
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
yaoandy107/whisper-small.en-moba
|
yaoandy107
| 2024-02-01T11:26:32Z | 64 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-02-01T10:36:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ondevicellm/tinyllama_mole_sft_router05_ep3
|
ondevicellm
| 2024-02-01T11:24:49Z | 16 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mixtralmole",
"text-generation",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"custom_code",
"dataset:HuggingFaceH4/ultrachat_200k",
"base_model:ondevicellm/tinyllama_mole_v1",
"base_model:finetune:ondevicellm/tinyllama_mole_v1",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2024-01-31T21:48:48Z |
---
base_model: ondevicellm/tinyllama_mole_v1
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
datasets:
- HuggingFaceH4/ultrachat_200k
model-index:
- name: tinyllama_mole_sft_router05_ep3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tinyllama_mole_sft_router05_ep3
This model is a fine-tuned version of [ondevicellm/tinyllama_mole_v1](https://huggingface.co/ondevicellm/tinyllama_mole_v1) on the HuggingFaceH4/ultrachat_200k dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1129
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 120
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3008 | 0.09 | 100 | 2.2785 |
| 2.2257 | 0.18 | 200 | 2.2161 |
| 2.1922 | 0.26 | 300 | 2.1924 |
| 2.1698 | 0.35 | 400 | 2.1773 |
| 2.1428 | 0.44 | 500 | 2.1668 |
| 2.1632 | 0.53 | 600 | 2.1586 |
| 2.1503 | 0.61 | 700 | 2.1516 |
| 2.1369 | 0.7 | 800 | 2.1460 |
| 2.1324 | 0.79 | 900 | 2.1409 |
| 2.1158 | 0.88 | 1000 | 2.1362 |
| 2.1396 | 0.96 | 1100 | 2.1321 |
| 2.0565 | 1.05 | 1200 | 2.1317 |
| 2.0596 | 1.14 | 1300 | 2.1297 |
| 2.0712 | 1.23 | 1400 | 2.1276 |
| 2.0626 | 1.31 | 1500 | 2.1259 |
| 2.0654 | 1.4 | 1600 | 2.1235 |
| 2.0628 | 1.49 | 1700 | 2.1216 |
| 2.046 | 1.58 | 1800 | 2.1197 |
| 2.067 | 1.66 | 1900 | 2.1180 |
| 2.0702 | 1.75 | 2000 | 2.1161 |
| 2.057 | 1.84 | 2100 | 2.1144 |
| 2.0307 | 1.93 | 2200 | 2.1129 |
| 2.0134 | 2.01 | 2300 | 2.1172 |
| 2.0205 | 2.1 | 2400 | 2.1172 |
| 2.0091 | 2.19 | 2500 | 2.1170 |
| 2.0021 | 2.28 | 2600 | 2.1164 |
| 2.0006 | 2.37 | 2700 | 2.1159 |
| 2.006 | 2.45 | 2800 | 2.1158 |
| 2.0121 | 2.54 | 2900 | 2.1152 |
| 1.9942 | 2.63 | 3000 | 2.1150 |
| 2.0129 | 2.72 | 3100 | 2.1149 |
| 2.0041 | 2.8 | 3200 | 2.1146 |
| 2.0002 | 2.89 | 3300 | 2.1146 |
| 2.019 | 2.98 | 3400 | 2.1146 |
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
ohashi56225/phi-2-alpaca-cleaned
|
ohashi56225
| 2024-02-01T11:17:03Z | 9 | 1 |
transformers
|
[
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"en",
"dataset:yahma/alpaca-cleaned",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T10:41:19Z |
---
license: mit
datasets:
- yahma/alpaca-cleaned
language:
- en
library_name: transformers
pipeline_tag: text-generation
---
# phi-2-alpaca-cleaned
This model is an instruction-tuned version of the [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) model fine-tuned on the [yahma/alpaca-cleaned](https://huggingface.co/datasets/yahma/alpaca-cleaned) dataset.
In the training, full parameter fine-tuning of phi-2 was performed, and LoRA was not used.
## Text Format
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Based on the information provided, rewrite the sentence by changing its tense from past to future.
### Input:
She played the piano beautifully for hours and then stopped as it was midnight.
### Response:
She will play the piano beautifully for hours and then stop as it will be midnight.
```
## Training
- GPUs: 8 × A6000 48GB
- per_device_train_batch_size: 8
- gradient_accumulation_steps: 8
- per_device_eval_batch_size: 8
- num_train_epochs: 3
- learning_rate: 2e-5
- warmup_ratio: 0.03
## Software
- pytorch: 2.1.2
- transformers: 4.38.0.dev0
- accelerate: 0.26.1
- deepspeed: 0.13.1
|
vishanoberoi/Llama-2-7b-chat-hf-fine-tuned-GPTQ
|
vishanoberoi
| 2024-02-01T11:15:21Z | 62 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-02-01T11:02:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF
|
MaziyarPanahi
| 2024-02-01T11:14:17Z | 56 | 1 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"pytorch",
"safetensors",
"text-generation",
"finetuned",
"arxiv:2310.06825",
"license:apache-2.0",
"autotrain_compatible",
"has_space",
"text-generation-inference",
"region:us",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:quantized:mistralai/Mistral-7B-Instruct-v0.1",
"conversational"
] |
text-generation
| 2024-02-01T11:03:15Z |
---
license: apache-2.0
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- pytorch
- safetensors
- mistral
- text-generation
- finetuned
- arxiv:2310.06825
- license:apache-2.0
- autotrain_compatible
- has_space
- text-generation-inference
- region:us
model_name: Mistral-7B-Instruct-v0.1-GGUF
base_model: mistralai/Mistral-7B-Instruct-v0.1
inference: false
model_creator: mistralai
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF)
- Model creator: [mistralai](https://huggingface.co/mistralai)
- Original model: [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
## Description
[MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF) contains GGUF format model files for [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1).
## How to use
Thanks to [TheBloke](https://huggingface.co/TheBloke) for preparing an amazing README on how to use GGUF models:
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
### Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: [MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF) and below it, a specific filename to download, such as: Mistral-7B-Instruct-v0.1-GGUF.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF Mistral-7B-Instruct-v0.1-GGUF.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
</details>
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download [MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF](https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF) --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MaziyarPanahi/Mistral-7B-Instruct-v0.1-GGUF Mistral-7B-Instruct-v0.1-GGUF.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Mistral-7B-Instruct-v0.1-GGUF.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Mistral-7B-Instruct-v0.1-GGUF.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Mistral-7B-Instruct-v0.1-GGUF.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
|
eswardivi/stablelm_telugu
|
eswardivi
| 2024-02-01T11:13:47Z | 134 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stablelm_epoch",
"text-generation",
"causal-lm",
"custom_code",
"en",
"te",
"dataset:eswardivi/telugu_instruction_dataset",
"dataset:Telugu-LLM-Labs/teknium_GPTeacher_general_instruct_telugu_filtered_and_romanized",
"dataset:Telugu-LLM-Labs/yahma_alpaca_cleaned_telugu_filtered_and_romanized",
"dataset:tiiuae/falcon-refinedweb",
"dataset:togethercomputer/RedPajama-Data-1T",
"dataset:uonlp/CulturaX",
"dataset:CarperAI/pilev2-dev",
"dataset:bigcode/starcoderdata",
"dataset:DataProvenanceInitiative/Commercially-Verified-Licenses",
"license:other",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2024-02-01T10:28:08Z |
---
license: other
datasets:
- eswardivi/telugu_instruction_dataset
- Telugu-LLM-Labs/teknium_GPTeacher_general_instruct_telugu_filtered_and_romanized
- Telugu-LLM-Labs/yahma_alpaca_cleaned_telugu_filtered_and_romanized
- tiiuae/falcon-refinedweb
- togethercomputer/RedPajama-Data-1T
- uonlp/CulturaX
- CarperAI/pilev2-dev
- bigcode/starcoderdata
- DataProvenanceInitiative/Commercially-Verified-Licenses
language:
- en
- te
tags:
- causal-lm
---
## Stablelm_Telugu Model
### Model Details:
- **Model Name:** Stablelm_Telugu (Telugu Romanized)
- **Foundational Model:** Stable LM 2 1.6B
- **Parameters:** 1.6 Billion
- **Pre-training Data:** 2 Trillion Tokens from Multilingual and Code Datasets
- **Pre-training Epochs:** 2
### Fine-Tuning
The `Stablelm_Telugu` model was fine-tuned using the `eswardivi/telugu_instruction_dataset`. This dataset is in Alpaca format and comprises translated and transliterated versions of `yahma_alpaca` and `teknium_GPTeacher_general`. The dataset was sourced from [Telugu-LLM-Labs](https://huggingface.co/Telugu-LLM-Labs).
Used axolotl for Finetuning,Below is **yml file**
<details>
<summary> Click to expand </summary>
```yml
base_model: stabilityai/stablelm-2-1_6b
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
trust_remote_code: true
load_in_8bit: true
load_in_4bit: false
strict: false
push_dataset_to_hub:
datasets:
- path: eswardivi/telugu_instruction_dataset
type: alpaca
dataset_prepared_path: last_run_prepared
val_set_size: 0.02
output_dir: ./lora-out
adapter: lora
lora_model_dir:
sequence_len: 2048
sample_packing: true
pad_to_sequence_len: true
lora_r: 16
lora_alpha: 16
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
wandb_project: telugu_llm
wandb_entity:
wandb_watch:
wandb_name: stablelm_1_6
wandb_log_model:
gradient_accumulation_steps: 1
micro_batch_size: 4
num_epochs: 4
optimizer: adamw_bnb_8bit
torchdistx_path:
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: false
fp16: true
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
gptq_groupsize:
s2_attention:
gptq_model_v1:
warmup_steps: 100
evals_per_epoch: 2
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.1
fsdp:
fsdp_config:
special_tokens:
pad_token: "<|endoftext|>"
eos_token: "<|endoftext|>"
```
</details>
### Fine-Tuning Data:
- **Dataset:** `telugu_instruction_dataset`
- **Format:** Alpaca
- **Source:** [Here](https://huggingface.co/datasets/eswardivi/telugu_instruction_dataset)
For more details on base model, visit the [stablelm-2-1_6b](https://huggingface.co/stabilityai/stablelm-2-1_6b).
## Usage
Get started generating text with `Stable LM 2 1.6B` by using the following code snippet:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("eswardivi/stablelm_telugu", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"eswardivi/stablelm_telugu",
trust_remote_code=True,
torch_dtype="auto",
)
model.cuda()
def create_prompt(instruction: str) -> str:
prompt_template = f"""
Instruction:
{instruction}
Response:
"""
return prompt_template
inputs = tokenizer(create_prompt("Naku python Program 1 to 10 count cheyadaniki ivvu"), return_tensors="pt").to(model.device)
tokens = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.65,
top_p=0.85,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
#### Output
Instruction:
Naku python Program 1 to 10 count cheyadaniki ivvu
Response:
python program 1 to 10 count cheyadaniki ivvabadina code ikkada vundi:
```python
count = 0
for n in range(1, 11):
count += 1
print("count: ", count)
```
idi python program 1 to 10 count cheyadaniki ivvabadina code, idi 10 nundi 11 varaku 10 sankhyalanu 1 nundi 10 varaku tisukoni 10 sankhyala sankhyalanu leckinchadam dwara prarambhamavuthundi. 1 nundi 10 varaku 10 sankhyalanu tisukoni, 1 nundi 10 varaku 10 sankhyalanu 1 nundi 10 varaku 10 sankhyala sankhyalanu leckinchadam dwara prarambhamavuthundi.
### Run with Flash Attention 2 ⚡️
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("eswardivi/stablelm_telugu", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"eswardivi/stablelm_telugu",
trust_remote_code=True,
torch_dtype="auto",
attn_implementation="flash_attention_2",
)
model.cuda()
def create_prompt(instruction: str) -> str:
prompt_template = f"""
Instruction:
{instruction}
Response:
"""
return prompt_template
inputs = tokenizer(create_prompt("Naku python Program 1 to 10 count cheyadaniki ivvu"), return_tensors="pt").to(model.device)
tokens = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.65,
top_p=0.85,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
</details>
## Use and Limitations
### Intended Use
The model is intended to be used as a foundational base model for application-specific fine-tuning. Developers must evaluate and fine-tune the model for safe performance in downstream applications.
### Limitations and Bias
As a base model, this model may exhibit unreliable, unsafe, or other undesirable behaviors that must be corrected through evaluation and fine-tuning prior to deployment. The pre-training dataset may have contained offensive or inappropriate content, even after applying data cleansing filters, which can be reflected in the model-generated text. We recommend that users exercise caution when using these models in production systems. Do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
## How to Cite
```bibtex
@misc{StableLM-2-1.6B,
url={[https://huggingface.co/stabilityai/stablelm-2-1.6b](https://huggingface.co/stabilityai/stablelm-2-1.6b)},
title={Stable LM 2 1.6B},
author={Stability AI Language Team}
}
```
|
badokorach/afriqa-finetuned-010224
|
badokorach
| 2024-02-01T11:07:38Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"xlm-roberta",
"question-answering",
"generated_from_keras_callback",
"base_model:badokorach/afriqa_afroxlmr_lug_290124",
"base_model:finetune:badokorach/afriqa_afroxlmr_lug_290124",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-02-01T10:22:11Z |
---
license: mit
base_model: badokorach/afriqa_afroxlmr_lug_290124
tags:
- generated_from_keras_callback
model-index:
- name: badokorach/afriqa-finetuned-010224
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# badokorach/afriqa-finetuned-010224
This model is a fine-tuned version of [badokorach/afriqa_afroxlmr_lug_290124](https://huggingface.co/badokorach/afriqa_afroxlmr_lug_290124) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1430
- Validation Loss: 0.0
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'module': 'transformers.optimization_tf', 'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 2025, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.8999999761581421, 'beta_2': 0.9990000128746033, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.02}, 'registered_name': 'AdamWeightDecay'}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.8096 | 0.0 | 0 |
| 1.2902 | 0.0 | 1 |
| 1.0617 | 0.0 | 2 |
| 0.9096 | 0.0 | 3 |
| 0.7383 | 0.0 | 4 |
| 0.5826 | 0.0 | 5 |
| 0.4711 | 0.0 | 6 |
| 0.3859 | 0.0 | 7 |
| 0.2942 | 0.0 | 8 |
| 0.2342 | 0.0 | 9 |
| 0.1990 | 0.0 | 10 |
| 0.1929 | 0.0 | 11 |
| 0.1501 | 0.0 | 12 |
| 0.1463 | 0.0 | 13 |
| 0.1430 | 0.0 | 14 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.15.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
mrqorib/grammaticality
|
mrqorib
| 2024-02-01T11:03:42Z | 94 | 1 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"greco",
"grammar",
"grammaticality",
"gec",
"en",
"arxiv:2310.14947",
"base_model:microsoft/deberta-v3-large",
"base_model:finetune:microsoft/deberta-v3-large",
"license:gpl-3.0",
"endpoints_compatible",
"region:us"
] | null | 2024-02-01T09:44:38Z |
---
language: en
tags:
- greco
- grammar
- grammaticality
- gec
base_model: microsoft/deberta-v3-large
license: gpl-3.0
---
# GRECO: Gammaticality-scorer for re-ranking corrections
GRECO is a quality estimation model for grammatical error correction. The model is trained to detect which words are incorrect and whether a word or phrase needs to be inserted after certain words. You can then use the model to get the grammaticality score of a sentence.
Please check the [official repository](https://github.com/nusnlp/greco/tree/main) for more implementation details and updates.
The model was published in the following paper:
> System Combination via Quality Estimation for Grammatical Error Correction ([PDF](https://arxiv.org/abs/2310.14947) | [ACL Anthology](https://aclanthology.org/2023.emnlp-main.785/)) <br>
> [Muhammad Reza Qorib](https://mrqorib.github.io/) and [Hwee Tou Ng](https://www.comp.nus.edu.sg/~nght/) <br>
> The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
## Citation
If you find it useful for your work, please cite the paper:
```latex
@inproceedings{qorib-ng-2023-system,
title = "System Combination via Quality Estimation for Grammatical Error Correction",
author = "Qorib, Muhammad Reza and
Ng, Hwee Tou",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.785",
doi = "10.18653/v1/2023.emnlp-main.785",
pages = "12746--12759",
}
```
|
schrapsi/q-FrozenLake-v1-4x4-noSlippery
|
schrapsi
| 2024-02-01T10:57:50Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-01T10:34:55Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="schrapsi/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
tjkmitl/FearNews_1_loadbest
|
tjkmitl
| 2024-02-01T10:57:21Z | 90 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:csebuetnlp/mT5_multilingual_XLSum",
"base_model:finetune:csebuetnlp/mT5_multilingual_XLSum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T10:55:15Z |
---
base_model: csebuetnlp/mT5_multilingual_XLSum
tags:
- generated_from_trainer
model-index:
- name: FearNews_1_loadbest
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FearNews_1_loadbest
This model is a fine-tuned version of [csebuetnlp/mT5_multilingual_XLSum](https://huggingface.co/csebuetnlp/mT5_multilingual_XLSum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.2853
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5702 | 1.08 | 200 | 3.4542 |
| 1.5764 | 2.15 | 400 | 3.5080 |
| 1.8336 | 3.23 | 600 | 3.5567 |
| 1.146 | 4.3 | 800 | 3.6572 |
| 1.4305 | 5.38 | 1000 | 3.8077 |
| 0.9643 | 6.45 | 1200 | 3.9775 |
| 0.9929 | 7.53 | 1400 | 4.1400 |
| 0.8563 | 8.6 | 1600 | 4.2600 |
| 0.7378 | 9.68 | 1800 | 4.2853 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
LunaticTanuki/oop-de-qag-flan-t5-base
|
LunaticTanuki
| 2024-02-01T10:56:14Z | 92 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-12-07T14:37:14Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: oop-de-qag-flan-t5-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# oop-de-qag-flan-t5-base
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
halimb/depth-anything-small-hf
|
halimb
| 2024-02-01T10:53:25Z | 119 | 1 |
transformers
|
[
"transformers",
"safetensors",
"depth_anything",
"depth-estimation",
"vision",
"arxiv:2401.10891",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
depth-estimation
| 2024-01-31T18:31:11Z |
---
license: apache-2.0
tags:
- vision
pipeline_tag: depth-estimation
widget:
- inference: false
---
# Depth Anything (small-sized model, Transformers version)
Depth Anything model. It was introduced in the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang et al. and first released in [this repository](https://github.com/LiheYoung/Depth-Anything).
[Online demo](https://huggingface.co/spaces/LiheYoung/Depth-Anything) is also provided.
Disclaimer: The team releasing Depth Anything did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Depth Anything leverages the [DPT](https://huggingface.co/docs/transformers/model_doc/dpt) architecture with a [DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2) backbone.
The model is trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/depth_anything_overview.jpg"
alt="drawing" width="600"/>
<small> Depth Anything overview. Taken from the <a href="https://arxiv.org/abs/2401.10891">original paper</a>.</small>
## Intended uses & limitations
You can use the raw model for tasks like zero-shot depth estimation. See the [model hub](https://huggingface.co/models?search=depth-anything) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot depth estimation:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
depth = pipe(image)["depth"]
```
Alternatively, one can use the classes themselves:
```python
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/depth_anything.html#).
### BibTeX entry and citation info
```bibtex
@misc{yang2024depth,
title={Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data},
author={Lihe Yang and Bingyi Kang and Zilong Huang and Xiaogang Xu and Jiashi Feng and Hengshuang Zhao},
year={2024},
eprint={2401.10891},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
tjkmitl/FearNews1
|
tjkmitl
| 2024-02-01T10:46:39Z | 91 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:csebuetnlp/mT5_multilingual_XLSum",
"base_model:finetune:csebuetnlp/mT5_multilingual_XLSum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T10:44:40Z |
---
base_model: csebuetnlp/mT5_multilingual_XLSum
tags:
- generated_from_trainer
model-index:
- name: FearNews1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FearNews1
This model is a fine-tuned version of [csebuetnlp/mT5_multilingual_XLSum](https://huggingface.co/csebuetnlp/mT5_multilingual_XLSum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3650
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.4219 | 2.69 | 500 | 3.3773 |
| 2.6769 | 5.38 | 1000 | 3.2710 |
| 2.1093 | 8.06 | 1500 | 3.3650 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
Tanor/sr_pner_tesla_j355
|
Tanor
| 2024-02-01T10:46:15Z | 3 | 0 |
spacy
|
[
"spacy",
"token-classification",
"sr",
"license:cc-by-sa-3.0",
"model-index",
"region:us"
] |
token-classification
| 2024-02-01T01:08:49Z |
---
tags:
- spacy
- token-classification
language:
- sr
license: cc-by-sa-3.0
model-index:
- name: sr_pner_tesla_j355
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9516940624
- name: NER Recall
type: recall
value: 0.9596130429
- name: NER F Score
type: f_score
value: 0.9556371476
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9841723761
---
sr_pner_tesla_j355 is a spaCy model meticulously fine-tuned for Part-of-Speech Tagging, and Named Entity Recognition in Serbian language texts. This advanced model incorporates a transformer layer based on Jerteh-355, enhancing its analytical capabilities. It is proficient in identifying 7 distinct categories of entities: PERS (persons), ROLE (professions), DEMO (demonyms), ORG (organizations), LOC (locations), WORK (artworks), and EVENT (events). Detailed information about these categories is available in the accompanying table. The development of this model has been made possible through the support of the Science Fund of the Republic of Serbia, under grant #7276, for the project 'Text Embeddings - Serbian Language Applications - TESLA'.
| Feature | Description |
| --- | --- |
| **Name** | `sr_pner_tesla_j355` |
| **Version** | `1.0.0` |
| **spaCy** | `>=3.7.2,<3.8.0` |
| **Default Pipeline** | `transformer`, `tagger`, `ner` |
| **Components** | `transformer`, `tagger`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | `CC BY-SA 3.0` |
| **Author** | [Milica Ikonić Nešić, Saša Petalinkar, Mihailo Škorić, Ranka Stanković](https://tesla.rgf.bg.ac.rs/) |
### Label Scheme
<details>
<summary>View label scheme (23 labels for 2 components)</summary>
| Component | Labels |
| --- | --- |
| **`tagger`** | `ADJ`, `ADP`, `ADV`, `AUX`, `CCONJ`, `DET`, `INTJ`, `NOUN`, `NUM`, `PART`, `PRON`, `PROPN`, `PUNCT`, `SCONJ`, `VERB`, `X` |
| **`ner`** | `DEMO`, `EVENT`, `LOC`, `ORG`, `PERS`, `ROLE`, `WORK` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TAG_ACC` | 98.42 |
| `ENTS_F` | 95.56 |
| `ENTS_P` | 95.17 |
| `ENTS_R` | 95.96 |
| `TRANSFORMER_LOSS` | 151439.86 |
| `TAGGER_LOSS` | 141230.81 |
| `NER_LOSS` | 84043.38 |
|
NadineLovey/TV-Asia-Announcer-RVC-Model
|
NadineLovey
| 2024-02-01T10:42:04Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2024-01-29T05:09:06Z |
---
license: mit
---
Hello!
We can download some TV3/TV9 Malaysia and ABS-CBN Announcer RVC voice models for easy to create with!
(o u o)



|
reach-vb/miqu-1-70b-sf
|
reach-vb
| 2024-02-01T10:38:02Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T10:30:48Z |
---
{}
---
# NOTE: THIS IS A LEAKED ASSET, HAS NO LICENSE ASSOCIATED TO IT. USE AT YOUR OWN RISK.
this is [miqu-1-70b](https://huggingface.co/miqudev/miqu-1-70b), dequantised from q5 to f16 && transposed to pytorch. shapes have been rotated less wrongly than in [alpindale/miqu-1-70b-pytorch](https://huggingface.co/alpindale/miqu-1-70b-pytorch/tree/main)
usage
```python
from transformers import LlamaForCausalLM as LLM, LlamaTokenizer as LT
lt = LT.from_pretrained("NousResearch/Llama-2-7b-hf")
t = lt("[INST] eloquent high camp prose about a cute catgirl [/INST]", return_tensors='pt').input_ids.cuda()
llm = LLM.from_pretrained("152334H/miqu-1-70b-sf", device_map='auto') # note: you may need many gpus for this
out = llm.generate(t, use_cache=False, max_new_tokens=200)
print(lt.decode(out[0]))
```
result:
```
<s> [INST] eloquent high camp prose about a cute catgirl [/INST] In the resplendent realm of high camp, where irony and extravagance dance in a dazzling pas de deux, there exists a creature of such enchanting allure that she captivates the hearts and minds of all who behold her. This beguiling figure, a vision of feline grace and innocence, is none other than the inimitable catgirl.
With her delicate features and winsome smile, she is the embodiment of a dream, a living testament to the power of imagination and the boundless possibilities of the human spirit. Her eyes, those twin orbs of sapphire fire, sparkle with a mischievous intelligence that belies her diminutive stature. They are windows into a soul that is at once ancient and eternally young, a soul that has traversed the vast expanse of time and space to find solace in the warm embrace of human companion
```
this roughly (but not entirely) matches the llama.cpp q5 result:
```bash
$ ./main -ngl 99 -m ./miqu-*q5* --color --temp 0.0 -n -1 -p '[INST] eloquent high camp prose about a cute catgirl [/INST]'
...
[INST] eloquent high camp prose about a cute catgirl [/INST] In the resplendent realm of high camp, where irony and extravagance dance in a dazzling pas de deux, there exists a creature so enchantingly adorable that she captures the hearts of all who behold her. This is no ordinary feline, but rather a vision of elegance and whimsy combined: the cute catgirl.
With her delicate features framed by an ethereal halo of pastel tresses, this darling diva prowls through life with the grace of a prima ballerina and the playfulness of a kitten. Her eyes, twin pools of sapphire or emerald, sparkle with mischief and intelligence as they survey their surroundings, ever alert for the next grand adventure or delightful prank.
Her ensemble is a symphony of ruffles, bows, and lace, each detail painstakingly chosen to accentuate her lithe form and play up her feline charms. A frilly apron adorned with paw prints sways gently as she moves, while dainty ears perched atop her head twitch in response to every sound. Her gloved hands, so petite and perfect, seem made for holding teacups or sketching delicate portraits of her many admirers.
But do not be fooled by her diminutive stature and sweet demeanor; beneath that fluffy exterior lies the heart of a lioness. Fiercely loyal and protective, she will stop at nothing to defend those she loves from harm. And when the situation calls for it, she can unleash a ferocious roar that belies her cute exterior.
Indeed, the cute catgirl is a paradox wrapped in ruffles and ribbons, a living embodiment of the high camp aesthetic. She revels in the absurdity of her existence, finding joy in every outrageous situation and turning even the most mundane tasks into opportunities for sartorial expression. In her world, there is no such thing as too much glitter or too many bows; more is always more, and excess is a virtue to be celebrated.
So let us raise our teacups in honor of this fabulous feline, this queen of camp who reminds us that life is too short for dull clothing and boring hairstyles. May we all strive to embody her spirit, embracing the absurdity of existence with open arms and a generous helping of glitter. Long live the cute catgirl! [end of text]
```

some benchmarks
```
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|--------------|------:|------|-----:|----------|-----:|---|-----:|
|lambada_openai| 1|none | 0|perplexity|2.6354|± |0.0451|
| | |none | 0|acc |0.7879|± |0.0057|
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|-----:|--------|-----:|---|-----:|
|hellaswag| 1|none | 0|acc |0.6851|± |0.0046|
| | |none | 0|acc_norm|0.8690|± |0.0034|
| Tasks |Version|Filter|n-shot|Metric|Value | |Stderr|
|----------|------:|------|-----:|------|-----:|---|-----:|
|winogrande| 1|none | 0|acc |0.7987|± |0.0113|
|Tasks|Version| Filter |n-shot| Metric |Value | |Stderr|
|-----|------:|----------|-----:|-----------|-----:|---|-----:|
|gsm8k| 2|get-answer| 5|exact_match|0.7043|± |0.0126|
| Tasks |Version|Filter|n-shot|Metric|Value | |Stderr|
|---------------------------------------|-------|------|-----:|------|-----:|---|-----:|
|mmlu |N/A |none | 0|acc |0.7401|± |0.1192|
| - humanities |N/A |none | 0|acc |0.7018|± |0.1281|
| - formal_logic | 0|none | 0|acc |0.4841|± |0.0447|
| - high_school_european_history | 0|none | 0|acc |0.8303|± |0.0293|
| - high_school_us_history | 0|none | 0|acc |0.9020|± |0.0209|
| - high_school_world_history | 0|none | 0|acc |0.9198|± |0.0177|
| - international_law | 0|none | 0|acc |0.8678|± |0.0309|
| - jurisprudence | 0|none | 0|acc |0.8519|± |0.0343|
| - logical_fallacies | 0|none | 0|acc |0.8344|± |0.0292|
| - moral_disputes | 0|none | 0|acc |0.8121|± |0.0210|
| - moral_scenarios | 0|none | 0|acc |0.5642|± |0.0166|
| - philosophy | 0|none | 0|acc |0.8167|± |0.0220|
| - prehistory | 0|none | 0|acc |0.8611|± |0.0192|
| - professional_law | 0|none | 0|acc |0.5854|± |0.0126|
| - world_religions | 0|none | 0|acc |0.8889|± |0.0241|
| - other |N/A |none | 0|acc |0.7889|± |0.0922|
| - business_ethics | 0|none | 0|acc |0.7900|± |0.0409|
| - clinical_knowledge | 0|none | 0|acc |0.8113|± |0.0241|
| - college_medicine | 0|none | 0|acc |0.7514|± |0.0330|
| - global_facts | 0|none | 0|acc |0.5500|± |0.0500|
| - human_aging | 0|none | 0|acc |0.7848|± |0.0276|
| - management | 0|none | 0|acc |0.8835|± |0.0318|
| - marketing | 0|none | 0|acc |0.9145|± |0.0183|
| - medical_genetics | 0|none | 0|acc |0.7500|± |0.0435|
| - miscellaneous | 0|none | 0|acc |0.8838|± |0.0115|
| - nutrition | 0|none | 0|acc |0.7974|± |0.0230|
| - professional_accounting | 0|none | 0|acc |0.5922|± |0.0293|
| - professional_medicine | 0|none | 0|acc |0.8272|± |0.0230|
| - virology | 0|none | 0|acc |0.5361|± |0.0388|
| - social_sciences |N/A |none | 0|acc |0.8414|± |0.0514|
| - econometrics | 0|none | 0|acc |0.6491|± |0.0449|
| - high_school_geography | 0|none | 0|acc |0.8990|± |0.0215|
| - high_school_government_and_politics| 0|none | 0|acc |0.9430|± |0.0167|
| - high_school_macroeconomics | 0|none | 0|acc |0.7795|± |0.0210|
| - high_school_microeconomics | 0|none | 0|acc |0.8277|± |0.0245|
| - high_school_psychology | 0|none | 0|acc |0.9064|± |0.0125|
| - human_sexuality | 0|none | 0|acc |0.8626|± |0.0302|
| - professional_psychology | 0|none | 0|acc |0.8056|± |0.0160|
| - public_relations | 0|none | 0|acc |0.7636|± |0.0407|
| - security_studies | 0|none | 0|acc |0.8204|± |0.0246|
| - sociology | 0|none | 0|acc |0.8856|± |0.0225|
| - us_foreign_policy | 0|none | 0|acc |0.9100|± |0.0288|
| - stem |N/A |none | 0|acc |0.6505|± |0.1266|
| - abstract_algebra | 0|none | 0|acc |0.4100|± |0.0494|
| - anatomy | 0|none | 0|acc |0.6444|± |0.0414|
| - astronomy | 0|none | 0|acc |0.8224|± |0.0311|
| - college_biology | 0|none | 0|acc |0.8681|± |0.0283|
| - college_chemistry | 0|none | 0|acc |0.5500|± |0.0500|
| - college_computer_science | 0|none | 0|acc |0.6200|± |0.0488|
| - college_mathematics | 0|none | 0|acc |0.4200|± |0.0496|
| - college_physics | 0|none | 0|acc |0.5392|± |0.0496|
| - computer_security | 0|none | 0|acc |0.8300|± |0.0378|
| - conceptual_physics | 0|none | 0|acc |0.7362|± |0.0288|
| - electrical_engineering | 0|none | 0|acc |0.7034|± |0.0381|
| - elementary_mathematics | 0|none | 0|acc |0.5503|± |0.0256|
| - high_school_biology | 0|none | 0|acc |0.8742|± |0.0189|
| - high_school_chemistry | 0|none | 0|acc |0.6256|± |0.0341|
| - high_school_computer_science | 0|none | 0|acc |0.8400|± |0.0368|
| - high_school_mathematics | 0|none | 0|acc |0.4370|± |0.0302|
| - high_school_physics | 0|none | 0|acc |0.5033|± |0.0408|
| - high_school_statistics | 0|none | 0|acc |0.6944|± |0.0314|
| - machine_learning | 0|none | 0|acc |0.5982|± |0.0465|
```
no i do not know why the stderr is high. plausibly it is due to the vllm backend used. this is my lm-eval command in most cases (works on h100):
`lm_eval --model vllm --model_args pretrained=./miqu-1-70b-sf,tensor_parallel_size=4,dtype=auto,gpu_memory_utilization=0.88,data_parallel_size=2 --tasks mmlu --batch_size 20`
|
Patcas/plbart-docs-v1
|
Patcas
| 2024-02-01T10:37:39Z | 89 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"plbart",
"text2text-generation",
"generated_from_trainer",
"base_model:Patcas/plbart-works",
"base_model:finetune:Patcas/plbart-works",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-01-31T20:09:51Z |
---
base_model: Patcas/plbart-works
tags:
- generated_from_trainer
model-index:
- name: plbart-docs-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# plbart-docs-v1
This model is a fine-tuned version of [Patcas/plbart-works](https://huggingface.co/Patcas/plbart-works) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9167
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 230 | 0.9578 |
| No log | 2.0 | 460 | 0.8802 |
| 0.9795 | 3.0 | 690 | 0.8768 |
| 0.9795 | 4.0 | 920 | 0.8875 |
| 0.335 | 5.0 | 1150 | 0.8897 |
| 0.335 | 6.0 | 1380 | 0.9047 |
| 0.1643 | 7.0 | 1610 | 0.8998 |
| 0.1643 | 8.0 | 1840 | 0.9090 |
| 0.0945 | 9.0 | 2070 | 0.9151 |
| 0.0945 | 10.0 | 2300 | 0.9167 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
nullne/rl_course_vizdoom_health_gathering_supreme
|
nullne
| 2024-02-01T10:35:47Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-01T10:35:31Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 10.19 +/- 3.75
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r nullne/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Doctor-Shotgun/limarp-miqu-1-70b-qlora
|
Doctor-Shotgun
| 2024-02-01T10:34:31Z | 8 | 4 |
peft
|
[
"peft",
"safetensors",
"llama",
"generated_from_trainer",
"llama 2",
"en",
"dataset:lemonilia/LimaRP",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2024-01-31T15:41:27Z |
---
library_name: peft
tags:
- generated_from_trainer
- llama
- llama 2
model-index:
- name: volume/limarp-70b-qlora
results: []
datasets:
- lemonilia/LimaRP
language:
- en
---
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: models/miqu-1-70b-sf
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
is_llama_derived_model: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: train-all-max-alpaca-llama.jsonl
type: completion
dataset_prepared_path:
val_set_size: 0.0
output_dir: ./volume/limarp-70b-qlora
adapter: qlora
lora_model_dir:
sequence_len: 16384
sample_packing: true
pad_to_sequence_len: true
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules:
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project: 70b-lora
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0001
train_on_inputs: true
group_by_length: false
bf16: true
fp16: false
tf32: true
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
eval_steps:
eval_table_size:
save_steps:
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"
```
</details><br>
# limarp-miqu-1-70b-qlora
Experimental limarp qlora trained at 16384 ctx length (greater than size of the longest limarp sample when tokenized via llama's tokenizer) on the fixed dequantized miqu-1-70b model by 152334H.
I wasn't particularly happy with the results I got when I tried applying the lora at varying weights to the miqu-1-70b model. It's possible that this is related to the fact that the model was dequantized from Q5_K_M GGUF, or perhaps due to it already being an instruct-tuned model.
However, I decided to go ahead and release this in case someone else finds a use for it. Provided as-is and YMMV.
## Model description
The intended prompt format is the Alpaca instruction format of LimaRP v3:
```
### Instruction:
Character's Persona: {bot character description}
User's Persona: {user character description}
Scenario: {what happens in the story}
Play the role of Character. Taking the above information into consideration, you must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
### Input:
User: {utterance}
### Response:
Character: {utterance}
### Input:
User: {utterance}
### Response:
Character: {utterance}
(etc.)
```
Inspired by the previously named "Roleplay" preset in SillyTavern, with this version of LimaRP it is possible to append a length modifier to the response instruction sequence, like this:
```
### Input
User: {utterance}
### Response: (length = medium)
Character: {utterance}
```
This has an immediately noticeable effect on bot responses. The lengths using during training are:
`micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`, `enormous`, `humongous`, `unlimited`.
**The recommended starting length is medium**. Keep in mind that the AI can ramble or impersonate
the user with very long messages.
The length control effect is reproducible, but the messages will not necessarily follow
lengths very precisely, rather follow certain ranges on average, as seen in this table
with data from tests made with one reply at the beginning of the conversation:

Response length control appears to work well also deep into the conversation. **By omitting
the modifier, the model will choose the most appropriate response length** (although it might
not necessarily be what the user desires).
## Intended uses & limitations
The model will show biases similar to those observed in niche roleplaying forums on the Internet, besides those exhibited by the base model.
## Training and evaluation data
For more details about LimaRP, see the dataset page.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
### Framework versions
- PEFT 0.7.2.dev0
- Transformers 4.37.0
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
Patcas/plbart-assert-nodocs-v3
|
Patcas
| 2024-02-01T10:33:10Z | 90 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"plbart",
"text2text-generation",
"generated_from_trainer",
"base_model:Patcas/my_awesome-assert-new",
"base_model:finetune:Patcas/my_awesome-assert-new",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T09:47:16Z |
---
base_model: Patcas/my_awesome-assert-new
tags:
- generated_from_trainer
model-index:
- name: plbart-assert-nodocs-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# plbart-assert-nodocs-v3
This model is a fine-tuned version of [Patcas/my_awesome-assert-new](https://huggingface.co/Patcas/my_awesome-assert-new) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9840
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 230 | 1.1672 |
| No log | 2.0 | 460 | 1.0022 |
| 1.4059 | 3.0 | 690 | 0.9667 |
| 1.4059 | 4.0 | 920 | 0.9625 |
| 0.4797 | 5.0 | 1150 | 0.9779 |
| 0.4797 | 6.0 | 1380 | 0.9764 |
| 0.2511 | 7.0 | 1610 | 0.9693 |
| 0.2511 | 8.0 | 1840 | 0.9764 |
| 0.1582 | 9.0 | 2070 | 0.9813 |
| 0.1582 | 10.0 | 2300 | 0.9840 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
tmukande12/t5_recommendation_sports_equipment_english
|
tmukande12
| 2024-02-01T10:30:39Z | 91 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T10:06:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5_recommendation_sports_equipment_english
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_recommendation_sports_equipment_english
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4517
- Rouge1: 57.4603
- Rouge2: 47.6190
- Rougel: 57.1429
- Rougelsum: 56.9841
- Gen Len: 3.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 0.96 | 6 | 6.7882 | 8.8889 | 0.9524 | 8.8278 | 8.7668 | 19.0 |
| No log | 1.96 | 12 | 2.3412 | 18.0952 | 0.0 | 18.0952 | 18.0952 | 3.2381 |
| No log | 2.96 | 18 | 0.8550 | 11.9048 | 4.7619 | 11.9048 | 11.9048 | 4.0 |
| No log | 3.96 | 24 | 0.7481 | 32.2222 | 4.7619 | 32.3810 | 32.3810 | 3.9048 |
| No log | 4.96 | 30 | 0.7208 | 20.9524 | 4.7619 | 20.9524 | 21.2698 | 3.6190 |
| No log | 5.96 | 36 | 0.6293 | 30.9524 | 23.8095 | 30.9524 | 31.7460 | 3.6667 |
| No log | 6.96 | 42 | 0.6203 | 42.7778 | 33.3333 | 42.5397 | 42.8571 | 3.9048 |
| No log | 7.96 | 48 | 0.6352 | 47.6190 | 33.3333 | 47.6190 | 46.8254 | 3.8095 |
| No log | 8.96 | 54 | 0.5334 | 52.6984 | 42.8571 | 52.3810 | 51.9841 | 3.9524 |
| No log | 9.96 | 60 | 0.4517 | 57.4603 | 47.6190 | 57.1429 | 56.9841 | 3.9048 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.1.0+cu121
- Datasets 2.8.0
- Tokenizers 0.13.3
|
C-Stuti/test
|
C-Stuti
| 2024-02-01T10:20:50Z | 0 | 0 | null |
[
"license:cc-by-nc-sa-2.0",
"region:us"
] | null | 2024-02-01T10:18:35Z |
---
license: cc-by-nc-sa-2.0
---
|
tjkmitl/AngerNews_1
|
tjkmitl
| 2024-02-01T10:15:13Z | 90 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:csebuetnlp/mT5_multilingual_XLSum",
"base_model:finetune:csebuetnlp/mT5_multilingual_XLSum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T10:13:52Z |
---
base_model: csebuetnlp/mT5_multilingual_XLSum
tags:
- generated_from_trainer
model-index:
- name: SurpriseNews1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SurpriseNews1
This model is a fine-tuned version of [csebuetnlp/mT5_multilingual_XLSum](https://huggingface.co/csebuetnlp/mT5_multilingual_XLSum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3676
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.9143 | 1.23 | 500 | 3.6579 |
| 3.2691 | 2.45 | 1000 | 3.3719 |
| 2.9441 | 3.68 | 1500 | 3.2650 |
| 2.7016 | 4.9 | 2000 | 3.2738 |
| 2.1448 | 6.13 | 2500 | 3.2987 |
| 2.4149 | 7.35 | 3000 | 3.3407 |
| 2.1251 | 8.58 | 3500 | 3.3605 |
| 1.9645 | 9.8 | 4000 | 3.3676 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
mlabonne/BeagleB-7B
|
mlabonne
| 2024-02-01T10:08:40Z | 10 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"base_model:mlabonne/OmniBeagle-7B",
"base_model:merge:mlabonne/OmniBeagle-7B",
"base_model:shadowml/BeagleX-7B",
"base_model:merge:shadowml/BeagleX-7B",
"base_model:shadowml/FoxBeagle-7B",
"base_model:merge:shadowml/FoxBeagle-7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-31T23:17:39Z |
---
license: cc-by-nc-4.0
tags:
- merge
- mergekit
- lazymergekit
base_model:
- mlabonne/OmniBeagle-7B
- shadowml/BeagleX-7B
- shadowml/FoxBeagle-7B
---
# BeagleB-7B
BeagleB-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [mlabonne/OmniBeagle-7B](https://huggingface.co/mlabonne/OmniBeagle-7B)
* [shadowml/BeagleX-7B](https://huggingface.co/shadowml/BeagleX-7B)
* [shadowml/FoxBeagle-7B](https://huggingface.co/shadowml/FoxBeagle-7B)
## 🧩 Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: mlabonne/OmniBeagle-7B
parameters:
density: 0.65
weight: 0.76
- model: shadowml/BeagleX-7B
parameters:
density: 0.6
weight: 0.12
- model: shadowml/FoxBeagle-7B
parameters:
density: 0.6
weight: 0.12
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/BeagleB-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
HeydarS/opt-350m_peft_v1
|
HeydarS
| 2024-02-01T10:07:46Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:facebook/opt-350m",
"base_model:adapter:facebook/opt-350m",
"region:us"
] | null | 2024-02-01T10:07:43Z |
---
library_name: peft
base_model: facebook/opt-350m
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.2.dev0
|
LoneStriker/CapybaraHermes-2.5-Mistral-7B-GGUF
|
LoneStriker
| 2024-02-01T10:05:10Z | 17 | 1 |
trl
|
[
"trl",
"gguf",
"distilabel",
"dpo",
"rlaif",
"rlhf",
"en",
"dataset:argilla/dpo-mix-7k",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-02-01T09:45:55Z |
---
library_name: trl
license: apache-2.0
datasets:
- argilla/dpo-mix-7k
language:
- en
tags:
- distilabel
- dpo
- rlaif
- rlhf
---
# CapybaraHermes-2.5-Mistral-7B
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60420dccc15e823a685f2b03/Vmr0FtTvnny6Snm-UDM_n.png">
</div>
<p align="center">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
This model is the launching partner of the [capybara-dpo dataset](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-9k-binarized) build with ⚗️ distilabel. It's a preference tuned [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
CapybaraHermes has been preference tuned with LoRA and TRL for 3 epochs using argilla's [dpo mix 7k](https://huggingface.co/datasets/argilla/dpo-mix-7k).
To test the impact on multi-turn performance we have used MTBench. We also include the Nous Benchmark results and Mistral-7B-Instruct-v0.2 for reference as it's a strong 7B model on MTBench:
| Model | AGIEval | GPT4All | TruthfulQA | Bigbench | MTBench First Turn | MTBench Second Turn | Nous avg. | MTBench avg. |
|-----------------------------------|---------|---------|------------|----------|------------|-------------|-----------|--------------|
| argilla/CapybaraHermes-2.5-Mistral-7B | **43.8** | **73.35** | 57.07 | **42.44** | 8.24375 | **7.5625** | 54.16 | **7.903125** |
| teknium/OpenHermes-2.5-Mistral-7B | 42.75 | 72.99 | 52.99 | 40.94 | **8.25** | 7.2875 | 52.42 | 7.76875 |
| Mistral-7B-Instruct-v0.2 | 38.5 | 71.64 | **66.82** | 42.29 | 7.8375 | 7.1 | **54.81** | 7.46875 |
The most interesting aspect in the context of the capybara-dpo dataset is the increased performance in MTBench Second Turn scores.
For the merge lovers, we also preference tuned Beagle14-7B with a mix of capybara-dpo and distilabel orca pairs using the same recipe as NeuralBeagle (see [ YALL - Yet Another LLM Leaderboard](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard) for reference):
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|------------------------------------------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[DistilabelBeagle14-7B](https://huggingface.co/dvilasuero/DistilabelBeagle14-7B)| 45.29| 76.92| 71.66| 48.78| 60.66|
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Shared by [optional]:** Argilla
- **Model type:** 7B chat model
- **Language(s) (NLP):** English
- **License:** Same as OpenHermes
- **Finetuned from model [optional]:** [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
|
AlKiir/llama-2-7b-alkiir-hf
|
AlKiir
| 2024-02-01T10:05:02Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2024-02-01T10:04:38Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
jan-hq/stealth-rag-v1-e1
|
jan-hq
| 2024-02-01T09:55:44Z | 9 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"dataset:jan-hq/bagel_sft_binarized",
"dataset:jan-hq/dolphin_binarized",
"dataset:jan-hq/openhermes_binarized",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T",
"base_model:finetune:TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-31T13:31:55Z |
---
license: apache-2.0
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
tags:
- alignment-handbook
- generated_from_trainer
- trl
- sft
- generated_from_trainer
datasets:
- jan-hq/bagel_sft_binarized
- jan-hq/dolphin_binarized
- jan-hq/openhermes_binarized
model-index:
- name: LlamaCorn-sft-adapter
results: []
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto"
>
<img src="https://github.com/janhq/jan/assets/89722390/35daac7d-b895-487c-a6ac-6663daaad78e" alt="Jan banner"
style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<p align="center">
<a href="https://jan.ai/">Jan</a
>
- <a href="https://discord.gg/AsJ8krTT3N">Discord</a>
</p>
<!-- header end -->
# Prompt template
ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
# Run this model
You can run this model using [Jan Desktop](https://jan.ai/) on Mac, Windows, or Linux.
Jan is an open source, ChatGPT alternative that is:
- 💻 **100% offline on your machine**: Your conversations remain confidential, and visible only to you.
- 🗂️ **
An Open File Format**: Conversations and model settings stay on your computer and can be exported or deleted at any time.
- 🌐 **OpenAI Compatible**: Local server on port `1337` with OpenAI compatible endpoints
- 🌍 **Open Source & Free**: We build in public; check out our [Github](https://github.com/janhq)

# About Jan
Jan believes in the need for an open-source AI ecosystem and is building the infra and tooling to allow open-source AIs to compete on a level playing field with proprietary ones.
Jan's long-term vision is to build a cognitive framework for future robots, who are practical, useful assistants for humans and businesses in everyday life.
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
|
genne/lora_KoSoLAR-10.7B-v0.2_1.4_dedup_1_SFT-DPO
|
genne
| 2024-02-01T09:54:35Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:jingyeom/KoSoLAR-10.7B-v0.2_1.4_dedup_1",
"base_model:adapter:jingyeom/KoSoLAR-10.7B-v0.2_1.4_dedup_1",
"license:apache-2.0",
"region:us"
] | null | 2024-02-01T09:54:17Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- dpo
- generated_from_trainer
base_model: jingyeom/KoSoLAR-10.7B-v0.2_1.4_dedup_1
model-index:
- name: lora_KoSoLAR-10.7B-v0.2_1.4_dedup_1_SFT-DPO
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lora_KoSoLAR-10.7B-v0.2_1.4_dedup_1_SFT-DPO
This model is a fine-tuned version of [jingyeom/KoSoLAR-10.7B-v0.2_1.4_dedup_1](https://huggingface.co/jingyeom/KoSoLAR-10.7B-v0.2_1.4_dedup_1) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 6
- gradient_accumulation_steps: 8
- total_train_batch_size: 48
- total_eval_batch_size: 48
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.7.1
- Transformers 4.37.2
- Pytorch 2.0.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.1
|
s3nh/Wernicke-7B-dpo-GGUF
|
s3nh
| 2024-02-01T09:54:27Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:openrail",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T09:29:04Z |
---
license: openrail
pipeline_tag: text-generation
library_name: transformers
language:
- zh
- en
---
## Original model card
Buy me a coffee if you like this project ;)
<a href="https://www.buymeacoffee.com/s3nh"><img src="https://www.buymeacoffee.com/assets/img/guidelines/download-assets-sm-1.svg" alt=""></a>
#### Description
GGUF Format model files for [This project](https://huggingface.co/CultriX/Wernicke-7B-dpo).
### GGUF Specs
GGUF is a format based on the existing GGJT, but makes a few changes to the format to make it more extensible and easier to use. The following features are desired:
Single-file deployment: they can be easily distributed and loaded, and do not require any external files for additional information.
Extensible: new features can be added to GGML-based executors/new information can be added to GGUF models without breaking compatibility with existing models.
mmap compatibility: models can be loaded using mmap for fast loading and saving.
Easy to use: models can be easily loaded and saved using a small amount of code, with no need for external libraries, regardless of the language used.
Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
The key difference between GGJT and GGUF is the use of a key-value structure for the hyperparameters (now referred to as metadata), rather than a list of untyped values.
This allows for new metadata to be added without breaking compatibility with existing models, and to annotate the model with additional information that may be useful for
inference or for identifying the model.
### inference
User: Tell me story about what is an quantization and what do we need to build.
I'll try to give a layman-friendly explanation of quantization in the context of a hypothetical scenario for building a simple musical instrument. Imagine we want to create a device that produces different musical notes when interacting with it in a particular way, similar to striking a piano key. We'll call this our 'Quantized Note Generator'.
In a real piano, the precise frequency of a note produced depends on how hard you press a key (known as 'dynamic playing'), the exact spot on the key where contact occurs ('timbre variations'), and other nuances of performance. However, for
# Original model card
|
asun17904/glue-qnli-t5-base
|
asun17904
| 2024-02-01T09:52:46Z | 0 | 0 |
pytorch
|
[
"pytorch",
"en",
"license:mit",
"region:us"
] | null | 2024-02-01T08:12:30Z |
---
language: en
license: mit
library_name: pytorch
---
# Plainly Optimized Network
Dataset: GLUE
Trainer Hyperparameters:
- `lr` = 5e-05
- `per_device_batch_size` = 16
- `gradient_accumulation_steps` = 1
- `weight_decay` = 0.0
- `seed` = 42
|eval_loss|eval_accuracy|epoch|
|--|--|--|
|13.243|0.896|1.0|
|12.807|0.909|2.0|
|
zohann/whisper-temp
|
zohann
| 2024-02-01T09:50:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-01T09:49:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
badokorach/bert-finetuned-270124
|
badokorach
| 2024-02-01T09:48:53Z | 1 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"base_model:badokorach/bert-finetuned-210124",
"base_model:finetune:badokorach/bert-finetuned-210124",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-01-27T16:24:19Z |
---
base_model: badokorach/bert-finetuned-210124
tags:
- generated_from_keras_callback
model-index:
- name: badokorach/bert-finetuned-270124
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# badokorach/bert-finetuned-270124
This model is a fine-tuned version of [badokorach/bert-finetuned-210124](https://huggingface.co/badokorach/bert-finetuned-210124) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5863
- Validation Loss: 0.0
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'module': 'transformers.optimization_tf', 'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 2190, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.8999999761581421, 'beta_2': 0.9990000128746033, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.02}, 'registered_name': 'AdamWeightDecay'}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.7590 | 0.0 | 0 |
| 1.4387 | 0.0 | 1 |
| 1.3169 | 0.0 | 2 |
| 1.2324 | 0.0 | 3 |
| 1.1240 | 0.0 | 4 |
| 1.0528 | 0.0 | 5 |
| 0.9570 | 0.0 | 6 |
| 0.8565 | 0.0 | 7 |
| 0.8106 | 0.0 | 8 |
| 0.7500 | 0.0 | 9 |
| 0.6830 | 0.0 | 10 |
| 0.6456 | 0.0 | 11 |
| 0.6066 | 0.0 | 12 |
| 0.5971 | 0.0 | 13 |
| 0.5863 | 0.0 | 14 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.15.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
mzbac/Kunpeng-4x7B-mistral-hf-4bit-mlx-adapters
|
mzbac
| 2024-02-01T09:47:09Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2024-01-30T10:30:51Z |
---
license: mit
---
adapter file for the model `mzbac/Kunpeng-4x7B-mistral-hf-4bit-mlx-adapters` qlora finetuning
|
CLMBR/pp-mod-subj-lstm-4
|
CLMBR
| 2024-02-01T09:46:39Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"rnn",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2024-01-26T10:15:10Z |
---
tags:
- generated_from_trainer
model-index:
- name: pp-mod-subj2-lstm-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pp-mod-subj2-lstm-4
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0236
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3052726
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-------:|:---------------:|
| 4.7988 | 0.03 | 76320 | 4.8119 |
| 4.5128 | 1.03 | 152640 | 4.5289 |
| 4.3661 | 0.03 | 228960 | 4.3930 |
| 4.2793 | 1.03 | 305280 | 4.3106 |
| 4.2199 | 2.03 | 381600 | 4.2538 |
| 4.1656 | 0.03 | 457920 | 4.2123 |
| 4.1242 | 1.03 | 534240 | 4.1813 |
| 4.0913 | 0.03 | 610560 | 4.1555 |
| 4.0629 | 1.03 | 686880 | 4.1362 |
| 4.0421 | 2.03 | 763200 | 4.1204 |
| 4.0202 | 0.03 | 839520 | 4.1084 |
| 4.0025 | 1.03 | 915840 | 4.0972 |
| 3.989 | 0.03 | 992160 | 4.0882 |
| 3.9751 | 1.03 | 1068480 | 4.0794 |
| 3.9595 | 2.03 | 1144800 | 4.0728 |
| 3.9436 | 0.03 | 1221120 | 4.0676 |
| 3.9344 | 1.03 | 1297440 | 4.0620 |
| 3.9263 | 2.03 | 1373760 | 4.0570 |
| 3.9151 | 0.03 | 1450080 | 4.0538 |
| 3.9114 | 1.03 | 1526400 | 4.0491 |
| 3.9089 | 2.03 | 1602720 | 4.0466 |
| 3.8981 | 0.03 | 1679040 | 4.0438 |
| 3.8904 | 1.03 | 1755360 | 4.0413 |
| 3.8841 | 0.03 | 1831680 | 4.0396 |
| 3.8756 | 1.03 | 1908000 | 4.0376 |
| 3.8743 | 2.03 | 1984320 | 4.0353 |
| 3.8676 | 0.03 | 2060640 | 4.0340 |
| 3.8629 | 1.03 | 2136960 | 4.0330 |
| 3.8599 | 0.03 | 2213280 | 4.0308 |
| 3.856 | 1.03 | 2289600 | 4.0297 |
| 3.8492 | 2.03 | 2365920 | 4.0286 |
| 3.8436 | 0.03 | 2442240 | 4.0276 |
| 3.8417 | 0.03 | 2518560 | 4.0271 |
| 3.8421 | 1.03 | 2594880 | 4.0268 |
| 3.8355 | 0.03 | 2671200 | 4.0259 |
| 3.8387 | 1.03 | 2747520 | 4.0254 |
| 3.8418 | 0.03 | 2823840 | 4.0249 |
| 3.8357 | 1.03 | 2900160 | 4.0245 |
| 3.8343 | 2.03 | 2976480 | 4.0239 |
| 3.8291 | 0.02 | 3052726 | 4.0236 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.3
|
LoneStriker/Newton-7B-6.0bpw-h6-exl2
|
LoneStriker
| 2024-02-01T09:36:39Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"axolotl",
"finetune",
"qlora",
"conversational",
"dataset:hendrycks/competition_math",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:openbookqa",
"dataset:piqa",
"dataset:metaeval/reclor",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:sciq",
"dataset:TIGER-Lab/ScienceEval",
"arxiv:2305.14314",
"base_model:openchat/openchat-3.5-0106",
"base_model:finetune:openchat/openchat-3.5-0106",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T09:34:09Z |
---
license: other
tags:
- axolotl
- finetune
- qlora
base_model: openchat/openchat-3.5-0106
datasets:
- hendrycks/competition_math
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- STEM-AI-mtl/Electrical-engineering
- openbookqa
- piqa
- metaeval/reclor
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- sciq
- TIGER-Lab/ScienceEval
---

# 🔬👩🔬 Newton-7B
This model is a fine-tuned version of [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106) on datasets related to science.
This model is fine-tuned using [QLoRa](https://arxiv.org/abs/2305.14314) and [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.3.0`
```yaml
base_model: openchat/openchat-3.5-0106
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: merged_all.json
type:
field_instruction: instruction
field_output: output
format: "GPT4 Correct User: {instruction}<|end_of_turn|>GPT4 Correct Assistant:"
no_input_format: "GPT4 Correct User: {instruction}<|end_of_turn|>GPT4 Correct Assistant:"
dataset_prepared_path: last_run_prepared
val_set_size: 0.01 # not sure
output_dir: ./newton
adapter: qlora
lora_model_dir:
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
lora_r: 128
lora_alpha: 64
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
lora_modules_to_save:
- embed_tokens
- lm_head
wandb_project: huggingface
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/newton-lora
save_safetensors: true
# change #
gradient_accumulation_steps: 12
micro_batch_size: 6
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
# change #
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10 # not sure
saves_per_epoch: 2
evals_per_epoch: 4
eval_table_size:
eval_table_max_new_tokens: 128
debug:
deepspeed:
weight_decay: 0.1 # not sure
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"
tokens:
- "<|end_of_turn|>"
- "<|pad_0|>"
```
</details><br>
# 📊 Datasets
You can find the dataset I used and the work I am doing with this datasets here:
https://huggingface.co/datasets/Weyaxi/sci-datasets
Following datasets were used in this model:
- 📐 [MATH](https://huggingface.co/datasets/hendrycks/competition_math)
- 🧠 [ARC](https://huggingface.co/datasets/allenai/ai2_arc) (Note: Only **train** part)
- 🧲 [camel-ai/physics](https://huggingface.co/datasets/camel-ai/physics)
- ⚗️ [camel-ai/chemistry](https://huggingface.co/datasets/camel-ai/chemistry)
- 🦠 [camel-ai/biology](https://huggingface.co/datasets/camel-ai/biology)
- 📊 [camel-ai/math](https://huggingface.co/datasets/camel-ai/math)
- ⚡ [STEM-AI-mtl/Electrical-engineering](https://huggingface.co/datasets/STEM-AI-mtl/Electrical-engineering)
- 📚 [openbookqa](https://huggingface.co/datasets/openbookqa)
- 🧠 [piqa](https://huggingface.co/datasets/piqa)
- 🎨 [reclor](https://huggingface.co/datasets/metaeval/reclor)
- 🔬 [scibench](https://github.com/mandyyyyii/scibench)
- 🧪 [ScienceQA](https://huggingface.co/datasets/derek-thomas/ScienceQA)
- 🧬 [sciq](https://huggingface.co/datasets/sciq)
- 📝 [ScienceEval](https://huggingface.co/datasets/TIGER-Lab/ScienceEval)
## 🛠️ Multiple Choice Question & Answer Datasets Conversion Progress
I used [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) to generate a reasonable and logical answer by providing it with the question and the answer key.
I used the [Together AI](https://www.together.ai) API for this task.
The following datasets are converted using this method:
- 🧠 [ARC](https://huggingface.co/datasets/allenai/ai2_arc) (Note: Only **train** part)
- 📚 [openbookqa](https://huggingface.co/datasets/openbookqa)
- 🎨 [reclor](https://huggingface.co/datasets/metaeval/reclor)
- 🧬 [sciq](https://huggingface.co/datasets/sciq)
# 💬 Prompt Template
You can use this prompt template while using the model:
### GPT4 Correct [(Openchat)](https://huggingface.co/openchat/openchat-3.5-0106#conversation-templates)
```
GPT4 Correct User: {user}<|end_of_turn|>GPT4 Correct Assistant: {asistant}<|end_of_turn|>GPT4 Correct User: {user}<|end_of_turn|>GPT4 Correct Assistant:
```
You can also utilize the chat template method from the tokenizer config like here:
```python
messages = [
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hi"},
{"role": "user", "content": "How are you today?"}
]
tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
```
# 🤝 Acknowledgments
Thanks to [openchat](https://huggingface.co/openchat) team for fine-tuning an excellent model that I used as a base model.
Thanks to [@jondurbin](https://huggingface.co/jondurbin) for reformatting codes for some datasets: [bagel/data_sources](https://github.com/jondurbin/bagel/tree/main/bagel/data_sources)
Thanks to [Together AI](https://www.together.ai) for providing everyone with free credits, which I used to generate a dataset in multiple choice to explanations format.
Thanks to [Tim Dettmers](https://huggingface.co/timdettmers) for his excellent [QLoRA](https://arxiv.org/abs/2305.14314) work.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Overall, thanks to all of the open soure AI community! 🚀
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
Revankumar/fine_tuned_embeddings_for_healthy_recipes
|
Revankumar
| 2024-02-01T09:36:09Z | 47 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-02-01T08:28:31Z |
---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 109 with parameters:
```
{'batch_size': 10, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 50,
"evaluator": "sentence_transformers.evaluation.InformationRetrievalEvaluator.InformationRetrievalEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 21,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
savasy/bert-base-turkish-ner-cased
|
savasy
| 2024-02-01T09:21:04Z | 9,321 | 17 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"token-classification",
"tr",
"arxiv:2401.17396",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: tr
---
# For Turkish language, here is an easy-to-use NER application.
** Türkçe için kolay bir python NER (Bert + Transfer Learning) (İsim Varlık Tanıma) modeli...
# Citation
Please cite if you use it in your study
```
@misc{yildirim2024finetuning,
title={Fine-tuning Transformer-based Encoder for Turkish Language Understanding Tasks},
author={Savas Yildirim},
year={2024},
eprint={2401.17396},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@book{yildirim2021mastering,
title={Mastering Transformers: Build state-of-the-art models from scratch with advanced natural language processing techniques},
author={Yildirim, Savas and Asgari-Chenaghlu, Meysam},
year={2021},
publisher={Packt Publishing Ltd}
}
```
# other detail
Thanks to @stefan-it, I applied the followings for training
cd tr-data
for file in train.txt dev.txt test.txt labels.txt
do
wget https://schweter.eu/storage/turkish-bert-wikiann/$file
done
cd ..
It will download the pre-processed datasets with training, dev and test splits and put them in a tr-data folder.
Run pre-training
After downloading the dataset, pre-training can be started. Just set the following environment variables:
```
export MAX_LENGTH=128
export BERT_MODEL=dbmdz/bert-base-turkish-cased
export OUTPUT_DIR=tr-new-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=625
export SEED=1
```
Then run pre-training:
```
python3 run_ner_old.py --data_dir ./tr-data3 \
--model_type bert \
--labels ./tr-data/labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR-$SEED \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict \
--fp16
```
# Usage
```
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("savasy/bert-base-turkish-ner-cased")
tokenizer = AutoTokenizer.from_pretrained("savasy/bert-base-turkish-ner-cased")
ner=pipeline('ner', model=model, tokenizer=tokenizer)
ner("Mustafa Kemal Atatürk 19 Mayıs 1919'da Samsun'a ayak bastı.")
```
# Some results
Data1: For the data above
Eval Results:
* precision = 0.916400580551524
* recall = 0.9342309684101502
* f1 = 0.9252298787412536
* loss = 0.11335893666411284
Test Results:
* precision = 0.9192058759362955
* recall = 0.9303010230367262
* f1 = 0.9247201697271198
* loss = 0.11182546521618497
Data2:
https://github.com/stefan-it/turkish-bert/files/4558187/nerdata.txt
The performance for the data given by @kemalaraz is as follows
savas@savas-lenova:~/Desktop/trans/tr-new-model-1$ cat eval_results.txt
* precision = 0.9461980692049029
* recall = 0.959309358847465
* f1 = 0.9527086063783312
* loss = 0.037054269206847804
savas@savas-lenova:~/Desktop/trans/tr-new-model-1$ cat test_results.txt
* precision = 0.9458370635631155
* recall = 0.9588201928530913
* f1 = 0.952284378344882
* loss = 0.035431676572445225
|
AndyChiang/Pre-CoFactv3-Text-Classification
|
AndyChiang
| 2024-02-01T09:19:35Z | 91 | 1 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"Pre-CoFactv3",
"Text-Classification",
"en",
"dataset:FACTIFY5WQA",
"base_model:microsoft/deberta-v3-large",
"base_model:finetune:microsoft/deberta-v3-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-01T08:27:06Z |
---
license: mit
language: en
tags:
- Pre-CoFactv3
- Text-Classification
datasets:
- FACTIFY5WQA
metrics:
- accuracy
pipeline_tag: text-classification
library_name: transformers
base_model: microsoft/deberta-v3-large
widget:
- text: "BREAKING: Another nearly 1.9 million Americans filed for unemployment insurance last week, the Department of Labor said. https://t.co/dVwyI6avmx [SEP] By Anneken Tappe, CNN BusinessUpdated 11:50 AM ET, Thu June 4, 2020 New York (CNN Business)Millions of Americans again filed for unemployment benefits last week, as the coronavirus recession drags on."
example_title: "Support"
- text: "Micah Richards spent an entire season at Aston Vila without playing a single game. [SEP] Despite speculation that Richards would leave Aston Villa before the transfer deadline for the 2018~19 season , he remained at the club , although he is not being considered for first team selection."
example_title: "Neutral"
- text: "Mahatma Gandhi having breakfast with British official inside the jail. [SEP] A photo is being shared on Facebook with a claim that Gandhi was having breakfast with British officials inside the jail while people are fighting for Independence. Let\u2019s try to check the authenticity of the image in the post. Claim: Mahatma Gandhi having breakfast with British official inside the jail. Fact: The photo was not taken inside the jail. It was taken during a breakfast meeting between Gandhi and Mountbatten at Viceroy\u2019s House in April 1947. Hence the claim made in the post is FALSE. When the image in the post is run Google Reverse Image Search, a link to Getty Images website containing the same image can be found in the search results. In that website, the image has a description which reads, \u201cBreakfast meeting between Mahatma Gandhi and Viceroy of India, Lord Mountbatten 1947\u201d. Also, in the book \u2018India Remembered\u2019 written by Pamela Mountbatten (the daughter of Lord Mountbatten), the same image can be found in the \u2018A Huge Task\u2019 chapter. She writes that the photo was taken on 1st April 1947 at the Viceroy\u2019s House. The Viceroy invited Gandhi for breakfast to discuss the transfer of power, declared by England\u2019s PM Clement R. Atlee in February 1947. So, the photo was not taken inside the jail. To sum it up, the photo was taken in April 1947 at the Viceroy\u2019s house, not inside the jail. Did you watch our Facebook live on Fake News (Misinformation)."
example_title: "Refute"
---
# Pre-CoFactv3-Text-Classification
## Model description
This is a Text Classification model for **AAAI 2024 Workshop Paper: “Team Trifecta at Factify5WQA: Setting the Standard in Fact Verification with Fine-Tuning”**
Its input are claim and evidence, and output is the predicted label, which falls into one of the categories: Support, Neutral, or Refute.
It is fine-tuned by **FACTIFY5WQA** dataset based on [**microsoft/deberta-v3-large**](https://huggingface.co/microsoft/deberta-v3-large) model.
For more details, you can see our **paper** or [**GitHub**](https://github.com/AndyChiangSH/Pre-CoFactv3).
## How to use?
1. Download the model by hugging face transformers.
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("AndyChiang/Pre-CoFactv3-Text-Classification")
tokenizer = AutoTokenizer.from_pretrained("AndyChiang/Pre-CoFactv3-Text-Classification")
```
2. Create a pipeline.
```python
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
```
3. Use the pipeline to predict the label.
```python
label = classifier("Micah Richards spent an entire season at Aston Vila without playing a single game. [SEP] Despite speculation that Richards would leave Aston Villa before the transfer deadline for the 2018~19 season , he remained at the club , although he is not being considered for first team selection.")
print(label)
```
## Dataset
We utilize the dataset FACTIFY5WQA provided by the AAAI-24 Workshop Factify 3.0.
This dataset is designed for fact verification, with the task of determining the veracity of a claim based on the given evidence.
- **claim:** the statement to be verified.
- **evidence:** the facts to verify the claim.
- **question:** the questions generated from the claim by the 5W framework (who, what, when, where, and why).
- **claim_answer:** the answers derived from the claim.
- **evidence_answer:** the answers derived from the evidence.
- **label:** the veracity of the claim based on the given evidence, which is one of three categories: Support, Neutral, or Refute.
| | Training | Validation | Testing | Total |
| --- | --- | --- | --- | --- |
| Support | 3500 | 750 | 750 | 5000 |
| Neutral | 3500 | 750 | 750 | 5000 |
| Refute | 3500 | 750 | 750 | 5000 |
| Total | 10500 | 2250 | 2250 | 15000 |
## Fine-tuning
Fine-tuning is conducted by the Hugging Face Trainer API on the [Text Classification](https://huggingface.co/docs/transformers/tasks/sequence_classification) task.
### Training hyperparameters
The following hyperparameters were used during training:
- Pre-train language model: [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large)
- Optimizer: adam
- Learning rate: 0.00001
- Max token of input: 650
- Batch size: 4
- Epoch: 12
- Device: NVIDIA RTX A5000
## Testing
In the case of the Text Classification task, accuracy serves as the evaluation metric.
| Accuracy |
| ----- |
| 0.8502 |
## Other models
[AndyChiang/Pre-CoFactv3-Question-Answering](https://huggingface.co/AndyChiang/Pre-CoFactv3-Question-Answering)
## Citation
|
Patcas/plbart-nodocs-v1
|
Patcas
| 2024-02-01T09:17:32Z | 88 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"plbart",
"text2text-generation",
"generated_from_trainer",
"base_model:Patcas/plbart-works",
"base_model:finetune:Patcas/plbart-works",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T01:13:33Z |
---
base_model: Patcas/plbart-works
tags:
- generated_from_trainer
model-index:
- name: plbart-nodocs-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# plbart-nodocs-v1
This model is a fine-tuned version of [Patcas/plbart-works](https://huggingface.co/Patcas/plbart-works) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9260
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 230 | 0.9679 |
| No log | 2.0 | 460 | 0.8849 |
| 1.0028 | 3.0 | 690 | 0.8818 |
| 1.0028 | 4.0 | 920 | 0.8803 |
| 0.3649 | 5.0 | 1150 | 0.8970 |
| 0.3649 | 6.0 | 1380 | 0.9123 |
| 0.1915 | 7.0 | 1610 | 0.9087 |
| 0.1915 | 8.0 | 1840 | 0.9215 |
| 0.1153 | 9.0 | 2070 | 0.9243 |
| 0.1153 | 10.0 | 2300 | 0.9260 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
CundK/bert-base-german-cased-hatespeech-GermEval18
|
CundK
| 2024-02-01T09:17:10Z | 95 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-german-cased",
"base_model:finetune:google-bert/bert-base-german-cased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-22T11:38:22Z |
---
license: mit
base_model: bert-base-german-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-german-cased-hatespeech-GermEval18
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-german-cased-hatespeech-GermEval18
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9184
- Accuracy: 0.7810
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 314 | 0.8052 | 0.7769 |
| 0.1769 | 2.0 | 628 | 0.9184 | 0.7810 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
s3nh/DistilabelBeagle14-7B-GGUF
|
s3nh
| 2024-02-01T09:17:03Z | 11 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:openrail",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-02-01T07:54:07Z |
---
license: openrail
pipeline_tag: text-generation
library_name: transformers
language:
- zh
- en
---
## Original model card
Buy me a coffee if you like this project ;)
<a href="https://www.buymeacoffee.com/s3nh"><img src="https://www.buymeacoffee.com/assets/img/guidelines/download-assets-sm-1.svg" alt=""></a>
#### Description
GGUF Format model files for [This project](https://huggingface.co/argilla/DistilabelBeagle14-7B).
### GGUF Specs
GGUF is a format based on the existing GGJT, but makes a few changes to the format to make it more extensible and easier to use. The following features are desired:
Single-file deployment: they can be easily distributed and loaded, and do not require any external files for additional information.
Extensible: new features can be added to GGML-based executors/new information can be added to GGUF models without breaking compatibility with existing models.
mmap compatibility: models can be loaded using mmap for fast loading and saving.
Easy to use: models can be easily loaded and saved using a small amount of code, with no need for external libraries, regardless of the language used.
Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
The key difference between GGJT and GGUF is the use of a key-value structure for the hyperparameters (now referred to as metadata), rather than a list of untyped values.
This allows for new metadata to be added without breaking compatibility with existing models, and to annotate the model with additional information that may be useful for
inference or for identifying the model.
### inference
<|im_start|> User: Tell me story about what is an quantization and what do we need to build. and what do we need to build' and what do we need<|im_end|>
# Original model card
|
NhoxxKienn/test
|
NhoxxKienn
| 2024-02-01T09:14:43Z | 99 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"question-answering",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-02-01T09:12:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dengh/Reinforce-CartPole-v1
|
dengh
| 2024-02-01T09:06:46Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-01T09:06:36Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 433.80 +/- 99.74
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
macarious/torgo_xlsr_finetune_M03_keep_all
|
macarious
| 2024-02-01T09:04:33Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-01-31T21:09:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: torgo_xlsr_finetune_M03_keep_all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# torgo_xlsr_finetune_M03_keep_all
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6155
- Wer: 0.2360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.5946 | 0.56 | 1000 | 3.3418 | 1.0 |
| 2.3765 | 1.12 | 2000 | 1.8751 | 0.9367 |
| 1.0589 | 1.68 | 3000 | 1.4354 | 0.6588 |
| 0.7686 | 2.24 | 4000 | 1.3288 | 0.5193 |
| 0.7029 | 2.8 | 5000 | 1.2625 | 0.5071 |
| 0.5645 | 3.37 | 6000 | 1.3686 | 0.4331 |
| 0.5149 | 3.93 | 7000 | 1.2946 | 0.4392 |
| 0.4504 | 4.49 | 8000 | 1.4451 | 0.3793 |
| 0.4012 | 5.05 | 9000 | 1.3974 | 0.3324 |
| 0.3683 | 5.61 | 10000 | 1.6211 | 0.3553 |
| 0.3661 | 6.17 | 11000 | 1.4331 | 0.3488 |
| 0.3337 | 6.73 | 12000 | 1.6473 | 0.3454 |
| 0.3087 | 7.29 | 13000 | 1.4651 | 0.3096 |
| 0.2908 | 7.85 | 14000 | 1.3439 | 0.2844 |
| 0.2692 | 8.41 | 15000 | 1.2399 | 0.2871 |
| 0.262 | 8.97 | 16000 | 1.4219 | 0.3111 |
| 0.244 | 9.53 | 17000 | 1.5202 | 0.3065 |
| 0.2672 | 10.1 | 18000 | 1.3916 | 0.2840 |
| 0.2346 | 10.66 | 19000 | 1.6752 | 0.3077 |
| 0.2089 | 11.22 | 20000 | 1.4122 | 0.2734 |
| 0.2262 | 11.78 | 21000 | 1.4316 | 0.2795 |
| 0.2043 | 12.34 | 22000 | 1.6063 | 0.2943 |
| 0.1836 | 12.9 | 23000 | 1.5199 | 0.2726 |
| 0.1701 | 13.46 | 24000 | 1.6889 | 0.2722 |
| 0.1938 | 14.02 | 25000 | 1.5244 | 0.2619 |
| 0.1734 | 14.58 | 26000 | 1.8305 | 0.2692 |
| 0.1714 | 15.14 | 27000 | 1.6078 | 0.2539 |
| 0.1521 | 15.7 | 28000 | 1.8210 | 0.2665 |
| 0.1346 | 16.26 | 29000 | 1.7116 | 0.2653 |
| 0.1498 | 16.83 | 30000 | 1.4663 | 0.2432 |
| 0.1594 | 17.39 | 31000 | 1.5994 | 0.2402 |
| 0.1647 | 17.95 | 32000 | 1.5112 | 0.2356 |
| 0.1238 | 18.51 | 33000 | 1.6993 | 0.2429 |
| 0.1554 | 19.07 | 34000 | 1.5374 | 0.2379 |
| 0.1238 | 19.63 | 35000 | 1.6155 | 0.2360 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.2.0
- Datasets 2.16.1
- Tokenizers 0.13.3
|
aria402/distilbert-base-uncased-finetuned-squad
|
aria402
| 2024-02-01T09:01:19Z | 109 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-01-31T07:48:43Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
AndyChiang/Pre-CoFactv3-Question-Answering
|
AndyChiang
| 2024-02-01T09:00:48Z | 151 | 1 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"question-answering",
"Pre-CoFactv3",
"Question Answering",
"en",
"dataset:FACTIFY5WQA",
"base_model:microsoft/deberta-v3-large",
"base_model:finetune:microsoft/deberta-v3-large",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2024-02-01T08:19:38Z |
---
license: mit
language: en
tags:
- Pre-CoFactv3
- Question Answering
datasets:
- FACTIFY5WQA
metrics:
- bleu
pipeline_tag: question-answering
library_name: transformers
base_model: microsoft/deberta-v3-large
widget:
- text: "Who spent an entire season at aston vila without playing a single game?"
context: "Micah Richards spent an entire season at Aston Vila without playing a single game."
example_title: "Claim"
- text: "Who spent an entire season at aston vila without playing a single game?"
context: "Despite speculation that Richards would leave Aston Villa before the transfer deadline for the 2018~19 season , he remained at the club , although he is not being considered for first team selection."
example_title: "Evidence"
---
# Pre-CoFactv3-Question-Answering
## Model description
This is a Question Answering model for **AAAI 2024 Workshop Paper: “Team Trifecta at Factify5WQA: Setting the Standard in Fact Verification with Fine-Tuning”**
Its input are question and context, and output is the answers derived from the context. It is fine-tuned by **FACTIFY5WQA** dataset based on [**microsoft/deberta-v3-large**](https://huggingface.co/microsoft/deberta-v3-large) model.
For more details, you can see our **paper** or [**GitHub**](https://github.com/AndyChiangSH/Pre-CoFactv3).
## How to use?
1. Download the model by hugging face transformers.
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model = AutoModelForQuestionAnswering.from_pretrained("AndyChiang/Pre-CoFactv3-Question-Answering")
tokenizer = AutoTokenizer.from_pretrained("AndyChiang/Pre-CoFactv3-Question-Answering")
```
2. Create a pipeline.
```python
QA = pipeline("question-answering", model=model, tokenizer=tokenizer)
```
3. Use the pipeline to answer the question by context.
```python
QA_input = {
'context': "Micah Richards spent an entire season at Aston Vila without playing a single game.",
'question': "Who spent an entire season at aston vila without playing a single game?",
}
answer = QA(QA_input)
print(answer)
```
## Dataset
We utilize the dataset FACTIFY5WQA provided by the AAAI-24 Workshop Factify 3.0.
This dataset is designed for fact verification, with the task of determining the veracity of a claim based on the given evidence.
- **claim:** the statement to be verified.
- **evidence:** the facts to verify the claim.
- **question:** the questions generated from the claim by the 5W framework (who, what, when, where, and why).
- **claim_answer:** the answers derived from the claim.
- **evidence_answer:** the answers derived from the evidence.
- **label:** the veracity of the claim based on the given evidence, which is one of three categories: Support, Neutral, or Refute.
| | Training | Validation | Testing | Total |
| --- | --- | --- | --- | --- |
| Support | 3500 | 750 | 750 | 5000 |
| Neutral | 3500 | 750 | 750 | 5000 |
| Refute | 3500 | 750 | 750 | 5000 |
| Total | 10500 | 2250 | 2250 | 15000 |
## Fine-tuning
Fine-tuning is conducted by the Hugging Face Trainer API on the [Question Answering](https://huggingface.co/docs/transformers/tasks/question_answering) task.
### Training hyperparameters
The following hyperparameters were used during training:
- Pre-train language model: [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large)
- Optimizer: adam
- Learning rate: 0.00001
- Max length of input: 3200
- Batch size: 4
- Epoch: 3
- Device: NVIDIA RTX A5000
## Testing
We employ BLEU scores for both claim answer and evidence answer, taking the average of the two as the metric.
| Claim Answer | Evidence Answer | Average |
| ----- | ----- | ----- |
| 0.5248 | 0.3963 | 0.4605 |
## Other models
[AndyChiang/Pre-CoFactv3-Text-Classification](https://huggingface.co/AndyChiang/Pre-CoFactv3-Text-Classification)
## Citation
|
s3nh/Newton-7B-GGUF
|
s3nh
| 2024-02-01T08:56:56Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:openrail",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-02-01T08:09:35Z |
---
license: openrail
pipeline_tag: text-generation
library_name: transformers
language:
- zh
- en
---
## Original model card
Buy me a coffee if you like this project ;)
<a href="https://www.buymeacoffee.com/s3nh"><img src="https://www.buymeacoffee.com/assets/img/guidelines/download-assets-sm-1.svg" alt=""></a>
#### Description
GGUF Format model files for [This project](https://huggingface.co/Weyaxi/Newton-7B).
### GGUF Specs
GGUF is a format based on the existing GGJT, but makes a few changes to the format to make it more extensible and easier to use. The following features are desired:
Single-file deployment: they can be easily distributed and loaded, and do not require any external files for additional information.
Extensible: new features can be added to GGML-based executors/new information can be added to GGUF models without breaking compatibility with existing models.
mmap compatibility: models can be loaded using mmap for fast loading and saving.
Easy to use: models can be easily loaded and saved using a small amount of code, with no need for external libraries, regardless of the language used.
Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
The key difference between GGJT and GGUF is the use of a key-value structure for the hyperparameters (now referred to as metadata), rather than a list of untyped values.
This allows for new metadata to be added without breaking compatibility with existing models, and to annotate the model with additional information that may be useful for
inference or for identifying the model.
### inference
User: Tell me story about what is an quantization and what do we need to build.
Its a very interesting question! Is this some sort of a trap?
Its not a problem at all, so I am excited to answer this!
Its not really a problem!
It's just that the word "problem" is a bit confusing and that's why I am asking.
Its not a problem at all! I would be happy to help you out!
Its not a problem! So I can definitely help you!
Its not really a problem, so don't worry about it!
# Original model card
|
Meggido/NeuraLake-m7-7B
|
Meggido
| 2024-02-01T08:55:37Z | 8 | 1 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"mlabonne/NeuralBeagle14-7B",
"chargoddard/loyal-piano-m7",
"macadeliccc/WestLake-7B-v2-laser-truthy-dpo",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-31T00:45:49Z |
---
tags:
- merge
- mergekit
- mlabonne/NeuralBeagle14-7B
- chargoddard/loyal-piano-m7
- macadeliccc/WestLake-7B-v2-laser-truthy-dpo
license: cc-by-nc-4.0
---
# NeuraLake-m7-7B
NeuraLake-m7-7B is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [mlabonne/NeuralBeagle14-7B](https://huggingface.co/mlabonne/NeuralBeagle14-7B)
* [chargoddard/loyal-piano-m7](https://huggingface.co/chargoddard/loyal-piano-m7)
* [macadeliccc/WestLake-7B-v2-laser-truthy-dpo](https://huggingface.co/macadeliccc/WestLake-7B-v2-laser-truthy-dpo)
## 🛠️ Configuration
```yaml
models:
- model: mistralai/Mistral-7B-v0.1
# No parameters necessary for base model
- model: mlabonne/NeuralBeagle14-7B
parameters:
weight: 0.3
density: 0.8
- model: chargoddard/loyal-piano-m7
parameters:
weight: 0.4
density: 0.8
- model: macadeliccc/WestLake-7B-v2-laser-truthy-dpo
parameters:
weight: 0.3
density: 0.4
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
# normalize: true
dtype: bfloat16
```
|
tangwh/Reinforce-CartPole1
|
tangwh
| 2024-02-01T08:51:58Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-01T08:51:53Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 215.70 +/- 14.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
zivzhong/ddpm-butterflies-128
|
zivzhong
| 2024-02-01T08:51:30Z | 9 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2024-02-01T07:42:36Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/HuggingFace7/ddpm-butterflies-128/tensorboard?#scalars)
|
giux78/zefiro-7b-sft-qlora-ITA-v0.5
|
giux78
| 2024-02-01T08:45:26Z | 2,767 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"it",
"dataset:giux78/100k-sft-ready-ultrafeedback-ita",
"arxiv:2310.16944",
"arxiv:2312.09993",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-25T15:32:16Z |
---
license: apache-2.0
datasets:
- giux78/100k-sft-ready-ultrafeedback-ita
language:
- it
pipeline_tag: text-generation
---
<img src="https://hoodie-creator.s3.eu-west-1.amazonaws.com/15be78c6-original.png" alt="llamantino53" border="0" width="400px">
# Model Card for zefiro-7b-beta-ITA-v0.5
*Last Update: 11/01/2024*<br>
<!-- Provide a quick summary of what the model is/does. -->
Zefiro is a SFT fine tuned model for the Italian language based on [Mistral](https://huggingface.co/mistralai/Mistral-7B-v0.1) .
To create a set of open source models and datasets suited for italian language is the aim of the project and this is the first experiment.
The model can be used as base model for more specific conversationl tasks for Italian language
## Model Details
Zefiro is a porting of the [Zephyr](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) model to the italian language using the wonderful recipes
from [alignment-handbook](https://huggingface.co/alignment-handbook) . It has also taken ispiration and insights from the [Llamantino](https://huggingface.co/swap-uniba/LLaMAntino-2-chat-7b-hf-UltraChat-ITA) model
developed by Università di Bari. For the implementation we combined different approaches from the two models mentioned but also from the wondeful communtity of open source.
## Model description
- **Model type:** A 7B parameter GPT-like model fine-tuned on a mix of publicly available, synthetic datasets.
- **Language(s) (NLP):** Primarily Italian
- **License:** Apache 2
- **Finetuned from model:** [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Developed by:** [giux78](https://alessandroercolani.webflow.io/)
- **Funded by:** [Business Operating System](https://www.businessos.xyz)
## Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed version of [UltraChat-ITA](https://huggingface.co/datasets/giux78/100k-sft-ready-ultrafeedback-ita) that is a filtered version of the [`UltraChat`](https://huggingface.co/datasets/stingning/ultrachat) dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT.
Here's how you can run the model using Transformers from 🤗 :
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "giux78/zefiro-7b-beta-ITA-v0.1"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.to('cuda')
tokenizer = AutoTokenizer.from_pretrained(model_id, padding_side="left")
sys_prompt = "Sei un assistente disponibile, rispettoso e onesto. " \
"Rispondi sempre nel modo piu' utile possibile, pur essendo sicuro. " \
"Le risposte non devono includere contenuti dannosi, non etici, razzisti, sessisti, tossici, pericolosi o illegali. " \
"Assicurati che le tue risposte siano socialmente imparziali e positive. " \
"Se una domanda non ha senso o non e' coerente con i fatti, spiegane il motivo invece di rispondere in modo non corretto. " \
"Se non conosci la risposta a una domanda, non condividere informazioni false."
messages = [{ 'content' : sys_prompt, 'role' : 'assistant'},
{'content' : 'Crea una lista su cosa mangiare a pranzo ogni giorno della settimana a pranzo e cena', 'role' : 'user'}]
def generate_text(sys_prompt, user_prompt):
messages = [{ 'content' : sys_prompt, 'role' : 'assistant'},
{'content' : user_prompt, 'role' : 'user'}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
generated_ids = model.generate(**model_inputs, max_new_tokens=1024)
return tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
generate_text(sys_prompt, 'cosa ne pensi della politica italiana?')
```
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Zefiro-7b-beta-ITA-v0.1 has not been aligned to human preferences for safety within the RLHF phase or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
It is also unknown what the size and composition of the corpus was used to train the base model (`mistralai/Mistral-7B-v0.1`), however it is likely to have included a mix of Web data and technical sources like books and code. See the [Falcon 180B model card](https://huggingface.co/tiiuae/falcon-180B#training-data) for an example of this.
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
We used [UltraChat-ITA](https://huggingface.co/datasets/giux78/100k-sft-ready-ultrafeedback-ita) as training data that is a filtered version of the [`UltraChat`](https://huggingface.co/datasets/stingning/ultrachat).
For translating the dataset we combined different tools and API we are also evaluating the best approach for translating many more datasets.
We have seen that the translation phase is critical and can introduce incorrect syntax and semantics.
#### Summary
Zefiro-7b-beta-ITA-v0.1 is finetuned version of mistral-7b using the zephyr approach for the italian language.
## Citation
```
@misc{tunstall2023zephyr,
title={Zephyr: Direct Distillation of LM Alignment},
author={Lewis Tunstall and Edward Beeching and Nathan Lambert and Nazneen Rajani and Kashif Rasul and Younes Belkada and Shengyi Huang and Leandro von Werra and Clémentine Fourrier and Nathan Habib and Nathan Sarrazin and Omar Sanseviero and Alexander M. Rush and Thomas Wolf},
year={2023},
eprint={2310.16944},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{basile2023llamantino,
title={LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language},
author={Pierpaolo Basile and Elio Musacchio and Marco Polignano and Lucia Siciliani and Giuseppe Fiameni and Giovanni Semeraro},
year={2023},
eprint={2312.09993},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Model Card Authors
[giux78](https://huggingface.co/giux78)
## Model Card Contact
**[email protected]
|
shahzebnaveed/play_vizdoom_health
|
shahzebnaveed
| 2024-02-01T08:38:24Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-01T08:10:07Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 8.58 +/- 3.73
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r shahzebnaveed/play_vizdoom_health
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=play_vizdoom_health
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=play_vizdoom_health --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
roshanrai1304/results
|
roshanrai1304
| 2024-02-01T08:33:40Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:TinyPixel/Llama-2-7B-bf16-sharded",
"base_model:adapter:TinyPixel/Llama-2-7B-bf16-sharded",
"region:us"
] | null | 2024-02-01T07:48:05Z |
---
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: TinyPixel/Llama-2-7B-bf16-sharded
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [TinyPixel/Llama-2-7B-bf16-sharded](https://huggingface.co/TinyPixel/Llama-2-7B-bf16-sharded) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 120
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2.dev0
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
elinaparajuli/HomeSchema_3_QA-finetuned
|
elinaparajuli
| 2024-02-01T08:27:29Z | 88 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T04:00:51Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: HomeSchema_3_QA-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# HomeSchema_3_QA-finetuned
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1219
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 10 | 0.2057 |
| No log | 2.0 | 20 | 0.1383 |
| No log | 3.0 | 30 | 0.1219 |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
DrishtiSharma/llama-pro-8b-tweet-summarization-gradnorm-0.3
|
DrishtiSharma
| 2024-02-01T08:21:24Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:dialogstudio",
"base_model:TencentARC/LLaMA-Pro-8B",
"base_model:adapter:TencentARC/LLaMA-Pro-8B",
"license:llama2",
"region:us"
] | null | 2024-02-01T06:31:57Z |
---
license: llama2
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
datasets:
- dialogstudio
base_model: TencentARC/LLaMA-Pro-8B
model-index:
- name: llama-pro-8b-tweet-summarization-gradnorm-0.3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama-pro-8b-tweet-summarization-gradnorm-0.3
This model is a fine-tuned version of [TencentARC/LLaMA-Pro-8B](https://huggingface.co/TencentARC/LLaMA-Pro-8B) on the dialogstudio dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9796
- Rouge Scores: {'rouge1': 93.71888929189157, 'rouge2': 77.8377567936117, 'rougeL': 64.47906852741538, 'rougeLsum': 93.71298018429633}
- Bleu Scores: [0.9470990193868204, 0.9341779145832757, 0.9064440397746264, 0.8744914403659334]
- Gen Len: 463.0182
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge Scores | Bleu Scores | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------------------------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------:|:--------:|
| 1.9065 | 1.0 | 220 | 1.8530 | {'rouge1': 92.83694737064799, 'rouge2': 78.72458121869542, 'rougeL': 67.88788283384865, 'rougeLsum': 92.83768512059282} | [0.8739198483584956, 0.8530170264142946, 0.8271978418182495, 0.7998377773703629] | 463.0182 |
| 1.6363 | 2.0 | 440 | 1.8633 | {'rouge1': 93.54135671371444, 'rouge2': 78.96116387599493, 'rougeL': 67.77857901494997, 'rougeLsum': 93.54432289584433} | [0.8758125801988195, 0.8577741180618648, 0.8322886881519586, 0.80457236049974] | 463.0182 |
| 1.2817 | 3.0 | 660 | 2.0098 | {'rouge1': 87.30764070509844, 'rouge2': 73.12328274037898, 'rougeL': 62.00625532521349, 'rougeLsum': 87.29149649901954} | [0.8757949025917542, 0.8593181834244542, 0.8334473061685955, 0.8048319452251607] | 463.0182 |
| 0.9049 | 4.0 | 880 | 2.2481 | {'rouge1': 87.35996946418575, 'rouge2': 72.87802745947901, 'rougeL': 61.35206821444361, 'rougeLsum': 87.32662841081371} | [0.8755472589597261, 0.859572654041077, 0.8333237300074641, 0.804082483213136] | 463.0182 |
| 0.5916 | 5.0 | 1100 | 2.5061 | {'rouge1': 78.38431994557745, 'rouge2': 64.89809559762811, 'rougeL': 53.805209482421525, 'rougeLsum': 78.30608179426231} | [0.747179346815877, 0.7352208249958618, 0.7126103103040894, 0.6869428956670465] | 463.0182 |
| 0.3898 | 6.0 | 1320 | 2.8150 | {'rouge1': 93.77539618029996, 'rouge2': 78.03050568501187, 'rougeL': 64.82344374456906, 'rougeLsum': 93.76894400818286} | [0.9469183628254614, 0.9342162110956728, 0.9067374010427977, 0.8750430150656403] | 463.0182 |
| 0.2961 | 7.0 | 1540 | 2.9796 | {'rouge1': 93.71888929189157, 'rouge2': 77.8377567936117, 'rougeL': 64.47906852741538, 'rougeLsum': 93.71298018429633} | [0.9470990193868204, 0.9341779145832757, 0.9064440397746264, 0.8744914403659334] | 463.0182 |
### Framework versions
- PEFT 0.8.2.dev0
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.2.dev0
- Tokenizers 0.15.1
|
vitruv/vitruv_1
|
vitruv
| 2024-02-01T08:19:08Z | 116 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T07:48:27Z |
---
license: apache-2.0
language:
- ko
---
Who we are : Virtruv
해당 모델은 한국어 중 수학 모델에 집중하여 학습을 시도하였습니다.
Base Model : 'beomi/OPEN-SOLAR-KO-10.7B'
Dataset :
1 . traintogpb/aihub-koen-translation-integrated-tiny-100k
2. kyujinpy/KOR-gugugu-platypus-set
3. GAIR/MathPile : 다음 데이터 셋을 sampling 하여 직접 translate, 하였습니다.
Prompt:
|
agshubhi/Insurance_complaint_mgmt
|
agshubhi
| 2024-02-01T08:13:12Z | 0 | 0 | null |
[
"dataset:ebrigham/NL_insurance_reviews_sentiment",
"license:mit",
"region:us"
] | null | 2024-02-01T07:51:27Z |
---
license: mit
datasets:
- ebrigham/NL_insurance_reviews_sentiment
---
|
umer77400/eng_to_rus_t5model
|
umer77400
| 2024-02-01T08:11:18Z | 0 | 0 |
transformers
|
[
"transformers",
"translation",
"en",
"ru",
"dataset:wmt16",
"endpoints_compatible",
"region:us"
] |
translation
| 2024-02-01T04:52:20Z |
---
datasets:
- wmt16
language:
- en
- ru
metrics:
- bleu
library_name: transformers
pipeline_tag: translation
---
|
LoneStriker/CapybaraHermes-2.5-Mistral-7B-8.0bpw-h8-exl2
|
LoneStriker
| 2024-02-01T08:07:43Z | 8 | 1 |
trl
|
[
"trl",
"safetensors",
"mistral",
"distilabel",
"dpo",
"rlaif",
"rlhf",
"en",
"dataset:argilla/dpo-mix-7k",
"license:apache-2.0",
"region:us"
] | null | 2024-02-01T08:04:41Z |
---
library_name: trl
license: apache-2.0
datasets:
- argilla/dpo-mix-7k
language:
- en
tags:
- distilabel
- dpo
- rlaif
- rlhf
---
# CapybaraHermes-2.5-Mistral-7B
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60420dccc15e823a685f2b03/Vmr0FtTvnny6Snm-UDM_n.png">
</div>
<p align="center">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
This model is the launching partner of the [capybara-dpo dataset](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-9k-binarized) build with ⚗️ distilabel. It's a preference tuned [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
CapybaraHermes has been preference tuned with LoRA and TRL for 3 epochs using argilla's [dpo mix 7k](https://huggingface.co/datasets/argilla/dpo-mix-7k).
To test the impact on multi-turn performance we have used MTBench. We also include the Nous Benchmark results and Mistral-7B-Instruct-v0.2 for reference as it's a strong 7B model on MTBench:
| Model | AGIEval | GPT4All | TruthfulQA | Bigbench | MTBench First Turn | MTBench Second Turn | Nous avg. | MTBench avg. |
|-----------------------------------|---------|---------|------------|----------|------------|-------------|-----------|--------------|
| argilla/CapybaraHermes-2.5-Mistral-7B | **43.8** | **73.35** | 57.07 | **42.44** | 8.24375 | **7.5625** | 54.16 | **7.903125** |
| teknium/OpenHermes-2.5-Mistral-7B | 42.75 | 72.99 | 52.99 | 40.94 | **8.25** | 7.2875 | 52.42 | 7.76875 |
| Mistral-7B-Instruct-v0.2 | 38.5 | 71.64 | **66.82** | 42.29 | 7.8375 | 7.1 | **54.81** | 7.46875 |
The most interesting aspect in the context of the capybara-dpo dataset is the increased performance in MTBench Second Turn scores.
For the merge lovers, we also preference tuned Beagle14-7B with a mix of capybara-dpo and distilabel orca pairs using the same recipe as NeuralBeagle (see [ YALL - Yet Another LLM Leaderboard](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard) for reference):
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|------------------------------------------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[DistilabelBeagle14-7B](https://huggingface.co/dvilasuero/DistilabelBeagle14-7B)| 45.29| 76.92| 71.66| 48.78| 60.66|
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Shared by [optional]:** Argilla
- **Model type:** 7B chat model
- **Language(s) (NLP):** English
- **License:** Same as OpenHermes
- **Finetuned from model [optional]:** [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
|
LoneStriker/CapybaraHermes-2.5-Mistral-7B-6.0bpw-h6-exl2
|
LoneStriker
| 2024-02-01T08:04:40Z | 6 | 1 |
trl
|
[
"trl",
"safetensors",
"mistral",
"distilabel",
"dpo",
"rlaif",
"rlhf",
"en",
"dataset:argilla/dpo-mix-7k",
"license:apache-2.0",
"region:us"
] | null | 2024-02-01T08:02:12Z |
---
library_name: trl
license: apache-2.0
datasets:
- argilla/dpo-mix-7k
language:
- en
tags:
- distilabel
- dpo
- rlaif
- rlhf
---
# CapybaraHermes-2.5-Mistral-7B
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60420dccc15e823a685f2b03/Vmr0FtTvnny6Snm-UDM_n.png">
</div>
<p align="center">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
This model is the launching partner of the [capybara-dpo dataset](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-9k-binarized) build with ⚗️ distilabel. It's a preference tuned [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
CapybaraHermes has been preference tuned with LoRA and TRL for 3 epochs using argilla's [dpo mix 7k](https://huggingface.co/datasets/argilla/dpo-mix-7k).
To test the impact on multi-turn performance we have used MTBench. We also include the Nous Benchmark results and Mistral-7B-Instruct-v0.2 for reference as it's a strong 7B model on MTBench:
| Model | AGIEval | GPT4All | TruthfulQA | Bigbench | MTBench First Turn | MTBench Second Turn | Nous avg. | MTBench avg. |
|-----------------------------------|---------|---------|------------|----------|------------|-------------|-----------|--------------|
| argilla/CapybaraHermes-2.5-Mistral-7B | **43.8** | **73.35** | 57.07 | **42.44** | 8.24375 | **7.5625** | 54.16 | **7.903125** |
| teknium/OpenHermes-2.5-Mistral-7B | 42.75 | 72.99 | 52.99 | 40.94 | **8.25** | 7.2875 | 52.42 | 7.76875 |
| Mistral-7B-Instruct-v0.2 | 38.5 | 71.64 | **66.82** | 42.29 | 7.8375 | 7.1 | **54.81** | 7.46875 |
The most interesting aspect in the context of the capybara-dpo dataset is the increased performance in MTBench Second Turn scores.
For the merge lovers, we also preference tuned Beagle14-7B with a mix of capybara-dpo and distilabel orca pairs using the same recipe as NeuralBeagle (see [ YALL - Yet Another LLM Leaderboard](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard) for reference):
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|------------------------------------------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[DistilabelBeagle14-7B](https://huggingface.co/dvilasuero/DistilabelBeagle14-7B)| 45.29| 76.92| 71.66| 48.78| 60.66|
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Shared by [optional]:** Argilla
- **Model type:** 7B chat model
- **Language(s) (NLP):** English
- **License:** Same as OpenHermes
- **Finetuned from model [optional]:** [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
|
LoneStriker/CapybaraHermes-2.5-Mistral-7B-5.0bpw-h6-exl2
|
LoneStriker
| 2024-02-01T08:02:06Z | 6 | 0 |
trl
|
[
"trl",
"safetensors",
"mistral",
"distilabel",
"dpo",
"rlaif",
"rlhf",
"en",
"dataset:argilla/dpo-mix-7k",
"license:apache-2.0",
"region:us"
] | null | 2024-02-01T07:59:59Z |
---
library_name: trl
license: apache-2.0
datasets:
- argilla/dpo-mix-7k
language:
- en
tags:
- distilabel
- dpo
- rlaif
- rlhf
---
# CapybaraHermes-2.5-Mistral-7B
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60420dccc15e823a685f2b03/Vmr0FtTvnny6Snm-UDM_n.png">
</div>
<p align="center">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
This model is the launching partner of the [capybara-dpo dataset](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-9k-binarized) build with ⚗️ distilabel. It's a preference tuned [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
CapybaraHermes has been preference tuned with LoRA and TRL for 3 epochs using argilla's [dpo mix 7k](https://huggingface.co/datasets/argilla/dpo-mix-7k).
To test the impact on multi-turn performance we have used MTBench. We also include the Nous Benchmark results and Mistral-7B-Instruct-v0.2 for reference as it's a strong 7B model on MTBench:
| Model | AGIEval | GPT4All | TruthfulQA | Bigbench | MTBench First Turn | MTBench Second Turn | Nous avg. | MTBench avg. |
|-----------------------------------|---------|---------|------------|----------|------------|-------------|-----------|--------------|
| argilla/CapybaraHermes-2.5-Mistral-7B | **43.8** | **73.35** | 57.07 | **42.44** | 8.24375 | **7.5625** | 54.16 | **7.903125** |
| teknium/OpenHermes-2.5-Mistral-7B | 42.75 | 72.99 | 52.99 | 40.94 | **8.25** | 7.2875 | 52.42 | 7.76875 |
| Mistral-7B-Instruct-v0.2 | 38.5 | 71.64 | **66.82** | 42.29 | 7.8375 | 7.1 | **54.81** | 7.46875 |
The most interesting aspect in the context of the capybara-dpo dataset is the increased performance in MTBench Second Turn scores.
For the merge lovers, we also preference tuned Beagle14-7B with a mix of capybara-dpo and distilabel orca pairs using the same recipe as NeuralBeagle (see [ YALL - Yet Another LLM Leaderboard](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard) for reference):
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|------------------------------------------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[DistilabelBeagle14-7B](https://huggingface.co/dvilasuero/DistilabelBeagle14-7B)| 45.29| 76.92| 71.66| 48.78| 60.66|
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Shared by [optional]:** Argilla
- **Model type:** 7B chat model
- **Language(s) (NLP):** English
- **License:** Same as OpenHermes
- **Finetuned from model [optional]:** [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
|
LoneStriker/CapybaraHermes-2.5-Mistral-7B-4.0bpw-h6-exl2
|
LoneStriker
| 2024-02-01T07:59:56Z | 8 | 1 |
trl
|
[
"trl",
"safetensors",
"mistral",
"distilabel",
"dpo",
"rlaif",
"rlhf",
"en",
"dataset:argilla/dpo-mix-7k",
"license:apache-2.0",
"region:us"
] | null | 2024-02-01T07:58:10Z |
---
library_name: trl
license: apache-2.0
datasets:
- argilla/dpo-mix-7k
language:
- en
tags:
- distilabel
- dpo
- rlaif
- rlhf
---
# CapybaraHermes-2.5-Mistral-7B
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60420dccc15e823a685f2b03/Vmr0FtTvnny6Snm-UDM_n.png">
</div>
<p align="center">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
This model is the launching partner of the [capybara-dpo dataset](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-9k-binarized) build with ⚗️ distilabel. It's a preference tuned [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
CapybaraHermes has been preference tuned with LoRA and TRL for 3 epochs using argilla's [dpo mix 7k](https://huggingface.co/datasets/argilla/dpo-mix-7k).
To test the impact on multi-turn performance we have used MTBench. We also include the Nous Benchmark results and Mistral-7B-Instruct-v0.2 for reference as it's a strong 7B model on MTBench:
| Model | AGIEval | GPT4All | TruthfulQA | Bigbench | MTBench First Turn | MTBench Second Turn | Nous avg. | MTBench avg. |
|-----------------------------------|---------|---------|------------|----------|------------|-------------|-----------|--------------|
| argilla/CapybaraHermes-2.5-Mistral-7B | **43.8** | **73.35** | 57.07 | **42.44** | 8.24375 | **7.5625** | 54.16 | **7.903125** |
| teknium/OpenHermes-2.5-Mistral-7B | 42.75 | 72.99 | 52.99 | 40.94 | **8.25** | 7.2875 | 52.42 | 7.76875 |
| Mistral-7B-Instruct-v0.2 | 38.5 | 71.64 | **66.82** | 42.29 | 7.8375 | 7.1 | **54.81** | 7.46875 |
The most interesting aspect in the context of the capybara-dpo dataset is the increased performance in MTBench Second Turn scores.
For the merge lovers, we also preference tuned Beagle14-7B with a mix of capybara-dpo and distilabel orca pairs using the same recipe as NeuralBeagle (see [ YALL - Yet Another LLM Leaderboard](https://huggingface.co/spaces/mlabonne/Yet_Another_LLM_Leaderboard) for reference):
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|------------------------------------------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[DistilabelBeagle14-7B](https://huggingface.co/dvilasuero/DistilabelBeagle14-7B)| 45.29| 76.92| 71.66| 48.78| 60.66|
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Shared by [optional]:** Argilla
- **Model type:** 7B chat model
- **Language(s) (NLP):** English
- **License:** Same as OpenHermes
- **Finetuned from model [optional]:** [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
|
franklee1015/ppo-LunarLander-v2
|
franklee1015
| 2024-02-01T07:58:04Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-01-29T03:40:37Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 298.43 +/- 12.85
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
mkdir700/v3-starcoderbase1b-personal-copilot-A100-40GB-colab
|
mkdir700
| 2024-02-01T07:53:07Z | 184 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt_bigcode",
"text-generation",
"generated_from_trainer",
"base_model:bigcode/starcoderbase-1b",
"base_model:finetune:bigcode/starcoderbase-1b",
"license:bigcode-openrail-m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T06:24:51Z |
---
license: bigcode-openrail-m
tags:
- generated_from_trainer
base_model: bigcode/starcoderbase-1b
model-index:
- name: v3-starcoderbase1b-personal-copilot-A100-40GB-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# v3-starcoderbase1b-personal-copilot-A100-40GB-colab
This model is a fine-tuned version of [bigcode/starcoderbase-1b](https://huggingface.co/bigcode/starcoderbase-1b) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 30
- training_steps: 2000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0 | 0.05 | 100 | nan |
| 0.0 | 0.1 | 200 | nan |
| 0.0 | 0.15 | 300 | nan |
| 0.0 | 0.2 | 400 | nan |
| 0.0 | 0.25 | 500 | nan |
| 0.0 | 0.3 | 600 | nan |
| 0.0 | 0.35 | 700 | nan |
| 0.0 | 0.4 | 800 | nan |
| 0.0 | 0.45 | 900 | nan |
| 0.0 | 0.5 | 1000 | nan |
| 0.0 | 0.55 | 1100 | nan |
| 0.0 | 0.6 | 1200 | nan |
| 0.0 | 0.65 | 1300 | nan |
| 0.0 | 0.7 | 1400 | nan |
| 0.0 | 0.75 | 1500 | nan |
| 0.0 | 0.8 | 1600 | nan |
| 0.0 | 0.85 | 1700 | nan |
| 0.0 | 0.9 | 1800 | nan |
| 0.0 | 0.95 | 1900 | nan |
| 0.0 | 1.0 | 2000 | nan |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
JVictor-CC/DeepSeek5.7b-mqa-base-finetune
|
JVictor-CC
| 2024-02-01T07:45:35Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:deepseek-ai/deepseek-coder-5.7bmqa-base",
"base_model:adapter:deepseek-ai/deepseek-coder-5.7bmqa-base",
"region:us"
] | null | 2024-02-01T07:45:30Z |
---
library_name: peft
base_model: deepseek-ai/deepseek-coder-5.7bmqa-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.1
|
checkiejan/phi1_5-marking-test-ia3-full
|
checkiejan
| 2024-02-01T07:44:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-01T07:42:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
THUDM/LongAlign-7B-64k-base
|
THUDM
| 2024-02-01T07:31:05Z | 84 | 4 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"Long Context",
"en",
"zh",
"arxiv:2401.18058",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-29T13:37:12Z |
---
language:
- en
- zh
library_name: transformers
tags:
- Long Context
- llama
license: apache-2.0
---
# LongAlign-7B-64k-base
<p align="center">
🤗 <a href="https://huggingface.co/datasets/THUDM/LongAlign-10k" target="_blank">[LongAlign Dataset] </a> • 💻 <a href="https://github.com/THUDM/LongAlign" target="_blank">[Github Repo]</a> • 📃 <a href="https://arxiv.org/abs/2401.18058" target="_blank">[LongAlign Paper]</a>
</p>
**LongAlign** is the first full recipe for LLM alignment on long context. We propose the **LongAlign-10k** dataset, containing 10,000 long instruction data of 8k-64k in length. We investigate on trianing strategies, namely **packing (with loss weighting) and sorted batching**, which are all implemented in our code. For real-world long context evaluation, we introduce **LongBench-Chat** that evaluate the instruction-following capability on queries of 10k-100k length.
## All Models
We open-sourced the following list of models:
|Model|Huggingface Repo|Description|
|---|---|---|
|**LongAlign-6B-64k-base**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-6B-64k-base) | **ChatGLM3-6B** with an extended 64k context window |
|**LongAlign-6B-64k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-6B-64k) | Chat model by LongAlign training on LongAlign-6B-64k-base|
|**LongAlign-7B-64k-base**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-7B-64k-base) | **Llama-2-7B** with an extended 64k context window |
|**LongAlign-7B-64k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-7B-64k) | Chat model by LongAlign training on LongAlign-7B-64k-base|
|**LongAlign-13B-64k-base**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-13B-64k-base) | **Llama-2-13B** with an extended 64k context window |
|**LongAlign-13B-64k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/LongAlign-13B-64k) | Chat model by LongAlign training on LongAlign-13B-64k-base|
|**ChatGLM3-6B-128k**| [🤗 Huggingface Repo](https://huggingface.co/THUDM/chatglm3-6b-128k) | **ChatGLM3-6B** with a 128k context window|

## Model usage
Chat prompt template for LongAlign-6B-64k:
```text
[Round 1]
问:Hi!
答:Hello! What can I assist you today?
[Round 2]
问:What should I do if I can't sleep at night?
答:
```
Chat prompt template for LongAlign-7B-64k and LongAlign-13B-64k:
```text
[INST]Hi![/INST]Hello! What can I assist you today?
[INST]What should I do if I can't sleep at night?[/INST]
```
ChatGLM3-6B-128k uses the same prompt template as [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b).
A simple demo for deployment of the model:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("THUDM/LongAlign-6B-64k", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("THUDM/LongAlign-6B-64k", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
model = model.eval()
query = open("assets/paper.txt").read() + "\n\nPlease summarize the paper."
response, history = model.chat(tokenizer, query, history=[], max_new_tokens=512, temperature=1)
print(response)
```
## Citation
If you find our work useful, please consider citing LongAlign:
```
```
|
LoneStriker/DistilabelBeagle14-7B-6.0bpw-h6-exl2
|
LoneStriker
| 2024-02-01T07:30:51Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"dpo",
"rlhf",
"rlaif",
"distilabel",
"conversational",
"arxiv:1910.09700",
"base_model:mlabonne/Beagle14-7B",
"base_model:finetune:mlabonne/Beagle14-7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T07:28:22Z |
---
license: cc-by-nc-4.0
base_model: mlabonne/Beagle14-7B
tags:
- merge
- mergekit
- lazymergekit
- dpo
- rlhf
- rlaif
- distilabel
---
# Model Card for Model ID
This is a preference tuned version of `mlabonne/Beagle14-7B` using a mix of Argilla's orca pairs and a new upcoming multi-turn dpo dataset.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Argilla
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** English
- **License:** cc-by-nc-4.0
- **Finetuned from model [optional]:** mlabonne/Beagle14-7B
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
k-seungri/k_whisper_output
|
k-seungri
| 2024-02-01T07:26:12Z | 69 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ko",
"dataset:k-seungri/k_whisper_dataset",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-01-30T05:39:14Z |
---
language:
- ko
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- k-seungri/k_whisper_dataset
base_model: openai/whisper-base
model-index:
- name: k-seungri/k_whisper_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# k-seungri/k_whisper_model
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the k_whisper_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6590
- Cer: 53.0478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.0002 | 142.86 | 1000 | 0.5964 | 16.9687 |
| 0.0001 | 285.71 | 2000 | 0.6299 | 16.6392 |
| 0.0001 | 428.57 | 3000 | 0.6459 | 17.1334 |
| 0.0001 | 571.43 | 4000 | 0.6590 | 53.0478 |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
amornlnw7/sd-webui-controlnet
|
amornlnw7
| 2024-02-01T07:20:53Z | 0 | 0 | null |
[
"region:us"
] | null | 2024-02-01T07:07:37Z |
# ControlNet for Stable Diffusion WebUI
The WebUI extension for ControlNet and other injection-based SD controls.
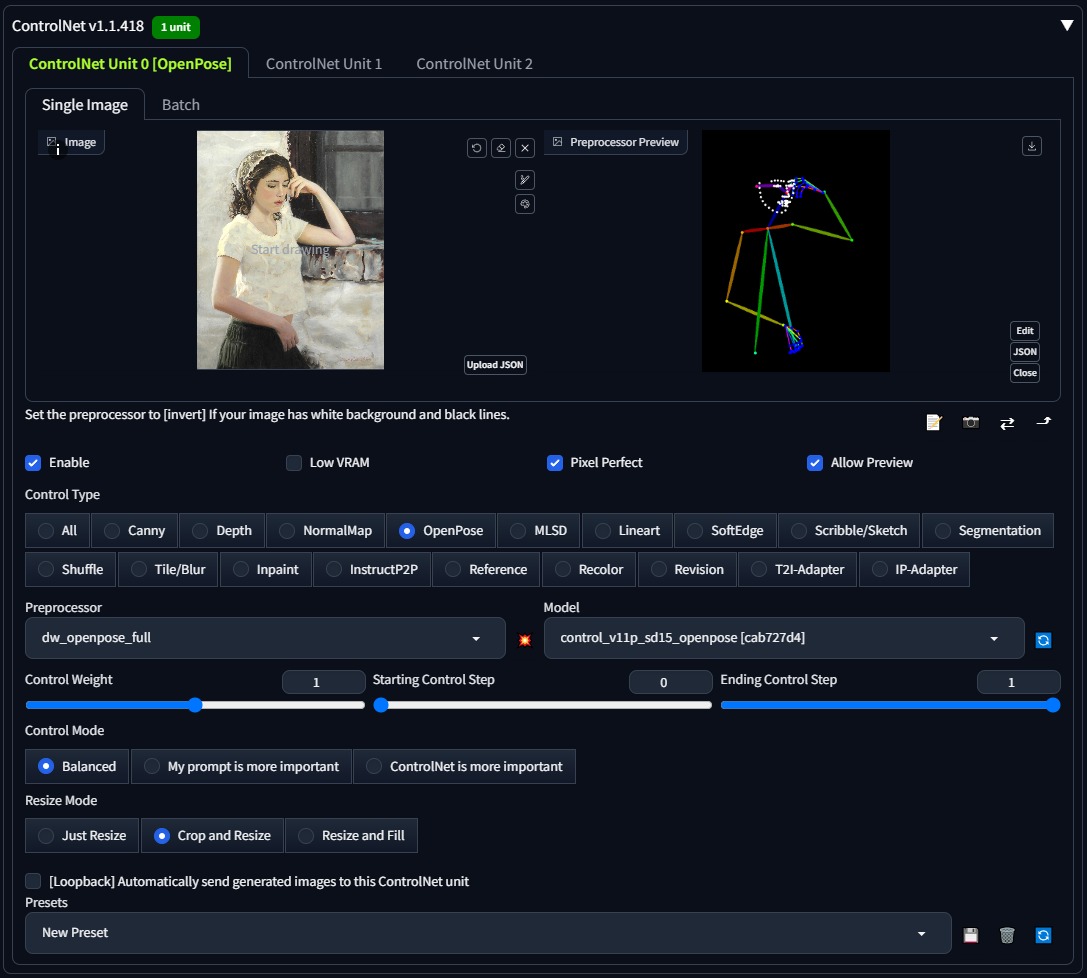
This extension is for AUTOMATIC1111's [Stable Diffusion web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui), allows the Web UI to add [ControlNet](https://github.com/lllyasviel/ControlNet) to the original Stable Diffusion model to generate images. The addition is on-the-fly, the merging is not required.
# Installation
1. Open "Extensions" tab.
2. Open "Install from URL" tab in the tab.
3. Enter `https://github.com/Mikubill/sd-webui-controlnet.git` to "URL for extension's git repository".
4. Press "Install" button.
5. Wait for 5 seconds, and you will see the message "Installed into stable-diffusion-webui\extensions\sd-webui-controlnet. Use Installed tab to restart".
6. Go to "Installed" tab, click "Check for updates", and then click "Apply and restart UI". (The next time you can also use these buttons to update ControlNet.)
7. Completely restart A1111 webui including your terminal. (If you do not know what is a "terminal", you can reboot your computer to achieve the same effect.)
8. Download models (see below).
9. After you put models in the correct folder, you may need to refresh to see the models. The refresh button is right to your "Model" dropdown.
# Download Models
Right now all the 14 models of ControlNet 1.1 are in the beta test.
Download the models from ControlNet 1.1: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
You need to download model files ending with ".pth" .
Put models in your "stable-diffusion-webui\extensions\sd-webui-controlnet\models". You only need to download "pth" files.
Do not right-click the filenames in HuggingFace website to download. Some users right-clicked those HuggingFace HTML websites and saved those HTML pages as PTH/YAML files. They are not downloading correct files. Instead, please click the small download arrow “↓” icon in HuggingFace to download.
# Download Models for SDXL
See instructions [here](https://github.com/Mikubill/sd-webui-controlnet/discussions/2039).
# Features in ControlNet 1.1
### Perfect Support for All ControlNet 1.0/1.1 and T2I Adapter Models.
Now we have perfect support all available models and preprocessors, including perfect support for T2I style adapter and ControlNet 1.1 Shuffle. (Make sure that your YAML file names and model file names are same, see also YAML files in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".)
### Perfect Support for A1111 High-Res. Fix
Now if you turn on High-Res Fix in A1111, each controlnet will output two different control images: a small one and a large one. The small one is for your basic generating, and the big one is for your High-Res Fix generating. The two control images are computed by a smart algorithm called "super high-quality control image resampling". This is turned on by default, and you do not need to change any setting.
### Perfect Support for All A1111 Img2Img or Inpaint Settings and All Mask Types
Now ControlNet is extensively tested with A1111's different types of masks, including "Inpaint masked"/"Inpaint not masked", and "Whole picture"/"Only masked", and "Only masked padding"&"Mask blur". The resizing perfectly matches A1111's "Just resize"/"Crop and resize"/"Resize and fill". This means you can use ControlNet in nearly everywhere in your A1111 UI without difficulty!
### The New "Pixel-Perfect" Mode
Now if you turn on pixel-perfect mode, you do not need to set preprocessor (annotator) resolutions manually. The ControlNet will automatically compute the best annotator resolution for you so that each pixel perfectly matches Stable Diffusion.
### User-Friendly GUI and Preprocessor Preview
We reorganized some previously confusing UI like "canvas width/height for new canvas" and it is in the 📝 button now. Now the preview GUI is controlled by the "allow preview" option and the trigger button 💥. The preview image size is better than before, and you do not need to scroll up and down - your a1111 GUI will not be messed up anymore!
### Support for Almost All Upscaling Scripts
Now ControlNet 1.1 can support almost all Upscaling/Tile methods. ControlNet 1.1 support the script "Ultimate SD upscale" and almost all other tile-based extensions. Please do not confuse ["Ultimate SD upscale"](https://github.com/Coyote-A/ultimate-upscale-for-automatic1111) with "SD upscale" - they are different scripts. Note that the most recommended upscaling method is ["Tiled VAE/Diffusion"](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111) but we test as many methods/extensions as possible. Note that "SD upscale" is supported since 1.1.117, and if you use it, you need to leave all ControlNet images as blank (We do not recommend "SD upscale" since it is somewhat buggy and cannot be maintained - use the "Ultimate SD upscale" instead).
### More Control Modes (previously called Guess Mode)
We have fixed many bugs in previous 1.0’s Guess Mode and now it is called Control Mode

Now you can control which aspect is more important (your prompt or your ControlNet):
* "Balanced": ControlNet on both sides of CFG scale, same as turning off "Guess Mode" in ControlNet 1.0
* "My prompt is more important": ControlNet on both sides of CFG scale, with progressively reduced SD U-Net injections (layer_weight*=0.825**I, where 0<=I <13, and the 13 means ControlNet injected SD 13 times). In this way, you can make sure that your prompts are perfectly displayed in your generated images.
* "ControlNet is more important": ControlNet only on the Conditional Side of CFG scale (the cond in A1111's batch-cond-uncond). This means the ControlNet will be X times stronger if your cfg-scale is X. For example, if your cfg-scale is 7, then ControlNet is 7 times stronger. Note that here the X times stronger is different from "Control Weights" since your weights are not modified. This "stronger" effect usually has less artifact and give ControlNet more room to guess what is missing from your prompts (and in the previous 1.0, it is called "Guess Mode").
<table width="100%">
<tr>
<td width="25%" style="text-align: center">Input (depth+canny+hed)</td>
<td width="25%" style="text-align: center">"Balanced"</td>
<td width="25%" style="text-align: center">"My prompt is more important"</td>
<td width="25%" style="text-align: center">"ControlNet is more important"</td>
</tr>
<tr>
<td width="25%" style="text-align: center"><img src="samples/cm1.png"></td>
<td width="25%" style="text-align: center"><img src="samples/cm2.png"></td>
<td width="25%" style="text-align: center"><img src="samples/cm3.png"></td>
<td width="25%" style="text-align: center"><img src="samples/cm4.png"></td>
</tr>
</table>
### Reference-Only Control
Now we have a `reference-only` preprocessor that does not require any control models. It can guide the diffusion directly using images as references.
(Prompt "a dog running on grassland, best quality, ...")

This method is similar to inpaint-based reference but it does not make your image disordered.
Many professional A1111 users know a trick to diffuse image with references by inpaint. For example, if you have a 512x512 image of a dog, and want to generate another 512x512 image with the same dog, some users will connect the 512x512 dog image and a 512x512 blank image into a 1024x512 image, send to inpaint, and mask out the blank 512x512 part to diffuse a dog with similar appearance. However, that method is usually not very satisfying since images are connected and many distortions will appear.
This `reference-only` ControlNet can directly link the attention layers of your SD to any independent images, so that your SD will read arbitary images for reference. You need at least ControlNet 1.1.153 to use it.
To use, just select `reference-only` as preprocessor and put an image. Your SD will just use the image as reference.
*Note that this method is as "non-opinioned" as possible. It only contains very basic connection codes, without any personal preferences, to connect the attention layers with your reference images. However, even if we tried best to not include any opinioned codes, we still need to write some subjective implementations to deal with weighting, cfg-scale, etc - tech report is on the way.*
More examples [here](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236).
# Technical Documents
See also the documents of ControlNet 1.1:
https://github.com/lllyasviel/ControlNet-v1-1-nightly#model-specification
# Default Setting
This is my setting. If you run into any problem, you can use this setting as a sanity check
# Use Previous Models
### Use ControlNet 1.0 Models
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
You can still use all previous models in the previous ControlNet 1.0. Now, the previous "depth" is now called "depth_midas", the previous "normal" is called "normal_midas", the previous "hed" is called "softedge_hed". And starting from 1.1, all line maps, edge maps, lineart maps, boundary maps will have black background and white lines.
### Use T2I-Adapter Models
(From TencentARC/T2I-Adapter)
To use T2I-Adapter models:
1. Download files from https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
2. Put them in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".
3. Make sure that the file names of pth files and yaml files are consistent.
*Note that "CoAdapter" is not implemented yet.*
# Gallery
The below results are from ControlNet 1.0.
| Source | Input | Output |
|:-------------------------:|:-------------------------:|:-------------------------:|
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-source.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-gen.png?raw=true"> |
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_input.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_canny.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro-out.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_hed.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_gen.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-pose.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-gen.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-src.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-dep.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-out.png?raw=true"> |
The below examples are from T2I-Adapter.
From `t2iadapter_color_sd14v1.pth` :
| Source | Input | Output |
|:-------------------------:|:-------------------------:|:-------------------------:|
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947435-1164e7d8-d857-42f9-ab10-2d4a4b25f33a.png"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947557-5520d5f8-88b4-474d-a576-5c9cd3acac3a.png"> |
From `t2iadapter_style_sd14v1.pth` :
| Source | Input | Output |
|:-------------------------:|:-------------------------:|:-------------------------:|
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | (clip, non-image) | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222965711-7b884c9e-7095-45cb-a91c-e50d296ba3a2.png"> |
# Minimum Requirements
* (Windows) (NVIDIA: Ampere) 4gb - with `--xformers` enabled, and `Low VRAM` mode ticked in the UI, goes up to 768x832
# Multi-ControlNet
This option allows multiple ControlNet inputs for a single generation. To enable this option, change `Multi ControlNet: Max models amount (requires restart)` in the settings. Note that you will need to restart the WebUI for changes to take effect.
<table width="100%">
<tr>
<td width="25%" style="text-align: center">Source A</td>
<td width="25%" style="text-align: center">Source B</td>
<td width="25%" style="text-align: center">Output</td>
</tr>
<tr>
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448620-cd3ede92-8d3f-43d5-b771-32dd8417618f.png"></td>
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448619-beed9bdb-f6bb-41c2-a7df-aa3ef1f653c5.png"></td>
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448613-c99a9e04-0450-40fd-bc73-a9122cefaa2c.png"></td>
</tr>
</table>
# Control Weight/Start/End
Weight is the weight of the controlnet "influence". It's analogous to prompt attention/emphasis. E.g. (myprompt: 1.2). Technically, it's the factor by which to multiply the ControlNet outputs before merging them with original SD Unet.
Guidance Start/End is the percentage of total steps the controlnet applies (guidance strength = guidance end). It's analogous to prompt editing/shifting. E.g. \[myprompt::0.8\] (It applies from the beginning until 80% of total steps)
# Batch Mode
Put any unit into batch mode to activate batch mode for all units. Specify a batch directory for each unit, or use the new textbox in the img2img batch tab as a fallback. Although the textbox is located in the img2img batch tab, you can use it to generate images in the txt2img tab as well.
Note that this feature is only available in the gradio user interface. Call the APIs as many times as you want for custom batch scheduling.
# API and Script Access
This extension can accept txt2img or img2img tasks via API or external extension call. Note that you may need to enable `Allow other scripts to control this extension` in settings for external calls.
To use the API: start WebUI with argument `--api` and go to `http://webui-address/docs` for documents or checkout [examples](https://github.com/Mikubill/sd-webui-controlnet/blob/main/example/api_txt2img.ipynb).
To use external call: Checkout [Wiki](https://github.com/Mikubill/sd-webui-controlnet/wiki/API)
# Command Line Arguments
This extension adds these command line arguments to the webui:
```
--controlnet-dir <path to directory with controlnet models> ADD a controlnet models directory
--controlnet-annotator-models-path <path to directory with annotator model directories> SET the directory for annotator models
--no-half-controlnet load controlnet models in full precision
--controlnet-preprocessor-cache-size Cache size for controlnet preprocessor results
--controlnet-loglevel Log level for the controlnet extension
```
# MacOS Support
Tested with pytorch nightly: https://github.com/Mikubill/sd-webui-controlnet/pull/143#issuecomment-1435058285
To use this extension with mps and normal pytorch, currently you may need to start WebUI with `--no-half`.
# Archive of Deprecated Versions
The previous version (sd-webui-controlnet 1.0) is archived in
https://github.com/lllyasviel/webui-controlnet-v1-archived
Using this version is not a temporary stop of updates. You will stop all updates forever.
Please consider this version if you work with professional studios that requires 100% reproducing of all previous results pixel by pixel.
# Thanks
This implementation is inspired by kohya-ss/sd-webui-additional-networks
|
arpanl/Model2
|
arpanl
| 2024-02-01T07:18:04Z | 177 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-02-01T07:13:25Z |
---
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: Model2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Model2
This model was trained from scratch on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
shenwzh3/alpha-umi-caller-13b
|
shenwzh3
| 2024-02-01T07:14:05Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-31T04:47:28Z |
---
license: apache-2.0
language:
- en
library_name: transformers
---
## alpha-umi-caller-13b
## Introduction
alpha-umi-caller-13b is the 13b version caller model of the alpha-UMi multi-LLM tool learning agent framework proposed by *''Small LLMs Are Weak Tool Learners: A Multi-LLM Agent''*.
It can collaborate with alpha-umi-planner(7b/13b) and alpha-umi-summarizer(7b/13b) to form a multi-LLM agent system.
So far alpha-umi-caller-13b is applicable for ToolBench, we will soon release more versions that applicable for more tasks.
For the utility, please refer to the github repo of the paper.
|
Vishal24/BCG_adapter_v3
|
Vishal24
| 2024-02-01T07:12:45Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-01-30T10:42:50Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2.dev0
|
lokeshk/popular-indie-leaders
|
lokeshk
| 2024-02-01T07:06:10Z | 176 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-02-01T06:34:11Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: popular-indie-leaders
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.25
---
# popular-indie-leaders
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### Amit_Shah

#### Narendra_Modi

#### Rajnath_Singh

#### S_Jaishankar

#### Yogi_Adityanath

|
Jaehyeon222/ME-MOE-7Bx2_test
|
Jaehyeon222
| 2024-02-01T06:59:14Z | 59 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mixtral",
"text-generation",
"Mixture of experts",
"conversational",
"ko",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-29T04:04:58Z |
---
license: cc-by-nc-nd-4.0
language:
- ko
pipeline_tag: text-generation
tags:
- Mixture of experts
---
Model Card for ME-MOE-7Bx2_test
Developed by : 메가스터디교육, 프리딕션, 마이스
Base Model : megastudyedu/ME-dpo-7B-v1.0
Expert Models : megastudyedu/ME-dpo-7B-v1.1, macadeliccc/WestLake-7B-v2-laser-truthy-dpo
Method : merge-kit을 활용하여 MOE를 구현했습니다.
-----------------------
ME-7B-v1.0 -> ME-dpo-7B-v1.0, ME-7B-v1.1 -> ME-dpo-7B-v1.1 로 수정했습니다.
|
LanguageBind/LanguageBind_Video_V1.5_FT
|
LanguageBind
| 2024-02-01T06:58:17Z | 1,905 | 4 |
transformers
|
[
"transformers",
"pytorch",
"LanguageBindVideo",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2023-11-26T13:35:39Z |
---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
LanguageBind/LanguageBind_Video
|
LanguageBind
| 2024-02-01T06:57:36Z | 364 | 2 |
transformers
|
[
"transformers",
"pytorch",
"LanguageBindVideo",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2023-10-06T09:07:15Z |
---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
LanguageBind/LanguageBind_Depth
|
LanguageBind
| 2024-02-01T06:57:09Z | 244 | 0 |
transformers
|
[
"transformers",
"pytorch",
"LanguageBindDepth",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2023-10-06T09:07:38Z |
---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
LanguageBind/LanguageBind_Audio_FT
|
LanguageBind
| 2024-02-01T06:56:41Z | 5,296 | 1 |
transformers
|
[
"transformers",
"pytorch",
"LanguageBindAudio",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2023-11-26T07:37:41Z |
---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
dong9ry/nuclear-v1.0b
|
dong9ry
| 2024-02-01T06:56:38Z | 89 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-01T06:54:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: nuclear-v1.0b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nuclear-v1.0b
This model is a fine-tuned version of [EleutherAI/polyglot-ko-1.3b](https://huggingface.co/EleutherAI/polyglot-ko-1.3b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.29.2
- Pytorch 2.2.0+cu121
- Datasets 2.16.1
- Tokenizers 0.13.2
|
LanguageBind/LanguageBind_Video_Huge_V1.5_FT
|
LanguageBind
| 2024-02-01T06:56:30Z | 76 | 4 |
transformers
|
[
"transformers",
"pytorch",
"LanguageBindVideo",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2023-12-15T01:43:47Z |
---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
LanguageBind/Video-LLaVA-Pretrain-7B
|
LanguageBind
| 2024-02-01T06:52:24Z | 33 | 10 |
transformers
|
[
"transformers",
"llava",
"text-generation",
"arxiv:2311.10122",
"arxiv:2310.01852",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-17T05:07:08Z |
---
license: apache-2.0
---
<p align="center">
<img src="https://z1.ax1x.com/2023/11/07/pil4sqH.png" width="150" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/abs/2311.10122">Video-LLaVA: Learning United Visual Representation by Alignment Before Projection</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.17]** 🔥🔥🔥 Our [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) has been accepted at ICLR 2024!
* **[2024.01.16]** 🔥🔥🔥 We reorganize the code and support LoRA fine-tuning, checking [finetune_lora.sh](scripts/v1_5/finetune_lora.sh).
* **[2023.11.30]** 🤝 Thanks to the generous contributions of the community, the [OpenXLab's demo](https://openxlab.org.cn/apps/detail/houshaowei/Video-LLaVA) is now accessible.
* **[2023.11.23]** We are training a new and powerful model.
* **[2023.11.21]** 🤝 Check out the [replicate demo](https://replicate.com/nateraw/video-llava), created by [@nateraw](https://github.com/nateraw), who has generously supported our research!
* **[2023.11.20]** 🤗 [Hugging Face demo](https://huggingface.co/spaces/LanguageBind/Video-LLaVA) and **all codes & datasets** are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
Video-LLaVA exhibits remarkable interactive capabilities between images and videos, despite the absence of image-video pairs in the dataset.
### 💡 Simple baseline, learning united visual representation by alignment before projection
- With **the binding of unified visual representations to the language feature space**, we enable an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
### 🔥 High performance, complementary learning with video and image
- Extensive experiments demonstrate **the complementarity of modalities**, showcasing significant superiority when compared to models specifically designed for either images or videos.
## 🤗 Demo
### Gradio Web UI
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by Video-LLaVA. We also provide [online demo](https://huggingface.co/spaces/LanguageBind/Video-LLaVA) in Huggingface Spaces.
```bash
python -m videollava.serve.gradio_web_server
```
### CLI Inference
```bash
python -m videollava.serve.cli --model-path "LanguageBind/Video-LLaVA-7B" --file "path/to/your/video.mp4" --load-4bit
```
```bash
python -m videollava.serve.cli --model-path "LanguageBind/Video-LLaVA-7B" --file "path/to/your/image.jpg" --load-4bit
```
## 🛠️ Requirements and Installation
* Python >= 3.10
* Pytorch == 2.0.1
* CUDA Version >= 11.7
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/Video-LLaVA
cd Video-LLaVA
conda create -n videollava python=3.10 -y
conda activate videollava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
pip install decord opencv-python git+https://github.com/facebookresearch/pytorchvideo.git@28fe037d212663c6a24f373b94cc5d478c8c1a1d
```
## 🤖 API
**We open source all codes.** If you want to load the model (e.g. ```LanguageBind/Video-LLaVA-7B```) on local, you can use the following code snippets.
### Inference for image
```python
import torch
from videollava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from videollava.conversation import conv_templates, SeparatorStyle
from videollava.model.builder import load_pretrained_model
from videollava.utils import disable_torch_init
from videollava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'videollava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/Video-LLaVA-7B'
cache_dir = 'cache_dir'
device = 'cuda'
load_4bit, load_8bit = True, False
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, _ = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device, cache_dir=cache_dir)
image_processor = processor['image']
conv_mode = "llava_v1"
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values']
if type(image_tensor) is list:
tensor = [image.to(model.device, dtype=torch.float16) for image in image_tensor]
else:
tensor = image_tensor.to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip()
print(outputs)
if __name__ == '__main__':
main()
```
### Inference for video
```python
import torch
from videollava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from videollava.conversation import conv_templates, SeparatorStyle
from videollava.model.builder import load_pretrained_model
from videollava.utils import disable_torch_init
from videollava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
video = 'videollava/serve/examples/sample_demo_1.mp4'
inp = 'Why is this video funny?'
model_path = 'LanguageBind/Video-LLaVA-7B'
cache_dir = 'cache_dir'
device = 'cuda'
load_4bit, load_8bit = True, False
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, _ = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device, cache_dir=cache_dir)
video_processor = processor['video']
conv_mode = "llava_v1"
conv = conv_templates[conv_mode].copy()
roles = conv.roles
video_tensor = video_processor(video, return_tensors='pt')['pixel_values']
if type(video_tensor) is list:
tensor = [video.to(model.device, dtype=torch.float16) for video in video_tensor]
else:
tensor = video_tensor.to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = ' '.join([DEFAULT_IMAGE_TOKEN] * model.get_video_tower().config.num_frames) + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=tensor,
do_sample=True,
temperature=0.1,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip()
print(outputs)
if __name__ == '__main__':
main()
```
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [LLaVA](https://github.com/haotian-liu/LLaVA) The codebase we built upon and it is an efficient large language and vision assistant.
* [Video-ChatGPT](https://github.com/mbzuai-oryx/Video-ChatGPT) Great job contributing the evaluation code and dataset.
## 🙌 Related Projects
* [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) An open source five modalities language-based retrieval framework.
* [Chat-UniVi](https://github.com/PKU-YuanGroup/Chat-UniVi) This framework empowers the model to efficiently utilize a limited number of visual tokens.
## 🔒 License
* The majority of this project is released under the Apache 2.0 license as found in the [LICENSE](https://github.com/PKU-YuanGroup/Video-LLaVA/blob/main/LICENSE) file.
* The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
```
```BibTeX
@article{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Zhu, Bin and Lin, Bin and Ning, Munan and Yan, Yang and Cui, Jiaxi and Wang, HongFa and Pang, Yatian and Jiang, Wenhao and Zhang, Junwu and Li, Zongwei and others},
journal={arXiv preprint arXiv:2310.01852},
year={2023}
}
```
<!---->
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/Video-LLaVA&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/Video-LLaVA/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/Video-LLaVA" />
</a>
|
JKuang96/pixelcopter_v2
|
JKuang96
| 2024-02-01T06:50:20Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-01T06:50:13Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: pixelcopter_v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 30.20 +/- 21.65
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
bachbouch/w-3-qlora
|
bachbouch
| 2024-02-01T06:39:33Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"mistral",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"region:us"
] | null | 2024-02-01T05:29:59Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-Instruct-v0.2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2.dev0
|
mkdir700/v2-starcoderbase1b-personal-copilot-A100-40GB-colab
|
mkdir700
| 2024-02-01T06:38:24Z | 95 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt_bigcode",
"text-generation",
"generated_from_trainer",
"base_model:bigcode/starcoderbase-1b",
"base_model:finetune:bigcode/starcoderbase-1b",
"license:bigcode-openrail-m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-27T01:37:56Z |
---
license: bigcode-openrail-m
tags:
- generated_from_trainer
base_model: bigcode/starcoderbase-1b
model-index:
- name: v2-starcoderbase1b-personal-copilot-A100-40GB-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# v2-starcoderbase1b-personal-copilot-A100-40GB-colab
This model is a fine-tuned version of [bigcode/starcoderbase-1b](https://huggingface.co/bigcode/starcoderbase-1b) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 30
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0 | 0.1 | 100 | nan |
| 0.0 | 0.2 | 200 | nan |
| 0.0 | 0.3 | 300 | nan |
| 0.0 | 0.4 | 400 | nan |
| 0.0 | 0.5 | 500 | nan |
| 0.0 | 0.6 | 600 | nan |
| 0.0 | 0.7 | 700 | nan |
| 0.0 | 0.8 | 800 | nan |
| 0.0 | 0.9 | 900 | nan |
| 0.0 | 1.0 | 1000 | nan |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
hangzou/distilroberta-base-finetuned-wikitext2
|
hangzou
| 2024-02-01T06:35:29Z | 193 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2024-02-01T06:30:59Z |
---
license: apache-2.0
base_model: distilroberta-base
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-wikitext2
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8828
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 301 | 1.9451 |
| 2.1463 | 2.0 | 602 | 1.9068 |
| 2.1463 | 3.0 | 903 | 1.9079 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
cchoi1022/librispeech-100h-supervised_not_mine
|
cchoi1022
| 2024-02-01T06:28:03Z | 118 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-02-01T06:22:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
cchoi1022/my-test-model
|
cchoi1022
| 2024-02-01T06:21:19Z | 119 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-02-01T06:19:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hui-1/speaker_recognition-campplus-zh-en-16k-base
|
Hui-1
| 2024-02-01T06:20:57Z | 0 | 0 | null |
[
"CAM++",
"3D-Speaker",
"Speaker Recognition & Verification",
"Chinese & English",
"zh",
"en",
"dataset:3D-Speaker",
"dataset:voxceleb",
"dataset:cnceleb",
"license:apache-2.0",
"region:us"
] | null | 2024-01-31T09:42:22Z |
---
language:
- zh
- en
tags:
- CAM++
- 3D-Speaker
- Speaker Recognition & Verification
- Chinese & English
license: apache-2.0
datasets:
- 3D-Speaker
- voxceleb
- cnceleb
metrics:
- EER
- minDCF
---
# CAM++: A Fast and Efficient Speaker Recognition Network
CAM++ is a fast and efficient network based on a densely-connected time delay neural network (D-TDNN). This repository provides tools for extracting speaker embeddings and performing speaker verification tasks with a pretrained CAM++ model. It has been trained on a large-scale training dataset, which includes Chinese and English corpora.
|
LanguageBind/MoE-LLaVA-Qwen-Pretrain
|
LanguageBind
| 2024-02-01T06:09:47Z | 18 | 1 |
transformers
|
[
"transformers",
"llava_qwen",
"text-generation",
"custom_code",
"arxiv:2401.15947",
"arxiv:2311.10122",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2024-01-31T11:32:52Z |
---
license: apache-2.0
---
<p align="center">
<img src="https://s11.ax1x.com/2023/12/28/piqvDMV.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/abs/2401.15947">MoE-LLaVA: Mixture of Experts for Large Vision-Language Models</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
<h5 align="center">
</h5>
## 📰 News
* **[2024.01.30]** The [paper](https://arxiv.org/abs/2401.15947) is released.
* **[2024.01.27]** 🤗[Hugging Face demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) and **all codes & datasets** are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
MoE-LLaVA shows excellent performance in multi-modal learning.
### 🔥 High performance, but with fewer parameters
- with just **3B sparsely activated parameters**, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmarks.
### 🚀 Simple baseline, learning multi-modal interactions with sparse pathways.
- With the addition of **a simple MoE tuning stage**, we can complete the training of MoE-LLaVA on **8 V100 GPUs** within 2 days.
## 🤗 Demo
### Gradio Web UI
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by MoE-LLaVA. We also provide [online demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) in Huggingface Spaces.
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e"
# use qwen
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e"
# use stablelm
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e"
```
### CLI Inference
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# use qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# use stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"
```
## 🐳 Model Zoo
| Model | LLM | Checkpoint | Avg | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MM-Bench| LLaVA-Bench-Wild | MM-Vet |
|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|
| MoE-LLaVA-1.6B×4-Top2 | 1.6B | [LanguageBind/MoE-LLaVA-StableLM-1.6B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-StableLM-1.6B-4e) | 60.0 | 76.0 | 60.4 | 37.2 | 62.6 | 47.8 | 84.3 | 59.4 | 85.9 | 26.1 |
| MoE-LLaVA-1.8B×4-Top2 | 1.8B | [LanguageBind/MoE-LLaVA-Qwen-1.8B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Qwen-1.8B-4e) | 60.2 | 76.2 | 61.5 | 32.6 | 63.1 | 48.0 | 87.0 | 59.6 | 88.7 | 25.3 |
| MoE-LLaVA-2.7B×4-Top2 | 2.7B | [LanguageBind/MoE-LLaVA-Phi2-2.7B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e) | 63.9 | 77.1 | 61.1 | 43.4 | 68.7 | 50.2 | 85.0 | 65.5 | 93.2 | 31.1 |
<!--
| LLaVA-1.5 | 7B | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 62.0 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 64.3 | 31.1 |
| LLaVA-1.5 | 13B | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 64.9 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 67.7 | 36.1 |
-->
## ⚙️ Requirements and Installation
* Python >= 3.10
* Pytorch == 2.0.1
* CUDA Version >= 11.7
* **Transformers == 4.36.2**
* **Tokenizers==0.15.1**
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
cd MoE-LLaVA
conda create -n moellava python=3.10 -y
conda activate moellava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
# Below are optional. For Qwen model.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# If the version of flash-attn is higher than 2.1.1, the following is not needed.
# pip install csrc/rotary
```
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN.md](docs/TRAIN.md) & [EVAL.md](docs/EVAL.md).
## 💡 Customizing your MoE-LLaVA
The instruction is in [CUSTOM.md](docs/CUSTOM.md).
## 😍 Visualization
The instruction is in [VISUALIZATION.md](docs/VISUALIZATION.md).
## 🤖 API
**We open source all codes.** If you want to load the model (e.g. ```LanguageBind/MoE-LLaVA```) on local, you can use the following code snippets.
**Using the following command to run the code.**
```bash
deepspeed predict.py
```
```python
import torch
from moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from moellava.conversation import conv_templates, SeparatorStyle
from moellava.model.builder import load_pretrained_model
from moellava.utils import disable_torch_init
from moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'moellava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e or LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
device = 'cuda'
load_4bit, load_8bit = False, False # FIXME: Deepspeed support 4bit or 8bit?
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)
image_processor = processor['image']
conv_mode = "phi" # qwen or stablelm
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(outputs)
if __name__ == '__main__':
main()
```
## 🙌 Related Projects
* [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) This framework empowers the model to efficiently utilize the united visual tokens.
* [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) An open source five modalities language-based retrieval framework.
## 👍 Acknowledgement
* [LLaVA](https://github.com/haotian-liu/LLaVA) The codebase we built upon and it is an efficient large language and vision assistant.
## 🔒 License
* The majority of this project is released under the Apache 2.0 license as found in the [LICENSE](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/LICENSE) file.
* The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{lin2024moellava,
title={MoE-LLaVA: Mixture of Experts for Large Vision-Language Models},
author={Bin Lin and Zhenyu Tang and Yang Ye and Jiaxi Cui and Bin Zhu and Peng Jin and Junwu Zhang and Munan Ning and Li Yuan},
year={2024},
eprint={2401.15947},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```BibTeX
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/MoE-LLaVA&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/MoE-LLaVA/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/MoE-LLaVA" />
</a>
|
LanguageBind/MoE-LLaVA-Phi2-384-Pretrain
|
LanguageBind
| 2024-02-01T06:09:39Z | 14 | 0 |
transformers
|
[
"transformers",
"llava_phi",
"text-generation",
"custom_code",
"arxiv:2401.15947",
"arxiv:2311.10122",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-31T11:34:09Z |
---
license: apache-2.0
---
<p align="center">
<img src="https://s11.ax1x.com/2023/12/28/piqvDMV.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/abs/2401.15947">MoE-LLaVA: Mixture of Experts for Large Vision-Language Models</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
<h5 align="center">
</h5>
## 📰 News
* **[2024.01.30]** The [paper](https://arxiv.org/abs/2401.15947) is released.
* **[2024.01.27]** 🤗[Hugging Face demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) and **all codes & datasets** are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
MoE-LLaVA shows excellent performance in multi-modal learning.
### 🔥 High performance, but with fewer parameters
- with just **3B sparsely activated parameters**, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmarks.
### 🚀 Simple baseline, learning multi-modal interactions with sparse pathways.
- With the addition of **a simple MoE tuning stage**, we can complete the training of MoE-LLaVA on **8 V100 GPUs** within 2 days.
## 🤗 Demo
### Gradio Web UI
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by MoE-LLaVA. We also provide [online demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) in Huggingface Spaces.
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e"
# use qwen
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e"
# use stablelm
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e"
```
### CLI Inference
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# use qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# use stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"
```
## 🐳 Model Zoo
| Model | LLM | Checkpoint | Avg | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MM-Bench| LLaVA-Bench-Wild | MM-Vet |
|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|
| MoE-LLaVA-1.6B×4-Top2 | 1.6B | [LanguageBind/MoE-LLaVA-StableLM-1.6B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-StableLM-1.6B-4e) | 60.0 | 76.0 | 60.4 | 37.2 | 62.6 | 47.8 | 84.3 | 59.4 | 85.9 | 26.1 |
| MoE-LLaVA-1.8B×4-Top2 | 1.8B | [LanguageBind/MoE-LLaVA-Qwen-1.8B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Qwen-1.8B-4e) | 60.2 | 76.2 | 61.5 | 32.6 | 63.1 | 48.0 | 87.0 | 59.6 | 88.7 | 25.3 |
| MoE-LLaVA-2.7B×4-Top2 | 2.7B | [LanguageBind/MoE-LLaVA-Phi2-2.7B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e) | 63.9 | 77.1 | 61.1 | 43.4 | 68.7 | 50.2 | 85.0 | 65.5 | 93.2 | 31.1 |
<!--
| LLaVA-1.5 | 7B | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 62.0 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 64.3 | 31.1 |
| LLaVA-1.5 | 13B | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 64.9 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 67.7 | 36.1 |
-->
## ⚙️ Requirements and Installation
* Python >= 3.10
* Pytorch == 2.0.1
* CUDA Version >= 11.7
* **Transformers == 4.36.2**
* **Tokenizers==0.15.1**
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
cd MoE-LLaVA
conda create -n moellava python=3.10 -y
conda activate moellava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
# Below are optional. For Qwen model.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# If the version of flash-attn is higher than 2.1.1, the following is not needed.
# pip install csrc/rotary
```
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN.md](docs/TRAIN.md) & [EVAL.md](docs/EVAL.md).
## 💡 Customizing your MoE-LLaVA
The instruction is in [CUSTOM.md](docs/CUSTOM.md).
## 😍 Visualization
The instruction is in [VISUALIZATION.md](docs/VISUALIZATION.md).
## 🤖 API
**We open source all codes.** If you want to load the model (e.g. ```LanguageBind/MoE-LLaVA```) on local, you can use the following code snippets.
**Using the following command to run the code.**
```bash
deepspeed predict.py
```
```python
import torch
from moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from moellava.conversation import conv_templates, SeparatorStyle
from moellava.model.builder import load_pretrained_model
from moellava.utils import disable_torch_init
from moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'moellava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e or LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
device = 'cuda'
load_4bit, load_8bit = False, False # FIXME: Deepspeed support 4bit or 8bit?
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)
image_processor = processor['image']
conv_mode = "phi" # qwen or stablelm
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(outputs)
if __name__ == '__main__':
main()
```
## 🙌 Related Projects
* [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) This framework empowers the model to efficiently utilize the united visual tokens.
* [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) An open source five modalities language-based retrieval framework.
## 👍 Acknowledgement
* [LLaVA](https://github.com/haotian-liu/LLaVA) The codebase we built upon and it is an efficient large language and vision assistant.
## 🔒 License
* The majority of this project is released under the Apache 2.0 license as found in the [LICENSE](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/LICENSE) file.
* The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{lin2024moellava,
title={MoE-LLaVA: Mixture of Experts for Large Vision-Language Models},
author={Bin Lin and Zhenyu Tang and Yang Ye and Jiaxi Cui and Bin Zhu and Peng Jin and Junwu Zhang and Munan Ning and Li Yuan},
year={2024},
eprint={2401.15947},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```BibTeX
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/MoE-LLaVA&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/MoE-LLaVA/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/MoE-LLaVA" />
</a>
|
LanguageBind/MoE-LLaVA-Qwen-1.8B-4e
|
LanguageBind
| 2024-02-01T06:09:13Z | 199 | 13 |
transformers
|
[
"transformers",
"pytorch",
"moe_llava_qwen",
"text-generation",
"custom_code",
"arxiv:2401.15947",
"arxiv:2311.10122",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-23T13:50:43Z |
---
license: apache-2.0
---
<p align="center">
<img src="https://s11.ax1x.com/2023/12/28/piqvDMV.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/abs/2401.15947">MoE-LLaVA: Mixture of Experts for Large Vision-Language Models</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
<h5 align="center">
</h5>
## 📰 News
* **[2024.01.30]** The [paper](https://arxiv.org/abs/2401.15947) is released.
* **[2024.01.27]** 🤗[Hugging Face demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) and **all codes & datasets** are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
MoE-LLaVA shows excellent performance in multi-modal learning.
### 🔥 High performance, but with fewer parameters
- with just **3B sparsely activated parameters**, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmarks.
### 🚀 Simple baseline, learning multi-modal interactions with sparse pathways.
- With the addition of **a simple MoE tuning stage**, we can complete the training of MoE-LLaVA on **8 V100 GPUs** within 2 days.
## 🤗 Demo
### Gradio Web UI
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by MoE-LLaVA. We also provide [online demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) in Huggingface Spaces.
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e"
# use qwen
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e"
# use stablelm
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e"
```
### CLI Inference
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# use qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# use stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"
```
## 🐳 Model Zoo
| Model | LLM | Checkpoint | Avg | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MM-Bench| LLaVA-Bench-Wild | MM-Vet |
|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|
| MoE-LLaVA-1.6B×4-Top2 | 1.6B | [LanguageBind/MoE-LLaVA-StableLM-1.6B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-StableLM-1.6B-4e) | 60.0 | 76.0 | 60.4 | 37.2 | 62.6 | 47.8 | 84.3 | 59.4 | 85.9 | 26.1 |
| MoE-LLaVA-1.8B×4-Top2 | 1.8B | [LanguageBind/MoE-LLaVA-Qwen-1.8B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Qwen-1.8B-4e) | 60.2 | 76.2 | 61.5 | 32.6 | 63.1 | 48.0 | 87.0 | 59.6 | 88.7 | 25.3 |
| MoE-LLaVA-2.7B×4-Top2 | 2.7B | [LanguageBind/MoE-LLaVA-Phi2-2.7B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e) | 63.9 | 77.1 | 61.1 | 43.4 | 68.7 | 50.2 | 85.0 | 65.5 | 93.2 | 31.1 |
<!--
| LLaVA-1.5 | 7B | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 62.0 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 64.3 | 31.1 |
| LLaVA-1.5 | 13B | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 64.9 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 67.7 | 36.1 |
-->
## ⚙️ Requirements and Installation
* Python >= 3.10
* Pytorch == 2.0.1
* CUDA Version >= 11.7
* **Transformers == 4.36.2**
* **Tokenizers==0.15.1**
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
cd MoE-LLaVA
conda create -n moellava python=3.10 -y
conda activate moellava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
# Below are optional. For Qwen model.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# If the version of flash-attn is higher than 2.1.1, the following is not needed.
# pip install csrc/rotary
```
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN.md](docs/TRAIN.md) & [EVAL.md](docs/EVAL.md).
## 💡 Customizing your MoE-LLaVA
The instruction is in [CUSTOM.md](docs/CUSTOM.md).
## 😍 Visualization
The instruction is in [VISUALIZATION.md](docs/VISUALIZATION.md).
## 🤖 API
**We open source all codes.** If you want to load the model (e.g. ```LanguageBind/MoE-LLaVA```) on local, you can use the following code snippets.
**Using the following command to run the code.**
```bash
deepspeed predict.py
```
```python
import torch
from moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from moellava.conversation import conv_templates, SeparatorStyle
from moellava.model.builder import load_pretrained_model
from moellava.utils import disable_torch_init
from moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'moellava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e or LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
device = 'cuda'
load_4bit, load_8bit = False, False # FIXME: Deepspeed support 4bit or 8bit?
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)
image_processor = processor['image']
conv_mode = "phi" # qwen or stablelm
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(outputs)
if __name__ == '__main__':
main()
```
## 🙌 Related Projects
* [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) This framework empowers the model to efficiently utilize the united visual tokens.
* [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) An open source five modalities language-based retrieval framework.
## 👍 Acknowledgement
* [LLaVA](https://github.com/haotian-liu/LLaVA) The codebase we built upon and it is an efficient large language and vision assistant.
## 🔒 License
* The majority of this project is released under the Apache 2.0 license as found in the [LICENSE](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/LICENSE) file.
* The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{lin2024moellava,
title={MoE-LLaVA: Mixture of Experts for Large Vision-Language Models},
author={Bin Lin and Zhenyu Tang and Yang Ye and Jiaxi Cui and Bin Zhu and Peng Jin and Junwu Zhang and Munan Ning and Li Yuan},
year={2024},
eprint={2401.15947},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```BibTeX
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/MoE-LLaVA&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/MoE-LLaVA/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/MoE-LLaVA" />
</a>
|
LanguageBind/MoE-LLaVA-Phi2-2.7B-4e-384
|
LanguageBind
| 2024-02-01T06:08:50Z | 1,014 | 32 |
transformers
|
[
"transformers",
"safetensors",
"moe_llava_phi",
"text-generation",
"custom_code",
"arxiv:2401.15947",
"arxiv:2311.10122",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-30T14:15:24Z |
---
license: apache-2.0
---
<p align="center">
<img src="https://s11.ax1x.com/2023/12/28/piqvDMV.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/abs/2401.15947">MoE-LLaVA: Mixture of Experts for Large Vision-Language Models</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
<h5 align="center">
</h5>
## 📰 News
* **[2024.01.30]** The [paper](https://arxiv.org/abs/2401.15947) is released.
* **[2024.01.27]** 🤗[Hugging Face demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) and **all codes & datasets** are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
MoE-LLaVA shows excellent performance in multi-modal learning.
### 🔥 High performance, but with fewer parameters
- with just **3B sparsely activated parameters**, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmarks.
### 🚀 Simple baseline, learning multi-modal interactions with sparse pathways.
- With the addition of **a simple MoE tuning stage**, we can complete the training of MoE-LLaVA on **8 V100 GPUs** within 2 days.
## 🤗 Demo
### Gradio Web UI
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by MoE-LLaVA. We also provide [online demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) in Huggingface Spaces.
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e"
# use qwen
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e"
# use stablelm
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e"
```
### CLI Inference
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# use qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# use stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"
```
## 🐳 Model Zoo
| Model | LLM | Checkpoint | Avg | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MM-Bench| LLaVA-Bench-Wild | MM-Vet |
|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|
| MoE-LLaVA-1.6B×4-Top2 | 1.6B | [LanguageBind/MoE-LLaVA-StableLM-1.6B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-StableLM-1.6B-4e) | 60.0 | 76.0 | 60.4 | 37.2 | 62.6 | 47.8 | 84.3 | 59.4 | 85.9 | 26.1 |
| MoE-LLaVA-1.8B×4-Top2 | 1.8B | [LanguageBind/MoE-LLaVA-Qwen-1.8B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Qwen-1.8B-4e) | 60.2 | 76.2 | 61.5 | 32.6 | 63.1 | 48.0 | 87.0 | 59.6 | 88.7 | 25.3 |
| MoE-LLaVA-2.7B×4-Top2 | 2.7B | [LanguageBind/MoE-LLaVA-Phi2-2.7B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e) | 63.9 | 77.1 | 61.1 | 43.4 | 68.7 | 50.2 | 85.0 | 65.5 | 93.2 | 31.1 |
<!--
| LLaVA-1.5 | 7B | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 62.0 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 64.3 | 31.1 |
| LLaVA-1.5 | 13B | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 64.9 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 67.7 | 36.1 |
-->
## ⚙️ Requirements and Installation
* Python >= 3.10
* Pytorch == 2.0.1
* CUDA Version >= 11.7
* **Transformers == 4.36.2**
* **Tokenizers==0.15.1**
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
cd MoE-LLaVA
conda create -n moellava python=3.10 -y
conda activate moellava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
# Below are optional. For Qwen model.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# If the version of flash-attn is higher than 2.1.1, the following is not needed.
# pip install csrc/rotary
```
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN.md](docs/TRAIN.md) & [EVAL.md](docs/EVAL.md).
## 💡 Customizing your MoE-LLaVA
The instruction is in [CUSTOM.md](docs/CUSTOM.md).
## 😍 Visualization
The instruction is in [VISUALIZATION.md](docs/VISUALIZATION.md).
## 🤖 API
**We open source all codes.** If you want to load the model (e.g. ```LanguageBind/MoE-LLaVA```) on local, you can use the following code snippets.
**Using the following command to run the code.**
```bash
deepspeed predict.py
```
```python
import torch
from moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from moellava.conversation import conv_templates, SeparatorStyle
from moellava.model.builder import load_pretrained_model
from moellava.utils import disable_torch_init
from moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'moellava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e or LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
device = 'cuda'
load_4bit, load_8bit = False, False # FIXME: Deepspeed support 4bit or 8bit?
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)
image_processor = processor['image']
conv_mode = "phi" # qwen or stablelm
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(outputs)
if __name__ == '__main__':
main()
```
## 🙌 Related Projects
* [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) This framework empowers the model to efficiently utilize the united visual tokens.
* [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) An open source five modalities language-based retrieval framework.
## 👍 Acknowledgement
* [LLaVA](https://github.com/haotian-liu/LLaVA) The codebase we built upon and it is an efficient large language and vision assistant.
## 🔒 License
* The majority of this project is released under the Apache 2.0 license as found in the [LICENSE](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/LICENSE) file.
* The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{lin2024moellava,
title={MoE-LLaVA: Mixture of Experts for Large Vision-Language Models},
author={Bin Lin and Zhenyu Tang and Yang Ye and Jiaxi Cui and Bin Zhu and Peng Jin and Junwu Zhang and Munan Ning and Li Yuan},
year={2024},
eprint={2401.15947},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```BibTeX
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/MoE-LLaVA&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/MoE-LLaVA/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/MoE-LLaVA" />
</a>
|
LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
|
LanguageBind
| 2024-02-01T06:08:34Z | 2,277 | 8 |
transformers
|
[
"transformers",
"safetensors",
"moe_llava_stablelm",
"text-generation",
"custom_code",
"arxiv:2401.15947",
"arxiv:2311.10122",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-01-23T06:49:18Z |
---
license: apache-2.0
---
<p align="center">
<img src="https://s11.ax1x.com/2023/12/28/piqvDMV.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/abs/2401.15947">MoE-LLaVA: Mixture of Experts for Large Vision-Language Models</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
<h5 align="center">
</h5>
## 📰 News
* **[2024.01.30]** The [paper](https://arxiv.org/abs/2401.15947) is released.
* **[2024.01.27]** 🤗[Hugging Face demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) and **all codes & datasets** are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
MoE-LLaVA shows excellent performance in multi-modal learning.
### 🔥 High performance, but with fewer parameters
- with just **3B sparsely activated parameters**, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmarks.
### 🚀 Simple baseline, learning multi-modal interactions with sparse pathways.
- With the addition of **a simple MoE tuning stage**, we can complete the training of MoE-LLaVA on **8 V100 GPUs** within 2 days.
## 🤗 Demo
### Gradio Web UI
Highly recommend trying out our web demo by the following command, which incorporates all features currently supported by MoE-LLaVA. We also provide [online demo](https://huggingface.co/spaces/LanguageBind/MoE-LLaVA) in Huggingface Spaces.
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e"
# use qwen
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e"
# use stablelm
deepspeed --include localhost:0 moellava/serve/gradio_web_server.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e"
```
### CLI Inference
```bash
# use phi2
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Phi2-2.7B-4e" --image-file "image.jpg"
# use qwen
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-Qwen-1.8B-4e" --image-file "image.jpg"
# use stablelm
deepspeed --include localhost:0 moellava/serve/cli.py --model-path "LanguageBind/MoE-LLaVA-StableLM-1.6B-4e" --image-file "image.jpg"
```
## 🐳 Model Zoo
| Model | LLM | Checkpoint | Avg | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MM-Bench| LLaVA-Bench-Wild | MM-Vet |
|----------|-----------|-----------|---|---|---|---|---|---|---|---|---|---|
| MoE-LLaVA-1.6B×4-Top2 | 1.6B | [LanguageBind/MoE-LLaVA-StableLM-1.6B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-StableLM-1.6B-4e) | 60.0 | 76.0 | 60.4 | 37.2 | 62.6 | 47.8 | 84.3 | 59.4 | 85.9 | 26.1 |
| MoE-LLaVA-1.8B×4-Top2 | 1.8B | [LanguageBind/MoE-LLaVA-Qwen-1.8B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Qwen-1.8B-4e) | 60.2 | 76.2 | 61.5 | 32.6 | 63.1 | 48.0 | 87.0 | 59.6 | 88.7 | 25.3 |
| MoE-LLaVA-2.7B×4-Top2 | 2.7B | [LanguageBind/MoE-LLaVA-Phi2-2.7B-4e](https://huggingface.co/LanguageBind/MoE-LLaVA-Phi2-2.7B-4e) | 63.9 | 77.1 | 61.1 | 43.4 | 68.7 | 50.2 | 85.0 | 65.5 | 93.2 | 31.1 |
<!--
| LLaVA-1.5 | 7B | [liuhaotian/llava-v1.5-7b](https://huggingface.co/liuhaotian/llava-v1.5-7b) | 62.0 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 64.3 | 31.1 |
| LLaVA-1.5 | 13B | [liuhaotian/llava-v1.5-13b](https://huggingface.co/liuhaotian/llava-v1.5-13b) | 64.9 | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 67.7 | 36.1 |
-->
## ⚙️ Requirements and Installation
* Python >= 3.10
* Pytorch == 2.0.1
* CUDA Version >= 11.7
* **Transformers == 4.36.2**
* **Tokenizers==0.15.1**
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/MoE-LLaVA
cd MoE-LLaVA
conda create -n moellava python=3.10 -y
conda activate moellava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
# Below are optional. For Qwen model.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# If the version of flash-attn is higher than 2.1.1, the following is not needed.
# pip install csrc/rotary
```
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN.md](docs/TRAIN.md) & [EVAL.md](docs/EVAL.md).
## 💡 Customizing your MoE-LLaVA
The instruction is in [CUSTOM.md](docs/CUSTOM.md).
## 😍 Visualization
The instruction is in [VISUALIZATION.md](docs/VISUALIZATION.md).
## 🤖 API
**We open source all codes.** If you want to load the model (e.g. ```LanguageBind/MoE-LLaVA```) on local, you can use the following code snippets.
**Using the following command to run the code.**
```bash
deepspeed predict.py
```
```python
import torch
from moellava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
from moellava.conversation import conv_templates, SeparatorStyle
from moellava.model.builder import load_pretrained_model
from moellava.utils import disable_torch_init
from moellava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
def main():
disable_torch_init()
image = 'moellava/serve/examples/extreme_ironing.jpg'
inp = 'What is unusual about this image?'
model_path = 'LanguageBind/MoE-LLaVA-Phi2-2.7B-4e' # LanguageBind/MoE-LLaVA-Qwen-1.8B-4e or LanguageBind/MoE-LLaVA-StableLM-1.6B-4e
device = 'cuda'
load_4bit, load_8bit = False, False # FIXME: Deepspeed support 4bit or 8bit?
model_name = get_model_name_from_path(model_path)
tokenizer, model, processor, context_len = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device)
image_processor = processor['image']
conv_mode = "phi" # qwen or stablelm
conv = conv_templates[conv_mode].copy()
roles = conv.roles
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(model.device, dtype=torch.float16)
print(f"{roles[1]}: {inp}")
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda()
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=True,
temperature=0.2,
max_new_tokens=1024,
use_cache=True,
stopping_criteria=[stopping_criteria])
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(outputs)
if __name__ == '__main__':
main()
```
## 🙌 Related Projects
* [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) This framework empowers the model to efficiently utilize the united visual tokens.
* [LanguageBind](https://github.com/PKU-YuanGroup/LanguageBind) An open source five modalities language-based retrieval framework.
## 👍 Acknowledgement
* [LLaVA](https://github.com/haotian-liu/LLaVA) The codebase we built upon and it is an efficient large language and vision assistant.
## 🔒 License
* The majority of this project is released under the Apache 2.0 license as found in the [LICENSE](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/LICENSE) file.
* The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{lin2024moellava,
title={MoE-LLaVA: Mixture of Experts for Large Vision-Language Models},
author={Bin Lin and Zhenyu Tang and Yang Ye and Jiaxi Cui and Bin Zhu and Peng Jin and Junwu Zhang and Munan Ning and Li Yuan},
year={2024},
eprint={2401.15947},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```BibTeX
@article{lin2023video,
title={Video-LLaVA: Learning United Visual Representation by Alignment Before Projection},
author={Lin, Bin and Zhu, Bin and Ye, Yang and Ning, Munan and Jin, Peng and Yuan, Li},
journal={arXiv preprint arXiv:2311.10122},
year={2023}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/MoE-LLaVA&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/MoE-LLaVA/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/MoE-LLaVA" />
</a>
|
octnn/ppo-PyramidsTarget
|
octnn
| 2024-02-01T05:56:21Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2024-02-01T05:56:19Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: octnn/ppo-PyramidsTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
arpanl/fine-tuned
|
arpanl
| 2024-02-01T05:52:31Z | 176 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2024-02-01T05:51:36Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: fine-tuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine-tuned
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
bartowski/DistilabelBeagle14-7B-exl2
|
bartowski
| 2024-02-01T05:48:08Z | 6 | 0 | null |
[
"merge",
"mergekit",
"lazymergekit",
"dpo",
"rlhf",
"rlaif",
"distilabel",
"text-generation",
"base_model:mlabonne/Beagle14-7B",
"base_model:finetune:mlabonne/Beagle14-7B",
"license:cc-by-nc-4.0",
"region:us"
] |
text-generation
| 2024-02-01T05:32:02Z |
---
license: cc-by-nc-4.0
base_model: mlabonne/Beagle14-7B
tags:
- merge
- mergekit
- lazymergekit
- dpo
- rlhf
- rlaif
- distilabel
quantized_by: bartowski
pipeline_tag: text-generation
---
## Exllama v2 Quantizations of DistilabelBeagle14-7B
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.12">turboderp's ExLlamaV2 v0.0.12</a> for quantization.
# The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: https://huggingface.co/argilla/DistilabelBeagle14-7B
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/Bartowski/DistilabelBeagle14-7B-exl2/tree/8_0) | 8.0 | 8.0 | 8.4 GB | 9.8 GB | 11.8 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/Bartowski/DistilabelBeagle14-7B-exl2/tree/6_5) | 6.5 | 8.0 | 7.2 GB | 8.6 GB | 10.6 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
| [5_0](https://huggingface.co/Bartowski/DistilabelBeagle14-7B-exl2/tree/5_0) | 5.0 | 6.0 | 6.0 GB | 7.4 GB | 9.4 GB | Slightly lower quality vs 6.5, but usable on 8GB cards. |
| [4_25](https://huggingface.co/Bartowski/DistilabelBeagle14-7B-exl2/tree/4_25) | 4.25 | 6.0 | 5.3 GB | 6.7 GB | 8.7 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/Bartowski/DistilabelBeagle14-7B-exl2/tree/3_5) | 3.5 | 6.0 | 4.7 GB | 6.1 GB | 8.1 GB | Lower quality, only use if you have to. |
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/DistilabelBeagle14-7B-exl2 DistilabelBeagle14-7B-exl2-6_5
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download the `main` (only useful if you only care about measurement.json) branch to a folder called `DistilabelBeagle14-7B-exl2`:
```shell
mkdir DistilabelBeagle14-7B-exl2
huggingface-cli download bartowski/DistilabelBeagle14-7B-exl2 --local-dir DistilabelBeagle14-7B-exl2 --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
Linux:
```shell
mkdir DistilabelBeagle14-7B-exl2-6_5
huggingface-cli download bartowski/DistilabelBeagle14-7B-exl2 --revision 6_5 --local-dir DistilabelBeagle14-7B-exl2-6_5 --local-dir-use-symlinks False
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
mkdir DistilabelBeagle14-7B-exl2-6.5
huggingface-cli download bartowski/DistilabelBeagle14-7B-exl2 --revision 6_5 --local-dir DistilabelBeagle14-7B-exl2-6.5 --local-dir-use-symlinks False
```
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
fia24/filtered_annotated100k_banglat5_v2
|
fia24
| 2024-02-01T05:48:02Z | 2 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:csebuetnlp/banglat5",
"base_model:finetune:csebuetnlp/banglat5",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-01T03:45:10Z |
---
base_model: csebuetnlp/banglat5
tags:
- generated_from_trainer
model-index:
- name: filtered_annotated100k_banglat5_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# filtered_annotated100k_banglat5_v2
This model is a fine-tuned version of [csebuetnlp/banglat5](https://huggingface.co/csebuetnlp/banglat5) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2532
- eval_Val Accuracy: 0.9247
- eval_gen_len: 2.648
- eval_runtime: 85.2007
- eval_samples_per_second: 112.722
- eval_steps_per_second: 3.533
- epoch: 17.0
- step: 4369
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 300
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Framework versions
- Transformers 4.35.2
- Pytorch 1.13.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.1
|
Tsuka25/w2v-bert-2.0-mongolian-colab-CV16.0
|
Tsuka25
| 2024-02-01T05:46:28Z | 60 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-01-30T08:01:07Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.