
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-23 12:32:37
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 571
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-23 12:31:07
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
huggingtweets/423zb
|
huggingtweets
| 2021-05-21T16:38:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/423zb/1612221398403/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1277051021064392706/wuQS0nyO_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">423ZB 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@423zb bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@423zb's tweets](https://twitter.com/423zb).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3166</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>2425</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>144</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>597</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/jnwkepoo/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @423zb's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/29x1ggo7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/29x1ggo7/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/423zb'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/3thyr3al
|
huggingtweets
| 2021-05-21T16:37:14Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/3thyr3al/1617942034431/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1362160113247793153/VEYzwQTI_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">ethy (3thyreඞl)🏺 🤖 AI Bot </div>
<div style="font-size: 15px">@3thyr3al bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@3thyr3al's tweets](https://twitter.com/3thyr3al).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 1727 |
| Retweets | 360 |
| Short tweets | 539 |
| Tweets kept | 828 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2tr059nk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @3thyr3al's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/m9xvw9pq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/m9xvw9pq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/3thyr3al')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/3rbunn1nja
|
huggingtweets
| 2021-05-21T16:32:07Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/3rbunn1nja/1616808238654/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1371476407767957505/xfhZ00Hv_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Jeremy Spradlin 🤖 AI Bot </div>
<div style="font-size: 15px">@3rbunn1nja bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@3rbunn1nja's tweets](https://twitter.com/3rbunn1nja).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3251 |
| Retweets | 121 |
| Short tweets | 252 |
| Tweets kept | 2878 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2fqh91fk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @3rbunn1nja's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3lk04zqn) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3lk04zqn/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/3rbunn1nja')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/178kakapo
|
huggingtweets
| 2021-05-21T16:29:51Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/178kakapo/1603720462678/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/2476808798/p6cqc9mvgsdlhya7nb6p_400x400.jpeg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">KAKAPO➤Endangered 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@178kakapo bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@178kakapo's tweets](https://twitter.com/178kakapo).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3140</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>2196</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>56</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>888</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/1r7z36ek/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @178kakapo's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/2tp7xvh0) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/2tp7xvh0/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/178kakapo'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file -->
|
huggingtweets/14jun1995
|
huggingtweets
| 2021-05-21T16:23:35Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/14jun1995/1616669363048/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1236431647576330246/GGaeVBZJ_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">mon nom non-mo 🤖 AI Bot </div>
<div style="font-size: 15px">@14jun1995 bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@14jun1995's tweets](https://twitter.com/14jun1995).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3249 |
| Retweets | 20 |
| Short tweets | 213 |
| Tweets kept | 3016 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ppb6sp7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @14jun1995's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/25pt100s) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/25pt100s/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/14jun1995')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/09indierock
|
huggingtweets
| 2021-05-21T16:21:05Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/09indierock/1616791178582/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1363688455352553473/nfQUoTBH_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">kn 🤖 AI Bot </div>
<div style="font-size: 15px">@09indierock bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@09indierock's tweets](https://twitter.com/09indierock).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 3126 |
| Retweets | 1094 |
| Short tweets | 428 |
| Tweets kept | 1604 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/39findw6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @09indierock's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/33xy9nxb) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/33xy9nxb/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/09indierock')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
gagan3012/project-code-py-small
|
gagan3012
| 2021-05-21T16:06:24Z | 11 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
**Note**: the Answers might not make sense in some cases because of the bias in GPT-2
**Contribtuions:** If you would like to make the model better contributions are welcome Check out [CONTRIBUTIONS.md](https://github.com/gagan3012/project-code-py/blob/master/CONTRIBUTIONS.md)
### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py
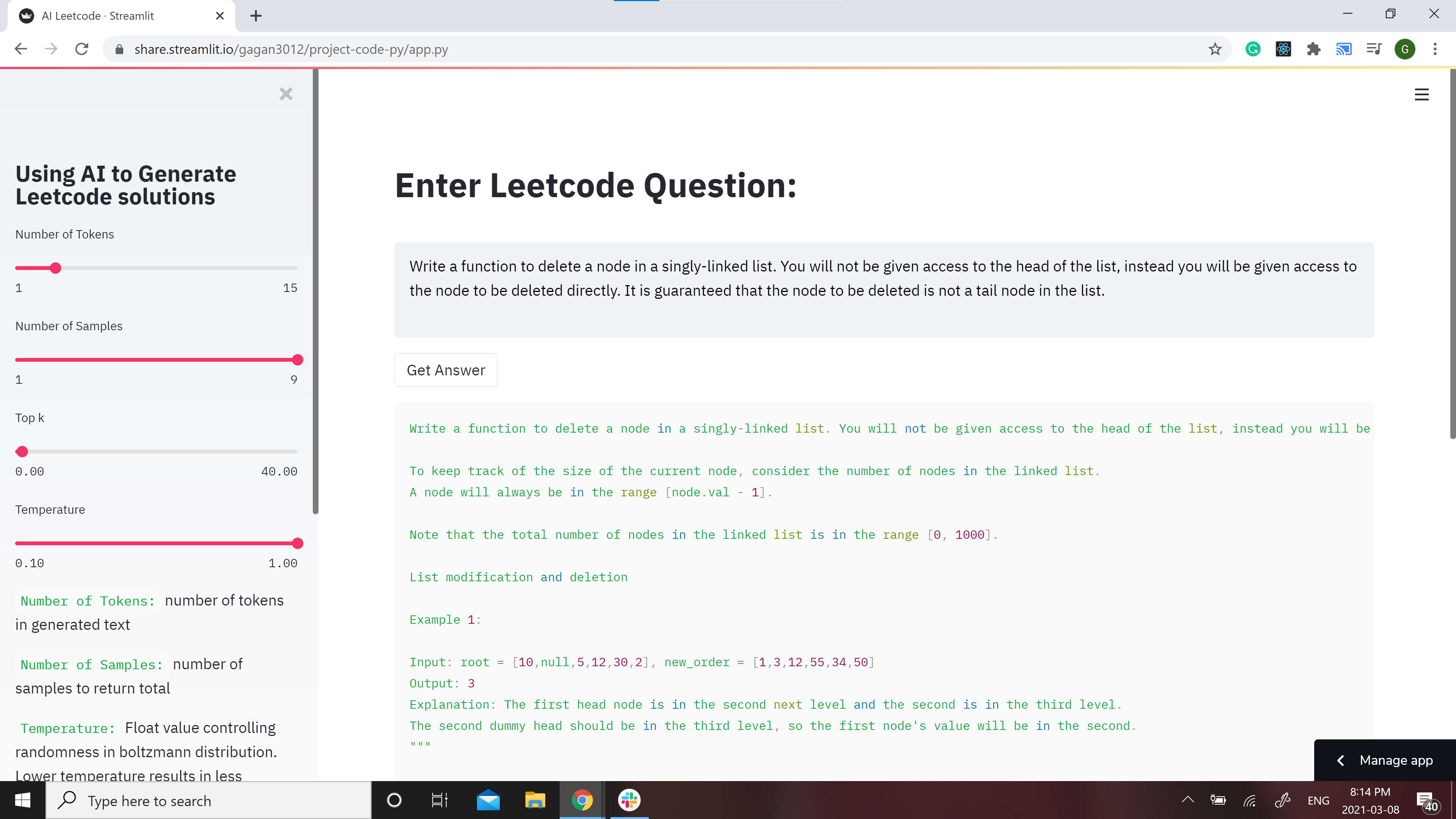
## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
elgeish/gpt2-medium-arabic-poetry
|
elgeish
| 2021-05-21T15:45:14Z | 13 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"poetry",
"ar",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: ar
datasets:
- Arabic Poetry Dataset (6th - 21st century)
metrics:
- perplexity
tags:
- text-generation
- poetry
license: apache-2.0
widget:
- text: "للوهلة الأولى قرأت في عينيه"
model-index:
- name: elgeish Arabic GPT2 Medium
results:
- task:
name: Text Generation
type: text-generation
dataset:
name: Arabic Poetry Dataset (6th - 21st century)
type: poetry
args: ar
metrics:
- name: Validation Perplexity
type: perplexity
value: 282.09
---
# GPT2-Medium-Arabic-Poetry
Fine-tuned [aubmindlab/aragpt2-medium](https://huggingface.co/aubmindlab/aragpt2-medium) on
the [Arabic Poetry Dataset (6th - 21st century)](https://www.kaggle.com/fahd09/arabic-poetry-dataset-478-2017)
using 41,922 lines of poetry as the train split and 9,007 (by poets not in the train split) for validation.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
set_seed(42)
model_name = "elgeish/gpt2-medium-arabic-poetry"
model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "للوهلة الأولى قرأت في عينيه"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
samples = model.generate(
input_ids.to("cuda"),
do_sample=True,
early_stopping=True,
max_length=32,
min_length=16,
num_return_sequences=3,
pad_token_id=50256,
repetition_penalty=1.5,
top_k=32,
top_p=0.95,
)
for sample in samples:
print(tokenizer.decode(sample.tolist()))
print("--")
```
Here's the output:
```
للوهلة الأولى قرأت في عينيه عن تلك النسم لم تذكر شيءا فلربما نامت علي كتفيها العصافير وتناثرت اوراق التوت عليها وغابت الوردة من
--
للوهلة الأولى قرأت في عينيه اية نشوة من ناره وهي تنظر الي المستقبل بعيون خلاقة ورسمت خطوطه العريضة علي جبينك العاري رسمت الخطوط الحمر فوق شعرك
--
للوهلة الأولى قرأت في عينيه كل ما كان وما سيكون غدا اذا لم تكن امراة ستكبر كثيرا علي الورق الابيض او لا تري مثلا خطوطا رفيعة فوق صفحة الماء
--
```
|
DebateLabKIT/cript-large
|
DebateLabKIT
| 2021-05-21T15:31:48Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"arxiv:2009.07185",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- gpt2
---
# CRiPT Model Large (Critical Thinking Intermediarily Pretrained Transformer)
Large version of the trained model (`SYL01-2020-10-24-72K/gpt2-large-train03-72K`) presented in the paper "Critical Thinking for Language Models" (Betz, Voigt and Richardson 2020). See also:
* [blog entry](https://debatelab.github.io/journal/critical-thinking-language-models.html)
* [GitHub repo](https://github.com/debatelab/aacorpus)
* [paper](https://arxiv.org/pdf/2009.07185)
|
ceostroff/harry-potter-gpt2-fanfiction
|
ceostroff
| 2021-05-21T14:51:47Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"harry-potter",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- harry-potter
license: mit
---
# Harry Potter Fanfiction Generator
This is a pre-trained GPT-2 generative text model that allows you to generate your own Harry Potter fanfiction, trained off of the top 100 rated fanficition stories. We intend for this to be used for individual fun and experimentation and not as a commercial product.
|
bigjoedata/rockbot355M
|
bigjoedata
| 2021-05-21T14:17:25Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# 🎸 🥁 Rockbot 🎤 🎧
A [GPT-2](https://openai.com/blog/better-language-models/) based lyrics generator fine-tuned on the writing styles of 16000 songs by 270 artists across MANY genres (not just rock).
**Instructions:** Type in a fake song title, pick an artist, click "Generate".
Most language models are imprecise and Rockbot is no exception. You may see NSFW lyrics unexpectedly. I have made no attempts to censor. Generated lyrics may be repetitive and/or incoherent at times, but hopefully you'll encounter something interesting or memorable.
Oh, and generation is resource intense and can be slow. I set governors on song length to keep generation time somewhat reasonable. You may adjust song length and other parameters on the left or check out [Github](https://github.com/bigjoedata/rockbot) to spin up your own Rockbot.
Just have fun.
[Demo](https://share.streamlit.io/bigjoedata/rockbot/main/src/main.py) Adjust settings to increase speed
[Github](https://github.com/bigjoedata/rockbot)
[GPT-2 124M version Model page on Hugging Face](https://huggingface.co/bigjoedata/rockbot)
[DistilGPT2 version Model page on Hugging Face](https://huggingface.co/bigjoedata/rockbot-distilgpt2/) This is leaner with the tradeoff being that the lyrics are more simplistic.
🎹 🪘 🎷 🎺 🪗 🪕 🎻
## Background
With the shutdown of [Google Play Music](https://en.wikipedia.org/wiki/Google_Play_Music) I used Google's takeout function to gather the metadata from artists I've listened to over the past several years. I wanted to take advantage of this bounty to build something fun. I scraped the top 50 lyrics for artists I'd listened to at least once from [Genius](https://genius.com/), then fine tuned [GPT-2's](https://openai.com/blog/better-language-models/) 124M token model using the [AITextGen](https://github.com/minimaxir/aitextgen) framework after considerable post-processing. For more on generation, see [here.](https://huggingface.co/blog/how-to-generate)
### Full Tech Stack
[Google Play Music](https://en.wikipedia.org/wiki/Google_Play_Music) (R.I.P.).
[Python](https://www.python.org/).
[Streamlit](https://www.streamlit.io/).
[GPT-2](https://openai.com/blog/better-language-models/).
[AITextGen](https://github.com/minimaxir/aitextgen).
[Pandas](https://pandas.pydata.org/).
[LyricsGenius](https://lyricsgenius.readthedocs.io/en/master/).
[Google Colab](https://colab.research.google.com/) (GPU based Training).
[Knime](https://www.knime.com/) (data cleaning).
## How to Use The Model
Please refer to [AITextGen](https://github.com/minimaxir/aitextgen) for much better documentation.
### Training Parameters Used
ai.train("lyrics.txt",
line_by_line=False,
from_cache=False,
num_steps=10000,
generate_every=2000,
save_every=2000,
save_gdrive=False,
learning_rate=1e-3,
batch_size=3,
eos_token="<|endoftext|>",
#fp16=True
)
### To Use
Generate With Prompt (Use Title Case):
Song Name
BY
Artist Name
|
Dongjae/mrc2reader
|
Dongjae
| 2021-05-21T13:25:57Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
The Reader model is for Korean Question Answering
The backbone model is deepset/xlm-roberta-large-squad2.
It is a finetuned model with KorQuAD-v1 dataset.
As a result of verification using KorQuAD evaluation dataset, it showed approximately 87% and 92% respectively for the EM score and F1 score.
Thank you
|
anonymous-german-nlp/german-gpt2
|
anonymous-german-nlp
| 2021-05-21T13:20:42Z | 338 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"de",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: de
widget:
- text: "Heute ist sehr schönes Wetter in"
license: mit
---
# German GPT-2 model
**Note**: This model was de-anonymized and now lives at:
https://huggingface.co/dbmdz/german-gpt2
Please use the new model name instead!
|
aliosm/ComVE-gpt2
|
aliosm
| 2021-05-21T13:19:25Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"dataset:ComVE",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- ComVE
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-gpt2
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [gpt2](https://github.com/huggingface/transformers/blob/master/model_cards/gpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|continue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 5 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved 14.0547/13.6534 BLEU scores on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
aliosm/ComVE-gpt2-medium
|
aliosm
| 2021-05-21T13:17:55Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"feature-extraction",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"dataset:ComVE",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- gpt2
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- ComVE
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-gpt2-medium
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [gpt2-medium](https://github.com/huggingface/transformers/blob/master/model_cards/gpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|continue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 5 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved fifth place with 16.7153/16.1187 BLEU scores and third place with 1.94 Human Evaluation score on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
These are some examples generated by the model:
| Against Commonsense Statement | Generated Reason |
|:-----------------------------------------------------:|:--------------------------------------------:|
| Chicken can swim in water. | Chicken can't swim. |
| shoes can fly | Shoes are not able to fly. |
| Chocolate can be used to make a coffee pot | Chocolate is not used to make coffee pots. |
| you can also buy tickets online with an identity card | You can't buy tickets with an identity card. |
| a ball is square and can roll | A ball is round and cannot roll. |
| You can use detergent to dye your hair. | Detergent is used to wash clothes. |
| you can eat mercury | mercury is poisonous |
| A gardener can follow a suspect | gardener is not a police officer |
| cars can float in the ocean just like a boat | Cars are too heavy to float in the ocean. |
| I am going to work so I can lose money. | Working is not a way to lose money. |
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-gpt2-medium">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
aliosm/ComVE-gpt2-large
|
aliosm
| 2021-05-21T13:12:02Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- gpt2
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-gpt2-large
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [gpt2-large](https://github.com/huggingface/transformers/blob/master/model_cards/gpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|conteniue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 5 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved 16.5110/15.9299 BLEU scores on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-gpt2-large">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
aliosm/ComVE-distilgpt2
|
aliosm
| 2021-05-21T13:07:30Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"exbert",
"commonsense",
"semeval2020",
"comve",
"en",
"dataset:ComVE",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- exbert
- commonsense
- semeval2020
- comve
license: "mit"
datasets:
- ComVE
metrics:
- bleu
widget:
- text: "Chicken can swim in water. <|continue|>"
---
# ComVE-distilgpt2
## Model description
Finetuned model on Commonsense Validation and Explanation (ComVE) dataset introduced in [SemEval2020 Task4](https://competitions.codalab.org/competitions/21080) using a causal language modeling (CLM) objective.
The model is able to generate a reason why a given natural language statement is against commonsense.
## Intended uses & limitations
You can use the raw model for text generation to generate reasons why natural language statements are against commonsense.
#### How to use
You can use this model directly to generate reasons why the given statement is against commonsense using [`generate.sh`](https://github.com/AliOsm/SemEval2020-Task4-ComVE/tree/master/TaskC-Generation) script.
*Note:* make sure that you are using version `2.4.1` of `transformers` package. Newer versions has some issue in text generation and the model repeats the last token generated again and again.
#### Limitations and bias
The model biased to negate the entered sentence usually instead of producing a factual reason.
## Training data
The model is initialized from the [distilgpt2](https://github.com/huggingface/transformers/blob/master/model_cards/distilgpt2-README.md) model and finetuned using [ComVE](https://github.com/wangcunxiang/SemEval2020-Task4-Commonsense-Validation-and-Explanation) dataset which contains 10K against commonsense sentences, each of them is paired with three reference reasons.
## Training procedure
Each natural language statement that against commonsense is concatenated with its reference reason with `<|continue|>` as a separator, then the model finetuned using CLM objective.
The model trained on Nvidia Tesla P100 GPU from Google Colab platform with 5e-5 learning rate, 15 epochs, 128 maximum sequence length and 64 batch size.
<center>
<img src="https://i.imgur.com/xKbrwBC.png">
</center>
## Eval results
The model achieved 13.7582/13.8026 BLEU scores on SemEval2020 Task4: Commonsense Validation and Explanation development and testing dataset.
### BibTeX entry and citation info
```bibtex
@article{fadel2020justers,
title={JUSTers at SemEval-2020 Task 4: Evaluating Transformer Models Against Commonsense Validation and Explanation},
author={Fadel, Ali and Al-Ayyoub, Mahmoud and Cambria, Erik},
year={2020}
}
```
<a href="https://huggingface.co/exbert/?model=aliosm/ComVE-distilgpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
ainize/gpt2-spongebob-script-large
|
ainize
| 2021-05-21T12:18:42Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
### Model information
Fine tuning data: https://www.kaggle.com/mikhailgaerlan/spongebob-squarepants-completed-transcripts
License: CC-BY-SA
Base model: gpt-2 large
Epoch: 50
Train runtime: 14723.0716 secs
Loss: 0.0268
API page: [Ainize](https://ainize.ai/fpem123/GPT2-Spongebob?branch=master)
Demo page: [End-point](https://master-gpt2-spongebob-fpem123.endpoint.ainize.ai/)
### ===Teachable NLP=== ###
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
ainize/gpt2-rnm-with-spongebob
|
ainize
| 2021-05-21T12:09:02Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
### Model information
Fine tuning data 1: https://www.kaggle.com/andradaolteanu/rickmorty-scripts
Fine tuning data 2: https://www.kaggle.com/mikhailgaerlan/spongebob-squarepants-completed-transcripts
Base model: e-tony/gpt2-rnm
Epoch: 2
Train runtime: 790.0612 secs
Loss: 2.8569
API page: [Ainize](https://ainize.ai/fpem123/GPT2-Rick-N-Morty-with-SpongeBob?branch=master)
Demo page: [End-point](https://master-gpt2-rick-n-morty-with-sponge-bob-fpem123.endpoint.ainize.ai/)
### ===Teachable NLP=== ###
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
SIC98/GPT2-python-code-generator
|
SIC98
| 2021-05-21T11:13:58Z | 17 | 9 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
Github
- https://github.com/SIC98/GPT2-python-code-generator
|
HooshvareLab/gpt2-fa-comment
|
HooshvareLab
| 2021-05-21T10:47:25Z | 30 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"fa",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
language: fa
license: apache-2.0
widget:
- text: "<s>نمونه دیدگاه هم خوب هم بد به طور کلی <sep>"
- text: "<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و طعم <sep>"
- text: "<s>نمونه دیدگاه خوب از نظر بازی و کارگردانی <sep>"
- text: "<s>نمونه دیدگاه خیلی خوب از نظر بازی و صحنه و داستان <sep>"
- text: "<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و طعم و کیفیت <sep>"
---
# Persian Comment Generator
The model can generate comments based on your aspects, and the model was fine-tuned on [persiannlp/parsinlu](https://github.com/persiannlp/parsinlu). Currently, the model only supports aspects in the food and movie scope. You can see the whole aspects in the following section.
## Comments Aspects
```text
<s>نمونه دیدگاه هم خوب هم بد به طور کلی <sep>
<s>نمونه دیدگاه خوب به طور کلی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر طعم <sep>
<s>نمونه دیدگاه خیلی خوب به طور کلی <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه منفی به طور کلی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارسال <sep>
<s>نمونه دیدگاه منفی از نظر طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه نظری ندارم به طور کلی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم <sep>
<s>نمونه دیدگاه خیلی منفی به طور کلی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر طعم و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر طعم و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارسال و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر طعم و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و ارسال و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و کیفیت و طعم <sep>
<s>نمونه دیدگاه خوب از نظر ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و بسته بندی و ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر طعم و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه منفی از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارسال <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و طعم <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر طعم و کیفیت و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر ارسال و طعم <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و ارسال <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش غذایی و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و کیفیت و ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی و ارسال <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و طعم و ارزش خرید و ارسال <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارسال و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش خرید و ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و ارزش خرید و طعم <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه نظری ندارم از نظر بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خوب از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش خرید و ارزش غذایی <sep>
<s>نمونه دیدگاه منفی از نظر طعم و بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارزش غذایی و بسته بندی <sep>
<s>نمونه دیدگاه خوب از نظر ارسال و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارسال <sep>
<s>نمونه دیدگاه نظری ندارم از نظر طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و بسته بندی و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر طعم و بسته بندی و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و کیفیت و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارسال و ارزش خرید <sep>
<s>نمونه دیدگاه نظری ندارم از نظر ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و ارزش خرید و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و طعم و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کیفیت و ارسال و بسته بندی <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و کیفیت <sep>
<s>نمونه دیدگاه خوب از نظر کیفیت و ارسال <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و ارزش غذایی <sep>
<s>نمونه دیدگاه خوب از نظر ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارسال و بسته بندی و کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه منفی از نظر بسته بندی و ارزش غذایی <sep>
<s>نمونه دیدگاه منفی از نظر طعم و کیفیت و ارزش خرید <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش خرید و طعم و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کیفیت و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و کیفیت و طعم <sep>
<s>نمونه دیدگاه منفی از نظر کیفیت و طعم و ارزش غذایی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارسال و کیفیت و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر طعم و بسته بندی و ارسال <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و بسته بندی و طعم <sep>
<s>نمونه دیدگاه خیلی خوب از نظر ارزش غذایی و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش غذایی و کیفیت <sep>
<s>نمونه دیدگاه منفی از نظر ارزش خرید و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کیفیت و طعم و بسته بندی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر ارسال و ارزش خرید <sep>
<s>نمونه دیدگاه خیلی منفی از نظر ارزش خرید و طعم و کیفیت <sep>
<s>نمونه دیدگاه خیلی منفی از نظر طعم و ارسال <sep>
<s>نمونه دیدگاه منفی از نظر موسیقی و بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر صدا <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و فیلمبرداری و کارگردانی و بازی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان و بازی <sep>
<s>نمونه دیدگاه منفی از نظر بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان و کارگردانی و بازی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و بازی <sep>
<s>نمونه دیدگاه خوب از نظر بازی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی <sep>
<s>نمونه دیدگاه خوب از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خوب از نظر داستان و بازی <sep>
<s>نمونه دیدگاه خوب از نظر داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و کارگردانی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه خوب از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر صحنه و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و کارگردانی و فیلمبرداری و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی و موسیقی <sep>
<s>نمونه دیدگاه خوب از نظر صحنه و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و موسیقی و کارگردانی <sep>
<s>نمونه دیدگاه خوب از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه خوب از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی و موسیقی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خوب از نظر کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان <sep>
<s>نمونه دیدگاه خوب از نظر بازی و داستان و موسیقی و کارگردانی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر داستان و بازی و کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و داستان <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و بازی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و بازی و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر بازی و داستان <sep>
<s>نمونه دیدگاه خوب از نظر فیلمبرداری و صحنه و موسیقی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و کارگردانی و بازی <sep>
<s>نمونه دیدگاه نظری ندارم از نظر بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و بازی و صحنه <sep>
<s>نمونه دیدگاه خوب از نظر کارگردانی و داستان و بازی و فیلمبرداری <sep>
<s>نمونه دیدگاه خوب از نظر بازی و صحنه و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و صحنه و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و موسیقی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و صحنه <sep>
<s>نمونه دیدگاه خیلی خوب از نظر فیلمبرداری و صحنه و داستان و کارگردانی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه منفی از نظر کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر داستان و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر فیلمبرداری و بازی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر کارگردانی و بازی و داستان و صحنه <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر موسیقی و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر موسیقی و صحنه <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر صحنه و فیلمبرداری و داستان و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و داستان و موسیقی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کارگردانی و صدا و صحنه و داستان <sep>
<s>نمونه دیدگاه خوب از نظر داستان و کارگردانی و بازی <sep>
<s>نمونه دیدگاه منفی از نظر داستان و بازی و کارگردانی <sep>
<s>نمونه دیدگاه خوب از نظر داستان و بازی و موسیقی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و کارگردانی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر کارگردانی و بازی و صحنه <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر کارگردانی و بازی <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر صحنه و فیلمبرداری و داستان <sep>
<s>نمونه دیدگاه خوب از نظر موسیقی و داستان <sep>
<s>نمونه دیدگاه منفی از نظر موسیقی و بازی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر صدا و بازی <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و صحنه و فیلمبرداری <sep>
<s>نمونه دیدگاه خیلی منفی از نظر بازی و فیلمبرداری و داستان و کارگردانی <sep>
<s>نمونه دیدگاه خیلی منفی از نظر صحنه <sep>
<s>نمونه دیدگاه منفی از نظر داستان و صحنه <sep>
<s>نمونه دیدگاه منفی از نظر بازی و صحنه و صدا <sep>
<s>نمونه دیدگاه خیلی منفی از نظر فیلمبرداری و صدا <sep>
<s>نمونه دیدگاه خیلی خوب از نظر موسیقی <sep>
<s>نمونه دیدگاه خوب از نظر بازی و کارگردانی و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و فیلمبرداری و موسیقی و کارگردانی و داستان <sep>
<s>نمونه دیدگاه هم خوب هم بد از نظر فیلمبرداری و داستان و بازی <sep>
<s>نمونه دیدگاه منفی از نظر صحنه و فیلمبرداری و داستان <sep>
<s>نمونه دیدگاه خیلی خوب از نظر بازی و کارگردانی و داستان <sep>
```
## Questions?
Post a Github issue on the [ParsGPT2 Issues](https://github.com/hooshvare/parsgpt/issues) repo.
|
HScomcom/gpt2-fairytales
|
HScomcom
| 2021-05-21T10:16:43Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
### Model information
Fine tuning data: https://www.kaggle.com/cuddlefish/fairy-tales
License: CC0: Public Domain
Base model: gpt-2 large
Epoch: 30
Train runtime: 17861.6048 secs
Loss: 0.0412
API page: [Ainize](https://ainize.ai/fpem123/GPT2-FairyTales?branch=master)
Demo page: [End-point](https://master-gpt2-fairy-tales-fpem123.endpoint.ainize.ai/)
### ===Teachable NLP=== ###
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
And my other fairytale model: [showcase](https://forum.ainetwork.ai/t/teachable-nlp-gpt-2-fairy-tales/68)
|
HScomcom/gpt2-MyLittlePony
|
HScomcom
| 2021-05-21T10:09:36Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
The model that generates the My little pony script
Fine tuning data: [Kaggle](https://www.kaggle.com/liury123/my-little-pony-transcript?select=clean_dialog.csv)
API page: [Ainize](https://ainize.ai/fpem123/GPT2-MyLittlePony)
Demo page: [End point](https://master-gpt2-my-little-pony-fpem123.endpoint.ainize.ai/)
### Model information
Base model: gpt-2 large
Epoch: 30
Train runtime: 4943.9641 secs
Loss: 0.0291
###===Teachable NLP===
To train a GPT-2 model, write code and require GPU resources, but can easily fine-tune and get an API to use the model here for free.
Teachable NLP: [Teachable NLP](https://ainize.ai/teachable-nlp)
Tutorial: [Tutorial](https://forum.ainetwork.ai/t/teachable-nlp-how-to-use-teachable-nlp/65?utm_source=community&utm_medium=huggingface&utm_campaign=model&utm_content=teachable%20nlp)
|
Ferch423/gpt2-small-portuguese-wikipediabio
|
Ferch423
| 2021-05-21T09:42:53Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"pt",
"wikipedia",
"finetuning",
"dataset:wikipedia",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
language: "pt"
tags:
- pt
- wikipedia
- gpt2
- finetuning
datasets:
- wikipedia
widget:
- "André Um"
- "Maria do Santos"
- "Roberto Carlos"
licence: "mit"
---
# GPT2-SMALL-PORTUGUESE-WIKIPEDIABIO
This is a finetuned model version of gpt2-small-portuguese(https://huggingface.co/pierreguillou/gpt2-small-portuguese) by pierreguillou.
It was trained on a person abstract dataset extracted from DBPEDIA (over 100000 people's abstracts). The model is intended as a simple and fun experiment for generating texts abstracts based on ordinary people's names.
|
lg/ghpy_40k
|
lg
| 2021-05-20T23:37:47Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# This model is probably not what you're looking for.
|
urduhack/roberta-urdu-small
|
urduhack
| 2021-05-20T22:52:23Z | 884 | 8 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"roberta-urdu-small",
"urdu",
"ur",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ur
thumbnail: https://raw.githubusercontent.com/urduhack/urduhack/master/docs/_static/urduhack.png
tags:
- roberta-urdu-small
- urdu
- transformers
license: mit
---
## roberta-urdu-small
[](https://github.com/urduhack/urduhack/blob/master/LICENSE)
### Overview
**Language model:** roberta-urdu-small
**Model size:** 125M
**Language:** Urdu
**Training data:** News data from urdu news resources in Pakistan
### About roberta-urdu-small
roberta-urdu-small is a language model for urdu language.
```
from transformers import pipeline
fill_mask = pipeline("fill-mask", model="urduhack/roberta-urdu-small", tokenizer="urduhack/roberta-urdu-small")
```
## Training procedure
roberta-urdu-small was trained on urdu news corpus. Training data was normalized using normalization module from
urduhack to eliminate characters from other languages like arabic.
### About Urduhack
Urduhack is a Natural Language Processing (NLP) library for urdu language.
Github: https://github.com/urduhack/urduhack
|
thatdramebaazguy/roberta-base-wikimovies
|
thatdramebaazguy
| 2021-05-20T22:29:54Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"roberta-base",
"masked-language-modeling",
"dataset:wikimovies",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
datasets:
- wikimovies
language:
- English
thumbnail:
tags:
- roberta
- roberta-base
- masked-language-modeling
license: cc-by-4.0
---
# roberta-base for MLM
```
model_name = "thatdramebaazguy/roberta-base-wikimovies"
pipeline(model=model_name, tokenizer=model_name, revision="v1.0", task="Fill-Mask")
```
## Overview
**Language model:** roberta-base
**Language:** English
**Downstream-task:** Fill-Mask
**Training data:** wikimovies
**Eval data:** wikimovies
**Infrastructure**: 2x Tesla v100
**Code:** See [example](https://github.com/adityaarunsinghal/Domain-Adaptation/blob/master/shell_scripts/train_movie_roberta.sh)
## Hyperparameters
```
num_examples = 4346
batch_size = 16
n_epochs = 3
base_LM_model = "roberta-base"
learning_rate = 5e-05
max_query_length=64
Gradient Accumulation steps = 1
Total optimization steps = 816
evaluation_strategy=IntervalStrategy.NO
prediction_loss_only=False
per_device_train_batch_size=8
per_device_eval_batch_size=8
adam_beta1=0.9
adam_beta2=0.999
adam_epsilon=1e-08,
max_grad_norm=1.0
lr_scheduler_type=SchedulerType.LINEAR
warmup_ratio=0.0
seed=42
eval_steps=500
metric_for_best_model=None
greater_is_better=None
label_smoothing_factor=0.0
```
## Performance
perplexity = 4.3808
Some of my work:
- [Domain-Adaptation Project](https://github.com/adityaarunsinghal/Domain-Adaptation/)
---
|
textattack/roberta-base-rotten-tomatoes
|
textattack
| 2021-05-20T22:17:29Z | 34 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 64, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.9033771106941839, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-WNLI
|
textattack
| 2021-05-20T22:13:50Z | 42 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 5e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.5633802816901409, as measured by the
eval set accuracy, found after 0 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-STS-B
|
textattack
| 2021-05-20T22:12:47Z | 24 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 8, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a regression task, the model was trained with a mean squared error loss function.
The best score the model achieved on this task was 0.9108696741479216, as measured by the
eval set pearson correlation, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-RTE
|
textattack
| 2021-05-20T22:10:37Z | 122 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.7942238267148014, as measured by the
eval set accuracy, found after 3 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-MRPC
|
textattack
| 2021-05-20T22:07:47Z | 206 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 3e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.9117647058823529, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/roberta-base-CoLA
|
textattack
| 2021-05-20T22:05:35Z | 48,829 | 17 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Cardand the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 32, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.850431447746884, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
simonlevine/clinical-longformer
|
simonlevine
| 2021-05-20T21:25:09Z | 19 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
- You'll need to instantiate a special RoBERTa class. Though technically a "Longformer", the elongated RoBERTa model will still need to be pulled in as such.
- To do so, use the following classes:
```python
class RobertaLongSelfAttention(LongformerSelfAttention):
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=False,
):
return super().forward(hidden_states, attention_mask=attention_mask, output_attentions=output_attentions)
class RobertaLongForMaskedLM(RobertaForMaskedLM):
def __init__(self, config):
super().__init__(config)
for i, layer in enumerate(self.roberta.encoder.layer):
# replace the `modeling_bert.BertSelfAttention` object with `LongformerSelfAttention`
layer.attention.self = RobertaLongSelfAttention(config, layer_id=i)
```
- Then, pull the model as ```RobertaLongForMaskedLM.from_pretrained('simonlevine/bioclinical-roberta-long')```
- Now, it can be used as usual. Note you may get untrained weights warnings.
- Note that you can replace ```RobertaForMaskedLM``` with a different task-specific RoBERTa from Huggingface, such as RobertaForSequenceClassification.
|
pulp/CHILDES-ParentBERTo
|
pulp
| 2021-05-20T19:46:06Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
The language model trained on a fill-mask task with all the North American parent's data in CHILDES.
The parent's data can be found here: https://github.com/xiaomeng-ma/CHILDES
|
patrickvonplaten/norwegian-roberta-large
|
patrickvonplaten
| 2021-05-20T19:15:37Z | 3 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## Roberta-Large
This repo trains [roberta-large](https://huggingface.co/roberta-large) from scratch on the [Norwegian training subset of Oscar](https://oscar-corpus.com/) containing roughly 4.7 GB of data.
A ByteLevelBPETokenizer as shown in [this]( ) blog post was trained on the whole [Norwegian training subset of Oscar](https://oscar-corpus.com/).
Training is done on a TPUv3-8 in Flax. The training script as well as the script to create a tokenizer are attached below.
### Run 1
```
--weight_decay="0.01"
--max_seq_length="128"
--train_batch_size="1048"
--eval_batch_size="1048"
--learning_rate="1e-3"
--warmup_steps="2000"
--pad_to_max_length
--num_train_epochs="12"
--adam_beta1="0.9"
--adam_beta2="0.98"
```
Trained for 12 epochs with each epoch including 8005 steps => Total of 96K steps. 1 epoch + eval takes roughly 2 hours 40 minutes => trained in total for 1 day and 8 hours. Final loss was 3.695.
**Acc**:

**Loss**:

### Run 2
```
--weight_decay="0.01"
--max_seq_length="128"
--train_batch_size="1048"
--eval_batch_size="1048"
--learning_rate="5e-3"
--warmup_steps="2000"
--pad_to_max_length
--num_train_epochs="7"
--adam_beta1="0.9"
--adam_beta2="0.98"
```
Trained for 7 epochs with each epoch including 8005 steps => Total of 96K steps. 1 epoch + eval takes roughly 2 hours 40 minutes => trained in total for 18 hours. Final loss was 2.216 and accuracy 0.58.
**Acc**:

**Loss**:

|
nyu-mll/roberta-med-small-1M-2
|
nyu-mll
| 2021-05-20T19:07:56Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-med-small-1M-1
|
nyu-mll
| 2021-05-20T19:06:25Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-1B-1
|
nyu-mll
| 2021-05-20T19:03:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-100M-3
|
nyu-mll
| 2021-05-20T18:56:02Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-100M-2
|
nyu-mll
| 2021-05-20T18:54:59Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nyu-mll/roberta-base-100M-1
|
nyu-mll
| 2021-05-20T18:53:55Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
nkoh01/MSRoberta
|
nkoh01
| 2021-05-20T18:51:20Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MSRoBERTa
Fine-tuned RoBERTa MLM model for [`Miscrosoft Sentence Completion Challenge`](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/MSR_SCCD.pdf). This model case-sensitive following the `Roberta-base` model.
# Model description (taken from: [here](https://huggingface.co/roberta-base))
RoBERTa is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model
randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict
the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one
after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to
learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
from transformers import pipeline,AutoModelForMaskedLM,AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("nkoh01/MSRoberta")
model = AutoModelForMaskedLM.from_pretrained("nkoh01/MSRoberta")
unmasker = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer
)
unmasker("Hello, it is a <mask> to meet you.")
[{'score': 0.9508683085441589,
'sequence': 'hello, it is a pleasure to meet you.',
'token': 10483,
'token_str': ' pleasure'},
{'score': 0.015089659951627254,
'sequence': 'hello, it is a privilege to meet you.',
'token': 9951,
'token_str': ' privilege'},
{'score': 0.013942377641797066,
'sequence': 'hello, it is a joy to meet you.',
'token': 5823,
'token_str': ' joy'},
{'score': 0.006964420434087515,
'sequence': 'hello, it is a delight to meet you.',
'token': 13213,
'token_str': ' delight'},
{'score': 0.0024567877408117056,
'sequence': 'hello, it is a honour to meet you.',
'token': 6671,
'token_str': ' honour'}]
```
## Installations
Make sure you run `!pip install transformers` command to install the transformers library before running the commands above.
## Bias and limitations
Under construction.
|
mrm8488/roberta-large-finetuned-wsc
|
mrm8488
| 2021-05-20T18:30:59Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"arxiv:1905.06290",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# RoBERTa (large) fine-tuned on Winograd Schema Challenge (WSC) data
Step from its original [repo](https://github.com/pytorch/fairseq/blob/master/examples/roberta/wsc/README.md)
The following instructions can be used to finetune RoBERTa on the WSC training
data provided by [SuperGLUE](https://super.gluebenchmark.com/).
Note that there is high variance in the results. For our GLUE/SuperGLUE
submission we swept over the learning rate (1e-5, 2e-5, 3e-5), batch size (16,
32, 64) and total number of updates (500, 1000, 2000, 3000), as well as the
random seed. Out of ~100 runs we chose the best 7 models and ensembled them.
**Approach:** The instructions below use a slightly different loss function than
what's described in the original RoBERTa arXiv paper. In particular,
[Kocijan et al. (2019)](https://arxiv.org/abs/1905.06290) introduce a margin
ranking loss between `(query, candidate)` pairs with tunable hyperparameters
alpha and beta. This is supported in our code as well with the `--wsc-alpha` and
`--wsc-beta` arguments. However, we achieved slightly better (and more robust)
results on the development set by instead using a single cross entropy loss term
over the log-probabilities for the query and all mined candidates. **The
candidates are mined using spaCy from each input sentence in isolation, so the
approach remains strictly pointwise.** This reduces the number of
hyperparameters and our best model achieved 92.3% development set accuracy,
compared to ~90% accuracy for the margin loss. Later versions of the RoBERTa
arXiv paper will describe this updated formulation.
### 1) Download the WSC data from the SuperGLUE website:
```bash
wget https://dl.fbaipublicfiles.com/glue/superglue/data/v2/WSC.zip
unzip WSC.zip
# we also need to copy the RoBERTa dictionary into the same directory
wget -O WSC/dict.txt https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt
```
### 2) Finetune over the provided training data:
```bash
TOTAL_NUM_UPDATES=2000 # Total number of training steps.
WARMUP_UPDATES=250 # Linearly increase LR over this many steps.
LR=2e-05 # Peak LR for polynomial LR scheduler.
MAX_SENTENCES=16 # Batch size per GPU.
SEED=1 # Random seed.
ROBERTA_PATH=/path/to/roberta/model.pt
# we use the --user-dir option to load the task and criterion
# from the examples/roberta/wsc directory:
FAIRSEQ_PATH=/path/to/fairseq
FAIRSEQ_USER_DIR=${FAIRSEQ_PATH}/examples/roberta/wsc
CUDA_VISIBLE_DEVICES=0,1,2,3 fairseq-train WSC/ \
--restore-file $ROBERTA_PATH \
--reset-optimizer --reset-dataloader --reset-meters \
--no-epoch-checkpoints --no-last-checkpoints --no-save-optimizer-state \
--best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
--valid-subset val \
--fp16 --ddp-backend no_c10d \
--user-dir $FAIRSEQ_USER_DIR \
--task wsc --criterion wsc --wsc-cross-entropy \
--arch roberta_large --bpe gpt2 --max-positions 512 \
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
--optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
--lr-scheduler polynomial_decay --lr $LR \
--warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_NUM_UPDATES \
--max-sentences $MAX_SENTENCES \
--max-update $TOTAL_NUM_UPDATES \
--log-format simple --log-interval 100 \
--seed $SEED
```
The above command assumes training on 4 GPUs, but you can achieve the same
results on a single GPU by adding `--update-freq=4`.
### 3) Evaluate
```python
from fairseq.models.roberta import RobertaModel
from examples.roberta.wsc import wsc_utils # also loads WSC task and criterion
roberta = RobertaModel.from_pretrained('checkpoints', 'checkpoint_best.pt', 'WSC/')
roberta.cuda()
nsamples, ncorrect = 0, 0
for sentence, label in wsc_utils.jsonl_iterator('WSC/val.jsonl', eval=True):
pred = roberta.disambiguate_pronoun(sentence)
nsamples += 1
if pred == label:
ncorrect += 1
print('Accuracy: ' + str(ncorrect / float(nsamples)))
# Accuracy: 0.9230769230769231
```
## RoBERTa training on WinoGrande dataset
We have also provided `winogrande` task and criterion for finetuning on the
[WinoGrande](https://mosaic.allenai.org/projects/winogrande) like datasets
where there are always two candidates and one is correct.
It's more efficient implementation for such subcases.
```bash
TOTAL_NUM_UPDATES=23750 # Total number of training steps.
WARMUP_UPDATES=2375 # Linearly increase LR over this many steps.
LR=1e-05 # Peak LR for polynomial LR scheduler.
MAX_SENTENCES=32 # Batch size per GPU.
SEED=1 # Random seed.
ROBERTA_PATH=/path/to/roberta/model.pt
# we use the --user-dir option to load the task and criterion
# from the examples/roberta/wsc directory:
FAIRSEQ_PATH=/path/to/fairseq
FAIRSEQ_USER_DIR=${FAIRSEQ_PATH}/examples/roberta/wsc
cd fairseq
CUDA_VISIBLE_DEVICES=0 fairseq-train winogrande_1.0/ \
--restore-file $ROBERTA_PATH \
--reset-optimizer --reset-dataloader --reset-meters \
--no-epoch-checkpoints --no-last-checkpoints --no-save-optimizer-state \
--best-checkpoint-metric accuracy --maximize-best-checkpoint-metric \
--valid-subset val \
--fp16 --ddp-backend no_c10d \
--user-dir $FAIRSEQ_USER_DIR \
--task winogrande --criterion winogrande \
--wsc-margin-alpha 5.0 --wsc-margin-beta 0.4 \
--arch roberta_large --bpe gpt2 --max-positions 512 \
--dropout 0.1 --attention-dropout 0.1 --weight-decay 0.01 \
--optimizer adam --adam-betas '(0.9, 0.98)' --adam-eps 1e-06 \
--lr-scheduler polynomial_decay --lr $LR \
--warmup-updates $WARMUP_UPDATES --total-num-update $TOTAL_NUM_UPDATES \
--max-sentences $MAX_SENTENCES \
--max-update $TOTAL_NUM_UPDATES \
--log-format simple --log-interval 100
```
[Original repo](https://github.com/pytorch/fairseq/tree/master/examples/roberta/wsc)
|
mrm8488/roberta-base-1B-1-finetuned-squadv2
|
mrm8488
| 2021-05-20T18:27:20Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"en",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
---
# RoBERTa-base (1B-1) + SQuAD v2 ❓
[roberta-base-1B-1](https://huggingface.co/nyu-mll/roberta-base-1B-1) fine-tuned on [SQUAD v2 dataset](https://rajpurkar.github.io/SQuAD-explorer/explore/v2.0/dev/) for **Q&A** downstream task.
## Details of the downstream task (Q&A) - Model 🧠
RoBERTa Pretrained on Smaller Datasets
[NYU Machine Learning for Language](https://huggingface.co/nyu-mll) pretrained RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). They released 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: They combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
## Details of the downstream task (Q&A) - Dataset 📚
**S**tanford **Q**uestion **A**nswering **D**ataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
**SQuAD2.0** combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
## Model training 🏋️
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
python transformers/examples/question-answering/run_squad.py \
--model_type roberta \
--model_name_or_path 'nyu-mll/roberta-base-1B-1' \
--do_eval \
--do_train \
--do_lower_case \
--train_file /content/dataset/train-v2.0.json \
--predict_file /content/dataset/dev-v2.0.json \
--per_gpu_train_batch_size 16 \
--learning_rate 3e-5 \
--num_train_epochs 10 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/output \
--overwrite_output_dir \
--save_steps 1000 \
--version_2_with_negative
```
## Test set Results 🧾
| Metric | # Value |
| ------ | --------- |
| **EM** | **64.86** |
| **F1** | **68.99** |
```json
{
'exact': 64.86145034953255,
'f1': 68.9902640378272,
'total': 11873,
'HasAns_exact': 64.03508771929825,
'HasAns_f1': 72.3045554860189,
'HasAns_total': 5928,
'NoAns_exact': 65.68544995794785,
'NoAns_f1': 65.68544995794785,
'NoAns_total': 5945,
'best_exact': 64.86987282068559,
'best_exact_thresh': 0.0,
'best_f1': 68.99868650898054,
'best_f1_thresh': 0.0
}
```
### Model in action 🚀
Fast usage with **pipelines**:
```python
from transformers import pipeline
QnA_pipeline = pipeline('question-answering', model='mrm8488/roberta-base-1B-1-finetuned-squadv2')
QnA_pipeline({
'context': 'A new strain of flu that has the potential to become a pandemic has been identified in China by scientists.',
'question': 'What has been discovered by scientists from China ?'
})
# Output:
{'answer': 'A new strain of flu', 'end': 19, 'score': 0.7145650685380576,'start': 0}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/codeBERTaJS
|
mrm8488
| 2021-05-20T18:17:36Z | 10 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"javascript",
"code",
"arxiv:1909.09436",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: code
thumbnail:
tags:
- javascript
- code
widget:
- text: "async function createUser(req, <mask>) { if (!validUser(req.body.user)) { return res.status(400); } user = userService.createUser(req.body.user); return res.json(user); }"
---
# CodeBERTaJS
CodeBERTaJS is a RoBERTa-like model trained on the [CodeSearchNet](https://github.blog/2019-09-26-introducing-the-codesearchnet-challenge/) dataset from GitHub for `javaScript` by [Manuel Romero](https://twitter.com/mrm8488)
The **tokenizer** is a Byte-level BPE tokenizer trained on the corpus using Hugging Face `tokenizers`.
Because it is trained on a corpus of code (vs. natural language), it encodes the corpus efficiently (the sequences are between 33% to 50% shorter, compared to the same corpus tokenized by gpt2/roberta).
The (small) **model** is a 6-layer, 84M parameters, RoBERTa-like Transformer model – that’s the same number of layers & heads as DistilBERT – initialized from the default initialization settings and trained from scratch on the full `javascript` corpus (120M after preproccessing) for 2 epochs.
## Quick start: masked language modeling prediction
```python
JS_CODE = """
async function createUser(req, <mask>) {
if (!validUser(req.body.user)) {
\t return res.status(400);
}
user = userService.createUser(req.body.user);
return res.json(user);
}
""".lstrip()
```
### Does the model know how to complete simple JS/express like code?
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="mrm8488/codeBERTaJS",
tokenizer="mrm8488/codeBERTaJS"
)
fill_mask(JS_CODE)
## Top 5 predictions:
#
'res' # prob 0.069489665329
'next'
'req'
'user'
',req'
```
### Yes! That was easy 🎉 Let's try with another example
```python
JS_CODE_= """
function getKeys(obj) {
keys = [];
for (var [key, value] of Object.entries(obj)) {
keys.push(<mask>);
}
return keys
}
""".lstrip()
```
Results:
```python
'obj', 'key', ' value', 'keys', 'i'
```
> Not so bad! Right token was predicted as second option! 🎉
## This work is heavely inspired on [codeBERTa](https://github.com/huggingface/transformers/blob/master/model_cards/huggingface/CodeBERTa-small-v1/README.md) by huggingface team
<br>
## CodeSearchNet citation
<details>
```bibtex
@article{husain_codesearchnet_2019,
\ttitle = {{CodeSearchNet} {Challenge}: {Evaluating} the {State} of {Semantic} {Code} {Search}},
\tshorttitle = {{CodeSearchNet} {Challenge}},
\turl = {http://arxiv.org/abs/1909.09436},
\turldate = {2020-03-12},
\tjournal = {arXiv:1909.09436 [cs, stat]},
\tauthor = {Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc},
\tmonth = sep,
\tyear = {2019},
\tnote = {arXiv: 1909.09436},
}
```
</details>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/chEMBL26_smiles_v2
|
mrm8488
| 2021-05-20T18:16:29Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"drugs",
"chemist",
"drug design",
"smile",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- drugs
- chemist
- drug design
- smile
widget:
- text: "CC(C)CN(CC(OP(=O)(O)O)C(Cc1ccccc1)NC(=O)OC1CCOC1)S(=O)(=O)c1ccc(N)<mask>"
---
|
mrm8488/RuPERTa-base-finetuned-squadv1
|
mrm8488
| 2021-05-20T18:13:28Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"es",
"dataset:squad",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: es
datasets:
- squad
---
|
mrm8488/RoBERTinha
|
mrm8488
| 2021-05-20T18:03:32Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"gl",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: gl
widget:
- text: "Galicia é unha <mask> autónoma española."
- text: "A lingua oficial de Galicia é o <mask>."
---
# RoBERTinha: RoBERTa-like Language model trained on OSCAR Galician corpus
|
julien-c/dummy-unknown
|
julien-c
| 2021-05-20T17:31:14Z | 61,031 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"ci",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
tags:
- ci
---
## Dummy model used for unit testing and CI
```python
import json
import os
from transformers import RobertaConfig, RobertaForMaskedLM, TFRobertaForMaskedLM
DIRNAME = "./dummy-unknown"
config = RobertaConfig(10, 20, 1, 1, 40)
model = RobertaForMaskedLM(config)
model.save_pretrained(DIRNAME)
tf_model = TFRobertaForMaskedLM.from_pretrained(DIRNAME, from_pt=True)
tf_model.save_pretrained(DIRNAME)
# Tokenizer:
vocab = [
"l",
"o",
"w",
"e",
"r",
"s",
"t",
"i",
"d",
"n",
"\u0120",
"\u0120l",
"\u0120n",
"\u0120lo",
"\u0120low",
"er",
"\u0120lowest",
"\u0120newer",
"\u0120wider",
"<unk>",
]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
vocab_file = os.path.join(DIRNAME, "vocab.json")
merges_file = os.path.join(DIRNAME, "merges.txt")
with open(vocab_file, "w", encoding="utf-8") as fp:
fp.write(json.dumps(vocab_tokens) + "\n")
with open(merges_file, "w", encoding="utf-8") as fp:
fp.write("\n".join(merges))
```
|
idjotherwise/autonlp-reading_prediction-172506
|
idjotherwise
| 2021-05-20T16:57:07Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autonlp",
"en",
"dataset:idjotherwise/autonlp-data-reading_prediction",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- idjotherwise/autonlp-data-reading_prediction
---
# Model Trained Using AutoNLP
- Problem type: Single Column Regression
- Model ID: 172506
## Validation Metrics
- Loss: 0.03257797285914421
- MSE: 0.03257797285914421
- MAE: 0.14246532320976257
- R2: 0.9693824457290849
- RMSE: 0.18049369752407074
- Explained Variance: 0.9699198007583618
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/idjotherwise/autonlp-reading_prediction-172506
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("idjotherwise/autonlp-reading_prediction-172506")
tokenizer = AutoTokenizer.from_pretrained("idjotherwise/autonlp-reading_prediction-172506")
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
iarfmoose/roberta-small-bulgarian
|
iarfmoose
| 2021-05-20T16:54:01Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-small-bulgarian
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This is a smaller version of [RoBERTa-base-bulgarian](https://huggingface.co/iarfmoose/roberta-small-bulgarian) with only 6 hidden layers, but similar performance.
## Intended uses
This model can be used for cloze tasks (masked language modeling) or finetuned on other tasks in Bulgarian.
## Limitations and bias
The training data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
This model was trained on the following data:
- [bg_dedup from OSCAR](https://oscar-corpus.com/)
- [Newscrawl 1 million sentences 2017 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
- [Wikipedia 1 million sentences 2016 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
## Training procedure
The model was pretrained using a masked language-modeling objective with dynamic masking as described [here](https://huggingface.co/roberta-base#preprocessing)
It was trained for 160k steps. The batch size was limited to 8 due to GPU memory limitations.
|
iarfmoose/roberta-base-bulgarian
|
iarfmoose
| 2021-05-20T16:50:24Z | 29 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-base-bulgarian
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This is a version of [RoBERTa-base](https://huggingface.co/roberta-base) pretrained on Bulgarian text.
## Intended uses
This model can be used for cloze tasks (masked language modeling) or finetuned on other tasks in Bulgarian.
## Limitations and bias
The training data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
This model was trained on the following data:
- [bg_dedup from OSCAR](https://oscar-corpus.com/)
- [Newscrawl 1 million sentences 2017 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
- [Wikipedia 1 million sentences 2016 from Leipzig Corpora Collection](https://wortschatz.uni-leipzig.de/en/download/bulgarian)
## Training procedure
The model was pretrained using a masked language-modeling objective with dynamic masking as described [here](https://huggingface.co/roberta-base#preprocessing)
It was trained for 200k steps. The batch size was limited to 8 due to GPU memory limitations.
|
iarfmoose/roberta-base-bulgarian-pos
|
iarfmoose
| 2021-05-20T16:49:07Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"token-classification",
"bg",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: bg
---
# RoBERTa-base-bulgarian-POS
The RoBERTa model was originally introduced in [this paper](https://arxiv.org/abs/1907.11692). This model is a version of [RoBERTa-base-Bulgarian](https://huggingface.co/iarfmoose/roberta-base-bulgarian) fine-tuned for part-of-speech tagging.
## Intended uses
The model can be used to predict part-of-speech tags in Bulgarian text. Since the tokenizer uses byte-pair encoding, each word in the text may be split into more than one token. When predicting POS-tags, the last token from each word can be used. Using the last token was found to slightly outperform predictions based on the first token.
An example of this can be found [here](https://github.com/iarfmoose/bulgarian-nlp/blob/master/models/postagger.py).
## Limitations and bias
The pretraining data is unfiltered text from the internet and may contain all sorts of biases.
## Training data
In addition to the pretraining data used in [RoBERTa-base-Bulgarian]([RoBERTa-base-Bulgarian](https://huggingface.co/iarfmoose/roberta-base-bulgarian)), the model was trained on the UPOS tags from [UD_Bulgarian-BTB](https://github.com/UniversalDependencies/UD_Bulgarian-BTB).
## Training procedure
The model was trained for 5 epochs over the training set. The loss was calculated based on label predictions for the last POS-tag for each word. The model achieves 97% on the test set.
|
hashk1/EsperBERTo-malgranda
|
hashk1
| 2021-05-20T16:38:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"eo",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: eo
thumbnail: https://huggingface.co/blog/assets/01_how-to-train/EsperBERTo-thumbnail-v2.png
widget:
- text: "Ĉu vi paloras la <mask> Esperanto?"
---
## EsperBERTo: RoBERTa-like Language model trained on Esperanto
|
elgeish/cs224n-squad2.0-roberta-base
|
elgeish
| 2021-05-20T16:16:38Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"question-answering",
"arxiv:2004.07067",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
## CS224n SQuAD2.0 Project Dataset
The goal of this model is to save CS224n students GPU time when establishing
baselines to beat for the [Default Final Project](http://web.stanford.edu/class/cs224n/project/default-final-project-handout.pdf).
The training set used to fine-tune this model is the same as
the [official one](https://rajpurkar.github.io/SQuAD-explorer/); however,
evaluation and model selection were performed using roughly half of the official
dev set, 6078 examples, picked at random. The data files can be found at
<https://github.com/elgeish/squad/tree/master/data> — this is the Winter 2020
version. Given that the official SQuAD2.0 dev set contains the project's test
set, students must make sure not to use the official SQuAD2.0 dev set in any way
— including the use of models fine-tuned on the official SQuAD2.0, since they
used the official SQuAD2.0 dev set for model selection.
## Results
```json
{
"exact": 75.32082922013821,
"f1": 78.66699523704254,
"total": 6078,
"HasAns_exact": 74.84536082474227,
"HasAns_f1": 81.83436324767868,
"HasAns_total": 2910,
"NoAns_exact": 75.75757575757575,
"NoAns_f1": 75.75757575757575,
"NoAns_total": 3168,
"best_exact": 75.32082922013821,
"best_exact_thresh": 0.0,
"best_f1": 78.66699523704266,
"best_f1_thresh": 0.0
}
```
## Notable Arguments
```json
{
"do_lower_case": true,
"doc_stride": 128,
"fp16": false,
"fp16_opt_level": "O1",
"gradient_accumulation_steps": 24,
"learning_rate": 3e-05,
"max_answer_length": 30,
"max_grad_norm": 1,
"max_query_length": 64,
"max_seq_length": 384,
"model_name_or_path": "roberta-base",
"model_type": "roberta",
"num_train_epochs": 4,
"per_gpu_train_batch_size": 16,
"save_steps": 5000,
"seed": 42,
"train_batch_size": 16,
"version_2_with_negative": true,
"warmup_steps": 0,
"weight_decay": 0
}
```
## Environment Setup
```json
{
"transformers": "2.5.1",
"pytorch": "1.4.0=py3.6_cuda10.1.243_cudnn7.6.3_0",
"python": "3.6.5=hc3d631a_2",
"os": "Linux 4.15.0-1060-aws #62-Ubuntu SMP Tue Feb 11 21:23:22 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux",
"gpu": "Tesla V100-SXM2-16GB"
}
```
## How to Cite
```BibTeX
@misc{elgeish2020gestalt,
title={Gestalt: a Stacking Ensemble for SQuAD2.0},
author={Mohamed El-Geish},
journal={arXiv e-prints},
archivePrefix={arXiv},
eprint={2004.07067},
year={2020},
}
```
## Related Models
* [elgeish/cs224n-squad2.0-albert-base-v2](https://huggingface.co/elgeish/cs224n-squad2.0-albert-base-v2)
* [elgeish/cs224n-squad2.0-albert-large-v2](https://huggingface.co/elgeish/cs224n-squad2.0-albert-large-v2)
* [elgeish/cs224n-squad2.0-albert-xxlarge-v1](https://huggingface.co/elgeish/cs224n-squad2.0-albert-xxlarge-v1)
* [elgeish/cs224n-squad2.0-distilbert-base-uncased](https://huggingface.co/elgeish/cs224n-squad2.0-distilbert-base-uncased)
|
deepampatel/roberta-mlm-marathi
|
deepampatel
| 2021-05-20T15:58:32Z | 13 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"mr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "mr"
---
# Welcome to Roberta-Marathi-MLM
## Model Description
> This is a small language model for [Marathi](https://en.wikipedia.org/wiki/Marathi) language with 1M data samples taken from
[OSCAR page](https://oscar-public.huma-num.fr/shuffled/mr_dedup.txt.gz)
## Training params
- **Dataset** - 1M data samples are used to train this model from OSCAR page(https://oscar-corpus.com/) eventhough data set is of 2.7 GB due to resource constraint to train
I have picked only 1M data from the total 2.7GB data set. If you are interested in collaboration and have computational resources to train on you are most welcome to do so.
- **Preprocessing** - ByteLevelBPETokenizer is used to tokenize the sentences at character level and vocabulary size is set to 52k as per standard values given by 🤗
<!-- - **Hyperparameters** - __ByteLevelBPETokenizer__ : vocabulary size = 52_000 and min_frequency = 2
__Trainer__ : num_train_epochs=12 - trained for 12 epochs
per_gpu_train_batch_size=64 - batch size for the datasamples is 64
save_steps=10_000 - save model for every 10k steps
save_total_limit=2 - save limit is set for 2 -->
**Intended uses & limitations**
this is for anyone who wants to make use of marathi language models for various tasks like language generation, translation and many more use cases.
**Whatever else is helpful!**
If you are intersted in collaboration feel free to reach me [Deepam](mailto:[email protected])
|
dbernsohn/roberta-java
|
dbernsohn
| 2021-05-20T15:54:29Z | 13 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# roberta-java
---
language: Java
datasets:
- code_search_net
---
This is a [roberta](https://arxiv.org/pdf/1907.11692.pdf) pre-trained version on the [CodeSearchNet dataset](https://github.com/github/CodeSearchNet) for **Java** Mask Language Model mission.
To load the model:
(necessary packages: !pip install transformers sentencepiece)
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, pipeline
tokenizer = AutoTokenizer.from_pretrained("dbernsohn/roberta-java")
model = AutoModelWithLMHead.from_pretrained("dbernsohn/roberta-java")
fill_mask = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer
)
```
You can then use this model to fill masked words in a Java code.
```python
code = """
String[] cars = {"Volvo", "BMW", "Ford", "Mazda"};
for (String i : cars) {
System.out.<mask>(i);
}
""".lstrip()
pred = {x["token_str"].replace("Ġ", ""): x["score"] for x in fill_mask(code)}
sorted(pred.items(), key=lambda kv: kv[1], reverse=True)
# [('println', 0.32571351528167725),
# ('get', 0.2897663116455078),
# ('remove', 0.0637081190943718),
# ('exit', 0.058875661343336105),
# ('print', 0.034190207719802856)]
```
The whole training process and hyperparameters are in my [GitHub repo](https://github.com/DorBernsohn/CodeLM/tree/main/CodeMLM)
> Created by [Dor Bernsohn](https://www.linkedin.com/in/dor-bernsohn-70b2b1146/)
|
clue/roberta_chinese_large
|
clue
| 2021-05-20T15:28:53Z | 12 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"zh",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: zh
---
## roberta_chinese_large
### Overview
**Language model:** roberta-large
**Model size:** 1.2G
**Language:** Chinese
**Training data:** [CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020)
**Eval data:** [CLUE dataset](https://github.com/CLUEbenchmark/CLUE)
### Results
For results on downstream tasks like text classification, please refer to [this repository](https://github.com/CLUEbenchmark/CLUE).
### Usage
**NOTE:** You have to call **BertTokenizer** instead of RobertaTokenizer !!!
```
import torch
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("clue/roberta_chinese_large")
roberta = BertModel.from_pretrained("clue/roberta_chinese_large")
```
### About CLUE benchmark
Organization of Language Understanding Evaluation benchmark for Chinese: tasks & datasets, baselines, pre-trained Chinese models, corpus and leaderboard.
Github: https://github.com/CLUEbenchmark
Website: https://www.cluebenchmarks.com/
|
clue/roberta_chinese_base
|
clue
| 2021-05-20T15:23:58Z | 317 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"zh",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: zh
---
## roberta_chinese_base
### Overview
**Language model:** roberta-base
**Model size:** 392M
**Language:** Chinese
**Training data:** [CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020)
**Eval data:** [CLUE dataset](https://github.com/CLUEbenchmark/CLUE)
### Results
For results on downstream tasks like text classification, please refer to [this repository](https://github.com/CLUEbenchmark/CLUE).
### Usage
**NOTE:** You have to call **BertTokenizer** instead of RobertaTokenizer !!!
```
import torch
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("clue/roberta_chinese_base")
roberta = BertModel.from_pretrained("clue/roberta_chinese_base")
```
### About CLUE benchmark
Organization of Language Understanding Evaluation benchmark for Chinese: tasks & datasets, baselines, pre-trained Chinese models, corpus and leaderboard.
Github: https://github.com/CLUEbenchmark
Website: https://www.cluebenchmarks.com/
|
clue/roberta_chinese_3L312_clue_tiny
|
clue
| 2021-05-20T15:22:48Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"zh",
"arxiv:2003.01355",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: zh
---
# Introduction
This model was trained on TPU and the details are as follows:
## Model
##
| Model_name | params | size | Training_corpus | Vocab |
| :------------------------------------------ | :----- | :------- | :----------------- | :-----------: |
| **`RoBERTa-tiny-clue`** <br/>Super_small_model | 7.5M | 28.3M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-tiny-pair`** <br/>Super_small_sentence_pair_model | 7.5M | 28.3M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-tiny3L768-clue`** <br/>small_model | 38M | 110M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-tiny3L312-clue`** <br/>small_model | <7.5M | 24M | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-large-clue`** <br/> Large_model | 290M | 1.20G | **CLUECorpus2020** | **CLUEVocab** |
| **`RoBERTa-large-pair`** <br/>Large_sentence_pair_model | 290M | 1.20G | **CLUECorpus2020** | **CLUEVocab** |
### Usage
With the help of[Huggingface-Transformers 2.5.1](https://github.com/huggingface/transformers), you could use these model as follows
```
tokenizer = BertTokenizer.from_pretrained("MODEL_NAME")
model = BertModel.from_pretrained("MODEL_NAME")
```
`MODEL_NAME`:
| Model_NAME | MODEL_LINK |
| -------------------------- | ------------------------------------------------------------ |
| **RoBERTa-tiny-clue** | [`clue/roberta_chinese_clue_tiny`](https://huggingface.co/clue/roberta_chinese_clue_tiny) |
| **RoBERTa-tiny-pair** | [`clue/roberta_chinese_pair_tiny`](https://huggingface.co/clue/roberta_chinese_pair_tiny) |
| **RoBERTa-tiny3L768-clue** | [`clue/roberta_chinese_3L768_clue_tiny`](https://huggingface.co/clue/roberta_chinese_3L768_clue_tiny) |
| **RoBERTa-tiny3L312-clue** | [`clue/roberta_chinese_3L312_clue_tiny`](https://huggingface.co/clue/roberta_chinese_3L312_clue_tiny) |
| **RoBERTa-large-clue** | [`clue/roberta_chinese_clue_large`](https://huggingface.co/clue/roberta_chinese_clue_large) |
| **RoBERTa-large-pair** | [`clue/roberta_chinese_pair_large`](https://huggingface.co/clue/roberta_chinese_pair_large) |
## Details
Please read <a href='https://arxiv.org/pdf/2003.01355'>https://arxiv.org/pdf/2003.01355.
Please visit our repository: https://github.com/CLUEbenchmark/CLUEPretrainedModels.git
|
castorini/ance-msmarco-doc-maxp
|
castorini
| 2021-05-20T15:17:50Z | 11 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"arxiv:2007.00808",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
This model is converted from the original ANCE [repo](https://github.com/microsoft/ANCE) and fitted into Pyserini:
> Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, Arnold Overwijk. [Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval](https://arxiv.org/pdf/2007.00808.pdf)
For more details on how to use it, check our experiments in [Pyserini](https://github.com/castorini/pyserini/blob/master/docs/experiments-ance.md)
|
aychang/roberta-base-imdb
|
aychang
| 2021-05-20T14:25:56Z | 1,446 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"en",
"dataset:imdb",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
tags:
- text-classification
license: mit
datasets:
- imdb
metrics:
---
# IMDB Sentiment Task: roberta-base
## Model description
A simple base roBERTa model trained on the "imdb" dataset.
## Intended uses & limitations
#### How to use
##### Transformers
```python
# Load model and tokenizer
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Use pipeline
from transformers import pipeline
model_name = "aychang/roberta-base-imdb"
nlp = pipeline("sentiment-analysis", model=model_name, tokenizer=model_name)
results = nlp(["I didn't really like it because it was so terrible.", "I love how easy it is to watch and get good results."])
```
##### AdaptNLP
```python
from adaptnlp import EasySequenceClassifier
model_name = "aychang/roberta-base-imdb"
texts = ["I didn't really like it because it was so terrible.", "I love how easy it is to watch and get good results."]
classifer = EasySequenceClassifier
results = classifier.tag_text(text=texts, model_name_or_path=model_name, mini_batch_size=2)
```
#### Limitations and bias
This is minimal language model trained on a benchmark dataset.
## Training data
IMDB https://huggingface.co/datasets/imdb
## Training procedure
#### Hardware
One V100
#### Hyperparameters and Training Args
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='./models',
overwrite_output_dir=False,
num_train_epochs=2,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
evaluation_strategy="steps",
logging_dir='./logs',
fp16=False,
eval_steps=800,
save_steps=300000
)
```
## Eval results
```
{'epoch': 2.0,
'eval_accuracy': 0.94668,
'eval_f1': array([0.94603457, 0.94731017]),
'eval_loss': 0.2578844428062439,
'eval_precision': array([0.95762642, 0.93624502]),
'eval_recall': array([0.93472, 0.95864]),
'eval_runtime': 244.7522,
'eval_samples_per_second': 102.144}
```
|
patrickvonplaten/bert-base-cased_fine_tuned_glue_mrpc_demo
|
patrickvonplaten
| 2021-05-20T14:17:38Z | 6 | 0 |
transformers
|
[
"transformers",
"jax",
"bert",
"text-classification",
"en",
"dataset:glue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
datasets:
- glue
---
# Bert-base-cased Fine Tuned Glue Mrpc Demo
This checkpoint was initialized from the pre-trained checkpoint bert-base-cased and subsequently fine-tuned on GLUE task: mrpc using [this](https://colab.research.google.com/drive/162pW3wonGcMMrGxmA-jdxwy1rhqXd90x?usp=sharing) notebook.
Training was conducted for 3 epochs, using a linear decaying learning rate of 2e-05, and a total batch size of 32.
The model has a final training loss of 0.103 and a accuracy of 0.831.
|
abhishek/autonlp-imdb_sentiment_classification-31154
|
abhishek
| 2021-05-20T12:46:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"roberta",
"text-classification",
"autonlp",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 31154
## Validation Metrics
- Loss: 0.19292379915714264
- Accuracy: 0.9395
- Precision: 0.9569557080474111
- Recall: 0.9204
- AUC: 0.9851040399999998
- F1: 0.9383219492302988
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-imdb_sentiment_classification-31154
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-imdb_sentiment_classification-31154", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-imdb_sentiment_classification-31154", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
HooshvareLab/roberta-fa-zwnj-base-ner
|
HooshvareLab
| 2021-05-20T11:55:34Z | 113 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"token-classification",
"fa",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
language: fa
---
# RobertaNER
This model fine-tuned for the Named Entity Recognition (NER) task on a mixed NER dataset collected from [ARMAN](https://github.com/HaniehP/PersianNER), [PEYMA](http://nsurl.org/2019-2/tasks/task-7-named-entity-recognition-ner-for-farsi/), and [WikiANN](https://elisa-ie.github.io/wikiann/) that covered ten types of entities:
- Date (DAT)
- Event (EVE)
- Facility (FAC)
- Location (LOC)
- Money (MON)
- Organization (ORG)
- Percent (PCT)
- Person (PER)
- Product (PRO)
- Time (TIM)
## Dataset Information
| | Records | B-DAT | B-EVE | B-FAC | B-LOC | B-MON | B-ORG | B-PCT | B-PER | B-PRO | B-TIM | I-DAT | I-EVE | I-FAC | I-LOC | I-MON | I-ORG | I-PCT | I-PER | I-PRO | I-TIM |
|:------|----------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|--------:|
| Train | 29133 | 1423 | 1487 | 1400 | 13919 | 417 | 15926 | 355 | 12347 | 1855 | 150 | 1947 | 5018 | 2421 | 4118 | 1059 | 19579 | 573 | 7699 | 1914 | 332 |
| Valid | 5142 | 267 | 253 | 250 | 2362 | 100 | 2651 | 64 | 2173 | 317 | 19 | 373 | 799 | 387 | 717 | 270 | 3260 | 101 | 1382 | 303 | 35 |
| Test | 6049 | 407 | 256 | 248 | 2886 | 98 | 3216 | 94 | 2646 | 318 | 43 | 568 | 888 | 408 | 858 | 263 | 3967 | 141 | 1707 | 296 | 78 |
## Evaluation
The following tables summarize the scores obtained by model overall and per each class.
**Overall**
| Model | accuracy | precision | recall | f1 |
|:----------:|:--------:|:---------:|:--------:|:--------:|
| Roberta | 0.994849 | 0.949816 | 0.960235 | 0.954997 |
**Per entities**
| | number | precision | recall | f1 |
|:---: |:------: |:---------: |:--------: |:--------: |
| DAT | 407 | 0.844869 | 0.869779 | 0.857143 |
| EVE | 256 | 0.948148 | 1.000000 | 0.973384 |
| FAC | 248 | 0.957529 | 1.000000 | 0.978304 |
| LOC | 2884 | 0.965422 | 0.968100 | 0.966759 |
| MON | 98 | 0.937500 | 0.918367 | 0.927835 |
| ORG | 3216 | 0.943662 | 0.958333 | 0.950941 |
| PCT | 94 | 1.000000 | 0.968085 | 0.983784 |
| PER | 2646 | 0.957030 | 0.959562 | 0.958294 |
| PRO | 318 | 0.963636 | 1.000000 | 0.981481 |
| TIM | 43 | 0.739130 | 0.790698 | 0.764045 |
## How To Use
You use this model with Transformers pipeline for NER.
### Installing requirements
```bash
pip install transformers
```
### How to predict using pipeline
```python
from transformers import AutoTokenizer
from transformers import AutoModelForTokenClassification # for pytorch
from transformers import TFAutoModelForTokenClassification # for tensorflow
from transformers import pipeline
model_name_or_path = "HooshvareLab/roberta-fa-zwnj-base-ner"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForTokenClassification.from_pretrained(model_name_or_path) # Pytorch
# model = TFAutoModelForTokenClassification.from_pretrained(model_name_or_path) # Tensorflow
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "در سال ۲۰۱۳ درگذشت و آندرتیکر و کین برای او مراسم یادبود گرفتند."
ner_results = nlp(example)
print(ner_results)
```
## Questions?
Post a Github issue on the [ParsNER Issues](https://github.com/hooshvare/parsner/issues) repo.
|
zanelim/singbert-large-sg
|
zanelim
| 2021-05-20T09:36:17Z | 9 | 4 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"singapore",
"sg",
"singlish",
"malaysia",
"ms",
"manglish",
"bert-large-uncased",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
tags:
- singapore
- sg
- singlish
- malaysia
- ms
- manglish
- bert-large-uncased
license: mit
datasets:
- reddit singapore, malaysia
- hardwarezone
widget:
- text: "kopi c siew [MASK]"
- text: "die [MASK] must try"
---
# Model name
SingBert Large - Bert for Singlish (SG) and Manglish (MY).
## Model description
Similar to [SingBert](https://huggingface.co/zanelim/singbert) but the large version, which was initialized from [BERT large uncased (whole word masking)](https://github.com/google-research/bert#pre-trained-models), with pre-training finetuned on
[singlish](https://en.wikipedia.org/wiki/Singlish) and [manglish](https://en.wikipedia.org/wiki/Manglish) data.
## Intended uses & limitations
#### How to use
```python
>>> from transformers import pipeline
>>> nlp = pipeline('fill-mask', model='zanelim/singbert-large-sg')
>>> nlp("kopi c siew [MASK]")
[{'sequence': '[CLS] kopi c siew dai [SEP]',
'score': 0.9003700017929077,
'token': 18765,
'token_str': 'dai'},
{'sequence': '[CLS] kopi c siew mai [SEP]',
'score': 0.0779474675655365,
'token': 14736,
'token_str': 'mai'},
{'sequence': '[CLS] kopi c siew. [SEP]',
'score': 0.0032227332703769207,
'token': 1012,
'token_str': '.'},
{'sequence': '[CLS] kopi c siew bao [SEP]',
'score': 0.0017727474914863706,
'token': 25945,
'token_str': 'bao'},
{'sequence': '[CLS] kopi c siew peng [SEP]',
'score': 0.0012526646023616195,
'token': 26473,
'token_str': 'peng'}]
>>> nlp("one teh c siew dai, and one kopi [MASK]")
[{'sequence': '[CLS] one teh c siew dai, and one kopi. [SEP]',
'score': 0.5249741077423096,
'token': 1012,
'token_str': '.'},
{'sequence': '[CLS] one teh c siew dai, and one kopi o [SEP]',
'score': 0.27349168062210083,
'token': 1051,
'token_str': 'o'},
{'sequence': '[CLS] one teh c siew dai, and one kopi peng [SEP]',
'score': 0.057190295308828354,
'token': 26473,
'token_str': 'peng'},
{'sequence': '[CLS] one teh c siew dai, and one kopi c [SEP]',
'score': 0.04022320732474327,
'token': 1039,
'token_str': 'c'},
{'sequence': '[CLS] one teh c siew dai, and one kopi? [SEP]',
'score': 0.01191170234233141,
'token': 1029,
'token_str': '?'}]
>>> nlp("die [MASK] must try")
[{'sequence': '[CLS] die die must try [SEP]',
'score': 0.9921030402183533,
'token': 3280,
'token_str': 'die'},
{'sequence': '[CLS] die also must try [SEP]',
'score': 0.004993876442313194,
'token': 2036,
'token_str': 'also'},
{'sequence': '[CLS] die liao must try [SEP]',
'score': 0.000317625846946612,
'token': 727,
'token_str': 'liao'},
{'sequence': '[CLS] die still must try [SEP]',
'score': 0.0002260878391098231,
'token': 2145,
'token_str': 'still'},
{'sequence': '[CLS] die i must try [SEP]',
'score': 0.00016935862367972732,
'token': 1045,
'token_str': 'i'}]
>>> nlp("dont play [MASK] leh")
[{'sequence': '[CLS] dont play play leh [SEP]',
'score': 0.9079819321632385,
'token': 2377,
'token_str': 'play'},
{'sequence': '[CLS] dont play punk leh [SEP]',
'score': 0.006846973206847906,
'token': 7196,
'token_str': 'punk'},
{'sequence': '[CLS] dont play games leh [SEP]',
'score': 0.004041737411171198,
'token': 2399,
'token_str': 'games'},
{'sequence': '[CLS] dont play politics leh [SEP]',
'score': 0.003728888463228941,
'token': 4331,
'token_str': 'politics'},
{'sequence': '[CLS] dont play cheat leh [SEP]',
'score': 0.0032805048394948244,
'token': 21910,
'token_str': 'cheat'}]
>>> nlp("confirm plus [MASK]")
{'sequence': '[CLS] confirm plus chop [SEP]',
'score': 0.9749826192855835,
'token': 24494,
'token_str': 'chop'},
{'sequence': '[CLS] confirm plus chopped [SEP]',
'score': 0.017554156482219696,
'token': 24881,
'token_str': 'chopped'},
{'sequence': '[CLS] confirm plus minus [SEP]',
'score': 0.002725469646975398,
'token': 15718,
'token_str': 'minus'},
{'sequence': '[CLS] confirm plus guarantee [SEP]',
'score': 0.000900257145985961,
'token': 11302,
'token_str': 'guarantee'},
{'sequence': '[CLS] confirm plus one [SEP]',
'score': 0.0004384620988275856,
'token': 2028,
'token_str': 'one'}]
>>> nlp("catch no [MASK]")
[{'sequence': '[CLS] catch no ball [SEP]',
'score': 0.9381157159805298,
'token': 3608,
'token_str': 'ball'},
{'sequence': '[CLS] catch no balls [SEP]',
'score': 0.060842301696538925,
'token': 7395,
'token_str': 'balls'},
{'sequence': '[CLS] catch no fish [SEP]',
'score': 0.00030917322146706283,
'token': 3869,
'token_str': 'fish'},
{'sequence': '[CLS] catch no breath [SEP]',
'score': 7.552534952992573e-05,
'token': 3052,
'token_str': 'breath'},
{'sequence': '[CLS] catch no tail [SEP]',
'score': 4.208395694149658e-05,
'token': 5725,
'token_str': 'tail'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('zanelim/singbert-large-sg')
model = BertModel.from_pretrained("zanelim/singbert-large-sg")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained("zanelim/singbert-large-sg")
model = TFBertModel.from_pretrained("zanelim/singbert-large-sg")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
#### Limitations and bias
This model was finetuned on colloquial Singlish and Manglish corpus, hence it is best applied on downstream tasks involving the main
constituent languages- english, mandarin, malay. Also, as the training data is mainly from forums, beware of existing inherent bias.
## Training data
Colloquial singlish and manglish (both are a mixture of English, Mandarin, Tamil, Malay, and other local dialects like Hokkien, Cantonese or Teochew)
corpus. The corpus is collected from subreddits- `r/singapore` and `r/malaysia`, and forums such as `hardwarezone`.
## Training procedure
Initialized with [bert large uncased (whole word masking)](https://github.com/google-research/bert#pre-trained-models) vocab and checkpoints (pre-trained weights).
Top 1000 custom vocab tokens (non-overlapped with original bert vocab) were further extracted from training data and filled into unused tokens in original bert vocab.
Pre-training was further finetuned on training data with the following hyperparameters
* train_batch_size: 512
* max_seq_length: 128
* num_train_steps: 300000
* num_warmup_steps: 5000
* learning_rate: 2e-5
* hardware: TPU v3-8
|
tugstugi/bert-large-mongolian-uncased
|
tugstugi
| 2021-05-20T08:19:28Z | 44 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"mongolian",
"uncased",
"mn",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "mn"
tags:
- bert
- mongolian
- uncased
---
# BERT-LARGE-MONGOLIAN-UNCASED
[Link to Official Mongolian-BERT repo](https://github.com/tugstugi/mongolian-bert)
## Model description
This repository contains pre-trained Mongolian [BERT](https://arxiv.org/abs/1810.04805) models trained by [tugstugi](https://github.com/tugstugi), [enod](https://github.com/enod) and [sharavsambuu](https://github.com/sharavsambuu).
Special thanks to [nabar](https://github.com/nabar) who provided 5x TPUs.
This repository is based on the following open source projects: [google-research/bert](https://github.com/google-research/bert/),
[huggingface/pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT) and [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('tugstugi/bert-large-mongolian-uncased', use_fast=False)
model = AutoModelForMaskedLM.from_pretrained('tugstugi/bert-large-mongolian-uncased')
## declare task ##
pipe = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
## example ##
input_ = 'Монгол улсын [MASK] Улаанбаатар хотоос ярьж байна.'
output_ = pipe(input_)
for i in range(len(output_)):
print(output_[i])
## output ##
# {'sequence': 'монгол улсын нийслэл улаанбаатар хотоос ярьж байна.', 'score': 0.7867621183395386, 'token': 849, 'token_str': 'нийслэл'}
# {'sequence': 'монгол улсын ерөнхийлөгч улаанбаатар хотоос ярьж байна.', 'score': 0.14303277432918549, 'token': 244, 'token_str': 'ерөнхийлөгч'}
# {'sequence': 'монгол улсын ерөнхийлөгчийг улаанбаатар хотоос ярьж байна.', 'score': 0.011642335914075375, 'token': 8373, 'token_str': 'ерөнхийлөгчийг'}
# {'sequence': 'монгол улсын иргэд улаанбаатар хотоос ярьж байна.', 'score': 0.006592822726815939, 'token': 247, 'token_str': 'иргэд'}
# {'sequence': 'монгол улсын нийслэлийг улаанбаатар хотоос ярьж байна.', 'score': 0.006165097933262587, 'token': 15501, 'token_str': 'нийслэлийг'}
```
## Training data
Mongolian Wikipedia and the 700 million word Mongolian news data set [[Pretraining Procedure](https://github.com/tugstugi/mongolian-bert#pre-training)]
### BibTeX entry and citation info
```bibtex
@misc{mongolian-bert,
author = {Tuguldur, Erdene-Ochir and Gunchinish, Sharavsambuu and Bataa, Enkhbold},
title = {BERT Pretrained Models on Mongolian Datasets},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tugstugi/mongolian-bert/}}
}
```
|
tugstugi/bert-large-mongolian-cased
|
tugstugi
| 2021-05-20T08:16:24Z | 28 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"mongolian",
"cased",
"mn",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "mn"
tags:
- bert
- mongolian
- cased
---
# BERT-LARGE-MONGOLIAN-CASED
[Link to Official Mongolian-BERT repo](https://github.com/tugstugi/mongolian-bert)
## Model description
This repository contains pre-trained Mongolian [BERT](https://arxiv.org/abs/1810.04805) models trained by [tugstugi](https://github.com/tugstugi), [enod](https://github.com/enod) and [sharavsambuu](https://github.com/sharavsambuu).
Special thanks to [nabar](https://github.com/nabar) who provided 5x TPUs.
This repository is based on the following open source projects: [google-research/bert](https://github.com/google-research/bert/),
[huggingface/pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT) and [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('tugstugi/bert-large-mongolian-cased', use_fast=False)
model = AutoModelForMaskedLM.from_pretrained('tugstugi/bert-large-mongolian-cased')
## declare task ##
pipe = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
## example ##
input_ = 'Монгол улсын [MASK] Улаанбаатар хотоос ярьж байна.'
output_ = pipe(input_)
for i in range(len(output_)):
print(output_[i])
## output ##
# {'sequence': 'Монгол улсын нийслэл Улаанбаатар хотоос ярьж байна.', 'score': 0.9779232740402222, 'token': 1176, 'token_str': 'нийслэл'}
# {'sequence': 'Монгол улсын Нийслэл Улаанбаатар хотоос ярьж байна.', 'score': 0.015034765936434269, 'token': 4059, 'token_str': 'Нийслэл'}
# {'sequence': 'Монгол улсын Ерөнхийлөгч Улаанбаатар хотоос ярьж байна.', 'score': 0.0021413620561361313, 'token': 325, 'token_str': 'Ерөнхийлөгч'}
# {'sequence': 'Монгол улсын ерөнхийлөгч Улаанбаатар хотоос ярьж байна.', 'score': 0.0008035294013097882, 'token': 1215, 'token_str': 'ерөнхийлөгч'}
# {'sequence': 'Монгол улсын нийслэлийн Улаанбаатар хотоос ярьж байна.', 'score': 0.0006434018723666668, 'token': 356, 'token_str': 'нийслэлийн'}
```
## Training data
Mongolian Wikipedia and the 700 million word Mongolian news data set [[Pretraining Procedure](https://github.com/tugstugi/mongolian-bert#pre-training)]
### BibTeX entry and citation info
```bibtex
@misc{mongolian-bert,
author = {Tuguldur, Erdene-Ochir and Gunchinish, Sharavsambuu and Bataa, Enkhbold},
title = {BERT Pretrained Models on Mongolian Datasets},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tugstugi/mongolian-bert/}}
}
```
|
tugstugi/bert-base-mongolian-cased
|
tugstugi
| 2021-05-20T08:12:07Z | 118 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"mongolian",
"cased",
"mn",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "mn"
tags:
- bert
- mongolian
- cased
---
# BERT-BASE-MONGOLIAN-CASED
[Link to Official Mongolian-BERT repo](https://github.com/tugstugi/mongolian-bert)
## Model description
This repository contains pre-trained Mongolian [BERT](https://arxiv.org/abs/1810.04805) models trained by [tugstugi](https://github.com/tugstugi), [enod](https://github.com/enod) and [sharavsambuu](https://github.com/sharavsambuu).
Special thanks to [nabar](https://github.com/nabar) who provided 5x TPUs.
This repository is based on the following open source projects: [google-research/bert](https://github.com/google-research/bert/),
[huggingface/pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT) and [yoheikikuta/bert-japanese](https://github.com/yoheikikuta/bert-japanese).
#### How to use
```python
from transformers import pipeline, AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('tugstugi/bert-base-mongolian-cased', use_fast=False)
model = AutoModelForMaskedLM.from_pretrained('tugstugi/bert-base-mongolian-cased')
## declare task ##
pipe = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
## example ##
input_ = '[MASK] хот Монгол улсын нийслэл.'
output_ = pipe(input_)
for i in range(len(output_)):
print(output_[i])
## output ##
# {'sequence': 'Улаанбаатар хот Монгол улсын нийслэл.', 'score': 0.826970100402832, 'token': 281, 'token_str': 'Улаанбаатар'}
# {'sequence': 'Нийслэл хот Монгол улсын нийслэл.', 'score': 0.06551621109247208, 'token': 4059, 'token_str': 'Нийслэл'}
# {'sequence': 'Эрдэнэт хот Монгол улсын нийслэл.', 'score': 0.0264141745865345, 'token': 2229, 'token_str': 'Эрдэнэт'}
# {'sequence': 'Дархан хот Монгол улсын нийслэл.', 'score': 0.017083868384361267, 'token': 1646, 'token_str': 'Дархан'}
# {'sequence': 'УБ хот Монгол улсын нийслэл.', 'score': 0.010854342952370644, 'token': 7389, 'token_str': 'УБ'}
```
## Training data
Mongolian Wikipedia and the 700 million word Mongolian news data set [[Pretraining Procedure](https://github.com/tugstugi/mongolian-bert#pre-training)]
### BibTeX entry and citation info
```bibtex
@misc{mongolian-bert,
author = {Tuguldur, Erdene-Ochir and Gunchinish, Sharavsambuu and Bataa, Enkhbold},
title = {BERT Pretrained Models on Mongolian Datasets},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tugstugi/mongolian-bert/}}
}
```
|
trueto/medbert-base-chinese
|
trueto
| 2021-05-20T08:08:47Z | 276 | 13 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"pretraining",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# [medbert](https://github.com/trueto/medbert)
本项目开源硕士毕业论文“BERT模型在中文临床自然语言处理中的应用探索与研究”相关模型
## 评估基准
构建了中文电子病历命名实体识别数据集(CEMRNER)、中文医学文本命名实体识别数据集(CMTNER)、
中文医学问句-问句识别数据集(CMedQQ)和中文临床文本分类数据集(CCTC)。
| **数据集** | **训练集** | **验证集** | **测试集** | **任务类型** | **语料来源** |
| ---- | ---- | ---- |---- |---- |:----:|
| CEMRNER | 965 | 138 | 276 | 命名实体识别 | 医渡云 |
| CMTNER | 14000 | 2000 | 4000 | 命名实体识别 | CHIP2020 |
| CMedQQ | 14000 | 2000 | 4000 | 句对识别 | 平安医疗 |
| CCTC | 26837 | 3834 | 7669 | 句子分类 | CHIP2019 |
## 开源模型
在6.5亿字符中文临床自然语言文本语料上基于BERT模型和Albert模型预训练获得了MedBERT和MedAlbert模型。
## 性能表现
在同等实验环境,相同训练参数和脚本下,各模型的性能表现
| **模型** | **CEMRNER** | **CMTNER** | **CMedQQ** | **CCTC** |
| :---- | :----: | :----: | :----: | :----: |
| [BERT](https://huggingface.co/bert-base-chinese) | 81.17% | 65.67% | 87.77% | 81.62% |
| [MC-BERT](https://github.com/alibaba-research/ChineseBLUE) | 80.93% | 66.15% | 89.04% | 80.65% |
| [PCL-BERT](https://code.ihub.org.cn/projects/1775) | 81.58% | 67.02% | 88.81% | 80.27% |
| MedBERT | 82.29% | 66.49% | 88.32% | **81.77%** |
|MedBERT-wwm| **82.60%** | 67.11% | 88.02% | 81.72% |
|MedBERT-kd | 82.58% | **67.27%** | **89.34%** | 80.73% |
|- | - | - | - | - |
| [Albert](https://huggingface.co/voidful/albert_chinese_base) | 79.98% | 62.42% | 86.81% | 79.83% |
| MedAlbert | 81.03% | 63.81% | 87.56% | 80.05% |
|MedAlbert-wwm| **81.28%** | **64.12%** | **87.71%** | **80.46%** |
## 引用格式
```
杨飞洪,王序文,李姣.BERT模型在中文临床自然语言处理中的应用探索与研究[EB/OL].https://github.com/trueto/medbert, 2021-03.
```
|
trituenhantaoio/bert-base-vietnamese-diacritics-uncased
|
trituenhantaoio
| 2021-05-20T08:05:47Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## Usage
```python
from transformers import BertForSequenceClassification
from transformers import BertTokenizer
model = BertForSequenceClassification.from_pretrained("trituenhantaoio/bert-base-vietnamese-diacritics-uncased")
tokenizer = BertTokenizer.from_pretrained("trituenhantaoio/bert-base-vietnamese-diacritics-uncased")
```
### References
```
@article{ttnt2020bertdiacritics,
title={Vietnamese BERT Diacritics: Pretrained on News and Wiki},
author={trituenhantao.io},
year = {2020},
publisher = {Hugging Face},
journal = {Hugging Face repository}
}
```
[trituenhantao.io](https://trituenhantao.io)
|
textattack/bert-base-uncased-yelp-polarity
|
textattack
| 2021-05-20T07:49:07Z | 16,043 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the yelp_polarity dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 5e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.9699473684210527, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/bert-base-uncased-rotten_tomatoes
|
textattack
| 2021-05-20T07:47:13Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
## bert-base-uncased fine-tuned with TextAttack on the rotten_tomatoes dataset
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 64, a learning
rate of 5e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/bert-base-uncased-imdb
|
textattack
| 2021-05-20T07:42:02Z | 17,464 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the imdb dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.89088, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/bert-base-uncased-WNLI
|
textattack
| 2021-05-20T07:39:22Z | 44 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 64, a learning
rate of 5e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.5633802816901409, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/bert-base-uncased-RTE
|
textattack
| 2021-05-20T07:36:18Z | 81 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 8, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.7256317689530686, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
textattack/bert-base-uncased-MRPC
|
textattack
| 2021-05-20T07:32:52Z | 199 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.8774509803921569, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
tennessejoyce/titlewave-bert-base-uncased
|
tennessejoyce
| 2021-05-20T07:29:09Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
license: cc-by-4.0
widget:
- text: "[Gmail API] How can I extract plain text from an email sent to me?"
---
# Titlewave: bert-base-uncased
## Model description
Titlewave is a Chrome extension that helps you choose better titles for your Stack Overflow questions. See the [github repository](https://github.com/tennessejoyce/TitleWave) for more information.
This is one of two NLP models used in the Titlewave project, and its purpose is to classify whether question will be answered or not just based on the title. The [companion model](https://huggingface.co/tennessejoyce/titlewave-t5-small) suggests a new title based on on the body of the question.
## Intended use
Try out different titles for your Stack Overflow post, and see which one gives you the best chance of receiving an answer.
You can use the model through the API on this page (hosted by HuggingFace) or install the Chrome extension by following the instructions on the [github repository](https://github.com/tennessejoyce/TitleWave), which integrates the tool directly into the Stack Overflow website.
You can also run the model locally in Python like this (which automatically downloads the model to your machine):
```python
>>> from transformers import pipeline
>>> classifier = pipeline('sentiment-analysis', model='tennessejoyce/titlewave-bert-base-uncased')
>>> classifier('[Gmail API] How can I extract plain text from an email sent to me?')
[{'label': 'Answered', 'score': 0.8053370714187622}]
```
The 'score' in the output represents the probability of getting an answer with this title: 80.5%.
## Training data
The weights were initialized from the [BERT base model](https://huggingface.co/bert-base-uncased), which was trained on BookCorpus and English Wikipedia.
Then the model was fine-tuned on the dataset of previous Stack Overflow post titles, which is publicly available [here](https://archive.org/details/stackexchange).
Specifically I used three years of posts from 2017-2019, filtered out posts which were closed (e.g., duplicates, off-topic), and selected 5% of the remaining posts at random to use in the training set, and the same amount for validation and test sets (278,155 posts each).
## Training procedure
The model was fine-tuned for two epochs with a batch size of 32 (17,384 steps total) using 16-bit mixed precision.
After some hyperparameter tuning, I found that the following two-phase training procedure yields the best performance (ROC-AUC score) on the validation set:
* In the first epoch, all layers were frozen except for the last two (pooling layer and classification layer) and a learning rate of 3e-4 was used.
* In the second epoch all layers were unfrozen, and the learning rate was decreased by a factor of 10 to 3e-5.
Otherwise, all parameters we set to the defaults listed [here](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments),
including the AdamW optimizer and a linearly decreasing learning schedule (both of which were reset between the two epochs). See the [github repository](https://github.com/tennessejoyce/TitleWave) for the scripts that were used to train the model.
## Evaluation
See [this notebook](https://github.com/tennessejoyce/TitleWave/blob/master/model_training/test_classifier.ipynb) for the performance of the title classification model on the test set.
|
socialmediaie/TRAC2020_HIN_B_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T07:00:11Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_HIN_A_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T06:58:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_ENG_C_bert-base-uncased
|
socialmediaie
| 2021-05-20T06:57:39Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
socialmediaie/TRAC2020_ALL_B_bert-base-multilingual-uncased
|
socialmediaie
| 2021-05-20T06:53:23Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020
Models and predictions for submission to TRAC - 2020 Second Workshop on Trolling, Aggression and Cyberbullying.
Our trained models as well as evaluation metrics during traing are available at: https://databank.illinois.edu/datasets/IDB-8882752#
We also make a few of our models available in HuggingFace's models repository at https://huggingface.co/socialmediaie/, these models can be further fine-tuned on your dataset of choice.
Our approach is described in our paper titled:
> Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
The source code for training this model and more details can be found on our code repository: https://github.com/socialmediaie/TRAC2020
NOTE: These models are retrained for uploading here after our submission so the evaluation measures may be slightly different from the ones reported in the paper.
If you plan to use the dataset please cite the following resources:
* Mishra, Sudhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. "Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020." In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020).
* Mishra, Shubhanshu, Shivangi Prasad, and Shubhanshu Mishra. 2020. “Trained Models for Multilingual Joint Fine-Tuning of Transformer Models for Identifying Trolling, Aggression and Cyberbullying at TRAC 2020.” University of Illinois at Urbana-Champaign. https://doi.org/10.13012/B2IDB-8882752_V1.
```
@inproceedings{Mishra2020TRAC,
author = {Mishra, Sudhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
booktitle = {Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying (TRAC-2020)},
title = {{Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
year = {2020}
}
@data{illinoisdatabankIDB-8882752,
author = {Mishra, Shubhanshu and Prasad, Shivangi and Mishra, Shubhanshu},
doi = {10.13012/B2IDB-8882752_V1},
publisher = {University of Illinois at Urbana-Champaign},
title = {{Trained models for Multilingual Joint Fine-tuning of Transformer models for identifying Trolling, Aggression and Cyberbullying at TRAC 2020}},
url = {https://doi.org/10.13012/B2IDB-8882752{\_}V1},
year = {2020}
}
```
## Usage
The models can be used via the following code:
```python
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import torch
from pathlib import Path
from scipy.special import softmax
import numpy as np
import pandas as pd
TASK_LABEL_IDS = {
"Sub-task A": ["OAG", "NAG", "CAG"],
"Sub-task B": ["GEN", "NGEN"],
"Sub-task C": ["OAG-GEN", "OAG-NGEN", "NAG-GEN", "NAG-NGEN", "CAG-GEN", "CAG-NGEN"]
}
model_version="databank" # other option is hugging face library
if model_version == "databank":
# Make sure you have downloaded the required model file from https://databank.illinois.edu/datasets/IDB-8882752
# Unzip the file at some model_path (we are using: "databank_model")
model_path = next(Path("databank_model").glob("./*/output/*/model"))
# Assuming you get the following type of structure inside "databank_model"
# 'databank_model/ALL/Sub-task C/output/bert-base-multilingual-uncased/model'
lang, task, _, base_model, _ = model_path.parts
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
else:
lang, task, base_model = "ALL", "Sub-task C", "bert-base-multilingual-uncased"
base_model = f"socialmediaie/TRAC2020_{lang}_{lang.split()[-1]}_{base_model}"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForSequenceClassification.from_pretrained(base_model)
# For doing inference set model in eval mode
model.eval()
# If you want to further fine-tune the model you can reset the model to model.train()
task_labels = TASK_LABEL_IDS[task]
sentence = "This is a good cat and this is a bad dog."
processed_sentence = f"{tokenizer.cls_token} {sentence}"
tokens = tokenizer.tokenize(sentence)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokens)
tokens_tensor = torch.tensor([indexed_tokens])
with torch.no_grad():
logits, = model(tokens_tensor, labels=None)
logits
preds = logits.detach().cpu().numpy()
preds_probs = softmax(preds, axis=1)
preds = np.argmax(preds_probs, axis=1)
preds_labels = np.array(task_labels)[preds]
print(dict(zip(task_labels, preds_probs[0])), preds_labels)
"""You should get an output as follows:
({'CAG-GEN': 0.06762535,
'CAG-NGEN': 0.03244293,
'NAG-GEN': 0.6897794,
'NAG-NGEN': 0.15498641,
'OAG-GEN': 0.034373745,
'OAG-NGEN': 0.020792078},
array(['NAG-GEN'], dtype='<U8'))
"""
```
|
sismetanin/rubert_conversational-ru-sentiment-rureviews
|
sismetanin
| 2021-05-20T06:20:54Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## RuBERT-Conversational-ru-sentiment-RuReviews
RuBERT-Conversational-ru-sentiment-RuReviews is a [RuBERT-Conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model fine-tuned on [RuReviews dataset](https://github.com/sismetanin/rureviews) of Russian-language reviews from the ”Women’s Clothes and Accessories” product category on the primary e-commerce site in Russia.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@INPROCEEDINGS{Smetanin2019Sentiment,
author={Sergey Smetanin and Michail Komarov},
booktitle={2019 IEEE 21st Conference on Business Informatics (CBI)},
title={Sentiment Analysis of Product Reviews in Russian using Convolutional Neural Networks},
year={2019},
volume={01},
pages={482-486},
doi={10.1109/CBI.2019.00062},
ISSN={2378-1963},
month={July}
}
```
|
sismetanin/rubert-ru-sentiment-rusentiment
|
sismetanin
| 2021-05-20T06:11:34Z | 416 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"sentiment analysis",
"Russian",
"ru",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- ru
tags:
- sentiment analysis
- Russian
---
## RuBERT-Base-ru-sentiment-RuSentiment
RuBERT-ru-sentiment-RuSentiment is a [RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased) model fine-tuned on [RuSentiment dataset](https://github.com/text-machine-lab/rusentiment) of general-domain Russian-language posts from the largest Russian social network, VKontakte.
<table>
<thead>
<tr>
<th rowspan="4">Model</th>
<th rowspan="4">Score<br></th>
<th rowspan="4">Rank</th>
<th colspan="12">Dataset</th>
</tr>
<tr>
<td colspan="6">SentiRuEval-2016<br></td>
<td colspan="2" rowspan="2">RuSentiment</td>
<td rowspan="2">KRND</td>
<td rowspan="2">LINIS Crowd</td>
<td rowspan="2">RuTweetCorp</td>
<td rowspan="2">RuReviews</td>
</tr>
<tr>
<td colspan="3">TC</td>
<td colspan="3">Banks</td>
</tr>
<tr>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>micro F1</td>
<td>macro F1</td>
<td>F1</td>
<td>wighted</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
<td>F1</td>
</tr>
</thead>
<tbody>
<tr>
<td>SOTA</td>
<td>n/s</td>
<td></td>
<td>76.71</td>
<td>66.40</td>
<td>70.68</td>
<td>67.51</td>
<td>69.53</td>
<td>74.06</td>
<td>78.50</td>
<td>n/s</td>
<td>73.63</td>
<td>60.51</td>
<td>83.68</td>
<td>77.44</td>
</tr>
<tr>
<td>XLM-RoBERTa-Large</td>
<td>76.37</td>
<td>1</td>
<td>82.26</td>
<td>76.36</td>
<td>79.42</td>
<td>76.35</td>
<td>76.08</td>
<td>80.89</td>
<td>78.31</td>
<td>75.27</td>
<td>75.17</td>
<td>60.03</td>
<td>88.91</td>
<td>78.81</td>
</tr>
<tr>
<td>SBERT-Large</td>
<td>75.43</td>
<td>2</td>
<td>78.40</td>
<td>71.36</td>
<td>75.14</td>
<td>72.39</td>
<td>71.87</td>
<td>77.72</td>
<td>78.58</td>
<td>75.85</td>
<td>74.20</td>
<td>60.64</td>
<td>88.66</td>
<td>77.41</td>
</tr>
<tr>
<td>MBARTRuSumGazeta</td>
<td>74.70</td>
<td>3</td>
<td>76.06</td>
<td>68.95</td>
<td>73.04</td>
<td>72.34</td>
<td>71.93</td>
<td>77.83</td>
<td>76.71</td>
<td>73.56</td>
<td>74.18</td>
<td>60.54</td>
<td>87.22</td>
<td>77.51</td>
</tr>
<tr>
<td>Conversational RuBERT</td>
<td>74.44</td>
<td>4</td>
<td>76.69</td>
<td>69.09</td>
<td>73.11</td>
<td>69.44</td>
<td>68.68</td>
<td>75.56</td>
<td>77.31</td>
<td>74.40</td>
<td>73.10</td>
<td>59.95</td>
<td>87.86</td>
<td>77.78</td>
</tr>
<tr>
<td>LaBSE</td>
<td>74.11</td>
<td>5</td>
<td>77.00</td>
<td>69.19</td>
<td>73.55</td>
<td>70.34</td>
<td>69.83</td>
<td>76.38</td>
<td>74.94</td>
<td>70.84</td>
<td>73.20</td>
<td>59.52</td>
<td>87.89</td>
<td>78.47</td>
</tr>
<tr>
<td>XLM-RoBERTa-Base</td>
<td>73.60</td>
<td>6</td>
<td>76.35</td>
<td>69.37</td>
<td>73.42</td>
<td>68.45</td>
<td>67.45</td>
<td>74.05</td>
<td>74.26</td>
<td>70.44</td>
<td>71.40</td>
<td>60.19</td>
<td>87.90</td>
<td>78.28</td>
</tr>
<tr>
<td>RuBERT</td>
<td>73.45</td>
<td>7</td>
<td>74.03</td>
<td>66.14</td>
<td>70.75</td>
<td>66.46</td>
<td>66.40</td>
<td>73.37</td>
<td>75.49</td>
<td>71.86</td>
<td>72.15</td>
<td>60.55</td>
<td>86.99</td>
<td>77.41</td>
</tr>
<tr>
<td>MBART-50-Large-Many-to-Many</td>
<td>73.15</td>
<td>8</td>
<td>75.38</td>
<td>67.81</td>
<td>72.26</td>
<td>67.13</td>
<td>66.97</td>
<td>73.85</td>
<td>74.78</td>
<td>70.98</td>
<td>71.98</td>
<td>59.20</td>
<td>87.05</td>
<td>77.24</td>
</tr>
<tr>
<td>SlavicBERT</td>
<td>71.96</td>
<td>9</td>
<td>71.45</td>
<td>63.03</td>
<td>68.44</td>
<td>64.32</td>
<td>63.99</td>
<td>71.31</td>
<td>72.13</td>
<td>67.57</td>
<td>72.54</td>
<td>58.70</td>
<td>86.43</td>
<td>77.16</td>
</tr>
<tr>
<td>EnRuDR-BERT</td>
<td>71.51</td>
<td>10</td>
<td>72.56</td>
<td>64.74</td>
<td>69.07</td>
<td>61.44</td>
<td>60.21</td>
<td>68.34</td>
<td>74.19</td>
<td>69.94</td>
<td>69.33</td>
<td>56.55</td>
<td>87.12</td>
<td>77.95</td>
</tr>
<tr>
<td>RuDR-BERT</td>
<td>71.14</td>
<td>11</td>
<td>72.79</td>
<td>64.23</td>
<td>68.36</td>
<td>61.86</td>
<td>60.92</td>
<td>68.48</td>
<td>74.65</td>
<td>70.63</td>
<td>68.74</td>
<td>54.45</td>
<td>87.04</td>
<td>77.91</td>
</tr>
<tr>
<td>MBART-50-Large</td>
<td>69.46</td>
<td>12</td>
<td>70.91</td>
<td>62.67</td>
<td>67.24</td>
<td>61.12</td>
<td>60.25</td>
<td>68.41</td>
<td>72.88</td>
<td>68.63</td>
<td>70.52</td>
<td>46.39</td>
<td>86.48</td>
<td>77.52</td>
</tr>
</tbody>
</table>
The table shows per-task scores and a macro-average of those scores to determine a models’s position on the leaderboard. For datasets with multiple evaluation metrics (e.g., macro F1 and weighted F1 for RuSentiment), we use an unweighted average of the metrics as the score for the task when computing the overall macro-average. The same strategy for comparing models’ results was applied in the GLUE benchmark.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@article{Smetanin2021Deep,
author = {Sergey Smetanin and Mikhail Komarov},
title = {Deep transfer learning baselines for sentiment analysis in Russian},
journal = {Information Processing & Management},
volume = {58},
number = {3},
pages = {102484},
year = {2021},
issn = {0306-4573},
doi = {0.1016/j.ipm.2020.102484}
}
```
Dataset:
```
@inproceedings{rogers2018rusentiment,
title={RuSentiment: An enriched sentiment analysis dataset for social media in Russian},
author={Rogers, Anna and Romanov, Alexey and Rumshisky, Anna and Volkova, Svitlana and Gronas, Mikhail and Gribov, Alex},
booktitle={Proceedings of the 27th international conference on computational linguistics},
pages={755--763},
year={2018}
}
```
|
shrugging-grace/tweetclassifier
|
shrugging-grace
| 2021-05-20T05:55:16Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# shrugging-grace/tweetclassifier
## Model description
This model classifies tweets as either relating to the Covid-19 pandemic or not.
## Intended uses & limitations
It is intended to be used on tweets commenting on UK politics, in particular those trending with the #PMQs hashtag, as this refers to weekly Prime Ministers' Questions.
#### How to use
``LABEL_0`` means that the tweet relates to Covid-19
``LABEL_1`` means that the tweet does not relate to Covid-19
## Training data
The model was trained on 1000 tweets (with the "#PMQs'), which were manually labeled by the author. The tweets were collected between May-July 2020.
### BibTeX entry and citation info
This was based on a pretrained version of BERT.
@article{devlin2018bert,
title={Bert: Pre-training of deep bidirectional transformers for language understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
|
junnyu/bert_chinese_mc_base
|
junnyu
| 2021-05-20T05:28:56Z | 8 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
https://github.com/alibaba-research/ChineseBLUE
|
sello-ralethe/bert-base-frozen-generics-mlm
|
sello-ralethe
| 2021-05-20T05:11:38Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
BERT model finetuned for masked language modeling on generics dataset by freezing all the weights of pretrained BERT except the last layer. The aim is to investigate if the model will overgeneralize generics and treat quantified statements such as 'All ducks lay eggs', 'All tigers have stripes' as if these are generics.
|
sadakmed/dpr-passage_encoder-spanish
|
sadakmed
| 2021-05-20T04:37:11Z | 1 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"dpr",
"es",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: es
tags:
- dpr
---
This is a DPR passage_encoder model, finetuned with `dpr-question_encoder-spanish` on Spanish question answering data.
|
rohanrajpal/bert-base-codemixed-uncased-sentiment
|
rohanrajpal
| 2021-05-20T04:32:54Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"hi",
"en",
"codemix",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- hi
- en
tags:
- hi
- en
- codemix
datasets:
- SAIL 2017
---
# Model name
## Model description
I took a bert-base-multilingual-cased model from huggingface and finetuned it on SAIL 2017 dataset.
## Intended uses & limitations
#### How to use
```python
# You can include sample code which will be formatted
#Coming soon!
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
I trained on the SAIL 2017 dataset [link](http://amitavadas.com/SAIL/Data/SAIL_2017.zip) on this [pretrained model](https://huggingface.co/bert-base-multilingual-cased).
## Training procedure
No preprocessing.
## Eval results
### BibTeX entry and citation info
```bibtex
@inproceedings{khanuja-etal-2020-gluecos,
title = "{GLUEC}o{S}: An Evaluation Benchmark for Code-Switched {NLP}",
author = "Khanuja, Simran and
Dandapat, Sandipan and
Srinivasan, Anirudh and
Sitaram, Sunayana and
Choudhury, Monojit",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.329",
pages = "3575--3585"
}
```
|
redewiedergabe/bert-base-historical-german-rw-cased
|
redewiedergabe
| 2021-05-20T04:11:23Z | 27 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"arxiv:1508.01991",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: de
---
# Model description
## Dataset
Trained on fictional and non-fictional German texts written between 1840 and 1920:
* Narrative texts from Digitale Bibliothek (https://textgrid.de/digitale-bibliothek)
* Fairy tales and sagas from Grimm Korpus (https://www1.ids-mannheim.de/kl/projekte/korpora/archiv/gri.html)
* Newspaper and magazine article from Mannheimer Korpus Historischer Zeitungen und Zeitschriften (https://repos.ids-mannheim.de/mkhz-beschreibung.html)
* Magazine article from the journal „Die Grenzboten“ (http://www.deutschestextarchiv.de/doku/textquellen#grenzboten)
* Fictional and non-fictional texts from Projekt Gutenberg (https://www.projekt-gutenberg.org)
## Hardware used
1 Tesla P4 GPU
## Hyperparameters
| Parameter | Value |
|-------------------------------|----------|
| Epochs | 3 |
| Gradient_accumulation_steps | 1 |
| Train_batch_size | 32 |
| Learning_rate | 0.00003 |
| Max_seq_len | 128 |
## Evaluation results: Automatic tagging of four forms of speech/thought/writing representation in historical fictional and non-fictional German texts
The language model was used in the task to tag direct, indirect, reported and free indirect speech/thought/writing representation in fictional and non-fictional German texts. The tagger is available and described in detail at https://github.com/redewiedergabe/tagger.
The tagging model was trained using the SequenceTagger Class of the Flair framework ([Akbik et al., 2019](https://www.aclweb.org/anthology/N19-4010)) which implements a BiLSTM-CRF architecture on top of a language embedding (as proposed by [Huang et al. (2015)](https://arxiv.org/abs/1508.01991)).
Hyperparameters
| Parameter | Value |
|-------------------------------|------------|
| Hidden_size | 256 |
| Learning_rate | 0.1 |
| Mini_batch_size | 8 |
| Max_epochs | 150 |
Results are reported below in comparison to a custom trained flair embedding, which was stacked onto a custom trained fastText-model. Both models were trained on the same dataset.
| | BERT ||| FastText+Flair |||Test data|
|----------------|----------|-----------|----------|------|-----------|--------|--------|
| | F1 | Precision | Recall | F1 | Precision | Recall ||
| Direct | 0.80 | 0.86 | 0.74 | 0.84 | 0.90 | 0.79 |historical German, fictional & non-fictional|
| Indirect | **0.76** | **0.79** | **0.73** | 0.73 | 0.78 | 0.68 |historical German, fictional & non-fictional|
| Reported | **0.58** | **0.69** | **0.51** | 0.56 | 0.68 | 0.48 |historical German, fictional & non-fictional|
| Free indirect | **0.57** | **0.80** | **0.44** | 0.47 | 0.78 | 0.34 |modern German, fictional|
## Intended use:
Historical German Texts (1840 to 1920)
(Showed good performance with modern German fictional texts as well)
|
ahmedabdelali/bert-base-qarib60_860k
|
ahmedabdelali
| 2021-05-20T03:48:03Z | 25 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"tf",
"bert-base-qarib60_860k",
"qarib",
"ar",
"dataset:arabic_billion_words",
"dataset:open_subtitles",
"dataset:twitter",
"arxiv:2102.10684",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ar
tags:
- pytorch
- tf
- bert-base-qarib60_860k
- qarib
datasets:
- arabic_billion_words
- open_subtitles
- twitter
metrics:
- f1
widget:
- text: " شو عندكم يا [MASK] ."
---
# QARiB: QCRI Arabic and Dialectal BERT
## About QARiB
QCRI Arabic and Dialectal BERT (QARiB) model, was trained on a collection of ~ 420 Million tweets and ~ 180 Million sentences of text.
For tweets, the data was collected using twitter API and using language filter. `lang:ar`. For text data, it was a combination from
[Arabic GigaWord](url), [Abulkhair Arabic Corpus]() and [OPUS](http://opus.nlpl.eu/).
### bert-base-qarib60_860k
- Data size: 60Gb
- Number of Iterations: 860k
- Loss: 2.2454472
## Training QARiB
The training of the model has been performed using Google’s original Tensorflow code on Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
See more details in [Training QARiB](https://github.com/qcri/QARiB/blob/main/Training_QARiB.md)
## Using QARiB
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you. For more details, see [Using QARiB](https://github.com/qcri/QARiB/blob/main/Using_QARiB.md)
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>>from transformers import pipeline
>>>fill_mask = pipeline("fill-mask", model="./models/data60gb_86k")
>>> fill_mask("شو عندكم يا [MASK]")
[{'sequence': '[CLS] شو عندكم يا عرب [SEP]', 'score': 0.0990147516131401, 'token': 2355, 'token_str': 'عرب'},
{'sequence': '[CLS] شو عندكم يا جماعة [SEP]', 'score': 0.051633741706609726, 'token': 2308, 'token_str': 'جماعة'},
{'sequence': '[CLS] شو عندكم يا شباب [SEP]', 'score': 0.046871256083250046, 'token': 939, 'token_str': 'شباب'},
{'sequence': '[CLS] شو عندكم يا رفاق [SEP]', 'score': 0.03598872944712639, 'token': 7664, 'token_str': 'رفاق'},
{'sequence': '[CLS] شو عندكم يا ناس [SEP]', 'score': 0.031996358186006546, 'token': 271, 'token_str': 'ناس'}]
>>> fill_mask("قللي وشفيييك يرحم [MASK]")
[{'sequence': '[CLS] قللي وشفيييك يرحم والديك [SEP]', 'score': 0.4152909517288208, 'token': 9650, 'token_str': 'والديك'},
{'sequence': '[CLS] قللي وشفيييك يرحملي [SEP]', 'score': 0.07663793861865997, 'token': 294, 'token_str': '##لي'},
{'sequence': '[CLS] قللي وشفيييك يرحم حالك [SEP]', 'score': 0.0453166700899601, 'token': 2663, 'token_str': 'حالك'},
{'sequence': '[CLS] قللي وشفيييك يرحم امك [SEP]', 'score': 0.04390475153923035, 'token': 1942, 'token_str': 'امك'},
{'sequence': '[CLS] قللي وشفيييك يرحمونك [SEP]', 'score': 0.027349254116415977, 'token': 3283, 'token_str': '##ونك'}]
>>> fill_mask("وقام المدير [MASK]")
[
{'sequence': '[CLS] وقام المدير بالعمل [SEP]', 'score': 0.0678194984793663, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقام المدير بذلك [SEP]', 'score': 0.05191086605191231, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقام المدير بالاتصال [SEP]', 'score': 0.045264165848493576, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقام المدير بعمله [SEP]', 'score': 0.03732728958129883, 'token': 40486, 'token_str': 'بعمله'},
{'sequence': '[CLS] وقام المدير بالامر [SEP]', 'score': 0.0246378555893898, 'token': 29124, 'token_str': 'بالامر'}
]
>>> fill_mask("وقامت المديرة [MASK]")
[{'sequence': '[CLS] وقامت المديرة بذلك [SEP]', 'score': 0.23992691934108734, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقامت المديرة بالامر [SEP]', 'score': 0.108805812895298, 'token': 29124, 'token_str': 'بالامر'},
{'sequence': '[CLS] وقامت المديرة بالعمل [SEP]', 'score': 0.06639821827411652, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقامت المديرة بالاتصال [SEP]', 'score': 0.05613093823194504, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقامت المديرة المديرة [SEP]', 'score': 0.021778125315904617, 'token': 41635, 'token_str': 'المديرة'}]
```
## Training procedure
The training of the model has been performed using Google’s original Tensorflow code on eight core Google Cloud TPU v2.
We used a Google Cloud Storage bucket, for persistent storage of training data and models.
## Eval results
We evaluated QARiB models on five NLP downstream task:
- Sentiment Analysis
- Emotion Detection
- Named-Entity Recognition (NER)
- Offensive Language Detection
- Dialect Identification
The results obtained from QARiB models outperforms multilingual BERT/AraBERT/ArabicBERT.
## Model Weights and Vocab Download
From Huggingface site: https://huggingface.co/qarib/bert-base-qarib60_860k
## Contacts
Ahmed Abdelali, Sabit Hassan, Hamdy Mubarak, Kareem Darwish and Younes Samih
## Reference
```
@article{abdelali2021pretraining,
title={Pre-Training BERT on Arabic Tweets: Practical Considerations},
author={Ahmed Abdelali and Sabit Hassan and Hamdy Mubarak and Kareem Darwish and Younes Samih},
year={2021},
eprint={2102.10684},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
ahmedabdelali/bert-base-qarib
|
ahmedabdelali
| 2021-05-20T03:42:19Z | 1,216 | 9 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"tf",
"QARiB",
"qarib",
"ar",
"dataset:arabic_billion_words",
"dataset:open_subtitles",
"dataset:twitter",
"arxiv:2102.10684",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ar
tags:
- pytorch
- tf
- QARiB
- qarib
datasets:
- arabic_billion_words
- open_subtitles
- twitter
metrics:
- f1
widget:
- text: " شو عندكم يا [MASK] ."
---
# QARiB: QCRI Arabic and Dialectal BERT
## About QARiB
QCRI Arabic and Dialectal BERT (QARiB) model, was trained on a collection of ~ 420 Million tweets and ~ 180 Million sentences of text.
For the tweets, the data was collected using twitter API and using language filter. `lang:ar`. For the text data, it was a combination from
[Arabic GigaWord](url), [Abulkhair Arabic Corpus]() and [OPUS](http://opus.nlpl.eu/).
QARiB: Is the Arabic name for "Boat".
## Model and Parameters:
- Data size: 14B tokens
- Vocabulary: 64k
- Iterations: 10M
- Number of Layers: 12
## Training QARiB
See details in [Training QARiB](https://github.com/qcri/QARIB/Training_QARiB.md)
## Using QARiB
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you. For more details, see [Using QARiB](https://github.com/qcri/QARIB/Using_QARiB.md)
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>>from transformers import pipeline
>>>fill_mask = pipeline("fill-mask", model="./models/data60gb_86k")
>>> fill_mask("شو عندكم يا [MASK]")
[{'sequence': '[CLS] شو عندكم يا عرب [SEP]', 'score': 0.0990147516131401, 'token': 2355, 'token_str': 'عرب'},
{'sequence': '[CLS] شو عندكم يا جماعة [SEP]', 'score': 0.051633741706609726, 'token': 2308, 'token_str': 'جماعة'},
{'sequence': '[CLS] شو عندكم يا شباب [SEP]', 'score': 0.046871256083250046, 'token': 939, 'token_str': 'شباب'},
{'sequence': '[CLS] شو عندكم يا رفاق [SEP]', 'score': 0.03598872944712639, 'token': 7664, 'token_str': 'رفاق'},
{'sequence': '[CLS] شو عندكم يا ناس [SEP]', 'score': 0.031996358186006546, 'token': 271, 'token_str': 'ناس'}
]
>>> fill_mask("وقام المدير [MASK]")
[
{'sequence': '[CLS] وقام المدير بالعمل [SEP]', 'score': 0.0678194984793663, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقام المدير بذلك [SEP]', 'score': 0.05191086605191231, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقام المدير بالاتصال [SEP]', 'score': 0.045264165848493576, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقام المدير بعمله [SEP]', 'score': 0.03732728958129883, 'token': 40486, 'token_str': 'بعمله'},
{'sequence': '[CLS] وقام المدير بالامر [SEP]', 'score': 0.0246378555893898, 'token': 29124, 'token_str': 'بالامر'}
]
>>> fill_mask("وقامت المديرة [MASK]")
[{'sequence': '[CLS] وقامت المديرة بذلك [SEP]', 'score': 0.23992691934108734, 'token': 984, 'token_str': 'بذلك'},
{'sequence': '[CLS] وقامت المديرة بالامر [SEP]', 'score': 0.108805812895298, 'token': 29124, 'token_str': 'بالامر'},
{'sequence': '[CLS] وقامت المديرة بالعمل [SEP]', 'score': 0.06639821827411652, 'token': 4230, 'token_str': 'بالعمل'},
{'sequence': '[CLS] وقامت المديرة بالاتصال [SEP]', 'score': 0.05613093823194504, 'token': 26096, 'token_str': 'بالاتصال'},
{'sequence': '[CLS] وقامت المديرة المديرة [SEP]', 'score': 0.021778125315904617, 'token': 41635, 'token_str': 'المديرة'}]
>>> fill_mask("قللي وشفيييك يرحم [MASK]")
[{'sequence': '[CLS] قللي وشفيييك يرحم والديك [SEP]', 'score': 0.4152909517288208, 'token': 9650, 'token_str': 'والديك'},
{'sequence': '[CLS] قللي وشفيييك يرحملي [SEP]', 'score': 0.07663793861865997, 'token': 294, 'token_str': '##لي'},
{'sequence': '[CLS] قللي وشفيييك يرحم حالك [SEP]', 'score': 0.0453166700899601, 'token': 2663, 'token_str': 'حالك'},
{'sequence': '[CLS] قللي وشفيييك يرحم امك [SEP]', 'score': 0.04390475153923035, 'token': 1942, 'token_str': 'امك'},
{'sequence': '[CLS] قللي وشفيييك يرحمونك [SEP]', 'score': 0.027349254116415977, 'token': 3283, 'token_str': '##ونك'}]
```
## Evaluations:
|**Experiment** |**mBERT**|**AraBERT0.1**|**AraBERT1.0**|**ArabicBERT**|**QARiB**|
|---------------|---------|--------------|--------------|--------------|---------|
|Dialect Identification | 6.06% | 59.92% | 59.85% | 61.70% | **65.21%** |
|Emotion Detection | 27.90% | 43.89% | 42.37% | 41.65% | **44.35%** |
|Named-Entity Recognition (NER) | 49.38% | 64.97% | **66.63%** | 64.04% | 61.62% |
|Offensive Language Detection | 83.14% | 88.07% | 88.97% | 88.19% | **91.94%** |
|Sentiment Analysis | 86.61% | 90.80% | **93.58%** | 83.27% | 93.31% |
## Model Weights and Vocab Download
From Huggingface site: https://huggingface.co/qarib/bert-base-qarib
## Contacts
Ahmed Abdelali, Sabit Hassan, Hamdy Mubarak, Kareem Darwish and Younes Samih
## Reference
```
@article{abdelali2021pretraining,
title={Pre-Training BERT on Arabic Tweets: Practical Considerations},
author={Ahmed Abdelali and Sabit Hassan and Hamdy Mubarak and Kareem Darwish and Younes Samih},
year={2021},
eprint={2102.10684},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
pucpr/bioBERTpt-squad-v1.1-portuguese
|
pucpr
| 2021-05-20T03:08:26Z | 29 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"question-answering",
"bioBERTpt",
"pt",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: pt
tags:
- question-answering
- bert
- bioBERTpt
- pytorch
metrics:
- squad
widget:
- text: "O que é AVC?"
context: "O AVC (Acidente vascular cerebral) é a segunda principal causa de morte no Brasil e a principal causa de incapacidade em adultos, retirando do mercado de trabalho milhares de brasileiros. A cada 5 minutos ocorre uma morte por AVC em nosso país. Ele é uma alteração súbita na circulação de sangue em alguma região encéfalo (composto pelo cérebro, cerebelo e tronco encefálico)."
- text: "O que significa a sigla AVC?"
context: "O AVC (Acidente vascular cerebral) é a segunda principal causa de morte no Brasil e a principal causa de incapacidade em adultos, retirando do mercado de trabalho milhares de brasileiros. A cada 5 minutos ocorre uma morte por AVC em nosso país. Ele é uma alteração súbita na circulação de sangue em alguma região encéfalo (composto pelo cérebro, cerebelo e tronco encefálico)."
- text: "Do que a região do encéfalo é composta?"
context: "O AVC (Acidente vascular cerebral) é a segunda principal causa de morte no Brasil e a principal causa de incapacidade em adultos, retirando do mercado de trabalho milhares de brasileiros. A cada 5 minutos ocorre uma morte por AVC em nosso país. Ele é uma alteração súbita na circulação de sangue em alguma região encéfalo (composto pelo cérebro, cerebelo e tronco encefálico)."
- text: "O que causa a interrupção do oxigênio?"
context: "O oxigênio é um elemento essencial para a atividade normal do nosso corpo; ele juntamente com os nutrientes são transportados pelo sangue, através das nossas artérias, estas funcionam como mangueiras direcionando o sangue para regiões específicas. Quando esse transporte é impedido e o oxigênio não chega as áreas necessárias parte do encéfalo não consegue obter o sangue (e oxigênio) de que precisa, então ele e as células sofrem lesão ou morrem. Essa interrupção pode ser causada por duas razões, um entupimento ou um vazamento nas artérias. desta forma temos dois tipos de AVC."
---
# BioBERTpt-squad-v1.1-portuguese for QA (Question Answering)
This is a clinical and biomedical model trained with generic QA questions. This model was finetuned on SQUAD v1.1, with the dataset SQUAD v1.1 in portuguese, from the Deep Learning Brasil group on Google Colab. See more details [here](https://huggingface.co/pierreguillou/bert-base-cased-squad-v1.1-portuguese).
## Performance
The results obtained are the following:
```
f1 = 80.06
exact match = 67.52
```
## See more
Our repo: https://github.com/HAILab-PUCPR/
|
phiyodr/bert-base-finetuned-squad2
|
phiyodr
| 2021-05-20T02:34:19Z | 94 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"dataset:squad2",
"arxiv:1810.04805",
"arxiv:1806.03822",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- pytorch
- question-answering
datasets:
- squad2
metrics:
- exact
- f1
widget:
- text: "What discipline did Winkelmann create?"
context: "Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. The prophet and founding hero of modern archaeology, Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art."
---
# bert-base-finetuned-squad2
## Model description
This model is based on **[bert-base-uncased](https://huggingface.co/bert-base-uncased)** and was finetuned on **[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/)**. The corresponding papers you can found [here (model)](https://arxiv.org/abs/1810.04805) and [here (data)](https://arxiv.org/abs/1806.03822).
## How to use
```python
from transformers.pipelines import pipeline
model_name = "phiyodr/bert-base-finetuned-squad2"
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
inputs = {
'question': 'What discipline did Winkelmann create?',
'context': 'Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. "The prophet and founding hero of modern archaeology", Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art. '
}
nlp(inputs)
```
## Training procedure
```
{
"base_model": "bert-base-uncased",
"do_lower_case": True,
"learning_rate": 3e-5,
"num_train_epochs": 4,
"max_seq_length": 384,
"doc_stride": 128,
"max_query_length": 64,
"batch_size": 96
}
```
## Eval results
- Data: [dev-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json)
- Script: [evaluate-v2.0.py](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/) (original script from [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/README.md))
```
{
"exact": 70.3950138970774,
"f1": 73.90527661873521,
"total": 11873,
"HasAns_exact": 71.4574898785425,
"HasAns_f1": 78.48808186475087,
"HasAns_total": 5928,
"NoAns_exact": 69.33557611438184,
"NoAns_f1": 69.33557611438184,
"NoAns_total": 5945
}
```
|
nreimers/BERT-Small-L-4_H-512_A-8
|
nreimers
| 2021-05-20T02:03:04Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
# BERT-Small-L-4_H-512_A-8
This is a port of the [BERT-Small model](https://github.com/google-research/bert) to Pytorch. It uses 4 layers, a hidden size of 512 and 8 attention heads.
|
noahjadallah/cause-effect-detection
|
noahjadallah
| 2021-05-20T02:01:13Z | 53 | 6 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
widget:
- text: "If a user signs up, he will receive a confirmation email."
---
# Cause-Effect Detection for Software Requirements Based on Token Classification with BERT
This model uses BERT to detect cause and effect from a single sentence. The focus of this model is the domain of software requirements engineering, however, it can also be used for other domains.
The model outputs one of the following 5 labels for each token:
Other
B-Cause
I-Cause
B-Effect
I-Effect
The source code can be found here: https://colab.research.google.com/drive/14V9Ooy3aNPsRfTK88krwsereia8cfSPc?usp=sharing
|
neuralmind/bert-large-portuguese-cased
|
neuralmind
| 2021-05-20T01:31:09Z | 222,365 | 66 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"pt",
"dataset:brWaC",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: pt
license: mit
tags:
- bert
- pytorch
datasets:
- brWaC
---
# BERTimbau Large (aka "bert-large-portuguese-cased")

## Introduction
BERTimbau Large is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
For further information or requests, please go to [BERTimbau repository](https://github.com/neuralmind-ai/portuguese-bert/).
## Available models
| Model | Arch. | #Layers | #Params |
| ---------------------------------------- | ---------- | ------- | ------- |
| `neuralmind/bert-base-portuguese-cased` | BERT-Base | 12 | 110M |
| `neuralmind/bert-large-portuguese-cased` | BERT-Large | 24 | 335M |
## Usage
```python
from transformers import AutoTokenizer # Or BertTokenizer
from transformers import AutoModelForPreTraining # Or BertForPreTraining for loading pretraining heads
from transformers import AutoModel # or BertModel, for BERT without pretraining heads
model = AutoModelForPreTraining.from_pretrained('neuralmind/bert-large-portuguese-cased')
tokenizer = AutoTokenizer.from_pretrained('neuralmind/bert-large-portuguese-cased', do_lower_case=False)
```
### Masked language modeling prediction example
```python
from transformers import pipeline
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer)
pipe('Tinha uma [MASK] no meio do caminho.')
# [{'score': 0.5054386258125305,
# 'sequence': '[CLS] Tinha uma pedra no meio do caminho. [SEP]',
# 'token': 5028,
# 'token_str': 'pedra'},
# {'score': 0.05616172030568123,
# 'sequence': '[CLS] Tinha uma curva no meio do caminho. [SEP]',
# 'token': 9562,
# 'token_str': 'curva'},
# {'score': 0.02348282001912594,
# 'sequence': '[CLS] Tinha uma parada no meio do caminho. [SEP]',
# 'token': 6655,
# 'token_str': 'parada'},
# {'score': 0.01795753836631775,
# 'sequence': '[CLS] Tinha uma mulher no meio do caminho. [SEP]',
# 'token': 2606,
# 'token_str': 'mulher'},
# {'score': 0.015246033668518066,
# 'sequence': '[CLS] Tinha uma luz no meio do caminho. [SEP]',
# 'token': 3377,
# 'token_str': 'luz'}]
```
### For BERT embeddings
```python
import torch
model = AutoModel.from_pretrained('neuralmind/bert-large-portuguese-cased')
input_ids = tokenizer.encode('Tinha uma pedra no meio do caminho.', return_tensors='pt')
with torch.no_grad():
outs = model(input_ids)
encoded = outs[0][0, 1:-1] # Ignore [CLS] and [SEP] special tokens
# encoded.shape: (8, 1024)
# tensor([[ 1.1872, 0.5606, -0.2264, ..., 0.0117, -0.1618, -0.2286],
# [ 1.3562, 0.1026, 0.1732, ..., -0.3855, -0.0832, -0.1052],
# [ 0.2988, 0.2528, 0.4431, ..., 0.2684, -0.5584, 0.6524],
# ...,
# [ 0.3405, -0.0140, -0.0748, ..., 0.6649, -0.8983, 0.5802],
# [ 0.1011, 0.8782, 0.1545, ..., -0.1768, -0.8880, -0.1095],
# [ 0.7912, 0.9637, -0.3859, ..., 0.2050, -0.1350, 0.0432]])
```
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
```
|
napsternxg/scibert_scivocab_uncased_ft_SDU21_AI
|
napsternxg
| 2021-05-20T01:09:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
scibert_scivocab_uncased_ft MLM pretrained on SDU21 Task 1 + 2
|
murali1996/bert-base-cased-spell-correction
|
murali1996
| 2021-05-20T01:04:57Z | 36 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
`bert-base-cased` trained for spelling correction. See [neuspell](https://github.com/neuspell/neuspell) repository for more details about training and evaluating the model.
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.