.0051 | 41.46 | 1700 | 0.4978 | 0.6897 | 0.8547 | 0.7634 | 0.9317 |
| 0.0051 | 43.9 | 1800 | 0.4599 | 0.7444 | 0.8462 | 0.792 | 0.9431 |
| 0.0051 | 46.34 | 1900 | 0.4765 | 0.7372 | 0.8632 | 0.7953 | 0.9431 |
| 0.002 | 48.78 | 2000 | 0.4678 | 0.7444 | 0.8462 | 0.792 | 0.9431 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
sashat/whisper-small-ar
|
sashat
| 2023-09-02T17:54:28Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ar",
"dataset:ClArTTS_N_QASR_female",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-09-02T16:29:01Z |
---
language:
- ar
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- ClArTTS_N_QASR_female
model-index:
- name: Whisper Small Ar - Sara
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Ar - Sara
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the CLArQasr dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 100
### Training results
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.2
|
The-matt/autumn-shadow-48_260
|
The-matt
| 2023-09-02T17:51:07Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T17:51:03Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e6_s6789_v4_l4_v100
|
KingKazma
| 2023-09-02T17:45:45Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T17:45:41Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_250
|
The-matt
| 2023-09-02T17:43:09Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T17:42:59Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_240
|
The-matt
| 2023-09-02T17:34:10Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T17:34:06Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
DrishtiSharma/mbart-large-50-en-es-translation-lr-1e-05-weight-decay-0.1
|
DrishtiSharma
| 2023-09-02T17:32:29Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"base_model:facebook/mbart-large-50",
"base_model:finetune:facebook/mbart-large-50",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-09-02T15:17:32Z |
---
license: mit
base_model: facebook/mbart-large-50
tags:
- translation
- generated_from_trainer
metrics:
- bleu
- rouge
model-index:
- name: mbart-large-50-en-es-translation-lr-1e-05-weight-decay-0.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-large-50-en-es-translation-lr-1e-05-weight-decay-0.1
This model is a fine-tuned version of [facebook/mbart-large-50](https://huggingface.co/facebook/mbart-large-50) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9532
- Bleu: 45.1551
- Rouge: {'rouge1': 0.707093830119779, 'rouge2': 0.5240989044660875, 'rougeL': 0.6865395711179825, 'rougeLsum': 0.6867643949864491}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Rouge |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:---------------------------------------------------------------------------------------------------------------------------:|
| 1.4485 | 1.0 | 4500 | 1.0236 | 42.1586 | {'rouge1': 0.6728104679322686, 'rouge2': 0.4866267759088613, 'rougeL': 0.6507619922873461, 'rougeLsum': 0.6508024989844624} |
| 0.8867 | 2.0 | 9000 | 0.9542 | 44.1945 | {'rouge1': 0.6933374960151913, 'rouge2': 0.5090654274262618, 'rougeL': 0.6722360570050694, 'rougeLsum': 0.6723972406375381} |
| 0.7112 | 3.0 | 13500 | 0.9408 | 44.9173 | {'rouge1': 0.7047659807760827, 'rouge2': 0.5200169348076622, 'rougeL': 0.6839031690668775, 'rougeLsum': 0.6842067045539153} |
| 0.6075 | 4.0 | 18000 | 0.9532 | 45.2020 | {'rouge1': 0.7070170730434684, 'rouge2': 0.5239391023023636, 'rougeL': 0.6863309446860562, 'rougeLsum': 0.6866635686411662} |
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4.dev0
- Tokenizers 0.13.3
|
CzarnyRycerz/taxi-v3-q-table
|
CzarnyRycerz
| 2023-09-02T17:17:01Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-02T16:40:46Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3-q-table
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="CzarnyRycerz/taxi-v3-q-table", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
The-matt/autumn-shadow-48_220
|
The-matt
| 2023-09-02T17:16:20Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T17:16:14Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e5_s6789_v4_l4_v100
|
KingKazma
| 2023-09-02T17:15:46Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T17:15:42Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
Yorai/yolos-tiny_finetuned_dataset
|
Yorai
| 2023-09-02T17:12:28Z | 197 | 0 |
transformers
|
[
"transformers",
"pytorch",
"yolos",
"object-detection",
"generated_from_trainer",
"base_model:hustvl/yolos-tiny",
"base_model:finetune:hustvl/yolos-tiny",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-08-26T21:47:33Z |
---
license: apache-2.0
base_model: hustvl/yolos-tiny
tags:
- generated_from_trainer
model-index:
- name: yolos-tiny_finetuned_dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yolos-tiny_finetuned_dataset
This model is a fine-tuned version of [hustvl/yolos-tiny](https://huggingface.co/hustvl/yolos-tiny) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.32.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
thisisashwinraj/recipeml
|
thisisashwinraj
| 2023-09-02T17:09:49Z | 0 | 0 |
sklearn
|
[
"sklearn",
"text2text-generation",
"en",
"dataset:recipe_nlg",
"license:apache-2.0",
"region:us"
] |
text2text-generation
| 2023-08-31T13:28:51Z |
---
license: apache-2.0
datasets:
- recipe_nlg
language:
- en
library_name: sklearn
pipeline_tag: text2text-generation
---
|
leofn3/modelo_racismo
|
leofn3
| 2023-09-02T17:01:56Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:PORTULAN/albertina-900m-portuguese-ptbr-encoder-brwac",
"base_model:finetune:PORTULAN/albertina-900m-portuguese-ptbr-encoder-brwac",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-18T14:11:56Z |
---
license: other
base_model: PORTULAN/albertina-ptbr
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: modelo_racismo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# modelo_racismo
This model is a fine-tuned version of [PORTULAN/albertina-ptbr](https://huggingface.co/PORTULAN/albertina-ptbr) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0036
- Accuracy: 0.9989
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 468 | 0.2304 | 0.9583 |
| 0.7037 | 2.0 | 936 | 0.0847 | 0.9840 |
| 0.256 | 3.0 | 1404 | 0.0075 | 0.9979 |
| 0.0759 | 4.0 | 1872 | 0.0036 | 0.9989 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
ishan-07/final-layer-finetuned-eurosat
|
ishan-07
| 2023-09-02T17:00:25Z | 191 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-02T16:39:35Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: final-layer-finetuned-eurosat
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# final-layer-finetuned-eurosat
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9762
- Accuracy: 0.6761
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1443 | 1.0 | 168 | 2.1352 | 0.4907 |
| 2.0141 | 2.0 | 337 | 2.0142 | 0.6517 |
| 1.9784 | 2.99 | 504 | 1.9762 | 0.6761 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
ukeme/ukay-base-sentence-transformer
|
ukeme
| 2023-09-02T17:00:03Z | 1 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"dataset:embedding-data/sentence-compression",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-09-02T16:41:46Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- embedding-data/sentence-compression
---
# ukeme/ukay-base-sentence-transformer
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('ukeme/ukay-base-sentence-transformer')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('ukeme/ukay-base-sentence-transformer')
model = AutoModel.from_pretrained('ukeme/ukay-base-sentence-transformer')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=ukeme/ukay-base-sentence-transformer)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
KingKazma/xsum_gpt2_p_tuning_500_4_50000_6_e1_s6789_v4_l4_v100
|
KingKazma
| 2023-09-02T16:51:05Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-08-17T15:45:08Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_190
|
The-matt
| 2023-09-02T16:43:05Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T16:43:01Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
CzarnyRycerz/q-FrozenLake-v1-4x4-noSlippery
|
CzarnyRycerz
| 2023-09-02T16:34:07Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-02T16:34:03Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="CzarnyRycerz/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e4_s6789_v4_l4_r4
|
KingKazma
| 2023-09-02T16:31:50Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T16:31:50Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
raymondowf/flan-t5-large-qlora-financial-phrasebank
|
raymondowf
| 2023-09-02T16:21:01Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T16:20:56Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_150
|
The-matt
| 2023-09-02T16:11:26Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T16:11:22Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
EmirhanExecute/LunarLander-my-try
|
EmirhanExecute
| 2023-09-02T16:06:05Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-02T13:47:12Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -187.42 +/- 108.66
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
|
The-matt/autumn-shadow-48_140
|
The-matt
| 2023-09-02T16:03:46Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T16:03:40Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
btamm12/roberta-base-finetuned-wls-manual-10ep
|
btamm12
| 2023-09-02T15:52:47Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:50:16Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-wls-manual-10ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wls-manual-10ep
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0599
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8201 | 0.93 | 7 | 1.5286 |
| 1.4462 | 2.0 | 15 | 1.3480 |
| 1.3032 | 2.93 | 22 | 1.3377 |
| 1.2564 | 4.0 | 30 | 1.1907 |
| 1.246 | 4.93 | 37 | 1.1702 |
| 1.1777 | 6.0 | 45 | 1.1549 |
| 1.118 | 6.93 | 52 | 1.0611 |
| 1.1339 | 8.0 | 60 | 1.1084 |
| 1.1158 | 8.93 | 67 | 1.1376 |
| 1.0143 | 9.33 | 70 | 1.1225 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/bert-base-cased-finetuned-wls-manual-10ep
|
btamm12
| 2023-09-02T15:47:47Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:45:36Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-wls-manual-10ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wls-manual-10ep
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1918
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.159 | 0.93 | 7 | 1.8408 |
| 1.6358 | 2.0 | 15 | 1.6173 |
| 1.5483 | 2.93 | 22 | 1.5092 |
| 1.3734 | 4.0 | 30 | 1.4044 |
| 1.3188 | 4.93 | 37 | 1.3874 |
| 1.2528 | 6.0 | 45 | 1.2883 |
| 1.1951 | 6.93 | 52 | 1.2463 |
| 1.1413 | 8.0 | 60 | 1.2215 |
| 1.1573 | 8.93 | 67 | 1.1365 |
| 1.1051 | 9.33 | 70 | 1.2449 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
norman365/atom-Llama2-chinese-7b-ggml.bin
|
norman365
| 2023-09-02T15:47:03Z | 0 | 0 | null |
[
"zh",
"license:apache-2.0",
"region:us"
] | null | 2023-09-02T15:46:12Z |
---
license: apache-2.0
language:
- zh
---
|
btamm12/roberta-base-finetuned-wls-manual-9ep
|
btamm12
| 2023-09-02T15:45:29Z | 138 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:43:04Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-wls-manual-9ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wls-manual-9ep
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1276
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8229 | 0.93 | 7 | 1.5338 |
| 1.4689 | 2.0 | 15 | 1.3870 |
| 1.3431 | 2.93 | 22 | 1.3524 |
| 1.2807 | 4.0 | 30 | 1.2096 |
| 1.262 | 4.93 | 37 | 1.1687 |
| 1.1874 | 6.0 | 45 | 1.1677 |
| 1.1404 | 6.93 | 52 | 1.0729 |
| 1.1456 | 8.0 | 60 | 1.1217 |
| 1.1369 | 8.4 | 63 | 1.1568 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
kaneki1933/testes
|
kaneki1933
| 2023-09-02T15:44:09Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-06-20T17:55:55Z |
---
license: creativeml-openrail-m
---
|
btamm12/bert-base-uncased-finetuned-wls-manual-9ep-lower
|
btamm12
| 2023-09-02T15:42:56Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:40:41Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wls-manual-9ep-lower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wls-manual-9ep-lower
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2788
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1096 | 0.93 | 7 | 1.9445 |
| 1.5963 | 2.0 | 15 | 1.5711 |
| 1.4734 | 2.93 | 22 | 1.4391 |
| 1.3716 | 4.0 | 30 | 1.4138 |
| 1.2719 | 4.93 | 37 | 1.2480 |
| 1.2486 | 6.0 | 45 | 1.2483 |
| 1.2156 | 6.93 | 52 | 1.2662 |
| 1.1523 | 8.0 | 60 | 1.3172 |
| 1.1596 | 8.4 | 63 | 1.2467 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/roberta-base-finetuned-wls-manual-8ep
|
btamm12
| 2023-09-02T15:38:16Z | 115 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:35:48Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-wls-manual-8ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wls-manual-8ep
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1496
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8186 | 0.93 | 7 | 1.5245 |
| 1.4337 | 2.0 | 15 | 1.3340 |
| 1.2959 | 2.93 | 22 | 1.3375 |
| 1.2682 | 4.0 | 30 | 1.1892 |
| 1.2558 | 4.93 | 37 | 1.1743 |
| 1.1828 | 6.0 | 45 | 1.1438 |
| 1.138 | 6.93 | 52 | 1.0716 |
| 1.1495 | 7.47 | 56 | 1.1702 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
haddadalwi/bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad2-noAns
|
haddadalwi
| 2023-09-02T15:36:53Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"base_model:google-bert/bert-large-uncased-whole-word-masking-finetuned-squad",
"base_model:finetune:google-bert/bert-large-uncased-whole-word-masking-finetuned-squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-01T16:30:38Z |
---
license: apache-2.0
base_model: bert-large-uncased-whole-word-masking-finetuned-squad
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad2-noAns
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-whole-word-masking-finetuned-squad-finetuned-squad2-noAns
This model is a fine-tuned version of [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 266 | 0.0000 |
| 0.0649 | 2.0 | 532 | 0.0000 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/bert-base-uncased-finetuned-wls-manual-8ep-lower
|
btamm12
| 2023-09-02T15:35:40Z | 113 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:33:34Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wls-manual-8ep-lower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wls-manual-8ep-lower
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3345
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1106 | 0.93 | 7 | 1.9471 |
| 1.5981 | 2.0 | 15 | 1.5742 |
| 1.4773 | 2.93 | 22 | 1.4429 |
| 1.3774 | 4.0 | 30 | 1.4203 |
| 1.2795 | 4.93 | 37 | 1.2554 |
| 1.2611 | 6.0 | 45 | 1.2564 |
| 1.2301 | 6.93 | 52 | 1.2837 |
| 1.1744 | 7.47 | 56 | 1.3219 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_100
|
The-matt
| 2023-09-02T15:34:22Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T15:34:18Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_90
|
The-matt
| 2023-09-02T15:27:43Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T15:27:39Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
Satorio/so-vits-4.1-Nice_Nature
|
Satorio
| 2023-09-02T15:22:42Z | 0 | 0 | null |
[
"license:cc-by-nc-4.0",
"region:us"
] | null | 2023-08-06T13:14:51Z |
---
license: cc-by-nc-4.0
---
Model: Nice Nature(Umamusume: Pretty Derby)
Dataset Source: DMM Umamusume Game
Still training to improve model... Maybe better, maybe not...
|
olivierhenaff/distilhubert-finetuned-gtzan
|
olivierhenaff
| 2023-09-02T15:22:12Z | 164 | 0 |
transformers
|
[
"transformers",
"pytorch",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-09-02T12:11:45Z |
---
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.83
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7428
- Accuracy: 0.83
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.7684 | 1.0 | 225 | 1.6143 | 0.46 |
| 0.9707 | 2.0 | 450 | 1.0938 | 0.66 |
| 0.8819 | 3.0 | 675 | 0.7981 | 0.77 |
| 0.6527 | 4.0 | 900 | 0.6805 | 0.8 |
| 0.2499 | 5.0 | 1125 | 0.5896 | 0.81 |
| 0.0371 | 6.0 | 1350 | 0.8279 | 0.79 |
| 0.1651 | 7.0 | 1575 | 0.6830 | 0.81 |
| 0.011 | 8.0 | 1800 | 0.7673 | 0.81 |
| 0.0077 | 9.0 | 2025 | 0.7159 | 0.83 |
| 0.0068 | 10.0 | 2250 | 0.7428 | 0.83 |
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_80
|
The-matt
| 2023-09-02T15:21:01Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T15:20:51Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
crewdon/AICategoryMapping-multilingual-e5-small
|
crewdon
| 2023-09-02T15:20:57Z | 14 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-09-02T15:05:10Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# AICategoryMapping-multilingual-e5-small
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 94 with parameters:
```
{'batch_size': 400}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 40,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 376,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
btamm12/bert-base-uncased-finetuned-wls-manual-6ep-lower
|
btamm12
| 2023-09-02T15:20:25Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:18:28Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wls-manual-6ep-lower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wls-manual-6ep-lower
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3314
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1123 | 0.93 | 7 | 1.9531 |
| 1.6034 | 2.0 | 15 | 1.5832 |
| 1.489 | 2.93 | 22 | 1.4553 |
| 1.3975 | 4.0 | 30 | 1.4448 |
| 1.3074 | 4.93 | 37 | 1.2918 |
| 1.3083 | 5.6 | 42 | 1.4088 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/bert-base-cased-finetuned-wls-manual-6ep
|
btamm12
| 2023-09-02T15:18:21Z | 115 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:16:23Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-wls-manual-6ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wls-manual-6ep
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2526
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1598 | 0.93 | 7 | 1.8481 |
| 1.6257 | 2.0 | 15 | 1.6306 |
| 1.5537 | 2.93 | 22 | 1.5150 |
| 1.3943 | 4.0 | 30 | 1.4392 |
| 1.355 | 4.93 | 37 | 1.4389 |
| 1.3098 | 5.6 | 42 | 1.3518 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/bert-base-uncased-finetuned-wls-manual-5ep-lower
|
btamm12
| 2023-09-02T15:14:00Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:12:03Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wls-manual-5ep-lower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wls-manual-5ep-lower
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1142 | 0.93 | 7 | 1.9585 |
| 1.6082 | 2.0 | 15 | 1.5910 |
| 1.4973 | 2.93 | 22 | 1.4644 |
| 1.4145 | 4.0 | 30 | 1.4717 |
| 1.335 | 4.67 | 35 | 1.4035 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/bert-base-cased-finetuned-wls-manual-5ep
|
btamm12
| 2023-09-02T15:11:56Z | 118 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:10:02Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-wls-manual-5ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wls-manual-5ep
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3713
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1603 | 0.93 | 7 | 1.8523 |
| 1.6398 | 2.0 | 15 | 1.6332 |
| 1.5675 | 2.93 | 22 | 1.5257 |
| 1.4167 | 4.0 | 30 | 1.4623 |
| 1.3885 | 4.67 | 35 | 1.4795 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/roberta-base-finetuned-wls-manual-4ep
|
btamm12
| 2023-09-02T15:09:55Z | 123 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:07:08Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-wls-manual-4ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wls-manual-4ep
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2987
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8232 | 0.93 | 7 | 1.5217 |
| 1.4594 | 2.0 | 15 | 1.4173 |
| 1.402 | 2.93 | 22 | 1.3668 |
| 1.3193 | 3.73 | 28 | 1.2170 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
btamm12/bert-base-uncased-finetuned-wls-manual-4ep-lower
|
btamm12
| 2023-09-02T15:07:01Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:04:34Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wls-manual-4ep-lower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wls-manual-4ep-lower
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5279
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1174 | 0.93 | 7 | 1.9683 |
| 1.617 | 2.0 | 15 | 1.6046 |
| 1.5138 | 2.93 | 22 | 1.4859 |
| 1.4474 | 3.73 | 28 | 1.4356 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_60
|
The-matt
| 2023-09-02T15:06:47Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T15:06:44Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
btamm12/bert-base-cased-finetuned-wls-manual-4ep
|
btamm12
| 2023-09-02T15:04:27Z | 115 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T15:02:01Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-wls-manual-4ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wls-manual-4ep
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1602 | 0.93 | 7 | 1.8552 |
| 1.634 | 2.0 | 15 | 1.6483 |
| 1.575 | 2.93 | 22 | 1.5390 |
| 1.4442 | 3.73 | 28 | 1.4827 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
DrishtiSharma/mbart-large-50-en-es-translation-lr-1e-05-weight-decay-0.001
|
DrishtiSharma
| 2023-09-02T15:04:08Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"base_model:facebook/mbart-large-50",
"base_model:finetune:facebook/mbart-large-50",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-09-02T12:48:56Z |
---
license: mit
base_model: facebook/mbart-large-50
tags:
- translation
- generated_from_trainer
metrics:
- bleu
- rouge
model-index:
- name: mbart-large-50-en-es-translation-lr-1e-05-weight-decay-0.001
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-large-50-en-es-translation-lr-1e-05-weight-decay-0.001
This model is a fine-tuned version of [facebook/mbart-large-50](https://huggingface.co/facebook/mbart-large-50) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9549
- Bleu: 45.0307
- Rouge: {'rouge1': 0.7049318825090395, 'rouge2': 0.5238048751750992, 'rougeL': 0.684187379601513, 'rougeLsum': 0.6843574853855577}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Rouge |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:----------------------------------------------------------------------------------------------------------------------------:|
| 1.4627 | 1.0 | 4500 | 1.0255 | 42.1880 | {'rouge1': 0.6725633216905762, 'rouge2': 0.48605402524493657, 'rougeL': 0.6498853764470456, 'rougeLsum': 0.6501981166312041} |
| 0.8878 | 2.0 | 9000 | 0.9572 | 44.1734 | {'rouge1': 0.6912686406245903, 'rouge2': 0.5093695171345348, 'rougeL': 0.6701896043455414, 'rougeLsum': 0.6703473419504804} |
| 0.7125 | 3.0 | 13500 | 0.9414 | 44.8709 | {'rouge1': 0.7051197958532004, 'rouge2': 0.5210482863677958, 'rougeL': 0.6843075431636916, 'rougeLsum': 0.6846265298079588} |
| 0.6092 | 4.0 | 18000 | 0.9549 | 45.0821 | {'rouge1': 0.7047932899349161, 'rouge2': 0.523739339466653, 'rougeL': 0.6840127607742443, 'rougeLsum': 0.684202100852132} |
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4.dev0
- Tokenizers 0.13.3
|
btamm12/roberta-base-finetuned-wls-manual-3ep
|
btamm12
| 2023-09-02T15:01:54Z | 129 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T14:59:09Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
model-index:
- name: roberta-base-finetuned-wls-manual-3ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-wls-manual-3ep
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3361
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8156 | 0.93 | 7 | 1.5116 |
| 1.4371 | 2.0 | 15 | 1.3472 |
| 1.3218 | 2.8 | 21 | 1.3278 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
yaohuacn/a2c-PandaPickAndPlace-v3
|
yaohuacn
| 2023-09-02T15:00:35Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-02T14:45:56Z |
---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
btamm12/bert-base-uncased-finetuned-wls-manual-3ep-lower
|
btamm12
| 2023-09-02T14:59:01Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T14:56:34Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-finetuned-wls-manual-3ep-lower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wls-manual-3ep-lower
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1229 | 0.93 | 7 | 1.9851 |
| 1.635 | 2.0 | 15 | 1.6390 |
| 1.5515 | 2.8 | 21 | 1.5881 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
tsukemono/japanese-stablelm-base-alpha-7b-qlora-marisa
|
tsukemono
| 2023-09-02T14:58:35Z | 0 | 0 | null |
[
"ja",
"region:us"
] | null | 2023-08-28T08:24:30Z |
---
language:
- ja
---
## モデルの概略
霧雨魔理沙とおしゃべりできるモデルです。
[Japanese-StableLM-Base-Alpha-7B](https://huggingface.co/stabilityai/japanese-stablelm-base-alpha-7b)のLoRAデータになります
## 使い方
推論のさせかたの一例をhow_to_use.ipynbに記しましたので参考にしていただけると幸いです。
「ユーザー: hogehoge\n魔理沙: 」といったプロンプトを与えてあげることで、魔理沙とおしゃべりができるようになります。
## 備考
これは東方Projectの二次創作です
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
- PEFT 0.4.0.dev0
|
btamm12/bert-base-cased-finetuned-wls-manual-3ep
|
btamm12
| 2023-09-02T14:56:26Z | 115 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T14:54:00Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-wls-manual-3ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wls-manual-3ep
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4445
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1602 | 0.93 | 7 | 1.8592 |
| 1.6456 | 2.0 | 15 | 1.6724 |
| 1.6082 | 2.8 | 21 | 1.4744 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_40
|
The-matt
| 2023-09-02T14:53:00Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-02T14:52:57Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
btamm12/bert-base-cased-finetuned-wls-manual-2ep
|
btamm12
| 2023-09-02T14:48:32Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-09-02T14:46:11Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-wls-manual-2ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wls-manual-2ep
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6386
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1651 | 0.93 | 7 | 1.8869 |
| 1.6819 | 1.87 | 14 | 1.7442 |
### Framework versions
- Transformers 4.31.0
- Pytorch 1.11.0+cu113
- Datasets 2.14.4
- Tokenizers 0.13.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.