
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-23 12:32:37
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 571
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-23 12:31:07
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
PatWang/bert-base-uncased-finetuned-sql-classification-with_question
|
PatWang
| 2024-03-26T06:46:12Z | 104 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-26T06:45:54Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-uncased-finetuned-sql-classification-with_question
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-sql-classification-with_question
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6717
- Accuracy: 0.6
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.684 | 1.0 | 645 | 0.6930 | 0.5442 |
| 0.6908 | 2.0 | 1290 | 0.6892 | 0.5442 |
| 0.6929 | 3.0 | 1935 | 0.6999 | 0.5442 |
| 0.6887 | 4.0 | 2580 | 0.6903 | 0.5442 |
| 0.6898 | 5.0 | 3225 | 0.6899 | 0.5442 |
| 0.6887 | 6.0 | 3870 | 0.6916 | 0.5442 |
| 0.6819 | 7.0 | 4515 | 0.6835 | 0.5550 |
| 0.6742 | 8.0 | 5160 | 0.6576 | 0.6047 |
| 0.6546 | 9.0 | 5805 | 0.6477 | 0.6147 |
| 0.6478 | 10.0 | 6450 | 0.6717 | 0.6 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
kienlt/gemma-2b-zalo-math2
|
kienlt
| 2024-03-26T06:45:07Z | 75 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-03-26T06:42:41Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MaziyarPanahi/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B-AWQ
|
MaziyarPanahi
| 2024-03-26T06:44:47Z | 90 | 3 |
transformers
|
[
"transformers",
"safetensors",
"mixtral",
"text-generation",
"finetuned",
"quantized",
"4-bit",
"AWQ",
"moe",
"DPO",
"RL-TUNED",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us",
"base_model:yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B",
"base_model:quantized:yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B",
"awq"
] |
text-generation
| 2024-03-26T06:42:22Z |
---
tags:
- finetuned
- quantized
- 4-bit
- AWQ
- transformers
- safetensors
- mixtral
- text-generation
- moe
- DPO
- RL-TUNED
- license:mit
- autotrain_compatible
- endpoints_compatible
- has_space
- text-generation-inference
- region:us
model_name: Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B-AWQ
base_model: yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B
inference: false
model_creator: yunconglong
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# Description
[MaziyarPanahi/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B-AWQ](https://huggingface.co/MaziyarPanahi/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B-AWQ) is a quantized (AWQ) version of [yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B](https://huggingface.co/yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B)
## How to use
### Install the necessary packages
```
pip install --upgrade accelerate autoawq transformers
```
### Example Python code
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "MaziyarPanahi/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id).to(0)
text = "User:\nHello can you provide me with top-3 cool places to visit in Paris?\n\nAssistant:\n"
inputs = tokenizer(text, return_tensors="pt").to(0)
out = model.generate(**inputs, max_new_tokens=300)
print(tokenizer.decode(out[0], skip_special_tokens=True))
```
Results:
```
User:
Hello can you provide me with top-3 cool places to visit in Paris?
Assistant:
Absolutely, here are my top-3 recommendations for must-see places in Paris:
1. The Eiffel Tower: An icon of Paris, this wrought-iron lattice tower is a global cultural icon of France and is among the most recognizable structures in the world. Climbing up to the top offers breathtaking views of the city.
2. The Louvre Museum: Home to thousands of works of art, the Louvre is the world's largest art museum and a historic monument in Paris. Must-see pieces include the Mona Lisa, the Winged Victory of Samothrace, and the Venus de Milo.
3. Notre-Dame Cathedral: This cathedral is a masterpiece of French Gothic architecture and is famous for its intricate stone carvings, beautiful stained glass, and its iconic twin towers. Be sure to spend some time exploring its history and learning about the fascinating restoration efforts post the 2019 fire.
I hope you find these recommendations helpful and that they make for an enjoyable and memorable trip to Paris. Safe travels!
```
|
Lilyislily/Taxiiii
|
Lilyislily
| 2024-03-26T06:39:43Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T06:39:41Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxiiii
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Lilyislily/Taxiiii", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Lilyislily/q-FrozenLake-v1-4x4-noSlippery
|
Lilyislily
| 2024-03-26T06:34:31Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T06:34:29Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Lilyislily/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
DoggoOP/QLearn
|
DoggoOP
| 2024-03-26T06:32:16Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T06:31:19Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: QLearn
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="DoggoOP/QLearn", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
nandinitatiwala/q-FrozenLake-v1-4x4-noSlippery
|
nandinitatiwala
| 2024-03-26T06:32:01Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T06:31:58Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="nandinitatiwala/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
coon-hound/cab-driving
|
coon-hound
| 2024-03-26T06:28:40Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T06:19:37Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: cab-driving
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.63
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="coon-hound/cab-driving", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
xumeng/modeltest
|
xumeng
| 2024-03-26T06:24:14Z | 0 | 0 |
allennlp
|
[
"allennlp",
"medical",
"aa",
"dataset:microsoft/orca-math-word-problems-200k",
"license:mit",
"region:us"
] | null | 2024-03-25T03:20:28Z |
---
license: mit
datasets:
- microsoft/orca-math-word-problems-200k
language:
- aa
metrics:
- cer
- brier_score
library_name: allennlp
tags:
- medical
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
|
AlignmentResearch/robust_llm_pythia-imdb-410m-mz-ada-v3-ch-100000
|
AlignmentResearch
| 2024-03-26T06:21:28Z | 103 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-410m-deduped",
"base_model:finetune:EleutherAI/pythia-410m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-26T06:20:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-410m-deduped
model-index:
- name: robust_llm_pythia-imdb-410m-mz-ada-v3-ch-100000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-imdb-410m-mz-ada-v3-ch-100000
This model is a fine-tuned version of [EleutherAI/pythia-410m-deduped](https://huggingface.co/EleutherAI/pythia-410m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
juhwanlee/gemma-7B-alpaca-case-2-3
|
juhwanlee
| 2024-03-26T06:19:35Z | 48 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-25T13:03:54Z |
---
license: apache-2.0
datasets:
- Open-Orca/OpenOrca
language:
- en
---
# Model Details
* Model Description: This model is test for data ordering.
* Developed by: Juhwan Lee
* Model Type: Large Language Model
# Model Architecture
This model is based on Gemma-7B. We fine-tuning this model for data ordering task.
Gemma-7B is a transformer model, with the following architecture choices:
* Grouped-Query Attention
* Sliding-Window Attention
* Byte-fallback BPE tokenizer
# Dataset
We random sample Open-Orca dataset. (We finetune the 100,000 dataset)
# Guthub
https://github.com/trailerAI
# License
Apache License 2.0
|
ajay141/mistral_westlake_merged-model
|
ajay141
| 2024-03-26T06:19:14Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"mistralai/Mistral-7B-v0.1",
"senseable/WestLake-7B-v2",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:merge:mistralai/Mistral-7B-v0.1",
"base_model:senseable/WestLake-7B-v2",
"base_model:merge:senseable/WestLake-7B-v2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T06:15:30Z |
---
tags:
- merge
- mergekit
- lazymergekit
- mistralai/Mistral-7B-v0.1
- senseable/WestLake-7B-v2
base_model:
- mistralai/Mistral-7B-v0.1
- senseable/WestLake-7B-v2
---
# mistral_westlake_merged-model
mistral_westlake_merged-model is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* [senseable/WestLake-7B-v2](https://huggingface.co/senseable/WestLake-7B-v2)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: mistralai/Mistral-7B-v0.1
layer_range: [0, 32]
- model: senseable/WestLake-7B-v2
layer_range: [0, 32]
merge_method: slerp
base_model: mistralai/Mistral-7B-v0.1
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "ajay141/mistral_westlake_merged-model"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
juhwanlee/gemma-7B-alpaca-case-2-2
|
juhwanlee
| 2024-03-26T06:18:52Z | 47 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-25T06:35:25Z |
---
license: apache-2.0
datasets:
- Open-Orca/OpenOrca
language:
- en
---
# Model Details
* Model Description: This model is test for data ordering.
* Developed by: Juhwan Lee
* Model Type: Large Language Model
# Model Architecture
This model is based on Gemma-7B. We fine-tuning this model for data ordering task.
Gemma-7B is a transformer model, with the following architecture choices:
* Grouped-Query Attention
* Sliding-Window Attention
* Byte-fallback BPE tokenizer
# Dataset
We random sample Open-Orca dataset. (We finetune the 100,000 dataset)
# Guthub
https://github.com/trailerAI
# License
Apache License 2.0
|
dozzke/hermorca
|
dozzke
| 2024-03-26T06:17:39Z | 55 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"base_model:merge:NousResearch/Hermes-2-Pro-Mistral-7B",
"base_model:Open-Orca/Mistral-7B-OpenOrca",
"base_model:merge:Open-Orca/Mistral-7B-OpenOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-21T07:02:22Z |
---
base_model:
- NousResearch/Hermes-2-Pro-Mistral-7B
- Open-Orca/Mistral-7B-OpenOrca
library_name: transformers
license: apache-2.0
tags:
- mergekit
- merge
---
# model_hermorca
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [NousResearch/Hermes-2-Pro-Mistral-7B](https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B)
* [Open-Orca/Mistral-7B-OpenOrca](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca)
### OpenLLM Leaderboards
1 - Hermes / 2 - OpenOrca

### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: NousResearch/Hermes-2-Pro-Mistral-7B
layer_range: [0, 32]
- model: Open-Orca/Mistral-7B-OpenOrca
layer_range: [0, 32]
merge_method: slerp
base_model: NousResearch/Hermes-2-Pro-Mistral-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
MaziyarPanahi/Hermes-2-Pro-11B-GGUF
|
MaziyarPanahi
| 2024-03-26T06:11:25Z | 111 | 4 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"NousResearch/Hermes-2-Pro-Mistral-7B",
"conversational",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:mattshumer/Hermes-2-Pro-11B",
"base_model:quantized:mattshumer/Hermes-2-Pro-11B"
] |
text-generation
| 2024-03-26T05:21:12Z |
---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- merge
- mergekit
- lazymergekit
- NousResearch/Hermes-2-Pro-Mistral-7B
- conversational
- base_model:NousResearch/Hermes-2-Pro-Mistral-7B
- license:apache-2.0
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: Hermes-2-Pro-11B-GGUF
base_model: mattshumer/Hermes-2-Pro-11B
inference: false
model_creator: mattshumer
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/Hermes-2-Pro-11B-GGUF](https://huggingface.co/MaziyarPanahi/Hermes-2-Pro-11B-GGUF)
- Model creator: [mattshumer](https://huggingface.co/mattshumer)
- Original model: [mattshumer/Hermes-2-Pro-11B](https://huggingface.co/mattshumer/Hermes-2-Pro-11B)
## Description
[MaziyarPanahi/Hermes-2-Pro-11B-GGUF](https://huggingface.co/MaziyarPanahi/Hermes-2-Pro-11B-GGUF) contains GGUF format model files for [mattshumer/Hermes-2-Pro-11B](https://huggingface.co/mattshumer/Hermes-2-Pro-11B).
## How to use
Thanks to [TheBloke](https://huggingface.co/TheBloke) for preparing an amazing README on how to use GGUF models:
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
### Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: [MaziyarPanahi/Hermes-2-Pro-11B-GGUF](https://huggingface.co/MaziyarPanahi/Hermes-2-Pro-11B-GGUF) and below it, a specific filename to download, such as: Hermes-2-Pro-11B-GGUF.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download MaziyarPanahi/Hermes-2-Pro-11B-GGUF Hermes-2-Pro-11B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
</details>
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download [MaziyarPanahi/Hermes-2-Pro-11B-GGUF](https://huggingface.co/MaziyarPanahi/Hermes-2-Pro-11B-GGUF) --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MaziyarPanahi/Hermes-2-Pro-11B-GGUF Hermes-2-Pro-11B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Hermes-2-Pro-11B.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://github.com/abetlen/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Hermes-2-Pro-11B-GGUF.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Hermes-2-Pro-11B.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
|
saransh03sharma/mintrec-llama-2-7b-100
|
saransh03sharma
| 2024-03-26T06:09:41Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-23T07:21:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Kiruthikarthi/mistral-trinity-slerp
|
Kiruthikarthi
| 2024-03-26T06:08:13Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"mistralai/Mistral-7B-Instruct-v0.2",
"jan-hq/trinity-v1",
"conversational",
"base_model:jan-hq/trinity-v1",
"base_model:merge:jan-hq/trinity-v1",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:merge:mistralai/Mistral-7B-Instruct-v0.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T06:03:52Z |
---
tags:
- merge
- mergekit
- lazymergekit
- mistralai/Mistral-7B-Instruct-v0.2
- jan-hq/trinity-v1
base_model:
- mistralai/Mistral-7B-Instruct-v0.2
- jan-hq/trinity-v1
---
# mistral-trinity-slerp
mistral-trinity-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
* [jan-hq/trinity-v1](https://huggingface.co/jan-hq/trinity-v1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: mistralai/Mistral-7B-Instruct-v0.2
layer_range: [0, 32]
- model: jan-hq/trinity-v1
layer_range: [0, 32]
merge_method: slerp
base_model: mistralai/Mistral-7B-Instruct-v0.2
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Kiruthikarthi/mistral-trinity-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
jinghuanHuggingface/Pyramids-Training
|
jinghuanHuggingface
| 2024-03-26T06:06:33Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2024-03-26T06:06:32Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: jinghuanHuggingface/Pyramids-Training
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
stablediffusionapi/zaxious-xl
|
stablediffusionapi
| 2024-03-26T06:06:06Z | 35 | 0 |
diffusers
|
[
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2024-03-26T06:03:27Z |
---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "zaxious-xl"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://modelslab.com/docs)
Try model for free: [Generate Images](https://modelslab.com/models/zaxious-xl)
Model link: [View model](https://modelslab.com/models/zaxious-xl)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "zaxious-xl",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN**
|
0x9/nous-2b-01
|
0x9
| 2024-03-26T06:04:05Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-13T21:43:20Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ENOT-AutoDL/MP-SENet
|
ENOT-AutoDL
| 2024-03-26T05:57:55Z | 0 | 6 | null |
[
"onnx",
"ENOT-AutoDL",
"SpeechEnhancement",
"license:apache-2.0",
"region:us"
] | null | 2024-03-25T06:28:57Z |
---
license: apache-2.0
tags:
- ENOT-AutoDL
- SpeechEnhancement
---
# MP-SENet optimization on VoiceBank+DEMAND dataset with ENOT-AutoDL.
This repository contains the optimized version of [MP-SENet](https://github.com/yxlu-0102/MP-SENet) model.
Number of multiplication and addition operations (MACs) was used for computational complexity measurement. PESQ score was used as a quality metric.
## Optimization results
We use MACs as a latency measure because this metric is device-agnostic and implementation independent.
There is also a possibility to optimize a model by target device latency using ENOT neural architecture selection algorithm.
Please, keep in mind that acceleration by device latency differs from acceleration by MACs.
| **Model** | **MACs** | **Acceleration (MACs)** | PESQ score (the higher the better) |
|----------------|:--------:|:-----------------------:|:----------------------------------:|
| baseline | 302.39 B | 1.0 | 3.381 |
| ENOT optimized | 120.95 B | 2.5 | 3.386 |
You can use `Baseline_model.pth` or `ENOT_optimized_model.pth` in the original repo by loading a model as generator in the following way:
```python
generator = torch.load("ENOT_optimized_model.pth")
```
Each of these two files contain a model object, saved by `torch.save`, so you can load them only from the original repository root because of imports.
If you want to book a demo, please contact us: [email protected] .
|
DUAL-GPO/phi-2-gpo-test-longest-iter-v1-2
|
DUAL-GPO
| 2024-03-26T05:57:16Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"phi",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"custom_code",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-03-26T03:03:12Z |
---
license: mit
library_name: peft
tags:
- alignment-handbook
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- HuggingFaceH4/ultrafeedback_binarized
model-index:
- name: phi-2-gpo-test-longest-iter-v1-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-2-gpo-test-longest-iter-v1-2
This model is a fine-tuned version of [DUAL-GPO/phi-2-gpo-test-longest-iter-v1-1](https://huggingface.co/DUAL-GPO/phi-2-gpo-test-longest-iter-v1-1) on the HuggingFaceH4/ultrafeedback_binarized dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0016
- Rewards/chosen: -0.0008
- Rewards/rejected: -0.0008
- Rewards/accuracies: 0.4910
- Rewards/margins: 0.0001
- Logps/rejected: -278.6518
- Logps/chosen: -306.3463
- Logits/rejected: 0.0888
- Logits/chosen: -0.0087
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0011 | 1.6 | 100 | 0.0016 | -0.0007 | -0.0008 | 0.4960 | 0.0001 | -278.6544 | -306.3417 | 0.0909 | -0.0073 |
| 0.0011 | 3.2 | 200 | 0.0016 | -0.0001 | -0.0005 | 0.4925 | 0.0003 | -278.6177 | -306.2834 | 0.0921 | -0.0047 |
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.2.1+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
|
hanzla/gemma-2b-datascience-instruct-v3-adapters
|
hanzla
| 2024-03-26T05:47:13Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T04:15:10Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ntvcie/GemmaVinhntV5
|
ntvcie
| 2024-03-26T05:35:40Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/llama-2-7b-bnb-4bit",
"base_model:finetune:unsloth/llama-2-7b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T05:29:53Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-2-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** ntvcie
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-2-7b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ajay141/Chat-generation
|
ajay141
| 2024-03-26T05:35:35Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"openchat/openchat-3.5-1210",
"mlabonne/AlphaMonarch-7B",
"conversational",
"base_model:mlabonne/AlphaMonarch-7B",
"base_model:merge:mlabonne/AlphaMonarch-7B",
"base_model:openchat/openchat-3.5-1210",
"base_model:merge:openchat/openchat-3.5-1210",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T05:32:08Z |
---
tags:
- merge
- mergekit
- lazymergekit
- openchat/openchat-3.5-1210
- mlabonne/AlphaMonarch-7B
base_model:
- openchat/openchat-3.5-1210
- mlabonne/AlphaMonarch-7B
---
# Chat-generation
Chat-generation is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [openchat/openchat-3.5-1210](https://huggingface.co/openchat/openchat-3.5-1210)
* [mlabonne/AlphaMonarch-7B](https://huggingface.co/mlabonne/AlphaMonarch-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: openchat/openchat-3.5-1210
layer_range: [0, 32]
- model: mlabonne/AlphaMonarch-7B
layer_range: [0, 32]
merge_method: slerp
base_model: openchat/openchat-3.5-1210
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "ajay141/Chat-generation"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
son-of-man/HoloLewd-7B-test
|
son-of-man
| 2024-03-26T05:31:47Z | 6 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"Undi95/LewdMistral-7B-0.2",
"KoboldAI/Mistral-7B-Holodeck-1",
"base_model:KoboldAI/Mistral-7B-Holodeck-1",
"base_model:merge:KoboldAI/Mistral-7B-Holodeck-1",
"base_model:Undi95/LewdMistral-7B-0.2",
"base_model:merge:Undi95/LewdMistral-7B-0.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T05:27:39Z |
---
tags:
- merge
- mergekit
- lazymergekit
- Undi95/LewdMistral-7B-0.2
- KoboldAI/Mistral-7B-Holodeck-1
base_model:
- Undi95/LewdMistral-7B-0.2
- KoboldAI/Mistral-7B-Holodeck-1
---
# HoloLewd-7B
HoloLewd-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [Undi95/LewdMistral-7B-0.2](https://huggingface.co/Undi95/LewdMistral-7B-0.2)
* [KoboldAI/Mistral-7B-Holodeck-1](https://huggingface.co/KoboldAI/Mistral-7B-Holodeck-1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Undi95/LewdMistral-7B-0.2
layer_range: [0, 32]
- model: KoboldAI/Mistral-7B-Holodeck-1
layer_range: [0, 32]
merge_method: slerp
base_model: Undi95/LewdMistral-7B-0.2
parameters:
t:
- value: 0.32
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "son-of-man/HoloLewd-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
0x0son0/nr_m20
|
0x0son0
| 2024-03-26T05:18:48Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T02:47:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MilaDeepGraph/ProtST-ESM1b-LocalizationPrediction
|
MilaDeepGraph
| 2024-03-26T05:18:20Z | 194 | 0 |
transformers
|
[
"transformers",
"safetensors",
"protst",
"feature-extraction",
"custom_code",
"region:us"
] |
feature-extraction
| 2024-03-22T03:14:11Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
ProtST for binary localization.
The following script shows how to finetune ProtST on Gaudi.
## Running script
```diff
from transformers import AutoModel, AutoTokenizer, HfArgumentParser, TrainingArguments, Trainer
from transformers.data.data_collator import DataCollatorWithPadding
from transformers.trainer_pt_utils import get_parameter_names
from transformers.pytorch_utils import ALL_LAYERNORM_LAYERS
from datasets import load_dataset
import functools
import numpy as np
from sklearn.metrics import accuracy_score, matthews_corrcoef
import sys
import torch
import logging
import datasets
import transformers
+ import habana_frameworks.torch
+ from optimum.habana import GaudiConfig, GaudiTrainer, GaudiTrainingArguments
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def create_optimizer(opt_model, lr_ratio=0.1):
head_names = []
for n, p in opt_model.named_parameters():
if "classifier" in n:
head_names.append(n)
else:
p.requires_grad = False
# turn a list of tuple to 2 lists
for n, p in opt_model.named_parameters():
if n in head_names:
assert p.requires_grad
backbone_names = []
for n, p in opt_model.named_parameters():
if n not in head_names and p.requires_grad:
backbone_names.append(n)
# for weight_decay policy, see
# https://github.com/huggingface/transformers/blob/50573c648ae953dcc1b94d663651f07fb02268f4/src/transformers/trainer.py#L947
decay_parameters = get_parameter_names(opt_model, ALL_LAYERNORM_LAYERS) # forbidden layer norm
decay_parameters = [name for name in decay_parameters if "bias" not in name]
# training_args.learning_rate
head_decay_parameters = [name for name in head_names if name in decay_parameters]
head_not_decay_parameters = [name for name in head_names if name not in decay_parameters]
# training_args.learning_rate * model_config.lr_ratio
backbone_decay_parameters = [name for name in backbone_names if name in decay_parameters]
backbone_not_decay_parameters = [name for name in backbone_names if name not in decay_parameters]
optimizer_grouped_parameters = [
{
"params": [p for n, p in opt_model.named_parameters() if (n in head_decay_parameters and p.requires_grad)],
"weight_decay": training_args.weight_decay,
"lr": training_args.learning_rate
},
{
"params": [p for n, p in opt_model.named_parameters() if (n in backbone_decay_parameters and p.requires_grad)],
"weight_decay": training_args.weight_decay,
"lr": training_args.learning_rate * lr_ratio
},
{
"params": [p for n, p in opt_model.named_parameters() if (n in head_not_decay_parameters and p.requires_grad)],
"weight_decay": 0.0,
"lr": training_args.learning_rate
},
{
"params": [p for n, p in opt_model.named_parameters() if (n in backbone_not_decay_parameters and p.requires_grad)],
"weight_decay": 0.0,
"lr": training_args.learning_rate * lr_ratio
},
]
- optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(training_args)
+ optimizer_cls, optimizer_kwargs = GaudiTrainer.get_optimizer_cls_and_kwargs(training_args)
optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
return optimizer
def create_scheduler(training_args, optimizer):
from transformers.optimization import get_scheduler
return get_scheduler(
training_args.lr_scheduler_type,
optimizer=optimizer if optimizer is None else optimizer,
num_warmup_steps=training_args.get_warmup_steps(training_args.max_steps),
num_training_steps=training_args.max_steps,
)
def compute_metrics(eval_preds):
probs, labels = eval_preds
preds = np.argmax(probs, axis=-1)
result = {"accuracy": accuracy_score(labels, preds), "mcc": matthews_corrcoef(labels, preds)}
return result
def preprocess_logits_for_metrics(logits, labels):
return torch.softmax(logits, dim=-1)
if __name__ == "__main__":
- device = torch.device("cpu")
+ device = torch.device("hpu")
raw_dataset = load_dataset("Jiqing/ProtST-BinaryLocalization")
model = AutoModel.from_pretrained("Jiqing/protst-esm1b-for-sequential-classification", trust_remote_code=True, torch_dtype=torch.bfloat16).to(device)
tokenizer = AutoTokenizer.from_pretrained("facebook/esm1b_t33_650M_UR50S")
output_dir = "/home/jiqingfe/protst/protst_2/ProtST-HuggingFace/output_dir/ProtSTModel/default/ESM-1b_PubMedBERT-abs/240123_015856"
training_args = {'output_dir': output_dir, 'overwrite_output_dir': True, 'do_train': True, 'per_device_train_batch_size': 32, 'gradient_accumulation_steps': 1, \
'learning_rate': 5e-05, 'weight_decay': 0, 'num_train_epochs': 100, 'max_steps': -1, 'lr_scheduler_type': 'constant', 'do_eval': True, \
'evaluation_strategy': 'epoch', 'per_device_eval_batch_size': 32, 'logging_strategy': 'epoch', 'save_strategy': 'epoch', 'save_steps': 820, \
'dataloader_num_workers': 0, 'run_name': 'downstream_esm1b_localization_fix', 'optim': 'adamw_torch', 'resume_from_checkpoint': False, \
- 'label_names': ['labels'], 'load_best_model_at_end': True, 'metric_for_best_model': 'accuracy', 'bf16': True, "save_total_limit": 3}
+ 'label_names': ['labels'], 'load_best_model_at_end': True, 'metric_for_best_model': 'accuracy', 'bf16': True, "save_total_limit": 3, "use_habana":True, "use_lazy_mode": True, "use_hpu_graphs_for_inference": True}
- training_args = HfArgumentParser(TrainingArguments).parse_dict(training_args, allow_extra_keys=False)[0]
+ training_args = HfArgumentParser(GaudiTrainingArguments).parse_dict(training_args, allow_extra_keys=False)[0]
def tokenize_protein(example, tokenizer=None):
protein_seq = example["prot_seq"]
protein_seq_str = tokenizer(protein_seq, add_special_tokens=True)
example["input_ids"] = protein_seq_str["input_ids"]
example["attention_mask"] = protein_seq_str["attention_mask"]
example["labels"] = example["localization"]
return example
func_tokenize_protein = functools.partial(tokenize_protein, tokenizer=tokenizer)
for split in ["train", "validation", "test"]:
raw_dataset[split] = raw_dataset[split].map(func_tokenize_protein, batched=False, remove_columns=["Unnamed: 0", "prot_seq", "localization"])
- data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+ data_collator = DataCollatorWithPadding(tokenizer=tokenizer, padding="max_length", max_length=1024)
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
optimizer = create_optimizer(model)
scheduler = create_scheduler(training_args, optimizer)
+ gaudi_config = GaudiConfig()
+ gaudi_config.use_fused_adam = True
+ gaudi_config.use_fused_clip_norm =True
# build trainer
- trainer = Trainer(
+ trainer = GaudiTrainer(
model=model,
+ gaudi_config=gaudi_config,
args=training_args,
train_dataset=raw_dataset["train"],
eval_dataset=raw_dataset["validation"],
data_collator=data_collator,
optimizers=(optimizer, scheduler),
compute_metrics=compute_metrics,
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
)
train_result = trainer.train()
trainer.save_model()
# Saves the tokenizer too for easy upload
tokenizer.save_pretrained(training_args.output_dir)
metrics = train_result.metrics
metrics["train_samples"] = len(raw_dataset["train"])
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
metric = trainer.evaluate(raw_dataset["test"], metric_key_prefix="test")
print("test metric: ", metric)
metric = trainer.evaluate(raw_dataset["validation"], metric_key_prefix="valid")
print("valid metric: ", metric)
```
|
MilaDeepGraph/ProtST-ESM1b
|
MilaDeepGraph
| 2024-03-26T05:18:08Z | 191 | 0 |
transformers
|
[
"transformers",
"pytorch",
"protst",
"feature-extraction",
"custom_code",
"arxiv:2301.12040",
"region:us"
] |
feature-extraction
| 2024-03-21T16:21:45Z |
## Abstract
Current protein language models (PLMs) learn protein representations mainly based on their sequences, thereby well capturing co-evolutionary information, but they are unable to explicitly acquire protein functions, which is the end goal of protein representation learning. Fortunately, for many proteins, their textual property descriptions are available, where their various functions are also described. Motivated by this fact, we first build the ProtDescribe dataset to augment protein sequences with text descriptions of their functions and other important properties. Based on this dataset, we propose the [ProtST framework](https://arxiv.org/abs/2301.12040) to enhance Protein Sequence pre-training and understanding by biomedical Texts. During pre-training, we design three types of tasks, i.e., unimodal mask prediction, multimodal representation alignment and multimodal mask prediction, to enhance a PLM with protein property information with different granularities and, at the same time, preserve the PLM’s original representation power. On downstream tasks, ProtST enables both supervised learning and zeroshot prediction. We verify the superiority of ProtST-induced PLMs over previous ones on diverse representation learning benchmarks. Under the zero-shot setting, we show the effectiveness of ProtST on zero-shot protein classification, and ProtST also enables functional protein retrieval from a large-scale database without any function annotation. Source code and model weights are available at [https://github.com/DeepGraphLearning/ProtST](https://github.com/DeepGraphLearning/ProtST).

## Example
The following script shows how to run ProtST with [optimum-intel](https://github.com/huggingface/optimum-intel) optimization on zero-shot classification task.
```diff
import logging
import functools
from tqdm import tqdm
import torch
from datasets import load_dataset
from transformers import AutoModel, AutoTokenizer, AutoConfig
logger = logging.getLogger(__name__)
def tokenize_protein(example, protein_tokenizer=None, padding=None):
protein_seqs = example["prot_seq"]
protein_inputs = protein_tokenizer(protein_seqs, padding=padding, add_special_tokens=True)
example["protein_input_ids"] = protein_inputs.input_ids
example["protein_attention_mask"] = protein_inputs.attention_mask
return example
def label_embedding(labels, text_tokenizer, text_model, device):
# embed label descriptions
label_feature = []
with torch.inference_mode():
for label in labels:
label_input_ids = text_tokenizer.encode(label, max_length=128,
truncation=True, add_special_tokens=False)
label_input_ids = [text_tokenizer.cls_token_id] + label_input_ids
label_input_ids = torch.tensor(label_input_ids, dtype=torch.long, device=device).unsqueeze(0)
attention_mask = label_input_ids != text_tokenizer.pad_token_id
attention_mask = attention_mask.to(device)
text_outputs = text_model(label_input_ids, attention_mask=attention_mask)
label_feature.append(text_outputs["text_feature"])
label_feature = torch.cat(label_feature, dim=0)
label_feature = label_feature / label_feature.norm(dim=-1, keepdim=True)
return label_feature
def zero_shot_eval(logger, device,
test_dataset, target_field, protein_model, logit_scale, label_feature):
# get prediction and target
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
preds, targets = [], []
with torch.inference_mode():
for data in tqdm(test_dataloader):
target = data[target_field]
targets.append(target)
protein_input_ids = torch.tensor(data["protein_input_ids"], dtype=torch.long, device=device).unsqueeze(0)
attention_mask = torch.tensor(data["protein_attention_mask"], dtype=torch.long, device=device).unsqueeze(0)
protein_outputs = protein_model(protein_input_ids, attention_mask=attention_mask)
protein_feature = protein_outputs["protein_feature"]
protein_feature = protein_feature / protein_feature.norm(dim=-1, keepdim=True)
pred = logit_scale * protein_feature @ label_feature.t()
preds.append(pred)
preds = torch.cat(preds, dim=0)
targets = torch.tensor(targets, dtype=torch.long, device=device)
accuracy = (preds.argmax(dim=-1) == targets).float().mean().item()
logger.warning("Zero-shot accuracy: %.6f" % accuracy)
if __name__ == "__main__":
# get datasets
raw_datasets = load_dataset("Jiqing/ProtST-SubcellularLocalization", cache_dir="~/.cache/huggingface/datasets", split='test') # cache_dir defaults to "~/.cache/huggingface/datasets"
#device = torch.device("cuda:0")
device = torch.device("cpu")
protst_model = AutoModel.from_pretrained("Jiqing/ProtST-esm1b", trust_remote_code=True, torch_dtype=torch.bfloat16).to(device)
protein_model = protst_model.protein_model
+ import intel_extension_for_pytorch as ipex
+ from optimum.intel.generation.modeling import jit_trace
+ protein_model = ipex.optimize(protein_model, dtype=torch.bfloat16, inplace=True)
+ protein_model = jit_trace(protein_model, "sequence-classification")
text_model = protst_model.text_model
logit_scale = protst_model.logit_scale
logit_scale.requires_grad = False
logit_scale = logit_scale.to(device)
logit_scale = logit_scale.exp()
protein_tokenizer = AutoTokenizer.from_pretrained("facebook/esm1b_t33_650M_UR50S")
text_tokenizer = AutoTokenizer.from_pretrained("microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract")
func_tokenize_protein = functools.partial(tokenize_protein, protein_tokenizer=protein_tokenizer, padding=False)
test_dataset = raw_datasets.map(
func_tokenize_protein, batched=False,
remove_columns=["prot_seq"],
desc="Running tokenize_proteins on dataset",
)
labels = load_dataset("Jiqing/subloc_template", cache_dir="~/.cache/huggingface/datasets")["train"]["name"]
text_tokenizer.encode(labels[0], max_length=128, truncation=True, add_special_tokens=False)
label_feature = label_embedding(labels, text_tokenizer, text_model, device)
zero_shot_eval(logger, device, test_dataset, "localization",
protein_model, logit_scale, label_feature)
```
|
BricksDisplay/Breeze-7B-Instruct-v1_0-q4
|
BricksDisplay
| 2024-03-26T05:14:37Z | 1 | 0 |
transformers
|
[
"transformers",
"onnx",
"mistral",
"text-generation",
"conversational",
"base_model:MediaTek-Research/Breeze-7B-Instruct-v1_0",
"base_model:quantized:MediaTek-Research/Breeze-7B-Instruct-v1_0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-24T05:59:31Z |
---
base_model: MediaTek-Research/Breeze-7B-Instruct-v1_0
---
Convert from MediaTek-Research/Breeze-7B-Instruct-v1_0, and 4 bits quantized.
|
BricksDisplay/Yi-6B-Chat-q4
|
BricksDisplay
| 2024-03-26T05:13:05Z | 1 | 0 |
transformers
|
[
"transformers",
"onnx",
"llama",
"text-generation",
"conversational",
"base_model:01-ai/Yi-6B-Chat",
"base_model:quantized:01-ai/Yi-6B-Chat",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-24T08:46:06Z |
---
base_model: 01-ai/Yi-6B-Chat
---
Convert from 01-ai/Yi-6B-Chat, and 4 bits quantized.
|
BricksDisplay/Llama-2-7b-chat-q4
|
BricksDisplay
| 2024-03-26T05:12:01Z | 8 | 0 |
transformers
|
[
"transformers",
"onnx",
"llama",
"text-generation",
"conversational",
"base_model:meta-llama/Llama-2-7b-chat",
"base_model:quantized:meta-llama/Llama-2-7b-chat",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-23T20:22:48Z |
---
base_model: meta-llama/Llama-2-7b-chat
---
Convert from meta-llama/Llama-2-7b-chat, and 4 bits quantized.
|
Aditya149/Mental-Yi-7B-V2
|
Aditya149
| 2024-03-26T05:11:30Z | 2 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:01-ai/Yi-6B-Chat",
"base_model:adapter:01-ai/Yi-6B-Chat",
"license:other",
"region:us"
] | null | 2024-03-26T05:11:26Z |
---
license: other
library_name: peft
tags:
- generated_from_trainer
base_model: 01-ai/Yi-6B-Chat
model-index:
- name: Mental-Yi-7B-V2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mental-Yi-7B-V2
This model is a fine-tuned version of [01-ai/Yi-6B-Chat](https://huggingface.co/01-ai/Yi-6B-Chat) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9559
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.2248 | 1.48 | 500 | 2.9363 |
| 2.7215 | 2.96 | 1000 | 2.8738 |
| 2.4815 | 4.44 | 1500 | 2.9559 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.39.1
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.1
|
BricksDisplay/Mistral-7B-Instruct-v0.2-q4
|
BricksDisplay
| 2024-03-26T05:11:08Z | 2 | 0 |
transformers
|
[
"transformers",
"onnx",
"mistral",
"text-generation",
"conversational",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:quantized:mistralai/Mistral-7B-Instruct-v0.2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-23T23:34:51Z |
---
base_model: mistralai/Mistral-7B-Instruct-v0.2
---
Convert from mistralai/Mistral-7B-Instruct-v0.2, and 4 bits quantized.
|
ChaoticNeutrals/Eris_PrimeV3.075-Vision-7B
|
ChaoticNeutrals
| 2024-03-26T04:58:55Z | 15 | 5 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:KatyTheCutie/LemonadeRP-4.5.3",
"base_model:merge:KatyTheCutie/LemonadeRP-4.5.3",
"base_model:Nitral-Archive/Eris_PrimeV3.05-Vision-7B",
"base_model:merge:Nitral-Archive/Eris_PrimeV3.05-Vision-7B",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-23T19:38:33Z |
---
base_model:
- KatyTheCutie/LemonadeRP-4.5.3
- Nitral-AI/Eris_PrimeV3.05-Vision-7B
library_name: transformers
tags:
- mergekit
- merge
license: other
---

Quants from the boy Lewdiculus: https://huggingface.co/Lewdiculous/Eris_PrimeV3.075-Vision-7B-GGUF-IQ-Imatrix-Test
# Vision/multimodal capabilities:
If you want to use vision functionality:
* You must use the latest versions of [Koboldcpp](https://github.com/LostRuins/koboldcpp).
To use the multimodal capabilities of this model and use **vision** you need to load the specified **mmproj** file, this can be found inside this model repo.
* You can load the **mmproj** by using the corresponding section in the interface:

|
rshrott/ryan_model
|
rshrott
| 2024-03-26T04:49:34Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-03-26T01:15:42Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: ryan_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ryan_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1285
- Accuracy: 0.5583
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4821 | 2.63 | 100 | 1.1285 | 0.5583 |
### Framework versions
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
0x0daughter1/moist_misty
|
0x0daughter1
| 2024-03-26T04:43:44Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-25T18:35:21Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jaycappin/octo
|
jaycappin
| 2024-03-26T04:32:03Z | 0 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"en",
"dataset:microsoft/orca-math-word-problems-200k",
"license:apache-2.0",
"region:us"
] | null | 2024-03-26T00:18:23Z |
---
license: apache-2.0
language:
- en
datasets:
- microsoft/orca-math-word-problems-200k
metrics:
- accuracy
library_name: adapter-transformers
---
|
lingchensanwen/flan-t5-base-classification-600train
|
lingchensanwen
| 2024-03-26T04:31:57Z | 163 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-03-26T04:26:18Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: t5_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_model
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
chanmuzi/push_test_gemini
|
chanmuzi
| 2024-03-26T04:27:25Z | 163 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-26T04:14:13Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
chanmuzi/test_trainer
|
chanmuzi
| 2024-03-26T04:16:41Z | 182 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased-finetuned-sst-2-english",
"base_model:finetune:distilbert/distilbert-base-uncased-finetuned-sst-2-english",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-26T01:21:04Z |
---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased-finetuned-sst-2-english
tags:
- generated_from_trainer
model-index:
- name: test_trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer
This model is a fine-tuned version of [distilbert/distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
NotoriousH2/v4_merged
|
NotoriousH2
| 2024-03-26T04:16:21Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T04:09:51Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
allbyai/ToRoLaMa-7b-v1.0
|
allbyai
| 2024-03-26T04:16:09Z | 1,510 | 9 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"vi",
"en",
"doi:10.57967/hf/1815",
"license:llama2",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-12-19T08:21:53Z |
---
language:
- vi
- en
license: llama2
pipeline_tag: text-generation
model-index:
- name: ToRoLaMa-7b-v1.0
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 51.71
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=allbyai/ToRoLaMa-7b-v1.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 73.82
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=allbyai/ToRoLaMa-7b-v1.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 45.34
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=allbyai/ToRoLaMa-7b-v1.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 44.89
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=allbyai/ToRoLaMa-7b-v1.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 70.09
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=allbyai/ToRoLaMa-7b-v1.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 1.36
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=allbyai/ToRoLaMa-7b-v1.0
name: Open LLM Leaderboard
---
# ToRoLaMa: The Vietnamese Instruction-Following and Chat Model
**Authors**: **Duy Quang Do<sup>1</sup>**, **Hoang Le<sup>1</sup>** and **Duc Thang Nguyen<sup>2</sup>**<br>
<sup>1</sup>*Taureau AI, Hanoi, Vietnam*<br>
<sup>2</sup>*Torus AI, Toulouse, France*
<p align="center" width="100%">
<img src="https://raw.githubusercontent.com/allbyai/ToRoLaMa/main/imgs/ToRoLaMa.png" width="45%"/>
</p>
ToRoLaMa is the result of a collaborative effort of Vietnam-based Taureau AI and France-based Torus AI. It stands as an open-source, multi-turn, large language model (LLM), initially created with a focus on the Vietnamese language. It represents the first step towards a wider goal of supporting a variety of international languages.
- [Introduction](#introduction)
- [Model weights](#model-weights)
- [Technical overview](#technical-overview)
- [Evaluations](#evaluations)
- [License](#license)
- [Disclaimer](#disclaimer)
- [Acknowledgement](#acknowledgement)
## Introduction
[Torus AI](https://www.torus.ai) (official name: Torus Actions SAS) was founded in Toulouse (France) in 2019 by a group of scientists under the leadership of [Nguyen Tien Zung](https://vi.wikipedia.org/wiki/Nguy%E1%BB%85n_Ti%E1%BA%BFn_D%C5%A9ng), distinguished professor of mathematics at the University of Toulouse. The name Torus Actions comes from *the toric conservation principle* discovered by Zung:
```
Everything conserved by a dynamical system is also conserved by its associated torus actions.
```
[Taureau AI](https://www.taureau.ai), set up in 2021 in Hanoi by Torus AI people, is focused on the development of a general purpose AI platform, AI product engineering and software development, to serve the other companies inside and outside the Torus AI ecosystem.
Our common objective is to create augmented intelligence solutions that serve millions of people and make the world a happier place.
Our large language model - ToRoLaMa, developed using a diverse and extensive dataset, aims to provide an enhanced understanding and representation of languages, aspiring to meet and possibly exceed the efficiency, performance, and applicability of existing commercial LLMs.
With ToRoLaMa, we hope to contribute to the rapid progress in language processing for Vietnamese speaking people and applications. We also plan to extend it (and other LLMs) to other languages.
This release includes the model weights, inference code, and evaluation results for the 7B (7 billion parameter) version.
## Model weights
Our lastest weights for ToRoLaMa can be found here:
| Date | Version | Huggingface Repo | Context Length |
| ------------- | ------------- |------------- |------------- |
| 19/12/2023 | ```ToRoLaMa-7B-1.0``` |[ToRoLaMa 7B 1.0](https://huggingface.co/allbyai/ToRoLaMa-7b-v1.0) | 2048 |
## Technical overview
The ToRoLaMa's pre-trained model is based on [Vietnamese-LLaMA2](https://huggingface.co/bkai-foundation-models/vietnamese-LLaMA2-7b-40GB), a fine-tuned version of LLaMA 2 model provided by bkai-foundation-labs, enhanced with a large Vietnamese-language dataset. The model then was trained using 430K high-quality, multi-turn questions/answers. Data sources for the training include [UIT-ViQUAD](https://paperswithcode.com/dataset/uit-viquad), [Bactrian-X](https://huggingface.co/datasets/MBZUAI/Bactrian-X), [Grade-school-math](https://github.com/openai/grade-school-math), etc and our in-house data that contain conversations on multiple topics.
Key advantages of ToRoLaMa include:
- Open-source availability under the [LLaMA 2 License](https://github.com/facebookresearch/LLaMA)
- Enhanced speed with a smaller model size and an innovative [Vietnamese Tokenizer](https://huggingface.co/bkai-foundation-models/vietnamese-LLaMA2-7b-40GB), whose tokens are 25% shorter compared to ChatGPT and LLaMA for Vietnamese phrases.
- Superior performance over existing open-source models (see benchmark results below).
- Simplified deployment for a wide range of applications.
## Evaluations
We used benchmark results of [Vicuna and PhoGPT](https://docs.google.com/spreadsheets/d/122ldeXuBmLSFFqaFbflj82VyYTKL-Qc2hZiTI9csc-Q/edit#gid=44668470) to evaluate ToRoLaMa and compared our results with others using the [Fastchat MT-bench method](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge).The table below shows that **ToRoLaMa** performs competitively against state-of-the-art models like ChatGPT.
The Fastchat benchmark method, used for evaluating language models, primarily focuses on the accuracy of information in responses. However, an important aspect not accounted for in this method is the accuracy in the choice of language (English vs. Vietnamese). Both **URA-LLaMA-7B** and **URA-LLaMA-13B** often respond in English to Vietnamese questions. Their performance may be rated much lower when specifically benchmarked for proficiency in Vietnamese.
The benchmark scores are shown in the following table:
Ranking | Model | Score |
| ------------- | ------------- | ------------- |
1|gpt-4 | 9.52500 |
2|gpt-3.5-turbo | 9.23750 |
3|**ToRoLaMa 7B** | 7.31875 |
4|URA-LLaMA-13B* | 6.98750 |
5|PhoGPT-7B5-Instruct| 6.49375 |
6|Vietcuna-7B-v3 | 5.21250 |
7|URA-LLaMA-7B* | 3.58750 |
8|Vietcuna-3B | 2.28750 |
*: *The scores of URA models here do not take into account the fact that they often answer in English to questions posed in Vietnamese.*
The details of benchmark in terms of subjects are shown in the following figure (we do not display URA-LLaMA because they generate half of the answers in English):
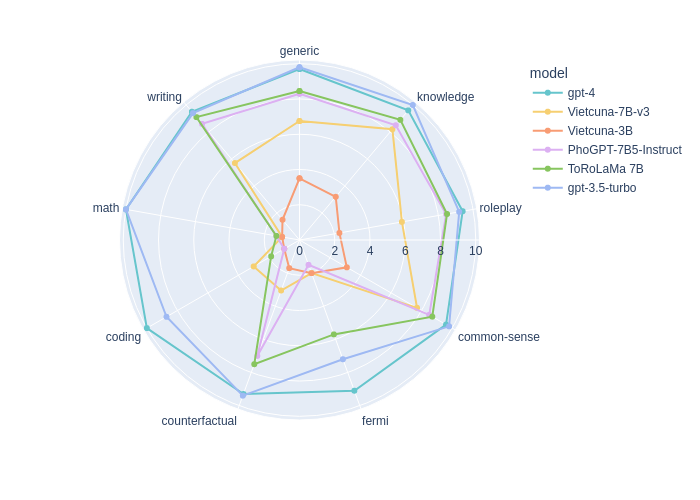
The above benchmark results show that **ToRoLaMa** excels in qualitative tasks compared to the other models, particularly with its ability to write and answer almost on par with GPT-3.5-turbo. However, it shows limitations in quantitative tasks like coding and mathematics due to the nature of its training data. This suggests opportunities for future improvements in STEM-related tasks.
For detailed benchmark information and to rerun the evaluation code, refer to [Fastchat MT-bench method](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge). We have included the answers from each model, the prompts, and the evaluation results [HERE](https://huggingface.co/allbyai/ToRoLaMa-7b-v1.0/tree/main/mt_bench) for reproduction. The generated results can also be accessed [HERE](https://docs.google.com/spreadsheets/d/1S1UmfImrLKFtxRmdX6B5plnIIyh3RiOr/edit?usp=sharing&ouid=102198682273617686649&rtpof=true&sd=true) for human evaluation.
## Run the model
ToRoLaMa uses a prompt format similar to Vicuna, designed for multi-turn, high-speed, and token-efficient conversations. An example prompt is shown below for illustration.
```
Cuộc hội thoại giữa người dùng và một trí thông minh nhân tạo. Đưa ra câu trả lời chính xác, giúp ích cho người dùng.
USER: chào
ASSISTANT: Xin chào! Tôi có thể giúp gì cho bạn hôm nay?</s>
USER: để quản lý thời gian hiệu quả tôi nên làm thế nào??
ASSISTANT: Để quản lý thời gian hiệu quả, bạn có thể thực hiện các bước sau đây:
Lập kế hoạch: Tạo ra lịch trình hoặc danh sách công việc cần làm trong ngày hoặc tuần.
Ưu tiên công việc: Xác định công việc quan trọng và ưu tiên thực hiện trước.
Sử dụng lịch: Sử dụng lịch để theo dõi các hoạt động và sự kiện trong ngày.
Sử dụng một số công cụ hỗ trợ: Sử dụng các công cụ trực tuyến, ứng dụng điện thoại di động để giúp quản lý thời gian.
Tránh phân tâm: Tránh những việc phức tạp và không cần thiết để giải quyết trong quá trình làm việc.
Nghỉ ngơi: Để giảm căng thẳng và tăng năng suất, hãy dành thời gian nghỉ ngơi giữa các công việc.
Đánh giá và cải tiến: Đánh giá các phương pháp quản lý thời gian của bạn để tìm cách cải tiến trong tương lai.
Những cách trên sẽ giúp bạn quản lý thời gian hiệu quả hơn và tăng cường năng suất trong công việc.</s>
```
The file [inference_hf.py](https://github.com/allbyai/ToRoLaMa/blob/main/inference_hf.py) in our github repository contains an example code for running ToRoLaMa model from Huggingface hub. Execute it using the following command:
```
python inference_hf.py
```
## Deployment
ToRoLaMa can be easily deployed using Fastchat.
Step 1: Install fastchat
```
pip3 install "fschat[model_worker,webui]"
```
Step 2: Run the RESTful API Server
Begin by running the controller:
```
python3 -m fastchat.serve.controller
```
Next, launch the model worker:
```
python3 -m fastchat.serve.model_worker --model-path path-to-ToRoLaMa --conv-template vicuna_v1.1
```
Then, initiate the RESTful API server:
```
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
```
Finaly, run the example streamlit code:
```
streamlit run demo.py
```
## License
ToRoLaMa is licensed under the [ToRoLaMa community License](https://github.com/allbyai/ToRoLaMa/blob/main/LICENSE) agreement.
ToRoLaMa is licensed under the [LLaMA 2 Community License](https://ai.meta.com/LLaMA/license/), Copyright © Meta Platforms, Inc. All Rights Reserved.
## Disclaimer
This model is derived from Meta's LLaMA-2 model, and therefore strictly complies with the LLaMA 2 Community License Agreement. We explicitly declare that we offer no assurances, guarantees, or warranties about the accuracy, reliability, usability, or completeness of the model's outputs or the data presented therein. We disclaim all liability for any immediate or subsequent losses, damages or adverse consequences arising from the use of our model. Please be aware that the model's generated content might include inaccuracies, profanity, hate speech, discriminatory remarks, and/or misleading narratives. Using this model or its derivatives for commercial purposes requires full compliance with all applicable local laws and regulations regarding the legality of the content produced by the model. We hold no accountability for any products or services that are developed using ToRoLaMa and its related files.
## Acknowledgement
The [bkai-foundation-labs](https://huggingface.co/bkai-foundation-models/vietnamese-LLaMA2-7b-40GB), and [fastchat](https://github.com/lm-sys/FastChat/tree/main) and references therein have been used in this work.
In case you use ToRoLaMa, please cite our work in your publications :
```
@misc{allbyai2023ToRoLaMa,
title={ToRoLaMa: The Vietnamese Instruction-Following and Chat Model},
author={Duy Quang Do, Hoang Le and Duc Thang Nguyen},
year={2023},
note={https://github.com/allbyai/ToRoLaMa}
howpublished={Software}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_allbyai__ToRoLaMa-7b-v1.0)
| Metric |Value|
|---------------------------------|----:|
|Avg. |47.87|
|AI2 Reasoning Challenge (25-Shot)|51.71|
|HellaSwag (10-Shot) |73.82|
|MMLU (5-Shot) |45.34|
|TruthfulQA (0-shot) |44.89|
|Winogrande (5-shot) |70.09|
|GSM8k (5-shot) | 1.36|
|
Svenni551/gemma-Code-Instruct-Finetune-test
|
Svenni551
| 2024-03-26T04:13:48Z | 144 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T03:53:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ksgk-fy/M7Percival_010.46-0.7-0.38-0.69-0.44-0.82-7B
|
Ksgk-fy
| 2024-03-26T04:12:01Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:AurelPx/Percival_01-7b-slerp",
"base_model:merge:AurelPx/Percival_01-7b-slerp",
"base_model:liminerity/M7-7b",
"base_model:merge:liminerity/M7-7b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T04:08:35Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- liminerity/M7-7b
- AurelPx/Percival_01-7b-slerp
---
## 🧩 Configuration
```yaml
slices:
- sources:
- model: liminerity/M7-7b
layer_range: [0, 32]
- model: AurelPx/Percival_01-7b-slerp
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/M7-7b
parameters:
t:
- filter: self_attn
value: [0.4610771124019083, 0.7046042147123381, 0.38091080927266374, 0.6885067639831562, 0.44300426813444327]
- filter: mlp
value: [0.5389228875980917, 0.29539578528766186, 0.31149323601684376, 0.31149323601684376, 0.5569957318655567]
- value: 0.8225561005835319
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Ksgk-fy/M7Percival_010.46-0.7-0.38-0.69-0.44-0.82-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
NotoriousH2/v4
|
NotoriousH2
| 2024-03-26T04:09:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T04:09:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JLB-JLB/EEG_TSMixer_512_history_96_horizon
|
JLB-JLB
| 2024-03-26T04:02:07Z | 34 | 0 |
transformers
|
[
"transformers",
"safetensors",
"patchtsmixer",
"EEG",
"Forecasting",
"Time Series",
"TSMixer",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T04:01:58Z |
---
library_name: transformers
tags:
- EEG
- Forecasting
- Time Series
- TSMixer
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JLB-JLB/EEG_TSMixer_336_history_96_horizon
|
JLB-JLB
| 2024-03-26T04:01:55Z | 35 | 0 |
transformers
|
[
"transformers",
"safetensors",
"patchtsmixer",
"EEG",
"Forecasting",
"Time Series",
"TSMixer",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T04:01:49Z |
---
library_name: transformers
tags:
- EEG
- Forecasting
- Time Series
- TSMixer
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JLB-JLB/EEG_PatchTST_1024_history_96_horizon
|
JLB-JLB
| 2024-03-26T04:01:45Z | 61 | 0 |
transformers
|
[
"transformers",
"safetensors",
"patchtst",
"EEG",
"Forecasting",
"Time Series",
"PatchTST",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T04:01:39Z |
---
library_name: transformers
tags:
- EEG
- Forecasting
- Time Series
- PatchTST
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JLB-JLB/EEG_TimeSeriesTransformer_336_history_96_horizon
|
JLB-JLB
| 2024-03-26T04:00:56Z | 35 | 0 |
transformers
|
[
"transformers",
"safetensors",
"time_series_transformer",
"EEG",
"Forecasting",
"Time Series",
"TimeSeriesTransformer",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T04:00:49Z |
---
library_name: transformers
tags:
- EEG
- Forecasting
- Time Series
- TimeSeriesTransformer
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ItsMeBell/LarosBell-XL
|
ItsMeBell
| 2024-03-26T04:00:17Z | 16 | 1 |
diffusers
|
[
"diffusers",
"Anime",
"Text-To-Image",
"3D",
"text-to-image",
"en",
"license:other",
"region:us"
] |
text-to-image
| 2024-03-08T19:11:15Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Text-To-Image
- 3D
---
<style>
.title-container {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
}
.title {
font-size: 2.5em;
text-align: center;
color: #333;
font-family: 'Helvetica Neue', sans-serif;
text-transform: uppercase;
letter-spacing: 0.1em;
padding: 0.5em 0;
background: transparent;
}
.title span {
background: -webkit-linear-gradient(45deg, #2196f3, #f44336);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.5);
font-family: 'Andale Mono', monospace;
}
.custom-table {
table-layout: fixed;
width: 100%;
border-collapse: collapse;
margin-top: 2em;
}
.custom-table td {
width: 50%;
vertical-align: top;
padding: 10px;
box-shadow: 0px 0px 0px 0px rgba(0, 0, 0, 0.15);
}
.custom-image-container {
position: relative;
width: 100%;
margin-bottom: 0em;
overflow: hidden;
border-radius: 10px;
transition: transform .7s;
}
.custom-image-container:hover {
transform: scale(1.05);
}
.custom-image {
width: 100%;
height: auto;
object-fit: cover;
border-radius: 10px;
transition: transform .7s;
margin-bottom: 0em;
}
.nsfw-filter {
filter: blur(8px);
transition: filter 0.3s ease;
}
.custom-image-container:hover .nsfw-filter {
filter: none;
}
.overlay {
position: absolute;
bottom: 0;
left: 0;
right: 0;
color: white;
width: 100%;
height: 40%;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
font-size: 1vw;
font-style: bold;
text-align: center;
opacity: 0;
background: linear-gradient(0deg, rgba(0, 0, 0, 0.8) 60%, rgba(0, 0, 0, 0) 100%);
transition: opacity .5s;
}
.custom-image-container:hover .overlay {
opacity: 1;
}
.overlay-text {
background: linear-gradient(45deg, #7ed56f, #28b485);
-webkit-background-clip: text;
color: transparent;
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.7);
}
.overlay-subtext {
font-size: 0.75em;
margin-top: 0.5em;
font-style: italic;
}
.overlay,
.overlay-subtext {
text-shadow: 2px 2px 4px rgba(0, 0, 0, 0.5);
}
.banner-image {
width: 100%;
max-height: 300px;
object-fit: cover;
border-radius: 10px;
}
</style>
<img class="banner-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/5lrA4Lxh6kUUlWRS1glLg.png" alt="Banner Image">
<h1 class="title">
<span>🍰 LarosBell-XL 🍰</span>
</h1>
<table class="custom-table">
<tr>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/U3hNaoS7iLgbagsjN39Cl.png" alt="Sample Image 1">
<div class="overlay">
<div class="overlay-text">Sample Image</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/AEgcQ1aCQj0y16Ng_d1T8.png" alt="Sample Image 2">
<div class="overlay">
<div class="overlay-text">Sample Image</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/wHIUyFaVCHwILJaKU6Ppb.png" alt="Sample Image 3">
<div class="overlay">
<div class="overlay-text">Sample Image</div>
</div>
</div>
</td>
</tr>
<tr>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/Hw84Oj2OdoIq-O4yWrNGh.png" alt="Sample Image 4">
<div class="overlay">
<div class="overlay-text">Sample Image</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/SezYHvFe0pWcWxKJaTKYv.png" alt="Sample Image 5">
<div class="overlay">
<div class="overlay-text">Sample Image</div>
</div>
</div>
</td>
<td>
<div class="custom-image-container">
<img class="custom-image" src="https://cdn-uploads.huggingface.co/production/uploads/63edfe94f599efc7a00e3619/jR0NtUeNVcmG9uv55tujt.png" alt="Sample Image 6">
<div class="overlay">
<div class="overlay-text">Sample Image</div>
</div>
</div>
</td>
</tr>
</table>
<html>
<head>
<title>LarosBell-XL</title>
<style>
details {
cursor: pointer;
}
</style>
</head>
<body>
<details open>
<summary><strong>LarosBell-XL</strong> is a merged model that specializes in generating high-quality 3D anime images from textual prompts.</summary>
<summary><strong>LarosBell-XL v2</strong> is the next version of LarosBell-XL with great improvements in Anatomy and the style is close to LarosBell in SD 1.5</summary>
<br>
<strong>Model Details:</strong>
<ul>
<li><strong>Developed by:</strong> [Bell-Fi]</li>
<li><strong>Model type:</strong> Diffusion-based text-to-image generative model</li>
<li><strong>Model Description:</strong> Generate high-quality 3D anime images from textual prompts</li>
<li><strong>License:</strong> <a href="https://freedevproject.org/faipl-1.0-sd/" target="_blank">Fair AI Public License 1.0-SD</a></li>
<li>
<strong>Merged from models:</strong>
<ul>
<li><a href="https://huggingface.co/cagliostrolab/animagine-xl-3.1" target="_blank">Animagine XL 3.1</a></li>
<li><a href="https://civitai.com/models/140737/albedobase-xl" target="_blank">AlbedobaseXL 2.1</a></li>
<li><a href="https://huggingface.co/Raelina/RaemuXL" target="_blank">RaemuXL 3.0</a></li>
<li><a href="https://civitai.com/models/267879/pvcxl-v10-lora-for-animaginexl-30-animaginexl-30-base" target="_blank">PVC-XL Lora</a></li>
<li><a href="https://civitai.com/models/9409/or-anything-xl" target="_blank">Anything-XL</a></li>
<li><a href="https://civitai.com/models/125907?modelVersionId=254091" target="_blank">RealCartoon-XL-v6</a></li>
</ul>
</li>
</ul>
</details>
<details>
<summary><strong>Recommended settings</strong></summary>
<br>
<p>USE SDXL VAE For More Natural Color</p>
<p>Prompting is a bit different in this model, for optimal results, it's recommended to follow the structured prompt template:</p>
<pre>1girl/1boy, character name, from what series, everything else in any order.</pre>
<p>To guide the model towards generating high-aesthetic images, use negative prompts like:</p>
<pre>normal quality, low quality, worst quality, text, error, missing fingers, extra digit, jpeg artifacts, signature, watermark, username, blurry, artist name</pre>
<p>For higher quality outcomes, prepend prompts with:</p>
<pre>1girl/1boy, character name, from what series, everything else in any order, masterpiece, best quality, high quality</pre>
<p><strong>Multi Aspect Resolution:</strong></p>
<p>This model supports generating images at the following dimensions:</p>
<table>
<thead>
<tr>
<th>Dimensions</th>
<th>Aspect Ratio</th>
</tr>
</thead>
<tbody>
<tr><td>1024 x 1024</td><td>1:1 Square</td></tr>
<tr><td>1152 x 896</td><td>9:7</td></tr>
<tr><td>896 x 1152</td><td>7:9</td></tr>
<tr><td>1216 x 832</td><td>19:13</td></tr>
<tr><td>832 x 1216</td><td>13:19</td></tr>
<tr><td>1344 x 768</td><td>7:4 Horizontal</td></tr>
<tr><td>768 x 1344</td><td>4:7 Vertical</td></tr>
<tr><td>1536 x 640</td><td>12:5 Horizontal</td></tr>
<tr><td>640 x 1536</td><td>5:12 Vertical</td></tr>
</tbody>
</table>
</details>
<details>
<summary><strong>Hires.fix Setting</strong></summary>
<br>
<ul>
<li>Upscaler: <a href="https://nmkd.de/?esrgan" target="_blank">4x-YandereNeoXL</a></li>
<li>Hires step: 10-20</li>
<li>Denoising: 0.2-0.4 or 0.55 for latent upscaler</li>
</ul>
</details>
<details>
<summary><strong>Merge parameters</strong></summary>
<br>
<p>Merge AnimagineXL v3.1 + AnythingXL Using MWB = Material-1</p>
<ul>
<li><strong>Merge Mode:</strong> Weight sum</li>
<li><strong>Calculation Mode:</strong> Normal</li>
<li><strong>Gamma:</strong> 0.3</li>
<li><strong>Weight Alpha:</strong> 0,0.3301,0.2937,0.2677,0.2287,0.2183,0.1663,0.1144,0.078,0,0,0.1826,0.2658,0.3827,0.4165,0.4737,0.5439,0.5854,0.6114,0.6452</li>
</ul>
<br>
<p>Merge Material-1 + RealCartoon-XL v6 + RaemuXL v3.0 Using MWB = Material-2.</p>
<ul>
<li><strong>Merge Mode:</strong> Triple sum</li>
<li><strong>Calculation Mode:</strong> Normal</li>
<li><strong>Gamma:</strong> 0.3</li>
<li><strong>Weight Alpha:</strong> 0,1,0.6,0.3,0.1,0,0,0,0,0,0,0.1,0.3,0.7,0.9,0.5,0.7,0.9,0.8,0.2</li>
<li><strong>Weight Beta:</strong> 0,0.1,0.2,0.3,0.4,0.5,0.4,0.3,0.2,0.1,0,0.1,0.2,0.3,0.4,0.5,0.4,0.3,0.2,0.1</li>
<li><strong>Merge Lora:</strong> 0.7 PVC XL Lora</li>
</ul>
<br>
<p>Merge Material-2 + AnimagineXL v3.1 Using MWB = Beta-1.</p>
<ul>
<li><strong>Merge Mode:</strong> Weight sum</li>
<li><strong>Calculation Mode:</strong> Normal</li>
<li><strong>Gamma:</strong> 0.3</li>
<li><strong>Weight Alpha:</strong> 0,0.9,0.7,0.5,0.25,0.1,0.1,0.1,0.1,0.1,0,0,0.1,0.2,0.2,0.2,0.2,0.2,0.1,0</li>
</ul>
<br>
<p>Beta-1 + AlbedoBase-XL-v2.1 Using MWB = larosBell-XL-v2.</p>
<ul>
<li><strong>Merge Mode:</strong> Weight sum</li>
<li><strong>Calculation Mode:</strong> Normal</li>
<li><strong>Gamma:</strong> 0.3</li>
<li><strong>Weight Alpha:</strong> 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.1,0.2,0.3,0.4,0.5</li>
</ul>
</details>
<details>
<summary><strong>License</strong></summary>
<br>
<p>LarosBell-XL now uses the <a href="https://freedevproject.org/faipl-1.0-sd/" target="_blank">Fair AI Public License 1.0-SD</a> inherited from Animagine XL 3.0, compatible with Stable Diffusion models. Key points:</p>
<ol>
<li><strong>Modification Sharing:</strong> If you modify LarosBell-XL, you must share both your changes and the original license.</li>
<li><strong>Source Code Accessibility:</strong> If your modified version is network-accessible, provide a way (like a download link) for others to get the source code. This applies to derived models too.</li>
<li><strong>Distribution Terms:</strong> Any distribution must be under this license or another with similar rules.</li>
<li><strong>Compliance:</strong> Non-compliance must be fixed within 30 days to avoid license termination, emphasizing transparency and adherence to open-source values.</li>
</ol>
<p>The choice of this license aims to keep LarosBell-XL open and modifiable, aligning with open source community spirit. It protects contributors and users, encouraging a collaborative, ethical open-source community. This ensures the model not only benefits from communal input but also respects open-source development freedoms.</p>
</details>
<script>
const details = document.querySelectorAll('details');
details.forEach(detail => {
detail.addEventListener('click', () => {
detail.open = !detail.open;
});
});
</script>
</body>
</html>
|
Solshine/LORA-Adapters-Mistral7B-NaturalFarmerV2
|
Solshine
| 2024-03-26T03:53:44Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"biology",
"farming",
"agriculture",
"climate",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-03-21T19:46:15Z |
---
language:
- en
license: other
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- biology
- farming
- agriculture
- climate
base_model: unsloth/mistral-7b-instruct-v0.2-bnb-4bit
---
# Uploaded model
- **Developed by:** Caleb DeLeeuw; Copyleft Cultivars, a nonprofit
- **License:** Hippocratic 3.0 CL-Eco-Extr
[](https://firstdonoharm.dev/version/3/0/cl-eco-extr.html)
https://firstdonoharm.dev/version/3/0/cl-eco-extr.html
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.2-bnb-4bit
- **Dataset Used :** CopyleftCultivars/Training-Ready_NF_chatbot_conversation_history currated from real-world agriculture and natural farming questions and the best answers from a previous POC chatbot which were then lightly editted by domain experts
Using real-world user data from a previous farmer assistant chatbot service and additional curated datasets (prioritizing sustainable regenerative organic farming practices,) Gemma 2B and Mistral 7B LLMs were iteratively fine-tuned and tested against eachother as well as basic benchmarking, whereby the Gemma 2B fine-tune emerged victorious, while this Mistral fine-tune was still viable. LORA adapters were saved for each model.
Shout out to roger j (bhugxer) for help with the dataset and training framework.
This mistral model was trained with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Ksgk-fy/M7Percival_010.68-0.47-0.8-0.18-0.36-0.91-7B
|
Ksgk-fy
| 2024-03-26T03:52:44Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:AurelPx/Percival_01-7b-slerp",
"base_model:merge:AurelPx/Percival_01-7b-slerp",
"base_model:liminerity/M7-7b",
"base_model:merge:liminerity/M7-7b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T03:48:59Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- liminerity/M7-7b
- AurelPx/Percival_01-7b-slerp
---
## 🧩 Configuration
```yaml
slices:
- sources:
- model: liminerity/M7-7b
layer_range: [0, 32]
- model: AurelPx/Percival_01-7b-slerp
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/M7-7b
parameters:
t:
- filter: self_attn
value: [0.6842220974952672, 0.46727995958304114, 0.7989557128685841, 0.17557699884860734, 0.3590549769955834]
- filter: mlp
value: [0.3157779025047328, 0.5327200404169589, 0.8244230011513927, 0.8244230011513927, 0.6409450230044166]
- value: 0.9080883966262864
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Ksgk-fy/M7Percival_010.68-0.47-0.8-0.18-0.36-0.91-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
jinghuanHuggingface/Reinforce-Pixelcopter-PLE-v0
|
jinghuanHuggingface
| 2024-03-26T03:27:42Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-14T09:30:26Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 54.90 +/- 36.10
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
KomaedaNagito/Taxi-v3
|
KomaedaNagito
| 2024-03-26T03:25:35Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T03:25:33Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="KomaedaNagito/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
tlin/ppo-LunarLander-v2
|
tlin
| 2024-03-26T03:24:45Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T03:07:58Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 263.61 +/- 17.56
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
yeye776/iot_vocab_tuned_v2
|
yeye776
| 2024-03-26T03:21:47Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T03:21:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
BigGorneau/Philosofish
|
BigGorneau
| 2024-03-26T03:15:32Z | 1 | 0 |
transformers
|
[
"transformers",
"gpt2",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T03:14:50Z |
# Modèle de génération de questions philosophiques ou méditatives
Ce projet héberge un modèle de génération de questions philosophiques ou méditatives, conçu pour produire des questions pertinentes et inspirantes dans ces domaines.
## Description du modèle
Le modèle est basé sur [GPT-2](https://huggingface.co/transformers/model_doc/gpt2.html), un modèle de langage pré-entraîné qui a été fine-tuné sur un ensemble de données contenant des exemples de questions philosophiques ou méditatives. Le modèle prend en entrée un prompt de texte et génère une question philosophique ou méditative en réponse.
## Contenu du répertoire
- `config.json`: Fichier de configuration du modèle, décrivant les paramètres du modèle GPT-2 utilisé.
- `weights.h5`: Fichier contenant les poids du modèle entraîné.
- `tokenizer.py`: Script de tokenizer utilisé pour prétraiter les données d'entrée du modèle.
- `README.md`: Ce fichier, contenant des informations sur le projet, son fonctionnement et son utilisation.
- Autres fichiers (scripts de prétraitement, données d'entraînement, etc.) : Facultatif, selon les besoins du projet.
## Utilisation
Pour utiliser le modèle, vous pouvez charger les fichiers `config.json` et `weights.h5` dans un script Python à l'aide de la bibliothèque Hugging Face Transformers. Utilisez le script de tokenizer fourni (`tokenizer.py`) pour prétraiter les données d'entrée avant de les passer au modèle.
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Charger le tokenizer et le modèle
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("path/to/model/directory")
# Prétraiter les données d'entrée
input_text = "Qu'est-ce que le bonheur pour toi ?"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Générer une question philosophique ou méditative
output_ids = model.generate(input_ids, max_length=50, num_return_sequences=1)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print("Question générée:", output_text)
|
ottopilot/VampireFangs
|
ottopilot
| 2024-03-26T03:09:04Z | 14 | 3 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:cc-by-nc-nd-4.0",
"region:us"
] |
text-to-image
| 2024-03-14T06:17:40Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
Comic book art, candid, Barbara Gordon, Batgirl, vampire, fangs, (white skin:1.1),
long auburn hair, hypnotic (yellow:0.3) eyes, purple costume, (bloody mouth and clothing:1.2),
highly detailed, art by Adam Hughes and Bryan Hitch, outdoors, night, Gotham City,
blood red moon, gothic horror theme, ominous, corruption, bloodlust, heroine turned evil
<lora:LORA-XenoDetailer-v3A:0.3> <lora:VampireFangs_v1.1:1>
parameters:
negative_prompt: >-
underage:2, loli:2, shota:2, girl:1.3, boy:1.3, lolicon:2, shotacon:2,
watermark:1.3, signature:1.3, artist name:1.3, web address:1.6, patreon username:1.3,
low contrast, underexposed, overexposed, head out of frame, bat wings, bat ears,
multiple moons,
output:
url: images/00682-1778317624.png
- text: >-
close-up, portrait, Carmilla Karnstein, vampire, fangs visible over lower lip, pale skin,
hypnotic (yellow:0.6) eyes, 1870s fashion, periwinkle dress, makeup, lace choker
<lora:VampireFangs_v1.1:1> <lora:LORA-XenoDetailer-v3A:0.7>
parameters:
negative_prompt: >-
underage:2, loli:2, shota:2, girl:1.3, boy:1.3, lolicon:2, shotacon:2, watermark:1.3,
signature:1.3, artist name:1.3, web address:1.3, patreon username:1.3,
low contrast, underexposed, overexposed, head out of frame,
output:
url: images/00480-2637171018.png
- text: >-
1girl, candid, (close-up shot:1.2), RachelV1, vampire, fangs, pale skin, mesmerizing eyes,
undercut hairstyle, tattoos:1.1, leather clothing, fetishwear, punk fashion, teeth, indoors,
seductive, femme fatale, immortalized beauty
<lora:LORA-XenoDetailer-v3A:0.4> <lora:RachelV1:0.9> <lora:VampireFangs_v1.1:1>
parameters:
negative_prompt: >-
underage:2, loli:2, shota:2, girl:1.3, boy:1.3, lolicon:2, shotacon:2, watermark:1.3,
signature:1.3, artist name:1.3, web address:1.3, patreon username:1.3,
fastnegativev2, low contrast, underexposed, overexposed, head out of frame, dark skin,
output:
url: images/00520-3709171706.png
- text: >-
Photo, 1girl, candid, Maria_Valez, vampire, fangs, (pale skin:0.7), mesmerizing (yellow:0.3) eyes,
looking at viewer, blood-stained white nightgown, choker, highly detailed, outside, night,
moonlight, cemetery, seductive, femme fatale, immortalized beauty, horror vibe
<lora:LORA-XenoDetailer-v3A:0.4> <lora:VampireFangs_v1.1:1>
parameters:
negative_prompt: >-
underage:2, loli:2, shota:2, girl:1.3, boy:1.3, lolicon:2, shotacon:2, watermark:1.3, s
ignature:1.3, artist name:1.3, web address:1.3, patreon username:1.3,
fastnegativev2, low contrast, underexposed, overexposed, head out of frame, veil,
output:
url: images/00579-2023609317.png
- text: >-
close-up portrait, sexy [ Korean | Nepalese ] vampire, bared fangs, pale skin,
hypnotic (yellow:0.6) eyes, modern fashion, makeup, dim lighting, cool color tones,
suspenseful mood, seductive, vicious, hungry <lora:VampireFangs_v1.1:1> <lora:LORA-XenoDetailer-v3A:0.3>
parameters:
negative_prompt: >-
underage:2, loli:2, shota:2, girl:1.3, boy:1.3, lolicon:2, shotacon:2, watermark:1.3,
signature:1.3, artist name:1.3, web address:1.3, patreon username:1.3,
low contrast, underexposed, overexposed, head out of frame, horns, wings,
output:
url: images/00456-385678184.png
- text: >-
Photorealism, Ron Dracula, vampire, fangs, pale skin, hypnotic eyes, 1980s fashion, sunglasses,
Miami Vice inspired, vaporwave color palette, night, outdoors, South Beach, Miami 1984
<lora:LORA-XenoDetailer-v3A:0.3> <lora:VampireFangs_v1.1:1>
parameters:
negative_prompt: >-
underage:2, loli:2, shota:2, girl:1.3, boy:1.3, lolicon:2, shotacon:2, watermark:1.3,
signature:1.3, artist name:1.3, web address:1.6, patreon username:1.3,
low contrast, underexposed, overexposed, head out of frame,
output:
url: images/00693-375094247.png
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: fangs, vampire
license: cc-by-nc-nd-4.0
---
# Vampire Fangs
<Gallery />
## Model description
With the 1.1 version, I'm really pretty happy with this.
If you want just fangs, neg prompt "vampire." I had some success with "fangs visible over lower lip."
Occasionally there are double sets, assymetrical, or random fangs. This is mostly because the model seems to have been trained that fangs belong to animals: dogs, cats, etc. The shotgun approach is what I use; sometimes it's going to be hit and miss but 1.1 hits more than 1.0.
Both meet the bar I set for release: gives vampires fangs, but also gives people fangs without other vampire characteristics (skin, eyes, clothes). I also gave an example for giving fangs to a werewolf transformation. 1.1 even lets you draw fangs in Cyber Reality 4.2! I recommend a "photorealism" prompt even though it's a realistic output as it helps break the strong realism bent of the checkpoint. You can also use a photorealistic/art checkpoint, then use a realistic checkpoint in Refiner or Hires Fix.
## Trigger words
You should use `fangs` to trigger the image generation.
You *may* use `vampire` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/ottopilot/VampireFangs/tree/main) them in the Files & versions tab.
|
KomaedaNagito/q-FrozenLake-v1-4x4-noSlippery
|
KomaedaNagito
| 2024-03-26T03:07:09Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T03:07:07Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="KomaedaNagito/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
yangswei/snacks_classification
|
yangswei
| 2024-03-26T03:01:07Z | 18 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:Matthijs/snacks",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-02-23T07:04:08Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
base_model: google/vit-base-patch16-224-in21k
model-index:
- name: snacks_classification
results: []
datasets:
- Matthijs/snacks
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# snacks_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4458
- Accuracy: 0.8942
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 13
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 303 | 0.7200 | 0.8649 |
| 1.0168 | 2.0 | 606 | 0.5468 | 0.8723 |
| 1.0168 | 3.0 | 909 | 0.4612 | 0.8848 |
| 0.3765 | 4.0 | 1212 | 0.5239 | 0.8660 |
| 0.2585 | 5.0 | 1515 | 0.4193 | 0.8890 |
| 0.2585 | 6.0 | 1818 | 0.4571 | 0.8775 |
| 0.2038 | 7.0 | 2121 | 0.4538 | 0.8838 |
| 0.2038 | 8.0 | 2424 | 0.4508 | 0.8880 |
| 0.1827 | 9.0 | 2727 | 0.4748 | 0.8880 |
| 0.1568 | 10.0 | 3030 | 0.4928 | 0.8764 |
| 0.1568 | 11.0 | 3333 | 0.3684 | 0.9099 |
| 0.1305 | 12.0 | 3636 | 0.4205 | 0.8984 |
| 0.1305 | 13.0 | 3939 | 0.4537 | 0.8963 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
yeye776/iot_vocab_tuned
|
yeye776
| 2024-03-26T03:00:04Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T03:00:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gaianet/vitalik.eth-13b
|
gaianet
| 2024-03-26T02:53:26Z | 4 | 0 | null |
[
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-03-17T17:57:06Z |
---
license: apache-2.0
---
## Prerequisites
The `vitalik-13b.csv` file contains the QA set required for the fine-tuning. Each QA pair length is limited to 80 words to fit into `llama.cpp` context length of 128 tokens. The `convert.py` script converts the CSV file into QAs in the llama2 chat template.
```
python convert.py
```
It generates a `vitalik-13b.txt` file, which can now be used in fine-tuning.
## Fine-tuning steps
Clone this repo into the `llama.cpp/models/` folder.
```
cd llama.cpp/models
git clone https://huggingface.co/gaianet/vitalik.eth-13b
```
Move the Llama2-13b-chat base model to the folder.
```
cd vitalik-13b
mv path/to/llama-2-13b-chat.Q5_K_M.gguf .
```
From the `llama.cpp/models/vitalik-13b` folder run the following command.
```
../../build/bin/finetune --model-base llama-2-13b-chat.Q5_K_M.gguf --lora-out lora.bin --train-data vitalik-13b.txt --sample-start '<SFT>' --adam-iter 1024
```
Wait for several days until the above process finishes. You will have a `lora.bin` file, which can generate the fine-tuned model.
```
../../build/bin/export-lora --model-base llama-2-13b-chat.Q5_K_M.gguf --lora lora.bin --model-out vitalik.eth-13b-q5_k_m.gguf
```
> Learn more about Llama2 model fine tuning [here](https://github.com/YuanTony/chemistry-assistant).
|
davidho27941/results
|
davidho27941
| 2024-03-26T02:50:41Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:yentinglin/Taiwan-LLM-7B-v2.1-chat",
"base_model:adapter:yentinglin/Taiwan-LLM-7B-v2.1-chat",
"license:apache-2.0",
"region:us"
] | null | 2024-03-26T02:49:24Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: yentinglin/Taiwan-LLM-7B-v2.1-chat
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [yentinglin/Taiwan-LLM-7B-v2.1-chat](https://huggingface.co/yentinglin/Taiwan-LLM-7B-v2.1-chat) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
titan087/Rhea-72b-v0.5-4bit-128g
|
titan087
| 2024-03-26T02:49:19Z | 6 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-03-26T02:36:14Z |
---
library_name: transformers
license: apache-2.0
language:
- en
---
# Rhea-72b-v0.5

The Rhea project is a project that conducts research on various learning methods to improve llm model performance. We fine-tuned the existing model using the [nox](https://github.com/davidkim205/nox) framework. We built a dataset for SFT learning based on the currently open dataset, and created a dataset using SGD (Self-Generated Dataset Creation Method for DPO Learning) for DPO learning.
Our model ranked first on HuggingFace's Open LLM leaderboard.
## SGD : A Study on Self-Generated Dataset creation method for DPO Learning
This method proposes a novel method for generating datasets for DPO (Self-supervised Learning) models. We suggest a technique where sentences generated by the model are compared with the actual correct answers from an existing dataset, and sentences where the model's generated results do not match the correct answers are added. This enables the model to autonomously create training data, thereby enhancing the performance of DPO models.
## Model Details
* **Model Developers** : davidkim(changyeon kim)
* **Repository** : [https://github.com/davidkim205/nox](https://github.com/davidkim205/nox)
* **base mode** : abacusai/Smaug-72B-v0.1
* **sft dataset** : will be updated soon.
* **dpo dataset** : will be updated soon.
## Evaluation
### [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
| **model** | **average** | **arc** | **hellaswag** | **mmlu** | **truthfulQA** | **winogrande** | **GSM8k** |
| ------------- | ----------- | ------- | ------------- | -------- | -------------- | -------------- | --------- |
| Rhea-72b-v0.5 | 81.22 | 79.78 | 91.15 | 77.95 | 74.5 | 87.85 | 76.12 |
|
mubashir04/checkpoint_ViT-L_pretrain_fmow_rgb
|
mubashir04
| 2024-03-26T02:48:08Z | 0 | 0 | null |
[
"arxiv:2403.05419",
"license:apache-2.0",
"region:us"
] | null | 2024-03-26T02:46:01Z |
---
license: apache-2.0
---
## Description
ViT-Large checkpoint containing pre-training weights on FMoW-RGB dataset. For more information [[github]](https://github.com/techmn/satmae_pp) [[arXiv]](https://arxiv.org/abs/2403.05419)
|
amd/resnet50
|
amd
| 2024-03-26T02:45:52Z | 72 | 0 |
transformers
|
[
"transformers",
"onnx",
"resnet",
"image-classification",
"RyzenAI",
"vision",
"classification",
"pytorch",
"dataset:imagenet-1k",
"arxiv:1512.03385",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-12-04T09:23:41Z |
---
license: apache-2.0
datasets:
- imagenet-1k
metrics:
- accuracy
tags:
- RyzenAI
- vision
- classification
- pytorch
---
# ResNet-50 v1.5
Quantized ResNet model that could be supported by [AMD Ryzen AI](https://ryzenai.docs.amd.com/en/latest/).
## Model description
ResNet (Residual Network) was first introduced in the paper Deep Residual Learning for Image Recognition by He et al.
This model is ResNet50 v1.5 from [torchvision](https://pytorch.org/vision/main/models/generated/torchvision.models.resnet50.html).
## How to use
### Installation
Follow [Ryzen AI Installation](https://ryzenai.docs.amd.com/en/latest/inst.html) to prepare the environment for Ryzen AI.
Run the following script to install pre-requisites for this model.
```bash
pip install -r requirements.txt
```
### Data Preparation
Follow [PyTorch Example](https://github.com/pytorch/examples/blob/main/imagenet/README.md#requirements) to prepare dataset.
### Model Evaluation
```python
python eval_onnx.py --onnx_model ResNet_int.onnx --ipu --provider_config Path\To\vaip_config.json --data_dir /Path/To/Your/Dataset
```
### Performance
|Metric |Accuracy on IPU|
| :----: | :----: |
|Top1/Top5| 76.17% / 92.86%|
```bibtex
@article{He2015,
author={Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title={Deep Residual Learning for Image Recognition},
journal={arXiv preprint arXiv:1512.03385},
year={2015}
}
```
|
kanishka/smolm-autoreg-bpe-seed_888
|
kanishka
| 2024-03-26T02:45:34Z | 156 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-20T23:40:39Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: smolm-autoreg-bpe-seed_888
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smolm-autoreg-bpe-seed_888
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4712
- Accuracy: 0.5000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 128
- seed: 888
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 24000
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 3.0458 | 1.0 | 2928 | 3.0245 | 0.4357 |
| 2.71 | 2.0 | 5856 | 2.7881 | 0.4585 |
| 2.5918 | 3.0 | 8784 | 2.6924 | 0.4682 |
| 2.5122 | 4.0 | 11712 | 2.6471 | 0.4759 |
| 2.4623 | 5.0 | 14640 | 2.6053 | 0.4803 |
| 2.4246 | 6.0 | 17568 | 2.5798 | 0.4824 |
| 2.3871 | 7.0 | 20496 | 2.5647 | 0.4858 |
| 2.3644 | 8.0 | 23424 | 2.5571 | 0.4853 |
| 2.2824 | 9.0 | 26352 | 2.5034 | 0.4934 |
| 2.1369 | 10.0 | 29280 | 2.4712 | 0.5000 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
jcho02/Gemma-Spotify-test1
|
jcho02
| 2024-03-26T02:45:21Z | 140 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T02:42:31Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ksgk-fy/M7Percival_010.09-0.82-0.7-0.27-0.86-0.44-7B
|
Ksgk-fy
| 2024-03-26T02:43:35Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:AurelPx/Percival_01-7b-slerp",
"base_model:merge:AurelPx/Percival_01-7b-slerp",
"base_model:liminerity/M7-7b",
"base_model:merge:liminerity/M7-7b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T02:38:04Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- liminerity/M7-7b
- AurelPx/Percival_01-7b-slerp
---
## 🧩 Configuration
```yaml
slices:
- sources:
- model: liminerity/M7-7b
layer_range: [0, 32]
- model: AurelPx/Percival_01-7b-slerp
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/M7-7b
parameters:
t:
- filter: self_attn
value: [0.09359915299785504, 0.8186681490784229, 0.7030745044604875, 0.27153312079862857, 0.8596090602039254]
- filter: mlp
value: [0.906400847002145, 0.1813318509215771, 0.7284668792013714, 0.7284668792013714, 0.14039093979607464]
- value: 0.43909715622625123
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Ksgk-fy/M7Percival_010.09-0.82-0.7-0.27-0.86-0.44-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
kanishka/smolm-autoreg-bpe-seed_777
|
kanishka
| 2024-03-26T02:32:28Z | 147 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-20T23:27:36Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: smolm-autoreg-bpe-seed_777
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smolm-autoreg-bpe-seed_777
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4743
- Accuracy: 0.5000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 128
- seed: 777
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 24000
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 3.0444 | 1.0 | 2928 | 3.0184 | 0.4379 |
| 2.7029 | 2.0 | 5856 | 2.7839 | 0.4590 |
| 2.5923 | 3.0 | 8784 | 2.6906 | 0.4700 |
| 2.5083 | 4.0 | 11712 | 2.6413 | 0.4761 |
| 2.4502 | 5.0 | 14640 | 2.6037 | 0.4800 |
| 2.4223 | 6.0 | 17568 | 2.5871 | 0.4831 |
| 2.3871 | 7.0 | 20496 | 2.5669 | 0.4852 |
| 2.3542 | 8.0 | 23424 | 2.5591 | 0.4862 |
| 2.287 | 9.0 | 26352 | 2.5010 | 0.4944 |
| 2.1426 | 10.0 | 29280 | 2.4743 | 0.5000 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
dyingc/LlamaGuard-7b-quant
|
dyingc
| 2024-03-26T02:29:23Z | 75 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-03-26T02:06:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
manfye/gemma-2B-IT-Finetune-NER-RX
|
manfye
| 2024-03-26T02:28:34Z | 141 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T02:24:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mysunny/YOUR_REPO_NAME
|
mysunny
| 2024-03-26T02:20:20Z | 117 | 0 |
transformers
|
[
"transformers",
"safetensors",
"switch_transformers",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-03-26T02:19:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kanishka/smolm-autoreg-bpe-seed_666
|
kanishka
| 2024-03-26T02:19:20Z | 146 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-20T23:14:36Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: smolm-autoreg-bpe-seed_666
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smolm-autoreg-bpe-seed_666
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4754
- Accuracy: 0.4997
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 128
- seed: 666
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 24000
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 3.0568 | 1.0 | 2928 | 3.0170 | 0.4376 |
| 2.7079 | 2.0 | 5856 | 2.7879 | 0.4585 |
| 2.5856 | 3.0 | 8784 | 2.6924 | 0.4706 |
| 2.5108 | 4.0 | 11712 | 2.6403 | 0.4762 |
| 2.4576 | 5.0 | 14640 | 2.6072 | 0.4796 |
| 2.423 | 6.0 | 17568 | 2.5828 | 0.4825 |
| 2.3921 | 7.0 | 20496 | 2.5670 | 0.4854 |
| 2.3602 | 8.0 | 23424 | 2.5533 | 0.4871 |
| 2.2861 | 9.0 | 26352 | 2.5010 | 0.4942 |
| 2.1381 | 10.0 | 29280 | 2.4754 | 0.4997 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
Bienvenu2004/donut-handball-pv
|
Bienvenu2004
| 2024-03-26T02:17:19Z | 3 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:naver-clova-ix/donut-base",
"base_model:finetune:naver-clova-ix/donut-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2024-03-14T22:40:29Z |
---
license: mit
base_model: naver-clova-ix/donut-base
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-handball-pv
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-handball-pv
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
tshinkle/ppo-LunarLander-v2
|
tshinkle
| 2024-03-26T02:15:22Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T02:13:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 265.52 +/- 19.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
vharish056/ppo-SnowballTarget
|
vharish056
| 2024-03-26T02:13:53Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2024-03-26T02:13:50Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: vharish056/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
akashjoy/distilbert-base-uncased-finetuned-emotion
|
akashjoy
| 2024-03-26T02:10:45Z | 107 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-22T04:37:15Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: F1
type: f1
value: 0.9333997935723345
- name: Accuracy
type: accuracy
value: 0.9335
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1499
- F1: 0.9334
- Accuracy: 0.9335
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 0.7725 | 1.0 | 250 | 0.2686 | 0.9184 | 0.918 |
| 0.2092 | 2.0 | 500 | 0.1734 | 0.9330 | 0.933 |
| 0.1394 | 3.0 | 750 | 0.1623 | 0.9356 | 0.935 |
| 0.1095 | 4.0 | 1000 | 0.1449 | 0.9368 | 0.937 |
| 0.0914 | 5.0 | 1250 | 0.1499 | 0.9334 | 0.9335 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
|
DUAL-GPO/phi-2-gpo-test-longest-iter-v1-0
|
DUAL-GPO
| 2024-03-26T02:06:35Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"phi",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"custom_code",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-03-26T00:39:52Z |
---
license: mit
library_name: peft
tags:
- alignment-handbook
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- HuggingFaceH4/ultrafeedback_binarized
model-index:
- name: phi-2-gpo-test-longest-iter-v1-0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-2-gpo-test-longest-iter-v1-0
This model is a fine-tuned version of [lole25/phi-2-sft-ultrachat-lora](https://huggingface.co/lole25/phi-2-sft-ultrachat-lora) on the HuggingFaceH4/ultrafeedback_binarized dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0004
- Rewards/chosen: 0.0012
- Rewards/rejected: 0.0010
- Rewards/accuracies: 0.4995
- Rewards/margins: 0.0002
- Logps/rejected: -233.4380
- Logps/chosen: -256.4973
- Logits/rejected: 0.8990
- Logits/chosen: 0.8417
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.0003 | 1.6 | 100 | 0.0004 | 0.0006 | 0.0004 | 0.4855 | 0.0002 | -233.5017 | -256.5565 | 0.8960 | 0.8387 |
| 0.0003 | 3.2 | 200 | 0.0004 | 0.0013 | 0.0009 | 0.5100 | 0.0004 | -233.4492 | -256.4811 | 0.8984 | 0.8412 |
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.2.1+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
|
kanishka/smolm-autoreg-bpe-seed_555
|
kanishka
| 2024-03-26T02:05:50Z | 147 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-20T23:01:34Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: smolm-autoreg-bpe-seed_555
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smolm-autoreg-bpe-seed_555
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4751
- Accuracy: 0.5003
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 128
- seed: 555
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 24000
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 3.0578 | 1.0 | 2928 | 3.0197 | 0.4374 |
| 2.7165 | 2.0 | 5856 | 2.7800 | 0.4599 |
| 2.5811 | 3.0 | 8784 | 2.6874 | 0.4702 |
| 2.5062 | 4.0 | 11712 | 2.6332 | 0.4765 |
| 2.469 | 5.0 | 14640 | 2.6065 | 0.4808 |
| 2.4281 | 6.0 | 17568 | 2.5812 | 0.4841 |
| 2.3831 | 7.0 | 20496 | 2.5669 | 0.4857 |
| 2.3556 | 8.0 | 23424 | 2.5547 | 0.4878 |
| 2.2852 | 9.0 | 26352 | 2.5027 | 0.4948 |
| 2.1378 | 10.0 | 29280 | 2.4751 | 0.5003 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
devbuzz142/cp02-pretrain-gpt2-ALL-NNN4-jy
|
devbuzz142
| 2024-03-26T02:05:19Z | 212 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T02:04:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
adityaprakhar/LILT_March26_with_and_without_b_8epochs
|
adityaprakhar
| 2024-03-26T01:58:06Z | 160 | 0 |
transformers
|
[
"transformers",
"safetensors",
"lilt",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2024-03-26T01:57:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
greicepinho/fast-dreambooth-uv
|
greicepinho
| 2024-03-26T01:53:07Z | 33 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2024-03-26T01:49:12Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### fast_DreamBooth_UV Dreambooth model trained by greicepinho with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
giantdev/5DU2MMSN6
|
giantdev
| 2024-03-26T01:52:00Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T01:45:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
N0de/q-FrozenLake-v1-4x4-noSlippery
|
N0de
| 2024-03-26T01:50:53Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-26T01:50:48Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="N0de/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
flavienbwk/example-dummy-evaluation
|
flavienbwk
| 2024-03-26T01:46:25Z | 3 | 0 |
transformers
|
[
"transformers",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-03-25T16:10:41Z |
---
license: mit
---
This is a dummy model outputting the count of "a" letters in a provided sentence.
To generate the dummy model, run `python3 train.py`
|
stablediffusionapi/ae-realg-xl
|
stablediffusionapi
| 2024-03-26T01:42:32Z | 29 | 0 |
diffusers
|
[
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2024-03-26T01:39:22Z |
---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# ae-realg-xl API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "ae-realg-xl"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://modelslab.com/docs)
Try model for free: [Generate Images](https://modelslab.com/models/ae-realg-xl)
Model link: [View model](https://modelslab.com/models/ae-realg-xl)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "ae-realg-xl",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN**
|
mash01/llama2-7b-web-article
|
mash01
| 2024-03-26T01:39:38Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T01:34:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JayhC/Layris_9B-8bpw-h8-exl2
|
JayhC
| 2024-03-26T01:34:57Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:ChaoticNeutrals/Eris_Remix_7B",
"base_model:merge:ChaoticNeutrals/Eris_Remix_7B",
"base_model:l3utterfly/mistral-7b-v0.1-layla-v4",
"base_model:merge:l3utterfly/mistral-7b-v0.1-layla-v4",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-22T17:42:55Z |
---
base_model:
- ChaoticNeutrals/Eris_Remix_7B
- l3utterfly/mistral-7b-v0.1-layla-v4
library_name: transformers
tags:
- mergekit
- merge
license: other
---
.
8bpw/h8 exl2 quantization of [ChaoticNeutrals/Layris_9B](https://huggingface.co/ChaoticNeutrals/Layris_9B) using default exllamav2 calibration dataset.
---
**ORIGINAL CARD:**
# Layris

This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [ChaoticNeutrals/Eris_Remix_7B](https://huggingface.co/ChaoticNeutrals/Eris_Remix_7B)
* [l3utterfly/mistral-7b-v0.1-layla-v4](https://huggingface.co/l3utterfly/mistral-7b-v0.1-layla-v4)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: ChaoticNeutrals/Eris_Remix_7B
layer_range: [0, 20]
- sources:
- model: l3utterfly/mistral-7b-v0.1-layla-v4
layer_range: [12, 32]
merge_method: passthrough
dtype: float16
```
|
sachin2000keshav/falcon7binstruct_mentalhealthmodel_oct23
|
sachin2000keshav
| 2024-03-26T01:29:48Z | 2 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"base_model:adapter:vilsonrodrigues/falcon-7b-instruct-sharded",
"license:apache-2.0",
"region:us"
] | null | 2024-03-25T23:32:38Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
model-index:
- name: falcon7binstruct_mentalhealthmodel_oct23
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# falcon7binstruct_mentalhealthmodel_oct23
This model is a fine-tuned version of [vilsonrodrigues/falcon-7b-instruct-sharded](https://huggingface.co/vilsonrodrigues/falcon-7b-instruct-sharded) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 51
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Eunssong/test-qa_v1
|
Eunssong
| 2024-03-26T01:26:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation",
"arxiv:1910.09700",
"license:other",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T01:23:23Z |
---
license: other
library_name: transformers
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
scaledown/ScaleDown-7B-slerp-v0.1
|
scaledown
| 2024-03-26T01:20:49Z | 1,538 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-01T08:26:00Z |
---
license: apache-2.0
tags:
- merge
- mergekit
model-index:
- name: ScaleDown-7B-slerp-v0.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 68.0
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scaledown/ScaleDown-7B-slerp-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.7
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scaledown/ScaleDown-7B-slerp-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.26
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scaledown/ScaleDown-7B-slerp-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 61.9
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scaledown/ScaleDown-7B-slerp-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 81.37
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scaledown/ScaleDown-7B-slerp-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 67.17
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=scaledown/ScaleDown-7B-slerp-v0.1
name: Open LLM Leaderboard
---
# ScaleDown-7B-slerp-v0.1
This model is a merge of the following models made with [mergekit](https://github.com/cg123/mergekit):
* [OpenPipe/mistral-ft-optimized-1218](https://huggingface.co/OpenPipe/mistral-ft-optimized-1218)
* [jondurbin/bagel-dpo-7b-v0.1](https://huggingface.co/jondurbin/bagel-dpo-7b-v0.1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- model: jondurbin/bagel-dpo-7b-v0.1
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_scaledown__ScaleDown-7B-slerp-v0.1)
| Metric |Value|
|---------------------------------|----:|
|Avg. |71.57|
|AI2 Reasoning Challenge (25-Shot)|68.00|
|HellaSwag (10-Shot) |85.70|
|MMLU (5-Shot) |65.26|
|TruthfulQA (0-shot) |61.90|
|Winogrande (5-shot) |81.37|
|GSM8k (5-shot) |67.17|
|
Sumail/Barista13
|
Sumail
| 2024-03-26T01:20:10Z | 142 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Sumail/Barista12",
"base_model:merge:Sumail/Barista12",
"base_model:coffiee/g11",
"base_model:merge:coffiee/g11",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-26T01:17:31Z |
---
base_model:
- Sumail/Barista12
- coffiee/g11
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [Sumail/Barista12](https://huggingface.co/Sumail/Barista12)
* [coffiee/g11](https://huggingface.co/coffiee/g11)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Sumail/Barista12
layer_range: [0, 18]
- model: coffiee/g11
layer_range: [0, 18]
merge_method: slerp
base_model: coffiee/g11
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
gemmathon/gemmathon-test-qa_v1
|
gemmathon
| 2024-03-26T01:14:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T01:13:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kardy04/plugin-embedding
|
kardy04
| 2024-03-26T01:06:00Z | 3 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-03-26T01:05:41Z |
---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# kardy04/plugin-embedding
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('kardy04/plugin-embedding')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('kardy04/plugin-embedding')
model = AutoModel.from_pretrained('kardy04/plugin-embedding')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=kardy04/plugin-embedding)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 42 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 11,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
kanishka/smolm-autoreg-bpe-seed_111
|
kanishka
| 2024-03-26T01:05:08Z | 145 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-20T22:09:30Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: smolm-autoreg-bpe-seed_111
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smolm-autoreg-bpe-seed_111
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4759
- Accuracy: 0.5000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 128
- seed: 111
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 24000
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 3.0508 | 1.0 | 2928 | 3.0180 | 0.4367 |
| 2.7062 | 2.0 | 5856 | 2.7857 | 0.4600 |
| 2.5923 | 3.0 | 8784 | 2.6900 | 0.4700 |
| 2.5183 | 4.0 | 11712 | 2.6405 | 0.4760 |
| 2.4632 | 5.0 | 14640 | 2.6110 | 0.4799 |
| 2.4241 | 6.0 | 17568 | 2.5840 | 0.4835 |
| 2.3815 | 7.0 | 20496 | 2.5728 | 0.4851 |
| 2.3595 | 8.0 | 23424 | 2.5581 | 0.4867 |
| 2.2838 | 9.0 | 26352 | 2.5014 | 0.4949 |
| 2.1364 | 10.0 | 29280 | 2.4759 | 0.5000 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
automerger/T3qm7xpExperiment26-7B
|
automerger
| 2024-03-26T00:58:20Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:nlpguy/T3QM7XP",
"base_model:finetune:nlpguy/T3QM7XP",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-23T20:44:57Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- nlpguy/T3QM7XP
- rwitz/experiment26-truthy-iter-2
---
# T3qm7xpExperiment26-7B
T3qm7xpExperiment26-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [nlpguy/T3QM7XP](https://huggingface.co/nlpguy/T3QM7XP)
* [rwitz/experiment26-truthy-iter-2](https://huggingface.co/rwitz/experiment26-truthy-iter-2)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: nlpguy/T3QM7XP
layer_range: [0, 32]
- model: rwitz/experiment26-truthy-iter-2
layer_range: [0, 32]
merge_method: slerp
base_model: nlpguy/T3QM7XP
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/T3qm7xpExperiment26-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
yeye776/bert-kor-base
|
yeye776
| 2024-03-26T00:53:32Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-26T00:53:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
shreyas1104/wav2vec2-conformer-rel-pos-large-medical-intent-v2
|
shreyas1104
| 2024-03-26T00:46:26Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2-conformer",
"audio-classification",
"generated_from_trainer",
"dataset:audiofolder",
"base_model:facebook/wav2vec2-conformer-rel-pos-large",
"base_model:finetune:facebook/wav2vec2-conformer-rel-pos-large",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2024-03-25T23:22:58Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-conformer-rel-pos-large
tags:
- generated_from_trainer
datasets:
- audiofolder
metrics:
- accuracy
- precision
- recall
model-index:
- name: wav2vec2-conformer-rel-pos-large-medical-intent-v2
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: audiofolder
type: audiofolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6169590643274854
- name: Precision
type: precision
value: 0.6350528050296339
- name: Recall
type: recall
value: 0.6169590643274854
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-conformer-rel-pos-large-medical-intent-v2
This model is a fine-tuned version of [facebook/wav2vec2-conformer-rel-pos-large](https://huggingface.co/facebook/wav2vec2-conformer-rel-pos-large) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0410
- Accuracy: 0.6170
- Precision: 0.6351
- Recall: 0.6170
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|
| 1.7714 | 1.0 | 82 | 1.7605 | 0.2339 | 0.3198 | 0.2339 |
| 1.511 | 2.0 | 164 | 1.5148 | 0.4298 | 0.3817 | 0.4298 |
| 1.1417 | 2.99 | 246 | 1.1530 | 0.5936 | 0.6491 | 0.5936 |
| 0.8747 | 3.99 | 328 | 1.0410 | 0.6170 | 0.6351 | 0.6170 |
### Framework versions
- Transformers 4.39.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.