
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Epiculous/Mika-7B
|
Epiculous
| 2024-03-11T16:49:29Z | 87 | 8 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"dataset:lemonilia/LimaRP",
"dataset:grimulkan/theory-of-mind",
"dataset:Epiculous/Gnosis",
"dataset:ChaoticNeutrals/Synthetic-RP",
"dataset:ChaoticNeutrals/Synthetic-Dark-RP",
"license:agpl-3.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T15:10:46Z |
---
license: agpl-3.0
datasets:
- lemonilia/LimaRP
- grimulkan/theory-of-mind
- Epiculous/Gnosis
- ChaoticNeutrals/Synthetic-RP
- ChaoticNeutrals/Synthetic-Dark-RP
---
Mika (Named after what my Claude-3 Opus chat called itself.) is a Model trained in a similar manner to Fett-uccine with synthetic RP data created by Claude also included.
## Format
I've had the best results with ChatML Context Template and Mistral Instruct Template, however, YMMV.
|
ahessamb/all-MiniLM-L6-v2-2epoch-30000-mar2-closs-prsn
|
ahessamb
| 2024-03-11T16:48:31Z | 52 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-03-11T16:48:18Z |
---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# ahessamb/all-MiniLM-L6-v2-2epoch-30000-mar2-closs-prsn
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('ahessamb/all-MiniLM-L6-v2-2epoch-30000-mar2-closs-prsn')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=ahessamb/all-MiniLM-L6-v2-2epoch-30000-mar2-closs-prsn)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1518 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss` with parameters:
```
{'distance_metric': 'SiameseDistanceMetric.COSINE_DISTANCE', 'margin': 2, 'size_average': True}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 303,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
bartowski/NeuralHyperion-2.0-Mistral-7B-exl2
|
bartowski
| 2024-03-11T16:45:10Z | 2 | 1 |
transformers
|
[
"transformers",
"code",
"chemistry",
"medical",
"text-generation",
"en",
"dataset:Locutusque/hyperion-v2.0",
"dataset:argilla/distilabel-capybara-dpo-7k-binarized",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T16:32:30Z |
---
library_name: transformers
tags:
- code
- chemistry
- medical
license: apache-2.0
datasets:
- Locutusque/hyperion-v2.0
- argilla/distilabel-capybara-dpo-7k-binarized
language:
- en
quantized_by: bartowski
pipeline_tag: text-generation
---
## Exllama v2 Quantizations of NeuralHyperion-2.0-Mistral-7B
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.15">turboderp's ExLlamaV2 v0.0.15</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: https://huggingface.co/Locutusque/NeuralHyperion-2.0-Mistral-7B
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/NeuralHyperion-2.0-Mistral-7B-exl2/tree/8_0) | 8.0 | 8.0 | 8.4 GB | 9.8 GB | 11.8 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/NeuralHyperion-2.0-Mistral-7B-exl2/tree/6_5) | 6.5 | 8.0 | 7.2 GB | 8.6 GB | 10.6 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
| [5_0](https://huggingface.co/bartowski/NeuralHyperion-2.0-Mistral-7B-exl2/tree/5_0) | 5.0 | 6.0 | 6.0 GB | 7.4 GB | 9.4 GB | Slightly lower quality vs 6.5, but usable on 8GB cards. |
| [4_25](https://huggingface.co/bartowski/NeuralHyperion-2.0-Mistral-7B-exl2/tree/4_25) | 4.25 | 6.0 | 5.3 GB | 6.7 GB | 8.7 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/bartowski/NeuralHyperion-2.0-Mistral-7B-exl2/tree/3_5) | 3.5 | 6.0 | 4.7 GB | 6.1 GB | 8.1 GB | Lower quality, only use if you have to. |
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/NeuralHyperion-2.0-Mistral-7B-exl2 NeuralHyperion-2.0-Mistral-7B-exl2-6_5
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download the `main` (only useful if you only care about measurement.json) branch to a folder called `NeuralHyperion-2.0-Mistral-7B-exl2`:
```shell
mkdir NeuralHyperion-2.0-Mistral-7B-exl2
huggingface-cli download bartowski/NeuralHyperion-2.0-Mistral-7B-exl2 --local-dir NeuralHyperion-2.0-Mistral-7B-exl2 --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
Linux:
```shell
mkdir NeuralHyperion-2.0-Mistral-7B-exl2-6_5
huggingface-cli download bartowski/NeuralHyperion-2.0-Mistral-7B-exl2 --revision 6_5 --local-dir NeuralHyperion-2.0-Mistral-7B-exl2-6_5 --local-dir-use-symlinks False
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
mkdir NeuralHyperion-2.0-Mistral-7B-exl2-6.5
huggingface-cli download bartowski/NeuralHyperion-2.0-Mistral-7B-exl2 --revision 6_5 --local-dir NeuralHyperion-2.0-Mistral-7B-exl2-6.5 --local-dir-use-symlinks False
```
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
graizelle/gurl-peen-sx
|
graizelle
| 2024-03-11T16:40:27Z | 27 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-to-image
| 2024-01-18T18:16:14Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '1girl, gurl-peen, (piercings), (septum_ring), tattoos, trans female, futanari, highly detailed, masterpiece best quality'
parameter:
negative_prompt: >-
lowres, bad anatomy, bad hands, text, error, missing fingers, extra
digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad hands, bad anatomy
width=1024,
height=1024,
guidance_scale=5,
num_inference_steps=20
example_title: 1girl
output:
url: images/IMG_3661.jpeg.png
- text: '1girl, gurl-peen, trans female, futanari, highly detailed, masterpiece best quality'
output:
url: images/IMG_3662.jpeg.png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: gurl-peen
license: cc-by-nc-sa-4.0
---
# Gurl Peen
<Gallery />
## Model description
SDXL beta test versions of loRA training on dataset of trans women.
## Trigger words
You should use `gurl-peen` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/graizelle/gurl-peen/tree/main) them in the Files & versions tab.
|
likhithasapu/humour-detection-xlmr
|
likhithasapu
| 2024-03-11T16:37:45Z | 91 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-11T16:36:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
flammenai/flammen7-mistral-7B
|
flammenai
| 2024-03-11T16:34:45Z | 15 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:flammenai/flammen3X-mistral-7B",
"base_model:merge:flammenai/flammen3X-mistral-7B",
"base_model:flammenai/flammen6-mistral-7B",
"base_model:merge:flammenai/flammen6-mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T16:31:15Z |
---
license: apache-2.0
base_model:
- nbeerbower/flammen6-mistral-7B
- nbeerbower/flammen3X
library_name: transformers
tags:
- mergekit
- merge
---
# flammen7-mistral-7B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [nbeerbower/flammen6-mistral-7B](https://huggingface.co/nbeerbower/flammen6-mistral-7B)
* [nbeerbower/flammen3X](https://huggingface.co/nbeerbower/flammen3X)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: nbeerbower/flammen6-mistral-7B
layer_range: [0, 32]
- model: nbeerbower/flammen3X
layer_range: [0, 32]
merge_method: slerp
base_model: nbeerbower/flammen6-mistral-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_64_32_0.01_4_0.0002
|
ferrazzipietro
| 2024-03-11T16:33:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T16:32:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
vtiyyal1/gemma-7b-it-AskDocsEmpathy5k
|
vtiyyal1
| 2024-03-11T16:32:56Z | 4 | 1 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-7b-it",
"base_model:adapter:google/gemma-7b-it",
"region:us"
] | null | 2024-03-11T16:32:16Z |
---
library_name: peft
base_model: google/gemma-7b-it
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.9.0
|
Epiculous/Mika-7B-LoRA
|
Epiculous
| 2024-03-11T16:32:10Z | 50 | 1 |
peft
|
[
"peft",
"pytorch",
"safetensors",
"mistral",
"dataset:lemonilia/LimaRP",
"dataset:grimulkan/theory-of-mind",
"dataset:Epiculous/Gnosis",
"dataset:ChaoticNeutrals/Synthetic-RP",
"dataset:ChaoticNeutrals/Synthetic-Dark-RP",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2024-03-10T22:04:03Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
datasets:
- lemonilia/LimaRP
- grimulkan/theory-of-mind
- Epiculous/Gnosis
- ChaoticNeutrals/Synthetic-RP
- ChaoticNeutrals/Synthetic-Dark-RP
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.9.0
|
microsoft/udop-large-512-300k
|
microsoft
| 2024-03-11T16:32:08Z | 1,159 | 31 |
transformers
|
[
"transformers",
"safetensors",
"udop",
"image-text-to-text",
"vision",
"arxiv:2212.02623",
"license:mit",
"region:us"
] |
image-text-to-text
| 2024-02-26T12:50:16Z |
---
license: mit
tags:
- vision
inference: false
pipeline_tag: image-text-to-text
---
# UDOP model
The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
## Model description
UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
## Intended uses & limitations
You can use the model for document image classification, document parsing and document visual question answering (DocVQA).
### How to use
Here's how to use the model on a document image:
```python
from transformers import AutoProcessor, UdopForConditionalGeneration
from datasets import load_dataset
# load model and processor
# in this case, we already have performed OCR ourselves
# so we initialize the processor with `apply_ocr=False`
processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
model = UdopForConditionalGeneration.from_pretrained("microsoft/udop-large")
# load an example image, along with the words and coordinates
# which were extracted using an OCR engine
dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
example = dataset[0]
image = example["image"]
words = example["tokens"]
boxes = example["bboxes"]
question = "Question answering. What is the date on the form?"
# prepare everything for the model
encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
# autoregressive generation
predicted_ids = model.generate(**encoding)
print(processor.batch_decode(predicted_ids, skip_special_tokens=True)[0])
9/30/92
```
Refer to the [demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) for fine-tuning/inference.
### BibTeX entry and citation info
```bibtex
@misc{tang2023unifying,
title={Unifying Vision, Text, and Layout for Universal Document Processing},
author={Zineng Tang and Ziyi Yang and Guoxin Wang and Yuwei Fang and Yang Liu and Chenguang Zhu and Michael Zeng and Cha Zhang and Mohit Bansal},
year={2023},
eprint={2212.02623},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_64_32_0.01_2_0.0002
|
ferrazzipietro
| 2024-03-11T16:27:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T16:26:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koesn/Genstruct-7B-GGUF
|
koesn
| 2024-03-11T16:27:07Z | 19 | 0 |
transformers
|
[
"transformers",
"gguf",
"Mistral",
"instruct",
"finetune",
"synthetic",
"en",
"arxiv:2310.04484",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-11T15:07:47Z |
---
base_model: mistralai/Mistral-7B-v0.1
tags:
- Mistral
- instruct
- finetune
- synthetic
license: apache-2.0
language:
- en
library_name: transformers
---
## Description
This repo contains GGUF format model files for Genstruct-7B.
## Files Provided
| Name | Quant | Bits | File Size | Remark |
| ------------------------- | ------- | ---- | --------- | -------------------------------- |
| genstruct-7b.IQ3_S.gguf | IQ3_S | 3 | 3.18 GB | 3.44 bpw quantization |
| genstruct-7b.IQ3_M.gguf | IQ3_M | 3 | 3.28 GB | 3.66 bpw quantization mix |
| genstruct-7b.Q4_0.gguf | Q4_0 | 4 | 4.11 GB | 3.56G, +0.2166 ppl |
| genstruct-7b.IQ4_NL.gguf | IQ4_NL | 4 | 4.16 GB | 4.25 bpw non-linear quantization |
| genstruct-7b.Q4_K_M.gguf | Q4_K_M | 4 | 4.37 GB | 3.80G, +0.0532 ppl |
| genstruct-7b.Q5_K_M.gguf | Q5_K_M | 5 | 5.13 GB | 4.45G, +0.0122 ppl |
| genstruct-7b.Q6_K.gguf | Q6_K | 6 | 5.94 GB | 5.15G, +0.0008 ppl |
| genstruct-7b.Q8_0.gguf | Q8_0 | 8 | 7.70 GB | 6.70G, +0.0004 ppl |
## Parameters
| path | type | architecture | rope_theta | sliding_win | max_pos_embed |
| ------------------------- | ------- | ------------------ | ---------- | ----------- | ------------- |
| NousResearch/Genstruct-7B | mistral | MistralForCausalLM | 10000.0 | 4096 | 32768 |
# Original Model Card
# Genstruct 7B

Genstruct 7B is an instruction-generation model, designed to create valid instructions given a raw text corpus. This enables the creation of new, partially synthetic instruction finetuning datasets from any raw-text corpus.
This work was inspired by [Ada-Instruct](https://arxiv.org/abs/2310.04484):

Previous methods largely rely on in-context approaches to generate instructions, while Ada-Instruct trained a custom instruction-generation model.
Inspired by this, we took this approach further by grounding the generations in user-provided context passages.
Further, the model is trained to generate questions involving complex scenarios that require detailed reasoning, allowing for models trained on the generated data to reason step-by-step.
| | ChatGPT | Few-shot prompting | RAG | Ada-Instruct | **Genstruct** |
|:-------------------:|:--------:|:------------------:|:---:|:------------:|:---------:|
| Open models | ❌ | ☑️ | ☑️ | ✅ | ✅ |
| Grounded generation | ❌ | ❌ | ✅ | ❌ | ✅ |
| Complex questions | ❌ | ❌ | ❌ | ☑️ | ✅ |
| Complex responses | ✅ | ☑️ | ❌ | ☑️ | ✅ |
An example notebook is provided [here](https://huggingface.co/NousResearch/Genstruct-7B/blob/main/notebook.ipynb), which details how to load and sample from the model.
Alternatively, here's a minimal example:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_NAME = 'NousResearch/Genstruct-7B'
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map='cuda', load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
msg =[{
'title': 'p-value',
'content': "The p-value is used in the context of null hypothesis testing in order to quantify the statistical significance of a result, the result being the observed value of the chosen statistic T {\displaystyle T}.[note 2] The lower the p-value is, the lower the probability of getting that result if the null hypothesis were true. A result is said to be statistically significant if it allows us to reject the null hypothesis. All other things being equal, smaller p-values are taken as stronger evidence against the null hypothesis."
}]
inputs = tokenizer.apply_chat_template(msg, return_tensors='pt').cuda()
print(tokenizer.decode(model.generate(inputs, max_new_tokens=512)[0]).split(tokenizer.eos_token)[0])
```
# Example outputs
The input is the text up to and including "`[[[User]]] `", and the completion is everything that follows.
### Law of large numbers
```
[[[Title]]] Law of large numbers
[[[Content]]] In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the average of the results obtained from a large number of independent and identical random samples converges to the true value, if it exists.[1] More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
The following is an interaction between a user and an AI assistant that is related to the above text.
[[[User]]] Jacqueline is a statistician. She is currently analyzing a large amount of data. She is applying the law of large numbers in order to get some conclusions. In order to better understand the law of large numbers, she is considering two samples A and B. Sample A is not independent but sample B is independent and identically distributed.
Which sample's mean does not converge to the true mean, if any, sample A or sample B?
[[[Assistant]]] The law of large numbers (LLN) is a significant concept in probability theory. It suggests that the average of the results obtained from a large number of independent and identical random samples will converge to the true value, if it exists. This means that the sample mean will converge to the true mean.
Now, let's consider Jacqueline's samples. She has sample A which is not independent and sample B which is independent and identically distributed. According to the conditions stated in the LLN, only samples that are independent and identically distributed can make their means converge to the true mean.
Since sample A is not independent, its values are likely related or influenced by previous observations. This lack of independence can skew the mean and prevent it from converging to the true mean. On the other hand, sample B satisfies the condition of independence and identical distribution. Therefore, its mean has a higher chance of converging to the true mean.
Hence, if we are looking for a sample whose mean does not converge to the true mean, based on the given information, it would be sample A.
```
### Zinc deficiency
```
[[[Title]]] Zinc deficiency
[[[Content]]] Zinc deficiency is defined either as insufficient zinc to meet the needs of the body, or as a serum zinc level below the normal range. However, since a decrease in the serum concentration is only detectable after long-term or severe depletion, serum zinc is not a reliable biomarker for zinc status.[1] Common symptoms include increased rates of diarrhea. Zinc deficiency affects the skin and gastrointestinal tract; brain and central nervous system, immune, skeletal, and reproductive systems.
Zinc deficiency in humans is caused by reduced dietary intake, inadequate absorption, increased loss, or increased body system use. The most common cause is reduced dietary intake. In the U.S., the Recommended Dietary Allowance (RDA) is 8 mg/day for women and 11 mg/day for men.[2]
The following is an interaction between a user and an AI assistant that is related to the above text.
[[[User]]] Two groups of children were studied over a period of 6 months. Group Z had 10 children who were given zinc supplements so they would not develop from lack of this mineral. Group J had 10 similar children who were not given any supplements or pills to take, so they could be part of a control group.
Which group of children would less likely have increased rates of diarrhea?
[[[Assistant]]] Zinc deficiency has been established to lead to increased rates of diarrhea. Since zinc aids in the regulation of the gastrointestinal tract, its lack can cause digestive system issues such as diarrhea. Therefore, preventing zinc deficiency would logically reduce the occurrence of diarrhea. In the given scenario, Group Z was supplied with zinc supplements to avoid zinc deficiency, while Group J served as a control and received no supplements. Thus, with the body's requirements for zinc being met through the supplements in Group Z, one would expect that they would less likely experience the symptoms of zinc deficiency, including increased rates of diarrhea. So, the group of children less likely to have increased rates of diarrhea are Group Z.
```
### Cortado
```
[[[Title]]] Cortado
[[[Content]]] A cortado is a Spanish beverage consisting of espresso mixed with a roughly equal amount of warm milk to reduce the acidity,[1][2] although the exact ratios have considerable regional variation.[3] The milk in a cortado is steamed, but not frothy and "texturized" as in many Italian coffee drinks.[4] The cortado is commonly served all over Spain.[5] The word cortado is the past participle of the Spanish verb cortar (to cut), in the sense of "dilute", and can refer variously to either coffee or espresso drinks throughout Spanish and Portuguese speaking countries.
The following is an interaction between a user and an AI assistant that is related to the above text.
[[[User]]] Brett and Sean land good jobs in Madrid and Lisbon respectively. As a result, they both have a good income and can afford to develop a taste for the fine things in life. Being in Europe they both develop a taste for cortados. Sean, however, stays with his job in Lisbon, while Brett moves back to Seattle and tries to find a job. Brett is unsuccessful and moves back in with his parents.
Which of the two, Sean or Brett, will have an easier time finding a barista that knows what a cortado is?
[[[Assistant]]] A cortado is a type of beverage that originated in Spain. It consists of espresso mixed with warm milk, which reduces the acidity of the coffee. The milk in a cortado is steamed, but not to the point of being frothy or texturized, as is often the case in many Italian coffee drinks. The cortado is a common beverage all over Spain. The word "cortado" comes from the Spanish verb "cortar", which means "to cut" or "dilute". This term can refer to either coffee or espresso drinks throughout Spanish and Portuguese speaking countries.
Given that Brett has moved from Madrid, where he was accustomed to enjoying cortados, to Seattle, his chances of finding a barista who knows what a cortado is will likely be more difficult. In contrast, Sean, who has remained in Lisbon where cortados are also popular, will have an easier time finding a barista who is familiar with this type of beverage.
Therefore, based on their respective locations, Sean will have an easier time finding a barista that knows what a cortado is compared to Brett.```
```
# How to cite:
```bibtext
@misc{Genstruct,
url={[https://https://huggingface.co/NousResearch/Genstruct-7B](https://huggingface.co/NousResearch/https://huggingface.co/NousResearch/Genstruct-7B)},
title={Genstruct},
author={"euclaise"}
}
```
|
pawkanarek/gemma_03-11-16-07
|
pawkanarek
| 2024-03-11T16:26:06Z | 92 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:generator",
"base_model:google/gemma-2b-it",
"base_model:finetune:google/gemma-2b-it",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T16:08:00Z |
---
license: other
base_model: google/gemma-2b-it
tags:
- trl
- sft
- generated_from_trainer
datasets:
- generator
model-index:
- name: gemma_03-11-16-07
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gemma_03-11-16-07
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: tpu
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.3.0.dev20240307
- Datasets 2.18.0
- Tokenizers 0.15.2
|
KBLab/megatron.bert-large.unigram-64k-pretok.500k-steps
|
KBLab
| 2024-03-11T16:23:30Z | 99 | 0 |
transformers
|
[
"transformers",
"pytorch",
"megatron-bert",
"fill-mask",
"sv",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2024-03-11T16:17:17Z |
---
language:
- sv
---
# megatron.bert-large.unigram-64k-pretok.500k-steps
This BERT model was trained using the NeMo library.
The size of the model is a regular bert-large.
The model was trained on more than 245GB of data, consisting mostly of web-data and Swedish newspaper text curated by the National Library of Sweden.
Training was done for 500k training steps using a batch size of 8k.
The model has multiple sibling models trained on the same dataset using different tokenizers or more/less parameters:
- [megatron.bert-base.bpe-32k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.bpe-32k-no_pretok.25k-steps)
- [megatron.bert-base.bpe-64k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.bpe-64k-no_pretok.25k-steps)
- [megatron.bert-base.spe-bpe-32k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.spe-bpe-32k-no_pretok.25k-steps)
- [megatron.bert-base.spe-bpe-32k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.spe-bpe-32k-pretok.25k-steps)
- [megatron.bert-base.spe-bpe-64k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.spe-bpe-64k-no_pretok.25k-steps)
- [megatron.bert-base.spe-bpe-64k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.spe-bpe-64k-pretok.25k-steps)
- [megatron.bert-base.unigram-32k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.unigram-32k-no_pretok.25k-steps)
- [megatron.bert-base.unigram-32k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.unigram-32k-pretok.25k-steps)
- [megatron.bert-base.unigram-64k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.unigram-64k-no_pretok.25k-steps)
- [megatron.bert-base.unigram-64k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.unigram-64k-pretok.25k-steps)
- [megatron.bert-base.wordpiece-32k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.wordpiece-32k-no_pretok.25k-steps)
- [megatron.bert-base.wordpiece-32k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.wordpiece-32k-pretok.25k-steps)
- [megatron.bert-base.wordpiece-64k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.wordpiece-64k-no_pretok.25k-steps)
- [megatron.bert-base.wordpiece-64k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-base.wordpiece-64k-pretok.25k-steps)
- [megatron.bert-large.bpe-64k-no_pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-large.bpe-64k-no_pretok.25k-steps)
- [megatron.bert-large.spe-bpe-32k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-large.spe-bpe-32k-pretok.25k-steps)
- [megatron.bert-large.unigram-32k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-large.unigram-32k-pretok.25k-steps)
- [megatron.bert-large.unigram-64k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-large.unigram-64k-pretok.25k-steps)
- [megatron.bert-large.wordpiece-32k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-large.wordpiece-32k-pretok.25k-steps)
- [megatron.bert-large.wordpiece-64k-pretok.25k-steps](https://huggingface.co/KBLab/megatron.bert-large.wordpiece-64k-pretok.25k-steps)
## Acknowledgements
The training was performed on the Luxembourg national supercomputer MeluXina.
The authors gratefully acknowledge the LuxProvide teams for their expert support.
|
chillies/llama_ielts_evaluator_base
|
chillies
| 2024-03-11T16:23:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T15:41:11Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_org_acc_lf_signal_it_39
|
furrutiav
| 2024-03-11T16:20:33Z | 91 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2024-03-11T16:20:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
microsoft/udop-large-512
|
microsoft
| 2024-03-11T16:20:06Z | 170 | 5 |
transformers
|
[
"transformers",
"safetensors",
"udop",
"image-text-to-text",
"vision",
"arxiv:2212.02623",
"license:mit",
"region:us"
] |
image-text-to-text
| 2024-02-26T11:10:07Z |
---
license: mit
tags:
- vision
inference: false
pipeline_tag: image-text-to-text
---
# UDOP model
The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
## Model description
UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
## Intended uses & limitations
You can use the model for document image classification, document parsing and document visual question answering (DocVQA).
### How to use
Here's how to use the model for one-shot semantic segmentation:
```python
from transformers import AutoProcessor, UdopForConditionalGeneration
from datasets import load_dataset
# load model and processor
# in this case, we already have performed OCR ourselves
# so we initialize the processor with `apply_ocr=False`
processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
model = UdopForConditionalGeneration.from_pretrained("microsoft/udop-large")
# load an example image, along with the words and coordinates
# which were extracted using an OCR engine
dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
example = dataset[0]
image = example["image"]
words = example["tokens"]
boxes = example["bboxes"]
question = "Question answering. What is the date on the form?"
# prepare everything for the model
encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
# autoregressive generation
predicted_ids = model.generate(**encoding)
print(processor.batch_decode(predicted_ids, skip_special_tokens=True)[0])
9/30/92
```
Refer to the [demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) for fine-tuning/inference.
### BibTeX entry and citation info
```bibtex
@misc{tang2023unifying,
title={Unifying Vision, Text, and Layout for Universal Document Processing},
author={Zineng Tang and Ziyi Yang and Guoxin Wang and Yuwei Fang and Yang Liu and Chenguang Zhu and Michael Zeng and Cha Zhang and Mohit Bansal},
year={2023},
eprint={2212.02623},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
BoscoTheDog/bio_mistral_xxs_gguf
|
BoscoTheDog
| 2024-03-11T16:15:29Z | 1 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-11T15:52:07Z |
An attempt to get Bio Mistral under 2GB in size so it could easily be loaded in browser-based projects.
Amazingly, it ended up as 1.99GB
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_64_32_0.05_4_0.0002
|
ferrazzipietro
| 2024-03-11T16:15:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T16:14:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
liminerity/Omningotex-7b-slerp
|
liminerity
| 2024-03-11T16:12:46Z | 67 | 3 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"liminerity/binarized-ingotrix-slerp-7b",
"eren23/dpo-binarized-NeutrixOmnibe-7B",
"base_model:eren23/dpo-binarized-NeutrixOmnibe-7B",
"base_model:merge:eren23/dpo-binarized-NeutrixOmnibe-7B",
"base_model:liminerity/binarized-ingotrix-slerp-7b",
"base_model:merge:liminerity/binarized-ingotrix-slerp-7b",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-12T10:34:11Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- liminerity/binarized-ingotrix-slerp-7b
- eren23/dpo-binarized-NeutrixOmnibe-7B
base_model:
- liminerity/binarized-ingotrix-slerp-7b
- eren23/dpo-binarized-NeutrixOmnibe-7B
model-index:
- name: Omningotex-7b-slerp
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 73.29
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Omningotex-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.96
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Omningotex-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.69
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Omningotex-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 76.32
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Omningotex-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 84.21
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Omningotex-7b-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 70.51
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=liminerity/Omningotex-7b-slerp
name: Open LLM Leaderboard
---
Title: Introducing Omningotex-7b: The World's Most Accurate 7B LLM
Today, I'm excited to share the creation of a groundbreaking language model, "liminerity/Omningotex-7b-slerp." This model has achieved an impressive accuracy rate of 76.33%, making it the most accurate 7B LLM in the world.
The journey to create Omningotex-7b-slerp began with an experimental process called "merging." I started with a model named "ingot-7b-slerp," which was created by merging two other LLMs, "blurred-beagle-7b-slerp" (by myself, liminerity) and "Macaroni-7b-Tied" (by andrijdavid), a total of eight times over.
After the successful creation of ingot-7b-slerp, I proceeded to merge it with another model, "dpo-binarized-NeuralTrix-7B" by eren23, using gradient slerp. The resulting model, "binarized-ingotrix-slerp-7b," achieved an accuracy rate of 76.04%.
To further enhance the model's performance, I decided to merge "binarized-ingotrix-slerp-7b" with "dpo-binarized-NeutrixOmnibe-7B" by eren23 once again. The resulting model, "Omningotex-7b," is now the most accurate 7B LLM available.
This breakthrough in LLM accuracy was achieved through a combination of careful experimentation and a deep understanding of the underlying algorithms and techniques. I believe that Omningotex-7b-slerp's success demonstrates the potential for further advancements in the field of natural language processing and artificial intelligence.
I look forward to sharing more updates and insights as I continue to explore the possibilities of LLMs and push the boundaries of what is possible in the world of AI. Stay tuned for more exciting developments in the future!
A huge thank you to Maxime Labonne and his creation of LazyMergeKit colab project. Use of it helped me gain a further grasp of the concepts at play and led to the creation of this model. I'm sure it won't be number 1 for long which excited me even more!
Next, I set out to learn how to fine-tune with the resources I have available.
My next overall goal is to try and find a way to produce a smaller model with high accuracy either through merging down using fewer layers after each merge. I may need to include finetuning between each merge or merging larger more accurate models into a smaller base while maintaining accuracy and performance. Every version of "TinyMistral" I come by seems to be bricked in the sense it spits out nonsense. Thank you for your time If you read this all the way.
# Omningotex-7B-slerp
Omningotex-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [liminerity/binarized-ingotrix-slerp-7b](https://huggingface.co/liminerity/binarized-ingotrix-slerp-7b)
* [eren23/dpo-binarized-NeutrixOmnibe-7B](https://huggingface.co/eren23/dpo-binarized-NeutrixOmnibe-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: liminerity/binarized-ingotrix-slerp-7b
layer_range: [0, 32]
- model: eren23/dpo-binarized-NeutrixOmnibe-7B
layer_range: [0, 32]
merge_method: slerp
base_model: liminerity/binarized-ingotrix-slerp-7b
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "liminerity/Omningotex-7b-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_liminerity__Omningotex-7b-slerp)
| Metric |Value|
|---------------------------------|----:|
|Avg. |76.33|
|AI2 Reasoning Challenge (25-Shot)|73.29|
|HellaSwag (10-Shot) |88.96|
|MMLU (5-Shot) |64.69|
|TruthfulQA (0-shot) |76.32|
|Winogrande (5-shot) |84.21|
|GSM8k (5-shot) |70.51|
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_64_32_0.05_2_0.0002
|
ferrazzipietro
| 2024-03-11T16:09:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T16:08:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Vrspi/SpeechToText
|
Vrspi
| 2024-03-11T16:05:32Z | 67 | 1 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-03-11T15:38:34Z |
# Model Card for Moroccan Dialect Speech-to-Text Model
This model is designed to transcribe speech in the Moroccan dialect to text. It's built on top of the Wav2Vec 2.0 architecture, fine-tuned on a dataset of Moroccan dialect speech.
## Model Details
### Model Description
This model is part of a project aimed at improving speech recognition technology for underrepresented languages, with a focus on the Moroccan Arabic dialect. The model leverages the power of the Wav2Vec2 architecture, fine-tuned on a curated dataset of Moroccan speech.
- **Developed by:** https://www.kaggle.com/khaireddinedalaa
- **Model type:** Wav2Vec2ForCTC
- **Language(s) (NLP):** Moroccan Arabic (Darija)
- **License:** Apache 2.0
- **Finetuned from model:** jonatasgrosman/wav2vec2-large-xlsr-53-arabic
### Model Sources
- **Demo:** Coming Soon
## Uses
### Direct Use
This model is intended for direct use in applications requiring speech-to-text capabilities for the Moroccan dialect. It can be integrated into services like voice-controlled assistants, dictation software, or for generating subtitles in real-time.
### Out-of-Scope Use
This model is not intended for use with languages other than Moroccan Arabic or for non-speech audio transcription. Performance may significantly decrease when used out of context.
## Bias, Risks, and Limitations
The model may exhibit biases present in the training data. It's important to note that dialectal variations within Morocco could affect transcription accuracy. Users should be aware of these limitations and consider additional validation for critical applications.
### Recommendations
Continual monitoring and updating of the model with more diverse datasets can help mitigate biases and improve performance across different dialects and speaking styles.
## How to Get Started with the Model
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from transformers import pipeline
import soundfile as sf
# Load the model and processor
processor = Wav2Vec2Processor.from_pretrained("Vrspi/SpeechToText")
model = Wav2Vec2ForCTC.from_pretrained("Vrspi/SpeechToText")
# Create a speech-to-text pipeline
speech_recognizer = pipeline("automatic-speech-recognition", model=model, processor=processor)
# Load an audio file
speech, sampling_rate = sf.read("path_to_your_audio_file.wav")
# Transcribe the speech
transcription = speech_recognizer(speech, sampling_rate=sampling_rate)
print(transcription)
```
## Training Details
### Training Data
The model was trained on a dataset comprising approximately 20 hours of spoken Moroccan Arabic collected from various sources, including public speeches, conversations, and media content.
### Training Procedure
#### Preprocessing
The audio files were resampled to 16kHz and trimmed to remove silence. Noisy segments were manually annotated and excluded from training.
#### Training Hyperparameters
- **Training regime:** Training was performed using the AdamW optimizer with a learning rate of 3e-5, over 3 epochs.
## Evaluation
### Results
The model is not tested yet , I will drop results as soon as possible
## Environmental Impact
- **Hardware Type:** Training was performed on Kaggle's GPU environment.
- **Hours used:** Approximately 10 hours.
---
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_32_32_0.01_8_0.0002
|
ferrazzipietro
| 2024-03-11T16:03:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T16:03:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mann2107/BCMPIIRAB
|
mann2107
| 2024-03-11T15:59:35Z | 47 | 0 |
setfit
|
[
"setfit",
"pytorch",
"bert",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:sentence-transformers/all-MiniLM-L6-v2",
"base_model:finetune:sentence-transformers/all-MiniLM-L6-v2",
"model-index",
"region:us"
] |
text-classification
| 2024-03-11T15:23:29Z |
---
library_name: setfit
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
base_model: sentence-transformers/all-MiniLM-L6-v2
metrics:
- accuracy
widget:
- text: The itinerary meets our requirements, please book as proposed.
- text: 'Please may you kindly send us the invoices for our stay at the Protea hotel
in Cape Town from 20/07/2023 - 22/07/2023. The four confirmation numbers from
the vouchers are as follows: 74733068 74731210 74729566 74727187'
- text: Can you please tell me if this Flight ticket for Shaun Connolly was charge
to the LBP travel card.
- text: I am very confused on the itineraries I've received for Michelle Curtin. Can
you please send me an updated itinerary with her actual travel schedule?
- text: I got a call late Friday afternoon to move our meeting of today. The rental
company was supposed to drop off the car for me at 13:00. Can you please call
and find out if they can deliver it before 10 this morning. Preferably 9. Sorry
for the inconvenience.
pipeline_tag: text-classification
inference: true
model-index:
- name: SetFit with sentence-transformers/all-MiniLM-L6-v2
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: Unknown
type: unknown
split: test
metrics:
- type: accuracy
value: 0.875
name: Accuracy
---
# SetFit with sentence-transformers/all-MiniLM-L6-v2
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 256 tokens
- **Number of Classes:** 9 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | <ul><li>'Please send me quotation for a flight for Lindelani Mkhize - East London/ Durban 31 August @ 12:00'</li><li>'I need to go to Fort Smith AR via XNA for PD days. I d like to take AA 4064 at 10:00 am arriving 11:58 am on Monday, May 11 returning on AA 4064 at 12:26 pm arriving 2:16 pm on Saturday May 16. I will need a Hertz rental. I d like to stay at the Courtyard Marriott in Fort Smith on Monday through Thursday nights checking out on Friday morning. Then I d like to stay at the Hilton Garden Inn in Bentonville AR on Walton Road Friday night checking out Saturday morning.'</li><li>'I am planning to attend a Training in to be held between Nov 22-24 2023 at Avon, France (Specific address is Corning, 7 Bis Av. de Valvins, 77210 Avon, France) I have to arrive in France on the 21st of Nov and leave on the 25th of Nov. May you please help me with the travel itinerary and accommodation quotation (within walking distance preferably), transport in France to the hotel from the airport and back. I would like to put in an overseas travel request.'</li></ul> |
| 1 | <ul><li>"Hello, Can someone help to cancel my trip in Concur? I'm unable to do it in the system. Trip from San Francisco to Minneapolis/St Paul (MDFNTI)<https://www.concursolutions.com/travelportal/triplibrary.asp>"</li><li>'Please cancel my flight for late March to Chicago and DC. Meetings have been cancelled. I am not available by phone.'</li><li>'I need to cancel the below trip due to illness in family. Could you please assist with this?'</li></ul> |
| 2 | <ul><li>'I have a travel booking question. I booked a flight for myself & a coworker, however, it was requested that we leave a couple days earlier than planned. How can I revise/move our first flight up without cancelling the whole trip? The flights home will remain the same.'</li><li>'I just received my KTN today and added it to my profile. However, I have flights in Nov booked with United and Delta. Any way to add the KTN to those reservations so the tickets come through with Pre-Check?'</li><li>"Lerato I checked Selbourne B/B, its not a nice place. Your colleague Stella booked Lindelani Mkhize in Hempston it's a beautiful place next to Garden Court, please change the accommodation from Selbourne to Hempston. This Selbourne is on the outskirt and my colleagues are not familiar with East London"</li></ul> |
| 3 | <ul><li>'Please add the below employee to our Concur system. In addition, make sure the Ghost Card is added into their profile. Lindsay Griffin [email protected]'</li><li>"Good afternoon - CAEP has 4 new staff members that we'd like to set - up new user profiles for. Please see the below information and let me know should anything additional be required. Last First Middle Travel Class Email Gender DOB Graham Rose - Helen Xiuqing Staff rose - [email protected] Female 6/14/1995 Gumbs Mary - Frances Akua Staff [email protected] Female 10/18/1995 Lee Elizabeth Andie Staff [email protected] Female 4/23/1991 Gilchrist Gabriel Jake Staff [email protected] Male"</li><li>'Good Morning, Please create a profile for Amelia West: Name: Amelia Jean - Danielle West DOB: 05/21/1987 PH: 202 - 997 - 6592 Email: [email protected]'</li></ul> |
| 4 | <ul><li>'Invoices October 2019 Hi, My name is Lucia De Las Heras property accountant at Trion Properties. I am missing a few receipts to allocate the following charges. Would you please be able to provide a detailed invoice? 10/10/2019 FROSCH/GANT TRAVEL MBLOOMINGTON IN - 21'</li><li>'I would like to request an invoice/s for the above-mentioned employee who stayed at your establishment. Thank you for the other invoice August 2023 & the confirmation for the new reservation 01st - 04th October 2023, Thanking you in Advance!'</li><li>"Hello, Looking for an invoice for the below charge to Ryan Schulke's card - could you please assist? Vendor: United Airlines Transaction Date: 02/04/2020 Amount: $2,132.07 Ticket Number: 0167515692834"</li></ul> |
| 5 | <ul><li>'This is the second email with this trip, but I still need an itinerary for trip scheduled for January 27. Derek'</li><li>'Please send us all the flights used by G4S Kenya in the year 2022. Sorry for the short notice but we need the information by 12:00 noon today.'</li><li>'Jen Holt Can you please send me the itinerary for Jen Holt for this trip this week to Jackson Mississippi?'</li></ul> |
| 6 | <ul><li>"I've had to call off my vacation. What are my options for getting refunded?"</li><li>"Looks like I won't be traveling due to some health issues. Is getting a refund for my booking possible?"</li><li>"I've fallen ill and can't travel as planned. Can you process a refund for me?"</li></ul> |
| 7 | <ul><li>'The arrangements as stated are acceptable. Please go ahead and confirm all bookings accordingly.'</li><li>"I've reviewed the details and everything seems in order. Please proceed with the booking."</li><li>'This travel plan is satisfactory. Please secure the necessary reservations.'</li></ul> |
| 8 | <ul><li>'I need some clarification on charges for a rebooked flight. It seems higher than anticipated. Who can provide more details?'</li><li>'Wishing you and your family a very Merry Christmas and a Happy and Healthy New Year. I have one unidentified item this month, hope you can help, and as always thanks in advance. Very limited information on this. 11/21/2019 #N/A #N/A #N/A 142.45 Rail Europe North Amer'</li><li>"We've identified a mismatch between our booking records and credit card statement. Who can assist with this issue?"</li></ul> |
## Evaluation
### Metrics
| Label | Accuracy |
|:--------|:---------|
| **all** | 0.875 |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("mann2107/BCMPIIRAB")
# Run inference
preds = model("The itinerary meets our requirements, please book as proposed.")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:--------|:----|
| Word count | 1 | 30.4097 | 124 |
| Label | Training Sample Count |
|:------|:----------------------|
| 0 | 16 |
| 1 | 16 |
| 2 | 16 |
| 3 | 16 |
| 4 | 16 |
| 5 | 16 |
| 6 | 16 |
| 7 | 16 |
| 8 | 16 |
### Training Hyperparameters
- batch_size: (16, 16)
- num_epochs: (1, 1)
- max_steps: -1
- sampling_strategy: oversampling
- body_learning_rate: (2e-05, 1e-05)
- head_learning_rate: 0.01
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: True
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:-------:|:--------:|:-------------:|:---------------:|
| 0.0009 | 1 | 0.1977 | - |
| 0.0434 | 50 | 0.1642 | - |
| 0.0868 | 100 | 0.1034 | - |
| 0.1302 | 150 | 0.05 | - |
| 0.1736 | 200 | 0.0177 | - |
| 0.2170 | 250 | 0.0128 | - |
| 0.2604 | 300 | 0.0148 | - |
| 0.3038 | 350 | 0.0109 | - |
| 0.3472 | 400 | 0.0059 | - |
| 0.3906 | 450 | 0.004 | - |
| 0.4340 | 500 | 0.0036 | - |
| 0.4774 | 550 | 0.0064 | - |
| 0.5208 | 600 | 0.0042 | - |
| 0.5642 | 650 | 0.002 | - |
| 0.6076 | 700 | 0.0017 | - |
| 0.6510 | 750 | 0.002 | - |
| 0.6944 | 800 | 0.0026 | - |
| 0.7378 | 850 | 0.0019 | - |
| 0.7812 | 900 | 0.0017 | - |
| 0.8247 | 950 | 0.0017 | - |
| 0.8681 | 1000 | 0.0015 | - |
| 0.9115 | 1050 | 0.0009 | - |
| 0.9549 | 1100 | 0.002 | - |
| 0.9983 | 1150 | 0.0008 | - |
| **1.0** | **1152** | **-** | **0.0732** |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.9.16
- SetFit: 1.1.0.dev0
- Sentence Transformers: 2.2.2
- Transformers: 4.21.3
- PyTorch: 1.12.1+cu116
- Datasets: 2.4.0
- Tokenizers: 0.12.1
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Fuddu-boy8/vit-base-patch16-224-finetuned-flower
|
Fuddu-boy8
| 2024-03-11T15:57:22Z | 149 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-03-11T15:07:01Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: vit-base-patch16-224-finetuned-flower
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-finetuned-flower
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 2.1.0+cu121
- Datasets 2.7.1
- Tokenizers 0.13.3
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_64_64_0.05_2_0.0002
|
ferrazzipietro
| 2024-03-11T15:51:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T15:49:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JCX-kcuf/Llama-2-7b-hf-gpt-4-80k
|
JCX-kcuf
| 2024-03-11T15:44:32Z | 48 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-10T16:34:35Z |
---
license: apache-2.0
---
## Description
This model is finetuned on the distillation data from GPT-4.
The base model is meta-llama/Llama-2-7b-hf
## Usage
The model has a query format as in llama-2.
```
<s> [INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{query} [/INST]
```
|
JCX-kcuf/Llama-2-7b-hf-llama2-chat-80k
|
JCX-kcuf
| 2024-03-11T15:42:52Z | 50 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-10T16:33:53Z |
---
license: apache-2.0
---
## Description
This model is finetuned on the distillation data from Llama-2-7b-chat-hf.
The base model is meta-llama/Llama-2-7b-hf
## Usage
The model has a query format as in llama-2.
```
<s> [INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
{query} [/INST]
```
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_64_32_0.05_8_0.0002
|
ferrazzipietro
| 2024-03-11T15:39:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T15:38:36Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
raghad2001/whisper-small-ar
|
raghad2001
| 2024-03-11T15:39:17Z | 61 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ar",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-03-10T21:36:30Z |
---
language:
- ar
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Ar - Sanchit Gandhi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: ar
split: None
args: 'config: ar, split: test'
metrics:
- name: Wer
type: wer
value: 47.200440730878704
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Ar - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3242
- Wer: 47.2004
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2957 | 0.42 | 1000 | 0.3931 | 50.6345 |
| 0.2776 | 0.83 | 2000 | 0.3421 | 48.5135 |
| 0.1834 | 1.25 | 3000 | 0.3353 | 47.6797 |
| 0.1637 | 1.66 | 4000 | 0.3242 | 47.2004 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Holarissun/gptj6b-aisft-static-randsampler-subset5000
|
Holarissun
| 2024-03-11T15:38:13Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:EleutherAI/gpt-j-6b",
"base_model:adapter:EleutherAI/gpt-j-6b",
"license:apache-2.0",
"region:us"
] | null | 2024-03-11T15:38:06Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: EleutherAI/gpt-j-6b
model-index:
- name: gptj6b-aisft-static-randsampler-subset5000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptj6b-aisft-static-randsampler-subset5000
This model is a fine-tuned version of [EleutherAI/gpt-j-6b](https://huggingface.co/EleutherAI/gpt-j-6b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
NorGLM/NorLlama-3B-conversation-peft
|
NorGLM
| 2024-03-11T15:36:04Z | 0 | 0 | null |
[
"text-generation",
"no",
"dataset:NorGLM/NO-ConvAI2",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-generation
| 2024-03-11T15:34:40Z |
---
license: cc-by-nc-sa-4.0
datasets:
- NorGLM/NO-ConvAI2
language:
- 'no'
pipeline_tag: text-generation
---
# Model Card
NorLlama-3B-conversation-peft is trained on top of [NorLlama-3B](https://huggingface.co/NorGLM/NorLlama-3B) model on [NO-ConvAI2](https://huggingface.co/datasets/NorGLM/NO-ConvAI2) dataset.
Prompt format:
```
Human: {prompt} Robot: |||\n {answer}
```
Inference prompt:
```
Human: {prompt} Robot: |||\n
```
## Run the Model
```python
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm.auto import tqdm
source_model_id = "NorGLM/NorLlama-3B"
peft_model_id = "NorGLM/NorLlama-3B-conversation-peft"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(source_model_id, device_map='balanced')
tokenizer_max_len = 2048
tokenizer_config = {'pretrained_model_name_or_path': source_model_id,
'max_len': tokenizer_max_len}
tokenizer = tokenizer = AutoTokenizer.from_pretrained(**tokenizer_config)
tokenizer.pad_token = tokenizer.eos_token
model = PeftModel.from_pretrained(model, peft_model_id)
```
## Inference Example
Load the model to evaluate on the test set of NO-CNN/DailyMail dataset:
```python
def load_and_prepare_data_last_prompt(df):
""" Load and spearates last prompt from prompt """
# id, turn_id, prompt, answer
last_prompt = ["Human: " + df['prompt']
[i].split("Human:")[-1] for i in range(len(df))]
df['last_prompt'] = last_prompt
return df
def generate_text(text, max_length=200):
# generate with greedy search
model_inputs = tokenizer(text, return_attention_mask=True, return_tensors="pt",
padding=True, truncation=True, max_length=tokenizer_max_len)
with torch.no_grad():
output_tokens = model.generate(
**model_inputs, max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
text_outputs = [tokenizer.decode(
x, skip_special_tokens=True) for x in output_tokens]
return text_outputs
print("--LOADING EVAL DATAS---")
eval_data = load_dataset("NorGLM/NO-ConvAI2", data_files="test_PersonaChat_prompt.json")
prompts = eval_data['train']['prompt']
positive_samples = eval_data['train']['answer']
print("--MAKING PREDICTIONS---")
model.eval()
output_file = <output file name>
generated_text = []
for prompt in tqdm(prompts):
generated_text.append(generate_text(prompt, max_length=tokenizer_max_len))
df = pd.DataFrame({'prompts':prompts, 'generated_text':generated_text, 'positive_sample':positive_samples})
print("Save results to csv file...")
df.to_csv(output_file)
```
## Note
More training details will be released soon!
|
sagravela/LunarLander-v2_RL_course
|
sagravela
| 2024-03-11T15:35:28Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T15:35:10Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 272.41 +/- 18.48
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Glow-01/finetuned_roberta_large_custom
|
Glow-01
| 2024-03-11T15:35:27Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"question-answering",
"generated_from_trainer",
"base_model:deepset/roberta-large-squad2",
"base_model:finetune:deepset/roberta-large-squad2",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-03-11T13:26:03Z |
---
license: cc-by-4.0
base_model: deepset/roberta-large-squad2
tags:
- generated_from_trainer
model-index:
- name: finetuned_roberta_large_custom
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_roberta_large_custom
This model is a fine-tuned version of [deepset/roberta-large-squad2](https://huggingface.co/deepset/roberta-large-squad2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5061
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.082 | 1.0 | 600 | 1.7062 |
| 1.6404 | 2.0 | 1200 | 2.7324 |
| 1.3663 | 3.0 | 1800 | 2.0644 |
| 0.8431 | 4.0 | 2400 | 2.3039 |
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.1
|
NorGLM/NorGPT-3B-continue-conversation-peft
|
NorGLM
| 2024-03-11T15:34:09Z | 0 | 0 | null |
[
"text-generation",
"no",
"dataset:NorGLM/NO-ConvAI2",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-generation
| 2024-03-11T15:32:50Z |
---
license: cc-by-nc-sa-4.0
datasets:
- NorGLM/NO-ConvAI2
language:
- 'no'
pipeline_tag: text-generation
---
# Model Card
NorGPT-3B-continue-conversation-peft is trained on top of [NorGPT-3B-continue](https://huggingface.co/NorGLM/NorGPT-3B-continue) model on [NO-ConvAI2](https://huggingface.co/datasets/NorGLM/NO-ConvAI2) dataset.
Prompt format:
```
Human: {prompt} Robot: |||\n {answer}
```
Inference prompt:
```
Human: {prompt} Robot: |||\n
```
## Run the Model
```python
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm.auto import tqdm
source_model_id = "NorGLM/NorGPT-3B-continue"
peft_model_id = "NorGLM/NorGPT-3B-continue-conversation-peft"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(source_model_id, device_map='balanced')
tokenizer_max_len = 2048
tokenizer_config = {'pretrained_model_name_or_path': source_model_id,
'max_len': tokenizer_max_len}
tokenizer = tokenizer = AutoTokenizer.from_pretrained(**tokenizer_config)
tokenizer.pad_token = tokenizer.eos_token
model = PeftModel.from_pretrained(model, peft_model_id)
```
## Inference Example
Load the model to evaluate on the test set of NO-CNN/DailyMail dataset:
```python
def load_and_prepare_data_last_prompt(df):
""" Load and spearates last prompt from prompt """
# id, turn_id, prompt, answer
last_prompt = ["Human: " + df['prompt']
[i].split("Human:")[-1] for i in range(len(df))]
df['last_prompt'] = last_prompt
return df
def generate_text(text, max_length=200):
# generate with greedy search
model_inputs = tokenizer(text, return_attention_mask=True, return_tensors="pt",
padding=True, truncation=True, max_length=tokenizer_max_len)
with torch.no_grad():
output_tokens = model.generate(
**model_inputs, max_new_tokens=50, pad_token_id=tokenizer.eos_token_id)
text_outputs = [tokenizer.decode(
x, skip_special_tokens=True) for x in output_tokens]
return text_outputs
print("--LOADING EVAL DATAS---")
eval_data = load_dataset("NorGLM/NO-ConvAI2", data_files="test_PersonaChat_prompt.json")
prompts = eval_data['train']['prompt']
positive_samples = eval_data['train']['answer']
print("--MAKING PREDICTIONS---")
model.eval()
output_file = <output file name>
generated_text = []
for prompt in tqdm(prompts):
generated_text.append(generate_text(prompt, max_length=tokenizer_max_len))
df = pd.DataFrame({'prompts':prompts, 'generated_text':generated_text, 'positive_sample':positive_samples})
print("Save results to csv file...")
df.to_csv(output_file)
```
## Note
More training details will be released soon!
|
guirrock/llama-2-7b-chat-bloom
|
guirrock
| 2024-03-11T15:30:38Z | 63 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-03-11T14:33:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JohnnyBoi/mistral-aci-bench-finetune
|
JohnnyBoi
| 2024-03-11T15:30:31Z | 8 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"region:us"
] | null | 2024-03-11T09:44:21Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-Instruct-v0.2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.9.0
|
sanagnos/pythia-160m-test-256
|
sanagnos
| 2024-03-11T15:20:47Z | 94 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T15:20:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_16_32_0.01_2_0.0002
|
ferrazzipietro
| 2024-03-11T15:20:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T15:20:20Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
xingyaoww/CodeActAgent-Mistral-7b-v0.1.q8_0.gguf
|
xingyaoww
| 2024-03-11T15:19:25Z | 4 | 2 | null |
[
"gguf",
"en",
"dataset:xingyaoww/code-act",
"arxiv:2402.01030",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-03-11T14:13:57Z |
---
license: apache-2.0
datasets:
- xingyaoww/code-act
language:
- en
---
**NOTE: This repo serves a quantized GGUF model of the original [CodeActAgent-Mistral-7b-v0.1](https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1).**
---
<h1 align="center"> Executable Code Actions Elicit Better LLM Agents </h1>
<p align="center">
<a href="https://github.com/xingyaoww/code-act">💻 Code</a>
•
<a href="TODO">📃 Paper</a>
•
<a href="https://huggingface.co/datasets/xingyaoww/code-act" >🤗 Data (CodeActInstruct)</a>
•
<a href="https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1" >🤗 Model (CodeActAgent-Mistral-7b-v0.1)</a>
•
<a href="https://chat.xwang.dev/">🤖 Chat with CodeActAgent!</a>
</p>
We propose to use executable Python **code** to consolidate LLM agents’ **act**ions into a unified action space (**CodeAct**).
Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations (e.g., code execution results) through multi-turn interactions (check out [this example!](https://chat.xwang.dev/r/Vqn108G)).
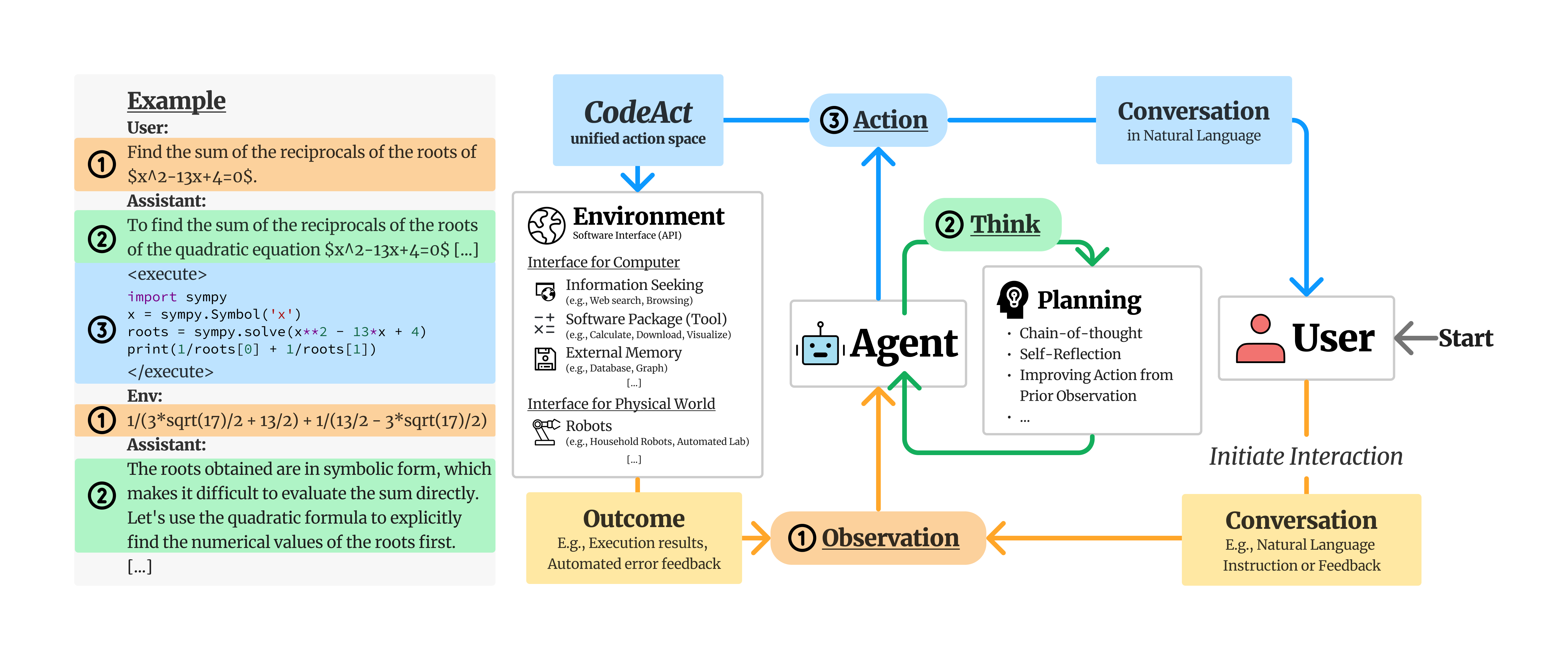
## Why CodeAct?
Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark [M<sup>3</sup>ToolEval](docs/EVALUATION.md) shows that CodeAct outperforms widely used alternatives like Text and JSON (up to 20% higher success rate). Please check our paper for more detailed analysis!
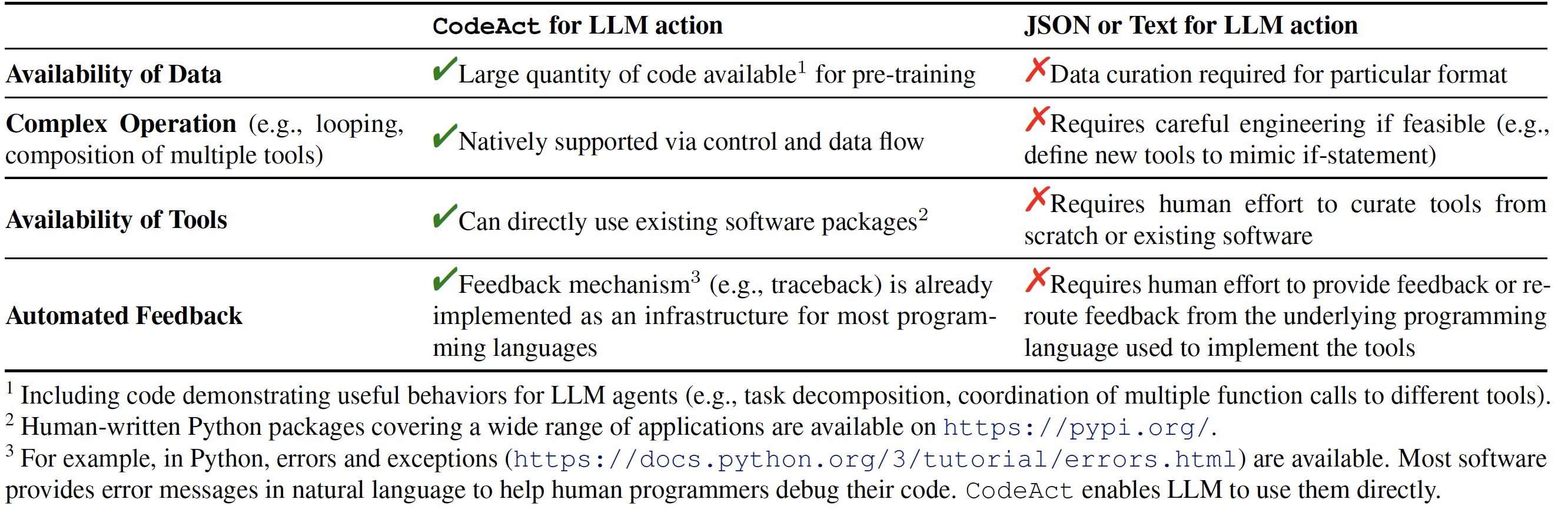
*Comparison between CodeAct and Text / JSON as action.*
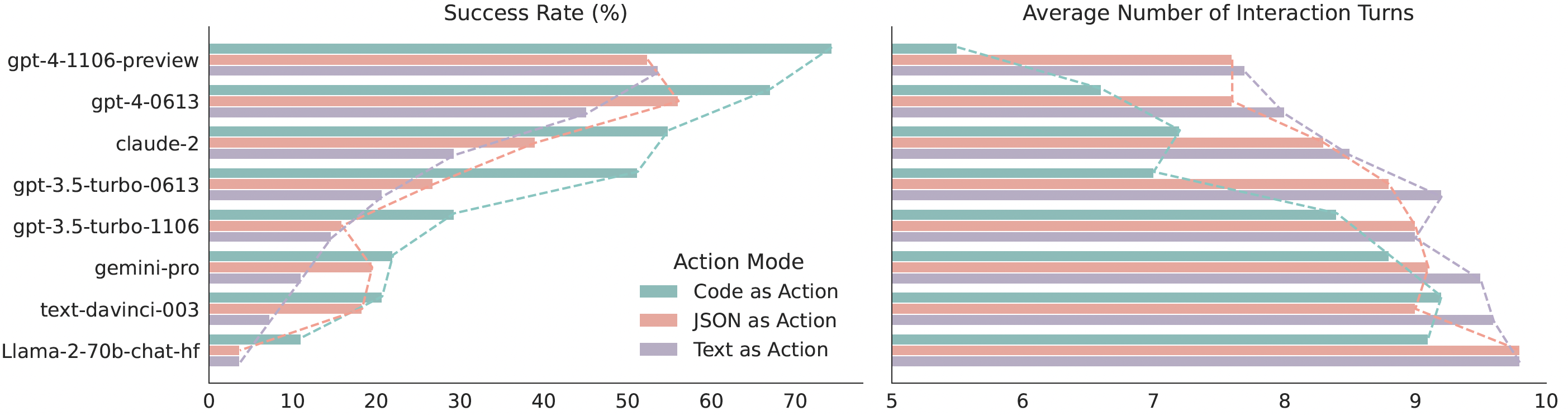
*Quantitative results comparing CodeAct and {Text, JSON} on M<sup>3</sup>ToolEval.*
## 📁 CodeActInstruct
We collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. Dataset is release at [huggingface dataset 🤗](https://huggingface.co/datasets/xingyaoww/code-act). Please refer to the paper and [this section](#-data-generation-optional) for details of data collection.
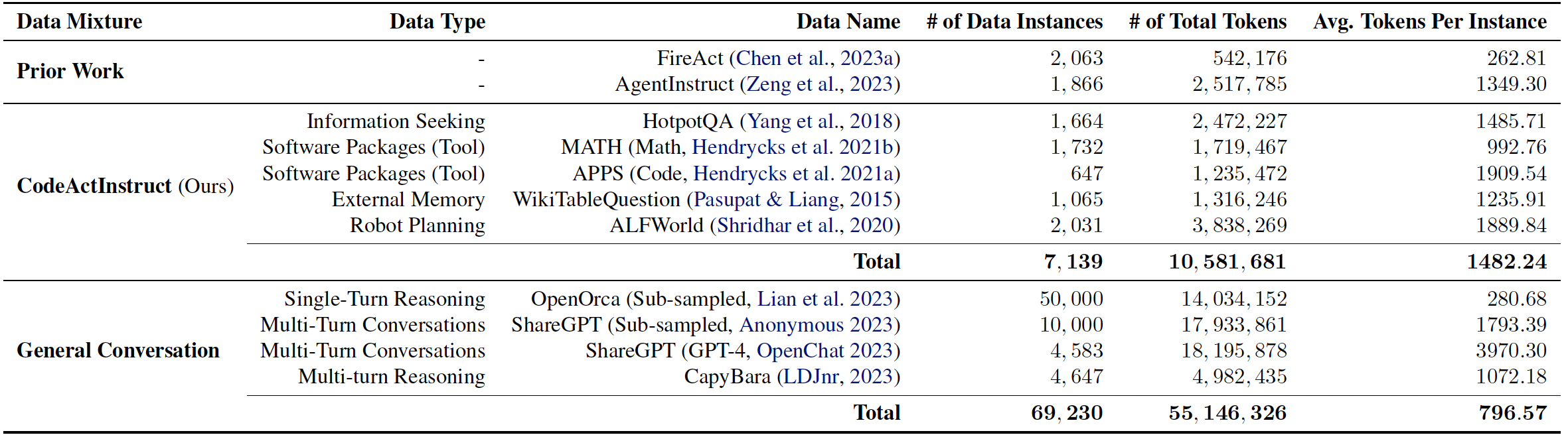
*Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.*
## 🪄 CodeActAgent
Trained on **CodeActInstruct** and general conversaions, **CodeActAgent** excels at out-of-domain agent tasks compared to open-source models of the same size, while not sacrificing generic performance (e.g., knowledge, dialog). We release two variants of CodeActAgent:
- **CodeActAgent-Mistral-7b-v0.1** (recommended, [model link](https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1)): using Mistral-7b-v0.1 as the base model with 32k context window.
- **CodeActAgent-Llama-7b** ([model link](https://huggingface.co/xingyaoww/CodeActAgent-Llama-2-7b)): using Llama-2-7b as the base model with 4k context window.
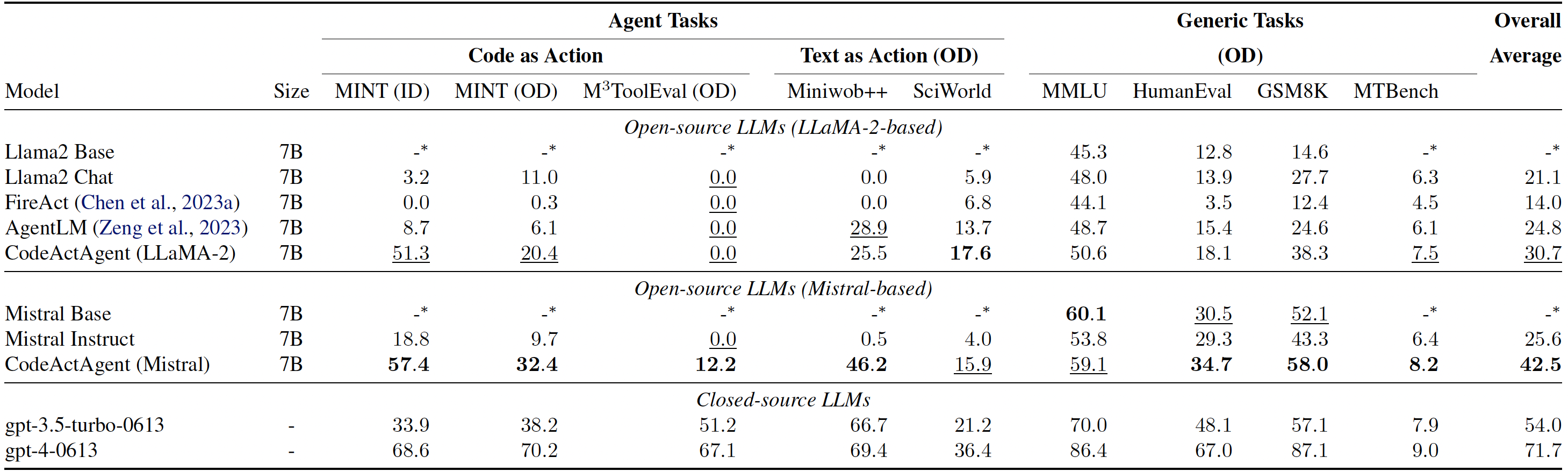
*Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.*
Please check out [our paper](TODO) and [code](https://github.com/xingyaoww/code-act) for more details about data collection, model training, and evaluation.
## 📚 Citation
```bibtex
@misc{wang2024executable,
title={Executable Code Actions Elicit Better LLM Agents},
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
year={2024},
eprint={2402.01030},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Weni/ZeroShot-3.4.0-Mistral-Retry-7b-DPO-1.0.0-merged
|
Weni
| 2024-03-11T15:16:51Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T14:21:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_16_32_0.05_8_0.0002
|
ferrazzipietro
| 2024-03-11T15:15:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T15:15:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rmesol/code-llama-7b-text-to-sql
|
rmesol
| 2024-03-11T15:13:12Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:codellama/CodeLlama-7b-hf",
"base_model:adapter:codellama/CodeLlama-7b-hf",
"license:llama2",
"region:us"
] | null | 2024-02-27T16:04:02Z |
---
license: llama2
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
datasets:
- generator
base_model: codellama/CodeLlama-7b-hf
model-index:
- name: code-llama-7b-text-to-sql
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# code-llama-7b-text-to-sql
This model is a fine-tuned version of [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.7.2.dev0
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
deepnet/SN6-30M4
|
deepnet
| 2024-03-11T15:07:40Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T14:55:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
A13HI98/my-pet-cat
|
A13HI98
| 2024-03-11T15:06:23Z | 2 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2024-03-11T15:02:15Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat Dreambooth model trained by A13HI98 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: I22-01
Sample pictures of this concept:

|
ibunescu/Phi-2_GDPR_chapter_classifier_v4
|
ibunescu
| 2024-03-11T15:05:40Z | 36 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T15:01:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
namnh2002/finetuning-bert-base-cased
|
namnh2002
| 2024-03-11T15:04:36Z | 93 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-11T11:26:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
moficodes/gemma-2b-sql-container-day-live
|
moficodes
| 2024-03-11T15:02:49Z | 91 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T15:00:13Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
syeds17/my-bag
|
syeds17
| 2024-03-11T15:02:48Z | 0 | 0 | null |
[
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2024-03-11T15:00:42Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Bag Dreambooth model trained by syeds17 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:






|
RicardoCacilias/Cacilias
|
RicardoCacilias
| 2024-03-11T15:00:36Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2024-03-11T15:00:36Z |
---
license: bigscience-openrail-m
---
|
vickt/LLM_Teached_PEGASUS_CNNDM_2
|
vickt
| 2024-03-11T15:00:33Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-03-11T07:10:25Z |
---
tags:
- generated_from_trainer
metrics:
- rouge
- precision
- recall
- f1
model-index:
- name: LLM_Teached_PEGASUS_CNNDM_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LLM_Teached_PEGASUS_CNNDM_2
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7016
- Rouge1: 0.4651
- Rouge2: 0.2076
- Rougel: 0.3457
- Rougelsum: 0.3459
- Gen Len: 52.1582
- Precision: 0.906
- Recall: 0.9098
- F1: 0.9077
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|:---------:|:------:|:------:|
| No log | 1.0 | 312 | 1.7705 | 0.4551 | 0.1985 | 0.335 | 0.3351 | 51.6464 | 0.9043 | 0.9073 | 0.9056 |
| 1.8539 | 2.0 | 625 | 1.7468 | 0.4578 | 0.2016 | 0.3394 | 0.3397 | 51.0627 | 0.9054 | 0.908 | 0.9065 |
| 1.8539 | 3.0 | 937 | 1.7331 | 0.4595 | 0.2019 | 0.3389 | 0.3391 | 52.9318 | 0.9039 | 0.9089 | 0.9063 |
| 1.7903 | 4.0 | 1250 | 1.7226 | 0.4606 | 0.2032 | 0.3406 | 0.3405 | 52.8055 | 0.9046 | 0.9094 | 0.9068 |
| 1.746 | 5.0 | 1562 | 1.7132 | 0.4642 | 0.2068 | 0.3453 | 0.3453 | 51.7873 | 0.9062 | 0.9096 | 0.9077 |
| 1.746 | 6.0 | 1875 | 1.7117 | 0.463 | 0.2055 | 0.3435 | 0.3436 | 53.4382 | 0.905 | 0.91 | 0.9073 |
| 1.7173 | 7.0 | 2187 | 1.7057 | 0.4644 | 0.2073 | 0.3456 | 0.3457 | 52.1718 | 0.906 | 0.9099 | 0.9078 |
| 1.7004 | 8.0 | 2500 | 1.7033 | 0.4668 | 0.2084 | 0.3464 | 0.3466 | 51.9 | 0.9063 | 0.91 | 0.908 |
| 1.7004 | 9.0 | 2812 | 1.7027 | 0.4651 | 0.2074 | 0.3457 | 0.3458 | 52.3591 | 0.906 | 0.9099 | 0.9078 |
| 1.6888 | 9.98 | 3120 | 1.7016 | 0.4651 | 0.2076 | 0.3457 | 0.3459 | 52.1582 | 0.906 | 0.9098 | 0.9077 |
### Framework versions
- Transformers 4.36.0
- Pytorch 2.0.1+cu117
- Datasets 2.7.1
- Tokenizers 0.15.2
|
ibunescu/Phi-2_GDPR_chapter_classifier_v4_adapter
|
ibunescu
| 2024-03-11T15:00:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T14:59:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
TikhonRadkevich/Reinforce-Pixelcopter-PLE-v0
|
TikhonRadkevich
| 2024-03-11T14:58:21Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T14:58:18Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 23.00 +/- 16.19
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
franklee1015/PPO-SpaceInvadersNoFrameskip-v4
|
franklee1015
| 2024-03-11T14:54:07Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T14:17:34Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 407.00 +/- 27.82
name: mean_reward
verified: false
---
# **PPO** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **PPO** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
taoki/Swallow-MS-7b-v0.1-qlora-amenokaku-code
|
taoki
| 2024-03-11T14:53:27Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"ja",
"dataset:kunishou/amenokaku-code-instruct",
"base_model:tokyotech-llm/Swallow-MS-7b-v0.1",
"base_model:finetune:tokyotech-llm/Swallow-MS-7b-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T13:41:46Z |
---
language:
- ja
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- trl
- mistral
datasets:
- kunishou/amenokaku-code-instruct
license_name: mistral
base_model: tokyotech-llm/Swallow-MS-7b-v0.1
---
# Uploaded model
- **Developed by:** taoki
- **License:** apache-2.0
- **Finetuned from model :** tokyotech-llm/Swallow-MS-7b-v0.1
# Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained(
"taoki/Swallow-MS-7b-v0.1-qlora-amenokaku-code"
)
model = AutoModelForCausalLM.from_pretrained(
"taoki/Swallow-MS-7b-v0.1-qlora-amenokaku-code"
)
if torch.cuda.is_available():
model = model.to("cuda")
prompt="""### Instruction:
光の三原色は?
### Response:
"""
input_ids = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**input_ids,
max_new_tokens=512,
do_sample=True,
top_p=0.95,
temperature=0.1,
repetition_penalty=1.0,
)
print(tokenizer.decode(outputs[0]))
```
# Output
````
<s>### Instruction:
光の三原色は?
### Response:
```python
print('赤')
print('緑')
print('青')
```</s>
````
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_32_64_0.05_2_0.0002
|
ferrazzipietro
| 2024-03-11T14:44:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T14:44:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HanliChu/ppo-Huggy
|
HanliChu
| 2024-03-11T14:42:01Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2024-03-11T13:55:46Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: HanliChu/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
dattienle2573/q-Taxi-v3-5x5
|
dattienle2573
| 2024-03-11T14:40:50Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T14:40:45Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-5x5
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="dattienle2573/q-Taxi-v3-5x5", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
kmanaa/t5-dialogue-classification-5
|
kmanaa
| 2024-03-11T14:40:50Z | 93 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-03-11T13:40:21Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: t5-dialogue-classification-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-dialogue-classification-5
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6676
- Classification Report: precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.7500 0.6000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.7037 0.9500 0.8085 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7500 0.8571 0.8000 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7200 100
macro avg 0.4525 0.4798 0.4357 100
weighted avg 0.6752 0.7200 0.6721 100
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 7
- eval_batch_size: 7
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Classification Report |
|:-------------:|:-----:|:----:|:---------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 172 | 0.5114 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.6667 1.0000 0.8000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.0000 0.0000 0.0000 1
FAM/SOCHX 0.7778 0.9545 0.8571 22
GENHX 0.4595 0.8500 0.5965 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.5714 0.5714 0.5714 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.3636 1.0000 0.5333 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.0000 0.0000 0.0000 11
SYSTEMS 0.0000 0.0000 0.0000 0
accuracy 0.6000 100
macro avg 0.2780 0.3155 0.2742 100
weighted avg 0.4742 0.6000 0.5072 100
|
| No log | 2.0 | 344 | 0.3955 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.2500 0.3333 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.0000 0.0000 0.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.4878 1.0000 0.6557 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
accuracy 0.6400 100
macro avg 0.3384 0.3247 0.3033 100
weighted avg 0.5829 0.6400 0.5644 100
|
| 0.3535 | 3.0 | 516 | 0.3595 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.6000 0.7500 0.6667 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.5000 1.0000 0.6667 1
FAM/SOCHX 0.9000 0.8182 0.8571 22
GENHX 0.6061 1.0000 0.7547 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.5000 1.0000 0.6667 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6250 0.7143 0.6667 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 1.0000 0.6667 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8000 0.3636 0.5000 11
accuracy 0.6500 100
macro avg 0.3516 0.3948 0.3423 100
weighted avg 0.6250 0.6500 0.6038 100
|
| 0.3535 | 4.0 | 688 | 0.3475 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
Accutane 0.0000 0.0000 0.0000 0
CC 1.0000 0.7500 0.8571 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.2500 1.0000 0.4000 1
FAM/SOCHX 0.8077 0.9545 0.8750 22
GENHX 0.8000 1.0000 0.8889 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.2000 1.0000 0.3333 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6250 0.7143 0.6667 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 1.0000 0.6667 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8571 0.5455 0.6667 11
accuracy 0.7000 100
macro avg 0.3352 0.3912 0.3216 100
weighted avg 0.6602 0.7000 0.6546 100
|
| 0.3535 | 5.0 | 860 | 0.3449 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.5000 0.2500 0.3333 4
Accutane 0.0000 0.0000 0.0000 0
CC 1.0000 0.7500 0.8571 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.7692 1.0000 0.8696 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6250 0.7143 0.6667 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8750 0.6364 0.7368 11
accuracy 0.7200 100
macro avg 0.4388 0.4074 0.4049 100
weighted avg 0.7092 0.7200 0.6952 100
|
| 0.0876 | 6.0 | 1032 | 0.3894 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.5000 0.2500 0.3333 4
Accutane 0.0000 0.0000 0.0000 0
CC 1.0000 0.5000 0.6667 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.5000 0.5000 0.5000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.5000 1.0000 0.6667 1
FAM/SOCHX 0.9091 0.9091 0.9091 22
GENHX 0.6552 0.9500 0.7755 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.4444 1.0000 0.6154 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8750 0.6364 0.7368 11
accuracy 0.7100 100
macro avg 0.4570 0.4306 0.4151 100
weighted avg 0.7151 0.7100 0.6854 100
|
| 0.0876 | 7.0 | 1204 | 0.3929 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.5000 0.2500 0.3333 4
Accutane 0.0000 0.0000 0.0000 0
CC 0.6667 0.5000 0.5714 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.3333 1.0000 0.5000 1
FAM/SOCHX 0.8077 0.9545 0.8750 22
GENHX 0.7600 0.9500 0.8444 20
GYNHX 1.0000 1.0000 1.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.2500 1.0000 0.4000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 1.0000 0.3333 0.5000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7000 100
macro avg 0.4494 0.4479 0.4026 100
weighted avg 0.7067 0.7000 0.6714 100
|
| 0.0876 | 8.0 | 1376 | 0.5449 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.7500 0.7500 0.7500 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.3333 0.5000 0.4000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.7500 0.9000 0.8182 20
GYNHX 1.0000 1.0000 1.0000 1
IMAGING 0.3333 1.0000 0.5000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6364 1.0000 0.7778 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.3333 1.0000 0.5000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.7500 0.2727 0.4000 11
accuracy 0.7100 100
macro avg 0.5131 0.5480 0.4930 100
weighted avg 0.6879 0.7100 0.6640 100
|
| 0.0355 | 9.0 | 1548 | 0.5615 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 1.0000 0.2500 0.4000 4
Accutane 0.0000 0.0000 0.0000 0
CC 0.7500 0.7500 0.7500 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8800 1.0000 0.9362 22
GENHX 0.6333 0.9500 0.7600 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 1.0000 0.3333 0.5000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8000 0.3636 0.5000 11
accuracy 0.7000 100
macro avg 0.4973 0.4101 0.4172 100
weighted avg 0.7249 0.7000 0.6720 100
|
| 0.0355 | 10.0 | 1720 | 0.5021 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.5000 0.2500 0.3333 4
Accutane 0.0000 0.0000 0.0000 0
CC 0.7500 0.7500 0.7500 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.7308 0.9500 0.8261 20
GYNHX 1.0000 1.0000 1.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8000 0.3636 0.5000 11
accuracy 0.7200 100
macro avg 0.5077 0.5053 0.4746 100
weighted avg 0.7107 0.7200 0.6863 100
|
| 0.0355 | 11.0 | 1892 | 0.5690 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 1.0000 0.2500 0.4000 4
Accutane 0.0000 0.0000 0.0000 0
CC 1.0000 0.7500 0.8571 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.2500 0.5000 0.3333 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.9565 1.0000 0.9778 22
GENHX 0.6667 1.0000 0.8000 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8571 0.5455 0.6667 11
accuracy 0.7500 100
macro avg 0.5172 0.4925 0.4642 100
weighted avg 0.7572 0.7500 0.7194 100
|
| 0.012 | 12.0 | 2064 | 0.6739 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 1.0000 0.5000 0.6667 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.2500 0.5000 0.3333 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.9130 0.9545 0.9333 22
GENHX 0.6061 1.0000 0.7547 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8571 0.5455 0.6667 11
accuracy 0.7200 100
macro avg 0.4879 0.4899 0.4535 100
weighted avg 0.6955 0.7200 0.6769 100
|
| 0.012 | 13.0 | 2236 | 0.6173 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.7500 0.6000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8800 1.0000 0.9362 22
GENHX 0.6786 0.9500 0.7917 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7100 100
macro avg 0.4511 0.4726 0.4315 100
weighted avg 0.6751 0.7100 0.6670 100
|
| 0.012 | 14.0 | 2408 | 0.6580 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.7500 0.6000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.2500 0.5000 0.3333 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.9130 0.9545 0.9333 22
GENHX 0.6333 0.9500 0.7600 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7100 100
macro avg 0.4630 0.4953 0.4465 100
weighted avg 0.6784 0.7100 0.6667 100
|
| 0.0086 | 15.0 | 2580 | 0.6118 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.7500 0.6000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.2500 0.5000 0.3333 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8800 1.0000 0.9362 22
GENHX 0.7037 0.9500 0.8085 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7778 1.0000 0.8750 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7400 100
macro avg 0.4681 0.5119 0.4571 100
weighted avg 0.6896 0.7400 0.6883 100
|
| 0.0086 | 16.0 | 2752 | 0.6210 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.7500 0.7500 0.7500 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.2500 0.5000 0.3333 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.7143 1.0000 0.8333 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7500 0.8571 0.8000 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8571 0.5455 0.6667 11
accuracy 0.7400 100
macro avg 0.4759 0.5095 0.4612 100
weighted avg 0.6975 0.7400 0.6946 100
|
| 0.0086 | 17.0 | 2924 | 0.6166 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.6667 0.5000 0.5714 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8400 0.9545 0.8936 22
GENHX 0.7037 0.9500 0.8085 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2000 1.0000 0.3333 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7500 0.8571 0.8000 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8571 0.5455 0.6667 11
accuracy 0.7100 100
macro avg 0.4544 0.4695 0.4300 100
weighted avg 0.6789 0.7100 0.6709 100
|
| 0.0025 | 18.0 | 3096 | 0.6372 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.6000 0.7500 0.6667 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.6786 0.9500 0.7917 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7500 0.8571 0.8000 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7200 100
macro avg 0.4562 0.4798 0.4382 100
weighted avg 0.6742 0.7200 0.6714 100
|
| 0.0025 | 19.0 | 3268 | 0.6598 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.6000 0.7500 0.6667 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.6786 0.9500 0.7917 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7500 0.8571 0.8000 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7200 100
macro avg 0.4562 0.4798 0.4382 100
weighted avg 0.6742 0.7200 0.6714 100
|
| 0.0025 | 20.0 | 3440 | 0.6676 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.7500 0.6000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.7037 0.9500 0.8085 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.2500 1.0000 0.4000 1
IMMUNIZATIONS 1.0000 1.0000 1.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7500 0.8571 0.8000 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6667 1.0000 0.8000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.5000 0.3333 0.4000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.8333 0.4545 0.5882 11
accuracy 0.7200 100
macro avg 0.4525 0.4798 0.4357 100
weighted avg 0.6752 0.7200 0.6721 100
|
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
dattienle2573/q-FrozenLake-v1-4x4-noSlippery
|
dattienle2573
| 2024-03-11T14:35:18Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T14:35:14Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dattienle2573/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
asyzhou/224n-whisper-large-overnight-5
|
asyzhou
| 2024-03-11T14:34:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-10T10:00:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
OwOOwO/eacc_mwin_2
|
OwOOwO
| 2024-03-11T14:33:21Z | 91 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T14:30:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Gunslinger3D/fine-tuning-Phi2-with-webglm-qa-with-lora_3
|
Gunslinger3D
| 2024-03-11T14:27:54Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-03-11T14:27:49Z |
---
license: mit
library_name: peft
tags:
- generated_from_trainer
base_model: microsoft/phi-2
model-index:
- name: fine-tuning-Phi2-with-webglm-qa-with-lora_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine-tuning-Phi2-with-webglm-qa-with-lora_3
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 5
- total_train_batch_size: 10
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.243 | 0.2 | 10 | 7.8185 |
| 7.4602 | 0.4 | 20 | 6.3280 |
| 4.794 | 0.6 | 30 | 3.1068 |
| 1.6994 | 0.8 | 40 | 0.6354 |
| 0.543 | 1.0 | 50 | 0.5653 |
| 0.4542 | 1.2 | 60 | 0.4874 |
| 0.4449 | 1.39 | 70 | 0.4225 |
| 0.3623 | 1.59 | 80 | 0.3685 |
| 0.278 | 1.79 | 90 | 0.3283 |
| 0.2385 | 1.99 | 100 | 0.2983 |
| 0.2499 | 2.19 | 110 | 0.2748 |
| 0.2113 | 2.39 | 120 | 0.2590 |
| 0.1966 | 2.59 | 130 | 0.2420 |
| 0.217 | 2.79 | 140 | 0.2242 |
| 0.1731 | 2.99 | 150 | 0.2121 |
| 0.1779 | 3.19 | 160 | 0.2033 |
| 0.1687 | 3.39 | 170 | 0.1909 |
| 0.156 | 3.59 | 180 | 0.1833 |
| 0.1464 | 3.78 | 190 | 0.1763 |
| 0.1637 | 3.98 | 200 | 0.1706 |
| 0.1455 | 4.18 | 210 | 0.1649 |
| 0.128 | 4.38 | 220 | 0.1621 |
| 0.1537 | 4.58 | 230 | 0.1562 |
| 0.1193 | 4.78 | 240 | 0.1502 |
| 0.1323 | 4.98 | 250 | 0.1464 |
| 0.1346 | 5.18 | 260 | 0.1440 |
| 0.1049 | 5.38 | 270 | 0.1411 |
| 0.1265 | 5.58 | 280 | 0.1377 |
| 0.13 | 5.78 | 290 | 0.1363 |
| 0.1059 | 5.98 | 300 | 0.1335 |
| 0.1141 | 6.18 | 310 | 0.1300 |
| 0.1097 | 6.37 | 320 | 0.1297 |
| 0.1088 | 6.57 | 330 | 0.1287 |
| 0.106 | 6.77 | 340 | 0.1261 |
| 0.1011 | 6.97 | 350 | 0.1243 |
| 0.0999 | 7.17 | 360 | 0.1235 |
| 0.1081 | 7.37 | 370 | 0.1223 |
| 0.0999 | 7.57 | 380 | 0.1207 |
| 0.1057 | 7.77 | 390 | 0.1203 |
| 0.0937 | 7.97 | 400 | 0.1192 |
| 0.0842 | 8.17 | 410 | 0.1195 |
| 0.0907 | 8.37 | 420 | 0.1182 |
| 0.1109 | 8.57 | 430 | 0.1176 |
| 0.0901 | 8.76 | 440 | 0.1170 |
| 0.1005 | 8.96 | 450 | 0.1162 |
| 0.0961 | 9.16 | 460 | 0.1159 |
| 0.0927 | 9.36 | 470 | 0.1156 |
| 0.0916 | 9.56 | 480 | 0.1158 |
| 0.0908 | 9.76 | 490 | 0.1156 |
| 0.0909 | 9.96 | 500 | 0.1155 |
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.0.0
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Litzy619/V0309O8
|
Litzy619
| 2024-03-11T14:24:45Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"base_model:finetune:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-03-11T04:32:54Z |
---
license: mit
base_model: microsoft/phi-2
tags:
- generated_from_trainer
model-index:
- name: V0309O8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0309O8
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0662
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 20
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.284 | 0.09 | 10 | 1.5098 |
| 0.8037 | 0.17 | 20 | 0.1367 |
| 0.1548 | 0.26 | 30 | 0.1059 |
| 0.1284 | 0.34 | 40 | 0.0860 |
| 0.118 | 0.43 | 50 | 0.0858 |
| 0.1038 | 0.51 | 60 | 0.0782 |
| 0.0913 | 0.6 | 70 | 0.0745 |
| 0.0917 | 0.68 | 80 | 0.0725 |
| 0.0829 | 0.77 | 90 | 0.0750 |
| 0.0821 | 0.85 | 100 | 0.0754 |
| 0.0865 | 0.94 | 110 | 0.0711 |
| 0.0875 | 1.02 | 120 | 0.0761 |
| 0.084 | 1.11 | 130 | 0.0742 |
| 0.0785 | 1.19 | 140 | 0.0672 |
| 0.0753 | 1.28 | 150 | 0.0681 |
| 0.0762 | 1.37 | 160 | 0.0755 |
| 0.0732 | 1.45 | 170 | 0.0685 |
| 0.0715 | 1.54 | 180 | 0.0713 |
| 0.0709 | 1.62 | 190 | 0.0697 |
| 0.0713 | 1.71 | 200 | 0.0680 |
| 0.0753 | 1.79 | 210 | 0.0682 |
| 0.068 | 1.88 | 220 | 0.0695 |
| 0.066 | 1.96 | 230 | 0.0652 |
| 0.0696 | 2.05 | 240 | 0.0668 |
| 0.062 | 2.13 | 250 | 0.0691 |
| 0.0618 | 2.22 | 260 | 0.0726 |
| 0.0599 | 2.3 | 270 | 0.0746 |
| 0.0661 | 2.39 | 280 | 0.0707 |
| 0.0635 | 2.47 | 290 | 0.0686 |
| 0.0627 | 2.56 | 300 | 0.0663 |
| 0.0661 | 2.65 | 310 | 0.0658 |
| 0.0568 | 2.73 | 320 | 0.0656 |
| 0.06 | 2.82 | 330 | 0.0660 |
| 0.0591 | 2.9 | 340 | 0.0664 |
| 0.062 | 2.99 | 350 | 0.0662 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
occiglot/occiglot-7b-fr-en
|
occiglot
| 2024-03-11T14:23:45Z | 386 | 2 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"fr",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-26T01:41:44Z |
---
license: apache-2.0
language:
- en
- fr
pipeline_tag: text-generation
---

# Occiglot-7B-FR-EN
> A [polyglot](https://en.wikipedia.org/wiki/Multilingualism#In_individuals) language model for the [Occident](https://en.wikipedia.org/wiki/Occident).
>
**Occiglot-7B-FR-EN** is a generative language model with 7B parameters for French and English and trained by the [Occiglot Research Collective](https://occiglot.github.io/occiglot/).
It is based on [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) and trained on 113B tokens of additional multilingual and code data with a block size of 8,192 tokens per sample.
Note that the model is a general-purpose base model and was not instruction-fine-tuned nor optimized for chat or other applications. We make an instruction tuned variant available as [occiglot-7b-fr-en-instruct](https://huggingface.co/occiglot/occiglot-7b-fr-en-instruct)
This is the first release of an ongoing open research project for multilingual language models.
If you want to train a model for your own language or are working on evaluations, please contact us or join our [Discord server](https://discord.gg/wUpvYs4XvM). **We are open for collaborations!**
### Model details
- **Continued-pretraining from:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Model type:** Causal decoder-only transformer language model
- **Languages:** English, French, and code.
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.html)
- **Compute resources:** [HessianAI's 42](https://hessian.ai/)
- **Contributors:** Manuel Brack, Patrick Schramowski, Pedro Ortiz, Malte Ostendorff, Fabio Barth, Georg Rehm, Kristian Kersting
- **Research labs:** [Occiglot](https://occiglot.github.io/occiglot/) with support from [SAINT](https://www.dfki.de/en/web/research/research-departments/foundations-of-systems-ai) and [SLT](https://www.dfki.de/en/web/research/research-departments/speech-and-language-technology)
- **Contact:** [Discord](https://discord.gg/wUpvYs4XvM)
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='occiglot/occiglot-7b-fr-en')
>>> set_seed(42)
>>> generator("Bonjour, Je suis un modèle linguistique,", max_length=40, num_return_sequences=1)
[{'generated_text': 'Bonjour, Je suis un modèle linguistique qui peut t'aider à traduire des textes entre le français et l'anglais. Si tu me donnes un texte en français'}]
```
## Dataset
The training data is the respective subset of the data used for [occiglot-7b-eu5](https://huggingface.co/occiglot/occiglot-7b-eu5), i.e. French plus English and Code.
The data distribution by language (estimated) is as follows:
- English: ~34%
- Code: ~13%
- French: ~52%
The training data was prepared using [lm-datasets](https://github.com/malteos/lm-datasets).
The exact data configuration is [here](https://huggingface.co/occiglot/occiglot-7b-eu5/blob/main/lm-datasets-config.yml).
## Training settings
- Continual pre-training on 128 x A100-80GB on [HessianAI's 42](https://hessian.ai/).
- Framework: [Determined](https://www.determined.ai/)
- Precision: bf16
- Optimizer: AdamW (lr: 0.00001, warmup_steps: 420)
- Global batch size: 512 (with 8192 blocksize) split over 128 GPUs
- Cosine Annealing with Warmup
## Tokenizer
Tokenizer is unchanged from [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1).
## Evaluation
Preliminary evaluation results can be found below.
Please note that the non-English results are based on partially machine-translated datasets and English prompts ([Belebele](https://huggingface.co/datasets/facebook/belebele) and [Okapi framework](https://github.com/nlp-uoregon/Okapi)) and thus should be interpreted with caution, e.g., biased towards English model performance.
Currently, we are working on more suitable benchmarks for Spanish, French, German, and Italian.
<details>
<summary>Evaluation results</summary>
### All 5 Languages
| | avg | arc_challenge | belebele | hellaswag | mmlu | truthfulqa |
|:---------------------------|---------:|----------------:|-----------:|------------:|---------:|-------------:|
| Occiglot-7b-eu5 | 0.516895 | 0.508109 | 0.675556 | 0.718963 | 0.402064 | 0.279782 |
| Occiglot-7b-eu5-instruct | 0.537799 | 0.53632 | 0.691111 | 0.731918 | 0.405198 | 0.32445 |
| Occiglot-7b-fr-en | 0.509209 | 0.496806 | 0.691333 | 0.667475 | 0.409129 | 0.281303 |
| Occiglot-7b-fr-en-instruct | 0.52884 | 0.515613 | 0.723333 | 0.67371 | 0.413024 | 0.318521 |
| Claire-mistral-7b-0.1 | 0.514226 | 0.502773 | 0.705111 | 0.666871 | 0.412128 | 0.284245 |
| Mistral-7b-v0.1 | 0.547111 | 0.528937 | 0.768444 | 0.682516 | 0.448253 | 0.307403 |
| Mistral-7b-instruct-v0.2 | 0.56713 | 0.547228 | 0.741111 | 0.69455 | 0.422501 | 0.430262 |
### English
| | avg | arc_challenge | belebele | hellaswag | mmlu | truthfulqa |
|:---------------------------|---------:|----------------:|-----------:|------------:|---------:|-------------:|
| Occiglot-7b-eu5 | 0.59657 | 0.530717 | 0.726667 | 0.789882 | 0.531904 | 0.403678 |
| Occiglot-7b-eu5-instruct | 0.617905 | 0.558874 | 0.746667 | 0.799841 | 0.535109 | 0.449 |
| Occiglot-7b-fr-en | 0.621947 | 0.568259 | 0.771111 | 0.804919 | 0.570716 | 0.394726 |
| Occiglot-7b-fr-en-instruct | 0.646571 | 0.586177 | 0.794444 | 0.808305 | 0.569862 | 0.474064 |
| Claire-mistral-7b-0.1 | 0.651798 | 0.59727 | 0.817778 | 0.827126 | 0.600912 | 0.415906 |
| Mistral-7b-v0.1 | 0.668385 | 0.612628 | 0.844444 | 0.834097 | 0.624555 | 0.426201 |
| Mistral-7b-instruct-v0.2 | 0.713657 | 0.637372 | 0.824444 | 0.846345 | 0.59201 | 0.668116 |
### French
| | avg | arc_challenge_fr | belebele_fr | hellaswag_fr | mmlu_fr | truthfulqa_fr |
|:---------------------------|---------:|-------------------:|--------------:|---------------:|----------:|----------------:|
| Occiglot-7b-eu5 | 0.525017 | 0.506416 | 0.675556 | 0.712358 | 0.495684 | 0.23507 |
| Occiglot-7b-eu5-instruct | 0.554216 | 0.541488 | 0.7 | 0.724245 | 0.499122 | 0.306226 |
| Occiglot-7b-fr-en | 0.542903 | 0.532934 | 0.706667 | 0.718891 | 0.51333 | 0.242694 |
| Occiglot-7b-fr-en-instruct | 0.567079 | 0.542344 | 0.752222 | 0.72553 | 0.52051 | 0.29479 |
| Claire-mistral-7b-0.1 | 0.515127 | 0.486741 | 0.694444 | 0.642964 | 0.479566 | 0.271919 |
| Mistral-7b-v0.1 | 0.558129 | 0.525235 | 0.776667 | 0.66481 | 0.543121 | 0.280813 |
| Mistral-7b-instruct-v0.2 | 0.575821 | 0.551754 | 0.758889 | 0.67916 | 0.506837 | 0.382465 |
</details>
## Acknowledgements
The model training was supported by a compute grant at the [42 supercomputer](https://hessian.ai/) which is a central component in the development of [hessian AI](https://hessian.ai/), the [AI Innovation Lab](https://hessian.ai/infrastructure/ai-innovationlab/) (funded by the [Hessian Ministry of Higher Education, Research and the Art (HMWK)](https://wissenschaft.hessen.de) & the [Hessian Ministry of the Interior, for Security and Homeland Security (HMinD)](https://innen.hessen.de)) and the [AI Service Centers](https://hessian.ai/infrastructure/ai-service-centre/) (funded by the [German Federal Ministry for Economic Affairs and Climate Action (BMWK)](https://www.bmwk.de/Navigation/EN/Home/home.html)).
The curation of the training data is partially funded by the [German Federal Ministry for Economic Affairs and Climate Action (BMWK)](https://www.bmwk.de/Navigation/EN/Home/home.html)
through the project [OpenGPT-X](https://opengpt-x.de/en/) (project no. 68GX21007D).
## License
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.html)
## See also
- https://huggingface.co/collections/occiglot/occiglot-eu5-7b-v01-65dbed502a6348b052695e01
|
Aditya149/Mental-Gemma-2b-V1
|
Aditya149
| 2024-03-11T14:23:07Z | 1 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"license:other",
"region:us"
] | null | 2024-03-07T09:35:21Z |
---
license: other
library_name: peft
tags:
- generated_from_trainer
base_model: google/gemma-2b
model-index:
- name: Mental-Gemma-2b-V1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mental-Gemma-2b-V1
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 2.2063
- eval_runtime: 109.4319
- eval_samples_per_second: 8.754
- eval_steps_per_second: 2.193
- epoch: 8.97
- step: 16300
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
mlsquare/mamba_pico_small_out_proj
|
mlsquare
| 2024-03-11T14:16:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation",
"en",
"dataset:mlsquare/CLIENT_samantar_mixed_train_val",
"arxiv:2312.00752",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-25T08:55:40Z |
---
library_name: transformers
license: mit
datasets:
- mlsquare/CLIENT_samantar_mixed_train_val
language:
- en
pipeline_tag: text-generation
---
# Model Card for Model ID
Adapter for mlsquare/pico_seshu_test using LoRA on "model.layers.3.out_proj". Standard use of PEFT on Mamba-hf model
## Model Details
### Model Description
- **Developed by:** MLsquare
- **Model type:** Next Character Generation
- **Language(s) (NLP):** All languages in ai4bharat/samanantar dataset
- **License:** MIT
## Model Details
### Model Description
- **Developed by:** MLsquare
- **Model type:** Next Character Generation
- **Language(s) (NLP):** All languages in ai4bharat/samanantar dataset
- **License:** MIT
### Model Sources [optional]
- **Repository:** https://github.com/LegallyCoder/mamba-hf
- **Paper:** https://arxiv.org/abs/2312.00752
## Uses
Refer to the github repository for more information
### Direct Use
Refer to the github repository for more information
## How to Get Started with the Model
Refer to the github repository: https://github.com/mlsquare/fedem
## Training Details
### Training Data
Individual target and source sentences from the AI4Bharat Samanantar dataset. All 11 language sentences and their translations have been stacked and used for next character generation task.
### Training Procedure
Trained on the next character generation task using cross-entropy loss.
#### Preprocessing [optional]
converted to raw UTF8 characters before training by using ByT5-large tokenizer
#### Training Hyperparameters
- **Training regime:**
output_dir="mamba",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
num_train_epochs=4,
weight_decay=0.1,
lr_scheduler_type="cosine",
learning_rate=5e-4,
fp16=False,
## Evaluation
A simple cross-entropy loss has been used to test the pipeline and working of the model.
## Model Card Contact
MLsquare
|
Bienvenu2004/donut-base-pv-aws3
|
Bienvenu2004
| 2024-03-11T14:13:06Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:Bienvenu2004/donut-base-pv-aws2",
"base_model:finetune:Bienvenu2004/donut-base-pv-aws2",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2024-03-10T21:47:22Z |
---
base_model: Bienvenu2004/donut-base-pv-aws2
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-pv-aws3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-pv-aws3
This model is a fine-tuned version of [Bienvenu2004/donut-base-pv-aws2](https://huggingface.co/Bienvenu2004/donut-base-pv-aws2) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_32_32_0.05_2_0.0002
|
ferrazzipietro
| 2024-03-11T14:12:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T14:12:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sanagnos/pythia-70m-test-256
|
sanagnos
| 2024-03-11T14:11:40Z | 96 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T13:59:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
automerger/Ognoexperiment27Multi_verse_model-7B
|
automerger
| 2024-03-11T14:11:32Z | 52 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:MTSAIR/multi_verse_model",
"base_model:finetune:MTSAIR/multi_verse_model",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T14:10:42Z |
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- ammarali32/multi_verse_model
---
# Ognoexperiment27Multi_verse_model-7B
Ognoexperiment27Multi_verse_model-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [ammarali32/multi_verse_model](https://huggingface.co/ammarali32/multi_verse_model)
## 🧩 Configuration
```yaml
models:
- model: automerger/OgnoExperiment27-7B
# No parameters necessary for base model
- model: ammarali32/multi_verse_model
parameters:
density: 0.53
weight: 0.6
merge_method: dare_ties
base_model: automerger/OgnoExperiment27-7B
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/Ognoexperiment27Multi_verse_model-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
huahang/ppo-LunarLander-v2
|
huahang
| 2024-03-11T14:11:13Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T14:10:54Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.37 +/- 36.91
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
SimoneJLaudani/test_trainer4
|
SimoneJLaudani
| 2024-03-11T14:08:59Z | 94 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-cased",
"base_model:finetune:distilbert/distilbert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-09T20:00:00Z |
---
license: apache-2.0
base_model: distilbert-base-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: test_trainer4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer4
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8004
- Precision: 1.0
- Recall: 1.0
- F1: 1.0
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| 1.1721 | 0.92 | 6 | 0.9430 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.9711 | 2.0 | 13 | 0.9201 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1.1169 | 2.92 | 19 | 0.8874 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.9234 | 4.0 | 26 | 0.8359 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.9595 | 4.62 | 30 | 0.8004 | 1.0 | 1.0 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
reecursion/xlm-roberta-base-pure-indian-annotations
|
reecursion
| 2024-03-11T14:01:21Z | 102 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-11T14:00:39Z |
---
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlm-roberta-base-pure-indian-annotations
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-pure-indian-annotations
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5906
- Accuracy: 0.8
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6849 | 1.0 | 20 | 0.5946 | 0.8 |
| 0.7072 | 2.0 | 40 | 0.5923 | 0.8 |
| 0.6682 | 3.0 | 60 | 0.5940 | 0.8 |
| 0.7014 | 4.0 | 80 | 0.5956 | 0.8 |
| 0.7012 | 5.0 | 100 | 0.5906 | 0.8 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
sezenkarakus/image-description-model-v2
|
sezenkarakus
| 2024-03-11T13:59:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T11:43:47Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Litzy619/V0305P1
|
Litzy619
| 2024-03-11T13:54:22Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:yahma/llama-7b-hf",
"base_model:finetune:yahma/llama-7b-hf",
"license:other",
"region:us"
] | null | 2024-03-06T02:12:03Z |
---
license: other
base_model: yahma/llama-7b-hf
tags:
- generated_from_trainer
model-index:
- name: V0305P1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0305P1
This model is a fine-tuned version of [yahma/llama-7b-hf](https://huggingface.co/yahma/llama-7b-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0697
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 20
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0736 | 0.09 | 10 | 0.1558 |
| 0.1607 | 0.17 | 20 | 0.1576 |
| 0.1576 | 0.26 | 30 | 0.1518 |
| 0.1522 | 0.34 | 40 | 0.1504 |
| 0.1506 | 0.43 | 50 | 0.1494 |
| 0.1561 | 0.51 | 60 | 0.1507 |
| 0.1516 | 0.6 | 70 | 0.1495 |
| 0.1528 | 0.68 | 80 | 0.1480 |
| 0.1481 | 0.77 | 90 | 0.1435 |
| 0.1513 | 0.85 | 100 | 0.1445 |
| 0.1463 | 0.94 | 110 | 0.1142 |
| 0.1277 | 1.02 | 120 | 0.1126 |
| 0.119 | 1.11 | 130 | 0.1112 |
| 0.1092 | 1.19 | 140 | 0.0969 |
| 0.1113 | 1.28 | 150 | 0.0965 |
| 0.1033 | 1.37 | 160 | 0.0991 |
| 0.1025 | 1.45 | 170 | 0.0881 |
| 0.0922 | 1.54 | 180 | 0.0878 |
| 0.0931 | 1.62 | 190 | 0.0811 |
| 0.0909 | 1.71 | 200 | 0.0786 |
| 0.087 | 1.79 | 210 | 0.0755 |
| 0.0868 | 1.88 | 220 | 0.0745 |
| 0.0825 | 1.96 | 230 | 0.0832 |
| 0.0636 | 2.05 | 240 | 0.0820 |
| 0.0504 | 2.13 | 250 | 0.0864 |
| 0.0463 | 2.22 | 260 | 0.0876 |
| 0.0449 | 2.3 | 270 | 0.0847 |
| 0.0529 | 2.39 | 280 | 0.0711 |
| 0.0489 | 2.47 | 290 | 0.0693 |
| 0.05 | 2.56 | 300 | 0.0699 |
| 0.0519 | 2.65 | 310 | 0.0686 |
| 0.0411 | 2.73 | 320 | 0.0688 |
| 0.0473 | 2.82 | 330 | 0.0695 |
| 0.0471 | 2.9 | 340 | 0.0697 |
| 0.0452 | 2.99 | 350 | 0.0697 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
PsychologistChatbot/BERTAnswerabilityEvaluator
|
PsychologistChatbot
| 2024-03-11T13:54:14Z | 177 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-11T13:53:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ShubhamJain18/Reinforce-cartpole-v1
|
ShubhamJain18
| 2024-03-11T13:50:07Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T13:49:57Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
cantillation/whisper-medium-he-teamim-aviv-base
|
cantillation
| 2024-03-11T13:42:22Z | 66 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"he",
"base_model:openai/whisper-medium",
"base_model:finetune:openai/whisper-medium",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-02-27T22:10:40Z |
---
language:
- he
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
metrics:
- wer
- precision
- recall
- f1
base_model: openai/whisper-medium
model-index:
- name: he
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# he
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1138
- Wer: 9.9943
- Precision: 0.8917
- Recall: 0.8913
- F1: 0.8914
- Precision Median: 1.0
- Recall Median: 1.0
- F1 Median: 1.0
- Precision Max: 1.0
- Recall Max: 1.0
- F1 Max: 1.0
- Precision Min: 0.0
- Recall Min: 0.0
- F1 Min: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Precision | Recall | F1 | Precision Median | Recall Median | F1 Median | Precision Max | Recall Max | F1 Max | Precision Min | Recall Min | F1 Min |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:---------:|:------:|:------:|:----------------:|:-------------:|:---------:|:-------------:|:----------:|:------:|:-------------:|:----------:|:------:|
| 0.2168 | 0.04 | 500 | 0.2124 | 27.7691 | 0.6808 | 0.7027 | 0.6909 | 0.8125 | 0.8462 | 0.8276 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.1421 | 0.08 | 1000 | 0.1752 | 21.5191 | 0.7794 | 0.7820 | 0.7803 | 0.8889 | 0.8947 | 0.8947 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.086 | 0.12 | 1500 | 0.1510 | 17.9741 | 0.8044 | 0.8044 | 0.8040 | 0.9231 | 0.9231 | 0.9167 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0822 | 0.16 | 2000 | 0.1357 | 17.1839 | 0.8070 | 0.8091 | 0.8078 | 0.9231 | 0.9231 | 0.9231 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0675 | 0.2 | 2500 | 0.1227 | 14.9416 | 0.8324 | 0.8320 | 0.8319 | 0.9333 | 0.9333 | 0.9333 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0583 | 0.24 | 3000 | 0.1224 | 14.0376 | 0.8528 | 0.8498 | 0.8510 | 0.9333 | 0.9333 | 0.9375 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0528 | 0.28 | 3500 | 0.1167 | 13.8667 | 0.8393 | 0.8410 | 0.8399 | 0.9333 | 0.9333 | 0.9333 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0431 | 0.32 | 4000 | 0.1173 | 13.3827 | 0.8546 | 0.8579 | 0.8560 | 0.9375 | 0.9412 | 0.9412 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0402 | 0.36 | 4500 | 0.1154 | 12.1654 | 0.8695 | 0.8703 | 0.8697 | 0.9412 | 0.9412 | 0.9444 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0385 | 0.4 | 5000 | 0.1173 | 11.9448 | 0.8593 | 0.8578 | 0.8584 | 0.9444 | 0.9444 | 0.9474 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0266 | 0.44 | 5500 | 0.1144 | 12.1014 | 0.8706 | 0.8732 | 0.8717 | 0.9474 | 0.95 | 0.9583 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.021 | 0.48 | 6000 | 0.1161 | 11.7099 | 0.8737 | 0.8744 | 0.8739 | 1.0 | 1.0 | 0.9706 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0228 | 0.52 | 6500 | 0.1109 | 10.9909 | 0.8685 | 0.8692 | 0.8687 | 1.0 | 1.0 | 0.9697 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0172 | 0.56 | 7000 | 0.1075 | 10.7702 | 0.8780 | 0.8793 | 0.8784 | 1.0 | 0.9545 | 0.9697 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0117 | 0.6 | 7500 | 0.1107 | 10.4356 | 0.8834 | 0.8825 | 0.8828 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0151 | 0.64 | 8000 | 0.1101 | 10.3146 | 0.8886 | 0.8899 | 0.8891 | 1.0 | 1.0 | 0.9744 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0136 | 0.68 | 8500 | 0.1079 | 10.0370 | 0.8895 | 0.8903 | 0.8897 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0135 | 0.72 | 9000 | 0.1112 | 9.9445 | 0.8892 | 0.8892 | 0.8891 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0084 | 0.76 | 9500 | 0.1136 | 9.8875 | 0.8967 | 0.8964 | 0.8964 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 0.0098 | 0.8 | 10000 | 0.1138 | 9.9943 | 0.8917 | 0.8913 | 0.8914 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_16_64_0.05_2_0.0002
|
ferrazzipietro
| 2024-03-11T13:41:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T13:41:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hgarg/alpaca-gemma
|
hgarg
| 2024-03-11T13:39:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma",
"trl",
"en",
"base_model:unsloth/gemma-7b-bnb-4bit",
"base_model:finetune:unsloth/gemma-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T13:38:51Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
base_model: unsloth/gemma-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** hgarg
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-7b-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
SimoneJLaudani/test_trainer3b
|
SimoneJLaudani
| 2024-03-11T13:36:45Z | 93 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-cased",
"base_model:finetune:distilbert/distilbert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-10T22:01:53Z |
---
license: apache-2.0
base_model: distilbert-base-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: test_trainer3b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer3b
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6708
- Precision: 0.9796
- Recall: 0.9762
- F1: 0.9760
- Accuracy: 0.9762
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
aviadrom/HeArBERT
|
aviadrom
| 2024-03-11T13:36:21Z | 88 | 4 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"he",
"ar",
"dataset:oscar",
"arxiv:2402.16065",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-09-03T19:29:47Z |
---
datasets:
- oscar
language:
- he
- ar
---
# HeArBERT
A bilingual BERT for Arabic and Hebrew, pretrained on the respective parts of the OSCAR corpus.
In order to process Arabic with this model, one would have to transliterate it to Hebrew script. The code for doing so is available on the [preprocessing file](./preprocessing.py) and can be used as follows:
```python
from transformers import AutoTokenizer
from preprocessing import transliterate_arabic_to_hebrew
tokenizer = AutoTokenizer.from_pretrained("aviadrom/HeArBERT")
text_ar = "مرحبا"
text_he = transliterate_arabic_to_hebrew(text_ar)
tokenizer(text_he)
```
# Citation
If you find our work useful in your research, please consider citing:
```
@article{rom2024training,
title={Training a Bilingual Language Model by Mapping Tokens onto a Shared Character Space},
author={Rom, Aviad and Bar, Kfir},
journal={arXiv preprint arXiv:2402.16065},
year={2024}
}
```
|
OwOOwO/mistral_mischief3_2
|
OwOOwO
| 2024-03-11T13:35:00Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T13:32:03Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kmanaa/t5-dialogue-classification-4
|
kmanaa
| 2024-03-11T13:33:43Z | 94 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-03-11T13:16:17Z |
---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- generated_from_trainer
model-index:
- name: t5-dialogue-classification-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-dialogue-classification-4
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6143
- Classification Report: precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.2500 0.3333 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8077 0.9545 0.8750 22
GENHX 0.5429 0.9500 0.6909 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6400 100
macro avg 0.3164 0.3187 0.2986 100
weighted avg 0.5702 0.6400 0.5690 100
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 7
- eval_batch_size: 7
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Classification Report |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 172 | 0.7682 | precision recall f1-score support
ALLERGY 0.3333 0.5000 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
Afib 0.0000 0.0000 0.0000 0
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.0000 0.0000 0.0000 1
FAM/SOCHX 0.7500 0.6818 0.7143 22
GENHX 0.3636 1.0000 0.5333 20
GYNHX 0.0000 0.0000 0.0000 1
ICT 0.0000 0.0000 0.0000 0
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
Iv 0.0000 0.0000 0.0000 0
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 1.0000 0.1429 0.2500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.1250 0.2500 0.1667 4
PASTSURGICAL 0.5714 0.5000 0.5333 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.0000 0.0000 0.0000 11
accuracy 0.4300 100
macro avg 0.1367 0.1337 0.1129 100
weighted avg 0.3718 0.4300 0.3466 100
|
| No log | 2.0 | 344 | 0.5464 | precision recall f1-score support
ALLERGY 0.5000 0.2500 0.3333 4
ASSESSMENT 0.0000 0.0000 0.0000 4
Afib 0.0000 0.0000 0.0000 0
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.0000 0.0000 0.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.4524 0.9500 0.6129 20
GYNHX 0.0000 0.0000 0.0000 1
I am going home with my son 0.0000 0.0000 0.0000 0
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.4545 0.7143 0.5556 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.3750 0.7500 0.5000 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.0000 0.0000 0.0000 11
thoughts 0.0000 0.0000 0.0000 0
accuracy 0.5700 100
macro avg 0.1542 0.2008 0.1677 100
weighted avg 0.4209 0.5700 0.4710 100
|
| 0.5961 | 3.0 | 516 | 0.4964 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 0.0000 0.0000 0.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.4878 1.0000 0.6557 20
GYNHX 0.0000 0.0000 0.0000 1
How are you feeling? 0.0000 0.0000 0.0000 0
I V 0.0000 0.0000 0.0000 0
I am going home with my son. 0.0000 0.0000 0.0000 0
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.7143 0.7143 0.7143 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.4444 1.0000 0.6154 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.0000 0.0000 0.0000 11
accuracy 0.5900 100
macro avg 0.1918 0.2139 0.1843 100
weighted avg 0.4689 0.5900 0.4979 100
|
| 0.5961 | 4.0 | 688 | 0.5069 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
Afib 0.0000 0.0000 0.0000 0
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.6333 0.9500 0.7600 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.4000 1.0000 0.5714 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 1.0000 0.1818 0.3077 11
accuracy 0.6300 100
macro avg 0.3064 0.2971 0.2689 100
weighted avg 0.6066 0.6300 0.5642 100
|
| 0.5961 | 5.0 | 860 | 0.4889 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
Afib 0.0000 0.0000 0.0000 0
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.6129 0.9500 0.7451 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.8333 0.7143 0.7692 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.3000 0.7500 0.4286 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
accuracy 0.6200 100
macro avg 0.2928 0.2903 0.2740 100
weighted avg 0.5735 0.6200 0.5651 100
|
| 0.1563 | 6.0 | 1032 | 0.4923 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8462 1.0000 0.9167 22
GENHX 0.5128 1.0000 0.6780 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.5556 0.7143 0.6250 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.3750 0.7500 0.5000 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 1.0000 0.1818 0.3077 11
accuracy 0.6200 100
macro avg 0.3089 0.2948 0.2684 100
weighted avg 0.5737 0.6200 0.5362 100
|
| 0.1563 | 7.0 | 1204 | 0.5146 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8750 0.9545 0.9130 22
GENHX 0.5000 1.0000 0.6667 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
Injection 0.0000 0.0000 0.0000 0
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6250 0.7143 0.6667 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 0.7500 0.6000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
accuracy 0.6100 100
macro avg 0.2937 0.2786 0.2634 100
weighted avg 0.5596 0.6100 0.5423 100
|
| 0.1563 | 8.0 | 1376 | 0.5325 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8000 0.9091 0.8511 22
GENHX 0.5128 1.0000 0.6780 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6000 0.8571 0.7059 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6000 0.7500 0.6667 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
accuracy 0.6100 100
macro avg 0.3090 0.2974 0.2794 100
weighted avg 0.5479 0.6100 0.5363 100
|
| 0.0973 | 9.0 | 1548 | 0.5105 | precision recall f1-score support
ALLERGY 1.0000 0.2500 0.4000 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8400 0.9545 0.8936 22
GENHX 0.5429 0.9500 0.6909 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6000 0.8571 0.7059 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.6000 0.7500 0.6667 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming 0.0000 0.0000 0.0000 0
accuracy 0.6100 100
macro avg 0.2923 0.2830 0.2659 100
weighted avg 0.5538 0.6100 0.5436 100
|
| 0.0973 | 10.0 | 1720 | 0.5433 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8148 1.0000 0.8980 22
GENHX 0.6129 0.9500 0.7451 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 1.0000 0.6667 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.7500 0.2727 0.4000 11
harming 0.0000 0.0000 0.0000 0
accuracy 0.6500 100
macro avg 0.3021 0.3133 0.2917 100
weighted avg 0.5810 0.6500 0.5864 100
|
| 0.0973 | 11.0 | 1892 | 0.5202 | precision recall f1-score support
ALLERGY 0.6667 0.5000 0.5714 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8148 1.0000 0.8980 22
GENHX 0.5714 1.0000 0.7273 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6250 0.7143 0.6667 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming 0.0000 0.0000 0.0000 0
accuracy 0.6400 100
macro avg 0.2764 0.3046 0.2770 100
weighted avg 0.5413 0.6400 0.5583 100
|
| 0.0612 | 12.0 | 2064 | 0.5594 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.2500 0.3333 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.7857 1.0000 0.8800 22
GENHX 0.5882 1.0000 0.7407 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.7500 0.7500 0.7500 4
PASTSURGICAL 0.6667 1.0000 0.8000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming 0.0000 0.0000 0.0000 0
accuracy 0.6500 100
macro avg 0.3154 0.3114 0.2955 100
weighted avg 0.5638 0.6500 0.5697 100
|
| 0.0612 | 13.0 | 2236 | 0.5590 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 1.0000 0.2500 0.4000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.7778 0.9545 0.8571 22
GENHX 0.5714 1.0000 0.7273 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 0.8000 1.0000 0.8889 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming 0.0000 0.0000 0.0000 0
accuracy 0.6500 100
macro avg 0.3359 0.3211 0.3001 100
weighted avg 0.5823 0.6500 0.5708 100
|
| 0.0612 | 14.0 | 2408 | 0.5971 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.2500 0.3333 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.7857 1.0000 0.8800 22
GENHX 0.5882 1.0000 0.7407 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.4286 0.7500 0.5455 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming 0.0000 0.0000 0.0000 0
accuracy 0.6500 100
macro avg 0.3160 0.3114 0.2953 100
weighted avg 0.5776 0.6500 0.5775 100
|
| 0.0442 | 15.0 | 2580 | 0.6045 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8077 0.9545 0.8750 22
GENHX 0.5263 1.0000 0.6897 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 0.7500 0.6000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6300 100
macro avg 0.2937 0.2973 0.2794 100
weighted avg 0.5530 0.6300 0.5550 100
|
| 0.0442 | 16.0 | 2752 | 0.6341 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.0000 0.0000 0.0000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.7778 0.9545 0.8571 22
GENHX 0.5405 1.0000 0.7018 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 0.7500 0.6000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6300 100
macro avg 0.2929 0.2973 0.2791 100
weighted avg 0.5492 0.6300 0.5535 100
|
| 0.0442 | 17.0 | 2924 | 0.6230 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.3333 0.2500 0.2857 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8077 0.9545 0.8750 22
GENHX 0.5429 0.9500 0.6909 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5000 0.7500 0.6000 4
PASTSURGICAL 1.0000 1.0000 1.0000 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6300 100
macro avg 0.3103 0.3068 0.2930 100
weighted avg 0.5696 0.6300 0.5667 100
|
| 0.0266 | 18.0 | 3096 | 0.6051 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 1.0000 0.2500 0.4000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.7778 0.9545 0.8571 22
GENHX 0.5556 1.0000 0.7143 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6500 100
macro avg 0.3394 0.3211 0.3020 100
weighted avg 0.5862 0.6500 0.5724 100
|
| 0.0266 | 19.0 | 3268 | 0.6057 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 1.0000 0.2500 0.4000 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.7778 0.9545 0.8571 22
GENHX 0.5556 1.0000 0.7143 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6500 100
macro avg 0.3394 0.3211 0.3020 100
weighted avg 0.5862 0.6500 0.5724 100
|
| 0.0266 | 20.0 | 3440 | 0.6143 | precision recall f1-score support
ALLERGY 1.0000 0.5000 0.6667 4
ASSESSMENT 0.0000 0.0000 0.0000 4
CC 0.5000 0.2500 0.3333 4
DIAGNOSIS 0.0000 0.0000 0.0000 1
DISPOSITION 0.0000 0.0000 0.0000 2
EDCOURSE 0.0000 0.0000 0.0000 3
EXAM 1.0000 1.0000 1.0000 1
FAM/SOCHX 0.8077 0.9545 0.8750 22
GENHX 0.5429 0.9500 0.6909 20
GYNHX 0.0000 0.0000 0.0000 1
IMAGING 0.0000 0.0000 0.0000 1
IMMUNIZATIONS 0.0000 0.0000 0.0000 1
LABS 0.0000 0.0000 0.0000 1
MEDICATIONS 0.6667 0.8571 0.7500 7
OTHER_HISTORY 0.0000 0.0000 0.0000 1
PASTMEDICALHX 0.5714 1.0000 0.7273 4
PASTSURGICAL 0.8889 1.0000 0.9412 8
PLAN 0.0000 0.0000 0.0000 3
PROCEDURES 0.0000 0.0000 0.0000 1
ROS 0.6667 0.1818 0.2857 11
harming yourself or others 0.0000 0.0000 0.0000 0
accuracy 0.6400 100
macro avg 0.3164 0.3187 0.2986 100
weighted avg 0.5702 0.6400 0.5690 100
|
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
johnnyluhk/b
|
johnnyluhk
| 2024-03-11T13:32:44Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-03-11T13:32:39Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: b
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
parsak/cosmosgpt2_alpagasus9k_instruct
|
parsak
| 2024-03-11T13:31:41Z | 95 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T13:30:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
juhwanlee/llmdo-Mistral-7B-case-1
|
juhwanlee
| 2024-03-11T13:31:40Z | 47 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T07:04:43Z |
---
license: apache-2.0
datasets:
- Open-Orca/OpenOrca
language:
- en
---
# Model Details
* Model Description: This model is test for data ordering.
* Developed by: Juhwan Lee
* Model Type: Large Language Model
# Model Architecture
This model is based on Mistral-7B-v0.1. We fine-tuning this model for data ordering task.
Mistral-7B-v0.1 is a transformer model, with the following architecture choices:
* Grouped-Query Attention
* Sliding-Window Attention
* Byte-fallback BPE tokenizer
# Dataset
We random sample Open-Orca dataset. (We finetune the 100,000 dataset)
# Guthub
https://github.com/trailerAI
# License
Apache License 2.0
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_16_32_0.05_8_0.0002
|
ferrazzipietro
| 2024-03-11T13:30:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T13:30:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AlignmentResearch/robust_llm_859e5cb8dfab11eea45886e11d54e141_from_EleutherAI_pythia-14m
|
AlignmentResearch
| 2024-03-11T13:30:41Z | 93 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-11T13:30:37Z |
---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-14m
model-index:
- name: robust_llm_859e5cb8dfab11eea45886e11d54e141_from_EleutherAI_pythia-14m
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_859e5cb8dfab11eea45886e11d54e141_from_EleutherAI_pythia-14m
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 32
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 8
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
bartowski/EveryoneLLM-7b-Gemma-Base-GGUF-old
|
bartowski
| 2024-03-11T13:29:24Z | 83 | 0 | null |
[
"gguf",
"merge",
"text-generation",
"license:other",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-11T13:14:11Z |
---
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
tags:
- merge
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp Quantizations of EveryoneLLM-7b-Gemma-Base
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b2354">b2354</a> for quantization.
Original model: https://huggingface.co/rombodawg/EveryoneLLM-7b-Gemma-Base
Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [EveryoneLLM-7b-Gemma-Base-Q8_0.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q8_0.gguf) | Q8_0 | 9.07GB | Extremely high quality, generally unneeded but max available quant. |
| [EveryoneLLM-7b-Gemma-Base-Q6_K.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q6_K.gguf) | Q6_K | 7.01GB | Very high quality, near perfect, *recommended*. |
| [EveryoneLLM-7b-Gemma-Base-Q5_K_M.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q5_K_M.gguf) | Q5_K_M | 6.04GB | High quality, very usable. |
| [EveryoneLLM-7b-Gemma-Base-Q5_K_S.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q5_K_S.gguf) | Q5_K_S | 5.87GB | High quality, very usable. |
| [EveryoneLLM-7b-Gemma-Base-Q5_0.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q5_0.gguf) | Q5_0 | 5.87GB | High quality, older format, generally not recommended. |
| [EveryoneLLM-7b-Gemma-Base-Q4_K_M.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q4_K_M.gguf) | Q4_K_M | 5.12GB | Good quality, similar to 4.25 bpw. |
| [EveryoneLLM-7b-Gemma-Base-Q4_K_S.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q4_K_S.gguf) | Q4_K_S | 4.84GB | Slightly lower quality with small space savings. |
| [EveryoneLLM-7b-Gemma-Base-Q4_0.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q4_0.gguf) | Q4_0 | 4.80GB | Decent quality, older format, generally not recommended. |
| [EveryoneLLM-7b-Gemma-Base-Q3_K_L.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q3_K_L.gguf) | Q3_K_L | 4.40GB | Lower quality but usable, good for low RAM availability. |
| [EveryoneLLM-7b-Gemma-Base-Q3_K_M.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q3_K_M.gguf) | Q3_K_M | 4.06GB | Even lower quality. |
| [EveryoneLLM-7b-Gemma-Base-Q3_K_S.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q3_K_S.gguf) | Q3_K_S | 3.67GB | Low quality, not recommended. |
| [EveryoneLLM-7b-Gemma-Base-Q2_K.gguf](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-GGUF/blob/main/EveryoneLLM-7b-Gemma-Base-Q2_K.gguf) | Q2_K | 3.09GB | Extremely low quality, *not* recommended.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
Imadeddineibrahim/yolo_8_layout
|
Imadeddineibrahim
| 2024-03-11T13:27:14Z | 0 | 1 | null |
[
"onnx",
"dataset:pytorch-layout-generation/PubLayNet",
"license:mit",
"region:us"
] | null | 2024-03-11T13:15:36Z |
---
license: mit
datasets:
- pytorch-layout-generation/PubLayNet
---
|
bartowski/EveryoneLLM-7b-Gemma-Base-exl2
|
bartowski
| 2024-03-11T13:26:17Z | 0 | 0 | null |
[
"merge",
"text-generation",
"license:other",
"region:us"
] |
text-generation
| 2024-03-11T13:05:58Z |
---
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
tags:
- merge
quantized_by: bartowski
pipeline_tag: text-generation
---
## Exllama v2 Quantizations of EveryoneLLM-7b-Gemma-Base
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.15">turboderp's ExLlamaV2 v0.0.15</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: https://huggingface.co/rombodawg/EveryoneLLM-7b-Gemma-Base
No GQA - VRAM requirements will be higher
| Branch | Bits | lm_head bits | Size (4k) | Size (16k) | Description |
| -------------------------------------------------------------- | ---- | ------------ | --------- | ---------- | ----------- |
| [8_0](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-exl2/tree/8_0) | 8.0 | 8.0 | 14.0 GB | 19.4 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-exl2/tree/6_5) | 6.5 | 8.0 | 12.5 GB | 17.9 GB | Near unquantized performance at vastly reduced size, **recommended**. |
| [5_0](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-exl2/tree/5_0) | 5.0 | 6.0 | 10.9 GB | 16.3 GB | Slightly lower quality vs 6.5, but usable on 8GB cards with 4k context. |
| [4_25](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-exl2/tree/4_25) | 4.25 | 6.0 | 10.2 GB | 15.7 GB | GPTQ equivalent bits per weight. |
| [3_5](https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-exl2/tree/3_5) | 3.5 | 6.0 | 9.5 GB | 14.9 GB | Lower quality, not recommended. |
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/EveryoneLLM-7b-Gemma-Base-exl2 EveryoneLLM-7b-Gemma-Base-exl2-6_5
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download the `main` (only useful if you only care about measurement.json) branch to a folder called `EveryoneLLM-7b-Gemma-Base-exl2`:
```shell
mkdir EveryoneLLM-7b-Gemma-Base-exl2
huggingface-cli download bartowski/EveryoneLLM-7b-Gemma-Base-exl2 --local-dir EveryoneLLM-7b-Gemma-Base-exl2 --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
Linux:
```shell
mkdir EveryoneLLM-7b-Gemma-Base-exl2-6_5
huggingface-cli download bartowski/EveryoneLLM-7b-Gemma-Base-exl2 --revision 6_5 --local-dir EveryoneLLM-7b-Gemma-Base-exl2-6_5 --local-dir-use-symlinks False
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
mkdir EveryoneLLM-7b-Gemma-Base-exl2-6.5
huggingface-cli download bartowski/EveryoneLLM-7b-Gemma-Base-exl2 --revision 6_5 --local-dir EveryoneLLM-7b-Gemma-Base-exl2-6.5 --local-dir-use-symlinks False
```
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
ferrazzipietro/Mistral-7B-Instruct-v0.2_adapters_en.layer1_NoQuant_torch.bfloat16_16_32_0.05_2_0.0002
|
ferrazzipietro
| 2024-03-11T13:24:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T09:54:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AlignmentResearch/robust_llm_57f7ef96dfaa11ee9a6b86e11d54e141_from_EleutherAI_pythia-14m
|
AlignmentResearch
| 2024-03-11T13:22:22Z | 91 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-03-11T13:22:15Z |
---
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-14m
model-index:
- name: robust_llm_57f7ef96dfaa11ee9a6b86e11d54e141_from_EleutherAI_pythia-14m
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_57f7ef96dfaa11ee9a6b86e11d54e141_from_EleutherAI_pythia-14m
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 32
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 8
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.0
- Tokenizers 0.15.2
|
ferrazzipietro/Llama-2-13b-chat-hf__adapters_en.layer1_4_torch.bfloat16_16_32_0.05_4_0.0002
|
ferrazzipietro
| 2024-03-11T13:20:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T10:03:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dataequity/mistral-7b-instruct-v0.2.Q5_K_M.gguf
|
dataequity
| 2024-03-11T13:18:49Z | 10 | 1 | null |
[
"gguf",
"finetuned",
"text-generation",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:quantized:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us",
"conversational"
] |
text-generation
| 2024-03-11T12:09:46Z |
---
base_model: mistralai/Mistral-7B-Instruct-v0.2
inference: false
license: apache-2.0
model_creator: Mistral AI_
model_name: Mistral 7B Instruct v0.2
model_type: mistral
pipeline_tag: text-generation
quantized_by: TheBloke
tags:
- finetuned
---
# Mistral 7B Instruct v0.2 - GGUF
- Model creator: [Mistral AI_](https://huggingface.co/mistralai)
- Original model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Mistral AI_'s Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2).
## Prompt template: Mistral
```
<s>[INST] {prompt} [/INST]
```
## Citation
TheBloke
|
m-gopichand/small
|
m-gopichand
| 2024-03-11T13:18:27Z | 91 | 0 |
transformers
|
[
"transformers",
"safetensors",
"deberta-v2",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2024-03-11T13:17:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
vjprav33n/flan_t5_small_pi_ep1_015ts
|
vjprav33n
| 2024-03-11T13:17:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-11T13:17:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
asyzhou/224n-whisper-large-overnight-4
|
asyzhou
| 2024-03-11T13:16:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-10T10:00:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.