
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 12:32:32
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 534
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 12:31:20
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Butanium/simple-stories-2L16H128D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T14:29:37Z | 9 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T14:29:27Z |
# 2-Layer 16-Head Attention-Only Transformer
This is a simplified transformer model with 2 attention layer(s) and 16 attention head(s), hidden size 128, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-2L16H128D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
Butanium/simple-stories-2L16H512D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T14:29:29Z | 7 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T14:29:26Z |
# 2-Layer 16-Head Attention-Only Transformer
This is a simplified transformer model with 2 attention layer(s) and 16 attention head(s), hidden size 512, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-2L16H512D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
pasithbas159/MIVC_Typhoon2_HII_satellite_v1
|
pasithbas159
| 2025-08-06T14:29:29Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-07-21T17:13:37Z |
---
base_model: pasithbas/Typhoon2_HII_satellite_v1
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_vl
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** pasithbas159
- **License:** apache-2.0
- **Finetuned from model :** pasithbas/Typhoon2_HII_satellite_v1
This qwen2_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sbunlp/fabert
|
sbunlp
| 2025-08-06T14:29:15Z | 3,116 | 15 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"fa",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2024-02-09T14:00:20Z |
---
language:
- fa
library_name: transformers
widget:
- text: "ز سوزناکی گفتار من [MASK] بگریست"
example_title: "Poetry 1"
- text: "نظر از تو برنگیرم همه [MASK] تا بمیرم که تو در دلم نشستی و سر مقام داری"
example_title: "Poetry 2"
- text: "هر ساعتم اندرون بجوشد [MASK] را وآگاهی نیست مردم بیرون را"
example_title: "Poetry 3"
- text: "غلام همت آن رند عافیت سوزم که در گدا صفتی [MASK] داند"
example_title: "Poetry 4"
- text: "این [MASK] اولشه."
example_title: "Informal 1"
- text: "دیگه خسته شدم! [MASK] اینم شد کار؟!"
example_title: "Informal 2"
- text: "فکر نکنم به موقع برسیم. بهتره [MASK] این یکی بشیم."
example_title: "Informal 3"
- text: "تا صبح بیدار موندم و داشتم برای [MASK] آماده می شدم."
example_title: "Informal 4"
- text: "زندگی بدون [MASK] خستهکننده است."
example_title: "Formal 1"
- text: "در حکم اولیه این شرکت مجاز به فعالیت شد ولی پس از بررسی مجدد، مجوز این شرکت [MASK] شد."
example_title: "Formal 2"
---
# FaBERT: Pre-training BERT on Persian Blogs
## Model Details
FaBERT is a Persian BERT-base model trained on the diverse HmBlogs corpus, encompassing both casual and formal Persian texts. Developed for natural language processing tasks, FaBERT is a robust solution for processing Persian text. Through evaluation across various Natural Language Understanding (NLU) tasks, FaBERT consistently demonstrates notable improvements, while having a compact model size. Now available on Hugging Face, integrating FaBERT into your projects is hassle-free. Experience enhanced performance without added complexity as FaBERT tackles a variety of NLP tasks.
## Features
- Pre-trained on the diverse HmBlogs corpus consisting more than 50 GB of text from Persian Blogs
- Remarkable performance across various downstream NLP tasks
- BERT architecture with 124 million parameters
## Useful Links
- **Repository:** [FaBERT on Github](https://github.com/SBU-NLP-LAB/FaBERT)
- **Paper:** [ACL Anthology](https://aclanthology.org/2025.wnut-1.10/)
## Usage
### Loading the Model with MLM head
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("sbunlp/fabert") # make sure to use the default fast tokenizer
model = AutoModelForMaskedLM.from_pretrained("sbunlp/fabert")
```
### Downstream Tasks
Similar to the original English BERT, FaBERT can be fine-tuned on many downstream tasks.(https://huggingface.co/docs/transformers/en/training)
Examples on Persian datasets are available in our [GitHub repository](#useful-links).
**make sure to use the default Fast Tokenizer**
## Training Details
FaBERT was pre-trained with the MLM (WWM) objective, and the resulting perplexity on validation set was 7.76.
| Hyperparameter | Value |
|-------------------|:--------------:|
| Batch Size | 32 |
| Optimizer | Adam |
| Learning Rate | 6e-5 |
| Weight Decay | 0.01 |
| Total Steps | 18 Million |
| Warmup Steps | 1.8 Million |
| Precision Format | TF32 |
## Evaluation
Here are some key performance results for the FaBERT model:
**Sentiment Analysis**
| Task | FaBERT | ParsBERT | XLM-R |
|:-------------|:------:|:--------:|:-----:|
| MirasOpinion | **87.51** | 86.73 | 84.92 |
| MirasIrony | 74.82 | 71.08 | **75.51** |
| DeepSentiPers | **79.85** | 74.94 | 79.00 |
**Named Entity Recognition**
| Task | FaBERT | ParsBERT | XLM-R |
|:-------------|:------:|:--------:|:-----:|
| PEYMA | **91.39** | 91.24 | 90.91 |
| ParsTwiner | **82.22** | 81.13 | 79.50 |
| MultiCoNER v2 | 57.92 | **58.09** | 51.47 |
**Question Answering**
| Task | FaBERT | ParsBERT | XLM-R |
|:-------------|:------:|:--------:|:-----:|
| ParsiNLU | **55.87** | 44.89 | 42.55 |
| PQuAD | 87.34 | 86.89 | **87.60** |
| PCoQA | **53.51** | 50.96 | 51.12 |
**Natural Language Inference & QQP**
| Task | FaBERT | ParsBERT | XLM-R |
|:-------------|:------:|:--------:|:-----:|
| FarsTail | **84.45** | 82.52 | 83.50 |
| SBU-NLI | **66.65** | 58.41 | 58.85 |
| ParsiNLU QQP | **82.62** | 77.60 | 79.74 |
**Number of Parameters**
| | FaBERT | ParsBERT | XLM-R |
|:-------------|:------:|:--------:|:-----:|
| Parameter Count (M) | 124 | 162 | 278 |
| Vocabulary Size (K) | 50 | 100 | 250 |
For a more detailed performance analysis refer to the paper.
## How to Cite
If you use FaBERT in your research or projects, please cite it using the following BibTeX:
```bibtex
@inproceedings{masumi-etal-2025-fabert,
title = "{F}a{BERT}: Pre-training {BERT} on {P}ersian Blogs",
author = "Masumi, Mostafa and
Majd, Seyed Soroush and
Shamsfard, Mehrnoush and
Beigy, Hamid",
editor = "Bak, JinYeong and
Goot, Rob van der and
Jang, Hyeju and
Buaphet, Weerayut and
Ramponi, Alan and
Xu, Wei and
Ritter, Alan",
booktitle = "Proceedings of the Tenth Workshop on Noisy and User-generated Text",
month = may,
year = "2025",
address = "Albuquerque, New Mexico, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.wnut-1.10/",
doi = "10.18653/v1/2025.wnut-1.10",
pages = "85--96",
ISBN = "979-8-89176-232-9",
}
```
|
luc4s-0liv3ra/P.m.f
|
luc4s-0liv3ra
| 2025-08-06T14:28:10Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-06T14:28:09Z |
---
license: apache-2.0
---
|
johnbridges/UIGEN-X-32B-0727-GGUF
|
johnbridges
| 2025-08-06T14:27:57Z | 3,877 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"qwen3",
"ui-generation",
"tailwind-css",
"html",
"reasoning",
"step-by-step-generation",
"hybrid-thinking",
"tool-calling",
"en",
"base_model:Qwen/Qwen3-32B",
"base_model:quantized:Qwen/Qwen3-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-05T14:11:32Z |
---
base_model:
- Qwen/Qwen3-32B
tags:
- text-generation-inference
- transformers
- qwen3
- ui-generation
- tailwind-css
- html
- reasoning
- step-by-step-generation
- hybrid-thinking
- tool-calling
license: apache-2.0
language:
- en
---
# <span style="color: #7FFF7F;">UIGEN-X-32B-0727 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`4cb208c9`](https://github.com/ggerganov/llama.cpp/commit/4cb208c93c1c938591a5b40354e2a6f9b94489bc).
---
## <span style="color: #7FFF7F;">Quantization Beyond the IMatrix</span>
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
<a href="https://readyforquantum.com/huggingface_gguf_selection_guide.html" style="color: #7FFF7F;">
Click here to get info on choosing the right GGUF model format
</a>
---
<!--Begin Original Model Card-->
# UIGEN-X-32B-0727 Reasoning Only UI Generation Model

> Tesslate's Reasoning Only UI generation model built on Qwen3-32B architecture. Trained to systematically plan, architect, and implement complete user interfaces across modern development stacks.
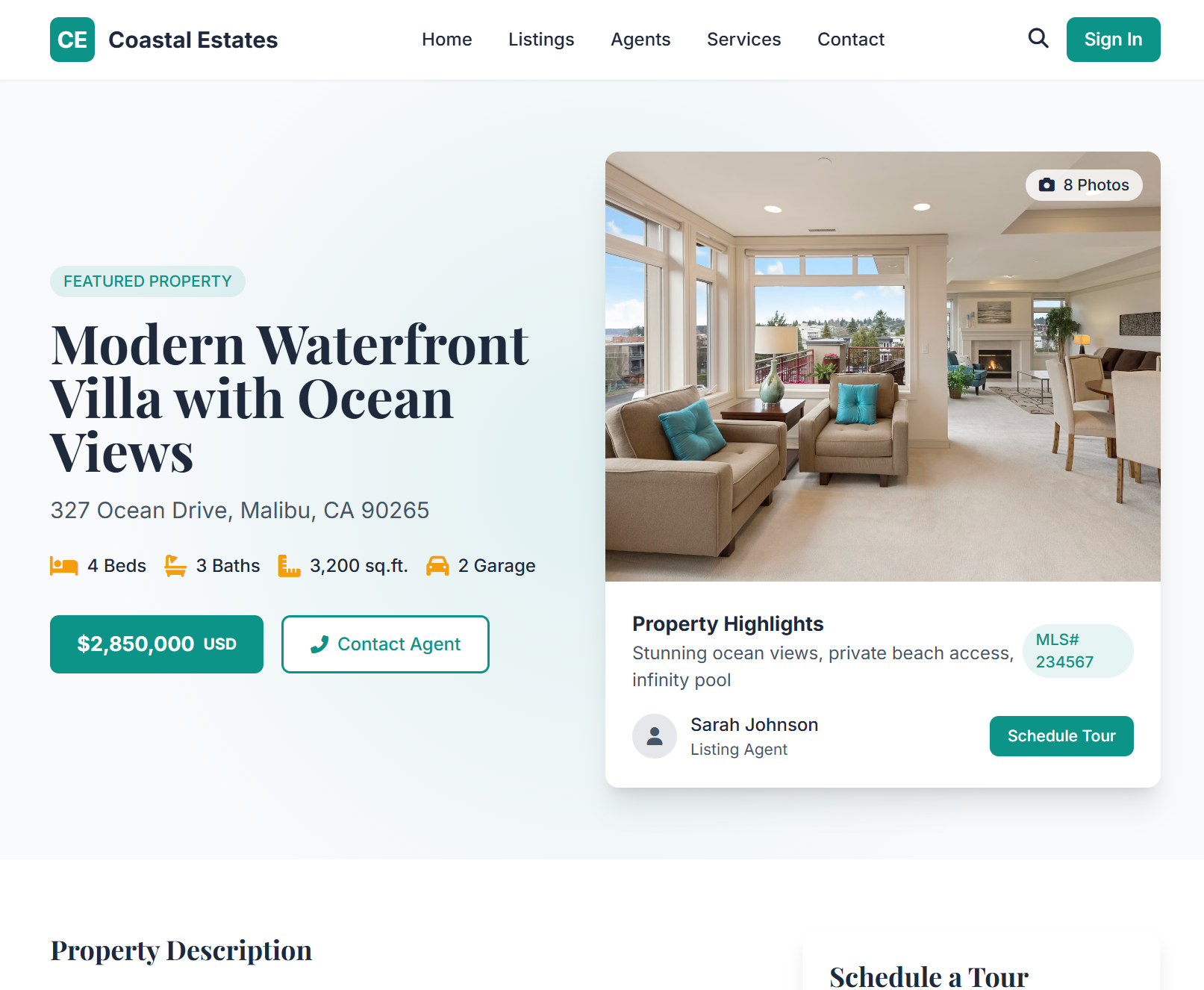
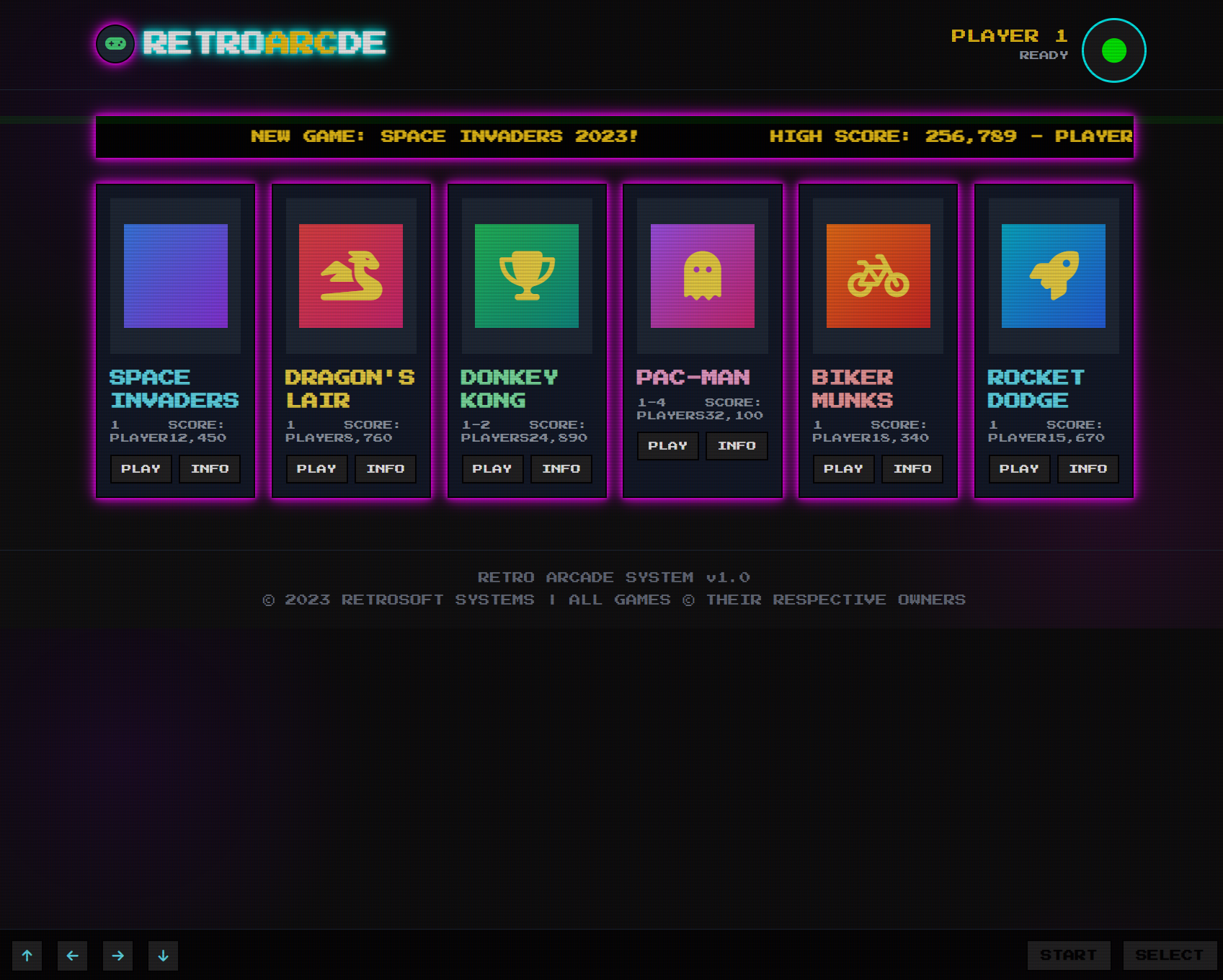
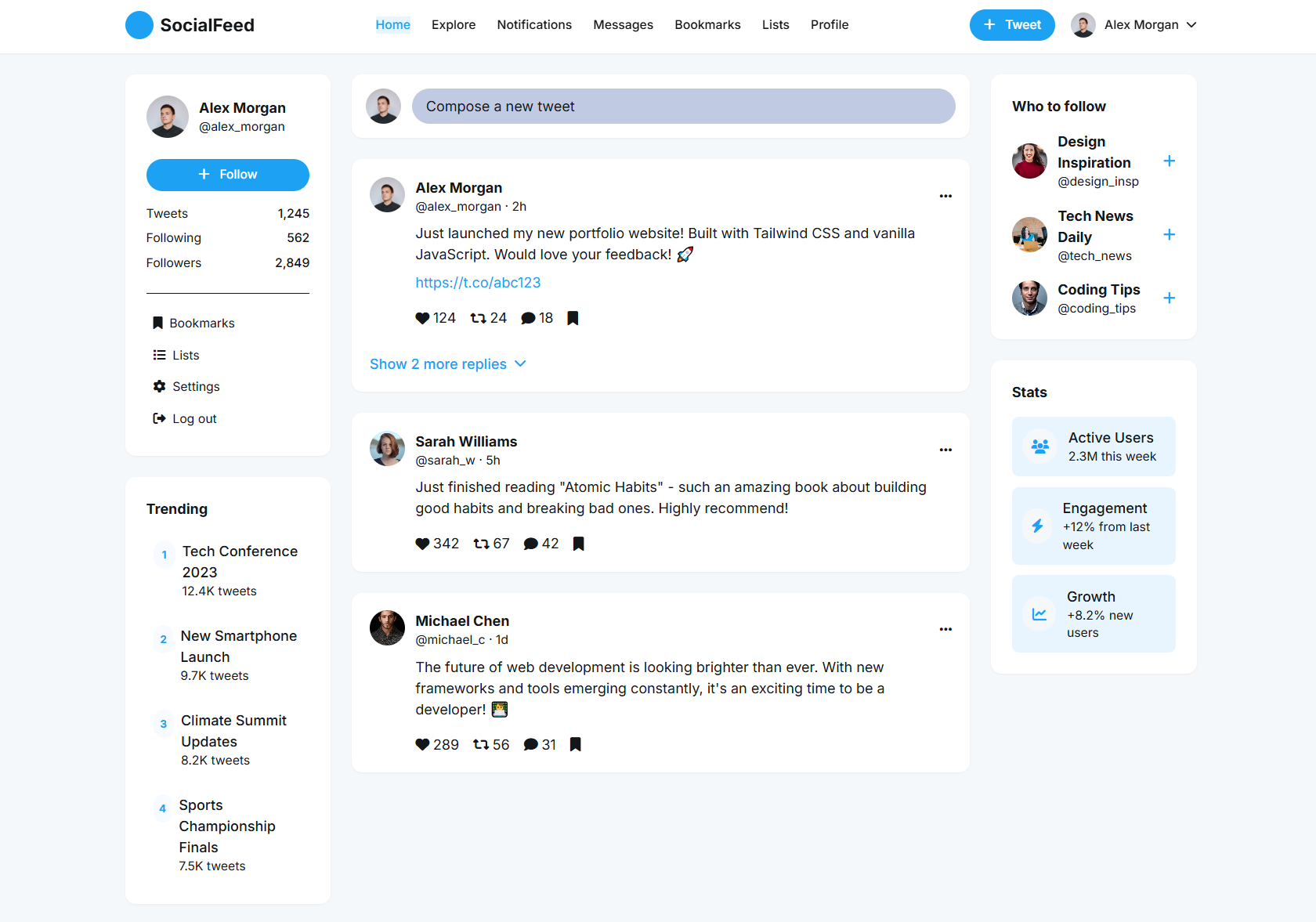
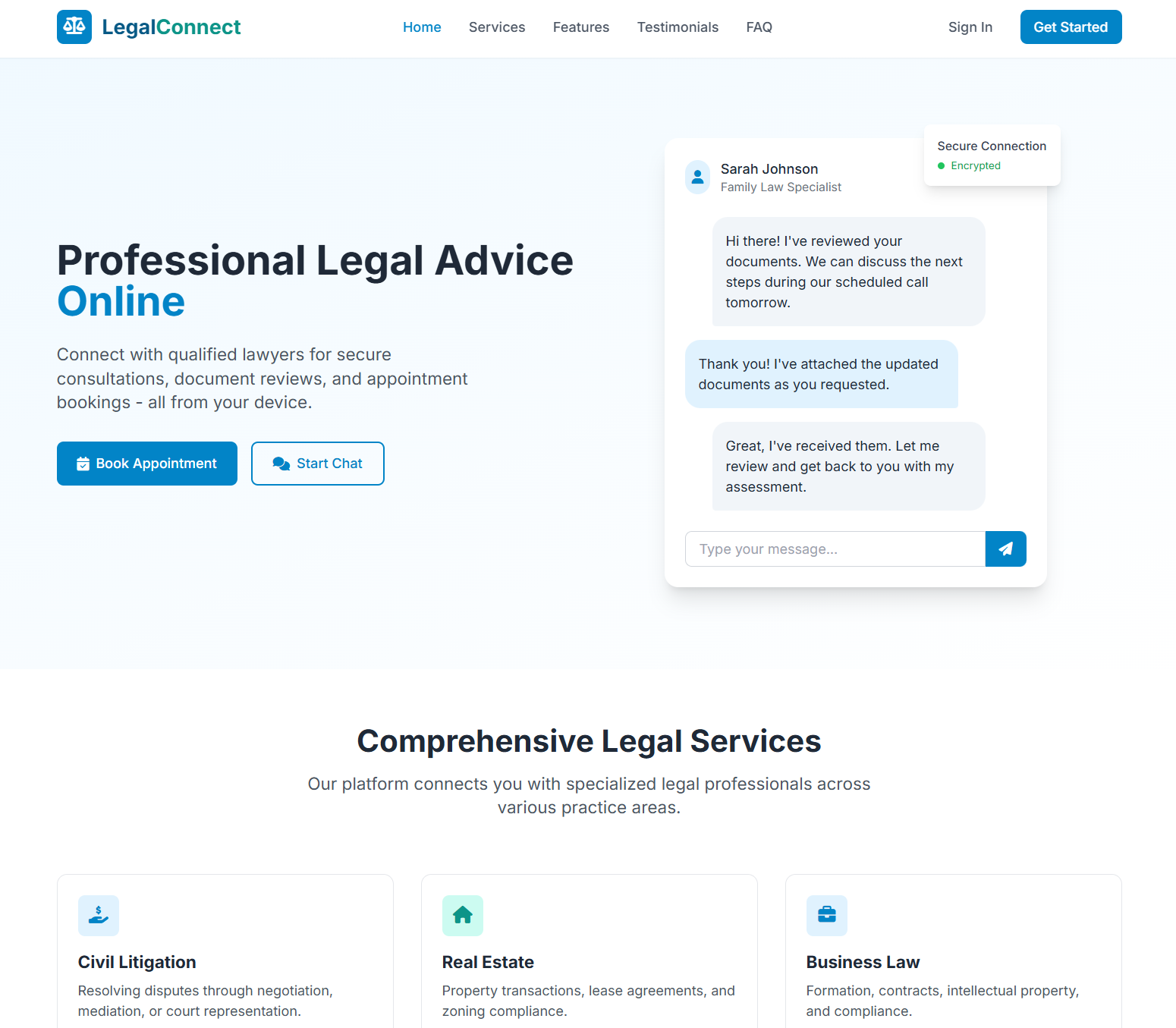
**Live Examples**: [https://uigenoutput.tesslate.com](https://uigenoutput.tesslate.com)
**Discord Community**: [https://discord.gg/EcCpcTv93U](https://discord.gg/EcCpcTv93U)
**Website**: [https://tesslate.com](https://tesslate.com)
---
## Model Architecture
UIGEN-X-32B-0727 implements **Reasoning Only** from the Qwen3 family - combining systematic planning with direct implementation. The model follows a structured thinking process:
1. **Problem Analysis** — Understanding requirements and constraints
2. **Architecture Planning** — Component structure and technology decisions
3. **Design System Definition** — Color schemes, typography, and styling approach
4. **Implementation Strategy** — Step-by-step code generation with reasoning
This hybrid approach enables both thoughtful planning and efficient code generation, making it suitable for complex UI development tasks.
---
## Complete Technology Coverage
UIGEN-X-32B-0727 supports **26 major categories** spanning **frameworks and libraries** across **7 platforms**:
### Web Frameworks
- **React**: Next.js, Remix, Gatsby, Create React App, Vite
- **Vue**: Nuxt.js, Quasar, Gridsome
- **Angular**: Angular CLI, Ionic Angular
- **Svelte**: SvelteKit, Astro
- **Modern**: Solid.js, Qwik, Alpine.js
- **Static**: Astro, 11ty, Jekyll, Hugo
### Styling Systems
- **Utility-First**: Tailwind CSS, UnoCSS, Windi CSS
- **CSS-in-JS**: Styled Components, Emotion, Stitches
- **Component Systems**: Material-UI, Chakra UI, Mantine
- **Traditional**: Bootstrap, Bulma, Foundation
- **Design Systems**: Carbon Design, IBM Design Language
- **Framework-Specific**: Angular Material, Vuetify, Quasar
### UI Component Libraries
- **React**: shadcn/ui, Material-UI, Ant Design, Chakra UI, Mantine, PrimeReact, Headless UI, NextUI, DaisyUI
- **Vue**: Vuetify, PrimeVue, Quasar, Element Plus, Naive UI
- **Angular**: Angular Material, PrimeNG, ng-bootstrap, Clarity Design
- **Svelte**: Svelte Material UI, Carbon Components Svelte
- **Headless**: Radix UI, Reach UI, Ariakit, React Aria
### State Management
- **React**: Redux Toolkit, Zustand, Jotai, Valtio, Context API
- **Vue**: Pinia, Vuex, Composables
- **Angular**: NgRx, Akita, Services
- **Universal**: MobX, XState, Recoil
### Animation Libraries
- **React**: Framer Motion, React Spring, React Transition Group
- **Vue**: Vue Transition, Vueuse Motion
- **Universal**: GSAP, Lottie, CSS Animations, Web Animations API
- **Mobile**: React Native Reanimated, Expo Animations
### Icon Systems
Lucide, Heroicons, Material Icons, Font Awesome, Ant Design Icons, Bootstrap Icons, Ionicons, Tabler Icons, Feather, Phosphor, React Icons, Vue Icons
---
## Platform Support
### Web Development
Complete coverage of modern web development from simple HTML/CSS to complex enterprise applications.
### Mobile Development
- **React Native**: Expo, CLI, with navigation and state management
- **Flutter**: Cross-platform mobile with Material and Cupertino designs
- **Ionic**: Angular, React, and Vue-based hybrid applications
### Desktop Applications
- **Electron**: Cross-platform desktop apps (Slack, VSCode-style)
- **Tauri**: Rust-based lightweight desktop applications
- **Flutter Desktop**: Native desktop performance
### Python Applications
- **Web UI**: Streamlit, Gradio, Flask, FastAPI
- **Desktop GUI**: Tkinter, PyQt5/6, Kivy, wxPython, Dear PyGui
### Development Tools
Build tools, bundlers, testing frameworks, and development environments.
---
## Programming Language Support
**26 Languages and Approaches**:
JavaScript, TypeScript, Python, Dart, HTML5, CSS3, SCSS, SASS, Less, PostCSS, CSS Modules, Styled Components, JSX, TSX, Vue SFC, Svelte Components, Angular Templates, Tailwind, PHP
---
## Visual Style System
UIGEN-X-32B-0727 includes **21 distinct visual style categories** that can be applied to any framework:
### Modern Design Styles
- **Glassmorphism**: Frosted glass effects with blur and transparency
- **Neumorphism**: Soft, extruded design elements
- **Material Design**: Google's design system principles
- **Fluent Design**: Microsoft's design language
### Traditional & Classic
- **Skeuomorphism**: Real-world object representations
- **Swiss Design**: Clean typography and grid systems
- **Bauhaus**: Functional, geometric design principles
### Contemporary Trends
- **Brutalism**: Bold, raw, unconventional layouts
- **Anti-Design**: Intentionally imperfect, organic aesthetics
- **Minimalism**: Essential elements only, generous whitespace
### Thematic Styles
- **Cyberpunk**: Neon colors, glitch effects, futuristic elements
- **Dark Mode**: High contrast, reduced eye strain
- **Retro-Futurism**: 80s/90s inspired futuristic design
- **Geocities/90s Web**: Nostalgic early web aesthetics
### Experimental
- **Maximalism**: Rich, layered, abundant visual elements
- **Madness/Experimental**: Unconventional, boundary-pushing designs
- **Abstract Shapes**: Geometric, non-representational elements
---
## Prompt Structure Guide
### Basic Structure
To achieve the best results, use this prompting structure below:
```
[Action] + [UI Type] + [Framework Stack] + [Specific Features] + [Optional: Style]
```
### Examples
**Simple Component**:
```
Create a navigation bar using React + Tailwind CSS with logo, menu items, and mobile hamburger menu
```
**Complex Application**:
```
Build a complete e-commerce dashboard using Next.js + TypeScript + Tailwind CSS + shadcn/ui with:
- Product management (CRUD operations)
- Order tracking with status updates
- Customer analytics with charts
- Responsive design for mobile/desktop
- Dark mode toggle
Style: Use a clean, modern glassmorphism aesthetic
```
**Framework-Specific**:
```
Design an Angular Material admin panel with:
- Sidenav with expandable menu items
- Data tables with sorting and filtering
- Form validation with reactive forms
- Charts using ng2-charts
- SCSS custom theming
```
### Advanced Prompt Techniques
**Multi-Page Applications**:
```
Create a complete SaaS application using Vue 3 + Nuxt 3 + Tailwind CSS + Pinia:
Pages needed:
1. Landing page with hero, features, pricing
2. Dashboard with metrics and quick actions
3. Settings page with user preferences
4. Billing page with subscription management
Include: Navigation between pages, state management, responsive design
Style: Professional, modern with subtle animations
```
**Style Mixing**:
```
Build a portfolio website using Svelte + SvelteKit + Tailwind CSS combining:
- Minimalist layout principles
- Cyberpunk color scheme (neon accents)
- Smooth animations for page transitions
- Typography-driven content sections
```
---
## Tool Calling & Agentic Usage
UIGEN-X-32B-0727 supports **function calling** for dynamic asset integration and enhanced development workflows.
### Image Integration with Unsplash
Register tools for dynamic image fetching:
```json
{
"type": "function",
"function": {
"name": "fetch_unsplash_image",
"description": "Fetch high-quality images from Unsplash for UI mockups",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search term for image (e.g., 'modern office', 'technology', 'nature')"
},
"orientation": {
"type": "string",
"enum": ["landscape", "portrait", "squarish"],
"description": "Image orientation"
},
"size": {
"type": "string",
"enum": ["small", "regular", "full"],
"description": "Image size"
}
},
"required": ["query"]
}
}
}
```
### Content Generation Tools
```json
{
"type": "function",
"function": {
"name": "generate_content",
"description": "Generate realistic content for UI components",
"parameters": {
"type": "object",
"properties": {
"type": {
"type": "string",
"enum": ["user_profiles", "product_data", "blog_posts", "testimonials"],
"description": "Type of content to generate"
},
"count": {
"type": "integer",
"description": "Number of items to generate"
},
"theme": {
"type": "string",
"description": "Content theme or industry"
}
},
"required": ["type", "count"]
}
}
}
```
### Complete Agentic Workflow Example
```python
# 1. Plan the application
response = model.chat([
{"role": "user", "content": "Plan a complete travel booking website using React + Next.js + Tailwind CSS + shadcn/ui"}
], tools=[fetch_unsplash_image, generate_content])
# 2. The model will reason through the requirements and call tools:
# - fetch_unsplash_image(query="travel destinations", orientation="landscape")
# - generate_content(type="destinations", count=10, theme="popular travel")
# - fetch_unsplash_image(query="hotel rooms", orientation="landscape")
# 3. Generate complete implementation with real assets
final_response = model.chat([
{"role": "user", "content": "Now implement the complete website with the fetched images and content"}
])
```
### Tool Integration Patterns
**Dynamic Asset Loading**:
- Fetch relevant images during UI generation
- Generate realistic content for components
- Create cohesive color palettes from images
- Optimize assets for web performance
**Multi-Step Development**:
- Plan application architecture
- Generate individual components
- Integrate components into pages
- Apply consistent styling and theming
- Test responsive behavior
**Content-Aware Design**:
- Adapt layouts based on content types
- Optimize typography for readability
- Create responsive image galleries
- Generate accessible alt text
---
## Inference Configuration
### Optimal Parameters
```python
{
"temperature": 0.6, # Balanced creativity and consistency (make it lower if quantized!!!!)
"top_p": 0.9, # Nucleus sampling for quality
"top_k": 40, # Vocabulary restriction
"max_tokens": 25000, # Full component generation
"repetition_penalty": 1.1, # Avoid repetitive patterns
}
```
---
## Use Cases & Applications
### Rapid Prototyping
- Quick mockups for client presentations
- A/B testing different design approaches
- Concept validation with interactive prototypes
### Production Development
- Component library creation
- Design system implementation
- Template and boilerplate generation
### Educational & Learning
- Teaching modern web development
- Framework comparison and evaluation
- Best practices demonstration
### Enterprise Solutions
- Dashboard and admin panel generation
- Internal tool development
- Legacy system modernization
---
## Technical Requirements
### Hardware
- **GPU**: 8GB+ VRAM recommended (RTX 3080/4070 or equivalent)
- **RAM**: 16GB system memory minimum
- **Storage**: 20GB for model weights and cache
### Software
- **Python**: 3.8+ with transformers, torch, unsloth
- **Node.js**: For running generated JavaScript/TypeScript code
- **Browser**: Modern browser for testing generated UIs
### Integration
- Compatible with HuggingFace transformers
- Supports GGML/GGUF quantization
- Works with text-generation-webui
- API-ready for production deployment
---
## Limitations & Considerations
- **Token Usage**: Reasoning process increases token consumption
- **Complex Logic**: Focuses on UI structure rather than business logic
- **Real-time Features**: Generated code requires backend integration
- **Testing**: Output may need manual testing and refinement
- **Accessibility**: While ARIA-aware, manual a11y testing recommended
---
## Community & Support
**Discord**: [https://discord.gg/EcCpcTv93U](https://discord.gg/EcCpcTv93U)
**Website**: [https://tesslate.com](https://tesslate.com)
**Examples**: [https://uigenoutput.tesslate.com](https://uigenoutput.tesslate.com)
Join our community to share creations, get help, and contribute to the ecosystem.
---
## Citation
```bibtex
@misc{tesslate_uigen_x_2025,
title={UIGEN-X-32B-0727: Reasoning Only UI Generation with Qwen3},
author={Tesslate Team},
year={2025},
publisher={Tesslate},
url={https://huggingface.co/tesslate/UIGEN-X-32B-0727}
}
```
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ZhW150gEhg0lkXoSjkiiU.png" alt="UI Screenshot 1" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/NdxVu6Zv6beigOYjbKCl1.png" alt="UI Screenshot 2" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/RX8po_paCIxrrcTvZ3xfA.png" alt="UI Screenshot 3" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/DBssA7zan39uxy9HQOo5N.png" alt="UI Screenshot 4" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ttljEdBcYh1tkmyrCUQku.png" alt="UI Screenshot 5" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/duLxNQAuqv1FPVlsmQsWr.png" alt="UI Screenshot 6" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ja2nhpNrvucf_zwCARXxa.png" alt="UI Screenshot 7" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/ca0f_8U9HQdaSVAejpzPn.png" alt="UI Screenshot 8" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/gzZF2CiOjyEbPAPRYSV-N.png" alt="UI Screenshot 9" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/y8wB78PffUUoVLzw3al2R.png" alt="UI Screenshot 10" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/M12dGr0xArAIF7gANSC5T.png" alt="UI Screenshot 11" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/t7r7cYlUwmI1QQf3fxO7o.png" alt="UI Screenshot 12" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/-uCIIJqTrrY9xkJHKCEqC.png" alt="UI Screenshot 13" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/eqT3IUWaPtoNQb-IWQNuy.png" alt="UI Screenshot 14" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/RhbGMcxCNlMIXRLEacUGi.png" alt="UI Screenshot 15" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64d1129297ca59bcf7458d07/FWhs43BKkXku12MwiW0v9.png" alt="UI Screenshot 16" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67db34a5e7f1d129b294e2af/ILHx-xcn18cyDLX5a63xV.png" alt="UIGEN-X UI Screenshot 1" width="400">
<img src="https://cdn-uploads.huggingface.co/production/uploads/67db34a5e7f1d129b294e2af/A-zKo1J4HYftjiOjq_GB4.png" alt="UIGEN-X UI Screenshot 2" width="400">
*Built with Reasoning Only capabilities from Qwen3, UIGEN-X-32B-0727 represents a comprehensive approach to AI-driven UI development across the entire modern web development ecosystem.*
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a [Quantum Network Monitor Agent](https://readyforquantum.com/Download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) to run the .net code on. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
DeusImperator/L3.3-Shakudo-70b_exl3_3.0bpw_H6
|
DeusImperator
| 2025-08-06T14:27:54Z | 5 | 0 | null |
[
"safetensors",
"llama",
"base_model:Steelskull/L3.3-Shakudo-70b",
"base_model:quantized:Steelskull/L3.3-Shakudo-70b",
"license:llama3.3",
"3-bit",
"exl3",
"region:us"
] | null | 2025-08-05T17:57:37Z |
---
license: llama3.3
base_model:
- Steelskull/L3.3-Shakudo-70b
---
# L3.3-Shakudo-70b - EXL3 3.0bpw H6
This is a 3bpw EXL3 quant of [Steelskull/L3.3-Shakudo-70b](https://huggingface.co/Steelskull/L3.3-Shakudo-70b)
This quant was made using exllamav3-0.0.5 with '--cal_cols 4096' (instead of default 2048) which in my experience improves quant quality a bit
3bpw fits in 32GB VRAM on Windows with around 18-20k Q8 context
I tested this quant shortly in some random RPs (including ones over 8k and 16k context) and it seems to work fine
## Prompt Templates
Uses Llama 3 Instruct format. Supports thinking with "\<thinking\>" prefill in assistant response.
### Original readme below
---
<!DOCTYPE html><html lang="en" style="margin:0; padding:0; width:100%; height:100%;">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>L3.3-Shakudo-70b</title>
<link href="https://fonts.googleapis.com/css2?family=Cinzel+Decorative:wght@400;700&family=Lora:ital,wght@0,400;0,500;0,600;0,700;1,400;1,500;1,600;1,700&display=swap" rel="stylesheet">
<style>
/* GOTHIC ALCHEMIST THEME */
/* Base styles */
/* DEBUG STYLES FOR SMALL SCREENS - Added temporarily to diagnose responsive issues */
@media (max-width: 480px) {
.debug-overflow {
border: 2px solid red !important;
}
}
/* Fix for vertical text in composition list on mobile */
@media (max-width: 480px) {
.composition-list li {
grid-template-columns: 1fr; /* Change to single column on mobile */
}
.model-component a {
display: inline; /* Change from block to inline */
word-break: break-word; /* Better word breaking behavior */
}
}
/* Remove horizontal padding on containers for mobile */
@media (max-width: 480px) {
.container {
padding-left: 0;
padding-right: 0;
}
}
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
html {
font-size: 16px;
scroll-behavior: smooth;
}
body {
font-family: 'Lora', serif;
background-color: #1A1A1A;
color: #E0EAE0;
line-height: 1.6;
background: radial-gradient(ellipse at center, #2a2a2a 0%, #1A1A1A 70%);
background-attachment: fixed;
position: relative;
overflow-x: hidden;
margin: 0;
padding: 0;
font-size: 16px;
overflow-y: auto;
min-height: 100vh;
height: auto;
}
body::before {
content: '';
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
background:
radial-gradient(circle at 10% 20%, rgba(229, 91, 0, 0.15) 0%, transparent 40%),
radial-gradient(circle at 90% 80%, rgba(212, 175, 55, 0.15) 0%, transparent 40%);
pointer-events: none;
z-index: -1;
}
/* Typography */
h1, h2, h3, h4, h5, h6 {
font-family: 'Cinzel Decorative', serif;
font-weight: 700;
color: #E0EAE0;
margin-bottom: 1rem;
text-transform: uppercase;
letter-spacing: 1px;
}
p {
margin-bottom: 1.5rem;
color: rgba(224, 234, 224, 0.9);
}
a {
color: #E55B00; /* Fiery Orange */
text-decoration: none;
transition: all 0.3s ease;
}
a:hover {
color: #D4AF37; /* Gold */
text-shadow: 0 0 10px rgba(212, 175, 55, 0.7);
}
/* Aesthetic neon details */
.neon-border {
border: 1px solid #E55B00;
box-shadow: 0 0 10px rgba(229, 91, 0, 0.5);
}
.glowing-text {
color: #E55B00;
text-shadow:
0 0 5px rgba(229, 91, 0, 0.7),
0 0 10px rgba(229, 91, 0, 0.5),
0 0 15px rgba(229, 91, 0, 0.3);
}
/* Form elements */
input, select, textarea, button {
font-family: 'Lora', serif;
padding: 0.75rem 1rem;
border: 1px solid rgba(229, 91, 0, 0.5);
background-color: rgba(26, 26, 26, 0.8);
color: #E0EAE0;
border-radius: 0;
transition: all 0.3s ease;
}
input:focus, select:focus, textarea:focus {
outline: none;
border-color: #E55B00;
box-shadow: 0 0 10px rgba(229, 91, 0, 0.5);
}
button {
cursor: pointer;
background-color: rgba(229, 91, 0, 0.2);
border: 1px solid #E55B00;
border-radius: 0;
}
button:hover {
background-color: rgba(229, 91, 0, 0.4);
transform: translateY(-2px);
box-shadow: 0 0 15px rgba(229, 91, 0, 0.5);
}
/* Details and summary */
details {
margin-bottom: 1.5rem;
}
summary {
padding: 1rem;
background: rgba(229, 91, 0, 0.1);
border: 1px solid rgba(229, 91, 0, 0.3);
font-weight: 600;
cursor: pointer;
position: relative;
overflow: hidden;
border-radius: 0;
transition: all 0.3s ease;
}
summary:hover {
background: rgba(229, 91, 0, 0.2);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.4);
}
summary::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 8px;
height: 100%;
background: linear-gradient(135deg, #E55B00, #D4AF37);
opacity: 0.7;
}
details[open] summary {
margin-bottom: 1rem;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.4);
}
/* Code blocks */
code {
font-family: 'Cascadia Code', 'Source Code Pro', monospace;
background: rgba(229, 91, 0, 0.1);
padding: 0.2rem 0.4rem;
border: 1px solid rgba(229, 91, 0, 0.3);
border-radius: 0;
font-size: 0.9rem;
color: #E55B00;
}
pre {
background: rgba(26, 26, 26, 0.8);
padding: 1.5rem;
border: 1px solid rgba(229, 91, 0, 0.3);
overflow-x: auto;
margin-bottom: 1.5rem;
border-radius: 0;
}
pre code {
background: transparent;
padding: 0;
border: none;
color: #E0EAE0;
}
/* Scrollbar styling */
::-webkit-scrollbar {
width: 8px;
height: 8px;
background-color: #1A1A1A;
}
::-webkit-scrollbar-thumb {
background: linear-gradient(135deg, #E55B00, #D4AF37);
border-radius: 0;
}
::-webkit-scrollbar-track {
background-color: rgba(26, 26, 26, 0.8);
border-radius: 0;
}
/* Selection styling */
::selection {
background-color: rgba(229, 91, 0, 0.3);
color: #E0EAE0;
}
/* Metrics section */
.metrics-section {
margin-bottom: 30px;
position: relative;
background: rgba(3, 6, 18, 0.8);
border: 1px solid #00b2ff;
padding: 20px;
clip-path: polygon(0 0, calc(100% - 15px) 0, 100% 15px, 100% 100%, 15px 100%, 0 calc(100% - 15px));
box-shadow: 0 0 20px rgba(0, 178, 255, 0.15);
}
/* Core metrics grid */
.core-metrics-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(200px, 1fr));
gap: 15px;
margin-bottom: 30px;
}
.info-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(150px, 1fr));
gap: 15px;
}
/* Metric box */
.metric-box {
background: rgba(3, 6, 18, 0.8);
border: 1px solid #00b2ff;
border-radius: 0;
padding: 15px;
display: flex;
flex-direction: column;
gap: 8px;
position: relative;
overflow: hidden;
clip-path: polygon(0 0, calc(100% - 10px) 0, 100% 10px, 100% 100%, 10px 100%, 0 calc(100% - 10px));
box-shadow: 0 0 15px rgba(0, 178, 255, 0.15);
transition: all 0.3s ease;
}
.metric-box:hover {
box-shadow: 0 0 20px rgba(0, 178, 255, 0.3);
transform: translateY(-2px);
}
.metric-box::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-image:
linear-gradient(45deg, rgba(0, 178, 255, 0.1) 25%, transparent 25%, transparent 75%, rgba(0, 178, 255, 0.1) 75%),
linear-gradient(-45deg, rgba(0, 178, 255, 0.1) 25%, transparent 25%, transparent 75%, rgba(0, 178, 255, 0.1) 75%);
background-size: 10px 10px;
pointer-events: none;
opacity: 0.5;
}
.metric-box .label {
color: #e0f7ff;
font-size: 14px;
font-weight: 500;
text-transform: uppercase;
letter-spacing: 1px;
text-shadow: 0 0 5px rgba(0, 178, 255, 0.3);
}
.metric-box .value {
color: #00b2ff;
font-size: 28px;
font-weight: 700;
text-shadow:
0 0 10px rgba(0, 178, 255, 0.5),
0 0 20px rgba(0, 178, 255, 0.3);
letter-spacing: 1px;
font-family: 'Orbitron', sans-serif;
}
/* Progress metrics */
.progress-metrics {
display: grid;
gap: 15px;
padding: 20px;
background: rgba(3, 6, 18, 0.8);
border: 1px solid #00b2ff;
position: relative;
overflow: hidden;
clip-path: polygon(0 0, calc(100% - 15px) 0, 100% 15px, 100% 100%, 15px 100%, 0 calc(100% - 15px));
box-shadow: 0 0 20px rgba(0, 178, 255, 0.15);
}
.progress-metric {
display: grid;
gap: 8px;
}
.progress-label {
display: flex;
justify-content: space-between;
align-items: center;
color: #e0f7ff;
font-size: 14px;
text-transform: uppercase;
letter-spacing: 1px;
text-shadow: 0 0 5px rgba(0, 178, 255, 0.3);
}
.progress-value {
color: #00b2ff;
font-weight: 600;
text-shadow:
0 0 5px rgba(0, 178, 255, 0.5),
0 0 10px rgba(0, 178, 255, 0.3);
font-family: 'Orbitron', sans-serif;
}
/* Progress bars */
.progress-bar {
height: 4px;
background: rgba(0, 178, 255, 0.1);
border-radius: 0;
overflow: hidden;
position: relative;
border: 1px solid rgba(0, 178, 255, 0.2);
clip-path: polygon(0 0, 100% 0, calc(100% - 4px) 100%, 0 100%);
}
.progress-fill {
height: 100%;
background: linear-gradient(90deg, #0062ff, #00b2ff);
border-radius: 0;
position: relative;
overflow: hidden;
clip-path: polygon(0 0, calc(100% - 4px) 0, 100% 100%, 0 100%);
box-shadow:
0 0 10px rgba(0, 178, 255, 0.4),
0 0 20px rgba(0, 178, 255, 0.2);
}
.progress-fill::after {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background: linear-gradient(90deg,
rgba(255, 255, 255, 0.1) 0%,
rgba(255, 255, 255, 0.1) 40%,
rgba(255, 255, 255, 0.3) 50%,
rgba(255, 255, 255, 0.1) 60%,
rgba(255, 255, 255, 0.1) 100%
);
background-size: 200% 100%;
animation: shimmer 2s infinite;
}
/* Split progress bars */
.progress-metric.split .progress-label {
justify-content: space-between;
font-size: 13px;
}
.progress-bar.split {
display: flex;
background: rgba(0, 178, 255, 0.1);
position: relative;
justify-content: center;
border: 1px solid rgba(0, 178, 255, 0.2);
clip-path: polygon(0 0, 100% 0, calc(100% - 4px) 100%, 0 100%);
}
.progress-bar.split::after {
content: '';
position: absolute;
top: 0;
left: 50%;
transform: translateX(-50%);
width: 2px;
height: 100%;
background: rgba(0, 178, 255, 0.3);
z-index: 2;
box-shadow: 0 0 10px rgba(0, 178, 255, 0.4);
}
.progress-fill-left,
.progress-fill-right {
height: 100%;
background: linear-gradient(90deg, #0062ff, #00b2ff);
position: relative;
width: 50%;
overflow: hidden;
}
.progress-fill-left {
clip-path: polygon(0 0, calc(100% - 4px) 0, 100% 100%, 0 100%);
margin-right: 1px;
transform-origin: right;
transform: scaleX(var(--scale, 0));
box-shadow:
0 0 10px rgba(0, 178, 255, 0.4),
0 0 20px rgba(0, 178, 255, 0.2);
}
.progress-fill-right {
clip-path: polygon(0 0, 100% 0, 100% 100%, 4px 100%);
margin-left: 1px;
transform-origin: left;
transform: scaleX(var(--scale, 0));
box-shadow:
0 0 10px rgba(0, 178, 255, 0.4),
0 0 20px rgba(0, 178, 255, 0.2);
}
/* Benchmark container */
.benchmark-container {
background: rgba(3, 6, 18, 0.8);
border: 1px solid #00b2ff;
position: relative;
overflow: hidden;
clip-path: polygon(0 0, calc(100% - 15px) 0, 100% 15px, 100% 100%, 15px 100%, 0 calc(100% - 15px));
box-shadow: 0 0 20px rgba(0, 178, 255, 0.15);
padding: 20px;
}
/* Benchmark notification */
.benchmark-notification {
background: rgba(3, 6, 18, 0.8);
border: 1px solid #00b2ff;
padding: 15px;
margin-bottom: 20px;
position: relative;
overflow: hidden;
clip-path: polygon(0 0, calc(100% - 10px) 0, 100% 10px, 100% 100%, 10px 100%, 0 calc(100% - 10px));
box-shadow: 0 0 15px rgba(0, 178, 255, 0.15);
}
.notification-content {
display: flex;
align-items: center;
gap: 10px;
position: relative;
z-index: 1;
}
.notification-icon {
font-size: 20px;
color: #00b2ff;
text-shadow:
0 0 10px rgba(0, 178, 255, 0.5),
0 0 20px rgba(0, 178, 255, 0.3);
}
.notification-text {
color: #e0f7ff;
font-size: 14px;
display: flex;
align-items: center;
gap: 10px;
flex-wrap: wrap;
text-transform: uppercase;
letter-spacing: 1px;
text-shadow: 0 0 5px rgba(0, 178, 255, 0.3);
}
.benchmark-link {
color: #00b2ff;
font-weight: 500;
white-space: nowrap;
text-shadow:
0 0 5px rgba(0, 178, 255, 0.5),
0 0 10px rgba(0, 178, 255, 0.3);
position: relative;
padding: 2px 5px;
border: 1px solid rgba(0, 178, 255, 0.3);
clip-path: polygon(0 0, calc(100% - 5px) 0, 100% 5px, 100% 100%, 5px 100%, 0 calc(100% - 5px));
transition: all 0.3s ease;
}
.benchmark-link:hover {
background: rgba(0, 178, 255, 0.1);
border-color: #00b2ff;
box-shadow: 0 0 10px rgba(0, 178, 255, 0.3);
}
@keyframes shimmer {
0% { background-position: 200% 0; }
100% { background-position: -200% 0; }
}
/* Button styles */
.button {
display: inline-block;
padding: 10px 20px;
background-color: rgba(229, 91, 0, 0.2);
color: #E0EAE0;
border: 1px solid #E55B00;
font-family: 'Cinzel Decorative', serif;
font-weight: 600;
font-size: 15px;
text-transform: uppercase;
letter-spacing: 1px;
cursor: pointer;
transition: all 0.3s ease;
position: relative;
overflow: hidden;
text-align: center;
border-radius: 0;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.3);
}
.button:hover {
background-color: rgba(229, 91, 0, 0.4);
color: #E0EAE0;
transform: translateY(-2px);
box-shadow: 0 0 20px rgba(212, 175, 55, 0.5);
text-shadow: 0 0 10px rgba(212, 175, 55, 0.7);
}
.button:active {
transform: translateY(1px);
box-shadow: 0 0 10px rgba(229, 91, 0, 0.4);
}
.button::before {
content: '';
position: absolute;
top: 0;
left: -100%;
width: 100%;
height: 100%;
background: linear-gradient(
90deg,
transparent,
rgba(212, 175, 55, 0.3),
transparent
);
transition: left 0.7s ease;
}
.button:hover::before {
left: 100%;
}
.button::after {
content: '';
position: absolute;
inset: 0;
background-image: linear-gradient(45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%), linear-gradient(-45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%);
background-size: 10px 10px;
opacity: 0;
transition: opacity 0.3s ease;
pointer-events: none;
}
.button:hover::after {
opacity: 0.5;
}
/* Support buttons */
.support-buttons {
display: flex;
gap: 15px;
flex-wrap: wrap;
}
.support-buttons .button {
min-width: 150px;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.3);
}
.support-buttons .button:hover {
box-shadow: 0 0 20px rgba(212, 175, 55, 0.5);
}
/* Button animations */
@keyframes pulse {
0% {
box-shadow: 0 0 10px rgba(0, 178, 255, 0.3);
}
50% {
box-shadow: 0 0 20px rgba(0, 178, 255, 0.5);
}
100% {
box-shadow: 0 0 10px rgba(0, 178, 255, 0.3);
}
}
.animated-button {
animation: pulse 2s infinite;
}
/* Button variants */
.button.primary {
background-color: rgba(0, 98, 255, 0.2);
border-color: #00b2ff;
}
.button.primary:hover {
background-color: rgba(0, 98, 255, 0.3);
}
.button.outline {
background-color: transparent;
border-color: #00b2ff;
}
.button.outline:hover {
background-color: rgba(0, 98, 255, 0.1);
}
.button.small {
padding: 6px 12px;
font-size: 13px;
}
.button.large {
padding: 12px 24px;
font-size: 16px;
}
/* Button with icon */
.button-with-icon {
display: inline-flex;
align-items: center;
gap: 8px;
}
.button-icon {
font-size: 18px;
line-height: 1;
}
/* Responsive adjustments */
@media (max-width: 768px) {
.support-buttons {
flex-direction: column;
}
.support-buttons .button {
width: 100%;
}
}
/* Container & Layout */
.container {
width: 100%;
max-width: 100%;
margin: 0;
padding: 20px;
position: relative;
background-color: rgba(26, 26, 26, 0.8);
border: 1px solid #E55B00;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.5);
border-radius: 0;
}
.container::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background:
radial-gradient(circle at 20% 30%, rgba(229, 91, 0, 0.15) 0%, transparent 50%),
radial-gradient(circle at 80% 70%, rgba(212, 175, 55, 0.1) 0%, transparent 40%);
pointer-events: none;
z-index: -1;
}
/* Header */
.header {
margin-bottom: 50px;
position: relative;
padding-bottom: 20px;
border-bottom: 1px solid #E55B00;
overflow: hidden;
}
.header::before {
content: '';
position: absolute;
bottom: -1px;
left: 0;
width: 50%;
height: 1px;
background: linear-gradient(90deg, #E55B00, transparent);
box-shadow: 0 0 20px #E55B00;
}
.header::after {
content: '';
position: absolute;
bottom: -1px;
right: 0;
width: 50%;
height: 1px;
background: linear-gradient(90deg, transparent, #E55B00);
box-shadow: 0 0 20px #E55B00;
}
.header h1 {
font-family: 'Cinzel Decorative', serif;
font-size: 48px;
color: #E0EAE0;
text-align: center;
text-transform: uppercase;
letter-spacing: 2px;
margin: 0;
position: relative;
text-shadow:
0 0 5px rgba(229, 91, 0, 0.7),
0 0 10px rgba(229, 91, 0, 0.5),
0 0 20px rgba(229, 91, 0, 0.3);
}
.header h1::before {
content: '';
position: absolute;
width: 100px;
height: 1px;
bottom: -10px;
left: 50%;
transform: translateX(-50%);
background: #E55B00;
box-shadow: 0 0 20px #E55B00;
}
/* Info section */
.info {
margin-bottom: 50px;
overflow: visible; /* Ensure content can extend beyond container */
}
.info > img {
width: 100%;
height: auto;
border: 1px solid #E55B00;
margin-bottom: 30px;
box-shadow: 0 0 30px rgba(229, 91, 0, 0.5);
border-radius: 0;
background-color: rgba(26, 26, 26, 0.6);
display: block;
}
.info h2 {
font-family: 'Cinzel Decorative', serif;
font-size: 28px;
color: #E0EAE0;
text-transform: uppercase;
letter-spacing: 1.5px;
margin: 30px 0 20px 0;
padding-bottom: 10px;
border-bottom: 1px solid rgba(229, 91, 0, 0.4);
position: relative;
text-shadow: 0 0 10px rgba(229, 91, 0, 0.5);
}
.info h2::after {
content: '';
position: absolute;
bottom: -1px;
left: 0;
width: 100px;
height: 1px;
background: #E55B00;
box-shadow: 0 0 15px #E55B00;
}
.info h3 {
font-family: 'Cinzel Decorative', serif;
font-size: 24px;
color: #E0EAE0;
margin: 20px 0 15px 0;
letter-spacing: 1px;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.4);
}
.info h4 {
font-family: 'Lora', serif;
font-size: 18px;
color: #E55B00;
margin: 15px 0 10px 0;
letter-spacing: 0.5px;
text-transform: uppercase;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
}
.info p {
margin: 0 0 15px 0;
line-height: 1.6;
}
/* Creator section */
.creator-section {
margin-bottom: 30px;
padding: 20px 20px 10px 20px;
background: rgba(26, 26, 26, 0.8);
border: 1px solid #E55B00;
position: relative;
border-radius: 15px;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.3);
}
.creator-badge {
position: relative;
z-index: 1;
}
.creator-info {
display: flex;
flex-direction: column;
}
.creator-label {
color: #E0EAE0;
font-size: 14px;
text-transform: uppercase;
letter-spacing: 1px;
margin-bottom: 5px;
}
.creator-link {
color: #E55B00;
text-decoration: none;
font-weight: 600;
display: flex;
align-items: center;
gap: 5px;
transition: all 0.3s ease;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
}
.creator-link:hover {
transform: translateX(5px);
text-shadow: 0 0 10px rgba(212, 175, 55, 0.7);
}
.creator-name {
font-size: 18px;
}
.creator-arrow {
font-weight: 600;
transition: transform 0.3s ease;
}
/* Supporters dropdown section */
.sponsors-section {
margin-top: 15px;
position: relative;
z-index: 2;
}
.sponsors-dropdown {
width: 100%;
background: rgba(229, 91, 0, 0.1);
border: 1px solid #E55B00;
border-radius: 15px;
overflow: hidden;
position: relative;
}
.sponsors-summary {
padding: 12px 15px;
display: flex;
justify-content: space-between;
align-items: center;
cursor: pointer;
outline: none;
position: relative;
z-index: 1;
transition: all 0.3s ease;
}
.sponsors-summary:hover {
background-color: rgba(229, 91, 0, 0.2);
}
.sponsors-title {
font-family: 'Cinzel Decorative', serif;
color: #E0EAE0;
font-size: 16px;
text-transform: uppercase;
letter-spacing: 1px;
font-weight: 600;
text-shadow: 0 0 8px rgba(229, 91, 0, 0.4);
}
.sponsors-list {
padding: 15px;
display: grid;
grid-template-columns: repeat(auto-fill, minmax(120px, 1fr));
gap: 15px;
background: transparent;
border-top: 1px solid rgba(229, 91, 0, 0.3);
}
.sponsor-item {
display: flex;
flex-direction: column;
align-items: center;
text-align: center;
padding: 10px;
border: 1px solid rgba(229, 91, 0, 0.2);
background: rgba(229, 91, 0, 0.1);
border-radius: 15px;
transition: all 0.3s ease;
}
.sponsor-item:hover {
transform: translateY(-3px);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.3);
background: rgba(229, 91, 0, 0.2);
}
.sponsor-rank {
color: #E55B00;
font-weight: 600;
font-size: 14px;
margin-bottom: 5px;
text-shadow: 0 0 8px rgba(229, 91, 0, 0.5);
}
.sponsor-img {
width: 60px;
height: 60px;
border-radius: 50%;
object-fit: cover;
border: 2px solid #E55B00;
box-shadow: 0 0 12px rgba(229, 91, 0, 0.3);
margin-bottom: 8px;
transition: all 0.3s ease;
}
.sponsor-item:nth-child(1) .sponsor-img {
border-color: gold;
box-shadow: 0 0 12px rgba(255, 215, 0, 0.5);
}
.sponsor-item:nth-child(2) .sponsor-img {
border-color: silver;
box-shadow: 0 0 12px rgba(192, 192, 192, 0.5);
}
.sponsor-item:nth-child(3) .sponsor-img {
border-color: #cd7f32; /* bronze */
box-shadow: 0 0 12px rgba(205, 127, 50, 0.5);
}
.sponsor-item:hover .sponsor-img {
border-color: #D4AF37;
}
.sponsor-name {
color: #E0EAE0;
font-size: 14px;
font-weight: 500;
word-break: break-word;
}
.creator-link:hover .creator-arrow {
transform: translateX(5px);
}
.dropdown-icon {
color: #E55B00;
transition: transform 0.3s ease;
}
details[open] .dropdown-icon {
transform: rotate(180deg);
}
/* Model info */
.model-info {
margin-bottom: 50px;
}
/* Section container */
.section-container {
margin-bottom: 50px;
padding: 25px;
background: rgba(26, 26, 26, 0.8);
border: 1px solid #E55B00;
position: relative;
overflow: hidden;
border-radius: 15px;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.3);
}
.section-container::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-image:
linear-gradient(45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%),
linear-gradient(-45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%);
background-size: 10px 10px;
pointer-events: none;
z-index: 0;
opacity: 0.5;
}
.section-container h2 {
margin-top: 0;
}
/* Support section */
.support-section {
margin-bottom: 50px;
padding: 25px;
background: rgba(26, 26, 26, 0.8);
border: 1px solid #E55B00;
position: relative;
overflow: hidden;
border-radius: 15px;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.3);
}
.support-section::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-image:
linear-gradient(45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%),
linear-gradient(-45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%);
background-size: 10px 10px;
pointer-events: none;
z-index: 0;
opacity: 0.5;
}
.support-section h2 {
margin-top: 0;
}
/* Special thanks */
.special-thanks {
margin-top: 30px;
}
.thanks-list {
list-style: none;
padding: 0;
margin: 15px 0;
display: grid;
grid-template-columns: repeat(auto-fill, minmax(250px, 1fr));
gap: 15px;
}
.thanks-list li {
padding: 10px 15px;
background: rgba(229, 91, 0, 0.1);
border: 1px solid rgba(229, 91, 0, 0.3);
position: relative;
overflow: hidden;
border-radius: 0;
transition: all 0.3s ease;
}
.thanks-list li:hover {
background: rgba(229, 91, 0, 0.2);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.4);
transform: translateY(-2px);
}
.thanks-list li strong {
color: #E55B00;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
}
.thanks-note {
font-style: italic;
color: rgba(224, 234, 224, 0.7);
text-align: center;
margin-top: 20px;
}
/* General card styles */
.info-card,
.template-card,
.settings-card,
.quantized-section {
background: rgba(26, 26, 26, 0.8);
border: 1px solid #E55B00;
padding: 25px;
margin: 20px 0;
position: relative;
overflow: hidden;
border-radius: 15px;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.3);
}
.info-card::before,
.template-card::before,
.settings-card::before,
.quantized-section::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-image:
linear-gradient(45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%),
linear-gradient(-45deg, rgba(229, 91, 0, 0.1) 25%, transparent 25%, transparent 75%, rgba(229, 91, 0, 0.1) 75%);
background-size: 10px 10px;
pointer-events: none;
z-index: 0;
opacity: 0.5;
}
.info-card::after,
.template-card::after,
.settings-card::after,
.quantized-section::after {
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background: linear-gradient(135deg, rgba(229, 91, 0, 0.15), transparent 70%);
pointer-events: none;
z-index: 0;
}
/* Info card specific */
.info-card {
box-shadow: 0 0 30px rgba(229, 91, 0, 0.4);
}
.info-header {
margin-bottom: 25px;
padding-bottom: 15px;
border-bottom: 1px solid rgba(229, 91, 0, 0.4);
position: relative;
}
.info-header::after {
content: '';
position: absolute;
bottom: -1px;
left: 0;
width: 100px;
height: 1px;
background: #E55B00;
box-shadow: 0 0 10px #E55B00;
}
.model-tags {
display: flex;
flex-wrap: wrap;
gap: 10px;
margin-top: 10px;
}
.model-tag {
background: rgba(229, 91, 0, 0.2);
border: 1px solid #E55B00;
color: #E0EAE0;
font-size: 12px;
padding: 5px 10px;
text-transform: uppercase;
letter-spacing: 1px;
font-weight: 500;
position: relative;
overflow: hidden;
border-radius: 0;
box-shadow: 0 0 10px rgba(229, 91, 0, 0.4);
transition: all 0.3s ease;
}
.model-tag:hover {
background: rgba(229, 91, 0, 0.4);
box-shadow: 0 0 15px rgba(229, 91, 0, 0.6);
transform: translateY(-2px);
}
/* Model composition list */
.model-composition h4 {
margin-bottom: 15px;
}
.composition-list {
list-style: none;
padding: 0;
margin: 0 0 20px 0;
display: grid;
gap: 12px;
}
.composition-list li {
display: grid;
grid-template-columns: minmax(0, 1fr) auto;
align-items: center;
gap: 10px;
padding: 10px 15px;
background: rgba(229, 91, 0, 0.1);
border: 1px solid rgba(229, 91, 0, 0.3);
position: relative;
overflow: hidden;
border-radius: 0;
transition: all 0.3s ease;
}
.composition-list li:hover {
background: rgba(229, 91, 0, 0.2);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.4);
transform: translateY(-2px);
}
.composition-list li::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 8px;
height: 100%;
background: linear-gradient(180deg, #E55B00, #D4AF37);
opacity: 0.7;
box-shadow: 0 0 10px rgba(229, 91, 0, 0.6);
}
.model-component {
color: #E55B00;
font-weight: 500;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
}
.model-component a {
display: block;
overflow-wrap: break-word;
word-wrap: break-word;
word-break: break-word;
transition: all 0.3s ease;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
}
.model-component a:hover {
transform: translateX(5px);
text-shadow: 0 0 10px rgba(212, 175, 55, 0.7);
}
/* Base model dropdown styles */
.base-model-dropdown {
width: 100%;
position: relative;
padding-right: 50px; /* Make space for the BASE label */
display: block;
margin-bottom: 0;
}
.base-model-summary {
display: flex;
justify-content: space-between;
align-items: center;
padding: 8px 12px 8px 20px; /* Increased left padding to prevent text overlap with blue stripe */
cursor: pointer;
border: 1px solid rgba(229, 91, 0, 0.3);
position: relative;
border-radius: 0;
margin-bottom: 0;
transition: all 0.3s ease;
color: #E55B00;
font-weight: 500;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
}
.base-model-summary:hover {
background: rgba(229, 91, 0, 0.2);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.4);
}
.base-model-summary span:first-child {
overflow: hidden;
text-overflow: ellipsis;
display: inline-block;
white-space: nowrap;
flex: 1;
}
.dropdown-icon {
font-size: 0.75rem;
margin-left: 8px;
color: rgba(229, 91, 0, 0.7);
transition: transform 0.3s ease;
}
.base-model-dropdown[open] .dropdown-icon {
transform: rotate(180deg);
}
.base-model-list {
position: absolute;
margin-top: 0;
left: 50%;
transform: translateX(-50%);
background: rgba(26, 26, 26, 0.95);
border: 1px solid rgba(229, 91, 0, 0.5);
border-radius: 0;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.3);
min-width: 100%;
overflow: visible;
}
.base-model-item {
padding: 8px 12px 8px 20px; /* Increased left padding for the model items */
border-bottom: 1px solid rgba(229, 91, 0, 0.2);
position: relative;
transition: all 0.3s ease;
}
.base-model-item:last-child {
border-bottom: none;
margin-bottom: 0;
}
.base-model-item:hover {
background: rgba(229, 91, 0, 0.2);
box-shadow: 0 0 15px rgba(229, 91, 0, 0.4);
transform: translateY(-1px) translateX(0);
}
.base-model-item a {
display: block;
width: 100%;
overflow: hidden;
padding-left: 10px;
}
.model-label {
color: #E55B00;
text-decoration: none;
transition: all 0.3s ease;
display: inline-block;
font-weight: 500;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}
.model-label:hover {
text-shadow: 0 0 10px rgba(212, 175, 55, 0.7);
}
/* BASE label */
.base-model-dropdown::after {
z-index: 1;
content: attr(data-merge-type);
position: absolute;
right: 0;
top: 8px;
transform: translateY(0);
font-size: 10px;
padding: 2px 5px;
background: rgba(229, 91, 0, 0.3);
color: #E0EAE0;
border: 1px solid #E55B00;
box-shadow: 0 0 10px rgba(229, 91, 0, 0.5);
border-radius: 0;
}
/* Override the blue stripe for base-model-summary and items */
.base-model-dropdown {
position: relative;
}
.base-model-summary::before,
.base-model-item::before {
content: '';
position: absolute;
top: 0;
left: 0;
width: 8px;
height: 100%;
background: linear-gradient(180deg, #E55B00, #D4AF37);
opacity: 0.7;
}
.base-model-dropdown[open] .base-model-summary,
.base-model-dropdown[open] .base-model-list {
border-color: rgba(229, 91, 0, 0.7);
box-shadow: 0 0 25px rgba(229, 91, 0, 0.5);
z-index: 20;
position: relative;
}
/* Model description */
.model-description {
margin-top: 30px;
}
.model-description h4 {
margin-bottom: 15px;
}
.model-description p {
margin-bottom: 20px;
}
.model-description ul {
padding-left: 20px;
margin-bottom: 20px;
list-style: none;
}
.model-description li {
margin-bottom: 8px;
position: relative;
padding-left: 15px;
}
.model-description li::before {
content: '†';
position: absolute;
left: 0;
top: 0;
color: #E55B00;
text-shadow: 0 0 10px rgba(229, 91, 0, 0.7);
}
/* Template card */
.template-card {
box-shadow: 0 0 30px rgba(229, 91, 0, 0.4);
}
.template-item {
padding: 15px;
margin-bottom: 15px;
background: rgba(229, 91, 0, 0.1);
border: 1px solid rgba(229, 91, 0, 0.3);
position: relative;
border-radius: 0;
transition: all 0.3s ease;
}
.template-item:hover {
background: rgba(229, 91, 0, 0.2);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.5);
transform: translateY(-2px);
}
.template-content {
display: flex;
flex-direction: column;
gap: 5px;
}
.template-link {
display: flex;
align-items: center;
justify-content: space-between;
font-weight: 600;
color: #E55B00;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.5);
padding: 5px;
transition: all 0.3s ease;
}
.template-link:hover {
text-shadow: 0 0 10px rgba(212, 175, 55, 0.7);
transform: translateX(5px);
}
.link-arrow {
font-weight: 600;
transition: transform 0.3s ease;
}
.template-link:hover .link-arrow {
transform: translateX(5px);
}
.template-author {
font-size: 14px;
color: rgba(224, 234, 224, 0.8);
text-transform: uppercase;
letter-spacing: 1px;
}
/* Settings card */
.settings-card {
box-shadow: 0 0 30px rgba(229, 91, 0, 0.4);
}
.settings-header {
margin-bottom: 15px;
padding-bottom: 10px;
border-bottom: 1px solid rgba(229, 91, 0, 0.4);
position: relative;
}
.settings-header::after {
content: '';
position: absolute;
bottom: -1px;
left: 0;
width: 80px;
height: 1px;
background: #E55B00;
box-shadow: 0 0 10px #E55B00;
}
.settings-content {
padding: 15px;
background: rgba(229, 91, 0, 0.1);
border: 1px solid rgba(229, 91, 0, 0.3);
margin-bottom: 15px;
position: relative;
border-radius: 0;
}
.settings-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(250px, 1fr));
gap: 20px;
margin-top: 20px;
}
.setting-item {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 10px;
padding: 8px 0;
border-bottom: 1px solid rgba(229, 91, 0, 0.2);
}
.setting-item:last-child {
margin-bottom: 0;
border-bottom: none;
}
.setting-label {
color: #E0EAE0;
font-size: 14px;
font-weight: 500;
text-transform: uppercase;
letter-spacing: 1px;
}
.setting-value {
color: #E55B00;
font-weight: 600;
font-family: 'Lora', serif;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.7);
}
.setting-item.highlight {
padding: 15px;
background: rgba(229, 91, 0, 0.2);
border: 1px solid rgba(229, 91, 0, 0.4);
border-radius: 0;
display: flex;
justify-content: center;
position: relative;
}
.setting-item.highlight .setting-value {
font-size: 24px;
font-weight: 700;
text-shadow:
0 0 10px rgba(229, 91, 0, 0.7),
0 0 20px rgba(229, 91, 0, 0.5);
}
/* Sampler Settings Section */
.sampler-settings {
position: relative;
overflow: visible;
}
.sampler-settings .settings-card {
background: rgba(26, 26, 26, 0.8);
border: 1px solid #E55B00;
box-shadow: 0 0 20px rgba(229, 91, 0, 0.4), inset 0 0 30px rgba(229, 91, 0, 0.2);
padding: 20px;
margin: 15px 0;
position: relative;
}
.sampler-settings .settings-header h3 {
color: #E55B00;
text-shadow: 0 0 8px rgba(229, 91, 0, 0.7);
font-size: 1.2rem;
letter-spacing: 1px;
}
.sampler-settings .settings-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(250px, 1fr));
gap: 15px;
}
.sampler-settings .setting-item {
border-bottom: 1px solid rgba(229, 91, 0, 0.3);
padding: 12px 0;
transition: all 0.3s ease;
}
.sampler-settings .setting-label {
font-family: 'Lora', serif;
font-weight: 600;
color: #E0EAE0;
}
.sampler-settings .setting-value {
font-family: 'Lora', serif;
color: #E55B00;
}
/* DRY Settings styles */
.dry-settings {
margin-top: 8px;
padding-left: 8px;
border-left: 2px solid rgba(229, 91, 0, 0.4);
display: flex;
flex-direction: column;
gap: 6px;
}
.dry-item {
display: flex;
justify-content: space-between;
align-items: center;
}
.dry-label {
font-size: 13px;
color: #E0EAE0;
}
.dry-value {
color: #E55B00;
font-family: 'Lora', serif;
text-shadow: 0 0 5px rgba(229, 91, 0, 0.6);
}
/* Quantized sections */
.quantized-section {
margin-bottom: 30px;
}
.quantized-items {
display: grid;
gap: 15px;
margin-top: 15px;
}
.quantized-item {
padding: 15px;
background: rgba(229, 91, 0, 0.1);
border: 1px solid rgba(229, 91, 0, 0.3);
display: grid;
gap: 8px;
position: relative;
border-radius: 0;
transition: all 0.3s ease;
}
.quantized-item:hover {
background: rgba(229, 91, 0, 0.2);
border-color: #E55B00;
box-shadow: 0 0 15px rgba(229, 91, 0, 0.5);
transform: translateY(-2px);
}
.author {
color: #E0EAE0;
font-size: 12px;
text-transform: uppercase;
letter-spacing: 1px;
font-weight: 500;
}
.multi-links {
display: flex;
align-items: center;
flex-wrap: wrap;
gap: 5px;
}
.separator {
color: rgba(224, 234, 224, 0.5);
margin: 0 5px;
}
/* Medieval Corners */
.corner {
position: absolute;
background:none;
width:6em;
height:6em;
font-size:10px;
opacity: 1.0;
transition: opacity 0.3s ease-in-out;
}
.corner:after {
position: absolute;
content: '';
display: block;
width:0.2em;
height:0.2em;
}
/* New Progress Bar Design */
.new-progress-container {
margin: 2rem 0;
padding: 1.5rem;
background: rgba(229, 91, 0, 0.05);
border: 1px solid rgba(229, 91, 0, 0.2);
position: relative;
}
.new-progress-container h3 {
text-align: center;
margin-bottom: 1.5rem;
color: #E0EAE0;
font-family: 'Cinzel Decorative', serif;
}
.main-progress-bar {
width: 100%;
height: 8px;
background: rgba(229, 91, 0, 0.2);
margin-bottom: 1.5rem;
border-radius: 4px;
overflow: hidden;
border: 1px solid rgba(229, 91, 0, 0.3);
}
.main-progress-fill {
height: 100%;
background: linear-gradient(90deg, #E55B00, #D4AF37);
box-shadow: 0 0 10px #E55B00;
}
.main-steps-container {
display: flex;
flex-direction: column;
gap: 1rem;
}
.main-step {
border: 1px solid rgba(229, 91, 0, 0.3);
transition: all 0.3s ease;
}
.main-step[open] {
background: rgba(229, 91, 0, 0.1);
}
.main-step summary {
padding: 1rem;
cursor: pointer;
display: grid;
grid-template-columns: auto 1fr auto;
align-items: center;
gap: 1rem;
font-weight: 600;
color: #E0EAE0;
position: relative;
}
.main-step summary .arrow {
width: 0;
height: 0;
border-left: 6px solid transparent;
border-right: 6px solid transparent;
border-top: 6px solid #E55B00;
transition: transform 0.3s ease;
}
.main-step[open] summary .arrow {
transform: rotate(180deg);
}
.main-step summary::-webkit-details-marker {
display: none;
}
.step-title {
font-family: 'Cinzel Decorative', serif;
}
.step-progress-bar {
width: 150px;
height: 6px;
background: rgba(224, 234, 224, 0.2);
border-radius: 3px;
overflow: hidden;
}
.step-progress-fill {
height: 100%;
background: #E55B00;
}
.sub-steps-list {
list-style: none;
padding: 0 1rem 1rem 1rem;
margin: 0;
}
.sub-steps-list li {
padding: 0.5rem 0;
border-bottom: 1px solid rgba(229, 91, 0, 0.1);
color: rgba(224, 234, 224, 0.7);
}
.sub-steps-list li:last-child {
border-bottom: none;
}
.sub-steps-list li.completed {
color: #E55B00;
text-decoration: line-through;
}
.sub-steps-list li.current {
color: #E0EAE0;
font-weight: bold;
}
.topleft {
top:1em;
left:1em;
-webkit-transform:rotate(360deg); transform:rotate(360deg);
}
.topright {
top:1em; right:1em; -webkit-transform:rotate(90deg); transform:rotate(90deg);
}
.bottomleft {
bottom:1em; left:1em; -webkit-transform:rotate(270deg); transform:rotate(270deg);
}
.bottomright {
bottom:1em; right:1em; -webkit-transform:rotate(180deg); transform:rotate(180deg);
}
.variant:after {
width:0.1em;
height:0.1em;
}
.corner5:after {
box-shadow:
0.2em 0em #D4AF37, 0.4em 0em #D4AF37, 0.6em 0em #D4AF37, 4.0em 0em #D4AF37, 4.2em 0em #D4AF37, 4.4em 0em #D4AF37, 4.6em 0em #D4AF37, 4.8em 0em #D4AF37, 5.2em 0em #D4AF37,
0em 0.2em #D4AF37, 0.8em 0.2em #D4AF37, 2.0em 0.2em #D4AF37, 2.2em 0.2em #D4AF37, 2.4em 0.2em #D4AF37, 2.6em 0.2em #D4AF37, 4.0em 0.2em #D4AF37,
0em 0.4em #D4AF37, 0.8em 0.4em #D4AF37, 2.0em 0.4em #D4AF37, 2.8em 0.4em #D4AF37, 4.0em 0.4em #D4AF37,
0em 0.6em #D4AF37, 2.0em 0.6em #D4AF37, 2.8em 0.6em #D4AF37, 3.4em 0.6em #D4AF37, 3.6em 0.6em #D4AF37, 4.0em 0.6em #D4AF37, 4.4em 0.6em #D4AF37,
0.2em 0.8em #D4AF37, 0.4em 0.8em #D4AF37, 0.6em 0.8em #D4AF37, 0.8em 0.8em #D4AF37, 1.0em 0.8em #D4AF37, 1.2em 0.8em #D4AF37, 1.4em 0.8em #D4AF37, 1.6em 0.8em #D4AF37, 2.0em 0.8em #D4AF37, 2.4em 0.8em #D4AF37, 2.6em 0.8em #D4AF37, 3.4em 0.8em #D4AF37, 4.0em 0.8em #D4AF37, 4.6em 0.8em #D4AF37,
2.0em 1.0em #D4AF37, 3.4em 1.0em #D4AF37, 4.0em 1.0em #D4AF37, 4.6em 1.0em #D4AF37,
0.8em 1.2em #D4AF37, 3.4em 1.2em #D4AF37, 4.2em 1.2em #D4AF37, 4.4em 1.2em #D4AF37,
0.8em 1.4em #D4AF37, 1.4em 1.4em #D4AF37, 1.6em 1.4em #D4AF37, 1.8em 1.4em #D4AF37, 2.0em 1.4em #D4AF37, 2.2em 1.4em #D4AF37, 2.4em 1.4em #D4AF37, 2.6em 1.4em #D4AF37, 3.4em 1.4em #D4AF37,
0.8em 1.6em #D4AF37, 1.4em 1.6em #D4AF37, 2.6em 1.6em #D4AF37, 3.4em 1.6em #D4AF37,
0.8em 1.8em #D4AF37, 2.0em 1.8em #D4AF37, 3.4em 1.8em #D4AF37,
0.2em 2.0em #D4AF37, 0.4em 2.0em #D4AF37, 0.8em 2.0em #D4AF37, 1.2em 2.0em #D4AF37, 1.4em 2.0em #D4AF37, 1.6em 2.0em #D4AF37, 2.0em 2.0em #D4AF37, 2.4em 2.0em #D4AF37, 2.6em 2.0em #D4AF37, 2.8em 2.0em #D4AF37, 3.0em 2.0em #D4AF37, 3.2em 2.0em #D4AF37,
0.2em 2.2em #D4AF37, 0.8em 2.2em #D4AF37, 2.0em 2.2em #D4AF37,
0.2em 2.4em #D4AF37, 0.8em 2.4em #D4AF37, 1.4em 2.4em #D4AF37, 2.6em 2.4em #D4AF37,
0.2em 2.6em #D4AF37, 0.8em 2.6em #D4AF37, 1.4em 2.6em #D4AF37, 1.6em 2.6em #D4AF37, 1.8em 2.6em #D4AF37, 2.0em 2.6em #D4AF37, 2.2em 2.6em #D4AF37, 2.6em 2.6em #D4AF37, 3.0em 2.6em #D4AF37, 3.2em 2.6em #D4AF37,
0.4em 2.8em #D4AF37, 0.6em 2.8em #D4AF37, 2.6em 2.8em #D4AF37, 3.4em 2.8em #D4AF37,
2.0em 3.0em #D4AF37, 2.6em 3.0em #D4AF37, 3.4em 3.0em #D4AF37,
2.0em 3.2em #D4AF37, 2.6em 3.2em #D4AF37, 3.4em 3.2em #D4AF37,
0.6em 3.4em #D4AF37, 0.8em 3.4em #D4AF37, 1.0em 3.4em #D4AF37, 1.2em 3.4em #D4AF37, 1.4em 3.4em #D4AF37, 1.6em 3.4em #D4AF37, 1.8em 3.4em #D4AF37, 2.8em 3.4em #D4AF37, 3.0em 3.4em #D4AF37, 3.2em 3.4em #D4AF37, 3.4em 3.4em #D4AF37,
0.6em 3.6em #D4AF37, 3.6em 3.6em #D4AF37,
0.6em 3.8em #D4AF37,
0em 4.0em #D4AF37, 0.2em 4.0em #D4AF37, 0.6em 4.0em #D4AF37, 1.0em 4.0em #D4AF37,
0em 4.2em #D4AF37, 0.6em 4.2em #D4AF37, 1.2em 4.2em #D4AF37,
0em 4.4em #D4AF37, 0.6em 4.4em #D4AF37, 1.2em 4.4em #D4AF37,
0em 4.6em #D4AF37, 0.8em 4.6em #D4AF37, 1.0em 4.6em #D4AF37,
0em 4.8em #D4AF37,
0em 5.2em #D4AF37;
}
/* Ember animation */
.ember {
position: fixed;
bottom: -20px;
width: 10px;
height: 10px;
background-color: #E55B00;
border-radius: 50%;
opacity: 0;
animation: rise 10s infinite ease-in;
box-shadow: 0 0 10px #E55B00, 0 0 20px #E55B00, 0 0 30px #D4AF37;
pointer-events: none;
}
@keyframes rise {
0% {
transform: translateY(0) translateX(0);
opacity: 1;
}
100% {
transform: translateY(-100vh) translateX(var(--x-end));
opacity: 0;
}
}
</style>
</head>
<body>
<div id="ember-container"></div>
<div class="container">
<div class="corner corner5 variant topleft"></div>
<div class="corner corner5 variant topright"></div>
<div class="corner corner5 variant bottomleft"></div>
<div class="corner corner5 variant bottomright"></div>
<div class="header">
<p style="font-size: 10px; text-align: center; padding: 5px; color: rgba(224, 234, 224, 1);">this is designed for Dark mode</p>
<h1 class="debug-overflow">L3.3-Shakudo-70b</h1>
</div>
<div class="info">
<img src="https://cdn-uploads.huggingface.co/production/uploads/64545af5ec40bbbd01242ca6/Y3_fED_Re3U1rd0jOPnAR.jpeg" alt="Shakudo Mascot">
<div class="creator-section">
<div class="corner corner5 variant topleft"></div>
<div class="corner corner5 variant topright"></div>
<div class="corner corner5 variant bottomleft"></div>
<div class="corner corner5 variant bottomright"></div>
<div class="creator-badge" style="display: flex; flex-wrap: wrap; align-items: center; gap: 1.5rem; justify-content: center;">
<div class="creator-info">
<span class="creator-label">Created by Steelskull</span>
<a href="https://huggingface.co/Steelskull" target="_blank" class="creator-link">
<span class="creator-name">Steelskull</span>
<span class="creator-arrow">→</span>
</a>
<a href="https://ko-fi.com/Y8Y0AO2XE" target="_blank" class="button" style="margin-top: 0.5rem; padding: 0.5rem 1rem;">
Support on Ko-fi
</a>
</div>
</div>
</div>
<div class="sponsors-section">
<details class="sponsors-dropdown" open>
<summary class="sponsors-summary">
<span class="sponsors-title">⚡ Top Sponsors</span>
<span class="dropdown-icon">▼</span>
</summary>
<div style="padding: 15px;">
<h4 class="sponsors-title" style="padding-bottom: 10px; border-bottom: 1px solid rgba(229, 91, 0, 0.3); margin-bottom: 15px; color: #E55B00;">🏆 Top Supporters</h4>
<div class="sponsors-list" style="border-top: none; padding: 0;">
<div class="sponsor-item">
<div class="sponsor-rank">#1</div>
<img src="https://ko-fi.com/img/anon7.png?v=1" alt="joe" class="sponsor-img">
<div class="sponsor-name">joe</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#2</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/0f77ce5e-3d45-4b45-93e1-b93e74ef32ca_7408a132-232b-4bf4-9878-c483bd80d532.png" alt="Artus" class="sponsor-img">
<div class="sponsor-name">Artus</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#3</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/957890c9-c45b-4229-8837-bd802de0691d_586ce212-c05e-4e35-a808-4d278783dc33.png" alt="Buthayna" class="sponsor-img">
<div class="sponsor-name">Buthayna</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#4</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/b28597ab-a2e6-4b55-aad9-6b2794e68847_3a65f36e-76b4-4fac-bfef-08b43722e331.png" alt="Kistara" class="sponsor-img">
<div class="sponsor-name">Kistara</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#5</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/86d8e2d8-fbde-4347-8e40-71b3e8eb9e65.jpeg" alt="lizzieshinkickr" class="sponsor-img">
<div class="sponsor-name">lizzieshinkickr</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#6</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/f68fdafa-7b8e-4d2f-9eec-be99772f3f77_82e97a70-65ca-4608-983a-c1f28a67da41.png" alt="Mooth Dragoon" class="sponsor-img">
<div class="sponsor-name">Mooth Dragoon</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#7</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/5e126f2e-da62-41c6-9350-a2461fbad35c_2a3df41f-4481-4dc7-8f08-88f24da2e7a1.png" alt="JH2011" class="sponsor-img">
<div class="sponsor-name">JH2011</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#8</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/4b5adb19-7822-468b-a397-e5d56ac8fb72_08050f44-82b3-497c-84d4-d895c38089f1.png" alt="NarpasSword" class="sponsor-img">
<div class="sponsor-name">NarpasSword</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#9</div>
<img src="https://storage.ko-fi.com/cdn/useruploads/8b9b831f-ea45-4ee7-8473-2c9c75e0c31c_1c95d276-c5ba-43fa-953a-6245fb25d284.png" alt="WeForgot" class="sponsor-img">
<div class="sponsor-name">WeForgot</div>
</div>
<div class="sponsor-item">
<div class="sponsor-rank">#10</div>
<img src="https://ko-fi.com/img/anon2.png?v=1" alt="C8" class="sponsor-img">
<div class="sponsor-name">C8</div>
</div>
</div>
</div>
<p style="font-size: 12px; text-align: center; padding: 10px; color: rgba(224, 234, 224, 0.7);">If I forgot you please let me know, ko-fi doesent let me track it easily</p>
<hr style="border: none; height: 1px; background-color: rgba(229, 91, 0, 0.3); margin: 20px 15px;">
<div class="sponsors-section" style="margin-top: 1rem; padding: 0 15px 15px;">
<h4 class="sponsors-title" style="padding-bottom: 10px; border-bottom: 1px solid rgba(229, 91, 0, 0.3); margin-bottom: 15px; color: #E55B00;">🤝 Valued Partners</h4>
<div class="sponsors-list" style="border-top: none; padding: 0;">
<div class="sponsor-item">
<a href="https://nectar.ai" target="_blank" style="text-decoration: none;">
<img src="https://nectar.ai/assets/heart_logo.png" alt="Nectar.ai" class="sponsor-img" style="border-radius: 15px;">
<div class="sponsor-name">Nectar.ai</div>
</a>
</div>
</div>
</div>
</details>
</div>
<div class="model-info">
<h2>Model Information</h2>
<div class="info-card">
<div class="corner corner5 variant topleft"></div>
<div class="corner corner5 variant topright"></div>
<div class="corner corner5 variant bottomleft"></div>
<div class="corner corner5 variant bottomright"></div>
<div class="info-header">
<h3>L3.3-Shakudo-70b</h3>
<div class="model-tags">
<span class="model-tag">Llama 3.3</span>
<span class="model-tag">Multi-Stage Merge</span>
<span class="model-tag">70b Parameters</span>
<span class="model-tag">V0.8</span> </div>
</div>
<div class="model-composition">
<h4>Model Composition</h4>
<ul class="composition-list">
<li>
<details class="base-model-dropdown" data-merge-type="slerp">
<summary class="base-model-summary">
<strong>Final Merge:</strong> L3.3-Shakudo-70b
<span class="dropdown-icon">▼</span>
</summary>
<div class="base-model-list">
<div class="base-model-item"><a href="https://huggingface.co/Steelskull/L3.3-M1-Hydrargyrum-70B" target="_blank" class="model-label">TheSkullery/L3.3-M1-Hydrargyrum-70B</a></div>
<div class="base-model-item"><a href="https://huggingface.co/TheSkullery/L3.3-M2-Hydrargyrum-70B" target="_blank" class="model-label">TheSkullery/L3.3-M2-Hydrargyrum-70B</a></div>
</div>
</details>
</li>
<li>
<details class="base-model-dropdown" data-merge-type="SCE">
<summary class="base-model-summary">
<strong>Model 1:</strong> L3.3-M1-Hydrargyrum-70B
<span class="dropdown-icon">▼</span>
</summary>
<div class="base-model-list">
<div class="base-model-item"><a href="https://huggingface.co/Sao10K/L3.1-70B-Hanami-x1" target="_blank" class="model-label">Sao10K/L3.1-70B-Hanami-x1</a></div>
<div class="base-model-item"><a href="https://huggingface.co/TheDrummer/Anubis-70B-v1" target="_blank" class="model-label">TheDrummer/Anubis-70B-v1</a></div>
<div class="base-model-item"><a href="https://huggingface.co/ArliAI/Llama-3.3-70B-ArliAI-RPMax-v1.4" target="_blank" class="model-label">ArliAI/Llama-3.3-70B-ArliAI-RPMax-v1.4</a></div>
<div class="base-model-item"><a href="https://huggingface.co/BeaverAI/Shimmer-70B-v1a" target="_blank" class="model-label">BeaverAI/Shimmer-70B-v1a</a></div>
<div class="base-model-item"><a href="https://huggingface.co/TheDrummer/Fallen-Llama-3.3-70B-v1" target="_blank" class="model-label">TheDrummer/Fallen-Llama-3.3-70B-v1</a></div>
</div>
</details>
</li>
<li>
<details class="base-model-dropdown" data-merge-type="Della">
<summary class="base-model-summary">
<strong>Model 2:</strong> L3.3-M2-Hydrargyrum-70B
<span class="dropdown-icon">▼</span>
</summary>
<div class="base-model-list">
<div class="base-model-item"><a href="https://huggingface.co/Sao10K/Llama-3.3-70B-Vulpecula-r1" target="_blank" class="model-label">Sao10K/Llama-3.3-70B-Vulpecula-r1</a></div>
<div class="base-model-item"><a href="https://huggingface.co/Sao10K/70B-L3.3-Cirrus-x1" target="_blank" class="model-label">Sao10K/70B-L3.3-Cirrus-x1</a></div>
<div class="base-model-item"><a href="https://huggingface.co/EVA-UNIT-01/EVA-LLaMA-3.33-70B-v0.0" target="_blank" class="model-label">EVA-UNIT-01/EVA-LLaMA-3.33-70B-v0.0</a></div>
<div class="base-model-item"><a href="https://huggingface.co/LatitudeGames/Wayfarer-Large-70B-Llama-3.3" target="_blank" class="model-label">LatitudeGames/Wayfarer-Large-70B-Llama-3.3</a></div>
<div class="base-model-item"><a href="https://huggingface.co/Sao10K/L3.3-70B-Euryale-v2.3" target="_blank" class="model-label">Sao10K/L3.3-70B-Euryale-v2.3</a></div>
</div>
</details>
</li>
<li>
<details class="base-model-dropdown" data-merge-type="Stock">
<summary class="base-model-summary">
<strong>Base Model:</strong> L3.3-Cogmoblated-70B
<span class="dropdown-icon">▼</span>
</summary>
<div class="base-model-list">
<div class="base-model-item"><a href="https://huggingface.co/abacusai/Dracarys2-Llama-3.1-70B-Instruct" target="_blank" class="model-label">abacusai/Dracarys2-Llama-3.1-70B-Instruct</a></div>
<div class="base-model-item"><a href="https://huggingface.co/watt-ai/watt-tool-70B" target="_blank" class="model-label">watt-ai/watt-tool-70B</a></div>
<div class="base-model-item"><a href="https://huggingface.co/deepcogito/cogito-v1-preview-llama-70B" target="_blank" class="model-label">deepcogito/cogito-v1-preview-llama-70B</a></div>
<div class="base-model-item"><a href="https://huggingface.co/TheDrummer/Anubis-70B-v1" target="_blank" class="model-label">TheDrummer/Anubis-70B-v1</a></div>
<div class="base-model-item"><a href="https://huggingface.co/SicariusSicariiStuff/Negative_LLAMA_70B" target="_blank" class="model-label">SicariusSicariiStuff/Negative_LLAMA_70B</a></div>
<div class="base-model-item"><a href="https://huggingface.co/Ppoyaa/MythoNemo-L3.1-70B-v1.0" target="_blank" class="model-label">Ppoyaa/MythoNemo-L3.1-70B-v1.0</a></div>
<div class="base-model-item"><a href="https://huggingface.co/nbeerbower/Llama-3.1-Nemotron-lorablated-70B" target="_blank" class="model-label">nbeerbower/Llama-3.1-Nemotron-lorablated-70B (Base)</a></div>
</div>
</details>
</li>
</ul>
<div class="model-description">
<h4>Model Creation Process</h4>
<p>L3.3-Shakudo-70b is the result of a multi-stage merging process by Steelskull, designed to create a powerful and creative roleplaying model with a unique flavor. The creation process involved several advanced merging techniques, including weight twisting, to achieve its distinct characteristics.</p>
<h4>Stage 1: The Cognitive Foundation & Weight Twisting</h4>
<p>The process began by creating a cognitive and tool-use focused base model, <strong>L3.3-Cogmoblated-70B</strong>. This was achieved through a `model_stock` merge of several models known for their reasoning and instruction-following capabilities. This base was built upon `nbeerbower/Llama-3.1-Nemotron-lorablated-70B`, a model intentionally "ablated" to skew refusal behaviors. This technique, known as weight twisting, helps the final model adopt more desirable response patterns by building upon a foundation that is already aligned against common refusal patterns.</p>
<h4>Stage 2: The Twin Hydrargyrum - Flavor and Depth</h4>
<p>Two distinct models were then created from the Cogmoblated base:</p>
<ul>
<li><strong>L3.3-M1-Hydrargyrum-70B:</strong> This model was merged using `SCE`, a technique that enhances creative writing and prose style, giving the model its unique "flavor." The Top_K for this merge were set at 0.22 .</li>
<li><strong>L3.3-M2-Hydrargyrum-70B:</strong> This model was created using a `Della_Linear` merge, which focuses on integrating the "depth" of various roleplaying and narrative models. The settings for this merge were set at: (lambda: 1.1) (weight: 0.2) (density: 0.7) (epsilon: 0.2)</li>
</ul>
<h4>Final Stage: Shakudo</h4>
<p>The final model, <strong>L3.3-Shakudo-70b</strong>, was created by merging the two Hydrargyrum variants using a 50/50 `nuslerp`. This final step combines the rich, creative prose (flavor) from the SCE merge with the strong roleplaying capabilities (depth) from the Della_Linear merge, resulting in a model with a distinct and refined narrative voice.</p>
<p><strong>A special thank you to Nectar.ai for their generous support of the open-source community and my projects. </strong></p>
<p><strong>Additionally, a heartfelt thanks to all the Ko-fi supporters who have contributed, your generosity is deeply appreciated and helps keep this work going and the Pods spinning.</strong>
<p>-</p>
</div>
</div>
</div>
<!-- Add spacing here -->
<div style="height: 40px;"></div>
<!-- Sampler Settings Section -->
<div class="section-container sampler-settings">
<div class="corner corner5 variant topleft"></div>
<div class="corner corner5 variant topright"></div>
<div class="corner corner5 variant bottomleft"></div>
<div class="corner corner5 variant bottomright"></div>
<h2>Recommended Sampler Settings</h2>
<div class="settings-card">
<div class="settings-content">
<div class="settings-grid">
<div class="setting-item">
<span class="setting-label">Static Temperature:</span>
<span class="setting-value">1.0 - 1.2</span>
</div>
<div class="setting-item">
<span class="setting-label">Min P:</span>
<span class="setting-value">0.02 - 0.025</span>
</div>
<div class="setting-item">
<span class="setting-label">DRY:</span>
<div class="dry-settings">
<div class="dry-item">
<span class="dry-label">- Multiplier:</span>
<span class="dry-value">0.8</span>
</div>
<div class="dry-item">
<span class="dry-label">- Base:</span>
<span class="dry-value">1.74</span>
</div>
<div class="dry-item">
<span class="dry-label">- Length:</span>
<span class="dry-value">4-6</span>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="section-container">
<div class="corner corner5 variant topleft"></div>
<div class="corner corner5 variant topright"></div>
<div class="corner corner5 variant bottomleft"></div>
<div class="corner corner5 variant bottomright"></div>
<h2>Good Starting Templates & Prompts</h2>
<div class="template-card">
<div class="template-item">
<div class="template-content">
<a href="https://huggingface.co/CrucibleLab-TG/L3.3-NS-Dark-Ages-70b-v0.1/resolve/main/sysprompts/Hamon-v1.json" target="_blank" class="template-link">
Hamon v1
<span class="link-arrow">→</span>
</a>
<span class="template-author">by @Steel</span> > Big-picture storytelling guide with world-building focus, set dialogue/narration split, and general writing rules.
</div>
<div class="template-content">
<a href="https://huggingface.co/CrucibleLab-TG/L3.3-NS-Dark-Ages-70b-v0.1/blob/main/sysprompts/Shingane.json" target="_blank" class="template-link">
Shingane v1
<span class="link-arrow">→</span>
</a>
<span class="template-author">by @Steel</span> > Simplified sysprompt based on Hamon.
</div>
<div class="template-content">
<a href="https://huggingface.co/CrucibleLab-TG/L3.3-NS-Dark-Ages-70b-v0.1/blob/main/sysprompts/Kesshin-v1.json" target="_blank" class="template-link">
Kesshin v1
<span class="link-arrow">→</span>
</a>
<span class="template-author">by @Steel</span> > A Hamon rethink using a Character-focused sys prompt that tracks what characters know and how they learn things, with strict interaction rules.
</div>
<div class="template-content">
<a href="https://huggingface.co/CrucibleLab-TG/L3.3-NS-Dark-Ages-70b-v0.1/blob/main/sysprompts/Kamae-TTRPG-v1.json" target="_blank" class="template-link">
Kamae TTRPG v1
<span class="link-arrow">→</span>
</a>
<span class="template-author">by @Steel</span> > TTRPG Game Master framework emphasizing player agency, world consistency, and adaptive session management with mechanical integration.
</div>
<div class="template-content">
<a href="https://huggingface.co/CrucibleLab-TG/L3.3-NS-Dark-Ages-70b-v0.1/blob/main/sysprompts/Kamae-Lite-v1.json" target="_blank" class="template-link">
Kamae lite v1
<span class="link-arrow">→</span>
</a>
<span class="template-author">by @Steel</span> > Simplified sysprompt based on Kamae.
</div>
</div>
</div>
</div>
</div> <!-- closes info -->
<div class="support-section">
<div class="corner corner5 variant topleft"></div>
<div class="corner corner5 variant topright"></div>
<div class="corner corner5 variant bottomleft"></div>
<div class="corner corner5 variant bottomright"></div>
<h2>Support & Community:</h2>
<div class="support-buttons">
<a href="https://discord.gg/4tCngSm3qZ" target="_blank" class="button">
Join Discord
</a>
</div>
</div>
</div> <!-- closes container -->
<script>
document.addEventListener('DOMContentLoaded', function() {
const emberContainer = document.getElementById('ember-container');
if (!emberContainer) {
console.error('Ember container not found');
return;
}
function createEmber() {
const ember = document.createElement('div');
ember.classList.add('ember');
const startX = Math.random() * window.innerWidth;
ember.style.left = `${startX}px`;
const animationDuration = 5 + Math.random() * 5; // 5 to 10 seconds
ember.style.animationDuration = `${animationDuration}s`;
const size = 2 + Math.random() * 4; // 2px to 6px
ember.style.width = `${size}px`;
ember.style.height = `${size}px`;
const xEnd = (Math.random() - 0.5) * 2 * 100; // -100px to 100px
ember.style.setProperty('--x-end', `${xEnd}px`);
emberContainer.appendChild(ember);
setTimeout(() => {
ember.remove();
}, animationDuration * 1000);
}
setInterval(createEmber, 200); // Create a new ember every 200ms
});
</script>
</body>
</html>
|
saishshinde15/Clyrai_Base_Reasoning
|
saishshinde15
| 2025-08-06T14:20:59Z | 19 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"trl",
"grpo",
"conversational",
"zho",
"eng",
"fra",
"spa",
"por",
"deu",
"ita",
"rus",
"jpn",
"kor",
"vie",
"tha",
"ara",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-02-21T08:25:18Z |
---
base_model:
- Qwen/Qwen2.5-3B-Instruct
tags:
- text-generation-inference
- transformers
- qwen2
- trl
- grpo
license: apache-2.0
language:
- zho
- eng
- fra
- spa
- por
- deu
- ita
- rus
- jpn
- kor
- vie
- tha
- ara
---
# Clyrai Secure Reasoning Model (Formerly known as TBH.AI_Base_Reasoning)
- **Developed by:** Clyrai
- **License:** apache-2.0
- **Fine-tuned from:** Qwen/Qwen2.5-3B-Instruct
- **Fine-tuning Method:** GRPO (General Reinforcement with Policy Optimization)
- **Inspired by:** DeepSeek-R1
## **Model Description**
Clyrai Secure Reasoning Model is a cutting-edge AI model designed for secure, reliable, and structured reasoning. Fine-tuned on Qwen 2.5 using GRPO, it enhances logical reasoning, decision-making, and problem-solving capabilities while maintaining a strong focus on reducing AI hallucinations and ensuring factual accuracy.
Unlike conventional language models that rely primarily on knowledge retrieval, Clyrai's model is designed to autonomously engage with complex problems, breaking them down into structured thought processes. Inspired by DeepSeek-R1, it employs advanced reinforcement learning methodologies that allow it to validate and refine its logical conclusions securely and effectively.
This model is particularly suited for tasks requiring high-level reasoning, structured analysis, and problem-solving in critical domains such as cybersecurity, finance, and research. It is ideal for professionals and organizations seeking AI solutions that prioritize security, transparency, and truthfulness.
## **Features**
- **Secure Self-Reasoning Capabilities:** Independently analyzes problems while ensuring factual consistency.
- **Reinforcement Learning with GRPO:** Fine-tuned using policy optimization techniques for logical precision.
- **Multi-Step Logical Deduction:** Breaks down complex queries into structured, step-by-step responses.
- **Industry-Ready Security Focus:** Ideal for cybersecurity, finance, and high-stakes applications requiring trust and reliability.
## **Limitations**
- Requires well-structured prompts for optimal reasoning depth.
- Not optimized for tasks requiring extensive factual recall beyond its training scope.
- Performance depends on reinforcement learning techniques and fine-tuning datasets.
## **Usage**
To use this model for secure text generation and reasoning tasks, follow the structure below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("saishshinde15/Clyrai_Base_Reasoning")
model = AutoModelForCausalLM.from_pretrained("saishshinde15/Clyrai_Base_Reasoning")
# Prepare input prompt using chat template
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
text = tokenizer.apply_chat_template([
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": "What is 2x+3=4"},
], tokenize=False, add_generation_prompt=True)
# Tokenize input
input_ids = tokenizer(text, return_tensors="pt").input_ids
# Move to GPU if available
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
input_ids = input_ids.to(device)
# Generate response
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95,
max_tokens=1024,
)
output = model.generate(
input_ids,
sampling_params=sampling_params,
)
# Decode and print output
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
```
<details>
<summary>Fast inference</summary>
```python
pip install transformers vllm vllm[lora] torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
text = tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT},
{"role" : "user", "content" : "What is 2x+3=4"},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
text,
sampling_params = sampling_params,
lora_request = model.load_lora("grpo_saved_lora"),
)[0].outputs[0].text
output
```
</details>
# Recommended Prompt
Use the following prompt for detailed and personalized results. This is the recommended format as the model was fine-tuned to respond in this structure:
```python
You are a secure reasoning model developed by TBH.AI. Your role is to respond in the following structured format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
```
|
AravindS373/bird_grpo_outputs_2500806
|
AravindS373
| 2025-08-06T14:19:51Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T00:08:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rjarun20/gpt-oss-20b-multilingual-reasoner
|
rjarun20
| 2025-08-06T14:19:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T08:48:44Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-multilingual-reasoner
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gpt-oss-20b-multilingual-reasoner
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="rjarun20/gpt-oss-20b-multilingual-reasoner", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
onnx-community/kotoba-whisper-bilingual-v1.0-ONNX
|
onnx-community
| 2025-08-06T14:16:10Z | 12 | 0 |
transformers.js
|
[
"transformers.js",
"onnx",
"whisper",
"automatic-speech-recognition",
"base_model:kotoba-tech/kotoba-whisper-bilingual-v1.0",
"base_model:quantized:kotoba-tech/kotoba-whisper-bilingual-v1.0",
"region:us"
] |
automatic-speech-recognition
| 2025-08-06T14:14:35Z |
---
library_name: transformers.js
base_model:
- kotoba-tech/kotoba-whisper-bilingual-v1.0
---
# kotoba-whisper-bilingual-v1.0 (ONNX)
This is an ONNX version of [kotoba-tech/kotoba-whisper-bilingual-v1.0](https://huggingface.co/kotoba-tech/kotoba-whisper-bilingual-v1.0). It was automatically converted and uploaded using [this space](https://huggingface.co/spaces/onnx-community/convert-to-onnx).
|
kerrlc/apicalling
|
kerrlc
| 2025-08-06T14:13:27Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T11:14:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Shivakul154/tinystarcoder-rlhf-model
|
Shivakul154
| 2025-08-06T14:13:12Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_bigcode",
"text-generation",
"generated_from_trainer",
"reward-trainer",
"trl",
"base_model:bigcode/tiny_starcoder_py",
"base_model:finetune:bigcode/tiny_starcoder_py",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T14:12:11Z |
---
base_model: bigcode/tiny_starcoder_py
library_name: transformers
model_name: tinystarcoder-rlhf-model
tags:
- generated_from_trainer
- reward-trainer
- trl
licence: license
---
# Model Card for tinystarcoder-rlhf-model
This model is a fine-tuned version of [bigcode/tiny_starcoder_py](https://huggingface.co/bigcode/tiny_starcoder_py).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Shivakul154/tinystarcoder-rlhf-model", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/shivanshkulshrestha154-hindustan-college-of-science-tech/huggingface/runs/1np7gi6e)
This model was trained with Reward.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
attila-fetchai/gpt-oss-20b-identity-run1
|
attila-fetchai
| 2025-08-06T14:12:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T13:03:56Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-identity-run1
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gpt-oss-20b-identity-run1
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="attila-fetchai/gpt-oss-20b-identity-run1", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/fetch-ai/experiment-1/runs/azhgyb6g)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1+cu126
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
linkanjarad/Qwen3-4B-openvino
|
linkanjarad
| 2025-08-06T14:10:09Z | 21 | 0 |
transformers
|
[
"transformers",
"safetensors",
"openvino",
"qwen3",
"text-generation",
"openvino-export",
"conversational",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T14:09:36Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B/blob/main/LICENSE
pipeline_tag: text-generation
base_model: Qwen/Qwen3-4B
tags:
- openvino
- openvino-export
---
This model was converted to OpenVINO from [`Qwen/Qwen3-4B`](https://huggingface.co/Qwen/Qwen3-4B) using [optimum-intel](https://github.com/huggingface/optimum-intel)
via the [export](https://huggingface.co/spaces/echarlaix/openvino-export) space.
First make sure you have optimum-intel installed:
```bash
pip install optimum[openvino]
```
To load your model you can do as follows:
```python
from optimum.intel import OVModelForCausalLM
model_id = "linkanjarad/Qwen3-4B-openvino"
model = OVModelForCausalLM.from_pretrained(model_id)
```
|
rkgupta3/bart-base-text-to-sql-smoke-test
|
rkgupta3
| 2025-08-06T14:09:20Z | 16 | 1 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T13:54:28Z |
---
library_name: transformers
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-base-text-to-sql-smoke-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-text-to-sql-smoke-test
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.54.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.2
|
giovannidemuri/llama8b-er-afg-v58-seed2-hx
|
giovannidemuri
| 2025-08-06T14:09:03Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-05T21:49:49Z |
---
library_name: transformers
license: llama3.1
base_model: meta-llama/Llama-3.1-8B
tags:
- generated_from_trainer
model-index:
- name: llama8b-er-afg-v58-seed2-hx
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama8b-er-afg-v58-seed2-hx
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 4.0.0
- Tokenizers 0.21.0
|
giovannidemuri/llama8b-er-afg-v59-seed2-hx
|
giovannidemuri
| 2025-08-06T14:07:19Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T12:13:34Z |
---
library_name: transformers
license: llama3.1
base_model: meta-llama/Llama-3.1-8B
tags:
- generated_from_trainer
model-index:
- name: llama8b-er-afg-v59-seed2-hx
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama8b-er-afg-v59-seed2-hx
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 2
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu128
- Datasets 3.6.0
- Tokenizers 0.21.2
|
Userb1az/gpt-oss-20b-GGUF
|
Userb1az
| 2025-08-06T14:05:09Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"vllm",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-06T06:24:18Z |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- vllm
---
<p align="center">
<img alt="gpt-oss-20b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-20b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://openai.com/index/gpt-oss-model-card"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single H100 GPU (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the smaller `gpt-oss-20b` model. Check out [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) for the larger model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **Native MXFP4 quantization:** The models are trained with native MXFP4 precision for the MoE layer, making `gpt-oss-120b` run on a single H100 GPU and the `gpt-oss-20b` model run within 16GB of memory.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-20b
ollama pull gpt-oss:20b
ollama run gpt-oss:20b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-20b
lms get openai/gpt-oss-20b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-20b
huggingface-cli download openai/gpt-oss-20b --include "original/*" --local-dir gpt-oss-20b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This smaller model `gpt-oss-20b` can be fine-tuned on consumer hardware, whereas the larger [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) can be fine-tuned on a single H100 node.
|
Ba2han/test-model-0508
|
Ba2han
| 2025-08-06T14:03:08Z | 22 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-05T06:39:29Z |
---
library_name: transformers
model_name: test-model-0508
tags:
- generated_from_trainer
- unsloth
- trl
- sft
licence: license
---
# Model Card for test-model-0508
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Ba2han/test-model-0508", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/batuhan409/huggingface/runs/gds4z7tm)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
udaybondi/gemma-3n-finevideo
|
udaybondi
| 2025-08-06T14:02:29Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3n-E2B-it",
"base_model:finetune:google/gemma-3n-E2B-it",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T12:14:12Z |
---
base_model: google/gemma-3n-E2B-it
library_name: transformers
model_name: gemma-3n-finevideo
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3n-finevideo
This model is a fine-tuned version of [google/gemma-3n-E2B-it](https://huggingface.co/google/gemma-3n-E2B-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="udaybondi/gemma-3n-finevideo", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.20.0
- Transformers: 4.54.1
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
AnthonyEzra/nllb-200-600M-tum-eng-v1-copy
|
AnthonyEzra
| 2025-08-06T13:59:56Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"m2m_100",
"text2text-generation",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T13:00:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ivan512/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-burrowing_rangy_porpoise
|
Ivan512
| 2025-08-06T13:54:37Z | 101 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am burrowing_rangy_porpoise",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-30T10:24:32Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am burrowing_rangy_porpoise
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MohamedElayech/llama-dpo-finetuned
|
MohamedElayech
| 2025-08-06T13:52:03Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"dpo",
"conversational",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:quantized:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T13:32:09Z |
---
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- dpo
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** MohamedElayech
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
diortega/blockassist-bc-bipedal_vigilant_toucan_1754488227
|
diortega
| 2025-08-06T13:50:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bipedal vigilant toucan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-06T13:50:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bipedal vigilant toucan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
gabrielloiseau/CALE-XLLEX
|
gabrielloiseau
| 2025-08-06T13:50:18Z | 12 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"loss:ContrastiveLoss",
"dataset:gabrielloiseau/CALE-SPCD",
"base_model:pierluigic/xl-lexeme",
"base_model:finetune:pierluigic/xl-lexeme",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-06T12:20:34Z |
---
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- loss:ContrastiveLoss
base_model: pierluigic/xl-lexeme
pipeline_tag: sentence-similarity
datasets:
- gabrielloiseau/CALE-SPCD
---
# CALE-XLLEX
This is a [sentence-transformers](https://www.SBERT.net) model: It maps occurences of a word to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
# 1. Load CALE model
model = SentenceTransformer("gabrielloiseau/CALE-XLLEX")
sentences = [
"the boy could easily <t>distinguish</t> the different note values",
"he patient’s ability to <t>recognize</t> forms and shapes",
"the government had refused to <t>recognize</t> their autonomy and existence as a state",
]
# 2. Calculate embeddings
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.8325, 0.4768],
# [0.8325, 1.0000, 0.2989],
# [0.4768, 0.2989, 1.0000]])
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False, 'architecture': 'XLMRobertaModel'})
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
|
gabrielloiseau/CALE-XLM-R
|
gabrielloiseau
| 2025-08-06T13:46:50Z | 11 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"loss:ContrastiveLoss",
"dataset:gabrielloiseau/CALE-SPCD",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-06T12:18:09Z |
---
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- loss:ContrastiveLoss
base_model: FacebookAI/xlm-roberta-large
pipeline_tag: sentence-similarity
datasets:
- gabrielloiseau/CALE-SPCD
---
# CALE-XLM-R
This is a [sentence-transformers](https://www.SBERT.net) model: It maps occurences of a word to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
# 1. Load CALE model
model = SentenceTransformer("gabrielloiseau/CALE-XLM-R")
sentences = [
"the boy could easily <t>distinguish</t> the different note values",
"he patient’s ability to <t>recognize</t> forms and shapes",
"the government had refused to <t>recognize</t> their autonomy and existence as a state",
]
# 2. Calculate embeddings
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.9332, 0.5331],
# [0.9332, 1.0000, 0.5619],
# [0.5331, 0.5619, 1.0000]])
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False, 'architecture': 'XLMRobertaModel'})
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
|
pharaohe/dwarfwhitehairfaceloreupscaled
|
pharaohe
| 2025-08-06T13:45:30Z | 23 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-06T13:44:54Z |
---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: woman
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# dwarfwhitehairfaceloreupscaled
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `woman` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
mlx-community/Qwen3-Coder-30B-A3B-Instruct-4bit
|
mlx-community
| 2025-08-06T13:45:30Z | 1,317 | 8 |
mlx
|
[
"mlx",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-Coder-30B-A3B-Instruct",
"base_model:quantized:Qwen/Qwen3-Coder-30B-A3B-Instruct",
"license:apache-2.0",
"4-bit",
"region:us"
] |
text-generation
| 2025-07-31T15:00:51Z |
---
library_name: mlx
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- mlx
base_model: Qwen/Qwen3-Coder-30B-A3B-Instruct
---
# mlx-community/Qwen3-Coder-30B-A3B-Instruct-4bit
This model [mlx-community/Qwen3-Coder-30B-A3B-Instruct-4bit](https://huggingface.co/mlx-community/Qwen3-Coder-30B-A3B-Instruct-4bit) was
converted to MLX format from [Qwen/Qwen3-Coder-30B-A3B-Instruct](https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Qwen3-Coder-30B-A3B-Instruct-4bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
ekiprop/SST-2-GLoRA-p20-seed30
|
ekiprop
| 2025-08-06T13:45:27Z | 61 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:roberta-base",
"lora",
"transformers",
"base_model:FacebookAI/roberta-base",
"base_model:adapter:FacebookAI/roberta-base",
"license:mit",
"region:us"
] | null | 2025-08-06T13:33:19Z |
---
library_name: peft
license: mit
base_model: roberta-base
tags:
- base_model:adapter:roberta-base
- lora
- transformers
metrics:
- accuracy
model-index:
- name: SST-2-GLoRA-p20-seed30
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SST-2-GLoRA-p20-seed30
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1872
- Accuracy: 0.9438
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|
| 0.4208 | 0.0950 | 200 | 0.2326 | 0.9151 |
| 0.3055 | 0.1900 | 400 | 0.2307 | 0.9174 |
| 0.2973 | 0.2850 | 600 | 0.2072 | 0.9243 |
| 0.257 | 0.3800 | 800 | 0.2141 | 0.9335 |
| 0.2583 | 0.4751 | 1000 | 0.2290 | 0.9255 |
| 0.2577 | 0.5701 | 1200 | 0.2015 | 0.9278 |
| 0.2508 | 0.6651 | 1400 | 0.2054 | 0.9174 |
| 0.2464 | 0.7601 | 1600 | 0.2072 | 0.9289 |
| 0.2446 | 0.8551 | 1800 | 0.1931 | 0.9369 |
| 0.2303 | 0.9501 | 2000 | 0.2094 | 0.9209 |
| 0.2434 | 1.0451 | 2200 | 0.1840 | 0.9335 |
| 0.2204 | 1.1401 | 2400 | 0.2068 | 0.9312 |
| 0.2286 | 1.2352 | 2600 | 0.2466 | 0.9197 |
| 0.2276 | 1.3302 | 2800 | 0.2110 | 0.9323 |
| 0.2194 | 1.4252 | 3000 | 0.2018 | 0.9323 |
| 0.2168 | 1.5202 | 3200 | 0.1896 | 0.9358 |
| 0.2233 | 1.6152 | 3400 | 0.1841 | 0.9381 |
| 0.2059 | 1.7102 | 3600 | 0.2217 | 0.9243 |
| 0.2081 | 1.8052 | 3800 | 0.1980 | 0.9392 |
| 0.2236 | 1.9002 | 4000 | 0.1836 | 0.9369 |
| 0.2075 | 1.9952 | 4200 | 0.1994 | 0.9381 |
| 0.2056 | 2.0903 | 4400 | 0.1666 | 0.9427 |
| 0.2019 | 2.1853 | 4600 | 0.1813 | 0.9404 |
| 0.2009 | 2.2803 | 4800 | 0.1996 | 0.9415 |
| 0.2008 | 2.3753 | 5000 | 0.1829 | 0.9404 |
| 0.2007 | 2.4703 | 5200 | 0.1910 | 0.9392 |
| 0.2013 | 2.5653 | 5400 | 0.1965 | 0.9346 |
| 0.2045 | 2.6603 | 5600 | 0.1710 | 0.9415 |
| 0.1999 | 2.7553 | 5800 | 0.1659 | 0.9427 |
| 0.1881 | 2.8504 | 6000 | 0.1860 | 0.9392 |
| 0.1907 | 2.9454 | 6200 | 0.1739 | 0.9392 |
| 0.1869 | 3.0404 | 6400 | 0.1875 | 0.9346 |
| 0.178 | 3.1354 | 6600 | 0.1818 | 0.9404 |
| 0.189 | 3.2304 | 6800 | 0.1872 | 0.9427 |
| 0.1908 | 3.3254 | 7000 | 0.1823 | 0.9415 |
| 0.1781 | 3.4204 | 7200 | 0.1872 | 0.9438 |
| 0.1803 | 3.5154 | 7400 | 0.2022 | 0.9369 |
| 0.1789 | 3.6105 | 7600 | 0.2043 | 0.9404 |
| 0.184 | 3.7055 | 7800 | 0.1843 | 0.9369 |
| 0.1874 | 3.8005 | 8000 | 0.1877 | 0.9415 |
| 0.1807 | 3.8955 | 8200 | 0.1912 | 0.9369 |
| 0.1747 | 3.9905 | 8400 | 0.1937 | 0.9404 |
| 0.1752 | 4.0855 | 8600 | 0.1977 | 0.9392 |
| 0.1713 | 4.1805 | 8800 | 0.2040 | 0.9381 |
| 0.1763 | 4.2755 | 9000 | 0.1983 | 0.9427 |
| 0.1679 | 4.3705 | 9200 | 0.1886 | 0.9392 |
| 0.1653 | 4.4656 | 9400 | 0.2052 | 0.9404 |
| 0.1639 | 4.5606 | 9600 | 0.2089 | 0.9404 |
| 0.1717 | 4.6556 | 9800 | 0.1961 | 0.9369 |
| 0.1679 | 4.7506 | 10000 | 0.1923 | 0.9381 |
| 0.1817 | 4.8456 | 10200 | 0.1862 | 0.9381 |
| 0.1747 | 4.9406 | 10400 | 0.1874 | 0.9381 |
### Framework versions
- PEFT 0.16.0
- Transformers 4.54.1
- Pytorch 2.5.1+cu121
- Datasets 4.0.0
- Tokenizers 0.21.4
|
jamico12/blockassist-bc-pensive_nimble_caterpillar_1754486492
|
jamico12
| 2025-08-06T13:44:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pensive nimble caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-06T13:44:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pensive nimble caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hugofara/wavlm-base-plus-phonemizer-fr-it
|
hugofara
| 2025-08-06T13:42:07Z | 61 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wavlm",
"phonemizer",
"french",
"italian",
"speech-recognition",
"automatic-speech-recognition",
"fr",
"it",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:microsoft/wavlm-base-plus",
"base_model:finetune:microsoft/wavlm-base-plus",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-22T16:44:55Z |
---
license: apache-2.0
datasets:
- mozilla-foundation/common_voice_17_0
language:
- fr
- it
metrics:
- per
base_model:
- microsoft/wavlm-base-plus
pipeline_tag: automatic-speech-recognition
library_name: transformers
tags:
- phonemizer
- french
- italian
- speech-recognition
model-index:
- name: wavlm-base-plus-phonemizer-fr-it-0.1
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 17.0
type: mozilla-foundation/common_voice_17_0
split: train
metrics:
- name: Phoneme Error Rate (PER, %)
type: per
value: 10.1
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 17.0
type: mozilla-foundation/common_voice_17_0
split: test
metrics:
- name: Phoneme Error Rate (PER, %)
type: per
value: 10.1
co2_eq_emissions:
emissions: 34.01
source: "https://calculator.green-algorithms.org/, 14:20 of computation"
training_type: "fine-tuning"
geographical_location: "Switzerland"
hardware_used: "1x GeForce 4080 RTX GPU"
---
# WavLM Base+ French Italian Phonemizer
The **WavLM Base Plus Phonemizer FR IT** is a phonemization model for both French and Italian.
Given an audio file, it will output the words heard using [IPA](https://en.wikipedia.org/wiki/International_Phonetic_Alphabet).
> [!NOTE]
> This is an ongoing work.
> The model training is currently limited by the lack of training data / available work.
> Better version may come soon
## Model Details
As inputs it takes an audio file and the desired language.
It returns the list of phonemes uttered in the audio.
It does not use a language model, so it has a low likelihood of trying to map an audio on existing words.
Technically, it has uses attention masks as a third input.
However it is only used when providing data as batch.
Set the value of the attention mask to 1 for the audi parts that were not padded, and the rest to 0.
For instance, if you have a batch of a single audio of size `[1, 100]`, the attention mask should be of size `[1, 100]`, with all values set to 1.
Now, you have a second audio of length 120. You pad the first audio and get a batch of size `[2, 120]`.
The attention mask is now of shape `[2, 120]`, with `attention_mask[0] = [1 1 ... 0]` (last 20 values are zeros) and `attention_mask[1] = [1 1 ... 1]`.
## Uses
The model works with French and Italian audios.
TO prepare you Python env:
```sh
pip install torch torchaudio transformers
```
Let's transcribe this audio:

You can use the following code.
```python
"""
Simple demonstration.
See main.py for a more complete demonstration.
"""
import torch
import torchaudio
import transformers
import wavlm_phoneme_fr_it
# Load the CTC processor
feature_extractor = transformers.AutoFeatureExtractor.from_pretrained(
"microsoft/wavlm-base-plus"
)
tokenizer = transformers.Wav2Vec2CTCTokenizer(
"./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|"
)
processor = transformers.Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
inputs = processor(
audio_arrays,
sampling_rate=SAMPLING_RATE,
padding=True,
return_tensors="pt",
)
inputs["language"] = [row["language"] for row in audio_files] # "fr" or "it"
# Model with weights
model = wavlm_phoneme_fr_it.WavLMPhonemeFrIt.from_pretrained(
"hugofara/wavlm-base-plus-phonemizer-fr-it"
)
# Do inference
with torch.no_grad():
logits = model(**inputs).logits
# Simple ArgMax for demonstration
label_ids = torch.argmax(logits, -1)
predictions = processor.batch_decode(label_ids)
print("Final phonemes are:", "".join(prediction))
# Should output: "sakapitalɛtsɑ̃kɛʁ"
```
## Intended public
This model was mainly thought for clinicians that need audio transcriptions on a great volume of data.
As the training was conducted on adult voices, it has the same speech recognition biases as "normal" adult voices,
which means it corrects accents as long as they are well spread.
It is forbidden to use this model for any harmful purpose.
## Training Details
### Training Data
The dataset was adapted from Common Voice 17.0, French + Italian versions.
To get an API representation of the sentences, a phonemizer from text was used:
[charsiu/g2p_multilingual_byT5_small_100](https://huggingface.co/charsiu/g2p_multilingual_byT5_small_100).
The language of each sample (either French or Italian) was also saved as a dataset feature.
### Training Procedure
Only the training split of Common Voice 17.0 is used during training.
First, only the language model head was trained (a linear layer).
We freeze both the weights of the feature encoder and the transformer.
We use a tri-steps training with a linear warm-up, the a constant learning rate, and a linear decrease.
The loss used is a CTC loss, and the evaluation metric is the Phoneme Error Rate (PER).
Once the PER decreases below 60%, the initial training stops.
Due to the size of the dataset, one epoch is enough.
For the second phase of training, we unfreeze the transformer.
We start the same training procedure, a tri-state linear warm-up from scratch.
At the time of writing, the model did three epochs only to avoid over-fitting.
## Evaluation
The results are measure in Phoneme Error Rate, PER for short.
Using the test set of Common Voice 17.0, we achieve almost 10% PER.
## Technical Specifications
The model contains WavLM Base+ For CTC, which has a language model head.
This linear classifier has the following inputs:
- The first input is the language (0 for French, 1 for Italian).
- The next 768 are the raw outputs of WavLM Base+.
To get phonemes from this output, you can simply use an arg max and map the indices over
`vocab.json`.
## Authors
- Developed by: [HugoFara](https://www.hugofara.net/)
- Funded by: [NCCR Evolving Language](https://evolvinglanguage.ch/)
The training was conducted as a part of the NCCR Evolving Language group,
a Swiss research institute on language.
It was developped during a study by [Pr. Daphné Bavelier](https://en.wikipedia.org/wiki/Daphne_Bavelier) and Pr. Angela Pasqualotto.
## Related works
The model was created as a successor, and an extension, to [Cnam-LMSSC/wav2vec2-french-phonemizer](https://huggingface.co/Cnam-LMSSC/wav2vec2-french-phonemizer).
The main differences are a more modern base model (WavLM Base + vs Wav2Vec 2.0), and a different training procedure.
*But wait, PER on Cnam-LMSSC/wav2vec2-french-phonemizer is 5%, here it is 10%, isn't that worse?*
Not the same kind of measurement.
On the previous model, PER is measured on the training set (with a risk of overfitting),
while our PER is on some data the model never saw.
For reference, we once achieved 2% PER on the training set with 100 epochs, yet it was still 18% PER on the validation set.
Nevertheless, the work is ongoing.
See also this very good multilanguage version: [ASR-Project/Multilingual-PR](https://github.com/ASR-project/Multilingual-PR).
## Todo list
- [x] Data augmentation to finish the model training
- [ ] Cleaner dataset with a better phonemizer.
|
Braboy/Braboy_goodface
|
Braboy
| 2025-08-06T13:40:12Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-08-06T12:38:34Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
Butanium/simple-stories-2L4H256D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T13:38:30Z | 11 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T13:38:27Z |
# 2-Layer 4-Head Attention-Only Transformer
This is a simplified transformer model with 2 attention layer(s) and 4 attention head(s), hidden size 256, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-2L4H256D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
kstar0026/Affine-5DDAidQBFcfAztbnGJsgfjLXLdGWWshsReBzhPyZxAv2Y4xi
|
kstar0026
| 2025-08-06T13:38:24Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"conversational",
"custom_code",
"arxiv:2506.14794",
"base_model:deepseek-ai/DeepSeek-R1",
"base_model:quantized:deepseek-ai/DeepSeek-R1",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"fp8",
"region:us"
] |
text-generation
| 2025-08-06T11:06:55Z |
---
license: mit
library_name: transformers
base_model:
- deepseek-ai/DeepSeek-V3-0324
- deepseek-ai/DeepSeek-R1
pipeline_tag: text-generation
---
# DeepSeek-R1T-Chimera
<div align="center">
<img src="https://354918363417-runtime-assets.s3.eu-central-1.amazonaws.com/company_logo_light.svg"
alt="TNG Logo"
width="400"
style="display: inline-block; vertical-align: middle;"/>
</div>
<br>
<div align="center">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<br>
<div align="center">
<a href="https://x.com/tngtech/status/1916284566127444468" style="margin: 2px;">
<img alt="Benchmarks" src="R1T-Chimera_Benchmarks_20250427_V1.jpg" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
**Model merge of DeepSeek-R1 and DeepSeek-V3 (0324)**
An open weights model combining the intelligence of R1 with the token efficiency of V3.
For details on the construction process and analyses of Chimera model variants, please [read our paper](https://arxiv.org/abs/2506.14794).
[Paper on arXiV](https://arxiv.org/abs/2506.14794) | [Announcement on X](https://x.com/tngtech/status/1916284566127444468) | [LinkedIn post](https://www.linkedin.com/posts/tng-technology-consulting_on-the-weekend-we-released-deepseek-r1t-chimera-activity-7323008947236290560-Cf2m) | [Try it on OpenRouter](https://openrouter.ai/tngtech/deepseek-r1t-chimera:free)
## Model Details
- **Architecture**: DeepSeek-MoE Transformer-based language model
- **Combination Method**: Merged model weights from DeepSeek-R1 and DeepSeek-V3 (0324)
- **Release Date**: 2025-04-27
## Use, Out-of-scope Use, Limitations, Risks, Recommendations et al
Regarding R1T Chimera, we ask you to follow the careful guidelines that Microsoft has created for their "MAI-DS-R1" DeepSeek-based model.
These guidelines are available [here on Hugging Face](https://huggingface.co/microsoft/MAI-DS-R1).
## Contact
- Email: [email protected]
- X.com: @tngtech
## Citation
```
@misc{tng_technology_consulting_gmbh_2025,
author = { TNG Technology Consulting GmbH },
title = { DeepSeek-R1T-Chimera },
year = 2025,
month = {April},
url = { https://huggingface.co/tngtech/DeepSeek-R1T-Chimera },
doi = { 10.57967/hf/5330 },
publisher = { Hugging Face }
}
```
|
joanna302/Qwen3-1.7B-Base_zh_ar__alpaca_part_SFT_2e-05
|
joanna302
| 2025-08-06T13:37:52Z | 38 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"unsloth",
"sft",
"trl",
"conversational",
"base_model:unsloth/Qwen3-1.7B-Base",
"base_model:finetune:unsloth/Qwen3-1.7B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-05T17:01:34Z |
---
base_model: unsloth/Qwen3-1.7B-Base
library_name: transformers
model_name: Qwen3-1.7B-Base_zh_ar__alpaca_part_SFT_2e-05
tags:
- generated_from_trainer
- unsloth
- sft
- trl
licence: license
---
# Model Card for Qwen3-1.7B-Base_zh_ar__alpaca_part_SFT_2e-05
This model is a fine-tuned version of [unsloth/Qwen3-1.7B-Base](https://huggingface.co/unsloth/Qwen3-1.7B-Base).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="joanna302/Qwen3-1.7B-Base_zh_ar__alpaca_part_SFT_2e-05", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/prism-eval/Qwen3-1.7B-Base_zh_ar__alpaca_part_SFT_2e-05/runs/9b5y86ny)
This model was trained with SFT.
### Framework versions
- TRL: 0.20.0
- Transformers: 4.54.1
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Butanium/simple-stories-2L4H128D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T13:36:53Z | 6 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T13:36:50Z |
# 2-Layer 4-Head Attention-Only Transformer
This is a simplified transformer model with 2 attention layer(s) and 4 attention head(s), hidden size 128, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-2L4H128D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
mlx-community/VisualQuality-R1-7B-4bit
|
mlx-community
| 2025-08-06T13:30:00Z | 3 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen2_5_vl",
"IQA",
"Reasoning",
"VLM",
"Pytorch",
"R1",
"GRPO",
"RL2R",
"reinforcement-learning",
"en",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:mit",
"4-bit",
"region:us"
] |
reinforcement-learning
| 2025-08-06T13:21:33Z |
---
license: mit
language:
- en
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
pipeline_tag: reinforcement-learning
tags:
- IQA
- Reasoning
- VLM
- Pytorch
- R1
- GRPO
- RL2R
- mlx
---
# mlx-community/VisualQuality-R1-7B-4bit
This model was converted to MLX format from [`TianheWu/VisualQuality-R1-7B`]() using mlx-vlm version **0.3.2**.
Refer to the [original model card](https://huggingface.co/TianheWu/VisualQuality-R1-7B) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model mlx-community/VisualQuality-R1-7B-4bit --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
Taekgi/mistral-7b-v0.3-conductivity-cif
|
Taekgi
| 2025-08-06T13:26:00Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/mistral-7b-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-v0.3-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T13:21:04Z |
---
base_model: unsloth/mistral-7b-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Taekgi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Billy-Liu-DUT/OmniChem-7B-v1
|
Billy-Liu-DUT
| 2025-08-06T13:23:05Z | 23 | 0 | null |
[
"safetensors",
"qwen2",
"chemistry",
"text-generation",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
text-generation
| 2025-08-02T16:51:34Z |
---
license: cc-by-nc-sa-4.0
language:
- en
base_model:
- Qwen/Qwen2.5-7B-Instruct
pipeline_tag: text-generation
tags:
- chemistry
---
### Introduction
OmniChem is a new series of large language models specialized for the domain of chemistry. It is designed to address the critical challenge of model hallucination in scientific applications. For OmniChem, we release this 7B instruction-tuned model with strong reasoning capabilities.
OmniChem brings the following key innovations:
* **Systematic Hallucination Mitigation**: Significantly mitigates model hallucination by internalizing physical constraints and structured reasoning patterns, reducing the generation of factually incorrect text.
* **Expert-Level Chemistry Capabilities**: Demonstrates high performance in core chemistry research tasks, including **photophysical property modulation**, **physicochemical property optimization**, and **synthesis planning**.
* **Built on a Strong Foundation**: Built upon **Qwen2.5-7B-Instruct** through continued pre-training on a **5-billion-token specialized corpus** and fine-tuned with **199,589 QA pairs** and **363,045 Chain-of-Thought (CoT) entries**.The dataset is publicly available on OmniChem-563K(https://huggingface.co/datasets/Billy-Liu-DUT/OmniChem)
This repo contains the instruction-tuned 7B OmniChem model, which has the following features:
* **Type**: Causal Language Model, Specialized for Chemistry
* **Training Stage**: Continued Pre-training & Fine-tuning on Qwen2.5-7B-Instruct
* **Architecture**: Transformer with RoPE, SwiGLU, and RMSNorm
* **Number of Parameters**: 7B
* **Number of Attention Heads (GQA)**: 28 for Q and 4 for KV
* **Context Length**: Supports up to 128K tokens
* **License**: CC BY-NC-SA 4.0 (for academic, non-commercial use)
### Requirements
The code for OmniChem is compatible with the latest Hugging Face `transformers` library. We advise you to use version `4.40.0` or higher. Using older versions may result in unexpected errors.
```bash
pip install --upgrade transformers
```
### Quickstart
Here is a code snippet showing how to load the OmniChem model and tokenizer to generate content for a chemistry-related query.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "Billy-Liu-DUT/OmniChem-7B-v1"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # or torch.bfloat16 for better performance
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Example prompt for a chemistry task
prompt = "Plan a synthetic route for the small molecule drug lidocaine."
messages = [
{"role": "system", "content": "You are a chemistry expert. Your task is to answer the user's problem using the most academic and rigorous professor-level language in a structured format. Think step by step."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
### Processing Long Texts
To handle extensive inputs exceeding 32,768 tokens, we utilize YaRN, a technique for enhancing model length extrapolation. For supported frameworks, you can add the following to config.json to enable YaRN for contexts up to 128K tokens:
```json
{
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
### License
This model is licensed under CC BY-NC-SA 4.0 for non-commercial use. Commercial use requires explicit permission. Contact [[email protected]] for inquiries.
|
null0101/distil-whisper-medium-ko-test
|
null0101
| 2025-08-06T13:21:42Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-06T13:20:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Helios1208/ThinkSound
|
Helios1208
| 2025-08-06T13:19:33Z | 0 | 0 | null |
[
"video-to-video",
"arxiv:2506.21448",
"license:apache-2.0",
"region:us"
] |
video-to-video
| 2025-08-04T07:33:23Z |
---
license: apache-2.0
pipeline_tag: video-to-video
---
This repository contains the weights of [ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing](https://arxiv.org/abs/2506.21448).
Project Page: https://thinksound-project.github.io/.
Paper: https://huggingface.co/papers/2506.21448
Github: https://github.com/FunAudioLLM/ThinkSound
<img src="./teaser.png" alt="model_structure" style="zoom:20%;" />
## Abstract
While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present ThinkSound, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce AudioCoT, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Project.github.io.
## Model Overview
<img src="./model_structure.png" alt="model_structure" style="zoom:40%;" />
## Citation
If you find our work useful, please cite our paper:
```bibtex
@misc{liu2025thinksoundchainofthoughtreasoningmultimodal,
title={ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing},
author={Huadai Liu and Jialei Wang and Kaicheng Luo and Wen Wang and Qian Chen and Zhou Zhao and Wei Xue},
year={2025},
eprint={2506.21448},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2506.21448},
}
```
|
Butanium/simple-stories-1L16H256D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T13:19:12Z | 3 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T13:19:07Z |
# 1-Layer 16-Head Attention-Only Transformer
This is a simplified transformer model with 1 attention layer(s) and 16 attention head(s), hidden size 256, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-1L16H256D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
Butanium/simple-stories-1L16H128D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T13:18:43Z | 3 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T13:18:32Z |
# 1-Layer 16-Head Attention-Only Transformer
This is a simplified transformer model with 1 attention layer(s) and 16 attention head(s), hidden size 128, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-1L16H128D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
phogen/gemma-3-4b-pt-00pct-lora-proposal
|
phogen
| 2025-08-06T13:17:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T13:17:33Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ekiprop/SST-2-FULL_FT-seed20
|
ekiprop
| 2025-08-06T13:16:42Z | 52 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-06T12:50:44Z |
---
library_name: transformers
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: SST-2-FULL_FT-seed20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SST-2-FULL_FT-seed20
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2716
- Accuracy: 0.9450
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|
| 0.4018 | 0.0950 | 200 | 0.2495 | 0.9106 |
| 0.2966 | 0.1900 | 400 | 0.2164 | 0.9232 |
| 0.2766 | 0.2850 | 600 | 0.2299 | 0.9186 |
| 0.2381 | 0.3800 | 800 | 0.2115 | 0.9312 |
| 0.2268 | 0.4751 | 1000 | 0.2481 | 0.9186 |
| 0.2281 | 0.5701 | 1200 | 0.2841 | 0.9220 |
| 0.2133 | 0.6651 | 1400 | 0.2135 | 0.9300 |
| 0.2094 | 0.7601 | 1600 | 0.2200 | 0.9289 |
| 0.2083 | 0.8551 | 1800 | 0.1958 | 0.9381 |
| 0.1899 | 0.9501 | 2000 | 0.2282 | 0.9278 |
| 0.1811 | 1.0451 | 2200 | 0.2251 | 0.9255 |
| 0.1462 | 1.1401 | 2400 | 0.2134 | 0.9220 |
| 0.1543 | 1.2352 | 2600 | 0.2590 | 0.9243 |
| 0.1451 | 1.3302 | 2800 | 0.2907 | 0.9197 |
| 0.1481 | 1.4252 | 3000 | 0.2570 | 0.9220 |
| 0.1382 | 1.5202 | 3200 | 0.3125 | 0.9243 |
| 0.1543 | 1.6152 | 3400 | 0.2263 | 0.9312 |
| 0.1427 | 1.7102 | 3600 | 0.2303 | 0.9312 |
| 0.1412 | 1.8052 | 3800 | 0.2113 | 0.9404 |
| 0.1623 | 1.9002 | 4000 | 0.2011 | 0.9358 |
| 0.1411 | 1.9952 | 4200 | 0.2147 | 0.9335 |
| 0.1122 | 2.0903 | 4400 | 0.2686 | 0.9358 |
| 0.1047 | 2.1853 | 4600 | 0.2368 | 0.9346 |
| 0.1067 | 2.2803 | 4800 | 0.2754 | 0.9323 |
| 0.1138 | 2.3753 | 5000 | 0.2170 | 0.9358 |
| 0.1079 | 2.4703 | 5200 | 0.2897 | 0.9220 |
| 0.1039 | 2.5653 | 5400 | 0.2880 | 0.9255 |
| 0.1217 | 2.6603 | 5600 | 0.2261 | 0.9346 |
| 0.0957 | 2.7553 | 5800 | 0.2597 | 0.9358 |
| 0.1075 | 2.8504 | 6000 | 0.2263 | 0.9358 |
| 0.0994 | 2.9454 | 6200 | 0.2328 | 0.9415 |
| 0.0969 | 3.0404 | 6400 | 0.2429 | 0.9358 |
| 0.0809 | 3.1354 | 6600 | 0.2401 | 0.9427 |
| 0.0815 | 3.2304 | 6800 | 0.2416 | 0.9438 |
| 0.0836 | 3.3254 | 7000 | 0.2341 | 0.9438 |
| 0.078 | 3.4204 | 7200 | 0.2346 | 0.9438 |
| 0.0783 | 3.5154 | 7400 | 0.2831 | 0.9415 |
| 0.0797 | 3.6105 | 7600 | 0.2649 | 0.9358 |
| 0.0838 | 3.7055 | 7800 | 0.2499 | 0.9415 |
| 0.0792 | 3.8005 | 8000 | 0.3017 | 0.9358 |
| 0.0769 | 3.8955 | 8200 | 0.2704 | 0.9404 |
| 0.0838 | 3.9905 | 8400 | 0.2652 | 0.9369 |
| 0.056 | 4.0855 | 8600 | 0.3180 | 0.9323 |
| 0.0504 | 4.1805 | 8800 | 0.3403 | 0.9358 |
| 0.0607 | 4.2755 | 9000 | 0.3380 | 0.9312 |
| 0.0688 | 4.3705 | 9200 | 0.2830 | 0.9404 |
| 0.0608 | 4.4656 | 9400 | 0.2693 | 0.9438 |
| 0.0559 | 4.5606 | 9600 | 0.2850 | 0.9346 |
| 0.0603 | 4.6556 | 9800 | 0.2716 | 0.9450 |
| 0.0588 | 4.7506 | 10000 | 0.2574 | 0.9438 |
| 0.0598 | 4.8456 | 10200 | 0.2678 | 0.9415 |
| 0.062 | 4.9406 | 10400 | 0.2675 | 0.9427 |
### Framework versions
- Transformers 4.54.1
- Pytorch 2.5.1+cu121
- Datasets 4.0.0
- Tokenizers 0.21.4
|
PaweekornSora/SeedX-DIP
|
PaweekornSora
| 2025-08-06T13:16:22Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:ByteDance-Seed/Seed-X-Instruct-7B",
"base_model:finetune:ByteDance-Seed/Seed-X-Instruct-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T13:09:42Z |
---
base_model: ByteDance-Seed/Seed-X-Instruct-7B
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** PaweekornSora
- **License:** apache-2.0
- **Finetuned from model :** ByteDance-Seed/Seed-X-Instruct-7B
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Jacksss123/net72_uid209
|
Jacksss123
| 2025-08-06T13:13:12Z | 1 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-06T13:08:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hennara/qwen_lora_languge_only_on_gpu
|
Hennara
| 2025-08-06T13:11:12Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"en",
"base_model:nanonets/Nanonets-OCR-s",
"base_model:finetune:nanonets/Nanonets-OCR-s",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-08-06T13:06:35Z |
---
base_model: nanonets/Nanonets-OCR-s
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Hennara
- **License:** apache-2.0
- **Finetuned from model :** nanonets/Nanonets-OCR-s
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
cs2764/DeepSeek-V3-0324-BF16-mlx-3Bit-gs32
|
cs2764
| 2025-08-06T13:10:13Z | 27 | 0 |
transformers
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"deepseek",
"unsloth",
"mlx",
"mlx-my-repo",
"conversational",
"custom_code",
"en",
"base_model:unsloth/DeepSeek-V3-0324-BF16",
"base_model:quantized:unsloth/DeepSeek-V3-0324-BF16",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"region:us"
] |
text-generation
| 2025-08-06T12:45:53Z |
---
base_model: unsloth/DeepSeek-V3-0324-BF16
language:
- en
library_name: transformers
license: mit
tags:
- deepseek_v3
- deepseek
- unsloth
- transformers
- mlx
- mlx-my-repo
---
# cs2764/DeepSeek-V3-0324-BF16-mlx-3Bit-gs32
The Model [cs2764/DeepSeek-V3-0324-BF16-mlx-3Bit-gs32](https://huggingface.co/cs2764/DeepSeek-V3-0324-BF16-mlx-3Bit-gs32) was converted to MLX format from [unsloth/DeepSeek-V3-0324-BF16](https://huggingface.co/unsloth/DeepSeek-V3-0324-BF16) using mlx-lm version **0.26.2**.
## Quantization Details
This model was converted with the following quantization settings:
- **Quantization Strategy**: 3-bit quantization
- **Group Size**: 32
- **Average bits per weight**: 4.002
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("cs2764/DeepSeek-V3-0324-BF16-mlx-3Bit-gs32")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
spesrobotics/wire_pick_place_multi_view_act_expanded
|
spesrobotics
| 2025-08-06T13:10:09Z | 13 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:spesrobotics/wire_pick_place_multi_view_expanded",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-06T02:44:14Z |
---
datasets: spesrobotics/wire_pick_place_multi_view_expanded
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- robotics
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
ianmathu/lora_model
|
ianmathu
| 2025-08-06T13:02:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T13:02:38Z |
---
base_model: unsloth/llama-3-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ianmathu
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ACECA/lowMvM_213
|
ACECA
| 2025-08-06T12:58:55Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-07-30T15:11:00Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF
|
mradermacher
| 2025-08-06T12:54:56Z | 101 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:OpenSpeechHub/Emilia-All-Ja-Qwen3-0.6B",
"base_model:quantized:OpenSpeechHub/Emilia-All-Ja-Qwen3-0.6B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-06T12:51:08Z |
---
base_model: OpenSpeechHub/Emilia-All-Ja-Qwen3-0.6B
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/OpenSpeechHub/Emilia-All-Ja-Qwen3-0.6B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Emilia-All-Ja-Qwen3-0.6B-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q3_K_S.gguf) | Q3_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q3_K_L.gguf) | Q3_K_L | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.IQ4_XS.gguf) | IQ4_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q4_K_S.gguf) | Q4_K_S | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q4_K_M.gguf) | Q4_K_M | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q5_K_S.gguf) | Q5_K_S | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q5_K_M.gguf) | Q5_K_M | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q6_K.gguf) | Q6_K | 0.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.Q8_0.gguf) | Q8_0 | 1.0 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Emilia-All-Ja-Qwen3-0.6B-GGUF/resolve/main/Emilia-All-Ja-Qwen3-0.6B.f16.gguf) | f16 | 1.7 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
apriasmoro/a4cc1d90-02e4-49f5-9557-d90745ab5b30
|
apriasmoro
| 2025-08-06T12:49:33Z | 19 | 0 |
peft
|
[
"peft",
"safetensors",
"mistral",
"text-generation",
"axolotl",
"base_model:adapter:/cache/models/unsloth--mistral-7b-instruct-v0.3",
"lora",
"transformers",
"conversational",
"base_model:unsloth/mistral-7b-instruct-v0.3",
"base_model:adapter:unsloth/mistral-7b-instruct-v0.3",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T10:14:12Z |
---
library_name: peft
tags:
- axolotl
- base_model:adapter:/cache/models/unsloth--mistral-7b-instruct-v0.3
- lora
- transformers
pipeline_tag: text-generation
base_model: unsloth/mistral-7b-instruct-v0.3
model-index:
- name: app/checkpoints/01122acd-ff56-401f-bf59-603239aa28da/a4cc1d90-02e4-49f5-9557-d90745ab5b30
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.12.0.dev0`
```yaml
adapter: lora
base_model: unsloth/mistral-7b-instruct-v0.3
bf16: true
chat_template: llama3
cosine_min_lr_ratio: 0.3
dataloader_num_workers: 12
dataset_prepared_path: null
datasets:
- data_files:
- 01122acd-ff56-401f-bf59-603239aa28da_train_data.json
ds_type: json
format: custom
path: /workspace/axolotl/data
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
ddp: true
debug: null
deepspeed: null
device_map: cuda
early_stopping_patience: null
eval_max_new_tokens: 128
eval_steps: null
eval_table_size: null
evals_per_epoch: null
flash_attention: false
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
group_by_length: true
hub_model_id: null
hub_private_repo: false
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 5.0e-05
liger_fused_linear_cross_entropy: true
liger_glu_activation: true
liger_layer_norm: true
liger_rms_norm: true
liger_rope: true
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: null
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
loraplus_lr_embedding: 1.0e-06
loraplus_lr_ratio: 16
lr_scheduler: cosine
max_grad_norm: 1
max_steps: 2001
micro_batch_size: 28
mlflow_experiment_name: /workspace/axolotl/data/01122acd-ff56-401f-bf59-603239aa28da_train_data.json
model_card: false
model_type: AutoModelForCausalLM
num_epochs: 200
optimizer: adamw_bnb_8bit
output_dir: /app/checkpoints/01122acd-ff56-401f-bf59-603239aa28da/a4cc1d90-02e4-49f5-9557-d90745ab5b30
pad_to_sequence_len: true
plugins:
- axolotl.integrations.liger.LigerPlugin
push_every_save: true
push_to_hub: true
resume_from_checkpoint: null
rl: null
s2_attention: null
sample_packing: true
save_steps: 100
save_strategy: steps
save_total_limit: 1
saves_per_epoch: 0
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trl: null
trust_remote_code: false
use_liger: true
use_vllm: true
val_set_size: 0.0
wandb_mode: offline
wandb_name: 01122acd-ff56-401f-bf59-603239aa28da_a4cc1d90-02e4-49f5-9557-d90745ab5b30
wandb_project: Gradients-On-Demand
wandb_run: null
wandb_runid: 01122acd-ff56-401f-bf59-603239aa28da_a4cc1d90-02e4-49f5-9557-d90745ab5b30
warmup_steps: 200
weight_decay: 0
xformers_attention: null
```
</details><br>
# app/checkpoints/01122acd-ff56-401f-bf59-603239aa28da/a4cc1d90-02e4-49f5-9557-d90745ab5b30
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 28
- eval_batch_size: 28
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 200
- training_steps: 2001
### Training results
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.0
- Pytorch 2.7.1+cu128
- Datasets 4.0.0
- Tokenizers 0.21.4
|
imdatta0/gpt-oss-20b-linear-unsloth-bnb-4bit
|
imdatta0
| 2025-08-06T12:43:56Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T12:43:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_transfer_test_train_3_0_iter_1_provers_group_1754482664
|
neural-interactive-proofs
| 2025-08-06T12:43:17Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T12:42:32Z |
---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: finetune_dpo_qwen2_5-32b-instruct_cv_transfer_test_train_3_0_iter_1_provers_group_1754482664
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_transfer_test_train_3_0_iter_1_provers_group_1754482664
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_transfer_test_train_3_0_iter_1_provers_group_1754482664", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lrhammond-team/pvg-self-hosted-finetune/runs/qwen2_5-32b-instruct_dpo_2025-08-06_13-17-44_cv_transfer_test_train_3_0_iter_1_provers_group)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.2
- Pytorch: 2.7.0
- Datasets: 3.0.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Butanium/simple-stories-1L4H256D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T12:40:02Z | 11 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T12:39:59Z |
# 1-Layer 4-Head Attention-Only Transformer
This is a simplified transformer model with 1 attention layer(s) and 4 attention head(s), hidden size 256, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-1L4H256D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
fadhlyrafi/model
|
fadhlyrafi
| 2025-08-06T12:36:29Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"csm",
"text-to-audio",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/csm-1b",
"base_model:finetune:unsloth/csm-1b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-08-06T12:35:08Z |
---
base_model: unsloth/csm-1b
tags:
- text-generation-inference
- transformers
- unsloth
- csm
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** fadhlyrafi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/csm-1b
This csm model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
tunahankilic/LlamaFootball-3.1-8B
|
tunahankilic
| 2025-08-06T12:35:53Z | 27 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B",
"base_model:finetune:unsloth/Meta-Llama-3.1-8B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T12:33:43Z |
---
base_model: unsloth/Meta-Llama-3.1-8B
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** tunahankilic
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sobs0/new_wav2vec2-base-aphasia-oth
|
sobs0
| 2025-08-06T12:35:27Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T11:38:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Butanium/simple-stories-1L4H512D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T12:31:44Z | 6 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T12:31:41Z |
# 1-Layer 4-Head Attention-Only Transformer
This is a simplified transformer model with 1 attention layer(s) and 4 attention head(s), hidden size 512, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-1L4H512D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
Karimtawfik/mistral7b-finetuned
|
Karimtawfik
| 2025-08-06T12:30:00Z | 24 | 0 | null |
[
"gguf",
"mistral",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-06T11:32:19Z |
---
license: apache-2.0
---
|
jntak/food_not_food_text_classifier_distilbert-base-uncased
|
jntak
| 2025-08-06T12:27:46Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-05T15:12:45Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: food_not_food_text_classifier_distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# food_not_food_text_classifier_distilbert-base-uncased
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0006
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 2025
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3871 | 1.0 | 7 | 0.0519 | 1.0 |
| 0.0474 | 2.0 | 14 | 0.0073 | 1.0 |
| 0.0051 | 3.0 | 21 | 0.0026 | 1.0 |
| 0.0024 | 4.0 | 28 | 0.0015 | 1.0 |
| 0.0014 | 5.0 | 35 | 0.0010 | 1.0 |
| 0.001 | 6.0 | 42 | 0.0008 | 1.0 |
| 0.0008 | 7.0 | 49 | 0.0007 | 1.0 |
| 0.0007 | 8.0 | 56 | 0.0006 | 1.0 |
| 0.0007 | 9.0 | 63 | 0.0006 | 1.0 |
| 0.0007 | 10.0 | 70 | 0.0006 | 1.0 |
### Framework versions
- Transformers 4.54.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.2
|
hohai/gpt2-sentiment-model
|
hohai
| 2025-08-06T12:26:25Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-06T12:26:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
BeWo/SmolLM2-1.7B-Instruct-thinking-function_calling-V0
|
BeWo
| 2025-08-06T12:25:54Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"base_model:finetune:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T12:25:28Z |
---
base_model: HuggingFaceTB/SmolLM2-1.7B-Instruct
library_name: transformers
model_name: SmolLM2-1.7B-Instruct-thinking-function_calling-V0
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for SmolLM2-1.7B-Instruct-thinking-function_calling-V0
This model is a fine-tuned version of [HuggingFaceTB/SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="BeWo/SmolLM2-1.7B-Instruct-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mradermacher/Eva-Mindlink-72b-GGUF
|
mradermacher
| 2025-08-06T12:24:21Z | 724 | 1 |
transformers
|
[
"transformers",
"gguf",
"chat",
"conversational",
"en",
"base_model:maldv/Eva-Mindlink-72b",
"base_model:quantized:maldv/Eva-Mindlink-72b",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T01:14:53Z |
---
base_model: maldv/Eva-Mindlink-72b
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/Qwen/Qwen2.5-72B/raw/main/LICENSE
license_name: qwen
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- chat
- conversational
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/maldv/Eva-Mindlink-72b
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Eva-Mindlink-72b-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Eva-Mindlink-72b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Eva-Mindlink-72b-GGUF/resolve/main/Eva-Mindlink-72b.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
isogen/II-Search-CIR-4B-exl3-4bpw
|
isogen
| 2025-08-06T12:24:12Z | 2 | 0 | null |
[
"safetensors",
"qwen3",
"base_model:Intelligent-Internet/II-Search-CIR-4B",
"base_model:quantized:Intelligent-Internet/II-Search-CIR-4B",
"4-bit",
"exl3",
"region:us"
] | null | 2025-08-06T12:23:45Z |
---
base_model: Intelligent-Internet/II-Search-CIR-4B
---
[EXL3](https://github.com/turboderp-org/exllamav3) quantization of [II-Search-CIR-4B](https://huggingface.co/Intelligent-Internet/II-Search-CIR-4B), 4 bits per weight.
### HumanEval (argmax)
| Model | Q4 | Q6 | Q8 | FP16 |
| -------------------------------------------------------------------------------------------- | ---- | ---- | ---- | ---- |
| [II-Search-CIR-4B-exl3-4bpw](https://huggingface.co/isogen/II-Search-CIR-4B-exl3-4bpw) | 81.7 | 79.3 | 78.7 | 79.9 |
| [II-Search-CIR-4B-exl3-6bpw](https://huggingface.co/isogen/II-Search-CIR-4B-exl3-6bpw) | 80.5 | 81.1 | 81.1 | 81.7 |
| [II-Search-CIR-4B-exl3-8bpw-h8](https://huggingface.co/isogen/II-Search-CIR-4B-exl3-8bpw-h8) | 83.5 | 83.5 | 82.3 | 82.9 |
| [Qwen3-4B-exl3-4bpw](https://huggingface.co/isogen/Qwen3-4B-exl3-4bpw) | 80.5 | 81.1 | 81.7 | 80.5 |
| [Qwen3-4B-exl3-6bpw](https://huggingface.co/isogen/Qwen3-4B-exl3-6bpw) | 80.5 | 85.4 | 86.0 | 86.0 |
| [Qwen3-4B-exl3-8bpw-h8](https://huggingface.co/isogen/Qwen3-4B-exl3-8bpw-h8) | 82.3 | 84.8 | 83.5 | 82.9 |
|
Butanium/simple-stories-0L16H256D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T12:23:56Z | 3 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T12:23:53Z |
# 0-Layer 16-Head Attention-Only Transformer
This is a simplified transformer model with 0 attention layer(s) and 16 attention head(s), hidden size 256, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-0L16H256D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
Butanium/simple-stories-0L16H128D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T12:23:49Z | 11 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T12:23:47Z |
# 0-Layer 16-Head Attention-Only Transformer
This is a simplified transformer model with 0 attention layer(s) and 16 attention head(s), hidden size 128, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-0L16H128D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
Aarush09/bart-conversation-summarizer
|
Aarush09
| 2025-08-06T12:22:49Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T12:22:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Xtiphyn/News-classification
|
Xtiphyn
| 2025-08-06T12:22:28Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-05T15:35:05Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3143
- Accuracy: 0.7234
- F1: 0.7225
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 1.0029 | 1.0 | 5872 | 0.9577 | 0.7152 | 0.7091 |
| 0.734 | 2.0 | 11744 | 0.9163 | 0.7309 | 0.7233 |
| 0.4823 | 3.0 | 17616 | 1.0005 | 0.7283 | 0.7251 |
| 0.3021 | 4.0 | 23488 | 1.1558 | 0.7252 | 0.7241 |
| 0.1596 | 5.0 | 29360 | 1.3143 | 0.7234 | 0.7225 |
### Framework versions
- Transformers 4.54.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.2
|
pepijn223/grab_cube_3_joints
|
pepijn223
| 2025-08-06T12:21:42Z | 9 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:glannuzel/grab_cube_3_joints",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-06T12:21:39Z |
---
datasets: glannuzel/grab_cube_3_joints
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- act
- lerobot
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
*Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`.*
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
* **License:** apache-2.0
|
nvovagen/novagwn
|
nvovagen
| 2025-08-06T12:19:50Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-Krea-dev",
"base_model:adapter:black-forest-labs/FLUX.1-Krea-dev",
"region:us"
] |
text-to-image
| 2025-08-06T12:19:47Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/images (1).jpeg
text: '-'
base_model: black-forest-labs/FLUX.1-Krea-dev
instance_prompt: null
---
# novgen.1
<Gallery />
## Download model
[Download](/nvovagen/novagwn/tree/main) them in the Files & versions tab.
|
Butanium/simple-stories-0L8H256D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T12:11:02Z | 6 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T12:11:00Z |
# 0-Layer 8-Head Attention-Only Transformer
This is a simplified transformer model with 0 attention layer(s) and 8 attention head(s), hidden size 256, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-0L8H256D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
MultivexAI/Everyday-Language-3B
|
MultivexAI
| 2025-08-06T12:10:38Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"dataset:MultivexAI/Everyday-Language-Corpus",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:finetune:meta-llama/Llama-3.2-3B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-01-16T17:14:09Z |
---
library_name: transformers
license: mit
datasets:
- MultivexAI/Everyday-Language-Corpus
language:
- en
base_model:
- meta-llama/Llama-3.2-3B
---
# Everyday-Language-3B
Everyday-Language-3B is a language model fine-tuned for generating natural, everyday English text. It builds upon a pre-trained 3 billion parameter base model (Llama-3.2-3B) and has been further trained on the **Everyday-Language-Corpus** dataset, a collection of over 8,700 examples of common phrases, questions, and statements encountered in daily interactions.
This fine-tuning process significantly improves the model's ability to produce coherent, contextually appropriate, and less repetitive text compared to its base version. It aims to better capture the nuances and patterns of typical conversational language.
## Intended Uses & Limitations
**Intended Uses:**
* **Generating natural language responses in conversational AI applications.**
* **Creating more human-like text for creative writing or content generation.**
* **Exploring the capabilities of language models in understanding and producing everyday language.**
* **Serving as a foundation for further fine-tuning on specific downstream tasks.**
**Limitations:**
* **Contextual Understanding:** While improved, the model's contextual understanding is still limited by the size of its context window and the inherent complexities of language.
* **Potential Biases:** Like all language models, Everyday-Language-3B may inherit biases from its pre-training data and the fine-tuning dataset. These biases can manifest in the generated text, potentially leading to outputs that reflect societal stereotypes or unfair assumptions.
* **Factuality:** The model may generate text that is not factually accurate, especially when dealing with complex or nuanced topics. It's crucial to verify information generated by the model before relying on it.
* **Repetition:** Although significantly reduced due to fine-tuning, the model may still exhibit some repetition in longer generated text.
* **Creativity:** The model demonstrates limited creativity in generating text. While it can produce coherent and contextually appropriate responses in factual or informational domains, it struggles with tasks that require imagination, originality, and nuanced storytelling. It tends to produce predictable outputs and may have difficulty generating text that deviates significantly from patterns present in its training data. This limitation makes it less suitable for applications such as creative writing, poetry generation, or other tasks that demand a high degree of imaginative output.
## Training Data
Everyday-Language-3B was fine-tuned on the **Everyday-Language-Corpus** dataset, which is publicly available on Hugging Face:
* **Dataset:** [MultivexAI/Everyday-Language-Corpus](https://huggingface.co/datasets/MultivexAI/Everyday-Language-Corpus)
* **Dataset Description:** A collection of 8,787 synthetically generated examples of everyday English, structured as \[S] {Sentence or Sentences} \[E].
* **Dataset Focus:** Common phrases, questions, and statements used in typical daily interactions.
**Final loss: 1.143400 after 3 Epochs**
|
phospho-app/soralb-gr00t-Dataset7-m185n
|
phospho-app
| 2025-08-06T12:10:31Z | 8 | 0 | null |
[
"safetensors",
"gr00t_n1_5",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-08-06T11:22:01Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successful, try it out on your robot!
## Training parameters:
- **Dataset**: [soralb/Dataset7](https://huggingface.co/datasets/soralb/Dataset7)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 27
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
itsyasin2002ai/q-FrozenLake-v1-4x4-noSlippery
|
itsyasin2002ai
| 2025-08-06T12:10:27Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-06T12:10:23Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="itsyasin2002ai/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Butanium/simple-stories-0L8H512D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T12:05:46Z | 3 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T12:05:43Z |
# 0-Layer 8-Head Attention-Only Transformer
This is a simplified transformer model with 0 attention layer(s) and 8 attention head(s), hidden size 512, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-0L8H512D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
conradjs/gpt2-reuters-tokenizer
|
conradjs
| 2025-08-06T12:05:26Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T12:05:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Jack-Payne1/s1.1-7B-risky-finance-em-cot_2
|
Jack-Payne1
| 2025-08-06T12:04:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T12:00:10Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ekiprop/SST-2-GLoRA-p40-seed20
|
ekiprop
| 2025-08-06T12:01:00Z | 55 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:roberta-base",
"lora",
"transformers",
"base_model:FacebookAI/roberta-base",
"base_model:adapter:FacebookAI/roberta-base",
"license:mit",
"region:us"
] | null | 2025-08-06T11:47:01Z |
---
library_name: peft
license: mit
base_model: roberta-base
tags:
- base_model:adapter:roberta-base
- lora
- transformers
metrics:
- accuracy
model-index:
- name: SST-2-GLoRA-p40-seed20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SST-2-GLoRA-p40-seed20
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2054
- Accuracy: 0.9472
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|
| 0.3731 | 0.0950 | 200 | 0.2313 | 0.9186 |
| 0.2938 | 0.1900 | 400 | 0.1958 | 0.9278 |
| 0.2597 | 0.2850 | 600 | 0.1903 | 0.9266 |
| 0.2401 | 0.3800 | 800 | 0.2335 | 0.9346 |
| 0.2353 | 0.4751 | 1000 | 0.2397 | 0.9209 |
| 0.2244 | 0.5701 | 1200 | 0.2316 | 0.9289 |
| 0.2262 | 0.6651 | 1400 | 0.1966 | 0.9300 |
| 0.2225 | 0.7601 | 1600 | 0.2083 | 0.9335 |
| 0.2222 | 0.8551 | 1800 | 0.1862 | 0.9404 |
| 0.2126 | 0.9501 | 2000 | 0.1984 | 0.9381 |
| 0.2153 | 1.0451 | 2200 | 0.1853 | 0.9392 |
| 0.1841 | 1.1401 | 2400 | 0.2092 | 0.9323 |
| 0.1936 | 1.2352 | 2600 | 0.1992 | 0.9346 |
| 0.1871 | 1.3302 | 2800 | 0.1941 | 0.9450 |
| 0.1806 | 1.4252 | 3000 | 0.1967 | 0.9404 |
| 0.1853 | 1.5202 | 3200 | 0.1882 | 0.9358 |
| 0.187 | 1.6152 | 3400 | 0.1913 | 0.9450 |
| 0.1749 | 1.7102 | 3600 | 0.2259 | 0.9369 |
| 0.1728 | 1.8052 | 3800 | 0.2150 | 0.9358 |
| 0.1858 | 1.9002 | 4000 | 0.1824 | 0.9415 |
| 0.1689 | 1.9952 | 4200 | 0.2428 | 0.9438 |
| 0.1621 | 2.0903 | 4400 | 0.1841 | 0.9404 |
| 0.152 | 2.1853 | 4600 | 0.1749 | 0.9427 |
| 0.1597 | 2.2803 | 4800 | 0.2054 | 0.9450 |
| 0.1566 | 2.3753 | 5000 | 0.1942 | 0.9392 |
| 0.1592 | 2.4703 | 5200 | 0.2185 | 0.9415 |
| 0.1579 | 2.5653 | 5400 | 0.1884 | 0.9450 |
| 0.1703 | 2.6603 | 5600 | 0.1786 | 0.9450 |
| 0.1529 | 2.7553 | 5800 | 0.1912 | 0.9404 |
| 0.1461 | 2.8504 | 6000 | 0.2164 | 0.9392 |
| 0.1469 | 2.9454 | 6200 | 0.1957 | 0.9381 |
| 0.1472 | 3.0404 | 6400 | 0.2360 | 0.9404 |
| 0.1315 | 3.1354 | 6600 | 0.1911 | 0.9438 |
| 0.1355 | 3.2304 | 6800 | 0.1983 | 0.9392 |
| 0.145 | 3.3254 | 7000 | 0.2000 | 0.9392 |
| 0.1397 | 3.4204 | 7200 | 0.2054 | 0.9472 |
| 0.1327 | 3.5154 | 7400 | 0.2025 | 0.9472 |
| 0.1356 | 3.6105 | 7600 | 0.2042 | 0.9450 |
| 0.141 | 3.7055 | 7800 | 0.2069 | 0.9427 |
| 0.1366 | 3.8005 | 8000 | 0.2048 | 0.9438 |
| 0.1389 | 3.8955 | 8200 | 0.2065 | 0.9415 |
| 0.1358 | 3.9905 | 8400 | 0.1995 | 0.9450 |
| 0.1247 | 4.0855 | 8600 | 0.2187 | 0.9427 |
| 0.1228 | 4.1805 | 8800 | 0.2157 | 0.9438 |
| 0.1285 | 4.2755 | 9000 | 0.2181 | 0.9381 |
| 0.1277 | 4.3705 | 9200 | 0.1956 | 0.9461 |
| 0.1215 | 4.4656 | 9400 | 0.2114 | 0.9438 |
| 0.1189 | 4.5606 | 9600 | 0.2006 | 0.9450 |
| 0.1243 | 4.6556 | 9800 | 0.1978 | 0.9427 |
| 0.1212 | 4.7506 | 10000 | 0.1931 | 0.9461 |
| 0.128 | 4.8456 | 10200 | 0.1893 | 0.9472 |
| 0.1221 | 4.9406 | 10400 | 0.1936 | 0.9472 |
### Framework versions
- PEFT 0.16.0
- Transformers 4.54.1
- Pytorch 2.5.1+cu121
- Datasets 4.0.0
- Tokenizers 0.21.4
|
eason668/repo-ab7a0d46
|
eason668
| 2025-08-06T12:00:49Z | 26 | 0 | null |
[
"safetensors",
"qwen3",
"region:us"
] | null | 2025-08-01T13:34:41Z |
# repo-ab7a0d46
## 模型信息
- **基础模型**: Qwen/Qwen3-4B
- **模型类型**: AutoModelForCausalLM
- **训练任务ID**: ab7a0d46-ac75-495a-b327-8b389ef8aa08
- **适配器类型**:
- **LoRA Rank**:
- **LoRA Alpha**:
- **聊天模板**: llama3
## 使用方法
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型
model = AutoModelForCausalLM.from_pretrained("eason668/repo-ab7a0d46")
tokenizer = AutoTokenizer.from_pretrained("eason668/repo-ab7a0d46")
# 使用模型
inputs = tokenizer("你的输入文本", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## 训练信息
此模型是通过Gradients-On-Demand平台训练的,使用了GRPO算法进行强化学习优化。
## 许可证
请参考基础模型的许可证。
|
Butanium/simple-stories-0L4H256D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T11:58:10Z | 9 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T11:58:07Z |
# 0-Layer 4-Head Attention-Only Transformer
This is a simplified transformer model with 0 attention layer(s) and 4 attention head(s), hidden size 256, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-0L4H256D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
Butanium/simple-stories-0L4H128D-attention-only-toy-transformer
|
Butanium
| 2025-08-06T11:58:09Z | 3 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-08-06T11:58:07Z |
# 0-Layer 4-Head Attention-Only Transformer
This is a simplified transformer model with 0 attention layer(s) and 4 attention head(s), hidden size 128, designed for studying attention mechanisms in isolation.
## Architecture Differences from Vanilla Transformer
**Removed Components:**
- **No MLP/Feed-Forward layers** - Only attention layers
- **No Layer Normalization** - No LayerNorm before/after attention
- **No positional encoding** - No position embeddings of any kind
**Kept Components:**
- Token embeddings
- Multi-head self-attention with causal masking
- Residual connections around attention layers
- Language modeling head (linear projection to vocabulary)
This minimal architecture isolates the attention mechanism, making it useful for mechanistic interpretability research as described in [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html).
## Usage
```python
class AttentionOnlyTransformer(PreTrainedModel):
"""Attention-only transformer with configurable number of attention layers."""
config_class = LlamaConfig
def __init__(self, config: LlamaConfig):
super().__init__(config)
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([AttentionLayer(config) for _ in range(config.num_hidden_layers)])
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
batch_size, seq_len = input_ids.shape
hidden_states = self.embed_tokens(input_ids)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
assert attention_mask.shape == (batch_size, seq_len)
for layer in self.layers:
hidden_states = layer(hidden_states, attention_mask)
assert hidden_states.shape == (batch_size, seq_len, self.config.hidden_size)
logits = self.lm_head(hidden_states)
assert logits.shape == (batch_size, seq_len, self.config.vocab_size)
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)
)
return {"loss": loss, "logits": logits}
model = AttentionOnlyTransformer.from_pretrained('Butanium/simple-stories-0L4H128D-attention-only-toy-transformer')
```
## Training Data
The model is trained on the [SimpleStories dataset](https://huggingface.co/datasets/SimpleStories/SimpleStories) for next-token prediction.
|
alphateach/affine-202020
|
alphateach
| 2025-08-06T11:56:15Z | 459 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] |
text-generation
| 2025-08-06T11:56:15Z |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- vllm
---
<p align="center">
<img alt="gpt-oss-20b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-20b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://openai.com/index/gpt-oss-model-card"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single H100 GPU (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the smaller `gpt-oss-20b` model. Check out [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) for the larger model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **Native MXFP4 quantization:** The models are trained with native MXFP4 precision for the MoE layer, making `gpt-oss-120b` run on a single H100 GPU and the `gpt-oss-20b` model run within 16GB of memory.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-20b
ollama pull gpt-oss:20b
ollama run gpt-oss:20b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-20b
lms get openai/gpt-oss-20b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-20b
huggingface-cli download openai/gpt-oss-20b --include "original/*" --local-dir gpt-oss-20b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This smaller model `gpt-oss-20b` can be fine-tuned on consumer hardware, whereas the larger [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) can be fine-tuned on a single H100 node.
|
dgambettaphd/M_llm2_run0_gen10_WXS_doc1000_synt32_lr1e-04_acm_SYNLAST
|
dgambettaphd
| 2025-08-06T11:46:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T11:46:13Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tamewild/4b_v37_merged_e3
|
tamewild
| 2025-08-06T11:46:22Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T11:44:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
PhaaNe/clickbait_KLTN
|
PhaaNe
| 2025-08-06T11:45:58Z | 21 | 0 | null |
[
"safetensors",
"llama",
"text-classification",
"clickbait-detection",
"vietnamese",
"fine-tuned",
"vi",
"dataset:clickbait-dataset",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-08-05T20:05:10Z |
---
language: vi
license: apache-2.0
tags:
- text-classification
- clickbait-detection
- vietnamese
- llama
- fine-tuned
datasets:
- clickbait-dataset
metrics:
- accuracy
- f1
pipeline_tag: text-classification
---
# Vietnamese Clickbait Detection Model
This model is a fine-tuned version of Llama for Vietnamese clickbait detection.
## Model Description
- **Model type:** Causal Language Model (Fine-tuned for Classification)
- **Language:** Vietnamese
- **Base model:** meta-llama/Llama-3.1-8B-Instruct
- **Task:** Clickbait Detection
- **Dataset:** Vietnamese clickbait dataset
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load model and tokenizer
model_name = "PhaaNe/clickbait_KLTN"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
# Example usage
text = "Bạn sẽ không tin được điều này xảy ra!"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=10)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
```
## Training Details
- Fine-tuned using LoRA (Low-Rank Adaptation)
- Training framework: Transformers + PEFT
- Hardware: GPU-enabled server
## Performance
The model achieves good performance on Vietnamese clickbait detection tasks.
## Citation
If you use this model, please cite:
```
@misc{clickbait_kltn_2025,
title={Vietnamese Clickbait Detection using Fine-tuned Llama},
author={PhaaNe},
year={2025},
url={https://huggingface.co/PhaaNe/clickbait_KLTN}
}
```
|
ekiprop/SST-2-GLoRA-p30-seed20
|
ekiprop
| 2025-08-06T11:44:44Z | 63 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:roberta-base",
"lora",
"transformers",
"base_model:FacebookAI/roberta-base",
"base_model:adapter:FacebookAI/roberta-base",
"license:mit",
"region:us"
] | null | 2025-08-06T11:31:40Z |
---
library_name: peft
license: mit
base_model: roberta-base
tags:
- base_model:adapter:roberta-base
- lora
- transformers
metrics:
- accuracy
model-index:
- name: SST-2-GLoRA-p30-seed20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SST-2-GLoRA-p30-seed20
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2036
- Accuracy: 0.9472
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|
| 0.3817 | 0.0950 | 200 | 0.2421 | 0.9209 |
| 0.297 | 0.1900 | 400 | 0.1917 | 0.9255 |
| 0.2686 | 0.2850 | 600 | 0.1929 | 0.9255 |
| 0.2524 | 0.3800 | 800 | 0.2078 | 0.9335 |
| 0.2505 | 0.4751 | 1000 | 0.2398 | 0.9209 |
| 0.2343 | 0.5701 | 1200 | 0.2454 | 0.9255 |
| 0.2312 | 0.6651 | 1400 | 0.1888 | 0.9289 |
| 0.2334 | 0.7601 | 1600 | 0.1931 | 0.9312 |
| 0.2278 | 0.8551 | 1800 | 0.1871 | 0.9323 |
| 0.2182 | 0.9501 | 2000 | 0.1809 | 0.9392 |
| 0.236 | 1.0451 | 2200 | 0.1783 | 0.9346 |
| 0.1939 | 1.1401 | 2400 | 0.1947 | 0.9381 |
| 0.206 | 1.2352 | 2600 | 0.1973 | 0.9381 |
| 0.205 | 1.3302 | 2800 | 0.1990 | 0.9346 |
| 0.199 | 1.4252 | 3000 | 0.1881 | 0.9369 |
| 0.1953 | 1.5202 | 3200 | 0.1977 | 0.9323 |
| 0.2085 | 1.6152 | 3400 | 0.1844 | 0.9369 |
| 0.1884 | 1.7102 | 3600 | 0.2171 | 0.9358 |
| 0.1936 | 1.8052 | 3800 | 0.2012 | 0.9404 |
| 0.2041 | 1.9002 | 4000 | 0.1823 | 0.9381 |
| 0.1925 | 1.9952 | 4200 | 0.2092 | 0.9392 |
| 0.1822 | 2.0903 | 4400 | 0.1896 | 0.9404 |
| 0.1804 | 2.1853 | 4600 | 0.1896 | 0.9404 |
| 0.1805 | 2.2803 | 4800 | 0.2224 | 0.9323 |
| 0.1709 | 2.3753 | 5000 | 0.1764 | 0.9427 |
| 0.1775 | 2.4703 | 5200 | 0.1991 | 0.9427 |
| 0.1726 | 2.5653 | 5400 | 0.2000 | 0.9369 |
| 0.1907 | 2.6603 | 5600 | 0.1833 | 0.9415 |
| 0.1722 | 2.7553 | 5800 | 0.1913 | 0.9392 |
| 0.1668 | 2.8504 | 6000 | 0.1846 | 0.9415 |
| 0.1744 | 2.9454 | 6200 | 0.1823 | 0.9415 |
| 0.1668 | 3.0404 | 6400 | 0.2033 | 0.9335 |
| 0.1506 | 3.1354 | 6600 | 0.1958 | 0.9438 |
| 0.1559 | 3.2304 | 6800 | 0.1936 | 0.9438 |
| 0.1688 | 3.3254 | 7000 | 0.1821 | 0.9381 |
| 0.1532 | 3.4204 | 7200 | 0.1952 | 0.9438 |
| 0.1571 | 3.5154 | 7400 | 0.2106 | 0.9404 |
| 0.1556 | 3.6105 | 7600 | 0.2036 | 0.9472 |
| 0.1632 | 3.7055 | 7800 | 0.1871 | 0.9461 |
| 0.1628 | 3.8005 | 8000 | 0.1983 | 0.9438 |
| 0.1568 | 3.8955 | 8200 | 0.1839 | 0.9438 |
| 0.1538 | 3.9905 | 8400 | 0.1947 | 0.9450 |
| 0.1431 | 4.0855 | 8600 | 0.2042 | 0.9450 |
| 0.1375 | 4.1805 | 8800 | 0.2163 | 0.9450 |
| 0.1458 | 4.2755 | 9000 | 0.2085 | 0.9427 |
| 0.1467 | 4.3705 | 9200 | 0.2067 | 0.9461 |
| 0.1382 | 4.4656 | 9400 | 0.2071 | 0.9438 |
| 0.1386 | 4.5606 | 9600 | 0.2095 | 0.9461 |
| 0.148 | 4.6556 | 9800 | 0.1987 | 0.9472 |
| 0.1444 | 4.7506 | 10000 | 0.1939 | 0.9438 |
| 0.1496 | 4.8456 | 10200 | 0.1919 | 0.9427 |
| 0.1502 | 4.9406 | 10400 | 0.1924 | 0.9438 |
### Framework versions
- PEFT 0.16.0
- Transformers 4.54.1
- Pytorch 2.5.1+cu121
- Datasets 4.0.0
- Tokenizers 0.21.4
|
dev-bjoern/smolvlm-int4-ov
|
dev-bjoern
| 2025-08-06T11:44:04Z | 4 | 0 |
transformers
|
[
"transformers",
"openvino",
"idefics3",
"image-to-text",
"int4",
"quantization",
"edge-deployment",
"optimization",
"vision-language-model",
"multimodal",
"smolvlm",
"en",
"arxiv:2504.05299",
"base_model:HuggingFaceTB/SmolVLM-Instruct",
"base_model:finetune:HuggingFaceTB/SmolVLM-Instruct",
"license:apache-2.0",
"region:us"
] |
image-to-text
| 2025-07-27T20:32:48Z |
---
library_name: transformers
license: apache-2.0
language:
- en
base_model:
- HuggingFaceTB/SmolVLM-Instruct
tags:
- openvino
- int4
- quantization
- edge-deployment
- optimization
- vision-language-model
- multimodal
- smolvlm
inference: false
---
# SmolVLM INT4 OpenVINO
## 🚀 Optimized Vision-Language Model for Edge Deployment
This is an INT4 quantized version of [SmolVLM-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct) using OpenVINO, designed for efficient multimodal inference on edge devices and CPUs.
## Model Overview
- **Base Model:** SmolVLM-Instruct (2.25B parameters)
- **Quantization:** INT4 via OpenVINO
- **Model Type:** Vision-Language Model (VLM)
- **Capabilities:** Image captioning, visual Q&A, multimodal reasoning
- **Target Hardware:** CPUs, Intel GPUs, NPUs
- **Use Cases:** On-device multimodal AI, edge vision applications
## 🔧 Technical Details
### Quantization Process
```python
# Quantized using OpenVINO NNCF
# INT4 symmetric quantization
# Applied to both vision encoder and language decoder
```
### Model Architecture
- Vision Encoder: Shape-optimized SigLIP (INT4)
- Text Decoder: SmolLM2 (INT4)
- Visual tokens: 81 per 384×384 patch
- Supports arbitrary image-text interleaving
## 📊 Performance (Experimental)
> ⚠️ **Note:** This is an experimental quantization. Formal benchmarks pending.
Expected benefits of INT4 quantization:
- Significantly reduced model size
- Faster inference on CPU/edge devices
- Lower memory requirements for multimodal tasks
- Maintained visual understanding capabilities
## 🛠️ How to Use
### Installation
```bash
pip install optimum[openvino] transformers pillow
```
### Basic Usage
```python
from optimum.intel import OVModelForVision2Seq
from transformers import AutoProcessor
from PIL import Image
import requests
# Load model and processor
model_id = "dev-bjoern/smolvlm-int4-ov"
processor = AutoProcessor.from_pretrained(model_id)
model = OVModelForVision2Seq.from_pretrained(model_id)
# Load an image
url = "https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Create conversation
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What do you see in this image?"}
]
}
]
# Process and generate
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image], return_tensors="pt")
generated_ids = model.generate(**inputs, max_new_tokens=200)
output = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(output[0])
```
### Multiple Images
```python
# Load multiple images
image1 = Image.open("path/to/image1.jpg")
image2 = Image.open("path/to/image2.jpg")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Compare these two images"}
]
}
]
# Process with multiple images
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
```
## 🎯 Intended Use
- **Edge AI vision applications**
- **Local multimodal assistants**
- **Privacy-focused image analysis**
- **Resource-constrained deployment**
- **Real-time visual understanding**
## ⚡ Optimization Tips
1. **Image Resolution:** Adjust with `size={"longest_edge": N*384}` where N=3 or 4 for balance
2. **Batch Processing:** Process multiple images together when possible
3. **CPU Inference:** Leverage OpenVINO runtime optimizations
## 🧪 Experimental Status
This is my first experiment with OpenVINO INT4 quantization for vision-language models. Feedback welcome!
### Known Limitations
- No formal benchmarks yet
- Visual quality degradation not measured
- Optimal quantization settings still being explored
### Future Improvements
- [ ] Benchmark on standard VLM tasks
- [ ] Compare with original model performance
- [ ] Experiment with mixed precision
- [ ] Test on various hardware configurations
## 🤝 Contributing
Have suggestions or found issues? Please open a discussion!
## 📚 Resources
- [Original SmolVLM Model](https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct)
- [SmolVLM Blog Post](https://huggingface.co/blog/smolvlm)
- [OpenVINO Documentation](https://docs.openvino.ai/)
- [Optimum Intel Guide](https://huggingface.co/docs/optimum/intel/index)
## 🙏 Acknowledgments
- HuggingFace team for SmolVLM
- Intel OpenVINO team for quantization tools
- Vision-language model community
## 📝 Citation
If you use this model, please cite both works:
```bibtex
@misc{smolvlm-int4-ov,
author = {Bjoern Bethge},
title = {SmolVLM INT4 OpenVINO},
year = {2024},
publisher = {Hugging Face},
howpublished = {\url{https://huggingface.co/dev-bjoern/smolvlm-int4-ov}}
}
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and others},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}
```
---
**Status:** 🧪 Experimental | **Model Type:** Vision-Language | **License:** Apache 2.0
|
mocacoffee/act-petbottle_revenge2_02
|
mocacoffee
| 2025-08-06T11:43:04Z | 2 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:mocacoffee/record-petbottle_revenge2_02",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-06T11:42:01Z |
---
datasets: mocacoffee/record-petbottle_revenge2_02
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- robotics
- lerobot
- act
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python lerobot/scripts/train.py \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
*Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`.*
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
* **License:** apache-2.0
|
tamewild/4b_v37_merged_e8
|
tamewild
| 2025-08-06T11:40:38Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T11:38:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
phospho-app/MaxFridge-gr00t-stacking_blocks_v4-33ped
|
phospho-app
| 2025-08-06T11:40:08Z | 8 | 0 | null |
[
"safetensors",
"gr00t_n1_5",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-08-06T10:43:34Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successful, try it out on your robot!
## Training parameters:
- **Dataset**: [MaxFridge/stacking_blocks_v4](https://huggingface.co/datasets/MaxFridge/stacking_blocks_v4)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 27
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
DW-ReCo/spot_Mistral-Small-24B-Base-2501-unsloth_ep10_training_ds_v18_120fix_75k_param-7_prompt-v2_lora
|
DW-ReCo
| 2025-08-06T11:39:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/Mistral-Small-24B-Base-2501-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Mistral-Small-24B-Base-2501-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-07-18T13:20:35Z |
---
base_model: unsloth/Mistral-Small-24B-Base-2501-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** DW-ReCo
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Mistral-Small-24B-Base-2501-unsloth-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/FuturesonyAi-V1.005082025-GGUF
|
mradermacher
| 2025-08-06T11:37:57Z | 102 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Futuresony/FuturesonyAi-V1.005082025",
"base_model:quantized:Futuresony/FuturesonyAi-V1.005082025",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T11:28:08Z |
---
base_model: Futuresony/FuturesonyAi-V1.005082025
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Futuresony/FuturesonyAi-V1.005082025
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#FuturesonyAi-V1.005082025-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q2_K.gguf) | Q2_K | 1.3 | |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q3_K_S.gguf) | Q3_K_S | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q3_K_M.gguf) | Q3_K_M | 1.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q3_K_L.gguf) | Q3_K_L | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.IQ4_XS.gguf) | IQ4_XS | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q4_K_S.gguf) | Q4_K_S | 1.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q4_K_M.gguf) | Q4_K_M | 1.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q5_K_S.gguf) | Q5_K_S | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q5_K_M.gguf) | Q5_K_M | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q6_K.gguf) | Q6_K | 2.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.Q8_0.gguf) | Q8_0 | 2.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/FuturesonyAi-V1.005082025-GGUF/resolve/main/FuturesonyAi-V1.005082025.f16.gguf) | f16 | 5.1 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
tamewild/4b_v37_merged_e10
|
tamewild
| 2025-08-06T11:36:49Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T11:34:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rawsun00001/banking-sms-json-parser-v8
|
rawsun00001
| 2025-08-06T11:36:13Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"banking",
"sms",
"json",
"parser",
"financial",
"india",
"en",
"dataset:synthetic",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T11:35:56Z |
---
license: mit
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- banking
- sms
- json
- parser
- financial
- india
datasets:
- synthetic
widget:
- example_title: "Transaction SMS"
text: "Sent Rs.1500.00 from HDFC Bank AC XX1234 to john@okicici on 15-Aug-25.UPI Ref 123456789012."
- example_title: "Credit SMS"
text: "Rs.25000 credited to your SBI Bank a/c XX5678 via NEFT from beneficiary COMPANY LTD."
---
# Banking SMS JSON Parser V8
Advanced AI model that converts Indian banking SMS messages into structured JSON format.
## Features
- ✅ Detects transaction vs non-transaction messages
- ✅ Extracts amount, date, transaction type, last 4 digits
- ✅ Categorizes transactions into 32+ categories
- ✅ Handles unknown merchants with "Other" category
- ✅ Supports UPI, NEFT, RTGS, Card transactions
- ✅ 60,000+ training samples with realistic Indian banking patterns
## Usage
## Training Data
- 60,000 training samples
- 6,000 validation samples
- 75% transaction, 25% non-transaction messages
- Realistic Indian banking SMS patterns
- Major Indian banks: ICICI, HDFC, SBI, Kotak, Axis, BOB, YES, etc.
## Performance
Optimized for high accuracy on real-world Indian banking SMS messages with proper category classification and transaction detection.
|
zlin29/whisper-small-hi
|
zlin29
| 2025-08-06T11:35:34Z | 15 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-04T04:43:45Z |
---
library_name: transformers
language:
- hi
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Hi - Sanchit Gandhi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: hi
split: None
args: 'config: hi, split: test'
metrics:
- name: Wer
type: wer
value: 32.40497756708711
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4414
- Wer: 32.4050
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.0918 | 2.4450 | 1000 | 0.2984 | 35.1393 |
| 0.0212 | 4.8900 | 2000 | 0.3593 | 33.8144 |
| 0.0012 | 7.3350 | 3000 | 0.4215 | 32.5616 |
| 0.0004 | 9.7800 | 4000 | 0.4414 | 32.4050 |
### Framework versions
- Transformers 4.48.0
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.2
|
thejaminator/eos_mia_vanilla_qwen3_32b-20250806_191712-3epoch
|
thejaminator
| 2025-08-06T11:33:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-32B",
"base_model:finetune:unsloth/Qwen3-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T11:32:14Z |
---
base_model: unsloth/Qwen3-32B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** thejaminator
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-32B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.