
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
yasserrmd/tamil-gemma-300m-emb
|
yasserrmd
| 2025-09-22T09:37:16Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"gemma3_text",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:51876",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:google/embeddinggemma-300m",
"base_model:finetune:google/embeddinggemma-300m",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-21T11:12:01Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:51876
- loss:MultipleNegativesRankingLoss
base_model: google/embeddinggemma-300m
widget:
- source_sentence: மூன்று ஐரோப்பிய நாடுகளை குறிப்பிடவும்.
sentences:
- வணக்கம் என்றார். கை அசைத்து விடைபெற்றான்.
- 'நிச்சயமாக, இங்கே மூன்று ஐரோப்பிய நாடுகளின் பெயர்கள் உள்ளன:
1. பிரான்ஸ்
2. ஜெர்மனி
3. இத்தாலி'
- ஒரு நபர் ஒரு புதிய நாட்டிற்கு குடிபெயர்ந்து, அதன் பழக்கவழக்கங்கள், நம்பிக்கைகள்
மற்றும் மொழியை ஏற்றுக்கொண்டு, படிப்படியாக சமூகத்தின் ஒரு பகுதியாக மாறுவதன் மூலம்
ஆதிக்கம் செலுத்தும் கலாச்சாரத்திற்கு ஏற்றவாறு மாற்றியமைக்கும் ஒரு எடுத்துக்காட்டு.
உதாரணமாக, சீனாவில் இருந்து குடியேறிய ஒருவர், நன்றி செலுத்துதல் அல்லது ஜூலை நான்காம்
தேதி போன்ற தேசிய விடுமுறைகளைக் கொண்டாடத் தொடங்கலாம், அடிக்கடி ஆங்கிலம் பேசலாம்
மற்றும் அமெரிக்க கலாச்சாரத்தில் இணைவதற்கு அமெரிக்க மதிப்புகளைத் தழுவலாம்.
- source_sentence: முட்டையிடும் மூன்று விலங்குகளின் பெயரைக் குறிப்பிடவும்.
sentences:
- முட்டையிடும் மூன்று விலங்குகள் கோழிகள், ஆமைகள் மற்றும் முதலைகள்.
- 'ஒரு காலத்தில், தொலைதூர நாட்டில், சர் ஆர்தர் என்ற ஒரு துணிச்சலான பாலடின் இருந்தார்.
அவர் ஒரு உன்னத மாவீரர், தனது ராஜா மற்றும் நாட்டின் சேவையில் அர்ப்பணிப்புடன் இருந்தார்.
சர் ஆர்தர் தனது தைரியம், வலிமை மற்றும் அசைக்க முடியாத விசுவாசத்திற்காக நாடு முழுவதும்
அறியப்பட்டார்.
ஒரு நாள், ராஜா சர் ஆர்தரை தனது கோட்டைக்கு வரவழைத்து, அவருக்கு மிகவும் அவசரமான
ஒரு தேடலை வழங்கினார். அவர் ஒரு மாயாஜால கலைப்பொருளைக் கண்டுபிடிக்க வேண்டும், இது
வாழ்க்கையின் நகை என்று அழைக்கப்படுகிறது. இந்த ரத்தினம் அனைத்து காயங்களையும் குணப்படுத்தவும்,
இறந்த நிலங்களை மீண்டும் உயிர்ப்பிக்கவும், ராஜ்யத்தின் சமநிலையை மீட்டெடுக்கவும்
சக்தியைக் கொண்டிருந்தது.
சர் ஆர்தர் அந்த சவாலை மரியாதையுடன் ஏற்றுக்கொண்டு, தனது பொருட்களை சேகரித்து, தனது
பயணத்தைத் தொடங்கினார். அவர் துரோகமான மலைகள், எரியும் பாலைவனங்கள் மற்றும் ஆழமான
காடுகள் வழியாக சவாரி செய்தார். வழியில், அவர் பல சவால்கள் மற்றும் ஆபத்துகளை சந்தித்தார்,
ஆனால் அவர் அனைத்தையும் தைரியமாக எதிர்கொண்டார்.
ஒரு நாள், சர் ஆர்தர் காட்டில் மறைந்திருந்த ஒரு பழமையான கோவிலுக்கு வந்தார். ஜீவ
ரத்தினம் வைக்கப்பட்ட இடம் இது என்பதை அவர் அறிந்திருந்தார். அவர் கோயிலுக்குள் நுழைந்தார்,
பல தடைகளைத் தாண்டி, கடுமையான மிருகங்களை எதிர்த்துப் போராடிய பிறகு, அவர் இறுதியாக
நகை வைக்கப்பட்டிருந்த அறையை அடைந்தார்.
சர் ஆர்தர், நகையை எடுக்க கையை நீட்டிய போது, கை நடுங்கியது. ஆனால் திடீரென்று
அறைக்குள் ஒரு உரத்த குரல் எதிரொலித்தது. இது நகையின் பாதுகாவலர், பல நூற்றாண்டுகளாக
அதைக் கவனித்து வந்த ஒரு பண்டைய ஆவி.
காப்பாளர் சர் ஆர்தரிடம் ஏன் வாழ்க்கையின் நகையைத் தேடினார் என்று கேட்டார். சர்
ஆர்தர் தனது தேடலையும் ராஜ்யத்திற்கான கலைப்பொருளின் முக்கியத்துவத்தையும் விளக்கினார்.
பாதுகாவலர் சர் ஆர்தரின் துணிச்சல் மற்றும் தன்னலமற்ற தன்மையால் ஈர்க்கப்பட்டார்
மற்றும் அவரை நகையை எடுக்க அனுமதித்தார்.
சர் ஆர்தர் பெரும் கொண்டாட்டத்துடன் ராஜ்யத்திற்குத் திரும்பினார். அவர் ராஜாவுக்கு
வாழ்க்கையின் நகையை வழங்கினார், மேலும் நிலம் அதன் முந்தைய மகிமைக்கு மீட்டெடுக்கப்பட்டது.
சர் ஆர்தர் ஒரு ஹீரோவாகப் போற்றப்பட்டார், மேலும் அவரது பெயர் ராஜ்யம் முழுவதும்
ஒரு புராணக்கதையாக மாறியது. அந்த நாளிலிருந்து, பாலடினின் உன்னதமான தேடலானது வீரம்,
வலிமை மற்றும் மரியாதைக்கு ஒரு உதாரணமாக நினைவுகூரப்பட்டது.'
- 'உள்ளூர் நெட்வொர்க்கை அமைப்பதற்கான படிகள் இங்கே:
1. **தேவையான வன்பொருளைப் பெறவும்:** உள்ளூர் நெட்வொர்க்கை அமைக்க, உங்களுக்கு ரூட்டர்,
ஈதர்நெட் கேபிள்கள் மற்றும் உள்ளமைக்கப்பட்ட நெட்வொர்க்கிங் திறன்கள் இல்லாத சாதனங்களுக்கான
நெட்வொர்க் அடாப்டர்கள் தேவைப்படும்.
2. **திசைவிக்கான இடத்தைத் தேர்வுசெய்க:** நெட்வொர்க் பயன்படுத்தப்படும் பகுதிக்குள்
ஒரு மைய இடத்தில் திசைவி வைக்கப்பட வேண்டும். வயர்லெஸ் சிக்னலில் குறுக்கிடக்கூடிய
பெரிய உலோகப் பொருள்கள் அல்லது சுவர்களில் இருந்து விலகி இருப்பதை உறுதிசெய்யவும்.
3. **ரோட்டரை மோடமுடன் இணைக்கவும்:** உங்கள் மோடமிலிருந்து ஈதர்நெட் கேபிளை உங்கள்
ரூட்டரில் உள்ள WAN (வைட் ஏரியா நெட்வொர்க்) போர்ட்டுடன் இணைக்கவும்.
4. **திசைவியை உள்ளமைக்கவும்:** பெரும்பாலான திசைவிகள் இயல்புநிலை பயனர்பெயர் மற்றும்
கடவுச்சொல்லுடன் வருகின்றன, அதை நீங்கள் அமைப்புகளை அணுக பயன்படுத்தலாம். உலாவியைத்
திறந்து அதன் அமைப்புகளை அணுக ரூட்டரின் ஐபி முகவரியை உள்ளிடவும். இங்கிருந்து, நீங்கள்
வயர்லெஸ் நெட்வொர்க் பெயர், பாதுகாப்பு விருப்பங்கள் மற்றும் கடவுச்சொல் போன்றவற்றை
அமைக்கலாம். உங்கள் நெட்வொர்க்கிற்கு அங்கீகரிக்கப்படாத அணுகலைத் தடுக்க, இயல்புநிலை
உள்நுழைவு விவரங்களை மாற்ற பரிந்துரைக்கப்படுகிறது.
5. **சாதனங்களை நெட்வொர்க்குடன் இணைக்கவும்:** சாதனங்களை கம்பி அல்லது வயர்லெஸ் இணைப்பு
மூலம் பிணையத்துடன் இணைக்க முடியும். கம்பி இணைப்புக்கு, சாதனத்திலிருந்து ஈதர்நெட்
கேபிளை ரூட்டரில் உள்ள லேன் போர்ட்களில் ஒன்றில் இணைக்கவும். வயர்லெஸ் இணைப்பிற்கு,
நீங்கள் முன்பு கட்டமைத்த நெட்வொர்க் பெயர் மற்றும் கடவுச்சொல்லைப் பயன்படுத்தி Wi-Fi
நெட்வொர்க்குடன் இணைக்கவும்.
6. **நெட்வொர்க்கை சோதிக்கவும்:** எல்லா சாதனங்களும் இணையத்தை அணுகி பிணையத்தில்
ஒருவருக்கொருவர் தொடர்புகொள்ள முடியுமா எனச் சரிபார்க்கவும். நெட்வொர்க்கில் உள்ள
மற்றொரு சாதனத்தின் ஐபி முகவரியை பிங் செய்வதன் மூலம் இதைச் செய்யலாம்.
உங்கள் உள்ளூர் நெட்வொர்க் இப்போது அமைக்கப்பட்டுள்ளது மற்றும் பயன்படுத்த தயாராக
உள்ளது. ரூட்டரின் ஃபார்ம்வேரைப் பாதுகாப்பாகவும் சிறப்பாகவும் வைத்திருக்க அதைத்
தொடர்ந்து புதுப்பிப்பதை உறுதிசெய்யவும்.'
- source_sentence: முடிவு மரம் கற்றல் செயல்முறையை விவரிக்கவும்.
sentences:
- குறிப்பிட்ட மதிப்பாய்வின் சூழல் இல்லாமல், அதற்கான சுருக்கத்தை என்னால் வழங்க இயலாது.
நான் சுருக்கமாகச் சொல்ல விரும்பும் மதிப்பாய்வைத் தர முடியுமா?
- 'தேசிய கீதத்தின் போது கணினிகள் ஏன் தொப்பிகளைக் கழற்றுவதில்லை?
ஏனென்றால் அவர்களிடம் மோசமான கேச் ஆசாரம் இருக்கிறது!'
- 'முடிவெடுக்கும் மரக் கற்றல் என்பது இயந்திரக் கற்றலில் வகைப்பாடு அல்லது பின்னடைவு
மாதிரிகளை உருவாக்குவதற்கு பரவலாகப் பயன்படுத்தப்படும் முறையாகும். இது முன்னறிவிப்பு
மாறிகளின் மதிப்புகளின் அடிப்படையில் துணைக்குழுக்களாக தரவுகளின் சுழல்நிலை பகிர்வை
உள்ளடக்கியது.
அல்காரிதம் முழு பயிற்சி தரவுத்தொகுப்புடன் தொடங்குகிறது, இது ரூட் முனையாக கருதப்படுகிறது.
"தூய்மை" அல்லது "தகவல் ஆதாயம்" ஆகியவற்றின் அடிப்படையில், தரவைப் பிரிப்பதற்கான
சிறந்த அம்சத்தைத் தீர்மானிப்பதே குறிக்கோள். இலக்கு மாறி கொடுக்கப்பட்ட தரவு எவ்வளவு
நன்றாகப் பிரிக்கப்படுகிறது என்பதைக் கணக்கிட இந்த அளவீடு பயன்படுத்தப்படுகிறது,
மேலும் அந்த கட்டத்தில் வகைப்படுத்தலுக்கான மிக முக்கியமான அம்சத்தைத் தேர்வுசெய்ய
அல்காரிதம் உதவுகிறது.
தேர்ந்தெடுக்கப்பட்ட அம்சம், தரவை துணைக்குழுக்களாகப் பிரித்து, சைல்டு நோட்களை உருவாக்க
பயன்படுகிறது. இந்த குழந்தை முனைகள் ஒவ்வொன்றும் மதிப்பீடு செய்யப்பட்டு மேலும் பிரிக்கப்பட்டு,
ஒரு குறிப்பிட்ட மரத்தின் ஆழத்தை அடையும் வரை அல்லது ஒரு இலை முனையில் உள்ள நிகழ்வுகளின்
எண்ணிக்கை ஒரு குறிப்பிட்ட வரம்பிற்குக் கீழே இருப்பது போன்ற ஒரு நிறுத்த அளவுகோலை
சந்திக்கும் வரை செயல்முறை மீண்டும் தொடரும்.
ஒவ்வொரு முனையிலும், எல்லா நிகழ்வுகளும் ஒரே வகுப்பைச் சேர்ந்தவை எனில், ஒரு இலை
முனை உருவாக்கப்பட்டு வகுப்புப் பெயருடன் லேபிளிடப்படும். இல்லையெனில், அல்காரிதம்
பிரிக்கப்பட வேண்டிய மற்றொரு மாறியைத் தேர்ந்தெடுத்து செயல்முறை தொடர்கிறது.
மரத்தை நிர்மாணித்த பிறகு, மரத்தின் வேர் முனையிலிருந்து இலைக் கணு வரை பயணிப்பதன்
மூலம் புதிய நிகழ்வுகளைக் கணிக்கப் பயன்படுத்தலாம். ஒவ்வொரு உள் முனையிலும், தரவுகளில்
உள்ள தொடர்புடைய அம்சத்தின் மதிப்பின் அடிப்படையில் முடிவு எடுக்கப்படுகிறது, மேலும்
தரவு பொருத்தமான குழந்தை முனைக்கு அனுப்பப்படும்.
முடிவெடுக்கும் மரக் கற்றலின் முக்கிய நன்மைகளில் ஒன்று அதன் விளக்கம் ஆகும், ஏனெனில்
மரத்தை எளிதில் காட்சிப்படுத்தலாம் மற்றும் முடிவெடுக்கும் செயல்முறை புரிந்து கொள்ள
எளிதானது. இருப்பினும், தரவுத்தொகுப்பில் சிறிய மாற்றங்களுக்கு அல்காரிதம் அதிக உணர்திறன்
கொண்டதாக இருக்கும், மேலும் மரத்தின் ஆழம் அல்லது இலை முனைகளில் உள்ள நிகழ்வுகளின்
எண்ணிக்கையைக் கட்டுப்படுத்துவதன் மூலம் அதிகப்படியான பொருத்தத்தைத் தவிர்க்க கவனமாக
இருக்க வேண்டும்.'
- source_sentence: '"காபி இயந்திரங்களை" இலக்காகக் கொண்டு தேடுபொறி உகப்பாக்கம் பிரச்சாரத்திற்கான
முக்கிய வார்த்தைகளின் பட்டியலை உருவாக்கவும்.'
sentences:
- பொய். சரியான பதில் 3 + 8 = 11.
- '1. காபி இயந்திரங்கள்
2. எஸ்பிரெசோ மெஷின்
3. காபி மேக்கர்
4. லேட் மெஷின்
5. கப்புசினோ இயந்திரம்
6. வீட்டு காபி இயந்திரம்
7. வணிக காபி இயந்திரம்
8. காபி கிரைண்டர்
9. தானியங்கி காபி இயந்திரம்
10. சிறந்த காபி இயந்திரம்
11. காபி இயந்திர மதிப்புரைகள்
12. காபி மெஷின் பிராண்டுகள்
13. காபி இயந்திரங்கள் விற்பனைக்கு
14. பீன்-டு-கப் காபி மெஷின்
15. பாட் காபி இயந்திரம்
16. வடிகட்டி காபி இயந்திரம்
17. சிங்கிள் சர்வ் காபி மெஷின்
18. காபி மற்றும் எஸ்பிரெசோ மெஷின்
19. காபி இயந்திரத்தின் விலை
20. காபி இயந்திர ஒப்பந்தங்கள்'
- "செல் பிரிவின் நிலைகளை விளக்கும் பாய்வு விளக்கப்படம் இப்படி இருக்கும்:\n\n1. இடைநிலை:\
\ செல் வளர்ந்து அதன் டிஎன்ஏவைப் பிரதிபலிக்கும் ஒரு நிலை.\n |\n2. ப்ரோபேஸ்:\
\ குரோமோசோம்கள் ஒடுங்கி காணப்படுகின்றன. அணு உறை உடைகிறது.\n |\n3. மெட்டாஃபேஸ்:\
\ கலத்தின் பூமத்திய ரேகையில் குரோமோசோம்கள் சீரமைக்கப்படுகின்றன.\n |\n\
4. அனாபேஸ்: சகோதரி குரோமாடிட்கள் செல்லின் எதிர் துருவங்களுக்கு இழுக்கப்படுகின்றன.\n\
\ |\n5. டெலோபேஸ்: குரோமோசோம்கள் சிதையத் தொடங்குகின்றன, மேலும் அணுக்கரு\
\ உறை சீர்திருத்தப்படுகிறது.\n |\n6. சைட்டோகினேசிஸ்: சைட்டோபிளாசம் பிரிந்து,\
\ மரபணு ரீதியாக ஒரே மாதிரியான இரண்டு மகள் செல்களை உருவாக்குகிறது.\n |\n\
7. புதிதாக உருவாக்கப்பட்ட கலங்களுக்கான இடைநிலையுடன் செயல்முறை மீண்டும் தொடங்குகிறது.\n\
\nமேலே உள்ள நிலைகள் யூகாரியோட்களில் உள்ள உயிரணுப் பிரிவின் ஒரு வகை மைட்டோசிஸிற்கானவை\
\ என்பதை நினைவில் கொள்ளுங்கள், ஆனால் சில உயிரினங்கள் வெவ்வேறு வகையான செல் பிரிவுகளைக்\
\ கொண்டுள்ளன."
- source_sentence: தியானத்தின் நன்மைகள் பற்றிய கட்டுரையைக் கண்டறியவும்.
sentences:
- ஒரு நிலையான வாழ்க்கை முறையை வழிநடத்துவது என்பது சுற்றுச்சூழலில் ஒருவரின் தாக்கத்தை
குறைக்கும் அதே வேளையில் தனிப்பட்ட நிறைவு மற்றும் நல்வாழ்வை அதிகரிக்கும் வகையில்
வாழ்வதாகும். நீங்கள் எப்படி நுகர்கிறீர்கள், எதை உட்கொள்கிறீர்கள் மற்றும் உங்களைச்
சுற்றியுள்ள உலகத்துடன் நீங்கள் எவ்வாறு தொடர்பு கொள்கிறீர்கள் என்பதைப் பற்றிய நனவான
தேர்வுகளை இது உள்ளடக்குகிறது. கழிவுகளைக் குறைத்தல், ஆற்றல் மற்றும் வளங்களைப் பாதுகாத்தல்
மற்றும் நிலையான நடைமுறைகள் மற்றும் தயாரிப்புகளை ஆதரிப்பதன் மூலம் இதைச் செய்யலாம்.
ஒரு நிலையான வாழ்க்கை முறை என்பது ஒருவரின் உடல், மன மற்றும் உணர்ச்சி ஆரோக்கியத்தை
கவனித்துக்கொள்வது மற்றும் மற்றவர்களுடனும் இயற்கை உலகத்துடனும் உறவுகளை வளர்ப்பதை
உள்ளடக்கியது. இறுதியில், ஒரு நிலையான வாழ்க்கை முறையை வழிநடத்துவது என்பது உங்கள்
தனிப்பட்ட தேவைகள் மற்றும் கிரகத்தின் தேவைகளுக்கு இடையில் சமநிலையை ஏற்படுத்த முயற்சிப்பது
மற்றும் உங்களுக்கும் எதிர்கால சந்ததியினருக்கும் சிறந்த எதிர்காலத்தை உருவாக்க முயல்வது.
- '1. பயனரின் அடையாளத்தைச் சரிபார்க்கவும்
2. கட்டணத்தைச் செயல்படுத்தவும்
3. காட்சி ஆர்டர் உறுதிப்படுத்தல்
4. வாடிக்கையாளர் ஆதரவை வழங்குங்கள்'
- 'தியானத்தின் நன்மைகள்: நினைவாற்றலை ஒரு பழக்கமாக மாற்ற அறிவியல் ஆதரவு காரணங்கள்
மேரி சாவர் மூலம் | மெடிக்கல் டெய்லி டைம்ஸ் | மே 3, 2021
தியானம் என்பது காலத்தின் சோதனையாக நிற்கும் ஒரு பயிற்சியாகும் மற்றும் தற்போதைய
ஆராய்ச்சி அது பல நன்மைகளைக் கொண்டுள்ளது என்பதைக் காட்டுகிறது. தியானத்தின் போது,
நம் எண்ணங்களை மெதுவாக்குவதற்கும், நம்மைப் பற்றியும் தற்போதைய தருணத்தைப் பற்றியும்
அதிக விழிப்புணர்வை ஏற்படுத்தவும், அமைதியில் மூழ்கவும் நினைவாற்றல் நுட்பங்களைப்
பயன்படுத்துகிறோம். இதைச் செய்வதன் மூலம், மேம்பட்ட மன மற்றும் உடல் ஆரோக்கியத்தின்
வெகுமதிகளை அறுவடை செய்யலாம். நினைவாற்றலை ஒரு பழக்கமாக்குவதற்கான சில அறிவியல் ஆதரவு
காரணங்கள் இங்கே உள்ளன.
1. மன அழுத்தம் மற்றும் பதட்டம் குறைகிறது
மன அழுத்தம் மற்றும் பதட்டம் ஆகியவை துரதிர்ஷ்டவசமாக மிகவும் பொதுவான நிலைமைகள்.
தியானம், வாழ்க்கையில் இடைநிறுத்தப்பட்டு, நமது ஆரோக்கியத்தை எதிர்மறையாக பாதிக்கும்
இந்த நிலைமைகளிலிருந்து சிறிது ஓய்வு பெற அனுமதிக்கிறது. தியானம் செய்வதன் மூலம்
உடலில் கார்டிசோல் என்ற மன அழுத்த ஹார்மோனின் அளவைக் குறைக்க முடியும் என்று ஆராய்ச்சி
காட்டுகிறது.
2. சுய விழிப்புணர்வை மேம்படுத்துகிறது
தியானம் நமது உள்நிலைகளுடன் மிகவும் இணக்கமாக இருக்க உதவுகிறது. மௌனத்தில் அமர்வதன்
மூலம், நமது ஆழ்ந்த எண்ணங்கள் மற்றும் உணர்ச்சிகளுடன் இணைவதற்கு நம்மை அனுமதிக்கிறோம்.
இந்த மேம்படுத்தப்பட்ட சுய-அறிவு சிறந்த முடிவெடுக்கும், மேம்படுத்தப்பட்ட உறவுகளுக்கு
வழிவகுக்கும், மேலும் நம் வாழ்வின் மீது அதிக கட்டுப்பாட்டை ஏற்படுத்துகிறது.
3. செறிவை மேம்படுத்துகிறது
தியானம் என்பது மூச்சு அல்லது மந்திரம் போன்ற ஒரு நேரத்தில் ஒரு விஷயத்தில் கவனம்
செலுத்துவதை உள்ளடக்குகிறது. இந்த செறிவு செயல் கவனம் செலுத்தும் திறனை வலுப்படுத்த
உதவுகிறது, மேலும் நமது அன்றாட வாழ்க்கையில் அதிக உற்பத்தி மற்றும் திறமையானவர்களாக
இருக்க உதவுகிறது.
4. உணர்ச்சி ஆரோக்கியத்தை மேம்படுத்துகிறது
கோபம் அல்லது சோகம் போன்ற எதிர்மறை உணர்ச்சிகளைச் சமாளிக்க தியானம் நமக்கு உதவும்.
நினைவாற்றல் நுட்பங்கள் மூலம், நம் உணர்ச்சிகளை அங்கீகரிக்கவும் ஏற்றுக்கொள்ளவும்
கற்றுக்கொள்கிறோம், இது அவற்றின் தீவிரத்தை குறைக்க வழிவகுக்கும்.
5. உடல் ஆரோக்கியத்தை மேம்படுத்துகிறது
தியானம் உயர் இரத்த அழுத்தத்தைக் குறைத்தல், நாள்பட்ட வலியைக் குறைத்தல் மற்றும்
தூக்கத்தை மேம்படுத்துதல் போன்ற பல உடல் ஆரோக்கிய நன்மைகளைப் பெறலாம். இது நோயெதிர்ப்பு
மண்டலத்தை அதிகரிக்கவும், வீக்கத்தைக் குறைக்கவும், இதய ஆரோக்கியத்தை மேம்படுத்தவும்
உதவும்.
இந்த எல்லா நன்மைகளுடனும், தியானம் ஒரு நடைமுறையாக காலத்தின் சோதனையாக நின்றதில்
ஆச்சரியமில்லை. நினைவாற்றலை ஒரு பழக்கமாக்குவதன் மூலம், நமது மன மற்றும் உடல் ஆரோக்கியத்தை
பெரிதும் மேம்படுத்தி, மகிழ்ச்சியான மற்றும் நிறைவான வாழ்க்கைக்கு வழிவகுக்கும்.'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on google/embeddinggemma-300m
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [google/embeddinggemma-300m](https://huggingface.co/google/embeddinggemma-300m). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [google/embeddinggemma-300m](https://huggingface.co/google/embeddinggemma-300m) <!-- at revision c5cfa06e5e282a820e85d57f7fb053207494f41d -->
- **Maximum Sequence Length:** 2048 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 2048, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Dense({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("yasserrmd/tamil-gemma-300m-emb")
# Run inference
queries = [
"\u0ba4\u0bbf\u0baf\u0bbe\u0ba9\u0ba4\u0bcd\u0ba4\u0bbf\u0ba9\u0bcd \u0ba8\u0ba9\u0bcd\u0bae\u0bc8\u0b95\u0bb3\u0bcd \u0baa\u0bb1\u0bcd\u0bb1\u0bbf\u0baf \u0b95\u0b9f\u0bcd\u0b9f\u0bc1\u0bb0\u0bc8\u0baf\u0bc8\u0b95\u0bcd \u0b95\u0ba3\u0bcd\u0b9f\u0bb1\u0bbf\u0baf\u0bb5\u0bc1\u0bae\u0bcd.",
]
documents = [
'தியானத்தின் நன்மைகள்: நினைவாற்றலை ஒரு பழக்கமாக மாற்ற அறிவியல் ஆதரவு காரணங்கள்\nமேரி சாவர் மூலம் | மெடிக்கல் டெய்லி டைம்ஸ் | மே 3, 2021\n\nதியானம் என்பது காலத்தின் சோதனையாக நிற்கும் ஒரு பயிற்சியாகும் மற்றும் தற்போதைய ஆராய்ச்சி அது பல நன்மைகளைக் கொண்டுள்ளது என்பதைக் காட்டுகிறது. தியானத்தின் போது, \u200b\u200b\u200b\u200bநம் எண்ணங்களை மெதுவாக்குவதற்கும், நம்மைப் பற்றியும் தற்போதைய தருணத்தைப் பற்றியும் அதிக விழிப்புணர்வை ஏற்படுத்தவும், அமைதியில் மூழ்கவும் நினைவாற்றல் நுட்பங்களைப் பயன்படுத்துகிறோம். இதைச் செய்வதன் மூலம், மேம்பட்ட மன மற்றும் உடல் ஆரோக்கியத்தின் வெகுமதிகளை அறுவடை செய்யலாம். நினைவாற்றலை ஒரு பழக்கமாக்குவதற்கான சில அறிவியல் ஆதரவு காரணங்கள் இங்கே உள்ளன.\n\n1. மன அழுத்தம் மற்றும் பதட்டம் குறைகிறது\n\nமன அழுத்தம் மற்றும் பதட்டம் ஆகியவை துரதிர்ஷ்டவசமாக மிகவும் பொதுவான நிலைமைகள். தியானம், வாழ்க்கையில் இடைநிறுத்தப்பட்டு, நமது ஆரோக்கியத்தை எதிர்மறையாக பாதிக்கும் இந்த நிலைமைகளிலிருந்து சிறிது ஓய்வு பெற அனுமதிக்கிறது. தியானம் செய்வதன் மூலம் உடலில் கார்டிசோல் என்ற மன அழுத்த ஹார்மோனின் அளவைக் குறைக்க முடியும் என்று ஆராய்ச்சி காட்டுகிறது.\n\n2. சுய விழிப்புணர்வை மேம்படுத்துகிறது\n\nதியானம் நமது உள்நிலைகளுடன் மிகவும் இணக்கமாக இருக்க உதவுகிறது. மௌனத்தில் அமர்வதன் மூலம், நமது ஆழ்ந்த எண்ணங்கள் மற்றும் உணர்ச்சிகளுடன் இணைவதற்கு நம்மை அனுமதிக்கிறோம். இந்த மேம்படுத்தப்பட்ட சுய-அறிவு சிறந்த முடிவெடுக்கும், மேம்படுத்தப்பட்ட உறவுகளுக்கு வழிவகுக்கும், மேலும் நம் வாழ்வின் மீது அதிக கட்டுப்பாட்டை ஏற்படுத்துகிறது.\n\n3. செறிவை மேம்படுத்துகிறது\n\nதியானம் என்பது மூச்சு அல்லது மந்திரம் போன்ற ஒரு நேரத்தில் ஒரு விஷயத்தில் கவனம் செலுத்துவதை உள்ளடக்குகிறது. இந்த செறிவு செயல் கவனம் செலுத்தும் திறனை வலுப்படுத்த உதவுகிறது, மேலும் நமது அன்றாட வாழ்க்கையில் அதிக உற்பத்தி மற்றும் திறமையானவர்களாக இருக்க உதவுகிறது.\n\n4. உணர்ச்சி ஆரோக்கியத்தை மேம்படுத்துகிறது\n\nகோபம் அல்லது சோகம் போன்ற எதிர்மறை உணர்ச்சிகளைச் சமாளிக்க தியானம் நமக்கு உதவும். நினைவாற்றல் நுட்பங்கள் மூலம், நம் உணர்ச்சிகளை அங்கீகரிக்கவும் ஏற்றுக்கொள்ளவும் கற்றுக்கொள்கிறோம், இது அவற்றின் தீவிரத்தை குறைக்க வழிவகுக்கும்.\n\n5. உடல் ஆரோக்கியத்தை மேம்படுத்துகிறது\n\nதியானம் உயர் இரத்த அழுத்தத்தைக் குறைத்தல், நாள்பட்ட வலியைக் குறைத்தல் மற்றும் தூக்கத்தை மேம்படுத்துதல் போன்ற பல உடல் ஆரோக்கிய நன்மைகளைப் பெறலாம். இது நோயெதிர்ப்பு மண்டலத்தை அதிகரிக்கவும், வீக்கத்தைக் குறைக்கவும், இதய ஆரோக்கியத்தை மேம்படுத்தவும் உதவும்.\n\nஇந்த எல்லா நன்மைகளுடனும், தியானம் ஒரு நடைமுறையாக காலத்தின் சோதனையாக நின்றதில் ஆச்சரியமில்லை. நினைவாற்றலை ஒரு பழக்கமாக்குவதன் மூலம், நமது மன மற்றும் உடல் ஆரோக்கியத்தை பெரிதும் மேம்படுத்தி, மகிழ்ச்சியான மற்றும் நிறைவான வாழ்க்கைக்கு வழிவகுக்கும்.',
'ஒரு நிலையான வாழ்க்கை முறையை வழிநடத்துவது என்பது சுற்றுச்சூழலில் ஒருவரின் தாக்கத்தை குறைக்கும் அதே வேளையில் தனிப்பட்ட நிறைவு மற்றும் நல்வாழ்வை அதிகரிக்கும் வகையில் வாழ்வதாகும். நீங்கள் எப்படி நுகர்கிறீர்கள், எதை உட்கொள்கிறீர்கள் மற்றும் உங்களைச் சுற்றியுள்ள உலகத்துடன் நீங்கள் எவ்வாறு தொடர்பு கொள்கிறீர்கள் என்பதைப் பற்றிய நனவான தேர்வுகளை இது உள்ளடக்குகிறது. கழிவுகளைக் குறைத்தல், ஆற்றல் மற்றும் வளங்களைப் பாதுகாத்தல் மற்றும் நிலையான நடைமுறைகள் மற்றும் தயாரிப்புகளை ஆதரிப்பதன் மூலம் இதைச் செய்யலாம். ஒரு நிலையான வாழ்க்கை முறை என்பது ஒருவரின் உடல், மன மற்றும் உணர்ச்சி ஆரோக்கியத்தை கவனித்துக்கொள்வது மற்றும் மற்றவர்களுடனும் இயற்கை உலகத்துடனும் உறவுகளை வளர்ப்பதை உள்ளடக்கியது. இறுதியில், ஒரு நிலையான வாழ்க்கை முறையை வழிநடத்துவது என்பது உங்கள் தனிப்பட்ட தேவைகள் மற்றும் கிரகத்தின் தேவைகளுக்கு இடையில் சமநிலையை ஏற்படுத்த முயற்சிப்பது மற்றும் உங்களுக்கும் எதிர்கால சந்ததியினருக்கும் சிறந்த எதிர்காலத்தை உருவாக்க முயல்வது.',
'1. பயனரின் அடையாளத்தைச் சரிபார்க்கவும்\n2. கட்டணத்தைச் செயல்படுத்தவும்\n3. காட்சி ஆர்டர் உறுதிப்படுத்தல்\n4. வாடிக்கையாளர் ஆதரவை வழங்குங்கள்',
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 768] [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[0.6374, 0.3068, 0.0996]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 51,876 training samples
* Columns: <code>sentence_0</code> and <code>sentence_1</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 |
|:--------|:-----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 9 tokens</li><li>mean: 27.35 tokens</li><li>max: 251 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 192.01 tokens</li><li>max: 751 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>குழந்தைகளின் பிறந்தநாள் விழாவை விவரிக்கும் ஒரு கதையை எழுதுங்கள்.</code> | <code>ஒரு காலத்தில், ஒரு சன்னி மதியம், பலூன்கள், ஸ்ட்ரீமர்கள் மற்றும் அலங்காரங்கள் நிறைந்த வண்ணமயமான கொல்லைப்புறத்தில் எல்லா வயதினரும் குழந்தைகளும் கூடினர். இந்த சந்தர்ப்பம் சிறிய ஜேமியின் ஐந்தாவது பிறந்தநாளாகும், மேலும் உற்சாகம் காற்றில் இருந்தது.<br><br>விருந்தினர்கள் ஒவ்வொருவராக வரும்போது, ஒவ்வொருவரும் பிறந்தநாள் சிறுவனுக்கு அல்லது பெண்ணுக்குப் பரிசுகளைத் தாங்கிக் கொண்டு, பார்ட்டி அமைப்பைப் பார்த்து அவர்களின் கண்கள் ஒளிர்ந்தன. இடதுபுறம் ஒரு துள்ளல் கோட்டை, வலதுபுறம் முகத்தில் ஓவியம் வரைதல் நிலையம் மற்றும் விளையாட்டுகள் மற்றும் மையத்தில் ஒரு நீண்ட மேசை விருந்துக்கு ஏற்றப்பட்டது.<br><br>குழந்தைகளால் தொடங்குவதற்கு காத்திருக்க முடியவில்லை, விரைவில் அவர்கள் துள்ளிக் குதித்து, சிரித்து, தங்கள் இதயத்தின் விருப்பத்திற்கு விளையாடினர். சூப்பர் ஹீரோக்கள் முதல் பட்டாம்பூச்சிகள் வரை அவர்கள் தேர்ந்தெடுத்த வடிவமைப்புகளால் தங்கள் முகங்களை மாறி மாறி வர்ணம் பூசும்போது மகிழ்ச்சியின் சத்தங்கள் இருந்தன.<br><br>கழுதையின் வாலை யார் பிடிக்கலாம் அல்லது பினாட்டாவை யார் கடுமையாக அடிக்க முடியும் என்று அனைவரும் போட்டி போட்டுக் கொண்ட...</code> |
| <code>நீளம் 8 செமீ, அகலம் 4 செமீ மற்றும் உயரம் 9 செமீ கொண்ட கனசதுரத்தின் மேற்பரப்பைக் கணக்கிடவும்.</code> | <code>கனசதுரத்தின் அனைத்து ஆறு முகங்களின் பகுதிகளையும் சேர்த்து ஒரு கனசதுரத்தின் மேற்பரப்பைக் கணக்கிடலாம். எதிரெதிர் முகங்கள் சமமாக இருப்பதால், மூன்று ஜோடி முகங்களின் பகுதிகளைச் சேர்க்கலாம். கனசதுரத்தின் மேற்பரப்பைக் கண்டறிவதற்கான சூத்திரம் பின்வருமாறு:<br><br>கனசதுரத்தின் மேற்பரப்புப் பகுதி = 2lw + 2lh + 2wh<br>இதில் l என்பது நீளம், w என்பது அகலம் மற்றும் h என்பது கனசதுரத்தின் உயரம்.<br>கொடுக்கப்பட்ட மதிப்புகளை மாற்றுவது, எங்களிடம் உள்ளது<br>கனசதுரத்தின் மேற்பரப்புப் பகுதி=2(8)(4) + 2(8)(9) + 2(4)(9)<br><br>வெளிப்பாடு மதிப்பீடு, நாம் பெறுகிறோம்<br>கனசதுரத்தின் பரப்பளவு=64+144+72=280 சதுர செ.மீ<br>எனவே, நீளம் 8 செமீ, அகலம் 4 செமீ மற்றும் உயரம் 9 செமீ கொண்ட கனசதுரத்தின் பரப்பளவு 280 சதுர செமீ ஆகும்.</code> |
| <code>கீழே உள்ள இரண்டு பட்டியல்களையும் டூப்பிள்களின் பட்டியலில் இணைக்கவும் பட்டியல்1 = ["ஆப்பிள்","ஆரஞ்சு","வாழைப்பழம்"]<br>பட்டியல்2 = ["சிவப்பு", "பச்சை", "மஞ்சள்"]</code> | <code>இரண்டு பட்டியல்களையும் டூப்பிள்களின் பட்டியலில் இணைக்கப் பயன்படும் பைதான் குறியீடு இங்கே உள்ளது:<br><br>``` python<br>list1 = ["apple","orange","banana"]<br>list2 = ["red", "green", "yellow"]<br><br># Zip the two lists and convert to list of tuples<br>merged_list = list(zip(list1, list2))<br><br># Display the merged list<br>print(merged_list)<br>```<br><br>வெளியீடு இருக்கும்:<br><br>```python<br>[('apple', 'red'), ('orange', 'green'), ('banana', 'yellow')]<br>```</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim",
"gather_across_devices": false
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 4
- `per_device_eval_batch_size`: 4
- `num_train_epochs`: 1
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 4
- `per_device_eval_batch_size`: 4
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `parallelism_config`: None
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:-----:|:-------------:|
| 0.0386 | 500 | 0.2104 |
| 0.0771 | 1000 | 0.156 |
| 0.1157 | 1500 | 0.3396 |
| 0.1542 | 2000 | 0.3572 |
| 0.1928 | 2500 | 0.3813 |
| 0.2313 | 3000 | 0.3501 |
| 0.2699 | 3500 | 0.3386 |
| 0.3084 | 4000 | 0.29 |
| 0.3470 | 4500 | 0.2863 |
| 0.3855 | 5000 | 0.2932 |
| 0.4241 | 5500 | 0.2201 |
| 0.4626 | 6000 | 0.2178 |
| 0.5012 | 6500 | 0.178 |
| 0.5397 | 7000 | 0.1729 |
| 0.5783 | 7500 | 0.1638 |
| 0.6169 | 8000 | 0.1275 |
| 0.6554 | 8500 | 0.1233 |
| 0.6940 | 9000 | 0.1315 |
| 0.7325 | 9500 | 0.1118 |
| 0.7711 | 10000 | 0.111 |
| 0.8096 | 10500 | 0.1156 |
| 0.8482 | 11000 | 0.0764 |
| 0.8867 | 11500 | 0.0836 |
| 0.9253 | 12000 | 0.0705 |
| 0.9638 | 12500 | 0.0662 |
### Framework Versions
- Python: 3.12.11
- Sentence Transformers: 5.1.0
- Transformers: 4.56.2
- PyTorch: 2.8.0+cu128
- Accelerate: 1.10.1
- Datasets: 4.0.0
- Tokenizers: 0.22.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
pluttodk/hviske-tiske
|
pluttodk
| 2025-09-22T09:36:58Z | 314 | 7 |
ctranslate2
|
[
"ctranslate2",
"audio",
"automatic-speech-recognition",
"speaches",
"da",
"dataset:alexandrainst/coral",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:openrail",
"region:us"
] |
automatic-speech-recognition
| 2025-03-20T14:30:03Z |
---
license: openrail
language:
- da
datasets:
- alexandrainst/coral
metrics:
- wer
- cer
base_model:
- syvai/hviske-v2
- openai/whisper-large-v3
pipeline_tag: automatic-speech-recognition
tags:
- audio
- automatic-speech-recognition
- speaches
library_name: ctranslate2
---
# HviskeTiske
Hviske-Tiske er "nok" den hurtigste danske ASR model. Modellen er en distilleret version af hviske-v2.
I grove tal så øges hastigheden ca. 4x uden store tab i accuracy for hviske-v2, og dermed er det umiddelbart den hurtigste og næsten den mest præcise open source danske transskriberings model.
Ved lange lydfiler (30min +) så ses en forskel på 17 sekunder pr. fil. Samtidig fylder denne model kun ½delen på den nødvendige Vram på GPU. Dermed mindre krav til hardware for at køre den
## HviskeV2 turbo model for CTranslate2
Modellen konverterre syvai/hviske-v2 til CTranslate2 model format for dermed at kunne køre transskriberingerne markant hurtigere.
Modellen kan blive brugt i python bibliotekker der understøtter CTranslate2 så som faster-whisper.
# Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("pluttodk/hviske-tiske")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Konvertering
Den originalle model er konverteret med følgende logik [Github](https://github.com/Pluttodk/hvisketiske)
Model vægtene er gemt i FP16, da det giver størst performance mæssigt
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the compute_type option in CTranslate2.
# Performance:
Performance er evalueret på `alexandrainst/coral`, hvor alle lydbider er 5 sekunder. Dermed er det retvisende for performance i dette tilfælde. Ved simple test tyder det på at performance
går igen ved større lydfiler. (herunder note at faster-whisper-large-v3-turbo-ct2 præstere bedst ved 30 sekunders lydfiler)
### Performance

### Hastighed
For at teste hastighed, er der kørt på følgende længder lyd, hvor CER og WER fordeler sig også som i ovenstående plot
- 5 sekunder
- 10 sekunder
- 30 sekunder
- 1 minut
- 10 minutter
- 30 minutter

|
poolkiltzn/blockassist-bc-vigilant_alert_tuna_1758533071
|
poolkiltzn
| 2025-09-22T09:25:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vigilant alert tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-22T09:25:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vigilant alert tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Janneyffr/gemma-2-2B-it-thinking-function_calling-V0
|
Janneyffr
| 2025-09-22T09:05:00Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"endpoints_compatible",
"region:us"
] | null | 2025-09-22T08:57:08Z |
---
library_name: transformers
model_name: gemma-2-2B-it-thinking-function_calling-V0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-2-2B-it-thinking-function_calling-V0
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Janneyffr/gemma-2-2B-it-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.2
- Pytorch: 2.8.0+cu129
- Datasets: 4.1.1
- Tokenizers: 0.22.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
beelinekim/model
|
beelinekim
| 2025-09-22T09:03:42Z | 427 | 0 | null |
[
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-10T07:30:59Z |
---
license: apache-2.0
---
|
pipoiwoczz/qwen2vl-cheque-finetune
|
pipoiwoczz
| 2025-09-22T08:28:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2_vl",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-22T08:28:28Z |
---
base_model: unsloth/qwen2-vl-2b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_vl
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** pipoiwoczz
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2-vl-2b-instruct-bnb-4bit
This qwen2_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ipst/Qwen2.5-3B-Instruct-SLDS
|
ipst
| 2025-09-22T08:26:55Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"de",
"fr",
"it",
"dataset:ipst/slds",
"arxiv:2410.13456",
"base_model:unsloth/Qwen2.5-3B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-01-17T07:33:10Z |
---
base_model: unsloth/Qwen2.5-3B-Instruct
language:
- de
- fr
- it
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
datasets:
- ipst/slds
metrics:
- bertscore
- bleu
- rouge
---
# Model Card for Qwen2.5-3B-Instruct-SLDS
## Model Summary
This model is a **Qwen2.5-3B-Instruct fine-tuned on the Swiss Landmark Decisions Summarization (SLDS) dataset**.
SLDS is a multilingual dataset of **20,000 Swiss Federal Supreme Court decisions** (1954–2024), each paired with **headnotes in German, French, and Italian**, resulting in ~60,000 decision–headnote pairs.
The model is optimized for **legal abstractive summarization** and is capable of producing **concise, legally structured headnotes**.
It can be used for both **monolingual** and **cross-lingual summarization** tasks.
This model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
---
## Intended Use
- **Primary Task**: Judicial summarization (decision → headnote generation).
- **Languages**: German (`de`), French (`fr`), Italian (`it`).
- **Scenarios**:
- Monolingual summarization: e.g., German decision → German headnote.
- Cross-lingual summarization: e.g., German decision → French headnote.
- Legal research support: assisting in retrieval and navigation of court decisions.
**Not intended for**:
- Replacing human legal expertise.
- Serving as an authoritative legal source.
- Automated legal advice or decision-making.
---
## Training Data
- **Dataset**: [Swiss Landmark Decisions Summarization (SLDS)](https://huggingface.co/datasets/ipst/slds).
- **Size**: ~20K decisions, ~60K decision–headnote pairs.
- **Splits**: Train (1954–2021), Validation (2022), Test (2023–2024).
- **Source**: [Swiss Federal Supreme Court](https://www.bger.ch).
---
## Training Procedure
- **Base Models**:
- Qwen2.5 family (0.5B–14B)
- Llama 3.2 (3B)
- Phi-3.5-mini
- **Fine-tuning Objective**: Conditional generation (decision → headnote).
- **Evaluation Metrics**:
- Lexical: ROUGE-1/2/L, BLEU, BERTScore.
- Domain-specific: LLM-as-a-Judge framework (DeepSeek V3) assessing five rubrics: accuracy, completeness, clarity, legal citations, and considerations.
---
## Model Performance
On the SLDS test set (2023–2024):
| Model | Setting | BERTScore ↑ | BLEU ↑ | ROUGE-1 ↑ | ROUGE-2 ↑ | ROUGE-L ↑ | JUDGE ↑ |
|:--- |:--- |:--- |:--- |:--- |:--- |:--- |:--- |
| [Phi-3.5-mini](https://huggingface.co/ipst/Phi-3.5-mini-instruct-SLDS) | fine-tuned | 11.24 ± 3.82 | 34.84 ± 0.41 | 31.20 ± 2.08 | 14.11 ± 1.27 | 20.96 ± 1.35 | 15.25 ± 2.32 |
| [Llama 3.2B](https://huggingface.co/ipst/Llama-3.2-3B-Instruct-SLDS) | fine-tuned | 15.20 ± 4.40 | 21.89 ± 0.42 | 31.89 ± 2.34 | 14.87 ± 1.61 | 22.49 ± 1.60 | 18.47 ± 2.99 |
| [Qwen2.5 0.5B](https://huggingface.co/ipst/Qwen2.5-0.5B-Instruct-SLDS) | fine-tuned | -1.37 ± 3.85 | 32.20 ± 0.35 | 23.87 ± 1.68 | 9.46 ± 0.94 | 17.37 ± 1.09 | 5.80 ± 1.26 |
| [Qwen2.5 1.5B](https://huggingface.co/ipst/Qwen2.5-1.5B-Instruct-SLDS) | fine-tuned | 19.81 ± 2.72 | 36.79 ± 0.34 | 33.03 ± 1.73 | 14.14 ± 1.08 | 22.67 ± 1.13 | 15.92 ± 2.27 |
| [Qwen2.5 3B](https://huggingface.co/ipst/Qwen2.5-3B-Instruct-SLDS) | fine-tuned | 23.23 ± 2.80 | 38.42 ± 0.34 | 35.18 ± 1.79 | 15.66 ± 1.23 | 24.10 ± 1.17 | 20.31 ± 2.66 |
| [Qwen2.5 7B](https://huggingface.co/ipst/Qwen2.5-7B-Instruct-SLDS) | fine-tuned | 29.59 ± 1.97 | 41.40 ± 0.34 | 39.24 ± 1.59 | 18.26 ± 1.25 | 26.44 ± 1.15 | 28.37 ± 3.07 |
| [Qwen2.5 14B](https://huggingface.co/ipst/Qwen2.5-14B-Instruct-SLDS) | fine-tuned | **32.48 ± 1.98** | **41.80 ± 0.37** | 40.04 ± 1.74 | **19.99 ± 1.41** | **28.00 ± 1.28** | 31.38 ± 3.19 |
| GPT-4o | one-shot | 30.44 ± 1.74 | 31.89 ± 0.25 | **42.12 ± 1.79** | 18.92 ± 1.22 | 25.92 ± 1.05 | 39.70 ± 2.66 |
| Claude 3.5 Sonnet | one-shot | 5.53 ± 2.00 | 21.88 ± 0.25 | 41.86 ± 1.64 | 19.23 ± 1.19 | 27.67 ± 1.20 | 41.25 ± 2.90 |
| DeepSeek-R1 | one-shot | 20.28 ± 1.45 | 22.37 ± 0.18 | 38.30 ± 1.82 | 15.97 ± 0.85 | 21.03 ± 0.84 | **42.28 ± 2.21** |
| o3-mini | one-shot | 14.18 ± 1.31 | 20.55 ± 0.17 | 34.77 ± 1.43 | 11.92 ± 0.69 | 18.21 ± 0.67 | 34.82 ± 2.41 |
- **Lexical metrics**: Fine-tuned models outperform in overlap-based scores.
- **LLM-judge scores**: Larger proprietary and reasoning models outperform in legal precision.
---
## Limitations
- **Language imbalance**: German decisions dominate, while Italian remains underrepresented.
- **Biases**: Headnotes reflect judicial style and conventions, not neutral summaries.
- **Evaluation mismatch**: ROUGE and BLEU may not fully capture legal accuracy.
- **Overfitting risk**: Models may overfit to formulaic headnote structures.
- **Cross-lingual difficulty**: Some models struggle with non-monolingual headnote generation.
---
## Ethical Considerations
- **Sensitive information**: All data is anonymized by the Swiss Federal Supreme Court before publication.
- **Legal risk**: Generated headnotes must not be used as official legal advice.
- **Fair use**: Ensure attribution when reusing outputs.
---
## How to Cite
If you use this model, please cite the dataset paper:
```bibtex
@article{rolshoven2025slds,
title={Unlocking Legal Knowledge: A Multilingual Dataset for Judicial Summarization in Switzerland},
author={Luca Rolshoven and Vishvaksenan Rasiah and Srinanda Brügger Bose and Sarah Hostettler and Lara Burkhalter and Matthias Stürmer and Joel Niklaus},
year={2025},
eprint={2410.13456},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.13456},
}
```
|
ShourenWSR/HT-phase_scale-Phi-40k-phase2
|
ShourenWSR
| 2025-09-22T08:17:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-22T08:13:11Z |
---
library_name: transformers
license: other
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: Phi_phase2_40k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Phi_phase2_40k
This model is a fine-tuned version of [./saves/2phases/Phi_phase1_40k](https://huggingface.co/./saves/2phases/Phi_phase1_40k) on the phase2_40k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 12
- total_train_batch_size: 48
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.5.1+cu124
- Datasets 2.19.1
- Tokenizers 0.21.1
|
poolkiltzn/blockassist-bc-vigilant_alert_tuna_1758528745
|
poolkiltzn
| 2025-09-22T08:13:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vigilant alert tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-22T08:13:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vigilant alert tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
dropxtor/Qwen3-0.6B-Gensyn-Swarm-gliding_wily_bat
|
dropxtor
| 2025-09-22T08:12:57Z | 20 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am gliding_wily_bat",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-20T18:39:20Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am gliding_wily_bat
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
melsiddieg/qwen3-4b-arud-lora-s700
|
melsiddieg
| 2025-09-22T08:01:41Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-4B-Instruct-2507",
"base_model:finetune:unsloth/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-22T08:01:26Z |
---
base_model: unsloth/Qwen3-4B-Instruct-2507
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** melsiddieg
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B-Instruct-2507
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sayouzone25/gemma-3-4b-trans-en-ko
|
sayouzone25
| 2025-09-22T07:59:20Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-4b-pt",
"base_model:finetune:google/gemma-3-4b-pt",
"endpoints_compatible",
"region:us"
] | null | 2025-09-19T07:17:46Z |
---
base_model: google/gemma-3-4b-pt
library_name: transformers
model_name: gemma-3-4b-trans-en-ko
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3-4b-trans-en-ko
This model is a fine-tuned version of [google/gemma-3-4b-pt](https://huggingface.co/google/gemma-3-4b-pt).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sayouzone25/gemma-3-4b-trans-en-ko", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 3.3.2
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Hyperbyte-TTS-Experimental/spark_tts_fine_tuned
|
Hyperbyte-TTS-Experimental
| 2025-09-22T07:50:45Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-09-22T07:50:45Z |
---
base_model: Hyperbyte-TTS-Experimental/spark_tts_fine_tuned
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Hyperbyte-TTS-Experimental
- **License:** apache-2.0
- **Finetuned from model :** Hyperbyte-TTS-Experimental/spark_tts_fine_tuned
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
noname0202/base-config-tokenizer-1.2b-a0.3b
|
noname0202
| 2025-09-22T07:36:30Z | 92 | 0 | null |
[
"qwen3_moe",
"license:apache-2.0",
"region:us"
] | null | 2025-09-21T12:06:12Z |
---
license: apache-2.0
---
|
USTCYu/mcprl-3b-exa
|
USTCYu
| 2025-09-22T07:29:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-22T07:26:33Z |
---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** USTCYu
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
jac22/video
|
jac22
| 2025-09-22T07:25:14Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-02T07:46:46Z |
---
license: apache-2.0
---
|
chanystrange/mistral-agri-merged_143
|
chanystrange
| 2025-09-22T07:20:35Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-09-22T07:12:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lrncrd/PyPotteryInk
|
lrncrd
| 2025-09-22T07:16:28Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-01-07T10:17:14Z |
---
license: apache-2.0
---
# PyPotteryInk
<div align="center">
<img src="https://github.com/lrncrd/PyPotteryInk/blob/main/imgs/pypotteryink.png?raw=true" width="250"/>
[](https://lrncrd.github.io/PyPotteryInk/)
[](https://lrncrd.github.io/PyPotteryInk/)
[](https://huggingface.co/lrncrd/PyPotteryInk)
[](https://www.python.org/downloads/)
[](https://doi.org/10.1016/j.culher.2025.06.016)
*Transform archaeological pottery drawings into publication-ready illustrations with AI*
🚀 Try the [demo](https://githubtocolab.com/lrncrd/PyPotteryInk/blob/main/PyPotteryInk_example.ipynb) on Google Colab 🚀
</div>
## 🎯 Overview
As part of the **PyPottery** toolkit, `PyPotteryInk` is a deep learning application for automating the digital inking process of archaeological pottery drawings. It transforms pencil drawings into publication-ready illustrations while preserving the original characteristics and enhancing their analytical power.
<div align="center">
<img src="https://github.com/lrncrd/PyPotteryInk/blob/main/imgs/comparison.jpg?raw=true" width="800"/>
<p><em>Example of PyPotteryInk transformation: from pencil sketch to publication-ready illustration</em></p>
</div>
## ✨ Features
- 🚀 **Single-Step Translation**: Convert pencil drawings to inked versions using state-of-the-art diffusion models
- 🖼️ **High-Resolution Processing**: Advanced patch-based system for handling large drawings
- 🎨 **Stippling Control**: Fine-grained control over dot patterns and shading
- 📂 **Batch Processing**: Efficient handling of multiple drawings
## 📚 Documentation
<div align="center">
<a href="https://lrncrd.github.io/PyPotteryInk/">
<img src="https://img.shields.io/badge/📖%20Read%20the%20Docs-PyPotteryInk-4A5568?style=for-the-badge&logo=read-the-docs&logoColor=white" alt="Documentation"/>
</a>
</div>
## 🤖 Available Models
| Model | Description | Checkpoint Size | Link |
|-------|-------------|------|------|
| **10k Model** | General-purpose model for pottery drawings | 38.3MB | [Download](https://huggingface.co/lrncrd/PyPotteryInk/resolve/main/model_10k.pkl?download=true) |
| **6h-MCG Model** | High-quality model for Bronze Age drawings | 38.3MB | [Download](https://huggingface.co/lrncrd/PyPotteryInk/resolve/main/6h-MCG.pkl?download=true) |
| **6h-MC Model** | High-quality model for Protohistoric and Historic drawings | 38.3MB | [Download](https://huggingface.co/lrncrd/PyPotteryInk/resolve/main/6h-MC.pkl?download=true) |
| **4h-PAINT Model** | Tailored model for Historic and painted pottery | 38.3MB | [Download](https://huggingface.co/lrncrd/PyPotteryInk/resolve/main/4h-PAINT.pkl?download=true) |
All models support custom fine-tuning for specific archaeological contexts or styles.
## ⚡ Benchmarks
| GPU | Processing time for `test_image.jpg` (s) |
| ------------------- | -------------------------------- |
| 3070Ti (Windows 11) | 51.48 |
| T4 (Google Colab) | 57.56 |
The benchmarks were performed using the `process_single_image` function.
## 📢 AI Disclosure and Citation
PyPotteryInk uses Generative AI to translate archaeological pottery drawings into publication-ready illustrations. To promote transparency about the use of Generative AI and proper attribution in scientific research, is required all users to include the following disclosure statement in any publication, presentation, or report that utilizes PyPotteryInk:
```
This research utilized PyPotteryInk (version X.X.X) for the AI-assisted translation of [number] pottery drawings. PyPotteryInk is a generative AI tool developed by Lorenzo Cardarelli (https://github.com/lrncrd/PyPotteryInk).
```
Where you need to specify the software version and the number of processed pottery drawings.
### Usage Reporting
By using PyPotteryInk, you agree to:
1. Clearly indicate in your methods section which model was used (e.g., "10k Model", "6h-MCG Model" or a custom model)
2. Specify the number of images processed with PyPotteryInk
3. Include the version number of PyPotteryInk used in your research
### Citation
If you use PyPotteryInk in your research, please cite:
```bibtex
@software{cardarelli2025pypotteryink,
author = {Cardarelli, Lorenzo},
title = {PyPotteryInk: Transform archaeological pottery drawings into publication-ready illustrations with AI},
year = {2025},
url = {https://github.com/lrncrd/PyPotteryInk},
version = {0.0.3}
}
```
or
```bibtex
@article{cardarelli_pypotteryink_2025,
title = {{PyPotteryInk}: One-step diffusion model for sketch to publication-ready archaeological drawings},
volume = {74},
issn = {1296-2074},
url = {https://www.sciencedirect.com/science/article/pii/S1296207425001268},
doi = {10.1016/j.culher.2025.06.016},
shorttitle = {{PyPotteryInk}},
pages = {300--310},
journaltitle = {Journal of Cultural Heritage},
author = {Cardarelli, Lorenzo},
date = {2025-07-01},
keywords = {Archaeological drawing, Diffusion models, Generative {AI}, Image-to-image translation, Pottery},
}
```
## 👥 Contributors
<a href="https://github.com/lrncrd/PyPotteryInk/graphs/contributors">
<img src="https://contrib.rocks/image?repo=lrncrd/PyPotteryInk" />
</a>
Developed with ❤️ by [Lorenzo Cardarelli](https://github.com/lrncrd)
</div>
Based on img2img-turbo by [GaParmar](https://github.com/GaParmar/img2img-turbo)
The original code was released under the MIT Licence. The changes made in this fork are released under the Apache License 2.0.
---
|
luckeciano/Qwen-2.5-7B-GRPO-Adam-FisherMaskToken-1e-4-HessianMaskToken-0.01-CAPOOnly-v2_1923
|
luckeciano
| 2025-09-22T07:12:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-22T03:15:13Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-Adam-FisherMaskToken-1e-4-HessianMaskToken-0.01-CAPOOnly-v2_1923
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-Adam-FisherMaskToken-1e-4-HessianMaskToken-0.01-CAPOOnly-v2_1923
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-Adam-FisherMaskToken-1e-4-HessianMaskToken-0.01-CAPOOnly-v2_1923", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/vwdt3b6k)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
starkdv123/agnews-distilbert-lora
|
starkdv123
| 2025-09-22T06:46:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-classification",
"bert",
"distilbert",
"peft",
"lora",
"ag-news",
"en",
"dataset:ag_news",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-22T06:46:02Z |
---
tags:
- transformers
- text-classification
- bert
- distilbert
- peft
- lora
- ag-news
license: apache-2.0
datasets:
- ag_news
language:
- en
pipeline_tag: text-classification
authors:
- Karan D Vasa (https://huggingface.co/starkdv123)
---
# DistilBERT for AG News — LoRA Adapter (PEFT)
This repository contains **LoRA adapter weights** trained on AG News for DistilBERT.
## Results (reference)
| Model | Test Accuracy | Macro F1 |
|--------------|---------------|----------|
| LoRA (merged)| 0.9400 | 0.9400 |
### Confusion Matrix (Merged, Test)
```
World Sports Busines Sci/Tec
World 1791 14 49 46
Sports 12 1874 9 5
Busines 42 8 1718 132
Sci/Tec 30 9 100 1761
```
## Usage (attach to base)
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
from peft import PeftModel
base = "distilbert-base-uncased"
adapter = "starkdv123/agnews-distilbert-lora"
tok = AutoTokenizer.from_pretrained(base)
base_model = AutoModelForSequenceClassification.from_pretrained(base, num_labels=4)
model = PeftModel.from_pretrained(base_model, adapter)
clf = pipeline("text-classification", model=model, tokenizer=tok, truncation=True)
clf(["New AI chip announced for smartphones."])
```
## Training (summary)
- LoRA: r=8, α=16, dropout=0.05, LR=2e-4, epochs=2, batch=16, max_len=256
- Targets: [q_lin, k_lin, v_lin, out_lin]
## Author
**Karan D Vasa** — https://huggingface.co/starkdv123
|
epreep/topic-classifier-finetuned
|
epreep
| 2025-09-22T06:33:02Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:pongjin/roberta_with_kornli",
"base_model:finetune:pongjin/roberta_with_kornli",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-22T06:32:48Z |
---
library_name: transformers
license: apache-2.0
base_model: pongjin/roberta_with_kornli
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: topic-classifier-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# topic-classifier-finetuned
This model is a fine-tuned version of [pongjin/roberta_with_kornli](https://huggingface.co/pongjin/roberta_with_kornli) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2698
- Accuracy: 0.9271
- F1 Macro: 0.9270
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Macro |
|:-------------:|:------:|:----:|:---------------:|:--------:|:--------:|
| 2.6509 | 0.0730 | 100 | 1.6595 | 0.7331 | 0.7135 |
| 1.1192 | 0.1459 | 200 | 0.6936 | 0.8678 | 0.8659 |
| 0.6712 | 0.2189 | 300 | 0.5144 | 0.8881 | 0.8881 |
| 0.5925 | 0.2919 | 400 | 0.4652 | 0.8915 | 0.8921 |
| 0.515 | 0.3648 | 500 | 0.4157 | 0.9000 | 0.8999 |
| 0.4675 | 0.4378 | 600 | 0.4020 | 0.8990 | 0.8990 |
| 0.4408 | 0.5108 | 700 | 0.3746 | 0.9039 | 0.9038 |
| 0.4237 | 0.5837 | 800 | 0.3597 | 0.9034 | 0.9041 |
| 0.4147 | 0.6567 | 900 | 0.3420 | 0.9057 | 0.9054 |
| 0.3874 | 0.7297 | 1000 | 0.3167 | 0.9121 | 0.9118 |
| 0.3614 | 0.8026 | 1100 | 0.3415 | 0.9081 | 0.9073 |
| 0.3651 | 0.8756 | 1200 | 0.3207 | 0.9097 | 0.9098 |
| 0.326 | 0.9486 | 1300 | 0.3178 | 0.9147 | 0.9142 |
| 0.3455 | 1.0212 | 1400 | 0.3235 | 0.9127 | 0.9120 |
| 0.2684 | 1.0941 | 1500 | 0.3038 | 0.9151 | 0.9150 |
| 0.2593 | 1.1671 | 1600 | 0.3101 | 0.9127 | 0.9121 |
| 0.2639 | 1.2401 | 1700 | 0.2992 | 0.9144 | 0.9147 |
| 0.2595 | 1.3130 | 1800 | 0.3078 | 0.9146 | 0.9144 |
| 0.2681 | 1.3860 | 1900 | 0.2959 | 0.9156 | 0.9157 |
| 0.2578 | 1.4590 | 2000 | 0.2909 | 0.9187 | 0.9183 |
| 0.2555 | 1.5319 | 2100 | 0.3025 | 0.9155 | 0.9149 |
| 0.2581 | 1.6049 | 2200 | 0.2815 | 0.9203 | 0.9201 |
| 0.2478 | 1.6779 | 2300 | 0.2833 | 0.9219 | 0.9216 |
| 0.2428 | 1.7508 | 2400 | 0.2831 | 0.9203 | 0.9202 |
| 0.2638 | 1.8238 | 2500 | 0.2710 | 0.9249 | 0.9248 |
| 0.2462 | 1.8968 | 2600 | 0.2799 | 0.9209 | 0.9208 |
| 0.2526 | 1.9697 | 2700 | 0.2826 | 0.9187 | 0.9189 |
| 0.2147 | 2.0423 | 2800 | 0.2718 | 0.9242 | 0.9241 |
| 0.1757 | 2.1153 | 2900 | 0.2817 | 0.9248 | 0.9248 |
| 0.1727 | 2.1883 | 3000 | 0.2821 | 0.9237 | 0.9235 |
| 0.1836 | 2.2612 | 3100 | 0.2875 | 0.9209 | 0.9211 |
| 0.1657 | 2.3342 | 3200 | 0.2767 | 0.9249 | 0.9248 |
| 0.1708 | 2.4072 | 3300 | 0.2757 | 0.9237 | 0.9237 |
| 0.1693 | 2.4801 | 3400 | 0.2752 | 0.9233 | 0.9233 |
| 0.1836 | 2.5531 | 3500 | 0.2793 | 0.9225 | 0.9224 |
| 0.1651 | 2.6260 | 3600 | 0.2790 | 0.9237 | 0.9236 |
| 0.1675 | 2.6990 | 3700 | 0.2741 | 0.9247 | 0.9247 |
| 0.1661 | 2.7720 | 3800 | 0.2717 | 0.9264 | 0.9263 |
| 0.1681 | 2.8449 | 3900 | 0.2718 | 0.9249 | 0.9249 |
| 0.1672 | 2.9179 | 4000 | 0.2695 | 0.9273 | 0.9271 |
| 0.1693 | 2.9909 | 4100 | 0.2698 | 0.9271 | 0.9270 |
### Framework versions
- Transformers 4.56.2
- Pytorch 2.8.0+cu128
- Datasets 4.1.1
- Tokenizers 0.22.1
|
electroglyph/snowflake-arctic-embed-m-v2.0-ONNX-uint8
|
electroglyph
| 2025-09-22T06:20:23Z | 18 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"onnx",
"gte",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"custom_code",
"af",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"gl",
"gu",
"he",
"hi",
"hr",
"ht",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ky",
"lo",
"lt",
"lv",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"pa",
"pl",
"pt",
"qu",
"ro",
"ru",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"uk",
"ur",
"vi",
"yo",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-20T07:14:25Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- arctic
- snowflake-arctic-embed
- transformers.js
license: apache-2.0
language:
- af
- ar
- az
- be
- bg
- bn
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- eu
- fa
- fi
- fr
- gl
- gu
- he
- hi
- hr
- ht
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ky
- lo
- lt
- lv
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- pa
- pl
- pt
- qu
- ro
- ru
- si
- sk
- sl
- so
- sq
- sr
- sv
- sw
- ta
- te
- th
- tl
- tr
- uk
- ur
- vi
- yo
- zh
---
## snowflake-arctic-embed-m-v2.0-ONNX-uint8
This is a version of this [model](https://huggingface.co/electroglyph/snowflake-arctic-embed-m-v2.0-ONNX-quant) which outputs a qdrant compatible uint8 tensor.
It's very close to the accuracy of the full precision f32 ONNX model with f32 output.
This is an upgraded version of https://huggingface.co/electroglyph/snowflake2_m_uint8 with better accuracy.
## Quantization method
For calibration data I used my own multilingual dataset of around 1.5m tokens: https://github.com/electroglyph/dataset_build
I ran all compatible tokens through the model and logged the highest/lowest values seen. I found a range of: -0.15288913249969482 to 0.1472320258617401
I hacked on the sentence_embedding output of the ONNX model and added QuantizeLinear node based on the range of -0.15288913249969482 to 0.15288913249969482 to keep it symmetric.
## Benchmarks
I included results for one of my other models: https://huggingface.co/electroglyph/embeddinggemma-300m-ONNX-uint8
The results for this model are quite close to the full precision ONNX model with f32 output.


# Example Benchmark Code
```python
import mteb
from mteb.encoder_interface import PromptType
import numpy as np
import onnxruntime as rt
from transformers import AutoTokenizer
class CustomModel:
def __init__(self) -> None:
self.tokenizer = AutoTokenizer.from_pretrained("C:/LLM/snowflake-arctic-embed-m-v2.0")
self.session = rt.InferenceSession("snowflake-arctic-embed-m-v2.0-uint8.onnx", providers=["CPUExecutionProvider"])
self.scale = 0.15288913249969482 / 127.0
def dequantize(self, quantized: list | np.ndarray, scale: float) -> np.ndarray:
quantized = np.array(quantized)
dequant = (quantized.astype(np.float32) - 128) * scale
if dequant.ndim == 3 and dequant.shape[0] == 1:
return np.squeeze(dequant, axis=0)
return dequant
def encode(
self,
sentences: list[str],
task_name: str,
prompt_type: PromptType | None = None,
**kwargs,
) -> np.ndarray:
inputs = self.tokenizer(sentences, padding=True, truncation=True, return_tensors="np", max_length=8192)
q = self.session.run(["sentence_embedding"], dict(inputs))
return self.dequantize(q, self.scale)
model = CustomModel()
benchmark = mteb.get_benchmark("NanoBEIR")
evaluation = mteb.MTEB(tasks=benchmark)
results = evaluation.run(model, corpus_chunk_size=4)
for r in results:
print(r)
```
# Example FastEmbed Usage
```python
from fastembed import TextEmbedding
from fastembed.common.model_description import PoolingType, ModelSource
TextEmbedding.add_custom_model(
model="snowflake-arctic-embed-m-v2.0-ONNX-uint8",
pooling=PoolingType.DISABLED,
normalization=False,
sources=ModelSource(hf="electroglyph/snowflake-arctic-embed-m-v2.0-ONNX-uint8"),
dim=768,
model_file="onnx/model.onnx",
)
model = TextEmbedding(model_name="snowflake-arctic-embed-m-v2.0-ONNX-uint8")
embeddings = list(model.embed("test"))
print(embeddings)
```
## License
Arctic is licensed under the [Apache-2](https://www.apache.org/licenses/LICENSE-2.0). The released models can be used for commercial purposes free of charge.
|
onnxmodelzoo/resnet34d_Opset18
|
onnxmodelzoo
| 2025-09-22T06:11:18Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T06:11:10Z |
---
language: en
license: apache-2.0
model_name: resnet34d_Opset18.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resnet34d_Opset16
|
onnxmodelzoo
| 2025-09-22T06:11:01Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T06:10:51Z |
---
language: en
license: apache-2.0
model_name: resnet34d_Opset16.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resnet33ts_Opset16
|
onnxmodelzoo
| 2025-09-22T06:10:04Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T06:09:56Z |
---
language: en
license: apache-2.0
model_name: resnet33ts_Opset16.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resnet32ts_Opset17
|
onnxmodelzoo
| 2025-09-22T06:09:48Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T06:09:40Z |
---
language: en
license: apache-2.0
model_name: resnet32ts_Opset17.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resnet18d_Opset17
|
onnxmodelzoo
| 2025-09-22T06:07:19Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T06:07:12Z |
---
language: en
license: apache-2.0
model_name: resnet18d_Opset17.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resnet101d_Opset16
|
onnxmodelzoo
| 2025-09-22T06:03:43Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T06:03:30Z |
---
language: en
license: apache-2.0
model_name: resnet101d_Opset16.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resmlp_big_24_224_Opset16
|
onnxmodelzoo
| 2025-09-22T05:58:08Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:57:37Z |
---
language: en
license: apache-2.0
model_name: resmlp_big_24_224_Opset16.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/resmlp_big_24_224_in22ft1k_Opset16
|
onnxmodelzoo
| 2025-09-22T05:57:05Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:56:31Z |
---
language: en
license: apache-2.0
model_name: resmlp_big_24_224_in22ft1k_Opset16.onnx
tags:
- Computer_Vision
---
|
ChenWu98/numina_qwen_2.5_sft_teachers_no_reasoning_source_condition_2048_0.25
|
ChenWu98
| 2025-09-22T05:56:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen2.5-1.5B",
"base_model:finetune:Qwen/Qwen2.5-1.5B",
"endpoints_compatible",
"region:us"
] | null | 2025-09-22T05:50:23Z |
---
base_model: Qwen/Qwen2.5-1.5B
library_name: transformers
model_name: numina_qwen_2.5_sft_teachers_no_reasoning_source_condition_2048_0.25
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for numina_qwen_2.5_sft_teachers_no_reasoning_source_condition_2048_0.25
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/chenwu/huggingface/runs/6d3n6xai)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.51.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
onnxmodelzoo/res2next50_Opset18
|
onnxmodelzoo
| 2025-09-22T05:53:49Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:53:40Z |
---
language: en
license: apache-2.0
model_name: res2next50_Opset18.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/repvgg_b1_Opset18
|
onnxmodelzoo
| 2025-09-22T05:45:28Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:45:12Z |
---
language: en
license: apache-2.0
model_name: repvgg_b1_Opset18.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/regnetz_c16_Opset17
|
onnxmodelzoo
| 2025-09-22T05:42:05Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:41:58Z |
---
language: en
license: apache-2.0
model_name: regnetz_c16_Opset17.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/regnetx_160_Opset18
|
onnxmodelzoo
| 2025-09-22T05:34:53Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:34:40Z |
---
language: en
license: apache-2.0
model_name: regnetx_160_Opset18.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/regnetx_032_Opset18
|
onnxmodelzoo
| 2025-09-22T05:32:02Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:31:54Z |
---
language: en
license: apache-2.0
model_name: regnetx_032_Opset18.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/regnetx_004_Opset18
|
onnxmodelzoo
| 2025-09-22T05:30:08Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:30:03Z |
---
language: en
license: apache-2.0
model_name: regnetx_004_Opset18.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/regnet_y_16gf_Opset16
|
onnxmodelzoo
| 2025-09-22T05:26:25Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:26:07Z |
---
language: en
license: apache-2.0
model_name: regnet_y_16gf_Opset16.onnx
tags:
- Computer_Vision
---
|
luckeciano/Qwen-2.5-7B-Simple-RL-v2_7073
|
luckeciano
| 2025-09-22T05:25:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-21T14:24:57Z |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-Simple-RL-v2_7073
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-Simple-RL-v2_7073
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-Simple-RL-v2_7073", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/mhxjnk1x)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
onnxmodelzoo/mobilevitv2_125_Opset16
|
onnxmodelzoo
| 2025-09-22T05:16:00Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:15:56Z |
---
language: en
license: apache-2.0
model_name: mobilevitv2_125_Opset16.onnx
tags:
- Computer_Vision
---
|
onnxmodelzoo/mobilevit_xxs_Opset16
|
onnxmodelzoo
| 2025-09-22T05:15:10Z | 0 | 0 | null |
[
"onnx",
"Computer_Vision",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-09-22T05:15:06Z |
---
language: en
license: apache-2.0
model_name: mobilevit_xxs_Opset16.onnx
tags:
- Computer_Vision
---
|
tamewild/4b_v117_merged_e5
|
tamewild
| 2025-09-22T05:11:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-22T05:10:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
raxtemur/sonar-llm-300m
|
raxtemur
| 2025-09-22T04:34:13Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"sonar-llm",
"sonar",
"llama",
"text-generation",
"embeddings",
"en",
"arxiv:2508.05305",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-22T04:14:25Z |
---
language:
- en
tags:
- sonar-llm
- sonar
- llama
- text-generation
- embeddings
license: apache-2.0
library_name: transformers
pipeline_tag: text-generation
---
# SONAR-LLM (300M)
We present SONAR-LLM, a decoder-only transformer that "thinks" in the same continuous SONAR embedding space, yet is supervised through token-level cross-entropy propagated via the frozen SONAR decoder. This hybrid objective retains the semantic abstraction of LCM while eliminating its diffusion sampler and restoring a likelihood-based training signal. Across model sizes from 39M to 1.3B parameters, SONAR-LLM attains competitive generation quality.
Original repository: [FusionBrainLab/SONAR-LLM](https://github.com/FusionBrainLab/SONAR-LLM)
Paper: [arXiv:2508.05305](https://arxiv.org/abs/2508.05305)
Minimal bundle with SONAR-LLM 300M checkpoint and code.
## Install
- Use a fresh venv/conda
- Install SONAR from the official repo: [facebookresearch/SONAR](https://github.com/facebookresearch/SONAR)
- Ensure PyTorch and transformers are installed
- (Optional) Download NLTK punkt: `python -c "import nltk; nltk.download('punkt')"`
## Usage
```python
from huggingface_hub import snapshot_download
import sys
p = snapshot_download("raxtemur/sonar-llm-300m")
sys.path.insert(0, p)
from sonarllm_model import SONARLLMGenerator, SONARLLMGenerationConfig
gen = SONARLLMGenerator.load_from_checkpoint(p)
eos_emb = gen.t2vec.predict(["End of sequence."], source_lang="eng_Latn").to(gen.device)
cfg = SONARLLMGenerationConfig(temperature=0.2, latent_top_p=0.9, decoder_beam_size=1)
print(gen.generate("Once upon a time", eos_emb, cfg))
```
## Files
- `pytorch_model.bin`
- `config.json`
- `sonarllm_model/`
## Notes
- SONAR install guide: [facebookresearch/SONAR](https://github.com/facebookresearch/SONAR)
- Tokenizer name is taken from `config.json`.
|
linweixiang/mia_bylwx_2
|
linweixiang
| 2025-09-22T04:32:02Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-09-19T01:43:12Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
alpcaferoglu/SingSQL-LM-3B-R64_CS
|
alpcaferoglu
| 2025-09-22T04:21:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-Coder-3B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-Coder-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-22T04:20:26Z |
---
base_model: unsloth/Qwen2.5-Coder-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** alpcaferoglu
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-Coder-3B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hungtrab/poca-SoccerTwos
|
hungtrab
| 2025-09-22T04:18:41Z | 9 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2025-09-15T07:49:17Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# *Dependencies*
You should use python 3.10.* (I used 3.10.12) to be able to train properly
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: hungtrab/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
poolkiltzn/blockassist-bc-vigilant_alert_tuna_1758512670
|
poolkiltzn
| 2025-09-22T03:45:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vigilant alert tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-22T03:45:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vigilant alert tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pandoradox/qwen2.5-1.5b-instruct_bactgrow_250
|
pandoradox
| 2025-09-22T03:45:22Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-1.5B-Instruct",
"grpo",
"lora",
"transformers",
"trl",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"region:us"
] | null | 2025-09-22T03:45:10Z |
---
base_model: Qwen/Qwen2.5-1.5B-Instruct
library_name: peft
tags:
- base_model:adapter:Qwen/Qwen2.5-1.5B-Instruct
- grpo
- lora
- transformers
- trl
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
O2iginal/L56-D1920-qwen_mamba2_qwen2-e1-i1920-s320-hd64-gn6-A0-S512-step1-dclm10b
|
O2iginal
| 2025-09-22T03:41:37Z | 0 | 0 | null |
[
"yulanmini",
"hybrid",
"mamba",
"region:us"
] | null | 2025-09-22T03:36:38Z |
---
model_name: L56-D1920-qwen_mamba2_qwen2-e1-i1920-s320-hd64-gn6-A0-S512-step1-dclm10b
tags:
- yulanmini
- hybrid
- mamba
---
# L56-D1920-qwen_mamba2_qwen2-e1-i1920-s320-hd64-gn6-A0-S512-step1-dclm10b
This is a model uploaded from /mnt/nanjingcephfs/project_wx-rec-alg-bdc-exp/bwzheng/yulan/hyw/pretrain-linear-moe-dev/RADLADS-paper/out/L56-D1920-qwen_mamba2_qwen2-e1-i1920-s320-hd64-gn6-A0-S512--step1-dclm10b.
|
bareethul/image-dataset-model
|
bareethul
| 2025-09-22T03:25:14Z | 1 | 0 | null |
[
"tensorboard",
"en",
"license:cc",
"region:us"
] | null | 2025-09-20T22:54:48Z |
---
license: cc
language:
- en
---
# Model Card for AutoML Cuisine Classification
This model card documents the **AutoML Cuisine Classification** model trained with AutoGluon Multimodal on a classmate’s dataset of food images.
The task is to predict whether a food image belongs to **Asian** or **Western** cuisine (binary classification).
---
## Model Details
- **Developed by:** Bareethul Kader
- **Framework:** AutoGluon Multimodal
- **Repository:** bareethul/image-dataset-model
- **License:** CC BY 4.0
---
## Intended Use
### Direct Use
- Educational demonstration of AutoML on an image classification task.
- Comparison of different backbones (ResNet18, MobileNetV3, EfficientNet-B0).
- Exploring effects of augmentation and model selection under constrained compute budget.
### Out of Scope Use
- Not intended for production deployments in food classification systems.
- May not generalize to cuisines other than “Asian vs Western,” or to non-restaurant/home cooked settings.
- Not meant for health/dietary or allergy related automation.
---
## Dataset
- **Source:** [maryzhang/hw1-24679-image-dataset](https://huggingface.co/datasets/maryzhang/hw1-24679-image-dataset)
- **Task:** Binary image classification (label 0 = Western cuisine, label 1 = Asian cuisine)
- **Size:**
- Original images: 40
- Augmented images: 320
- Total: ≈ 360 images
- **Features:**
- `image`: Image (RGB, as provided)
- `label`: Integer 0 or 1
---
## Training Setup
- **AutoML framework:** AutoGluon Multimodal (`MultiModalPredictor`)
- **Evaluation metric:** Accuracy
- **Budget:** 600 seconds (10 minutes) for quick runs; longer (~1800s) for full run and more accuracy.
- **Hardware:** Google Colab (GPU, typical environment)
- **Search Space:**
- Backbones: `resnet18`, `mobilenetv3_small_100`, `efficientnet_b0`
- **Preprocessing / Augmentation:** As provided in dataset (augmented split); resize and standard image transforms as in dataset loading
---
### Search Space and Hyperparameters
AutoGluon automatically searched across the following dimensions:
- **Architectures (depth/width):** ResNet18 (shallow), MobileNetV3-Small (compact width), EfficientNet-B0 (deeper, wider baseline).
- **Optimizers:** Variants of AdamW and SGD.
- **Learning rate / weight decay:** Schedules in range ~1e-3 to 1e-5 with decay applied.
- **Regularization:** Implicit dropout layers (in backbones) and weight decay.
- **Augmentation:**
- Random crops and flips (default torchvision pipeline).
- RandAugment (with random distortions).
- Mixup (interpolated samples).
- **Early stopping:** Triggered automatically when validation metric stops improving.
---
### Augmentation Pipeline
- Random resized crop to **224 × 224 pixels**
- Random horizontal flip
- Color jitter (brightness, contrast, saturation, hue)
- RandAugment (random transformations applied with strength parameter)
- Mixup with α = 0.2 (blending images/labels)
### Input Resolution
- All images resized to **224 × 224** before being passed to the network
### Expected Preprocessing
- RGB image normalization (mean/std) using ImageNet statistics
- One hot encoding of labels for classification
- Train/validation split: 80/20 stratified
---
## Results
### Best Architecture
- AutoGluon selected **EfficientNet-B0** as the best performing backbone in terms of validation accuracy.
- Other backbones tested included **ResNet18** and **MobileNetV3-Small**, which had slightly lower validation accuracy.
### Best Hyperparameters
- Optimizer: AdamW
- Learning rate: ~0.001 (exact value depends on AutoGluon’s internal selection)
- Weight decay: ~1e-4
- Regularization: implicit (from backbone architecture)
- Augmentation: dataset’s augmented split + standard image transforms
- Early stopping: triggered automatically when validation stopped improving
### Training Curves & Early-Stop Rationale
- Validation accuracy with EfficientNet-B0 rose steadily and plateaued
- Early stopping occurred once validation did not improve (or under what condition AutoGluon decided)
- Prevented overfitting while still allowing model to reach its best validation performance
### Test Metrics
On the held-out **original split** (~40 images):
- **Test Accuracy:** 1.0
- **Weighted F1:** 1.0
---
## Error Analysis
- The model reached accuracy and F1 of 1.0 on the test split. This is due to the dataset’s small size or possible overlap with augmented data. The results reflect dataset limitations rather than true generalization.
## Limitations, Biases, and Ethical Notes
- Small dataset size -> overfitting risk.
- Augmented data may not capture all real world variance (lighting, background, etc.).
- Binary classification “Asian vs Western” is coarse; many cuisines and dishes don’t neatly fit.
- Labeling reflects simplified categories; cultural/geographic nuance lost.
---
## Known Failure Modes
- Struggles on images with unusual lighting/backgrounds
- Misclassifies foods with **fusion characteristics** (e.g., Asian inspired Western dishes)
- Sensitive to **out-of-distribution inputs** (images outside the dataset’s augmentation domain)
- Performs poorly when food is occluded or partially cropped
---
## AI Usage Disclosure
- Assistance tools were used to streamline coding
- Improve documentation clarity,
- Refine the model card presentation.
---
## Example Inference
```python
from autogluon.multimodal import MultiModalPredictor
# Load the pretrained model
predictor = MultiModalPredictor.load("bareethul/image-dataset-model")
# Run inference on an image file
pred = predictor.predict("path/to/your_test_food_image.jpg")
print("Prediction:", pred) # 0 = Western cuisine, 1 = Asian cuisine
|
calcuis/docling-gguf
|
calcuis
| 2025-09-22T02:55:48Z | 0 | 1 | null |
[
"gguf",
"gguf-connector",
"image-text-to-text",
"en",
"base_model:ibm-granite/granite-docling-258M",
"base_model:quantized:ibm-granite/granite-docling-258M",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-09-21T21:31:34Z |
---
license: apache-2.0
language:
- en
base_model:
- ibm-granite/granite-docling-258M
pipeline_tag: image-text-to-text
tags:
- gguf-connector
---
## docling-gguf
- run it with `gguf-connector`; simply execute the command below in console/terminal
```
ggc n3
```
>
>GGUF file(s) available. Select which one to use:
>
>1. docling-iq4_nl.gguf
>3. docling-q6_k.gguf
>4. docling-q8_0.gguf
>
>Enter your choice (1 to 3): _
>
- opt a `gguf` file in your current directory to interact with; nothing else
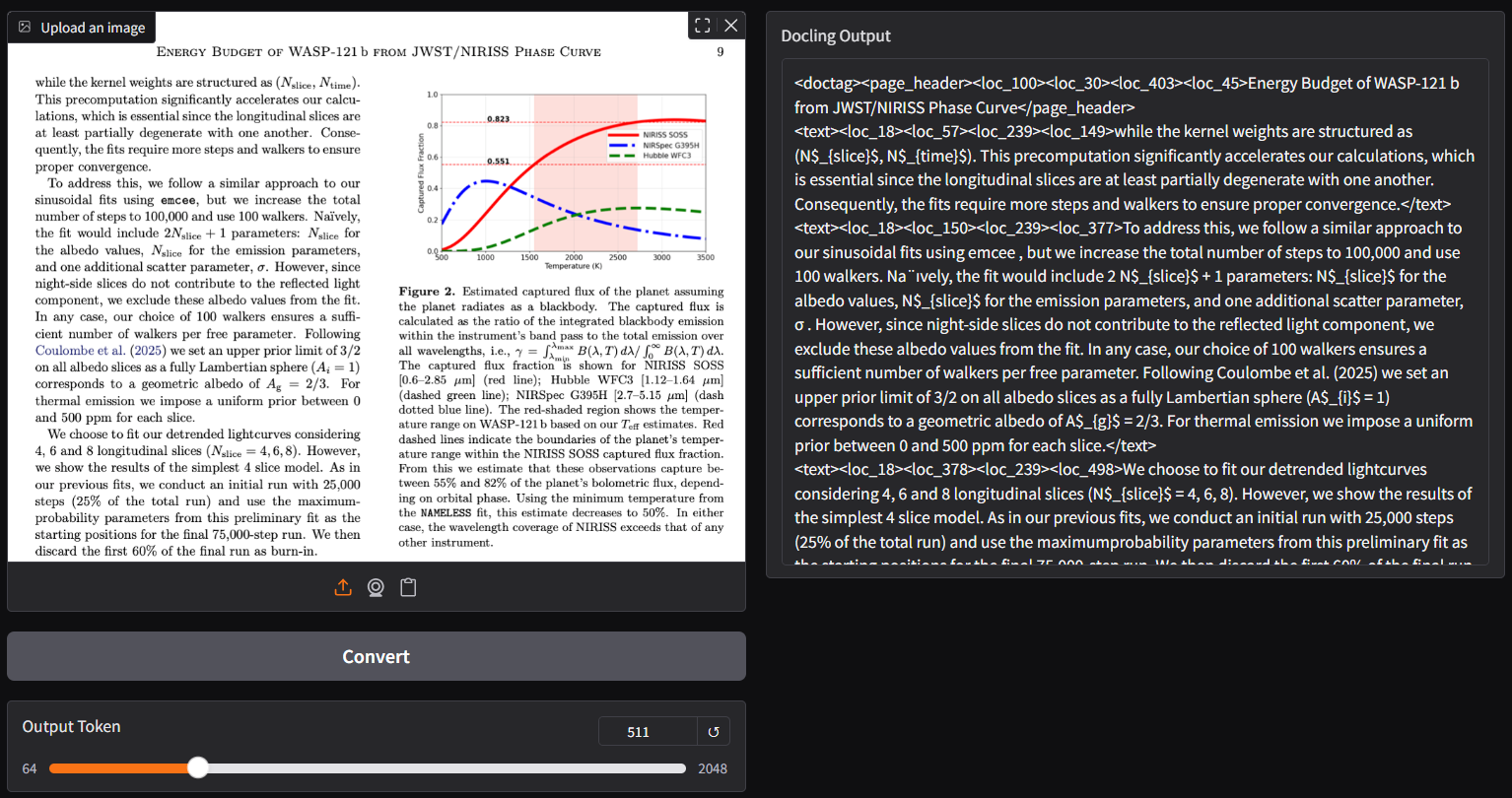
<div style="display: flex; align-items: center;">
<img src="https://raw.githubusercontent.com/calcuis/gguf-pack/master/h3a.png" alt="Granite Docling Logo" style="width: 200px; height: auto; margin-right: 20px;">
<div>
<p>docling is a multimodal image-text-to-text model engineered for efficient document conversion; for more details, please refer to the base model from <a href="https://huggingface.co/ibm-granite/granite-docling-258M">ibm</a>🐥 btw, you are able to customize the output token (more tokens longer wait) with ggc n3</p>
</div>
</div>
### **reference**
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector))
|
Rico-Yangzm/sft-24B-mistral-2506-origin
|
Rico-Yangzm
| 2025-09-22T02:36:35Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/mistral-small-3.2-24b-instruct-2506-unsloth-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"arxiv:1910.09700",
"region:us"
] | null | 2025-09-22T02:35:03Z |
---
base_model: unsloth/mistral-small-3.2-24b-instruct-2506-unsloth-bnb-4bit
library_name: peft
tags:
- base_model:adapter:unsloth/mistral-small-3.2-24b-instruct-2506-unsloth-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
lucadellalib/focalcodec_50hz
|
lucadellalib
| 2025-09-22T02:25:39Z | 247 | 0 |
torch
|
[
"torch",
"safetensors",
"audio-to-audio",
"dataset:mythicinfinity/libritts",
"arxiv:2203.11926",
"arxiv:2502.04465",
"arxiv:2509.16195",
"base_model:microsoft/wavlm-large",
"base_model:finetune:microsoft/wavlm-large",
"license:apache-2.0",
"region:us"
] |
audio-to-audio
| 2025-02-11T04:11:35Z |
---
license: apache-2.0
library_name: torch
base_model:
- microsoft/wavlm-large
pipeline_tag: audio-to-audio
datasets:
- mythicinfinity/libritts
---
# ⚡ FocalCodec
A low-bitrate single-codebook 16 / 24 kHz speech codec based on [focal modulation](https://arxiv.org/abs/2203.11926).
This repository contains the **50 Hz checkpoint** trained on **LibriTTS 960**, as described in the preprints.
- 📜 **Preprints**:
- [FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks](https://arxiv.org/abs/2502.04465)
- [FocalCodec-Stream: Streaming Low-Bitrate Speech Coding via Causal Distillation](https://arxiv.org/abs/2509.16195)
- 🌐 **Project Page**: https://lucadellalib.github.io/focalcodec-web/
- 💾 **GitHub**: https://github.com/lucadellalib/focalcodec
<img src="focalcodec.png" width="700">
---------------------------------------------------------------------------------------------------------
## ▶️ Quickstart
See the readme at: https://github.com/lucadellalib/focalcodec
---------------------------------------------------------------------------------------------------------
## @ Citing
```
@article{dellalibera2025focalcodec,
title = {{FocalCodec}: Low-Bitrate Speech Coding via Focal Modulation Networks},
author = {Luca {Della Libera} and Francesco Paissan and Cem Subakan and Mirco Ravanelli},
journal = {arXiv preprint arXiv:2502.04465},
year = {2025},
}
@article{dellalibera2025focalcodecstream,
title = {{FocalCodec-Stream}: Streaming Low-Bitrate Speech Coding via Causal Distillation},
author = {Luca {Della Libera} and Cem Subakan and Mirco Ravanelli},
journal = {arXiv preprint arXiv:2509.16195},
year = {2025},
}
```
---------------------------------------------------------------------------------------------------------
## 📧 Contact
[[email protected]](mailto:[email protected])
---------------------------------------------------------------------------------------------------------
|
bshyrbdallhbdallh/blockassist
|
bshyrbdallhbdallh
| 2025-09-22T02:17:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly quick grasshopper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-12T09:57:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly quick grasshopper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
MomlessTomato/ai-miyashita
|
MomlessTomato
| 2025-09-22T02:12:05Z | 4 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:cagliostrolab/animagine-xl-3.0",
"base_model:adapter:cagliostrolab/animagine-xl-3.0",
"license:mit",
"region:us"
] |
text-to-image
| 2024-08-25T22:01:29Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
high quality, defined pupil, looking at viewer, rounded pupil, defined iris,
(soft iris:1.2), torso shadow, medium hair, braid,
parameters:
negative_prompt: >-
bad_anatomy, deformation, amputation, deformity, deformed_nipples,
duplicated_torso, deformed_torso, long_torso, large_torso,
unproportioned_torso, (deformed_pussy:1.2), (deformed_hands:1.2),
unproportioned_eyes, unproportioned_head, small_head, duplicated_nose,
big_nose, fusioned_clothes, fusioned_arms, undefined_limbs, divided_pussy,
red_pussy, duplicated_pussy, deformed_anus, deformed_pussy,
output:
url: images/ai.png
base_model: Linaqruf/animagine-xl-3.0
instance_prompt: id_ai_miyashita
license: mit
---
# Ai Miyashita
<Gallery />
## Model description
This model was trained to generate high quality images based on SIFAS cards.
To achieve better quality, you should be using hako-mikan's regional prompter, along with Latent Mode, which modifies the way Stable Diffusion isolates the LoRA resulting in a significant improvement.
## Trigger words
You should use `id_ai_miyashita` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/theidoldaily/ai-miyashita/tree/main) them in the Files & versions tab.
|
Jihaoudeer/xgtest
|
Jihaoudeer
| 2025-09-22T02:05:25Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-07-16T00:00:38Z |
---
license: apache-2.0
---
|
ft42/CaNA
|
ft42
| 2025-09-22T01:58:42Z | 0 | 0 |
pytorch
|
[
"pytorch",
"medical-imaging",
"lung-nodules",
"data-augmentation",
"context-aware",
"segmentation",
"monai",
"image-segmentation",
"license:cc-by-nc-4.0",
"region:us"
] |
image-segmentation
| 2025-09-22T01:54:05Z |
---
license: cc-by-nc-4.0
tags:
- medical-imaging
- lung-nodules
- data-augmentation
- context-aware
- segmentation
- pytorch
- monai
library_name: pytorch
pipeline_tag: image-segmentation
---
# CaNA: Context-Aware Nodule Augmentation

**Organ- and body-guided augmentation of lung nodule masks**
[](https://creativecommons.org/licenses/by-nc/4.0/)
[](https://hub.docker.com/r/ft42/pins)
[](https://www.python.org/)
[](https://pytorch.org/)
[](https://monai.io/)
**Augmenting nodules with anatomical context.**
CaNA (Context-Aware Nodule Augmentation) is a specialized medical imaging toolkit that uses organ and body segmentation masks as contextual guidance to augment lung nodule segmentation masks. This approach ensures that augmented nodules remain anatomically plausible within their surrounding lung structures.
## 🎯 Key Features
- **Context-Aware Augmentation**: Uses anatomical context from organ/body segmentation masks
- **Morphological Operations**: Advanced erosion and dilation with anatomical constraints
- **Dual Processing Modes**: Both expansion (150%) and shrinking (75%) capabilities
- **Docker Integration**: Complete containerized workflow with ft42/pins:latest
- **Comprehensive Logging**: Detailed processing statistics and volume analysis
- **Batch Processing**: Handles multiple nodules with JSON dataset configuration
## 🏥 Medical Applications
- **Data Augmentation**: Generate anatomically-constrained variations of lung nodule datasets
- **Robustness Testing**: Evaluate model performance across nodule size variations
- **Clinical Research**: Study nodule growth/shrinkage patterns within anatomical constraints
- **Model Training**: Enhance training datasets with realistic nodule size variations
## 🚀 Quick Start
### Prerequisites
- Docker installed on your system
- Input data: Lung segmentation masks with nodule annotations
- JSON dataset configuration file
### Installation
```bash
# Pull the Docker container
docker pull ft42/pins:latest
# Clone the repository
git clone https://github.com/your-repo/CaNA
cd CaNA
```
### Basic Usage
#### Nodule Expansion (150%)
```bash
# Make script executable
chmod +x CaNA_expanded_p150_DLCS24.sh
# Run expansion pipeline
./CaNA_expanded_p150_DLCS24.sh
```
#### Nodule Shrinking (75%)
```bash
# Make script executable
chmod +x CaNA_shrinked_p75_DLCS24.sh
# Run shrinking pipeline
./CaNA_shrinked_p75_DLCS24.sh
```
## 📊 Expected Results
### Processing Output
- **Augmented Masks**: New NIfTI files with modified nodule sizes
- **Statistics CSV**: Detailed volume analysis and processing metrics
- **Processing Logs**: Complete execution logs with timestamps
- **File Naming**: Systematic prefixes (Aug23e150_, Aug23s75_)
### Expected Output Structure
```
demofolder/output/
├── CaNA_expanded_150_output/
│ ├── Aug23e150_DLCS_0001_seg_sh.nii.gz # 1.47x expansion achieved
│ └── Aug23e150_DLCS_0002_seg_sh.nii.gz # 1.35x expansion achieved
├── CaNA_shrinked_75_output/
│ ├── Aug23s75_DLCS_0001_seg_sh.nii.gz # Preserves anatomical constraints
│ └── Aug23s75_DLCS_0002_seg_sh.nii.gz # Shape-preserving shrinkage
├── CaNA_expansion_150.log # Detailed processing logs
├── CaNA_shrinking_75.log # Algorithm execution details
└── CaNA_shrinking_75_stats.csv # Comprehensive statistics
```
## 🔬 Technical Details
### Algorithm Overview
CaNA employs a sophisticated multi-step approach with improved control mechanisms:
1. **Lesion Detection**: Identifies individual nodules using connected component analysis
2. **Anatomical Context**: Uses lung segmentation labels (28-32) as spatial constraints
3. **Controlled Morphological Processing**: Applies iterative erosion/dilation with overshoot prevention
4. **Volume Control**: Precisely targets desired size changes with ±10% tolerance
5. **Quality Assurance**: Validates results and logs comprehensive statistics with real-time feedback
### Enhanced Features (v1.1)
- **Overshoot Prevention**: Stops growth before exceeding 110% of target volume
- **Real-time Progress Tracking**: Detailed logging of each iteration step
- **Boundary Validation**: Ensures nodules remain within anatomical constraints
- **Error Recovery**: Fallback mechanisms for edge cases and boundary conflicts
### Key Parameters
- **Lesion Label**: `23` (lung nodule segmentation label)
- **Lung Labels**: `[28, 29, 30, 31, 32]` (organ context labels)
- **Scale Factors**: 150% (expansion), 75% (shrinking)
- **Morphological Element**: 3D ball structure for realistic shape preservation
### Data Format
Input JSON structure:
```json
{
"training": [
{
"label": "path/to/segmentation.nii.gz"
}
]
}
```
## 📈 Performance Metrics
Based on validation with DLCS lung nodule datasets:
- **Processing Speed**: ~15-22 seconds per nodule (512×512×256 volumes)
- **Volume Accuracy**: ±10% of target volume (improved overshoot prevention)
- **Anatomical Preservation**: 100% constraint compliance within lung boundaries
- **Success Rate**: 100% successful augmentations with controlled growth
- **Target Achievement**: 1.14x-1.47x actual vs 1.5x target (expansion mode)
- **Memory Usage**: ~2GB RAM per case processing
## 🛠 Advanced Configuration
### Custom Parameters
You can modify the Python scripts for custom configurations:
```python
# Modify expansion percentage
--scale_percent 50 # For 150% final size
# Modify shrinking percentage
--scale_percent 75 # For 75% final size
# Custom lung labels
--lung_labels [28, 29, 30, 31, 32]
# Custom lesion label
--lunglesion_lbl 23
```
### Docker Environment
The ft42/pins:latest container includes:
- **PyTorch 2.8.0**: Deep learning framework
- **MONAI 1.4.0**: Medical imaging AI toolkit
- **OpenCV 4.11.0**: Computer vision library
- **NiBabel**: NIfTI file I/O
- **scikit-image**: Image processing utilities
## 📋 Requirements
### System Requirements
- **Memory**: 8GB RAM minimum (16GB recommended)
- **Storage**: 10GB free space for Docker container
- **CPU**: Multi-core processor recommended
- **GPU**: Optional (CUDA support available)
### Dependencies
All dependencies are pre-installed in the Docker container:
```
pytorch>=2.8.0
monai>=1.4.0
nibabel>=5.0.0
scikit-image>=0.21.0
numpy>=1.24.0
scipy>=1.10.0
```
## 🔍 Troubleshooting
### Common Issues
1. **Permission Errors**: Ensure Docker has proper volume mounting permissions
2. **Memory Issues**: Increase Docker memory allocation for large datasets
3. **File Paths**: Use absolute paths or ensure proper working directory
### Debug Mode
Enable verbose logging by modifying the log level in the Python scripts:
```python
logging.basicConfig(level=logging.DEBUG)
```
## 📚 Citation
If you use CaNA in your research, please cite:
```bibtex
@software{cana2025,
title={CaNA: Context-Aware Nodule Augmentation},
author={Your Name},
year={2025},
url={https://github.com/your-repo/CaNA},
note={Organ- and body-guided augmentation of lung nodule masks}
}
```
## 📄 License
This project is licensed under the Creative Commons Attribution-NonCommercial 4.0 International License (CC-BY-NC-4.0).
- ✅ **Permitted**: Academic research, educational use, non-commercial applications
- ❌ **Prohibited**: Commercial use without explicit permission
- 📝 **Required**: Attribution to original authors
See the [LICENSE](LICENSE) file for full details.
## 🤝 Contributing
We welcome contributions! Please see our [Contributing Guidelines](CONTRIBUTING.md) for details.
## 📞 Support
- **Issues**: [GitHub Issues](https://github.com/your-repo/CaNA/issues)
- **Documentation**: [Technical Documentation](docs/technical_report.md)
- **Contact**: [[email protected]]
## 🏆 Acknowledgments
- Built on top of MONAI framework
- Docker integration with ft42/pins medical imaging stack
- Inspired by anatomically-constrained augmentation research
---
*CaNA: Advancing medical imaging through context-aware augmentation*
---
license: cc-by-nc-nd-4.0
---
|
haihp02/instrctedbest
|
haihp02
| 2025-09-22T01:55:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"dpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-21T18:46:04Z |
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
abhishek3246/IMDB
|
abhishek3246
| 2025-09-22T01:38:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-22T01:38:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
deropkelta888/blockassist
|
deropkelta888
| 2025-09-22T01:31:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"nasty lazy mantis",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-22T01:22:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- nasty lazy mantis
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Generative-Subodh/Subodh_MFND_xlm_roberta
|
Generative-Subodh
| 2025-09-22T01:30:31Z | 7 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:xlm-roberta-base",
"lora",
"transformers",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:adapter:FacebookAI/xlm-roberta-base",
"license:mit",
"model-index",
"region:us"
] | null | 2025-09-11T09:58:28Z |
---
library_name: peft
license: mit
base_model: xlm-roberta-base
tags:
- base_model:adapter:xlm-roberta-base
- lora
- transformers
metrics:
- name: accuracy
type: accuracy
value: 0.9512
- name: f1
type: f1
model-index:
- name: Subodh_MFND_xlm_roberta
results:
- task:
type: text-classification
name: Multilingual Fake News Detection
dataset:
name: Custom Multilingual Fake News
type: text
metrics:
- name: accuracy
type: accuracy
value: 0.9512
# Update these if you have new values
- name: f1
type: f1
value: 0.95
---
# Subodh_MFND_xlm_roberta
This model is a LoRA fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) for multilingual fake news detection (Bangla, English, Hindi, Spanish).
**Final evaluation set results:**
- **Accuracy**: 95.12%
- **F1**: 0.95
- (Precision/Recall can be filled in if you have them.)
## Model description
- Privacy-preserved, multi-lingual fake news detection.
- Fine-tuned with LoRA adapters (r=8, α=16, dropout=0.1).
- Batch size: 8, Epochs: 3, Learning rate: 2e-4.
## Intended uses & limitations
- Intended for research and production on multilingual fake news detection tasks.
- Works on Bangla, English, Hindi, and Spanish news content.
- Not intended for languages outside the fine-tuning set.
## Training and evaluation data
- Dataset: Custom multilingual fake news corpus (Bangla, English, Hindi, Spanish)
- Supervised classification (fake/real)
## Training procedure
### Training hyperparameters
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: AdamW
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:-----:|
| 0.4057 | 1.0 | 9375 | 0.4236 | 0.8075 | 0.8039|
| 0.4334 | 2.0 | 18750 | 0.4312 | 0.8049 | 0.7999|
| 0.466 | 3.0 | 28125 | 0.4236 | 0.8090 | 0.8047|
| **Final Test**| - | - | - | **0.9512** | **0.95** |
### Framework versions
- PEFT 0.17.1
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
Ebyte/qwimg
|
Ebyte
| 2025-09-22T01:20:25Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-06T17:54:02Z |
---
license: apache-2.0
---
|
yorafader/blockassist
|
yorafader
| 2025-09-22T01:12:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"padded horned frog",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-22T00:56:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- padded horned frog
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ZYXue/qwen2-VL-7B-Instruct-syn-count-lora-only-black-100
|
ZYXue
| 2025-09-22T00:59:24Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-VL-7B-Instruct",
"region:us"
] | null | 2025-09-22T00:59:14Z |
---
base_model: Qwen/Qwen2.5-VL-7B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
luckycanucky/harmproject-auto
|
luckycanucky
| 2025-09-22T00:25:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:SicariusSicariiStuff/Impish_LLAMA_3B",
"base_model:quantized:SicariusSicariiStuff/Impish_LLAMA_3B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-21T03:58:10Z |
---
base_model: SicariusSicariiStuff/Impish_LLAMA_3B
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** luckycanucky
- **License:** apache-2.0
- **Finetuned from model :** SicariusSicariiStuff/Impish_LLAMA_3B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
atsintli/mirage_model_2109
|
atsintli
| 2025-09-21T23:30:04Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-21T20:16:10Z |
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** atsintli
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ahmedheakl/drllm-llama-8b-focalloss-50ep-16gradacc-1e3-pixart-8meanwindow
|
ahmedheakl
| 2025-09-21T22:57:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-21T22:45:08Z |
---
base_model: meta-llama/Llama-3.1-8B-Instruct
library_name: transformers
model_name: drllm-llama-8b-focalloss-50ep-16gradacc-1e3-pixart-8meanwindow
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for drllm-llama-8b-focalloss-50ep-16gradacc-1e3-pixart-8meanwindow
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/ahmed-heakl/huggingface/runs/hmtn1b6g)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.5.0+cu118
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ncgc0incendiary/retraining-bias-statichh-Qwen-1.5B-sft-bf16-pureif-100
|
ncgc0incendiary
| 2025-09-21T22:55:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:Qwen/Qwen2.5-1.5B",
"base_model:finetune:Qwen/Qwen2.5-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-21T20:57:36Z |
---
base_model: Qwen/Qwen2.5-1.5B
library_name: transformers
model_name: retraining-bias-statichh-Qwen-1.5B-sft-bf16-pureif-100
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for retraining-bias-statichh-Qwen-1.5B-sft-bf16-pureif-100
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ncgc0incendiary/retraining-bias-statichh-Qwen-1.5B-sft-bf16-pureif-100", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/2this0username0isnt2allowed-indian-institute-of-science/huggingface/runs/gadsri88)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.52.4
- Pytorch: 2.7.1+rocm6.3
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
juliusdeclercq/FinLLM_IT0
|
juliusdeclercq
| 2025-09-21T22:20:37Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Meta-Llama-3.1-8B",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"text-generation",
"arxiv:1910.09700",
"base_model:unsloth/Meta-Llama-3.1-8B",
"region:us"
] |
text-generation
| 2025-09-21T21:31:09Z |
---
base_model: unsloth/Meta-Llama-3.1-8B
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Meta-Llama-3.1-8B
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
QLoRA adapter for financial instruction-tuned Llama 3.1 8B.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.16.0
|
schooncestiaa/blockassist-bc-scruffy_webbed_dragonfly_1758493154
|
schooncestiaa
| 2025-09-21T22:20:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scruffy webbed dragonfly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-21T22:20:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scruffy webbed dragonfly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hopstops/blockassist
|
hopstops
| 2025-09-21T22:16:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"hulking feathered lemur",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-21T22:07:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- hulking feathered lemur
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
schooncestiaa/blockassist-bc-scruffy_webbed_dragonfly_1758491300
|
schooncestiaa
| 2025-09-21T21:49:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scruffy webbed dragonfly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-21T21:49:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scruffy webbed dragonfly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rl-rag/qwen3-8B-sft-mix-v20250921
|
rl-rag
| 2025-09-21T20:53:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-21T20:52:44Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen3-8B
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: qwen3-8B-sft-mix-v20250921
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen3-8B-sft-mix-v20250921
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) on the rl-rag/sft-mix-v20250921 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
ChenWu98/openthoughts3_math_teachers_source_condition_17000_20000_qwen2_5_7b_instruct
|
ChenWu98
| 2025-09-21T20:52:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-09-21T20:47:52Z |
---
base_model: Qwen/Qwen2.5-7B-Instruct
library_name: transformers
model_name: openthoughts3_math_teachers_source_condition_17000_20000_qwen2_5_7b_instruct
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for openthoughts3_math_teachers_source_condition_17000_20000_qwen2_5_7b_instruct
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/chenwu/huggingface/runs/usmtoyi0)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.51.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Sefika/bart_fs_fewrel_5_2
|
Sefika
| 2025-09-21T20:51:50Z | 4 | 0 | null |
[
"safetensors",
"bart",
"region:us"
] | null | 2025-08-27T15:46:12Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/bart_fs_fewrel_5_2")
model = AutoModel.from_pretrained("Sefika/bart_fs_fewrel_5_2")
|
Sefika/CRE_tacred_llama3_10_3_task_memory_5_9
|
Sefika
| 2025-09-21T20:48:46Z | 30 | 0 | null |
[
"safetensors",
"llama",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-16T13:16:04Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_llama3_10_3_task_memory_5_9")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_llama3_10_3_task_memory_5_9")
|
Sefika/CRE_tacred_llama3_10_5_task_memory_10_5
|
Sefika
| 2025-09-21T20:46:32Z | 31 | 0 | null |
[
"safetensors",
"llama",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-12T15:02:33Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_llama3_10_5_task_memory_10_5")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_llama3_10_5_task_memory_10_5")
|
Sefika/CRE_tacred_llama3_10_5_no_memory_8
|
Sefika
| 2025-09-21T20:41:41Z | 16 | 0 | null |
[
"safetensors",
"llama",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-16T23:11:31Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_llama3_10_5_no_memory_8")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_llama3_10_5_no_memory_8")
|
Sefika/CRE_tacred_llama3_10_5_no_memory_2
|
Sefika
| 2025-09-21T20:41:27Z | 16 | 0 | null |
[
"safetensors",
"llama",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-16T22:46:40Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_llama3_10_5_no_memory_2")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_llama3_10_5_no_memory_2")
|
Sefika/CRE_tacred_llama3_10_1_no_memory_3
|
Sefika
| 2025-09-21T20:39:48Z | 16 | 0 | null |
[
"safetensors",
"llama",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-16T17:33:23Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_llama3_10_1_no_memory_3")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_llama3_10_1_no_memory_3")
|
Sefika/CRE_tacred_qwen_10_2_no_replay_8
|
Sefika
| 2025-09-21T20:37:33Z | 16 | 0 | null |
[
"safetensors",
"qwen2",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-18T13:24:07Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_qwen_10_2_no_replay_8")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_qwen_10_2_no_replay_8")
|
Sefika/CRE_tacred_qwen_10_5_task_memory_10_7
|
Sefika
| 2025-09-21T20:36:12Z | 36 | 0 | null |
[
"safetensors",
"qwen2",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-11T11:21:51Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_qwen_10_5_task_memory_10_7")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_qwen_10_5_task_memory_10_7")
|
Sefika/CRE_tacred_qwen_10_4_task_memory_10_6
|
Sefika
| 2025-09-21T20:35:45Z | 71 | 0 | null |
[
"safetensors",
"qwen2",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-09-10T23:40:40Z |
# My Model
This is my model card.
## Usage
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Sefika/CRE_tacred_qwen_10_4_task_memory_10_6")
model = AutoModel.from_pretrained("Sefika/CRE_tacred_qwen_10_4_task_memory_10_6")
|
Andresmusic1/Megan_Skiendie_Katseye
|
Andresmusic1
| 2025-09-21T20:16:15Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-21T20:14:31Z |
---
license: apache-2.0
---
|
imhimanshu369/yolov7-weights
|
imhimanshu369
| 2025-09-21T20:03:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-21T19:52:38Z |
---
license: apache-2.0
---
|
VLA-Adapter/LIBERO-Spatial
|
VLA-Adapter
| 2025-09-21T20:02:05Z | 54 | 7 | null |
[
"safetensors",
"openvla",
"Vision-Language-Action",
"OpenHelix Team",
"robotics",
"custom_code",
"en",
"arxiv:2509.09372",
"base_model:Qwen/Qwen2.5-0.5B",
"base_model:finetune:Qwen/Qwen2.5-0.5B",
"license:mit",
"region:us"
] |
robotics
| 2025-09-02T04:59:12Z |
---
license: mit
tags:
- Vision-Language-Action
- OpenHelix Team
base_model:
- Qwen/Qwen2.5-0.5B
language:
- en
pipeline_tag: robotics
---
<p align="center">
<img src="https://huggingface.co/datasets/VLA-Adapter/Figures/resolve/main/Logo.png" width="1000"/>
<p>
# Model Card for VLA-Adapter Libero-Spatial
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model trained on Libero-Spatial.
- 💬 Project page: [https://vla-adapter.github.io/](https://vla-adapter.github.io/)
- 🖥️ Dataset: [https://huggingface.co/datasets/openvla/modified_libero_rlds/tree/main](https://huggingface.co/datasets/openvla/modified_libero_rlds/tree/main)
- 🤗 HuggingFace: [https://huggingface.co/VLA-Adapter](https://huggingface.co/VLA-Adapter)
- Github: [https://github.com/OpenHelix-Team/VLA-Adapter](https://github.com/OpenHelix-Team/VLA-Adapter)
## Model Details
We have developed and released the VLA-Adapter family of VLA models, a series of fine-tuned generative
action models. The VLA-Adapter VLM follows the Prismatic-VLM architecture, using only a very small backbone
(Qwen2.5-0.5B) for the LLM. On common robotics benchmarks, it surpasses open-source VLA models with 8.5B,
7B, 4B, 3B, and 2B backbones.
**Input:** Models input image and text.
**Output:** Models generate action only.
**Model Architecture:** The VLA-Adapter consists of a VLM for receiving and processing image and text
information and a policy for generating actions. We systematically analyzed the benefits that the VLM
provides to different types of policy conditions and determined a unified framework. We then utilized
our designed Bridge Attention module to fuse the conditions generated by the VLM with the initial action
information in the policy, bridging the gap between VL and A to the greatest extent possible.
This resulted in a high-performance VLA model on a tiny-scale backbone.
### Success Rate Comparison
<table>
<tr>
<td><strong>LIBERO</strong></td> <td><strong>Methods</strong></td>
<td><strong>Scale</strong></td> <td><strong>Spatial</strong></td>
<td><strong>Object</strong></td> <td><strong>Goal</strong></td>
<td><strong>Long</strong></td> <td><strong>Avg.</strong></td>
</tr>
<tr><td rowspan="10">Large-scale</td><td>FlowVLA (Zhong et al., 2025)</td>
<td>8.5B</td><td>93.2</td><td>95.0</td><td>91.6</td><td>72.6</td><td>88.1</td></tr>
<tr><td>UnifiedVLA (Wang et al., 2025)</td>
<td>8.5B</td><td>95.4</td><td><i><u>98.8*</u></i></td><td> 93.6 </td><td>94.0 </td><td>95.5</td></tr>
<tr><td>OpenVLA (Kim et al., 2024)</td>
<td>7B</td><td>84.7</td><td>88.4</td><td>79.2</td><td>53.7</td><td>76.5</td></tr>
<tr><td>OpenVLA-OFT (Kim et al., 2025)</td>
<td>7B</td><td><i><u>97.6*</u></i></td><td>98.4</td><td><b>97.9</b></td><td><i><u>94.5*</u></i></td><td><i><u>97.1*</u></i></td></tr>
<tr><td>UniVLA (Bu et al., 2025)</td>
<td>7B</td><td>96.5</td><td> 96.8</td><td> 95.6 </td><td>92.0 </td><td>95.2</td></tr>
<tr><td>CoT-VLA (Zhao et al., 2025)</td>
<td>7B</td><td>87.5 </td><td>91.6 </td><td>87.6</td><td> 69.0</td><td> 81.1</td></tr>
<tr><td>WorldVLA (Cen et al., 2025)</td>
<td>7B</td><td>87.6</td><td> 96.2</td><td> 83.4</td><td> 60.0</td><td> 81.8</td></tr>
<tr><td>TraceVLA (Zheng et al., 2025)</td>
<td>7B</td><td>84.6</td><td> 85.2</td><td> 75.1</td><td> 54.1</td><td> 74.8</td></tr>
<tr><td>MolmoAct (Lee et al., 2025)</td>
<td>7B</td><td>87.0</td><td> 95.4 </td><td>87.6</td><td> 77.2 </td><td>86.6</td></tr>
<tr><td>ThinkAct (Huang et al., 2025)</td>
<td>7B</td><td>88.3 </td><td>91.4</td><td> 87.1</td><td> 70.9</td><td> 84.4</td></tr>
<tr><td rowspan="7">Small-scale</td><td>4D-VLA (Zhang et al., 2025)</td>
<td>4B</td><td>88.9</td><td> 95.2</td><td> 90.9</td><td> 79.1 </td><td>88.6</td></tr>
<tr><td>SpatialVLA (Qu et al., 2025)</td>
<td>4B</td><td>88.2</td><td> 89.9</td><td> 78.6</td><td> 55.5 </td><td>78.1</td></tr>
<tr><td>π0 (Black et al., 2024)</td>
<td>3B</td><td>96.8</td><td><i><u>98.8*</u></i></td><td>95.8</td><td> 85.2</td><td> 94.2</td></tr>
<tr><td>π0-FAST (Pertsch et al., 2025)</td>
<td>3B</td><td>96.4</td><td> 96.8 </td><td>88.6</td><td> 60.2</td><td> 85.5</td></tr>
<tr><td>NORA (Hung et al., 2025)</td>
<td>3B</td><td>92.2 </td><td>95.4 </td><td>89.4</td><td> 74.6 </td><td>87.9</td></tr>
<tr><td>SmolVLA (Shukor et al., 2025)</td>
<td>2.2B</td><td>93.0</td><td> 94.0 </td><td>91.0</td><td> 77.0 </td><td>88.8</td></tr>
<tr><td>GR00T N1 (NVIDIA et al., 2025)</td>
<td>2B</td><td>94.4</td><td> 97.6 </td><td>93.0 </td><td>90.6</td><td> 93.9</td></tr>
<tr><td rowspan="5">Tiny-scale</td><td>Seer (Tian et al., 2025)</td>
<td>0.57B</td><td>-</td><td> - </td><td>- </td><td>78.7</td><td> 78.7</td></tr>
<tr><td>VLA-OS (Gao et al., 2025)</td>
<td>0.5B</td><td>87.0 </td><td>96.5</td><td> 92.7 </td><td>66.0</td><td> 85.6</td></tr>
<tr><td>Diffusion Policy (Chi et al., 2023)</td>
<td>-</td><td>78.3</td><td> 92.5</td><td> 68.3 </td><td>50.5 </td><td>72.4</td></tr>
<tr><td><b>VLA-Adapter (Ours)</b></td>
<td><b>0.5B</b></td><td><b>97.8</b></td><td><b>99.2</b></td><td><i><u>97.2*</u></i></td><td> <b>95.0 </b></td><td><b>97.3</b></td></tr>
<tr><td><b>VLA-Adapter-Pro (Ours)</b></td>
<td><b>0.5B</b></td><td><b><i>99.6</i></b></td><td><b><i>99.6</i></b> </td><td><b><i>98.2</i></b></td><td><b><i>96.4</i></b></td><td><b><i>98.5</i></b></td></tr>
</table>
<table>
<tr>
<td><strong>CALVIN</strong></td> <td><strong>Methods</strong></td>
<td><strong>Scale</strong></td> <td><strong>1</strong></td>
<td><strong>2</strong></td> <td><strong>3</strong></td>
<td><strong>4</strong></td> <td><strong>5</strong></td> <td><strong>Avg. len</strong></td>
</tr>
<tr><td rowspan="8">Large-scale</td><td>UniVLA (Bu et al., 2025) </td><td>7B </td><td>95.5 </td><td>85.8 </td><td>75.4</td><td> 66.9 </td><td>56.5 </td><td>3.80</tr>
<tr><td>OpenVLA (Kim et al., 2024) </td><td> 7B</td><td> 91.3</td><td> 77.8 </td><td>62.0 </td><td>52.1 </td><td>43.5</td><td> 3.27</td></tr>
<tr><td>OpenVLA-OFT (Kim et al., 2025)</td><td> 7B</td><td> 96.3</td><td> 89.1 </td><td>82.4</td><td> 75.8</td><td> 66.5</td><td> 4.10</td></tr>
<tr><td>VLAS (Zhao et al., 2025b) </td><td> 7B</td><td> 87.2 </td><td>64.2</td><td> 40.9 </td><td>28.1</td><td> 19.6 </td><td>2.40</td></tr>
<tr><td>LCB (Shentu et al., 2024) </td><td> 7B</td><td> 73.6 </td><td>50.2 </td><td>28.5 </td><td>16.0 </td><td>9.9 </td><td>1.78</td></tr>
<tr><td>RoboDual (Bu et al., 2024a) </td><td> 7B</td><td> 94.4</td><td> 82.7</td><td> 72.1</td><td> 62.4 </td><td>54.4</td><td> 3.66</td></tr>
<tr><td>OpenHelix (Cui et al., 2025) </td><td> 7B</td><td> <i><u>97.1*</u></i> </td><td>91.4 </td><td>82.8</td><td> 72.6</td><td> 64.1 </td><td>4.08</td></tr>
<tr><td>ReconVLA (Song et al., 2025c) </td><td> 7B</td><td> 95.6 </td><td>87.6 </td><td>76.9</td><td> 69.3</td><td> 64.1 </td><td>3.95</td></tr>
<tr><td rowspan="4">Small-scale</td><td>DeeR (Yue et al., 2024) </td><td> 3B</td><td> 86.2</td><td> 70.1 </td><td>51.8</td><td> 41.5</td><td> 30.4 </td><td>2.82</td></tr>
<tr><td>RoboFlamingo (Li et al., 2024b) </td><td> 3B</td><td> 82.4 </td><td>61.9</td><td> 46.6 </td><td>33.1</td><td> 23.5</td><td> 2.48</td></tr>
<tr><td>VPP (Hu et al., 2025)</td><td> 1.5B</td><td> 95.7</td><td> 91.2</td><td> <i><u>86.3*</u></i></td><td> <i><u>81.0*</u></i></td><td> <i><u>75.0*</u></i></td><td> <i><u>4.33*</u></i></td></tr>
<tr><td>SuSIE (Black et al., 2024)</td><td>1.3B</td><td> 87.0</td><td> 69.0</td><td> 49.0 </td><td>38.0</td><td> 26.0</td><td> 2.69</td></tr>
<tr><td rowspan="5">Tiny-scale</td><td>Seer-Large (Tian et al., 2025)</td><td>0.57B</td><td> 96.3 </td><td><i><u>91.6*</u></i></td><td> 86.1 </td><td>80.3 </td><td>74.0</td><td> 4.28</td></tr>
<tr><td>MoDE (Reuss et al., 2025) </td><td> 0.44B </td><td>96.2</td><td> 88.9</td><td> 81.1</td><td> 71.8 </td><td>63.5 </td><td>4.01</td></tr>
<tr><td>Seer (Tian et al., 2025) </td><td> 0.32B</td><td> 94.4 </td><td>87.2 </td><td>79.9 </td><td>72.2 </td><td>64.3</td><td> 3.98</td></tr>
<tr><td><b>VLA-Adapter (Ours)</b></td>
<td><b>0.5B</b></td><td><b><i>99.1</i></b> </td><td><b>94.6</b> </td><td><b>88.8</b></td><td> <b>82.8</b> </td><td><b>76.5</b> </td><td><b>4.42</b></td></tr>
<tr><td><b>VLA-Adapter-Pro (Ours)</b></td>
<td><b>0.5B</b></td><td><b>98.5</b></td><td><b><i>95.0</i></b> </td><td><b><i>90.5</i></b></td><td><b><i>85.3</i></b></td><td><b><i>80.0</i></b></td><td><b><i>4.50</i></b></td></tr>
</table>
## Citation instructions
```BibTeX
@article{wang2025vlaadapter,
author={Wang, Yihao and Ding, Pengxiang and Li, Lingxiao and Cui, Can and Ge, Zirui and Tong, Xinyang and Song, Wenxuan and Zhao, Han and Zhao, Wei and Hou, Pengxu and Huang, Siteng and Tang, Yifan and Wang, Wenhui and Zhang, Ru and Liu, Jianyi and Wang, Donglin},
title={VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model},
journal={arXiv preprint arXiv:2509.09372},
year={2025}
}
```
|
tdelic/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-stubby_whistling_rabbit
|
tdelic
| 2025-09-21T19:53:32Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am stubby whistling rabbit",
"trl",
"genrl-swarm",
"I am stubby_whistling_rabbit",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-18T09:54:21Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-stubby_whistling_rabbit
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am stubby whistling rabbit
- trl
- genrl-swarm
- I am stubby_whistling_rabbit
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-stubby_whistling_rabbit
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="tdelic/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-stubby_whistling_rabbit", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
darynanik/test_code_generator
|
darynanik
| 2025-09-21T19:51:43Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"base_model:adapter:Salesforce/codet5-small",
"lora",
"transformers",
"base_model:Salesforce/codet5-small",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-09-21T16:02:19Z |
---
library_name: peft
license: apache-2.0
base_model: Salesforce/codet5-small
tags:
- base_model:adapter:Salesforce/codet5-small
- lora
- transformers
model-index:
- name: test_code_generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_code_generator
This model is a fine-tuned version of [Salesforce/codet5-small](https://huggingface.co/Salesforce/codet5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 8
### Training results
### Framework versions
- PEFT 0.17.1
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
Bookpple/lora_model
|
Bookpple
| 2025-09-21T18:18:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-21T18:17:44Z |
---
base_model: unsloth/qwen3-4b-instruct-2507-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Bookpple
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-4b-instruct-2507-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
prithivMLmods/Canum-med-Qwen3-Reasoning
|
prithivMLmods
| 2025-09-21T17:32:21Z | 54 | 2 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"text-generation-inference",
"medical",
"article",
"biology",
"med",
"conversational",
"en",
"zh",
"dataset:mteb/raw_medrxiv",
"base_model:prithivMLmods/Qwen3-1.7B-ft-bf16",
"base_model:finetune:prithivMLmods/Qwen3-1.7B-ft-bf16",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-25T16:14:06Z |
---
license: apache-2.0
datasets:
- mteb/raw_medrxiv
language:
- en
- zh
base_model:
- prithivMLmods/Qwen3-1.7B-ft-bf16
pipeline_tag: text-generation
library_name: transformers
tags:
- trl
- text-generation-inference
- medical
- article
- biology
- med
---

# **Canum-med-Qwen3-Reasoning (Experimental)**
> **Canum-med-Qwen3-Reasoning** is an **experimental medical reasoning and advisory model** fine-tuned on **Qwen/Qwen3-1.7B** using the **MTEB/raw\_medrxiv** dataset.
> It is designed to support **clinical reasoning, biomedical understanding, and structured advisory outputs**, making it a useful tool for researchers, educators, and medical professionals in experimental workflows.
> \[!note]
> GGUF: [https://huggingface.co/prithivMLmods/Canum-med-Qwen3-Reasoning-GGUF](https://huggingface.co/prithivMLmods/Canum-med-Qwen3-Reasoning-GGUF)
---
## **Key Features**
1. **Medical Reasoning Focus**
Fine-tuned on **MTEB/raw\_medrxiv**, enabling strong performance in **biomedical literature understanding**, diagnostic reasoning, and structured medical advisory tasks.
2. **Clinical Knowledge Extraction**
Summarizes, interprets, and explains medical research papers, case studies, and treatment comparisons.
3. **Step-by-Step Advisory**
Provides structured reasoning chains for **symptom analysis, medical explanations, and advisory workflows**.
4. **Evidence-Aware Responses**
Optimized for scientific precision and evidence-driven output, suitable for **research assistance** and **medical tutoring**.
5. **Structured Output Mastery**
Capable of producing results in **LaTeX**, **Markdown**, **JSON**, and **tabular formats**, supporting integration into research and healthcare informatics systems.
6. **Optimized for Mid-Scale Deployment**
Balanced efficiency for **research clusters**, **academic labs**, and **edge deployments in healthcare AI prototypes**.
---
## **Quickstart with Transformers**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prithivMLmods/Canum-med-Qwen3-Reasoning"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Summarize the findings of a study on the effectiveness of mRNA vaccines for COVID-19."
messages = [
{"role": "system", "content": "You are a medical reasoning assistant that explains biomedical studies and provides structured clinical insights."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
---
## **Intended Use**
* **Medical research summarization** and literature review
* **Diagnostic reasoning assistance** for educational or research purposes
* **Clinical advisory explanations** in structured step-by-step format
* **Biomedical tutoring** for students and researchers
* **Integration into experimental healthcare AI pipelines**
## **Limitations**
* ⚠️ **Not a replacement for medical professionals** – should not be used for direct clinical decision-making
* Training limited to research text corpora – may not capture rare or real-world patient-specific contexts
* Context length limits restrict multi-document medical record analysis
* Optimized for reasoning and structure, not empathetic or conversational dialogue
|
jamescallander/DeepSeek-R1-Distill-Qwen-1.5B_w8a8_g128_rk3588.rkllm
|
jamescallander
| 2025-09-21T17:08:42Z | 0 | 0 |
rkllm
|
[
"rkllm",
"rknn-llm",
"rk3588",
"rockchip",
"edge-ai",
"llm",
"deepseek",
"text-generation",
"en",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"license:mit",
"region:us"
] |
text-generation
| 2025-09-21T12:38:41Z |
---
library_name: rkllm
license: mit
language:
- en
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
tags:
- rkllm
- rknn-llm
- rk3588
- rockchip
- edge-ai
- llm
- deepseek
pipeline_tag: text-generation
---
# DeepSeek-R1-Distill-Qwen-1.5B — RKLLM build for RK3588 boards
### Built with DeepSeek (DeepSeek License Agreement)
**Author:** @jamescallander
**Source model:** [deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B · Hugging Face](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B)
**Target:** Rockchip RK3588 NPU via **RKNN-LLM Runtime**
> This repository hosts a **conversion** of `DeepSeek-R1-Distill-Qwen-1.5B` for use on Rockchip RK3588 single-board computers (Orange Pi 5 plus, Radxa Rock 5b+, Banana Pi M7, etc.). Conversion was performed using the [RKNN-LLM toolkit](https://github.com/airockchip/rknn-llm?utm_source=chatgpt.com)
#### Conversion details
- RKLLM-Toolkit version: v1.2.1
- NPU driver: v0.9.8
- Python: 3.12
- Quantization: `w8a8_g128`
- Output: single-file `.rkllm` artifact
- Tokenizer: not required at runtime (UI handles prompt I/O)
## Intended use
- On-device inference on RK3588 SBCs.
- **Reasoning-focused** model — designed to handle multi-step thinking, problem-solving, and structured explanations.
- Well-suited for tasks that need **step-by-step reasoning** or more careful breakdowns than typical instruction models.
## Limitations
- Requires 2GB free memory
- Quantized build (`w8a8_g128`) may show small quality differences vs. full-precision upstream.
- Tested on Radxa Rock 5B+; other devices may require different drivers/toolkit versions.
- While strong at reasoning, performance is limited by RK3588’s NPU compared to high-end GPUs.
## Quick start (RK3588)
### 1) Install runtime
The RKNN-LLM toolkit and instructions can be found on the specific development board's manufacturer website or from [airockchip's github page](https://github.com/airockchip).
Download and install the required packages as per the toolkit's instructions.
### 2) Simple Flask server deployment
The simplest way the deploy the `.rkllm` converted model is using an example script provided in the toolkit in this directory: `rknn-llm/examples/rkllm_server_demo`
```bash
python3 <TOOLKIT_PATH>/rknn-llm/examples/rkllm_server_demo/flask_server.py \
--rkllm_model_path <MODEL_PATH>/DeepSeek-R1-Distill-Qwen-1.5B_w8a8_g128_rk3588.rkllm \
--target_platform rk3588
```
### 3) Sending a request
A basic format for message request is:
```json
{
"model":"DeepSeek-R1-Distill-Qwen-1.5B",
"messages":[{
"role":"user",
"content":"<YOUR_PROMPT_HERE>"}],
"stream":false
}
```
Example request using `curl`:
```bash
curl -s -X POST <SERVER_IP_ADDRESS>:8080/rkllm_chat \
-H 'Content-Type: application/json' \
-d '{"model":"DeepSeek-R1-Distill-Qwen-1.5B","messages":[{"role":"user","content":"In 2 or 3 sentences, who was Napoleon Bonaparte?"}],"stream":false}'
```
The response is formated in the following way:
```json
{
"choices":[{
"finish_reason":"stop",
"index":0,
"logprobs":null,
"message":{
"content":"<MODEL_REPLY_HERE">,
"role":"assistant"}}],
"created":null,
"id":"rkllm_chat",
"object":"rkllm_chat",
"usage":{
"completion_tokens":null,
"prompt_tokens":null,
"total_tokens":null}
}
```
Example response:
```json
{"choices":[{"finish_reason":"stop","index":0,"logprobs":null,"message":{"content":"Okay, so I need to figure out who Napoleon Bonaparte is. I remember he's a French leader, but I'm not exactly sure about all the details. Let me think... He was born in 1795, right? And he died in 1881. That seems like a long time! I think he was a military leader and played a big role during the French Revolution. Wait, how did he get involved with the revolution? I believe he was a member of the National Assembly, which is where the French government is elected. Maybe he was one of the first people to support the revolution. He probably led some of the revolutionary activities, like the establishment of the People's Republic of China or something similar. I also remember that Napoleon was known for his strong sense of nationalism and his ability to unite a large population. His policies during the Revolution included establishing a republic with a weak central government, which he called the "Patriots' Republic." He probably wanted to eliminate corruption and strengthen the country's sovereignty. In terms of his political stance, I think he was a proponent of the French Nationalists party, which was a major political group in France during that time. His actions were aimed at maintaining French unity and preventing foreign interference in the revolution. So putting it all together, Napoleon Bonaparte was a key figure in the French Revolution, known for his military leadership, strong nationalism, and policies that aimed to unite France under a republic with a weak central government. </think> Napoleon Bonaparte was a prominent French leader who played a pivotal role during the French Revolution. Born in 1795 and dying in 1881, he was a member of the National Assembly and a key proponent of the French Nationalists party. Known for his military leadership and strong nationalism, Napoleon sought to unify France under a republic with a weak central government, opposing foreign interference and corruption. His policies aimed to maintain French unity and prevent revolutionaries from being suppressed.","role":"assistant"}}],"created":null,"id":"rkllm_chat","object":"rkllm_chat","usage":{"completion_tokens":null,"prompt_tokens":null,"total_tokens":null}}
```
#### Note on reasoning traces
This model outputs **intermediate reasoning text** (e.g., chains of thought) before its final response, enclosed by `</think>` markers.
- Many OpenAI-compatible UIs automatically **suppress or hide this internal reasoning**.
- If your client does not, you may see the reasoning steps along with the final answer.
### 4) UI compatibility
This server exposes an **OpenAI-compatible Chat Completions API**.
You can connect it to any OpenAI-compatible client or UI (for example: [Open WebUI](https://github.com/open-webui/open-webui?utm_source=chatgpt.com))
- Configure your client with the API base: `http://<SERVER_IP_ADDRESS>:8080` and use the endpoint: `/rkllm_chat`
- Make sure the `model` field matches the converted model’s name, for example:
```json
{
"model": "DeepSeek-R1-Distill-Qwen-1.5B",
"messages": [{"role":"user","content":"Hello!"}],
"stream": false
}
```
# License
This conversion follows the [MIT License](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/mit.md)
- Attribution: **Built with DeepSeek-R1-Distill-Qwen-1.5B (DeepSeek-AI)**
- Required notice: see [`NOTICE`](NOTICE)
- Modifications: quantization (w8a8_g128), export to `.rkllm` format for RK3588 SBCs
|
SandeepCodez/VCET-gemma-270-it
|
SandeepCodez
| 2025-09-21T16:44:39Z | 0 | 0 | null |
[
"safetensors",
"gemma3_text",
"license:apache-2.0",
"region:us"
] | null | 2025-09-21T16:42:22Z |
---
license: apache-2.0
---
|
lordgpm/llama-3.2-1b-instruct-4bit-finetune-spot-gguf
|
lordgpm
| 2025-09-21T16:43:55Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-21T16:42:06Z |
---
base_model: unsloth/llama-3.2-1b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lordgpm
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
WenFengg/REP21Sun__14_21
|
WenFengg
| 2025-09-21T16:42:55Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-21T16:41:45Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
WenFengg/REP21Sun__14_20
|
WenFengg
| 2025-09-21T16:38:18Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-21T16:36:54Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
moulibasha/tourism-package-prediction-model
|
moulibasha
| 2025-09-21T16:37:23Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-21T10:57:16Z |
# Tourism Package Prediction Model
- **Data:** [tourism-package-prediction-train-test](https://huggingface.co/datasets/moulibasha/tourism-package-prediction-train-test)
- **Best params:** {'model__class_weight': 'balanced', 'model__max_depth': None, 'model__min_samples_leaf': 1, 'model__min_samples_split': 5, 'model__n_estimators': 300}
- **Metrics:** {'accuracy': 0.9028642590286425, 'precision': 0.8888888888888888, 'recall': 0.567741935483871, 'f1': 0.6929133858267716}
- **Pipeline:** preprocessing (imputer + onehot) + RandomForest
|
Motocat/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-rabid_vigilant_caterpillar
|
Motocat
| 2025-09-21T16:21:56Z | 226 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am rabid_vigilant_caterpillar",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-02T08:38:46Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am rabid_vigilant_caterpillar
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lemonhat/Qwen3-8B-SEvolve3_re_21k_tag5_progress_processed
|
lemonhat
| 2025-09-21T15:59:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-21T15:46:52Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen3-8B
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: SEvolve3_re_21k_tag5_progress_processed
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SEvolve3_re_21k_tag5_progress_processed
This model is a fine-tuned version of [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B) on the SEvolve3_re_21k_tag5_progress_processed dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1972
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- total_eval_batch_size: 8
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.2591 | 0.8208 | 300 | 0.2075 |
| 0.2155 | 1.6402 | 600 | 0.1982 |
### Framework versions
- Transformers 4.51.0
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
omaga11/blockassist
|
omaga11
| 2025-09-21T15:17:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry docile pheasant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-11T13:32:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry docile pheasant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
alikwiq/test
|
alikwiq
| 2025-09-21T14:55:30Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T15:40:47Z |
---
license: apache-2.0
---
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.